diff options
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
6475 files changed, 376269 insertions, 312 deletions
diff --git a/.envrc b/.envrc new file mode 100644 index 0000000000..34fe568ce9 --- /dev/null +++ b/.envrc @@ -0,0 +1,6 @@ +# Configure the local PATH to contain tools which are fetched ad-hoc +# from Nix. + +export PATH="${PWD}/bin:${PATH}" +export NIX_PATH="nixpkgs=${PWD}/default.nix" +export REPO_ROOT="${PWD}" diff --git a/.git-blame-ignore-revs b/.git-blame-ignore-revs new file mode 100644 index 0000000000..572b385fef --- /dev/null +++ b/.git-blame-ignore-revs @@ -0,0 +1,23 @@ +# This file contains commits that should be ignored when calculating +# git blame layers. +# +# You should add it to your local configuration using: +# git config blame.ignoreRevsFile .git-blame-ignore-revs + +# style(3p/nix): Reformat project in Google C++ style +0f2cf531f705d370321843e5ba9135b2ebdb5d19 + +# style(3p/nix): Reformat all includes to match new style +c758de9d22506eb279c5abe61f621e5c8f61af95 + +# style(3p/nix): Reformat all includes to match new style +c758de9d22506eb279c5abe61f621e5c8f61af95 + +# style(3p/nix): Add braces around single-line conditionals +867055133d3f487e52dd44149f76347c2c28bf10 + +# style(3p/nix): Add braces around single-line for-loops +1841d93ccbe5792a17f5b9a22e65ec898c7c2668 + +# style(3p/nix): Final act in the brace-wrapping saga +39087321811e81e26a1a47d6967df1088dcf0e95 diff --git a/.gitignore b/.gitignore index aebe7c0908..0b135e7034 100644 --- a/.gitignore +++ b/.gitignore @@ -1,241 +1,7 @@ -/fuzz-commit-graph -/fuzz_corpora -/fuzz-pack-headers -/fuzz-pack-idx -/GIT-BUILD-OPTIONS -/GIT-CFLAGS -/GIT-LDFLAGS -/GIT-PREFIX -/GIT-PERL-DEFINES -/GIT-PERL-HEADER -/GIT-PYTHON-VARS -/GIT-SCRIPT-DEFINES -/GIT-USER-AGENT -/GIT-VERSION-FILE -/bin-wrappers/ -/git -/git-add -/git-add--interactive -/git-am -/git-annotate -/git-apply -/git-archimport -/git-archive -/git-bisect -/git-bisect--helper -/git-blame -/git-branch -/git-bundle -/git-cat-file -/git-check-attr -/git-check-ignore -/git-check-mailmap -/git-check-ref-format -/git-checkout -/git-checkout-index -/git-cherry -/git-cherry-pick -/git-clean -/git-clone -/git-column -/git-commit -/git-commit-graph -/git-commit-tree -/git-config -/git-count-objects -/git-credential -/git-credential-cache -/git-credential-cache--daemon -/git-credential-store -/git-cvsexportcommit -/git-cvsimport -/git-cvsserver -/git-daemon -/git-diff -/git-diff-files -/git-diff-index -/git-diff-tree -/git-difftool -/git-difftool--helper -/git-describe -/git-env--helper -/git-fast-export -/git-fast-import -/git-fetch -/git-fetch-pack -/git-filter-branch -/git-fmt-merge-msg -/git-for-each-ref -/git-format-patch -/git-fsck -/git-fsck-objects -/git-gc -/git-get-tar-commit-id -/git-grep -/git-hash-object -/git-help -/git-http-backend -/git-http-fetch -/git-http-push -/git-imap-send -/git-index-pack -/git-init -/git-init-db -/git-interpret-trailers -/git-instaweb -/git-legacy-stash -/git-log -/git-ls-files -/git-ls-remote -/git-ls-tree -/git-mailinfo -/git-mailsplit -/git-merge -/git-merge-base -/git-merge-index -/git-merge-file -/git-merge-tree -/git-merge-octopus -/git-merge-one-file -/git-merge-ours -/git-merge-recursive -/git-merge-resolve -/git-merge-subtree -/git-mergetool -/git-mergetool--lib -/git-mktag -/git-mktree -/git-multi-pack-index -/git-mv -/git-name-rev -/git-notes -/git-p4 -/git-pack-redundant -/git-pack-objects -/git-pack-refs -/git-parse-remote -/git-patch-id -/git-prune -/git-prune-packed -/git-pull -/git-push -/git-quiltimport -/git-range-diff -/git-read-tree -/git-rebase -/git-rebase--preserve-merges -/git-receive-pack -/git-reflog -/git-remote -/git-remote-http -/git-remote-https -/git-remote-ftp -/git-remote-ftps -/git-remote-fd -/git-remote-ext -/git-remote-testpy -/git-remote-testsvn -/git-repack -/git-replace -/git-request-pull -/git-rerere -/git-reset -/git-restore -/git-rev-list -/git-rev-parse -/git-revert -/git-rm -/git-send-email -/git-send-pack -/git-serve -/git-sh-i18n -/git-sh-i18n--envsubst -/git-sh-setup -/git-sh-i18n -/git-shell -/git-shortlog -/git-show -/git-show-branch -/git-show-index -/git-show-ref -/git-sparse-checkout -/git-stage -/git-stash -/git-status -/git-stripspace -/git-submodule -/git-submodule--helper -/git-svn -/git-switch -/git-symbolic-ref -/git-tag -/git-unpack-file -/git-unpack-objects -/git-update-index -/git-update-ref -/git-update-server-info -/git-upload-archive -/git-upload-pack -/git-var -/git-verify-commit -/git-verify-pack -/git-verify-tag -/git-web--browse -/git-whatchanged -/git-worktree -/git-write-tree -/git-core-*/?* -/gitweb/GITWEB-BUILD-OPTIONS -/gitweb/gitweb.cgi -/gitweb/static/gitweb.js -/gitweb/static/gitweb.min.* -/command-list.h -*.tar.gz -*.dsc -*.deb -/git.spec -*.exe -*.[aos] -*.py[co] -.depend/ -*.gcda -*.gcno -*.gcov -/coverage-untested-functions -/cover_db/ -/cover_db_html/ -*+ -/config.mak -/autom4te.cache -/config.cache -/config.log -/config.status -/config.mak.autogen -/config.mak.append -/configure -/.vscode/ -/tags -/TAGS -/cscope* -*.hcc -*.obj -*.lib -*.res -*.sln -*.suo -*.ncb -*.vcproj -*.user -*.idb -*.pdb -*.ilk -*.iobj -*.ipdb -*.dll -.vs/ -Debug/ -Release/ -/UpgradeLog*.htm -/git.VC.VC.opendb -/git.VC.db -*.dSYM +# Ignore the garbage folder, in which I slowly assemble a bunch of +# trash locally that might be valuable in the future. +garbage/ + +# Ignore Nix result symlinks +result +result-* diff --git a/.gitmodules b/.gitmodules deleted file mode 100644 index cbeebdab7a..0000000000 --- a/.gitmodules +++ /dev/null @@ -1,4 +0,0 @@ -[submodule "sha1collisiondetection"] - path = sha1collisiondetection - url = https://github.com/cr-marcstevens/sha1collisiondetection.git - branch = master diff --git a/.rgignore b/.rgignore new file mode 100644 index 0000000000..6c19dfbda4 --- /dev/null +++ b/.rgignore @@ -0,0 +1 @@ +third_party/git diff --git a/LICENSE b/LICENSE new file mode 100644 index 0000000000..904a76ed04 --- /dev/null +++ b/LICENSE @@ -0,0 +1,21 @@ +The MIT License (MIT) + +Copyright (c) 2019 Vincent Ambo + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/README.md b/README.md index 9d4564c8aa..82daa7a746 100644 --- a/README.md +++ b/README.md @@ -1,66 +1,85 @@ -[](https://dev.azure.com/git/git/_build/latest?definitionId=11) - -Git - fast, scalable, distributed revision control system -========================================================= - -Git is a fast, scalable, distributed revision control system with an -unusually rich command set that provides both high-level operations -and full access to internals. - -Git is an Open Source project covered by the GNU General Public -License version 2 (some parts of it are under different licenses, -compatible with the GPLv2). It was originally written by Linus -Torvalds with help of a group of hackers around the net. - -Please read the file [INSTALL][] for installation instructions. - -Many Git online resources are accessible from <https://git-scm.com/> -including full documentation and Git related tools. - -See [Documentation/gittutorial.txt][] to get started, then see -[Documentation/giteveryday.txt][] for a useful minimum set of commands, and -`Documentation/git-<commandname>.txt` for documentation of each command. -If git has been correctly installed, then the tutorial can also be -read with `man gittutorial` or `git help tutorial`, and the -documentation of each command with `man git-<commandname>` or `git help -<commandname>`. - -CVS users may also want to read [Documentation/gitcvs-migration.txt][] -(`man gitcvs-migration` or `git help cvs-migration` if git is -installed). - -The user discussion and development of Git take place on the Git -mailing list -- everyone is welcome to post bug reports, feature -requests, comments and patches to git@vger.kernel.org (read -[Documentation/SubmittingPatches][] for instructions on patch submission). -To subscribe to the list, send an email with just "subscribe git" in -the body to majordomo@vger.kernel.org. The mailing list archives are -available at <https://lore.kernel.org/git/>, -<http://marc.info/?l=git> and other archival sites. - -Issues which are security relevant should be disclosed privately to -the Git Security mailing list <git-security@googlegroups.com>. - -The maintainer frequently sends the "What's cooking" reports that -list the current status of various development topics to the mailing -list. The discussion following them give a good reference for -project status, development direction and remaining tasks. - -The name "git" was given by Linus Torvalds when he wrote the very -first version. He described the tool as "the stupid content tracker" -and the name as (depending on your mood): - - - random three-letter combination that is pronounceable, and not - actually used by any common UNIX command. The fact that it is a - mispronunciation of "get" may or may not be relevant. - - stupid. contemptible and despicable. simple. Take your pick from the - dictionary of slang. - - "global information tracker": you're in a good mood, and it actually - works for you. Angels sing, and a light suddenly fills the room. - - "goddamn idiotic truckload of sh*t": when it breaks - -[INSTALL]: INSTALL -[Documentation/gittutorial.txt]: Documentation/gittutorial.txt -[Documentation/giteveryday.txt]: Documentation/giteveryday.txt -[Documentation/gitcvs-migration.txt]: Documentation/gitcvs-migration.txt -[Documentation/SubmittingPatches]: Documentation/SubmittingPatches +depot +===== + +[](https://builds.sr.ht/~tazjin/depot/master?) + +This repository is the [monorepo][] for my personal tools and infrastructure. +Everything in here is built using [Nix][] with an automatic attribute-set layout +that mirrors the filesystem layout of the repository (this might feel familiar +to users of Bazel). + +This repository used to be hosted on GitHub, but for a variety of reasons I have +decided to take over the management of personal infrastructure - of which this +repository is a core component. + +If you've ended up here and have no idea who I am, feel free to follow me [on +Twitter][]. + +# Highlights + +## Tools + +* `tools/emacs` contains my personal Emacs configuration (packages & config) +* `fun/aoc2019` contains solutions for a handful of Advent of Code 2019 + challenges, before I ran out of interest +* `tools/blog_cli` contains my tool for writing new blog posts and storing them + in the DNS zone +* `tools/cheddar` contains a source code and Markdown rendering tool + that is integrated with my cgit instance to render files in various + views +* `ops/kms_pass.nix` is a tiny tool that emulates the user-interface of `pass`, + but actually uses Google Cloud KMS for secret decryption +* `ops/kontemplate` contains my Kubernetes resource templating tool (with which + the services in this repository are deployed!) +* `ops/besadii` contains a tool that runs as the git + `post-receive`-hook on my git server to trigger builds on sourcehut. + +## Packages / Libraries + +* `nix/buildGo` implements a Nix library that can build Go software in the style + of Bazel's `rules_go`. Go programs in this repository are built using this + library. +* `nix/buildLisp` implements a Nix library that can build Common Lisp + software. Currently only SBCL is supported. Lisp programs in this + repository are built using this library. +* `tools/emacs-pkgs` contains various Emacs libraries that my Emacs setup uses, + for example: + * `dottime.el` provides [dottime][] in the Emacs modeline + * `nix-util.el` provides editing utilities for Nix files + * `term-switcher.el` is an ivy-function for switching between vterm buffers +* `net/alcoholic_jwt` contains an easy-to-use JWT-validation library for Rust +* `net/crimp` contains a high-level HTTP client using cURL for Rust + +## Services + +Services in this repository are deployed on a Google Kubernetes Engine cluster +using [Nixery](). + +* `web/blog` and `web/homepage` contain my blog and website setup + (serving at [tazj.in][]) +* `web/cgit-taz` contains a slightly patched version of `cgit` that serves my + git web interface at [git.tazj.in][] +* `ops/journaldriver` contains a small Rust daemon that can forward logs from + journald to Stackdriver Logging + +## Miscellaneous + +Presentations I've given in the past are in the `presentations` folder, these +cover a variety of topics and some of them have links to recordings. + +There's a few fun things in the `fun/` folder, often with context given in the +README. Check out my [list of the best tools][best-tools] for example. + +# Contributing + +If you'd like to contribute to any of the tools in here, please check out the +[contribution guidelines](/tree/docs/CONTRIBUTING.md). + +[monorepo]: https://en.wikipedia.org/wiki/Monorepo +[Nix]: https://nixos.org/nix +[on Twitter]: https://twitter.com/tazjin +[Nixery]: https://github.com/google/nixery +[tazj.in]: https://tazj.in +[git.tazj.in]: https://git.tazj.in +[best-tools]: /about/fun/best-tools/README.md +[dottime]: https://dotti.me diff --git a/bin/__dispatch.sh b/bin/__dispatch.sh new file mode 100755 index 0000000000..7a18b8b834 --- /dev/null +++ b/bin/__dispatch.sh @@ -0,0 +1,56 @@ +#!/usr/bin/env bash +# This script dispatches invocations transparently to programs instantiated from +# Nix. +# +# To add a new tool, insert it into the case statement below by setting `attr` +# to the key in nixpkgs which represents the program you want to run. +set -ueo pipefail + +readonly REPO_ROOT=$(dirname $0)/.. +TARGET_TOOL=$(basename $0) + +case "${TARGET_TOOL}" in + terraform) + attr="third_party.terraform-gcp" + ;; + kontemplate) + attr="kontemplate" + ;; + stern) + attr="third_party.stern" + ;; + kms_pass) + attr="ops.kms_pass" + TARGET_TOOL="pass" + ;; + aoc2019) + attr="fun.aoc2019.${1}" + ;; + rink) + attr="third_party.rink" + ;; + age) + attr="third_party.age" + ;; + age-keygen) + attr="third_party.age" + ;; + rebuilder) + attr="ops.nixos.rebuilder" + ;; + meson) + attr="third_party.meson" + ;; + ninja) + attr="third_party.ninja" + ;; + *) + echo "The tool '${TARGET_TOOL}' is currently not installed in this repository." + exit 1 + ;; +esac + +result=$(nix-build --no-out-link --attr "${attr}" "${REPO_ROOT}") +PATH="${result}/bin:$PATH" + +exec "${TARGET_TOOL}" "${@}" diff --git a/bin/age b/bin/age new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/age @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/age-keygen b/bin/age-keygen new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/age-keygen @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/aoc2019 b/bin/aoc2019 new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/aoc2019 @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/kms_pass b/bin/kms_pass new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/kms_pass @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/kontemplate b/bin/kontemplate new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/kontemplate @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/meson b/bin/meson new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/meson @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/ninja b/bin/ninja new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/ninja @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/rebuilder b/bin/rebuilder new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/rebuilder @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/rink b/bin/rink new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/rink @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/stern b/bin/stern new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/stern @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/bin/terraform b/bin/terraform new file mode 120000 index 0000000000..8390ec9c96 --- /dev/null +++ b/bin/terraform @@ -0,0 +1 @@ +__dispatch.sh \ No newline at end of file diff --git a/ci-builds.nix b/ci-builds.nix new file mode 100644 index 0000000000..cbed7b87d1 --- /dev/null +++ b/ci-builds.nix @@ -0,0 +1,37 @@ +# This file defines the derivations that should be built by CI. +# +# The plan is still to implement recursive tree traversal +# automatically and detect all derivations that have `meta.enableCI = +# true`, but this is currently more effort than it would save me. + +with (import ./default.nix {}); [ + fun.amsterdump + fun.gemma + fun.quinistry + fun.watchblob + fun.wcl + lisp.dns + nix.buildLisp.example + nix.yants.tests + ops."posix_mq.rs" + ops.besadii + ops.journaldriver + ops.kms_pass + ops.kontemplate + ops.mq_cli + ops.nixos.camdenSystem + third_party.cgit + third_party.git + third_party.lisp # will build all third-party libraries + third_party.nix + tools.cheddar + tools.emacs + web.blog + web.cgit-taz + web.tvl + + # Nugget is not currently built because it depends on various things + # (such as chromium-vaapi) that don't work in CI. + # + # ops.nixos.nuggetSystem +] diff --git a/default.nix b/default.nix new file mode 100644 index 0000000000..cf70c704a9 --- /dev/null +++ b/default.nix @@ -0,0 +1,66 @@ +# This file sets up the top-level package set by traversing the package tree +# (see read-tree.nix for details) and constructing a matching attribute set +# tree. +# +# This makes packages accessible via the Nixery instance that is configured to +# use this repository as its nixpkgs source. + +{ ... }@args: + +with builtins; + +let + # This definition of fix is identical to <nixpkgs>.lib.fix, but the global + # package set is not available here. + fix = f: let x = f x; in x; + + # Global configuration that all packages are called with. + config = depot: { + inherit depot; + + # Pass third_party as 'pkgs' (for compatibility with external + # imports for certain subdirectories) + pkgs = depot.third_party; + + kms = { + project = "tazjins-infrastructure"; + region = "europe-north1"; + keyring = "tazjins-keys"; + key = "kontemplate-key"; + }; + }; + + readTree' = import ./nix/readTree {}; + + localPkgs = readTree: { + fun = readTree ./fun; + nix = readTree ./nix; + ops = readTree ./ops; + lisp = readTree ./lisp; + presentations = readTree ./presentations; + third_party = readTree ./third_party; + tools = readTree ./tools; + web = readTree ./web; + }; +in fix(self: { + config = config self; + + # Elevate 'lib' from nixpkgs + lib = import (self.third_party.nixpkgsSrc + "/lib"); + + # Expose readTree for downstream repo consumers. + readTree = { + __functor = x: (readTree' x.config); + config = self.config; + }; +} + +# Add local packages as structured by readTree +// (localPkgs (readTree' (self.config // { inherit (self) lib; }))) + +# Load overrides into the top-level. +# +# This can be used to move things from third_party into the top-level, too (such +# as `lib`). +// (readTree' { depot = self; pkgs = self.third_party; }) ./overrides +) diff --git a/docs/CODE_OF_CONDUCT.md b/docs/CODE_OF_CONDUCT.md new file mode 100644 index 0000000000..0e46bbedb0 --- /dev/null +++ b/docs/CODE_OF_CONDUCT.md @@ -0,0 +1,29 @@ +A SERMON ON ETHICS AND LOVE +=========================== + +One day Mal-2 asked the messenger spirit Saint Gulik to approach the +Goddess and request Her presence for some desperate advice. Shortly +afterwards the radio came on by itself, and an ethereal female Voice +said **YES?** + +"O! Eris! Blessed Mother of Man! Queen of Chaos! Daughter of Discord! +Concubine of Confusion! O! Exquisite Lady, I beseech You to lift a +heavy burden from my heart!" + +**WHAT BOTHERS YOU, MAL? YOU DON'T SOUND WELL.** + +"I am filled with fear and tormented with terrible visions of pain. +Everywhere people are hurting one another, the planet is rampant with +injustices, whole societies plunder groups of their own people, +mothers imprison sons, children perish while brothers war. O, woe." + +**WHAT IS THE MATTER WITH THAT, IF IT IS WHAT YOU WANT TO DO?** + +"But nobody Wants it! Everybody hates it." + +**OH. WELL, THEN *STOP*.** + +At which moment She turned herself into an aspirin commercial and left +The Polyfather stranded alone with his species. + +SINISTER DEXTER HAS A BROKEN SPIROMETER. diff --git a/docs/CONTRIBUTING.md b/docs/CONTRIBUTING.md new file mode 100644 index 0000000000..df61c7ff70 --- /dev/null +++ b/docs/CONTRIBUTING.md @@ -0,0 +1,119 @@ +Contribution Guidelines +======================= + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Contribution Guidelines](#contribution-guidelines) + - [Before making a change](#before-making-a-change) + - [Commit messages](#commit-messages) + - [Commit content](#commit-content) + - [Code quality](#code-quality) + - [Builds & tests](#builds--tests) + +<!-- markdown-toc end --> + +This is a loose set of "guidelines" for contributing to my depot. Please note +that I will not accept any patches that don't follow these guidelines. + +Also consider the [code of conduct](/tree/docs/CODE_OF_CONDUCT.md). No really, +you should. + +## Before making a change + +Before making a change, consider your motivation for making the change. +Documentation updates, bug fixes and the like are *always* welcome. + +When adding a feature you should consider whether it is only useful for your +particular use-case or whether it is generally applicable for other users of the +project. + +When in doubt - just ask! You can reach out to me via +[mail](mailto:mail@tazj.in) or on Twitter / IRC / etc. + +## Commit messages + +All commit messages should be structured like this: + +``` +type(scope): Subject line with at most a 68 character length + +Body of the commit message with an empty line between subject and +body. This text should explain what the change does and why it has +been made, *especially* if it introduces a new feature. + +Relevant issues should be mentioned if they exist. +``` + +Where `type` can be one of: + +* `feat`: A new feature has been introduced +* `fix`: An issue of some kind has been fixed +* `docs`: Documentation or comments have been updated +* `style`: Formatting changes only +* `refactor`: Hopefully self-explanatory! +* `test`: Added missing tests / fixed tests +* `chore`: Maintenance work + +And `scope` should refer to some kind of logical grouping inside of the project. + +Please take a look at the existing commit log for examples. + +## Commit content + +Multiple changes should be divided into multiple git commits whenever possible. +Common sense applies. + +The fix for a single-line whitespace issue is fine to include in a different +commit. Introducing a new feature and refactoring (unrelated) code in the same +commit is not fine. + +`git commit -a` is generally **taboo**. + +In my experience making "sane" commits becomes *significantly* easier as +developer tooling is improved. The interface to `git` that I recommend is +[magit][]. Even if you are not yet an Emacs user, it makes sense to install +Emacs just to be able to use magit - it is really that good. + +For staging sane chunks on the command line with only git, consider `git add +-p`. + +## Code quality + +This one should go without saying - but please ensure that your code quality +does not fall below the rest of the project. This is of course very subjective, +but as an example if you place code that throws away errors into a block in +which errors are handled properly your change will be rejected. + +In my experience there is a strong correlation between the visual appearance of +a code block and its quality. This is a simple way to sanity-check your work +while squinting and keeping some distance from your screen ;-) + +## Builds & tests + +My projects are built using [Nix][] to avoid "build pollution" via the user's +environment. + +If you have Nix installed and are contributing to a project tracked in this +repository, you can usually build the project by calling `nix-build -A +path.to.project`. + +For example, to build a project located at `tools/foo` you would call `nix-build +-A tools.foo` + +If the project has tests, check that they still work before submitting your +change. + +## Submitting patches + +When making a change, please create an appropriate commit locally and send it to +me using either `git send-email` or `git format-patch`. The email address to use +for depot reviews is `depot@tazj.in`, which is a [public group][]. + +I recognise that most people are used to a GitHub-style workflow. If you run +into issues with the above but would still like to contribute, feel free to +reach out to me. + +[magit]: https://magit.vc/ +[Nix]: https://nixos.org/nix/ +[public group]: https://groups.google.com/a/tazj.in/forum/?hl=en#!forum/depot diff --git a/fun/amsterdump/default.nix b/fun/amsterdump/default.nix new file mode 100644 index 0000000000..0d98c9a7ab --- /dev/null +++ b/fun/amsterdump/default.nix @@ -0,0 +1,13 @@ +{ depot, ... }: + +depot.nix.buildGo.program { + name = "amsterdump"; + srcs = [ + ./main.go + ]; + + deps = with depot.third_party; map (p: p.gopkg) [ + # gopkgs."golang.org".x.oauth2.google + gopkgs."googlemaps.github.io".maps + ]; +} diff --git a/fun/amsterdump/listings-20200105.json b/fun/amsterdump/listings-20200105.json new file mode 100644 index 0000000000..251598312a --- /dev/null +++ b/fun/amsterdump/listings-20200105.json @@ -0,0 +1,2326 @@ +[ + { + "address": "Sumatrakade 577, 1019 PS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87026792-sumatrakade-577/?navigateSource=toppositie", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.5 km", + "value": 20475 + }, + "duration": { + "value": 2467, + "text": "41m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.2 km", + "value": 3187 + }, + "duration": { + "value": 727, + "text": "12m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Spuistraat 253, 1012 VR Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-86705763-spuistraat-253-hs/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.2 km", + "value": 14151 + }, + "duration": { + "value": 1901, + "text": "31m41s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.5 km", + "value": 1459 + }, + "duration": { + "value": 522, + "text": "8m42s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Melis Stokehof 84, 1064 JE Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87036254-melis-stokehof-84/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "16.1 km", + "value": 16086 + }, + "duration": { + "value": 2166, + "text": "36m6s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "7.3 km", + "value": 7317 + }, + "duration": { + "value": 1772, + "text": "29m32s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Churchill-laan 91D, 1078 DK Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41533400-churchill-laan-91-d/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.6 km", + "value": 11590 + }, + "duration": { + "value": 1921, + "text": "32m1s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.7 km", + "value": 5749 + }, + "duration": { + "value": 1609, + "text": "26m49s" + }, + "duration_in_traffic": null + } + }, + { + "address": "De Boelelaan 745, 1082 RS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41687804-de-boelelaan-745/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "9.5 km", + "value": 9466 + }, + "duration": { + "value": 907, + "text": "15m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.7 km", + "value": 6659 + }, + "duration": { + "value": 1147, + "text": "19m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Leeuwendalersweg 15G, 1055 JE Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41679332-leeuwendalersweg-15-g/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.4 km", + "value": 11359 + }, + "duration": { + "value": 1596, + "text": "26m36s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.5 km", + "value": 6526 + }, + "duration": { + "value": 1364, + "text": "22m44s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Singel 449, 1012 XG Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87899154-singel-449-1/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.2 km", + "value": 14169 + }, + "duration": { + "value": 1911, + "text": "31m51s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.9 km", + "value": 1945 + }, + "duration": { + "value": 568, + "text": "9m28s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Jan van Zutphenstraat 211, 1069 RR Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41671501-jan-van-zutphenstraat-211/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "10.2 km", + "value": 10160 + }, + "duration": { + "value": 1647, + "text": "27m27s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "9.1 km", + "value": 9145 + }, + "duration": { + "value": 2311, + "text": "38m31s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Parnassusweg 977, Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41670908-parnassusweg-977/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "9.6 km", + "value": 9578 + }, + "duration": { + "value": 996, + "text": "16m36s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.8 km", + "value": 6780 + }, + "duration": { + "value": 1236, + "text": "20m36s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Esplanade de Meer 179, 1098 WJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87995311-esplanade-de-meer-179/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.4 km", + "value": 17441 + }, + "duration": { + "value": 2107, + "text": "35m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "7.0 km", + "value": 6989 + }, + "duration": { + "value": 1600, + "text": "26m40s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Hoofdweg 538, 1055 AB Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41521204-hoofdweg-538/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.1 km", + "value": 14073 + }, + "duration": { + "value": 1892, + "text": "31m32s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.5 km", + "value": 6468 + }, + "duration": { + "value": 1320, + "text": "22m0s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Hoofdweg 538, 1055 AB Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41521204-hoofdweg-538/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.1 km", + "value": 14073 + }, + "duration": { + "value": 1892, + "text": "31m32s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.5 km", + "value": 6468 + }, + "duration": { + "value": 1320, + "text": "22m0s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Hoofdweg 538, 1055 AB Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41521204-hoofdweg-538/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.1 km", + "value": 14073 + }, + "duration": { + "value": 1892, + "text": "31m32s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.5 km", + "value": 6468 + }, + "duration": { + "value": 1320, + "text": "22m0s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Annie Romeinplein 18, 1103 JL Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87985710-annie-romeinplein-18/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.4 km", + "value": 17402 + }, + "duration": { + "value": 1869, + "text": "31m9s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "10.1 km", + "value": 10129 + }, + "duration": { + "value": 1308, + "text": "21m48s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Vechtstraat 185, 1079 JJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41512041-vechtstraat-185-ii/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.9 km", + "value": 11877 + }, + "duration": { + "value": 1876, + "text": "31m16s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "7.0 km", + "value": 6992 + }, + "duration": { + "value": 2142, + "text": "35m42s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Westerdok 240, 1013 BH Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41553306-westerdok-240/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "18.3 km", + "value": 18332 + }, + "duration": { + "value": 1816, + "text": "30m16s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.7 km", + "value": 1748 + }, + "duration": { + "value": 715, + "text": "11m55s" + }, + "duration_in_traffic": null + } + }, + { + "address": "IJburglaan 701, 1087 BS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87898167-ijburglaan-701/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "24.5 km", + "value": 24471 + }, + "duration": { + "value": 2556, + "text": "42m36s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "7.1 km", + "value": 7097 + }, + "duration": { + "value": 935, + "text": "15m35s" + }, + "duration_in_traffic": null + } + }, + { + "address": "IJdoornlaan 1497, 1034 Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87041092-ijdoornlaan-1497-a/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.5 km", + "value": 19524 + }, + "duration": { + "value": 2620, + "text": "43m40s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.7 km", + "value": 4704 + }, + "duration": { + "value": 1139, + "text": "18m59s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 577, 1019 PS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87026792-sumatrakade-577/?navigateSource=toppositie", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.5 km", + "value": 20475 + }, + "duration": { + "value": 2467, + "text": "41m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.2 km", + "value": 3187 + }, + "duration": { + "value": 727, + "text": "12m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "George Sliekerkade 18, 1087 KK Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87030790-george-sliekerkade-18/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "24.8 km", + "value": 24761 + }, + "duration": { + "value": 2843, + "text": "47m23s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "8.0 km", + "value": 7958 + }, + "duration": { + "value": 1183, + "text": "19m43s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 265, 1019 PK Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41662773-sumatrakade-265/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.6 km", + "value": 20638 + }, + "duration": { + "value": 2587, + "text": "43m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.4 km", + "value": 3350 + }, + "duration": { + "value": 847, + "text": "14m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Koggestraat 5, 1012 TA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41531104-koggestraat-5-2/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.9 km", + "value": 17938 + }, + "duration": { + "value": 1748, + "text": "29m8s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.0 km", + "value": 981 + }, + "duration": { + "value": 393, + "text": "6m33s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Warmoesstraat 139B, 1012 JB Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41524099-warmoesstraat-139-b/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "18.1 km", + "value": 18072 + }, + "duration": { + "value": 1835, + "text": "30m35s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.0 km", + "value": 964 + }, + "duration": { + "value": 315, + "text": "5m15s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Parnassusweg 35, 1077 Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41579167-parnassusweg-35-i/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "10.0 km", + "value": 9986 + }, + "duration": { + "value": 1329, + "text": "22m9s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.8 km", + "value": 5754 + }, + "duration": { + "value": 1568, + "text": "26m8s" + }, + "duration_in_traffic": null + } + }, + { + "address": "De Boelelaan 389, 1082 RH Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87890510-de-boelelaan-389/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "9.6 km", + "value": 9650 + }, + "duration": { + "value": 1048, + "text": "17m28s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.9 km", + "value": 6852 + }, + "duration": { + "value": 1288, + "text": "21m28s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Theo Frenkelhof 96, 1087 JA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87995272-theo-frenkelhof-96/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "24.9 km", + "value": 24874 + }, + "duration": { + "value": 2928, + "text": "48m48s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "8.1 km", + "value": 8101 + }, + "duration": { + "value": 1268, + "text": "21m8s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Veembroederhof 207, 1019 HD Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41539826-veembroederhof-207/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.7 km", + "value": 19731 + }, + "duration": { + "value": 2402, + "text": "40m2s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.8 km", + "value": 1845 + }, + "duration": { + "value": 501, + "text": "8m21s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Nieuwe Passeerdersstraat 174, 1016 XP Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41537370-nieuwe-passeerdersstraat-174/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "12.3 km", + "value": 12345 + }, + "duration": { + "value": 1885, + "text": "31m25s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.9 km", + "value": 2937 + }, + "duration": { + "value": 978, + "text": "16m18s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Jan van Galenstraat 1K, 1051 KE Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41513735-jan-van-galenstraat-1-k/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.0 km", + "value": 14042 + }, + "duration": { + "value": 2071, + "text": "34m31s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.1 km", + "value": 4104 + }, + "duration": { + "value": 859, + "text": "14m19s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Joan Melchior Kemperstraat 128, 1051 TX Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87924023-joan-melchior-kemperstraat-128-3/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "15.6 km", + "value": 15558 + }, + "duration": { + "value": 2675, + "text": "44m35s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.2 km", + "value": 4220 + }, + "duration": { + "value": 1015, + "text": "16m55s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Javakade 560, 1019 SE Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41438193-javakade-560/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.2 km", + "value": 20218 + }, + "duration": { + "value": 2508, + "text": "41m48s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.1 km", + "value": 2114 + }, + "duration": { + "value": 718, + "text": "11m58s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Saxen Weimarlaan 32, 1075 BZ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41427768-saxen-weimarlaan-32-ii/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "13.7 km", + "value": 13707 + }, + "duration": { + "value": 1836, + "text": "30m36s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.5 km", + "value": 5516 + }, + "duration": { + "value": 1557, + "text": "25m57s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Zeedijk 125C, 1012 AW Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87892979-zeedijk-125-c/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "18.1 km", + "value": 18074 + }, + "duration": { + "value": 1845, + "text": "30m45s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.0 km", + "value": 1031 + }, + "duration": { + "value": 269, + "text": "4m29s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 577, 1019 PS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87026792-sumatrakade-577/?navigateSource=toppositie", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.5 km", + "value": 20475 + }, + "duration": { + "value": 2467, + "text": "41m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.2 km", + "value": 3187 + }, + "duration": { + "value": 727, + "text": "12m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Revaleiland 89, 1013 AX Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41685704-revaleiland-89/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.0 km", + "value": 20043 + }, + "duration": { + "value": 2208, + "text": "36m48s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.2 km", + "value": 3244 + }, + "duration": { + "value": 941, + "text": "15m41s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Rozengracht 42A, 1016 ND Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41685113-rozengracht-42-a/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "13.2 km", + "value": 13195 + }, + "duration": { + "value": 1977, + "text": "32m57s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.8 km", + "value": 1826 + }, + "duration": { + "value": 621, + "text": "10m21s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Rembrandtplein 7, 1017 CV Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87903367-rembrandtplein-7-1/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.3 km", + "value": 14276 + }, + "duration": { + "value": 1998, + "text": "33m18s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.0 km", + "value": 2033 + }, + "duration": { + "value": 574, + "text": "9m34s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Leenhofstraat 69, 1067 LA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41576354-leenhofstraat-69-4/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.1 km", + "value": 14143 + }, + "duration": { + "value": 2126, + "text": "35m26s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "10.4 km", + "value": 10374 + }, + "duration": { + "value": 1974, + "text": "32m54s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Bolestein 300, 1081 ED Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41575228-bolestein-300/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "12.1 km", + "value": 12120 + }, + "duration": { + "value": 1939, + "text": "32m19s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "12.2 km", + "value": 12165 + }, + "duration": { + "value": 1692, + "text": "28m12s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Westerdoksdijk 263b, 1013 AD Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41562746-westerdoksdijk-263-b-pp/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "18.2 km", + "value": 18157 + }, + "duration": { + "value": 1687, + "text": "28m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.4 km", + "value": 1358 + }, + "duration": { + "value": 420, + "text": "7m0s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Brederodestraat 89, 1054 VC Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87916974-brederodestraat-89-hs/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "10.4 km", + "value": 10450 + }, + "duration": { + "value": 1677, + "text": "27m57s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.4 km", + "value": 4382 + }, + "duration": { + "value": 1384, + "text": "23m4s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Kon. Wilhelminaplein 222, 1062 KT Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41427806-koningin-wilhelminaplein-222/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "9.1 km", + "value": 9070 + }, + "duration": { + "value": 987, + "text": "16m27s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "14.1 km", + "value": 14135 + }, + "duration": { + "value": 1734, + "text": "28m54s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Tweede Hugo de Grootstraat 45, 1052 LE Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-40342170-tweede-hugo-de-grootstraat-45-c/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.8 km", + "value": 20802 + }, + "duration": { + "value": 2309, + "text": "38m29s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.8 km", + "value": 3825 + }, + "duration": { + "value": 826, + "text": "13m46s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Eerste Constantijn Huygensstraat 102, 1054 BZ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41687869-eerste-constantijn-huygensstraat-102-3/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.2 km", + "value": 11214 + }, + "duration": { + "value": 1758, + "text": "29m18s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.0 km", + "value": 3035 + }, + "duration": { + "value": 1210, + "text": "20m10s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Gustav Mahlerlaan 483, 1082 LS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41685852-gustav-mahlerlaan-483/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "9.3 km", + "value": 9292 + }, + "duration": { + "value": 776, + "text": "12m56s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.5 km", + "value": 6485 + }, + "duration": { + "value": 1016, + "text": "16m56s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Gustav Mahlerlaan 439, 1082 LS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41685850-gustav-mahlerlaan-439/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "9.3 km", + "value": 9255 + }, + "duration": { + "value": 748, + "text": "12m28s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "6.4 km", + "value": 6448 + }, + "duration": { + "value": 988, + "text": "16m28s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Kruitberghof 94, 1104 CA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87033407-kruitberghof-94/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.2 km", + "value": 19210 + }, + "duration": { + "value": 2214, + "text": "36m54s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "10.9 km", + "value": 10911 + }, + "duration": { + "value": 1273, + "text": "21m13s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Kerkstraat 322, 1017 HC Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87900649-kerkstraat-322-c/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "13.3 km", + "value": 13310 + }, + "duration": { + "value": 1928, + "text": "32m8s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.4 km", + "value": 2441 + }, + "duration": { + "value": 884, + "text": "14m44s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Boerhaaveplein 12, 1091 AS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87928778-boerhaaveplein-12-1/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.7 km", + "value": 19690 + }, + "duration": { + "value": 2090, + "text": "34m50s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.7 km", + "value": 2710 + }, + "duration": { + "value": 652, + "text": "10m52s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 577, 1019 PS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87026792-sumatrakade-577/?navigateSource=toppositie", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.5 km", + "value": 20475 + }, + "duration": { + "value": 2467, + "text": "41m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.2 km", + "value": 3187 + }, + "duration": { + "value": 727, + "text": "12m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Boylestraat 12I, 1098 PC Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87924456-boylestraat-12-i/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.1 km", + "value": 21067 + }, + "duration": { + "value": 2701, + "text": "45m1s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.4 km", + "value": 5436 + }, + "duration": { + "value": 1594, + "text": "26m34s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Kanaalstraat 88C, 1054 XL Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41557413-kanaalstraat-88-c/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.3 km", + "value": 11336 + }, + "duration": { + "value": 1664, + "text": "27m44s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.1 km", + "value": 4135 + }, + "duration": { + "value": 1201, + "text": "20m1s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Borneokade 285, 1019 XG Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huis-40216702-borneokade-285/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "22.9 km", + "value": 22862 + }, + "duration": { + "value": 2931, + "text": "48m51s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.6 km", + "value": 5573 + }, + "duration": { + "value": 1191, + "text": "19m51s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Spadinalaan, 1031 Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41426177-spadinalaan-240/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.1 km", + "value": 19133 + }, + "duration": { + "value": 2325, + "text": "38m45s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.4 km", + "value": 1372 + }, + "duration": { + "value": 1000, + "text": "16m40s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Pontsteiger 295, 1013 AH Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41532923-pontsteiger-295/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.6 km", + "value": 19557 + }, + "duration": { + "value": 2137, + "text": "35m37s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.8 km", + "value": 2758 + }, + "duration": { + "value": 870, + "text": "14m30s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Wielingenstraat 30, 1078 KL Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41660066-wielingenstraat-30-g/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.3 km", + "value": 11329 + }, + "duration": { + "value": 1469, + "text": "24m29s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.9 km", + "value": 4865 + }, + "duration": { + "value": 908, + "text": "15m8s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Karspeldreef 1443, 1104 SE Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87901941-karspeldreef-1443/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.1 km", + "value": 19138 + }, + "duration": { + "value": 2162, + "text": "36m2s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "10.8 km", + "value": 10839 + }, + "duration": { + "value": 1221, + "text": "20m21s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Joan Muyskenweg 4, 1096 CJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41412597-joan-muyskenweg-4-h4/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.1 km", + "value": 17067 + }, + "duration": { + "value": 2267, + "text": "37m47s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.8 km", + "value": 5777 + }, + "duration": { + "value": 1332, + "text": "22m12s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Wibautstraat 70, 1091 GN Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41686330-wibautstraat-70-y/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "15.5 km", + "value": 15460 + }, + "duration": { + "value": 1524, + "text": "25m24s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.1 km", + "value": 3108 + }, + "duration": { + "value": 415, + "text": "6m55s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Balistraat 16D, 1094 JL Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-41675497-balistraat-16-d/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.0 km", + "value": 21009 + }, + "duration": { + "value": 2349, + "text": "39m9s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.2 km", + "value": 4210 + }, + "duration": { + "value": 860, + "text": "14m20s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Wamelplein 32, 1106 DP Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87035710-wamelplein-32/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.4 km", + "value": 19383 + }, + "duration": { + "value": 1694, + "text": "28m14s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "12.7 km", + "value": 12699 + }, + "duration": { + "value": 1585, + "text": "26m25s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Osdorperweg 664, 1067 SZ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huis-87858446-osdorperweg-664/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "13.7 km", + "value": 13735 + }, + "duration": { + "value": 2914, + "text": "48m34s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "12.5 km", + "value": 12469 + }, + "duration": { + "value": 3245, + "text": "54m5s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Utrechtsestraat 106, 1017 VS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87031649-utrechtsestraat-106-2/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "13.3 km", + "value": 13300 + }, + "duration": { + "value": 2112, + "text": "35m12s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.9 km", + "value": 2944 + }, + "duration": { + "value": 811, + "text": "13m31s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Vossiusstraat 17, 1054 ES Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87026796-vossiusstraat-17-1/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "16.2 km", + "value": 16171 + }, + "duration": { + "value": 2115, + "text": "35m15s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.3 km", + "value": 3285 + }, + "duration": { + "value": 1087, + "text": "18m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 577, 1019 PS Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87026792-sumatrakade-577/?navigateSource=toppositie", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.5 km", + "value": 20475 + }, + "duration": { + "value": 2467, + "text": "41m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.2 km", + "value": 3187 + }, + "duration": { + "value": 727, + "text": "12m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Singel 449A, 1012 WP Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-86774627-singel-449-a/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "14.2 km", + "value": 14172 + }, + "duration": { + "value": 1914, + "text": "31m54s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.9 km", + "value": 1948 + }, + "duration": { + "value": 571, + "text": "9m31s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Gordijnensteeg 1, 1012 BT Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87925802-gordijnensteeg-1/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.6 km", + "value": 21578 + }, + "duration": { + "value": 2076, + "text": "34m36s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.0 km", + "value": 1046 + }, + "duration": { + "value": 285, + "text": "4m45s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Reguliersdwarsstraat 125, 1017 BL Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-87804538-reguliersdwarsstraat-125-2/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.3 km", + "value": 21342 + }, + "duration": { + "value": 2235, + "text": "37m15s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.2 km", + "value": 2168 + }, + "duration": { + "value": 651, + "text": "10m51s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Saxen Weimarlaan 32, 1075 BZ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/appartement-86783378-saxen-weimarlaan-32-2/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "13.7 km", + "value": 13707 + }, + "duration": { + "value": 1836, + "text": "30m36s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.5 km", + "value": 5516 + }, + "duration": { + "value": 1557, + "text": "25m57s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Joan Muyskenweg 4, 1096 CJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40896531-joan-muyskenweg-4a-t-m-4h/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.1 km", + "value": 17067 + }, + "duration": { + "value": 2267, + "text": "37m47s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.8 km", + "value": 5777 + }, + "duration": { + "value": 1332, + "text": "22m12s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Volkerakstraat & Krammerstraat, 1078 AV Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40405375-wielingenstraat-volkerakstraat-krammerstraat-eendrachtstraat/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "11.4 km", + "value": 11405 + }, + "duration": { + "value": 1518, + "text": "25m18s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.9 km", + "value": 4941 + }, + "duration": { + "value": 957, + "text": "15m57s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Pontsteiger, 1013 AH Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40133931-pontsteiger/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "19.4 km", + "value": 19399 + }, + "duration": { + "value": 2020, + "text": "33m40s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.6 km", + "value": 2600 + }, + "duration": { + "value": 753, + "text": "12m33s" + }, + "duration_in_traffic": null + } + }, + { + "address": "153 S Pearl St, Albany, NY 12202, USA", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-41409333-de-halve-maen/?navigateSource=resultlist", + "schiphol": { + "status": "ZERO_RESULTS", + "distance": { + "text": "", + "value": 0 + }, + "duration": { + "value": 0, + "text": "" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "ZERO_RESULTS", + "distance": { + "text": "", + "value": 0 + }, + "duration": { + "value": 0, + "text": "" + }, + "duration_in_traffic": null + } + }, + { + "address": "Stokerkade 2, 1019 XA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-48914398-borneokade-255-313-stuurmankade-146-264-stokerkade-2-60-patio-woningen/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "22.7 km", + "value": 22749 + }, + "duration": { + "value": 2848, + "text": "47m28s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "5.5 km", + "value": 5460 + }, + "duration": { + "value": 1108, + "text": "18m28s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Tweede Hugo de Grootstraat, Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-49624585-tweede-hugo-de-grootstraat/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.0 km", + "value": 20980 + }, + "duration": { + "value": 2473, + "text": "41m13s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "4.0 km", + "value": 4003 + }, + "duration": { + "value": 990, + "text": "16m30s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Westerdoksdijk 243, 1013 AD Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-48925492-westerdoksdijk-243-t-m-271-d/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "18.2 km", + "value": 18168 + }, + "duration": { + "value": 1694, + "text": "28m14s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "1.4 km", + "value": 1369 + }, + "duration": { + "value": 427, + "text": "7m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Javakade 440, 1019 SC Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-48914339-javakade-440-618-imogirituin-6-8/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "20.6 km", + "value": 20578 + }, + "duration": { + "value": 2544, + "text": "42m24s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.2 km", + "value": 2211 + }, + "duration": { + "value": 786, + "text": "13m6s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Nieuwe Passeerdersstraat, 1016 XJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40176801-nieuwe-passeerdersstraat/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "12.4 km", + "value": 12361 + }, + "duration": { + "value": 1897, + "text": "31m37s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.9 km", + "value": 2922 + }, + "duration": { + "value": 967, + "text": "16m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Nieuwe Passeerdersstraat, 1016 XJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40176801-nieuwe-passeerdersstraat/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "12.4 km", + "value": 12361 + }, + "duration": { + "value": 1897, + "text": "31m37s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "2.9 km", + "value": 2922 + }, + "duration": { + "value": 967, + "text": "16m7s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 13, 1019 BJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-48925472-sumatrakade-13-1295/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.2 km", + "value": 21157 + }, + "duration": { + "value": 2599, + "text": "43m19s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.9 km", + "value": 3868 + }, + "duration": { + "value": 859, + "text": "14m19s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Sumatrakade 13, 1019 BJ Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-48925472-sumatrakade-13-1295/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "21.2 km", + "value": 21157 + }, + "duration": { + "value": 2599, + "text": "43m19s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "3.9 km", + "value": 3868 + }, + "duration": { + "value": 859, + "text": "14m19s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Westerdoksdijk 4, 1013 AA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40544531-westerdok-en-westerdoksdijk-4-6-106-t-m-270-en-35-t-m-49-89-t-m-101/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.9 km", + "value": 17924 + }, + "duration": { + "value": 1687, + "text": "28m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "0.9 km", + "value": 919 + }, + "duration": { + "value": 693, + "text": "11m33s" + }, + "duration_in_traffic": null + } + }, + { + "address": "Westerdoksdijk 4, 1013 AA Amsterdam, Netherlands", + "url": "https://www.funda.nl/en/huur/amsterdam/huurcomplex-40544531-westerdok-en-westerdoksdijk-4-6-106-t-m-270-en-35-t-m-49-89-t-m-101/?navigateSource=resultlist", + "schiphol": { + "status": "OK", + "distance": { + "text": "17.9 km", + "value": 17924 + }, + "duration": { + "value": 1687, + "text": "28m7s" + }, + "duration_in_traffic": null + }, + "centraal": { + "status": "OK", + "distance": { + "text": "0.9 km", + "value": 919 + }, + "duration": { + "value": 693, + "text": "11m33s" + }, + "duration_in_traffic": null + } + } +] diff --git a/fun/amsterdump/main.go b/fun/amsterdump/main.go new file mode 100644 index 0000000000..77f7392f4b --- /dev/null +++ b/fun/amsterdump/main.go @@ -0,0 +1,108 @@ +// Amsterdump is a small program that populates a BigQuery table with +// a matrix of origin points scattered around Amsterdam and each +// respective points travel time to a given destination. +// +// The two destinations used here are the Schiphol Airport and +// Amsterdam Central station. +// +// To accomplish this the Google Maps Distance Matrix API [1] is +// queried with the points. A visualisation is later done using +// BigQuery GeoViz[2]. +// +// [1]: https://developers.google.com/maps/documentation/distance-matrix/start#quotas +// [2]: https://bigquerygeoviz.appspot.com/ +package main + +import ( + "context" + "encoding/json" + "fmt" + "io/ioutil" + "log" + "os" + + "googlemaps.github.io/maps" +) + +func failOn(err error, msg string) { + if err != nil { + log.Fatalln(msg, err) + } +} + +type LocationResult struct { + Address string `json:"address"` + URL string `json:"url"` + Schiphol *maps.DistanceMatrixElement `json:"schiphol"` + Centraal *maps.DistanceMatrixElement `json:"centraal"` +} + +type Listing struct { + URL string `json:"url"` + Address string `json:"address"` +} + +func requestMatrix(ctx context.Context, client *maps.Client, listings []Listing) { + origins := make([]string, len(listings)) + for i, l := range listings { + origins[i] = l.Address + } + + request := &maps.DistanceMatrixRequest{ + Mode: maps.TravelModeTransit, + Units: maps.UnitsMetric, + Origins: origins, + + Destinations: []string{ + "Schiphol Airport", + "Amsterdam Centraal", + }, + } + + response, err := client.DistanceMatrix(ctx, request) + failOn(err, "could not retrieve distance matrix:") + + for idx, addr := range response.OriginAddresses { + result := LocationResult{ + Address: addr, + URL: listings[idx].URL, + Schiphol: response.Rows[idx].Elements[0], + Centraal: response.Rows[idx].Elements[1], + } + + j, _ := json.Marshal(result) + fmt.Println(string(j)) + } +} + +func main() { + var listings []Listing + input, err := ioutil.ReadFile("fun/amsterdump/input.json") + failOn(err, "could not read input file:") + + err = json.Unmarshal(input, &listings) + failOn(err, "could not deserialise listings:") + + ctx := context.Background() + apiKey := os.Getenv("MAPS_API_KEY") + if apiKey == "" { + log.Fatalln("API key must be supplied via MAPS_API_KEY") + } + + client, err := maps.NewClient(maps.WithAPIKey(apiKey)) + failOn(err, "could not create Google Maps API client:") + + var chunk []Listing + for _, l := range listings { + if len(chunk) == 25 { + requestMatrix(ctx, client, chunk) + chunk = []Listing{} + } else { + chunk = append(chunk, l) + } + } + + if len(chunk) > 1 { + requestMatrix(ctx, client, chunk) + } +} diff --git a/fun/amsterdump/scrape.el b/fun/amsterdump/scrape.el new file mode 100644 index 0000000000..f5537c2c8f --- /dev/null +++ b/fun/amsterdump/scrape.el @@ -0,0 +1,25 @@ +;; Scraping funda.nl (this file is just notes and snippets, not full code) +;; +;; Begin by copying whole page into buffer (out of inspect element +;; because encoding is difficult) + +(beginning-of-buffer) + +;; zap everything that isn't a relevant result +(keep-lines "data-object-url-tracking\\|img alt") + +;; mark all spans, move them to the end of the buffer +(cl-letf (((symbol-function 'read-regexp) + (lambda (&rest _) "</span>"))) + (mc/mark-all-in-region-regexp (point-min) (point-max))) + +;; mark all images lines (these contain street addresses for things +;; with images), clear up and join with previous +;; +;; mark all: data-image-error-fallback + +;; delete all lines that don't either contain a span or an img tag +;; (there are duplicates) +(keep-lines "span class\\|img alt") + +;; do some manual cleanup from the hrefs and done diff --git a/fun/aoc2019/default.nix b/fun/aoc2019/default.nix new file mode 100644 index 0000000000..5f1f248c50 --- /dev/null +++ b/fun/aoc2019/default.nix @@ -0,0 +1,22 @@ +# Solutions for Advent of Code 2019, written in Emacs Lisp. +# +# For each day a new file is created as "solution-day$n.el". +{ depot, ... }: + +let + inherit (builtins) attrNames filter head listToAttrs match readDir; + dir = readDir ./.; + matchSolution = match "solution-(.*)\.el"; + isSolution = f: (matchSolution f) != null; + getDay = f: head (matchSolution f); + + solutionFiles = filter (e: dir."${e}" == "regular" && isSolution e) (attrNames dir); + solutions = map (f: let day = getDay f; in { + name = day; + value = depot.writeElispBin { # TODO(tazjin): move writeElispBin to depot.nix + name = "aoc2019"; + deps = p: with p; [ dash s ht ]; + src = ./. + ("/" + f); + }; + }) solutionFiles; +in listToAttrs solutions diff --git a/fun/aoc2019/solution-day1.el b/fun/aoc2019/solution-day1.el new file mode 100644 index 0000000000..d805c22ec8 --- /dev/null +++ b/fun/aoc2019/solution-day1.el @@ -0,0 +1,28 @@ +;; Advent of Code 2019 - Day 1 +(require 'dash) + +;; Puzzle 1: + +(defvar day-1/input + '(83285 96868 121640 51455 128067 128390 141809 52325 68310 140707 124520 149678 + 87961 52040 133133 52203 117483 85643 84414 86558 65402 122692 88565 61895 + 126271 128802 140363 109764 53600 114391 98973 124467 99574 69140 144856 + 56809 149944 138738 128823 82776 77557 51994 74322 64716 114506 124074 + 73096 97066 96731 149307 135626 121413 69575 98581 50570 60754 94843 72165 + 146504 53290 63491 50936 79644 119081 70218 85849 133228 114550 131943 + 67288 68499 80512 148872 99264 119723 68295 90348 146534 52661 99146 95993 + 130363 78956 126736 82065 77227 129950 97946 132345 107137 79623 148477 + 88928 118911 75277 97162 80664 149742 88983 74518)) + +(defun calculate-fuel (mass) + (- (/ mass 3) 2)) + +(message "Solution to day1/1: %d" (apply #'+ (-map #'calculate-fuel day-1/input))) + +;; Puzzle 2: +(defun calculate-recursive-fuel (mass) + (let ((fuel (calculate-fuel mass))) + (if (< fuel 0) 0 + (+ fuel (calculate-recursive-fuel fuel))))) + +(message "Solution to day1/2: %d" (apply #'+ (-map #'calculate-recursive-fuel day-1/input))) diff --git a/fun/aoc2019/solution-day2.el b/fun/aoc2019/solution-day2.el new file mode 100644 index 0000000000..6ecac1e201 --- /dev/null +++ b/fun/aoc2019/solution-day2.el @@ -0,0 +1,53 @@ +;; -*- lexical-binding: t; -*- +;; Advent of Code 2019 - Day 2 +(require 'dash) +(require 'ht) + +(defvar day2/input + [1 0 0 3 1 1 2 3 1 3 4 3 1 5 0 3 2 1 9 19 1 19 5 23 1 13 23 27 1 27 6 31 + 2 31 6 35 2 6 35 39 1 39 5 43 1 13 43 47 1 6 47 51 2 13 51 55 1 10 55 + 59 1 59 5 63 1 10 63 67 1 67 5 71 1 71 10 75 1 9 75 79 2 13 79 83 1 9 + 83 87 2 87 13 91 1 10 91 95 1 95 9 99 1 13 99 103 2 103 13 107 1 107 10 + 111 2 10 111 115 1 115 9 119 2 119 6 123 1 5 123 127 1 5 127 131 1 10 + 131 135 1 135 6 139 1 10 139 143 1 143 6 147 2 147 13 151 1 5 151 155 1 + 155 5 159 1 159 2 163 1 163 9 0 99 2 14 0 0]) + +;; Puzzle 1 + +(defun day2/single-op (f state idx) + (let* ((a (aref state (aref state (+ 1 idx)))) + (b (aref state (aref state (+ 2 idx)))) + (p (aref state (+ 3 idx))) + (result (funcall f a b))) + (aset state p (funcall f a b)))) + +(defun day2/operate (state idx) + (pcase (aref state idx) + (99 (aref state 0)) + (1 (day2/single-op #'+ state idx) + (day2/operate state (+ 4 idx))) + (2 (day2/single-op #'* state idx) + (day2/operate state (+ 4 idx))) + (other (error "Unknown opcode: %s" other)))) + +(defun day2/program-with-inputs (noun verb) + (let* ((input (copy-tree day2/input t))) + (aset input 1 noun) + (aset input 2 verb) + (day2/operate input 0))) + +(message "Solution to day2/1: %s" (day2/program-with-inputs 12 2)) + +;; Puzzle 2 +(let* ((used (ht)) + (noun 0) + (verb 0) + (result (day2/program-with-inputs noun verb))) + (while (/= 19690720 result) + (setq noun (random 100)) + (setq verb (random 100)) + (unless (ht-get used (format "%d%d" noun verb)) + (ht-set used (format "%d%d" noun verb) t) + (setq result (day2/program-with-inputs noun verb)))) + + (message "Solution to day2/2: %s%s" noun verb)) diff --git a/fun/aoc2019/solution-day3.el b/fun/aoc2019/solution-day3.el new file mode 100644 index 0000000000..b7dfdd245f --- /dev/null +++ b/fun/aoc2019/solution-day3.el @@ -0,0 +1,64 @@ +;; -*- lexical-binding: t; -*- +;; Advent of Code 2019 - Day 3 + +(require 'cl-lib) +(require 'dash) +(require 'ht) +(require 's) + +(defvar day3/input/wire1 + "R1010,D422,L354,U494,L686,U894,R212,U777,L216,U9,L374,U77,R947,U385,L170,U916,R492,D553,L992,D890,L531,U360,R128,U653,L362,U522,R817,U198,L126,D629,L569,U300,L241,U145,R889,D196,L450,D576,L319,D147,R985,U889,L941,U837,L608,D77,L864,U911,L270,D869,R771,U132,L249,U603,L36,D328,L597,U992,L733,D370,L947,D595,L308,U536,L145,U318,R55,D773,R175,D505,R483,D13,R780,U778,R445,D107,R490,U245,L587,U502,R446,U639,R150,U35,L455,D522,R866,U858,R394,D975,R513,D378,R58,D646,L374,D675,R209,U228,R530,U543,L480,U677,L912,D164,L573,U587,L784,D626,L994,U250,L215,U985,R684,D79,L877,U811,L766,U617,L665,D246,L408,U800,L360,D272,L436,U138,R240,U735,L681,U68,L608,D59,R532,D808,L104,U968,R887,U819,R346,U698,L317,U582,R516,U55,L303,U607,L457,U479,L510,D366,L583,U519,R878,D195,R970,D267,R842,U784,R9,D946,R833,D238,L232,D94,L860,D47,L346,U951,R491,D745,R849,U273,R263,U392,L341,D808,R696,U326,R886,D296,L865,U833,R241,U644,R729,D216,R661,D712,L466,D699,L738,U5,L556,D693,R912,D13,R48,U63,L877,U628,L689,D929,R74,U924,R612,U153,R417,U425,L879,D378,R79,D248,L3,U519,R366,U281,R439,D823,R149,D668,R326,D342,L213,D735,R504,U265,L718,D842,L565,U105,L214,U963,R518,D681,R642,U170,L111,U6,R697,U572,R18,U331,L618,D255,R534,D322,L399,U595,L246,U651,L836,U757,R417,D795,R291,U759,L568,U965,R828,D570,R350,U317,R338,D173,L74,D833,L650,D844,L70,U913,R594,U407,R674,D684,L481,D564,L128,D277,R851,D274,L435,D582,R469,U729,R387,D818,R443,U504,R414,U8,L842,U845,R275,U986,R53,U660,R661,D225,R614,U159,R477") + +(defvar day3/input/wire2 + "L1010,D698,R442,U660,L719,U702,L456,D86,R938,D177,L835,D639,R166,D285,L694,U468,L569,D104,L234,D574,L669,U299,L124,D275,L179,D519,R617,U72,L985,D248,R257,D276,L759,D834,R490,U864,L406,U181,R911,U873,R261,D864,R260,U759,R648,U158,R308,D386,L835,D27,L745,U91,R840,U707,R275,U543,L663,U736,L617,D699,R924,U103,R225,U455,R708,U319,R569,U38,R315,D432,L179,D975,R519,D546,L295,U680,L685,U603,R262,D250,R7,U171,R261,U519,L832,U534,L471,U431,L474,U886,R10,D179,L79,D555,R452,U452,L832,U863,L367,U538,L237,D160,R441,U605,R942,U259,L811,D552,R646,D353,L225,D94,L35,D307,R752,U23,R698,U610,L379,D932,R698,D751,R178,D347,R325,D156,R471,D555,R558,D593,R773,U2,L955,U764,L735,U438,R364,D640,L757,U534,R919,U409,R361,U407,R336,D808,R877,D648,R610,U198,R340,U94,R795,D667,R811,U975,L965,D224,R565,D681,L64,U567,R621,U922,L665,U329,R242,U592,L727,D481,L339,U402,R213,D280,R656,U169,R976,D962,L294,D505,L251,D689,L497,U133,R230,D441,L90,D220,L896,D657,L500,U331,R502,U723,R762,D613,L447,D256,L226,U309,L935,U384,L740,D459,R309,D707,R952,D747,L304,D105,R977,D539,R941,D21,R291,U216,R132,D543,R515,U453,L854,D42,R982,U102,L469,D639,R559,D68,R302,U734,R980,D214,R107,D191,L730,D793,L63,U17,R807,U196,R412,D592,R330,D941,L87,D291,L44,D94,L272,D780,R968,U837,L712,D704,R163,U981,R537,U778,R220,D303,L196,D951,R163,D446,R11,D623,L72,D778,L158,U660,L189,D510,L247,D716,L89,U887,L115,U114,L36,U81,R927,U293,L265,U183,R331,D267,R745,D298,L561,D918,R299,U810,L322,U679,L739,D854,L581,U34,L862,D779,R23") + +;; Puzzle 1 + +(defun wire-from (raw) + (-map (lambda (s) + (cons (substring s 0 1) (string-to-number (substring s 1)))) + (s-split "," raw))) + +(defun day3/move (x y next) + (cl-flet ((steps (by op) + (-map op (reverse (number-sequence 1 by))))) + (pcase next + (`("L" . ,by) (steps by (lambda (n) (cons (- x n) y)))) + (`("R" . ,by) (steps by (lambda (n) (cons (+ x n) y)))) + (`("U" . ,by) (steps by (lambda (n) (cons x (+ y n))))) + (`("D" . ,by) (steps by (lambda (n) (cons x (- y n)))))))) + +(defun day3/wire-points (wire) + (let ((points (ht)) + (point-list (-reduce-from + (lambda (acc point) + (-let* (((x . y) (car acc)) + (next (day3/move x y point))) + (-concat next acc))) + '((0 . 0)) wire))) + (-map (-lambda ((s . p)) (ht-set! points p s)) + (-zip (reverse (number-sequence 0 (- (length point-list) 1))) point-list)) + (ht-remove! points '(0 . 0)) + points)) + +(defun day3/closest-intersection (crossed-points) + (car (-sort #'< + (-map (-lambda ((x . y)) + (+ (abs x) (abs y))) + crossed-points)))) + +(defun day3/minimum-steps (wire1 wire2 crossed) + (car (-sort #'< + (-map (-lambda (p) + (+ (ht-get wire1 p) (ht-get wire2 p))) + crossed)))) + +;; Example: +(let* ((wire1-points (day3/wire-points (wire-from day3/input/wire1))) + (wire2-points (day3/wire-points (wire-from day3/input/wire2))) + (crossed-points (-filter (lambda (p) (ht-contains? wire1-points p)) + (ht-keys wire2-points)))) + (message "Solution for day3/1: %d" (day3/closest-intersection crossed-points)) + (message "Solution for day3/2: %d" (day3/minimum-steps wire1-points + wire2-points + crossed-points))) diff --git a/fun/aoc2019/solution-day4.el b/fun/aoc2019/solution-day4.el new file mode 100644 index 0000000000..2805f3f4e9 --- /dev/null +++ b/fun/aoc2019/solution-day4.el @@ -0,0 +1,73 @@ +;; -*- lexical-binding: t; -*- +;; Advent of Code 2019 - Day 4 + +(require 'cl-lib) +(require 'dash) + +;; Puzzle 1 + +(defun day4/to-digits (num) + "Convert NUM to a list of its digits." + (cl-labels ((steps (n digits) + (if (= n 0) digits + (steps (/ n 10) (cons (% n 10) digits))))) + (steps num '()))) + +(defvar day4/input (-map #'day4/to-digits (number-sequence 128392 643281))) + +(defun day4/filter-password (digits) + "Determines whether the given rules match the supplied + number." + + (and + ;; It is a six digit number + (= 6 (length digits)) + + ;; Value is within the range given in puzzle input + ;; (noop because the range is generated from the input) + + ;; Two adjacent digits are the same (like 22 in 122345). + (car (-reduce-from (-lambda ((acc . prev) next) + (cons (or acc (= prev next)) next)) + '(nil . 0) digits)) + + ;; Going from left to right, the digits never decrease; they only + ;; ever increase or stay the same (like 111123 or 135679). + (car (-reduce-from (-lambda ((acc . prev) next) + (cons (and acc (>= next prev)) next)) + '(t . 0) digits)))) + +;; Puzzle 2 +;; +;; Additional criteria: If there's matching digits, they're not in a group. + +(cl-defstruct day4/acc state prev count) + +(defun day4/filter-longer-groups (digits) + (let ((res (-reduce-from + (lambda (acc next) + (cond ;; sequence is broken and count was at 1 -> + ;; match! + ((and (= (day4/acc-count acc) 2) + (/= (day4/acc-prev acc) next)) + (setf (day4/acc-state acc) t)) + + ;; sequence continues, counter increment! + ((= (day4/acc-prev acc) next) + (setf (day4/acc-count acc) (+ 1 (day4/acc-count acc)))) + + ;; sequence broken, reset counter + ((/= (day4/acc-prev acc) next) + (setf (day4/acc-count acc) 1))) + + (setf (day4/acc-prev acc) next) + acc) + (make-day4/acc :prev 0 :count 0) digits))) + (or (day4/acc-state res) + (= 2 (day4/acc-count res))))) + +(let* ((simple (-filter #'day4/filter-password day4/input)) + (complex (-filter #'day4/filter-longer-groups simple))) + (message "Solution to day4/1: %d" (length simple)) + (message "Solution to day4/2: %d" (length complex))) + diff --git a/fun/avatar.jpeg b/fun/avatar.jpeg new file mode 100644 index 0000000000..f38f056578 --- /dev/null +++ b/fun/avatar.jpeg Binary files differdiff --git a/fun/defer_rs/.gitignore b/fun/defer_rs/.gitignore new file mode 100644 index 0000000000..6aa106405a --- /dev/null +++ b/fun/defer_rs/.gitignore @@ -0,0 +1,3 @@ +/target/ +**/*.rs.bk +Cargo.lock diff --git a/fun/defer_rs/Cargo.toml b/fun/defer_rs/Cargo.toml new file mode 100644 index 0000000000..0fcd60373f --- /dev/null +++ b/fun/defer_rs/Cargo.toml @@ -0,0 +1,6 @@ +[package] +name = "defer" +version = "0.1.0" +authors = ["Vincent Ambo <tazjin@gmail.com>"] + +[dependencies] diff --git a/fun/defer_rs/README.md b/fun/defer_rs/README.md new file mode 100644 index 0000000000..160158d177 --- /dev/null +++ b/fun/defer_rs/README.md @@ -0,0 +1,53 @@ +defer in Rust +============= + +After a Hacker News discussion about implementing Go's `defer` keyword in C++, +I stumbled upon [this comment](https://news.ycombinator.com/item?id=15523589) +and more specifically this response to it by "Occivink": + +> There's plenty of one-time cases where you don't want to declare an entire +> class but still enjoy scope-based functions. + +Specificall the "don't want to declare an entire class" suggests that languages +like C++ have high friction for explaining your desired invariant (cleanup is +run when `$thing` is destroyed) to the compiler. + +It seems like most languages either hand-wave this away (*cough* Java *cough*) +or use what seems like a workaround (`defer`). + +Rust has the so-called `Drop` trait, which is a typeclass that contains a single +method with no return value that is run when a variable is dropped (i.e. goes out +of scope). + +This works fine for most general cases - i.e. closing file handlers - but can +get complicated if other use-cases of `defer` are considered: + +* returning an error-value by mutating a reference in the enclosing scope (oh boy) +* deferring a decision about when/whether to run cleanup to the caller + +While thinking about how to do this with the `Drop` trait I realised that `defer` +can actually be trivially implemented in Rust, using `Drop`. + +A simple implementation of `defer` can be seen in [defer.rs](examples/defer.rs), +an implementation using shared mutable state for error returns is in the file +[defer-with-error.rs](examples/defer-with-error.rs) and an implementation that +allows cleanup to be *cancelled* (don't _actually_ do this, it leaks a pointer) +is in [undefer.rs](examples/undefer.rs). + +Whether any of this is actually useful is not up to me to decide. I haven't +actually had a real-life need for this. + +You can run the examples with `cargo run --example defer`, etc. + +## Notes + +* `Drop` is not guaranteed to run in case of panics or program aborts, if you + need support for that check out [scopeguard](https://github.com/bluss/scopeguard) +* `undefer` could be implemented safely by, for example, carrying a boolean that + by default causes execution to happen but can be flipped to disable it + +## Further reading: + +* [The Pain Of Real Linear Types in Rust](https://gankro.github.io/blah/linear-rust/) +* [Go's defer](https://tour.golang.org/flowcontrol/12) +* [Rust's Drop](https://doc.rust-lang.org/std/ops/trait.Drop.html) diff --git a/fun/defer_rs/examples/defer-with-error.rs b/fun/defer_rs/examples/defer-with-error.rs new file mode 100644 index 0000000000..26d56d77cf --- /dev/null +++ b/fun/defer_rs/examples/defer-with-error.rs @@ -0,0 +1,70 @@ +// Go's defer in Rust, with error value return. + +use std::rc::Rc; +use std::sync::RwLock; + +struct Defer<F: Fn()> { + f: F +} + +impl <F: Fn()> Drop for Defer<F> { + fn drop(&mut self) { + (self.f)() + } +} + +// Only added this for Go-syntax familiarity ;-) +fn defer<F: Fn()>(f: F) -> Defer<F> { + Defer { f } +} + +// Convenience type synonym. This is a reference-counted smart pointer to +// a shareable, mutable variable. +// Rust does not allow willy-nilly mutation of shared variables, so explicit +// write-locking must be performed. +type ErrorHandle<T> = Rc<RwLock<Option<T>>>; + +/////////////////// +// Usage example // +/////////////////// + +#[derive(Debug)] // Debug trait for some default way to print the type. +enum Error { DropError } + +fn main() { + // Create a place to store the error. + let drop_err: ErrorHandle<Error> = Default::default(); // create empty error + + // Introduce an arbitrary scope block (so that we still have control after + // the defer runs): + { + let mut i = 1; + + // Rc types are safe to clone and share for multiple ownership. + let err_handle = drop_err.clone(); + + // Call defer and let the closure own the cloned handle to the error: + let token = defer(move || { + // do something! + println!("Value is: {}", i); + + // ... oh no, it went wrong! + *err_handle.write().unwrap() = Some(Error::DropError); + }); + + i += 1; + println!("Value is: {}", i); + + // token goes out of scope here - drop() is called. + } + + match *drop_err.read().unwrap() { + Some(ref err) => println!("Oh no, an error occured: {:?}!", err), + None => println!("Phew, everything went well.") + }; +} + +// Prints: +// Value is: 2 +// Value is: 1 +// Oh no, an error occured: DropError! diff --git a/fun/defer_rs/examples/defer.rs b/fun/defer_rs/examples/defer.rs new file mode 100644 index 0000000000..eadac795f8 --- /dev/null +++ b/fun/defer_rs/examples/defer.rs @@ -0,0 +1,31 @@ +// Go's defer in Rust! + +struct Defer<F: Fn()> { + f: F +} + +impl <F: Fn()> Drop for Defer<F> { + fn drop(&mut self) { + (self.f)() + } +} + +// Only added this for Go-syntax familiarity ;-) +fn defer<F: Fn()>(f: F) -> Defer<F> { + Defer { f } +} + +fn main() { + let mut i = 1; + + // Calling it "token" ... could be something else. The lifetime of this + // controls when the action is run. + let _token = defer(move || println!("Value is: {}", i)); + + i += 1; + println!("Value is: {}", i); +} + +// Prints: +// Value is: 2 +// Value is: 1 diff --git a/fun/defer_rs/examples/undefer.rs b/fun/defer_rs/examples/undefer.rs new file mode 100644 index 0000000000..17ad8a6b54 --- /dev/null +++ b/fun/defer_rs/examples/undefer.rs @@ -0,0 +1,40 @@ +// Go's defer in Rust, with a little twist! + +struct Defer<F: Fn()> { + f: F +} + +impl <F: Fn()> Drop for Defer<F> { + fn drop(&mut self) { + (self.f)() + } +} + +// Only added this for Go-syntax familiarity ;-) +fn defer<F: Fn()>(f: F) -> Defer<F> { + Defer { f } +} + +// Changed your mind about the defer? +// (Note: This leaks the closure! Don't actually do this!) +fn undefer<F: Fn()>(token: Defer<F>) { + use std::mem; + mem::forget(token); +} + +fn main() { + let mut i = 1; + + // Calling it "token" ... could be something else. The lifetime of this + // controls when the action is run. + let token = defer(move || println!("Value is: {}", i)); + + i += 1; + println!("Value is: {}", i); + + // Oh, now I changed my mind about the previous defer: + undefer(token); +} + +// Prints: +// Value is: 2 diff --git a/fun/dt/CMakeLists.txt b/fun/dt/CMakeLists.txt new file mode 100644 index 0000000000..85b659fea8 --- /dev/null +++ b/fun/dt/CMakeLists.txt @@ -0,0 +1,16 @@ +# -*- mode: cmake; -*- +cmake_minimum_required(VERSION 3.16) +project(dt) +add_executable(dt dt.cc) +find_package(absl REQUIRED) + +target_link_libraries(dt + absl::flags + absl::flags_parse + absl::hash + absl::time + absl::strings + farmhash +) + +install(TARGETS dt DESTINATION bin) diff --git a/fun/dt/README.md b/fun/dt/README.md new file mode 100644 index 0000000000..ee43d56064 --- /dev/null +++ b/fun/dt/README.md @@ -0,0 +1,11 @@ +dt +== + +It's got a purpose. + +## Usage: + +``` +nix-build -E '(import (builtins.fetchGit "https://git.tazj.in/") {}).fun.dt' +./result/bin/dt --one ... --two ... +``` diff --git a/fun/dt/default.nix b/fun/dt/default.nix new file mode 100644 index 0000000000..a1a82d361b --- /dev/null +++ b/fun/dt/default.nix @@ -0,0 +1,14 @@ +{ depot, pkgs, ... }: + +let + stdenv = with pkgs; overrideCC clangStdenv clang_9; + abseil_cpp = pkgs.abseil_cpp.override { inherit stdenv; }; +in stdenv.mkDerivation { + name = "dt"; + src = ./.; + nativeBuildInputs = [ pkgs.cmake ]; + buildInputs = with pkgs; [ + abseil_cpp + farmhash + ]; +} diff --git a/fun/dt/dt.cc b/fun/dt/dt.cc new file mode 100644 index 0000000000..5c4c3da768 --- /dev/null +++ b/fun/dt/dt.cc @@ -0,0 +1,79 @@ +#include <iostream> +#include <vector> + +#include "absl/flags/flag.h" +#include "absl/flags/parse.h" +#include "absl/hash/hash.h" +#include "absl/strings/str_cat.h" +#include "absl/time/clock.h" +#include "absl/time/time.h" +#include "absl/types/optional.h" +#include "farmhash.h" + +ABSL_FLAG(std::vector<std::string>, words, {}, "words to use"); + +struct Result { + std::string a; + int ec; + absl::optional<std::string> p; +}; + +std::string which(const std::vector<std::string>& words) { + uint64_t fp; + std::string word; + + for (const auto& w : words) { + auto nfp = util::Fingerprint64(w); + if (nfp > fp) { + fp = nfp; + word = w; + } + } + + return word; +} + +Result decide(const std::vector<std::string>& words) { + auto input = absl::FormatTime("%Y%m%d", absl::Now(), absl::UTCTimeZone()); + for (const auto& w : words) { + input += w; + } + + auto base = util::Fingerprint64(input); + Result result = { "nope" }; + + if (base % 10 == 0) { + result.a = "ca"; + } else if (base % 8 == 0) { + result.a = "c1"; + result.p = which(words); + } else if (base % 6 == 0) { + result.a = "skip"; + } else if (base % 3 == 0) { + result.a = "e1"; + result.ec = base % 10; + result.p = which(words); + } else if (base % 2 == 0) { + result.a = "ea"; + result.ec = base % 10; + } + + return result; +} + +int main(int argc, char *argv[]) { + absl::ParseCommandLine(argc, argv); + + auto words = absl::GetFlag(FLAGS_words); + if (words.size() < 2) { + std::cerr << "needs at least two!" << std::endl; + return 1; + } + + auto result = decide(words); + std::cout << result.a + << (result.p.has_value() ? absl::StrCat(" ", "(", result.p.value(), ")") + : "") + << (result.ec > 0 ? absl::StrCat(": ", result.ec) : "") + << std::endl; +} diff --git a/fun/elblog/.gitignore b/fun/elblog/.gitignore new file mode 100644 index 0000000000..c531d9867f --- /dev/null +++ b/fun/elblog/.gitignore @@ -0,0 +1 @@ +*.elc diff --git a/fun/elblog/README.md b/fun/elblog/README.md new file mode 100644 index 0000000000..994b1138ef --- /dev/null +++ b/fun/elblog/README.md @@ -0,0 +1,11 @@ +elblog +====== + +This is a simple blogging software written in Emacs Lisp. + +The idea is that it should be able to do most of the things [my actual blog][] +does at the moment. + +No documentation exists for now besides the commit messages, but it works! + +[my actual blog]: https://www.tazj.in/ diff --git a/fun/elblog/blog.css b/fun/elblog/blog.css new file mode 100644 index 0000000000..0d021f78e8 --- /dev/null +++ b/fun/elblog/blog.css @@ -0,0 +1,37 @@ +<style type="text/css"> +body { + margin: 40px auto; + max-width: 800px; + line-height: 1.6; + font-size: 18px; + color: #383838; + padding: 0 10px +} +h1, h2, h3 { + line-height: 1.2 +} +.footer { + text-align: right; +} +.lod { + text-align: center; +} +.unstyled-link { + color: inherit; + text-decoration: none; +} +.uncoloured-link { + color: inherit; +} +.date { + text-align: right; + font-style: italic; + float: right; +} +.inline { + display: inline; +} +.navigation { + text-align: center; +} +</style> diff --git a/fun/elblog/blog.el b/fun/elblog/blog.el new file mode 100644 index 0000000000..102aa37914 --- /dev/null +++ b/fun/elblog/blog.el @@ -0,0 +1,123 @@ +;;; blog.el --- A simple org-mode & elnode blog software. +;;; -*- lexical-binding: t; -*- + +(require 'dash) +(require 'elnode) +(require 'f) +(require 'ht) + +;; Definition of customization options + +(defgroup elblog nil + "Configuration for the Emacs Lisp blog software" + :link '(url-link "https://github.com/tazjin/elblog")) + +(defcustom elblog-port 8010 + "Port to run elblog's HTTP server on" + :group 'elblog + :type 'integer) + +(defcustom elblog-host "localhost" + "Host for elblog's HTTP server to listen on" + :group 'elblog + :type 'string) + +(defcustom elblog-title "Elblog" + "Title text for this elblog instance" + :group 'elblog + :type 'string) + +(defcustom elblog-article-directory nil + "Directory in which elblog articles are stored" + :group 'elblog + :type 'string) + +(defcustom elblog-additional-routes '() + "Additional Elnode routes to register in the Elblog instance" + :group 'elblog + :type '(alist :key-type regexp :value-type function)) + +;; Declare user-configurable variables needed at runtime. + +(defvar elblog-articles (ht-create) + "A hash-table of blog articles. This is used for looking up articles from + URL fragments as well as for rendering the index.") + +;; HTML templating setup + +(defun template-preamble () + "Templates the preamble snippet with the correct blog title." + (format (f-read-text "preamble.html") elblog-title)) + +(defun configure-org-html-export () + "Configure org-mode settings for elblog's HTML templating to work correctly." + (setq org-html-postamble t) + (setq org-html-doctype "html5") + (setq org-html-head-include-scripts nil) + (setq org-html-style-default (f-read-text "blog.css")) + (setq org-html-preamble-format `(("en" ,(template-preamble)))) + (setq org-html-postamble-format `(("en" ,(f-read-text "postamble.html"))))) + +;; Article fetching & rendering functions + +(defun render-org-buffer (input-buffer &optional force) + "Renders an org-mode buffer as HTML and returns the name of the output buffer." + (letrec ((output-buffer (concat (buffer-name input-buffer) "-rendered")) + ;; Don't re-render articles unless forced. + (must-render (or force + (not (get-buffer output-buffer))))) + (if (and input-buffer must-render) + (with-current-buffer input-buffer + (org-export-to-buffer 'html output-buffer nil nil t))) + (if input-buffer output-buffer nil))) + +(defun get-buffer-string (buffer) + "Returns the contents of the specified buffer as a string." + (with-current-buffer (get-buffer buffer) + (buffer-string))) + +(defvar-local article-not-found + '(404 . "<html><body><p>Oh no, the article was not found.</p></body></html>")) + +(defvar-local text-html '("Content-Type" . "text/html")) + +(defun render-article (article) + "Renders an article, if it exists." + (letrec ((rendered (-some->> + (ht-get elblog-articles article) + (concat elblog-article-directory) + (find-file) + (render-org-buffer)))) + (if rendered `(200 . ,(get-buffer-string rendered)) + article-not-found))) + +(defun blog-post-handler (httpcon) + "This handler servers a blog post from the configured blog post directory." + (let ((response (render-article (elnode-http-mapping httpcon 1)))) + (elnode-http-start httpcon (car response) text-html) + (elnode-http-return httpcon (cdr response)))) + +;; Web server implementation + +(defvar elblog-routes + '(("^.*//\\(.*\\)" . blog-post-handler)) + "The default routes available in elblog. They can be extended by the user +by setting the elblog-additional-routes customize option.") + +(defun elblog-handler (httpcon) + (elnode-hostpath-dispatcher + httpcon + (-concat elblog-additional-routes elblog-routes))) + +(defun start-elblog () + (interactive) + (configure-org-html-export) + (elnode-start 'elblog-handler + :port elblog-port + :host elblog-host)) + +(defun stop-elblog () + (interactive) + (elnode-stop elblog-port)) + +(provide 'elblog) diff --git a/fun/elblog/postamble.html b/fun/elblog/postamble.html new file mode 100644 index 0000000000..16a26218a0 --- /dev/null +++ b/fun/elblog/postamble.html @@ -0,0 +1,9 @@ +<hr> +<footer><p class="footer">Served with <a class="uncoloured-link" href="https://github.com/tazjin/elblog">Emacs</a>.</p> + <p class="footer"> + <a class="uncoloured-link" href="https://twitter.com/tazjin">Twitter</a> + | + <a class="uncoloured-link" href="mailto:blog@tazj.in">Mail</a> + </p> + <p class="lod">ಠ_ಠ</p> +</footer> diff --git a/fun/elblog/preamble.html b/fun/elblog/preamble.html new file mode 100644 index 0000000000..be74b9207e --- /dev/null +++ b/fun/elblog/preamble.html @@ -0,0 +1,6 @@ +<header> + <h1> + <a class="unstyled-link" href="/">%s</a> + </h1> + <hr> +</header> diff --git a/fun/gemma/CODE_OF_CONDUCT.md b/fun/gemma/CODE_OF_CONDUCT.md new file mode 100644 index 0000000000..c4013ac13e --- /dev/null +++ b/fun/gemma/CODE_OF_CONDUCT.md @@ -0,0 +1,20 @@ +A SERMON ON ETHICS AND LOVE +=========================== + +One day Mal-2 asked the messenger spirit Saint Gulik to approach the Goddess and request Her presence for some desperate advice. Shortly afterwards the radio came on by itself, and an ethereal female Voice said **YES?** + +"O! Eris! Blessed Mother of Man! Queen of Chaos! Daughter of Discord! Concubine of Confusion! O! Exquisite Lady, I beseech You to lift a heavy burden from my heart!" + +**WHAT BOTHERS YOU, MAL? YOU DON'T SOUND WELL.** + +"I am filled with fear and tormented with terrible visions of pain. Everywhere people are hurting one another, the planet is rampant with injustices, whole societies plunder groups of their own people, mothers imprison sons, children perish while brothers war. O, woe." + +**WHAT IS THE MATTER WITH THAT, IF IT IS WHAT YOU WANT TO DO?** + +"But nobody Wants it! Everybody hates it." + +**OH. WELL, THEN *STOP*.** + +At which moment She turned herself into an aspirin commercial and left The Polyfather stranded alone with his species. + +SINISTER DEXTER HAS A BROKEN SPIROMETER. diff --git a/fun/gemma/LICENSE b/fun/gemma/LICENSE new file mode 100644 index 0000000000..94a9ed024d --- /dev/null +++ b/fun/gemma/LICENSE @@ -0,0 +1,674 @@ + GNU GENERAL PUBLIC LICENSE + Version 3, 29 June 2007 + + Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/> + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + + Preamble + + The GNU General Public License is a free, copyleft license for +software and other kinds of works. + + The licenses for most software and other practical works are designed +to take away your freedom to share and change the works. By contrast, +the GNU General Public License is intended to guarantee your freedom to +share and change all versions of a program--to make sure it remains free +software for all its users. We, the Free Software Foundation, use the +GNU General Public License for most of our software; it applies also to +any other work released this way by its authors. You can apply it to +your programs, too. + + When we speak of free software, we are referring to freedom, not +price. Our General Public Licenses are designed to make sure that you +have the freedom to distribute copies of free software (and charge for +them if you wish), that you receive source code or can get it if you +want it, that you can change the software or use pieces of it in new +free programs, and that you know you can do these things. + + To protect your rights, we need to prevent others from denying you +these rights or asking you to surrender the rights. Therefore, you have +certain responsibilities if you distribute copies of the software, or if +you modify it: responsibilities to respect the freedom of others. + + For example, if you distribute copies of such a program, whether +gratis or for a fee, you must pass on to the recipients the same +freedoms that you received. You must make sure that they, too, receive +or can get the source code. And you must show them these terms so they +know their rights. + + Developers that use the GNU GPL protect your rights with two steps: +(1) assert copyright on the software, and (2) offer you this License +giving you legal permission to copy, distribute and/or modify it. + + For the developers' and authors' protection, the GPL clearly explains +that there is no warranty for this free software. For both users' and +authors' sake, the GPL requires that modified versions be marked as +changed, so that their problems will not be attributed erroneously to +authors of previous versions. + + Some devices are designed to deny users access to install or run +modified versions of the software inside them, although the manufacturer +can do so. This is fundamentally incompatible with the aim of +protecting users' freedom to change the software. The systematic +pattern of such abuse occurs in the area of products for individuals to +use, which is precisely where it is most unacceptable. Therefore, we +have designed this version of the GPL to prohibit the practice for those +products. If such problems arise substantially in other domains, we +stand ready to extend this provision to those domains in future versions +of the GPL, as needed to protect the freedom of users. + + Finally, every program is threatened constantly by software patents. +States should not allow patents to restrict development and use of +software on general-purpose computers, but in those that do, we wish to +avoid the special danger that patents applied to a free program could +make it effectively proprietary. To prevent this, the GPL assures that +patents cannot be used to render the program non-free. + + The precise terms and conditions for copying, distribution and +modification follow. + + TERMS AND CONDITIONS + + 0. Definitions. + + "This License" refers to version 3 of the GNU General Public License. + + "Copyright" also means copyright-like laws that apply to other kinds of +works, such as semiconductor masks. + + "The Program" refers to any copyrightable work licensed under this +License. Each licensee is addressed as "you". "Licensees" and +"recipients" may be individuals or organizations. + + To "modify" a work means to copy from or adapt all or part of the work +in a fashion requiring copyright permission, other than the making of an +exact copy. The resulting work is called a "modified version" of the +earlier work or a work "based on" the earlier work. + + A "covered work" means either the unmodified Program or a work based +on the Program. + + To "propagate" a work means to do anything with it that, without +permission, would make you directly or secondarily liable for +infringement under applicable copyright law, except executing it on a +computer or modifying a private copy. Propagation includes copying, +distribution (with or without modification), making available to the +public, and in some countries other activities as well. + + To "convey" a work means any kind of propagation that enables other +parties to make or receive copies. Mere interaction with a user through +a computer network, with no transfer of a copy, is not conveying. + + An interactive user interface displays "Appropriate Legal Notices" +to the extent that it includes a convenient and prominently visible +feature that (1) displays an appropriate copyright notice, and (2) +tells the user that there is no warranty for the work (except to the +extent that warranties are provided), that licensees may convey the +work under this License, and how to view a copy of this License. If +the interface presents a list of user commands or options, such as a +menu, a prominent item in the list meets this criterion. + + 1. Source Code. + + The "source code" for a work means the preferred form of the work +for making modifications to it. "Object code" means any non-source +form of a work. + + A "Standard Interface" means an interface that either is an official +standard defined by a recognized standards body, or, in the case of +interfaces specified for a particular programming language, one that +is widely used among developers working in that language. + + The "System Libraries" of an executable work include anything, other +than the work as a whole, that (a) is included in the normal form of +packaging a Major Component, but which is not part of that Major +Component, and (b) serves only to enable use of the work with that +Major Component, or to implement a Standard Interface for which an +implementation is available to the public in source code form. A +"Major Component", in this context, means a major essential component +(kernel, window system, and so on) of the specific operating system +(if any) on which the executable work runs, or a compiler used to +produce the work, or an object code interpreter used to run it. + + The "Corresponding Source" for a work in object code form means all +the source code needed to generate, install, and (for an executable +work) run the object code and to modify the work, including scripts to +control those activities. However, it does not include the work's +System Libraries, or general-purpose tools or generally available free +programs which are used unmodified in performing those activities but +which are not part of the work. For example, Corresponding Source +includes interface definition files associated with source files for +the work, and the source code for shared libraries and dynamically +linked subprograms that the work is specifically designed to require, +such as by intimate data communication or control flow between those +subprograms and other parts of the work. + + The Corresponding Source need not include anything that users +can regenerate automatically from other parts of the Corresponding +Source. + + The Corresponding Source for a work in source code form is that +same work. + + 2. Basic Permissions. + + All rights granted under this License are granted for the term of +copyright on the Program, and are irrevocable provided the stated +conditions are met. This License explicitly affirms your unlimited +permission to run the unmodified Program. The output from running a +covered work is covered by this License only if the output, given its +content, constitutes a covered work. This License acknowledges your +rights of fair use or other equivalent, as provided by copyright law. + + You may make, run and propagate covered works that you do not +convey, without conditions so long as your license otherwise remains +in force. You may convey covered works to others for the sole purpose +of having them make modifications exclusively for you, or provide you +with facilities for running those works, provided that you comply with +the terms of this License in conveying all material for which you do +not control copyright. Those thus making or running the covered works +for you must do so exclusively on your behalf, under your direction +and control, on terms that prohibit them from making any copies of +your copyrighted material outside their relationship with you. + + Conveying under any other circumstances is permitted solely under +the conditions stated below. Sublicensing is not allowed; section 10 +makes it unnecessary. + + 3. Protecting Users' Legal Rights From Anti-Circumvention Law. + + No covered work shall be deemed part of an effective technological +measure under any applicable law fulfilling obligations under article +11 of the WIPO copyright treaty adopted on 20 December 1996, or +similar laws prohibiting or restricting circumvention of such +measures. + + When you convey a covered work, you waive any legal power to forbid +circumvention of technological measures to the extent such circumvention +is effected by exercising rights under this License with respect to +the covered work, and you disclaim any intention to limit operation or +modification of the work as a means of enforcing, against the work's +users, your or third parties' legal rights to forbid circumvention of +technological measures. + + 4. Conveying Verbatim Copies. + + You may convey verbatim copies of the Program's source code as you +receive it, in any medium, provided that you conspicuously and +appropriately publish on each copy an appropriate copyright notice; +keep intact all notices stating that this License and any +non-permissive terms added in accord with section 7 apply to the code; +keep intact all notices of the absence of any warranty; and give all +recipients a copy of this License along with the Program. + + You may charge any price or no price for each copy that you convey, +and you may offer support or warranty protection for a fee. + + 5. Conveying Modified Source Versions. + + You may convey a work based on the Program, or the modifications to +produce it from the Program, in the form of source code under the +terms of section 4, provided that you also meet all of these conditions: + + a) The work must carry prominent notices stating that you modified + it, and giving a relevant date. + + b) The work must carry prominent notices stating that it is + released under this License and any conditions added under section + 7. This requirement modifies the requirement in section 4 to + "keep intact all notices". + + c) You must license the entire work, as a whole, under this + License to anyone who comes into possession of a copy. This + License will therefore apply, along with any applicable section 7 + additional terms, to the whole of the work, and all its parts, + regardless of how they are packaged. This License gives no + permission to license the work in any other way, but it does not + invalidate such permission if you have separately received it. + + d) If the work has interactive user interfaces, each must display + Appropriate Legal Notices; however, if the Program has interactive + interfaces that do not display Appropriate Legal Notices, your + work need not make them do so. + + A compilation of a covered work with other separate and independent +works, which are not by their nature extensions of the covered work, +and which are not combined with it such as to form a larger program, +in or on a volume of a storage or distribution medium, is called an +"aggregate" if the compilation and its resulting copyright are not +used to limit the access or legal rights of the compilation's users +beyond what the individual works permit. Inclusion of a covered work +in an aggregate does not cause this License to apply to the other +parts of the aggregate. + + 6. Conveying Non-Source Forms. + + You may convey a covered work in object code form under the terms +of sections 4 and 5, provided that you also convey the +machine-readable Corresponding Source under the terms of this License, +in one of these ways: + + a) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by the + Corresponding Source fixed on a durable physical medium + customarily used for software interchange. + + b) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by a + written offer, valid for at least three years and valid for as + long as you offer spare parts or customer support for that product + model, to give anyone who possesses the object code either (1) a + copy of the Corresponding Source for all the software in the + product that is covered by this License, on a durable physical + medium customarily used for software interchange, for a price no + more than your reasonable cost of physically performing this + conveying of source, or (2) access to copy the + Corresponding Source from a network server at no charge. + + c) Convey individual copies of the object code with a copy of the + written offer to provide the Corresponding Source. This + alternative is allowed only occasionally and noncommercially, and + only if you received the object code with such an offer, in accord + with subsection 6b. + + d) Convey the object code by offering access from a designated + place (gratis or for a charge), and offer equivalent access to the + Corresponding Source in the same way through the same place at no + further charge. You need not require recipients to copy the + Corresponding Source along with the object code. If the place to + copy the object code is a network server, the Corresponding Source + may be on a different server (operated by you or a third party) + that supports equivalent copying facilities, provided you maintain + clear directions next to the object code saying where to find the + Corresponding Source. Regardless of what server hosts the + Corresponding Source, you remain obligated to ensure that it is + available for as long as needed to satisfy these requirements. + + e) Convey the object code using peer-to-peer transmission, provided + you inform other peers where the object code and Corresponding + Source of the work are being offered to the general public at no + charge under subsection 6d. + + A separable portion of the object code, whose source code is excluded +from the Corresponding Source as a System Library, need not be +included in conveying the object code work. + + A "User Product" is either (1) a "consumer product", which means any +tangible personal property which is normally used for personal, family, +or household purposes, or (2) anything designed or sold for incorporation +into a dwelling. In determining whether a product is a consumer product, +doubtful cases shall be resolved in favor of coverage. For a particular +product received by a particular user, "normally used" refers to a +typical or common use of that class of product, regardless of the status +of the particular user or of the way in which the particular user +actually uses, or expects or is expected to use, the product. A product +is a consumer product regardless of whether the product has substantial +commercial, industrial or non-consumer uses, unless such uses represent +the only significant mode of use of the product. + + "Installation Information" for a User Product means any methods, +procedures, authorization keys, or other information required to install +and execute modified versions of a covered work in that User Product from +a modified version of its Corresponding Source. The information must +suffice to ensure that the continued functioning of the modified object +code is in no case prevented or interfered with solely because +modification has been made. + + If you convey an object code work under this section in, or with, or +specifically for use in, a User Product, and the conveying occurs as +part of a transaction in which the right of possession and use of the +User Product is transferred to the recipient in perpetuity or for a +fixed term (regardless of how the transaction is characterized), the +Corresponding Source conveyed under this section must be accompanied +by the Installation Information. But this requirement does not apply +if neither you nor any third party retains the ability to install +modified object code on the User Product (for example, the work has +been installed in ROM). + + The requirement to provide Installation Information does not include a +requirement to continue to provide support service, warranty, or updates +for a work that has been modified or installed by the recipient, or for +the User Product in which it has been modified or installed. Access to a +network may be denied when the modification itself materially and +adversely affects the operation of the network or violates the rules and +protocols for communication across the network. + + Corresponding Source conveyed, and Installation Information provided, +in accord with this section must be in a format that is publicly +documented (and with an implementation available to the public in +source code form), and must require no special password or key for +unpacking, reading or copying. + + 7. Additional Terms. + + "Additional permissions" are terms that supplement the terms of this +License by making exceptions from one or more of its conditions. +Additional permissions that are applicable to the entire Program shall +be treated as though they were included in this License, to the extent +that they are valid under applicable law. If additional permissions +apply only to part of the Program, that part may be used separately +under those permissions, but the entire Program remains governed by +this License without regard to the additional permissions. + + When you convey a copy of a covered work, you may at your option +remove any additional permissions from that copy, or from any part of +it. (Additional permissions may be written to require their own +removal in certain cases when you modify the work.) You may place +additional permissions on material, added by you to a covered work, +for which you have or can give appropriate copyright permission. + + Notwithstanding any other provision of this License, for material you +add to a covered work, you may (if authorized by the copyright holders of +that material) supplement the terms of this License with terms: + + a) Disclaiming warranty or limiting liability differently from the + terms of sections 15 and 16 of this License; or + + b) Requiring preservation of specified reasonable legal notices or + author attributions in that material or in the Appropriate Legal + Notices displayed by works containing it; or + + c) Prohibiting misrepresentation of the origin of that material, or + requiring that modified versions of such material be marked in + reasonable ways as different from the original version; or + + d) Limiting the use for publicity purposes of names of licensors or + authors of the material; or + + e) Declining to grant rights under trademark law for use of some + trade names, trademarks, or service marks; or + + f) Requiring indemnification of licensors and authors of that + material by anyone who conveys the material (or modified versions of + it) with contractual assumptions of liability to the recipient, for + any liability that these contractual assumptions directly impose on + those licensors and authors. + + All other non-permissive additional terms are considered "further +restrictions" within the meaning of section 10. If the Program as you +received it, or any part of it, contains a notice stating that it is +governed by this License along with a term that is a further +restriction, you may remove that term. If a license document contains +a further restriction but permits relicensing or conveying under this +License, you may add to a covered work material governed by the terms +of that license document, provided that the further restriction does +not survive such relicensing or conveying. + + If you add terms to a covered work in accord with this section, you +must place, in the relevant source files, a statement of the +additional terms that apply to those files, or a notice indicating +where to find the applicable terms. + + Additional terms, permissive or non-permissive, may be stated in the +form of a separately written license, or stated as exceptions; +the above requirements apply either way. + + 8. Termination. + + You may not propagate or modify a covered work except as expressly +provided under this License. Any attempt otherwise to propagate or +modify it is void, and will automatically terminate your rights under +this License (including any patent licenses granted under the third +paragraph of section 11). + + However, if you cease all violation of this License, then your +license from a particular copyright holder is reinstated (a) +provisionally, unless and until the copyright holder explicitly and +finally terminates your license, and (b) permanently, if the copyright +holder fails to notify you of the violation by some reasonable means +prior to 60 days after the cessation. + + Moreover, your license from a particular copyright holder is +reinstated permanently if the copyright holder notifies you of the +violation by some reasonable means, this is the first time you have +received notice of violation of this License (for any work) from that +copyright holder, and you cure the violation prior to 30 days after +your receipt of the notice. + + Termination of your rights under this section does not terminate the +licenses of parties who have received copies or rights from you under +this License. If your rights have been terminated and not permanently +reinstated, you do not qualify to receive new licenses for the same +material under section 10. + + 9. Acceptance Not Required for Having Copies. + + You are not required to accept this License in order to receive or +run a copy of the Program. Ancillary propagation of a covered work +occurring solely as a consequence of using peer-to-peer transmission +to receive a copy likewise does not require acceptance. However, +nothing other than this License grants you permission to propagate or +modify any covered work. These actions infringe copyright if you do +not accept this License. Therefore, by modifying or propagating a +covered work, you indicate your acceptance of this License to do so. + + 10. Automatic Licensing of Downstream Recipients. + + Each time you convey a covered work, the recipient automatically +receives a license from the original licensors, to run, modify and +propagate that work, subject to this License. You are not responsible +for enforcing compliance by third parties with this License. + + An "entity transaction" is a transaction transferring control of an +organization, or substantially all assets of one, or subdividing an +organization, or merging organizations. If propagation of a covered +work results from an entity transaction, each party to that +transaction who receives a copy of the work also receives whatever +licenses to the work the party's predecessor in interest had or could +give under the previous paragraph, plus a right to possession of the +Corresponding Source of the work from the predecessor in interest, if +the predecessor has it or can get it with reasonable efforts. + + You may not impose any further restrictions on the exercise of the +rights granted or affirmed under this License. For example, you may +not impose a license fee, royalty, or other charge for exercise of +rights granted under this License, and you may not initiate litigation +(including a cross-claim or counterclaim in a lawsuit) alleging that +any patent claim is infringed by making, using, selling, offering for +sale, or importing the Program or any portion of it. + + 11. Patents. + + A "contributor" is a copyright holder who authorizes use under this +License of the Program or a work on which the Program is based. The +work thus licensed is called the contributor's "contributor version". + + A contributor's "essential patent claims" are all patent claims +owned or controlled by the contributor, whether already acquired or +hereafter acquired, that would be infringed by some manner, permitted +by this License, of making, using, or selling its contributor version, +but do not include claims that would be infringed only as a +consequence of further modification of the contributor version. For +purposes of this definition, "control" includes the right to grant +patent sublicenses in a manner consistent with the requirements of +this License. + + Each contributor grants you a non-exclusive, worldwide, royalty-free +patent license under the contributor's essential patent claims, to +make, use, sell, offer for sale, import and otherwise run, modify and +propagate the contents of its contributor version. + + In the following three paragraphs, a "patent license" is any express +agreement or commitment, however denominated, not to enforce a patent +(such as an express permission to practice a patent or covenant not to +sue for patent infringement). To "grant" such a patent license to a +party means to make such an agreement or commitment not to enforce a +patent against the party. + + If you convey a covered work, knowingly relying on a patent license, +and the Corresponding Source of the work is not available for anyone +to copy, free of charge and under the terms of this License, through a +publicly available network server or other readily accessible means, +then you must either (1) cause the Corresponding Source to be so +available, or (2) arrange to deprive yourself of the benefit of the +patent license for this particular work, or (3) arrange, in a manner +consistent with the requirements of this License, to extend the patent +license to downstream recipients. "Knowingly relying" means you have +actual knowledge that, but for the patent license, your conveying the +covered work in a country, or your recipient's use of the covered work +in a country, would infringe one or more identifiable patents in that +country that you have reason to believe are valid. + + If, pursuant to or in connection with a single transaction or +arrangement, you convey, or propagate by procuring conveyance of, a +covered work, and grant a patent license to some of the parties +receiving the covered work authorizing them to use, propagate, modify +or convey a specific copy of the covered work, then the patent license +you grant is automatically extended to all recipients of the covered +work and works based on it. + + A patent license is "discriminatory" if it does not include within +the scope of its coverage, prohibits the exercise of, or is +conditioned on the non-exercise of one or more of the rights that are +specifically granted under this License. You may not convey a covered +work if you are a party to an arrangement with a third party that is +in the business of distributing software, under which you make payment +to the third party based on the extent of your activity of conveying +the work, and under which the third party grants, to any of the +parties who would receive the covered work from you, a discriminatory +patent license (a) in connection with copies of the covered work +conveyed by you (or copies made from those copies), or (b) primarily +for and in connection with specific products or compilations that +contain the covered work, unless you entered into that arrangement, +or that patent license was granted, prior to 28 March 2007. + + Nothing in this License shall be construed as excluding or limiting +any implied license or other defenses to infringement that may +otherwise be available to you under applicable patent law. + + 12. No Surrender of Others' Freedom. + + If conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot convey a +covered work so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you may +not convey it at all. For example, if you agree to terms that obligate you +to collect a royalty for further conveying from those to whom you convey +the Program, the only way you could satisfy both those terms and this +License would be to refrain entirely from conveying the Program. + + 13. Use with the GNU Affero General Public License. + + Notwithstanding any other provision of this License, you have +permission to link or combine any covered work with a work licensed +under version 3 of the GNU Affero General Public License into a single +combined work, and to convey the resulting work. The terms of this +License will continue to apply to the part which is the covered work, +but the special requirements of the GNU Affero General Public License, +section 13, concerning interaction through a network will apply to the +combination as such. + + 14. Revised Versions of this License. + + The Free Software Foundation may publish revised and/or new versions of +the GNU General Public License from time to time. Such new versions will +be similar in spirit to the present version, but may differ in detail to +address new problems or concerns. + + Each version is given a distinguishing version number. If the +Program specifies that a certain numbered version of the GNU General +Public License "or any later version" applies to it, you have the +option of following the terms and conditions either of that numbered +version or of any later version published by the Free Software +Foundation. If the Program does not specify a version number of the +GNU General Public License, you may choose any version ever published +by the Free Software Foundation. + + If the Program specifies that a proxy can decide which future +versions of the GNU General Public License can be used, that proxy's +public statement of acceptance of a version permanently authorizes you +to choose that version for the Program. + + Later license versions may give you additional or different +permissions. However, no additional obligations are imposed on any +author or copyright holder as a result of your choosing to follow a +later version. + + 15. Disclaimer of Warranty. + + THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY +APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT +HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY +OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, +THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR +PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM +IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF +ALL NECESSARY SERVICING, REPAIR OR CORRECTION. + + 16. Limitation of Liability. + + IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING +WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS +THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY +GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE +USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF +DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD +PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), +EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF +SUCH DAMAGES. + + 17. Interpretation of Sections 15 and 16. + + If the disclaimer of warranty and limitation of liability provided +above cannot be given local legal effect according to their terms, +reviewing courts shall apply local law that most closely approximates +an absolute waiver of all civil liability in connection with the +Program, unless a warranty or assumption of liability accompanies a +copy of the Program in return for a fee. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Programs + + If you develop a new program, and you want it to be of the greatest +possible use to the public, the best way to achieve this is to make it +free software which everyone can redistribute and change under these terms. + + To do so, attach the following notices to the program. It is safest +to attach them to the start of each source file to most effectively +state the exclusion of warranty; and each file should have at least +the "copyright" line and a pointer to where the full notice is found. + + <one line to give the program's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This program is free software: you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation, either version 3 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License + along with this program. If not, see <http://www.gnu.org/licenses/>. + +Also add information on how to contact you by electronic and paper mail. + + If the program does terminal interaction, make it output a short +notice like this when it starts in an interactive mode: + + <program> Copyright (C) <year> <name of author> + This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'. + This is free software, and you are welcome to redistribute it + under certain conditions; type `show c' for details. + +The hypothetical commands `show w' and `show c' should show the appropriate +parts of the General Public License. Of course, your program's commands +might be different; for a GUI interface, you would use an "about box". + + You should also get your employer (if you work as a programmer) or school, +if any, to sign a "copyright disclaimer" for the program, if necessary. +For more information on this, and how to apply and follow the GNU GPL, see +<http://www.gnu.org/licenses/>. + + The GNU General Public License does not permit incorporating your program +into proprietary programs. If your program is a subroutine library, you +may consider it more useful to permit linking proprietary applications with +the library. If this is what you want to do, use the GNU Lesser General +Public License instead of this License. But first, please read +<http://www.gnu.org/philosophy/why-not-lgpl.html>. diff --git a/fun/gemma/README.md b/fun/gemma/README.md new file mode 100644 index 0000000000..064742c009 --- /dev/null +++ b/fun/gemma/README.md @@ -0,0 +1,96 @@ +# Gemma + +Gemma is a simple application to track *recurring* tasks, named after Gemma +Hartley who [wrote an article][] about task distribution issues in households. + +## Background + +(Skip this if you just want the technical bits) + +Gemma's article launched a discussion in my friend circle about what causes an +uneven distribution of household workload. I theorised that this is not so much +a gender issue, but mostly a discoverability issue. + +Usually one person in a household is aware of what needs to be done, but in many +cases the "overhead" of delegating the tasks would actually take more time than +simply doing the task. + +I theorise further that the person (or people) who do a smaller share of the +household work would often do the work if they had a convenient way to become +aware of what needs to be done. Many times the "household manager" has the +function of tracking non-obvious tasks like when bedsheets were last changed - +shouldn't it be possible to actually distribute this information somehow? + +## The Project + +This project is an initial attempt at sketching out a little application that +aids with reminding users of recurring tasks. Some basic ideas: + +* The system should be blame-free. +* There should be as little usage overhead as possible so that people actually + do use it. +* It should work mostly passively without much user interaction. + +I believe that the basic (*very* simple) idea behind Gemma solves these issues. +Unfortunately my living situation changed before I actually got to test this out +in a real-life situation involving multiple people, but feedback from other +potential test subjects would be welcome! :) + +## Overview + +Gemma is a Common Lisp application in which a list of recurring tasks is +declared, together with the *maximum interval* at which they should be completed +(in days). Example: + +```lisp +;; Bathroom tasks +(deftask bathroom/wipe-mirror 7) +(deftask bathroom/wipe-counter 7) + +;; Bedroom tasks +(deftask bedroom/change-sheets 7) +(deftask bedroom/vacuum 10) + +;; Kitchen tasks +(deftask kitchen/trash 3) +(deftask kitchen/wipe-counters 3) +(deftask kitchen/vacuum 5 "Kitchen has more crumbs and such!") + +;; Entire place +(deftask clean-windows 60) +``` + +These tasks are marked with their last completion time and tracked by Gemma. A +simple Elm-based frontend application displays the tasks sorted by their +"urgency" and features a button to mark a task as completed: + + + +Marking a task as completed resets its counter and moves it to the bottom of the +task list. + +In theory this *should be it*, the frontend is made available to household +members in some easily accessible place (e.g. an old phone glued to the fridge!) +and people should attempt to develop a habit of checking what needs to be done +occasionally. + +The "household manager" still exists as a role of the household because someone +is entering the tasks into the application, but if my theory about people not +actually being actively *unwilling* to do tasks is correct this could help a +lot. + +## Usage + +(*Note*: Gemma is alpha software so the below is clearly not the final goal) + +Right now using this is non-trivial, but I'll eventually make a better +distribution. Basically you need to know Common Lisp (in which case you'll know +how to get the backend running) and have `elm-reactor` installed to run the +development version of the frontend application. + +Gemma is configured via a configuration file that should be located either at +`/etc/gemma/config.lisp` or at a custom location specified via the environment +variable `GEMMA_CONFIG`. Have a look at the `config.lisp` file in the repository +root for an example. + +[wrote an article]: http://www.harpersbazaar.com/culture/features/a12063822/emotional-labor-gender-equality/ diff --git a/fun/gemma/config.lisp b/fun/gemma/config.lisp new file mode 100644 index 0000000000..54f8e5f344 --- /dev/null +++ b/fun/gemma/config.lisp @@ -0,0 +1,21 @@ +;; Example configuration file for Gemma + +(config :port 4242 + :data-dir "/tmp/gemma/") + +(deftask bathroom/wipe-mirror 7) +(deftask bathroom/wipe-counter 7) + +;; Bedroom tasks +(deftask bedroom/change-sheets 7) +(deftask bedroom/vacuum 10) + +;; Kitchen tasks +(deftask kitchen/normal-trash 3) +(deftask kitchen/green-trash 5) +(deftask kitchen/blue-trash 5) +(deftask kitchen/wipe-counters 3) +(deftask kitchen/vacuum 5 "Kitchen has more crumbs and such!") + +;; Entire place +(deftask clean-windows 60) diff --git a/fun/gemma/default.nix b/fun/gemma/default.nix new file mode 100644 index 0000000000..55612106d2 --- /dev/null +++ b/fun/gemma/default.nix @@ -0,0 +1,50 @@ +{ depot, ... }: + +let + inherit (depot) elmPackages; + inherit (depot.third_party) cacert iana-etc libredirect stdenv runCommandNoCC writeText; + + frontend = stdenv.mkDerivation { + name = "gemma-frontend.html"; + src = ./frontend; + buildInputs = [ cacert iana-etc elmPackages.elm ]; + + # The individual Elm packages this requires are not packaged and I + # can't be bothered to do that now, so lets open the escape hatch: + outputHashAlgo = "sha256"; + outputHash = "000xhds5bsig3kbi7dhgbv9h7myacf34bqvw7avvz7m5mwnqlqg7"; + + phases = [ "unpackPhase" "buildPhase" ]; + buildPhase = '' + export NIX_REDIRECTS=/etc/protocols=${iana-etc}/etc/protocols \ + LD_PRELOAD=${libredirect}/lib/libredirect.so + + export SYSTEM_CERTIFICATE_PATH=${cacert}/etc/ssl/certs + + mkdir .home && export HOME="$PWD/.home" + elm-make --yes Main.elm --output $out + ''; + }; + + injectFrontend = writeText "gemma-frontend.lisp" '' + (in-package :gemma) + (setq *static-file-location* "${runCommandNoCC "frontend" {} '' + mkdir -p $out + cp ${frontend} $out/index.html + ''}/") + ''; +in depot.nix.buildLisp.program { + name = "gemma"; + + deps = with depot.third_party.lisp; [ + cl-json + cl-prevalence + hunchentoot + local-time + ]; + + srcs = [ + ./src/gemma.lisp + injectFrontend + ]; +} diff --git a/fun/gemma/frontend/Main.elm b/fun/gemma/frontend/Main.elm new file mode 100644 index 0000000000..e449908e49 --- /dev/null +++ b/fun/gemma/frontend/Main.elm @@ -0,0 +1,221 @@ +-- Copyright (C) 2016-2017 Vincent Ambo <mail@tazj.in> +-- +-- This file is part of Gemma. +-- +-- Gemma is free software: you can redistribute it and/or modify it +-- under the terms of the GNU General Public License as published by +-- the Free Software Foundation, either version 3 of the License, or +-- (at your option) any later version. + + +module Main exposing (..) + +import Html exposing (Html, text, div, span) +import Html.Attributes exposing (style) +import Json.Decode exposing (..) +import Http +import Time + + +-- Material design imports + +import Material +import Material.Card as Card +import Material.Color as Color +import Material.Grid exposing (grid, cell, size, Device(..)) +import Material.Layout as Layout +import Material.Scheme as Scheme +import Material.Options as Options +import Material.Elevation as Elevation +import Material.Button as Button + + +-- API interface to Gemma + + +type alias Task = + { name : String + , description : Maybe String + , remaining : Int + } + + +emptyStringFilter s = + if s == "" then + Nothing + else + Just s + + +decodeEmptyString : Decoder (Maybe String) +decodeEmptyString = + map emptyStringFilter string + + +decodeTask : Decoder Task +decodeTask = + map3 Task + (field "name" string) + (field "description" decodeEmptyString) + (field "remaining" int) + + +loadTasks : Cmd Msg +loadTasks = + let + request = + Http.get "/tasks" (list decodeTask) + in + Http.send NewTasks request + + +completeTask : Task -> Cmd Msg +completeTask task = + let + request = + Http.getString + (String.concat + [ "/complete?task=" + , task.name + ] + ) + in + Http.send (\_ -> LoadTasks) request + + + +-- Elm architecture implementation + + +type Msg + = None + | LoadTasks + | NewTasks (Result Http.Error (List Task)) + | Mdl (Material.Msg Msg) + | Complete Task + + +type alias Model = + { tasks : List Task + , error : Maybe String + , mdl : Material.Model + } + + +update : Msg -> Model -> ( Model, Cmd Msg ) +update msg model = + case msg of + LoadTasks -> + ( model, loadTasks ) + + Complete task -> + ( model, completeTask task ) + + NewTasks (Ok tasks) -> + ( { model | tasks = tasks, error = Nothing }, Cmd.none ) + + NewTasks (Err err) -> + ( { model | error = Just (toString err) }, Cmd.none ) + + _ -> + ( model, Cmd.none ) + + + +-- View implementation + + +white = + Color.text Color.white + + +taskColor : Task -> Color.Hue +taskColor task = + if task.remaining > 2 then + Color.Green + else if task.remaining < 0 then + Color.Red + else + Color.Yellow + + +within : Task -> String +within task = + if task.remaining < 0 then + "This task is overdue!" + else if task.remaining > 2 then + String.concat + [ "Relax, this task has " + , toString task.remaining + , " days left before it is due." + ] + else + String.concat + [ "This task should be completed within " + , toString task.remaining + , " days. Consider doing it now!" + ] + + +renderTask : Model -> Task -> Html Msg +renderTask model task = + Card.view + [ Color.background (Color.color (taskColor task) Color.S800) + , Elevation.e3 + ] + [ Card.title [] [ Card.head [ white ] [ text task.name ] ] + , Card.text [ white ] + [ text (Maybe.withDefault "" task.description) + , Html.br [] [] + , text (within task) + ] + , Card.actions + [ Card.border ] + [ Button.render Mdl + [ 0 ] + model.mdl + [ white, Button.ripple, Button.accent, Options.onClick (Complete task) ] + [ text "Completed" ] + ] + ] + + +gemmaView : Model -> Html Msg +gemmaView model = + grid [] + (List.map (\t -> cell [ size All 4 ] [ renderTask model t ]) + model.tasks + ) + + +view : Model -> Html Msg +view model = + gemmaView model |> Scheme.top + + + +-- subscriptions : Model -> Sub Msg + + +subscriptions model = + Sub.batch + [ Material.subscriptions Mdl model + , Time.every (15 * Time.second) (\_ -> LoadTasks) + ] + + +main : Program Never Model Msg +main = + let + model = + { tasks = [] + , error = Nothing + , mdl = Material.model + } + in + Html.program + { init = ( model, Cmd.batch [ loadTasks, Material.init Mdl ] ) + , view = view + , update = update + , subscriptions = subscriptions + } diff --git a/fun/gemma/frontend/elm-package.json b/fun/gemma/frontend/elm-package.json new file mode 100644 index 0000000000..2ae541ae0b --- /dev/null +++ b/fun/gemma/frontend/elm-package.json @@ -0,0 +1,17 @@ +{ + "version": "1.0.0", + "summary": "helpful summary of your project, less than 80 characters", + "repository": "https://github.com/user/project.git", + "license": "BSD3", + "source-directories": [ + "." + ], + "exposed-modules": [], + "dependencies": { + "elm-lang/core": "5.1.1 <= v < 6.0.0", + "elm-lang/html": "2.0.0 <= v < 3.0.0", + "elm-lang/http": "1.0.0 <= v < 2.0.0", + "debois/elm-mdl": "8.1.0 <= v < 9.0.0" + }, + "elm-version": "0.18.0 <= v < 0.19.0" +} diff --git a/fun/gemma/src/gemma.lisp b/fun/gemma/src/gemma.lisp new file mode 100644 index 0000000000..20a76caae6 --- /dev/null +++ b/fun/gemma/src/gemma.lisp @@ -0,0 +1,192 @@ +;; Copyright (C) 2016-2020 Vincent Ambo <mail@tazj.in> +;; +;; This file is part of Gemma. +;; +;; Gemma is free software: you can redistribute it and/or modify it +;; under the terms of the GNU General Public License as published by +;; the Free Software Foundation, either version 3 of the License, or +;; (at your option) any later version. + +(defpackage gemma + (:use :cl + :local-time + :cl-json) + (:import-from :sb-posix :getenv) + (:shadowing-import-from :sb-posix :getcwd) + (:export :start-gemma :config :main)) +(in-package :gemma) + +;; TODO: Store an average of how many days it was between task +;; completions. Some of the current numbers are just guesses +;; anyways. + +(defmacro in-case-of (x &body body) + "Evaluate BODY if X is non-nil, binding the value of X to IT." + `(let ((it ,x)) + (when it ,@body))) + +;; Set default configuration parameters +(defvar *gemma-port* 4242 + "Port on which the Gemma web server listens.") + +(defvar *gemma-acceptor* nil + "Hunchentoot acceptor for Gemma's web server.") + +(defvar *static-file-location* "frontend/" + "Folder from which to serve static assets. If built inside of Nix, + the path is injected during the build.") + +(defvar *p-tasks* nil + "All tasks registered in this Gemma instance.") + +(defun initialise-persistence (data-dir) + (setq *p-tasks* (cl-prevalence:make-prevalence-system data-dir)) + + ;; Initialise database ID counter + (or (> (length (cl-prevalence:find-all-objects *p-tasks* 'task)) 0) + (cl-prevalence:tx-create-id-counter *p-tasks*))) + +(defun config (&key port data-dir) + "Configuration function for use in the Gemma configuration file." + + (in-package :gemma) + (in-case-of port (defparameter *gemma-port* it)) + (initialise-persistence (or data-dir "data/"))) + +;; +;; Define task management system +;; + +(defclass task () + ((id :reader id + :initarg :id) + + ;; (Unique) name of the task + (name :type symbol + :initarg :name + :accessor name-of) + + ;; Maximum completion interval + (days :type integer + :initarg :days + :accessor days-of) + + ;; Optional description + (description :type string + :initarg :description + :accessor description-of) + + ;; Last completion time + (done-at :type timestamp + :initarg :done-at + :accessor last-done-at))) + +(defmacro deftask (task-name days &optional description) + (unless (get-task task-name) + `(progn (cl-prevalence:tx-create-object + *p-tasks* + 'task + (quote ((name ,task-name) + (days ,days) + (description ,(or description "")) + (done-at ,(now))))) + (cl-prevalence:snapshot *p-tasks*)))) + +(defun get-task (name) + (cl-prevalence:find-object-with-slot *p-tasks* 'task 'name name)) + +(defun list-tasks () + (cl-prevalence:find-all-objects *p-tasks* 'task)) + +(defun days-remaining (task) + "Returns the number of days remaining before the supplied TASK reaches its +maximum interval." + (let* ((expires-at (timestamp+ (last-done-at task) + (days-of task) :day)) + (secs-until-expiry (timestamp-difference expires-at (now)))) + (round (/ secs-until-expiry 60 60 24)))) + +(defun sort-tasks (tasks) + "Sorts TASKS in descending order by number of days remaining." + (sort (copy-list tasks) + (lambda (t1 t2) (< (days-remaining t1) + (days-remaining t2))))) + +(defun complete-task (name &optional at) + "Mark the task with NAME as completed, either now or AT specified time." + (cl-prevalence:tx-change-object-slots *p-tasks* 'task + (id (get-task name)) + `((done-at ,(or at (now))))) + (cl-prevalence:snapshot *p-tasks*)) + +;; +;; Define web API +;; + +(defun response-for (task) + "Create a response object to be JSON encoded for TASK." + `((:name . ,(name-of task)) + (:description . ,(description-of task)) + (:remaining . ,(days-remaining task)))) + +(defun start-gemma () + (in-package :gemma) + + ;; Load configuration + (load (pathname (or (getenv "GEMMA_CONFIG") + "/etc/gemma/config.lisp"))) + + ;; Set up web server + (setq *gemma-acceptor* (make-instance 'hunchentoot:easy-acceptor + :port *gemma-port* + :document-root *static-file-location*)) + (hunchentoot:start *gemma-acceptor*) + + ;; Task listing handler + (hunchentoot:define-easy-handler + (get-tasks :uri "/tasks") () + + (setf (hunchentoot:content-type*) "application/json") + (setf (hunchentoot:header-out "Access-Control-Allow-Origin") "*") + (encode-json-to-string + ;; Construct a frontend-friendly representation of the tasks. + (mapcar #'response-for (sort-tasks (list-tasks))))) + + ;; Task completion handler + (hunchentoot:define-easy-handler + (complete-task-handler :uri "/complete") (task) + (setf (hunchentoot:content-type*) "application/json") + (let* ((key (find-symbol (camel-case-to-lisp task) "GEMMA"))) + (format t "Marking task ~A as completed" key) + (complete-task key) + (encode-json-to-string (response-for (get-task key)))))) + +(defun main () + "This function serves as the entrypoint for ASDF-built executables. + It joins the Hunchentoot server thread to keep the process running + for as long as the server is alive." + + (start-gemma) + (sb-thread:join-thread + (find-if (lambda (th) + (string= (sb-thread:thread-name th) + (format nil "hunchentoot-listener-*:~A" *gemma-port*))) + (sb-thread:list-all-threads)))) + +;; Experimentation / testing stuff + +(defun randomise-completion-times () + "Set some random completion timestamps for all tasks" + (mapcar + (lambda (task) + (complete-task (name-of task) + (timestamp- (now) + (random 14) + :day))) + (cl-prevalence:find-all-objects *p-tasks* 'task))) + +(defun clear-all-tasks () + (mapcar (lambda (task) (cl-prevalence:tx-delete-object *p-tasks* 'task (id task))) + (cl-prevalence:find-all-objects *p-tasks* 'task))) + +;; (randomise-completion-times) diff --git a/fun/idual/README.md b/fun/idual/README.md new file mode 100644 index 0000000000..922047617f --- /dev/null +++ b/fun/idual/README.md @@ -0,0 +1,34 @@ +# iDual light control + +This folder contains some tooling for controlling iDual LED lights +(which use infrared controls) using a "Broadlink RM Pro" infrared +controller. + +The supported colour codes of the iDual remote are stored in +`codes.txt`. + +The point of this is to make it possible for me to automate my lights +in the morning, so that I can actually get out of bed. + +## Capturing codes + +Capturing codes is relatively easy, assuming that the broadlink device +is set up: + +```python +import broadlink +import base64 + +devices = broadlink.discover(timeout=5) +devices[0].auth() +``` + +For each code, the procedure is as follows: + +```python +devices[0].find_rf_packet() +# wait until this returns True + +devices[0].check_data() +# this will return the code +``` diff --git a/fun/idual/default.nix b/fun/idual/default.nix new file mode 100644 index 0000000000..1ac87ab47f --- /dev/null +++ b/fun/idual/default.nix @@ -0,0 +1,24 @@ +{ pkgs, lib, ... }: + +let + inherit (pkgs) python python3 python3Packages; + + opts = { + pname = "idualctl"; + version = "0.1"; + src = ./.; + + propagatedBuildInputs = [ + python.broadlink + ]; + }; + package = python3Packages.buildPythonPackage opts; + script = python3Packages.buildPythonApplication opts; +in { + inherit script; + python = python3.withPackages (_: [ package ]); + setAlarm = pkgs.writeShellScriptBin "set-alarm" '' + echo "setting an alarm for ''${1}" + ${pkgs.systemd}/bin/systemd-run --user --on-calendar="''${1} Europe/London" --unit=light-alarm.service + ''; +} diff --git a/fun/idual/idual/__init__.py b/fun/idual/idual/__init__.py new file mode 100644 index 0000000000..4c5519d0ad --- /dev/null +++ b/fun/idual/idual/__init__.py @@ -0,0 +1,65 @@ +import base64 +import broadlink +import time +import sys + +commands = { + # system commands + 'on' : 'JgBIAAABK5AVERQ2FBEUERQSFBEUERQSFBEUNhQ2FDUUNhQ2FDYUNRU1FBIUERQRFBIUERQRFBIUERQ2FDYUNRQ2FDYUNhQ1FQANBQ==', + 'off' : 'JgBIAAABLJAUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDUVNRQ2FDYUNhQRFDYUERQSFBEUERQSFBEUNhQRFDYUNhQ2FDUUNhQ2FAANBQ==', + 'darker' : 'JgBIAAABLI8VERQ2FBEUERURFBEUEhQRFBEUNhQ2FDYUNRU1FDYUNhQRFBIUERQRFDYUEhQRFBEVNRQ2FDYUNhQRFDYUNhQ1FQANBQ==', + 'brighter' : 'JgBIAAABLI8VERQ2FBEUERQSFBEUEhQRFBEUNhQ2FDUVNRQ2FDYUNRU1FBIUERQ2FBEUEhQRFBEUEhQ1FTUUEhQ1FTUUNhQ2FAANBQ==', + + # presets + 'candle' : 'JgBQAAABKZISExI4EhMSFBITEhQRFBITEhQROBI4EjgSOBE4EjgSOBI4ERQSExIUEjgRFBITEhQSExI4EjgROBIUEjcSOBI4EgAFJgABKUkSAA0FAAAAAAAAAAA=', + 'bulb' : 'JgBYAAABK5AUERQ2FBEVERQRFBEVERQRFBEVNRQ2FDYUNRU1FDYUNhQRFDYUNRURFBEUEhQRFBEUNhQRFREUNhQ1FDYUNhQ2FAAFIwABKkgVAAxOAAErRxUADQU=', + 'sun' : 'JgBQAAABLI8VERQ2FBEUERURFBEUEhQRFBEUNhQ2FDYUNRU1FTUUNhQSFDUUEhQ2FBEUERURFBEUNhQSFDUUEhQ2FDUVNRQ2FAAFJQABK0cVAA0FAAAAAAAAAAA=', + 'cold' : 'JgBQAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDYUNRQ2FDYUNhQ1FTUUEhQRFBEUEhQRFBIUERQRFDYUNhQ2FDYUNRQ2FAAFJAABK0cVAA0FAAAAAAAAAAA=', + 'eve_dark' : 'JgBQAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDYUNRU1FDYUNhQRFDYUERQSFDUUEhQRFBIUNRQSFDUUNhQSFDUUNhQ2FAAFIwABLEYVAA0FAAAAAAAAAAA=', + 'eve_fade' : 'JgBIAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDYUNRQ2FDYUNhQ1FDYUNhQRFDYUERQSFBEUEhQRFBEUNhQSEzYUNhQ2FAANBQ==', + 'reading' : 'JgBQAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDUVNRQ2FDYUNhQ1FDYUEhQ1FBIUERQRFBIUERQSFDUUEhQ1FTUUNhQ2FAAFJAABK0YVAA0FAAAAAAAAAAA=', + 'yoga' : 'JgBYAAABLI8VERQ1FREUERQSFBEUERURFBEUNhQ1FTUUNhQ2FDYUNRURFBEUNhQRFBIUERMSExMTNxM2ExMTNxM2EzcTNxM3EwAFJQABKkgTAAxRAAErRxUADQU=', + 'morning' : 'JgBQAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDUVNRQ2FDYUNRU1FDYUERURFDUVERQRFBIUERQRFTUUNhQRFDYUNhQ2FAAFIwABK0cVAA0FAAAAAAAAAAA=', + 'colours' : 'JgBQAAABLI8VERQ2FBEUERQSFBEUERURFBEUNhQ1FTUUNhQ2FDYUNRQSFBEUERQ2FDYUERQSFBEUNhQ1FTUUEhQRFDYUNRU1FAAFJAABKkcVAA0FAAAAAAAAAAA=', + 'random' : 'JgBQAAABK5AUEhQ1FREUERQSFBEUERQSExIUNhQ1EzcTNxM3EzYTNxMTEhMTNxM2ExMTEhMSExMTNxM2ExMTEhM3EzcTNhM3EwAFJQABK0cVAA0FAAAAAAAAAAA=', + 'island' : 'JgBQAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDUVNRQ2FDYUNRU1FBIUNRURFBEUEhQRFBEUEhQ1FREUNhQ1FDYUNhQ2FAAFIwABK0cVAA0FAAAAAAAAAAA=', + 'forest' : 'JgBQAAABK5AUEhQ1FREUERQSFBEUERQSFBEUNhQ1FTUUNhQ2FDUVNRQSFBEUNhQRFDYUERQSFBEUNhQ2FBEUNhQRFDYUNhQ1FQAFIwABK0cVAA0FAAAAAAAAAAA=', + 'ocean' : 'JgBQAAABK5AUEhQ1FREUERQSFBEUERQRFREUNhQ1FTUUNhQ2FDUVNRQ2FBEUEhQ1FTUUEhQRFBEUEhQ1FTUUEhQRFDYUNRU1FAAFJAABK0cVAA0FAAAAAAAAAAA=', + 'fire' : 'JgBQAAABK5AUERQ2FBEUEhQRFBEUEhQRFBEUNhQ2FDUVNRQ2FDYUNRU1FBIUNRU1FBIUERQRFBIUERQ2FBEUEhQ1FTUUNhQ2FAAFIwABLEYVAA0FAAAAAAAAAAA=', + 'love' : 'JgBQAAABL5AUEhQ1FREUERQSFBEUERQSFBEUNhQ1FDYUNhQ2FDUVNRQSFDUUNhQSFBEUERQSFBEUNhQRFBIUNRQ2FDYUNhQ1FAAFJAABK0cVAA0FAAAAAAAAAAA=', + + # colour commands + 'red' : 'JgBIAAABK5AUERQ2FBEUEhQRFBEVERQRFBEUNhQ2FDYUNRU1FDYUNhQRFDYUNhQ1FREUERQSFBEUNhQRFBIUERQ2FDUVNRQ2FAANBQ==', + 'yellow' : 'JgBIAAABLI8UEhQ2FBEUERQSFBEUEhMSFBEUNhQ2FDUUNhQ2FDYUNRQ2FDYUNhQRFBIUERQRFBIUERQSExIUNhQ1FDYUNhQ2FAANBQ==', + 'green' : 'JgBIAAABK5AUEhQ1FREUERQSFBEUERQSFBEUNhQ1FDYUNhQ2FDUVNRQSFBEUERQ2FBIUERQRFBIUNRU1FDYUERQ2FDYUNhQ1FQANBQ==', + 'blue' : 'JgBIAAABK5AUERQ2FBEUEhQRFBITEhQRFBEUNhQ2FDYUNRQ2FDYUNhQ2ExIUNhQRFDYUERQSExIUERQ2FBEUNhQSEzYUNhQ2FAANBQ==', + 'saturate' : 'JgBIAAABK5AUERQ2FBEUEhQRFBIUERQRFBEUNhQ2FDYUNRU1FDYUNhQRFDYUERQ2FDYUERQSFBEUNhQRFDYUERQSFDUUNhQ2FAANBQ==', + 'desaturate' : 'JgBIAAABLI8VERQ2FBEUERQSFBEUERURFBEUNhQ1FTUUNhQ2FDYUNRQ2FDYUNhQ1FREUERQSFBEUERQSFBEUERQ2FDYUNhQ1FQANBQ==', +} + +def cmd(name): + return base64.b64decode(commands[name]) + +class LightController: + def __init__(self): + self.devices = broadlink.discover(timeout=10, max_devices=2) + if self.devices == []: + raise Exception('no devices found') + for device in self.devices: + device.auth() + + def send_cmd(self, name, iterations=5): + "Send a command, repeatedly for reliability" + packet = cmd(name) + for i in range(iterations): + for device in self.devices: + device.send_data(packet) + + def wakey(self): + "Turn on the lights in the morning, try repeatedly for reasons." + print('Turning on the lights. Wakey, wakey!') + for i in range(5): + self.send_cmd('sun') + time.sleep(0.3) + self.send_cmd('on') + time.sleep(0.3) diff --git a/fun/idual/idualctl b/fun/idual/idualctl new file mode 100644 index 0000000000..10a85eba0a --- /dev/null +++ b/fun/idual/idualctl @@ -0,0 +1,39 @@ +#!/usr/bin/env python + +import idual +import sys + +def help(): + print('Available commands:') + for cmd in idual.commands: + print('- ' + cmd) + sys.exit(0) + +def handle(ctrl, cmd): + if cmd == 'help': + help() + elif cmd == 'wakey': + ctrl.wakey() + sys.exit(0) + elif cmd == 'on': + print('Turning on the lights') + ctrl.send_cmd(cmd) + elif cmd == 'off': + print('Turning off the lights') + ctrl.send_cmd(cmd) + elif cmd in idual.commands: + print('Sending ' + cmd + '-command') + ctrl.send_cmd(cmd) + else: + print('unknown command \'' + cmd + '\'') + sys.exit(1) + +if __name__ == "__main__": + if len(sys.argv) == 1: + help() + + print('Initialising light controller') + ctrl = idual.LightController() + + for cmd in sys.argv[1:]: + handle(ctrl, cmd) diff --git a/fun/idual/setup.py b/fun/idual/setup.py new file mode 100644 index 0000000000..f10c3b86f2 --- /dev/null +++ b/fun/idual/setup.py @@ -0,0 +1,15 @@ +#!/usr/bin/env python +# -*- coding: utf-8 -*- +from setuptools import setup + +setup( + name='idualctl', + version='0.1', + author='Vincent Ambo', + author_email='mail@tazj.in', + url='https://git.tazj.in/about/fun/idual', + packages=['idual'], + scripts = ['idualctl'], + install_requires=['broadlink>=0.13.2'], + include_package_data=True, +) diff --git a/fun/logo/depot-logo.png b/fun/logo/depot-logo.png new file mode 100644 index 0000000000..5d4d0b5c04 --- /dev/null +++ b/fun/logo/depot-logo.png Binary files differdiff --git a/fun/logo/depot-logo.xcf b/fun/logo/depot-logo.xcf new file mode 100644 index 0000000000..3bf6a67131 --- /dev/null +++ b/fun/logo/depot-logo.xcf Binary files differdiff --git a/fun/quinistry/.gitignore b/fun/quinistry/.gitignore new file mode 100644 index 0000000000..622119552e --- /dev/null +++ b/fun/quinistry/.gitignore @@ -0,0 +1,2 @@ +.idea/ +quinistry \ No newline at end of file diff --git a/fun/quinistry/README.md b/fun/quinistry/README.md new file mode 100644 index 0000000000..de197a219e --- /dev/null +++ b/fun/quinistry/README.md @@ -0,0 +1,63 @@ +Quinistry +========= + +*A simple Docker registry quine.* + +## What? + +This is an example project for a from-scratch implementation of an HTTP server compatible with the [Docker Registry V2][] +protocol. + +It serves a single image called `quinistry:latest` which is a Docker image that runs quinistry itself, therefore it is a +sort of Docker registry [quine][]. + +The official documentation does not contain enough information to actually implement this protocol (which I assume is +intentional), but a bit of trial&error lead there anyways. I've added comments to parts of the code to clear up things +that may be helpful to other developers in the future. + +## Example + +``` +# Run quinistry: +vincent@urdhva ~/go/src/github.com/tazjin/quinistry (git)-[master] % ./quinistry +2017/03/16 14:11:56 Starting quinistry + +# Pull the quinistry image from itself: +vincent@urdhva ~ % docker pull localhost:8080/quinistry +Using default tag: latest +latest: Pulling from quinistry +7bf1a8b18466: Already exists +Digest: sha256:d5cd4490901ef04b4e28e4ccc03a1d25fe3461200cf4d7166aab86fcd495e22e +Status: Downloaded newer image for localhost:8080/quinistry:latest + +# Quinistry will log: +2017/03/16 14:14:03 Acknowleding V2 API: GET /v2/ +2017/03/16 14:14:03 Serving manifest: GET /v2/quinistry/manifests/latest +2017/03/16 14:14:03 Serving config: GET /v2/quinistry/blobs/sha256:fbb165c48849de16017aa398aa9bb08fd1c00eaa7c150b6c2af37312913db279 + +# Run the downloaded image: +vincent@urdhva ~ % docker run -p 8090:8080 localhost:8080/quinistry +2017/03/16 13:15:18 Starting quinistry + +# And download it again from itself: +vincent@urdhva ~ % docker pull localhost:8090/quinistry +Using default tag: latest +latest: Pulling from quinistry +7bf1a8b18466: Already exists +Digest: sha256:11141d95ddce0bac9ffa32ab1e8bc94748ed923e87762c68858dc41d11a46d3f +Status: Downloaded newer image for localhost:8090/quinistry:latest +``` + +## Building + +Quinistry creates a Docker image that only contains a statically linked `main` binary. As this package makes use of +`net/http`, Go will (by default) link against `libc` for DNS resolution and create a dynamic binary instead. + +To disable this, `build` the project with `-tags netgo`: + +``` +go build -tags netgo +``` + +[Docker Registry V2]: https://docs.docker.com/registry/spec/api/ +[quine]: https://en.wikipedia.org/wiki/Quine_(computing) \ No newline at end of file diff --git a/fun/quinistry/const.go b/fun/quinistry/const.go new file mode 100644 index 0000000000..173fa9efc3 --- /dev/null +++ b/fun/quinistry/const.go @@ -0,0 +1,12 @@ +package main + +// HTTP content types + +const ImageConfigMediaType string = "application/vnd.docker.container.image.v1+json" +const ManifestMediaType string = "application/vnd.docker.distribution.manifest.v2+json" +const LayerMediaType string = "application/vnd.docker.image.rootfs.diff.tar.gzip" + +// HTTP header names + +const ContentType string = "Content-Type" +const DigestHeader string = "Docker-Content-Digest" diff --git a/fun/quinistry/default.nix b/fun/quinistry/default.nix new file mode 100644 index 0000000000..b12c5e6f0c --- /dev/null +++ b/fun/quinistry/default.nix @@ -0,0 +1,11 @@ +{ depot, ... }: + +depot.nix.buildGo.program { + name = "quinistry"; + srcs = [ + ./const.go + ./image.go + ./main.go + ./types.go + ]; +} diff --git a/fun/quinistry/image.go b/fun/quinistry/image.go new file mode 100644 index 0000000000..3daeac34d6 --- /dev/null +++ b/fun/quinistry/image.go @@ -0,0 +1,150 @@ +// The code in this file creates a Docker image layer containing the binary of the +// application itself. + +package main + +import ( + "archive/tar" + "bytes" + "compress/gzip" + "crypto/sha256" + "encoding/json" + "fmt" + "io/ioutil" + "log" + "os" + "time" +) + +// This function creates a Docker-image digest (i.e. SHA256 hash with +// algorithm-specification prefix) +func Digest(b []byte) string { + hash := sha256.New() + hash.Write(b) + + return fmt.Sprintf("sha256:%x", hash.Sum(nil)) +} + +func GetImageOfCurrentExecutable() Image { + binary := getCurrentBinary() + tarArchive := createTarArchive(&map[string][]byte{ + "/main": binary, + }) + + configJson, configElem := createConfig([]string{Digest(tarArchive)}) + compressed := gzipArchive("Quinistry image", tarArchive) + manifest := createManifest(&configElem, &compressed) + manifestJson, _ := json.Marshal(manifest) + + return Image{ + Layer: compressed, + LayerDigest: Digest(compressed), + Manifest: manifestJson, + ManifestDigest: Digest(manifestJson), + Config: configJson, + ConfigDigest: Digest(configJson), + } + +} + +func getCurrentBinary() []byte { + path, _ := os.Executable() + file, _ := ioutil.ReadFile(path) + return file +} + +func createTarArchive(files *map[string][]byte) []byte { + buf := new(bytes.Buffer) + w := tar.NewWriter(buf) + + for name, file := range *files { + hdr := &tar.Header{ + Name: name, + // Everything is executable \o/ + Mode: 0755, + Size: int64(len(file)), + } + w.WriteHeader(hdr) + w.Write(file) + } + + if err := w.Close(); err != nil { + log.Fatalln(err) + os.Exit(1) + } + + return buf.Bytes() +} + +func gzipArchive(name string, archive []byte) []byte { + buf := new(bytes.Buffer) + w := gzip.NewWriter(buf) + w.Name = name + w.Write(archive) + + if err := w.Close(); err != nil { + log.Fatalln(err) + os.Exit(1) + } + + return buf.Bytes() +} + +func createConfig(layerDigests []string) (configJson []byte, elem Element) { + now := time.Now() + + imageConfig := &ImageConfig{ + Cmd: []string{"/main"}, + Env: []string{"PATH=/"}, + } + + rootFs := RootFs{ + DiffIds: layerDigests, + Type: "layers", + } + + history := []History{ + { + Created: now, + CreatedBy: "Quinistry magic", + }, + } + + config := Config{ + Created: now, + Author: "tazjin", + Architecture: "amd64", + Os: "linux", + Config: imageConfig, + RootFs: rootFs, + History: history, + } + + configJson, _ = json.Marshal(config) + + elem = Element{ + MediaType: ImageConfigMediaType, + Size: len(configJson), + Digest: Digest(configJson), + } + + return +} + +func createManifest(config *Element, layer *[]byte) Manifest { + layers := []Element{ + { + MediaType: LayerMediaType, + Size: len(*layer), + // Layers must contain the digest of the *gzipped* layer. + Digest: Digest(*layer), + }, + } + + return Manifest{ + SchemaVersion: 2, + MediaType: ManifestMediaType, + Config: *config, + Layers: layers, + } +} diff --git a/fun/quinistry/k8s/child.yaml b/fun/quinistry/k8s/child.yaml new file mode 100644 index 0000000000..aa2e318262 --- /dev/null +++ b/fun/quinistry/k8s/child.yaml @@ -0,0 +1,27 @@ +# This is a child quinistry, running via an image served off the parent. +--- +apiVersion: extensions/v1beta1 +kind: DaemonSet +metadata: + name: quinistry-gen2 + labels: + k8s-app: quinistry + quinistry/role: child + quinistry/generation: '2' +spec: + template: + metadata: + labels: + k8s-app: quinistry + quinistry/role: child + quinistry/generation: '2' + spec: + containers: + - name: quinistry + # Bootstrap via Docker Hub (or any other registry) + image: localhost:5000/quinistry + ports: + - name: registry + containerPort: 8080 + # Incremented hostPort, + hostPort: 5001 diff --git a/fun/quinistry/k8s/parent.yaml b/fun/quinistry/k8s/parent.yaml new file mode 100644 index 0000000000..0db2fe300e --- /dev/null +++ b/fun/quinistry/k8s/parent.yaml @@ -0,0 +1,27 @@ +# This is a bootstrapped Quinistry DaemonSet. The initial image +# comes from Docker Hub +--- +apiVersion: extensions/v1beta1 +kind: DaemonSet +metadata: + name: quinistry + labels: + k8s-app: quinistry + quinistry/role: parent + quinistry/generation: '1' +spec: + template: + metadata: + labels: + k8s-app: quinistry + quinistry/role: parent + quinistry/generation: '1' + spec: + containers: + - name: quinistry + # Bootstrap via Docker Hub (or any other registry) + image: tazjin/quinistry + ports: + - name: registry + containerPort: 8080 + hostPort: 5000 diff --git a/fun/quinistry/main.go b/fun/quinistry/main.go new file mode 100644 index 0000000000..50b47418d1 --- /dev/null +++ b/fun/quinistry/main.go @@ -0,0 +1,57 @@ +package main + +import ( + "fmt" + "log" + "net/http" +) + +func main() { + log.Println("Starting quinistry") + + image := GetImageOfCurrentExecutable() + + layerUri := fmt.Sprintf("/v2/quinistry/blobs/%s", image.LayerDigest) + configUri := fmt.Sprintf("/v2/quinistry/blobs/%s", image.ConfigDigest) + + log.Fatal(http.ListenAndServe(":8080", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { + // Acknowledge that we speak V2 + if r.RequestURI == "/v2/" { + logRequest("Acknowleding V2 API", r) + fmt.Fprintln(w) + return + } + + // Serve manifest + if r.RequestURI == "/v2/quinistry/manifests/latest" { + logRequest("Serving manifest", r) + w.Header().Set(ContentType, ManifestMediaType) + w.Header().Add(DigestHeader, image.ManifestDigest) + w.Write(image.Manifest) + return + } + + // Serve actual image layer + if r.RequestURI == layerUri { + logRequest("Serving image layer blob", r) + w.Header().Add(DigestHeader, image.LayerDigest) + w.Write(image.Layer) + return + } + + // Serve image config + if r.RequestURI == configUri { + logRequest("Serving config", r) + w.Header().Set("Content-Type", ImageConfigMediaType) + w.Header().Set(DigestHeader, image.ConfigDigest) + w.Write(image.Config) + return + } + + log.Printf("Unhandled request: %v\n", *r) + }))) +} + +func logRequest(msg string, r *http.Request) { + log.Printf("%s: %s %s\n", msg, r.Method, r.RequestURI) +} diff --git a/fun/quinistry/types.go b/fun/quinistry/types.go new file mode 100644 index 0000000000..498cbac2f2 --- /dev/null +++ b/fun/quinistry/types.go @@ -0,0 +1,79 @@ +package main + +import "time" + +// This type represents the rootfs-key of the Docker image config. +// It specifies the digest (i.e. usually SHA256 hash) of the tar'ed, but NOT +// compressed image layers. +type RootFs struct { + // The digests of the non-compressed FS layers. + DiffIds []string `json:"diff_ids"` + + // Type should always be set to "layers" + Type string `json:"type"` +} + +// This type represents an entry in the Docker image config's history key. +// Every history element "belongs" to a filesystem layer. +type History struct { + Created time.Time `json:"created"` + CreatedBy string `json:"created_by"` +} + +// This type represents runtime-configuration for the Docker image. +// A lot of possible keys are omitted here, see: +// https://github.com/docker/docker/blob/master/image/spec/v1.2.md#image-json-description +type ImageConfig struct { + Cmd []string + Env []string +} + +// This type represents the Docker image configuration +type Config struct { + Created time.Time `json:"created"` + Author string `json:"author"` + + // Architecture should be "amd64" + Architecture string `json:"architecture"` + + // OS should be "linux" + Os string `json:"os"` + + // Configuration can be set to 'nil', in which case all options have to be + // supplied at container launch time. + Config *ImageConfig `json:"config"` + + // Filesystem layers and history elements have to be in the same order. + RootFs RootFs `json:"rootfs"` + History []History `json:"history"` +} + +// This type represents any manifest +type Element struct { + MediaType string `json:"mediaType"` + Size int `json:"size"` + Digest string `json:"digest"` +} + +// This type represents a Docker image manifest as used by the registry +// protocol V2. +type Manifest struct { + SchemaVersion int `json:"schemaVersion"` // Must be 2 + MediaType string `json:"mediaType"` // Use ManifestMediaType const + Config Element `json:"config"` + Layers []Element `json:"layers"` +} + +// A really "dumb" representation of an image, with its data blob and related +// metadata. +// Note: This is not a registry API type. +type Image struct { + Layer []byte + LayerDigest string + + Manifest []byte + ManifestDigest string + + Config []byte + ConfigDigest string +} diff --git a/fun/streamTVL/default.nix b/fun/streamTVL/default.nix new file mode 100644 index 0000000000..da7c00ce4b --- /dev/null +++ b/fun/streamTVL/default.nix @@ -0,0 +1,19 @@ +{ depot, ... }: + +depot.third_party.writeShellScriptBin "start-tvl-stream" '' + env LD_LIBRARY_PATH=/run/opengl-driver/lib/ ${depot.third_party.ffmpeg}/bin/ffmpeg \ + -vsync 0 \ + -hwaccel cuvid \ + -init_hw_device cuda=0 -filter_hw_device 0 \ + -f x11grab \ + -video_size 1920x1080 \ + -framerate 60 \ + -thread_queue_size 256 \ + -i :0.0+0,0 \ + -filter:v "format=nv12,hwupload,scale_npp=w=1280:h=720:interp_algo=lanczos" \ + -c:v h264_nvenc \ + -preset:v llhq \ + -rc:v cbr_ld_hq \ + -an \ + -f flv rtmp://tazj.in:1935/tvl +'' diff --git a/fun/wallpapers/bio_thehost_1920.webp b/fun/wallpapers/bio_thehost_1920.webp new file mode 100644 index 0000000000..1b904c06fa --- /dev/null +++ b/fun/wallpapers/bio_thehost_1920.webp Binary files differdiff --git a/fun/wallpapers/busride2_1920.webp b/fun/wallpapers/busride2_1920.webp new file mode 100644 index 0000000000..ad6ec446f6 --- /dev/null +++ b/fun/wallpapers/busride2_1920.webp Binary files differdiff --git a/fun/wallpapers/by_belltowers_2880.webp b/fun/wallpapers/by_belltowers_2880.webp new file mode 100644 index 0000000000..f7477f1689 --- /dev/null +++ b/fun/wallpapers/by_belltowers_2880.webp Binary files differdiff --git a/fun/wallpapers/by_crossing_2560.webp b/fun/wallpapers/by_crossing_2560.webp new file mode 100644 index 0000000000..efa263790b --- /dev/null +++ b/fun/wallpapers/by_crossing_2560.webp Binary files differdiff --git a/fun/wallpapers/by_gathering3_2880.webp b/fun/wallpapers/by_gathering3_2880.webp new file mode 100644 index 0000000000..e6b83bdcd4 --- /dev/null +++ b/fun/wallpapers/by_gathering3_2880.webp Binary files differdiff --git a/fun/wallpapers/by_mainservers1_1920.webp b/fun/wallpapers/by_mainservers1_1920.webp new file mode 100644 index 0000000000..f88d237e2b --- /dev/null +++ b/fun/wallpapers/by_mainservers1_1920.webp Binary files differdiff --git a/fun/wallpapers/by_warmachines1_2560.webp b/fun/wallpapers/by_warmachines1_2560.webp new file mode 100644 index 0000000000..848bf62bd7 --- /dev/null +++ b/fun/wallpapers/by_warmachines1_2560.webp Binary files differdiff --git a/fun/wallpapers/by_warmachines3_1920.webp b/fun/wallpapers/by_warmachines3_1920.webp new file mode 100644 index 0000000000..6002ad695a --- /dev/null +++ b/fun/wallpapers/by_warmachines3_1920.webp Binary files differdiff --git a/fun/wallpapers/clever-man_2880.webp b/fun/wallpapers/clever-man_2880.webp new file mode 100644 index 0000000000..eb4d3f1bfa --- /dev/null +++ b/fun/wallpapers/clever-man_2880.webp Binary files differdiff --git a/fun/wallpapers/december1994_1920.webp b/fun/wallpapers/december1994_1920.webp new file mode 100644 index 0000000000..d2c4da8018 --- /dev/null +++ b/fun/wallpapers/december1994_1920.webp Binary files differdiff --git a/fun/wallpapers/flyby_1920.webp b/fun/wallpapers/flyby_1920.webp new file mode 100644 index 0000000000..8df5b1132e --- /dev/null +++ b/fun/wallpapers/flyby_1920.webp Binary files differdiff --git a/fun/wallpapers/gaussfraktarna_1920_badge.webp b/fun/wallpapers/gaussfraktarna_1920_badge.webp new file mode 100644 index 0000000000..3274a3a2d2 --- /dev/null +++ b/fun/wallpapers/gaussfraktarna_1920_badge.webp Binary files differdiff --git a/fun/wallpapers/kraftahq_1920.webp b/fun/wallpapers/kraftahq_1920.webp new file mode 100644 index 0000000000..62a6debf47 --- /dev/null +++ b/fun/wallpapers/kraftahq_1920.webp Binary files differdiff --git a/fun/wallpapers/peripheral2_1920.webp b/fun/wallpapers/peripheral2_1920.webp new file mode 100644 index 0000000000..e454072ac4 --- /dev/null +++ b/fun/wallpapers/peripheral2_1920.webp Binary files differdiff --git a/fun/wallpapers/ship14_1920.webp b/fun/wallpapers/ship14_1920.webp new file mode 100644 index 0000000000..502f5dac90 --- /dev/null +++ b/fun/wallpapers/ship14_1920.webp Binary files differdiff --git a/fun/wallpapers/shipyard_1920.webp b/fun/wallpapers/shipyard_1920.webp new file mode 100644 index 0000000000..3d4115305d --- /dev/null +++ b/fun/wallpapers/shipyard_1920.webp Binary files differdiff --git a/fun/wallpapers/specky_1920.webp b/fun/wallpapers/specky_1920.webp new file mode 100644 index 0000000000..b8246618be --- /dev/null +++ b/fun/wallpapers/specky_1920.webp Binary files differdiff --git a/fun/wallpapers/summerlove2_1920.webp b/fun/wallpapers/summerlove2_1920.webp new file mode 100644 index 0000000000..d64a1cb867 --- /dev/null +++ b/fun/wallpapers/summerlove2_1920.webp Binary files differdiff --git a/fun/wallpapers/t50_1920_badge.webp b/fun/wallpapers/t50_1920_badge.webp new file mode 100644 index 0000000000..f8cb6107f3 --- /dev/null +++ b/fun/wallpapers/t50_1920_badge.webp Binary files differdiff --git a/fun/wallpapers/theflood1_1920.webp b/fun/wallpapers/theflood1_1920.webp new file mode 100644 index 0000000000..335efb0571 --- /dev/null +++ b/fun/wallpapers/theflood1_1920.webp Binary files differdiff --git a/fun/wallpapers/thelan_1920.webp b/fun/wallpapers/thelan_1920.webp new file mode 100644 index 0000000000..55e6c22ad2 --- /dev/null +++ b/fun/wallpapers/thelan_1920.webp Binary files differdiff --git a/fun/wallpapers/vadrare_1920_badge.webp b/fun/wallpapers/vadrare_1920_badge.webp new file mode 100644 index 0000000000..887c891da3 --- /dev/null +++ b/fun/wallpapers/vadrare_1920_badge.webp Binary files differdiff --git a/fun/watchblob/README.md b/fun/watchblob/README.md new file mode 100644 index 0000000000..712c96cd95 --- /dev/null +++ b/fun/watchblob/README.md @@ -0,0 +1,35 @@ +Watchblob - WatchGuard VPN on Linux +=================================== + +This tiny helper tool makes it possible to use WatchGuard / Firebox / <<whatever +they are actually called>> VPNs that use multi-factor authentication on Linux. + +Rather than using OpenVPN's built-in dynamic challenge/response protocol, WatchGuard +has opted for a separate implementation negotiating credentials outside of the +OpenVPN protocol, which makes it impossible to start those connections solely by +using the `openvpn` CLI and configuration files. + +What this application does has been reverse-engineered from the "WatchGuard Mobile VPN +with SSL" application on OS X. + +I've published a [blog post](https://www.tazj.in/en/1486830338) describing the process +and what is actually going on in this protocol. + +## Installation + +Make sure you have Go installed and `GOPATH` configured, then simply +`go get github.com/tazjin/watchblob/...`. + +## Usage + +Right now the usage is very simple. Make sure you have the correct OpenVPN client +config ready (this is normally supplied by the WatchGuard UI) simply run: + +``` +watchblob vpnserver.somedomain.org username p4ssw0rd +``` + +The server responds with a challenge which is displayed to the user, wait until you +receive the SMS code or whatever and enter it. `watchblob` then completes the +credential negotiation and you may proceed to log in with OpenVPN using your username +and *the OTP token* (**not** your password) as credentials. diff --git a/fun/watchblob/default.nix b/fun/watchblob/default.nix new file mode 100644 index 0000000000..dc32e4d1ce --- /dev/null +++ b/fun/watchblob/default.nix @@ -0,0 +1,13 @@ +{ depot, ... }: + +depot.nix.buildGo.program { + name = "watchblob"; + srcs = [ + ./main.go + ./urls.go + ]; + + deps = with depot.third_party; [ + gopkgs."golang.org".x.crypto.ssh.terminal.gopkg + ]; +} diff --git a/fun/watchblob/main.go b/fun/watchblob/main.go new file mode 100644 index 0000000000..a7ab65d3d1 --- /dev/null +++ b/fun/watchblob/main.go @@ -0,0 +1,108 @@ +package main + +import ( + "bufio" + "encoding/xml" + "fmt" + "golang.org/x/crypto/ssh/terminal" + "net/http" + "os" + "strings" + "syscall" +) + +// The XML response returned by the WatchGuard server +type Resp struct { + Action string `xml:"action"` + LogonStatus int `xml:"logon_status"` + LogonId int `xml:"logon_id"` + Error string `xml:"errStr"` + Challenge string `xml:"chaStr"` +} + +func main() { + args := os.Args[1:] + + if len(args) != 1 { + fmt.Fprintln(os.Stderr, "Usage: watchblob <vpn-host>") + os.Exit(1) + } + + host := args[0] + + username, password, err := readCredentials() + if err != nil { + fmt.Fprintf(os.Stderr, "Could not read credentials: %v\n", err) + } + + fmt.Printf("Requesting challenge from %s as user %s\n", host, username) + challenge, err := triggerChallengeResponse(&host, &username, &password) + + if err != nil || challenge.LogonStatus != 4 { + fmt.Fprintln(os.Stderr, "Did not receive challenge from server") + fmt.Fprintf(os.Stderr, "Response: %v\nError: %v\n", challenge, err) + os.Exit(1) + } + + token := getToken(&challenge) + err = logon(&host, &challenge, &token) + + if err != nil { + fmt.Fprintf(os.Stderr, "Logon failed: %v\n", err) + os.Exit(1) + } + + fmt.Printf("Login succeeded, you may now (quickly) authenticate OpenVPN with %s as your password\n", token) +} + +func readCredentials() (string, string, error) { + fmt.Printf("Username: ") + reader := bufio.NewReader(os.Stdin) + username, err := reader.ReadString('\n') + + fmt.Printf("Password: ") + password, err := terminal.ReadPassword(syscall.Stdin) + fmt.Println() + + // If an error occured, I don't care about which one it is. + return strings.TrimSpace(username), strings.TrimSpace(string(password)), err +} + +func triggerChallengeResponse(host *string, username *string, password *string) (r Resp, err error) { + return request(templateUrl(host, templateChallengeTriggerUri(username, password))) +} + +func getToken(challenge *Resp) string { + fmt.Println(challenge.Challenge) + + reader := bufio.NewReader(os.Stdin) + token, _ := reader.ReadString('\n') + + return strings.TrimSpace(token) +} + +func logon(host *string, challenge *Resp, token *string) (err error) { + resp, err := request(templateUrl(host, templateResponseUri(challenge.LogonId, token))) + if err != nil { + return + } + + if resp.LogonStatus != 1 { + err = fmt.Errorf("Challenge/response authentication failed: %v", resp) + } + + return +} + +func request(url string) (r Resp, err error) { + resp, err := http.Get(url) + if err != nil { + return + } + + defer resp.Body.Close() + decoder := xml.NewDecoder(resp.Body) + + err = decoder.Decode(&r) + return +} diff --git a/fun/watchblob/main_test.go b/fun/watchblob/main_test.go new file mode 100644 index 0000000000..1af52d0cd4 --- /dev/null +++ b/fun/watchblob/main_test.go @@ -0,0 +1,96 @@ +package main + +import ( + "encoding/xml" + "reflect" + "testing" +) + +func TestUnmarshalChallengeRespones(t *testing.T) { + var testXml string = ` +<?xml version="1.0" encoding="UTF-8"?> +<resp> + <action>sslvpn_logon</action> + <logon_status>4</logon_status> + <auth-domain-list> + <auth-domain> + <name>RADIUS</name> + </auth-domain> + </auth-domain-list> + <logon_id>441</logon_id> + <chaStr>Enter Your 6 Digit Passcode </chaStr> +</resp>` + + var r Resp + xml.Unmarshal([]byte(testXml), &r) + + expected := Resp{ + Action: "sslvpn_logon", + LogonStatus: 4, + LogonId: 441, + Challenge: "Enter Your 6 Digit Passcode ", + } + + assertEqual(t, expected, r) +} + +func TestUnmarshalLoginError(t *testing.T) { + var testXml string = ` +<?xml version="1.0" encoding="UTF-8"?> +<resp> + <action>sslvpn_logon</action> + <logon_status>2</logon_status> + <auth-domain-list> + <auth-domain> + <name>RADIUS</name> + </auth-domain> + </auth-domain-list> + <errStr>501</errStr> +</resp>` + + var r Resp + xml.Unmarshal([]byte(testXml), &r) + + expected := Resp{ + Action: "sslvpn_logon", + LogonStatus: 2, + Error: "501", + } + + assertEqual(t, expected, r) +} + +func TestUnmarshalLoginSuccess(t *testing.T) { + var testXml string = ` +<?xml version="1.0" encoding="UTF-8"?> +<resp> + <action>sslvpn_logon</action> + <logon_status>1</logon_status> + <auth-domain-list> + <auth-domain> + <name>RADIUS</name> + </auth-domain> + </auth-domain-list> +</resp> +` + var r Resp + xml.Unmarshal([]byte(testXml), &r) + + expected := Resp{ + Action: "sslvpn_logon", + LogonStatus: 1, + } + + assertEqual(t, expected, r) +} + +func assertEqual(t *testing.T, expected interface{}, result interface{}) { + if !reflect.DeepEqual(expected, result) { + t.Errorf( + "Unmarshaled values did not match.\nExpected: %v\nResult: %v\n", + expected, result, + ) + + t.Fail() + } +} diff --git a/fun/watchblob/urls.go b/fun/watchblob/urls.go new file mode 100644 index 0000000000..37f65e0fae --- /dev/null +++ b/fun/watchblob/urls.go @@ -0,0 +1,37 @@ +package main + +import ( + "fmt" + "net/url" + "strconv" +) + +const urlFormat string = "https://%s%s" +const uriFormat = "/?%s" + +func templateChallengeTriggerUri(username *string, password *string) string { + v := url.Values{} + v.Set("action", "sslvpn_logon") + v.Set("style", "fw_logon_progress.xsl") + v.Set("fw_logon_type", "logon") + v.Set("fw_domain", "Firebox-DB") + v.Set("fw_username", *username) + v.Set("fw_password", *password) + + return fmt.Sprintf(uriFormat, v.Encode()) +} + +func templateResponseUri(logonId int, token *string) string { + v := url.Values{} + v.Set("action", "sslvpn_logon") + v.Set("style", "fw_logon_progress.xsl") + v.Set("fw_logon_type", "response") + v.Set("response", *token) + v.Set("fw_logon_id", strconv.Itoa(logonId)) + + return fmt.Sprintf(uriFormat, v.Encode()) +} + +func templateUrl(baseUrl *string, uri string) string { + return fmt.Sprintf(urlFormat, *baseUrl, uri) +} diff --git a/fun/wcl/default.nix b/fun/wcl/default.nix new file mode 100644 index 0000000000..e4d9804c80 --- /dev/null +++ b/fun/wcl/default.nix @@ -0,0 +1,14 @@ +{ depot, ... }: + +depot.nix.buildLisp.program { + name = "wc"; + + srcs = [ + ./wc.lisp + ]; + + deps = with depot.third_party.lisp; [ + unix-opts + iterate + ]; +} diff --git a/fun/wcl/wc.lisp b/fun/wcl/wc.lisp new file mode 100644 index 0000000000..83c7e8c4f1 --- /dev/null +++ b/fun/wcl/wc.lisp @@ -0,0 +1,34 @@ +(defpackage wc + (:use #:cl #:iterate) + (:export :main)) +(in-package :wc) +(declaim (optimize (speed 3) (safety 0))) + +(defun main () + (let ((filename (cadr (opts:argv))) + (space (char-code #\Space)) + (newline (char-code #\Newline))) + (with-open-file (file-stream filename :element-type '(unsigned-byte 8)) + (iter + (for byte in-stream file-stream using #'read-byte) + (for previous-byte previous byte) + (for is-newline = (eql newline byte)) + + ;; Count each byte + (sum 1 into bytes) + + ;; Count every newline + (counting is-newline into newlines) + + ;; Count every "word", unless the preceding character already + ;; was a space or we are at the beginning of the file. + (when (or (eql space previous-byte) + (eql newline previous-byte) + (not previous-byte)) + (next-iteration)) + + (counting (or is-newline (eql space byte)) + into words) + + (declare (fixnum bytes newlines words)) + (finally (format t " ~A ~A ~A ~A~%" newlines words bytes filename)))))) diff --git a/lisp/dns/README.md b/lisp/dns/README.md new file mode 100644 index 0000000000..c95d2e9a68 --- /dev/null +++ b/lisp/dns/README.md @@ -0,0 +1,75 @@ +dns +=== + +This library is a DNS-over-HTTPS client for Common Lisp. + +The ambition is to transform it into a fully-featured DNS resolver +instead of piggy-backing on the HTTPS implementation, but ... +baby-steps! + +Note that there is no Common Lisp HTTP client that fully supports the +HTTP2 protocol at the moment, so you can not expect this library to +provide equivalent performance to a native DNS resolver (yet). + +## API + +The API is kept as simple as it can be. + +### Types + +The types of this library are implemented as several structs that +support binary (de-)serialisation via [lisp-binary][]. + +The existing structs are as follows and directly implement the +corresponding definitions from [RFC 1035][]: + +* `dns-header` +* `dns-question` +* `dns-rr` +* `dns-message` + +All relevant field accessors for these structs are exported and can be +used to inspect query results. + +### Functions + +All lookup functions are of the type `(function (string &key doh-url) +(dns-message))` and signal a `dns:doh-error` condition for +unsuccessful requests. + +If `:doh-url` is unspecified, Google's public DNS-over-HTTPS servers +at [dns.google][https://dns.google] will be used. + +Currently implemented lookup functions: + +* `lookup-a` +* `lookup-mx` +* `lookup-txt` + +## Example usage + +```lisp +DNS> (dns-message-answer (lookup-a "git.tazj.in.")) +#(#S(DNS-RR + :NAME #S(QNAME :START-AT 29 :NAMES #(12)) + :TYPE A + :CLASS 1 + :TTL 286 + :RDLENGTH 4 + :RDATA #(34 98 120 189))) +``` + +## TODO + +Various things in this library are currently broken because I only +implemented it to work for my blog setup, but these things will be +ironed out. + +Most importantly, the following needs to be fixed: + +* Each qname *fragment* needs to track its offset, not each qname. +* The RDATA for a TXT record can have multiple counted strings. +* qnames should be canonicalised after parsing. + +[lisp-binary]: https://github.com/j3pic/lisp-binary +[RFC 1035]: https://tools.ietf.org/html/rfc1035 diff --git a/lisp/dns/client.lisp b/lisp/dns/client.lisp new file mode 100644 index 0000000000..cee7bceb54 --- /dev/null +++ b/lisp/dns/client.lisp @@ -0,0 +1,85 @@ +;; Implementation of a DoH-client, see RFC 8484 (DNS Queries over +;; HTTPS (DoH)) + +(in-package #:dns) + +(defvar *doh-base-url* "https://dns.google/resolve" + "Base URL of the service providing DNS-over-HTTP(S). Defaults to the + Google-hosted API.") + +(define-condition doh-error (error) + ((query-name :initarg :query-name + :reader doh-error-query-name + :type string) + (query-type :initarg :query-type + :reader doh-error-query-type + :type string) + (doh-url :initarg :doh-url + :reader doh-error-doh-url + :type string) + (status-code :initarg :status-code + :reader doh-error-status-code + :type integer) + (response-body :initarg :response-body + :reader doh-error-response-body + :type (or nil (vector (unsigned-byte 8)) string))) + + (:report (lambda (condition stream) + (let ((url (doh-error-doh-url condition)) + (status (doh-error-status-code condition)) + (body (doh-error-response-body condition))) + (format stream "DoH service at '~A' responded with non-success (~A): ~%~%~A" + url status body))))) + +(defun lookup-generic (name type doh-url) + (multiple-value-bind (body status) + (drakma:http-request doh-url + :decode-content t + ;; TODO(tazjin): Figure out why 'want-stream' doesn't work + :parameters `(("type" . ,type) + ("name" . ,name) + ("ct" . "application/dns-message"))) + (if (= 200 status) + (dns-message-answer + (read-binary 'dns-message (flexi-streams:make-in-memory-input-stream body))) + + (restart-case (error 'doh-error + :query-name name + :query-type type + :doh-url doh-url + :status-code status + :response-body body) + (call-with-other-name (new-name) + :interactive (lambda () (list (the string (read)))) + :test (lambda (c) (typep c 'doh-error)) + (lookup-generic new-name type doh-url)) + + (call-with-other-type (new-type) + :interactive (lambda () (list (the string (read)))) + :test (lambda (c) (typep c 'doh-error)) + (lookup-generic name new-type doh-url)) + + (call-with-other-url (new-url) + :interactive (lambda () (list (the string (read)))) + :test (lambda (c) (typep c 'doh-error)) + (lookup-generic name type new-url)))))) + +(defun lookup-a (name &key (doh-url *doh-base-url*)) + "Look up the A records at NAME." + (lookup-generic name "A" doh-url)) + +(defun lookup-txt (name &key (doh-url *doh-base-url*)) + "Look up the TXT records at NAME." + (lookup-generic name "TXT" doh-url)) + +(defun lookup-mx (name &key (doh-url *doh-base-url*)) + "Look up the MX records at NAME." + (lookup-generic name "MX" doh-url)) + +(defun lookup-cname (name &key (doh-url *doh-base-url*)) + "Look up the CNAME records at NAME." + (lookup-generic name "CNAME" doh-url)) + +(defun lookup-ns (name &key (doh-url *doh-base-url*)) + "Look up the NS records at NAME." + (lookup-generic name "NS" doh-url)) diff --git a/lisp/dns/default.nix b/lisp/dns/default.nix new file mode 100644 index 0000000000..43e7ea5030 --- /dev/null +++ b/lisp/dns/default.nix @@ -0,0 +1,17 @@ +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "dns"; + + deps = with depot.third_party.lisp; [ + drakma + lisp-binary + iterate + ]; + + srcs = [ + ./package.lisp + ./message.lisp + ./client.lisp + ]; +} diff --git a/lisp/dns/message.lisp b/lisp/dns/message.lisp new file mode 100644 index 0000000000..46243ac8d3 --- /dev/null +++ b/lisp/dns/message.lisp @@ -0,0 +1,407 @@ +(in-package :dns) + +;; 3.3. Standard RRs + +;; The following RR definitions are expected to occur, at least +;; potentially, in all classes. In particular, NS, SOA, CNAME, and PTR +;; will be used in all classes, and have the same format in all classes. +;; Because their RDATA format is known, all domain names in the RDATA +;; section of these RRs may be compressed. + +;; <domain-name> is a domain name represented as a series of labels, and +;; terminated by a label with zero length. <character-string> is a single +;; length octet followed by that number of characters. <character-string> +;; is treated as binary information, and can be up to 256 characters in +;; length (including the length octet). + + +;; 3.3.11. NS RDATA format + +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; / NSDNAME / +;; / / +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ + +;; where: + +;; NSDNAME A <domain-name> which specifies a host which should be +;; authoritative for the specified class and domain. + +;; NS records cause both the usual additional section processing to locate +;; a type A record, and, when used in a referral, a special search of the +;; zone in which they reside for glue information. + +;; The NS RR states that the named host should be expected to have a zone +;; starting at owner name of the specified class. Note that the class may +;; not indicate the protocol family which should be used to communicate +;; with the host, although it is typically a strong hint. For example, +;; hosts which are name servers for either Internet (IN) or Hesiod (HS) +;; class information are normally queried using IN class protocols. + +;; 3.3.12. PTR RDATA format + +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; / PTRDNAME / +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ + +;; where: + +;; PTRDNAME A <domain-name> which points to some location in the +;; domain name space. + +;; PTR records cause no additional section processing. These RRs are used +;; in special domains to point to some other location in the domain space. +;; These records are simple data, and don't imply any special processing +;; similar to that performed by CNAME, which identifies aliases. See the +;; description of the IN-ADDR.ARPA domain for an example. + +;; 3.3.13. SOA RDATA format + +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; / MNAME / +;; / / +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; / RNAME / +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; | SERIAL | +;; | | +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; | REFRESH | +;; | | +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; | RETRY | +;; | | +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; | EXPIRE | +;; | | +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; | MINIMUM | +;; | | +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ + +;; where: + +;; MNAME The <domain-name> of the name server that was the +;; original or primary source of data for this zone. + +;; RNAME A <domain-name> which specifies the mailbox of the +;; person responsible for this zone. + +;; SERIAL The unsigned 32 bit version number of the original copy +;; of the zone. Zone transfers preserve this value. This +;; value wraps and should be compared using sequence space +;; arithmetic. + +;; REFRESH A 32 bit time interval before the zone should be +;; refreshed. + +;; RETRY A 32 bit time interval that should elapse before a +;; failed refresh should be retried. + +;; EXPIRE A 32 bit time value that specifies the upper limit on +;; the time interval that can elapse before the zone is no +;; longer authoritative. + +;; MINIMUM The unsigned 32 bit minimum TTL field that should be +;; exported with any RR from this zone. + +;; SOA records cause no additional section processing. + +;; All times are in units of seconds. + +;; Most of these fields are pertinent only for name server maintenance +;; operations. However, MINIMUM is used in all query operations that +;; retrieve RRs from a zone. Whenever a RR is sent in a response to a +;; query, the TTL field is set to the maximum of the TTL field from the RR +;; and the MINIMUM field in the appropriate SOA. Thus MINIMUM is a lower +;; bound on the TTL field for all RRs in a zone. Note that this use of +;; MINIMUM should occur when the RRs are copied into the response and not +;; when the zone is loaded from a master file or via a zone transfer. The +;; reason for this provison is to allow future dynamic update facilities to +;; change the SOA RR with known semantics. + + +;; 3.3.14. TXT RDATA format + +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ +;; / TXT-DATA / +;; +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ + +;; where: + +;; TXT-DATA + +;; TXT RRs are used to hold descriptive text. The semantics of the text +;; depends on the domain where it is found. + +(defbinary dns-header (:byte-order :big-endian) + ;; A 16 bit identifier assigned by the program that + ;; generates any kind of query. This identifier is copied + ;; the corresponding reply and can be used by the requester + ;; to match up replies to outstanding queries. + (id 0 :type 16) + + ;; A one bit field that specifies whether this message is a + ;; query (0), or a response (1). + (qr 0 :type 1) + + ;; A four bit field that specifies kind of query in this + ;; message. This value is set by the originator of a query + ;; and copied into the response. The values are: + ;; + ;; 0 a standard query (QUERY) + ;; 1 an inverse query (IQUERY) + ;; 2 a server status request (STATUS) + ;; 3-15 reserved for future use + (opcode 0 :type 4) + + ;; Authoritative Answer - this bit is valid in responses, + ;; and specifies that the responding name server is an + ;; authority for the domain name in question section. + (aa nil :type 1) + + ;; TrunCation - specifies that this message was truncated + ;; due to length greater than that permitted on the + ;; transmission channel. + (tc nil :type 1) + + ;; Recursion Desired - this bit may be set in a query and + ;; is copied into the response. If RD is set, it directs + ;; the name server to pursue the query recursively. + ;; Recursive query support is optional. + (rd nil :type 1) + + ;; Recursion Available - this be is set or cleared in a + ;; response, and denotes whether recursive query support is + ;; available in the name server. + (ra nil :type 1) + + ;; Reserved for future use. Must be zero in all queries and + ;; responses. + (z 0 :type 3) + + ;; Response code - this 4 bit field is set as part of + ;; responses. The values have the following + ;; interpretation: + ;; 0 No error condition + ;; 1 Format error - The name server was + ;; unable to interpret the query. + ;; 2 Server failure - The name server was + ;; unable to process this query due to a + ;; problem with the name server. + ;; 3 Name Error - Meaningful only for + ;; responses from an authoritative name + ;; server, this code signifies that the + ;; domain name referenced in the query does + ;; not exist. + ;; 4 Not Implemented - The name server does + ;; not support the requested kind of query. + ;; 5 Refused - The name server refuses to + ;; perform the specified operation for + ;; policy reasons. For example, a name + ;; server may not wish to provide the + ;; information to the particular requester, + ;; or a name server may not wish to perform + ;; a particular operation (e.g., zone + ;; transfer) for particular data. + ;; 6-15 Reserved for future use. + (rcode 0 :type 4) + + ;; an unsigned 16 bit integer specifying the number of + ;; entries in the question section. + (qdcount 0 :type 16) + + ;; an unsigned 16 bit integer specifying the number of + ;; resource records in the answer section. + (ancount 0 :type 16) + + ;; an unsigned 16 bit integer specifying the number of name + ;; server resource records in the authority records + ;; section. + (nscount 0 :type 16) + + ;; an unsigned 16 bit integer specifying the number of + ;; resource records in the additional records section. + (arcount 0 :type 16)) + + +;; Representation of DNS QNAMEs. +;; +;; A QNAME can be either made up entirely of labels, which is +;; basically a list of strings, or be terminated with a pointer to an +;; offset within the original message. + +(deftype qname-field () + '(or + ;; pointer + (unsigned-byte 14) + ;; label + string)) + +(defstruct qname + (start-at 0 :type (unsigned-byte 14)) + (names #() :type (vector qname-field))) + +;; Domain names in questions and resource records are represented as a +;; sequence of labels, where each label consists of a length octet +;; followed by that number of octets. +;; +;; The domain name terminates with the zero length octet for the null +;; label of the root. Note that this field may be an odd number of +;; octets; no padding is used. +(declaim (ftype (function (stream) (values qname integer)) read-qname)) +(defun read-qname (stream) + "Reads a DNS QNAME from STREAM." + + (let ((start-at (file-position stream))) + (iter (for byte next (read-byte stream)) + ;; Each fragment is collected into this byte vector pre-allocated + ;; with the correct size. + (for fragment = (make-array byte :element-type '(unsigned-byte 8) + :fill-pointer 0)) + + ;; If the bit sequence (1 1) is encountered at the beginning of + ;; the fragment, a qname pointer is being read. + (let ((byte-copy byte)) + (when (equal #b11 (lisp-binary/integer:pop-bits 2 8 byte-copy)) + (let ((next (read-byte stream))) + (lisp-binary/integer:push-bits byte-copy 8 next) + (collect next into fragments result-type vector) + (sum 2 into size) + (finish)))) + + ;; Total size is needed, count for each iteration byte, plus its + ;; own value. + (sum (+ 1 byte) into size) + (until (equal byte 0)) + + ;; On each iteration, this will interpret the current byte as an + ;; unsigned integer and read from STREAM an equivalent amount of + ;; times to assemble the current fragment. + ;; + ;; Advancing the stream like this also ensures that the next + ;; iteration occurs on a new fragment or the final terminating + ;; byte. + (dotimes (_ byte (collect (babel:octets-to-string fragment) + into fragments result-type vector)) + (vector-push (read-byte stream) fragment)) + + (finally (return (values (make-qname :start-at start-at + :names fragments) + size)))))) + +(declaim (ftype (function (stream qname)) write-qname)) +(defun write-qname (stream qname) + "Write a DNS qname to STREAM." + + ;; Write each fragment starting with its (byte-) length, followed by + ;; the bytes. + (iter (for fragment in-vector (qname-names qname)) + (for bytes = (babel:string-to-octets fragment)) + (write-byte (length bytes) stream) + (iter (for byte in-vector bytes) + (write-byte byte stream))) + + ;; Always finish off the serialisation with a null-byte! + (write-byte 0 stream)) + +(define-enum dns-type 2 + (:byte-order :big-endian) + + ;; http://www.iana.org/assignments/dns-parameters/dns-parameters.xhtml + (A 1) + (NS 2) + (CNAME 5) + (SOA 6) + (PTR 12) + (MX 15) + (TXT 16) + (SRV 33) + (AAAA 28) + + ;; ANY typically wants SOA, MX, NS and MX + (ANY 255)) + +(defbinary dns-question (:byte-order :big-endian :export t) + ;; a domain name represented + (qname "" :type (custom :lisp-type qname + :reader #'read-qname + :writer #'write-qname)) + + ;; a two octet code which specifies the type of the query. + (qtype 0 :type dns-type) + + ;; a two octet code that specifies the class of the query. For + ;; example, the QCLASS field is IN for the Internet. + (qclass 0 :type 16)) + +(defbinary dns-rr (:byte-order :big-endian :export t) + (name nil :type (custom :lisp-type qname + :reader #'read-qname + :writer #'write-qname)) + + ;; two octets containing one of the RR type codes. This field + ;; specifies the meaning of the data in the RDATA field. + (type 0 :type dns-type) + + ;; two octets which specify the class of the data in the RDATA + ;; field. + (class 0 :type 16) + + ;; a 32 bit unsigned integer that specifies the time interval (in + ;; seconds) that the resource record may be cached before it should + ;; be discarded. Zero values are interpreted to mean that the RR + ;; can only be used for the transaction in progress, and should not + ;; be cached. + (ttl 0 :type 32) + + ;; an unsigned 16 bit integer that specifies the length in octets + ;; of the RDATA field. + (rdlength 0 :type 16) + + ;; a variable length string of octets that describes the resource. + ;; The format of this information varies according to the TYPE and + ;; CLASS of the resource record. For example, the if the TYPE is A + ;; and the CLASS is IN, the RDATA field is a 4 octet ARPA Internet + ;; address. + (rdata #() :type (eval (case type + ;; A 32-bit internet address in its + ;; canonical representation of 4 integers. + ((A) '(simple-array (unsigned-byte 8) (4))) + + ;; TODO(tazjin): Deal with multiple strings in single RRDATA + ;; One or more <character-string>s. + ((TXT) '(counted-string 1)) + + ;; A <domain-name> which specifies the + ;; canonical or primary name for the + ;; owner. The owner name is an alias. + ((CNAME) '(custom + :lisp-type qname + :reader #'read-qname + :writer #'write-qname)) + + ;; A <domain-name> which specifies a host + ;; which should be authoritative for the + ;; specified class and domain. + ((NS) '(custom + :lisp-type qname + :reader #'read-qname + :writer #'write-qname)) + (otherwise `(simple-array (unsigned-byte 8) (,rdlength))))))) + +(defbinary dns-message (:byte-order :big-endian :export t) + (header nil :type dns-header) + + ;; the question for the name server + (question #() :type (simple-array dns-question ((dns-header-qdcount header)))) + + ;; ;; RRs answering the question + ;; (answer #() :type (simple-array (unsigned-byte 8) (16))) + (answer #() :type (simple-array dns-rr ((dns-header-ancount header)))) + + ;; ;; ;; RRs pointing toward an authority + (authority #() :type (simple-array dns-rr ((dns-header-nscount header)))) + + ;; ;; RRs holding additional information + (additional #() :type (simple-array dns-rr ((dns-header-arcount header))))) diff --git a/lisp/dns/package.lisp b/lisp/dns/package.lisp new file mode 100644 index 0000000000..2b8bfaa8bc --- /dev/null +++ b/lisp/dns/package.lisp @@ -0,0 +1,11 @@ +(defpackage #:dns + (:documentation "Simple DNS resolver in Common Lisp") + (:use #:cl #:iterate #:lisp-binary) + (:export + ;; Individual lookup functions + #:lookup-txt #:lookup-mx #:lookup-cname #:lookup-a #:lookup-ns + + ;; Useful accessors + #:dns-message-header #:dns-message-answer #:dns-message-question + #:dns-rr-name #:dns-rr-type #:dns-rr-ttl #:dns-rr-rdata + #:dns-question-qname #:dns-question-qtype)) diff --git a/net/alcoholic_jwt/.gitignore b/net/alcoholic_jwt/.gitignore new file mode 100644 index 0000000000..143b1ca014 --- /dev/null +++ b/net/alcoholic_jwt/.gitignore @@ -0,0 +1,4 @@ + +/target/ +**/*.rs.bk +Cargo.lock diff --git a/net/alcoholic_jwt/Cargo.toml b/net/alcoholic_jwt/Cargo.toml new file mode 100644 index 0000000000..40db6b7bd1 --- /dev/null +++ b/net/alcoholic_jwt/Cargo.toml @@ -0,0 +1,16 @@ +[package] +name = "alcoholic_jwt" +description = "Library for validation of RS256 JWTs" +version = "1.0.0" +authors = ["Vincent Ambo <vincent@aprila.no>"] +keywords = ["jwt", "token", "jwks"] +categories = ["authentication"] +license = "GPL-3.0-or-later" +repository = "https://github.com/aprilabank/alcoholic_jwt" + +[dependencies] +base64 = "0.10" +openssl = "0.10" +serde = "1.0" +serde_derive = "1.0" +serde_json = "1.0" diff --git a/net/alcoholic_jwt/LICENSE b/net/alcoholic_jwt/LICENSE new file mode 100644 index 0000000000..94a9ed024d --- /dev/null +++ b/net/alcoholic_jwt/LICENSE @@ -0,0 +1,674 @@ + GNU GENERAL PUBLIC LICENSE + Version 3, 29 June 2007 + + Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/> + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + + Preamble + + The GNU General Public License is a free, copyleft license for +software and other kinds of works. + + The licenses for most software and other practical works are designed +to take away your freedom to share and change the works. By contrast, +the GNU General Public License is intended to guarantee your freedom to +share and change all versions of a program--to make sure it remains free +software for all its users. We, the Free Software Foundation, use the +GNU General Public License for most of our software; it applies also to +any other work released this way by its authors. You can apply it to +your programs, too. + + When we speak of free software, we are referring to freedom, not +price. Our General Public Licenses are designed to make sure that you +have the freedom to distribute copies of free software (and charge for +them if you wish), that you receive source code or can get it if you +want it, that you can change the software or use pieces of it in new +free programs, and that you know you can do these things. + + To protect your rights, we need to prevent others from denying you +these rights or asking you to surrender the rights. Therefore, you have +certain responsibilities if you distribute copies of the software, or if +you modify it: responsibilities to respect the freedom of others. + + For example, if you distribute copies of such a program, whether +gratis or for a fee, you must pass on to the recipients the same +freedoms that you received. You must make sure that they, too, receive +or can get the source code. And you must show them these terms so they +know their rights. + + Developers that use the GNU GPL protect your rights with two steps: +(1) assert copyright on the software, and (2) offer you this License +giving you legal permission to copy, distribute and/or modify it. + + For the developers' and authors' protection, the GPL clearly explains +that there is no warranty for this free software. For both users' and +authors' sake, the GPL requires that modified versions be marked as +changed, so that their problems will not be attributed erroneously to +authors of previous versions. + + Some devices are designed to deny users access to install or run +modified versions of the software inside them, although the manufacturer +can do so. This is fundamentally incompatible with the aim of +protecting users' freedom to change the software. The systematic +pattern of such abuse occurs in the area of products for individuals to +use, which is precisely where it is most unacceptable. Therefore, we +have designed this version of the GPL to prohibit the practice for those +products. If such problems arise substantially in other domains, we +stand ready to extend this provision to those domains in future versions +of the GPL, as needed to protect the freedom of users. + + Finally, every program is threatened constantly by software patents. +States should not allow patents to restrict development and use of +software on general-purpose computers, but in those that do, we wish to +avoid the special danger that patents applied to a free program could +make it effectively proprietary. To prevent this, the GPL assures that +patents cannot be used to render the program non-free. + + The precise terms and conditions for copying, distribution and +modification follow. + + TERMS AND CONDITIONS + + 0. Definitions. + + "This License" refers to version 3 of the GNU General Public License. + + "Copyright" also means copyright-like laws that apply to other kinds of +works, such as semiconductor masks. + + "The Program" refers to any copyrightable work licensed under this +License. Each licensee is addressed as "you". "Licensees" and +"recipients" may be individuals or organizations. + + To "modify" a work means to copy from or adapt all or part of the work +in a fashion requiring copyright permission, other than the making of an +exact copy. The resulting work is called a "modified version" of the +earlier work or a work "based on" the earlier work. + + A "covered work" means either the unmodified Program or a work based +on the Program. + + To "propagate" a work means to do anything with it that, without +permission, would make you directly or secondarily liable for +infringement under applicable copyright law, except executing it on a +computer or modifying a private copy. Propagation includes copying, +distribution (with or without modification), making available to the +public, and in some countries other activities as well. + + To "convey" a work means any kind of propagation that enables other +parties to make or receive copies. Mere interaction with a user through +a computer network, with no transfer of a copy, is not conveying. + + An interactive user interface displays "Appropriate Legal Notices" +to the extent that it includes a convenient and prominently visible +feature that (1) displays an appropriate copyright notice, and (2) +tells the user that there is no warranty for the work (except to the +extent that warranties are provided), that licensees may convey the +work under this License, and how to view a copy of this License. If +the interface presents a list of user commands or options, such as a +menu, a prominent item in the list meets this criterion. + + 1. Source Code. + + The "source code" for a work means the preferred form of the work +for making modifications to it. "Object code" means any non-source +form of a work. + + A "Standard Interface" means an interface that either is an official +standard defined by a recognized standards body, or, in the case of +interfaces specified for a particular programming language, one that +is widely used among developers working in that language. + + The "System Libraries" of an executable work include anything, other +than the work as a whole, that (a) is included in the normal form of +packaging a Major Component, but which is not part of that Major +Component, and (b) serves only to enable use of the work with that +Major Component, or to implement a Standard Interface for which an +implementation is available to the public in source code form. A +"Major Component", in this context, means a major essential component +(kernel, window system, and so on) of the specific operating system +(if any) on which the executable work runs, or a compiler used to +produce the work, or an object code interpreter used to run it. + + The "Corresponding Source" for a work in object code form means all +the source code needed to generate, install, and (for an executable +work) run the object code and to modify the work, including scripts to +control those activities. However, it does not include the work's +System Libraries, or general-purpose tools or generally available free +programs which are used unmodified in performing those activities but +which are not part of the work. For example, Corresponding Source +includes interface definition files associated with source files for +the work, and the source code for shared libraries and dynamically +linked subprograms that the work is specifically designed to require, +such as by intimate data communication or control flow between those +subprograms and other parts of the work. + + The Corresponding Source need not include anything that users +can regenerate automatically from other parts of the Corresponding +Source. + + The Corresponding Source for a work in source code form is that +same work. + + 2. Basic Permissions. + + All rights granted under this License are granted for the term of +copyright on the Program, and are irrevocable provided the stated +conditions are met. This License explicitly affirms your unlimited +permission to run the unmodified Program. The output from running a +covered work is covered by this License only if the output, given its +content, constitutes a covered work. This License acknowledges your +rights of fair use or other equivalent, as provided by copyright law. + + You may make, run and propagate covered works that you do not +convey, without conditions so long as your license otherwise remains +in force. You may convey covered works to others for the sole purpose +of having them make modifications exclusively for you, or provide you +with facilities for running those works, provided that you comply with +the terms of this License in conveying all material for which you do +not control copyright. Those thus making or running the covered works +for you must do so exclusively on your behalf, under your direction +and control, on terms that prohibit them from making any copies of +your copyrighted material outside their relationship with you. + + Conveying under any other circumstances is permitted solely under +the conditions stated below. Sublicensing is not allowed; section 10 +makes it unnecessary. + + 3. Protecting Users' Legal Rights From Anti-Circumvention Law. + + No covered work shall be deemed part of an effective technological +measure under any applicable law fulfilling obligations under article +11 of the WIPO copyright treaty adopted on 20 December 1996, or +similar laws prohibiting or restricting circumvention of such +measures. + + When you convey a covered work, you waive any legal power to forbid +circumvention of technological measures to the extent such circumvention +is effected by exercising rights under this License with respect to +the covered work, and you disclaim any intention to limit operation or +modification of the work as a means of enforcing, against the work's +users, your or third parties' legal rights to forbid circumvention of +technological measures. + + 4. Conveying Verbatim Copies. + + You may convey verbatim copies of the Program's source code as you +receive it, in any medium, provided that you conspicuously and +appropriately publish on each copy an appropriate copyright notice; +keep intact all notices stating that this License and any +non-permissive terms added in accord with section 7 apply to the code; +keep intact all notices of the absence of any warranty; and give all +recipients a copy of this License along with the Program. + + You may charge any price or no price for each copy that you convey, +and you may offer support or warranty protection for a fee. + + 5. Conveying Modified Source Versions. + + You may convey a work based on the Program, or the modifications to +produce it from the Program, in the form of source code under the +terms of section 4, provided that you also meet all of these conditions: + + a) The work must carry prominent notices stating that you modified + it, and giving a relevant date. + + b) The work must carry prominent notices stating that it is + released under this License and any conditions added under section + 7. This requirement modifies the requirement in section 4 to + "keep intact all notices". + + c) You must license the entire work, as a whole, under this + License to anyone who comes into possession of a copy. This + License will therefore apply, along with any applicable section 7 + additional terms, to the whole of the work, and all its parts, + regardless of how they are packaged. This License gives no + permission to license the work in any other way, but it does not + invalidate such permission if you have separately received it. + + d) If the work has interactive user interfaces, each must display + Appropriate Legal Notices; however, if the Program has interactive + interfaces that do not display Appropriate Legal Notices, your + work need not make them do so. + + A compilation of a covered work with other separate and independent +works, which are not by their nature extensions of the covered work, +and which are not combined with it such as to form a larger program, +in or on a volume of a storage or distribution medium, is called an +"aggregate" if the compilation and its resulting copyright are not +used to limit the access or legal rights of the compilation's users +beyond what the individual works permit. Inclusion of a covered work +in an aggregate does not cause this License to apply to the other +parts of the aggregate. + + 6. Conveying Non-Source Forms. + + You may convey a covered work in object code form under the terms +of sections 4 and 5, provided that you also convey the +machine-readable Corresponding Source under the terms of this License, +in one of these ways: + + a) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by the + Corresponding Source fixed on a durable physical medium + customarily used for software interchange. + + b) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by a + written offer, valid for at least three years and valid for as + long as you offer spare parts or customer support for that product + model, to give anyone who possesses the object code either (1) a + copy of the Corresponding Source for all the software in the + product that is covered by this License, on a durable physical + medium customarily used for software interchange, for a price no + more than your reasonable cost of physically performing this + conveying of source, or (2) access to copy the + Corresponding Source from a network server at no charge. + + c) Convey individual copies of the object code with a copy of the + written offer to provide the Corresponding Source. This + alternative is allowed only occasionally and noncommercially, and + only if you received the object code with such an offer, in accord + with subsection 6b. + + d) Convey the object code by offering access from a designated + place (gratis or for a charge), and offer equivalent access to the + Corresponding Source in the same way through the same place at no + further charge. You need not require recipients to copy the + Corresponding Source along with the object code. If the place to + copy the object code is a network server, the Corresponding Source + may be on a different server (operated by you or a third party) + that supports equivalent copying facilities, provided you maintain + clear directions next to the object code saying where to find the + Corresponding Source. Regardless of what server hosts the + Corresponding Source, you remain obligated to ensure that it is + available for as long as needed to satisfy these requirements. + + e) Convey the object code using peer-to-peer transmission, provided + you inform other peers where the object code and Corresponding + Source of the work are being offered to the general public at no + charge under subsection 6d. + + A separable portion of the object code, whose source code is excluded +from the Corresponding Source as a System Library, need not be +included in conveying the object code work. + + A "User Product" is either (1) a "consumer product", which means any +tangible personal property which is normally used for personal, family, +or household purposes, or (2) anything designed or sold for incorporation +into a dwelling. In determining whether a product is a consumer product, +doubtful cases shall be resolved in favor of coverage. For a particular +product received by a particular user, "normally used" refers to a +typical or common use of that class of product, regardless of the status +of the particular user or of the way in which the particular user +actually uses, or expects or is expected to use, the product. A product +is a consumer product regardless of whether the product has substantial +commercial, industrial or non-consumer uses, unless such uses represent +the only significant mode of use of the product. + + "Installation Information" for a User Product means any methods, +procedures, authorization keys, or other information required to install +and execute modified versions of a covered work in that User Product from +a modified version of its Corresponding Source. The information must +suffice to ensure that the continued functioning of the modified object +code is in no case prevented or interfered with solely because +modification has been made. + + If you convey an object code work under this section in, or with, or +specifically for use in, a User Product, and the conveying occurs as +part of a transaction in which the right of possession and use of the +User Product is transferred to the recipient in perpetuity or for a +fixed term (regardless of how the transaction is characterized), the +Corresponding Source conveyed under this section must be accompanied +by the Installation Information. But this requirement does not apply +if neither you nor any third party retains the ability to install +modified object code on the User Product (for example, the work has +been installed in ROM). + + The requirement to provide Installation Information does not include a +requirement to continue to provide support service, warranty, or updates +for a work that has been modified or installed by the recipient, or for +the User Product in which it has been modified or installed. Access to a +network may be denied when the modification itself materially and +adversely affects the operation of the network or violates the rules and +protocols for communication across the network. + + Corresponding Source conveyed, and Installation Information provided, +in accord with this section must be in a format that is publicly +documented (and with an implementation available to the public in +source code form), and must require no special password or key for +unpacking, reading or copying. + + 7. Additional Terms. + + "Additional permissions" are terms that supplement the terms of this +License by making exceptions from one or more of its conditions. +Additional permissions that are applicable to the entire Program shall +be treated as though they were included in this License, to the extent +that they are valid under applicable law. If additional permissions +apply only to part of the Program, that part may be used separately +under those permissions, but the entire Program remains governed by +this License without regard to the additional permissions. + + When you convey a copy of a covered work, you may at your option +remove any additional permissions from that copy, or from any part of +it. (Additional permissions may be written to require their own +removal in certain cases when you modify the work.) You may place +additional permissions on material, added by you to a covered work, +for which you have or can give appropriate copyright permission. + + Notwithstanding any other provision of this License, for material you +add to a covered work, you may (if authorized by the copyright holders of +that material) supplement the terms of this License with terms: + + a) Disclaiming warranty or limiting liability differently from the + terms of sections 15 and 16 of this License; or + + b) Requiring preservation of specified reasonable legal notices or + author attributions in that material or in the Appropriate Legal + Notices displayed by works containing it; or + + c) Prohibiting misrepresentation of the origin of that material, or + requiring that modified versions of such material be marked in + reasonable ways as different from the original version; or + + d) Limiting the use for publicity purposes of names of licensors or + authors of the material; or + + e) Declining to grant rights under trademark law for use of some + trade names, trademarks, or service marks; or + + f) Requiring indemnification of licensors and authors of that + material by anyone who conveys the material (or modified versions of + it) with contractual assumptions of liability to the recipient, for + any liability that these contractual assumptions directly impose on + those licensors and authors. + + All other non-permissive additional terms are considered "further +restrictions" within the meaning of section 10. If the Program as you +received it, or any part of it, contains a notice stating that it is +governed by this License along with a term that is a further +restriction, you may remove that term. If a license document contains +a further restriction but permits relicensing or conveying under this +License, you may add to a covered work material governed by the terms +of that license document, provided that the further restriction does +not survive such relicensing or conveying. + + If you add terms to a covered work in accord with this section, you +must place, in the relevant source files, a statement of the +additional terms that apply to those files, or a notice indicating +where to find the applicable terms. + + Additional terms, permissive or non-permissive, may be stated in the +form of a separately written license, or stated as exceptions; +the above requirements apply either way. + + 8. Termination. + + You may not propagate or modify a covered work except as expressly +provided under this License. Any attempt otherwise to propagate or +modify it is void, and will automatically terminate your rights under +this License (including any patent licenses granted under the third +paragraph of section 11). + + However, if you cease all violation of this License, then your +license from a particular copyright holder is reinstated (a) +provisionally, unless and until the copyright holder explicitly and +finally terminates your license, and (b) permanently, if the copyright +holder fails to notify you of the violation by some reasonable means +prior to 60 days after the cessation. + + Moreover, your license from a particular copyright holder is +reinstated permanently if the copyright holder notifies you of the +violation by some reasonable means, this is the first time you have +received notice of violation of this License (for any work) from that +copyright holder, and you cure the violation prior to 30 days after +your receipt of the notice. + + Termination of your rights under this section does not terminate the +licenses of parties who have received copies or rights from you under +this License. If your rights have been terminated and not permanently +reinstated, you do not qualify to receive new licenses for the same +material under section 10. + + 9. Acceptance Not Required for Having Copies. + + You are not required to accept this License in order to receive or +run a copy of the Program. Ancillary propagation of a covered work +occurring solely as a consequence of using peer-to-peer transmission +to receive a copy likewise does not require acceptance. However, +nothing other than this License grants you permission to propagate or +modify any covered work. These actions infringe copyright if you do +not accept this License. Therefore, by modifying or propagating a +covered work, you indicate your acceptance of this License to do so. + + 10. Automatic Licensing of Downstream Recipients. + + Each time you convey a covered work, the recipient automatically +receives a license from the original licensors, to run, modify and +propagate that work, subject to this License. You are not responsible +for enforcing compliance by third parties with this License. + + An "entity transaction" is a transaction transferring control of an +organization, or substantially all assets of one, or subdividing an +organization, or merging organizations. If propagation of a covered +work results from an entity transaction, each party to that +transaction who receives a copy of the work also receives whatever +licenses to the work the party's predecessor in interest had or could +give under the previous paragraph, plus a right to possession of the +Corresponding Source of the work from the predecessor in interest, if +the predecessor has it or can get it with reasonable efforts. + + You may not impose any further restrictions on the exercise of the +rights granted or affirmed under this License. For example, you may +not impose a license fee, royalty, or other charge for exercise of +rights granted under this License, and you may not initiate litigation +(including a cross-claim or counterclaim in a lawsuit) alleging that +any patent claim is infringed by making, using, selling, offering for +sale, or importing the Program or any portion of it. + + 11. Patents. + + A "contributor" is a copyright holder who authorizes use under this +License of the Program or a work on which the Program is based. The +work thus licensed is called the contributor's "contributor version". + + A contributor's "essential patent claims" are all patent claims +owned or controlled by the contributor, whether already acquired or +hereafter acquired, that would be infringed by some manner, permitted +by this License, of making, using, or selling its contributor version, +but do not include claims that would be infringed only as a +consequence of further modification of the contributor version. For +purposes of this definition, "control" includes the right to grant +patent sublicenses in a manner consistent with the requirements of +this License. + + Each contributor grants you a non-exclusive, worldwide, royalty-free +patent license under the contributor's essential patent claims, to +make, use, sell, offer for sale, import and otherwise run, modify and +propagate the contents of its contributor version. + + In the following three paragraphs, a "patent license" is any express +agreement or commitment, however denominated, not to enforce a patent +(such as an express permission to practice a patent or covenant not to +sue for patent infringement). To "grant" such a patent license to a +party means to make such an agreement or commitment not to enforce a +patent against the party. + + If you convey a covered work, knowingly relying on a patent license, +and the Corresponding Source of the work is not available for anyone +to copy, free of charge and under the terms of this License, through a +publicly available network server or other readily accessible means, +then you must either (1) cause the Corresponding Source to be so +available, or (2) arrange to deprive yourself of the benefit of the +patent license for this particular work, or (3) arrange, in a manner +consistent with the requirements of this License, to extend the patent +license to downstream recipients. "Knowingly relying" means you have +actual knowledge that, but for the patent license, your conveying the +covered work in a country, or your recipient's use of the covered work +in a country, would infringe one or more identifiable patents in that +country that you have reason to believe are valid. + + If, pursuant to or in connection with a single transaction or +arrangement, you convey, or propagate by procuring conveyance of, a +covered work, and grant a patent license to some of the parties +receiving the covered work authorizing them to use, propagate, modify +or convey a specific copy of the covered work, then the patent license +you grant is automatically extended to all recipients of the covered +work and works based on it. + + A patent license is "discriminatory" if it does not include within +the scope of its coverage, prohibits the exercise of, or is +conditioned on the non-exercise of one or more of the rights that are +specifically granted under this License. You may not convey a covered +work if you are a party to an arrangement with a third party that is +in the business of distributing software, under which you make payment +to the third party based on the extent of your activity of conveying +the work, and under which the third party grants, to any of the +parties who would receive the covered work from you, a discriminatory +patent license (a) in connection with copies of the covered work +conveyed by you (or copies made from those copies), or (b) primarily +for and in connection with specific products or compilations that +contain the covered work, unless you entered into that arrangement, +or that patent license was granted, prior to 28 March 2007. + + Nothing in this License shall be construed as excluding or limiting +any implied license or other defenses to infringement that may +otherwise be available to you under applicable patent law. + + 12. No Surrender of Others' Freedom. + + If conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot convey a +covered work so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you may +not convey it at all. For example, if you agree to terms that obligate you +to collect a royalty for further conveying from those to whom you convey +the Program, the only way you could satisfy both those terms and this +License would be to refrain entirely from conveying the Program. + + 13. Use with the GNU Affero General Public License. + + Notwithstanding any other provision of this License, you have +permission to link or combine any covered work with a work licensed +under version 3 of the GNU Affero General Public License into a single +combined work, and to convey the resulting work. The terms of this +License will continue to apply to the part which is the covered work, +but the special requirements of the GNU Affero General Public License, +section 13, concerning interaction through a network will apply to the +combination as such. + + 14. Revised Versions of this License. + + The Free Software Foundation may publish revised and/or new versions of +the GNU General Public License from time to time. Such new versions will +be similar in spirit to the present version, but may differ in detail to +address new problems or concerns. + + Each version is given a distinguishing version number. If the +Program specifies that a certain numbered version of the GNU General +Public License "or any later version" applies to it, you have the +option of following the terms and conditions either of that numbered +version or of any later version published by the Free Software +Foundation. If the Program does not specify a version number of the +GNU General Public License, you may choose any version ever published +by the Free Software Foundation. + + If the Program specifies that a proxy can decide which future +versions of the GNU General Public License can be used, that proxy's +public statement of acceptance of a version permanently authorizes you +to choose that version for the Program. + + Later license versions may give you additional or different +permissions. However, no additional obligations are imposed on any +author or copyright holder as a result of your choosing to follow a +later version. + + 15. Disclaimer of Warranty. + + THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY +APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT +HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY +OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, +THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR +PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM +IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF +ALL NECESSARY SERVICING, REPAIR OR CORRECTION. + + 16. Limitation of Liability. + + IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING +WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS +THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY +GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE +USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF +DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD +PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), +EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF +SUCH DAMAGES. + + 17. Interpretation of Sections 15 and 16. + + If the disclaimer of warranty and limitation of liability provided +above cannot be given local legal effect according to their terms, +reviewing courts shall apply local law that most closely approximates +an absolute waiver of all civil liability in connection with the +Program, unless a warranty or assumption of liability accompanies a +copy of the Program in return for a fee. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Programs + + If you develop a new program, and you want it to be of the greatest +possible use to the public, the best way to achieve this is to make it +free software which everyone can redistribute and change under these terms. + + To do so, attach the following notices to the program. It is safest +to attach them to the start of each source file to most effectively +state the exclusion of warranty; and each file should have at least +the "copyright" line and a pointer to where the full notice is found. + + <one line to give the program's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This program is free software: you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation, either version 3 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License + along with this program. If not, see <http://www.gnu.org/licenses/>. + +Also add information on how to contact you by electronic and paper mail. + + If the program does terminal interaction, make it output a short +notice like this when it starts in an interactive mode: + + <program> Copyright (C) <year> <name of author> + This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'. + This is free software, and you are welcome to redistribute it + under certain conditions; type `show c' for details. + +The hypothetical commands `show w' and `show c' should show the appropriate +parts of the General Public License. Of course, your program's commands +might be different; for a GUI interface, you would use an "about box". + + You should also get your employer (if you work as a programmer) or school, +if any, to sign a "copyright disclaimer" for the program, if necessary. +For more information on this, and how to apply and follow the GNU GPL, see +<http://www.gnu.org/licenses/>. + + The GNU General Public License does not permit incorporating your program +into proprietary programs. If your program is a subroutine library, you +may consider it more useful to permit linking proprietary applications with +the library. If this is what you want to do, use the GNU Lesser General +Public License instead of this License. But first, please read +<http://www.gnu.org/philosophy/why-not-lgpl.html>. diff --git a/net/alcoholic_jwt/README.md b/net/alcoholic_jwt/README.md new file mode 100644 index 0000000000..b9ff57df4b --- /dev/null +++ b/net/alcoholic_jwt/README.md @@ -0,0 +1,62 @@ +alcoholic_jwt +============= + +[](https://travis-ci.org/aprilabank/alcoholic_jwt) + +This is a library for **validation** of **RS256** JWTs using keys from +a JWKS. Nothing more, nothing less. + +RS256 is the most commonly used asymmetric signature mechanism for +JWTs, encountered in for example [Google][]'s or [Aprila][]'s APIs. + +The name of the library stems from the potential side-effects of +trying to use the other Rust libraries that are made for similar +purposes. + +## Usage overview + +You are retrieving JWTs from some authentication provider that uses +`RS256` signatures and provides its public keys in [JWKS][] format. + +Example for a token that provides the key ID used for signing in the +[`kid` claim][]: + +```rust +extern crate alcoholic_jwt; + +use alcoholic_jwt::{JWKS, Validation, validate, token_kid}; + +// The function implied here would usually perform an HTTP-GET +// on the JWKS-URL for an authentication provider and deserialize +// the result into the `alcoholic_jwt::JWKS`-struct. +let jwks: JWKS = jwks_fetching_function(); + +let token: String = some_token_fetching_function(); + +// Several types of built-in validations are provided: +let validations = vec![ + Validation::Issuer("auth.test.aprila.no".into()), + Validation::SubjectPresent, +]; + +// If a JWKS contains multiple keys, the correct KID first +// needs to be fetched from the token headers. +let kid = token_kid(&token) + .expect("Failed to decode token headers") + .expect("No 'kid' claim present in token"); + +let jwk = jwks.find(&kid).expect("Specified key not found in set"); + +validate(token, jwk, validations).expect("Token validation has failed!"); +``` + +## Under the hood + +This library aims to only use trustworthy off-the-shelf components to +do the work. Cryptographic operations are provided by the `openssl` +crate, JSON-serialisation is provided by `serde_json`. + +[Google]: https://www.google.com/ +[Aprila]: https://www.aprila.no/ +[JWKS]: https://tools.ietf.org/html/rfc7517 +[`kid` claim]: https://tools.ietf.org/html/rfc7515#section-4.1.4 diff --git a/net/alcoholic_jwt/src/lib.rs b/net/alcoholic_jwt/src/lib.rs new file mode 100644 index 0000000000..c98bee6150 --- /dev/null +++ b/net/alcoholic_jwt/src/lib.rs @@ -0,0 +1,451 @@ +// Copyright (C) 2018 Aprila Bank ASA +// +// alcoholic_jwt is free software: you can redistribute it and/or +// modify it under the terms of the GNU General Public License as +// published by the Free Software Foundation, either version 3 of the +// License, or (at your option) any later version. +// +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. +// +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <http://www.gnu.org/licenses/>. + +//! Implements a library for for **validation** of **RS256** JWTs +//! using keys from a JWKS. Nothing more, nothing less. +//! +//! The name of the library stems from the potential side-effects of +//! trying to use the other Rust libraries that are made for similar +//! purposes. +//! +//! This library is specifically aimed at developers that consume +//! tokens from services which provide their RSA public keys in +//! [JWKS][] format. +//! +//! ## Usage example (token with `kid`-claim) +//! +//! ```rust +//! # extern crate serde_json; +//! extern crate alcoholic_jwt; +//! +//! use alcoholic_jwt::{JWKS, Validation, validate, token_kid}; +//! +//! # fn some_token_fetching_function() -> &'static str { +//! # "eyJraWQiOiI4ckRxOFB3MEZaY2FvWFdURVZRbzcrVGYyWXpTTDFmQnhOS1BDZWJhYWk0PSIsImFsZyI6IlJTMjU2IiwidHlwIjoiSldUIn0.eyJpc3MiOiJhdXRoLnRlc3QuYXByaWxhLm5vIiwiaWF0IjoxNTM2MDUwNjkzLCJleHAiOjE1MzYwNTQyOTMsInN1YiI6IjQyIiwiZXh0Ijoic21va2V0ZXN0IiwicHJ2IjoiYXJpc3RpIiwic2NwIjoicHJvY2VzcyJ9.gOLsv98109qLkmRK6Dn7WWRHLW7o8W78WZcWvFZoxPLzVO0qvRXXRLYc9h5chpfvcWreLZ4f1cOdvxv31_qnCRSQQPOeQ7r7hj_sPEDzhKjk-q2aoNHaGGJg1vabI--9EFkFsGQfoS7UbMMssS44dgR68XEnKtjn0Vys-Vzbvz_CBSCH6yQhRLik2SU2jR2L7BoFvh4LGZ6EKoQWzm8Z-CHXLGLUs4Hp5aPhF46dGzgAzwlPFW4t9G4DciX1uB4vv1XnfTc5wqJch6ltjKMde1GZwLR757a8dJSBcmGWze3UNE2YH_VLD7NCwH2kkqr3gh8rn7lWKG4AUIYPxsw9CB" +//! # } +//! +//! # fn jwks_fetching_function() -> JWKS { +//! # let jwks_json = "{\"keys\":[{\"kty\":\"RSA\",\"alg\":\"RS256\",\"use\":\"sig\",\"kid\":\"8rDq8Pw0FZcaoXWTEVQo7+Tf2YzSL1fBxNKPCebaai4=\",\"n\":\"l4UTgk1zr-8C8utt0E57DtBV6qqAPWzVRrIuQS2j0_hp2CviaNl5XzGRDnB8gwk0Hx95YOhJupAe6RNq5ok3fDdxL7DLvppJNRLz3Ag9CsmDLcbXgNEQys33fBJaPw1v3GcaFC4tisU5p-o1f5RfWwvwdBtdBfGiwT1GRvbc5sFx6M4iYjg9uv1lNKW60PqSJW4iDYrfqzZmB0zF1SJ0BL_rnQZ1Wi_UkFmNe9arM8W9tI9T3Ie59HITFuyVSTCt6qQEtSfa1e5PiBaVuV3qoFI2jPBiVZQ6LPGBWEDyz4QtrHLdECPPoTF30NN6TSVwwlRbCuUUrdNdXdjYe2dMFQ\",\"e\":\"DhaD5zC7mzaDvHO192wKT_9sfsVmdy8w8T8C9VG17_b1jG2srd3cmc6Ycw-0blDf53Wrpi9-KGZXKHX6_uIuJK249WhkP7N1SHrTJxO0sUJ8AhK482PLF09Qtu6cUfJqY1X1y1S2vACJZItU4Vjr3YAfiVGQXeA8frAf7Sm4O1CBStCyg6yCcIbGojII0jfh2vSB-GD9ok1F69Nmk-R-bClyqMCV_Oq-5a0gqClVS8pDyGYMgKTww2RHgZaFSUcG13KeLMQsG2UOB2OjSC8FkOXK00NBlAjU3d0Vv-IamaLIszO7FQBY3Oh0uxNOvIE9ofQyCOpB-xIK6V9CTTphxw\"}]}"; +//! # serde_json::from_str(jwks_json).unwrap() +//! # } +//! # +//! // The function implied here would usually perform an HTTP-GET +//! // on the JWKS-URL for an authentication provider and deserialize +//! // the result into the `alcoholic_jwt::JWKS`-struct. +//! let jwks: JWKS = jwks_fetching_function(); +//! +//! let token = some_token_fetching_function(); +//! +//! // Several types of built-in validations are provided: +//! let validations = vec![ +//! Validation::Issuer("auth.test.aprila.no".into()), +//! Validation::SubjectPresent, +//! ]; +//! +//! // If a JWKS contains multiple keys, the correct KID first +//! // needs to be fetched from the token headers. +//! let kid = token_kid(&token) +//! .expect("Failed to decode token headers") +//! .expect("No 'kid' claim present in token"); +//! +//! let jwk = jwks.find(&kid).expect("Specified key not found in set"); +//! +//! validate(token, jwk, validations).expect("Token validation has failed!"); +//! ``` +//! +//! [JWKS]: https://tools.ietf.org/html/rfc7517 + +#[macro_use] extern crate serde_derive; + +extern crate base64; +extern crate openssl; +extern crate serde; +extern crate serde_json; + +use base64::{URL_SAFE_NO_PAD, Config, DecodeError}; +use openssl::bn::BigNum; +use openssl::error::ErrorStack; +use openssl::hash::MessageDigest; +use openssl::pkey::{Public, PKey}; +use openssl::rsa::Rsa; +use openssl::sign::Verifier; +use serde::de::DeserializeOwned; +use serde_json::Value; +use std::time::{UNIX_EPOCH, Duration, SystemTime}; + +#[cfg(test)] +mod tests; + +/// URL-safe character set without padding that allows trailing bits, +/// which appear in some JWT implementations. +/// +/// Note: The functions on `base64::Config` are not marked `const`, +/// and the constructors are not exported, which is why this is +/// implemented as a function. +fn jwt_forgiving() -> Config { + URL_SAFE_NO_PAD.decode_allow_trailing_bits(true) +} + +/// JWT algorithm used. The only supported algorithm is currently +/// RS256. +#[derive(Clone, Deserialize, Debug)] +enum KeyAlgorithm { RS256 } + +/// Type of key contained in a JWT. The only supported key type is +/// currently RSA. +#[derive(Clone, Deserialize, Debug)] +enum KeyType { RSA } + +/// Representation of a single JSON Web Key. See [RFC +/// 7517](https://tools.ietf.org/html/rfc7517#section-4). +#[allow(dead_code)] // kty & alg only constrain deserialisation, but aren't used +#[derive(Clone, Debug, Deserialize)] +pub struct JWK { + kty: KeyType, + alg: Option<KeyAlgorithm>, + kid: Option<String>, + + // Shared modulus + n: String, + + // Public key exponent + e: String, +} + +/// Representation of a set of JSON Web Keys. See [RFC +/// 7517](https://tools.ietf.org/html/rfc7517#section-5). +#[derive(Clone, Debug, Deserialize)] +pub struct JWKS { + // This is a vector instead of some kind of map-like structure + // because key IDs are in fact optional. + // + // Technically having multiple keys with the same KID would not + // violate the JWKS-definition either, but behaviour in that case + // is unspecified. + keys: Vec<JWK>, +} + +impl JWKS { + /// Attempt to find a JWK by its key ID. + pub fn find(&self, kid: &str) -> Option<&JWK> { + self.keys.iter().find(|jwk| jwk.kid == Some(kid.into())) + } +} + +/// Representation of an undecoded JSON Web Token. See [RFC +/// 7519](https://tools.ietf.org/html/rfc7519). +struct JWT<'a> (&'a str); + +/// Representation of a decoded and validated JSON Web Token. +/// +/// Specific claim fields are only decoded internally in the library +/// for validation purposes, while it is generally up to the consumer +/// of the validated JWT what structure they would like to impose. +pub struct ValidJWT { + /// JOSE header of the JSON Web Token. Certain fields are + /// guaranteed to be present in this header, consult section 5 of + /// RFC7519 for more information. + pub headers: Value, + + /// Claims (i.e. primary data) contained in the JSON Web Token. + /// While there are several registered and recommended headers + /// (consult section 4.1 of RFC7519), the presence of no field is + /// guaranteed in these. + pub claims: Value, +} + +/// Possible token claim validations. This enumeration only covers +/// common use-cases, for other types of validations the user is +/// encouraged to inspect the claim set manually. +pub enum Validation { + /// Validate that the issuer ("iss") claim matches a specified + /// value. + Issuer(String), + + /// Validate that the audience ("aud") claim matches a specified + /// value. + Audience(String), + + /// Validate that a subject value is present. + SubjectPresent, + + /// Validate that the expiry time of the token ("exp"-claim) has + /// not yet been reached. + NotExpired, +} + +/// Possible results of a token validation. +#[derive(Debug)] +pub enum ValidationError { + /// Invalid number of token components (not a JWT?) + InvalidComponents, + + /// Token segments had invalid base64-encoding. + InvalidBase64(DecodeError), + + /// Decoding of the provided JWK failed. + InvalidJWK, + + /// Signature validation failed, i.e. because of a non-matching + /// public key. + InvalidSignature, + + /// An OpenSSL operation failed along the way at a point at which + /// a more specific error variant could not be constructed. + OpenSSL(ErrorStack), + + /// JSON decoding into a provided type failed. + JSON(serde_json::Error), + + /// One or more claim validations failed. This variant contains + /// human-readable validation errors. + InvalidClaims(Vec<&'static str>), +} + +type JWTResult<T> = Result<T, ValidationError>; + +impl From<ErrorStack> for ValidationError { + fn from(err: ErrorStack) -> Self { ValidationError::OpenSSL(err) } +} + +impl From<serde_json::Error> for ValidationError { + fn from(err: serde_json::Error) -> Self { ValidationError::JSON(err) } +} + +impl From<DecodeError> for ValidationError { + fn from(err: DecodeError) -> Self { ValidationError::InvalidBase64(err) } +} + +/// Attempt to extract the `kid`-claim out of a JWT's header claims. +/// +/// This function is normally used when a token provider has multiple +/// public keys in rotation at the same time that could all still have +/// valid tokens issued under them. +/// +/// This is only safe if the key set containing the currently allowed +/// key IDs is fetched from a trusted source. +pub fn token_kid(token: &str) -> JWTResult<Option<String>> { + // Fetch the header component of the JWT by splitting it out and + // dismissing the rest. + let parts: Vec<&str> = token.splitn(2, '.').collect(); + if parts.len() != 2 { + return Err(ValidationError::InvalidComponents); + } + + // Decode only the first part of the token into a specialised + // representation: + #[derive(Deserialize)] + struct KidOnly { + kid: Option<String>, + } + + let kid_only: KidOnly = deserialize_part(parts[0])?; + + Ok(kid_only.kid) +} + +/// Validate the signature of a JSON Web Token and optionally apply +/// claim validations. Signatures are always verified before claims, +/// and if a signature verification passes *all* claim validations are +/// run and returned. +/// +/// If validation succeeds a representation of the token is returned +/// that contains the header and claims as simple JSON values. +/// +/// It is the user's task to ensure that the correct JWK is passed in +/// for validation. +pub fn validate(token: &str, + jwk: &JWK, + validations: Vec<Validation>) -> JWTResult<ValidJWT> { + let jwt = JWT(token); + let public_key = public_key_from_jwk(&jwk)?; + validate_jwt_signature(&jwt, public_key)?; + + // Split out all three parts of the JWT this time, deserialising + // the first and second as appropriate. + let parts: Vec<&str> = jwt.0.splitn(3, '.').collect(); + if parts.len() != 3 { + // This is unlikely considering that validation has already + // been performed at this point, but better safe than sorry. + return Err(ValidationError::InvalidComponents) + } + + // Perform claim validations before constructing the valid token: + let partial_claims = deserialize_part(parts[1])?; + validate_claims(partial_claims, validations)?; + + let headers = deserialize_part(parts[0])?; + let claims = deserialize_part(parts[1])?; + let valid_jwt = ValidJWT { headers, claims }; + + Ok(valid_jwt) +} + +// Internal implementation +// +// The functions in the following section are not part of the public +// API of this library. + +/// Decode a single key fragment (base64-url encoded integer) to an +/// OpenSSL BigNum. +fn decode_fragment(fragment: &str) -> JWTResult<BigNum> { + let bytes = base64::decode_config(fragment, jwt_forgiving()) + .map_err(|_| ValidationError::InvalidJWK)?; + + BigNum::from_slice(&bytes).map_err(Into::into) +} + +/// Decode an RSA public key from a JWK by constructing it directly +/// from the public RSA key fragments. +fn public_key_from_jwk(jwk: &JWK) -> JWTResult<Rsa<Public>> { + let jwk_n = decode_fragment(&jwk.n)?; + let jwk_e = decode_fragment(&jwk.e)?; + Rsa::from_public_components(jwk_n, jwk_e).map_err(Into::into) +} + +/// Decode a base64-URL encoded string and deserialise the resulting +/// JSON. +fn deserialize_part<T: DeserializeOwned>(part: &str) -> JWTResult<T> { + let json = base64::decode_config(part, jwt_forgiving())?; + serde_json::from_slice(&json).map_err(Into::into) +} + +/// Validate the signature on a JWT using a provided public key. +/// +/// A JWT is made up of three components (headers, claims, signature) +/// - only the first two are part of the signed data. +fn validate_jwt_signature(jwt: &JWT, key: Rsa<Public>) -> JWTResult<()> { + let key = PKey::from_rsa(key)?; + let mut verifier = Verifier::new(MessageDigest::sha256(), &key)?; + + // Split the token from the back to a maximum of two elements. + // There are technically three components using the same separator + // ('.'), but we are interested in the first two together and + // splitting them is unnecessary. + let token_parts: Vec<&str> = jwt.0.rsplitn(2, '.').collect(); + if token_parts.len() != 2 { + return Err(ValidationError::InvalidComponents); + } + + // Second element of the vector will be the signed payload. + let data = token_parts[1]; + + // First element of the vector will be the (encoded) signature. + let sig_b64 = token_parts[0]; + let sig = base64::decode_config(sig_b64, jwt_forgiving())?; + + // Verify signature by inserting the payload data and checking it + // against the decoded signature. + verifier.update(data.as_bytes())?; + + match verifier.verify(&sig)? { + true => Ok(()), + false => Err(ValidationError::InvalidSignature), + } +} + +/// Internal helper struct for claims that are relevant for claim +/// validations. +#[derive(Deserialize)] +struct PartialClaims { + aud: Option<String>, + iss: Option<String>, + sub: Option<String>, + exp: Option<u64>, +} + +/// Apply a single validation to the claim set of a token. +fn apply_validation(claims: &PartialClaims, + validation: Validation) -> Result<(), &'static str> { + match validation { + // Validate that an 'iss' claim is present and matches the + // supplied value. + Validation::Issuer(iss) => { + match claims.iss { + None => Err("'iss' claim is missing"), + Some(ref claim) => if *claim == iss { + Ok(()) + } else { + Err("'iss' claim does not match") + } + } + }, + + // Validate that an 'aud' claim is present and matches the + // supplied value. + Validation::Audience(aud) => { + match claims.aud { + None => Err("'aud' claim is missing"), + Some(ref claim) => if *claim == aud { + Ok(()) + } else { + Err("'aud' claim does not match") + } + } + }, + + Validation::SubjectPresent => match claims.sub { + Some(_) => Ok(()), + None => Err("'sub' claim is missing"), + }, + + Validation::NotExpired => match claims.exp { + None => Err("'exp' claim is missing"), + Some(exp) => { + // Determine the current timestamp in seconds since + // the UNIX epoch. + let now = SystemTime::now() + .duration_since(UNIX_EPOCH) + // this is an unrecoverable, critical error. There + // aren't many ways this can occur, other than + // system time being set into the far future or + // this library being used in some sort of future + // museum. + .expect("system time is likely incorrect"); + + // Convert the expiry time (which is also in epoch + // seconds) to a duration. + let exp_duration = Duration::from_secs(exp); + + // The token has not expired if the expiry duration is + // larger than (i.e. in the future from) the current + // time. + if exp_duration > now { + Ok(()) + } else { + Err("token has expired") + } + } + }, + } +} + +/// Apply all requested validations to a partial claim set. +fn validate_claims(claims: PartialClaims, + validations: Vec<Validation>) -> JWTResult<()> { + let validation_errors: Vec<_> = validations.into_iter() + .map(|v| apply_validation(&claims, v)) + .filter_map(|result| match result { + Ok(_) => None, + Err(err) => Some(err), + }) + .collect(); + + if validation_errors.is_empty() { + Ok(()) + } else { + Err(ValidationError::InvalidClaims(validation_errors)) + } +} diff --git a/net/alcoholic_jwt/src/tests.rs b/net/alcoholic_jwt/src/tests.rs new file mode 100644 index 0000000000..81890986f8 --- /dev/null +++ b/net/alcoholic_jwt/src/tests.rs @@ -0,0 +1,61 @@ +// Copyright (C) 2018 Aprila Bank ASA +// +// alcoholic_jwt is free software: you can redistribute it and/or +// modify it under the terms of the GNU General Public License as +// published by the Free Software Foundation, either version 3 of the +// License, or (at your option) any later version. +// +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. +// +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <http://www.gnu.org/licenses/>. + +use super::*; + +#[test] +fn test_fragment_decoding() { + let fragment = "ngRRjNbXgPW29oNtF0JgsyyfTwPyEL0u_X16s453X2AOc33XGFxVKLEQ7R_TiMenaKcr-tPifYqgps_deyi0XOr4I3SOdOMtAVKDZJCANe--CANOHZb-meIfjKhCHisvT90fm5Apd6qPRVsXsZ7A8pmClZHKM5fwZUkBv8NsPLm2Xy2sGOZIiwP_7z8m3j0abUzniPQsx2b3xcWimB9vRtshFHN1KgPUf1ALQ5xzLfJnlFkCxC7kmOxKC7_NpQ4kJR_DKzKFV_r3HxTqf-jddHcXIrrMcLQXCSyeLQtLaz7whQ4F-EfL42z4XgwPr4ji3sct2gWL13EqlbE5DDxLKQ"; + let bignum = decode_fragment(fragment).expect("Failed to decode fragment"); + + let expected = "19947781743618558124649689124245117083485690334420160711273532766920651190711502679542723943527557680293732686428091794139998732541701457212387600480039297092835433997837314251024513773285252960725418984381935183495143908023024822433135775773958512751261112853383693442999603704969543668619221464654540065497665889289271044207667765128672709218996183649696030570183970367596949687544839066873508106034650634722970893169823917299050098551447676778961773465887890052852528696684907153295689693676910831376066659456592813140662563597179711588277621736656871685099184755908108451080261403193680966083938080206832839445289"; + assert_eq!(expected, format!("{}", bignum), "Decoded fragment should match "); +} + +#[test] +fn test_decode_find_jwks() { + let json = "{\"keys\":[{\"kty\":\"RSA\",\"alg\":\"RS256\",\"use\":\"sig\",\"kid\":\"mUjI\\/rIMLLtung35BKZfdbrqtlEAAYJ4JX\\/SKvnLxJc=\",\"n\":\"ngRRjNbXgPW29oNtF0JgsyyfTwPyEL0u_X16s453X2AOc33XGFxVKLEQ7R_TiMenaKcr-tPifYqgps_deyi0XOr4I3SOdOMtAVKDZJCANe--CANOHZb-meIfjKhCHisvT90fm5Apd6qPRVsXsZ7A8pmClZHKM5fwZUkBv8NsPLm2Xy2sGOZIiwP_7z8m3j0abUzniPQsx2b3xcWimB9vRtshFHN1KgPUf1ALQ5xzLfJnlFkCxC7kmOxKC7_NpQ4kJR_DKzKFV_r3HxTqf-jddHcXIrrMcLQXCSyeLQtLaz7whQ4F-EfL42z4XgwPr4ji3sct2gWL13EqlbE5DDxLKQ\",\"e\":\"GK7oLCDbNPAF59LhvyseqcG04hDnPs58qGYolr_HHmaR4lulWJ90ozx6e4Ut363yKG2p9vwvivR5UIC-aLPtqT2qr-OtjhBFzUFVaMGZ6mPCvMKk0AgMYdOHvWTgBSqQtNJTvl1yYLnhcWyoE2fLQhoEbY9qUyCBCEOScXOZRDpnmBtz5I8q5yYMV6a920J24T_IYbxHgkGcEU2SGg-b1cOMD7Rja7vCfV---CQ2pR4leQ0jufzudDoe7z3mziJm-Ihcdrz2Ujy5kPEMdz6R55prJ-ENKrkD_X4u5aSlSRaetwmHS3oAVkjr1JwUNbqnpM-kOqieqHEp8LUmez-Znw\"}]}"; + let jwks: JWKS = serde_json::from_str(json).expect("Failed to decode JWKS"); + let jwk = jwks.find("mUjI/rIMLLtung35BKZfdbrqtlEAAYJ4JX/SKvnLxJc=") + .expect("Failed to find required JWK"); + + public_key_from_jwk(&jwk).expect("Failed to construct public key from JWK"); +} + +#[test] +fn test_token_kid() { + let jwt = "eyJraWQiOiI4ckRxOFB3MEZaY2FvWFdURVZRbzcrVGYyWXpTTDFmQnhOS1BDZWJhYWk0PSIsImFsZyI6IlJTMjU2IiwidHlwIjoiSldUIn0.eyJpc3MiOiJhdXRoLnRlc3QuYXByaWxhLm5vIiwiaWF0IjoxNTM2MDUwNjkzLCJleHAiOjE1MzYwNTQyOTMsInN1YiI6IjQyIiwiZXh0Ijoic21va2V0ZXN0IiwicHJ2IjoiYXJpc3RpIiwic2NwIjoicHJvY2VzcyJ9.gOLsv98109qLkmRK6Dn7WWRHLW7o8W78WZcWvFZoxPLzVO0qvRXXRLYc9h5chpfvcWreLZ4f1cOdvxv31_qnCRSQQPOeQ7r7hj_sPEDzhKjk-q2aoNHaGGJg1vabI--9EFkFsGQfoS7UbMMssS44dgR68XEnKtjn0Vys-Vzbvz_CBSCH6yQhRLik2SU2jR2L7BoFvh4LGZ6EKoQWzm8Z-CHXLGLUs4Hp5aPhF46dGzgAzwlPFW4t9G4DciX1uB4vv1XnfTc5wqJch6ltjKMde1GZwLR757a8dJSBcmGWze3UNE2YH_VLD7NCwH2kkqr3gh8rn7lWKG4AUIYPxsw9CB"; + + let kid = token_kid(&jwt).expect("Failed to extract token KID"); + assert_eq!(Some("8rDq8Pw0FZcaoXWTEVQo7+Tf2YzSL1fBxNKPCebaai4=".into()), + kid, "Extracted KID did not match expected KID"); +} + +#[test] +fn test_validate_jwt() { + let jwks_json = "{\"keys\":[{\"kty\":\"RSA\",\"alg\":\"RS256\",\"use\":\"sig\",\"kid\":\"8rDq8Pw0FZcaoXWTEVQo7+Tf2YzSL1fBxNKPCebaai4=\",\"n\":\"l4UTgk1zr-8C8utt0E57DtBV6qqAPWzVRrIuQS2j0_hp2CviaNl5XzGRDnB8gwk0Hx95YOhJupAe6RNq5ok3fDdxL7DLvppJNRLz3Ag9CsmDLcbXgNEQys33fBJaPw1v3GcaFC4tisU5p-o1f5RfWwvwdBtdBfGiwT1GRvbc5sFx6M4iYjg9uv1lNKW60PqSJW4iDYrfqzZmB0zF1SJ0BL_rnQZ1Wi_UkFmNe9arM8W9tI9T3Ie59HITFuyVSTCt6qQEtSfa1e5PiBaVuV3qoFI2jPBiVZQ6LPGBWEDyz4QtrHLdECPPoTF30NN6TSVwwlRbCuUUrdNdXdjYe2dMFQ\",\"e\":\"DhaD5zC7mzaDvHO192wKT_9sfsVmdy8w8T8C9VG17_b1jG2srd3cmc6Ycw-0blDf53Wrpi9-KGZXKHX6_uIuJK249WhkP7N1SHrTJxO0sUJ8AhK482PLF09Qtu6cUfJqY1X1y1S2vACJZItU4Vjr3YAfiVGQXeA8frAf7Sm4O1CBStCyg6yCcIbGojII0jfh2vSB-GD9ok1F69Nmk-R-bClyqMCV_Oq-5a0gqClVS8pDyGYMgKTww2RHgZaFSUcG13KeLMQsG2UOB2OjSC8FkOXK00NBlAjU3d0Vv-IamaLIszO7FQBY3Oh0uxNOvIE9ofQyCOpB-xIK6V9CTTphxw\"}]}"; + + let jwks: JWKS = serde_json::from_str(jwks_json) + .expect("Failed to decode JWKS"); + + let jwk = jwks.find("8rDq8Pw0FZcaoXWTEVQo7+Tf2YzSL1fBxNKPCebaai4=") + .expect("Failed to find required JWK"); + + let pkey = public_key_from_jwk(&jwk).expect("Failed to construct public key"); + + let jwt = JWT("eyJraWQiOiI4ckRxOFB3MEZaY2FvWFdURVZRbzcrVGYyWXpTTDFmQnhOS1BDZWJhYWk0PSIsImFsZyI6IlJTMjU2IiwidHlwIjoiSldUIn0.eyJpc3MiOiJhdXRoLnRlc3QuYXByaWxhLm5vIiwiaWF0IjoxNTM2MDUwNjkzLCJleHAiOjE1MzYwNTQyOTMsInN1YiI6IjQyIiwiZXh0Ijoic21va2V0ZXN0IiwicHJ2IjoiYXJpc3RpIiwic2NwIjoicHJvY2VzcyJ9.gOLsv98109qLkmRK6Dn7WWRHLW7o8W78WZcWvFZoxPLzVO0qvRXXRLYc9h5chpfvcWreLZ4f1cOdvxv31_qnCRSQQPOeQ7r7hj_sPEDzhKjk-q2aoNHaGGJg1vabI--9EFkFsGQfoS7UbMMssS44dgR68XEnKtjn0Vys-Vzbvz_CBSCH6yQhRLik2SU2jR2L7BoFvh4LGZ6EKoQWzm8Z-CHXLGLUs4Hp5aPhF46dGzgAzwlPFW4t9G4DciX1uB4vv1XnfTc5wqJch6ltjKMde1GZwLR757a8dJSBcmGWze3UNE2YH_VLD7NCwH2kkqr3gh8rn7lWKG4AUIYPxsw9CB".into()); + + validate_jwt_signature(&jwt, pkey).expect("Validation failed unexpectedly"); +} diff --git a/net/crimp/.gitignore b/net/crimp/.gitignore new file mode 100644 index 0000000000..693699042b --- /dev/null +++ b/net/crimp/.gitignore @@ -0,0 +1,3 @@ +/target +**/*.rs.bk +Cargo.lock diff --git a/net/crimp/Cargo.toml b/net/crimp/Cargo.toml new file mode 100644 index 0000000000..13c80f1f69 --- /dev/null +++ b/net/crimp/Cargo.toml @@ -0,0 +1,18 @@ +[package] +name = "crimp" +description = "Higher-level Rust API for cURL bindings" +version = "0.2.2" +authors = ["Vincent Ambo <mail@tazj.in>"] +keywords = [ "http", "curl" ] +categories = [ "api-bindings" ] +license = "GPL-3.0-or-later" +repository = "https://github.com/tazjin/crimp" + +[features] +default = [ "json" ] +json = [ "serde", "serde_json"] + +[dependencies] +curl = "0.4" +serde = { version = "1.0", optional = true } +serde_json = { version = "1.0", optional = true } diff --git a/net/crimp/LICENSE b/net/crimp/LICENSE new file mode 100644 index 0000000000..94a9ed024d --- /dev/null +++ b/net/crimp/LICENSE @@ -0,0 +1,674 @@ + GNU GENERAL PUBLIC LICENSE + Version 3, 29 June 2007 + + Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/> + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + + Preamble + + The GNU General Public License is a free, copyleft license for +software and other kinds of works. + + The licenses for most software and other practical works are designed +to take away your freedom to share and change the works. By contrast, +the GNU General Public License is intended to guarantee your freedom to +share and change all versions of a program--to make sure it remains free +software for all its users. We, the Free Software Foundation, use the +GNU General Public License for most of our software; it applies also to +any other work released this way by its authors. You can apply it to +your programs, too. + + When we speak of free software, we are referring to freedom, not +price. Our General Public Licenses are designed to make sure that you +have the freedom to distribute copies of free software (and charge for +them if you wish), that you receive source code or can get it if you +want it, that you can change the software or use pieces of it in new +free programs, and that you know you can do these things. + + To protect your rights, we need to prevent others from denying you +these rights or asking you to surrender the rights. Therefore, you have +certain responsibilities if you distribute copies of the software, or if +you modify it: responsibilities to respect the freedom of others. + + For example, if you distribute copies of such a program, whether +gratis or for a fee, you must pass on to the recipients the same +freedoms that you received. You must make sure that they, too, receive +or can get the source code. And you must show them these terms so they +know their rights. + + Developers that use the GNU GPL protect your rights with two steps: +(1) assert copyright on the software, and (2) offer you this License +giving you legal permission to copy, distribute and/or modify it. + + For the developers' and authors' protection, the GPL clearly explains +that there is no warranty for this free software. For both users' and +authors' sake, the GPL requires that modified versions be marked as +changed, so that their problems will not be attributed erroneously to +authors of previous versions. + + Some devices are designed to deny users access to install or run +modified versions of the software inside them, although the manufacturer +can do so. This is fundamentally incompatible with the aim of +protecting users' freedom to change the software. The systematic +pattern of such abuse occurs in the area of products for individuals to +use, which is precisely where it is most unacceptable. Therefore, we +have designed this version of the GPL to prohibit the practice for those +products. If such problems arise substantially in other domains, we +stand ready to extend this provision to those domains in future versions +of the GPL, as needed to protect the freedom of users. + + Finally, every program is threatened constantly by software patents. +States should not allow patents to restrict development and use of +software on general-purpose computers, but in those that do, we wish to +avoid the special danger that patents applied to a free program could +make it effectively proprietary. To prevent this, the GPL assures that +patents cannot be used to render the program non-free. + + The precise terms and conditions for copying, distribution and +modification follow. + + TERMS AND CONDITIONS + + 0. Definitions. + + "This License" refers to version 3 of the GNU General Public License. + + "Copyright" also means copyright-like laws that apply to other kinds of +works, such as semiconductor masks. + + "The Program" refers to any copyrightable work licensed under this +License. Each licensee is addressed as "you". "Licensees" and +"recipients" may be individuals or organizations. + + To "modify" a work means to copy from or adapt all or part of the work +in a fashion requiring copyright permission, other than the making of an +exact copy. The resulting work is called a "modified version" of the +earlier work or a work "based on" the earlier work. + + A "covered work" means either the unmodified Program or a work based +on the Program. + + To "propagate" a work means to do anything with it that, without +permission, would make you directly or secondarily liable for +infringement under applicable copyright law, except executing it on a +computer or modifying a private copy. Propagation includes copying, +distribution (with or without modification), making available to the +public, and in some countries other activities as well. + + To "convey" a work means any kind of propagation that enables other +parties to make or receive copies. Mere interaction with a user through +a computer network, with no transfer of a copy, is not conveying. + + An interactive user interface displays "Appropriate Legal Notices" +to the extent that it includes a convenient and prominently visible +feature that (1) displays an appropriate copyright notice, and (2) +tells the user that there is no warranty for the work (except to the +extent that warranties are provided), that licensees may convey the +work under this License, and how to view a copy of this License. If +the interface presents a list of user commands or options, such as a +menu, a prominent item in the list meets this criterion. + + 1. Source Code. + + The "source code" for a work means the preferred form of the work +for making modifications to it. "Object code" means any non-source +form of a work. + + A "Standard Interface" means an interface that either is an official +standard defined by a recognized standards body, or, in the case of +interfaces specified for a particular programming language, one that +is widely used among developers working in that language. + + The "System Libraries" of an executable work include anything, other +than the work as a whole, that (a) is included in the normal form of +packaging a Major Component, but which is not part of that Major +Component, and (b) serves only to enable use of the work with that +Major Component, or to implement a Standard Interface for which an +implementation is available to the public in source code form. A +"Major Component", in this context, means a major essential component +(kernel, window system, and so on) of the specific operating system +(if any) on which the executable work runs, or a compiler used to +produce the work, or an object code interpreter used to run it. + + The "Corresponding Source" for a work in object code form means all +the source code needed to generate, install, and (for an executable +work) run the object code and to modify the work, including scripts to +control those activities. However, it does not include the work's +System Libraries, or general-purpose tools or generally available free +programs which are used unmodified in performing those activities but +which are not part of the work. For example, Corresponding Source +includes interface definition files associated with source files for +the work, and the source code for shared libraries and dynamically +linked subprograms that the work is specifically designed to require, +such as by intimate data communication or control flow between those +subprograms and other parts of the work. + + The Corresponding Source need not include anything that users +can regenerate automatically from other parts of the Corresponding +Source. + + The Corresponding Source for a work in source code form is that +same work. + + 2. Basic Permissions. + + All rights granted under this License are granted for the term of +copyright on the Program, and are irrevocable provided the stated +conditions are met. This License explicitly affirms your unlimited +permission to run the unmodified Program. The output from running a +covered work is covered by this License only if the output, given its +content, constitutes a covered work. This License acknowledges your +rights of fair use or other equivalent, as provided by copyright law. + + You may make, run and propagate covered works that you do not +convey, without conditions so long as your license otherwise remains +in force. You may convey covered works to others for the sole purpose +of having them make modifications exclusively for you, or provide you +with facilities for running those works, provided that you comply with +the terms of this License in conveying all material for which you do +not control copyright. Those thus making or running the covered works +for you must do so exclusively on your behalf, under your direction +and control, on terms that prohibit them from making any copies of +your copyrighted material outside their relationship with you. + + Conveying under any other circumstances is permitted solely under +the conditions stated below. Sublicensing is not allowed; section 10 +makes it unnecessary. + + 3. Protecting Users' Legal Rights From Anti-Circumvention Law. + + No covered work shall be deemed part of an effective technological +measure under any applicable law fulfilling obligations under article +11 of the WIPO copyright treaty adopted on 20 December 1996, or +similar laws prohibiting or restricting circumvention of such +measures. + + When you convey a covered work, you waive any legal power to forbid +circumvention of technological measures to the extent such circumvention +is effected by exercising rights under this License with respect to +the covered work, and you disclaim any intention to limit operation or +modification of the work as a means of enforcing, against the work's +users, your or third parties' legal rights to forbid circumvention of +technological measures. + + 4. Conveying Verbatim Copies. + + You may convey verbatim copies of the Program's source code as you +receive it, in any medium, provided that you conspicuously and +appropriately publish on each copy an appropriate copyright notice; +keep intact all notices stating that this License and any +non-permissive terms added in accord with section 7 apply to the code; +keep intact all notices of the absence of any warranty; and give all +recipients a copy of this License along with the Program. + + You may charge any price or no price for each copy that you convey, +and you may offer support or warranty protection for a fee. + + 5. Conveying Modified Source Versions. + + You may convey a work based on the Program, or the modifications to +produce it from the Program, in the form of source code under the +terms of section 4, provided that you also meet all of these conditions: + + a) The work must carry prominent notices stating that you modified + it, and giving a relevant date. + + b) The work must carry prominent notices stating that it is + released under this License and any conditions added under section + 7. This requirement modifies the requirement in section 4 to + "keep intact all notices". + + c) You must license the entire work, as a whole, under this + License to anyone who comes into possession of a copy. This + License will therefore apply, along with any applicable section 7 + additional terms, to the whole of the work, and all its parts, + regardless of how they are packaged. This License gives no + permission to license the work in any other way, but it does not + invalidate such permission if you have separately received it. + + d) If the work has interactive user interfaces, each must display + Appropriate Legal Notices; however, if the Program has interactive + interfaces that do not display Appropriate Legal Notices, your + work need not make them do so. + + A compilation of a covered work with other separate and independent +works, which are not by their nature extensions of the covered work, +and which are not combined with it such as to form a larger program, +in or on a volume of a storage or distribution medium, is called an +"aggregate" if the compilation and its resulting copyright are not +used to limit the access or legal rights of the compilation's users +beyond what the individual works permit. Inclusion of a covered work +in an aggregate does not cause this License to apply to the other +parts of the aggregate. + + 6. Conveying Non-Source Forms. + + You may convey a covered work in object code form under the terms +of sections 4 and 5, provided that you also convey the +machine-readable Corresponding Source under the terms of this License, +in one of these ways: + + a) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by the + Corresponding Source fixed on a durable physical medium + customarily used for software interchange. + + b) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by a + written offer, valid for at least three years and valid for as + long as you offer spare parts or customer support for that product + model, to give anyone who possesses the object code either (1) a + copy of the Corresponding Source for all the software in the + product that is covered by this License, on a durable physical + medium customarily used for software interchange, for a price no + more than your reasonable cost of physically performing this + conveying of source, or (2) access to copy the + Corresponding Source from a network server at no charge. + + c) Convey individual copies of the object code with a copy of the + written offer to provide the Corresponding Source. This + alternative is allowed only occasionally and noncommercially, and + only if you received the object code with such an offer, in accord + with subsection 6b. + + d) Convey the object code by offering access from a designated + place (gratis or for a charge), and offer equivalent access to the + Corresponding Source in the same way through the same place at no + further charge. You need not require recipients to copy the + Corresponding Source along with the object code. If the place to + copy the object code is a network server, the Corresponding Source + may be on a different server (operated by you or a third party) + that supports equivalent copying facilities, provided you maintain + clear directions next to the object code saying where to find the + Corresponding Source. Regardless of what server hosts the + Corresponding Source, you remain obligated to ensure that it is + available for as long as needed to satisfy these requirements. + + e) Convey the object code using peer-to-peer transmission, provided + you inform other peers where the object code and Corresponding + Source of the work are being offered to the general public at no + charge under subsection 6d. + + A separable portion of the object code, whose source code is excluded +from the Corresponding Source as a System Library, need not be +included in conveying the object code work. + + A "User Product" is either (1) a "consumer product", which means any +tangible personal property which is normally used for personal, family, +or household purposes, or (2) anything designed or sold for incorporation +into a dwelling. In determining whether a product is a consumer product, +doubtful cases shall be resolved in favor of coverage. For a particular +product received by a particular user, "normally used" refers to a +typical or common use of that class of product, regardless of the status +of the particular user or of the way in which the particular user +actually uses, or expects or is expected to use, the product. A product +is a consumer product regardless of whether the product has substantial +commercial, industrial or non-consumer uses, unless such uses represent +the only significant mode of use of the product. + + "Installation Information" for a User Product means any methods, +procedures, authorization keys, or other information required to install +and execute modified versions of a covered work in that User Product from +a modified version of its Corresponding Source. The information must +suffice to ensure that the continued functioning of the modified object +code is in no case prevented or interfered with solely because +modification has been made. + + If you convey an object code work under this section in, or with, or +specifically for use in, a User Product, and the conveying occurs as +part of a transaction in which the right of possession and use of the +User Product is transferred to the recipient in perpetuity or for a +fixed term (regardless of how the transaction is characterized), the +Corresponding Source conveyed under this section must be accompanied +by the Installation Information. But this requirement does not apply +if neither you nor any third party retains the ability to install +modified object code on the User Product (for example, the work has +been installed in ROM). + + The requirement to provide Installation Information does not include a +requirement to continue to provide support service, warranty, or updates +for a work that has been modified or installed by the recipient, or for +the User Product in which it has been modified or installed. Access to a +network may be denied when the modification itself materially and +adversely affects the operation of the network or violates the rules and +protocols for communication across the network. + + Corresponding Source conveyed, and Installation Information provided, +in accord with this section must be in a format that is publicly +documented (and with an implementation available to the public in +source code form), and must require no special password or key for +unpacking, reading or copying. + + 7. Additional Terms. + + "Additional permissions" are terms that supplement the terms of this +License by making exceptions from one or more of its conditions. +Additional permissions that are applicable to the entire Program shall +be treated as though they were included in this License, to the extent +that they are valid under applicable law. If additional permissions +apply only to part of the Program, that part may be used separately +under those permissions, but the entire Program remains governed by +this License without regard to the additional permissions. + + When you convey a copy of a covered work, you may at your option +remove any additional permissions from that copy, or from any part of +it. (Additional permissions may be written to require their own +removal in certain cases when you modify the work.) You may place +additional permissions on material, added by you to a covered work, +for which you have or can give appropriate copyright permission. + + Notwithstanding any other provision of this License, for material you +add to a covered work, you may (if authorized by the copyright holders of +that material) supplement the terms of this License with terms: + + a) Disclaiming warranty or limiting liability differently from the + terms of sections 15 and 16 of this License; or + + b) Requiring preservation of specified reasonable legal notices or + author attributions in that material or in the Appropriate Legal + Notices displayed by works containing it; or + + c) Prohibiting misrepresentation of the origin of that material, or + requiring that modified versions of such material be marked in + reasonable ways as different from the original version; or + + d) Limiting the use for publicity purposes of names of licensors or + authors of the material; or + + e) Declining to grant rights under trademark law for use of some + trade names, trademarks, or service marks; or + + f) Requiring indemnification of licensors and authors of that + material by anyone who conveys the material (or modified versions of + it) with contractual assumptions of liability to the recipient, for + any liability that these contractual assumptions directly impose on + those licensors and authors. + + All other non-permissive additional terms are considered "further +restrictions" within the meaning of section 10. If the Program as you +received it, or any part of it, contains a notice stating that it is +governed by this License along with a term that is a further +restriction, you may remove that term. If a license document contains +a further restriction but permits relicensing or conveying under this +License, you may add to a covered work material governed by the terms +of that license document, provided that the further restriction does +not survive such relicensing or conveying. + + If you add terms to a covered work in accord with this section, you +must place, in the relevant source files, a statement of the +additional terms that apply to those files, or a notice indicating +where to find the applicable terms. + + Additional terms, permissive or non-permissive, may be stated in the +form of a separately written license, or stated as exceptions; +the above requirements apply either way. + + 8. Termination. + + You may not propagate or modify a covered work except as expressly +provided under this License. Any attempt otherwise to propagate or +modify it is void, and will automatically terminate your rights under +this License (including any patent licenses granted under the third +paragraph of section 11). + + However, if you cease all violation of this License, then your +license from a particular copyright holder is reinstated (a) +provisionally, unless and until the copyright holder explicitly and +finally terminates your license, and (b) permanently, if the copyright +holder fails to notify you of the violation by some reasonable means +prior to 60 days after the cessation. + + Moreover, your license from a particular copyright holder is +reinstated permanently if the copyright holder notifies you of the +violation by some reasonable means, this is the first time you have +received notice of violation of this License (for any work) from that +copyright holder, and you cure the violation prior to 30 days after +your receipt of the notice. + + Termination of your rights under this section does not terminate the +licenses of parties who have received copies or rights from you under +this License. If your rights have been terminated and not permanently +reinstated, you do not qualify to receive new licenses for the same +material under section 10. + + 9. Acceptance Not Required for Having Copies. + + You are not required to accept this License in order to receive or +run a copy of the Program. Ancillary propagation of a covered work +occurring solely as a consequence of using peer-to-peer transmission +to receive a copy likewise does not require acceptance. However, +nothing other than this License grants you permission to propagate or +modify any covered work. These actions infringe copyright if you do +not accept this License. Therefore, by modifying or propagating a +covered work, you indicate your acceptance of this License to do so. + + 10. Automatic Licensing of Downstream Recipients. + + Each time you convey a covered work, the recipient automatically +receives a license from the original licensors, to run, modify and +propagate that work, subject to this License. You are not responsible +for enforcing compliance by third parties with this License. + + An "entity transaction" is a transaction transferring control of an +organization, or substantially all assets of one, or subdividing an +organization, or merging organizations. If propagation of a covered +work results from an entity transaction, each party to that +transaction who receives a copy of the work also receives whatever +licenses to the work the party's predecessor in interest had or could +give under the previous paragraph, plus a right to possession of the +Corresponding Source of the work from the predecessor in interest, if +the predecessor has it or can get it with reasonable efforts. + + You may not impose any further restrictions on the exercise of the +rights granted or affirmed under this License. For example, you may +not impose a license fee, royalty, or other charge for exercise of +rights granted under this License, and you may not initiate litigation +(including a cross-claim or counterclaim in a lawsuit) alleging that +any patent claim is infringed by making, using, selling, offering for +sale, or importing the Program or any portion of it. + + 11. Patents. + + A "contributor" is a copyright holder who authorizes use under this +License of the Program or a work on which the Program is based. The +work thus licensed is called the contributor's "contributor version". + + A contributor's "essential patent claims" are all patent claims +owned or controlled by the contributor, whether already acquired or +hereafter acquired, that would be infringed by some manner, permitted +by this License, of making, using, or selling its contributor version, +but do not include claims that would be infringed only as a +consequence of further modification of the contributor version. For +purposes of this definition, "control" includes the right to grant +patent sublicenses in a manner consistent with the requirements of +this License. + + Each contributor grants you a non-exclusive, worldwide, royalty-free +patent license under the contributor's essential patent claims, to +make, use, sell, offer for sale, import and otherwise run, modify and +propagate the contents of its contributor version. + + In the following three paragraphs, a "patent license" is any express +agreement or commitment, however denominated, not to enforce a patent +(such as an express permission to practice a patent or covenant not to +sue for patent infringement). To "grant" such a patent license to a +party means to make such an agreement or commitment not to enforce a +patent against the party. + + If you convey a covered work, knowingly relying on a patent license, +and the Corresponding Source of the work is not available for anyone +to copy, free of charge and under the terms of this License, through a +publicly available network server or other readily accessible means, +then you must either (1) cause the Corresponding Source to be so +available, or (2) arrange to deprive yourself of the benefit of the +patent license for this particular work, or (3) arrange, in a manner +consistent with the requirements of this License, to extend the patent +license to downstream recipients. "Knowingly relying" means you have +actual knowledge that, but for the patent license, your conveying the +covered work in a country, or your recipient's use of the covered work +in a country, would infringe one or more identifiable patents in that +country that you have reason to believe are valid. + + If, pursuant to or in connection with a single transaction or +arrangement, you convey, or propagate by procuring conveyance of, a +covered work, and grant a patent license to some of the parties +receiving the covered work authorizing them to use, propagate, modify +or convey a specific copy of the covered work, then the patent license +you grant is automatically extended to all recipients of the covered +work and works based on it. + + A patent license is "discriminatory" if it does not include within +the scope of its coverage, prohibits the exercise of, or is +conditioned on the non-exercise of one or more of the rights that are +specifically granted under this License. You may not convey a covered +work if you are a party to an arrangement with a third party that is +in the business of distributing software, under which you make payment +to the third party based on the extent of your activity of conveying +the work, and under which the third party grants, to any of the +parties who would receive the covered work from you, a discriminatory +patent license (a) in connection with copies of the covered work +conveyed by you (or copies made from those copies), or (b) primarily +for and in connection with specific products or compilations that +contain the covered work, unless you entered into that arrangement, +or that patent license was granted, prior to 28 March 2007. + + Nothing in this License shall be construed as excluding or limiting +any implied license or other defenses to infringement that may +otherwise be available to you under applicable patent law. + + 12. No Surrender of Others' Freedom. + + If conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot convey a +covered work so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you may +not convey it at all. For example, if you agree to terms that obligate you +to collect a royalty for further conveying from those to whom you convey +the Program, the only way you could satisfy both those terms and this +License would be to refrain entirely from conveying the Program. + + 13. Use with the GNU Affero General Public License. + + Notwithstanding any other provision of this License, you have +permission to link or combine any covered work with a work licensed +under version 3 of the GNU Affero General Public License into a single +combined work, and to convey the resulting work. The terms of this +License will continue to apply to the part which is the covered work, +but the special requirements of the GNU Affero General Public License, +section 13, concerning interaction through a network will apply to the +combination as such. + + 14. Revised Versions of this License. + + The Free Software Foundation may publish revised and/or new versions of +the GNU General Public License from time to time. Such new versions will +be similar in spirit to the present version, but may differ in detail to +address new problems or concerns. + + Each version is given a distinguishing version number. If the +Program specifies that a certain numbered version of the GNU General +Public License "or any later version" applies to it, you have the +option of following the terms and conditions either of that numbered +version or of any later version published by the Free Software +Foundation. If the Program does not specify a version number of the +GNU General Public License, you may choose any version ever published +by the Free Software Foundation. + + If the Program specifies that a proxy can decide which future +versions of the GNU General Public License can be used, that proxy's +public statement of acceptance of a version permanently authorizes you +to choose that version for the Program. + + Later license versions may give you additional or different +permissions. However, no additional obligations are imposed on any +author or copyright holder as a result of your choosing to follow a +later version. + + 15. Disclaimer of Warranty. + + THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY +APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT +HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY +OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, +THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR +PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM +IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF +ALL NECESSARY SERVICING, REPAIR OR CORRECTION. + + 16. Limitation of Liability. + + IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING +WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS +THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY +GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE +USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF +DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD +PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), +EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF +SUCH DAMAGES. + + 17. Interpretation of Sections 15 and 16. + + If the disclaimer of warranty and limitation of liability provided +above cannot be given local legal effect according to their terms, +reviewing courts shall apply local law that most closely approximates +an absolute waiver of all civil liability in connection with the +Program, unless a warranty or assumption of liability accompanies a +copy of the Program in return for a fee. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Programs + + If you develop a new program, and you want it to be of the greatest +possible use to the public, the best way to achieve this is to make it +free software which everyone can redistribute and change under these terms. + + To do so, attach the following notices to the program. It is safest +to attach them to the start of each source file to most effectively +state the exclusion of warranty; and each file should have at least +the "copyright" line and a pointer to where the full notice is found. + + <one line to give the program's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This program is free software: you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation, either version 3 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License + along with this program. If not, see <http://www.gnu.org/licenses/>. + +Also add information on how to contact you by electronic and paper mail. + + If the program does terminal interaction, make it output a short +notice like this when it starts in an interactive mode: + + <program> Copyright (C) <year> <name of author> + This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'. + This is free software, and you are welcome to redistribute it + under certain conditions; type `show c' for details. + +The hypothetical commands `show w' and `show c' should show the appropriate +parts of the General Public License. Of course, your program's commands +might be different; for a GUI interface, you would use an "about box". + + You should also get your employer (if you work as a programmer) or school, +if any, to sign a "copyright disclaimer" for the program, if necessary. +For more information on this, and how to apply and follow the GNU GPL, see +<http://www.gnu.org/licenses/>. + + The GNU General Public License does not permit incorporating your program +into proprietary programs. If your program is a subroutine library, you +may consider it more useful to permit linking proprietary applications with +the library. If this is what you want to do, use the GNU Lesser General +Public License instead of this License. But first, please read +<http://www.gnu.org/philosophy/why-not-lgpl.html>. diff --git a/net/crimp/README.md b/net/crimp/README.md new file mode 100644 index 0000000000..791c354fc1 --- /dev/null +++ b/net/crimp/README.md @@ -0,0 +1,15 @@ +crimp +===== + +[](https://travis-ci.org/tazjin/crimp) +[](https://crates.io/crates/crimp) +[](https://docs.rs/crimp) + +Crimp is an HTTP client interface on top of the [Rust bindings][] to +cURL. + +The documentation for this crate is primarily in the [module +documentation][] + +[Rust bindings]: https://docs.rs/curl +[module documentation]: https://docs.rs/crimp diff --git a/net/crimp/src/lib.rs b/net/crimp/src/lib.rs new file mode 100644 index 0000000000..b52ebc3ef0 --- /dev/null +++ b/net/crimp/src/lib.rs @@ -0,0 +1,502 @@ +// crimp - Higher-level Rust cURL API +// +// Copyright (C) 2019 Vincent Ambo +// +// This program is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. +// +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. +// +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <http://www.gnu.org/licenses/>. + +//! # crimp +//! +//! This library provides a simplified API over the [cURL Rust +//! bindings][] that resemble that of higher-level libraries such as +//! [reqwest][]. All calls are synchronous. +//! +//! `crimp` is intended to be used in situations where HTTP client +//! functionality is desired without adding a significant number of +//! dependencies or sacrificing too much usability. +//! +//! Using `crimp` to make HTTP requests is done using a simple +//! builder-pattern style API. For example, to make a `GET`-request +//! and print the result to `stdout`: +//! +//! ```rust +//! use crimp::Request; +//! +//! let response = Request::get("http://httpbin.org/get") +//! .user_agent("crimp test suite").unwrap() +//! .send().unwrap() +//! .as_string().unwrap(); +//! +//! println!("Status: {}\nBody: {}", response.status, response.body); +//! # assert_eq!(response.status, 200); +//! ``` +//! +//! If a feature from the underlying cURL library is missing, the +//! `Request::raw` method can be used as an escape hatch to deal with +//! the handle directly. Should you find yourself doing this, please +//! [file an issue][]. +//! +//! `crimp` does not currently expose functionality for re-using a +//! cURL Easy handle, meaning that keep-alive of HTTP connections and +//! the like is not supported. +//! +//! ## Cargo features +//! +//! All optional features are enabled by default. +//! +//! * `json`: Adds `Request::json` and `Response::as_json` methods +//! which can be used for convenient serialisation of +//! request/response bodies using `serde_json`. This feature adds a +//! dependency on the `serde` and `serde_json` crates. +//! +//! ## Initialisation +//! +//! It is recommended to call the underlying `curl::init` method +//! (re-exported as `crimp::init`) when launching your application to +//! initialise the cURL library. This is not required, but will +//! otherwise occur the first time a request is made. +//! +//! [cURL Rust bindings]: https://docs.rs/curl +//! [reqwest]: https://docs.rs/reqwest +//! [file an issue]: https://github.com/tazjin/crimp/issues + +extern crate curl; + +#[cfg(feature = "json")] extern crate serde; +#[cfg(feature = "json")] extern crate serde_json; + +pub use curl::init; + +use curl::easy::{Auth, Easy, Form, List, Transfer, ReadError, WriteError}; +use std::collections::HashMap; +use std::io::Write; +use std::path::Path; +use std::string::{FromUtf8Error, ToString}; +use std::time::Duration; + +#[cfg(feature = "json")] use serde::Serialize; +#[cfg(feature = "json")] use serde::de::DeserializeOwned; + +#[cfg(test)] +mod tests; + +/// HTTP method to use for the request. +enum Method { + Get, Post, Put, Patch, Delete +} + +/// Certificate types for client-certificate key pairs. +pub enum CertType { + P12, PEM, DER +} + +/// Builder structure for an HTTP request. +/// +/// This is the primary API-type in `crimp`. After creating a new +/// request its parameters are modified using the various builder +/// methods until it is consumed by `send()`. +pub struct Request<'a> { + url: &'a str, + method: Method, + handle: Easy, + headers: List, + body: Body<'a>, +} + +enum Body<'a> { + NoBody, + Form(Form), + + Bytes { + content_type: &'a str, + data: &'a [u8], + }, + + #[cfg(feature = "json")] + Json(Vec<u8>), +} + +/// HTTP responses structure containing response data and headers. +/// +/// By default the `send()` function of the `Request` structure will +/// return a `Response<Vec<u8>>`. Convenience helpers exist for +/// decoding a string via `Response::as_string` or to a +/// `serde`-compatible type with `Response::as_json` (if the +/// `json`-feature is enabled). +#[derive(Debug, PartialEq)] +pub struct Response<T> { + /// HTTP status code of the response. + pub status: u32, + + /// HTTP headers returned from the remote. + pub headers: HashMap<String, String>, + + /// Body data from the HTTP response. + pub body: T, +} + +impl <'a> Request<'a> { + /// Initiate an HTTP request with the given method and URL. + fn new(method: Method, url: &'a str) -> Self { + Request { + url, + method, + handle: Easy::new(), + headers: List::new(), + body: Body::NoBody, + } + } + + /// Initiate a GET request with the given URL. + pub fn get(url: &'a str) -> Self { Request::new(Method::Get, url) } + + /// Initiate a POST request with the given URL. + pub fn post(url: &'a str) -> Self { Request::new(Method::Post, url) } + + /// Initiate a PUT request with the given URL. + pub fn put(url: &'a str) -> Self { Request::new(Method::Put, url) } + + /// Initiate a PATCH request with the given URL. + pub fn patch(url: &'a str) -> Self { Request::new(Method::Patch, url) } + + /// Initiate a DELETE request with the given URL. + pub fn delete(url: &'a str) -> Self { Request::new(Method::Delete, url) } + + /// Add an HTTP header to a request. + pub fn header(mut self, k: &str, v: &str) -> Result<Self, curl::Error> { + self.headers.append(&format!("{}: {}", k, v))?; + Ok(self) + } + + /// Set the `User-Agent` for this request. By default this will be + /// set to cURL's standard user agent. + pub fn user_agent(mut self, agent: &str) -> Result<Self, curl::Error> { + self.handle.useragent(agent)?; + Ok(self) + } + + /// Set the `Authorization` header to a `Bearer` value with the + /// supplied token. + pub fn bearer_auth(mut self, token: &str) -> Result<Self, curl::Error> { + self.headers.append(&format!("Authorization: Bearer {}", token))?; + Ok(self) + } + + /// Set the `Authorization` header to a basic authentication value + /// from the supplied username and password. + pub fn basic_auth(mut self, username: &str, password: &str) -> Result<Self, curl::Error> { + let mut auth = Auth::new(); + auth.basic(true); + self.handle.username(username)?; + self.handle.password(password)?; + self.handle.http_auth(&auth)?; + Ok(self) + } + + /// Configure a TLS client certificate on the request. + /// + /// Depending on whether the certificate file contains the private + /// key or not, calling `tls_client_key` may be required in + /// addition. + /// + /// Consult the documentation for the `ssl_cert` and `ssl_key` + /// functions in `curl::easy::Easy2` for details on supported + /// formats and defaults. + pub fn tls_client_cert<P: AsRef<Path>>(mut self, cert_type: CertType, cert: P) + -> Result<Self, curl::Error> { + self.handle.ssl_cert(cert)?; + self.handle.ssl_cert_type(match cert_type { + CertType::P12 => "P12", + CertType::PEM => "PEM", + CertType::DER => "DER", + })?; + + Ok(self) + } + + /// Configure a TLS client certificate key on the request. + /// + /// Note that this does **not** need to be called again for + /// PKCS12-encoded key pairs which are set via `tls_client_cert`. + /// + /// Currently only PEM-encoded key files are supported. + pub fn tls_client_key<P: AsRef<Path>>(mut self, key: P) -> Result<Self, curl::Error> { + self.handle.ssl_key(key)?; + Ok(self) + } + + /// Configure an encryption password for a TLS client certificate + /// key on the request. + /// + /// This is required in case of an encrypted private key that + /// should be used. + pub fn tls_key_password(mut self, password: &str) -> Result<Self, curl::Error> { + self.handle.key_password(password)?; + Ok(self) + } + + /// Configure a timeout for the request after which the request + /// will be aborted. + pub fn timeout(mut self, timeout: Duration) -> Result<Self, curl::Error> { + self.handle.timeout(timeout)?; + Ok(self) + } + + /// Set custom configuration on the cURL `Easy` handle. + /// + /// This function can be considered an "escape-hatch" from the + /// high-level API which lets users access the internal + /// `curl::easy::Easy` handle and configure options on it + /// directly. + /// + /// ``` + /// # use crimp::Request; + /// let response = Request::get("https://httpbin.org/get") + /// .with_handle(|mut handle| handle.referer("Example-Referer")).unwrap() + /// .send().unwrap(); + /// # + /// # assert!(response.is_success()); + /// ``` + pub fn with_handle<F>(mut self, function: F) -> Result<Self, curl::Error> + where F: FnOnce(&mut Easy) -> Result<(), curl::Error> { + function(&mut self.handle)?; + Ok(self) + } + + /// Add a byte-array body to a request using the specified + /// `Content-Type`. + pub fn body(mut self, content_type: &'a str, data: &'a [u8]) -> Self { + self.body = Body::Bytes { data, content_type }; + self + } + + /// Add a form-encoded body to a request using the `curl::Form` + /// type. + /// + /// ```rust + /// # extern crate curl; + /// # extern crate serde_json; + /// # use crimp::*; + /// # use serde_json::{Value, json}; + /// use curl::easy::Form; + /// + /// let mut form = Form::new(); + /// form.part("some-name") + /// .contents("some-data".as_bytes()) + /// .add().unwrap(); + /// + /// let response = Request::post("https://httpbin.org/post") + /// .user_agent("crimp test suite").unwrap() + /// .form(form) + /// .send().unwrap(); + /// # + /// # assert_eq!(200, response.status, "form POST should succeed"); + /// # assert_eq!( + /// # response.as_json::<Value>().unwrap().body.get("form").unwrap(), + /// # &json!({"some-name": "some-data"}), + /// # "posted form data should match", + /// # ); + /// ``` + /// + /// See the documentation of `curl::easy::Form` for details on how + /// to construct a form body. + pub fn form(mut self, form: Form) -> Self { + self.body = Body::Form(form); + self + } + + /// Add a JSON-encoded body from a serializable type. + #[cfg(feature = "json")] + pub fn json<T: Serialize>(mut self, body: &T) -> Result<Self, serde_json::Error> { + let json = serde_json::to_vec(body)?; + self.body = Body::Json(json); + Ok(self) + } + + /// Send the HTTP request and return a response structure + /// containing the raw body. + pub fn send(mut self) -> Result<Response<Vec<u8>>, curl::Error> { + // Configure request basics: + self.handle.url(self.url)?; + + match self.method { + Method::Get => self.handle.get(true)?, + Method::Post => self.handle.post(true)?, + Method::Put => self.handle.put(true)?, + Method::Patch => self.handle.custom_request("PATCH")?, + Method::Delete => self.handle.custom_request("DELETE")?, + } + + // Create structures in which to store the response data: + let mut headers = HashMap::new(); + let mut body = vec![]; + + // Submit a form value to cURL if it is set and proceed + // pretending that there is no body, as the handling of this + // type of body happens under-the-hood. + if let Body::Form(form) = self.body { + self.handle.httppost(form)?; + self.body = Body::NoBody; + } + + // Optionally set content type if a body payload is configured + // and configure the expected body size (or form payload). + match self.body { + Body::Bytes { content_type, data } => { + self.handle.post_field_size(data.len() as u64)?; + self.headers.append(&format!("Content-Type: {}", content_type))?; + }, + + #[cfg(feature = "json")] + Body::Json(ref data) => { + self.handle.post_field_size(data.len() as u64)?; + self.headers.append("Content-Type: application/json")?; + }, + + // Do not set content-type header at all if there is no + // body, or if the form handler was invoked above. + _ => (), + }; + + // Configure headers on the request: + self.handle.http_headers(self.headers)?; + + { + // Take a scoped transfer from the Easy handle. This makes it + // possible to write data into the above local buffers without + // fighting the borrow-checker: + let mut transfer = self.handle.transfer(); + + // Write the payload if it exists: + match self.body { + Body::Bytes { data, .. } => chunked_read_function(&mut transfer, data)?, + + #[cfg(feature = "json")] + Body::Json(ref json) => chunked_read_function(&mut transfer, json)?, + + // Do nothing if there is no body or if the body is a + // form. + _ => (), + }; + + // Read one header per invocation. Request processing is + // terminated if any header is malformed: + transfer.header_function(|header| { + // Headers are expected to be valid UTF-8 data. If they + // are not, the conversion is lossy. + // + // Technically it is legal for HTTP requests to use + // different encodings, but we don't interface with such + // services for hygienic reasons. + let header = String::from_utf8_lossy(header); + let split = header.splitn(2, ':').collect::<Vec<_>>(); + + // "Malformed" headers are skipped. In most cases this + // will only be the HTTP version statement. + if split.len() != 2 { + return true; + } + + headers.insert( + split[0].trim().to_string(), split[1].trim().to_string() + ); + true + })?; + + // Read the body to the allocated buffer. + transfer.write_function(|data| { + let len = data.len(); + body.write_all(data) + .map(|_| len) + .map_err(|_| WriteError::Pause) + })?; + + transfer.perform()?; + } + + Ok(Response { + status: self.handle.response_code()?, + headers, + body + }) + } +} + +/// Provide a data chunk potentially larger than cURL's initial write +/// buffer to the data reading callback by tracking the offset off +/// already written data. +/// +/// As we manually set the expected upload size, cURL will call the +/// read callback repeatedly until it has all the data it needs. +fn chunked_read_function<'easy, 'data>(transfer: &mut Transfer<'easy, 'data>, + data: &'data [u8]) -> Result<(), curl::Error> { + let mut data = data; + + transfer.read_function(move |mut into| { + let written = into.write(data) + .map_err(|_| ReadError::Abort)?; + + data = &data[written..]; + + Ok(written) + }) +} + +impl <T> Response<T> { + /// Check whether the status code of this HTTP response is a + /// success (i.e. in the 200-299 range). + pub fn is_success(&self) -> bool { + self.status >= 200 && self.status < 300 + } + + /// Check whether a request succeeded using `Request::is_success` + /// and let users provide a closure that creates a custom error + /// from the request if it did not. + /// + /// This function exists for convenience to avoid having to write + /// repetitive `if !response.is_success() { ... }` blocks. + pub fn error_for_status<F, E>(self, closure: F) -> Result<Self, E> + where F: FnOnce(Self) -> E { + if !self.is_success() { + return Err(closure(self)) + } + + Ok(self) + } +} + +impl Response<Vec<u8>> { + /// Attempt to parse the HTTP response body as a UTF-8 encoded + /// string. + pub fn as_string(self) -> Result<Response<String>, FromUtf8Error> { + let body = String::from_utf8(self.body)?; + + Ok(Response { + body, + status: self.status, + headers: self.headers, + }) + } + + /// Attempt to deserialize the HTTP response body from JSON. + #[cfg(feature = "json")] + pub fn as_json<T: DeserializeOwned>(self) -> Result<Response<T>, serde_json::Error> { + let deserialized = serde_json::from_slice(&self.body)?; + + Ok(Response { + body: deserialized, + status: self.status, + headers: self.headers, + }) + } +} diff --git a/net/crimp/src/tests.rs b/net/crimp/src/tests.rs new file mode 100644 index 0000000000..6c2bc4f5b3 --- /dev/null +++ b/net/crimp/src/tests.rs @@ -0,0 +1,152 @@ +// All tests expect an httpbin instance to be available at +// `http://localhost:4662`. +// +// This is easily spun up using Docker by running: +// +// docker run --rm -p 4662:80 kennethreitz/httpbin + +use super::*; +use serde_json::{Value, json}; + +// These tests check whether the correct HTTP method is used in the +// requests. + +#[test] +fn test_http_get() { + let resp = Request::get("http://127.0.0.1:4662/get") + .send().expect("failed to send request"); + + assert!(resp.is_success(), "request should have succeeded"); +} + +#[test] +fn test_http_delete() { + let resp = Request::delete("http://127.0.0.1:4662/delete") + .send().expect("failed to send request"); + + assert_eq!(200, resp.status, "response status should be 200 OK"); +} + +#[test] +fn test_http_put() { + let resp = Request::put("http://127.0.0.1:4662/put") + .send().expect("failed to send request"); + + assert_eq!(200, resp.status, "response status should be 200 OK"); +} + +#[test] +fn test_http_patch() { + let resp = Request::patch("http://127.0.0.1:4662/patch") + .send().expect("failed to send request"); + + assert_eq!(200, resp.status, "response status should be 200 OK"); +} + +// These tests perform various requests with different body payloads +// and verify that those were received correctly by the remote side. + +#[test] +fn test_http_post() { + let body = "test body"; + let response = Request::post("http://127.0.0.1:4662/post") + .user_agent("crimp test suite").expect("failed to set user-agent") + .timeout(Duration::from_secs(5)).expect("failed to set request timeout") + .body("text/plain", &body.as_bytes()) + .send().expect("failed to send request") + .as_json::<Value>().expect("failed to deserialize response"); + + let data = response.body; + + assert_eq!(200, response.status, "response status should be 200 OK"); + + assert_eq!(data.get("data").unwrap(), &json!("test body"), + "test body should have been POSTed"); + + assert_eq!( + data.get("headers").unwrap().get("Content-Type").unwrap(), + &json!("text/plain"), + "Content-Type should be `text/plain`", + ); +} + +#[cfg(feature = "json")] #[test] +fn test_http_post_json() { + let body = json!({ + "purpose": "testing!" + }); + + let response = Request::post("http://127.0.0.1:4662/post") + .user_agent("crimp test suite").expect("failed to set user-agent") + .timeout(Duration::from_secs(5)).expect("failed to set request timeout") + .json(&body).expect("request serialization failed") + .send().expect("failed to send request") + .as_json::<Value>().expect("failed to deserialize response"); + + + let data = response.body; + + assert_eq!(200, response.status, "response status should be 200 OK"); + + assert_eq!(data.get("json").unwrap(), &body, + "test body should have been POSTed"); + + assert_eq!( + data.get("headers").unwrap().get("Content-Type").unwrap(), + &json!("application/json"), + "Content-Type should be `application/json`", + ); +} + +// Tests for different authentication methods that are supported +// out-of-the-box: + +#[test] +fn test_bearer_auth() { + let response = Request::get("http://127.0.0.1:4662/bearer") + .bearer_auth("some-token").expect("failed to set auth header") + .send().expect("failed to send request"); + + assert!(response.is_success(), "authorized request should succeed"); +} + +#[test] +fn test_basic_auth() { + let request = Request::get("http://127.0.0.1:4662/basic-auth/alan_watts/oneness"); + + let response = request + .basic_auth("alan_watts", "oneness").expect("failed to set auth header") + .send().expect("failed to send request"); + + assert!(response.is_success(), "authorized request should succeed"); +} + +#[test] +fn test_large_body() { + // By default cURL buffers seem to be 2^16 bytes in size. The test + // size is therefore 2^16+1. + const BODY_SIZE: usize = 65537; + + let resp = Request::post("http://127.0.0.1:4662/post") + .body("application/octet-stream", &[0; BODY_SIZE]) + .send().expect("sending request") + .as_json::<Value>().expect("JSON deserialisation"); + + // httpbin returns the uploaded data as a string in the `data` + // field. + let data = resp.body.get("data").unwrap().as_str().unwrap(); + + assert_eq!(BODY_SIZE, data.len(), "uploaded data length should be correct"); +} + +// Tests for various other features. + +#[test] +fn test_error_for_status() { + let response = Request::get("http://127.0.0.1:4662/patch") + .send().expect("failed to send request") + .error_for_status(|resp| format!("Response error code: {}", resp.status)); + + assert_eq!(Err("Response error code: 405".into()), response, + "returned error should be converted into Result::Err"); +} diff --git a/net/stomp_erl/.gitignore b/net/stomp_erl/.gitignore new file mode 100644 index 0000000000..8e46d5a07f --- /dev/null +++ b/net/stomp_erl/.gitignore @@ -0,0 +1,10 @@ +.eunit +deps +*.o +*.beam +*.plt +erl_crash.dump +ebin +rel/example_project +.concrete/DEV_MODE +.rebar diff --git a/net/stomp_erl/Makefile b/net/stomp_erl/Makefile new file mode 100644 index 0000000000..b3bc54673d --- /dev/null +++ b/net/stomp_erl/Makefile @@ -0,0 +1,8 @@ +PROJECT = stomp +PROJECT_DESCRIPTION = STOMP client for Erlang +PROJECT_VERSION = 0.1.0 + +# Whitespace to be used when creating files from templates. +SP = 4 + +include erlang.mk diff --git a/net/stomp_erl/README.md b/net/stomp_erl/README.md new file mode 100644 index 0000000000..21c95a11a2 --- /dev/null +++ b/net/stomp_erl/README.md @@ -0,0 +1,78 @@ +STOMP on Erlang +=============== + +`stomp.erl` is a simple Erlang client for the [STOMP protocol][] in version 1.2. + +Currently only subscribing to queues is supported. + +It provides an application called `stomp` which takes configuration of the form: + +```erlang +[{stomp, #{host => "stomp-server.somedomain.sexy", % required + port => 61613, % optional + login => <<"someuser">>, % optional + passcode => <<"hunter2>>, % optional + }}]. +``` + +## Types + +The following types are used in `stomp.erl`, you can include them from +`stomp.hrl`: + +```erlang +%% Client ack modes, refer to the STOMP protocol documentation +-type ack_mode() :: client | client_individual | auto. + +%% Subscriptions are enumerated from 0 +-type sub_id() :: integer(). + +%% Message IDs (for acknowledgements) are simple strings. They are +%% extracted from the 'ack' field of the header in client or client-individual +%% mode, and from the 'message-id' field in auto mode. +-type message_id() :: binary(). + +%% A STOMP message as received from a queue subscription +-record(stomp_msg, { headers :: #{ binary() => binary() }, + body :: binary() }. +-type stomp_msg() :: #stomp_msg{}. +``` + +Once the application starts it will register a process under the name +`stomp_worker` and expose the following API: + +## Subscribing to a queue + +```erlang +%% Subscribe to a destination, receive the subscription ID +-spec subscribe(binary(), % Destination (e.g. <<"/queue/lizards">>) + ack_mode(), % Client-acknowledgement mode + -> {ok, sub_id()}. +``` + +This synchronous call subscribes to a message queue. The `stomp_worker` will +link itself to the caller and forward received messages as +`{msg, sub_id(), stomp_msg()}`. + +Depending on the acknowledgement mode specified on connecting, the subscriber +may have to acknowledge receival of messages. + +## Acknowledging messages + +```erlang +%% Acknowledge a message ID. +%% This is not required in auto mode. In client mode it will acknowledge the +%% received messages up to the ID specified. In client-individual mode every +%% single message has to be acknowledged. +-spec ack(sub_id(), message_id()) -> ok. + +%% Explicitly "unacknowledge" a message +-spec nack(sub_id(), message_id()) -> ok. +``` + +Both of these calls are asynchronous and will return immediately. Note that in +the case of the `stomp_worker` crashing before a message acknowledgement is +handled, the message *may* be delivered again. Your consumer needs to be able to +handle this. + +[STOMP protocol]: https://stomp.github.io/stomp-specification-1.2.html diff --git a/net/stomp_erl/include/stomp.hrl b/net/stomp_erl/include/stomp.hrl new file mode 100644 index 0000000000..30c933b563 --- /dev/null +++ b/net/stomp_erl/include/stomp.hrl @@ -0,0 +1,22 @@ +%% Client ack modes, refer to the STOMP protocol documentation +-type ack_mode() :: client | client_individual | auto. + +%% Subscriptions are enumerated from 0 +-type sub_id() :: integer(). + +%% Message IDs (for acknowledgements) are simple strings. They are +%% extracted from the 'ack' field of the header in client or client-individual +%% mode, and from the 'message-id' field in auto mode. +-type message_id() :: binary(). + +%% A destination can be a queue, or something else. +%% Example: <<"/queue/lizards">> +-type destination() :: binary(). + +%% A STOMP message as received from a queue subscription +-record(stomp_msg, { headers :: #{ binary() => binary() }, + body :: binary() }). +-type stomp_msg() :: #stomp_msg{}. + +%% STOMP frame components +-type headers() :: #{binary() => binary()}. diff --git a/net/stomp_erl/src/stomp.app.src b/net/stomp_erl/src/stomp.app.src new file mode 100644 index 0000000000..baf0e271d1 --- /dev/null +++ b/net/stomp_erl/src/stomp.app.src @@ -0,0 +1,7 @@ +{application, stomp, [{description, "STOMP client for Erlang"}, + {vsn, "0.1.0"}, + {modules, [stomp_app, stomp_sup, stomp_worker]}, + {registered, [stomp_worker]}, + {env, []}, + {applications, [kernel, stdlib]}, + {mod, {stomp_app, []}}]}. diff --git a/net/stomp_erl/src/stomp_app.erl b/net/stomp_erl/src/stomp_app.erl new file mode 100644 index 0000000000..2ba3e69f99 --- /dev/null +++ b/net/stomp_erl/src/stomp_app.erl @@ -0,0 +1,11 @@ +-module(stomp_app). +-behaviour(application). + +-export([start/2]). +-export([stop/1]). + +start(_Type, _Args) -> + stomp_sup:start_link(). + +stop(_State) -> + ok. diff --git a/net/stomp_erl/src/stomp_sup.erl b/net/stomp_erl/src/stomp_sup.erl new file mode 100644 index 0000000000..3a298bc9bf --- /dev/null +++ b/net/stomp_erl/src/stomp_sup.erl @@ -0,0 +1,22 @@ +-module(stomp_sup). +-behaviour(supervisor). + +-export([start_link/0]). +-export([init/1]). + +start_link() -> + supervisor:start_link({local, ?MODULE}, ?MODULE, []). + +init([]) -> + Procs = [stomp_spec()], + {ok, {{one_for_one, 1, 5}, Procs}}. + +%% Private + +stomp_spec() -> + #{id => stomp_proc, + start => {stomp_worker, start_link, []}, + restart => permanent, + shutdown => 5000, + type => worker, + module => [stomp_worker]}. diff --git a/net/stomp_erl/src/stomp_worker.erl b/net/stomp_erl/src/stomp_worker.erl new file mode 100644 index 0000000000..80981d37ab --- /dev/null +++ b/net/stomp_erl/src/stomp_worker.erl @@ -0,0 +1,193 @@ +-module(stomp_worker). +-behaviour(gen_server). + +%% API. +-export([start_link/0]). + +%% gen_server. +-export([init/1]). +-export([handle_call/3]). +-export([handle_cast/2]). +-export([handle_info/2]). +-export([terminate/2]). +-export([code_change/3]). + +%% Testing +-compile(export_all). + +-include("stomp.hrl"). + +%% State of a stomp_worker +-record(state, {connection :: port(), + next_sub :: sub_id(), + subscriptions :: #{ destination() => sub_id() }, + subscribers :: #{ destination() => pid() } + }). +-type state() :: #state{}. + +%% API implementation + +-spec start_link() -> {ok, pid()}. +start_link() -> + {ok, Pid} = gen_server:start_link(?MODULE, [], []), + register(?MODULE, Pid), + {ok, Pid}. + +%% gen_server implementation + +-spec init(any()) -> {ok, state()}. +init(_Args) -> + %% Fetch configuration from app config + {ok, Host} = application:get_env(stomp, host), + Port = application:get_env(stomp, port, 61613), + Login = application:get_env(stomp, login), + Pass = application:get_env(stomp, passcode), + + %% Catch exit signals from linked processes (subscribers dying) + process_flag(trap_exit, true), + + %% Establish connection + {ok, Conn} = connect(Host, Port, Login, Pass), + + {ok, #state{connection = Conn, + next_sub = 0, + subscriptions = #{}, + subscribers = #{}}}. + +%% Handle subscription calls +handle_call({subscribe, Dest, Ack}, From, State) -> + %% Subscribe to new destination + SubId = State#state.next_sub, + ok = subscribe(State#state.connection, SubId, Dest, Ack), + + %% Add subscription and subscriber to state + Subscriptions = maps:put(SubId, Dest, State#state.subscriptions), + Subscribers = maps:put(SubId, From, State#state.subscribers), + NextSub = SubId + 1, + NewState = State#state{subscriptions = Subscriptions, + subscribers = Subscribers, + next_sub = NextSub }, + + {reply, {ok, SubId}, NewState}; +handle_call(_Req, _From, State) -> + {reply, ignored, State}. + +handle_info({tcp, Conn, Frame}, State) when Conn =:= State#state.connection -> + handle_frame(Frame, State); +handle_info(_Msg, State) -> + {noreply, State}. + +%% Unused gen_server callbacks + +handle_cast(_Msg, State) -> + {noreply, State}. + +terminate(_Reason, _State) -> + ok. + +code_change(_OldVsn, State, _Extra) -> + {ok, State}. + +%% Private functions + +-spec connect(list(), integer(), any(), any()) -> {ok, port()}. +connect(Host, Port, Login, Pass) -> + %% STOMP CONNECT frame + Connect = connect_frame(Host, Login, Pass), + + %% TODO: Configurable buffer size + %% Frames larger than the user-level buffer will be truncated, so it should + %% never be smaller than the largest expected messages. + {ok, Socket} = gen_tcp:connect(Host, Port, [binary, + {packet, line}, + {line_delimiter, $\0}, + {buffer, 262144}]), + + ok = gen_tcp:send(Socket, Connect), + {ok, Socket}. + +-spec subscribe(port(), sub_id(), destination(), ack_mode()) -> ok. +subscribe(Socket, Id, Queue, Ack) -> + {ok, SubscribeFrame} = subscribe_frame(Id, Queue, Ack), + gen_tcp:send(Socket, SubscribeFrame). + +%%% Parsing STOMP frames + +handle_frame(<<"MESSAGE", "\n", _Frame/binary>>, State) -> + {noreply, State}; +handle_frame(Frame, State) -> + io:format("Received unknown frame ~p", [Frame]), + {noreply, State}. + + +%% Parse out headers into a map +-spec parse_headers(binary()) -> headers(). +parse_headers(HeadersBin) -> + Headers = binary:split(HeadersBin, <<"\n">>, [global]), + ToPairs = fun(H, M) -> [K,V | []] = binary:split(H, <<":">>), + maps:put(K, V, M) + end, + {ok, lists:mapfoldl(ToPairs, #{}, Headers)}. + +%%% Making STOMP protocol frames + +%% Format a header +-spec format_header({binary(), binary()}) -> binary(). +format_header({Key, Val}) -> + <<Key/binary, ":", Val/binary, "\n">>. + +%% Build a single STOMP frame +-spec make_frame(binary(), + headers(), + binary()) + -> {ok, iolist()}. +make_frame(Command, HeaderMap, Body) -> + Headers = lists:map(fun format_header/1, maps:to_list(HeaderMap)), + Frame = [Command, <<"\n">>, Headers, <<"\n">>, Body, <<0>>], + {ok, Frame}. + +%%% Default frames + +-spec connect_frame(list(), any(), any()) -> iolist(). +connect_frame(Host, {ok, Login}, {ok, Pass}) -> + make_frame(<<"CONNECT">>, + #{<<"accept-version">> => <<"1.2">>, + <<"host">> => Host, + <<"login">> => Login, + <<"passcode">> => Pass, + <<"heart-beat">> => <<"0,5000">>}, + []); +connect_frame(Host, _Login, _Pass) -> + make_frame(<<"CONNECT">>, + #{<<"accept-version">> => <<"1.2">>, + <<"host">> => Host, + %% Expect a server heartbeat every 5 seconds, let the server + %% expect one every 10. We don't actually check this and just + %% echo server heartbeats. + %% TODO: For now the server is told not to expect replies due to + %% a weird behaviour. + <<"heart-beat">> => <<"0,5000">>}, + []). + + +-spec subscribe_frame(sub_id(), destination(), ack_mode()) -> iolist(). +subscribe_frame(Id, Queue, Ack) -> + make_frame(<<"SUBSCRIBE">>, + #{<<"id">> => integer_to_binary(Id), + <<"destination">> => Queue, + <<"ack">> => ack_mode_to_binary(Ack)}, + []). + +-spec ack_mode_to_binary(ack_mode()) -> binary(). +ack_mode_to_binary(AckMode) -> + case AckMode of + auto -> <<"auto">>; + client -> <<"client">>; + client_individual -> <<"client-individual">> + end. + +%% -spec ack_frame(binary()) -> iolist(). +%% ack_frame(MessageID) -> +%% make_frame(<<"ACK">>, +%% [{"id", MessageID}], +%% []). diff --git a/nix/buildGo/.skip-subtree b/nix/buildGo/.skip-subtree new file mode 100644 index 0000000000..8db1f814f6 --- /dev/null +++ b/nix/buildGo/.skip-subtree @@ -0,0 +1,2 @@ +Subdirectories of this folder should not be imported since they are +internal to buildGo.nix and incompatible with readTree. diff --git a/nix/buildGo/README.md b/nix/buildGo/README.md new file mode 100644 index 0000000000..37e0c06933 --- /dev/null +++ b/nix/buildGo/README.md @@ -0,0 +1,140 @@ +buildGo.nix +=========== + +This is an alternative [Nix][] build system for [Go][]. It supports building Go +libraries and programs, and even automatically generating Protobuf & gRPC +libraries. + +*Note:* This will probably end up being folded into [Nixery][]. + +## Background + +Most language-specific Nix tooling outsources the build to existing +language-specific build tooling, which essentially means that Nix ends up being +a wrapper around all sorts of external build systems. + +However, systems like [Bazel][] take an alternative approach in which the +compiler is invoked directly and the composition of programs and libraries stays +within a single homogeneous build system. + +Users don't need to learn per-language build systems and especially for +companies with large monorepo-setups ([like Google][]) this has huge +productivity impact. + +This project is an attempt to prove that Nix can be used in a similar style to +build software directly, rather than shelling out to other build systems. + +## Example + +Given a program layout like this: + +``` +. +├── lib <-- some library component +│ ├── bar.go +│ └── foo.go +├── api.proto <-- gRPC API definition +├── main.go <-- program implementation +└── default.nix <-- build instructions +``` + +The contents of `default.nix` could look like this: + +```nix +{ buildGo }: + +let + api = buildGo.grpc { + name = "someapi"; + proto = ./api.proto; + }; + + lib = buildGo.package { + name = "somelib"; + srcs = [ + ./lib/bar.go + ./lib/foo.go + ]; + }; +in buildGo.program { + name = "my-program"; + deps = [ api lib ]; + + srcs = [ + ./main.go + ]; +} +``` + +(If you don't know how to read Nix, check out [nix-1p][]) + +## Usage + +`buildGo` exposes five different functions: + +* `buildGo.program`: Build a Go binary out of the specified source files. + + | parameter | type | use | required? | + |-----------|-------------------------|------------------------------------------------|-----------| + | `name` | `string` | Name of the program (and resulting executable) | yes | + | `srcs` | `list<path>` | List of paths to source files | yes | + | `deps` | `list<drv>` | List of dependencies (i.e. other Go libraries) | no | + | `x_defs` | `attrs<string, string>` | Attribute set of linker vars (i.e. `-X`-flags) | no | + +* `buildGo.package`: Build a Go library out of the specified source files. + + | parameter | type | use | required? | + |-----------|--------------|------------------------------------------------|-----------| + | `name` | `string` | Name of the library | yes | + | `srcs` | `list<path>` | List of paths to source files | yes | + | `deps` | `list<drv>` | List of dependencies (i.e. other Go libraries) | no | + | `path` | `string` | Go import path for the resulting library | no | + +* `buildGo.external`: Build an externally defined Go library or program. + + This function performs analysis on the supplied source code (which + can use the standard Go tooling layout) and creates a tree of all + the packages contained within. + + This exists for compatibility with external libraries that were not + defined using buildGo. + + | parameter | type | use | required? | + |-----------|----------------|-----------------------------------------------|-----------| + | `path` | `string` | Go import path for the resulting package | yes | + | `src` | `path` | Path to the source **directory** | yes | + | `deps` | `list<drv>` | List of dependencies (i.e. other Go packages) | no | + + For some examples of how `buildGo.external` is used, check out + [`proto.nix`](./proto.nix). + +* `buildGo.proto`: Build a Go library out of the specified Protobuf definition. + + | parameter | type | use | required? | + |-------------|-------------|--------------------------------------------------|-----------| + | `name` | `string` | Name for the resulting library | yes | + | `proto` | `path` | Path to the Protobuf definition file | yes | + | `path` | `string` | Import path for the resulting Go library | no | + | `extraDeps` | `list<drv>` | Additional Go dependencies to add to the library | no | + +* `buildGo.grpc`: Build a Go library out of the specified gRPC definition. + + The parameters are identical to `buildGo.proto`. + +## Current status + +This project is work-in-progress. Crucially it is lacking the following features: + +* feature flag parity with Bazel's Go rules +* documentation building +* test execution + +There are still some open questions around how to structure some of those +features in Nix. + +[Nix]: https://nixos.org/nix/ +[Go]: https://golang.org/ +[Nixery]: https://github.com/google/nixery +[Bazel]: https://bazel.build/ +[like Google]: https://ai.google/research/pubs/pub45424 +[nix-1p]: https://github.com/tazjin/nix-1p diff --git a/nix/buildGo/default.nix b/nix/buildGo/default.nix new file mode 100644 index 0000000000..03c0b2bc4b --- /dev/null +++ b/nix/buildGo/default.nix @@ -0,0 +1,129 @@ +# Copyright 2019 Google LLC. +# SPDX-License-Identifier: Apache-2.0 +# +# buildGo provides Nix functions to build Go packages in the style of Bazel's +# rules_go. + +{ pkgs ? import <nixpkgs> {} +, ... }: + +let + inherit (builtins) + attrNames + baseNameOf + dirOf + elemAt + filter + listToAttrs + map + match + readDir + replaceStrings + toString; + + inherit (pkgs) lib go runCommand fetchFromGitHub protobuf symlinkJoin; + + # Helpers for low-level Go compiler invocations + spaceOut = lib.concatStringsSep " "; + + includeDepSrc = dep: "-I ${dep}"; + includeSources = deps: spaceOut (map includeDepSrc deps); + + includeDepLib = dep: "-L ${dep}"; + includeLibs = deps: spaceOut (map includeDepLib deps); + + srcBasename = src: elemAt (match "([a-z0-9]{32}\-)?(.*\.go)" (baseNameOf src)) 1; + srcCopy = path: src: "cp ${src} $out/${path}/${srcBasename src}"; + srcList = path: srcs: lib.concatStringsSep "\n" (map (srcCopy path) srcs); + + allDeps = deps: lib.unique (lib.flatten (deps ++ (map (d: d.goDeps) deps))); + + xFlags = x_defs: spaceOut (map (k: "-X ${k}=${x_defs."${k}"}") (attrNames x_defs)); + + pathToName = p: replaceStrings ["/"] ["_"] (toString p); + + # Add an `overrideGo` attribute to a function result that works + # similar to `overrideAttrs`, but is used specifically for the + # arguments passed to Go builders. + makeOverridable = f: orig: (f orig) // { + overrideGo = new: makeOverridable f (orig // (new orig)); + }; + + # High-level build functions + + # Build a Go program out of the specified files and dependencies. + program = { name, srcs, deps ? [], x_defs ? {} }: + let uniqueDeps = allDeps deps; + in runCommand name {} '' + ${go}/bin/go tool compile -o ${name}.a -trimpath=$PWD -trimpath=${go} ${includeSources uniqueDeps} ${spaceOut srcs} + mkdir -p $out/bin + export GOROOT_FINAL=go + ${go}/bin/go tool link -o $out/bin/${name} -buildid nix ${xFlags x_defs} ${includeLibs uniqueDeps} ${name}.a + ''; + + # Build a Go library assembled out of the specified files. + # + # This outputs both the sources and compiled binary, as both are + # needed when downstream packages depend on it. + package = { name, srcs, deps ? [], path ? name, sfiles ? [] }: + let + uniqueDeps = allDeps deps; + + # The build steps below need to be executed conditionally for Go + # assembly if the analyser detected any *.s files. + # + # This is required for several popular packages (e.g. x/sys). + ifAsm = do: lib.optionalString (sfiles != []) do; + asmBuild = ifAsm '' + ${go}/bin/go tool asm -trimpath $PWD -I $PWD -I ${go}/share/go/pkg/include -D GOOS_linux -D GOARCH_amd64 -gensymabis -o ./symabis ${spaceOut sfiles} + ${go}/bin/go tool asm -trimpath $PWD -I $PWD -I ${go}/share/go/pkg/include -D GOOS_linux -D GOARCH_amd64 -o ./asm.o ${spaceOut sfiles} + ''; + asmLink = ifAsm "-symabis ./symabis -asmhdr $out/go_asm.h"; + asmPack = ifAsm '' + ${go}/bin/go tool pack r $out/${path}.a ./asm.o + ''; + in (runCommand "golib-${name}" {} '' + mkdir -p $out/${path} + ${srcList path (map (s: "${s}") srcs)} + ${asmBuild} + ${go}/bin/go tool compile -pack ${asmLink} -o $out/${path}.a -trimpath=$PWD -trimpath=${go} -p ${path} ${includeSources uniqueDeps} ${spaceOut srcs} + ${asmPack} + '') // { goDeps = uniqueDeps; goImportPath = path; }; + + # Build a tree of Go libraries out of an external Go source + # directory that follows the standard Go layout and was not built + # with buildGo.nix. + # + # The derivation for each actual package will reside in an attribute + # named "gopkg", and an attribute named "gobin" for binaries. + external = import ./external { inherit pkgs program package; }; + + # Import support libraries needed for protobuf & gRPC support + protoLibs = import ./proto.nix { + inherit external; + }; + + # Build a Go library out of the specified protobuf definition. + proto = { name, proto, path ? name, extraDeps ? [] }: (makeOverridable package) { + inherit name path; + deps = [ protoLibs.goProto.proto.gopkg ] ++ extraDeps; + srcs = lib.singleton (runCommand "goproto-${name}.pb.go" {} '' + cp ${proto} ${baseNameOf proto} + ${protobuf}/bin/protoc --plugin=${protoLibs.goProto.protoc-gen-go.gopkg}/bin/protoc-gen-go \ + --go_out=plugins=grpc,import_path=${baseNameOf path}:. ${baseNameOf proto} + mv *.pb.go $out + ''); + }; + + # Build a Go library out of the specified gRPC definition. + grpc = args: proto (args // { extraDeps = [ protoLibs.goGrpc.gopkg ]; }); + +in { + # Only the high-level builder functions are exposed, but made + # overrideable. + program = makeOverridable program; + package = makeOverridable package; + proto = makeOverridable proto; + grpc = makeOverridable grpc; + external = makeOverridable external; +} diff --git a/nix/buildGo/example/default.nix b/nix/buildGo/example/default.nix new file mode 100644 index 0000000000..5abed1fbbc --- /dev/null +++ b/nix/buildGo/example/default.nix @@ -0,0 +1,47 @@ +# Copyright 2019 Google LLC. +# SPDX-License-Identifier: Apache-2.0 + +# This file provides examples for how to use the various builder +# functions provided by `buildGo`. +# +# The features used in the example are not exhaustive, but should give +# users a quick introduction to how to use buildGo. + +let + buildGo = import ../buildGo.nix {}; + + # Example use of buildGo.package, which creates an importable Go + # package from the specified source files. + examplePackage = buildGo.package { + name = "example"; + srcs = [ + ./lib.go + ]; + }; + + # Example use of buildGo.proto, which generates a Go library from a + # Protobuf definition file. + exampleProto = buildGo.proto { + name = "exampleproto"; + proto = ./thing.proto; + }; + + # Example use of buildGo.program, which builds an executable using + # the specified name and dependencies (which in turn must have been + # created via buildGo.package etc.) +in buildGo.program { + name = "example"; + + srcs = [ + ./main.go + ]; + + deps = [ + examplePackage + exampleProto + ]; + + x_defs = { + "main.Flag" = "successfully"; + }; +} diff --git a/nix/buildGo/example/lib.go b/nix/buildGo/example/lib.go new file mode 100644 index 0000000000..8a61370e99 --- /dev/null +++ b/nix/buildGo/example/lib.go @@ -0,0 +1,9 @@ +// Copyright 2019 Google LLC. +// SPDX-License-Identifier: Apache-2.0 + +package example + +// UUID returns a totally random, carefully chosen UUID +func UUID() string { + return "3640932f-ad40-4bc9-b45d-f504a0f5910a" +} diff --git a/nix/buildGo/example/main.go b/nix/buildGo/example/main.go new file mode 100644 index 0000000000..bbcedbff87 --- /dev/null +++ b/nix/buildGo/example/main.go @@ -0,0 +1,25 @@ +// Copyright 2019 Google LLC. +// SPDX-License-Identifier: Apache-2.0 +// +// Package main provides a tiny example program for the Bazel-style +// Nix build system for Go. + +package main + +import ( + "example" + "exampleproto" + "fmt" +) + +var Flag string = "unsuccessfully" + +func main() { + thing := exampleproto.Thing{ + Id: example.UUID(), + KindOfThing: "test thing", + } + + fmt.Printf("The thing is a %s with ID %q\n", thing.Id, thing.KindOfThing) + fmt.Printf("The flag has been %s set\n", Flag) +} diff --git a/nix/buildGo/example/thing.proto b/nix/buildGo/example/thing.proto new file mode 100644 index 0000000000..0cb34124df --- /dev/null +++ b/nix/buildGo/example/thing.proto @@ -0,0 +1,10 @@ +// Copyright 2019 Google LLC. +// SPDX-License-Identifier: Apache-2.0 + +syntax = "proto3"; +package exampleProto; + +message Thing { + string id = 1; + string kind_of_thing = 2; +} diff --git a/nix/buildGo/external/default.nix b/nix/buildGo/external/default.nix new file mode 100644 index 0000000000..48f678688e --- /dev/null +++ b/nix/buildGo/external/default.nix @@ -0,0 +1,95 @@ +# Copyright 2019 Google LLC. +# SPDX-License-Identifier: Apache-2.0 +{ pkgs, program, package }: + +let + inherit (builtins) + elemAt + foldl' + fromJSON + head + length + listToAttrs + readFile + replaceStrings + tail + throw; + + inherit (pkgs) lib runCommand go jq ripgrep; + + pathToName = p: replaceStrings ["/"] ["_"] (toString p); + + # Collect all non-vendored dependencies from the Go standard library + # into a file that can be used to filter them out when processing + # dependencies. + stdlibPackages = runCommand "stdlib-pkgs.json" {} '' + export HOME=$PWD + export GOPATH=/dev/null + ${go}/bin/go list all | \ + ${ripgrep}/bin/rg -v 'vendor' | \ + ${jq}/bin/jq -R '.' | \ + ${jq}/bin/jq -c -s 'map({key: ., value: true}) | from_entries' \ + > $out + ''; + + analyser = program { + name = "analyser"; + + srcs = [ + ./main.go + ]; + + x_defs = { + "main.stdlibList" = "${stdlibPackages}"; + }; + }; + + mkset = path: value: + if path == [] then { gopkg = value; } + else { "${head path}" = mkset (tail path) value; }; + + last = l: elemAt l ((length l) - 1); + + toPackage = self: src: path: depMap: entry: + let + localDeps = map (d: lib.attrByPath (d ++ [ "gopkg" ]) ( + throw "missing local dependency '${lib.concatStringsSep "." d}' in '${path}'" + ) self) entry.localDeps; + + foreignDeps = map (d: lib.attrByPath [ d ] ( + throw "missing foreign dependency '${d}' in '${path}'" + ) depMap) entry.foreignDeps; + + args = { + srcs = map (f: src + ("/" + f)) entry.files; + deps = localDeps ++ foreignDeps; + }; + + libArgs = args // { + name = pathToName entry.name; + path = lib.concatStringsSep "/" ([ path ] ++ entry.locator); + sfiles = map (f: src + ("/" + f)) entry.sfiles; + }; + + binArgs = args // { + name = (last ((lib.splitString "/" path) ++ entry.locator)); + }; + in if entry.isCommand then (program binArgs) else (package libArgs); + +in { src, path, deps ? [] }: let + # Build a map of dependencies (from their import paths to their + # derivation) so that they can be conditionally imported only in + # sub-packages that require them. + depMap = listToAttrs (map (d: { + name = d.goImportPath; + value = d; + }) deps); + + name = pathToName path; + analysisOutput = runCommand "${name}-structure.json" {} '' + ${analyser}/bin/analyser -path ${path} -source ${src} > $out + ''; + analysis = fromJSON (readFile analysisOutput); +in lib.fix(self: foldl' lib.recursiveUpdate {} ( + map (entry: mkset entry.locator (toPackage self src path depMap entry)) analysis +)) diff --git a/nix/buildGo/external/main.go b/nix/buildGo/external/main.go new file mode 100644 index 0000000000..aa4a813d32 --- /dev/null +++ b/nix/buildGo/external/main.go @@ -0,0 +1,186 @@ +// Copyright 2019 Google LLC. +// SPDX-License-Identifier: Apache-2.0 + +// This tool analyses external (i.e. not built with `buildGo.nix`) Go +// packages to determine a build plan that Nix can import. +package main + +import ( + "encoding/json" + "flag" + "fmt" + "go/build" + "io/ioutil" + "log" + "os" + "path" + "path/filepath" + "strings" +) + +// Path to a JSON file describing all standard library import paths. +// This file is generated and set here by Nix during the build +// process. +var stdlibList string + +// pkg describes a single Go package within the specified source +// directory. +// +// Return information includes the local (relative from project root) +// and external (none-stdlib) dependencies of this package. +type pkg struct { + Name string `json:"name"` + Locator []string `json:"locator"` + Files []string `json:"files"` + SFiles []string `json:"sfiles"` + LocalDeps [][]string `json:"localDeps"` + ForeignDeps []string `json:"foreignDeps"` + IsCommand bool `json:"isCommand"` +} + +// findGoDirs returns a filepath.WalkFunc that identifies all +// directories that contain Go source code in a certain tree. +func findGoDirs(at string) ([]string, error) { + dirSet := make(map[string]bool) + + err := filepath.Walk(at, func(path string, info os.FileInfo, err error) error { + name := info.Name() + // Skip folders that are guaranteed to not be relevant + if info.IsDir() && (name == "testdata" || name == ".git") { + return filepath.SkipDir + } + + // If the current file is a Go file, then the directory is popped + // (i.e. marked as a Go directory). + if !info.IsDir() && strings.HasSuffix(name, ".go") && !strings.HasSuffix(name, "_test.go") { + dirSet[filepath.Dir(path)] = true + } + + return nil + }) + + if err != nil { + return nil, err + } + + goDirs := []string{} + for k, _ := range dirSet { + goDirs = append(goDirs, k) + } + + return goDirs, nil +} + +// analysePackage loads and analyses the imports of a single Go +// package, returning the data that is required by the Nix code to +// generate a derivation for this package. +func analysePackage(root, source, importpath string, stdlib map[string]bool) (pkg, error) { + ctx := build.Default + ctx.CgoEnabled = false + + p, err := ctx.ImportDir(source, build.IgnoreVendor) + if err != nil { + return pkg{}, err + } + + local := [][]string{} + foreign := []string{} + + for _, i := range p.Imports { + if stdlib[i] { + continue + } + + if i == importpath { + local = append(local, []string{}) + } else if strings.HasPrefix(i, importpath) { + local = append(local, strings.Split(strings.TrimPrefix(i, importpath+"/"), "/")) + } else { + foreign = append(foreign, i) + } + } + + prefix := strings.TrimPrefix(source, root+"/") + + locator := []string{} + if len(prefix) != len(source) { + locator = strings.Split(prefix, "/") + } else { + // Otherwise, the locator is empty since its the root package and + // no prefix should be added to files. + prefix = "" + } + + files := []string{} + for _, f := range p.GoFiles { + files = append(files, path.Join(prefix, f)) + } + + sfiles := []string{} + for _, f := range p.SFiles { + sfiles = append(sfiles, path.Join(prefix, f)) + } + + return pkg{ + Name: path.Join(importpath, prefix), + Locator: locator, + Files: files, + SFiles: sfiles, + LocalDeps: local, + ForeignDeps: foreign, + IsCommand: p.IsCommand(), + }, nil +} + +func loadStdlibPkgs(from string) (pkgs map[string]bool, err error) { + f, err := ioutil.ReadFile(from) + if err != nil { + return + } + + err = json.Unmarshal(f, &pkgs) + return +} + +func main() { + source := flag.String("source", "", "path to directory with sources to process") + path := flag.String("path", "", "import path for the package") + + flag.Parse() + + if *source == "" { + log.Fatalf("-source flag must be specified") + } + + stdlibPkgs, err := loadStdlibPkgs(stdlibList) + if err != nil { + log.Fatalf("failed to load standard library index from %q: %s\n", stdlibList, err) + } + + goDirs, err := findGoDirs(*source) + if err != nil { + log.Fatalf("failed to walk source directory '%s': %s\n", source, err) + } + + all := []pkg{} + for _, d := range goDirs { + analysed, err := analysePackage(*source, d, *path, stdlibPkgs) + + // If the Go source analysis returned "no buildable Go files", + // that directory should be skipped. + // + // This might be due to `+build` flags on the platform and other + // reasons (such as test files). + if _, ok := err.(*build.NoGoError); ok { + continue + } + + if err != nil { + log.Fatalf("failed to analyse package at %q: %s", d, err) + } + all = append(all, analysed) + } + + j, _ := json.Marshal(all) + fmt.Println(string(j)) +} diff --git a/nix/buildGo/proto.nix b/nix/buildGo/proto.nix new file mode 100644 index 0000000000..2ece948ebd --- /dev/null +++ b/nix/buildGo/proto.nix @@ -0,0 +1,84 @@ +# Copyright 2019 Google LLC. +# SPDX-License-Identifier: Apache-2.0 +# +# This file provides derivations for the dependencies of a gRPC +# service in Go. + +{ external }: + +let + inherit (builtins) fetchGit map; +in rec { + goProto = external { + path = "github.com/golang/protobuf"; + src = fetchGit { + url = "https://github.com/golang/protobuf"; + rev = "ed6926b37a637426117ccab59282c3839528a700"; + }; + }; + + xnet = external { + path = "golang.org/x/net"; + + src = fetchGit { + url = "https://go.googlesource.com/net"; + rev = "ffdde105785063a81acd95bdf89ea53f6e0aac2d"; + }; + + deps = map (p: p.gopkg) [ + xtext.secure.bidirule + xtext.unicode.bidi + xtext.unicode.norm + ]; + }; + + xsys = external { + path = "golang.org/x/sys"; + src = fetchGit { + url = "https://go.googlesource.com/sys"; + rev = "bd437916bb0eb726b873ee8e9b2dcf212d32e2fd"; + }; + }; + + xtext = external { + path = "golang.org/x/text"; + src = fetchGit { + url = "https://go.googlesource.com/text"; + rev = "cbf43d21aaebfdfeb81d91a5f444d13a3046e686"; + }; + }; + + genproto = external { + path = "google.golang.org/genproto"; + src = fetchGit { + url = "https://github.com/google/go-genproto"; + rev = "83cc0476cb11ea0da33dacd4c6354ab192de6fe6"; + }; + + deps = with goProto; map (p: p.gopkg) [ + proto + ptypes.any + ]; + }; + + goGrpc = external { + path = "google.golang.org/grpc"; + deps = map (p: p.gopkg) ([ + xnet.trace + xnet.http2 + xsys.unix + xnet.http2.hpack + genproto.googleapis.rpc.status + ] ++ (with goProto; [ + proto + ptypes + ptypes.duration + ptypes.timestamp + ])); + + src = fetchGit { + url = "https://github.com/grpc/grpc-go"; + rev = "d8e3da36ac481ef00e510ca119f6b68177713689"; + }; + }; +} diff --git a/nix/buildLisp/README.md b/nix/buildLisp/README.md new file mode 100644 index 0000000000..8e45f3479c --- /dev/null +++ b/nix/buildLisp/README.md @@ -0,0 +1,96 @@ +buildLisp.nix +============= + +This is a build system for Common Lisp, written in Nix. + +It aims to offer an alternative to ASDF for users who live in a +Nix-based ecosystem. This offers several advantages over ASDF: + +* Simpler (logic-less) package definitions +* Easy linking of native dependencies (from Nix) +* Composability with Nix tooling for other languages +* Effective, per-system caching strategies +* Easy overriding of dependencies and whatnot +* ... and more! + +The project is still in its early stages and some important +restrictions should be highlighted: + +* There is no separate abstraction for tests at the moment (i.e. they + are built and run as programs) +* Only SBCL is supported (though the plan is to add support for at + least ABCL and Clozure CL, and maybe make it extensible) + +## Usage + +`buildLisp` exposes four different functions: + +* `buildLisp.library`: Builds a collection of Lisp files into a library. + + | parameter | type | use | required? | + |-----------|--------------|-------------------------------|-----------| + | `name` | `string` | Name of the library | yes | + | `srcs` | `list<path>` | List of paths to source files | yes | + | `deps` | `list<drv>` | List of dependencies | no | + | `native` | `list<drv>` | List of native dependencies | no | + + The output of invoking this is a directory containing a FASL file + that is the concatenated result of all compiled sources. + +* `buildLisp.program`: Builds an executable program out of Lisp files. + + | parameter | type | use | required? | + |-----------|--------------|-------------------------------|-----------| + | `name` | `string` | Name of the program | yes | + | `srcs` | `list<path>` | List of paths to source files | yes | + | `deps` | `list<drv>` | List of dependencies | no | + | `native` | `list<drv>` | List of native dependencies | no | + | `main` | `string` | Entrypoint function | no | + + The `main` parameter should be the name of a function and defaults + to `${name}:main` (i.e. the *exported* `main` function of the + package named after the program). + + The output of invoking this is a directory containing a + `bin/${name}`. + +* `buildLisp.bundled`: Creates a virtual dependency on a built-in library. + + Certain libraries ship with Lisp implementations, for example + UIOP/ASDF are commonly included but many implementations also ship + internals (such as SBCLs various `sb-*` libraries). + + This function takes a single string argument that is the name of a + built-in library and returns a "package" that simply requires this + library. + +* `buildLisp.sbclWith`: Creates an SBCL pre-loaded with various dependencies. + + This function takes a single argument which is a list of Lisp + libraries programs or programs. It creates an SBCL that is + pre-loaded with all of that Lisp code and can be used as the host + for e.g. Sly or SLIME. + +## Example + +Using buildLisp could look like this: + +```nix +{ buildLisp, lispPkgs }: + +let libExample = buildLisp.library { + name = "lib-example"; + srcs = [ ./lib.lisp ]; + + deps = with lispPkgs; [ + (buildLisp.bundled "sb-posix") + iterate + cl-ppcre + ]; +}; +in buildLisp.program { + name = "example"; + deps = [ libExample ]; + srcs = [ ./main.lisp ]; +} +``` diff --git a/nix/buildLisp/default.nix b/nix/buildLisp/default.nix new file mode 100644 index 0000000000..0e94ed6223 --- /dev/null +++ b/nix/buildLisp/default.nix @@ -0,0 +1,184 @@ +# buildLisp provides Nix functions to build Common Lisp packages, +# targeting SBCL. +# +# buildLisp is designed to enforce conventions and do away with the +# free-for-all of existing Lisp build systems. + +{ pkgs ? import <nixpkgs> {}, ... }: + +let + inherit (builtins) map elemAt match filter; + inherit (pkgs) lib runCommandNoCC makeWrapper writeText writeShellScriptBin sbcl; + + # + # Internal helper definitions + # + + # 'genLoadLisp' generates Lisp code that instructs SBCL to load all + # the provided Lisp libraries. + genLoadLisp = deps: lib.concatStringsSep "\n" + (map (lib: "(load \"${lib}/${lib.lispName}.fasl\")") (allDeps deps)); + + # 'genCompileLisp' generates a Lisp file that instructs SBCL to + # compile the provided list of Lisp source files to $out. + genCompileLisp = srcs: deps: writeText "compile.lisp" '' + ;; This file compiles the specified sources into the Nix build + ;; directory, creating one FASL file for each source. + (require 'sb-posix) + + ${genLoadLisp deps} + + (defun nix-compile-lisp (file srcfile) + (let ((outfile (make-pathname :type "fasl" + :directory (or (sb-posix:getenv "NIX_BUILD_TOP") + (error "not running in a Nix build")) + :defaults srcfile))) + (multiple-value-bind (_outfile _warnings-p failure-p) + (compile-file srcfile :output-file outfile) + (if failure-p (sb-posix:exit 1) + (progn + ;; For the case of multiple files belonging to the same + ;; library being compiled, load them in order: + (load outfile) + + ;; Write them to the FASL list in the same order: + (format file "cat ~a~%" (namestring outfile))))))) + + (let ((*compile-verbose* t) + ;; FASL files are compiled into the working directory of the + ;; build and *then* moved to the correct out location. + (pwd (sb-posix:getcwd))) + + (with-open-file (file "cat_fasls" + :direction :output + :if-does-not-exist :create) + + ;; These forms were inserted by the Nix build: + ${ + lib.concatStringsSep "\n" (map (src: "(nix-compile-lisp file \"${src}\")") srcs) + } + )) + ''; + + # 'dependsOn' determines whether Lisp library 'b' depends on 'a'. + dependsOn = a: b: builtins.elem a b.lispDeps; + + # 'allDeps' flattens the list of dependencies (and their + # dependencies) into one ordered list of unique deps. + allDeps = deps: (lib.toposort dependsOn (lib.unique ( + lib.flatten (deps ++ (map (d: d.lispDeps) deps)) + ))).result; + + # 'allNative' extracts all native dependencies of a dependency list + # to ensure that library load paths are set correctly during all + # compilations and program assembly. + allNative = native: deps: lib.unique ( + lib.flatten (native ++ (map (d: d.lispNativeDeps) deps)) + ); + + # 'genDumpLisp' generates a Lisp file that instructs SBCL to dump + # the currently loaded image as an executable to $out/bin/$name. + # + # TODO(tazjin): Compression is currently unsupported because the + # SBCL in nixpkgs is, by default, not compiled with zlib support. + genDumpLisp = name: main: deps: writeText "dump.lisp" '' + (require 'sb-posix) + + ${genLoadLisp deps} + + (let* ((bindir (concatenate 'string (sb-posix:getenv "out") "/bin")) + (outpath (make-pathname :name "${name}" + :directory bindir))) + (save-lisp-and-die outpath + :executable t + :toplevel (function ${main}) + :purify t)) + ;; + ''; + + # Add an `overrideLisp` attribute to a function result that works + # similar to `overrideAttrs`, but is used specifically for the + # arguments passed to Lisp builders. + makeOverridable = f: orig: (f orig) // { + overrideLisp = new: makeOverridable f (orig // (new orig)); + }; + + # + # Public API functions + # + + # 'library' builds a list of Common Lisp files into a single FASL + # which can then be loaded into SBCL. + library = { name, srcs, deps ? [], native ? [] }: + let + lispNativeDeps = (allNative native deps); + lispDeps = allDeps deps; + in runCommandNoCC "${name}-cllib" { + LD_LIBRARY_PATH = lib.makeLibraryPath lispNativeDeps; + LANG = "C.UTF-8"; + } '' + ${sbcl}/bin/sbcl --script ${genCompileLisp srcs lispDeps} + + echo "Compilation finished, assembling FASL files" + + # FASL files can be combined by simply concatenating them + # together, but it needs to be in the compilation order. + mkdir $out + + chmod +x cat_fasls + ./cat_fasls > $out/${name}.fasl + '' // { + inherit lispNativeDeps lispDeps; + lispName = name; + lispBinary = false; + }; + + # 'program' creates an executable containing a dumped image of the + # specified sources and dependencies. + program = { name, main ? "${name}:main", srcs, deps ? [], native ? [] }: + let + lispDeps = allDeps deps; + libPath = lib.makeLibraryPath (allNative native lispDeps); + selfLib = library { + inherit name srcs native; + deps = lispDeps; + }; + in runCommandNoCC "${name}" { + nativeBuildInputs = [ makeWrapper ]; + LD_LIBRARY_PATH = libPath; + } '' + mkdir -p $out/bin + + ${sbcl}/bin/sbcl --script ${ + genDumpLisp name main ([ selfLib ] ++ lispDeps) + } + + wrapProgram $out/bin/${name} --prefix LD_LIBRARY_PATH : "${libPath}" + '' // { + lispName = name; + lispDeps = [ selfLib ]; + lispNativeDeps = native; + lispBinary = true; + }; + + # 'bundled' creates a "library" that calls 'require' on a built-in + # package, such as any of SBCL's sb-* packages. + bundled = name: (makeOverridable library) { + inherit name; + srcs = lib.singleton (builtins.toFile "${name}.lisp" "(require '${name})"); + }; + + # 'sbclWith' creates an image with the specified libraries / + # programs loaded. + sbclWith = deps: + let lispDeps = filter (d: !d.lispBinary) (allDeps deps); + in writeShellScriptBin "sbcl" '' + export LD_LIBRARY_PATH=${lib.makeLibraryPath (allNative [] lispDeps)}; + exec ${sbcl}/bin/sbcl ${lib.optionalString (deps != []) "--load ${writeText "load.lisp" (genLoadLisp lispDeps)}"} $@ + ''; +in { + library = makeOverridable library; + program = makeOverridable program; + sbclWith = makeOverridable sbclWith; + bundled = makeOverridable bundled; +} diff --git a/nix/buildLisp/example/default.nix b/nix/buildLisp/example/default.nix new file mode 100644 index 0000000000..6a518e4964 --- /dev/null +++ b/nix/buildLisp/example/default.nix @@ -0,0 +1,32 @@ +{ depot, ... }: + +let + inherit (depot.nix) buildLisp; + + # Example Lisp library. + # + # Currently the `name` attribute is only used for the derivation + # itself, it has no practical implications. + libExample = buildLisp.library { + name = "lib-example"; + srcs = [ + ./lib.lisp + ]; + }; + +# Example Lisp program. +# +# This builds & writes an executable for a program using the library +# above to disk. +# +# By default, buildLisp.program expects the entry point to be +# `$name:main`. This can be overridden by configuring the `main` +# attribute. +in buildLisp.program { + name = "example"; + deps = [ libExample ]; + + srcs = [ + ./main.lisp + ]; +} diff --git a/nix/buildLisp/example/lib.lisp b/nix/buildLisp/example/lib.lisp new file mode 100644 index 0000000000..e557de4ae5 --- /dev/null +++ b/nix/buildLisp/example/lib.lisp @@ -0,0 +1,6 @@ +(defpackage lib-example + (:use :cl) + (:export :who)) +(in-package :lib-example) + +(defun who () "edef") diff --git a/nix/buildLisp/example/main.lisp b/nix/buildLisp/example/main.lisp new file mode 100644 index 0000000000..a29390cf4d --- /dev/null +++ b/nix/buildLisp/example/main.lisp @@ -0,0 +1,7 @@ +(defpackage example + (:use :cl :lib-example) + (:export :main)) +(in-package :example) + +(defun main () + (format t "i <3 ~A~%" (who))) diff --git a/nix/readTree/README.md b/nix/readTree/README.md new file mode 100644 index 0000000000..c93cf2bfdd --- /dev/null +++ b/nix/readTree/README.md @@ -0,0 +1,81 @@ +readTree +======== + +This is a Nix program that builds up an attribute set tree for a large +repository based on the filesystem layout. + +It is in fact the tool that lays out the attribute set of this repository. + +As an example, consider a root (`.`) of a repository and a layout such as: + +``` +. +├── third_party +│ ├── default.nix +│ └── rustpkgs +│ ├── aho-corasick.nix +│ └── serde.nix +└── tools + ├── cheddar + │ └── default.nix + └── roquefort.nix +``` + +When `readTree` is called on that tree, it will construct an attribute set with +this shape: + +```nix +{ + tools = { + cheddar = ...; + roquefort = ...; + }; + + third_party = { + # the `default.nix` of this folder might have had arbitrary other + # attributes here, such as this: + favouriteColour = "orange"; + + rustpkgs = { + aho-corasick = ...; + serde = ...; + }; + }; +} +``` + +Every imported Nix file that yields an attribute set will have a `__readTree = +true;` attribute merged into it. + +## Traversal logic + +`readTree` will follow any subdirectories of a tree and import all Nix files, +with some exceptions: + +* A folder can declare that its children are off-limit by containing a + `.skip-subtree` file. Since the content of the file is not checked, it can be + useful to leave a note for a human in the file. +* If a folder contains a `default.nix` file, no *sibling* Nix files will be + imported - however children are traversed as normal. +* If a folder contains a `default.nix` it is loaded and, if it evaluates to a + set, *merged* with the children. If it evaluates to anything else the children + are *not traversed*. + +Traversal is lazy, `readTree` will only build up the tree as requested. This +currently has the downside that directories with no importable files end up in +the tree as empty nodes (`{}`). + +## Import structure + +`readTree` is called with two parameters: The arguments to pass to all imports, +and the initial path at which to start the traversal. + +The package headers in this repository follow the form `{ pkgs, ... }:` where +`pkgs` is a fixed-point of the entire package tree (see the `default.nix` at the +root of the depot). + +In theory `readTree` can pass arguments of different shapes, but I have found +this to be a good solution for the most part. + +Note that `readTree` does not currently make functions overridable, though it is +feasible that it could do that in the future. diff --git a/nix/readTree/default.nix b/nix/readTree/default.nix new file mode 100644 index 0000000000..c48928ee19 --- /dev/null +++ b/nix/readTree/default.nix @@ -0,0 +1,63 @@ +{ ... }: + +args: initPath: + +let + inherit (builtins) + attrNames + baseNameOf + filter + hasAttr + head + length + listToAttrs + map + match + isAttrs + readDir; + + argsWithPath = parts: args // { + locatedAt = parts; + }; + + # The marker is added to every set that was imported directly by + # readTree. + importWithMark = path: parts: + let imported = import path (argsWithPath parts); + in if (isAttrs imported) + then imported // { __readTree = true; } + else imported; + + nixFileName = file: + let res = match "(.*)\.nix" file; + in if res == null then null else head res; + + readTree = path: parts: + let + dir = readDir path; + self = importWithMark path parts; + joinChild = c: path + ("/" + c); + + # Import subdirectories of the current one, unless the special + # `.skip-subtree` file exists which makes readTree ignore the + # children. + # + # This file can optionally contain information on why the tree + # should be ignored, but its content is not inspected by + # readTree + filterDir = f: dir."${f}" == "directory"; + children = if hasAttr ".skip-subtree" dir then [] else map (c: { + name = c; + value = readTree (joinChild c) (parts ++ [ c ]); + }) (filter filterDir (attrNames dir)); + + # Import Nix files + nixFiles = filter (f: f != null) (map nixFileName (attrNames dir)); + nixChildren = map (c: let p = joinChild (c + ".nix"); in { + name = c; + value = importWithMark p (parts ++ [ c ]); + }) nixFiles; + in if dir ? "default.nix" + then (if isAttrs self then self // (listToAttrs children) else self) + else listToAttrs (nixChildren ++ children); +in readTree initPath [ (baseNameOf initPath) ] diff --git a/nix/tailscale/default.nix b/nix/tailscale/default.nix new file mode 100644 index 0000000000..a21af7d115 --- /dev/null +++ b/nix/tailscale/default.nix @@ -0,0 +1,30 @@ +# This file defines a Nix helper function to create Tailscale ACL files. +# +# https://tailscale.com/kb/1018/install-acls + +{ depot, ... }: + +with depot.nix.yants; + +let + inherit (builtins) toFile toJSON; + + acl = struct "acl" { + Action = enum [ "accept" "reject" ]; + Users = list string; + Ports = list string; + }; + + acls = list entry; + + aclConfig = struct "aclConfig" { + # Static group mappings from group names to lists of users + Groups = option (attrs (list string)); + + # Hostname aliases to use in place of IPs + Hosts = option (attrs string); + + # Actual ACL entries + ACLs = list acl; + }; +in config: toFile "tailscale-acl.json" (toJSON (aclConfig config)) diff --git a/nix/yants/README.md b/nix/yants/README.md new file mode 100644 index 0000000000..d17ea61b52 --- /dev/null +++ b/nix/yants/README.md @@ -0,0 +1,88 @@ +yants +===== + +This is a tiny type-checker for data in Nix, written in Nix. + +# Features + +* Checking of primitive types (`int`, `string` etc.) +* Checking polymorphic types (`option`, `list`, `either`) +* Defining & checking struct/record types +* Defining & matching enum types +* Defining & matching sum types +* Defining function signatures (including curried functions) +* Types are composable! `option string`! `list (either int (option float))`! +* Type errors also compose! + +Currently lacking: + +* Any kind of inference +* Convenient syntax for attribute-set function signatures + +## Primitives & simple polymorphism + +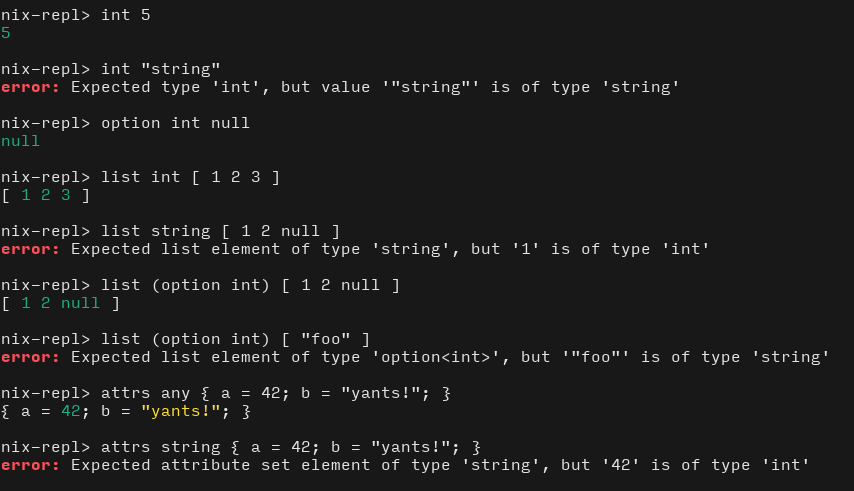 + +## Structs + +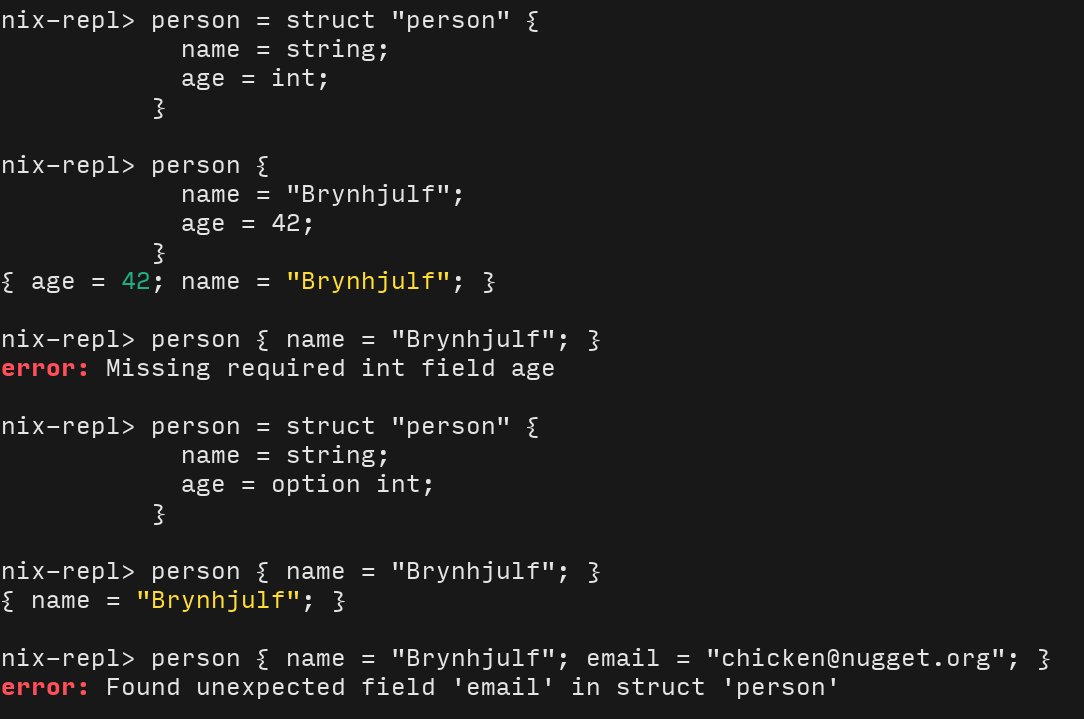 + +## Nested structs! + +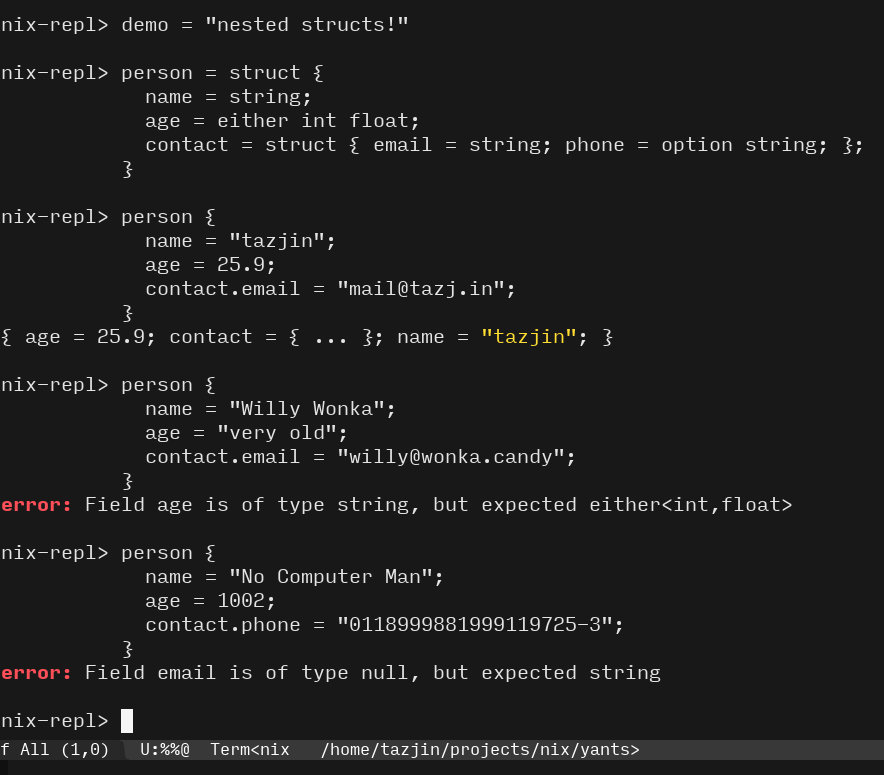 + +## Enums! + +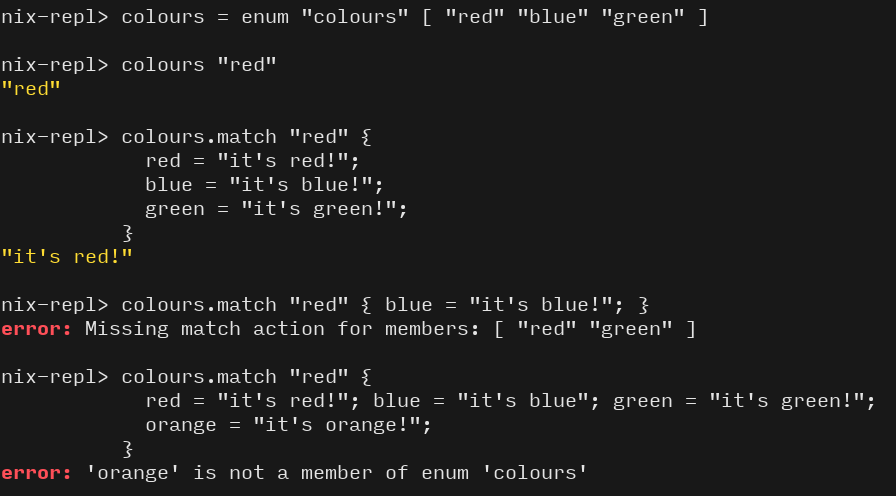 + +## Functions! + +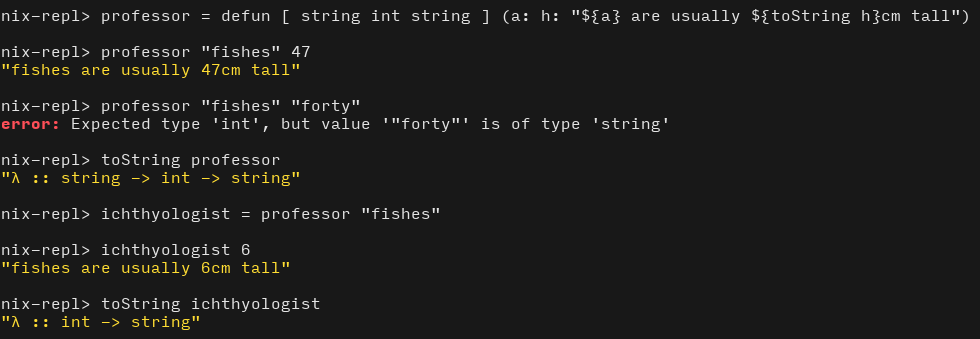 + +# Usage + +Yants can be imported from its `default.nix`. A single attribute (`lib`) can be +passed, which will otherwise be imported from `<nixpkgs>`. + +TIP: You do not need to clone my whole repository to use Yants! It is split out +into the `nix/yants` branch which you can clone with, for example, `git clone -b +nix/yants https://git.tazj.in yants`. + +Examples for the most common import methods would be: + +1. Import into scope with `with`: + ```nix + with (import ./default.nix {}); + # ... Nix code that uses yants ... + ``` + +2. Import as a named variable: + ```nix + let yants = import ./default.nix {}; + in yants.string "foo" # or other uses ... + ```` + +3. Overlay into `pkgs.lib`: + ```nix + # wherever you import your package set (e.g. from <nixpkgs>): + import <nixpkgs> { + overlays = [ + (self: super: { + lib = super.lib // { yants = import ./default.nix { inherit (super) lib; }; }; + }) + ]; + } + + # yants now lives at lib.yants, besides the other library functions! + ``` + +Please see my [Nix one-pager](https://github.com/tazjin/nix-1p) for more generic +information about the Nix language and what the above constructs mean. + +# Stability + +The current API of Yants is **not yet** considered stable, but it works fine and +should continue to do so even if used at an older version. + +Yants' tests use Nix versions above 2.2 - compatibility with older versions is +not guaranteed. diff --git a/nix/yants/default.nix b/nix/yants/default.nix new file mode 100644 index 0000000000..aacc156b43 --- /dev/null +++ b/nix/yants/default.nix @@ -0,0 +1,298 @@ +# Copyright 2019 Google LLC +# SPDX-License-Identifier: Apache-2.0 +# +# Provides a "type-system" for Nix that provides various primitive & +# polymorphic types as well as the ability to define & check records. +# +# All types (should) compose as expected. + +{ lib ? (import <nixpkgs> {}).lib, ... }: + +with builtins; let + prettyPrint = lib.generators.toPretty {}; + + # typedef' :: struct { + # name = string; + # checkType = function; (a -> result) + # checkToBool = option function; (result -> bool) + # toError = option function; (a -> result -> string) + # def = option any; + # match = option function; + # } -> type + # -> (a -> b) + # -> (b -> bool) + # -> (a -> b -> string) + # -> type + # + # This function creates an attribute set that acts as a type. + # + # It receives a type name, a function that is used to perform a + # check on an arbitrary value, a function that can translate the + # return of that check to a boolean that informs whether the value + # is type-conformant, and a function that can construct error + # messages from the check result. + # + # This function is the low-level primitive used to create types. For + # many cases the higher-level 'typedef' function is more appropriate. + typedef' = { name, checkType + , checkToBool ? (result: result.ok) + , toError ? (_: result: result.err) + , def ? null + , match ? null }: { + inherit name checkToBool toError; + + # check :: a -> bool + # + # This function is used to determine whether a given type is + # conformant. + check = value: checkToBool (checkType value); + + # checkType :: a -> struct { ok = bool; err = option string; } + # + # This function checks whether the passed value is type conformant + # and returns an optional type error string otherwise. + inherit checkType; + + # __functor :: a -> a + # + # This function checks whether the passed value is type conformant + # and throws an error if it is not. + # + # The name of this function is a special attribute in Nix that + # makes it possible to execute a type attribute set like a normal + # function. + __functor = self: value: + let result = self.checkType value; + in if checkToBool result then value + else throw (toError value result); + }; + + typeError = type: val: + "expected type '${type}', but value '${prettyPrint val}' is of type '${typeOf val}'"; + + # typedef :: string -> (a -> bool) -> type + # + # typedef is the simplified version of typedef' which uses a default + # error message constructor. + typedef = name: check: typedef' { + inherit name; + checkType = check; + checkToBool = r: r; + toError = value: _result: typeError name value; + }; + + checkEach = name: t: l: foldl' (acc: e: + let res = t.checkType e; + isT = t.checkToBool res; + in { + ok = acc.ok && isT; + err = if isT + then acc.err + else acc.err + "${prettyPrint e}: ${t.toError e res}\n"; + }) { ok = true; err = "expected type ${name}, but found:\n"; } l; +in lib.fix (self: { + # Primitive types + any = typedef "any" (_: true); + int = typedef "int" isInt; + bool = typedef "bool" isBool; + float = typedef "float" isFloat; + string = typedef "string" isString; + path = typedef "path" (x: typeOf x == "path"); + drv = typedef "derivation" (x: isAttrs x && x ? "type" && x.type == "derivation"); + function = typedef "function" (x: isFunction x || (isAttrs x && x ? "__functor" + && isFunction x.__functor)); + + # Type for types themselves. Useful when defining polymorphic types. + type = typedef "type" (x: + isAttrs x + && hasAttr "name" x && self.string.check x.name + && hasAttr "checkType" x && self.function.check x.checkType + && hasAttr "checkToBool" x && self.function.check x.checkToBool + && hasAttr "toError" x && self.function.check x.toError + ); + + # Polymorphic types + option = t: typedef' rec { + name = "option<${t.name}>"; + checkType = v: + let res = t.checkType v; + in { + ok = isNull v || (self.type t).checkToBool res; + err = "expected type ${name}, but value does not conform to '${t.name}': " + + t.toError v res; + }; + }; + + eitherN = tn: typedef "either<${concatStringsSep ", " (map (x: x.name) tn)}>" + (x: any (t: (self.type t).check x) tn); + + either = t1: t2: self.eitherN [ t1 t2 ]; + + list = t: typedef' rec { + name = "list<${t.name}>"; + + checkType = v: if isList v + then checkEach name (self.type t) v + else { + ok = false; + err = typeError name v; + }; + }; + + attrs = t: typedef' rec { + name = "attrs<${t.name}>"; + + checkType = v: if isAttrs v + then checkEach name (self.type t) (attrValues v) + else { + ok = false; + err = typeError name v; + }; + }; + + # Structs / record types + # + # Checks that all fields match their declared types, no optional + # fields are missing and no unexpected fields occur in the struct. + # + # Anonymous structs are supported (e.g. for nesting) by omitting the + # name. + # + # TODO: Support open records? + struct = + # Struct checking is more involved than the simpler types above. + # To make the actual type definition more readable, several + # helpers are defined below. + let + # checkField checks an individual field of the struct against + # its definition and creates a typecheck result. These results + # are aggregated during the actual checking. + checkField = def: name: value: let result = def.checkType value; in rec { + ok = def.checkToBool result; + err = if !ok && isNull value + then "missing required ${def.name} field '${name}'\n" + else "field '${name}': ${def.toError value result}\n"; + }; + + # checkExtraneous determines whether a (closed) struct contains + # any fields that are not part of the definition. + checkExtraneous = def: has: acc: + if (length has) == 0 then acc + else if (hasAttr (head has) def) + then checkExtraneous def (tail has) acc + else checkExtraneous def (tail has) { + ok = false; + err = acc.err + "unexpected struct field '${head has}'\n"; + }; + + # checkStruct combines all structure checks and creates one + # typecheck result from them + checkStruct = def: value: + let + init = { ok = true; err = ""; }; + extraneous = checkExtraneous def (attrNames value) init; + + checkedFields = map (n: + let v = if hasAttr n value then value."${n}" else null; + in checkField def."${n}" n v) (attrNames def); + + combined = foldl' (acc: res: { + ok = acc.ok && res.ok; + err = if !res.ok then acc.err + res.err else acc.err; + }) init checkedFields; + in { + ok = combined.ok && extraneous.ok; + err = combined.err + extraneous.err; + }; + + struct' = name: def: typedef' { + inherit name def; + checkType = value: if isAttrs value + then (checkStruct (self.attrs self.type def) value) + else { ok = false; err = typeError name value; }; + + toError = _: result: "expected '${name}'-struct, but found:\n" + result.err; + }; + in arg: if isString arg then (struct' arg) else (struct' "anon" arg); + + # Enums & pattern matching + enum = + let + plain = name: def: typedef' { + inherit name def; + + checkType = (x: isString x && elem x def); + checkToBool = x: x; + toError = value: _: "'${prettyPrint value} is not a member of enum ${name}"; + }; + enum' = name: def: lib.fix (e: (plain name def) // { + match = x: actions: deepSeq (map e (attrNames actions)) ( + let + actionKeys = attrNames actions; + missing = foldl' (m: k: if (elem k actionKeys) then m else m ++ [ k ]) [] def; + in if (length missing) > 0 + then throw "Missing match action for members: ${prettyPrint missing}" + else actions."${e x}"); + }); + in arg: if isString arg then (enum' arg) else (enum' "anon" arg); + + # Sum types + # + # The representation of a sum type is an attribute set with only one + # value, where the key of the value denotes the variant of the type. + sum = + let + plain = name: def: typedef' { + inherit name def; + checkType = (x: + let variant = elemAt (attrNames x) 0; + in if isAttrs x && length (attrNames x) == 1 && hasAttr variant def + then let t = def."${variant}"; + v = x."${variant}"; + res = t.checkType v; + in if t.checkToBool res + then { ok = true; } + else { + ok = false; + err = "while checking '${name}' variant '${variant}': " + + t.toError v res; + } + else { ok = false; err = typeError name x; } + ); + }; + sum' = name: def: lib.fix (s: (plain name def) // { + match = x: actions: + let variant = deepSeq (s x) (elemAt (attrNames x) 0); + actionKeys = attrNames actions; + defKeys = attrNames def; + missing = foldl' (m: k: if (elem k actionKeys) then m else m ++ [ k ]) [] defKeys; + in if (length missing) > 0 + then throw "Missing match action for variants: ${prettyPrint missing}" + else actions."${variant}" x."${variant}"; + }); + in arg: if isString arg then (sum' arg) else (sum' "anon" arg); + + # Typed function definitions + # + # These definitions wrap the supplied function in type-checking + # forms that are evaluated when the function is called. + # + # Note that typed functions themselves are not types and can not be + # used to check values for conformity. + defun = + let + mkFunc = sig: f: { + inherit sig; + __toString = self: foldl' (s: t: "${s} -> ${t.name}") + "λ :: ${(head self.sig).name}" (tail self.sig); + __functor = _: f; + }; + + defun' = sig: func: if length sig > 2 + then mkFunc sig (x: defun' (tail sig) (func ((head sig) x))) + else mkFunc sig (x: ((head (tail sig)) (func ((head sig) x)))); + + in sig: func: if length sig < 2 + then (throw "Signature must at least have two types (a -> b)") + else defun' sig func; +}) diff --git a/nix/yants/screenshots/enums.png b/nix/yants/screenshots/enums.png new file mode 100644 index 0000000000..71673e7ab6 --- /dev/null +++ b/nix/yants/screenshots/enums.png Binary files differdiff --git a/nix/yants/screenshots/functions.png b/nix/yants/screenshots/functions.png new file mode 100644 index 0000000000..30ed50f832 --- /dev/null +++ b/nix/yants/screenshots/functions.png Binary files differdiff --git a/nix/yants/screenshots/nested-structs.png b/nix/yants/screenshots/nested-structs.png new file mode 100644 index 0000000000..6b03ed65ce --- /dev/null +++ b/nix/yants/screenshots/nested-structs.png Binary files differdiff --git a/nix/yants/screenshots/simple.png b/nix/yants/screenshots/simple.png new file mode 100644 index 0000000000..05a302cc6b --- /dev/null +++ b/nix/yants/screenshots/simple.png Binary files differdiff --git a/nix/yants/screenshots/structs.png b/nix/yants/screenshots/structs.png new file mode 100644 index 0000000000..fcbcf6415f --- /dev/null +++ b/nix/yants/screenshots/structs.png Binary files differdiff --git a/nix/yants/tests/default.nix b/nix/yants/tests/default.nix new file mode 100644 index 0000000000..b006f8b832 --- /dev/null +++ b/nix/yants/tests/default.nix @@ -0,0 +1,94 @@ +{ depot, pkgs, ... }: + +with builtins; +with depot.nix.yants; + +# Note: Derivations are not included in the tests below as they cause +# issues with deepSeq. + +deepSeq rec { + # Test that all primitive types match + primitives = [ + (int 15) + (bool false) + (float 13.37) + (string "Hello!") + (function (x: x * 2)) + (path /nix) + ]; + + # Test that polymorphic types work as intended + poly = [ + (option int null) + (list string [ "foo" "bar" ]) + (either int float 42) + ]; + + # Test that structures work as planned. + person = struct "person" { + name = string; + age = int; + + contact = option (struct { + email = string; + phone = option string; + }); + }; + + testPerson = person { + name = "Brynhjulf"; + age = 42; + contact.email = "brynhjulf@yants.nix"; + }; + + # Test enum definitions & matching + colour = enum "colour" [ "red" "blue" "green" ]; + testMatch = colour.match "red" { + red = "It is in fact red!"; + blue = throw "It should not be blue!"; + green = throw "It should not be green!"; + }; + + # Test sum type definitions + creature = sum "creature" { + human = struct { + name = string; + age = option int; + }; + + pet = enum "pet" [ "dog" "lizard" "cat" ]; + }; + + testSum = creature { + human = { + name = "Brynhjulf"; + age = 42; + }; + }; + + testSumMatch = creature.match testSum { + human = v: "It's a human named ${v.name}"; + pet = v: throw "It's not supposed to be a pet!"; + }; + + # Test curried function definitions + func = defun [ string int string ] + (name: age: "${name} is ${toString age} years old"); + + testFunc = func "Brynhjulf" 42; + + # Test that all types are types. + testTypes = map type [ + any bool drv float int string path + + (attrs int) + (eitherN [ int string bool ]) + (either int string) + (enum [ "foo" "bar" ]) + (list string) + (option int) + (option (list string)) + (struct { a = int; b = option string; }) + (sum { a = int; b = option string; }) + ]; +} (pkgs.writeText "yants-tests" "All tests passed!") diff --git a/ops/besadii/default.nix b/ops/besadii/default.nix new file mode 100644 index 0000000000..31f2705d73 --- /dev/null +++ b/ops/besadii/default.nix @@ -0,0 +1,12 @@ +# This program is used as a git post-update hook to trigger builds on +# sourcehut. +{ depot, ... }: + +depot.buildGo.program { + name = "besadii"; + srcs = [ ./main.go ]; + + x_defs = { + "main.gitBin" = "${depot.third_party.git}/bin/git"; + }; +} diff --git a/ops/besadii/main.go b/ops/besadii/main.go new file mode 100644 index 0000000000..72bba769f5 --- /dev/null +++ b/ops/besadii/main.go @@ -0,0 +1,203 @@ +// Copyright 2019 Google LLC. +// SPDX-License-Identifier: Apache-2.0 +// +// besadii is a small CLI tool that triggers depot builds on +// builds.sr.ht +// +// It is designed to run as a post-update git hook on the server +// hosting the depot. +package main + +import ( + "bufio" + "bytes" + "encoding/json" + "fmt" + "io/ioutil" + "log/syslog" + "net/http" + "os" + "os/exec" + "strings" +) + +var gitBin = "git" +var branchPrefix = "refs/heads/" + +// This value is set by the git hook invocation when a branch is +// removed, builds should not be triggered in that case. +var deletedBranch = "0000000000000000000000000000000000000000" + +// Represents an updated reference as passed to besadii by git +// +// https://git-scm.com/docs/githooks#pre-receive +type refUpdate struct { + name string + old string + new string +} + +// Represents a builds.sr.ht build object as described on +// https://man.sr.ht/builds.sr.ht/api.md +type Build struct { + Manifest string `json:"manifest"` + Note string `json:"note"` + Tags []string `json:"tags"` +} + +// Represents a build trigger object as described on <the docs for +// this are currently down> +type Trigger struct { + Action string `json:"action"` + Condition string `json:"condition"` + To string `json:"to"` +} + +// Represents a build manifest for sourcehut. +type Manifest struct { + Image string `json:"image"` + Sources []string `json:"sources"` + Secrets []string `json:"secrets"` + Tasks [](map[string]string) `json:"tasks"` + Triggers []Trigger `json:"triggers"` +} + +func prepareManifest(commit string) string { + m := Manifest{ + Image: "nixos/latest", + Sources: []string{"https://git.tazj.in/"}, + + // secret for cachix/tazjin + Secrets: []string{"f7f02546-4d95-44f7-a98e-d61fdded8b5b"}, + + Tasks: [](map[string]string){ + {"setup": `# sourcehut does not censor secrets in builds, hence this hack: +echo -n 'export CACHIX_SIGNING_KEY=' >> ~/.buildenv +cat ~/.cachix-tazjin >> ~/.buildenv +nix-env -iA third_party.cachix -f git.tazj.in +cachix use tazjin +cd git.tazj.in +git checkout ` + commit}, + + {"build": `cd git.tazj.in +nix-build ci-builds.nix > built-paths`}, + + {"cache": `cd git.tazj.in +cat built-paths | cachix push tazjin`}, + }, + + Triggers: []Trigger{ + Trigger{Action: "email", Condition: "failure", To: "mail@tazj.in"}, + }, + } + + j, _ := json.Marshal(m) + return string(j) +} + +// Trigger a build of a given branch & commit on builds.sr.ht +func triggerBuild(log *syslog.Writer, token, branch, commit string) { + build := Build{ + Manifest: prepareManifest(commit), + Note: fmt.Sprintf("Build of '%s' at '%s'", branch, commit), + Tags: []string{ + // my branch names tend to contain slashes, which are not valid + // identifiers in sourcehut. + "depot", strings.ReplaceAll(branch, "/", "_"), + }, + } + + body, _ := json.Marshal(build) + reader := ioutil.NopCloser(bytes.NewReader(body)) + + req, err := http.NewRequest("POST", "https://builds.sr.ht/api/jobs", reader) + if err != nil { + log.Err(fmt.Sprintf("failed to create an HTTP request: %s", err)) + os.Exit(1) + } + + req.Header.Add("Authorization", "token "+token) + req.Header.Add("Content-Type", "application/json") + + resp, err := http.DefaultClient.Do(req) + if err != nil { + // This might indicate a temporary error on the sourcehut side, do + // not fail the whole program. + log.Err(fmt.Sprintf("failed to send builds.sr.ht request:", err)) + return + } + defer resp.Body.Close() + + if resp.StatusCode != 200 { + respBody, _ := ioutil.ReadAll(resp.Body) + log.Err(fmt.Sprintf("received non-success response from builds.sr.ht: %s (%v)", respBody, resp.Status)) + } else { + fmt.Fprintf(log, "triggered builds.sr.ht job for branch '%s' at commit '%s'", branch, commit) + } +} + +func parseRefUpdates() ([]refUpdate, error) { + var updates []refUpdate + + scanner := bufio.NewScanner(os.Stdin) + for scanner.Scan() { + line := scanner.Text() + fragments := strings.Split(line, " ") + + if len(fragments) != 3 { + return nil, fmt.Errorf("invalid ref update: '%s'", line) + } + + update := refUpdate{ + old: fragments[0], + new: fragments[1], + name: fragments[2], + } + + if strings.HasPrefix(update.name, branchPrefix) && update.new != deletedBranch { + update.name = strings.TrimPrefix(update.name, branchPrefix) + updates = append(updates, update) + } + } + + if err := scanner.Err(); err != nil { + return nil, err + } + + return updates, nil +} + +func main() { + log, err := syslog.New(syslog.LOG_INFO|syslog.LOG_USER, "besadii") + if err != nil { + fmt.Printf("failed to open syslog: %s\n", err) + os.Exit(1) + } + + // Before triggering builds, it is important that git + // update-server-info is run so that cgit correctly serves the + // repository. + err = exec.Command(gitBin, "update-server-info").Run() + if err != nil { + log.Alert("failed to run 'git update-server-info' for depot!") + os.Exit(1) + } + + token, err := ioutil.ReadFile("/etc/secrets/srht-token") + if err != nil { + log.Alert("sourcehot token could not be read") + os.Exit(1) + } + + updates, err := parseRefUpdates() + if err != nil { + log.Err(fmt.Sprintf("could not parse updated refs:", err)) + os.Exit(1) + } + + fmt.Fprintf(log, "triggering builds for %v refs", len(updates)) + + for _, update := range updates { + triggerBuild(log, string(token), update.name, update.new) + } +} diff --git a/ops/infra/.skip-subtree b/ops/infra/.skip-subtree new file mode 100644 index 0000000000..cee24b7579 --- /dev/null +++ b/ops/infra/.skip-subtree @@ -0,0 +1,2 @@ +Code under //ops/infra is mostly configuration for other tools, not +Nix derivations to be built. diff --git a/ops/infra/dns/import b/ops/infra/dns/import new file mode 100755 index 0000000000..e79e426b55 --- /dev/null +++ b/ops/infra/dns/import @@ -0,0 +1,11 @@ +#!/bin/sh +set -ue + +# Imports a zone file into a Google Cloud DNS zone of the same name +readonly ZONE="${1}" + +gcloud dns record-sets import "${ZONE}" \ + --project composite-watch-759 \ + --zone-file-format \ + --delete-all-existing \ + --zone "${ZONE}" diff --git a/ops/infra/dns/kontemplate-works b/ops/infra/dns/kontemplate-works new file mode 100644 index 0000000000..326a129d21 --- /dev/null +++ b/ops/infra/dns/kontemplate-works @@ -0,0 +1,15 @@ +;; -*- mode: zone; -*- +;; Do not delete these +kontemplate.works. 21600 IN NS ns-cloud-d1.googledomains.com. +kontemplate.works. 21600 IN NS ns-cloud-d2.googledomains.com. +kontemplate.works. 21600 IN NS ns-cloud-d3.googledomains.com. +kontemplate.works. 21600 IN NS ns-cloud-d4.googledomains.com. +kontemplate.works. 21600 IN SOA ns-cloud-d1.googledomains.com. cloud-dns-hostmaster.google.com. 4 21600 3600 259200 300 + +;; Github site setup +kontemplate.works. 60 IN A 185.199.108.153 +kontemplate.works. 60 IN A 185.199.109.153 +kontemplate.works. 60 IN A 185.199.110.153 +kontemplate.works. 60 IN A 185.199.111.153 + +www.kontemplate.works. 60 IN CNAME tazjin.github.io. diff --git a/ops/infra/dns/oslo-pub b/ops/infra/dns/oslo-pub new file mode 100644 index 0000000000..674687484b --- /dev/null +++ b/ops/infra/dns/oslo-pub @@ -0,0 +1,8 @@ +;; Do not delete these +oslo.pub. 21600 IN NS ns-cloud-c1.googledomains.com. +oslo.pub. 21600 IN NS ns-cloud-c2.googledomains.com. +oslo.pub. 21600 IN NS ns-cloud-c3.googledomains.com. +oslo.pub. 21600 IN NS ns-cloud-c4.googledomains.com. +oslo.pub. 21600 IN SOA ns-cloud-c1.googledomains.com. cloud-dns-hostmaster.google.com. 4 21600 3600 1209600 300 + +oslo.pub. 60 IN A 46.21.106.241 diff --git a/ops/infra/dns/root-tazj-in b/ops/infra/dns/root-tazj-in new file mode 100644 index 0000000000..43db5834a0 --- /dev/null +++ b/ops/infra/dns/root-tazj-in @@ -0,0 +1,33 @@ +;; -*- mode: zone; -*- +;; Do not delete these +tazj.in. 21600 IN NS ns-cloud-a1.googledomains.com. +tazj.in. 21600 IN NS ns-cloud-a2.googledomains.com. +tazj.in. 21600 IN NS ns-cloud-a3.googledomains.com. +tazj.in. 21600 IN NS ns-cloud-a4.googledomains.com. +tazj.in. 21600 IN SOA ns-cloud-a1.googledomains.com. cloud-dns-hostmaster.google.com. 123 21600 3600 1209600 300 + +;; Email setup +tazj.in. 300 IN MX 1 aspmx.l.google.com. +tazj.in. 300 IN MX 5 alt1.aspmx.l.google.com. +tazj.in. 300 IN MX 5 alt2.aspmx.l.google.com. +tazj.in. 300 IN MX 10 alt3.aspmx.l.google.com. +tazj.in. 300 IN MX 10 alt4.aspmx.l.google.com. +tazj.in. 300 IN TXT "v=spf1 include:_spf.google.com ~all" +google._domainkey.tazj.in. 21600 IN TXT "v=DKIM1; k=rsa; p=MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA9AphX/WJf8zVXQB5Jk0Ry1MI6ARa6vEyAoJtpjpt9Nbm7XU4qVWFRJm+L0VFd5EZ5YDPJTIZ90lJE3/B8vae2ipnoGbJbj8LaVSzzIPMbWmhPhX3fkLJFdkv7xRDMDn730iYXRlfkgv6GsqbS8vZt7mzxx4mpnePTI323yjRVkwRW8nGVbsmB25ZoG1/0985" "kg4mSYxzWeJ2ozCPFhT4sfMtZMXe/4QEkJz/zkod29KZfFJmLgEaf73WLdBX8kdwbhuh2PYXt/PwzUrRzF5ujVCsSaTZwdRVPErcf+yo4NvedelTjjs8rFVfoJiaDD1q2bQ3w0gDEBWPdC2VP7k9zwIDAQAB" + +;; Site verifications +tazj.in. 3600 IN TXT "keybase-site-verification=gC4kzEmnLzY7F669PjN-pw2Cf__xHqcxQ08Gb-W9dhE" +tazj.in. 300 IN TXT "google-site-verification=d3_MI1OwD6q2OT42Vvh0I9w2u3Q5KFBu-PieNUE1Fig" +www.tazj.in. 3600 IN TXT "keybase-site-verification=ER8m_byyqAhzeIy9TyzkAU1H2p2yHtpvImuB_XrRF2U" + +;; Blog "storage engine" +blog.tazj.in. 21600 IN NS ns-cloud-c1.googledomains.com. +blog.tazj.in. 21600 IN NS ns-cloud-c2.googledomains.com. +blog.tazj.in. 21600 IN NS ns-cloud-c3.googledomains.com. +blog.tazj.in. 21600 IN NS ns-cloud-c4.googledomains.com. + +;; Webpage records setup +tazj.in. 300 IN A 34.98.120.189 +www.tazj.in. 300 IN A 34.98.120.189 +git.tazj.in. 300 IN A 34.98.120.189 +files.tazj.in. 300 IN CNAME c.storage.googleapis.com. diff --git a/ops/infra/gcp/.gitignore b/ops/infra/gcp/.gitignore new file mode 100644 index 0000000000..96c7538dda --- /dev/null +++ b/ops/infra/gcp/.gitignore @@ -0,0 +1,3 @@ +.terraform +*.tfstate +*.tfstate.backup diff --git a/ops/infra/gcp/default.tf b/ops/infra/gcp/default.tf new file mode 100644 index 0000000000..d2e31090b5 --- /dev/null +++ b/ops/infra/gcp/default.tf @@ -0,0 +1,116 @@ +# Terraform configuration for the GCP project 'tazjins-infrastructure' + +provider "google" { + project = "tazjins-infrastructure" + region = "europe-north1" + version = "~> 2.20" +} + +# Configure a storage bucket in which to keep Terraform state and +# other data, such as Nixery's layers. +resource "google_storage_bucket" "tazjins-data" { + name = "tazjins-data" + location = "EU" +} + +terraform { + backend "gcs" { + bucket = "tazjins-data" + prefix = "terraform" + } +} + +# Configure enabled APIs +resource "google_project_services" "primary" { + project = "tazjins-infrastructure" + services = [ + "bigquery-json.googleapis.com", + "bigquerystorage.googleapis.com", + "cloudapis.googleapis.com", + "cloudbuild.googleapis.com", + "clouddebugger.googleapis.com", + "cloudfunctions.googleapis.com", + "cloudkms.googleapis.com", + "cloudtrace.googleapis.com", + "compute.googleapis.com", + "container.googleapis.com", + "containerregistry.googleapis.com", + "datastore.googleapis.com", + "distance-matrix-backend.googleapis.com", + "dns.googleapis.com", + "gmail.googleapis.com", + "iam.googleapis.com", + "iamcredentials.googleapis.com", + "logging.googleapis.com", + "monitoring.googleapis.com", + "oslogin.googleapis.com", + "pubsub.googleapis.com", + "run.googleapis.com", + "secretmanager.googleapis.com", + "servicemanagement.googleapis.com", + "serviceusage.googleapis.com", + "sourcerepo.googleapis.com", + "sql-component.googleapis.com", + "storage-api.googleapis.com", + "storage-component.googleapis.com", + ] +} + + +# Configure the main Kubernetes cluster in which services are deployed +resource "google_container_cluster" "primary" { + name = "tazjin-cluster" + location = "europe-north1" + + remove_default_node_pool = true + initial_node_count = 1 +} + +resource "google_container_node_pool" "primary_nodes" { + name = "primary-nodes" + location = "europe-north1" + cluster = google_container_cluster.primary.name + node_count = 1 + + node_config { + preemptible = true + machine_type = "n1-standard-2" + + oauth_scopes = [ + "storage-rw", + "logging-write", + "monitoring", + "https://www.googleapis.com/auth/source.read_only", + ] + } +} + +# Configure a service account for which GCS URL signing keys can be created. +resource "google_service_account" "nixery" { + account_id = "nixery" + display_name = "Nixery service account" +} + +# Configure Cloud KMS for secret encryption +resource "google_kms_key_ring" "tazjins_keys" { + name = "tazjins-keys" + location = "europe-north1" + + lifecycle { + prevent_destroy = true + } +} + +resource "google_kms_crypto_key" "kontemplate_key" { + name = "kontemplate-key" + key_ring = google_kms_key_ring.tazjins_keys.id + + lifecycle { + prevent_destroy = true + } +} + +# Configure the git repository that contains everything. +resource "google_sourcerepo_repository" "depot" { + name = "depot" +} diff --git a/ops/infra/kubernetes/cgit/config.yaml b/ops/infra/kubernetes/cgit/config.yaml new file mode 100644 index 0000000000..73392adaad --- /dev/null +++ b/ops/infra/kubernetes/cgit/config.yaml @@ -0,0 +1,80 @@ +--- +apiVersion: v1 +kind: Secret +metadata: + name: gcsr-secrets +type: Opaque +data: + username: "Z2l0LXRhemppbi5nbWFpbC5jb20=" + # This credential is a GCSR 'gitcookie' token. + password: '{{ passLookup "gcsr-tazjin-password" | b64enc }}' + # This credential is an OAuth token for builds.sr.ht + sourcehut: '{{ passLookup "sr.ht-token" | b64enc }}' +--- +apiVersion: apps/v1 +kind: Deployment +metadata: + name: cgit + labels: + app: cgit +spec: + replicas: 1 + selector: + matchLabels: + app: cgit + template: + metadata: + labels: + app: cgit + spec: + securityContext: + runAsUser: 1000 + runAsGroup: 1000 + fsGroup: 1000 + containers: + - name: cgit + image: nixery.local/shell/web.cgit-taz:{{ gitHEAD }} + command: [ "cgit-launch" ] + env: + - name: HOME + value: /git + volumeMounts: + - name: git-volume + mountPath: /git + - name: sync-gcsr + image: nixery.local/shell/ops.sync-gcsr:{{ gitHEAD }} + command: [ "sync-gcsr" ] + env: + - name: SYNC_USER + valueFrom: + secretKeyRef: + name: gcsr-secrets + key: username + - name: SYNC_PASS + valueFrom: + secretKeyRef: + name: gcsr-secrets + key: password + - name: SRHT_TOKEN + valueFrom: + secretKeyRef: + name: gcsr-secrets + key: sourcehut + volumeMounts: + - name: git-volume + mountPath: /git + volumes: + - name: git-volume + emptyDir: {} +--- +apiVersion: v1 +kind: Service +metadata: + name: cgit +spec: + selector: + app: cgit + ports: + - protocol: TCP + port: 80 + targetPort: 8080 diff --git a/ops/infra/kubernetes/gemma/config.lisp b/ops/infra/kubernetes/gemma/config.lisp new file mode 100644 index 0000000000..517a658cf1 --- /dev/null +++ b/ops/infra/kubernetes/gemma/config.lisp @@ -0,0 +1,19 @@ +(config :port 4242 + :data-dir "/var/lib/gemma/") + +(deftask bathroom/wipe-mirror 7) +(deftask bathroom/wipe-counter 7) + +;; Bedroom tasks +(deftask bedroom/change-sheets 7) +(deftask bedroom/vacuum 10) + +;; Kitchen tasks +(deftask kitchen/normal-trash 3) +(deftask kitchen/green-trash 5) +(deftask kitchen/blue-trash 5) +(deftask kitchen/wipe-counters 3) +(deftask kitchen/vacuum 5 "Kitchen has more crumbs and such!") + +;; Entire place +(deftask clean-windows 60) diff --git a/ops/infra/kubernetes/https-cert/cert.yaml b/ops/infra/kubernetes/https-cert/cert.yaml new file mode 100644 index 0000000000..c7a85275ae --- /dev/null +++ b/ops/infra/kubernetes/https-cert/cert.yaml @@ -0,0 +1,8 @@ +--- +apiVersion: networking.gke.io/v1beta1 +kind: ManagedCertificate +metadata: + name: {{ .domain | replace "." "-" }} +spec: + domains: + - {{ .domain }} diff --git a/ops/infra/kubernetes/https-lb/ingress.yaml b/ops/infra/kubernetes/https-lb/ingress.yaml new file mode 100644 index 0000000000..930affec7a --- /dev/null +++ b/ops/infra/kubernetes/https-lb/ingress.yaml @@ -0,0 +1,43 @@ +# This resource configures the HTTPS load balancer that is used as the +# entrypoint to all HTTPS services running in the cluster. +--- +apiVersion: extensions/v1beta1 +kind: Ingress +metadata: + name: https-ingress + annotations: + networking.gke.io/managed-certificates: tazj-in, git-tazj-in, www-tazj-in, oslo-pub +spec: + rules: + # Route website to, well, the website ... + - host: tazj.in + http: + paths: + - path: /* + backend: + serviceName: website + servicePort: 8080 + # Same for www.* (the redirect is handled by the website nginx) + - host: www.tazj.in + http: + paths: + - path: /* + backend: + serviceName: website + servicePort: 8080 + # Route git.tazj.in to the cgit pods + - host: git.tazj.in + http: + paths: + - path: /* + backend: + serviceName: nginx + servicePort: 6756 + # Route oslo.pub to the nginx instance which serves redirects + - host: oslo.pub + http: + paths: + - path: / + backend: + serviceName: nginx + servicePort: 6756 diff --git a/ops/infra/kubernetes/nginx/nginx.conf b/ops/infra/kubernetes/nginx/nginx.conf new file mode 100644 index 0000000000..918aa60678 --- /dev/null +++ b/ops/infra/kubernetes/nginx/nginx.conf @@ -0,0 +1,59 @@ +daemon off; +worker_processes 1; +error_log stderr; +pid /run/nginx.pid; + +events { + worker_connections 1024; +} + +http { + log_format json_combined escape=json + '{' + '"time_local":"$time_local",' + '"remote_addr":"$remote_addr",' + '"remote_user":"$remote_user",' + '"request":"$request",' + '"status": "$status",' + '"body_bytes_sent":"$body_bytes_sent",' + '"request_time":"$request_time",' + '"http_referrer":"$http_referer",' + '"http_user_agent":"$http_user_agent"' + '}'; + + access_log /dev/stdout json_combined; + + sendfile on; + keepalive_timeout 65; + + server { + listen 80 default_server; + location / { + return 200 "ok"; + } + } + + server { + listen 80; + server_name oslo.pub; + + location / { + return 302 https://www.google.com/maps/d/viewer?mid=1pJIYY9cuEdt9DuMTbb4etBVq7hs; + } + } + + server { + listen 80; + server_name git.tazj.in; + + # Static assets must always hit the root. + location ~ ^/(favicon\.ico|cgit\.(css|png))$ { + proxy_pass http://cgit; + } + + # Everything else hits the depot directly. + location / { + proxy_pass http://cgit/cgit.cgi/depot/; + } + } +} diff --git a/ops/infra/kubernetes/nginx/nginx.yaml b/ops/infra/kubernetes/nginx/nginx.yaml new file mode 100644 index 0000000000..61678a85bc --- /dev/null +++ b/ops/infra/kubernetes/nginx/nginx.yaml @@ -0,0 +1,60 @@ +# Deploy an nginx instance which serves ... redirects. +--- +apiVersion: v1 +kind: ConfigMap +metadata: + name: nginx-conf +data: + nginx.conf: {{ insertFile "nginx.conf" | toJson }} +--- +apiVersion: apps/v1 +kind: Deployment +metadata: + name: nginx + labels: + app: nginx +spec: + replicas: 2 + selector: + matchLabels: + app: nginx + template: + metadata: + labels: + app: nginx + config: {{ insertFile "nginx.conf" | sha1sum }} + spec: + containers: + - name: nginx + image: nixery.local/shell/third_party.nginx:{{ .version }} + command: ["/bin/bash", "-c"] + args: + - | + cd /run + echo 'nogroup:x:30000:nobody' >> /etc/group + echo 'nobody:x:30000:30000:nobody:/tmp:/bin/bash' >> /etc/passwd + exec nginx -c /etc/nginx/nginx.conf + volumeMounts: + - name: nginx-conf + mountPath: /etc/nginx + - name: nginx-rundir + mountPath: /run + volumes: + - name: nginx-conf + configMap: + name: nginx-conf + - name: nginx-rundir + emptyDir: {} +--- +apiVersion: v1 +kind: Service +metadata: + name: nginx +spec: + type: NodePort + selector: + app: nginx + ports: + - protocol: TCP + port: 6756 + targetPort: 80 diff --git a/ops/infra/kubernetes/nixery/config.yaml b/ops/infra/kubernetes/nixery/config.yaml new file mode 100644 index 0000000000..0775e79b58 --- /dev/null +++ b/ops/infra/kubernetes/nixery/config.yaml @@ -0,0 +1,67 @@ +# Deploys an instance of Nixery into the cluster. +# +# The service via which Nixery is exposed has a private DNS entry +# pointing to it, which makes it possible to resolve `nixery.local` +# in-cluster without things getting nasty. +--- +apiVersion: apps/v1 +kind: Deployment +metadata: + name: nixery + namespace: kube-public + labels: + app: nixery +spec: + replicas: 1 + selector: + matchLabels: + app: nixery + template: + metadata: + labels: + app: nixery + spec: + containers: + - name: nixery + image: eu.gcr.io/tazjins-infrastructure/nixery:{{ .version }} + volumeMounts: + - name: nixery-secrets + mountPath: /var/nixery + env: + - name: BUCKET + value: {{ .bucket}} + - name: PORT + value: "{{ .port }}" + - name: GOOGLE_APPLICATION_CREDENTIALS + value: /var/nixery/gcs-key.json + - name: GCS_SIGNING_KEY + value: /var/nixery/gcs-key.pem + - name: GCS_SIGNING_ACCOUNT + value: {{ .account }} + - name: GIT_SSH_COMMAND + value: 'ssh -F /var/nixery/ssh_config' + - name: NIXERY_PKGS_REPO + value: {{ .repo }} + - name: NIX_POPULARITY_URL + value: 'https://storage.googleapis.com/nixery-layers/popularity/{{ .popularity }}' + volumes: + - name: nixery-secrets + secret: + secretName: nixery-secrets + defaultMode: 256 +--- +apiVersion: v1 +kind: Service +metadata: + name: nixery + namespace: kube-public + annotations: + cloud.google.com/load-balancer-type: "Internal" +spec: + selector: + app: nixery + type: LoadBalancer + ports: + - protocol: TCP + port: 80 + targetPort: 8080 diff --git a/ops/infra/kubernetes/nixery/id_nixery.pub b/ops/infra/kubernetes/nixery/id_nixery.pub new file mode 100644 index 0000000000..dc3fd617d0 --- /dev/null +++ b/ops/infra/kubernetes/nixery/id_nixery.pub @@ -0,0 +1 @@ +ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCzBM6ydst77jDHNcTFWKD9Fw4SReqyNEEp2MtQBk2wt94U4yLp8MQIuNeOEn1GaDEX4RGCxqai/2UVF1w9ZNdU+v2fXcKWfkKuGQH2XcNfXor2cVNObd40H78++iZiv3nmM/NaEdkTbTBbi925cRy9u5FgItDgsJlyKNRglCb0fr6KlgpvWjL20dp/eeZ8a/gLniHK8PnEsgERQSvJnsyFpxxVhxtoUiyLWpXDl4npf/rQr0eRDf4Q5sN/nbTwksapPHfze8dKcaoA7A2NqT3bJ6DPGrwVCzGRtGw/SXJwFwmmtAl9O6BklpeReyiknSxc+KOtrjDW6O0r6yvymD5Z nixery diff --git a/ops/infra/kubernetes/nixery/known_hosts b/ops/infra/kubernetes/nixery/known_hosts new file mode 100644 index 0000000000..7faf21f69b --- /dev/null +++ b/ops/infra/kubernetes/nixery/known_hosts @@ -0,0 +1,3 @@ +github.com ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAq2A7hRGmdnm9tUDbO9IDSwBK6TbQa+PXYPCPy6rbTrTtw7PHkccKrpp0yVhp5HdEIcKr6pLlVDBfOLX9QUsyCOV0wzfjIJNlGEYsdlLJizHhbn2mUjvSAHQqZETYP81eFzLQNnPHt4EVVUh7VfDESU84KezmD5QlWpXLmvU31/yMf+Se8xhHTvKSCZIFImWwoG6mbUoWf9nzpIoaSjB+weqqUUmpaaasXVal72J+UX2B+2RPW3RcT0eOzQgqlJL3RKrTJvdsjE3JEAvGq3lGHSZXy28G3skua2SmVi/w4yCE6gbODqnTWlg7+wC604ydGXA8VJiS5ap43JXiUFFAaQ== +140.82.118.4 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAq2A7hRGmdnm9tUDbO9IDSwBK6TbQa+PXYPCPy6rbTrTtw7PHkccKrpp0yVhp5HdEIcKr6pLlVDBfOLX9QUsyCOV0wzfjIJNlGEYsdlLJizHhbn2mUjvSAHQqZETYP81eFzLQNnPHt4EVVUh7VfDESU84KezmD5QlWpXLmvU31/yMf+Se8xhHTvKSCZIFImWwoG6mbUoWf9nzpIoaSjB+weqqUUmpaaasXVal72J+UX2B+2RPW3RcT0eOzQgqlJL3RKrTJvdsjE3JEAvGq3lGHSZXy28G3skua2SmVi/w4yCE6gbODqnTWlg7+wC604ydGXA8VJiS5ap43JXiUFFAaQ== +[source.developers.google.com]:2022,[172.253.120.82]:2022 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBB5Iy4/cq/gt/fPqe3uyMy4jwv1Alc94yVPxmnwNhBzJqEV5gRPiRk5u4/JJMbbu9QUVAguBABxL7sBZa5PH/xY= diff --git a/ops/infra/kubernetes/nixery/secrets.yaml b/ops/infra/kubernetes/nixery/secrets.yaml new file mode 100644 index 0000000000..d9a674d2c9 --- /dev/null +++ b/ops/infra/kubernetes/nixery/secrets.yaml @@ -0,0 +1,18 @@ +# The secrets below are encrypted using keys stored in Cloud KMS and +# templated in by kontemplate when deploying. +# +# Not all of the values are actually secret (see the matching) +--- +apiVersion: v1 +kind: Secret +metadata: + name: nixery-secrets + namespace: kube-public +type: Opaque +data: + gcs-key.json: {{ passLookup "nixery-gcs-json" | b64enc }} + gcs-key.pem: {{ passLookup "nixery-gcs-pem" | b64enc }} + id_nixery: {{ printf "%s\n" (passLookup "nixery-ssh-private") | b64enc }} + id_nixery.pub: {{ insertFile "id_nixery.pub" | b64enc }} + known_hosts: {{ insertFile "known_hosts" | b64enc }} + ssh_config: {{ insertFile "ssh_config" | b64enc }} diff --git a/ops/infra/kubernetes/nixery/ssh_config b/ops/infra/kubernetes/nixery/ssh_config new file mode 100644 index 0000000000..78afbb0b03 --- /dev/null +++ b/ops/infra/kubernetes/nixery/ssh_config @@ -0,0 +1,4 @@ +Match host * + User tazjin@google.com + IdentityFile /var/nixery/id_nixery + UserKnownHostsFile /var/nixery/known_hosts diff --git a/ops/infra/kubernetes/primary-cluster.yaml b/ops/infra/kubernetes/primary-cluster.yaml new file mode 100644 index 0000000000..3d601b80cd --- /dev/null +++ b/ops/infra/kubernetes/primary-cluster.yaml @@ -0,0 +1,38 @@ +# Kontemplate configuration for the primary GKE cluster in the project +# 'tazjins-infrastructure'. +--- +context: gke_tazjins-infrastructure_europe-north1_tazjin-cluster +include: + # SSL certificates (provisioned by Google) + - name: tazj-in-cert + path: https-cert + values: + domain: tazj.in + - name: www-tazj-in-cert + path: https-cert + values: + domain: www.tazj.in + - name: git-tazj-in-cert + path: https-cert + values: + domain: git.tazj.in + - name: oslo-pub-cert + path: https-cert + values: + domain: oslo.pub + + # Services + - name: nixery + values: + port: 8080 + version: xkm36vrbcnzxdccybzdrx4qzfcfqfrhg + bucket: tazjins-data + account: nixery@tazjins-infrastructure.iam.gserviceaccount.com + repo: ssh://tazjin@gmail.com@source.developers.google.com:2022/p/tazjins-infrastructure/r/depot + popularity: 'popularity-nixos-unstable-3140fa89c51233397f496f49014f6b23216667c2.json' + - name: website + - name: cgit + - name: https-lb + - name: nginx + values: + version: a349d5e9145ae9a6c89f62ec631f01fb180de546 diff --git a/ops/infra/kubernetes/website/config.yaml b/ops/infra/kubernetes/website/config.yaml new file mode 100644 index 0000000000..02de735b05 --- /dev/null +++ b/ops/infra/kubernetes/website/config.yaml @@ -0,0 +1,37 @@ +--- +apiVersion: apps/v1 +kind: Deployment +metadata: + name: website + labels: + app: website +spec: + replicas: 3 + selector: + matchLabels: + app: website + template: + metadata: + labels: + app: website + spec: + containers: + - name: website + image: nixery.local/shell/web.homepage:{{ gitHEAD }} + env: + - name: CONTAINER_SETUP + value: "true" + command: [ "homepage" ] +--- +apiVersion: v1 +kind: Service +metadata: + name: website +spec: + type: NodePort + selector: + app: website + ports: + - protocol: TCP + port: 8080 + targetPort: 8080 diff --git a/ops/journaldriver/.gitignore b/ops/journaldriver/.gitignore new file mode 100644 index 0000000000..29e65519ba --- /dev/null +++ b/ops/journaldriver/.gitignore @@ -0,0 +1,3 @@ +result +/target +**/*.rs.bk diff --git a/ops/journaldriver/Cargo.lock b/ops/journaldriver/Cargo.lock new file mode 100644 index 0000000000..40bdc96280 --- /dev/null +++ b/ops/journaldriver/Cargo.lock @@ -0,0 +1,816 @@ +[[package]] +name = "aho-corasick" +version = "0.6.8" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "memchr 2.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "ascii" +version = "0.9.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "atty" +version = "0.2.11" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "termion 1.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "backtrace" +version = "0.3.9" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "backtrace-sys 0.1.24 (registry+https://github.com/rust-lang/crates.io-index)", + "cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "rustc-demangle 0.1.9 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "backtrace-sys" +version = "0.1.24" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cc 1.0.25 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "base64" +version = "0.9.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "byteorder 1.2.6 (registry+https://github.com/rust-lang/crates.io-index)", + "safemem 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "bitflags" +version = "1.0.4" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "byteorder" +version = "1.2.6" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cc" +version = "1.0.25" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cfg-if" +version = "0.1.5" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "chrono" +version = "0.4.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "num-integer 0.1.39 (registry+https://github.com/rust-lang/crates.io-index)", + "num-traits 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)", + "time 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "chunked_transfer" +version = "0.3.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cloudabi" +version = "0.0.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "cookie" +version = "0.11.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "time 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", + "url 1.7.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "core-foundation" +version = "0.5.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "core-foundation-sys 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "core-foundation-sys" +version = "0.5.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "cstr-argument" +version = "0.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "memchr 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "env_logger" +version = "0.5.13" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "atty 0.2.11 (registry+https://github.com/rust-lang/crates.io-index)", + "humantime 1.1.1 (registry+https://github.com/rust-lang/crates.io-index)", + "log 0.4.5 (registry+https://github.com/rust-lang/crates.io-index)", + "regex 1.0.5 (registry+https://github.com/rust-lang/crates.io-index)", + "termcolor 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "failure" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "backtrace 0.3.9 (registry+https://github.com/rust-lang/crates.io-index)", + "failure_derive 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "failure_derive" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)", + "syn 0.14.9 (registry+https://github.com/rust-lang/crates.io-index)", + "synstructure 0.9.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "foreign-types" +version = "0.3.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "foreign-types-shared 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "foreign-types-shared" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "fuchsia-zircon" +version = "0.3.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)", + "fuchsia-zircon-sys 0.3.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "fuchsia-zircon-sys" +version = "0.3.3" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "humantime" +version = "1.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "quick-error 1.2.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "idna" +version = "0.1.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "matches 0.1.8 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-bidi 0.3.4 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-normalization 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "itoa" +version = "0.4.3" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "journaldriver" +version = "1.1.0" +dependencies = [ + "chrono 0.4.6 (registry+https://github.com/rust-lang/crates.io-index)", + "env_logger 0.5.13 (registry+https://github.com/rust-lang/crates.io-index)", + "failure 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "log 0.4.5 (registry+https://github.com/rust-lang/crates.io-index)", + "medallion 2.2.3 (registry+https://github.com/rust-lang/crates.io-index)", + "pkg-config 0.3.14 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_derive 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_json 1.0.32 (registry+https://github.com/rust-lang/crates.io-index)", + "systemd 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)", + "ureq 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "lazy_static" +version = "1.1.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "version_check 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "libc" +version = "0.2.43" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "libsystemd-sys" +version = "0.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "pkg-config 0.3.14 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "log" +version = "0.4.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "matches" +version = "0.1.8" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "medallion" +version = "2.2.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "base64 0.9.3 (registry+https://github.com/rust-lang/crates.io-index)", + "openssl 0.10.12 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_derive 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_json 1.0.32 (registry+https://github.com/rust-lang/crates.io-index)", + "time 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "memchr" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "memchr" +version = "2.1.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "version_check 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "native-tls" +version = "0.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "openssl 0.10.12 (registry+https://github.com/rust-lang/crates.io-index)", + "openssl-probe 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "openssl-sys 0.9.36 (registry+https://github.com/rust-lang/crates.io-index)", + "schannel 0.1.14 (registry+https://github.com/rust-lang/crates.io-index)", + "security-framework 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "security-framework-sys 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "tempfile 3.0.4 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "num-integer" +version = "0.1.39" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "num-traits 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "num-traits" +version = "0.2.6" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "openssl" +version = "0.10.12" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)", + "cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "foreign-types 0.3.2 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "openssl-sys 0.9.36 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "openssl-probe" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "openssl-sys" +version = "0.9.36" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cc 1.0.25 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "pkg-config 0.3.14 (registry+https://github.com/rust-lang/crates.io-index)", + "vcpkg 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "percent-encoding" +version = "1.0.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "pkg-config" +version = "0.3.14" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "proc-macro2" +version = "0.4.20" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "qstring" +version = "0.6.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "percent-encoding 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "quick-error" +version = "1.2.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "quote" +version = "0.6.8" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "rand" +version = "0.5.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cloudabi 0.0.3 (registry+https://github.com/rust-lang/crates.io-index)", + "fuchsia-zircon 0.3.3 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "rand_core 0.2.2 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "rand_core" +version = "0.2.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "rand_core 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "rand_core" +version = "0.3.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "redox_syscall" +version = "0.1.40" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "redox_termios" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "redox_syscall 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "regex" +version = "1.0.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "aho-corasick 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)", + "memchr 2.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "regex-syntax 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)", + "thread_local 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", + "utf8-ranges 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "regex-syntax" +version = "0.6.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "ucd-util 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "remove_dir_all" +version = "0.5.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "rustc-demangle" +version = "0.1.9" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "ryu" +version = "0.2.6" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "safemem" +version = "0.3.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "schannel" +version = "0.1.14" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "security-framework" +version = "0.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "core-foundation 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "core-foundation-sys 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "security-framework-sys 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "security-framework-sys" +version = "0.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "core-foundation-sys 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "serde" +version = "1.0.79" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "serde_derive" +version = "1.0.79" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)", + "syn 0.15.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "serde_json" +version = "1.0.32" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "itoa 0.4.3 (registry+https://github.com/rust-lang/crates.io-index)", + "ryu 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "syn" +version = "0.14.9" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "syn" +version = "0.15.8" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "synstructure" +version = "0.9.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)", + "syn 0.14.9 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "systemd" +version = "0.3.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cstr-argument 0.0.2 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "libsystemd-sys 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "log 0.4.5 (registry+https://github.com/rust-lang/crates.io-index)", + "utf8-cstr 0.1.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "tempfile" +version = "3.0.4" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "rand 0.5.5 (registry+https://github.com/rust-lang/crates.io-index)", + "redox_syscall 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", + "remove_dir_all 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "termcolor" +version = "1.0.4" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "wincolor 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "termion" +version = "1.5.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "redox_syscall 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", + "redox_termios 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "thread_local" +version = "0.3.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "time" +version = "0.1.40" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)", + "redox_syscall 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "ucd-util" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unicode-bidi" +version = "0.3.4" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "matches 0.1.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "unicode-normalization" +version = "0.1.7" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unicode-xid" +version = "0.1.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "ureq" +version = "0.6.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "ascii 0.9.1 (registry+https://github.com/rust-lang/crates.io-index)", + "base64 0.9.3 (registry+https://github.com/rust-lang/crates.io-index)", + "chunked_transfer 0.3.1 (registry+https://github.com/rust-lang/crates.io-index)", + "cookie 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "native-tls 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "qstring 0.6.0 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_json 1.0.32 (registry+https://github.com/rust-lang/crates.io-index)", + "url 1.7.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "url" +version = "1.7.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "idna 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "matches 0.1.8 (registry+https://github.com/rust-lang/crates.io-index)", + "percent-encoding 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "utf8-cstr" +version = "0.1.6" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "utf8-ranges" +version = "1.0.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "vcpkg" +version = "0.2.6" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "version_check" +version = "0.1.5" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "winapi" +version = "0.3.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi-i686-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi-x86_64-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "winapi-i686-pc-windows-gnu" +version = "0.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "winapi-util" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "winapi-x86_64-pc-windows-gnu" +version = "0.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "wincolor" +version = "1.0.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi-util 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[metadata] +"checksum aho-corasick 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)" = "68f56c7353e5a9547cbd76ed90f7bb5ffc3ba09d4ea9bd1d8c06c8b1142eeb5a" +"checksum ascii 0.9.1 (registry+https://github.com/rust-lang/crates.io-index)" = "a5fc969a8ce2c9c0c4b0429bb8431544f6658283c8326ba5ff8c762b75369335" +"checksum atty 0.2.11 (registry+https://github.com/rust-lang/crates.io-index)" = "9a7d5b8723950951411ee34d271d99dddcc2035a16ab25310ea2c8cfd4369652" +"checksum backtrace 0.3.9 (registry+https://github.com/rust-lang/crates.io-index)" = "89a47830402e9981c5c41223151efcced65a0510c13097c769cede7efb34782a" +"checksum backtrace-sys 0.1.24 (registry+https://github.com/rust-lang/crates.io-index)" = "c66d56ac8dabd07f6aacdaf633f4b8262f5b3601a810a0dcddffd5c22c69daa0" +"checksum base64 0.9.3 (registry+https://github.com/rust-lang/crates.io-index)" = "489d6c0ed21b11d038c31b6ceccca973e65d73ba3bd8ecb9a2babf5546164643" +"checksum bitflags 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)" = "228047a76f468627ca71776ecdebd732a3423081fcf5125585bcd7c49886ce12" +"checksum byteorder 1.2.6 (registry+https://github.com/rust-lang/crates.io-index)" = "90492c5858dd7d2e78691cfb89f90d273a2800fc11d98f60786e5d87e2f83781" +"checksum cc 1.0.25 (registry+https://github.com/rust-lang/crates.io-index)" = "f159dfd43363c4d08055a07703eb7a3406b0dac4d0584d96965a3262db3c9d16" +"checksum cfg-if 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)" = "0c4e7bb64a8ebb0d856483e1e682ea3422f883c5f5615a90d51a2c82fe87fdd3" +"checksum chrono 0.4.6 (registry+https://github.com/rust-lang/crates.io-index)" = "45912881121cb26fad7c38c17ba7daa18764771836b34fab7d3fbd93ed633878" +"checksum chunked_transfer 0.3.1 (registry+https://github.com/rust-lang/crates.io-index)" = "498d20a7aaf62625b9bf26e637cf7736417cde1d0c99f1d04d1170229a85cf87" +"checksum cloudabi 0.0.3 (registry+https://github.com/rust-lang/crates.io-index)" = "ddfc5b9aa5d4507acaf872de71051dfd0e309860e88966e1051e462a077aac4f" +"checksum cookie 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "1465f8134efa296b4c19db34d909637cb2bf0f7aaf21299e23e18fa29ac557cf" +"checksum core-foundation 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)" = "286e0b41c3a20da26536c6000a280585d519fd07b3956b43aed8a79e9edce980" +"checksum core-foundation-sys 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)" = "716c271e8613ace48344f723b60b900a93150271e5be206212d052bbc0883efa" +"checksum cstr-argument 0.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "514570a4b719329df37f93448a70df2baac553020d0eb43a8dfa9c1f5ba7b658" +"checksum env_logger 0.5.13 (registry+https://github.com/rust-lang/crates.io-index)" = "15b0a4d2e39f8420210be8b27eeda28029729e2fd4291019455016c348240c38" +"checksum failure 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "7efb22686e4a466b1ec1a15c2898f91fa9cb340452496dca654032de20ff95b9" +"checksum failure_derive 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "946d0e98a50d9831f5d589038d2ca7f8f455b1c21028c0db0e84116a12696426" +"checksum foreign-types 0.3.2 (registry+https://github.com/rust-lang/crates.io-index)" = "f6f339eb8adc052cd2ca78910fda869aefa38d22d5cb648e6485e4d3fc06f3b1" +"checksum foreign-types-shared 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "00b0228411908ca8685dba7fc2cdd70ec9990a6e753e89b6ac91a84c40fbaf4b" +"checksum fuchsia-zircon 0.3.3 (registry+https://github.com/rust-lang/crates.io-index)" = "2e9763c69ebaae630ba35f74888db465e49e259ba1bc0eda7d06f4a067615d82" +"checksum fuchsia-zircon-sys 0.3.3 (registry+https://github.com/rust-lang/crates.io-index)" = "3dcaa9ae7725d12cdb85b3ad99a434db70b468c09ded17e012d86b5c1010f7a7" +"checksum humantime 1.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "0484fda3e7007f2a4a0d9c3a703ca38c71c54c55602ce4660c419fd32e188c9e" +"checksum idna 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)" = "38f09e0f0b1fb55fdee1f17470ad800da77af5186a1a76c026b679358b7e844e" +"checksum itoa 0.4.3 (registry+https://github.com/rust-lang/crates.io-index)" = "1306f3464951f30e30d12373d31c79fbd52d236e5e896fd92f96ec7babbbe60b" +"checksum lazy_static 1.1.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ca488b89a5657b0a2ecd45b95609b3e848cf1755da332a0da46e2b2b1cb371a7" +"checksum libc 0.2.43 (registry+https://github.com/rust-lang/crates.io-index)" = "76e3a3ef172f1a0b9a9ff0dd1491ae5e6c948b94479a3021819ba7d860c8645d" +"checksum libsystemd-sys 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "e751b723417158e0949ba470bee4affd6f1dd6b67622b5240d79186631b6a0d9" +"checksum log 0.4.5 (registry+https://github.com/rust-lang/crates.io-index)" = "d4fcce5fa49cc693c312001daf1d13411c4a5283796bac1084299ea3e567113f" +"checksum matches 0.1.8 (registry+https://github.com/rust-lang/crates.io-index)" = "7ffc5c5338469d4d3ea17d269fa8ea3512ad247247c30bd2df69e68309ed0a08" +"checksum medallion 2.2.3 (registry+https://github.com/rust-lang/crates.io-index)" = "b2e6f0713b388174fc3de9b63a0a63dfcee191a8abc8e06c0a9c6d80821c1891" +"checksum memchr 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "148fab2e51b4f1cfc66da2a7c32981d1d3c083a803978268bb11fe4b86925e7a" +"checksum memchr 2.1.0 (registry+https://github.com/rust-lang/crates.io-index)" = "4b3629fe9fdbff6daa6c33b90f7c08355c1aca05a3d01fa8063b822fcf185f3b" +"checksum native-tls 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "8b0a7bd714e83db15676d31caf968ad7318e9cc35f93c85a90231c8f22867549" +"checksum num-integer 0.1.39 (registry+https://github.com/rust-lang/crates.io-index)" = "e83d528d2677f0518c570baf2b7abdcf0cd2d248860b68507bdcb3e91d4c0cea" +"checksum num-traits 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)" = "0b3a5d7cc97d6d30d8b9bc8fa19bf45349ffe46241e8816f50f62f6d6aaabee1" +"checksum openssl 0.10.12 (registry+https://github.com/rust-lang/crates.io-index)" = "5e2e79eede055813a3ac52fb3915caf8e1c9da2dec1587871aec9f6f7b48508d" +"checksum openssl-probe 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "77af24da69f9d9341038eba93a073b1fdaaa1b788221b00a69bce9e762cb32de" +"checksum openssl-sys 0.9.36 (registry+https://github.com/rust-lang/crates.io-index)" = "409d77eeb492a1aebd6eb322b2ee72ff7c7496b4434d98b3bf8be038755de65e" +"checksum percent-encoding 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)" = "31010dd2e1ac33d5b46a5b413495239882813e0369f8ed8a5e266f173602f831" +"checksum pkg-config 0.3.14 (registry+https://github.com/rust-lang/crates.io-index)" = "676e8eb2b1b4c9043511a9b7bea0915320d7e502b0a079fb03f9635a5252b18c" +"checksum proc-macro2 0.4.20 (registry+https://github.com/rust-lang/crates.io-index)" = "3d7b7eaaa90b4a90a932a9ea6666c95a389e424eff347f0f793979289429feee" +"checksum qstring 0.6.0 (registry+https://github.com/rust-lang/crates.io-index)" = "545ec057a36a93e25fb5883baed912e4984af4e2543bbf0e3463d962e0408469" +"checksum quick-error 1.2.2 (registry+https://github.com/rust-lang/crates.io-index)" = "9274b940887ce9addde99c4eee6b5c44cc494b182b97e73dc8ffdcb3397fd3f0" +"checksum quote 0.6.8 (registry+https://github.com/rust-lang/crates.io-index)" = "dd636425967c33af890042c483632d33fa7a18f19ad1d7ea72e8998c6ef8dea5" +"checksum rand 0.5.5 (registry+https://github.com/rust-lang/crates.io-index)" = "e464cd887e869cddcae8792a4ee31d23c7edd516700695608f5b98c67ee0131c" +"checksum rand_core 0.2.2 (registry+https://github.com/rust-lang/crates.io-index)" = "1961a422c4d189dfb50ffa9320bf1f2a9bd54ecb92792fb9477f99a1045f3372" +"checksum rand_core 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)" = "0905b6b7079ec73b314d4c748701f6931eb79fd97c668caa3f1899b22b32c6db" +"checksum redox_syscall 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)" = "c214e91d3ecf43e9a4e41e578973adeb14b474f2bee858742d127af75a0112b1" +"checksum redox_termios 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "7e891cfe48e9100a70a3b6eb652fef28920c117d366339687bd5576160db0f76" +"checksum regex 1.0.5 (registry+https://github.com/rust-lang/crates.io-index)" = "2069749032ea3ec200ca51e4a31df41759190a88edca0d2d86ee8bedf7073341" +"checksum regex-syntax 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)" = "747ba3b235651f6e2f67dfa8bcdcd073ddb7c243cb21c442fc12395dfcac212d" +"checksum remove_dir_all 0.5.1 (registry+https://github.com/rust-lang/crates.io-index)" = "3488ba1b9a2084d38645c4c08276a1752dcbf2c7130d74f1569681ad5d2799c5" +"checksum rustc-demangle 0.1.9 (registry+https://github.com/rust-lang/crates.io-index)" = "bcfe5b13211b4d78e5c2cadfebd7769197d95c639c35a50057eb4c05de811395" +"checksum ryu 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)" = "7153dd96dade874ab973e098cb62fcdbb89a03682e46b144fd09550998d4a4a7" +"checksum safemem 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)" = "8dca453248a96cb0749e36ccdfe2b0b4e54a61bfef89fb97ec621eb8e0a93dd9" +"checksum schannel 0.1.14 (registry+https://github.com/rust-lang/crates.io-index)" = "0e1a231dc10abf6749cfa5d7767f25888d484201accbd919b66ab5413c502d56" +"checksum security-framework 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "697d3f3c23a618272ead9e1fb259c1411102b31c6af8b93f1d64cca9c3b0e8e0" +"checksum security-framework-sys 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "ab01dfbe5756785b5b4d46e0289e5a18071dfa9a7c2b24213ea00b9ef9b665bf" +"checksum serde 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)" = "84257ccd054dc351472528c8587b4de2dbf0dc0fe2e634030c1a90bfdacebaa9" +"checksum serde_derive 1.0.79 (registry+https://github.com/rust-lang/crates.io-index)" = "31569d901045afbff7a9479f793177fe9259819aff10ab4f89ef69bbc5f567fe" +"checksum serde_json 1.0.32 (registry+https://github.com/rust-lang/crates.io-index)" = "43344e7ce05d0d8280c5940cabb4964bea626aa58b1ec0e8c73fa2a8512a38ce" +"checksum syn 0.14.9 (registry+https://github.com/rust-lang/crates.io-index)" = "261ae9ecaa397c42b960649561949d69311f08eeaea86a65696e6e46517cf741" +"checksum syn 0.15.8 (registry+https://github.com/rust-lang/crates.io-index)" = "356d1c5043597c40489e9af2d2498c7fefc33e99b7d75b43be336c8a59b3e45e" +"checksum synstructure 0.9.0 (registry+https://github.com/rust-lang/crates.io-index)" = "85bb9b7550d063ea184027c9b8c20ac167cd36d3e06b3a40bceb9d746dc1a7b7" +"checksum systemd 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)" = "1b62a732355787f960c25536210ae0a981aca2e5dae9dab8491bdae39613ce48" +"checksum tempfile 3.0.4 (registry+https://github.com/rust-lang/crates.io-index)" = "55c1195ef8513f3273d55ff59fe5da6940287a0d7a98331254397f464833675b" +"checksum termcolor 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)" = "4096add70612622289f2fdcdbd5086dc81c1e2675e6ae58d6c4f62a16c6d7f2f" +"checksum termion 1.5.1 (registry+https://github.com/rust-lang/crates.io-index)" = "689a3bdfaab439fd92bc87df5c4c78417d3cbe537487274e9b0b2dce76e92096" +"checksum thread_local 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)" = "c6b53e329000edc2b34dbe8545fd20e55a333362d0a321909685a19bd28c3f1b" +"checksum time 0.1.40 (registry+https://github.com/rust-lang/crates.io-index)" = "d825be0eb33fda1a7e68012d51e9c7f451dc1a69391e7fdc197060bb8c56667b" +"checksum ucd-util 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "fd2be2d6639d0f8fe6cdda291ad456e23629558d466e2789d2c3e9892bda285d" +"checksum unicode-bidi 0.3.4 (registry+https://github.com/rust-lang/crates.io-index)" = "49f2bd0c6468a8230e1db229cff8029217cf623c767ea5d60bfbd42729ea54d5" +"checksum unicode-normalization 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)" = "6a0180bc61fc5a987082bfa111f4cc95c4caff7f9799f3e46df09163a937aa25" +"checksum unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)" = "fc72304796d0818e357ead4e000d19c9c174ab23dc11093ac919054d20a6a7fc" +"checksum ureq 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)" = "5f3f941c0434783c82e46d30508834be5f3c1f2c85dd1b98f0681984c7be8e03" +"checksum url 1.7.1 (registry+https://github.com/rust-lang/crates.io-index)" = "2a321979c09843d272956e73700d12c4e7d3d92b2ee112b31548aef0d4efc5a6" +"checksum utf8-cstr 0.1.6 (registry+https://github.com/rust-lang/crates.io-index)" = "55bcbb425141152b10d5693095950b51c3745d019363fc2929ffd8f61449b628" +"checksum utf8-ranges 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)" = "fd70f467df6810094968e2fce0ee1bd0e87157aceb026a8c083bcf5e25b9efe4" +"checksum vcpkg 0.2.6 (registry+https://github.com/rust-lang/crates.io-index)" = "def296d3eb3b12371b2c7d0e83bfe1403e4db2d7a0bba324a12b21c4ee13143d" +"checksum version_check 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)" = "914b1a6776c4c929a602fafd8bc742e06365d4bcbe48c30f9cca5824f70dc9dd" +"checksum winapi 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)" = "92c1eb33641e276cfa214a0522acad57be5c56b10cb348b3c5117db75f3ac4b0" +"checksum winapi-i686-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6" +"checksum winapi-util 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "afc5508759c5bf4285e61feb862b6083c8480aec864fa17a81fdec6f69b461ab" +"checksum winapi-x86_64-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f" +"checksum wincolor 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)" = "561ed901ae465d6185fa7864d63fbd5720d0ef718366c9a4dc83cf6170d7e9ba" diff --git a/ops/journaldriver/Cargo.toml b/ops/journaldriver/Cargo.toml new file mode 100644 index 0000000000..248b22807f --- /dev/null +++ b/ops/journaldriver/Cargo.toml @@ -0,0 +1,21 @@ +[package] +name = "journaldriver" +version = "1.1.0" +authors = ["Vincent Ambo <mail@tazj.in>"] +license = "GPL-3.0-or-later" + +[dependencies] +chrono = { version = "0.4", features = [ "serde" ]} +env_logger = "0.5" +failure = "0.1" +lazy_static = "1.0" +log = "0.4" +medallion = "2.2" +serde = "1.0" +serde_derive = "1.0" +serde_json = "1.0" +systemd = "0.3" +ureq = { version = "0.6.2", features = [ "json" ]} + +[build-dependencies] +pkg-config = "0.3" diff --git a/ops/journaldriver/README.md b/ops/journaldriver/README.md new file mode 100644 index 0000000000..4dc9de0f61 --- /dev/null +++ b/ops/journaldriver/README.md @@ -0,0 +1,152 @@ +journaldriver +============= + +This is a small daemon used to forward logs from `journald` (systemd's +logging service) to [Stackdriver Logging][]. + +Many existing log services are written in inefficient dynamic +languages with error-prone "cover every possible use-case" +configuration. `journaldriver` instead aims to fit a specific use-case +very well, instead of covering every possible logging setup. + +`journaldriver` can be run on GCP-instances with no additional +configuration as authentication tokens are retrieved from the +[metadata server][]. + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Features](#features) +- [Usage on Google Cloud Platform](#usage-on-google-cloud-platform) +- [Usage outside of Google Cloud Platform](#usage-outside-of-google-cloud-platform) +- [Log levels / severities / priorities](#log-levels--severities--priorities) +- [NixOS module](#nixos-module) +- [Stackdriver Error Reporting](#stackdriver-error-reporting) + +<!-- markdown-toc end --> + +# Features + +* `journaldriver` persists the last forwarded position in the journal + and will resume forwarding at the same position after a restart +* `journaldriver` will recognise log entries in JSON format and + forward them appropriately to make structured log entries available + in Stackdriver +* `journaldriver` can be used outside of GCP by configuring static + credentials +* `journaldriver` will recognise journald's log priority levels and + convert them into equivalent Stackdriver log severity levels + +# Usage on Google Cloud Platform + +`journaldriver` does not require any configuration when running on GCP +instances. + +1. Install `journaldriver` on the instance from which you wish to + forward logs. + +2. Ensure that the instance has the appropriate permissions to write + to Stackdriver. Google continously changes how IAM is implemented + on GCP, so you will have to refer to [Google's documentation][]. + + By default instances have the required permissions if Stackdriver + Logging support is enabled in the project. + +3. Start `journaldriver`, for example via `systemd`. + +# Usage outside of Google Cloud Platform + +When running outside of GCP, the following extra steps need to be +performed: + +1. Create a Google Cloud Platform service account with the "Log + Writer" role and download its private key in JSON-format. +2. When starting `journaldriver`, configure the following environment + variables: + + * `GOOGLE_CLOUD_PROJECT`: Name of the GCP project to which logs + should be written. + * `GOOGLE_APPLICATION_CREDENTIALS`: Filesystem path to the + JSON-file containing the service account's private key. + * `LOG_STREAM`: Name of the target log stream in Stackdriver Logging. + This will be automatically created if it does not yet exist. + * `LOG_NAME`: Name of the target log to write to. This defaults to + `journaldriver` if unset, but it is recommended to - for + example - set it to the machine hostname. + +# Log levels / severities / priorities + +`journaldriver` recognises [journald's priorities][] and converts them +into [equivalent severities][] in Stackdriver. Both sets of values +correspond to standard `syslog` priorities. + +The easiest way to emit log messages with priorites from an +application is to use [priority prefixes][], which are compatible with +structured log messages. + +For example, to emit a simple warning message (structured and +unstructured): + +``` +$ echo '<4>{"fnord":true, "msg":"structured log (warning)"}' | systemd-cat +$ echo '<4>unstructured log (warning)' | systemd-cat +``` + +# NixOS module + +The NixOS package repository [contains a module][] for setting up +`journaldriver` on NixOS machines. NixOS by default uses `systemd` for +service management and `journald` for logging, which means that log +output from most services will be captured automatically. + +On a GCP instance the only required option is this: + +```nix +services.journaldriver.enable = true; +``` + +When running outside of GCP, the configuration looks as follows: + +```nix +services.journaldriver = { + enable = true; + logStream = "prod-environment"; + logName = "hostname"; + googleCloudProject = "gcp-project-name"; + applicationCredentials = keyFile; +}; +``` + +**Note**: The `journaldriver`-module is included in stable releases of +NixOS since NixOS 18.09. + +# Stackdriver Error Reporting + +The [Stackdriver Error Reporting][] service of Google's monitoring +toolbox supports automatically detecting and correlating errors from +log entries. + +To use this functionality log messages must be logged in the expected +[log format][]. + +*Note*: Reporting errors from non-GCP instances requires that the +`LOG_STREAM` environment variable is set to the special value +`global`. + +This value changes the monitored resource descriptor from a log stream +to the project-global stream. Due to a limitation in Stackdriver Error +Reporting, this is the only way to correctly ingest errors from +non-GCP machines. Please see [issue #4][] for more information about +this. + +[Stackdriver Logging]: https://cloud.google.com/logging/ +[metadata server]: https://cloud.google.com/compute/docs/storing-retrieving-metadata +[Google's documentation]: https://cloud.google.com/logging/docs/access-control +[NixOS]: https://nixos.org/ +[contains a module]: https://github.com/NixOS/nixpkgs/pull/42134 +[journald's priorities]: http://0pointer.de/public/systemd-man/sd-daemon.html +[equivalent severities]: https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry#logseverity +[priority prefixes]: http://0pointer.de/public/systemd-man/sd-daemon.html +[Stackdriver Error Reporting]: https://cloud.google.com/error-reporting/ +[log format]: https://cloud.google.com/error-reporting/docs/formatting-error-messages +[issue #4]: https://github.com/tazjin/journaldriver/issues/4 diff --git a/ops/journaldriver/build.rs b/ops/journaldriver/build.rs new file mode 100644 index 0000000000..d64c82a88a --- /dev/null +++ b/ops/journaldriver/build.rs @@ -0,0 +1,6 @@ +extern crate pkg_config; + +fn main() { + pkg_config::probe_library("libsystemd") + .expect("Could not probe libsystemd"); +} diff --git a/ops/journaldriver/default.nix b/ops/journaldriver/default.nix new file mode 100644 index 0000000000..cc274094a9 --- /dev/null +++ b/ops/journaldriver/default.nix @@ -0,0 +1,11 @@ +{ depot, ... }: + +with depot.third_party; + +naersk.buildPackage { + src = ./.; + + buildInputs = [ + pkgconfig openssl systemd.dev + ]; +} diff --git a/ops/journaldriver/src/main.rs b/ops/journaldriver/src/main.rs new file mode 100644 index 0000000000..a57bb3505d --- /dev/null +++ b/ops/journaldriver/src/main.rs @@ -0,0 +1,665 @@ +// Copyright (C) 2018 Vincent Ambo <mail@tazj.in> +// +// journaldriver is free software: you can redistribute it and/or +// modify it under the terms of the GNU General Public License as +// published by the Free Software Foundation, either version 3 of the +// License, or (at your option) any later version. +// +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. +// +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <http://www.gnu.org/licenses/>. + +//! This file implements journaldriver, a small application that +//! forwards logs from journald (systemd's log facility) to +//! Stackdriver Logging. +//! +//! Log entries are read continously from journald and are forwarded +//! to Stackdriver in batches. +//! +//! Stackdriver Logging has a concept of monitored resources. In the +//! simplest case this monitored resource will be the GCE instance on +//! which journaldriver is running. +//! +//! Information about the instance, the project and required security +//! credentials are retrieved from Google's metadata instance on GCP. +//! +//! To run journaldriver on non-GCP machines, users must specify the +//! `GOOGLE_APPLICATION_CREDENTIALS`, `GOOGLE_CLOUD_PROJECT` and +//! `LOG_NAME` environment variables. + +#[macro_use] extern crate failure; +#[macro_use] extern crate log; +#[macro_use] extern crate serde_derive; +#[macro_use] extern crate serde_json; +#[macro_use] extern crate lazy_static; + +extern crate chrono; +extern crate env_logger; +extern crate medallion; +extern crate serde; +extern crate systemd; +extern crate ureq; + +use chrono::offset::LocalResult; +use chrono::prelude::*; +use failure::ResultExt; +use serde_json::{from_str, Value}; +use std::env; +use std::fs::{self, File, rename}; +use std::io::{self, Read, ErrorKind, Write}; +use std::mem; +use std::path::PathBuf; +use std::process; +use std::time::{Duration, Instant}; +use systemd::journal::*; + +#[cfg(test)] +mod tests; + +const LOGGING_SERVICE: &str = "https://logging.googleapis.com/google.logging.v2.LoggingServiceV2"; +const ENTRIES_WRITE_URL: &str = "https://logging.googleapis.com/v2/entries:write"; +const METADATA_TOKEN_URL: &str = "http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token"; +const METADATA_ID_URL: &str = "http://metadata.google.internal/computeMetadata/v1/instance/id"; +const METADATA_ZONE_URL: &str = "http://metadata.google.internal/computeMetadata/v1/instance/zone"; +const METADATA_PROJECT_URL: &str = "http://metadata.google.internal/computeMetadata/v1/project/project-id"; + +/// Convenience type alias for results using failure's `Error` type. +type Result<T> = std::result::Result<T, failure::Error>; + +/// Representation of static service account credentials for GCP. +#[derive(Debug, Deserialize)] +struct Credentials { + /// PEM encoded private key + private_key: String, + + /// `kid` of this private key + private_key_id: String, + + /// "email" address of the service account + client_email: String, +} + +lazy_static! { + /// ID of the GCP project to which to send logs. + static ref PROJECT_ID: String = get_project_id(); + + /// Name of the log to write to (this should only be manually + /// configured if not running on GCP): + static ref LOG_NAME: String = env::var("LOG_NAME") + .unwrap_or("journaldriver".into()); + + /// Service account credentials (if configured) + static ref SERVICE_ACCOUNT_CREDENTIALS: Option<Credentials> = + env::var("GOOGLE_APPLICATION_CREDENTIALS").ok() + .and_then(|path| File::open(path).ok()) + .and_then(|file| serde_json::from_reader(file).ok()); + + /// Descriptor of the currently monitored instance. Refer to the + /// documentation of `determine_monitored_resource` for more + /// information. + static ref MONITORED_RESOURCE: Value = determine_monitored_resource(); + + /// Path to the directory in which journaldriver should persist + /// its cursor state. + static ref CURSOR_DIR: PathBuf = env::var("CURSOR_POSITION_DIR") + .unwrap_or("/var/lib/journaldriver".into()) + .into(); + + /// Path to the cursor position file itself. + static ref CURSOR_FILE: PathBuf = { + let mut path = CURSOR_DIR.clone(); + path.push("cursor.pos"); + path + }; + + /// Path to the temporary file used for cursor position writes. + static ref CURSOR_TMP_FILE: PathBuf = { + let mut path = CURSOR_DIR.clone(); + path.push("cursor.tmp"); + path + }; +} + +/// Convenience helper for retrieving values from the metadata server. +fn get_metadata(url: &str) -> Result<String> { + let response = ureq::get(url) + .set("Metadata-Flavor", "Google") + .timeout_connect(5000) + .timeout_read(5000) + .call(); + + if response.ok() { + // Whitespace is trimmed to remove newlines from responses. + let body = response.into_string() + .context("Failed to decode metadata response")? + .trim().to_string(); + + Ok(body) + } else { + let status = response.status_line().to_string(); + let body = response.into_string() + .unwrap_or_else(|e| format!("Metadata body error: {}", e)); + bail!("Metadata failure: {} ({})", body, status) + } +} + +/// Convenience helper for determining the project ID. +fn get_project_id() -> String { + env::var("GOOGLE_CLOUD_PROJECT") + .map_err(Into::into) + .or_else(|_: failure::Error| get_metadata(METADATA_PROJECT_URL)) + .expect("Could not determine project ID") +} + +/// Determines the monitored resource descriptor used in Stackdriver +/// logs. On GCP this will be set to the instance ID as returned by +/// the metadata server. +/// +/// On non-GCP machines the value is determined by using the +/// `GOOGLE_CLOUD_PROJECT` and `LOG_STREAM` environment variables. +/// +/// [issue #4]: https://github.com/tazjin/journaldriver/issues/4 +fn determine_monitored_resource() -> Value { + if let Ok(log) = env::var("LOG_STREAM") { + // The special value `global` is recognised as a log stream name that + // results in a `global`-type resource descriptor. This is useful in + // cases where Stackdriver Error Reporting is intended to be used on + // a non-GCE instance. See [issue #4][] for details. + if log == "global" { + return json!({ + "type": "global", + "labels": { + "project_id": PROJECT_ID.as_str(), + } + }); + } + + json!({ + "type": "logging_log", + "labels": { + "project_id": PROJECT_ID.as_str(), + "name": log, + } + }) + } else { + let instance_id = get_metadata(METADATA_ID_URL) + .expect("Could not determine instance ID"); + + let zone = get_metadata(METADATA_ZONE_URL) + .expect("Could not determine instance zone"); + + json!({ + "type": "gce_instance", + "labels": { + "project_id": PROJECT_ID.as_str(), + "instance_id": instance_id, + "zone": zone, + } + }) + } +} + +/// Represents the response returned by the metadata server's token +/// endpoint. The token is normally valid for an hour. +#[derive(Deserialize)] +struct TokenResponse { + expires_in: u64, + access_token: String, +} + +/// Struct used to store a token together with a sensible +/// representation of when it expires. +struct Token { + token: String, + fetched_at: Instant, + expires: Duration, +} + +impl Token { + /// Does this token need to be renewed? + fn is_expired(&self) -> bool { + self.fetched_at.elapsed() > self.expires + } +} + +/// Retrieves a token from the GCP metadata service. Retrieving these +/// tokens requires no additional authentication. +fn get_metadata_token() -> Result<Token> { + let body = get_metadata(METADATA_TOKEN_URL)?; + let token: TokenResponse = from_str(&body)?; + + debug!("Fetched new token from metadata service"); + + Ok(Token { + fetched_at: Instant::now(), + expires: Duration::from_secs(token.expires_in / 2), + token: token.access_token, + }) +} + +/// Signs a token using static client credentials configured for a +/// service account. This service account must have been given the +/// `Log Writer` role in Google Cloud IAM. +/// +/// The process for creating and signing these tokens is described +/// here: +/// +/// https://developers.google.com/identity/protocols/OAuth2ServiceAccount#jwt-auth +fn sign_service_account_token(credentials: &Credentials) -> Result<Token> { + use medallion::{Algorithm, Header, Payload}; + + let iat = Utc::now(); + let exp = iat.checked_add_signed(chrono::Duration::seconds(3600)) + .ok_or_else(|| format_err!("Failed to calculate token expiry"))?; + + let header = Header { + alg: Algorithm::RS256, + headers: Some(json!({ + "kid": credentials.private_key_id, + })), + }; + + let payload: Payload<()> = Payload { + iss: Some(credentials.client_email.clone()), + sub: Some(credentials.client_email.clone()), + aud: Some(LOGGING_SERVICE.to_string()), + iat: Some(iat.timestamp() as u64), + exp: Some(exp.timestamp() as u64), + ..Default::default() + }; + + let token = medallion::Token::new(header, payload) + .sign(credentials.private_key.as_bytes()) + .context("Signing service account token failed")?; + + debug!("Signed new service account token"); + + Ok(Token { + token, + fetched_at: Instant::now(), + expires: Duration::from_secs(3000), + }) +} + +/// Retrieve the authentication token either by using static client +/// credentials, or by talking to the metadata server. +/// +/// Which behaviour is used is controlled by the environment variable +/// `GOOGLE_APPLICATION_CREDENTIALS`, which should be configured to +/// point at a JSON private key file if service account authentication +/// is to be used. +fn get_token() -> Result<Token> { + if let Some(credentials) = SERVICE_ACCOUNT_CREDENTIALS.as_ref() { + sign_service_account_token(credentials) + } else { + get_metadata_token() + } +} + +/// This structure represents the different types of payloads +/// supported by journaldriver. +/// +/// Currently log entries can either contain plain text messages or +/// structured payloads in JSON-format. +#[derive(Debug, Serialize, PartialEq)] +#[serde(untagged)] +enum Payload { + TextPayload { + #[serde(rename = "textPayload")] + text_payload: String, + }, + JsonPayload { + #[serde(rename = "jsonPayload")] + json_payload: Value, + }, +} + +/// Attempt to parse a log message as JSON and return it as a +/// structured payload. If parsing fails, return the entry in plain +/// text format. +fn message_to_payload(message: Option<String>) -> Payload { + match message { + None => Payload::TextPayload { text_payload: "empty log entry".into() }, + Some(text_payload) => { + // Attempt to deserialize the text payload as a generic + // JSON value. + if let Ok(json_payload) = serde_json::from_str::<Value>(&text_payload) { + // If JSON-parsing succeeded on the payload, check + // whether we parsed an object (Stackdriver does not + // expect other types of JSON payload) and return it + // in that case. + if json_payload.is_object() { + return Payload::JsonPayload { json_payload } + } + } + + Payload::TextPayload { text_payload } + } + } +} + +/// Attempt to parse journald's microsecond timestamps into a UTC +/// timestamp. +/// +/// Parse errors are dismissed and returned as empty options: There +/// simply aren't any useful fallback mechanisms other than defaulting +/// to ingestion time for journaldriver's use-case. +fn parse_microseconds(input: String) -> Option<DateTime<Utc>> { + if input.len() != 16 { + return None; + } + + let seconds: i64 = (&input[..10]).parse().ok()?; + let micros: u32 = (&input[10..]).parse().ok()?; + + match Utc.timestamp_opt(seconds, micros * 1000) { + LocalResult::Single(time) => Some(time), + _ => None, + } +} + +/// Converts a journald log message priority to a +/// Stackdriver-compatible severity number. +/// +/// Both Stackdriver and journald specify equivalent +/// severities/priorities. Conveniently, the names are the same. +/// Inconveniently, the numbers are not. +/// +/// For more information on the journald priorities, consult these +/// man-pages: +/// +/// * systemd.journal-fields(7) (section 'PRIORITY') +/// * sd-daemon(3) +/// * systemd.exec(5) (section 'SyslogLevelPrefix') +/// +/// Note that priorities can be logged by applications via the prefix +/// concept described in these man pages, without interfering with +/// structured JSON-payloads. +/// +/// For more information on the Stackdriver severity levels, please +/// consult Google's documentation: +/// +/// https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry#LogSeverity +/// +/// Any unknown priority values result in no severity being set. +fn priority_to_severity(priority: String) -> Option<u32> { + match priority.as_ref() { + "0" => Some(800), // emerg + "1" => Some(700), // alert + "2" => Some(600), // crit + "3" => Some(500), // err + "4" => Some(400), // warning + "5" => Some(300), // notice + "6" => Some(200), // info + "7" => Some(100), // debug + _ => None, + } +} + +/// This structure represents a log entry in the format expected by +/// the Stackdriver API. +#[derive(Debug, Serialize)] +#[serde(rename_all = "camelCase")] +struct LogEntry { + labels: Value, + + #[serde(skip_serializing_if = "Option::is_none")] + timestamp: Option<DateTime<Utc>>, + + #[serde(flatten)] + payload: Payload, + + // https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry#LogSeverity + #[serde(skip_serializing_if = "Option::is_none")] + severity: Option<u32>, +} + +impl From<JournalRecord> for LogEntry { + // Converts from the fields contained in a journald record to the + // representation required by Stackdriver Logging. + // + // The fields are documented in systemd.journal-fields(7). + fn from(mut record: JournalRecord) -> LogEntry { + // The message field is technically just a convention, but + // journald seems to default to it when ingesting unit + // output. + let payload = message_to_payload(record.remove("MESSAGE")); + + // Presumably this is always set, but who can be sure + // about anything in this world. + let hostname = record.remove("_HOSTNAME"); + + // The unit is seemingly missing on kernel entries, but + // present on all others. + let unit = record.remove("_SYSTEMD_UNIT"); + + // The source timestamp (if present) is specified in + // microseconds since epoch. + // + // If it is not present or can not be parsed, journaldriver + // will not send a timestamp for the log entry and it will + // default to the ingestion time. + let timestamp = record + .remove("_SOURCE_REALTIME_TIMESTAMP") + .and_then(parse_microseconds); + + // Journald uses syslogd's concept of priority. No idea if this is + // always present, but it's optional in the Stackdriver API, so we just + // omit it if we can't find or parse it. + let severity = record + .remove("PRIORITY") + .and_then(priority_to_severity); + + LogEntry { + payload, + timestamp, + labels: json!({ + "host": hostname, + "unit": unit.unwrap_or_else(|| "syslog".into()), + }), + severity, + } + } +} + +/// Attempt to read from the journal. If no new entry is present, +/// await the next one up to the specified timeout. +fn receive_next_record(timeout: Duration, journal: &mut Journal) + -> Result<Option<JournalRecord>> { + let next_record = journal.next_record()?; + if next_record.is_some() { + return Ok(next_record); + } + + Ok(journal.await_next_record(Some(timeout))?) +} + +/// This function starts a double-looped, blocking receiver. It will +/// buffer messages for half a second before flushing them to +/// Stackdriver. +fn receiver_loop(mut journal: Journal) -> Result<()> { + let mut token = get_token()?; + + let mut buf: Vec<LogEntry> = Vec::new(); + let iteration = Duration::from_millis(500); + + loop { + trace!("Beginning outer iteration"); + let now = Instant::now(); + + loop { + if now.elapsed() > iteration { + break; + } + + if let Ok(Some(entry)) = receive_next_record(iteration, &mut journal) { + trace!("Received a new entry"); + buf.push(entry.into()); + } + } + + if !buf.is_empty() { + let to_flush = mem::replace(&mut buf, Vec::new()); + flush(&mut token, to_flush, journal.cursor()?)?; + } + + trace!("Done outer iteration"); + } +} + +/// Writes the current cursor into `/var/journaldriver/cursor.pos`. To +/// avoid issues with journaldriver being terminated while the cursor +/// is still being written, this will first write the cursor into a +/// temporary file and then move it. +fn persist_cursor(cursor: String) -> Result<()> { + // This code exists to aid in tracking down if there are other + // causes of issue #2 than what has already been taken care of. + // + // One theory is that journald (or the Rust library to interface + // with it) may occasionally return empty cursor strings. If this + // is ever the case, we would like to know about it. + if cursor.is_empty() { + error!("Received empty journald cursor position, refusing to persist!"); + error!("Please report this message at https://github.com/tazjin/journaldriver/issues/2"); + return Ok(()) + } + + let mut file = File::create(&*CURSOR_TMP_FILE) + .context("Failed to create cursor file")?; + + write!(file, "{}", cursor).context("Failed to write cursor file")?; + + rename(&*CURSOR_TMP_FILE, &*CURSOR_FILE) + .context("Failed to move cursor file") + .map_err(Into::into) +} + +/// Flushes all drained records to Stackdriver. Any Stackdriver +/// message can at most contain 1000 log entries which means they are +/// chunked up here. +/// +/// In some cases large payloads seem to cause errors in Stackdriver - +/// the chunks are therefore made smaller here. +/// +/// If flushing is successful the last cursor position will be +/// persisted to disk. +fn flush(token: &mut Token, + entries: Vec<LogEntry>, + cursor: String) -> Result<()> { + if token.is_expired() { + debug!("Refreshing Google metadata access token"); + let new_token = get_token()?; + mem::replace(token, new_token); + } + + for chunk in entries.chunks(750) { + let request = prepare_request(chunk); + if let Err(write_error) = write_entries(token, request) { + error!("Failed to write {} entries: {}", chunk.len(), write_error) + } else { + debug!("Wrote {} entries to Stackdriver", chunk.len()) + } + } + + persist_cursor(cursor) +} + +/// Convert a slice of log entries into the format expected by +/// Stackdriver. This format is documented here: +/// +/// https://cloud.google.com/logging/docs/reference/v2/rest/v2/entries/write +fn prepare_request(entries: &[LogEntry]) -> Value { + json!({ + "logName": format!("projects/{}/logs/{}", PROJECT_ID.as_str(), LOG_NAME.as_str()), + "resource": &*MONITORED_RESOURCE, + "entries": entries, + "partialSuccess": true + }) +} + +/// Perform the log entry insertion in Stackdriver Logging. +fn write_entries(token: &Token, request: Value) -> Result<()> { + let response = ureq::post(ENTRIES_WRITE_URL) + .set("Authorization", format!("Bearer {}", token.token).as_str()) + // The timeout values are set relatively high, not because of + // an expectation of Stackdriver being slow but just to + // eventually hit an error case in case of network troubles. + // Presumably no request in a functioning environment will + // ever hit these limits. + .timeout_connect(2000) + .timeout_read(5000) + .send_json(request); + + if response.ok() { + Ok(()) + } else { + let status = response.status_line().to_string(); + let body = response.into_string() + .unwrap_or_else(|_| "no response body".into()); + bail!("Write failure: {} ({})", body, status) + } +} + +/// Attempt to read the initial cursor position from the configured +/// file. If there is no initial cursor position set, read from the +/// tail of the log. +/// +/// The only "acceptable" error when reading the cursor position is +/// the cursor position file not existing, other errors are fatal +/// because they indicate a misconfiguration of journaldriver. +fn initial_cursor() -> Result<JournalSeek> { + let read_result: io::Result<String> = (|| { + let mut contents = String::new(); + let mut file = File::open(&*CURSOR_FILE)?; + file.read_to_string(&mut contents)?; + Ok(contents.trim().into()) + })(); + + match read_result { + Ok(cursor) => Ok(JournalSeek::Cursor { cursor }), + Err(ref err) if err.kind() == ErrorKind::NotFound => { + info!("No previous cursor position, reading from journal tail"); + Ok(JournalSeek::Tail) + }, + Err(err) => { + (Err(err).context("Could not read cursor position"))? + } + } +} + +fn main () { + env_logger::init(); + + // The directory in which cursor positions are persisted should + // have been created: + if !CURSOR_DIR.exists() { + error!("Cursor directory at '{:?}' does not exist", *CURSOR_DIR); + process::exit(1); + } + + let cursor_position_dir = CURSOR_FILE.parent() + .expect("Invalid cursor position file path"); + + fs::create_dir_all(cursor_position_dir) + .expect("Could not create directory to store cursor position in"); + + let mut journal = Journal::open(JournalFiles::All, false, true) + .expect("Failed to open systemd journal"); + + let seek_position = initial_cursor() + .expect("Failed to determine initial cursor position"); + + match journal.seek(seek_position) { + Ok(cursor) => info!("Opened journal at cursor '{}'", cursor), + Err(err) => { + error!("Failed to set initial journal position: {}", err); + process::exit(1) + } + } + + receiver_loop(journal).expect("log receiver encountered an unexpected error"); +} diff --git a/ops/journaldriver/src/tests.rs b/ops/journaldriver/src/tests.rs new file mode 100644 index 0000000000..779add7a70 --- /dev/null +++ b/ops/journaldriver/src/tests.rs @@ -0,0 +1,95 @@ +use super::*; +use serde_json::to_string; + +#[test] +fn test_text_entry_serialization() { + let entry = LogEntry { + labels: Value::Null, + timestamp: None, + payload: Payload::TextPayload { + text_payload: "test entry".into(), + }, + severity: None, + }; + + let expected = "{\"labels\":null,\"textPayload\":\"test entry\"}"; + let result = to_string(&entry).expect("serialization failed"); + + assert_eq!(expected, result, "Plain text payload should serialize correctly") +} + +#[test] +fn test_json_entry_serialization() { + let entry = LogEntry { + labels: Value::Null, + timestamp: None, + payload: Payload::JsonPayload { + json_payload: json!({ + "message": "JSON test" + }) + }, + severity: None, + }; + + let expected = "{\"labels\":null,\"jsonPayload\":{\"message\":\"JSON test\"}}"; + let result = to_string(&entry).expect("serialization failed"); + + assert_eq!(expected, result, "JSOn payload should serialize correctly") +} + +#[test] +fn test_plain_text_payload() { + let message = "plain text payload".into(); + let payload = message_to_payload(Some(message)); + let expected = Payload::TextPayload { + text_payload: "plain text payload".into(), + }; + + assert_eq!(expected, payload, "Plain text payload should be detected correctly"); +} + +#[test] +fn test_empty_payload() { + let payload = message_to_payload(None); + let expected = Payload::TextPayload { + text_payload: "empty log entry".into(), + }; + + assert_eq!(expected, payload, "Empty payload should be handled correctly"); +} + +#[test] +fn test_json_payload() { + let message = "{\"someKey\":\"someValue\", \"otherKey\": 42}".into(); + let payload = message_to_payload(Some(message)); + let expected = Payload::JsonPayload { + json_payload: json!({ + "someKey": "someValue", + "otherKey": 42 + }) + }; + + assert_eq!(expected, payload, "JSON payload should be detected correctly"); +} + +#[test] +fn test_json_no_object() { + // This message can be parsed as valid JSON, but it is not an + // object - it should be returned as a plain-text payload. + let message = "42".into(); + let payload = message_to_payload(Some(message)); + let expected = Payload::TextPayload { + text_payload: "42".into(), + }; + + assert_eq!(expected, payload, "Non-object JSON payload should be plain text"); +} + +#[test] +fn test_parse_microseconds() { + let input: String = "1529175149291187".into(); + let expected: DateTime<Utc> = "2018-06-16T18:52:29.291187Z" + .to_string().parse().unwrap(); + + assert_eq!(Some(expected), parse_microseconds(input)); +} diff --git a/ops/kms_pass.nix b/ops/kms_pass.nix new file mode 100644 index 0000000000..2399559b4d --- /dev/null +++ b/ops/kms_pass.nix @@ -0,0 +1,61 @@ +# This tool mimics a subset of the interface of 'pass', but uses +# Google Cloud KMS for encryption. +# +# It is intended to be compatible with how 'kontemplate' invokes +# 'pass.' +# +# Only the 'show' and 'insert' commands are supported. + +{ depot, kms, ... }: + +let inherit (depot.third_party) google-cloud-sdk tree writeShellScriptBin; +in (writeShellScriptBin "pass" '' + set -eo pipefail + + CMD="$1" + readonly SECRET=$2 + readonly SECRETS_DIR=${./secrets} + readonly SECRET_PATH="$SECRETS_DIR/$SECRET" + + function secret_check { + if [[ -z $SECRET ]]; then + echo 'Secret must be specified' + exit 1 + fi + } + + if [[ -z $CMD ]]; then + CMD="ls" + fi + + case "$CMD" in + ls) + ${tree}/bin/tree $SECRETS_DIR + ;; + show) + secret_check + ${google-cloud-sdk}/bin/gcloud kms decrypt \ + --project ${kms.project} \ + --location ${kms.region} \ + --keyring ${kms.keyring} \ + --key ${kms.key} \ + --ciphertext-file $SECRET_PATH \ + --plaintext-file - + ;; + insert) + secret_check + ${google-cloud-sdk}/bin/gcloud kms encrypt \ + --project ${kms.project} \ + --location ${kms.region} \ + --keyring ${kms.keyring} \ + --key ${kms.key} \ + --ciphertext-file $SECRET_PATH \ + --plaintext-file - + echo "Inserted secret '$SECRET'" + ;; + *) + echo "Usage: pass show/insert <secret>" + exit 1 + ;; + esac +'') // { meta.enableCI = true; } diff --git a/ops/kontemplate/.gitignore b/ops/kontemplate/.gitignore new file mode 100644 index 0000000000..53a04aab3a --- /dev/null +++ b/ops/kontemplate/.gitignore @@ -0,0 +1,2 @@ +.idea/ +release/ diff --git a/ops/kontemplate/LICENSE b/ops/kontemplate/LICENSE new file mode 100644 index 0000000000..94a9ed024d --- /dev/null +++ b/ops/kontemplate/LICENSE @@ -0,0 +1,674 @@ + GNU GENERAL PUBLIC LICENSE + Version 3, 29 June 2007 + + Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/> + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + + Preamble + + The GNU General Public License is a free, copyleft license for +software and other kinds of works. + + The licenses for most software and other practical works are designed +to take away your freedom to share and change the works. By contrast, +the GNU General Public License is intended to guarantee your freedom to +share and change all versions of a program--to make sure it remains free +software for all its users. We, the Free Software Foundation, use the +GNU General Public License for most of our software; it applies also to +any other work released this way by its authors. You can apply it to +your programs, too. + + When we speak of free software, we are referring to freedom, not +price. Our General Public Licenses are designed to make sure that you +have the freedom to distribute copies of free software (and charge for +them if you wish), that you receive source code or can get it if you +want it, that you can change the software or use pieces of it in new +free programs, and that you know you can do these things. + + To protect your rights, we need to prevent others from denying you +these rights or asking you to surrender the rights. Therefore, you have +certain responsibilities if you distribute copies of the software, or if +you modify it: responsibilities to respect the freedom of others. + + For example, if you distribute copies of such a program, whether +gratis or for a fee, you must pass on to the recipients the same +freedoms that you received. You must make sure that they, too, receive +or can get the source code. And you must show them these terms so they +know their rights. + + Developers that use the GNU GPL protect your rights with two steps: +(1) assert copyright on the software, and (2) offer you this License +giving you legal permission to copy, distribute and/or modify it. + + For the developers' and authors' protection, the GPL clearly explains +that there is no warranty for this free software. For both users' and +authors' sake, the GPL requires that modified versions be marked as +changed, so that their problems will not be attributed erroneously to +authors of previous versions. + + Some devices are designed to deny users access to install or run +modified versions of the software inside them, although the manufacturer +can do so. This is fundamentally incompatible with the aim of +protecting users' freedom to change the software. The systematic +pattern of such abuse occurs in the area of products for individuals to +use, which is precisely where it is most unacceptable. Therefore, we +have designed this version of the GPL to prohibit the practice for those +products. If such problems arise substantially in other domains, we +stand ready to extend this provision to those domains in future versions +of the GPL, as needed to protect the freedom of users. + + Finally, every program is threatened constantly by software patents. +States should not allow patents to restrict development and use of +software on general-purpose computers, but in those that do, we wish to +avoid the special danger that patents applied to a free program could +make it effectively proprietary. To prevent this, the GPL assures that +patents cannot be used to render the program non-free. + + The precise terms and conditions for copying, distribution and +modification follow. + + TERMS AND CONDITIONS + + 0. Definitions. + + "This License" refers to version 3 of the GNU General Public License. + + "Copyright" also means copyright-like laws that apply to other kinds of +works, such as semiconductor masks. + + "The Program" refers to any copyrightable work licensed under this +License. Each licensee is addressed as "you". "Licensees" and +"recipients" may be individuals or organizations. + + To "modify" a work means to copy from or adapt all or part of the work +in a fashion requiring copyright permission, other than the making of an +exact copy. The resulting work is called a "modified version" of the +earlier work or a work "based on" the earlier work. + + A "covered work" means either the unmodified Program or a work based +on the Program. + + To "propagate" a work means to do anything with it that, without +permission, would make you directly or secondarily liable for +infringement under applicable copyright law, except executing it on a +computer or modifying a private copy. Propagation includes copying, +distribution (with or without modification), making available to the +public, and in some countries other activities as well. + + To "convey" a work means any kind of propagation that enables other +parties to make or receive copies. Mere interaction with a user through +a computer network, with no transfer of a copy, is not conveying. + + An interactive user interface displays "Appropriate Legal Notices" +to the extent that it includes a convenient and prominently visible +feature that (1) displays an appropriate copyright notice, and (2) +tells the user that there is no warranty for the work (except to the +extent that warranties are provided), that licensees may convey the +work under this License, and how to view a copy of this License. If +the interface presents a list of user commands or options, such as a +menu, a prominent item in the list meets this criterion. + + 1. Source Code. + + The "source code" for a work means the preferred form of the work +for making modifications to it. "Object code" means any non-source +form of a work. + + A "Standard Interface" means an interface that either is an official +standard defined by a recognized standards body, or, in the case of +interfaces specified for a particular programming language, one that +is widely used among developers working in that language. + + The "System Libraries" of an executable work include anything, other +than the work as a whole, that (a) is included in the normal form of +packaging a Major Component, but which is not part of that Major +Component, and (b) serves only to enable use of the work with that +Major Component, or to implement a Standard Interface for which an +implementation is available to the public in source code form. A +"Major Component", in this context, means a major essential component +(kernel, window system, and so on) of the specific operating system +(if any) on which the executable work runs, or a compiler used to +produce the work, or an object code interpreter used to run it. + + The "Corresponding Source" for a work in object code form means all +the source code needed to generate, install, and (for an executable +work) run the object code and to modify the work, including scripts to +control those activities. However, it does not include the work's +System Libraries, or general-purpose tools or generally available free +programs which are used unmodified in performing those activities but +which are not part of the work. For example, Corresponding Source +includes interface definition files associated with source files for +the work, and the source code for shared libraries and dynamically +linked subprograms that the work is specifically designed to require, +such as by intimate data communication or control flow between those +subprograms and other parts of the work. + + The Corresponding Source need not include anything that users +can regenerate automatically from other parts of the Corresponding +Source. + + The Corresponding Source for a work in source code form is that +same work. + + 2. Basic Permissions. + + All rights granted under this License are granted for the term of +copyright on the Program, and are irrevocable provided the stated +conditions are met. This License explicitly affirms your unlimited +permission to run the unmodified Program. The output from running a +covered work is covered by this License only if the output, given its +content, constitutes a covered work. This License acknowledges your +rights of fair use or other equivalent, as provided by copyright law. + + You may make, run and propagate covered works that you do not +convey, without conditions so long as your license otherwise remains +in force. You may convey covered works to others for the sole purpose +of having them make modifications exclusively for you, or provide you +with facilities for running those works, provided that you comply with +the terms of this License in conveying all material for which you do +not control copyright. Those thus making or running the covered works +for you must do so exclusively on your behalf, under your direction +and control, on terms that prohibit them from making any copies of +your copyrighted material outside their relationship with you. + + Conveying under any other circumstances is permitted solely under +the conditions stated below. Sublicensing is not allowed; section 10 +makes it unnecessary. + + 3. Protecting Users' Legal Rights From Anti-Circumvention Law. + + No covered work shall be deemed part of an effective technological +measure under any applicable law fulfilling obligations under article +11 of the WIPO copyright treaty adopted on 20 December 1996, or +similar laws prohibiting or restricting circumvention of such +measures. + + When you convey a covered work, you waive any legal power to forbid +circumvention of technological measures to the extent such circumvention +is effected by exercising rights under this License with respect to +the covered work, and you disclaim any intention to limit operation or +modification of the work as a means of enforcing, against the work's +users, your or third parties' legal rights to forbid circumvention of +technological measures. + + 4. Conveying Verbatim Copies. + + You may convey verbatim copies of the Program's source code as you +receive it, in any medium, provided that you conspicuously and +appropriately publish on each copy an appropriate copyright notice; +keep intact all notices stating that this License and any +non-permissive terms added in accord with section 7 apply to the code; +keep intact all notices of the absence of any warranty; and give all +recipients a copy of this License along with the Program. + + You may charge any price or no price for each copy that you convey, +and you may offer support or warranty protection for a fee. + + 5. Conveying Modified Source Versions. + + You may convey a work based on the Program, or the modifications to +produce it from the Program, in the form of source code under the +terms of section 4, provided that you also meet all of these conditions: + + a) The work must carry prominent notices stating that you modified + it, and giving a relevant date. + + b) The work must carry prominent notices stating that it is + released under this License and any conditions added under section + 7. This requirement modifies the requirement in section 4 to + "keep intact all notices". + + c) You must license the entire work, as a whole, under this + License to anyone who comes into possession of a copy. This + License will therefore apply, along with any applicable section 7 + additional terms, to the whole of the work, and all its parts, + regardless of how they are packaged. This License gives no + permission to license the work in any other way, but it does not + invalidate such permission if you have separately received it. + + d) If the work has interactive user interfaces, each must display + Appropriate Legal Notices; however, if the Program has interactive + interfaces that do not display Appropriate Legal Notices, your + work need not make them do so. + + A compilation of a covered work with other separate and independent +works, which are not by their nature extensions of the covered work, +and which are not combined with it such as to form a larger program, +in or on a volume of a storage or distribution medium, is called an +"aggregate" if the compilation and its resulting copyright are not +used to limit the access or legal rights of the compilation's users +beyond what the individual works permit. Inclusion of a covered work +in an aggregate does not cause this License to apply to the other +parts of the aggregate. + + 6. Conveying Non-Source Forms. + + You may convey a covered work in object code form under the terms +of sections 4 and 5, provided that you also convey the +machine-readable Corresponding Source under the terms of this License, +in one of these ways: + + a) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by the + Corresponding Source fixed on a durable physical medium + customarily used for software interchange. + + b) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by a + written offer, valid for at least three years and valid for as + long as you offer spare parts or customer support for that product + model, to give anyone who possesses the object code either (1) a + copy of the Corresponding Source for all the software in the + product that is covered by this License, on a durable physical + medium customarily used for software interchange, for a price no + more than your reasonable cost of physically performing this + conveying of source, or (2) access to copy the + Corresponding Source from a network server at no charge. + + c) Convey individual copies of the object code with a copy of the + written offer to provide the Corresponding Source. This + alternative is allowed only occasionally and noncommercially, and + only if you received the object code with such an offer, in accord + with subsection 6b. + + d) Convey the object code by offering access from a designated + place (gratis or for a charge), and offer equivalent access to the + Corresponding Source in the same way through the same place at no + further charge. You need not require recipients to copy the + Corresponding Source along with the object code. If the place to + copy the object code is a network server, the Corresponding Source + may be on a different server (operated by you or a third party) + that supports equivalent copying facilities, provided you maintain + clear directions next to the object code saying where to find the + Corresponding Source. Regardless of what server hosts the + Corresponding Source, you remain obligated to ensure that it is + available for as long as needed to satisfy these requirements. + + e) Convey the object code using peer-to-peer transmission, provided + you inform other peers where the object code and Corresponding + Source of the work are being offered to the general public at no + charge under subsection 6d. + + A separable portion of the object code, whose source code is excluded +from the Corresponding Source as a System Library, need not be +included in conveying the object code work. + + A "User Product" is either (1) a "consumer product", which means any +tangible personal property which is normally used for personal, family, +or household purposes, or (2) anything designed or sold for incorporation +into a dwelling. In determining whether a product is a consumer product, +doubtful cases shall be resolved in favor of coverage. For a particular +product received by a particular user, "normally used" refers to a +typical or common use of that class of product, regardless of the status +of the particular user or of the way in which the particular user +actually uses, or expects or is expected to use, the product. A product +is a consumer product regardless of whether the product has substantial +commercial, industrial or non-consumer uses, unless such uses represent +the only significant mode of use of the product. + + "Installation Information" for a User Product means any methods, +procedures, authorization keys, or other information required to install +and execute modified versions of a covered work in that User Product from +a modified version of its Corresponding Source. The information must +suffice to ensure that the continued functioning of the modified object +code is in no case prevented or interfered with solely because +modification has been made. + + If you convey an object code work under this section in, or with, or +specifically for use in, a User Product, and the conveying occurs as +part of a transaction in which the right of possession and use of the +User Product is transferred to the recipient in perpetuity or for a +fixed term (regardless of how the transaction is characterized), the +Corresponding Source conveyed under this section must be accompanied +by the Installation Information. But this requirement does not apply +if neither you nor any third party retains the ability to install +modified object code on the User Product (for example, the work has +been installed in ROM). + + The requirement to provide Installation Information does not include a +requirement to continue to provide support service, warranty, or updates +for a work that has been modified or installed by the recipient, or for +the User Product in which it has been modified or installed. Access to a +network may be denied when the modification itself materially and +adversely affects the operation of the network or violates the rules and +protocols for communication across the network. + + Corresponding Source conveyed, and Installation Information provided, +in accord with this section must be in a format that is publicly +documented (and with an implementation available to the public in +source code form), and must require no special password or key for +unpacking, reading or copying. + + 7. Additional Terms. + + "Additional permissions" are terms that supplement the terms of this +License by making exceptions from one or more of its conditions. +Additional permissions that are applicable to the entire Program shall +be treated as though they were included in this License, to the extent +that they are valid under applicable law. If additional permissions +apply only to part of the Program, that part may be used separately +under those permissions, but the entire Program remains governed by +this License without regard to the additional permissions. + + When you convey a copy of a covered work, you may at your option +remove any additional permissions from that copy, or from any part of +it. (Additional permissions may be written to require their own +removal in certain cases when you modify the work.) You may place +additional permissions on material, added by you to a covered work, +for which you have or can give appropriate copyright permission. + + Notwithstanding any other provision of this License, for material you +add to a covered work, you may (if authorized by the copyright holders of +that material) supplement the terms of this License with terms: + + a) Disclaiming warranty or limiting liability differently from the + terms of sections 15 and 16 of this License; or + + b) Requiring preservation of specified reasonable legal notices or + author attributions in that material or in the Appropriate Legal + Notices displayed by works containing it; or + + c) Prohibiting misrepresentation of the origin of that material, or + requiring that modified versions of such material be marked in + reasonable ways as different from the original version; or + + d) Limiting the use for publicity purposes of names of licensors or + authors of the material; or + + e) Declining to grant rights under trademark law for use of some + trade names, trademarks, or service marks; or + + f) Requiring indemnification of licensors and authors of that + material by anyone who conveys the material (or modified versions of + it) with contractual assumptions of liability to the recipient, for + any liability that these contractual assumptions directly impose on + those licensors and authors. + + All other non-permissive additional terms are considered "further +restrictions" within the meaning of section 10. If the Program as you +received it, or any part of it, contains a notice stating that it is +governed by this License along with a term that is a further +restriction, you may remove that term. If a license document contains +a further restriction but permits relicensing or conveying under this +License, you may add to a covered work material governed by the terms +of that license document, provided that the further restriction does +not survive such relicensing or conveying. + + If you add terms to a covered work in accord with this section, you +must place, in the relevant source files, a statement of the +additional terms that apply to those files, or a notice indicating +where to find the applicable terms. + + Additional terms, permissive or non-permissive, may be stated in the +form of a separately written license, or stated as exceptions; +the above requirements apply either way. + + 8. Termination. + + You may not propagate or modify a covered work except as expressly +provided under this License. Any attempt otherwise to propagate or +modify it is void, and will automatically terminate your rights under +this License (including any patent licenses granted under the third +paragraph of section 11). + + However, if you cease all violation of this License, then your +license from a particular copyright holder is reinstated (a) +provisionally, unless and until the copyright holder explicitly and +finally terminates your license, and (b) permanently, if the copyright +holder fails to notify you of the violation by some reasonable means +prior to 60 days after the cessation. + + Moreover, your license from a particular copyright holder is +reinstated permanently if the copyright holder notifies you of the +violation by some reasonable means, this is the first time you have +received notice of violation of this License (for any work) from that +copyright holder, and you cure the violation prior to 30 days after +your receipt of the notice. + + Termination of your rights under this section does not terminate the +licenses of parties who have received copies or rights from you under +this License. If your rights have been terminated and not permanently +reinstated, you do not qualify to receive new licenses for the same +material under section 10. + + 9. Acceptance Not Required for Having Copies. + + You are not required to accept this License in order to receive or +run a copy of the Program. Ancillary propagation of a covered work +occurring solely as a consequence of using peer-to-peer transmission +to receive a copy likewise does not require acceptance. However, +nothing other than this License grants you permission to propagate or +modify any covered work. These actions infringe copyright if you do +not accept this License. Therefore, by modifying or propagating a +covered work, you indicate your acceptance of this License to do so. + + 10. Automatic Licensing of Downstream Recipients. + + Each time you convey a covered work, the recipient automatically +receives a license from the original licensors, to run, modify and +propagate that work, subject to this License. You are not responsible +for enforcing compliance by third parties with this License. + + An "entity transaction" is a transaction transferring control of an +organization, or substantially all assets of one, or subdividing an +organization, or merging organizations. If propagation of a covered +work results from an entity transaction, each party to that +transaction who receives a copy of the work also receives whatever +licenses to the work the party's predecessor in interest had or could +give under the previous paragraph, plus a right to possession of the +Corresponding Source of the work from the predecessor in interest, if +the predecessor has it or can get it with reasonable efforts. + + You may not impose any further restrictions on the exercise of the +rights granted or affirmed under this License. For example, you may +not impose a license fee, royalty, or other charge for exercise of +rights granted under this License, and you may not initiate litigation +(including a cross-claim or counterclaim in a lawsuit) alleging that +any patent claim is infringed by making, using, selling, offering for +sale, or importing the Program or any portion of it. + + 11. Patents. + + A "contributor" is a copyright holder who authorizes use under this +License of the Program or a work on which the Program is based. The +work thus licensed is called the contributor's "contributor version". + + A contributor's "essential patent claims" are all patent claims +owned or controlled by the contributor, whether already acquired or +hereafter acquired, that would be infringed by some manner, permitted +by this License, of making, using, or selling its contributor version, +but do not include claims that would be infringed only as a +consequence of further modification of the contributor version. For +purposes of this definition, "control" includes the right to grant +patent sublicenses in a manner consistent with the requirements of +this License. + + Each contributor grants you a non-exclusive, worldwide, royalty-free +patent license under the contributor's essential patent claims, to +make, use, sell, offer for sale, import and otherwise run, modify and +propagate the contents of its contributor version. + + In the following three paragraphs, a "patent license" is any express +agreement or commitment, however denominated, not to enforce a patent +(such as an express permission to practice a patent or covenant not to +sue for patent infringement). To "grant" such a patent license to a +party means to make such an agreement or commitment not to enforce a +patent against the party. + + If you convey a covered work, knowingly relying on a patent license, +and the Corresponding Source of the work is not available for anyone +to copy, free of charge and under the terms of this License, through a +publicly available network server or other readily accessible means, +then you must either (1) cause the Corresponding Source to be so +available, or (2) arrange to deprive yourself of the benefit of the +patent license for this particular work, or (3) arrange, in a manner +consistent with the requirements of this License, to extend the patent +license to downstream recipients. "Knowingly relying" means you have +actual knowledge that, but for the patent license, your conveying the +covered work in a country, or your recipient's use of the covered work +in a country, would infringe one or more identifiable patents in that +country that you have reason to believe are valid. + + If, pursuant to or in connection with a single transaction or +arrangement, you convey, or propagate by procuring conveyance of, a +covered work, and grant a patent license to some of the parties +receiving the covered work authorizing them to use, propagate, modify +or convey a specific copy of the covered work, then the patent license +you grant is automatically extended to all recipients of the covered +work and works based on it. + + A patent license is "discriminatory" if it does not include within +the scope of its coverage, prohibits the exercise of, or is +conditioned on the non-exercise of one or more of the rights that are +specifically granted under this License. You may not convey a covered +work if you are a party to an arrangement with a third party that is +in the business of distributing software, under which you make payment +to the third party based on the extent of your activity of conveying +the work, and under which the third party grants, to any of the +parties who would receive the covered work from you, a discriminatory +patent license (a) in connection with copies of the covered work +conveyed by you (or copies made from those copies), or (b) primarily +for and in connection with specific products or compilations that +contain the covered work, unless you entered into that arrangement, +or that patent license was granted, prior to 28 March 2007. + + Nothing in this License shall be construed as excluding or limiting +any implied license or other defenses to infringement that may +otherwise be available to you under applicable patent law. + + 12. No Surrender of Others' Freedom. + + If conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot convey a +covered work so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you may +not convey it at all. For example, if you agree to terms that obligate you +to collect a royalty for further conveying from those to whom you convey +the Program, the only way you could satisfy both those terms and this +License would be to refrain entirely from conveying the Program. + + 13. Use with the GNU Affero General Public License. + + Notwithstanding any other provision of this License, you have +permission to link or combine any covered work with a work licensed +under version 3 of the GNU Affero General Public License into a single +combined work, and to convey the resulting work. The terms of this +License will continue to apply to the part which is the covered work, +but the special requirements of the GNU Affero General Public License, +section 13, concerning interaction through a network will apply to the +combination as such. + + 14. Revised Versions of this License. + + The Free Software Foundation may publish revised and/or new versions of +the GNU General Public License from time to time. Such new versions will +be similar in spirit to the present version, but may differ in detail to +address new problems or concerns. + + Each version is given a distinguishing version number. If the +Program specifies that a certain numbered version of the GNU General +Public License "or any later version" applies to it, you have the +option of following the terms and conditions either of that numbered +version or of any later version published by the Free Software +Foundation. If the Program does not specify a version number of the +GNU General Public License, you may choose any version ever published +by the Free Software Foundation. + + If the Program specifies that a proxy can decide which future +versions of the GNU General Public License can be used, that proxy's +public statement of acceptance of a version permanently authorizes you +to choose that version for the Program. + + Later license versions may give you additional or different +permissions. However, no additional obligations are imposed on any +author or copyright holder as a result of your choosing to follow a +later version. + + 15. Disclaimer of Warranty. + + THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY +APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT +HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY +OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, +THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR +PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM +IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF +ALL NECESSARY SERVICING, REPAIR OR CORRECTION. + + 16. Limitation of Liability. + + IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING +WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS +THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY +GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE +USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF +DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD +PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), +EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF +SUCH DAMAGES. + + 17. Interpretation of Sections 15 and 16. + + If the disclaimer of warranty and limitation of liability provided +above cannot be given local legal effect according to their terms, +reviewing courts shall apply local law that most closely approximates +an absolute waiver of all civil liability in connection with the +Program, unless a warranty or assumption of liability accompanies a +copy of the Program in return for a fee. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Programs + + If you develop a new program, and you want it to be of the greatest +possible use to the public, the best way to achieve this is to make it +free software which everyone can redistribute and change under these terms. + + To do so, attach the following notices to the program. It is safest +to attach them to the start of each source file to most effectively +state the exclusion of warranty; and each file should have at least +the "copyright" line and a pointer to where the full notice is found. + + <one line to give the program's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This program is free software: you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation, either version 3 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License + along with this program. If not, see <http://www.gnu.org/licenses/>. + +Also add information on how to contact you by electronic and paper mail. + + If the program does terminal interaction, make it output a short +notice like this when it starts in an interactive mode: + + <program> Copyright (C) <year> <name of author> + This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'. + This is free software, and you are welcome to redistribute it + under certain conditions; type `show c' for details. + +The hypothetical commands `show w' and `show c' should show the appropriate +parts of the General Public License. Of course, your program's commands +might be different; for a GUI interface, you would use an "about box". + + You should also get your employer (if you work as a programmer) or school, +if any, to sign a "copyright disclaimer" for the program, if necessary. +For more information on this, and how to apply and follow the GNU GPL, see +<http://www.gnu.org/licenses/>. + + The GNU General Public License does not permit incorporating your program +into proprietary programs. If your program is a subroutine library, you +may consider it more useful to permit linking proprietary applications with +the library. If this is what you want to do, use the GNU Lesser General +Public License instead of this License. But first, please read +<http://www.gnu.org/philosophy/why-not-lgpl.html>. diff --git a/ops/kontemplate/README.md b/ops/kontemplate/README.md new file mode 100644 index 0000000000..998e61a619 --- /dev/null +++ b/ops/kontemplate/README.md @@ -0,0 +1,186 @@ +Kontemplate - A simple Kubernetes templater +=========================================== + +[Kontemplate][] is a simple CLI tool that can take sets of Kubernetes resource +files with placeholders and insert values per environment. + +This tool was made because in many cases all I want in terms of Kubernetes +configuration is simple value interpolation per environment (i.e. Kubernetes +cluster), but with the same deployment files. + +In my experience this is often enough and more complex solutions such as +[Helm][] are not required. + +Check out a Kontemplate setup example and the feature list below! + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Kontemplate - A simple Kubernetes templater](#kontemplate---a-simple-kubernetes-templater) + - [Features](#features) + - [Example](#example) + - [Installation](#installation) + - [Homebrew](#homebrew) + - [Arch Linux](#arch-linux) + - [Building repeatably from source](#building-repeatably-from-source) + - [Building from source](#building-from-source) + - [Usage](#usage) + - [Contributing](#contributing) + +<!-- markdown-toc end --> + +## Features + +* [Simple, yet powerful templates](docs/templates.md) +* [Clean cluster configuration files](docs/cluster-config.md) +* [Resources organised as simple resource sets](docs/resource-sets.md) +* Integration with pass +* Integration with kubectl + +## Example + +Kontemplate lets you describe resources as you normally would in a simple folder structure: + +``` +. +├── prod-cluster.yaml +└── some-api + ├── deployment.yaml + └── service.yaml +``` + +This example has all resources belonging to `some-api` (no file naming conventions enforced at all!) in the `some-api` +folder and the configuration for the cluster `prod-cluster` in the corresponding file. + +Lets take a short look at `prod-cluster.yaml`: + +```yaml +--- +context: k8s.prod.mydomain.com +global: + globalVar: lizards +include: + - name: some-api + values: + version: 1.0-0e6884d + importantFeature: true + apiPort: 4567 +``` + +Those values are then templated into the resource files of `some-api`. That's it! + +You can also set up more complicated folder structures for organisation, for example: + +``` +. +├── api +│ ├── image-api +│ │ └── deployment.yaml +│ └── music-api +│ └── deployment.yaml +│ │ └── default.json +├── frontend +│ ├── main-app +│ │ ├── deployment.yaml +│ │ └── service.yaml +│ └── user-page +│ ├── deployment.yaml +│ └── service.yaml +├── prod-cluster.yaml +└── test-cluster.yaml +``` + +And selectively template or apply resources with a command such as +`kontemplate apply test-cluster.yaml --include api --include frontend/user-page` +to only update the `api` resource sets and the `frontend/user-page` resource set. + +## Installation + +It is recommended to install Kontemplate from the [Nix](https://nixos.org/) package set, +where it is available since NixOS 17.09 as `kontemplate`. + +If using Nix is not an option for you, several other methods of installation are +available: + +### Binary releases + +Signed binary releases are available on the [releases page][] for Linux, OS X, FreeBSD and +Windows. + +Releases are signed with the GPG key `DCF34CFAC1AC44B87E26333136EE34814F6D294A`. + +### Building from source + +You can clone Kontemplate either by cloning the full +[depot][https://git.tazj.in/] or by just cloning the kontemplate +subtree like so: + + git clone -b kontemplate https://git.tazj.in kontemplate + +The `go` tooling can be used as normal with this cloned repository. In +a full clone of the dpeot, Nix can be used to build Kontemplate: + + nix-build -A ops.kontemplate + +## Usage + +You must have `kubectl` installed to use Kontemplate effectively. + +``` +usage: kontemplate [<flags>] <command> [<args> ...] + +simple Kubernetes resource templating + +Flags: + -h, --help Show context-sensitive help (also try --help-long and --help-man). + -i, --include=INCLUDE ... Resource sets to include explicitly + -e, --exclude=EXCLUDE ... Resource sets to exclude explicitly + +Commands: + help [<command>...] + Show help. + + template <file> + Template resource sets and print them + + apply [<flags>] <file> + Template resources and pass to 'kubectl apply' + + replace <file> + Template resources and pass to 'kubectl replace' + + delete <file> + Template resources and pass to 'kubectl delete' + + create <file> + Template resources and pass to 'kubectl create' + +``` + +Examples: + +``` +# Look at output for a specific resource set and check to see if it's correct ... +kontemplate template example/prod-cluster.yaml -i some-api + +# ... maybe do a dry-run to see what kubectl would do: +kontemplate apply example/prod-cluster.yaml --dry-run + +# And actually apply it if you like what you see: +kontemplate apply example/prod-cluster.yaml +``` + +Check out the feature list and the individual feature documentation above. Then you should be good to go! + +## Contributing + +Feel free to contribute pull requests, file bugs and open issues with feature suggestions! + +Kontemplate is licensed under the GPLv3, a copy of the license and its terms can be found +in the `LICENSE` file. + +Please follow the [code of conduct](CODE_OF_CONDUCT.md). + +[Kontemplate]: http://kontemplate.works +[Helm]: https://helm.sh/ +[releases page]: https://github.com/tazjin/kontemplate/releases diff --git a/ops/kontemplate/build-release.sh b/ops/kontemplate/build-release.sh new file mode 100755 index 0000000000..e4258c53dd --- /dev/null +++ b/ops/kontemplate/build-release.sh @@ -0,0 +1,75 @@ +#!/usr/bin/env bash +set -ueo pipefail + +# Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +# +# This file is part of Kontemplate. +# +# Kontemplate is free software: you can redistribute it and/or modify +# it under the terms of the GNU General Public License as published by +# the Free Software Foundation, either version 3 of the License, or +# (at your option) any later version. + +readonly GIT_HASH="$(git rev-parse --short HEAD)" +readonly LDFLAGS="-X main.gitHash=${GIT_HASH} -w -s" +readonly VERSION="1.8.0-${GIT_HASH}" + +function binary-name() { + local os="${1}" + local target="${2}" + if [ "${os}" = "windows" ]; then + echo -n "${target}/kontemplate.exe" + else + echo -n "${target}/kontemplate" + fi +} + +function build-for() { + local os="${1}" + local arch="${2}" + local target="release/${os}/${arch}" + local bin=$(binary-name "${os}" "${target}") + + echo "Building kontemplate for ${os}-${arch} in ${target}" + + mkdir -p "${target}" + + env GOOS="${os}" GOARCH="${arch}" go build \ + -ldflags "${LDFLAGS}" \ + -o "${bin}" \ + -tags netgo +} + +function sign-for() { + local os="${1}" + local arch="${2}" + local target="release/${os}/${arch}" + local bin=$(binary-name "${os}" "${target}") + local tar="release/kontemplate-${VERSION}-${os}-${arch}.tar.gz" + + echo "Packing release into ${tar}" + tar czvf "${tar}" -C "${target}" $(basename "${bin}") + + local hash=$(sha256sum "${tar}") + echo "Signing kontemplate release tarball for ${os}-${arch} with SHA256 ${hash}" + gpg --armor --detach-sig --sign "${tar}" +} + +case "${1}" in + "build") + # Build releases for various operating systems: + build-for "linux" "amd64" + build-for "darwin" "amd64" + build-for "windows" "amd64" + build-for "freebsd" "amd64" + exit 0 + ;; + "sign") + # Bundle and sign releases: + sign-for "linux" "amd64" + sign-for "darwin" "amd64" + sign-for "windows" "amd64" + sign-for "freebsd" "amd64" + exit 0 + ;; +esac diff --git a/ops/kontemplate/context/context.go b/ops/kontemplate/context/context.go new file mode 100644 index 0000000000..2d0378a0ec --- /dev/null +++ b/ops/kontemplate/context/context.go @@ -0,0 +1,266 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +package context + +import ( + "fmt" + "path" + "strings" + + "github.com/tazjin/kontemplate/util" +) + +type ResourceSet struct { + // Name of the resource set. This can be used in include/exclude statements during kontemplate runs. + Name string `json:"name"` + + // Path to the folder containing the files for this resource set. This defaults to the value of the 'name' field + // if unset. + Path string `json:"path"` + + // Values to include when interpolating resources from this resource set. + Values map[string]interface{} `json:"values"` + + // Args to pass on to kubectl for this resource set. + Args []string `json:"args"` + + // Nested resource sets to include + Include []ResourceSet `json:"include"` + + // Parent resource set for flattened resource sets. Should not be manually specified. + Parent string +} + +type Context struct { + // The name of the kubectl context + Name string `json:"context"` + + // Global variables that should be accessible by all resource sets + Global map[string]interface{} `json:"global"` + + // File names of YAML or JSON files including extra variables that should be globally accessible + VariableImportFiles []string `json:"import"` + + // The resource sets to include in this context + ResourceSets []ResourceSet `json:"include"` + + // Variables imported from additional files + ImportedVars map[string]interface{} + + // Explicitly set variables (via `--var`) that should override all others + ExplicitVars map[string]interface{} + + // This field represents the absolute path to the context base directory and should not be manually specified. + BaseDir string +} + +func contextLoadingError(filename string, cause error) error { + return fmt.Errorf("Context loading failed on file %s due to: \n%v", filename, cause) +} + +// Attempt to load and deserialise a Context from the specified file. +func LoadContext(filename string, explicitVars *[]string) (*Context, error) { + var ctx Context + err := util.LoadData(filename, &ctx) + + if err != nil { + return nil, contextLoadingError(filename, err) + } + + ctx.BaseDir = path.Dir(filename) + + // Prepare the resource sets by resolving parents etc. + ctx.ResourceSets = flattenPrepareResourceSetPaths(&ctx.BaseDir, &ctx.ResourceSets) + + // Add variables explicitly specified on the command line + ctx.ExplicitVars, err = loadExplicitVars(explicitVars) + if err != nil { + return nil, fmt.Errorf("Error setting explicit variables: %v\n", err) + } + + // Add variables loaded from import files + ctx.ImportedVars, err = ctx.loadImportedVariables() + if err != nil { + return nil, contextLoadingError(filename, err) + } + + // Merge variables defined at different levels. The + // `mergeContextValues` function is documented with the merge + // hierarchy. + ctx.ResourceSets = ctx.mergeContextValues() + + if err != nil { + return nil, contextLoadingError(filename, err) + } + + return &ctx, nil +} + +// Kontemplate supports specifying additional variable files with the +// `import` keyword. This function loads those variable files and +// merges them together with the context's other global variables. +func (ctx *Context) loadImportedVariables() (map[string]interface{}, error) { + allImportedVars := make(map[string]interface{}) + + for _, file := range ctx.VariableImportFiles { + // Ensure that the filename is not merged with the baseDir if + // it is set to an absolute path. + var filePath string + if path.IsAbs(file) { + filePath = file + } else { + filePath = path.Join(ctx.BaseDir, file) + } + + var importedVars map[string]interface{} + err := util.LoadData(filePath, &importedVars) + + if err != nil { + return nil, err + } + + allImportedVars = *util.Merge(&allImportedVars, &importedVars) + } + + return allImportedVars, nil +} + +// Correctly prepares the file paths for resource sets by inferring implicit paths and flattening resource set +// collections, i.e. resource sets that themselves have an additional 'include' field set. +// Those will be regarded as a short-hand for including multiple resource sets from a subfolder. +// See https://github.com/tazjin/kontemplate/issues/9 for more information. +func flattenPrepareResourceSetPaths(baseDir *string, rs *[]ResourceSet) []ResourceSet { + flattened := make([]ResourceSet, 0) + + for _, r := range *rs { + // If a path is not explicitly specified it should default to the resource set name. + // This is also the classic behaviour prior to kontemplate 1.2 + if r.Path == "" { + r.Path = r.Name + } + + // Paths are made absolute by resolving them relative to the context base, + // unless absolute paths were specified. + if !path.IsAbs(r.Path) { + r.Path = path.Join(*baseDir, r.Path) + } + + if len(r.Include) == 0 { + flattened = append(flattened, r) + } else { + for _, subResourceSet := range r.Include { + if subResourceSet.Path == "" { + subResourceSet.Path = subResourceSet.Name + } + + subResourceSet.Parent = r.Name + subResourceSet.Name = path.Join(r.Name, subResourceSet.Name) + subResourceSet.Path = path.Join(r.Path, subResourceSet.Path) + subResourceSet.Values = *util.Merge(&r.Values, &subResourceSet.Values) + flattened = append(flattened, subResourceSet) + } + } + } + + return flattened +} + +// Merges the context and resource set variables according in the +// desired precedence order. +// +// For now the reasoning behind the merge order is from least specific +// in relation to the cluster configuration, which means that the +// precedence is (in ascending order): +// +// 1. Default values in resource sets. +// 2. Values imported from files (via `import:`) +// 3. Global values in a cluster configuration +// 4. Values set in a resource set's `include`-section +// 5. Explicit values set on the CLI (`--var`) +// +// For a discussion on the reasoning behind this order, please consult +// https://github.com/tazjin/kontemplate/issues/142 +func (ctx *Context) mergeContextValues() []ResourceSet { + updated := make([]ResourceSet, len(ctx.ResourceSets)) + + // Merging has to happen separately for every individual + // resource set to make use of the default values: + for i, rs := range ctx.ResourceSets { + // Begin by loading default values from the resource + // sets configuration. + // + // Resource sets are used across different cluster + // contexts and the default values in them have the + // lowest precedence. + defaultValues := loadDefaultValues(&rs, ctx) + + // Continue by merging default values with values + // imported from external files. Those values are also + // used across cluster contexts, but have higher + // precedence than defaults. + merged := util.Merge(defaultValues, &ctx.ImportedVars) + + // Merge global values defined in the cluster context: + merged = util.Merge(merged, &ctx.Global) + + // Merge values configured in the resource set's + // `include` section: + merged = util.Merge(merged, &rs.Values) + + // Merge values defined explicitly on the CLI: + merged = util.Merge(merged, &ctx.ExplicitVars) + + // Continue with the newly merged resource set: + rs.Values = *merged + updated[i] = rs + } + + return updated +} + +// Loads default values for a resource set collection from +// path/to/set/default.{json|yaml}. +func loadDefaultValues(rs *ResourceSet, c *Context) *map[string]interface{} { + var defaultVars map[string]interface{} + + for _, filename := range util.DefaultFilenames { + err := util.LoadData(path.Join(rs.Path, filename), &defaultVars) + if err == nil { + return &defaultVars + } + } + + // The actual error is not inspected here. The reasoning for + // this is that in case of serious problems (e.g. permission + // issues with the folder / folder not existing) failure will + // occur a bit later anyways. + // + // Otherwise we'd have to differentiate between + // file-not-found-errors (no default values specified) and + // other errors here. + return &rs.Values +} + +// Prepares the variables specified explicitly via `--var` when +// executing kontemplate for adding to the context. +func loadExplicitVars(vars *[]string) (map[string]interface{}, error) { + explicitVars := make(map[string]interface{}, len(*vars)) + + for _, v := range *vars { + varParts := strings.SplitN(v, "=", 2) + if len(varParts) != 2 { + return nil, fmt.Errorf(`invalid explicit variable provided (%s), name and value should be separated with "="`, v) + } + + explicitVars[varParts[0]] = varParts[1] + } + + return explicitVars, nil +} diff --git a/ops/kontemplate/context/context_test.go b/ops/kontemplate/context/context_test.go new file mode 100644 index 0000000000..7ecd9d587d --- /dev/null +++ b/ops/kontemplate/context/context_test.go @@ -0,0 +1,353 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +package context + +import ( + "reflect" + "testing" +) + +var noExplicitVars []string = make([]string, 0) + +func TestLoadFlatContextFromFile(t *testing.T) { + ctx, err := LoadContext("testdata/flat-test.yaml", &noExplicitVars) + + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + Global: map[string]interface{}{ + "globalVar": "lizards", + }, + ResourceSets: []ResourceSet{ + { + Name: "some-api", + Path: "testdata/some-api", + Values: map[string]interface{}{ + "apiPort": float64(4567), // yep! + "importantFeature": true, + "version": "1.0-0e6884d", + "globalVar": "lizards", + }, + Include: nil, + Parent: "", + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded context and expected context did not match") + t.Fail() + } +} + +func TestLoadContextWithArgs(t *testing.T) { + ctx, err := LoadContext("testdata/flat-with-args-test.yaml", &noExplicitVars) + + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + ResourceSets: []ResourceSet{ + { + Name: "some-api", + Path: "testdata/some-api", + Values: make(map[string]interface{}, 0), + Args: []string{ + "--as=some-user", + "--as-group=hello:world", + "--as-banana", + "true", + }, + Include: nil, + Parent: "", + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded context and expected context did not match") + t.Fail() + } +} + +func TestLoadContextWithResourceSetCollections(t *testing.T) { + ctx, err := LoadContext("testdata/collections-test.yaml", &noExplicitVars) + + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + Global: map[string]interface{}{ + "globalVar": "lizards", + }, + ResourceSets: []ResourceSet{ + { + Name: "some-api", + Path: "testdata/some-api", + Values: map[string]interface{}{ + "apiPort": float64(4567), // yep! + "importantFeature": true, + "version": "1.0-0e6884d", + "globalVar": "lizards", + }, + Include: nil, + Parent: "", + }, + { + Name: "collection/nested", + Path: "testdata/collection/nested", + Values: map[string]interface{}{ + "lizards": "good", + "globalVar": "lizards", + }, + Include: nil, + Parent: "collection", + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded context and expected context did not match") + t.Fail() + } + +} + +func TestSubresourceVariableInheritance(t *testing.T) { + ctx, err := LoadContext("testdata/parent-variables.yaml", &noExplicitVars) + + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + ResourceSets: []ResourceSet{ + { + Name: "parent/child", + Path: "testdata/parent/child", + Values: map[string]interface{}{ + "foo": "bar", + "bar": "baz", + }, + Include: nil, + Parent: "parent", + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded and expected context did not match") + t.Fail() + } +} + +func TestSubresourceVariableInheritanceOverride(t *testing.T) { + ctx, err := LoadContext("testdata/parent-variable-override.yaml", &noExplicitVars) + + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + ResourceSets: []ResourceSet{ + { + Name: "parent/child", + Path: "testdata/parent/child", + Values: map[string]interface{}{ + "foo": "newvalue", + }, + Include: nil, + Parent: "parent", + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded and expected context did not match") + t.Fail() + } +} + +func TestDefaultValuesLoading(t *testing.T) { + ctx, err := LoadContext("testdata/default-loading.yaml", &noExplicitVars) + if err != nil { + t.Error(err) + t.Fail() + } + + rs := ctx.ResourceSets[0] + if rs.Values["defaultValues"] != "loaded" { + t.Errorf("Default values not loaded from YAML file") + t.Fail() + } + + if rs.Values["override"] != "notAtAll" { + t.Error("Default values should not override other values") + t.Fail() + } +} + +func TestImportValuesLoading(t *testing.T) { + ctx, err := LoadContext("testdata/import-vars-simple.yaml", &noExplicitVars) + if err != nil { + t.Error(err) + t.Fail() + } + + expected := map[string]interface{}{ + "override": "true", + "music": map[string]interface{}{ + "artist": "Pallida", + "track": "Tractor Beam", + }, + } + + if !reflect.DeepEqual(ctx.ImportedVars, expected) { + t.Error("Expected imported values after loading imports did not match!") + t.Fail() + } +} + +func TestExplicitPathLoading(t *testing.T) { + ctx, err := LoadContext("testdata/explicit-path.yaml", &noExplicitVars) + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + ResourceSets: []ResourceSet{ + { + Name: "some-api-europe", + Path: "testdata/some-api", + Values: map[string]interface{}{ + "location": "europe", + }, + Include: nil, + Parent: "", + }, + { + Name: "some-api-asia", + Path: "testdata/some-api", + Values: map[string]interface{}{ + "location": "asia", + }, + Include: nil, + Parent: "", + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded context and expected context did not match") + t.Fail() + } +} + +func TestExplicitSubresourcePathLoading(t *testing.T) { + ctx, err := LoadContext("testdata/explicit-subresource-path.yaml", &noExplicitVars) + if err != nil { + t.Error(err) + t.Fail() + } + + expected := Context{ + Name: "k8s.prod.mydomain.com", + ResourceSets: []ResourceSet{ + { + Name: "parent/child", + Path: "testdata/parent-path/child-path", + Parent: "parent", + Values: make(map[string]interface{}, 0), + }, + }, + BaseDir: "testdata", + ImportedVars: make(map[string]interface{}, 0), + ExplicitVars: make(map[string]interface{}, 0), + } + + if !reflect.DeepEqual(*ctx, expected) { + t.Error("Loaded context and expected context did not match") + t.Fail() + } +} + +func TestSetVariablesFromArguments(t *testing.T) { + vars := []string{"version=some-service-version"} + ctx, _ := LoadContext("testdata/default-loading.yaml", &vars) + + if version := ctx.ExplicitVars["version"]; version != "some-service-version" { + t.Errorf(`Expected variable "version" to have value "some-service-version" but was "%s"`, version) + } +} + +func TestSetInvalidVariablesFromArguments(t *testing.T) { + vars := []string{"version: some-service-version"} + _, err := LoadContext("testdata/default-loading.yaml", &vars) + + if err == nil { + t.Error("Expected invalid variable to return an error") + } +} + +// This test ensures that variables are merged in the correct order. +// Please consult the test data in `testdata/merging`. +func TestValueMergePrecedence(t *testing.T) { + cliVars:= []string{"cliVar=cliVar"} + ctx, _ := LoadContext("testdata/merging/context.yaml", &cliVars) + + expected := map[string]interface{}{ + "defaultVar": "defaultVar", + "importVar": "importVar", + "globalVar": "globalVar", + "includeVar": "includeVar", + "cliVar": "cliVar", + } + + result := ctx.ResourceSets[0].Values + + if !reflect.DeepEqual(expected, result) { + t.Errorf("Merged values did not match expected result: \n%v", result) + t.Fail() + } +} diff --git a/ops/kontemplate/context/testdata/collections-test.yaml b/ops/kontemplate/context/testdata/collections-test.yaml new file mode 100644 index 0000000000..a619c8cfdd --- /dev/null +++ b/ops/kontemplate/context/testdata/collections-test.yaml @@ -0,0 +1,15 @@ +--- +context: k8s.prod.mydomain.com +global: + globalVar: lizards +include: + - name: some-api + values: + version: 1.0-0e6884d + importantFeature: true + apiPort: 4567 + - name: collection + include: + - name: nested + values: + lizards: good diff --git a/ops/kontemplate/context/testdata/default-loading.yaml b/ops/kontemplate/context/testdata/default-loading.yaml new file mode 100644 index 0000000000..d589c99b4e --- /dev/null +++ b/ops/kontemplate/context/testdata/default-loading.yaml @@ -0,0 +1,6 @@ +--- +context: default-loading +include: + - name: default + values: + override: notAtAll \ No newline at end of file diff --git a/ops/kontemplate/context/testdata/default/default.yaml b/ops/kontemplate/context/testdata/default/default.yaml new file mode 100644 index 0000000000..0ffa3cd81f --- /dev/null +++ b/ops/kontemplate/context/testdata/default/default.yaml @@ -0,0 +1,2 @@ +defaultValues: loaded +override: noop \ No newline at end of file diff --git a/ops/kontemplate/context/testdata/explicit-path.yaml b/ops/kontemplate/context/testdata/explicit-path.yaml new file mode 100644 index 0000000000..2c81f83c09 --- /dev/null +++ b/ops/kontemplate/context/testdata/explicit-path.yaml @@ -0,0 +1,11 @@ +--- +context: k8s.prod.mydomain.com +include: + - name: some-api-europe + path: some-api + values: + location: europe + - name: some-api-asia + path: some-api + values: + location: asia diff --git a/ops/kontemplate/context/testdata/explicit-subresource-path.yaml b/ops/kontemplate/context/testdata/explicit-subresource-path.yaml new file mode 100644 index 0000000000..6cf8618322 --- /dev/null +++ b/ops/kontemplate/context/testdata/explicit-subresource-path.yaml @@ -0,0 +1,8 @@ +--- +context: k8s.prod.mydomain.com +include: + - name: parent + path: parent-path + include: + - name: child + path: child-path diff --git a/ops/kontemplate/context/testdata/flat-test.yaml b/ops/kontemplate/context/testdata/flat-test.yaml new file mode 100644 index 0000000000..dd7804f719 --- /dev/null +++ b/ops/kontemplate/context/testdata/flat-test.yaml @@ -0,0 +1,10 @@ +--- +context: k8s.prod.mydomain.com +global: + globalVar: lizards +include: + - name: some-api + values: + version: 1.0-0e6884d + importantFeature: true + apiPort: 4567 diff --git a/ops/kontemplate/context/testdata/flat-with-args-test.yaml b/ops/kontemplate/context/testdata/flat-with-args-test.yaml new file mode 100644 index 0000000000..29d3334fb5 --- /dev/null +++ b/ops/kontemplate/context/testdata/flat-with-args-test.yaml @@ -0,0 +1,9 @@ +--- +context: k8s.prod.mydomain.com +include: + - name: some-api + args: + - --as=some-user + - --as-group=hello:world + - --as-banana + - "true" diff --git a/ops/kontemplate/context/testdata/import-vars-simple.yaml b/ops/kontemplate/context/testdata/import-vars-simple.yaml new file mode 100644 index 0000000000..12244e1ab1 --- /dev/null +++ b/ops/kontemplate/context/testdata/import-vars-simple.yaml @@ -0,0 +1,5 @@ +--- +context: k8s.prod.mydomain.com +import: + - test-vars.yaml +include: [] diff --git a/ops/kontemplate/context/testdata/merging/context.yaml b/ops/kontemplate/context/testdata/merging/context.yaml new file mode 100644 index 0000000000..df30d3d8cb --- /dev/null +++ b/ops/kontemplate/context/testdata/merging/context.yaml @@ -0,0 +1,15 @@ +# This context file is intended to test the merge hierarchy of +# variables defined at different levels. +--- +context: merging.in.kontemplate.works +global: + globalVar: globalVar + includeVar: should be overridden (global) + cliVar: should be overridden (global) +import: + - import-vars.yaml +include: + - name: resource + values: + includeVar: includeVar + cliVar: should be overridden (include) diff --git a/ops/kontemplate/context/testdata/merging/import-vars.yaml b/ops/kontemplate/context/testdata/merging/import-vars.yaml new file mode 100644 index 0000000000..2a51352571 --- /dev/null +++ b/ops/kontemplate/context/testdata/merging/import-vars.yaml @@ -0,0 +1,4 @@ +importVar: importVar +globalVar: should be overridden (import) +includeVar: should be overridden (import) +cliVar: should be overridden (import) diff --git a/ops/kontemplate/context/testdata/merging/resource/default.yaml b/ops/kontemplate/context/testdata/merging/resource/default.yaml new file mode 100644 index 0000000000..040a19aaba --- /dev/null +++ b/ops/kontemplate/context/testdata/merging/resource/default.yaml @@ -0,0 +1,5 @@ +defaultVar: defaultVar +importVar: should be overridden (default) +globalVar: should be overridden (default) +includeVar: should be overridden (default) +cliVar: should be overridden (default) diff --git a/ops/kontemplate/context/testdata/merging/resource/output.yaml b/ops/kontemplate/context/testdata/merging/resource/output.yaml new file mode 100644 index 0000000000..5920b27207 --- /dev/null +++ b/ops/kontemplate/context/testdata/merging/resource/output.yaml @@ -0,0 +1,5 @@ +defaultVar: {{ .defaultVar }} +importVar: {{ .importVar }} +globalVar: {{ .globalVar }} +includeVar: {{ .includeVar }} +cliVar: {{ .cliVar }} diff --git a/ops/kontemplate/context/testdata/parent-variable-override.yaml b/ops/kontemplate/context/testdata/parent-variable-override.yaml new file mode 100644 index 0000000000..42676c3028 --- /dev/null +++ b/ops/kontemplate/context/testdata/parent-variable-override.yaml @@ -0,0 +1,10 @@ +--- +context: k8s.prod.mydomain.com +include: + - name: parent + values: + foo: bar + include: + - name: child + values: + foo: newvalue diff --git a/ops/kontemplate/context/testdata/parent-variables.yaml b/ops/kontemplate/context/testdata/parent-variables.yaml new file mode 100644 index 0000000000..8459fd3040 --- /dev/null +++ b/ops/kontemplate/context/testdata/parent-variables.yaml @@ -0,0 +1,10 @@ +--- +context: k8s.prod.mydomain.com +include: + - name: parent + values: + foo: bar + include: + - name: child + values: + bar: baz diff --git a/ops/kontemplate/context/testdata/test-vars-override.yaml b/ops/kontemplate/context/testdata/test-vars-override.yaml new file mode 100644 index 0000000000..5215c559c1 --- /dev/null +++ b/ops/kontemplate/context/testdata/test-vars-override.yaml @@ -0,0 +1,3 @@ +--- +override: 3 +place: Oslo diff --git a/ops/kontemplate/context/testdata/test-vars.yaml b/ops/kontemplate/context/testdata/test-vars.yaml new file mode 100644 index 0000000000..af27bdc455 --- /dev/null +++ b/ops/kontemplate/context/testdata/test-vars.yaml @@ -0,0 +1,5 @@ +--- +override: 'true' +music: + artist: Pallida + track: Tractor Beam diff --git a/ops/kontemplate/default.nix b/ops/kontemplate/default.nix new file mode 100644 index 0000000000..9085f31c30 --- /dev/null +++ b/ops/kontemplate/default.nix @@ -0,0 +1,36 @@ +# Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +# +# This file is part of Kontemplate. +# +# Kontemplate is free software: you can redistribute it and/or modify +# it under the terms of the GNU General Public License as published by +# the Free Software Foundation, either version 3 of the License, or +# (at your option) any later version. +# +# This file is the Nix derivation used to install Kontemplate on +# Nix-based systems. + +{ depot, ... }: + +with depot.third_party; buildGoPackage rec { + name = "kontemplate-${version}"; + version = "master"; + src = ./.; + goPackagePath = "github.com/tazjin/kontemplate"; + goDeps = ./deps.nix; + buildInputs = [ parallel ]; + + # Enable checks and configure check-phase to include vet: + doCheck = true; + preCheck = '' + for pkg in $(getGoDirs ""); do + buildGoDir vet "$pkg" + done + ''; + + meta = with lib; { + description = "A resource templating helper for Kubernetes"; + homepage = "http://kontemplate.works/"; + license = licenses.gpl3; + }; +} diff --git a/ops/kontemplate/deps.nix b/ops/kontemplate/deps.nix new file mode 100644 index 0000000000..7693968bd5 --- /dev/null +++ b/ops/kontemplate/deps.nix @@ -0,0 +1,111 @@ +# This file was generated by https://github.com/kamilchm/go2nix v1.3.0 +[ + { + goPackagePath = "github.com/Masterminds/goutils"; + fetch = { + type = "git"; + url = "https://github.com/Masterminds/goutils"; + rev = "41ac8693c5c10a92ea1ff5ac3a7f95646f6123b0"; + sha256 = "180px47gj936qyk5bkv5mbbgiil9abdjq6kwkf7sq70vyi9mcfiq"; + }; + } + { + goPackagePath = "github.com/Masterminds/semver"; + fetch = { + type = "git"; + url = "https://github.com/Masterminds/semver"; + rev = "5bc3b9184d48f1412b300b87a200cf020d9254cf"; + sha256 = "1vdfm653v50jf63cw0kg2hslx50cn4mk6lj3p51bi11jrg48kfng"; + }; + } + { + goPackagePath = "github.com/Masterminds/sprig"; + fetch = { + type = "git"; + url = "https://github.com/Masterminds/sprig"; + rev = "6f509977777c33eae63b2136d97f7b976cb971cc"; + sha256 = "05h9k6fhjxnpwlihj3z02q9kvqvnq53jix0ab84sx0666bci3cdh"; + }; + } + { + goPackagePath = "github.com/alecthomas/template"; + fetch = { + type = "git"; + url = "https://github.com/alecthomas/template"; + rev = "fb15b899a75114aa79cc930e33c46b577cc664b1"; + sha256 = "1vlasv4dgycydh5wx6jdcvz40zdv90zz1h7836z7lhsi2ymvii26"; + }; + } + { + goPackagePath = "github.com/alecthomas/units"; + fetch = { + type = "git"; + url = "https://github.com/alecthomas/units"; + rev = "c3de453c63f4bdb4dadffab9805ec00426c505f7"; + sha256 = "0js37zlgv37y61j4a2d46jh72xm5kxmpaiw0ya9v944bjpc386my"; + }; + } + { + goPackagePath = "github.com/ghodss/yaml"; + fetch = { + type = "git"; + url = "https://github.com/ghodss/yaml"; + rev = "25d852aebe32c875e9c044af3eef9c7dc6bc777f"; + sha256 = "1w9yq0bxzygc4qwkwwiy7k1k1yviaspcqqv18255k2xkjv5ipccz"; + }; + } + { + goPackagePath = "github.com/google/uuid"; + fetch = { + type = "git"; + url = "https://github.com/google/uuid"; + rev = "c2e93f3ae59f2904160ceaab466009f965df46d6"; + sha256 = "0zw8fvl6jqg0fmv6kmvhss0g4gkrbvgyvl2zgy5wdbdlgp4fja0h"; + }; + } + { + goPackagePath = "github.com/huandu/xstrings"; + fetch = { + type = "git"; + url = "https://github.com/huandu/xstrings"; + rev = "8bbcf2f9ccb55755e748b7644164cd4bdce94c1d"; + sha256 = "1ivvc95514z63k7cpz71l0dwlanffmsh1pijhaqmp41kfiby8rsx"; + }; + } + { + goPackagePath = "github.com/imdario/mergo"; + fetch = { + type = "git"; + url = "https://github.com/imdario/mergo"; + rev = "4c317f2286be3bd0c4f1a0e622edc6398ec4656d"; + sha256 = "0bihha1qsgfjk14yv1hwddv3d8dzxpbjlaxwwyys6lhgxz1cr9h9"; + }; + } + { + goPackagePath = "golang.org/x/crypto"; + fetch = { + type = "git"; + url = "https://go.googlesource.com/crypto"; + rev = "9756ffdc24725223350eb3266ffb92590d28f278"; + sha256 = "0q7hxaaq6lp0v8qqzifvysl47z5rfdlrxkh3d29vsl3wyby3dxl8"; + }; + } + { + goPackagePath = "gopkg.in/alecthomas/kingpin.v2"; + fetch = { + type = "git"; + url = "https://gopkg.in/alecthomas/kingpin.v2"; + rev = "947dcec5ba9c011838740e680966fd7087a71d0d"; + sha256 = "0mndnv3hdngr3bxp7yxfd47cas4prv98sqw534mx7vp38gd88n5r"; + }; + } + { + goPackagePath = "gopkg.in/yaml.v2"; + fetch = { + type = "git"; + url = "https://gopkg.in/yaml.v2"; + rev = "51d6538a90f86fe93ac480b35f37b2be17fef232"; + sha256 = "01wj12jzsdqlnidpyjssmj0r4yavlqy7dwrg7adqd8dicjc4ncsa"; + }; + } +] diff --git a/ops/kontemplate/docs/cluster-config.md b/ops/kontemplate/docs/cluster-config.md new file mode 100644 index 0000000000..4e87016179 --- /dev/null +++ b/ops/kontemplate/docs/cluster-config.md @@ -0,0 +1,106 @@ +Cluster configuration +========================== + +Every cluster (or "environment") that requires individual configuration is specified in +a very simple YAML file in Kontemplate. + +An example file for a hypothetical test environment could look like this: + +```yaml +--- +context: k8s.test.mydomain.com +global: + clusterName: test-cluster + defaultReplicas: 2 +import: + - test-secrets.yaml +include: + - name: gateway + path: tools/nginx + values: + tlsDomains: + - test.oslo.pub + - test.tazj.in + - path: backend + values: + env: test + include: + - name: blog + values: + url: test.tazj.in + - name: pub-service +``` + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Cluster configuration](#cluster-configuration) + - [Fields](#fields) + - [`context`](#context) + - [`global`](#global) + - [`import`](#import) + - [`include`](#include) + - [External variables](#external-variables) + +<!-- markdown-toc end --> + +## Fields + +This is documentation for the individual fields in a cluster context file. + +### `context` + +The `context` field contains the name of the kubectl-context. You can list context names with +'kubectl config get-contexts'. + +This must be set here so that Kontemplate can use the correct context when calling kubectl. + +This field is **required** for `kubectl`-wrapping commands. It can be left out if only the `template`-command is used. + +### `global` + +The `global` field contains a key/value map of variables that should be available to all resource +sets in the cluster. + +This field is **optional**. + +### `import` + +The `import` field contains the file names of additional YAML or JSON files from which global +variables should be loaded. Using this field makes it possible to keep certain configuration that +is the same for some, but not all, clusters in a common place. + +This field is **optional**. + +### `include` + +The `include` field contains the actual resource sets to be included in the cluster. + +Information about the structure of resource sets can be found in the [resource set documentation][]. + +This field is **required**. + +## External variables + +As mentioned above, extra variables can be loaded from additional YAML or JSON files. Assuming you +have a file called `test-secrets.yaml` which contains variables that should be shared between a `test` +and `dev` cluster, you could import it in your context as such: + +```yaml +# test-secrets.yaml: +mySecretVar: foo-bar-12345 + +# test-cluster.yaml: +context: k8s.test.mydomain.com +import: + - test-secrets.yaml + +# dev-cluster.yaml: +context: k8s.dev.mydomain.com +import: + - test-secrets.yaml +``` + +The variable `mySecretVar` is then available as a global variable. + +[resource set documentation]: resource-sets.md diff --git a/ops/kontemplate/docs/resource-sets.md b/ops/kontemplate/docs/resource-sets.md new file mode 100644 index 0000000000..1444dd4912 --- /dev/null +++ b/ops/kontemplate/docs/resource-sets.md @@ -0,0 +1,170 @@ +Resource Sets +================ + +Resource sets are collections of Kubernetes resources that should be passed to `kubectl` together. + +Technically a resource set is simply a folder with a few YAML and/or JSON templates in it. + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Resource Sets](#resource-sets) +- [Creating resource sets](#creating-resource-sets) + - [Default variables](#default-variables) +- [Including resource sets](#including-resource-sets) + - [Fields](#fields) + - [`name`](#name) + - [`path`](#path) + - [`values`](#values) + - [`args`](#args) + - [`include`](#include) + - [Multiple includes](#multiple-includes) + - [Nesting resource sets](#nesting-resource-sets) + - [Caveats](#caveats) + +<!-- markdown-toc end --> + +# Creating resource sets + +Simply create a folder in your Kontemplate repository and place a YAML or JSON file in it. These +files get interpreted as [templates][] during Kontemplate runs and variables (as well as template +logic or functions) will be interpolated. + +Refer to the template documentation for information on how to write templates. + +## Default variables + +Sometimes it is useful to specify default values for variables that should be interpolated during +a run if the [cluster configuration][] does not specify a variable explicitly. + +This can be done simply by placing a `default.yaml` or `default.json` file in the resource set +folder and filling it with key/value pairs of the intended default variables. + +Kontemplate will error during interpolation if any variables are left unspecified. + +# Including resource sets + +Under the cluster configuration `include` key resource sets are included and required variables +are specified. For example: + +```yaml +include: + - name: some-api + values: + version: 1.2-SNAPSHOT +``` + +This will include a resource set from a folder called `some-api` and set the specified `version` variable. + +## Fields + +The available fields when including a resource set are these: + +### `name` + +The `name` field contains the name of the resource set. This name can be used to refer to the resource set +when specifying explicit includes or excludes during a run. + +By default it is assumed that the `name` is the path to the resource set folder, but this can be overridden. + +This field is **required**. + +### `path` + +The `path` field specifies an explicit path to a resource set folder in the case that it should differ from +the resource set's `name`. + +This field is **optional**. + +### `values` + +The `values` field specifies key/values pairs of variables that should be available during templating. + +This field is **optional**. + +### `args` + +The `args` field specifies a list of arguments that should be passed to `kubectl`. + +This field is **optional**. + +### `include` + +The `include` field specifies additional resource sets that should be included and that should inherit the +variables of this resource set. + +The fully qualified names of "nested" resource sets are set to `${PARENT_NAME}/${CHILD_NAME}` and paths are +merged in the same way. + +This makes it easy to organise different resource sets as "groups" to include / exclude them collectively +during runs. + +This field is **optional**. + +## Multiple includes + +Resource sets can be included multiple times with different configurations. In this case it is recommended +to set the `path` and `name` fields explicitly. For example: + +```yaml +include: + - name: forwarder-europe + path: tools/forwarder + values: + source: europe + - name: forwarder-asia + path: tools/forwarder + values: + source: asia +``` + +The two different configurations can be referred to by their set names, but will use the same resource +templates with different configurations. + +## Nesting resource sets + +As mentioned above for the `include` field, resource sets can be nested. This lets users group resource +sets in logical ways using simple folder structures. + +Assuming a folder structure like: + +``` +├── backend +│ ├── auth-api +│ ├── message-api +│ └── order-api +└── frontend + ├── app-page + └── login-page +``` + +With each of these folders being a resource set, they could be included in a cluster configuration like so: + +```yaml +include: + - name: backend + include: + - name: auth-api + - name: message-api + - name: order-api + - name: frontend: + include: + - name: app-page + - name: login-page +``` + +Kontemplate could then be run with, for example, `--include backend` to only include the resource sets nested +in the backend group. Specific resource sets can also be targeted, for example as `--include backend/order-api`. + +Variables specified in the parent resource set are inherited by the children. + +### Caveats + +Two caveats apply that users should be aware of: + +1. The parent resource set can not contain any resource templates itself. + +2. Only one level of nesting is supported. Specifying `include` again on a nested resource set will be ignored. + +[templates]: templates.md +[cluster configuration]: cluster-config.md diff --git a/ops/kontemplate/docs/templates.md b/ops/kontemplate/docs/templates.md new file mode 100644 index 0000000000..32da205108 --- /dev/null +++ b/ops/kontemplate/docs/templates.md @@ -0,0 +1,153 @@ +Kontemplate templates +===================== + +The template file format is based on Go's [templating engine][] in combination +with a small extension library called [sprig][] that adds additional template +functions. + +Go templates can either simply display variables or build more complicated +*pipelines* in which variables are passed to functions for further processing, +or in which conditionals are evaluated for more complex template logic. + +It is recommended that you check out the Golang [documentation][] for the templating +engine in addition to the cherry-picked features listed here. + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Kontemplate templates](#kontemplate-templates) + - [Basic variable interpolation](#basic-variable-interpolation) + - [Example:](#example) + - [Template functions](#template-functions) + - [Examples:](#examples) + - [Conditionals & ranges](#conditionals--ranges) + - [Caveats](#caveats) + +<!-- markdown-toc end --> + +## Basic variable interpolation + +The basic template format uses `{{ .variableName }}` as the interpolation format. + +### Example: + +Assuming that you include a resource set as such: + +``` +- name: api-gateway + values: + internalHost: http://my-internal-host/ +``` + +And the api-gateway resource set includes a ConfigMap (some fields left out for +the example): + +``` +# api-gateway/configmap.yaml: +--- +kind: ConfigMap +metadata: + name: api-gateway-config +data: + internalHost: {{ .internalHost }} +``` + +The resulting output will be: + +``` + +--- +kind: ConfigMap +metadata: + name: api-gateway-config +data: + internalHost: http://my-internal-host/ +``` + +## Template functions + +Go templates support template functions which you can think of as a sort of +shell-like pipeline where text flows through transformations from left to +right. + +Some template functions come from Go's standard library and are listed in the +[Go documentation][]. In addition the functions declared by [sprig][] are +available in kontemplate, as well as five custom functions: + +* `json`: Encodes any supplied data structure as JSON. +* `gitHEAD`: Retrieves the commit hash at Git `HEAD`. +* `passLookup`: Looks up the supplied key in [pass][]. +* `insertFile`: Insert the contents of the given file in the resource + set folder as a string. +* `insertTemplate`: Insert the contents of the given template in the resource + set folder as a string. + +## Examples: + +``` +# With the following values: +name: Donald +certKeyPath: my-website/cert-key + +# The following interpolations are possible: + +{{ .name | upper }} +-> DONALD + +{{ .name | upper | repeat 2 }} +-> DONALD DONALD + +{{ .certKeyPath | passLookup }} +-> Returns content of 'my-website/cert-key' from pass + +{{ gitHEAD }} +-> Returns the Git commit hash at HEAD. +``` + +## Conditionals & ranges + +Some logic is supported in Golang templates and can be used in Kontemplate, too. + +With the following values: + +``` +useKube2IAM: true +servicePorts: + - 8080 + - 9090 +``` + +The following interpolations are possible: + +``` +# Conditionally insert something in the template: +metadata: + annotations: + foo: bar + {{ if .useKube2IAM -}} iam.amazonaws.com/role: my-api {{- end }} +``` + +``` +# Iterate over a list of values +ports: + {{ range .servicePorts }} + - port: {{ . }} + {{ end }} +``` + +Check out the Golang documentation (linked above) for more information about template logic. + +## Caveats + +Kontemplate does not by itself parse any of the content of the templates, which +means that it does not validate whether the resources you supply are valid YAML +or JSON. + +You can perform some validation by using `kontemplate apply --dry-run` which +will make use of the Dry-Run functionality in `kubectl`. + +[templating engine]: https://golang.org/pkg/text/template/ +[documentation]: https://golang.org/pkg/text/template/ +[sprig]: http://masterminds.github.io/sprig/ +[Go documentation]: https://golang.org/pkg/text/template/#hdr-Functions +[pass]: https://www.passwordstore.org/ diff --git a/ops/kontemplate/docs/tips-and-tricks.md b/ops/kontemplate/docs/tips-and-tricks.md new file mode 100644 index 0000000000..5401ac91e5 --- /dev/null +++ b/ops/kontemplate/docs/tips-and-tricks.md @@ -0,0 +1,77 @@ +Kontemplate tips & tricks +========================= + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +**Table of Contents** + +- [Kontemplate tips & tricks](#kontemplate-tips--tricks) + - [Update Deployments when ConfigMaps change](#update-deployments-when-configmaps-change) + - [direnv & pass](#direnv--pass) + +<!-- markdown-toc end --> + +## Update Deployments when ConfigMaps change + +Kubernetes does [not currently][] have the ability to perform rolling updates +of Deployments and other resource types when `ConfigMap` or `Secret` objects +are updated. + +It is possible to make use of annotations and templating functions in +Kontemplate to force updates to these resources anyways. + +For example: + +```yaml +# A ConfigMap that contains some configuration for your app +--- +kind: ConfigMap +metadata: + name: app-config +data: + app.conf: | + name: {{ .appName }} + foo: bar +``` + +Now whenever the `appName` variable changes or we make an edit to the +`ConfigMap` we would like to update the `Deployment` making use of it, too. We +can do this by adding a hash of the parsed template to the annotations of the +created `Pod` objects: + +```yaml + +--- +kind: Deployment +metadata: + name: app +spec: + template: + metadata: + annotations: + configHash: {{ insertTemplate "app-config.yaml" | sha256sum }} + spec: + containers: + - name: app + # Some details omitted ... + volumeMounts: + - name: config + mountPath: /etc/app/ + volumes: + - name: config + configMap: + name: app-config +``` + +Now any change to the `ConfigMap` - either by directly editing the yaml file or +via a changed template variable - will cause the annotation to change, +triggering a rolling update of all relevant pods. + +## direnv & pass + +Users of `pass` may have multiple different password stores on their machines. +Assuming that `kontemplate` configuration exists somewhere on the filesystem +per project, it is easy to use [direnv][] to switch to the correct +`PASSWORD_STORE_DIR` variable when entering the folder. + +[not currently]: https://github.com/kubernetes/kubernetes/issues/22368 +[direnv]: https://direnv.net/ diff --git a/ops/kontemplate/example/other-config.yaml b/ops/kontemplate/example/other-config.yaml new file mode 100644 index 0000000000..87370569c4 --- /dev/null +++ b/ops/kontemplate/example/other-config.yaml @@ -0,0 +1,7 @@ +--- +apiVersion: extensions/v1beta1 +kind: ConfigMap +metadata: + name: other-config +data: + globalData: {{ .globalVar }} diff --git a/ops/kontemplate/example/prod-cluster.json b/ops/kontemplate/example/prod-cluster.json new file mode 100644 index 0000000000..70e2365f17 --- /dev/null +++ b/ops/kontemplate/example/prod-cluster.json @@ -0,0 +1,16 @@ +{ + "context": "k8s.prod.mydomain.com", + "global": { + "globalVar": "lizards" + }, + "include": [ + { + "name": "some-api", + "values": { + "version": "1.0-SNAPSHOT-0e6884d", + "importantFeature": true, + "apiPort": 4567 + } + } + ] +} diff --git a/ops/kontemplate/example/prod-cluster.yaml b/ops/kontemplate/example/prod-cluster.yaml new file mode 100644 index 0000000000..9f300a4920 --- /dev/null +++ b/ops/kontemplate/example/prod-cluster.yaml @@ -0,0 +1,17 @@ +--- +context: k8s.prod.mydomain.com +global: + globalVar: lizards +include: + # By default resource sets are included from a folder with the same + # name as the resource set's name + - name: some-api + values: + version: 1.0-0e6884d + importantFeature: true + apiPort: 4567 + + # Paths can also be specified manually (and point at single template + # files!) + - name: other-config + path: other-config.yaml diff --git a/ops/kontemplate/example/some-api/some-api.yaml b/ops/kontemplate/example/some-api/some-api.yaml new file mode 100644 index 0000000000..f0188f9dbd --- /dev/null +++ b/ops/kontemplate/example/some-api/some-api.yaml @@ -0,0 +1,52 @@ +--- +apiVersion: v1 +kind: Secret +metadata: + name: secret-certificate +data: + cert.pem: {{ passLookup "my/secret/certificate" | b64enc }} +--- +apiVersion: extensions/v1beta1 +kind: ConfigMap +metadata: + name: some-config +data: + # The content of the example configuration file is templated in here + # by the 'insertFile' function and indented for YAML-compatibility + # with the 'indent' function: + some.cfg: | +{{ insertFile "some.cfg" | indent 4 }} +--- +apiVersion: extensions/v1beta1 +kind: Deployment +metadata: + name: some-api +spec: + replicas: 1 + template: + metadata: + labels: + app: some-api + spec: + containers: + - image: my.container.repo/some-api:{{ .version }} + name: some-api + env: + - name: ENABLE_IMPORTANT_FEATURE + value: {{ .importantFeature }} + - name: SOME_GLOBAL_VAR + value: {{ .globalVar }} +--- +apiVersion: v1 +kind: Service +metadata: + name: some-api + labels: + app: some-api +spec: + selector: + app: some-api + ports: + - port: 80 + targetPort: {{ .apiPort }} + name: http diff --git a/ops/kontemplate/example/some-api/some.cfg b/ops/kontemplate/example/some-api/some.cfg new file mode 100644 index 0000000000..733d5e1678 --- /dev/null +++ b/ops/kontemplate/example/some-api/some.cfg @@ -0,0 +1,4 @@ +{ + "something": 1542, + "other-thing": "да" +} diff --git a/ops/kontemplate/image/Dockerfile b/ops/kontemplate/image/Dockerfile new file mode 100644 index 0000000000..a40fa83b08 --- /dev/null +++ b/ops/kontemplate/image/Dockerfile @@ -0,0 +1,15 @@ +FROM alpine:3.10 + +ADD hashes /root/hashes +ADD https://storage.googleapis.com/kubernetes-release/release/v1.15.3/bin/linux/amd64/kubectl /usr/bin/kubectl +ADD https://github.com/tazjin/kontemplate/releases/download/v1.8.0/kontemplate-1.8.0-6c3b299-linux-amd64.tar.gz /tmp/kontemplate.tar.gz + +# Pass release version is 1.7.3 +ADD https://raw.githubusercontent.com/zx2c4/password-store/74fdfb5022f317ad48d449e29543710bdad1afda/src/password-store.sh /usr/bin/pass + +RUN sha256sum -c /root/hashes && \ + apk add -U bash tree gnupg git && \ + chmod +x /usr/bin/kubectl /usr/bin/pass && \ + tar xzvf /tmp/kontemplate.tar.gz && \ + mv kontemplate /usr/bin/kontemplate && \ + /usr/bin/kontemplate version diff --git a/ops/kontemplate/image/README.md b/ops/kontemplate/image/README.md new file mode 100644 index 0000000000..fe04765401 --- /dev/null +++ b/ops/kontemplate/image/README.md @@ -0,0 +1,12 @@ +Kontemplate Docker image +======================== + +This builds a simple Docker image available on the Docker Hub as `tazjin/kontemplate`. + +Builds are automated based on the Dockerfile contained here. + +It contains both `kontemplate` and `kubectl` and can be used as part of container-based +CI pipelines. + +`pass` and its dependencies are also installed to enable the use of the `passLookup` +template function if desired. diff --git a/ops/kontemplate/image/hashes b/ops/kontemplate/image/hashes new file mode 100644 index 0000000000..bfd87c0201 --- /dev/null +++ b/ops/kontemplate/image/hashes @@ -0,0 +1,2 @@ +a39dfdd77e4655acaabe301285cf389cb5fc8145060f5677dc93db1cc20911a4 /tmp/kontemplate.tar.gz +6e805054a1fb2280abb53f75b57a1b92bf9c66ffe0d2cdcd46e81b079d93c322 /usr/bin/kubectl diff --git a/ops/kontemplate/main.go b/ops/kontemplate/main.go new file mode 100644 index 0000000000..e55d42465c --- /dev/null +++ b/ops/kontemplate/main.go @@ -0,0 +1,242 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. + +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <http://www.gnu.org/licenses/>. + +package main + +import ( + "fmt" + "os" + "os/exec" + "strings" + + "github.com/tazjin/kontemplate/context" + "github.com/tazjin/kontemplate/templater" + "gopkg.in/alecthomas/kingpin.v2" +) + +const version string = "1.8.0" + +// This variable will be initialised by the Go linker during the builder +var gitHash string + +var ( + app = kingpin.New("kontemplate", "simple Kubernetes resource templating") + + // Global flags + includes = app.Flag("include", "Resource sets to include explicitly").Short('i').Strings() + excludes = app.Flag("exclude", "Resource sets to exclude explicitly").Short('e').Strings() + variables = app.Flag("var", "Provide variables to templates explicitly").Strings() + kubectlBin = app.Flag("kubectl", "Path to the kubectl binary (default 'kubectl')").Default("kubectl").String() + + // Commands + template = app.Command("template", "Template resource sets and print them") + templateFile = template.Arg("file", "Cluster configuration file to use").Required().String() + templateOutputDir = template.Flag("output", "Output directory in which to save templated files instead of printing them").Short('o').String() + + apply = app.Command("apply", "Template resources and pass to 'kubectl apply'") + applyFile = apply.Arg("file", "Cluster configuration file to use").Required().String() + applyDryRun = apply.Flag("dry-run", "Print remote operations without executing them").Default("false").Bool() + + replace = app.Command("replace", "Template resources and pass to 'kubectl replace'") + replaceFile = replace.Arg("file", "Cluster configuration file to use").Required().String() + + delete = app.Command("delete", "Template resources and pass to 'kubectl delete'") + deleteFile = delete.Arg("file", "Cluster configuration file to use").Required().String() + + create = app.Command("create", "Template resources and pass to 'kubectl create'") + createFile = create.Arg("file", "Cluster configuration file to use").Required().String() + + versionCmd = app.Command("version", "Show kontemplate version") +) + +func main() { + app.HelpFlag.Short('h') + + switch kingpin.MustParse(app.Parse(os.Args[1:])) { + case template.FullCommand(): + templateCommand() + + case apply.FullCommand(): + applyCommand() + + case replace.FullCommand(): + replaceCommand() + + case delete.FullCommand(): + deleteCommand() + + case create.FullCommand(): + createCommand() + + case versionCmd.FullCommand(): + versionCommand() + } +} + +func versionCommand() { + if gitHash == "" { + fmt.Printf("Kontemplate version %s (git commit unknown)\n", version) + } else { + fmt.Printf("Kontemplate version %s (git commit: %s)\n", version, gitHash) + } +} + +func templateCommand() { + _, resourceSets := loadContextAndResources(templateFile) + + for _, rs := range *resourceSets { + if len(rs.Resources) == 0 { + fmt.Fprintf(os.Stderr, "Warning: Resource set '%s' does not exist or contains no valid templates\n", rs.Name) + continue + } + + if *templateOutputDir != "" { + templateIntoDirectory(templateOutputDir, rs) + } else { + for _, r := range rs.Resources { + fmt.Fprintf(os.Stderr, "Rendered file %s/%s:\n", rs.Name, r.Filename) + fmt.Println(r.Rendered) + } + } + } +} + +func templateIntoDirectory(outputDir *string, rs templater.RenderedResourceSet) { + // Attempt to create the output directory if it does not + // already exist: + if err := os.MkdirAll(*templateOutputDir, 0775); err != nil { + app.Fatalf("Could not create output directory: %v\n", err) + } + + // Nested resource sets may contain slashes in their names. + // These are replaced with dashes for the purpose of writing a + // flat list of output files: + setName := strings.Replace(rs.Name, "/", "-", -1) + + for _, r := range rs.Resources { + filename := fmt.Sprintf("%s/%s-%s", *templateOutputDir, setName, r.Filename) + fmt.Fprintf(os.Stderr, "Writing file %s\n", filename) + + file, err := os.Create(filename) + if err != nil { + app.Fatalf("Could not create file %s: %v\n", filename, err) + } + + _, err = fmt.Fprintf(file, r.Rendered) + if err != nil { + app.Fatalf("Error writing file %s: %v\n", filename, err) + } + } +} + +func applyCommand() { + ctx, resources := loadContextAndResources(applyFile) + + var kubectlArgs []string + + if *applyDryRun { + kubectlArgs = []string{"apply", "-f", "-", "--dry-run"} + } else { + kubectlArgs = []string{"apply", "-f", "-"} + } + + if err := runKubectlWithResources(ctx, &kubectlArgs, resources); err != nil { + failWithKubectlError(err) + } +} + +func replaceCommand() { + ctx, resources := loadContextAndResources(replaceFile) + args := []string{"replace", "--save-config=true", "-f", "-"} + + if err := runKubectlWithResources(ctx, &args, resources); err != nil { + failWithKubectlError(err) + } +} + +func deleteCommand() { + ctx, resources := loadContextAndResources(deleteFile) + args := []string{"delete", "-f", "-"} + + if err := runKubectlWithResources(ctx, &args, resources); err != nil { + failWithKubectlError(err) + } +} + +func createCommand() { + ctx, resources := loadContextAndResources(createFile) + args := []string{"create", "--save-config=true", "-f", "-"} + + if err := runKubectlWithResources(ctx, &args, resources); err != nil { + failWithKubectlError(err) + } +} + +func loadContextAndResources(file *string) (*context.Context, *[]templater.RenderedResourceSet) { + ctx, err := context.LoadContext(*file, variables) + if err != nil { + app.Fatalf("Error loading context: %v\n", err) + } + + resources, err := templater.LoadAndApplyTemplates(includes, excludes, ctx) + if err != nil { + app.Fatalf("Error templating resource sets: %v\n", err) + } + + return ctx, &resources +} + +func runKubectlWithResources(c *context.Context, kubectlArgs *[]string, resourceSets *[]templater.RenderedResourceSet) error { + argsWithContext := append(*kubectlArgs, fmt.Sprintf("--context=%s", c.Name)) + + for _, rs := range *resourceSets { + if len(rs.Resources) == 0 { + fmt.Fprintf(os.Stderr, "Warning: Resource set '%s' contains no valid templates\n", rs.Name) + continue + } + + argsWithResourceSetArgs := append(argsWithContext, rs.Args...) + + kubectl := exec.Command(*kubectlBin, argsWithResourceSetArgs...) + + stdin, err := kubectl.StdinPipe() + if err != nil { + return fmt.Errorf("kubectl error: %v", err) + } + + kubectl.Stdout = os.Stdout + kubectl.Stderr = os.Stderr + + if err = kubectl.Start(); err != nil { + return fmt.Errorf("kubectl error: %v", err) + } + + for _, r := range rs.Resources { + fmt.Printf("Passing file %s/%s to kubectl\n", rs.Name, r.Filename) + fmt.Fprintln(stdin, r.Rendered) + } + stdin.Close() + + if err = kubectl.Wait(); err != nil { + return err + } + } + + return nil +} + +func failWithKubectlError(err error) { + app.Fatalf("Kubectl error: %v\n", err) +} diff --git a/ops/kontemplate/release.nix b/ops/kontemplate/release.nix new file mode 100644 index 0000000000..4af08f50c7 --- /dev/null +++ b/ops/kontemplate/release.nix @@ -0,0 +1,54 @@ +# Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +# +# This file is part of Kontemplate. +# +# Kontemplate is free software: you can redistribute it and/or modify +# it under the terms of the GNU General Public License as published by +# the Free Software Foundation, either version 3 of the License, or +# (at your option) any later version. +# +# This file is the Nix derivation used to build release binaries for +# several different architectures and operating systems. + +let pkgs = import ((import <nixpkgs> {}).fetchFromGitHub { + owner = "NixOS"; + repo = "nixpkgs-channels"; + rev = "541d9cce8af7a490fb9085305939569567cb58e6"; + sha256 = "0jgz72hhzkd5vyq5v69vpljjlnf0lqaz7fh327bvb3cvmwbfxrja"; +}) {}; +in with pkgs; buildGoPackage rec { + name = "kontemplate-${version}"; + version = "master"; + src = ./.; + goPackagePath = "github.com/tazjin/kontemplate"; + goDeps = ./deps.nix; + + # This configuration enables the building of statically linked + # executables. For some reason, those will have multiple references + # to the Go compiler's installation path in them, which is the + # reason for setting the 'allowGoReference' flag. + dontStrip = true; # Linker configuration handles stripping + allowGoReference = true; + CGO_ENABLED="0"; + GOCACHE="off"; + + # Configure release builds via the "build-matrix" script: + buildInputs = [ git ]; + buildPhase = '' + cd go/src/${goPackagePath} + patchShebangs build-release.sh + ./build-release.sh build + ''; + + outputs = [ "out" ]; + installPhase = '' + mkdir $out + cp -r release/ $out + ''; + + meta = with lib; { + description = "A resource templating helper for Kubernetes"; + homepage = "http://kontemplate.works/"; + license = licenses.gpl3; + }; +} diff --git a/ops/kontemplate/templater/dns.go b/ops/kontemplate/templater/dns.go new file mode 100644 index 0000000000..6cd974dd93 --- /dev/null +++ b/ops/kontemplate/templater/dns.go @@ -0,0 +1,35 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. +// +// This file contains the implementation of a template function for retrieving +// IP addresses from DNS + +package templater + +import ( + "fmt" + "net" + "os" +) + +func GetIPsFromDNS(host string) ([]interface{}, error) { + fmt.Fprintf(os.Stderr, "Attempting to look up IP for %s in DNS\n", host) + ips, err := net.LookupIP(host) + + if err != nil { + return nil, fmt.Errorf("IP address lookup failed: %v", err) + } + + var result []interface{} = make([]interface{}, len(ips)) + for i, ip := range ips { + result[i] = ip + } + + return result, nil +} diff --git a/ops/kontemplate/templater/pass.go b/ops/kontemplate/templater/pass.go new file mode 100644 index 0000000000..f7fbcb433d --- /dev/null +++ b/ops/kontemplate/templater/pass.go @@ -0,0 +1,34 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. +// +// This file contains the implementation of a template function for retrieving +// variables from 'pass', the standard UNIX password manager. + +package templater + +import ( + "fmt" + "os" + "os/exec" + "strings" +) + +func GetFromPass(key string) (string, error) { + fmt.Fprintf(os.Stderr, "Attempting to look up %s in pass\n", key) + pass := exec.Command("pass", "show", key) + + output, err := pass.CombinedOutput() + if err != nil { + return "", fmt.Errorf("Pass lookup failed: %s (%v)", output, err) + } + + trimmed := strings.TrimSpace(string(output)) + + return trimmed, nil +} diff --git a/ops/kontemplate/templater/templater.go b/ops/kontemplate/templater/templater.go new file mode 100644 index 0000000000..a8f0c670a6 --- /dev/null +++ b/ops/kontemplate/templater/templater.go @@ -0,0 +1,236 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +package templater + +import ( + "bytes" + "encoding/json" + "fmt" + "io/ioutil" + "os" + "os/exec" + "path" + "strings" + "text/template" + + "github.com/Masterminds/sprig" + "github.com/tazjin/kontemplate/context" + "github.com/tazjin/kontemplate/util" +) + +const failOnMissingKeys string = "missingkey=error" + +type RenderedResource struct { + Filename string + Rendered string +} + +type RenderedResourceSet struct { + Name string + Resources []RenderedResource + Args []string +} + +func LoadAndApplyTemplates(include *[]string, exclude *[]string, c *context.Context) ([]RenderedResourceSet, error) { + limitedResourceSets := applyLimits(&c.ResourceSets, include, exclude) + renderedResourceSets := make([]RenderedResourceSet, 0) + + if len(*limitedResourceSets) == 0 { + return renderedResourceSets, fmt.Errorf("No valid resource sets included!") + } + + for _, rs := range *limitedResourceSets { + set, err := processResourceSet(c, &rs) + + if err != nil { + return nil, err + } + + renderedResourceSets = append(renderedResourceSets, *set) + } + + return renderedResourceSets, nil +} + +func processResourceSet(ctx *context.Context, rs *context.ResourceSet) (*RenderedResourceSet, error) { + fmt.Fprintf(os.Stderr, "Loading resources for %s\n", rs.Name) + + fileInfo, err := os.Stat(rs.Path) + if err != nil { + return nil, err + } + + var files []os.FileInfo + var resources []RenderedResource + + // Treat single-file resource paths separately from resource + // sets containing multiple templates + if fileInfo.IsDir() { + // Explicitly discard this error, which will give us an empty + // list of files instead. + // This will end up printing a warning to the user, but it + // won't stop the rest of the process. + files, _ = ioutil.ReadDir(rs.Path) + resources, err = processFiles(ctx, rs, files) + if err != nil { + return nil, err + } + } else { + resource, err := templateFile(ctx, rs, rs.Path) + if err != nil { + return nil, err + } + + resources = []RenderedResource{resource} + } + + return &RenderedResourceSet{ + Name: rs.Name, + Resources: resources, + Args: rs.Args, + }, nil +} + +func processFiles(ctx *context.Context, rs *context.ResourceSet, files []os.FileInfo) ([]RenderedResource, error) { + resources := make([]RenderedResource, 0) + + for _, file := range files { + if !file.IsDir() && isResourceFile(file) { + path := path.Join(rs.Path, file.Name()) + res, err := templateFile(ctx, rs, path) + + if err != nil { + return resources, err + } + + resources = append(resources, res) + } + } + + return resources, nil +} + +func templateFile(ctx *context.Context, rs *context.ResourceSet, filepath string) (RenderedResource, error) { + var resource RenderedResource + + tpl, err := template.New(path.Base(filepath)).Funcs(templateFuncs(ctx, rs)).Option(failOnMissingKeys).ParseFiles(filepath) + if err != nil { + return resource, fmt.Errorf("Could not load template %s: %v", filepath, err) + } + + var b bytes.Buffer + err = tpl.Execute(&b, rs.Values) + if err != nil { + return resource, fmt.Errorf("Error while templating %s: %v", filepath, err) + } + + resource = RenderedResource{ + Filename: path.Base(filepath), + Rendered: b.String(), + } + + return resource, nil +} + +// Applies the limits of explicitly included or excluded resources and returns the updated resource set. +// Exclude takes priority over include +func applyLimits(rs *[]context.ResourceSet, include *[]string, exclude *[]string) *[]context.ResourceSet { + if len(*include) == 0 && len(*exclude) == 0 { + return rs + } + + // Exclude excluded resource sets + excluded := make([]context.ResourceSet, 0) + for _, r := range *rs { + if !matchesResourceSet(exclude, &r) { + excluded = append(excluded, r) + } + } + + // Include included resource sets + if len(*include) == 0 { + return &excluded + } + included := make([]context.ResourceSet, 0) + for _, r := range excluded { + if matchesResourceSet(include, &r) { + included = append(included, r) + } + } + + return &included +} + +// Check whether an include/exclude string slice matches a resource set +func matchesResourceSet(s *[]string, rs *context.ResourceSet) bool { + for _, r := range *s { + r = strings.TrimSuffix(r, "/") + if r == rs.Name || r == rs.Parent { + return true + } + } + + return false +} + +func templateFuncs(c *context.Context, rs *context.ResourceSet) template.FuncMap { + m := sprig.TxtFuncMap() + m["json"] = func(data interface{}) string { + b, _ := json.Marshal(data) + return string(b) + } + m["passLookup"] = GetFromPass + m["gitHEAD"] = func() (string, error) { + out, err := exec.Command("git", "-C", c.BaseDir, "rev-parse", "HEAD").Output() + if err != nil { + return "", err + } + output := strings.TrimSpace(string(out)) + return output, nil + } + m["lookupIPAddr"] = GetIPsFromDNS + m["insertFile"] = func(file string) (string, error) { + data, err := ioutil.ReadFile(path.Join(rs.Path, file)) + if err != nil { + return "", err + } + + return string(data), nil + } + m["insertTemplate"] = func(file string) (string, error) { + data, err := templateFile(c, rs, path.Join(rs.Path, file)) + if err != nil { + return "", err + } + + return data.Rendered, nil + } + m["default"] = func(defaultVal interface{}, varName string) interface{} { + if val, ok := rs.Values[varName]; ok { + return val + } + + return defaultVal + } + return m +} + +// Checks whether a file is a resource file (i.e. is YAML or JSON) and not a default values file. +func isResourceFile(f os.FileInfo) bool { + for _, defaultFile := range util.DefaultFilenames { + if f.Name() == defaultFile { + return false + } + } + + return strings.HasSuffix(f.Name(), "yaml") || + strings.HasSuffix(f.Name(), "yml") || + strings.HasSuffix(f.Name(), "json") +} diff --git a/ops/kontemplate/templater/templater_test.go b/ops/kontemplate/templater/templater_test.go new file mode 100644 index 0000000000..c20858c203 --- /dev/null +++ b/ops/kontemplate/templater/templater_test.go @@ -0,0 +1,205 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +package templater + +import ( + "github.com/tazjin/kontemplate/context" + "reflect" + "strings" + "testing" +) + +func TestApplyNoLimits(t *testing.T) { + resources := []context.ResourceSet{ + { + Name: "testResourceSet1", + }, + { + Name: "testResourceSet2", + }, + } + + result := applyLimits(&resources, &[]string{}, &[]string{}) + + if !reflect.DeepEqual(resources, *result) { + t.Error("Resource set slice changed, but shouldn't have.") + t.Errorf("Expected: %v\nResult: %v\n", resources, *result) + t.Fail() + } +} + +func TestApplyIncludeLimits(t *testing.T) { + resources := []context.ResourceSet{ + { + Name: "testResourceSet1", + }, + { + Name: "testResourceSet2", + }, + { + Name: "testResourceSet3", + Parent: "included", + }, + } + + includes := []string{"testResourceSet1", "included"} + + result := applyLimits(&resources, &includes, &[]string{}) + + expected := []context.ResourceSet{ + { + Name: "testResourceSet1", + }, + { + Name: "testResourceSet3", + Parent: "included", + }, + } + + if !reflect.DeepEqual(expected, *result) { + t.Error("Result does not contain expected resource sets.") + t.Errorf("Expected: %v\nResult: %v\n", expected, *result) + t.Fail() + } +} + +func TestApplyExcludeLimits(t *testing.T) { + resources := []context.ResourceSet{ + { + Name: "testResourceSet1", + }, + { + Name: "testResourceSet2", + }, + { + Name: "testResourceSet3", + Parent: "included", + }, + } + + exclude := []string{"testResourceSet2"} + + result := applyLimits(&resources, &[]string{}, &exclude) + + expected := []context.ResourceSet{ + { + Name: "testResourceSet1", + }, + { + Name: "testResourceSet3", + Parent: "included", + }, + } + + if !reflect.DeepEqual(expected, *result) { + t.Error("Result does not contain expected resource sets.") + t.Errorf("Expected: %v\nResult: %v\n", expected, *result) + t.Fail() + } +} + +func TestApplyLimitsExcludeIncludePrecedence(t *testing.T) { + resources := []context.ResourceSet{ + { + Name: "collection/nested1", + Parent: "collection", + }, + { + Name: "collection/nested2", + Parent: "collection", + }, + { + Name: "collection/nested3", + Parent: "collection", + }, + { + Name: "something-else", + }, + } + + include := []string{"collection"} + exclude := []string{"collection/nested2"} + + result := applyLimits(&resources, &include, &exclude) + + expected := []context.ResourceSet{ + { + Name: "collection/nested1", + Parent: "collection", + }, + { + Name: "collection/nested3", + Parent: "collection", + }, + } + + if !reflect.DeepEqual(expected, *result) { + t.Error("Result does not contain expected resource sets.") + t.Errorf("Expected: %v\nResult: %v\n", expected, *result) + t.Fail() + } +} + +func TestFailOnMissingKeys(t *testing.T) { + ctx := context.Context{} + resourceSet := context.ResourceSet{} + + _, err := templateFile(&ctx, &resourceSet, "testdata/test-template.txt") + + if err == nil { + t.Errorf("Template with missing keys should have failed.\n") + t.Fail() + } + + if !strings.Contains(err.Error(), "map has no entry for key \"testName\"") { + t.Errorf("Templating failed with unexpected error: %v\n", err) + } +} + +func TestDefaultTemplateFunction(t *testing.T) { + ctx := context.Context{} + resourceSet := context.ResourceSet{} + + res, err := templateFile(&ctx, &resourceSet, "testdata/test-default.txt") + + if err != nil { + t.Errorf("Templating with default values should have succeeded.\n") + t.Fail() + } + + if res.Rendered != "defaultValue\n" { + t.Error("Result does not contain expected rendered default value.") + t.Fail() + } +} + +func TestInsertTemplateFunction(t *testing.T) { + ctx := context.Context{} + resourceSet := context.ResourceSet{ + Path: "testdata", + Values: map[string]interface{}{ + "testName": "TestInsertTemplateFunction", + }, + } + + res, err := templateFile(&ctx, &resourceSet, "testdata/test-insertTemplate.txt") + + if err != nil { + t.Error(err) + t.Errorf("Templating with an insertTemplate call should have succeeded.\n") + t.Fail() + } + + if res.Rendered != "Inserting \"Template for test TestInsertTemplateFunction\".\n" { + t.Error("Result does not contain expected rendered template value.") + t.Error(res.Rendered) + t.Fail() + } +} diff --git a/ops/kontemplate/templater/testdata/test-default.txt b/ops/kontemplate/templater/testdata/test-default.txt new file mode 100644 index 0000000000..4f7997bd69 --- /dev/null +++ b/ops/kontemplate/templater/testdata/test-default.txt @@ -0,0 +1 @@ +{{ default "defaultValue" "missingVar" }} diff --git a/ops/kontemplate/templater/testdata/test-insertTemplate.txt b/ops/kontemplate/templater/testdata/test-insertTemplate.txt new file mode 100644 index 0000000000..8155e174fe --- /dev/null +++ b/ops/kontemplate/templater/testdata/test-insertTemplate.txt @@ -0,0 +1 @@ +Inserting "{{ insertTemplate "test-template.txt" | trim }}". diff --git a/ops/kontemplate/templater/testdata/test-template.txt b/ops/kontemplate/templater/testdata/test-template.txt new file mode 100644 index 0000000000..06f1cfc630 --- /dev/null +++ b/ops/kontemplate/templater/testdata/test-template.txt @@ -0,0 +1 @@ +Template for test {{ .testName }} diff --git a/ops/kontemplate/util/util.go b/ops/kontemplate/util/util.go new file mode 100644 index 0000000000..56fa1e3fc9 --- /dev/null +++ b/ops/kontemplate/util/util.go @@ -0,0 +1,58 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +package util + +import ( + "io/ioutil" + + "github.com/ghodss/yaml" +) + +// Filenames excluded from templating for the purpose of containing default variable values inside a resource set. +var DefaultFilenames []string = []string{"default.yml", "default.yaml", "default.json"} + +// Merges two maps together. Values from the second map override values in the first map. +// The returned map is new if anything was changed. +func Merge(in1 *map[string]interface{}, in2 *map[string]interface{}) *map[string]interface{} { + if in1 == nil || len(*in1) == 0 { + return in2 + } + + if in2 == nil || len(*in2) == 0 { + return in1 + } + + new := make(map[string]interface{}) + for k, v := range *in1 { + new[k] = v + } + + for k, v := range *in2 { + new[k] = v + } + + return &new +} + +// Loads either a YAML or JSON file from the specified path and +// deserialises it into the provided interface. +func LoadData(filename string, addr interface{}) error { + file, err := ioutil.ReadFile(filename) + if err != nil { + return err + } + + err = yaml.Unmarshal(file, addr) + if err != nil { + return err + } + + return nil +} diff --git a/ops/kontemplate/util/util_test.go b/ops/kontemplate/util/util_test.go new file mode 100644 index 0000000000..53c5608175 --- /dev/null +++ b/ops/kontemplate/util/util_test.go @@ -0,0 +1,83 @@ +// Copyright (C) 2016-2019 Vincent Ambo <mail@tazj.in> +// +// This file is part of Kontemplate. +// +// Kontemplate is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. + +package util + +import ( + "reflect" + "testing" +) + +func TestMergeWithEmptyMap(t *testing.T) { + testMap := map[string]interface{}{ + "foo": "bar", + } + + empty := make(map[string]interface{}) + + res1 := Merge(&testMap, &empty) + res2 := Merge(&empty, &testMap) + + if res1 != &testMap || res2 != &testMap { + t.Error("A new map was returned incorrectly.") + t.Fail() + } +} + +func TestMergeWithNilMap(t *testing.T) { + testMap := map[string]interface{}{ + "foo": "bar", + } + + res1 := Merge(&testMap, nil) + res2 := Merge(nil, &testMap) + + if res1 != &testMap || res2 != &testMap { + t.Error("A new map was returned incorrectly.") + t.Fail() + } +} + +func TestMergeMaps(t *testing.T) { + map1 := map[string]interface{}{ + "foo": "bar", + } + + map2 := map[string]interface{}{ + "bar": "baz", + } + + result := Merge(&map1, &map2) + expected := map[string]interface{}{ + "foo": "bar", + "bar": "baz", + } + + if !reflect.DeepEqual(*result, expected) { + t.Error("Maps were merged incorrectly.") + t.Fail() + } +} + +func TestMergeMapsPrecedence(t *testing.T) { + map1 := map[string]interface{}{ + "foo": "incorrect", + } + + map2 := map[string]interface{}{ + "foo": "correct", + } + + result := Merge(&map1, &map2) + + if (*result)["foo"] != "correct" { + t.Error("Map merge precedence test failed.") + t.Fail() + } +} diff --git a/ops/mq_cli/.gitignore b/ops/mq_cli/.gitignore new file mode 100644 index 0000000000..5bd19a47c3 --- /dev/null +++ b/ops/mq_cli/.gitignore @@ -0,0 +1,4 @@ +/target/ +**/*.rs.bk +.idea/ +*.iml diff --git a/ops/mq_cli/CODE_OF_CONDUCT.md b/ops/mq_cli/CODE_OF_CONDUCT.md new file mode 100644 index 0000000000..c4013ac13e --- /dev/null +++ b/ops/mq_cli/CODE_OF_CONDUCT.md @@ -0,0 +1,20 @@ +A SERMON ON ETHICS AND LOVE +=========================== + +One day Mal-2 asked the messenger spirit Saint Gulik to approach the Goddess and request Her presence for some desperate advice. Shortly afterwards the radio came on by itself, and an ethereal female Voice said **YES?** + +"O! Eris! Blessed Mother of Man! Queen of Chaos! Daughter of Discord! Concubine of Confusion! O! Exquisite Lady, I beseech You to lift a heavy burden from my heart!" + +**WHAT BOTHERS YOU, MAL? YOU DON'T SOUND WELL.** + +"I am filled with fear and tormented with terrible visions of pain. Everywhere people are hurting one another, the planet is rampant with injustices, whole societies plunder groups of their own people, mothers imprison sons, children perish while brothers war. O, woe." + +**WHAT IS THE MATTER WITH THAT, IF IT IS WHAT YOU WANT TO DO?** + +"But nobody Wants it! Everybody hates it." + +**OH. WELL, THEN *STOP*.** + +At which moment She turned herself into an aspirin commercial and left The Polyfather stranded alone with his species. + +SINISTER DEXTER HAS A BROKEN SPIROMETER. diff --git a/ops/mq_cli/Cargo.lock b/ops/mq_cli/Cargo.lock new file mode 100644 index 0000000000..f418d77c34 --- /dev/null +++ b/ops/mq_cli/Cargo.lock @@ -0,0 +1,159 @@ +# This file is automatically @generated by Cargo. +# It is not intended for manual editing. +[[package]] +name = "ansi_term" +version = "0.11.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "atty" +version = "0.2.14" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "hermit-abi 0.1.6 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "bitflags" +version = "1.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cc" +version = "1.0.50" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cfg-if" +version = "0.1.10" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "clap" +version = "2.33.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "ansi_term 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)", + "atty 0.2.14 (registry+https://github.com/rust-lang/crates.io-index)", + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "strsim 0.8.0 (registry+https://github.com/rust-lang/crates.io-index)", + "textwrap 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-width 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)", + "vec_map 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "hermit-abi" +version = "0.1.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "libc" +version = "0.2.66" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "mq" +version = "1.0.0" +dependencies = [ + "clap 2.33.0 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "nix 0.16.1 (registry+https://github.com/rust-lang/crates.io-index)", + "posix_mq 0.9.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "nix" +version = "0.16.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "cc 1.0.50 (registry+https://github.com/rust-lang/crates.io-index)", + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "void 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "posix_mq" +version = "0.9.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "nix 0.16.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "strsim" +version = "0.8.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "textwrap" +version = "0.11.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "unicode-width 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "unicode-width" +version = "0.1.7" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "vec_map" +version = "0.8.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "void" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "winapi" +version = "0.3.8" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi-i686-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi-x86_64-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "winapi-i686-pc-windows-gnu" +version = "0.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "winapi-x86_64-pc-windows-gnu" +version = "0.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[metadata] +"checksum ansi_term 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ee49baf6cb617b853aa8d93bf420db2383fab46d314482ca2803b40d5fde979b" +"checksum atty 0.2.14 (registry+https://github.com/rust-lang/crates.io-index)" = "d9b39be18770d11421cdb1b9947a45dd3f37e93092cbf377614828a319d5fee8" +"checksum bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "cf1de2fe8c75bc145a2f577add951f8134889b4795d47466a54a5c846d691693" +"checksum cc 1.0.50 (registry+https://github.com/rust-lang/crates.io-index)" = "95e28fa049fda1c330bcf9d723be7663a899c4679724b34c81e9f5a326aab8cd" +"checksum cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)" = "4785bdd1c96b2a846b2bd7cc02e86b6b3dbf14e7e53446c4f54c92a361040822" +"checksum clap 2.33.0 (registry+https://github.com/rust-lang/crates.io-index)" = "5067f5bb2d80ef5d68b4c87db81601f0b75bca627bc2ef76b141d7b846a3c6d9" +"checksum hermit-abi 0.1.6 (registry+https://github.com/rust-lang/crates.io-index)" = "eff2656d88f158ce120947499e971d743c05dbcbed62e5bd2f38f1698bbc3772" +"checksum libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)" = "d515b1f41455adea1313a4a2ac8a8a477634fbae63cc6100e3aebb207ce61558" +"checksum nix 0.16.1 (registry+https://github.com/rust-lang/crates.io-index)" = "dd0eaf8df8bab402257e0a5c17a254e4cc1f72a93588a1ddfb5d356c801aa7cb" +"checksum posix_mq 0.9.0 (registry+https://github.com/rust-lang/crates.io-index)" = "13ae339e13cc96902a4597a5aab6b76473093969c55d36ba33f6a7bf3268573f" +"checksum strsim 0.8.0 (registry+https://github.com/rust-lang/crates.io-index)" = "8ea5119cdb4c55b55d432abb513a0429384878c15dde60cc77b1c99de1a95a6a" +"checksum textwrap 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "d326610f408c7a4eb6f51c37c330e496b08506c9457c9d34287ecc38809fb060" +"checksum unicode-width 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)" = "caaa9d531767d1ff2150b9332433f32a24622147e5ebb1f26409d5da67afd479" +"checksum vec_map 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)" = "05c78687fb1a80548ae3250346c3db86a80a7cdd77bda190189f2d0a0987c81a" +"checksum void 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "6a02e4885ed3bc0f2de90ea6dd45ebcbb66dacffe03547fadbb0eeae2770887d" +"checksum winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)" = "8093091eeb260906a183e6ae1abdba2ef5ef2257a21801128899c3fc699229c6" +"checksum winapi-i686-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6" +"checksum winapi-x86_64-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f" diff --git a/ops/mq_cli/Cargo.toml b/ops/mq_cli/Cargo.toml new file mode 100644 index 0000000000..b412d88787 --- /dev/null +++ b/ops/mq_cli/Cargo.toml @@ -0,0 +1,10 @@ +[package] +name = "mq" +version = "1.0.0" +authors = ["Vincent Ambo <mail@tazj.in>"] + +[dependencies] +clap = "2.33" +libc = "0.2" +nix = "0.16" +posix_mq = "0.9" diff --git a/ops/mq_cli/LICENSE b/ops/mq_cli/LICENSE new file mode 100644 index 0000000000..e289cbab81 --- /dev/null +++ b/ops/mq_cli/LICENSE @@ -0,0 +1,22 @@ +MIT License + +Copyright (c) 2017-2018 Langler AS +Copyright (c) 2019-2020 Vincent Ambo + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/ops/mq_cli/README.md b/ops/mq_cli/README.md new file mode 100644 index 0000000000..e612553e74 --- /dev/null +++ b/ops/mq_cli/README.md @@ -0,0 +1,31 @@ +mq-cli +====== + +This project provides a very simple CLI interface to [POSIX message queues][]. + +It can be used to create and inspect queues, as well as send and +receive messages from them. + +``` +1.0.0 +Administrate and inspect POSIX message queues + +USAGE: + mq <SUBCOMMAND> + +FLAGS: + -h, --help Prints help information + -V, --version Prints version information + +SUBCOMMANDS: + create Create a new queue + help Prints this message or the help of the given subcommand(s) + inspect inspect details about a queue + ls list message queues + receive Receive a message from a queue + rlimit Get the message queue rlimit + send Send a message to a queue +``` + + +[POSIX message queues]: https://linux.die.net/man/7/mq_overview diff --git a/ops/mq_cli/default.nix b/ops/mq_cli/default.nix new file mode 100644 index 0000000000..6b0e32009a --- /dev/null +++ b/ops/mq_cli/default.nix @@ -0,0 +1,3 @@ +{ depot, ... }: + +depot.third_party.naersk.buildPackage ./. diff --git a/ops/mq_cli/src/main.rs b/ops/mq_cli/src/main.rs new file mode 100644 index 0000000000..55ff006429 --- /dev/null +++ b/ops/mq_cli/src/main.rs @@ -0,0 +1,223 @@ +extern crate clap; +extern crate posix_mq; +extern crate libc; +extern crate nix; + +use clap::{App, SubCommand, Arg, ArgMatches, AppSettings}; +use posix_mq::{Name, Queue, Message}; +use std::fs::{read_dir, File}; +use std::io::{self, Read, Write}; +use std::process::exit; + +fn run_ls() { + let mqueues = read_dir("/dev/mqueue") + .expect("Could not read message queues"); + + for queue in mqueues { + let path = queue.unwrap().path(); + let status = { + let mut file = File::open(&path) + .expect("Could not open queue file"); + + let mut content = String::new(); + file.read_to_string(&mut content).expect("Could not read queue file"); + + content + }; + + let queue_name = path.components().last().unwrap() + .as_os_str() + .to_string_lossy(); + + println!("/{}: {}", queue_name, status) + }; +} + +fn run_inspect(queue_name: &str) { + let name = Name::new(queue_name).expect("Invalid queue name"); + let queue = Queue::open(name).expect("Could not open queue"); + + println!("Queue {}:\n", queue_name); + println!("Max. message size: {} bytes", queue.max_size()); + println!("Max. # of pending messages: {}", queue.max_pending()); +} + +fn run_create(cmd: &ArgMatches) { + if let Some(rlimit) = cmd.value_of("rlimit") { + set_rlimit(rlimit.parse().expect("Invalid rlimit value")); + } + + let name = Name::new(cmd.value_of("queue").unwrap()) + .expect("Invalid queue name"); + + let max_pending: i64 = cmd.value_of("max-pending").unwrap().parse().unwrap(); + let max_size: i64 = cmd.value_of("max-size").unwrap().parse().unwrap(); + + let queue = Queue::create(name, max_pending, max_size * 1024); + + match queue { + Ok(_) => println!("Queue created successfully"), + Err(e) => { + writeln!(io::stderr(), "Could not create queue: {}", e).ok(); + exit(1); + }, + }; +} + +fn run_receive(queue_name: &str) { + let name = Name::new(queue_name).expect("Invalid queue name"); + let queue = Queue::open(name).expect("Could not open queue"); + + let message = match queue.receive() { + Ok(msg) => msg, + Err(e) => { + writeln!(io::stderr(), "Failed to receive message: {}", e).ok(); + exit(1); + } + }; + + // Attempt to write the message out as a string, but write out raw bytes if it turns out to not + // be UTF-8 encoded data. + match String::from_utf8(message.data.clone()) { + Ok(string) => println!("{}", string), + Err(_) => { + writeln!(io::stderr(), "Message not UTF-8 encoded!").ok(); + io::stdout().write(message.data.as_ref()).ok(); + } + }; +} + +fn run_send(queue_name: &str, content: &str) { + let name = Name::new(queue_name).expect("Invalid queue name"); + let queue = Queue::open(name).expect("Could not open queue"); + + let message = Message { + data: content.as_bytes().to_vec(), + priority: 0, + }; + + match queue.send(&message) { + Ok(_) => (), + Err(e) => { + writeln!(io::stderr(), "Could not send message: {}", e).ok(); + exit(1); + } + } +} + +fn run_rlimit() { + let mut rlimit = libc::rlimit { + rlim_cur: 0, + rlim_max: 0, + }; + + let mut errno = 0; + unsafe { + let res = libc::getrlimit(libc::RLIMIT_MSGQUEUE, &mut rlimit); + if res != 0 { + errno = nix::errno::errno(); + } + }; + + if errno != 0 { + writeln!(io::stderr(), "Could not get message queue rlimit: {}", errno).ok(); + } else { + println!("Message queue rlimit:"); + println!("Current limit: {}", rlimit.rlim_cur); + println!("Maximum limit: {}", rlimit.rlim_max); + } +} + +fn set_rlimit(new_limit: u64) { + let rlimit = libc::rlimit { + rlim_cur: new_limit, + rlim_max: new_limit, + }; + + let mut errno: i32 = 0; + unsafe { + let res = libc::setrlimit(libc::RLIMIT_MSGQUEUE, &rlimit); + if res != 0 { + errno = nix::errno::errno(); + } + } + + match errno { + 0 => println!("Set RLIMIT_MSGQUEUE hard limit to {}", new_limit), + _ => { + // Not mapping these error codes to messages for now, the user can + // look up the meaning in setrlimit(2). + panic!("Could not set hard limit: {}", errno); + } + }; +} + +fn main() { + let ls = SubCommand::with_name("ls").about("list message queues"); + + let queue_arg = Arg::with_name("queue").required(true).takes_value(true); + + let rlimit_arg = Arg::with_name("rlimit") + .help("RLIMIT_MSGQUEUE to set for this command") + .long("rlimit") + .takes_value(true); + + let inspect = SubCommand::with_name("inspect") + .about("inspect details about a queue") + .arg(&queue_arg); + + let create = SubCommand::with_name("create") + .about("Create a new queue") + .arg(&queue_arg) + .arg(&rlimit_arg) + .arg(Arg::with_name("max-size") + .help("maximum message size (in kB)") + .long("max-size") + .required(true) + .takes_value(true)) + .arg(Arg::with_name("max-pending") + .help("maximum # of pending messages") + .long("max-pending") + .required(true) + .takes_value(true)); + + let receive = SubCommand::with_name("receive") + .about("Receive a message from a queue") + .arg(&queue_arg); + + let send = SubCommand::with_name("send") + .about("Send a message to a queue") + .arg(&queue_arg) + .arg(Arg::with_name("message") + .help("the message to send") + .required(true)); + + let rlimit = SubCommand::with_name("rlimit") + .about("Get the message queue rlimit") + .setting(AppSettings::SubcommandRequiredElseHelp); + + let matches = App::new("mq") + .setting(AppSettings::SubcommandRequiredElseHelp) + .version("1.0.0") + .about("Administrate and inspect POSIX message queues") + .subcommand(ls) + .subcommand(inspect) + .subcommand(create) + .subcommand(receive) + .subcommand(send) + .subcommand(rlimit) + .get_matches(); + + match matches.subcommand() { + ("ls", _) => run_ls(), + ("inspect", Some(cmd)) => run_inspect(cmd.value_of("queue").unwrap()), + ("create", Some(cmd)) => run_create(cmd), + ("receive", Some(cmd)) => run_receive(cmd.value_of("queue").unwrap()), + ("send", Some(cmd)) => run_send( + cmd.value_of("queue").unwrap(), + cmd.value_of("message").unwrap() + ), + ("rlimit", _) => run_rlimit(), + _ => unimplemented!(), + } +} diff --git a/ops/nixos/.gitignore b/ops/nixos/.gitignore new file mode 100644 index 0000000000..773fa16670 --- /dev/null +++ b/ops/nixos/.gitignore @@ -0,0 +1,3 @@ +hardware-configuration.nix +local-configuration.nix +result diff --git a/ops/nixos/README.md b/ops/nixos/README.md new file mode 100644 index 0000000000..9e88193dad --- /dev/null +++ b/ops/nixos/README.md @@ -0,0 +1,19 @@ +NixOS configuration +=================== + +My NixOS configuration! It configures most of the packages I require +on my systems, sets up Emacs the way I need and does a bunch of other +interesting things. + +System configuration lives in folders for each machine and a custom +fixed point evaluation (similar to standard NixOS module +configuration) is used to combine configuration together. + +Building `ops.nixos.rebuilder` yields a script that will automatically +build and activate the newest configuration based on the current +hostname. + +## Configured hosts: + +* `nugget` - desktop computer at home +* ~~`urdhva` - T470s~~ (currently with edef) diff --git a/ops/nixos/camden/default.nix b/ops/nixos/camden/default.nix new file mode 100644 index 0000000000..2eb8976da1 --- /dev/null +++ b/ops/nixos/camden/default.nix @@ -0,0 +1,367 @@ +# This file configures camden.tazj.in, my homeserver. +{ depot, pkgs, lib, ... }: + +config: let + nixpkgs = import depot.third_party.nixpkgsSrc { + config.allowUnfree = true; + }; +in lib.fix(self: { + # camden is intended to boot unattended, despite having an encrypted + # root partition. + # + # The below configuration uses an externally connected USB drive + # that contains a LUKS key file to unlock the disk automatically at + # boot. + # + # TODO(tazjin): Configure LUKS unlocking via SSH instead. + boot = { + initrd = { + availableKernelModules = [ + "ahci" "xhci_pci" "usbhid" "usb_storage" "sd_mod" "sdhci_pci" + "rtsx_usb_sdmmc" "r8169" + ]; + + kernelModules = [ "dm-snapshot" ]; + + luks.devices.camden-crypt = { + fallbackToPassword = true; + device = "/dev/disk/by-label/camden-crypt"; + keyFile = "/dev/sdb"; + keyFileSize = 4096; + }; + }; + + loader = { + systemd-boot.enable = true; + efi.canTouchEfiVariables = true; + }; + + cleanTmpDir = true; + }; + + fileSystems = { + "/" = { + device = "/dev/disk/by-label/camden-root"; + fsType = "ext4"; + }; + + "/home" = { + device = "/dev/disk/by-label/camden-home"; + fsType = "ext4"; + }; + + "/boot" = { + device = "/dev/disk/by-label/BOOT"; + fsType = "vfat"; + }; + }; + + nix = { + maxJobs = lib.mkDefault 4; + + nixPath = [ + "depot=/home/tazjin/depot" + "nixpkgs=${depot.third_party.nixpkgsSrc}" + ]; + + trustedUsers = [ "root" "tazjin" ]; + + binaryCaches = [ + "https://tazjin.cachix.org" + ]; + + binaryCachePublicKeys = [ + "tazjin.cachix.org-1:IZkgLeqfOr1kAZjypItHMg1NoBjm4zX9Zzep8oRSh7U=" + ]; + }; + nixpkgs.pkgs = nixpkgs; + + powerManagement.cpuFreqGovernor = lib.mkDefault "powersave"; + + networking = { + hostName = "camden"; + interfaces.enp1s0.useDHCP = true; + interfaces.enp1s0.ipv6.addresses = [ + { + address = "2a01:4b00:821a:ce02::5"; + prefixLength = 64; + } + ]; + + firewall.enable = false; + }; + + time.timeZone = "UTC"; + + # System-wide application setup + programs.fish.enable = true; + programs.mosh.enable = true; + + environment.systemPackages = + # programs from the depot + (with depot; [ + fun.idual.script + fun.idual.setAlarm + third_party.git + third_party.honk + third_party.pounce + ]) ++ + + # programs from nixpkgs + (with nixpkgs; [ + bat + curl + direnv + emacs26-nox + gnupg + htop + jq + pass + pciutils + ripgrep + ]); + + users = { + # Set up my own user for logging in and doing things ... + users.tazjin = { + isNormalUser = true; + uid = 1000; + extraGroups = [ "git" "wheel" ]; + shell = nixpkgs.fish; + }; + + # Set up a user & group for general git shenanigans + groups.git = {}; + users.git = { + group = "git"; + isNormalUser = false; + }; + }; + + # Services setup + services.openssh.enable = true; + services.haveged.enable = true; + + # Join Tailscale into home network + services.tailscale.enable = true; + + # Allow sudo-ing via the forwarded SSH agent. + security.pam.enableSSHAgentAuth = true; + + # Run cgit for the depot. The onion here is nginx(thttpd(cgit)). + systemd.services.cgit = { + wantedBy = [ "multi-user.target" ]; + script = "${depot.web.cgit-taz}/bin/cgit-launch"; + + serviceConfig = { + Restart = "on-failure"; + User = "git"; + Group = "git"; + }; + }; + + # Run honk as the ActivityPub server, using all the fancy systemd + # magic. + systemd.services.honk = { + wantedBy = [ "multi-user.target" ]; + script = lib.concatStringsSep " " [ + "${depot.third_party.honk}/bin/honk" + "-datadir /var/lib/honk" + "-viewdir ${depot.third_party.honk.src}" + ]; + + serviceConfig = { + Restart = "always"; + DynamicUser = true; + StateDirectory = "honk"; + WorkingDirectory = "/var/lib/honk"; + }; + }; + + # NixOS 20.03 broke nginx and I can't be bothered to debug it + # anymore, all solution attempts have failed, so here's a + # brute-force fix. + systemd.services.fix-nginx = { + script = "${nixpkgs.coreutils}/bin/chown -R nginx: /var/spool/nginx"; + + serviceConfig = { + User = "root"; + Type = "oneshot"; + }; + }; + + systemd.timers.fix-nginx = { + wantedBy = [ "multi-user.target" ]; + timerConfig = { + OnCalendar = "minutely"; + }; + }; + + # Provision a TLS certificate outside of nginx to avoid + # nixpkgs#38144 + security.acme = { + acceptTerms = true; + email = "mail@tazj.in"; + + certs."tazj.in" = { + user = "nginx"; + group = "nginx"; + webroot = "/var/lib/acme/acme-challenge"; + extraDomains = { + "git.tazj.in" = null; + "www.tazj.in" = null; + + # Local domains (for this machine only) + "camden.tazj.in" = null; + "git.camden.tazj.in" = null; + }; + postRun = "systemctl reload nginx"; + }; + + certs."tvl.fyi" = { + user = "nginx"; + group = "nginx"; + webroot = "/var/lib/acme/acme-challenge"; + postRun = "systemctl reload nginx"; + }; + }; + + # Forward logs to Google Cloud Platform + services.journaldriver = { + enable = true; + logStream = "home"; + googleCloudProject = "tazjins-infrastructure"; + applicationCredentials = "/etc/gcp/key.json"; + }; + + # serve my website + services.nginx = { + enable = true; + enableReload = true; + package = with nixpkgs; nginx.override { + modules = [ nginxModules.rtmp ]; + }; + + recommendedTlsSettings = true; + recommendedGzipSettings = true; + recommendedProxySettings = true; + + + appendConfig = '' + rtmp_auto_push on; + rtmp { + server { + listen 1935; + chunk_size 4000; + + application tvl { + live on; + + allow publish 88.98.195.213; + allow publish 10.0.1.0/24; + deny publish all; + + allow play all; + } + } + } + ''; + + commonHttpConfig = '' + log_format json_combined escape=json + '{' + '"remote_addr":"$remote_addr",' + '"method":"$request_method",' + '"uri":"$request_uri",' + '"status":$status,' + '"request_size":$request_length,' + '"response_size":$body_bytes_sent,' + '"response_time":$request_time,' + '"referrer":"$http_referer",' + '"user_agent":"$http_user_agent"' + '}'; + + access_log syslog:server=unix:/dev/log,nohostname json_combined; + ''; + + virtualHosts.homepage = { + serverName = "tazj.in"; + serverAliases = [ "camden.tazj.in" ]; + default = true; + useACMEHost = "tazj.in"; + root = depot.web.homepage; + addSSL = true; + + extraConfig = '' + ${depot.web.blog.oldRedirects} + + add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always; + + location ~* \.(webp|woff2)$ { + add_header Cache-Control "public, max-age=31536000"; + } + + location /blog/ { + alias ${depot.web.blog.rendered}/; + + if ($request_uri ~ ^/(.*)\.html$) { + return 302 /$1; + } + + try_files $uri $uri.html $uri/ =404; + } + + location /blobs/ { + alias /var/www/blobs/; + } + ''; + }; + + virtualHosts.tvl = { + serverName = "tvl.fyi"; + useACMEHost = "tvl.fyi"; + root = depot.web.tvl; + addSSL = true; + + extraConfig = '' + add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always; + + rewrite ^/meet/?$ https://meet.google.com/mng-biyw-xbb last; + + location ~* \.(webp|woff2)$ { + add_header Cache-Control "public, max-age=31536000"; + } + ''; + }; + + virtualHosts.cgit = { + serverName = "git.tazj.in"; + serverAliases = [ "git.camden.tazj.in" ]; + useACMEHost = "tazj.in"; + addSSL = true; + + extraConfig = '' + # Static assets must always hit the root. + location ~ ^/(favicon\.ico|cgit\.(css|png))$ { + proxy_pass http://localhost:2448; + } + + # Everything else hits the depot directly. + location / { + proxy_pass http://localhost:2448/cgit.cgi/depot/; + } + ''; + }; + }; + + # Timer units that can be started with systemd-run to set my alarm. + systemd.user.services.light-alarm = { + script = "${depot.fun.idual.script}/bin/idualctl wakey"; + postStart = "${pkgs.systemd}/bin/systemctl --user stop light-alarm.timer"; + serviceConfig = { + Type = "oneshot"; + }; + }; + + system.stateVersion = "19.09"; +}) diff --git a/ops/nixos/default.nix b/ops/nixos/default.nix new file mode 100644 index 0000000000..040bfeb6e2 --- /dev/null +++ b/ops/nixos/default.nix @@ -0,0 +1,42 @@ +{ depot, lib, ... }: + +let + inherit (builtins) foldl'; + + systemFor = configs: (depot.third_party.nixos { + configuration = lib.fix(config: + foldl' lib.recursiveUpdate {} (map (c: c config) configs) + ); + }).system; + + rebuilder = depot.third_party.writeShellScriptBin "rebuilder" '' + set -ue + if [[ $EUID -ne 0 ]]; then + echo "Oh no! Only root is allowed to rebuild the system!" >&2 + exit 1 + fi + + case $HOSTNAME in + nugget) + echo "Rebuilding NixOS for //ops/nixos/nugget" + system=$(nix-build -E '(import <depot> {}).ops.nixos.nuggetSystem' --no-out-link) + ;; + camden) + echo "Rebuilding NixOS for //ops/nixos/camden" + system=$(nix-build -E '(import <depot> {}).ops.nixos.camdenSystem' --no-out-link) + ;; + *) + echo "$HOSTNAME is not a known NixOS host!" >&2 + exit 1 + ;; + esac + + nix-env -p /nix/var/nix/profiles/system --set $system + $system/bin/switch-to-configuration switch + ''; +in { + inherit rebuilder; + + nuggetSystem = systemFor [ depot.ops.nixos.nugget ]; + camdenSystem = systemFor [ depot.ops.nixos.camden ]; +} diff --git a/ops/nixos/dotfiles/config.fish b/ops/nixos/dotfiles/config.fish new file mode 100644 index 0000000000..de2c99ae60 --- /dev/null +++ b/ops/nixos/dotfiles/config.fish @@ -0,0 +1,40 @@ +# Configure classic prompt +set fish_color_user --bold blue +set fish_color_cwd --bold white + +# Enable colour hints in VCS prompt: +set __fish_git_prompt_showcolorhints yes +set __fish_git_prompt_color_prefix purple +set __fish_git_prompt_color_suffix purple + +# Fish configuration +set fish_greeting "" +set PATH $HOME/.local/bin $HOME/.cargo/bin $PATH + +# Editor configuration +set -gx EDITOR "emacsclient" +set -gx ALTERNATE_EDITOR "emacs -q -nw" +set -gx VISUAL "emacsclient" + +# Miscellaneous +eval (direnv hook fish) + +# Useful command aliases +alias gpr 'git pull --rebase' +alias gco 'git checkout' +alias gf 'git fetch' +alias gap 'git add -p' +alias pbcopy 'xclip -selection clipboard' +alias edit 'emacsclient -n' +alias servedir 'nix-shell -p haskellPackages.wai-app-static --run warp' + +# Old habits die hard (also ls is just easier to type): +alias ls 'exa' + +# Fix up nix-env & friends for Nix 2.0 +export NIX_REMOTE=daemon + +# Fix display of fish in emacs' term-mode: +function fish_title + true +end diff --git a/ops/nixos/dotfiles/msmtprc b/ops/nixos/dotfiles/msmtprc new file mode 100644 index 0000000000..624b6a77fc --- /dev/null +++ b/ops/nixos/dotfiles/msmtprc @@ -0,0 +1,16 @@ +defaults + +port 587 +tls on +tls_trust_file /etc/ssl/certs/ca-certificates.crt + +# Runbox mail +account runbox +from mail@tazj.in +host mail.runbox.com +auth on +user mail@tazj.in +passwordeval pass show general/runbox-tazjin + +# Use Runbox as default +account default : runbox diff --git a/ops/nixos/dotfiles/notmuch-config b/ops/nixos/dotfiles/notmuch-config new file mode 100644 index 0000000000..a490774e63 --- /dev/null +++ b/ops/nixos/dotfiles/notmuch-config @@ -0,0 +1,21 @@ +# .notmuch-config - Configuration file for the notmuch mail system +# +# For more information about notmuch, see https://notmuchmail.org + +[database] +path=/home/vincent/mail + +[user] +name=Vincent Ambo +primary_email=mail@tazj.in +other_email=tazjin@gmail.com; + +[new] +tags=unread;inbox; +ignore= + +[search] +exclude_tags=deleted;spam;draft; + +[maildir] +synchronize_flags=true diff --git a/ops/nixos/dotfiles/offlineimaprc b/ops/nixos/dotfiles/offlineimaprc new file mode 100644 index 0000000000..78315447e4 --- /dev/null +++ b/ops/nixos/dotfiles/offlineimaprc @@ -0,0 +1,39 @@ +[general] +accounts = tazjin, gmail + +[DEFAULT] +ssl = yes +sslcacertfile = /etc/ssl/certs/ca-certificates.crt + +# Private GMail account (old): +[Account gmail] +maxage = 90 +localrepository = gmail-local +remoterepository = gmail-remote +synclabels = yes + +[Repository gmail-local] +type = GmailMaildir +localfolders = ~/mail/gmail + +[Repository gmail-remote] +type = Gmail +remoteuser = tazjin@gmail.com +remotepassfile = ~/.config/mail/gmail-pass +folderfilter = lambda folder: folder == 'INBOX' + +# Main private account: +[Account tazjin] +localrepository = tazjin-local +remoterepository = tazjin-remote + +[Repository tazjin-local] +type = Maildir +localfolders = ~/mail/tazjin + +[Repository tazjin-remote] +type = IMAP +remotehost = mail.runbox.com +remoteuser = mail@tazj.in +remotepassfile = ~/.config/mail/tazjin-pass +auth_mechanisms = LOGIN diff --git a/ops/nixos/mail.nix b/ops/nixos/mail.nix new file mode 100644 index 0000000000..ba4ebfa060 --- /dev/null +++ b/ops/nixos/mail.nix @@ -0,0 +1,77 @@ +# This file configures offlineimap, notmuch and MSMTP. +# +# Some manual configuration is required the first time this is +# applied: +# +# 1. Credential setup. +# 2. Linking of MSMTP config (ln -s /etc/msmtprc ~/.msmtprc) +# 3. Linking of notmuch config (ln -s /etc/notmuch-config ~/.notmuch-config) + +{ config, lib, pkgs, ... }: + +let offlineImapConfig = pkgs.writeText "offlineimaprc" + (builtins.readFile ./dotfiles/offlineimaprc); + +msmtpConfig = pkgs.writeText "msmtprc" + (builtins.readFile ./dotfiles/msmtprc); + +notmuchConfig = pkgs.writeText "notmuch-config" + (builtins.readFile ./dotfiles/notmuch-config); + +tagConfig = pkgs.writeText "notmuch-tags" '' + # Tag emacs-devel mailing list: + -inbox +emacs-devel -- to:emacs-devel@gnu.org OR cc:emacs-devel@gnu.org + + # Tag nix-devel mailing list & discourse: + -inbox +nix-devel -- to:nix-devel@googlegroups.com OR from:nixos1@discoursemail.com + + # Tag my own mail (from other devices) as sent: + -inbox +sent -- from:mail@tazj.in + + # Drafts are always read, duh. + -unread -- tag:draft +''; + +notmuchIndex = pkgs.writeShellScriptBin "notmuch-index" '' + echo "Indexing new mails in notmuch" + + # Index new mail + ${pkgs.notmuch}/bin/notmuch new + + # Apply tags + cat ${tagConfig} | ${pkgs.notmuch}/bin/notmuch tag --batch + + echo "Done indexing new mails" +''; +in { + # Enable OfflineIMAP timer & service: + systemd.user.timers.offlineimap = { + description = "OfflineIMAP timer"; + wantedBy = [ "timers.target" ]; + + timerConfig = { + Unit = "offlineimap.service"; + OnCalendar = "*:0/2"; # every 2 minutes + Persistent = "true"; # persist timer state after reboots + }; + }; + + systemd.user.services.offlineimap = { + description = "OfflineIMAP service"; + path = with pkgs; [ pass notmuch ]; + + serviceConfig = { + Type = "oneshot"; + ExecStart = "${pkgs.offlineimap}/bin/offlineimap -u syslog -o -c ${offlineImapConfig}"; + ExecStartPost = "${notmuchIndex}/bin/notmuch-index"; + TimeoutStartSec = "2min"; + }; + }; + + # Link configuration files to /etc/ (from where they will be linked + # further): + environment.etc = { + "msmtprc".source = msmtpConfig; + "notmuch-config".source = notmuchConfig; + }; +} diff --git a/ops/nixos/modules/.skip-subtree b/ops/nixos/modules/.skip-subtree new file mode 100644 index 0000000000..80d92f2eb4 --- /dev/null +++ b/ops/nixos/modules/.skip-subtree @@ -0,0 +1 @@ +The files in this folder are NixOS modules, not readTree-importables. diff --git a/ops/nixos/modules/v4l2loopback.nix b/ops/nixos/modules/v4l2loopback.nix new file mode 100644 index 0000000000..636b2ff6cf --- /dev/null +++ b/ops/nixos/modules/v4l2loopback.nix @@ -0,0 +1,12 @@ +{ config, lib, pkgs, ... }: + +{ + boot = { + extraModulePackages = [ config.boot.kernelPackages.v4l2loopback ]; + kernelModules = [ "v4l2loopback" ]; + extraModprobeConfig = '' + options v4l2loopback exclusive_caps=1 + ''; + }; +} + diff --git a/ops/nixos/nugget/default.nix b/ops/nixos/nugget/default.nix new file mode 100644 index 0000000000..185123e77c --- /dev/null +++ b/ops/nixos/nugget/default.nix @@ -0,0 +1,262 @@ +# This file configures nugget, my home desktop machine. +{ depot, lib, ... }: + +config: let + nixpkgs = import depot.third_party.nixpkgsSrc { + config.allowUnfree = true; + }; + + lieer = (depot.third_party.lieer {}); + + # google-c-style is installed only on nugget because other + # machines get it from, eh, elsewhere. + nuggetEmacs = (depot.tools.emacs.overrideEmacs(epkgs: epkgs ++ [ + depot.third_party.emacsPackages.google-c-style + ])); +in depot.lib.fix(self: { + imports = [ + ../modules/v4l2loopback.nix + ]; + + hardware = { + pulseaudio.enable = true; + cpu.intel.updateMicrocode = true; + u2f.enable = true; + }; + + boot = { + cleanTmpDir = true; + kernelModules = [ "kvm-intel" ]; + + loader = { + timeout = 3; + systemd-boot.enable = true; + efi.canTouchEfiVariables = false; + }; + + initrd = { + luks.devices.nugget-crypt.device = "/dev/disk/by-label/nugget-crypt"; + availableKernelModules = [ "xhci_pci" "ehci_pci" "ahci" "usb_storage" "usbhid" "sd_mod" ]; + kernelModules = [ "dm-snapshot" ]; + }; + }; + + nix = { + package = depot.third_party.nix; + nixPath = [ + "depot=/home/tazjin/depot" + "nixpkgs=${depot.third_party.nixpkgsSrc}" + ]; + }; + + nixpkgs.pkgs = nixpkgs; + + networking = { + hostName = "nugget"; + useDHCP = false; + interfaces.eno1.useDHCP = true; + interfaces.wlp7s0.useDHCP = true; + + # Don't use ISP's DNS servers: + nameservers = [ + "8.8.8.8" + "8.8.4.4" + ]; + + # Open Chromecast-related ports & servedir + firewall.enable = false; + firewall.allowedTCPPorts = [ 4242 5556 5558 ]; + + # Connect to the WiFi to let the Chromecast work. + wireless.enable = true; + wireless.networks = { + "How do I computer?" = { + psk = "washyourface"; + }; + }; + }; + + # Generate an immutable /etc/resolv.conf from the nameserver settings + # above (otherwise DHCP overwrites it): + environment.etc."resolv.conf" = with lib; { + source = depot.third_party.writeText "resolv.conf" '' + ${concatStringsSep "\n" (map (ns: "nameserver ${ns}") self.networking.nameservers)} + options edns0 + ''; + }; + + time.timeZone = "Europe/London"; + + environment.systemPackages = + # programs from the depot + (with depot; [ + fun.idual.script + lieer + nuggetEmacs + ops.kontemplate + third_party.ffmpeg + third_party.git + ]) ++ + + # programs from nixpkgs + (with nixpkgs; [ + age + bat + cachix + chromium + clang-manpages + clang-tools + clang_9 + curl + direnv + dnsutils + exa + fd + gnupg + go + google-chrome + google-cloud-sdk + guile + htop + i3lock + imagemagick + jq + keybase-gui + kubectl + meson + miller + msmtp + nix-prefetch-github + notmuch + openssh + openssl + pass + pavucontrol + pinentry + pinentry-emacs + pwgen + ripgrep + rustup + sbcl + scrot + spotify + steam + tokei + tree + unzip + vlc + xclip + yubico-piv-tool + yubikey-personalization + ]); + + fileSystems = { + "/".device = "/dev/disk/by-label/nugget-root"; + "/boot".device = "/dev/disk/by-label/EFI"; + "/home".device = "/dev/disk/by-label/nugget-home"; + }; + + # Configure user account + users.extraUsers.tazjin = { + extraGroups = [ "wheel" "audio" ]; + isNormalUser = true; + uid = 1000; + shell = nixpkgs.fish; + }; + + security.sudo = { + enable = true; + extraConfig = "wheel ALL=(ALL:ALL) SETENV: ALL"; + }; + + fonts = { + fonts = with nixpkgs; [ + corefonts + dejavu_fonts + jetbrains-mono + noto-fonts-cjk + noto-fonts-emoji + ]; + + fontconfig = { + hinting.enable = true; + subpixel.lcdfilter = "light"; + + defaultFonts = { + monospace = [ "JetBrains Mono" ]; + }; + }; + }; + + # Configure location (Vauxhall, London) for services that need it. + location = { + latitude = 51.4819109; + longitude = -0.1252998; + }; + + programs.fish.enable = true; + programs.ssh.startAgent = true; + + services.redshift.enable = true; + services.openssh.enable = true; + services.keybase.enable = true; + + # Required for Yubikey usage as smartcard + services.pcscd.enable = true; + services.udev.packages = [ + nixpkgs.yubikey-personalization + ]; + + services.xserver = { + enable = true; + layout = "us"; + xkbOptions = "caps:super"; + exportConfiguration = true; + videoDrivers = [ "nvidia" ]; + + displayManager = { + # Give EXWM permission to control the session. + sessionCommands = "${nixpkgs.xorg.xhost}/bin/xhost +SI:localuser:$USER"; + + lightdm.enable = true; + lightdm.greeters.gtk.clock-format = "%H·%M"; + }; + + windowManager.session = lib.singleton { + name = "exwm"; + start = "${nuggetEmacs}/bin/tazjins-emacs"; + }; + }; + + # Do not restart the display manager automatically + systemd.services.display-manager.restartIfChanged = lib.mkForce false; + + # Configure email setup + systemd.user.services.lieer-tazjin = { + description = "Synchronise mail@tazj.in via lieer"; + script = "${lieer}/bin/gmi sync"; + + serviceConfig = { + WorkingDirectory = "%h/mail/account.tazjin"; + Type = "oneshot"; + }; + }; + + systemd.user.timers.lieer-tazjin = { + wantedBy = [ "timers.target" ]; + + timerConfig = { + OnActiveSec = "1"; + OnUnitActiveSec = "180"; + }; + }; + + # Use Tailscale \o/ + services.tailscale.enable = true; + + # nugget has an SSD + services.fstrim.enable = true; + + # ... and other nonsense. + system.stateVersion = "19.09"; +}) diff --git a/ops/posix_mq.rs/.gitignore b/ops/posix_mq.rs/.gitignore new file mode 100644 index 0000000000..e5b6fdb28e --- /dev/null +++ b/ops/posix_mq.rs/.gitignore @@ -0,0 +1,3 @@ +/target/ +**/*.rs.bk +.idea/ diff --git a/ops/posix_mq.rs/CODE_OF_CONDUCT.md b/ops/posix_mq.rs/CODE_OF_CONDUCT.md new file mode 100644 index 0000000000..c4013ac13e --- /dev/null +++ b/ops/posix_mq.rs/CODE_OF_CONDUCT.md @@ -0,0 +1,20 @@ +A SERMON ON ETHICS AND LOVE +=========================== + +One day Mal-2 asked the messenger spirit Saint Gulik to approach the Goddess and request Her presence for some desperate advice. Shortly afterwards the radio came on by itself, and an ethereal female Voice said **YES?** + +"O! Eris! Blessed Mother of Man! Queen of Chaos! Daughter of Discord! Concubine of Confusion! O! Exquisite Lady, I beseech You to lift a heavy burden from my heart!" + +**WHAT BOTHERS YOU, MAL? YOU DON'T SOUND WELL.** + +"I am filled with fear and tormented with terrible visions of pain. Everywhere people are hurting one another, the planet is rampant with injustices, whole societies plunder groups of their own people, mothers imprison sons, children perish while brothers war. O, woe." + +**WHAT IS THE MATTER WITH THAT, IF IT IS WHAT YOU WANT TO DO?** + +"But nobody Wants it! Everybody hates it." + +**OH. WELL, THEN *STOP*.** + +At which moment She turned herself into an aspirin commercial and left The Polyfather stranded alone with his species. + +SINISTER DEXTER HAS A BROKEN SPIROMETER. diff --git a/ops/posix_mq.rs/Cargo.lock b/ops/posix_mq.rs/Cargo.lock new file mode 100644 index 0000000000..fdd0086c4d --- /dev/null +++ b/ops/posix_mq.rs/Cargo.lock @@ -0,0 +1,54 @@ +# This file is automatically @generated by Cargo. +# It is not intended for manual editing. +[[package]] +name = "bitflags" +version = "1.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cc" +version = "1.0.50" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cfg-if" +version = "0.1.10" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "libc" +version = "0.2.66" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "nix" +version = "0.16.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "cc 1.0.50 (registry+https://github.com/rust-lang/crates.io-index)", + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "void 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "posix_mq" +version = "0.9.0" +dependencies = [ + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "nix 0.16.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "void" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[metadata] +"checksum bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "cf1de2fe8c75bc145a2f577add951f8134889b4795d47466a54a5c846d691693" +"checksum cc 1.0.50 (registry+https://github.com/rust-lang/crates.io-index)" = "95e28fa049fda1c330bcf9d723be7663a899c4679724b34c81e9f5a326aab8cd" +"checksum cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)" = "4785bdd1c96b2a846b2bd7cc02e86b6b3dbf14e7e53446c4f54c92a361040822" +"checksum libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)" = "d515b1f41455adea1313a4a2ac8a8a477634fbae63cc6100e3aebb207ce61558" +"checksum nix 0.16.1 (registry+https://github.com/rust-lang/crates.io-index)" = "dd0eaf8df8bab402257e0a5c17a254e4cc1f72a93588a1ddfb5d356c801aa7cb" +"checksum void 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "6a02e4885ed3bc0f2de90ea6dd45ebcbb66dacffe03547fadbb0eeae2770887d" diff --git a/ops/posix_mq.rs/Cargo.toml b/ops/posix_mq.rs/Cargo.toml new file mode 100644 index 0000000000..d72e87a3dc --- /dev/null +++ b/ops/posix_mq.rs/Cargo.toml @@ -0,0 +1,11 @@ +[package] +name = "posix_mq" +version = "0.9.0" +authors = ["Vincent Ambo <mail@tazj.in>"] +description = "(Higher-level) Rust bindings to POSIX message queues" +license = "MIT" +repository = "https://git.tazj.in/tree/ops/posix_mq.rs" + +[dependencies] +nix = "0.16" +libc = "0.2" diff --git a/ops/posix_mq.rs/LICENSE b/ops/posix_mq.rs/LICENSE new file mode 100644 index 0000000000..2389546b13 --- /dev/null +++ b/ops/posix_mq.rs/LICENSE @@ -0,0 +1,21 @@ +MIT License + +Copyright (c) 2017-2020 Vincent Ambo + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/ops/posix_mq.rs/README.md b/ops/posix_mq.rs/README.md new file mode 100644 index 0000000000..9370c6c087 --- /dev/null +++ b/ops/posix_mq.rs/README.md @@ -0,0 +1,33 @@ +posix_mq +======== + +[](https://travis-ci.org/aprilabank/posix_mq.rs) +[](https://crates.io/crates/posix_mq) + +This is a simple, relatively high-level library for the POSIX [message queue API][]. It wraps the lower-level API in a +simpler interface with more robust error handling. + +Check out this project's [sister library][] in Kotlin. + +Usage example: + +```rust +// Values that need to undergo validation are wrapped in safe types: +let name = Name::new("/test-queue").unwrap(); + +// Queue creation with system defaults is simple: +let queue = Queue::open_or_create(name).expect("Opening queue failed"); + +// Sending a message: +let message = Message { + data: "test-message".as_bytes().to_vec(), + priority: 0, +}; +queue.send(&message).expect("message sending failed"); + +// ... and receiving it! +let result = queue.receive().expect("message receiving failed"); +``` + +[message queue API]: https://linux.die.net/man/7/mq_overview +[sister library]: https://github.com/aprilabank/posix_mq.kt diff --git a/ops/posix_mq.rs/default.nix b/ops/posix_mq.rs/default.nix new file mode 100644 index 0000000000..6b0e32009a --- /dev/null +++ b/ops/posix_mq.rs/default.nix @@ -0,0 +1,3 @@ +{ depot, ... }: + +depot.third_party.naersk.buildPackage ./. diff --git a/ops/posix_mq.rs/src/error.rs b/ops/posix_mq.rs/src/error.rs new file mode 100644 index 0000000000..1ef585c01e --- /dev/null +++ b/ops/posix_mq.rs/src/error.rs @@ -0,0 +1,130 @@ +use nix; +use std::error; +use std::fmt; +use std::io; +use std::num; + +/// This module implements a simple error type to match the errors that can be thrown from the C +/// functions as well as some extra errors resulting from internal validations. +/// +/// As this crate exposes an opinionated API to the POSIX queues certain errors have been +/// ignored: +/// +/// * ETIMEDOUT: The low-level timed functions are not exported and this error can not occur. +/// * EAGAIN: Non-blocking queue calls are not supported. +/// * EINVAL: Same reason as ETIMEDOUT +/// * EMSGSIZE: The message size is immutable after queue creation and this crate checks it. +/// * ENAMETOOLONG: This crate performs name validation +/// +/// If an unexpected error is encountered it will be wrapped appropriately and should be reported +/// as a bug on https://github.com/aprilabank/posix_mq.rs + +#[derive(Debug)] +pub enum Error { + // These errors are raised inside of the library + InvalidQueueName(&'static str), + ValueReadingError(io::Error), + MessageSizeExceeded(), + MaximumMessageSizeExceeded(), + MaximumMessageCountExceeded(), + + // These errors match what is described in the man pages (from mq_overview(7) onwards). + PermissionDenied(), + InvalidQueueDescriptor(), + QueueCallInterrupted(), + QueueAlreadyExists(), + QueueNotFound(), + InsufficientMemory(), + InsufficientSpace(), + + // These two are (hopefully) unlikely in modern systems + ProcessFileDescriptorLimitReached(), + SystemFileDescriptorLimitReached(), + + // If an unhandled / unknown / unexpected error occurs this error will be used. + // In those cases bug reports would be welcome! + UnknownForeignError(nix::errno::Errno), + + // Some other unexpected / unknown error occured. This is probably an error from + // the nix crate. Bug reports also welcome for this! + UnknownInternalError(Option<nix::Error>), +} + +impl error::Error for Error { + fn description(&self) -> &str { + use Error::*; + match *self { + // This error contains more sensible description strings already + InvalidQueueName(e) => e, + ValueReadingError(_) => "error reading system configuration for message queues", + MessageSizeExceeded() => "message is larger than maximum size for specified queue", + MaximumMessageSizeExceeded() => "specified queue message size exceeds system maximum", + MaximumMessageCountExceeded() => "specified queue message count exceeds system maximum", + PermissionDenied() => "permission to the specified queue was denied", + InvalidQueueDescriptor() => "the internal queue descriptor was invalid", + QueueCallInterrupted() => "queue method interrupted by signal", + QueueAlreadyExists() => "the specified queue already exists", + QueueNotFound() => "the specified queue could not be found", + InsufficientMemory() => "insufficient memory to call queue method", + InsufficientSpace() => "insufficient space to call queue method", + ProcessFileDescriptorLimitReached() => + "maximum number of process file descriptors reached", + SystemFileDescriptorLimitReached() => + "maximum number of system file descriptors reached", + UnknownForeignError(_) => "unknown foreign error occured: please report a bug!", + UnknownInternalError(_) => "unknown internal error occured: please report a bug!", + } + } +} + +impl fmt::Display for Error { + fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { + // Explicitly import this to gain access to Error::description() + use std::error::Error; + f.write_str(self.description()) + } +} + +/// This from implementation is used to translate errors from the lower-level +/// C-calls into sensible Rust errors. +impl From<nix::Error> for Error { + fn from(e: nix::Error) -> Self { + match e { + nix::Error::Sys(e) => match_errno(e), + _ => Error::UnknownInternalError(Some(e)), + } + } +} + +// This implementation is used when reading system queue settings. +impl From<io::Error> for Error { + fn from(e: io::Error) -> Self { + Error::ValueReadingError(e) + } +} + +// This implementation is used when parsing system queue settings. The unknown error is returned +// here because the system is probably seriously broken if those files don't contain numbers. +impl From<num::ParseIntError> for Error { + fn from(_: num::ParseIntError) -> Self { + Error::UnknownInternalError(None) + } +} + + +fn match_errno(err: nix::errno::Errno) -> Error { + use nix::errno::Errno::*; + + match err { + EACCES => Error::PermissionDenied(), + EBADF => Error::InvalidQueueDescriptor(), + EINTR => Error::QueueCallInterrupted(), + EEXIST => Error::QueueAlreadyExists(), + EMFILE => Error::ProcessFileDescriptorLimitReached(), + ENFILE => Error::SystemFileDescriptorLimitReached(), + ENOENT => Error::QueueNotFound(), + ENOMEM => Error::InsufficientMemory(), + ENOSPC => Error::InsufficientSpace(), + _ => Error::UnknownForeignError(err), + } +} diff --git a/ops/posix_mq.rs/src/lib.rs b/ops/posix_mq.rs/src/lib.rs new file mode 100644 index 0000000000..057601eccf --- /dev/null +++ b/ops/posix_mq.rs/src/lib.rs @@ -0,0 +1,269 @@ +extern crate nix; +extern crate libc; + +use error::Error; +use libc::mqd_t; +use nix::mqueue; +use nix::sys::stat; +use std::ffi::CString; +use std::fs::File; +use std::io::Read; +use std::string::ToString; +use std::ops::Drop; + +pub mod error; + +#[cfg(test)] +mod tests; + +/// Wrapper type for queue names that performs basic validation of queue names before calling +/// out to C code. +#[derive(Debug, Clone, PartialEq)] +pub struct Name(CString); + +impl Name { + pub fn new<S: ToString>(s: S) -> Result<Self, Error> { + let string = s.to_string(); + + if !string.starts_with('/') { + return Err(Error::InvalidQueueName("Queue name must start with '/'")); + } + + // The C library has a special error return for this case, so I assume people must actually + // have tried just using '/' as a queue name. + if string.len() == 1 { + return Err(Error::InvalidQueueName( + "Queue name must be a slash followed by one or more characters" + )); + } + + if string.len() > 255 { + return Err(Error::InvalidQueueName("Queue name must not exceed 255 characters")); + } + + if string.matches('/').count() > 1 { + return Err(Error::InvalidQueueName("Queue name can not contain more than one slash")); + } + + // TODO: What error is being thrown away here? Is it possible? + Ok(Name(CString::new(string).unwrap())) + } +} + +#[derive(Debug, Clone, PartialEq)] +pub struct Message { + pub data: Vec<u8>, + pub priority: u32, +} + +/// Represents an open queue descriptor to a POSIX message queue. This carries information +/// about the queue's limitations (i.e. maximum message size and maximum message count). +#[derive(Debug)] +pub struct Queue { + name: Name, + + /// Internal file/queue descriptor. + queue_descriptor: mqd_t, + + /// Maximum number of pending messages in this queue. + max_pending: i64, + + /// Maximum size of this queue. + max_size: usize, +} + +impl Queue { + /// Creates a new queue and fails if it already exists. + /// By default the queue will be read/writable by the current user with no access for other + /// users. + /// Linux users can change this setting themselves by modifying the queue file in /dev/mqueue. + pub fn create(name: Name, max_pending: i64, max_size: i64) -> Result<Queue, Error> { + if max_pending > read_i64_from_file(MSG_MAX)? { + return Err(Error::MaximumMessageCountExceeded()); + } + + if max_size > read_i64_from_file(MSGSIZE_MAX)? { + return Err(Error::MaximumMessageSizeExceeded()); + } + + let oflags = { + let mut flags = mqueue::MQ_OFlag::empty(); + // Put queue in r/w mode + flags.toggle(mqueue::MQ_OFlag::O_RDWR); + // Enable queue creation + flags.toggle(mqueue::MQ_OFlag::O_CREAT); + // Fail if queue exists already + flags.toggle(mqueue::MQ_OFlag::O_EXCL); + flags + }; + + let attr = mqueue::MqAttr::new( + 0, max_pending, max_size, 0 + ); + + let queue_descriptor = mqueue::mq_open( + &name.0, + oflags, + default_mode(), + Some(&attr), + )?; + + Ok(Queue { + name, + queue_descriptor, + max_pending, + max_size: max_size as usize, + }) + } + + /// Opens an existing queue. + pub fn open(name: Name) -> Result<Queue, Error> { + // No extra flags need to be constructed as the default is to open and fail if the + // queue does not exist yet - which is what we want here. + let oflags = mqueue::MQ_OFlag::O_RDWR; + let queue_descriptor = mqueue::mq_open( + &name.0, + oflags, + default_mode(), + None, + )?; + + let attr = mq_getattr(queue_descriptor)?; + + Ok(Queue { + name, + queue_descriptor, + max_pending: attr.mq_maxmsg, + max_size: attr.mq_msgsize as usize, + }) + } + + /// Opens an existing queue or creates a new queue with the OS default settings. + pub fn open_or_create(name: Name) -> Result<Queue, Error> { + let oflags = { + let mut flags = mqueue::MQ_OFlag::empty(); + // Put queue in r/w mode + flags.toggle(mqueue::MQ_OFlag::O_RDWR); + // Enable queue creation + flags.toggle(mqueue::MQ_OFlag::O_CREAT); + flags + }; + + let default_pending = read_i64_from_file(MSG_DEFAULT)?; + let default_size = read_i64_from_file(MSGSIZE_DEFAULT)?; + let attr = mqueue::MqAttr::new( + 0, default_pending, default_size, 0 + ); + + let queue_descriptor = mqueue::mq_open( + &name.0, + oflags, + default_mode(), + Some(&attr), + )?; + + let actual_attr = mq_getattr(queue_descriptor)?; + + Ok(Queue { + name, + queue_descriptor, + max_pending: actual_attr.mq_maxmsg, + max_size: actual_attr.mq_msgsize as usize, + }) + } + + /// Delete a message queue from the system. This method will make the queue unavailable for + /// other processes after their current queue descriptors have been closed. + pub fn delete(self) -> Result<(), Error> { + mqueue::mq_unlink(&self.name.0)?; + drop(self); + Ok(()) + } + + /// Send a message to the message queue. + /// If the queue is full this call will block until a message has been consumed. + pub fn send(&self, msg: &Message) -> Result<(), Error> { + if msg.data.len() > self.max_size as usize { + return Err(Error::MessageSizeExceeded()); + } + + mqueue::mq_send( + self.queue_descriptor, + msg.data.as_ref(), + msg.priority, + ).map_err(|e| e.into()) + } + + /// Receive a message from the message queue. + /// If the queue is empty this call will block until a message arrives. + pub fn receive(&self) -> Result<Message, Error> { + let mut data: Vec<u8> = vec![0; self.max_size as usize]; + let mut priority: u32 = 0; + + let msg_size = mqueue::mq_receive( + self.queue_descriptor, + data.as_mut(), + &mut priority, + )?; + + data.truncate(msg_size); + Ok(Message { data, priority }) + } + + pub fn max_pending(&self) -> i64 { + self.max_pending + } + + pub fn max_size(&self) -> usize { + self.max_size + } +} + +impl Drop for Queue { + fn drop(&mut self) { + // Attempt to close the queue descriptor and discard any possible errors. + // The only error thrown in the C-code is EINVAL, which would mean that the + // descriptor has already been closed. + mqueue::mq_close(self.queue_descriptor).ok(); + } +} + +// Creates the default queue mode (0600). +fn default_mode() -> stat::Mode { + let mut mode = stat::Mode::empty(); + mode.toggle(stat::Mode::S_IRUSR); + mode.toggle(stat::Mode::S_IWUSR); + mode +} + +/// This file defines the default number of maximum pending messages in a queue. +const MSG_DEFAULT: &'static str = "/proc/sys/fs/mqueue/msg_default"; + +/// This file defines the system maximum number of pending messages in a queue. +const MSG_MAX: &'static str = "/proc/sys/fs/mqueue/msg_max"; + +/// This file defines the default maximum size of messages in a queue. +const MSGSIZE_DEFAULT: &'static str = "/proc/sys/fs/mqueue/msgsize_default"; + +/// This file defines the system maximum size for messages in a queue. +const MSGSIZE_MAX: &'static str = "/proc/sys/fs/mqueue/msgsize_max"; + +/// This method is used in combination with the above constants to find system limits. +fn read_i64_from_file(name: &str) -> Result<i64, Error> { + let mut file = File::open(name.to_string())?; + let mut content = String::new(); + file.read_to_string(&mut content)?; + Ok(content.trim().parse()?) +} + +/// The mq_getattr implementation in the nix crate hides the maximum message size and count, which +/// is very impractical. +/// To work around it, this method calls the C-function directly. +fn mq_getattr(mqd: mqd_t) -> Result<libc::mq_attr, Error> { + use std::mem; + let mut attr = unsafe { mem::uninitialized::<libc::mq_attr>() }; + let res = unsafe { libc::mq_getattr(mqd, &mut attr) }; + nix::errno::Errno::result(res) + .map(|_| attr) + .map_err(|e| e.into()) +} diff --git a/ops/posix_mq.rs/src/tests.rs b/ops/posix_mq.rs/src/tests.rs new file mode 100644 index 0000000000..7a08876aea --- /dev/null +++ b/ops/posix_mq.rs/src/tests.rs @@ -0,0 +1,22 @@ +use super::*; + +#[test] +fn test_open_delete() { + // Simple test with default queue settings + let name = Name::new("/test-queue").unwrap(); + let queue = Queue::open_or_create(name) + .expect("Opening queue failed"); + + let message = Message { + data: "test-message".as_bytes().to_vec(), + priority: 0, + }; + + queue.send(&message).expect("message sending failed"); + + let result = queue.receive().expect("message receiving failed"); + + assert_eq!(message, result); + + queue.delete().expect("deleting queue failed"); +} diff --git a/ops/secrets/.skip-subtree b/ops/secrets/.skip-subtree new file mode 100644 index 0000000000..25dba2a344 --- /dev/null +++ b/ops/secrets/.skip-subtree @@ -0,0 +1 @@ +No Nix derivations under //ops/secrets diff --git a/ops/secrets/gcsr-tazjin-password b/ops/secrets/gcsr-tazjin-password new file mode 100644 index 0000000000..5893de1315 --- /dev/null +++ b/ops/secrets/gcsr-tazjin-password Binary files differdiff --git a/ops/secrets/gmaps-api-key b/ops/secrets/gmaps-api-key new file mode 100644 index 0000000000..6a45226460 --- /dev/null +++ b/ops/secrets/gmaps-api-key Binary files differdiff --git a/ops/secrets/nixery-gcs-json b/ops/secrets/nixery-gcs-json new file mode 100644 index 0000000000..b8b5445116 --- /dev/null +++ b/ops/secrets/nixery-gcs-json Binary files differdiff --git a/ops/secrets/nixery-gcs-pem b/ops/secrets/nixery-gcs-pem new file mode 100644 index 0000000000..798a1e5a66 --- /dev/null +++ b/ops/secrets/nixery-gcs-pem Binary files differdiff --git a/ops/secrets/nixery-ssh-private b/ops/secrets/nixery-ssh-private new file mode 100644 index 0000000000..5c4ff20233 --- /dev/null +++ b/ops/secrets/nixery-ssh-private Binary files differdiff --git a/ops/secrets/sr.ht-token b/ops/secrets/sr.ht-token new file mode 100644 index 0000000000..53eb0d16b0 --- /dev/null +++ b/ops/secrets/sr.ht-token Binary files differdiff --git a/overrides/default.nix b/overrides/default.nix new file mode 100644 index 0000000000..8bc49dec47 --- /dev/null +++ b/overrides/default.nix @@ -0,0 +1,13 @@ +# This file is used to move things from nested attribute sets to the +# top-level. +{ depot, ... }: + +{ + buildGo = depot.nix.buildGo; # TODO(tazjin): remove this + + # These packages must be exposed for compatibility with buildGo. + # + # Despite buildGo being tracked in this tree, I want it to be possible + # for external users to import it with the default nixpkgs layout. + inherit (depot.third_party) go ripgrep; +} diff --git a/overrides/elmPackages/default.nix b/overrides/elmPackages/default.nix new file mode 100644 index 0000000000..3df44420a6 --- /dev/null +++ b/overrides/elmPackages/default.nix @@ -0,0 +1,10 @@ +# Gemma needs an older version of Elm to be built. Updating it to +# the newer version is a lot of effort. +{ pkgs, ... }: + +(import (pkgs.fetchFromGitHub { + owner = "NixOS"; + repo = "nixpkgs"; + rev = "14f9ee66e63077539252f8b4550049381a082518"; + sha256 = "1wn7nmb1cqfk2j91l3rwc6yhimfkzxprb8wknw5wi57yhq9m6lv1"; +}) {}).elmPackages diff --git a/overrides/kontemplate/default.nix b/overrides/kontemplate/default.nix new file mode 100644 index 0000000000..6147d1f465 --- /dev/null +++ b/overrides/kontemplate/default.nix @@ -0,0 +1,13 @@ +{ depot, ... }: + +with depot; + +third_party.writeShellScriptBin "kontemplate" '' + export PATH="${ops.kms_pass}/bin:$PATH" + + if [[ -z $1 ]]; then + exec ${ops.kontemplate}/bin/kontemplate + fi + + exec ${ops.kontemplate}/bin/kontemplate $1 ${./../..}/ops/infra/kubernetes/primary-cluster.yaml ''${@:2} +'' diff --git a/overrides/writeElispBin/default.nix b/overrides/writeElispBin/default.nix new file mode 100644 index 0000000000..f2c81a2c02 --- /dev/null +++ b/overrides/writeElispBin/default.nix @@ -0,0 +1,23 @@ +{ pkgs, ... }: + +{ name, src, deps ? (_: []), emacs ? pkgs.emacs26-nox }: + +let + inherit (pkgs) emacsPackages emacsPackagesGen writeTextFile; + inherit (builtins) isString toFile; + + finalEmacs = (emacsPackagesGen emacs).emacsWithPackages deps; + + srcFile = if isString src + then toFile "${name}.el" src + else src; +in writeTextFile { + inherit name; + executable = true; + destination = "/bin/${name}"; + + text = '' + #!/bin/sh + ${finalEmacs}/bin/emacs --batch --no-site-file --script ${srcFile} $@ + ''; +} diff --git a/presentations/bootstrapping-2018/README.md b/presentations/bootstrapping-2018/README.md new file mode 100644 index 0000000000..e9573ae3f2 --- /dev/null +++ b/presentations/bootstrapping-2018/README.md @@ -0,0 +1,5 @@ +These are the slides for a talk I gave at the Norwegian Unix User Group on +2018-03-13. + +There is more information and a recording on the [event +page](https://www.nuug.no/aktiviteter/20180313-reproduible-compiler/). diff --git a/presentations/bootstrapping-2018/default.nix b/presentations/bootstrapping-2018/default.nix new file mode 100644 index 0000000000..0dff14b2a1 --- /dev/null +++ b/presentations/bootstrapping-2018/default.nix @@ -0,0 +1,50 @@ +# This derivation builds the LaTeX presentation. + +{ pkgs, ... }: + +with pkgs; + +let tex = texlive.combine { + inherit (texlive) + beamer + beamertheme-metropolis + etoolbox + euenc + extsizes + fontspec + lualibs + luaotfload + luatex + minted + ms + pgfopts + scheme-basic + translator; +}; +in stdenv.mkDerivation { + name = "nuug-bootstrapping-slides"; + src = ./.; + + FONTCONFIG_FILE = makeFontsConf { + fontDirectories = [ fira fira-code fira-mono ]; + }; + + buildInputs = [ tex fira fira-code fira-mono ]; + buildPhase = '' + # LaTeX needs a cache folder in /home/ ... + mkdir home + export HOME=$PWD/home + # ${tex}/bin/luaotfload-tool -ufv + + # As usual, TeX needs to be run twice ... + function run() { + ${tex}/bin/lualatex presentation.tex + } + run && run + ''; + + installPhase = '' + mkdir -p $out + cp presentation.pdf $out/ + ''; +} diff --git a/presentations/bootstrapping-2018/drake-meme.png b/presentations/bootstrapping-2018/drake-meme.png new file mode 100644 index 0000000000..4b03675438 --- /dev/null +++ b/presentations/bootstrapping-2018/drake-meme.png Binary files differdiff --git a/presentations/bootstrapping-2018/nixos-logo.png b/presentations/bootstrapping-2018/nixos-logo.png new file mode 100644 index 0000000000..ce0c98c2ca --- /dev/null +++ b/presentations/bootstrapping-2018/nixos-logo.png Binary files differdiff --git a/presentations/bootstrapping-2018/notes.org b/presentations/bootstrapping-2018/notes.org new file mode 100644 index 0000000000..363d75352e --- /dev/null +++ b/presentations/bootstrapping-2018/notes.org @@ -0,0 +1,89 @@ +#+TITLE: Bootstrapping, reproducibility, etc. +#+AUTHOR: Vincent Ambo +#+DATE: <2018-03-10 Sat> + +* Compiler bootstrapping + This section contains notes about compiler bootstrapping, the + history thereof, which compilers need it - and so on: + +** C + +** Haskell + - self-hosted compiler (GHC) + +** Common Lisp + CL is fairly interesting in this space because it is a language + that is defined via an ANSI standard that compiler implementations + normally actually follow! + + CL has several ecosystem components that focus on making + abstracting away implementation-specific calls and if a self-hosted + compiler is written in CL using those components it can be + cross-bootstrapped. + +** Python + +* A note on runtimes + Sometimes the compiler just isn't enough ... + +** LLVM +** JVM + +* References + https://github.com/mame/quine-relay + https://manishearth.github.io/blog/2016/12/02/reflections-on-rusting-trust/ + https://tests.reproducible-builds.org/debian/reproducible.html + +* Slide thoughts: + 1. Hardware trust has been discussed here a bunch, most recently + during the puri.sm talk. Hardware trust is important, as we see + with IME, but it's striking that people often take a leap to "I'm + now on my trusted Debian with free software". + + Unless you built it yourself from scratch (Spoiler: you haven't) + you're placing trust in what is basically foreign binary blobs. + + Agenda: Implications/attack vectors of this, state of the chicken + & egg, the topic of reproducibility, what can you do? (Nix!) + + 2. Chicken-and-egg issue + + It's an important milestone for a language to become self-hosted: + You begin doing a kind of dogfeeding, you begin to enforce + reliability & consistency guarantees to avoid having to redo your + own codebase constantly and so on. + + However, the implication is now that you need your own compiler + to compile itself. + + Common examples: + - C/C++ compilers needed to build C/C++ compilers: + + GCC 4.7 was the last version of GCC that could be built with a + standard C-compiler, nowadays it is mostly written in C++. + + Certain versions of GCC can be built with LLVM/Clang. + + Clang/LLVM can be compiled by itself and also GCC. + + - Rust was originally written in OCAML but moved to being + self-hosted in 2011. Currently rustc-releases are always built + with a copy of the previous release. + + It's relatively new so we can build the chain all the way. + + Notable exceptions: Some popular languages are not self-hosted, + for example Clojure. Languages also have runtimes, which may be + written in something else (e.g. Haskell -> C runtime) +* How to help: + Most of this advice is about reproducible builds, not bootstrapping, + as that is a much harder project. + + - fix reproducibility issues listed in Debian's issue tracker (focus + on non-Debian specific ones though) + - experiment with NixOS / GuixSD to get a better grasp on the + problem space of reproducibility + + If you want to contribute to bootstrapping, look at + bootstrappable.org and their wiki. Several initiatives such as MES + could need help! diff --git a/presentations/bootstrapping-2018/presentation.pdf b/presentations/bootstrapping-2018/presentation.pdf new file mode 100644 index 0000000000..7f435fe5b5 --- /dev/null +++ b/presentations/bootstrapping-2018/presentation.pdf Binary files differdiff --git a/presentations/bootstrapping-2018/presentation.tex b/presentations/bootstrapping-2018/presentation.tex new file mode 100644 index 0000000000..d3aa613375 --- /dev/null +++ b/presentations/bootstrapping-2018/presentation.tex @@ -0,0 +1,251 @@ +\documentclass[12pt]{beamer} +\usetheme{metropolis} +\newenvironment{code}{\ttfamily}{\par} +\title{Where does \textit{your} compiler come from?} +\date{2018-03-13} +\author{Vincent Ambo} +\institute{Norwegian Unix User Group} +\begin{document} + \maketitle + + %% Slide 1: + \section{Introduction} + + %% Slide 2: + \begin{frame}{Chicken and egg} + Self-hosted compilers are often built using themselves, for example: + + \begin{itemize} + \item C-family compilers bootstrap themselves \& each other + \item (Some!) Common Lisp compilers can bootstrap each other + \item \texttt{rustc} bootstraps itself with a previous version + \item ... same for many other languages! + \end{itemize} + \end{frame} + + \begin{frame}{Chicken, egg and ... lizard?} + It's not just compilers: Languages have runtimes, too. + + \begin{itemize} + \item JVM is implemented in C++ + \item Erlang-VM is C + \item Haskell runtime is C + \end{itemize} + + ... we can't ever get away from C, can we? + \end{frame} + + %% Slide 3: + \begin{frame}{Trusting Trust} + \begin{center} + \huge{Could this be exploited?} + \end{center} + \end{frame} + + %% Slide 4: + \begin{frame}{Short interlude: A quine} + \begin{center} + \begin{code} + ((lambda (x) (list x (list 'quote x))) + \newline\vspace*{6mm} '(lambda (x) (list x (list 'quote x)))) + \end{code} + \end{center} + \end{frame} + + %% Slide 5: + \begin{frame}{Short interlude: Quine Relay} + \begin{center} + \includegraphics[ + keepaspectratio=true, + height=\textheight + ]{quine-relay.png} + \end{center} + \end{frame} + + %% Slide 6: + \begin{frame}{Trusting Trust} + An attack described by Ken Thompson in 1983: + + \begin{enumerate} + \item Modify a compiler to detect when it's compiling itself. + \item Let the modification insert \textit{itself} into the new compiler. + \item Add arbitrary attack code to the modification. + \item \textit{Optional!} Remove the attack from the source after compilation. + \end{enumerate} + \end{frame} + + %% Slide 7: + \begin{frame}{Damage potential?} + \begin{center} + \large{Let your imagination run wild!} + \end{center} + \end{frame} + + %% Slide 8: + \section{Countermeasures} + + %% Slide 9: + \begin{frame}{Diverse Double-Compiling} + Assume we have: + + \begin{itemize} + \item Target language compilers $A$ and $T$ + \item The source code of $A$: $ S_{A} $ + \end{itemize} + \end{frame} + + %% Slide 10: + \begin{frame}{Diverse Double-Compiling} + Apply the first stage (functional equivalence): + + \begin{itemize} + \item $ X = A(S_{A})$ + \item $ Y = T(S_{A})$ + \end{itemize} + + Apply the second stage (bit-for-bit equivalence): + + \begin{itemize} + \item $ V = X(S_{A})$ + \item $ W = Y(S_{A})$ + \end{itemize} + + Now we have a new problem: Reproducibility! + \end{frame} + + %% Slide 11: + \begin{frame}{Reproducibility} + Bit-for-bit equivalent output is hard, for example: + + \begin{itemize} + \item Timestamps in output artifacts + \item Non-deterministic linking order in concurrent builds + \item Non-deterministic VM \& memory states in outputs + \item Randomness in builds (sic!) + \end{itemize} + \end{frame} + + \begin{frame}{Reproducibility} + \begin{center} + Without reproducibility, we can never trust that any shipped + binary matches the source code! + \end{center} + \end{frame} + + %% Slide 12: + \section{(Partial) State of the Union} + + \begin{frame}{The Desired State} + \begin{center} + \begin{enumerate} + \item Full-source bootstrap! + \item All packages reproducible! + \end{enumerate} + \end{center} + \end{frame} + + %% Slide 13: + \begin{frame}{Bootstrapping Debian} + \begin{itemize} + \item Sparse information on the Debian-wiki + \item Bootstrapping discussions mostly resolve around new architectures + \item GCC is compiled by depending on previous versions of GCC + \end{itemize} + \end{frame} + + \begin{frame}{Reproducing Debian} + Debian has a very active effort for reproducible builds: + + \begin{itemize} + \item Organised information about reproducibility status + \item Over 90\% reproducibility in Debian package base! + \end{itemize} + \end{frame} + + \begin{frame}{Short interlude: Nix} + \begin{center} + \includegraphics[ + keepaspectratio=true, + height=0.7\textheight + ]{nixos-logo.png} + \end{center} + \end{frame} + + \begin{frame}{Short interlude: Nix} + \begin{center} + \includegraphics[ + keepaspectratio=true, + height=0.90\textheight + ]{drake-meme.png} + \end{center} + \end{frame} + + \begin{frame}{Short interlude: Nix} + \begin{center} + \includegraphics[ + keepaspectratio=true, + height=0.7\textheight + ]{nixos-logo.png} + \end{center} + \end{frame} + + \begin{frame}{Bootstrapping NixOS} + Nix evaluation can not recurse forever: The bootstrap can not + simply depend on a previous GCC. + + Workaround: \texttt{bootstrap-tools} tarball from a previous + binary cache is fetched and used. + + An unfortunate magic binary blob ... + \end{frame} + + \begin{frame}{Reproducing NixOS} + Not all reproducibility patches have been ported from Debian. + + However: Builds are fully repeatable via the Nix fundamentals! + \end{frame} + + \section{Future Developments} + + \begin{frame}{Bootstrappable: stage0} + Hand-rolled ``Cthulhu's Path to Madness'' hex-programs: + + \begin{itemize} + \item No non-auditable binary blobs + \item Aims for understandability by 70\% of programmers + \item End goal is a full-source bootstrap of GCC + \end{itemize} + \end{frame} + + + \begin{frame}{Bootstrappable: MES} + Bootstrapping the ``Maxwell Equations of Software'': + + \begin{itemize} + \item Minimal C-compiler written in Scheme + \item Minimal Scheme-interpreter (currently in C, but intended to + be rewritten in stage0 macros) + \item End goal is full-source bootstrap of the entire GuixSD + \end{itemize} + \end{frame} + + \begin{frame}{Other platforms} + \begin{itemize} + \item Nix for Darwin is actively maintained + \item F-Droid Android repository works towards fully reproducible + builds of (open) Android software + \item Mobile devices (phones, tablets, etc.) are a lost cause at + the moment + \end{itemize} + \end{frame} + + \begin{frame}{Thanks!} + Resources: + \begin{itemize} + \item bootstrappable.org + \item reproducible-builds.org + \end{itemize} + + @tazjin | mail@tazj.in + \end{frame} +\end{document} diff --git a/presentations/bootstrapping-2018/quine-relay.png b/presentations/bootstrapping-2018/quine-relay.png new file mode 100644 index 0000000000..5644dc3900 --- /dev/null +++ b/presentations/bootstrapping-2018/quine-relay.png Binary files differdiff --git a/presentations/bootstrapping-2018/result.pdfpc b/presentations/bootstrapping-2018/result.pdfpc new file mode 100644 index 0000000000..b0fa6c9a0e --- /dev/null +++ b/presentations/bootstrapping-2018/result.pdfpc @@ -0,0 +1,142 @@ +[file] +result +[last_saved_slide] +10 +[font_size] +20000 +[notes] +### 1 +- previous discussions of hardware trust (e.g. purism presentation) +- people leap to "now I'm on my trusted Debian!" +- unless you built it from scratch (spoiler: you haven't) you're *trusting* someone + +Agenda: Implications of trust with focus on bootstrap paths and reproducibility, plus how you can help.### 2 +self-hosting: +- C-family: GCC pre/post 4.7, Clang +- Common Lisp: Sunshine land! (with SBCL) +- rustc: Bootstrap based on previous versions (C++ transpiler underway!) +- many other languages also work this way! + +(Noteable counterexample: Clojure is written in Java!)### 3 + +- compilers are just one bit, the various runtimes exist, too!### 4 + +Could this be exploited? + +People don't think about where their compiler comes from. + +Even if they do, they may only go so far as to say "I'll just recompile it using <other compiler>". + +Unfortunately, spoiler alert, life isn't that easy in the computer world and yes, exploitation is possible.### 5 + +- describe what a quine is +- classic Lisp quine +- explain demo quine +- demo demo quine + +- this is interesting, but not useful - can quines do more than that?### 6 + +- quine-relay: "art project" with 128-language circular quine + +- show source of quine-relay + +- (demo quine relay?) + +- side-note: this program is very, very trustworthy!### 7 + +Ken Thompson (designer of UNIX and a couple other things!) received Turing award in 1983, and described attack in speech. + +- figure out how to detect self-compilation +- make that modification a quine +- insert modification into new compiler +- add attack code to modification +- remove attack from source, distributed binary will still be compromised! it's like evolution :)### 8 + +damage potential is basically infinite: + +- classic "login" attack +=> also applicable to other credentials + +- attack (weaken) crypto algorithms + +- you can probably think of more!### 10 + +idea being: potential vulnerability would have to work across compilers: + +the more compilers we can introduce (e.g. more architectures, different versions, different compilers), the harder it gets for a vulnerability to survive all of those + +The more compilers, the merrier! Lisps are pretty good at this.### 11 + +if we get a bit-mismatch after DDC, not all hope is lost: Maybe the thing just isn't reproducible! + +- many reasons for failures +- timestamps are a classic! artifacts can be build logs, metadata in ZIP-files or whatever +- non-determinism is the devil +- sometimes people actively introduce build-randomness (NaCl)### 12 + +- Does that binary download on the project's website really match the source? + +- Your Linux packages are signed by someone - cool - but what does that mean?### 13 + +Two things should be achieved - gross oversimplification - to get to the ideal "desired state of the union": + +1. full-source bootstrap: without ever introducing any binaries, go from nothing to a full Linux distribution + +2. when packages are distributed, we should be able to know the expected output of a source package beforehand + +=> suddenly binary distributions become a cache! But more on Nix later.### 14 + +- Debian project does not seem as concerned with bootstrapping as with reproducibility +- Debian mostly bootstraps on new architectures (using cross-compilation and similar techniques, from an existing binary base) +- core bootstrap (GCC & friends) is performed with previous Debian version and depending on GCC### 15 + +... however! Debian cares about reproducibility. + +- automated testing of reproducibility +- information about the status of all packages is made available in repos +- Over 90% packages of packages are reproducible! + +< show reproducible builds website > + +Debian is still fundamentally a binary distribution though, but it doesn't have to be that way.### 16 + +Nix - a purely functional package manager + +It's not a new project (10+ years), been discussed here before, has multiple components: package manager, language, NixOS. + +Instead of describing *how* to build a thing, Nix describes *what* to build:### 17 +### 19 + +In Nix, it's impossible to say "GCC is the result of applying GCC to the GCC source", because that happens to be infinite recursion. + +Bootstrapping in Nix works by introducing a binary pinned by its full-hash, which was built on some previous Nix version. + +Unfortunately also just a magic binary blob ... ### 20 + +NixOS is not actively porting all of Debian's reproducibility patches, but builds are fully repeatable: + +- introducing a malicious compiler would produce a different input hash -> different package + +Future slide: hope is not lost! Things are underway.### 21 + +- bootstrappable.org (demo?) is an umbrella page for several projects working on bootstrappability + +- stage0 is an important piece: manually, small, auditable Hex programs to get to a Hex macro expander + +- end goal is a full-source bootrap, but pieces are missing### 22 + +MES is out of the GuixSD circles (explain Guix, GNU Hurd joke) + +- idea being that once you have a Lisp, you have all of computing (as Alan Key said) + +- includes MesCC in Scheme -> can *almost* make a working tinyCC -> can *almost* make a working gcc 4.7 + +- minimal Scheme interpreter, currently built in C to get the higher-level stuff to work, goal is rewrite in hex +- bootstrapping Guix is the end goal### 23 + +- userspace in Darwin has a Nix project +- unsure about other BSDs, but if anyone knows - input welcome! +- F-Droid has reproducible Android packages, but that's also userspace only +- All other mobile platforms are a lost cause + +Generally, all closed-source software is impossible to trust. diff --git a/contrib/credential/netrc/test.netrc.gpg b/presentations/erlang-2016/.skip-subtree index e69de29bb2..e69de29bb2 100644 --- a/contrib/credential/netrc/test.netrc.gpg +++ b/presentations/erlang-2016/.skip-subtree diff --git a/presentations/erlang-2016/README.md b/presentations/erlang-2016/README.md new file mode 100644 index 0000000000..e1b6c83b99 --- /dev/null +++ b/presentations/erlang-2016/README.md @@ -0,0 +1,6 @@ +These are the slides for a presentation I gave for the Oslo javaBin meetup in +2016. + +Unfortunately there is no recording of the presentation due to a technical error +(video was recorded, but no audio). This is a bit of a shame because I think +these are some of the best slides I've ever made. diff --git a/presentations/erlang-2016/presentation.md b/presentations/erlang-2016/presentation.md new file mode 100644 index 0000000000..526564b882 --- /dev/null +++ b/presentations/erlang-2016/presentation.md @@ -0,0 +1,222 @@ +slidenumbers: true +Erlang. +====== + +### Fault-tolerant, concurrent programming. + +--- + +## A brief history of Erlang + +--- + + + + +^ Telefontornet in Stockholm, around 1890. Used until 1913. + +--- + + + +^ Telephones were operated manually at Switchboards. Anyone old enough to remember? I'm certainly not. + +--- + + + +^ Eventually we did that in software, and we got better at it over time. Ericsson AXD 301, first commercial Erlang switch. But lets take a step back. + +--- + +## Phone switches must be ... + +Highly concurrent + +Fault-tolerant + +Distributed + +(Fast!) + + + +--- + +## ... and so is Erlang! + +--- + +## Erlang as a whole: + +- Unique process model (actors!) +- Built-in fault-tolerance & error handling +- Distributed processes +- Three parts! + +--- + +## Part 1: Erlang, the language + +- Functional +- Prolog-inspired syntax +- Everything is immutable +- *Extreme* pattern-matching + +--- +### Hello Joe + +```erlang +hello_joe. +``` + +--- +### Hello Joe + +```erlang +-module(hello1). +-export([hello_joe/0]). + +hello_joe() -> + hello_joe. +``` + +--- +### Hello Joe + +```erlang +-module(hello1). +-export([hello_joe/0]). + +hello_joe() -> + hello_joe. + +% 1> c(hello1). +% {ok,hello1} +% 2> hello1:hello_joe(). +% hello_joe +``` + +--- +### Hello Joe + +```erlang +-module(hello2). +-export([hello/1]). + +hello(Name) -> + io:format("Hello ~s!~n", [Name]). + +% 3> c(hello2). +% {ok,hello2} +% 4> hello2:hello("Joe"). +% Hello Joe! +% ok +``` + +--- + +## [fit] Hello ~~world~~ Joe is boring! +## [fit] Lets do it with processes. + +--- +### Hello Server + +```erlang +-module(hello_server). +-export([start_server/0]). + +start_server() -> + spawn(fun() -> server() end). + +server() -> + receive + {greet, Name} -> + io:format("Hello ~s!~n", [Name]), + server() + end. +``` + +--- + +## [fit] Some issues with that ... + +- What about unused messages? +- What if the server crashes? + +--- + +## [fit] Part 2: Open Telecom Platform + +### **It's called Erlang/OTP for a reason.** + +--- + +# OTP: An Application Framework + +- Supervision - keep processes alive! + +- OTP Behaviours - common process patterns + +- Extensive standard library + +- Error handling, debuggers, testing, ... + +- Lots more! + +^ Standard library includes lots of things from simple network libraries over testing frameworks to cryptography, complete LDAP clients etc. + +--- + +# Supervision + +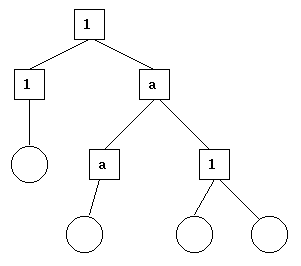 + +^ Supervision keeps processes alive, different restart behaviours, everything should be supervised to avoid "process" (and therefore memory) leaks + +--- + +# OTP Behaviours + +* `gen_server` +* `gen_statem` +* `gen_event` +* `supervisor` + +^ gen = generic. explain server, explain statem, event = event handling with registered handlers, supervisor ... + +--- + +`gen_server` + +--- + +## [fit] Part 3: BEAM + +### Bogdan/Bjørn Erlang Abstract machine + +--- + +## A VM for Erlang + +* Many were written, BEAM survived +* Concurrent garbage-collection +* Lower-level bytecode than JVM +* Very open to new languages + (Elixir, LFE, Joxa, ...) + +--- + +## What next? + +* Ole's talk, obviously! +* Learn You Some Erlang! + www.learnyousomeerlang.com +* Watch *Erlang the Movie* +* (soon!) Join the Oslo BEAM meetup group + +--- + +# [fit] Questions? + +`@tazjin` diff --git a/presentations/erlang-2016/presentation.pdf b/presentations/erlang-2016/presentation.pdf new file mode 100644 index 0000000000..ec8d996704 --- /dev/null +++ b/presentations/erlang-2016/presentation.pdf Binary files differdiff --git a/presentations/erlang-2016/src/hello.erl b/presentations/erlang-2016/src/hello.erl new file mode 100644 index 0000000000..56404a0c5a --- /dev/null +++ b/presentations/erlang-2016/src/hello.erl @@ -0,0 +1,5 @@ +-module(hello). +-export([hello_joe/0]). + +hello_joe() -> + hello_joe. diff --git a/presentations/erlang-2016/src/hello1.erl b/presentations/erlang-2016/src/hello1.erl new file mode 100644 index 0000000000..ca78261399 --- /dev/null +++ b/presentations/erlang-2016/src/hello1.erl @@ -0,0 +1,5 @@ +-module(hello1). +-export([hello_joe/0]). + +hello_joe() -> + hello_joe. diff --git a/presentations/erlang-2016/src/hello2.erl b/presentations/erlang-2016/src/hello2.erl new file mode 100644 index 0000000000..2d1f6c84c4 --- /dev/null +++ b/presentations/erlang-2016/src/hello2.erl @@ -0,0 +1,11 @@ +-module(hello2). +-export([hello/1]). + +hello(Name) -> + io:format("Hey ~s!~n", [Name]). + +% 3> c(hello2). +% {ok,hello2} +% 4> hello2:hello("Joe"). +% Hello Joe! +% ok diff --git a/presentations/erlang-2016/src/hello_server.erl b/presentations/erlang-2016/src/hello_server.erl new file mode 100644 index 0000000000..01df14ac57 --- /dev/null +++ b/presentations/erlang-2016/src/hello_server.erl @@ -0,0 +1,12 @@ +-module(hello_server). +-export([start_server/0, server/0]). + +start_server() -> + spawn(fun() -> server() end). + +server() -> + receive + {greet, Name} -> + io:format("Hello ~s!~n", [Name]), + hello_server:server() + end. diff --git a/presentations/erlang-2016/src/hello_server2.erl b/presentations/erlang-2016/src/hello_server2.erl new file mode 100644 index 0000000000..24bb934ee5 --- /dev/null +++ b/presentations/erlang-2016/src/hello_server2.erl @@ -0,0 +1,36 @@ +-module(hello_server2). +-behaviour(gen_server). +-compile(export_all). + +%%% Start callback for supervisor +start_link() -> + gen_server:start_link({local, ?MODULE}, ?MODULE, [], []). + +%%% gen_server callbacks + +init([]) -> + {ok, sets:new()}. + +handle_call({greet, Name}, _From, State) -> + io:format("Hello ~s!~n", [Name]), + NewState = sets:add_element(Name, State), + {reply, ok, NewState}; + +handle_call({bye, Name}, _From, State) -> + io:format("Goodbye ~s!~n", [Name]), + NewState = sets:del_element(Name, State), + {reply, ok, NewState}. + +terminate(normal, State) -> + [io:format("Goodbye ~s!~n", [Name]) || Name <- State], + ok. + +%%% Unused gen_server callbacks +code_change(_OldVsn, State, _Extra) -> + {ok, State}. + +handle_info(_Info, State) -> + {noreply, State}. + +handle_cast(_Request, State) -> + {noreply, State}. diff --git a/presentations/erlang-2016/src/hello_sup.erl b/presentations/erlang-2016/src/hello_sup.erl new file mode 100644 index 0000000000..7fee0928c5 --- /dev/null +++ b/presentations/erlang-2016/src/hello_sup.erl @@ -0,0 +1,24 @@ +-module(hello_sup). +-behaviour(supervisor). +-export([start_link/0, init/1]). + +%%% Module API + +start_link() -> + supervisor:start_link({local, ?MODULE}, ?MODULE, []). + +%%% Supervisor callbacks + +init([]) -> + Children = [hello_spec()], + {ok, { {one_for_one, 5, 10}, Children}}. + +%%% Private + +hello_spec() -> + #{id => hello_server2, + start => {hello_server2, start_link, []}, + restart => permanent, + shutdown => 5000, + type => worker, + module => [hello_server2]}. diff --git a/presentations/servant-2016/Makefile b/presentations/servant-2016/Makefile new file mode 100644 index 0000000000..96115ec2cb --- /dev/null +++ b/presentations/servant-2016/Makefile @@ -0,0 +1,8 @@ +all: slides + +slides: + lualatex --shell-escape slides.tex + +clean: + rm -f slides.aux slides.log slides.nav \ + slides.out slides.toc slides.snm diff --git a/presentations/servant-2016/README.md b/presentations/servant-2016/README.md new file mode 100644 index 0000000000..8cfb04a424 --- /dev/null +++ b/presentations/servant-2016/README.md @@ -0,0 +1,7 @@ +These are the slides for my presentation about [servant][] at [Oslo Haskell][]. + +A full video recording of the presentation is available [on Vimeo][]. + +[servant]: https://haskell-servant.github.io/ +[Oslo Haskell]: http://www.meetup.com/Oslo-Haskell/events/227107530/ +[on Vimeo]: https://vimeo.com/153901805 diff --git a/presentations/servant-2016/slides.pdf b/presentations/servant-2016/slides.pdf new file mode 100644 index 0000000000..842a667e1b --- /dev/null +++ b/presentations/servant-2016/slides.pdf Binary files differdiff --git a/presentations/servant-2016/slides.pdfpc b/presentations/servant-2016/slides.pdfpc new file mode 100644 index 0000000000..ed46003768 --- /dev/null +++ b/presentations/servant-2016/slides.pdfpc @@ -0,0 +1,75 @@ +[file] +slides.pdf +[font_size] +10897 +[notes] +### 1 +13### 2 +Let's talk about servant, which is several things: +API description DSL, we'll speak about how this DSL works +and why it's at the type level + +Interpretations of the types resulting from that DSL, for example in +web servers or API clients + +Servant is commonly used or implementing services with APIs, or for accessing +other APIs with a simple, typed client +### 3 +Why type-level DSLs? +Type-level DSL: express *something*, e.g. endpoints of API, on type level by combining types. Types can be uninhabited + +Phil Wadler's: expression problem: things should be extensible both in the cases of a type, and in the functions operating on the type +Normal data types: can't add new constructors easily +Servant lifts thisup to simply allow the declaration of new types that can be included in the DSL, and new interpretations that can be attached to the types through typeclasses + +APIs become first-class citizens, can pass them around, combine them etc, they are separate from interpretations such as server implementations. In contrast, in most webframeworks, API declaration is implicit + +(Mention previous attemps at type-safe web, Yesod / web-routes + boomerang etc) +### 4 +Three extensions are necessary: +TypeOperators lets us use infix operators on the type level as constructors +DataKinds promotes new type declarations to the kind level, makes type-level literals (strings and natural numbers) available, lets us use type-level lists and pairs in combination with typeoperators +TypeFamilies: Type-level functions, map one set of types to another, come in two forms (type families, non-injective; data families, injective), more powerful than associated types +### 5 +Here you can see servant's general syntax, we define an API type as a simple alias of some other type combinations +strings are type-level strings, not actually values, represent path elements +endpoints are separated by :<|>, all endpoints end in a method with content types and return types +Capture captures path segments, but there are other combinators, for example for headers +Everything that is used from the request is expressed in types, enforcing checkability, no "escape hatch" inside handlers to get request +Every combinator has associated interpretations through typeclasses +### 6 +Explain type alias, point out Capture +Server is a type level function (type family), as mentioned earlier +### 7 +If we expand server (in ghci with kind!) we can see the actual type of the +function +### 8 +Lets speak about some interpretations of these things +### 9 +Servant server is the main interpretation that people are interested in, it's used +for taking a type specification and creating a server from it +Based on WAI, the web application interface, common abstraction for web servers which came out of the Yesod project. Implemented by the web server warp, which Yesod runs on +### 10 +Explain snippet, path gets removed from server type (irrelevant for handler), +route extracts string to value level +### 11 +Explain echo server quickly +### 12 +servant client allows generation of Haskell functions that query the API with the same types +this makes for easy to use RPC for example +### 13 +A lot of other interpretations exist for all kinds of things, mock servers for testing, foreign functions in various languages, documentation ... +### 14 +Demo! +1. Go quickly through code +2. Run server, query with curl +3. Open javascript function +4. Show JS code in the thing +5. Open the map itself +6. Open GHCi, use client +7. Generate docs +### 15 +Conclusion +Servant is pretty good, it's very easy to get started and it's great to raise the level of things that the compiler can tell you about when you do them wrong. +### 16 +Drawbacks. diff --git a/presentations/servant-2016/slides.tex b/presentations/servant-2016/slides.tex new file mode 100644 index 0000000000..d5947eb942 --- /dev/null +++ b/presentations/servant-2016/slides.tex @@ -0,0 +1,137 @@ +\documentclass[12pt]{beamer} +\usetheme{metropolis} +\usepackage{minted} + +\newenvironment{code}{\ttfamily}{\par} + +\title{servant} +\subtitle{Defining web APIs at the type-level} + +\begin{document} +\metroset{titleformat frame=smallcaps} +\setminted{fontsize=\scriptsize} + + +\maketitle + +\section{Introduction} + +\begin{frame}{Type-level DSLs?} + \begin{itemize} + \item (Uninhabited) types with attached ``meaning'' + \item The Expression Problem (Wadler 1998) + \item API representation and interpretation are separated + \item APIs become first-class citizens + \end{itemize} +\end{frame} + +\begin{frame}{Haskell extensions} + \begin{itemize} + \item TypeOperators + \item DataKinds + \item TypeFamilies + \end{itemize} +\end{frame} + +\begin{frame}[fragile]{A servant example} + \begin{minted}{haskell} + type PubAPI = "pubs" :> Get ’[JSON] [Pub] + :<|> "pubs" :> "tagged" + :> Capture "tag" Text + :> Get ’[JSON] [Pub] + \end{minted} +\end{frame} + +\begin{frame}[fragile]{Computed types} + \begin{minted}{haskell} + type TaggedPubs = "tagged" :> Capture "tag" Text :> ... + + taggedPubsHandler :: Server TaggedPubs + taggedPubsHandler tag = ... + \end{minted} +\end{frame} + +\begin{frame}[fragile]{Computed types} + \begin{minted}{haskell} + type TaggedPubs = "tagged" :> Capture "tag" Text :> ... + + taggedPubsHandler :: Server TaggedPubs + taggedPubsHandler tag = ... + + Server TaggedPubs ~ + Text -> EitherT ServantErr IO [Pub] + \end{minted} +\end{frame} + +\section{Interpretations} + +\begin{frame}{servant-server} + The one everyone is interested in! + + \begin{itemize} + \item Based on WAI, can run on warp + \item Interprets combinators with a simple \texttt{HasServer c} class + \item Easy to use! + \end{itemize} +\end{frame} + +\begin{frame}[fragile]{HasServer ...} + \begin{minted}{haskell} + instance (KnownSymbol path, HasServer sublayout) + => HasServer (path :> sublayout) where + type ServerT (path :> sublayout) m = ServerT sublayout m + + route ... + where + pathString = symbolVal (Proxy :: Proxy path) + \end{minted} +\end{frame} + +\begin{frame}[fragile]{Server example} + \begin{minted}{haskell} + type Echo = Capture "echo" Text :> Get ’[PlainText] Text + + echoAPI :: Proxy Echo + echoAPI = Proxy + + echoServer :: Server Echo + echoServer = return + \end{minted} +\end{frame} + +\begin{frame}{servant-client} + \begin{itemize} + \item Generates Haskell client functions for API + \item Same types as API specification: For RPC the whole ``web layer'' is abstracted away + \item Also easy to use! + \end{itemize} +\end{frame} + +\begin{frame}{servant-docs, servant-js ...} + Many other interpretations exist already, for example: + \begin{itemize} + \item Documentation generation + \item Foreign function export (e.g. Elm, JavaScript) + \item Mock-server generation + \end{itemize} +\end{frame} + +\section{Demo} + +\section{Conclusion} + +\begin{frame}{Drawbacks} + \begin{itemize} + \item Haskell has no custom open kinds (yet) + \item Proxies are ugly + \item Errors can be a bit daunting + \end{itemize} +\end{frame} + +\begin{frame}{Questions?} + Ølkartet: github.com/tazjin/pubkartet \\ + Slides: github.com/tazjin/servant-presentation + + @tazjin +\end{frame} +\end{document} diff --git a/presentations/systemd-2016/.gitignore b/presentations/systemd-2016/.gitignore new file mode 100644 index 0000000000..1a38620fe9 --- /dev/null +++ b/presentations/systemd-2016/.gitignore @@ -0,0 +1,6 @@ +slides.aux +slides.log +slides.nav +slides.out +slides.snm +slides.toc diff --git a/presentations/systemd-2016/.skip-subtree b/presentations/systemd-2016/.skip-subtree new file mode 100644 index 0000000000..108b3507dd --- /dev/null +++ b/presentations/systemd-2016/.skip-subtree @@ -0,0 +1 @@ +No Nix files will ever be under this tree ... diff --git a/presentations/systemd-2016/Makefile b/presentations/systemd-2016/Makefile new file mode 100644 index 0000000000..ac5dde3cb3 --- /dev/null +++ b/presentations/systemd-2016/Makefile @@ -0,0 +1,11 @@ +all: slides.pdf + +slides.toc: + lualatex slides.tex + +slides.pdf: slides.toc + lualatex slides.tex + +clean: + rm -f slides.aux slides.log slides.nav \ + slides.out slides.toc slides.snm diff --git a/presentations/systemd-2016/README.md b/presentations/systemd-2016/README.md new file mode 100644 index 0000000000..7f004b7d14 --- /dev/null +++ b/presentations/systemd-2016/README.md @@ -0,0 +1,6 @@ +This repository contains the slides for my systemd presentation at Hackeriet. + +Requires LaTeX, [beamer][] and the [metropolis][] theme. + +[beamer]: http://mirror.hmc.edu/ctan/macros/latex/contrib/beamer/ +[metropolis]: https://github.com/matze/mtheme diff --git a/presentations/systemd-2016/demo/demo-error.service b/presentations/systemd-2016/demo/demo-error.service new file mode 100644 index 0000000000..b2d4c9d347 --- /dev/null +++ b/presentations/systemd-2016/demo/demo-error.service @@ -0,0 +1,7 @@ +[Unit] +Description=Demonstrate failing units +OnFailure=demo-notify@%n.service + +[Service] +Type=oneshot +ExecStart=/usr/bin/false diff --git a/presentations/systemd-2016/demo/demo-limits.slice b/presentations/systemd-2016/demo/demo-limits.slice new file mode 100644 index 0000000000..998185d261 --- /dev/null +++ b/presentations/systemd-2016/demo/demo-limits.slice @@ -0,0 +1,7 @@ +[Unit] +Description=Limited resources demo +DefaultDependencies=no +Before=slices.target + +[Slice] +CPUQuota=10% diff --git a/presentations/systemd-2016/demo/demo-notify@.service b/presentations/systemd-2016/demo/demo-notify@.service new file mode 100644 index 0000000000..e25524b4e2 --- /dev/null +++ b/presentations/systemd-2016/demo/demo-notify@.service @@ -0,0 +1,6 @@ +[Unit] +Description=Demonstrate systemd templating by sending a notification + +[Service] +Type=oneshot +ExecStart=/usr/bin/notify-send 'Systemd notification' '%i' diff --git a/presentations/systemd-2016/demo/demo-path.path b/presentations/systemd-2016/demo/demo-path.path new file mode 100644 index 0000000000..87f1342da9 --- /dev/null +++ b/presentations/systemd-2016/demo/demo-path.path @@ -0,0 +1,6 @@ +[Unit] +Description=Demonstrate systemd path units + +[Path] +DirectoryNotEmpty=/tmp/hackeriet +Unit=demo.service diff --git a/presentations/systemd-2016/demo/demo-stress.service b/presentations/systemd-2016/demo/demo-stress.service new file mode 100644 index 0000000000..7e14f13e29 --- /dev/null +++ b/presentations/systemd-2016/demo/demo-stress.service @@ -0,0 +1,6 @@ +[Unit] +Description=Stress test CPU + +[Service] +Slice=demo.slice +ExecStart=/usr/bin/stress -c 5 diff --git a/presentations/systemd-2016/demo/demo-timer.timer b/presentations/systemd-2016/demo/demo-timer.timer new file mode 100644 index 0000000000..34eccb98b0 --- /dev/null +++ b/presentations/systemd-2016/demo/demo-timer.timer @@ -0,0 +1,12 @@ +[Unit] +Description=Demonstrate systemd timers + +[Timer] +OnActiveSec=2 +OnUnitActiveSec=5 +AccuracySec=5 +Unit=demo.service +# OnCalendar=Thu,Fri 2016-*-1,5 11:12:13 + +[Install] +WantedBy=multi-user.target diff --git a/presentations/systemd-2016/demo/demo.service b/presentations/systemd-2016/demo/demo.service new file mode 100644 index 0000000000..fcc710ad93 --- /dev/null +++ b/presentations/systemd-2016/demo/demo.service @@ -0,0 +1,6 @@ +[Unit] +Description=Demo unit for systemd + +[Service] +Type=oneshot +ExecStart=/usr/bin/echo "Systemd unit activated. Hello Hackeriet." diff --git a/presentations/systemd-2016/demo/notes.md b/presentations/systemd-2016/demo/notes.md new file mode 100644 index 0000000000..b4866b1642 --- /dev/null +++ b/presentations/systemd-2016/demo/notes.md @@ -0,0 +1,27 @@ +# simple oneshot + +Run `demo-notify@hello.service` + +# simple timer + +Run `demo-timer.timer`, show both + +# enabling + +Enable `demo-timer.timer`, go to symlink folder, disable + +# OnError + +Show & run `demo-error.service` + +# cgroups demo + +Start `demo-stress.service` without, show in htop, stop +Show slice unit, start slice unit +Add Slice=demo-limits.slice +daemon-reload +Start stress again + +# Proper service + +Look at nginx unit diff --git a/presentations/systemd-2016/slides.pdf b/presentations/systemd-2016/slides.pdf new file mode 100644 index 0000000000..384db2a6e0 --- /dev/null +++ b/presentations/systemd-2016/slides.pdf Binary files differdiff --git a/presentations/systemd-2016/slides.pdfpc b/presentations/systemd-2016/slides.pdfpc new file mode 100644 index 0000000000..99326bd8bf --- /dev/null +++ b/presentations/systemd-2016/slides.pdfpc @@ -0,0 +1,85 @@ +[file] +slides.pdf +[notes] +### 1 +### 2 +Let's start off by looking at what an init system is, how they used to work and what systemd does different before we go into more systemd-specific details. +### 3 +system processes that are started include for example FS mounts, network settings, powertop... +system services are long-running processes such as daemons, e.g. SSH, database or web servers, session managers, udev ... + +orphans: Process whose parent has finished somehow, gets adopted by init system +-> when a process terminates its parent must call wait() to get its exit() code, if there is no init system adopting orphans the process would become a zombie +### 4 +Before systemd there were simple init systems that just did the tasks listed on the previous slide. +Init scripts -> increased greatly in complexity over time, look at incomprehensible skeleton for Debian service init scripts +Runlevels -> things such as single-user mode, full multiuser mode, reboot, halt + +Init will run all the scripts, but it will not do much more than print information on success/failure of started scripts + +Init scripts run strictly sequential + +Init is unaware of inter-service dependencies, expressed through prefixing scripts with numbers etc. + +Init will not watch processes after system is booted -> crashing daemons will not automatically restart +### 5 +### 6 +How systemd came to be + +Considering the lack of process monitoring, problematic things about init scripts -> legacy init systems have drawbacks + +Apple had already built launchd, a more featured init system that monitored running processes, could automatically restart them and allowed for certain advanced features -> however it is awful to use and wrap your head around + +Lennart Poettering of Pulseaudio fame and Kay Sievers decided to implement a new init system to address these problems, while taking certain clues from Apple's design +### 7 +Systemd's design goals +### 8 +No more init scripts with opaque effects -> services are clearly defined units +Unit dependencies -> systemd can figure out what can be started in parallel +Process supervision: Unit can be configured in many ways, e.g. always restart, only restart on success etc +Service logs: We'll talk more about this later +### 9 +Units are the core component of systemd that users deal with. They define services and everything else that systemd needs to start and manage. +Note that all these are the names of the respective man page on a system with systemd installed +Types: +systemd.service - processes controlled by systemd +systemd.target - equivalent to "runlevels", grouping of units for synchronisation +systemd.timer - more powerful replacement of cron that starts other units +systemd.path - systemd equvialent of inotify, watches files/folders -> launches units +systemd.socket - expose local IPC or network sockets, launch units on connections +systemd.device - trigger units when certain devices are connected +systemd.mount - systemd equivalent of fstab entries +systemd.swap - like mount +systemd.slice - unit groups for resource management purposes +... and a few more specialised ones +### 10 +Linux cgroups are a new resource management feature added quite a long time ago, but not used much. +Cgroups can be created manually and processes can be moved into them in order to control resource utilisation +Few people used them before systemd, limits.conf was often much easier but not as fine-grained +Systemd changed this +### 11 +Systemd collects standard output and stderr from all processes into its journal system +they provide a tool for querying the log, for example grouping service logs together with correct timestamps, querying, +### 12 +Systemd tooling, most important one is systemctl for general service management +journalctl is the query and management tool for journald +systemd-analyze is used for figuring out performance issues, for example by analysing the boot process, can make cool graphs of dependencies +systemd-cgtop is like top, but not on a process level - it's on a cgroup/slice level, shows combined usage of cgroups +systemd-cgls lists contents of systemd's cgroups to see which services are in what group +there also exist a bunch of others that we'll skip for now +### 13 +### 14 +### 15 +Systemd criticism comes from many directions and usually focuses on a few points +feature-creep: systemd is absorbing a lot of different services +### 16 +explain diagram a bit +### 17 +opaque: as a result, systemd has a lot more internal complexity that people can't easily wrap your mind around. However I argue that unless you're using something like suckless' sinit with your own scripts, you probably have no idea what your init does today anyways +unstable: this was definitely true even in the first stable release, with the binary log format getting corrupted for example. I haven't personally experienced any trouble with it recently though. +Another thing is that services start depending on systemd when they shouldn't, a problem for the BSD world (who cares (hey christoph!)) +### 18 +Despite criticism, systemd was adopted rapidly by large portions of the Linux +Initially in RedHat, because Poettering and co work there and it was clear from the beginning that it would be there +ArchLinux (which I'm using) and a few others followed suit quite quickly +Eventually, the big Debian init system discussion - after a lot of flaming - led to Debian adopting it as well, which had a ripple effect for related distros such as Ubuntu which abandoned upstart for it. \ No newline at end of file diff --git a/presentations/systemd-2016/slides.tex b/presentations/systemd-2016/slides.tex new file mode 100644 index 0000000000..c613cefd7e --- /dev/null +++ b/presentations/systemd-2016/slides.tex @@ -0,0 +1,160 @@ +\documentclass[12pt]{beamer} +\usetheme{metropolis} + +\newenvironment{code}{\ttfamily}{\par} + +\title{systemd} +\subtitle{The standard Linux init system} + +\begin{document} +\metroset{titleformat frame=smallcaps} + +\maketitle + +\section{Introduction} + +\begin{frame}{What is an init system?} + An init system is the first userspace process (PID 1) started in a UNIX-like system. It handles: + + \begin{itemize} + \item Starting system processes and services to prepare the environment + \item Adopting and ``reaping'' orphaned processes + \end{itemize} +\end{frame} + +\begin{frame}{Classical init systems} + Init systems before systemd - such as SysVinit - were very simple. + + \begin{itemize} + \item Services and processes to run are organised into ``init scripts'' + \item Scripts are linked to specific runlevels + \item Init system is configured to boot into a runlevel + \end{itemize} + +\end{frame} + +\section{systemd} + +\begin{frame}{Can we do better?} + \begin{itemize} + \item ``legacy'' init systems have a lot of drawbacks + \item Apple is taking a different approach on OS X + \item Systemd project was founded to address these issues + \end{itemize} +\end{frame} + +\begin{frame}{Systemd design goals} + \begin{itemize} + \item Expressing service dependencies + \item Monitoring service status + \item Enable parallel service startups + \item Ease of use + \end{itemize} +\end{frame} + +\begin{frame}{Systemd - the basics} + \begin{itemize} + \item No scripts are executed, only declarative units + \item Units have explicit dependencies + \item Processes are supervised + \item cgroups are utilised to apply resource limits + \item Service logs are managed and centrally queryable + \item Much more! + \end{itemize} +\end{frame} + +\begin{frame}{Systemd units} + Units specify how and what to start. Several types exist: + \begin{code} + \small + \begin{columns}[T,onlytextwidth] + \column{0.5\textwidth} + \begin{itemize} + \item systemd.service + \item systemd.target + \item systemd.timer + \item systemd.path + \item systemd.socket + \end{itemize} + \column{0.5\textwidth} + \begin{itemize} + \item systemd.device + \item systemd.mount + \item systemd.swap + \item systemd.slice + \end{itemize} + \end{columns} + \end{code} +\end{frame} + + +\begin{frame}{Resource management} + Systemd utilises Linux \texttt{cgroups} for resource management, specifically CPU, disk I/O and memory usage. + + \begin{itemize} + \item Hierarchical setup of groups makes it easy to limit resources for a set of services + \item Units can be attached to a \texttt{systemd.slice} for controlling resources for a group of services + \item Resource limits can also be specified directly in the unit + \end{itemize} +\end{frame} + +\begin{frame}{journald} + Systemd comes with an integrated log management solution, replacing software such as \texttt{syslog-ng}. + \begin{itemize} + \item All process output is collected in the journal + \item \texttt{journalctl} tool provides many options for querying and tailing logs + \item Children of processes automatically log to the journal as well + \item \textbf{Caveat:} Hard to learn initially + \end{itemize} +\end{frame} + +\begin{frame}{Systemd tooling} + A variety of CLI-tools exist for managing systemd systems. + \begin{code} + \begin{itemize} + \item systemctl + \item journalctl + \item systemd-analyze + \item systemd-cgtop + \item systemd-cgls + \end{itemize} + \end{code} + + Let's look at some of them. +\end{frame} + +\section{Demo} + +\section{Controversies} + +\begin{frame}{Systemd criticism} + Systemd has been heavily criticised, usually focusing around a few points: + \begin{itemize} + \item Feature-creep: Systemd absorbs more and more other services + \end{itemize} +\end{frame} + +\begin{frame}{Systemd criticism} + \includegraphics[keepaspectratio=true,width=\textwidth]{systemdcomponents.png} +\end{frame} + +\begin{frame}{Systemd criticism} + Systemd has been heavily criticised, usually focusing around a few points: + \begin{itemize} + \item Feature-creep: Systemd absorbs more and more other services + \item Opaque: systemd's inner workings are harder to understand than old \texttt{init} + \item Unstable: development is quick and breakage happens + \end{itemize} +\end{frame} + +\begin{frame}{Systemd adoption} + Systemd was initially adopted by RedHat (and related distributions). + + It spread quickly to others, for example ArchLinux. + + Debian and Ubuntu were the last major players who decided to adopt it, but not without drama. +\end{frame} + +\section{Questions?} + +\end{document} diff --git a/presentations/systemd-2016/systemdcomponents.png b/presentations/systemd-2016/systemdcomponents.png new file mode 100644 index 0000000000..a22c762f7e --- /dev/null +++ b/presentations/systemd-2016/systemdcomponents.png Binary files differdiff --git a/sha1collisiondetection b/sha1collisiondetection deleted file mode 160000 -Subproject 855827c583bc30645ba427885caa40c5b81764d diff --git a/third_party/README.md b/third_party/README.md new file mode 100644 index 0000000000..267f234697 --- /dev/null +++ b/third_party/README.md @@ -0,0 +1,13 @@ +Third-Party Code +================ + +Code under this folder is one of the following: + +1. Externally developed dependencies which have been imported ("vendored") into + this repository. These dependencies come with their own licenses and whatever + else. + +2. Code that is developed inside of this repository, but released to an external + repository via [Copybara][]. + +[Copybara]: https://github.com/google/copybara diff --git a/third_party/abseil_cpp/.clang-format b/third_party/abseil_cpp/.clang-format new file mode 100644 index 0000000000..06ea346a10 --- /dev/null +++ b/third_party/abseil_cpp/.clang-format @@ -0,0 +1,4 @@ +--- +Language: Cpp +BasedOnStyle: Google +... diff --git a/third_party/abseil_cpp/.gitignore b/third_party/abseil_cpp/.gitignore new file mode 100644 index 0000000000..d54fa5a91f --- /dev/null +++ b/third_party/abseil_cpp/.gitignore @@ -0,0 +1,15 @@ +# Ignore all bazel-* symlinks. +/bazel-* +# Ignore Bazel verbose explanations +--verbose_explanations +# Ignore CMake usual build directory +build +# Ignore Vim files +*.swp +# Ignore QtCreator Project file +CMakeLists.txt.user +# Ignore VS Code files +.vscode/* +# Ignore generated python artifacts +*.pyc +copts/__pycache__/ diff --git a/third_party/abseil_cpp/ABSEIL_ISSUE_TEMPLATE.md b/third_party/abseil_cpp/ABSEIL_ISSUE_TEMPLATE.md new file mode 100644 index 0000000000..ed5461f166 --- /dev/null +++ b/third_party/abseil_cpp/ABSEIL_ISSUE_TEMPLATE.md @@ -0,0 +1,22 @@ +Please submit a new Abseil Issue using the template below: + +## [Short title of proposed API change(s)] + +-------------------------------------------------------------------------------- +-------------------------------------------------------------------------------- + +## Background + +[Provide the background information that is required in order to evaluate the +proposed API changes. No controversial claims should be made here. If there are +design constraints that need to be considered, they should be presented here +**along with justification for those constraints**. Linking to other docs is +good, but please keep the **pertinent information as self contained** as +possible in this section.] + +## Proposed API Change (s) + +[Please clearly describe the API change(s) being proposed. If multiple changes, +please keep them clearly distinguished. When possible, **use example code +snippets to illustrate before-after API usages**. List pros-n-cons. Highlight +the main questions that you want to be answered. Given the Abseil project compatibility requirements, describe why the API change is safe.] diff --git a/third_party/abseil_cpp/AUTHORS b/third_party/abseil_cpp/AUTHORS new file mode 100644 index 0000000000..976d31defc --- /dev/null +++ b/third_party/abseil_cpp/AUTHORS @@ -0,0 +1,6 @@ +# This is the list of Abseil authors for copyright purposes. +# +# This does not necessarily list everyone who has contributed code, since in +# some cases, their employer may be the copyright holder. To see the full list +# of contributors, see the revision history in source control. +Google Inc. diff --git a/third_party/abseil_cpp/CMake/AbseilDll.cmake b/third_party/abseil_cpp/CMake/AbseilDll.cmake new file mode 100644 index 0000000000..a5c9bc0d0f --- /dev/null +++ b/third_party/abseil_cpp/CMake/AbseilDll.cmake @@ -0,0 +1,509 @@ +include(CMakeParseArguments) + +set(ABSL_INTERNAL_DLL_FILES + "algorithm/algorithm.h" + "algorithm/container.h" + "base/attributes.h" + "base/call_once.h" + "base/casts.h" + "base/config.h" + "base/const_init.h" + "base/dynamic_annotations.cc" + "base/dynamic_annotations.h" + "base/internal/atomic_hook.h" + "base/internal/bits.h" + "base/internal/cycleclock.cc" + "base/internal/cycleclock.h" + "base/internal/direct_mmap.h" + "base/internal/endian.h" + "base/internal/errno_saver.h" + "base/internal/exponential_biased.cc" + "base/internal/exponential_biased.h" + "base/internal/fast_type_id.h" + "base/internal/hide_ptr.h" + "base/internal/identity.h" + "base/internal/invoke.h" + "base/internal/inline_variable.h" + "base/internal/low_level_alloc.cc" + "base/internal/low_level_alloc.h" + "base/internal/low_level_scheduling.h" + "base/internal/per_thread_tls.h" + "base/internal/periodic_sampler.cc" + "base/internal/periodic_sampler.h" + "base/internal/pretty_function.h" + "base/internal/raw_logging.cc" + "base/internal/raw_logging.h" + "base/internal/scheduling_mode.h" + "base/internal/scoped_set_env.cc" + "base/internal/scoped_set_env.h" + "base/internal/strerror.h" + "base/internal/strerror.cc" + "base/internal/spinlock.cc" + "base/internal/spinlock.h" + "base/internal/spinlock_wait.cc" + "base/internal/spinlock_wait.h" + "base/internal/sysinfo.cc" + "base/internal/sysinfo.h" + "base/internal/thread_annotations.h" + "base/internal/thread_identity.cc" + "base/internal/thread_identity.h" + "base/internal/throw_delegate.cc" + "base/internal/throw_delegate.h" + "base/internal/tsan_mutex_interface.h" + "base/internal/unaligned_access.h" + "base/internal/unscaledcycleclock.cc" + "base/internal/unscaledcycleclock.h" + "base/log_severity.cc" + "base/log_severity.h" + "base/macros.h" + "base/optimization.h" + "base/options.h" + "base/policy_checks.h" + "base/port.h" + "base/thread_annotations.h" + "container/btree_map.h" + "container/btree_set.h" + "container/fixed_array.h" + "container/flat_hash_map.h" + "container/flat_hash_set.h" + "container/inlined_vector.h" + "container/internal/btree.h" + "container/internal/btree_container.h" + "container/internal/common.h" + "container/internal/compressed_tuple.h" + "container/internal/container_memory.h" + "container/internal/counting_allocator.h" + "container/internal/hash_function_defaults.h" + "container/internal/hash_policy_traits.h" + "container/internal/hashtable_debug.h" + "container/internal/hashtable_debug_hooks.h" + "container/internal/hashtablez_sampler.cc" + "container/internal/hashtablez_sampler.h" + "container/internal/hashtablez_sampler_force_weak_definition.cc" + "container/internal/have_sse.h" + "container/internal/inlined_vector.h" + "container/internal/layout.h" + "container/internal/node_hash_policy.h" + "container/internal/raw_hash_map.h" + "container/internal/raw_hash_set.cc" + "container/internal/raw_hash_set.h" + "container/internal/tracked.h" + "container/node_hash_map.h" + "container/node_hash_set.h" + "debugging/failure_signal_handler.cc" + "debugging/failure_signal_handler.h" + "debugging/leak_check.h" + "debugging/leak_check_disable.cc" + "debugging/stacktrace.cc" + "debugging/stacktrace.h" + "debugging/symbolize.cc" + "debugging/symbolize.h" + "debugging/internal/address_is_readable.cc" + "debugging/internal/address_is_readable.h" + "debugging/internal/demangle.cc" + "debugging/internal/demangle.h" + "debugging/internal/elf_mem_image.cc" + "debugging/internal/elf_mem_image.h" + "debugging/internal/examine_stack.cc" + "debugging/internal/examine_stack.h" + "debugging/internal/stack_consumption.cc" + "debugging/internal/stack_consumption.h" + "debugging/internal/stacktrace_config.h" + "debugging/internal/symbolize.h" + "debugging/internal/vdso_support.cc" + "debugging/internal/vdso_support.h" + "functional/internal/front_binder.h" + "functional/bind_front.h" + "functional/function_ref.h" + "functional/internal/function_ref.h" + "hash/hash.h" + "hash/internal/city.h" + "hash/internal/city.cc" + "hash/internal/hash.h" + "hash/internal/hash.cc" + "hash/internal/spy_hash_state.h" + "memory/memory.h" + "meta/type_traits.h" + "numeric/int128.cc" + "numeric/int128.h" + "random/bernoulli_distribution.h" + "random/beta_distribution.h" + "random/bit_gen_ref.h" + "random/discrete_distribution.cc" + "random/discrete_distribution.h" + "random/distributions.h" + "random/exponential_distribution.h" + "random/gaussian_distribution.cc" + "random/gaussian_distribution.h" + "random/internal/distributions.h" + "random/internal/distribution_caller.h" + "random/internal/fast_uniform_bits.h" + "random/internal/fastmath.h" + "random/internal/gaussian_distribution_gentables.cc" + "random/internal/generate_real.h" + "random/internal/iostream_state_saver.h" + "random/internal/nonsecure_base.h" + "random/internal/pcg_engine.h" + "random/internal/platform.h" + "random/internal/pool_urbg.cc" + "random/internal/pool_urbg.h" + "random/internal/randen_round_keys.cc" + "random/internal/randen.cc" + "random/internal/randen.h" + "random/internal/randen_detect.cc" + "random/internal/randen_detect.h" + "random/internal/randen_engine.h" + "random/internal/randen_hwaes.cc" + "random/internal/randen_hwaes.h" + "random/internal/randen_slow.cc" + "random/internal/randen_slow.h" + "random/internal/randen_traits.h" + "random/internal/salted_seed_seq.h" + "random/internal/seed_material.cc" + "random/internal/seed_material.h" + "random/internal/sequence_urbg.h" + "random/internal/traits.h" + "random/internal/uniform_helper.h" + "random/internal/wide_multiply.h" + "random/log_uniform_int_distribution.h" + "random/poisson_distribution.h" + "random/random.h" + "random/seed_gen_exception.cc" + "random/seed_gen_exception.h" + "random/seed_sequences.cc" + "random/seed_sequences.h" + "random/uniform_int_distribution.h" + "random/uniform_real_distribution.h" + "random/zipf_distribution.h" + "status/status.h" + "status/status.cc" + "status/status_payload_printer.h" + "status/status_payload_printer.cc" + "strings/ascii.cc" + "strings/ascii.h" + "strings/charconv.cc" + "strings/charconv.h" + "strings/cord.cc" + "strings/cord.h" + "strings/escaping.cc" + "strings/escaping.h" + "strings/internal/cord_internal.h" + "strings/internal/charconv_bigint.cc" + "strings/internal/charconv_bigint.h" + "strings/internal/charconv_parse.cc" + "strings/internal/charconv_parse.h" + "strings/internal/stl_type_traits.h" + "strings/match.cc" + "strings/match.h" + "strings/numbers.cc" + "strings/numbers.h" + "strings/str_format.h" + "strings/str_cat.cc" + "strings/str_cat.h" + "strings/str_join.h" + "strings/str_replace.cc" + "strings/str_replace.h" + "strings/str_split.cc" + "strings/str_split.h" + "strings/string_view.cc" + "strings/string_view.h" + "strings/strip.h" + "strings/substitute.cc" + "strings/substitute.h" + "strings/internal/char_map.h" + "strings/internal/escaping.h" + "strings/internal/escaping.cc" + "strings/internal/memutil.cc" + "strings/internal/memutil.h" + "strings/internal/ostringstream.cc" + "strings/internal/ostringstream.h" + "strings/internal/pow10_helper.cc" + "strings/internal/pow10_helper.h" + "strings/internal/resize_uninitialized.h" + "strings/internal/str_format/arg.cc" + "strings/internal/str_format/arg.h" + "strings/internal/str_format/bind.cc" + "strings/internal/str_format/bind.h" + "strings/internal/str_format/checker.h" + "strings/internal/str_format/extension.cc" + "strings/internal/str_format/extension.h" + "strings/internal/str_format/float_conversion.cc" + "strings/internal/str_format/float_conversion.h" + "strings/internal/str_format/output.cc" + "strings/internal/str_format/output.h" + "strings/internal/str_format/parser.cc" + "strings/internal/str_format/parser.h" + "strings/internal/str_join_internal.h" + "strings/internal/str_split_internal.h" + "strings/internal/utf8.cc" + "strings/internal/utf8.h" + "synchronization/barrier.cc" + "synchronization/barrier.h" + "synchronization/blocking_counter.cc" + "synchronization/blocking_counter.h" + "synchronization/mutex.cc" + "synchronization/mutex.h" + "synchronization/notification.cc" + "synchronization/notification.h" + "synchronization/internal/create_thread_identity.cc" + "synchronization/internal/create_thread_identity.h" + "synchronization/internal/graphcycles.cc" + "synchronization/internal/graphcycles.h" + "synchronization/internal/kernel_timeout.h" + "synchronization/internal/per_thread_sem.cc" + "synchronization/internal/per_thread_sem.h" + "synchronization/internal/thread_pool.h" + "synchronization/internal/waiter.cc" + "synchronization/internal/waiter.h" + "time/civil_time.cc" + "time/civil_time.h" + "time/clock.cc" + "time/clock.h" + "time/duration.cc" + "time/format.cc" + "time/time.cc" + "time/time.h" + "time/internal/cctz/include/cctz/civil_time.h" + "time/internal/cctz/include/cctz/civil_time_detail.h" + "time/internal/cctz/include/cctz/time_zone.h" + "time/internal/cctz/include/cctz/zone_info_source.h" + "time/internal/cctz/src/civil_time_detail.cc" + "time/internal/cctz/src/time_zone_fixed.cc" + "time/internal/cctz/src/time_zone_fixed.h" + "time/internal/cctz/src/time_zone_format.cc" + "time/internal/cctz/src/time_zone_if.cc" + "time/internal/cctz/src/time_zone_if.h" + "time/internal/cctz/src/time_zone_impl.cc" + "time/internal/cctz/src/time_zone_impl.h" + "time/internal/cctz/src/time_zone_info.cc" + "time/internal/cctz/src/time_zone_info.h" + "time/internal/cctz/src/time_zone_libc.cc" + "time/internal/cctz/src/time_zone_libc.h" + "time/internal/cctz/src/time_zone_lookup.cc" + "time/internal/cctz/src/time_zone_posix.cc" + "time/internal/cctz/src/time_zone_posix.h" + "time/internal/cctz/src/tzfile.h" + "time/internal/cctz/src/zone_info_source.cc" + "types/any.h" + "types/bad_any_cast.cc" + "types/bad_any_cast.h" + "types/bad_optional_access.cc" + "types/bad_optional_access.h" + "types/bad_variant_access.cc" + "types/bad_variant_access.h" + "types/compare.h" + "types/internal/conformance_aliases.h" + "types/internal/conformance_archetype.h" + "types/internal/conformance_profile.h" + "types/internal/parentheses.h" + "types/internal/transform_args.h" + "types/internal/variant.h" + "types/optional.h" + "types/internal/optional.h" + "types/span.h" + "types/internal/span.h" + "types/variant.h" + "utility/utility.h" +) + +set(ABSL_INTERNAL_DLL_TARGETS + "stacktrace" + "symbolize" + "examine_stack" + "failure_signal_handler" + "debugging_internal" + "demangle_internal" + "leak_check" + "leak_check_disable" + "stack_consumption" + "debugging" + "hash" + "spy_hash_state" + "city" + "memory" + "strings" + "strings_internal" + "cord" + "str_format" + "str_format_internal" + "pow10_helper" + "int128" + "numeric" + "utility" + "any" + "bad_any_cast" + "bad_any_cast_impl" + "span" + "optional" + "bad_optional_access" + "bad_variant_access" + "variant" + "compare" + "algorithm" + "algorithm_container" + "graphcycles_internal" + "kernel_timeout_internal" + "synchronization" + "thread_pool" + "bind_front" + "function_ref" + "atomic_hook" + "log_severity" + "raw_logging_internal" + "spinlock_wait" + "config" + "dynamic_annotations" + "core_headers" + "malloc_internal" + "base_internal" + "base" + "throw_delegate" + "pretty_function" + "endian" + "bits" + "exponential_biased" + "periodic_sampler" + "scoped_set_env" + "type_traits" + "meta" + "random_random" + "random_bit_gen_ref" + "random_distributions" + "random_seed_gen_exception" + "random_seed_sequences" + "random_internal_traits" + "random_internal_distribution_caller" + "random_internal_distributions" + "random_internal_fast_uniform_bits" + "random_internal_seed_material" + "random_internal_pool_urbg" + "random_internal_explicit_seed_seq" + "random_internal_sequence_urbg" + "random_internal_salted_seed_seq" + "random_internal_iostream_state_saver" + "random_internal_generate_real" + "random_internal_wide_multiply" + "random_internal_fastmath" + "random_internal_nonsecure_base" + "random_internal_pcg_engine" + "random_internal_randen_engine" + "random_internal_platform" + "random_internal_randen" + "random_internal_randen_slow" + "random_internal_randen_hwaes" + "random_internal_randen_hwaes_impl" + "random_internal_uniform_helper" + "status" + "time" + "civil_time" + "time_zone" + "container" + "btree" + "compressed_tuple" + "fixed_array" + "inlined_vector_internal" + "inlined_vector" + "counting_allocator" + "flat_hash_map" + "flat_hash_set" + "node_hash_map" + "node_hash_set" + "container_memory" + "hash_function_defaults" + "hash_policy_traits" + "hashtablez_sampler" + "hashtable_debug" + "hashtable_debug_hooks" + "have_sse" + "node_hash_policy" + "raw_hash_map" + "container_common" + "raw_hash_set" + "layout" + "tracked" +) + +function(absl_internal_dll_contains) + cmake_parse_arguments(ABSL_INTERNAL_DLL + "" + "OUTPUT;TARGET" + "" + ${ARGN} + ) + + STRING(REGEX REPLACE "^absl::" "" _target ${ABSL_INTERNAL_DLL_TARGET}) + + list(FIND + ABSL_INTERNAL_DLL_TARGETS + "${_target}" + _index) + + if (${_index} GREATER -1) + set(${ABSL_INTERNAL_DLL_OUTPUT} 1 PARENT_SCOPE) + else() + set(${ABSL_INTERNAL_DLL_OUTPUT} 0 PARENT_SCOPE) + endif() +endfunction() + +function(absl_internal_dll_targets) + cmake_parse_arguments(ABSL_INTERNAL_DLL + "" + "OUTPUT" + "DEPS" + ${ARGN} + ) + + set(_deps "") + foreach(dep IN LISTS ABSL_INTERNAL_DLL_DEPS) + absl_internal_dll_contains(TARGET ${dep} OUTPUT _contains) + if (_contains) + list(APPEND _deps abseil_dll) + else() + list(APPEND _deps ${dep}) + endif() + endforeach() + + # Because we may have added the DLL multiple times + list(REMOVE_DUPLICATES _deps) + set(${ABSL_INTERNAL_DLL_OUTPUT} "${_deps}" PARENT_SCOPE) +endfunction() + +function(absl_make_dll) + add_library( + abseil_dll + SHARED + "${ABSL_INTERNAL_DLL_FILES}" + ) + target_link_libraries( + abseil_dll + PRIVATE + ${ABSL_DEFAULT_LINKOPTS} + ) + set_property(TARGET abseil_dll PROPERTY LINKER_LANGUAGE "CXX") + target_include_directories( + abseil_dll + PUBLIC + "$<BUILD_INTERFACE:${ABSL_COMMON_INCLUDE_DIRS}>" + $<INSTALL_INTERFACE:${ABSL_INSTALL_INCLUDEDIR}> + ) + + target_compile_options( + abseil_dll + PRIVATE + ${ABSL_DEFAULT_COPTS} + ) + + target_compile_definitions( + abseil_dll + PRIVATE + ABSL_BUILD_DLL + NOMINMAX + INTERFACE + ${ABSL_CC_LIB_DEFINES} + ) + install(TARGETS abseil_dll EXPORT ${PROJECT_NAME}Targets + RUNTIME DESTINATION ${ABSL_INSTALL_BINDIR} + LIBRARY DESTINATION ${ABSL_INSTALL_LIBDIR} + ARCHIVE DESTINATION ${ABSL_INSTALL_LIBDIR} + ) +endfunction() diff --git a/third_party/abseil_cpp/CMake/AbseilHelpers.cmake b/third_party/abseil_cpp/CMake/AbseilHelpers.cmake new file mode 100644 index 0000000000..86ff9eba2a --- /dev/null +++ b/third_party/abseil_cpp/CMake/AbseilHelpers.cmake @@ -0,0 +1,353 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +include(CMakeParseArguments) +include(AbseilConfigureCopts) +include(AbseilDll) +include(AbseilInstallDirs) + +# The IDE folder for Abseil that will be used if Abseil is included in a CMake +# project that sets +# set_property(GLOBAL PROPERTY USE_FOLDERS ON) +# For example, Visual Studio supports folders. +set(ABSL_IDE_FOLDER Abseil) + +# absl_cc_library() +# +# CMake function to imitate Bazel's cc_library rule. +# +# Parameters: +# NAME: name of target (see Note) +# HDRS: List of public header files for the library +# SRCS: List of source files for the library +# DEPS: List of other libraries to be linked in to the binary targets +# COPTS: List of private compile options +# DEFINES: List of public defines +# LINKOPTS: List of link options +# PUBLIC: Add this so that this library will be exported under absl:: +# Also in IDE, target will appear in Abseil folder while non PUBLIC will be in Abseil/internal. +# TESTONLY: When added, this target will only be built if user passes -DABSL_RUN_TESTS=ON to CMake. +# +# Note: +# By default, absl_cc_library will always create a library named absl_${NAME}, +# and alias target absl::${NAME}. The absl:: form should always be used. +# This is to reduce namespace pollution. +# +# absl_cc_library( +# NAME +# awesome +# HDRS +# "a.h" +# SRCS +# "a.cc" +# ) +# absl_cc_library( +# NAME +# fantastic_lib +# SRCS +# "b.cc" +# DEPS +# absl::awesome # not "awesome" ! +# PUBLIC +# ) +# +# absl_cc_library( +# NAME +# main_lib +# ... +# DEPS +# absl::fantastic_lib +# ) +# +# TODO: Implement "ALWAYSLINK" +function(absl_cc_library) + cmake_parse_arguments(ABSL_CC_LIB + "DISABLE_INSTALL;PUBLIC;TESTONLY" + "NAME" + "HDRS;SRCS;COPTS;DEFINES;LINKOPTS;DEPS" + ${ARGN} + ) + + if(ABSL_CC_LIB_TESTONLY AND NOT ABSL_RUN_TESTS) + return() + endif() + + if(ABSL_ENABLE_INSTALL) + set(_NAME "${ABSL_CC_LIB_NAME}") + else() + set(_NAME "absl_${ABSL_CC_LIB_NAME}") + endif() + + # Check if this is a header-only library + # Note that as of February 2019, many popular OS's (for example, Ubuntu + # 16.04 LTS) only come with cmake 3.5 by default. For this reason, we can't + # use list(FILTER...) + set(ABSL_CC_SRCS "${ABSL_CC_LIB_SRCS}") + foreach(src_file IN LISTS ABSL_CC_SRCS) + if(${src_file} MATCHES ".*\\.(h|inc)") + list(REMOVE_ITEM ABSL_CC_SRCS "${src_file}") + endif() + endforeach() + + if("${ABSL_CC_SRCS}" STREQUAL "") + set(ABSL_CC_LIB_IS_INTERFACE 1) + else() + set(ABSL_CC_LIB_IS_INTERFACE 0) + endif() + + # Determine this build target's relationship to the DLL. It's one of four things: + # 1. "dll" -- This target is part of the DLL + # 2. "dll_dep" -- This target is not part of the DLL, but depends on the DLL. + # Note that we assume any target not in the DLL depends on the + # DLL. This is not a technical necessity but a convenience + # which happens to be true, because nearly every target is + # part of the DLL. + # 3. "shared" -- This is a shared library, perhaps on a non-windows platform + # where DLL doesn't make sense. + # 4. "static" -- This target does not depend on the DLL and should be built + # statically. + if (${ABSL_BUILD_DLL}) + absl_internal_dll_contains(TARGET ${_NAME} OUTPUT _in_dll) + if (${_in_dll}) + # This target should be replaced by the DLL + set(_build_type "dll") + set(ABSL_CC_LIB_IS_INTERFACE 1) + else() + # Building a DLL, but this target is not part of the DLL + set(_build_type "dll_dep") + endif() + elseif(BUILD_SHARED_LIBS) + set(_build_type "shared") + else() + set(_build_type "static") + endif() + + if(NOT ABSL_CC_LIB_IS_INTERFACE) + if(${_build_type} STREQUAL "dll_dep") + # This target depends on the DLL. When adding dependencies to this target, + # any depended-on-target which is contained inside the DLL is replaced + # with a dependency on the DLL. + add_library(${_NAME} STATIC "") + target_sources(${_NAME} PRIVATE ${ABSL_CC_LIB_SRCS} ${ABSL_CC_LIB_HDRS}) + absl_internal_dll_targets( + DEPS ${ABSL_CC_LIB_DEPS} + OUTPUT _dll_deps + ) + target_link_libraries(${_NAME} + PUBLIC ${_dll_deps} + PRIVATE + ${ABSL_CC_LIB_LINKOPTS} + ${ABSL_DEFAULT_LINKOPTS} + ) + + if (ABSL_CC_LIB_TESTONLY) + set(_gtest_link_define "GTEST_LINKED_AS_SHARED_LIBRARY=1") + else() + set(_gtest_link_define) + endif() + + target_compile_definitions(${_NAME} + PUBLIC + ABSL_CONSUME_DLL + "${_gtest_link_define}" + ) + + elseif(${_build_type} STREQUAL "static" OR ${_build_type} STREQUAL "shared") + add_library(${_NAME} "") + target_sources(${_NAME} PRIVATE ${ABSL_CC_LIB_SRCS} ${ABSL_CC_LIB_HDRS}) + target_link_libraries(${_NAME} + PUBLIC ${ABSL_CC_LIB_DEPS} + PRIVATE + ${ABSL_CC_LIB_LINKOPTS} + ${ABSL_DEFAULT_LINKOPTS} + ) + else() + message(FATAL_ERROR "Invalid build type: ${_build_type}") + endif() + + # Linker language can be inferred from sources, but in the case of DLLs we + # don't have any .cc files so it would be ambiguous. We could set it + # explicitly only in the case of DLLs but, because "CXX" is always the + # correct linker language for static or for shared libraries, we set it + # unconditionally. + set_property(TARGET ${_NAME} PROPERTY LINKER_LANGUAGE "CXX") + + target_include_directories(${_NAME} + PUBLIC + "$<BUILD_INTERFACE:${ABSL_COMMON_INCLUDE_DIRS}>" + $<INSTALL_INTERFACE:${ABSL_INSTALL_INCLUDEDIR}> + ) + target_compile_options(${_NAME} + PRIVATE ${ABSL_CC_LIB_COPTS}) + target_compile_definitions(${_NAME} PUBLIC ${ABSL_CC_LIB_DEFINES}) + + # Add all Abseil targets to a a folder in the IDE for organization. + if(ABSL_CC_LIB_PUBLIC) + set_property(TARGET ${_NAME} PROPERTY FOLDER ${ABSL_IDE_FOLDER}) + elseif(ABSL_CC_LIB_TESTONLY) + set_property(TARGET ${_NAME} PROPERTY FOLDER ${ABSL_IDE_FOLDER}/test) + else() + set_property(TARGET ${_NAME} PROPERTY FOLDER ${ABSL_IDE_FOLDER}/internal) + endif() + + # INTERFACE libraries can't have the CXX_STANDARD property set + set_property(TARGET ${_NAME} PROPERTY CXX_STANDARD ${ABSL_CXX_STANDARD}) + set_property(TARGET ${_NAME} PROPERTY CXX_STANDARD_REQUIRED ON) + + # When being installed, we lose the absl_ prefix. We want to put it back + # to have properly named lib files. This is a no-op when we are not being + # installed. + if(ABSL_ENABLE_INSTALL) + set_target_properties(${_NAME} PROPERTIES + OUTPUT_NAME "absl_${_NAME}" + ) + endif() + else() + # Generating header-only library + add_library(${_NAME} INTERFACE) + target_include_directories(${_NAME} + INTERFACE + "$<BUILD_INTERFACE:${ABSL_COMMON_INCLUDE_DIRS}>" + $<INSTALL_INTERFACE:${ABSL_INSTALL_INCLUDEDIR}> + ) + + if (${_build_type} STREQUAL "dll") + set(ABSL_CC_LIB_DEPS abseil_dll) + endif() + + target_link_libraries(${_NAME} + INTERFACE + ${ABSL_CC_LIB_DEPS} + ${ABSL_CC_LIB_LINKOPTS} + ${ABSL_DEFAULT_LINKOPTS} + ) + target_compile_definitions(${_NAME} INTERFACE ${ABSL_CC_LIB_DEFINES}) + endif() + + # TODO currently we don't install googletest alongside abseil sources, so + # installed abseil can't be tested. + if(NOT ABSL_CC_LIB_TESTONLY AND ABSL_ENABLE_INSTALL) + install(TARGETS ${_NAME} EXPORT ${PROJECT_NAME}Targets + RUNTIME DESTINATION ${ABSL_INSTALL_BINDIR} + LIBRARY DESTINATION ${ABSL_INSTALL_LIBDIR} + ARCHIVE DESTINATION ${ABSL_INSTALL_LIBDIR} + ) + endif() + + add_library(absl::${ABSL_CC_LIB_NAME} ALIAS ${_NAME}) +endfunction() + +# absl_cc_test() +# +# CMake function to imitate Bazel's cc_test rule. +# +# Parameters: +# NAME: name of target (see Usage below) +# SRCS: List of source files for the binary +# DEPS: List of other libraries to be linked in to the binary targets +# COPTS: List of private compile options +# DEFINES: List of public defines +# LINKOPTS: List of link options +# +# Note: +# By default, absl_cc_test will always create a binary named absl_${NAME}. +# This will also add it to ctest list as absl_${NAME}. +# +# Usage: +# absl_cc_library( +# NAME +# awesome +# HDRS +# "a.h" +# SRCS +# "a.cc" +# PUBLIC +# ) +# +# absl_cc_test( +# NAME +# awesome_test +# SRCS +# "awesome_test.cc" +# DEPS +# absl::awesome +# gmock +# gtest_main +# ) +function(absl_cc_test) + if(NOT ABSL_RUN_TESTS) + return() + endif() + + cmake_parse_arguments(ABSL_CC_TEST + "" + "NAME" + "SRCS;COPTS;DEFINES;LINKOPTS;DEPS" + ${ARGN} + ) + + set(_NAME "absl_${ABSL_CC_TEST_NAME}") + + add_executable(${_NAME} "") + target_sources(${_NAME} PRIVATE ${ABSL_CC_TEST_SRCS}) + target_include_directories(${_NAME} + PUBLIC ${ABSL_COMMON_INCLUDE_DIRS} + PRIVATE ${GMOCK_INCLUDE_DIRS} ${GTEST_INCLUDE_DIRS} + ) + + if (${ABSL_BUILD_DLL}) + target_compile_definitions(${_NAME} + PUBLIC + ${ABSL_CC_TEST_DEFINES} + ABSL_CONSUME_DLL + GTEST_LINKED_AS_SHARED_LIBRARY=1 + ) + + # Replace dependencies on targets inside the DLL with abseil_dll itself. + absl_internal_dll_targets( + DEPS ${ABSL_CC_TEST_DEPS} + OUTPUT ABSL_CC_TEST_DEPS + ) + else() + target_compile_definitions(${_NAME} + PUBLIC + ${ABSL_CC_TEST_DEFINES} + ) + endif() + target_compile_options(${_NAME} + PRIVATE ${ABSL_CC_TEST_COPTS} + ) + + target_link_libraries(${_NAME} + PUBLIC ${ABSL_CC_TEST_DEPS} + PRIVATE ${ABSL_CC_TEST_LINKOPTS} + ) + # Add all Abseil targets to a folder in the IDE for organization. + set_property(TARGET ${_NAME} PROPERTY FOLDER ${ABSL_IDE_FOLDER}/test) + + set_property(TARGET ${_NAME} PROPERTY CXX_STANDARD ${ABSL_CXX_STANDARD}) + set_property(TARGET ${_NAME} PROPERTY CXX_STANDARD_REQUIRED ON) + + add_test(NAME ${_NAME} COMMAND ${_NAME}) +endfunction() + + +function(check_target my_target) + if(NOT TARGET ${my_target}) + message(FATAL_ERROR " ABSL: compiling absl requires a ${my_target} CMake target in your project, + see CMake/README.md for more details") + endif(NOT TARGET ${my_target}) +endfunction() diff --git a/third_party/abseil_cpp/CMake/AbseilInstallDirs.cmake b/third_party/abseil_cpp/CMake/AbseilInstallDirs.cmake new file mode 100644 index 0000000000..b67272f830 --- /dev/null +++ b/third_party/abseil_cpp/CMake/AbseilInstallDirs.cmake @@ -0,0 +1,20 @@ +include(GNUInstallDirs) + +# absl_VERSION is only set if we are an LTS release being installed, in which +# case it may be into a system directory and so we need to make subdirectories +# for each installed version of Abseil. This mechanism is implemented in +# Abseil's internal Copybara (https://github.com/google/copybara) workflows and +# isn't visible in the CMake buildsystem itself. + +if(absl_VERSION) + set(ABSL_SUBDIR "${PROJECT_NAME}_${PROJECT_VERSION}") + set(ABSL_INSTALL_BINDIR "${CMAKE_INSTALL_BINDIR}/${ABSL_SUBDIR}") + set(ABSL_INSTALL_CONFIGDIR "${CMAKE_INSTALL_LIBDIR}/cmake/${ABSL_SUBDIR}") + set(ABSL_INSTALL_INCLUDEDIR "${CMAKE_INSTALL_INCLUDEDIR}/{ABSL_SUBDIR}") + set(ABSL_INSTALL_LIBDIR "${CMAKE_INSTALL_LIBDIR}/${ABSL_SUBDIR}") +else() + set(ABSL_INSTALL_BINDIR "${CMAKE_INSTALL_BINDIR}") + set(ABSL_INSTALL_CONFIGDIR "${CMAKE_INSTALL_LIBDIR}/cmake/${PROJECT_NAME}") + set(ABSL_INSTALL_INCLUDEDIR "${CMAKE_INSTALL_INCLUDEDIR}") + set(ABSL_INSTALL_LIBDIR "${CMAKE_INSTALL_LIBDIR}") +endif() \ No newline at end of file diff --git a/third_party/abseil_cpp/CMake/Googletest/CMakeLists.txt.in b/third_party/abseil_cpp/CMake/Googletest/CMakeLists.txt.in new file mode 100644 index 0000000000..994dac0bf7 --- /dev/null +++ b/third_party/abseil_cpp/CMake/Googletest/CMakeLists.txt.in @@ -0,0 +1,26 @@ +cmake_minimum_required(VERSION 2.8.2) + +project(googletest-external NONE) + +include(ExternalProject) +if(${ABSL_USE_GOOGLETEST_HEAD}) + ExternalProject_Add(googletest + GIT_REPOSITORY https://github.com/google/googletest.git + GIT_TAG master + SOURCE_DIR "${absl_gtest_src_dir}" + BINARY_DIR "${absl_gtest_build_dir}" + CONFIGURE_COMMAND "" + BUILD_COMMAND "" + INSTALL_COMMAND "" + TEST_COMMAND "" + ) +else() + ExternalProject_Add(googletest + SOURCE_DIR "${absl_gtest_src_dir}" + BINARY_DIR "${absl_gtest_build_dir}" + CONFIGURE_COMMAND "" + BUILD_COMMAND "" + INSTALL_COMMAND "" + TEST_COMMAND "" + ) +endif() \ No newline at end of file diff --git a/third_party/abseil_cpp/CMake/Googletest/DownloadGTest.cmake b/third_party/abseil_cpp/CMake/Googletest/DownloadGTest.cmake new file mode 100644 index 0000000000..9d071c9170 --- /dev/null +++ b/third_party/abseil_cpp/CMake/Googletest/DownloadGTest.cmake @@ -0,0 +1,41 @@ +# Integrates googletest at configure time. Based on the instructions at +# https://github.com/google/googletest/tree/master/googletest#incorporating-into-an-existing-cmake-project + +# Set up the external googletest project, downloading the latest from Github +# master if requested. +configure_file( + ${CMAKE_CURRENT_LIST_DIR}/CMakeLists.txt.in + ${CMAKE_BINARY_DIR}/googletest-external/CMakeLists.txt +) + +set(ABSL_SAVE_CMAKE_CXX_FLAGS ${CMAKE_CXX_FLAGS}) +set(ABSL_SAVE_CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}) +if (BUILD_SHARED_LIBS) + set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin) + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -DGTEST_CREATE_SHARED_LIBRARY=1") +endif() + +# Configure and build the googletest source. +execute_process(COMMAND ${CMAKE_COMMAND} -G "${CMAKE_GENERATOR}" . + RESULT_VARIABLE result + WORKING_DIRECTORY ${CMAKE_BINARY_DIR}/googletest-external ) +if(result) + message(FATAL_ERROR "CMake step for googletest failed: ${result}") +endif() + +execute_process(COMMAND ${CMAKE_COMMAND} --build . + RESULT_VARIABLE result + WORKING_DIRECTORY ${CMAKE_BINARY_DIR}/googletest-external) +if(result) + message(FATAL_ERROR "Build step for googletest failed: ${result}") +endif() + +set(CMAKE_CXX_FLAGS ${ABSL_SAVE_CMAKE_CXX_FLAGS}) +set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${ABSL_SAVE_CMAKE_RUNTIME_OUTPUT_DIRECTORY}) + +# Prevent overriding the parent project's compiler/linker settings on Windows +set(gtest_force_shared_crt ON CACHE BOOL "" FORCE) + +# Add googletest directly to our build. This defines the gtest and gtest_main +# targets. +add_subdirectory(${absl_gtest_src_dir} ${absl_gtest_build_dir} EXCLUDE_FROM_ALL) diff --git a/third_party/abseil_cpp/CMake/README.md b/third_party/abseil_cpp/CMake/README.md new file mode 100644 index 0000000000..8f73475a16 --- /dev/null +++ b/third_party/abseil_cpp/CMake/README.md @@ -0,0 +1,101 @@ +# Abseil CMake Build Instructions + +Abseil comes with a CMake build script ([CMakeLists.txt](../CMakeLists.txt)) +that can be used on a wide range of platforms ("C" stands for cross-platform.). +If you don't have CMake installed already, you can download it for free from +<https://www.cmake.org/>. + +CMake works by generating native makefiles or build projects that can +be used in the compiler environment of your choice. + +For API/ABI compatibility reasons, we strongly recommend building Abseil in a +subdirectory of your project or as an embedded dependency. + +## Incorporating Abseil Into a CMake Project + +The recommendations below are similar to those for using CMake within the +googletest framework +(<https://github.com/google/googletest/blob/master/googletest/README.md#incorporating-into-an-existing-cmake-project>) + +### Step-by-Step Instructions + +1. If you want to build the Abseil tests, integrate the Abseil dependency +[Google Test](https://github.com/google/googletest) into your CMake project. To disable Abseil tests, you have to pass +`-DBUILD_TESTING=OFF` when configuring your project with CMake. + +2. Download Abseil and copy it into a subdirectory in your CMake project or add +Abseil as a [git submodule](https://git-scm.com/docs/git-submodule) in your +CMake project. + +3. You can then use the CMake command +[`add_subdirectory()`](https://cmake.org/cmake/help/latest/command/add_subdirectory.html) +to include Abseil directly in your CMake project. + +4. Add the **absl::** target you wish to use to the +[`target_link_libraries()`](https://cmake.org/cmake/help/latest/command/target_link_libraries.html) +section of your executable or of your library.<br> +Here is a short CMakeLists.txt example of a project file using Abseil. + +```cmake +cmake_minimum_required(VERSION 3.5) +project(my_project) + +# Pick the C++ standard to compile with. +# Abseil currently supports C++11, C++14, and C++17. +set(CMAKE_CXX_STANDARD 11) + +add_subdirectory(abseil-cpp) + +add_executable(my_exe source.cpp) +target_link_libraries(my_exe absl::base absl::synchronization absl::strings) +``` + +### Running Abseil Tests with CMake + +Use the `-DABSL_RUN_TESTS=ON` flag to run Abseil tests. Note that if the `-DBUILD_TESTING=OFF` flag is passed then Abseil tests will not be run. + +You will need to provide Abseil with a Googletest dependency. There are two +options for how to do this: + +* Use `-DABSL_USE_GOOGLETEST_HEAD`. This will automatically download the latest +Googletest source into the build directory at configure time. Googletest will +then be compiled directly alongside Abseil's tests. +* Manually integrate Googletest with your build. See +https://github.com/google/googletest/blob/master/googletest/README.md#using-cmake +for more information on using Googletest in a CMake project. + +For example, to run just the Abseil tests, you could use this script: + +``` +cd path/to/abseil-cpp +mkdir build +cd build +cmake -DABSL_USE_GOOGLETEST_HEAD=ON -DABSL_RUN_TESTS=ON .. +make -j +ctest +``` + +Currently, we only run our tests with CMake in a Linux environment, but we are +working on the rest of our supported platforms. See +https://github.com/abseil/abseil-cpp/projects/1 and +https://github.com/abseil/abseil-cpp/issues/109 for more information. + +### Available Abseil CMake Public Targets + +Here's a non-exhaustive list of Abseil CMake public targets: + +```cmake +absl::algorithm +absl::base +absl::debugging +absl::flat_hash_map +absl::flags +absl::memory +absl::meta +absl::numeric +absl::random_random +absl::strings +absl::synchronization +absl::time +absl::utility +``` diff --git a/third_party/abseil_cpp/CMake/abslConfig.cmake.in b/third_party/abseil_cpp/CMake/abslConfig.cmake.in new file mode 100644 index 0000000000..62d246d01e --- /dev/null +++ b/third_party/abseil_cpp/CMake/abslConfig.cmake.in @@ -0,0 +1,8 @@ +# absl CMake configuration file. + +include(CMakeFindDependencyMacro) +find_dependency(Threads) + +@PACKAGE_INIT@ + +include ("${CMAKE_CURRENT_LIST_DIR}/@PROJECT_NAME@Targets.cmake") diff --git a/third_party/abseil_cpp/CMake/install_test_project/CMakeLists.txt b/third_party/abseil_cpp/CMake/install_test_project/CMakeLists.txt new file mode 100644 index 0000000000..06b797e9ed --- /dev/null +++ b/third_party/abseil_cpp/CMake/install_test_project/CMakeLists.txt @@ -0,0 +1,27 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# A simple CMakeLists.txt for testing cmake installation + +cmake_minimum_required(VERSION 3.5) +project(absl_cmake_testing CXX) + +set(CMAKE_CXX_STANDARD 11) + +add_executable(simple simple.cc) + +find_package(absl REQUIRED) + +target_link_libraries(simple absl::strings) diff --git a/third_party/abseil_cpp/CMake/install_test_project/simple.cc b/third_party/abseil_cpp/CMake/install_test_project/simple.cc new file mode 100644 index 0000000000..e9e352912b --- /dev/null +++ b/third_party/abseil_cpp/CMake/install_test_project/simple.cc @@ -0,0 +1,23 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <iostream> +#include "absl/strings/substitute.h" + +int main(int argc, char** argv) { + for (int i = 0; i < argc; ++i) { + std::cout << absl::Substitute("Arg $0: $1\n", i, argv[i]); + } +} diff --git a/third_party/abseil_cpp/CMake/install_test_project/test.sh b/third_party/abseil_cpp/CMake/install_test_project/test.sh new file mode 100755 index 0000000000..99989b031d --- /dev/null +++ b/third_party/abseil_cpp/CMake/install_test_project/test.sh @@ -0,0 +1,144 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# "Unit" and integration tests for Absl CMake installation + +# TODO(absl-team): This script isn't fully hermetic because +# -DABSL_USE_GOOGLETEST_HEAD=ON means that this script isn't pinned to a fixed +# version of GoogleTest. This means that an upstream change to GoogleTest could +# break this test. Fix this by allowing this script to pin to a known-good +# version of GoogleTest. + +# Fail on any error. Treat unset variables an error. Print commands as executed. +set -euox pipefail + +install_absl() { + pushd "${absl_build_dir}" + if [[ "${#}" -eq 1 ]]; then + cmake -DCMAKE_INSTALL_PREFIX="${1}" "${absl_dir}" + else + cmake "${absl_dir}" + fi + cmake --build . --target install -- -j + popd +} + +uninstall_absl() { + xargs rm < "${absl_build_dir}"/install_manifest.txt + rm -rf "${absl_build_dir}" + mkdir -p "${absl_build_dir}" +} + +lts_install="" + +while getopts ":l" lts; do + case "${lts}" in + l ) + lts_install="true" + ;; + esac +done + +absl_dir=/abseil-cpp +absl_build_dir=/buildfs/absl-build +project_dir="${absl_dir}"/CMake/install_test_project +project_build_dir=/buildfs/project-build + +mkdir -p "${absl_build_dir}" +mkdir -p "${project_build_dir}" + +if [[ "${lts_install}" ]]; then + install_dir="/usr/local" +else + install_dir="${project_build_dir}"/install +fi +mkdir -p "${install_dir}" + +# Test build, install, and link against installed abseil +pushd "${project_build_dir}" +if [[ "${lts_install}" ]]; then + install_absl + cmake "${project_dir}" +else + install_absl "${install_dir}" + cmake "${project_dir}" -DCMAKE_PREFIX_PATH="${install_dir}" +fi + +cmake --build . --target simple + +output="$(${project_build_dir}/simple "printme" 2>&1)" +if [[ "${output}" != *"Arg 1: printme"* ]]; then + echo "Faulty output on simple project:" + echo "${output}" + exit 1 +fi + +popd + +# Test that we haven't accidentally made absl::abslblah +pushd "${install_dir}" + +# Starting in CMake 3.12 the default install dir is lib$bit_width +if [[ -d lib64 ]]; then + libdir="lib64" +elif [[ -d lib ]]; then + libdir="lib" +else + echo "ls *, */*, */*/*:" + ls * + ls */* + ls */*/* + echo "unknown lib dir" +fi + +if [[ "${lts_install}" ]]; then + # LTS versions append the date of the release to the subdir. + # 9999/99/99 is the dummy date used in the local_lts workflow. + absl_subdir="absl_99999999" +else + absl_subdir="absl" +fi + +if ! grep absl::strings "${libdir}/cmake/${absl_subdir}/abslTargets.cmake"; then + cat "${libdir}"/cmake/absl/abslTargets.cmake + echo "CMake targets named incorrectly" + exit 1 +fi + +uninstall_absl +popd + +if [[ ! "${lts_install}" ]]; then + # Test that we warn if installed without a prefix or a system prefix + output="$(install_absl 2>&1)" + if [[ "${output}" != *"Please set CMAKE_INSTALL_PREFIX"* ]]; then + echo "Install without prefix didn't warn as expected. Output:" + echo "${output}" + exit 1 + fi + uninstall_absl + + output="$(install_absl /usr 2>&1)" + if [[ "${output}" != *"Please set CMAKE_INSTALL_PREFIX"* ]]; then + echo "Install with /usr didn't warn as expected. Output:" + echo "${output}" + exit 1 + fi + uninstall_absl +fi + +echo "Install test complete!" +exit 0 diff --git a/third_party/abseil_cpp/CMakeLists.txt b/third_party/abseil_cpp/CMakeLists.txt new file mode 100644 index 0000000000..1ef35cfd22 --- /dev/null +++ b/third_party/abseil_cpp/CMakeLists.txt @@ -0,0 +1,181 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +# Most widely used distributions have cmake 3.5 or greater available as of March +# 2019. A notable exception is RHEL-7 (CentOS7). You can install a current +# version of CMake by first installing Extra Packages for Enterprise Linux +# (https://fedoraproject.org/wiki/EPEL#Extra_Packages_for_Enterprise_Linux_.28EPEL.29) +# and then issuing `yum install cmake3` on the command line. +cmake_minimum_required(VERSION 3.5) + +# Compiler id for Apple Clang is now AppleClang. +cmake_policy(SET CMP0025 NEW) + +# if command can use IN_LIST +cmake_policy(SET CMP0057 NEW) + +# Project version variables are the empty string if version is unspecified +cmake_policy(SET CMP0048 NEW) + +project(absl CXX) + +# Output directory is correct by default for most build setups. However, when +# building Abseil as a DLL, it is important to have the DLL in the same +# directory as the executable using it. Thus, we put all executables in a single +# /bin directory. +set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin) + +# when absl is included as subproject (i.e. using add_subdirectory(abseil-cpp)) +# in the source tree of a project that uses it, install rules are disabled. +if(NOT "^${CMAKE_SOURCE_DIR}$" STREQUAL "^${PROJECT_SOURCE_DIR}$") + set(ABSL_ENABLE_INSTALL FALSE) +else() + set(ABSL_ENABLE_INSTALL TRUE) +endif() + +list(APPEND CMAKE_MODULE_PATH + ${CMAKE_CURRENT_LIST_DIR}/CMake + ${CMAKE_CURRENT_LIST_DIR}/absl/copts +) + +# Linking Abseil to shared libraries (such as Nix) requires PIC. +set(CMAKE_POSITION_INDEPENDENT_CODE TRUE) + +include(AbseilInstallDirs) +include(CMakePackageConfigHelpers) +include(AbseilDll) +include(AbseilHelpers) + + +## +## Using absl targets +## +## all public absl targets are +## exported with the absl:: prefix +## +## e.g absl::base absl::synchronization absl::strings .... +## +## DO NOT rely on the internal targets outside of the prefix + + +# include current path +list(APPEND ABSL_COMMON_INCLUDE_DIRS ${CMAKE_CURRENT_SOURCE_DIR}) + +if("${CMAKE_CXX_COMPILER_ID}" MATCHES "Clang") + set(ABSL_USING_CLANG ON) +else() + set(ABSL_USING_CLANG OFF) +endif() + +# find dependencies +## pthread +find_package(Threads REQUIRED) + +option(ABSL_USE_EXTERNAL_GOOGLETEST + "If ON, Abseil will assume that the targets for GoogleTest are already provided by the including project. This makes sense when Abseil is used with add_subproject." OFF) + + +option(ABSL_USE_GOOGLETEST_HEAD + "If ON, abseil will download HEAD from googletest at config time." OFF) + +set(ABSL_LOCAL_GOOGLETEST_DIR "/usr/src/googletest" CACHE PATH + "If ABSL_USE_GOOGLETEST_HEAD is OFF, specifies the directory of a local googletest checkout." + ) + +option(ABSL_RUN_TESTS "If ON, Abseil tests will be run." OFF) + +if(${ABSL_RUN_TESTS}) + # enable CTest. This will set BUILD_TESTING to ON unless otherwise specified + # on the command line + include(CTest) + enable_testing() +endif() + +## check targets +if(BUILD_TESTING) + if (NOT ABSL_USE_EXTERNAL_GOOGLETEST) + set(absl_gtest_build_dir ${CMAKE_BINARY_DIR}/googletest-build) + if(${ABSL_USE_GOOGLETEST_HEAD}) + set(absl_gtest_src_dir ${CMAKE_BINARY_DIR}/googletest-src) + else() + set(absl_gtest_src_dir ${ABSL_LOCAL_GOOGLETEST_DIR}) + endif() + include(CMake/Googletest/DownloadGTest.cmake) + endif() + + check_target(gtest) + check_target(gtest_main) + check_target(gmock) + + list(APPEND ABSL_TEST_COMMON_LIBRARIES + gtest_main + gtest + gmock + ${CMAKE_THREAD_LIBS_INIT} + ) +endif() + +add_subdirectory(absl) + +if(ABSL_ENABLE_INSTALL) + # absl:lts-remove-begin(system installation is supported for LTS releases) + # We don't support system-wide installation + list(APPEND SYSTEM_INSTALL_DIRS "/usr/local" "/usr" "/opt/" "/opt/local" "c:/Program Files/${PROJECT_NAME}") + if(NOT DEFINED CMAKE_INSTALL_PREFIX OR CMAKE_INSTALL_PREFIX IN_LIST SYSTEM_INSTALL_DIRS) + message(WARNING "\ + The default and system-level install directories are unsupported except in LTS \ + releases of Abseil. Please set CMAKE_INSTALL_PREFIX to install Abseil in your \ + source or build tree directly.\ + ") + endif() + # absl:lts-remove-end + + # install as a subdirectory only + install(EXPORT ${PROJECT_NAME}Targets + NAMESPACE absl:: + DESTINATION "${ABSL_INSTALL_CONFIGDIR}" + ) + + configure_package_config_file( + CMake/abslConfig.cmake.in + "${PROJECT_BINARY_DIR}/${PROJECT_NAME}Config.cmake" + INSTALL_DESTINATION "${ABSL_INSTALL_CONFIGDIR}" + ) + install(FILES "${PROJECT_BINARY_DIR}/${PROJECT_NAME}Config.cmake" + DESTINATION "${ABSL_INSTALL_CONFIGDIR}" + ) + + # Abseil only has a version in LTS releases. This mechanism is accomplished + # Abseil's internal Copybara (https://github.com/google/copybara) workflows and + # isn't visible in the CMake buildsystem itself. + if(absl_VERSION) + write_basic_package_version_file( + "${PROJECT_BINARY_DIR}/${PROJECT_NAME}ConfigVersion.cmake" + COMPATIBILITY ExactVersion + ) + + install(FILES "${PROJECT_BINARY_DIR}/${PROJECT_NAME}ConfigVersion.cmake" + DESTINATION ${ABSL_INSTALL_CONFIGDIR} + ) + endif() # absl_VERSION + + install(DIRECTORY absl + DESTINATION ${ABSL_INSTALL_INCLUDEDIR} + FILES_MATCHING + PATTERN "*.inc" + PATTERN "*.h" + ) +endif() # ABSL_ENABLE_INSTALL diff --git a/third_party/abseil_cpp/CONTRIBUTING.md b/third_party/abseil_cpp/CONTRIBUTING.md new file mode 100644 index 0000000000..9dadae9376 --- /dev/null +++ b/third_party/abseil_cpp/CONTRIBUTING.md @@ -0,0 +1,141 @@ +# How to Contribute to Abseil + +We'd love to accept your patches and contributions to this project. There are +just a few small guidelines you need to follow. + +NOTE: If you are new to GitHub, please start by reading [Pull Request +howto](https://help.github.com/articles/about-pull-requests/) + +## Contributor License Agreement + +Contributions to this project must be accompanied by a Contributor License +Agreement. You (or your employer) retain the copyright to your contribution, +this simply gives us permission to use and redistribute your contributions as +part of the project. Head over to <https://cla.developers.google.com/> to see +your current agreements on file or to sign a new one. + +You generally only need to submit a CLA once, so if you've already submitted one +(even if it was for a different project), you probably don't need to do it +again. + +## Contribution Guidelines + +Potential contributors sometimes ask us if the Abseil project is the appropriate +home for their utility library code or for specific functions implementing +missing portions of the standard. Often, the answer to this question is "no". +We’d like to articulate our thinking on this issue so that our choices can be +understood by everyone and so that contributors can have a better intuition +about whether Abseil might be interested in adopting a new library. + +### Priorities + +Although our mission is to augment the C++ standard library, our goal is not to +provide a full forward-compatible implementation of the latest standard. For us +to consider a library for inclusion in Abseil, it is not enough that a library +is useful. We generally choose to release a library when it meets at least one +of the following criteria: + +* **Widespread usage** - Using our internal codebase to help gauge usage, most + of the libraries we've released have tens of thousands of users. +* **Anticipated widespread usage** - Pre-adoption of some standard-compliant + APIs may not have broad adoption initially but can be expected to pick up + usage when it replaces legacy APIs. `absl::from_chars`, for example, + replaces existing code that converts strings to numbers and will therefore + likely see usage growth. +* **High impact** - APIs that provide a key solution to a specific problem, + such as `absl::FixedArray`, have higher impact than usage numbers may signal + and are released because of their importance. +* **Direct support for a library that falls under one of the above** - When we + want access to a smaller library as an implementation detail for a + higher-priority library we plan to release, we may release it, as we did + with portions of `absl/meta/type_traits.h`. One consequence of this is that + the presence of a library in Abseil does not necessarily mean that other + similar libraries would be a high priority. + +### API Freeze Consequences + +Via the +[Abseil Compatibility Guidelines](https://abseil.io/about/compatibility), we +have promised a large degree of API stability. In particular, we will not make +backward-incompatible changes to released APIs without also shipping a tool or +process that can upgrade our users' code. We are not yet at the point of easily +releasing such tools. Therefore, at this time, shipping a library establishes an +API contract which is borderline unchangeable. (We can add new functionality, +but we cannot easily change existing behavior.) This constraint forces us to +very carefully review all APIs that we ship. + + +## Coding Style + +To keep the source consistent, readable, diffable and easy to merge, we use a +fairly rigid coding style, as defined by the +[google-styleguide](https://github.com/google/styleguide) project. All patches +will be expected to conform to the style outlined +[here](https://google.github.io/styleguide/cppguide.html). + +## Guidelines for Pull Requests + +* If you are a Googler, it is preferable to first create an internal CL and + have it reviewed and submitted. The code propagation process will deliver + the change to GitHub. + +* Create **small PRs** that are narrowly focused on **addressing a single + concern**. We often receive PRs that are trying to fix several things at a + time, but if only one fix is considered acceptable, nothing gets merged and + both author's & review's time is wasted. Create more PRs to address + different concerns and everyone will be happy. + +* For speculative changes, consider opening an [Abseil + issue](https://github.com/abseil/abseil-cpp/issues) and discussing it first. + If you are suggesting a behavioral or API change, consider starting with an + [Abseil proposal template](ABSEIL_ISSUE_TEMPLATE.md). + +* Provide a good **PR description** as a record of **what** change is being + made and **why** it was made. Link to a GitHub issue if it exists. + +* Don't fix code style and formatting unless you are already changing that + line to address an issue. Formatting of modified lines may be done using + `git clang-format`. PRs with irrelevant changes won't be merged. If + you do want to fix formatting or style, do that in a separate PR. + +* Unless your PR is trivial, you should expect there will be reviewer comments + that you'll need to address before merging. We expect you to be reasonably + responsive to those comments, otherwise the PR will be closed after 2-3 + weeks of inactivity. + +* Maintain **clean commit history** and use **meaningful commit messages**. + PRs with messy commit history are difficult to review and won't be merged. + Use `rebase -i upstream/master` to curate your commit history and/or to + bring in latest changes from master (but avoid rebasing in the middle of a + code review). + +* Keep your PR up to date with upstream/master (if there are merge conflicts, + we can't really merge your change). + +* **All tests need to be passing** before your change can be merged. We + recommend you **run tests locally** (see below) + +* Exceptions to the rules can be made if there's a compelling reason for doing + so. That is - the rules are here to serve us, not the other way around, and + the rules need to be serving their intended purpose to be valuable. + +* All submissions, including submissions by project members, require review. + +## Running Tests + +If you have [Bazel](https://bazel.build/) installed, use `bazel test +--test_tag_filters="-benchmark" ...` to run the unit tests. + +If you are running the Linux operating system and have +[Docker](https://www.docker.com/) installed, you can also run the `linux_*.sh` +scripts under the `ci/`(https://github.com/abseil/abseil-cpp/tree/master/ci) +directory to test Abseil under a variety of conditions. + +## Abseil Committers + +The current members of the Abseil engineering team are the only committers at +present. + +## Release Process + +Abseil lives at head, where latest-and-greatest code can be found. diff --git a/third_party/abseil_cpp/FAQ.md b/third_party/abseil_cpp/FAQ.md new file mode 100644 index 0000000000..78028fc09f --- /dev/null +++ b/third_party/abseil_cpp/FAQ.md @@ -0,0 +1,164 @@ +# Abseil FAQ + +## Is Abseil the right home for my utility library? + +Most often the answer to the question is "no." As both the [About +Abseil](https://abseil.io/about/) page and our [contributing +guidelines](https://github.com/abseil/abseil-cpp/blob/master/CONTRIBUTING.md#contribution-guidelines) +explain, Abseil contains a variety of core C++ library code that is widely used +at [Google](https://www.google.com/). As such, Abseil's primary purpose is to be +used as a dependency by Google's open source C++ projects. While we do hope that +Abseil is also useful to the C++ community at large, this added constraint also +means that we are unlikely to accept a contribution of utility code that isn't +already widely used by Google. + +## How to I set the C++ dialect used to build Abseil? + +The short answer is that whatever mechanism you choose, you need to make sure +that you set this option consistently at the global level for your entire +project. If, for example, you want to set the C++ dialect to C++17, with +[Bazel](https://bazel/build/) as the build system and `gcc` or `clang` as the +compiler, there several ways to do this: +* Pass `--cxxopt=-std=c++17` on the command line (for example, `bazel build + --cxxopt=-std=c++17 ...`) +* Set the environment variable `BAZEL_CXXOPTS` (for example, + `BAZEL_CXXOPTS=-std=c++17`) +* Add `build --cxxopt=-std=c++17` to your [`.bazelrc` + file](https://docs.bazel.build/versions/master/guide.html#bazelrc) + +If you are using CMake as the build system, you'll need to add a line like +`set(CMAKE_CXX_STANDARD 17)` to your top level `CMakeLists.txt` file. See the +[CMake build +instructions](https://github.com/abseil/abseil-cpp/blob/master/CMake/README.md) +for more information. + +For a longer answer to this question and to understand why some other approaches +don't work, see the answer to ["What is ABI and why don't you recommend using a +pre-compiled version of +Abseil?"](#what-is-abi-and-why-dont-you-recommend-using-a-pre-compiled-version-of-abseil) + +## What is ABI and why don't you recommend using a pre-compiled version of Abseil? + +For the purposes of this discussion, you can think of +[ABI](https://en.wikipedia.org/wiki/Application_binary_interface) as the +compiled representation of the interfaces in code. This is in contrast to +[API](https://en.wikipedia.org/wiki/Application_programming_interface), which +you can think of as the interfaces as defined by the code itself. [Abseil has a +strong promise of API compatibility, but does not make any promise of ABI +compatibility](https://abseil.io/about/compatibility). Let's take a look at what +this means in practice. + +You might be tempted to do something like this in a +[Bazel](https://bazel.build/) `BUILD` file: + +``` +# DON'T DO THIS!!! +cc_library( + name = "my_library", + srcs = ["my_library.cc"], + copts = ["-std=c++17"], # May create a mixed-mode compile! + deps = ["@com_google_absl//absl/strings"], +) +``` + +Applying `-std=c++17` to an individual target in your `BUILD` file is going to +compile that specific target in C++17 mode, but it isn't going to ensure the +Abseil library is built in C++17 mode, since the Abseil library itself is a +different build target. If your code includes an Abseil header, then your +program may contain conflicting definitions of the same +class/function/variable/enum, etc. As a rule, all compile options that affect +the ABI of a program need to be applied to the entire build on a global basis. + +C++ has something called the [One Definition +Rule](https://en.wikipedia.org/wiki/One_Definition_Rule) (ODR). C++ doesn't +allow multiple definitions of the same class/function/variable/enum, etc. ODR +violations sometimes result in linker errors, but linkers do not always catch +violations. Uncaught ODR violations can result in strange runtime behaviors or +crashes that can be hard to debug. + +If you build the Abseil library and your code using different compile options +that affect ABI, there is a good chance you will run afoul of the One Definition +Rule. Examples of GCC compile options that affect ABI include (but aren't +limited to) language dialect (e.g. `-std=`), optimization level (e.g. `-O2`), +code generation flags (e.g. `-fexceptions`), and preprocessor defines +(e.g. `-DNDEBUG`). + +If you use a pre-compiled version of Abseil, (for example, from your Linux +distribution package manager or from something like +[vcpkg](https://github.com/microsoft/vcpkg)) you have to be very careful to +ensure ABI compatibility across the components of your program. The only way you +can be sure your program is going to be correct regarding ABI is to ensure +you've used the exact same compile options as were used to build the +pre-compiled library. This does not mean that Abseil cannot work as part of a +Linux distribution since a knowledgeable binary packager will have ensured that +all packages have been built with consistent compile options. This is one of the +reasons we warn against - though do not outright reject - using Abseil as a +pre-compiled library. + +Another possible way that you might afoul of ABI issues is if you accidentally +include two versions of Abseil in your program. Multiple versions of Abseil can +end up within the same binary if your program uses the Abseil library and +another library also transitively depends on Abseil (resulting in what is +sometimes called the diamond dependency problem). In cases such as this you must +structure your build so that all libraries use the same version of Abseil. +[Abseil's strong promise of API compatibility between +releases](https://abseil.io/about/compatibility) means the latest "HEAD" release +of Abseil is almost certainly the right choice if you are doing as we recommend +and building all of your code from source. + +For these reasons we recommend you avoid pre-compiled code and build the Abseil +library yourself in a consistent manner with the rest of your code. + +## What is "live at head" and how do I do it? + +From Abseil's point-of-view, "live at head" means that every Abseil source +release (which happens on an almost daily basis) is either API compatible with +the previous release, or comes with an automated tool that you can run over code +to make it compatible. In practice, the need to use an automated tool is +extremely rare. This means that upgrading from one source release to another +should be a routine practice that can and should be performed often. + +We recommend you update to the [latest commit in the `master` branch of +Abseil](https://github.com/abseil/abseil-cpp/commits/master) as often as +possible. Not only will you pick up bug fixes more quickly, but if you have good +automated testing, you will catch and be able to fix any [Hyrum's +Law](https://www.hyrumslaw.com/) dependency problems on an incremental basis +instead of being overwhelmed by them and having difficulty isolating them if you +wait longer between updates. + +If you are using the [Bazel](https://bazel.build/) build system and its +[external dependencies](https://docs.bazel.build/versions/master/external.html) +feature, updating the +[`http_archive`](https://docs.bazel.build/versions/master/repo/http.html#http_archive) +rule in your +[`WORKSPACE`](https://docs.bazel.build/versions/master/be/workspace.html) for +`com_google_abseil` to point to the [latest commit in the `master` branch of +Abseil](https://github.com/abseil/abseil-cpp/commits/master) is all you need to +do. For example, on February 11, 2020, the latest commit to the master branch +was `98eb410c93ad059f9bba1bf43f5bb916fc92a5ea`. To update to this commit, you +would add the following snippet to your `WORKSPACE` file: + +``` +http_archive( + name = "com_google_absl", + urls = ["https://github.com/abseil/abseil-cpp/archive/98eb410c93ad059f9bba1bf43f5bb916fc92a5ea.zip"], # 2020-02-11T18:50:53Z + strip_prefix = "abseil-cpp-98eb410c93ad059f9bba1bf43f5bb916fc92a5ea", + sha256 = "aabf6c57e3834f8dc3873a927f37eaf69975d4b28117fc7427dfb1c661542a87", +) +``` + +To get the `sha256` of this URL, run `curl -sL --output - +https://github.com/abseil/abseil-cpp/archive/98eb410c93ad059f9bba1bf43f5bb916fc92a5ea.zip +| sha256sum -`. + +You can commit the updated `WORKSPACE` file to your source control every time +you update, and if you have good automated testing, you might even consider +automating this. + +One thing we don't recommend is using GitHub's `master.zip` files (for example +[https://github.com/abseil/abseil-cpp/archive/master.zip](https://github.com/abseil/abseil-cpp/archive/master.zip)), +which are always the latest commit in the `master` branch, to implement live at +head. Since these `master.zip` URLs are not versioned, you will lose build +reproducibility. In addition, some build systems, including Bazel, will simply +cache this file, which means you won't actually be updating to the latest +release until your cache is cleared or invalidated. diff --git a/third_party/abseil_cpp/LICENSE b/third_party/abseil_cpp/LICENSE new file mode 100644 index 0000000000..ccd61dcfe3 --- /dev/null +++ b/third_party/abseil_cpp/LICENSE @@ -0,0 +1,203 @@ + + Apache License + Version 2.0, January 2004 + https://www.apache.org/licenses/ + + TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION + + 1. Definitions. + + "License" shall mean the terms and conditions for use, reproduction, + and distribution as defined by Sections 1 through 9 of this document. + + "Licensor" shall mean the copyright owner or entity authorized by + the copyright owner that is granting the License. + + "Legal Entity" shall mean the union of the acting entity and all + other entities that control, are controlled by, or are under common + control with that entity. For the purposes of this definition, + "control" means (i) the power, direct or indirect, to cause the + direction or management of such entity, whether by contract or + otherwise, or (ii) ownership of fifty percent (50%) or more of the + outstanding shares, or (iii) beneficial ownership of such entity. + + "You" (or "Your") shall mean an individual or Legal Entity + exercising permissions granted by this License. + + "Source" form shall mean the preferred form for making modifications, + including but not limited to software source code, documentation + source, and configuration files. + + "Object" form shall mean any form resulting from mechanical + transformation or translation of a Source form, including but + not limited to compiled object code, generated documentation, + and conversions to other media types. + + "Work" shall mean the work of authorship, whether in Source or + Object form, made available under the License, as indicated by a + copyright notice that is included in or attached to the work + (an example is provided in the Appendix below). + + "Derivative Works" shall mean any work, whether in Source or Object + form, that is based on (or derived from) the Work and for which the + editorial revisions, annotations, elaborations, or other modifications + represent, as a whole, an original work of authorship. For the purposes + of this License, Derivative Works shall not include works that remain + separable from, or merely link (or bind by name) to the interfaces of, + the Work and Derivative Works thereof. + + "Contribution" shall mean any work of authorship, including + the original version of the Work and any modifications or additions + to that Work or Derivative Works thereof, that is intentionally + submitted to Licensor for inclusion in the Work by the copyright owner + or by an individual or Legal Entity authorized to submit on behalf of + the copyright owner. For the purposes of this definition, "submitted" + means any form of electronic, verbal, or written communication sent + to the Licensor or its representatives, including but not limited to + communication on electronic mailing lists, source code control systems, + and issue tracking systems that are managed by, or on behalf of, the + Licensor for the purpose of discussing and improving the Work, but + excluding communication that is conspicuously marked or otherwise + designated in writing by the copyright owner as "Not a Contribution." + + "Contributor" shall mean Licensor and any individual or Legal Entity + on behalf of whom a Contribution has been received by Licensor and + subsequently incorporated within the Work. + + 2. Grant of Copyright License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + copyright license to reproduce, prepare Derivative Works of, + publicly display, publicly perform, sublicense, and distribute the + Work and such Derivative Works in Source or Object form. + + 3. Grant of Patent License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + (except as stated in this section) patent license to make, have made, + use, offer to sell, sell, import, and otherwise transfer the Work, + where such license applies only to those patent claims licensable + by such Contributor that are necessarily infringed by their + Contribution(s) alone or by combination of their Contribution(s) + with the Work to which such Contribution(s) was submitted. If You + institute patent litigation against any entity (including a + cross-claim or counterclaim in a lawsuit) alleging that the Work + or a Contribution incorporated within the Work constitutes direct + or contributory patent infringement, then any patent licenses + granted to You under this License for that Work shall terminate + as of the date such litigation is filed. + + 4. Redistribution. You may reproduce and distribute copies of the + Work or Derivative Works thereof in any medium, with or without + modifications, and in Source or Object form, provided that You + meet the following conditions: + + (a) You must give any other recipients of the Work or + Derivative Works a copy of this License; and + + (b) You must cause any modified files to carry prominent notices + stating that You changed the files; and + + (c) You must retain, in the Source form of any Derivative Works + that You distribute, all copyright, patent, trademark, and + attribution notices from the Source form of the Work, + excluding those notices that do not pertain to any part of + the Derivative Works; and + + (d) If the Work includes a "NOTICE" text file as part of its + distribution, then any Derivative Works that You distribute must + include a readable copy of the attribution notices contained + within such NOTICE file, excluding those notices that do not + pertain to any part of the Derivative Works, in at least one + of the following places: within a NOTICE text file distributed + as part of the Derivative Works; within the Source form or + documentation, if provided along with the Derivative Works; or, + within a display generated by the Derivative Works, if and + wherever such third-party notices normally appear. The contents + of the NOTICE file are for informational purposes only and + do not modify the License. You may add Your own attribution + notices within Derivative Works that You distribute, alongside + or as an addendum to the NOTICE text from the Work, provided + that such additional attribution notices cannot be construed + as modifying the License. + + You may add Your own copyright statement to Your modifications and + may provide additional or different license terms and conditions + for use, reproduction, or distribution of Your modifications, or + for any such Derivative Works as a whole, provided Your use, + reproduction, and distribution of the Work otherwise complies with + the conditions stated in this License. + + 5. Submission of Contributions. Unless You explicitly state otherwise, + any Contribution intentionally submitted for inclusion in the Work + by You to the Licensor shall be under the terms and conditions of + this License, without any additional terms or conditions. + Notwithstanding the above, nothing herein shall supersede or modify + the terms of any separate license agreement you may have executed + with Licensor regarding such Contributions. + + 6. Trademarks. This License does not grant permission to use the trade + names, trademarks, service marks, or product names of the Licensor, + except as required for reasonable and customary use in describing the + origin of the Work and reproducing the content of the NOTICE file. + + 7. Disclaimer of Warranty. Unless required by applicable law or + agreed to in writing, Licensor provides the Work (and each + Contributor provides its Contributions) on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or + implied, including, without limitation, any warranties or conditions + of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A + PARTICULAR PURPOSE. You are solely responsible for determining the + appropriateness of using or redistributing the Work and assume any + risks associated with Your exercise of permissions under this License. + + 8. Limitation of Liability. In no event and under no legal theory, + whether in tort (including negligence), contract, or otherwise, + unless required by applicable law (such as deliberate and grossly + negligent acts) or agreed to in writing, shall any Contributor be + liable to You for damages, including any direct, indirect, special, + incidental, or consequential damages of any character arising as a + result of this License or out of the use or inability to use the + Work (including but not limited to damages for loss of goodwill, + work stoppage, computer failure or malfunction, or any and all + other commercial damages or losses), even if such Contributor + has been advised of the possibility of such damages. + + 9. Accepting Warranty or Additional Liability. While redistributing + the Work or Derivative Works thereof, You may choose to offer, + and charge a fee for, acceptance of support, warranty, indemnity, + or other liability obligations and/or rights consistent with this + License. However, in accepting such obligations, You may act only + on Your own behalf and on Your sole responsibility, not on behalf + of any other Contributor, and only if You agree to indemnify, + defend, and hold each Contributor harmless for any liability + incurred by, or claims asserted against, such Contributor by reason + of your accepting any such warranty or additional liability. + + END OF TERMS AND CONDITIONS + + APPENDIX: How to apply the Apache License to your work. + + To apply the Apache License to your work, attach the following + boilerplate notice, with the fields enclosed by brackets "[]" + replaced with your own identifying information. (Don't include + the brackets!) The text should be enclosed in the appropriate + comment syntax for the file format. We also recommend that a + file or class name and description of purpose be included on the + same "printed page" as the copyright notice for easier + identification within third-party archives. + + Copyright [yyyy] [name of copyright owner] + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at + + https://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and + limitations under the License. + diff --git a/third_party/abseil_cpp/LTS.md b/third_party/abseil_cpp/LTS.md new file mode 100644 index 0000000000..ade8b17c73 --- /dev/null +++ b/third_party/abseil_cpp/LTS.md @@ -0,0 +1,16 @@ +# Long Term Support (LTS) Branches + +This repository contains periodic snapshots of the Abseil codebase that are +Long Term Support (LTS) branches. An LTS branch allows you to use a known +version of Abseil without interfering with other projects which may also, in +turn, use Abseil. (For more information about our releases, see the +[Abseil Release Management](https://abseil.io/about/releases) guide.) + +## LTS Branches + +The following lists LTS branches and the dates on which they have been released: + +* [LTS Branch December 18, 2018](https://github.com/abseil/abseil-cpp/tree/lts_2018_12_18/) +* [LTS Branch June 20, 2018](https://github.com/abseil/abseil-cpp/tree/lts_2018_06_20/) +* [LTS Branch August 8, 2019](https://github.com/abseil/abseil-cpp/tree/lts_2019_08_08/) +* [LTS Branch February 25, 2020](https://github.com/abseil/abseil-cpp/tree/lts_2020_02_25/) diff --git a/third_party/abseil_cpp/README.md b/third_party/abseil_cpp/README.md new file mode 100644 index 0000000000..85de569658 --- /dev/null +++ b/third_party/abseil_cpp/README.md @@ -0,0 +1,114 @@ +# Abseil - C++ Common Libraries + +The repository contains the Abseil C++ library code. Abseil is an open-source +collection of C++ code (compliant to C++11) designed to augment the C++ +standard library. + +## Table of Contents + +- [About Abseil](#about) +- [Quickstart](#quickstart) +- [Building Abseil](#build) +- [Codemap](#codemap) +- [License](#license) +- [Links](#links) + +<a name="about"></a> +## About Abseil + +Abseil is an open-source collection of C++ library code designed to augment +the C++ standard library. The Abseil library code is collected from Google's +own C++ code base, has been extensively tested and used in production, and +is the same code we depend on in our daily coding lives. + +In some cases, Abseil provides pieces missing from the C++ standard; in +others, Abseil provides alternatives to the standard for special needs +we've found through usage in the Google code base. We denote those cases +clearly within the library code we provide you. + +Abseil is not meant to be a competitor to the standard library; we've +just found that many of these utilities serve a purpose within our code +base, and we now want to provide those resources to the C++ community as +a whole. + +<a name="quickstart"></a> +## Quickstart + +If you want to just get started, make sure you at least run through the +[Abseil Quickstart](https://abseil.io/docs/cpp/quickstart). The Quickstart +contains information about setting up your development environment, downloading +the Abseil code, running tests, and getting a simple binary working. + +<a name="build"></a> +## Building Abseil + +[Bazel](https://bazel.build) is the official build system for Abseil, +which is supported on most major platforms (Linux, Windows, macOS, for example) +and compilers. See the [quickstart](https://abseil.io/docs/cpp/quickstart) for +more information on building Abseil using the Bazel build system. + +<a name="cmake"></a> +If you require CMake support, please check the +[CMake build instructions](CMake/README.md). + +## Codemap + +Abseil contains the following C++ library components: + +* [`base`](absl/base/) Abseil Fundamentals + <br /> The `base` library contains initialization code and other code which + all other Abseil code depends on. Code within `base` may not depend on any + other code (other than the C++ standard library). +* [`algorithm`](absl/algorithm/) + <br /> The `algorithm` library contains additions to the C++ `<algorithm>` + library and container-based versions of such algorithms. +* [`container`](absl/container/) + <br /> The `container` library contains additional STL-style containers, + including Abseil's unordered "Swiss table" containers. +* [`debugging`](absl/debugging/) + <br /> The `debugging` library contains code useful for enabling leak + checks, and stacktrace and symbolization utilities. +* [`hash`](absl/hash/) + <br /> The `hash` library contains the hashing framework and default hash + functor implementations for hashable types in Abseil. +* [`memory`](absl/memory/) + <br /> The `memory` library contains C++11-compatible versions of + `std::make_unique()` and related memory management facilities. +* [`meta`](absl/meta/) + <br /> The `meta` library contains C++11-compatible versions of type checks + available within C++14 and C++17 versions of the C++ `<type_traits>` library. +* [`numeric`](absl/numeric/) + <br /> The `numeric` library contains C++11-compatible 128-bit integers. +* [`strings`](absl/strings/) + <br /> The `strings` library contains a variety of strings routines and + utilities, including a C++11-compatible version of the C++17 + `std::string_view` type. +* [`synchronization`](absl/synchronization/) + <br /> The `synchronization` library contains concurrency primitives (Abseil's + `absl::Mutex` class, an alternative to `std::mutex`) and a variety of + synchronization abstractions. +* [`time`](absl/time/) + <br /> The `time` library contains abstractions for computing with absolute + points in time, durations of time, and formatting and parsing time within + time zones. +* [`types`](absl/types/) + <br /> The `types` library contains non-container utility types, like a + C++11-compatible version of the C++17 `std::optional` type. +* [`utility`](absl/utility/) + <br /> The `utility` library contains utility and helper code. + +## License + +The Abseil C++ library is licensed under the terms of the Apache +license. See [LICENSE](LICENSE) for more information. + +## Links + +For more information about Abseil: + +* Consult our [Abseil Introduction](https://abseil.io/about/intro) +* Read [Why Adopt Abseil](https://abseil.io/about/philosophy) to understand our + design philosophy. +* Peruse our + [Abseil Compatibility Guarantees](https://abseil.io/about/compatibility) to + understand both what we promise to you, and what we expect of you in return. diff --git a/third_party/abseil_cpp/UPGRADES.md b/third_party/abseil_cpp/UPGRADES.md new file mode 100644 index 0000000000..35599d0878 --- /dev/null +++ b/third_party/abseil_cpp/UPGRADES.md @@ -0,0 +1,17 @@ +# C++ Upgrade Tools + +Abseil may occassionally release API-breaking changes. As noted in our +[Compatibility Guidelines][compatibility-guide], we will aim to provide a tool +to do the work of effecting such API-breaking changes, when absolutely +necessary. + +These tools will be listed on the [C++ Upgrade Tools][upgrade-tools] guide on +https://abseil.io. + +For more information, the [C++ Automated Upgrade Guide][api-upgrades-guide] +outlines this process. + +[compatibility-guide]: https://abseil.io/about/compatibility +[api-upgrades-guide]: https://abseil.io/docs/cpp/tools/api-upgrades +[upgrade-tools]: https://abseil.io/docs/cpp/tools/upgrades/ + diff --git a/third_party/abseil_cpp/WORKSPACE b/third_party/abseil_cpp/WORKSPACE new file mode 100644 index 0000000000..f2b1046446 --- /dev/null +++ b/third_party/abseil_cpp/WORKSPACE @@ -0,0 +1,45 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +workspace(name = "com_google_absl") +load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive") + +# GoogleTest/GoogleMock framework. Used by most unit-tests. +http_archive( + name = "com_google_googletest", + urls = ["https://github.com/google/googletest/archive/b6cd405286ed8635ece71c72f118e659f4ade3fb.zip"], # 2019-01-07 + strip_prefix = "googletest-b6cd405286ed8635ece71c72f118e659f4ade3fb", + sha256 = "ff7a82736e158c077e76188232eac77913a15dac0b22508c390ab3f88e6d6d86", +) + +# Google benchmark. +http_archive( + name = "com_github_google_benchmark", + urls = ["https://github.com/google/benchmark/archive/16703ff83c1ae6d53e5155df3bb3ab0bc96083be.zip"], + strip_prefix = "benchmark-16703ff83c1ae6d53e5155df3bb3ab0bc96083be", + sha256 = "59f918c8ccd4d74b6ac43484467b500f1d64b40cc1010daa055375b322a43ba3", +) + +# C++ rules for Bazel. +http_archive( + name = "rules_cc", + sha256 = "9a446e9dd9c1bb180c86977a8dc1e9e659550ae732ae58bd2e8fd51e15b2c91d", + strip_prefix = "rules_cc-262ebec3c2296296526740db4aefce68c80de7fa", + urls = [ + "https://mirror.bazel.build/github.com/bazelbuild/rules_cc/archive/262ebec3c2296296526740db4aefce68c80de7fa.zip", + "https://github.com/bazelbuild/rules_cc/archive/262ebec3c2296296526740db4aefce68c80de7fa.zip", + ], +) diff --git a/third_party/abseil_cpp/absl/BUILD.bazel b/third_party/abseil_cpp/absl/BUILD.bazel new file mode 100644 index 0000000000..f7fc2a7f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/BUILD.bazel @@ -0,0 +1,60 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load( + ":compiler_config_setting.bzl", + "create_llvm_config", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +create_llvm_config( + name = "llvm_compiler", + visibility = [":__subpackages__"], +) + +config_setting( + name = "osx", + constraint_values = [ + "@bazel_tools//platforms:osx", + ], +) + +config_setting( + name = "ios", + constraint_values = [ + "@bazel_tools//platforms:ios", + ], +) + +config_setting( + name = "windows", + constraint_values = [ + "@bazel_tools//platforms:x86_64", + "@bazel_tools//platforms:windows", + ], + visibility = [":__subpackages__"], +) + +config_setting( + name = "ppc", + values = { + "cpu": "ppc", + }, + visibility = [":__subpackages__"], +) diff --git a/third_party/abseil_cpp/absl/CMakeLists.txt b/third_party/abseil_cpp/absl/CMakeLists.txt new file mode 100644 index 0000000000..fbfa7822b5 --- /dev/null +++ b/third_party/abseil_cpp/absl/CMakeLists.txt @@ -0,0 +1,37 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +add_subdirectory(base) +add_subdirectory(algorithm) +add_subdirectory(container) +add_subdirectory(debugging) +add_subdirectory(flags) +add_subdirectory(functional) +add_subdirectory(hash) +add_subdirectory(memory) +add_subdirectory(meta) +add_subdirectory(numeric) +add_subdirectory(random) +add_subdirectory(status) +add_subdirectory(strings) +add_subdirectory(synchronization) +add_subdirectory(time) +add_subdirectory(types) +add_subdirectory(utility) + +if (${ABSL_BUILD_DLL}) + absl_make_dll() +endif() diff --git a/third_party/abseil_cpp/absl/abseil.podspec.gen.py b/third_party/abseil_cpp/absl/abseil.podspec.gen.py new file mode 100755 index 0000000000..6aefb794df --- /dev/null +++ b/third_party/abseil_cpp/absl/abseil.podspec.gen.py @@ -0,0 +1,229 @@ +#!/usr/bin/env python3 +# -*- coding: utf-8 -*- +"""This script generates abseil.podspec from all BUILD.bazel files. + +This is expected to run on abseil git repository with Bazel 1.0 on Linux. +It recursively analyzes BUILD.bazel files using query command of Bazel to +dump its build rules in XML format. From these rules, it constructs podspec +structure. +""" + +import argparse +import collections +import os +import re +import subprocess +import xml.etree.ElementTree + +# Template of root podspec. +SPEC_TEMPLATE = """ +# This file has been automatically generated from a script. +# Please make modifications to `abseil.podspec.gen.py` instead. +Pod::Spec.new do |s| + s.name = 'abseil' + s.version = '${version}' + s.summary = 'Abseil Common Libraries (C++) from Google' + s.homepage = 'https://abseil.io' + s.license = 'Apache License, Version 2.0' + s.authors = { 'Abseil Team' => 'abseil-io@googlegroups.com' } + s.source = { + :git => 'https://github.com/abseil/abseil-cpp.git', + :tag => '${tag}', + } + s.module_name = 'absl' + s.header_mappings_dir = 'absl' + s.header_dir = 'absl' + s.libraries = 'c++' + s.compiler_flags = '-Wno-everything' + s.pod_target_xcconfig = { + 'USER_HEADER_SEARCH_PATHS' => '$(inherited) "$(PODS_TARGET_SRCROOT)"', + 'USE_HEADERMAP' => 'NO', + 'ALWAYS_SEARCH_USER_PATHS' => 'NO', + } + s.ios.deployment_target = '7.0' + s.osx.deployment_target = '10.9' + s.tvos.deployment_target = '9.0' + s.watchos.deployment_target = '2.0' +""" + +# Rule object representing the rule of Bazel BUILD. +Rule = collections.namedtuple( + "Rule", "type name package srcs hdrs textual_hdrs deps visibility testonly") + + +def get_elem_value(elem, name): + """Returns the value of XML element with the given name.""" + for child in elem: + if child.attrib.get("name") != name: + continue + if child.tag == "string": + return child.attrib.get("value") + if child.tag == "boolean": + return child.attrib.get("value") == "true" + if child.tag == "list": + return [nested_child.attrib.get("value") for nested_child in child] + raise "Cannot recognize tag: " + child.tag + return None + + +def normalize_paths(paths): + """Returns the list of normalized path.""" + # e.g. ["//absl/strings:dir/header.h"] -> ["absl/strings/dir/header.h"] + return [path.lstrip("/").replace(":", "/") for path in paths] + + +def parse_rule(elem, package): + """Returns a rule from bazel XML rule.""" + return Rule( + type=elem.attrib["class"], + name=get_elem_value(elem, "name"), + package=package, + srcs=normalize_paths(get_elem_value(elem, "srcs") or []), + hdrs=normalize_paths(get_elem_value(elem, "hdrs") or []), + textual_hdrs=normalize_paths(get_elem_value(elem, "textual_hdrs") or []), + deps=get_elem_value(elem, "deps") or [], + visibility=get_elem_value(elem, "visibility") or [], + testonly=get_elem_value(elem, "testonly") or False) + + +def read_build(package): + """Runs bazel query on given package file and returns all cc rules.""" + result = subprocess.check_output( + ["bazel", "query", package + ":all", "--output", "xml"]) + root = xml.etree.ElementTree.fromstring(result) + return [ + parse_rule(elem, package) + for elem in root + if elem.tag == "rule" and elem.attrib["class"].startswith("cc_") + ] + + +def collect_rules(root_path): + """Collects and returns all rules from root path recursively.""" + rules = [] + for cur, _, _ in os.walk(root_path): + build_path = os.path.join(cur, "BUILD.bazel") + if os.path.exists(build_path): + rules.extend(read_build("//" + cur)) + return rules + + +def relevant_rule(rule): + """Returns true if a given rule is relevant when generating a podspec.""" + return ( + # cc_library only (ignore cc_test, cc_binary) + rule.type == "cc_library" and + # ignore empty rule + (rule.hdrs + rule.textual_hdrs + rule.srcs) and + # ignore test-only rule + not rule.testonly) + + +def get_spec_var(depth): + """Returns the name of variable for spec with given depth.""" + return "s" if depth == 0 else "s{}".format(depth) + + +def get_spec_name(label): + """Converts the label of bazel rule to the name of podspec.""" + assert label.startswith("//absl/"), "{} doesn't start with //absl/".format( + label) + # e.g. //absl/apple/banana -> abseil/apple/banana + return "abseil/" + label[7:] + + +def write_podspec(f, rules, args): + """Writes a podspec from given rules and args.""" + rule_dir = build_rule_directory(rules)["abseil"] + # Write root part with given arguments + spec = re.sub(r"\$\{(\w+)\}", lambda x: args[x.group(1)], + SPEC_TEMPLATE).lstrip() + f.write(spec) + # Write all target rules + write_podspec_map(f, rule_dir, 0) + f.write("end\n") + + +def build_rule_directory(rules): + """Builds a tree-style rule directory from given rules.""" + rule_dir = {} + for rule in rules: + cur = rule_dir + for frag in get_spec_name(rule.package).split("/"): + cur = cur.setdefault(frag, {}) + cur[rule.name] = rule + return rule_dir + + +def write_podspec_map(f, cur_map, depth): + """Writes podspec from rule map recursively.""" + for key, value in sorted(cur_map.items()): + indent = " " * (depth + 1) + f.write("{indent}{var0}.subspec '{key}' do |{var1}|\n".format( + indent=indent, + key=key, + var0=get_spec_var(depth), + var1=get_spec_var(depth + 1))) + if isinstance(value, dict): + write_podspec_map(f, value, depth + 1) + else: + write_podspec_rule(f, value, depth + 1) + f.write("{indent}end\n".format(indent=indent)) + + +def write_podspec_rule(f, rule, depth): + """Writes podspec from given rule.""" + indent = " " * (depth + 1) + spec_var = get_spec_var(depth) + # Puts all files in hdrs, textual_hdrs, and srcs into source_files. + # Since CocoaPods treats header_files a bit differently from bazel, + # this won't generate a header_files field so that all source_files + # are considered as header files. + srcs = sorted(set(rule.hdrs + rule.textual_hdrs + rule.srcs)) + write_indented_list( + f, "{indent}{var}.source_files = ".format(indent=indent, var=spec_var), + srcs) + # Writes dependencies of this rule. + for dep in sorted(rule.deps): + name = get_spec_name(dep.replace(":", "/")) + f.write("{indent}{var}.dependency '{dep}'\n".format( + indent=indent, var=spec_var, dep=name)) + + +def write_indented_list(f, leading, values): + """Writes leading values in an indented style.""" + f.write(leading) + f.write((",\n" + " " * len(leading)).join("'{}'".format(v) for v in values)) + f.write("\n") + + +def generate(args): + """Generates a podspec file from all BUILD files under absl directory.""" + rules = filter(relevant_rule, collect_rules("absl")) + with open(args.output, "wt") as f: + write_podspec(f, rules, vars(args)) + + +def main(): + parser = argparse.ArgumentParser( + description="Generates abseil.podspec from BUILD.bazel") + parser.add_argument( + "-v", "--version", help="The version of podspec", required=True) + parser.add_argument( + "-t", + "--tag", + default=None, + help="The name of git tag (default: version)") + parser.add_argument( + "-o", + "--output", + default="abseil.podspec", + help="The name of output file (default: abseil.podspec)") + args = parser.parse_args() + if args.tag is None: + args.tag = args.version + generate(args) + + +if __name__ == "__main__": + main() diff --git a/third_party/abseil_cpp/absl/algorithm/BUILD.bazel b/third_party/abseil_cpp/absl/algorithm/BUILD.bazel new file mode 100644 index 0000000000..229cd713a2 --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/BUILD.bazel @@ -0,0 +1,91 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "algorithm", + hdrs = ["algorithm.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + ], +) + +cc_test( + name = "algorithm_test", + size = "small", + srcs = ["algorithm_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":algorithm", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "algorithm_benchmark", + srcs = ["equal_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + deps = [ + ":algorithm", + "//absl/base:core_headers", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "container", + hdrs = [ + "container.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":algorithm", + "//absl/base:core_headers", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "container_test", + srcs = ["container_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":container", + "//absl/base", + "//absl/base:core_headers", + "//absl/memory", + "//absl/types:span", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/algorithm/CMakeLists.txt b/third_party/abseil_cpp/absl/algorithm/CMakeLists.txt new file mode 100644 index 0000000000..56cd0fb85b --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/CMakeLists.txt @@ -0,0 +1,69 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + algorithm + HDRS + "algorithm.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + PUBLIC +) + +absl_cc_test( + NAME + algorithm_test + SRCS + "algorithm_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::algorithm + gmock_main +) + +absl_cc_library( + NAME + algorithm_container + HDRS + "container.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::algorithm + absl::core_headers + absl::meta + PUBLIC +) + +absl_cc_test( + NAME + container_test + SRCS + "container_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::algorithm_container + absl::base + absl::core_headers + absl::memory + absl::span + gmock_main +) diff --git a/third_party/abseil_cpp/absl/algorithm/algorithm.h b/third_party/abseil_cpp/absl/algorithm/algorithm.h new file mode 100644 index 0000000000..e9b4733872 --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/algorithm.h @@ -0,0 +1,159 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: algorithm.h +// ----------------------------------------------------------------------------- +// +// This header file contains Google extensions to the standard <algorithm> C++ +// header. + +#ifndef ABSL_ALGORITHM_ALGORITHM_H_ +#define ABSL_ALGORITHM_ALGORITHM_H_ + +#include <algorithm> +#include <iterator> +#include <type_traits> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace algorithm_internal { + +// Performs comparisons with operator==, similar to C++14's `std::equal_to<>`. +struct EqualTo { + template <typename T, typename U> + bool operator()(const T& a, const U& b) const { + return a == b; + } +}; + +template <typename InputIter1, typename InputIter2, typename Pred> +bool EqualImpl(InputIter1 first1, InputIter1 last1, InputIter2 first2, + InputIter2 last2, Pred pred, std::input_iterator_tag, + std::input_iterator_tag) { + while (true) { + if (first1 == last1) return first2 == last2; + if (first2 == last2) return false; + if (!pred(*first1, *first2)) return false; + ++first1; + ++first2; + } +} + +template <typename InputIter1, typename InputIter2, typename Pred> +bool EqualImpl(InputIter1 first1, InputIter1 last1, InputIter2 first2, + InputIter2 last2, Pred&& pred, std::random_access_iterator_tag, + std::random_access_iterator_tag) { + return (last1 - first1 == last2 - first2) && + std::equal(first1, last1, first2, std::forward<Pred>(pred)); +} + +// When we are using our own internal predicate that just applies operator==, we +// forward to the non-predicate form of std::equal. This enables an optimization +// in libstdc++ that can result in std::memcmp being used for integer types. +template <typename InputIter1, typename InputIter2> +bool EqualImpl(InputIter1 first1, InputIter1 last1, InputIter2 first2, + InputIter2 last2, algorithm_internal::EqualTo /* unused */, + std::random_access_iterator_tag, + std::random_access_iterator_tag) { + return (last1 - first1 == last2 - first2) && + std::equal(first1, last1, first2); +} + +template <typename It> +It RotateImpl(It first, It middle, It last, std::true_type) { + return std::rotate(first, middle, last); +} + +template <typename It> +It RotateImpl(It first, It middle, It last, std::false_type) { + std::rotate(first, middle, last); + return std::next(first, std::distance(middle, last)); +} + +} // namespace algorithm_internal + +// equal() +// +// Compares the equality of two ranges specified by pairs of iterators, using +// the given predicate, returning true iff for each corresponding iterator i1 +// and i2 in the first and second range respectively, pred(*i1, *i2) == true +// +// This comparison takes at most min(`last1` - `first1`, `last2` - `first2`) +// invocations of the predicate. Additionally, if InputIter1 and InputIter2 are +// both random-access iterators, and `last1` - `first1` != `last2` - `first2`, +// then the predicate is never invoked and the function returns false. +// +// This is a C++11-compatible implementation of C++14 `std::equal`. See +// https://en.cppreference.com/w/cpp/algorithm/equal for more information. +template <typename InputIter1, typename InputIter2, typename Pred> +bool equal(InputIter1 first1, InputIter1 last1, InputIter2 first2, + InputIter2 last2, Pred&& pred) { + return algorithm_internal::EqualImpl( + first1, last1, first2, last2, std::forward<Pred>(pred), + typename std::iterator_traits<InputIter1>::iterator_category{}, + typename std::iterator_traits<InputIter2>::iterator_category{}); +} + +// Overload of equal() that performs comparison of two ranges specified by pairs +// of iterators using operator==. +template <typename InputIter1, typename InputIter2> +bool equal(InputIter1 first1, InputIter1 last1, InputIter2 first2, + InputIter2 last2) { + return absl::equal(first1, last1, first2, last2, + algorithm_internal::EqualTo{}); +} + +// linear_search() +// +// Performs a linear search for `value` using the iterator `first` up to +// but not including `last`, returning true if [`first`, `last`) contains an +// element equal to `value`. +// +// A linear search is of O(n) complexity which is guaranteed to make at most +// n = (`last` - `first`) comparisons. A linear search over short containers +// may be faster than a binary search, even when the container is sorted. +template <typename InputIterator, typename EqualityComparable> +bool linear_search(InputIterator first, InputIterator last, + const EqualityComparable& value) { + return std::find(first, last, value) != last; +} + +// rotate() +// +// Performs a left rotation on a range of elements (`first`, `last`) such that +// `middle` is now the first element. `rotate()` returns an iterator pointing to +// the first element before rotation. This function is exactly the same as +// `std::rotate`, but fixes a bug in gcc +// <= 4.9 where `std::rotate` returns `void` instead of an iterator. +// +// The complexity of this algorithm is the same as that of `std::rotate`, but if +// `ForwardIterator` is not a random-access iterator, then `absl::rotate` +// performs an additional pass over the range to construct the return value. +template <typename ForwardIterator> +ForwardIterator rotate(ForwardIterator first, ForwardIterator middle, + ForwardIterator last) { + return algorithm_internal::RotateImpl( + first, middle, last, + std::is_same<decltype(std::rotate(first, middle, last)), + ForwardIterator>()); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_ALGORITHM_ALGORITHM_H_ diff --git a/third_party/abseil_cpp/absl/algorithm/algorithm_test.cc b/third_party/abseil_cpp/absl/algorithm/algorithm_test.cc new file mode 100644 index 0000000000..81fccb6135 --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/algorithm_test.cc @@ -0,0 +1,182 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/algorithm/algorithm.h" + +#include <algorithm> +#include <list> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" + +namespace { + +TEST(EqualTest, DefaultComparisonRandomAccess) { + std::vector<int> v1{1, 2, 3}; + std::vector<int> v2 = v1; + std::vector<int> v3 = {1, 2}; + std::vector<int> v4 = {1, 2, 4}; + + EXPECT_TRUE(absl::equal(v1.begin(), v1.end(), v2.begin(), v2.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v3.begin(), v3.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v4.begin(), v4.end())); +} + +TEST(EqualTest, DefaultComparison) { + std::list<int> lst1{1, 2, 3}; + std::list<int> lst2 = lst1; + std::list<int> lst3{1, 2}; + std::list<int> lst4{1, 2, 4}; + + EXPECT_TRUE(absl::equal(lst1.begin(), lst1.end(), lst2.begin(), lst2.end())); + EXPECT_FALSE(absl::equal(lst1.begin(), lst1.end(), lst3.begin(), lst3.end())); + EXPECT_FALSE(absl::equal(lst1.begin(), lst1.end(), lst4.begin(), lst4.end())); +} + +TEST(EqualTest, EmptyRange) { + std::vector<int> v1{1, 2, 3}; + std::vector<int> empty1; + std::vector<int> empty2; + + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), empty1.begin(), empty1.end())); + EXPECT_FALSE(absl::equal(empty1.begin(), empty1.end(), v1.begin(), v1.end())); + EXPECT_TRUE( + absl::equal(empty1.begin(), empty1.end(), empty2.begin(), empty2.end())); +} + +TEST(EqualTest, MixedIterTypes) { + std::vector<int> v1{1, 2, 3}; + std::list<int> lst1{v1.begin(), v1.end()}; + std::list<int> lst2{1, 2, 4}; + std::list<int> lst3{1, 2}; + + EXPECT_TRUE(absl::equal(v1.begin(), v1.end(), lst1.begin(), lst1.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), lst2.begin(), lst2.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), lst3.begin(), lst3.end())); +} + +TEST(EqualTest, MixedValueTypes) { + std::vector<int> v1{1, 2, 3}; + std::vector<char> v2{1, 2, 3}; + std::vector<char> v3{1, 2}; + std::vector<char> v4{1, 2, 4}; + + EXPECT_TRUE(absl::equal(v1.begin(), v1.end(), v2.begin(), v2.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v3.begin(), v3.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v4.begin(), v4.end())); +} + +TEST(EqualTest, WeirdIterators) { + std::vector<bool> v1{true, false}; + std::vector<bool> v2 = v1; + std::vector<bool> v3{true}; + std::vector<bool> v4{true, true, true}; + + EXPECT_TRUE(absl::equal(v1.begin(), v1.end(), v2.begin(), v2.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v3.begin(), v3.end())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v4.begin(), v4.end())); +} + +TEST(EqualTest, CustomComparison) { + int n[] = {1, 2, 3, 4}; + std::vector<int*> v1{&n[0], &n[1], &n[2]}; + std::vector<int*> v2 = v1; + std::vector<int*> v3{&n[0], &n[1], &n[3]}; + std::vector<int*> v4{&n[0], &n[1]}; + + auto eq = [](int* a, int* b) { return *a == *b; }; + + EXPECT_TRUE(absl::equal(v1.begin(), v1.end(), v2.begin(), v2.end(), eq)); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v3.begin(), v3.end(), eq)); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v4.begin(), v4.end(), eq)); +} + +TEST(EqualTest, MoveOnlyPredicate) { + std::vector<int> v1{1, 2, 3}; + std::vector<int> v2{4, 5, 6}; + + // move-only equality predicate + struct Eq { + Eq() = default; + Eq(Eq &&) = default; + Eq(const Eq &) = delete; + Eq &operator=(const Eq &) = delete; + bool operator()(const int a, const int b) const { return a == b; } + }; + + EXPECT_TRUE(absl::equal(v1.begin(), v1.end(), v1.begin(), v1.end(), Eq())); + EXPECT_FALSE(absl::equal(v1.begin(), v1.end(), v2.begin(), v2.end(), Eq())); +} + +struct CountingTrivialPred { + int* count; + bool operator()(int, int) const { + ++*count; + return true; + } +}; + +TEST(EqualTest, RandomAccessComplexity) { + std::vector<int> v1{1, 1, 3}; + std::vector<int> v2 = v1; + std::vector<int> v3{1, 2}; + + do { + int count = 0; + absl::equal(v1.begin(), v1.end(), v2.begin(), v2.end(), + CountingTrivialPred{&count}); + EXPECT_LE(count, 3); + } while (std::next_permutation(v2.begin(), v2.end())); + + int count = 0; + absl::equal(v1.begin(), v1.end(), v3.begin(), v3.end(), + CountingTrivialPred{&count}); + EXPECT_EQ(count, 0); +} + +class LinearSearchTest : public testing::Test { + protected: + LinearSearchTest() : container_{1, 2, 3} {} + + static bool Is3(int n) { return n == 3; } + static bool Is4(int n) { return n == 4; } + + std::vector<int> container_; +}; + +TEST_F(LinearSearchTest, linear_search) { + EXPECT_TRUE(absl::linear_search(container_.begin(), container_.end(), 3)); + EXPECT_FALSE(absl::linear_search(container_.begin(), container_.end(), 4)); +} + +TEST_F(LinearSearchTest, linear_searchConst) { + const std::vector<int> *const const_container = &container_; + EXPECT_TRUE( + absl::linear_search(const_container->begin(), const_container->end(), 3)); + EXPECT_FALSE( + absl::linear_search(const_container->begin(), const_container->end(), 4)); +} + +TEST(RotateTest, Rotate) { + std::vector<int> v{0, 1, 2, 3, 4}; + EXPECT_EQ(*absl::rotate(v.begin(), v.begin() + 2, v.end()), 0); + EXPECT_THAT(v, testing::ElementsAreArray({2, 3, 4, 0, 1})); + + std::list<int> l{0, 1, 2, 3, 4}; + EXPECT_EQ(*absl::rotate(l.begin(), std::next(l.begin(), 3), l.end()), 0); + EXPECT_THAT(l, testing::ElementsAreArray({3, 4, 0, 1, 2})); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/algorithm/container.h b/third_party/abseil_cpp/absl/algorithm/container.h new file mode 100644 index 0000000000..d72532decf --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/container.h @@ -0,0 +1,1727 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: container.h +// ----------------------------------------------------------------------------- +// +// This header file provides Container-based versions of algorithmic functions +// within the C++ standard library. The following standard library sets of +// functions are covered within this file: +// +// * Algorithmic <iterator> functions +// * Algorithmic <numeric> functions +// * <algorithm> functions +// +// The standard library functions operate on iterator ranges; the functions +// within this API operate on containers, though many return iterator ranges. +// +// All functions within this API are named with a `c_` prefix. Calls such as +// `absl::c_xx(container, ...) are equivalent to std:: functions such as +// `std::xx(std::begin(cont), std::end(cont), ...)`. Functions that act on +// iterators but not conceptually on iterator ranges (e.g. `std::iter_swap`) +// have no equivalent here. +// +// For template parameter and variable naming, `C` indicates the container type +// to which the function is applied, `Pred` indicates the predicate object type +// to be used by the function and `T` indicates the applicable element type. + +#ifndef ABSL_ALGORITHM_CONTAINER_H_ +#define ABSL_ALGORITHM_CONTAINER_H_ + +#include <algorithm> +#include <cassert> +#include <iterator> +#include <numeric> +#include <type_traits> +#include <unordered_map> +#include <unordered_set> +#include <utility> +#include <vector> + +#include "absl/algorithm/algorithm.h" +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_algorithm_internal { + +// NOTE: it is important to defer to ADL lookup for building with C++ modules, +// especially for headers like <valarray> which are not visible from this file +// but specialize std::begin and std::end. +using std::begin; +using std::end; + +// The type of the iterator given by begin(c) (possibly std::begin(c)). +// ContainerIter<const vector<T>> gives vector<T>::const_iterator, +// while ContainerIter<vector<T>> gives vector<T>::iterator. +template <typename C> +using ContainerIter = decltype(begin(std::declval<C&>())); + +// An MSVC bug involving template parameter substitution requires us to use +// decltype() here instead of just std::pair. +template <typename C1, typename C2> +using ContainerIterPairType = + decltype(std::make_pair(ContainerIter<C1>(), ContainerIter<C2>())); + +template <typename C> +using ContainerDifferenceType = + decltype(std::distance(std::declval<ContainerIter<C>>(), + std::declval<ContainerIter<C>>())); + +template <typename C> +using ContainerPointerType = + typename std::iterator_traits<ContainerIter<C>>::pointer; + +// container_algorithm_internal::c_begin and +// container_algorithm_internal::c_end are abbreviations for proper ADL +// lookup of std::begin and std::end, i.e. +// using std::begin; +// using std::end; +// std::foo(begin(c), end(c); +// becomes +// std::foo(container_algorithm_internal::begin(c), +// container_algorithm_internal::end(c)); +// These are meant for internal use only. + +template <typename C> +ContainerIter<C> c_begin(C& c) { return begin(c); } + +template <typename C> +ContainerIter<C> c_end(C& c) { return end(c); } + +template <typename T> +struct IsUnorderedContainer : std::false_type {}; + +template <class Key, class T, class Hash, class KeyEqual, class Allocator> +struct IsUnorderedContainer< + std::unordered_map<Key, T, Hash, KeyEqual, Allocator>> : std::true_type {}; + +template <class Key, class Hash, class KeyEqual, class Allocator> +struct IsUnorderedContainer<std::unordered_set<Key, Hash, KeyEqual, Allocator>> + : std::true_type {}; + +// container_algorithm_internal::c_size. It is meant for internal use only. + +template <class C> +auto c_size(C& c) -> decltype(c.size()) { + return c.size(); +} + +template <class T, std::size_t N> +constexpr std::size_t c_size(T (&)[N]) { + return N; +} + +} // namespace container_algorithm_internal + +// PUBLIC API + +//------------------------------------------------------------------------------ +// Abseil algorithm.h functions +//------------------------------------------------------------------------------ + +// c_linear_search() +// +// Container-based version of absl::linear_search() for performing a linear +// search within a container. +template <typename C, typename EqualityComparable> +bool c_linear_search(const C& c, EqualityComparable&& value) { + return linear_search(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<EqualityComparable>(value)); +} + +//------------------------------------------------------------------------------ +// <iterator> algorithms +//------------------------------------------------------------------------------ + +// c_distance() +// +// Container-based version of the <iterator> `std::distance()` function to +// return the number of elements within a container. +template <typename C> +container_algorithm_internal::ContainerDifferenceType<const C> c_distance( + const C& c) { + return std::distance(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Non-modifying sequence operations +//------------------------------------------------------------------------------ + +// c_all_of() +// +// Container-based version of the <algorithm> `std::all_of()` function to +// test a condition on all elements within a container. +template <typename C, typename Pred> +bool c_all_of(const C& c, Pred&& pred) { + return std::all_of(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_any_of() +// +// Container-based version of the <algorithm> `std::any_of()` function to +// test if any element in a container fulfills a condition. +template <typename C, typename Pred> +bool c_any_of(const C& c, Pred&& pred) { + return std::any_of(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_none_of() +// +// Container-based version of the <algorithm> `std::none_of()` function to +// test if no elements in a container fulfil a condition. +template <typename C, typename Pred> +bool c_none_of(const C& c, Pred&& pred) { + return std::none_of(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_for_each() +// +// Container-based version of the <algorithm> `std::for_each()` function to +// apply a function to a container's elements. +template <typename C, typename Function> +decay_t<Function> c_for_each(C&& c, Function&& f) { + return std::for_each(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Function>(f)); +} + +// c_find() +// +// Container-based version of the <algorithm> `std::find()` function to find +// the first element containing the passed value within a container value. +template <typename C, typename T> +container_algorithm_internal::ContainerIter<C> c_find(C& c, T&& value) { + return std::find(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<T>(value)); +} + +// c_find_if() +// +// Container-based version of the <algorithm> `std::find_if()` function to find +// the first element in a container matching the given condition. +template <typename C, typename Pred> +container_algorithm_internal::ContainerIter<C> c_find_if(C& c, Pred&& pred) { + return std::find_if(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_find_if_not() +// +// Container-based version of the <algorithm> `std::find_if_not()` function to +// find the first element in a container not matching the given condition. +template <typename C, typename Pred> +container_algorithm_internal::ContainerIter<C> c_find_if_not(C& c, + Pred&& pred) { + return std::find_if_not(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_find_end() +// +// Container-based version of the <algorithm> `std::find_end()` function to +// find the last subsequence within a container. +template <typename Sequence1, typename Sequence2> +container_algorithm_internal::ContainerIter<Sequence1> c_find_end( + Sequence1& sequence, Sequence2& subsequence) { + return std::find_end(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + container_algorithm_internal::c_begin(subsequence), + container_algorithm_internal::c_end(subsequence)); +} + +// Overload of c_find_end() for using a predicate evaluation other than `==` as +// the function's test condition. +template <typename Sequence1, typename Sequence2, typename BinaryPredicate> +container_algorithm_internal::ContainerIter<Sequence1> c_find_end( + Sequence1& sequence, Sequence2& subsequence, BinaryPredicate&& pred) { + return std::find_end(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + container_algorithm_internal::c_begin(subsequence), + container_algorithm_internal::c_end(subsequence), + std::forward<BinaryPredicate>(pred)); +} + +// c_find_first_of() +// +// Container-based version of the <algorithm> `std::find_first_of()` function to +// find the first element within the container that is also within the options +// container. +template <typename C1, typename C2> +container_algorithm_internal::ContainerIter<C1> c_find_first_of(C1& container, + C2& options) { + return std::find_first_of(container_algorithm_internal::c_begin(container), + container_algorithm_internal::c_end(container), + container_algorithm_internal::c_begin(options), + container_algorithm_internal::c_end(options)); +} + +// Overload of c_find_first_of() for using a predicate evaluation other than +// `==` as the function's test condition. +template <typename C1, typename C2, typename BinaryPredicate> +container_algorithm_internal::ContainerIter<C1> c_find_first_of( + C1& container, C2& options, BinaryPredicate&& pred) { + return std::find_first_of(container_algorithm_internal::c_begin(container), + container_algorithm_internal::c_end(container), + container_algorithm_internal::c_begin(options), + container_algorithm_internal::c_end(options), + std::forward<BinaryPredicate>(pred)); +} + +// c_adjacent_find() +// +// Container-based version of the <algorithm> `std::adjacent_find()` function to +// find equal adjacent elements within a container. +template <typename Sequence> +container_algorithm_internal::ContainerIter<Sequence> c_adjacent_find( + Sequence& sequence) { + return std::adjacent_find(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_adjacent_find() for using a predicate evaluation other than +// `==` as the function's test condition. +template <typename Sequence, typename BinaryPredicate> +container_algorithm_internal::ContainerIter<Sequence> c_adjacent_find( + Sequence& sequence, BinaryPredicate&& pred) { + return std::adjacent_find(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<BinaryPredicate>(pred)); +} + +// c_count() +// +// Container-based version of the <algorithm> `std::count()` function to count +// values that match within a container. +template <typename C, typename T> +container_algorithm_internal::ContainerDifferenceType<const C> c_count( + const C& c, T&& value) { + return std::count(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<T>(value)); +} + +// c_count_if() +// +// Container-based version of the <algorithm> `std::count_if()` function to +// count values matching a condition within a container. +template <typename C, typename Pred> +container_algorithm_internal::ContainerDifferenceType<const C> c_count_if( + const C& c, Pred&& pred) { + return std::count_if(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_mismatch() +// +// Container-based version of the <algorithm> `std::mismatch()` function to +// return the first element where two ordered containers differ. +template <typename C1, typename C2> +container_algorithm_internal::ContainerIterPairType<C1, C2> +c_mismatch(C1& c1, C2& c2) { + return std::mismatch(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2)); +} + +// Overload of c_mismatch() for using a predicate evaluation other than `==` as +// the function's test condition. +template <typename C1, typename C2, typename BinaryPredicate> +container_algorithm_internal::ContainerIterPairType<C1, C2> +c_mismatch(C1& c1, C2& c2, BinaryPredicate&& pred) { + return std::mismatch(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + std::forward<BinaryPredicate>(pred)); +} + +// c_equal() +// +// Container-based version of the <algorithm> `std::equal()` function to +// test whether two containers are equal. +// +// NOTE: the semantics of c_equal() are slightly different than those of +// equal(): while the latter iterates over the second container only up to the +// size of the first container, c_equal() also checks whether the container +// sizes are equal. This better matches expectations about c_equal() based on +// its signature. +// +// Example: +// vector v1 = <1, 2, 3>; +// vector v2 = <1, 2, 3, 4>; +// equal(std::begin(v1), std::end(v1), std::begin(v2)) returns true +// c_equal(v1, v2) returns false + +template <typename C1, typename C2> +bool c_equal(const C1& c1, const C2& c2) { + return ((container_algorithm_internal::c_size(c1) == + container_algorithm_internal::c_size(c2)) && + std::equal(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2))); +} + +// Overload of c_equal() for using a predicate evaluation other than `==` as +// the function's test condition. +template <typename C1, typename C2, typename BinaryPredicate> +bool c_equal(const C1& c1, const C2& c2, BinaryPredicate&& pred) { + return ((container_algorithm_internal::c_size(c1) == + container_algorithm_internal::c_size(c2)) && + std::equal(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + std::forward<BinaryPredicate>(pred))); +} + +// c_is_permutation() +// +// Container-based version of the <algorithm> `std::is_permutation()` function +// to test whether a container is a permutation of another. +template <typename C1, typename C2> +bool c_is_permutation(const C1& c1, const C2& c2) { + using std::begin; + using std::end; + return c1.size() == c2.size() && + std::is_permutation(begin(c1), end(c1), begin(c2)); +} + +// Overload of c_is_permutation() for using a predicate evaluation other than +// `==` as the function's test condition. +template <typename C1, typename C2, typename BinaryPredicate> +bool c_is_permutation(const C1& c1, const C2& c2, BinaryPredicate&& pred) { + using std::begin; + using std::end; + return c1.size() == c2.size() && + std::is_permutation(begin(c1), end(c1), begin(c2), + std::forward<BinaryPredicate>(pred)); +} + +// c_search() +// +// Container-based version of the <algorithm> `std::search()` function to search +// a container for a subsequence. +template <typename Sequence1, typename Sequence2> +container_algorithm_internal::ContainerIter<Sequence1> c_search( + Sequence1& sequence, Sequence2& subsequence) { + return std::search(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + container_algorithm_internal::c_begin(subsequence), + container_algorithm_internal::c_end(subsequence)); +} + +// Overload of c_search() for using a predicate evaluation other than +// `==` as the function's test condition. +template <typename Sequence1, typename Sequence2, typename BinaryPredicate> +container_algorithm_internal::ContainerIter<Sequence1> c_search( + Sequence1& sequence, Sequence2& subsequence, BinaryPredicate&& pred) { + return std::search(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + container_algorithm_internal::c_begin(subsequence), + container_algorithm_internal::c_end(subsequence), + std::forward<BinaryPredicate>(pred)); +} + +// c_search_n() +// +// Container-based version of the <algorithm> `std::search_n()` function to +// search a container for the first sequence of N elements. +template <typename Sequence, typename Size, typename T> +container_algorithm_internal::ContainerIter<Sequence> c_search_n( + Sequence& sequence, Size count, T&& value) { + return std::search_n(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), count, + std::forward<T>(value)); +} + +// Overload of c_search_n() for using a predicate evaluation other than +// `==` as the function's test condition. +template <typename Sequence, typename Size, typename T, + typename BinaryPredicate> +container_algorithm_internal::ContainerIter<Sequence> c_search_n( + Sequence& sequence, Size count, T&& value, BinaryPredicate&& pred) { + return std::search_n(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), count, + std::forward<T>(value), + std::forward<BinaryPredicate>(pred)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Modifying sequence operations +//------------------------------------------------------------------------------ + +// c_copy() +// +// Container-based version of the <algorithm> `std::copy()` function to copy a +// container's elements into an iterator. +template <typename InputSequence, typename OutputIterator> +OutputIterator c_copy(const InputSequence& input, OutputIterator output) { + return std::copy(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), output); +} + +// c_copy_n() +// +// Container-based version of the <algorithm> `std::copy_n()` function to copy a +// container's first N elements into an iterator. +template <typename C, typename Size, typename OutputIterator> +OutputIterator c_copy_n(const C& input, Size n, OutputIterator output) { + return std::copy_n(container_algorithm_internal::c_begin(input), n, output); +} + +// c_copy_if() +// +// Container-based version of the <algorithm> `std::copy_if()` function to copy +// a container's elements satisfying some condition into an iterator. +template <typename InputSequence, typename OutputIterator, typename Pred> +OutputIterator c_copy_if(const InputSequence& input, OutputIterator output, + Pred&& pred) { + return std::copy_if(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), output, + std::forward<Pred>(pred)); +} + +// c_copy_backward() +// +// Container-based version of the <algorithm> `std::copy_backward()` function to +// copy a container's elements in reverse order into an iterator. +template <typename C, typename BidirectionalIterator> +BidirectionalIterator c_copy_backward(const C& src, + BidirectionalIterator dest) { + return std::copy_backward(container_algorithm_internal::c_begin(src), + container_algorithm_internal::c_end(src), dest); +} + +// c_move() +// +// Container-based version of the <algorithm> `std::move()` function to move +// a container's elements into an iterator. +template <typename C, typename OutputIterator> +OutputIterator c_move(C&& src, OutputIterator dest) { + return std::move(container_algorithm_internal::c_begin(src), + container_algorithm_internal::c_end(src), dest); +} + +// c_move_backward() +// +// Container-based version of the <algorithm> `std::move_backward()` function to +// move a container's elements into an iterator in reverse order. +template <typename C, typename BidirectionalIterator> +BidirectionalIterator c_move_backward(C&& src, BidirectionalIterator dest) { + return std::move_backward(container_algorithm_internal::c_begin(src), + container_algorithm_internal::c_end(src), dest); +} + +// c_swap_ranges() +// +// Container-based version of the <algorithm> `std::swap_ranges()` function to +// swap a container's elements with another container's elements. +template <typename C1, typename C2> +container_algorithm_internal::ContainerIter<C2> c_swap_ranges(C1& c1, C2& c2) { + return std::swap_ranges(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2)); +} + +// c_transform() +// +// Container-based version of the <algorithm> `std::transform()` function to +// transform a container's elements using the unary operation, storing the +// result in an iterator pointing to the last transformed element in the output +// range. +template <typename InputSequence, typename OutputIterator, typename UnaryOp> +OutputIterator c_transform(const InputSequence& input, OutputIterator output, + UnaryOp&& unary_op) { + return std::transform(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), output, + std::forward<UnaryOp>(unary_op)); +} + +// Overload of c_transform() for performing a transformation using a binary +// predicate. +template <typename InputSequence1, typename InputSequence2, + typename OutputIterator, typename BinaryOp> +OutputIterator c_transform(const InputSequence1& input1, + const InputSequence2& input2, OutputIterator output, + BinaryOp&& binary_op) { + return std::transform(container_algorithm_internal::c_begin(input1), + container_algorithm_internal::c_end(input1), + container_algorithm_internal::c_begin(input2), output, + std::forward<BinaryOp>(binary_op)); +} + +// c_replace() +// +// Container-based version of the <algorithm> `std::replace()` function to +// replace a container's elements of some value with a new value. The container +// is modified in place. +template <typename Sequence, typename T> +void c_replace(Sequence& sequence, const T& old_value, const T& new_value) { + std::replace(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), old_value, + new_value); +} + +// c_replace_if() +// +// Container-based version of the <algorithm> `std::replace_if()` function to +// replace a container's elements of some value with a new value based on some +// condition. The container is modified in place. +template <typename C, typename Pred, typename T> +void c_replace_if(C& c, Pred&& pred, T&& new_value) { + std::replace_if(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred), std::forward<T>(new_value)); +} + +// c_replace_copy() +// +// Container-based version of the <algorithm> `std::replace_copy()` function to +// replace a container's elements of some value with a new value and return the +// results within an iterator. +template <typename C, typename OutputIterator, typename T> +OutputIterator c_replace_copy(const C& c, OutputIterator result, T&& old_value, + T&& new_value) { + return std::replace_copy(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), result, + std::forward<T>(old_value), + std::forward<T>(new_value)); +} + +// c_replace_copy_if() +// +// Container-based version of the <algorithm> `std::replace_copy_if()` function +// to replace a container's elements of some value with a new value based on +// some condition, and return the results within an iterator. +template <typename C, typename OutputIterator, typename Pred, typename T> +OutputIterator c_replace_copy_if(const C& c, OutputIterator result, Pred&& pred, + T&& new_value) { + return std::replace_copy_if(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), result, + std::forward<Pred>(pred), + std::forward<T>(new_value)); +} + +// c_fill() +// +// Container-based version of the <algorithm> `std::fill()` function to fill a +// container with some value. +template <typename C, typename T> +void c_fill(C& c, T&& value) { + std::fill(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), std::forward<T>(value)); +} + +// c_fill_n() +// +// Container-based version of the <algorithm> `std::fill_n()` function to fill +// the first N elements in a container with some value. +template <typename C, typename Size, typename T> +void c_fill_n(C& c, Size n, T&& value) { + std::fill_n(container_algorithm_internal::c_begin(c), n, + std::forward<T>(value)); +} + +// c_generate() +// +// Container-based version of the <algorithm> `std::generate()` function to +// assign a container's elements to the values provided by the given generator. +template <typename C, typename Generator> +void c_generate(C& c, Generator&& gen) { + std::generate(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Generator>(gen)); +} + +// c_generate_n() +// +// Container-based version of the <algorithm> `std::generate_n()` function to +// assign a container's first N elements to the values provided by the given +// generator. +template <typename C, typename Size, typename Generator> +container_algorithm_internal::ContainerIter<C> c_generate_n(C& c, Size n, + Generator&& gen) { + return std::generate_n(container_algorithm_internal::c_begin(c), n, + std::forward<Generator>(gen)); +} + +// Note: `c_xx()` <algorithm> container versions for `remove()`, `remove_if()`, +// and `unique()` are omitted, because it's not clear whether or not such +// functions should call erase on their supplied sequences afterwards. Either +// behavior would be surprising for a different set of users. + +// c_remove_copy() +// +// Container-based version of the <algorithm> `std::remove_copy()` function to +// copy a container's elements while removing any elements matching the given +// `value`. +template <typename C, typename OutputIterator, typename T> +OutputIterator c_remove_copy(const C& c, OutputIterator result, T&& value) { + return std::remove_copy(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), result, + std::forward<T>(value)); +} + +// c_remove_copy_if() +// +// Container-based version of the <algorithm> `std::remove_copy_if()` function +// to copy a container's elements while removing any elements matching the given +// condition. +template <typename C, typename OutputIterator, typename Pred> +OutputIterator c_remove_copy_if(const C& c, OutputIterator result, + Pred&& pred) { + return std::remove_copy_if(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), result, + std::forward<Pred>(pred)); +} + +// c_unique_copy() +// +// Container-based version of the <algorithm> `std::unique_copy()` function to +// copy a container's elements while removing any elements containing duplicate +// values. +template <typename C, typename OutputIterator> +OutputIterator c_unique_copy(const C& c, OutputIterator result) { + return std::unique_copy(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), result); +} + +// Overload of c_unique_copy() for using a predicate evaluation other than +// `==` for comparing uniqueness of the element values. +template <typename C, typename OutputIterator, typename BinaryPredicate> +OutputIterator c_unique_copy(const C& c, OutputIterator result, + BinaryPredicate&& pred) { + return std::unique_copy(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), result, + std::forward<BinaryPredicate>(pred)); +} + +// c_reverse() +// +// Container-based version of the <algorithm> `std::reverse()` function to +// reverse a container's elements. +template <typename Sequence> +void c_reverse(Sequence& sequence) { + std::reverse(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// c_reverse_copy() +// +// Container-based version of the <algorithm> `std::reverse()` function to +// reverse a container's elements and write them to an iterator range. +template <typename C, typename OutputIterator> +OutputIterator c_reverse_copy(const C& sequence, OutputIterator result) { + return std::reverse_copy(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + result); +} + +// c_rotate() +// +// Container-based version of the <algorithm> `std::rotate()` function to +// shift a container's elements leftward such that the `middle` element becomes +// the first element in the container. +template <typename C, + typename Iterator = container_algorithm_internal::ContainerIter<C>> +Iterator c_rotate(C& sequence, Iterator middle) { + return absl::rotate(container_algorithm_internal::c_begin(sequence), middle, + container_algorithm_internal::c_end(sequence)); +} + +// c_rotate_copy() +// +// Container-based version of the <algorithm> `std::rotate_copy()` function to +// shift a container's elements leftward such that the `middle` element becomes +// the first element in a new iterator range. +template <typename C, typename OutputIterator> +OutputIterator c_rotate_copy( + const C& sequence, + container_algorithm_internal::ContainerIter<const C> middle, + OutputIterator result) { + return std::rotate_copy(container_algorithm_internal::c_begin(sequence), + middle, container_algorithm_internal::c_end(sequence), + result); +} + +// c_shuffle() +// +// Container-based version of the <algorithm> `std::shuffle()` function to +// randomly shuffle elements within the container using a `gen()` uniform random +// number generator. +template <typename RandomAccessContainer, typename UniformRandomBitGenerator> +void c_shuffle(RandomAccessContainer& c, UniformRandomBitGenerator&& gen) { + std::shuffle(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<UniformRandomBitGenerator>(gen)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Partition functions +//------------------------------------------------------------------------------ + +// c_is_partitioned() +// +// Container-based version of the <algorithm> `std::is_partitioned()` function +// to test whether all elements in the container for which `pred` returns `true` +// precede those for which `pred` is `false`. +template <typename C, typename Pred> +bool c_is_partitioned(const C& c, Pred&& pred) { + return std::is_partitioned(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_partition() +// +// Container-based version of the <algorithm> `std::partition()` function +// to rearrange all elements in a container in such a way that all elements for +// which `pred` returns `true` precede all those for which it returns `false`, +// returning an iterator to the first element of the second group. +template <typename C, typename Pred> +container_algorithm_internal::ContainerIter<C> c_partition(C& c, Pred&& pred) { + return std::partition(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_stable_partition() +// +// Container-based version of the <algorithm> `std::stable_partition()` function +// to rearrange all elements in a container in such a way that all elements for +// which `pred` returns `true` precede all those for which it returns `false`, +// preserving the relative ordering between the two groups. The function returns +// an iterator to the first element of the second group. +template <typename C, typename Pred> +container_algorithm_internal::ContainerIter<C> c_stable_partition(C& c, + Pred&& pred) { + return std::stable_partition(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +// c_partition_copy() +// +// Container-based version of the <algorithm> `std::partition_copy()` function +// to partition a container's elements and return them into two iterators: one +// for which `pred` returns `true`, and one for which `pred` returns `false.` + +template <typename C, typename OutputIterator1, typename OutputIterator2, + typename Pred> +std::pair<OutputIterator1, OutputIterator2> c_partition_copy( + const C& c, OutputIterator1 out_true, OutputIterator2 out_false, + Pred&& pred) { + return std::partition_copy(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), out_true, + out_false, std::forward<Pred>(pred)); +} + +// c_partition_point() +// +// Container-based version of the <algorithm> `std::partition_point()` function +// to return the first element of an already partitioned container for which +// the given `pred` is not `true`. +template <typename C, typename Pred> +container_algorithm_internal::ContainerIter<C> c_partition_point(C& c, + Pred&& pred) { + return std::partition_point(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Pred>(pred)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Sorting functions +//------------------------------------------------------------------------------ + +// c_sort() +// +// Container-based version of the <algorithm> `std::sort()` function +// to sort elements in ascending order of their values. +template <typename C> +void c_sort(C& c) { + std::sort(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// Overload of c_sort() for performing a `comp` comparison other than the +// default `operator<`. +template <typename C, typename Compare> +void c_sort(C& c, Compare&& comp) { + std::sort(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +// c_stable_sort() +// +// Container-based version of the <algorithm> `std::stable_sort()` function +// to sort elements in ascending order of their values, preserving the order +// of equivalents. +template <typename C> +void c_stable_sort(C& c) { + std::stable_sort(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// Overload of c_stable_sort() for performing a `comp` comparison other than the +// default `operator<`. +template <typename C, typename Compare> +void c_stable_sort(C& c, Compare&& comp) { + std::stable_sort(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +// c_is_sorted() +// +// Container-based version of the <algorithm> `std::is_sorted()` function +// to evaluate whether the given container is sorted in ascending order. +template <typename C> +bool c_is_sorted(const C& c) { + return std::is_sorted(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// c_is_sorted() overload for performing a `comp` comparison other than the +// default `operator<`. +template <typename C, typename Compare> +bool c_is_sorted(const C& c, Compare&& comp) { + return std::is_sorted(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +// c_partial_sort() +// +// Container-based version of the <algorithm> `std::partial_sort()` function +// to rearrange elements within a container such that elements before `middle` +// are sorted in ascending order. +template <typename RandomAccessContainer> +void c_partial_sort( + RandomAccessContainer& sequence, + container_algorithm_internal::ContainerIter<RandomAccessContainer> middle) { + std::partial_sort(container_algorithm_internal::c_begin(sequence), middle, + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_partial_sort() for performing a `comp` comparison other than +// the default `operator<`. +template <typename RandomAccessContainer, typename Compare> +void c_partial_sort( + RandomAccessContainer& sequence, + container_algorithm_internal::ContainerIter<RandomAccessContainer> middle, + Compare&& comp) { + std::partial_sort(container_algorithm_internal::c_begin(sequence), middle, + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_partial_sort_copy() +// +// Container-based version of the <algorithm> `std::partial_sort_copy()` +// function to sort elements within a container such that elements before +// `middle` are sorted in ascending order, and return the result within an +// iterator. +template <typename C, typename RandomAccessContainer> +container_algorithm_internal::ContainerIter<RandomAccessContainer> +c_partial_sort_copy(const C& sequence, RandomAccessContainer& result) { + return std::partial_sort_copy(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + container_algorithm_internal::c_begin(result), + container_algorithm_internal::c_end(result)); +} + +// Overload of c_partial_sort_copy() for performing a `comp` comparison other +// than the default `operator<`. +template <typename C, typename RandomAccessContainer, typename Compare> +container_algorithm_internal::ContainerIter<RandomAccessContainer> +c_partial_sort_copy(const C& sequence, RandomAccessContainer& result, + Compare&& comp) { + return std::partial_sort_copy(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + container_algorithm_internal::c_begin(result), + container_algorithm_internal::c_end(result), + std::forward<Compare>(comp)); +} + +// c_is_sorted_until() +// +// Container-based version of the <algorithm> `std::is_sorted_until()` function +// to return the first element within a container that is not sorted in +// ascending order as an iterator. +template <typename C> +container_algorithm_internal::ContainerIter<C> c_is_sorted_until(C& c) { + return std::is_sorted_until(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// Overload of c_is_sorted_until() for performing a `comp` comparison other than +// the default `operator<`. +template <typename C, typename Compare> +container_algorithm_internal::ContainerIter<C> c_is_sorted_until( + C& c, Compare&& comp) { + return std::is_sorted_until(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +// c_nth_element() +// +// Container-based version of the <algorithm> `std::nth_element()` function +// to rearrange the elements within a container such that the `nth` element +// would be in that position in an ordered sequence; other elements may be in +// any order, except that all preceding `nth` will be less than that element, +// and all following `nth` will be greater than that element. +template <typename RandomAccessContainer> +void c_nth_element( + RandomAccessContainer& sequence, + container_algorithm_internal::ContainerIter<RandomAccessContainer> nth) { + std::nth_element(container_algorithm_internal::c_begin(sequence), nth, + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_nth_element() for performing a `comp` comparison other than +// the default `operator<`. +template <typename RandomAccessContainer, typename Compare> +void c_nth_element( + RandomAccessContainer& sequence, + container_algorithm_internal::ContainerIter<RandomAccessContainer> nth, + Compare&& comp) { + std::nth_element(container_algorithm_internal::c_begin(sequence), nth, + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Binary Search +//------------------------------------------------------------------------------ + +// c_lower_bound() +// +// Container-based version of the <algorithm> `std::lower_bound()` function +// to return an iterator pointing to the first element in a sorted container +// which does not compare less than `value`. +template <typename Sequence, typename T> +container_algorithm_internal::ContainerIter<Sequence> c_lower_bound( + Sequence& sequence, T&& value) { + return std::lower_bound(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value)); +} + +// Overload of c_lower_bound() for performing a `comp` comparison other than +// the default `operator<`. +template <typename Sequence, typename T, typename Compare> +container_algorithm_internal::ContainerIter<Sequence> c_lower_bound( + Sequence& sequence, T&& value, Compare&& comp) { + return std::lower_bound(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value), std::forward<Compare>(comp)); +} + +// c_upper_bound() +// +// Container-based version of the <algorithm> `std::upper_bound()` function +// to return an iterator pointing to the first element in a sorted container +// which is greater than `value`. +template <typename Sequence, typename T> +container_algorithm_internal::ContainerIter<Sequence> c_upper_bound( + Sequence& sequence, T&& value) { + return std::upper_bound(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value)); +} + +// Overload of c_upper_bound() for performing a `comp` comparison other than +// the default `operator<`. +template <typename Sequence, typename T, typename Compare> +container_algorithm_internal::ContainerIter<Sequence> c_upper_bound( + Sequence& sequence, T&& value, Compare&& comp) { + return std::upper_bound(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value), std::forward<Compare>(comp)); +} + +// c_equal_range() +// +// Container-based version of the <algorithm> `std::equal_range()` function +// to return an iterator pair pointing to the first and last elements in a +// sorted container which compare equal to `value`. +template <typename Sequence, typename T> +container_algorithm_internal::ContainerIterPairType<Sequence, Sequence> +c_equal_range(Sequence& sequence, T&& value) { + return std::equal_range(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value)); +} + +// Overload of c_equal_range() for performing a `comp` comparison other than +// the default `operator<`. +template <typename Sequence, typename T, typename Compare> +container_algorithm_internal::ContainerIterPairType<Sequence, Sequence> +c_equal_range(Sequence& sequence, T&& value, Compare&& comp) { + return std::equal_range(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value), std::forward<Compare>(comp)); +} + +// c_binary_search() +// +// Container-based version of the <algorithm> `std::binary_search()` function +// to test if any element in the sorted container contains a value equivalent to +// 'value'. +template <typename Sequence, typename T> +bool c_binary_search(Sequence&& sequence, T&& value) { + return std::binary_search(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value)); +} + +// Overload of c_binary_search() for performing a `comp` comparison other than +// the default `operator<`. +template <typename Sequence, typename T, typename Compare> +bool c_binary_search(Sequence&& sequence, T&& value, Compare&& comp) { + return std::binary_search(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value), + std::forward<Compare>(comp)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Merge functions +//------------------------------------------------------------------------------ + +// c_merge() +// +// Container-based version of the <algorithm> `std::merge()` function +// to merge two sorted containers into a single sorted iterator. +template <typename C1, typename C2, typename OutputIterator> +OutputIterator c_merge(const C1& c1, const C2& c2, OutputIterator result) { + return std::merge(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), result); +} + +// Overload of c_merge() for performing a `comp` comparison other than +// the default `operator<`. +template <typename C1, typename C2, typename OutputIterator, typename Compare> +OutputIterator c_merge(const C1& c1, const C2& c2, OutputIterator result, + Compare&& comp) { + return std::merge(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), result, + std::forward<Compare>(comp)); +} + +// c_inplace_merge() +// +// Container-based version of the <algorithm> `std::inplace_merge()` function +// to merge a supplied iterator `middle` into a container. +template <typename C> +void c_inplace_merge(C& c, + container_algorithm_internal::ContainerIter<C> middle) { + std::inplace_merge(container_algorithm_internal::c_begin(c), middle, + container_algorithm_internal::c_end(c)); +} + +// Overload of c_inplace_merge() for performing a merge using a `comp` other +// than `operator<`. +template <typename C, typename Compare> +void c_inplace_merge(C& c, + container_algorithm_internal::ContainerIter<C> middle, + Compare&& comp) { + std::inplace_merge(container_algorithm_internal::c_begin(c), middle, + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +// c_includes() +// +// Container-based version of the <algorithm> `std::includes()` function +// to test whether a sorted container `c1` entirely contains another sorted +// container `c2`. +template <typename C1, typename C2> +bool c_includes(const C1& c1, const C2& c2) { + return std::includes(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2)); +} + +// Overload of c_includes() for performing a merge using a `comp` other than +// `operator<`. +template <typename C1, typename C2, typename Compare> +bool c_includes(const C1& c1, const C2& c2, Compare&& comp) { + return std::includes(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), + std::forward<Compare>(comp)); +} + +// c_set_union() +// +// Container-based version of the <algorithm> `std::set_union()` function +// to return an iterator containing the union of two containers; duplicate +// values are not copied into the output. +template <typename C1, typename C2, typename OutputIterator, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_union(const C1& c1, const C2& c2, OutputIterator output) { + return std::set_union(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output); +} + +// Overload of c_set_union() for performing a merge using a `comp` other than +// `operator<`. +template <typename C1, typename C2, typename OutputIterator, typename Compare, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_union(const C1& c1, const C2& c2, OutputIterator output, + Compare&& comp) { + return std::set_union(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output, + std::forward<Compare>(comp)); +} + +// c_set_intersection() +// +// Container-based version of the <algorithm> `std::set_intersection()` function +// to return an iterator containing the intersection of two containers. +template <typename C1, typename C2, typename OutputIterator, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_intersection(const C1& c1, const C2& c2, + OutputIterator output) { + return std::set_intersection(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output); +} + +// Overload of c_set_intersection() for performing a merge using a `comp` other +// than `operator<`. +template <typename C1, typename C2, typename OutputIterator, typename Compare, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_intersection(const C1& c1, const C2& c2, + OutputIterator output, Compare&& comp) { + return std::set_intersection(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output, + std::forward<Compare>(comp)); +} + +// c_set_difference() +// +// Container-based version of the <algorithm> `std::set_difference()` function +// to return an iterator containing elements present in the first container but +// not in the second. +template <typename C1, typename C2, typename OutputIterator, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_difference(const C1& c1, const C2& c2, + OutputIterator output) { + return std::set_difference(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output); +} + +// Overload of c_set_difference() for performing a merge using a `comp` other +// than `operator<`. +template <typename C1, typename C2, typename OutputIterator, typename Compare, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_difference(const C1& c1, const C2& c2, + OutputIterator output, Compare&& comp) { + return std::set_difference(container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output, + std::forward<Compare>(comp)); +} + +// c_set_symmetric_difference() +// +// Container-based version of the <algorithm> `std::set_symmetric_difference()` +// function to return an iterator containing elements present in either one +// container or the other, but not both. +template <typename C1, typename C2, typename OutputIterator, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_symmetric_difference(const C1& c1, const C2& c2, + OutputIterator output) { + return std::set_symmetric_difference( + container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output); +} + +// Overload of c_set_symmetric_difference() for performing a merge using a +// `comp` other than `operator<`. +template <typename C1, typename C2, typename OutputIterator, typename Compare, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C1>::value, + void>::type, + typename = typename std::enable_if< + !container_algorithm_internal::IsUnorderedContainer<C2>::value, + void>::type> +OutputIterator c_set_symmetric_difference(const C1& c1, const C2& c2, + OutputIterator output, + Compare&& comp) { + return std::set_symmetric_difference( + container_algorithm_internal::c_begin(c1), + container_algorithm_internal::c_end(c1), + container_algorithm_internal::c_begin(c2), + container_algorithm_internal::c_end(c2), output, + std::forward<Compare>(comp)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Heap functions +//------------------------------------------------------------------------------ + +// c_push_heap() +// +// Container-based version of the <algorithm> `std::push_heap()` function +// to push a value onto a container heap. +template <typename RandomAccessContainer> +void c_push_heap(RandomAccessContainer& sequence) { + std::push_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_push_heap() for performing a push operation on a heap using a +// `comp` other than `operator<`. +template <typename RandomAccessContainer, typename Compare> +void c_push_heap(RandomAccessContainer& sequence, Compare&& comp) { + std::push_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_pop_heap() +// +// Container-based version of the <algorithm> `std::pop_heap()` function +// to pop a value from a heap container. +template <typename RandomAccessContainer> +void c_pop_heap(RandomAccessContainer& sequence) { + std::pop_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_pop_heap() for performing a pop operation on a heap using a +// `comp` other than `operator<`. +template <typename RandomAccessContainer, typename Compare> +void c_pop_heap(RandomAccessContainer& sequence, Compare&& comp) { + std::pop_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_make_heap() +// +// Container-based version of the <algorithm> `std::make_heap()` function +// to make a container a heap. +template <typename RandomAccessContainer> +void c_make_heap(RandomAccessContainer& sequence) { + std::make_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_make_heap() for performing heap comparisons using a +// `comp` other than `operator<` +template <typename RandomAccessContainer, typename Compare> +void c_make_heap(RandomAccessContainer& sequence, Compare&& comp) { + std::make_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_sort_heap() +// +// Container-based version of the <algorithm> `std::sort_heap()` function +// to sort a heap into ascending order (after which it is no longer a heap). +template <typename RandomAccessContainer> +void c_sort_heap(RandomAccessContainer& sequence) { + std::sort_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_sort_heap() for performing heap comparisons using a +// `comp` other than `operator<` +template <typename RandomAccessContainer, typename Compare> +void c_sort_heap(RandomAccessContainer& sequence, Compare&& comp) { + std::sort_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_is_heap() +// +// Container-based version of the <algorithm> `std::is_heap()` function +// to check whether the given container is a heap. +template <typename RandomAccessContainer> +bool c_is_heap(const RandomAccessContainer& sequence) { + return std::is_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_is_heap() for performing heap comparisons using a +// `comp` other than `operator<` +template <typename RandomAccessContainer, typename Compare> +bool c_is_heap(const RandomAccessContainer& sequence, Compare&& comp) { + return std::is_heap(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_is_heap_until() +// +// Container-based version of the <algorithm> `std::is_heap_until()` function +// to find the first element in a given container which is not in heap order. +template <typename RandomAccessContainer> +container_algorithm_internal::ContainerIter<RandomAccessContainer> +c_is_heap_until(RandomAccessContainer& sequence) { + return std::is_heap_until(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_is_heap_until() for performing heap comparisons using a +// `comp` other than `operator<` +template <typename RandomAccessContainer, typename Compare> +container_algorithm_internal::ContainerIter<RandomAccessContainer> +c_is_heap_until(RandomAccessContainer& sequence, Compare&& comp) { + return std::is_heap_until(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Min/max +//------------------------------------------------------------------------------ + +// c_min_element() +// +// Container-based version of the <algorithm> `std::min_element()` function +// to return an iterator pointing to the element with the smallest value, using +// `operator<` to make the comparisons. +template <typename Sequence> +container_algorithm_internal::ContainerIter<Sequence> c_min_element( + Sequence& sequence) { + return std::min_element(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_min_element() for performing a `comp` comparison other than +// `operator<`. +template <typename Sequence, typename Compare> +container_algorithm_internal::ContainerIter<Sequence> c_min_element( + Sequence& sequence, Compare&& comp) { + return std::min_element(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_max_element() +// +// Container-based version of the <algorithm> `std::max_element()` function +// to return an iterator pointing to the element with the largest value, using +// `operator<` to make the comparisons. +template <typename Sequence> +container_algorithm_internal::ContainerIter<Sequence> c_max_element( + Sequence& sequence) { + return std::max_element(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence)); +} + +// Overload of c_max_element() for performing a `comp` comparison other than +// `operator<`. +template <typename Sequence, typename Compare> +container_algorithm_internal::ContainerIter<Sequence> c_max_element( + Sequence& sequence, Compare&& comp) { + return std::max_element(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<Compare>(comp)); +} + +// c_minmax_element() +// +// Container-based version of the <algorithm> `std::minmax_element()` function +// to return a pair of iterators pointing to the elements containing the +// smallest and largest values, respectively, using `operator<` to make the +// comparisons. +template <typename C> +container_algorithm_internal::ContainerIterPairType<C, C> +c_minmax_element(C& c) { + return std::minmax_element(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// Overload of c_minmax_element() for performing `comp` comparisons other than +// `operator<`. +template <typename C, typename Compare> +container_algorithm_internal::ContainerIterPairType<C, C> +c_minmax_element(C& c, Compare&& comp) { + return std::minmax_element(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +//------------------------------------------------------------------------------ +// <algorithm> Lexicographical Comparisons +//------------------------------------------------------------------------------ + +// c_lexicographical_compare() +// +// Container-based version of the <algorithm> `std::lexicographical_compare()` +// function to lexicographically compare (e.g. sort words alphabetically) two +// container sequences. The comparison is performed using `operator<`. Note +// that capital letters ("A-Z") have ASCII values less than lowercase letters +// ("a-z"). +template <typename Sequence1, typename Sequence2> +bool c_lexicographical_compare(Sequence1&& sequence1, Sequence2&& sequence2) { + return std::lexicographical_compare( + container_algorithm_internal::c_begin(sequence1), + container_algorithm_internal::c_end(sequence1), + container_algorithm_internal::c_begin(sequence2), + container_algorithm_internal::c_end(sequence2)); +} + +// Overload of c_lexicographical_compare() for performing a lexicographical +// comparison using a `comp` operator instead of `operator<`. +template <typename Sequence1, typename Sequence2, typename Compare> +bool c_lexicographical_compare(Sequence1&& sequence1, Sequence2&& sequence2, + Compare&& comp) { + return std::lexicographical_compare( + container_algorithm_internal::c_begin(sequence1), + container_algorithm_internal::c_end(sequence1), + container_algorithm_internal::c_begin(sequence2), + container_algorithm_internal::c_end(sequence2), + std::forward<Compare>(comp)); +} + +// c_next_permutation() +// +// Container-based version of the <algorithm> `std::next_permutation()` function +// to rearrange a container's elements into the next lexicographically greater +// permutation. +template <typename C> +bool c_next_permutation(C& c) { + return std::next_permutation(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// Overload of c_next_permutation() for performing a lexicographical +// comparison using a `comp` operator instead of `operator<`. +template <typename C, typename Compare> +bool c_next_permutation(C& c, Compare&& comp) { + return std::next_permutation(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +// c_prev_permutation() +// +// Container-based version of the <algorithm> `std::prev_permutation()` function +// to rearrange a container's elements into the next lexicographically lesser +// permutation. +template <typename C> +bool c_prev_permutation(C& c) { + return std::prev_permutation(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c)); +} + +// Overload of c_prev_permutation() for performing a lexicographical +// comparison using a `comp` operator instead of `operator<`. +template <typename C, typename Compare> +bool c_prev_permutation(C& c, Compare&& comp) { + return std::prev_permutation(container_algorithm_internal::c_begin(c), + container_algorithm_internal::c_end(c), + std::forward<Compare>(comp)); +} + +//------------------------------------------------------------------------------ +// <numeric> algorithms +//------------------------------------------------------------------------------ + +// c_iota() +// +// Container-based version of the <algorithm> `std::iota()` function +// to compute successive values of `value`, as if incremented with `++value` +// after each element is written. and write them to the container. +template <typename Sequence, typename T> +void c_iota(Sequence& sequence, T&& value) { + std::iota(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(value)); +} +// c_accumulate() +// +// Container-based version of the <algorithm> `std::accumulate()` function +// to accumulate the element values of a container to `init` and return that +// accumulation by value. +// +// Note: Due to a language technicality this function has return type +// absl::decay_t<T>. As a user of this function you can casually read +// this as "returns T by value" and assume it does the right thing. +template <typename Sequence, typename T> +decay_t<T> c_accumulate(const Sequence& sequence, T&& init) { + return std::accumulate(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(init)); +} + +// Overload of c_accumulate() for using a binary operations other than +// addition for computing the accumulation. +template <typename Sequence, typename T, typename BinaryOp> +decay_t<T> c_accumulate(const Sequence& sequence, T&& init, + BinaryOp&& binary_op) { + return std::accumulate(container_algorithm_internal::c_begin(sequence), + container_algorithm_internal::c_end(sequence), + std::forward<T>(init), + std::forward<BinaryOp>(binary_op)); +} + +// c_inner_product() +// +// Container-based version of the <algorithm> `std::inner_product()` function +// to compute the cumulative inner product of container element pairs. +// +// Note: Due to a language technicality this function has return type +// absl::decay_t<T>. As a user of this function you can casually read +// this as "returns T by value" and assume it does the right thing. +template <typename Sequence1, typename Sequence2, typename T> +decay_t<T> c_inner_product(const Sequence1& factors1, const Sequence2& factors2, + T&& sum) { + return std::inner_product(container_algorithm_internal::c_begin(factors1), + container_algorithm_internal::c_end(factors1), + container_algorithm_internal::c_begin(factors2), + std::forward<T>(sum)); +} + +// Overload of c_inner_product() for using binary operations other than +// `operator+` (for computing the accumulation) and `operator*` (for computing +// the product between the two container's element pair). +template <typename Sequence1, typename Sequence2, typename T, + typename BinaryOp1, typename BinaryOp2> +decay_t<T> c_inner_product(const Sequence1& factors1, const Sequence2& factors2, + T&& sum, BinaryOp1&& op1, BinaryOp2&& op2) { + return std::inner_product(container_algorithm_internal::c_begin(factors1), + container_algorithm_internal::c_end(factors1), + container_algorithm_internal::c_begin(factors2), + std::forward<T>(sum), std::forward<BinaryOp1>(op1), + std::forward<BinaryOp2>(op2)); +} + +// c_adjacent_difference() +// +// Container-based version of the <algorithm> `std::adjacent_difference()` +// function to compute the difference between each element and the one preceding +// it and write it to an iterator. +template <typename InputSequence, typename OutputIt> +OutputIt c_adjacent_difference(const InputSequence& input, + OutputIt output_first) { + return std::adjacent_difference(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), + output_first); +} + +// Overload of c_adjacent_difference() for using a binary operation other than +// subtraction to compute the adjacent difference. +template <typename InputSequence, typename OutputIt, typename BinaryOp> +OutputIt c_adjacent_difference(const InputSequence& input, + OutputIt output_first, BinaryOp&& op) { + return std::adjacent_difference(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), + output_first, std::forward<BinaryOp>(op)); +} + +// c_partial_sum() +// +// Container-based version of the <algorithm> `std::partial_sum()` function +// to compute the partial sum of the elements in a sequence and write them +// to an iterator. The partial sum is the sum of all element values so far in +// the sequence. +template <typename InputSequence, typename OutputIt> +OutputIt c_partial_sum(const InputSequence& input, OutputIt output_first) { + return std::partial_sum(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), + output_first); +} + +// Overload of c_partial_sum() for using a binary operation other than addition +// to compute the "partial sum". +template <typename InputSequence, typename OutputIt, typename BinaryOp> +OutputIt c_partial_sum(const InputSequence& input, OutputIt output_first, + BinaryOp&& op) { + return std::partial_sum(container_algorithm_internal::c_begin(input), + container_algorithm_internal::c_end(input), + output_first, std::forward<BinaryOp>(op)); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_ALGORITHM_CONTAINER_H_ diff --git a/third_party/abseil_cpp/absl/algorithm/container_test.cc b/third_party/abseil_cpp/absl/algorithm/container_test.cc new file mode 100644 index 0000000000..0a4abe9462 --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/container_test.cc @@ -0,0 +1,1031 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/algorithm/container.h" + +#include <functional> +#include <initializer_list> +#include <iterator> +#include <list> +#include <memory> +#include <ostream> +#include <random> +#include <set> +#include <unordered_set> +#include <utility> +#include <valarray> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/casts.h" +#include "absl/base/macros.h" +#include "absl/memory/memory.h" +#include "absl/types/span.h" + +namespace { + +using ::testing::Each; +using ::testing::ElementsAre; +using ::testing::Gt; +using ::testing::IsNull; +using ::testing::Lt; +using ::testing::Pointee; +using ::testing::Truly; +using ::testing::UnorderedElementsAre; + +// Most of these tests just check that the code compiles, not that it +// does the right thing. That's fine since the functions just forward +// to the STL implementation. +class NonMutatingTest : public testing::Test { + protected: + std::unordered_set<int> container_ = {1, 2, 3}; + std::list<int> sequence_ = {1, 2, 3}; + std::vector<int> vector_ = {1, 2, 3}; + int array_[3] = {1, 2, 3}; +}; + +struct AccumulateCalls { + void operator()(int value) { + calls.push_back(value); + } + std::vector<int> calls; +}; + +bool Predicate(int value) { return value < 3; } +bool BinPredicate(int v1, int v2) { return v1 < v2; } +bool Equals(int v1, int v2) { return v1 == v2; } +bool IsOdd(int x) { return x % 2 != 0; } + + +TEST_F(NonMutatingTest, Distance) { + EXPECT_EQ(container_.size(), absl::c_distance(container_)); + EXPECT_EQ(sequence_.size(), absl::c_distance(sequence_)); + EXPECT_EQ(vector_.size(), absl::c_distance(vector_)); + EXPECT_EQ(ABSL_ARRAYSIZE(array_), absl::c_distance(array_)); + + // Works with a temporary argument. + EXPECT_EQ(vector_.size(), absl::c_distance(std::vector<int>(vector_))); +} + +TEST_F(NonMutatingTest, Distance_OverloadedBeginEnd) { + // Works with classes which have custom ADL-selected overloads of std::begin + // and std::end. + std::initializer_list<int> a = {1, 2, 3}; + std::valarray<int> b = {1, 2, 3}; + EXPECT_EQ(3, absl::c_distance(a)); + EXPECT_EQ(3, absl::c_distance(b)); + + // It is assumed that other c_* functions use the same mechanism for + // ADL-selecting begin/end overloads. +} + +TEST_F(NonMutatingTest, ForEach) { + AccumulateCalls c = absl::c_for_each(container_, AccumulateCalls()); + // Don't rely on the unordered_set's order. + std::sort(c.calls.begin(), c.calls.end()); + EXPECT_EQ(vector_, c.calls); + + // Works with temporary container, too. + AccumulateCalls c2 = + absl::c_for_each(std::unordered_set<int>(container_), AccumulateCalls()); + std::sort(c2.calls.begin(), c2.calls.end()); + EXPECT_EQ(vector_, c2.calls); +} + +TEST_F(NonMutatingTest, FindReturnsCorrectType) { + auto it = absl::c_find(container_, 3); + EXPECT_EQ(3, *it); + absl::c_find(absl::implicit_cast<const std::list<int>&>(sequence_), 3); +} + +TEST_F(NonMutatingTest, FindIf) { absl::c_find_if(container_, Predicate); } + +TEST_F(NonMutatingTest, FindIfNot) { + absl::c_find_if_not(container_, Predicate); +} + +TEST_F(NonMutatingTest, FindEnd) { + absl::c_find_end(sequence_, vector_); + absl::c_find_end(vector_, sequence_); +} + +TEST_F(NonMutatingTest, FindEndWithPredicate) { + absl::c_find_end(sequence_, vector_, BinPredicate); + absl::c_find_end(vector_, sequence_, BinPredicate); +} + +TEST_F(NonMutatingTest, FindFirstOf) { + absl::c_find_first_of(container_, sequence_); + absl::c_find_first_of(sequence_, container_); +} + +TEST_F(NonMutatingTest, FindFirstOfWithPredicate) { + absl::c_find_first_of(container_, sequence_, BinPredicate); + absl::c_find_first_of(sequence_, container_, BinPredicate); +} + +TEST_F(NonMutatingTest, AdjacentFind) { absl::c_adjacent_find(sequence_); } + +TEST_F(NonMutatingTest, AdjacentFindWithPredicate) { + absl::c_adjacent_find(sequence_, BinPredicate); +} + +TEST_F(NonMutatingTest, Count) { EXPECT_EQ(1, absl::c_count(container_, 3)); } + +TEST_F(NonMutatingTest, CountIf) { + EXPECT_EQ(2, absl::c_count_if(container_, Predicate)); + const std::unordered_set<int>& const_container = container_; + EXPECT_EQ(2, absl::c_count_if(const_container, Predicate)); +} + +TEST_F(NonMutatingTest, Mismatch) { + absl::c_mismatch(container_, sequence_); + absl::c_mismatch(sequence_, container_); +} + +TEST_F(NonMutatingTest, MismatchWithPredicate) { + absl::c_mismatch(container_, sequence_, BinPredicate); + absl::c_mismatch(sequence_, container_, BinPredicate); +} + +TEST_F(NonMutatingTest, Equal) { + EXPECT_TRUE(absl::c_equal(vector_, sequence_)); + EXPECT_TRUE(absl::c_equal(sequence_, vector_)); + EXPECT_TRUE(absl::c_equal(sequence_, array_)); + EXPECT_TRUE(absl::c_equal(array_, vector_)); + + // Test that behavior appropriately differs from that of equal(). + std::vector<int> vector_plus = {1, 2, 3}; + vector_plus.push_back(4); + EXPECT_FALSE(absl::c_equal(vector_plus, sequence_)); + EXPECT_FALSE(absl::c_equal(sequence_, vector_plus)); + EXPECT_FALSE(absl::c_equal(array_, vector_plus)); +} + +TEST_F(NonMutatingTest, EqualWithPredicate) { + EXPECT_TRUE(absl::c_equal(vector_, sequence_, Equals)); + EXPECT_TRUE(absl::c_equal(sequence_, vector_, Equals)); + EXPECT_TRUE(absl::c_equal(array_, sequence_, Equals)); + EXPECT_TRUE(absl::c_equal(vector_, array_, Equals)); + + // Test that behavior appropriately differs from that of equal(). + std::vector<int> vector_plus = {1, 2, 3}; + vector_plus.push_back(4); + EXPECT_FALSE(absl::c_equal(vector_plus, sequence_, Equals)); + EXPECT_FALSE(absl::c_equal(sequence_, vector_plus, Equals)); + EXPECT_FALSE(absl::c_equal(vector_plus, array_, Equals)); +} + +TEST_F(NonMutatingTest, IsPermutation) { + auto vector_permut_ = vector_; + std::next_permutation(vector_permut_.begin(), vector_permut_.end()); + EXPECT_TRUE(absl::c_is_permutation(vector_permut_, sequence_)); + EXPECT_TRUE(absl::c_is_permutation(sequence_, vector_permut_)); + + // Test that behavior appropriately differs from that of is_permutation(). + std::vector<int> vector_plus = {1, 2, 3}; + vector_plus.push_back(4); + EXPECT_FALSE(absl::c_is_permutation(vector_plus, sequence_)); + EXPECT_FALSE(absl::c_is_permutation(sequence_, vector_plus)); +} + +TEST_F(NonMutatingTest, IsPermutationWithPredicate) { + auto vector_permut_ = vector_; + std::next_permutation(vector_permut_.begin(), vector_permut_.end()); + EXPECT_TRUE(absl::c_is_permutation(vector_permut_, sequence_, Equals)); + EXPECT_TRUE(absl::c_is_permutation(sequence_, vector_permut_, Equals)); + + // Test that behavior appropriately differs from that of is_permutation(). + std::vector<int> vector_plus = {1, 2, 3}; + vector_plus.push_back(4); + EXPECT_FALSE(absl::c_is_permutation(vector_plus, sequence_, Equals)); + EXPECT_FALSE(absl::c_is_permutation(sequence_, vector_plus, Equals)); +} + +TEST_F(NonMutatingTest, Search) { + absl::c_search(sequence_, vector_); + absl::c_search(vector_, sequence_); + absl::c_search(array_, sequence_); +} + +TEST_F(NonMutatingTest, SearchWithPredicate) { + absl::c_search(sequence_, vector_, BinPredicate); + absl::c_search(vector_, sequence_, BinPredicate); +} + +TEST_F(NonMutatingTest, SearchN) { absl::c_search_n(sequence_, 3, 1); } + +TEST_F(NonMutatingTest, SearchNWithPredicate) { + absl::c_search_n(sequence_, 3, 1, BinPredicate); +} + +TEST_F(NonMutatingTest, LowerBound) { + std::list<int>::iterator i = absl::c_lower_bound(sequence_, 3); + ASSERT_TRUE(i != sequence_.end()); + EXPECT_EQ(2, std::distance(sequence_.begin(), i)); + EXPECT_EQ(3, *i); +} + +TEST_F(NonMutatingTest, LowerBoundWithPredicate) { + std::vector<int> v(vector_); + std::sort(v.begin(), v.end(), std::greater<int>()); + std::vector<int>::iterator i = absl::c_lower_bound(v, 3, std::greater<int>()); + EXPECT_TRUE(i == v.begin()); + EXPECT_EQ(3, *i); +} + +TEST_F(NonMutatingTest, UpperBound) { + std::list<int>::iterator i = absl::c_upper_bound(sequence_, 1); + ASSERT_TRUE(i != sequence_.end()); + EXPECT_EQ(1, std::distance(sequence_.begin(), i)); + EXPECT_EQ(2, *i); +} + +TEST_F(NonMutatingTest, UpperBoundWithPredicate) { + std::vector<int> v(vector_); + std::sort(v.begin(), v.end(), std::greater<int>()); + std::vector<int>::iterator i = absl::c_upper_bound(v, 1, std::greater<int>()); + EXPECT_EQ(3, i - v.begin()); + EXPECT_TRUE(i == v.end()); +} + +TEST_F(NonMutatingTest, EqualRange) { + std::pair<std::list<int>::iterator, std::list<int>::iterator> p = + absl::c_equal_range(sequence_, 2); + EXPECT_EQ(1, std::distance(sequence_.begin(), p.first)); + EXPECT_EQ(2, std::distance(sequence_.begin(), p.second)); +} + +TEST_F(NonMutatingTest, EqualRangeArray) { + auto p = absl::c_equal_range(array_, 2); + EXPECT_EQ(1, std::distance(std::begin(array_), p.first)); + EXPECT_EQ(2, std::distance(std::begin(array_), p.second)); +} + +TEST_F(NonMutatingTest, EqualRangeWithPredicate) { + std::vector<int> v(vector_); + std::sort(v.begin(), v.end(), std::greater<int>()); + std::pair<std::vector<int>::iterator, std::vector<int>::iterator> p = + absl::c_equal_range(v, 2, std::greater<int>()); + EXPECT_EQ(1, std::distance(v.begin(), p.first)); + EXPECT_EQ(2, std::distance(v.begin(), p.second)); +} + +TEST_F(NonMutatingTest, BinarySearch) { + EXPECT_TRUE(absl::c_binary_search(vector_, 2)); + EXPECT_TRUE(absl::c_binary_search(std::vector<int>(vector_), 2)); +} + +TEST_F(NonMutatingTest, BinarySearchWithPredicate) { + std::vector<int> v(vector_); + std::sort(v.begin(), v.end(), std::greater<int>()); + EXPECT_TRUE(absl::c_binary_search(v, 2, std::greater<int>())); + EXPECT_TRUE( + absl::c_binary_search(std::vector<int>(v), 2, std::greater<int>())); +} + +TEST_F(NonMutatingTest, MinElement) { + std::list<int>::iterator i = absl::c_min_element(sequence_); + ASSERT_TRUE(i != sequence_.end()); + EXPECT_EQ(*i, 1); +} + +TEST_F(NonMutatingTest, MinElementWithPredicate) { + std::list<int>::iterator i = + absl::c_min_element(sequence_, std::greater<int>()); + ASSERT_TRUE(i != sequence_.end()); + EXPECT_EQ(*i, 3); +} + +TEST_F(NonMutatingTest, MaxElement) { + std::list<int>::iterator i = absl::c_max_element(sequence_); + ASSERT_TRUE(i != sequence_.end()); + EXPECT_EQ(*i, 3); +} + +TEST_F(NonMutatingTest, MaxElementWithPredicate) { + std::list<int>::iterator i = + absl::c_max_element(sequence_, std::greater<int>()); + ASSERT_TRUE(i != sequence_.end()); + EXPECT_EQ(*i, 1); +} + +TEST_F(NonMutatingTest, LexicographicalCompare) { + EXPECT_FALSE(absl::c_lexicographical_compare(sequence_, sequence_)); + + std::vector<int> v; + v.push_back(1); + v.push_back(2); + v.push_back(4); + + EXPECT_TRUE(absl::c_lexicographical_compare(sequence_, v)); + EXPECT_TRUE(absl::c_lexicographical_compare(std::list<int>(sequence_), v)); +} + +TEST_F(NonMutatingTest, LexicographicalCopmareWithPredicate) { + EXPECT_FALSE(absl::c_lexicographical_compare(sequence_, sequence_, + std::greater<int>())); + + std::vector<int> v; + v.push_back(1); + v.push_back(2); + v.push_back(4); + + EXPECT_TRUE( + absl::c_lexicographical_compare(v, sequence_, std::greater<int>())); + EXPECT_TRUE(absl::c_lexicographical_compare( + std::vector<int>(v), std::list<int>(sequence_), std::greater<int>())); +} + +TEST_F(NonMutatingTest, Includes) { + std::set<int> s(vector_.begin(), vector_.end()); + s.insert(4); + EXPECT_TRUE(absl::c_includes(s, vector_)); +} + +TEST_F(NonMutatingTest, IncludesWithPredicate) { + std::vector<int> v = {3, 2, 1}; + std::set<int, std::greater<int>> s(v.begin(), v.end()); + s.insert(4); + EXPECT_TRUE(absl::c_includes(s, v, std::greater<int>())); +} + +class NumericMutatingTest : public testing::Test { + protected: + std::list<int> list_ = {1, 2, 3}; + std::vector<int> output_; +}; + +TEST_F(NumericMutatingTest, Iota) { + absl::c_iota(list_, 5); + std::list<int> expected{5, 6, 7}; + EXPECT_EQ(list_, expected); +} + +TEST_F(NonMutatingTest, Accumulate) { + EXPECT_EQ(absl::c_accumulate(sequence_, 4), 1 + 2 + 3 + 4); +} + +TEST_F(NonMutatingTest, AccumulateWithBinaryOp) { + EXPECT_EQ(absl::c_accumulate(sequence_, 4, std::multiplies<int>()), + 1 * 2 * 3 * 4); +} + +TEST_F(NonMutatingTest, AccumulateLvalueInit) { + int lvalue = 4; + EXPECT_EQ(absl::c_accumulate(sequence_, lvalue), 1 + 2 + 3 + 4); +} + +TEST_F(NonMutatingTest, AccumulateWithBinaryOpLvalueInit) { + int lvalue = 4; + EXPECT_EQ(absl::c_accumulate(sequence_, lvalue, std::multiplies<int>()), + 1 * 2 * 3 * 4); +} + +TEST_F(NonMutatingTest, InnerProduct) { + EXPECT_EQ(absl::c_inner_product(sequence_, vector_, 1000), + 1000 + 1 * 1 + 2 * 2 + 3 * 3); +} + +TEST_F(NonMutatingTest, InnerProductWithBinaryOps) { + EXPECT_EQ(absl::c_inner_product(sequence_, vector_, 10, + std::multiplies<int>(), std::plus<int>()), + 10 * (1 + 1) * (2 + 2) * (3 + 3)); +} + +TEST_F(NonMutatingTest, InnerProductLvalueInit) { + int lvalue = 1000; + EXPECT_EQ(absl::c_inner_product(sequence_, vector_, lvalue), + 1000 + 1 * 1 + 2 * 2 + 3 * 3); +} + +TEST_F(NonMutatingTest, InnerProductWithBinaryOpsLvalueInit) { + int lvalue = 10; + EXPECT_EQ(absl::c_inner_product(sequence_, vector_, lvalue, + std::multiplies<int>(), std::plus<int>()), + 10 * (1 + 1) * (2 + 2) * (3 + 3)); +} + +TEST_F(NumericMutatingTest, AdjacentDifference) { + auto last = absl::c_adjacent_difference(list_, std::back_inserter(output_)); + *last = 1000; + std::vector<int> expected{1, 2 - 1, 3 - 2, 1000}; + EXPECT_EQ(output_, expected); +} + +TEST_F(NumericMutatingTest, AdjacentDifferenceWithBinaryOp) { + auto last = absl::c_adjacent_difference(list_, std::back_inserter(output_), + std::multiplies<int>()); + *last = 1000; + std::vector<int> expected{1, 2 * 1, 3 * 2, 1000}; + EXPECT_EQ(output_, expected); +} + +TEST_F(NumericMutatingTest, PartialSum) { + auto last = absl::c_partial_sum(list_, std::back_inserter(output_)); + *last = 1000; + std::vector<int> expected{1, 1 + 2, 1 + 2 + 3, 1000}; + EXPECT_EQ(output_, expected); +} + +TEST_F(NumericMutatingTest, PartialSumWithBinaryOp) { + auto last = absl::c_partial_sum(list_, std::back_inserter(output_), + std::multiplies<int>()); + *last = 1000; + std::vector<int> expected{1, 1 * 2, 1 * 2 * 3, 1000}; + EXPECT_EQ(output_, expected); +} + +TEST_F(NonMutatingTest, LinearSearch) { + EXPECT_TRUE(absl::c_linear_search(container_, 3)); + EXPECT_FALSE(absl::c_linear_search(container_, 4)); +} + +TEST_F(NonMutatingTest, AllOf) { + const std::vector<int>& v = vector_; + EXPECT_FALSE(absl::c_all_of(v, [](int x) { return x > 1; })); + EXPECT_TRUE(absl::c_all_of(v, [](int x) { return x > 0; })); +} + +TEST_F(NonMutatingTest, AnyOf) { + const std::vector<int>& v = vector_; + EXPECT_TRUE(absl::c_any_of(v, [](int x) { return x > 2; })); + EXPECT_FALSE(absl::c_any_of(v, [](int x) { return x > 5; })); +} + +TEST_F(NonMutatingTest, NoneOf) { + const std::vector<int>& v = vector_; + EXPECT_FALSE(absl::c_none_of(v, [](int x) { return x > 2; })); + EXPECT_TRUE(absl::c_none_of(v, [](int x) { return x > 5; })); +} + +TEST_F(NonMutatingTest, MinMaxElementLess) { + std::pair<std::vector<int>::const_iterator, std::vector<int>::const_iterator> + p = absl::c_minmax_element(vector_, std::less<int>()); + EXPECT_TRUE(p.first == vector_.begin()); + EXPECT_TRUE(p.second == vector_.begin() + 2); +} + +TEST_F(NonMutatingTest, MinMaxElementGreater) { + std::pair<std::vector<int>::const_iterator, std::vector<int>::const_iterator> + p = absl::c_minmax_element(vector_, std::greater<int>()); + EXPECT_TRUE(p.first == vector_.begin() + 2); + EXPECT_TRUE(p.second == vector_.begin()); +} + +TEST_F(NonMutatingTest, MinMaxElementNoPredicate) { + std::pair<std::vector<int>::const_iterator, std::vector<int>::const_iterator> + p = absl::c_minmax_element(vector_); + EXPECT_TRUE(p.first == vector_.begin()); + EXPECT_TRUE(p.second == vector_.begin() + 2); +} + +class SortingTest : public testing::Test { + protected: + std::list<int> sorted_ = {1, 2, 3, 4}; + std::list<int> unsorted_ = {2, 4, 1, 3}; + std::list<int> reversed_ = {4, 3, 2, 1}; +}; + +TEST_F(SortingTest, IsSorted) { + EXPECT_TRUE(absl::c_is_sorted(sorted_)); + EXPECT_FALSE(absl::c_is_sorted(unsorted_)); + EXPECT_FALSE(absl::c_is_sorted(reversed_)); +} + +TEST_F(SortingTest, IsSortedWithPredicate) { + EXPECT_FALSE(absl::c_is_sorted(sorted_, std::greater<int>())); + EXPECT_FALSE(absl::c_is_sorted(unsorted_, std::greater<int>())); + EXPECT_TRUE(absl::c_is_sorted(reversed_, std::greater<int>())); +} + +TEST_F(SortingTest, IsSortedUntil) { + EXPECT_EQ(1, *absl::c_is_sorted_until(unsorted_)); + EXPECT_EQ(4, *absl::c_is_sorted_until(unsorted_, std::greater<int>())); +} + +TEST_F(SortingTest, NthElement) { + std::vector<int> unsorted = {2, 4, 1, 3}; + absl::c_nth_element(unsorted, unsorted.begin() + 2); + EXPECT_THAT(unsorted, + ElementsAre(Lt(3), Lt(3), 3, Gt(3))); + absl::c_nth_element(unsorted, unsorted.begin() + 2, std::greater<int>()); + EXPECT_THAT(unsorted, + ElementsAre(Gt(2), Gt(2), 2, Lt(2))); +} + +TEST(MutatingTest, IsPartitioned) { + EXPECT_TRUE( + absl::c_is_partitioned(std::vector<int>{1, 3, 5, 2, 4, 6}, IsOdd)); + EXPECT_FALSE( + absl::c_is_partitioned(std::vector<int>{1, 2, 3, 4, 5, 6}, IsOdd)); + EXPECT_FALSE( + absl::c_is_partitioned(std::vector<int>{2, 4, 6, 1, 3, 5}, IsOdd)); +} + +TEST(MutatingTest, Partition) { + std::vector<int> actual = {1, 2, 3, 4, 5}; + absl::c_partition(actual, IsOdd); + EXPECT_THAT(actual, Truly([](const std::vector<int>& c) { + return absl::c_is_partitioned(c, IsOdd); + })); +} + +TEST(MutatingTest, StablePartition) { + std::vector<int> actual = {1, 2, 3, 4, 5}; + absl::c_stable_partition(actual, IsOdd); + EXPECT_THAT(actual, ElementsAre(1, 3, 5, 2, 4)); +} + +TEST(MutatingTest, PartitionCopy) { + const std::vector<int> initial = {1, 2, 3, 4, 5}; + std::vector<int> odds, evens; + auto ends = absl::c_partition_copy(initial, back_inserter(odds), + back_inserter(evens), IsOdd); + *ends.first = 7; + *ends.second = 6; + EXPECT_THAT(odds, ElementsAre(1, 3, 5, 7)); + EXPECT_THAT(evens, ElementsAre(2, 4, 6)); +} + +TEST(MutatingTest, PartitionPoint) { + const std::vector<int> initial = {1, 3, 5, 2, 4}; + auto middle = absl::c_partition_point(initial, IsOdd); + EXPECT_EQ(2, *middle); +} + +TEST(MutatingTest, CopyMiddle) { + const std::vector<int> initial = {4, -1, -2, -3, 5}; + const std::list<int> input = {1, 2, 3}; + const std::vector<int> expected = {4, 1, 2, 3, 5}; + + std::list<int> test_list(initial.begin(), initial.end()); + absl::c_copy(input, ++test_list.begin()); + EXPECT_EQ(std::list<int>(expected.begin(), expected.end()), test_list); + + std::vector<int> test_vector = initial; + absl::c_copy(input, test_vector.begin() + 1); + EXPECT_EQ(expected, test_vector); +} + +TEST(MutatingTest, CopyFrontInserter) { + const std::list<int> initial = {4, 5}; + const std::list<int> input = {1, 2, 3}; + const std::list<int> expected = {3, 2, 1, 4, 5}; + + std::list<int> test_list = initial; + absl::c_copy(input, std::front_inserter(test_list)); + EXPECT_EQ(expected, test_list); +} + +TEST(MutatingTest, CopyBackInserter) { + const std::vector<int> initial = {4, 5}; + const std::list<int> input = {1, 2, 3}; + const std::vector<int> expected = {4, 5, 1, 2, 3}; + + std::list<int> test_list(initial.begin(), initial.end()); + absl::c_copy(input, std::back_inserter(test_list)); + EXPECT_EQ(std::list<int>(expected.begin(), expected.end()), test_list); + + std::vector<int> test_vector = initial; + absl::c_copy(input, std::back_inserter(test_vector)); + EXPECT_EQ(expected, test_vector); +} + +TEST(MutatingTest, CopyN) { + const std::vector<int> initial = {1, 2, 3, 4, 5}; + const std::vector<int> expected = {1, 2}; + std::vector<int> actual; + absl::c_copy_n(initial, 2, back_inserter(actual)); + EXPECT_EQ(expected, actual); +} + +TEST(MutatingTest, CopyIf) { + const std::list<int> input = {1, 2, 3}; + std::vector<int> output; + absl::c_copy_if(input, std::back_inserter(output), + [](int i) { return i != 2; }); + EXPECT_THAT(output, ElementsAre(1, 3)); +} + +TEST(MutatingTest, CopyBackward) { + std::vector<int> actual = {1, 2, 3, 4, 5}; + std::vector<int> expected = {1, 2, 1, 2, 3}; + absl::c_copy_backward(absl::MakeSpan(actual.data(), 3), actual.end()); + EXPECT_EQ(expected, actual); +} + +TEST(MutatingTest, Move) { + std::vector<std::unique_ptr<int>> src; + src.emplace_back(absl::make_unique<int>(1)); + src.emplace_back(absl::make_unique<int>(2)); + src.emplace_back(absl::make_unique<int>(3)); + src.emplace_back(absl::make_unique<int>(4)); + src.emplace_back(absl::make_unique<int>(5)); + + std::vector<std::unique_ptr<int>> dest = {}; + absl::c_move(src, std::back_inserter(dest)); + EXPECT_THAT(src, Each(IsNull())); + EXPECT_THAT(dest, ElementsAre(Pointee(1), Pointee(2), Pointee(3), Pointee(4), + Pointee(5))); +} + +TEST(MutatingTest, MoveBackward) { + std::vector<std::unique_ptr<int>> actual; + actual.emplace_back(absl::make_unique<int>(1)); + actual.emplace_back(absl::make_unique<int>(2)); + actual.emplace_back(absl::make_unique<int>(3)); + actual.emplace_back(absl::make_unique<int>(4)); + actual.emplace_back(absl::make_unique<int>(5)); + auto subrange = absl::MakeSpan(actual.data(), 3); + absl::c_move_backward(subrange, actual.end()); + EXPECT_THAT(actual, ElementsAre(IsNull(), IsNull(), Pointee(1), Pointee(2), + Pointee(3))); +} + +TEST(MutatingTest, MoveWithRvalue) { + auto MakeRValueSrc = [] { + std::vector<std::unique_ptr<int>> src; + src.emplace_back(absl::make_unique<int>(1)); + src.emplace_back(absl::make_unique<int>(2)); + src.emplace_back(absl::make_unique<int>(3)); + return src; + }; + + std::vector<std::unique_ptr<int>> dest = MakeRValueSrc(); + absl::c_move(MakeRValueSrc(), std::back_inserter(dest)); + EXPECT_THAT(dest, ElementsAre(Pointee(1), Pointee(2), Pointee(3), Pointee(1), + Pointee(2), Pointee(3))); +} + +TEST(MutatingTest, SwapRanges) { + std::vector<int> odds = {2, 4, 6}; + std::vector<int> evens = {1, 3, 5}; + absl::c_swap_ranges(odds, evens); + EXPECT_THAT(odds, ElementsAre(1, 3, 5)); + EXPECT_THAT(evens, ElementsAre(2, 4, 6)); +} + +TEST_F(NonMutatingTest, Transform) { + std::vector<int> x{0, 2, 4}, y, z; + auto end = absl::c_transform(x, back_inserter(y), std::negate<int>()); + EXPECT_EQ(std::vector<int>({0, -2, -4}), y); + *end = 7; + EXPECT_EQ(std::vector<int>({0, -2, -4, 7}), y); + + y = {1, 3, 0}; + end = absl::c_transform(x, y, back_inserter(z), std::plus<int>()); + EXPECT_EQ(std::vector<int>({1, 5, 4}), z); + *end = 7; + EXPECT_EQ(std::vector<int>({1, 5, 4, 7}), z); +} + +TEST(MutatingTest, Replace) { + const std::vector<int> initial = {1, 2, 3, 1, 4, 5}; + const std::vector<int> expected = {4, 2, 3, 4, 4, 5}; + + std::vector<int> test_vector = initial; + absl::c_replace(test_vector, 1, 4); + EXPECT_EQ(expected, test_vector); + + std::list<int> test_list(initial.begin(), initial.end()); + absl::c_replace(test_list, 1, 4); + EXPECT_EQ(std::list<int>(expected.begin(), expected.end()), test_list); +} + +TEST(MutatingTest, ReplaceIf) { + std::vector<int> actual = {1, 2, 3, 4, 5}; + const std::vector<int> expected = {0, 2, 0, 4, 0}; + + absl::c_replace_if(actual, IsOdd, 0); + EXPECT_EQ(expected, actual); +} + +TEST(MutatingTest, ReplaceCopy) { + const std::vector<int> initial = {1, 2, 3, 1, 4, 5}; + const std::vector<int> expected = {4, 2, 3, 4, 4, 5}; + + std::vector<int> actual; + absl::c_replace_copy(initial, back_inserter(actual), 1, 4); + EXPECT_EQ(expected, actual); +} + +TEST(MutatingTest, Sort) { + std::vector<int> test_vector = {2, 3, 1, 4}; + absl::c_sort(test_vector); + EXPECT_THAT(test_vector, ElementsAre(1, 2, 3, 4)); +} + +TEST(MutatingTest, SortWithPredicate) { + std::vector<int> test_vector = {2, 3, 1, 4}; + absl::c_sort(test_vector, std::greater<int>()); + EXPECT_THAT(test_vector, ElementsAre(4, 3, 2, 1)); +} + +// For absl::c_stable_sort tests. Needs an operator< that does not cover all +// fields so that the test can check the sort preserves order of equal elements. +struct Element { + int key; + int value; + friend bool operator<(const Element& e1, const Element& e2) { + return e1.key < e2.key; + } + // Make gmock print useful diagnostics. + friend std::ostream& operator<<(std::ostream& o, const Element& e) { + return o << "{" << e.key << ", " << e.value << "}"; + } +}; + +MATCHER_P2(IsElement, key, value, "") { + return arg.key == key && arg.value == value; +} + +TEST(MutatingTest, StableSort) { + std::vector<Element> test_vector = {{1, 1}, {2, 1}, {2, 0}, {1, 0}, {2, 2}}; + absl::c_stable_sort(test_vector); + EXPECT_THAT( + test_vector, + ElementsAre(IsElement(1, 1), IsElement(1, 0), IsElement(2, 1), + IsElement(2, 0), IsElement(2, 2))); +} + +TEST(MutatingTest, StableSortWithPredicate) { + std::vector<Element> test_vector = {{1, 1}, {2, 1}, {2, 0}, {1, 0}, {2, 2}}; + absl::c_stable_sort(test_vector, [](const Element& e1, const Element& e2) { + return e2 < e1; + }); + EXPECT_THAT( + test_vector, + ElementsAre(IsElement(2, 1), IsElement(2, 0), IsElement(2, 2), + IsElement(1, 1), IsElement(1, 0))); +} + +TEST(MutatingTest, ReplaceCopyIf) { + const std::vector<int> initial = {1, 2, 3, 4, 5}; + const std::vector<int> expected = {0, 2, 0, 4, 0}; + + std::vector<int> actual; + absl::c_replace_copy_if(initial, back_inserter(actual), IsOdd, 0); + EXPECT_EQ(expected, actual); +} + +TEST(MutatingTest, Fill) { + std::vector<int> actual(5); + absl::c_fill(actual, 1); + EXPECT_THAT(actual, ElementsAre(1, 1, 1, 1, 1)); +} + +TEST(MutatingTest, FillN) { + std::vector<int> actual(5, 0); + absl::c_fill_n(actual, 2, 1); + EXPECT_THAT(actual, ElementsAre(1, 1, 0, 0, 0)); +} + +TEST(MutatingTest, Generate) { + std::vector<int> actual(5); + int x = 0; + absl::c_generate(actual, [&x]() { return ++x; }); + EXPECT_THAT(actual, ElementsAre(1, 2, 3, 4, 5)); +} + +TEST(MutatingTest, GenerateN) { + std::vector<int> actual(5, 0); + int x = 0; + absl::c_generate_n(actual, 3, [&x]() { return ++x; }); + EXPECT_THAT(actual, ElementsAre(1, 2, 3, 0, 0)); +} + +TEST(MutatingTest, RemoveCopy) { + std::vector<int> actual; + absl::c_remove_copy(std::vector<int>{1, 2, 3}, back_inserter(actual), 2); + EXPECT_THAT(actual, ElementsAre(1, 3)); +} + +TEST(MutatingTest, RemoveCopyIf) { + std::vector<int> actual; + absl::c_remove_copy_if(std::vector<int>{1, 2, 3}, back_inserter(actual), + IsOdd); + EXPECT_THAT(actual, ElementsAre(2)); +} + +TEST(MutatingTest, UniqueCopy) { + std::vector<int> actual; + absl::c_unique_copy(std::vector<int>{1, 2, 2, 2, 3, 3, 2}, + back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(1, 2, 3, 2)); +} + +TEST(MutatingTest, UniqueCopyWithPredicate) { + std::vector<int> actual; + absl::c_unique_copy(std::vector<int>{1, 2, 3, -1, -2, -3, 1}, + back_inserter(actual), + [](int x, int y) { return (x < 0) == (y < 0); }); + EXPECT_THAT(actual, ElementsAre(1, -1, 1)); +} + +TEST(MutatingTest, Reverse) { + std::vector<int> test_vector = {1, 2, 3, 4}; + absl::c_reverse(test_vector); + EXPECT_THAT(test_vector, ElementsAre(4, 3, 2, 1)); + + std::list<int> test_list = {1, 2, 3, 4}; + absl::c_reverse(test_list); + EXPECT_THAT(test_list, ElementsAre(4, 3, 2, 1)); +} + +TEST(MutatingTest, ReverseCopy) { + std::vector<int> actual; + absl::c_reverse_copy(std::vector<int>{1, 2, 3, 4}, back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(4, 3, 2, 1)); +} + +TEST(MutatingTest, Rotate) { + std::vector<int> actual = {1, 2, 3, 4}; + auto it = absl::c_rotate(actual, actual.begin() + 2); + EXPECT_THAT(actual, testing::ElementsAreArray({3, 4, 1, 2})); + EXPECT_EQ(*it, 1); +} + +TEST(MutatingTest, RotateCopy) { + std::vector<int> initial = {1, 2, 3, 4}; + std::vector<int> actual; + auto end = + absl::c_rotate_copy(initial, initial.begin() + 2, back_inserter(actual)); + *end = 5; + EXPECT_THAT(actual, ElementsAre(3, 4, 1, 2, 5)); +} + +TEST(MutatingTest, Shuffle) { + std::vector<int> actual = {1, 2, 3, 4, 5}; + absl::c_shuffle(actual, std::random_device()); + EXPECT_THAT(actual, UnorderedElementsAre(1, 2, 3, 4, 5)); +} + +TEST(MutatingTest, PartialSort) { + std::vector<int> sequence{5, 3, 42, 0}; + absl::c_partial_sort(sequence, sequence.begin() + 2); + EXPECT_THAT(absl::MakeSpan(sequence.data(), 2), ElementsAre(0, 3)); + absl::c_partial_sort(sequence, sequence.begin() + 2, std::greater<int>()); + EXPECT_THAT(absl::MakeSpan(sequence.data(), 2), ElementsAre(42, 5)); +} + +TEST(MutatingTest, PartialSortCopy) { + const std::vector<int> initial = {5, 3, 42, 0}; + std::vector<int> actual(2); + absl::c_partial_sort_copy(initial, actual); + EXPECT_THAT(actual, ElementsAre(0, 3)); + absl::c_partial_sort_copy(initial, actual, std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(42, 5)); +} + +TEST(MutatingTest, Merge) { + std::vector<int> actual; + absl::c_merge(std::vector<int>{1, 3, 5}, std::vector<int>{2, 4}, + back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(1, 2, 3, 4, 5)); +} + +TEST(MutatingTest, MergeWithComparator) { + std::vector<int> actual; + absl::c_merge(std::vector<int>{5, 3, 1}, std::vector<int>{4, 2}, + back_inserter(actual), std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(5, 4, 3, 2, 1)); +} + +TEST(MutatingTest, InplaceMerge) { + std::vector<int> actual = {1, 3, 5, 2, 4}; + absl::c_inplace_merge(actual, actual.begin() + 3); + EXPECT_THAT(actual, ElementsAre(1, 2, 3, 4, 5)); +} + +TEST(MutatingTest, InplaceMergeWithComparator) { + std::vector<int> actual = {5, 3, 1, 4, 2}; + absl::c_inplace_merge(actual, actual.begin() + 3, std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(5, 4, 3, 2, 1)); +} + +class SetOperationsTest : public testing::Test { + protected: + std::vector<int> a_ = {1, 2, 3}; + std::vector<int> b_ = {1, 3, 5}; + + std::vector<int> a_reversed_ = {3, 2, 1}; + std::vector<int> b_reversed_ = {5, 3, 1}; +}; + +TEST_F(SetOperationsTest, SetUnion) { + std::vector<int> actual; + absl::c_set_union(a_, b_, back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(1, 2, 3, 5)); +} + +TEST_F(SetOperationsTest, SetUnionWithComparator) { + std::vector<int> actual; + absl::c_set_union(a_reversed_, b_reversed_, back_inserter(actual), + std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(5, 3, 2, 1)); +} + +TEST_F(SetOperationsTest, SetIntersection) { + std::vector<int> actual; + absl::c_set_intersection(a_, b_, back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(1, 3)); +} + +TEST_F(SetOperationsTest, SetIntersectionWithComparator) { + std::vector<int> actual; + absl::c_set_intersection(a_reversed_, b_reversed_, back_inserter(actual), + std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(3, 1)); +} + +TEST_F(SetOperationsTest, SetDifference) { + std::vector<int> actual; + absl::c_set_difference(a_, b_, back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(2)); +} + +TEST_F(SetOperationsTest, SetDifferenceWithComparator) { + std::vector<int> actual; + absl::c_set_difference(a_reversed_, b_reversed_, back_inserter(actual), + std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(2)); +} + +TEST_F(SetOperationsTest, SetSymmetricDifference) { + std::vector<int> actual; + absl::c_set_symmetric_difference(a_, b_, back_inserter(actual)); + EXPECT_THAT(actual, ElementsAre(2, 5)); +} + +TEST_F(SetOperationsTest, SetSymmetricDifferenceWithComparator) { + std::vector<int> actual; + absl::c_set_symmetric_difference(a_reversed_, b_reversed_, + back_inserter(actual), std::greater<int>()); + EXPECT_THAT(actual, ElementsAre(5, 2)); +} + +TEST(HeapOperationsTest, WithoutComparator) { + std::vector<int> heap = {1, 2, 3}; + EXPECT_FALSE(absl::c_is_heap(heap)); + absl::c_make_heap(heap); + EXPECT_TRUE(absl::c_is_heap(heap)); + heap.push_back(4); + EXPECT_EQ(3, absl::c_is_heap_until(heap) - heap.begin()); + absl::c_push_heap(heap); + EXPECT_EQ(4, heap[0]); + absl::c_pop_heap(heap); + EXPECT_EQ(4, heap[3]); + absl::c_make_heap(heap); + absl::c_sort_heap(heap); + EXPECT_THAT(heap, ElementsAre(1, 2, 3, 4)); + EXPECT_FALSE(absl::c_is_heap(heap)); +} + +TEST(HeapOperationsTest, WithComparator) { + using greater = std::greater<int>; + std::vector<int> heap = {3, 2, 1}; + EXPECT_FALSE(absl::c_is_heap(heap, greater())); + absl::c_make_heap(heap, greater()); + EXPECT_TRUE(absl::c_is_heap(heap, greater())); + heap.push_back(0); + EXPECT_EQ(3, absl::c_is_heap_until(heap, greater()) - heap.begin()); + absl::c_push_heap(heap, greater()); + EXPECT_EQ(0, heap[0]); + absl::c_pop_heap(heap, greater()); + EXPECT_EQ(0, heap[3]); + absl::c_make_heap(heap, greater()); + absl::c_sort_heap(heap, greater()); + EXPECT_THAT(heap, ElementsAre(3, 2, 1, 0)); + EXPECT_FALSE(absl::c_is_heap(heap, greater())); +} + +TEST(MutatingTest, PermutationOperations) { + std::vector<int> initial = {1, 2, 3, 4}; + std::vector<int> permuted = initial; + + absl::c_next_permutation(permuted); + EXPECT_TRUE(absl::c_is_permutation(initial, permuted)); + EXPECT_TRUE(absl::c_is_permutation(initial, permuted, std::equal_to<int>())); + + std::vector<int> permuted2 = initial; + absl::c_prev_permutation(permuted2, std::greater<int>()); + EXPECT_EQ(permuted, permuted2); + + absl::c_prev_permutation(permuted); + EXPECT_EQ(initial, permuted); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/algorithm/equal_benchmark.cc b/third_party/abseil_cpp/absl/algorithm/equal_benchmark.cc new file mode 100644 index 0000000000..7bf62c9a7f --- /dev/null +++ b/third_party/abseil_cpp/absl/algorithm/equal_benchmark.cc @@ -0,0 +1,126 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdint> +#include <cstring> + +#include "benchmark/benchmark.h" +#include "absl/algorithm/algorithm.h" + +namespace { + +// The range of sequence sizes to benchmark. +constexpr int kMinBenchmarkSize = 1024; +constexpr int kMaxBenchmarkSize = 8 * 1024 * 1024; + +// A user-defined type for use in equality benchmarks. Note that we expect +// std::memcmp to win for this type: libstdc++'s std::equal only defers to +// memcmp for integral types. This is because it is not straightforward to +// guarantee that std::memcmp would produce a result "as-if" compared by +// operator== for other types (example gotchas: NaN floats, structs with +// padding). +struct EightBits { + explicit EightBits(int /* unused */) : data(0) {} + bool operator==(const EightBits& rhs) const { return data == rhs.data; } + uint8_t data; +}; + +template <typename T> +void BM_absl_equal_benchmark(benchmark::State& state) { + std::vector<T> xs(state.range(0), T(0)); + std::vector<T> ys = xs; + while (state.KeepRunning()) { + const bool same = absl::equal(xs.begin(), xs.end(), ys.begin(), ys.end()); + benchmark::DoNotOptimize(same); + } +} + +template <typename T> +void BM_std_equal_benchmark(benchmark::State& state) { + std::vector<T> xs(state.range(0), T(0)); + std::vector<T> ys = xs; + while (state.KeepRunning()) { + const bool same = std::equal(xs.begin(), xs.end(), ys.begin()); + benchmark::DoNotOptimize(same); + } +} + +template <typename T> +void BM_memcmp_benchmark(benchmark::State& state) { + std::vector<T> xs(state.range(0), T(0)); + std::vector<T> ys = xs; + while (state.KeepRunning()) { + const bool same = + std::memcmp(xs.data(), ys.data(), xs.size() * sizeof(T)) == 0; + benchmark::DoNotOptimize(same); + } +} + +// The expectation is that the compiler should be able to elide the equality +// comparison altogether for sufficiently simple types. +template <typename T> +void BM_absl_equal_self_benchmark(benchmark::State& state) { + std::vector<T> xs(state.range(0), T(0)); + while (state.KeepRunning()) { + const bool same = absl::equal(xs.begin(), xs.end(), xs.begin(), xs.end()); + benchmark::DoNotOptimize(same); + } +} + +BENCHMARK_TEMPLATE(BM_absl_equal_benchmark, uint8_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_std_equal_benchmark, uint8_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_memcmp_benchmark, uint8_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_absl_equal_self_benchmark, uint8_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); + +BENCHMARK_TEMPLATE(BM_absl_equal_benchmark, uint16_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_std_equal_benchmark, uint16_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_memcmp_benchmark, uint16_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_absl_equal_self_benchmark, uint16_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); + +BENCHMARK_TEMPLATE(BM_absl_equal_benchmark, uint32_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_std_equal_benchmark, uint32_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_memcmp_benchmark, uint32_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_absl_equal_self_benchmark, uint32_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); + +BENCHMARK_TEMPLATE(BM_absl_equal_benchmark, uint64_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_std_equal_benchmark, uint64_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_memcmp_benchmark, uint64_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_absl_equal_self_benchmark, uint64_t) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); + +BENCHMARK_TEMPLATE(BM_absl_equal_benchmark, EightBits) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_std_equal_benchmark, EightBits) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_memcmp_benchmark, EightBits) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); +BENCHMARK_TEMPLATE(BM_absl_equal_self_benchmark, EightBits) + ->Range(kMinBenchmarkSize, kMaxBenchmarkSize); + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/BUILD.bazel b/third_party/abseil_cpp/absl/base/BUILD.bazel new file mode 100644 index 0000000000..76122dab30 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/BUILD.bazel @@ -0,0 +1,793 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "atomic_hook", + hdrs = ["internal/atomic_hook.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ":core_headers", + ], +) + +cc_library( + name = "errno_saver", + hdrs = ["internal/errno_saver.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [":config"], +) + +cc_library( + name = "log_severity", + srcs = ["log_severity.cc"], + hdrs = ["log_severity.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":core_headers", + ], +) + +cc_library( + name = "raw_logging_internal", + srcs = ["internal/raw_logging.cc"], + hdrs = ["internal/raw_logging.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":atomic_hook", + ":config", + ":core_headers", + ":log_severity", + ], +) + +cc_library( + name = "spinlock_wait", + srcs = [ + "internal/spinlock_akaros.inc", + "internal/spinlock_linux.inc", + "internal/spinlock_posix.inc", + "internal/spinlock_wait.cc", + "internal/spinlock_win32.inc", + ], + hdrs = ["internal/spinlock_wait.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/base:__pkg__", + ], + deps = [ + ":base_internal", + ":core_headers", + ":errno_saver", + ], +) + +cc_library( + name = "config", + hdrs = [ + "config.h", + "options.h", + "policy_checks.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, +) + +cc_library( + name = "dynamic_annotations", + srcs = ["dynamic_annotations.cc"], + hdrs = ["dynamic_annotations.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, +) + +cc_library( + name = "core_headers", + srcs = [ + "internal/thread_annotations.h", + ], + hdrs = [ + "attributes.h", + "const_init.h", + "macros.h", + "optimization.h", + "port.h", + "thread_annotations.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ], +) + +cc_library( + name = "malloc_internal", + srcs = [ + "internal/low_level_alloc.cc", + ], + hdrs = [ + "internal/direct_mmap.h", + "internal/low_level_alloc.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = select({ + "//absl:windows": [], + "//conditions:default": ["-pthread"], + }) + ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//visibility:public", + ], + deps = [ + ":base", + ":base_internal", + ":config", + ":core_headers", + ":dynamic_annotations", + ":raw_logging_internal", + ], +) + +cc_library( + name = "base_internal", + hdrs = [ + "internal/hide_ptr.h", + "internal/identity.h", + "internal/inline_variable.h", + "internal/invoke.h", + "internal/scheduling_mode.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + "//absl/meta:type_traits", + ], +) + +cc_library( + name = "base", + srcs = [ + "internal/cycleclock.cc", + "internal/spinlock.cc", + "internal/sysinfo.cc", + "internal/thread_identity.cc", + "internal/unscaledcycleclock.cc", + ], + hdrs = [ + "call_once.h", + "casts.h", + "internal/cycleclock.h", + "internal/low_level_scheduling.h", + "internal/per_thread_tls.h", + "internal/spinlock.h", + "internal/sysinfo.h", + "internal/thread_identity.h", + "internal/tsan_mutex_interface.h", + "internal/unscaledcycleclock.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = select({ + "//absl:windows": [ + "-DEFAULTLIB:advapi32.lib", + ], + "//conditions:default": ["-pthread"], + }) + ABSL_DEFAULT_LINKOPTS, + deps = [ + ":atomic_hook", + ":base_internal", + ":config", + ":core_headers", + ":dynamic_annotations", + ":log_severity", + ":raw_logging_internal", + ":spinlock_wait", + "//absl/meta:type_traits", + ], +) + +cc_library( + name = "atomic_hook_test_helper", + testonly = 1, + srcs = ["internal/atomic_hook_test_helper.cc"], + hdrs = ["internal/atomic_hook_test_helper.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":atomic_hook", + ":core_headers", + ], +) + +cc_test( + name = "atomic_hook_test", + size = "small", + srcs = ["internal/atomic_hook_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":atomic_hook", + ":atomic_hook_test_helper", + ":core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "bit_cast_test", + size = "small", + srcs = [ + "bit_cast_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base", + ":core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "throw_delegate", + srcs = ["internal/throw_delegate.cc"], + hdrs = ["internal/throw_delegate.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ":raw_logging_internal", + ], +) + +cc_test( + name = "throw_delegate_test", + srcs = ["throw_delegate_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":throw_delegate", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "errno_saver_test", + size = "small", + srcs = ["internal/errno_saver_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":errno_saver", + ":strerror", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "exception_testing", + testonly = 1, + hdrs = ["internal/exception_testing.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "pretty_function", + hdrs = ["internal/pretty_function.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//absl:__subpackages__"], +) + +cc_library( + name = "exception_safety_testing", + testonly = 1, + srcs = ["internal/exception_safety_testing.cc"], + hdrs = ["internal/exception_safety_testing.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":pretty_function", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/utility", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "exception_safety_testing_test", + srcs = ["exception_safety_testing_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":exception_safety_testing", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "inline_variable_test", + size = "small", + srcs = [ + "inline_variable_test.cc", + "inline_variable_test_a.cc", + "inline_variable_test_b.cc", + "internal/inline_variable_testing.h", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base_internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "invoke_test", + size = "small", + srcs = ["invoke_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base_internal", + "//absl/memory", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +# Common test library made available for use in non-absl code that overrides +# AbslInternalSpinLockDelay and AbslInternalSpinLockWake. +cc_library( + name = "spinlock_test_common", + testonly = 1, + srcs = ["spinlock_test_common.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base", + ":base_internal", + ":core_headers", + "//absl/synchronization", + "@com_google_googletest//:gtest", + ], + alwayslink = 1, +) + +cc_test( + name = "spinlock_test", + size = "medium", + srcs = ["spinlock_test_common.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base", + ":base_internal", + ":core_headers", + "//absl/synchronization", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "spinlock_benchmark_common", + testonly = 1, + srcs = ["internal/spinlock_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/base:__pkg__", + ], + deps = [ + ":base", + ":base_internal", + ":raw_logging_internal", + "//absl/synchronization", + "@com_github_google_benchmark//:benchmark_main", + ], + alwayslink = 1, +) + +cc_binary( + name = "spinlock_benchmark", + testonly = 1, + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":spinlock_benchmark_common", + ], +) + +cc_library( + name = "endian", + hdrs = [ + "internal/endian.h", + "internal/unaligned_access.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":core_headers", + ], +) + +cc_test( + name = "endian_test", + srcs = ["internal/endian_test.cc"], + copts = ABSL_TEST_COPTS, + deps = [ + ":config", + ":endian", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "config_test", + srcs = ["config_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + "//absl/synchronization:thread_pool", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "call_once_test", + srcs = ["call_once_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base", + ":core_headers", + "//absl/synchronization", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "raw_logging_test", + srcs = ["raw_logging_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":raw_logging_internal", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "sysinfo_test", + size = "small", + srcs = ["internal/sysinfo_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base", + "//absl/synchronization", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "low_level_alloc_test", + size = "medium", + srcs = ["internal/low_level_alloc_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["no_test_ios_x86_64"], + deps = [ + ":malloc_internal", + "//absl/container:node_hash_map", + ], +) + +cc_test( + name = "thread_identity_test", + size = "small", + srcs = ["internal/thread_identity_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":base", + ":core_headers", + "//absl/synchronization", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "thread_identity_benchmark", + srcs = ["internal/thread_identity_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":base", + "//absl/synchronization", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "bits", + hdrs = ["internal/bits.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ":core_headers", + ], +) + +cc_test( + name = "bits_test", + size = "small", + srcs = ["internal/bits_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "exponential_biased", + srcs = ["internal/exponential_biased.cc"], + hdrs = ["internal/exponential_biased.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ":core_headers", + ], +) + +cc_test( + name = "exponential_biased_test", + size = "small", + srcs = ["internal/exponential_biased_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + ":exponential_biased", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "periodic_sampler", + srcs = ["internal/periodic_sampler.cc"], + hdrs = ["internal/periodic_sampler.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":core_headers", + ":exponential_biased", + ], +) + +cc_test( + name = "periodic_sampler_test", + size = "small", + srcs = ["internal/periodic_sampler_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + ":core_headers", + ":periodic_sampler", + "@com_google_googletest//:gtest_main", + ], +) + +cc_binary( + name = "periodic_sampler_benchmark", + testonly = 1, + srcs = ["internal/periodic_sampler_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":core_headers", + ":periodic_sampler", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "scoped_set_env", + testonly = 1, + srcs = ["internal/scoped_set_env.cc"], + hdrs = ["internal/scoped_set_env.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ":raw_logging_internal", + ], +) + +cc_test( + name = "scoped_set_env_test", + size = "small", + srcs = ["internal/scoped_set_env_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":scoped_set_env", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "log_severity_test", + size = "small", + srcs = ["log_severity_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":log_severity", + "//absl/flags:flag_internal", + "//absl/flags:marshalling", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "strerror", + srcs = ["internal/strerror.cc"], + hdrs = ["internal/strerror.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ":core_headers", + ":errno_saver", + ], +) + +cc_test( + name = "strerror_test", + size = "small", + srcs = ["internal/strerror_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":strerror", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_binary( + name = "strerror_benchmark", + testonly = 1, + srcs = ["internal/strerror_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strerror", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "fast_type_id", + hdrs = ["internal/fast_type_id.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":config", + ], +) + +cc_test( + name = "fast_type_id_test", + size = "small", + srcs = ["internal/fast_type_id_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":fast_type_id", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "unique_small_name_test", + size = "small", + srcs = ["internal/unique_small_name_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + linkstatic = 1, + deps = [ + ":core_headers", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/base/CMakeLists.txt b/third_party/abseil_cpp/absl/base/CMakeLists.txt new file mode 100644 index 0000000000..292998b3bf --- /dev/null +++ b/third_party/abseil_cpp/absl/base/CMakeLists.txt @@ -0,0 +1,700 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +find_library(LIBRT rt) + +absl_cc_library( + NAME + atomic_hook + HDRS + "internal/atomic_hook.h" + DEPS + absl::config + absl::core_headers + COPTS + ${ABSL_DEFAULT_COPTS} +) + +absl_cc_library( + NAME + errno_saver + HDRS + "internal/errno_saver.h" + DEPS + absl::config + COPTS + ${ABSL_DEFAULT_COPTS} +) + +absl_cc_library( + NAME + log_severity + HDRS + "log_severity.h" + SRCS + "log_severity.cc" + DEPS + absl::core_headers + COPTS + ${ABSL_DEFAULT_COPTS} +) + +absl_cc_library( + NAME + raw_logging_internal + HDRS + "internal/raw_logging.h" + SRCS + "internal/raw_logging.cc" + DEPS + absl::atomic_hook + absl::config + absl::core_headers + absl::log_severity + COPTS + ${ABSL_DEFAULT_COPTS} +) + +absl_cc_library( + NAME + spinlock_wait + HDRS + "internal/spinlock_wait.h" + SRCS + "internal/spinlock_akaros.inc" + "internal/spinlock_linux.inc" + "internal/spinlock_posix.inc" + "internal/spinlock_wait.cc" + "internal/spinlock_win32.inc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base_internal + absl::core_headers + absl::errno_saver +) + +absl_cc_library( + NAME + config + HDRS + "config.h" + "options.h" + "policy_checks.h" + COPTS + ${ABSL_DEFAULT_COPTS} + PUBLIC +) + +absl_cc_library( + NAME + dynamic_annotations + HDRS + "dynamic_annotations.h" + SRCS + "dynamic_annotations.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + PUBLIC +) + +absl_cc_library( + NAME + core_headers + HDRS + "attributes.h" + "const_init.h" + "macros.h" + "optimization.h" + "port.h" + "thread_annotations.h" + "internal/thread_annotations.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + PUBLIC +) + +absl_cc_library( + NAME + malloc_internal + HDRS + "internal/direct_mmap.h" + "internal/low_level_alloc.h" + SRCS + "internal/low_level_alloc.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base + absl::base_internal + absl::config + absl::core_headers + absl::dynamic_annotations + absl::raw_logging_internal + Threads::Threads +) + +absl_cc_library( + NAME + base_internal + HDRS + "internal/hide_ptr.h" + "internal/identity.h" + "internal/inline_variable.h" + "internal/invoke.h" + "internal/scheduling_mode.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::type_traits +) + +absl_cc_library( + NAME + base + HDRS + "call_once.h" + "casts.h" + "internal/cycleclock.h" + "internal/low_level_scheduling.h" + "internal/per_thread_tls.h" + "internal/spinlock.h" + "internal/sysinfo.h" + "internal/thread_identity.h" + "internal/tsan_mutex_interface.h" + "internal/unscaledcycleclock.h" + SRCS + "internal/cycleclock.cc" + "internal/spinlock.cc" + "internal/sysinfo.cc" + "internal/thread_identity.cc" + "internal/unscaledcycleclock.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + $<$<BOOL:${LIBRT}>:-lrt> + $<$<BOOL:${MINGW}>:"advapi32"> + DEPS + absl::atomic_hook + absl::base_internal + absl::config + absl::core_headers + absl::dynamic_annotations + absl::log_severity + absl::raw_logging_internal + absl::spinlock_wait + absl::type_traits + Threads::Threads + PUBLIC +) + +absl_cc_library( + NAME + throw_delegate + HDRS + "internal/throw_delegate.h" + SRCS + "internal/throw_delegate.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::raw_logging_internal +) + +absl_cc_library( + NAME + exception_testing + HDRS + "internal/exception_testing.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + gtest + TESTONLY +) + +absl_cc_library( + NAME + pretty_function + HDRS + "internal/pretty_function.h" + COPTS + ${ABSL_DEFAULT_COPTS} +) + +absl_cc_library( + NAME + exception_safety_testing + HDRS + "internal/exception_safety_testing.h" + SRCS + "internal/exception_safety_testing.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::config + absl::pretty_function + absl::memory + absl::meta + absl::strings + absl::utility + gtest + TESTONLY +) + +absl_cc_test( + NAME + absl_exception_safety_testing_test + SRCS + "exception_safety_testing_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::exception_safety_testing + absl::memory + gtest_main +) + +absl_cc_library( + NAME + atomic_hook_test_helper + SRCS + "internal/atomic_hook_test_helper.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::atomic_hook + absl::core_headers + TESTONLY +) + +absl_cc_test( + NAME + atomic_hook_test + SRCS + "internal/atomic_hook_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::atomic_hook_test_helper + absl::atomic_hook + absl::core_headers + gmock + gtest_main +) + +absl_cc_test( + NAME + bit_cast_test + SRCS + "bit_cast_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::core_headers + gtest_main +) + +absl_cc_test( + NAME + errno_saver_test + SRCS + "internal/errno_saver_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::errno_saver + absl::strerror + gmock + gtest_main +) + +absl_cc_test( + NAME + throw_delegate_test + SRCS + "throw_delegate_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::config + absl::throw_delegate + gtest_main +) + +absl_cc_test( + NAME + inline_variable_test + SRCS + "internal/inline_variable_testing.h" + "inline_variable_test.cc" + "inline_variable_test_a.cc" + "inline_variable_test_b.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base_internal + gtest_main +) + +absl_cc_test( + NAME + invoke_test + SRCS + "invoke_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base_internal + absl::memory + absl::strings + gmock + gtest_main +) + +absl_cc_library( + NAME + spinlock_test_common + SRCS + "spinlock_test_common.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::base_internal + absl::core_headers + absl::synchronization + gtest + TESTONLY +) + +# On bazel BUILD this target use "alwayslink = 1" which is not implemented here +absl_cc_test( + NAME + spinlock_test + SRCS + "spinlock_test_common.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::base_internal + absl::core_headers + absl::synchronization + gtest_main +) + +absl_cc_library( + NAME + endian + HDRS + "internal/endian.h" + "internal/unaligned_access.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers + PUBLIC +) + +absl_cc_test( + NAME + endian_test + SRCS + "internal/endian_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::config + absl::endian + gtest_main +) + +absl_cc_test( + NAME + config_test + SRCS + "config_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::config + absl::synchronization + gtest_main +) + +absl_cc_test( + NAME + call_once_test + SRCS + "call_once_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::core_headers + absl::synchronization + gtest_main +) + +absl_cc_test( + NAME + raw_logging_test + SRCS + "raw_logging_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::raw_logging_internal + absl::strings + gtest_main +) + +absl_cc_test( + NAME + sysinfo_test + SRCS + "internal/sysinfo_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::synchronization + gtest_main +) + +absl_cc_test( + NAME + low_level_alloc_test + SRCS + "internal/low_level_alloc_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::malloc_internal + absl::node_hash_map + Threads::Threads +) + +absl_cc_test( + NAME + thread_identity_test + SRCS + "internal/thread_identity_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::core_headers + absl::synchronization + Threads::Threads + gtest_main +) + +absl_cc_library( + NAME + bits + HDRS + "internal/bits.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers +) + +absl_cc_test( + NAME + bits_test + SRCS + "internal/bits_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::bits + gtest_main +) + +absl_cc_library( + NAME + exponential_biased + SRCS + "internal/exponential_biased.cc" + HDRS + "internal/exponential_biased.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers +) + +absl_cc_test( + NAME + exponential_biased_test + SRCS + "internal/exponential_biased_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::exponential_biased + absl::strings + gmock_main +) + +absl_cc_library( + NAME + periodic_sampler + SRCS + "internal/periodic_sampler.cc" + HDRS + "internal/periodic_sampler.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::exponential_biased +) + +absl_cc_test( + NAME + periodic_sampler_test + SRCS + "internal/periodic_sampler_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::core_headers + absl::periodic_sampler + gmock_main +) + +absl_cc_library( + NAME + scoped_set_env + SRCS + "internal/scoped_set_env.cc" + HDRS + "internal/scoped_set_env.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::raw_logging_internal +) + +absl_cc_test( + NAME + scoped_set_env_test + SRCS + "internal/scoped_set_env_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::scoped_set_env + gtest_main +) + +absl_cc_test( + NAME + cmake_thread_test + SRCS + "internal/cmake_thread_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base +) + +absl_cc_test( + NAME + log_severity_test + SRCS + "log_severity_test.cc" + DEPS + absl::flags_internal + absl::flags_marshalling + absl::log_severity + absl::strings + gmock + gtest_main +) + +absl_cc_library( + NAME + strerror + SRCS + "internal/strerror.cc" + HDRS + "internal/strerror.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::core_headers + absl::errno_saver +) + +absl_cc_test( + NAME + strerror_test + SRCS + "internal/strerror_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strerror + absl::strings + gmock + gtest_main +) + +absl_cc_library( + NAME + fast_type_id + HDRS + "internal/fast_type_id.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config +) + +absl_cc_test( + NAME + fast_type_id_test + SRCS + "internal/fast_type_id_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::fast_type_id + gtest_main +) diff --git a/third_party/abseil_cpp/absl/base/attributes.h b/third_party/abseil_cpp/absl/base/attributes.h new file mode 100644 index 0000000000..c4fd81b002 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/attributes.h @@ -0,0 +1,623 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This header file defines macros for declaring attributes for functions, +// types, and variables. +// +// These macros are used within Abseil and allow the compiler to optimize, where +// applicable, certain function calls. +// +// This file is used for both C and C++! +// +// Most macros here are exposing GCC or Clang features, and are stubbed out for +// other compilers. +// +// GCC attributes documentation: +// https://gcc.gnu.org/onlinedocs/gcc-4.7.0/gcc/Function-Attributes.html +// https://gcc.gnu.org/onlinedocs/gcc-4.7.0/gcc/Variable-Attributes.html +// https://gcc.gnu.org/onlinedocs/gcc-4.7.0/gcc/Type-Attributes.html +// +// Most attributes in this file are already supported by GCC 4.7. However, some +// of them are not supported in older version of Clang. Thus, we check +// `__has_attribute()` first. If the check fails, we check if we are on GCC and +// assume the attribute exists on GCC (which is verified on GCC 4.7). +// +// ----------------------------------------------------------------------------- +// Sanitizer Attributes +// ----------------------------------------------------------------------------- +// +// Sanitizer-related attributes are not "defined" in this file (and indeed +// are not defined as such in any file). To utilize the following +// sanitizer-related attributes within your builds, define the following macros +// within your build using a `-D` flag, along with the given value for +// `-fsanitize`: +// +// * `ADDRESS_SANITIZER` + `-fsanitize=address` (Clang, GCC 4.8) +// * `MEMORY_SANITIZER` + `-fsanitize=memory` (Clang-only) +// * `THREAD_SANITIZER` + `-fsanitize=thread` (Clang, GCC 4.8+) +// * `UNDEFINED_BEHAVIOR_SANITIZER` + `-fsanitize=undefined` (Clang, GCC 4.9+) +// * `CONTROL_FLOW_INTEGRITY` + `-fsanitize=cfi` (Clang-only) +// +// Example: +// +// // Enable branches in the Abseil code that are tagged for ASan: +// $ bazel build --copt=-DADDRESS_SANITIZER --copt=-fsanitize=address +// --linkopt=-fsanitize=address *target* +// +// Since these macro names are only supported by GCC and Clang, we only check +// for `__GNUC__` (GCC or Clang) and the above macros. +#ifndef ABSL_BASE_ATTRIBUTES_H_ +#define ABSL_BASE_ATTRIBUTES_H_ + +// ABSL_HAVE_ATTRIBUTE +// +// A function-like feature checking macro that is a wrapper around +// `__has_attribute`, which is defined by GCC 5+ and Clang and evaluates to a +// nonzero constant integer if the attribute is supported or 0 if not. +// +// It evaluates to zero if `__has_attribute` is not defined by the compiler. +// +// GCC: https://gcc.gnu.org/gcc-5/changes.html +// Clang: https://clang.llvm.org/docs/LanguageExtensions.html +#ifdef __has_attribute +#define ABSL_HAVE_ATTRIBUTE(x) __has_attribute(x) +#else +#define ABSL_HAVE_ATTRIBUTE(x) 0 +#endif + +// ABSL_HAVE_CPP_ATTRIBUTE +// +// A function-like feature checking macro that accepts C++11 style attributes. +// It's a wrapper around `__has_cpp_attribute`, defined by ISO C++ SD-6 +// (https://en.cppreference.com/w/cpp/experimental/feature_test). If we don't +// find `__has_cpp_attribute`, will evaluate to 0. +#if defined(__cplusplus) && defined(__has_cpp_attribute) +// NOTE: requiring __cplusplus above should not be necessary, but +// works around https://bugs.llvm.org/show_bug.cgi?id=23435. +#define ABSL_HAVE_CPP_ATTRIBUTE(x) __has_cpp_attribute(x) +#else +#define ABSL_HAVE_CPP_ATTRIBUTE(x) 0 +#endif + +// ----------------------------------------------------------------------------- +// Function Attributes +// ----------------------------------------------------------------------------- +// +// GCC: https://gcc.gnu.org/onlinedocs/gcc/Function-Attributes.html +// Clang: https://clang.llvm.org/docs/AttributeReference.html + +// ABSL_PRINTF_ATTRIBUTE +// ABSL_SCANF_ATTRIBUTE +// +// Tells the compiler to perform `printf` format string checking if the +// compiler supports it; see the 'format' attribute in +// <https://gcc.gnu.org/onlinedocs/gcc-4.7.0/gcc/Function-Attributes.html>. +// +// Note: As the GCC manual states, "[s]ince non-static C++ methods +// have an implicit 'this' argument, the arguments of such methods +// should be counted from two, not one." +#if ABSL_HAVE_ATTRIBUTE(format) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_PRINTF_ATTRIBUTE(string_index, first_to_check) \ + __attribute__((__format__(__printf__, string_index, first_to_check))) +#define ABSL_SCANF_ATTRIBUTE(string_index, first_to_check) \ + __attribute__((__format__(__scanf__, string_index, first_to_check))) +#else +#define ABSL_PRINTF_ATTRIBUTE(string_index, first_to_check) +#define ABSL_SCANF_ATTRIBUTE(string_index, first_to_check) +#endif + +// ABSL_ATTRIBUTE_ALWAYS_INLINE +// ABSL_ATTRIBUTE_NOINLINE +// +// Forces functions to either inline or not inline. Introduced in gcc 3.1. +#if ABSL_HAVE_ATTRIBUTE(always_inline) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_ALWAYS_INLINE __attribute__((always_inline)) +#define ABSL_HAVE_ATTRIBUTE_ALWAYS_INLINE 1 +#else +#define ABSL_ATTRIBUTE_ALWAYS_INLINE +#endif + +#if ABSL_HAVE_ATTRIBUTE(noinline) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_NOINLINE __attribute__((noinline)) +#define ABSL_HAVE_ATTRIBUTE_NOINLINE 1 +#else +#define ABSL_ATTRIBUTE_NOINLINE +#endif + +// ABSL_ATTRIBUTE_NO_TAIL_CALL +// +// Prevents the compiler from optimizing away stack frames for functions which +// end in a call to another function. +#if ABSL_HAVE_ATTRIBUTE(disable_tail_calls) +#define ABSL_HAVE_ATTRIBUTE_NO_TAIL_CALL 1 +#define ABSL_ATTRIBUTE_NO_TAIL_CALL __attribute__((disable_tail_calls)) +#elif defined(__GNUC__) && !defined(__clang__) +#define ABSL_HAVE_ATTRIBUTE_NO_TAIL_CALL 1 +#define ABSL_ATTRIBUTE_NO_TAIL_CALL \ + __attribute__((optimize("no-optimize-sibling-calls"))) +#else +#define ABSL_ATTRIBUTE_NO_TAIL_CALL +#define ABSL_HAVE_ATTRIBUTE_NO_TAIL_CALL 0 +#endif + +// ABSL_ATTRIBUTE_WEAK +// +// Tags a function as weak for the purposes of compilation and linking. +// Weak attributes currently do not work properly in LLVM's Windows backend, +// so disable them there. See https://bugs.llvm.org/show_bug.cgi?id=37598 +// for further information. +// The MinGW compiler doesn't complain about the weak attribute until the link +// step, presumably because Windows doesn't use ELF binaries. +#if (ABSL_HAVE_ATTRIBUTE(weak) || \ + (defined(__GNUC__) && !defined(__clang__))) && \ + !(defined(__llvm__) && defined(_WIN32)) && !defined(__MINGW32__) +#undef ABSL_ATTRIBUTE_WEAK +#define ABSL_ATTRIBUTE_WEAK __attribute__((weak)) +#define ABSL_HAVE_ATTRIBUTE_WEAK 1 +#else +#define ABSL_ATTRIBUTE_WEAK +#define ABSL_HAVE_ATTRIBUTE_WEAK 0 +#endif + +// ABSL_ATTRIBUTE_NONNULL +// +// Tells the compiler either (a) that a particular function parameter +// should be a non-null pointer, or (b) that all pointer arguments should +// be non-null. +// +// Note: As the GCC manual states, "[s]ince non-static C++ methods +// have an implicit 'this' argument, the arguments of such methods +// should be counted from two, not one." +// +// Args are indexed starting at 1. +// +// For non-static class member functions, the implicit `this` argument +// is arg 1, and the first explicit argument is arg 2. For static class member +// functions, there is no implicit `this`, and the first explicit argument is +// arg 1. +// +// Example: +// +// /* arg_a cannot be null, but arg_b can */ +// void Function(void* arg_a, void* arg_b) ABSL_ATTRIBUTE_NONNULL(1); +// +// class C { +// /* arg_a cannot be null, but arg_b can */ +// void Method(void* arg_a, void* arg_b) ABSL_ATTRIBUTE_NONNULL(2); +// +// /* arg_a cannot be null, but arg_b can */ +// static void StaticMethod(void* arg_a, void* arg_b) +// ABSL_ATTRIBUTE_NONNULL(1); +// }; +// +// If no arguments are provided, then all pointer arguments should be non-null. +// +// /* No pointer arguments may be null. */ +// void Function(void* arg_a, void* arg_b, int arg_c) ABSL_ATTRIBUTE_NONNULL(); +// +// NOTE: The GCC nonnull attribute actually accepts a list of arguments, but +// ABSL_ATTRIBUTE_NONNULL does not. +#if ABSL_HAVE_ATTRIBUTE(nonnull) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_NONNULL(arg_index) __attribute__((nonnull(arg_index))) +#else +#define ABSL_ATTRIBUTE_NONNULL(...) +#endif + +// ABSL_ATTRIBUTE_NORETURN +// +// Tells the compiler that a given function never returns. +#if ABSL_HAVE_ATTRIBUTE(noreturn) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_NORETURN __attribute__((noreturn)) +#elif defined(_MSC_VER) +#define ABSL_ATTRIBUTE_NORETURN __declspec(noreturn) +#else +#define ABSL_ATTRIBUTE_NORETURN +#endif + +// ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS +// +// Tells the AddressSanitizer (or other memory testing tools) to ignore a given +// function. Useful for cases when a function reads random locations on stack, +// calls _exit from a cloned subprocess, deliberately accesses buffer +// out of bounds or does other scary things with memory. +// NOTE: GCC supports AddressSanitizer(asan) since 4.8. +// https://gcc.gnu.org/gcc-4.8/changes.html +#if defined(__GNUC__) +#define ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS __attribute__((no_sanitize_address)) +#else +#define ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS +#endif + +// ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY +// +// Tells the MemorySanitizer to relax the handling of a given function. All +// "Use of uninitialized value" warnings from such functions will be suppressed, +// and all values loaded from memory will be considered fully initialized. +// This attribute is similar to the ADDRESS_SANITIZER attribute above, but deals +// with initialized-ness rather than addressability issues. +// NOTE: MemorySanitizer(msan) is supported by Clang but not GCC. +#if defined(__clang__) +#define ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY __attribute__((no_sanitize_memory)) +#else +#define ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY +#endif + +// ABSL_ATTRIBUTE_NO_SANITIZE_THREAD +// +// Tells the ThreadSanitizer to not instrument a given function. +// NOTE: GCC supports ThreadSanitizer(tsan) since 4.8. +// https://gcc.gnu.org/gcc-4.8/changes.html +#if defined(__GNUC__) +#define ABSL_ATTRIBUTE_NO_SANITIZE_THREAD __attribute__((no_sanitize_thread)) +#else +#define ABSL_ATTRIBUTE_NO_SANITIZE_THREAD +#endif + +// ABSL_ATTRIBUTE_NO_SANITIZE_UNDEFINED +// +// Tells the UndefinedSanitizer to ignore a given function. Useful for cases +// where certain behavior (eg. division by zero) is being used intentionally. +// NOTE: GCC supports UndefinedBehaviorSanitizer(ubsan) since 4.9. +// https://gcc.gnu.org/gcc-4.9/changes.html +#if defined(__GNUC__) && \ + (defined(UNDEFINED_BEHAVIOR_SANITIZER) || defined(ADDRESS_SANITIZER)) +#define ABSL_ATTRIBUTE_NO_SANITIZE_UNDEFINED \ + __attribute__((no_sanitize("undefined"))) +#else +#define ABSL_ATTRIBUTE_NO_SANITIZE_UNDEFINED +#endif + +// ABSL_ATTRIBUTE_NO_SANITIZE_CFI +// +// Tells the ControlFlowIntegrity sanitizer to not instrument a given function. +// See https://clang.llvm.org/docs/ControlFlowIntegrity.html for details. +#if defined(__GNUC__) && defined(CONTROL_FLOW_INTEGRITY) +#define ABSL_ATTRIBUTE_NO_SANITIZE_CFI __attribute__((no_sanitize("cfi"))) +#else +#define ABSL_ATTRIBUTE_NO_SANITIZE_CFI +#endif + +// ABSL_ATTRIBUTE_NO_SANITIZE_SAFESTACK +// +// Tells the SafeStack to not instrument a given function. +// See https://clang.llvm.org/docs/SafeStack.html for details. +#if defined(__GNUC__) && defined(SAFESTACK_SANITIZER) +#define ABSL_ATTRIBUTE_NO_SANITIZE_SAFESTACK \ + __attribute__((no_sanitize("safe-stack"))) +#else +#define ABSL_ATTRIBUTE_NO_SANITIZE_SAFESTACK +#endif + +// ABSL_ATTRIBUTE_RETURNS_NONNULL +// +// Tells the compiler that a particular function never returns a null pointer. +#if ABSL_HAVE_ATTRIBUTE(returns_nonnull) || \ + (defined(__GNUC__) && \ + (__GNUC__ > 5 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 9)) && \ + !defined(__clang__)) +#define ABSL_ATTRIBUTE_RETURNS_NONNULL __attribute__((returns_nonnull)) +#else +#define ABSL_ATTRIBUTE_RETURNS_NONNULL +#endif + +// ABSL_HAVE_ATTRIBUTE_SECTION +// +// Indicates whether labeled sections are supported. Weak symbol support is +// a prerequisite. Labeled sections are not supported on Darwin/iOS. +#ifdef ABSL_HAVE_ATTRIBUTE_SECTION +#error ABSL_HAVE_ATTRIBUTE_SECTION cannot be directly set +#elif (ABSL_HAVE_ATTRIBUTE(section) || \ + (defined(__GNUC__) && !defined(__clang__))) && \ + !defined(__APPLE__) && ABSL_HAVE_ATTRIBUTE_WEAK +#define ABSL_HAVE_ATTRIBUTE_SECTION 1 + +// ABSL_ATTRIBUTE_SECTION +// +// Tells the compiler/linker to put a given function into a section and define +// `__start_ ## name` and `__stop_ ## name` symbols to bracket the section. +// This functionality is supported by GNU linker. Any function annotated with +// `ABSL_ATTRIBUTE_SECTION` must not be inlined, or it will be placed into +// whatever section its caller is placed into. +// +#ifndef ABSL_ATTRIBUTE_SECTION +#define ABSL_ATTRIBUTE_SECTION(name) \ + __attribute__((section(#name))) __attribute__((noinline)) +#endif + + +// ABSL_ATTRIBUTE_SECTION_VARIABLE +// +// Tells the compiler/linker to put a given variable into a section and define +// `__start_ ## name` and `__stop_ ## name` symbols to bracket the section. +// This functionality is supported by GNU linker. +#ifndef ABSL_ATTRIBUTE_SECTION_VARIABLE +#define ABSL_ATTRIBUTE_SECTION_VARIABLE(name) __attribute__((section(#name))) +#endif + +// ABSL_DECLARE_ATTRIBUTE_SECTION_VARS +// +// A weak section declaration to be used as a global declaration +// for ABSL_ATTRIBUTE_SECTION_START|STOP(name) to compile and link +// even without functions with ABSL_ATTRIBUTE_SECTION(name). +// ABSL_DEFINE_ATTRIBUTE_SECTION should be in the exactly one file; it's +// a no-op on ELF but not on Mach-O. +// +#ifndef ABSL_DECLARE_ATTRIBUTE_SECTION_VARS +#define ABSL_DECLARE_ATTRIBUTE_SECTION_VARS(name) \ + extern char __start_##name[] ABSL_ATTRIBUTE_WEAK; \ + extern char __stop_##name[] ABSL_ATTRIBUTE_WEAK +#endif +#ifndef ABSL_DEFINE_ATTRIBUTE_SECTION_VARS +#define ABSL_INIT_ATTRIBUTE_SECTION_VARS(name) +#define ABSL_DEFINE_ATTRIBUTE_SECTION_VARS(name) +#endif + +// ABSL_ATTRIBUTE_SECTION_START +// +// Returns `void*` pointers to start/end of a section of code with +// functions having ABSL_ATTRIBUTE_SECTION(name). +// Returns 0 if no such functions exist. +// One must ABSL_DECLARE_ATTRIBUTE_SECTION_VARS(name) for this to compile and +// link. +// +#define ABSL_ATTRIBUTE_SECTION_START(name) \ + (reinterpret_cast<void *>(__start_##name)) +#define ABSL_ATTRIBUTE_SECTION_STOP(name) \ + (reinterpret_cast<void *>(__stop_##name)) + +#else // !ABSL_HAVE_ATTRIBUTE_SECTION + +#define ABSL_HAVE_ATTRIBUTE_SECTION 0 + +// provide dummy definitions +#define ABSL_ATTRIBUTE_SECTION(name) +#define ABSL_ATTRIBUTE_SECTION_VARIABLE(name) +#define ABSL_INIT_ATTRIBUTE_SECTION_VARS(name) +#define ABSL_DEFINE_ATTRIBUTE_SECTION_VARS(name) +#define ABSL_DECLARE_ATTRIBUTE_SECTION_VARS(name) +#define ABSL_ATTRIBUTE_SECTION_START(name) (reinterpret_cast<void *>(0)) +#define ABSL_ATTRIBUTE_SECTION_STOP(name) (reinterpret_cast<void *>(0)) + +#endif // ABSL_ATTRIBUTE_SECTION + +// ABSL_ATTRIBUTE_STACK_ALIGN_FOR_OLD_LIBC +// +// Support for aligning the stack on 32-bit x86. +#if ABSL_HAVE_ATTRIBUTE(force_align_arg_pointer) || \ + (defined(__GNUC__) && !defined(__clang__)) +#if defined(__i386__) +#define ABSL_ATTRIBUTE_STACK_ALIGN_FOR_OLD_LIBC \ + __attribute__((force_align_arg_pointer)) +#define ABSL_REQUIRE_STACK_ALIGN_TRAMPOLINE (0) +#elif defined(__x86_64__) +#define ABSL_REQUIRE_STACK_ALIGN_TRAMPOLINE (1) +#define ABSL_ATTRIBUTE_STACK_ALIGN_FOR_OLD_LIBC +#else // !__i386__ && !__x86_64 +#define ABSL_REQUIRE_STACK_ALIGN_TRAMPOLINE (0) +#define ABSL_ATTRIBUTE_STACK_ALIGN_FOR_OLD_LIBC +#endif // __i386__ +#else +#define ABSL_ATTRIBUTE_STACK_ALIGN_FOR_OLD_LIBC +#define ABSL_REQUIRE_STACK_ALIGN_TRAMPOLINE (0) +#endif + +// ABSL_MUST_USE_RESULT +// +// Tells the compiler to warn about unused results. +// +// When annotating a function, it must appear as the first part of the +// declaration or definition. The compiler will warn if the return value from +// such a function is unused: +// +// ABSL_MUST_USE_RESULT Sprocket* AllocateSprocket(); +// AllocateSprocket(); // Triggers a warning. +// +// When annotating a class, it is equivalent to annotating every function which +// returns an instance. +// +// class ABSL_MUST_USE_RESULT Sprocket {}; +// Sprocket(); // Triggers a warning. +// +// Sprocket MakeSprocket(); +// MakeSprocket(); // Triggers a warning. +// +// Note that references and pointers are not instances: +// +// Sprocket* SprocketPointer(); +// SprocketPointer(); // Does *not* trigger a warning. +// +// ABSL_MUST_USE_RESULT allows using cast-to-void to suppress the unused result +// warning. For that, warn_unused_result is used only for clang but not for gcc. +// https://gcc.gnu.org/bugzilla/show_bug.cgi?id=66425 +// +// Note: past advice was to place the macro after the argument list. +#if ABSL_HAVE_ATTRIBUTE(nodiscard) +#define ABSL_MUST_USE_RESULT [[nodiscard]] +#elif defined(__clang__) && ABSL_HAVE_ATTRIBUTE(warn_unused_result) +#define ABSL_MUST_USE_RESULT __attribute__((warn_unused_result)) +#else +#define ABSL_MUST_USE_RESULT +#endif + +// ABSL_ATTRIBUTE_HOT, ABSL_ATTRIBUTE_COLD +// +// Tells GCC that a function is hot or cold. GCC can use this information to +// improve static analysis, i.e. a conditional branch to a cold function +// is likely to be not-taken. +// This annotation is used for function declarations. +// +// Example: +// +// int foo() ABSL_ATTRIBUTE_HOT; +#if ABSL_HAVE_ATTRIBUTE(hot) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_HOT __attribute__((hot)) +#else +#define ABSL_ATTRIBUTE_HOT +#endif + +#if ABSL_HAVE_ATTRIBUTE(cold) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_COLD __attribute__((cold)) +#else +#define ABSL_ATTRIBUTE_COLD +#endif + +// ABSL_XRAY_ALWAYS_INSTRUMENT, ABSL_XRAY_NEVER_INSTRUMENT, ABSL_XRAY_LOG_ARGS +// +// We define the ABSL_XRAY_ALWAYS_INSTRUMENT and ABSL_XRAY_NEVER_INSTRUMENT +// macro used as an attribute to mark functions that must always or never be +// instrumented by XRay. Currently, this is only supported in Clang/LLVM. +// +// For reference on the LLVM XRay instrumentation, see +// http://llvm.org/docs/XRay.html. +// +// A function with the XRAY_ALWAYS_INSTRUMENT macro attribute in its declaration +// will always get the XRay instrumentation sleds. These sleds may introduce +// some binary size and runtime overhead and must be used sparingly. +// +// These attributes only take effect when the following conditions are met: +// +// * The file/target is built in at least C++11 mode, with a Clang compiler +// that supports XRay attributes. +// * The file/target is built with the -fxray-instrument flag set for the +// Clang/LLVM compiler. +// * The function is defined in the translation unit (the compiler honors the +// attribute in either the definition or the declaration, and must match). +// +// There are cases when, even when building with XRay instrumentation, users +// might want to control specifically which functions are instrumented for a +// particular build using special-case lists provided to the compiler. These +// special case lists are provided to Clang via the +// -fxray-always-instrument=... and -fxray-never-instrument=... flags. The +// attributes in source take precedence over these special-case lists. +// +// To disable the XRay attributes at build-time, users may define +// ABSL_NO_XRAY_ATTRIBUTES. Do NOT define ABSL_NO_XRAY_ATTRIBUTES on specific +// packages/targets, as this may lead to conflicting definitions of functions at +// link-time. +// +// XRay isn't currently supported on Android: +// https://github.com/android/ndk/issues/368 +#if ABSL_HAVE_CPP_ATTRIBUTE(clang::xray_always_instrument) && \ + !defined(ABSL_NO_XRAY_ATTRIBUTES) && !defined(__ANDROID__) +#define ABSL_XRAY_ALWAYS_INSTRUMENT [[clang::xray_always_instrument]] +#define ABSL_XRAY_NEVER_INSTRUMENT [[clang::xray_never_instrument]] +#if ABSL_HAVE_CPP_ATTRIBUTE(clang::xray_log_args) +#define ABSL_XRAY_LOG_ARGS(N) \ + [[clang::xray_always_instrument, clang::xray_log_args(N)]] +#else +#define ABSL_XRAY_LOG_ARGS(N) [[clang::xray_always_instrument]] +#endif +#else +#define ABSL_XRAY_ALWAYS_INSTRUMENT +#define ABSL_XRAY_NEVER_INSTRUMENT +#define ABSL_XRAY_LOG_ARGS(N) +#endif + +// ABSL_ATTRIBUTE_REINITIALIZES +// +// Indicates that a member function reinitializes the entire object to a known +// state, independent of the previous state of the object. +// +// The clang-tidy check bugprone-use-after-move allows member functions marked +// with this attribute to be called on objects that have been moved from; +// without the attribute, this would result in a use-after-move warning. +#if ABSL_HAVE_CPP_ATTRIBUTE(clang::reinitializes) +#define ABSL_ATTRIBUTE_REINITIALIZES [[clang::reinitializes]] +#else +#define ABSL_ATTRIBUTE_REINITIALIZES +#endif + +// ----------------------------------------------------------------------------- +// Variable Attributes +// ----------------------------------------------------------------------------- + +// ABSL_ATTRIBUTE_UNUSED +// +// Prevents the compiler from complaining about variables that appear unused. +#if ABSL_HAVE_ATTRIBUTE(unused) || (defined(__GNUC__) && !defined(__clang__)) +#undef ABSL_ATTRIBUTE_UNUSED +#define ABSL_ATTRIBUTE_UNUSED __attribute__((__unused__)) +#else +#define ABSL_ATTRIBUTE_UNUSED +#endif + +// ABSL_ATTRIBUTE_INITIAL_EXEC +// +// Tells the compiler to use "initial-exec" mode for a thread-local variable. +// See http://people.redhat.com/drepper/tls.pdf for the gory details. +#if ABSL_HAVE_ATTRIBUTE(tls_model) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_INITIAL_EXEC __attribute__((tls_model("initial-exec"))) +#else +#define ABSL_ATTRIBUTE_INITIAL_EXEC +#endif + +// ABSL_ATTRIBUTE_PACKED +// +// Instructs the compiler not to use natural alignment for a tagged data +// structure, but instead to reduce its alignment to 1. This attribute can +// either be applied to members of a structure or to a structure in its +// entirety. Applying this attribute (judiciously) to a structure in its +// entirety to optimize the memory footprint of very commonly-used structs is +// fine. Do not apply this attribute to a structure in its entirety if the +// purpose is to control the offsets of the members in the structure. Instead, +// apply this attribute only to structure members that need it. +// +// When applying ABSL_ATTRIBUTE_PACKED only to specific structure members the +// natural alignment of structure members not annotated is preserved. Aligned +// member accesses are faster than non-aligned member accesses even if the +// targeted microprocessor supports non-aligned accesses. +#if ABSL_HAVE_ATTRIBUTE(packed) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_PACKED __attribute__((__packed__)) +#else +#define ABSL_ATTRIBUTE_PACKED +#endif + +// ABSL_ATTRIBUTE_FUNC_ALIGN +// +// Tells the compiler to align the function start at least to certain +// alignment boundary +#if ABSL_HAVE_ATTRIBUTE(aligned) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_ATTRIBUTE_FUNC_ALIGN(bytes) __attribute__((aligned(bytes))) +#else +#define ABSL_ATTRIBUTE_FUNC_ALIGN(bytes) +#endif + +// ABSL_CONST_INIT +// +// A variable declaration annotated with the `ABSL_CONST_INIT` attribute will +// not compile (on supported platforms) unless the variable has a constant +// initializer. This is useful for variables with static and thread storage +// duration, because it guarantees that they will not suffer from the so-called +// "static init order fiasco". Prefer to put this attribute on the most visible +// declaration of the variable, if there's more than one, because code that +// accesses the variable can then use the attribute for optimization. +// +// Example: +// +// class MyClass { +// public: +// ABSL_CONST_INIT static MyType my_var; +// }; +// +// MyType MyClass::my_var = MakeMyType(...); +// +// Note that this attribute is redundant if the variable is declared constexpr. +#if ABSL_HAVE_CPP_ATTRIBUTE(clang::require_constant_initialization) +#define ABSL_CONST_INIT [[clang::require_constant_initialization]] +#else +#define ABSL_CONST_INIT +#endif // ABSL_HAVE_CPP_ATTRIBUTE(clang::require_constant_initialization) + +#endif // ABSL_BASE_ATTRIBUTES_H_ diff --git a/third_party/abseil_cpp/absl/base/bit_cast_test.cc b/third_party/abseil_cpp/absl/base/bit_cast_test.cc new file mode 100644 index 0000000000..8a3a41ea02 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/bit_cast_test.cc @@ -0,0 +1,109 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Unit test for bit_cast template. + +#include <cstdint> +#include <cstring> + +#include "gtest/gtest.h" +#include "absl/base/casts.h" +#include "absl/base/macros.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +template <int N> +struct marshall { char buf[N]; }; + +template <typename T> +void TestMarshall(const T values[], int num_values) { + for (int i = 0; i < num_values; ++i) { + T t0 = values[i]; + marshall<sizeof(T)> m0 = absl::bit_cast<marshall<sizeof(T)> >(t0); + T t1 = absl::bit_cast<T>(m0); + marshall<sizeof(T)> m1 = absl::bit_cast<marshall<sizeof(T)> >(t1); + ASSERT_EQ(0, memcmp(&t0, &t1, sizeof(T))); + ASSERT_EQ(0, memcmp(&m0, &m1, sizeof(T))); + } +} + +// Convert back and forth to an integral type. The C++ standard does +// not guarantee this will work, but we test that this works on all the +// platforms we support. +// +// Likewise, we below make assumptions about sizeof(float) and +// sizeof(double) which the standard does not guarantee, but which hold on the +// platforms we support. + +template <typename T, typename I> +void TestIntegral(const T values[], int num_values) { + for (int i = 0; i < num_values; ++i) { + T t0 = values[i]; + I i0 = absl::bit_cast<I>(t0); + T t1 = absl::bit_cast<T>(i0); + I i1 = absl::bit_cast<I>(t1); + ASSERT_EQ(0, memcmp(&t0, &t1, sizeof(T))); + ASSERT_EQ(i0, i1); + } +} + +TEST(BitCast, Bool) { + static const bool bool_list[] = { false, true }; + TestMarshall<bool>(bool_list, ABSL_ARRAYSIZE(bool_list)); +} + +TEST(BitCast, Int32) { + static const int32_t int_list[] = + { 0, 1, 100, 2147483647, -1, -100, -2147483647, -2147483647-1 }; + TestMarshall<int32_t>(int_list, ABSL_ARRAYSIZE(int_list)); +} + +TEST(BitCast, Int64) { + static const int64_t int64_list[] = + { 0, 1, 1LL << 40, -1, -(1LL<<40) }; + TestMarshall<int64_t>(int64_list, ABSL_ARRAYSIZE(int64_list)); +} + +TEST(BitCast, Uint64) { + static const uint64_t uint64_list[] = + { 0, 1, 1LLU << 40, 1LLU << 63 }; + TestMarshall<uint64_t>(uint64_list, ABSL_ARRAYSIZE(uint64_list)); +} + +TEST(BitCast, Float) { + static const float float_list[] = + { 0.0f, 1.0f, -1.0f, 10.0f, -10.0f, + 1e10f, 1e20f, 1e-10f, 1e-20f, + 2.71828f, 3.14159f }; + TestMarshall<float>(float_list, ABSL_ARRAYSIZE(float_list)); + TestIntegral<float, int>(float_list, ABSL_ARRAYSIZE(float_list)); + TestIntegral<float, unsigned>(float_list, ABSL_ARRAYSIZE(float_list)); +} + +TEST(BitCast, Double) { + static const double double_list[] = + { 0.0, 1.0, -1.0, 10.0, -10.0, + 1e10, 1e100, 1e-10, 1e-100, + 2.718281828459045, + 3.141592653589793238462643383279502884197169399375105820974944 }; + TestMarshall<double>(double_list, ABSL_ARRAYSIZE(double_list)); + TestIntegral<double, int64_t>(double_list, ABSL_ARRAYSIZE(double_list)); + TestIntegral<double, uint64_t>(double_list, ABSL_ARRAYSIZE(double_list)); +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/call_once.h b/third_party/abseil_cpp/absl/base/call_once.h new file mode 100644 index 0000000000..bc5ec93704 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/call_once.h @@ -0,0 +1,226 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: call_once.h +// ----------------------------------------------------------------------------- +// +// This header file provides an Abseil version of `std::call_once` for invoking +// a given function at most once, across all threads. This Abseil version is +// faster than the C++11 version and incorporates the C++17 argument-passing +// fix, so that (for example) non-const references may be passed to the invoked +// function. + +#ifndef ABSL_BASE_CALL_ONCE_H_ +#define ABSL_BASE_CALL_ONCE_H_ + +#include <algorithm> +#include <atomic> +#include <cstdint> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/invoke.h" +#include "absl/base/internal/low_level_scheduling.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/internal/spinlock_wait.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class once_flag; + +namespace base_internal { +std::atomic<uint32_t>* ControlWord(absl::once_flag* flag); +} // namespace base_internal + +// call_once() +// +// For all invocations using a given `once_flag`, invokes a given `fn` exactly +// once across all threads. The first call to `call_once()` with a particular +// `once_flag` argument (that does not throw an exception) will run the +// specified function with the provided `args`; other calls with the same +// `once_flag` argument will not run the function, but will wait +// for the provided function to finish running (if it is still running). +// +// This mechanism provides a safe, simple, and fast mechanism for one-time +// initialization in a multi-threaded process. +// +// Example: +// +// class MyInitClass { +// public: +// ... +// mutable absl::once_flag once_; +// +// MyInitClass* init() const { +// absl::call_once(once_, &MyInitClass::Init, this); +// return ptr_; +// } +// +template <typename Callable, typename... Args> +void call_once(absl::once_flag& flag, Callable&& fn, Args&&... args); + +// once_flag +// +// Objects of this type are used to distinguish calls to `call_once()` and +// ensure the provided function is only invoked once across all threads. This +// type is not copyable or movable. However, it has a `constexpr` +// constructor, and is safe to use as a namespace-scoped global variable. +class once_flag { + public: + constexpr once_flag() : control_(0) {} + once_flag(const once_flag&) = delete; + once_flag& operator=(const once_flag&) = delete; + + private: + friend std::atomic<uint32_t>* base_internal::ControlWord(once_flag* flag); + std::atomic<uint32_t> control_; +}; + +//------------------------------------------------------------------------------ +// End of public interfaces. +// Implementation details follow. +//------------------------------------------------------------------------------ + +namespace base_internal { + +// Like call_once, but uses KERNEL_ONLY scheduling. Intended to be used to +// initialize entities used by the scheduler implementation. +template <typename Callable, typename... Args> +void LowLevelCallOnce(absl::once_flag* flag, Callable&& fn, Args&&... args); + +// Disables scheduling while on stack when scheduling mode is non-cooperative. +// No effect for cooperative scheduling modes. +class SchedulingHelper { + public: + explicit SchedulingHelper(base_internal::SchedulingMode mode) : mode_(mode) { + if (mode_ == base_internal::SCHEDULE_KERNEL_ONLY) { + guard_result_ = base_internal::SchedulingGuard::DisableRescheduling(); + } + } + + ~SchedulingHelper() { + if (mode_ == base_internal::SCHEDULE_KERNEL_ONLY) { + base_internal::SchedulingGuard::EnableRescheduling(guard_result_); + } + } + + private: + base_internal::SchedulingMode mode_; + bool guard_result_; +}; + +// Bit patterns for call_once state machine values. Internal implementation +// detail, not for use by clients. +// +// The bit patterns are arbitrarily chosen from unlikely values, to aid in +// debugging. However, kOnceInit must be 0, so that a zero-initialized +// once_flag will be valid for immediate use. +enum { + kOnceInit = 0, + kOnceRunning = 0x65C2937B, + kOnceWaiter = 0x05A308D2, + // A very small constant is chosen for kOnceDone so that it fit in a single + // compare with immediate instruction for most common ISAs. This is verified + // for x86, POWER and ARM. + kOnceDone = 221, // Random Number +}; + +template <typename Callable, typename... Args> +ABSL_ATTRIBUTE_NOINLINE +void CallOnceImpl(std::atomic<uint32_t>* control, + base_internal::SchedulingMode scheduling_mode, Callable&& fn, + Args&&... args) { +#ifndef NDEBUG + { + uint32_t old_control = control->load(std::memory_order_relaxed); + if (old_control != kOnceInit && + old_control != kOnceRunning && + old_control != kOnceWaiter && + old_control != kOnceDone) { + ABSL_RAW_LOG(FATAL, "Unexpected value for control word: 0x%lx", + static_cast<unsigned long>(old_control)); // NOLINT + } + } +#endif // NDEBUG + static const base_internal::SpinLockWaitTransition trans[] = { + {kOnceInit, kOnceRunning, true}, + {kOnceRunning, kOnceWaiter, false}, + {kOnceDone, kOnceDone, true}}; + + // Must do this before potentially modifying control word's state. + base_internal::SchedulingHelper maybe_disable_scheduling(scheduling_mode); + // Short circuit the simplest case to avoid procedure call overhead. + // The base_internal::SpinLockWait() call returns either kOnceInit or + // kOnceDone. If it returns kOnceDone, it must have loaded the control word + // with std::memory_order_acquire and seen a value of kOnceDone. + uint32_t old_control = kOnceInit; + if (control->compare_exchange_strong(old_control, kOnceRunning, + std::memory_order_relaxed) || + base_internal::SpinLockWait(control, ABSL_ARRAYSIZE(trans), trans, + scheduling_mode) == kOnceInit) { + base_internal::Invoke(std::forward<Callable>(fn), + std::forward<Args>(args)...); + // The call to SpinLockWake below is an optimization, because the waiter + // in SpinLockWait is waiting with a short timeout. The atomic load/store + // sequence is slightly faster than an atomic exchange: + // old_control = control->exchange(base_internal::kOnceDone, + // std::memory_order_release); + // We opt for a slightly faster case when there are no waiters, in spite + // of longer tail latency when there are waiters. + old_control = control->load(std::memory_order_relaxed); + control->store(base_internal::kOnceDone, std::memory_order_release); + if (old_control == base_internal::kOnceWaiter) { + base_internal::SpinLockWake(control, true); + } + } // else *control is already kOnceDone +} + +inline std::atomic<uint32_t>* ControlWord(once_flag* flag) { + return &flag->control_; +} + +template <typename Callable, typename... Args> +void LowLevelCallOnce(absl::once_flag* flag, Callable&& fn, Args&&... args) { + std::atomic<uint32_t>* once = base_internal::ControlWord(flag); + uint32_t s = once->load(std::memory_order_acquire); + if (ABSL_PREDICT_FALSE(s != base_internal::kOnceDone)) { + base_internal::CallOnceImpl(once, base_internal::SCHEDULE_KERNEL_ONLY, + std::forward<Callable>(fn), + std::forward<Args>(args)...); + } +} + +} // namespace base_internal + +template <typename Callable, typename... Args> +void call_once(absl::once_flag& flag, Callable&& fn, Args&&... args) { + std::atomic<uint32_t>* once = base_internal::ControlWord(&flag); + uint32_t s = once->load(std::memory_order_acquire); + if (ABSL_PREDICT_FALSE(s != base_internal::kOnceDone)) { + base_internal::CallOnceImpl( + once, base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL, + std::forward<Callable>(fn), std::forward<Args>(args)...); + } +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_CALL_ONCE_H_ diff --git a/third_party/abseil_cpp/absl/base/call_once_test.cc b/third_party/abseil_cpp/absl/base/call_once_test.cc new file mode 100644 index 0000000000..11d26c44d1 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/call_once_test.cc @@ -0,0 +1,107 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/call_once.h" + +#include <thread> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/const_init.h" +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +absl::once_flag once; + +ABSL_CONST_INIT Mutex counters_mu(absl::kConstInit); + +int running_thread_count ABSL_GUARDED_BY(counters_mu) = 0; +int call_once_invoke_count ABSL_GUARDED_BY(counters_mu) = 0; +int call_once_finished_count ABSL_GUARDED_BY(counters_mu) = 0; +int call_once_return_count ABSL_GUARDED_BY(counters_mu) = 0; +bool done_blocking ABSL_GUARDED_BY(counters_mu) = false; + +// Function to be called from absl::call_once. Waits for a notification. +void WaitAndIncrement() { + counters_mu.Lock(); + ++call_once_invoke_count; + counters_mu.Unlock(); + + counters_mu.LockWhen(Condition(&done_blocking)); + ++call_once_finished_count; + counters_mu.Unlock(); +} + +void ThreadBody() { + counters_mu.Lock(); + ++running_thread_count; + counters_mu.Unlock(); + + absl::call_once(once, WaitAndIncrement); + + counters_mu.Lock(); + ++call_once_return_count; + counters_mu.Unlock(); +} + +// Returns true if all threads are set up for the test. +bool ThreadsAreSetup(void*) ABSL_EXCLUSIVE_LOCKS_REQUIRED(counters_mu) { + // All ten threads must be running, and WaitAndIncrement should be blocked. + return running_thread_count == 10 && call_once_invoke_count == 1; +} + +TEST(CallOnceTest, ExecutionCount) { + std::vector<std::thread> threads; + + // Start 10 threads all calling call_once on the same once_flag. + for (int i = 0; i < 10; ++i) { + threads.emplace_back(ThreadBody); + } + + + // Wait until all ten threads have started, and WaitAndIncrement has been + // invoked. + counters_mu.LockWhen(Condition(ThreadsAreSetup, nullptr)); + + // WaitAndIncrement should have been invoked by exactly one call_once() + // instance. That thread should be blocking on a notification, and all other + // call_once instances should be blocking as well. + EXPECT_EQ(call_once_invoke_count, 1); + EXPECT_EQ(call_once_finished_count, 0); + EXPECT_EQ(call_once_return_count, 0); + + // Allow WaitAndIncrement to finish executing. Once it does, the other + // call_once waiters will be unblocked. + done_blocking = true; + counters_mu.Unlock(); + + for (std::thread& thread : threads) { + thread.join(); + } + + counters_mu.Lock(); + EXPECT_EQ(call_once_invoke_count, 1); + EXPECT_EQ(call_once_finished_count, 1); + EXPECT_EQ(call_once_return_count, 10); + counters_mu.Unlock(); +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/casts.h b/third_party/abseil_cpp/absl/base/casts.h new file mode 100644 index 0000000000..322cc1d243 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/casts.h @@ -0,0 +1,184 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: casts.h +// ----------------------------------------------------------------------------- +// +// This header file defines casting templates to fit use cases not covered by +// the standard casts provided in the C++ standard. As with all cast operations, +// use these with caution and only if alternatives do not exist. + +#ifndef ABSL_BASE_CASTS_H_ +#define ABSL_BASE_CASTS_H_ + +#include <cstring> +#include <memory> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/identity.h" +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace internal_casts { + +template <class Dest, class Source> +struct is_bitcastable + : std::integral_constant< + bool, + sizeof(Dest) == sizeof(Source) && + type_traits_internal::is_trivially_copyable<Source>::value && + type_traits_internal::is_trivially_copyable<Dest>::value && + std::is_default_constructible<Dest>::value> {}; + +} // namespace internal_casts + +// implicit_cast() +// +// Performs an implicit conversion between types following the language +// rules for implicit conversion; if an implicit conversion is otherwise +// allowed by the language in the given context, this function performs such an +// implicit conversion. +// +// Example: +// +// // If the context allows implicit conversion: +// From from; +// To to = from; +// +// // Such code can be replaced by: +// implicit_cast<To>(from); +// +// An `implicit_cast()` may also be used to annotate numeric type conversions +// that, although safe, may produce compiler warnings (such as `long` to `int`). +// Additionally, an `implicit_cast()` is also useful within return statements to +// indicate a specific implicit conversion is being undertaken. +// +// Example: +// +// return implicit_cast<double>(size_in_bytes) / capacity_; +// +// Annotating code with `implicit_cast()` allows you to explicitly select +// particular overloads and template instantiations, while providing a safer +// cast than `reinterpret_cast()` or `static_cast()`. +// +// Additionally, an `implicit_cast()` can be used to allow upcasting within a +// type hierarchy where incorrect use of `static_cast()` could accidentally +// allow downcasting. +// +// Finally, an `implicit_cast()` can be used to perform implicit conversions +// from unrelated types that otherwise couldn't be implicitly cast directly; +// C++ will normally only implicitly cast "one step" in such conversions. +// +// That is, if C is a type which can be implicitly converted to B, with B being +// a type that can be implicitly converted to A, an `implicit_cast()` can be +// used to convert C to B (which the compiler can then implicitly convert to A +// using language rules). +// +// Example: +// +// // Assume an object C is convertible to B, which is implicitly convertible +// // to A +// A a = implicit_cast<B>(C); +// +// Such implicit cast chaining may be useful within template logic. +template <typename To> +constexpr To implicit_cast(typename absl::internal::identity_t<To> to) { + return to; +} + +// bit_cast() +// +// Performs a bitwise cast on a type without changing the underlying bit +// representation of that type's value. The two types must be of the same size +// and both types must be trivially copyable. As with most casts, use with +// caution. A `bit_cast()` might be needed when you need to temporarily treat a +// type as some other type, such as in the following cases: +// +// * Serialization (casting temporarily to `char *` for those purposes is +// always allowed by the C++ standard) +// * Managing the individual bits of a type within mathematical operations +// that are not normally accessible through that type +// * Casting non-pointer types to pointer types (casting the other way is +// allowed by `reinterpret_cast()` but round-trips cannot occur the other +// way). +// +// Example: +// +// float f = 3.14159265358979; +// int i = bit_cast<int32_t>(f); +// // i = 0x40490fdb +// +// Casting non-pointer types to pointer types and then dereferencing them +// traditionally produces undefined behavior. +// +// Example: +// +// // WRONG +// float f = 3.14159265358979; // WRONG +// int i = * reinterpret_cast<int*>(&f); // WRONG +// +// The address-casting method produces undefined behavior according to the ISO +// C++ specification section [basic.lval]. Roughly, this section says: if an +// object in memory has one type, and a program accesses it with a different +// type, the result is undefined behavior for most values of "different type". +// +// Such casting results in type punning: holding an object in memory of one type +// and reading its bits back using a different type. A `bit_cast()` avoids this +// issue by implementing its casts using `memcpy()`, which avoids introducing +// this undefined behavior. +// +// NOTE: The requirements here are more strict than the bit_cast of standard +// proposal p0476 due to the need for workarounds and lack of intrinsics. +// Specifically, this implementation also requires `Dest` to be +// default-constructible. +template < + typename Dest, typename Source, + typename std::enable_if<internal_casts::is_bitcastable<Dest, Source>::value, + int>::type = 0> +inline Dest bit_cast(const Source& source) { + Dest dest; + memcpy(static_cast<void*>(std::addressof(dest)), + static_cast<const void*>(std::addressof(source)), sizeof(dest)); + return dest; +} + +// NOTE: This overload is only picked if the requirements of bit_cast are not +// met. It is therefore UB, but is provided temporarily as previous versions of +// this function template were unchecked. Do not use this in new code. +template < + typename Dest, typename Source, + typename std::enable_if< + !internal_casts::is_bitcastable<Dest, Source>::value, int>::type = 0> +ABSL_DEPRECATED( + "absl::bit_cast type requirements were violated. Update the types being " + "used such that they are the same size and are both TriviallyCopyable.") +inline Dest bit_cast(const Source& source) { + static_assert(sizeof(Dest) == sizeof(Source), + "Source and destination types should have equal sizes."); + + Dest dest; + memcpy(&dest, &source, sizeof(dest)); + return dest; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_CASTS_H_ diff --git a/third_party/abseil_cpp/absl/base/config.h b/third_party/abseil_cpp/absl/base/config.h new file mode 100644 index 0000000000..f54466deeb --- /dev/null +++ b/third_party/abseil_cpp/absl/base/config.h @@ -0,0 +1,664 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: config.h +// ----------------------------------------------------------------------------- +// +// This header file defines a set of macros for checking the presence of +// important compiler and platform features. Such macros can be used to +// produce portable code by parameterizing compilation based on the presence or +// lack of a given feature. +// +// We define a "feature" as some interface we wish to program to: for example, +// a library function or system call. A value of `1` indicates support for +// that feature; any other value indicates the feature support is undefined. +// +// Example: +// +// Suppose a programmer wants to write a program that uses the 'mmap()' system +// call. The Abseil macro for that feature (`ABSL_HAVE_MMAP`) allows you to +// selectively include the `mmap.h` header and bracket code using that feature +// in the macro: +// +// #include "absl/base/config.h" +// +// #ifdef ABSL_HAVE_MMAP +// #include "sys/mman.h" +// #endif //ABSL_HAVE_MMAP +// +// ... +// #ifdef ABSL_HAVE_MMAP +// void *ptr = mmap(...); +// ... +// #endif // ABSL_HAVE_MMAP + +#ifndef ABSL_BASE_CONFIG_H_ +#define ABSL_BASE_CONFIG_H_ + +// Included for the __GLIBC__ macro (or similar macros on other systems). +#include <limits.h> + +#ifdef __cplusplus +// Included for __GLIBCXX__, _LIBCPP_VERSION +#include <cstddef> +#endif // __cplusplus + +#if defined(__APPLE__) +// Included for TARGET_OS_IPHONE, __IPHONE_OS_VERSION_MIN_REQUIRED, +// __IPHONE_8_0. +#include <Availability.h> +#include <TargetConditionals.h> +#endif + +#include "absl/base/options.h" +#include "absl/base/policy_checks.h" + +// Helper macro to convert a CPP variable to a string literal. +#define ABSL_INTERNAL_DO_TOKEN_STR(x) #x +#define ABSL_INTERNAL_TOKEN_STR(x) ABSL_INTERNAL_DO_TOKEN_STR(x) + +// ----------------------------------------------------------------------------- +// Abseil namespace annotations +// ----------------------------------------------------------------------------- + +// ABSL_NAMESPACE_BEGIN/ABSL_NAMESPACE_END +// +// An annotation placed at the beginning/end of each `namespace absl` scope. +// This is used to inject an inline namespace. +// +// The proper way to write Abseil code in the `absl` namespace is: +// +// namespace absl { +// ABSL_NAMESPACE_BEGIN +// +// void Foo(); // absl::Foo(). +// +// ABSL_NAMESPACE_END +// } // namespace absl +// +// Users of Abseil should not use these macros, because users of Abseil should +// not write `namespace absl {` in their own code for any reason. (Abseil does +// not support forward declarations of its own types, nor does it support +// user-provided specialization of Abseil templates. Code that violates these +// rules may be broken without warning.) +#if !defined(ABSL_OPTION_USE_INLINE_NAMESPACE) || \ + !defined(ABSL_OPTION_INLINE_NAMESPACE_NAME) +#error options.h is misconfigured. +#endif + +// Check that ABSL_OPTION_INLINE_NAMESPACE_NAME is neither "head" nor "" +#if defined(__cplusplus) && ABSL_OPTION_USE_INLINE_NAMESPACE == 1 + +#define ABSL_INTERNAL_INLINE_NAMESPACE_STR \ + ABSL_INTERNAL_TOKEN_STR(ABSL_OPTION_INLINE_NAMESPACE_NAME) + +static_assert(ABSL_INTERNAL_INLINE_NAMESPACE_STR[0] != '\0', + "options.h misconfigured: ABSL_OPTION_INLINE_NAMESPACE_NAME must " + "not be empty."); +static_assert(ABSL_INTERNAL_INLINE_NAMESPACE_STR[0] != 'h' || + ABSL_INTERNAL_INLINE_NAMESPACE_STR[1] != 'e' || + ABSL_INTERNAL_INLINE_NAMESPACE_STR[2] != 'a' || + ABSL_INTERNAL_INLINE_NAMESPACE_STR[3] != 'd' || + ABSL_INTERNAL_INLINE_NAMESPACE_STR[4] != '\0', + "options.h misconfigured: ABSL_OPTION_INLINE_NAMESPACE_NAME must " + "be changed to a new, unique identifier name."); + +#endif + +#if ABSL_OPTION_USE_INLINE_NAMESPACE == 0 +#define ABSL_NAMESPACE_BEGIN +#define ABSL_NAMESPACE_END +#elif ABSL_OPTION_USE_INLINE_NAMESPACE == 1 +#define ABSL_NAMESPACE_BEGIN \ + inline namespace ABSL_OPTION_INLINE_NAMESPACE_NAME { +#define ABSL_NAMESPACE_END } +#else +#error options.h is misconfigured. +#endif + +// ----------------------------------------------------------------------------- +// Compiler Feature Checks +// ----------------------------------------------------------------------------- + +// ABSL_HAVE_BUILTIN() +// +// Checks whether the compiler supports a Clang Feature Checking Macro, and if +// so, checks whether it supports the provided builtin function "x" where x +// is one of the functions noted in +// https://clang.llvm.org/docs/LanguageExtensions.html +// +// Note: Use this macro to avoid an extra level of #ifdef __has_builtin check. +// http://releases.llvm.org/3.3/tools/clang/docs/LanguageExtensions.html +#ifdef __has_builtin +#define ABSL_HAVE_BUILTIN(x) __has_builtin(x) +#else +#define ABSL_HAVE_BUILTIN(x) 0 +#endif + +#if defined(__is_identifier) +#define ABSL_INTERNAL_HAS_KEYWORD(x) !(__is_identifier(x)) +#else +#define ABSL_INTERNAL_HAS_KEYWORD(x) 0 +#endif + +// ABSL_HAVE_TLS is defined to 1 when __thread should be supported. +// We assume __thread is supported on Linux when compiled with Clang or compiled +// against libstdc++ with _GLIBCXX_HAVE_TLS defined. +#ifdef ABSL_HAVE_TLS +#error ABSL_HAVE_TLS cannot be directly set +#elif defined(__linux__) && (defined(__clang__) || defined(_GLIBCXX_HAVE_TLS)) +#define ABSL_HAVE_TLS 1 +#endif + +// ABSL_HAVE_STD_IS_TRIVIALLY_DESTRUCTIBLE +// +// Checks whether `std::is_trivially_destructible<T>` is supported. +// +// Notes: All supported compilers using libc++ support this feature, as does +// gcc >= 4.8.1 using libstdc++, and Visual Studio. +#ifdef ABSL_HAVE_STD_IS_TRIVIALLY_DESTRUCTIBLE +#error ABSL_HAVE_STD_IS_TRIVIALLY_DESTRUCTIBLE cannot be directly set +#elif defined(_LIBCPP_VERSION) || \ + (!defined(__clang__) && defined(__GNUC__) && defined(__GLIBCXX__) && \ + (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 8))) || \ + defined(_MSC_VER) +#define ABSL_HAVE_STD_IS_TRIVIALLY_DESTRUCTIBLE 1 +#endif + +// ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE +// +// Checks whether `std::is_trivially_default_constructible<T>` and +// `std::is_trivially_copy_constructible<T>` are supported. + +// ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE +// +// Checks whether `std::is_trivially_copy_assignable<T>` is supported. + +// Notes: Clang with libc++ supports these features, as does gcc >= 5.1 with +// either libc++ or libstdc++, and Visual Studio (but not NVCC). +#if defined(ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE) +#error ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE cannot be directly set +#elif defined(ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE) +#error ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE cannot directly set +#elif (defined(__clang__) && defined(_LIBCPP_VERSION)) || \ + (!defined(__clang__) && defined(__GNUC__) && \ + (__GNUC__ > 7 || (__GNUC__ == 7 && __GNUC_MINOR__ >= 4)) && \ + (defined(_LIBCPP_VERSION) || defined(__GLIBCXX__))) || \ + (defined(_MSC_VER) && !defined(__NVCC__)) +#define ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE 1 +#define ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE 1 +#endif + +// ABSL_HAVE_SOURCE_LOCATION_CURRENT +// +// Indicates whether `absl::SourceLocation::current()` will return useful +// information in some contexts. +#ifndef ABSL_HAVE_SOURCE_LOCATION_CURRENT +#if ABSL_INTERNAL_HAS_KEYWORD(__builtin_LINE) && \ + ABSL_INTERNAL_HAS_KEYWORD(__builtin_FILE) +#define ABSL_HAVE_SOURCE_LOCATION_CURRENT 1 +#endif +#endif + +// ABSL_HAVE_THREAD_LOCAL +// +// Checks whether C++11's `thread_local` storage duration specifier is +// supported. +#ifdef ABSL_HAVE_THREAD_LOCAL +#error ABSL_HAVE_THREAD_LOCAL cannot be directly set +#elif defined(__APPLE__) +// Notes: +// * Xcode's clang did not support `thread_local` until version 8, and +// even then not for all iOS < 9.0. +// * Xcode 9.3 started disallowing `thread_local` for 32-bit iOS simulator +// targeting iOS 9.x. +// * Xcode 10 moves the deployment target check for iOS < 9.0 to link time +// making __has_feature unreliable there. +// +// Otherwise, `__has_feature` is only supported by Clang so it has be inside +// `defined(__APPLE__)` check. +#if __has_feature(cxx_thread_local) && \ + !(TARGET_OS_IPHONE && __IPHONE_OS_VERSION_MIN_REQUIRED < __IPHONE_9_0) +#define ABSL_HAVE_THREAD_LOCAL 1 +#endif +#else // !defined(__APPLE__) +#define ABSL_HAVE_THREAD_LOCAL 1 +#endif + +// There are platforms for which TLS should not be used even though the compiler +// makes it seem like it's supported (Android NDK < r12b for example). +// This is primarily because of linker problems and toolchain misconfiguration: +// Abseil does not intend to support this indefinitely. Currently, the newest +// toolchain that we intend to support that requires this behavior is the +// r11 NDK - allowing for a 5 year support window on that means this option +// is likely to be removed around June of 2021. +// TLS isn't supported until NDK r12b per +// https://developer.android.com/ndk/downloads/revision_history.html +// Since NDK r16, `__NDK_MAJOR__` and `__NDK_MINOR__` are defined in +// <android/ndk-version.h>. For NDK < r16, users should define these macros, +// e.g. `-D__NDK_MAJOR__=11 -D__NKD_MINOR__=0` for NDK r11. +#if defined(__ANDROID__) && defined(__clang__) +#if __has_include(<android/ndk-version.h>) +#include <android/ndk-version.h> +#endif // __has_include(<android/ndk-version.h>) +#if defined(__ANDROID__) && defined(__clang__) && defined(__NDK_MAJOR__) && \ + defined(__NDK_MINOR__) && \ + ((__NDK_MAJOR__ < 12) || ((__NDK_MAJOR__ == 12) && (__NDK_MINOR__ < 1))) +#undef ABSL_HAVE_TLS +#undef ABSL_HAVE_THREAD_LOCAL +#endif +#endif // defined(__ANDROID__) && defined(__clang__) + +// ABSL_HAVE_INTRINSIC_INT128 +// +// Checks whether the __int128 compiler extension for a 128-bit integral type is +// supported. +// +// Note: __SIZEOF_INT128__ is defined by Clang and GCC when __int128 is +// supported, but we avoid using it in certain cases: +// * On Clang: +// * Building using Clang for Windows, where the Clang runtime library has +// 128-bit support only on LP64 architectures, but Windows is LLP64. +// * On Nvidia's nvcc: +// * nvcc also defines __GNUC__ and __SIZEOF_INT128__, but not all versions +// actually support __int128. +#ifdef ABSL_HAVE_INTRINSIC_INT128 +#error ABSL_HAVE_INTRINSIC_INT128 cannot be directly set +#elif defined(__SIZEOF_INT128__) +#if (defined(__clang__) && !defined(_WIN32)) || \ + (defined(__CUDACC__) && __CUDACC_VER_MAJOR__ >= 9) || \ + (defined(__GNUC__) && !defined(__clang__) && !defined(__CUDACC__)) +#define ABSL_HAVE_INTRINSIC_INT128 1 +#elif defined(__CUDACC__) +// __CUDACC_VER__ is a full version number before CUDA 9, and is defined to a +// string explaining that it has been removed starting with CUDA 9. We use +// nested #ifs because there is no short-circuiting in the preprocessor. +// NOTE: `__CUDACC__` could be undefined while `__CUDACC_VER__` is defined. +#if __CUDACC_VER__ >= 70000 +#define ABSL_HAVE_INTRINSIC_INT128 1 +#endif // __CUDACC_VER__ >= 70000 +#endif // defined(__CUDACC__) +#endif // ABSL_HAVE_INTRINSIC_INT128 + +// ABSL_HAVE_EXCEPTIONS +// +// Checks whether the compiler both supports and enables exceptions. Many +// compilers support a "no exceptions" mode that disables exceptions. +// +// Generally, when ABSL_HAVE_EXCEPTIONS is not defined: +// +// * Code using `throw` and `try` may not compile. +// * The `noexcept` specifier will still compile and behave as normal. +// * The `noexcept` operator may still return `false`. +// +// For further details, consult the compiler's documentation. +#ifdef ABSL_HAVE_EXCEPTIONS +#error ABSL_HAVE_EXCEPTIONS cannot be directly set. + +#elif defined(__clang__) + +#if __clang_major__ > 3 || (__clang_major__ == 3 && __clang_minor__ >= 6) +// Clang >= 3.6 +#if __has_feature(cxx_exceptions) +#define ABSL_HAVE_EXCEPTIONS 1 +#endif // __has_feature(cxx_exceptions) +#else +// Clang < 3.6 +// http://releases.llvm.org/3.6.0/tools/clang/docs/ReleaseNotes.html#the-exceptions-macro +#if defined(__EXCEPTIONS) && __has_feature(cxx_exceptions) +#define ABSL_HAVE_EXCEPTIONS 1 +#endif // defined(__EXCEPTIONS) && __has_feature(cxx_exceptions) +#endif // __clang_major__ > 3 || (__clang_major__ == 3 && __clang_minor__ >= 6) + +// Handle remaining special cases and default to exceptions being supported. +#elif !(defined(__GNUC__) && (__GNUC__ < 5) && !defined(__EXCEPTIONS)) && \ + !(defined(__GNUC__) && (__GNUC__ >= 5) && !defined(__cpp_exceptions)) && \ + !(defined(_MSC_VER) && !defined(_CPPUNWIND)) +#define ABSL_HAVE_EXCEPTIONS 1 +#endif + +// ----------------------------------------------------------------------------- +// Platform Feature Checks +// ----------------------------------------------------------------------------- + +// Currently supported operating systems and associated preprocessor +// symbols: +// +// Linux and Linux-derived __linux__ +// Android __ANDROID__ (implies __linux__) +// Linux (non-Android) __linux__ && !__ANDROID__ +// Darwin (macOS and iOS) __APPLE__ +// Akaros (http://akaros.org) __ros__ +// Windows _WIN32 +// NaCL __native_client__ +// AsmJS __asmjs__ +// WebAssembly __wasm__ +// Fuchsia __Fuchsia__ +// +// Note that since Android defines both __ANDROID__ and __linux__, one +// may probe for either Linux or Android by simply testing for __linux__. + +// ABSL_HAVE_MMAP +// +// Checks whether the platform has an mmap(2) implementation as defined in +// POSIX.1-2001. +#ifdef ABSL_HAVE_MMAP +#error ABSL_HAVE_MMAP cannot be directly set +#elif defined(__linux__) || defined(__APPLE__) || defined(__FreeBSD__) || \ + defined(__ros__) || defined(__native_client__) || defined(__asmjs__) || \ + defined(__wasm__) || defined(__Fuchsia__) || defined(__sun) || \ + defined(__ASYLO__) +#define ABSL_HAVE_MMAP 1 +#endif + +// ABSL_HAVE_PTHREAD_GETSCHEDPARAM +// +// Checks whether the platform implements the pthread_(get|set)schedparam(3) +// functions as defined in POSIX.1-2001. +#ifdef ABSL_HAVE_PTHREAD_GETSCHEDPARAM +#error ABSL_HAVE_PTHREAD_GETSCHEDPARAM cannot be directly set +#elif defined(__linux__) || defined(__APPLE__) || defined(__FreeBSD__) || \ + defined(__ros__) +#define ABSL_HAVE_PTHREAD_GETSCHEDPARAM 1 +#endif + +// ABSL_HAVE_SCHED_YIELD +// +// Checks whether the platform implements sched_yield(2) as defined in +// POSIX.1-2001. +#ifdef ABSL_HAVE_SCHED_YIELD +#error ABSL_HAVE_SCHED_YIELD cannot be directly set +#elif defined(__linux__) || defined(__ros__) || defined(__native_client__) +#define ABSL_HAVE_SCHED_YIELD 1 +#endif + +// ABSL_HAVE_SEMAPHORE_H +// +// Checks whether the platform supports the <semaphore.h> header and sem_init(3) +// family of functions as standardized in POSIX.1-2001. +// +// Note: While Apple provides <semaphore.h> for both iOS and macOS, it is +// explicitly deprecated and will cause build failures if enabled for those +// platforms. We side-step the issue by not defining it here for Apple +// platforms. +#ifdef ABSL_HAVE_SEMAPHORE_H +#error ABSL_HAVE_SEMAPHORE_H cannot be directly set +#elif defined(__linux__) || defined(__ros__) +#define ABSL_HAVE_SEMAPHORE_H 1 +#endif + +// ABSL_HAVE_ALARM +// +// Checks whether the platform supports the <signal.h> header and alarm(2) +// function as standardized in POSIX.1-2001. +#ifdef ABSL_HAVE_ALARM +#error ABSL_HAVE_ALARM cannot be directly set +#elif defined(__GOOGLE_GRTE_VERSION__) +// feature tests for Google's GRTE +#define ABSL_HAVE_ALARM 1 +#elif defined(__GLIBC__) +// feature test for glibc +#define ABSL_HAVE_ALARM 1 +#elif defined(_MSC_VER) +// feature tests for Microsoft's library +#elif defined(__MINGW32__) +// mingw32 doesn't provide alarm(2): +// https://osdn.net/projects/mingw/scm/git/mingw-org-wsl/blobs/5.2-trunk/mingwrt/include/unistd.h +// mingw-w64 provides a no-op implementation: +// https://sourceforge.net/p/mingw-w64/mingw-w64/ci/master/tree/mingw-w64-crt/misc/alarm.c +#elif defined(__EMSCRIPTEN__) +// emscripten doesn't support signals +#elif defined(__Fuchsia__) +// Signals don't exist on fuchsia. +#elif defined(__native_client__) +#else +// other standard libraries +#define ABSL_HAVE_ALARM 1 +#endif + +// ABSL_IS_LITTLE_ENDIAN +// ABSL_IS_BIG_ENDIAN +// +// Checks the endianness of the platform. +// +// Notes: uses the built in endian macros provided by GCC (since 4.6) and +// Clang (since 3.2); see +// https://gcc.gnu.org/onlinedocs/cpp/Common-Predefined-Macros.html. +// Otherwise, if _WIN32, assume little endian. Otherwise, bail with an error. +#if defined(ABSL_IS_BIG_ENDIAN) +#error "ABSL_IS_BIG_ENDIAN cannot be directly set." +#endif +#if defined(ABSL_IS_LITTLE_ENDIAN) +#error "ABSL_IS_LITTLE_ENDIAN cannot be directly set." +#endif + +#if (defined(__BYTE_ORDER__) && defined(__ORDER_LITTLE_ENDIAN__) && \ + __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__) +#define ABSL_IS_LITTLE_ENDIAN 1 +#elif defined(__BYTE_ORDER__) && defined(__ORDER_BIG_ENDIAN__) && \ + __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__ +#define ABSL_IS_BIG_ENDIAN 1 +#elif defined(_WIN32) +#define ABSL_IS_LITTLE_ENDIAN 1 +#else +#error "absl endian detection needs to be set up for your compiler" +#endif + +// macOS 10.13 and iOS 10.11 don't let you use <any>, <optional>, or <variant> +// even though the headers exist and are publicly noted to work. See +// https://github.com/abseil/abseil-cpp/issues/207 and +// https://developer.apple.com/documentation/xcode_release_notes/xcode_10_release_notes +// libc++ spells out the availability requirements in the file +// llvm-project/libcxx/include/__config via the #define +// _LIBCPP_AVAILABILITY_BAD_OPTIONAL_ACCESS. +#if defined(__APPLE__) && defined(_LIBCPP_VERSION) && \ + ((defined(__ENVIRONMENT_MAC_OS_X_VERSION_MIN_REQUIRED__) && \ + __ENVIRONMENT_MAC_OS_X_VERSION_MIN_REQUIRED__ < 101400) || \ + (defined(__ENVIRONMENT_IPHONE_OS_VERSION_MIN_REQUIRED__) && \ + __ENVIRONMENT_IPHONE_OS_VERSION_MIN_REQUIRED__ < 120000) || \ + (defined(__ENVIRONMENT_WATCH_OS_VERSION_MIN_REQUIRED__) && \ + __ENVIRONMENT_WATCH_OS_VERSION_MIN_REQUIRED__ < 120000) || \ + (defined(__ENVIRONMENT_TV_OS_VERSION_MIN_REQUIRED__) && \ + __ENVIRONMENT_TV_OS_VERSION_MIN_REQUIRED__ < 50000)) +#define ABSL_INTERNAL_APPLE_CXX17_TYPES_UNAVAILABLE 1 +#else +#define ABSL_INTERNAL_APPLE_CXX17_TYPES_UNAVAILABLE 0 +#endif + +// ABSL_HAVE_STD_ANY +// +// Checks whether C++17 std::any is available by checking whether <any> exists. +#ifdef ABSL_HAVE_STD_ANY +#error "ABSL_HAVE_STD_ANY cannot be directly set." +#endif + +#ifdef __has_include +#if __has_include(<any>) && __cplusplus >= 201703L && \ + !ABSL_INTERNAL_APPLE_CXX17_TYPES_UNAVAILABLE +#define ABSL_HAVE_STD_ANY 1 +#endif +#endif + +// ABSL_HAVE_STD_OPTIONAL +// +// Checks whether C++17 std::optional is available. +#ifdef ABSL_HAVE_STD_OPTIONAL +#error "ABSL_HAVE_STD_OPTIONAL cannot be directly set." +#endif + +#ifdef __has_include +#if __has_include(<optional>) && __cplusplus >= 201703L && \ + !ABSL_INTERNAL_APPLE_CXX17_TYPES_UNAVAILABLE +#define ABSL_HAVE_STD_OPTIONAL 1 +#endif +#endif + +// ABSL_HAVE_STD_VARIANT +// +// Checks whether C++17 std::variant is available. +#ifdef ABSL_HAVE_STD_VARIANT +#error "ABSL_HAVE_STD_VARIANT cannot be directly set." +#endif + +#ifdef __has_include +#if __has_include(<variant>) && __cplusplus >= 201703L && \ + !ABSL_INTERNAL_APPLE_CXX17_TYPES_UNAVAILABLE +#define ABSL_HAVE_STD_VARIANT 1 +#endif +#endif + +// ABSL_HAVE_STD_STRING_VIEW +// +// Checks whether C++17 std::string_view is available. +#ifdef ABSL_HAVE_STD_STRING_VIEW +#error "ABSL_HAVE_STD_STRING_VIEW cannot be directly set." +#endif + +#ifdef __has_include +#if __has_include(<string_view>) && __cplusplus >= 201703L +#define ABSL_HAVE_STD_STRING_VIEW 1 +#endif +#endif + +// For MSVC, `__has_include` is supported in VS 2017 15.3, which is later than +// the support for <optional>, <any>, <string_view>, <variant>. So we use +// _MSC_VER to check whether we have VS 2017 RTM (when <optional>, <any>, +// <string_view>, <variant> is implemented) or higher. Also, `__cplusplus` is +// not correctly set by MSVC, so we use `_MSVC_LANG` to check the language +// version. +// TODO(zhangxy): fix tests before enabling aliasing for `std::any`. +#if defined(_MSC_VER) && _MSC_VER >= 1910 && \ + ((defined(_MSVC_LANG) && _MSVC_LANG > 201402) || __cplusplus > 201402) +// #define ABSL_HAVE_STD_ANY 1 +#define ABSL_HAVE_STD_OPTIONAL 1 +#define ABSL_HAVE_STD_VARIANT 1 +#define ABSL_HAVE_STD_STRING_VIEW 1 +#endif + +// ABSL_USES_STD_ANY +// +// Indicates whether absl::any is an alias for std::any. +#if !defined(ABSL_OPTION_USE_STD_ANY) +#error options.h is misconfigured. +#elif ABSL_OPTION_USE_STD_ANY == 0 || \ + (ABSL_OPTION_USE_STD_ANY == 2 && !defined(ABSL_HAVE_STD_ANY)) +#undef ABSL_USES_STD_ANY +#elif ABSL_OPTION_USE_STD_ANY == 1 || \ + (ABSL_OPTION_USE_STD_ANY == 2 && defined(ABSL_HAVE_STD_ANY)) +#define ABSL_USES_STD_ANY 1 +#else +#error options.h is misconfigured. +#endif + +// ABSL_USES_STD_OPTIONAL +// +// Indicates whether absl::optional is an alias for std::optional. +#if !defined(ABSL_OPTION_USE_STD_OPTIONAL) +#error options.h is misconfigured. +#elif ABSL_OPTION_USE_STD_OPTIONAL == 0 || \ + (ABSL_OPTION_USE_STD_OPTIONAL == 2 && !defined(ABSL_HAVE_STD_OPTIONAL)) +#undef ABSL_USES_STD_OPTIONAL +#elif ABSL_OPTION_USE_STD_OPTIONAL == 1 || \ + (ABSL_OPTION_USE_STD_OPTIONAL == 2 && defined(ABSL_HAVE_STD_OPTIONAL)) +#define ABSL_USES_STD_OPTIONAL 1 +#else +#error options.h is misconfigured. +#endif + +// ABSL_USES_STD_VARIANT +// +// Indicates whether absl::variant is an alias for std::variant. +#if !defined(ABSL_OPTION_USE_STD_VARIANT) +#error options.h is misconfigured. +#elif ABSL_OPTION_USE_STD_VARIANT == 0 || \ + (ABSL_OPTION_USE_STD_VARIANT == 2 && !defined(ABSL_HAVE_STD_VARIANT)) +#undef ABSL_USES_STD_VARIANT +#elif ABSL_OPTION_USE_STD_VARIANT == 1 || \ + (ABSL_OPTION_USE_STD_VARIANT == 2 && defined(ABSL_HAVE_STD_VARIANT)) +#define ABSL_USES_STD_VARIANT 1 +#else +#error options.h is misconfigured. +#endif + +// ABSL_USES_STD_STRING_VIEW +// +// Indicates whether absl::string_view is an alias for std::string_view. +#if !defined(ABSL_OPTION_USE_STD_STRING_VIEW) +#error options.h is misconfigured. +#elif ABSL_OPTION_USE_STD_STRING_VIEW == 0 || \ + (ABSL_OPTION_USE_STD_STRING_VIEW == 2 && \ + !defined(ABSL_HAVE_STD_STRING_VIEW)) +#undef ABSL_USES_STD_STRING_VIEW +#elif ABSL_OPTION_USE_STD_STRING_VIEW == 1 || \ + (ABSL_OPTION_USE_STD_STRING_VIEW == 2 && \ + defined(ABSL_HAVE_STD_STRING_VIEW)) +#define ABSL_USES_STD_STRING_VIEW 1 +#else +#error options.h is misconfigured. +#endif + +// In debug mode, MSVC 2017's std::variant throws a EXCEPTION_ACCESS_VIOLATION +// SEH exception from emplace for variant<SomeStruct> when constructing the +// struct can throw. This defeats some of variant_test and +// variant_exception_safety_test. +#if defined(_MSC_VER) && _MSC_VER >= 1700 && defined(_DEBUG) +#define ABSL_INTERNAL_MSVC_2017_DBG_MODE +#endif + +// ABSL_INTERNAL_MANGLED_NS +// ABSL_INTERNAL_MANGLED_BACKREFERENCE +// +// Internal macros for building up mangled names in our internal fork of CCTZ. +// This implementation detail is only needed and provided for the MSVC build. +// +// These macros both expand to string literals. ABSL_INTERNAL_MANGLED_NS is +// the mangled spelling of the `absl` namespace, and +// ABSL_INTERNAL_MANGLED_BACKREFERENCE is a back-reference integer representing +// the proper count to skip past the CCTZ fork namespace names. (This number +// is one larger when there is an inline namespace name to skip.) +#if defined(_MSC_VER) +#if ABSL_OPTION_USE_INLINE_NAMESPACE == 0 +#define ABSL_INTERNAL_MANGLED_NS "absl" +#define ABSL_INTERNAL_MANGLED_BACKREFERENCE "5" +#else +#define ABSL_INTERNAL_MANGLED_NS \ + ABSL_INTERNAL_TOKEN_STR(ABSL_OPTION_INLINE_NAMESPACE_NAME) "@absl" +#define ABSL_INTERNAL_MANGLED_BACKREFERENCE "6" +#endif +#endif + +#undef ABSL_INTERNAL_HAS_KEYWORD + +// ABSL_DLL +// +// When building Abseil as a DLL, this macro expands to `__declspec(dllexport)` +// so we can annotate symbols appropriately as being exported. When used in +// headers consuming a DLL, this macro expands to `__declspec(dllimport)` so +// that consumers know the symbol is defined inside the DLL. In all other cases, +// the macro expands to nothing. +#if defined(_MSC_VER) +#if defined(ABSL_BUILD_DLL) +#define ABSL_DLL __declspec(dllexport) +#elif defined(ABSL_CONSUME_DLL) +#define ABSL_DLL __declspec(dllimport) +#else +#define ABSL_DLL +#endif +#else +#define ABSL_DLL +#endif // defined(_MSC_VER) + +#endif // ABSL_BASE_CONFIG_H_ diff --git a/third_party/abseil_cpp/absl/base/config_test.cc b/third_party/abseil_cpp/absl/base/config_test.cc new file mode 100644 index 0000000000..7e0c033de5 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/config_test.cc @@ -0,0 +1,60 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/config.h" + +#include <cstdint> + +#include "gtest/gtest.h" +#include "absl/synchronization/internal/thread_pool.h" + +namespace { + +TEST(ConfigTest, Endianness) { + union { + uint32_t value; + uint8_t data[sizeof(uint32_t)]; + } number; + number.data[0] = 0x00; + number.data[1] = 0x01; + number.data[2] = 0x02; + number.data[3] = 0x03; +#if defined(ABSL_IS_LITTLE_ENDIAN) && defined(ABSL_IS_BIG_ENDIAN) +#error Both ABSL_IS_LITTLE_ENDIAN and ABSL_IS_BIG_ENDIAN are defined +#elif defined(ABSL_IS_LITTLE_ENDIAN) + EXPECT_EQ(UINT32_C(0x03020100), number.value); +#elif defined(ABSL_IS_BIG_ENDIAN) + EXPECT_EQ(UINT32_C(0x00010203), number.value); +#else +#error Unknown endianness +#endif +} + +#if defined(ABSL_HAVE_THREAD_LOCAL) +TEST(ConfigTest, ThreadLocal) { + static thread_local int mine_mine_mine = 16; + EXPECT_EQ(16, mine_mine_mine); + { + absl::synchronization_internal::ThreadPool pool(1); + pool.Schedule([&] { + EXPECT_EQ(16, mine_mine_mine); + mine_mine_mine = 32; + EXPECT_EQ(32, mine_mine_mine); + }); + } + EXPECT_EQ(16, mine_mine_mine); +} +#endif + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/const_init.h b/third_party/abseil_cpp/absl/base/const_init.h new file mode 100644 index 0000000000..16520b61d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/const_init.h @@ -0,0 +1,76 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// kConstInit +// ----------------------------------------------------------------------------- +// +// A constructor tag used to mark an object as safe for use as a global +// variable, avoiding the usual lifetime issues that can affect globals. + +#ifndef ABSL_BASE_CONST_INIT_H_ +#define ABSL_BASE_CONST_INIT_H_ + +#include "absl/base/config.h" + +// In general, objects with static storage duration (such as global variables) +// can trigger tricky object lifetime situations. Attempting to access them +// from the constructors or destructors of other global objects can result in +// undefined behavior, unless their constructors and destructors are designed +// with this issue in mind. +// +// The normal way to deal with this issue in C++11 is to use constant +// initialization and trivial destructors. +// +// Constant initialization is guaranteed to occur before any other code +// executes. Constructors that are declared 'constexpr' are eligible for +// constant initialization. You can annotate a variable declaration with the +// ABSL_CONST_INIT macro to express this intent. For compilers that support +// it, this annotation will cause a compilation error for declarations that +// aren't subject to constant initialization (perhaps because a runtime value +// was passed as a constructor argument). +// +// On program shutdown, lifetime issues can be avoided on global objects by +// ensuring that they contain trivial destructors. A class has a trivial +// destructor unless it has a user-defined destructor, a virtual method or base +// class, or a data member or base class with a non-trivial destructor of its +// own. Objects with static storage duration and a trivial destructor are not +// cleaned up on program shutdown, and are thus safe to access from other code +// running during shutdown. +// +// For a few core Abseil classes, we make a best effort to allow for safe global +// instances, even though these classes have non-trivial destructors. These +// objects can be created with the absl::kConstInit tag. For example: +// ABSL_CONST_INIT absl::Mutex global_mutex(absl::kConstInit); +// +// The line above declares a global variable of type absl::Mutex which can be +// accessed at any point during startup or shutdown. global_mutex's destructor +// will still run, but will not invalidate the object. Note that C++ specifies +// that accessing an object after its destructor has run results in undefined +// behavior, but this pattern works on the toolchains we support. +// +// The absl::kConstInit tag should only be used to define objects with static +// or thread_local storage duration. + +namespace absl { +ABSL_NAMESPACE_BEGIN + +enum ConstInitType { + kConstInit, +}; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_CONST_INIT_H_ diff --git a/third_party/abseil_cpp/absl/base/dynamic_annotations.cc b/third_party/abseil_cpp/absl/base/dynamic_annotations.cc new file mode 100644 index 0000000000..21e822e53c --- /dev/null +++ b/third_party/abseil_cpp/absl/base/dynamic_annotations.cc @@ -0,0 +1,129 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <stdlib.h> +#include <string.h> + +#include "absl/base/dynamic_annotations.h" + +#ifndef __has_feature +#define __has_feature(x) 0 +#endif + +/* Compiler-based ThreadSanitizer defines + DYNAMIC_ANNOTATIONS_EXTERNAL_IMPL = 1 + and provides its own definitions of the functions. */ + +#ifndef DYNAMIC_ANNOTATIONS_EXTERNAL_IMPL +# define DYNAMIC_ANNOTATIONS_EXTERNAL_IMPL 0 +#endif + +/* Each function is empty and called (via a macro) only in debug mode. + The arguments are captured by dynamic tools at runtime. */ + +#if DYNAMIC_ANNOTATIONS_EXTERNAL_IMPL == 0 && !defined(__native_client__) + +#if __has_feature(memory_sanitizer) +#include <sanitizer/msan_interface.h> +#endif + +#ifdef __cplusplus +extern "C" { +#endif + +void AnnotateRWLockCreate(const char *, int, + const volatile void *){} +void AnnotateRWLockDestroy(const char *, int, + const volatile void *){} +void AnnotateRWLockAcquired(const char *, int, + const volatile void *, long){} +void AnnotateRWLockReleased(const char *, int, + const volatile void *, long){} +void AnnotateBenignRace(const char *, int, + const volatile void *, + const char *){} +void AnnotateBenignRaceSized(const char *, int, + const volatile void *, + size_t, + const char *) {} +void AnnotateThreadName(const char *, int, + const char *){} +void AnnotateIgnoreReadsBegin(const char *, int){} +void AnnotateIgnoreReadsEnd(const char *, int){} +void AnnotateIgnoreWritesBegin(const char *, int){} +void AnnotateIgnoreWritesEnd(const char *, int){} +void AnnotateEnableRaceDetection(const char *, int, int){} +void AnnotateMemoryIsInitialized(const char *, int, + const volatile void *mem, size_t size) { +#if __has_feature(memory_sanitizer) + __msan_unpoison(mem, size); +#else + (void)mem; + (void)size; +#endif +} + +void AnnotateMemoryIsUninitialized(const char *, int, + const volatile void *mem, size_t size) { +#if __has_feature(memory_sanitizer) + __msan_allocated_memory(mem, size); +#else + (void)mem; + (void)size; +#endif +} + +static int GetRunningOnValgrind(void) { +#ifdef RUNNING_ON_VALGRIND + if (RUNNING_ON_VALGRIND) return 1; +#endif + char *running_on_valgrind_str = getenv("RUNNING_ON_VALGRIND"); + if (running_on_valgrind_str) { + return strcmp(running_on_valgrind_str, "0") != 0; + } + return 0; +} + +/* See the comments in dynamic_annotations.h */ +int RunningOnValgrind(void) { + static volatile int running_on_valgrind = -1; + int local_running_on_valgrind = running_on_valgrind; + /* C doesn't have thread-safe initialization of statics, and we + don't want to depend on pthread_once here, so hack it. */ + ANNOTATE_BENIGN_RACE(&running_on_valgrind, "safe hack"); + if (local_running_on_valgrind == -1) + running_on_valgrind = local_running_on_valgrind = GetRunningOnValgrind(); + return local_running_on_valgrind; +} + +/* See the comments in dynamic_annotations.h */ +double ValgrindSlowdown(void) { + /* Same initialization hack as in RunningOnValgrind(). */ + static volatile double slowdown = 0.0; + double local_slowdown = slowdown; + ANNOTATE_BENIGN_RACE(&slowdown, "safe hack"); + if (RunningOnValgrind() == 0) { + return 1.0; + } + if (local_slowdown == 0.0) { + char *env = getenv("VALGRIND_SLOWDOWN"); + slowdown = local_slowdown = env ? atof(env) : 50.0; + } + return local_slowdown; +} + +#ifdef __cplusplus +} // extern "C" +#endif +#endif /* DYNAMIC_ANNOTATIONS_EXTERNAL_IMPL == 0 */ diff --git a/third_party/abseil_cpp/absl/base/dynamic_annotations.h b/third_party/abseil_cpp/absl/base/dynamic_annotations.h new file mode 100644 index 0000000000..2d98526075 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/dynamic_annotations.h @@ -0,0 +1,386 @@ +/* + * Copyright 2017 The Abseil Authors. + * + * Licensed under the Apache License, Version 2.0 (the "License"); + * you may not use this file except in compliance with the License. + * You may obtain a copy of the License at + * + * https://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ +/* This file defines dynamic annotations for use with dynamic analysis + tool such as valgrind, PIN, etc. + + Dynamic annotation is a source code annotation that affects + the generated code (that is, the annotation is not a comment). + Each such annotation is attached to a particular + instruction and/or to a particular object (address) in the program. + + The annotations that should be used by users are macros in all upper-case + (e.g., ANNOTATE_THREAD_NAME). + + Actual implementation of these macros may differ depending on the + dynamic analysis tool being used. + + This file supports the following configurations: + - Dynamic Annotations enabled (with static thread-safety warnings disabled). + In this case, macros expand to functions implemented by Thread Sanitizer, + when building with TSan. When not provided an external implementation, + dynamic_annotations.cc provides no-op implementations. + + - Static Clang thread-safety warnings enabled. + When building with a Clang compiler that supports thread-safety warnings, + a subset of annotations can be statically-checked at compile-time. We + expand these macros to static-inline functions that can be analyzed for + thread-safety, but afterwards elided when building the final binary. + + - All annotations are disabled. + If neither Dynamic Annotations nor Clang thread-safety warnings are + enabled, then all annotation-macros expand to empty. */ + +#ifndef ABSL_BASE_DYNAMIC_ANNOTATIONS_H_ +#define ABSL_BASE_DYNAMIC_ANNOTATIONS_H_ + +#ifndef DYNAMIC_ANNOTATIONS_ENABLED +# define DYNAMIC_ANNOTATIONS_ENABLED 0 +#endif + +#if DYNAMIC_ANNOTATIONS_ENABLED != 0 + + /* ------------------------------------------------------------- + Annotations that suppress errors. It is usually better to express the + program's synchronization using the other annotations, but these can + be used when all else fails. */ + + /* Report that we may have a benign race at "pointer", with size + "sizeof(*(pointer))". "pointer" must be a non-void* pointer. Insert at the + point where "pointer" has been allocated, preferably close to the point + where the race happens. See also ANNOTATE_BENIGN_RACE_STATIC. */ + #define ANNOTATE_BENIGN_RACE(pointer, description) \ + AnnotateBenignRaceSized(__FILE__, __LINE__, pointer, \ + sizeof(*(pointer)), description) + + /* Same as ANNOTATE_BENIGN_RACE(address, description), but applies to + the memory range [address, address+size). */ + #define ANNOTATE_BENIGN_RACE_SIZED(address, size, description) \ + AnnotateBenignRaceSized(__FILE__, __LINE__, address, size, description) + + /* Enable (enable!=0) or disable (enable==0) race detection for all threads. + This annotation could be useful if you want to skip expensive race analysis + during some period of program execution, e.g. during initialization. */ + #define ANNOTATE_ENABLE_RACE_DETECTION(enable) \ + AnnotateEnableRaceDetection(__FILE__, __LINE__, enable) + + /* ------------------------------------------------------------- + Annotations useful for debugging. */ + + /* Report the current thread name to a race detector. */ + #define ANNOTATE_THREAD_NAME(name) \ + AnnotateThreadName(__FILE__, __LINE__, name) + + /* ------------------------------------------------------------- + Annotations useful when implementing locks. They are not + normally needed by modules that merely use locks. + The "lock" argument is a pointer to the lock object. */ + + /* Report that a lock has been created at address "lock". */ + #define ANNOTATE_RWLOCK_CREATE(lock) \ + AnnotateRWLockCreate(__FILE__, __LINE__, lock) + + /* Report that a linker initialized lock has been created at address "lock". + */ +#ifdef THREAD_SANITIZER + #define ANNOTATE_RWLOCK_CREATE_STATIC(lock) \ + AnnotateRWLockCreateStatic(__FILE__, __LINE__, lock) +#else + #define ANNOTATE_RWLOCK_CREATE_STATIC(lock) ANNOTATE_RWLOCK_CREATE(lock) +#endif + + /* Report that the lock at address "lock" is about to be destroyed. */ + #define ANNOTATE_RWLOCK_DESTROY(lock) \ + AnnotateRWLockDestroy(__FILE__, __LINE__, lock) + + /* Report that the lock at address "lock" has been acquired. + is_w=1 for writer lock, is_w=0 for reader lock. */ + #define ANNOTATE_RWLOCK_ACQUIRED(lock, is_w) \ + AnnotateRWLockAcquired(__FILE__, __LINE__, lock, is_w) + + /* Report that the lock at address "lock" is about to be released. */ + #define ANNOTATE_RWLOCK_RELEASED(lock, is_w) \ + AnnotateRWLockReleased(__FILE__, __LINE__, lock, is_w) + +#else /* DYNAMIC_ANNOTATIONS_ENABLED == 0 */ + + #define ANNOTATE_RWLOCK_CREATE(lock) /* empty */ + #define ANNOTATE_RWLOCK_CREATE_STATIC(lock) /* empty */ + #define ANNOTATE_RWLOCK_DESTROY(lock) /* empty */ + #define ANNOTATE_RWLOCK_ACQUIRED(lock, is_w) /* empty */ + #define ANNOTATE_RWLOCK_RELEASED(lock, is_w) /* empty */ + #define ANNOTATE_BENIGN_RACE(address, description) /* empty */ + #define ANNOTATE_BENIGN_RACE_SIZED(address, size, description) /* empty */ + #define ANNOTATE_THREAD_NAME(name) /* empty */ + #define ANNOTATE_ENABLE_RACE_DETECTION(enable) /* empty */ + +#endif /* DYNAMIC_ANNOTATIONS_ENABLED */ + +/* These annotations are also made available to LLVM's Memory Sanitizer */ +#if DYNAMIC_ANNOTATIONS_ENABLED == 1 || defined(MEMORY_SANITIZER) + #define ANNOTATE_MEMORY_IS_INITIALIZED(address, size) \ + AnnotateMemoryIsInitialized(__FILE__, __LINE__, address, size) + + #define ANNOTATE_MEMORY_IS_UNINITIALIZED(address, size) \ + AnnotateMemoryIsUninitialized(__FILE__, __LINE__, address, size) +#else + #define ANNOTATE_MEMORY_IS_INITIALIZED(address, size) /* empty */ + #define ANNOTATE_MEMORY_IS_UNINITIALIZED(address, size) /* empty */ +#endif /* DYNAMIC_ANNOTATIONS_ENABLED || MEMORY_SANITIZER */ + +#if defined(__clang__) && !defined(SWIG) + + #if DYNAMIC_ANNOTATIONS_ENABLED == 0 + #define ANNOTALYSIS_ENABLED + #endif + + /* When running in opt-mode, GCC will issue a warning, if these attributes are + compiled. Only include them when compiling using Clang. */ + #define ATTRIBUTE_IGNORE_READS_BEGIN \ + __attribute((exclusive_lock_function("*"))) + #define ATTRIBUTE_IGNORE_READS_END \ + __attribute((unlock_function("*"))) +#else + #define ATTRIBUTE_IGNORE_READS_BEGIN /* empty */ + #define ATTRIBUTE_IGNORE_READS_END /* empty */ +#endif /* defined(__clang__) && ... */ + +#if (DYNAMIC_ANNOTATIONS_ENABLED != 0) || defined(ANNOTALYSIS_ENABLED) + #define ANNOTATIONS_ENABLED +#endif + +#if (DYNAMIC_ANNOTATIONS_ENABLED != 0) + + /* Request the analysis tool to ignore all reads in the current thread + until ANNOTATE_IGNORE_READS_END is called. + Useful to ignore intentional racey reads, while still checking + other reads and all writes. + See also ANNOTATE_UNPROTECTED_READ. */ + #define ANNOTATE_IGNORE_READS_BEGIN() \ + AnnotateIgnoreReadsBegin(__FILE__, __LINE__) + + /* Stop ignoring reads. */ + #define ANNOTATE_IGNORE_READS_END() \ + AnnotateIgnoreReadsEnd(__FILE__, __LINE__) + + /* Similar to ANNOTATE_IGNORE_READS_BEGIN, but ignore writes instead. */ + #define ANNOTATE_IGNORE_WRITES_BEGIN() \ + AnnotateIgnoreWritesBegin(__FILE__, __LINE__) + + /* Stop ignoring writes. */ + #define ANNOTATE_IGNORE_WRITES_END() \ + AnnotateIgnoreWritesEnd(__FILE__, __LINE__) + +/* Clang provides limited support for static thread-safety analysis + through a feature called Annotalysis. We configure macro-definitions + according to whether Annotalysis support is available. */ +#elif defined(ANNOTALYSIS_ENABLED) + + #define ANNOTATE_IGNORE_READS_BEGIN() \ + StaticAnnotateIgnoreReadsBegin(__FILE__, __LINE__) + + #define ANNOTATE_IGNORE_READS_END() \ + StaticAnnotateIgnoreReadsEnd(__FILE__, __LINE__) + + #define ANNOTATE_IGNORE_WRITES_BEGIN() \ + StaticAnnotateIgnoreWritesBegin(__FILE__, __LINE__) + + #define ANNOTATE_IGNORE_WRITES_END() \ + StaticAnnotateIgnoreWritesEnd(__FILE__, __LINE__) + +#else + #define ANNOTATE_IGNORE_READS_BEGIN() /* empty */ + #define ANNOTATE_IGNORE_READS_END() /* empty */ + #define ANNOTATE_IGNORE_WRITES_BEGIN() /* empty */ + #define ANNOTATE_IGNORE_WRITES_END() /* empty */ +#endif + +/* Implement the ANNOTATE_IGNORE_READS_AND_WRITES_* annotations using the more + primitive annotations defined above. */ +#if defined(ANNOTATIONS_ENABLED) + + /* Start ignoring all memory accesses (both reads and writes). */ + #define ANNOTATE_IGNORE_READS_AND_WRITES_BEGIN() \ + do { \ + ANNOTATE_IGNORE_READS_BEGIN(); \ + ANNOTATE_IGNORE_WRITES_BEGIN(); \ + }while (0) + + /* Stop ignoring both reads and writes. */ + #define ANNOTATE_IGNORE_READS_AND_WRITES_END() \ + do { \ + ANNOTATE_IGNORE_WRITES_END(); \ + ANNOTATE_IGNORE_READS_END(); \ + }while (0) + +#else + #define ANNOTATE_IGNORE_READS_AND_WRITES_BEGIN() /* empty */ + #define ANNOTATE_IGNORE_READS_AND_WRITES_END() /* empty */ +#endif + +/* Use the macros above rather than using these functions directly. */ +#include <stddef.h> +#ifdef __cplusplus +extern "C" { +#endif +void AnnotateRWLockCreate(const char *file, int line, + const volatile void *lock); +void AnnotateRWLockCreateStatic(const char *file, int line, + const volatile void *lock); +void AnnotateRWLockDestroy(const char *file, int line, + const volatile void *lock); +void AnnotateRWLockAcquired(const char *file, int line, + const volatile void *lock, long is_w); /* NOLINT */ +void AnnotateRWLockReleased(const char *file, int line, + const volatile void *lock, long is_w); /* NOLINT */ +void AnnotateBenignRace(const char *file, int line, + const volatile void *address, + const char *description); +void AnnotateBenignRaceSized(const char *file, int line, + const volatile void *address, + size_t size, + const char *description); +void AnnotateThreadName(const char *file, int line, + const char *name); +void AnnotateEnableRaceDetection(const char *file, int line, int enable); +void AnnotateMemoryIsInitialized(const char *file, int line, + const volatile void *mem, size_t size); +void AnnotateMemoryIsUninitialized(const char *file, int line, + const volatile void *mem, size_t size); + +/* Annotations expand to these functions, when Dynamic Annotations are enabled. + These functions are either implemented as no-op calls, if no Sanitizer is + attached, or provided with externally-linked implementations by a library + like ThreadSanitizer. */ +void AnnotateIgnoreReadsBegin(const char *file, int line) + ATTRIBUTE_IGNORE_READS_BEGIN; +void AnnotateIgnoreReadsEnd(const char *file, int line) + ATTRIBUTE_IGNORE_READS_END; +void AnnotateIgnoreWritesBegin(const char *file, int line); +void AnnotateIgnoreWritesEnd(const char *file, int line); + +#if defined(ANNOTALYSIS_ENABLED) +/* When Annotalysis is enabled without Dynamic Annotations, the use of + static-inline functions allows the annotations to be read at compile-time, + while still letting the compiler elide the functions from the final build. + + TODO(delesley) -- The exclusive lock here ignores writes as well, but + allows IGNORE_READS_AND_WRITES to work properly. */ +#pragma GCC diagnostic push +#pragma GCC diagnostic ignored "-Wunused-function" +static inline void StaticAnnotateIgnoreReadsBegin(const char *file, int line) + ATTRIBUTE_IGNORE_READS_BEGIN { (void)file; (void)line; } +static inline void StaticAnnotateIgnoreReadsEnd(const char *file, int line) + ATTRIBUTE_IGNORE_READS_END { (void)file; (void)line; } +static inline void StaticAnnotateIgnoreWritesBegin( + const char *file, int line) { (void)file; (void)line; } +static inline void StaticAnnotateIgnoreWritesEnd( + const char *file, int line) { (void)file; (void)line; } +#pragma GCC diagnostic pop +#endif + +/* Return non-zero value if running under valgrind. + + If "valgrind.h" is included into dynamic_annotations.cc, + the regular valgrind mechanism will be used. + See http://valgrind.org/docs/manual/manual-core-adv.html about + RUNNING_ON_VALGRIND and other valgrind "client requests". + The file "valgrind.h" may be obtained by doing + svn co svn://svn.valgrind.org/valgrind/trunk/include + + If for some reason you can't use "valgrind.h" or want to fake valgrind, + there are two ways to make this function return non-zero: + - Use environment variable: export RUNNING_ON_VALGRIND=1 + - Make your tool intercept the function RunningOnValgrind() and + change its return value. + */ +int RunningOnValgrind(void); + +/* ValgrindSlowdown returns: + * 1.0, if (RunningOnValgrind() == 0) + * 50.0, if (RunningOnValgrind() != 0 && getenv("VALGRIND_SLOWDOWN") == NULL) + * atof(getenv("VALGRIND_SLOWDOWN")) otherwise + This function can be used to scale timeout values: + EXAMPLE: + for (;;) { + DoExpensiveBackgroundTask(); + SleepForSeconds(5 * ValgrindSlowdown()); + } + */ +double ValgrindSlowdown(void); + +#ifdef __cplusplus +} +#endif + +/* ANNOTATE_UNPROTECTED_READ is the preferred way to annotate racey reads. + + Instead of doing + ANNOTATE_IGNORE_READS_BEGIN(); + ... = x; + ANNOTATE_IGNORE_READS_END(); + one can use + ... = ANNOTATE_UNPROTECTED_READ(x); */ +#if defined(__cplusplus) && defined(ANNOTATIONS_ENABLED) +template <typename T> +inline T ANNOTATE_UNPROTECTED_READ(const volatile T &x) { /* NOLINT */ + ANNOTATE_IGNORE_READS_BEGIN(); + T res = x; + ANNOTATE_IGNORE_READS_END(); + return res; + } +#else + #define ANNOTATE_UNPROTECTED_READ(x) (x) +#endif + +#if DYNAMIC_ANNOTATIONS_ENABLED != 0 && defined(__cplusplus) + /* Apply ANNOTATE_BENIGN_RACE_SIZED to a static variable. */ + #define ANNOTATE_BENIGN_RACE_STATIC(static_var, description) \ + namespace { \ + class static_var ## _annotator { \ + public: \ + static_var ## _annotator() { \ + ANNOTATE_BENIGN_RACE_SIZED(&static_var, \ + sizeof(static_var), \ + # static_var ": " description); \ + } \ + }; \ + static static_var ## _annotator the ## static_var ## _annotator;\ + } // namespace +#else /* DYNAMIC_ANNOTATIONS_ENABLED == 0 */ + #define ANNOTATE_BENIGN_RACE_STATIC(static_var, description) /* empty */ +#endif /* DYNAMIC_ANNOTATIONS_ENABLED */ + +#ifdef ADDRESS_SANITIZER +/* Describe the current state of a contiguous container such as e.g. + * std::vector or std::string. For more details see + * sanitizer/common_interface_defs.h, which is provided by the compiler. */ +#include <sanitizer/common_interface_defs.h> +#define ANNOTATE_CONTIGUOUS_CONTAINER(beg, end, old_mid, new_mid) \ + __sanitizer_annotate_contiguous_container(beg, end, old_mid, new_mid) +#define ADDRESS_SANITIZER_REDZONE(name) \ + struct { char x[8] __attribute__ ((aligned (8))); } name +#else +#define ANNOTATE_CONTIGUOUS_CONTAINER(beg, end, old_mid, new_mid) +#define ADDRESS_SANITIZER_REDZONE(name) static_assert(true, "") +#endif // ADDRESS_SANITIZER + +/* Undefine the macros intended only in this file. */ +#undef ANNOTALYSIS_ENABLED +#undef ANNOTATIONS_ENABLED +#undef ATTRIBUTE_IGNORE_READS_BEGIN +#undef ATTRIBUTE_IGNORE_READS_END + +#endif /* ABSL_BASE_DYNAMIC_ANNOTATIONS_H_ */ diff --git a/third_party/abseil_cpp/absl/base/exception_safety_testing_test.cc b/third_party/abseil_cpp/absl/base/exception_safety_testing_test.cc new file mode 100644 index 0000000000..a59be29e91 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/exception_safety_testing_test.cc @@ -0,0 +1,956 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/exception_safety_testing.h" + +#ifdef ABSL_HAVE_EXCEPTIONS + +#include <cstddef> +#include <exception> +#include <iostream> +#include <list> +#include <type_traits> +#include <vector> + +#include "gtest/gtest-spi.h" +#include "gtest/gtest.h" +#include "absl/memory/memory.h" + +namespace testing { + +namespace { + +using ::testing::exceptions_internal::SetCountdown; +using ::testing::exceptions_internal::TestException; +using ::testing::exceptions_internal::UnsetCountdown; + +// EXPECT_NO_THROW can't inspect the thrown inspection in general. +template <typename F> +void ExpectNoThrow(const F& f) { + try { + f(); + } catch (const TestException& e) { + ADD_FAILURE() << "Unexpected exception thrown from " << e.what(); + } +} + +TEST(ThrowingValueTest, Throws) { + SetCountdown(); + EXPECT_THROW(ThrowingValue<> bomb, TestException); + + // It's not guaranteed that every operator only throws *once*. The default + // ctor only throws once, though, so use it to make sure we only throw when + // the countdown hits 0 + SetCountdown(2); + ExpectNoThrow([]() { ThrowingValue<> bomb; }); + ExpectNoThrow([]() { ThrowingValue<> bomb; }); + EXPECT_THROW(ThrowingValue<> bomb, TestException); + + UnsetCountdown(); +} + +// Tests that an operation throws when the countdown is at 0, doesn't throw when +// the countdown doesn't hit 0, and doesn't modify the state of the +// ThrowingValue if it throws +template <typename F> +void TestOp(const F& f) { + ExpectNoThrow(f); + + SetCountdown(); + EXPECT_THROW(f(), TestException); + UnsetCountdown(); +} + +TEST(ThrowingValueTest, ThrowingCtors) { + ThrowingValue<> bomb; + + TestOp([]() { ThrowingValue<> bomb(1); }); + TestOp([&]() { ThrowingValue<> bomb1 = bomb; }); + TestOp([&]() { ThrowingValue<> bomb1 = std::move(bomb); }); +} + +TEST(ThrowingValueTest, ThrowingAssignment) { + ThrowingValue<> bomb, bomb1; + + TestOp([&]() { bomb = bomb1; }); + TestOp([&]() { bomb = std::move(bomb1); }); + + // Test that when assignment throws, the assignment should fail (lhs != rhs) + // and strong guarantee fails (lhs != lhs_copy). + { + ThrowingValue<> lhs(39), rhs(42); + ThrowingValue<> lhs_copy(lhs); + SetCountdown(); + EXPECT_THROW(lhs = rhs, TestException); + UnsetCountdown(); + EXPECT_NE(lhs, rhs); + EXPECT_NE(lhs_copy, lhs); + } + { + ThrowingValue<> lhs(39), rhs(42); + ThrowingValue<> lhs_copy(lhs), rhs_copy(rhs); + SetCountdown(); + EXPECT_THROW(lhs = std::move(rhs), TestException); + UnsetCountdown(); + EXPECT_NE(lhs, rhs_copy); + EXPECT_NE(lhs_copy, lhs); + } +} + +TEST(ThrowingValueTest, ThrowingComparisons) { + ThrowingValue<> bomb1, bomb2; + TestOp([&]() { return bomb1 == bomb2; }); + TestOp([&]() { return bomb1 != bomb2; }); + TestOp([&]() { return bomb1 < bomb2; }); + TestOp([&]() { return bomb1 <= bomb2; }); + TestOp([&]() { return bomb1 > bomb2; }); + TestOp([&]() { return bomb1 >= bomb2; }); +} + +TEST(ThrowingValueTest, ThrowingArithmeticOps) { + ThrowingValue<> bomb1(1), bomb2(2); + + TestOp([&bomb1]() { +bomb1; }); + TestOp([&bomb1]() { -bomb1; }); + TestOp([&bomb1]() { ++bomb1; }); + TestOp([&bomb1]() { bomb1++; }); + TestOp([&bomb1]() { --bomb1; }); + TestOp([&bomb1]() { bomb1--; }); + + TestOp([&]() { bomb1 + bomb2; }); + TestOp([&]() { bomb1 - bomb2; }); + TestOp([&]() { bomb1* bomb2; }); + TestOp([&]() { bomb1 / bomb2; }); + TestOp([&]() { bomb1 << 1; }); + TestOp([&]() { bomb1 >> 1; }); +} + +TEST(ThrowingValueTest, ThrowingLogicalOps) { + ThrowingValue<> bomb1, bomb2; + + TestOp([&bomb1]() { !bomb1; }); + TestOp([&]() { bomb1&& bomb2; }); + TestOp([&]() { bomb1 || bomb2; }); +} + +TEST(ThrowingValueTest, ThrowingBitwiseOps) { + ThrowingValue<> bomb1, bomb2; + + TestOp([&bomb1]() { ~bomb1; }); + TestOp([&]() { bomb1& bomb2; }); + TestOp([&]() { bomb1 | bomb2; }); + TestOp([&]() { bomb1 ^ bomb2; }); +} + +TEST(ThrowingValueTest, ThrowingCompoundAssignmentOps) { + ThrowingValue<> bomb1(1), bomb2(2); + + TestOp([&]() { bomb1 += bomb2; }); + TestOp([&]() { bomb1 -= bomb2; }); + TestOp([&]() { bomb1 *= bomb2; }); + TestOp([&]() { bomb1 /= bomb2; }); + TestOp([&]() { bomb1 %= bomb2; }); + TestOp([&]() { bomb1 &= bomb2; }); + TestOp([&]() { bomb1 |= bomb2; }); + TestOp([&]() { bomb1 ^= bomb2; }); + TestOp([&]() { bomb1 *= bomb2; }); +} + +TEST(ThrowingValueTest, ThrowingStreamOps) { + ThrowingValue<> bomb; + + TestOp([&]() { + std::istringstream stream; + stream >> bomb; + }); + TestOp([&]() { + std::stringstream stream; + stream << bomb; + }); +} + +// Tests the operator<< of ThrowingValue by forcing ConstructorTracker to emit +// a nonfatal failure that contains the string representation of the Thrower +TEST(ThrowingValueTest, StreamOpsOutput) { + using ::testing::TypeSpec; + exceptions_internal::ConstructorTracker ct(exceptions_internal::countdown); + + // Test default spec list (kEverythingThrows) + EXPECT_NONFATAL_FAILURE( + { + using Thrower = ThrowingValue<TypeSpec{}>; + auto thrower = Thrower(123); + thrower.~Thrower(); + }, + "ThrowingValue<>(123)"); + + // Test with one item in spec list (kNoThrowCopy) + EXPECT_NONFATAL_FAILURE( + { + using Thrower = ThrowingValue<TypeSpec::kNoThrowCopy>; + auto thrower = Thrower(234); + thrower.~Thrower(); + }, + "ThrowingValue<kNoThrowCopy>(234)"); + + // Test with multiple items in spec list (kNoThrowMove, kNoThrowNew) + EXPECT_NONFATAL_FAILURE( + { + using Thrower = + ThrowingValue<TypeSpec::kNoThrowMove | TypeSpec::kNoThrowNew>; + auto thrower = Thrower(345); + thrower.~Thrower(); + }, + "ThrowingValue<kNoThrowMove | kNoThrowNew>(345)"); + + // Test with all items in spec list (kNoThrowCopy, kNoThrowMove, kNoThrowNew) + EXPECT_NONFATAL_FAILURE( + { + using Thrower = ThrowingValue<static_cast<TypeSpec>(-1)>; + auto thrower = Thrower(456); + thrower.~Thrower(); + }, + "ThrowingValue<kNoThrowCopy | kNoThrowMove | kNoThrowNew>(456)"); +} + +template <typename F> +void TestAllocatingOp(const F& f) { + ExpectNoThrow(f); + + SetCountdown(); + EXPECT_THROW(f(), exceptions_internal::TestBadAllocException); + UnsetCountdown(); +} + +TEST(ThrowingValueTest, ThrowingAllocatingOps) { + // make_unique calls unqualified operator new, so these exercise the + // ThrowingValue overloads. + TestAllocatingOp([]() { return absl::make_unique<ThrowingValue<>>(1); }); + TestAllocatingOp([]() { return absl::make_unique<ThrowingValue<>[]>(2); }); +} + +TEST(ThrowingValueTest, NonThrowingMoveCtor) { + ThrowingValue<TypeSpec::kNoThrowMove> nothrow_ctor; + + SetCountdown(); + ExpectNoThrow([¬hrow_ctor]() { + ThrowingValue<TypeSpec::kNoThrowMove> nothrow1 = std::move(nothrow_ctor); + }); + UnsetCountdown(); +} + +TEST(ThrowingValueTest, NonThrowingMoveAssign) { + ThrowingValue<TypeSpec::kNoThrowMove> nothrow_assign1, nothrow_assign2; + + SetCountdown(); + ExpectNoThrow([¬hrow_assign1, ¬hrow_assign2]() { + nothrow_assign1 = std::move(nothrow_assign2); + }); + UnsetCountdown(); +} + +TEST(ThrowingValueTest, ThrowingCopyCtor) { + ThrowingValue<> tv; + + TestOp([&]() { ThrowingValue<> tv_copy(tv); }); +} + +TEST(ThrowingValueTest, ThrowingCopyAssign) { + ThrowingValue<> tv1, tv2; + + TestOp([&]() { tv1 = tv2; }); +} + +TEST(ThrowingValueTest, NonThrowingCopyCtor) { + ThrowingValue<TypeSpec::kNoThrowCopy> nothrow_ctor; + + SetCountdown(); + ExpectNoThrow([¬hrow_ctor]() { + ThrowingValue<TypeSpec::kNoThrowCopy> nothrow1(nothrow_ctor); + }); + UnsetCountdown(); +} + +TEST(ThrowingValueTest, NonThrowingCopyAssign) { + ThrowingValue<TypeSpec::kNoThrowCopy> nothrow_assign1, nothrow_assign2; + + SetCountdown(); + ExpectNoThrow([¬hrow_assign1, ¬hrow_assign2]() { + nothrow_assign1 = nothrow_assign2; + }); + UnsetCountdown(); +} + +TEST(ThrowingValueTest, ThrowingSwap) { + ThrowingValue<> bomb1, bomb2; + TestOp([&]() { std::swap(bomb1, bomb2); }); +} + +TEST(ThrowingValueTest, NonThrowingSwap) { + ThrowingValue<TypeSpec::kNoThrowMove> bomb1, bomb2; + ExpectNoThrow([&]() { std::swap(bomb1, bomb2); }); +} + +TEST(ThrowingValueTest, NonThrowingAllocation) { + ThrowingValue<TypeSpec::kNoThrowNew>* allocated; + ThrowingValue<TypeSpec::kNoThrowNew>* array; + + ExpectNoThrow([&allocated]() { + allocated = new ThrowingValue<TypeSpec::kNoThrowNew>(1); + delete allocated; + }); + ExpectNoThrow([&array]() { + array = new ThrowingValue<TypeSpec::kNoThrowNew>[2]; + delete[] array; + }); +} + +TEST(ThrowingValueTest, NonThrowingDelete) { + auto* allocated = new ThrowingValue<>(1); + auto* array = new ThrowingValue<>[2]; + + SetCountdown(); + ExpectNoThrow([allocated]() { delete allocated; }); + SetCountdown(); + ExpectNoThrow([array]() { delete[] array; }); + + UnsetCountdown(); +} + +TEST(ThrowingValueTest, NonThrowingPlacementDelete) { + constexpr int kArrayLen = 2; + // We intentionally create extra space to store the tag allocated by placement + // new[]. + constexpr int kStorageLen = 4; + + alignas(ThrowingValue<>) unsigned char buf[sizeof(ThrowingValue<>)]; + alignas(ThrowingValue<>) unsigned char + array_buf[sizeof(ThrowingValue<>[kStorageLen])]; + auto* placed = new (&buf) ThrowingValue<>(1); + auto placed_array = new (&array_buf) ThrowingValue<>[kArrayLen]; + + SetCountdown(); + ExpectNoThrow([placed, &buf]() { + placed->~ThrowingValue<>(); + ThrowingValue<>::operator delete(placed, &buf); + }); + + SetCountdown(); + ExpectNoThrow([&, placed_array]() { + for (int i = 0; i < kArrayLen; ++i) placed_array[i].~ThrowingValue<>(); + ThrowingValue<>::operator delete[](placed_array, &array_buf); + }); + + UnsetCountdown(); +} + +TEST(ThrowingValueTest, NonThrowingDestructor) { + auto* allocated = new ThrowingValue<>(); + + SetCountdown(); + ExpectNoThrow([allocated]() { delete allocated; }); + UnsetCountdown(); +} + +TEST(ThrowingBoolTest, ThrowingBool) { + ThrowingBool t = true; + + // Test that it's contextually convertible to bool + if (t) { // NOLINT(whitespace/empty_if_body) + } + EXPECT_TRUE(t); + + TestOp([&]() { (void)!t; }); +} + +TEST(ThrowingAllocatorTest, MemoryManagement) { + // Just exercise the memory management capabilities under LSan to make sure we + // don't leak. + ThrowingAllocator<int> int_alloc; + int* ip = int_alloc.allocate(1); + int_alloc.deallocate(ip, 1); + int* i_array = int_alloc.allocate(2); + int_alloc.deallocate(i_array, 2); + + ThrowingAllocator<ThrowingValue<>> tv_alloc; + ThrowingValue<>* ptr = tv_alloc.allocate(1); + tv_alloc.deallocate(ptr, 1); + ThrowingValue<>* tv_array = tv_alloc.allocate(2); + tv_alloc.deallocate(tv_array, 2); +} + +TEST(ThrowingAllocatorTest, CallsGlobalNew) { + ThrowingAllocator<ThrowingValue<>, AllocSpec::kNoThrowAllocate> nothrow_alloc; + ThrowingValue<>* ptr; + + SetCountdown(); + // This will only throw if ThrowingValue::new is called. + ExpectNoThrow([&]() { ptr = nothrow_alloc.allocate(1); }); + nothrow_alloc.deallocate(ptr, 1); + + UnsetCountdown(); +} + +TEST(ThrowingAllocatorTest, ThrowingConstructors) { + ThrowingAllocator<int> int_alloc; + int* ip = nullptr; + + SetCountdown(); + EXPECT_THROW(ip = int_alloc.allocate(1), TestException); + ExpectNoThrow([&]() { ip = int_alloc.allocate(1); }); + + *ip = 1; + SetCountdown(); + EXPECT_THROW(int_alloc.construct(ip, 2), TestException); + EXPECT_EQ(*ip, 1); + int_alloc.deallocate(ip, 1); + + UnsetCountdown(); +} + +TEST(ThrowingAllocatorTest, NonThrowingConstruction) { + { + ThrowingAllocator<int, AllocSpec::kNoThrowAllocate> int_alloc; + int* ip = nullptr; + + SetCountdown(); + ExpectNoThrow([&]() { ip = int_alloc.allocate(1); }); + + SetCountdown(); + ExpectNoThrow([&]() { int_alloc.construct(ip, 2); }); + + EXPECT_EQ(*ip, 2); + int_alloc.deallocate(ip, 1); + + UnsetCountdown(); + } + + { + ThrowingAllocator<int> int_alloc; + int* ip = nullptr; + ExpectNoThrow([&]() { ip = int_alloc.allocate(1); }); + ExpectNoThrow([&]() { int_alloc.construct(ip, 2); }); + EXPECT_EQ(*ip, 2); + int_alloc.deallocate(ip, 1); + } + + { + ThrowingAllocator<ThrowingValue<>, AllocSpec::kNoThrowAllocate> + nothrow_alloc; + ThrowingValue<>* ptr; + + SetCountdown(); + ExpectNoThrow([&]() { ptr = nothrow_alloc.allocate(1); }); + + SetCountdown(); + ExpectNoThrow( + [&]() { nothrow_alloc.construct(ptr, 2, testing::nothrow_ctor); }); + + EXPECT_EQ(ptr->Get(), 2); + nothrow_alloc.destroy(ptr); + nothrow_alloc.deallocate(ptr, 1); + + UnsetCountdown(); + } + + { + ThrowingAllocator<int> a; + + SetCountdown(); + ExpectNoThrow([&]() { ThrowingAllocator<double> a1 = a; }); + + SetCountdown(); + ExpectNoThrow([&]() { ThrowingAllocator<double> a1 = std::move(a); }); + + UnsetCountdown(); + } +} + +TEST(ThrowingAllocatorTest, ThrowingAllocatorConstruction) { + ThrowingAllocator<int> a; + TestOp([]() { ThrowingAllocator<int> a; }); + TestOp([&]() { a.select_on_container_copy_construction(); }); +} + +TEST(ThrowingAllocatorTest, State) { + ThrowingAllocator<int> a1, a2; + EXPECT_NE(a1, a2); + + auto a3 = a1; + EXPECT_EQ(a3, a1); + int* ip = a1.allocate(1); + EXPECT_EQ(a3, a1); + a3.deallocate(ip, 1); + EXPECT_EQ(a3, a1); +} + +TEST(ThrowingAllocatorTest, InVector) { + std::vector<ThrowingValue<>, ThrowingAllocator<ThrowingValue<>>> v; + for (int i = 0; i < 20; ++i) v.push_back({}); + for (int i = 0; i < 20; ++i) v.pop_back(); +} + +TEST(ThrowingAllocatorTest, InList) { + std::list<ThrowingValue<>, ThrowingAllocator<ThrowingValue<>>> l; + for (int i = 0; i < 20; ++i) l.push_back({}); + for (int i = 0; i < 20; ++i) l.pop_back(); + for (int i = 0; i < 20; ++i) l.push_front({}); + for (int i = 0; i < 20; ++i) l.pop_front(); +} + +template <typename TesterInstance, typename = void> +struct NullaryTestValidator : public std::false_type {}; + +template <typename TesterInstance> +struct NullaryTestValidator< + TesterInstance, + absl::void_t<decltype(std::declval<TesterInstance>().Test())>> + : public std::true_type {}; + +template <typename TesterInstance> +bool HasNullaryTest(const TesterInstance&) { + return NullaryTestValidator<TesterInstance>::value; +} + +void DummyOp(void*) {} + +template <typename TesterInstance, typename = void> +struct UnaryTestValidator : public std::false_type {}; + +template <typename TesterInstance> +struct UnaryTestValidator< + TesterInstance, + absl::void_t<decltype(std::declval<TesterInstance>().Test(DummyOp))>> + : public std::true_type {}; + +template <typename TesterInstance> +bool HasUnaryTest(const TesterInstance&) { + return UnaryTestValidator<TesterInstance>::value; +} + +TEST(ExceptionSafetyTesterTest, IncompleteTypesAreNotTestable) { + using T = exceptions_internal::UninitializedT; + auto op = [](T* t) {}; + auto inv = [](T*) { return testing::AssertionSuccess(); }; + auto fac = []() { return absl::make_unique<T>(); }; + + // Test that providing operation and inveriants still does not allow for the + // the invocation of .Test() and .Test(op) because it lacks a factory + auto without_fac = + testing::MakeExceptionSafetyTester().WithOperation(op).WithContracts( + inv, testing::strong_guarantee); + EXPECT_FALSE(HasNullaryTest(without_fac)); + EXPECT_FALSE(HasUnaryTest(without_fac)); + + // Test that providing contracts and factory allows the invocation of + // .Test(op) but does not allow for .Test() because it lacks an operation + auto without_op = testing::MakeExceptionSafetyTester() + .WithContracts(inv, testing::strong_guarantee) + .WithFactory(fac); + EXPECT_FALSE(HasNullaryTest(without_op)); + EXPECT_TRUE(HasUnaryTest(without_op)); + + // Test that providing operation and factory still does not allow for the + // the invocation of .Test() and .Test(op) because it lacks contracts + auto without_inv = + testing::MakeExceptionSafetyTester().WithOperation(op).WithFactory(fac); + EXPECT_FALSE(HasNullaryTest(without_inv)); + EXPECT_FALSE(HasUnaryTest(without_inv)); +} + +struct ExampleStruct {}; + +std::unique_ptr<ExampleStruct> ExampleFunctionFactory() { + return absl::make_unique<ExampleStruct>(); +} + +void ExampleFunctionOperation(ExampleStruct*) {} + +testing::AssertionResult ExampleFunctionContract(ExampleStruct*) { + return testing::AssertionSuccess(); +} + +struct { + std::unique_ptr<ExampleStruct> operator()() const { + return ExampleFunctionFactory(); + } +} example_struct_factory; + +struct { + void operator()(ExampleStruct*) const {} +} example_struct_operation; + +struct { + testing::AssertionResult operator()(ExampleStruct* example_struct) const { + return ExampleFunctionContract(example_struct); + } +} example_struct_contract; + +auto example_lambda_factory = []() { return ExampleFunctionFactory(); }; + +auto example_lambda_operation = [](ExampleStruct*) {}; + +auto example_lambda_contract = [](ExampleStruct* example_struct) { + return ExampleFunctionContract(example_struct); +}; + +// Testing that function references, pointers, structs with operator() and +// lambdas can all be used with ExceptionSafetyTester +TEST(ExceptionSafetyTesterTest, MixedFunctionTypes) { + // function reference + EXPECT_TRUE(testing::MakeExceptionSafetyTester() + .WithFactory(ExampleFunctionFactory) + .WithOperation(ExampleFunctionOperation) + .WithContracts(ExampleFunctionContract) + .Test()); + + // function pointer + EXPECT_TRUE(testing::MakeExceptionSafetyTester() + .WithFactory(&ExampleFunctionFactory) + .WithOperation(&ExampleFunctionOperation) + .WithContracts(&ExampleFunctionContract) + .Test()); + + // struct + EXPECT_TRUE(testing::MakeExceptionSafetyTester() + .WithFactory(example_struct_factory) + .WithOperation(example_struct_operation) + .WithContracts(example_struct_contract) + .Test()); + + // lambda + EXPECT_TRUE(testing::MakeExceptionSafetyTester() + .WithFactory(example_lambda_factory) + .WithOperation(example_lambda_operation) + .WithContracts(example_lambda_contract) + .Test()); +} + +struct NonNegative { + bool operator==(const NonNegative& other) const { return i == other.i; } + int i; +}; + +testing::AssertionResult CheckNonNegativeInvariants(NonNegative* g) { + if (g->i >= 0) { + return testing::AssertionSuccess(); + } + return testing::AssertionFailure() + << "i should be non-negative but is " << g->i; +} + +struct { + template <typename T> + void operator()(T* t) const { + (*t)(); + } +} invoker; + +auto tester = + testing::MakeExceptionSafetyTester().WithOperation(invoker).WithContracts( + CheckNonNegativeInvariants); +auto strong_tester = tester.WithContracts(testing::strong_guarantee); + +struct FailsBasicGuarantee : public NonNegative { + void operator()() { + --i; + ThrowingValue<> bomb; + ++i; + } +}; + +TEST(ExceptionCheckTest, BasicGuaranteeFailure) { + EXPECT_FALSE(tester.WithInitialValue(FailsBasicGuarantee{}).Test()); +} + +struct FollowsBasicGuarantee : public NonNegative { + void operator()() { + ++i; + ThrowingValue<> bomb; + } +}; + +TEST(ExceptionCheckTest, BasicGuarantee) { + EXPECT_TRUE(tester.WithInitialValue(FollowsBasicGuarantee{}).Test()); +} + +TEST(ExceptionCheckTest, StrongGuaranteeFailure) { + EXPECT_FALSE(strong_tester.WithInitialValue(FailsBasicGuarantee{}).Test()); + EXPECT_FALSE(strong_tester.WithInitialValue(FollowsBasicGuarantee{}).Test()); +} + +struct BasicGuaranteeWithExtraContracts : public NonNegative { + // After operator(), i is incremented. If operator() throws, i is set to 9999 + void operator()() { + int old_i = i; + i = kExceptionSentinel; + ThrowingValue<> bomb; + i = ++old_i; + } + + static constexpr int kExceptionSentinel = 9999; +}; +constexpr int BasicGuaranteeWithExtraContracts::kExceptionSentinel; + +TEST(ExceptionCheckTest, BasicGuaranteeWithExtraContracts) { + auto tester_with_val = + tester.WithInitialValue(BasicGuaranteeWithExtraContracts{}); + EXPECT_TRUE(tester_with_val.Test()); + EXPECT_TRUE( + tester_with_val + .WithContracts([](BasicGuaranteeWithExtraContracts* o) { + if (o->i == BasicGuaranteeWithExtraContracts::kExceptionSentinel) { + return testing::AssertionSuccess(); + } + return testing::AssertionFailure() + << "i should be " + << BasicGuaranteeWithExtraContracts::kExceptionSentinel + << ", but is " << o->i; + }) + .Test()); +} + +struct FollowsStrongGuarantee : public NonNegative { + void operator()() { ThrowingValue<> bomb; } +}; + +TEST(ExceptionCheckTest, StrongGuarantee) { + EXPECT_TRUE(tester.WithInitialValue(FollowsStrongGuarantee{}).Test()); + EXPECT_TRUE(strong_tester.WithInitialValue(FollowsStrongGuarantee{}).Test()); +} + +struct HasReset : public NonNegative { + void operator()() { + i = -1; + ThrowingValue<> bomb; + i = 1; + } + + void reset() { i = 0; } +}; + +testing::AssertionResult CheckHasResetContracts(HasReset* h) { + h->reset(); + return testing::AssertionResult(h->i == 0); +} + +TEST(ExceptionCheckTest, ModifyingChecker) { + auto set_to_1000 = [](FollowsBasicGuarantee* g) { + g->i = 1000; + return testing::AssertionSuccess(); + }; + auto is_1000 = [](FollowsBasicGuarantee* g) { + return testing::AssertionResult(g->i == 1000); + }; + auto increment = [](FollowsStrongGuarantee* g) { + ++g->i; + return testing::AssertionSuccess(); + }; + + EXPECT_FALSE(tester.WithInitialValue(FollowsBasicGuarantee{}) + .WithContracts(set_to_1000, is_1000) + .Test()); + EXPECT_TRUE(strong_tester.WithInitialValue(FollowsStrongGuarantee{}) + .WithContracts(increment) + .Test()); + EXPECT_TRUE(testing::MakeExceptionSafetyTester() + .WithInitialValue(HasReset{}) + .WithContracts(CheckHasResetContracts) + .Test(invoker)); +} + +TEST(ExceptionSafetyTesterTest, ResetsCountdown) { + auto test = + testing::MakeExceptionSafetyTester() + .WithInitialValue(ThrowingValue<>()) + .WithContracts([](ThrowingValue<>*) { return AssertionSuccess(); }) + .WithOperation([](ThrowingValue<>*) {}); + ASSERT_TRUE(test.Test()); + // If the countdown isn't reset because there were no exceptions thrown, then + // this will fail with a termination from an unhandled exception + EXPECT_TRUE(test.Test()); +} + +struct NonCopyable : public NonNegative { + NonCopyable(const NonCopyable&) = delete; + NonCopyable() : NonNegative{0} {} + + void operator()() { ThrowingValue<> bomb; } +}; + +TEST(ExceptionCheckTest, NonCopyable) { + auto factory = []() { return absl::make_unique<NonCopyable>(); }; + EXPECT_TRUE(tester.WithFactory(factory).Test()); + EXPECT_TRUE(strong_tester.WithFactory(factory).Test()); +} + +struct NonEqualityComparable : public NonNegative { + void operator()() { ThrowingValue<> bomb; } + + void ModifyOnThrow() { + ++i; + ThrowingValue<> bomb; + static_cast<void>(bomb); + --i; + } +}; + +TEST(ExceptionCheckTest, NonEqualityComparable) { + auto nec_is_strong = [](NonEqualityComparable* nec) { + return testing::AssertionResult(nec->i == NonEqualityComparable().i); + }; + auto strong_nec_tester = tester.WithInitialValue(NonEqualityComparable{}) + .WithContracts(nec_is_strong); + + EXPECT_TRUE(strong_nec_tester.Test()); + EXPECT_FALSE(strong_nec_tester.Test( + [](NonEqualityComparable* n) { n->ModifyOnThrow(); })); +} + +template <typename T> +struct ExhaustivenessTester { + void operator()() { + successes |= 1; + T b1; + static_cast<void>(b1); + successes |= (1 << 1); + T b2; + static_cast<void>(b2); + successes |= (1 << 2); + T b3; + static_cast<void>(b3); + successes |= (1 << 3); + } + + bool operator==(const ExhaustivenessTester<ThrowingValue<>>&) const { + return true; + } + + static unsigned char successes; +}; + +struct { + template <typename T> + testing::AssertionResult operator()(ExhaustivenessTester<T>*) const { + return testing::AssertionSuccess(); + } +} CheckExhaustivenessTesterContracts; + +template <typename T> +unsigned char ExhaustivenessTester<T>::successes = 0; + +TEST(ExceptionCheckTest, Exhaustiveness) { + auto exhaust_tester = testing::MakeExceptionSafetyTester() + .WithContracts(CheckExhaustivenessTesterContracts) + .WithOperation(invoker); + + EXPECT_TRUE( + exhaust_tester.WithInitialValue(ExhaustivenessTester<int>{}).Test()); + EXPECT_EQ(ExhaustivenessTester<int>::successes, 0xF); + + EXPECT_TRUE( + exhaust_tester.WithInitialValue(ExhaustivenessTester<ThrowingValue<>>{}) + .WithContracts(testing::strong_guarantee) + .Test()); + EXPECT_EQ(ExhaustivenessTester<ThrowingValue<>>::successes, 0xF); +} + +struct LeaksIfCtorThrows : private exceptions_internal::TrackedObject { + LeaksIfCtorThrows() : TrackedObject(ABSL_PRETTY_FUNCTION) { + ++counter; + ThrowingValue<> v; + static_cast<void>(v); + --counter; + } + LeaksIfCtorThrows(const LeaksIfCtorThrows&) noexcept + : TrackedObject(ABSL_PRETTY_FUNCTION) {} + static int counter; +}; +int LeaksIfCtorThrows::counter = 0; + +TEST(ExceptionCheckTest, TestLeakyCtor) { + testing::TestThrowingCtor<LeaksIfCtorThrows>(); + EXPECT_EQ(LeaksIfCtorThrows::counter, 1); + LeaksIfCtorThrows::counter = 0; +} + +struct Tracked : private exceptions_internal::TrackedObject { + Tracked() : TrackedObject(ABSL_PRETTY_FUNCTION) {} +}; + +TEST(ConstructorTrackerTest, CreatedBefore) { + Tracked a, b, c; + exceptions_internal::ConstructorTracker ct(exceptions_internal::countdown); +} + +TEST(ConstructorTrackerTest, CreatedAfter) { + exceptions_internal::ConstructorTracker ct(exceptions_internal::countdown); + Tracked a, b, c; +} + +TEST(ConstructorTrackerTest, NotDestroyedAfter) { + alignas(Tracked) unsigned char storage[sizeof(Tracked)]; + EXPECT_NONFATAL_FAILURE( + { + exceptions_internal::ConstructorTracker ct( + exceptions_internal::countdown); + new (&storage) Tracked(); + }, + "not destroyed"); +} + +TEST(ConstructorTrackerTest, DestroyedTwice) { + exceptions_internal::ConstructorTracker ct(exceptions_internal::countdown); + EXPECT_NONFATAL_FAILURE( + { + Tracked t; + t.~Tracked(); + }, + "re-destroyed"); +} + +TEST(ConstructorTrackerTest, ConstructedTwice) { + exceptions_internal::ConstructorTracker ct(exceptions_internal::countdown); + alignas(Tracked) unsigned char storage[sizeof(Tracked)]; + EXPECT_NONFATAL_FAILURE( + { + new (&storage) Tracked(); + new (&storage) Tracked(); + reinterpret_cast<Tracked*>(&storage)->~Tracked(); + }, + "re-constructed"); +} + +TEST(ThrowingValueTraitsTest, RelationalOperators) { + ThrowingValue<> a, b; + EXPECT_TRUE((std::is_convertible<decltype(a == b), bool>::value)); + EXPECT_TRUE((std::is_convertible<decltype(a != b), bool>::value)); + EXPECT_TRUE((std::is_convertible<decltype(a < b), bool>::value)); + EXPECT_TRUE((std::is_convertible<decltype(a <= b), bool>::value)); + EXPECT_TRUE((std::is_convertible<decltype(a > b), bool>::value)); + EXPECT_TRUE((std::is_convertible<decltype(a >= b), bool>::value)); +} + +TEST(ThrowingAllocatorTraitsTest, Assignablility) { + EXPECT_TRUE(absl::is_move_assignable<ThrowingAllocator<int>>::value); + EXPECT_TRUE(absl::is_copy_assignable<ThrowingAllocator<int>>::value); + EXPECT_TRUE(std::is_nothrow_move_assignable<ThrowingAllocator<int>>::value); + EXPECT_TRUE(std::is_nothrow_copy_assignable<ThrowingAllocator<int>>::value); +} + +} // namespace + +} // namespace testing + +#endif // ABSL_HAVE_EXCEPTIONS diff --git a/third_party/abseil_cpp/absl/base/inline_variable_test.cc b/third_party/abseil_cpp/absl/base/inline_variable_test.cc new file mode 100644 index 0000000000..37a40e1e40 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/inline_variable_test.cc @@ -0,0 +1,64 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <type_traits> + +#include "absl/base/internal/inline_variable.h" +#include "absl/base/internal/inline_variable_testing.h" + +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace inline_variable_testing_internal { +namespace { + +TEST(InlineVariableTest, Constexpr) { + static_assert(inline_variable_foo.value == 5, ""); + static_assert(other_inline_variable_foo.value == 5, ""); + static_assert(inline_variable_int == 5, ""); + static_assert(other_inline_variable_int == 5, ""); +} + +TEST(InlineVariableTest, DefaultConstructedIdentityEquality) { + EXPECT_EQ(get_foo_a().value, 5); + EXPECT_EQ(get_foo_b().value, 5); + EXPECT_EQ(&get_foo_a(), &get_foo_b()); +} + +TEST(InlineVariableTest, DefaultConstructedIdentityInequality) { + EXPECT_NE(&inline_variable_foo, &other_inline_variable_foo); +} + +TEST(InlineVariableTest, InitializedIdentityEquality) { + EXPECT_EQ(get_int_a(), 5); + EXPECT_EQ(get_int_b(), 5); + EXPECT_EQ(&get_int_a(), &get_int_b()); +} + +TEST(InlineVariableTest, InitializedIdentityInequality) { + EXPECT_NE(&inline_variable_int, &other_inline_variable_int); +} + +TEST(InlineVariableTest, FunPtrType) { + static_assert( + std::is_same<void(*)(), + std::decay<decltype(inline_variable_fun_ptr)>::type>::value, + ""); +} + +} // namespace +} // namespace inline_variable_testing_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/inline_variable_test_a.cc b/third_party/abseil_cpp/absl/base/inline_variable_test_a.cc new file mode 100644 index 0000000000..f96a58d9b4 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/inline_variable_test_a.cc @@ -0,0 +1,27 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/inline_variable_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace inline_variable_testing_internal { + +const Foo& get_foo_a() { return inline_variable_foo; } + +const int& get_int_a() { return inline_variable_int; } + +} // namespace inline_variable_testing_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/inline_variable_test_b.cc b/third_party/abseil_cpp/absl/base/inline_variable_test_b.cc new file mode 100644 index 0000000000..038adc30a9 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/inline_variable_test_b.cc @@ -0,0 +1,27 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/inline_variable_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace inline_variable_testing_internal { + +const Foo& get_foo_b() { return inline_variable_foo; } + +const int& get_int_b() { return inline_variable_int; } + +} // namespace inline_variable_testing_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/atomic_hook.h b/third_party/abseil_cpp/absl/base/internal/atomic_hook.h new file mode 100644 index 0000000000..ae21cd7fe5 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/atomic_hook.h @@ -0,0 +1,200 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_ATOMIC_HOOK_H_ +#define ABSL_BASE_INTERNAL_ATOMIC_HOOK_H_ + +#include <atomic> +#include <cassert> +#include <cstdint> +#include <utility> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" + +#if defined(_MSC_VER) && !defined(__clang__) +#define ABSL_HAVE_WORKING_CONSTEXPR_STATIC_INIT 0 +#else +#define ABSL_HAVE_WORKING_CONSTEXPR_STATIC_INIT 1 +#endif + +#if defined(_MSC_VER) +#define ABSL_HAVE_WORKING_ATOMIC_POINTER 0 +#else +#define ABSL_HAVE_WORKING_ATOMIC_POINTER 1 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +template <typename T> +class AtomicHook; + +// To workaround AtomicHook not being constant-initializable on some platforms, +// prefer to annotate instances with `ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES` +// instead of `ABSL_CONST_INIT`. +#if ABSL_HAVE_WORKING_CONSTEXPR_STATIC_INIT +#define ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES ABSL_CONST_INIT +#else +#define ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES +#endif + +// `AtomicHook` is a helper class, templatized on a raw function pointer type, +// for implementing Abseil customization hooks. It is a callable object that +// dispatches to the registered hook. Objects of type `AtomicHook` must have +// static or thread storage duration. +// +// A default constructed object performs a no-op (and returns a default +// constructed object) if no hook has been registered. +// +// Hooks can be pre-registered via constant initialization, for example: +// +// ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES static AtomicHook<void(*)()> +// my_hook(DefaultAction); +// +// and then changed at runtime via a call to `Store()`. +// +// Reads and writes guarantee memory_order_acquire/memory_order_release +// semantics. +template <typename ReturnType, typename... Args> +class AtomicHook<ReturnType (*)(Args...)> { + public: + using FnPtr = ReturnType (*)(Args...); + + // Constructs an object that by default performs a no-op (and + // returns a default constructed object) when no hook as been registered. + constexpr AtomicHook() : AtomicHook(DummyFunction) {} + + // Constructs an object that by default dispatches to/returns the + // pre-registered default_fn when no hook has been registered at runtime. +#if ABSL_HAVE_WORKING_ATOMIC_POINTER && ABSL_HAVE_WORKING_CONSTEXPR_STATIC_INIT + explicit constexpr AtomicHook(FnPtr default_fn) + : hook_(default_fn), default_fn_(default_fn) {} +#elif ABSL_HAVE_WORKING_CONSTEXPR_STATIC_INIT + explicit constexpr AtomicHook(FnPtr default_fn) + : hook_(kUninitialized), default_fn_(default_fn) {} +#else + // As of January 2020, on all known versions of MSVC this constructor runs in + // the global constructor sequence. If `Store()` is called by a dynamic + // initializer, we want to preserve the value, even if this constructor runs + // after the call to `Store()`. If not, `hook_` will be + // zero-initialized by the linker and we have no need to set it. + // https://developercommunity.visualstudio.com/content/problem/336946/class-with-constexpr-constructor-not-using-static.html + explicit constexpr AtomicHook(FnPtr default_fn) + : /* hook_(deliberately omitted), */ default_fn_(default_fn) { + static_assert(kUninitialized == 0, "here we rely on zero-initialization"); + } +#endif + + // Stores the provided function pointer as the value for this hook. + // + // This is intended to be called once. Multiple calls are legal only if the + // same function pointer is provided for each call. The store is implemented + // as a memory_order_release operation, and read accesses are implemented as + // memory_order_acquire. + void Store(FnPtr fn) { + bool success = DoStore(fn); + static_cast<void>(success); + assert(success); + } + + // Invokes the registered callback. If no callback has yet been registered, a + // default-constructed object of the appropriate type is returned instead. + template <typename... CallArgs> + ReturnType operator()(CallArgs&&... args) const { + return DoLoad()(std::forward<CallArgs>(args)...); + } + + // Returns the registered callback, or nullptr if none has been registered. + // Useful if client code needs to conditionalize behavior based on whether a + // callback was registered. + // + // Note that atomic_hook.Load()() and atomic_hook() have different semantics: + // operator()() will perform a no-op if no callback was registered, while + // Load()() will dereference a null function pointer. Prefer operator()() to + // Load()() unless you must conditionalize behavior on whether a hook was + // registered. + FnPtr Load() const { + FnPtr ptr = DoLoad(); + return (ptr == DummyFunction) ? nullptr : ptr; + } + + private: + static ReturnType DummyFunction(Args...) { + return ReturnType(); + } + + // Current versions of MSVC (as of September 2017) have a broken + // implementation of std::atomic<T*>: Its constructor attempts to do the + // equivalent of a reinterpret_cast in a constexpr context, which is not + // allowed. + // + // This causes an issue when building with LLVM under Windows. To avoid this, + // we use a less-efficient, intptr_t-based implementation on Windows. +#if ABSL_HAVE_WORKING_ATOMIC_POINTER + // Return the stored value, or DummyFunction if no value has been stored. + FnPtr DoLoad() const { return hook_.load(std::memory_order_acquire); } + + // Store the given value. Returns false if a different value was already + // stored to this object. + bool DoStore(FnPtr fn) { + assert(fn); + FnPtr expected = default_fn_; + const bool store_succeeded = hook_.compare_exchange_strong( + expected, fn, std::memory_order_acq_rel, std::memory_order_acquire); + const bool same_value_already_stored = (expected == fn); + return store_succeeded || same_value_already_stored; + } + + std::atomic<FnPtr> hook_; +#else // !ABSL_HAVE_WORKING_ATOMIC_POINTER + // Use a sentinel value unlikely to be the address of an actual function. + static constexpr intptr_t kUninitialized = 0; + + static_assert(sizeof(intptr_t) >= sizeof(FnPtr), + "intptr_t can't contain a function pointer"); + + FnPtr DoLoad() const { + const intptr_t value = hook_.load(std::memory_order_acquire); + if (value == kUninitialized) { + return default_fn_; + } + return reinterpret_cast<FnPtr>(value); + } + + bool DoStore(FnPtr fn) { + assert(fn); + const auto value = reinterpret_cast<intptr_t>(fn); + intptr_t expected = kUninitialized; + const bool store_succeeded = hook_.compare_exchange_strong( + expected, value, std::memory_order_acq_rel, std::memory_order_acquire); + const bool same_value_already_stored = (expected == value); + return store_succeeded || same_value_already_stored; + } + + std::atomic<intptr_t> hook_; +#endif + + const FnPtr default_fn_; +}; + +#undef ABSL_HAVE_WORKING_ATOMIC_POINTER +#undef ABSL_HAVE_WORKING_CONSTEXPR_STATIC_INIT + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_ATOMIC_HOOK_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/atomic_hook_test.cc b/third_party/abseil_cpp/absl/base/internal/atomic_hook_test.cc new file mode 100644 index 0000000000..e577a8fd93 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/atomic_hook_test.cc @@ -0,0 +1,97 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/atomic_hook.h" + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/atomic_hook_test_helper.h" + +namespace { + +using ::testing::Eq; + +int value = 0; +void TestHook(int x) { value = x; } + +TEST(AtomicHookTest, NoDefaultFunction) { + ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES static absl::base_internal::AtomicHook< + void (*)(int)> + hook; + value = 0; + + // Test the default DummyFunction. + EXPECT_TRUE(hook.Load() == nullptr); + EXPECT_EQ(value, 0); + hook(1); + EXPECT_EQ(value, 0); + + // Test a stored hook. + hook.Store(TestHook); + EXPECT_TRUE(hook.Load() == TestHook); + EXPECT_EQ(value, 0); + hook(1); + EXPECT_EQ(value, 1); + + // Calling Store() with the same hook should not crash. + hook.Store(TestHook); + EXPECT_TRUE(hook.Load() == TestHook); + EXPECT_EQ(value, 1); + hook(2); + EXPECT_EQ(value, 2); +} + +TEST(AtomicHookTest, WithDefaultFunction) { + // Set the default value to TestHook at compile-time. + ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES static absl::base_internal::AtomicHook< + void (*)(int)> + hook(TestHook); + value = 0; + + // Test the default value is TestHook. + EXPECT_TRUE(hook.Load() == TestHook); + EXPECT_EQ(value, 0); + hook(1); + EXPECT_EQ(value, 1); + + // Calling Store() with the same hook should not crash. + hook.Store(TestHook); + EXPECT_TRUE(hook.Load() == TestHook); + EXPECT_EQ(value, 1); + hook(2); + EXPECT_EQ(value, 2); +} + +ABSL_CONST_INIT int override_func_calls = 0; +void OverrideFunc() { override_func_calls++; } +static struct OverrideInstaller { + OverrideInstaller() { absl::atomic_hook_internal::func.Store(OverrideFunc); } +} override_installer; + +TEST(AtomicHookTest, DynamicInitFromAnotherTU) { + // MSVC 14.2 doesn't do constexpr static init correctly; in particular it + // tends to sequence static init (i.e. defaults) of `AtomicHook` objects + // after their dynamic init (i.e. overrides), overwriting whatever value was + // written during dynamic init. This regression test validates the fix. + // https://developercommunity.visualstudio.com/content/problem/336946/class-with-constexpr-constructor-not-using-static.html + EXPECT_THAT(absl::atomic_hook_internal::default_func_calls, Eq(0)); + EXPECT_THAT(override_func_calls, Eq(0)); + absl::atomic_hook_internal::func(); + EXPECT_THAT(absl::atomic_hook_internal::default_func_calls, Eq(0)); + EXPECT_THAT(override_func_calls, Eq(1)); + EXPECT_THAT(absl::atomic_hook_internal::func.Load(), Eq(OverrideFunc)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/atomic_hook_test_helper.cc b/third_party/abseil_cpp/absl/base/internal/atomic_hook_test_helper.cc new file mode 100644 index 0000000000..537d47cd2d --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/atomic_hook_test_helper.cc @@ -0,0 +1,32 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/atomic_hook_test_helper.h" + +#include "absl/base/attributes.h" +#include "absl/base/internal/atomic_hook.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace atomic_hook_internal { + +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES absl::base_internal::AtomicHook<VoidF> + func(DefaultFunc); +ABSL_CONST_INIT int default_func_calls = 0; +void DefaultFunc() { default_func_calls++; } +void RegisterFunc(VoidF f) { func.Store(f); } + +} // namespace atomic_hook_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/atomic_hook_test_helper.h b/third_party/abseil_cpp/absl/base/internal/atomic_hook_test_helper.h new file mode 100644 index 0000000000..3e72b4977d --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/atomic_hook_test_helper.h @@ -0,0 +1,34 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_ATOMIC_HOOK_TEST_HELPER_H_ +#define ABSL_BASE_ATOMIC_HOOK_TEST_HELPER_H_ + +#include "absl/base/internal/atomic_hook.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace atomic_hook_internal { + +using VoidF = void (*)(); +extern absl::base_internal::AtomicHook<VoidF> func; +extern int default_func_calls; +void DefaultFunc(); +void RegisterFunc(VoidF func); + +} // namespace atomic_hook_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_ATOMIC_HOOK_TEST_HELPER_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/bits.h b/third_party/abseil_cpp/absl/base/internal/bits.h new file mode 100644 index 0000000000..14c51d8b30 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/bits.h @@ -0,0 +1,218 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_BITS_H_ +#define ABSL_BASE_INTERNAL_BITS_H_ + +// This file contains bitwise ops which are implementation details of various +// absl libraries. + +#include <cstdint> + +#include "absl/base/config.h" + +// Clang on Windows has __builtin_clzll; otherwise we need to use the +// windows intrinsic functions. +#if defined(_MSC_VER) && !defined(__clang__) +#include <intrin.h> +#if defined(_M_X64) +#pragma intrinsic(_BitScanReverse64) +#pragma intrinsic(_BitScanForward64) +#endif +#pragma intrinsic(_BitScanReverse) +#pragma intrinsic(_BitScanForward) +#endif + +#include "absl/base/attributes.h" + +#if defined(_MSC_VER) && !defined(__clang__) +// We can achieve something similar to attribute((always_inline)) with MSVC by +// using the __forceinline keyword, however this is not perfect. MSVC is +// much less aggressive about inlining, and even with the __forceinline keyword. +#define ABSL_BASE_INTERNAL_FORCEINLINE __forceinline +#else +// Use default attribute inline. +#define ABSL_BASE_INTERNAL_FORCEINLINE inline ABSL_ATTRIBUTE_ALWAYS_INLINE +#endif + + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +ABSL_BASE_INTERNAL_FORCEINLINE int CountLeadingZeros64Slow(uint64_t n) { + int zeroes = 60; + if (n >> 32) { + zeroes -= 32; + n >>= 32; + } + if (n >> 16) { + zeroes -= 16; + n >>= 16; + } + if (n >> 8) { + zeroes -= 8; + n >>= 8; + } + if (n >> 4) { + zeroes -= 4; + n >>= 4; + } + return "\4\3\2\2\1\1\1\1\0\0\0\0\0\0\0"[n] + zeroes; +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountLeadingZeros64(uint64_t n) { +#if defined(_MSC_VER) && !defined(__clang__) && defined(_M_X64) + // MSVC does not have __buitin_clzll. Use _BitScanReverse64. + unsigned long result = 0; // NOLINT(runtime/int) + if (_BitScanReverse64(&result, n)) { + return 63 - result; + } + return 64; +#elif defined(_MSC_VER) && !defined(__clang__) + // MSVC does not have __buitin_clzll. Compose two calls to _BitScanReverse + unsigned long result = 0; // NOLINT(runtime/int) + if ((n >> 32) && _BitScanReverse(&result, n >> 32)) { + return 31 - result; + } + if (_BitScanReverse(&result, n)) { + return 63 - result; + } + return 64; +#elif defined(__GNUC__) || defined(__clang__) + // Use __builtin_clzll, which uses the following instructions: + // x86: bsr + // ARM64: clz + // PPC: cntlzd + static_assert(sizeof(unsigned long long) == sizeof(n), // NOLINT(runtime/int) + "__builtin_clzll does not take 64-bit arg"); + + // Handle 0 as a special case because __builtin_clzll(0) is undefined. + if (n == 0) { + return 64; + } + return __builtin_clzll(n); +#else + return CountLeadingZeros64Slow(n); +#endif +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountLeadingZeros32Slow(uint64_t n) { + int zeroes = 28; + if (n >> 16) { + zeroes -= 16; + n >>= 16; + } + if (n >> 8) { + zeroes -= 8; + n >>= 8; + } + if (n >> 4) { + zeroes -= 4; + n >>= 4; + } + return "\4\3\2\2\1\1\1\1\0\0\0\0\0\0\0"[n] + zeroes; +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountLeadingZeros32(uint32_t n) { +#if defined(_MSC_VER) && !defined(__clang__) + unsigned long result = 0; // NOLINT(runtime/int) + if (_BitScanReverse(&result, n)) { + return 31 - result; + } + return 32; +#elif defined(__GNUC__) || defined(__clang__) + // Use __builtin_clz, which uses the following instructions: + // x86: bsr + // ARM64: clz + // PPC: cntlzd + static_assert(sizeof(int) == sizeof(n), + "__builtin_clz does not take 32-bit arg"); + + // Handle 0 as a special case because __builtin_clz(0) is undefined. + if (n == 0) { + return 32; + } + return __builtin_clz(n); +#else + return CountLeadingZeros32Slow(n); +#endif +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountTrailingZerosNonZero64Slow(uint64_t n) { + int c = 63; + n &= ~n + 1; + if (n & 0x00000000FFFFFFFF) c -= 32; + if (n & 0x0000FFFF0000FFFF) c -= 16; + if (n & 0x00FF00FF00FF00FF) c -= 8; + if (n & 0x0F0F0F0F0F0F0F0F) c -= 4; + if (n & 0x3333333333333333) c -= 2; + if (n & 0x5555555555555555) c -= 1; + return c; +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountTrailingZerosNonZero64(uint64_t n) { +#if defined(_MSC_VER) && !defined(__clang__) && defined(_M_X64) + unsigned long result = 0; // NOLINT(runtime/int) + _BitScanForward64(&result, n); + return result; +#elif defined(_MSC_VER) && !defined(__clang__) + unsigned long result = 0; // NOLINT(runtime/int) + if (static_cast<uint32_t>(n) == 0) { + _BitScanForward(&result, n >> 32); + return result + 32; + } + _BitScanForward(&result, n); + return result; +#elif defined(__GNUC__) || defined(__clang__) + static_assert(sizeof(unsigned long long) == sizeof(n), // NOLINT(runtime/int) + "__builtin_ctzll does not take 64-bit arg"); + return __builtin_ctzll(n); +#else + return CountTrailingZerosNonZero64Slow(n); +#endif +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountTrailingZerosNonZero32Slow(uint32_t n) { + int c = 31; + n &= ~n + 1; + if (n & 0x0000FFFF) c -= 16; + if (n & 0x00FF00FF) c -= 8; + if (n & 0x0F0F0F0F) c -= 4; + if (n & 0x33333333) c -= 2; + if (n & 0x55555555) c -= 1; + return c; +} + +ABSL_BASE_INTERNAL_FORCEINLINE int CountTrailingZerosNonZero32(uint32_t n) { +#if defined(_MSC_VER) && !defined(__clang__) + unsigned long result = 0; // NOLINT(runtime/int) + _BitScanForward(&result, n); + return result; +#elif defined(__GNUC__) || defined(__clang__) + static_assert(sizeof(int) == sizeof(n), + "__builtin_ctz does not take 32-bit arg"); + return __builtin_ctz(n); +#else + return CountTrailingZerosNonZero32Slow(n); +#endif +} + +#undef ABSL_BASE_INTERNAL_FORCEINLINE + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_BITS_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/bits_test.cc b/third_party/abseil_cpp/absl/base/internal/bits_test.cc new file mode 100644 index 0000000000..7855fa6297 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/bits_test.cc @@ -0,0 +1,97 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/bits.h" + +#include "gtest/gtest.h" + +namespace { + +int CLZ64(uint64_t n) { + int fast = absl::base_internal::CountLeadingZeros64(n); + int slow = absl::base_internal::CountLeadingZeros64Slow(n); + EXPECT_EQ(fast, slow) << n; + return fast; +} + +TEST(BitsTest, CountLeadingZeros64) { + EXPECT_EQ(64, CLZ64(uint64_t{})); + EXPECT_EQ(0, CLZ64(~uint64_t{})); + + for (int index = 0; index < 64; index++) { + uint64_t x = static_cast<uint64_t>(1) << index; + const auto cnt = 63 - index; + ASSERT_EQ(cnt, CLZ64(x)) << index; + ASSERT_EQ(cnt, CLZ64(x + x - 1)) << index; + } +} + +int CLZ32(uint32_t n) { + int fast = absl::base_internal::CountLeadingZeros32(n); + int slow = absl::base_internal::CountLeadingZeros32Slow(n); + EXPECT_EQ(fast, slow) << n; + return fast; +} + +TEST(BitsTest, CountLeadingZeros32) { + EXPECT_EQ(32, CLZ32(uint32_t{})); + EXPECT_EQ(0, CLZ32(~uint32_t{})); + + for (int index = 0; index < 32; index++) { + uint32_t x = static_cast<uint32_t>(1) << index; + const auto cnt = 31 - index; + ASSERT_EQ(cnt, CLZ32(x)) << index; + ASSERT_EQ(cnt, CLZ32(x + x - 1)) << index; + ASSERT_EQ(CLZ64(x), CLZ32(x) + 32); + } +} + +int CTZ64(uint64_t n) { + int fast = absl::base_internal::CountTrailingZerosNonZero64(n); + int slow = absl::base_internal::CountTrailingZerosNonZero64Slow(n); + EXPECT_EQ(fast, slow) << n; + return fast; +} + +TEST(BitsTest, CountTrailingZerosNonZero64) { + EXPECT_EQ(0, CTZ64(~uint64_t{})); + + for (int index = 0; index < 64; index++) { + uint64_t x = static_cast<uint64_t>(1) << index; + const auto cnt = index; + ASSERT_EQ(cnt, CTZ64(x)) << index; + ASSERT_EQ(cnt, CTZ64(~(x - 1))) << index; + } +} + +int CTZ32(uint32_t n) { + int fast = absl::base_internal::CountTrailingZerosNonZero32(n); + int slow = absl::base_internal::CountTrailingZerosNonZero32Slow(n); + EXPECT_EQ(fast, slow) << n; + return fast; +} + +TEST(BitsTest, CountTrailingZerosNonZero32) { + EXPECT_EQ(0, CTZ32(~uint32_t{})); + + for (int index = 0; index < 32; index++) { + uint32_t x = static_cast<uint32_t>(1) << index; + const auto cnt = index; + ASSERT_EQ(cnt, CTZ32(x)) << index; + ASSERT_EQ(cnt, CTZ32(~(x - 1))) << index; + } +} + + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/cmake_thread_test.cc b/third_party/abseil_cpp/absl/base/internal/cmake_thread_test.cc new file mode 100644 index 0000000000..f70bb24eb7 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/cmake_thread_test.cc @@ -0,0 +1,22 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <iostream> +#include "absl/base/internal/thread_identity.h" + +int main() { + auto* tid = absl::base_internal::CurrentThreadIdentityIfPresent(); + // Make sure the above call can't be optimized out + std::cout << (void*)tid << std::endl; +} diff --git a/third_party/abseil_cpp/absl/base/internal/cycleclock.cc b/third_party/abseil_cpp/absl/base/internal/cycleclock.cc new file mode 100644 index 0000000000..0e65005b89 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/cycleclock.cc @@ -0,0 +1,107 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// The implementation of CycleClock::Frequency. +// +// NOTE: only i386 and x86_64 have been well tested. +// PPC, sparc, alpha, and ia64 are based on +// http://peter.kuscsik.com/wordpress/?p=14 +// with modifications by m3b. See also +// https://setisvn.ssl.berkeley.edu/svn/lib/fftw-3.0.1/kernel/cycle.h + +#include "absl/base/internal/cycleclock.h" + +#include <atomic> +#include <chrono> // NOLINT(build/c++11) + +#include "absl/base/internal/unscaledcycleclock.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +#if ABSL_USE_UNSCALED_CYCLECLOCK + +namespace { + +#ifdef NDEBUG +#ifdef ABSL_INTERNAL_UNSCALED_CYCLECLOCK_FREQUENCY_IS_CPU_FREQUENCY +// Not debug mode and the UnscaledCycleClock frequency is the CPU +// frequency. Scale the CycleClock to prevent overflow if someone +// tries to represent the time as cycles since the Unix epoch. +static constexpr int32_t kShift = 1; +#else +// Not debug mode and the UnscaledCycleClock isn't operating at the +// raw CPU frequency. There is no need to do any scaling, so don't +// needlessly sacrifice precision. +static constexpr int32_t kShift = 0; +#endif +#else +// In debug mode use a different shift to discourage depending on a +// particular shift value. +static constexpr int32_t kShift = 2; +#endif + +static constexpr double kFrequencyScale = 1.0 / (1 << kShift); +static std::atomic<CycleClockSourceFunc> cycle_clock_source; + +CycleClockSourceFunc LoadCycleClockSource() { + // Optimize for the common case (no callback) by first doing a relaxed load; + // this is significantly faster on non-x86 platforms. + if (cycle_clock_source.load(std::memory_order_relaxed) == nullptr) { + return nullptr; + } + // This corresponds to the store(std::memory_order_release) in + // CycleClockSource::Register, and makes sure that any updates made prior to + // registering the callback are visible to this thread before the callback is + // invoked. + return cycle_clock_source.load(std::memory_order_acquire); +} + +} // namespace + +int64_t CycleClock::Now() { + auto fn = LoadCycleClockSource(); + if (fn == nullptr) { + return base_internal::UnscaledCycleClock::Now() >> kShift; + } + return fn() >> kShift; +} + +double CycleClock::Frequency() { + return kFrequencyScale * base_internal::UnscaledCycleClock::Frequency(); +} + +void CycleClockSource::Register(CycleClockSourceFunc source) { + // Corresponds to the load(std::memory_order_acquire) in LoadCycleClockSource. + cycle_clock_source.store(source, std::memory_order_release); +} + +#else + +int64_t CycleClock::Now() { + return std::chrono::duration_cast<std::chrono::nanoseconds>( + std::chrono::steady_clock::now().time_since_epoch()) + .count(); +} + +double CycleClock::Frequency() { + return 1e9; +} + +#endif + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/cycleclock.h b/third_party/abseil_cpp/absl/base/internal/cycleclock.h new file mode 100644 index 0000000000..a18b584445 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/cycleclock.h @@ -0,0 +1,94 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// ----------------------------------------------------------------------------- +// File: cycleclock.h +// ----------------------------------------------------------------------------- +// +// This header file defines a `CycleClock`, which yields the value and frequency +// of a cycle counter that increments at a rate that is approximately constant. +// +// NOTE: +// +// The cycle counter frequency is not necessarily related to the core clock +// frequency and should not be treated as such. That is, `CycleClock` cycles are +// not necessarily "CPU cycles" and code should not rely on that behavior, even +// if experimentally observed. +// +// An arbitrary offset may have been added to the counter at power on. +// +// On some platforms, the rate and offset of the counter may differ +// slightly when read from different CPUs of a multiprocessor. Usually, +// we try to ensure that the operating system adjusts values periodically +// so that values agree approximately. If you need stronger guarantees, +// consider using alternate interfaces. +// +// The CPU is not required to maintain the ordering of a cycle counter read +// with respect to surrounding instructions. + +#ifndef ABSL_BASE_INTERNAL_CYCLECLOCK_H_ +#define ABSL_BASE_INTERNAL_CYCLECLOCK_H_ + +#include <cstdint> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// ----------------------------------------------------------------------------- +// CycleClock +// ----------------------------------------------------------------------------- +class CycleClock { + public: + // CycleClock::Now() + // + // Returns the value of a cycle counter that counts at a rate that is + // approximately constant. + static int64_t Now(); + + // CycleClock::Frequency() + // + // Returns the amount by which `CycleClock::Now()` increases per second. Note + // that this value may not necessarily match the core CPU clock frequency. + static double Frequency(); + + private: + CycleClock() = delete; // no instances + CycleClock(const CycleClock&) = delete; + CycleClock& operator=(const CycleClock&) = delete; +}; + +using CycleClockSourceFunc = int64_t (*)(); + +class CycleClockSource { + private: + // CycleClockSource::Register() + // + // Register a function that provides an alternate source for the unscaled CPU + // cycle count value. The source function must be async signal safe, must not + // call CycleClock::Now(), and must have a frequency that matches that of the + // unscaled clock used by CycleClock. A nullptr value resets CycleClock to use + // the default source. + static void Register(CycleClockSourceFunc source); +}; + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_CYCLECLOCK_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/direct_mmap.h b/third_party/abseil_cpp/absl/base/internal/direct_mmap.h new file mode 100644 index 0000000000..16accf0966 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/direct_mmap.h @@ -0,0 +1,166 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Functions for directly invoking mmap() via syscall, avoiding the case where +// mmap() has been locally overridden. + +#ifndef ABSL_BASE_INTERNAL_DIRECT_MMAP_H_ +#define ABSL_BASE_INTERNAL_DIRECT_MMAP_H_ + +#include "absl/base/config.h" + +#if ABSL_HAVE_MMAP + +#include <sys/mman.h> + +#ifdef __linux__ + +#include <sys/types.h> +#ifdef __BIONIC__ +#include <sys/syscall.h> +#else +#include <syscall.h> +#endif + +#include <linux/unistd.h> +#include <unistd.h> +#include <cerrno> +#include <cstdarg> +#include <cstdint> + +#ifdef __mips__ +// Include definitions of the ABI currently in use. +#ifdef __BIONIC__ +// Android doesn't have sgidefs.h, but does have asm/sgidefs.h, which has the +// definitions we need. +#include <asm/sgidefs.h> +#else +#include <sgidefs.h> +#endif // __BIONIC__ +#endif // __mips__ + +// SYS_mmap and SYS_munmap are not defined in Android. +#ifdef __BIONIC__ +extern "C" void* __mmap2(void*, size_t, int, int, int, size_t); +#if defined(__NR_mmap) && !defined(SYS_mmap) +#define SYS_mmap __NR_mmap +#endif +#ifndef SYS_munmap +#define SYS_munmap __NR_munmap +#endif +#endif // __BIONIC__ + +#if defined(__NR_mmap2) && !defined(SYS_mmap2) +#define SYS_mmap2 __NR_mmap2 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// Platform specific logic extracted from +// https://chromium.googlesource.com/linux-syscall-support/+/master/linux_syscall_support.h +inline void* DirectMmap(void* start, size_t length, int prot, int flags, int fd, + off64_t offset) noexcept { +#if defined(__i386__) || defined(__ARM_ARCH_3__) || defined(__ARM_EABI__) || \ + (defined(__mips__) && _MIPS_SIM == _MIPS_SIM_ABI32) || \ + (defined(__PPC__) && !defined(__PPC64__)) || \ + (defined(__riscv) && __riscv_xlen == 32) || \ + (defined(__s390__) && !defined(__s390x__)) + // On these architectures, implement mmap with mmap2. + static int pagesize = 0; + if (pagesize == 0) { +#if defined(__wasm__) || defined(__asmjs__) + pagesize = getpagesize(); +#else + pagesize = sysconf(_SC_PAGESIZE); +#endif + } + if (offset < 0 || offset % pagesize != 0) { + errno = EINVAL; + return MAP_FAILED; + } +#ifdef __BIONIC__ + // SYS_mmap2 has problems on Android API level <= 16. + // Workaround by invoking __mmap2() instead. + return __mmap2(start, length, prot, flags, fd, offset / pagesize); +#else + return reinterpret_cast<void*>( + syscall(SYS_mmap2, start, length, prot, flags, fd, + static_cast<off_t>(offset / pagesize))); +#endif +#elif defined(__s390x__) + // On s390x, mmap() arguments are passed in memory. + unsigned long buf[6] = {reinterpret_cast<unsigned long>(start), // NOLINT + static_cast<unsigned long>(length), // NOLINT + static_cast<unsigned long>(prot), // NOLINT + static_cast<unsigned long>(flags), // NOLINT + static_cast<unsigned long>(fd), // NOLINT + static_cast<unsigned long>(offset)}; // NOLINT + return reinterpret_cast<void*>(syscall(SYS_mmap, buf)); +#elif defined(__x86_64__) +// The x32 ABI has 32 bit longs, but the syscall interface is 64 bit. +// We need to explicitly cast to an unsigned 64 bit type to avoid implicit +// sign extension. We can't cast pointers directly because those are +// 32 bits, and gcc will dump ugly warnings about casting from a pointer +// to an integer of a different size. We also need to make sure __off64_t +// isn't truncated to 32-bits under x32. +#define MMAP_SYSCALL_ARG(x) ((uint64_t)(uintptr_t)(x)) + return reinterpret_cast<void*>( + syscall(SYS_mmap, MMAP_SYSCALL_ARG(start), MMAP_SYSCALL_ARG(length), + MMAP_SYSCALL_ARG(prot), MMAP_SYSCALL_ARG(flags), + MMAP_SYSCALL_ARG(fd), static_cast<uint64_t>(offset))); +#undef MMAP_SYSCALL_ARG +#else // Remaining 64-bit aritectures. + static_assert(sizeof(unsigned long) == 8, "Platform is not 64-bit"); + return reinterpret_cast<void*>( + syscall(SYS_mmap, start, length, prot, flags, fd, offset)); +#endif +} + +inline int DirectMunmap(void* start, size_t length) { + return static_cast<int>(syscall(SYS_munmap, start, length)); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#else // !__linux__ + +// For non-linux platforms where we have mmap, just dispatch directly to the +// actual mmap()/munmap() methods. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +inline void* DirectMmap(void* start, size_t length, int prot, int flags, int fd, + off_t offset) { + return mmap(start, length, prot, flags, fd, offset); +} + +inline int DirectMunmap(void* start, size_t length) { + return munmap(start, length); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // __linux__ + +#endif // ABSL_HAVE_MMAP + +#endif // ABSL_BASE_INTERNAL_DIRECT_MMAP_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/endian.h b/third_party/abseil_cpp/absl/base/internal/endian.h new file mode 100644 index 0000000000..9677530e8d --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/endian.h @@ -0,0 +1,266 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_ENDIAN_H_ +#define ABSL_BASE_INTERNAL_ENDIAN_H_ + +// The following guarantees declaration of the byte swap functions +#ifdef _MSC_VER +#include <stdlib.h> // NOLINT(build/include) +#elif defined(__FreeBSD__) +#include <sys/endian.h> +#elif defined(__GLIBC__) +#include <byteswap.h> // IWYU pragma: export +#endif + +#include <cstdint> +#include "absl/base/config.h" +#include "absl/base/internal/unaligned_access.h" +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Use compiler byte-swapping intrinsics if they are available. 32-bit +// and 64-bit versions are available in Clang and GCC as of GCC 4.3.0. +// The 16-bit version is available in Clang and GCC only as of GCC 4.8.0. +// For simplicity, we enable them all only for GCC 4.8.0 or later. +#if defined(__clang__) || \ + (defined(__GNUC__) && \ + ((__GNUC__ == 4 && __GNUC_MINOR__ >= 8) || __GNUC__ >= 5)) +inline uint64_t gbswap_64(uint64_t host_int) { + return __builtin_bswap64(host_int); +} +inline uint32_t gbswap_32(uint32_t host_int) { + return __builtin_bswap32(host_int); +} +inline uint16_t gbswap_16(uint16_t host_int) { + return __builtin_bswap16(host_int); +} + +#elif defined(_MSC_VER) +inline uint64_t gbswap_64(uint64_t host_int) { + return _byteswap_uint64(host_int); +} +inline uint32_t gbswap_32(uint32_t host_int) { + return _byteswap_ulong(host_int); +} +inline uint16_t gbswap_16(uint16_t host_int) { + return _byteswap_ushort(host_int); +} + +#else +inline uint64_t gbswap_64(uint64_t host_int) { +#if defined(__GNUC__) && defined(__x86_64__) && !defined(__APPLE__) + // Adapted from /usr/include/byteswap.h. Not available on Mac. + if (__builtin_constant_p(host_int)) { + return __bswap_constant_64(host_int); + } else { + uint64_t result; + __asm__("bswap %0" : "=r"(result) : "0"(host_int)); + return result; + } +#elif defined(__GLIBC__) + return bswap_64(host_int); +#else + return (((host_int & uint64_t{0xFF}) << 56) | + ((host_int & uint64_t{0xFF00}) << 40) | + ((host_int & uint64_t{0xFF0000}) << 24) | + ((host_int & uint64_t{0xFF000000}) << 8) | + ((host_int & uint64_t{0xFF00000000}) >> 8) | + ((host_int & uint64_t{0xFF0000000000}) >> 24) | + ((host_int & uint64_t{0xFF000000000000}) >> 40) | + ((host_int & uint64_t{0xFF00000000000000}) >> 56)); +#endif // bswap_64 +} + +inline uint32_t gbswap_32(uint32_t host_int) { +#if defined(__GLIBC__) + return bswap_32(host_int); +#else + return (((host_int & uint32_t{0xFF}) << 24) | + ((host_int & uint32_t{0xFF00}) << 8) | + ((host_int & uint32_t{0xFF0000}) >> 8) | + ((host_int & uint32_t{0xFF000000}) >> 24)); +#endif +} + +inline uint16_t gbswap_16(uint16_t host_int) { +#if defined(__GLIBC__) + return bswap_16(host_int); +#else + return (((host_int & uint16_t{0xFF}) << 8) | + ((host_int & uint16_t{0xFF00}) >> 8)); +#endif +} + +#endif // intrinsics available + +#ifdef ABSL_IS_LITTLE_ENDIAN + +// Definitions for ntohl etc. that don't require us to include +// netinet/in.h. We wrap gbswap_32 and gbswap_16 in functions rather +// than just #defining them because in debug mode, gcc doesn't +// correctly handle the (rather involved) definitions of bswap_32. +// gcc guarantees that inline functions are as fast as macros, so +// this isn't a performance hit. +inline uint16_t ghtons(uint16_t x) { return gbswap_16(x); } +inline uint32_t ghtonl(uint32_t x) { return gbswap_32(x); } +inline uint64_t ghtonll(uint64_t x) { return gbswap_64(x); } + +#elif defined ABSL_IS_BIG_ENDIAN + +// These definitions are simpler on big-endian machines +// These are functions instead of macros to avoid self-assignment warnings +// on calls such as "i = ghtnol(i);". This also provides type checking. +inline uint16_t ghtons(uint16_t x) { return x; } +inline uint32_t ghtonl(uint32_t x) { return x; } +inline uint64_t ghtonll(uint64_t x) { return x; } + +#else +#error \ + "Unsupported byte order: Either ABSL_IS_BIG_ENDIAN or " \ + "ABSL_IS_LITTLE_ENDIAN must be defined" +#endif // byte order + +inline uint16_t gntohs(uint16_t x) { return ghtons(x); } +inline uint32_t gntohl(uint32_t x) { return ghtonl(x); } +inline uint64_t gntohll(uint64_t x) { return ghtonll(x); } + +// Utilities to convert numbers between the current hosts's native byte +// order and little-endian byte order +// +// Load/Store methods are alignment safe +namespace little_endian { +// Conversion functions. +#ifdef ABSL_IS_LITTLE_ENDIAN + +inline uint16_t FromHost16(uint16_t x) { return x; } +inline uint16_t ToHost16(uint16_t x) { return x; } + +inline uint32_t FromHost32(uint32_t x) { return x; } +inline uint32_t ToHost32(uint32_t x) { return x; } + +inline uint64_t FromHost64(uint64_t x) { return x; } +inline uint64_t ToHost64(uint64_t x) { return x; } + +inline constexpr bool IsLittleEndian() { return true; } + +#elif defined ABSL_IS_BIG_ENDIAN + +inline uint16_t FromHost16(uint16_t x) { return gbswap_16(x); } +inline uint16_t ToHost16(uint16_t x) { return gbswap_16(x); } + +inline uint32_t FromHost32(uint32_t x) { return gbswap_32(x); } +inline uint32_t ToHost32(uint32_t x) { return gbswap_32(x); } + +inline uint64_t FromHost64(uint64_t x) { return gbswap_64(x); } +inline uint64_t ToHost64(uint64_t x) { return gbswap_64(x); } + +inline constexpr bool IsLittleEndian() { return false; } + +#endif /* ENDIAN */ + +// Functions to do unaligned loads and stores in little-endian order. +inline uint16_t Load16(const void *p) { + return ToHost16(ABSL_INTERNAL_UNALIGNED_LOAD16(p)); +} + +inline void Store16(void *p, uint16_t v) { + ABSL_INTERNAL_UNALIGNED_STORE16(p, FromHost16(v)); +} + +inline uint32_t Load32(const void *p) { + return ToHost32(ABSL_INTERNAL_UNALIGNED_LOAD32(p)); +} + +inline void Store32(void *p, uint32_t v) { + ABSL_INTERNAL_UNALIGNED_STORE32(p, FromHost32(v)); +} + +inline uint64_t Load64(const void *p) { + return ToHost64(ABSL_INTERNAL_UNALIGNED_LOAD64(p)); +} + +inline void Store64(void *p, uint64_t v) { + ABSL_INTERNAL_UNALIGNED_STORE64(p, FromHost64(v)); +} + +} // namespace little_endian + +// Utilities to convert numbers between the current hosts's native byte +// order and big-endian byte order (same as network byte order) +// +// Load/Store methods are alignment safe +namespace big_endian { +#ifdef ABSL_IS_LITTLE_ENDIAN + +inline uint16_t FromHost16(uint16_t x) { return gbswap_16(x); } +inline uint16_t ToHost16(uint16_t x) { return gbswap_16(x); } + +inline uint32_t FromHost32(uint32_t x) { return gbswap_32(x); } +inline uint32_t ToHost32(uint32_t x) { return gbswap_32(x); } + +inline uint64_t FromHost64(uint64_t x) { return gbswap_64(x); } +inline uint64_t ToHost64(uint64_t x) { return gbswap_64(x); } + +inline constexpr bool IsLittleEndian() { return true; } + +#elif defined ABSL_IS_BIG_ENDIAN + +inline uint16_t FromHost16(uint16_t x) { return x; } +inline uint16_t ToHost16(uint16_t x) { return x; } + +inline uint32_t FromHost32(uint32_t x) { return x; } +inline uint32_t ToHost32(uint32_t x) { return x; } + +inline uint64_t FromHost64(uint64_t x) { return x; } +inline uint64_t ToHost64(uint64_t x) { return x; } + +inline constexpr bool IsLittleEndian() { return false; } + +#endif /* ENDIAN */ + +// Functions to do unaligned loads and stores in big-endian order. +inline uint16_t Load16(const void *p) { + return ToHost16(ABSL_INTERNAL_UNALIGNED_LOAD16(p)); +} + +inline void Store16(void *p, uint16_t v) { + ABSL_INTERNAL_UNALIGNED_STORE16(p, FromHost16(v)); +} + +inline uint32_t Load32(const void *p) { + return ToHost32(ABSL_INTERNAL_UNALIGNED_LOAD32(p)); +} + +inline void Store32(void *p, uint32_t v) { + ABSL_INTERNAL_UNALIGNED_STORE32(p, FromHost32(v)); +} + +inline uint64_t Load64(const void *p) { + return ToHost64(ABSL_INTERNAL_UNALIGNED_LOAD64(p)); +} + +inline void Store64(void *p, uint64_t v) { + ABSL_INTERNAL_UNALIGNED_STORE64(p, FromHost64(v)); +} + +} // namespace big_endian + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_ENDIAN_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/endian_test.cc b/third_party/abseil_cpp/absl/base/internal/endian_test.cc new file mode 100644 index 0000000000..a1691b1f82 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/endian_test.cc @@ -0,0 +1,263 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/endian.h" + +#include <algorithm> +#include <cstdint> +#include <limits> +#include <random> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +const uint64_t kInitialNumber{0x0123456789abcdef}; +const uint64_t k64Value{kInitialNumber}; +const uint32_t k32Value{0x01234567}; +const uint16_t k16Value{0x0123}; +const int kNumValuesToTest = 1000000; +const int kRandomSeed = 12345; + +#if defined(ABSL_IS_BIG_ENDIAN) +const uint64_t kInitialInNetworkOrder{kInitialNumber}; +const uint64_t k64ValueLE{0xefcdab8967452301}; +const uint32_t k32ValueLE{0x67452301}; +const uint16_t k16ValueLE{0x2301}; + +const uint64_t k64ValueBE{kInitialNumber}; +const uint32_t k32ValueBE{k32Value}; +const uint16_t k16ValueBE{k16Value}; +#elif defined(ABSL_IS_LITTLE_ENDIAN) +const uint64_t kInitialInNetworkOrder{0xefcdab8967452301}; +const uint64_t k64ValueLE{kInitialNumber}; +const uint32_t k32ValueLE{k32Value}; +const uint16_t k16ValueLE{k16Value}; + +const uint64_t k64ValueBE{0xefcdab8967452301}; +const uint32_t k32ValueBE{0x67452301}; +const uint16_t k16ValueBE{0x2301}; +#endif + +std::vector<uint16_t> GenerateAllUint16Values() { + std::vector<uint16_t> result; + result.reserve(size_t{1} << (sizeof(uint16_t) * 8)); + for (uint32_t i = std::numeric_limits<uint16_t>::min(); + i <= std::numeric_limits<uint16_t>::max(); ++i) { + result.push_back(static_cast<uint16_t>(i)); + } + return result; +} + +template<typename T> +std::vector<T> GenerateRandomIntegers(size_t num_values_to_test) { + std::vector<T> result; + result.reserve(num_values_to_test); + std::mt19937_64 rng(kRandomSeed); + for (size_t i = 0; i < num_values_to_test; ++i) { + result.push_back(rng()); + } + return result; +} + +void ManualByteSwap(char* bytes, int length) { + if (length == 1) + return; + + EXPECT_EQ(0, length % 2); + for (int i = 0; i < length / 2; ++i) { + int j = (length - 1) - i; + using std::swap; + swap(bytes[i], bytes[j]); + } +} + +template<typename T> +inline T UnalignedLoad(const char* p) { + static_assert( + sizeof(T) == 1 || sizeof(T) == 2 || sizeof(T) == 4 || sizeof(T) == 8, + "Unexpected type size"); + + switch (sizeof(T)) { + case 1: return *reinterpret_cast<const T*>(p); + case 2: + return ABSL_INTERNAL_UNALIGNED_LOAD16(p); + case 4: + return ABSL_INTERNAL_UNALIGNED_LOAD32(p); + case 8: + return ABSL_INTERNAL_UNALIGNED_LOAD64(p); + default: + // Suppresses invalid "not all control paths return a value" on MSVC + return {}; + } +} + +template <typename T, typename ByteSwapper> +static void GBSwapHelper(const std::vector<T>& host_values_to_test, + const ByteSwapper& byte_swapper) { + // Test byte_swapper against a manual byte swap. + for (typename std::vector<T>::const_iterator it = host_values_to_test.begin(); + it != host_values_to_test.end(); ++it) { + T host_value = *it; + + char actual_value[sizeof(host_value)]; + memcpy(actual_value, &host_value, sizeof(host_value)); + byte_swapper(actual_value); + + char expected_value[sizeof(host_value)]; + memcpy(expected_value, &host_value, sizeof(host_value)); + ManualByteSwap(expected_value, sizeof(host_value)); + + ASSERT_EQ(0, memcmp(actual_value, expected_value, sizeof(host_value))) + << "Swap output for 0x" << std::hex << host_value << " does not match. " + << "Expected: 0x" << UnalignedLoad<T>(expected_value) << "; " + << "actual: 0x" << UnalignedLoad<T>(actual_value); + } +} + +void Swap16(char* bytes) { + ABSL_INTERNAL_UNALIGNED_STORE16( + bytes, gbswap_16(ABSL_INTERNAL_UNALIGNED_LOAD16(bytes))); +} + +void Swap32(char* bytes) { + ABSL_INTERNAL_UNALIGNED_STORE32( + bytes, gbswap_32(ABSL_INTERNAL_UNALIGNED_LOAD32(bytes))); +} + +void Swap64(char* bytes) { + ABSL_INTERNAL_UNALIGNED_STORE64( + bytes, gbswap_64(ABSL_INTERNAL_UNALIGNED_LOAD64(bytes))); +} + +TEST(EndianessTest, Uint16) { + GBSwapHelper(GenerateAllUint16Values(), &Swap16); +} + +TEST(EndianessTest, Uint32) { + GBSwapHelper(GenerateRandomIntegers<uint32_t>(kNumValuesToTest), &Swap32); +} + +TEST(EndianessTest, Uint64) { + GBSwapHelper(GenerateRandomIntegers<uint64_t>(kNumValuesToTest), &Swap64); +} + +TEST(EndianessTest, ghtonll_gntohll) { + // Test that absl::ghtonl compiles correctly + uint32_t test = 0x01234567; + EXPECT_EQ(absl::gntohl(absl::ghtonl(test)), test); + + uint64_t comp = absl::ghtonll(kInitialNumber); + EXPECT_EQ(comp, kInitialInNetworkOrder); + comp = absl::gntohll(kInitialInNetworkOrder); + EXPECT_EQ(comp, kInitialNumber); + + // Test that htonll and ntohll are each others' inverse functions on a + // somewhat assorted batch of numbers. 37 is chosen to not be anything + // particularly nice base 2. + uint64_t value = 1; + for (int i = 0; i < 100; ++i) { + comp = absl::ghtonll(absl::gntohll(value)); + EXPECT_EQ(value, comp); + comp = absl::gntohll(absl::ghtonll(value)); + EXPECT_EQ(value, comp); + value *= 37; + } +} + +TEST(EndianessTest, little_endian) { + // Check little_endian uint16_t. + uint64_t comp = little_endian::FromHost16(k16Value); + EXPECT_EQ(comp, k16ValueLE); + comp = little_endian::ToHost16(k16ValueLE); + EXPECT_EQ(comp, k16Value); + + // Check little_endian uint32_t. + comp = little_endian::FromHost32(k32Value); + EXPECT_EQ(comp, k32ValueLE); + comp = little_endian::ToHost32(k32ValueLE); + EXPECT_EQ(comp, k32Value); + + // Check little_endian uint64_t. + comp = little_endian::FromHost64(k64Value); + EXPECT_EQ(comp, k64ValueLE); + comp = little_endian::ToHost64(k64ValueLE); + EXPECT_EQ(comp, k64Value); + + // Check little-endian Load and store functions. + uint16_t u16Buf; + uint32_t u32Buf; + uint64_t u64Buf; + + little_endian::Store16(&u16Buf, k16Value); + EXPECT_EQ(u16Buf, k16ValueLE); + comp = little_endian::Load16(&u16Buf); + EXPECT_EQ(comp, k16Value); + + little_endian::Store32(&u32Buf, k32Value); + EXPECT_EQ(u32Buf, k32ValueLE); + comp = little_endian::Load32(&u32Buf); + EXPECT_EQ(comp, k32Value); + + little_endian::Store64(&u64Buf, k64Value); + EXPECT_EQ(u64Buf, k64ValueLE); + comp = little_endian::Load64(&u64Buf); + EXPECT_EQ(comp, k64Value); +} + +TEST(EndianessTest, big_endian) { + // Check big-endian Load and store functions. + uint16_t u16Buf; + uint32_t u32Buf; + uint64_t u64Buf; + + unsigned char buffer[10]; + big_endian::Store16(&u16Buf, k16Value); + EXPECT_EQ(u16Buf, k16ValueBE); + uint64_t comp = big_endian::Load16(&u16Buf); + EXPECT_EQ(comp, k16Value); + + big_endian::Store32(&u32Buf, k32Value); + EXPECT_EQ(u32Buf, k32ValueBE); + comp = big_endian::Load32(&u32Buf); + EXPECT_EQ(comp, k32Value); + + big_endian::Store64(&u64Buf, k64Value); + EXPECT_EQ(u64Buf, k64ValueBE); + comp = big_endian::Load64(&u64Buf); + EXPECT_EQ(comp, k64Value); + + big_endian::Store16(buffer + 1, k16Value); + EXPECT_EQ(u16Buf, k16ValueBE); + comp = big_endian::Load16(buffer + 1); + EXPECT_EQ(comp, k16Value); + + big_endian::Store32(buffer + 1, k32Value); + EXPECT_EQ(u32Buf, k32ValueBE); + comp = big_endian::Load32(buffer + 1); + EXPECT_EQ(comp, k32Value); + + big_endian::Store64(buffer + 1, k64Value); + EXPECT_EQ(u64Buf, k64ValueBE); + comp = big_endian::Load64(buffer + 1); + EXPECT_EQ(comp, k64Value); +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/errno_saver.h b/third_party/abseil_cpp/absl/base/internal/errno_saver.h new file mode 100644 index 0000000000..251de510fc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/errno_saver.h @@ -0,0 +1,43 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_ERRNO_SAVER_H_ +#define ABSL_BASE_INTERNAL_ERRNO_SAVER_H_ + +#include <cerrno> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// `ErrnoSaver` captures the value of `errno` upon construction and restores it +// upon deletion. It is used in low-level code and must be super fast. Do not +// add instrumentation, even in debug modes. +class ErrnoSaver { + public: + ErrnoSaver() : saved_errno_(errno) {} + ~ErrnoSaver() { errno = saved_errno_; } + int operator()() const { return saved_errno_; } + + private: + const int saved_errno_; +}; + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_ERRNO_SAVER_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/errno_saver_test.cc b/third_party/abseil_cpp/absl/base/internal/errno_saver_test.cc new file mode 100644 index 0000000000..e9b742c588 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/errno_saver_test.cc @@ -0,0 +1,45 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/errno_saver.h" + +#include <cerrno> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/strerror.h" + +namespace { +using ::testing::Eq; + +struct ErrnoPrinter { + int no; +}; +std::ostream &operator<<(std::ostream &os, ErrnoPrinter ep) { + return os << absl::base_internal::StrError(ep.no) << " [" << ep.no << "]"; +} +bool operator==(ErrnoPrinter one, ErrnoPrinter two) { return one.no == two.no; } + +TEST(ErrnoSaverTest, Works) { + errno = EDOM; + { + absl::base_internal::ErrnoSaver errno_saver; + EXPECT_THAT(ErrnoPrinter{errno}, Eq(ErrnoPrinter{EDOM})); + errno = ERANGE; + EXPECT_THAT(ErrnoPrinter{errno}, Eq(ErrnoPrinter{ERANGE})); + EXPECT_THAT(ErrnoPrinter{errno_saver()}, Eq(ErrnoPrinter{EDOM})); + } + EXPECT_THAT(ErrnoPrinter{errno}, Eq(ErrnoPrinter{EDOM})); +} +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/exception_safety_testing.cc b/third_party/abseil_cpp/absl/base/internal/exception_safety_testing.cc new file mode 100644 index 0000000000..6ccac41864 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/exception_safety_testing.cc @@ -0,0 +1,79 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/exception_safety_testing.h" + +#ifdef ABSL_HAVE_EXCEPTIONS + +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" + +namespace testing { + +exceptions_internal::NoThrowTag nothrow_ctor; + +exceptions_internal::StrongGuaranteeTagType strong_guarantee; + +exceptions_internal::ExceptionSafetyTestBuilder<> MakeExceptionSafetyTester() { + return {}; +} + +namespace exceptions_internal { + +int countdown = -1; + +ConstructorTracker* ConstructorTracker::current_tracker_instance_ = nullptr; + +void MaybeThrow(absl::string_view msg, bool throw_bad_alloc) { + if (countdown-- == 0) { + if (throw_bad_alloc) throw TestBadAllocException(msg); + throw TestException(msg); + } +} + +testing::AssertionResult FailureMessage(const TestException& e, + int countdown) noexcept { + return testing::AssertionFailure() << "Exception thrown from " << e.what(); +} + +std::string GetSpecString(TypeSpec spec) { + std::string out; + absl::string_view sep; + const auto append = [&](absl::string_view s) { + absl::StrAppend(&out, sep, s); + sep = " | "; + }; + if (static_cast<bool>(TypeSpec::kNoThrowCopy & spec)) { + append("kNoThrowCopy"); + } + if (static_cast<bool>(TypeSpec::kNoThrowMove & spec)) { + append("kNoThrowMove"); + } + if (static_cast<bool>(TypeSpec::kNoThrowNew & spec)) { + append("kNoThrowNew"); + } + return out; +} + +std::string GetSpecString(AllocSpec spec) { + return static_cast<bool>(AllocSpec::kNoThrowAllocate & spec) + ? "kNoThrowAllocate" + : ""; +} + +} // namespace exceptions_internal + +} // namespace testing + +#endif // ABSL_HAVE_EXCEPTIONS diff --git a/third_party/abseil_cpp/absl/base/internal/exception_safety_testing.h b/third_party/abseil_cpp/absl/base/internal/exception_safety_testing.h new file mode 100644 index 0000000000..6ba89d05df --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/exception_safety_testing.h @@ -0,0 +1,1101 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Utilities for testing exception-safety + +#ifndef ABSL_BASE_INTERNAL_EXCEPTION_SAFETY_TESTING_H_ +#define ABSL_BASE_INTERNAL_EXCEPTION_SAFETY_TESTING_H_ + +#include "absl/base/config.h" + +#ifdef ABSL_HAVE_EXCEPTIONS + +#include <cstddef> +#include <cstdint> +#include <functional> +#include <initializer_list> +#include <iosfwd> +#include <string> +#include <tuple> +#include <unordered_map> + +#include "gtest/gtest.h" +#include "absl/base/internal/pretty_function.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" +#include "absl/strings/substitute.h" +#include "absl/utility/utility.h" + +namespace testing { + +enum class TypeSpec; +enum class AllocSpec; + +constexpr TypeSpec operator|(TypeSpec a, TypeSpec b) { + using T = absl::underlying_type_t<TypeSpec>; + return static_cast<TypeSpec>(static_cast<T>(a) | static_cast<T>(b)); +} + +constexpr TypeSpec operator&(TypeSpec a, TypeSpec b) { + using T = absl::underlying_type_t<TypeSpec>; + return static_cast<TypeSpec>(static_cast<T>(a) & static_cast<T>(b)); +} + +constexpr AllocSpec operator|(AllocSpec a, AllocSpec b) { + using T = absl::underlying_type_t<AllocSpec>; + return static_cast<AllocSpec>(static_cast<T>(a) | static_cast<T>(b)); +} + +constexpr AllocSpec operator&(AllocSpec a, AllocSpec b) { + using T = absl::underlying_type_t<AllocSpec>; + return static_cast<AllocSpec>(static_cast<T>(a) & static_cast<T>(b)); +} + +namespace exceptions_internal { + +std::string GetSpecString(TypeSpec); +std::string GetSpecString(AllocSpec); + +struct NoThrowTag {}; +struct StrongGuaranteeTagType {}; + +// A simple exception class. We throw this so that test code can catch +// exceptions specifically thrown by ThrowingValue. +class TestException { + public: + explicit TestException(absl::string_view msg) : msg_(msg) {} + virtual ~TestException() {} + virtual const char* what() const noexcept { return msg_.c_str(); } + + private: + std::string msg_; +}; + +// TestBadAllocException exists because allocation functions must throw an +// exception which can be caught by a handler of std::bad_alloc. We use a child +// class of std::bad_alloc so we can customise the error message, and also +// derive from TestException so we don't accidentally end up catching an actual +// bad_alloc exception in TestExceptionSafety. +class TestBadAllocException : public std::bad_alloc, public TestException { + public: + explicit TestBadAllocException(absl::string_view msg) : TestException(msg) {} + using TestException::what; +}; + +extern int countdown; + +// Allows the countdown variable to be set manually (defaulting to the initial +// value of 0) +inline void SetCountdown(int i = 0) { countdown = i; } +// Sets the countdown to the terminal value -1 +inline void UnsetCountdown() { SetCountdown(-1); } + +void MaybeThrow(absl::string_view msg, bool throw_bad_alloc = false); + +testing::AssertionResult FailureMessage(const TestException& e, + int countdown) noexcept; + +struct TrackedAddress { + bool is_alive; + std::string description; +}; + +// Inspects the constructions and destructions of anything inheriting from +// TrackedObject. This allows us to safely "leak" TrackedObjects, as +// ConstructorTracker will destroy everything left over in its destructor. +class ConstructorTracker { + public: + explicit ConstructorTracker(int count) : countdown_(count) { + assert(current_tracker_instance_ == nullptr); + current_tracker_instance_ = this; + } + + ~ConstructorTracker() { + assert(current_tracker_instance_ == this); + current_tracker_instance_ = nullptr; + + for (auto& it : address_map_) { + void* address = it.first; + TrackedAddress& tracked_address = it.second; + if (tracked_address.is_alive) { + ADD_FAILURE() << ErrorMessage(address, tracked_address.description, + countdown_, "Object was not destroyed."); + } + } + } + + static void ObjectConstructed(void* address, std::string description) { + if (!CurrentlyTracking()) return; + + TrackedAddress& tracked_address = + current_tracker_instance_->address_map_[address]; + if (tracked_address.is_alive) { + ADD_FAILURE() << ErrorMessage( + address, tracked_address.description, + current_tracker_instance_->countdown_, + "Object was re-constructed. Current object was constructed by " + + description); + } + tracked_address = {true, std::move(description)}; + } + + static void ObjectDestructed(void* address) { + if (!CurrentlyTracking()) return; + + auto it = current_tracker_instance_->address_map_.find(address); + // Not tracked. Ignore. + if (it == current_tracker_instance_->address_map_.end()) return; + + TrackedAddress& tracked_address = it->second; + if (!tracked_address.is_alive) { + ADD_FAILURE() << ErrorMessage(address, tracked_address.description, + current_tracker_instance_->countdown_, + "Object was re-destroyed."); + } + tracked_address.is_alive = false; + } + + private: + static bool CurrentlyTracking() { + return current_tracker_instance_ != nullptr; + } + + static std::string ErrorMessage(void* address, + const std::string& address_description, + int countdown, + const std::string& error_description) { + return absl::Substitute( + "With coundtown at $0:\n" + " $1\n" + " Object originally constructed by $2\n" + " Object address: $3\n", + countdown, error_description, address_description, address); + } + + std::unordered_map<void*, TrackedAddress> address_map_; + int countdown_; + + static ConstructorTracker* current_tracker_instance_; +}; + +class TrackedObject { + public: + TrackedObject(const TrackedObject&) = delete; + TrackedObject(TrackedObject&&) = delete; + + protected: + explicit TrackedObject(std::string description) { + ConstructorTracker::ObjectConstructed(this, std::move(description)); + } + + ~TrackedObject() noexcept { ConstructorTracker::ObjectDestructed(this); } +}; +} // namespace exceptions_internal + +extern exceptions_internal::NoThrowTag nothrow_ctor; + +extern exceptions_internal::StrongGuaranteeTagType strong_guarantee; + +// A test class which is convertible to bool. The conversion can be +// instrumented to throw at a controlled time. +class ThrowingBool { + public: + ThrowingBool(bool b) noexcept : b_(b) {} // NOLINT(runtime/explicit) + operator bool() const { // NOLINT + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return b_; + } + + private: + bool b_; +}; + +/* + * Configuration enum for the ThrowingValue type that defines behavior for the + * lifetime of the instance. Use testing::nothrow_ctor to prevent the integer + * constructor from throwing. + * + * kEverythingThrows: Every operation can throw an exception + * kNoThrowCopy: Copy construction and copy assignment will not throw + * kNoThrowMove: Move construction and move assignment will not throw + * kNoThrowNew: Overloaded operators new and new[] will not throw + */ +enum class TypeSpec { + kEverythingThrows = 0, + kNoThrowCopy = 1, + kNoThrowMove = 1 << 1, + kNoThrowNew = 1 << 2, +}; + +/* + * A testing class instrumented to throw an exception at a controlled time. + * + * ThrowingValue implements a slightly relaxed version of the Regular concept -- + * that is it's a value type with the expected semantics. It also implements + * arithmetic operations. It doesn't implement member and pointer operators + * like operator-> or operator[]. + * + * ThrowingValue can be instrumented to have certain operations be noexcept by + * using compile-time bitfield template arguments. That is, to make an + * ThrowingValue which has noexcept move construction/assignment and noexcept + * copy construction/assignment, use the following: + * ThrowingValue<testing::kNoThrowMove | testing::kNoThrowCopy> my_thrwr{val}; + */ +template <TypeSpec Spec = TypeSpec::kEverythingThrows> +class ThrowingValue : private exceptions_internal::TrackedObject { + static constexpr bool IsSpecified(TypeSpec spec) { + return static_cast<bool>(Spec & spec); + } + + static constexpr int kDefaultValue = 0; + static constexpr int kBadValue = 938550620; + + public: + ThrowingValue() : TrackedObject(GetInstanceString(kDefaultValue)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ = kDefaultValue; + } + + ThrowingValue(const ThrowingValue& other) noexcept( + IsSpecified(TypeSpec::kNoThrowCopy)) + : TrackedObject(GetInstanceString(other.dummy_)) { + if (!IsSpecified(TypeSpec::kNoThrowCopy)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + } + dummy_ = other.dummy_; + } + + ThrowingValue(ThrowingValue&& other) noexcept( + IsSpecified(TypeSpec::kNoThrowMove)) + : TrackedObject(GetInstanceString(other.dummy_)) { + if (!IsSpecified(TypeSpec::kNoThrowMove)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + } + dummy_ = other.dummy_; + } + + explicit ThrowingValue(int i) : TrackedObject(GetInstanceString(i)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ = i; + } + + ThrowingValue(int i, exceptions_internal::NoThrowTag) noexcept + : TrackedObject(GetInstanceString(i)), dummy_(i) {} + + // absl expects nothrow destructors + ~ThrowingValue() noexcept = default; + + ThrowingValue& operator=(const ThrowingValue& other) noexcept( + IsSpecified(TypeSpec::kNoThrowCopy)) { + dummy_ = kBadValue; + if (!IsSpecified(TypeSpec::kNoThrowCopy)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + } + dummy_ = other.dummy_; + return *this; + } + + ThrowingValue& operator=(ThrowingValue&& other) noexcept( + IsSpecified(TypeSpec::kNoThrowMove)) { + dummy_ = kBadValue; + if (!IsSpecified(TypeSpec::kNoThrowMove)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + } + dummy_ = other.dummy_; + return *this; + } + + // Arithmetic Operators + ThrowingValue operator+(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ + other.dummy_, nothrow_ctor); + } + + ThrowingValue operator+() const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_, nothrow_ctor); + } + + ThrowingValue operator-(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ - other.dummy_, nothrow_ctor); + } + + ThrowingValue operator-() const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(-dummy_, nothrow_ctor); + } + + ThrowingValue& operator++() { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + ++dummy_; + return *this; + } + + ThrowingValue operator++(int) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + auto out = ThrowingValue(dummy_, nothrow_ctor); + ++dummy_; + return out; + } + + ThrowingValue& operator--() { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + --dummy_; + return *this; + } + + ThrowingValue operator--(int) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + auto out = ThrowingValue(dummy_, nothrow_ctor); + --dummy_; + return out; + } + + ThrowingValue operator*(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ * other.dummy_, nothrow_ctor); + } + + ThrowingValue operator/(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ / other.dummy_, nothrow_ctor); + } + + ThrowingValue operator%(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ % other.dummy_, nothrow_ctor); + } + + ThrowingValue operator<<(int shift) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ << shift, nothrow_ctor); + } + + ThrowingValue operator>>(int shift) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ >> shift, nothrow_ctor); + } + + // Comparison Operators + // NOTE: We use `ThrowingBool` instead of `bool` because most STL + // types/containers requires T to be convertible to bool. + friend ThrowingBool operator==(const ThrowingValue& a, + const ThrowingValue& b) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return a.dummy_ == b.dummy_; + } + friend ThrowingBool operator!=(const ThrowingValue& a, + const ThrowingValue& b) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return a.dummy_ != b.dummy_; + } + friend ThrowingBool operator<(const ThrowingValue& a, + const ThrowingValue& b) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return a.dummy_ < b.dummy_; + } + friend ThrowingBool operator<=(const ThrowingValue& a, + const ThrowingValue& b) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return a.dummy_ <= b.dummy_; + } + friend ThrowingBool operator>(const ThrowingValue& a, + const ThrowingValue& b) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return a.dummy_ > b.dummy_; + } + friend ThrowingBool operator>=(const ThrowingValue& a, + const ThrowingValue& b) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return a.dummy_ >= b.dummy_; + } + + // Logical Operators + ThrowingBool operator!() const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return !dummy_; + } + + ThrowingBool operator&&(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return dummy_ && other.dummy_; + } + + ThrowingBool operator||(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return dummy_ || other.dummy_; + } + + // Bitwise Logical Operators + ThrowingValue operator~() const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(~dummy_, nothrow_ctor); + } + + ThrowingValue operator&(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ & other.dummy_, nothrow_ctor); + } + + ThrowingValue operator|(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ | other.dummy_, nothrow_ctor); + } + + ThrowingValue operator^(const ThrowingValue& other) const { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return ThrowingValue(dummy_ ^ other.dummy_, nothrow_ctor); + } + + // Compound Assignment operators + ThrowingValue& operator+=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ += other.dummy_; + return *this; + } + + ThrowingValue& operator-=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ -= other.dummy_; + return *this; + } + + ThrowingValue& operator*=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ *= other.dummy_; + return *this; + } + + ThrowingValue& operator/=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ /= other.dummy_; + return *this; + } + + ThrowingValue& operator%=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ %= other.dummy_; + return *this; + } + + ThrowingValue& operator&=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ &= other.dummy_; + return *this; + } + + ThrowingValue& operator|=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ |= other.dummy_; + return *this; + } + + ThrowingValue& operator^=(const ThrowingValue& other) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ ^= other.dummy_; + return *this; + } + + ThrowingValue& operator<<=(int shift) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ <<= shift; + return *this; + } + + ThrowingValue& operator>>=(int shift) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ >>= shift; + return *this; + } + + // Pointer operators + void operator&() const = delete; // NOLINT(runtime/operator) + + // Stream operators + friend std::ostream& operator<<(std::ostream& os, const ThrowingValue& tv) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return os << GetInstanceString(tv.dummy_); + } + + friend std::istream& operator>>(std::istream& is, const ThrowingValue&) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + return is; + } + + // Memory management operators + // Args.. allows us to overload regular and placement new in one shot + template <typename... Args> + static void* operator new(size_t s, Args&&... args) noexcept( + IsSpecified(TypeSpec::kNoThrowNew)) { + if (!IsSpecified(TypeSpec::kNoThrowNew)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION, true); + } + return ::operator new(s, std::forward<Args>(args)...); + } + + template <typename... Args> + static void* operator new[](size_t s, Args&&... args) noexcept( + IsSpecified(TypeSpec::kNoThrowNew)) { + if (!IsSpecified(TypeSpec::kNoThrowNew)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION, true); + } + return ::operator new[](s, std::forward<Args>(args)...); + } + + // Abseil doesn't support throwing overloaded operator delete. These are + // provided so a throwing operator-new can clean up after itself. + // + // We provide both regular and templated operator delete because if only the + // templated version is provided as we did with operator new, the compiler has + // no way of knowing which overload of operator delete to call. See + // https://en.cppreference.com/w/cpp/memory/new/operator_delete and + // https://en.cppreference.com/w/cpp/language/delete for the gory details. + void operator delete(void* p) noexcept { ::operator delete(p); } + + template <typename... Args> + void operator delete(void* p, Args&&... args) noexcept { + ::operator delete(p, std::forward<Args>(args)...); + } + + void operator delete[](void* p) noexcept { return ::operator delete[](p); } + + template <typename... Args> + void operator delete[](void* p, Args&&... args) noexcept { + return ::operator delete[](p, std::forward<Args>(args)...); + } + + // Non-standard access to the actual contained value. No need for this to + // throw. + int& Get() noexcept { return dummy_; } + const int& Get() const noexcept { return dummy_; } + + private: + static std::string GetInstanceString(int dummy) { + return absl::StrCat("ThrowingValue<", + exceptions_internal::GetSpecString(Spec), ">(", dummy, + ")"); + } + + int dummy_; +}; +// While not having to do with exceptions, explicitly delete comma operator, to +// make sure we don't use it on user-supplied types. +template <TypeSpec Spec, typename T> +void operator,(const ThrowingValue<Spec>&, T&&) = delete; +template <TypeSpec Spec, typename T> +void operator,(T&&, const ThrowingValue<Spec>&) = delete; + +/* + * Configuration enum for the ThrowingAllocator type that defines behavior for + * the lifetime of the instance. + * + * kEverythingThrows: Calls to the member functions may throw + * kNoThrowAllocate: Calls to the member functions will not throw + */ +enum class AllocSpec { + kEverythingThrows = 0, + kNoThrowAllocate = 1, +}; + +/* + * An allocator type which is instrumented to throw at a controlled time, or not + * to throw, using AllocSpec. The supported settings are the default of every + * function which is allowed to throw in a conforming allocator possibly + * throwing, or nothing throws, in line with the ABSL_ALLOCATOR_THROWS + * configuration macro. + */ +template <typename T, AllocSpec Spec = AllocSpec::kEverythingThrows> +class ThrowingAllocator : private exceptions_internal::TrackedObject { + static constexpr bool IsSpecified(AllocSpec spec) { + return static_cast<bool>(Spec & spec); + } + + public: + using pointer = T*; + using const_pointer = const T*; + using reference = T&; + using const_reference = const T&; + using void_pointer = void*; + using const_void_pointer = const void*; + using value_type = T; + using size_type = size_t; + using difference_type = ptrdiff_t; + + using is_nothrow = + std::integral_constant<bool, Spec == AllocSpec::kNoThrowAllocate>; + using propagate_on_container_copy_assignment = std::true_type; + using propagate_on_container_move_assignment = std::true_type; + using propagate_on_container_swap = std::true_type; + using is_always_equal = std::false_type; + + ThrowingAllocator() : TrackedObject(GetInstanceString(next_id_)) { + exceptions_internal::MaybeThrow(ABSL_PRETTY_FUNCTION); + dummy_ = std::make_shared<const int>(next_id_++); + } + + template <typename U> + ThrowingAllocator(const ThrowingAllocator<U, Spec>& other) noexcept // NOLINT + : TrackedObject(GetInstanceString(*other.State())), + dummy_(other.State()) {} + + // According to C++11 standard [17.6.3.5], Table 28, the move/copy ctors of + // allocator shall not exit via an exception, thus they are marked noexcept. + ThrowingAllocator(const ThrowingAllocator& other) noexcept + : TrackedObject(GetInstanceString(*other.State())), + dummy_(other.State()) {} + + template <typename U> + ThrowingAllocator(ThrowingAllocator<U, Spec>&& other) noexcept // NOLINT + : TrackedObject(GetInstanceString(*other.State())), + dummy_(std::move(other.State())) {} + + ThrowingAllocator(ThrowingAllocator&& other) noexcept + : TrackedObject(GetInstanceString(*other.State())), + dummy_(std::move(other.State())) {} + + ~ThrowingAllocator() noexcept = default; + + ThrowingAllocator& operator=(const ThrowingAllocator& other) noexcept { + dummy_ = other.State(); + return *this; + } + + template <typename U> + ThrowingAllocator& operator=( + const ThrowingAllocator<U, Spec>& other) noexcept { + dummy_ = other.State(); + return *this; + } + + template <typename U> + ThrowingAllocator& operator=(ThrowingAllocator<U, Spec>&& other) noexcept { + dummy_ = std::move(other.State()); + return *this; + } + + template <typename U> + struct rebind { + using other = ThrowingAllocator<U, Spec>; + }; + + pointer allocate(size_type n) noexcept( + IsSpecified(AllocSpec::kNoThrowAllocate)) { + ReadStateAndMaybeThrow(ABSL_PRETTY_FUNCTION); + return static_cast<pointer>(::operator new(n * sizeof(T))); + } + + pointer allocate(size_type n, const_void_pointer) noexcept( + IsSpecified(AllocSpec::kNoThrowAllocate)) { + return allocate(n); + } + + void deallocate(pointer ptr, size_type) noexcept { + ReadState(); + ::operator delete(static_cast<void*>(ptr)); + } + + template <typename U, typename... Args> + void construct(U* ptr, Args&&... args) noexcept( + IsSpecified(AllocSpec::kNoThrowAllocate)) { + ReadStateAndMaybeThrow(ABSL_PRETTY_FUNCTION); + ::new (static_cast<void*>(ptr)) U(std::forward<Args>(args)...); + } + + template <typename U> + void destroy(U* p) noexcept { + ReadState(); + p->~U(); + } + + size_type max_size() const noexcept { + return (std::numeric_limits<difference_type>::max)() / sizeof(value_type); + } + + ThrowingAllocator select_on_container_copy_construction() noexcept( + IsSpecified(AllocSpec::kNoThrowAllocate)) { + auto& out = *this; + ReadStateAndMaybeThrow(ABSL_PRETTY_FUNCTION); + return out; + } + + template <typename U> + bool operator==(const ThrowingAllocator<U, Spec>& other) const noexcept { + return dummy_ == other.dummy_; + } + + template <typename U> + bool operator!=(const ThrowingAllocator<U, Spec>& other) const noexcept { + return dummy_ != other.dummy_; + } + + template <typename, AllocSpec> + friend class ThrowingAllocator; + + private: + static std::string GetInstanceString(int dummy) { + return absl::StrCat("ThrowingAllocator<", + exceptions_internal::GetSpecString(Spec), ">(", dummy, + ")"); + } + + const std::shared_ptr<const int>& State() const { return dummy_; } + std::shared_ptr<const int>& State() { return dummy_; } + + void ReadState() { + // we know that this will never be true, but the compiler doesn't, so this + // should safely force a read of the value. + if (*dummy_ < 0) std::abort(); + } + + void ReadStateAndMaybeThrow(absl::string_view msg) const { + if (!IsSpecified(AllocSpec::kNoThrowAllocate)) { + exceptions_internal::MaybeThrow( + absl::Substitute("Allocator id $0 threw from $1", *dummy_, msg)); + } + } + + static int next_id_; + std::shared_ptr<const int> dummy_; +}; + +template <typename T, AllocSpec Spec> +int ThrowingAllocator<T, Spec>::next_id_ = 0; + +// Tests for resource leaks by attempting to construct a T using args repeatedly +// until successful, using the countdown method. Side effects can then be +// tested for resource leaks. +template <typename T, typename... Args> +void TestThrowingCtor(Args&&... args) { + struct Cleanup { + ~Cleanup() { exceptions_internal::UnsetCountdown(); } + } c; + for (int count = 0;; ++count) { + exceptions_internal::ConstructorTracker ct(count); + exceptions_internal::SetCountdown(count); + try { + T temp(std::forward<Args>(args)...); + static_cast<void>(temp); + break; + } catch (const exceptions_internal::TestException&) { + } + } +} + +// Tests the nothrow guarantee of the provided nullary operation. If the an +// exception is thrown, the result will be AssertionFailure(). Otherwise, it +// will be AssertionSuccess(). +template <typename Operation> +testing::AssertionResult TestNothrowOp(const Operation& operation) { + struct Cleanup { + Cleanup() { exceptions_internal::SetCountdown(); } + ~Cleanup() { exceptions_internal::UnsetCountdown(); } + } c; + try { + operation(); + return testing::AssertionSuccess(); + } catch (const exceptions_internal::TestException&) { + return testing::AssertionFailure() + << "TestException thrown during call to operation() when nothrow " + "guarantee was expected."; + } catch (...) { + return testing::AssertionFailure() + << "Unknown exception thrown during call to operation() when " + "nothrow guarantee was expected."; + } +} + +namespace exceptions_internal { + +// Dummy struct for ExceptionSafetyTestBuilder<> partial state. +struct UninitializedT {}; + +template <typename T> +class DefaultFactory { + public: + explicit DefaultFactory(const T& t) : t_(t) {} + std::unique_ptr<T> operator()() const { return absl::make_unique<T>(t_); } + + private: + T t_; +}; + +template <size_t LazyContractsCount, typename LazyFactory, + typename LazyOperation> +using EnableIfTestable = typename absl::enable_if_t< + LazyContractsCount != 0 && + !std::is_same<LazyFactory, UninitializedT>::value && + !std::is_same<LazyOperation, UninitializedT>::value>; + +template <typename Factory = UninitializedT, + typename Operation = UninitializedT, typename... Contracts> +class ExceptionSafetyTestBuilder; + +} // namespace exceptions_internal + +/* + * Constructs an empty ExceptionSafetyTestBuilder. All + * ExceptionSafetyTestBuilder objects are immutable and all With[thing] mutation + * methods return new instances of ExceptionSafetyTestBuilder. + * + * In order to test a T for exception safety, a factory for that T, a testable + * operation, and at least one contract callback returning an assertion + * result must be applied using the respective methods. + */ +exceptions_internal::ExceptionSafetyTestBuilder<> MakeExceptionSafetyTester(); + +namespace exceptions_internal { +template <typename T> +struct IsUniquePtr : std::false_type {}; + +template <typename T, typename D> +struct IsUniquePtr<std::unique_ptr<T, D>> : std::true_type {}; + +template <typename Factory> +struct FactoryPtrTypeHelper { + using type = decltype(std::declval<const Factory&>()()); + + static_assert(IsUniquePtr<type>::value, "Factories must return a unique_ptr"); +}; + +template <typename Factory> +using FactoryPtrType = typename FactoryPtrTypeHelper<Factory>::type; + +template <typename Factory> +using FactoryElementType = typename FactoryPtrType<Factory>::element_type; + +template <typename T> +class ExceptionSafetyTest { + using Factory = std::function<std::unique_ptr<T>()>; + using Operation = std::function<void(T*)>; + using Contract = std::function<AssertionResult(T*)>; + + public: + template <typename... Contracts> + explicit ExceptionSafetyTest(const Factory& f, const Operation& op, + const Contracts&... contracts) + : factory_(f), operation_(op), contracts_{WrapContract(contracts)...} {} + + AssertionResult Test() const { + for (int count = 0;; ++count) { + exceptions_internal::ConstructorTracker ct(count); + + for (const auto& contract : contracts_) { + auto t_ptr = factory_(); + try { + SetCountdown(count); + operation_(t_ptr.get()); + // Unset for the case that the operation throws no exceptions, which + // would leave the countdown set and break the *next* exception safety + // test after this one. + UnsetCountdown(); + return AssertionSuccess(); + } catch (const exceptions_internal::TestException& e) { + if (!contract(t_ptr.get())) { + return AssertionFailure() << e.what() << " failed contract check"; + } + } + } + } + } + + private: + template <typename ContractFn> + Contract WrapContract(const ContractFn& contract) { + return [contract](T* t_ptr) { return AssertionResult(contract(t_ptr)); }; + } + + Contract WrapContract(StrongGuaranteeTagType) { + return [this](T* t_ptr) { return AssertionResult(*factory_() == *t_ptr); }; + } + + Factory factory_; + Operation operation_; + std::vector<Contract> contracts_; +}; + +/* + * Builds a tester object that tests if performing a operation on a T follows + * exception safety guarantees. Verification is done via contract assertion + * callbacks applied to T instances post-throw. + * + * Template parameters for ExceptionSafetyTestBuilder: + * + * - Factory: The factory object (passed in via tester.WithFactory(...) or + * tester.WithInitialValue(...)) must be invocable with the signature + * `std::unique_ptr<T> operator()() const` where T is the type being tested. + * It is used for reliably creating identical T instances to test on. + * + * - Operation: The operation object (passsed in via tester.WithOperation(...) + * or tester.Test(...)) must be invocable with the signature + * `void operator()(T*) const` where T is the type being tested. It is used + * for performing steps on a T instance that may throw and that need to be + * checked for exception safety. Each call to the operation will receive a + * fresh T instance so it's free to modify and destroy the T instances as it + * pleases. + * + * - Contracts...: The contract assertion callback objects (passed in via + * tester.WithContracts(...)) must be invocable with the signature + * `testing::AssertionResult operator()(T*) const` where T is the type being + * tested. Contract assertion callbacks are provided T instances post-throw. + * They must return testing::AssertionSuccess when the type contracts of the + * provided T instance hold. If the type contracts of the T instance do not + * hold, they must return testing::AssertionFailure. Execution order of + * Contracts... is unspecified. They will each individually get a fresh T + * instance so they are free to modify and destroy the T instances as they + * please. + */ +template <typename Factory, typename Operation, typename... Contracts> +class ExceptionSafetyTestBuilder { + public: + /* + * Returns a new ExceptionSafetyTestBuilder with an included T factory based + * on the provided T instance. The existing factory will not be included in + * the newly created tester instance. The created factory returns a new T + * instance by copy-constructing the provided const T& t. + * + * Preconditions for tester.WithInitialValue(const T& t): + * + * - The const T& t object must be copy-constructible where T is the type + * being tested. For non-copy-constructible objects, use the method + * tester.WithFactory(...). + */ + template <typename T> + ExceptionSafetyTestBuilder<DefaultFactory<T>, Operation, Contracts...> + WithInitialValue(const T& t) const { + return WithFactory(DefaultFactory<T>(t)); + } + + /* + * Returns a new ExceptionSafetyTestBuilder with the provided T factory + * included. The existing factory will not be included in the newly-created + * tester instance. This method is intended for use with types lacking a copy + * constructor. Types that can be copy-constructed should instead use the + * method tester.WithInitialValue(...). + */ + template <typename NewFactory> + ExceptionSafetyTestBuilder<absl::decay_t<NewFactory>, Operation, Contracts...> + WithFactory(const NewFactory& new_factory) const { + return {new_factory, operation_, contracts_}; + } + + /* + * Returns a new ExceptionSafetyTestBuilder with the provided testable + * operation included. The existing operation will not be included in the + * newly created tester. + */ + template <typename NewOperation> + ExceptionSafetyTestBuilder<Factory, absl::decay_t<NewOperation>, Contracts...> + WithOperation(const NewOperation& new_operation) const { + return {factory_, new_operation, contracts_}; + } + + /* + * Returns a new ExceptionSafetyTestBuilder with the provided MoreContracts... + * combined with the Contracts... that were already included in the instance + * on which the method was called. Contracts... cannot be removed or replaced + * once added to an ExceptionSafetyTestBuilder instance. A fresh object must + * be created in order to get an empty Contracts... list. + * + * In addition to passing in custom contract assertion callbacks, this method + * accepts `testing::strong_guarantee` as an argument which checks T instances + * post-throw against freshly created T instances via operator== to verify + * that any state changes made during the execution of the operation were + * properly rolled back. + */ + template <typename... MoreContracts> + ExceptionSafetyTestBuilder<Factory, Operation, Contracts..., + absl::decay_t<MoreContracts>...> + WithContracts(const MoreContracts&... more_contracts) const { + return { + factory_, operation_, + std::tuple_cat(contracts_, std::tuple<absl::decay_t<MoreContracts>...>( + more_contracts...))}; + } + + /* + * Returns a testing::AssertionResult that is the reduced result of the + * exception safety algorithm. The algorithm short circuits and returns + * AssertionFailure after the first contract callback returns an + * AssertionFailure. Otherwise, if all contract callbacks return an + * AssertionSuccess, the reduced result is AssertionSuccess. + * + * The passed-in testable operation will not be saved in a new tester instance + * nor will it modify/replace the existing tester instance. This is useful + * when each operation being tested is unique and does not need to be reused. + * + * Preconditions for tester.Test(const NewOperation& new_operation): + * + * - May only be called after at least one contract assertion callback and a + * factory or initial value have been provided. + */ + template < + typename NewOperation, + typename = EnableIfTestable<sizeof...(Contracts), Factory, NewOperation>> + testing::AssertionResult Test(const NewOperation& new_operation) const { + return TestImpl(new_operation, absl::index_sequence_for<Contracts...>()); + } + + /* + * Returns a testing::AssertionResult that is the reduced result of the + * exception safety algorithm. The algorithm short circuits and returns + * AssertionFailure after the first contract callback returns an + * AssertionFailure. Otherwise, if all contract callbacks return an + * AssertionSuccess, the reduced result is AssertionSuccess. + * + * Preconditions for tester.Test(): + * + * - May only be called after at least one contract assertion callback, a + * factory or initial value and a testable operation have been provided. + */ + template < + typename LazyOperation = Operation, + typename = EnableIfTestable<sizeof...(Contracts), Factory, LazyOperation>> + testing::AssertionResult Test() const { + return Test(operation_); + } + + private: + template <typename, typename, typename...> + friend class ExceptionSafetyTestBuilder; + + friend ExceptionSafetyTestBuilder<> testing::MakeExceptionSafetyTester(); + + ExceptionSafetyTestBuilder() {} + + ExceptionSafetyTestBuilder(const Factory& f, const Operation& o, + const std::tuple<Contracts...>& i) + : factory_(f), operation_(o), contracts_(i) {} + + template <typename SelectedOperation, size_t... Indices> + testing::AssertionResult TestImpl(SelectedOperation selected_operation, + absl::index_sequence<Indices...>) const { + return ExceptionSafetyTest<FactoryElementType<Factory>>( + factory_, selected_operation, std::get<Indices>(contracts_)...) + .Test(); + } + + Factory factory_; + Operation operation_; + std::tuple<Contracts...> contracts_; +}; + +} // namespace exceptions_internal + +} // namespace testing + +#endif // ABSL_HAVE_EXCEPTIONS + +#endif // ABSL_BASE_INTERNAL_EXCEPTION_SAFETY_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/exception_testing.h b/third_party/abseil_cpp/absl/base/internal/exception_testing.h new file mode 100644 index 0000000000..01b5465571 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/exception_testing.h @@ -0,0 +1,42 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Testing utilities for ABSL types which throw exceptions. + +#ifndef ABSL_BASE_INTERNAL_EXCEPTION_TESTING_H_ +#define ABSL_BASE_INTERNAL_EXCEPTION_TESTING_H_ + +#include "gtest/gtest.h" +#include "absl/base/config.h" + +// ABSL_BASE_INTERNAL_EXPECT_FAIL tests either for a specified thrown exception +// if exceptions are enabled, or for death with a specified text in the error +// message +#ifdef ABSL_HAVE_EXCEPTIONS + +#define ABSL_BASE_INTERNAL_EXPECT_FAIL(expr, exception_t, text) \ + EXPECT_THROW(expr, exception_t) + +#elif defined(__ANDROID__) +// Android asserts do not log anywhere that gtest can currently inspect. +// So we expect exit, but cannot match the message. +#define ABSL_BASE_INTERNAL_EXPECT_FAIL(expr, exception_t, text) \ + EXPECT_DEATH(expr, ".*") +#else +#define ABSL_BASE_INTERNAL_EXPECT_FAIL(expr, exception_t, text) \ + EXPECT_DEATH_IF_SUPPORTED(expr, text) + +#endif + +#endif // ABSL_BASE_INTERNAL_EXCEPTION_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/exponential_biased.cc b/third_party/abseil_cpp/absl/base/internal/exponential_biased.cc new file mode 100644 index 0000000000..1b30c061e3 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/exponential_biased.cc @@ -0,0 +1,93 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/exponential_biased.h" + +#include <stdint.h> + +#include <algorithm> +#include <atomic> +#include <cmath> +#include <limits> + +#include "absl/base/attributes.h" +#include "absl/base/optimization.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// The algorithm generates a random number between 0 and 1 and applies the +// inverse cumulative distribution function for an exponential. Specifically: +// Let m be the inverse of the sample period, then the probability +// distribution function is m*exp(-mx) so the CDF is +// p = 1 - exp(-mx), so +// q = 1 - p = exp(-mx) +// log_e(q) = -mx +// -log_e(q)/m = x +// log_2(q) * (-log_e(2) * 1/m) = x +// In the code, q is actually in the range 1 to 2**26, hence the -26 below +int64_t ExponentialBiased::GetSkipCount(int64_t mean) { + if (ABSL_PREDICT_FALSE(!initialized_)) { + Initialize(); + } + + uint64_t rng = NextRandom(rng_); + rng_ = rng; + + // Take the top 26 bits as the random number + // (This plus the 1<<58 sampling bound give a max possible step of + // 5194297183973780480 bytes.) + // The uint32_t cast is to prevent a (hard-to-reproduce) NAN + // under piii debug for some binaries. + double q = static_cast<uint32_t>(rng >> (kPrngNumBits - 26)) + 1.0; + // Put the computed p-value through the CDF of a geometric. + double interval = bias_ + (std::log2(q) - 26) * (-std::log(2.0) * mean); + // Very large values of interval overflow int64_t. To avoid that, we will + // cheat and clamp any huge values to (int64_t max)/2. This is a potential + // source of bias, but the mean would need to be such a large value that it's + // not likely to come up. For example, with a mean of 1e18, the probability of + // hitting this condition is about 1/1000. For a mean of 1e17, standard + // calculators claim that this event won't happen. + if (interval > static_cast<double>(std::numeric_limits<int64_t>::max() / 2)) { + // Assume huge values are bias neutral, retain bias for next call. + return std::numeric_limits<int64_t>::max() / 2; + } + double value = std::round(interval); + bias_ = interval - value; + return value; +} + +int64_t ExponentialBiased::GetStride(int64_t mean) { + return GetSkipCount(mean - 1) + 1; +} + +void ExponentialBiased::Initialize() { + // We don't get well distributed numbers from `this` so we call NextRandom() a + // bunch to mush the bits around. We use a global_rand to handle the case + // where the same thread (by memory address) gets created and destroyed + // repeatedly. + ABSL_CONST_INIT static std::atomic<uint32_t> global_rand(0); + uint64_t r = reinterpret_cast<uint64_t>(this) + + global_rand.fetch_add(1, std::memory_order_relaxed); + for (int i = 0; i < 20; ++i) { + r = NextRandom(r); + } + rng_ = r; + initialized_ = true; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/exponential_biased.h b/third_party/abseil_cpp/absl/base/internal/exponential_biased.h new file mode 100644 index 0000000000..94f79a3378 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/exponential_biased.h @@ -0,0 +1,130 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_EXPONENTIAL_BIASED_H_ +#define ABSL_BASE_INTERNAL_EXPONENTIAL_BIASED_H_ + +#include <stdint.h> + +#include "absl/base/config.h" +#include "absl/base/macros.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// ExponentialBiased provides a small and fast random number generator for a +// rounded exponential distribution. This generator manages very little state, +// and imposes no synchronization overhead. This makes it useful in specialized +// scenarios requiring minimum overhead, such as stride based periodic sampling. +// +// ExponentialBiased provides two closely related functions, GetSkipCount() and +// GetStride(), both returning a rounded integer defining a number of events +// required before some event with a given mean probability occurs. +// +// The distribution is useful to generate a random wait time or some periodic +// event with a given mean probability. For example, if an action is supposed to +// happen on average once every 'N' events, then we can get a random 'stride' +// counting down how long before the event to happen. For example, if we'd want +// to sample one in every 1000 'Frobber' calls, our code could look like this: +// +// Frobber::Frobber() { +// stride_ = exponential_biased_.GetStride(1000); +// } +// +// void Frobber::Frob(int arg) { +// if (--stride == 0) { +// SampleFrob(arg); +// stride_ = exponential_biased_.GetStride(1000); +// } +// ... +// } +// +// The rounding of the return value creates a bias, especially for smaller means +// where the distribution of the fraction is not evenly distributed. We correct +// this bias by tracking the fraction we rounded up or down on each iteration, +// effectively tracking the distance between the cumulative value, and the +// rounded cumulative value. For example, given a mean of 2: +// +// raw = 1.63076, cumulative = 1.63076, rounded = 2, bias = -0.36923 +// raw = 0.14624, cumulative = 1.77701, rounded = 2, bias = 0.14624 +// raw = 4.93194, cumulative = 6.70895, rounded = 7, bias = -0.06805 +// raw = 0.24206, cumulative = 6.95101, rounded = 7, bias = 0.24206 +// etc... +// +// Adjusting with rounding bias is relatively trivial: +// +// double value = bias_ + exponential_distribution(mean)(); +// double rounded_value = std::round(value); +// bias_ = value - rounded_value; +// return rounded_value; +// +// This class is thread-compatible. +class ExponentialBiased { + public: + // The number of bits set by NextRandom. + static constexpr int kPrngNumBits = 48; + + // `GetSkipCount()` returns the number of events to skip before some chosen + // event happens. For example, randomly tossing a coin, we will on average + // throw heads once before we get tails. We can simulate random coin tosses + // using GetSkipCount() as: + // + // ExponentialBiased eb; + // for (...) { + // int number_of_heads_before_tail = eb.GetSkipCount(1); + // for (int flips = 0; flips < number_of_heads_before_tail; ++flips) { + // printf("head..."); + // } + // printf("tail\n"); + // } + // + int64_t GetSkipCount(int64_t mean); + + // GetStride() returns the number of events required for a specific event to + // happen. See the class comments for a usage example. `GetStride()` is + // equivalent to `GetSkipCount(mean - 1) + 1`. When to use `GetStride()` or + // `GetSkipCount()` depends mostly on what best fits the use case. + int64_t GetStride(int64_t mean); + + // Computes a random number in the range [0, 1<<(kPrngNumBits+1) - 1] + // + // This is public to enable testing. + static uint64_t NextRandom(uint64_t rnd); + + private: + void Initialize(); + + uint64_t rng_{0}; + double bias_{0}; + bool initialized_{false}; +}; + +// Returns the next prng value. +// pRNG is: aX+b mod c with a = 0x5DEECE66D, b = 0xB, c = 1<<48 +// This is the lrand64 generator. +inline uint64_t ExponentialBiased::NextRandom(uint64_t rnd) { + const uint64_t prng_mult = uint64_t{0x5DEECE66D}; + const uint64_t prng_add = 0xB; + const uint64_t prng_mod_power = 48; + const uint64_t prng_mod_mask = + ~((~static_cast<uint64_t>(0)) << prng_mod_power); + return (prng_mult * rnd + prng_add) & prng_mod_mask; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_EXPONENTIAL_BIASED_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/exponential_biased_test.cc b/third_party/abseil_cpp/absl/base/internal/exponential_biased_test.cc new file mode 100644 index 0000000000..90a482d2a9 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/exponential_biased_test.cc @@ -0,0 +1,199 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/exponential_biased.h" + +#include <stddef.h> + +#include <cmath> +#include <cstdint> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/str_cat.h" + +using ::testing::Ge; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +MATCHER_P2(IsBetween, a, b, + absl::StrCat(std::string(negation ? "isn't" : "is"), " between ", a, + " and ", b)) { + return a <= arg && arg <= b; +} + +// Tests of the quality of the random numbers generated +// This uses the Anderson Darling test for uniformity. +// See "Evaluating the Anderson-Darling Distribution" by Marsaglia +// for details. + +// Short cut version of ADinf(z), z>0 (from Marsaglia) +// This returns the p-value for Anderson Darling statistic in +// the limit as n-> infinity. For finite n, apply the error fix below. +double AndersonDarlingInf(double z) { + if (z < 2) { + return exp(-1.2337141 / z) / sqrt(z) * + (2.00012 + + (0.247105 - + (0.0649821 - (0.0347962 - (0.011672 - 0.00168691 * z) * z) * z) * + z) * + z); + } + return exp( + -exp(1.0776 - + (2.30695 - + (0.43424 - (0.082433 - (0.008056 - 0.0003146 * z) * z) * z) * z) * + z)); +} + +// Corrects the approximation error in AndersonDarlingInf for small values of n +// Add this to AndersonDarlingInf to get a better approximation +// (from Marsaglia) +double AndersonDarlingErrFix(int n, double x) { + if (x > 0.8) { + return (-130.2137 + + (745.2337 - + (1705.091 - (1950.646 - (1116.360 - 255.7844 * x) * x) * x) * x) * + x) / + n; + } + double cutoff = 0.01265 + 0.1757 / n; + if (x < cutoff) { + double t = x / cutoff; + t = sqrt(t) * (1 - t) * (49 * t - 102); + return t * (0.0037 / (n * n) + 0.00078 / n + 0.00006) / n; + } else { + double t = (x - cutoff) / (0.8 - cutoff); + t = -0.00022633 + + (6.54034 - (14.6538 - (14.458 - (8.259 - 1.91864 * t) * t) * t) * t) * + t; + return t * (0.04213 + 0.01365 / n) / n; + } +} + +// Returns the AndersonDarling p-value given n and the value of the statistic +double AndersonDarlingPValue(int n, double z) { + double ad = AndersonDarlingInf(z); + double errfix = AndersonDarlingErrFix(n, ad); + return ad + errfix; +} + +double AndersonDarlingStatistic(const std::vector<double>& random_sample) { + int n = random_sample.size(); + double ad_sum = 0; + for (int i = 0; i < n; i++) { + ad_sum += (2 * i + 1) * + std::log(random_sample[i] * (1 - random_sample[n - 1 - i])); + } + double ad_statistic = -n - 1 / static_cast<double>(n) * ad_sum; + return ad_statistic; +} + +// Tests if the array of doubles is uniformly distributed. +// Returns the p-value of the Anderson Darling Statistic +// for the given set of sorted random doubles +// See "Evaluating the Anderson-Darling Distribution" by +// Marsaglia and Marsaglia for details. +double AndersonDarlingTest(const std::vector<double>& random_sample) { + double ad_statistic = AndersonDarlingStatistic(random_sample); + double p = AndersonDarlingPValue(random_sample.size(), ad_statistic); + return p; +} + +TEST(ExponentialBiasedTest, CoinTossDemoWithGetSkipCount) { + ExponentialBiased eb; + for (int runs = 0; runs < 10; ++runs) { + for (int flips = eb.GetSkipCount(1); flips > 0; --flips) { + printf("head..."); + } + printf("tail\n"); + } + int heads = 0; + for (int i = 0; i < 10000000; i += 1 + eb.GetSkipCount(1)) { + ++heads; + } + printf("Heads = %d (%f%%)\n", heads, 100.0 * heads / 10000000); +} + +TEST(ExponentialBiasedTest, SampleDemoWithStride) { + ExponentialBiased eb; + int stride = eb.GetStride(10); + int samples = 0; + for (int i = 0; i < 10000000; ++i) { + if (--stride == 0) { + ++samples; + stride = eb.GetStride(10); + } + } + printf("Samples = %d (%f%%)\n", samples, 100.0 * samples / 10000000); +} + + +// Testing that NextRandom generates uniform random numbers. Applies the +// Anderson-Darling test for uniformity +TEST(ExponentialBiasedTest, TestNextRandom) { + for (auto n : std::vector<int>({ + 10, // Check short-range correlation + 100, 1000, + 10000 // Make sure there's no systemic error + })) { + uint64_t x = 1; + // This assumes that the prng returns 48 bit numbers + uint64_t max_prng_value = static_cast<uint64_t>(1) << 48; + // Initialize. + for (int i = 1; i <= 20; i++) { + x = ExponentialBiased::NextRandom(x); + } + std::vector<uint64_t> int_random_sample(n); + // Collect samples + for (int i = 0; i < n; i++) { + int_random_sample[i] = x; + x = ExponentialBiased::NextRandom(x); + } + // First sort them... + std::sort(int_random_sample.begin(), int_random_sample.end()); + std::vector<double> random_sample(n); + // Convert them to uniform randoms (in the range [0,1]) + for (int i = 0; i < n; i++) { + random_sample[i] = + static_cast<double>(int_random_sample[i]) / max_prng_value; + } + // Now compute the Anderson-Darling statistic + double ad_pvalue = AndersonDarlingTest(random_sample); + EXPECT_GT(std::min(ad_pvalue, 1 - ad_pvalue), 0.0001) + << "prng is not uniform: n = " << n << " p = " << ad_pvalue; + } +} + +// The generator needs to be available as a thread_local and as a static +// variable. +TEST(ExponentialBiasedTest, InitializationModes) { + ABSL_CONST_INIT static ExponentialBiased eb_static; + EXPECT_THAT(eb_static.GetSkipCount(2), Ge(0)); + +#if ABSL_HAVE_THREAD_LOCAL + thread_local ExponentialBiased eb_thread; + EXPECT_THAT(eb_thread.GetSkipCount(2), Ge(0)); +#endif + + ExponentialBiased eb_stack; + EXPECT_THAT(eb_stack.GetSkipCount(2), Ge(0)); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/fast_type_id.h b/third_party/abseil_cpp/absl/base/internal/fast_type_id.h new file mode 100644 index 0000000000..3db59e8374 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/fast_type_id.h @@ -0,0 +1,48 @@ +// +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_FAST_TYPE_ID_H_ +#define ABSL_BASE_INTERNAL_FAST_TYPE_ID_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +template <typename Type> +struct FastTypeTag { + constexpr static char dummy_var = 0; +}; + +template <typename Type> +constexpr char FastTypeTag<Type>::dummy_var; + +// FastTypeId<Type>() evaluates at compile/link-time to a unique pointer for the +// passed-in type. These are meant to be good match for keys into maps or +// straight up comparisons. +using FastTypeIdType = const void*; + +template <typename Type> +constexpr inline FastTypeIdType FastTypeId() { + return &FastTypeTag<Type>::dummy_var; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_FAST_TYPE_ID_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/fast_type_id_test.cc b/third_party/abseil_cpp/absl/base/internal/fast_type_id_test.cc new file mode 100644 index 0000000000..16f3c1458b --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/fast_type_id_test.cc @@ -0,0 +1,123 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/fast_type_id.h" + +#include <cstdint> +#include <map> +#include <vector> + +#include "gtest/gtest.h" + +namespace { +namespace bi = absl::base_internal; + +// NOLINTNEXTLINE +#define PRIM_TYPES(A) \ + A(bool) \ + A(short) \ + A(unsigned short) \ + A(int) \ + A(unsigned int) \ + A(long) \ + A(unsigned long) \ + A(long long) \ + A(unsigned long long) \ + A(float) \ + A(double) \ + A(long double) + +TEST(FastTypeIdTest, PrimitiveTypes) { + bi::FastTypeIdType type_ids[] = { +#define A(T) bi::FastTypeId<T>(), + PRIM_TYPES(A) +#undef A +#define A(T) bi::FastTypeId<const T>(), + PRIM_TYPES(A) +#undef A +#define A(T) bi::FastTypeId<volatile T>(), + PRIM_TYPES(A) +#undef A +#define A(T) bi::FastTypeId<const volatile T>(), + PRIM_TYPES(A) +#undef A + }; + size_t total_type_ids = sizeof(type_ids) / sizeof(bi::FastTypeIdType); + + for (int i = 0; i < total_type_ids; ++i) { + EXPECT_EQ(type_ids[i], type_ids[i]); + for (int j = 0; j < i; ++j) { + EXPECT_NE(type_ids[i], type_ids[j]); + } + } +} + +#define FIXED_WIDTH_TYPES(A) \ + A(int8_t) \ + A(uint8_t) \ + A(int16_t) \ + A(uint16_t) \ + A(int32_t) \ + A(uint32_t) \ + A(int64_t) \ + A(uint64_t) + +TEST(FastTypeIdTest, FixedWidthTypes) { + bi::FastTypeIdType type_ids[] = { +#define A(T) bi::FastTypeId<T>(), + FIXED_WIDTH_TYPES(A) +#undef A +#define A(T) bi::FastTypeId<const T>(), + FIXED_WIDTH_TYPES(A) +#undef A +#define A(T) bi::FastTypeId<volatile T>(), + FIXED_WIDTH_TYPES(A) +#undef A +#define A(T) bi::FastTypeId<const volatile T>(), + FIXED_WIDTH_TYPES(A) +#undef A + }; + size_t total_type_ids = sizeof(type_ids) / sizeof(bi::FastTypeIdType); + + for (int i = 0; i < total_type_ids; ++i) { + EXPECT_EQ(type_ids[i], type_ids[i]); + for (int j = 0; j < i; ++j) { + EXPECT_NE(type_ids[i], type_ids[j]); + } + } +} + +TEST(FastTypeIdTest, AliasTypes) { + using int_alias = int; + EXPECT_EQ(bi::FastTypeId<int_alias>(), bi::FastTypeId<int>()); +} + +TEST(FastTypeIdTest, TemplateSpecializations) { + EXPECT_NE(bi::FastTypeId<std::vector<int>>(), + bi::FastTypeId<std::vector<long>>()); + + EXPECT_NE((bi::FastTypeId<std::map<int, float>>()), + (bi::FastTypeId<std::map<int, double>>())); +} + +struct Base {}; +struct Derived : Base {}; +struct PDerived : private Base {}; + +TEST(FastTypeIdTest, Inheritance) { + EXPECT_NE(bi::FastTypeId<Base>(), bi::FastTypeId<Derived>()); + EXPECT_NE(bi::FastTypeId<Base>(), bi::FastTypeId<PDerived>()); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/hide_ptr.h b/third_party/abseil_cpp/absl/base/internal/hide_ptr.h new file mode 100644 index 0000000000..1dba80909a --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/hide_ptr.h @@ -0,0 +1,51 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_HIDE_PTR_H_ +#define ABSL_BASE_INTERNAL_HIDE_PTR_H_ + +#include <cstdint> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// Arbitrary value with high bits set. Xor'ing with it is unlikely +// to map one valid pointer to another valid pointer. +constexpr uintptr_t HideMask() { + return (uintptr_t{0xF03A5F7BU} << (sizeof(uintptr_t) - 4) * 8) | 0xF03A5F7BU; +} + +// Hide a pointer from the leak checker. For internal use only. +// Differs from absl::IgnoreLeak(ptr) in that absl::IgnoreLeak(ptr) causes ptr +// and all objects reachable from ptr to be ignored by the leak checker. +template <class T> +inline uintptr_t HidePtr(T* ptr) { + return reinterpret_cast<uintptr_t>(ptr) ^ HideMask(); +} + +// Return a pointer that has been hidden from the leak checker. +// For internal use only. +template <class T> +inline T* UnhidePtr(uintptr_t hidden) { + return reinterpret_cast<T*>(hidden ^ HideMask()); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_HIDE_PTR_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/identity.h b/third_party/abseil_cpp/absl/base/internal/identity.h new file mode 100644 index 0000000000..a3154ed7bc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/identity.h @@ -0,0 +1,37 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_IDENTITY_H_ +#define ABSL_BASE_INTERNAL_IDENTITY_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace internal { + +template <typename T> +struct identity { + typedef T type; +}; + +template <typename T> +using identity_t = typename identity<T>::type; + +} // namespace internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_IDENTITY_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/inline_variable.h b/third_party/abseil_cpp/absl/base/internal/inline_variable.h new file mode 100644 index 0000000000..130d8c2476 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/inline_variable.h @@ -0,0 +1,107 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_INLINE_VARIABLE_EMULATION_H_ +#define ABSL_BASE_INTERNAL_INLINE_VARIABLE_EMULATION_H_ + +#include <type_traits> + +#include "absl/base/internal/identity.h" + +// File: +// This file define a macro that allows the creation of or emulation of C++17 +// inline variables based on whether or not the feature is supported. + +//////////////////////////////////////////////////////////////////////////////// +// Macro: ABSL_INTERNAL_INLINE_CONSTEXPR(type, name, init) +// +// Description: +// Expands to the equivalent of an inline constexpr instance of the specified +// `type` and `name`, initialized to the value `init`. If the compiler being +// used is detected as supporting actual inline variables as a language +// feature, then the macro expands to an actual inline variable definition. +// +// Requires: +// `type` is a type that is usable in an extern variable declaration. +// +// Requires: `name` is a valid identifier +// +// Requires: +// `init` is an expression that can be used in the following definition: +// constexpr type name = init; +// +// Usage: +// +// // Equivalent to: `inline constexpr size_t variant_npos = -1;` +// ABSL_INTERNAL_INLINE_CONSTEXPR(size_t, variant_npos, -1); +// +// Differences in implementation: +// For a direct, language-level inline variable, decltype(name) will be the +// type that was specified along with const qualification, whereas for +// emulated inline variables, decltype(name) may be different (in practice +// it will likely be a reference type). +//////////////////////////////////////////////////////////////////////////////// + +#ifdef __cpp_inline_variables + +// Clang's -Wmissing-variable-declarations option erroneously warned that +// inline constexpr objects need to be pre-declared. This has now been fixed, +// but we will need to support this workaround for people building with older +// versions of clang. +// +// Bug: https://bugs.llvm.org/show_bug.cgi?id=35862 +// +// Note: +// identity_t is used here so that the const and name are in the +// appropriate place for pointer types, reference types, function pointer +// types, etc.. +#if defined(__clang__) +#define ABSL_INTERNAL_EXTERN_DECL(type, name) \ + extern const ::absl::internal::identity_t<type> name; +#else // Otherwise, just define the macro to do nothing. +#define ABSL_INTERNAL_EXTERN_DECL(type, name) +#endif // defined(__clang__) + +// See above comment at top of file for details. +#define ABSL_INTERNAL_INLINE_CONSTEXPR(type, name, init) \ + ABSL_INTERNAL_EXTERN_DECL(type, name) \ + inline constexpr ::absl::internal::identity_t<type> name = init + +#else + +// See above comment at top of file for details. +// +// Note: +// identity_t is used here so that the const and name are in the +// appropriate place for pointer types, reference types, function pointer +// types, etc.. +#define ABSL_INTERNAL_INLINE_CONSTEXPR(var_type, name, init) \ + template <class /*AbslInternalDummy*/ = void> \ + struct AbslInternalInlineVariableHolder##name { \ + static constexpr ::absl::internal::identity_t<var_type> kInstance = init; \ + }; \ + \ + template <class AbslInternalDummy> \ + constexpr ::absl::internal::identity_t<var_type> \ + AbslInternalInlineVariableHolder##name<AbslInternalDummy>::kInstance; \ + \ + static constexpr const ::absl::internal::identity_t<var_type>& \ + name = /* NOLINT */ \ + AbslInternalInlineVariableHolder##name<>::kInstance; \ + static_assert(sizeof(void (*)(decltype(name))) != 0, \ + "Silence unused variable warnings.") + +#endif // __cpp_inline_variables + +#endif // ABSL_BASE_INTERNAL_INLINE_VARIABLE_EMULATION_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/inline_variable_testing.h b/third_party/abseil_cpp/absl/base/internal/inline_variable_testing.h new file mode 100644 index 0000000000..3856b9f80f --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/inline_variable_testing.h @@ -0,0 +1,46 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INLINE_VARIABLE_TESTING_H_ +#define ABSL_BASE_INLINE_VARIABLE_TESTING_H_ + +#include "absl/base/internal/inline_variable.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace inline_variable_testing_internal { + +struct Foo { + int value = 5; +}; + +ABSL_INTERNAL_INLINE_CONSTEXPR(Foo, inline_variable_foo, {}); +ABSL_INTERNAL_INLINE_CONSTEXPR(Foo, other_inline_variable_foo, {}); + +ABSL_INTERNAL_INLINE_CONSTEXPR(int, inline_variable_int, 5); +ABSL_INTERNAL_INLINE_CONSTEXPR(int, other_inline_variable_int, 5); + +ABSL_INTERNAL_INLINE_CONSTEXPR(void(*)(), inline_variable_fun_ptr, nullptr); + +const Foo& get_foo_a(); +const Foo& get_foo_b(); + +const int& get_int_a(); +const int& get_int_b(); + +} // namespace inline_variable_testing_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INLINE_VARIABLE_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/invoke.h b/third_party/abseil_cpp/absl/base/internal/invoke.h new file mode 100644 index 0000000000..c4eceebd7c --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/invoke.h @@ -0,0 +1,187 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// absl::base_internal::Invoke(f, args...) is an implementation of +// INVOKE(f, args...) from section [func.require] of the C++ standard. +// +// [func.require] +// Define INVOKE (f, t1, t2, ..., tN) as follows: +// 1. (t1.*f)(t2, ..., tN) when f is a pointer to a member function of a class T +// and t1 is an object of type T or a reference to an object of type T or a +// reference to an object of a type derived from T; +// 2. ((*t1).*f)(t2, ..., tN) when f is a pointer to a member function of a +// class T and t1 is not one of the types described in the previous item; +// 3. t1.*f when N == 1 and f is a pointer to member data of a class T and t1 is +// an object of type T or a reference to an object of type T or a reference +// to an object of a type derived from T; +// 4. (*t1).*f when N == 1 and f is a pointer to member data of a class T and t1 +// is not one of the types described in the previous item; +// 5. f(t1, t2, ..., tN) in all other cases. +// +// The implementation is SFINAE-friendly: substitution failure within Invoke() +// isn't an error. + +#ifndef ABSL_BASE_INTERNAL_INVOKE_H_ +#define ABSL_BASE_INTERNAL_INVOKE_H_ + +#include <algorithm> +#include <type_traits> +#include <utility> + +#include "absl/meta/type_traits.h" + +// The following code is internal implementation detail. See the comment at the +// top of this file for the API documentation. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// The five classes below each implement one of the clauses from the definition +// of INVOKE. The inner class template Accept<F, Args...> checks whether the +// clause is applicable; static function template Invoke(f, args...) does the +// invocation. +// +// By separating the clause selection logic from invocation we make sure that +// Invoke() does exactly what the standard says. + +template <typename Derived> +struct StrippedAccept { + template <typename... Args> + struct Accept : Derived::template AcceptImpl<typename std::remove_cv< + typename std::remove_reference<Args>::type>::type...> {}; +}; + +// (t1.*f)(t2, ..., tN) when f is a pointer to a member function of a class T +// and t1 is an object of type T or a reference to an object of type T or a +// reference to an object of a type derived from T. +struct MemFunAndRef : StrippedAccept<MemFunAndRef> { + template <typename... Args> + struct AcceptImpl : std::false_type {}; + + template <typename MemFunType, typename C, typename Obj, typename... Args> + struct AcceptImpl<MemFunType C::*, Obj, Args...> + : std::integral_constant<bool, std::is_base_of<C, Obj>::value && + absl::is_function<MemFunType>::value> { + }; + + template <typename MemFun, typename Obj, typename... Args> + static decltype((std::declval<Obj>().* + std::declval<MemFun>())(std::declval<Args>()...)) + Invoke(MemFun&& mem_fun, Obj&& obj, Args&&... args) { + return (std::forward<Obj>(obj).* + std::forward<MemFun>(mem_fun))(std::forward<Args>(args)...); + } +}; + +// ((*t1).*f)(t2, ..., tN) when f is a pointer to a member function of a +// class T and t1 is not one of the types described in the previous item. +struct MemFunAndPtr : StrippedAccept<MemFunAndPtr> { + template <typename... Args> + struct AcceptImpl : std::false_type {}; + + template <typename MemFunType, typename C, typename Ptr, typename... Args> + struct AcceptImpl<MemFunType C::*, Ptr, Args...> + : std::integral_constant<bool, !std::is_base_of<C, Ptr>::value && + absl::is_function<MemFunType>::value> { + }; + + template <typename MemFun, typename Ptr, typename... Args> + static decltype(((*std::declval<Ptr>()).* + std::declval<MemFun>())(std::declval<Args>()...)) + Invoke(MemFun&& mem_fun, Ptr&& ptr, Args&&... args) { + return ((*std::forward<Ptr>(ptr)).* + std::forward<MemFun>(mem_fun))(std::forward<Args>(args)...); + } +}; + +// t1.*f when N == 1 and f is a pointer to member data of a class T and t1 is +// an object of type T or a reference to an object of type T or a reference +// to an object of a type derived from T. +struct DataMemAndRef : StrippedAccept<DataMemAndRef> { + template <typename... Args> + struct AcceptImpl : std::false_type {}; + + template <typename R, typename C, typename Obj> + struct AcceptImpl<R C::*, Obj> + : std::integral_constant<bool, std::is_base_of<C, Obj>::value && + !absl::is_function<R>::value> {}; + + template <typename DataMem, typename Ref> + static decltype(std::declval<Ref>().*std::declval<DataMem>()) Invoke( + DataMem&& data_mem, Ref&& ref) { + return std::forward<Ref>(ref).*std::forward<DataMem>(data_mem); + } +}; + +// (*t1).*f when N == 1 and f is a pointer to member data of a class T and t1 +// is not one of the types described in the previous item. +struct DataMemAndPtr : StrippedAccept<DataMemAndPtr> { + template <typename... Args> + struct AcceptImpl : std::false_type {}; + + template <typename R, typename C, typename Ptr> + struct AcceptImpl<R C::*, Ptr> + : std::integral_constant<bool, !std::is_base_of<C, Ptr>::value && + !absl::is_function<R>::value> {}; + + template <typename DataMem, typename Ptr> + static decltype((*std::declval<Ptr>()).*std::declval<DataMem>()) Invoke( + DataMem&& data_mem, Ptr&& ptr) { + return (*std::forward<Ptr>(ptr)).*std::forward<DataMem>(data_mem); + } +}; + +// f(t1, t2, ..., tN) in all other cases. +struct Callable { + // Callable doesn't have Accept because it's the last clause that gets picked + // when none of the previous clauses are applicable. + template <typename F, typename... Args> + static decltype(std::declval<F>()(std::declval<Args>()...)) Invoke( + F&& f, Args&&... args) { + return std::forward<F>(f)(std::forward<Args>(args)...); + } +}; + +// Resolves to the first matching clause. +template <typename... Args> +struct Invoker { + typedef typename std::conditional< + MemFunAndRef::Accept<Args...>::value, MemFunAndRef, + typename std::conditional< + MemFunAndPtr::Accept<Args...>::value, MemFunAndPtr, + typename std::conditional< + DataMemAndRef::Accept<Args...>::value, DataMemAndRef, + typename std::conditional<DataMemAndPtr::Accept<Args...>::value, + DataMemAndPtr, Callable>::type>::type>:: + type>::type type; +}; + +// The result type of Invoke<F, Args...>. +template <typename F, typename... Args> +using InvokeT = decltype(Invoker<F, Args...>::type::Invoke( + std::declval<F>(), std::declval<Args>()...)); + +// Invoke(f, args...) is an implementation of INVOKE(f, args...) from section +// [func.require] of the C++ standard. +template <typename F, typename... Args> +InvokeT<F, Args...> Invoke(F&& f, Args&&... args) { + return Invoker<F, Args...>::type::Invoke(std::forward<F>(f), + std::forward<Args>(args)...); +} +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_INVOKE_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/low_level_alloc.cc b/third_party/abseil_cpp/absl/base/internal/low_level_alloc.cc new file mode 100644 index 0000000000..1bf94438d6 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/low_level_alloc.cc @@ -0,0 +1,620 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// A low-level allocator that can be used by other low-level +// modules without introducing dependency cycles. +// This allocator is slow and wasteful of memory; +// it should not be used when performance is key. + +#include "absl/base/internal/low_level_alloc.h" + +#include <type_traits> + +#include "absl/base/call_once.h" +#include "absl/base/config.h" +#include "absl/base/internal/direct_mmap.h" +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/macros.h" +#include "absl/base/thread_annotations.h" + +// LowLevelAlloc requires that the platform support low-level +// allocation of virtual memory. Platforms lacking this cannot use +// LowLevelAlloc. +#ifndef ABSL_LOW_LEVEL_ALLOC_MISSING + +#ifndef _WIN32 +#include <pthread.h> +#include <signal.h> +#include <sys/mman.h> +#include <unistd.h> +#else +#include <windows.h> +#endif + +#include <string.h> +#include <algorithm> +#include <atomic> +#include <cerrno> +#include <cstddef> +#include <new> // for placement-new + +#include "absl/base/dynamic_annotations.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" + +// MAP_ANONYMOUS +#if defined(__APPLE__) +// For mmap, Linux defines both MAP_ANONYMOUS and MAP_ANON and says MAP_ANON is +// deprecated. In Darwin, MAP_ANON is all there is. +#if !defined MAP_ANONYMOUS +#define MAP_ANONYMOUS MAP_ANON +#endif // !MAP_ANONYMOUS +#endif // __APPLE__ + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// A first-fit allocator with amortized logarithmic free() time. + +// --------------------------------------------------------------------------- +static const int kMaxLevel = 30; + +namespace { +// This struct describes one allocated block, or one free block. +struct AllocList { + struct Header { + // Size of entire region, including this field. Must be + // first. Valid in both allocated and unallocated blocks. + uintptr_t size; + + // kMagicAllocated or kMagicUnallocated xor this. + uintptr_t magic; + + // Pointer to parent arena. + LowLevelAlloc::Arena *arena; + + // Aligns regions to 0 mod 2*sizeof(void*). + void *dummy_for_alignment; + } header; + + // Next two fields: in unallocated blocks: freelist skiplist data + // in allocated blocks: overlaps with client data + + // Levels in skiplist used. + int levels; + + // Actually has levels elements. The AllocList node may not have room + // for all kMaxLevel entries. See max_fit in LLA_SkiplistLevels(). + AllocList *next[kMaxLevel]; +}; +} // namespace + +// --------------------------------------------------------------------------- +// A trivial skiplist implementation. This is used to keep the freelist +// in address order while taking only logarithmic time per insert and delete. + +// An integer approximation of log2(size/base) +// Requires size >= base. +static int IntLog2(size_t size, size_t base) { + int result = 0; + for (size_t i = size; i > base; i >>= 1) { // i == floor(size/2**result) + result++; + } + // floor(size / 2**result) <= base < floor(size / 2**(result-1)) + // => log2(size/(base+1)) <= result < 1+log2(size/base) + // => result ~= log2(size/base) + return result; +} + +// Return a random integer n: p(n)=1/(2**n) if 1 <= n; p(n)=0 if n < 1. +static int Random(uint32_t *state) { + uint32_t r = *state; + int result = 1; + while ((((r = r*1103515245 + 12345) >> 30) & 1) == 0) { + result++; + } + *state = r; + return result; +} + +// Return a number of skiplist levels for a node of size bytes, where +// base is the minimum node size. Compute level=log2(size / base)+n +// where n is 1 if random is false and otherwise a random number generated with +// the standard distribution for a skiplist: See Random() above. +// Bigger nodes tend to have more skiplist levels due to the log2(size / base) +// term, so first-fit searches touch fewer nodes. "level" is clipped so +// level<kMaxLevel and next[level-1] will fit in the node. +// 0 < LLA_SkiplistLevels(x,y,false) <= LLA_SkiplistLevels(x,y,true) < kMaxLevel +static int LLA_SkiplistLevels(size_t size, size_t base, uint32_t *random) { + // max_fit is the maximum number of levels that will fit in a node for the + // given size. We can't return more than max_fit, no matter what the + // random number generator says. + size_t max_fit = (size - offsetof(AllocList, next)) / sizeof(AllocList *); + int level = IntLog2(size, base) + (random != nullptr ? Random(random) : 1); + if (static_cast<size_t>(level) > max_fit) level = static_cast<int>(max_fit); + if (level > kMaxLevel-1) level = kMaxLevel - 1; + ABSL_RAW_CHECK(level >= 1, "block not big enough for even one level"); + return level; +} + +// Return "atleast", the first element of AllocList *head s.t. *atleast >= *e. +// For 0 <= i < head->levels, set prev[i] to "no_greater", where no_greater +// points to the last element at level i in the AllocList less than *e, or is +// head if no such element exists. +static AllocList *LLA_SkiplistSearch(AllocList *head, + AllocList *e, AllocList **prev) { + AllocList *p = head; + for (int level = head->levels - 1; level >= 0; level--) { + for (AllocList *n; (n = p->next[level]) != nullptr && n < e; p = n) { + } + prev[level] = p; + } + return (head->levels == 0) ? nullptr : prev[0]->next[0]; +} + +// Insert element *e into AllocList *head. Set prev[] as LLA_SkiplistSearch. +// Requires that e->levels be previously set by the caller (using +// LLA_SkiplistLevels()) +static void LLA_SkiplistInsert(AllocList *head, AllocList *e, + AllocList **prev) { + LLA_SkiplistSearch(head, e, prev); + for (; head->levels < e->levels; head->levels++) { // extend prev pointers + prev[head->levels] = head; // to all *e's levels + } + for (int i = 0; i != e->levels; i++) { // add element to list + e->next[i] = prev[i]->next[i]; + prev[i]->next[i] = e; + } +} + +// Remove element *e from AllocList *head. Set prev[] as LLA_SkiplistSearch(). +// Requires that e->levels be previous set by the caller (using +// LLA_SkiplistLevels()) +static void LLA_SkiplistDelete(AllocList *head, AllocList *e, + AllocList **prev) { + AllocList *found = LLA_SkiplistSearch(head, e, prev); + ABSL_RAW_CHECK(e == found, "element not in freelist"); + for (int i = 0; i != e->levels && prev[i]->next[i] == e; i++) { + prev[i]->next[i] = e->next[i]; + } + while (head->levels > 0 && head->next[head->levels - 1] == nullptr) { + head->levels--; // reduce head->levels if level unused + } +} + +// --------------------------------------------------------------------------- +// Arena implementation + +// Metadata for an LowLevelAlloc arena instance. +struct LowLevelAlloc::Arena { + // Constructs an arena with the given LowLevelAlloc flags. + explicit Arena(uint32_t flags_value); + + base_internal::SpinLock mu; + // Head of free list, sorted by address + AllocList freelist ABSL_GUARDED_BY(mu); + // Count of allocated blocks + int32_t allocation_count ABSL_GUARDED_BY(mu); + // flags passed to NewArena + const uint32_t flags; + // Result of sysconf(_SC_PAGESIZE) + const size_t pagesize; + // Lowest power of two >= max(16, sizeof(AllocList)) + const size_t round_up; + // Smallest allocation block size + const size_t min_size; + // PRNG state + uint32_t random ABSL_GUARDED_BY(mu); +}; + +namespace { +// Static storage space for the lazily-constructed, default global arena +// instances. We require this space because the whole point of LowLevelAlloc +// is to avoid relying on malloc/new. +alignas(LowLevelAlloc::Arena) unsigned char default_arena_storage[sizeof( + LowLevelAlloc::Arena)]; +alignas(LowLevelAlloc::Arena) unsigned char unhooked_arena_storage[sizeof( + LowLevelAlloc::Arena)]; +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING +alignas( + LowLevelAlloc::Arena) unsigned char unhooked_async_sig_safe_arena_storage + [sizeof(LowLevelAlloc::Arena)]; +#endif + +// We must use LowLevelCallOnce here to construct the global arenas, rather than +// using function-level statics, to avoid recursively invoking the scheduler. +absl::once_flag create_globals_once; + +void CreateGlobalArenas() { + new (&default_arena_storage) + LowLevelAlloc::Arena(LowLevelAlloc::kCallMallocHook); + new (&unhooked_arena_storage) LowLevelAlloc::Arena(0); +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + new (&unhooked_async_sig_safe_arena_storage) + LowLevelAlloc::Arena(LowLevelAlloc::kAsyncSignalSafe); +#endif +} + +// Returns a global arena that does not call into hooks. Used by NewArena() +// when kCallMallocHook is not set. +LowLevelAlloc::Arena* UnhookedArena() { + base_internal::LowLevelCallOnce(&create_globals_once, CreateGlobalArenas); + return reinterpret_cast<LowLevelAlloc::Arena*>(&unhooked_arena_storage); +} + +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING +// Returns a global arena that is async-signal safe. Used by NewArena() when +// kAsyncSignalSafe is set. +LowLevelAlloc::Arena *UnhookedAsyncSigSafeArena() { + base_internal::LowLevelCallOnce(&create_globals_once, CreateGlobalArenas); + return reinterpret_cast<LowLevelAlloc::Arena *>( + &unhooked_async_sig_safe_arena_storage); +} +#endif + +} // namespace + +// Returns the default arena, as used by LowLevelAlloc::Alloc() and friends. +LowLevelAlloc::Arena *LowLevelAlloc::DefaultArena() { + base_internal::LowLevelCallOnce(&create_globals_once, CreateGlobalArenas); + return reinterpret_cast<LowLevelAlloc::Arena*>(&default_arena_storage); +} + +// magic numbers to identify allocated and unallocated blocks +static const uintptr_t kMagicAllocated = 0x4c833e95U; +static const uintptr_t kMagicUnallocated = ~kMagicAllocated; + +namespace { +class ABSL_SCOPED_LOCKABLE ArenaLock { + public: + explicit ArenaLock(LowLevelAlloc::Arena *arena) + ABSL_EXCLUSIVE_LOCK_FUNCTION(arena->mu) + : arena_(arena) { +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if ((arena->flags & LowLevelAlloc::kAsyncSignalSafe) != 0) { + sigset_t all; + sigfillset(&all); + mask_valid_ = pthread_sigmask(SIG_BLOCK, &all, &mask_) == 0; + } +#endif + arena_->mu.Lock(); + } + ~ArenaLock() { ABSL_RAW_CHECK(left_, "haven't left Arena region"); } + void Leave() ABSL_UNLOCK_FUNCTION() { + arena_->mu.Unlock(); +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if (mask_valid_) { + const int err = pthread_sigmask(SIG_SETMASK, &mask_, nullptr); + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_sigmask failed: %d", err); + } + } +#endif + left_ = true; + } + + private: + bool left_ = false; // whether left region +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + bool mask_valid_ = false; + sigset_t mask_; // old mask of blocked signals +#endif + LowLevelAlloc::Arena *arena_; + ArenaLock(const ArenaLock &) = delete; + ArenaLock &operator=(const ArenaLock &) = delete; +}; +} // namespace + +// create an appropriate magic number for an object at "ptr" +// "magic" should be kMagicAllocated or kMagicUnallocated +inline static uintptr_t Magic(uintptr_t magic, AllocList::Header *ptr) { + return magic ^ reinterpret_cast<uintptr_t>(ptr); +} + +namespace { +size_t GetPageSize() { +#ifdef _WIN32 + SYSTEM_INFO system_info; + GetSystemInfo(&system_info); + return std::max(system_info.dwPageSize, system_info.dwAllocationGranularity); +#elif defined(__wasm__) || defined(__asmjs__) + return getpagesize(); +#else + return sysconf(_SC_PAGESIZE); +#endif +} + +size_t RoundedUpBlockSize() { + // Round up block sizes to a power of two close to the header size. + size_t round_up = 16; + while (round_up < sizeof(AllocList::Header)) { + round_up += round_up; + } + return round_up; +} + +} // namespace + +LowLevelAlloc::Arena::Arena(uint32_t flags_value) + : mu(base_internal::SCHEDULE_KERNEL_ONLY), + allocation_count(0), + flags(flags_value), + pagesize(GetPageSize()), + round_up(RoundedUpBlockSize()), + min_size(2 * round_up), + random(0) { + freelist.header.size = 0; + freelist.header.magic = + Magic(kMagicUnallocated, &freelist.header); + freelist.header.arena = this; + freelist.levels = 0; + memset(freelist.next, 0, sizeof(freelist.next)); +} + +// L < meta_data_arena->mu +LowLevelAlloc::Arena *LowLevelAlloc::NewArena(int32_t flags) { + Arena *meta_data_arena = DefaultArena(); +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if ((flags & LowLevelAlloc::kAsyncSignalSafe) != 0) { + meta_data_arena = UnhookedAsyncSigSafeArena(); + } else // NOLINT(readability/braces) +#endif + if ((flags & LowLevelAlloc::kCallMallocHook) == 0) { + meta_data_arena = UnhookedArena(); + } + Arena *result = + new (AllocWithArena(sizeof (*result), meta_data_arena)) Arena(flags); + return result; +} + +// L < arena->mu, L < arena->arena->mu +bool LowLevelAlloc::DeleteArena(Arena *arena) { + ABSL_RAW_CHECK( + arena != nullptr && arena != DefaultArena() && arena != UnhookedArena(), + "may not delete default arena"); + ArenaLock section(arena); + if (arena->allocation_count != 0) { + section.Leave(); + return false; + } + while (arena->freelist.next[0] != nullptr) { + AllocList *region = arena->freelist.next[0]; + size_t size = region->header.size; + arena->freelist.next[0] = region->next[0]; + ABSL_RAW_CHECK( + region->header.magic == Magic(kMagicUnallocated, ®ion->header), + "bad magic number in DeleteArena()"); + ABSL_RAW_CHECK(region->header.arena == arena, + "bad arena pointer in DeleteArena()"); + ABSL_RAW_CHECK(size % arena->pagesize == 0, + "empty arena has non-page-aligned block size"); + ABSL_RAW_CHECK(reinterpret_cast<uintptr_t>(region) % arena->pagesize == 0, + "empty arena has non-page-aligned block"); + int munmap_result; +#ifdef _WIN32 + munmap_result = VirtualFree(region, 0, MEM_RELEASE); + ABSL_RAW_CHECK(munmap_result != 0, + "LowLevelAlloc::DeleteArena: VitualFree failed"); +#else +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if ((arena->flags & LowLevelAlloc::kAsyncSignalSafe) == 0) { + munmap_result = munmap(region, size); + } else { + munmap_result = base_internal::DirectMunmap(region, size); + } +#else + munmap_result = munmap(region, size); +#endif // ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if (munmap_result != 0) { + ABSL_RAW_LOG(FATAL, "LowLevelAlloc::DeleteArena: munmap failed: %d", + errno); + } +#endif // _WIN32 + } + section.Leave(); + arena->~Arena(); + Free(arena); + return true; +} + +// --------------------------------------------------------------------------- + +// Addition, checking for overflow. The intent is to die if an external client +// manages to push through a request that would cause arithmetic to fail. +static inline uintptr_t CheckedAdd(uintptr_t a, uintptr_t b) { + uintptr_t sum = a + b; + ABSL_RAW_CHECK(sum >= a, "LowLevelAlloc arithmetic overflow"); + return sum; +} + +// Return value rounded up to next multiple of align. +// align must be a power of two. +static inline uintptr_t RoundUp(uintptr_t addr, uintptr_t align) { + return CheckedAdd(addr, align - 1) & ~(align - 1); +} + +// Equivalent to "return prev->next[i]" but with sanity checking +// that the freelist is in the correct order, that it +// consists of regions marked "unallocated", and that no two regions +// are adjacent in memory (they should have been coalesced). +// L >= arena->mu +static AllocList *Next(int i, AllocList *prev, LowLevelAlloc::Arena *arena) { + ABSL_RAW_CHECK(i < prev->levels, "too few levels in Next()"); + AllocList *next = prev->next[i]; + if (next != nullptr) { + ABSL_RAW_CHECK( + next->header.magic == Magic(kMagicUnallocated, &next->header), + "bad magic number in Next()"); + ABSL_RAW_CHECK(next->header.arena == arena, "bad arena pointer in Next()"); + if (prev != &arena->freelist) { + ABSL_RAW_CHECK(prev < next, "unordered freelist"); + ABSL_RAW_CHECK(reinterpret_cast<char *>(prev) + prev->header.size < + reinterpret_cast<char *>(next), + "malformed freelist"); + } + } + return next; +} + +// Coalesce list item "a" with its successor if they are adjacent. +static void Coalesce(AllocList *a) { + AllocList *n = a->next[0]; + if (n != nullptr && reinterpret_cast<char *>(a) + a->header.size == + reinterpret_cast<char *>(n)) { + LowLevelAlloc::Arena *arena = a->header.arena; + a->header.size += n->header.size; + n->header.magic = 0; + n->header.arena = nullptr; + AllocList *prev[kMaxLevel]; + LLA_SkiplistDelete(&arena->freelist, n, prev); + LLA_SkiplistDelete(&arena->freelist, a, prev); + a->levels = LLA_SkiplistLevels(a->header.size, arena->min_size, + &arena->random); + LLA_SkiplistInsert(&arena->freelist, a, prev); + } +} + +// Adds block at location "v" to the free list +// L >= arena->mu +static void AddToFreelist(void *v, LowLevelAlloc::Arena *arena) { + AllocList *f = reinterpret_cast<AllocList *>( + reinterpret_cast<char *>(v) - sizeof (f->header)); + ABSL_RAW_CHECK(f->header.magic == Magic(kMagicAllocated, &f->header), + "bad magic number in AddToFreelist()"); + ABSL_RAW_CHECK(f->header.arena == arena, + "bad arena pointer in AddToFreelist()"); + f->levels = LLA_SkiplistLevels(f->header.size, arena->min_size, + &arena->random); + AllocList *prev[kMaxLevel]; + LLA_SkiplistInsert(&arena->freelist, f, prev); + f->header.magic = Magic(kMagicUnallocated, &f->header); + Coalesce(f); // maybe coalesce with successor + Coalesce(prev[0]); // maybe coalesce with predecessor +} + +// Frees storage allocated by LowLevelAlloc::Alloc(). +// L < arena->mu +void LowLevelAlloc::Free(void *v) { + if (v != nullptr) { + AllocList *f = reinterpret_cast<AllocList *>( + reinterpret_cast<char *>(v) - sizeof (f->header)); + LowLevelAlloc::Arena *arena = f->header.arena; + ArenaLock section(arena); + AddToFreelist(v, arena); + ABSL_RAW_CHECK(arena->allocation_count > 0, "nothing in arena to free"); + arena->allocation_count--; + section.Leave(); + } +} + +// allocates and returns a block of size bytes, to be freed with Free() +// L < arena->mu +static void *DoAllocWithArena(size_t request, LowLevelAlloc::Arena *arena) { + void *result = nullptr; + if (request != 0) { + AllocList *s; // will point to region that satisfies request + ArenaLock section(arena); + // round up with header + size_t req_rnd = RoundUp(CheckedAdd(request, sizeof (s->header)), + arena->round_up); + for (;;) { // loop until we find a suitable region + // find the minimum levels that a block of this size must have + int i = LLA_SkiplistLevels(req_rnd, arena->min_size, nullptr) - 1; + if (i < arena->freelist.levels) { // potential blocks exist + AllocList *before = &arena->freelist; // predecessor of s + while ((s = Next(i, before, arena)) != nullptr && + s->header.size < req_rnd) { + before = s; + } + if (s != nullptr) { // we found a region + break; + } + } + // we unlock before mmap() both because mmap() may call a callback hook, + // and because it may be slow. + arena->mu.Unlock(); + // mmap generous 64K chunks to decrease + // the chances/impact of fragmentation: + size_t new_pages_size = RoundUp(req_rnd, arena->pagesize * 16); + void *new_pages; +#ifdef _WIN32 + new_pages = VirtualAlloc(0, new_pages_size, + MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); + ABSL_RAW_CHECK(new_pages != nullptr, "VirtualAlloc failed"); +#else +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if ((arena->flags & LowLevelAlloc::kAsyncSignalSafe) != 0) { + new_pages = base_internal::DirectMmap(nullptr, new_pages_size, + PROT_WRITE|PROT_READ, MAP_ANONYMOUS|MAP_PRIVATE, -1, 0); + } else { + new_pages = mmap(nullptr, new_pages_size, PROT_WRITE | PROT_READ, + MAP_ANONYMOUS | MAP_PRIVATE, -1, 0); + } +#else + new_pages = mmap(nullptr, new_pages_size, PROT_WRITE | PROT_READ, + MAP_ANONYMOUS | MAP_PRIVATE, -1, 0); +#endif // ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + if (new_pages == MAP_FAILED) { + ABSL_RAW_LOG(FATAL, "mmap error: %d", errno); + } + +#endif // _WIN32 + arena->mu.Lock(); + s = reinterpret_cast<AllocList *>(new_pages); + s->header.size = new_pages_size; + // Pretend the block is allocated; call AddToFreelist() to free it. + s->header.magic = Magic(kMagicAllocated, &s->header); + s->header.arena = arena; + AddToFreelist(&s->levels, arena); // insert new region into free list + } + AllocList *prev[kMaxLevel]; + LLA_SkiplistDelete(&arena->freelist, s, prev); // remove from free list + // s points to the first free region that's big enough + if (CheckedAdd(req_rnd, arena->min_size) <= s->header.size) { + // big enough to split + AllocList *n = reinterpret_cast<AllocList *> + (req_rnd + reinterpret_cast<char *>(s)); + n->header.size = s->header.size - req_rnd; + n->header.magic = Magic(kMagicAllocated, &n->header); + n->header.arena = arena; + s->header.size = req_rnd; + AddToFreelist(&n->levels, arena); + } + s->header.magic = Magic(kMagicAllocated, &s->header); + ABSL_RAW_CHECK(s->header.arena == arena, ""); + arena->allocation_count++; + section.Leave(); + result = &s->levels; + } + ANNOTATE_MEMORY_IS_UNINITIALIZED(result, request); + return result; +} + +void *LowLevelAlloc::Alloc(size_t request) { + void *result = DoAllocWithArena(request, DefaultArena()); + return result; +} + +void *LowLevelAlloc::AllocWithArena(size_t request, Arena *arena) { + ABSL_RAW_CHECK(arena != nullptr, "must pass a valid arena"); + void *result = DoAllocWithArena(request, arena); + return result; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_LOW_LEVEL_ALLOC_MISSING diff --git a/third_party/abseil_cpp/absl/base/internal/low_level_alloc.h b/third_party/abseil_cpp/absl/base/internal/low_level_alloc.h new file mode 100644 index 0000000000..db91951c82 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/low_level_alloc.h @@ -0,0 +1,126 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_LOW_LEVEL_ALLOC_H_ +#define ABSL_BASE_INTERNAL_LOW_LEVEL_ALLOC_H_ + +// A simple thread-safe memory allocator that does not depend on +// mutexes or thread-specific data. It is intended to be used +// sparingly, and only when malloc() would introduce an unwanted +// dependency, such as inside the heap-checker, or the Mutex +// implementation. + +// IWYU pragma: private, include "base/low_level_alloc.h" + +#include <sys/types.h> + +#include <cstdint> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" + +// LowLevelAlloc requires that the platform support low-level +// allocation of virtual memory. Platforms lacking this cannot use +// LowLevelAlloc. +#ifdef ABSL_LOW_LEVEL_ALLOC_MISSING +#error ABSL_LOW_LEVEL_ALLOC_MISSING cannot be directly set +#elif !defined(ABSL_HAVE_MMAP) && !defined(_WIN32) +#define ABSL_LOW_LEVEL_ALLOC_MISSING 1 +#endif + +// Using LowLevelAlloc with kAsyncSignalSafe isn't supported on Windows or +// asm.js / WebAssembly. +// See https://kripken.github.io/emscripten-site/docs/porting/pthreads.html +// for more information. +#ifdef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING +#error ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING cannot be directly set +#elif defined(_WIN32) || defined(__asmjs__) || defined(__wasm__) +#define ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING 1 +#endif + +#include <cstddef> + +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +class LowLevelAlloc { + public: + struct Arena; // an arena from which memory may be allocated + + // Returns a pointer to a block of at least "request" bytes + // that have been newly allocated from the specific arena. + // for Alloc() call the DefaultArena() is used. + // Returns 0 if passed request==0. + // Does not return 0 under other circumstances; it crashes if memory + // is not available. + static void *Alloc(size_t request) ABSL_ATTRIBUTE_SECTION(malloc_hook); + static void *AllocWithArena(size_t request, Arena *arena) + ABSL_ATTRIBUTE_SECTION(malloc_hook); + + // Deallocates a region of memory that was previously allocated with + // Alloc(). Does nothing if passed 0. "s" must be either 0, + // or must have been returned from a call to Alloc() and not yet passed to + // Free() since that call to Alloc(). The space is returned to the arena + // from which it was allocated. + static void Free(void *s) ABSL_ATTRIBUTE_SECTION(malloc_hook); + + // ABSL_ATTRIBUTE_SECTION(malloc_hook) for Alloc* and Free + // are to put all callers of MallocHook::Invoke* in this module + // into special section, + // so that MallocHook::GetCallerStackTrace can function accurately. + + // Create a new arena. + // The root metadata for the new arena is allocated in the + // meta_data_arena; the DefaultArena() can be passed for meta_data_arena. + // These values may be ored into flags: + enum { + // Report calls to Alloc() and Free() via the MallocHook interface. + // Set in the DefaultArena. + kCallMallocHook = 0x0001, + +#ifndef ABSL_LOW_LEVEL_ALLOC_ASYNC_SIGNAL_SAFE_MISSING + // Make calls to Alloc(), Free() be async-signal-safe. Not set in + // DefaultArena(). Not supported on all platforms. + kAsyncSignalSafe = 0x0002, +#endif + }; + // Construct a new arena. The allocation of the underlying metadata honors + // the provided flags. For example, the call NewArena(kAsyncSignalSafe) + // is itself async-signal-safe, as well as generatating an arena that provides + // async-signal-safe Alloc/Free. + static Arena *NewArena(int32_t flags); + + // Destroys an arena allocated by NewArena and returns true, + // provided no allocated blocks remain in the arena. + // If allocated blocks remain in the arena, does nothing and + // returns false. + // It is illegal to attempt to destroy the DefaultArena(). + static bool DeleteArena(Arena *arena); + + // The default arena that always exists. + static Arena *DefaultArena(); + + private: + LowLevelAlloc(); // no instances +}; + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_LOW_LEVEL_ALLOC_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/low_level_alloc_test.cc b/third_party/abseil_cpp/absl/base/internal/low_level_alloc_test.cc new file mode 100644 index 0000000000..2f2eaffa03 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/low_level_alloc_test.cc @@ -0,0 +1,162 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/low_level_alloc.h" + +#include <stdint.h> +#include <stdio.h> +#include <stdlib.h> +#include <thread> // NOLINT(build/c++11) +#include <unordered_map> +#include <utility> + +#include "absl/container/node_hash_map.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { + +// This test doesn't use gtest since it needs to test that everything +// works before main(). +#define TEST_ASSERT(x) \ + if (!(x)) { \ + printf("TEST_ASSERT(%s) FAILED ON LINE %d\n", #x, __LINE__); \ + abort(); \ + } + +// a block of memory obtained from the allocator +struct BlockDesc { + char *ptr; // pointer to memory + int len; // number of bytes + int fill; // filled with data starting with this +}; + +// Check that the pattern placed in the block d +// by RandomizeBlockDesc is still there. +static void CheckBlockDesc(const BlockDesc &d) { + for (int i = 0; i != d.len; i++) { + TEST_ASSERT((d.ptr[i] & 0xff) == ((d.fill + i) & 0xff)); + } +} + +// Fill the block "*d" with a pattern +// starting with a random byte. +static void RandomizeBlockDesc(BlockDesc *d) { + d->fill = rand() & 0xff; + for (int i = 0; i != d->len; i++) { + d->ptr[i] = (d->fill + i) & 0xff; + } +} + +// Use to indicate to the malloc hooks that +// this calls is from LowLevelAlloc. +static bool using_low_level_alloc = false; + +// n times, toss a coin, and based on the outcome +// either allocate a new block or deallocate an old block. +// New blocks are placed in a std::unordered_map with a random key +// and initialized with RandomizeBlockDesc(). +// If keys conflict, the older block is freed. +// Old blocks are always checked with CheckBlockDesc() +// before being freed. At the end of the run, +// all remaining allocated blocks are freed. +// If use_new_arena is true, use a fresh arena, and then delete it. +// If call_malloc_hook is true and user_arena is true, +// allocations and deallocations are reported via the MallocHook +// interface. +static void Test(bool use_new_arena, bool call_malloc_hook, int n) { + typedef absl::node_hash_map<int, BlockDesc> AllocMap; + AllocMap allocated; + AllocMap::iterator it; + BlockDesc block_desc; + int rnd; + LowLevelAlloc::Arena *arena = 0; + if (use_new_arena) { + int32_t flags = call_malloc_hook ? LowLevelAlloc::kCallMallocHook : 0; + arena = LowLevelAlloc::NewArena(flags); + } + for (int i = 0; i != n; i++) { + if (i != 0 && i % 10000 == 0) { + printf("."); + fflush(stdout); + } + + switch (rand() & 1) { // toss a coin + case 0: // coin came up heads: add a block + using_low_level_alloc = true; + block_desc.len = rand() & 0x3fff; + block_desc.ptr = + reinterpret_cast<char *>( + arena == 0 + ? LowLevelAlloc::Alloc(block_desc.len) + : LowLevelAlloc::AllocWithArena(block_desc.len, arena)); + using_low_level_alloc = false; + RandomizeBlockDesc(&block_desc); + rnd = rand(); + it = allocated.find(rnd); + if (it != allocated.end()) { + CheckBlockDesc(it->second); + using_low_level_alloc = true; + LowLevelAlloc::Free(it->second.ptr); + using_low_level_alloc = false; + it->second = block_desc; + } else { + allocated[rnd] = block_desc; + } + break; + case 1: // coin came up tails: remove a block + it = allocated.begin(); + if (it != allocated.end()) { + CheckBlockDesc(it->second); + using_low_level_alloc = true; + LowLevelAlloc::Free(it->second.ptr); + using_low_level_alloc = false; + allocated.erase(it); + } + break; + } + } + // remove all remaining blocks + while ((it = allocated.begin()) != allocated.end()) { + CheckBlockDesc(it->second); + using_low_level_alloc = true; + LowLevelAlloc::Free(it->second.ptr); + using_low_level_alloc = false; + allocated.erase(it); + } + if (use_new_arena) { + TEST_ASSERT(LowLevelAlloc::DeleteArena(arena)); + } +} + +// LowLevelAlloc is designed to be safe to call before main(). +static struct BeforeMain { + BeforeMain() { + Test(false, false, 50000); + Test(true, false, 50000); + Test(true, true, 50000); + } +} before_main; + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +int main(int argc, char *argv[]) { + // The actual test runs in the global constructor of `before_main`. + printf("PASS\n"); + return 0; +} diff --git a/third_party/abseil_cpp/absl/base/internal/low_level_scheduling.h b/third_party/abseil_cpp/absl/base/internal/low_level_scheduling.h new file mode 100644 index 0000000000..961cc981b8 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/low_level_scheduling.h @@ -0,0 +1,107 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Core interfaces and definitions used by by low-level interfaces such as +// SpinLock. + +#ifndef ABSL_BASE_INTERNAL_LOW_LEVEL_SCHEDULING_H_ +#define ABSL_BASE_INTERNAL_LOW_LEVEL_SCHEDULING_H_ + +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/macros.h" + +// The following two declarations exist so SchedulingGuard may friend them with +// the appropriate language linkage. These callbacks allow libc internals, such +// as function level statics, to schedule cooperatively when locking. +extern "C" bool __google_disable_rescheduling(void); +extern "C" void __google_enable_rescheduling(bool disable_result); + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +class SchedulingHelper; // To allow use of SchedulingGuard. +class SpinLock; // To allow use of SchedulingGuard. + +// SchedulingGuard +// Provides guard semantics that may be used to disable cooperative rescheduling +// of the calling thread within specific program blocks. This is used to +// protect resources (e.g. low-level SpinLocks or Domain code) that cooperative +// scheduling depends on. +// +// Domain implementations capable of rescheduling in reaction to involuntary +// kernel thread actions (e.g blocking due to a pagefault or syscall) must +// guarantee that an annotated thread is not allowed to (cooperatively) +// reschedule until the annotated region is complete. +// +// It is an error to attempt to use a cooperatively scheduled resource (e.g. +// Mutex) within a rescheduling-disabled region. +// +// All methods are async-signal safe. +class SchedulingGuard { + public: + // Returns true iff the calling thread may be cooperatively rescheduled. + static bool ReschedulingIsAllowed(); + + private: + // Disable cooperative rescheduling of the calling thread. It may still + // initiate scheduling operations (e.g. wake-ups), however, it may not itself + // reschedule. Nestable. The returned result is opaque, clients should not + // attempt to interpret it. + // REQUIRES: Result must be passed to a pairing EnableScheduling(). + static bool DisableRescheduling(); + + // Marks the end of a rescheduling disabled region, previously started by + // DisableRescheduling(). + // REQUIRES: Pairs with innermost call (and result) of DisableRescheduling(). + static void EnableRescheduling(bool disable_result); + + // A scoped helper for {Disable, Enable}Rescheduling(). + // REQUIRES: destructor must run in same thread as constructor. + struct ScopedDisable { + ScopedDisable() { disabled = SchedulingGuard::DisableRescheduling(); } + ~ScopedDisable() { SchedulingGuard::EnableRescheduling(disabled); } + + bool disabled; + }; + + // Access to SchedulingGuard is explicitly white-listed. + friend class SchedulingHelper; + friend class SpinLock; + + SchedulingGuard(const SchedulingGuard&) = delete; + SchedulingGuard& operator=(const SchedulingGuard&) = delete; +}; + +//------------------------------------------------------------------------------ +// End of public interfaces. +//------------------------------------------------------------------------------ + +inline bool SchedulingGuard::ReschedulingIsAllowed() { + return false; +} + +inline bool SchedulingGuard::DisableRescheduling() { + return false; +} + +inline void SchedulingGuard::EnableRescheduling(bool /* disable_result */) { + return; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_LOW_LEVEL_SCHEDULING_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/per_thread_tls.h b/third_party/abseil_cpp/absl/base/internal/per_thread_tls.h new file mode 100644 index 0000000000..cf5e97a047 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/per_thread_tls.h @@ -0,0 +1,52 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_PER_THREAD_TLS_H_ +#define ABSL_BASE_INTERNAL_PER_THREAD_TLS_H_ + +// This header defines two macros: +// +// If the platform supports thread-local storage: +// +// * ABSL_PER_THREAD_TLS_KEYWORD is the C keyword needed to declare a +// thread-local variable +// * ABSL_PER_THREAD_TLS is 1 +// +// Otherwise: +// +// * ABSL_PER_THREAD_TLS_KEYWORD is empty +// * ABSL_PER_THREAD_TLS is 0 +// +// Microsoft C supports thread-local storage. +// GCC supports it if the appropriate version of glibc is available, +// which the programmer can indicate by defining ABSL_HAVE_TLS + +#include "absl/base/port.h" // For ABSL_HAVE_TLS + +#if defined(ABSL_PER_THREAD_TLS) +#error ABSL_PER_THREAD_TLS cannot be directly set +#elif defined(ABSL_PER_THREAD_TLS_KEYWORD) +#error ABSL_PER_THREAD_TLS_KEYWORD cannot be directly set +#elif defined(ABSL_HAVE_TLS) +#define ABSL_PER_THREAD_TLS_KEYWORD __thread +#define ABSL_PER_THREAD_TLS 1 +#elif defined(_MSC_VER) +#define ABSL_PER_THREAD_TLS_KEYWORD __declspec(thread) +#define ABSL_PER_THREAD_TLS 1 +#else +#define ABSL_PER_THREAD_TLS_KEYWORD +#define ABSL_PER_THREAD_TLS 0 +#endif + +#endif // ABSL_BASE_INTERNAL_PER_THREAD_TLS_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/periodic_sampler.cc b/third_party/abseil_cpp/absl/base/internal/periodic_sampler.cc new file mode 100644 index 0000000000..520dabbaa0 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/periodic_sampler.cc @@ -0,0 +1,53 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/periodic_sampler.h" + +#include <atomic> + +#include "absl/base/internal/exponential_biased.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +int64_t PeriodicSamplerBase::GetExponentialBiased(int period) noexcept { + return rng_.GetStride(period); +} + +bool PeriodicSamplerBase::SubtleConfirmSample() noexcept { + int current_period = period(); + + // Deal with period case 0 (always off) and 1 (always on) + if (ABSL_PREDICT_FALSE(current_period < 2)) { + stride_ = 0; + return current_period == 1; + } + + // Check if this is the first call to Sample() + if (ABSL_PREDICT_FALSE(stride_ == 1)) { + stride_ = static_cast<uint64_t>(-GetExponentialBiased(current_period)); + if (static_cast<int64_t>(stride_) < -1) { + ++stride_; + return false; + } + } + + stride_ = static_cast<uint64_t>(-GetExponentialBiased(current_period)); + return true; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/periodic_sampler.h b/third_party/abseil_cpp/absl/base/internal/periodic_sampler.h new file mode 100644 index 0000000000..f8a86796b1 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/periodic_sampler.h @@ -0,0 +1,211 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_PERIODIC_SAMPLER_H_ +#define ABSL_BASE_INTERNAL_PERIODIC_SAMPLER_H_ + +#include <stdint.h> + +#include <atomic> + +#include "absl/base/internal/exponential_biased.h" +#include "absl/base/optimization.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// PeriodicSamplerBase provides the basic period sampler implementation. +// +// This is the base class for the templated PeriodicSampler class, which holds +// a global std::atomic value identified by a user defined tag, such that +// each specific PeriodSampler implementation holds its own global period. +// +// PeriodicSamplerBase is thread-compatible except where stated otherwise. +class PeriodicSamplerBase { + public: + // PeriodicSamplerBase is trivial / copyable / movable / destructible. + PeriodicSamplerBase() = default; + PeriodicSamplerBase(PeriodicSamplerBase&&) = default; + PeriodicSamplerBase(const PeriodicSamplerBase&) = default; + + // Returns true roughly once every `period` calls. This is established by a + // randomly picked `stride` that is counted down on each call to `Sample`. + // This stride is picked such that the probability of `Sample()` returning + // true is 1 in `period`. + inline bool Sample() noexcept; + + // The below methods are intended for optimized use cases where the + // size of the inlined fast path code is highly important. Applications + // should use the `Sample()` method unless they have proof that their + // specific use case requires the optimizations offered by these methods. + // + // An example of such a use case is SwissTable sampling. All sampling checks + // are in inlined SwissTable methods, and the number of call sites is huge. + // In this case, the inlined code size added to each translation unit calling + // SwissTable methods is non-trivial. + // + // The `SubtleMaybeSample()` function spuriously returns true even if the + // function should not be sampled, applications MUST match each call to + // 'SubtleMaybeSample()' returning true with a `SubtleConfirmSample()` call, + // and use the result of the latter as the sampling decision. + // In other words: the code should logically be equivalent to: + // + // if (SubtleMaybeSample() && SubtleConfirmSample()) { + // // Sample this call + // } + // + // In the 'inline-size' optimized case, the `SubtleConfirmSample()` call can + // be placed out of line, for example, the typical use case looks as follows: + // + // // --- frobber.h ----------- + // void FrobberSampled(); + // + // inline void FrobberImpl() { + // // ... + // } + // + // inline void Frobber() { + // if (ABSL_PREDICT_FALSE(sampler.SubtleMaybeSample())) { + // FrobberSampled(); + // } else { + // FrobberImpl(); + // } + // } + // + // // --- frobber.cc ----------- + // void FrobberSampled() { + // if (!sampler.SubtleConfirmSample())) { + // // Spurious false positive + // FrobberImpl(); + // return; + // } + // + // // Sampled execution + // // ... + // } + inline bool SubtleMaybeSample() noexcept; + bool SubtleConfirmSample() noexcept; + + protected: + // We explicitly don't use a virtual destructor as this class is never + // virtually destroyed, and it keeps the class trivial, which avoids TLS + // prologue and epilogue code for our TLS instances. + ~PeriodicSamplerBase() = default; + + // Returns the next stride for our sampler. + // This function is virtual for testing purposes only. + virtual int64_t GetExponentialBiased(int period) noexcept; + + private: + // Returns the current period of this sampler. Thread-safe. + virtual int period() const noexcept = 0; + + // Keep and decrement stride_ as an unsigned integer, but compare the value + // to zero casted as a signed int. clang and msvc do not create optimum code + // if we use signed for the combined decrement and sign comparison. + // + // Below 3 alternative options, all compiles generate the best code + // using the unsigned increment <---> signed int comparison option. + // + // Option 1: + // int64_t stride_; + // if (ABSL_PREDICT_TRUE(++stride_ < 0)) { ... } + // + // GCC x64 (OK) : https://gcc.godbolt.org/z/R5MzzA + // GCC ppc (OK) : https://gcc.godbolt.org/z/z7NZAt + // Clang x64 (BAD): https://gcc.godbolt.org/z/t4gPsd + // ICC x64 (OK) : https://gcc.godbolt.org/z/rE6s8W + // MSVC x64 (OK) : https://gcc.godbolt.org/z/ARMXqS + // + // Option 2: + // int64_t stride_ = 0; + // if (ABSL_PREDICT_TRUE(--stride_ >= 0)) { ... } + // + // GCC x64 (OK) : https://gcc.godbolt.org/z/jSQxYK + // GCC ppc (OK) : https://gcc.godbolt.org/z/VJdYaA + // Clang x64 (BAD): https://gcc.godbolt.org/z/Xm4NjX + // ICC x64 (OK) : https://gcc.godbolt.org/z/4snaFd + // MSVC x64 (BAD): https://gcc.godbolt.org/z/BgnEKE + // + // Option 3: + // uint64_t stride_; + // if (ABSL_PREDICT_TRUE(static_cast<int64_t>(++stride_) < 0)) { ... } + // + // GCC x64 (OK) : https://gcc.godbolt.org/z/bFbfPy + // GCC ppc (OK) : https://gcc.godbolt.org/z/S9KkUE + // Clang x64 (OK) : https://gcc.godbolt.org/z/UYzRb4 + // ICC x64 (OK) : https://gcc.godbolt.org/z/ptTNfD + // MSVC x64 (OK) : https://gcc.godbolt.org/z/76j4-5 + uint64_t stride_ = 0; + ExponentialBiased rng_; +}; + +inline bool PeriodicSamplerBase::SubtleMaybeSample() noexcept { + // See comments on `stride_` for the unsigned increment / signed compare. + if (ABSL_PREDICT_TRUE(static_cast<int64_t>(++stride_) < 0)) { + return false; + } + return true; +} + +inline bool PeriodicSamplerBase::Sample() noexcept { + return ABSL_PREDICT_FALSE(SubtleMaybeSample()) ? SubtleConfirmSample() + : false; +} + +// PeriodicSampler is a concreted periodic sampler implementation. +// The user provided Tag identifies the implementation, and is required to +// isolate the global state of this instance from other instances. +// +// Typical use case: +// +// struct HashTablezTag {}; +// thread_local PeriodicSampler sampler; +// +// void HashTableSamplingLogic(...) { +// if (sampler.Sample()) { +// HashTableSlowSamplePath(...); +// } +// } +// +template <typename Tag, int default_period = 0> +class PeriodicSampler final : public PeriodicSamplerBase { + public: + ~PeriodicSampler() = default; + + int period() const noexcept final { + return period_.load(std::memory_order_relaxed); + } + + // Sets the global period for this sampler. Thread-safe. + // Setting a period of 0 disables the sampler, i.e., every call to Sample() + // will return false. Setting a period of 1 puts the sampler in 'always on' + // mode, i.e., every call to Sample() returns true. + static void SetGlobalPeriod(int period) { + period_.store(period, std::memory_order_relaxed); + } + + private: + static std::atomic<int> period_; +}; + +template <typename Tag, int default_period> +std::atomic<int> PeriodicSampler<Tag, default_period>::period_(default_period); + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_PERIODIC_SAMPLER_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/periodic_sampler_benchmark.cc b/third_party/abseil_cpp/absl/base/internal/periodic_sampler_benchmark.cc new file mode 100644 index 0000000000..5ad469ce79 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/periodic_sampler_benchmark.cc @@ -0,0 +1,79 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "benchmark/benchmark.h" +#include "absl/base/internal/periodic_sampler.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { + +template <typename Sampler> +void BM_Sample(Sampler* sampler, benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(sampler); + benchmark::DoNotOptimize(sampler->Sample()); + } +} + +template <typename Sampler> +void BM_SampleMinunumInlined(Sampler* sampler, benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(sampler); + if (ABSL_PREDICT_FALSE(sampler->SubtleMaybeSample())) { + benchmark::DoNotOptimize(sampler->SubtleConfirmSample()); + } + } +} + +void BM_PeriodicSampler_TinySample(benchmark::State& state) { + struct Tag {}; + PeriodicSampler<Tag, 10> sampler; + BM_Sample(&sampler, state); +} +BENCHMARK(BM_PeriodicSampler_TinySample); + +void BM_PeriodicSampler_ShortSample(benchmark::State& state) { + struct Tag {}; + PeriodicSampler<Tag, 1024> sampler; + BM_Sample(&sampler, state); +} +BENCHMARK(BM_PeriodicSampler_ShortSample); + +void BM_PeriodicSampler_LongSample(benchmark::State& state) { + struct Tag {}; + PeriodicSampler<Tag, 1024 * 1024> sampler; + BM_Sample(&sampler, state); +} +BENCHMARK(BM_PeriodicSampler_LongSample); + +void BM_PeriodicSampler_LongSampleMinunumInlined(benchmark::State& state) { + struct Tag {}; + PeriodicSampler<Tag, 1024 * 1024> sampler; + BM_SampleMinunumInlined(&sampler, state); +} +BENCHMARK(BM_PeriodicSampler_LongSampleMinunumInlined); + +void BM_PeriodicSampler_Disabled(benchmark::State& state) { + struct Tag {}; + PeriodicSampler<Tag, 0> sampler; + BM_Sample(&sampler, state); +} +BENCHMARK(BM_PeriodicSampler_Disabled); + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/periodic_sampler_test.cc b/third_party/abseil_cpp/absl/base/internal/periodic_sampler_test.cc new file mode 100644 index 0000000000..3b301e37ab --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/periodic_sampler_test.cc @@ -0,0 +1,177 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/periodic_sampler.h" + +#include <thread> // NOLINT(build/c++11) + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/macros.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { + +using testing::Eq; +using testing::Return; +using testing::StrictMock; + +class MockPeriodicSampler : public PeriodicSamplerBase { + public: + virtual ~MockPeriodicSampler() = default; + + MOCK_METHOD(int, period, (), (const, noexcept)); + MOCK_METHOD(int64_t, GetExponentialBiased, (int), (noexcept)); +}; + +TEST(PeriodicSamplerBaseTest, Sample) { + StrictMock<MockPeriodicSampler> sampler; + + EXPECT_CALL(sampler, period()).Times(3).WillRepeatedly(Return(16)); + EXPECT_CALL(sampler, GetExponentialBiased(16)) + .WillOnce(Return(2)) + .WillOnce(Return(3)) + .WillOnce(Return(4)); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_TRUE(sampler.Sample()); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); + EXPECT_TRUE(sampler.Sample()); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); +} + +TEST(PeriodicSamplerBaseTest, ImmediatelySample) { + StrictMock<MockPeriodicSampler> sampler; + + EXPECT_CALL(sampler, period()).Times(2).WillRepeatedly(Return(16)); + EXPECT_CALL(sampler, GetExponentialBiased(16)) + .WillOnce(Return(1)) + .WillOnce(Return(2)) + .WillOnce(Return(3)); + + EXPECT_TRUE(sampler.Sample()); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_TRUE(sampler.Sample()); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); +} + +TEST(PeriodicSamplerBaseTest, Disabled) { + StrictMock<MockPeriodicSampler> sampler; + + EXPECT_CALL(sampler, period()).Times(3).WillRepeatedly(Return(0)); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); +} + +TEST(PeriodicSamplerBaseTest, AlwaysOn) { + StrictMock<MockPeriodicSampler> sampler; + + EXPECT_CALL(sampler, period()).Times(3).WillRepeatedly(Return(1)); + + EXPECT_TRUE(sampler.Sample()); + EXPECT_TRUE(sampler.Sample()); + EXPECT_TRUE(sampler.Sample()); +} + +TEST(PeriodicSamplerBaseTest, Disable) { + StrictMock<MockPeriodicSampler> sampler; + + EXPECT_CALL(sampler, period()).WillOnce(Return(16)); + EXPECT_CALL(sampler, GetExponentialBiased(16)).WillOnce(Return(3)); + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); + + EXPECT_CALL(sampler, period()).Times(2).WillRepeatedly(Return(0)); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); +} + +TEST(PeriodicSamplerBaseTest, Enable) { + StrictMock<MockPeriodicSampler> sampler; + + EXPECT_CALL(sampler, period()).WillOnce(Return(0)); + EXPECT_FALSE(sampler.Sample()); + + EXPECT_CALL(sampler, period()).Times(2).WillRepeatedly(Return(16)); + EXPECT_CALL(sampler, GetExponentialBiased(16)) + .Times(2) + .WillRepeatedly(Return(3)); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); + EXPECT_TRUE(sampler.Sample()); + + EXPECT_FALSE(sampler.Sample()); + EXPECT_FALSE(sampler.Sample()); +} + +TEST(PeriodicSamplerTest, ConstructConstInit) { + struct Tag {}; + ABSL_CONST_INIT static PeriodicSampler<Tag> sampler; + (void)sampler; +} + +TEST(PeriodicSamplerTest, DefaultPeriod0) { + struct Tag {}; + PeriodicSampler<Tag> sampler; + EXPECT_THAT(sampler.period(), Eq(0)); +} + +TEST(PeriodicSamplerTest, DefaultPeriod) { + struct Tag {}; + PeriodicSampler<Tag, 100> sampler; + EXPECT_THAT(sampler.period(), Eq(100)); +} + +TEST(PeriodicSamplerTest, SetGlobalPeriod) { + struct Tag1 {}; + struct Tag2 {}; + PeriodicSampler<Tag1, 25> sampler1; + PeriodicSampler<Tag2, 50> sampler2; + + EXPECT_THAT(sampler1.period(), Eq(25)); + EXPECT_THAT(sampler2.period(), Eq(50)); + + std::thread thread([] { + PeriodicSampler<Tag1, 25> sampler1; + PeriodicSampler<Tag2, 50> sampler2; + EXPECT_THAT(sampler1.period(), Eq(25)); + EXPECT_THAT(sampler2.period(), Eq(50)); + sampler1.SetGlobalPeriod(10); + sampler2.SetGlobalPeriod(20); + }); + thread.join(); + + EXPECT_THAT(sampler1.period(), Eq(10)); + EXPECT_THAT(sampler2.period(), Eq(20)); +} + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/pretty_function.h b/third_party/abseil_cpp/absl/base/internal/pretty_function.h new file mode 100644 index 0000000000..35d51676dc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/pretty_function.h @@ -0,0 +1,33 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_PRETTY_FUNCTION_H_ +#define ABSL_BASE_INTERNAL_PRETTY_FUNCTION_H_ + +// ABSL_PRETTY_FUNCTION +// +// In C++11, __func__ gives the undecorated name of the current function. That +// is, "main", not "int main()". Various compilers give extra macros to get the +// decorated function name, including return type and arguments, to +// differentiate between overload sets. ABSL_PRETTY_FUNCTION is a portable +// version of these macros which forwards to the correct macro on each compiler. +#if defined(_MSC_VER) +#define ABSL_PRETTY_FUNCTION __FUNCSIG__ +#elif defined(__GNUC__) +#define ABSL_PRETTY_FUNCTION __PRETTY_FUNCTION__ +#else +#error "Unsupported compiler" +#endif + +#endif // ABSL_BASE_INTERNAL_PRETTY_FUNCTION_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/raw_logging.cc b/third_party/abseil_cpp/absl/base/internal/raw_logging.cc new file mode 100644 index 0000000000..40cea55061 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/raw_logging.cc @@ -0,0 +1,240 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/raw_logging.h" + +#include <stddef.h> +#include <cstdarg> +#include <cstdio> +#include <cstdlib> +#include <cstring> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/internal/atomic_hook.h" +#include "absl/base/log_severity.h" + +// We know how to perform low-level writes to stderr in POSIX and Windows. For +// these platforms, we define the token ABSL_LOW_LEVEL_WRITE_SUPPORTED. +// Much of raw_logging.cc becomes a no-op when we can't output messages, +// although a FATAL ABSL_RAW_LOG message will still abort the process. + +// ABSL_HAVE_POSIX_WRITE is defined when the platform provides posix write() +// (as from unistd.h) +// +// This preprocessor token is also defined in raw_io.cc. If you need to copy +// this, consider moving both to config.h instead. +#if defined(__linux__) || defined(__APPLE__) || defined(__FreeBSD__) || \ + defined(__Fuchsia__) || defined(__native_client__) || \ + defined(__EMSCRIPTEN__) || defined(__ASYLO__) + +#include <unistd.h> + +#define ABSL_HAVE_POSIX_WRITE 1 +#define ABSL_LOW_LEVEL_WRITE_SUPPORTED 1 +#else +#undef ABSL_HAVE_POSIX_WRITE +#endif + +// ABSL_HAVE_SYSCALL_WRITE is defined when the platform provides the syscall +// syscall(SYS_write, /*int*/ fd, /*char* */ buf, /*size_t*/ len); +// for low level operations that want to avoid libc. +#if (defined(__linux__) || defined(__FreeBSD__)) && !defined(__ANDROID__) +#include <sys/syscall.h> +#define ABSL_HAVE_SYSCALL_WRITE 1 +#define ABSL_LOW_LEVEL_WRITE_SUPPORTED 1 +#else +#undef ABSL_HAVE_SYSCALL_WRITE +#endif + +#ifdef _WIN32 +#include <io.h> + +#define ABSL_HAVE_RAW_IO 1 +#define ABSL_LOW_LEVEL_WRITE_SUPPORTED 1 +#else +#undef ABSL_HAVE_RAW_IO +#endif + +// TODO(gfalcon): We want raw-logging to work on as many platforms as possible. +// Explicitly #error out when not ABSL_LOW_LEVEL_WRITE_SUPPORTED, except for a +// whitelisted set of platforms for which we expect not to be able to raw log. + +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES static absl::base_internal::AtomicHook< + absl::raw_logging_internal::LogPrefixHook> + log_prefix_hook; +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES static absl::base_internal::AtomicHook< + absl::raw_logging_internal::AbortHook> + abort_hook; + +#ifdef ABSL_LOW_LEVEL_WRITE_SUPPORTED +static const char kTruncated[] = " ... (message truncated)\n"; + +// sprintf the format to the buffer, adjusting *buf and *size to reflect the +// consumed bytes, and return whether the message fit without truncation. If +// truncation occurred, if possible leave room in the buffer for the message +// kTruncated[]. +inline static bool VADoRawLog(char** buf, int* size, const char* format, + va_list ap) ABSL_PRINTF_ATTRIBUTE(3, 0); +inline static bool VADoRawLog(char** buf, int* size, + const char* format, va_list ap) { + int n = vsnprintf(*buf, *size, format, ap); + bool result = true; + if (n < 0 || n > *size) { + result = false; + if (static_cast<size_t>(*size) > sizeof(kTruncated)) { + n = *size - sizeof(kTruncated); // room for truncation message + } else { + n = 0; // no room for truncation message + } + } + *size -= n; + *buf += n; + return result; +} +#endif // ABSL_LOW_LEVEL_WRITE_SUPPORTED + +static constexpr int kLogBufSize = 3000; + +namespace { + +// CAVEAT: vsnprintf called from *DoRawLog below has some (exotic) code paths +// that invoke malloc() and getenv() that might acquire some locks. + +// Helper for RawLog below. +// *DoRawLog writes to *buf of *size and move them past the written portion. +// It returns true iff there was no overflow or error. +bool DoRawLog(char** buf, int* size, const char* format, ...) + ABSL_PRINTF_ATTRIBUTE(3, 4); +bool DoRawLog(char** buf, int* size, const char* format, ...) { + va_list ap; + va_start(ap, format); + int n = vsnprintf(*buf, *size, format, ap); + va_end(ap); + if (n < 0 || n > *size) return false; + *size -= n; + *buf += n; + return true; +} + +void RawLogVA(absl::LogSeverity severity, const char* file, int line, + const char* format, va_list ap) ABSL_PRINTF_ATTRIBUTE(4, 0); +void RawLogVA(absl::LogSeverity severity, const char* file, int line, + const char* format, va_list ap) { + char buffer[kLogBufSize]; + char* buf = buffer; + int size = sizeof(buffer); +#ifdef ABSL_LOW_LEVEL_WRITE_SUPPORTED + bool enabled = true; +#else + bool enabled = false; +#endif + +#ifdef ABSL_MIN_LOG_LEVEL + if (severity < static_cast<absl::LogSeverity>(ABSL_MIN_LOG_LEVEL) && + severity < absl::LogSeverity::kFatal) { + enabled = false; + } +#endif + + auto log_prefix_hook_ptr = log_prefix_hook.Load(); + if (log_prefix_hook_ptr) { + enabled = log_prefix_hook_ptr(severity, file, line, &buf, &size); + } else { + if (enabled) { + DoRawLog(&buf, &size, "[%s : %d] RAW: ", file, line); + } + } + const char* const prefix_end = buf; + +#ifdef ABSL_LOW_LEVEL_WRITE_SUPPORTED + if (enabled) { + bool no_chop = VADoRawLog(&buf, &size, format, ap); + if (no_chop) { + DoRawLog(&buf, &size, "\n"); + } else { + DoRawLog(&buf, &size, "%s", kTruncated); + } + absl::raw_logging_internal::SafeWriteToStderr(buffer, strlen(buffer)); + } +#else + static_cast<void>(format); + static_cast<void>(ap); +#endif + + // Abort the process after logging a FATAL message, even if the output itself + // was suppressed. + if (severity == absl::LogSeverity::kFatal) { + abort_hook(file, line, buffer, prefix_end, buffer + kLogBufSize); + abort(); + } +} + +} // namespace + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace raw_logging_internal { +void SafeWriteToStderr(const char *s, size_t len) { +#if defined(ABSL_HAVE_SYSCALL_WRITE) + syscall(SYS_write, STDERR_FILENO, s, len); +#elif defined(ABSL_HAVE_POSIX_WRITE) + write(STDERR_FILENO, s, len); +#elif defined(ABSL_HAVE_RAW_IO) + _write(/* stderr */ 2, s, len); +#else + // stderr logging unsupported on this platform + (void) s; + (void) len; +#endif +} + +void RawLog(absl::LogSeverity severity, const char* file, int line, + const char* format, ...) ABSL_PRINTF_ATTRIBUTE(4, 5); +void RawLog(absl::LogSeverity severity, const char* file, int line, + const char* format, ...) { + va_list ap; + va_start(ap, format); + RawLogVA(severity, file, line, format, ap); + va_end(ap); +} + +// Non-formatting version of RawLog(). +// +// TODO(gfalcon): When string_view no longer depends on base, change this +// interface to take its message as a string_view instead. +static void DefaultInternalLog(absl::LogSeverity severity, const char* file, + int line, const std::string& message) { + RawLog(severity, file, line, "%s", message.c_str()); +} + +bool RawLoggingFullySupported() { +#ifdef ABSL_LOW_LEVEL_WRITE_SUPPORTED + return true; +#else // !ABSL_LOW_LEVEL_WRITE_SUPPORTED + return false; +#endif // !ABSL_LOW_LEVEL_WRITE_SUPPORTED +} + +ABSL_DLL ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES + absl::base_internal::AtomicHook<InternalLogFunction> + internal_log_function(DefaultInternalLog); + +void RegisterInternalLogFunction(InternalLogFunction func) { + internal_log_function.Store(func); +} + +} // namespace raw_logging_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/raw_logging.h b/third_party/abseil_cpp/absl/base/internal/raw_logging.h new file mode 100644 index 0000000000..418d6c856f --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/raw_logging.h @@ -0,0 +1,183 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Thread-safe logging routines that do not allocate any memory or +// acquire any locks, and can therefore be used by low-level memory +// allocation, synchronization, and signal-handling code. + +#ifndef ABSL_BASE_INTERNAL_RAW_LOGGING_H_ +#define ABSL_BASE_INTERNAL_RAW_LOGGING_H_ + +#include <string> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/internal/atomic_hook.h" +#include "absl/base/log_severity.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" + +// This is similar to LOG(severity) << format..., but +// * it is to be used ONLY by low-level modules that can't use normal LOG() +// * it is designed to be a low-level logger that does not allocate any +// memory and does not need any locks, hence: +// * it logs straight and ONLY to STDERR w/o buffering +// * it uses an explicit printf-format and arguments list +// * it will silently chop off really long message strings +// Usage example: +// ABSL_RAW_LOG(ERROR, "Failed foo with %i: %s", status, error); +// This will print an almost standard log line like this to stderr only: +// E0821 211317 file.cc:123] RAW: Failed foo with 22: bad_file + +#define ABSL_RAW_LOG(severity, ...) \ + do { \ + constexpr const char* absl_raw_logging_internal_basename = \ + ::absl::raw_logging_internal::Basename(__FILE__, \ + sizeof(__FILE__) - 1); \ + ::absl::raw_logging_internal::RawLog(ABSL_RAW_LOGGING_INTERNAL_##severity, \ + absl_raw_logging_internal_basename, \ + __LINE__, __VA_ARGS__); \ + } while (0) + +// Similar to CHECK(condition) << message, but for low-level modules: +// we use only ABSL_RAW_LOG that does not allocate memory. +// We do not want to provide args list here to encourage this usage: +// if (!cond) ABSL_RAW_LOG(FATAL, "foo ...", hard_to_compute_args); +// so that the args are not computed when not needed. +#define ABSL_RAW_CHECK(condition, message) \ + do { \ + if (ABSL_PREDICT_FALSE(!(condition))) { \ + ABSL_RAW_LOG(FATAL, "Check %s failed: %s", #condition, message); \ + } \ + } while (0) + +// ABSL_INTERNAL_LOG and ABSL_INTERNAL_CHECK work like the RAW variants above, +// except that if the richer log library is linked into the binary, we dispatch +// to that instead. This is potentially useful for internal logging and +// assertions, where we are using RAW_LOG neither for its async-signal-safety +// nor for its non-allocating nature, but rather because raw logging has very +// few other dependencies. +// +// The API is a subset of the above: each macro only takes two arguments. Use +// StrCat if you need to build a richer message. +#define ABSL_INTERNAL_LOG(severity, message) \ + do { \ + ::absl::raw_logging_internal::internal_log_function( \ + ABSL_RAW_LOGGING_INTERNAL_##severity, __FILE__, __LINE__, message); \ + } while (0) + +#define ABSL_INTERNAL_CHECK(condition, message) \ + do { \ + if (ABSL_PREDICT_FALSE(!(condition))) { \ + std::string death_message = "Check " #condition " failed: "; \ + death_message += std::string(message); \ + ABSL_INTERNAL_LOG(FATAL, death_message); \ + } \ + } while (0) + +#define ABSL_RAW_LOGGING_INTERNAL_INFO ::absl::LogSeverity::kInfo +#define ABSL_RAW_LOGGING_INTERNAL_WARNING ::absl::LogSeverity::kWarning +#define ABSL_RAW_LOGGING_INTERNAL_ERROR ::absl::LogSeverity::kError +#define ABSL_RAW_LOGGING_INTERNAL_FATAL ::absl::LogSeverity::kFatal +#define ABSL_RAW_LOGGING_INTERNAL_LEVEL(severity) \ + ::absl::NormalizeLogSeverity(severity) + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace raw_logging_internal { + +// Helper function to implement ABSL_RAW_LOG +// Logs format... at "severity" level, reporting it +// as called from file:line. +// This does not allocate memory or acquire locks. +void RawLog(absl::LogSeverity severity, const char* file, int line, + const char* format, ...) ABSL_PRINTF_ATTRIBUTE(4, 5); + +// Writes the provided buffer directly to stderr, in a safe, low-level manner. +// +// In POSIX this means calling write(), which is async-signal safe and does +// not malloc. If the platform supports the SYS_write syscall, we invoke that +// directly to side-step any libc interception. +void SafeWriteToStderr(const char *s, size_t len); + +// compile-time function to get the "base" filename, that is, the part of +// a filename after the last "/" or "\" path separator. The search starts at +// the end of the string; the second parameter is the length of the string. +constexpr const char* Basename(const char* fname, int offset) { + return offset == 0 || fname[offset - 1] == '/' || fname[offset - 1] == '\\' + ? fname + offset + : Basename(fname, offset - 1); +} + +// For testing only. +// Returns true if raw logging is fully supported. When it is not +// fully supported, no messages will be emitted, but a log at FATAL +// severity will cause an abort. +// +// TODO(gfalcon): Come up with a better name for this method. +bool RawLoggingFullySupported(); + +// Function type for a raw_logging customization hook for suppressing messages +// by severity, and for writing custom prefixes on non-suppressed messages. +// +// The installed hook is called for every raw log invocation. The message will +// be logged to stderr only if the hook returns true. FATAL errors will cause +// the process to abort, even if writing to stderr is suppressed. The hook is +// also provided with an output buffer, where it can write a custom log message +// prefix. +// +// The raw_logging system does not allocate memory or grab locks. User-provided +// hooks must avoid these operations, and must not throw exceptions. +// +// 'severity' is the severity level of the message being written. +// 'file' and 'line' are the file and line number where the ABSL_RAW_LOG macro +// was located. +// 'buffer' and 'buf_size' are pointers to the buffer and buffer size. If the +// hook writes a prefix, it must increment *buffer and decrement *buf_size +// accordingly. +using LogPrefixHook = bool (*)(absl::LogSeverity severity, const char* file, + int line, char** buffer, int* buf_size); + +// Function type for a raw_logging customization hook called to abort a process +// when a FATAL message is logged. If the provided AbortHook() returns, the +// logging system will call abort(). +// +// 'file' and 'line' are the file and line number where the ABSL_RAW_LOG macro +// was located. +// The NUL-terminated logged message lives in the buffer between 'buf_start' +// and 'buf_end'. 'prefix_end' points to the first non-prefix character of the +// buffer (as written by the LogPrefixHook.) +using AbortHook = void (*)(const char* file, int line, const char* buf_start, + const char* prefix_end, const char* buf_end); + +// Internal logging function for ABSL_INTERNAL_LOG to dispatch to. +// +// TODO(gfalcon): When string_view no longer depends on base, change this +// interface to take its message as a string_view instead. +using InternalLogFunction = void (*)(absl::LogSeverity severity, + const char* file, int line, + const std::string& message); + +ABSL_DLL ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES extern base_internal::AtomicHook< + InternalLogFunction> + internal_log_function; + +void RegisterInternalLogFunction(InternalLogFunction func); + +} // namespace raw_logging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_RAW_LOGGING_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/scheduling_mode.h b/third_party/abseil_cpp/absl/base/internal/scheduling_mode.h new file mode 100644 index 0000000000..8be5ab6dd3 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/scheduling_mode.h @@ -0,0 +1,58 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Core interfaces and definitions used by by low-level interfaces such as +// SpinLock. + +#ifndef ABSL_BASE_INTERNAL_SCHEDULING_MODE_H_ +#define ABSL_BASE_INTERNAL_SCHEDULING_MODE_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// Used to describe how a thread may be scheduled. Typically associated with +// the declaration of a resource supporting synchronized access. +// +// SCHEDULE_COOPERATIVE_AND_KERNEL: +// Specifies that when waiting, a cooperative thread (e.g. a Fiber) may +// reschedule (using base::scheduling semantics); allowing other cooperative +// threads to proceed. +// +// SCHEDULE_KERNEL_ONLY: (Also described as "non-cooperative") +// Specifies that no cooperative scheduling semantics may be used, even if the +// current thread is itself cooperatively scheduled. This means that +// cooperative threads will NOT allow other cooperative threads to execute in +// their place while waiting for a resource of this type. Host operating system +// semantics (e.g. a futex) may still be used. +// +// When optional, clients should strongly prefer SCHEDULE_COOPERATIVE_AND_KERNEL +// by default. SCHEDULE_KERNEL_ONLY should only be used for resources on which +// base::scheduling (e.g. the implementation of a Scheduler) may depend. +// +// NOTE: Cooperative resources may not be nested below non-cooperative ones. +// This means that it is invalid to to acquire a SCHEDULE_COOPERATIVE_AND_KERNEL +// resource if a SCHEDULE_KERNEL_ONLY resource is already held. +enum SchedulingMode { + SCHEDULE_KERNEL_ONLY = 0, // Allow scheduling only the host OS. + SCHEDULE_COOPERATIVE_AND_KERNEL, // Also allow cooperative scheduling. +}; + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_SCHEDULING_MODE_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/scoped_set_env.cc b/third_party/abseil_cpp/absl/base/internal/scoped_set_env.cc new file mode 100644 index 0000000000..8a934cb511 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/scoped_set_env.cc @@ -0,0 +1,81 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/scoped_set_env.h" + +#ifdef _WIN32 +#include <windows.h> +#endif + +#include <cstdlib> + +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +namespace { + +#ifdef _WIN32 +const int kMaxEnvVarValueSize = 1024; +#endif + +void SetEnvVar(const char* name, const char* value) { +#ifdef _WIN32 + SetEnvironmentVariableA(name, value); +#else + if (value == nullptr) { + ::unsetenv(name); + } else { + ::setenv(name, value, 1); + } +#endif +} + +} // namespace + +ScopedSetEnv::ScopedSetEnv(const char* var_name, const char* new_value) + : var_name_(var_name), was_unset_(false) { +#ifdef _WIN32 + char buf[kMaxEnvVarValueSize]; + auto get_res = GetEnvironmentVariableA(var_name_.c_str(), buf, sizeof(buf)); + ABSL_INTERNAL_CHECK(get_res < sizeof(buf), "value exceeds buffer size"); + + if (get_res == 0) { + was_unset_ = (GetLastError() == ERROR_ENVVAR_NOT_FOUND); + } else { + old_value_.assign(buf, get_res); + } + + SetEnvironmentVariableA(var_name_.c_str(), new_value); +#else + const char* val = ::getenv(var_name_.c_str()); + if (val == nullptr) { + was_unset_ = true; + } else { + old_value_ = val; + } +#endif + + SetEnvVar(var_name_.c_str(), new_value); +} + +ScopedSetEnv::~ScopedSetEnv() { + SetEnvVar(var_name_.c_str(), was_unset_ ? nullptr : old_value_.c_str()); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/scoped_set_env.h b/third_party/abseil_cpp/absl/base/internal/scoped_set_env.h new file mode 100644 index 0000000000..19ec7b5d8a --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/scoped_set_env.h @@ -0,0 +1,45 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_SCOPED_SET_ENV_H_ +#define ABSL_BASE_INTERNAL_SCOPED_SET_ENV_H_ + +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +class ScopedSetEnv { + public: + ScopedSetEnv(const char* var_name, const char* new_value); + ~ScopedSetEnv(); + + private: + std::string var_name_; + std::string old_value_; + + // True if the environment variable was initially not set. + bool was_unset_; +}; + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_SCOPED_SET_ENV_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/scoped_set_env_test.cc b/third_party/abseil_cpp/absl/base/internal/scoped_set_env_test.cc new file mode 100644 index 0000000000..5cbad246c6 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/scoped_set_env_test.cc @@ -0,0 +1,99 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifdef _WIN32 +#include <windows.h> +#endif + +#include "gtest/gtest.h" +#include "absl/base/internal/scoped_set_env.h" + +namespace { + +using absl::base_internal::ScopedSetEnv; + +std::string GetEnvVar(const char* name) { +#ifdef _WIN32 + char buf[1024]; + auto get_res = GetEnvironmentVariableA(name, buf, sizeof(buf)); + if (get_res >= sizeof(buf)) { + return "TOO_BIG"; + } + + if (get_res == 0) { + return "UNSET"; + } + + return std::string(buf, get_res); +#else + const char* val = ::getenv(name); + if (val == nullptr) { + return "UNSET"; + } + + return val; +#endif +} + +TEST(ScopedSetEnvTest, SetNonExistingVarToString) { + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "UNSET"); + + { + ScopedSetEnv scoped_set("SCOPED_SET_ENV_TEST_VAR", "value"); + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "value"); + } + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "UNSET"); +} + +TEST(ScopedSetEnvTest, SetNonExistingVarToNull) { + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "UNSET"); + + { + ScopedSetEnv scoped_set("SCOPED_SET_ENV_TEST_VAR", nullptr); + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "UNSET"); + } + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "UNSET"); +} + +TEST(ScopedSetEnvTest, SetExistingVarToString) { + ScopedSetEnv scoped_set("SCOPED_SET_ENV_TEST_VAR", "value"); + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "value"); + + { + ScopedSetEnv scoped_set("SCOPED_SET_ENV_TEST_VAR", "new_value"); + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "new_value"); + } + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "value"); +} + +TEST(ScopedSetEnvTest, SetExistingVarToNull) { + ScopedSetEnv scoped_set("SCOPED_SET_ENV_TEST_VAR", "value"); + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "value"); + + { + ScopedSetEnv scoped_set("SCOPED_SET_ENV_TEST_VAR", nullptr); + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "UNSET"); + } + + EXPECT_EQ(GetEnvVar("SCOPED_SET_ENV_TEST_VAR"), "value"); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock.cc b/third_party/abseil_cpp/absl/base/internal/spinlock.cc new file mode 100644 index 0000000000..a7d44f3eb0 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock.cc @@ -0,0 +1,220 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/spinlock.h" + +#include <algorithm> +#include <atomic> +#include <limits> + +#include "absl/base/attributes.h" +#include "absl/base/internal/atomic_hook.h" +#include "absl/base/internal/cycleclock.h" +#include "absl/base/internal/spinlock_wait.h" +#include "absl/base/internal/sysinfo.h" /* For NumCPUs() */ +#include "absl/base/call_once.h" + +// Description of lock-word: +// 31..00: [............................3][2][1][0] +// +// [0]: kSpinLockHeld +// [1]: kSpinLockCooperative +// [2]: kSpinLockDisabledScheduling +// [31..3]: ONLY kSpinLockSleeper OR +// Wait time in cycles >> PROFILE_TIMESTAMP_SHIFT +// +// Detailed descriptions: +// +// Bit [0]: The lock is considered held iff kSpinLockHeld is set. +// +// Bit [1]: Eligible waiters (e.g. Fibers) may co-operatively reschedule when +// contended iff kSpinLockCooperative is set. +// +// Bit [2]: This bit is exclusive from bit [1]. It is used only by a +// non-cooperative lock. When set, indicates that scheduling was +// successfully disabled when the lock was acquired. May be unset, +// even if non-cooperative, if a ThreadIdentity did not yet exist at +// time of acquisition. +// +// Bit [3]: If this is the only upper bit ([31..3]) set then this lock was +// acquired without contention, however, at least one waiter exists. +// +// Otherwise, bits [31..3] represent the time spent by the current lock +// holder to acquire the lock. There may be outstanding waiter(s). + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES static base_internal::AtomicHook<void (*)( + const void *lock, int64_t wait_cycles)> + submit_profile_data; + +void RegisterSpinLockProfiler(void (*fn)(const void *contendedlock, + int64_t wait_cycles)) { + submit_profile_data.Store(fn); +} + +// Static member variable definitions. +constexpr uint32_t SpinLock::kSpinLockHeld; +constexpr uint32_t SpinLock::kSpinLockCooperative; +constexpr uint32_t SpinLock::kSpinLockDisabledScheduling; +constexpr uint32_t SpinLock::kSpinLockSleeper; +constexpr uint32_t SpinLock::kWaitTimeMask; + +// Uncommon constructors. +SpinLock::SpinLock(base_internal::SchedulingMode mode) + : lockword_(IsCooperative(mode) ? kSpinLockCooperative : 0) { + ABSL_TSAN_MUTEX_CREATE(this, __tsan_mutex_not_static); +} + +// Monitor the lock to see if its value changes within some time period +// (adaptive_spin_count loop iterations). The last value read from the lock +// is returned from the method. +uint32_t SpinLock::SpinLoop() { + // We are already in the slow path of SpinLock, initialize the + // adaptive_spin_count here. + ABSL_CONST_INIT static absl::once_flag init_adaptive_spin_count; + ABSL_CONST_INIT static int adaptive_spin_count = 0; + base_internal::LowLevelCallOnce(&init_adaptive_spin_count, []() { + adaptive_spin_count = base_internal::NumCPUs() > 1 ? 1000 : 1; + }); + + int c = adaptive_spin_count; + uint32_t lock_value; + do { + lock_value = lockword_.load(std::memory_order_relaxed); + } while ((lock_value & kSpinLockHeld) != 0 && --c > 0); + return lock_value; +} + +void SpinLock::SlowLock() { + uint32_t lock_value = SpinLoop(); + lock_value = TryLockInternal(lock_value, 0); + if ((lock_value & kSpinLockHeld) == 0) { + return; + } + + base_internal::SchedulingMode scheduling_mode; + if ((lock_value & kSpinLockCooperative) != 0) { + scheduling_mode = base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL; + } else { + scheduling_mode = base_internal::SCHEDULE_KERNEL_ONLY; + } + + // The lock was not obtained initially, so this thread needs to wait for + // it. Record the current timestamp in the local variable wait_start_time + // so the total wait time can be stored in the lockword once this thread + // obtains the lock. + int64_t wait_start_time = CycleClock::Now(); + uint32_t wait_cycles = 0; + int lock_wait_call_count = 0; + while ((lock_value & kSpinLockHeld) != 0) { + // If the lock is currently held, but not marked as having a sleeper, mark + // it as having a sleeper. + if ((lock_value & kWaitTimeMask) == 0) { + // Here, just "mark" that the thread is going to sleep. Don't store the + // lock wait time in the lock as that will cause the current lock + // owner to think it experienced contention. + if (lockword_.compare_exchange_strong( + lock_value, lock_value | kSpinLockSleeper, + std::memory_order_relaxed, std::memory_order_relaxed)) { + // Successfully transitioned to kSpinLockSleeper. Pass + // kSpinLockSleeper to the SpinLockWait routine to properly indicate + // the last lock_value observed. + lock_value |= kSpinLockSleeper; + } else if ((lock_value & kSpinLockHeld) == 0) { + // Lock is free again, so try and acquire it before sleeping. The + // new lock state will be the number of cycles this thread waited if + // this thread obtains the lock. + lock_value = TryLockInternal(lock_value, wait_cycles); + continue; // Skip the delay at the end of the loop. + } + } + + // SpinLockDelay() calls into fiber scheduler, we need to see + // synchronization there to avoid false positives. + ABSL_TSAN_MUTEX_PRE_DIVERT(this, 0); + // Wait for an OS specific delay. + base_internal::SpinLockDelay(&lockword_, lock_value, ++lock_wait_call_count, + scheduling_mode); + ABSL_TSAN_MUTEX_POST_DIVERT(this, 0); + // Spin again after returning from the wait routine to give this thread + // some chance of obtaining the lock. + lock_value = SpinLoop(); + wait_cycles = EncodeWaitCycles(wait_start_time, CycleClock::Now()); + lock_value = TryLockInternal(lock_value, wait_cycles); + } +} + +void SpinLock::SlowUnlock(uint32_t lock_value) { + base_internal::SpinLockWake(&lockword_, + false); // wake waiter if necessary + + // If our acquisition was contended, collect contentionz profile info. We + // reserve a unitary wait time to represent that a waiter exists without our + // own acquisition having been contended. + if ((lock_value & kWaitTimeMask) != kSpinLockSleeper) { + const uint64_t wait_cycles = DecodeWaitCycles(lock_value); + ABSL_TSAN_MUTEX_PRE_DIVERT(this, 0); + submit_profile_data(this, wait_cycles); + ABSL_TSAN_MUTEX_POST_DIVERT(this, 0); + } +} + +// We use the upper 29 bits of the lock word to store the time spent waiting to +// acquire this lock. This is reported by contentionz profiling. Since the +// lower bits of the cycle counter wrap very quickly on high-frequency +// processors we divide to reduce the granularity to 2^kProfileTimestampShift +// sized units. On a 4Ghz machine this will lose track of wait times greater +// than (2^29/4 Ghz)*128 =~ 17.2 seconds. Such waits should be extremely rare. +static constexpr int kProfileTimestampShift = 7; + +// We currently reserve the lower 3 bits. +static constexpr int kLockwordReservedShift = 3; + +uint32_t SpinLock::EncodeWaitCycles(int64_t wait_start_time, + int64_t wait_end_time) { + static const int64_t kMaxWaitTime = + std::numeric_limits<uint32_t>::max() >> kLockwordReservedShift; + int64_t scaled_wait_time = + (wait_end_time - wait_start_time) >> kProfileTimestampShift; + + // Return a representation of the time spent waiting that can be stored in + // the lock word's upper bits. + uint32_t clamped = static_cast<uint32_t>( + std::min(scaled_wait_time, kMaxWaitTime) << kLockwordReservedShift); + + if (clamped == 0) { + return kSpinLockSleeper; // Just wake waiters, but don't record contention. + } + // Bump up value if necessary to avoid returning kSpinLockSleeper. + const uint32_t kMinWaitTime = + kSpinLockSleeper + (1 << kLockwordReservedShift); + if (clamped == kSpinLockSleeper) { + return kMinWaitTime; + } + return clamped; +} + +uint64_t SpinLock::DecodeWaitCycles(uint32_t lock_value) { + // Cast to uint32_t first to ensure bits [63:32] are cleared. + const uint64_t scaled_wait_time = + static_cast<uint32_t>(lock_value & kWaitTimeMask); + return scaled_wait_time << (kProfileTimestampShift - kLockwordReservedShift); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock.h b/third_party/abseil_cpp/absl/base/internal/spinlock.h new file mode 100644 index 0000000000..2222398b16 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock.h @@ -0,0 +1,230 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// Most users requiring mutual exclusion should use Mutex. +// SpinLock is provided for use in three situations: +// - for use in code that Mutex itself depends on +// - to get a faster fast-path release under low contention (without an +// atomic read-modify-write) In return, SpinLock has worse behaviour under +// contention, which is why Mutex is preferred in most situations. +// - for async signal safety (see below) + +// SpinLock is async signal safe. If a spinlock is used within a signal +// handler, all code that acquires the lock must ensure that the signal cannot +// arrive while they are holding the lock. Typically, this is done by blocking +// the signal. + +#ifndef ABSL_BASE_INTERNAL_SPINLOCK_H_ +#define ABSL_BASE_INTERNAL_SPINLOCK_H_ + +#include <stdint.h> +#include <sys/types.h> + +#include <atomic> + +#include "absl/base/attributes.h" +#include "absl/base/const_init.h" +#include "absl/base/dynamic_annotations.h" +#include "absl/base/internal/low_level_scheduling.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/internal/tsan_mutex_interface.h" +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/base/thread_annotations.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +class ABSL_LOCKABLE SpinLock { + public: + SpinLock() : lockword_(kSpinLockCooperative) { + ABSL_TSAN_MUTEX_CREATE(this, __tsan_mutex_not_static); + } + + // Constructors that allow non-cooperative spinlocks to be created for use + // inside thread schedulers. Normal clients should not use these. + explicit SpinLock(base_internal::SchedulingMode mode); + + // Constructor for global SpinLock instances. See absl/base/const_init.h. + constexpr SpinLock(absl::ConstInitType, base_internal::SchedulingMode mode) + : lockword_(IsCooperative(mode) ? kSpinLockCooperative : 0) {} + + ~SpinLock() { ABSL_TSAN_MUTEX_DESTROY(this, __tsan_mutex_not_static); } + + // Acquire this SpinLock. + inline void Lock() ABSL_EXCLUSIVE_LOCK_FUNCTION() { + ABSL_TSAN_MUTEX_PRE_LOCK(this, 0); + if (!TryLockImpl()) { + SlowLock(); + } + ABSL_TSAN_MUTEX_POST_LOCK(this, 0, 0); + } + + // Try to acquire this SpinLock without blocking and return true if the + // acquisition was successful. If the lock was not acquired, false is + // returned. If this SpinLock is free at the time of the call, TryLock + // will return true with high probability. + inline bool TryLock() ABSL_EXCLUSIVE_TRYLOCK_FUNCTION(true) { + ABSL_TSAN_MUTEX_PRE_LOCK(this, __tsan_mutex_try_lock); + bool res = TryLockImpl(); + ABSL_TSAN_MUTEX_POST_LOCK( + this, __tsan_mutex_try_lock | (res ? 0 : __tsan_mutex_try_lock_failed), + 0); + return res; + } + + // Release this SpinLock, which must be held by the calling thread. + inline void Unlock() ABSL_UNLOCK_FUNCTION() { + ABSL_TSAN_MUTEX_PRE_UNLOCK(this, 0); + uint32_t lock_value = lockword_.load(std::memory_order_relaxed); + lock_value = lockword_.exchange(lock_value & kSpinLockCooperative, + std::memory_order_release); + + if ((lock_value & kSpinLockDisabledScheduling) != 0) { + base_internal::SchedulingGuard::EnableRescheduling(true); + } + if ((lock_value & kWaitTimeMask) != 0) { + // Collect contentionz profile info, and speed the wakeup of any waiter. + // The wait_cycles value indicates how long this thread spent waiting + // for the lock. + SlowUnlock(lock_value); + } + ABSL_TSAN_MUTEX_POST_UNLOCK(this, 0); + } + + // Determine if the lock is held. When the lock is held by the invoking + // thread, true will always be returned. Intended to be used as + // CHECK(lock.IsHeld()). + inline bool IsHeld() const { + return (lockword_.load(std::memory_order_relaxed) & kSpinLockHeld) != 0; + } + + protected: + // These should not be exported except for testing. + + // Store number of cycles between wait_start_time and wait_end_time in a + // lock value. + static uint32_t EncodeWaitCycles(int64_t wait_start_time, + int64_t wait_end_time); + + // Extract number of wait cycles in a lock value. + static uint64_t DecodeWaitCycles(uint32_t lock_value); + + // Provide access to protected method above. Use for testing only. + friend struct SpinLockTest; + + private: + // lockword_ is used to store the following: + // + // bit[0] encodes whether a lock is being held. + // bit[1] encodes whether a lock uses cooperative scheduling. + // bit[2] encodes whether a lock disables scheduling. + // bit[3:31] encodes time a lock spent on waiting as a 29-bit unsigned int. + static constexpr uint32_t kSpinLockHeld = 1; + static constexpr uint32_t kSpinLockCooperative = 2; + static constexpr uint32_t kSpinLockDisabledScheduling = 4; + static constexpr uint32_t kSpinLockSleeper = 8; + // Includes kSpinLockSleeper. + static constexpr uint32_t kWaitTimeMask = + ~(kSpinLockHeld | kSpinLockCooperative | kSpinLockDisabledScheduling); + + // Returns true if the provided scheduling mode is cooperative. + static constexpr bool IsCooperative( + base_internal::SchedulingMode scheduling_mode) { + return scheduling_mode == base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL; + } + + uint32_t TryLockInternal(uint32_t lock_value, uint32_t wait_cycles); + void SlowLock() ABSL_ATTRIBUTE_COLD; + void SlowUnlock(uint32_t lock_value) ABSL_ATTRIBUTE_COLD; + uint32_t SpinLoop(); + + inline bool TryLockImpl() { + uint32_t lock_value = lockword_.load(std::memory_order_relaxed); + return (TryLockInternal(lock_value, 0) & kSpinLockHeld) == 0; + } + + std::atomic<uint32_t> lockword_; + + SpinLock(const SpinLock&) = delete; + SpinLock& operator=(const SpinLock&) = delete; +}; + +// Corresponding locker object that arranges to acquire a spinlock for +// the duration of a C++ scope. +class ABSL_SCOPED_LOCKABLE SpinLockHolder { + public: + inline explicit SpinLockHolder(SpinLock* l) ABSL_EXCLUSIVE_LOCK_FUNCTION(l) + : lock_(l) { + l->Lock(); + } + inline ~SpinLockHolder() ABSL_UNLOCK_FUNCTION() { lock_->Unlock(); } + + SpinLockHolder(const SpinLockHolder&) = delete; + SpinLockHolder& operator=(const SpinLockHolder&) = delete; + + private: + SpinLock* lock_; +}; + +// Register a hook for profiling support. +// +// The function pointer registered here will be called whenever a spinlock is +// contended. The callback is given an opaque handle to the contended spinlock +// and the number of wait cycles. This is thread-safe, but only a single +// profiler can be registered. It is an error to call this function multiple +// times with different arguments. +void RegisterSpinLockProfiler(void (*fn)(const void* lock, + int64_t wait_cycles)); + +//------------------------------------------------------------------------------ +// Public interface ends here. +//------------------------------------------------------------------------------ + +// If (result & kSpinLockHeld) == 0, then *this was successfully locked. +// Otherwise, returns last observed value for lockword_. +inline uint32_t SpinLock::TryLockInternal(uint32_t lock_value, + uint32_t wait_cycles) { + if ((lock_value & kSpinLockHeld) != 0) { + return lock_value; + } + + uint32_t sched_disabled_bit = 0; + if ((lock_value & kSpinLockCooperative) == 0) { + // For non-cooperative locks we must make sure we mark ourselves as + // non-reschedulable before we attempt to CompareAndSwap. + if (base_internal::SchedulingGuard::DisableRescheduling()) { + sched_disabled_bit = kSpinLockDisabledScheduling; + } + } + + if (!lockword_.compare_exchange_strong( + lock_value, + kSpinLockHeld | lock_value | wait_cycles | sched_disabled_bit, + std::memory_order_acquire, std::memory_order_relaxed)) { + base_internal::SchedulingGuard::EnableRescheduling(sched_disabled_bit != 0); + } + + return lock_value; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_SPINLOCK_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_akaros.inc b/third_party/abseil_cpp/absl/base/internal/spinlock_akaros.inc new file mode 100644 index 0000000000..bc468940fc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_akaros.inc @@ -0,0 +1,35 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file is an Akaros-specific part of spinlock_wait.cc + +#include <atomic> + +#include "absl/base/internal/scheduling_mode.h" + +extern "C" { + +ABSL_ATTRIBUTE_WEAK void AbslInternalSpinLockDelay( + std::atomic<uint32_t>* /* lock_word */, uint32_t /* value */, + int /* loop */, absl::base_internal::SchedulingMode /* mode */) { + // In Akaros, one must take care not to call anything that could cause a + // malloc(), a blocking system call, or a uthread_yield() while holding a + // spinlock. Our callers assume will not call into libraries or other + // arbitrary code. +} + +ABSL_ATTRIBUTE_WEAK void AbslInternalSpinLockWake( + std::atomic<uint32_t>* /* lock_word */, bool /* all */) {} + +} // extern "C" diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_benchmark.cc b/third_party/abseil_cpp/absl/base/internal/spinlock_benchmark.cc new file mode 100644 index 0000000000..0451c65f95 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_benchmark.cc @@ -0,0 +1,52 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// See also //absl/synchronization:mutex_benchmark for a comparison of SpinLock +// and Mutex performance under varying levels of contention. + +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/internal/spinlock.h" +#include "absl/synchronization/internal/create_thread_identity.h" +#include "benchmark/benchmark.h" + +namespace { + +template <absl::base_internal::SchedulingMode scheduling_mode> +static void BM_SpinLock(benchmark::State& state) { + // Ensure a ThreadIdentity is installed. + ABSL_INTERNAL_CHECK( + absl::synchronization_internal::GetOrCreateCurrentThreadIdentity() != + nullptr, + "GetOrCreateCurrentThreadIdentity() failed"); + + static auto* spinlock = new absl::base_internal::SpinLock(scheduling_mode); + for (auto _ : state) { + absl::base_internal::SpinLockHolder holder(spinlock); + } +} + +BENCHMARK_TEMPLATE(BM_SpinLock, + absl::base_internal::SCHEDULE_KERNEL_ONLY) + ->UseRealTime() + ->Threads(1) + ->ThreadPerCpu(); + +BENCHMARK_TEMPLATE(BM_SpinLock, + absl::base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL) + ->UseRealTime() + ->Threads(1) + ->ThreadPerCpu(); + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_linux.inc b/third_party/abseil_cpp/absl/base/internal/spinlock_linux.inc new file mode 100644 index 0000000000..e31c6ed477 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_linux.inc @@ -0,0 +1,74 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file is a Linux-specific part of spinlock_wait.cc + +#include <linux/futex.h> +#include <sys/syscall.h> +#include <unistd.h> + +#include <atomic> +#include <climits> +#include <cstdint> +#include <ctime> + +#include "absl/base/attributes.h" +#include "absl/base/internal/errno_saver.h" + +// The SpinLock lockword is `std::atomic<uint32_t>`. Here we assert that +// `std::atomic<uint32_t>` is bitwise equivalent of the `int` expected +// by SYS_futex. We also assume that reads/writes done to the lockword +// by SYS_futex have rational semantics with regard to the +// std::atomic<> API. C++ provides no guarantees of these assumptions, +// but they are believed to hold in practice. +static_assert(sizeof(std::atomic<uint32_t>) == sizeof(int), + "SpinLock lockword has the wrong size for a futex"); + +// Some Android headers are missing these definitions even though they +// support these futex operations. +#ifdef __BIONIC__ +#ifndef SYS_futex +#define SYS_futex __NR_futex +#endif +#ifndef FUTEX_PRIVATE_FLAG +#define FUTEX_PRIVATE_FLAG 128 +#endif +#endif + +#if defined(__NR_futex_time64) && !defined(SYS_futex_time64) +#define SYS_futex_time64 __NR_futex_time64 +#endif + +#if defined(SYS_futex_time64) && !defined(SYS_futex) +#define SYS_futex SYS_futex_time64 +#endif + +extern "C" { + +ABSL_ATTRIBUTE_WEAK void AbslInternalSpinLockDelay( + std::atomic<uint32_t> *w, uint32_t value, int loop, + absl::base_internal::SchedulingMode) { + absl::base_internal::ErrnoSaver errno_saver; + struct timespec tm; + tm.tv_sec = 0; + tm.tv_nsec = absl::base_internal::SpinLockSuggestedDelayNS(loop); + syscall(SYS_futex, w, FUTEX_WAIT | FUTEX_PRIVATE_FLAG, value, &tm); +} + +ABSL_ATTRIBUTE_WEAK void AbslInternalSpinLockWake(std::atomic<uint32_t> *w, + bool all) { + syscall(SYS_futex, w, FUTEX_WAKE | FUTEX_PRIVATE_FLAG, all ? INT_MAX : 1, 0); +} + +} // extern "C" diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_posix.inc b/third_party/abseil_cpp/absl/base/internal/spinlock_posix.inc new file mode 100644 index 0000000000..fcd21b151b --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_posix.inc @@ -0,0 +1,46 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file is a Posix-specific part of spinlock_wait.cc + +#include <sched.h> + +#include <atomic> +#include <ctime> + +#include "absl/base/internal/errno_saver.h" +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/port.h" + +extern "C" { + +ABSL_ATTRIBUTE_WEAK void AbslInternalSpinLockDelay( + std::atomic<uint32_t>* /* lock_word */, uint32_t /* value */, int loop, + absl::base_internal::SchedulingMode /* mode */) { + absl::base_internal::ErrnoSaver errno_saver; + if (loop == 0) { + } else if (loop == 1) { + sched_yield(); + } else { + struct timespec tm; + tm.tv_sec = 0; + tm.tv_nsec = absl::base_internal::SpinLockSuggestedDelayNS(loop); + nanosleep(&tm, nullptr); + } +} + +ABSL_ATTRIBUTE_WEAK void AbslInternalSpinLockWake( + std::atomic<uint32_t>* /* lock_word */, bool /* all */) {} + +} // extern "C" diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_wait.cc b/third_party/abseil_cpp/absl/base/internal/spinlock_wait.cc new file mode 100644 index 0000000000..fa824be1c0 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_wait.cc @@ -0,0 +1,81 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// The OS-specific header included below must provide two calls: +// AbslInternalSpinLockDelay() and AbslInternalSpinLockWake(). +// See spinlock_wait.h for the specs. + +#include <atomic> +#include <cstdint> + +#include "absl/base/internal/spinlock_wait.h" + +#if defined(_WIN32) +#include "absl/base/internal/spinlock_win32.inc" +#elif defined(__linux__) +#include "absl/base/internal/spinlock_linux.inc" +#elif defined(__akaros__) +#include "absl/base/internal/spinlock_akaros.inc" +#else +#include "absl/base/internal/spinlock_posix.inc" +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// See spinlock_wait.h for spec. +uint32_t SpinLockWait(std::atomic<uint32_t> *w, int n, + const SpinLockWaitTransition trans[], + base_internal::SchedulingMode scheduling_mode) { + int loop = 0; + for (;;) { + uint32_t v = w->load(std::memory_order_acquire); + int i; + for (i = 0; i != n && v != trans[i].from; i++) { + } + if (i == n) { + SpinLockDelay(w, v, ++loop, scheduling_mode); // no matching transition + } else if (trans[i].to == v || // null transition + w->compare_exchange_strong(v, trans[i].to, + std::memory_order_acquire, + std::memory_order_relaxed)) { + if (trans[i].done) return v; + } + } +} + +static std::atomic<uint64_t> delay_rand; + +// Return a suggested delay in nanoseconds for iteration number "loop" +int SpinLockSuggestedDelayNS(int loop) { + // Weak pseudo-random number generator to get some spread between threads + // when many are spinning. + uint64_t r = delay_rand.load(std::memory_order_relaxed); + r = 0x5deece66dLL * r + 0xb; // numbers from nrand48() + delay_rand.store(r, std::memory_order_relaxed); + + if (loop < 0 || loop > 32) { // limit loop to 0..32 + loop = 32; + } + const int kMinDelay = 128 << 10; // 128us + // Double delay every 8 iterations, up to 16x (2ms). + int delay = kMinDelay << (loop / 8); + // Randomize in delay..2*delay range, for resulting 128us..4ms range. + return delay | ((delay - 1) & static_cast<int>(r)); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_wait.h b/third_party/abseil_cpp/absl/base/internal/spinlock_wait.h new file mode 100644 index 0000000000..169bc749fb --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_wait.h @@ -0,0 +1,93 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_SPINLOCK_WAIT_H_ +#define ABSL_BASE_INTERNAL_SPINLOCK_WAIT_H_ + +// Operations to make atomic transitions on a word, and to allow +// waiting for those transitions to become possible. + +#include <stdint.h> +#include <atomic> + +#include "absl/base/internal/scheduling_mode.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// SpinLockWait() waits until it can perform one of several transitions from +// "from" to "to". It returns when it performs a transition where done==true. +struct SpinLockWaitTransition { + uint32_t from; + uint32_t to; + bool done; +}; + +// Wait until *w can transition from trans[i].from to trans[i].to for some i +// satisfying 0<=i<n && trans[i].done, atomically make the transition, +// then return the old value of *w. Make any other atomic transitions +// where !trans[i].done, but continue waiting. +uint32_t SpinLockWait(std::atomic<uint32_t> *w, int n, + const SpinLockWaitTransition trans[], + SchedulingMode scheduling_mode); + +// If possible, wake some thread that has called SpinLockDelay(w, ...). If +// "all" is true, wake all such threads. This call is a hint, and on some +// systems it may be a no-op; threads calling SpinLockDelay() will always wake +// eventually even if SpinLockWake() is never called. +void SpinLockWake(std::atomic<uint32_t> *w, bool all); + +// Wait for an appropriate spin delay on iteration "loop" of a +// spin loop on location *w, whose previously observed value was "value". +// SpinLockDelay() may do nothing, may yield the CPU, may sleep a clock tick, +// or may wait for a delay that can be truncated by a call to SpinLockWake(w). +// In all cases, it must return in bounded time even if SpinLockWake() is not +// called. +void SpinLockDelay(std::atomic<uint32_t> *w, uint32_t value, int loop, + base_internal::SchedulingMode scheduling_mode); + +// Helper used by AbslInternalSpinLockDelay. +// Returns a suggested delay in nanoseconds for iteration number "loop". +int SpinLockSuggestedDelayNS(int loop); + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +// In some build configurations we pass --detect-odr-violations to the +// gold linker. This causes it to flag weak symbol overrides as ODR +// violations. Because ODR only applies to C++ and not C, +// --detect-odr-violations ignores symbols not mangled with C++ names. +// By changing our extension points to be extern "C", we dodge this +// check. +extern "C" { +void AbslInternalSpinLockWake(std::atomic<uint32_t> *w, bool all); +void AbslInternalSpinLockDelay( + std::atomic<uint32_t> *w, uint32_t value, int loop, + absl::base_internal::SchedulingMode scheduling_mode); +} + +inline void absl::base_internal::SpinLockWake(std::atomic<uint32_t> *w, + bool all) { + AbslInternalSpinLockWake(w, all); +} + +inline void absl::base_internal::SpinLockDelay( + std::atomic<uint32_t> *w, uint32_t value, int loop, + absl::base_internal::SchedulingMode scheduling_mode) { + AbslInternalSpinLockDelay(w, value, loop, scheduling_mode); +} + +#endif // ABSL_BASE_INTERNAL_SPINLOCK_WAIT_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/spinlock_win32.inc b/third_party/abseil_cpp/absl/base/internal/spinlock_win32.inc new file mode 100644 index 0000000000..78654b5b59 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/spinlock_win32.inc @@ -0,0 +1,37 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file is a Win32-specific part of spinlock_wait.cc + +#include <windows.h> +#include <atomic> +#include "absl/base/internal/scheduling_mode.h" + +extern "C" { + +void AbslInternalSpinLockDelay(std::atomic<uint32_t>* /* lock_word */, + uint32_t /* value */, int loop, + absl::base_internal::SchedulingMode /* mode */) { + if (loop == 0) { + } else if (loop == 1) { + Sleep(0); + } else { + Sleep(absl::base_internal::SpinLockSuggestedDelayNS(loop) / 1000000); + } +} + +void AbslInternalSpinLockWake(std::atomic<uint32_t>* /* lock_word */, + bool /* all */) {} + +} // extern "C" diff --git a/third_party/abseil_cpp/absl/base/internal/strerror.cc b/third_party/abseil_cpp/absl/base/internal/strerror.cc new file mode 100644 index 0000000000..af181513cd --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/strerror.cc @@ -0,0 +1,75 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/strerror.h" + +#include <cerrno> +#include <cstddef> +#include <cstdio> +#include <cstring> +#include <string> +#include <type_traits> + +#include "absl/base/attributes.h" +#include "absl/base/internal/errno_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { +const char* StrErrorAdaptor(int errnum, char* buf, size_t buflen) { +#if defined(_WIN32) + int rc = strerror_s(buf, buflen, errnum); + buf[buflen - 1] = '\0'; // guarantee NUL termination + if (rc == 0 && strncmp(buf, "Unknown error", buflen) == 0) *buf = '\0'; + return buf; +#else +#if defined(__GLIBC__) || defined(__APPLE__) + // Use the BSD sys_errlist API provided by GNU glibc and others to + // avoid any need to copy the message into the local buffer first. + if (0 <= errnum && errnum < sys_nerr) { + if (const char* p = sys_errlist[errnum]) { + return p; + } + } +#endif + // The type of `ret` is platform-specific; both of these branches must compile + // either way but only one will execute on any given platform: + auto ret = strerror_r(errnum, buf, buflen); + if (std::is_same<decltype(ret), int>::value) { + // XSI `strerror_r`; `ret` is `int`: + if (ret) *buf = '\0'; + return buf; + } else { + // GNU `strerror_r`; `ret` is `char *`: + return reinterpret_cast<const char*>(ret); + } +#endif +} +} // namespace + +std::string StrError(int errnum) { + absl::base_internal::ErrnoSaver errno_saver; + char buf[100]; + const char* str = StrErrorAdaptor(errnum, buf, sizeof buf); + if (*str == '\0') { + snprintf(buf, sizeof buf, "Unknown error %d", errnum); + str = buf; + } + return str; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/strerror.h b/third_party/abseil_cpp/absl/base/internal/strerror.h new file mode 100644 index 0000000000..350097366e --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/strerror.h @@ -0,0 +1,39 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_STRERROR_H_ +#define ABSL_BASE_INTERNAL_STRERROR_H_ + +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// A portable and thread-safe alternative to C89's `strerror`. +// +// The C89 specification of `strerror` is not suitable for use in a +// multi-threaded application as the returned string may be changed by calls to +// `strerror` from another thread. The many non-stdlib alternatives differ +// enough in their names, availability, and semantics to justify this wrapper +// around them. `errno` will not be modified by a call to `absl::StrError`. +std::string StrError(int errnum); + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_STRERROR_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/strerror_benchmark.cc b/third_party/abseil_cpp/absl/base/internal/strerror_benchmark.cc new file mode 100644 index 0000000000..d8ca86b95b --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/strerror_benchmark.cc @@ -0,0 +1,38 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cerrno> +#include <cstdio> +#include <string> + +#include "absl/base/internal/strerror.h" +#include "benchmark/benchmark.h" + +namespace { +#if defined(__GLIBC__) || defined(__APPLE__) +void BM_SysErrList(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::string(sys_errlist[ERANGE])); + } +} +BENCHMARK(BM_SysErrList); +#endif + +void BM_AbslStrError(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(absl::base_internal::StrError(ERANGE)); + } +} +BENCHMARK(BM_AbslStrError); +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/strerror_test.cc b/third_party/abseil_cpp/absl/base/internal/strerror_test.cc new file mode 100644 index 0000000000..a53da97f92 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/strerror_test.cc @@ -0,0 +1,86 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/strerror.h" + +#include <atomic> +#include <cerrno> +#include <cstdio> +#include <cstring> +#include <string> +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/match.h" + +namespace { +using ::testing::AnyOf; +using ::testing::Eq; + +TEST(StrErrorTest, ValidErrorCode) { + errno = ERANGE; + EXPECT_THAT(absl::base_internal::StrError(EDOM), Eq(strerror(EDOM))); + EXPECT_THAT(errno, Eq(ERANGE)); +} + +TEST(StrErrorTest, InvalidErrorCode) { + errno = ERANGE; + EXPECT_THAT(absl::base_internal::StrError(-1), + AnyOf(Eq("No error information"), Eq("Unknown error -1"))); + EXPECT_THAT(errno, Eq(ERANGE)); +} + +TEST(StrErrorTest, MultipleThreads) { + // In this test, we will start up 2 threads and have each one call + // StrError 1000 times, each time with a different errnum. We + // expect that StrError(errnum) will return a string equal to the + // one returned by strerror(errnum), if the code is known. Since + // strerror is known to be thread-hostile, collect all the expected + // strings up front. + const int kNumCodes = 1000; + std::vector<std::string> expected_strings(kNumCodes); + for (int i = 0; i < kNumCodes; ++i) { + expected_strings[i] = strerror(i); + } + + std::atomic_int counter(0); + auto thread_fun = [&]() { + for (int i = 0; i < kNumCodes; ++i) { + ++counter; + errno = ERANGE; + const std::string value = absl::base_internal::StrError(i); + // Only the GNU implementation is guaranteed to provide the + // string "Unknown error nnn". POSIX doesn't say anything. + if (!absl::StartsWith(value, "Unknown error ")) { + EXPECT_THAT(absl::base_internal::StrError(i), Eq(expected_strings[i])); + } + EXPECT_THAT(errno, Eq(ERANGE)); + } + }; + + const int kNumThreads = 100; + std::vector<std::thread> threads; + for (int i = 0; i < kNumThreads; ++i) { + threads.push_back(std::thread(thread_fun)); + } + for (auto& thread : threads) { + thread.join(); + } + + EXPECT_THAT(counter, Eq(kNumThreads * kNumCodes)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/sysinfo.cc b/third_party/abseil_cpp/absl/base/internal/sysinfo.cc new file mode 100644 index 0000000000..6c69683faf --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/sysinfo.cc @@ -0,0 +1,425 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/sysinfo.h" + +#include "absl/base/attributes.h" + +#ifdef _WIN32 +#include <windows.h> +#else +#include <fcntl.h> +#include <pthread.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> +#endif + +#ifdef __linux__ +#include <sys/syscall.h> +#endif + +#if defined(__APPLE__) || defined(__FreeBSD__) +#include <sys/sysctl.h> +#endif + +#if defined(__myriad2__) +#include <rtems.h> +#endif + +#include <string.h> +#include <cassert> +#include <cstdint> +#include <cstdio> +#include <cstdlib> +#include <ctime> +#include <limits> +#include <thread> // NOLINT(build/c++11) +#include <utility> +#include <vector> + +#include "absl/base/call_once.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/internal/unscaledcycleclock.h" +#include "absl/base/thread_annotations.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +static int GetNumCPUs() { +#if defined(__myriad2__) + return 1; +#else + // Other possibilities: + // - Read /sys/devices/system/cpu/online and use cpumask_parse() + // - sysconf(_SC_NPROCESSORS_ONLN) + return std::thread::hardware_concurrency(); +#endif +} + +#if defined(_WIN32) + +static double GetNominalCPUFrequency() { +#if WINAPI_FAMILY_PARTITION(WINAPI_PARTITION_APP) && \ + !WINAPI_FAMILY_PARTITION(WINAPI_PARTITION_DESKTOP) + // UWP apps don't have access to the registry and currently don't provide an + // API informing about CPU nominal frequency. + return 1.0; +#else +#pragma comment(lib, "advapi32.lib") // For Reg* functions. + HKEY key; + // Use the Reg* functions rather than the SH functions because shlwapi.dll + // pulls in gdi32.dll which makes process destruction much more costly. + if (RegOpenKeyExA(HKEY_LOCAL_MACHINE, + "HARDWARE\\DESCRIPTION\\System\\CentralProcessor\\0", 0, + KEY_READ, &key) == ERROR_SUCCESS) { + DWORD type = 0; + DWORD data = 0; + DWORD data_size = sizeof(data); + auto result = RegQueryValueExA(key, "~MHz", 0, &type, + reinterpret_cast<LPBYTE>(&data), &data_size); + RegCloseKey(key); + if (result == ERROR_SUCCESS && type == REG_DWORD && + data_size == sizeof(data)) { + return data * 1e6; // Value is MHz. + } + } + return 1.0; +#endif // WINAPI_PARTITION_APP && !WINAPI_PARTITION_DESKTOP +} + +#elif defined(CTL_HW) && defined(HW_CPU_FREQ) + +static double GetNominalCPUFrequency() { + unsigned freq; + size_t size = sizeof(freq); + int mib[2] = {CTL_HW, HW_CPU_FREQ}; + if (sysctl(mib, 2, &freq, &size, nullptr, 0) == 0) { + return static_cast<double>(freq); + } + return 1.0; +} + +#else + +// Helper function for reading a long from a file. Returns true if successful +// and the memory location pointed to by value is set to the value read. +static bool ReadLongFromFile(const char *file, long *value) { + bool ret = false; + int fd = open(file, O_RDONLY); + if (fd != -1) { + char line[1024]; + char *err; + memset(line, '\0', sizeof(line)); + int len = read(fd, line, sizeof(line) - 1); + if (len <= 0) { + ret = false; + } else { + const long temp_value = strtol(line, &err, 10); + if (line[0] != '\0' && (*err == '\n' || *err == '\0')) { + *value = temp_value; + ret = true; + } + } + close(fd); + } + return ret; +} + +#if defined(ABSL_INTERNAL_UNSCALED_CYCLECLOCK_FREQUENCY_IS_CPU_FREQUENCY) + +// Reads a monotonic time source and returns a value in +// nanoseconds. The returned value uses an arbitrary epoch, not the +// Unix epoch. +static int64_t ReadMonotonicClockNanos() { + struct timespec t; +#ifdef CLOCK_MONOTONIC_RAW + int rc = clock_gettime(CLOCK_MONOTONIC_RAW, &t); +#else + int rc = clock_gettime(CLOCK_MONOTONIC, &t); +#endif + if (rc != 0) { + perror("clock_gettime() failed"); + abort(); + } + return int64_t{t.tv_sec} * 1000000000 + t.tv_nsec; +} + +class UnscaledCycleClockWrapperForInitializeFrequency { + public: + static int64_t Now() { return base_internal::UnscaledCycleClock::Now(); } +}; + +struct TimeTscPair { + int64_t time; // From ReadMonotonicClockNanos(). + int64_t tsc; // From UnscaledCycleClock::Now(). +}; + +// Returns a pair of values (monotonic kernel time, TSC ticks) that +// approximately correspond to each other. This is accomplished by +// doing several reads and picking the reading with the lowest +// latency. This approach is used to minimize the probability that +// our thread was preempted between clock reads. +static TimeTscPair GetTimeTscPair() { + int64_t best_latency = std::numeric_limits<int64_t>::max(); + TimeTscPair best; + for (int i = 0; i < 10; ++i) { + int64_t t0 = ReadMonotonicClockNanos(); + int64_t tsc = UnscaledCycleClockWrapperForInitializeFrequency::Now(); + int64_t t1 = ReadMonotonicClockNanos(); + int64_t latency = t1 - t0; + if (latency < best_latency) { + best_latency = latency; + best.time = t0; + best.tsc = tsc; + } + } + return best; +} + +// Measures and returns the TSC frequency by taking a pair of +// measurements approximately `sleep_nanoseconds` apart. +static double MeasureTscFrequencyWithSleep(int sleep_nanoseconds) { + auto t0 = GetTimeTscPair(); + struct timespec ts; + ts.tv_sec = 0; + ts.tv_nsec = sleep_nanoseconds; + while (nanosleep(&ts, &ts) != 0 && errno == EINTR) {} + auto t1 = GetTimeTscPair(); + double elapsed_ticks = t1.tsc - t0.tsc; + double elapsed_time = (t1.time - t0.time) * 1e-9; + return elapsed_ticks / elapsed_time; +} + +// Measures and returns the TSC frequency by calling +// MeasureTscFrequencyWithSleep(), doubling the sleep interval until the +// frequency measurement stabilizes. +static double MeasureTscFrequency() { + double last_measurement = -1.0; + int sleep_nanoseconds = 1000000; // 1 millisecond. + for (int i = 0; i < 8; ++i) { + double measurement = MeasureTscFrequencyWithSleep(sleep_nanoseconds); + if (measurement * 0.99 < last_measurement && + last_measurement < measurement * 1.01) { + // Use the current measurement if it is within 1% of the + // previous measurement. + return measurement; + } + last_measurement = measurement; + sleep_nanoseconds *= 2; + } + return last_measurement; +} + +#endif // ABSL_INTERNAL_UNSCALED_CYCLECLOCK_FREQUENCY_IS_CPU_FREQUENCY + +static double GetNominalCPUFrequency() { + long freq = 0; + + // Google's production kernel has a patch to export the TSC + // frequency through sysfs. If the kernel is exporting the TSC + // frequency use that. There are issues where cpuinfo_max_freq + // cannot be relied on because the BIOS may be exporting an invalid + // p-state (on x86) or p-states may be used to put the processor in + // a new mode (turbo mode). Essentially, those frequencies cannot + // always be relied upon. The same reasons apply to /proc/cpuinfo as + // well. + if (ReadLongFromFile("/sys/devices/system/cpu/cpu0/tsc_freq_khz", &freq)) { + return freq * 1e3; // Value is kHz. + } + +#if defined(ABSL_INTERNAL_UNSCALED_CYCLECLOCK_FREQUENCY_IS_CPU_FREQUENCY) + // On these platforms, the TSC frequency is the nominal CPU + // frequency. But without having the kernel export it directly + // though /sys/devices/system/cpu/cpu0/tsc_freq_khz, there is no + // other way to reliably get the TSC frequency, so we have to + // measure it ourselves. Some CPUs abuse cpuinfo_max_freq by + // exporting "fake" frequencies for implementing new features. For + // example, Intel's turbo mode is enabled by exposing a p-state + // value with a higher frequency than that of the real TSC + // rate. Because of this, we prefer to measure the TSC rate + // ourselves on i386 and x86-64. + return MeasureTscFrequency(); +#else + + // If CPU scaling is in effect, we want to use the *maximum* + // frequency, not whatever CPU speed some random processor happens + // to be using now. + if (ReadLongFromFile("/sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq", + &freq)) { + return freq * 1e3; // Value is kHz. + } + + return 1.0; +#endif // !ABSL_INTERNAL_UNSCALED_CYCLECLOCK_FREQUENCY_IS_CPU_FREQUENCY +} + +#endif + +ABSL_CONST_INIT static once_flag init_num_cpus_once; +ABSL_CONST_INIT static int num_cpus = 0; + +// NumCPUs() may be called before main() and before malloc is properly +// initialized, therefore this must not allocate memory. +int NumCPUs() { + base_internal::LowLevelCallOnce( + &init_num_cpus_once, []() { num_cpus = GetNumCPUs(); }); + return num_cpus; +} + +// A default frequency of 0.0 might be dangerous if it is used in division. +ABSL_CONST_INIT static once_flag init_nominal_cpu_frequency_once; +ABSL_CONST_INIT static double nominal_cpu_frequency = 1.0; + +// NominalCPUFrequency() may be called before main() and before malloc is +// properly initialized, therefore this must not allocate memory. +double NominalCPUFrequency() { + base_internal::LowLevelCallOnce( + &init_nominal_cpu_frequency_once, + []() { nominal_cpu_frequency = GetNominalCPUFrequency(); }); + return nominal_cpu_frequency; +} + +#if defined(_WIN32) + +pid_t GetTID() { + return pid_t{GetCurrentThreadId()}; +} + +#elif defined(__linux__) + +#ifndef SYS_gettid +#define SYS_gettid __NR_gettid +#endif + +pid_t GetTID() { + return syscall(SYS_gettid); +} + +#elif defined(__akaros__) + +pid_t GetTID() { + // Akaros has a concept of "vcore context", which is the state the program + // is forced into when we need to make a user-level scheduling decision, or + // run a signal handler. This is analogous to the interrupt context that a + // CPU might enter if it encounters some kind of exception. + // + // There is no current thread context in vcore context, but we need to give + // a reasonable answer if asked for a thread ID (e.g., in a signal handler). + // Thread 0 always exists, so if we are in vcore context, we return that. + // + // Otherwise, we know (since we are using pthreads) that the uthread struct + // current_uthread is pointing to is the first element of a + // struct pthread_tcb, so we extract and return the thread ID from that. + // + // TODO(dcross): Akaros anticipates moving the thread ID to the uthread + // structure at some point. We should modify this code to remove the cast + // when that happens. + if (in_vcore_context()) + return 0; + return reinterpret_cast<struct pthread_tcb *>(current_uthread)->id; +} + +#elif defined(__myriad2__) + +pid_t GetTID() { + uint32_t tid; + rtems_task_ident(RTEMS_SELF, 0, &tid); + return tid; +} + +#else + +// Fallback implementation of GetTID using pthread_getspecific. +ABSL_CONST_INIT static once_flag tid_once; +ABSL_CONST_INIT static pthread_key_t tid_key; +ABSL_CONST_INIT static absl::base_internal::SpinLock tid_lock( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); + +// We set a bit per thread in this array to indicate that an ID is in +// use. ID 0 is unused because it is the default value returned by +// pthread_getspecific(). +ABSL_CONST_INIT static std::vector<uint32_t> *tid_array + ABSL_GUARDED_BY(tid_lock) = nullptr; +static constexpr int kBitsPerWord = 32; // tid_array is uint32_t. + +// Returns the TID to tid_array. +static void FreeTID(void *v) { + intptr_t tid = reinterpret_cast<intptr_t>(v); + int word = tid / kBitsPerWord; + uint32_t mask = ~(1u << (tid % kBitsPerWord)); + absl::base_internal::SpinLockHolder lock(&tid_lock); + assert(0 <= word && static_cast<size_t>(word) < tid_array->size()); + (*tid_array)[word] &= mask; +} + +static void InitGetTID() { + if (pthread_key_create(&tid_key, FreeTID) != 0) { + // The logging system calls GetTID() so it can't be used here. + perror("pthread_key_create failed"); + abort(); + } + + // Initialize tid_array. + absl::base_internal::SpinLockHolder lock(&tid_lock); + tid_array = new std::vector<uint32_t>(1); + (*tid_array)[0] = 1; // ID 0 is never-allocated. +} + +// Return a per-thread small integer ID from pthread's thread-specific data. +pid_t GetTID() { + absl::call_once(tid_once, InitGetTID); + + intptr_t tid = reinterpret_cast<intptr_t>(pthread_getspecific(tid_key)); + if (tid != 0) { + return tid; + } + + int bit; // tid_array[word] = 1u << bit; + size_t word; + { + // Search for the first unused ID. + absl::base_internal::SpinLockHolder lock(&tid_lock); + // First search for a word in the array that is not all ones. + word = 0; + while (word < tid_array->size() && ~(*tid_array)[word] == 0) { + ++word; + } + if (word == tid_array->size()) { + tid_array->push_back(0); // No space left, add kBitsPerWord more IDs. + } + // Search for a zero bit in the word. + bit = 0; + while (bit < kBitsPerWord && (((*tid_array)[word] >> bit) & 1) != 0) { + ++bit; + } + tid = (word * kBitsPerWord) + bit; + (*tid_array)[word] |= 1u << bit; // Mark the TID as allocated. + } + + if (pthread_setspecific(tid_key, reinterpret_cast<void *>(tid)) != 0) { + perror("pthread_setspecific failed"); + abort(); + } + + return static_cast<pid_t>(tid); +} + +#endif + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/sysinfo.h b/third_party/abseil_cpp/absl/base/internal/sysinfo.h new file mode 100644 index 0000000000..7246d5dd95 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/sysinfo.h @@ -0,0 +1,66 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file includes routines to find out characteristics +// of the machine a program is running on. It is undoubtedly +// system-dependent. + +// Functions listed here that accept a pid_t as an argument act on the +// current process if the pid_t argument is 0 +// All functions here are thread-hostile due to file caching unless +// commented otherwise. + +#ifndef ABSL_BASE_INTERNAL_SYSINFO_H_ +#define ABSL_BASE_INTERNAL_SYSINFO_H_ + +#ifndef _WIN32 +#include <sys/types.h> +#endif + +#include <cstdint> + +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// Nominal core processor cycles per second of each processor. This is _not_ +// necessarily the frequency of the CycleClock counter (see cycleclock.h) +// Thread-safe. +double NominalCPUFrequency(); + +// Number of logical processors (hyperthreads) in system. Thread-safe. +int NumCPUs(); + +// Return the thread id of the current thread, as told by the system. +// No two currently-live threads implemented by the OS shall have the same ID. +// Thread ids of exited threads may be reused. Multiple user-level threads +// may have the same thread ID if multiplexed on the same OS thread. +// +// On Linux, you may send a signal to the resulting ID with kill(). However, +// it is recommended for portability that you use pthread_kill() instead. +#ifdef _WIN32 +// On Windows, process id and thread id are of the same type according to the +// return types of GetProcessId() and GetThreadId() are both DWORD, an unsigned +// 32-bit type. +using pid_t = uint32_t; +#endif +pid_t GetTID(); + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_SYSINFO_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/sysinfo_test.cc b/third_party/abseil_cpp/absl/base/internal/sysinfo_test.cc new file mode 100644 index 0000000000..fa8b88b1dc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/sysinfo_test.cc @@ -0,0 +1,100 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/sysinfo.h" + +#ifndef _WIN32 +#include <sys/types.h> +#include <unistd.h> +#endif + +#include <thread> // NOLINT(build/c++11) +#include <unordered_set> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/synchronization/barrier.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { + +TEST(SysinfoTest, NumCPUs) { + EXPECT_NE(NumCPUs(), 0) + << "NumCPUs() should not have the default value of 0"; +} + +TEST(SysinfoTest, NominalCPUFrequency) { +#if !(defined(__aarch64__) && defined(__linux__)) && !defined(__EMSCRIPTEN__) + EXPECT_GE(NominalCPUFrequency(), 1000.0) + << "NominalCPUFrequency() did not return a reasonable value"; +#else + // Aarch64 cannot read the CPU frequency from sysfs, so we get back 1.0. + // Emscripten does not have a sysfs to read from at all. + EXPECT_EQ(NominalCPUFrequency(), 1.0) + << "CPU frequency detection was fixed! Please update unittest."; +#endif +} + +TEST(SysinfoTest, GetTID) { + EXPECT_EQ(GetTID(), GetTID()); // Basic compile and equality test. +#ifdef __native_client__ + // Native Client has a race condition bug that leads to memory + // exaustion when repeatedly creating and joining threads. + // https://bugs.chromium.org/p/nativeclient/issues/detail?id=1027 + return; +#endif + // Test that TIDs are unique to each thread. + // Uses a few loops to exercise implementations that reallocate IDs. + for (int i = 0; i < 10; ++i) { + constexpr int kNumThreads = 10; + Barrier all_threads_done(kNumThreads); + std::vector<std::thread> threads; + + Mutex mutex; + std::unordered_set<pid_t> tids; + + for (int j = 0; j < kNumThreads; ++j) { + threads.push_back(std::thread([&]() { + pid_t id = GetTID(); + { + MutexLock lock(&mutex); + ASSERT_TRUE(tids.find(id) == tids.end()); + tids.insert(id); + } + // We can't simply join the threads here. The threads need to + // be alive otherwise the TID might have been reallocated to + // another live thread. + all_threads_done.Block(); + })); + } + for (auto& thread : threads) { + thread.join(); + } + } +} + +#ifdef __linux__ +TEST(SysinfoTest, LinuxGetTID) { + // On Linux, for the main thread, GetTID()==getpid() is guaranteed by the API. + EXPECT_EQ(GetTID(), getpid()); +} +#endif + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/thread_annotations.h b/third_party/abseil_cpp/absl/base/internal/thread_annotations.h new file mode 100644 index 0000000000..4dab6a9c15 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/thread_annotations.h @@ -0,0 +1,271 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: thread_annotations.h +// ----------------------------------------------------------------------------- +// +// WARNING: This is a backwards compatible header and it will be removed after +// the migration to prefixed thread annotations is finished; please include +// "absl/base/thread_annotations.h". +// +// This header file contains macro definitions for thread safety annotations +// that allow developers to document the locking policies of multi-threaded +// code. The annotations can also help program analysis tools to identify +// potential thread safety issues. +// +// These annotations are implemented using compiler attributes. Using the macros +// defined here instead of raw attributes allow for portability and future +// compatibility. +// +// When referring to mutexes in the arguments of the attributes, you should +// use variable names or more complex expressions (e.g. my_object->mutex_) +// that evaluate to a concrete mutex object whenever possible. If the mutex +// you want to refer to is not in scope, you may use a member pointer +// (e.g. &MyClass::mutex_) to refer to a mutex in some (unknown) object. + +#ifndef ABSL_BASE_INTERNAL_THREAD_ANNOTATIONS_H_ +#define ABSL_BASE_INTERNAL_THREAD_ANNOTATIONS_H_ + +#if defined(__clang__) +#define THREAD_ANNOTATION_ATTRIBUTE__(x) __attribute__((x)) +#else +#define THREAD_ANNOTATION_ATTRIBUTE__(x) // no-op +#endif + +// GUARDED_BY() +// +// Documents if a shared field or global variable needs to be protected by a +// mutex. GUARDED_BY() allows the user to specify a particular mutex that +// should be held when accessing the annotated variable. +// +// Although this annotation (and PT_GUARDED_BY, below) cannot be applied to +// local variables, a local variable and its associated mutex can often be +// combined into a small class or struct, thereby allowing the annotation. +// +// Example: +// +// class Foo { +// Mutex mu_; +// int p1_ GUARDED_BY(mu_); +// ... +// }; +#define GUARDED_BY(x) THREAD_ANNOTATION_ATTRIBUTE__(guarded_by(x)) + +// PT_GUARDED_BY() +// +// Documents if the memory location pointed to by a pointer should be guarded +// by a mutex when dereferencing the pointer. +// +// Example: +// class Foo { +// Mutex mu_; +// int *p1_ PT_GUARDED_BY(mu_); +// ... +// }; +// +// Note that a pointer variable to a shared memory location could itself be a +// shared variable. +// +// Example: +// +// // `q_`, guarded by `mu1_`, points to a shared memory location that is +// // guarded by `mu2_`: +// int *q_ GUARDED_BY(mu1_) PT_GUARDED_BY(mu2_); +#define PT_GUARDED_BY(x) THREAD_ANNOTATION_ATTRIBUTE__(pt_guarded_by(x)) + +// ACQUIRED_AFTER() / ACQUIRED_BEFORE() +// +// Documents the acquisition order between locks that can be held +// simultaneously by a thread. For any two locks that need to be annotated +// to establish an acquisition order, only one of them needs the annotation. +// (i.e. You don't have to annotate both locks with both ACQUIRED_AFTER +// and ACQUIRED_BEFORE.) +// +// As with GUARDED_BY, this is only applicable to mutexes that are shared +// fields or global variables. +// +// Example: +// +// Mutex m1_; +// Mutex m2_ ACQUIRED_AFTER(m1_); +#define ACQUIRED_AFTER(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(acquired_after(__VA_ARGS__)) + +#define ACQUIRED_BEFORE(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(acquired_before(__VA_ARGS__)) + +// EXCLUSIVE_LOCKS_REQUIRED() / SHARED_LOCKS_REQUIRED() +// +// Documents a function that expects a mutex to be held prior to entry. +// The mutex is expected to be held both on entry to, and exit from, the +// function. +// +// An exclusive lock allows read-write access to the guarded data member(s), and +// only one thread can acquire a lock exclusively at any one time. A shared lock +// allows read-only access, and any number of threads can acquire a shared lock +// concurrently. +// +// Generally, non-const methods should be annotated with +// EXCLUSIVE_LOCKS_REQUIRED, while const methods should be annotated with +// SHARED_LOCKS_REQUIRED. +// +// Example: +// +// Mutex mu1, mu2; +// int a GUARDED_BY(mu1); +// int b GUARDED_BY(mu2); +// +// void foo() EXCLUSIVE_LOCKS_REQUIRED(mu1, mu2) { ... } +// void bar() const SHARED_LOCKS_REQUIRED(mu1, mu2) { ... } +#define EXCLUSIVE_LOCKS_REQUIRED(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(exclusive_locks_required(__VA_ARGS__)) + +#define SHARED_LOCKS_REQUIRED(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(shared_locks_required(__VA_ARGS__)) + +// LOCKS_EXCLUDED() +// +// Documents the locks acquired in the body of the function. These locks +// cannot be held when calling this function (as Abseil's `Mutex` locks are +// non-reentrant). +#define LOCKS_EXCLUDED(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(locks_excluded(__VA_ARGS__)) + +// LOCK_RETURNED() +// +// Documents a function that returns a mutex without acquiring it. For example, +// a public getter method that returns a pointer to a private mutex should +// be annotated with LOCK_RETURNED. +#define LOCK_RETURNED(x) \ + THREAD_ANNOTATION_ATTRIBUTE__(lock_returned(x)) + +// LOCKABLE +// +// Documents if a class/type is a lockable type (such as the `Mutex` class). +#define LOCKABLE \ + THREAD_ANNOTATION_ATTRIBUTE__(lockable) + +// SCOPED_LOCKABLE +// +// Documents if a class does RAII locking (such as the `MutexLock` class). +// The constructor should use `LOCK_FUNCTION()` to specify the mutex that is +// acquired, and the destructor should use `UNLOCK_FUNCTION()` with no +// arguments; the analysis will assume that the destructor unlocks whatever the +// constructor locked. +#define SCOPED_LOCKABLE \ + THREAD_ANNOTATION_ATTRIBUTE__(scoped_lockable) + +// EXCLUSIVE_LOCK_FUNCTION() +// +// Documents functions that acquire a lock in the body of a function, and do +// not release it. +#define EXCLUSIVE_LOCK_FUNCTION(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(exclusive_lock_function(__VA_ARGS__)) + +// SHARED_LOCK_FUNCTION() +// +// Documents functions that acquire a shared (reader) lock in the body of a +// function, and do not release it. +#define SHARED_LOCK_FUNCTION(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(shared_lock_function(__VA_ARGS__)) + +// UNLOCK_FUNCTION() +// +// Documents functions that expect a lock to be held on entry to the function, +// and release it in the body of the function. +#define UNLOCK_FUNCTION(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(unlock_function(__VA_ARGS__)) + +// EXCLUSIVE_TRYLOCK_FUNCTION() / SHARED_TRYLOCK_FUNCTION() +// +// Documents functions that try to acquire a lock, and return success or failure +// (or a non-boolean value that can be interpreted as a boolean). +// The first argument should be `true` for functions that return `true` on +// success, or `false` for functions that return `false` on success. The second +// argument specifies the mutex that is locked on success. If unspecified, this +// mutex is assumed to be `this`. +#define EXCLUSIVE_TRYLOCK_FUNCTION(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(exclusive_trylock_function(__VA_ARGS__)) + +#define SHARED_TRYLOCK_FUNCTION(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(shared_trylock_function(__VA_ARGS__)) + +// ASSERT_EXCLUSIVE_LOCK() / ASSERT_SHARED_LOCK() +// +// Documents functions that dynamically check to see if a lock is held, and fail +// if it is not held. +#define ASSERT_EXCLUSIVE_LOCK(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(assert_exclusive_lock(__VA_ARGS__)) + +#define ASSERT_SHARED_LOCK(...) \ + THREAD_ANNOTATION_ATTRIBUTE__(assert_shared_lock(__VA_ARGS__)) + +// NO_THREAD_SAFETY_ANALYSIS +// +// Turns off thread safety checking within the body of a particular function. +// This annotation is used to mark functions that are known to be correct, but +// the locking behavior is more complicated than the analyzer can handle. +#define NO_THREAD_SAFETY_ANALYSIS \ + THREAD_ANNOTATION_ATTRIBUTE__(no_thread_safety_analysis) + +//------------------------------------------------------------------------------ +// Tool-Supplied Annotations +//------------------------------------------------------------------------------ + +// TS_UNCHECKED should be placed around lock expressions that are not valid +// C++ syntax, but which are present for documentation purposes. These +// annotations will be ignored by the analysis. +#define TS_UNCHECKED(x) "" + +// TS_FIXME is used to mark lock expressions that are not valid C++ syntax. +// It is used by automated tools to mark and disable invalid expressions. +// The annotation should either be fixed, or changed to TS_UNCHECKED. +#define TS_FIXME(x) "" + +// Like NO_THREAD_SAFETY_ANALYSIS, this turns off checking within the body of +// a particular function. However, this attribute is used to mark functions +// that are incorrect and need to be fixed. It is used by automated tools to +// avoid breaking the build when the analysis is updated. +// Code owners are expected to eventually fix the routine. +#define NO_THREAD_SAFETY_ANALYSIS_FIXME NO_THREAD_SAFETY_ANALYSIS + +// Similar to NO_THREAD_SAFETY_ANALYSIS_FIXME, this macro marks a GUARDED_BY +// annotation that needs to be fixed, because it is producing thread safety +// warning. It disables the GUARDED_BY. +#define GUARDED_BY_FIXME(x) + +// Disables warnings for a single read operation. This can be used to avoid +// warnings when it is known that the read is not actually involved in a race, +// but the compiler cannot confirm that. +#define TS_UNCHECKED_READ(x) thread_safety_analysis::ts_unchecked_read(x) + + +namespace thread_safety_analysis { + +// Takes a reference to a guarded data member, and returns an unguarded +// reference. +template <typename T> +inline const T& ts_unchecked_read(const T& v) NO_THREAD_SAFETY_ANALYSIS { + return v; +} + +template <typename T> +inline T& ts_unchecked_read(T& v) NO_THREAD_SAFETY_ANALYSIS { + return v; +} + +} // namespace thread_safety_analysis + +#endif // ABSL_BASE_INTERNAL_THREAD_ANNOTATIONS_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/thread_identity.cc b/third_party/abseil_cpp/absl/base/internal/thread_identity.cc new file mode 100644 index 0000000000..d63a04ae91 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/thread_identity.cc @@ -0,0 +1,152 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/thread_identity.h" + +#ifndef _WIN32 +#include <pthread.h> +#include <signal.h> +#endif + +#include <atomic> +#include <cassert> +#include <memory> + +#include "absl/base/call_once.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +#if ABSL_THREAD_IDENTITY_MODE != ABSL_THREAD_IDENTITY_MODE_USE_CPP11 +namespace { +// Used to co-ordinate one-time creation of our pthread_key +absl::once_flag init_thread_identity_key_once; +pthread_key_t thread_identity_pthread_key; +std::atomic<bool> pthread_key_initialized(false); + +void AllocateThreadIdentityKey(ThreadIdentityReclaimerFunction reclaimer) { + pthread_key_create(&thread_identity_pthread_key, reclaimer); + pthread_key_initialized.store(true, std::memory_order_release); +} +} // namespace +#endif + +#if ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_TLS || \ + ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_CPP11 +// The actual TLS storage for a thread's currently associated ThreadIdentity. +// This is referenced by inline accessors in the header. +// "protected" visibility ensures that if multiple instances of Abseil code +// exist within a process (via dlopen() or similar), references to +// thread_identity_ptr from each instance of the code will refer to +// *different* instances of this ptr. +#ifdef __GNUC__ +__attribute__((visibility("protected"))) +#endif // __GNUC__ +#if ABSL_PER_THREAD_TLS +// Prefer __thread to thread_local as benchmarks indicate it is a bit faster. +ABSL_PER_THREAD_TLS_KEYWORD ThreadIdentity* thread_identity_ptr = nullptr; +#elif defined(ABSL_HAVE_THREAD_LOCAL) +thread_local ThreadIdentity* thread_identity_ptr = nullptr; +#endif // ABSL_PER_THREAD_TLS +#endif // TLS or CPP11 + +void SetCurrentThreadIdentity( + ThreadIdentity* identity, ThreadIdentityReclaimerFunction reclaimer) { + assert(CurrentThreadIdentityIfPresent() == nullptr); + // Associate our destructor. + // NOTE: This call to pthread_setspecific is currently the only immovable + // barrier to CurrentThreadIdentity() always being async signal safe. +#if ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC + // NOTE: Not async-safe. But can be open-coded. + absl::call_once(init_thread_identity_key_once, AllocateThreadIdentityKey, + reclaimer); + +#if defined(__EMSCRIPTEN__) || defined(__MINGW32__) + // Emscripten and MinGW pthread implementations does not support signals. + // See https://kripken.github.io/emscripten-site/docs/porting/pthreads.html + // for more information. + pthread_setspecific(thread_identity_pthread_key, + reinterpret_cast<void*>(identity)); +#else + // We must mask signals around the call to setspecific as with current glibc, + // a concurrent getspecific (needed for GetCurrentThreadIdentityIfPresent()) + // may zero our value. + // + // While not officially async-signal safe, getspecific within a signal handler + // is otherwise OK. + sigset_t all_signals; + sigset_t curr_signals; + sigfillset(&all_signals); + pthread_sigmask(SIG_SETMASK, &all_signals, &curr_signals); + pthread_setspecific(thread_identity_pthread_key, + reinterpret_cast<void*>(identity)); + pthread_sigmask(SIG_SETMASK, &curr_signals, nullptr); +#endif // !__EMSCRIPTEN__ && !__MINGW32__ + +#elif ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_TLS + // NOTE: Not async-safe. But can be open-coded. + absl::call_once(init_thread_identity_key_once, AllocateThreadIdentityKey, + reclaimer); + pthread_setspecific(thread_identity_pthread_key, + reinterpret_cast<void*>(identity)); + thread_identity_ptr = identity; +#elif ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_CPP11 + thread_local std::unique_ptr<ThreadIdentity, ThreadIdentityReclaimerFunction> + holder(identity, reclaimer); + thread_identity_ptr = identity; +#else +#error Unimplemented ABSL_THREAD_IDENTITY_MODE +#endif +} + +#if ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_TLS || \ + ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_CPP11 + +// Please see the comment on `CurrentThreadIdentityIfPresent` in +// thread_identity.h. Because DLLs cannot expose thread_local variables in +// headers, we opt for the correct-but-slower option of placing the definition +// of this function only in a translation unit inside DLL. +#if defined(ABSL_BUILD_DLL) || defined(ABSL_CONSUME_DLL) +ThreadIdentity* CurrentThreadIdentityIfPresent() { return thread_identity_ptr; } +#endif +#endif + +void ClearCurrentThreadIdentity() { +#if ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_TLS || \ + ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_CPP11 + thread_identity_ptr = nullptr; +#elif ABSL_THREAD_IDENTITY_MODE == \ + ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC + // pthread_setspecific expected to clear value on destruction + assert(CurrentThreadIdentityIfPresent() == nullptr); +#endif +} + +#if ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC +ThreadIdentity* CurrentThreadIdentityIfPresent() { + bool initialized = pthread_key_initialized.load(std::memory_order_acquire); + if (!initialized) { + return nullptr; + } + return reinterpret_cast<ThreadIdentity*>( + pthread_getspecific(thread_identity_pthread_key)); +} +#endif + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/thread_identity.h b/third_party/abseil_cpp/absl/base/internal/thread_identity.h new file mode 100644 index 0000000000..ceb109b41c --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/thread_identity.h @@ -0,0 +1,259 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Each active thread has an ThreadIdentity that may represent the thread in +// various level interfaces. ThreadIdentity objects are never deallocated. +// When a thread terminates, its ThreadIdentity object may be reused for a +// thread created later. + +#ifndef ABSL_BASE_INTERNAL_THREAD_IDENTITY_H_ +#define ABSL_BASE_INTERNAL_THREAD_IDENTITY_H_ + +#ifndef _WIN32 +#include <pthread.h> +// Defines __GOOGLE_GRTE_VERSION__ (via glibc-specific features.h) when +// supported. +#include <unistd.h> +#endif + +#include <atomic> +#include <cstdint> + +#include "absl/base/config.h" +#include "absl/base/internal/per_thread_tls.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +struct SynchLocksHeld; +struct SynchWaitParams; + +namespace base_internal { + +class SpinLock; +struct ThreadIdentity; + +// Used by the implementation of absl::Mutex and absl::CondVar. +struct PerThreadSynch { + // The internal representation of absl::Mutex and absl::CondVar rely + // on the alignment of PerThreadSynch. Both store the address of the + // PerThreadSynch in the high-order bits of their internal state, + // which means the low kLowZeroBits of the address of PerThreadSynch + // must be zero. + static constexpr int kLowZeroBits = 8; + static constexpr int kAlignment = 1 << kLowZeroBits; + + // Returns the associated ThreadIdentity. + // This can be implemented as a cast because we guarantee + // PerThreadSynch is the first element of ThreadIdentity. + ThreadIdentity* thread_identity() { + return reinterpret_cast<ThreadIdentity*>(this); + } + + PerThreadSynch *next; // Circular waiter queue; initialized to 0. + PerThreadSynch *skip; // If non-zero, all entries in Mutex queue + // up to and including "skip" have same + // condition as this, and will be woken later + bool may_skip; // if false while on mutex queue, a mutex unlocker + // is using this PerThreadSynch as a terminator. Its + // skip field must not be filled in because the loop + // might then skip over the terminator. + + // The wait parameters of the current wait. waitp is null if the + // thread is not waiting. Transitions from null to non-null must + // occur before the enqueue commit point (state = kQueued in + // Enqueue() and CondVarEnqueue()). Transitions from non-null to + // null must occur after the wait is finished (state = kAvailable in + // Mutex::Block() and CondVar::WaitCommon()). This field may be + // changed only by the thread that describes this PerThreadSynch. A + // special case is Fer(), which calls Enqueue() on another thread, + // but with an identical SynchWaitParams pointer, thus leaving the + // pointer unchanged. + SynchWaitParams *waitp; + + bool suppress_fatal_errors; // If true, try to proceed even in the face of + // broken invariants. This is used within fatal + // signal handlers to improve the chances of + // debug logging information being output + // successfully. + + intptr_t readers; // Number of readers in mutex. + int priority; // Priority of thread (updated every so often). + + // When priority will next be read (cycles). + int64_t next_priority_read_cycles; + + // State values: + // kAvailable: This PerThreadSynch is available. + // kQueued: This PerThreadSynch is unavailable, it's currently queued on a + // Mutex or CondVar waistlist. + // + // Transitions from kQueued to kAvailable require a release + // barrier. This is needed as a waiter may use "state" to + // independently observe that it's no longer queued. + // + // Transitions from kAvailable to kQueued require no barrier, they + // are externally ordered by the Mutex. + enum State { + kAvailable, + kQueued + }; + std::atomic<State> state; + + bool maybe_unlocking; // Valid at head of Mutex waiter queue; + // true if UnlockSlow could be searching + // for a waiter to wake. Used for an optimization + // in Enqueue(). true is always a valid value. + // Can be reset to false when the unlocker or any + // writer releases the lock, or a reader fully releases + // the lock. It may not be set to false by a reader + // that decrements the count to non-zero. + // protected by mutex spinlock + + bool wake; // This thread is to be woken from a Mutex. + + // If "x" is on a waiter list for a mutex, "x->cond_waiter" is true iff the + // waiter is waiting on the mutex as part of a CV Wait or Mutex Await. + // + // The value of "x->cond_waiter" is meaningless if "x" is not on a + // Mutex waiter list. + bool cond_waiter; + + // Locks held; used during deadlock detection. + // Allocated in Synch_GetAllLocks() and freed in ReclaimThreadIdentity(). + SynchLocksHeld *all_locks; +}; + +struct ThreadIdentity { + // Must be the first member. The Mutex implementation requires that + // the PerThreadSynch object associated with each thread is + // PerThreadSynch::kAlignment aligned. We provide this alignment on + // ThreadIdentity itself. + PerThreadSynch per_thread_synch; + + // Private: Reserved for absl::synchronization_internal::Waiter. + struct WaiterState { + char data[128]; + } waiter_state; + + // Used by PerThreadSem::{Get,Set}ThreadBlockedCounter(). + std::atomic<int>* blocked_count_ptr; + + // The following variables are mostly read/written just by the + // thread itself. The only exception is that these are read by + // a ticker thread as a hint. + std::atomic<int> ticker; // Tick counter, incremented once per second. + std::atomic<int> wait_start; // Ticker value when thread started waiting. + std::atomic<bool> is_idle; // Has thread become idle yet? + + ThreadIdentity* next; +}; + +// Returns the ThreadIdentity object representing the calling thread; guaranteed +// to be unique for its lifetime. The returned object will remain valid for the +// program's lifetime; although it may be re-assigned to a subsequent thread. +// If one does not exist, return nullptr instead. +// +// Does not malloc(*), and is async-signal safe. +// [*] Technically pthread_setspecific() does malloc on first use; however this +// is handled internally within tcmalloc's initialization already. +// +// New ThreadIdentity objects can be constructed and associated with a thread +// by calling GetOrCreateCurrentThreadIdentity() in per-thread-sem.h. +ThreadIdentity* CurrentThreadIdentityIfPresent(); + +using ThreadIdentityReclaimerFunction = void (*)(void*); + +// Sets the current thread identity to the given value. 'reclaimer' is a +// pointer to the global function for cleaning up instances on thread +// destruction. +void SetCurrentThreadIdentity(ThreadIdentity* identity, + ThreadIdentityReclaimerFunction reclaimer); + +// Removes the currently associated ThreadIdentity from the running thread. +// This must be called from inside the ThreadIdentityReclaimerFunction, and only +// from that function. +void ClearCurrentThreadIdentity(); + +// May be chosen at compile time via: -DABSL_FORCE_THREAD_IDENTITY_MODE=<mode +// index> +#ifdef ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC +#error ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC cannot be direcly set +#else +#define ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC 0 +#endif + +#ifdef ABSL_THREAD_IDENTITY_MODE_USE_TLS +#error ABSL_THREAD_IDENTITY_MODE_USE_TLS cannot be direcly set +#else +#define ABSL_THREAD_IDENTITY_MODE_USE_TLS 1 +#endif + +#ifdef ABSL_THREAD_IDENTITY_MODE_USE_CPP11 +#error ABSL_THREAD_IDENTITY_MODE_USE_CPP11 cannot be direcly set +#else +#define ABSL_THREAD_IDENTITY_MODE_USE_CPP11 2 +#endif + +#ifdef ABSL_THREAD_IDENTITY_MODE +#error ABSL_THREAD_IDENTITY_MODE cannot be direcly set +#elif defined(ABSL_FORCE_THREAD_IDENTITY_MODE) +#define ABSL_THREAD_IDENTITY_MODE ABSL_FORCE_THREAD_IDENTITY_MODE +#elif defined(_WIN32) && !defined(__MINGW32__) +#define ABSL_THREAD_IDENTITY_MODE ABSL_THREAD_IDENTITY_MODE_USE_CPP11 +#elif ABSL_PER_THREAD_TLS && defined(__GOOGLE_GRTE_VERSION__) && \ + (__GOOGLE_GRTE_VERSION__ >= 20140228L) +// Support for async-safe TLS was specifically added in GRTEv4. It's not +// present in the upstream eglibc. +// Note: Current default for production systems. +#define ABSL_THREAD_IDENTITY_MODE ABSL_THREAD_IDENTITY_MODE_USE_TLS +#else +#define ABSL_THREAD_IDENTITY_MODE \ + ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC +#endif + +#if ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_TLS || \ + ABSL_THREAD_IDENTITY_MODE == ABSL_THREAD_IDENTITY_MODE_USE_CPP11 + +#if ABSL_PER_THREAD_TLS +ABSL_CONST_INIT extern ABSL_PER_THREAD_TLS_KEYWORD ThreadIdentity* + thread_identity_ptr; +#elif defined(ABSL_HAVE_THREAD_LOCAL) +ABSL_CONST_INIT extern thread_local ThreadIdentity* thread_identity_ptr; +#else +#error Thread-local storage not detected on this platform +#endif + +// thread_local variables cannot be in headers exposed by DLLs. However, it is +// important for performance reasons in general that +// `CurrentThreadIdentityIfPresent` be inlined. This is not possible across a +// DLL boundary so, with DLLs, we opt to have the function not be inlined. Note +// that `CurrentThreadIdentityIfPresent` is declared above so we can exclude +// this entire inline definition when compiling as a DLL. +#if !defined(ABSL_BUILD_DLL) && !defined(ABSL_CONSUME_DLL) +inline ThreadIdentity* CurrentThreadIdentityIfPresent() { + return thread_identity_ptr; +} +#endif + +#elif ABSL_THREAD_IDENTITY_MODE != \ + ABSL_THREAD_IDENTITY_MODE_USE_POSIX_SETSPECIFIC +#error Unknown ABSL_THREAD_IDENTITY_MODE +#endif + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_THREAD_IDENTITY_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/thread_identity_benchmark.cc b/third_party/abseil_cpp/absl/base/internal/thread_identity_benchmark.cc new file mode 100644 index 0000000000..0ae10f2b1e --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/thread_identity_benchmark.cc @@ -0,0 +1,38 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "benchmark/benchmark.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/synchronization/internal/create_thread_identity.h" +#include "absl/synchronization/internal/per_thread_sem.h" + +namespace { + +void BM_SafeCurrentThreadIdentity(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::synchronization_internal::GetOrCreateCurrentThreadIdentity()); + } +} +BENCHMARK(BM_SafeCurrentThreadIdentity); + +void BM_UnsafeCurrentThreadIdentity(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::base_internal::CurrentThreadIdentityIfPresent()); + } +} +BENCHMARK(BM_UnsafeCurrentThreadIdentity); + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/thread_identity_test.cc b/third_party/abseil_cpp/absl/base/internal/thread_identity_test.cc new file mode 100644 index 0000000000..624d5b96b6 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/thread_identity_test.cc @@ -0,0 +1,129 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/thread_identity.h" + +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/macros.h" +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/internal/per_thread_sem.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { + +ABSL_CONST_INIT static absl::base_internal::SpinLock map_lock( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); +ABSL_CONST_INIT static int num_identities_reused ABSL_GUARDED_BY(map_lock); + +static const void* const kCheckNoIdentity = reinterpret_cast<void*>(1); + +static void TestThreadIdentityCurrent(const void* assert_no_identity) { + ThreadIdentity* identity; + + // We have to test this conditionally, because if the test framework relies + // on Abseil, then some previous action may have already allocated an + // identity. + if (assert_no_identity == kCheckNoIdentity) { + identity = CurrentThreadIdentityIfPresent(); + EXPECT_TRUE(identity == nullptr); + } + + identity = synchronization_internal::GetOrCreateCurrentThreadIdentity(); + EXPECT_TRUE(identity != nullptr); + ThreadIdentity* identity_no_init; + identity_no_init = CurrentThreadIdentityIfPresent(); + EXPECT_TRUE(identity == identity_no_init); + + // Check that per_thread_synch is correctly aligned. + EXPECT_EQ(0, reinterpret_cast<intptr_t>(&identity->per_thread_synch) % + PerThreadSynch::kAlignment); + EXPECT_EQ(identity, identity->per_thread_synch.thread_identity()); + + absl::base_internal::SpinLockHolder l(&map_lock); + num_identities_reused++; +} + +TEST(ThreadIdentityTest, BasicIdentityWorks) { + // This tests for the main() thread. + TestThreadIdentityCurrent(nullptr); +} + +TEST(ThreadIdentityTest, BasicIdentityWorksThreaded) { + // Now try the same basic test with multiple threads being created and + // destroyed. This makes sure that: + // - New threads are created without a ThreadIdentity. + // - We re-allocate ThreadIdentity objects from the free-list. + // - If a thread implementation chooses to recycle threads, that + // correct re-initialization occurs. + static const int kNumLoops = 3; + static const int kNumThreads = 400; + for (int iter = 0; iter < kNumLoops; iter++) { + std::vector<std::thread> threads; + for (int i = 0; i < kNumThreads; ++i) { + threads.push_back( + std::thread(TestThreadIdentityCurrent, kCheckNoIdentity)); + } + for (auto& thread : threads) { + thread.join(); + } + } + + // We should have recycled ThreadIdentity objects above; while (external) + // library threads allocating their own identities may preclude some + // reuse, we should have sufficient repetitions to exclude this. + absl::base_internal::SpinLockHolder l(&map_lock); + EXPECT_LT(kNumThreads, num_identities_reused); +} + +TEST(ThreadIdentityTest, ReusedThreadIdentityMutexTest) { + // This test repeatly creates and joins a series of threads, each of + // which acquires and releases shared Mutex locks. This verifies + // Mutex operations work correctly under a reused + // ThreadIdentity. Note that the most likely failure mode of this + // test is a crash or deadlock. + static const int kNumLoops = 10; + static const int kNumThreads = 12; + static const int kNumMutexes = 3; + static const int kNumLockLoops = 5; + + Mutex mutexes[kNumMutexes]; + for (int iter = 0; iter < kNumLoops; ++iter) { + std::vector<std::thread> threads; + for (int thread = 0; thread < kNumThreads; ++thread) { + threads.push_back(std::thread([&]() { + for (int l = 0; l < kNumLockLoops; ++l) { + for (int m = 0; m < kNumMutexes; ++m) { + MutexLock lock(&mutexes[m]); + } + } + })); + } + for (auto& thread : threads) { + thread.join(); + } + } +} + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/throw_delegate.cc b/third_party/abseil_cpp/absl/base/internal/throw_delegate.cc new file mode 100644 index 0000000000..c055f75d9d --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/throw_delegate.cc @@ -0,0 +1,108 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/throw_delegate.h" + +#include <cstdlib> +#include <functional> +#include <new> +#include <stdexcept> +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +namespace { +template <typename T> +[[noreturn]] void Throw(const T& error) { +#ifdef ABSL_HAVE_EXCEPTIONS + throw error; +#else + ABSL_RAW_LOG(FATAL, "%s", error.what()); + std::abort(); +#endif +} +} // namespace + +void ThrowStdLogicError(const std::string& what_arg) { + Throw(std::logic_error(what_arg)); +} +void ThrowStdLogicError(const char* what_arg) { + Throw(std::logic_error(what_arg)); +} +void ThrowStdInvalidArgument(const std::string& what_arg) { + Throw(std::invalid_argument(what_arg)); +} +void ThrowStdInvalidArgument(const char* what_arg) { + Throw(std::invalid_argument(what_arg)); +} + +void ThrowStdDomainError(const std::string& what_arg) { + Throw(std::domain_error(what_arg)); +} +void ThrowStdDomainError(const char* what_arg) { + Throw(std::domain_error(what_arg)); +} + +void ThrowStdLengthError(const std::string& what_arg) { + Throw(std::length_error(what_arg)); +} +void ThrowStdLengthError(const char* what_arg) { + Throw(std::length_error(what_arg)); +} + +void ThrowStdOutOfRange(const std::string& what_arg) { + Throw(std::out_of_range(what_arg)); +} +void ThrowStdOutOfRange(const char* what_arg) { + Throw(std::out_of_range(what_arg)); +} + +void ThrowStdRuntimeError(const std::string& what_arg) { + Throw(std::runtime_error(what_arg)); +} +void ThrowStdRuntimeError(const char* what_arg) { + Throw(std::runtime_error(what_arg)); +} + +void ThrowStdRangeError(const std::string& what_arg) { + Throw(std::range_error(what_arg)); +} +void ThrowStdRangeError(const char* what_arg) { + Throw(std::range_error(what_arg)); +} + +void ThrowStdOverflowError(const std::string& what_arg) { + Throw(std::overflow_error(what_arg)); +} +void ThrowStdOverflowError(const char* what_arg) { + Throw(std::overflow_error(what_arg)); +} + +void ThrowStdUnderflowError(const std::string& what_arg) { + Throw(std::underflow_error(what_arg)); +} +void ThrowStdUnderflowError(const char* what_arg) { + Throw(std::underflow_error(what_arg)); +} + +void ThrowStdBadFunctionCall() { Throw(std::bad_function_call()); } + +void ThrowStdBadAlloc() { Throw(std::bad_alloc()); } + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/internal/throw_delegate.h b/third_party/abseil_cpp/absl/base/internal/throw_delegate.h new file mode 100644 index 0000000000..075f527254 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/throw_delegate.h @@ -0,0 +1,75 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_THROW_DELEGATE_H_ +#define ABSL_BASE_INTERNAL_THROW_DELEGATE_H_ + +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// Helper functions that allow throwing exceptions consistently from anywhere. +// The main use case is for header-based libraries (eg templates), as they will +// be built by many different targets with their own compiler options. +// In particular, this will allow a safe way to throw exceptions even if the +// caller is compiled with -fno-exceptions. This is intended for implementing +// things like map<>::at(), which the standard documents as throwing an +// exception on error. +// +// Using other techniques like #if tricks could lead to ODR violations. +// +// You shouldn't use it unless you're writing code that you know will be built +// both with and without exceptions and you need to conform to an interface +// that uses exceptions. + +[[noreturn]] void ThrowStdLogicError(const std::string& what_arg); +[[noreturn]] void ThrowStdLogicError(const char* what_arg); +[[noreturn]] void ThrowStdInvalidArgument(const std::string& what_arg); +[[noreturn]] void ThrowStdInvalidArgument(const char* what_arg); +[[noreturn]] void ThrowStdDomainError(const std::string& what_arg); +[[noreturn]] void ThrowStdDomainError(const char* what_arg); +[[noreturn]] void ThrowStdLengthError(const std::string& what_arg); +[[noreturn]] void ThrowStdLengthError(const char* what_arg); +[[noreturn]] void ThrowStdOutOfRange(const std::string& what_arg); +[[noreturn]] void ThrowStdOutOfRange(const char* what_arg); +[[noreturn]] void ThrowStdRuntimeError(const std::string& what_arg); +[[noreturn]] void ThrowStdRuntimeError(const char* what_arg); +[[noreturn]] void ThrowStdRangeError(const std::string& what_arg); +[[noreturn]] void ThrowStdRangeError(const char* what_arg); +[[noreturn]] void ThrowStdOverflowError(const std::string& what_arg); +[[noreturn]] void ThrowStdOverflowError(const char* what_arg); +[[noreturn]] void ThrowStdUnderflowError(const std::string& what_arg); +[[noreturn]] void ThrowStdUnderflowError(const char* what_arg); + +[[noreturn]] void ThrowStdBadFunctionCall(); +[[noreturn]] void ThrowStdBadAlloc(); + +// ThrowStdBadArrayNewLength() cannot be consistently supported because +// std::bad_array_new_length is missing in libstdc++ until 4.9.0. +// https://gcc.gnu.org/onlinedocs/gcc-4.8.3/libstdc++/api/a01379_source.html +// https://gcc.gnu.org/onlinedocs/gcc-4.9.0/libstdc++/api/a01327_source.html +// libcxx (as of 3.2) and msvc (as of 2015) both have it. +// [[noreturn]] void ThrowStdBadArrayNewLength(); + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_THROW_DELEGATE_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/tsan_mutex_interface.h b/third_party/abseil_cpp/absl/base/internal/tsan_mutex_interface.h new file mode 100644 index 0000000000..2a510603bc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/tsan_mutex_interface.h @@ -0,0 +1,66 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file is intended solely for spinlock.h. +// It provides ThreadSanitizer annotations for custom mutexes. +// See <sanitizer/tsan_interface.h> for meaning of these annotations. + +#ifndef ABSL_BASE_INTERNAL_TSAN_MUTEX_INTERFACE_H_ +#define ABSL_BASE_INTERNAL_TSAN_MUTEX_INTERFACE_H_ + +// ABSL_INTERNAL_HAVE_TSAN_INTERFACE +// Macro intended only for internal use. +// +// Checks whether LLVM Thread Sanitizer interfaces are available. +// First made available in LLVM 5.0 (Sep 2017). +#ifdef ABSL_INTERNAL_HAVE_TSAN_INTERFACE +#error "ABSL_INTERNAL_HAVE_TSAN_INTERFACE cannot be directly set." +#endif + +#if defined(THREAD_SANITIZER) && defined(__has_include) +#if __has_include(<sanitizer/tsan_interface.h>) +#define ABSL_INTERNAL_HAVE_TSAN_INTERFACE 1 +#endif +#endif + +#ifdef ABSL_INTERNAL_HAVE_TSAN_INTERFACE +#include <sanitizer/tsan_interface.h> + +#define ABSL_TSAN_MUTEX_CREATE __tsan_mutex_create +#define ABSL_TSAN_MUTEX_DESTROY __tsan_mutex_destroy +#define ABSL_TSAN_MUTEX_PRE_LOCK __tsan_mutex_pre_lock +#define ABSL_TSAN_MUTEX_POST_LOCK __tsan_mutex_post_lock +#define ABSL_TSAN_MUTEX_PRE_UNLOCK __tsan_mutex_pre_unlock +#define ABSL_TSAN_MUTEX_POST_UNLOCK __tsan_mutex_post_unlock +#define ABSL_TSAN_MUTEX_PRE_SIGNAL __tsan_mutex_pre_signal +#define ABSL_TSAN_MUTEX_POST_SIGNAL __tsan_mutex_post_signal +#define ABSL_TSAN_MUTEX_PRE_DIVERT __tsan_mutex_pre_divert +#define ABSL_TSAN_MUTEX_POST_DIVERT __tsan_mutex_post_divert + +#else + +#define ABSL_TSAN_MUTEX_CREATE(...) +#define ABSL_TSAN_MUTEX_DESTROY(...) +#define ABSL_TSAN_MUTEX_PRE_LOCK(...) +#define ABSL_TSAN_MUTEX_POST_LOCK(...) +#define ABSL_TSAN_MUTEX_PRE_UNLOCK(...) +#define ABSL_TSAN_MUTEX_POST_UNLOCK(...) +#define ABSL_TSAN_MUTEX_PRE_SIGNAL(...) +#define ABSL_TSAN_MUTEX_POST_SIGNAL(...) +#define ABSL_TSAN_MUTEX_PRE_DIVERT(...) +#define ABSL_TSAN_MUTEX_POST_DIVERT(...) + +#endif + +#endif // ABSL_BASE_INTERNAL_TSAN_MUTEX_INTERFACE_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/unaligned_access.h b/third_party/abseil_cpp/absl/base/internal/unaligned_access.h new file mode 100644 index 0000000000..6be56c865b --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/unaligned_access.h @@ -0,0 +1,158 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_BASE_INTERNAL_UNALIGNED_ACCESS_H_ +#define ABSL_BASE_INTERNAL_UNALIGNED_ACCESS_H_ + +#include <string.h> + +#include <cstdint> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" + +// unaligned APIs + +// Portable handling of unaligned loads, stores, and copies. + +// The unaligned API is C++ only. The declarations use C++ features +// (namespaces, inline) which are absent or incompatible in C. +#if defined(__cplusplus) + +#if defined(ADDRESS_SANITIZER) || defined(THREAD_SANITIZER) ||\ + defined(MEMORY_SANITIZER) +// Consider we have an unaligned load/store of 4 bytes from address 0x...05. +// AddressSanitizer will treat it as a 3-byte access to the range 05:07 and +// will miss a bug if 08 is the first unaddressable byte. +// ThreadSanitizer will also treat this as a 3-byte access to 05:07 and will +// miss a race between this access and some other accesses to 08. +// MemorySanitizer will correctly propagate the shadow on unaligned stores +// and correctly report bugs on unaligned loads, but it may not properly +// update and report the origin of the uninitialized memory. +// For all three tools, replacing an unaligned access with a tool-specific +// callback solves the problem. + +// Make sure uint16_t/uint32_t/uint64_t are defined. +#include <stdint.h> + +extern "C" { +uint16_t __sanitizer_unaligned_load16(const void *p); +uint32_t __sanitizer_unaligned_load32(const void *p); +uint64_t __sanitizer_unaligned_load64(const void *p); +void __sanitizer_unaligned_store16(void *p, uint16_t v); +void __sanitizer_unaligned_store32(void *p, uint32_t v); +void __sanitizer_unaligned_store64(void *p, uint64_t v); +} // extern "C" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +inline uint16_t UnalignedLoad16(const void *p) { + return __sanitizer_unaligned_load16(p); +} + +inline uint32_t UnalignedLoad32(const void *p) { + return __sanitizer_unaligned_load32(p); +} + +inline uint64_t UnalignedLoad64(const void *p) { + return __sanitizer_unaligned_load64(p); +} + +inline void UnalignedStore16(void *p, uint16_t v) { + __sanitizer_unaligned_store16(p, v); +} + +inline void UnalignedStore32(void *p, uint32_t v) { + __sanitizer_unaligned_store32(p, v); +} + +inline void UnalignedStore64(void *p, uint64_t v) { + __sanitizer_unaligned_store64(p, v); +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#define ABSL_INTERNAL_UNALIGNED_LOAD16(_p) \ + (absl::base_internal::UnalignedLoad16(_p)) +#define ABSL_INTERNAL_UNALIGNED_LOAD32(_p) \ + (absl::base_internal::UnalignedLoad32(_p)) +#define ABSL_INTERNAL_UNALIGNED_LOAD64(_p) \ + (absl::base_internal::UnalignedLoad64(_p)) + +#define ABSL_INTERNAL_UNALIGNED_STORE16(_p, _val) \ + (absl::base_internal::UnalignedStore16(_p, _val)) +#define ABSL_INTERNAL_UNALIGNED_STORE32(_p, _val) \ + (absl::base_internal::UnalignedStore32(_p, _val)) +#define ABSL_INTERNAL_UNALIGNED_STORE64(_p, _val) \ + (absl::base_internal::UnalignedStore64(_p, _val)) + +#else + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +inline uint16_t UnalignedLoad16(const void *p) { + uint16_t t; + memcpy(&t, p, sizeof t); + return t; +} + +inline uint32_t UnalignedLoad32(const void *p) { + uint32_t t; + memcpy(&t, p, sizeof t); + return t; +} + +inline uint64_t UnalignedLoad64(const void *p) { + uint64_t t; + memcpy(&t, p, sizeof t); + return t; +} + +inline void UnalignedStore16(void *p, uint16_t v) { memcpy(p, &v, sizeof v); } + +inline void UnalignedStore32(void *p, uint32_t v) { memcpy(p, &v, sizeof v); } + +inline void UnalignedStore64(void *p, uint64_t v) { memcpy(p, &v, sizeof v); } + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#define ABSL_INTERNAL_UNALIGNED_LOAD16(_p) \ + (absl::base_internal::UnalignedLoad16(_p)) +#define ABSL_INTERNAL_UNALIGNED_LOAD32(_p) \ + (absl::base_internal::UnalignedLoad32(_p)) +#define ABSL_INTERNAL_UNALIGNED_LOAD64(_p) \ + (absl::base_internal::UnalignedLoad64(_p)) + +#define ABSL_INTERNAL_UNALIGNED_STORE16(_p, _val) \ + (absl::base_internal::UnalignedStore16(_p, _val)) +#define ABSL_INTERNAL_UNALIGNED_STORE32(_p, _val) \ + (absl::base_internal::UnalignedStore32(_p, _val)) +#define ABSL_INTERNAL_UNALIGNED_STORE64(_p, _val) \ + (absl::base_internal::UnalignedStore64(_p, _val)) + +#endif + +#endif // defined(__cplusplus), end of unaligned API + +#endif // ABSL_BASE_INTERNAL_UNALIGNED_ACCESS_H_ diff --git a/third_party/abseil_cpp/absl/base/internal/unique_small_name_test.cc b/third_party/abseil_cpp/absl/base/internal/unique_small_name_test.cc new file mode 100644 index 0000000000..ff8c2b3fb4 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/unique_small_name_test.cc @@ -0,0 +1,77 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "gtest/gtest.h" +#include "absl/base/optimization.h" +#include "absl/strings/string_view.h" + +// This test by itself does not do anything fancy, but it serves as binary I can +// query in shell test. + +namespace { + +template <class T> +void DoNotOptimize(const T& var) { +#ifdef __GNUC__ + asm volatile("" : "+m"(const_cast<T&>(var))); +#else + std::cout << (void*)&var; +#endif +} + +int very_long_int_variable_name ABSL_INTERNAL_UNIQUE_SMALL_NAME() = 0; +char very_long_str_variable_name[] ABSL_INTERNAL_UNIQUE_SMALL_NAME() = "abc"; + +TEST(UniqueSmallName, NonAutomaticVar) { + EXPECT_EQ(very_long_int_variable_name, 0); + EXPECT_EQ(absl::string_view(very_long_str_variable_name), "abc"); +} + +int VeryLongFreeFunctionName() ABSL_INTERNAL_UNIQUE_SMALL_NAME(); + +TEST(UniqueSmallName, FreeFunction) { + DoNotOptimize(&VeryLongFreeFunctionName); + + EXPECT_EQ(VeryLongFreeFunctionName(), 456); +} + +int VeryLongFreeFunctionName() { return 456; } + +struct VeryLongStructName { + explicit VeryLongStructName(int i); + + int VeryLongMethodName() ABSL_INTERNAL_UNIQUE_SMALL_NAME(); + + static int VeryLongStaticMethodName() ABSL_INTERNAL_UNIQUE_SMALL_NAME(); + + private: + int fld; +}; + +TEST(UniqueSmallName, Struct) { + VeryLongStructName var(10); + + DoNotOptimize(var); + DoNotOptimize(&VeryLongStructName::VeryLongMethodName); + DoNotOptimize(&VeryLongStructName::VeryLongStaticMethodName); + + EXPECT_EQ(var.VeryLongMethodName(), 10); + EXPECT_EQ(VeryLongStructName::VeryLongStaticMethodName(), 123); +} + +VeryLongStructName::VeryLongStructName(int i) : fld(i) {} +int VeryLongStructName::VeryLongMethodName() { return fld; } +int VeryLongStructName::VeryLongStaticMethodName() { return 123; } + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/internal/unscaledcycleclock.cc b/third_party/abseil_cpp/absl/base/internal/unscaledcycleclock.cc new file mode 100644 index 0000000000..f1e7bbef84 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/unscaledcycleclock.cc @@ -0,0 +1,140 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/unscaledcycleclock.h" + +#if ABSL_USE_UNSCALED_CYCLECLOCK + +#if defined(_WIN32) +#include <intrin.h> +#endif + +#if defined(__powerpc__) || defined(__ppc__) +#ifdef __GLIBC__ +#include <sys/platform/ppc.h> +#elif defined(__FreeBSD__) +#include <sys/sysctl.h> +#include <sys/types.h> +#endif +#endif + +#include "absl/base/internal/sysinfo.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +#if defined(__i386__) + +int64_t UnscaledCycleClock::Now() { + int64_t ret; + __asm__ volatile("rdtsc" : "=A"(ret)); + return ret; +} + +double UnscaledCycleClock::Frequency() { + return base_internal::NominalCPUFrequency(); +} + +#elif defined(__x86_64__) + +int64_t UnscaledCycleClock::Now() { + uint64_t low, high; + __asm__ volatile("rdtsc" : "=a"(low), "=d"(high)); + return (high << 32) | low; +} + +double UnscaledCycleClock::Frequency() { + return base_internal::NominalCPUFrequency(); +} + +#elif defined(__powerpc__) || defined(__ppc__) + +int64_t UnscaledCycleClock::Now() { +#ifdef __GLIBC__ + return __ppc_get_timebase(); +#else +#ifdef __powerpc64__ + int64_t tbr; + asm volatile("mfspr %0, 268" : "=r"(tbr)); + return tbr; +#else + int32_t tbu, tbl, tmp; + asm volatile( + "0:\n" + "mftbu %[hi32]\n" + "mftb %[lo32]\n" + "mftbu %[tmp]\n" + "cmpw %[tmp],%[hi32]\n" + "bne 0b\n" + : [ hi32 ] "=r"(tbu), [ lo32 ] "=r"(tbl), [ tmp ] "=r"(tmp)); + return (static_cast<int64_t>(tbu) << 32) | tbl; +#endif +#endif +} + +double UnscaledCycleClock::Frequency() { +#ifdef __GLIBC__ + return __ppc_get_timebase_freq(); +#elif defined(__FreeBSD__) + static once_flag init_timebase_frequency_once; + static double timebase_frequency = 0.0; + base_internal::LowLevelCallOnce(&init_timebase_frequency_once, [&]() { + size_t length = sizeof(timebase_frequency); + sysctlbyname("kern.timecounter.tc.timebase.frequency", &timebase_frequency, + &length, nullptr, 0); + }); + return timebase_frequency; +#else +#error Must implement UnscaledCycleClock::Frequency() +#endif +} + +#elif defined(__aarch64__) + +// System timer of ARMv8 runs at a different frequency than the CPU's. +// The frequency is fixed, typically in the range 1-50MHz. It can be +// read at CNTFRQ special register. We assume the OS has set up +// the virtual timer properly. +int64_t UnscaledCycleClock::Now() { + int64_t virtual_timer_value; + asm volatile("mrs %0, cntvct_el0" : "=r"(virtual_timer_value)); + return virtual_timer_value; +} + +double UnscaledCycleClock::Frequency() { + uint64_t aarch64_timer_frequency; + asm volatile("mrs %0, cntfrq_el0" : "=r"(aarch64_timer_frequency)); + return aarch64_timer_frequency; +} + +#elif defined(_M_IX86) || defined(_M_X64) + +#pragma intrinsic(__rdtsc) + +int64_t UnscaledCycleClock::Now() { + return __rdtsc(); +} + +double UnscaledCycleClock::Frequency() { + return base_internal::NominalCPUFrequency(); +} + +#endif + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USE_UNSCALED_CYCLECLOCK diff --git a/third_party/abseil_cpp/absl/base/internal/unscaledcycleclock.h b/third_party/abseil_cpp/absl/base/internal/unscaledcycleclock.h new file mode 100644 index 0000000000..cdce9bf8a8 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/internal/unscaledcycleclock.h @@ -0,0 +1,124 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// UnscaledCycleClock +// An UnscaledCycleClock yields the value and frequency of a cycle counter +// that increments at a rate that is approximately constant. +// This class is for internal / whitelisted use only, you should consider +// using CycleClock instead. +// +// Notes: +// The cycle counter frequency is not necessarily the core clock frequency. +// That is, CycleCounter cycles are not necessarily "CPU cycles". +// +// An arbitrary offset may have been added to the counter at power on. +// +// On some platforms, the rate and offset of the counter may differ +// slightly when read from different CPUs of a multiprocessor. Usually, +// we try to ensure that the operating system adjusts values periodically +// so that values agree approximately. If you need stronger guarantees, +// consider using alternate interfaces. +// +// The CPU is not required to maintain the ordering of a cycle counter read +// with respect to surrounding instructions. + +#ifndef ABSL_BASE_INTERNAL_UNSCALEDCYCLECLOCK_H_ +#define ABSL_BASE_INTERNAL_UNSCALEDCYCLECLOCK_H_ + +#include <cstdint> + +#if defined(__APPLE__) +#include <TargetConditionals.h> +#endif + +#include "absl/base/port.h" + +// The following platforms have an implementation of a hardware counter. +#if defined(__i386__) || defined(__x86_64__) || defined(__aarch64__) || \ + defined(__powerpc__) || defined(__ppc__) || \ + defined(_M_IX86) || defined(_M_X64) +#define ABSL_HAVE_UNSCALED_CYCLECLOCK_IMPLEMENTATION 1 +#else +#define ABSL_HAVE_UNSCALED_CYCLECLOCK_IMPLEMENTATION 0 +#endif + +// The following platforms often disable access to the hardware +// counter (through a sandbox) even if the underlying hardware has a +// usable counter. The CycleTimer interface also requires a *scaled* +// CycleClock that runs at atleast 1 MHz. We've found some Android +// ARM64 devices where this is not the case, so we disable it by +// default on Android ARM64. +#if defined(__native_client__) || \ + (defined(TARGET_OS_IPHONE) && TARGET_OS_IPHONE) || \ + (defined(__ANDROID__) && defined(__aarch64__)) +#define ABSL_USE_UNSCALED_CYCLECLOCK_DEFAULT 0 +#else +#define ABSL_USE_UNSCALED_CYCLECLOCK_DEFAULT 1 +#endif + +// UnscaledCycleClock is an optional internal feature. +// Use "#if ABSL_USE_UNSCALED_CYCLECLOCK" to test for its presence. +// Can be overridden at compile-time via -DABSL_USE_UNSCALED_CYCLECLOCK=0|1 +#if !defined(ABSL_USE_UNSCALED_CYCLECLOCK) +#define ABSL_USE_UNSCALED_CYCLECLOCK \ + (ABSL_HAVE_UNSCALED_CYCLECLOCK_IMPLEMENTATION && \ + ABSL_USE_UNSCALED_CYCLECLOCK_DEFAULT) +#endif + +#if ABSL_USE_UNSCALED_CYCLECLOCK + +// This macro can be used to test if UnscaledCycleClock::Frequency() +// is NominalCPUFrequency() on a particular platform. +#if (defined(__i386__) || defined(__x86_64__) || \ + defined(_M_IX86) || defined(_M_X64)) +#define ABSL_INTERNAL_UNSCALED_CYCLECLOCK_FREQUENCY_IS_CPU_FREQUENCY +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +class UnscaledCycleClockWrapperForGetCurrentTime; +} // namespace time_internal + +namespace base_internal { +class CycleClock; +class UnscaledCycleClockWrapperForInitializeFrequency; + +class UnscaledCycleClock { + private: + UnscaledCycleClock() = delete; + + // Return the value of a cycle counter that counts at a rate that is + // approximately constant. + static int64_t Now(); + + // Return the how much UnscaledCycleClock::Now() increases per second. + // This is not necessarily the core CPU clock frequency. + // It may be the nominal value report by the kernel, rather than a measured + // value. + static double Frequency(); + + // Whitelisted friends. + friend class base_internal::CycleClock; + friend class time_internal::UnscaledCycleClockWrapperForGetCurrentTime; + friend class base_internal::UnscaledCycleClockWrapperForInitializeFrequency; +}; + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USE_UNSCALED_CYCLECLOCK + +#endif // ABSL_BASE_INTERNAL_UNSCALEDCYCLECLOCK_H_ diff --git a/third_party/abseil_cpp/absl/base/invoke_test.cc b/third_party/abseil_cpp/absl/base/invoke_test.cc new file mode 100644 index 0000000000..6aa613c913 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/invoke_test.cc @@ -0,0 +1,223 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/invoke.h" + +#include <functional> +#include <memory> +#include <string> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { +namespace { + +int Function(int a, int b) { return a - b; } + +int Sink(std::unique_ptr<int> p) { + return *p; +} + +std::unique_ptr<int> Factory(int n) { + return make_unique<int>(n); +} + +void NoOp() {} + +struct ConstFunctor { + int operator()(int a, int b) const { return a - b; } +}; + +struct MutableFunctor { + int operator()(int a, int b) { return a - b; } +}; + +struct EphemeralFunctor { + int operator()(int a, int b) && { return a - b; } +}; + +struct OverloadedFunctor { + template <typename... Args> + std::string operator()(const Args&... args) & { + return StrCat("&", args...); + } + template <typename... Args> + std::string operator()(const Args&... args) const& { + return StrCat("const&", args...); + } + template <typename... Args> + std::string operator()(const Args&... args) && { + return StrCat("&&", args...); + } +}; + +struct Class { + int Method(int a, int b) { return a - b; } + int ConstMethod(int a, int b) const { return a - b; } + int RefMethod(int a, int b) & { return a - b; } + int RefRefMethod(int a, int b) && { return a - b; } + int NoExceptMethod(int a, int b) noexcept { return a - b; } + int VolatileMethod(int a, int b) volatile { return a - b; } + + int member; +}; + +struct FlipFlop { + int ConstMethod() const { return member; } + FlipFlop operator*() const { return {-member}; } + + int member; +}; + +// CallMaybeWithArg(f) resolves either to Invoke(f) or Invoke(f, 42), depending +// on which one is valid. +template <typename F> +decltype(Invoke(std::declval<const F&>())) CallMaybeWithArg(const F& f) { + return Invoke(f); +} + +template <typename F> +decltype(Invoke(std::declval<const F&>(), 42)) CallMaybeWithArg(const F& f) { + return Invoke(f, 42); +} + +TEST(InvokeTest, Function) { + EXPECT_EQ(1, Invoke(Function, 3, 2)); + EXPECT_EQ(1, Invoke(&Function, 3, 2)); +} + +TEST(InvokeTest, NonCopyableArgument) { + EXPECT_EQ(42, Invoke(Sink, make_unique<int>(42))); +} + +TEST(InvokeTest, NonCopyableResult) { + EXPECT_THAT(Invoke(Factory, 42), ::testing::Pointee(42)); +} + +TEST(InvokeTest, VoidResult) { + Invoke(NoOp); +} + +TEST(InvokeTest, ConstFunctor) { + EXPECT_EQ(1, Invoke(ConstFunctor(), 3, 2)); +} + +TEST(InvokeTest, MutableFunctor) { + MutableFunctor f; + EXPECT_EQ(1, Invoke(f, 3, 2)); + EXPECT_EQ(1, Invoke(MutableFunctor(), 3, 2)); +} + +TEST(InvokeTest, EphemeralFunctor) { + EphemeralFunctor f; + EXPECT_EQ(1, Invoke(std::move(f), 3, 2)); + EXPECT_EQ(1, Invoke(EphemeralFunctor(), 3, 2)); +} + +TEST(InvokeTest, OverloadedFunctor) { + OverloadedFunctor f; + const OverloadedFunctor& cf = f; + + EXPECT_EQ("&", Invoke(f)); + EXPECT_EQ("& 42", Invoke(f, " 42")); + + EXPECT_EQ("const&", Invoke(cf)); + EXPECT_EQ("const& 42", Invoke(cf, " 42")); + + EXPECT_EQ("&&", Invoke(std::move(f))); + EXPECT_EQ("&& 42", Invoke(std::move(f), " 42")); +} + +TEST(InvokeTest, ReferenceWrapper) { + ConstFunctor cf; + MutableFunctor mf; + EXPECT_EQ(1, Invoke(std::cref(cf), 3, 2)); + EXPECT_EQ(1, Invoke(std::ref(cf), 3, 2)); + EXPECT_EQ(1, Invoke(std::ref(mf), 3, 2)); +} + +TEST(InvokeTest, MemberFunction) { + std::unique_ptr<Class> p(new Class); + std::unique_ptr<const Class> cp(new Class); + std::unique_ptr<volatile Class> vp(new Class); + + EXPECT_EQ(1, Invoke(&Class::Method, p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::Method, p.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::Method, *p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::RefMethod, p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::RefMethod, p.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::RefMethod, *p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::RefRefMethod, std::move(*p), 3, 2)); // NOLINT + EXPECT_EQ(1, Invoke(&Class::NoExceptMethod, p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::NoExceptMethod, p.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::NoExceptMethod, *p, 3, 2)); + + EXPECT_EQ(1, Invoke(&Class::ConstMethod, p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::ConstMethod, p.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::ConstMethod, *p, 3, 2)); + + EXPECT_EQ(1, Invoke(&Class::ConstMethod, cp, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::ConstMethod, cp.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::ConstMethod, *cp, 3, 2)); + + EXPECT_EQ(1, Invoke(&Class::VolatileMethod, p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::VolatileMethod, p.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::VolatileMethod, *p, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::VolatileMethod, vp, 3, 2)); + EXPECT_EQ(1, Invoke(&Class::VolatileMethod, vp.get(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::VolatileMethod, *vp, 3, 2)); + + EXPECT_EQ(1, Invoke(&Class::Method, make_unique<Class>(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::ConstMethod, make_unique<Class>(), 3, 2)); + EXPECT_EQ(1, Invoke(&Class::ConstMethod, make_unique<const Class>(), 3, 2)); +} + +TEST(InvokeTest, DataMember) { + std::unique_ptr<Class> p(new Class{42}); + std::unique_ptr<const Class> cp(new Class{42}); + EXPECT_EQ(42, Invoke(&Class::member, p)); + EXPECT_EQ(42, Invoke(&Class::member, *p)); + EXPECT_EQ(42, Invoke(&Class::member, p.get())); + + Invoke(&Class::member, p) = 42; + Invoke(&Class::member, p.get()) = 42; + + EXPECT_EQ(42, Invoke(&Class::member, cp)); + EXPECT_EQ(42, Invoke(&Class::member, *cp)); + EXPECT_EQ(42, Invoke(&Class::member, cp.get())); +} + +TEST(InvokeTest, FlipFlop) { + FlipFlop obj = {42}; + // This call could resolve to (obj.*&FlipFlop::ConstMethod)() or + // ((*obj).*&FlipFlop::ConstMethod)(). We verify that it's the former. + EXPECT_EQ(42, Invoke(&FlipFlop::ConstMethod, obj)); + EXPECT_EQ(42, Invoke(&FlipFlop::member, obj)); +} + +TEST(InvokeTest, SfinaeFriendly) { + CallMaybeWithArg(NoOp); + EXPECT_THAT(CallMaybeWithArg(Factory), ::testing::Pointee(42)); +} + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/log_severity.cc b/third_party/abseil_cpp/absl/base/log_severity.cc new file mode 100644 index 0000000000..72312afd36 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/log_severity.cc @@ -0,0 +1,27 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/log_severity.h" + +#include <ostream> + +namespace absl { +ABSL_NAMESPACE_BEGIN + +std::ostream& operator<<(std::ostream& os, absl::LogSeverity s) { + if (s == absl::NormalizeLogSeverity(s)) return os << absl::LogSeverityName(s); + return os << "absl::LogSeverity(" << static_cast<int>(s) << ")"; +} +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/log_severity.h b/third_party/abseil_cpp/absl/base/log_severity.h new file mode 100644 index 0000000000..65a3b16672 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/log_severity.h @@ -0,0 +1,121 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_BASE_INTERNAL_LOG_SEVERITY_H_ +#define ABSL_BASE_INTERNAL_LOG_SEVERITY_H_ + +#include <array> +#include <ostream> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::LogSeverity +// +// Four severity levels are defined. Logging APIs should terminate the program +// when a message is logged at severity `kFatal`; the other levels have no +// special semantics. +// +// Values other than the four defined levels (e.g. produced by `static_cast`) +// are valid, but their semantics when passed to a function, macro, or flag +// depend on the function, macro, or flag. The usual behavior is to normalize +// such values to a defined severity level, however in some cases values other +// than the defined levels are useful for comparison. +// +// Exmaple: +// +// // Effectively disables all logging: +// SetMinLogLevel(static_cast<absl::LogSeverity>(100)); +// +// Abseil flags may be defined with type `LogSeverity`. Dependency layering +// constraints require that the `AbslParseFlag()` overload be declared and +// defined in the flags library itself rather than here. The `AbslUnparseFlag()` +// overload is defined there as well for consistency. +// +// absl::LogSeverity Flag String Representation +// +// An `absl::LogSeverity` has a string representation used for parsing +// command-line flags based on the enumerator name (e.g. `kFatal`) or +// its unprefixed name (without the `k`) in any case-insensitive form. (E.g. +// "FATAL", "fatal" or "Fatal" are all valid.) Unparsing such flags produces an +// unprefixed string representation in all caps (e.g. "FATAL") or an integer. +// +// Additionally, the parser accepts arbitrary integers (as if the type were +// `int`). +// +// Examples: +// +// --my_log_level=kInfo +// --my_log_level=INFO +// --my_log_level=info +// --my_log_level=0 +// +// Unparsing a flag produces the same result as `absl::LogSeverityName()` for +// the standard levels and a base-ten integer otherwise. +enum class LogSeverity : int { + kInfo = 0, + kWarning = 1, + kError = 2, + kFatal = 3, +}; + +// LogSeverities() +// +// Returns an iterable of all standard `absl::LogSeverity` values, ordered from +// least to most severe. +constexpr std::array<absl::LogSeverity, 4> LogSeverities() { + return {{absl::LogSeverity::kInfo, absl::LogSeverity::kWarning, + absl::LogSeverity::kError, absl::LogSeverity::kFatal}}; +} + +// LogSeverityName() +// +// Returns the all-caps string representation (e.g. "INFO") of the specified +// severity level if it is one of the standard levels and "UNKNOWN" otherwise. +constexpr const char* LogSeverityName(absl::LogSeverity s) { + return s == absl::LogSeverity::kInfo + ? "INFO" + : s == absl::LogSeverity::kWarning + ? "WARNING" + : s == absl::LogSeverity::kError + ? "ERROR" + : s == absl::LogSeverity::kFatal ? "FATAL" : "UNKNOWN"; +} + +// NormalizeLogSeverity() +// +// Values less than `kInfo` normalize to `kInfo`; values greater than `kFatal` +// normalize to `kError` (**NOT** `kFatal`). +constexpr absl::LogSeverity NormalizeLogSeverity(absl::LogSeverity s) { + return s < absl::LogSeverity::kInfo + ? absl::LogSeverity::kInfo + : s > absl::LogSeverity::kFatal ? absl::LogSeverity::kError : s; +} +constexpr absl::LogSeverity NormalizeLogSeverity(int s) { + return absl::NormalizeLogSeverity(static_cast<absl::LogSeverity>(s)); +} + +// operator<< +// +// The exact representation of a streamed `absl::LogSeverity` is deliberately +// unspecified; do not rely on it. +std::ostream& operator<<(std::ostream& os, absl::LogSeverity s); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_INTERNAL_LOG_SEVERITY_H_ diff --git a/third_party/abseil_cpp/absl/base/log_severity_test.cc b/third_party/abseil_cpp/absl/base/log_severity_test.cc new file mode 100644 index 0000000000..2c6872b00a --- /dev/null +++ b/third_party/abseil_cpp/absl/base/log_severity_test.cc @@ -0,0 +1,204 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/log_severity.h" + +#include <cstdint> +#include <ios> +#include <limits> +#include <ostream> +#include <sstream> +#include <string> +#include <tuple> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/flags/internal/flag.h" +#include "absl/flags/marshalling.h" +#include "absl/strings/str_cat.h" + +namespace { +using ::testing::Eq; +using ::testing::IsFalse; +using ::testing::IsTrue; +using ::testing::TestWithParam; +using ::testing::Values; + +std::string StreamHelper(absl::LogSeverity value) { + std::ostringstream stream; + stream << value; + return stream.str(); +} + +TEST(StreamTest, Works) { + EXPECT_THAT(StreamHelper(static_cast<absl::LogSeverity>(-100)), + Eq("absl::LogSeverity(-100)")); + EXPECT_THAT(StreamHelper(absl::LogSeverity::kInfo), Eq("INFO")); + EXPECT_THAT(StreamHelper(absl::LogSeverity::kWarning), Eq("WARNING")); + EXPECT_THAT(StreamHelper(absl::LogSeverity::kError), Eq("ERROR")); + EXPECT_THAT(StreamHelper(absl::LogSeverity::kFatal), Eq("FATAL")); + EXPECT_THAT(StreamHelper(static_cast<absl::LogSeverity>(4)), + Eq("absl::LogSeverity(4)")); +} + +static_assert( + absl::flags_internal::FlagUseOneWordStorage<absl::LogSeverity>::value, + "Flags of type absl::LogSeverity ought to be lock-free."); + +using ParseFlagFromOutOfRangeIntegerTest = TestWithParam<int64_t>; +INSTANTIATE_TEST_SUITE_P( + Instantiation, ParseFlagFromOutOfRangeIntegerTest, + Values(static_cast<int64_t>(std::numeric_limits<int>::min()) - 1, + static_cast<int64_t>(std::numeric_limits<int>::max()) + 1)); +TEST_P(ParseFlagFromOutOfRangeIntegerTest, ReturnsError) { + const std::string to_parse = absl::StrCat(GetParam()); + absl::LogSeverity value; + std::string error; + EXPECT_THAT(absl::ParseFlag(to_parse, &value, &error), IsFalse()) << value; +} + +using ParseFlagFromAlmostOutOfRangeIntegerTest = TestWithParam<int>; +INSTANTIATE_TEST_SUITE_P(Instantiation, + ParseFlagFromAlmostOutOfRangeIntegerTest, + Values(std::numeric_limits<int>::min(), + std::numeric_limits<int>::max())); +TEST_P(ParseFlagFromAlmostOutOfRangeIntegerTest, YieldsExpectedValue) { + const auto expected = static_cast<absl::LogSeverity>(GetParam()); + const std::string to_parse = absl::StrCat(GetParam()); + absl::LogSeverity value; + std::string error; + ASSERT_THAT(absl::ParseFlag(to_parse, &value, &error), IsTrue()) << error; + EXPECT_THAT(value, Eq(expected)); +} + +using ParseFlagFromIntegerMatchingEnumeratorTest = + TestWithParam<std::tuple<absl::string_view, absl::LogSeverity>>; +INSTANTIATE_TEST_SUITE_P( + Instantiation, ParseFlagFromIntegerMatchingEnumeratorTest, + Values(std::make_tuple("0", absl::LogSeverity::kInfo), + std::make_tuple(" 0", absl::LogSeverity::kInfo), + std::make_tuple("-0", absl::LogSeverity::kInfo), + std::make_tuple("+0", absl::LogSeverity::kInfo), + std::make_tuple("00", absl::LogSeverity::kInfo), + std::make_tuple("0 ", absl::LogSeverity::kInfo), + std::make_tuple("0x0", absl::LogSeverity::kInfo), + std::make_tuple("1", absl::LogSeverity::kWarning), + std::make_tuple("+1", absl::LogSeverity::kWarning), + std::make_tuple("2", absl::LogSeverity::kError), + std::make_tuple("3", absl::LogSeverity::kFatal))); +TEST_P(ParseFlagFromIntegerMatchingEnumeratorTest, YieldsExpectedValue) { + const absl::string_view to_parse = std::get<0>(GetParam()); + const absl::LogSeverity expected = std::get<1>(GetParam()); + absl::LogSeverity value; + std::string error; + ASSERT_THAT(absl::ParseFlag(to_parse, &value, &error), IsTrue()) << error; + EXPECT_THAT(value, Eq(expected)); +} + +using ParseFlagFromOtherIntegerTest = + TestWithParam<std::tuple<absl::string_view, int>>; +INSTANTIATE_TEST_SUITE_P(Instantiation, ParseFlagFromOtherIntegerTest, + Values(std::make_tuple("-1", -1), + std::make_tuple("4", 4), + std::make_tuple("010", 10), + std::make_tuple("0x10", 16))); +TEST_P(ParseFlagFromOtherIntegerTest, YieldsExpectedValue) { + const absl::string_view to_parse = std::get<0>(GetParam()); + const auto expected = static_cast<absl::LogSeverity>(std::get<1>(GetParam())); + absl::LogSeverity value; + std::string error; + ASSERT_THAT(absl::ParseFlag(to_parse, &value, &error), IsTrue()) << error; + EXPECT_THAT(value, Eq(expected)); +} + +using ParseFlagFromEnumeratorTest = + TestWithParam<std::tuple<absl::string_view, absl::LogSeverity>>; +INSTANTIATE_TEST_SUITE_P( + Instantiation, ParseFlagFromEnumeratorTest, + Values(std::make_tuple("INFO", absl::LogSeverity::kInfo), + std::make_tuple("info", absl::LogSeverity::kInfo), + std::make_tuple("kInfo", absl::LogSeverity::kInfo), + std::make_tuple("iNfO", absl::LogSeverity::kInfo), + std::make_tuple("kInFo", absl::LogSeverity::kInfo), + std::make_tuple("WARNING", absl::LogSeverity::kWarning), + std::make_tuple("warning", absl::LogSeverity::kWarning), + std::make_tuple("kWarning", absl::LogSeverity::kWarning), + std::make_tuple("WaRnInG", absl::LogSeverity::kWarning), + std::make_tuple("KwArNiNg", absl::LogSeverity::kWarning), + std::make_tuple("ERROR", absl::LogSeverity::kError), + std::make_tuple("error", absl::LogSeverity::kError), + std::make_tuple("kError", absl::LogSeverity::kError), + std::make_tuple("eRrOr", absl::LogSeverity::kError), + std::make_tuple("kErRoR", absl::LogSeverity::kError), + std::make_tuple("FATAL", absl::LogSeverity::kFatal), + std::make_tuple("fatal", absl::LogSeverity::kFatal), + std::make_tuple("kFatal", absl::LogSeverity::kFatal), + std::make_tuple("FaTaL", absl::LogSeverity::kFatal), + std::make_tuple("KfAtAl", absl::LogSeverity::kFatal))); +TEST_P(ParseFlagFromEnumeratorTest, YieldsExpectedValue) { + const absl::string_view to_parse = std::get<0>(GetParam()); + const absl::LogSeverity expected = std::get<1>(GetParam()); + absl::LogSeverity value; + std::string error; + ASSERT_THAT(absl::ParseFlag(to_parse, &value, &error), IsTrue()) << error; + EXPECT_THAT(value, Eq(expected)); +} + +using ParseFlagFromGarbageTest = TestWithParam<absl::string_view>; +INSTANTIATE_TEST_SUITE_P(Instantiation, ParseFlagFromGarbageTest, + Values("", "\0", " ", "garbage", "kkinfo", "I")); +TEST_P(ParseFlagFromGarbageTest, ReturnsError) { + const absl::string_view to_parse = GetParam(); + absl::LogSeverity value; + std::string error; + EXPECT_THAT(absl::ParseFlag(to_parse, &value, &error), IsFalse()) << value; +} + +using UnparseFlagToEnumeratorTest = + TestWithParam<std::tuple<absl::LogSeverity, absl::string_view>>; +INSTANTIATE_TEST_SUITE_P( + Instantiation, UnparseFlagToEnumeratorTest, + Values(std::make_tuple(absl::LogSeverity::kInfo, "INFO"), + std::make_tuple(absl::LogSeverity::kWarning, "WARNING"), + std::make_tuple(absl::LogSeverity::kError, "ERROR"), + std::make_tuple(absl::LogSeverity::kFatal, "FATAL"))); +TEST_P(UnparseFlagToEnumeratorTest, ReturnsExpectedValueAndRoundTrips) { + const absl::LogSeverity to_unparse = std::get<0>(GetParam()); + const absl::string_view expected = std::get<1>(GetParam()); + const std::string stringified_value = absl::UnparseFlag(to_unparse); + EXPECT_THAT(stringified_value, Eq(expected)); + absl::LogSeverity reparsed_value; + std::string error; + EXPECT_THAT(absl::ParseFlag(stringified_value, &reparsed_value, &error), + IsTrue()); + EXPECT_THAT(reparsed_value, Eq(to_unparse)); +} + +using UnparseFlagToOtherIntegerTest = TestWithParam<int>; +INSTANTIATE_TEST_SUITE_P(Instantiation, UnparseFlagToOtherIntegerTest, + Values(std::numeric_limits<int>::min(), -1, 4, + std::numeric_limits<int>::max())); +TEST_P(UnparseFlagToOtherIntegerTest, ReturnsExpectedValueAndRoundTrips) { + const absl::LogSeverity to_unparse = + static_cast<absl::LogSeverity>(GetParam()); + const std::string expected = absl::StrCat(GetParam()); + const std::string stringified_value = absl::UnparseFlag(to_unparse); + EXPECT_THAT(stringified_value, Eq(expected)); + absl::LogSeverity reparsed_value; + std::string error; + EXPECT_THAT(absl::ParseFlag(stringified_value, &reparsed_value, &error), + IsTrue()); + EXPECT_THAT(reparsed_value, Eq(to_unparse)); +} +} // namespace diff --git a/third_party/abseil_cpp/absl/base/macros.h b/third_party/abseil_cpp/absl/base/macros.h new file mode 100644 index 0000000000..ea1da65ba2 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/macros.h @@ -0,0 +1,226 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: macros.h +// ----------------------------------------------------------------------------- +// +// This header file defines the set of language macros used within Abseil code. +// For the set of macros used to determine supported compilers and platforms, +// see absl/base/config.h instead. +// +// This code is compiled directly on many platforms, including client +// platforms like Windows, Mac, and embedded systems. Before making +// any changes here, make sure that you're not breaking any platforms. + +#ifndef ABSL_BASE_MACROS_H_ +#define ABSL_BASE_MACROS_H_ + +#include <cassert> +#include <cstddef> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" + +// ABSL_ARRAYSIZE() +// +// Returns the number of elements in an array as a compile-time constant, which +// can be used in defining new arrays. If you use this macro on a pointer by +// mistake, you will get a compile-time error. +#define ABSL_ARRAYSIZE(array) \ + (sizeof(::absl::macros_internal::ArraySizeHelper(array))) + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace macros_internal { +// Note: this internal template function declaration is used by ABSL_ARRAYSIZE. +// The function doesn't need a definition, as we only use its type. +template <typename T, size_t N> +auto ArraySizeHelper(const T (&array)[N]) -> char (&)[N]; +} // namespace macros_internal +ABSL_NAMESPACE_END +} // namespace absl + +// ABSL_FALLTHROUGH_INTENDED +// +// Annotates implicit fall-through between switch labels, allowing a case to +// indicate intentional fallthrough and turn off warnings about any lack of a +// `break` statement. The ABSL_FALLTHROUGH_INTENDED macro should be followed by +// a semicolon and can be used in most places where `break` can, provided that +// no statements exist between it and the next switch label. +// +// Example: +// +// switch (x) { +// case 40: +// case 41: +// if (truth_is_out_there) { +// ++x; +// ABSL_FALLTHROUGH_INTENDED; // Use instead of/along with annotations +// // in comments +// } else { +// return x; +// } +// case 42: +// ... +// +// Notes: when compiled with clang in C++11 mode, the ABSL_FALLTHROUGH_INTENDED +// macro is expanded to the [[clang::fallthrough]] attribute, which is analysed +// when performing switch labels fall-through diagnostic +// (`-Wimplicit-fallthrough`). See clang documentation on language extensions +// for details: +// https://clang.llvm.org/docs/AttributeReference.html#fallthrough-clang-fallthrough +// +// When used with unsupported compilers, the ABSL_FALLTHROUGH_INTENDED macro +// has no effect on diagnostics. In any case this macro has no effect on runtime +// behavior and performance of code. +#ifdef ABSL_FALLTHROUGH_INTENDED +#error "ABSL_FALLTHROUGH_INTENDED should not be defined." +#endif + +// TODO(zhangxy): Use c++17 standard [[fallthrough]] macro, when supported. +#if defined(__clang__) && defined(__has_warning) +#if __has_feature(cxx_attributes) && __has_warning("-Wimplicit-fallthrough") +#define ABSL_FALLTHROUGH_INTENDED [[clang::fallthrough]] +#endif +#elif defined(__GNUC__) && __GNUC__ >= 7 +#define ABSL_FALLTHROUGH_INTENDED [[gnu::fallthrough]] +#endif + +#ifndef ABSL_FALLTHROUGH_INTENDED +#define ABSL_FALLTHROUGH_INTENDED \ + do { \ + } while (0) +#endif + +// ABSL_DEPRECATED() +// +// Marks a deprecated class, struct, enum, function, method and variable +// declarations. The macro argument is used as a custom diagnostic message (e.g. +// suggestion of a better alternative). +// +// Examples: +// +// class ABSL_DEPRECATED("Use Bar instead") Foo {...}; +// +// ABSL_DEPRECATED("Use Baz() instead") void Bar() {...} +// +// template <typename T> +// ABSL_DEPRECATED("Use DoThat() instead") +// void DoThis(); +// +// Every usage of a deprecated entity will trigger a warning when compiled with +// clang's `-Wdeprecated-declarations` option. This option is turned off by +// default, but the warnings will be reported by clang-tidy. +#if defined(__clang__) && __cplusplus >= 201103L +#define ABSL_DEPRECATED(message) __attribute__((deprecated(message))) +#endif + +#ifndef ABSL_DEPRECATED +#define ABSL_DEPRECATED(message) +#endif + +// ABSL_BAD_CALL_IF() +// +// Used on a function overload to trap bad calls: any call that matches the +// overload will cause a compile-time error. This macro uses a clang-specific +// "enable_if" attribute, as described at +// https://clang.llvm.org/docs/AttributeReference.html#enable-if +// +// Overloads which use this macro should be bracketed by +// `#ifdef ABSL_BAD_CALL_IF`. +// +// Example: +// +// int isdigit(int c); +// #ifdef ABSL_BAD_CALL_IF +// int isdigit(int c) +// ABSL_BAD_CALL_IF(c <= -1 || c > 255, +// "'c' must have the value of an unsigned char or EOF"); +// #endif // ABSL_BAD_CALL_IF +#if ABSL_HAVE_ATTRIBUTE(enable_if) +#define ABSL_BAD_CALL_IF(expr, msg) \ + __attribute__((enable_if(expr, "Bad call trap"), unavailable(msg))) +#endif + +// ABSL_ASSERT() +// +// In C++11, `assert` can't be used portably within constexpr functions. +// ABSL_ASSERT functions as a runtime assert but works in C++11 constexpr +// functions. Example: +// +// constexpr double Divide(double a, double b) { +// return ABSL_ASSERT(b != 0), a / b; +// } +// +// This macro is inspired by +// https://akrzemi1.wordpress.com/2017/05/18/asserts-in-constexpr-functions/ +#if defined(NDEBUG) +#define ABSL_ASSERT(expr) \ + (false ? static_cast<void>(expr) : static_cast<void>(0)) +#else +#define ABSL_ASSERT(expr) \ + (ABSL_PREDICT_TRUE((expr)) ? static_cast<void>(0) \ + : [] { assert(false && #expr); }()) // NOLINT +#endif + +// `ABSL_INTERNAL_HARDENING_ABORT()` controls how `ABSL_HARDENING_ASSERT()` +// aborts the program in release mode (when NDEBUG is defined). The +// implementation should abort the program as quickly as possible and ideally it +// should not be possible to ignore the abort request. +#if (ABSL_HAVE_BUILTIN(__builtin_trap) && \ + ABSL_HAVE_BUILTIN(__builtin_unreachable)) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_INTERNAL_HARDENING_ABORT() \ + do { \ + __builtin_trap(); \ + __builtin_unreachable(); \ + } while (false) +#else +#define ABSL_INTERNAL_HARDENING_ABORT() abort() +#endif + +// ABSL_HARDENING_ASSERT() +// +// `ABSL_HARDENING_ASSERT()` is like `ABSL_ASSERT()`, but used to implement +// runtime assertions that should be enabled in hardened builds even when +// `NDEBUG` is defined. +// +// When `NDEBUG` is not defined, `ABSL_HARDENING_ASSERT()` is identical to +// `ABSL_ASSERT()`. +// +// See `ABSL_OPTION_HARDENED` in `absl/base/options.h` for more information on +// hardened mode. +#if ABSL_OPTION_HARDENED == 1 && defined(NDEBUG) +#define ABSL_HARDENING_ASSERT(expr) \ + (ABSL_PREDICT_TRUE((expr)) ? static_cast<void>(0) \ + : [] { ABSL_INTERNAL_HARDENING_ABORT(); }()) +#else +#define ABSL_HARDENING_ASSERT(expr) ABSL_ASSERT(expr) +#endif + +#ifdef ABSL_HAVE_EXCEPTIONS +#define ABSL_INTERNAL_TRY try +#define ABSL_INTERNAL_CATCH_ANY catch (...) +#define ABSL_INTERNAL_RETHROW do { throw; } while (false) +#else // ABSL_HAVE_EXCEPTIONS +#define ABSL_INTERNAL_TRY if (true) +#define ABSL_INTERNAL_CATCH_ANY else if (false) +#define ABSL_INTERNAL_RETHROW do {} while (false) +#endif // ABSL_HAVE_EXCEPTIONS + +#endif // ABSL_BASE_MACROS_H_ diff --git a/third_party/abseil_cpp/absl/base/optimization.h b/third_party/abseil_cpp/absl/base/optimization.h new file mode 100644 index 0000000000..92bf9cd388 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/optimization.h @@ -0,0 +1,241 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: optimization.h +// ----------------------------------------------------------------------------- +// +// This header file defines portable macros for performance optimization. + +#ifndef ABSL_BASE_OPTIMIZATION_H_ +#define ABSL_BASE_OPTIMIZATION_H_ + +#include "absl/base/config.h" + +// ABSL_BLOCK_TAIL_CALL_OPTIMIZATION +// +// Instructs the compiler to avoid optimizing tail-call recursion. Use of this +// macro is useful when you wish to preserve the existing function order within +// a stack trace for logging, debugging, or profiling purposes. +// +// Example: +// +// int f() { +// int result = g(); +// ABSL_BLOCK_TAIL_CALL_OPTIMIZATION(); +// return result; +// } +#if defined(__pnacl__) +#define ABSL_BLOCK_TAIL_CALL_OPTIMIZATION() if (volatile int x = 0) { (void)x; } +#elif defined(__clang__) +// Clang will not tail call given inline volatile assembly. +#define ABSL_BLOCK_TAIL_CALL_OPTIMIZATION() __asm__ __volatile__("") +#elif defined(__GNUC__) +// GCC will not tail call given inline volatile assembly. +#define ABSL_BLOCK_TAIL_CALL_OPTIMIZATION() __asm__ __volatile__("") +#elif defined(_MSC_VER) +#include <intrin.h> +// The __nop() intrinsic blocks the optimisation. +#define ABSL_BLOCK_TAIL_CALL_OPTIMIZATION() __nop() +#else +#define ABSL_BLOCK_TAIL_CALL_OPTIMIZATION() if (volatile int x = 0) { (void)x; } +#endif + +// ABSL_CACHELINE_SIZE +// +// Explicitly defines the size of the L1 cache for purposes of alignment. +// Setting the cacheline size allows you to specify that certain objects be +// aligned on a cacheline boundary with `ABSL_CACHELINE_ALIGNED` declarations. +// (See below.) +// +// NOTE: this macro should be replaced with the following C++17 features, when +// those are generally available: +// +// * `std::hardware_constructive_interference_size` +// * `std::hardware_destructive_interference_size` +// +// See http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0154r1.html +// for more information. +#if defined(__GNUC__) +// Cache line alignment +#if defined(__i386__) || defined(__x86_64__) +#define ABSL_CACHELINE_SIZE 64 +#elif defined(__powerpc64__) +#define ABSL_CACHELINE_SIZE 128 +#elif defined(__aarch64__) +// We would need to read special register ctr_el0 to find out L1 dcache size. +// This value is a good estimate based on a real aarch64 machine. +#define ABSL_CACHELINE_SIZE 64 +#elif defined(__arm__) +// Cache line sizes for ARM: These values are not strictly correct since +// cache line sizes depend on implementations, not architectures. There +// are even implementations with cache line sizes configurable at boot +// time. +#if defined(__ARM_ARCH_5T__) +#define ABSL_CACHELINE_SIZE 32 +#elif defined(__ARM_ARCH_7A__) +#define ABSL_CACHELINE_SIZE 64 +#endif +#endif + +#ifndef ABSL_CACHELINE_SIZE +// A reasonable default guess. Note that overestimates tend to waste more +// space, while underestimates tend to waste more time. +#define ABSL_CACHELINE_SIZE 64 +#endif + +// ABSL_CACHELINE_ALIGNED +// +// Indicates that the declared object be cache aligned using +// `ABSL_CACHELINE_SIZE` (see above). Cacheline aligning objects allows you to +// load a set of related objects in the L1 cache for performance improvements. +// Cacheline aligning objects properly allows constructive memory sharing and +// prevents destructive (or "false") memory sharing. +// +// NOTE: this macro should be replaced with usage of `alignas()` using +// `std::hardware_constructive_interference_size` and/or +// `std::hardware_destructive_interference_size` when available within C++17. +// +// See http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0154r1.html +// for more information. +// +// On some compilers, `ABSL_CACHELINE_ALIGNED` expands to an `__attribute__` +// or `__declspec` attribute. For compilers where this is not known to work, +// the macro expands to nothing. +// +// No further guarantees are made here. The result of applying the macro +// to variables and types is always implementation-defined. +// +// WARNING: It is easy to use this attribute incorrectly, even to the point +// of causing bugs that are difficult to diagnose, crash, etc. It does not +// of itself guarantee that objects are aligned to a cache line. +// +// NOTE: Some compilers are picky about the locations of annotations such as +// this attribute, so prefer to put it at the beginning of your declaration. +// For example, +// +// ABSL_CACHELINE_ALIGNED static Foo* foo = ... +// +// class ABSL_CACHELINE_ALIGNED Bar { ... +// +// Recommendations: +// +// 1) Consult compiler documentation; this comment is not kept in sync as +// toolchains evolve. +// 2) Verify your use has the intended effect. This often requires inspecting +// the generated machine code. +// 3) Prefer applying this attribute to individual variables. Avoid +// applying it to types. This tends to localize the effect. +#define ABSL_CACHELINE_ALIGNED __attribute__((aligned(ABSL_CACHELINE_SIZE))) +#elif defined(_MSC_VER) +#define ABSL_CACHELINE_SIZE 64 +#define ABSL_CACHELINE_ALIGNED __declspec(align(ABSL_CACHELINE_SIZE)) +#else +#define ABSL_CACHELINE_SIZE 64 +#define ABSL_CACHELINE_ALIGNED +#endif + +// ABSL_PREDICT_TRUE, ABSL_PREDICT_FALSE +// +// Enables the compiler to prioritize compilation using static analysis for +// likely paths within a boolean branch. +// +// Example: +// +// if (ABSL_PREDICT_TRUE(expression)) { +// return result; // Faster if more likely +// } else { +// return 0; +// } +// +// Compilers can use the information that a certain branch is not likely to be +// taken (for instance, a CHECK failure) to optimize for the common case in +// the absence of better information (ie. compiling gcc with `-fprofile-arcs`). +// +// Recommendation: Modern CPUs dynamically predict branch execution paths, +// typically with accuracy greater than 97%. As a result, annotating every +// branch in a codebase is likely counterproductive; however, annotating +// specific branches that are both hot and consistently mispredicted is likely +// to yield performance improvements. +#if ABSL_HAVE_BUILTIN(__builtin_expect) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_PREDICT_FALSE(x) (__builtin_expect(x, 0)) +#define ABSL_PREDICT_TRUE(x) (__builtin_expect(false || (x), true)) +#else +#define ABSL_PREDICT_FALSE(x) (x) +#define ABSL_PREDICT_TRUE(x) (x) +#endif + +// ABSL_INTERNAL_ASSUME(cond) +// Informs the compiler than a condition is always true and that it can assume +// it to be true for optimization purposes. The call has undefined behavior if +// the condition is false. +// In !NDEBUG mode, the condition is checked with an assert(). +// NOTE: The expression must not have side effects, as it will only be evaluated +// in some compilation modes and not others. +// +// Example: +// +// int x = ...; +// ABSL_INTERNAL_ASSUME(x >= 0); +// // The compiler can optimize the division to a simple right shift using the +// // assumption specified above. +// int y = x / 16; +// +#if !defined(NDEBUG) +#define ABSL_INTERNAL_ASSUME(cond) assert(cond) +#elif ABSL_HAVE_BUILTIN(__builtin_assume) +#define ABSL_INTERNAL_ASSUME(cond) __builtin_assume(cond) +#elif defined(__GNUC__) || ABSL_HAVE_BUILTIN(__builtin_unreachable) +#define ABSL_INTERNAL_ASSUME(cond) \ + do { \ + if (!(cond)) __builtin_unreachable(); \ + } while (0) +#elif defined(_MSC_VER) +#define ABSL_INTERNAL_ASSUME(cond) __assume(cond) +#else +#define ABSL_INTERNAL_ASSUME(cond) \ + do { \ + static_cast<void>(false && (cond)); \ + } while (0) +#endif + +// ABSL_INTERNAL_UNIQUE_SMALL_NAME(cond) +// This macro forces small unique name on a static file level symbols like +// static local variables or static functions. This is intended to be used in +// macro definitions to optimize the cost of generated code. Do NOT use it on +// symbols exported from translation unit since it may casue a link time +// conflict. +// +// Example: +// +// #define MY_MACRO(txt) +// namespace { +// char VeryVeryLongVarName[] ABSL_INTERNAL_UNIQUE_SMALL_NAME() = txt; +// const char* VeryVeryLongFuncName() ABSL_INTERNAL_UNIQUE_SMALL_NAME(); +// const char* VeryVeryLongFuncName() { return txt; } +// } +// + +#if defined(__GNUC__) +#define ABSL_INTERNAL_UNIQUE_SMALL_NAME2(x) #x +#define ABSL_INTERNAL_UNIQUE_SMALL_NAME1(x) ABSL_INTERNAL_UNIQUE_SMALL_NAME2(x) +#define ABSL_INTERNAL_UNIQUE_SMALL_NAME() \ + asm(ABSL_INTERNAL_UNIQUE_SMALL_NAME1(.absl.__COUNTER__)) +#else +#define ABSL_INTERNAL_UNIQUE_SMALL_NAME() +#endif + +#endif // ABSL_BASE_OPTIMIZATION_H_ diff --git a/third_party/abseil_cpp/absl/base/options.h b/third_party/abseil_cpp/absl/base/options.h new file mode 100644 index 0000000000..230bf1eecc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/options.h @@ -0,0 +1,238 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: options.h +// ----------------------------------------------------------------------------- +// +// This file contains Abseil configuration options for setting specific +// implementations instead of letting Abseil determine which implementation to +// use at compile-time. Setting these options may be useful for package or build +// managers who wish to guarantee ABI stability within binary builds (which are +// otherwise difficult to enforce). +// +// *** IMPORTANT NOTICE FOR PACKAGE MANAGERS: It is important that +// maintainers of package managers who wish to package Abseil read and +// understand this file! *** +// +// Abseil contains a number of possible configuration endpoints, based on +// parameters such as the detected platform, language version, or command-line +// flags used to invoke the underlying binary. As is the case with all +// libraries, binaries which contain Abseil code must ensure that separate +// packages use the same compiled copy of Abseil to avoid a diamond dependency +// problem, which can occur if two packages built with different Abseil +// configuration settings are linked together. Diamond dependency problems in +// C++ may manifest as violations to the One Definition Rule (ODR) (resulting in +// linker errors), or undefined behavior (resulting in crashes). +// +// Diamond dependency problems can be avoided if all packages utilize the same +// exact version of Abseil. Building from source code with the same compilation +// parameters is the easiest way to avoid such dependency problems. However, for +// package managers who cannot control such compilation parameters, we are +// providing the file to allow you to inject ABI (Application Binary Interface) +// stability across builds. Settings options in this file will neither change +// API nor ABI, providing a stable copy of Abseil between packages. +// +// Care must be taken to keep options within these configurations isolated +// from any other dynamic settings, such as command-line flags which could alter +// these options. This file is provided specifically to help build and package +// managers provide a stable copy of Abseil within their libraries and binaries; +// other developers should not have need to alter the contents of this file. +// +// ----------------------------------------------------------------------------- +// Usage +// ----------------------------------------------------------------------------- +// +// For any particular package release, set the appropriate definitions within +// this file to whatever value makes the most sense for your package(s). Note +// that, by default, most of these options, at the moment, affect the +// implementation of types; future options may affect other implementation +// details. +// +// NOTE: the defaults within this file all assume that Abseil can select the +// proper Abseil implementation at compile-time, which will not be sufficient +// to guarantee ABI stability to package managers. + +#ifndef ABSL_BASE_OPTIONS_H_ +#define ABSL_BASE_OPTIONS_H_ + +// Include a standard library header to allow configuration based on the +// standard library in use. +#ifdef __cplusplus +#include <ciso646> +#endif + +// ----------------------------------------------------------------------------- +// Type Compatibility Options +// ----------------------------------------------------------------------------- +// +// ABSL_OPTION_USE_STD_ANY +// +// This option controls whether absl::any is implemented as an alias to +// std::any, or as an independent implementation. +// +// A value of 0 means to use Abseil's implementation. This requires only C++11 +// support, and is expected to work on every toolchain we support. +// +// A value of 1 means to use an alias to std::any. This requires that all code +// using Abseil is built in C++17 mode or later. +// +// A value of 2 means to detect the C++ version being used to compile Abseil, +// and use an alias only if a working std::any is available. This option is +// useful when you are building your entire program, including all of its +// dependencies, from source. It should not be used otherwise -- for example, +// if you are distributing Abseil in a binary package manager -- since in +// mode 2, absl::any will name a different type, with a different mangled name +// and binary layout, depending on the compiler flags passed by the end user. +// For more info, see https://abseil.io/about/design/dropin-types. +// +// User code should not inspect this macro. To check in the preprocessor if +// absl::any is a typedef of std::any, use the feature macro ABSL_USES_STD_ANY. + +#define ABSL_OPTION_USE_STD_ANY 2 + + +// ABSL_OPTION_USE_STD_OPTIONAL +// +// This option controls whether absl::optional is implemented as an alias to +// std::optional, or as an independent implementation. +// +// A value of 0 means to use Abseil's implementation. This requires only C++11 +// support, and is expected to work on every toolchain we support. +// +// A value of 1 means to use an alias to std::optional. This requires that all +// code using Abseil is built in C++17 mode or later. +// +// A value of 2 means to detect the C++ version being used to compile Abseil, +// and use an alias only if a working std::optional is available. This option +// is useful when you are building your program from source. It should not be +// used otherwise -- for example, if you are distributing Abseil in a binary +// package manager -- since in mode 2, absl::optional will name a different +// type, with a different mangled name and binary layout, depending on the +// compiler flags passed by the end user. For more info, see +// https://abseil.io/about/design/dropin-types. + +// User code should not inspect this macro. To check in the preprocessor if +// absl::optional is a typedef of std::optional, use the feature macro +// ABSL_USES_STD_OPTIONAL. + +#define ABSL_OPTION_USE_STD_OPTIONAL 2 + + +// ABSL_OPTION_USE_STD_STRING_VIEW +// +// This option controls whether absl::string_view is implemented as an alias to +// std::string_view, or as an independent implementation. +// +// A value of 0 means to use Abseil's implementation. This requires only C++11 +// support, and is expected to work on every toolchain we support. +// +// A value of 1 means to use an alias to std::string_view. This requires that +// all code using Abseil is built in C++17 mode or later. +// +// A value of 2 means to detect the C++ version being used to compile Abseil, +// and use an alias only if a working std::string_view is available. This +// option is useful when you are building your program from source. It should +// not be used otherwise -- for example, if you are distributing Abseil in a +// binary package manager -- since in mode 2, absl::string_view will name a +// different type, with a different mangled name and binary layout, depending on +// the compiler flags passed by the end user. For more info, see +// https://abseil.io/about/design/dropin-types. +// +// User code should not inspect this macro. To check in the preprocessor if +// absl::string_view is a typedef of std::string_view, use the feature macro +// ABSL_USES_STD_STRING_VIEW. + +#define ABSL_OPTION_USE_STD_STRING_VIEW 2 + +// ABSL_OPTION_USE_STD_VARIANT +// +// This option controls whether absl::variant is implemented as an alias to +// std::variant, or as an independent implementation. +// +// A value of 0 means to use Abseil's implementation. This requires only C++11 +// support, and is expected to work on every toolchain we support. +// +// A value of 1 means to use an alias to std::variant. This requires that all +// code using Abseil is built in C++17 mode or later. +// +// A value of 2 means to detect the C++ version being used to compile Abseil, +// and use an alias only if a working std::variant is available. This option +// is useful when you are building your program from source. It should not be +// used otherwise -- for example, if you are distributing Abseil in a binary +// package manager -- since in mode 2, absl::variant will name a different +// type, with a different mangled name and binary layout, depending on the +// compiler flags passed by the end user. For more info, see +// https://abseil.io/about/design/dropin-types. +// +// User code should not inspect this macro. To check in the preprocessor if +// absl::variant is a typedef of std::variant, use the feature macro +// ABSL_USES_STD_VARIANT. + +#define ABSL_OPTION_USE_STD_VARIANT 2 + + +// ABSL_OPTION_USE_INLINE_NAMESPACE +// ABSL_OPTION_INLINE_NAMESPACE_NAME +// +// These options controls whether all entities in the absl namespace are +// contained within an inner inline namespace. This does not affect the +// user-visible API of Abseil, but it changes the mangled names of all symbols. +// +// This can be useful as a version tag if you are distributing Abseil in +// precompiled form. This will prevent a binary library build of Abseil with +// one inline namespace being used with headers configured with a different +// inline namespace name. Binary packagers are reminded that Abseil does not +// guarantee any ABI stability in Abseil, so any update of Abseil or +// configuration change in such a binary package should be combined with a +// new, unique value for the inline namespace name. +// +// A value of 0 means not to use inline namespaces. +// +// A value of 1 means to use an inline namespace with the given name inside +// namespace absl. If this is set, ABSL_OPTION_INLINE_NAMESPACE_NAME must also +// be changed to a new, unique identifier name. In particular "head" is not +// allowed. + +#define ABSL_OPTION_USE_INLINE_NAMESPACE 0 +#define ABSL_OPTION_INLINE_NAMESPACE_NAME head + +// ABSL_OPTION_HARDENED +// +// This option enables a "hardened" build in release mode (in this context, +// release mode is defined as a build where the `NDEBUG` macro is defined). +// +// A value of 0 means that "hardened" mode is not enabled. +// +// A value of 1 means that "hardened" mode is enabled. +// +// Hardened builds have additional security checks enabled when `NDEBUG` is +// defined. Defining `NDEBUG` is normally used to turn `assert()` macro into a +// no-op, as well as disabling other bespoke program consistency checks. By +// defining ABSL_OPTION_HARDENED to 1, a select set of checks remain enabled in +// release mode. These checks guard against programming errors that may lead to +// security vulnerabilities. In release mode, when one of these programming +// errors is encountered, the program will immediately abort, possibly without +// any attempt at logging. +// +// The checks enabled by this option are not free; they do incur runtime cost. +// +// The checks enabled by this option are always active when `NDEBUG` is not +// defined, even in the case when ABSL_OPTION_HARDENED is defined to 0. The +// checks enabled by this option may abort the program in a different way and +// log additional information when `NDEBUG` is not defined. + +#define ABSL_OPTION_HARDENED 0 + +#endif // ABSL_BASE_OPTIONS_H_ diff --git a/third_party/abseil_cpp/absl/base/policy_checks.h b/third_party/abseil_cpp/absl/base/policy_checks.h new file mode 100644 index 0000000000..4dfa49e54a --- /dev/null +++ b/third_party/abseil_cpp/absl/base/policy_checks.h @@ -0,0 +1,111 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: policy_checks.h +// ----------------------------------------------------------------------------- +// +// This header enforces a minimum set of policies at build time, such as the +// supported compiler and library versions. Unsupported configurations are +// reported with `#error`. This enforcement is best effort, so successfully +// compiling this header does not guarantee a supported configuration. + +#ifndef ABSL_BASE_POLICY_CHECKS_H_ +#define ABSL_BASE_POLICY_CHECKS_H_ + +// Included for the __GLIBC_PREREQ macro used below. +#include <limits.h> + +// Included for the _STLPORT_VERSION macro used below. +#if defined(__cplusplus) +#include <cstddef> +#endif + +// ----------------------------------------------------------------------------- +// Operating System Check +// ----------------------------------------------------------------------------- + +#if defined(__CYGWIN__) +#error "Cygwin is not supported." +#endif + +// ----------------------------------------------------------------------------- +// Compiler Check +// ----------------------------------------------------------------------------- + +// We support MSVC++ 14.0 update 2 and later. +// This minimum will go up. +#if defined(_MSC_FULL_VER) && _MSC_FULL_VER < 190023918 && !defined(__clang__) +#error "This package requires Visual Studio 2015 Update 2 or higher." +#endif + +// We support gcc 4.7 and later. +// This minimum will go up. +#if defined(__GNUC__) && !defined(__clang__) +#if __GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 7) +#error "This package requires gcc 4.7 or higher." +#endif +#endif + +// We support Apple Xcode clang 4.2.1 (version 421.11.65) and later. +// This corresponds to Apple Xcode version 4.5. +// This minimum will go up. +#if defined(__apple_build_version__) && __apple_build_version__ < 4211165 +#error "This package requires __apple_build_version__ of 4211165 or higher." +#endif + +// ----------------------------------------------------------------------------- +// C++ Version Check +// ----------------------------------------------------------------------------- + +// Enforce C++11 as the minimum. Note that Visual Studio has not +// advanced __cplusplus despite being good enough for our purposes, so +// so we exempt it from the check. +#if defined(__cplusplus) && !defined(_MSC_VER) +#if __cplusplus < 201103L +#error "C++ versions less than C++11 are not supported." +#endif +#endif + +// ----------------------------------------------------------------------------- +// Standard Library Check +// ----------------------------------------------------------------------------- + +#if defined(_STLPORT_VERSION) +#error "STLPort is not supported." +#endif + +// ----------------------------------------------------------------------------- +// `char` Size Check +// ----------------------------------------------------------------------------- + +// Abseil currently assumes CHAR_BIT == 8. If you would like to use Abseil on a +// platform where this is not the case, please provide us with the details about +// your platform so we can consider relaxing this requirement. +#if CHAR_BIT != 8 +#error "Abseil assumes CHAR_BIT == 8." +#endif + +// ----------------------------------------------------------------------------- +// `int` Size Check +// ----------------------------------------------------------------------------- + +// Abseil currently assumes that an int is 4 bytes. If you would like to use +// Abseil on a platform where this is not the case, please provide us with the +// details about your platform so we can consider relaxing this requirement. +#if INT_MAX < 2147483647 +#error "Abseil assumes that int is at least 4 bytes. " +#endif + +#endif // ABSL_BASE_POLICY_CHECKS_H_ diff --git a/third_party/abseil_cpp/absl/base/port.h b/third_party/abseil_cpp/absl/base/port.h new file mode 100644 index 0000000000..6c28068d4f --- /dev/null +++ b/third_party/abseil_cpp/absl/base/port.h @@ -0,0 +1,26 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This files is a forwarding header for other headers containing various +// portability macros and functions. +// This file is used for both C and C++! + +#ifndef ABSL_BASE_PORT_H_ +#define ABSL_BASE_PORT_H_ + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/optimization.h" + +#endif // ABSL_BASE_PORT_H_ diff --git a/third_party/abseil_cpp/absl/base/raw_logging_test.cc b/third_party/abseil_cpp/absl/base/raw_logging_test.cc new file mode 100644 index 0000000000..3d30bd3861 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/raw_logging_test.cc @@ -0,0 +1,79 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This test serves primarily as a compilation test for base/raw_logging.h. +// Raw logging testing is covered by logging_unittest.cc, which is not as +// portable as this test. + +#include "absl/base/internal/raw_logging.h" + +#include <tuple> + +#include "gtest/gtest.h" +#include "absl/strings/str_cat.h" + +namespace { + +TEST(RawLoggingCompilationTest, Log) { + ABSL_RAW_LOG(INFO, "RAW INFO: %d", 1); + ABSL_RAW_LOG(INFO, "RAW INFO: %d %d", 1, 2); + ABSL_RAW_LOG(INFO, "RAW INFO: %d %d %d", 1, 2, 3); + ABSL_RAW_LOG(INFO, "RAW INFO: %d %d %d %d", 1, 2, 3, 4); + ABSL_RAW_LOG(INFO, "RAW INFO: %d %d %d %d %d", 1, 2, 3, 4, 5); + ABSL_RAW_LOG(WARNING, "RAW WARNING: %d", 1); + ABSL_RAW_LOG(ERROR, "RAW ERROR: %d", 1); +} + +TEST(RawLoggingCompilationTest, PassingCheck) { + ABSL_RAW_CHECK(true, "RAW CHECK"); +} + +// Not all platforms support output from raw log, so we don't verify any +// particular output for RAW check failures (expecting the empty string +// accomplishes this). This test is primarily a compilation test, but we +// are verifying process death when EXPECT_DEATH works for a platform. +const char kExpectedDeathOutput[] = ""; + +TEST(RawLoggingDeathTest, FailingCheck) { + EXPECT_DEATH_IF_SUPPORTED(ABSL_RAW_CHECK(1 == 0, "explanation"), + kExpectedDeathOutput); +} + +TEST(RawLoggingDeathTest, LogFatal) { + EXPECT_DEATH_IF_SUPPORTED(ABSL_RAW_LOG(FATAL, "my dog has fleas"), + kExpectedDeathOutput); +} + +TEST(InternalLog, CompilationTest) { + ABSL_INTERNAL_LOG(INFO, "Internal Log"); + std::string log_msg = "Internal Log"; + ABSL_INTERNAL_LOG(INFO, log_msg); + + ABSL_INTERNAL_LOG(INFO, log_msg + " 2"); + + float d = 1.1f; + ABSL_INTERNAL_LOG(INFO, absl::StrCat("Internal log ", 3, " + ", d)); +} + +TEST(InternalLogDeathTest, FailingCheck) { + EXPECT_DEATH_IF_SUPPORTED(ABSL_INTERNAL_CHECK(1 == 0, "explanation"), + kExpectedDeathOutput); +} + +TEST(InternalLogDeathTest, LogFatal) { + EXPECT_DEATH_IF_SUPPORTED(ABSL_INTERNAL_LOG(FATAL, "my dog has fleas"), + kExpectedDeathOutput); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/base/spinlock_test_common.cc b/third_party/abseil_cpp/absl/base/spinlock_test_common.cc new file mode 100644 index 0000000000..b68c51a1dc --- /dev/null +++ b/third_party/abseil_cpp/absl/base/spinlock_test_common.cc @@ -0,0 +1,265 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// A bunch of threads repeatedly hash an array of ints protected by a +// spinlock. If the spinlock is working properly, all elements of the +// array should be equal at the end of the test. + +#include <cstdint> +#include <limits> +#include <random> +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/low_level_scheduling.h" +#include "absl/base/internal/scheduling_mode.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/internal/sysinfo.h" +#include "absl/base/macros.h" +#include "absl/synchronization/blocking_counter.h" +#include "absl/synchronization/notification.h" + +constexpr int32_t kNumThreads = 10; +constexpr int32_t kIters = 1000; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// This is defined outside of anonymous namespace so that it can be +// a friend of SpinLock to access protected methods for testing. +struct SpinLockTest { + static uint32_t EncodeWaitCycles(int64_t wait_start_time, + int64_t wait_end_time) { + return SpinLock::EncodeWaitCycles(wait_start_time, wait_end_time); + } + static uint64_t DecodeWaitCycles(uint32_t lock_value) { + return SpinLock::DecodeWaitCycles(lock_value); + } +}; + +namespace { + +static constexpr int kArrayLength = 10; +static uint32_t values[kArrayLength]; + +ABSL_CONST_INIT static SpinLock static_cooperative_spinlock( + absl::kConstInit, base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL); +ABSL_CONST_INIT static SpinLock static_noncooperative_spinlock( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); + +// Simple integer hash function based on the public domain lookup2 hash. +// http://burtleburtle.net/bob/c/lookup2.c +static uint32_t Hash32(uint32_t a, uint32_t c) { + uint32_t b = 0x9e3779b9UL; // The golden ratio; an arbitrary value. + a -= b; a -= c; a ^= (c >> 13); + b -= c; b -= a; b ^= (a << 8); + c -= a; c -= b; c ^= (b >> 13); + a -= b; a -= c; a ^= (c >> 12); + b -= c; b -= a; b ^= (a << 16); + c -= a; c -= b; c ^= (b >> 5); + a -= b; a -= c; a ^= (c >> 3); + b -= c; b -= a; b ^= (a << 10); + c -= a; c -= b; c ^= (b >> 15); + return c; +} + +static void TestFunction(int thread_salt, SpinLock* spinlock) { + for (int i = 0; i < kIters; i++) { + SpinLockHolder h(spinlock); + for (int j = 0; j < kArrayLength; j++) { + const int index = (j + thread_salt) % kArrayLength; + values[index] = Hash32(values[index], thread_salt); + std::this_thread::yield(); + } + } +} + +static void ThreadedTest(SpinLock* spinlock) { + std::vector<std::thread> threads; + for (int i = 0; i < kNumThreads; ++i) { + threads.push_back(std::thread(TestFunction, i, spinlock)); + } + for (auto& thread : threads) { + thread.join(); + } + + SpinLockHolder h(spinlock); + for (int i = 1; i < kArrayLength; i++) { + EXPECT_EQ(values[0], values[i]); + } +} + +TEST(SpinLock, StackNonCooperativeDisablesScheduling) { + SpinLock spinlock(base_internal::SCHEDULE_KERNEL_ONLY); + spinlock.Lock(); + EXPECT_FALSE(base_internal::SchedulingGuard::ReschedulingIsAllowed()); + spinlock.Unlock(); +} + +TEST(SpinLock, StaticNonCooperativeDisablesScheduling) { + static_noncooperative_spinlock.Lock(); + EXPECT_FALSE(base_internal::SchedulingGuard::ReschedulingIsAllowed()); + static_noncooperative_spinlock.Unlock(); +} + +TEST(SpinLock, WaitCyclesEncoding) { + // These are implementation details not exported by SpinLock. + const int kProfileTimestampShift = 7; + const int kLockwordReservedShift = 3; + const uint32_t kSpinLockSleeper = 8; + + // We should be able to encode up to (1^kMaxCycleBits - 1) without clamping + // but the lower kProfileTimestampShift will be dropped. + const int kMaxCyclesShift = + 32 - kLockwordReservedShift + kProfileTimestampShift; + const uint64_t kMaxCycles = (int64_t{1} << kMaxCyclesShift) - 1; + + // These bits should be zero after encoding. + const uint32_t kLockwordReservedMask = (1 << kLockwordReservedShift) - 1; + + // These bits are dropped when wait cycles are encoded. + const uint64_t kProfileTimestampMask = (1 << kProfileTimestampShift) - 1; + + // Test a bunch of random values + std::default_random_engine generator; + // Shift to avoid overflow below. + std::uniform_int_distribution<uint64_t> time_distribution( + 0, std::numeric_limits<uint64_t>::max() >> 4); + std::uniform_int_distribution<uint64_t> cycle_distribution(0, kMaxCycles); + + for (int i = 0; i < 100; i++) { + int64_t start_time = time_distribution(generator); + int64_t cycles = cycle_distribution(generator); + int64_t end_time = start_time + cycles; + uint32_t lock_value = SpinLockTest::EncodeWaitCycles(start_time, end_time); + EXPECT_EQ(0, lock_value & kLockwordReservedMask); + uint64_t decoded = SpinLockTest::DecodeWaitCycles(lock_value); + EXPECT_EQ(0, decoded & kProfileTimestampMask); + EXPECT_EQ(cycles & ~kProfileTimestampMask, decoded); + } + + // Test corner cases + int64_t start_time = time_distribution(generator); + EXPECT_EQ(kSpinLockSleeper, + SpinLockTest::EncodeWaitCycles(start_time, start_time)); + EXPECT_EQ(0, SpinLockTest::DecodeWaitCycles(0)); + EXPECT_EQ(0, SpinLockTest::DecodeWaitCycles(kLockwordReservedMask)); + EXPECT_EQ(kMaxCycles & ~kProfileTimestampMask, + SpinLockTest::DecodeWaitCycles(~kLockwordReservedMask)); + + // Check that we cannot produce kSpinLockSleeper during encoding. + int64_t sleeper_cycles = + kSpinLockSleeper << (kProfileTimestampShift - kLockwordReservedShift); + uint32_t sleeper_value = + SpinLockTest::EncodeWaitCycles(start_time, start_time + sleeper_cycles); + EXPECT_NE(sleeper_value, kSpinLockSleeper); + + // Test clamping + uint32_t max_value = + SpinLockTest::EncodeWaitCycles(start_time, start_time + kMaxCycles); + uint64_t max_value_decoded = SpinLockTest::DecodeWaitCycles(max_value); + uint64_t expected_max_value_decoded = kMaxCycles & ~kProfileTimestampMask; + EXPECT_EQ(expected_max_value_decoded, max_value_decoded); + + const int64_t step = (1 << kProfileTimestampShift); + uint32_t after_max_value = + SpinLockTest::EncodeWaitCycles(start_time, start_time + kMaxCycles + step); + uint64_t after_max_value_decoded = + SpinLockTest::DecodeWaitCycles(after_max_value); + EXPECT_EQ(expected_max_value_decoded, after_max_value_decoded); + + uint32_t before_max_value = SpinLockTest::EncodeWaitCycles( + start_time, start_time + kMaxCycles - step); + uint64_t before_max_value_decoded = + SpinLockTest::DecodeWaitCycles(before_max_value); + EXPECT_GT(expected_max_value_decoded, before_max_value_decoded); +} + +TEST(SpinLockWithThreads, StackSpinLock) { + SpinLock spinlock; + ThreadedTest(&spinlock); +} + +TEST(SpinLockWithThreads, StackCooperativeSpinLock) { + SpinLock spinlock(base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL); + ThreadedTest(&spinlock); +} + +TEST(SpinLockWithThreads, StackNonCooperativeSpinLock) { + SpinLock spinlock(base_internal::SCHEDULE_KERNEL_ONLY); + ThreadedTest(&spinlock); +} + +TEST(SpinLockWithThreads, StaticCooperativeSpinLock) { + ThreadedTest(&static_cooperative_spinlock); +} + +TEST(SpinLockWithThreads, StaticNonCooperativeSpinLock) { + ThreadedTest(&static_noncooperative_spinlock); +} + +TEST(SpinLockWithThreads, DoesNotDeadlock) { + struct Helper { + static void NotifyThenLock(Notification* locked, SpinLock* spinlock, + BlockingCounter* b) { + locked->WaitForNotification(); // Wait for LockThenWait() to hold "s". + b->DecrementCount(); + SpinLockHolder l(spinlock); + } + + static void LockThenWait(Notification* locked, SpinLock* spinlock, + BlockingCounter* b) { + SpinLockHolder l(spinlock); + locked->Notify(); + b->Wait(); + } + + static void DeadlockTest(SpinLock* spinlock, int num_spinners) { + Notification locked; + BlockingCounter counter(num_spinners); + std::vector<std::thread> threads; + + threads.push_back( + std::thread(Helper::LockThenWait, &locked, spinlock, &counter)); + for (int i = 0; i < num_spinners; ++i) { + threads.push_back( + std::thread(Helper::NotifyThenLock, &locked, spinlock, &counter)); + } + + for (auto& thread : threads) { + thread.join(); + } + } + }; + + SpinLock stack_cooperative_spinlock( + base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL); + SpinLock stack_noncooperative_spinlock(base_internal::SCHEDULE_KERNEL_ONLY); + Helper::DeadlockTest(&stack_cooperative_spinlock, + base_internal::NumCPUs() * 2); + Helper::DeadlockTest(&stack_noncooperative_spinlock, + base_internal::NumCPUs() * 2); + Helper::DeadlockTest(&static_cooperative_spinlock, + base_internal::NumCPUs() * 2); + Helper::DeadlockTest(&static_noncooperative_spinlock, + base_internal::NumCPUs() * 2); +} + +} // namespace +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/base/thread_annotations.h b/third_party/abseil_cpp/absl/base/thread_annotations.h new file mode 100644 index 0000000000..5f51c0c2d2 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/thread_annotations.h @@ -0,0 +1,280 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: thread_annotations.h +// ----------------------------------------------------------------------------- +// +// This header file contains macro definitions for thread safety annotations +// that allow developers to document the locking policies of multi-threaded +// code. The annotations can also help program analysis tools to identify +// potential thread safety issues. +// +// These annotations are implemented using compiler attributes. Using the macros +// defined here instead of raw attributes allow for portability and future +// compatibility. +// +// When referring to mutexes in the arguments of the attributes, you should +// use variable names or more complex expressions (e.g. my_object->mutex_) +// that evaluate to a concrete mutex object whenever possible. If the mutex +// you want to refer to is not in scope, you may use a member pointer +// (e.g. &MyClass::mutex_) to refer to a mutex in some (unknown) object. + +#ifndef ABSL_BASE_THREAD_ANNOTATIONS_H_ +#define ABSL_BASE_THREAD_ANNOTATIONS_H_ + +#include "absl/base/config.h" +// TODO(mbonadei): Remove after the backward compatibility period. +#include "absl/base/internal/thread_annotations.h" // IWYU pragma: export + +#if defined(__clang__) +#define ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(x) __attribute__((x)) +#else +#define ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(x) // no-op +#endif + +// ABSL_GUARDED_BY() +// +// Documents if a shared field or global variable needs to be protected by a +// mutex. ABSL_GUARDED_BY() allows the user to specify a particular mutex that +// should be held when accessing the annotated variable. +// +// Although this annotation (and ABSL_PT_GUARDED_BY, below) cannot be applied to +// local variables, a local variable and its associated mutex can often be +// combined into a small class or struct, thereby allowing the annotation. +// +// Example: +// +// class Foo { +// Mutex mu_; +// int p1_ ABSL_GUARDED_BY(mu_); +// ... +// }; +#define ABSL_GUARDED_BY(x) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(guarded_by(x)) + +// ABSL_PT_GUARDED_BY() +// +// Documents if the memory location pointed to by a pointer should be guarded +// by a mutex when dereferencing the pointer. +// +// Example: +// class Foo { +// Mutex mu_; +// int *p1_ ABSL_PT_GUARDED_BY(mu_); +// ... +// }; +// +// Note that a pointer variable to a shared memory location could itself be a +// shared variable. +// +// Example: +// +// // `q_`, guarded by `mu1_`, points to a shared memory location that is +// // guarded by `mu2_`: +// int *q_ ABSL_GUARDED_BY(mu1_) ABSL_PT_GUARDED_BY(mu2_); +#define ABSL_PT_GUARDED_BY(x) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(pt_guarded_by(x)) + +// ABSL_ACQUIRED_AFTER() / ABSL_ACQUIRED_BEFORE() +// +// Documents the acquisition order between locks that can be held +// simultaneously by a thread. For any two locks that need to be annotated +// to establish an acquisition order, only one of them needs the annotation. +// (i.e. You don't have to annotate both locks with both ABSL_ACQUIRED_AFTER +// and ABSL_ACQUIRED_BEFORE.) +// +// As with ABSL_GUARDED_BY, this is only applicable to mutexes that are shared +// fields or global variables. +// +// Example: +// +// Mutex m1_; +// Mutex m2_ ABSL_ACQUIRED_AFTER(m1_); +#define ABSL_ACQUIRED_AFTER(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(acquired_after(__VA_ARGS__)) + +#define ABSL_ACQUIRED_BEFORE(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(acquired_before(__VA_ARGS__)) + +// ABSL_EXCLUSIVE_LOCKS_REQUIRED() / ABSL_SHARED_LOCKS_REQUIRED() +// +// Documents a function that expects a mutex to be held prior to entry. +// The mutex is expected to be held both on entry to, and exit from, the +// function. +// +// An exclusive lock allows read-write access to the guarded data member(s), and +// only one thread can acquire a lock exclusively at any one time. A shared lock +// allows read-only access, and any number of threads can acquire a shared lock +// concurrently. +// +// Generally, non-const methods should be annotated with +// ABSL_EXCLUSIVE_LOCKS_REQUIRED, while const methods should be annotated with +// ABSL_SHARED_LOCKS_REQUIRED. +// +// Example: +// +// Mutex mu1, mu2; +// int a ABSL_GUARDED_BY(mu1); +// int b ABSL_GUARDED_BY(mu2); +// +// void foo() ABSL_EXCLUSIVE_LOCKS_REQUIRED(mu1, mu2) { ... } +// void bar() const ABSL_SHARED_LOCKS_REQUIRED(mu1, mu2) { ... } +#define ABSL_EXCLUSIVE_LOCKS_REQUIRED(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE( \ + exclusive_locks_required(__VA_ARGS__)) + +#define ABSL_SHARED_LOCKS_REQUIRED(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(shared_locks_required(__VA_ARGS__)) + +// ABSL_LOCKS_EXCLUDED() +// +// Documents the locks acquired in the body of the function. These locks +// cannot be held when calling this function (as Abseil's `Mutex` locks are +// non-reentrant). +#define ABSL_LOCKS_EXCLUDED(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(locks_excluded(__VA_ARGS__)) + +// ABSL_LOCK_RETURNED() +// +// Documents a function that returns a mutex without acquiring it. For example, +// a public getter method that returns a pointer to a private mutex should +// be annotated with ABSL_LOCK_RETURNED. +#define ABSL_LOCK_RETURNED(x) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(lock_returned(x)) + +// ABSL_LOCKABLE +// +// Documents if a class/type is a lockable type (such as the `Mutex` class). +#define ABSL_LOCKABLE ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(lockable) + +// ABSL_SCOPED_LOCKABLE +// +// Documents if a class does RAII locking (such as the `MutexLock` class). +// The constructor should use `LOCK_FUNCTION()` to specify the mutex that is +// acquired, and the destructor should use `UNLOCK_FUNCTION()` with no +// arguments; the analysis will assume that the destructor unlocks whatever the +// constructor locked. +#define ABSL_SCOPED_LOCKABLE \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(scoped_lockable) + +// ABSL_EXCLUSIVE_LOCK_FUNCTION() +// +// Documents functions that acquire a lock in the body of a function, and do +// not release it. +#define ABSL_EXCLUSIVE_LOCK_FUNCTION(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE( \ + exclusive_lock_function(__VA_ARGS__)) + +// ABSL_SHARED_LOCK_FUNCTION() +// +// Documents functions that acquire a shared (reader) lock in the body of a +// function, and do not release it. +#define ABSL_SHARED_LOCK_FUNCTION(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(shared_lock_function(__VA_ARGS__)) + +// ABSL_UNLOCK_FUNCTION() +// +// Documents functions that expect a lock to be held on entry to the function, +// and release it in the body of the function. +#define ABSL_UNLOCK_FUNCTION(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(unlock_function(__VA_ARGS__)) + +// ABSL_EXCLUSIVE_TRYLOCK_FUNCTION() / ABSL_SHARED_TRYLOCK_FUNCTION() +// +// Documents functions that try to acquire a lock, and return success or failure +// (or a non-boolean value that can be interpreted as a boolean). +// The first argument should be `true` for functions that return `true` on +// success, or `false` for functions that return `false` on success. The second +// argument specifies the mutex that is locked on success. If unspecified, this +// mutex is assumed to be `this`. +#define ABSL_EXCLUSIVE_TRYLOCK_FUNCTION(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE( \ + exclusive_trylock_function(__VA_ARGS__)) + +#define ABSL_SHARED_TRYLOCK_FUNCTION(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE( \ + shared_trylock_function(__VA_ARGS__)) + +// ABSL_ASSERT_EXCLUSIVE_LOCK() / ABSL_ASSERT_SHARED_LOCK() +// +// Documents functions that dynamically check to see if a lock is held, and fail +// if it is not held. +#define ABSL_ASSERT_EXCLUSIVE_LOCK(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(assert_exclusive_lock(__VA_ARGS__)) + +#define ABSL_ASSERT_SHARED_LOCK(...) \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(assert_shared_lock(__VA_ARGS__)) + +// ABSL_NO_THREAD_SAFETY_ANALYSIS +// +// Turns off thread safety checking within the body of a particular function. +// This annotation is used to mark functions that are known to be correct, but +// the locking behavior is more complicated than the analyzer can handle. +#define ABSL_NO_THREAD_SAFETY_ANALYSIS \ + ABSL_INTERNAL_THREAD_ANNOTATION_ATTRIBUTE(no_thread_safety_analysis) + +//------------------------------------------------------------------------------ +// Tool-Supplied Annotations +//------------------------------------------------------------------------------ + +// ABSL_TS_UNCHECKED should be placed around lock expressions that are not valid +// C++ syntax, but which are present for documentation purposes. These +// annotations will be ignored by the analysis. +#define ABSL_TS_UNCHECKED(x) "" + +// ABSL_TS_FIXME is used to mark lock expressions that are not valid C++ syntax. +// It is used by automated tools to mark and disable invalid expressions. +// The annotation should either be fixed, or changed to ABSL_TS_UNCHECKED. +#define ABSL_TS_FIXME(x) "" + +// Like ABSL_NO_THREAD_SAFETY_ANALYSIS, this turns off checking within the body +// of a particular function. However, this attribute is used to mark functions +// that are incorrect and need to be fixed. It is used by automated tools to +// avoid breaking the build when the analysis is updated. +// Code owners are expected to eventually fix the routine. +#define ABSL_NO_THREAD_SAFETY_ANALYSIS_FIXME ABSL_NO_THREAD_SAFETY_ANALYSIS + +// Similar to ABSL_NO_THREAD_SAFETY_ANALYSIS_FIXME, this macro marks a +// ABSL_GUARDED_BY annotation that needs to be fixed, because it is producing +// thread safety warning. It disables the ABSL_GUARDED_BY. +#define ABSL_GUARDED_BY_FIXME(x) + +// Disables warnings for a single read operation. This can be used to avoid +// warnings when it is known that the read is not actually involved in a race, +// but the compiler cannot confirm that. +#define ABSL_TS_UNCHECKED_READ(x) absl::base_internal::ts_unchecked_read(x) + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace base_internal { + +// Takes a reference to a guarded data member, and returns an unguarded +// reference. +// Do not used this function directly, use ABSL_TS_UNCHECKED_READ instead. +template <typename T> +inline const T& ts_unchecked_read(const T& v) ABSL_NO_THREAD_SAFETY_ANALYSIS { + return v; +} + +template <typename T> +inline T& ts_unchecked_read(T& v) ABSL_NO_THREAD_SAFETY_ANALYSIS { + return v; +} + +} // namespace base_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_BASE_THREAD_ANNOTATIONS_H_ diff --git a/third_party/abseil_cpp/absl/base/throw_delegate_test.cc b/third_party/abseil_cpp/absl/base/throw_delegate_test.cc new file mode 100644 index 0000000000..5ba4ce55e6 --- /dev/null +++ b/third_party/abseil_cpp/absl/base/throw_delegate_test.cc @@ -0,0 +1,107 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/internal/throw_delegate.h" + +#include <functional> +#include <new> +#include <stdexcept> + +#include "absl/base/config.h" +#include "gtest/gtest.h" + +namespace { + +using absl::base_internal::ThrowStdLogicError; +using absl::base_internal::ThrowStdInvalidArgument; +using absl::base_internal::ThrowStdDomainError; +using absl::base_internal::ThrowStdLengthError; +using absl::base_internal::ThrowStdOutOfRange; +using absl::base_internal::ThrowStdRuntimeError; +using absl::base_internal::ThrowStdRangeError; +using absl::base_internal::ThrowStdOverflowError; +using absl::base_internal::ThrowStdUnderflowError; +using absl::base_internal::ThrowStdBadFunctionCall; +using absl::base_internal::ThrowStdBadAlloc; + +constexpr const char* what_arg = "The quick brown fox jumps over the lazy dog"; + +template <typename E> +void ExpectThrowChar(void (*f)(const char*)) { +#ifdef ABSL_HAVE_EXCEPTIONS + try { + f(what_arg); + FAIL() << "Didn't throw"; + } catch (const E& e) { + EXPECT_STREQ(e.what(), what_arg); + } +#else + EXPECT_DEATH_IF_SUPPORTED(f(what_arg), what_arg); +#endif +} + +template <typename E> +void ExpectThrowString(void (*f)(const std::string&)) { +#ifdef ABSL_HAVE_EXCEPTIONS + try { + f(what_arg); + FAIL() << "Didn't throw"; + } catch (const E& e) { + EXPECT_STREQ(e.what(), what_arg); + } +#else + EXPECT_DEATH_IF_SUPPORTED(f(what_arg), what_arg); +#endif +} + +template <typename E> +void ExpectThrowNoWhat(void (*f)()) { +#ifdef ABSL_HAVE_EXCEPTIONS + try { + f(); + FAIL() << "Didn't throw"; + } catch (const E& e) { + } +#else + EXPECT_DEATH_IF_SUPPORTED(f(), ""); +#endif +} + +TEST(ThrowHelper, Test) { + // Not using EXPECT_THROW because we want to check the .what() message too. + ExpectThrowChar<std::logic_error>(ThrowStdLogicError); + ExpectThrowChar<std::invalid_argument>(ThrowStdInvalidArgument); + ExpectThrowChar<std::domain_error>(ThrowStdDomainError); + ExpectThrowChar<std::length_error>(ThrowStdLengthError); + ExpectThrowChar<std::out_of_range>(ThrowStdOutOfRange); + ExpectThrowChar<std::runtime_error>(ThrowStdRuntimeError); + ExpectThrowChar<std::range_error>(ThrowStdRangeError); + ExpectThrowChar<std::overflow_error>(ThrowStdOverflowError); + ExpectThrowChar<std::underflow_error>(ThrowStdUnderflowError); + + ExpectThrowString<std::logic_error>(ThrowStdLogicError); + ExpectThrowString<std::invalid_argument>(ThrowStdInvalidArgument); + ExpectThrowString<std::domain_error>(ThrowStdDomainError); + ExpectThrowString<std::length_error>(ThrowStdLengthError); + ExpectThrowString<std::out_of_range>(ThrowStdOutOfRange); + ExpectThrowString<std::runtime_error>(ThrowStdRuntimeError); + ExpectThrowString<std::range_error>(ThrowStdRangeError); + ExpectThrowString<std::overflow_error>(ThrowStdOverflowError); + ExpectThrowString<std::underflow_error>(ThrowStdUnderflowError); + + ExpectThrowNoWhat<std::bad_function_call>(ThrowStdBadFunctionCall); + ExpectThrowNoWhat<std::bad_alloc>(ThrowStdBadAlloc); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/compiler_config_setting.bzl b/third_party/abseil_cpp/absl/compiler_config_setting.bzl new file mode 100644 index 0000000000..66962294d0 --- /dev/null +++ b/third_party/abseil_cpp/absl/compiler_config_setting.bzl @@ -0,0 +1,38 @@ +# +# Copyright 2018 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Creates config_setting that allows selecting based on 'compiler' value.""" + +def create_llvm_config(name, visibility): + # The "do_not_use_tools_cpp_compiler_present" attribute exists to + # distinguish between older versions of Bazel that do not support + # "@bazel_tools//tools/cpp:compiler" flag_value, and newer ones that do. + # In the future, the only way to select on the compiler will be through + # flag_values{"@bazel_tools//tools/cpp:compiler"} and the else branch can + # be removed. + if hasattr(cc_common, "do_not_use_tools_cpp_compiler_present"): + native.config_setting( + name = name, + flag_values = { + "@bazel_tools//tools/cpp:compiler": "llvm", + }, + visibility = visibility, + ) + else: + native.config_setting( + name = name, + values = {"compiler": "llvm"}, + visibility = visibility, + ) diff --git a/third_party/abseil_cpp/absl/container/BUILD.bazel b/third_party/abseil_cpp/absl/container/BUILD.bazel new file mode 100644 index 0000000000..069212354c --- /dev/null +++ b/third_party/abseil_cpp/absl/container/BUILD.bazel @@ -0,0 +1,916 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "compressed_tuple", + hdrs = ["internal/compressed_tuple.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/utility", + ], +) + +cc_test( + name = "compressed_tuple_test", + srcs = ["internal/compressed_tuple_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":compressed_tuple", + ":test_instance_tracker", + "//absl/memory", + "//absl/types:any", + "//absl/types:optional", + "//absl/utility", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "fixed_array", + hdrs = ["fixed_array.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":compressed_tuple", + "//absl/algorithm", + "//absl/base:core_headers", + "//absl/base:dynamic_annotations", + "//absl/base:throw_delegate", + "//absl/memory", + ], +) + +cc_test( + name = "fixed_array_test", + srcs = ["fixed_array_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":counting_allocator", + ":fixed_array", + "//absl/base:config", + "//absl/base:exception_testing", + "//absl/hash:hash_testing", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "fixed_array_exception_safety_test", + srcs = ["fixed_array_exception_safety_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":fixed_array", + "//absl/base:config", + "//absl/base:exception_safety_testing", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "fixed_array_benchmark", + srcs = ["fixed_array_benchmark.cc"], + copts = ABSL_TEST_COPTS + ["$(STACK_FRAME_UNLIMITED)"], + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + deps = [ + ":fixed_array", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "inlined_vector_internal", + hdrs = ["internal/inlined_vector.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":compressed_tuple", + "//absl/base:core_headers", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/types:span", + ], +) + +cc_library( + name = "inlined_vector", + hdrs = ["inlined_vector.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":inlined_vector_internal", + "//absl/algorithm", + "//absl/base:core_headers", + "//absl/base:throw_delegate", + "//absl/memory", + ], +) + +cc_library( + name = "counting_allocator", + testonly = 1, + hdrs = ["internal/counting_allocator.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = ["//absl/base:config"], +) + +cc_test( + name = "inlined_vector_test", + srcs = ["inlined_vector_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":counting_allocator", + ":inlined_vector", + ":test_instance_tracker", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:exception_testing", + "//absl/base:raw_logging_internal", + "//absl/hash:hash_testing", + "//absl/memory", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "inlined_vector_benchmark", + srcs = ["inlined_vector_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + deps = [ + ":inlined_vector", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/strings", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "inlined_vector_exception_safety_test", + srcs = ["inlined_vector_exception_safety_test.cc"], + copts = ABSL_TEST_COPTS, + deps = [ + ":inlined_vector", + "//absl/base:config", + "//absl/base:exception_safety_testing", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "test_instance_tracker", + testonly = 1, + srcs = ["internal/test_instance_tracker.cc"], + hdrs = ["internal/test_instance_tracker.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = ["//absl/types:compare"], +) + +cc_test( + name = "test_instance_tracker_test", + srcs = ["internal/test_instance_tracker_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":test_instance_tracker", + "@com_google_googletest//:gtest_main", + ], +) + +NOTEST_TAGS_NONMOBILE = [ + "no_test_darwin_x86_64", + "no_test_loonix", +] + +NOTEST_TAGS_MOBILE = [ + "no_test_android_arm", + "no_test_android_arm64", + "no_test_android_x86", + "no_test_ios_x86_64", +] + +NOTEST_TAGS = NOTEST_TAGS_MOBILE + NOTEST_TAGS_NONMOBILE + +cc_library( + name = "flat_hash_map", + hdrs = ["flat_hash_map.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":container_memory", + ":hash_function_defaults", + ":raw_hash_map", + "//absl/algorithm:container", + "//absl/memory", + ], +) + +cc_test( + name = "flat_hash_map_test", + srcs = ["flat_hash_map_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":flat_hash_map", + ":hash_generator_testing", + ":unordered_map_constructor_test", + ":unordered_map_lookup_test", + ":unordered_map_members_test", + ":unordered_map_modifiers_test", + "//absl/base:raw_logging_internal", + "//absl/types:any", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "flat_hash_set", + hdrs = ["flat_hash_set.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":container_memory", + ":hash_function_defaults", + ":raw_hash_set", + "//absl/algorithm:container", + "//absl/base:core_headers", + "//absl/memory", + ], +) + +cc_test( + name = "flat_hash_set_test", + srcs = ["flat_hash_set_test.cc"], + copts = ABSL_TEST_COPTS + ["-DUNORDERED_SET_CXX17"], + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":flat_hash_set", + ":hash_generator_testing", + ":unordered_set_constructor_test", + ":unordered_set_lookup_test", + ":unordered_set_members_test", + ":unordered_set_modifiers_test", + "//absl/base:raw_logging_internal", + "//absl/memory", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "node_hash_map", + hdrs = ["node_hash_map.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":container_memory", + ":hash_function_defaults", + ":node_hash_policy", + ":raw_hash_map", + "//absl/algorithm:container", + "//absl/memory", + ], +) + +cc_test( + name = "node_hash_map_test", + srcs = ["node_hash_map_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":hash_generator_testing", + ":node_hash_map", + ":tracked", + ":unordered_map_constructor_test", + ":unordered_map_lookup_test", + ":unordered_map_members_test", + ":unordered_map_modifiers_test", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "node_hash_set", + hdrs = ["node_hash_set.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_function_defaults", + ":node_hash_policy", + ":raw_hash_set", + "//absl/algorithm:container", + "//absl/memory", + ], +) + +cc_test( + name = "node_hash_set_test", + srcs = ["node_hash_set_test.cc"], + copts = ABSL_TEST_COPTS + ["-DUNORDERED_SET_CXX17"], + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":node_hash_set", + ":unordered_set_constructor_test", + ":unordered_set_lookup_test", + ":unordered_set_members_test", + ":unordered_set_modifiers_test", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "container_memory", + hdrs = ["internal/container_memory.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/memory", + "//absl/meta:type_traits", + "//absl/utility", + ], +) + +cc_test( + name = "container_memory_test", + srcs = ["internal/container_memory_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":container_memory", + ":test_instance_tracker", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "hash_function_defaults", + hdrs = ["internal/hash_function_defaults.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/hash", + "//absl/strings", + "//absl/strings:cord", + ], +) + +cc_test( + name = "hash_function_defaults_test", + srcs = ["internal/hash_function_defaults_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS, + deps = [ + ":hash_function_defaults", + "//absl/hash", + "//absl/random", + "//absl/strings", + "//absl/strings:cord", + "//absl/strings:cord_test_helpers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "hash_generator_testing", + testonly = 1, + srcs = ["internal/hash_generator_testing.cc"], + hdrs = ["internal/hash_generator_testing.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_policy_testing", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/strings", + ], +) + +cc_library( + name = "hash_policy_testing", + testonly = 1, + hdrs = ["internal/hash_policy_testing.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/hash", + "//absl/strings", + ], +) + +cc_test( + name = "hash_policy_testing_test", + srcs = ["internal/hash_policy_testing_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_policy_testing", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "hash_policy_traits", + hdrs = ["internal/hash_policy_traits.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/meta:type_traits"], +) + +cc_test( + name = "hash_policy_traits_test", + srcs = ["internal/hash_policy_traits_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_policy_traits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "hashtable_debug", + hdrs = ["internal/hashtable_debug.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hashtable_debug_hooks", + ], +) + +cc_library( + name = "hashtable_debug_hooks", + hdrs = ["internal/hashtable_debug_hooks.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + ], +) + +cc_library( + name = "hashtablez_sampler", + srcs = [ + "internal/hashtablez_sampler.cc", + "internal/hashtablez_sampler_force_weak_definition.cc", + ], + hdrs = ["internal/hashtablez_sampler.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":have_sse", + "//absl/base", + "//absl/base:core_headers", + "//absl/base:exponential_biased", + "//absl/debugging:stacktrace", + "//absl/memory", + "//absl/synchronization", + "//absl/utility", + ], +) + +cc_test( + name = "hashtablez_sampler_test", + srcs = ["internal/hashtablez_sampler_test.cc"], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hashtablez_sampler", + ":have_sse", + "//absl/base:core_headers", + "//absl/synchronization", + "//absl/synchronization:thread_pool", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "node_hash_policy", + hdrs = ["internal/node_hash_policy.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_test( + name = "node_hash_policy_test", + srcs = ["internal/node_hash_policy_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_policy_traits", + ":node_hash_policy", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "raw_hash_map", + hdrs = ["internal/raw_hash_map.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":container_memory", + ":raw_hash_set", + "//absl/base:throw_delegate", + ], +) + +cc_library( + name = "have_sse", + hdrs = ["internal/have_sse.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], +) + +cc_library( + name = "common", + hdrs = ["internal/common.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/meta:type_traits", + "//absl/types:optional", + ], +) + +cc_library( + name = "raw_hash_set", + srcs = ["internal/raw_hash_set.cc"], + hdrs = ["internal/raw_hash_set.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":common", + ":compressed_tuple", + ":container_memory", + ":hash_policy_traits", + ":hashtable_debug_hooks", + ":hashtablez_sampler", + ":have_sse", + ":layout", + "//absl/base:bits", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/utility", + ], +) + +cc_test( + name = "raw_hash_set_test", + srcs = ["internal/raw_hash_set_test.cc"], + copts = ABSL_TEST_COPTS, + linkstatic = 1, + tags = NOTEST_TAGS, + deps = [ + ":container_memory", + ":hash_function_defaults", + ":hash_policy_testing", + ":hashtable_debug", + ":raw_hash_set", + "//absl/base", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "raw_hash_set_allocator_test", + size = "small", + srcs = ["internal/raw_hash_set_allocator_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":raw_hash_set", + ":tracked", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "layout", + hdrs = ["internal/layout.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:core_headers", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/types:span", + "//absl/utility", + ], +) + +cc_test( + name = "layout_test", + size = "small", + srcs = ["internal/layout_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS, + visibility = ["//visibility:private"], + deps = [ + ":layout", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/types:span", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "tracked", + testonly = 1, + hdrs = ["internal/tracked.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + ], +) + +cc_library( + name = "unordered_map_constructor_test", + testonly = 1, + hdrs = ["internal/unordered_map_constructor_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_generator_testing", + ":hash_policy_testing", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_map_lookup_test", + testonly = 1, + hdrs = ["internal/unordered_map_lookup_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_generator_testing", + ":hash_policy_testing", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_map_modifiers_test", + testonly = 1, + hdrs = ["internal/unordered_map_modifiers_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_generator_testing", + ":hash_policy_testing", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_set_constructor_test", + testonly = 1, + hdrs = ["internal/unordered_set_constructor_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_generator_testing", + ":hash_policy_testing", + "//absl/meta:type_traits", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_set_members_test", + testonly = 1, + hdrs = ["internal/unordered_set_members_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/meta:type_traits", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_map_members_test", + testonly = 1, + hdrs = ["internal/unordered_map_members_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/meta:type_traits", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_set_lookup_test", + testonly = 1, + hdrs = ["internal/unordered_set_lookup_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_generator_testing", + ":hash_policy_testing", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "unordered_set_modifiers_test", + testonly = 1, + hdrs = ["internal/unordered_set_modifiers_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash_generator_testing", + ":hash_policy_testing", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "unordered_set_test", + srcs = ["internal/unordered_set_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":unordered_set_constructor_test", + ":unordered_set_lookup_test", + ":unordered_set_members_test", + ":unordered_set_modifiers_test", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "unordered_map_test", + srcs = ["internal/unordered_map_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = NOTEST_TAGS_NONMOBILE, + deps = [ + ":unordered_map_constructor_test", + ":unordered_map_lookup_test", + ":unordered_map_members_test", + ":unordered_map_modifiers_test", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "btree", + srcs = [ + "internal/btree.h", + "internal/btree_container.h", + ], + hdrs = [ + "btree_map.h", + "btree_set.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:public"], + deps = [ + ":common", + ":compressed_tuple", + ":container_memory", + ":layout", + "//absl/base:core_headers", + "//absl/base:throw_delegate", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/strings:cord", + "//absl/types:compare", + "//absl/utility", + ], +) + +cc_library( + name = "btree_test_common", + testonly = 1, + hdrs = ["btree_test.h"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + ":btree", + ":flat_hash_set", + "//absl/strings", + "//absl/strings:cord", + "//absl/time", + ], +) + +cc_test( + name = "btree_test", + size = "large", + srcs = [ + "btree_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + shard_count = 10, + visibility = ["//visibility:private"], + deps = [ + ":btree", + ":btree_test_common", + ":counting_allocator", + ":test_instance_tracker", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/flags:flag", + "//absl/hash:hash_testing", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/types:compare", + "@com_google_googletest//:gtest_main", + ], +) + +cc_binary( + name = "btree_benchmark", + testonly = 1, + srcs = [ + "btree_benchmark.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":btree", + ":btree_test_common", + ":flat_hash_map", + ":flat_hash_set", + ":hashtable_debug", + "//absl/base:raw_logging_internal", + "//absl/flags:flag", + "//absl/hash", + "//absl/memory", + "//absl/strings:cord", + "//absl/strings:str_format", + "//absl/time", + "@com_github_google_benchmark//:benchmark_main", + ], +) diff --git a/third_party/abseil_cpp/absl/container/CMakeLists.txt b/third_party/abseil_cpp/absl/container/CMakeLists.txt new file mode 100644 index 0000000000..13d9695763 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/CMakeLists.txt @@ -0,0 +1,900 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +# This is deprecated and will be removed in the future. It also doesn't do +# anything anyways. Prefer to use the library associated with the API you are +# using. +absl_cc_library( + NAME + container + PUBLIC +) + +absl_cc_library( + NAME + btree + HDRS + "btree_map.h" + "btree_set.h" + "internal/btree.h" + "internal/btree_container.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::container_common + absl::compare + absl::compressed_tuple + absl::container_memory + absl::cord + absl::core_headers + absl::layout + absl::memory + absl::strings + absl::throw_delegate + absl::type_traits + absl::utility +) + +absl_cc_library( + NAME + btree_test_common + hdrs + "btree_test.h" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::btree + absl::cord + absl::flat_hash_set + absl::strings + absl::time + TESTONLY +) + +absl_cc_test( + NAME + btree_test + SRCS + "btree_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::btree + absl::btree_test_common + absl::compare + absl::core_headers + absl::counting_allocator + absl::flags + absl::hash_testing + absl::raw_logging_internal + absl::strings + absl::test_instance_tracker + absl::type_traits + gmock_main +) + +absl_cc_library( + NAME + compressed_tuple + HDRS + "internal/compressed_tuple.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::utility + PUBLIC +) + +absl_cc_test( + NAME + compressed_tuple_test + SRCS + "internal/compressed_tuple_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::any + absl::compressed_tuple + absl::memory + absl::optional + absl::test_instance_tracker + absl::utility + gmock_main +) + +absl_cc_library( + NAME + fixed_array + HDRS + "fixed_array.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::compressed_tuple + absl::algorithm + absl::core_headers + absl::dynamic_annotations + absl::throw_delegate + absl::memory + PUBLIC +) + +absl_cc_test( + NAME + fixed_array_test + SRCS + "fixed_array_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::fixed_array + absl::counting_allocator + absl::config + absl::exception_testing + absl::hash_testing + absl::memory + gmock_main +) + +absl_cc_test( + NAME + fixed_array_exception_safety_test + SRCS + "fixed_array_exception_safety_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::fixed_array + absl::config + absl::exception_safety_testing + gmock_main +) + +absl_cc_library( + NAME + inlined_vector_internal + HDRS + "internal/inlined_vector.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::compressed_tuple + absl::core_headers + absl::memory + absl::span + absl::type_traits + PUBLIC +) + +absl_cc_library( + NAME + inlined_vector + HDRS + "inlined_vector.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::algorithm + absl::core_headers + absl::inlined_vector_internal + absl::throw_delegate + absl::memory + PUBLIC +) + +absl_cc_library( + NAME + counting_allocator + HDRS + "internal/counting_allocator.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config +) + +absl_cc_test( + NAME + inlined_vector_test + SRCS + "inlined_vector_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::counting_allocator + absl::inlined_vector + absl::test_instance_tracker + absl::config + absl::core_headers + absl::exception_testing + absl::hash_testing + absl::memory + absl::raw_logging_internal + absl::strings + gmock_main +) + +absl_cc_test( + NAME + inlined_vector_exception_safety_test + SRCS + "inlined_vector_exception_safety_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::inlined_vector + absl::config + absl::exception_safety_testing + gmock_main +) + +absl_cc_library( + NAME + test_instance_tracker + HDRS + "internal/test_instance_tracker.h" + SRCS + "internal/test_instance_tracker.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::compare + TESTONLY +) + +absl_cc_test( + NAME + test_instance_tracker_test + SRCS + "internal/test_instance_tracker_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::test_instance_tracker + gmock_main +) + +absl_cc_library( + NAME + flat_hash_map + HDRS + "flat_hash_map.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::container_memory + absl::hash_function_defaults + absl::raw_hash_map + absl::algorithm_container + absl::memory + PUBLIC +) + +absl_cc_test( + NAME + flat_hash_map_test + SRCS + "flat_hash_map_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flat_hash_map + absl::hash_generator_testing + absl::unordered_map_constructor_test + absl::unordered_map_lookup_test + absl::unordered_map_members_test + absl::unordered_map_modifiers_test + absl::any + absl::raw_logging_internal + gmock_main +) + +absl_cc_library( + NAME + flat_hash_set + HDRS + "flat_hash_set.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::container_memory + absl::hash_function_defaults + absl::raw_hash_set + absl::algorithm_container + absl::core_headers + absl::memory + PUBLIC +) + +absl_cc_test( + NAME + flat_hash_set_test + SRCS + "flat_hash_set_test.cc" + COPTS + ${ABSL_TEST_COPTS} + "-DUNORDERED_SET_CXX17" + DEPS + absl::flat_hash_set + absl::hash_generator_testing + absl::unordered_set_constructor_test + absl::unordered_set_lookup_test + absl::unordered_set_members_test + absl::unordered_set_modifiers_test + absl::memory + absl::raw_logging_internal + absl::strings + gmock_main +) + +absl_cc_library( + NAME + node_hash_map + HDRS + "node_hash_map.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::container_memory + absl::hash_function_defaults + absl::node_hash_policy + absl::raw_hash_map + absl::algorithm_container + absl::memory + PUBLIC +) + +absl_cc_test( + NAME + node_hash_map_test + SRCS + "node_hash_map_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::node_hash_map + absl::tracked + absl::unordered_map_constructor_test + absl::unordered_map_lookup_test + absl::unordered_map_members_test + absl::unordered_map_modifiers_test + gmock_main +) + +absl_cc_library( + NAME + node_hash_set + HDRS + "node_hash_set.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::hash_function_defaults + absl::node_hash_policy + absl::raw_hash_set + absl::algorithm_container + absl::memory + PUBLIC +) + +absl_cc_test( + NAME + node_hash_set_test + SRCS + "node_hash_set_test.cc" + COPTS + ${ABSL_TEST_COPTS} + "-DUNORDERED_SET_CXX17" + DEPS + absl::hash_generator_testing + absl::node_hash_set + absl::unordered_set_constructor_test + absl::unordered_set_lookup_test + absl::unordered_set_members_test + absl::unordered_set_modifiers_test + gmock_main +) + +absl_cc_library( + NAME + container_memory + HDRS + "internal/container_memory.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::memory + absl::type_traits + absl::utility + PUBLIC +) + +absl_cc_test( + NAME + container_memory_test + SRCS + "internal/container_memory_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::container_memory + absl::strings + absl::test_instance_tracker + gmock_main +) + +absl_cc_library( + NAME + hash_function_defaults + HDRS + "internal/hash_function_defaults.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::cord + absl::hash + absl::strings + PUBLIC +) + +absl_cc_test( + NAME + hash_function_defaults_test + SRCS + "internal/hash_function_defaults_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::cord + absl::cord_test_helpers + absl::hash_function_defaults + absl::hash + absl::random_random + absl::strings + gmock_main +) + +absl_cc_library( + NAME + hash_generator_testing + HDRS + "internal/hash_generator_testing.h" + SRCS + "internal/hash_generator_testing.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_policy_testing + absl::memory + absl::meta + absl::strings + TESTONLY +) + +absl_cc_library( + NAME + hash_policy_testing + HDRS + "internal/hash_policy_testing.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash + absl::strings + TESTONLY +) + +absl_cc_test( + NAME + hash_policy_testing_test + SRCS + "internal/hash_policy_testing_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_policy_testing + gmock_main +) + +absl_cc_library( + NAME + hash_policy_traits + HDRS + "internal/hash_policy_traits.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::meta + PUBLIC +) + +absl_cc_test( + NAME + hash_policy_traits_test + SRCS + "internal/hash_policy_traits_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_policy_traits + gmock_main +) + +absl_cc_library( + NAME + hashtablez_sampler + HDRS + "internal/hashtablez_sampler.h" + SRCS + "internal/hashtablez_sampler.cc" + "internal/hashtablez_sampler_force_weak_definition.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base + absl::exponential_biased + absl::have_sse + absl::synchronization +) + +absl_cc_test( + NAME + hashtablez_sampler_test + SRCS + "internal/hashtablez_sampler_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hashtablez_sampler + absl::have_sse + gmock_main +) + +absl_cc_library( + NAME + hashtable_debug + HDRS + "internal/hashtable_debug.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::hashtable_debug_hooks +) + +absl_cc_library( + NAME + hashtable_debug_hooks + HDRS + "internal/hashtable_debug_hooks.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + PUBLIC +) + +absl_cc_library( + NAME + have_sse + HDRS + "internal/have_sse.h" + COPTS + ${ABSL_DEFAULT_COPTS} +) + +absl_cc_library( + NAME + node_hash_policy + HDRS + "internal/node_hash_policy.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + PUBLIC +) + +absl_cc_test( + NAME + node_hash_policy_test + SRCS + "internal/node_hash_policy_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_policy_traits + absl::node_hash_policy + gmock_main +) + +absl_cc_library( + NAME + raw_hash_map + HDRS + "internal/raw_hash_map.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::container_memory + absl::raw_hash_set + absl::throw_delegate + PUBLIC +) + +absl_cc_library( + NAME + container_common + HDRS + "internal/common.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::type_traits +) + +absl_cc_library( + NAME + raw_hash_set + HDRS + "internal/raw_hash_set.h" + SRCS + "internal/raw_hash_set.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bits + absl::compressed_tuple + absl::config + absl::container_common + absl::container_memory + absl::core_headers + absl::endian + absl::hash_policy_traits + absl::hashtable_debug_hooks + absl::have_sse + absl::layout + absl::memory + absl::meta + absl::optional + absl::utility + absl::hashtablez_sampler + PUBLIC +) + +absl_cc_test( + NAME + raw_hash_set_test + SRCS + "internal/raw_hash_set_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::container_memory + absl::hash_function_defaults + absl::hash_policy_testing + absl::hashtable_debug + absl::raw_hash_set + absl::base + absl::core_headers + absl::raw_logging_internal + absl::strings + gmock_main +) + +absl_cc_test( + NAME + raw_hash_set_allocator_test + SRCS + "internal/raw_hash_set_allocator_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::raw_hash_set + absl::tracked + absl::core_headers + gmock_main +) + +absl_cc_library( + NAME + layout + HDRS + "internal/layout.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::meta + absl::strings + absl::span + absl::utility + PUBLIC +) + +absl_cc_test( + NAME + layout_test + SRCS + "internal/layout_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::layout + absl::core_headers + absl::raw_logging_internal + absl::span + gmock_main +) + +absl_cc_library( + NAME + tracked + HDRS + "internal/tracked.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::config + TESTONLY +) + +absl_cc_library( + NAME + unordered_map_constructor_test + HDRS + "internal/unordered_map_constructor_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::hash_policy_testing + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_map_lookup_test + HDRS + "internal/unordered_map_lookup_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::hash_policy_testing + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_map_members_test + HDRS + "internal/unordered_map_members_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::type_traits + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_map_modifiers_test + HDRS + "internal/unordered_map_modifiers_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::hash_policy_testing + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_set_constructor_test + HDRS + "internal/unordered_set_constructor_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::hash_policy_testing + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_set_lookup_test + HDRS + "internal/unordered_set_lookup_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::hash_policy_testing + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_set_members_test + HDRS + "internal/unordered_set_members_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::type_traits + gmock + TESTONLY +) + +absl_cc_library( + NAME + unordered_set_modifiers_test + HDRS + "internal/unordered_set_modifiers_test.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::hash_generator_testing + absl::hash_policy_testing + gmock + TESTONLY +) + +absl_cc_test( + NAME + unordered_set_test + SRCS + "internal/unordered_set_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::unordered_set_constructor_test + absl::unordered_set_lookup_test + absl::unordered_set_members_test + absl::unordered_set_modifiers_test + gmock_main +) + +absl_cc_test( + NAME + unordered_map_test + SRCS + "internal/unordered_map_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::unordered_map_constructor_test + absl::unordered_map_lookup_test + absl::unordered_map_members_test + absl::unordered_map_modifiers_test + gmock_main +) diff --git a/third_party/abseil_cpp/absl/container/btree_benchmark.cc b/third_party/abseil_cpp/absl/container/btree_benchmark.cc new file mode 100644 index 0000000000..467986768a --- /dev/null +++ b/third_party/abseil_cpp/absl/container/btree_benchmark.cc @@ -0,0 +1,735 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <stdint.h> + +#include <algorithm> +#include <functional> +#include <map> +#include <numeric> +#include <random> +#include <set> +#include <string> +#include <type_traits> +#include <unordered_map> +#include <unordered_set> +#include <vector> + +#include "absl/base/internal/raw_logging.h" +#include "absl/container/btree_map.h" +#include "absl/container/btree_set.h" +#include "absl/container/btree_test.h" +#include "absl/container/flat_hash_map.h" +#include "absl/container/flat_hash_set.h" +#include "absl/container/internal/hashtable_debug.h" +#include "absl/flags/flag.h" +#include "absl/hash/hash.h" +#include "absl/memory/memory.h" +#include "absl/strings/cord.h" +#include "absl/strings/str_format.h" +#include "absl/time/time.h" +#include "benchmark/benchmark.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +constexpr size_t kBenchmarkValues = 1 << 20; + +// How many times we add and remove sub-batches in one batch of *AddRem +// benchmarks. +constexpr size_t kAddRemBatchSize = 1 << 2; + +// Generates n values in the range [0, 4 * n]. +template <typename V> +std::vector<V> GenerateValues(int n) { + constexpr int kSeed = 23; + return GenerateValuesWithSeed<V>(n, 4 * n, kSeed); +} + +// Benchmark insertion of values into a container. +template <typename T> +void BM_InsertImpl(benchmark::State& state, bool sorted) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + + std::vector<V> values = GenerateValues<V>(kBenchmarkValues); + if (sorted) { + std::sort(values.begin(), values.end()); + } + T container(values.begin(), values.end()); + + // Remove and re-insert 10% of the keys per batch. + const int batch_size = (kBenchmarkValues + 9) / 10; + while (state.KeepRunningBatch(batch_size)) { + state.PauseTiming(); + const auto i = static_cast<int>(state.iterations()); + + for (int j = i; j < i + batch_size; j++) { + int x = j % kBenchmarkValues; + container.erase(key_of_value(values[x])); + } + + state.ResumeTiming(); + + for (int j = i; j < i + batch_size; j++) { + int x = j % kBenchmarkValues; + container.insert(values[x]); + } + } +} + +template <typename T> +void BM_Insert(benchmark::State& state) { + BM_InsertImpl<T>(state, false); +} + +template <typename T> +void BM_InsertSorted(benchmark::State& state) { + BM_InsertImpl<T>(state, true); +} + +// container::insert sometimes returns a pair<iterator, bool> and sometimes +// returns an iterator (for multi- containers). +template <typename Iter> +Iter GetIterFromInsert(const std::pair<Iter, bool>& pair) { + return pair.first; +} +template <typename Iter> +Iter GetIterFromInsert(const Iter iter) { + return iter; +} + +// Benchmark insertion of values into a container at the end. +template <typename T> +void BM_InsertEnd(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + + T container; + const int kSize = 10000; + for (int i = 0; i < kSize; ++i) { + container.insert(Generator<V>(kSize)(i)); + } + V v = Generator<V>(kSize)(kSize - 1); + typename T::key_type k = key_of_value(v); + + auto it = container.find(k); + while (state.KeepRunning()) { + // Repeatedly removing then adding v. + container.erase(it); + it = GetIterFromInsert(container.insert(v)); + } +} + +// Benchmark inserting the first few elements in a container. In b-tree, this is +// when the root node grows. +template <typename T> +void BM_InsertSmall(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + + const int kSize = 8; + std::vector<V> values = GenerateValues<V>(kSize); + T container; + + while (state.KeepRunningBatch(kSize)) { + for (int i = 0; i < kSize; ++i) { + benchmark::DoNotOptimize(container.insert(values[i])); + } + state.PauseTiming(); + // Do not measure the time it takes to clear the container. + container.clear(); + state.ResumeTiming(); + } +} + +template <typename T> +void BM_LookupImpl(benchmark::State& state, bool sorted) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + + std::vector<V> values = GenerateValues<V>(kBenchmarkValues); + if (sorted) { + std::sort(values.begin(), values.end()); + } + T container(values.begin(), values.end()); + + while (state.KeepRunning()) { + int idx = state.iterations() % kBenchmarkValues; + benchmark::DoNotOptimize(container.find(key_of_value(values[idx]))); + } +} + +// Benchmark lookup of values in a container. +template <typename T> +void BM_Lookup(benchmark::State& state) { + BM_LookupImpl<T>(state, false); +} + +// Benchmark lookup of values in a full container, meaning that values +// are inserted in-order to take advantage of biased insertion, which +// yields a full tree. +template <typename T> +void BM_FullLookup(benchmark::State& state) { + BM_LookupImpl<T>(state, true); +} + +// Benchmark deletion of values from a container. +template <typename T> +void BM_Delete(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + std::vector<V> values = GenerateValues<V>(kBenchmarkValues); + T container(values.begin(), values.end()); + + // Remove and re-insert 10% of the keys per batch. + const int batch_size = (kBenchmarkValues + 9) / 10; + while (state.KeepRunningBatch(batch_size)) { + const int i = state.iterations(); + + for (int j = i; j < i + batch_size; j++) { + int x = j % kBenchmarkValues; + container.erase(key_of_value(values[x])); + } + + state.PauseTiming(); + for (int j = i; j < i + batch_size; j++) { + int x = j % kBenchmarkValues; + container.insert(values[x]); + } + state.ResumeTiming(); + } +} + +// Benchmark deletion of multiple values from a container. +template <typename T> +void BM_DeleteRange(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + std::vector<V> values = GenerateValues<V>(kBenchmarkValues); + T container(values.begin(), values.end()); + + // Remove and re-insert 10% of the keys per batch. + const int batch_size = (kBenchmarkValues + 9) / 10; + while (state.KeepRunningBatch(batch_size)) { + const int i = state.iterations(); + + const int start_index = i % kBenchmarkValues; + + state.PauseTiming(); + { + std::vector<V> removed; + removed.reserve(batch_size); + auto itr = container.find(key_of_value(values[start_index])); + auto start = itr; + for (int j = 0; j < batch_size; j++) { + if (itr == container.end()) { + state.ResumeTiming(); + container.erase(start, itr); + state.PauseTiming(); + itr = container.begin(); + start = itr; + } + removed.push_back(*itr++); + } + + state.ResumeTiming(); + container.erase(start, itr); + state.PauseTiming(); + + container.insert(removed.begin(), removed.end()); + } + state.ResumeTiming(); + } +} + +// Benchmark steady-state insert (into first half of range) and remove (from +// second half of range), treating the container approximately like a queue with +// log-time access for all elements. This benchmark does not test the case where +// insertion and removal happen in the same region of the tree. This benchmark +// counts two value constructors. +template <typename T> +void BM_QueueAddRem(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + + ABSL_RAW_CHECK(kBenchmarkValues % 2 == 0, "for performance"); + + T container; + + const size_t half = kBenchmarkValues / 2; + std::vector<int> remove_keys(half); + std::vector<int> add_keys(half); + + // We want to do the exact same work repeatedly, and the benchmark can end + // after a different number of iterations depending on the speed of the + // individual run so we use a large batch size here and ensure that we do + // deterministic work every batch. + while (state.KeepRunningBatch(half * kAddRemBatchSize)) { + state.PauseTiming(); + + container.clear(); + + for (size_t i = 0; i < half; ++i) { + remove_keys[i] = i; + add_keys[i] = i; + } + constexpr int kSeed = 5; + std::mt19937_64 rand(kSeed); + std::shuffle(remove_keys.begin(), remove_keys.end(), rand); + std::shuffle(add_keys.begin(), add_keys.end(), rand); + + // Note needs lazy generation of values. + Generator<V> g(kBenchmarkValues * kAddRemBatchSize); + + for (size_t i = 0; i < half; ++i) { + container.insert(g(add_keys[i])); + container.insert(g(half + remove_keys[i])); + } + + // There are three parts each of size "half": + // 1 is being deleted from [offset - half, offset) + // 2 is standing [offset, offset + half) + // 3 is being inserted into [offset + half, offset + 2 * half) + size_t offset = 0; + + for (size_t i = 0; i < kAddRemBatchSize; ++i) { + std::shuffle(remove_keys.begin(), remove_keys.end(), rand); + std::shuffle(add_keys.begin(), add_keys.end(), rand); + offset += half; + + state.ResumeTiming(); + for (size_t idx = 0; idx < half; ++idx) { + container.erase(key_of_value(g(offset - half + remove_keys[idx]))); + container.insert(g(offset + half + add_keys[idx])); + } + state.PauseTiming(); + } + state.ResumeTiming(); + } +} + +// Mixed insertion and deletion in the same range using pre-constructed values. +template <typename T> +void BM_MixedAddRem(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + + ABSL_RAW_CHECK(kBenchmarkValues % 2 == 0, "for performance"); + + T container; + + // Create two random shuffles + std::vector<int> remove_keys(kBenchmarkValues); + std::vector<int> add_keys(kBenchmarkValues); + + // We want to do the exact same work repeatedly, and the benchmark can end + // after a different number of iterations depending on the speed of the + // individual run so we use a large batch size here and ensure that we do + // deterministic work every batch. + while (state.KeepRunningBatch(kBenchmarkValues * kAddRemBatchSize)) { + state.PauseTiming(); + + container.clear(); + + constexpr int kSeed = 7; + std::mt19937_64 rand(kSeed); + + std::vector<V> values = GenerateValues<V>(kBenchmarkValues * 2); + + // Insert the first half of the values (already in random order) + container.insert(values.begin(), values.begin() + kBenchmarkValues); + + // Insert the first half of the values (already in random order) + for (size_t i = 0; i < kBenchmarkValues; ++i) { + // remove_keys and add_keys will be swapped before each round, + // therefore fill add_keys here w/ the keys being inserted, so + // they'll be the first to be removed. + remove_keys[i] = i + kBenchmarkValues; + add_keys[i] = i; + } + + for (size_t i = 0; i < kAddRemBatchSize; ++i) { + remove_keys.swap(add_keys); + std::shuffle(remove_keys.begin(), remove_keys.end(), rand); + std::shuffle(add_keys.begin(), add_keys.end(), rand); + + state.ResumeTiming(); + for (size_t idx = 0; idx < kBenchmarkValues; ++idx) { + container.erase(key_of_value(values[remove_keys[idx]])); + container.insert(values[add_keys[idx]]); + } + state.PauseTiming(); + } + state.ResumeTiming(); + } +} + +// Insertion at end, removal from the beginning. This benchmark +// counts two value constructors. +// TODO(ezb): we could add a GenerateNext version of generator that could reduce +// noise for string-like types. +template <typename T> +void BM_Fifo(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + + T container; + // Need lazy generation of values as state.max_iterations is large. + Generator<V> g(kBenchmarkValues + state.max_iterations); + + for (int i = 0; i < kBenchmarkValues; i++) { + container.insert(g(i)); + } + + while (state.KeepRunning()) { + container.erase(container.begin()); + container.insert(container.end(), g(state.iterations() + kBenchmarkValues)); + } +} + +// Iteration (forward) through the tree +template <typename T> +void BM_FwdIter(benchmark::State& state) { + using V = typename remove_pair_const<typename T::value_type>::type; + using R = typename T::value_type const*; + + std::vector<V> values = GenerateValues<V>(kBenchmarkValues); + T container(values.begin(), values.end()); + + auto iter = container.end(); + + R r = nullptr; + + while (state.KeepRunning()) { + if (iter == container.end()) iter = container.begin(); + r = &(*iter); + ++iter; + } + + benchmark::DoNotOptimize(r); +} + +// Benchmark random range-construction of a container. +template <typename T> +void BM_RangeConstructionImpl(benchmark::State& state, bool sorted) { + using V = typename remove_pair_const<typename T::value_type>::type; + + std::vector<V> values = GenerateValues<V>(kBenchmarkValues); + if (sorted) { + std::sort(values.begin(), values.end()); + } + { + T container(values.begin(), values.end()); + } + + while (state.KeepRunning()) { + T container(values.begin(), values.end()); + benchmark::DoNotOptimize(container); + } +} + +template <typename T> +void BM_InsertRangeRandom(benchmark::State& state) { + BM_RangeConstructionImpl<T>(state, false); +} + +template <typename T> +void BM_InsertRangeSorted(benchmark::State& state) { + BM_RangeConstructionImpl<T>(state, true); +} + +#define STL_ORDERED_TYPES(value) \ + using stl_set_##value = std::set<value>; \ + using stl_map_##value = std::map<value, intptr_t>; \ + using stl_multiset_##value = std::multiset<value>; \ + using stl_multimap_##value = std::multimap<value, intptr_t> + +using StdString = std::string; +STL_ORDERED_TYPES(int32_t); +STL_ORDERED_TYPES(int64_t); +STL_ORDERED_TYPES(StdString); +STL_ORDERED_TYPES(Cord); +STL_ORDERED_TYPES(Time); + +#define STL_UNORDERED_TYPES(value) \ + using stl_unordered_set_##value = std::unordered_set<value>; \ + using stl_unordered_map_##value = std::unordered_map<value, intptr_t>; \ + using flat_hash_set_##value = flat_hash_set<value>; \ + using flat_hash_map_##value = flat_hash_map<value, intptr_t>; \ + using stl_unordered_multiset_##value = std::unordered_multiset<value>; \ + using stl_unordered_multimap_##value = \ + std::unordered_multimap<value, intptr_t> + +#define STL_UNORDERED_TYPES_CUSTOM_HASH(value, hash) \ + using stl_unordered_set_##value = std::unordered_set<value, hash>; \ + using stl_unordered_map_##value = std::unordered_map<value, intptr_t, hash>; \ + using flat_hash_set_##value = flat_hash_set<value, hash>; \ + using flat_hash_map_##value = flat_hash_map<value, intptr_t, hash>; \ + using stl_unordered_multiset_##value = std::unordered_multiset<value, hash>; \ + using stl_unordered_multimap_##value = \ + std::unordered_multimap<value, intptr_t, hash> + +STL_UNORDERED_TYPES_CUSTOM_HASH(Cord, absl::Hash<absl::Cord>); + +STL_UNORDERED_TYPES(int32_t); +STL_UNORDERED_TYPES(int64_t); +STL_UNORDERED_TYPES(StdString); +STL_UNORDERED_TYPES_CUSTOM_HASH(Time, absl::Hash<absl::Time>); + +#define BTREE_TYPES(value) \ + using btree_256_set_##value = \ + btree_set<value, std::less<value>, std::allocator<value>>; \ + using btree_256_map_##value = \ + btree_map<value, intptr_t, std::less<value>, \ + std::allocator<std::pair<const value, intptr_t>>>; \ + using btree_256_multiset_##value = \ + btree_multiset<value, std::less<value>, std::allocator<value>>; \ + using btree_256_multimap_##value = \ + btree_multimap<value, intptr_t, std::less<value>, \ + std::allocator<std::pair<const value, intptr_t>>> + +BTREE_TYPES(int32_t); +BTREE_TYPES(int64_t); +BTREE_TYPES(StdString); +BTREE_TYPES(Cord); +BTREE_TYPES(Time); + +#define MY_BENCHMARK4(type, func) \ + void BM_##type##_##func(benchmark::State& state) { BM_##func<type>(state); } \ + BENCHMARK(BM_##type##_##func) + +#define MY_BENCHMARK3(type) \ + MY_BENCHMARK4(type, Insert); \ + MY_BENCHMARK4(type, InsertSorted); \ + MY_BENCHMARK4(type, InsertEnd); \ + MY_BENCHMARK4(type, InsertSmall); \ + MY_BENCHMARK4(type, Lookup); \ + MY_BENCHMARK4(type, FullLookup); \ + MY_BENCHMARK4(type, Delete); \ + MY_BENCHMARK4(type, DeleteRange); \ + MY_BENCHMARK4(type, QueueAddRem); \ + MY_BENCHMARK4(type, MixedAddRem); \ + MY_BENCHMARK4(type, Fifo); \ + MY_BENCHMARK4(type, FwdIter); \ + MY_BENCHMARK4(type, InsertRangeRandom); \ + MY_BENCHMARK4(type, InsertRangeSorted) + +#define MY_BENCHMARK2_SUPPORTS_MULTI_ONLY(type) \ + MY_BENCHMARK3(stl_##type); \ + MY_BENCHMARK3(stl_unordered_##type); \ + MY_BENCHMARK3(btree_256_##type) + +#define MY_BENCHMARK2(type) \ + MY_BENCHMARK2_SUPPORTS_MULTI_ONLY(type); \ + MY_BENCHMARK3(flat_hash_##type) + +// Define MULTI_TESTING to see benchmarks for multi-containers also. +// +// You can use --copt=-DMULTI_TESTING. +#ifdef MULTI_TESTING +#define MY_BENCHMARK(type) \ + MY_BENCHMARK2(set_##type); \ + MY_BENCHMARK2(map_##type); \ + MY_BENCHMARK2_SUPPORTS_MULTI_ONLY(multiset_##type); \ + MY_BENCHMARK2_SUPPORTS_MULTI_ONLY(multimap_##type) +#else +#define MY_BENCHMARK(type) \ + MY_BENCHMARK2(set_##type); \ + MY_BENCHMARK2(map_##type) +#endif + +MY_BENCHMARK(int32_t); +MY_BENCHMARK(int64_t); +MY_BENCHMARK(StdString); +MY_BENCHMARK(Cord); +MY_BENCHMARK(Time); + +// Define a type whose size and cost of moving are independently customizable. +// When sizeof(value_type) increases, we expect btree to no longer have as much +// cache-locality advantage over STL. When cost of moving increases, we expect +// btree to actually do more work than STL because it has to move values around +// and STL doesn't have to. +template <int Size, int Copies> +struct BigType { + BigType() : BigType(0) {} + explicit BigType(int x) { std::iota(values.begin(), values.end(), x); } + + void Copy(const BigType& other) { + for (int i = 0; i < Size && i < Copies; ++i) values[i] = other.values[i]; + // If Copies > Size, do extra copies. + for (int i = Size, idx = 0; i < Copies; ++i) { + int64_t tmp = other.values[idx]; + benchmark::DoNotOptimize(tmp); + idx = idx + 1 == Size ? 0 : idx + 1; + } + } + + BigType(const BigType& other) { Copy(other); } + BigType& operator=(const BigType& other) { + Copy(other); + return *this; + } + + // Compare only the first Copies elements if Copies is less than Size. + bool operator<(const BigType& other) const { + return std::lexicographical_compare( + values.begin(), values.begin() + std::min(Size, Copies), + other.values.begin(), other.values.begin() + std::min(Size, Copies)); + } + bool operator==(const BigType& other) const { + return std::equal(values.begin(), values.begin() + std::min(Size, Copies), + other.values.begin()); + } + + // Support absl::Hash. + template <typename State> + friend State AbslHashValue(State h, const BigType& b) { + for (int i = 0; i < Size && i < Copies; ++i) + h = State::combine(std::move(h), b.values[i]); + return h; + } + + std::array<int64_t, Size> values; +}; + +#define BIG_TYPE_BENCHMARKS(SIZE, COPIES) \ + using stl_set_size##SIZE##copies##COPIES = std::set<BigType<SIZE, COPIES>>; \ + using stl_map_size##SIZE##copies##COPIES = \ + std::map<BigType<SIZE, COPIES>, intptr_t>; \ + using stl_multiset_size##SIZE##copies##COPIES = \ + std::multiset<BigType<SIZE, COPIES>>; \ + using stl_multimap_size##SIZE##copies##COPIES = \ + std::multimap<BigType<SIZE, COPIES>, intptr_t>; \ + using stl_unordered_set_size##SIZE##copies##COPIES = \ + std::unordered_set<BigType<SIZE, COPIES>, \ + absl::Hash<BigType<SIZE, COPIES>>>; \ + using stl_unordered_map_size##SIZE##copies##COPIES = \ + std::unordered_map<BigType<SIZE, COPIES>, intptr_t, \ + absl::Hash<BigType<SIZE, COPIES>>>; \ + using flat_hash_set_size##SIZE##copies##COPIES = \ + flat_hash_set<BigType<SIZE, COPIES>>; \ + using flat_hash_map_size##SIZE##copies##COPIES = \ + flat_hash_map<BigType<SIZE, COPIES>, intptr_t>; \ + using stl_unordered_multiset_size##SIZE##copies##COPIES = \ + std::unordered_multiset<BigType<SIZE, COPIES>, \ + absl::Hash<BigType<SIZE, COPIES>>>; \ + using stl_unordered_multimap_size##SIZE##copies##COPIES = \ + std::unordered_multimap<BigType<SIZE, COPIES>, intptr_t, \ + absl::Hash<BigType<SIZE, COPIES>>>; \ + using btree_256_set_size##SIZE##copies##COPIES = \ + btree_set<BigType<SIZE, COPIES>>; \ + using btree_256_map_size##SIZE##copies##COPIES = \ + btree_map<BigType<SIZE, COPIES>, intptr_t>; \ + using btree_256_multiset_size##SIZE##copies##COPIES = \ + btree_multiset<BigType<SIZE, COPIES>>; \ + using btree_256_multimap_size##SIZE##copies##COPIES = \ + btree_multimap<BigType<SIZE, COPIES>, intptr_t>; \ + MY_BENCHMARK(size##SIZE##copies##COPIES) + +// Define BIG_TYPE_TESTING to see benchmarks for more big types. +// +// You can use --copt=-DBIG_TYPE_TESTING. +#ifndef NODESIZE_TESTING +#ifdef BIG_TYPE_TESTING +BIG_TYPE_BENCHMARKS(1, 4); +BIG_TYPE_BENCHMARKS(4, 1); +BIG_TYPE_BENCHMARKS(4, 4); +BIG_TYPE_BENCHMARKS(1, 8); +BIG_TYPE_BENCHMARKS(8, 1); +BIG_TYPE_BENCHMARKS(8, 8); +BIG_TYPE_BENCHMARKS(1, 16); +BIG_TYPE_BENCHMARKS(16, 1); +BIG_TYPE_BENCHMARKS(16, 16); +BIG_TYPE_BENCHMARKS(1, 32); +BIG_TYPE_BENCHMARKS(32, 1); +BIG_TYPE_BENCHMARKS(32, 32); +#else +BIG_TYPE_BENCHMARKS(32, 32); +#endif +#endif + +// Benchmark using unique_ptrs to large value types. In order to be able to use +// the same benchmark code as the other types, use a type that holds a +// unique_ptr and has a copy constructor. +template <int Size> +struct BigTypePtr { + BigTypePtr() : BigTypePtr(0) {} + explicit BigTypePtr(int x) { + ptr = absl::make_unique<BigType<Size, Size>>(x); + } + BigTypePtr(const BigTypePtr& other) { + ptr = absl::make_unique<BigType<Size, Size>>(*other.ptr); + } + BigTypePtr(BigTypePtr&& other) noexcept = default; + BigTypePtr& operator=(const BigTypePtr& other) { + ptr = absl::make_unique<BigType<Size, Size>>(*other.ptr); + } + BigTypePtr& operator=(BigTypePtr&& other) noexcept = default; + + bool operator<(const BigTypePtr& other) const { return *ptr < *other.ptr; } + bool operator==(const BigTypePtr& other) const { return *ptr == *other.ptr; } + + std::unique_ptr<BigType<Size, Size>> ptr; +}; + +template <int Size> +double ContainerInfo(const btree_set<BigTypePtr<Size>>& b) { + const double bytes_used = + b.bytes_used() + b.size() * sizeof(BigType<Size, Size>); + const double bytes_per_value = bytes_used / b.size(); + BtreeContainerInfoLog(b, bytes_used, bytes_per_value); + return bytes_per_value; +} +template <int Size> +double ContainerInfo(const btree_map<int, BigTypePtr<Size>>& b) { + const double bytes_used = + b.bytes_used() + b.size() * sizeof(BigType<Size, Size>); + const double bytes_per_value = bytes_used / b.size(); + BtreeContainerInfoLog(b, bytes_used, bytes_per_value); + return bytes_per_value; +} + +#define BIG_TYPE_PTR_BENCHMARKS(SIZE) \ + using stl_set_size##SIZE##copies##SIZE##ptr = std::set<BigType<SIZE, SIZE>>; \ + using stl_map_size##SIZE##copies##SIZE##ptr = \ + std::map<int, BigType<SIZE, SIZE>>; \ + using stl_unordered_set_size##SIZE##copies##SIZE##ptr = \ + std::unordered_set<BigType<SIZE, SIZE>, \ + absl::Hash<BigType<SIZE, SIZE>>>; \ + using stl_unordered_map_size##SIZE##copies##SIZE##ptr = \ + std::unordered_map<int, BigType<SIZE, SIZE>>; \ + using flat_hash_set_size##SIZE##copies##SIZE##ptr = \ + flat_hash_set<BigType<SIZE, SIZE>>; \ + using flat_hash_map_size##SIZE##copies##SIZE##ptr = \ + flat_hash_map<int, BigTypePtr<SIZE>>; \ + using btree_256_set_size##SIZE##copies##SIZE##ptr = \ + btree_set<BigTypePtr<SIZE>>; \ + using btree_256_map_size##SIZE##copies##SIZE##ptr = \ + btree_map<int, BigTypePtr<SIZE>>; \ + MY_BENCHMARK3(stl_set_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(stl_unordered_set_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(flat_hash_set_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(btree_256_set_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(stl_map_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(stl_unordered_map_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(flat_hash_map_size##SIZE##copies##SIZE##ptr); \ + MY_BENCHMARK3(btree_256_map_size##SIZE##copies##SIZE##ptr) + +BIG_TYPE_PTR_BENCHMARKS(32); + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/btree_map.h b/third_party/abseil_cpp/absl/container/btree_map.h new file mode 100644 index 0000000000..bb450eadde --- /dev/null +++ b/third_party/abseil_cpp/absl/container/btree_map.h @@ -0,0 +1,759 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: btree_map.h +// ----------------------------------------------------------------------------- +// +// This header file defines B-tree maps: sorted associative containers mapping +// keys to values. +// +// * `absl::btree_map<>` +// * `absl::btree_multimap<>` +// +// These B-tree types are similar to the corresponding types in the STL +// (`std::map` and `std::multimap`) and generally conform to the STL interfaces +// of those types. However, because they are implemented using B-trees, they +// are more efficient in most situations. +// +// Unlike `std::map` and `std::multimap`, which are commonly implemented using +// red-black tree nodes, B-tree maps use more generic B-tree nodes able to hold +// multiple values per node. Holding multiple values per node often makes +// B-tree maps perform better than their `std::map` counterparts, because +// multiple entries can be checked within the same cache hit. +// +// However, these types should not be considered drop-in replacements for +// `std::map` and `std::multimap` as there are some API differences, which are +// noted in this header file. +// +// Importantly, insertions and deletions may invalidate outstanding iterators, +// pointers, and references to elements. Such invalidations are typically only +// an issue if insertion and deletion operations are interleaved with the use of +// more than one iterator, pointer, or reference simultaneously. For this +// reason, `insert()` and `erase()` return a valid iterator at the current +// position. + +#ifndef ABSL_CONTAINER_BTREE_MAP_H_ +#define ABSL_CONTAINER_BTREE_MAP_H_ + +#include "absl/container/internal/btree.h" // IWYU pragma: export +#include "absl/container/internal/btree_container.h" // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::btree_map<> +// +// An `absl::btree_map<K, V>` is an ordered associative container of +// unique keys and associated values designed to be a more efficient replacement +// for `std::map` (in most cases). +// +// Keys are sorted using an (optional) comparison function, which defaults to +// `std::less<K>`. +// +// An `absl::btree_map<K, V>` uses a default allocator of +// `std::allocator<std::pair<const K, V>>` to allocate (and deallocate) +// nodes, and construct and destruct values within those nodes. You may +// instead specify a custom allocator `A` (which in turn requires specifying a +// custom comparator `C`) as in `absl::btree_map<K, V, C, A>`. +// +template <typename Key, typename Value, typename Compare = std::less<Key>, + typename Alloc = std::allocator<std::pair<const Key, Value>>> +class btree_map + : public container_internal::btree_map_container< + container_internal::btree<container_internal::map_params< + Key, Value, Compare, Alloc, /*TargetNodeSize=*/256, + /*Multi=*/false>>> { + using Base = typename btree_map::btree_map_container; + + public: + // Constructors and Assignment Operators + // + // A `btree_map` supports the same overload set as `std::map` + // for construction and assignment: + // + // * Default constructor + // + // absl::btree_map<int, std::string> map1; + // + // * Initializer List constructor + // + // absl::btree_map<int, std::string> map2 = + // {{1, "huey"}, {2, "dewey"}, {3, "louie"},}; + // + // * Copy constructor + // + // absl::btree_map<int, std::string> map3(map2); + // + // * Copy assignment operator + // + // absl::btree_map<int, std::string> map4; + // map4 = map3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::btree_map<int, std::string> map5(std::move(map4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::btree_map<int, std::string> map6; + // map6 = std::move(map5); + // + // * Range constructor + // + // std::vector<std::pair<int, std::string>> v = {{1, "a"}, {2, "b"}}; + // absl::btree_map<int, std::string> map7(v.begin(), v.end()); + btree_map() {} + using Base::Base; + + // btree_map::begin() + // + // Returns an iterator to the beginning of the `btree_map`. + using Base::begin; + + // btree_map::cbegin() + // + // Returns a const iterator to the beginning of the `btree_map`. + using Base::cbegin; + + // btree_map::end() + // + // Returns an iterator to the end of the `btree_map`. + using Base::end; + + // btree_map::cend() + // + // Returns a const iterator to the end of the `btree_map`. + using Base::cend; + + // btree_map::empty() + // + // Returns whether or not the `btree_map` is empty. + using Base::empty; + + // btree_map::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `btree_map` under current memory constraints. This value can be thought + // of as the largest value of `std::distance(begin(), end())` for a + // `btree_map<Key, T>`. + using Base::max_size; + + // btree_map::size() + // + // Returns the number of elements currently within the `btree_map`. + using Base::size; + + // btree_map::clear() + // + // Removes all elements from the `btree_map`. Invalidates any references, + // pointers, or iterators referring to contained elements. + using Base::clear; + + // btree_map::erase() + // + // Erases elements within the `btree_map`. If an erase occurs, any references, + // pointers, or iterators are invalidated. + // Overloads are listed below. + // + // iterator erase(iterator position): + // iterator erase(const_iterator position): + // + // Erases the element at `position` of the `btree_map`, returning + // the iterator pointing to the element after the one that was erased + // (or end() if none exists). + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning + // the iterator pointing to the element after the interval that was erased + // (or end() if none exists). + // + // template <typename K> size_type erase(const K& key): + // + // Erases the element with the matching key, if it exists, returning the + // number of elements erased. + using Base::erase; + + // btree_map::insert() + // + // Inserts an element of the specified value into the `btree_map`, + // returning an iterator pointing to the newly inserted element, provided that + // an element with the given key does not already exist. If an insertion + // occurs, any references, pointers, or iterators are invalidated. + // Overloads are listed below. + // + // std::pair<iterator,bool> insert(const value_type& value): + // + // Inserts a value into the `btree_map`. Returns a pair consisting of an + // iterator to the inserted element (or to the element that prevented the + // insertion) and a bool denoting whether the insertion took place. + // + // std::pair<iterator,bool> insert(value_type&& value): + // + // Inserts a moveable value into the `btree_map`. Returns a pair + // consisting of an iterator to the inserted element (or to the element that + // prevented the insertion) and a bool denoting whether the insertion took + // place. + // + // iterator insert(const_iterator hint, const value_type& value): + // iterator insert(const_iterator hint, value_type&& value): + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element, or to the existing element that prevented the + // insertion. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // void insert(std::initializer_list<init_type> ilist): + // + // Inserts the elements within the initializer list `ilist`. + using Base::insert; + + // btree_map::insert_or_assign() + // + // Inserts an element of the specified value into the `btree_map` provided + // that a value with the given key does not already exist, or replaces the + // corresponding mapped type with the forwarded `obj` argument if a key for + // that value already exists, returning an iterator pointing to the newly + // inserted element. Overloads are listed below. + // + // pair<iterator, bool> insert_or_assign(const key_type& k, M&& obj): + // pair<iterator, bool> insert_or_assign(key_type&& k, M&& obj): + // + // Inserts/Assigns (or moves) the element of the specified key into the + // `btree_map`. If the returned bool is true, insertion took place, and if + // it's false, assignment took place. + // + // iterator insert_or_assign(const_iterator hint, + // const key_type& k, M&& obj): + // iterator insert_or_assign(const_iterator hint, key_type&& k, M&& obj): + // + // Inserts/Assigns (or moves) the element of the specified key into the + // `btree_map` using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. + using Base::insert_or_assign; + + // btree_map::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_map`, provided that no element with the given key + // already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. Prefer `try_emplace()` unless your key is not + // copyable or moveable. + // + // If an insertion occurs, any references, pointers, or iterators are + // invalidated. + using Base::emplace; + + // btree_map::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_map`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search, and only inserts + // provided that no element with the given key already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. Prefer `try_emplace()` unless your key is not + // copyable or moveable. + // + // If an insertion occurs, any references, pointers, or iterators are + // invalidated. + using Base::emplace_hint; + + // btree_map::try_emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_map`, provided that no element with the given key + // already exists. Unlike `emplace()`, if an element with the given key + // already exists, we guarantee that no element is constructed. + // + // If an insertion occurs, any references, pointers, or iterators are + // invalidated. + // + // Overloads are listed below. + // + // std::pair<iterator, bool> try_emplace(const key_type& k, Args&&... args): + // std::pair<iterator, bool> try_emplace(key_type&& k, Args&&... args): + // + // Inserts (via copy or move) the element of the specified key into the + // `btree_map`. + // + // iterator try_emplace(const_iterator hint, + // const key_type& k, Args&&... args): + // iterator try_emplace(const_iterator hint, key_type&& k, Args&&... args): + // + // Inserts (via copy or move) the element of the specified key into the + // `btree_map` using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. + using Base::try_emplace; + + // btree_map::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the element at the indicated position and returns a node handle + // owning that extracted data. + // + // template <typename K> node_type extract(const K& k): + // + // Extracts the element with the key matching the passed key value and + // returns a node handle owning that extracted data. If the `btree_map` + // does not contain an element with a matching key, this function returns an + // empty node handle. + // + // NOTE: In this context, `node_type` refers to the C++17 concept of a + // move-only type that owns and provides access to the elements in associative + // containers (https://en.cppreference.com/w/cpp/container/node_handle). + // It does NOT refer to the data layout of the underlying btree. + using Base::extract; + + // btree_map::merge() + // + // Extracts elements from a given `source` btree_map into this + // `btree_map`. If the destination `btree_map` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // btree_map::swap(btree_map& other) + // + // Exchanges the contents of this `btree_map` with those of the `other` + // btree_map, avoiding invocation of any move, copy, or swap operations on + // individual elements. + // + // All iterators and references on the `btree_map` remain valid, excepting + // for the past-the-end iterator, which is invalidated. + using Base::swap; + + // btree_map::at() + // + // Returns a reference to the mapped value of the element with key equivalent + // to the passed key. + using Base::at; + + // btree_map::contains() + // + // template <typename K> bool contains(const K& key) const: + // + // Determines whether an element comparing equal to the given `key` exists + // within the `btree_map`, returning `true` if so or `false` otherwise. + // + // Supports heterogeneous lookup, provided that the map is provided a + // compatible heterogeneous comparator. + using Base::contains; + + // btree_map::count() + // + // template <typename K> size_type count(const K& key) const: + // + // Returns the number of elements comparing equal to the given `key` within + // the `btree_map`. Note that this function will return either `1` or `0` + // since duplicate elements are not allowed within a `btree_map`. + // + // Supports heterogeneous lookup, provided that the map is provided a + // compatible heterogeneous comparator. + using Base::count; + + // btree_map::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `btree_map`. + using Base::equal_range; + + // btree_map::find() + // + // template <typename K> iterator find(const K& key): + // template <typename K> const_iterator find(const K& key) const: + // + // Finds an element with the passed `key` within the `btree_map`. + // + // Supports heterogeneous lookup, provided that the map is provided a + // compatible heterogeneous comparator. + using Base::find; + + // btree_map::operator[]() + // + // Returns a reference to the value mapped to the passed key within the + // `btree_map`, performing an `insert()` if the key does not already + // exist. + // + // If an insertion occurs, any references, pointers, or iterators are + // invalidated. Otherwise iterators are not affected and references are not + // invalidated. Overloads are listed below. + // + // T& operator[](key_type&& key): + // T& operator[](const key_type& key): + // + // Inserts a value_type object constructed in-place if the element with the + // given key does not exist. + using Base::operator[]; + + // btree_map::get_allocator() + // + // Returns the allocator function associated with this `btree_map`. + using Base::get_allocator; + + // btree_map::key_comp(); + // + // Returns the key comparator associated with this `btree_map`. + using Base::key_comp; + + // btree_map::value_comp(); + // + // Returns the value comparator associated with this `btree_map`. + using Base::value_comp; +}; + +// absl::swap(absl::btree_map<>, absl::btree_map<>) +// +// Swaps the contents of two `absl::btree_map` containers. +template <typename K, typename V, typename C, typename A> +void swap(btree_map<K, V, C, A> &x, btree_map<K, V, C, A> &y) { + return x.swap(y); +} + +// absl::erase_if(absl::btree_map<>, Pred) +// +// Erases all elements that satisfy the predicate pred from the container. +template <typename K, typename V, typename C, typename A, typename Pred> +void erase_if(btree_map<K, V, C, A> &map, Pred pred) { + for (auto it = map.begin(); it != map.end();) { + if (pred(*it)) { + it = map.erase(it); + } else { + ++it; + } + } +} + +// absl::btree_multimap +// +// An `absl::btree_multimap<K, V>` is an ordered associative container of +// keys and associated values designed to be a more efficient replacement for +// `std::multimap` (in most cases). Unlike `absl::btree_map`, a B-tree multimap +// allows multiple elements with equivalent keys. +// +// Keys are sorted using an (optional) comparison function, which defaults to +// `std::less<K>`. +// +// An `absl::btree_multimap<K, V>` uses a default allocator of +// `std::allocator<std::pair<const K, V>>` to allocate (and deallocate) +// nodes, and construct and destruct values within those nodes. You may +// instead specify a custom allocator `A` (which in turn requires specifying a +// custom comparator `C`) as in `absl::btree_multimap<K, V, C, A>`. +// +template <typename Key, typename Value, typename Compare = std::less<Key>, + typename Alloc = std::allocator<std::pair<const Key, Value>>> +class btree_multimap + : public container_internal::btree_multimap_container< + container_internal::btree<container_internal::map_params< + Key, Value, Compare, Alloc, /*TargetNodeSize=*/256, + /*Multi=*/true>>> { + using Base = typename btree_multimap::btree_multimap_container; + + public: + // Constructors and Assignment Operators + // + // A `btree_multimap` supports the same overload set as `std::multimap` + // for construction and assignment: + // + // * Default constructor + // + // absl::btree_multimap<int, std::string> map1; + // + // * Initializer List constructor + // + // absl::btree_multimap<int, std::string> map2 = + // {{1, "huey"}, {2, "dewey"}, {3, "louie"},}; + // + // * Copy constructor + // + // absl::btree_multimap<int, std::string> map3(map2); + // + // * Copy assignment operator + // + // absl::btree_multimap<int, std::string> map4; + // map4 = map3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::btree_multimap<int, std::string> map5(std::move(map4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::btree_multimap<int, std::string> map6; + // map6 = std::move(map5); + // + // * Range constructor + // + // std::vector<std::pair<int, std::string>> v = {{1, "a"}, {2, "b"}}; + // absl::btree_multimap<int, std::string> map7(v.begin(), v.end()); + btree_multimap() {} + using Base::Base; + + // btree_multimap::begin() + // + // Returns an iterator to the beginning of the `btree_multimap`. + using Base::begin; + + // btree_multimap::cbegin() + // + // Returns a const iterator to the beginning of the `btree_multimap`. + using Base::cbegin; + + // btree_multimap::end() + // + // Returns an iterator to the end of the `btree_multimap`. + using Base::end; + + // btree_multimap::cend() + // + // Returns a const iterator to the end of the `btree_multimap`. + using Base::cend; + + // btree_multimap::empty() + // + // Returns whether or not the `btree_multimap` is empty. + using Base::empty; + + // btree_multimap::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `btree_multimap` under current memory constraints. This value can be + // thought of as the largest value of `std::distance(begin(), end())` for a + // `btree_multimap<Key, T>`. + using Base::max_size; + + // btree_multimap::size() + // + // Returns the number of elements currently within the `btree_multimap`. + using Base::size; + + // btree_multimap::clear() + // + // Removes all elements from the `btree_multimap`. Invalidates any references, + // pointers, or iterators referring to contained elements. + using Base::clear; + + // btree_multimap::erase() + // + // Erases elements within the `btree_multimap`. If an erase occurs, any + // references, pointers, or iterators are invalidated. + // Overloads are listed below. + // + // iterator erase(iterator position): + // iterator erase(const_iterator position): + // + // Erases the element at `position` of the `btree_multimap`, returning + // the iterator pointing to the element after the one that was erased + // (or end() if none exists). + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning + // the iterator pointing to the element after the interval that was erased + // (or end() if none exists). + // + // template <typename K> size_type erase(const K& key): + // + // Erases the elements matching the key, if any exist, returning the + // number of elements erased. + using Base::erase; + + // btree_multimap::insert() + // + // Inserts an element of the specified value into the `btree_multimap`, + // returning an iterator pointing to the newly inserted element. + // Any references, pointers, or iterators are invalidated. Overloads are + // listed below. + // + // iterator insert(const value_type& value): + // + // Inserts a value into the `btree_multimap`, returning an iterator to the + // inserted element. + // + // iterator insert(value_type&& value): + // + // Inserts a moveable value into the `btree_multimap`, returning an iterator + // to the inserted element. + // + // iterator insert(const_iterator hint, const value_type& value): + // iterator insert(const_iterator hint, value_type&& value): + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // void insert(std::initializer_list<init_type> ilist): + // + // Inserts the elements within the initializer list `ilist`. + using Base::insert; + + // btree_multimap::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_multimap`. Any references, pointers, or iterators are + // invalidated. + using Base::emplace; + + // btree_multimap::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_multimap`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search. + // + // Any references, pointers, or iterators are invalidated. + using Base::emplace_hint; + + // btree_multimap::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the element at the indicated position and returns a node handle + // owning that extracted data. + // + // template <typename K> node_type extract(const K& k): + // + // Extracts the element with the key matching the passed key value and + // returns a node handle owning that extracted data. If the `btree_multimap` + // does not contain an element with a matching key, this function returns an + // empty node handle. + // + // NOTE: In this context, `node_type` refers to the C++17 concept of a + // move-only type that owns and provides access to the elements in associative + // containers (https://en.cppreference.com/w/cpp/container/node_handle). + // It does NOT refer to the data layout of the underlying btree. + using Base::extract; + + // btree_multimap::merge() + // + // Extracts elements from a given `source` btree_multimap into this + // `btree_multimap`. If the destination `btree_multimap` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // btree_multimap::swap(btree_multimap& other) + // + // Exchanges the contents of this `btree_multimap` with those of the `other` + // btree_multimap, avoiding invocation of any move, copy, or swap operations + // on individual elements. + // + // All iterators and references on the `btree_multimap` remain valid, + // excepting for the past-the-end iterator, which is invalidated. + using Base::swap; + + // btree_multimap::contains() + // + // template <typename K> bool contains(const K& key) const: + // + // Determines whether an element comparing equal to the given `key` exists + // within the `btree_multimap`, returning `true` if so or `false` otherwise. + // + // Supports heterogeneous lookup, provided that the map is provided a + // compatible heterogeneous comparator. + using Base::contains; + + // btree_multimap::count() + // + // template <typename K> size_type count(const K& key) const: + // + // Returns the number of elements comparing equal to the given `key` within + // the `btree_multimap`. + // + // Supports heterogeneous lookup, provided that the map is provided a + // compatible heterogeneous comparator. + using Base::count; + + // btree_multimap::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `btree_multimap`. + using Base::equal_range; + + // btree_multimap::find() + // + // template <typename K> iterator find(const K& key): + // template <typename K> const_iterator find(const K& key) const: + // + // Finds an element with the passed `key` within the `btree_multimap`. + // + // Supports heterogeneous lookup, provided that the map is provided a + // compatible heterogeneous comparator. + using Base::find; + + // btree_multimap::get_allocator() + // + // Returns the allocator function associated with this `btree_multimap`. + using Base::get_allocator; + + // btree_multimap::key_comp(); + // + // Returns the key comparator associated with this `btree_multimap`. + using Base::key_comp; + + // btree_multimap::value_comp(); + // + // Returns the value comparator associated with this `btree_multimap`. + using Base::value_comp; +}; + +// absl::swap(absl::btree_multimap<>, absl::btree_multimap<>) +// +// Swaps the contents of two `absl::btree_multimap` containers. +template <typename K, typename V, typename C, typename A> +void swap(btree_multimap<K, V, C, A> &x, btree_multimap<K, V, C, A> &y) { + return x.swap(y); +} + +// absl::erase_if(absl::btree_multimap<>, Pred) +// +// Erases all elements that satisfy the predicate pred from the container. +template <typename K, typename V, typename C, typename A, typename Pred> +void erase_if(btree_multimap<K, V, C, A> &map, Pred pred) { + for (auto it = map.begin(); it != map.end();) { + if (pred(*it)) { + it = map.erase(it); + } else { + ++it; + } + } +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_BTREE_MAP_H_ diff --git a/third_party/abseil_cpp/absl/container/btree_set.h b/third_party/abseil_cpp/absl/container/btree_set.h new file mode 100644 index 0000000000..d3e78866a7 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/btree_set.h @@ -0,0 +1,683 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: btree_set.h +// ----------------------------------------------------------------------------- +// +// This header file defines B-tree sets: sorted associative containers of +// values. +// +// * `absl::btree_set<>` +// * `absl::btree_multiset<>` +// +// These B-tree types are similar to the corresponding types in the STL +// (`std::set` and `std::multiset`) and generally conform to the STL interfaces +// of those types. However, because they are implemented using B-trees, they +// are more efficient in most situations. +// +// Unlike `std::set` and `std::multiset`, which are commonly implemented using +// red-black tree nodes, B-tree sets use more generic B-tree nodes able to hold +// multiple values per node. Holding multiple values per node often makes +// B-tree sets perform better than their `std::set` counterparts, because +// multiple entries can be checked within the same cache hit. +// +// However, these types should not be considered drop-in replacements for +// `std::set` and `std::multiset` as there are some API differences, which are +// noted in this header file. +// +// Importantly, insertions and deletions may invalidate outstanding iterators, +// pointers, and references to elements. Such invalidations are typically only +// an issue if insertion and deletion operations are interleaved with the use of +// more than one iterator, pointer, or reference simultaneously. For this +// reason, `insert()` and `erase()` return a valid iterator at the current +// position. + +#ifndef ABSL_CONTAINER_BTREE_SET_H_ +#define ABSL_CONTAINER_BTREE_SET_H_ + +#include "absl/container/internal/btree.h" // IWYU pragma: export +#include "absl/container/internal/btree_container.h" // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::btree_set<> +// +// An `absl::btree_set<K>` is an ordered associative container of unique key +// values designed to be a more efficient replacement for `std::set` (in most +// cases). +// +// Keys are sorted using an (optional) comparison function, which defaults to +// `std::less<K>`. +// +// An `absl::btree_set<K>` uses a default allocator of `std::allocator<K>` to +// allocate (and deallocate) nodes, and construct and destruct values within +// those nodes. You may instead specify a custom allocator `A` (which in turn +// requires specifying a custom comparator `C`) as in +// `absl::btree_set<K, C, A>`. +// +template <typename Key, typename Compare = std::less<Key>, + typename Alloc = std::allocator<Key>> +class btree_set + : public container_internal::btree_set_container< + container_internal::btree<container_internal::set_params< + Key, Compare, Alloc, /*TargetNodeSize=*/256, + /*Multi=*/false>>> { + using Base = typename btree_set::btree_set_container; + + public: + // Constructors and Assignment Operators + // + // A `btree_set` supports the same overload set as `std::set` + // for construction and assignment: + // + // * Default constructor + // + // absl::btree_set<std::string> set1; + // + // * Initializer List constructor + // + // absl::btree_set<std::string> set2 = + // {{"huey"}, {"dewey"}, {"louie"},}; + // + // * Copy constructor + // + // absl::btree_set<std::string> set3(set2); + // + // * Copy assignment operator + // + // absl::btree_set<std::string> set4; + // set4 = set3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::btree_set<std::string> set5(std::move(set4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::btree_set<std::string> set6; + // set6 = std::move(set5); + // + // * Range constructor + // + // std::vector<std::string> v = {"a", "b"}; + // absl::btree_set<std::string> set7(v.begin(), v.end()); + btree_set() {} + using Base::Base; + + // btree_set::begin() + // + // Returns an iterator to the beginning of the `btree_set`. + using Base::begin; + + // btree_set::cbegin() + // + // Returns a const iterator to the beginning of the `btree_set`. + using Base::cbegin; + + // btree_set::end() + // + // Returns an iterator to the end of the `btree_set`. + using Base::end; + + // btree_set::cend() + // + // Returns a const iterator to the end of the `btree_set`. + using Base::cend; + + // btree_set::empty() + // + // Returns whether or not the `btree_set` is empty. + using Base::empty; + + // btree_set::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `btree_set` under current memory constraints. This value can be thought + // of as the largest value of `std::distance(begin(), end())` for a + // `btree_set<Key>`. + using Base::max_size; + + // btree_set::size() + // + // Returns the number of elements currently within the `btree_set`. + using Base::size; + + // btree_set::clear() + // + // Removes all elements from the `btree_set`. Invalidates any references, + // pointers, or iterators referring to contained elements. + using Base::clear; + + // btree_set::erase() + // + // Erases elements within the `btree_set`. Overloads are listed below. + // + // iterator erase(iterator position): + // iterator erase(const_iterator position): + // + // Erases the element at `position` of the `btree_set`, returning + // the iterator pointing to the element after the one that was erased + // (or end() if none exists). + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning + // the iterator pointing to the element after the interval that was erased + // (or end() if none exists). + // + // template <typename K> size_type erase(const K& key): + // + // Erases the element with the matching key, if it exists, returning the + // number of elements erased. + using Base::erase; + + // btree_set::insert() + // + // Inserts an element of the specified value into the `btree_set`, + // returning an iterator pointing to the newly inserted element, provided that + // an element with the given key does not already exist. If an insertion + // occurs, any references, pointers, or iterators are invalidated. + // Overloads are listed below. + // + // std::pair<iterator,bool> insert(const value_type& value): + // + // Inserts a value into the `btree_set`. Returns a pair consisting of an + // iterator to the inserted element (or to the element that prevented the + // insertion) and a bool denoting whether the insertion took place. + // + // std::pair<iterator,bool> insert(value_type&& value): + // + // Inserts a moveable value into the `btree_set`. Returns a pair + // consisting of an iterator to the inserted element (or to the element that + // prevented the insertion) and a bool denoting whether the insertion took + // place. + // + // iterator insert(const_iterator hint, const value_type& value): + // iterator insert(const_iterator hint, value_type&& value): + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element, or to the existing element that prevented the + // insertion. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // void insert(std::initializer_list<init_type> ilist): + // + // Inserts the elements within the initializer list `ilist`. + using Base::insert; + + // btree_set::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_set`, provided that no element with the given key + // already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. + // + // If an insertion occurs, any references, pointers, or iterators are + // invalidated. + using Base::emplace; + + // btree_set::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_set`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search, and only inserts + // provided that no element with the given key already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. + // + // If an insertion occurs, any references, pointers, or iterators are + // invalidated. + using Base::emplace_hint; + + // btree_set::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the element at the indicated position and returns a node handle + // owning that extracted data. + // + // template <typename K> node_type extract(const K& k): + // + // Extracts the element with the key matching the passed key value and + // returns a node handle owning that extracted data. If the `btree_set` + // does not contain an element with a matching key, this function returns an + // empty node handle. + // + // NOTE: In this context, `node_type` refers to the C++17 concept of a + // move-only type that owns and provides access to the elements in associative + // containers (https://en.cppreference.com/w/cpp/container/node_handle). + // It does NOT refer to the data layout of the underlying btree. + using Base::extract; + + // btree_set::merge() + // + // Extracts elements from a given `source` btree_set into this + // `btree_set`. If the destination `btree_set` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // btree_set::swap(btree_set& other) + // + // Exchanges the contents of this `btree_set` with those of the `other` + // btree_set, avoiding invocation of any move, copy, or swap operations on + // individual elements. + // + // All iterators and references on the `btree_set` remain valid, excepting + // for the past-the-end iterator, which is invalidated. + using Base::swap; + + // btree_set::contains() + // + // template <typename K> bool contains(const K& key) const: + // + // Determines whether an element comparing equal to the given `key` exists + // within the `btree_set`, returning `true` if so or `false` otherwise. + // + // Supports heterogeneous lookup, provided that the set is provided a + // compatible heterogeneous comparator. + using Base::contains; + + // btree_set::count() + // + // template <typename K> size_type count(const K& key) const: + // + // Returns the number of elements comparing equal to the given `key` within + // the `btree_set`. Note that this function will return either `1` or `0` + // since duplicate elements are not allowed within a `btree_set`. + // + // Supports heterogeneous lookup, provided that the set is provided a + // compatible heterogeneous comparator. + using Base::count; + + // btree_set::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `btree_set`. + using Base::equal_range; + + // btree_set::find() + // + // template <typename K> iterator find(const K& key): + // template <typename K> const_iterator find(const K& key) const: + // + // Finds an element with the passed `key` within the `btree_set`. + // + // Supports heterogeneous lookup, provided that the set is provided a + // compatible heterogeneous comparator. + using Base::find; + + // btree_set::get_allocator() + // + // Returns the allocator function associated with this `btree_set`. + using Base::get_allocator; + + // btree_set::key_comp(); + // + // Returns the key comparator associated with this `btree_set`. + using Base::key_comp; + + // btree_set::value_comp(); + // + // Returns the value comparator associated with this `btree_set`. The keys to + // sort the elements are the values themselves, therefore `value_comp` and its + // sibling member function `key_comp` are equivalent. + using Base::value_comp; +}; + +// absl::swap(absl::btree_set<>, absl::btree_set<>) +// +// Swaps the contents of two `absl::btree_set` containers. +template <typename K, typename C, typename A> +void swap(btree_set<K, C, A> &x, btree_set<K, C, A> &y) { + return x.swap(y); +} + +// absl::erase_if(absl::btree_set<>, Pred) +// +// Erases all elements that satisfy the predicate pred from the container. +template <typename K, typename C, typename A, typename Pred> +void erase_if(btree_set<K, C, A> &set, Pred pred) { + for (auto it = set.begin(); it != set.end();) { + if (pred(*it)) { + it = set.erase(it); + } else { + ++it; + } + } +} + +// absl::btree_multiset<> +// +// An `absl::btree_multiset<K>` is an ordered associative container of +// keys and associated values designed to be a more efficient replacement +// for `std::multiset` (in most cases). Unlike `absl::btree_set`, a B-tree +// multiset allows equivalent elements. +// +// Keys are sorted using an (optional) comparison function, which defaults to +// `std::less<K>`. +// +// An `absl::btree_multiset<K>` uses a default allocator of `std::allocator<K>` +// to allocate (and deallocate) nodes, and construct and destruct values within +// those nodes. You may instead specify a custom allocator `A` (which in turn +// requires specifying a custom comparator `C`) as in +// `absl::btree_multiset<K, C, A>`. +// +template <typename Key, typename Compare = std::less<Key>, + typename Alloc = std::allocator<Key>> +class btree_multiset + : public container_internal::btree_multiset_container< + container_internal::btree<container_internal::set_params< + Key, Compare, Alloc, /*TargetNodeSize=*/256, + /*Multi=*/true>>> { + using Base = typename btree_multiset::btree_multiset_container; + + public: + // Constructors and Assignment Operators + // + // A `btree_multiset` supports the same overload set as `std::set` + // for construction and assignment: + // + // * Default constructor + // + // absl::btree_multiset<std::string> set1; + // + // * Initializer List constructor + // + // absl::btree_multiset<std::string> set2 = + // {{"huey"}, {"dewey"}, {"louie"},}; + // + // * Copy constructor + // + // absl::btree_multiset<std::string> set3(set2); + // + // * Copy assignment operator + // + // absl::btree_multiset<std::string> set4; + // set4 = set3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::btree_multiset<std::string> set5(std::move(set4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::btree_multiset<std::string> set6; + // set6 = std::move(set5); + // + // * Range constructor + // + // std::vector<std::string> v = {"a", "b"}; + // absl::btree_multiset<std::string> set7(v.begin(), v.end()); + btree_multiset() {} + using Base::Base; + + // btree_multiset::begin() + // + // Returns an iterator to the beginning of the `btree_multiset`. + using Base::begin; + + // btree_multiset::cbegin() + // + // Returns a const iterator to the beginning of the `btree_multiset`. + using Base::cbegin; + + // btree_multiset::end() + // + // Returns an iterator to the end of the `btree_multiset`. + using Base::end; + + // btree_multiset::cend() + // + // Returns a const iterator to the end of the `btree_multiset`. + using Base::cend; + + // btree_multiset::empty() + // + // Returns whether or not the `btree_multiset` is empty. + using Base::empty; + + // btree_multiset::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `btree_multiset` under current memory constraints. This value can be + // thought of as the largest value of `std::distance(begin(), end())` for a + // `btree_multiset<Key>`. + using Base::max_size; + + // btree_multiset::size() + // + // Returns the number of elements currently within the `btree_multiset`. + using Base::size; + + // btree_multiset::clear() + // + // Removes all elements from the `btree_multiset`. Invalidates any references, + // pointers, or iterators referring to contained elements. + using Base::clear; + + // btree_multiset::erase() + // + // Erases elements within the `btree_multiset`. Overloads are listed below. + // + // iterator erase(iterator position): + // iterator erase(const_iterator position): + // + // Erases the element at `position` of the `btree_multiset`, returning + // the iterator pointing to the element after the one that was erased + // (or end() if none exists). + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning + // the iterator pointing to the element after the interval that was erased + // (or end() if none exists). + // + // template <typename K> size_type erase(const K& key): + // + // Erases the elements matching the key, if any exist, returning the + // number of elements erased. + using Base::erase; + + // btree_multiset::insert() + // + // Inserts an element of the specified value into the `btree_multiset`, + // returning an iterator pointing to the newly inserted element. + // Any references, pointers, or iterators are invalidated. Overloads are + // listed below. + // + // iterator insert(const value_type& value): + // + // Inserts a value into the `btree_multiset`, returning an iterator to the + // inserted element. + // + // iterator insert(value_type&& value): + // + // Inserts a moveable value into the `btree_multiset`, returning an iterator + // to the inserted element. + // + // iterator insert(const_iterator hint, const value_type& value): + // iterator insert(const_iterator hint, value_type&& value): + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // void insert(std::initializer_list<init_type> ilist): + // + // Inserts the elements within the initializer list `ilist`. + using Base::insert; + + // btree_multiset::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_multiset`. Any references, pointers, or iterators are + // invalidated. + using Base::emplace; + + // btree_multiset::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `btree_multiset`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search. + // + // Any references, pointers, or iterators are invalidated. + using Base::emplace_hint; + + // btree_multiset::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the element at the indicated position and returns a node handle + // owning that extracted data. + // + // template <typename K> node_type extract(const K& k): + // + // Extracts the element with the key matching the passed key value and + // returns a node handle owning that extracted data. If the `btree_multiset` + // does not contain an element with a matching key, this function returns an + // empty node handle. + // + // NOTE: In this context, `node_type` refers to the C++17 concept of a + // move-only type that owns and provides access to the elements in associative + // containers (https://en.cppreference.com/w/cpp/container/node_handle). + // It does NOT refer to the data layout of the underlying btree. + using Base::extract; + + // btree_multiset::merge() + // + // Extracts elements from a given `source` btree_multiset into this + // `btree_multiset`. If the destination `btree_multiset` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // btree_multiset::swap(btree_multiset& other) + // + // Exchanges the contents of this `btree_multiset` with those of the `other` + // btree_multiset, avoiding invocation of any move, copy, or swap operations + // on individual elements. + // + // All iterators and references on the `btree_multiset` remain valid, + // excepting for the past-the-end iterator, which is invalidated. + using Base::swap; + + // btree_multiset::contains() + // + // template <typename K> bool contains(const K& key) const: + // + // Determines whether an element comparing equal to the given `key` exists + // within the `btree_multiset`, returning `true` if so or `false` otherwise. + // + // Supports heterogeneous lookup, provided that the set is provided a + // compatible heterogeneous comparator. + using Base::contains; + + // btree_multiset::count() + // + // template <typename K> size_type count(const K& key) const: + // + // Returns the number of elements comparing equal to the given `key` within + // the `btree_multiset`. + // + // Supports heterogeneous lookup, provided that the set is provided a + // compatible heterogeneous comparator. + using Base::count; + + // btree_multiset::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `btree_multiset`. + using Base::equal_range; + + // btree_multiset::find() + // + // template <typename K> iterator find(const K& key): + // template <typename K> const_iterator find(const K& key) const: + // + // Finds an element with the passed `key` within the `btree_multiset`. + // + // Supports heterogeneous lookup, provided that the set is provided a + // compatible heterogeneous comparator. + using Base::find; + + // btree_multiset::get_allocator() + // + // Returns the allocator function associated with this `btree_multiset`. + using Base::get_allocator; + + // btree_multiset::key_comp(); + // + // Returns the key comparator associated with this `btree_multiset`. + using Base::key_comp; + + // btree_multiset::value_comp(); + // + // Returns the value comparator associated with this `btree_multiset`. The + // keys to sort the elements are the values themselves, therefore `value_comp` + // and its sibling member function `key_comp` are equivalent. + using Base::value_comp; +}; + +// absl::swap(absl::btree_multiset<>, absl::btree_multiset<>) +// +// Swaps the contents of two `absl::btree_multiset` containers. +template <typename K, typename C, typename A> +void swap(btree_multiset<K, C, A> &x, btree_multiset<K, C, A> &y) { + return x.swap(y); +} + +// absl::erase_if(absl::btree_multiset<>, Pred) +// +// Erases all elements that satisfy the predicate pred from the container. +template <typename K, typename C, typename A, typename Pred> +void erase_if(btree_multiset<K, C, A> &set, Pred pred) { + for (auto it = set.begin(); it != set.end();) { + if (pred(*it)) { + it = set.erase(it); + } else { + ++it; + } + } +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_BTREE_SET_H_ diff --git a/third_party/abseil_cpp/absl/container/btree_test.cc b/third_party/abseil_cpp/absl/container/btree_test.cc new file mode 100644 index 0000000000..bbdb5f42a6 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/btree_test.cc @@ -0,0 +1,2410 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/btree_test.h" + +#include <cstdint> +#include <map> +#include <memory> +#include <stdexcept> +#include <string> +#include <type_traits> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/container/btree_map.h" +#include "absl/container/btree_set.h" +#include "absl/container/internal/counting_allocator.h" +#include "absl/container/internal/test_instance_tracker.h" +#include "absl/flags/flag.h" +#include "absl/hash/hash_testing.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" +#include "absl/types/compare.h" + +ABSL_FLAG(int, test_values, 10000, "The number of values to use for tests"); + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::absl::test_internal::CopyableMovableInstance; +using ::absl::test_internal::InstanceTracker; +using ::absl::test_internal::MovableOnlyInstance; +using ::testing::ElementsAre; +using ::testing::ElementsAreArray; +using ::testing::IsEmpty; +using ::testing::Pair; + +template <typename T, typename U> +void CheckPairEquals(const T &x, const U &y) { + ABSL_INTERNAL_CHECK(x == y, "Values are unequal."); +} + +template <typename T, typename U, typename V, typename W> +void CheckPairEquals(const std::pair<T, U> &x, const std::pair<V, W> &y) { + CheckPairEquals(x.first, y.first); + CheckPairEquals(x.second, y.second); +} +} // namespace + +// The base class for a sorted associative container checker. TreeType is the +// container type to check and CheckerType is the container type to check +// against. TreeType is expected to be btree_{set,map,multiset,multimap} and +// CheckerType is expected to be {set,map,multiset,multimap}. +template <typename TreeType, typename CheckerType> +class base_checker { + public: + using key_type = typename TreeType::key_type; + using value_type = typename TreeType::value_type; + using key_compare = typename TreeType::key_compare; + using pointer = typename TreeType::pointer; + using const_pointer = typename TreeType::const_pointer; + using reference = typename TreeType::reference; + using const_reference = typename TreeType::const_reference; + using size_type = typename TreeType::size_type; + using difference_type = typename TreeType::difference_type; + using iterator = typename TreeType::iterator; + using const_iterator = typename TreeType::const_iterator; + using reverse_iterator = typename TreeType::reverse_iterator; + using const_reverse_iterator = typename TreeType::const_reverse_iterator; + + public: + base_checker() : const_tree_(tree_) {} + base_checker(const base_checker &other) + : tree_(other.tree_), const_tree_(tree_), checker_(other.checker_) {} + template <typename InputIterator> + base_checker(InputIterator b, InputIterator e) + : tree_(b, e), const_tree_(tree_), checker_(b, e) {} + + iterator begin() { return tree_.begin(); } + const_iterator begin() const { return tree_.begin(); } + iterator end() { return tree_.end(); } + const_iterator end() const { return tree_.end(); } + reverse_iterator rbegin() { return tree_.rbegin(); } + const_reverse_iterator rbegin() const { return tree_.rbegin(); } + reverse_iterator rend() { return tree_.rend(); } + const_reverse_iterator rend() const { return tree_.rend(); } + + template <typename IterType, typename CheckerIterType> + IterType iter_check(IterType tree_iter, CheckerIterType checker_iter) const { + if (tree_iter == tree_.end()) { + ABSL_INTERNAL_CHECK(checker_iter == checker_.end(), + "Checker iterator not at end."); + } else { + CheckPairEquals(*tree_iter, *checker_iter); + } + return tree_iter; + } + template <typename IterType, typename CheckerIterType> + IterType riter_check(IterType tree_iter, CheckerIterType checker_iter) const { + if (tree_iter == tree_.rend()) { + ABSL_INTERNAL_CHECK(checker_iter == checker_.rend(), + "Checker iterator not at rend."); + } else { + CheckPairEquals(*tree_iter, *checker_iter); + } + return tree_iter; + } + void value_check(const value_type &v) { + typename KeyOfValue<typename TreeType::key_type, + typename TreeType::value_type>::type key_of_value; + const key_type &key = key_of_value(v); + CheckPairEquals(*find(key), v); + lower_bound(key); + upper_bound(key); + equal_range(key); + contains(key); + count(key); + } + void erase_check(const key_type &key) { + EXPECT_FALSE(tree_.contains(key)); + EXPECT_EQ(tree_.find(key), const_tree_.end()); + EXPECT_FALSE(const_tree_.contains(key)); + EXPECT_EQ(const_tree_.find(key), tree_.end()); + EXPECT_EQ(tree_.equal_range(key).first, + const_tree_.equal_range(key).second); + } + + iterator lower_bound(const key_type &key) { + return iter_check(tree_.lower_bound(key), checker_.lower_bound(key)); + } + const_iterator lower_bound(const key_type &key) const { + return iter_check(tree_.lower_bound(key), checker_.lower_bound(key)); + } + iterator upper_bound(const key_type &key) { + return iter_check(tree_.upper_bound(key), checker_.upper_bound(key)); + } + const_iterator upper_bound(const key_type &key) const { + return iter_check(tree_.upper_bound(key), checker_.upper_bound(key)); + } + std::pair<iterator, iterator> equal_range(const key_type &key) { + std::pair<typename CheckerType::iterator, typename CheckerType::iterator> + checker_res = checker_.equal_range(key); + std::pair<iterator, iterator> tree_res = tree_.equal_range(key); + iter_check(tree_res.first, checker_res.first); + iter_check(tree_res.second, checker_res.second); + return tree_res; + } + std::pair<const_iterator, const_iterator> equal_range( + const key_type &key) const { + std::pair<typename CheckerType::const_iterator, + typename CheckerType::const_iterator> + checker_res = checker_.equal_range(key); + std::pair<const_iterator, const_iterator> tree_res = tree_.equal_range(key); + iter_check(tree_res.first, checker_res.first); + iter_check(tree_res.second, checker_res.second); + return tree_res; + } + iterator find(const key_type &key) { + return iter_check(tree_.find(key), checker_.find(key)); + } + const_iterator find(const key_type &key) const { + return iter_check(tree_.find(key), checker_.find(key)); + } + bool contains(const key_type &key) const { return find(key) != end(); } + size_type count(const key_type &key) const { + size_type res = checker_.count(key); + EXPECT_EQ(res, tree_.count(key)); + return res; + } + + base_checker &operator=(const base_checker &other) { + tree_ = other.tree_; + checker_ = other.checker_; + return *this; + } + + int erase(const key_type &key) { + int size = tree_.size(); + int res = checker_.erase(key); + EXPECT_EQ(res, tree_.count(key)); + EXPECT_EQ(res, tree_.erase(key)); + EXPECT_EQ(tree_.count(key), 0); + EXPECT_EQ(tree_.size(), size - res); + erase_check(key); + return res; + } + iterator erase(iterator iter) { + key_type key = iter.key(); + int size = tree_.size(); + int count = tree_.count(key); + auto checker_iter = checker_.lower_bound(key); + for (iterator tmp(tree_.lower_bound(key)); tmp != iter; ++tmp) { + ++checker_iter; + } + auto checker_next = checker_iter; + ++checker_next; + checker_.erase(checker_iter); + iter = tree_.erase(iter); + EXPECT_EQ(tree_.size(), checker_.size()); + EXPECT_EQ(tree_.size(), size - 1); + EXPECT_EQ(tree_.count(key), count - 1); + if (count == 1) { + erase_check(key); + } + return iter_check(iter, checker_next); + } + + void erase(iterator begin, iterator end) { + int size = tree_.size(); + int count = std::distance(begin, end); + auto checker_begin = checker_.lower_bound(begin.key()); + for (iterator tmp(tree_.lower_bound(begin.key())); tmp != begin; ++tmp) { + ++checker_begin; + } + auto checker_end = + end == tree_.end() ? checker_.end() : checker_.lower_bound(end.key()); + if (end != tree_.end()) { + for (iterator tmp(tree_.lower_bound(end.key())); tmp != end; ++tmp) { + ++checker_end; + } + } + const auto checker_ret = checker_.erase(checker_begin, checker_end); + const auto tree_ret = tree_.erase(begin, end); + EXPECT_EQ(std::distance(checker_.begin(), checker_ret), + std::distance(tree_.begin(), tree_ret)); + EXPECT_EQ(tree_.size(), checker_.size()); + EXPECT_EQ(tree_.size(), size - count); + } + + void clear() { + tree_.clear(); + checker_.clear(); + } + void swap(base_checker &other) { + tree_.swap(other.tree_); + checker_.swap(other.checker_); + } + + void verify() const { + tree_.verify(); + EXPECT_EQ(tree_.size(), checker_.size()); + + // Move through the forward iterators using increment. + auto checker_iter = checker_.begin(); + const_iterator tree_iter(tree_.begin()); + for (; tree_iter != tree_.end(); ++tree_iter, ++checker_iter) { + CheckPairEquals(*tree_iter, *checker_iter); + } + + // Move through the forward iterators using decrement. + for (int n = tree_.size() - 1; n >= 0; --n) { + iter_check(tree_iter, checker_iter); + --tree_iter; + --checker_iter; + } + EXPECT_EQ(tree_iter, tree_.begin()); + EXPECT_EQ(checker_iter, checker_.begin()); + + // Move through the reverse iterators using increment. + auto checker_riter = checker_.rbegin(); + const_reverse_iterator tree_riter(tree_.rbegin()); + for (; tree_riter != tree_.rend(); ++tree_riter, ++checker_riter) { + CheckPairEquals(*tree_riter, *checker_riter); + } + + // Move through the reverse iterators using decrement. + for (int n = tree_.size() - 1; n >= 0; --n) { + riter_check(tree_riter, checker_riter); + --tree_riter; + --checker_riter; + } + EXPECT_EQ(tree_riter, tree_.rbegin()); + EXPECT_EQ(checker_riter, checker_.rbegin()); + } + + const TreeType &tree() const { return tree_; } + + size_type size() const { + EXPECT_EQ(tree_.size(), checker_.size()); + return tree_.size(); + } + size_type max_size() const { return tree_.max_size(); } + bool empty() const { + EXPECT_EQ(tree_.empty(), checker_.empty()); + return tree_.empty(); + } + + protected: + TreeType tree_; + const TreeType &const_tree_; + CheckerType checker_; +}; + +namespace { +// A checker for unique sorted associative containers. TreeType is expected to +// be btree_{set,map} and CheckerType is expected to be {set,map}. +template <typename TreeType, typename CheckerType> +class unique_checker : public base_checker<TreeType, CheckerType> { + using super_type = base_checker<TreeType, CheckerType>; + + public: + using iterator = typename super_type::iterator; + using value_type = typename super_type::value_type; + + public: + unique_checker() : super_type() {} + unique_checker(const unique_checker &other) : super_type(other) {} + template <class InputIterator> + unique_checker(InputIterator b, InputIterator e) : super_type(b, e) {} + unique_checker &operator=(const unique_checker &) = default; + + // Insertion routines. + std::pair<iterator, bool> insert(const value_type &v) { + int size = this->tree_.size(); + std::pair<typename CheckerType::iterator, bool> checker_res = + this->checker_.insert(v); + std::pair<iterator, bool> tree_res = this->tree_.insert(v); + CheckPairEquals(*tree_res.first, *checker_res.first); + EXPECT_EQ(tree_res.second, checker_res.second); + EXPECT_EQ(this->tree_.size(), this->checker_.size()); + EXPECT_EQ(this->tree_.size(), size + tree_res.second); + return tree_res; + } + iterator insert(iterator position, const value_type &v) { + int size = this->tree_.size(); + std::pair<typename CheckerType::iterator, bool> checker_res = + this->checker_.insert(v); + iterator tree_res = this->tree_.insert(position, v); + CheckPairEquals(*tree_res, *checker_res.first); + EXPECT_EQ(this->tree_.size(), this->checker_.size()); + EXPECT_EQ(this->tree_.size(), size + checker_res.second); + return tree_res; + } + template <typename InputIterator> + void insert(InputIterator b, InputIterator e) { + for (; b != e; ++b) { + insert(*b); + } + } +}; + +// A checker for multiple sorted associative containers. TreeType is expected +// to be btree_{multiset,multimap} and CheckerType is expected to be +// {multiset,multimap}. +template <typename TreeType, typename CheckerType> +class multi_checker : public base_checker<TreeType, CheckerType> { + using super_type = base_checker<TreeType, CheckerType>; + + public: + using iterator = typename super_type::iterator; + using value_type = typename super_type::value_type; + + public: + multi_checker() : super_type() {} + multi_checker(const multi_checker &other) : super_type(other) {} + template <class InputIterator> + multi_checker(InputIterator b, InputIterator e) : super_type(b, e) {} + multi_checker &operator=(const multi_checker &) = default; + + // Insertion routines. + iterator insert(const value_type &v) { + int size = this->tree_.size(); + auto checker_res = this->checker_.insert(v); + iterator tree_res = this->tree_.insert(v); + CheckPairEquals(*tree_res, *checker_res); + EXPECT_EQ(this->tree_.size(), this->checker_.size()); + EXPECT_EQ(this->tree_.size(), size + 1); + return tree_res; + } + iterator insert(iterator position, const value_type &v) { + int size = this->tree_.size(); + auto checker_res = this->checker_.insert(v); + iterator tree_res = this->tree_.insert(position, v); + CheckPairEquals(*tree_res, *checker_res); + EXPECT_EQ(this->tree_.size(), this->checker_.size()); + EXPECT_EQ(this->tree_.size(), size + 1); + return tree_res; + } + template <typename InputIterator> + void insert(InputIterator b, InputIterator e) { + for (; b != e; ++b) { + insert(*b); + } + } +}; + +template <typename T, typename V> +void DoTest(const char *name, T *b, const std::vector<V> &values) { + typename KeyOfValue<typename T::key_type, V>::type key_of_value; + + T &mutable_b = *b; + const T &const_b = *b; + + // Test insert. + for (int i = 0; i < values.size(); ++i) { + mutable_b.insert(values[i]); + mutable_b.value_check(values[i]); + } + ASSERT_EQ(mutable_b.size(), values.size()); + + const_b.verify(); + + // Test copy constructor. + T b_copy(const_b); + EXPECT_EQ(b_copy.size(), const_b.size()); + for (int i = 0; i < values.size(); ++i) { + CheckPairEquals(*b_copy.find(key_of_value(values[i])), values[i]); + } + + // Test range constructor. + T b_range(const_b.begin(), const_b.end()); + EXPECT_EQ(b_range.size(), const_b.size()); + for (int i = 0; i < values.size(); ++i) { + CheckPairEquals(*b_range.find(key_of_value(values[i])), values[i]); + } + + // Test range insertion for values that already exist. + b_range.insert(b_copy.begin(), b_copy.end()); + b_range.verify(); + + // Test range insertion for new values. + b_range.clear(); + b_range.insert(b_copy.begin(), b_copy.end()); + EXPECT_EQ(b_range.size(), b_copy.size()); + for (int i = 0; i < values.size(); ++i) { + CheckPairEquals(*b_range.find(key_of_value(values[i])), values[i]); + } + + // Test assignment to self. Nothing should change. + b_range.operator=(b_range); + EXPECT_EQ(b_range.size(), b_copy.size()); + + // Test assignment of new values. + b_range.clear(); + b_range = b_copy; + EXPECT_EQ(b_range.size(), b_copy.size()); + + // Test swap. + b_range.clear(); + b_range.swap(b_copy); + EXPECT_EQ(b_copy.size(), 0); + EXPECT_EQ(b_range.size(), const_b.size()); + for (int i = 0; i < values.size(); ++i) { + CheckPairEquals(*b_range.find(key_of_value(values[i])), values[i]); + } + b_range.swap(b_copy); + + // Test non-member function swap. + swap(b_range, b_copy); + EXPECT_EQ(b_copy.size(), 0); + EXPECT_EQ(b_range.size(), const_b.size()); + for (int i = 0; i < values.size(); ++i) { + CheckPairEquals(*b_range.find(key_of_value(values[i])), values[i]); + } + swap(b_range, b_copy); + + // Test erase via values. + for (int i = 0; i < values.size(); ++i) { + mutable_b.erase(key_of_value(values[i])); + // Erasing a non-existent key should have no effect. + ASSERT_EQ(mutable_b.erase(key_of_value(values[i])), 0); + } + + const_b.verify(); + EXPECT_EQ(const_b.size(), 0); + + // Test erase via iterators. + mutable_b = b_copy; + for (int i = 0; i < values.size(); ++i) { + mutable_b.erase(mutable_b.find(key_of_value(values[i]))); + } + + const_b.verify(); + EXPECT_EQ(const_b.size(), 0); + + // Test insert with hint. + for (int i = 0; i < values.size(); i++) { + mutable_b.insert(mutable_b.upper_bound(key_of_value(values[i])), values[i]); + } + + const_b.verify(); + + // Test range erase. + mutable_b.erase(mutable_b.begin(), mutable_b.end()); + EXPECT_EQ(mutable_b.size(), 0); + const_b.verify(); + + // First half. + mutable_b = b_copy; + typename T::iterator mutable_iter_end = mutable_b.begin(); + for (int i = 0; i < values.size() / 2; ++i) ++mutable_iter_end; + mutable_b.erase(mutable_b.begin(), mutable_iter_end); + EXPECT_EQ(mutable_b.size(), values.size() - values.size() / 2); + const_b.verify(); + + // Second half. + mutable_b = b_copy; + typename T::iterator mutable_iter_begin = mutable_b.begin(); + for (int i = 0; i < values.size() / 2; ++i) ++mutable_iter_begin; + mutable_b.erase(mutable_iter_begin, mutable_b.end()); + EXPECT_EQ(mutable_b.size(), values.size() / 2); + const_b.verify(); + + // Second quarter. + mutable_b = b_copy; + mutable_iter_begin = mutable_b.begin(); + for (int i = 0; i < values.size() / 4; ++i) ++mutable_iter_begin; + mutable_iter_end = mutable_iter_begin; + for (int i = 0; i < values.size() / 4; ++i) ++mutable_iter_end; + mutable_b.erase(mutable_iter_begin, mutable_iter_end); + EXPECT_EQ(mutable_b.size(), values.size() - values.size() / 4); + const_b.verify(); + + mutable_b.clear(); +} + +template <typename T> +void ConstTest() { + using value_type = typename T::value_type; + typename KeyOfValue<typename T::key_type, value_type>::type key_of_value; + + T mutable_b; + const T &const_b = mutable_b; + + // Insert a single value into the container and test looking it up. + value_type value = Generator<value_type>(2)(2); + mutable_b.insert(value); + EXPECT_TRUE(mutable_b.contains(key_of_value(value))); + EXPECT_NE(mutable_b.find(key_of_value(value)), const_b.end()); + EXPECT_TRUE(const_b.contains(key_of_value(value))); + EXPECT_NE(const_b.find(key_of_value(value)), mutable_b.end()); + EXPECT_EQ(*const_b.lower_bound(key_of_value(value)), value); + EXPECT_EQ(const_b.upper_bound(key_of_value(value)), const_b.end()); + EXPECT_EQ(*const_b.equal_range(key_of_value(value)).first, value); + + // We can only create a non-const iterator from a non-const container. + typename T::iterator mutable_iter(mutable_b.begin()); + EXPECT_EQ(mutable_iter, const_b.begin()); + EXPECT_NE(mutable_iter, const_b.end()); + EXPECT_EQ(const_b.begin(), mutable_iter); + EXPECT_NE(const_b.end(), mutable_iter); + typename T::reverse_iterator mutable_riter(mutable_b.rbegin()); + EXPECT_EQ(mutable_riter, const_b.rbegin()); + EXPECT_NE(mutable_riter, const_b.rend()); + EXPECT_EQ(const_b.rbegin(), mutable_riter); + EXPECT_NE(const_b.rend(), mutable_riter); + + // We can create a const iterator from a non-const iterator. + typename T::const_iterator const_iter(mutable_iter); + EXPECT_EQ(const_iter, mutable_b.begin()); + EXPECT_NE(const_iter, mutable_b.end()); + EXPECT_EQ(mutable_b.begin(), const_iter); + EXPECT_NE(mutable_b.end(), const_iter); + typename T::const_reverse_iterator const_riter(mutable_riter); + EXPECT_EQ(const_riter, mutable_b.rbegin()); + EXPECT_NE(const_riter, mutable_b.rend()); + EXPECT_EQ(mutable_b.rbegin(), const_riter); + EXPECT_NE(mutable_b.rend(), const_riter); + + // Make sure various methods can be invoked on a const container. + const_b.verify(); + ASSERT_TRUE(!const_b.empty()); + EXPECT_EQ(const_b.size(), 1); + EXPECT_GT(const_b.max_size(), 0); + EXPECT_TRUE(const_b.contains(key_of_value(value))); + EXPECT_EQ(const_b.count(key_of_value(value)), 1); +} + +template <typename T, typename C> +void BtreeTest() { + ConstTest<T>(); + + using V = typename remove_pair_const<typename T::value_type>::type; + const std::vector<V> random_values = GenerateValuesWithSeed<V>( + absl::GetFlag(FLAGS_test_values), 4 * absl::GetFlag(FLAGS_test_values), + testing::GTEST_FLAG(random_seed)); + + unique_checker<T, C> container; + + // Test key insertion/deletion in sorted order. + std::vector<V> sorted_values(random_values); + std::sort(sorted_values.begin(), sorted_values.end()); + DoTest("sorted: ", &container, sorted_values); + + // Test key insertion/deletion in reverse sorted order. + std::reverse(sorted_values.begin(), sorted_values.end()); + DoTest("rsorted: ", &container, sorted_values); + + // Test key insertion/deletion in random order. + DoTest("random: ", &container, random_values); +} + +template <typename T, typename C> +void BtreeMultiTest() { + ConstTest<T>(); + + using V = typename remove_pair_const<typename T::value_type>::type; + const std::vector<V> random_values = GenerateValuesWithSeed<V>( + absl::GetFlag(FLAGS_test_values), 4 * absl::GetFlag(FLAGS_test_values), + testing::GTEST_FLAG(random_seed)); + + multi_checker<T, C> container; + + // Test keys in sorted order. + std::vector<V> sorted_values(random_values); + std::sort(sorted_values.begin(), sorted_values.end()); + DoTest("sorted: ", &container, sorted_values); + + // Test keys in reverse sorted order. + std::reverse(sorted_values.begin(), sorted_values.end()); + DoTest("rsorted: ", &container, sorted_values); + + // Test keys in random order. + DoTest("random: ", &container, random_values); + + // Test keys in random order w/ duplicates. + std::vector<V> duplicate_values(random_values); + duplicate_values.insert(duplicate_values.end(), random_values.begin(), + random_values.end()); + DoTest("duplicates:", &container, duplicate_values); + + // Test all identical keys. + std::vector<V> identical_values(100); + std::fill(identical_values.begin(), identical_values.end(), + Generator<V>(2)(2)); + DoTest("identical: ", &container, identical_values); +} + +template <typename T> +struct PropagatingCountingAlloc : public CountingAllocator<T> { + using propagate_on_container_copy_assignment = std::true_type; + using propagate_on_container_move_assignment = std::true_type; + using propagate_on_container_swap = std::true_type; + + using Base = CountingAllocator<T>; + using Base::Base; + + template <typename U> + explicit PropagatingCountingAlloc(const PropagatingCountingAlloc<U> &other) + : Base(other.bytes_used_) {} + + template <typename U> + struct rebind { + using other = PropagatingCountingAlloc<U>; + }; +}; + +template <typename T> +void BtreeAllocatorTest() { + using value_type = typename T::value_type; + + int64_t bytes1 = 0, bytes2 = 0; + PropagatingCountingAlloc<T> allocator1(&bytes1); + PropagatingCountingAlloc<T> allocator2(&bytes2); + Generator<value_type> generator(1000); + + // Test that we allocate properly aligned memory. If we don't, then Layout + // will assert fail. + auto unused1 = allocator1.allocate(1); + auto unused2 = allocator2.allocate(1); + + // Test copy assignment + { + T b1(typename T::key_compare(), allocator1); + T b2(typename T::key_compare(), allocator2); + + int64_t original_bytes1 = bytes1; + b1.insert(generator(0)); + EXPECT_GT(bytes1, original_bytes1); + + // This should propagate the allocator. + b1 = b2; + EXPECT_EQ(b1.size(), 0); + EXPECT_EQ(b2.size(), 0); + EXPECT_EQ(bytes1, original_bytes1); + + for (int i = 1; i < 1000; i++) { + b1.insert(generator(i)); + } + + // We should have allocated out of allocator2. + EXPECT_GT(bytes2, bytes1); + } + + // Test move assignment + { + T b1(typename T::key_compare(), allocator1); + T b2(typename T::key_compare(), allocator2); + + int64_t original_bytes1 = bytes1; + b1.insert(generator(0)); + EXPECT_GT(bytes1, original_bytes1); + + // This should propagate the allocator. + b1 = std::move(b2); + EXPECT_EQ(b1.size(), 0); + EXPECT_EQ(bytes1, original_bytes1); + + for (int i = 1; i < 1000; i++) { + b1.insert(generator(i)); + } + + // We should have allocated out of allocator2. + EXPECT_GT(bytes2, bytes1); + } + + // Test swap + { + T b1(typename T::key_compare(), allocator1); + T b2(typename T::key_compare(), allocator2); + + int64_t original_bytes1 = bytes1; + b1.insert(generator(0)); + EXPECT_GT(bytes1, original_bytes1); + + // This should swap the allocators. + swap(b1, b2); + EXPECT_EQ(b1.size(), 0); + EXPECT_EQ(b2.size(), 1); + EXPECT_GT(bytes1, original_bytes1); + + for (int i = 1; i < 1000; i++) { + b1.insert(generator(i)); + } + + // We should have allocated out of allocator2. + EXPECT_GT(bytes2, bytes1); + } + + allocator1.deallocate(unused1, 1); + allocator2.deallocate(unused2, 1); +} + +template <typename T> +void BtreeMapTest() { + using value_type = typename T::value_type; + using mapped_type = typename T::mapped_type; + + mapped_type m = Generator<mapped_type>(0)(0); + (void)m; + + T b; + + // Verify we can insert using operator[]. + for (int i = 0; i < 1000; i++) { + value_type v = Generator<value_type>(1000)(i); + b[v.first] = v.second; + } + EXPECT_EQ(b.size(), 1000); + + // Test whether we can use the "->" operator on iterators and + // reverse_iterators. This stresses the btree_map_params::pair_pointer + // mechanism. + EXPECT_EQ(b.begin()->first, Generator<value_type>(1000)(0).first); + EXPECT_EQ(b.begin()->second, Generator<value_type>(1000)(0).second); + EXPECT_EQ(b.rbegin()->first, Generator<value_type>(1000)(999).first); + EXPECT_EQ(b.rbegin()->second, Generator<value_type>(1000)(999).second); +} + +template <typename T> +void BtreeMultiMapTest() { + using mapped_type = typename T::mapped_type; + mapped_type m = Generator<mapped_type>(0)(0); + (void)m; +} + +template <typename K, int N = 256> +void SetTest() { + EXPECT_EQ( + sizeof(absl::btree_set<K>), + 2 * sizeof(void *) + sizeof(typename absl::btree_set<K>::size_type)); + using BtreeSet = absl::btree_set<K>; + using CountingBtreeSet = + absl::btree_set<K, std::less<K>, PropagatingCountingAlloc<K>>; + BtreeTest<BtreeSet, std::set<K>>(); + BtreeAllocatorTest<CountingBtreeSet>(); +} + +template <typename K, int N = 256> +void MapTest() { + EXPECT_EQ( + sizeof(absl::btree_map<K, K>), + 2 * sizeof(void *) + sizeof(typename absl::btree_map<K, K>::size_type)); + using BtreeMap = absl::btree_map<K, K>; + using CountingBtreeMap = + absl::btree_map<K, K, std::less<K>, + PropagatingCountingAlloc<std::pair<const K, K>>>; + BtreeTest<BtreeMap, std::map<K, K>>(); + BtreeAllocatorTest<CountingBtreeMap>(); + BtreeMapTest<BtreeMap>(); +} + +TEST(Btree, set_int32) { SetTest<int32_t>(); } +TEST(Btree, set_int64) { SetTest<int64_t>(); } +TEST(Btree, set_string) { SetTest<std::string>(); } +TEST(Btree, set_cord) { SetTest<absl::Cord>(); } +TEST(Btree, set_pair) { SetTest<std::pair<int, int>>(); } +TEST(Btree, map_int32) { MapTest<int32_t>(); } +TEST(Btree, map_int64) { MapTest<int64_t>(); } +TEST(Btree, map_string) { MapTest<std::string>(); } +TEST(Btree, map_cord) { MapTest<absl::Cord>(); } +TEST(Btree, map_pair) { MapTest<std::pair<int, int>>(); } + +template <typename K, int N = 256> +void MultiSetTest() { + EXPECT_EQ( + sizeof(absl::btree_multiset<K>), + 2 * sizeof(void *) + sizeof(typename absl::btree_multiset<K>::size_type)); + using BtreeMSet = absl::btree_multiset<K>; + using CountingBtreeMSet = + absl::btree_multiset<K, std::less<K>, PropagatingCountingAlloc<K>>; + BtreeMultiTest<BtreeMSet, std::multiset<K>>(); + BtreeAllocatorTest<CountingBtreeMSet>(); +} + +template <typename K, int N = 256> +void MultiMapTest() { + EXPECT_EQ(sizeof(absl::btree_multimap<K, K>), + 2 * sizeof(void *) + + sizeof(typename absl::btree_multimap<K, K>::size_type)); + using BtreeMMap = absl::btree_multimap<K, K>; + using CountingBtreeMMap = + absl::btree_multimap<K, K, std::less<K>, + PropagatingCountingAlloc<std::pair<const K, K>>>; + BtreeMultiTest<BtreeMMap, std::multimap<K, K>>(); + BtreeMultiMapTest<BtreeMMap>(); + BtreeAllocatorTest<CountingBtreeMMap>(); +} + +TEST(Btree, multiset_int32) { MultiSetTest<int32_t>(); } +TEST(Btree, multiset_int64) { MultiSetTest<int64_t>(); } +TEST(Btree, multiset_string) { MultiSetTest<std::string>(); } +TEST(Btree, multiset_cord) { MultiSetTest<absl::Cord>(); } +TEST(Btree, multiset_pair) { MultiSetTest<std::pair<int, int>>(); } +TEST(Btree, multimap_int32) { MultiMapTest<int32_t>(); } +TEST(Btree, multimap_int64) { MultiMapTest<int64_t>(); } +TEST(Btree, multimap_string) { MultiMapTest<std::string>(); } +TEST(Btree, multimap_cord) { MultiMapTest<absl::Cord>(); } +TEST(Btree, multimap_pair) { MultiMapTest<std::pair<int, int>>(); } + +struct CompareIntToString { + bool operator()(const std::string &a, const std::string &b) const { + return a < b; + } + bool operator()(const std::string &a, int b) const { + return a < absl::StrCat(b); + } + bool operator()(int a, const std::string &b) const { + return absl::StrCat(a) < b; + } + using is_transparent = void; +}; + +struct NonTransparentCompare { + template <typename T, typename U> + bool operator()(const T &t, const U &u) const { + // Treating all comparators as transparent can cause inefficiencies (see + // N3657 C++ proposal). Test that for comparators without 'is_transparent' + // alias (like this one), we do not attempt heterogeneous lookup. + EXPECT_TRUE((std::is_same<T, U>())); + return t < u; + } +}; + +template <typename T> +bool CanEraseWithEmptyBrace(T t, decltype(t.erase({})) *) { + return true; +} + +template <typename T> +bool CanEraseWithEmptyBrace(T, ...) { + return false; +} + +template <typename T> +void TestHeterogeneous(T table) { + auto lb = table.lower_bound("3"); + EXPECT_EQ(lb, table.lower_bound(3)); + EXPECT_NE(lb, table.lower_bound(4)); + EXPECT_EQ(lb, table.lower_bound({"3"})); + EXPECT_NE(lb, table.lower_bound({})); + + auto ub = table.upper_bound("3"); + EXPECT_EQ(ub, table.upper_bound(3)); + EXPECT_NE(ub, table.upper_bound(5)); + EXPECT_EQ(ub, table.upper_bound({"3"})); + EXPECT_NE(ub, table.upper_bound({})); + + auto er = table.equal_range("3"); + EXPECT_EQ(er, table.equal_range(3)); + EXPECT_NE(er, table.equal_range(4)); + EXPECT_EQ(er, table.equal_range({"3"})); + EXPECT_NE(er, table.equal_range({})); + + auto it = table.find("3"); + EXPECT_EQ(it, table.find(3)); + EXPECT_NE(it, table.find(4)); + EXPECT_EQ(it, table.find({"3"})); + EXPECT_NE(it, table.find({})); + + EXPECT_TRUE(table.contains(3)); + EXPECT_FALSE(table.contains(4)); + EXPECT_TRUE(table.count({"3"})); + EXPECT_FALSE(table.contains({})); + + EXPECT_EQ(1, table.count(3)); + EXPECT_EQ(0, table.count(4)); + EXPECT_EQ(1, table.count({"3"})); + EXPECT_EQ(0, table.count({})); + + auto copy = table; + copy.erase(3); + EXPECT_EQ(table.size() - 1, copy.size()); + copy.erase(4); + EXPECT_EQ(table.size() - 1, copy.size()); + copy.erase({"5"}); + EXPECT_EQ(table.size() - 2, copy.size()); + EXPECT_FALSE(CanEraseWithEmptyBrace(table, nullptr)); + + // Also run it with const T&. + if (std::is_class<T>()) TestHeterogeneous<const T &>(table); +} + +TEST(Btree, HeterogeneousLookup) { + TestHeterogeneous(btree_set<std::string, CompareIntToString>{"1", "3", "5"}); + TestHeterogeneous(btree_map<std::string, int, CompareIntToString>{ + {"1", 1}, {"3", 3}, {"5", 5}}); + TestHeterogeneous( + btree_multiset<std::string, CompareIntToString>{"1", "3", "5"}); + TestHeterogeneous(btree_multimap<std::string, int, CompareIntToString>{ + {"1", 1}, {"3", 3}, {"5", 5}}); + + // Only maps have .at() + btree_map<std::string, int, CompareIntToString> map{ + {"", -1}, {"1", 1}, {"3", 3}, {"5", 5}}; + EXPECT_EQ(1, map.at(1)); + EXPECT_EQ(3, map.at({"3"})); + EXPECT_EQ(-1, map.at({})); + const auto &cmap = map; + EXPECT_EQ(1, cmap.at(1)); + EXPECT_EQ(3, cmap.at({"3"})); + EXPECT_EQ(-1, cmap.at({})); +} + +TEST(Btree, NoHeterogeneousLookupWithoutAlias) { + using StringSet = absl::btree_set<std::string, NonTransparentCompare>; + StringSet s; + ASSERT_TRUE(s.insert("hello").second); + ASSERT_TRUE(s.insert("world").second); + EXPECT_TRUE(s.end() == s.find("blah")); + EXPECT_TRUE(s.begin() == s.lower_bound("hello")); + EXPECT_EQ(1, s.count("world")); + EXPECT_TRUE(s.contains("hello")); + EXPECT_TRUE(s.contains("world")); + EXPECT_FALSE(s.contains("blah")); + + using StringMultiSet = + absl::btree_multiset<std::string, NonTransparentCompare>; + StringMultiSet ms; + ms.insert("hello"); + ms.insert("world"); + ms.insert("world"); + EXPECT_TRUE(ms.end() == ms.find("blah")); + EXPECT_TRUE(ms.begin() == ms.lower_bound("hello")); + EXPECT_EQ(2, ms.count("world")); + EXPECT_TRUE(ms.contains("hello")); + EXPECT_TRUE(ms.contains("world")); + EXPECT_FALSE(ms.contains("blah")); +} + +TEST(Btree, DefaultTransparent) { + { + // `int` does not have a default transparent comparator. + // The input value is converted to key_type. + btree_set<int> s = {1}; + double d = 1.1; + EXPECT_EQ(s.begin(), s.find(d)); + EXPECT_TRUE(s.contains(d)); + } + + { + // `std::string` has heterogeneous support. + btree_set<std::string> s = {"A"}; + EXPECT_EQ(s.begin(), s.find(absl::string_view("A"))); + EXPECT_TRUE(s.contains(absl::string_view("A"))); + } +} + +class StringLike { + public: + StringLike() = default; + + StringLike(const char *s) : s_(s) { // NOLINT + ++constructor_calls_; + } + + bool operator<(const StringLike &a) const { return s_ < a.s_; } + + static void clear_constructor_call_count() { constructor_calls_ = 0; } + + static int constructor_calls() { return constructor_calls_; } + + private: + static int constructor_calls_; + std::string s_; +}; + +int StringLike::constructor_calls_ = 0; + +TEST(Btree, HeterogeneousLookupDoesntDegradePerformance) { + using StringSet = absl::btree_set<StringLike>; + StringSet s; + for (int i = 0; i < 100; ++i) { + ASSERT_TRUE(s.insert(absl::StrCat(i).c_str()).second); + } + StringLike::clear_constructor_call_count(); + s.find("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); + + StringLike::clear_constructor_call_count(); + s.contains("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); + + StringLike::clear_constructor_call_count(); + s.count("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); + + StringLike::clear_constructor_call_count(); + s.lower_bound("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); + + StringLike::clear_constructor_call_count(); + s.upper_bound("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); + + StringLike::clear_constructor_call_count(); + s.equal_range("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); + + StringLike::clear_constructor_call_count(); + s.erase("50"); + ASSERT_EQ(1, StringLike::constructor_calls()); +} + +// Verify that swapping btrees swaps the key comparison functors and that we can +// use non-default constructible comparators. +struct SubstringLess { + SubstringLess() = delete; + explicit SubstringLess(int length) : n(length) {} + bool operator()(const std::string &a, const std::string &b) const { + return absl::string_view(a).substr(0, n) < + absl::string_view(b).substr(0, n); + } + int n; +}; + +TEST(Btree, SwapKeyCompare) { + using SubstringSet = absl::btree_set<std::string, SubstringLess>; + SubstringSet s1(SubstringLess(1), SubstringSet::allocator_type()); + SubstringSet s2(SubstringLess(2), SubstringSet::allocator_type()); + + ASSERT_TRUE(s1.insert("a").second); + ASSERT_FALSE(s1.insert("aa").second); + + ASSERT_TRUE(s2.insert("a").second); + ASSERT_TRUE(s2.insert("aa").second); + ASSERT_FALSE(s2.insert("aaa").second); + + swap(s1, s2); + + ASSERT_TRUE(s1.insert("b").second); + ASSERT_TRUE(s1.insert("bb").second); + ASSERT_FALSE(s1.insert("bbb").second); + + ASSERT_TRUE(s2.insert("b").second); + ASSERT_FALSE(s2.insert("bb").second); +} + +TEST(Btree, UpperBoundRegression) { + // Regress a bug where upper_bound would default-construct a new key_compare + // instead of copying the existing one. + using SubstringSet = absl::btree_set<std::string, SubstringLess>; + SubstringSet my_set(SubstringLess(3)); + my_set.insert("aab"); + my_set.insert("abb"); + // We call upper_bound("aaa"). If this correctly uses the length 3 + // comparator, aaa < aab < abb, so we should get aab as the result. + // If it instead uses the default-constructed length 2 comparator, + // aa == aa < ab, so we'll get abb as our result. + SubstringSet::iterator it = my_set.upper_bound("aaa"); + ASSERT_TRUE(it != my_set.end()); + EXPECT_EQ("aab", *it); +} + +TEST(Btree, Comparison) { + const int kSetSize = 1201; + absl::btree_set<int64_t> my_set; + for (int i = 0; i < kSetSize; ++i) { + my_set.insert(i); + } + absl::btree_set<int64_t> my_set_copy(my_set); + EXPECT_TRUE(my_set_copy == my_set); + EXPECT_TRUE(my_set == my_set_copy); + EXPECT_FALSE(my_set_copy != my_set); + EXPECT_FALSE(my_set != my_set_copy); + + my_set.insert(kSetSize); + EXPECT_FALSE(my_set_copy == my_set); + EXPECT_FALSE(my_set == my_set_copy); + EXPECT_TRUE(my_set_copy != my_set); + EXPECT_TRUE(my_set != my_set_copy); + + my_set.erase(kSetSize - 1); + EXPECT_FALSE(my_set_copy == my_set); + EXPECT_FALSE(my_set == my_set_copy); + EXPECT_TRUE(my_set_copy != my_set); + EXPECT_TRUE(my_set != my_set_copy); + + absl::btree_map<std::string, int64_t> my_map; + for (int i = 0; i < kSetSize; ++i) { + my_map[std::string(i, 'a')] = i; + } + absl::btree_map<std::string, int64_t> my_map_copy(my_map); + EXPECT_TRUE(my_map_copy == my_map); + EXPECT_TRUE(my_map == my_map_copy); + EXPECT_FALSE(my_map_copy != my_map); + EXPECT_FALSE(my_map != my_map_copy); + + ++my_map_copy[std::string(7, 'a')]; + EXPECT_FALSE(my_map_copy == my_map); + EXPECT_FALSE(my_map == my_map_copy); + EXPECT_TRUE(my_map_copy != my_map); + EXPECT_TRUE(my_map != my_map_copy); + + my_map_copy = my_map; + my_map["hello"] = kSetSize; + EXPECT_FALSE(my_map_copy == my_map); + EXPECT_FALSE(my_map == my_map_copy); + EXPECT_TRUE(my_map_copy != my_map); + EXPECT_TRUE(my_map != my_map_copy); + + my_map.erase(std::string(kSetSize - 1, 'a')); + EXPECT_FALSE(my_map_copy == my_map); + EXPECT_FALSE(my_map == my_map_copy); + EXPECT_TRUE(my_map_copy != my_map); + EXPECT_TRUE(my_map != my_map_copy); +} + +TEST(Btree, RangeCtorSanity) { + std::vector<int> ivec; + ivec.push_back(1); + std::map<int, int> imap; + imap.insert(std::make_pair(1, 2)); + absl::btree_multiset<int> tmset(ivec.begin(), ivec.end()); + absl::btree_multimap<int, int> tmmap(imap.begin(), imap.end()); + absl::btree_set<int> tset(ivec.begin(), ivec.end()); + absl::btree_map<int, int> tmap(imap.begin(), imap.end()); + EXPECT_EQ(1, tmset.size()); + EXPECT_EQ(1, tmmap.size()); + EXPECT_EQ(1, tset.size()); + EXPECT_EQ(1, tmap.size()); +} + +TEST(Btree, BtreeMapCanHoldMoveOnlyTypes) { + absl::btree_map<std::string, std::unique_ptr<std::string>> m; + + std::unique_ptr<std::string> &v = m["A"]; + EXPECT_TRUE(v == nullptr); + v.reset(new std::string("X")); + + auto iter = m.find("A"); + EXPECT_EQ("X", *iter->second); +} + +TEST(Btree, InitializerListConstructor) { + absl::btree_set<std::string> set({"a", "b"}); + EXPECT_EQ(set.count("a"), 1); + EXPECT_EQ(set.count("b"), 1); + + absl::btree_multiset<int> mset({1, 1, 4}); + EXPECT_EQ(mset.count(1), 2); + EXPECT_EQ(mset.count(4), 1); + + absl::btree_map<int, int> map({{1, 5}, {2, 10}}); + EXPECT_EQ(map[1], 5); + EXPECT_EQ(map[2], 10); + + absl::btree_multimap<int, int> mmap({{1, 5}, {1, 10}}); + auto range = mmap.equal_range(1); + auto it = range.first; + ASSERT_NE(it, range.second); + EXPECT_EQ(it->second, 5); + ASSERT_NE(++it, range.second); + EXPECT_EQ(it->second, 10); + EXPECT_EQ(++it, range.second); +} + +TEST(Btree, InitializerListInsert) { + absl::btree_set<std::string> set; + set.insert({"a", "b"}); + EXPECT_EQ(set.count("a"), 1); + EXPECT_EQ(set.count("b"), 1); + + absl::btree_multiset<int> mset; + mset.insert({1, 1, 4}); + EXPECT_EQ(mset.count(1), 2); + EXPECT_EQ(mset.count(4), 1); + + absl::btree_map<int, int> map; + map.insert({{1, 5}, {2, 10}}); + // Test that inserting one element using an initializer list also works. + map.insert({3, 15}); + EXPECT_EQ(map[1], 5); + EXPECT_EQ(map[2], 10); + EXPECT_EQ(map[3], 15); + + absl::btree_multimap<int, int> mmap; + mmap.insert({{1, 5}, {1, 10}}); + auto range = mmap.equal_range(1); + auto it = range.first; + ASSERT_NE(it, range.second); + EXPECT_EQ(it->second, 5); + ASSERT_NE(++it, range.second); + EXPECT_EQ(it->second, 10); + EXPECT_EQ(++it, range.second); +} + +template <typename Compare, typename K> +void AssertKeyCompareToAdapted() { + using Adapted = typename key_compare_to_adapter<Compare>::type; + static_assert(!std::is_same<Adapted, Compare>::value, + "key_compare_to_adapter should have adapted this comparator."); + static_assert( + std::is_same<absl::weak_ordering, + absl::result_of_t<Adapted(const K &, const K &)>>::value, + "Adapted comparator should be a key-compare-to comparator."); +} +template <typename Compare, typename K> +void AssertKeyCompareToNotAdapted() { + using Unadapted = typename key_compare_to_adapter<Compare>::type; + static_assert( + std::is_same<Unadapted, Compare>::value, + "key_compare_to_adapter shouldn't have adapted this comparator."); + static_assert( + std::is_same<bool, + absl::result_of_t<Unadapted(const K &, const K &)>>::value, + "Un-adapted comparator should return bool."); +} + +TEST(Btree, KeyCompareToAdapter) { + AssertKeyCompareToAdapted<std::less<std::string>, std::string>(); + AssertKeyCompareToAdapted<std::greater<std::string>, std::string>(); + AssertKeyCompareToAdapted<std::less<absl::string_view>, absl::string_view>(); + AssertKeyCompareToAdapted<std::greater<absl::string_view>, + absl::string_view>(); + AssertKeyCompareToAdapted<std::less<absl::Cord>, absl::Cord>(); + AssertKeyCompareToAdapted<std::greater<absl::Cord>, absl::Cord>(); + AssertKeyCompareToNotAdapted<std::less<int>, int>(); + AssertKeyCompareToNotAdapted<std::greater<int>, int>(); +} + +TEST(Btree, RValueInsert) { + InstanceTracker tracker; + + absl::btree_set<MovableOnlyInstance> set; + set.insert(MovableOnlyInstance(1)); + set.insert(MovableOnlyInstance(3)); + MovableOnlyInstance two(2); + set.insert(set.find(MovableOnlyInstance(3)), std::move(two)); + auto it = set.find(MovableOnlyInstance(2)); + ASSERT_NE(it, set.end()); + ASSERT_NE(++it, set.end()); + EXPECT_EQ(it->value(), 3); + + absl::btree_multiset<MovableOnlyInstance> mset; + MovableOnlyInstance zero(0); + MovableOnlyInstance zero2(0); + mset.insert(std::move(zero)); + mset.insert(mset.find(MovableOnlyInstance(0)), std::move(zero2)); + EXPECT_EQ(mset.count(MovableOnlyInstance(0)), 2); + + absl::btree_map<int, MovableOnlyInstance> map; + std::pair<const int, MovableOnlyInstance> p1 = {1, MovableOnlyInstance(5)}; + std::pair<const int, MovableOnlyInstance> p2 = {2, MovableOnlyInstance(10)}; + std::pair<const int, MovableOnlyInstance> p3 = {3, MovableOnlyInstance(15)}; + map.insert(std::move(p1)); + map.insert(std::move(p3)); + map.insert(map.find(3), std::move(p2)); + ASSERT_NE(map.find(2), map.end()); + EXPECT_EQ(map.find(2)->second.value(), 10); + + absl::btree_multimap<int, MovableOnlyInstance> mmap; + std::pair<const int, MovableOnlyInstance> p4 = {1, MovableOnlyInstance(5)}; + std::pair<const int, MovableOnlyInstance> p5 = {1, MovableOnlyInstance(10)}; + mmap.insert(std::move(p4)); + mmap.insert(mmap.find(1), std::move(p5)); + auto range = mmap.equal_range(1); + auto it1 = range.first; + ASSERT_NE(it1, range.second); + EXPECT_EQ(it1->second.value(), 10); + ASSERT_NE(++it1, range.second); + EXPECT_EQ(it1->second.value(), 5); + EXPECT_EQ(++it1, range.second); + + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.swaps(), 0); +} + +} // namespace + +class BtreeNodePeer { + public: + // Yields the size of a leaf node with a specific number of values. + template <typename ValueType> + constexpr static size_t GetTargetNodeSize(size_t target_values_per_node) { + return btree_node< + set_params<ValueType, std::less<ValueType>, std::allocator<ValueType>, + /*TargetNodeSize=*/256, // This parameter isn't used here. + /*Multi=*/false>>::SizeWithNValues(target_values_per_node); + } + + // Yields the number of values in a (non-root) leaf node for this set. + template <typename Set> + constexpr static size_t GetNumValuesPerNode() { + return btree_node<typename Set::params_type>::kNodeValues; + } +}; + +namespace { + +// A btree set with a specific number of values per node. +template <typename Key, int TargetValuesPerNode, typename Cmp = std::less<Key>> +class SizedBtreeSet + : public btree_set_container<btree< + set_params<Key, Cmp, std::allocator<Key>, + BtreeNodePeer::GetTargetNodeSize<Key>(TargetValuesPerNode), + /*Multi=*/false>>> { + using Base = typename SizedBtreeSet::btree_set_container; + + public: + SizedBtreeSet() {} + using Base::Base; +}; + +template <typename Set> +void ExpectOperationCounts(const int expected_moves, + const int expected_comparisons, + const std::vector<int> &values, + InstanceTracker *tracker, Set *set) { + for (const int v : values) set->insert(MovableOnlyInstance(v)); + set->clear(); + EXPECT_EQ(tracker->moves(), expected_moves); + EXPECT_EQ(tracker->comparisons(), expected_comparisons); + EXPECT_EQ(tracker->copies(), 0); + EXPECT_EQ(tracker->swaps(), 0); + tracker->ResetCopiesMovesSwaps(); +} + +// Note: when the values in this test change, it is expected to have an impact +// on performance. +TEST(Btree, MovesComparisonsCopiesSwapsTracking) { + InstanceTracker tracker; + // Note: this is minimum number of values per node. + SizedBtreeSet<MovableOnlyInstance, /*TargetValuesPerNode=*/3> set3; + // Note: this is the default number of values per node for a set of int32s + // (with 64-bit pointers). + SizedBtreeSet<MovableOnlyInstance, /*TargetValuesPerNode=*/61> set61; + SizedBtreeSet<MovableOnlyInstance, /*TargetValuesPerNode=*/100> set100; + + // Don't depend on flags for random values because then the expectations will + // fail if the flags change. + std::vector<int> values = + GenerateValuesWithSeed<int>(10000, 1 << 22, /*seed=*/23); + + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<decltype(set3)>(), 3); + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<decltype(set61)>(), 61); + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<decltype(set100)>(), 100); + if (sizeof(void *) == 8) { + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<absl::btree_set<int32_t>>(), + BtreeNodePeer::GetNumValuesPerNode<decltype(set61)>()); + } + + // Test key insertion/deletion in random order. + ExpectOperationCounts(45281, 132551, values, &tracker, &set3); + ExpectOperationCounts(386718, 129807, values, &tracker, &set61); + ExpectOperationCounts(586761, 130310, values, &tracker, &set100); + + // Test key insertion/deletion in sorted order. + std::sort(values.begin(), values.end()); + ExpectOperationCounts(26638, 92134, values, &tracker, &set3); + ExpectOperationCounts(20208, 87757, values, &tracker, &set61); + ExpectOperationCounts(20124, 96583, values, &tracker, &set100); + + // Test key insertion/deletion in reverse sorted order. + std::reverse(values.begin(), values.end()); + ExpectOperationCounts(49951, 119325, values, &tracker, &set3); + ExpectOperationCounts(338813, 118266, values, &tracker, &set61); + ExpectOperationCounts(534529, 125279, values, &tracker, &set100); +} + +struct MovableOnlyInstanceThreeWayCompare { + absl::weak_ordering operator()(const MovableOnlyInstance &a, + const MovableOnlyInstance &b) const { + return a.compare(b); + } +}; + +// Note: when the values in this test change, it is expected to have an impact +// on performance. +TEST(Btree, MovesComparisonsCopiesSwapsTrackingThreeWayCompare) { + InstanceTracker tracker; + // Note: this is minimum number of values per node. + SizedBtreeSet<MovableOnlyInstance, /*TargetValuesPerNode=*/3, + MovableOnlyInstanceThreeWayCompare> + set3; + // Note: this is the default number of values per node for a set of int32s + // (with 64-bit pointers). + SizedBtreeSet<MovableOnlyInstance, /*TargetValuesPerNode=*/61, + MovableOnlyInstanceThreeWayCompare> + set61; + SizedBtreeSet<MovableOnlyInstance, /*TargetValuesPerNode=*/100, + MovableOnlyInstanceThreeWayCompare> + set100; + + // Don't depend on flags for random values because then the expectations will + // fail if the flags change. + std::vector<int> values = + GenerateValuesWithSeed<int>(10000, 1 << 22, /*seed=*/23); + + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<decltype(set3)>(), 3); + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<decltype(set61)>(), 61); + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<decltype(set100)>(), 100); + if (sizeof(void *) == 8) { + EXPECT_EQ(BtreeNodePeer::GetNumValuesPerNode<absl::btree_set<int32_t>>(), + BtreeNodePeer::GetNumValuesPerNode<decltype(set61)>()); + } + + // Test key insertion/deletion in random order. + ExpectOperationCounts(45281, 122560, values, &tracker, &set3); + ExpectOperationCounts(386718, 119816, values, &tracker, &set61); + ExpectOperationCounts(586761, 120319, values, &tracker, &set100); + + // Test key insertion/deletion in sorted order. + std::sort(values.begin(), values.end()); + ExpectOperationCounts(26638, 92134, values, &tracker, &set3); + ExpectOperationCounts(20208, 87757, values, &tracker, &set61); + ExpectOperationCounts(20124, 96583, values, &tracker, &set100); + + // Test key insertion/deletion in reverse sorted order. + std::reverse(values.begin(), values.end()); + ExpectOperationCounts(49951, 109326, values, &tracker, &set3); + ExpectOperationCounts(338813, 108267, values, &tracker, &set61); + ExpectOperationCounts(534529, 115280, values, &tracker, &set100); +} + +struct NoDefaultCtor { + int num; + explicit NoDefaultCtor(int i) : num(i) {} + + friend bool operator<(const NoDefaultCtor &a, const NoDefaultCtor &b) { + return a.num < b.num; + } +}; + +TEST(Btree, BtreeMapCanHoldNoDefaultCtorTypes) { + absl::btree_map<NoDefaultCtor, NoDefaultCtor> m; + + for (int i = 1; i <= 99; ++i) { + SCOPED_TRACE(i); + EXPECT_TRUE(m.emplace(NoDefaultCtor(i), NoDefaultCtor(100 - i)).second); + } + EXPECT_FALSE(m.emplace(NoDefaultCtor(78), NoDefaultCtor(0)).second); + + auto iter99 = m.find(NoDefaultCtor(99)); + ASSERT_NE(iter99, m.end()); + EXPECT_EQ(iter99->second.num, 1); + + auto iter1 = m.find(NoDefaultCtor(1)); + ASSERT_NE(iter1, m.end()); + EXPECT_EQ(iter1->second.num, 99); + + auto iter50 = m.find(NoDefaultCtor(50)); + ASSERT_NE(iter50, m.end()); + EXPECT_EQ(iter50->second.num, 50); + + auto iter25 = m.find(NoDefaultCtor(25)); + ASSERT_NE(iter25, m.end()); + EXPECT_EQ(iter25->second.num, 75); +} + +TEST(Btree, BtreeMultimapCanHoldNoDefaultCtorTypes) { + absl::btree_multimap<NoDefaultCtor, NoDefaultCtor> m; + + for (int i = 1; i <= 99; ++i) { + SCOPED_TRACE(i); + m.emplace(NoDefaultCtor(i), NoDefaultCtor(100 - i)); + } + + auto iter99 = m.find(NoDefaultCtor(99)); + ASSERT_NE(iter99, m.end()); + EXPECT_EQ(iter99->second.num, 1); + + auto iter1 = m.find(NoDefaultCtor(1)); + ASSERT_NE(iter1, m.end()); + EXPECT_EQ(iter1->second.num, 99); + + auto iter50 = m.find(NoDefaultCtor(50)); + ASSERT_NE(iter50, m.end()); + EXPECT_EQ(iter50->second.num, 50); + + auto iter25 = m.find(NoDefaultCtor(25)); + ASSERT_NE(iter25, m.end()); + EXPECT_EQ(iter25->second.num, 75); +} + +TEST(Btree, MapAt) { + absl::btree_map<int, int> map = {{1, 2}, {2, 4}}; + EXPECT_EQ(map.at(1), 2); + EXPECT_EQ(map.at(2), 4); + map.at(2) = 8; + const absl::btree_map<int, int> &const_map = map; + EXPECT_EQ(const_map.at(1), 2); + EXPECT_EQ(const_map.at(2), 8); +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW(map.at(3), std::out_of_range); +#else + EXPECT_DEATH_IF_SUPPORTED(map.at(3), "absl::btree_map::at"); +#endif +} + +TEST(Btree, BtreeMultisetEmplace) { + const int value_to_insert = 123456; + absl::btree_multiset<int> s; + auto iter = s.emplace(value_to_insert); + ASSERT_NE(iter, s.end()); + EXPECT_EQ(*iter, value_to_insert); + auto iter2 = s.emplace(value_to_insert); + EXPECT_NE(iter2, iter); + ASSERT_NE(iter2, s.end()); + EXPECT_EQ(*iter2, value_to_insert); + auto result = s.equal_range(value_to_insert); + EXPECT_EQ(std::distance(result.first, result.second), 2); +} + +TEST(Btree, BtreeMultisetEmplaceHint) { + const int value_to_insert = 123456; + absl::btree_multiset<int> s; + auto iter = s.emplace(value_to_insert); + ASSERT_NE(iter, s.end()); + EXPECT_EQ(*iter, value_to_insert); + auto emplace_iter = s.emplace_hint(iter, value_to_insert); + EXPECT_NE(emplace_iter, iter); + ASSERT_NE(emplace_iter, s.end()); + EXPECT_EQ(*emplace_iter, value_to_insert); +} + +TEST(Btree, BtreeMultimapEmplace) { + const int key_to_insert = 123456; + const char value0[] = "a"; + absl::btree_multimap<int, std::string> s; + auto iter = s.emplace(key_to_insert, value0); + ASSERT_NE(iter, s.end()); + EXPECT_EQ(iter->first, key_to_insert); + EXPECT_EQ(iter->second, value0); + const char value1[] = "b"; + auto iter2 = s.emplace(key_to_insert, value1); + EXPECT_NE(iter2, iter); + ASSERT_NE(iter2, s.end()); + EXPECT_EQ(iter2->first, key_to_insert); + EXPECT_EQ(iter2->second, value1); + auto result = s.equal_range(key_to_insert); + EXPECT_EQ(std::distance(result.first, result.second), 2); +} + +TEST(Btree, BtreeMultimapEmplaceHint) { + const int key_to_insert = 123456; + const char value0[] = "a"; + absl::btree_multimap<int, std::string> s; + auto iter = s.emplace(key_to_insert, value0); + ASSERT_NE(iter, s.end()); + EXPECT_EQ(iter->first, key_to_insert); + EXPECT_EQ(iter->second, value0); + const char value1[] = "b"; + auto emplace_iter = s.emplace_hint(iter, key_to_insert, value1); + EXPECT_NE(emplace_iter, iter); + ASSERT_NE(emplace_iter, s.end()); + EXPECT_EQ(emplace_iter->first, key_to_insert); + EXPECT_EQ(emplace_iter->second, value1); +} + +TEST(Btree, ConstIteratorAccessors) { + absl::btree_set<int> set; + for (int i = 0; i < 100; ++i) { + set.insert(i); + } + + auto it = set.cbegin(); + auto r_it = set.crbegin(); + for (int i = 0; i < 100; ++i, ++it, ++r_it) { + ASSERT_EQ(*it, i); + ASSERT_EQ(*r_it, 99 - i); + } + EXPECT_EQ(it, set.cend()); + EXPECT_EQ(r_it, set.crend()); +} + +TEST(Btree, StrSplitCompatible) { + const absl::btree_set<std::string> split_set = absl::StrSplit("a,b,c", ','); + const absl::btree_set<std::string> expected_set = {"a", "b", "c"}; + + EXPECT_EQ(split_set, expected_set); +} + +// We can't use EXPECT_EQ/etc. to compare absl::weak_ordering because they +// convert literal 0 to int and absl::weak_ordering can only be compared with +// literal 0. Defining this function allows for avoiding ClangTidy warnings. +bool Identity(const bool b) { return b; } + +TEST(Btree, ValueComp) { + absl::btree_set<int> s; + EXPECT_TRUE(s.value_comp()(1, 2)); + EXPECT_FALSE(s.value_comp()(2, 2)); + EXPECT_FALSE(s.value_comp()(2, 1)); + + absl::btree_map<int, int> m1; + EXPECT_TRUE(m1.value_comp()(std::make_pair(1, 0), std::make_pair(2, 0))); + EXPECT_FALSE(m1.value_comp()(std::make_pair(2, 0), std::make_pair(2, 0))); + EXPECT_FALSE(m1.value_comp()(std::make_pair(2, 0), std::make_pair(1, 0))); + + absl::btree_map<std::string, int> m2; + EXPECT_TRUE(Identity( + m2.value_comp()(std::make_pair("a", 0), std::make_pair("b", 0)) < 0)); + EXPECT_TRUE(Identity( + m2.value_comp()(std::make_pair("b", 0), std::make_pair("b", 0)) == 0)); + EXPECT_TRUE(Identity( + m2.value_comp()(std::make_pair("b", 0), std::make_pair("a", 0)) > 0)); +} + +TEST(Btree, DefaultConstruction) { + absl::btree_set<int> s; + absl::btree_map<int, int> m; + absl::btree_multiset<int> ms; + absl::btree_multimap<int, int> mm; + + EXPECT_TRUE(s.empty()); + EXPECT_TRUE(m.empty()); + EXPECT_TRUE(ms.empty()); + EXPECT_TRUE(mm.empty()); +} + +TEST(Btree, SwissTableHashable) { + static constexpr int kValues = 10000; + std::vector<int> values(kValues); + std::iota(values.begin(), values.end(), 0); + std::vector<std::pair<int, int>> map_values; + for (int v : values) map_values.emplace_back(v, -v); + + using set = absl::btree_set<int>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly({ + set{}, + set{1}, + set{2}, + set{1, 2}, + set{2, 1}, + set(values.begin(), values.end()), + set(values.rbegin(), values.rend()), + })); + + using mset = absl::btree_multiset<int>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly({ + mset{}, + mset{1}, + mset{1, 1}, + mset{2}, + mset{2, 2}, + mset{1, 2}, + mset{1, 1, 2}, + mset{1, 2, 2}, + mset{1, 1, 2, 2}, + mset(values.begin(), values.end()), + mset(values.rbegin(), values.rend()), + })); + + using map = absl::btree_map<int, int>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly({ + map{}, + map{{1, 0}}, + map{{1, 1}}, + map{{2, 0}}, + map{{2, 2}}, + map{{1, 0}, {2, 1}}, + map(map_values.begin(), map_values.end()), + map(map_values.rbegin(), map_values.rend()), + })); + + using mmap = absl::btree_multimap<int, int>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly({ + mmap{}, + mmap{{1, 0}}, + mmap{{1, 1}}, + mmap{{1, 0}, {1, 1}}, + mmap{{1, 1}, {1, 0}}, + mmap{{2, 0}}, + mmap{{2, 2}}, + mmap{{1, 0}, {2, 1}}, + mmap(map_values.begin(), map_values.end()), + mmap(map_values.rbegin(), map_values.rend()), + })); +} + +TEST(Btree, ComparableSet) { + absl::btree_set<int> s1 = {1, 2}; + absl::btree_set<int> s2 = {2, 3}; + EXPECT_LT(s1, s2); + EXPECT_LE(s1, s2); + EXPECT_LE(s1, s1); + EXPECT_GT(s2, s1); + EXPECT_GE(s2, s1); + EXPECT_GE(s1, s1); +} + +TEST(Btree, ComparableSetsDifferentLength) { + absl::btree_set<int> s1 = {1, 2}; + absl::btree_set<int> s2 = {1, 2, 3}; + EXPECT_LT(s1, s2); + EXPECT_LE(s1, s2); + EXPECT_GT(s2, s1); + EXPECT_GE(s2, s1); +} + +TEST(Btree, ComparableMultiset) { + absl::btree_multiset<int> s1 = {1, 2}; + absl::btree_multiset<int> s2 = {2, 3}; + EXPECT_LT(s1, s2); + EXPECT_LE(s1, s2); + EXPECT_LE(s1, s1); + EXPECT_GT(s2, s1); + EXPECT_GE(s2, s1); + EXPECT_GE(s1, s1); +} + +TEST(Btree, ComparableMap) { + absl::btree_map<int, int> s1 = {{1, 2}}; + absl::btree_map<int, int> s2 = {{2, 3}}; + EXPECT_LT(s1, s2); + EXPECT_LE(s1, s2); + EXPECT_LE(s1, s1); + EXPECT_GT(s2, s1); + EXPECT_GE(s2, s1); + EXPECT_GE(s1, s1); +} + +TEST(Btree, ComparableMultimap) { + absl::btree_multimap<int, int> s1 = {{1, 2}}; + absl::btree_multimap<int, int> s2 = {{2, 3}}; + EXPECT_LT(s1, s2); + EXPECT_LE(s1, s2); + EXPECT_LE(s1, s1); + EXPECT_GT(s2, s1); + EXPECT_GE(s2, s1); + EXPECT_GE(s1, s1); +} + +TEST(Btree, ComparableSetWithCustomComparator) { + // As specified by + // http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2012/n3337.pdf section + // [container.requirements.general].12, ordering associative containers always + // uses default '<' operator + // - even if otherwise the container uses custom functor. + absl::btree_set<int, std::greater<int>> s1 = {1, 2}; + absl::btree_set<int, std::greater<int>> s2 = {2, 3}; + EXPECT_LT(s1, s2); + EXPECT_LE(s1, s2); + EXPECT_LE(s1, s1); + EXPECT_GT(s2, s1); + EXPECT_GE(s2, s1); + EXPECT_GE(s1, s1); +} + +TEST(Btree, EraseReturnsIterator) { + absl::btree_set<int> set = {1, 2, 3, 4, 5}; + auto result_it = set.erase(set.begin(), set.find(3)); + EXPECT_EQ(result_it, set.find(3)); + result_it = set.erase(set.find(5)); + EXPECT_EQ(result_it, set.end()); +} + +TEST(Btree, ExtractAndInsertNodeHandleSet) { + absl::btree_set<int> src1 = {1, 2, 3, 4, 5}; + auto nh = src1.extract(src1.find(3)); + EXPECT_THAT(src1, ElementsAre(1, 2, 4, 5)); + absl::btree_set<int> other; + absl::btree_set<int>::insert_return_type res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(3)); + EXPECT_EQ(res.position, other.find(3)); + EXPECT_TRUE(res.inserted); + EXPECT_TRUE(res.node.empty()); + + absl::btree_set<int> src2 = {3, 4}; + nh = src2.extract(src2.find(3)); + EXPECT_THAT(src2, ElementsAre(4)); + res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(3)); + EXPECT_EQ(res.position, other.find(3)); + EXPECT_FALSE(res.inserted); + ASSERT_FALSE(res.node.empty()); + EXPECT_EQ(res.node.value(), 3); +} + +template <typename Set> +void TestExtractWithTrackingForSet() { + InstanceTracker tracker; + { + Set s; + // Add enough elements to make sure we test internal nodes too. + const size_t kSize = 1000; + while (s.size() < kSize) { + s.insert(MovableOnlyInstance(s.size())); + } + for (int i = 0; i < kSize; ++i) { + // Extract with key + auto nh = s.extract(MovableOnlyInstance(i)); + EXPECT_EQ(s.size(), kSize - 1); + EXPECT_EQ(nh.value().value(), i); + // Insert with node + s.insert(std::move(nh)); + EXPECT_EQ(s.size(), kSize); + + // Extract with iterator + auto it = s.find(MovableOnlyInstance(i)); + nh = s.extract(it); + EXPECT_EQ(s.size(), kSize - 1); + EXPECT_EQ(nh.value().value(), i); + // Insert with node and hint + s.insert(s.begin(), std::move(nh)); + EXPECT_EQ(s.size(), kSize); + } + } + EXPECT_EQ(0, tracker.instances()); +} + +template <typename Map> +void TestExtractWithTrackingForMap() { + InstanceTracker tracker; + { + Map m; + // Add enough elements to make sure we test internal nodes too. + const size_t kSize = 1000; + while (m.size() < kSize) { + m.insert( + {CopyableMovableInstance(m.size()), MovableOnlyInstance(m.size())}); + } + for (int i = 0; i < kSize; ++i) { + // Extract with key + auto nh = m.extract(CopyableMovableInstance(i)); + EXPECT_EQ(m.size(), kSize - 1); + EXPECT_EQ(nh.key().value(), i); + EXPECT_EQ(nh.mapped().value(), i); + // Insert with node + m.insert(std::move(nh)); + EXPECT_EQ(m.size(), kSize); + + // Extract with iterator + auto it = m.find(CopyableMovableInstance(i)); + nh = m.extract(it); + EXPECT_EQ(m.size(), kSize - 1); + EXPECT_EQ(nh.key().value(), i); + EXPECT_EQ(nh.mapped().value(), i); + // Insert with node and hint + m.insert(m.begin(), std::move(nh)); + EXPECT_EQ(m.size(), kSize); + } + } + EXPECT_EQ(0, tracker.instances()); +} + +TEST(Btree, ExtractTracking) { + TestExtractWithTrackingForSet<absl::btree_set<MovableOnlyInstance>>(); + TestExtractWithTrackingForSet<absl::btree_multiset<MovableOnlyInstance>>(); + TestExtractWithTrackingForMap< + absl::btree_map<CopyableMovableInstance, MovableOnlyInstance>>(); + TestExtractWithTrackingForMap< + absl::btree_multimap<CopyableMovableInstance, MovableOnlyInstance>>(); +} + +TEST(Btree, ExtractAndInsertNodeHandleMultiSet) { + absl::btree_multiset<int> src1 = {1, 2, 3, 3, 4, 5}; + auto nh = src1.extract(src1.find(3)); + EXPECT_THAT(src1, ElementsAre(1, 2, 3, 4, 5)); + absl::btree_multiset<int> other; + auto res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(3)); + EXPECT_EQ(res, other.find(3)); + + absl::btree_multiset<int> src2 = {3, 4}; + nh = src2.extract(src2.find(3)); + EXPECT_THAT(src2, ElementsAre(4)); + res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(3, 3)); + EXPECT_EQ(res, ++other.find(3)); +} + +TEST(Btree, ExtractAndInsertNodeHandleMap) { + absl::btree_map<int, int> src1 = {{1, 2}, {3, 4}, {5, 6}}; + auto nh = src1.extract(src1.find(3)); + EXPECT_THAT(src1, ElementsAre(Pair(1, 2), Pair(5, 6))); + absl::btree_map<int, int> other; + absl::btree_map<int, int>::insert_return_type res = + other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(Pair(3, 4))); + EXPECT_EQ(res.position, other.find(3)); + EXPECT_TRUE(res.inserted); + EXPECT_TRUE(res.node.empty()); + + absl::btree_map<int, int> src2 = {{3, 6}}; + nh = src2.extract(src2.find(3)); + EXPECT_TRUE(src2.empty()); + res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(Pair(3, 4))); + EXPECT_EQ(res.position, other.find(3)); + EXPECT_FALSE(res.inserted); + ASSERT_FALSE(res.node.empty()); + EXPECT_EQ(res.node.key(), 3); + EXPECT_EQ(res.node.mapped(), 6); +} + +TEST(Btree, ExtractAndInsertNodeHandleMultiMap) { + absl::btree_multimap<int, int> src1 = {{1, 2}, {3, 4}, {5, 6}}; + auto nh = src1.extract(src1.find(3)); + EXPECT_THAT(src1, ElementsAre(Pair(1, 2), Pair(5, 6))); + absl::btree_multimap<int, int> other; + auto res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(Pair(3, 4))); + EXPECT_EQ(res, other.find(3)); + + absl::btree_multimap<int, int> src2 = {{3, 6}}; + nh = src2.extract(src2.find(3)); + EXPECT_TRUE(src2.empty()); + res = other.insert(std::move(nh)); + EXPECT_THAT(other, ElementsAre(Pair(3, 4), Pair(3, 6))); + EXPECT_EQ(res, ++other.begin()); +} + +// For multisets, insert with hint also affects correctness because we need to +// insert immediately before the hint if possible. +struct InsertMultiHintData { + int key; + int not_key; + bool operator==(const InsertMultiHintData other) const { + return key == other.key && not_key == other.not_key; + } +}; + +struct InsertMultiHintDataKeyCompare { + using is_transparent = void; + bool operator()(const InsertMultiHintData a, + const InsertMultiHintData b) const { + return a.key < b.key; + } + bool operator()(const int a, const InsertMultiHintData b) const { + return a < b.key; + } + bool operator()(const InsertMultiHintData a, const int b) const { + return a.key < b; + } +}; + +TEST(Btree, InsertHintNodeHandle) { + // For unique sets, insert with hint is just a performance optimization. + // Test that insert works correctly when the hint is right or wrong. + { + absl::btree_set<int> src = {1, 2, 3, 4, 5}; + auto nh = src.extract(src.find(3)); + EXPECT_THAT(src, ElementsAre(1, 2, 4, 5)); + absl::btree_set<int> other = {0, 100}; + // Test a correct hint. + auto it = other.insert(other.lower_bound(3), std::move(nh)); + EXPECT_THAT(other, ElementsAre(0, 3, 100)); + EXPECT_EQ(it, other.find(3)); + + nh = src.extract(src.find(5)); + // Test an incorrect hint. + it = other.insert(other.end(), std::move(nh)); + EXPECT_THAT(other, ElementsAre(0, 3, 5, 100)); + EXPECT_EQ(it, other.find(5)); + } + + absl::btree_multiset<InsertMultiHintData, InsertMultiHintDataKeyCompare> src = + {{1, 2}, {3, 4}, {3, 5}}; + auto nh = src.extract(src.lower_bound(3)); + EXPECT_EQ(nh.value(), (InsertMultiHintData{3, 4})); + absl::btree_multiset<InsertMultiHintData, InsertMultiHintDataKeyCompare> + other = {{3, 1}, {3, 2}, {3, 3}}; + auto it = other.insert(--other.end(), std::move(nh)); + EXPECT_THAT( + other, ElementsAre(InsertMultiHintData{3, 1}, InsertMultiHintData{3, 2}, + InsertMultiHintData{3, 4}, InsertMultiHintData{3, 3})); + EXPECT_EQ(it, --(--other.end())); + + nh = src.extract(src.find(3)); + EXPECT_EQ(nh.value(), (InsertMultiHintData{3, 5})); + it = other.insert(other.begin(), std::move(nh)); + EXPECT_THAT(other, + ElementsAre(InsertMultiHintData{3, 5}, InsertMultiHintData{3, 1}, + InsertMultiHintData{3, 2}, InsertMultiHintData{3, 4}, + InsertMultiHintData{3, 3})); + EXPECT_EQ(it, other.begin()); +} + +struct IntCompareToCmp { + absl::weak_ordering operator()(int a, int b) const { + if (a < b) return absl::weak_ordering::less; + if (a > b) return absl::weak_ordering::greater; + return absl::weak_ordering::equivalent; + } +}; + +TEST(Btree, MergeIntoUniqueContainers) { + absl::btree_set<int, IntCompareToCmp> src1 = {1, 2, 3}; + absl::btree_multiset<int> src2 = {3, 4, 4, 5}; + absl::btree_set<int> dst; + + dst.merge(src1); + EXPECT_TRUE(src1.empty()); + EXPECT_THAT(dst, ElementsAre(1, 2, 3)); + dst.merge(src2); + EXPECT_THAT(src2, ElementsAre(3, 4)); + EXPECT_THAT(dst, ElementsAre(1, 2, 3, 4, 5)); +} + +TEST(Btree, MergeIntoUniqueContainersWithCompareTo) { + absl::btree_set<int, IntCompareToCmp> src1 = {1, 2, 3}; + absl::btree_multiset<int> src2 = {3, 4, 4, 5}; + absl::btree_set<int, IntCompareToCmp> dst; + + dst.merge(src1); + EXPECT_TRUE(src1.empty()); + EXPECT_THAT(dst, ElementsAre(1, 2, 3)); + dst.merge(src2); + EXPECT_THAT(src2, ElementsAre(3, 4)); + EXPECT_THAT(dst, ElementsAre(1, 2, 3, 4, 5)); +} + +TEST(Btree, MergeIntoMultiContainers) { + absl::btree_set<int, IntCompareToCmp> src1 = {1, 2, 3}; + absl::btree_multiset<int> src2 = {3, 4, 4, 5}; + absl::btree_multiset<int> dst; + + dst.merge(src1); + EXPECT_TRUE(src1.empty()); + EXPECT_THAT(dst, ElementsAre(1, 2, 3)); + dst.merge(src2); + EXPECT_TRUE(src2.empty()); + EXPECT_THAT(dst, ElementsAre(1, 2, 3, 3, 4, 4, 5)); +} + +TEST(Btree, MergeIntoMultiContainersWithCompareTo) { + absl::btree_set<int, IntCompareToCmp> src1 = {1, 2, 3}; + absl::btree_multiset<int> src2 = {3, 4, 4, 5}; + absl::btree_multiset<int, IntCompareToCmp> dst; + + dst.merge(src1); + EXPECT_TRUE(src1.empty()); + EXPECT_THAT(dst, ElementsAre(1, 2, 3)); + dst.merge(src2); + EXPECT_TRUE(src2.empty()); + EXPECT_THAT(dst, ElementsAre(1, 2, 3, 3, 4, 4, 5)); +} + +TEST(Btree, MergeIntoMultiMapsWithDifferentComparators) { + absl::btree_map<int, int, IntCompareToCmp> src1 = {{1, 1}, {2, 2}, {3, 3}}; + absl::btree_multimap<int, int, std::greater<int>> src2 = { + {5, 5}, {4, 1}, {4, 4}, {3, 2}}; + absl::btree_multimap<int, int> dst; + + dst.merge(src1); + EXPECT_TRUE(src1.empty()); + EXPECT_THAT(dst, ElementsAre(Pair(1, 1), Pair(2, 2), Pair(3, 3))); + dst.merge(src2); + EXPECT_TRUE(src2.empty()); + EXPECT_THAT(dst, ElementsAre(Pair(1, 1), Pair(2, 2), Pair(3, 3), Pair(3, 2), + Pair(4, 1), Pair(4, 4), Pair(5, 5))); +} + +struct KeyCompareToWeakOrdering { + template <typename T> + absl::weak_ordering operator()(const T &a, const T &b) const { + return a < b ? absl::weak_ordering::less + : a == b ? absl::weak_ordering::equivalent + : absl::weak_ordering::greater; + } +}; + +struct KeyCompareToStrongOrdering { + template <typename T> + absl::strong_ordering operator()(const T &a, const T &b) const { + return a < b ? absl::strong_ordering::less + : a == b ? absl::strong_ordering::equal + : absl::strong_ordering::greater; + } +}; + +TEST(Btree, UserProvidedKeyCompareToComparators) { + absl::btree_set<int, KeyCompareToWeakOrdering> weak_set = {1, 2, 3}; + EXPECT_TRUE(weak_set.contains(2)); + EXPECT_FALSE(weak_set.contains(4)); + + absl::btree_set<int, KeyCompareToStrongOrdering> strong_set = {1, 2, 3}; + EXPECT_TRUE(strong_set.contains(2)); + EXPECT_FALSE(strong_set.contains(4)); +} + +TEST(Btree, TryEmplaceBasicTest) { + absl::btree_map<int, std::string> m; + + // Should construct a string from the literal. + m.try_emplace(1, "one"); + EXPECT_EQ(1, m.size()); + + // Try other string constructors and const lvalue key. + const int key(42); + m.try_emplace(key, 3, 'a'); + m.try_emplace(2, std::string("two")); + + EXPECT_TRUE(std::is_sorted(m.begin(), m.end())); + EXPECT_THAT(m, ElementsAreArray(std::vector<std::pair<int, std::string>>{ + {1, "one"}, {2, "two"}, {42, "aaa"}})); +} + +TEST(Btree, TryEmplaceWithHintWorks) { + // Use a counting comparator here to verify that hint is used. + int calls = 0; + auto cmp = [&calls](int x, int y) { + ++calls; + return x < y; + }; + using Cmp = decltype(cmp); + + absl::btree_map<int, int, Cmp> m(cmp); + for (int i = 0; i < 128; ++i) { + m.emplace(i, i); + } + + // Sanity check for the comparator + calls = 0; + m.emplace(127, 127); + EXPECT_GE(calls, 4); + + // Try with begin hint: + calls = 0; + auto it = m.try_emplace(m.begin(), -1, -1); + EXPECT_EQ(129, m.size()); + EXPECT_EQ(it, m.begin()); + EXPECT_LE(calls, 2); + + // Try with end hint: + calls = 0; + std::pair<int, int> pair1024 = {1024, 1024}; + it = m.try_emplace(m.end(), pair1024.first, pair1024.second); + EXPECT_EQ(130, m.size()); + EXPECT_EQ(it, --m.end()); + EXPECT_LE(calls, 2); + + // Try value already present, bad hint; ensure no duplicate added: + calls = 0; + it = m.try_emplace(m.end(), 16, 17); + EXPECT_EQ(130, m.size()); + EXPECT_GE(calls, 4); + EXPECT_EQ(it, m.find(16)); + + // Try value already present, hint points directly to it: + calls = 0; + it = m.try_emplace(it, 16, 17); + EXPECT_EQ(130, m.size()); + EXPECT_LE(calls, 2); + EXPECT_EQ(it, m.find(16)); + + m.erase(2); + EXPECT_EQ(129, m.size()); + auto hint = m.find(3); + // Try emplace in the middle of two other elements. + calls = 0; + m.try_emplace(hint, 2, 2); + EXPECT_EQ(130, m.size()); + EXPECT_LE(calls, 2); + + EXPECT_TRUE(std::is_sorted(m.begin(), m.end())); +} + +TEST(Btree, TryEmplaceWithBadHint) { + absl::btree_map<int, int> m = {{1, 1}, {9, 9}}; + + // Bad hint (too small), should still emplace: + auto it = m.try_emplace(m.begin(), 2, 2); + EXPECT_EQ(it, ++m.begin()); + EXPECT_THAT(m, ElementsAreArray( + std::vector<std::pair<int, int>>{{1, 1}, {2, 2}, {9, 9}})); + + // Bad hint, too large this time: + it = m.try_emplace(++(++m.begin()), 0, 0); + EXPECT_EQ(it, m.begin()); + EXPECT_THAT(m, ElementsAreArray(std::vector<std::pair<int, int>>{ + {0, 0}, {1, 1}, {2, 2}, {9, 9}})); +} + +TEST(Btree, TryEmplaceMaintainsSortedOrder) { + absl::btree_map<int, std::string> m; + std::pair<int, std::string> pair5 = {5, "five"}; + + // Test both lvalue & rvalue emplace. + m.try_emplace(10, "ten"); + m.try_emplace(pair5.first, pair5.second); + EXPECT_EQ(2, m.size()); + EXPECT_TRUE(std::is_sorted(m.begin(), m.end())); + + int int100{100}; + m.try_emplace(int100, "hundred"); + m.try_emplace(1, "one"); + EXPECT_EQ(4, m.size()); + EXPECT_TRUE(std::is_sorted(m.begin(), m.end())); +} + +TEST(Btree, TryEmplaceWithHintAndNoValueArgsWorks) { + absl::btree_map<int, int> m; + m.try_emplace(m.end(), 1); + EXPECT_EQ(0, m[1]); +} + +TEST(Btree, TryEmplaceWithHintAndMultipleValueArgsWorks) { + absl::btree_map<int, std::string> m; + m.try_emplace(m.end(), 1, 10, 'a'); + EXPECT_EQ(std::string(10, 'a'), m[1]); +} + +TEST(Btree, MoveAssignmentAllocatorPropagation) { + InstanceTracker tracker; + + int64_t bytes1 = 0, bytes2 = 0; + PropagatingCountingAlloc<MovableOnlyInstance> allocator1(&bytes1); + PropagatingCountingAlloc<MovableOnlyInstance> allocator2(&bytes2); + std::less<MovableOnlyInstance> cmp; + + // Test propagating allocator_type. + { + absl::btree_set<MovableOnlyInstance, std::less<MovableOnlyInstance>, + PropagatingCountingAlloc<MovableOnlyInstance>> + set1(cmp, allocator1), set2(cmp, allocator2); + + for (int i = 0; i < 100; ++i) set1.insert(MovableOnlyInstance(i)); + + tracker.ResetCopiesMovesSwaps(); + set2 = std::move(set1); + EXPECT_EQ(tracker.moves(), 0); + } + // Test non-propagating allocator_type with equal allocators. + { + absl::btree_set<MovableOnlyInstance, std::less<MovableOnlyInstance>, + CountingAllocator<MovableOnlyInstance>> + set1(cmp, allocator1), set2(cmp, allocator1); + + for (int i = 0; i < 100; ++i) set1.insert(MovableOnlyInstance(i)); + + tracker.ResetCopiesMovesSwaps(); + set2 = std::move(set1); + EXPECT_EQ(tracker.moves(), 0); + } + // Test non-propagating allocator_type with different allocators. + { + absl::btree_set<MovableOnlyInstance, std::less<MovableOnlyInstance>, + CountingAllocator<MovableOnlyInstance>> + set1(cmp, allocator1), set2(cmp, allocator2); + + for (int i = 0; i < 100; ++i) set1.insert(MovableOnlyInstance(i)); + + tracker.ResetCopiesMovesSwaps(); + set2 = std::move(set1); + EXPECT_GE(tracker.moves(), 100); + } +} + +TEST(Btree, EmptyTree) { + absl::btree_set<int> s; + EXPECT_TRUE(s.empty()); + EXPECT_EQ(s.size(), 0); + EXPECT_GT(s.max_size(), 0); +} + +bool IsEven(int k) { return k % 2 == 0; } + +TEST(Btree, EraseIf) { + // Test that erase_if works with all the container types and supports lambdas. + { + absl::btree_set<int> s = {1, 3, 5, 6, 100}; + erase_if(s, [](int k) { return k > 3; }); + EXPECT_THAT(s, ElementsAre(1, 3)); + } + { + absl::btree_multiset<int> s = {1, 3, 3, 5, 6, 6, 100}; + erase_if(s, [](int k) { return k <= 3; }); + EXPECT_THAT(s, ElementsAre(5, 6, 6, 100)); + } + { + absl::btree_map<int, int> m = {{1, 1}, {3, 3}, {6, 6}, {100, 100}}; + erase_if(m, [](std::pair<const int, int> kv) { return kv.first > 3; }); + EXPECT_THAT(m, ElementsAre(Pair(1, 1), Pair(3, 3))); + } + { + absl::btree_multimap<int, int> m = {{1, 1}, {3, 3}, {3, 6}, + {6, 6}, {6, 7}, {100, 6}}; + erase_if(m, [](std::pair<const int, int> kv) { return kv.second == 6; }); + EXPECT_THAT(m, ElementsAre(Pair(1, 1), Pair(3, 3), Pair(6, 7))); + } + // Test that erasing all elements from a large set works and test support for + // function pointers. + { + absl::btree_set<int> s; + for (int i = 0; i < 1000; ++i) s.insert(2 * i); + erase_if(s, IsEven); + EXPECT_THAT(s, IsEmpty()); + } + // Test that erase_if supports other format of function pointers. + { + absl::btree_set<int> s = {1, 3, 5, 6, 100}; + erase_if(s, &IsEven); + EXPECT_THAT(s, ElementsAre(1, 3, 5)); + } +} + +TEST(Btree, InsertOrAssign) { + absl::btree_map<int, int> m = {{1, 1}, {3, 3}}; + using value_type = typename decltype(m)::value_type; + + auto ret = m.insert_or_assign(4, 4); + EXPECT_EQ(*ret.first, value_type(4, 4)); + EXPECT_TRUE(ret.second); + ret = m.insert_or_assign(3, 100); + EXPECT_EQ(*ret.first, value_type(3, 100)); + EXPECT_FALSE(ret.second); + + auto hint_ret = m.insert_or_assign(ret.first, 3, 200); + EXPECT_EQ(*hint_ret, value_type(3, 200)); + hint_ret = m.insert_or_assign(m.find(1), 0, 1); + EXPECT_EQ(*hint_ret, value_type(0, 1)); + // Test with bad hint. + hint_ret = m.insert_or_assign(m.end(), -1, 1); + EXPECT_EQ(*hint_ret, value_type(-1, 1)); + + EXPECT_THAT(m, ElementsAre(Pair(-1, 1), Pair(0, 1), Pair(1, 1), Pair(3, 200), + Pair(4, 4))); +} + +TEST(Btree, InsertOrAssignMovableOnly) { + absl::btree_map<int, MovableOnlyInstance> m; + using value_type = typename decltype(m)::value_type; + + auto ret = m.insert_or_assign(4, MovableOnlyInstance(4)); + EXPECT_EQ(*ret.first, value_type(4, MovableOnlyInstance(4))); + EXPECT_TRUE(ret.second); + ret = m.insert_or_assign(4, MovableOnlyInstance(100)); + EXPECT_EQ(*ret.first, value_type(4, MovableOnlyInstance(100))); + EXPECT_FALSE(ret.second); + + auto hint_ret = m.insert_or_assign(ret.first, 3, MovableOnlyInstance(200)); + EXPECT_EQ(*hint_ret, value_type(3, MovableOnlyInstance(200))); + + EXPECT_EQ(m.size(), 2); +} + +TEST(Btree, BitfieldArgument) { + union { + int n : 1; + }; + n = 0; + absl::btree_map<int, int> m; + m.erase(n); + m.count(n); + m.find(n); + m.contains(n); + m.equal_range(n); + m.insert_or_assign(n, n); + m.insert_or_assign(m.end(), n, n); + m.try_emplace(n); + m.try_emplace(m.end(), n); + m.at(n); + m[n]; +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/btree_test.h b/third_party/abseil_cpp/absl/container/btree_test.h new file mode 100644 index 0000000000..624908072d --- /dev/null +++ b/third_party/abseil_cpp/absl/container/btree_test.h @@ -0,0 +1,166 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_BTREE_TEST_H_ +#define ABSL_CONTAINER_BTREE_TEST_H_ + +#include <algorithm> +#include <cassert> +#include <random> +#include <string> +#include <utility> +#include <vector> + +#include "absl/container/btree_map.h" +#include "absl/container/btree_set.h" +#include "absl/container/flat_hash_set.h" +#include "absl/strings/cord.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// Like remove_const but propagates the removal through std::pair. +template <typename T> +struct remove_pair_const { + using type = typename std::remove_const<T>::type; +}; +template <typename T, typename U> +struct remove_pair_const<std::pair<T, U> > { + using type = std::pair<typename remove_pair_const<T>::type, + typename remove_pair_const<U>::type>; +}; + +// Utility class to provide an accessor for a key given a value. The default +// behavior is to treat the value as a pair and return the first element. +template <typename K, typename V> +struct KeyOfValue { + struct type { + const K& operator()(const V& p) const { return p.first; } + }; +}; + +// Partial specialization of KeyOfValue class for when the key and value are +// the same type such as in set<> and btree_set<>. +template <typename K> +struct KeyOfValue<K, K> { + struct type { + const K& operator()(const K& k) const { return k; } + }; +}; + +inline char* GenerateDigits(char buf[16], unsigned val, unsigned maxval) { + assert(val <= maxval); + constexpr unsigned kBase = 64; // avoid integer division. + unsigned p = 15; + buf[p--] = 0; + while (maxval > 0) { + buf[p--] = ' ' + (val % kBase); + val /= kBase; + maxval /= kBase; + } + return buf + p + 1; +} + +template <typename K> +struct Generator { + int maxval; + explicit Generator(int m) : maxval(m) {} + K operator()(int i) const { + assert(i <= maxval); + return K(i); + } +}; + +template <> +struct Generator<absl::Time> { + int maxval; + explicit Generator(int m) : maxval(m) {} + absl::Time operator()(int i) const { return absl::FromUnixMillis(i); } +}; + +template <> +struct Generator<std::string> { + int maxval; + explicit Generator(int m) : maxval(m) {} + std::string operator()(int i) const { + char buf[16]; + return GenerateDigits(buf, i, maxval); + } +}; + +template <> +struct Generator<Cord> { + int maxval; + explicit Generator(int m) : maxval(m) {} + Cord operator()(int i) const { + char buf[16]; + return Cord(GenerateDigits(buf, i, maxval)); + } +}; + +template <typename T, typename U> +struct Generator<std::pair<T, U> > { + Generator<typename remove_pair_const<T>::type> tgen; + Generator<typename remove_pair_const<U>::type> ugen; + + explicit Generator(int m) : tgen(m), ugen(m) {} + std::pair<T, U> operator()(int i) const { + return std::make_pair(tgen(i), ugen(i)); + } +}; + +// Generate n values for our tests and benchmarks. Value range is [0, maxval]. +inline std::vector<int> GenerateNumbersWithSeed(int n, int maxval, int seed) { + // NOTE: Some tests rely on generated numbers not changing between test runs. + // We use std::minstd_rand0 because it is well-defined, but don't use + // std::uniform_int_distribution because platforms use different algorithms. + std::minstd_rand0 rng(seed); + + std::vector<int> values; + absl::flat_hash_set<int> unique_values; + if (values.size() < n) { + for (int i = values.size(); i < n; i++) { + int value; + do { + value = static_cast<int>(rng()) % (maxval + 1); + } while (!unique_values.insert(value).second); + + values.push_back(value); + } + } + return values; +} + +// Generates n values in the range [0, maxval]. +template <typename V> +std::vector<V> GenerateValuesWithSeed(int n, int maxval, int seed) { + const std::vector<int> nums = GenerateNumbersWithSeed(n, maxval, seed); + Generator<V> gen(maxval); + std::vector<V> vec; + + vec.reserve(n); + for (int i = 0; i < n; i++) { + vec.push_back(gen(nums[i])); + } + + return vec; +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_BTREE_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/fixed_array.h b/third_party/abseil_cpp/absl/container/fixed_array.h new file mode 100644 index 0000000000..adf0dc8088 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/fixed_array.h @@ -0,0 +1,527 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: fixed_array.h +// ----------------------------------------------------------------------------- +// +// A `FixedArray<T>` represents a non-resizable array of `T` where the length of +// the array can be determined at run-time. It is a good replacement for +// non-standard and deprecated uses of `alloca()` and variable length arrays +// within the GCC extension. (See +// https://gcc.gnu.org/onlinedocs/gcc/Variable-Length.html). +// +// `FixedArray` allocates small arrays inline, keeping performance fast by +// avoiding heap operations. It also helps reduce the chances of +// accidentally overflowing your stack if large input is passed to +// your function. + +#ifndef ABSL_CONTAINER_FIXED_ARRAY_H_ +#define ABSL_CONTAINER_FIXED_ARRAY_H_ + +#include <algorithm> +#include <cassert> +#include <cstddef> +#include <initializer_list> +#include <iterator> +#include <limits> +#include <memory> +#include <new> +#include <type_traits> + +#include "absl/algorithm/algorithm.h" +#include "absl/base/dynamic_annotations.h" +#include "absl/base/internal/throw_delegate.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" +#include "absl/container/internal/compressed_tuple.h" +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +constexpr static auto kFixedArrayUseDefault = static_cast<size_t>(-1); + +// ----------------------------------------------------------------------------- +// FixedArray +// ----------------------------------------------------------------------------- +// +// A `FixedArray` provides a run-time fixed-size array, allocating a small array +// inline for efficiency. +// +// Most users should not specify an `inline_elements` argument and let +// `FixedArray` automatically determine the number of elements +// to store inline based on `sizeof(T)`. If `inline_elements` is specified, the +// `FixedArray` implementation will use inline storage for arrays with a +// length <= `inline_elements`. +// +// Note that a `FixedArray` constructed with a `size_type` argument will +// default-initialize its values by leaving trivially constructible types +// uninitialized (e.g. int, int[4], double), and others default-constructed. +// This matches the behavior of c-style arrays and `std::array`, but not +// `std::vector`. +// +// Note that `FixedArray` does not provide a public allocator; if it requires a +// heap allocation, it will do so with global `::operator new[]()` and +// `::operator delete[]()`, even if T provides class-scope overrides for these +// operators. +template <typename T, size_t N = kFixedArrayUseDefault, + typename A = std::allocator<T>> +class FixedArray { + static_assert(!std::is_array<T>::value || std::extent<T>::value > 0, + "Arrays with unknown bounds cannot be used with FixedArray."); + + static constexpr size_t kInlineBytesDefault = 256; + + using AllocatorTraits = std::allocator_traits<A>; + // std::iterator_traits isn't guaranteed to be SFINAE-friendly until C++17, + // but this seems to be mostly pedantic. + template <typename Iterator> + using EnableIfForwardIterator = absl::enable_if_t<std::is_convertible< + typename std::iterator_traits<Iterator>::iterator_category, + std::forward_iterator_tag>::value>; + static constexpr bool NoexceptCopyable() { + return std::is_nothrow_copy_constructible<StorageElement>::value && + absl::allocator_is_nothrow<allocator_type>::value; + } + static constexpr bool NoexceptMovable() { + return std::is_nothrow_move_constructible<StorageElement>::value && + absl::allocator_is_nothrow<allocator_type>::value; + } + static constexpr bool DefaultConstructorIsNonTrivial() { + return !absl::is_trivially_default_constructible<StorageElement>::value; + } + + public: + using allocator_type = typename AllocatorTraits::allocator_type; + using value_type = typename AllocatorTraits::value_type; + using pointer = typename AllocatorTraits::pointer; + using const_pointer = typename AllocatorTraits::const_pointer; + using reference = value_type&; + using const_reference = const value_type&; + using size_type = typename AllocatorTraits::size_type; + using difference_type = typename AllocatorTraits::difference_type; + using iterator = pointer; + using const_iterator = const_pointer; + using reverse_iterator = std::reverse_iterator<iterator>; + using const_reverse_iterator = std::reverse_iterator<const_iterator>; + + static constexpr size_type inline_elements = + (N == kFixedArrayUseDefault ? kInlineBytesDefault / sizeof(value_type) + : static_cast<size_type>(N)); + + FixedArray( + const FixedArray& other, + const allocator_type& a = allocator_type()) noexcept(NoexceptCopyable()) + : FixedArray(other.begin(), other.end(), a) {} + + FixedArray( + FixedArray&& other, + const allocator_type& a = allocator_type()) noexcept(NoexceptMovable()) + : FixedArray(std::make_move_iterator(other.begin()), + std::make_move_iterator(other.end()), a) {} + + // Creates an array object that can store `n` elements. + // Note that trivially constructible elements will be uninitialized. + explicit FixedArray(size_type n, const allocator_type& a = allocator_type()) + : storage_(n, a) { + if (DefaultConstructorIsNonTrivial()) { + memory_internal::ConstructRange(storage_.alloc(), storage_.begin(), + storage_.end()); + } + } + + // Creates an array initialized with `n` copies of `val`. + FixedArray(size_type n, const value_type& val, + const allocator_type& a = allocator_type()) + : storage_(n, a) { + memory_internal::ConstructRange(storage_.alloc(), storage_.begin(), + storage_.end(), val); + } + + // Creates an array initialized with the size and contents of `init_list`. + FixedArray(std::initializer_list<value_type> init_list, + const allocator_type& a = allocator_type()) + : FixedArray(init_list.begin(), init_list.end(), a) {} + + // Creates an array initialized with the elements from the input + // range. The array's size will always be `std::distance(first, last)`. + // REQUIRES: Iterator must be a forward_iterator or better. + template <typename Iterator, EnableIfForwardIterator<Iterator>* = nullptr> + FixedArray(Iterator first, Iterator last, + const allocator_type& a = allocator_type()) + : storage_(std::distance(first, last), a) { + memory_internal::CopyRange(storage_.alloc(), storage_.begin(), first, last); + } + + ~FixedArray() noexcept { + for (auto* cur = storage_.begin(); cur != storage_.end(); ++cur) { + AllocatorTraits::destroy(storage_.alloc(), cur); + } + } + + // Assignments are deleted because they break the invariant that the size of a + // `FixedArray` never changes. + void operator=(FixedArray&&) = delete; + void operator=(const FixedArray&) = delete; + + // FixedArray::size() + // + // Returns the length of the fixed array. + size_type size() const { return storage_.size(); } + + // FixedArray::max_size() + // + // Returns the largest possible value of `std::distance(begin(), end())` for a + // `FixedArray<T>`. This is equivalent to the most possible addressable bytes + // over the number of bytes taken by T. + constexpr size_type max_size() const { + return (std::numeric_limits<difference_type>::max)() / sizeof(value_type); + } + + // FixedArray::empty() + // + // Returns whether or not the fixed array is empty. + bool empty() const { return size() == 0; } + + // FixedArray::memsize() + // + // Returns the memory size of the fixed array in bytes. + size_t memsize() const { return size() * sizeof(value_type); } + + // FixedArray::data() + // + // Returns a const T* pointer to elements of the `FixedArray`. This pointer + // can be used to access (but not modify) the contained elements. + const_pointer data() const { return AsValueType(storage_.begin()); } + + // Overload of FixedArray::data() to return a T* pointer to elements of the + // fixed array. This pointer can be used to access and modify the contained + // elements. + pointer data() { return AsValueType(storage_.begin()); } + + // FixedArray::operator[] + // + // Returns a reference the ith element of the fixed array. + // REQUIRES: 0 <= i < size() + reference operator[](size_type i) { + ABSL_HARDENING_ASSERT(i < size()); + return data()[i]; + } + + // Overload of FixedArray::operator()[] to return a const reference to the + // ith element of the fixed array. + // REQUIRES: 0 <= i < size() + const_reference operator[](size_type i) const { + ABSL_HARDENING_ASSERT(i < size()); + return data()[i]; + } + + // FixedArray::at + // + // Bounds-checked access. Returns a reference to the ith element of the + // fiexed array, or throws std::out_of_range + reference at(size_type i) { + if (ABSL_PREDICT_FALSE(i >= size())) { + base_internal::ThrowStdOutOfRange("FixedArray::at failed bounds check"); + } + return data()[i]; + } + + // Overload of FixedArray::at() to return a const reference to the ith element + // of the fixed array. + const_reference at(size_type i) const { + if (ABSL_PREDICT_FALSE(i >= size())) { + base_internal::ThrowStdOutOfRange("FixedArray::at failed bounds check"); + } + return data()[i]; + } + + // FixedArray::front() + // + // Returns a reference to the first element of the fixed array. + reference front() { + ABSL_HARDENING_ASSERT(!empty()); + return data()[0]; + } + + // Overload of FixedArray::front() to return a reference to the first element + // of a fixed array of const values. + const_reference front() const { + ABSL_HARDENING_ASSERT(!empty()); + return data()[0]; + } + + // FixedArray::back() + // + // Returns a reference to the last element of the fixed array. + reference back() { + ABSL_HARDENING_ASSERT(!empty()); + return data()[size() - 1]; + } + + // Overload of FixedArray::back() to return a reference to the last element + // of a fixed array of const values. + const_reference back() const { + ABSL_HARDENING_ASSERT(!empty()); + return data()[size() - 1]; + } + + // FixedArray::begin() + // + // Returns an iterator to the beginning of the fixed array. + iterator begin() { return data(); } + + // Overload of FixedArray::begin() to return a const iterator to the + // beginning of the fixed array. + const_iterator begin() const { return data(); } + + // FixedArray::cbegin() + // + // Returns a const iterator to the beginning of the fixed array. + const_iterator cbegin() const { return begin(); } + + // FixedArray::end() + // + // Returns an iterator to the end of the fixed array. + iterator end() { return data() + size(); } + + // Overload of FixedArray::end() to return a const iterator to the end of the + // fixed array. + const_iterator end() const { return data() + size(); } + + // FixedArray::cend() + // + // Returns a const iterator to the end of the fixed array. + const_iterator cend() const { return end(); } + + // FixedArray::rbegin() + // + // Returns a reverse iterator from the end of the fixed array. + reverse_iterator rbegin() { return reverse_iterator(end()); } + + // Overload of FixedArray::rbegin() to return a const reverse iterator from + // the end of the fixed array. + const_reverse_iterator rbegin() const { + return const_reverse_iterator(end()); + } + + // FixedArray::crbegin() + // + // Returns a const reverse iterator from the end of the fixed array. + const_reverse_iterator crbegin() const { return rbegin(); } + + // FixedArray::rend() + // + // Returns a reverse iterator from the beginning of the fixed array. + reverse_iterator rend() { return reverse_iterator(begin()); } + + // Overload of FixedArray::rend() for returning a const reverse iterator + // from the beginning of the fixed array. + const_reverse_iterator rend() const { + return const_reverse_iterator(begin()); + } + + // FixedArray::crend() + // + // Returns a reverse iterator from the beginning of the fixed array. + const_reverse_iterator crend() const { return rend(); } + + // FixedArray::fill() + // + // Assigns the given `value` to all elements in the fixed array. + void fill(const value_type& val) { std::fill(begin(), end(), val); } + + // Relational operators. Equality operators are elementwise using + // `operator==`, while order operators order FixedArrays lexicographically. + friend bool operator==(const FixedArray& lhs, const FixedArray& rhs) { + return absl::equal(lhs.begin(), lhs.end(), rhs.begin(), rhs.end()); + } + + friend bool operator!=(const FixedArray& lhs, const FixedArray& rhs) { + return !(lhs == rhs); + } + + friend bool operator<(const FixedArray& lhs, const FixedArray& rhs) { + return std::lexicographical_compare(lhs.begin(), lhs.end(), rhs.begin(), + rhs.end()); + } + + friend bool operator>(const FixedArray& lhs, const FixedArray& rhs) { + return rhs < lhs; + } + + friend bool operator<=(const FixedArray& lhs, const FixedArray& rhs) { + return !(rhs < lhs); + } + + friend bool operator>=(const FixedArray& lhs, const FixedArray& rhs) { + return !(lhs < rhs); + } + + template <typename H> + friend H AbslHashValue(H h, const FixedArray& v) { + return H::combine(H::combine_contiguous(std::move(h), v.data(), v.size()), + v.size()); + } + + private: + // StorageElement + // + // For FixedArrays with a C-style-array value_type, StorageElement is a POD + // wrapper struct called StorageElementWrapper that holds the value_type + // instance inside. This is needed for construction and destruction of the + // entire array regardless of how many dimensions it has. For all other cases, + // StorageElement is just an alias of value_type. + // + // Maintainer's Note: The simpler solution would be to simply wrap value_type + // in a struct whether it's an array or not. That causes some paranoid + // diagnostics to misfire, believing that 'data()' returns a pointer to a + // single element, rather than the packed array that it really is. + // e.g.: + // + // FixedArray<char> buf(1); + // sprintf(buf.data(), "foo"); + // + // error: call to int __builtin___sprintf_chk(etc...) + // will always overflow destination buffer [-Werror] + // + template <typename OuterT, typename InnerT = absl::remove_extent_t<OuterT>, + size_t InnerN = std::extent<OuterT>::value> + struct StorageElementWrapper { + InnerT array[InnerN]; + }; + + using StorageElement = + absl::conditional_t<std::is_array<value_type>::value, + StorageElementWrapper<value_type>, value_type>; + + static pointer AsValueType(pointer ptr) { return ptr; } + static pointer AsValueType(StorageElementWrapper<value_type>* ptr) { + return std::addressof(ptr->array); + } + + static_assert(sizeof(StorageElement) == sizeof(value_type), ""); + static_assert(alignof(StorageElement) == alignof(value_type), ""); + + class NonEmptyInlinedStorage { + public: + StorageElement* data() { return reinterpret_cast<StorageElement*>(buff_); } + void AnnotateConstruct(size_type n); + void AnnotateDestruct(size_type n); + +#ifdef ADDRESS_SANITIZER + void* RedzoneBegin() { return &redzone_begin_; } + void* RedzoneEnd() { return &redzone_end_ + 1; } +#endif // ADDRESS_SANITIZER + + private: + ADDRESS_SANITIZER_REDZONE(redzone_begin_); + alignas(StorageElement) char buff_[sizeof(StorageElement[inline_elements])]; + ADDRESS_SANITIZER_REDZONE(redzone_end_); + }; + + class EmptyInlinedStorage { + public: + StorageElement* data() { return nullptr; } + void AnnotateConstruct(size_type) {} + void AnnotateDestruct(size_type) {} + }; + + using InlinedStorage = + absl::conditional_t<inline_elements == 0, EmptyInlinedStorage, + NonEmptyInlinedStorage>; + + // Storage + // + // An instance of Storage manages the inline and out-of-line memory for + // instances of FixedArray. This guarantees that even when construction of + // individual elements fails in the FixedArray constructor body, the + // destructor for Storage will still be called and out-of-line memory will be + // properly deallocated. + // + class Storage : public InlinedStorage { + public: + Storage(size_type n, const allocator_type& a) + : size_alloc_(n, a), data_(InitializeData()) {} + + ~Storage() noexcept { + if (UsingInlinedStorage(size())) { + InlinedStorage::AnnotateDestruct(size()); + } else { + AllocatorTraits::deallocate(alloc(), AsValueType(begin()), size()); + } + } + + size_type size() const { return size_alloc_.template get<0>(); } + StorageElement* begin() const { return data_; } + StorageElement* end() const { return begin() + size(); } + allocator_type& alloc() { return size_alloc_.template get<1>(); } + + private: + static bool UsingInlinedStorage(size_type n) { + return n <= inline_elements; + } + + StorageElement* InitializeData() { + if (UsingInlinedStorage(size())) { + InlinedStorage::AnnotateConstruct(size()); + return InlinedStorage::data(); + } else { + return reinterpret_cast<StorageElement*>( + AllocatorTraits::allocate(alloc(), size())); + } + } + + // `CompressedTuple` takes advantage of EBCO for stateless `allocator_type`s + container_internal::CompressedTuple<size_type, allocator_type> size_alloc_; + StorageElement* data_; + }; + + Storage storage_; +}; + +template <typename T, size_t N, typename A> +constexpr size_t FixedArray<T, N, A>::kInlineBytesDefault; + +template <typename T, size_t N, typename A> +constexpr typename FixedArray<T, N, A>::size_type + FixedArray<T, N, A>::inline_elements; + +template <typename T, size_t N, typename A> +void FixedArray<T, N, A>::NonEmptyInlinedStorage::AnnotateConstruct( + typename FixedArray<T, N, A>::size_type n) { +#ifdef ADDRESS_SANITIZER + if (!n) return; + ANNOTATE_CONTIGUOUS_CONTAINER(data(), RedzoneEnd(), RedzoneEnd(), data() + n); + ANNOTATE_CONTIGUOUS_CONTAINER(RedzoneBegin(), data(), data(), RedzoneBegin()); +#endif // ADDRESS_SANITIZER + static_cast<void>(n); // Mark used when not in asan mode +} + +template <typename T, size_t N, typename A> +void FixedArray<T, N, A>::NonEmptyInlinedStorage::AnnotateDestruct( + typename FixedArray<T, N, A>::size_type n) { +#ifdef ADDRESS_SANITIZER + if (!n) return; + ANNOTATE_CONTIGUOUS_CONTAINER(data(), RedzoneEnd(), data() + n, RedzoneEnd()); + ANNOTATE_CONTIGUOUS_CONTAINER(RedzoneBegin(), data(), RedzoneBegin(), data()); +#endif // ADDRESS_SANITIZER + static_cast<void>(n); // Mark used when not in asan mode +} +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_FIXED_ARRAY_H_ diff --git a/third_party/abseil_cpp/absl/container/fixed_array_benchmark.cc b/third_party/abseil_cpp/absl/container/fixed_array_benchmark.cc new file mode 100644 index 0000000000..3c7a5a7234 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/fixed_array_benchmark.cc @@ -0,0 +1,67 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <stddef.h> + +#include <string> + +#include "benchmark/benchmark.h" +#include "absl/container/fixed_array.h" + +namespace { + +// For benchmarking -- simple class with constructor and destructor that +// set an int to a constant.. +class SimpleClass { + public: + SimpleClass() : i(3) {} + ~SimpleClass() { i = 0; } + + private: + int i; +}; + +template <typename C, size_t stack_size> +void BM_FixedArray(benchmark::State& state) { + const int size = state.range(0); + for (auto _ : state) { + absl::FixedArray<C, stack_size> fa(size); + benchmark::DoNotOptimize(fa.data()); + } +} +BENCHMARK_TEMPLATE(BM_FixedArray, char, absl::kFixedArrayUseDefault) + ->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, char, 0)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, char, 1)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, char, 16)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, char, 256)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, char, 65536)->Range(0, 1 << 16); + +BENCHMARK_TEMPLATE(BM_FixedArray, SimpleClass, absl::kFixedArrayUseDefault) + ->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, SimpleClass, 0)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, SimpleClass, 1)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, SimpleClass, 16)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, SimpleClass, 256)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, SimpleClass, 65536)->Range(0, 1 << 16); + +BENCHMARK_TEMPLATE(BM_FixedArray, std::string, absl::kFixedArrayUseDefault) + ->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, std::string, 0)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, std::string, 1)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, std::string, 16)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, std::string, 256)->Range(0, 1 << 16); +BENCHMARK_TEMPLATE(BM_FixedArray, std::string, 65536)->Range(0, 1 << 16); + +} // namespace diff --git a/third_party/abseil_cpp/absl/container/fixed_array_exception_safety_test.cc b/third_party/abseil_cpp/absl/container/fixed_array_exception_safety_test.cc new file mode 100644 index 0000000000..a5bb009d98 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/fixed_array_exception_safety_test.cc @@ -0,0 +1,202 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/config.h" +#include "absl/container/fixed_array.h" + +#ifdef ABSL_HAVE_EXCEPTIONS + +#include <initializer_list> + +#include "gtest/gtest.h" +#include "absl/base/internal/exception_safety_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +constexpr size_t kInlined = 25; +constexpr size_t kSmallSize = kInlined / 2; +constexpr size_t kLargeSize = kInlined * 2; + +constexpr int kInitialValue = 5; +constexpr int kUpdatedValue = 10; + +using ::testing::TestThrowingCtor; + +using Thrower = testing::ThrowingValue<testing::TypeSpec::kEverythingThrows>; +using ThrowAlloc = + testing::ThrowingAllocator<Thrower, testing::AllocSpec::kEverythingThrows>; +using MoveThrower = testing::ThrowingValue<testing::TypeSpec::kNoThrowMove>; +using MoveThrowAlloc = + testing::ThrowingAllocator<MoveThrower, + testing::AllocSpec::kEverythingThrows>; + +using FixedArr = absl::FixedArray<Thrower, kInlined>; +using FixedArrWithAlloc = absl::FixedArray<Thrower, kInlined, ThrowAlloc>; + +using MoveFixedArr = absl::FixedArray<MoveThrower, kInlined>; +using MoveFixedArrWithAlloc = + absl::FixedArray<MoveThrower, kInlined, MoveThrowAlloc>; + +TEST(FixedArrayExceptionSafety, CopyConstructor) { + auto small = FixedArr(kSmallSize); + TestThrowingCtor<FixedArr>(small); + + auto large = FixedArr(kLargeSize); + TestThrowingCtor<FixedArr>(large); +} + +TEST(FixedArrayExceptionSafety, CopyConstructorWithAlloc) { + auto small = FixedArrWithAlloc(kSmallSize); + TestThrowingCtor<FixedArrWithAlloc>(small); + + auto large = FixedArrWithAlloc(kLargeSize); + TestThrowingCtor<FixedArrWithAlloc>(large); +} + +TEST(FixedArrayExceptionSafety, MoveConstructor) { + TestThrowingCtor<FixedArr>(FixedArr(kSmallSize)); + TestThrowingCtor<FixedArr>(FixedArr(kLargeSize)); + + // TypeSpec::kNoThrowMove + TestThrowingCtor<MoveFixedArr>(MoveFixedArr(kSmallSize)); + TestThrowingCtor<MoveFixedArr>(MoveFixedArr(kLargeSize)); +} + +TEST(FixedArrayExceptionSafety, MoveConstructorWithAlloc) { + TestThrowingCtor<FixedArrWithAlloc>(FixedArrWithAlloc(kSmallSize)); + TestThrowingCtor<FixedArrWithAlloc>(FixedArrWithAlloc(kLargeSize)); + + // TypeSpec::kNoThrowMove + TestThrowingCtor<MoveFixedArrWithAlloc>(MoveFixedArrWithAlloc(kSmallSize)); + TestThrowingCtor<MoveFixedArrWithAlloc>(MoveFixedArrWithAlloc(kLargeSize)); +} + +TEST(FixedArrayExceptionSafety, SizeConstructor) { + TestThrowingCtor<FixedArr>(kSmallSize); + TestThrowingCtor<FixedArr>(kLargeSize); +} + +TEST(FixedArrayExceptionSafety, SizeConstructorWithAlloc) { + TestThrowingCtor<FixedArrWithAlloc>(kSmallSize); + TestThrowingCtor<FixedArrWithAlloc>(kLargeSize); +} + +TEST(FixedArrayExceptionSafety, SizeValueConstructor) { + TestThrowingCtor<FixedArr>(kSmallSize, Thrower()); + TestThrowingCtor<FixedArr>(kLargeSize, Thrower()); +} + +TEST(FixedArrayExceptionSafety, SizeValueConstructorWithAlloc) { + TestThrowingCtor<FixedArrWithAlloc>(kSmallSize, Thrower()); + TestThrowingCtor<FixedArrWithAlloc>(kLargeSize, Thrower()); +} + +TEST(FixedArrayExceptionSafety, IteratorConstructor) { + auto small = FixedArr(kSmallSize); + TestThrowingCtor<FixedArr>(small.begin(), small.end()); + + auto large = FixedArr(kLargeSize); + TestThrowingCtor<FixedArr>(large.begin(), large.end()); +} + +TEST(FixedArrayExceptionSafety, IteratorConstructorWithAlloc) { + auto small = FixedArrWithAlloc(kSmallSize); + TestThrowingCtor<FixedArrWithAlloc>(small.begin(), small.end()); + + auto large = FixedArrWithAlloc(kLargeSize); + TestThrowingCtor<FixedArrWithAlloc>(large.begin(), large.end()); +} + +TEST(FixedArrayExceptionSafety, InitListConstructor) { + constexpr int small_inlined = 3; + using SmallFixedArr = absl::FixedArray<Thrower, small_inlined>; + + TestThrowingCtor<SmallFixedArr>(std::initializer_list<Thrower>{}); + // Test inlined allocation + TestThrowingCtor<SmallFixedArr>( + std::initializer_list<Thrower>{Thrower{}, Thrower{}}); + // Test out of line allocation + TestThrowingCtor<SmallFixedArr>(std::initializer_list<Thrower>{ + Thrower{}, Thrower{}, Thrower{}, Thrower{}, Thrower{}}); +} + +TEST(FixedArrayExceptionSafety, InitListConstructorWithAlloc) { + constexpr int small_inlined = 3; + using SmallFixedArrWithAlloc = + absl::FixedArray<Thrower, small_inlined, ThrowAlloc>; + + TestThrowingCtor<SmallFixedArrWithAlloc>(std::initializer_list<Thrower>{}); + // Test inlined allocation + TestThrowingCtor<SmallFixedArrWithAlloc>( + std::initializer_list<Thrower>{Thrower{}, Thrower{}}); + // Test out of line allocation + TestThrowingCtor<SmallFixedArrWithAlloc>(std::initializer_list<Thrower>{ + Thrower{}, Thrower{}, Thrower{}, Thrower{}, Thrower{}}); +} + +template <typename FixedArrT> +testing::AssertionResult ReadMemory(FixedArrT* fixed_arr) { + // Marked volatile to prevent optimization. Used for running asan tests. + volatile int sum = 0; + for (const auto& thrower : *fixed_arr) { + sum += thrower.Get(); + } + return testing::AssertionSuccess() << "Values sum to [" << sum << "]"; +} + +TEST(FixedArrayExceptionSafety, Fill) { + auto test_fill = testing::MakeExceptionSafetyTester() + .WithContracts(ReadMemory<FixedArr>) + .WithOperation([&](FixedArr* fixed_arr_ptr) { + auto thrower = + Thrower(kUpdatedValue, testing::nothrow_ctor); + fixed_arr_ptr->fill(thrower); + }); + + EXPECT_TRUE( + test_fill.WithInitialValue(FixedArr(kSmallSize, Thrower(kInitialValue))) + .Test()); + EXPECT_TRUE( + test_fill.WithInitialValue(FixedArr(kLargeSize, Thrower(kInitialValue))) + .Test()); +} + +TEST(FixedArrayExceptionSafety, FillWithAlloc) { + auto test_fill = testing::MakeExceptionSafetyTester() + .WithContracts(ReadMemory<FixedArrWithAlloc>) + .WithOperation([&](FixedArrWithAlloc* fixed_arr_ptr) { + auto thrower = + Thrower(kUpdatedValue, testing::nothrow_ctor); + fixed_arr_ptr->fill(thrower); + }); + + EXPECT_TRUE(test_fill + .WithInitialValue( + FixedArrWithAlloc(kSmallSize, Thrower(kInitialValue))) + .Test()); + EXPECT_TRUE(test_fill + .WithInitialValue( + FixedArrWithAlloc(kLargeSize, Thrower(kInitialValue))) + .Test()); +} + +} // namespace + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HAVE_EXCEPTIONS diff --git a/third_party/abseil_cpp/absl/container/fixed_array_test.cc b/third_party/abseil_cpp/absl/container/fixed_array_test.cc new file mode 100644 index 0000000000..064a88a239 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/fixed_array_test.cc @@ -0,0 +1,836 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/fixed_array.h" + +#include <stdio.h> + +#include <cstring> +#include <list> +#include <memory> +#include <numeric> +#include <scoped_allocator> +#include <stdexcept> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/exception_testing.h" +#include "absl/base/options.h" +#include "absl/container/internal/counting_allocator.h" +#include "absl/hash/hash_testing.h" +#include "absl/memory/memory.h" + +using ::testing::ElementsAreArray; + +namespace { + +// Helper routine to determine if a absl::FixedArray used stack allocation. +template <typename ArrayType> +static bool IsOnStack(const ArrayType& a) { + return a.size() <= ArrayType::inline_elements; +} + +class ConstructionTester { + public: + ConstructionTester() : self_ptr_(this), value_(0) { constructions++; } + ~ConstructionTester() { + assert(self_ptr_ == this); + self_ptr_ = nullptr; + destructions++; + } + + // These are incremented as elements are constructed and destructed so we can + // be sure all elements are properly cleaned up. + static int constructions; + static int destructions; + + void CheckConstructed() { assert(self_ptr_ == this); } + + void set(int value) { value_ = value; } + int get() { return value_; } + + private: + // self_ptr_ should always point to 'this' -- that's how we can be sure the + // constructor has been called. + ConstructionTester* self_ptr_; + int value_; +}; + +int ConstructionTester::constructions = 0; +int ConstructionTester::destructions = 0; + +// ThreeInts will initialize its three ints to the value stored in +// ThreeInts::counter. The constructor increments counter so that each object +// in an array of ThreeInts will have different values. +class ThreeInts { + public: + ThreeInts() { + x_ = counter; + y_ = counter; + z_ = counter; + ++counter; + } + + static int counter; + + int x_, y_, z_; +}; + +int ThreeInts::counter = 0; + +TEST(FixedArrayTest, CopyCtor) { + absl::FixedArray<int, 10> on_stack(5); + std::iota(on_stack.begin(), on_stack.end(), 0); + absl::FixedArray<int, 10> stack_copy = on_stack; + EXPECT_THAT(stack_copy, ElementsAreArray(on_stack)); + EXPECT_TRUE(IsOnStack(stack_copy)); + + absl::FixedArray<int, 10> allocated(15); + std::iota(allocated.begin(), allocated.end(), 0); + absl::FixedArray<int, 10> alloced_copy = allocated; + EXPECT_THAT(alloced_copy, ElementsAreArray(allocated)); + EXPECT_FALSE(IsOnStack(alloced_copy)); +} + +TEST(FixedArrayTest, MoveCtor) { + absl::FixedArray<std::unique_ptr<int>, 10> on_stack(5); + for (int i = 0; i < 5; ++i) { + on_stack[i] = absl::make_unique<int>(i); + } + + absl::FixedArray<std::unique_ptr<int>, 10> stack_copy = std::move(on_stack); + for (int i = 0; i < 5; ++i) EXPECT_EQ(*(stack_copy[i]), i); + EXPECT_EQ(stack_copy.size(), on_stack.size()); + + absl::FixedArray<std::unique_ptr<int>, 10> allocated(15); + for (int i = 0; i < 15; ++i) { + allocated[i] = absl::make_unique<int>(i); + } + + absl::FixedArray<std::unique_ptr<int>, 10> alloced_copy = + std::move(allocated); + for (int i = 0; i < 15; ++i) EXPECT_EQ(*(alloced_copy[i]), i); + EXPECT_EQ(allocated.size(), alloced_copy.size()); +} + +TEST(FixedArrayTest, SmallObjects) { + // Small object arrays + { + // Short arrays should be on the stack + absl::FixedArray<int> array(4); + EXPECT_TRUE(IsOnStack(array)); + } + + { + // Large arrays should be on the heap + absl::FixedArray<int> array(1048576); + EXPECT_FALSE(IsOnStack(array)); + } + + { + // Arrays of <= default size should be on the stack + absl::FixedArray<int, 100> array(100); + EXPECT_TRUE(IsOnStack(array)); + } + + { + // Arrays of > default size should be on the heap + absl::FixedArray<int, 100> array(101); + EXPECT_FALSE(IsOnStack(array)); + } + + { + // Arrays with different size elements should use approximately + // same amount of stack space + absl::FixedArray<int> array1(0); + absl::FixedArray<char> array2(0); + EXPECT_LE(sizeof(array1), sizeof(array2) + 100); + EXPECT_LE(sizeof(array2), sizeof(array1) + 100); + } + + { + // Ensure that vectors are properly constructed inside a fixed array. + absl::FixedArray<std::vector<int>> array(2); + EXPECT_EQ(0, array[0].size()); + EXPECT_EQ(0, array[1].size()); + } + + { + // Regardless of absl::FixedArray implementation, check that a type with a + // low alignment requirement and a non power-of-two size is initialized + // correctly. + ThreeInts::counter = 1; + absl::FixedArray<ThreeInts> array(2); + EXPECT_EQ(1, array[0].x_); + EXPECT_EQ(1, array[0].y_); + EXPECT_EQ(1, array[0].z_); + EXPECT_EQ(2, array[1].x_); + EXPECT_EQ(2, array[1].y_); + EXPECT_EQ(2, array[1].z_); + } +} + +TEST(FixedArrayTest, AtThrows) { + absl::FixedArray<int> a = {1, 2, 3}; + EXPECT_EQ(a.at(2), 3); + ABSL_BASE_INTERNAL_EXPECT_FAIL(a.at(3), std::out_of_range, + "failed bounds check"); +} + +TEST(FixedArrayTest, Hardened) { +#if !defined(NDEBUG) || ABSL_OPTION_HARDENED + absl::FixedArray<int> a = {1, 2, 3}; + EXPECT_EQ(a[2], 3); + EXPECT_DEATH_IF_SUPPORTED(a[3], ""); + EXPECT_DEATH_IF_SUPPORTED(a[-1], ""); + + absl::FixedArray<int> empty(0); + EXPECT_DEATH_IF_SUPPORTED(empty[0], ""); + EXPECT_DEATH_IF_SUPPORTED(empty[-1], ""); + EXPECT_DEATH_IF_SUPPORTED(empty.front(), ""); + EXPECT_DEATH_IF_SUPPORTED(empty.back(), ""); +#endif +} + +TEST(FixedArrayRelationalsTest, EqualArrays) { + for (int i = 0; i < 10; ++i) { + absl::FixedArray<int, 5> a1(i); + std::iota(a1.begin(), a1.end(), 0); + absl::FixedArray<int, 5> a2(a1.begin(), a1.end()); + + EXPECT_TRUE(a1 == a2); + EXPECT_FALSE(a1 != a2); + EXPECT_TRUE(a2 == a1); + EXPECT_FALSE(a2 != a1); + EXPECT_FALSE(a1 < a2); + EXPECT_FALSE(a1 > a2); + EXPECT_FALSE(a2 < a1); + EXPECT_FALSE(a2 > a1); + EXPECT_TRUE(a1 <= a2); + EXPECT_TRUE(a1 >= a2); + EXPECT_TRUE(a2 <= a1); + EXPECT_TRUE(a2 >= a1); + } +} + +TEST(FixedArrayRelationalsTest, UnequalArrays) { + for (int i = 1; i < 10; ++i) { + absl::FixedArray<int, 5> a1(i); + std::iota(a1.begin(), a1.end(), 0); + absl::FixedArray<int, 5> a2(a1.begin(), a1.end()); + --a2[i / 2]; + + EXPECT_FALSE(a1 == a2); + EXPECT_TRUE(a1 != a2); + EXPECT_FALSE(a2 == a1); + EXPECT_TRUE(a2 != a1); + EXPECT_FALSE(a1 < a2); + EXPECT_TRUE(a1 > a2); + EXPECT_TRUE(a2 < a1); + EXPECT_FALSE(a2 > a1); + EXPECT_FALSE(a1 <= a2); + EXPECT_TRUE(a1 >= a2); + EXPECT_TRUE(a2 <= a1); + EXPECT_FALSE(a2 >= a1); + } +} + +template <int stack_elements> +static void TestArray(int n) { + SCOPED_TRACE(n); + SCOPED_TRACE(stack_elements); + ConstructionTester::constructions = 0; + ConstructionTester::destructions = 0; + { + absl::FixedArray<ConstructionTester, stack_elements> array(n); + + EXPECT_THAT(array.size(), n); + EXPECT_THAT(array.memsize(), sizeof(ConstructionTester) * n); + EXPECT_THAT(array.begin() + n, array.end()); + + // Check that all elements were constructed + for (int i = 0; i < n; i++) { + array[i].CheckConstructed(); + } + // Check that no other elements were constructed + EXPECT_THAT(ConstructionTester::constructions, n); + + // Test operator[] + for (int i = 0; i < n; i++) { + array[i].set(i); + } + for (int i = 0; i < n; i++) { + EXPECT_THAT(array[i].get(), i); + EXPECT_THAT(array.data()[i].get(), i); + } + + // Test data() + for (int i = 0; i < n; i++) { + array.data()[i].set(i + 1); + } + for (int i = 0; i < n; i++) { + EXPECT_THAT(array[i].get(), i + 1); + EXPECT_THAT(array.data()[i].get(), i + 1); + } + } // Close scope containing 'array'. + + // Check that all constructed elements were destructed. + EXPECT_EQ(ConstructionTester::constructions, + ConstructionTester::destructions); +} + +template <int elements_per_inner_array, int inline_elements> +static void TestArrayOfArrays(int n) { + SCOPED_TRACE(n); + SCOPED_TRACE(inline_elements); + SCOPED_TRACE(elements_per_inner_array); + ConstructionTester::constructions = 0; + ConstructionTester::destructions = 0; + { + using InnerArray = ConstructionTester[elements_per_inner_array]; + // Heap-allocate the FixedArray to avoid blowing the stack frame. + auto array_ptr = + absl::make_unique<absl::FixedArray<InnerArray, inline_elements>>(n); + auto& array = *array_ptr; + + ASSERT_EQ(array.size(), n); + ASSERT_EQ(array.memsize(), + sizeof(ConstructionTester) * elements_per_inner_array * n); + ASSERT_EQ(array.begin() + n, array.end()); + + // Check that all elements were constructed + for (int i = 0; i < n; i++) { + for (int j = 0; j < elements_per_inner_array; j++) { + (array[i])[j].CheckConstructed(); + } + } + // Check that no other elements were constructed + ASSERT_EQ(ConstructionTester::constructions, n * elements_per_inner_array); + + // Test operator[] + for (int i = 0; i < n; i++) { + for (int j = 0; j < elements_per_inner_array; j++) { + (array[i])[j].set(i * elements_per_inner_array + j); + } + } + for (int i = 0; i < n; i++) { + for (int j = 0; j < elements_per_inner_array; j++) { + ASSERT_EQ((array[i])[j].get(), i * elements_per_inner_array + j); + ASSERT_EQ((array.data()[i])[j].get(), i * elements_per_inner_array + j); + } + } + + // Test data() + for (int i = 0; i < n; i++) { + for (int j = 0; j < elements_per_inner_array; j++) { + (array.data()[i])[j].set((i + 1) * elements_per_inner_array + j); + } + } + for (int i = 0; i < n; i++) { + for (int j = 0; j < elements_per_inner_array; j++) { + ASSERT_EQ((array[i])[j].get(), (i + 1) * elements_per_inner_array + j); + ASSERT_EQ((array.data()[i])[j].get(), + (i + 1) * elements_per_inner_array + j); + } + } + } // Close scope containing 'array'. + + // Check that all constructed elements were destructed. + EXPECT_EQ(ConstructionTester::constructions, + ConstructionTester::destructions); +} + +TEST(IteratorConstructorTest, NonInline) { + int const kInput[] = {2, 3, 5, 7, 11, 13, 17}; + absl::FixedArray<int, ABSL_ARRAYSIZE(kInput) - 1> const fixed( + kInput, kInput + ABSL_ARRAYSIZE(kInput)); + ASSERT_EQ(ABSL_ARRAYSIZE(kInput), fixed.size()); + for (size_t i = 0; i < ABSL_ARRAYSIZE(kInput); ++i) { + ASSERT_EQ(kInput[i], fixed[i]); + } +} + +TEST(IteratorConstructorTest, Inline) { + int const kInput[] = {2, 3, 5, 7, 11, 13, 17}; + absl::FixedArray<int, ABSL_ARRAYSIZE(kInput)> const fixed( + kInput, kInput + ABSL_ARRAYSIZE(kInput)); + ASSERT_EQ(ABSL_ARRAYSIZE(kInput), fixed.size()); + for (size_t i = 0; i < ABSL_ARRAYSIZE(kInput); ++i) { + ASSERT_EQ(kInput[i], fixed[i]); + } +} + +TEST(IteratorConstructorTest, NonPod) { + char const* kInput[] = {"red", "orange", "yellow", "green", + "blue", "indigo", "violet"}; + absl::FixedArray<std::string> const fixed(kInput, + kInput + ABSL_ARRAYSIZE(kInput)); + ASSERT_EQ(ABSL_ARRAYSIZE(kInput), fixed.size()); + for (size_t i = 0; i < ABSL_ARRAYSIZE(kInput); ++i) { + ASSERT_EQ(kInput[i], fixed[i]); + } +} + +TEST(IteratorConstructorTest, FromEmptyVector) { + std::vector<int> const empty; + absl::FixedArray<int> const fixed(empty.begin(), empty.end()); + EXPECT_EQ(0, fixed.size()); + EXPECT_EQ(empty.size(), fixed.size()); +} + +TEST(IteratorConstructorTest, FromNonEmptyVector) { + int const kInput[] = {2, 3, 5, 7, 11, 13, 17}; + std::vector<int> const items(kInput, kInput + ABSL_ARRAYSIZE(kInput)); + absl::FixedArray<int> const fixed(items.begin(), items.end()); + ASSERT_EQ(items.size(), fixed.size()); + for (size_t i = 0; i < items.size(); ++i) { + ASSERT_EQ(items[i], fixed[i]); + } +} + +TEST(IteratorConstructorTest, FromBidirectionalIteratorRange) { + int const kInput[] = {2, 3, 5, 7, 11, 13, 17}; + std::list<int> const items(kInput, kInput + ABSL_ARRAYSIZE(kInput)); + absl::FixedArray<int> const fixed(items.begin(), items.end()); + EXPECT_THAT(fixed, testing::ElementsAreArray(kInput)); +} + +TEST(InitListConstructorTest, InitListConstruction) { + absl::FixedArray<int> fixed = {1, 2, 3}; + EXPECT_THAT(fixed, testing::ElementsAreArray({1, 2, 3})); +} + +TEST(FillConstructorTest, NonEmptyArrays) { + absl::FixedArray<int> stack_array(4, 1); + EXPECT_THAT(stack_array, testing::ElementsAreArray({1, 1, 1, 1})); + + absl::FixedArray<int, 0> heap_array(4, 1); + EXPECT_THAT(stack_array, testing::ElementsAreArray({1, 1, 1, 1})); +} + +TEST(FillConstructorTest, EmptyArray) { + absl::FixedArray<int> empty_fill(0, 1); + absl::FixedArray<int> empty_size(0); + EXPECT_EQ(empty_fill, empty_size); +} + +TEST(FillConstructorTest, NotTriviallyCopyable) { + std::string str = "abcd"; + absl::FixedArray<std::string> strings = {str, str, str, str}; + + absl::FixedArray<std::string> array(4, str); + EXPECT_EQ(array, strings); +} + +TEST(FillConstructorTest, Disambiguation) { + absl::FixedArray<size_t> a(1, 2); + EXPECT_THAT(a, testing::ElementsAre(2)); +} + +TEST(FixedArrayTest, ManySizedArrays) { + std::vector<int> sizes; + for (int i = 1; i < 100; i++) sizes.push_back(i); + for (int i = 100; i <= 1000; i += 100) sizes.push_back(i); + for (int n : sizes) { + TestArray<0>(n); + TestArray<1>(n); + TestArray<64>(n); + TestArray<1000>(n); + } +} + +TEST(FixedArrayTest, ManySizedArraysOfArraysOf1) { + for (int n = 1; n < 1000; n++) { + ASSERT_NO_FATAL_FAILURE((TestArrayOfArrays<1, 0>(n))); + ASSERT_NO_FATAL_FAILURE((TestArrayOfArrays<1, 1>(n))); + ASSERT_NO_FATAL_FAILURE((TestArrayOfArrays<1, 64>(n))); + ASSERT_NO_FATAL_FAILURE((TestArrayOfArrays<1, 1000>(n))); + } +} + +TEST(FixedArrayTest, ManySizedArraysOfArraysOf2) { + for (int n = 1; n < 1000; n++) { + TestArrayOfArrays<2, 0>(n); + TestArrayOfArrays<2, 1>(n); + TestArrayOfArrays<2, 64>(n); + TestArrayOfArrays<2, 1000>(n); + } +} + +// If value_type is put inside of a struct container, +// we might evoke this error in a hardened build unless data() is carefully +// written, so check on that. +// error: call to int __builtin___sprintf_chk(etc...) +// will always overflow destination buffer [-Werror] +TEST(FixedArrayTest, AvoidParanoidDiagnostics) { + absl::FixedArray<char, 32> buf(32); + sprintf(buf.data(), "foo"); // NOLINT(runtime/printf) +} + +TEST(FixedArrayTest, TooBigInlinedSpace) { + struct TooBig { + char c[1 << 20]; + }; // too big for even one on the stack + + // Simulate the data members of absl::FixedArray, a pointer and a size_t. + struct Data { + TooBig* p; + size_t size; + }; + + // Make sure TooBig objects are not inlined for 0 or default size. + static_assert(sizeof(absl::FixedArray<TooBig, 0>) == sizeof(Data), + "0-sized absl::FixedArray should have same size as Data."); + static_assert(alignof(absl::FixedArray<TooBig, 0>) == alignof(Data), + "0-sized absl::FixedArray should have same alignment as Data."); + static_assert(sizeof(absl::FixedArray<TooBig>) == sizeof(Data), + "default-sized absl::FixedArray should have same size as Data"); + static_assert( + alignof(absl::FixedArray<TooBig>) == alignof(Data), + "default-sized absl::FixedArray should have same alignment as Data."); +} + +// PickyDelete EXPECTs its class-scope deallocation funcs are unused. +struct PickyDelete { + PickyDelete() {} + ~PickyDelete() {} + void operator delete(void* p) { + EXPECT_TRUE(false) << __FUNCTION__; + ::operator delete(p); + } + void operator delete[](void* p) { + EXPECT_TRUE(false) << __FUNCTION__; + ::operator delete[](p); + } +}; + +TEST(FixedArrayTest, UsesGlobalAlloc) { absl::FixedArray<PickyDelete, 0> a(5); } + +TEST(FixedArrayTest, Data) { + static const int kInput[] = {2, 3, 5, 7, 11, 13, 17}; + absl::FixedArray<int> fa(std::begin(kInput), std::end(kInput)); + EXPECT_EQ(fa.data(), &*fa.begin()); + EXPECT_EQ(fa.data(), &fa[0]); + + const absl::FixedArray<int>& cfa = fa; + EXPECT_EQ(cfa.data(), &*cfa.begin()); + EXPECT_EQ(cfa.data(), &cfa[0]); +} + +TEST(FixedArrayTest, Empty) { + absl::FixedArray<int> empty(0); + absl::FixedArray<int> inline_filled(1); + absl::FixedArray<int, 0> heap_filled(1); + EXPECT_TRUE(empty.empty()); + EXPECT_FALSE(inline_filled.empty()); + EXPECT_FALSE(heap_filled.empty()); +} + +TEST(FixedArrayTest, FrontAndBack) { + absl::FixedArray<int, 3 * sizeof(int)> inlined = {1, 2, 3}; + EXPECT_EQ(inlined.front(), 1); + EXPECT_EQ(inlined.back(), 3); + + absl::FixedArray<int, 0> allocated = {1, 2, 3}; + EXPECT_EQ(allocated.front(), 1); + EXPECT_EQ(allocated.back(), 3); + + absl::FixedArray<int> one_element = {1}; + EXPECT_EQ(one_element.front(), one_element.back()); +} + +TEST(FixedArrayTest, ReverseIteratorInlined) { + absl::FixedArray<int, 5 * sizeof(int)> a = {0, 1, 2, 3, 4}; + + int counter = 5; + for (absl::FixedArray<int>::reverse_iterator iter = a.rbegin(); + iter != a.rend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + + counter = 5; + for (absl::FixedArray<int>::const_reverse_iterator iter = a.rbegin(); + iter != a.rend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + + counter = 5; + for (auto iter = a.crbegin(); iter != a.crend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); +} + +TEST(FixedArrayTest, ReverseIteratorAllocated) { + absl::FixedArray<int, 0> a = {0, 1, 2, 3, 4}; + + int counter = 5; + for (absl::FixedArray<int>::reverse_iterator iter = a.rbegin(); + iter != a.rend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + + counter = 5; + for (absl::FixedArray<int>::const_reverse_iterator iter = a.rbegin(); + iter != a.rend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + + counter = 5; + for (auto iter = a.crbegin(); iter != a.crend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); +} + +TEST(FixedArrayTest, Fill) { + absl::FixedArray<int, 5 * sizeof(int)> inlined(5); + int fill_val = 42; + inlined.fill(fill_val); + for (int i : inlined) EXPECT_EQ(i, fill_val); + + absl::FixedArray<int, 0> allocated(5); + allocated.fill(fill_val); + for (int i : allocated) EXPECT_EQ(i, fill_val); + + // It doesn't do anything, just make sure this compiles. + absl::FixedArray<int> empty(0); + empty.fill(fill_val); +} + +#ifndef __GNUC__ +TEST(FixedArrayTest, DefaultCtorDoesNotValueInit) { + using T = char; + constexpr auto capacity = 10; + using FixedArrType = absl::FixedArray<T, capacity>; + constexpr auto scrubbed_bits = 0x95; + constexpr auto length = capacity / 2; + + alignas(FixedArrType) unsigned char buff[sizeof(FixedArrType)]; + std::memset(std::addressof(buff), scrubbed_bits, sizeof(FixedArrType)); + + FixedArrType* arr = + ::new (static_cast<void*>(std::addressof(buff))) FixedArrType(length); + EXPECT_THAT(*arr, testing::Each(scrubbed_bits)); + arr->~FixedArrType(); +} +#endif // __GNUC__ + +TEST(AllocatorSupportTest, CountInlineAllocations) { + constexpr size_t inlined_size = 4; + using Alloc = absl::container_internal::CountingAllocator<int>; + using AllocFxdArr = absl::FixedArray<int, inlined_size, Alloc>; + + int64_t allocated = 0; + int64_t active_instances = 0; + + { + const int ia[] = {0, 1, 2, 3, 4, 5, 6, 7}; + + Alloc alloc(&allocated, &active_instances); + + AllocFxdArr arr(ia, ia + inlined_size, alloc); + static_cast<void>(arr); + } + + EXPECT_EQ(allocated, 0); + EXPECT_EQ(active_instances, 0); +} + +TEST(AllocatorSupportTest, CountOutoflineAllocations) { + constexpr size_t inlined_size = 4; + using Alloc = absl::container_internal::CountingAllocator<int>; + using AllocFxdArr = absl::FixedArray<int, inlined_size, Alloc>; + + int64_t allocated = 0; + int64_t active_instances = 0; + + { + const int ia[] = {0, 1, 2, 3, 4, 5, 6, 7}; + Alloc alloc(&allocated, &active_instances); + + AllocFxdArr arr(ia, ia + ABSL_ARRAYSIZE(ia), alloc); + + EXPECT_EQ(allocated, arr.size() * sizeof(int)); + static_cast<void>(arr); + } + + EXPECT_EQ(active_instances, 0); +} + +TEST(AllocatorSupportTest, CountCopyInlineAllocations) { + constexpr size_t inlined_size = 4; + using Alloc = absl::container_internal::CountingAllocator<int>; + using AllocFxdArr = absl::FixedArray<int, inlined_size, Alloc>; + + int64_t allocated1 = 0; + int64_t allocated2 = 0; + int64_t active_instances = 0; + Alloc alloc(&allocated1, &active_instances); + Alloc alloc2(&allocated2, &active_instances); + + { + int initial_value = 1; + + AllocFxdArr arr1(inlined_size / 2, initial_value, alloc); + + EXPECT_EQ(allocated1, 0); + + AllocFxdArr arr2(arr1, alloc2); + + EXPECT_EQ(allocated2, 0); + static_cast<void>(arr1); + static_cast<void>(arr2); + } + + EXPECT_EQ(active_instances, 0); +} + +TEST(AllocatorSupportTest, CountCopyOutoflineAllocations) { + constexpr size_t inlined_size = 4; + using Alloc = absl::container_internal::CountingAllocator<int>; + using AllocFxdArr = absl::FixedArray<int, inlined_size, Alloc>; + + int64_t allocated1 = 0; + int64_t allocated2 = 0; + int64_t active_instances = 0; + Alloc alloc(&allocated1, &active_instances); + Alloc alloc2(&allocated2, &active_instances); + + { + int initial_value = 1; + + AllocFxdArr arr1(inlined_size * 2, initial_value, alloc); + + EXPECT_EQ(allocated1, arr1.size() * sizeof(int)); + + AllocFxdArr arr2(arr1, alloc2); + + EXPECT_EQ(allocated2, inlined_size * 2 * sizeof(int)); + static_cast<void>(arr1); + static_cast<void>(arr2); + } + + EXPECT_EQ(active_instances, 0); +} + +TEST(AllocatorSupportTest, SizeValAllocConstructor) { + using testing::AllOf; + using testing::Each; + using testing::SizeIs; + + constexpr size_t inlined_size = 4; + using Alloc = absl::container_internal::CountingAllocator<int>; + using AllocFxdArr = absl::FixedArray<int, inlined_size, Alloc>; + + { + auto len = inlined_size / 2; + auto val = 0; + int64_t allocated = 0; + AllocFxdArr arr(len, val, Alloc(&allocated)); + + EXPECT_EQ(allocated, 0); + EXPECT_THAT(arr, AllOf(SizeIs(len), Each(0))); + } + + { + auto len = inlined_size * 2; + auto val = 0; + int64_t allocated = 0; + AllocFxdArr arr(len, val, Alloc(&allocated)); + + EXPECT_EQ(allocated, len * sizeof(int)); + EXPECT_THAT(arr, AllOf(SizeIs(len), Each(0))); + } +} + +#ifdef ADDRESS_SANITIZER +TEST(FixedArrayTest, AddressSanitizerAnnotations1) { + absl::FixedArray<int, 32> a(10); + int* raw = a.data(); + raw[0] = 0; + raw[9] = 0; + EXPECT_DEATH_IF_SUPPORTED(raw[-2] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[-1] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[10] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[31] = 0, "container-overflow"); +} + +TEST(FixedArrayTest, AddressSanitizerAnnotations2) { + absl::FixedArray<char, 17> a(12); + char* raw = a.data(); + raw[0] = 0; + raw[11] = 0; + EXPECT_DEATH_IF_SUPPORTED(raw[-7] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[-1] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[12] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[17] = 0, "container-overflow"); +} + +TEST(FixedArrayTest, AddressSanitizerAnnotations3) { + absl::FixedArray<uint64_t, 20> a(20); + uint64_t* raw = a.data(); + raw[0] = 0; + raw[19] = 0; + EXPECT_DEATH_IF_SUPPORTED(raw[-1] = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[20] = 0, "container-overflow"); +} + +TEST(FixedArrayTest, AddressSanitizerAnnotations4) { + absl::FixedArray<ThreeInts> a(10); + ThreeInts* raw = a.data(); + raw[0] = ThreeInts(); + raw[9] = ThreeInts(); + // Note: raw[-1] is pointing to 12 bytes before the container range. However, + // there is only a 8-byte red zone before the container range, so we only + // access the last 4 bytes of the struct to make sure it stays within the red + // zone. + EXPECT_DEATH_IF_SUPPORTED(raw[-1].z_ = 0, "container-overflow"); + EXPECT_DEATH_IF_SUPPORTED(raw[10] = ThreeInts(), "container-overflow"); + // The actual size of storage is kDefaultBytes=256, 21*12 = 252, + // so reading raw[21] should still trigger the correct warning. + EXPECT_DEATH_IF_SUPPORTED(raw[21] = ThreeInts(), "container-overflow"); +} +#endif // ADDRESS_SANITIZER + +TEST(FixedArrayTest, AbslHashValueWorks) { + using V = absl::FixedArray<int>; + std::vector<V> cases; + + // Generate a variety of vectors some of these are small enough for the inline + // space but are stored out of line. + for (int i = 0; i < 10; ++i) { + V v(i); + for (int j = 0; j < i; ++j) { + v[j] = j; + } + cases.push_back(v); + } + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(cases)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/container/flat_hash_map.h b/third_party/abseil_cpp/absl/container/flat_hash_map.h new file mode 100644 index 0000000000..fcb70d861f --- /dev/null +++ b/third_party/abseil_cpp/absl/container/flat_hash_map.h @@ -0,0 +1,600 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: flat_hash_map.h +// ----------------------------------------------------------------------------- +// +// An `absl::flat_hash_map<K, V>` is an unordered associative container of +// unique keys and associated values designed to be a more efficient replacement +// for `std::unordered_map`. Like `unordered_map`, search, insertion, and +// deletion of map elements can be done as an `O(1)` operation. However, +// `flat_hash_map` (and other unordered associative containers known as the +// collection of Abseil "Swiss tables") contain other optimizations that result +// in both memory and computation advantages. +// +// In most cases, your default choice for a hash map should be a map of type +// `flat_hash_map`. + +#ifndef ABSL_CONTAINER_FLAT_HASH_MAP_H_ +#define ABSL_CONTAINER_FLAT_HASH_MAP_H_ + +#include <cstddef> +#include <new> +#include <type_traits> +#include <utility> + +#include "absl/algorithm/container.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/hash_function_defaults.h" // IWYU pragma: export +#include "absl/container/internal/raw_hash_map.h" // IWYU pragma: export +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +template <class K, class V> +struct FlatHashMapPolicy; +} // namespace container_internal + +// ----------------------------------------------------------------------------- +// absl::flat_hash_map +// ----------------------------------------------------------------------------- +// +// An `absl::flat_hash_map<K, V>` is an unordered associative container which +// has been optimized for both speed and memory footprint in most common use +// cases. Its interface is similar to that of `std::unordered_map<K, V>` with +// the following notable differences: +// +// * Requires keys that are CopyConstructible +// * Requires values that are MoveConstructible +// * Supports heterogeneous lookup, through `find()`, `operator[]()` and +// `insert()`, provided that the map is provided a compatible heterogeneous +// hashing function and equality operator. +// * Invalidates any references and pointers to elements within the table after +// `rehash()`. +// * Contains a `capacity()` member function indicating the number of element +// slots (open, deleted, and empty) within the hash map. +// * Returns `void` from the `erase(iterator)` overload. +// +// By default, `flat_hash_map` uses the `absl::Hash` hashing framework. +// All fundamental and Abseil types that support the `absl::Hash` framework have +// a compatible equality operator for comparing insertions into `flat_hash_map`. +// If your type is not yet supported by the `absl::Hash` framework, see +// absl/hash/hash.h for information on extending Abseil hashing to user-defined +// types. +// +// NOTE: A `flat_hash_map` stores its value types directly inside its +// implementation array to avoid memory indirection. Because a `flat_hash_map` +// is designed to move data when rehashed, map values will not retain pointer +// stability. If you require pointer stability, or if your values are large, +// consider using `absl::flat_hash_map<Key, std::unique_ptr<Value>>` instead. +// If your types are not moveable or you require pointer stability for keys, +// consider `absl::node_hash_map`. +// +// Example: +// +// // Create a flat hash map of three strings (that map to strings) +// absl::flat_hash_map<std::string, std::string> ducks = +// {{"a", "huey"}, {"b", "dewey"}, {"c", "louie"}}; +// +// // Insert a new element into the flat hash map +// ducks.insert({"d", "donald"}); +// +// // Force a rehash of the flat hash map +// ducks.rehash(0); +// +// // Find the element with the key "b" +// std::string search_key = "b"; +// auto result = ducks.find(search_key); +// if (result != ducks.end()) { +// std::cout << "Result: " << result->second << std::endl; +// } +template <class K, class V, + class Hash = absl::container_internal::hash_default_hash<K>, + class Eq = absl::container_internal::hash_default_eq<K>, + class Allocator = std::allocator<std::pair<const K, V>>> +class flat_hash_map : public absl::container_internal::raw_hash_map< + absl::container_internal::FlatHashMapPolicy<K, V>, + Hash, Eq, Allocator> { + using Base = typename flat_hash_map::raw_hash_map; + + public: + // Constructors and Assignment Operators + // + // A flat_hash_map supports the same overload set as `std::unordered_map` + // for construction and assignment: + // + // * Default constructor + // + // // No allocation for the table's elements is made. + // absl::flat_hash_map<int, std::string> map1; + // + // * Initializer List constructor + // + // absl::flat_hash_map<int, std::string> map2 = + // {{1, "huey"}, {2, "dewey"}, {3, "louie"},}; + // + // * Copy constructor + // + // absl::flat_hash_map<int, std::string> map3(map2); + // + // * Copy assignment operator + // + // // Hash functor and Comparator are copied as well + // absl::flat_hash_map<int, std::string> map4; + // map4 = map3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::flat_hash_map<int, std::string> map5(std::move(map4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::flat_hash_map<int, std::string> map6; + // map6 = std::move(map5); + // + // * Range constructor + // + // std::vector<std::pair<int, std::string>> v = {{1, "a"}, {2, "b"}}; + // absl::flat_hash_map<int, std::string> map7(v.begin(), v.end()); + flat_hash_map() {} + using Base::Base; + + // flat_hash_map::begin() + // + // Returns an iterator to the beginning of the `flat_hash_map`. + using Base::begin; + + // flat_hash_map::cbegin() + // + // Returns a const iterator to the beginning of the `flat_hash_map`. + using Base::cbegin; + + // flat_hash_map::cend() + // + // Returns a const iterator to the end of the `flat_hash_map`. + using Base::cend; + + // flat_hash_map::end() + // + // Returns an iterator to the end of the `flat_hash_map`. + using Base::end; + + // flat_hash_map::capacity() + // + // Returns the number of element slots (assigned, deleted, and empty) + // available within the `flat_hash_map`. + // + // NOTE: this member function is particular to `absl::flat_hash_map` and is + // not provided in the `std::unordered_map` API. + using Base::capacity; + + // flat_hash_map::empty() + // + // Returns whether or not the `flat_hash_map` is empty. + using Base::empty; + + // flat_hash_map::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `flat_hash_map` under current memory constraints. This value can be thought + // of the largest value of `std::distance(begin(), end())` for a + // `flat_hash_map<K, V>`. + using Base::max_size; + + // flat_hash_map::size() + // + // Returns the number of elements currently within the `flat_hash_map`. + using Base::size; + + // flat_hash_map::clear() + // + // Removes all elements from the `flat_hash_map`. Invalidates any references, + // pointers, or iterators referring to contained elements. + // + // NOTE: this operation may shrink the underlying buffer. To avoid shrinking + // the underlying buffer call `erase(begin(), end())`. + using Base::clear; + + // flat_hash_map::erase() + // + // Erases elements within the `flat_hash_map`. Erasing does not trigger a + // rehash. Overloads are listed below. + // + // void erase(const_iterator pos): + // + // Erases the element at `position` of the `flat_hash_map`, returning + // `void`. + // + // NOTE: returning `void` in this case is different than that of STL + // containers in general and `std::unordered_map` in particular (which + // return an iterator to the element following the erased element). If that + // iterator is needed, simply post increment the iterator: + // + // map.erase(it++); + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning an + // iterator pointing to `last`. + // + // size_type erase(const key_type& key): + // + // Erases the element with the matching key, if it exists. + using Base::erase; + + // flat_hash_map::insert() + // + // Inserts an element of the specified value into the `flat_hash_map`, + // returning an iterator pointing to the newly inserted element, provided that + // an element with the given key does not already exist. If rehashing occurs + // due to the insertion, all iterators are invalidated. Overloads are listed + // below. + // + // std::pair<iterator,bool> insert(const init_type& value): + // + // Inserts a value into the `flat_hash_map`. Returns a pair consisting of an + // iterator to the inserted element (or to the element that prevented the + // insertion) and a bool denoting whether the insertion took place. + // + // std::pair<iterator,bool> insert(T&& value): + // std::pair<iterator,bool> insert(init_type&& value): + // + // Inserts a moveable value into the `flat_hash_map`. Returns a pair + // consisting of an iterator to the inserted element (or to the element that + // prevented the insertion) and a bool denoting whether the insertion took + // place. + // + // iterator insert(const_iterator hint, const init_type& value): + // iterator insert(const_iterator hint, T&& value): + // iterator insert(const_iterator hint, init_type&& value); + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element, or to the existing element that prevented the + // insertion. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently, for `flat_hash_map` we guarantee the + // first match is inserted. + // + // void insert(std::initializer_list<init_type> ilist): + // + // Inserts the elements within the initializer list `ilist`. + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently within the initializer list, for + // `flat_hash_map` we guarantee the first match is inserted. + using Base::insert; + + // flat_hash_map::insert_or_assign() + // + // Inserts an element of the specified value into the `flat_hash_map` provided + // that a value with the given key does not already exist, or replaces it with + // the element value if a key for that value already exists, returning an + // iterator pointing to the newly inserted element. If rehashing occurs due + // to the insertion, all existing iterators are invalidated. Overloads are + // listed below. + // + // pair<iterator, bool> insert_or_assign(const init_type& k, T&& obj): + // pair<iterator, bool> insert_or_assign(init_type&& k, T&& obj): + // + // Inserts/Assigns (or moves) the element of the specified key into the + // `flat_hash_map`. + // + // iterator insert_or_assign(const_iterator hint, + // const init_type& k, T&& obj): + // iterator insert_or_assign(const_iterator hint, init_type&& k, T&& obj): + // + // Inserts/Assigns (or moves) the element of the specified key into the + // `flat_hash_map` using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. + using Base::insert_or_assign; + + // flat_hash_map::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `flat_hash_map`, provided that no element with the given key + // already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. Prefer `try_emplace()` unless your key is not + // copyable or moveable. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace; + + // flat_hash_map::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `flat_hash_map`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search, and only inserts + // provided that no element with the given key already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. Prefer `try_emplace()` unless your key is not + // copyable or moveable. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace_hint; + + // flat_hash_map::try_emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `flat_hash_map`, provided that no element with the given key + // already exists. Unlike `emplace()`, if an element with the given key + // already exists, we guarantee that no element is constructed. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + // Overloads are listed below. + // + // pair<iterator, bool> try_emplace(const key_type& k, Args&&... args): + // pair<iterator, bool> try_emplace(key_type&& k, Args&&... args): + // + // Inserts (via copy or move) the element of the specified key into the + // `flat_hash_map`. + // + // iterator try_emplace(const_iterator hint, + // const init_type& k, Args&&... args): + // iterator try_emplace(const_iterator hint, init_type&& k, Args&&... args): + // + // Inserts (via copy or move) the element of the specified key into the + // `flat_hash_map` using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. + // + // All `try_emplace()` overloads make the same guarantees regarding rvalue + // arguments as `std::unordered_map::try_emplace()`, namely that these + // functions will not move from rvalue arguments if insertions do not happen. + using Base::try_emplace; + + // flat_hash_map::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the key,value pair of the element at the indicated position and + // returns a node handle owning that extracted data. + // + // node_type extract(const key_type& x): + // + // Extracts the key,value pair of the element with a key matching the passed + // key value and returns a node handle owning that extracted data. If the + // `flat_hash_map` does not contain an element with a matching key, this + // function returns an empty node handle. + using Base::extract; + + // flat_hash_map::merge() + // + // Extracts elements from a given `source` flat hash map into this + // `flat_hash_map`. If the destination `flat_hash_map` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // flat_hash_map::swap(flat_hash_map& other) + // + // Exchanges the contents of this `flat_hash_map` with those of the `other` + // flat hash map, avoiding invocation of any move, copy, or swap operations on + // individual elements. + // + // All iterators and references on the `flat_hash_map` remain valid, excepting + // for the past-the-end iterator, which is invalidated. + // + // `swap()` requires that the flat hash map's hashing and key equivalence + // functions be Swappable, and are exchanged using unqualified calls to + // non-member `swap()`. If the map's allocator has + // `std::allocator_traits<allocator_type>::propagate_on_container_swap::value` + // set to `true`, the allocators are also exchanged using an unqualified call + // to non-member `swap()`; otherwise, the allocators are not swapped. + using Base::swap; + + // flat_hash_map::rehash(count) + // + // Rehashes the `flat_hash_map`, setting the number of slots to be at least + // the passed value. If the new number of slots increases the load factor more + // than the current maximum load factor + // (`count` < `size()` / `max_load_factor()`), then the new number of slots + // will be at least `size()` / `max_load_factor()`. + // + // To force a rehash, pass rehash(0). + // + // NOTE: unlike behavior in `std::unordered_map`, references are also + // invalidated upon a `rehash()`. + using Base::rehash; + + // flat_hash_map::reserve(count) + // + // Sets the number of slots in the `flat_hash_map` to the number needed to + // accommodate at least `count` total elements without exceeding the current + // maximum load factor, and may rehash the container if needed. + using Base::reserve; + + // flat_hash_map::at() + // + // Returns a reference to the mapped value of the element with key equivalent + // to the passed key. + using Base::at; + + // flat_hash_map::contains() + // + // Determines whether an element with a key comparing equal to the given `key` + // exists within the `flat_hash_map`, returning `true` if so or `false` + // otherwise. + using Base::contains; + + // flat_hash_map::count(const Key& key) const + // + // Returns the number of elements with a key comparing equal to the given + // `key` within the `flat_hash_map`. note that this function will return + // either `1` or `0` since duplicate keys are not allowed within a + // `flat_hash_map`. + using Base::count; + + // flat_hash_map::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `flat_hash_map`. + using Base::equal_range; + + // flat_hash_map::find() + // + // Finds an element with the passed `key` within the `flat_hash_map`. + using Base::find; + + // flat_hash_map::operator[]() + // + // Returns a reference to the value mapped to the passed key within the + // `flat_hash_map`, performing an `insert()` if the key does not already + // exist. + // + // If an insertion occurs and results in a rehashing of the container, all + // iterators are invalidated. Otherwise iterators are not affected and + // references are not invalidated. Overloads are listed below. + // + // T& operator[](const Key& key): + // + // Inserts an init_type object constructed in-place if the element with the + // given key does not exist. + // + // T& operator[](Key&& key): + // + // Inserts an init_type object constructed in-place provided that an element + // with the given key does not exist. + using Base::operator[]; + + // flat_hash_map::bucket_count() + // + // Returns the number of "buckets" within the `flat_hash_map`. Note that + // because a flat hash map contains all elements within its internal storage, + // this value simply equals the current capacity of the `flat_hash_map`. + using Base::bucket_count; + + // flat_hash_map::load_factor() + // + // Returns the current load factor of the `flat_hash_map` (the average number + // of slots occupied with a value within the hash map). + using Base::load_factor; + + // flat_hash_map::max_load_factor() + // + // Manages the maximum load factor of the `flat_hash_map`. Overloads are + // listed below. + // + // float flat_hash_map::max_load_factor() + // + // Returns the current maximum load factor of the `flat_hash_map`. + // + // void flat_hash_map::max_load_factor(float ml) + // + // Sets the maximum load factor of the `flat_hash_map` to the passed value. + // + // NOTE: This overload is provided only for API compatibility with the STL; + // `flat_hash_map` will ignore any set load factor and manage its rehashing + // internally as an implementation detail. + using Base::max_load_factor; + + // flat_hash_map::get_allocator() + // + // Returns the allocator function associated with this `flat_hash_map`. + using Base::get_allocator; + + // flat_hash_map::hash_function() + // + // Returns the hashing function used to hash the keys within this + // `flat_hash_map`. + using Base::hash_function; + + // flat_hash_map::key_eq() + // + // Returns the function used for comparing keys equality. + using Base::key_eq; +}; + +// erase_if(flat_hash_map<>, Pred) +// +// Erases all elements that satisfy the predicate `pred` from the container `c`. +template <typename K, typename V, typename H, typename E, typename A, + typename Predicate> +void erase_if(flat_hash_map<K, V, H, E, A>& c, Predicate pred) { + container_internal::EraseIf(pred, &c); +} + +namespace container_internal { + +template <class K, class V> +struct FlatHashMapPolicy { + using slot_policy = container_internal::map_slot_policy<K, V>; + using slot_type = typename slot_policy::slot_type; + using key_type = K; + using mapped_type = V; + using init_type = std::pair</*non const*/ key_type, mapped_type>; + + template <class Allocator, class... Args> + static void construct(Allocator* alloc, slot_type* slot, Args&&... args) { + slot_policy::construct(alloc, slot, std::forward<Args>(args)...); + } + + template <class Allocator> + static void destroy(Allocator* alloc, slot_type* slot) { + slot_policy::destroy(alloc, slot); + } + + template <class Allocator> + static void transfer(Allocator* alloc, slot_type* new_slot, + slot_type* old_slot) { + slot_policy::transfer(alloc, new_slot, old_slot); + } + + template <class F, class... Args> + static decltype(absl::container_internal::DecomposePair( + std::declval<F>(), std::declval<Args>()...)) + apply(F&& f, Args&&... args) { + return absl::container_internal::DecomposePair(std::forward<F>(f), + std::forward<Args>(args)...); + } + + static size_t space_used(const slot_type*) { return 0; } + + static std::pair<const K, V>& element(slot_type* slot) { return slot->value; } + + static V& value(std::pair<const K, V>* kv) { return kv->second; } + static const V& value(const std::pair<const K, V>* kv) { return kv->second; } +}; + +} // namespace container_internal + +namespace container_algorithm_internal { + +// Specialization of trait in absl/algorithm/container.h +template <class Key, class T, class Hash, class KeyEqual, class Allocator> +struct IsUnorderedContainer< + absl::flat_hash_map<Key, T, Hash, KeyEqual, Allocator>> : std::true_type {}; + +} // namespace container_algorithm_internal + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_FLAT_HASH_MAP_H_ diff --git a/third_party/abseil_cpp/absl/container/flat_hash_map_test.cc b/third_party/abseil_cpp/absl/container/flat_hash_map_test.cc new file mode 100644 index 0000000000..2823c32bbe --- /dev/null +++ b/third_party/abseil_cpp/absl/container/flat_hash_map_test.cc @@ -0,0 +1,273 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/flat_hash_map.h" + +#include <memory> + +#include "absl/base/internal/raw_logging.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/unordered_map_constructor_test.h" +#include "absl/container/internal/unordered_map_lookup_test.h" +#include "absl/container/internal/unordered_map_members_test.h" +#include "absl/container/internal/unordered_map_modifiers_test.h" +#include "absl/types/any.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { +using ::absl::container_internal::hash_internal::Enum; +using ::absl::container_internal::hash_internal::EnumClass; +using ::testing::_; +using ::testing::IsEmpty; +using ::testing::Pair; +using ::testing::UnorderedElementsAre; + +// Check that absl::flat_hash_map works in a global constructor. +struct BeforeMain { + BeforeMain() { + absl::flat_hash_map<int, int> x; + x.insert({1, 1}); + ABSL_RAW_CHECK(x.find(0) == x.end(), "x should not contain 0"); + auto it = x.find(1); + ABSL_RAW_CHECK(it != x.end(), "x should contain 1"); + ABSL_RAW_CHECK(it->second, "1 should map to 1"); + } +}; +const BeforeMain before_main; + +template <class K, class V> +using Map = flat_hash_map<K, V, StatefulTestingHash, StatefulTestingEqual, + Alloc<std::pair<const K, V>>>; + +static_assert(!std::is_standard_layout<NonStandardLayout>(), ""); + +using MapTypes = + ::testing::Types<Map<int, int>, Map<std::string, int>, + Map<Enum, std::string>, Map<EnumClass, int>, + Map<int, NonStandardLayout>, Map<NonStandardLayout, int>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashMap, ConstructorTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashMap, LookupTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashMap, MembersTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashMap, ModifiersTest, MapTypes); + +using UniquePtrMapTypes = ::testing::Types<Map<int, std::unique_ptr<int>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashMap, UniquePtrModifiersTest, + UniquePtrMapTypes); + +TEST(FlatHashMap, StandardLayout) { + struct Int { + explicit Int(size_t value) : value(value) {} + Int() : value(0) { ADD_FAILURE(); } + Int(const Int& other) : value(other.value) { ADD_FAILURE(); } + Int(Int&&) = default; + bool operator==(const Int& other) const { return value == other.value; } + size_t value; + }; + static_assert(std::is_standard_layout<Int>(), ""); + + struct Hash { + size_t operator()(const Int& obj) const { return obj.value; } + }; + + // Verify that neither the key nor the value get default-constructed or + // copy-constructed. + { + flat_hash_map<Int, Int, Hash> m; + m.try_emplace(Int(1), Int(2)); + m.try_emplace(Int(3), Int(4)); + m.erase(Int(1)); + m.rehash(2 * m.bucket_count()); + } + { + flat_hash_map<Int, Int, Hash> m; + m.try_emplace(Int(1), Int(2)); + m.try_emplace(Int(3), Int(4)); + m.erase(Int(1)); + m.clear(); + } +} + +// gcc becomes unhappy if this is inside the method, so pull it out here. +struct balast {}; + +TEST(FlatHashMap, IteratesMsan) { + // Because SwissTable randomizes on pointer addresses, we keep old tables + // around to ensure we don't reuse old memory. + std::vector<absl::flat_hash_map<int, balast>> garbage; + for (int i = 0; i < 100; ++i) { + absl::flat_hash_map<int, balast> t; + for (int j = 0; j < 100; ++j) { + t[j]; + for (const auto& p : t) EXPECT_THAT(p, Pair(_, _)); + } + garbage.push_back(std::move(t)); + } +} + +// Demonstration of the "Lazy Key" pattern. This uses heterogeneous insert to +// avoid creating expensive key elements when the item is already present in the +// map. +struct LazyInt { + explicit LazyInt(size_t value, int* tracker) + : value(value), tracker(tracker) {} + + explicit operator size_t() const { + ++*tracker; + return value; + } + + size_t value; + int* tracker; +}; + +struct Hash { + using is_transparent = void; + int* tracker; + size_t operator()(size_t obj) const { + ++*tracker; + return obj; + } + size_t operator()(const LazyInt& obj) const { + ++*tracker; + return obj.value; + } +}; + +struct Eq { + using is_transparent = void; + bool operator()(size_t lhs, size_t rhs) const { + return lhs == rhs; + } + bool operator()(size_t lhs, const LazyInt& rhs) const { + return lhs == rhs.value; + } +}; + +TEST(FlatHashMap, LazyKeyPattern) { + // hashes are only guaranteed in opt mode, we use assertions to track internal + // state that can cause extra calls to hash. + int conversions = 0; + int hashes = 0; + flat_hash_map<size_t, size_t, Hash, Eq> m(0, Hash{&hashes}); + m.reserve(3); + + m[LazyInt(1, &conversions)] = 1; + EXPECT_THAT(m, UnorderedElementsAre(Pair(1, 1))); + EXPECT_EQ(conversions, 1); +#ifdef NDEBUG + EXPECT_EQ(hashes, 1); +#endif + + m[LazyInt(1, &conversions)] = 2; + EXPECT_THAT(m, UnorderedElementsAre(Pair(1, 2))); + EXPECT_EQ(conversions, 1); +#ifdef NDEBUG + EXPECT_EQ(hashes, 2); +#endif + + m.try_emplace(LazyInt(2, &conversions), 3); + EXPECT_THAT(m, UnorderedElementsAre(Pair(1, 2), Pair(2, 3))); + EXPECT_EQ(conversions, 2); +#ifdef NDEBUG + EXPECT_EQ(hashes, 3); +#endif + + m.try_emplace(LazyInt(2, &conversions), 4); + EXPECT_THAT(m, UnorderedElementsAre(Pair(1, 2), Pair(2, 3))); + EXPECT_EQ(conversions, 2); +#ifdef NDEBUG + EXPECT_EQ(hashes, 4); +#endif +} + +TEST(FlatHashMap, BitfieldArgument) { + union { + int n : 1; + }; + n = 0; + flat_hash_map<int, int> m; + m.erase(n); + m.count(n); + m.prefetch(n); + m.find(n); + m.contains(n); + m.equal_range(n); + m.insert_or_assign(n, n); + m.insert_or_assign(m.end(), n, n); + m.try_emplace(n); + m.try_emplace(m.end(), n); + m.at(n); + m[n]; +} + +TEST(FlatHashMap, MergeExtractInsert) { + // We can't test mutable keys, or non-copyable keys with flat_hash_map. + // Test that the nodes have the proper API. + absl::flat_hash_map<int, int> m = {{1, 7}, {2, 9}}; + auto node = m.extract(1); + EXPECT_TRUE(node); + EXPECT_EQ(node.key(), 1); + EXPECT_EQ(node.mapped(), 7); + EXPECT_THAT(m, UnorderedElementsAre(Pair(2, 9))); + + node.mapped() = 17; + m.insert(std::move(node)); + EXPECT_THAT(m, UnorderedElementsAre(Pair(1, 17), Pair(2, 9))); +} + +bool FirstIsEven(std::pair<const int, int> p) { return p.first % 2 == 0; } + +TEST(FlatHashMap, EraseIf) { + // Erase all elements. + { + flat_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, [](std::pair<const int, int>) { return true; }); + EXPECT_THAT(s, IsEmpty()); + } + // Erase no elements. + { + flat_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, [](std::pair<const int, int>) { return false; }); + EXPECT_THAT(s, UnorderedElementsAre(Pair(1, 1), Pair(2, 2), Pair(3, 3), + Pair(4, 4), Pair(5, 5))); + } + // Erase specific elements. + { + flat_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, + [](std::pair<const int, int> kvp) { return kvp.first % 2 == 1; }); + EXPECT_THAT(s, UnorderedElementsAre(Pair(2, 2), Pair(4, 4))); + } + // Predicate is function reference. + { + flat_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, FirstIsEven); + EXPECT_THAT(s, UnorderedElementsAre(Pair(1, 1), Pair(3, 3), Pair(5, 5))); + } + // Predicate is function pointer. + { + flat_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, &FirstIsEven); + EXPECT_THAT(s, UnorderedElementsAre(Pair(1, 1), Pair(3, 3), Pair(5, 5))); + } +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/flat_hash_set.h b/third_party/abseil_cpp/absl/container/flat_hash_set.h new file mode 100644 index 0000000000..94be6e3d13 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/flat_hash_set.h @@ -0,0 +1,503 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: flat_hash_set.h +// ----------------------------------------------------------------------------- +// +// An `absl::flat_hash_set<T>` is an unordered associative container designed to +// be a more efficient replacement for `std::unordered_set`. Like +// `unordered_set`, search, insertion, and deletion of set elements can be done +// as an `O(1)` operation. However, `flat_hash_set` (and other unordered +// associative containers known as the collection of Abseil "Swiss tables") +// contain other optimizations that result in both memory and computation +// advantages. +// +// In most cases, your default choice for a hash set should be a set of type +// `flat_hash_set`. +#ifndef ABSL_CONTAINER_FLAT_HASH_SET_H_ +#define ABSL_CONTAINER_FLAT_HASH_SET_H_ + +#include <type_traits> +#include <utility> + +#include "absl/algorithm/container.h" +#include "absl/base/macros.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/hash_function_defaults.h" // IWYU pragma: export +#include "absl/container/internal/raw_hash_set.h" // IWYU pragma: export +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +template <typename T> +struct FlatHashSetPolicy; +} // namespace container_internal + +// ----------------------------------------------------------------------------- +// absl::flat_hash_set +// ----------------------------------------------------------------------------- +// +// An `absl::flat_hash_set<T>` is an unordered associative container which has +// been optimized for both speed and memory footprint in most common use cases. +// Its interface is similar to that of `std::unordered_set<T>` with the +// following notable differences: +// +// * Requires keys that are CopyConstructible +// * Supports heterogeneous lookup, through `find()` and `insert()`, provided +// that the set is provided a compatible heterogeneous hashing function and +// equality operator. +// * Invalidates any references and pointers to elements within the table after +// `rehash()`. +// * Contains a `capacity()` member function indicating the number of element +// slots (open, deleted, and empty) within the hash set. +// * Returns `void` from the `erase(iterator)` overload. +// +// By default, `flat_hash_set` uses the `absl::Hash` hashing framework. All +// fundamental and Abseil types that support the `absl::Hash` framework have a +// compatible equality operator for comparing insertions into `flat_hash_map`. +// If your type is not yet supported by the `absl::Hash` framework, see +// absl/hash/hash.h for information on extending Abseil hashing to user-defined +// types. +// +// NOTE: A `flat_hash_set` stores its keys directly inside its implementation +// array to avoid memory indirection. Because a `flat_hash_set` is designed to +// move data when rehashed, set keys will not retain pointer stability. If you +// require pointer stability, consider using +// `absl::flat_hash_set<std::unique_ptr<T>>`. If your type is not moveable and +// you require pointer stability, consider `absl::node_hash_set` instead. +// +// Example: +// +// // Create a flat hash set of three strings +// absl::flat_hash_set<std::string> ducks = +// {"huey", "dewey", "louie"}; +// +// // Insert a new element into the flat hash set +// ducks.insert("donald"); +// +// // Force a rehash of the flat hash set +// ducks.rehash(0); +// +// // See if "dewey" is present +// if (ducks.contains("dewey")) { +// std::cout << "We found dewey!" << std::endl; +// } +template <class T, class Hash = absl::container_internal::hash_default_hash<T>, + class Eq = absl::container_internal::hash_default_eq<T>, + class Allocator = std::allocator<T>> +class flat_hash_set + : public absl::container_internal::raw_hash_set< + absl::container_internal::FlatHashSetPolicy<T>, Hash, Eq, Allocator> { + using Base = typename flat_hash_set::raw_hash_set; + + public: + // Constructors and Assignment Operators + // + // A flat_hash_set supports the same overload set as `std::unordered_map` + // for construction and assignment: + // + // * Default constructor + // + // // No allocation for the table's elements is made. + // absl::flat_hash_set<std::string> set1; + // + // * Initializer List constructor + // + // absl::flat_hash_set<std::string> set2 = + // {{"huey"}, {"dewey"}, {"louie"},}; + // + // * Copy constructor + // + // absl::flat_hash_set<std::string> set3(set2); + // + // * Copy assignment operator + // + // // Hash functor and Comparator are copied as well + // absl::flat_hash_set<std::string> set4; + // set4 = set3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::flat_hash_set<std::string> set5(std::move(set4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::flat_hash_set<std::string> set6; + // set6 = std::move(set5); + // + // * Range constructor + // + // std::vector<std::string> v = {"a", "b"}; + // absl::flat_hash_set<std::string> set7(v.begin(), v.end()); + flat_hash_set() {} + using Base::Base; + + // flat_hash_set::begin() + // + // Returns an iterator to the beginning of the `flat_hash_set`. + using Base::begin; + + // flat_hash_set::cbegin() + // + // Returns a const iterator to the beginning of the `flat_hash_set`. + using Base::cbegin; + + // flat_hash_set::cend() + // + // Returns a const iterator to the end of the `flat_hash_set`. + using Base::cend; + + // flat_hash_set::end() + // + // Returns an iterator to the end of the `flat_hash_set`. + using Base::end; + + // flat_hash_set::capacity() + // + // Returns the number of element slots (assigned, deleted, and empty) + // available within the `flat_hash_set`. + // + // NOTE: this member function is particular to `absl::flat_hash_set` and is + // not provided in the `std::unordered_map` API. + using Base::capacity; + + // flat_hash_set::empty() + // + // Returns whether or not the `flat_hash_set` is empty. + using Base::empty; + + // flat_hash_set::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `flat_hash_set` under current memory constraints. This value can be thought + // of the largest value of `std::distance(begin(), end())` for a + // `flat_hash_set<T>`. + using Base::max_size; + + // flat_hash_set::size() + // + // Returns the number of elements currently within the `flat_hash_set`. + using Base::size; + + // flat_hash_set::clear() + // + // Removes all elements from the `flat_hash_set`. Invalidates any references, + // pointers, or iterators referring to contained elements. + // + // NOTE: this operation may shrink the underlying buffer. To avoid shrinking + // the underlying buffer call `erase(begin(), end())`. + using Base::clear; + + // flat_hash_set::erase() + // + // Erases elements within the `flat_hash_set`. Erasing does not trigger a + // rehash. Overloads are listed below. + // + // void erase(const_iterator pos): + // + // Erases the element at `position` of the `flat_hash_set`, returning + // `void`. + // + // NOTE: returning `void` in this case is different than that of STL + // containers in general and `std::unordered_set` in particular (which + // return an iterator to the element following the erased element). If that + // iterator is needed, simply post increment the iterator: + // + // set.erase(it++); + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning an + // iterator pointing to `last`. + // + // size_type erase(const key_type& key): + // + // Erases the element with the matching key, if it exists. + using Base::erase; + + // flat_hash_set::insert() + // + // Inserts an element of the specified value into the `flat_hash_set`, + // returning an iterator pointing to the newly inserted element, provided that + // an element with the given key does not already exist. If rehashing occurs + // due to the insertion, all iterators are invalidated. Overloads are listed + // below. + // + // std::pair<iterator,bool> insert(const T& value): + // + // Inserts a value into the `flat_hash_set`. Returns a pair consisting of an + // iterator to the inserted element (or to the element that prevented the + // insertion) and a bool denoting whether the insertion took place. + // + // std::pair<iterator,bool> insert(T&& value): + // + // Inserts a moveable value into the `flat_hash_set`. Returns a pair + // consisting of an iterator to the inserted element (or to the element that + // prevented the insertion) and a bool denoting whether the insertion took + // place. + // + // iterator insert(const_iterator hint, const T& value): + // iterator insert(const_iterator hint, T&& value): + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element, or to the existing element that prevented the + // insertion. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently, for `flat_hash_set` we guarantee the + // first match is inserted. + // + // void insert(std::initializer_list<T> ilist): + // + // Inserts the elements within the initializer list `ilist`. + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently within the initializer list, for + // `flat_hash_set` we guarantee the first match is inserted. + using Base::insert; + + // flat_hash_set::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `flat_hash_set`, provided that no element with the given key + // already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace; + + // flat_hash_set::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `flat_hash_set`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search, and only inserts + // provided that no element with the given key already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace_hint; + + // flat_hash_set::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the element at the indicated position and returns a node handle + // owning that extracted data. + // + // node_type extract(const key_type& x): + // + // Extracts the element with the key matching the passed key value and + // returns a node handle owning that extracted data. If the `flat_hash_set` + // does not contain an element with a matching key, this function returns an + // empty node handle. + using Base::extract; + + // flat_hash_set::merge() + // + // Extracts elements from a given `source` flat hash map into this + // `flat_hash_set`. If the destination `flat_hash_set` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // flat_hash_set::swap(flat_hash_set& other) + // + // Exchanges the contents of this `flat_hash_set` with those of the `other` + // flat hash map, avoiding invocation of any move, copy, or swap operations on + // individual elements. + // + // All iterators and references on the `flat_hash_set` remain valid, excepting + // for the past-the-end iterator, which is invalidated. + // + // `swap()` requires that the flat hash set's hashing and key equivalence + // functions be Swappable, and are exchaged using unqualified calls to + // non-member `swap()`. If the map's allocator has + // `std::allocator_traits<allocator_type>::propagate_on_container_swap::value` + // set to `true`, the allocators are also exchanged using an unqualified call + // to non-member `swap()`; otherwise, the allocators are not swapped. + using Base::swap; + + // flat_hash_set::rehash(count) + // + // Rehashes the `flat_hash_set`, setting the number of slots to be at least + // the passed value. If the new number of slots increases the load factor more + // than the current maximum load factor + // (`count` < `size()` / `max_load_factor()`), then the new number of slots + // will be at least `size()` / `max_load_factor()`. + // + // To force a rehash, pass rehash(0). + // + // NOTE: unlike behavior in `std::unordered_set`, references are also + // invalidated upon a `rehash()`. + using Base::rehash; + + // flat_hash_set::reserve(count) + // + // Sets the number of slots in the `flat_hash_set` to the number needed to + // accommodate at least `count` total elements without exceeding the current + // maximum load factor, and may rehash the container if needed. + using Base::reserve; + + // flat_hash_set::contains() + // + // Determines whether an element comparing equal to the given `key` exists + // within the `flat_hash_set`, returning `true` if so or `false` otherwise. + using Base::contains; + + // flat_hash_set::count(const Key& key) const + // + // Returns the number of elements comparing equal to the given `key` within + // the `flat_hash_set`. note that this function will return either `1` or `0` + // since duplicate elements are not allowed within a `flat_hash_set`. + using Base::count; + + // flat_hash_set::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `flat_hash_set`. + using Base::equal_range; + + // flat_hash_set::find() + // + // Finds an element with the passed `key` within the `flat_hash_set`. + using Base::find; + + // flat_hash_set::bucket_count() + // + // Returns the number of "buckets" within the `flat_hash_set`. Note that + // because a flat hash map contains all elements within its internal storage, + // this value simply equals the current capacity of the `flat_hash_set`. + using Base::bucket_count; + + // flat_hash_set::load_factor() + // + // Returns the current load factor of the `flat_hash_set` (the average number + // of slots occupied with a value within the hash map). + using Base::load_factor; + + // flat_hash_set::max_load_factor() + // + // Manages the maximum load factor of the `flat_hash_set`. Overloads are + // listed below. + // + // float flat_hash_set::max_load_factor() + // + // Returns the current maximum load factor of the `flat_hash_set`. + // + // void flat_hash_set::max_load_factor(float ml) + // + // Sets the maximum load factor of the `flat_hash_set` to the passed value. + // + // NOTE: This overload is provided only for API compatibility with the STL; + // `flat_hash_set` will ignore any set load factor and manage its rehashing + // internally as an implementation detail. + using Base::max_load_factor; + + // flat_hash_set::get_allocator() + // + // Returns the allocator function associated with this `flat_hash_set`. + using Base::get_allocator; + + // flat_hash_set::hash_function() + // + // Returns the hashing function used to hash the keys within this + // `flat_hash_set`. + using Base::hash_function; + + // flat_hash_set::key_eq() + // + // Returns the function used for comparing keys equality. + using Base::key_eq; +}; + +// erase_if(flat_hash_set<>, Pred) +// +// Erases all elements that satisfy the predicate `pred` from the container `c`. +template <typename T, typename H, typename E, typename A, typename Predicate> +void erase_if(flat_hash_set<T, H, E, A>& c, Predicate pred) { + container_internal::EraseIf(pred, &c); +} + +namespace container_internal { + +template <class T> +struct FlatHashSetPolicy { + using slot_type = T; + using key_type = T; + using init_type = T; + using constant_iterators = std::true_type; + + template <class Allocator, class... Args> + static void construct(Allocator* alloc, slot_type* slot, Args&&... args) { + absl::allocator_traits<Allocator>::construct(*alloc, slot, + std::forward<Args>(args)...); + } + + template <class Allocator> + static void destroy(Allocator* alloc, slot_type* slot) { + absl::allocator_traits<Allocator>::destroy(*alloc, slot); + } + + template <class Allocator> + static void transfer(Allocator* alloc, slot_type* new_slot, + slot_type* old_slot) { + construct(alloc, new_slot, std::move(*old_slot)); + destroy(alloc, old_slot); + } + + static T& element(slot_type* slot) { return *slot; } + + template <class F, class... Args> + static decltype(absl::container_internal::DecomposeValue( + std::declval<F>(), std::declval<Args>()...)) + apply(F&& f, Args&&... args) { + return absl::container_internal::DecomposeValue( + std::forward<F>(f), std::forward<Args>(args)...); + } + + static size_t space_used(const T*) { return 0; } +}; +} // namespace container_internal + +namespace container_algorithm_internal { + +// Specialization of trait in absl/algorithm/container.h +template <class Key, class Hash, class KeyEqual, class Allocator> +struct IsUnorderedContainer<absl::flat_hash_set<Key, Hash, KeyEqual, Allocator>> + : std::true_type {}; + +} // namespace container_algorithm_internal + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_FLAT_HASH_SET_H_ diff --git a/third_party/abseil_cpp/absl/container/flat_hash_set_test.cc b/third_party/abseil_cpp/absl/container/flat_hash_set_test.cc new file mode 100644 index 0000000000..8f6f9944ca --- /dev/null +++ b/third_party/abseil_cpp/absl/container/flat_hash_set_test.cc @@ -0,0 +1,178 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/flat_hash_set.h" + +#include <vector> + +#include "absl/base/internal/raw_logging.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/unordered_set_constructor_test.h" +#include "absl/container/internal/unordered_set_lookup_test.h" +#include "absl/container/internal/unordered_set_members_test.h" +#include "absl/container/internal/unordered_set_modifiers_test.h" +#include "absl/memory/memory.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::absl::container_internal::hash_internal::Enum; +using ::absl::container_internal::hash_internal::EnumClass; +using ::testing::IsEmpty; +using ::testing::Pointee; +using ::testing::UnorderedElementsAre; +using ::testing::UnorderedElementsAreArray; + +// Check that absl::flat_hash_set works in a global constructor. +struct BeforeMain { + BeforeMain() { + absl::flat_hash_set<int> x; + x.insert(1); + ABSL_RAW_CHECK(!x.contains(0), "x should not contain 0"); + ABSL_RAW_CHECK(x.contains(1), "x should contain 1"); + } +}; +const BeforeMain before_main; + +template <class T> +using Set = + absl::flat_hash_set<T, StatefulTestingHash, StatefulTestingEqual, Alloc<T>>; + +using SetTypes = + ::testing::Types<Set<int>, Set<std::string>, Set<Enum>, Set<EnumClass>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashSet, ConstructorTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashSet, LookupTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashSet, MembersTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(FlatHashSet, ModifiersTest, SetTypes); + +TEST(FlatHashSet, EmplaceString) { + std::vector<std::string> v = {"a", "b"}; + absl::flat_hash_set<absl::string_view> hs(v.begin(), v.end()); + EXPECT_THAT(hs, UnorderedElementsAreArray(v)); +} + +TEST(FlatHashSet, BitfieldArgument) { + union { + int n : 1; + }; + n = 0; + absl::flat_hash_set<int> s = {n}; + s.insert(n); + s.insert(s.end(), n); + s.insert({n}); + s.erase(n); + s.count(n); + s.prefetch(n); + s.find(n); + s.contains(n); + s.equal_range(n); +} + +TEST(FlatHashSet, MergeExtractInsert) { + struct Hash { + size_t operator()(const std::unique_ptr<int>& p) const { return *p; } + }; + struct Eq { + bool operator()(const std::unique_ptr<int>& a, + const std::unique_ptr<int>& b) const { + return *a == *b; + } + }; + absl::flat_hash_set<std::unique_ptr<int>, Hash, Eq> set1, set2; + set1.insert(absl::make_unique<int>(7)); + set1.insert(absl::make_unique<int>(17)); + + set2.insert(absl::make_unique<int>(7)); + set2.insert(absl::make_unique<int>(19)); + + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(7), Pointee(17))); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7), Pointee(19))); + + set1.merge(set2); + + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(7), Pointee(17), Pointee(19))); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7))); + + auto node = set1.extract(absl::make_unique<int>(7)); + EXPECT_TRUE(node); + EXPECT_THAT(node.value(), Pointee(7)); + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(17), Pointee(19))); + + auto insert_result = set2.insert(std::move(node)); + EXPECT_FALSE(node); + EXPECT_FALSE(insert_result.inserted); + EXPECT_TRUE(insert_result.node); + EXPECT_THAT(insert_result.node.value(), Pointee(7)); + EXPECT_EQ(**insert_result.position, 7); + EXPECT_NE(insert_result.position->get(), insert_result.node.value().get()); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7))); + + node = set1.extract(absl::make_unique<int>(17)); + EXPECT_TRUE(node); + EXPECT_THAT(node.value(), Pointee(17)); + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(19))); + + node.value() = absl::make_unique<int>(23); + + insert_result = set2.insert(std::move(node)); + EXPECT_FALSE(node); + EXPECT_TRUE(insert_result.inserted); + EXPECT_FALSE(insert_result.node); + EXPECT_EQ(**insert_result.position, 23); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7), Pointee(23))); +} + +bool IsEven(int k) { return k % 2 == 0; } + +TEST(FlatHashSet, EraseIf) { + // Erase all elements. + { + flat_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, [](int) { return true; }); + EXPECT_THAT(s, IsEmpty()); + } + // Erase no elements. + { + flat_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, [](int) { return false; }); + EXPECT_THAT(s, UnorderedElementsAre(1, 2, 3, 4, 5)); + } + // Erase specific elements. + { + flat_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, [](int k) { return k % 2 == 1; }); + EXPECT_THAT(s, UnorderedElementsAre(2, 4)); + } + // Predicate is function reference. + { + flat_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, IsEven); + EXPECT_THAT(s, UnorderedElementsAre(1, 3, 5)); + } + // Predicate is function pointer. + { + flat_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, &IsEven); + EXPECT_THAT(s, UnorderedElementsAre(1, 3, 5)); + } +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/inlined_vector.h b/third_party/abseil_cpp/absl/container/inlined_vector.h new file mode 100644 index 0000000000..f18dd4c785 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/inlined_vector.h @@ -0,0 +1,845 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: inlined_vector.h +// ----------------------------------------------------------------------------- +// +// This header file contains the declaration and definition of an "inlined +// vector" which behaves in an equivalent fashion to a `std::vector`, except +// that storage for small sequences of the vector are provided inline without +// requiring any heap allocation. +// +// An `absl::InlinedVector<T, N>` specifies the default capacity `N` as one of +// its template parameters. Instances where `size() <= N` hold contained +// elements in inline space. Typically `N` is very small so that sequences that +// are expected to be short do not require allocations. +// +// An `absl::InlinedVector` does not usually require a specific allocator. If +// the inlined vector grows beyond its initial constraints, it will need to +// allocate (as any normal `std::vector` would). This is usually performed with +// the default allocator (defined as `std::allocator<T>`). Optionally, a custom +// allocator type may be specified as `A` in `absl::InlinedVector<T, N, A>`. + +#ifndef ABSL_CONTAINER_INLINED_VECTOR_H_ +#define ABSL_CONTAINER_INLINED_VECTOR_H_ + +#include <algorithm> +#include <cassert> +#include <cstddef> +#include <cstdlib> +#include <cstring> +#include <initializer_list> +#include <iterator> +#include <memory> +#include <type_traits> +#include <utility> + +#include "absl/algorithm/algorithm.h" +#include "absl/base/internal/throw_delegate.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" +#include "absl/container/internal/inlined_vector.h" +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +// ----------------------------------------------------------------------------- +// InlinedVector +// ----------------------------------------------------------------------------- +// +// An `absl::InlinedVector` is designed to be a drop-in replacement for +// `std::vector` for use cases where the vector's size is sufficiently small +// that it can be inlined. If the inlined vector does grow beyond its estimated +// capacity, it will trigger an initial allocation on the heap, and will behave +// as a `std:vector`. The API of the `absl::InlinedVector` within this file is +// designed to cover the same API footprint as covered by `std::vector`. +template <typename T, size_t N, typename A = std::allocator<T>> +class InlinedVector { + static_assert(N > 0, "`absl::InlinedVector` requires an inlined capacity."); + + using Storage = inlined_vector_internal::Storage<T, N, A>; + + using AllocatorTraits = typename Storage::AllocatorTraits; + using RValueReference = typename Storage::RValueReference; + using MoveIterator = typename Storage::MoveIterator; + using IsMemcpyOk = typename Storage::IsMemcpyOk; + + template <typename Iterator> + using IteratorValueAdapter = + typename Storage::template IteratorValueAdapter<Iterator>; + using CopyValueAdapter = typename Storage::CopyValueAdapter; + using DefaultValueAdapter = typename Storage::DefaultValueAdapter; + + template <typename Iterator> + using EnableIfAtLeastForwardIterator = absl::enable_if_t< + inlined_vector_internal::IsAtLeastForwardIterator<Iterator>::value>; + template <typename Iterator> + using DisableIfAtLeastForwardIterator = absl::enable_if_t< + !inlined_vector_internal::IsAtLeastForwardIterator<Iterator>::value>; + + public: + using allocator_type = typename Storage::allocator_type; + using value_type = typename Storage::value_type; + using pointer = typename Storage::pointer; + using const_pointer = typename Storage::const_pointer; + using size_type = typename Storage::size_type; + using difference_type = typename Storage::difference_type; + using reference = typename Storage::reference; + using const_reference = typename Storage::const_reference; + using iterator = typename Storage::iterator; + using const_iterator = typename Storage::const_iterator; + using reverse_iterator = typename Storage::reverse_iterator; + using const_reverse_iterator = typename Storage::const_reverse_iterator; + + // --------------------------------------------------------------------------- + // InlinedVector Constructors and Destructor + // --------------------------------------------------------------------------- + + // Creates an empty inlined vector with a value-initialized allocator. + InlinedVector() noexcept(noexcept(allocator_type())) : storage_() {} + + // Creates an empty inlined vector with a copy of `alloc`. + explicit InlinedVector(const allocator_type& alloc) noexcept + : storage_(alloc) {} + + // Creates an inlined vector with `n` copies of `value_type()`. + explicit InlinedVector(size_type n, + const allocator_type& alloc = allocator_type()) + : storage_(alloc) { + storage_.Initialize(DefaultValueAdapter(), n); + } + + // Creates an inlined vector with `n` copies of `v`. + InlinedVector(size_type n, const_reference v, + const allocator_type& alloc = allocator_type()) + : storage_(alloc) { + storage_.Initialize(CopyValueAdapter(v), n); + } + + // Creates an inlined vector with copies of the elements of `list`. + InlinedVector(std::initializer_list<value_type> list, + const allocator_type& alloc = allocator_type()) + : InlinedVector(list.begin(), list.end(), alloc) {} + + // Creates an inlined vector with elements constructed from the provided + // forward iterator range [`first`, `last`). + // + // NOTE: the `enable_if` prevents ambiguous interpretation between a call to + // this constructor with two integral arguments and a call to the above + // `InlinedVector(size_type, const_reference)` constructor. + template <typename ForwardIterator, + EnableIfAtLeastForwardIterator<ForwardIterator>* = nullptr> + InlinedVector(ForwardIterator first, ForwardIterator last, + const allocator_type& alloc = allocator_type()) + : storage_(alloc) { + storage_.Initialize(IteratorValueAdapter<ForwardIterator>(first), + std::distance(first, last)); + } + + // Creates an inlined vector with elements constructed from the provided input + // iterator range [`first`, `last`). + template <typename InputIterator, + DisableIfAtLeastForwardIterator<InputIterator>* = nullptr> + InlinedVector(InputIterator first, InputIterator last, + const allocator_type& alloc = allocator_type()) + : storage_(alloc) { + std::copy(first, last, std::back_inserter(*this)); + } + + // Creates an inlined vector by copying the contents of `other` using + // `other`'s allocator. + InlinedVector(const InlinedVector& other) + : InlinedVector(other, *other.storage_.GetAllocPtr()) {} + + // Creates an inlined vector by copying the contents of `other` using `alloc`. + InlinedVector(const InlinedVector& other, const allocator_type& alloc) + : storage_(alloc) { + if (IsMemcpyOk::value && !other.storage_.GetIsAllocated()) { + storage_.MemcpyFrom(other.storage_); + } else { + storage_.Initialize(IteratorValueAdapter<const_pointer>(other.data()), + other.size()); + } + } + + // Creates an inlined vector by moving in the contents of `other` without + // allocating. If `other` contains allocated memory, the newly-created inlined + // vector will take ownership of that memory. However, if `other` does not + // contain allocated memory, the newly-created inlined vector will perform + // element-wise move construction of the contents of `other`. + // + // NOTE: since no allocation is performed for the inlined vector in either + // case, the `noexcept(...)` specification depends on whether moving the + // underlying objects can throw. It is assumed assumed that... + // a) move constructors should only throw due to allocation failure. + // b) if `value_type`'s move constructor allocates, it uses the same + // allocation function as the inlined vector's allocator. + // Thus, the move constructor is non-throwing if the allocator is non-throwing + // or `value_type`'s move constructor is specified as `noexcept`. + InlinedVector(InlinedVector&& other) noexcept( + absl::allocator_is_nothrow<allocator_type>::value || + std::is_nothrow_move_constructible<value_type>::value) + : storage_(*other.storage_.GetAllocPtr()) { + if (IsMemcpyOk::value) { + storage_.MemcpyFrom(other.storage_); + + other.storage_.SetInlinedSize(0); + } else if (other.storage_.GetIsAllocated()) { + storage_.SetAllocatedData(other.storage_.GetAllocatedData(), + other.storage_.GetAllocatedCapacity()); + storage_.SetAllocatedSize(other.storage_.GetSize()); + + other.storage_.SetInlinedSize(0); + } else { + IteratorValueAdapter<MoveIterator> other_values( + MoveIterator(other.storage_.GetInlinedData())); + + inlined_vector_internal::ConstructElements( + storage_.GetAllocPtr(), storage_.GetInlinedData(), &other_values, + other.storage_.GetSize()); + + storage_.SetInlinedSize(other.storage_.GetSize()); + } + } + + // Creates an inlined vector by moving in the contents of `other` with a copy + // of `alloc`. + // + // NOTE: if `other`'s allocator is not equal to `alloc`, even if `other` + // contains allocated memory, this move constructor will still allocate. Since + // allocation is performed, this constructor can only be `noexcept` if the + // specified allocator is also `noexcept`. + InlinedVector(InlinedVector&& other, const allocator_type& alloc) noexcept( + absl::allocator_is_nothrow<allocator_type>::value) + : storage_(alloc) { + if (IsMemcpyOk::value) { + storage_.MemcpyFrom(other.storage_); + + other.storage_.SetInlinedSize(0); + } else if ((*storage_.GetAllocPtr() == *other.storage_.GetAllocPtr()) && + other.storage_.GetIsAllocated()) { + storage_.SetAllocatedData(other.storage_.GetAllocatedData(), + other.storage_.GetAllocatedCapacity()); + storage_.SetAllocatedSize(other.storage_.GetSize()); + + other.storage_.SetInlinedSize(0); + } else { + storage_.Initialize( + IteratorValueAdapter<MoveIterator>(MoveIterator(other.data())), + other.size()); + } + } + + ~InlinedVector() {} + + // --------------------------------------------------------------------------- + // InlinedVector Member Accessors + // --------------------------------------------------------------------------- + + // `InlinedVector::empty()` + // + // Returns whether the inlined vector contains no elements. + bool empty() const noexcept { return !size(); } + + // `InlinedVector::size()` + // + // Returns the number of elements in the inlined vector. + size_type size() const noexcept { return storage_.GetSize(); } + + // `InlinedVector::max_size()` + // + // Returns the maximum number of elements the inlined vector can hold. + size_type max_size() const noexcept { + // One bit of the size storage is used to indicate whether the inlined + // vector contains allocated memory. As a result, the maximum size that the + // inlined vector can express is half of the max for `size_type`. + return (std::numeric_limits<size_type>::max)() / 2; + } + + // `InlinedVector::capacity()` + // + // Returns the number of elements that could be stored in the inlined vector + // without requiring a reallocation. + // + // NOTE: for most inlined vectors, `capacity()` should be equal to the + // template parameter `N`. For inlined vectors which exceed this capacity, + // they will no longer be inlined and `capacity()` will equal the capactity of + // the allocated memory. + size_type capacity() const noexcept { + return storage_.GetIsAllocated() ? storage_.GetAllocatedCapacity() + : storage_.GetInlinedCapacity(); + } + + // `InlinedVector::data()` + // + // Returns a `pointer` to the elements of the inlined vector. This pointer + // can be used to access and modify the contained elements. + // + // NOTE: only elements within [`data()`, `data() + size()`) are valid. + pointer data() noexcept { + return storage_.GetIsAllocated() ? storage_.GetAllocatedData() + : storage_.GetInlinedData(); + } + + // Overload of `InlinedVector::data()` that returns a `const_pointer` to the + // elements of the inlined vector. This pointer can be used to access but not + // modify the contained elements. + // + // NOTE: only elements within [`data()`, `data() + size()`) are valid. + const_pointer data() const noexcept { + return storage_.GetIsAllocated() ? storage_.GetAllocatedData() + : storage_.GetInlinedData(); + } + + // `InlinedVector::operator[](...)` + // + // Returns a `reference` to the `i`th element of the inlined vector. + reference operator[](size_type i) { + ABSL_HARDENING_ASSERT(i < size()); + return data()[i]; + } + + // Overload of `InlinedVector::operator[](...)` that returns a + // `const_reference` to the `i`th element of the inlined vector. + const_reference operator[](size_type i) const { + ABSL_HARDENING_ASSERT(i < size()); + return data()[i]; + } + + // `InlinedVector::at(...)` + // + // Returns a `reference` to the `i`th element of the inlined vector. + // + // NOTE: if `i` is not within the required range of `InlinedVector::at(...)`, + // in both debug and non-debug builds, `std::out_of_range` will be thrown. + reference at(size_type i) { + if (ABSL_PREDICT_FALSE(i >= size())) { + base_internal::ThrowStdOutOfRange( + "`InlinedVector::at(size_type)` failed bounds check"); + } + return data()[i]; + } + + // Overload of `InlinedVector::at(...)` that returns a `const_reference` to + // the `i`th element of the inlined vector. + // + // NOTE: if `i` is not within the required range of `InlinedVector::at(...)`, + // in both debug and non-debug builds, `std::out_of_range` will be thrown. + const_reference at(size_type i) const { + if (ABSL_PREDICT_FALSE(i >= size())) { + base_internal::ThrowStdOutOfRange( + "`InlinedVector::at(size_type) const` failed bounds check"); + } + return data()[i]; + } + + // `InlinedVector::front()` + // + // Returns a `reference` to the first element of the inlined vector. + reference front() { + ABSL_HARDENING_ASSERT(!empty()); + return data()[0]; + } + + // Overload of `InlinedVector::front()` that returns a `const_reference` to + // the first element of the inlined vector. + const_reference front() const { + ABSL_HARDENING_ASSERT(!empty()); + return data()[0]; + } + + // `InlinedVector::back()` + // + // Returns a `reference` to the last element of the inlined vector. + reference back() { + ABSL_HARDENING_ASSERT(!empty()); + return data()[size() - 1]; + } + + // Overload of `InlinedVector::back()` that returns a `const_reference` to the + // last element of the inlined vector. + const_reference back() const { + ABSL_HARDENING_ASSERT(!empty()); + return data()[size() - 1]; + } + + // `InlinedVector::begin()` + // + // Returns an `iterator` to the beginning of the inlined vector. + iterator begin() noexcept { return data(); } + + // Overload of `InlinedVector::begin()` that returns a `const_iterator` to + // the beginning of the inlined vector. + const_iterator begin() const noexcept { return data(); } + + // `InlinedVector::end()` + // + // Returns an `iterator` to the end of the inlined vector. + iterator end() noexcept { return data() + size(); } + + // Overload of `InlinedVector::end()` that returns a `const_iterator` to the + // end of the inlined vector. + const_iterator end() const noexcept { return data() + size(); } + + // `InlinedVector::cbegin()` + // + // Returns a `const_iterator` to the beginning of the inlined vector. + const_iterator cbegin() const noexcept { return begin(); } + + // `InlinedVector::cend()` + // + // Returns a `const_iterator` to the end of the inlined vector. + const_iterator cend() const noexcept { return end(); } + + // `InlinedVector::rbegin()` + // + // Returns a `reverse_iterator` from the end of the inlined vector. + reverse_iterator rbegin() noexcept { return reverse_iterator(end()); } + + // Overload of `InlinedVector::rbegin()` that returns a + // `const_reverse_iterator` from the end of the inlined vector. + const_reverse_iterator rbegin() const noexcept { + return const_reverse_iterator(end()); + } + + // `InlinedVector::rend()` + // + // Returns a `reverse_iterator` from the beginning of the inlined vector. + reverse_iterator rend() noexcept { return reverse_iterator(begin()); } + + // Overload of `InlinedVector::rend()` that returns a `const_reverse_iterator` + // from the beginning of the inlined vector. + const_reverse_iterator rend() const noexcept { + return const_reverse_iterator(begin()); + } + + // `InlinedVector::crbegin()` + // + // Returns a `const_reverse_iterator` from the end of the inlined vector. + const_reverse_iterator crbegin() const noexcept { return rbegin(); } + + // `InlinedVector::crend()` + // + // Returns a `const_reverse_iterator` from the beginning of the inlined + // vector. + const_reverse_iterator crend() const noexcept { return rend(); } + + // `InlinedVector::get_allocator()` + // + // Returns a copy of the inlined vector's allocator. + allocator_type get_allocator() const { return *storage_.GetAllocPtr(); } + + // --------------------------------------------------------------------------- + // InlinedVector Member Mutators + // --------------------------------------------------------------------------- + + // `InlinedVector::operator=(...)` + // + // Replaces the elements of the inlined vector with copies of the elements of + // `list`. + InlinedVector& operator=(std::initializer_list<value_type> list) { + assign(list.begin(), list.end()); + + return *this; + } + + // Overload of `InlinedVector::operator=(...)` that replaces the elements of + // the inlined vector with copies of the elements of `other`. + InlinedVector& operator=(const InlinedVector& other) { + if (ABSL_PREDICT_TRUE(this != std::addressof(other))) { + const_pointer other_data = other.data(); + assign(other_data, other_data + other.size()); + } + + return *this; + } + + // Overload of `InlinedVector::operator=(...)` that moves the elements of + // `other` into the inlined vector. + // + // NOTE: as a result of calling this overload, `other` is left in a valid but + // unspecified state. + InlinedVector& operator=(InlinedVector&& other) { + if (ABSL_PREDICT_TRUE(this != std::addressof(other))) { + if (IsMemcpyOk::value || other.storage_.GetIsAllocated()) { + inlined_vector_internal::DestroyElements(storage_.GetAllocPtr(), data(), + size()); + storage_.DeallocateIfAllocated(); + storage_.MemcpyFrom(other.storage_); + + other.storage_.SetInlinedSize(0); + } else { + storage_.Assign(IteratorValueAdapter<MoveIterator>( + MoveIterator(other.storage_.GetInlinedData())), + other.size()); + } + } + + return *this; + } + + // `InlinedVector::assign(...)` + // + // Replaces the contents of the inlined vector with `n` copies of `v`. + void assign(size_type n, const_reference v) { + storage_.Assign(CopyValueAdapter(v), n); + } + + // Overload of `InlinedVector::assign(...)` that replaces the contents of the + // inlined vector with copies of the elements of `list`. + void assign(std::initializer_list<value_type> list) { + assign(list.begin(), list.end()); + } + + // Overload of `InlinedVector::assign(...)` to replace the contents of the + // inlined vector with the range [`first`, `last`). + // + // NOTE: this overload is for iterators that are "forward" category or better. + template <typename ForwardIterator, + EnableIfAtLeastForwardIterator<ForwardIterator>* = nullptr> + void assign(ForwardIterator first, ForwardIterator last) { + storage_.Assign(IteratorValueAdapter<ForwardIterator>(first), + std::distance(first, last)); + } + + // Overload of `InlinedVector::assign(...)` to replace the contents of the + // inlined vector with the range [`first`, `last`). + // + // NOTE: this overload is for iterators that are "input" category. + template <typename InputIterator, + DisableIfAtLeastForwardIterator<InputIterator>* = nullptr> + void assign(InputIterator first, InputIterator last) { + size_type i = 0; + for (; i < size() && first != last; ++i, static_cast<void>(++first)) { + data()[i] = *first; + } + + erase(data() + i, data() + size()); + std::copy(first, last, std::back_inserter(*this)); + } + + // `InlinedVector::resize(...)` + // + // Resizes the inlined vector to contain `n` elements. + // + // NOTE: If `n` is smaller than `size()`, extra elements are destroyed. If `n` + // is larger than `size()`, new elements are value-initialized. + void resize(size_type n) { + ABSL_HARDENING_ASSERT(n <= max_size()); + storage_.Resize(DefaultValueAdapter(), n); + } + + // Overload of `InlinedVector::resize(...)` that resizes the inlined vector to + // contain `n` elements. + // + // NOTE: if `n` is smaller than `size()`, extra elements are destroyed. If `n` + // is larger than `size()`, new elements are copied-constructed from `v`. + void resize(size_type n, const_reference v) { + ABSL_HARDENING_ASSERT(n <= max_size()); + storage_.Resize(CopyValueAdapter(v), n); + } + + // `InlinedVector::insert(...)` + // + // Inserts a copy of `v` at `pos`, returning an `iterator` to the newly + // inserted element. + iterator insert(const_iterator pos, const_reference v) { + return emplace(pos, v); + } + + // Overload of `InlinedVector::insert(...)` that inserts `v` at `pos` using + // move semantics, returning an `iterator` to the newly inserted element. + iterator insert(const_iterator pos, RValueReference v) { + return emplace(pos, std::move(v)); + } + + // Overload of `InlinedVector::insert(...)` that inserts `n` contiguous copies + // of `v` starting at `pos`, returning an `iterator` pointing to the first of + // the newly inserted elements. + iterator insert(const_iterator pos, size_type n, const_reference v) { + ABSL_HARDENING_ASSERT(pos >= begin()); + ABSL_HARDENING_ASSERT(pos <= end()); + + if (ABSL_PREDICT_TRUE(n != 0)) { + value_type dealias = v; + return storage_.Insert(pos, CopyValueAdapter(dealias), n); + } else { + return const_cast<iterator>(pos); + } + } + + // Overload of `InlinedVector::insert(...)` that inserts copies of the + // elements of `list` starting at `pos`, returning an `iterator` pointing to + // the first of the newly inserted elements. + iterator insert(const_iterator pos, std::initializer_list<value_type> list) { + return insert(pos, list.begin(), list.end()); + } + + // Overload of `InlinedVector::insert(...)` that inserts the range [`first`, + // `last`) starting at `pos`, returning an `iterator` pointing to the first + // of the newly inserted elements. + // + // NOTE: this overload is for iterators that are "forward" category or better. + template <typename ForwardIterator, + EnableIfAtLeastForwardIterator<ForwardIterator>* = nullptr> + iterator insert(const_iterator pos, ForwardIterator first, + ForwardIterator last) { + ABSL_HARDENING_ASSERT(pos >= begin()); + ABSL_HARDENING_ASSERT(pos <= end()); + + if (ABSL_PREDICT_TRUE(first != last)) { + return storage_.Insert(pos, IteratorValueAdapter<ForwardIterator>(first), + std::distance(first, last)); + } else { + return const_cast<iterator>(pos); + } + } + + // Overload of `InlinedVector::insert(...)` that inserts the range [`first`, + // `last`) starting at `pos`, returning an `iterator` pointing to the first + // of the newly inserted elements. + // + // NOTE: this overload is for iterators that are "input" category. + template <typename InputIterator, + DisableIfAtLeastForwardIterator<InputIterator>* = nullptr> + iterator insert(const_iterator pos, InputIterator first, InputIterator last) { + ABSL_HARDENING_ASSERT(pos >= begin()); + ABSL_HARDENING_ASSERT(pos <= end()); + + size_type index = std::distance(cbegin(), pos); + for (size_type i = index; first != last; ++i, static_cast<void>(++first)) { + insert(data() + i, *first); + } + + return iterator(data() + index); + } + + // `InlinedVector::emplace(...)` + // + // Constructs and inserts an element using `args...` in the inlined vector at + // `pos`, returning an `iterator` pointing to the newly emplaced element. + template <typename... Args> + iterator emplace(const_iterator pos, Args&&... args) { + ABSL_HARDENING_ASSERT(pos >= begin()); + ABSL_HARDENING_ASSERT(pos <= end()); + + value_type dealias(std::forward<Args>(args)...); + return storage_.Insert(pos, + IteratorValueAdapter<MoveIterator>( + MoveIterator(std::addressof(dealias))), + 1); + } + + // `InlinedVector::emplace_back(...)` + // + // Constructs and inserts an element using `args...` in the inlined vector at + // `end()`, returning a `reference` to the newly emplaced element. + template <typename... Args> + reference emplace_back(Args&&... args) { + return storage_.EmplaceBack(std::forward<Args>(args)...); + } + + // `InlinedVector::push_back(...)` + // + // Inserts a copy of `v` in the inlined vector at `end()`. + void push_back(const_reference v) { static_cast<void>(emplace_back(v)); } + + // Overload of `InlinedVector::push_back(...)` for inserting `v` at `end()` + // using move semantics. + void push_back(RValueReference v) { + static_cast<void>(emplace_back(std::move(v))); + } + + // `InlinedVector::pop_back()` + // + // Destroys the element at `back()`, reducing the size by `1`. + void pop_back() noexcept { + ABSL_HARDENING_ASSERT(!empty()); + + AllocatorTraits::destroy(*storage_.GetAllocPtr(), data() + (size() - 1)); + storage_.SubtractSize(1); + } + + // `InlinedVector::erase(...)` + // + // Erases the element at `pos`, returning an `iterator` pointing to where the + // erased element was located. + // + // NOTE: may return `end()`, which is not dereferencable. + iterator erase(const_iterator pos) { + ABSL_HARDENING_ASSERT(pos >= begin()); + ABSL_HARDENING_ASSERT(pos < end()); + + return storage_.Erase(pos, pos + 1); + } + + // Overload of `InlinedVector::erase(...)` that erases every element in the + // range [`from`, `to`), returning an `iterator` pointing to where the first + // erased element was located. + // + // NOTE: may return `end()`, which is not dereferencable. + iterator erase(const_iterator from, const_iterator to) { + ABSL_HARDENING_ASSERT(from >= begin()); + ABSL_HARDENING_ASSERT(from <= to); + ABSL_HARDENING_ASSERT(to <= end()); + + if (ABSL_PREDICT_TRUE(from != to)) { + return storage_.Erase(from, to); + } else { + return const_cast<iterator>(from); + } + } + + // `InlinedVector::clear()` + // + // Destroys all elements in the inlined vector, setting the size to `0` and + // deallocating any held memory. + void clear() noexcept { + inlined_vector_internal::DestroyElements(storage_.GetAllocPtr(), data(), + size()); + storage_.DeallocateIfAllocated(); + + storage_.SetInlinedSize(0); + } + + // `InlinedVector::reserve(...)` + // + // Ensures that there is enough room for at least `n` elements. + void reserve(size_type n) { storage_.Reserve(n); } + + // `InlinedVector::shrink_to_fit()` + // + // Reduces memory usage by freeing unused memory. After being called, calls to + // `capacity()` will be equal to `max(N, size())`. + // + // If `size() <= N` and the inlined vector contains allocated memory, the + // elements will all be moved to the inlined space and the allocated memory + // will be deallocated. + // + // If `size() > N` and `size() < capacity()`, the elements will be moved to a + // smaller allocation. + void shrink_to_fit() { + if (storage_.GetIsAllocated()) { + storage_.ShrinkToFit(); + } + } + + // `InlinedVector::swap(...)` + // + // Swaps the contents of the inlined vector with `other`. + void swap(InlinedVector& other) { + if (ABSL_PREDICT_TRUE(this != std::addressof(other))) { + storage_.Swap(std::addressof(other.storage_)); + } + } + + private: + template <typename H, typename TheT, size_t TheN, typename TheA> + friend H AbslHashValue(H h, const absl::InlinedVector<TheT, TheN, TheA>& a); + + Storage storage_; +}; + +// ----------------------------------------------------------------------------- +// InlinedVector Non-Member Functions +// ----------------------------------------------------------------------------- + +// `swap(...)` +// +// Swaps the contents of two inlined vectors. +template <typename T, size_t N, typename A> +void swap(absl::InlinedVector<T, N, A>& a, + absl::InlinedVector<T, N, A>& b) noexcept(noexcept(a.swap(b))) { + a.swap(b); +} + +// `operator==(...)` +// +// Tests for value-equality of two inlined vectors. +template <typename T, size_t N, typename A> +bool operator==(const absl::InlinedVector<T, N, A>& a, + const absl::InlinedVector<T, N, A>& b) { + auto a_data = a.data(); + auto b_data = b.data(); + return absl::equal(a_data, a_data + a.size(), b_data, b_data + b.size()); +} + +// `operator!=(...)` +// +// Tests for value-inequality of two inlined vectors. +template <typename T, size_t N, typename A> +bool operator!=(const absl::InlinedVector<T, N, A>& a, + const absl::InlinedVector<T, N, A>& b) { + return !(a == b); +} + +// `operator<(...)` +// +// Tests whether the value of an inlined vector is less than the value of +// another inlined vector using a lexicographical comparison algorithm. +template <typename T, size_t N, typename A> +bool operator<(const absl::InlinedVector<T, N, A>& a, + const absl::InlinedVector<T, N, A>& b) { + auto a_data = a.data(); + auto b_data = b.data(); + return std::lexicographical_compare(a_data, a_data + a.size(), b_data, + b_data + b.size()); +} + +// `operator>(...)` +// +// Tests whether the value of an inlined vector is greater than the value of +// another inlined vector using a lexicographical comparison algorithm. +template <typename T, size_t N, typename A> +bool operator>(const absl::InlinedVector<T, N, A>& a, + const absl::InlinedVector<T, N, A>& b) { + return b < a; +} + +// `operator<=(...)` +// +// Tests whether the value of an inlined vector is less than or equal to the +// value of another inlined vector using a lexicographical comparison algorithm. +template <typename T, size_t N, typename A> +bool operator<=(const absl::InlinedVector<T, N, A>& a, + const absl::InlinedVector<T, N, A>& b) { + return !(b < a); +} + +// `operator>=(...)` +// +// Tests whether the value of an inlined vector is greater than or equal to the +// value of another inlined vector using a lexicographical comparison algorithm. +template <typename T, size_t N, typename A> +bool operator>=(const absl::InlinedVector<T, N, A>& a, + const absl::InlinedVector<T, N, A>& b) { + return !(a < b); +} + +// `AbslHashValue(...)` +// +// Provides `absl::Hash` support for `absl::InlinedVector`. It is uncommon to +// call this directly. +template <typename H, typename T, size_t N, typename A> +H AbslHashValue(H h, const absl::InlinedVector<T, N, A>& a) { + auto size = a.size(); + return H::combine(H::combine_contiguous(std::move(h), a.data(), size), size); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INLINED_VECTOR_H_ diff --git a/third_party/abseil_cpp/absl/container/inlined_vector_benchmark.cc b/third_party/abseil_cpp/absl/container/inlined_vector_benchmark.cc new file mode 100644 index 0000000000..b8dafe9323 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/inlined_vector_benchmark.cc @@ -0,0 +1,807 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <array> +#include <string> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/container/inlined_vector.h" +#include "absl/strings/str_cat.h" + +namespace { + +void BM_InlinedVectorFill(benchmark::State& state) { + const int len = state.range(0); + absl::InlinedVector<int, 8> v; + v.reserve(len); + for (auto _ : state) { + v.resize(0); // Use resize(0) as InlinedVector releases storage on clear(). + for (int i = 0; i < len; ++i) { + v.push_back(i); + } + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_InlinedVectorFill)->Range(1, 256); + +void BM_InlinedVectorFillRange(benchmark::State& state) { + const int len = state.range(0); + const std::vector<int> src(len, len); + absl::InlinedVector<int, 8> v; + v.reserve(len); + for (auto _ : state) { + benchmark::DoNotOptimize(src); + v.assign(src.begin(), src.end()); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_InlinedVectorFillRange)->Range(1, 256); + +void BM_StdVectorFill(benchmark::State& state) { + const int len = state.range(0); + std::vector<int> v; + v.reserve(len); + for (auto _ : state) { + v.clear(); + for (int i = 0; i < len; ++i) { + v.push_back(i); + } + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_StdVectorFill)->Range(1, 256); + +// The purpose of the next two benchmarks is to verify that +// absl::InlinedVector is efficient when moving is more efficent than +// copying. To do so, we use strings that are larger than the short +// string optimization. +bool StringRepresentedInline(std::string s) { + const char* chars = s.data(); + std::string s1 = std::move(s); + return s1.data() != chars; +} + +int GetNonShortStringOptimizationSize() { + for (int i = 24; i <= 192; i *= 2) { + if (!StringRepresentedInline(std::string(i, 'A'))) { + return i; + } + } + ABSL_RAW_LOG( + FATAL, + "Failed to find a string larger than the short string optimization"); + return -1; +} + +void BM_InlinedVectorFillString(benchmark::State& state) { + const int len = state.range(0); + const int no_sso = GetNonShortStringOptimizationSize(); + std::string strings[4] = {std::string(no_sso, 'A'), std::string(no_sso, 'B'), + std::string(no_sso, 'C'), std::string(no_sso, 'D')}; + + for (auto _ : state) { + absl::InlinedVector<std::string, 8> v; + for (int i = 0; i < len; i++) { + v.push_back(strings[i & 3]); + } + } + state.SetItemsProcessed(static_cast<int64_t>(state.iterations()) * len); +} +BENCHMARK(BM_InlinedVectorFillString)->Range(0, 1024); + +void BM_StdVectorFillString(benchmark::State& state) { + const int len = state.range(0); + const int no_sso = GetNonShortStringOptimizationSize(); + std::string strings[4] = {std::string(no_sso, 'A'), std::string(no_sso, 'B'), + std::string(no_sso, 'C'), std::string(no_sso, 'D')}; + + for (auto _ : state) { + std::vector<std::string> v; + for (int i = 0; i < len; i++) { + v.push_back(strings[i & 3]); + } + } + state.SetItemsProcessed(static_cast<int64_t>(state.iterations()) * len); +} +BENCHMARK(BM_StdVectorFillString)->Range(0, 1024); + +struct Buffer { // some arbitrary structure for benchmarking. + char* base; + int length; + int capacity; + void* user_data; +}; + +void BM_InlinedVectorAssignments(benchmark::State& state) { + const int len = state.range(0); + using BufferVec = absl::InlinedVector<Buffer, 2>; + + BufferVec src; + src.resize(len); + + BufferVec dst; + for (auto _ : state) { + benchmark::DoNotOptimize(dst); + benchmark::DoNotOptimize(src); + dst = src; + } +} +BENCHMARK(BM_InlinedVectorAssignments) + ->Arg(0) + ->Arg(1) + ->Arg(2) + ->Arg(3) + ->Arg(4) + ->Arg(20); + +void BM_CreateFromContainer(benchmark::State& state) { + for (auto _ : state) { + absl::InlinedVector<int, 4> src{1, 2, 3}; + benchmark::DoNotOptimize(src); + absl::InlinedVector<int, 4> dst(std::move(src)); + benchmark::DoNotOptimize(dst); + } +} +BENCHMARK(BM_CreateFromContainer); + +struct LargeCopyableOnly { + LargeCopyableOnly() : d(1024, 17) {} + LargeCopyableOnly(const LargeCopyableOnly& o) = default; + LargeCopyableOnly& operator=(const LargeCopyableOnly& o) = default; + + std::vector<int> d; +}; + +struct LargeCopyableSwappable { + LargeCopyableSwappable() : d(1024, 17) {} + + LargeCopyableSwappable(const LargeCopyableSwappable& o) = default; + + LargeCopyableSwappable& operator=(LargeCopyableSwappable o) { + using std::swap; + swap(*this, o); + return *this; + } + + friend void swap(LargeCopyableSwappable& a, LargeCopyableSwappable& b) { + using std::swap; + swap(a.d, b.d); + } + + std::vector<int> d; +}; + +struct LargeCopyableMovable { + LargeCopyableMovable() : d(1024, 17) {} + // Use implicitly defined copy and move. + + std::vector<int> d; +}; + +struct LargeCopyableMovableSwappable { + LargeCopyableMovableSwappable() : d(1024, 17) {} + LargeCopyableMovableSwappable(const LargeCopyableMovableSwappable& o) = + default; + LargeCopyableMovableSwappable(LargeCopyableMovableSwappable&& o) = default; + + LargeCopyableMovableSwappable& operator=(LargeCopyableMovableSwappable o) { + using std::swap; + swap(*this, o); + return *this; + } + LargeCopyableMovableSwappable& operator=(LargeCopyableMovableSwappable&& o) = + default; + + friend void swap(LargeCopyableMovableSwappable& a, + LargeCopyableMovableSwappable& b) { + using std::swap; + swap(a.d, b.d); + } + + std::vector<int> d; +}; + +template <typename ElementType> +void BM_SwapElements(benchmark::State& state) { + const int len = state.range(0); + using Vec = absl::InlinedVector<ElementType, 32>; + Vec a(len); + Vec b; + for (auto _ : state) { + using std::swap; + benchmark::DoNotOptimize(a); + benchmark::DoNotOptimize(b); + swap(a, b); + } +} +BENCHMARK_TEMPLATE(BM_SwapElements, LargeCopyableOnly)->Range(0, 1024); +BENCHMARK_TEMPLATE(BM_SwapElements, LargeCopyableSwappable)->Range(0, 1024); +BENCHMARK_TEMPLATE(BM_SwapElements, LargeCopyableMovable)->Range(0, 1024); +BENCHMARK_TEMPLATE(BM_SwapElements, LargeCopyableMovableSwappable) + ->Range(0, 1024); + +// The following benchmark is meant to track the efficiency of the vector size +// as a function of stored type via the benchmark label. It is not meant to +// output useful sizeof operator performance. The loop is a dummy operation +// to fulfill the requirement of running the benchmark. +template <typename VecType> +void BM_Sizeof(benchmark::State& state) { + int size = 0; + for (auto _ : state) { + VecType vec; + size = sizeof(vec); + } + state.SetLabel(absl::StrCat("sz=", size)); +} +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<char, 1>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<char, 4>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<char, 7>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<char, 8>); + +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<int, 1>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<int, 4>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<int, 7>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<int, 8>); + +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<void*, 1>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<void*, 4>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<void*, 7>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<void*, 8>); + +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<std::string, 1>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<std::string, 4>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<std::string, 7>); +BENCHMARK_TEMPLATE(BM_Sizeof, absl::InlinedVector<std::string, 8>); + +void BM_InlinedVectorIndexInlined(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v[4]); + } +} +BENCHMARK(BM_InlinedVectorIndexInlined); + +void BM_InlinedVectorIndexExternal(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v[4]); + } +} +BENCHMARK(BM_InlinedVectorIndexExternal); + +void BM_StdVectorIndex(benchmark::State& state) { + std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v[4]); + } +} +BENCHMARK(BM_StdVectorIndex); + +void BM_InlinedVectorDataInlined(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.data()); + } +} +BENCHMARK(BM_InlinedVectorDataInlined); + +void BM_InlinedVectorDataExternal(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.data()); + } + state.SetItemsProcessed(16 * static_cast<int64_t>(state.iterations())); +} +BENCHMARK(BM_InlinedVectorDataExternal); + +void BM_StdVectorData(benchmark::State& state) { + std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.data()); + } + state.SetItemsProcessed(16 * static_cast<int64_t>(state.iterations())); +} +BENCHMARK(BM_StdVectorData); + +void BM_InlinedVectorSizeInlined(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.size()); + } +} +BENCHMARK(BM_InlinedVectorSizeInlined); + +void BM_InlinedVectorSizeExternal(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.size()); + } +} +BENCHMARK(BM_InlinedVectorSizeExternal); + +void BM_StdVectorSize(benchmark::State& state) { + std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.size()); + } +} +BENCHMARK(BM_StdVectorSize); + +void BM_InlinedVectorEmptyInlined(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.empty()); + } +} +BENCHMARK(BM_InlinedVectorEmptyInlined); + +void BM_InlinedVectorEmptyExternal(benchmark::State& state) { + absl::InlinedVector<int, 8> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.empty()); + } +} +BENCHMARK(BM_InlinedVectorEmptyExternal); + +void BM_StdVectorEmpty(benchmark::State& state) { + std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; + for (auto _ : state) { + benchmark::DoNotOptimize(v); + benchmark::DoNotOptimize(v.empty()); + } +} +BENCHMARK(BM_StdVectorEmpty); + +constexpr size_t kInlinedCapacity = 4; +constexpr size_t kLargeSize = kInlinedCapacity * 2; +constexpr size_t kSmallSize = kInlinedCapacity / 2; +constexpr size_t kBatchSize = 100; + +#define ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_FunctionTemplate, T) \ + BENCHMARK_TEMPLATE(BM_FunctionTemplate, T, kLargeSize); \ + BENCHMARK_TEMPLATE(BM_FunctionTemplate, T, kSmallSize) + +#define ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_FunctionTemplate, T) \ + BENCHMARK_TEMPLATE(BM_FunctionTemplate, T, kLargeSize, kLargeSize); \ + BENCHMARK_TEMPLATE(BM_FunctionTemplate, T, kLargeSize, kSmallSize); \ + BENCHMARK_TEMPLATE(BM_FunctionTemplate, T, kSmallSize, kLargeSize); \ + BENCHMARK_TEMPLATE(BM_FunctionTemplate, T, kSmallSize, kSmallSize) + +template <typename T> +using InlVec = absl::InlinedVector<T, kInlinedCapacity>; + +struct TrivialType { + size_t val; +}; + +class NontrivialType { + public: + ABSL_ATTRIBUTE_NOINLINE NontrivialType() : val_() { + benchmark::DoNotOptimize(*this); + } + + ABSL_ATTRIBUTE_NOINLINE NontrivialType(const NontrivialType& other) + : val_(other.val_) { + benchmark::DoNotOptimize(*this); + } + + ABSL_ATTRIBUTE_NOINLINE NontrivialType& operator=( + const NontrivialType& other) { + val_ = other.val_; + benchmark::DoNotOptimize(*this); + return *this; + } + + ABSL_ATTRIBUTE_NOINLINE ~NontrivialType() noexcept { + benchmark::DoNotOptimize(*this); + } + + private: + size_t val_; +}; + +template <typename T, typename PrepareVecFn, typename TestVecFn> +void BatchedBenchmark(benchmark::State& state, PrepareVecFn prepare_vec, + TestVecFn test_vec) { + std::array<InlVec<T>, kBatchSize> vector_batch{}; + + while (state.KeepRunningBatch(kBatchSize)) { + // Prepare batch + state.PauseTiming(); + for (size_t i = 0; i < kBatchSize; ++i) { + prepare_vec(vector_batch.data() + i, i); + } + benchmark::DoNotOptimize(vector_batch); + state.ResumeTiming(); + + // Test batch + for (size_t i = 0; i < kBatchSize; ++i) { + test_vec(vector_batch.data() + i, i); + } + } +} + +template <typename T, size_t ToSize> +void BM_ConstructFromSize(benchmark::State& state) { + using VecT = InlVec<T>; + auto size = ToSize; + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->~VecT(); }, + /* test_vec = */ + [&](void* ptr, size_t) { + benchmark::DoNotOptimize(size); + ::new (ptr) VecT(size); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromSize, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromSize, NontrivialType); + +template <typename T, size_t ToSize> +void BM_ConstructFromSizeRef(benchmark::State& state) { + using VecT = InlVec<T>; + auto size = ToSize; + auto ref = T(); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->~VecT(); }, + /* test_vec = */ + [&](void* ptr, size_t) { + benchmark::DoNotOptimize(size); + benchmark::DoNotOptimize(ref); + ::new (ptr) VecT(size, ref); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromSizeRef, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromSizeRef, NontrivialType); + +template <typename T, size_t ToSize> +void BM_ConstructFromRange(benchmark::State& state) { + using VecT = InlVec<T>; + std::array<T, ToSize> arr{}; + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->~VecT(); }, + /* test_vec = */ + [&](void* ptr, size_t) { + benchmark::DoNotOptimize(arr); + ::new (ptr) VecT(arr.begin(), arr.end()); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromRange, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromRange, NontrivialType); + +template <typename T, size_t ToSize> +void BM_ConstructFromCopy(benchmark::State& state) { + using VecT = InlVec<T>; + VecT other_vec(ToSize); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { vec->~VecT(); }, + /* test_vec = */ + [&](void* ptr, size_t) { + benchmark::DoNotOptimize(other_vec); + ::new (ptr) VecT(other_vec); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromCopy, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromCopy, NontrivialType); + +template <typename T, size_t ToSize> +void BM_ConstructFromMove(benchmark::State& state) { + using VecT = InlVec<T>; + std::array<VecT, kBatchSize> vector_batch{}; + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [&](InlVec<T>* vec, size_t i) { + vector_batch[i].clear(); + vector_batch[i].resize(ToSize); + vec->~VecT(); + }, + /* test_vec = */ + [&](void* ptr, size_t i) { + benchmark::DoNotOptimize(vector_batch[i]); + ::new (ptr) VecT(std::move(vector_batch[i])); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromMove, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_ConstructFromMove, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_AssignSizeRef(benchmark::State& state) { + auto size = ToSize; + auto ref = T(); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->resize(FromSize); }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t) { + benchmark::DoNotOptimize(size); + benchmark::DoNotOptimize(ref); + vec->assign(size, ref); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignSizeRef, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignSizeRef, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_AssignRange(benchmark::State& state) { + std::array<T, ToSize> arr{}; + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->resize(FromSize); }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t) { + benchmark::DoNotOptimize(arr); + vec->assign(arr.begin(), arr.end()); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignRange, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignRange, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_AssignFromCopy(benchmark::State& state) { + InlVec<T> other_vec(ToSize); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->resize(FromSize); }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t) { + benchmark::DoNotOptimize(other_vec); + *vec = other_vec; + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignFromCopy, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignFromCopy, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_AssignFromMove(benchmark::State& state) { + using VecT = InlVec<T>; + std::array<VecT, kBatchSize> vector_batch{}; + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [&](InlVec<T>* vec, size_t i) { + vector_batch[i].clear(); + vector_batch[i].resize(ToSize); + vec->resize(FromSize); + }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t i) { + benchmark::DoNotOptimize(vector_batch[i]); + *vec = std::move(vector_batch[i]); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignFromMove, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_AssignFromMove, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_ResizeSize(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [](InlVec<T>* vec, size_t) { vec->resize(ToSize); }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_ResizeSize, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_ResizeSize, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_ResizeSizeRef(benchmark::State& state) { + auto t = T(); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t) { + benchmark::DoNotOptimize(t); + vec->resize(ToSize, t); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_ResizeSizeRef, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_ResizeSizeRef, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_InsertSizeRef(benchmark::State& state) { + auto t = T(); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t) { + benchmark::DoNotOptimize(t); + auto* pos = vec->data() + (vec->size() / 2); + vec->insert(pos, t); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_InsertSizeRef, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_InsertSizeRef, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_InsertRange(benchmark::State& state) { + InlVec<T> other_vec(ToSize); + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t) { + benchmark::DoNotOptimize(other_vec); + auto* pos = vec->data() + (vec->size() / 2); + vec->insert(pos, other_vec.begin(), other_vec.end()); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_InsertRange, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_InsertRange, NontrivialType); + +template <typename T, size_t FromSize> +void BM_EmplaceBack(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [](InlVec<T>* vec, size_t) { vec->emplace_back(); }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_EmplaceBack, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_EmplaceBack, NontrivialType); + +template <typename T, size_t FromSize> +void BM_PopBack(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [](InlVec<T>* vec, size_t) { vec->pop_back(); }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_PopBack, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_PopBack, NontrivialType); + +template <typename T, size_t FromSize> +void BM_EraseOne(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [](InlVec<T>* vec, size_t) { + auto* pos = vec->data() + (vec->size() / 2); + vec->erase(pos); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_EraseOne, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_EraseOne, NontrivialType); + +template <typename T, size_t FromSize> +void BM_EraseRange(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [](InlVec<T>* vec, size_t) { + auto* pos = vec->data() + (vec->size() / 2); + vec->erase(pos, pos + 1); + }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_EraseRange, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_EraseRange, NontrivialType); + +template <typename T, size_t FromSize> +void BM_Clear(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ [](InlVec<T>* vec, size_t) { vec->resize(FromSize); }, + /* test_vec = */ [](InlVec<T>* vec, size_t) { vec->clear(); }); +} +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_Clear, TrivialType); +ABSL_INTERNAL_BENCHMARK_ONE_SIZE(BM_Clear, NontrivialType); + +template <typename T, size_t FromSize, size_t ToCapacity> +void BM_Reserve(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(FromSize); + }, + /* test_vec = */ + [](InlVec<T>* vec, size_t) { vec->reserve(ToCapacity); }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_Reserve, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_Reserve, NontrivialType); + +template <typename T, size_t FromCapacity, size_t ToCapacity> +void BM_ShrinkToFit(benchmark::State& state) { + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [](InlVec<T>* vec, size_t) { + vec->clear(); + vec->resize(ToCapacity); + vec->reserve(FromCapacity); + }, + /* test_vec = */ [](InlVec<T>* vec, size_t) { vec->shrink_to_fit(); }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_ShrinkToFit, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_ShrinkToFit, NontrivialType); + +template <typename T, size_t FromSize, size_t ToSize> +void BM_Swap(benchmark::State& state) { + using VecT = InlVec<T>; + std::array<VecT, kBatchSize> vector_batch{}; + BatchedBenchmark<T>( + state, + /* prepare_vec = */ + [&](InlVec<T>* vec, size_t i) { + vector_batch[i].clear(); + vector_batch[i].resize(ToSize); + vec->resize(FromSize); + }, + /* test_vec = */ + [&](InlVec<T>* vec, size_t i) { + using std::swap; + benchmark::DoNotOptimize(vector_batch[i]); + swap(*vec, vector_batch[i]); + }); +} +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_Swap, TrivialType); +ABSL_INTERNAL_BENCHMARK_TWO_SIZE(BM_Swap, NontrivialType); + +} // namespace diff --git a/third_party/abseil_cpp/absl/container/inlined_vector_exception_safety_test.cc b/third_party/abseil_cpp/absl/container/inlined_vector_exception_safety_test.cc new file mode 100644 index 0000000000..0e6a05b5f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/inlined_vector_exception_safety_test.cc @@ -0,0 +1,508 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/inlined_vector.h" + +#include "absl/base/config.h" + +#if defined(ABSL_HAVE_EXCEPTIONS) + +#include <array> +#include <initializer_list> +#include <iterator> +#include <memory> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/base/internal/exception_safety_testing.h" + +namespace { + +constexpr size_t kInlinedCapacity = 4; +constexpr size_t kLargeSize = kInlinedCapacity * 2; +constexpr size_t kSmallSize = kInlinedCapacity / 2; + +using Thrower = testing::ThrowingValue<>; +using MovableThrower = testing::ThrowingValue<testing::TypeSpec::kNoThrowMove>; +using ThrowAlloc = testing::ThrowingAllocator<Thrower>; + +using ThrowerVec = absl::InlinedVector<Thrower, kInlinedCapacity>; +using MovableThrowerVec = absl::InlinedVector<MovableThrower, kInlinedCapacity>; + +using ThrowAllocThrowerVec = + absl::InlinedVector<Thrower, kInlinedCapacity, ThrowAlloc>; +using ThrowAllocMovableThrowerVec = + absl::InlinedVector<MovableThrower, kInlinedCapacity, ThrowAlloc>; + +// In GCC, if an element of a `std::initializer_list` throws during construction +// the elements that were constructed before it are not destroyed. This causes +// incorrect exception safety test failures. Thus, `testing::nothrow_ctor` is +// required. See: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=66139 +#define ABSL_INTERNAL_MAKE_INIT_LIST(T, N) \ + (N > kInlinedCapacity \ + ? std::initializer_list<T>{T(0, testing::nothrow_ctor), \ + T(1, testing::nothrow_ctor), \ + T(2, testing::nothrow_ctor), \ + T(3, testing::nothrow_ctor), \ + T(4, testing::nothrow_ctor), \ + T(5, testing::nothrow_ctor), \ + T(6, testing::nothrow_ctor), \ + T(7, testing::nothrow_ctor)} \ + \ + : std::initializer_list<T>{T(0, testing::nothrow_ctor), \ + T(1, testing::nothrow_ctor)}) +static_assert(kLargeSize == 8, "Must update ABSL_INTERNAL_MAKE_INIT_LIST(...)"); +static_assert(kSmallSize == 2, "Must update ABSL_INTERNAL_MAKE_INIT_LIST(...)"); + +template <typename TheVecT, size_t... TheSizes> +class TestParams { + public: + using VecT = TheVecT; + constexpr static size_t GetSizeAt(size_t i) { return kSizes[1 + i]; } + + private: + constexpr static size_t kSizes[1 + sizeof...(TheSizes)] = {1, TheSizes...}; +}; + +using NoSizeTestParams = + ::testing::Types<TestParams<ThrowerVec>, TestParams<MovableThrowerVec>, + TestParams<ThrowAllocThrowerVec>, + TestParams<ThrowAllocMovableThrowerVec>>; + +using OneSizeTestParams = + ::testing::Types<TestParams<ThrowerVec, kLargeSize>, + TestParams<ThrowerVec, kSmallSize>, + TestParams<MovableThrowerVec, kLargeSize>, + TestParams<MovableThrowerVec, kSmallSize>, + TestParams<ThrowAllocThrowerVec, kLargeSize>, + TestParams<ThrowAllocThrowerVec, kSmallSize>, + TestParams<ThrowAllocMovableThrowerVec, kLargeSize>, + TestParams<ThrowAllocMovableThrowerVec, kSmallSize>>; + +using TwoSizeTestParams = ::testing::Types< + TestParams<ThrowerVec, kLargeSize, kLargeSize>, + TestParams<ThrowerVec, kLargeSize, kSmallSize>, + TestParams<ThrowerVec, kSmallSize, kLargeSize>, + TestParams<ThrowerVec, kSmallSize, kSmallSize>, + TestParams<MovableThrowerVec, kLargeSize, kLargeSize>, + TestParams<MovableThrowerVec, kLargeSize, kSmallSize>, + TestParams<MovableThrowerVec, kSmallSize, kLargeSize>, + TestParams<MovableThrowerVec, kSmallSize, kSmallSize>, + TestParams<ThrowAllocThrowerVec, kLargeSize, kLargeSize>, + TestParams<ThrowAllocThrowerVec, kLargeSize, kSmallSize>, + TestParams<ThrowAllocThrowerVec, kSmallSize, kLargeSize>, + TestParams<ThrowAllocThrowerVec, kSmallSize, kSmallSize>, + TestParams<ThrowAllocMovableThrowerVec, kLargeSize, kLargeSize>, + TestParams<ThrowAllocMovableThrowerVec, kLargeSize, kSmallSize>, + TestParams<ThrowAllocMovableThrowerVec, kSmallSize, kLargeSize>, + TestParams<ThrowAllocMovableThrowerVec, kSmallSize, kSmallSize>>; + +template <typename> +struct NoSizeTest : ::testing::Test {}; +TYPED_TEST_SUITE(NoSizeTest, NoSizeTestParams); + +template <typename> +struct OneSizeTest : ::testing::Test {}; +TYPED_TEST_SUITE(OneSizeTest, OneSizeTestParams); + +template <typename> +struct TwoSizeTest : ::testing::Test {}; +TYPED_TEST_SUITE(TwoSizeTest, TwoSizeTestParams); + +template <typename VecT> +bool InlinedVectorInvariants(VecT* vec) { + if (*vec != *vec) return false; + if (vec->size() > vec->capacity()) return false; + if (vec->size() > vec->max_size()) return false; + if (vec->capacity() > vec->max_size()) return false; + if (vec->data() != std::addressof(vec->at(0))) return false; + if (vec->data() != vec->begin()) return false; + if (*vec->data() != *vec->begin()) return false; + if (vec->begin() > vec->end()) return false; + if ((vec->end() - vec->begin()) != vec->size()) return false; + if (std::distance(vec->begin(), vec->end()) != vec->size()) return false; + return true; +} + +// Function that always returns false is correct, but refactoring is required +// for clarity. It's needed to express that, as a contract, certain operations +// should not throw at all. Execution of this function means an exception was +// thrown and thus the test should fail. +// TODO(johnsoncj): Add `testing::NoThrowGuarantee` to the framework +template <typename VecT> +bool NoThrowGuarantee(VecT* /* vec */) { + return false; +} + +TYPED_TEST(NoSizeTest, DefaultConstructor) { + using VecT = typename TypeParam::VecT; + using allocator_type = typename VecT::allocator_type; + + testing::TestThrowingCtor<VecT>(); + + testing::TestThrowingCtor<VecT>(allocator_type{}); +} + +TYPED_TEST(OneSizeTest, SizeConstructor) { + using VecT = typename TypeParam::VecT; + using allocator_type = typename VecT::allocator_type; + constexpr static auto size = TypeParam::GetSizeAt(0); + + testing::TestThrowingCtor<VecT>(size); + + testing::TestThrowingCtor<VecT>(size, allocator_type{}); +} + +TYPED_TEST(OneSizeTest, SizeRefConstructor) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + using allocator_type = typename VecT::allocator_type; + constexpr static auto size = TypeParam::GetSizeAt(0); + + testing::TestThrowingCtor<VecT>(size, value_type{}); + + testing::TestThrowingCtor<VecT>(size, value_type{}, allocator_type{}); +} + +TYPED_TEST(OneSizeTest, InitializerListConstructor) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + using allocator_type = typename VecT::allocator_type; + constexpr static auto size = TypeParam::GetSizeAt(0); + + testing::TestThrowingCtor<VecT>( + ABSL_INTERNAL_MAKE_INIT_LIST(value_type, size)); + + testing::TestThrowingCtor<VecT>( + ABSL_INTERNAL_MAKE_INIT_LIST(value_type, size), allocator_type{}); +} + +TYPED_TEST(OneSizeTest, RangeConstructor) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + using allocator_type = typename VecT::allocator_type; + constexpr static auto size = TypeParam::GetSizeAt(0); + + std::array<value_type, size> arr{}; + + testing::TestThrowingCtor<VecT>(arr.begin(), arr.end()); + + testing::TestThrowingCtor<VecT>(arr.begin(), arr.end(), allocator_type{}); +} + +TYPED_TEST(OneSizeTest, CopyConstructor) { + using VecT = typename TypeParam::VecT; + using allocator_type = typename VecT::allocator_type; + constexpr static auto size = TypeParam::GetSizeAt(0); + + VecT other_vec{size}; + + testing::TestThrowingCtor<VecT>(other_vec); + + testing::TestThrowingCtor<VecT>(other_vec, allocator_type{}); +} + +TYPED_TEST(OneSizeTest, MoveConstructor) { + using VecT = typename TypeParam::VecT; + using allocator_type = typename VecT::allocator_type; + constexpr static auto size = TypeParam::GetSizeAt(0); + + if (!absl::allocator_is_nothrow<allocator_type>::value) { + testing::TestThrowingCtor<VecT>(VecT{size}); + + testing::TestThrowingCtor<VecT>(VecT{size}, allocator_type{}); + } +} + +TYPED_TEST(TwoSizeTest, Assign) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + constexpr static auto from_size = TypeParam::GetSizeAt(0); + constexpr static auto to_size = TypeParam::GetSizeAt(1); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{from_size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + *vec = ABSL_INTERNAL_MAKE_INIT_LIST(value_type, to_size); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + VecT other_vec{to_size}; + *vec = other_vec; + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + VecT other_vec{to_size}; + *vec = std::move(other_vec); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + value_type val{}; + vec->assign(to_size, val); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + vec->assign(ABSL_INTERNAL_MAKE_INIT_LIST(value_type, to_size)); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + std::array<value_type, to_size> arr{}; + vec->assign(arr.begin(), arr.end()); + })); +} + +TYPED_TEST(TwoSizeTest, Resize) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + constexpr static auto from_size = TypeParam::GetSizeAt(0); + constexpr static auto to_size = TypeParam::GetSizeAt(1); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{from_size}) + .WithContracts(InlinedVectorInvariants<VecT>, + testing::strong_guarantee); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + vec->resize(to_size); // + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + vec->resize(to_size, value_type{}); // + })); +} + +TYPED_TEST(OneSizeTest, Insert) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + constexpr static auto from_size = TypeParam::GetSizeAt(0); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{from_size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + vec->insert(it, value_type{}); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + vec->insert(it, value_type{}); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->end(); + vec->insert(it, value_type{}); + })); +} + +TYPED_TEST(TwoSizeTest, Insert) { + using VecT = typename TypeParam::VecT; + using value_type = typename VecT::value_type; + constexpr static auto from_size = TypeParam::GetSizeAt(0); + constexpr static auto count = TypeParam::GetSizeAt(1); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{from_size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + vec->insert(it, count, value_type{}); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + vec->insert(it, count, value_type{}); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->end(); + vec->insert(it, count, value_type{}); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + vec->insert(it, ABSL_INTERNAL_MAKE_INIT_LIST(value_type, count)); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + vec->insert(it, ABSL_INTERNAL_MAKE_INIT_LIST(value_type, count)); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->end(); + vec->insert(it, ABSL_INTERNAL_MAKE_INIT_LIST(value_type, count)); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + std::array<value_type, count> arr{}; + vec->insert(it, arr.begin(), arr.end()); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + std::array<value_type, count> arr{}; + vec->insert(it, arr.begin(), arr.end()); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->end(); + std::array<value_type, count> arr{}; + vec->insert(it, arr.begin(), arr.end()); + })); +} + +TYPED_TEST(OneSizeTest, EmplaceBack) { + using VecT = typename TypeParam::VecT; + constexpr static auto size = TypeParam::GetSizeAt(0); + + // For testing calls to `emplace_back(...)` that reallocate. + VecT full_vec{size}; + full_vec.resize(full_vec.capacity()); + + // For testing calls to `emplace_back(...)` that don't reallocate. + VecT nonfull_vec{size}; + nonfull_vec.reserve(size + 1); + + auto tester = testing::MakeExceptionSafetyTester().WithContracts( + InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.WithInitialValue(nonfull_vec).Test([](VecT* vec) { + vec->emplace_back(); + })); + + EXPECT_TRUE(tester.WithInitialValue(full_vec).Test( + [](VecT* vec) { vec->emplace_back(); })); +} + +TYPED_TEST(OneSizeTest, PopBack) { + using VecT = typename TypeParam::VecT; + constexpr static auto size = TypeParam::GetSizeAt(0); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{size}) + .WithContracts(NoThrowGuarantee<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + vec->pop_back(); // + })); +} + +TYPED_TEST(OneSizeTest, Erase) { + using VecT = typename TypeParam::VecT; + constexpr static auto size = TypeParam::GetSizeAt(0); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + vec->erase(it); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + vec->erase(it); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() - 1); + vec->erase(it); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + vec->erase(it, it); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + vec->erase(it, it); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() - 1); + vec->erase(it, it); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin(); + vec->erase(it, it + 1); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() / 2); + vec->erase(it, it + 1); + })); + EXPECT_TRUE(tester.Test([](VecT* vec) { + auto it = vec->begin() + (vec->size() - 1); + vec->erase(it, it + 1); + })); +} + +TYPED_TEST(OneSizeTest, Clear) { + using VecT = typename TypeParam::VecT; + constexpr static auto size = TypeParam::GetSizeAt(0); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{size}) + .WithContracts(NoThrowGuarantee<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + vec->clear(); // + })); +} + +TYPED_TEST(TwoSizeTest, Reserve) { + using VecT = typename TypeParam::VecT; + constexpr static auto from_size = TypeParam::GetSizeAt(0); + constexpr static auto to_capacity = TypeParam::GetSizeAt(1); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{from_size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { vec->reserve(to_capacity); })); +} + +TYPED_TEST(OneSizeTest, ShrinkToFit) { + using VecT = typename TypeParam::VecT; + constexpr static auto size = TypeParam::GetSizeAt(0); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + vec->shrink_to_fit(); // + })); +} + +TYPED_TEST(TwoSizeTest, Swap) { + using VecT = typename TypeParam::VecT; + constexpr static auto from_size = TypeParam::GetSizeAt(0); + constexpr static auto to_size = TypeParam::GetSizeAt(1); + + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(VecT{from_size}) + .WithContracts(InlinedVectorInvariants<VecT>); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + VecT other_vec{to_size}; + vec->swap(other_vec); + })); + + EXPECT_TRUE(tester.Test([](VecT* vec) { + using std::swap; + VecT other_vec{to_size}; + swap(*vec, other_vec); + })); +} + +} // namespace + +#endif // defined(ABSL_HAVE_EXCEPTIONS) diff --git a/third_party/abseil_cpp/absl/container/inlined_vector_test.cc b/third_party/abseil_cpp/absl/container/inlined_vector_test.cc new file mode 100644 index 0000000000..415c60d9f1 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/inlined_vector_test.cc @@ -0,0 +1,1811 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/inlined_vector.h" + +#include <algorithm> +#include <forward_list> +#include <list> +#include <memory> +#include <scoped_allocator> +#include <sstream> +#include <stdexcept> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/exception_testing.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/base/options.h" +#include "absl/container/internal/counting_allocator.h" +#include "absl/container/internal/test_instance_tracker.h" +#include "absl/hash/hash_testing.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" + +namespace { + +using absl::container_internal::CountingAllocator; +using absl::test_internal::CopyableMovableInstance; +using absl::test_internal::CopyableOnlyInstance; +using absl::test_internal::InstanceTracker; +using testing::AllOf; +using testing::Each; +using testing::ElementsAre; +using testing::ElementsAreArray; +using testing::Eq; +using testing::Gt; +using testing::PrintToString; + +using IntVec = absl::InlinedVector<int, 8>; + +MATCHER_P(SizeIs, n, "") { + return testing::ExplainMatchResult(n, arg.size(), result_listener); +} + +MATCHER_P(CapacityIs, n, "") { + return testing::ExplainMatchResult(n, arg.capacity(), result_listener); +} + +MATCHER_P(ValueIs, e, "") { + return testing::ExplainMatchResult(e, arg.value(), result_listener); +} + +// TODO(bsamwel): Add support for movable-only types. + +// Test fixture for typed tests on BaseCountedInstance derived classes, see +// test_instance_tracker.h. +template <typename T> +class InstanceTest : public ::testing::Test {}; +TYPED_TEST_SUITE_P(InstanceTest); + +// A simple reference counted class to make sure that the proper elements are +// destroyed in the erase(begin, end) test. +class RefCounted { + public: + RefCounted(int value, int* count) : value_(value), count_(count) { Ref(); } + + RefCounted(const RefCounted& v) : value_(v.value_), count_(v.count_) { + Ref(); + } + + ~RefCounted() { + Unref(); + count_ = nullptr; + } + + friend void swap(RefCounted& a, RefCounted& b) { + using std::swap; + swap(a.value_, b.value_); + swap(a.count_, b.count_); + } + + RefCounted& operator=(RefCounted v) { + using std::swap; + swap(*this, v); + return *this; + } + + void Ref() const { + ABSL_RAW_CHECK(count_ != nullptr, ""); + ++(*count_); + } + + void Unref() const { + --(*count_); + ABSL_RAW_CHECK(*count_ >= 0, ""); + } + + int value_; + int* count_; +}; + +using RefCountedVec = absl::InlinedVector<RefCounted, 8>; + +// A class with a vtable pointer +class Dynamic { + public: + virtual ~Dynamic() {} +}; + +using DynamicVec = absl::InlinedVector<Dynamic, 8>; + +// Append 0..len-1 to *v +template <typename Container> +static void Fill(Container* v, int len, int offset = 0) { + for (int i = 0; i < len; i++) { + v->push_back(i + offset); + } +} + +static IntVec Fill(int len, int offset = 0) { + IntVec v; + Fill(&v, len, offset); + return v; +} + +TEST(IntVec, SimpleOps) { + for (int len = 0; len < 20; len++) { + IntVec v; + const IntVec& cv = v; // const alias + + Fill(&v, len); + EXPECT_EQ(len, v.size()); + EXPECT_LE(len, v.capacity()); + + for (int i = 0; i < len; i++) { + EXPECT_EQ(i, v[i]); + EXPECT_EQ(i, v.at(i)); + } + EXPECT_EQ(v.begin(), v.data()); + EXPECT_EQ(cv.begin(), cv.data()); + + int counter = 0; + for (IntVec::iterator iter = v.begin(); iter != v.end(); ++iter) { + EXPECT_EQ(counter, *iter); + counter++; + } + EXPECT_EQ(counter, len); + + counter = 0; + for (IntVec::const_iterator iter = v.begin(); iter != v.end(); ++iter) { + EXPECT_EQ(counter, *iter); + counter++; + } + EXPECT_EQ(counter, len); + + counter = 0; + for (IntVec::const_iterator iter = v.cbegin(); iter != v.cend(); ++iter) { + EXPECT_EQ(counter, *iter); + counter++; + } + EXPECT_EQ(counter, len); + + if (len > 0) { + EXPECT_EQ(0, v.front()); + EXPECT_EQ(len - 1, v.back()); + v.pop_back(); + EXPECT_EQ(len - 1, v.size()); + for (int i = 0; i < v.size(); ++i) { + EXPECT_EQ(i, v[i]); + EXPECT_EQ(i, v.at(i)); + } + } + } +} + +TEST(IntVec, PopBackNoOverflow) { + IntVec v = {1}; + v.pop_back(); + EXPECT_EQ(v.size(), 0); +} + +TEST(IntVec, AtThrows) { + IntVec v = {1, 2, 3}; + EXPECT_EQ(v.at(2), 3); + ABSL_BASE_INTERNAL_EXPECT_FAIL(v.at(3), std::out_of_range, + "failed bounds check"); +} + +TEST(IntVec, ReverseIterator) { + for (int len = 0; len < 20; len++) { + IntVec v; + Fill(&v, len); + + int counter = len; + for (IntVec::reverse_iterator iter = v.rbegin(); iter != v.rend(); ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + + counter = len; + for (IntVec::const_reverse_iterator iter = v.rbegin(); iter != v.rend(); + ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + + counter = len; + for (IntVec::const_reverse_iterator iter = v.crbegin(); iter != v.crend(); + ++iter) { + counter--; + EXPECT_EQ(counter, *iter); + } + EXPECT_EQ(counter, 0); + } +} + +TEST(IntVec, Erase) { + for (int len = 1; len < 20; len++) { + for (int i = 0; i < len; ++i) { + IntVec v; + Fill(&v, len); + v.erase(v.begin() + i); + EXPECT_EQ(len - 1, v.size()); + for (int j = 0; j < i; ++j) { + EXPECT_EQ(j, v[j]); + } + for (int j = i; j < len - 1; ++j) { + EXPECT_EQ(j + 1, v[j]); + } + } + } +} + +TEST(IntVec, Hardened) { + IntVec v; + Fill(&v, 10); + EXPECT_EQ(v[9], 9); +#if !defined(NDEBUG) || ABSL_OPTION_HARDENED + EXPECT_DEATH_IF_SUPPORTED(v[10], ""); + EXPECT_DEATH_IF_SUPPORTED(v[-1], ""); +#endif +} + +// At the end of this test loop, the elements between [erase_begin, erase_end) +// should have reference counts == 0, and all others elements should have +// reference counts == 1. +TEST(RefCountedVec, EraseBeginEnd) { + for (int len = 1; len < 20; ++len) { + for (int erase_begin = 0; erase_begin < len; ++erase_begin) { + for (int erase_end = erase_begin; erase_end <= len; ++erase_end) { + std::vector<int> counts(len, 0); + RefCountedVec v; + for (int i = 0; i < len; ++i) { + v.push_back(RefCounted(i, &counts[i])); + } + + int erase_len = erase_end - erase_begin; + + v.erase(v.begin() + erase_begin, v.begin() + erase_end); + + EXPECT_EQ(len - erase_len, v.size()); + + // Check the elements before the first element erased. + for (int i = 0; i < erase_begin; ++i) { + EXPECT_EQ(i, v[i].value_); + } + + // Check the elements after the first element erased. + for (int i = erase_begin; i < v.size(); ++i) { + EXPECT_EQ(i + erase_len, v[i].value_); + } + + // Check that the elements at the beginning are preserved. + for (int i = 0; i < erase_begin; ++i) { + EXPECT_EQ(1, counts[i]); + } + + // Check that the erased elements are destroyed + for (int i = erase_begin; i < erase_end; ++i) { + EXPECT_EQ(0, counts[i]); + } + + // Check that the elements at the end are preserved. + for (int i = erase_end; i < len; ++i) { + EXPECT_EQ(1, counts[i]); + } + } + } + } +} + +struct NoDefaultCtor { + explicit NoDefaultCtor(int) {} +}; +struct NoCopy { + NoCopy() {} + NoCopy(const NoCopy&) = delete; +}; +struct NoAssign { + NoAssign() {} + NoAssign& operator=(const NoAssign&) = delete; +}; +struct MoveOnly { + MoveOnly() {} + MoveOnly(MoveOnly&&) = default; + MoveOnly& operator=(MoveOnly&&) = default; +}; +TEST(InlinedVectorTest, NoDefaultCtor) { + absl::InlinedVector<NoDefaultCtor, 1> v(10, NoDefaultCtor(2)); + (void)v; +} +TEST(InlinedVectorTest, NoCopy) { + absl::InlinedVector<NoCopy, 1> v(10); + (void)v; +} +TEST(InlinedVectorTest, NoAssign) { + absl::InlinedVector<NoAssign, 1> v(10); + (void)v; +} +TEST(InlinedVectorTest, MoveOnly) { + absl::InlinedVector<MoveOnly, 2> v; + v.push_back(MoveOnly{}); + v.push_back(MoveOnly{}); + v.push_back(MoveOnly{}); + v.erase(v.begin()); + v.push_back(MoveOnly{}); + v.erase(v.begin(), v.begin() + 1); + v.insert(v.begin(), MoveOnly{}); + v.emplace(v.begin()); + v.emplace(v.begin(), MoveOnly{}); +} +TEST(InlinedVectorTest, Noexcept) { + EXPECT_TRUE(std::is_nothrow_move_constructible<IntVec>::value); + EXPECT_TRUE((std::is_nothrow_move_constructible< + absl::InlinedVector<MoveOnly, 2>>::value)); + + struct MoveCanThrow { + MoveCanThrow(MoveCanThrow&&) {} + }; + EXPECT_EQ(absl::default_allocator_is_nothrow::value, + (std::is_nothrow_move_constructible< + absl::InlinedVector<MoveCanThrow, 2>>::value)); +} + +TEST(InlinedVectorTest, EmplaceBack) { + absl::InlinedVector<std::pair<std::string, int>, 1> v; + + auto& inlined_element = v.emplace_back("answer", 42); + EXPECT_EQ(&inlined_element, &v[0]); + EXPECT_EQ(inlined_element.first, "answer"); + EXPECT_EQ(inlined_element.second, 42); + + auto& allocated_element = v.emplace_back("taxicab", 1729); + EXPECT_EQ(&allocated_element, &v[1]); + EXPECT_EQ(allocated_element.first, "taxicab"); + EXPECT_EQ(allocated_element.second, 1729); +} + +TEST(InlinedVectorTest, ShrinkToFitGrowingVector) { + absl::InlinedVector<std::pair<std::string, int>, 1> v; + + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 1); + + v.emplace_back("answer", 42); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 1); + + v.emplace_back("taxicab", 1729); + EXPECT_GE(v.capacity(), 2); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 2); + + v.reserve(100); + EXPECT_GE(v.capacity(), 100); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 2); +} + +TEST(InlinedVectorTest, ShrinkToFitEdgeCases) { + { + absl::InlinedVector<std::pair<std::string, int>, 1> v; + v.emplace_back("answer", 42); + v.emplace_back("taxicab", 1729); + EXPECT_GE(v.capacity(), 2); + v.pop_back(); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 1); + EXPECT_EQ(v[0].first, "answer"); + EXPECT_EQ(v[0].second, 42); + } + + { + absl::InlinedVector<std::string, 2> v(100); + v.resize(0); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 2); // inlined capacity + } + + { + absl::InlinedVector<std::string, 2> v(100); + v.resize(1); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 2); // inlined capacity + } + + { + absl::InlinedVector<std::string, 2> v(100); + v.resize(2); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 2); + } + + { + absl::InlinedVector<std::string, 2> v(100); + v.resize(3); + v.shrink_to_fit(); + EXPECT_EQ(v.capacity(), 3); + } +} + +TEST(IntVec, Insert) { + for (int len = 0; len < 20; len++) { + for (int pos = 0; pos <= len; pos++) { + { + // Single element + std::vector<int> std_v; + Fill(&std_v, len); + IntVec v; + Fill(&v, len); + + std_v.insert(std_v.begin() + pos, 9999); + IntVec::iterator it = v.insert(v.cbegin() + pos, 9999); + EXPECT_THAT(v, ElementsAreArray(std_v)); + EXPECT_EQ(it, v.cbegin() + pos); + } + { + // n elements + std::vector<int> std_v; + Fill(&std_v, len); + IntVec v; + Fill(&v, len); + + IntVec::size_type n = 5; + std_v.insert(std_v.begin() + pos, n, 9999); + IntVec::iterator it = v.insert(v.cbegin() + pos, n, 9999); + EXPECT_THAT(v, ElementsAreArray(std_v)); + EXPECT_EQ(it, v.cbegin() + pos); + } + { + // Iterator range (random access iterator) + std::vector<int> std_v; + Fill(&std_v, len); + IntVec v; + Fill(&v, len); + + const std::vector<int> input = {9999, 8888, 7777}; + std_v.insert(std_v.begin() + pos, input.cbegin(), input.cend()); + IntVec::iterator it = + v.insert(v.cbegin() + pos, input.cbegin(), input.cend()); + EXPECT_THAT(v, ElementsAreArray(std_v)); + EXPECT_EQ(it, v.cbegin() + pos); + } + { + // Iterator range (forward iterator) + std::vector<int> std_v; + Fill(&std_v, len); + IntVec v; + Fill(&v, len); + + const std::forward_list<int> input = {9999, 8888, 7777}; + std_v.insert(std_v.begin() + pos, input.cbegin(), input.cend()); + IntVec::iterator it = + v.insert(v.cbegin() + pos, input.cbegin(), input.cend()); + EXPECT_THAT(v, ElementsAreArray(std_v)); + EXPECT_EQ(it, v.cbegin() + pos); + } + { + // Iterator range (input iterator) + std::vector<int> std_v; + Fill(&std_v, len); + IntVec v; + Fill(&v, len); + + std_v.insert(std_v.begin() + pos, {9999, 8888, 7777}); + std::istringstream input("9999 8888 7777"); + IntVec::iterator it = + v.insert(v.cbegin() + pos, std::istream_iterator<int>(input), + std::istream_iterator<int>()); + EXPECT_THAT(v, ElementsAreArray(std_v)); + EXPECT_EQ(it, v.cbegin() + pos); + } + { + // Initializer list + std::vector<int> std_v; + Fill(&std_v, len); + IntVec v; + Fill(&v, len); + + std_v.insert(std_v.begin() + pos, {9999, 8888}); + IntVec::iterator it = v.insert(v.cbegin() + pos, {9999, 8888}); + EXPECT_THAT(v, ElementsAreArray(std_v)); + EXPECT_EQ(it, v.cbegin() + pos); + } + } + } +} + +TEST(RefCountedVec, InsertConstructorDestructor) { + // Make sure the proper construction/destruction happen during insert + // operations. + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + for (int pos = 0; pos <= len; pos++) { + SCOPED_TRACE(pos); + std::vector<int> counts(len, 0); + int inserted_count = 0; + RefCountedVec v; + for (int i = 0; i < len; ++i) { + SCOPED_TRACE(i); + v.push_back(RefCounted(i, &counts[i])); + } + + EXPECT_THAT(counts, Each(Eq(1))); + + RefCounted insert_element(9999, &inserted_count); + EXPECT_EQ(1, inserted_count); + v.insert(v.begin() + pos, insert_element); + EXPECT_EQ(2, inserted_count); + // Check that the elements at the end are preserved. + EXPECT_THAT(counts, Each(Eq(1))); + EXPECT_EQ(2, inserted_count); + } + } +} + +TEST(IntVec, Resize) { + for (int len = 0; len < 20; len++) { + IntVec v; + Fill(&v, len); + + // Try resizing up and down by k elements + static const int kResizeElem = 1000000; + for (int k = 0; k < 10; k++) { + // Enlarging resize + v.resize(len + k, kResizeElem); + EXPECT_EQ(len + k, v.size()); + EXPECT_LE(len + k, v.capacity()); + for (int i = 0; i < len + k; i++) { + if (i < len) { + EXPECT_EQ(i, v[i]); + } else { + EXPECT_EQ(kResizeElem, v[i]); + } + } + + // Shrinking resize + v.resize(len, kResizeElem); + EXPECT_EQ(len, v.size()); + EXPECT_LE(len, v.capacity()); + for (int i = 0; i < len; i++) { + EXPECT_EQ(i, v[i]); + } + } + } +} + +TEST(IntVec, InitWithLength) { + for (int len = 0; len < 20; len++) { + IntVec v(len, 7); + EXPECT_EQ(len, v.size()); + EXPECT_LE(len, v.capacity()); + for (int i = 0; i < len; i++) { + EXPECT_EQ(7, v[i]); + } + } +} + +TEST(IntVec, CopyConstructorAndAssignment) { + for (int len = 0; len < 20; len++) { + IntVec v; + Fill(&v, len); + EXPECT_EQ(len, v.size()); + EXPECT_LE(len, v.capacity()); + + IntVec v2(v); + EXPECT_TRUE(v == v2) << PrintToString(v) << PrintToString(v2); + + for (int start_len = 0; start_len < 20; start_len++) { + IntVec v3; + Fill(&v3, start_len, 99); // Add dummy elements that should go away + v3 = v; + EXPECT_TRUE(v == v3) << PrintToString(v) << PrintToString(v3); + } + } +} + +TEST(IntVec, AliasingCopyAssignment) { + for (int len = 0; len < 20; ++len) { + IntVec original; + Fill(&original, len); + IntVec dup = original; + dup = *&dup; + EXPECT_EQ(dup, original); + } +} + +TEST(IntVec, MoveConstructorAndAssignment) { + for (int len = 0; len < 20; len++) { + IntVec v_in; + const int inlined_capacity = v_in.capacity(); + Fill(&v_in, len); + EXPECT_EQ(len, v_in.size()); + EXPECT_LE(len, v_in.capacity()); + + { + IntVec v_temp(v_in); + auto* old_data = v_temp.data(); + IntVec v_out(std::move(v_temp)); + EXPECT_TRUE(v_in == v_out) << PrintToString(v_in) << PrintToString(v_out); + if (v_in.size() > inlined_capacity) { + // Allocation is moved as a whole, data stays in place. + EXPECT_TRUE(v_out.data() == old_data); + } else { + EXPECT_FALSE(v_out.data() == old_data); + } + } + for (int start_len = 0; start_len < 20; start_len++) { + IntVec v_out; + Fill(&v_out, start_len, 99); // Add dummy elements that should go away + IntVec v_temp(v_in); + auto* old_data = v_temp.data(); + v_out = std::move(v_temp); + EXPECT_TRUE(v_in == v_out) << PrintToString(v_in) << PrintToString(v_out); + if (v_in.size() > inlined_capacity) { + // Allocation is moved as a whole, data stays in place. + EXPECT_TRUE(v_out.data() == old_data); + } else { + EXPECT_FALSE(v_out.data() == old_data); + } + } + } +} + +class NotTriviallyDestructible { + public: + NotTriviallyDestructible() : p_(new int(1)) {} + explicit NotTriviallyDestructible(int i) : p_(new int(i)) {} + + NotTriviallyDestructible(const NotTriviallyDestructible& other) + : p_(new int(*other.p_)) {} + + NotTriviallyDestructible& operator=(const NotTriviallyDestructible& other) { + p_ = absl::make_unique<int>(*other.p_); + return *this; + } + + bool operator==(const NotTriviallyDestructible& other) const { + return *p_ == *other.p_; + } + + private: + std::unique_ptr<int> p_; +}; + +TEST(AliasingTest, Emplace) { + for (int i = 2; i < 20; ++i) { + absl::InlinedVector<NotTriviallyDestructible, 10> vec; + for (int j = 0; j < i; ++j) { + vec.push_back(NotTriviallyDestructible(j)); + } + vec.emplace(vec.begin(), vec[0]); + EXPECT_EQ(vec[0], vec[1]); + vec.emplace(vec.begin() + i / 2, vec[i / 2]); + EXPECT_EQ(vec[i / 2], vec[i / 2 + 1]); + vec.emplace(vec.end() - 1, vec.back()); + EXPECT_EQ(vec[vec.size() - 2], vec.back()); + } +} + +TEST(AliasingTest, InsertWithCount) { + for (int i = 1; i < 20; ++i) { + absl::InlinedVector<NotTriviallyDestructible, 10> vec; + for (int j = 0; j < i; ++j) { + vec.push_back(NotTriviallyDestructible(j)); + } + for (int n = 0; n < 5; ++n) { + // We use back where we can because it's guaranteed to become invalidated + vec.insert(vec.begin(), n, vec.back()); + auto b = vec.begin(); + EXPECT_TRUE( + std::all_of(b, b + n, [&vec](const NotTriviallyDestructible& x) { + return x == vec.back(); + })); + + auto m_idx = vec.size() / 2; + vec.insert(vec.begin() + m_idx, n, vec.back()); + auto m = vec.begin() + m_idx; + EXPECT_TRUE( + std::all_of(m, m + n, [&vec](const NotTriviallyDestructible& x) { + return x == vec.back(); + })); + + // We want distinct values so the equality test is meaningful, + // vec[vec.size() - 1] is also almost always invalidated. + auto old_e = vec.size() - 1; + auto val = vec[old_e]; + vec.insert(vec.end(), n, vec[old_e]); + auto e = vec.begin() + old_e; + EXPECT_TRUE(std::all_of( + e, e + n, + [&val](const NotTriviallyDestructible& x) { return x == val; })); + } + } +} + +TEST(OverheadTest, Storage) { + // Check for size overhead. + // In particular, ensure that std::allocator doesn't cost anything to store. + // The union should be absorbing some of the allocation bookkeeping overhead + // in the larger vectors, leaving only the size_ field as overhead. + EXPECT_EQ(2 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 1>) - 1 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 2>) - 2 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 3>) - 3 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 4>) - 4 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 5>) - 5 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 6>) - 6 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 7>) - 7 * sizeof(int*)); + EXPECT_EQ(1 * sizeof(int*), + sizeof(absl::InlinedVector<int*, 8>) - 8 * sizeof(int*)); +} + +TEST(IntVec, Clear) { + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + IntVec v; + Fill(&v, len); + v.clear(); + EXPECT_EQ(0, v.size()); + EXPECT_EQ(v.begin(), v.end()); + } +} + +TEST(IntVec, Reserve) { + for (int len = 0; len < 20; len++) { + IntVec v; + Fill(&v, len); + + for (int newlen = 0; newlen < 100; newlen++) { + const int* start_rep = v.data(); + v.reserve(newlen); + const int* final_rep = v.data(); + if (newlen <= len) { + EXPECT_EQ(start_rep, final_rep); + } + EXPECT_LE(newlen, v.capacity()); + + // Filling up to newlen should not change rep + while (v.size() < newlen) { + v.push_back(0); + } + EXPECT_EQ(final_rep, v.data()); + } + } +} + +TEST(StringVec, SelfRefPushBack) { + std::vector<std::string> std_v; + absl::InlinedVector<std::string, 4> v; + const std::string s = "A quite long string to ensure heap."; + std_v.push_back(s); + v.push_back(s); + for (int i = 0; i < 20; ++i) { + EXPECT_THAT(v, ElementsAreArray(std_v)); + + v.push_back(v.back()); + std_v.push_back(std_v.back()); + } + EXPECT_THAT(v, ElementsAreArray(std_v)); +} + +TEST(StringVec, SelfRefPushBackWithMove) { + std::vector<std::string> std_v; + absl::InlinedVector<std::string, 4> v; + const std::string s = "A quite long string to ensure heap."; + std_v.push_back(s); + v.push_back(s); + for (int i = 0; i < 20; ++i) { + EXPECT_EQ(v.back(), std_v.back()); + + v.push_back(std::move(v.back())); + std_v.push_back(std::move(std_v.back())); + } + EXPECT_EQ(v.back(), std_v.back()); +} + +TEST(StringVec, SelfMove) { + const std::string s = "A quite long string to ensure heap."; + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + absl::InlinedVector<std::string, 8> v; + for (int i = 0; i < len; ++i) { + SCOPED_TRACE(i); + v.push_back(s); + } + // Indirection necessary to avoid compiler warning. + v = std::move(*(&v)); + // Ensure that the inlined vector is still in a valid state by copying it. + // We don't expect specific contents since a self-move results in an + // unspecified valid state. + std::vector<std::string> copy(v.begin(), v.end()); + } +} + +TEST(IntVec, Swap) { + for (int l1 = 0; l1 < 20; l1++) { + SCOPED_TRACE(l1); + for (int l2 = 0; l2 < 20; l2++) { + SCOPED_TRACE(l2); + IntVec a = Fill(l1, 0); + IntVec b = Fill(l2, 100); + { + using std::swap; + swap(a, b); + } + EXPECT_EQ(l1, b.size()); + EXPECT_EQ(l2, a.size()); + for (int i = 0; i < l1; i++) { + SCOPED_TRACE(i); + EXPECT_EQ(i, b[i]); + } + for (int i = 0; i < l2; i++) { + SCOPED_TRACE(i); + EXPECT_EQ(100 + i, a[i]); + } + } + } +} + +TYPED_TEST_P(InstanceTest, Swap) { + using Instance = TypeParam; + using InstanceVec = absl::InlinedVector<Instance, 8>; + for (int l1 = 0; l1 < 20; l1++) { + SCOPED_TRACE(l1); + for (int l2 = 0; l2 < 20; l2++) { + SCOPED_TRACE(l2); + InstanceTracker tracker; + InstanceVec a, b; + const size_t inlined_capacity = a.capacity(); + auto min_len = std::min(l1, l2); + auto max_len = std::max(l1, l2); + for (int i = 0; i < l1; i++) a.push_back(Instance(i)); + for (int i = 0; i < l2; i++) b.push_back(Instance(100 + i)); + EXPECT_EQ(tracker.instances(), l1 + l2); + tracker.ResetCopiesMovesSwaps(); + { + using std::swap; + swap(a, b); + } + EXPECT_EQ(tracker.instances(), l1 + l2); + if (a.size() > inlined_capacity && b.size() > inlined_capacity) { + EXPECT_EQ(tracker.swaps(), 0); // Allocations are swapped. + EXPECT_EQ(tracker.moves(), 0); + } else if (a.size() <= inlined_capacity && b.size() <= inlined_capacity) { + EXPECT_EQ(tracker.swaps(), min_len); + EXPECT_EQ((tracker.moves() ? tracker.moves() : tracker.copies()), + max_len - min_len); + } else { + // One is allocated and the other isn't. The allocation is transferred + // without copying elements, and the inlined instances are copied/moved. + EXPECT_EQ(tracker.swaps(), 0); + EXPECT_EQ((tracker.moves() ? tracker.moves() : tracker.copies()), + min_len); + } + + EXPECT_EQ(l1, b.size()); + EXPECT_EQ(l2, a.size()); + for (int i = 0; i < l1; i++) { + EXPECT_EQ(i, b[i].value()); + } + for (int i = 0; i < l2; i++) { + EXPECT_EQ(100 + i, a[i].value()); + } + } + } +} + +TEST(IntVec, EqualAndNotEqual) { + IntVec a, b; + EXPECT_TRUE(a == b); + EXPECT_FALSE(a != b); + + a.push_back(3); + EXPECT_FALSE(a == b); + EXPECT_TRUE(a != b); + + b.push_back(3); + EXPECT_TRUE(a == b); + EXPECT_FALSE(a != b); + + b.push_back(7); + EXPECT_FALSE(a == b); + EXPECT_TRUE(a != b); + + a.push_back(6); + EXPECT_FALSE(a == b); + EXPECT_TRUE(a != b); + + a.clear(); + b.clear(); + for (int i = 0; i < 100; i++) { + a.push_back(i); + b.push_back(i); + EXPECT_TRUE(a == b); + EXPECT_FALSE(a != b); + + b[i] = b[i] + 1; + EXPECT_FALSE(a == b); + EXPECT_TRUE(a != b); + + b[i] = b[i] - 1; // Back to before + EXPECT_TRUE(a == b); + EXPECT_FALSE(a != b); + } +} + +TEST(IntVec, RelationalOps) { + IntVec a, b; + EXPECT_FALSE(a < b); + EXPECT_FALSE(b < a); + EXPECT_FALSE(a > b); + EXPECT_FALSE(b > a); + EXPECT_TRUE(a <= b); + EXPECT_TRUE(b <= a); + EXPECT_TRUE(a >= b); + EXPECT_TRUE(b >= a); + b.push_back(3); + EXPECT_TRUE(a < b); + EXPECT_FALSE(b < a); + EXPECT_FALSE(a > b); + EXPECT_TRUE(b > a); + EXPECT_TRUE(a <= b); + EXPECT_FALSE(b <= a); + EXPECT_FALSE(a >= b); + EXPECT_TRUE(b >= a); +} + +TYPED_TEST_P(InstanceTest, CountConstructorsDestructors) { + using Instance = TypeParam; + using InstanceVec = absl::InlinedVector<Instance, 8>; + InstanceTracker tracker; + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + tracker.ResetCopiesMovesSwaps(); + + InstanceVec v; + const size_t inlined_capacity = v.capacity(); + for (int i = 0; i < len; i++) { + v.push_back(Instance(i)); + } + EXPECT_EQ(tracker.instances(), len); + EXPECT_GE(tracker.copies() + tracker.moves(), + len); // More due to reallocation. + tracker.ResetCopiesMovesSwaps(); + + // Enlarging resize() must construct some objects + tracker.ResetCopiesMovesSwaps(); + v.resize(len + 10, Instance(100)); + EXPECT_EQ(tracker.instances(), len + 10); + if (len <= inlined_capacity && len + 10 > inlined_capacity) { + EXPECT_EQ(tracker.copies() + tracker.moves(), 10 + len); + } else { + // Only specify a minimum number of copies + moves. We don't want to + // depend on the reallocation policy here. + EXPECT_GE(tracker.copies() + tracker.moves(), + 10); // More due to reallocation. + } + + // Shrinking resize() must destroy some objects + tracker.ResetCopiesMovesSwaps(); + v.resize(len, Instance(100)); + EXPECT_EQ(tracker.instances(), len); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 0); + + // reserve() must not increase the number of initialized objects + SCOPED_TRACE("reserve"); + v.reserve(len + 1000); + EXPECT_EQ(tracker.instances(), len); + EXPECT_EQ(tracker.copies() + tracker.moves(), len); + + // pop_back() and erase() must destroy one object + if (len > 0) { + tracker.ResetCopiesMovesSwaps(); + v.pop_back(); + EXPECT_EQ(tracker.instances(), len - 1); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 0); + + if (!v.empty()) { + tracker.ResetCopiesMovesSwaps(); + v.erase(v.begin()); + EXPECT_EQ(tracker.instances(), len - 2); + EXPECT_EQ(tracker.copies() + tracker.moves(), len - 2); + } + } + + tracker.ResetCopiesMovesSwaps(); + int instances_before_empty_erase = tracker.instances(); + v.erase(v.begin(), v.begin()); + EXPECT_EQ(tracker.instances(), instances_before_empty_erase); + EXPECT_EQ(tracker.copies() + tracker.moves(), 0); + } +} + +TYPED_TEST_P(InstanceTest, CountConstructorsDestructorsOnCopyConstruction) { + using Instance = TypeParam; + using InstanceVec = absl::InlinedVector<Instance, 8>; + InstanceTracker tracker; + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + tracker.ResetCopiesMovesSwaps(); + + InstanceVec v; + for (int i = 0; i < len; i++) { + v.push_back(Instance(i)); + } + EXPECT_EQ(tracker.instances(), len); + EXPECT_GE(tracker.copies() + tracker.moves(), + len); // More due to reallocation. + tracker.ResetCopiesMovesSwaps(); + { // Copy constructor should create 'len' more instances. + InstanceVec v_copy(v); + EXPECT_EQ(tracker.instances(), len + len); + EXPECT_EQ(tracker.copies(), len); + EXPECT_EQ(tracker.moves(), 0); + } + EXPECT_EQ(tracker.instances(), len); + } +} + +TYPED_TEST_P(InstanceTest, CountConstructorsDestructorsOnMoveConstruction) { + using Instance = TypeParam; + using InstanceVec = absl::InlinedVector<Instance, 8>; + InstanceTracker tracker; + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + tracker.ResetCopiesMovesSwaps(); + + InstanceVec v; + const size_t inlined_capacity = v.capacity(); + for (int i = 0; i < len; i++) { + v.push_back(Instance(i)); + } + EXPECT_EQ(tracker.instances(), len); + EXPECT_GE(tracker.copies() + tracker.moves(), + len); // More due to reallocation. + tracker.ResetCopiesMovesSwaps(); + { + InstanceVec v_copy(std::move(v)); + if (len > inlined_capacity) { + // Allocation is moved as a whole. + EXPECT_EQ(tracker.instances(), len); + EXPECT_EQ(tracker.live_instances(), len); + // Tests an implementation detail, don't rely on this in your code. + EXPECT_EQ(v.size(), 0); // NOLINT misc-use-after-move + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 0); + } else { + EXPECT_EQ(tracker.instances(), len + len); + if (Instance::supports_move()) { + EXPECT_EQ(tracker.live_instances(), len); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), len); + } else { + EXPECT_EQ(tracker.live_instances(), len + len); + EXPECT_EQ(tracker.copies(), len); + EXPECT_EQ(tracker.moves(), 0); + } + } + EXPECT_EQ(tracker.swaps(), 0); + } + } +} + +TYPED_TEST_P(InstanceTest, CountConstructorsDestructorsOnAssignment) { + using Instance = TypeParam; + using InstanceVec = absl::InlinedVector<Instance, 8>; + InstanceTracker tracker; + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + for (int longorshort = 0; longorshort <= 1; ++longorshort) { + SCOPED_TRACE(longorshort); + tracker.ResetCopiesMovesSwaps(); + + InstanceVec longer, shorter; + for (int i = 0; i < len; i++) { + longer.push_back(Instance(i)); + shorter.push_back(Instance(i)); + } + longer.push_back(Instance(len)); + EXPECT_EQ(tracker.instances(), len + len + 1); + EXPECT_GE(tracker.copies() + tracker.moves(), + len + len + 1); // More due to reallocation. + + tracker.ResetCopiesMovesSwaps(); + if (longorshort) { + shorter = longer; + EXPECT_EQ(tracker.instances(), (len + 1) + (len + 1)); + EXPECT_GE(tracker.copies() + tracker.moves(), + len + 1); // More due to reallocation. + } else { + longer = shorter; + EXPECT_EQ(tracker.instances(), len + len); + EXPECT_EQ(tracker.copies() + tracker.moves(), len); + } + } + } +} + +TYPED_TEST_P(InstanceTest, CountConstructorsDestructorsOnMoveAssignment) { + using Instance = TypeParam; + using InstanceVec = absl::InlinedVector<Instance, 8>; + InstanceTracker tracker; + for (int len = 0; len < 20; len++) { + SCOPED_TRACE(len); + for (int longorshort = 0; longorshort <= 1; ++longorshort) { + SCOPED_TRACE(longorshort); + tracker.ResetCopiesMovesSwaps(); + + InstanceVec longer, shorter; + const int inlined_capacity = longer.capacity(); + for (int i = 0; i < len; i++) { + longer.push_back(Instance(i)); + shorter.push_back(Instance(i)); + } + longer.push_back(Instance(len)); + EXPECT_EQ(tracker.instances(), len + len + 1); + EXPECT_GE(tracker.copies() + tracker.moves(), + len + len + 1); // More due to reallocation. + + tracker.ResetCopiesMovesSwaps(); + int src_len; + if (longorshort) { + src_len = len + 1; + shorter = std::move(longer); + } else { + src_len = len; + longer = std::move(shorter); + } + if (src_len > inlined_capacity) { + // Allocation moved as a whole. + EXPECT_EQ(tracker.instances(), src_len); + EXPECT_EQ(tracker.live_instances(), src_len); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 0); + } else { + // Elements are all copied. + EXPECT_EQ(tracker.instances(), src_len + src_len); + if (Instance::supports_move()) { + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), src_len); + EXPECT_EQ(tracker.live_instances(), src_len); + } else { + EXPECT_EQ(tracker.copies(), src_len); + EXPECT_EQ(tracker.moves(), 0); + EXPECT_EQ(tracker.live_instances(), src_len + src_len); + } + } + EXPECT_EQ(tracker.swaps(), 0); + } + } +} + +TEST(CountElemAssign, SimpleTypeWithInlineBacking) { + for (size_t original_size = 0; original_size <= 5; ++original_size) { + SCOPED_TRACE(original_size); + // Original contents are [12345, 12345, ...] + std::vector<int> original_contents(original_size, 12345); + + absl::InlinedVector<int, 2> v(original_contents.begin(), + original_contents.end()); + v.assign(2, 123); + EXPECT_THAT(v, AllOf(SizeIs(2), ElementsAre(123, 123))); + if (original_size <= 2) { + // If the original had inline backing, it should stay inline. + EXPECT_EQ(2, v.capacity()); + } + } +} + +TEST(CountElemAssign, SimpleTypeWithAllocation) { + for (size_t original_size = 0; original_size <= 5; ++original_size) { + SCOPED_TRACE(original_size); + // Original contents are [12345, 12345, ...] + std::vector<int> original_contents(original_size, 12345); + + absl::InlinedVector<int, 2> v(original_contents.begin(), + original_contents.end()); + v.assign(3, 123); + EXPECT_THAT(v, AllOf(SizeIs(3), ElementsAre(123, 123, 123))); + EXPECT_LE(v.size(), v.capacity()); + } +} + +TYPED_TEST_P(InstanceTest, CountElemAssignInlineBacking) { + using Instance = TypeParam; + for (size_t original_size = 0; original_size <= 5; ++original_size) { + SCOPED_TRACE(original_size); + // Original contents are [12345, 12345, ...] + std::vector<Instance> original_contents(original_size, Instance(12345)); + + absl::InlinedVector<Instance, 2> v(original_contents.begin(), + original_contents.end()); + v.assign(2, Instance(123)); + EXPECT_THAT(v, AllOf(SizeIs(2), ElementsAre(ValueIs(123), ValueIs(123)))); + if (original_size <= 2) { + // If the original had inline backing, it should stay inline. + EXPECT_EQ(2, v.capacity()); + } + } +} + +template <typename Instance> +void InstanceCountElemAssignWithAllocationTest() { + for (size_t original_size = 0; original_size <= 5; ++original_size) { + SCOPED_TRACE(original_size); + // Original contents are [12345, 12345, ...] + std::vector<Instance> original_contents(original_size, Instance(12345)); + + absl::InlinedVector<Instance, 2> v(original_contents.begin(), + original_contents.end()); + v.assign(3, Instance(123)); + EXPECT_THAT(v, AllOf(SizeIs(3), ElementsAre(ValueIs(123), ValueIs(123), + ValueIs(123)))); + EXPECT_LE(v.size(), v.capacity()); + } +} +TEST(CountElemAssign, WithAllocationCopyableInstance) { + InstanceCountElemAssignWithAllocationTest<CopyableOnlyInstance>(); +} +TEST(CountElemAssign, WithAllocationCopyableMovableInstance) { + InstanceCountElemAssignWithAllocationTest<CopyableMovableInstance>(); +} + +TEST(RangedConstructor, SimpleType) { + std::vector<int> source_v = {4, 5, 6}; + // First try to fit in inline backing + absl::InlinedVector<int, 4> v(source_v.begin(), source_v.end()); + EXPECT_EQ(3, v.size()); + EXPECT_EQ(4, v.capacity()); // Indication that we're still on inlined storage + EXPECT_EQ(4, v[0]); + EXPECT_EQ(5, v[1]); + EXPECT_EQ(6, v[2]); + + // Now, force a re-allocate + absl::InlinedVector<int, 2> realloc_v(source_v.begin(), source_v.end()); + EXPECT_EQ(3, realloc_v.size()); + EXPECT_LT(2, realloc_v.capacity()); + EXPECT_EQ(4, realloc_v[0]); + EXPECT_EQ(5, realloc_v[1]); + EXPECT_EQ(6, realloc_v[2]); +} + +// Test for ranged constructors using Instance as the element type and +// SourceContainer as the source container type. +template <typename Instance, typename SourceContainer, int inlined_capacity> +void InstanceRangedConstructorTestForContainer() { + InstanceTracker tracker; + SourceContainer source_v = {Instance(0), Instance(1)}; + tracker.ResetCopiesMovesSwaps(); + absl::InlinedVector<Instance, inlined_capacity> v(source_v.begin(), + source_v.end()); + EXPECT_EQ(2, v.size()); + EXPECT_LT(1, v.capacity()); + EXPECT_EQ(0, v[0].value()); + EXPECT_EQ(1, v[1].value()); + EXPECT_EQ(tracker.copies(), 2); + EXPECT_EQ(tracker.moves(), 0); +} + +template <typename Instance, int inlined_capacity> +void InstanceRangedConstructorTestWithCapacity() { + // Test with const and non-const, random access and non-random-access sources. + // TODO(bsamwel): Test with an input iterator source. + { + SCOPED_TRACE("std::list"); + InstanceRangedConstructorTestForContainer<Instance, std::list<Instance>, + inlined_capacity>(); + { + SCOPED_TRACE("const std::list"); + InstanceRangedConstructorTestForContainer< + Instance, const std::list<Instance>, inlined_capacity>(); + } + { + SCOPED_TRACE("std::vector"); + InstanceRangedConstructorTestForContainer<Instance, std::vector<Instance>, + inlined_capacity>(); + } + { + SCOPED_TRACE("const std::vector"); + InstanceRangedConstructorTestForContainer< + Instance, const std::vector<Instance>, inlined_capacity>(); + } + } +} + +TYPED_TEST_P(InstanceTest, RangedConstructor) { + using Instance = TypeParam; + SCOPED_TRACE("capacity=1"); + InstanceRangedConstructorTestWithCapacity<Instance, 1>(); + SCOPED_TRACE("capacity=2"); + InstanceRangedConstructorTestWithCapacity<Instance, 2>(); +} + +TEST(RangedConstructor, ElementsAreConstructed) { + std::vector<std::string> source_v = {"cat", "dog"}; + + // Force expansion and re-allocation of v. Ensures that when the vector is + // expanded that new elements are constructed. + absl::InlinedVector<std::string, 1> v(source_v.begin(), source_v.end()); + EXPECT_EQ("cat", v[0]); + EXPECT_EQ("dog", v[1]); +} + +TEST(RangedAssign, SimpleType) { + // Test for all combinations of original sizes (empty and non-empty inline, + // and out of line) and target sizes. + for (size_t original_size = 0; original_size <= 5; ++original_size) { + SCOPED_TRACE(original_size); + // Original contents are [12345, 12345, ...] + std::vector<int> original_contents(original_size, 12345); + + for (size_t target_size = 0; target_size <= 5; ++target_size) { + SCOPED_TRACE(target_size); + + // New contents are [3, 4, ...] + std::vector<int> new_contents; + for (size_t i = 0; i < target_size; ++i) { + new_contents.push_back(i + 3); + } + + absl::InlinedVector<int, 3> v(original_contents.begin(), + original_contents.end()); + v.assign(new_contents.begin(), new_contents.end()); + + EXPECT_EQ(new_contents.size(), v.size()); + EXPECT_LE(new_contents.size(), v.capacity()); + if (target_size <= 3 && original_size <= 3) { + // Storage should stay inline when target size is small. + EXPECT_EQ(3, v.capacity()); + } + EXPECT_THAT(v, ElementsAreArray(new_contents)); + } + } +} + +// Returns true if lhs and rhs have the same value. +template <typename Instance> +static bool InstanceValuesEqual(const Instance& lhs, const Instance& rhs) { + return lhs.value() == rhs.value(); +} + +// Test for ranged assign() using Instance as the element type and +// SourceContainer as the source container type. +template <typename Instance, typename SourceContainer> +void InstanceRangedAssignTestForContainer() { + // Test for all combinations of original sizes (empty and non-empty inline, + // and out of line) and target sizes. + for (size_t original_size = 0; original_size <= 5; ++original_size) { + SCOPED_TRACE(original_size); + // Original contents are [12345, 12345, ...] + std::vector<Instance> original_contents(original_size, Instance(12345)); + + for (size_t target_size = 0; target_size <= 5; ++target_size) { + SCOPED_TRACE(target_size); + + // New contents are [3, 4, ...] + // Generate data using a non-const container, because SourceContainer + // itself may be const. + // TODO(bsamwel): Test with an input iterator. + std::vector<Instance> new_contents_in; + for (size_t i = 0; i < target_size; ++i) { + new_contents_in.push_back(Instance(i + 3)); + } + SourceContainer new_contents(new_contents_in.begin(), + new_contents_in.end()); + + absl::InlinedVector<Instance, 3> v(original_contents.begin(), + original_contents.end()); + v.assign(new_contents.begin(), new_contents.end()); + + EXPECT_EQ(new_contents.size(), v.size()); + EXPECT_LE(new_contents.size(), v.capacity()); + if (target_size <= 3 && original_size <= 3) { + // Storage should stay inline when target size is small. + EXPECT_EQ(3, v.capacity()); + } + EXPECT_TRUE(std::equal(v.begin(), v.end(), new_contents.begin(), + InstanceValuesEqual<Instance>)); + } + } +} + +TYPED_TEST_P(InstanceTest, RangedAssign) { + using Instance = TypeParam; + // Test with const and non-const, random access and non-random-access sources. + // TODO(bsamwel): Test with an input iterator source. + SCOPED_TRACE("std::list"); + InstanceRangedAssignTestForContainer<Instance, std::list<Instance>>(); + SCOPED_TRACE("const std::list"); + InstanceRangedAssignTestForContainer<Instance, const std::list<Instance>>(); + SCOPED_TRACE("std::vector"); + InstanceRangedAssignTestForContainer<Instance, std::vector<Instance>>(); + SCOPED_TRACE("const std::vector"); + InstanceRangedAssignTestForContainer<Instance, const std::vector<Instance>>(); +} + +TEST(InitializerListConstructor, SimpleTypeWithInlineBacking) { + EXPECT_THAT((absl::InlinedVector<int, 4>{4, 5, 6}), + AllOf(SizeIs(3), CapacityIs(4), ElementsAre(4, 5, 6))); +} + +TEST(InitializerListConstructor, SimpleTypeWithReallocationRequired) { + EXPECT_THAT((absl::InlinedVector<int, 2>{4, 5, 6}), + AllOf(SizeIs(3), CapacityIs(Gt(2)), ElementsAre(4, 5, 6))); +} + +TEST(InitializerListConstructor, DisparateTypesInList) { + EXPECT_THAT((absl::InlinedVector<int, 2>{-7, 8ULL}), ElementsAre(-7, 8)); + + EXPECT_THAT((absl::InlinedVector<std::string, 2>{"foo", std::string("bar")}), + ElementsAre("foo", "bar")); +} + +TEST(InitializerListConstructor, ComplexTypeWithInlineBacking) { + EXPECT_THAT((absl::InlinedVector<CopyableMovableInstance, 1>{ + CopyableMovableInstance(0)}), + AllOf(SizeIs(1), CapacityIs(1), ElementsAre(ValueIs(0)))); +} + +TEST(InitializerListConstructor, ComplexTypeWithReallocationRequired) { + EXPECT_THAT( + (absl::InlinedVector<CopyableMovableInstance, 1>{ + CopyableMovableInstance(0), CopyableMovableInstance(1)}), + AllOf(SizeIs(2), CapacityIs(Gt(1)), ElementsAre(ValueIs(0), ValueIs(1)))); +} + +TEST(InitializerListAssign, SimpleTypeFitsInlineBacking) { + for (size_t original_size = 0; original_size <= 4; ++original_size) { + SCOPED_TRACE(original_size); + + absl::InlinedVector<int, 2> v1(original_size, 12345); + const size_t original_capacity_v1 = v1.capacity(); + v1.assign({3}); + EXPECT_THAT( + v1, AllOf(SizeIs(1), CapacityIs(original_capacity_v1), ElementsAre(3))); + + absl::InlinedVector<int, 2> v2(original_size, 12345); + const size_t original_capacity_v2 = v2.capacity(); + v2 = {3}; + EXPECT_THAT( + v2, AllOf(SizeIs(1), CapacityIs(original_capacity_v2), ElementsAre(3))); + } +} + +TEST(InitializerListAssign, SimpleTypeDoesNotFitInlineBacking) { + for (size_t original_size = 0; original_size <= 4; ++original_size) { + SCOPED_TRACE(original_size); + absl::InlinedVector<int, 2> v1(original_size, 12345); + v1.assign({3, 4, 5}); + EXPECT_THAT(v1, AllOf(SizeIs(3), ElementsAre(3, 4, 5))); + EXPECT_LE(3, v1.capacity()); + + absl::InlinedVector<int, 2> v2(original_size, 12345); + v2 = {3, 4, 5}; + EXPECT_THAT(v2, AllOf(SizeIs(3), ElementsAre(3, 4, 5))); + EXPECT_LE(3, v2.capacity()); + } +} + +TEST(InitializerListAssign, DisparateTypesInList) { + absl::InlinedVector<int, 2> v_int1; + v_int1.assign({-7, 8ULL}); + EXPECT_THAT(v_int1, ElementsAre(-7, 8)); + + absl::InlinedVector<int, 2> v_int2; + v_int2 = {-7, 8ULL}; + EXPECT_THAT(v_int2, ElementsAre(-7, 8)); + + absl::InlinedVector<std::string, 2> v_string1; + v_string1.assign({"foo", std::string("bar")}); + EXPECT_THAT(v_string1, ElementsAre("foo", "bar")); + + absl::InlinedVector<std::string, 2> v_string2; + v_string2 = {"foo", std::string("bar")}; + EXPECT_THAT(v_string2, ElementsAre("foo", "bar")); +} + +TYPED_TEST_P(InstanceTest, InitializerListAssign) { + using Instance = TypeParam; + for (size_t original_size = 0; original_size <= 4; ++original_size) { + SCOPED_TRACE(original_size); + absl::InlinedVector<Instance, 2> v(original_size, Instance(12345)); + const size_t original_capacity = v.capacity(); + v.assign({Instance(3)}); + EXPECT_THAT(v, AllOf(SizeIs(1), CapacityIs(original_capacity), + ElementsAre(ValueIs(3)))); + } + for (size_t original_size = 0; original_size <= 4; ++original_size) { + SCOPED_TRACE(original_size); + absl::InlinedVector<Instance, 2> v(original_size, Instance(12345)); + v.assign({Instance(3), Instance(4), Instance(5)}); + EXPECT_THAT( + v, AllOf(SizeIs(3), ElementsAre(ValueIs(3), ValueIs(4), ValueIs(5)))); + EXPECT_LE(3, v.capacity()); + } +} + +REGISTER_TYPED_TEST_CASE_P(InstanceTest, Swap, CountConstructorsDestructors, + CountConstructorsDestructorsOnCopyConstruction, + CountConstructorsDestructorsOnMoveConstruction, + CountConstructorsDestructorsOnAssignment, + CountConstructorsDestructorsOnMoveAssignment, + CountElemAssignInlineBacking, RangedConstructor, + RangedAssign, InitializerListAssign); + +using InstanceTypes = + ::testing::Types<CopyableOnlyInstance, CopyableMovableInstance>; +INSTANTIATE_TYPED_TEST_CASE_P(InstanceTestOnTypes, InstanceTest, InstanceTypes); + +TEST(DynamicVec, DynamicVecCompiles) { + DynamicVec v; + (void)v; +} + +TEST(AllocatorSupportTest, Constructors) { + using MyAlloc = CountingAllocator<int>; + using AllocVec = absl::InlinedVector<int, 4, MyAlloc>; + const int ia[] = {0, 1, 2, 3, 4, 5, 6, 7}; + int64_t allocated = 0; + MyAlloc alloc(&allocated); + { AllocVec ABSL_ATTRIBUTE_UNUSED v; } + { AllocVec ABSL_ATTRIBUTE_UNUSED v(alloc); } + { AllocVec ABSL_ATTRIBUTE_UNUSED v(ia, ia + ABSL_ARRAYSIZE(ia), alloc); } + { AllocVec ABSL_ATTRIBUTE_UNUSED v({1, 2, 3}, alloc); } + + AllocVec v2; + { AllocVec ABSL_ATTRIBUTE_UNUSED v(v2, alloc); } + { AllocVec ABSL_ATTRIBUTE_UNUSED v(std::move(v2), alloc); } +} + +TEST(AllocatorSupportTest, CountAllocations) { + using MyAlloc = CountingAllocator<int>; + using AllocVec = absl::InlinedVector<int, 4, MyAlloc>; + const int ia[] = {0, 1, 2, 3, 4, 5, 6, 7}; + int64_t allocated = 0; + MyAlloc alloc(&allocated); + { + AllocVec ABSL_ATTRIBUTE_UNUSED v(ia, ia + 4, alloc); + EXPECT_THAT(allocated, 0); + } + EXPECT_THAT(allocated, 0); + { + AllocVec ABSL_ATTRIBUTE_UNUSED v(ia, ia + ABSL_ARRAYSIZE(ia), alloc); + EXPECT_THAT(allocated, v.size() * sizeof(int)); + } + EXPECT_THAT(allocated, 0); + { + AllocVec v(4, 1, alloc); + EXPECT_THAT(allocated, 0); + + int64_t allocated2 = 0; + MyAlloc alloc2(&allocated2); + AllocVec v2(v, alloc2); + EXPECT_THAT(allocated2, 0); + + int64_t allocated3 = 0; + MyAlloc alloc3(&allocated3); + AllocVec v3(std::move(v), alloc3); + EXPECT_THAT(allocated3, 0); + } + EXPECT_THAT(allocated, 0); + { + AllocVec v(8, 2, alloc); + EXPECT_THAT(allocated, v.size() * sizeof(int)); + + int64_t allocated2 = 0; + MyAlloc alloc2(&allocated2); + AllocVec v2(v, alloc2); + EXPECT_THAT(allocated2, v2.size() * sizeof(int)); + + int64_t allocated3 = 0; + MyAlloc alloc3(&allocated3); + AllocVec v3(std::move(v), alloc3); + EXPECT_THAT(allocated3, v3.size() * sizeof(int)); + } + EXPECT_EQ(allocated, 0); + { + // Test shrink_to_fit deallocations. + AllocVec v(8, 2, alloc); + EXPECT_EQ(allocated, 8 * sizeof(int)); + v.resize(5); + EXPECT_EQ(allocated, 8 * sizeof(int)); + v.shrink_to_fit(); + EXPECT_EQ(allocated, 5 * sizeof(int)); + v.resize(4); + EXPECT_EQ(allocated, 5 * sizeof(int)); + v.shrink_to_fit(); + EXPECT_EQ(allocated, 0); + } +} + +TEST(AllocatorSupportTest, SwapBothAllocated) { + using MyAlloc = CountingAllocator<int>; + using AllocVec = absl::InlinedVector<int, 4, MyAlloc>; + int64_t allocated1 = 0; + int64_t allocated2 = 0; + { + const int ia1[] = {0, 1, 2, 3, 4, 5, 6, 7}; + const int ia2[] = {0, 1, 2, 3, 4, 5, 6, 7, 8}; + MyAlloc a1(&allocated1); + MyAlloc a2(&allocated2); + AllocVec v1(ia1, ia1 + ABSL_ARRAYSIZE(ia1), a1); + AllocVec v2(ia2, ia2 + ABSL_ARRAYSIZE(ia2), a2); + EXPECT_LT(v1.capacity(), v2.capacity()); + EXPECT_THAT(allocated1, v1.capacity() * sizeof(int)); + EXPECT_THAT(allocated2, v2.capacity() * sizeof(int)); + v1.swap(v2); + EXPECT_THAT(v1, ElementsAreArray(ia2)); + EXPECT_THAT(v2, ElementsAreArray(ia1)); + EXPECT_THAT(allocated1, v2.capacity() * sizeof(int)); + EXPECT_THAT(allocated2, v1.capacity() * sizeof(int)); + } + EXPECT_THAT(allocated1, 0); + EXPECT_THAT(allocated2, 0); +} + +TEST(AllocatorSupportTest, SwapOneAllocated) { + using MyAlloc = CountingAllocator<int>; + using AllocVec = absl::InlinedVector<int, 4, MyAlloc>; + int64_t allocated1 = 0; + int64_t allocated2 = 0; + { + const int ia1[] = {0, 1, 2, 3, 4, 5, 6, 7}; + const int ia2[] = {0, 1, 2, 3}; + MyAlloc a1(&allocated1); + MyAlloc a2(&allocated2); + AllocVec v1(ia1, ia1 + ABSL_ARRAYSIZE(ia1), a1); + AllocVec v2(ia2, ia2 + ABSL_ARRAYSIZE(ia2), a2); + EXPECT_THAT(allocated1, v1.capacity() * sizeof(int)); + EXPECT_THAT(allocated2, 0); + v1.swap(v2); + EXPECT_THAT(v1, ElementsAreArray(ia2)); + EXPECT_THAT(v2, ElementsAreArray(ia1)); + EXPECT_THAT(allocated1, v2.capacity() * sizeof(int)); + EXPECT_THAT(allocated2, 0); + EXPECT_TRUE(v2.get_allocator() == a1); + EXPECT_TRUE(v1.get_allocator() == a2); + } + EXPECT_THAT(allocated1, 0); + EXPECT_THAT(allocated2, 0); +} + +TEST(AllocatorSupportTest, ScopedAllocatorWorksInlined) { + using StdVector = std::vector<int, CountingAllocator<int>>; + using Alloc = CountingAllocator<StdVector>; + using ScopedAlloc = std::scoped_allocator_adaptor<Alloc>; + using AllocVec = absl::InlinedVector<StdVector, 1, ScopedAlloc>; + + int64_t total_allocated_byte_count = 0; + + AllocVec inlined_case(ScopedAlloc(Alloc(+&total_allocated_byte_count))); + + // Called only once to remain inlined + inlined_case.emplace_back(); + + int64_t absl_responsible_for_count = total_allocated_byte_count; + + // MSVC's allocator preemptively allocates in debug mode +#if !defined(_MSC_VER) + EXPECT_EQ(absl_responsible_for_count, 0); +#endif // !defined(_MSC_VER) + + inlined_case[0].emplace_back(); + EXPECT_GT(total_allocated_byte_count, absl_responsible_for_count); + + inlined_case.clear(); + inlined_case.shrink_to_fit(); + EXPECT_EQ(total_allocated_byte_count, 0); +} + +TEST(AllocatorSupportTest, ScopedAllocatorWorksAllocated) { + using StdVector = std::vector<int, CountingAllocator<int>>; + using Alloc = CountingAllocator<StdVector>; + using ScopedAlloc = std::scoped_allocator_adaptor<Alloc>; + using AllocVec = absl::InlinedVector<StdVector, 1, ScopedAlloc>; + + int64_t total_allocated_byte_count = 0; + + AllocVec allocated_case(ScopedAlloc(Alloc(+&total_allocated_byte_count))); + + // Called twice to force into being allocated + allocated_case.emplace_back(); + allocated_case.emplace_back(); + + int64_t absl_responsible_for_count = total_allocated_byte_count; + EXPECT_GT(absl_responsible_for_count, 0); + + allocated_case[1].emplace_back(); + EXPECT_GT(total_allocated_byte_count, absl_responsible_for_count); + + allocated_case.clear(); + allocated_case.shrink_to_fit(); + EXPECT_EQ(total_allocated_byte_count, 0); +} + +TEST(AllocatorSupportTest, SizeAllocConstructor) { + constexpr int inlined_size = 4; + using Alloc = CountingAllocator<int>; + using AllocVec = absl::InlinedVector<int, inlined_size, Alloc>; + + { + auto len = inlined_size / 2; + int64_t allocated = 0; + auto v = AllocVec(len, Alloc(&allocated)); + + // Inline storage used; allocator should not be invoked + EXPECT_THAT(allocated, 0); + EXPECT_THAT(v, AllOf(SizeIs(len), Each(0))); + } + + { + auto len = inlined_size * 2; + int64_t allocated = 0; + auto v = AllocVec(len, Alloc(&allocated)); + + // Out of line storage used; allocation of 8 elements expected + EXPECT_THAT(allocated, len * sizeof(int)); + EXPECT_THAT(v, AllOf(SizeIs(len), Each(0))); + } +} + +TEST(InlinedVectorTest, MinimumAllocatorCompilesUsingTraits) { + using T = int; + using A = std::allocator<T>; + using ATraits = absl::allocator_traits<A>; + + struct MinimumAllocator { + using value_type = T; + + value_type* allocate(size_t n) { + A a; + return ATraits::allocate(a, n); + } + + void deallocate(value_type* p, size_t n) { + A a; + ATraits::deallocate(a, p, n); + } + }; + + absl::InlinedVector<T, 1, MinimumAllocator> vec; + vec.emplace_back(); + vec.resize(0); +} + +TEST(InlinedVectorTest, AbslHashValueWorks) { + using V = absl::InlinedVector<int, 4>; + std::vector<V> cases; + + // Generate a variety of vectors some of these are small enough for the inline + // space but are stored out of line. + for (int i = 0; i < 10; ++i) { + V v; + for (int j = 0; j < i; ++j) { + v.push_back(j); + } + cases.push_back(v); + v.resize(i % 4); + cases.push_back(v); + } + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(cases)); +} + +} // anonymous namespace diff --git a/third_party/abseil_cpp/absl/container/internal/btree.h b/third_party/abseil_cpp/absl/container/internal/btree.h new file mode 100644 index 0000000000..b23138f095 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/btree.h @@ -0,0 +1,2629 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// A btree implementation of the STL set and map interfaces. A btree is smaller +// and generally also faster than STL set/map (refer to the benchmarks below). +// The red-black tree implementation of STL set/map has an overhead of 3 +// pointers (left, right and parent) plus the node color information for each +// stored value. So a set<int32_t> consumes 40 bytes for each value stored in +// 64-bit mode. This btree implementation stores multiple values on fixed +// size nodes (usually 256 bytes) and doesn't store child pointers for leaf +// nodes. The result is that a btree_set<int32_t> may use much less memory per +// stored value. For the random insertion benchmark in btree_bench.cc, a +// btree_set<int32_t> with node-size of 256 uses 5.1 bytes per stored value. +// +// The packing of multiple values on to each node of a btree has another effect +// besides better space utilization: better cache locality due to fewer cache +// lines being accessed. Better cache locality translates into faster +// operations. +// +// CAVEATS +// +// Insertions and deletions on a btree can cause splitting, merging or +// rebalancing of btree nodes. And even without these operations, insertions +// and deletions on a btree will move values around within a node. In both +// cases, the result is that insertions and deletions can invalidate iterators +// pointing to values other than the one being inserted/deleted. Therefore, this +// container does not provide pointer stability. This is notably different from +// STL set/map which takes care to not invalidate iterators on insert/erase +// except, of course, for iterators pointing to the value being erased. A +// partial workaround when erasing is available: erase() returns an iterator +// pointing to the item just after the one that was erased (or end() if none +// exists). + +#ifndef ABSL_CONTAINER_INTERNAL_BTREE_H_ +#define ABSL_CONTAINER_INTERNAL_BTREE_H_ + +#include <algorithm> +#include <cassert> +#include <cstddef> +#include <cstdint> +#include <cstring> +#include <functional> +#include <iterator> +#include <limits> +#include <new> +#include <string> +#include <type_traits> +#include <utility> + +#include "absl/base/macros.h" +#include "absl/container/internal/common.h" +#include "absl/container/internal/compressed_tuple.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/layout.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/cord.h" +#include "absl/strings/string_view.h" +#include "absl/types/compare.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// A helper class that indicates if the Compare parameter is a key-compare-to +// comparator. +template <typename Compare, typename T> +using btree_is_key_compare_to = + std::is_convertible<absl::result_of_t<Compare(const T &, const T &)>, + absl::weak_ordering>; + +struct StringBtreeDefaultLess { + using is_transparent = void; + + StringBtreeDefaultLess() = default; + + // Compatibility constructor. + StringBtreeDefaultLess(std::less<std::string>) {} // NOLINT + StringBtreeDefaultLess(std::less<string_view>) {} // NOLINT + + absl::weak_ordering operator()(absl::string_view lhs, + absl::string_view rhs) const { + return compare_internal::compare_result_as_ordering(lhs.compare(rhs)); + } + StringBtreeDefaultLess(std::less<absl::Cord>) {} // NOLINT + absl::weak_ordering operator()(const absl::Cord &lhs, + const absl::Cord &rhs) const { + return compare_internal::compare_result_as_ordering(lhs.Compare(rhs)); + } + absl::weak_ordering operator()(const absl::Cord &lhs, + absl::string_view rhs) const { + return compare_internal::compare_result_as_ordering(lhs.Compare(rhs)); + } + absl::weak_ordering operator()(absl::string_view lhs, + const absl::Cord &rhs) const { + return compare_internal::compare_result_as_ordering(-rhs.Compare(lhs)); + } +}; + +struct StringBtreeDefaultGreater { + using is_transparent = void; + + StringBtreeDefaultGreater() = default; + + StringBtreeDefaultGreater(std::greater<std::string>) {} // NOLINT + StringBtreeDefaultGreater(std::greater<string_view>) {} // NOLINT + + absl::weak_ordering operator()(absl::string_view lhs, + absl::string_view rhs) const { + return compare_internal::compare_result_as_ordering(rhs.compare(lhs)); + } + StringBtreeDefaultGreater(std::greater<absl::Cord>) {} // NOLINT + absl::weak_ordering operator()(const absl::Cord &lhs, + const absl::Cord &rhs) const { + return compare_internal::compare_result_as_ordering(rhs.Compare(lhs)); + } + absl::weak_ordering operator()(const absl::Cord &lhs, + absl::string_view rhs) const { + return compare_internal::compare_result_as_ordering(-lhs.Compare(rhs)); + } + absl::weak_ordering operator()(absl::string_view lhs, + const absl::Cord &rhs) const { + return compare_internal::compare_result_as_ordering(rhs.Compare(lhs)); + } +}; + +// A helper class to convert a boolean comparison into a three-way "compare-to" +// comparison that returns a negative value to indicate less-than, zero to +// indicate equality and a positive value to indicate greater-than. This helper +// class is specialized for less<std::string>, greater<std::string>, +// less<string_view>, greater<string_view>, less<absl::Cord>, and +// greater<absl::Cord>. +// +// key_compare_to_adapter is provided so that btree users +// automatically get the more efficient compare-to code when using common +// google string types with common comparison functors. +// These string-like specializations also turn on heterogeneous lookup by +// default. +template <typename Compare> +struct key_compare_to_adapter { + using type = Compare; +}; + +template <> +struct key_compare_to_adapter<std::less<std::string>> { + using type = StringBtreeDefaultLess; +}; + +template <> +struct key_compare_to_adapter<std::greater<std::string>> { + using type = StringBtreeDefaultGreater; +}; + +template <> +struct key_compare_to_adapter<std::less<absl::string_view>> { + using type = StringBtreeDefaultLess; +}; + +template <> +struct key_compare_to_adapter<std::greater<absl::string_view>> { + using type = StringBtreeDefaultGreater; +}; + +template <> +struct key_compare_to_adapter<std::less<absl::Cord>> { + using type = StringBtreeDefaultLess; +}; + +template <> +struct key_compare_to_adapter<std::greater<absl::Cord>> { + using type = StringBtreeDefaultGreater; +}; + +template <typename Key, typename Compare, typename Alloc, int TargetNodeSize, + bool Multi, typename SlotPolicy> +struct common_params { + // If Compare is a common comparator for a string-like type, then we adapt it + // to use heterogeneous lookup and to be a key-compare-to comparator. + using key_compare = typename key_compare_to_adapter<Compare>::type; + // A type which indicates if we have a key-compare-to functor or a plain old + // key-compare functor. + using is_key_compare_to = btree_is_key_compare_to<key_compare, Key>; + + using allocator_type = Alloc; + using key_type = Key; + using size_type = std::make_signed<size_t>::type; + using difference_type = ptrdiff_t; + + // True if this is a multiset or multimap. + using is_multi_container = std::integral_constant<bool, Multi>; + + using slot_policy = SlotPolicy; + using slot_type = typename slot_policy::slot_type; + using value_type = typename slot_policy::value_type; + using init_type = typename slot_policy::mutable_value_type; + using pointer = value_type *; + using const_pointer = const value_type *; + using reference = value_type &; + using const_reference = const value_type &; + + enum { + kTargetNodeSize = TargetNodeSize, + + // Upper bound for the available space for values. This is largest for leaf + // nodes, which have overhead of at least a pointer + 4 bytes (for storing + // 3 field_types and an enum). + kNodeValueSpace = + TargetNodeSize - /*minimum overhead=*/(sizeof(void *) + 4), + }; + + // This is an integral type large enough to hold as many + // ValueSize-values as will fit a node of TargetNodeSize bytes. + using node_count_type = + absl::conditional_t<(kNodeValueSpace / sizeof(value_type) > + (std::numeric_limits<uint8_t>::max)()), + uint16_t, uint8_t>; // NOLINT + + // The following methods are necessary for passing this struct as PolicyTraits + // for node_handle and/or are used within btree. + static value_type &element(slot_type *slot) { + return slot_policy::element(slot); + } + static const value_type &element(const slot_type *slot) { + return slot_policy::element(slot); + } + template <class... Args> + static void construct(Alloc *alloc, slot_type *slot, Args &&... args) { + slot_policy::construct(alloc, slot, std::forward<Args>(args)...); + } + static void construct(Alloc *alloc, slot_type *slot, slot_type *other) { + slot_policy::construct(alloc, slot, other); + } + static void destroy(Alloc *alloc, slot_type *slot) { + slot_policy::destroy(alloc, slot); + } + static void transfer(Alloc *alloc, slot_type *new_slot, slot_type *old_slot) { + construct(alloc, new_slot, old_slot); + destroy(alloc, old_slot); + } + static void swap(Alloc *alloc, slot_type *a, slot_type *b) { + slot_policy::swap(alloc, a, b); + } + static void move(Alloc *alloc, slot_type *src, slot_type *dest) { + slot_policy::move(alloc, src, dest); + } + static void move(Alloc *alloc, slot_type *first, slot_type *last, + slot_type *result) { + slot_policy::move(alloc, first, last, result); + } +}; + +// A parameters structure for holding the type parameters for a btree_map. +// Compare and Alloc should be nothrow copy-constructible. +template <typename Key, typename Data, typename Compare, typename Alloc, + int TargetNodeSize, bool Multi> +struct map_params : common_params<Key, Compare, Alloc, TargetNodeSize, Multi, + map_slot_policy<Key, Data>> { + using super_type = typename map_params::common_params; + using mapped_type = Data; + // This type allows us to move keys when it is safe to do so. It is safe + // for maps in which value_type and mutable_value_type are layout compatible. + using slot_policy = typename super_type::slot_policy; + using slot_type = typename super_type::slot_type; + using value_type = typename super_type::value_type; + using init_type = typename super_type::init_type; + + using key_compare = typename super_type::key_compare; + // Inherit from key_compare for empty base class optimization. + struct value_compare : private key_compare { + value_compare() = default; + explicit value_compare(const key_compare &cmp) : key_compare(cmp) {} + + template <typename T, typename U> + auto operator()(const T &left, const U &right) const + -> decltype(std::declval<key_compare>()(left.first, right.first)) { + return key_compare::operator()(left.first, right.first); + } + }; + using is_map_container = std::true_type; + + static const Key &key(const value_type &value) { return value.first; } + static const Key &key(const init_type &init) { return init.first; } + static const Key &key(const slot_type *s) { return slot_policy::key(s); } + static mapped_type &value(value_type *value) { return value->second; } +}; + +// This type implements the necessary functions from the +// absl::container_internal::slot_type interface. +template <typename Key> +struct set_slot_policy { + using slot_type = Key; + using value_type = Key; + using mutable_value_type = Key; + + static value_type &element(slot_type *slot) { return *slot; } + static const value_type &element(const slot_type *slot) { return *slot; } + + template <typename Alloc, class... Args> + static void construct(Alloc *alloc, slot_type *slot, Args &&... args) { + absl::allocator_traits<Alloc>::construct(*alloc, slot, + std::forward<Args>(args)...); + } + + template <typename Alloc> + static void construct(Alloc *alloc, slot_type *slot, slot_type *other) { + absl::allocator_traits<Alloc>::construct(*alloc, slot, std::move(*other)); + } + + template <typename Alloc> + static void destroy(Alloc *alloc, slot_type *slot) { + absl::allocator_traits<Alloc>::destroy(*alloc, slot); + } + + template <typename Alloc> + static void swap(Alloc * /*alloc*/, slot_type *a, slot_type *b) { + using std::swap; + swap(*a, *b); + } + + template <typename Alloc> + static void move(Alloc * /*alloc*/, slot_type *src, slot_type *dest) { + *dest = std::move(*src); + } + + template <typename Alloc> + static void move(Alloc *alloc, slot_type *first, slot_type *last, + slot_type *result) { + for (slot_type *src = first, *dest = result; src != last; ++src, ++dest) + move(alloc, src, dest); + } +}; + +// A parameters structure for holding the type parameters for a btree_set. +// Compare and Alloc should be nothrow copy-constructible. +template <typename Key, typename Compare, typename Alloc, int TargetNodeSize, + bool Multi> +struct set_params : common_params<Key, Compare, Alloc, TargetNodeSize, Multi, + set_slot_policy<Key>> { + using value_type = Key; + using slot_type = typename set_params::common_params::slot_type; + using value_compare = typename set_params::common_params::key_compare; + using is_map_container = std::false_type; + + static const Key &key(const value_type &value) { return value; } + static const Key &key(const slot_type *slot) { return *slot; } +}; + +// An adapter class that converts a lower-bound compare into an upper-bound +// compare. Note: there is no need to make a version of this adapter specialized +// for key-compare-to functors because the upper-bound (the first value greater +// than the input) is never an exact match. +template <typename Compare> +struct upper_bound_adapter { + explicit upper_bound_adapter(const Compare &c) : comp(c) {} + template <typename K1, typename K2> + bool operator()(const K1 &a, const K2 &b) const { + // Returns true when a is not greater than b. + return !compare_internal::compare_result_as_less_than(comp(b, a)); + } + + private: + Compare comp; +}; + +enum class MatchKind : uint8_t { kEq, kNe }; + +template <typename V, bool IsCompareTo> +struct SearchResult { + V value; + MatchKind match; + + static constexpr bool HasMatch() { return true; } + bool IsEq() const { return match == MatchKind::kEq; } +}; + +// When we don't use CompareTo, `match` is not present. +// This ensures that callers can't use it accidentally when it provides no +// useful information. +template <typename V> +struct SearchResult<V, false> { + V value; + + static constexpr bool HasMatch() { return false; } + static constexpr bool IsEq() { return false; } +}; + +// A node in the btree holding. The same node type is used for both internal +// and leaf nodes in the btree, though the nodes are allocated in such a way +// that the children array is only valid in internal nodes. +template <typename Params> +class btree_node { + using is_key_compare_to = typename Params::is_key_compare_to; + using is_multi_container = typename Params::is_multi_container; + using field_type = typename Params::node_count_type; + using allocator_type = typename Params::allocator_type; + using slot_type = typename Params::slot_type; + + public: + using params_type = Params; + using key_type = typename Params::key_type; + using value_type = typename Params::value_type; + using pointer = typename Params::pointer; + using const_pointer = typename Params::const_pointer; + using reference = typename Params::reference; + using const_reference = typename Params::const_reference; + using key_compare = typename Params::key_compare; + using size_type = typename Params::size_type; + using difference_type = typename Params::difference_type; + + // Btree decides whether to use linear node search as follows: + // - If the key is arithmetic and the comparator is std::less or + // std::greater, choose linear. + // - Otherwise, choose binary. + // TODO(ezb): Might make sense to add condition(s) based on node-size. + using use_linear_search = std::integral_constant< + bool, + std::is_arithmetic<key_type>::value && + (std::is_same<std::less<key_type>, key_compare>::value || + std::is_same<std::greater<key_type>, key_compare>::value)>; + + // This class is organized by gtl::Layout as if it had the following + // structure: + // // A pointer to the node's parent. + // btree_node *parent; + // + // // The position of the node in the node's parent. + // field_type position; + // // The index of the first populated value in `values`. + // // TODO(ezb): right now, `start` is always 0. Update insertion/merge + // // logic to allow for floating storage within nodes. + // field_type start; + // // The index after the last populated value in `values`. Currently, this + // // is the same as the count of values. + // field_type finish; + // // The maximum number of values the node can hold. This is an integer in + // // [1, kNodeValues] for root leaf nodes, kNodeValues for non-root leaf + // // nodes, and kInternalNodeMaxCount (as a sentinel value) for internal + // // nodes (even though there are still kNodeValues values in the node). + // // TODO(ezb): make max_count use only 4 bits and record log2(capacity) + // // to free extra bits for is_root, etc. + // field_type max_count; + // + // // The array of values. The capacity is `max_count` for leaf nodes and + // // kNodeValues for internal nodes. Only the values in + // // [start, finish) have been initialized and are valid. + // slot_type values[max_count]; + // + // // The array of child pointers. The keys in children[i] are all less + // // than key(i). The keys in children[i + 1] are all greater than key(i). + // // There are 0 children for leaf nodes and kNodeValues + 1 children for + // // internal nodes. + // btree_node *children[kNodeValues + 1]; + // + // This class is only constructed by EmptyNodeType. Normally, pointers to the + // layout above are allocated, cast to btree_node*, and de-allocated within + // the btree implementation. + ~btree_node() = default; + btree_node(btree_node const &) = delete; + btree_node &operator=(btree_node const &) = delete; + + // Public for EmptyNodeType. + constexpr static size_type Alignment() { + static_assert(LeafLayout(1).Alignment() == InternalLayout().Alignment(), + "Alignment of all nodes must be equal."); + return InternalLayout().Alignment(); + } + + protected: + btree_node() = default; + + private: + using layout_type = absl::container_internal::Layout<btree_node *, field_type, + slot_type, btree_node *>; + constexpr static size_type SizeWithNValues(size_type n) { + return layout_type(/*parent*/ 1, + /*position, start, finish, max_count*/ 4, + /*values*/ n, + /*children*/ 0) + .AllocSize(); + } + // A lower bound for the overhead of fields other than values in a leaf node. + constexpr static size_type MinimumOverhead() { + return SizeWithNValues(1) - sizeof(value_type); + } + + // Compute how many values we can fit onto a leaf node taking into account + // padding. + constexpr static size_type NodeTargetValues(const int begin, const int end) { + return begin == end ? begin + : SizeWithNValues((begin + end) / 2 + 1) > + params_type::kTargetNodeSize + ? NodeTargetValues(begin, (begin + end) / 2) + : NodeTargetValues((begin + end) / 2 + 1, end); + } + + enum { + kTargetNodeSize = params_type::kTargetNodeSize, + kNodeTargetValues = NodeTargetValues(0, params_type::kTargetNodeSize), + + // We need a minimum of 3 values per internal node in order to perform + // splitting (1 value for the two nodes involved in the split and 1 value + // propagated to the parent as the delimiter for the split). + kNodeValues = kNodeTargetValues >= 3 ? kNodeTargetValues : 3, + + // The node is internal (i.e. is not a leaf node) if and only if `max_count` + // has this value. + kInternalNodeMaxCount = 0, + }; + + // Leaves can have less than kNodeValues values. + constexpr static layout_type LeafLayout(const int max_values = kNodeValues) { + return layout_type(/*parent*/ 1, + /*position, start, finish, max_count*/ 4, + /*values*/ max_values, + /*children*/ 0); + } + constexpr static layout_type InternalLayout() { + return layout_type(/*parent*/ 1, + /*position, start, finish, max_count*/ 4, + /*values*/ kNodeValues, + /*children*/ kNodeValues + 1); + } + constexpr static size_type LeafSize(const int max_values = kNodeValues) { + return LeafLayout(max_values).AllocSize(); + } + constexpr static size_type InternalSize() { + return InternalLayout().AllocSize(); + } + + // N is the index of the type in the Layout definition. + // ElementType<N> is the Nth type in the Layout definition. + template <size_type N> + inline typename layout_type::template ElementType<N> *GetField() { + // We assert that we don't read from values that aren't there. + assert(N < 3 || !leaf()); + return InternalLayout().template Pointer<N>(reinterpret_cast<char *>(this)); + } + template <size_type N> + inline const typename layout_type::template ElementType<N> *GetField() const { + assert(N < 3 || !leaf()); + return InternalLayout().template Pointer<N>( + reinterpret_cast<const char *>(this)); + } + void set_parent(btree_node *p) { *GetField<0>() = p; } + field_type &mutable_finish() { return GetField<1>()[2]; } + slot_type *slot(int i) { return &GetField<2>()[i]; } + slot_type *start_slot() { return slot(start()); } + slot_type *finish_slot() { return slot(finish()); } + const slot_type *slot(int i) const { return &GetField<2>()[i]; } + void set_position(field_type v) { GetField<1>()[0] = v; } + void set_start(field_type v) { GetField<1>()[1] = v; } + void set_finish(field_type v) { GetField<1>()[2] = v; } + // This method is only called by the node init methods. + void set_max_count(field_type v) { GetField<1>()[3] = v; } + + public: + // Whether this is a leaf node or not. This value doesn't change after the + // node is created. + bool leaf() const { return GetField<1>()[3] != kInternalNodeMaxCount; } + + // Getter for the position of this node in its parent. + field_type position() const { return GetField<1>()[0]; } + + // Getter for the offset of the first value in the `values` array. + field_type start() const { + // TODO(ezb): when floating storage is implemented, return GetField<1>()[1]; + assert(GetField<1>()[1] == 0); + return 0; + } + + // Getter for the offset after the last value in the `values` array. + field_type finish() const { return GetField<1>()[2]; } + + // Getters for the number of values stored in this node. + field_type count() const { + assert(finish() >= start()); + return finish() - start(); + } + field_type max_count() const { + // Internal nodes have max_count==kInternalNodeMaxCount. + // Leaf nodes have max_count in [1, kNodeValues]. + const field_type max_count = GetField<1>()[3]; + return max_count == field_type{kInternalNodeMaxCount} + ? field_type{kNodeValues} + : max_count; + } + + // Getter for the parent of this node. + btree_node *parent() const { return *GetField<0>(); } + // Getter for whether the node is the root of the tree. The parent of the + // root of the tree is the leftmost node in the tree which is guaranteed to + // be a leaf. + bool is_root() const { return parent()->leaf(); } + void make_root() { + assert(parent()->is_root()); + set_parent(parent()->parent()); + } + + // Getters for the key/value at position i in the node. + const key_type &key(int i) const { return params_type::key(slot(i)); } + reference value(int i) { return params_type::element(slot(i)); } + const_reference value(int i) const { return params_type::element(slot(i)); } + + // Getters/setter for the child at position i in the node. + btree_node *child(int i) const { return GetField<3>()[i]; } + btree_node *start_child() const { return child(start()); } + btree_node *&mutable_child(int i) { return GetField<3>()[i]; } + void clear_child(int i) { + absl::container_internal::SanitizerPoisonObject(&mutable_child(i)); + } + void set_child(int i, btree_node *c) { + absl::container_internal::SanitizerUnpoisonObject(&mutable_child(i)); + mutable_child(i) = c; + c->set_position(i); + } + void init_child(int i, btree_node *c) { + set_child(i, c); + c->set_parent(this); + } + + // Returns the position of the first value whose key is not less than k. + template <typename K> + SearchResult<int, is_key_compare_to::value> lower_bound( + const K &k, const key_compare &comp) const { + return use_linear_search::value ? linear_search(k, comp) + : binary_search(k, comp); + } + // Returns the position of the first value whose key is greater than k. + template <typename K> + int upper_bound(const K &k, const key_compare &comp) const { + auto upper_compare = upper_bound_adapter<key_compare>(comp); + return use_linear_search::value ? linear_search(k, upper_compare).value + : binary_search(k, upper_compare).value; + } + + template <typename K, typename Compare> + SearchResult<int, btree_is_key_compare_to<Compare, key_type>::value> + linear_search(const K &k, const Compare &comp) const { + return linear_search_impl(k, start(), finish(), comp, + btree_is_key_compare_to<Compare, key_type>()); + } + + template <typename K, typename Compare> + SearchResult<int, btree_is_key_compare_to<Compare, key_type>::value> + binary_search(const K &k, const Compare &comp) const { + return binary_search_impl(k, start(), finish(), comp, + btree_is_key_compare_to<Compare, key_type>()); + } + + // Returns the position of the first value whose key is not less than k using + // linear search performed using plain compare. + template <typename K, typename Compare> + SearchResult<int, false> linear_search_impl( + const K &k, int s, const int e, const Compare &comp, + std::false_type /* IsCompareTo */) const { + while (s < e) { + if (!comp(key(s), k)) { + break; + } + ++s; + } + return {s}; + } + + // Returns the position of the first value whose key is not less than k using + // linear search performed using compare-to. + template <typename K, typename Compare> + SearchResult<int, true> linear_search_impl( + const K &k, int s, const int e, const Compare &comp, + std::true_type /* IsCompareTo */) const { + while (s < e) { + const absl::weak_ordering c = comp(key(s), k); + if (c == 0) { + return {s, MatchKind::kEq}; + } else if (c > 0) { + break; + } + ++s; + } + return {s, MatchKind::kNe}; + } + + // Returns the position of the first value whose key is not less than k using + // binary search performed using plain compare. + template <typename K, typename Compare> + SearchResult<int, false> binary_search_impl( + const K &k, int s, int e, const Compare &comp, + std::false_type /* IsCompareTo */) const { + while (s != e) { + const int mid = (s + e) >> 1; + if (comp(key(mid), k)) { + s = mid + 1; + } else { + e = mid; + } + } + return {s}; + } + + // Returns the position of the first value whose key is not less than k using + // binary search performed using compare-to. + template <typename K, typename CompareTo> + SearchResult<int, true> binary_search_impl( + const K &k, int s, int e, const CompareTo &comp, + std::true_type /* IsCompareTo */) const { + if (is_multi_container::value) { + MatchKind exact_match = MatchKind::kNe; + while (s != e) { + const int mid = (s + e) >> 1; + const absl::weak_ordering c = comp(key(mid), k); + if (c < 0) { + s = mid + 1; + } else { + e = mid; + if (c == 0) { + // Need to return the first value whose key is not less than k, + // which requires continuing the binary search if this is a + // multi-container. + exact_match = MatchKind::kEq; + } + } + } + return {s, exact_match}; + } else { // Not a multi-container. + while (s != e) { + const int mid = (s + e) >> 1; + const absl::weak_ordering c = comp(key(mid), k); + if (c < 0) { + s = mid + 1; + } else if (c > 0) { + e = mid; + } else { + return {mid, MatchKind::kEq}; + } + } + return {s, MatchKind::kNe}; + } + } + + // Emplaces a value at position i, shifting all existing values and + // children at positions >= i to the right by 1. + template <typename... Args> + void emplace_value(size_type i, allocator_type *alloc, Args &&... args); + + // Removes the value at position i, shifting all existing values and children + // at positions > i to the left by 1. + void remove_value(int i, allocator_type *alloc); + + // Removes the values at positions [i, i + to_erase), shifting all values + // after that range to the left by to_erase. Does not change children at all. + void remove_values_ignore_children(int i, int to_erase, + allocator_type *alloc); + + // Rebalances a node with its right sibling. + void rebalance_right_to_left(int to_move, btree_node *right, + allocator_type *alloc); + void rebalance_left_to_right(int to_move, btree_node *right, + allocator_type *alloc); + + // Splits a node, moving a portion of the node's values to its right sibling. + void split(int insert_position, btree_node *dest, allocator_type *alloc); + + // Merges a node with its right sibling, moving all of the values and the + // delimiting key in the parent node onto itself. + void merge(btree_node *src, allocator_type *alloc); + + // Node allocation/deletion routines. + void init_leaf(btree_node *parent, int max_count) { + set_parent(parent); + set_position(0); + set_start(0); + set_finish(0); + set_max_count(max_count); + absl::container_internal::SanitizerPoisonMemoryRegion( + start_slot(), max_count * sizeof(slot_type)); + } + void init_internal(btree_node *parent) { + init_leaf(parent, kNodeValues); + // Set `max_count` to a sentinel value to indicate that this node is + // internal. + set_max_count(kInternalNodeMaxCount); + absl::container_internal::SanitizerPoisonMemoryRegion( + &mutable_child(start()), (kNodeValues + 1) * sizeof(btree_node *)); + } + void destroy(allocator_type *alloc) { + for (int i = start(); i < finish(); ++i) { + value_destroy(i, alloc); + } + } + + public: + // Exposed only for tests. + static bool testonly_uses_linear_node_search() { + return use_linear_search::value; + } + + private: + template <typename... Args> + void value_init(const size_type i, allocator_type *alloc, Args &&... args) { + absl::container_internal::SanitizerUnpoisonObject(slot(i)); + params_type::construct(alloc, slot(i), std::forward<Args>(args)...); + } + void value_destroy(const size_type i, allocator_type *alloc) { + params_type::destroy(alloc, slot(i)); + absl::container_internal::SanitizerPoisonObject(slot(i)); + } + + // Transfers value from slot `src_i` in `src` to slot `dest_i` in `this`. + void transfer(const size_type dest_i, const size_type src_i, btree_node *src, + allocator_type *alloc) { + absl::container_internal::SanitizerUnpoisonObject(slot(dest_i)); + params_type::transfer(alloc, slot(dest_i), src->slot(src_i)); + absl::container_internal::SanitizerPoisonObject(src->slot(src_i)); + } + + // Move n values starting at value i in this node into the values starting at + // value j in dest_node. + void uninitialized_move_n(const size_type n, const size_type i, + const size_type j, btree_node *dest_node, + allocator_type *alloc) { + absl::container_internal::SanitizerUnpoisonMemoryRegion( + dest_node->slot(j), n * sizeof(slot_type)); + for (slot_type *src = slot(i), *end = src + n, *dest = dest_node->slot(j); + src != end; ++src, ++dest) { + params_type::construct(alloc, dest, src); + } + } + + // Destroys a range of n values, starting at index i. + void value_destroy_n(const size_type i, const size_type n, + allocator_type *alloc) { + for (int j = 0; j < n; ++j) { + value_destroy(i + j, alloc); + } + } + + template <typename P> + friend class btree; + template <typename N, typename R, typename P> + friend struct btree_iterator; + friend class BtreeNodePeer; +}; + +template <typename Node, typename Reference, typename Pointer> +struct btree_iterator { + private: + using key_type = typename Node::key_type; + using size_type = typename Node::size_type; + using params_type = typename Node::params_type; + + using node_type = Node; + using normal_node = typename std::remove_const<Node>::type; + using const_node = const Node; + using normal_pointer = typename params_type::pointer; + using normal_reference = typename params_type::reference; + using const_pointer = typename params_type::const_pointer; + using const_reference = typename params_type::const_reference; + using slot_type = typename params_type::slot_type; + + using iterator = + btree_iterator<normal_node, normal_reference, normal_pointer>; + using const_iterator = + btree_iterator<const_node, const_reference, const_pointer>; + + public: + // These aliases are public for std::iterator_traits. + using difference_type = typename Node::difference_type; + using value_type = typename params_type::value_type; + using pointer = Pointer; + using reference = Reference; + using iterator_category = std::bidirectional_iterator_tag; + + btree_iterator() : node(nullptr), position(-1) {} + explicit btree_iterator(Node *n) : node(n), position(n->start()) {} + btree_iterator(Node *n, int p) : node(n), position(p) {} + + // NOTE: this SFINAE allows for implicit conversions from iterator to + // const_iterator, but it specifically avoids defining copy constructors so + // that btree_iterator can be trivially copyable. This is for performance and + // binary size reasons. + template <typename N, typename R, typename P, + absl::enable_if_t< + std::is_same<btree_iterator<N, R, P>, iterator>::value && + std::is_same<btree_iterator, const_iterator>::value, + int> = 0> + btree_iterator(const btree_iterator<N, R, P> &other) // NOLINT + : node(other.node), position(other.position) {} + + private: + // This SFINAE allows explicit conversions from const_iterator to + // iterator, but also avoids defining a copy constructor. + // NOTE: the const_cast is safe because this constructor is only called by + // non-const methods and the container owns the nodes. + template <typename N, typename R, typename P, + absl::enable_if_t< + std::is_same<btree_iterator<N, R, P>, const_iterator>::value && + std::is_same<btree_iterator, iterator>::value, + int> = 0> + explicit btree_iterator(const btree_iterator<N, R, P> &other) + : node(const_cast<node_type *>(other.node)), position(other.position) {} + + // Increment/decrement the iterator. + void increment() { + if (node->leaf() && ++position < node->finish()) { + return; + } + increment_slow(); + } + void increment_slow(); + + void decrement() { + if (node->leaf() && --position >= node->start()) { + return; + } + decrement_slow(); + } + void decrement_slow(); + + public: + bool operator==(const iterator &other) const { + return node == other.node && position == other.position; + } + bool operator==(const const_iterator &other) const { + return node == other.node && position == other.position; + } + bool operator!=(const iterator &other) const { + return node != other.node || position != other.position; + } + bool operator!=(const const_iterator &other) const { + return node != other.node || position != other.position; + } + + // Accessors for the key/value the iterator is pointing at. + reference operator*() const { + ABSL_HARDENING_ASSERT(node != nullptr); + ABSL_HARDENING_ASSERT(node->start() <= position); + ABSL_HARDENING_ASSERT(node->finish() > position); + return node->value(position); + } + pointer operator->() const { return &operator*(); } + + btree_iterator &operator++() { + increment(); + return *this; + } + btree_iterator &operator--() { + decrement(); + return *this; + } + btree_iterator operator++(int) { + btree_iterator tmp = *this; + ++*this; + return tmp; + } + btree_iterator operator--(int) { + btree_iterator tmp = *this; + --*this; + return tmp; + } + + private: + template <typename Params> + friend class btree; + template <typename Tree> + friend class btree_container; + template <typename Tree> + friend class btree_set_container; + template <typename Tree> + friend class btree_map_container; + template <typename Tree> + friend class btree_multiset_container; + template <typename N, typename R, typename P> + friend struct btree_iterator; + template <typename TreeType, typename CheckerType> + friend class base_checker; + + const key_type &key() const { return node->key(position); } + slot_type *slot() { return node->slot(position); } + + // The node in the tree the iterator is pointing at. + Node *node; + // The position within the node of the tree the iterator is pointing at. + // NOTE: this is an int rather than a field_type because iterators can point + // to invalid positions (such as -1) in certain circumstances. + int position; +}; + +template <typename Params> +class btree { + using node_type = btree_node<Params>; + using is_key_compare_to = typename Params::is_key_compare_to; + + // We use a static empty node for the root/leftmost/rightmost of empty btrees + // in order to avoid branching in begin()/end(). + struct alignas(node_type::Alignment()) EmptyNodeType : node_type { + using field_type = typename node_type::field_type; + node_type *parent; + field_type position = 0; + field_type start = 0; + field_type finish = 0; + // max_count must be != kInternalNodeMaxCount (so that this node is regarded + // as a leaf node). max_count() is never called when the tree is empty. + field_type max_count = node_type::kInternalNodeMaxCount + 1; + +#ifdef _MSC_VER + // MSVC has constexpr code generations bugs here. + EmptyNodeType() : parent(this) {} +#else + constexpr EmptyNodeType(node_type *p) : parent(p) {} +#endif + }; + + static node_type *EmptyNode() { +#ifdef _MSC_VER + static EmptyNodeType *empty_node = new EmptyNodeType; + // This assert fails on some other construction methods. + assert(empty_node->parent == empty_node); + return empty_node; +#else + static constexpr EmptyNodeType empty_node( + const_cast<EmptyNodeType *>(&empty_node)); + return const_cast<EmptyNodeType *>(&empty_node); +#endif + } + + enum { + kNodeValues = node_type::kNodeValues, + kMinNodeValues = kNodeValues / 2, + }; + + struct node_stats { + using size_type = typename Params::size_type; + + node_stats(size_type l, size_type i) : leaf_nodes(l), internal_nodes(i) {} + + node_stats &operator+=(const node_stats &other) { + leaf_nodes += other.leaf_nodes; + internal_nodes += other.internal_nodes; + return *this; + } + + size_type leaf_nodes; + size_type internal_nodes; + }; + + public: + using key_type = typename Params::key_type; + using value_type = typename Params::value_type; + using size_type = typename Params::size_type; + using difference_type = typename Params::difference_type; + using key_compare = typename Params::key_compare; + using value_compare = typename Params::value_compare; + using allocator_type = typename Params::allocator_type; + using reference = typename Params::reference; + using const_reference = typename Params::const_reference; + using pointer = typename Params::pointer; + using const_pointer = typename Params::const_pointer; + using iterator = btree_iterator<node_type, reference, pointer>; + using const_iterator = typename iterator::const_iterator; + using reverse_iterator = std::reverse_iterator<iterator>; + using const_reverse_iterator = std::reverse_iterator<const_iterator>; + using node_handle_type = node_handle<Params, Params, allocator_type>; + + // Internal types made public for use by btree_container types. + using params_type = Params; + using slot_type = typename Params::slot_type; + + private: + // For use in copy_or_move_values_in_order. + const value_type &maybe_move_from_iterator(const_iterator it) { return *it; } + value_type &&maybe_move_from_iterator(iterator it) { return std::move(*it); } + + // Copies or moves (depending on the template parameter) the values in + // other into this btree in their order in other. This btree must be empty + // before this method is called. This method is used in copy construction, + // copy assignment, and move assignment. + template <typename Btree> + void copy_or_move_values_in_order(Btree *other); + + // Validates that various assumptions/requirements are true at compile time. + constexpr static bool static_assert_validation(); + + public: + btree(const key_compare &comp, const allocator_type &alloc); + + btree(const btree &other); + btree(btree &&other) noexcept + : root_(std::move(other.root_)), + rightmost_(absl::exchange(other.rightmost_, EmptyNode())), + size_(absl::exchange(other.size_, 0)) { + other.mutable_root() = EmptyNode(); + } + + ~btree() { + // Put static_asserts in destructor to avoid triggering them before the type + // is complete. + static_assert(static_assert_validation(), "This call must be elided."); + clear(); + } + + // Assign the contents of other to *this. + btree &operator=(const btree &other); + btree &operator=(btree &&other) noexcept; + + iterator begin() { return iterator(leftmost()); } + const_iterator begin() const { return const_iterator(leftmost()); } + iterator end() { return iterator(rightmost_, rightmost_->finish()); } + const_iterator end() const { + return const_iterator(rightmost_, rightmost_->finish()); + } + reverse_iterator rbegin() { return reverse_iterator(end()); } + const_reverse_iterator rbegin() const { + return const_reverse_iterator(end()); + } + reverse_iterator rend() { return reverse_iterator(begin()); } + const_reverse_iterator rend() const { + return const_reverse_iterator(begin()); + } + + // Finds the first element whose key is not less than key. + template <typename K> + iterator lower_bound(const K &key) { + return internal_end(internal_lower_bound(key)); + } + template <typename K> + const_iterator lower_bound(const K &key) const { + return internal_end(internal_lower_bound(key)); + } + + // Finds the first element whose key is greater than key. + template <typename K> + iterator upper_bound(const K &key) { + return internal_end(internal_upper_bound(key)); + } + template <typename K> + const_iterator upper_bound(const K &key) const { + return internal_end(internal_upper_bound(key)); + } + + // Finds the range of values which compare equal to key. The first member of + // the returned pair is equal to lower_bound(key). The second member pair of + // the pair is equal to upper_bound(key). + template <typename K> + std::pair<iterator, iterator> equal_range(const K &key) { + return {lower_bound(key), upper_bound(key)}; + } + template <typename K> + std::pair<const_iterator, const_iterator> equal_range(const K &key) const { + return {lower_bound(key), upper_bound(key)}; + } + + // Inserts a value into the btree only if it does not already exist. The + // boolean return value indicates whether insertion succeeded or failed. + // Requirement: if `key` already exists in the btree, does not consume `args`. + // Requirement: `key` is never referenced after consuming `args`. + template <typename... Args> + std::pair<iterator, bool> insert_unique(const key_type &key, Args &&... args); + + // Inserts with hint. Checks to see if the value should be placed immediately + // before `position` in the tree. If so, then the insertion will take + // amortized constant time. If not, the insertion will take amortized + // logarithmic time as if a call to insert_unique() were made. + // Requirement: if `key` already exists in the btree, does not consume `args`. + // Requirement: `key` is never referenced after consuming `args`. + template <typename... Args> + std::pair<iterator, bool> insert_hint_unique(iterator position, + const key_type &key, + Args &&... args); + + // Insert a range of values into the btree. + template <typename InputIterator> + void insert_iterator_unique(InputIterator b, InputIterator e); + + // Inserts a value into the btree. + template <typename ValueType> + iterator insert_multi(const key_type &key, ValueType &&v); + + // Inserts a value into the btree. + template <typename ValueType> + iterator insert_multi(ValueType &&v) { + return insert_multi(params_type::key(v), std::forward<ValueType>(v)); + } + + // Insert with hint. Check to see if the value should be placed immediately + // before position in the tree. If it does, then the insertion will take + // amortized constant time. If not, the insertion will take amortized + // logarithmic time as if a call to insert_multi(v) were made. + template <typename ValueType> + iterator insert_hint_multi(iterator position, ValueType &&v); + + // Insert a range of values into the btree. + template <typename InputIterator> + void insert_iterator_multi(InputIterator b, InputIterator e); + + // Erase the specified iterator from the btree. The iterator must be valid + // (i.e. not equal to end()). Return an iterator pointing to the node after + // the one that was erased (or end() if none exists). + // Requirement: does not read the value at `*iter`. + iterator erase(iterator iter); + + // Erases range. Returns the number of keys erased and an iterator pointing + // to the element after the last erased element. + std::pair<size_type, iterator> erase_range(iterator begin, iterator end); + + // Erases the specified key from the btree. Returns 1 if an element was + // erased and 0 otherwise. + template <typename K> + size_type erase_unique(const K &key); + + // Erases all of the entries matching the specified key from the + // btree. Returns the number of elements erased. + template <typename K> + size_type erase_multi(const K &key); + + // Finds the iterator corresponding to a key or returns end() if the key is + // not present. + template <typename K> + iterator find(const K &key) { + return internal_end(internal_find(key)); + } + template <typename K> + const_iterator find(const K &key) const { + return internal_end(internal_find(key)); + } + + // Returns a count of the number of times the key appears in the btree. + template <typename K> + size_type count_unique(const K &key) const { + const iterator begin = internal_find(key); + if (begin.node == nullptr) { + // The key doesn't exist in the tree. + return 0; + } + return 1; + } + // Returns a count of the number of times the key appears in the btree. + template <typename K> + size_type count_multi(const K &key) const { + const auto range = equal_range(key); + return std::distance(range.first, range.second); + } + + // Clear the btree, deleting all of the values it contains. + void clear(); + + // Swaps the contents of `this` and `other`. + void swap(btree &other); + + const key_compare &key_comp() const noexcept { + return root_.template get<0>(); + } + template <typename K1, typename K2> + bool compare_keys(const K1 &a, const K2 &b) const { + return compare_internal::compare_result_as_less_than(key_comp()(a, b)); + } + + value_compare value_comp() const { return value_compare(key_comp()); } + + // Verifies the structure of the btree. + void verify() const; + + // Size routines. + size_type size() const { return size_; } + size_type max_size() const { return (std::numeric_limits<size_type>::max)(); } + bool empty() const { return size_ == 0; } + + // The height of the btree. An empty tree will have height 0. + size_type height() const { + size_type h = 0; + if (!empty()) { + // Count the length of the chain from the leftmost node up to the + // root. We actually count from the root back around to the level below + // the root, but the calculation is the same because of the circularity + // of that traversal. + const node_type *n = root(); + do { + ++h; + n = n->parent(); + } while (n != root()); + } + return h; + } + + // The number of internal, leaf and total nodes used by the btree. + size_type leaf_nodes() const { return internal_stats(root()).leaf_nodes; } + size_type internal_nodes() const { + return internal_stats(root()).internal_nodes; + } + size_type nodes() const { + node_stats stats = internal_stats(root()); + return stats.leaf_nodes + stats.internal_nodes; + } + + // The total number of bytes used by the btree. + size_type bytes_used() const { + node_stats stats = internal_stats(root()); + if (stats.leaf_nodes == 1 && stats.internal_nodes == 0) { + return sizeof(*this) + node_type::LeafSize(root()->max_count()); + } else { + return sizeof(*this) + stats.leaf_nodes * node_type::LeafSize() + + stats.internal_nodes * node_type::InternalSize(); + } + } + + // The average number of bytes used per value stored in the btree. + static double average_bytes_per_value() { + // Returns the number of bytes per value on a leaf node that is 75% + // full. Experimentally, this matches up nicely with the computed number of + // bytes per value in trees that had their values inserted in random order. + return node_type::LeafSize() / (kNodeValues * 0.75); + } + + // The fullness of the btree. Computed as the number of elements in the btree + // divided by the maximum number of elements a tree with the current number + // of nodes could hold. A value of 1 indicates perfect space + // utilization. Smaller values indicate space wastage. + // Returns 0 for empty trees. + double fullness() const { + if (empty()) return 0.0; + return static_cast<double>(size()) / (nodes() * kNodeValues); + } + // The overhead of the btree structure in bytes per node. Computed as the + // total number of bytes used by the btree minus the number of bytes used for + // storing elements divided by the number of elements. + // Returns 0 for empty trees. + double overhead() const { + if (empty()) return 0.0; + return (bytes_used() - size() * sizeof(value_type)) / + static_cast<double>(size()); + } + + // The allocator used by the btree. + allocator_type get_allocator() const { return allocator(); } + + private: + // Internal accessor routines. + node_type *root() { return root_.template get<2>(); } + const node_type *root() const { return root_.template get<2>(); } + node_type *&mutable_root() noexcept { return root_.template get<2>(); } + key_compare *mutable_key_comp() noexcept { return &root_.template get<0>(); } + + // The leftmost node is stored as the parent of the root node. + node_type *leftmost() { return root()->parent(); } + const node_type *leftmost() const { return root()->parent(); } + + // Allocator routines. + allocator_type *mutable_allocator() noexcept { + return &root_.template get<1>(); + } + const allocator_type &allocator() const noexcept { + return root_.template get<1>(); + } + + // Allocates a correctly aligned node of at least size bytes using the + // allocator. + node_type *allocate(const size_type size) { + return reinterpret_cast<node_type *>( + absl::container_internal::Allocate<node_type::Alignment()>( + mutable_allocator(), size)); + } + + // Node creation/deletion routines. + node_type *new_internal_node(node_type *parent) { + node_type *n = allocate(node_type::InternalSize()); + n->init_internal(parent); + return n; + } + node_type *new_leaf_node(node_type *parent) { + node_type *n = allocate(node_type::LeafSize()); + n->init_leaf(parent, kNodeValues); + return n; + } + node_type *new_leaf_root_node(const int max_count) { + node_type *n = allocate(node_type::LeafSize(max_count)); + n->init_leaf(/*parent=*/n, max_count); + return n; + } + + // Deletion helper routines. + void erase_same_node(iterator begin, iterator end); + iterator erase_from_leaf_node(iterator begin, size_type to_erase); + iterator rebalance_after_delete(iterator iter); + + // Deallocates a node of a certain size in bytes using the allocator. + void deallocate(const size_type size, node_type *node) { + absl::container_internal::Deallocate<node_type::Alignment()>( + mutable_allocator(), node, size); + } + + void delete_internal_node(node_type *node) { + node->destroy(mutable_allocator()); + deallocate(node_type::InternalSize(), node); + } + void delete_leaf_node(node_type *node) { + node->destroy(mutable_allocator()); + deallocate(node_type::LeafSize(node->max_count()), node); + } + + // Rebalances or splits the node iter points to. + void rebalance_or_split(iterator *iter); + + // Merges the values of left, right and the delimiting key on their parent + // onto left, removing the delimiting key and deleting right. + void merge_nodes(node_type *left, node_type *right); + + // Tries to merge node with its left or right sibling, and failing that, + // rebalance with its left or right sibling. Returns true if a merge + // occurred, at which point it is no longer valid to access node. Returns + // false if no merging took place. + bool try_merge_or_rebalance(iterator *iter); + + // Tries to shrink the height of the tree by 1. + void try_shrink(); + + iterator internal_end(iterator iter) { + return iter.node != nullptr ? iter : end(); + } + const_iterator internal_end(const_iterator iter) const { + return iter.node != nullptr ? iter : end(); + } + + // Emplaces a value into the btree immediately before iter. Requires that + // key(v) <= iter.key() and (--iter).key() <= key(v). + template <typename... Args> + iterator internal_emplace(iterator iter, Args &&... args); + + // Returns an iterator pointing to the first value >= the value "iter" is + // pointing at. Note that "iter" might be pointing to an invalid location such + // as iter.position == iter.node->finish(). This routine simply moves iter up + // in the tree to a valid location. + // Requires: iter.node is non-null. + template <typename IterType> + static IterType internal_last(IterType iter); + + // Returns an iterator pointing to the leaf position at which key would + // reside in the tree. We provide 2 versions of internal_locate. The first + // version uses a less-than comparator and is incapable of distinguishing when + // there is an exact match. The second version is for the key-compare-to + // specialization and distinguishes exact matches. The key-compare-to + // specialization allows the caller to avoid a subsequent comparison to + // determine if an exact match was made, which is important for keys with + // expensive comparison, such as strings. + template <typename K> + SearchResult<iterator, is_key_compare_to::value> internal_locate( + const K &key) const; + + template <typename K> + SearchResult<iterator, false> internal_locate_impl( + const K &key, std::false_type /* IsCompareTo */) const; + + template <typename K> + SearchResult<iterator, true> internal_locate_impl( + const K &key, std::true_type /* IsCompareTo */) const; + + // Internal routine which implements lower_bound(). + template <typename K> + iterator internal_lower_bound(const K &key) const; + + // Internal routine which implements upper_bound(). + template <typename K> + iterator internal_upper_bound(const K &key) const; + + // Internal routine which implements find(). + template <typename K> + iterator internal_find(const K &key) const; + + // Deletes a node and all of its children. + void internal_clear(node_type *node); + + // Verifies the tree structure of node. + int internal_verify(const node_type *node, const key_type *lo, + const key_type *hi) const; + + node_stats internal_stats(const node_type *node) const { + // The root can be a static empty node. + if (node == nullptr || (node == root() && empty())) { + return node_stats(0, 0); + } + if (node->leaf()) { + return node_stats(1, 0); + } + node_stats res(0, 1); + for (int i = node->start(); i <= node->finish(); ++i) { + res += internal_stats(node->child(i)); + } + return res; + } + + public: + // Exposed only for tests. + static bool testonly_uses_linear_node_search() { + return node_type::testonly_uses_linear_node_search(); + } + + private: + // We use compressed tuple in order to save space because key_compare and + // allocator_type are usually empty. + absl::container_internal::CompressedTuple<key_compare, allocator_type, + node_type *> + root_; + + // A pointer to the rightmost node. Note that the leftmost node is stored as + // the root's parent. + node_type *rightmost_; + + // Number of values. + size_type size_; +}; + +//// +// btree_node methods +template <typename P> +template <typename... Args> +inline void btree_node<P>::emplace_value(const size_type i, + allocator_type *alloc, + Args &&... args) { + assert(i >= start()); + assert(i <= finish()); + // Shift old values to create space for new value and then construct it in + // place. + if (i < finish()) { + value_init(finish(), alloc, slot(finish() - 1)); + for (size_type j = finish() - 1; j > i; --j) + params_type::move(alloc, slot(j - 1), slot(j)); + value_destroy(i, alloc); + } + value_init(i, alloc, std::forward<Args>(args)...); + set_finish(finish() + 1); + + if (!leaf() && finish() > i + 1) { + for (int j = finish(); j > i + 1; --j) { + set_child(j, child(j - 1)); + } + clear_child(i + 1); + } +} + +template <typename P> +inline void btree_node<P>::remove_value(const int i, allocator_type *alloc) { + if (!leaf() && finish() > i + 1) { + assert(child(i + 1)->count() == 0); + for (size_type j = i + 1; j < finish(); ++j) { + set_child(j, child(j + 1)); + } + clear_child(finish()); + } + + remove_values_ignore_children(i, /*to_erase=*/1, alloc); +} + +template <typename P> +inline void btree_node<P>::remove_values_ignore_children( + const int i, const int to_erase, allocator_type *alloc) { + params_type::move(alloc, slot(i + to_erase), finish_slot(), slot(i)); + value_destroy_n(finish() - to_erase, to_erase, alloc); + set_finish(finish() - to_erase); +} + +template <typename P> +void btree_node<P>::rebalance_right_to_left(const int to_move, + btree_node *right, + allocator_type *alloc) { + assert(parent() == right->parent()); + assert(position() + 1 == right->position()); + assert(right->count() >= count()); + assert(to_move >= 1); + assert(to_move <= right->count()); + + // 1) Move the delimiting value in the parent to the left node. + value_init(finish(), alloc, parent()->slot(position())); + + // 2) Move the (to_move - 1) values from the right node to the left node. + right->uninitialized_move_n(to_move - 1, right->start(), finish() + 1, this, + alloc); + + // 3) Move the new delimiting value to the parent from the right node. + params_type::move(alloc, right->slot(to_move - 1), + parent()->slot(position())); + + // 4) Shift the values in the right node to their correct position. + params_type::move(alloc, right->slot(to_move), right->finish_slot(), + right->start_slot()); + + // 5) Destroy the now-empty to_move entries in the right node. + right->value_destroy_n(right->finish() - to_move, to_move, alloc); + + if (!leaf()) { + // Move the child pointers from the right to the left node. + for (int i = 0; i < to_move; ++i) { + init_child(finish() + i + 1, right->child(i)); + } + for (int i = right->start(); i <= right->finish() - to_move; ++i) { + assert(i + to_move <= right->max_count()); + right->init_child(i, right->child(i + to_move)); + right->clear_child(i + to_move); + } + } + + // Fixup `finish` on the left and right nodes. + set_finish(finish() + to_move); + right->set_finish(right->finish() - to_move); +} + +template <typename P> +void btree_node<P>::rebalance_left_to_right(const int to_move, + btree_node *right, + allocator_type *alloc) { + assert(parent() == right->parent()); + assert(position() + 1 == right->position()); + assert(count() >= right->count()); + assert(to_move >= 1); + assert(to_move <= count()); + + // Values in the right node are shifted to the right to make room for the + // new to_move values. Then, the delimiting value in the parent and the + // other (to_move - 1) values in the left node are moved into the right node. + // Lastly, a new delimiting value is moved from the left node into the + // parent, and the remaining empty left node entries are destroyed. + + if (right->count() >= to_move) { + // The original location of the right->count() values are sufficient to hold + // the new to_move entries from the parent and left node. + + // 1) Shift existing values in the right node to their correct positions. + right->uninitialized_move_n(to_move, right->finish() - to_move, + right->finish(), right, alloc); + for (slot_type *src = right->slot(right->finish() - to_move - 1), + *dest = right->slot(right->finish() - 1), + *end = right->start_slot(); + src >= end; --src, --dest) { + params_type::move(alloc, src, dest); + } + + // 2) Move the delimiting value in the parent to the right node. + params_type::move(alloc, parent()->slot(position()), + right->slot(to_move - 1)); + + // 3) Move the (to_move - 1) values from the left node to the right node. + params_type::move(alloc, slot(finish() - (to_move - 1)), finish_slot(), + right->start_slot()); + } else { + // The right node does not have enough initialized space to hold the new + // to_move entries, so part of them will move to uninitialized space. + + // 1) Shift existing values in the right node to their correct positions. + right->uninitialized_move_n(right->count(), right->start(), + right->start() + to_move, right, alloc); + + // 2) Move the delimiting value in the parent to the right node. + right->value_init(to_move - 1, alloc, parent()->slot(position())); + + // 3) Move the (to_move - 1) values from the left node to the right node. + const size_type uninitialized_remaining = to_move - right->count() - 1; + uninitialized_move_n(uninitialized_remaining, + finish() - uninitialized_remaining, right->finish(), + right, alloc); + params_type::move(alloc, slot(finish() - (to_move - 1)), + slot(finish() - uninitialized_remaining), + right->start_slot()); + } + + // 4) Move the new delimiting value to the parent from the left node. + params_type::move(alloc, slot(finish() - to_move), + parent()->slot(position())); + + // 5) Destroy the now-empty to_move entries in the left node. + value_destroy_n(finish() - to_move, to_move, alloc); + + if (!leaf()) { + // Move the child pointers from the left to the right node. + for (int i = right->finish(); i >= right->start(); --i) { + right->init_child(i + to_move, right->child(i)); + right->clear_child(i); + } + for (int i = 1; i <= to_move; ++i) { + right->init_child(i - 1, child(finish() - to_move + i)); + clear_child(finish() - to_move + i); + } + } + + // Fixup the counts on the left and right nodes. + set_finish(finish() - to_move); + right->set_finish(right->finish() + to_move); +} + +template <typename P> +void btree_node<P>::split(const int insert_position, btree_node *dest, + allocator_type *alloc) { + assert(dest->count() == 0); + assert(max_count() == kNodeValues); + + // We bias the split based on the position being inserted. If we're + // inserting at the beginning of the left node then bias the split to put + // more values on the right node. If we're inserting at the end of the + // right node then bias the split to put more values on the left node. + if (insert_position == start()) { + dest->set_finish(dest->start() + finish() - 1); + } else if (insert_position == kNodeValues) { + dest->set_finish(dest->start()); + } else { + dest->set_finish(dest->start() + count() / 2); + } + set_finish(finish() - dest->count()); + assert(count() >= 1); + + // Move values from the left sibling to the right sibling. + uninitialized_move_n(dest->count(), finish(), dest->start(), dest, alloc); + + // Destroy the now-empty entries in the left node. + value_destroy_n(finish(), dest->count(), alloc); + + // The split key is the largest value in the left sibling. + --mutable_finish(); + parent()->emplace_value(position(), alloc, finish_slot()); + value_destroy(finish(), alloc); + parent()->init_child(position() + 1, dest); + + if (!leaf()) { + for (int i = dest->start(), j = finish() + 1; i <= dest->finish(); + ++i, ++j) { + assert(child(j) != nullptr); + dest->init_child(i, child(j)); + clear_child(j); + } + } +} + +template <typename P> +void btree_node<P>::merge(btree_node *src, allocator_type *alloc) { + assert(parent() == src->parent()); + assert(position() + 1 == src->position()); + + // Move the delimiting value to the left node. + value_init(finish(), alloc, parent()->slot(position())); + + // Move the values from the right to the left node. + src->uninitialized_move_n(src->count(), src->start(), finish() + 1, this, + alloc); + + // Destroy the now-empty entries in the right node. + src->value_destroy_n(src->start(), src->count(), alloc); + + if (!leaf()) { + // Move the child pointers from the right to the left node. + for (int i = src->start(), j = finish() + 1; i <= src->finish(); ++i, ++j) { + init_child(j, src->child(i)); + src->clear_child(i); + } + } + + // Fixup `finish` on the src and dest nodes. + set_finish(start() + 1 + count() + src->count()); + src->set_finish(src->start()); + + // Remove the value on the parent node. + parent()->remove_value(position(), alloc); +} + +//// +// btree_iterator methods +template <typename N, typename R, typename P> +void btree_iterator<N, R, P>::increment_slow() { + if (node->leaf()) { + assert(position >= node->finish()); + btree_iterator save(*this); + while (position == node->finish() && !node->is_root()) { + assert(node->parent()->child(node->position()) == node); + position = node->position(); + node = node->parent(); + } + // TODO(ezb): assert we aren't incrementing end() instead of handling. + if (position == node->finish()) { + *this = save; + } + } else { + assert(position < node->finish()); + node = node->child(position + 1); + while (!node->leaf()) { + node = node->start_child(); + } + position = node->start(); + } +} + +template <typename N, typename R, typename P> +void btree_iterator<N, R, P>::decrement_slow() { + if (node->leaf()) { + assert(position <= -1); + btree_iterator save(*this); + while (position < node->start() && !node->is_root()) { + assert(node->parent()->child(node->position()) == node); + position = node->position() - 1; + node = node->parent(); + } + // TODO(ezb): assert we aren't decrementing begin() instead of handling. + if (position < node->start()) { + *this = save; + } + } else { + assert(position >= node->start()); + node = node->child(position); + while (!node->leaf()) { + node = node->child(node->finish()); + } + position = node->finish() - 1; + } +} + +//// +// btree methods +template <typename P> +template <typename Btree> +void btree<P>::copy_or_move_values_in_order(Btree *other) { + static_assert(std::is_same<btree, Btree>::value || + std::is_same<const btree, Btree>::value, + "Btree type must be same or const."); + assert(empty()); + + // We can avoid key comparisons because we know the order of the + // values is the same order we'll store them in. + auto iter = other->begin(); + if (iter == other->end()) return; + insert_multi(maybe_move_from_iterator(iter)); + ++iter; + for (; iter != other->end(); ++iter) { + // If the btree is not empty, we can just insert the new value at the end + // of the tree. + internal_emplace(end(), maybe_move_from_iterator(iter)); + } +} + +template <typename P> +constexpr bool btree<P>::static_assert_validation() { + static_assert(std::is_nothrow_copy_constructible<key_compare>::value, + "Key comparison must be nothrow copy constructible"); + static_assert(std::is_nothrow_copy_constructible<allocator_type>::value, + "Allocator must be nothrow copy constructible"); + static_assert(type_traits_internal::is_trivially_copyable<iterator>::value, + "iterator not trivially copyable."); + + // Note: We assert that kTargetValues, which is computed from + // Params::kTargetNodeSize, must fit the node_type::field_type. + static_assert( + kNodeValues < (1 << (8 * sizeof(typename node_type::field_type))), + "target node size too large"); + + // Verify that key_compare returns an absl::{weak,strong}_ordering or bool. + using compare_result_type = + absl::result_of_t<key_compare(key_type, key_type)>; + static_assert( + std::is_same<compare_result_type, bool>::value || + std::is_convertible<compare_result_type, absl::weak_ordering>::value, + "key comparison function must return absl::{weak,strong}_ordering or " + "bool."); + + // Test the assumption made in setting kNodeValueSpace. + static_assert(node_type::MinimumOverhead() >= sizeof(void *) + 4, + "node space assumption incorrect"); + + return true; +} + +template <typename P> +btree<P>::btree(const key_compare &comp, const allocator_type &alloc) + : root_(comp, alloc, EmptyNode()), rightmost_(EmptyNode()), size_(0) {} + +template <typename P> +btree<P>::btree(const btree &other) + : btree(other.key_comp(), other.allocator()) { + copy_or_move_values_in_order(&other); +} + +template <typename P> +template <typename... Args> +auto btree<P>::insert_unique(const key_type &key, Args &&... args) + -> std::pair<iterator, bool> { + if (empty()) { + mutable_root() = rightmost_ = new_leaf_root_node(1); + } + + auto res = internal_locate(key); + iterator &iter = res.value; + + if (res.HasMatch()) { + if (res.IsEq()) { + // The key already exists in the tree, do nothing. + return {iter, false}; + } + } else { + iterator last = internal_last(iter); + if (last.node && !compare_keys(key, last.key())) { + // The key already exists in the tree, do nothing. + return {last, false}; + } + } + return {internal_emplace(iter, std::forward<Args>(args)...), true}; +} + +template <typename P> +template <typename... Args> +inline auto btree<P>::insert_hint_unique(iterator position, const key_type &key, + Args &&... args) + -> std::pair<iterator, bool> { + if (!empty()) { + if (position == end() || compare_keys(key, position.key())) { + if (position == begin() || compare_keys(std::prev(position).key(), key)) { + // prev.key() < key < position.key() + return {internal_emplace(position, std::forward<Args>(args)...), true}; + } + } else if (compare_keys(position.key(), key)) { + ++position; + if (position == end() || compare_keys(key, position.key())) { + // {original `position`}.key() < key < {current `position`}.key() + return {internal_emplace(position, std::forward<Args>(args)...), true}; + } + } else { + // position.key() == key + return {position, false}; + } + } + return insert_unique(key, std::forward<Args>(args)...); +} + +template <typename P> +template <typename InputIterator> +void btree<P>::insert_iterator_unique(InputIterator b, InputIterator e) { + for (; b != e; ++b) { + insert_hint_unique(end(), params_type::key(*b), *b); + } +} + +template <typename P> +template <typename ValueType> +auto btree<P>::insert_multi(const key_type &key, ValueType &&v) -> iterator { + if (empty()) { + mutable_root() = rightmost_ = new_leaf_root_node(1); + } + + iterator iter = internal_upper_bound(key); + if (iter.node == nullptr) { + iter = end(); + } + return internal_emplace(iter, std::forward<ValueType>(v)); +} + +template <typename P> +template <typename ValueType> +auto btree<P>::insert_hint_multi(iterator position, ValueType &&v) -> iterator { + if (!empty()) { + const key_type &key = params_type::key(v); + if (position == end() || !compare_keys(position.key(), key)) { + if (position == begin() || + !compare_keys(key, std::prev(position).key())) { + // prev.key() <= key <= position.key() + return internal_emplace(position, std::forward<ValueType>(v)); + } + } else { + ++position; + if (position == end() || !compare_keys(position.key(), key)) { + // {original `position`}.key() < key < {current `position`}.key() + return internal_emplace(position, std::forward<ValueType>(v)); + } + } + } + return insert_multi(std::forward<ValueType>(v)); +} + +template <typename P> +template <typename InputIterator> +void btree<P>::insert_iterator_multi(InputIterator b, InputIterator e) { + for (; b != e; ++b) { + insert_hint_multi(end(), *b); + } +} + +template <typename P> +auto btree<P>::operator=(const btree &other) -> btree & { + if (this != &other) { + clear(); + + *mutable_key_comp() = other.key_comp(); + if (absl::allocator_traits< + allocator_type>::propagate_on_container_copy_assignment::value) { + *mutable_allocator() = other.allocator(); + } + + copy_or_move_values_in_order(&other); + } + return *this; +} + +template <typename P> +auto btree<P>::operator=(btree &&other) noexcept -> btree & { + if (this != &other) { + clear(); + + using std::swap; + if (absl::allocator_traits< + allocator_type>::propagate_on_container_copy_assignment::value) { + // Note: `root_` also contains the allocator and the key comparator. + swap(root_, other.root_); + swap(rightmost_, other.rightmost_); + swap(size_, other.size_); + } else { + if (allocator() == other.allocator()) { + swap(mutable_root(), other.mutable_root()); + swap(*mutable_key_comp(), *other.mutable_key_comp()); + swap(rightmost_, other.rightmost_); + swap(size_, other.size_); + } else { + // We aren't allowed to propagate the allocator and the allocator is + // different so we can't take over its memory. We must move each element + // individually. We need both `other` and `this` to have `other`s key + // comparator while moving the values so we can't swap the key + // comparators. + *mutable_key_comp() = other.key_comp(); + copy_or_move_values_in_order(&other); + } + } + } + return *this; +} + +template <typename P> +auto btree<P>::erase(iterator iter) -> iterator { + bool internal_delete = false; + if (!iter.node->leaf()) { + // Deletion of a value on an internal node. First, move the largest value + // from our left child here, then delete that position (in remove_value() + // below). We can get to the largest value from our left child by + // decrementing iter. + iterator internal_iter(iter); + --iter; + assert(iter.node->leaf()); + params_type::move(mutable_allocator(), iter.node->slot(iter.position), + internal_iter.node->slot(internal_iter.position)); + internal_delete = true; + } + + // Delete the key from the leaf. + iter.node->remove_value(iter.position, mutable_allocator()); + --size_; + + // We want to return the next value after the one we just erased. If we + // erased from an internal node (internal_delete == true), then the next + // value is ++(++iter). If we erased from a leaf node (internal_delete == + // false) then the next value is ++iter. Note that ++iter may point to an + // internal node and the value in the internal node may move to a leaf node + // (iter.node) when rebalancing is performed at the leaf level. + + iterator res = rebalance_after_delete(iter); + + // If we erased from an internal node, advance the iterator. + if (internal_delete) { + ++res; + } + return res; +} + +template <typename P> +auto btree<P>::rebalance_after_delete(iterator iter) -> iterator { + // Merge/rebalance as we walk back up the tree. + iterator res(iter); + bool first_iteration = true; + for (;;) { + if (iter.node == root()) { + try_shrink(); + if (empty()) { + return end(); + } + break; + } + if (iter.node->count() >= kMinNodeValues) { + break; + } + bool merged = try_merge_or_rebalance(&iter); + // On the first iteration, we should update `res` with `iter` because `res` + // may have been invalidated. + if (first_iteration) { + res = iter; + first_iteration = false; + } + if (!merged) { + break; + } + iter.position = iter.node->position(); + iter.node = iter.node->parent(); + } + + // Adjust our return value. If we're pointing at the end of a node, advance + // the iterator. + if (res.position == res.node->finish()) { + res.position = res.node->finish() - 1; + ++res; + } + + return res; +} + +template <typename P> +auto btree<P>::erase_range(iterator begin, iterator end) + -> std::pair<size_type, iterator> { + difference_type count = std::distance(begin, end); + assert(count >= 0); + + if (count == 0) { + return {0, begin}; + } + + if (count == size_) { + clear(); + return {count, this->end()}; + } + + if (begin.node == end.node) { + erase_same_node(begin, end); + size_ -= count; + return {count, rebalance_after_delete(begin)}; + } + + const size_type target_size = size_ - count; + while (size_ > target_size) { + if (begin.node->leaf()) { + const size_type remaining_to_erase = size_ - target_size; + const size_type remaining_in_node = begin.node->finish() - begin.position; + begin = erase_from_leaf_node( + begin, (std::min)(remaining_to_erase, remaining_in_node)); + } else { + begin = erase(begin); + } + } + return {count, begin}; +} + +template <typename P> +void btree<P>::erase_same_node(iterator begin, iterator end) { + assert(begin.node == end.node); + assert(end.position > begin.position); + + node_type *node = begin.node; + size_type to_erase = end.position - begin.position; + if (!node->leaf()) { + // Delete all children between begin and end. + for (size_type i = 0; i < to_erase; ++i) { + internal_clear(node->child(begin.position + i + 1)); + } + // Rotate children after end into new positions. + for (size_type i = begin.position + to_erase + 1; i <= node->finish(); + ++i) { + node->set_child(i - to_erase, node->child(i)); + node->clear_child(i); + } + } + node->remove_values_ignore_children(begin.position, to_erase, + mutable_allocator()); + + // Do not need to update rightmost_, because + // * either end == this->end(), and therefore node == rightmost_, and still + // exists + // * or end != this->end(), and therefore rightmost_ hasn't been erased, since + // it wasn't covered in [begin, end) +} + +template <typename P> +auto btree<P>::erase_from_leaf_node(iterator begin, size_type to_erase) + -> iterator { + node_type *node = begin.node; + assert(node->leaf()); + assert(node->finish() > begin.position); + assert(begin.position + to_erase <= node->finish()); + + node->remove_values_ignore_children(begin.position, to_erase, + mutable_allocator()); + + size_ -= to_erase; + + return rebalance_after_delete(begin); +} + +template <typename P> +template <typename K> +auto btree<P>::erase_unique(const K &key) -> size_type { + const iterator iter = internal_find(key); + if (iter.node == nullptr) { + // The key doesn't exist in the tree, return nothing done. + return 0; + } + erase(iter); + return 1; +} + +template <typename P> +template <typename K> +auto btree<P>::erase_multi(const K &key) -> size_type { + const iterator begin = internal_lower_bound(key); + if (begin.node == nullptr) { + // The key doesn't exist in the tree, return nothing done. + return 0; + } + // Delete all of the keys between begin and upper_bound(key). + const iterator end = internal_end(internal_upper_bound(key)); + return erase_range(begin, end).first; +} + +template <typename P> +void btree<P>::clear() { + if (!empty()) { + internal_clear(root()); + } + mutable_root() = EmptyNode(); + rightmost_ = EmptyNode(); + size_ = 0; +} + +template <typename P> +void btree<P>::swap(btree &other) { + using std::swap; + if (absl::allocator_traits< + allocator_type>::propagate_on_container_swap::value) { + // Note: `root_` also contains the allocator and the key comparator. + swap(root_, other.root_); + } else { + // It's undefined behavior if the allocators are unequal here. + assert(allocator() == other.allocator()); + swap(mutable_root(), other.mutable_root()); + swap(*mutable_key_comp(), *other.mutable_key_comp()); + } + swap(rightmost_, other.rightmost_); + swap(size_, other.size_); +} + +template <typename P> +void btree<P>::verify() const { + assert(root() != nullptr); + assert(leftmost() != nullptr); + assert(rightmost_ != nullptr); + assert(empty() || size() == internal_verify(root(), nullptr, nullptr)); + assert(leftmost() == (++const_iterator(root(), -1)).node); + assert(rightmost_ == (--const_iterator(root(), root()->finish())).node); + assert(leftmost()->leaf()); + assert(rightmost_->leaf()); +} + +template <typename P> +void btree<P>::rebalance_or_split(iterator *iter) { + node_type *&node = iter->node; + int &insert_position = iter->position; + assert(node->count() == node->max_count()); + assert(kNodeValues == node->max_count()); + + // First try to make room on the node by rebalancing. + node_type *parent = node->parent(); + if (node != root()) { + if (node->position() > parent->start()) { + // Try rebalancing with our left sibling. + node_type *left = parent->child(node->position() - 1); + assert(left->max_count() == kNodeValues); + if (left->count() < kNodeValues) { + // We bias rebalancing based on the position being inserted. If we're + // inserting at the end of the right node then we bias rebalancing to + // fill up the left node. + int to_move = (kNodeValues - left->count()) / + (1 + (insert_position < kNodeValues)); + to_move = (std::max)(1, to_move); + + if (insert_position - to_move >= node->start() || + left->count() + to_move < kNodeValues) { + left->rebalance_right_to_left(to_move, node, mutable_allocator()); + + assert(node->max_count() - node->count() == to_move); + insert_position = insert_position - to_move; + if (insert_position < node->start()) { + insert_position = insert_position + left->count() + 1; + node = left; + } + + assert(node->count() < node->max_count()); + return; + } + } + } + + if (node->position() < parent->finish()) { + // Try rebalancing with our right sibling. + node_type *right = parent->child(node->position() + 1); + assert(right->max_count() == kNodeValues); + if (right->count() < kNodeValues) { + // We bias rebalancing based on the position being inserted. If we're + // inserting at the beginning of the left node then we bias rebalancing + // to fill up the right node. + int to_move = (kNodeValues - right->count()) / + (1 + (insert_position > node->start())); + to_move = (std::max)(1, to_move); + + if (insert_position <= node->finish() - to_move || + right->count() + to_move < kNodeValues) { + node->rebalance_left_to_right(to_move, right, mutable_allocator()); + + if (insert_position > node->finish()) { + insert_position = insert_position - node->count() - 1; + node = right; + } + + assert(node->count() < node->max_count()); + return; + } + } + } + + // Rebalancing failed, make sure there is room on the parent node for a new + // value. + assert(parent->max_count() == kNodeValues); + if (parent->count() == kNodeValues) { + iterator parent_iter(node->parent(), node->position()); + rebalance_or_split(&parent_iter); + } + } else { + // Rebalancing not possible because this is the root node. + // Create a new root node and set the current root node as the child of the + // new root. + parent = new_internal_node(parent); + parent->init_child(parent->start(), root()); + mutable_root() = parent; + // If the former root was a leaf node, then it's now the rightmost node. + assert(!parent->start_child()->leaf() || + parent->start_child() == rightmost_); + } + + // Split the node. + node_type *split_node; + if (node->leaf()) { + split_node = new_leaf_node(parent); + node->split(insert_position, split_node, mutable_allocator()); + if (rightmost_ == node) rightmost_ = split_node; + } else { + split_node = new_internal_node(parent); + node->split(insert_position, split_node, mutable_allocator()); + } + + if (insert_position > node->finish()) { + insert_position = insert_position - node->count() - 1; + node = split_node; + } +} + +template <typename P> +void btree<P>::merge_nodes(node_type *left, node_type *right) { + left->merge(right, mutable_allocator()); + if (right->leaf()) { + if (rightmost_ == right) rightmost_ = left; + delete_leaf_node(right); + } else { + delete_internal_node(right); + } +} + +template <typename P> +bool btree<P>::try_merge_or_rebalance(iterator *iter) { + node_type *parent = iter->node->parent(); + if (iter->node->position() > parent->start()) { + // Try merging with our left sibling. + node_type *left = parent->child(iter->node->position() - 1); + assert(left->max_count() == kNodeValues); + if (1 + left->count() + iter->node->count() <= kNodeValues) { + iter->position += 1 + left->count(); + merge_nodes(left, iter->node); + iter->node = left; + return true; + } + } + if (iter->node->position() < parent->finish()) { + // Try merging with our right sibling. + node_type *right = parent->child(iter->node->position() + 1); + assert(right->max_count() == kNodeValues); + if (1 + iter->node->count() + right->count() <= kNodeValues) { + merge_nodes(iter->node, right); + return true; + } + // Try rebalancing with our right sibling. We don't perform rebalancing if + // we deleted the first element from iter->node and the node is not + // empty. This is a small optimization for the common pattern of deleting + // from the front of the tree. + if (right->count() > kMinNodeValues && + (iter->node->count() == 0 || iter->position > iter->node->start())) { + int to_move = (right->count() - iter->node->count()) / 2; + to_move = (std::min)(to_move, right->count() - 1); + iter->node->rebalance_right_to_left(to_move, right, mutable_allocator()); + return false; + } + } + if (iter->node->position() > parent->start()) { + // Try rebalancing with our left sibling. We don't perform rebalancing if + // we deleted the last element from iter->node and the node is not + // empty. This is a small optimization for the common pattern of deleting + // from the back of the tree. + node_type *left = parent->child(iter->node->position() - 1); + if (left->count() > kMinNodeValues && + (iter->node->count() == 0 || iter->position < iter->node->finish())) { + int to_move = (left->count() - iter->node->count()) / 2; + to_move = (std::min)(to_move, left->count() - 1); + left->rebalance_left_to_right(to_move, iter->node, mutable_allocator()); + iter->position += to_move; + return false; + } + } + return false; +} + +template <typename P> +void btree<P>::try_shrink() { + if (root()->count() > 0) { + return; + } + // Deleted the last item on the root node, shrink the height of the tree. + if (root()->leaf()) { + assert(size() == 0); + delete_leaf_node(root()); + mutable_root() = rightmost_ = EmptyNode(); + } else { + node_type *child = root()->start_child(); + child->make_root(); + delete_internal_node(root()); + mutable_root() = child; + } +} + +template <typename P> +template <typename IterType> +inline IterType btree<P>::internal_last(IterType iter) { + assert(iter.node != nullptr); + while (iter.position == iter.node->finish()) { + iter.position = iter.node->position(); + iter.node = iter.node->parent(); + if (iter.node->leaf()) { + iter.node = nullptr; + break; + } + } + return iter; +} + +template <typename P> +template <typename... Args> +inline auto btree<P>::internal_emplace(iterator iter, Args &&... args) + -> iterator { + if (!iter.node->leaf()) { + // We can't insert on an internal node. Instead, we'll insert after the + // previous value which is guaranteed to be on a leaf node. + --iter; + ++iter.position; + } + const int max_count = iter.node->max_count(); + allocator_type *alloc = mutable_allocator(); + if (iter.node->count() == max_count) { + // Make room in the leaf for the new item. + if (max_count < kNodeValues) { + // Insertion into the root where the root is smaller than the full node + // size. Simply grow the size of the root node. + assert(iter.node == root()); + iter.node = + new_leaf_root_node((std::min<int>)(kNodeValues, 2 * max_count)); + // Transfer the values from the old root to the new root. + node_type *old_root = root(); + node_type *new_root = iter.node; + for (int i = old_root->start(), f = old_root->finish(); i < f; ++i) { + new_root->transfer(i, i, old_root, alloc); + } + new_root->set_finish(old_root->finish()); + old_root->set_finish(old_root->start()); + delete_leaf_node(old_root); + mutable_root() = rightmost_ = new_root; + } else { + rebalance_or_split(&iter); + } + } + iter.node->emplace_value(iter.position, alloc, std::forward<Args>(args)...); + ++size_; + return iter; +} + +template <typename P> +template <typename K> +inline auto btree<P>::internal_locate(const K &key) const + -> SearchResult<iterator, is_key_compare_to::value> { + return internal_locate_impl(key, is_key_compare_to()); +} + +template <typename P> +template <typename K> +inline auto btree<P>::internal_locate_impl( + const K &key, std::false_type /* IsCompareTo */) const + -> SearchResult<iterator, false> { + iterator iter(const_cast<node_type *>(root())); + for (;;) { + iter.position = iter.node->lower_bound(key, key_comp()).value; + // NOTE: we don't need to walk all the way down the tree if the keys are + // equal, but determining equality would require doing an extra comparison + // on each node on the way down, and we will need to go all the way to the + // leaf node in the expected case. + if (iter.node->leaf()) { + break; + } + iter.node = iter.node->child(iter.position); + } + return {iter}; +} + +template <typename P> +template <typename K> +inline auto btree<P>::internal_locate_impl( + const K &key, std::true_type /* IsCompareTo */) const + -> SearchResult<iterator, true> { + iterator iter(const_cast<node_type *>(root())); + for (;;) { + SearchResult<int, true> res = iter.node->lower_bound(key, key_comp()); + iter.position = res.value; + if (res.match == MatchKind::kEq) { + return {iter, MatchKind::kEq}; + } + if (iter.node->leaf()) { + break; + } + iter.node = iter.node->child(iter.position); + } + return {iter, MatchKind::kNe}; +} + +template <typename P> +template <typename K> +auto btree<P>::internal_lower_bound(const K &key) const -> iterator { + iterator iter(const_cast<node_type *>(root())); + for (;;) { + iter.position = iter.node->lower_bound(key, key_comp()).value; + if (iter.node->leaf()) { + break; + } + iter.node = iter.node->child(iter.position); + } + return internal_last(iter); +} + +template <typename P> +template <typename K> +auto btree<P>::internal_upper_bound(const K &key) const -> iterator { + iterator iter(const_cast<node_type *>(root())); + for (;;) { + iter.position = iter.node->upper_bound(key, key_comp()); + if (iter.node->leaf()) { + break; + } + iter.node = iter.node->child(iter.position); + } + return internal_last(iter); +} + +template <typename P> +template <typename K> +auto btree<P>::internal_find(const K &key) const -> iterator { + auto res = internal_locate(key); + if (res.HasMatch()) { + if (res.IsEq()) { + return res.value; + } + } else { + const iterator iter = internal_last(res.value); + if (iter.node != nullptr && !compare_keys(key, iter.key())) { + return iter; + } + } + return {nullptr, 0}; +} + +template <typename P> +void btree<P>::internal_clear(node_type *node) { + if (!node->leaf()) { + for (int i = node->start(); i <= node->finish(); ++i) { + internal_clear(node->child(i)); + } + delete_internal_node(node); + } else { + delete_leaf_node(node); + } +} + +template <typename P> +int btree<P>::internal_verify(const node_type *node, const key_type *lo, + const key_type *hi) const { + assert(node->count() > 0); + assert(node->count() <= node->max_count()); + if (lo) { + assert(!compare_keys(node->key(node->start()), *lo)); + } + if (hi) { + assert(!compare_keys(*hi, node->key(node->finish() - 1))); + } + for (int i = node->start() + 1; i < node->finish(); ++i) { + assert(!compare_keys(node->key(i), node->key(i - 1))); + } + int count = node->count(); + if (!node->leaf()) { + for (int i = node->start(); i <= node->finish(); ++i) { + assert(node->child(i) != nullptr); + assert(node->child(i)->parent() == node); + assert(node->child(i)->position() == i); + count += internal_verify(node->child(i), + i == node->start() ? lo : &node->key(i - 1), + i == node->finish() ? hi : &node->key(i)); + } + } + return count; +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_BTREE_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/btree_container.h b/third_party/abseil_cpp/absl/container/internal/btree_container.h new file mode 100644 index 0000000000..734c90ef3d --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/btree_container.h @@ -0,0 +1,672 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_BTREE_CONTAINER_H_ +#define ABSL_CONTAINER_INTERNAL_BTREE_CONTAINER_H_ + +#include <algorithm> +#include <initializer_list> +#include <iterator> +#include <utility> + +#include "absl/base/internal/throw_delegate.h" +#include "absl/container/internal/btree.h" // IWYU pragma: export +#include "absl/container/internal/common.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// A common base class for btree_set, btree_map, btree_multiset, and +// btree_multimap. +template <typename Tree> +class btree_container { + using params_type = typename Tree::params_type; + + protected: + // Alias used for heterogeneous lookup functions. + // `key_arg<K>` evaluates to `K` when the functors are transparent and to + // `key_type` otherwise. It permits template argument deduction on `K` for the + // transparent case. + template <class K> + using key_arg = + typename KeyArg<IsTransparent<typename Tree::key_compare>::value>:: + template type<K, typename Tree::key_type>; + + public: + using key_type = typename Tree::key_type; + using value_type = typename Tree::value_type; + using size_type = typename Tree::size_type; + using difference_type = typename Tree::difference_type; + using key_compare = typename Tree::key_compare; + using value_compare = typename Tree::value_compare; + using allocator_type = typename Tree::allocator_type; + using reference = typename Tree::reference; + using const_reference = typename Tree::const_reference; + using pointer = typename Tree::pointer; + using const_pointer = typename Tree::const_pointer; + using iterator = typename Tree::iterator; + using const_iterator = typename Tree::const_iterator; + using reverse_iterator = typename Tree::reverse_iterator; + using const_reverse_iterator = typename Tree::const_reverse_iterator; + using node_type = typename Tree::node_handle_type; + + // Constructors/assignments. + btree_container() : tree_(key_compare(), allocator_type()) {} + explicit btree_container(const key_compare &comp, + const allocator_type &alloc = allocator_type()) + : tree_(comp, alloc) {} + btree_container(const btree_container &other) = default; + btree_container(btree_container &&other) noexcept = default; + btree_container &operator=(const btree_container &other) = default; + btree_container &operator=(btree_container &&other) noexcept( + std::is_nothrow_move_assignable<Tree>::value) = default; + + // Iterator routines. + iterator begin() { return tree_.begin(); } + const_iterator begin() const { return tree_.begin(); } + const_iterator cbegin() const { return tree_.begin(); } + iterator end() { return tree_.end(); } + const_iterator end() const { return tree_.end(); } + const_iterator cend() const { return tree_.end(); } + reverse_iterator rbegin() { return tree_.rbegin(); } + const_reverse_iterator rbegin() const { return tree_.rbegin(); } + const_reverse_iterator crbegin() const { return tree_.rbegin(); } + reverse_iterator rend() { return tree_.rend(); } + const_reverse_iterator rend() const { return tree_.rend(); } + const_reverse_iterator crend() const { return tree_.rend(); } + + // Lookup routines. + template <typename K = key_type> + iterator find(const key_arg<K> &key) { + return tree_.find(key); + } + template <typename K = key_type> + const_iterator find(const key_arg<K> &key) const { + return tree_.find(key); + } + template <typename K = key_type> + bool contains(const key_arg<K> &key) const { + return find(key) != end(); + } + template <typename K = key_type> + iterator lower_bound(const key_arg<K> &key) { + return tree_.lower_bound(key); + } + template <typename K = key_type> + const_iterator lower_bound(const key_arg<K> &key) const { + return tree_.lower_bound(key); + } + template <typename K = key_type> + iterator upper_bound(const key_arg<K> &key) { + return tree_.upper_bound(key); + } + template <typename K = key_type> + const_iterator upper_bound(const key_arg<K> &key) const { + return tree_.upper_bound(key); + } + template <typename K = key_type> + std::pair<iterator, iterator> equal_range(const key_arg<K> &key) { + return tree_.equal_range(key); + } + template <typename K = key_type> + std::pair<const_iterator, const_iterator> equal_range( + const key_arg<K> &key) const { + return tree_.equal_range(key); + } + + // Deletion routines. Note that there is also a deletion routine that is + // specific to btree_set_container/btree_multiset_container. + + // Erase the specified iterator from the btree. The iterator must be valid + // (i.e. not equal to end()). Return an iterator pointing to the node after + // the one that was erased (or end() if none exists). + iterator erase(const_iterator iter) { return tree_.erase(iterator(iter)); } + iterator erase(iterator iter) { return tree_.erase(iter); } + iterator erase(const_iterator first, const_iterator last) { + return tree_.erase_range(iterator(first), iterator(last)).second; + } + + // Extract routines. + node_type extract(iterator position) { + // Use Move instead of Transfer, because the rebalancing code expects to + // have a valid object to scribble metadata bits on top of. + auto node = CommonAccess::Move<node_type>(get_allocator(), position.slot()); + erase(position); + return node; + } + node_type extract(const_iterator position) { + return extract(iterator(position)); + } + + public: + // Utility routines. + void clear() { tree_.clear(); } + void swap(btree_container &other) { tree_.swap(other.tree_); } + void verify() const { tree_.verify(); } + + // Size routines. + size_type size() const { return tree_.size(); } + size_type max_size() const { return tree_.max_size(); } + bool empty() const { return tree_.empty(); } + + friend bool operator==(const btree_container &x, const btree_container &y) { + if (x.size() != y.size()) return false; + return std::equal(x.begin(), x.end(), y.begin()); + } + + friend bool operator!=(const btree_container &x, const btree_container &y) { + return !(x == y); + } + + friend bool operator<(const btree_container &x, const btree_container &y) { + return std::lexicographical_compare(x.begin(), x.end(), y.begin(), y.end()); + } + + friend bool operator>(const btree_container &x, const btree_container &y) { + return y < x; + } + + friend bool operator<=(const btree_container &x, const btree_container &y) { + return !(y < x); + } + + friend bool operator>=(const btree_container &x, const btree_container &y) { + return !(x < y); + } + + // The allocator used by the btree. + allocator_type get_allocator() const { return tree_.get_allocator(); } + + // The key comparator used by the btree. + key_compare key_comp() const { return tree_.key_comp(); } + value_compare value_comp() const { return tree_.value_comp(); } + + // Support absl::Hash. + template <typename State> + friend State AbslHashValue(State h, const btree_container &b) { + for (const auto &v : b) { + h = State::combine(std::move(h), v); + } + return State::combine(std::move(h), b.size()); + } + + protected: + Tree tree_; +}; + +// A common base class for btree_set and btree_map. +template <typename Tree> +class btree_set_container : public btree_container<Tree> { + using super_type = btree_container<Tree>; + using params_type = typename Tree::params_type; + using init_type = typename params_type::init_type; + using is_key_compare_to = typename params_type::is_key_compare_to; + friend class BtreeNodePeer; + + protected: + template <class K> + using key_arg = typename super_type::template key_arg<K>; + + public: + using key_type = typename Tree::key_type; + using value_type = typename Tree::value_type; + using size_type = typename Tree::size_type; + using key_compare = typename Tree::key_compare; + using allocator_type = typename Tree::allocator_type; + using iterator = typename Tree::iterator; + using const_iterator = typename Tree::const_iterator; + using node_type = typename super_type::node_type; + using insert_return_type = InsertReturnType<iterator, node_type>; + + // Inherit constructors. + using super_type::super_type; + btree_set_container() {} + + // Range constructor. + template <class InputIterator> + btree_set_container(InputIterator b, InputIterator e, + const key_compare &comp = key_compare(), + const allocator_type &alloc = allocator_type()) + : super_type(comp, alloc) { + insert(b, e); + } + + // Initializer list constructor. + btree_set_container(std::initializer_list<init_type> init, + const key_compare &comp = key_compare(), + const allocator_type &alloc = allocator_type()) + : btree_set_container(init.begin(), init.end(), comp, alloc) {} + + // Lookup routines. + template <typename K = key_type> + size_type count(const key_arg<K> &key) const { + return this->tree_.count_unique(key); + } + + // Insertion routines. + std::pair<iterator, bool> insert(const value_type &v) { + return this->tree_.insert_unique(params_type::key(v), v); + } + std::pair<iterator, bool> insert(value_type &&v) { + return this->tree_.insert_unique(params_type::key(v), std::move(v)); + } + template <typename... Args> + std::pair<iterator, bool> emplace(Args &&... args) { + init_type v(std::forward<Args>(args)...); + return this->tree_.insert_unique(params_type::key(v), std::move(v)); + } + iterator insert(const_iterator position, const value_type &v) { + return this->tree_ + .insert_hint_unique(iterator(position), params_type::key(v), v) + .first; + } + iterator insert(const_iterator position, value_type &&v) { + return this->tree_ + .insert_hint_unique(iterator(position), params_type::key(v), + std::move(v)) + .first; + } + template <typename... Args> + iterator emplace_hint(const_iterator position, Args &&... args) { + init_type v(std::forward<Args>(args)...); + return this->tree_ + .insert_hint_unique(iterator(position), params_type::key(v), + std::move(v)) + .first; + } + template <typename InputIterator> + void insert(InputIterator b, InputIterator e) { + this->tree_.insert_iterator_unique(b, e); + } + void insert(std::initializer_list<init_type> init) { + this->tree_.insert_iterator_unique(init.begin(), init.end()); + } + insert_return_type insert(node_type &&node) { + if (!node) return {this->end(), false, node_type()}; + std::pair<iterator, bool> res = + this->tree_.insert_unique(params_type::key(CommonAccess::GetSlot(node)), + CommonAccess::GetSlot(node)); + if (res.second) { + CommonAccess::Destroy(&node); + return {res.first, true, node_type()}; + } else { + return {res.first, false, std::move(node)}; + } + } + iterator insert(const_iterator hint, node_type &&node) { + if (!node) return this->end(); + std::pair<iterator, bool> res = this->tree_.insert_hint_unique( + iterator(hint), params_type::key(CommonAccess::GetSlot(node)), + CommonAccess::GetSlot(node)); + if (res.second) CommonAccess::Destroy(&node); + return res.first; + } + + // Deletion routines. + template <typename K = key_type> + size_type erase(const key_arg<K> &key) { + return this->tree_.erase_unique(key); + } + using super_type::erase; + + // Node extraction routines. + template <typename K = key_type> + node_type extract(const key_arg<K> &key) { + auto it = this->find(key); + return it == this->end() ? node_type() : extract(it); + } + using super_type::extract; + + // Merge routines. + // Moves elements from `src` into `this`. If the element already exists in + // `this`, it is left unmodified in `src`. + template < + typename T, + typename absl::enable_if_t< + absl::conjunction< + std::is_same<value_type, typename T::value_type>, + std::is_same<allocator_type, typename T::allocator_type>, + std::is_same<typename params_type::is_map_container, + typename T::params_type::is_map_container>>::value, + int> = 0> + void merge(btree_container<T> &src) { // NOLINT + for (auto src_it = src.begin(); src_it != src.end();) { + if (insert(std::move(*src_it)).second) { + src_it = src.erase(src_it); + } else { + ++src_it; + } + } + } + + template < + typename T, + typename absl::enable_if_t< + absl::conjunction< + std::is_same<value_type, typename T::value_type>, + std::is_same<allocator_type, typename T::allocator_type>, + std::is_same<typename params_type::is_map_container, + typename T::params_type::is_map_container>>::value, + int> = 0> + void merge(btree_container<T> &&src) { + merge(src); + } +}; + +// Base class for btree_map. +template <typename Tree> +class btree_map_container : public btree_set_container<Tree> { + using super_type = btree_set_container<Tree>; + using params_type = typename Tree::params_type; + + private: + template <class K> + using key_arg = typename super_type::template key_arg<K>; + + public: + using key_type = typename Tree::key_type; + using mapped_type = typename params_type::mapped_type; + using value_type = typename Tree::value_type; + using key_compare = typename Tree::key_compare; + using allocator_type = typename Tree::allocator_type; + using iterator = typename Tree::iterator; + using const_iterator = typename Tree::const_iterator; + + // Inherit constructors. + using super_type::super_type; + btree_map_container() {} + + // Insertion routines. + // Note: the nullptr template arguments and extra `const M&` overloads allow + // for supporting bitfield arguments. + // Note: when we call `std::forward<M>(obj)` twice, it's safe because + // insert_unique/insert_hint_unique are guaranteed to not consume `obj` when + // `ret.second` is false. + template <class M> + std::pair<iterator, bool> insert_or_assign(const key_type &k, const M &obj) { + const std::pair<iterator, bool> ret = this->tree_.insert_unique(k, k, obj); + if (!ret.second) ret.first->second = obj; + return ret; + } + template <class M, key_type * = nullptr> + std::pair<iterator, bool> insert_or_assign(key_type &&k, const M &obj) { + const std::pair<iterator, bool> ret = + this->tree_.insert_unique(k, std::move(k), obj); + if (!ret.second) ret.first->second = obj; + return ret; + } + template <class M, M * = nullptr> + std::pair<iterator, bool> insert_or_assign(const key_type &k, M &&obj) { + const std::pair<iterator, bool> ret = + this->tree_.insert_unique(k, k, std::forward<M>(obj)); + if (!ret.second) ret.first->second = std::forward<M>(obj); + return ret; + } + template <class M, key_type * = nullptr, M * = nullptr> + std::pair<iterator, bool> insert_or_assign(key_type &&k, M &&obj) { + const std::pair<iterator, bool> ret = + this->tree_.insert_unique(k, std::move(k), std::forward<M>(obj)); + if (!ret.second) ret.first->second = std::forward<M>(obj); + return ret; + } + template <class M> + iterator insert_or_assign(const_iterator position, const key_type &k, + const M &obj) { + const std::pair<iterator, bool> ret = + this->tree_.insert_hint_unique(iterator(position), k, k, obj); + if (!ret.second) ret.first->second = obj; + return ret.first; + } + template <class M, key_type * = nullptr> + iterator insert_or_assign(const_iterator position, key_type &&k, + const M &obj) { + const std::pair<iterator, bool> ret = this->tree_.insert_hint_unique( + iterator(position), k, std::move(k), obj); + if (!ret.second) ret.first->second = obj; + return ret.first; + } + template <class M, M * = nullptr> + iterator insert_or_assign(const_iterator position, const key_type &k, + M &&obj) { + const std::pair<iterator, bool> ret = this->tree_.insert_hint_unique( + iterator(position), k, k, std::forward<M>(obj)); + if (!ret.second) ret.first->second = std::forward<M>(obj); + return ret.first; + } + template <class M, key_type * = nullptr, M * = nullptr> + iterator insert_or_assign(const_iterator position, key_type &&k, M &&obj) { + const std::pair<iterator, bool> ret = this->tree_.insert_hint_unique( + iterator(position), k, std::move(k), std::forward<M>(obj)); + if (!ret.second) ret.first->second = std::forward<M>(obj); + return ret.first; + } + template <typename... Args> + std::pair<iterator, bool> try_emplace(const key_type &k, Args &&... args) { + return this->tree_.insert_unique( + k, std::piecewise_construct, std::forward_as_tuple(k), + std::forward_as_tuple(std::forward<Args>(args)...)); + } + template <typename... Args> + std::pair<iterator, bool> try_emplace(key_type &&k, Args &&... args) { + // Note: `key_ref` exists to avoid a ClangTidy warning about moving from `k` + // and then using `k` unsequenced. This is safe because the move is into a + // forwarding reference and insert_unique guarantees that `key` is never + // referenced after consuming `args`. + const key_type &key_ref = k; + return this->tree_.insert_unique( + key_ref, std::piecewise_construct, std::forward_as_tuple(std::move(k)), + std::forward_as_tuple(std::forward<Args>(args)...)); + } + template <typename... Args> + iterator try_emplace(const_iterator hint, const key_type &k, + Args &&... args) { + return this->tree_ + .insert_hint_unique(iterator(hint), k, std::piecewise_construct, + std::forward_as_tuple(k), + std::forward_as_tuple(std::forward<Args>(args)...)) + .first; + } + template <typename... Args> + iterator try_emplace(const_iterator hint, key_type &&k, Args &&... args) { + // Note: `key_ref` exists to avoid a ClangTidy warning about moving from `k` + // and then using `k` unsequenced. This is safe because the move is into a + // forwarding reference and insert_hint_unique guarantees that `key` is + // never referenced after consuming `args`. + const key_type &key_ref = k; + return this->tree_ + .insert_hint_unique(iterator(hint), key_ref, std::piecewise_construct, + std::forward_as_tuple(std::move(k)), + std::forward_as_tuple(std::forward<Args>(args)...)) + .first; + } + mapped_type &operator[](const key_type &k) { + return try_emplace(k).first->second; + } + mapped_type &operator[](key_type &&k) { + return try_emplace(std::move(k)).first->second; + } + + template <typename K = key_type> + mapped_type &at(const key_arg<K> &key) { + auto it = this->find(key); + if (it == this->end()) + base_internal::ThrowStdOutOfRange("absl::btree_map::at"); + return it->second; + } + template <typename K = key_type> + const mapped_type &at(const key_arg<K> &key) const { + auto it = this->find(key); + if (it == this->end()) + base_internal::ThrowStdOutOfRange("absl::btree_map::at"); + return it->second; + } +}; + +// A common base class for btree_multiset and btree_multimap. +template <typename Tree> +class btree_multiset_container : public btree_container<Tree> { + using super_type = btree_container<Tree>; + using params_type = typename Tree::params_type; + using init_type = typename params_type::init_type; + using is_key_compare_to = typename params_type::is_key_compare_to; + + template <class K> + using key_arg = typename super_type::template key_arg<K>; + + public: + using key_type = typename Tree::key_type; + using value_type = typename Tree::value_type; + using size_type = typename Tree::size_type; + using key_compare = typename Tree::key_compare; + using allocator_type = typename Tree::allocator_type; + using iterator = typename Tree::iterator; + using const_iterator = typename Tree::const_iterator; + using node_type = typename super_type::node_type; + + // Inherit constructors. + using super_type::super_type; + btree_multiset_container() {} + + // Range constructor. + template <class InputIterator> + btree_multiset_container(InputIterator b, InputIterator e, + const key_compare &comp = key_compare(), + const allocator_type &alloc = allocator_type()) + : super_type(comp, alloc) { + insert(b, e); + } + + // Initializer list constructor. + btree_multiset_container(std::initializer_list<init_type> init, + const key_compare &comp = key_compare(), + const allocator_type &alloc = allocator_type()) + : btree_multiset_container(init.begin(), init.end(), comp, alloc) {} + + // Lookup routines. + template <typename K = key_type> + size_type count(const key_arg<K> &key) const { + return this->tree_.count_multi(key); + } + + // Insertion routines. + iterator insert(const value_type &v) { return this->tree_.insert_multi(v); } + iterator insert(value_type &&v) { + return this->tree_.insert_multi(std::move(v)); + } + iterator insert(const_iterator position, const value_type &v) { + return this->tree_.insert_hint_multi(iterator(position), v); + } + iterator insert(const_iterator position, value_type &&v) { + return this->tree_.insert_hint_multi(iterator(position), std::move(v)); + } + template <typename InputIterator> + void insert(InputIterator b, InputIterator e) { + this->tree_.insert_iterator_multi(b, e); + } + void insert(std::initializer_list<init_type> init) { + this->tree_.insert_iterator_multi(init.begin(), init.end()); + } + template <typename... Args> + iterator emplace(Args &&... args) { + return this->tree_.insert_multi(init_type(std::forward<Args>(args)...)); + } + template <typename... Args> + iterator emplace_hint(const_iterator position, Args &&... args) { + return this->tree_.insert_hint_multi( + iterator(position), init_type(std::forward<Args>(args)...)); + } + iterator insert(node_type &&node) { + if (!node) return this->end(); + iterator res = + this->tree_.insert_multi(params_type::key(CommonAccess::GetSlot(node)), + CommonAccess::GetSlot(node)); + CommonAccess::Destroy(&node); + return res; + } + iterator insert(const_iterator hint, node_type &&node) { + if (!node) return this->end(); + iterator res = this->tree_.insert_hint_multi( + iterator(hint), + std::move(params_type::element(CommonAccess::GetSlot(node)))); + CommonAccess::Destroy(&node); + return res; + } + + // Deletion routines. + template <typename K = key_type> + size_type erase(const key_arg<K> &key) { + return this->tree_.erase_multi(key); + } + using super_type::erase; + + // Node extraction routines. + template <typename K = key_type> + node_type extract(const key_arg<K> &key) { + auto it = this->find(key); + return it == this->end() ? node_type() : extract(it); + } + using super_type::extract; + + // Merge routines. + // Moves all elements from `src` into `this`. + template < + typename T, + typename absl::enable_if_t< + absl::conjunction< + std::is_same<value_type, typename T::value_type>, + std::is_same<allocator_type, typename T::allocator_type>, + std::is_same<typename params_type::is_map_container, + typename T::params_type::is_map_container>>::value, + int> = 0> + void merge(btree_container<T> &src) { // NOLINT + insert(std::make_move_iterator(src.begin()), + std::make_move_iterator(src.end())); + src.clear(); + } + + template < + typename T, + typename absl::enable_if_t< + absl::conjunction< + std::is_same<value_type, typename T::value_type>, + std::is_same<allocator_type, typename T::allocator_type>, + std::is_same<typename params_type::is_map_container, + typename T::params_type::is_map_container>>::value, + int> = 0> + void merge(btree_container<T> &&src) { + merge(src); + } +}; + +// A base class for btree_multimap. +template <typename Tree> +class btree_multimap_container : public btree_multiset_container<Tree> { + using super_type = btree_multiset_container<Tree>; + using params_type = typename Tree::params_type; + + public: + using mapped_type = typename params_type::mapped_type; + + // Inherit constructors. + using super_type::super_type; + btree_multimap_container() {} +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_BTREE_CONTAINER_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/common.h b/third_party/abseil_cpp/absl/container/internal/common.h new file mode 100644 index 0000000000..8990f29472 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/common.h @@ -0,0 +1,203 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_CONTAINER_H_ +#define ABSL_CONTAINER_INTERNAL_CONTAINER_H_ + +#include <cassert> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/types/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class, class = void> +struct IsTransparent : std::false_type {}; +template <class T> +struct IsTransparent<T, absl::void_t<typename T::is_transparent>> + : std::true_type {}; + +template <bool is_transparent> +struct KeyArg { + // Transparent. Forward `K`. + template <typename K, typename key_type> + using type = K; +}; + +template <> +struct KeyArg<false> { + // Not transparent. Always use `key_type`. + template <typename K, typename key_type> + using type = key_type; +}; + +// The node_handle concept from C++17. +// We specialize node_handle for sets and maps. node_handle_base holds the +// common API of both. +template <typename PolicyTraits, typename Alloc> +class node_handle_base { + protected: + using slot_type = typename PolicyTraits::slot_type; + + public: + using allocator_type = Alloc; + + constexpr node_handle_base() = default; + node_handle_base(node_handle_base&& other) noexcept { + *this = std::move(other); + } + ~node_handle_base() { destroy(); } + node_handle_base& operator=(node_handle_base&& other) noexcept { + destroy(); + if (!other.empty()) { + alloc_ = other.alloc_; + PolicyTraits::transfer(alloc(), slot(), other.slot()); + other.reset(); + } + return *this; + } + + bool empty() const noexcept { return !alloc_; } + explicit operator bool() const noexcept { return !empty(); } + allocator_type get_allocator() const { return *alloc_; } + + protected: + friend struct CommonAccess; + + struct transfer_tag_t {}; + node_handle_base(transfer_tag_t, const allocator_type& a, slot_type* s) + : alloc_(a) { + PolicyTraits::transfer(alloc(), slot(), s); + } + + struct move_tag_t {}; + node_handle_base(move_tag_t, const allocator_type& a, slot_type* s) + : alloc_(a) { + PolicyTraits::construct(alloc(), slot(), s); + } + + void destroy() { + if (!empty()) { + PolicyTraits::destroy(alloc(), slot()); + reset(); + } + } + + void reset() { + assert(alloc_.has_value()); + alloc_ = absl::nullopt; + } + + slot_type* slot() const { + assert(!empty()); + return reinterpret_cast<slot_type*>(std::addressof(slot_space_)); + } + allocator_type* alloc() { return std::addressof(*alloc_); } + + private: + absl::optional<allocator_type> alloc_ = {}; + alignas(slot_type) mutable unsigned char slot_space_[sizeof(slot_type)] = {}; +}; + +// For sets. +template <typename Policy, typename PolicyTraits, typename Alloc, + typename = void> +class node_handle : public node_handle_base<PolicyTraits, Alloc> { + using Base = node_handle_base<PolicyTraits, Alloc>; + + public: + using value_type = typename PolicyTraits::value_type; + + constexpr node_handle() {} + + value_type& value() const { return PolicyTraits::element(this->slot()); } + + private: + friend struct CommonAccess; + + using Base::Base; +}; + +// For maps. +template <typename Policy, typename PolicyTraits, typename Alloc> +class node_handle<Policy, PolicyTraits, Alloc, + absl::void_t<typename Policy::mapped_type>> + : public node_handle_base<PolicyTraits, Alloc> { + using Base = node_handle_base<PolicyTraits, Alloc>; + using slot_type = typename PolicyTraits::slot_type; + + public: + using key_type = typename Policy::key_type; + using mapped_type = typename Policy::mapped_type; + + constexpr node_handle() {} + + auto key() const -> decltype(PolicyTraits::key(std::declval<slot_type*>())) { + return PolicyTraits::key(this->slot()); + } + + mapped_type& mapped() const { + return PolicyTraits::value(&PolicyTraits::element(this->slot())); + } + + private: + friend struct CommonAccess; + + using Base::Base; +}; + +// Provide access to non-public node-handle functions. +struct CommonAccess { + template <typename Node> + static auto GetSlot(const Node& node) -> decltype(node.slot()) { + return node.slot(); + } + + template <typename Node> + static void Destroy(Node* node) { + node->destroy(); + } + + template <typename Node> + static void Reset(Node* node) { + node->reset(); + } + + template <typename T, typename... Args> + static T Transfer(Args&&... args) { + return T(typename T::transfer_tag_t{}, std::forward<Args>(args)...); + } + + template <typename T, typename... Args> + static T Move(Args&&... args) { + return T(typename T::move_tag_t{}, std::forward<Args>(args)...); + } +}; + +// Implement the insert_return_type<> concept of C++17. +template <class Iterator, class NodeType> +struct InsertReturnType { + Iterator position; + bool inserted; + NodeType node; +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_CONTAINER_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/compressed_tuple.h b/third_party/abseil_cpp/absl/container/internal/compressed_tuple.h new file mode 100644 index 0000000000..02bfd03f6c --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/compressed_tuple.h @@ -0,0 +1,290 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Helper class to perform the Empty Base Optimization. +// Ts can contain classes and non-classes, empty or not. For the ones that +// are empty classes, we perform the optimization. If all types in Ts are empty +// classes, then CompressedTuple<Ts...> is itself an empty class. +// +// To access the members, use member get<N>() function. +// +// Eg: +// absl::container_internal::CompressedTuple<int, T1, T2, T3> value(7, t1, t2, +// t3); +// assert(value.get<0>() == 7); +// T1& t1 = value.get<1>(); +// const T2& t2 = value.get<2>(); +// ... +// +// https://en.cppreference.com/w/cpp/language/ebo + +#ifndef ABSL_CONTAINER_INTERNAL_COMPRESSED_TUPLE_H_ +#define ABSL_CONTAINER_INTERNAL_COMPRESSED_TUPLE_H_ + +#include <initializer_list> +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/utility/utility.h" + +#if defined(_MSC_VER) && !defined(__NVCC__) +// We need to mark these classes with this declspec to ensure that +// CompressedTuple happens. +#define ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC __declspec(empty_bases) +#else +#define ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <typename... Ts> +class CompressedTuple; + +namespace internal_compressed_tuple { + +template <typename D, size_t I> +struct Elem; +template <typename... B, size_t I> +struct Elem<CompressedTuple<B...>, I> + : std::tuple_element<I, std::tuple<B...>> {}; +template <typename D, size_t I> +using ElemT = typename Elem<D, I>::type; + +// Use the __is_final intrinsic if available. Where it's not available, classes +// declared with the 'final' specifier cannot be used as CompressedTuple +// elements. +// TODO(sbenza): Replace this with std::is_final in C++14. +template <typename T> +constexpr bool IsFinal() { +#if defined(__clang__) || defined(__GNUC__) + return __is_final(T); +#else + return false; +#endif +} + +// We can't use EBCO on other CompressedTuples because that would mean that we +// derive from multiple Storage<> instantiations with the same I parameter, +// and potentially from multiple identical Storage<> instantiations. So anytime +// we use type inheritance rather than encapsulation, we mark +// CompressedTupleImpl, to make this easy to detect. +struct uses_inheritance {}; + +template <typename T> +constexpr bool ShouldUseBase() { + return std::is_class<T>::value && std::is_empty<T>::value && !IsFinal<T>() && + !std::is_base_of<uses_inheritance, T>::value; +} + +// The storage class provides two specializations: +// - For empty classes, it stores T as a base class. +// - For everything else, it stores T as a member. +template <typename T, size_t I, +#if defined(_MSC_VER) + bool UseBase = + ShouldUseBase<typename std::enable_if<true, T>::type>()> +#else + bool UseBase = ShouldUseBase<T>()> +#endif +struct Storage { + T value; + constexpr Storage() = default; + template <typename V> + explicit constexpr Storage(absl::in_place_t, V&& v) + : value(absl::forward<V>(v)) {} + constexpr const T& get() const& { return value; } + T& get() & { return value; } + constexpr const T&& get() const&& { return absl::move(*this).value; } + T&& get() && { return std::move(*this).value; } +}; + +template <typename T, size_t I> +struct ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC Storage<T, I, true> : T { + constexpr Storage() = default; + + template <typename V> + explicit constexpr Storage(absl::in_place_t, V&& v) + : T(absl::forward<V>(v)) {} + + constexpr const T& get() const& { return *this; } + T& get() & { return *this; } + constexpr const T&& get() const&& { return absl::move(*this); } + T&& get() && { return std::move(*this); } +}; + +template <typename D, typename I, bool ShouldAnyUseBase> +struct ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC CompressedTupleImpl; + +template <typename... Ts, size_t... I, bool ShouldAnyUseBase> +struct ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC CompressedTupleImpl< + CompressedTuple<Ts...>, absl::index_sequence<I...>, ShouldAnyUseBase> + // We use the dummy identity function through std::integral_constant to + // convince MSVC of accepting and expanding I in that context. Without it + // you would get: + // error C3548: 'I': parameter pack cannot be used in this context + : uses_inheritance, + Storage<Ts, std::integral_constant<size_t, I>::value>... { + constexpr CompressedTupleImpl() = default; + template <typename... Vs> + explicit constexpr CompressedTupleImpl(absl::in_place_t, Vs&&... args) + : Storage<Ts, I>(absl::in_place, absl::forward<Vs>(args))... {} + friend CompressedTuple<Ts...>; +}; + +template <typename... Ts, size_t... I> +struct ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC CompressedTupleImpl< + CompressedTuple<Ts...>, absl::index_sequence<I...>, false> + // We use the dummy identity function as above... + : Storage<Ts, std::integral_constant<size_t, I>::value, false>... { + constexpr CompressedTupleImpl() = default; + template <typename... Vs> + explicit constexpr CompressedTupleImpl(absl::in_place_t, Vs&&... args) + : Storage<Ts, I, false>(absl::in_place, absl::forward<Vs>(args))... {} + friend CompressedTuple<Ts...>; +}; + +std::false_type Or(std::initializer_list<std::false_type>); +std::true_type Or(std::initializer_list<bool>); + +// MSVC requires this to be done separately rather than within the declaration +// of CompressedTuple below. +template <typename... Ts> +constexpr bool ShouldAnyUseBase() { + return decltype( + Or({std::integral_constant<bool, ShouldUseBase<Ts>()>()...})){}; +} + +template <typename T, typename V> +using TupleElementMoveConstructible = + typename std::conditional<std::is_reference<T>::value, + std::is_convertible<V, T>, + std::is_constructible<T, V&&>>::type; + +template <bool SizeMatches, class T, class... Vs> +struct TupleMoveConstructible : std::false_type {}; + +template <class... Ts, class... Vs> +struct TupleMoveConstructible<true, CompressedTuple<Ts...>, Vs...> + : std::integral_constant< + bool, absl::conjunction< + TupleElementMoveConstructible<Ts, Vs&&>...>::value> {}; + +template <typename T> +struct compressed_tuple_size; + +template <typename... Es> +struct compressed_tuple_size<CompressedTuple<Es...>> + : public std::integral_constant<std::size_t, sizeof...(Es)> {}; + +template <class T, class... Vs> +struct TupleItemsMoveConstructible + : std::integral_constant< + bool, TupleMoveConstructible<compressed_tuple_size<T>::value == + sizeof...(Vs), + T, Vs...>::value> {}; + +} // namespace internal_compressed_tuple + +// Helper class to perform the Empty Base Class Optimization. +// Ts can contain classes and non-classes, empty or not. For the ones that +// are empty classes, we perform the CompressedTuple. If all types in Ts are +// empty classes, then CompressedTuple<Ts...> is itself an empty class. (This +// does not apply when one or more of those empty classes is itself an empty +// CompressedTuple.) +// +// To access the members, use member .get<N>() function. +// +// Eg: +// absl::container_internal::CompressedTuple<int, T1, T2, T3> value(7, t1, t2, +// t3); +// assert(value.get<0>() == 7); +// T1& t1 = value.get<1>(); +// const T2& t2 = value.get<2>(); +// ... +// +// https://en.cppreference.com/w/cpp/language/ebo +template <typename... Ts> +class ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC CompressedTuple + : private internal_compressed_tuple::CompressedTupleImpl< + CompressedTuple<Ts...>, absl::index_sequence_for<Ts...>, + internal_compressed_tuple::ShouldAnyUseBase<Ts...>()> { + private: + template <int I> + using ElemT = internal_compressed_tuple::ElemT<CompressedTuple, I>; + + template <int I> + using StorageT = internal_compressed_tuple::Storage<ElemT<I>, I>; + + public: + // There seems to be a bug in MSVC dealing in which using '=default' here will + // cause the compiler to ignore the body of other constructors. The work- + // around is to explicitly implement the default constructor. +#if defined(_MSC_VER) + constexpr CompressedTuple() : CompressedTuple::CompressedTupleImpl() {} +#else + constexpr CompressedTuple() = default; +#endif + explicit constexpr CompressedTuple(const Ts&... base) + : CompressedTuple::CompressedTupleImpl(absl::in_place, base...) {} + + template <typename First, typename... Vs, + absl::enable_if_t< + absl::conjunction< + // Ensure we are not hiding default copy/move constructors. + absl::negation<std::is_same<void(CompressedTuple), + void(absl::decay_t<First>)>>, + internal_compressed_tuple::TupleItemsMoveConstructible< + CompressedTuple<Ts...>, First, Vs...>>::value, + bool> = true> + explicit constexpr CompressedTuple(First&& first, Vs&&... base) + : CompressedTuple::CompressedTupleImpl(absl::in_place, + absl::forward<First>(first), + absl::forward<Vs>(base)...) {} + + template <int I> + ElemT<I>& get() & { + return internal_compressed_tuple::Storage<ElemT<I>, I>::get(); + } + + template <int I> + constexpr const ElemT<I>& get() const& { + return StorageT<I>::get(); + } + + template <int I> + ElemT<I>&& get() && { + return std::move(*this).StorageT<I>::get(); + } + + template <int I> + constexpr const ElemT<I>&& get() const&& { + return absl::move(*this).StorageT<I>::get(); + } +}; + +// Explicit specialization for a zero-element tuple +// (needed to avoid ambiguous overloads for the default constructor). +template <> +class ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC CompressedTuple<> {}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#undef ABSL_INTERNAL_COMPRESSED_TUPLE_DECLSPEC + +#endif // ABSL_CONTAINER_INTERNAL_COMPRESSED_TUPLE_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/compressed_tuple_test.cc b/third_party/abseil_cpp/absl/container/internal/compressed_tuple_test.cc new file mode 100644 index 0000000000..62a7483ee3 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/compressed_tuple_test.cc @@ -0,0 +1,409 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/compressed_tuple.h" + +#include <memory> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/test_instance_tracker.h" +#include "absl/memory/memory.h" +#include "absl/types/any.h" +#include "absl/types/optional.h" +#include "absl/utility/utility.h" + +// These are declared at global scope purely so that error messages +// are smaller and easier to understand. +enum class CallType { kConstRef, kConstMove }; + +template <int> +struct Empty { + constexpr CallType value() const& { return CallType::kConstRef; } + constexpr CallType value() const&& { return CallType::kConstMove; } +}; + +template <typename T> +struct NotEmpty { + T value; +}; + +template <typename T, typename U> +struct TwoValues { + T value1; + U value2; +}; + + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using absl::test_internal::CopyableMovableInstance; +using absl::test_internal::InstanceTracker; + +TEST(CompressedTupleTest, Sizeof) { + EXPECT_EQ(sizeof(int), sizeof(CompressedTuple<int>)); + EXPECT_EQ(sizeof(int), sizeof(CompressedTuple<int, Empty<0>>)); + EXPECT_EQ(sizeof(int), sizeof(CompressedTuple<int, Empty<0>, Empty<1>>)); + EXPECT_EQ(sizeof(int), + sizeof(CompressedTuple<int, Empty<0>, Empty<1>, Empty<2>>)); + + EXPECT_EQ(sizeof(TwoValues<int, double>), + sizeof(CompressedTuple<int, NotEmpty<double>>)); + EXPECT_EQ(sizeof(TwoValues<int, double>), + sizeof(CompressedTuple<int, Empty<0>, NotEmpty<double>>)); + EXPECT_EQ(sizeof(TwoValues<int, double>), + sizeof(CompressedTuple<int, Empty<0>, NotEmpty<double>, Empty<1>>)); +} + +TEST(CompressedTupleTest, OneMoveOnRValueConstructionTemp) { + InstanceTracker tracker; + CompressedTuple<CopyableMovableInstance> x1(CopyableMovableInstance(1)); + EXPECT_EQ(tracker.instances(), 1); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_LE(tracker.moves(), 1); + EXPECT_EQ(x1.get<0>().value(), 1); +} + +TEST(CompressedTupleTest, OneMoveOnRValueConstructionMove) { + InstanceTracker tracker; + + CopyableMovableInstance i1(1); + CompressedTuple<CopyableMovableInstance> x1(std::move(i1)); + EXPECT_EQ(tracker.instances(), 2); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_LE(tracker.moves(), 1); + EXPECT_EQ(x1.get<0>().value(), 1); +} + +TEST(CompressedTupleTest, OneMoveOnRValueConstructionMixedTypes) { + InstanceTracker tracker; + CopyableMovableInstance i1(1); + CopyableMovableInstance i2(2); + Empty<0> empty; + CompressedTuple<CopyableMovableInstance, CopyableMovableInstance&, Empty<0>> + x1(std::move(i1), i2, empty); + EXPECT_EQ(x1.get<0>().value(), 1); + EXPECT_EQ(x1.get<1>().value(), 2); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 1); +} + +struct IncompleteType; +CompressedTuple<CopyableMovableInstance, IncompleteType&, Empty<0>> +MakeWithIncomplete(CopyableMovableInstance i1, + IncompleteType& t, // NOLINT + Empty<0> empty) { + return CompressedTuple<CopyableMovableInstance, IncompleteType&, Empty<0>>{ + std::move(i1), t, empty}; +} + +struct IncompleteType {}; +TEST(CompressedTupleTest, OneMoveOnRValueConstructionWithIncompleteType) { + InstanceTracker tracker; + CopyableMovableInstance i1(1); + Empty<0> empty; + struct DerivedType : IncompleteType {int value = 0;}; + DerivedType fd; + fd.value = 7; + + CompressedTuple<CopyableMovableInstance, IncompleteType&, Empty<0>> x1 = + MakeWithIncomplete(std::move(i1), fd, empty); + + EXPECT_EQ(x1.get<0>().value(), 1); + EXPECT_EQ(static_cast<DerivedType&>(x1.get<1>()).value, 7); + + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 2); +} + +TEST(CompressedTupleTest, + OneMoveOnRValueConstructionMixedTypes_BraceInitPoisonPillExpected) { + InstanceTracker tracker; + CopyableMovableInstance i1(1); + CopyableMovableInstance i2(2); + CompressedTuple<CopyableMovableInstance, CopyableMovableInstance&, Empty<0>> + x1(std::move(i1), i2, {}); // NOLINT + EXPECT_EQ(x1.get<0>().value(), 1); + EXPECT_EQ(x1.get<1>().value(), 2); + EXPECT_EQ(tracker.instances(), 3); + // We are forced into the `const Ts&...` constructor (invoking copies) + // because we need it to deduce the type of `{}`. + // std::tuple also has this behavior. + // Note, this test is proof that this is expected behavior, but it is not + // _desired_ behavior. + EXPECT_EQ(tracker.copies(), 1); + EXPECT_EQ(tracker.moves(), 0); +} + +TEST(CompressedTupleTest, OneCopyOnLValueConstruction) { + InstanceTracker tracker; + CopyableMovableInstance i1(1); + + CompressedTuple<CopyableMovableInstance> x1(i1); + EXPECT_EQ(tracker.copies(), 1); + EXPECT_EQ(tracker.moves(), 0); + + tracker.ResetCopiesMovesSwaps(); + + CopyableMovableInstance i2(2); + const CopyableMovableInstance& i2_ref = i2; + CompressedTuple<CopyableMovableInstance> x2(i2_ref); + EXPECT_EQ(tracker.copies(), 1); + EXPECT_EQ(tracker.moves(), 0); +} + +TEST(CompressedTupleTest, OneMoveOnRValueAccess) { + InstanceTracker tracker; + CopyableMovableInstance i1(1); + CompressedTuple<CopyableMovableInstance> x(std::move(i1)); + tracker.ResetCopiesMovesSwaps(); + + CopyableMovableInstance i2 = std::move(x).get<0>(); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 1); +} + +TEST(CompressedTupleTest, OneCopyOnLValueAccess) { + InstanceTracker tracker; + + CompressedTuple<CopyableMovableInstance> x(CopyableMovableInstance(0)); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 1); + + CopyableMovableInstance t = x.get<0>(); + EXPECT_EQ(tracker.copies(), 1); + EXPECT_EQ(tracker.moves(), 1); +} + +TEST(CompressedTupleTest, ZeroCopyOnRefAccess) { + InstanceTracker tracker; + + CompressedTuple<CopyableMovableInstance> x(CopyableMovableInstance(0)); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 1); + + CopyableMovableInstance& t1 = x.get<0>(); + const CopyableMovableInstance& t2 = x.get<0>(); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 1); + EXPECT_EQ(t1.value(), 0); + EXPECT_EQ(t2.value(), 0); +} + +TEST(CompressedTupleTest, Access) { + struct S { + std::string x; + }; + CompressedTuple<int, Empty<0>, S> x(7, {}, S{"ABC"}); + EXPECT_EQ(sizeof(x), sizeof(TwoValues<int, S>)); + EXPECT_EQ(7, x.get<0>()); + EXPECT_EQ("ABC", x.get<2>().x); +} + +TEST(CompressedTupleTest, NonClasses) { + CompressedTuple<int, const char*> x(7, "ABC"); + EXPECT_EQ(7, x.get<0>()); + EXPECT_STREQ("ABC", x.get<1>()); +} + +TEST(CompressedTupleTest, MixClassAndNonClass) { + CompressedTuple<int, const char*, Empty<0>, NotEmpty<double>> x(7, "ABC", {}, + {1.25}); + struct Mock { + int v; + const char* p; + double d; + }; + EXPECT_EQ(sizeof(x), sizeof(Mock)); + EXPECT_EQ(7, x.get<0>()); + EXPECT_STREQ("ABC", x.get<1>()); + EXPECT_EQ(1.25, x.get<3>().value); +} + +TEST(CompressedTupleTest, Nested) { + CompressedTuple<int, CompressedTuple<int>, + CompressedTuple<int, CompressedTuple<int>>> + x(1, CompressedTuple<int>(2), + CompressedTuple<int, CompressedTuple<int>>(3, CompressedTuple<int>(4))); + EXPECT_EQ(1, x.get<0>()); + EXPECT_EQ(2, x.get<1>().get<0>()); + EXPECT_EQ(3, x.get<2>().get<0>()); + EXPECT_EQ(4, x.get<2>().get<1>().get<0>()); + + CompressedTuple<Empty<0>, Empty<0>, + CompressedTuple<Empty<0>, CompressedTuple<Empty<0>>>> + y; + std::set<Empty<0>*> empties{&y.get<0>(), &y.get<1>(), &y.get<2>().get<0>(), + &y.get<2>().get<1>().get<0>()}; +#ifdef _MSC_VER + // MSVC has a bug where many instances of the same base class are layed out in + // the same address when using __declspec(empty_bases). + // This will be fixed in a future version of MSVC. + int expected = 1; +#else + int expected = 4; +#endif + EXPECT_EQ(expected, sizeof(y)); + EXPECT_EQ(expected, empties.size()); + EXPECT_EQ(sizeof(y), sizeof(Empty<0>) * empties.size()); + + EXPECT_EQ(4 * sizeof(char), + sizeof(CompressedTuple<CompressedTuple<char, char>, + CompressedTuple<char, char>>)); + EXPECT_TRUE((std::is_empty<CompressedTuple<Empty<0>, Empty<1>>>::value)); + + // Make sure everything still works when things are nested. + struct CT_Empty : CompressedTuple<Empty<0>> {}; + CompressedTuple<Empty<0>, CT_Empty> nested_empty; + auto contained = nested_empty.get<0>(); + auto nested = nested_empty.get<1>().get<0>(); + EXPECT_TRUE((std::is_same<decltype(contained), decltype(nested)>::value)); +} + +TEST(CompressedTupleTest, Reference) { + int i = 7; + std::string s = "Very long string that goes in the heap"; + CompressedTuple<int, int&, std::string, std::string&> x(i, i, s, s); + + // Sanity check. We should have not moved from `s` + EXPECT_EQ(s, "Very long string that goes in the heap"); + + EXPECT_EQ(x.get<0>(), x.get<1>()); + EXPECT_NE(&x.get<0>(), &x.get<1>()); + EXPECT_EQ(&x.get<1>(), &i); + + EXPECT_EQ(x.get<2>(), x.get<3>()); + EXPECT_NE(&x.get<2>(), &x.get<3>()); + EXPECT_EQ(&x.get<3>(), &s); +} + +TEST(CompressedTupleTest, NoElements) { + CompressedTuple<> x; + static_cast<void>(x); // Silence -Wunused-variable. + EXPECT_TRUE(std::is_empty<CompressedTuple<>>::value); +} + +TEST(CompressedTupleTest, MoveOnlyElements) { + CompressedTuple<std::unique_ptr<std::string>> str_tup( + absl::make_unique<std::string>("str")); + + CompressedTuple<CompressedTuple<std::unique_ptr<std::string>>, + std::unique_ptr<int>> + x(std::move(str_tup), absl::make_unique<int>(5)); + + EXPECT_EQ(*x.get<0>().get<0>(), "str"); + EXPECT_EQ(*x.get<1>(), 5); + + std::unique_ptr<std::string> x0 = std::move(x.get<0>()).get<0>(); + std::unique_ptr<int> x1 = std::move(x).get<1>(); + + EXPECT_EQ(*x0, "str"); + EXPECT_EQ(*x1, 5); +} + +TEST(CompressedTupleTest, MoveConstructionMoveOnlyElements) { + CompressedTuple<std::unique_ptr<std::string>> base( + absl::make_unique<std::string>("str")); + EXPECT_EQ(*base.get<0>(), "str"); + + CompressedTuple<std::unique_ptr<std::string>> copy(std::move(base)); + EXPECT_EQ(*copy.get<0>(), "str"); +} + +TEST(CompressedTupleTest, AnyElements) { + any a(std::string("str")); + CompressedTuple<any, any&> x(any(5), a); + EXPECT_EQ(absl::any_cast<int>(x.get<0>()), 5); + EXPECT_EQ(absl::any_cast<std::string>(x.get<1>()), "str"); + + a = 0.5f; + EXPECT_EQ(absl::any_cast<float>(x.get<1>()), 0.5); +} + +TEST(CompressedTupleTest, Constexpr) { + struct NonTrivialStruct { + constexpr NonTrivialStruct() = default; + constexpr int value() const { return v; } + int v = 5; + }; + struct TrivialStruct { + TrivialStruct() = default; + constexpr int value() const { return v; } + int v; + }; + constexpr CompressedTuple<int, double, CompressedTuple<int>, Empty<0>> x( + 7, 1.25, CompressedTuple<int>(5), {}); + constexpr int x0 = x.get<0>(); + constexpr double x1 = x.get<1>(); + constexpr int x2 = x.get<2>().get<0>(); + constexpr CallType x3 = x.get<3>().value(); + + EXPECT_EQ(x0, 7); + EXPECT_EQ(x1, 1.25); + EXPECT_EQ(x2, 5); + EXPECT_EQ(x3, CallType::kConstRef); + +#if !defined(__GNUC__) || defined(__clang__) || __GNUC__ > 4 + constexpr CompressedTuple<Empty<0>, TrivialStruct, int> trivial = {}; + constexpr CallType trivial0 = trivial.get<0>().value(); + constexpr int trivial1 = trivial.get<1>().value(); + constexpr int trivial2 = trivial.get<2>(); + + EXPECT_EQ(trivial0, CallType::kConstRef); + EXPECT_EQ(trivial1, 0); + EXPECT_EQ(trivial2, 0); +#endif + + constexpr CompressedTuple<Empty<0>, NonTrivialStruct, absl::optional<int>> + non_trivial = {}; + constexpr CallType non_trivial0 = non_trivial.get<0>().value(); + constexpr int non_trivial1 = non_trivial.get<1>().value(); + constexpr absl::optional<int> non_trivial2 = non_trivial.get<2>(); + + EXPECT_EQ(non_trivial0, CallType::kConstRef); + EXPECT_EQ(non_trivial1, 5); + EXPECT_EQ(non_trivial2, absl::nullopt); + + static constexpr char data[] = "DEF"; + constexpr CompressedTuple<const char*> z(data); + constexpr const char* z1 = z.get<0>(); + EXPECT_EQ(std::string(z1), std::string(data)); + +#if defined(__clang__) + // An apparent bug in earlier versions of gcc claims these are ambiguous. + constexpr int x2m = absl::move(x.get<2>()).get<0>(); + constexpr CallType x3m = absl::move(x).get<3>().value(); + EXPECT_EQ(x2m, 5); + EXPECT_EQ(x3m, CallType::kConstMove); +#endif +} + +#if defined(__clang__) || defined(__GNUC__) +TEST(CompressedTupleTest, EmptyFinalClass) { + struct S final { + int f() const { return 5; } + }; + CompressedTuple<S> x; + EXPECT_EQ(x.get<0>().f(), 5); +} +#endif + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/container_memory.h b/third_party/abseil_cpp/absl/container/internal/container_memory.h new file mode 100644 index 0000000000..536ea398eb --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/container_memory.h @@ -0,0 +1,445 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_CONTAINER_MEMORY_H_ +#define ABSL_CONTAINER_INTERNAL_CONTAINER_MEMORY_H_ + +#ifdef ADDRESS_SANITIZER +#include <sanitizer/asan_interface.h> +#endif + +#ifdef MEMORY_SANITIZER +#include <sanitizer/msan_interface.h> +#endif + +#include <cassert> +#include <cstddef> +#include <memory> +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <size_t Alignment> +struct alignas(Alignment) AlignedType {}; + +// Allocates at least n bytes aligned to the specified alignment. +// Alignment must be a power of 2. It must be positive. +// +// Note that many allocators don't honor alignment requirements above certain +// threshold (usually either alignof(std::max_align_t) or alignof(void*)). +// Allocate() doesn't apply alignment corrections. If the underlying allocator +// returns insufficiently alignment pointer, that's what you are going to get. +template <size_t Alignment, class Alloc> +void* Allocate(Alloc* alloc, size_t n) { + static_assert(Alignment > 0, ""); + assert(n && "n must be positive"); + using M = AlignedType<Alignment>; + using A = typename absl::allocator_traits<Alloc>::template rebind_alloc<M>; + using AT = typename absl::allocator_traits<Alloc>::template rebind_traits<M>; + A mem_alloc(*alloc); + void* p = AT::allocate(mem_alloc, (n + sizeof(M) - 1) / sizeof(M)); + assert(reinterpret_cast<uintptr_t>(p) % Alignment == 0 && + "allocator does not respect alignment"); + return p; +} + +// The pointer must have been previously obtained by calling +// Allocate<Alignment>(alloc, n). +template <size_t Alignment, class Alloc> +void Deallocate(Alloc* alloc, void* p, size_t n) { + static_assert(Alignment > 0, ""); + assert(n && "n must be positive"); + using M = AlignedType<Alignment>; + using A = typename absl::allocator_traits<Alloc>::template rebind_alloc<M>; + using AT = typename absl::allocator_traits<Alloc>::template rebind_traits<M>; + A mem_alloc(*alloc); + AT::deallocate(mem_alloc, static_cast<M*>(p), + (n + sizeof(M) - 1) / sizeof(M)); +} + +namespace memory_internal { + +// Constructs T into uninitialized storage pointed by `ptr` using the args +// specified in the tuple. +template <class Alloc, class T, class Tuple, size_t... I> +void ConstructFromTupleImpl(Alloc* alloc, T* ptr, Tuple&& t, + absl::index_sequence<I...>) { + absl::allocator_traits<Alloc>::construct( + *alloc, ptr, std::get<I>(std::forward<Tuple>(t))...); +} + +template <class T, class F> +struct WithConstructedImplF { + template <class... Args> + decltype(std::declval<F>()(std::declval<T>())) operator()( + Args&&... args) const { + return std::forward<F>(f)(T(std::forward<Args>(args)...)); + } + F&& f; +}; + +template <class T, class Tuple, size_t... Is, class F> +decltype(std::declval<F>()(std::declval<T>())) WithConstructedImpl( + Tuple&& t, absl::index_sequence<Is...>, F&& f) { + return WithConstructedImplF<T, F>{std::forward<F>(f)}( + std::get<Is>(std::forward<Tuple>(t))...); +} + +template <class T, size_t... Is> +auto TupleRefImpl(T&& t, absl::index_sequence<Is...>) + -> decltype(std::forward_as_tuple(std::get<Is>(std::forward<T>(t))...)) { + return std::forward_as_tuple(std::get<Is>(std::forward<T>(t))...); +} + +// Returns a tuple of references to the elements of the input tuple. T must be a +// tuple. +template <class T> +auto TupleRef(T&& t) -> decltype( + TupleRefImpl(std::forward<T>(t), + absl::make_index_sequence< + std::tuple_size<typename std::decay<T>::type>::value>())) { + return TupleRefImpl( + std::forward<T>(t), + absl::make_index_sequence< + std::tuple_size<typename std::decay<T>::type>::value>()); +} + +template <class F, class K, class V> +decltype(std::declval<F>()(std::declval<const K&>(), std::piecewise_construct, + std::declval<std::tuple<K>>(), std::declval<V>())) +DecomposePairImpl(F&& f, std::pair<std::tuple<K>, V> p) { + const auto& key = std::get<0>(p.first); + return std::forward<F>(f)(key, std::piecewise_construct, std::move(p.first), + std::move(p.second)); +} + +} // namespace memory_internal + +// Constructs T into uninitialized storage pointed by `ptr` using the args +// specified in the tuple. +template <class Alloc, class T, class Tuple> +void ConstructFromTuple(Alloc* alloc, T* ptr, Tuple&& t) { + memory_internal::ConstructFromTupleImpl( + alloc, ptr, std::forward<Tuple>(t), + absl::make_index_sequence< + std::tuple_size<typename std::decay<Tuple>::type>::value>()); +} + +// Constructs T using the args specified in the tuple and calls F with the +// constructed value. +template <class T, class Tuple, class F> +decltype(std::declval<F>()(std::declval<T>())) WithConstructed( + Tuple&& t, F&& f) { + return memory_internal::WithConstructedImpl<T>( + std::forward<Tuple>(t), + absl::make_index_sequence< + std::tuple_size<typename std::decay<Tuple>::type>::value>(), + std::forward<F>(f)); +} + +// Given arguments of an std::pair's consructor, PairArgs() returns a pair of +// tuples with references to the passed arguments. The tuples contain +// constructor arguments for the first and the second elements of the pair. +// +// The following two snippets are equivalent. +// +// 1. std::pair<F, S> p(args...); +// +// 2. auto a = PairArgs(args...); +// std::pair<F, S> p(std::piecewise_construct, +// std::move(p.first), std::move(p.second)); +inline std::pair<std::tuple<>, std::tuple<>> PairArgs() { return {}; } +template <class F, class S> +std::pair<std::tuple<F&&>, std::tuple<S&&>> PairArgs(F&& f, S&& s) { + return {std::piecewise_construct, std::forward_as_tuple(std::forward<F>(f)), + std::forward_as_tuple(std::forward<S>(s))}; +} +template <class F, class S> +std::pair<std::tuple<const F&>, std::tuple<const S&>> PairArgs( + const std::pair<F, S>& p) { + return PairArgs(p.first, p.second); +} +template <class F, class S> +std::pair<std::tuple<F&&>, std::tuple<S&&>> PairArgs(std::pair<F, S>&& p) { + return PairArgs(std::forward<F>(p.first), std::forward<S>(p.second)); +} +template <class F, class S> +auto PairArgs(std::piecewise_construct_t, F&& f, S&& s) + -> decltype(std::make_pair(memory_internal::TupleRef(std::forward<F>(f)), + memory_internal::TupleRef(std::forward<S>(s)))) { + return std::make_pair(memory_internal::TupleRef(std::forward<F>(f)), + memory_internal::TupleRef(std::forward<S>(s))); +} + +// A helper function for implementing apply() in map policies. +template <class F, class... Args> +auto DecomposePair(F&& f, Args&&... args) + -> decltype(memory_internal::DecomposePairImpl( + std::forward<F>(f), PairArgs(std::forward<Args>(args)...))) { + return memory_internal::DecomposePairImpl( + std::forward<F>(f), PairArgs(std::forward<Args>(args)...)); +} + +// A helper function for implementing apply() in set policies. +template <class F, class Arg> +decltype(std::declval<F>()(std::declval<const Arg&>(), std::declval<Arg>())) +DecomposeValue(F&& f, Arg&& arg) { + const auto& key = arg; + return std::forward<F>(f)(key, std::forward<Arg>(arg)); +} + +// Helper functions for asan and msan. +inline void SanitizerPoisonMemoryRegion(const void* m, size_t s) { +#ifdef ADDRESS_SANITIZER + ASAN_POISON_MEMORY_REGION(m, s); +#endif +#ifdef MEMORY_SANITIZER + __msan_poison(m, s); +#endif + (void)m; + (void)s; +} + +inline void SanitizerUnpoisonMemoryRegion(const void* m, size_t s) { +#ifdef ADDRESS_SANITIZER + ASAN_UNPOISON_MEMORY_REGION(m, s); +#endif +#ifdef MEMORY_SANITIZER + __msan_unpoison(m, s); +#endif + (void)m; + (void)s; +} + +template <typename T> +inline void SanitizerPoisonObject(const T* object) { + SanitizerPoisonMemoryRegion(object, sizeof(T)); +} + +template <typename T> +inline void SanitizerUnpoisonObject(const T* object) { + SanitizerUnpoisonMemoryRegion(object, sizeof(T)); +} + +namespace memory_internal { + +// If Pair is a standard-layout type, OffsetOf<Pair>::kFirst and +// OffsetOf<Pair>::kSecond are equivalent to offsetof(Pair, first) and +// offsetof(Pair, second) respectively. Otherwise they are -1. +// +// The purpose of OffsetOf is to avoid calling offsetof() on non-standard-layout +// type, which is non-portable. +template <class Pair, class = std::true_type> +struct OffsetOf { + static constexpr size_t kFirst = static_cast<size_t>(-1); + static constexpr size_t kSecond = static_cast<size_t>(-1); +}; + +template <class Pair> +struct OffsetOf<Pair, typename std::is_standard_layout<Pair>::type> { + static constexpr size_t kFirst = offsetof(Pair, first); + static constexpr size_t kSecond = offsetof(Pair, second); +}; + +template <class K, class V> +struct IsLayoutCompatible { + private: + struct Pair { + K first; + V second; + }; + + // Is P layout-compatible with Pair? + template <class P> + static constexpr bool LayoutCompatible() { + return std::is_standard_layout<P>() && sizeof(P) == sizeof(Pair) && + alignof(P) == alignof(Pair) && + memory_internal::OffsetOf<P>::kFirst == + memory_internal::OffsetOf<Pair>::kFirst && + memory_internal::OffsetOf<P>::kSecond == + memory_internal::OffsetOf<Pair>::kSecond; + } + + public: + // Whether pair<const K, V> and pair<K, V> are layout-compatible. If they are, + // then it is safe to store them in a union and read from either. + static constexpr bool value = std::is_standard_layout<K>() && + std::is_standard_layout<Pair>() && + memory_internal::OffsetOf<Pair>::kFirst == 0 && + LayoutCompatible<std::pair<K, V>>() && + LayoutCompatible<std::pair<const K, V>>(); +}; + +} // namespace memory_internal + +// The internal storage type for key-value containers like flat_hash_map. +// +// It is convenient for the value_type of a flat_hash_map<K, V> to be +// pair<const K, V>; the "const K" prevents accidental modification of the key +// when dealing with the reference returned from find() and similar methods. +// However, this creates other problems; we want to be able to emplace(K, V) +// efficiently with move operations, and similarly be able to move a +// pair<K, V> in insert(). +// +// The solution is this union, which aliases the const and non-const versions +// of the pair. This also allows flat_hash_map<const K, V> to work, even though +// that has the same efficiency issues with move in emplace() and insert() - +// but people do it anyway. +// +// If kMutableKeys is false, only the value member can be accessed. +// +// If kMutableKeys is true, key can be accessed through all slots while value +// and mutable_value must be accessed only via INITIALIZED slots. Slots are +// created and destroyed via mutable_value so that the key can be moved later. +// +// Accessing one of the union fields while the other is active is safe as +// long as they are layout-compatible, which is guaranteed by the definition of +// kMutableKeys. For C++11, the relevant section of the standard is +// https://timsong-cpp.github.io/cppwp/n3337/class.mem#19 (9.2.19) +template <class K, class V> +union map_slot_type { + map_slot_type() {} + ~map_slot_type() = delete; + using value_type = std::pair<const K, V>; + using mutable_value_type = + std::pair<absl::remove_const_t<K>, absl::remove_const_t<V>>; + + value_type value; + mutable_value_type mutable_value; + absl::remove_const_t<K> key; +}; + +template <class K, class V> +struct map_slot_policy { + using slot_type = map_slot_type<K, V>; + using value_type = std::pair<const K, V>; + using mutable_value_type = std::pair<K, V>; + + private: + static void emplace(slot_type* slot) { + // The construction of union doesn't do anything at runtime but it allows us + // to access its members without violating aliasing rules. + new (slot) slot_type; + } + // If pair<const K, V> and pair<K, V> are layout-compatible, we can accept one + // or the other via slot_type. We are also free to access the key via + // slot_type::key in this case. + using kMutableKeys = memory_internal::IsLayoutCompatible<K, V>; + + public: + static value_type& element(slot_type* slot) { return slot->value; } + static const value_type& element(const slot_type* slot) { + return slot->value; + } + + static const K& key(const slot_type* slot) { + return kMutableKeys::value ? slot->key : slot->value.first; + } + + template <class Allocator, class... Args> + static void construct(Allocator* alloc, slot_type* slot, Args&&... args) { + emplace(slot); + if (kMutableKeys::value) { + absl::allocator_traits<Allocator>::construct(*alloc, &slot->mutable_value, + std::forward<Args>(args)...); + } else { + absl::allocator_traits<Allocator>::construct(*alloc, &slot->value, + std::forward<Args>(args)...); + } + } + + // Construct this slot by moving from another slot. + template <class Allocator> + static void construct(Allocator* alloc, slot_type* slot, slot_type* other) { + emplace(slot); + if (kMutableKeys::value) { + absl::allocator_traits<Allocator>::construct( + *alloc, &slot->mutable_value, std::move(other->mutable_value)); + } else { + absl::allocator_traits<Allocator>::construct(*alloc, &slot->value, + std::move(other->value)); + } + } + + template <class Allocator> + static void destroy(Allocator* alloc, slot_type* slot) { + if (kMutableKeys::value) { + absl::allocator_traits<Allocator>::destroy(*alloc, &slot->mutable_value); + } else { + absl::allocator_traits<Allocator>::destroy(*alloc, &slot->value); + } + } + + template <class Allocator> + static void transfer(Allocator* alloc, slot_type* new_slot, + slot_type* old_slot) { + emplace(new_slot); + if (kMutableKeys::value) { + absl::allocator_traits<Allocator>::construct( + *alloc, &new_slot->mutable_value, std::move(old_slot->mutable_value)); + } else { + absl::allocator_traits<Allocator>::construct(*alloc, &new_slot->value, + std::move(old_slot->value)); + } + destroy(alloc, old_slot); + } + + template <class Allocator> + static void swap(Allocator* alloc, slot_type* a, slot_type* b) { + if (kMutableKeys::value) { + using std::swap; + swap(a->mutable_value, b->mutable_value); + } else { + value_type tmp = std::move(a->value); + absl::allocator_traits<Allocator>::destroy(*alloc, &a->value); + absl::allocator_traits<Allocator>::construct(*alloc, &a->value, + std::move(b->value)); + absl::allocator_traits<Allocator>::destroy(*alloc, &b->value); + absl::allocator_traits<Allocator>::construct(*alloc, &b->value, + std::move(tmp)); + } + } + + template <class Allocator> + static void move(Allocator* alloc, slot_type* src, slot_type* dest) { + if (kMutableKeys::value) { + dest->mutable_value = std::move(src->mutable_value); + } else { + absl::allocator_traits<Allocator>::destroy(*alloc, &dest->value); + absl::allocator_traits<Allocator>::construct(*alloc, &dest->value, + std::move(src->value)); + } + } + + template <class Allocator> + static void move(Allocator* alloc, slot_type* first, slot_type* last, + slot_type* result) { + for (slot_type *src = first, *dest = result; src != last; ++src, ++dest) + move(alloc, src, dest); + } +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_CONTAINER_MEMORY_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/container_memory_test.cc b/third_party/abseil_cpp/absl/container/internal/container_memory_test.cc new file mode 100644 index 0000000000..6a7fcd29ba --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/container_memory_test.cc @@ -0,0 +1,256 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/container_memory.h" + +#include <cstdint> +#include <tuple> +#include <typeindex> +#include <typeinfo> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/test_instance_tracker.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::absl::test_internal::CopyableMovableInstance; +using ::absl::test_internal::InstanceTracker; +using ::testing::_; +using ::testing::ElementsAre; +using ::testing::Gt; +using ::testing::Pair; + +TEST(Memory, AlignmentLargerThanBase) { + std::allocator<int8_t> alloc; + void* mem = Allocate<2>(&alloc, 3); + EXPECT_EQ(0, reinterpret_cast<uintptr_t>(mem) % 2); + memcpy(mem, "abc", 3); + Deallocate<2>(&alloc, mem, 3); +} + +TEST(Memory, AlignmentSmallerThanBase) { + std::allocator<int64_t> alloc; + void* mem = Allocate<2>(&alloc, 3); + EXPECT_EQ(0, reinterpret_cast<uintptr_t>(mem) % 2); + memcpy(mem, "abc", 3); + Deallocate<2>(&alloc, mem, 3); +} + +std::map<std::type_index, int>& AllocationMap() { + static auto* map = new std::map<std::type_index, int>; + return *map; +} + +template <typename T> +struct TypeCountingAllocator { + TypeCountingAllocator() = default; + template <typename U> + TypeCountingAllocator(const TypeCountingAllocator<U>&) {} // NOLINT + + using value_type = T; + + T* allocate(size_t n, const void* = nullptr) { + AllocationMap()[typeid(T)] += n; + return std::allocator<T>().allocate(n); + } + void deallocate(T* p, std::size_t n) { + AllocationMap()[typeid(T)] -= n; + return std::allocator<T>().deallocate(p, n); + } +}; + +TEST(Memory, AllocateDeallocateMatchType) { + TypeCountingAllocator<int> alloc; + void* mem = Allocate<1>(&alloc, 1); + // Verify that it was allocated + EXPECT_THAT(AllocationMap(), ElementsAre(Pair(_, Gt(0)))); + Deallocate<1>(&alloc, mem, 1); + // Verify that the deallocation matched. + EXPECT_THAT(AllocationMap(), ElementsAre(Pair(_, 0))); +} + +class Fixture : public ::testing::Test { + using Alloc = std::allocator<std::string>; + + public: + Fixture() { ptr_ = std::allocator_traits<Alloc>::allocate(*alloc(), 1); } + ~Fixture() override { + std::allocator_traits<Alloc>::destroy(*alloc(), ptr_); + std::allocator_traits<Alloc>::deallocate(*alloc(), ptr_, 1); + } + std::string* ptr() { return ptr_; } + Alloc* alloc() { return &alloc_; } + + private: + Alloc alloc_; + std::string* ptr_; +}; + +TEST_F(Fixture, ConstructNoArgs) { + ConstructFromTuple(alloc(), ptr(), std::forward_as_tuple()); + EXPECT_EQ(*ptr(), ""); +} + +TEST_F(Fixture, ConstructOneArg) { + ConstructFromTuple(alloc(), ptr(), std::forward_as_tuple("abcde")); + EXPECT_EQ(*ptr(), "abcde"); +} + +TEST_F(Fixture, ConstructTwoArg) { + ConstructFromTuple(alloc(), ptr(), std::forward_as_tuple(5, 'a')); + EXPECT_EQ(*ptr(), "aaaaa"); +} + +TEST(PairArgs, NoArgs) { + EXPECT_THAT(PairArgs(), + Pair(std::forward_as_tuple(), std::forward_as_tuple())); +} + +TEST(PairArgs, TwoArgs) { + EXPECT_EQ( + std::make_pair(std::forward_as_tuple(1), std::forward_as_tuple('A')), + PairArgs(1, 'A')); +} + +TEST(PairArgs, Pair) { + EXPECT_EQ( + std::make_pair(std::forward_as_tuple(1), std::forward_as_tuple('A')), + PairArgs(std::make_pair(1, 'A'))); +} + +TEST(PairArgs, Piecewise) { + EXPECT_EQ( + std::make_pair(std::forward_as_tuple(1), std::forward_as_tuple('A')), + PairArgs(std::piecewise_construct, std::forward_as_tuple(1), + std::forward_as_tuple('A'))); +} + +TEST(WithConstructed, Simple) { + EXPECT_EQ(1, WithConstructed<absl::string_view>( + std::make_tuple(std::string("a")), + [](absl::string_view str) { return str.size(); })); +} + +template <class F, class Arg> +decltype(DecomposeValue(std::declval<F>(), std::declval<Arg>())) +DecomposeValueImpl(int, F&& f, Arg&& arg) { + return DecomposeValue(std::forward<F>(f), std::forward<Arg>(arg)); +} + +template <class F, class Arg> +const char* DecomposeValueImpl(char, F&& f, Arg&& arg) { + return "not decomposable"; +} + +template <class F, class Arg> +decltype(DecomposeValueImpl(0, std::declval<F>(), std::declval<Arg>())) +TryDecomposeValue(F&& f, Arg&& arg) { + return DecomposeValueImpl(0, std::forward<F>(f), std::forward<Arg>(arg)); +} + +TEST(DecomposeValue, Decomposable) { + auto f = [](const int& x, int&& y) { + EXPECT_EQ(&x, &y); + EXPECT_EQ(42, x); + return 'A'; + }; + EXPECT_EQ('A', TryDecomposeValue(f, 42)); +} + +TEST(DecomposeValue, NotDecomposable) { + auto f = [](void*) { + ADD_FAILURE() << "Must not be called"; + return 'A'; + }; + EXPECT_STREQ("not decomposable", TryDecomposeValue(f, 42)); +} + +template <class F, class... Args> +decltype(DecomposePair(std::declval<F>(), std::declval<Args>()...)) +DecomposePairImpl(int, F&& f, Args&&... args) { + return DecomposePair(std::forward<F>(f), std::forward<Args>(args)...); +} + +template <class F, class... Args> +const char* DecomposePairImpl(char, F&& f, Args&&... args) { + return "not decomposable"; +} + +template <class F, class... Args> +decltype(DecomposePairImpl(0, std::declval<F>(), std::declval<Args>()...)) +TryDecomposePair(F&& f, Args&&... args) { + return DecomposePairImpl(0, std::forward<F>(f), std::forward<Args>(args)...); +} + +TEST(DecomposePair, Decomposable) { + auto f = [](const int& x, std::piecewise_construct_t, std::tuple<int&&> k, + std::tuple<double>&& v) { + EXPECT_EQ(&x, &std::get<0>(k)); + EXPECT_EQ(42, x); + EXPECT_EQ(0.5, std::get<0>(v)); + return 'A'; + }; + EXPECT_EQ('A', TryDecomposePair(f, 42, 0.5)); + EXPECT_EQ('A', TryDecomposePair(f, std::make_pair(42, 0.5))); + EXPECT_EQ('A', TryDecomposePair(f, std::piecewise_construct, + std::make_tuple(42), std::make_tuple(0.5))); +} + +TEST(DecomposePair, NotDecomposable) { + auto f = [](...) { + ADD_FAILURE() << "Must not be called"; + return 'A'; + }; + EXPECT_STREQ("not decomposable", + TryDecomposePair(f)); + EXPECT_STREQ("not decomposable", + TryDecomposePair(f, std::piecewise_construct, std::make_tuple(), + std::make_tuple(0.5))); +} + +TEST(MapSlotPolicy, ConstKeyAndValue) { + using slot_policy = map_slot_policy<const CopyableMovableInstance, + const CopyableMovableInstance>; + using slot_type = typename slot_policy::slot_type; + + union Slots { + Slots() {} + ~Slots() {} + slot_type slots[100]; + } slots; + + std::allocator< + std::pair<const CopyableMovableInstance, const CopyableMovableInstance>> + alloc; + InstanceTracker tracker; + slot_policy::construct(&alloc, &slots.slots[0], CopyableMovableInstance(1), + CopyableMovableInstance(1)); + for (int i = 0; i < 99; ++i) { + slot_policy::transfer(&alloc, &slots.slots[i + 1], &slots.slots[i]); + } + slot_policy::destroy(&alloc, &slots.slots[99]); + + EXPECT_EQ(tracker.copies(), 0); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/counting_allocator.h b/third_party/abseil_cpp/absl/container/internal/counting_allocator.h new file mode 100644 index 0000000000..927cf08255 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/counting_allocator.h @@ -0,0 +1,114 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_COUNTING_ALLOCATOR_H_ +#define ABSL_CONTAINER_INTERNAL_COUNTING_ALLOCATOR_H_ + +#include <cstdint> +#include <memory> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// This is a stateful allocator, but the state lives outside of the +// allocator (in whatever test is using the allocator). This is odd +// but helps in tests where the allocator is propagated into nested +// containers - that chain of allocators uses the same state and is +// thus easier to query for aggregate allocation information. +template <typename T> +class CountingAllocator { + public: + using Allocator = std::allocator<T>; + using AllocatorTraits = std::allocator_traits<Allocator>; + using value_type = typename AllocatorTraits::value_type; + using pointer = typename AllocatorTraits::pointer; + using const_pointer = typename AllocatorTraits::const_pointer; + using size_type = typename AllocatorTraits::size_type; + using difference_type = typename AllocatorTraits::difference_type; + + CountingAllocator() = default; + explicit CountingAllocator(int64_t* bytes_used) : bytes_used_(bytes_used) {} + CountingAllocator(int64_t* bytes_used, int64_t* instance_count) + : bytes_used_(bytes_used), instance_count_(instance_count) {} + + template <typename U> + CountingAllocator(const CountingAllocator<U>& x) + : bytes_used_(x.bytes_used_), instance_count_(x.instance_count_) {} + + pointer allocate( + size_type n, + typename AllocatorTraits::const_void_pointer hint = nullptr) { + Allocator allocator; + pointer ptr = AllocatorTraits::allocate(allocator, n, hint); + if (bytes_used_ != nullptr) { + *bytes_used_ += n * sizeof(T); + } + return ptr; + } + + void deallocate(pointer p, size_type n) { + Allocator allocator; + AllocatorTraits::deallocate(allocator, p, n); + if (bytes_used_ != nullptr) { + *bytes_used_ -= n * sizeof(T); + } + } + + template <typename U, typename... Args> + void construct(U* p, Args&&... args) { + Allocator allocator; + AllocatorTraits::construct(allocator, p, std::forward<Args>(args)...); + if (instance_count_ != nullptr) { + *instance_count_ += 1; + } + } + + template <typename U> + void destroy(U* p) { + Allocator allocator; + AllocatorTraits::destroy(allocator, p); + if (instance_count_ != nullptr) { + *instance_count_ -= 1; + } + } + + template <typename U> + class rebind { + public: + using other = CountingAllocator<U>; + }; + + friend bool operator==(const CountingAllocator& a, + const CountingAllocator& b) { + return a.bytes_used_ == b.bytes_used_ && + a.instance_count_ == b.instance_count_; + } + + friend bool operator!=(const CountingAllocator& a, + const CountingAllocator& b) { + return !(a == b); + } + + int64_t* bytes_used_ = nullptr; + int64_t* instance_count_ = nullptr; +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_COUNTING_ALLOCATOR_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hash_function_defaults.h b/third_party/abseil_cpp/absl/container/internal/hash_function_defaults.h new file mode 100644 index 0000000000..0683422ad8 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_function_defaults.h @@ -0,0 +1,161 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Define the default Hash and Eq functions for SwissTable containers. +// +// std::hash<T> and std::equal_to<T> are not appropriate hash and equal +// functions for SwissTable containers. There are two reasons for this. +// +// SwissTable containers are power of 2 sized containers: +// +// This means they use the lower bits of the hash value to find the slot for +// each entry. The typical hash function for integral types is the identity. +// This is a very weak hash function for SwissTable and any power of 2 sized +// hashtable implementation which will lead to excessive collisions. For +// SwissTable we use murmur3 style mixing to reduce collisions to a minimum. +// +// SwissTable containers support heterogeneous lookup: +// +// In order to make heterogeneous lookup work, hash and equal functions must be +// polymorphic. At the same time they have to satisfy the same requirements the +// C++ standard imposes on hash functions and equality operators. That is: +// +// if hash_default_eq<T>(a, b) returns true for any a and b of type T, then +// hash_default_hash<T>(a) must equal hash_default_hash<T>(b) +// +// For SwissTable containers this requirement is relaxed to allow a and b of +// any and possibly different types. Note that like the standard the hash and +// equal functions are still bound to T. This is important because some type U +// can be hashed by/tested for equality differently depending on T. A notable +// example is `const char*`. `const char*` is treated as a c-style string when +// the hash function is hash<std::string> but as a pointer when the hash +// function is hash<void*>. +// +#ifndef ABSL_CONTAINER_INTERNAL_HASH_FUNCTION_DEFAULTS_H_ +#define ABSL_CONTAINER_INTERNAL_HASH_FUNCTION_DEFAULTS_H_ + +#include <stdint.h> +#include <cstddef> +#include <memory> +#include <string> +#include <type_traits> + +#include "absl/base/config.h" +#include "absl/hash/hash.h" +#include "absl/strings/cord.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// The hash of an object of type T is computed by using absl::Hash. +template <class T, class E = void> +struct HashEq { + using Hash = absl::Hash<T>; + using Eq = std::equal_to<T>; +}; + +struct StringHash { + using is_transparent = void; + + size_t operator()(absl::string_view v) const { + return absl::Hash<absl::string_view>{}(v); + } + size_t operator()(const absl::Cord& v) const { + return absl::Hash<absl::Cord>{}(v); + } +}; + +// Supports heterogeneous lookup for string-like elements. +struct StringHashEq { + using Hash = StringHash; + struct Eq { + using is_transparent = void; + bool operator()(absl::string_view lhs, absl::string_view rhs) const { + return lhs == rhs; + } + bool operator()(const absl::Cord& lhs, const absl::Cord& rhs) const { + return lhs == rhs; + } + bool operator()(const absl::Cord& lhs, absl::string_view rhs) const { + return lhs == rhs; + } + bool operator()(absl::string_view lhs, const absl::Cord& rhs) const { + return lhs == rhs; + } + }; +}; + +template <> +struct HashEq<std::string> : StringHashEq {}; +template <> +struct HashEq<absl::string_view> : StringHashEq {}; +template <> +struct HashEq<absl::Cord> : StringHashEq {}; + +// Supports heterogeneous lookup for pointers and smart pointers. +template <class T> +struct HashEq<T*> { + struct Hash { + using is_transparent = void; + template <class U> + size_t operator()(const U& ptr) const { + return absl::Hash<const T*>{}(HashEq::ToPtr(ptr)); + } + }; + struct Eq { + using is_transparent = void; + template <class A, class B> + bool operator()(const A& a, const B& b) const { + return HashEq::ToPtr(a) == HashEq::ToPtr(b); + } + }; + + private: + static const T* ToPtr(const T* ptr) { return ptr; } + template <class U, class D> + static const T* ToPtr(const std::unique_ptr<U, D>& ptr) { + return ptr.get(); + } + template <class U> + static const T* ToPtr(const std::shared_ptr<U>& ptr) { + return ptr.get(); + } +}; + +template <class T, class D> +struct HashEq<std::unique_ptr<T, D>> : HashEq<T*> {}; +template <class T> +struct HashEq<std::shared_ptr<T>> : HashEq<T*> {}; + +// This header's visibility is restricted. If you need to access the default +// hasher please use the container's ::hasher alias instead. +// +// Example: typename Hash = typename absl::flat_hash_map<K, V>::hasher +template <class T> +using hash_default_hash = typename container_internal::HashEq<T>::Hash; + +// This header's visibility is restricted. If you need to access the default +// key equal please use the container's ::key_equal alias instead. +// +// Example: typename Eq = typename absl::flat_hash_map<K, V, Hash>::key_equal +template <class T> +using hash_default_eq = typename container_internal::HashEq<T>::Eq; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_HASH_FUNCTION_DEFAULTS_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hash_function_defaults_test.cc b/third_party/abseil_cpp/absl/container/internal/hash_function_defaults_test.cc new file mode 100644 index 0000000000..2d05a0b72a --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_function_defaults_test.cc @@ -0,0 +1,383 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hash_function_defaults.h" + +#include <functional> +#include <type_traits> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/random/random.h" +#include "absl/strings/cord.h" +#include "absl/strings/cord_test_helpers.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::testing::Types; + +TEST(Eq, Int32) { + hash_default_eq<int32_t> eq; + EXPECT_TRUE(eq(1, 1u)); + EXPECT_TRUE(eq(1, char{1})); + EXPECT_TRUE(eq(1, true)); + EXPECT_TRUE(eq(1, double{1.1})); + EXPECT_FALSE(eq(1, char{2})); + EXPECT_FALSE(eq(1, 2u)); + EXPECT_FALSE(eq(1, false)); + EXPECT_FALSE(eq(1, 2.)); +} + +TEST(Hash, Int32) { + hash_default_hash<int32_t> hash; + auto h = hash(1); + EXPECT_EQ(h, hash(1u)); + EXPECT_EQ(h, hash(char{1})); + EXPECT_EQ(h, hash(true)); + EXPECT_EQ(h, hash(double{1.1})); + EXPECT_NE(h, hash(2u)); + EXPECT_NE(h, hash(char{2})); + EXPECT_NE(h, hash(false)); + EXPECT_NE(h, hash(2.)); +} + +enum class MyEnum { A, B, C, D }; + +TEST(Eq, Enum) { + hash_default_eq<MyEnum> eq; + EXPECT_TRUE(eq(MyEnum::A, MyEnum::A)); + EXPECT_FALSE(eq(MyEnum::A, MyEnum::B)); +} + +TEST(Hash, Enum) { + hash_default_hash<MyEnum> hash; + + for (MyEnum e : {MyEnum::A, MyEnum::B, MyEnum::C}) { + auto h = hash(e); + EXPECT_EQ(h, hash_default_hash<int>{}(static_cast<int>(e))); + EXPECT_NE(h, hash(MyEnum::D)); + } +} + +using StringTypes = ::testing::Types<std::string, absl::string_view>; + +template <class T> +struct EqString : ::testing::Test { + hash_default_eq<T> key_eq; +}; + +TYPED_TEST_SUITE(EqString, StringTypes); + +template <class T> +struct HashString : ::testing::Test { + hash_default_hash<T> hasher; +}; + +TYPED_TEST_SUITE(HashString, StringTypes); + +TYPED_TEST(EqString, Works) { + auto eq = this->key_eq; + EXPECT_TRUE(eq("a", "a")); + EXPECT_TRUE(eq("a", absl::string_view("a"))); + EXPECT_TRUE(eq("a", std::string("a"))); + EXPECT_FALSE(eq("a", "b")); + EXPECT_FALSE(eq("a", absl::string_view("b"))); + EXPECT_FALSE(eq("a", std::string("b"))); +} + +TYPED_TEST(HashString, Works) { + auto hash = this->hasher; + auto h = hash("a"); + EXPECT_EQ(h, hash(absl::string_view("a"))); + EXPECT_EQ(h, hash(std::string("a"))); + EXPECT_NE(h, hash(absl::string_view("b"))); + EXPECT_NE(h, hash(std::string("b"))); +} + +struct NoDeleter { + template <class T> + void operator()(const T* ptr) const {} +}; + +using PointerTypes = + ::testing::Types<const int*, int*, std::unique_ptr<const int>, + std::unique_ptr<const int, NoDeleter>, + std::unique_ptr<int>, std::unique_ptr<int, NoDeleter>, + std::shared_ptr<const int>, std::shared_ptr<int>>; + +template <class T> +struct EqPointer : ::testing::Test { + hash_default_eq<T> key_eq; +}; + +TYPED_TEST_SUITE(EqPointer, PointerTypes); + +template <class T> +struct HashPointer : ::testing::Test { + hash_default_hash<T> hasher; +}; + +TYPED_TEST_SUITE(HashPointer, PointerTypes); + +TYPED_TEST(EqPointer, Works) { + int dummy; + auto eq = this->key_eq; + auto sptr = std::make_shared<int>(); + std::shared_ptr<const int> csptr = sptr; + int* ptr = sptr.get(); + const int* cptr = ptr; + std::unique_ptr<int, NoDeleter> uptr(ptr); + std::unique_ptr<const int, NoDeleter> cuptr(ptr); + + EXPECT_TRUE(eq(ptr, cptr)); + EXPECT_TRUE(eq(ptr, sptr)); + EXPECT_TRUE(eq(ptr, uptr)); + EXPECT_TRUE(eq(ptr, csptr)); + EXPECT_TRUE(eq(ptr, cuptr)); + EXPECT_FALSE(eq(&dummy, cptr)); + EXPECT_FALSE(eq(&dummy, sptr)); + EXPECT_FALSE(eq(&dummy, uptr)); + EXPECT_FALSE(eq(&dummy, csptr)); + EXPECT_FALSE(eq(&dummy, cuptr)); +} + +TEST(Hash, DerivedAndBase) { + struct Base {}; + struct Derived : Base {}; + + hash_default_hash<Base*> hasher; + + Base base; + Derived derived; + EXPECT_NE(hasher(&base), hasher(&derived)); + EXPECT_EQ(hasher(static_cast<Base*>(&derived)), hasher(&derived)); + + auto dp = std::make_shared<Derived>(); + EXPECT_EQ(hasher(static_cast<Base*>(dp.get())), hasher(dp)); +} + +TEST(Hash, FunctionPointer) { + using Func = int (*)(); + hash_default_hash<Func> hasher; + hash_default_eq<Func> eq; + + Func p1 = [] { return 1; }, p2 = [] { return 2; }; + EXPECT_EQ(hasher(p1), hasher(p1)); + EXPECT_TRUE(eq(p1, p1)); + + EXPECT_NE(hasher(p1), hasher(p2)); + EXPECT_FALSE(eq(p1, p2)); +} + +TYPED_TEST(HashPointer, Works) { + int dummy; + auto hash = this->hasher; + auto sptr = std::make_shared<int>(); + std::shared_ptr<const int> csptr = sptr; + int* ptr = sptr.get(); + const int* cptr = ptr; + std::unique_ptr<int, NoDeleter> uptr(ptr); + std::unique_ptr<const int, NoDeleter> cuptr(ptr); + + EXPECT_EQ(hash(ptr), hash(cptr)); + EXPECT_EQ(hash(ptr), hash(sptr)); + EXPECT_EQ(hash(ptr), hash(uptr)); + EXPECT_EQ(hash(ptr), hash(csptr)); + EXPECT_EQ(hash(ptr), hash(cuptr)); + EXPECT_NE(hash(&dummy), hash(cptr)); + EXPECT_NE(hash(&dummy), hash(sptr)); + EXPECT_NE(hash(&dummy), hash(uptr)); + EXPECT_NE(hash(&dummy), hash(csptr)); + EXPECT_NE(hash(&dummy), hash(cuptr)); +} + +TEST(EqCord, Works) { + hash_default_eq<absl::Cord> eq; + const absl::string_view a_string_view = "a"; + const absl::Cord a_cord(a_string_view); + const absl::string_view b_string_view = "b"; + const absl::Cord b_cord(b_string_view); + + EXPECT_TRUE(eq(a_cord, a_cord)); + EXPECT_TRUE(eq(a_cord, a_string_view)); + EXPECT_TRUE(eq(a_string_view, a_cord)); + EXPECT_FALSE(eq(a_cord, b_cord)); + EXPECT_FALSE(eq(a_cord, b_string_view)); + EXPECT_FALSE(eq(b_string_view, a_cord)); +} + +TEST(HashCord, Works) { + hash_default_hash<absl::Cord> hash; + const absl::string_view a_string_view = "a"; + const absl::Cord a_cord(a_string_view); + const absl::string_view b_string_view = "b"; + const absl::Cord b_cord(b_string_view); + + EXPECT_EQ(hash(a_cord), hash(a_cord)); + EXPECT_EQ(hash(b_cord), hash(b_cord)); + EXPECT_EQ(hash(a_string_view), hash(a_cord)); + EXPECT_EQ(hash(b_string_view), hash(b_cord)); + EXPECT_EQ(hash(absl::Cord("")), hash("")); + EXPECT_EQ(hash(absl::Cord()), hash(absl::string_view())); + + EXPECT_NE(hash(a_cord), hash(b_cord)); + EXPECT_NE(hash(a_cord), hash(b_string_view)); + EXPECT_NE(hash(a_string_view), hash(b_cord)); + EXPECT_NE(hash(a_string_view), hash(b_string_view)); +} + +void NoOpReleaser(absl::string_view data, void* arg) {} + +TEST(HashCord, FragmentedCordWorks) { + hash_default_hash<absl::Cord> hash; + absl::Cord c = absl::MakeFragmentedCord({"a", "b", "c"}); + EXPECT_FALSE(c.TryFlat().has_value()); + EXPECT_EQ(hash(c), hash("abc")); +} + +TEST(HashCord, FragmentedLongCordWorks) { + hash_default_hash<absl::Cord> hash; + // Crete some large strings which do not fit on the stack. + std::string a(65536, 'a'); + std::string b(65536, 'b'); + absl::Cord c = absl::MakeFragmentedCord({a, b}); + EXPECT_FALSE(c.TryFlat().has_value()); + EXPECT_EQ(hash(c), hash(a + b)); +} + +TEST(HashCord, RandomCord) { + hash_default_hash<absl::Cord> hash; + auto bitgen = absl::BitGen(); + for (int i = 0; i < 1000; ++i) { + const int number_of_segments = absl::Uniform(bitgen, 0, 10); + std::vector<std::string> pieces; + for (size_t s = 0; s < number_of_segments; ++s) { + std::string str; + str.resize(absl::Uniform(bitgen, 0, 4096)); + // MSVC needed the explicit return type in the lambda. + std::generate(str.begin(), str.end(), [&]() -> char { + return static_cast<char>(absl::Uniform<unsigned char>(bitgen)); + }); + pieces.push_back(str); + } + absl::Cord c = absl::MakeFragmentedCord(pieces); + EXPECT_EQ(hash(c), hash(std::string(c))); + } +} + +// Cartesian product of (std::string, absl::string_view) +// with (std::string, absl::string_view, const char*, absl::Cord). +using StringTypesCartesianProduct = Types< + // clang-format off + std::pair<absl::Cord, std::string>, + std::pair<absl::Cord, absl::string_view>, + std::pair<absl::Cord, absl::Cord>, + std::pair<absl::Cord, const char*>, + + std::pair<std::string, absl::Cord>, + std::pair<absl::string_view, absl::Cord>, + + std::pair<absl::string_view, std::string>, + std::pair<absl::string_view, absl::string_view>, + std::pair<absl::string_view, const char*>>; +// clang-format on + +constexpr char kFirstString[] = "abc123"; +constexpr char kSecondString[] = "ijk456"; + +template <typename T> +struct StringLikeTest : public ::testing::Test { + typename T::first_type a1{kFirstString}; + typename T::second_type b1{kFirstString}; + typename T::first_type a2{kSecondString}; + typename T::second_type b2{kSecondString}; + hash_default_eq<typename T::first_type> eq; + hash_default_hash<typename T::first_type> hash; +}; + +TYPED_TEST_CASE_P(StringLikeTest); + +TYPED_TEST_P(StringLikeTest, Eq) { + EXPECT_TRUE(this->eq(this->a1, this->b1)); + EXPECT_TRUE(this->eq(this->b1, this->a1)); +} + +TYPED_TEST_P(StringLikeTest, NotEq) { + EXPECT_FALSE(this->eq(this->a1, this->b2)); + EXPECT_FALSE(this->eq(this->b2, this->a1)); +} + +TYPED_TEST_P(StringLikeTest, HashEq) { + EXPECT_EQ(this->hash(this->a1), this->hash(this->b1)); + EXPECT_EQ(this->hash(this->a2), this->hash(this->b2)); + // It would be a poor hash function which collides on these strings. + EXPECT_NE(this->hash(this->a1), this->hash(this->b2)); +} + +TYPED_TEST_SUITE(StringLikeTest, StringTypesCartesianProduct); + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +enum Hash : size_t { + kStd = 0x2, // std::hash +#ifdef _MSC_VER + kExtension = kStd, // In MSVC, std::hash == ::hash +#else // _MSC_VER + kExtension = 0x4, // ::hash (GCC extension) +#endif // _MSC_VER +}; + +// H is a bitmask of Hash enumerations. +// Hashable<H> is hashable via all means specified in H. +template <int H> +struct Hashable { + static constexpr bool HashableBy(Hash h) { return h & H; } +}; + +namespace std { +template <int H> +struct hash<Hashable<H>> { + template <class E = Hashable<H>, + class = typename std::enable_if<E::HashableBy(kStd)>::type> + size_t operator()(E) const { + return kStd; + } +}; +} // namespace std + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +template <class T> +size_t Hash(const T& v) { + return hash_default_hash<T>()(v); +} + +TEST(Delegate, HashDispatch) { + EXPECT_EQ(Hash(kStd), Hash(Hashable<kStd>())); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/hash_generator_testing.cc b/third_party/abseil_cpp/absl/container/internal/hash_generator_testing.cc new file mode 100644 index 0000000000..75c4db6c36 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_generator_testing.cc @@ -0,0 +1,74 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hash_generator_testing.h" + +#include <deque> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace hash_internal { +namespace { + +class RandomDeviceSeedSeq { + public: + using result_type = typename std::random_device::result_type; + + template <class Iterator> + void generate(Iterator start, Iterator end) { + while (start != end) { + *start = gen_(); + ++start; + } + } + + private: + std::random_device gen_; +}; + +} // namespace + +std::mt19937_64* GetSharedRng() { + RandomDeviceSeedSeq seed_seq; + static auto* rng = new std::mt19937_64(seed_seq); + return rng; +} + +std::string Generator<std::string>::operator()() const { + // NOLINTNEXTLINE(runtime/int) + std::uniform_int_distribution<short> chars(0x20, 0x7E); + std::string res; + res.resize(32); + std::generate(res.begin(), res.end(), + [&]() { return chars(*GetSharedRng()); }); + return res; +} + +absl::string_view Generator<absl::string_view>::operator()() const { + static auto* arena = new std::deque<std::string>(); + // NOLINTNEXTLINE(runtime/int) + std::uniform_int_distribution<short> chars(0x20, 0x7E); + arena->emplace_back(); + auto& res = arena->back(); + res.resize(32); + std::generate(res.begin(), res.end(), + [&]() { return chars(*GetSharedRng()); }); + return res; +} + +} // namespace hash_internal +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/hash_generator_testing.h b/third_party/abseil_cpp/absl/container/internal/hash_generator_testing.h new file mode 100644 index 0000000000..6869fe45e8 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_generator_testing.h @@ -0,0 +1,161 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Generates random values for testing. Specialized only for the few types we +// care about. + +#ifndef ABSL_CONTAINER_INTERNAL_HASH_GENERATOR_TESTING_H_ +#define ABSL_CONTAINER_INTERNAL_HASH_GENERATOR_TESTING_H_ + +#include <stdint.h> + +#include <algorithm> +#include <iosfwd> +#include <random> +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/container/internal/hash_policy_testing.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace hash_internal { +namespace generator_internal { + +template <class Container, class = void> +struct IsMap : std::false_type {}; + +template <class Map> +struct IsMap<Map, absl::void_t<typename Map::mapped_type>> : std::true_type {}; + +} // namespace generator_internal + +std::mt19937_64* GetSharedRng(); + +enum Enum { + kEnumEmpty, + kEnumDeleted, +}; + +enum class EnumClass : uint64_t { + kEmpty, + kDeleted, +}; + +inline std::ostream& operator<<(std::ostream& o, const EnumClass& ec) { + return o << static_cast<uint64_t>(ec); +} + +template <class T, class E = void> +struct Generator; + +template <class T> +struct Generator<T, typename std::enable_if<std::is_integral<T>::value>::type> { + T operator()() const { + std::uniform_int_distribution<T> dist; + return dist(*GetSharedRng()); + } +}; + +template <> +struct Generator<Enum> { + Enum operator()() const { + std::uniform_int_distribution<typename std::underlying_type<Enum>::type> + dist; + while (true) { + auto variate = dist(*GetSharedRng()); + if (variate != kEnumEmpty && variate != kEnumDeleted) + return static_cast<Enum>(variate); + } + } +}; + +template <> +struct Generator<EnumClass> { + EnumClass operator()() const { + std::uniform_int_distribution< + typename std::underlying_type<EnumClass>::type> + dist; + while (true) { + EnumClass variate = static_cast<EnumClass>(dist(*GetSharedRng())); + if (variate != EnumClass::kEmpty && variate != EnumClass::kDeleted) + return static_cast<EnumClass>(variate); + } + } +}; + +template <> +struct Generator<std::string> { + std::string operator()() const; +}; + +template <> +struct Generator<absl::string_view> { + absl::string_view operator()() const; +}; + +template <> +struct Generator<NonStandardLayout> { + NonStandardLayout operator()() const { + return NonStandardLayout(Generator<std::string>()()); + } +}; + +template <class K, class V> +struct Generator<std::pair<K, V>> { + std::pair<K, V> operator()() const { + return std::pair<K, V>(Generator<typename std::decay<K>::type>()(), + Generator<typename std::decay<V>::type>()()); + } +}; + +template <class... Ts> +struct Generator<std::tuple<Ts...>> { + std::tuple<Ts...> operator()() const { + return std::tuple<Ts...>(Generator<typename std::decay<Ts>::type>()()...); + } +}; + +template <class T> +struct Generator<std::unique_ptr<T>> { + std::unique_ptr<T> operator()() const { + return absl::make_unique<T>(Generator<T>()()); + } +}; + +template <class U> +struct Generator<U, absl::void_t<decltype(std::declval<U&>().key()), + decltype(std::declval<U&>().value())>> + : Generator<std::pair< + typename std::decay<decltype(std::declval<U&>().key())>::type, + typename std::decay<decltype(std::declval<U&>().value())>::type>> {}; + +template <class Container> +using GeneratedType = decltype( + std::declval<const Generator< + typename std::conditional<generator_internal::IsMap<Container>::value, + typename Container::value_type, + typename Container::key_type>::type>&>()()); + +} // namespace hash_internal +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_HASH_GENERATOR_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hash_policy_testing.h b/third_party/abseil_cpp/absl/container/internal/hash_policy_testing.h new file mode 100644 index 0000000000..01c40d2e5c --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_policy_testing.h @@ -0,0 +1,184 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Utilities to help tests verify that hash tables properly handle stateful +// allocators and hash functions. + +#ifndef ABSL_CONTAINER_INTERNAL_HASH_POLICY_TESTING_H_ +#define ABSL_CONTAINER_INTERNAL_HASH_POLICY_TESTING_H_ + +#include <cstdlib> +#include <limits> +#include <memory> +#include <ostream> +#include <type_traits> +#include <utility> +#include <vector> + +#include "absl/hash/hash.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace hash_testing_internal { + +template <class Derived> +struct WithId { + WithId() : id_(next_id<Derived>()) {} + WithId(const WithId& that) : id_(that.id_) {} + WithId(WithId&& that) : id_(that.id_) { that.id_ = 0; } + WithId& operator=(const WithId& that) { + id_ = that.id_; + return *this; + } + WithId& operator=(WithId&& that) { + id_ = that.id_; + that.id_ = 0; + return *this; + } + + size_t id() const { return id_; } + + friend bool operator==(const WithId& a, const WithId& b) { + return a.id_ == b.id_; + } + friend bool operator!=(const WithId& a, const WithId& b) { return !(a == b); } + + protected: + explicit WithId(size_t id) : id_(id) {} + + private: + size_t id_; + + template <class T> + static size_t next_id() { + // 0 is reserved for moved from state. + static size_t gId = 1; + return gId++; + } +}; + +} // namespace hash_testing_internal + +struct NonStandardLayout { + NonStandardLayout() {} + explicit NonStandardLayout(std::string s) : value(std::move(s)) {} + virtual ~NonStandardLayout() {} + + friend bool operator==(const NonStandardLayout& a, + const NonStandardLayout& b) { + return a.value == b.value; + } + friend bool operator!=(const NonStandardLayout& a, + const NonStandardLayout& b) { + return a.value != b.value; + } + + template <typename H> + friend H AbslHashValue(H h, const NonStandardLayout& v) { + return H::combine(std::move(h), v.value); + } + + std::string value; +}; + +struct StatefulTestingHash + : absl::container_internal::hash_testing_internal::WithId< + StatefulTestingHash> { + template <class T> + size_t operator()(const T& t) const { + return absl::Hash<T>{}(t); + } +}; + +struct StatefulTestingEqual + : absl::container_internal::hash_testing_internal::WithId< + StatefulTestingEqual> { + template <class T, class U> + bool operator()(const T& t, const U& u) const { + return t == u; + } +}; + +// It is expected that Alloc() == Alloc() for all allocators so we cannot use +// WithId base. We need to explicitly assign ids. +template <class T = int> +struct Alloc : std::allocator<T> { + using propagate_on_container_swap = std::true_type; + + // Using old paradigm for this to ensure compatibility. + explicit Alloc(size_t id = 0) : id_(id) {} + + Alloc(const Alloc&) = default; + Alloc& operator=(const Alloc&) = default; + + template <class U> + Alloc(const Alloc<U>& that) : std::allocator<T>(that), id_(that.id()) {} + + template <class U> + struct rebind { + using other = Alloc<U>; + }; + + size_t id() const { return id_; } + + friend bool operator==(const Alloc& a, const Alloc& b) { + return a.id_ == b.id_; + } + friend bool operator!=(const Alloc& a, const Alloc& b) { return !(a == b); } + + private: + size_t id_ = (std::numeric_limits<size_t>::max)(); +}; + +template <class Map> +auto items(const Map& m) -> std::vector< + std::pair<typename Map::key_type, typename Map::mapped_type>> { + using std::get; + std::vector<std::pair<typename Map::key_type, typename Map::mapped_type>> res; + res.reserve(m.size()); + for (const auto& v : m) res.emplace_back(get<0>(v), get<1>(v)); + return res; +} + +template <class Set> +auto keys(const Set& s) + -> std::vector<typename std::decay<typename Set::key_type>::type> { + std::vector<typename std::decay<typename Set::key_type>::type> res; + res.reserve(s.size()); + for (const auto& v : s) res.emplace_back(v); + return res; +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +// ABSL_UNORDERED_SUPPORTS_ALLOC_CTORS is false for glibcxx versions +// where the unordered containers are missing certain constructors that +// take allocator arguments. This test is defined ad-hoc for the platforms +// we care about (notably Crosstool 17) because libstdcxx's useless +// versioning scheme precludes a more principled solution. +// From GCC-4.9 Changelog: (src: https://gcc.gnu.org/gcc-4.9/changes.html) +// "the unordered associative containers in <unordered_map> and <unordered_set> +// meet the allocator-aware container requirements;" +#if (defined(__GLIBCXX__) && __GLIBCXX__ <= 20140425 ) || \ +( __GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 9 )) +#define ABSL_UNORDERED_SUPPORTS_ALLOC_CTORS 0 +#else +#define ABSL_UNORDERED_SUPPORTS_ALLOC_CTORS 1 +#endif + +#endif // ABSL_CONTAINER_INTERNAL_HASH_POLICY_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hash_policy_testing_test.cc b/third_party/abseil_cpp/absl/container/internal/hash_policy_testing_test.cc new file mode 100644 index 0000000000..f0b20fe345 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_policy_testing_test.cc @@ -0,0 +1,45 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hash_policy_testing.h" + +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +TEST(_, Hash) { + StatefulTestingHash h1; + EXPECT_EQ(1, h1.id()); + StatefulTestingHash h2; + EXPECT_EQ(2, h2.id()); + StatefulTestingHash h1c(h1); + EXPECT_EQ(1, h1c.id()); + StatefulTestingHash h2m(std::move(h2)); + EXPECT_EQ(2, h2m.id()); + EXPECT_EQ(0, h2.id()); + StatefulTestingHash h3; + EXPECT_EQ(3, h3.id()); + h3 = StatefulTestingHash(); + EXPECT_EQ(4, h3.id()); + h3 = std::move(h1); + EXPECT_EQ(1, h3.id()); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/hash_policy_traits.h b/third_party/abseil_cpp/absl/container/internal/hash_policy_traits.h new file mode 100644 index 0000000000..3e1209c6eb --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_policy_traits.h @@ -0,0 +1,191 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_HASH_POLICY_TRAITS_H_ +#define ABSL_CONTAINER_INTERNAL_HASH_POLICY_TRAITS_H_ + +#include <cstddef> +#include <memory> +#include <type_traits> +#include <utility> + +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// Defines how slots are initialized/destroyed/moved. +template <class Policy, class = void> +struct hash_policy_traits { + private: + struct ReturnKey { + // We return `Key` here. + // When Key=T&, we forward the lvalue reference. + // When Key=T, we return by value to avoid a dangling reference. + // eg, for string_hash_map. + template <class Key, class... Args> + Key operator()(Key&& k, const Args&...) const { + return std::forward<Key>(k); + } + }; + + template <class P = Policy, class = void> + struct ConstantIteratorsImpl : std::false_type {}; + + template <class P> + struct ConstantIteratorsImpl<P, absl::void_t<typename P::constant_iterators>> + : P::constant_iterators {}; + + public: + // The actual object stored in the hash table. + using slot_type = typename Policy::slot_type; + + // The type of the keys stored in the hashtable. + using key_type = typename Policy::key_type; + + // The argument type for insertions into the hashtable. This is different + // from value_type for increased performance. See initializer_list constructor + // and insert() member functions for more details. + using init_type = typename Policy::init_type; + + using reference = decltype(Policy::element(std::declval<slot_type*>())); + using pointer = typename std::remove_reference<reference>::type*; + using value_type = typename std::remove_reference<reference>::type; + + // Policies can set this variable to tell raw_hash_set that all iterators + // should be constant, even `iterator`. This is useful for set-like + // containers. + // Defaults to false if not provided by the policy. + using constant_iterators = ConstantIteratorsImpl<>; + + // PRECONDITION: `slot` is UNINITIALIZED + // POSTCONDITION: `slot` is INITIALIZED + template <class Alloc, class... Args> + static void construct(Alloc* alloc, slot_type* slot, Args&&... args) { + Policy::construct(alloc, slot, std::forward<Args>(args)...); + } + + // PRECONDITION: `slot` is INITIALIZED + // POSTCONDITION: `slot` is UNINITIALIZED + template <class Alloc> + static void destroy(Alloc* alloc, slot_type* slot) { + Policy::destroy(alloc, slot); + } + + // Transfers the `old_slot` to `new_slot`. Any memory allocated by the + // allocator inside `old_slot` to `new_slot` can be transferred. + // + // OPTIONAL: defaults to: + // + // clone(new_slot, std::move(*old_slot)); + // destroy(old_slot); + // + // PRECONDITION: `new_slot` is UNINITIALIZED and `old_slot` is INITIALIZED + // POSTCONDITION: `new_slot` is INITIALIZED and `old_slot` is + // UNINITIALIZED + template <class Alloc> + static void transfer(Alloc* alloc, slot_type* new_slot, slot_type* old_slot) { + transfer_impl(alloc, new_slot, old_slot, 0); + } + + // PRECONDITION: `slot` is INITIALIZED + // POSTCONDITION: `slot` is INITIALIZED + template <class P = Policy> + static auto element(slot_type* slot) -> decltype(P::element(slot)) { + return P::element(slot); + } + + // Returns the amount of memory owned by `slot`, exclusive of `sizeof(*slot)`. + // + // If `slot` is nullptr, returns the constant amount of memory owned by any + // full slot or -1 if slots own variable amounts of memory. + // + // PRECONDITION: `slot` is INITIALIZED or nullptr + template <class P = Policy> + static size_t space_used(const slot_type* slot) { + return P::space_used(slot); + } + + // Provides generalized access to the key for elements, both for elements in + // the table and for elements that have not yet been inserted (or even + // constructed). We would like an API that allows us to say: `key(args...)` + // but we cannot do that for all cases, so we use this more general API that + // can be used for many things, including the following: + // + // - Given an element in a table, get its key. + // - Given an element initializer, get its key. + // - Given `emplace()` arguments, get the element key. + // + // Implementations of this must adhere to a very strict technical + // specification around aliasing and consuming arguments: + // + // Let `value_type` be the result type of `element()` without ref- and + // cv-qualifiers. The first argument is a functor, the rest are constructor + // arguments for `value_type`. Returns `std::forward<F>(f)(k, xs...)`, where + // `k` is the element key, and `xs...` are the new constructor arguments for + // `value_type`. It's allowed for `k` to alias `xs...`, and for both to alias + // `ts...`. The key won't be touched once `xs...` are used to construct an + // element; `ts...` won't be touched at all, which allows `apply()` to consume + // any rvalues among them. + // + // If `value_type` is constructible from `Ts&&...`, `Policy::apply()` must not + // trigger a hard compile error unless it originates from `f`. In other words, + // `Policy::apply()` must be SFINAE-friendly. If `value_type` is not + // constructible from `Ts&&...`, either SFINAE or a hard compile error is OK. + // + // If `Ts...` is `[cv] value_type[&]` or `[cv] init_type[&]`, + // `Policy::apply()` must work. A compile error is not allowed, SFINAE or not. + template <class F, class... Ts, class P = Policy> + static auto apply(F&& f, Ts&&... ts) + -> decltype(P::apply(std::forward<F>(f), std::forward<Ts>(ts)...)) { + return P::apply(std::forward<F>(f), std::forward<Ts>(ts)...); + } + + // Returns the "key" portion of the slot. + // Used for node handle manipulation. + template <class P = Policy> + static auto key(slot_type* slot) + -> decltype(P::apply(ReturnKey(), element(slot))) { + return P::apply(ReturnKey(), element(slot)); + } + + // Returns the "value" (as opposed to the "key") portion of the element. Used + // by maps to implement `operator[]`, `at()` and `insert_or_assign()`. + template <class T, class P = Policy> + static auto value(T* elem) -> decltype(P::value(elem)) { + return P::value(elem); + } + + private: + // Use auto -> decltype as an enabler. + template <class Alloc, class P = Policy> + static auto transfer_impl(Alloc* alloc, slot_type* new_slot, + slot_type* old_slot, int) + -> decltype((void)P::transfer(alloc, new_slot, old_slot)) { + P::transfer(alloc, new_slot, old_slot); + } + template <class Alloc> + static void transfer_impl(Alloc* alloc, slot_type* new_slot, + slot_type* old_slot, char) { + construct(alloc, new_slot, std::move(element(old_slot))); + destroy(alloc, old_slot); + } +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_HASH_POLICY_TRAITS_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hash_policy_traits_test.cc b/third_party/abseil_cpp/absl/container/internal/hash_policy_traits_test.cc new file mode 100644 index 0000000000..6ef8b9e05f --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hash_policy_traits_test.cc @@ -0,0 +1,144 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hash_policy_traits.h" + +#include <functional> +#include <memory> +#include <new> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::testing::MockFunction; +using ::testing::Return; +using ::testing::ReturnRef; + +using Alloc = std::allocator<int>; +using Slot = int; + +struct PolicyWithoutOptionalOps { + using slot_type = Slot; + using key_type = Slot; + using init_type = Slot; + + static std::function<void(void*, Slot*, Slot)> construct; + static std::function<void(void*, Slot*)> destroy; + + static std::function<Slot&(Slot*)> element; + static int apply(int v) { return apply_impl(v); } + static std::function<int(int)> apply_impl; + static std::function<Slot&(Slot*)> value; +}; + +std::function<void(void*, Slot*, Slot)> PolicyWithoutOptionalOps::construct; +std::function<void(void*, Slot*)> PolicyWithoutOptionalOps::destroy; + +std::function<Slot&(Slot*)> PolicyWithoutOptionalOps::element; +std::function<int(int)> PolicyWithoutOptionalOps::apply_impl; +std::function<Slot&(Slot*)> PolicyWithoutOptionalOps::value; + +struct PolicyWithOptionalOps : PolicyWithoutOptionalOps { + static std::function<void(void*, Slot*, Slot*)> transfer; +}; + +std::function<void(void*, Slot*, Slot*)> PolicyWithOptionalOps::transfer; + +struct Test : ::testing::Test { + Test() { + PolicyWithoutOptionalOps::construct = [&](void* a1, Slot* a2, Slot a3) { + construct.Call(a1, a2, std::move(a3)); + }; + PolicyWithoutOptionalOps::destroy = [&](void* a1, Slot* a2) { + destroy.Call(a1, a2); + }; + + PolicyWithoutOptionalOps::element = [&](Slot* a1) -> Slot& { + return element.Call(a1); + }; + PolicyWithoutOptionalOps::apply_impl = [&](int a1) -> int { + return apply.Call(a1); + }; + PolicyWithoutOptionalOps::value = [&](Slot* a1) -> Slot& { + return value.Call(a1); + }; + + PolicyWithOptionalOps::transfer = [&](void* a1, Slot* a2, Slot* a3) { + return transfer.Call(a1, a2, a3); + }; + } + + std::allocator<int> alloc; + int a = 53; + + MockFunction<void(void*, Slot*, Slot)> construct; + MockFunction<void(void*, Slot*)> destroy; + + MockFunction<Slot&(Slot*)> element; + MockFunction<int(int)> apply; + MockFunction<Slot&(Slot*)> value; + + MockFunction<void(void*, Slot*, Slot*)> transfer; +}; + +TEST_F(Test, construct) { + EXPECT_CALL(construct, Call(&alloc, &a, 53)); + hash_policy_traits<PolicyWithoutOptionalOps>::construct(&alloc, &a, 53); +} + +TEST_F(Test, destroy) { + EXPECT_CALL(destroy, Call(&alloc, &a)); + hash_policy_traits<PolicyWithoutOptionalOps>::destroy(&alloc, &a); +} + +TEST_F(Test, element) { + int b = 0; + EXPECT_CALL(element, Call(&a)).WillOnce(ReturnRef(b)); + EXPECT_EQ(&b, &hash_policy_traits<PolicyWithoutOptionalOps>::element(&a)); +} + +TEST_F(Test, apply) { + EXPECT_CALL(apply, Call(42)).WillOnce(Return(1337)); + EXPECT_EQ(1337, (hash_policy_traits<PolicyWithoutOptionalOps>::apply(42))); +} + +TEST_F(Test, value) { + int b = 0; + EXPECT_CALL(value, Call(&a)).WillOnce(ReturnRef(b)); + EXPECT_EQ(&b, &hash_policy_traits<PolicyWithoutOptionalOps>::value(&a)); +} + +TEST_F(Test, without_transfer) { + int b = 42; + EXPECT_CALL(element, Call(&b)).WillOnce(::testing::ReturnRef(b)); + EXPECT_CALL(construct, Call(&alloc, &a, b)); + EXPECT_CALL(destroy, Call(&alloc, &b)); + hash_policy_traits<PolicyWithoutOptionalOps>::transfer(&alloc, &a, &b); +} + +TEST_F(Test, with_transfer) { + int b = 42; + EXPECT_CALL(transfer, Call(&alloc, &a, &b)); + hash_policy_traits<PolicyWithOptionalOps>::transfer(&alloc, &a, &b); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/hashtable_debug.h b/third_party/abseil_cpp/absl/container/internal/hashtable_debug.h new file mode 100644 index 0000000000..19d52121d6 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hashtable_debug.h @@ -0,0 +1,110 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This library provides APIs to debug the probing behavior of hash tables. +// +// In general, the probing behavior is a black box for users and only the +// side effects can be measured in the form of performance differences. +// These APIs give a glimpse on the actual behavior of the probing algorithms in +// these hashtables given a specified hash function and a set of elements. +// +// The probe count distribution can be used to assess the quality of the hash +// function for that particular hash table. Note that a hash function that +// performs well in one hash table implementation does not necessarily performs +// well in a different one. +// +// This library supports std::unordered_{set,map}, dense_hash_{set,map} and +// absl::{flat,node,string}_hash_{set,map}. + +#ifndef ABSL_CONTAINER_INTERNAL_HASHTABLE_DEBUG_H_ +#define ABSL_CONTAINER_INTERNAL_HASHTABLE_DEBUG_H_ + +#include <cstddef> +#include <algorithm> +#include <type_traits> +#include <vector> + +#include "absl/container/internal/hashtable_debug_hooks.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// Returns the number of probes required to lookup `key`. Returns 0 for a +// search with no collisions. Higher values mean more hash collisions occurred; +// however, the exact meaning of this number varies according to the container +// type. +template <typename C> +size_t GetHashtableDebugNumProbes( + const C& c, const typename C::key_type& key) { + return absl::container_internal::hashtable_debug_internal:: + HashtableDebugAccess<C>::GetNumProbes(c, key); +} + +// Gets a histogram of the number of probes for each elements in the container. +// The sum of all the values in the vector is equal to container.size(). +template <typename C> +std::vector<size_t> GetHashtableDebugNumProbesHistogram(const C& container) { + std::vector<size_t> v; + for (auto it = container.begin(); it != container.end(); ++it) { + size_t num_probes = GetHashtableDebugNumProbes( + container, + absl::container_internal::hashtable_debug_internal::GetKey<C>(*it, 0)); + v.resize((std::max)(v.size(), num_probes + 1)); + v[num_probes]++; + } + return v; +} + +struct HashtableDebugProbeSummary { + size_t total_elements; + size_t total_num_probes; + double mean; +}; + +// Gets a summary of the probe count distribution for the elements in the +// container. +template <typename C> +HashtableDebugProbeSummary GetHashtableDebugProbeSummary(const C& container) { + auto probes = GetHashtableDebugNumProbesHistogram(container); + HashtableDebugProbeSummary summary = {}; + for (size_t i = 0; i < probes.size(); ++i) { + summary.total_elements += probes[i]; + summary.total_num_probes += probes[i] * i; + } + summary.mean = 1.0 * summary.total_num_probes / summary.total_elements; + return summary; +} + +// Returns the number of bytes requested from the allocator by the container +// and not freed. +template <typename C> +size_t AllocatedByteSize(const C& c) { + return absl::container_internal::hashtable_debug_internal:: + HashtableDebugAccess<C>::AllocatedByteSize(c); +} + +// Returns a tight lower bound for AllocatedByteSize(c) where `c` is of type `C` +// and `c.size()` is equal to `num_elements`. +template <typename C> +size_t LowerBoundAllocatedByteSize(size_t num_elements) { + return absl::container_internal::hashtable_debug_internal:: + HashtableDebugAccess<C>::LowerBoundAllocatedByteSize(num_elements); +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_HASHTABLE_DEBUG_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hashtable_debug_hooks.h b/third_party/abseil_cpp/absl/container/internal/hashtable_debug_hooks.h new file mode 100644 index 0000000000..3e9ea5954e --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hashtable_debug_hooks.h @@ -0,0 +1,85 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Provides the internal API for hashtable_debug.h. + +#ifndef ABSL_CONTAINER_INTERNAL_HASHTABLE_DEBUG_HOOKS_H_ +#define ABSL_CONTAINER_INTERNAL_HASHTABLE_DEBUG_HOOKS_H_ + +#include <cstddef> + +#include <algorithm> +#include <type_traits> +#include <vector> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace hashtable_debug_internal { + +// If it is a map, call get<0>(). +using std::get; +template <typename T, typename = typename T::mapped_type> +auto GetKey(const typename T::value_type& pair, int) -> decltype(get<0>(pair)) { + return get<0>(pair); +} + +// If it is not a map, return the value directly. +template <typename T> +const typename T::key_type& GetKey(const typename T::key_type& key, char) { + return key; +} + +// Containers should specialize this to provide debug information for that +// container. +template <class Container, typename Enabler = void> +struct HashtableDebugAccess { + // Returns the number of probes required to find `key` in `c`. The "number of + // probes" is a concept that can vary by container. Implementations should + // return 0 when `key` was found in the minimum number of operations and + // should increment the result for each non-trivial operation required to find + // `key`. + // + // The default implementation uses the bucket api from the standard and thus + // works for `std::unordered_*` containers. + static size_t GetNumProbes(const Container& c, + const typename Container::key_type& key) { + if (!c.bucket_count()) return {}; + size_t num_probes = 0; + size_t bucket = c.bucket(key); + for (auto it = c.begin(bucket), e = c.end(bucket);; ++it, ++num_probes) { + if (it == e) return num_probes; + if (c.key_eq()(key, GetKey<Container>(*it, 0))) return num_probes; + } + } + + // Returns the number of bytes requested from the allocator by the container + // and not freed. + // + // static size_t AllocatedByteSize(const Container& c); + + // Returns a tight lower bound for AllocatedByteSize(c) where `c` is of type + // `Container` and `c.size()` is equal to `num_elements`. + // + // static size_t LowerBoundAllocatedByteSize(size_t num_elements); +}; + +} // namespace hashtable_debug_internal +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_HASHTABLE_DEBUG_HOOKS_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler.cc b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler.cc new file mode 100644 index 0000000000..886524f180 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler.cc @@ -0,0 +1,269 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hashtablez_sampler.h" + +#include <atomic> +#include <cassert> +#include <cmath> +#include <functional> +#include <limits> + +#include "absl/base/attributes.h" +#include "absl/base/internal/exponential_biased.h" +#include "absl/container/internal/have_sse.h" +#include "absl/debugging/stacktrace.h" +#include "absl/memory/memory.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +constexpr int HashtablezInfo::kMaxStackDepth; + +namespace { +ABSL_CONST_INIT std::atomic<bool> g_hashtablez_enabled{ + false +}; +ABSL_CONST_INIT std::atomic<int32_t> g_hashtablez_sample_parameter{1 << 10}; +ABSL_CONST_INIT std::atomic<int32_t> g_hashtablez_max_samples{1 << 20}; + +#if defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) +ABSL_PER_THREAD_TLS_KEYWORD absl::base_internal::ExponentialBiased + g_exponential_biased_generator; +#endif + +} // namespace + +#if defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) +ABSL_PER_THREAD_TLS_KEYWORD int64_t global_next_sample = 0; +#endif // defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) + +HashtablezSampler& HashtablezSampler::Global() { + static auto* sampler = new HashtablezSampler(); + return *sampler; +} + +HashtablezSampler::DisposeCallback HashtablezSampler::SetDisposeCallback( + DisposeCallback f) { + return dispose_.exchange(f, std::memory_order_relaxed); +} + +HashtablezInfo::HashtablezInfo() { PrepareForSampling(); } +HashtablezInfo::~HashtablezInfo() = default; + +void HashtablezInfo::PrepareForSampling() { + capacity.store(0, std::memory_order_relaxed); + size.store(0, std::memory_order_relaxed); + num_erases.store(0, std::memory_order_relaxed); + max_probe_length.store(0, std::memory_order_relaxed); + total_probe_length.store(0, std::memory_order_relaxed); + hashes_bitwise_or.store(0, std::memory_order_relaxed); + hashes_bitwise_and.store(~size_t{}, std::memory_order_relaxed); + + create_time = absl::Now(); + // The inliner makes hardcoded skip_count difficult (especially when combined + // with LTO). We use the ability to exclude stacks by regex when encoding + // instead. + depth = absl::GetStackTrace(stack, HashtablezInfo::kMaxStackDepth, + /* skip_count= */ 0); + dead = nullptr; +} + +HashtablezSampler::HashtablezSampler() + : dropped_samples_(0), size_estimate_(0), all_(nullptr), dispose_(nullptr) { + absl::MutexLock l(&graveyard_.init_mu); + graveyard_.dead = &graveyard_; +} + +HashtablezSampler::~HashtablezSampler() { + HashtablezInfo* s = all_.load(std::memory_order_acquire); + while (s != nullptr) { + HashtablezInfo* next = s->next; + delete s; + s = next; + } +} + +void HashtablezSampler::PushNew(HashtablezInfo* sample) { + sample->next = all_.load(std::memory_order_relaxed); + while (!all_.compare_exchange_weak(sample->next, sample, + std::memory_order_release, + std::memory_order_relaxed)) { + } +} + +void HashtablezSampler::PushDead(HashtablezInfo* sample) { + if (auto* dispose = dispose_.load(std::memory_order_relaxed)) { + dispose(*sample); + } + + absl::MutexLock graveyard_lock(&graveyard_.init_mu); + absl::MutexLock sample_lock(&sample->init_mu); + sample->dead = graveyard_.dead; + graveyard_.dead = sample; +} + +HashtablezInfo* HashtablezSampler::PopDead() { + absl::MutexLock graveyard_lock(&graveyard_.init_mu); + + // The list is circular, so eventually it collapses down to + // graveyard_.dead == &graveyard_ + // when it is empty. + HashtablezInfo* sample = graveyard_.dead; + if (sample == &graveyard_) return nullptr; + + absl::MutexLock sample_lock(&sample->init_mu); + graveyard_.dead = sample->dead; + sample->PrepareForSampling(); + return sample; +} + +HashtablezInfo* HashtablezSampler::Register() { + int64_t size = size_estimate_.fetch_add(1, std::memory_order_relaxed); + if (size > g_hashtablez_max_samples.load(std::memory_order_relaxed)) { + size_estimate_.fetch_sub(1, std::memory_order_relaxed); + dropped_samples_.fetch_add(1, std::memory_order_relaxed); + return nullptr; + } + + HashtablezInfo* sample = PopDead(); + if (sample == nullptr) { + // Resurrection failed. Hire a new warlock. + sample = new HashtablezInfo(); + PushNew(sample); + } + + return sample; +} + +void HashtablezSampler::Unregister(HashtablezInfo* sample) { + PushDead(sample); + size_estimate_.fetch_sub(1, std::memory_order_relaxed); +} + +int64_t HashtablezSampler::Iterate( + const std::function<void(const HashtablezInfo& stack)>& f) { + HashtablezInfo* s = all_.load(std::memory_order_acquire); + while (s != nullptr) { + absl::MutexLock l(&s->init_mu); + if (s->dead == nullptr) { + f(*s); + } + s = s->next; + } + + return dropped_samples_.load(std::memory_order_relaxed); +} + +static bool ShouldForceSampling() { + enum ForceState { + kDontForce, + kForce, + kUninitialized + }; + ABSL_CONST_INIT static std::atomic<ForceState> global_state{ + kUninitialized}; + ForceState state = global_state.load(std::memory_order_relaxed); + if (ABSL_PREDICT_TRUE(state == kDontForce)) return false; + + if (state == kUninitialized) { + state = AbslContainerInternalSampleEverything() ? kForce : kDontForce; + global_state.store(state, std::memory_order_relaxed); + } + return state == kForce; +} + +HashtablezInfo* SampleSlow(int64_t* next_sample) { + if (ABSL_PREDICT_FALSE(ShouldForceSampling())) { + *next_sample = 1; + return HashtablezSampler::Global().Register(); + } + +#if !defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) + *next_sample = std::numeric_limits<int64_t>::max(); + return nullptr; +#else + bool first = *next_sample < 0; + *next_sample = g_exponential_biased_generator.GetStride( + g_hashtablez_sample_parameter.load(std::memory_order_relaxed)); + // Small values of interval are equivalent to just sampling next time. + ABSL_ASSERT(*next_sample >= 1); + + // g_hashtablez_enabled can be dynamically flipped, we need to set a threshold + // low enough that we will start sampling in a reasonable time, so we just use + // the default sampling rate. + if (!g_hashtablez_enabled.load(std::memory_order_relaxed)) return nullptr; + + // We will only be negative on our first count, so we should just retry in + // that case. + if (first) { + if (ABSL_PREDICT_TRUE(--*next_sample > 0)) return nullptr; + return SampleSlow(next_sample); + } + + return HashtablezSampler::Global().Register(); +#endif +} + +void UnsampleSlow(HashtablezInfo* info) { + HashtablezSampler::Global().Unregister(info); +} + +void RecordInsertSlow(HashtablezInfo* info, size_t hash, + size_t distance_from_desired) { + // SwissTables probe in groups of 16, so scale this to count items probes and + // not offset from desired. + size_t probe_length = distance_from_desired; +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 + probe_length /= 16; +#else + probe_length /= 8; +#endif + + info->hashes_bitwise_and.fetch_and(hash, std::memory_order_relaxed); + info->hashes_bitwise_or.fetch_or(hash, std::memory_order_relaxed); + info->max_probe_length.store( + std::max(info->max_probe_length.load(std::memory_order_relaxed), + probe_length), + std::memory_order_relaxed); + info->total_probe_length.fetch_add(probe_length, std::memory_order_relaxed); + info->size.fetch_add(1, std::memory_order_relaxed); +} + +void SetHashtablezEnabled(bool enabled) { + g_hashtablez_enabled.store(enabled, std::memory_order_release); +} + +void SetHashtablezSampleParameter(int32_t rate) { + if (rate > 0) { + g_hashtablez_sample_parameter.store(rate, std::memory_order_release); + } else { + ABSL_RAW_LOG(ERROR, "Invalid hashtablez sample rate: %lld", + static_cast<long long>(rate)); // NOLINT(runtime/int) + } +} + +void SetHashtablezMaxSamples(int32_t max) { + if (max > 0) { + g_hashtablez_max_samples.store(max, std::memory_order_release); + } else { + ABSL_RAW_LOG(ERROR, "Invalid hashtablez max samples: %lld", + static_cast<long long>(max)); // NOLINT(runtime/int) + } +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler.h b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler.h new file mode 100644 index 0000000000..308119cf17 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler.h @@ -0,0 +1,292 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: hashtablez_sampler.h +// ----------------------------------------------------------------------------- +// +// This header file defines the API for a low level library to sample hashtables +// and collect runtime statistics about them. +// +// `HashtablezSampler` controls the lifecycle of `HashtablezInfo` objects which +// store information about a single sample. +// +// `Record*` methods store information into samples. +// `Sample()` and `Unsample()` make use of a single global sampler with +// properties controlled by the flags hashtablez_enabled, +// hashtablez_sample_rate, and hashtablez_max_samples. +// +// WARNING +// +// Using this sampling API may cause sampled Swiss tables to use the global +// allocator (operator `new`) in addition to any custom allocator. If you +// are using a table in an unusual circumstance where allocation or calling a +// linux syscall is unacceptable, this could interfere. +// +// This utility is internal-only. Use at your own risk. + +#ifndef ABSL_CONTAINER_INTERNAL_HASHTABLEZ_SAMPLER_H_ +#define ABSL_CONTAINER_INTERNAL_HASHTABLEZ_SAMPLER_H_ + +#include <atomic> +#include <functional> +#include <memory> +#include <vector> + +#include "absl/base/internal/per_thread_tls.h" +#include "absl/base/optimization.h" +#include "absl/container/internal/have_sse.h" +#include "absl/synchronization/mutex.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// Stores information about a sampled hashtable. All mutations to this *must* +// be made through `Record*` functions below. All reads from this *must* only +// occur in the callback to `HashtablezSampler::Iterate`. +struct HashtablezInfo { + // Constructs the object but does not fill in any fields. + HashtablezInfo(); + ~HashtablezInfo(); + HashtablezInfo(const HashtablezInfo&) = delete; + HashtablezInfo& operator=(const HashtablezInfo&) = delete; + + // Puts the object into a clean state, fills in the logically `const` members, + // blocking for any readers that are currently sampling the object. + void PrepareForSampling() ABSL_EXCLUSIVE_LOCKS_REQUIRED(init_mu); + + // These fields are mutated by the various Record* APIs and need to be + // thread-safe. + std::atomic<size_t> capacity; + std::atomic<size_t> size; + std::atomic<size_t> num_erases; + std::atomic<size_t> max_probe_length; + std::atomic<size_t> total_probe_length; + std::atomic<size_t> hashes_bitwise_or; + std::atomic<size_t> hashes_bitwise_and; + + // `HashtablezSampler` maintains intrusive linked lists for all samples. See + // comments on `HashtablezSampler::all_` for details on these. `init_mu` + // guards the ability to restore the sample to a pristine state. This + // prevents races with sampling and resurrecting an object. + absl::Mutex init_mu; + HashtablezInfo* next; + HashtablezInfo* dead ABSL_GUARDED_BY(init_mu); + + // All of the fields below are set by `PrepareForSampling`, they must not be + // mutated in `Record*` functions. They are logically `const` in that sense. + // These are guarded by init_mu, but that is not externalized to clients, who + // can only read them during `HashtablezSampler::Iterate` which will hold the + // lock. + static constexpr int kMaxStackDepth = 64; + absl::Time create_time; + int32_t depth; + void* stack[kMaxStackDepth]; +}; + +inline void RecordRehashSlow(HashtablezInfo* info, size_t total_probe_length) { +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 + total_probe_length /= 16; +#else + total_probe_length /= 8; +#endif + info->total_probe_length.store(total_probe_length, std::memory_order_relaxed); + info->num_erases.store(0, std::memory_order_relaxed); +} + +inline void RecordStorageChangedSlow(HashtablezInfo* info, size_t size, + size_t capacity) { + info->size.store(size, std::memory_order_relaxed); + info->capacity.store(capacity, std::memory_order_relaxed); + if (size == 0) { + // This is a clear, reset the total/num_erases too. + RecordRehashSlow(info, 0); + } +} + +void RecordInsertSlow(HashtablezInfo* info, size_t hash, + size_t distance_from_desired); + +inline void RecordEraseSlow(HashtablezInfo* info) { + info->size.fetch_sub(1, std::memory_order_relaxed); + info->num_erases.fetch_add(1, std::memory_order_relaxed); +} + +HashtablezInfo* SampleSlow(int64_t* next_sample); +void UnsampleSlow(HashtablezInfo* info); + +class HashtablezInfoHandle { + public: + explicit HashtablezInfoHandle() : info_(nullptr) {} + explicit HashtablezInfoHandle(HashtablezInfo* info) : info_(info) {} + ~HashtablezInfoHandle() { + if (ABSL_PREDICT_TRUE(info_ == nullptr)) return; + UnsampleSlow(info_); + } + + HashtablezInfoHandle(const HashtablezInfoHandle&) = delete; + HashtablezInfoHandle& operator=(const HashtablezInfoHandle&) = delete; + + HashtablezInfoHandle(HashtablezInfoHandle&& o) noexcept + : info_(absl::exchange(o.info_, nullptr)) {} + HashtablezInfoHandle& operator=(HashtablezInfoHandle&& o) noexcept { + if (ABSL_PREDICT_FALSE(info_ != nullptr)) { + UnsampleSlow(info_); + } + info_ = absl::exchange(o.info_, nullptr); + return *this; + } + + inline void RecordStorageChanged(size_t size, size_t capacity) { + if (ABSL_PREDICT_TRUE(info_ == nullptr)) return; + RecordStorageChangedSlow(info_, size, capacity); + } + + inline void RecordRehash(size_t total_probe_length) { + if (ABSL_PREDICT_TRUE(info_ == nullptr)) return; + RecordRehashSlow(info_, total_probe_length); + } + + inline void RecordInsert(size_t hash, size_t distance_from_desired) { + if (ABSL_PREDICT_TRUE(info_ == nullptr)) return; + RecordInsertSlow(info_, hash, distance_from_desired); + } + + inline void RecordErase() { + if (ABSL_PREDICT_TRUE(info_ == nullptr)) return; + RecordEraseSlow(info_); + } + + friend inline void swap(HashtablezInfoHandle& lhs, + HashtablezInfoHandle& rhs) { + std::swap(lhs.info_, rhs.info_); + } + + private: + friend class HashtablezInfoHandlePeer; + HashtablezInfo* info_; +}; + +#if defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) +#error ABSL_INTERNAL_HASHTABLEZ_SAMPLE cannot be directly set +#endif // defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) + +#if defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) +extern ABSL_PER_THREAD_TLS_KEYWORD int64_t global_next_sample; +#endif // ABSL_PER_THREAD_TLS + +// Returns an RAII sampling handle that manages registration and unregistation +// with the global sampler. +inline HashtablezInfoHandle Sample() { +#if defined(ABSL_INTERNAL_HASHTABLEZ_SAMPLE) + if (ABSL_PREDICT_TRUE(--global_next_sample > 0)) { + return HashtablezInfoHandle(nullptr); + } + return HashtablezInfoHandle(SampleSlow(&global_next_sample)); +#else + return HashtablezInfoHandle(nullptr); +#endif // !ABSL_PER_THREAD_TLS +} + +// Holds samples and their associated stack traces with a soft limit of +// `SetHashtablezMaxSamples()`. +// +// Thread safe. +class HashtablezSampler { + public: + // Returns a global Sampler. + static HashtablezSampler& Global(); + + HashtablezSampler(); + ~HashtablezSampler(); + + // Registers for sampling. Returns an opaque registration info. + HashtablezInfo* Register(); + + // Unregisters the sample. + void Unregister(HashtablezInfo* sample); + + // The dispose callback will be called on all samples the moment they are + // being unregistered. Only affects samples that are unregistered after the + // callback has been set. + // Returns the previous callback. + using DisposeCallback = void (*)(const HashtablezInfo&); + DisposeCallback SetDisposeCallback(DisposeCallback f); + + // Iterates over all the registered `StackInfo`s. Returning the number of + // samples that have been dropped. + int64_t Iterate(const std::function<void(const HashtablezInfo& stack)>& f); + + private: + void PushNew(HashtablezInfo* sample); + void PushDead(HashtablezInfo* sample); + HashtablezInfo* PopDead(); + + std::atomic<size_t> dropped_samples_; + std::atomic<size_t> size_estimate_; + + // Intrusive lock free linked lists for tracking samples. + // + // `all_` records all samples (they are never removed from this list) and is + // terminated with a `nullptr`. + // + // `graveyard_.dead` is a circular linked list. When it is empty, + // `graveyard_.dead == &graveyard`. The list is circular so that + // every item on it (even the last) has a non-null dead pointer. This allows + // `Iterate` to determine if a given sample is live or dead using only + // information on the sample itself. + // + // For example, nodes [A, B, C, D, E] with [A, C, E] alive and [B, D] dead + // looks like this (G is the Graveyard): + // + // +---+ +---+ +---+ +---+ +---+ + // all -->| A |--->| B |--->| C |--->| D |--->| E | + // | | | | | | | | | | + // +---+ | | +->| |-+ | | +->| |-+ | | + // | G | +---+ | +---+ | +---+ | +---+ | +---+ + // | | | | | | + // | | --------+ +--------+ | + // +---+ | + // ^ | + // +--------------------------------------+ + // + std::atomic<HashtablezInfo*> all_; + HashtablezInfo graveyard_; + + std::atomic<DisposeCallback> dispose_; +}; + +// Enables or disables sampling for Swiss tables. +void SetHashtablezEnabled(bool enabled); + +// Sets the rate at which Swiss tables will be sampled. +void SetHashtablezSampleParameter(int32_t rate); + +// Sets a soft max for the number of samples that will be kept. +void SetHashtablezMaxSamples(int32_t max); + +// Configuration override. +// This allows process-wide sampling without depending on order of +// initialization of static storage duration objects. +// The definition of this constant is weak, which allows us to inject a +// different value for it at link time. +extern "C" bool AbslContainerInternalSampleEverything(); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_HASHTABLEZ_SAMPLER_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler_force_weak_definition.cc b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler_force_weak_definition.cc new file mode 100644 index 0000000000..78b9d362ac --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler_force_weak_definition.cc @@ -0,0 +1,30 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hashtablez_sampler.h" + +#include "absl/base/attributes.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// See hashtablez_sampler.h for details. +extern "C" ABSL_ATTRIBUTE_WEAK bool AbslContainerInternalSampleEverything() { + return false; +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler_test.cc b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler_test.cc new file mode 100644 index 0000000000..b4c4ff92e7 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/hashtablez_sampler_test.cc @@ -0,0 +1,359 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/hashtablez_sampler.h" + +#include <atomic> +#include <limits> +#include <random> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/container/internal/have_sse.h" +#include "absl/synchronization/blocking_counter.h" +#include "absl/synchronization/internal/thread_pool.h" +#include "absl/synchronization/mutex.h" +#include "absl/synchronization/notification.h" +#include "absl/time/clock.h" +#include "absl/time/time.h" + +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 +constexpr int kProbeLength = 16; +#else +constexpr int kProbeLength = 8; +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +class HashtablezInfoHandlePeer { + public: + static bool IsSampled(const HashtablezInfoHandle& h) { + return h.info_ != nullptr; + } + + static HashtablezInfo* GetInfo(HashtablezInfoHandle* h) { return h->info_; } +}; + +namespace { +using ::absl::synchronization_internal::ThreadPool; +using ::testing::IsEmpty; +using ::testing::UnorderedElementsAre; + +std::vector<size_t> GetSizes(HashtablezSampler* s) { + std::vector<size_t> res; + s->Iterate([&](const HashtablezInfo& info) { + res.push_back(info.size.load(std::memory_order_acquire)); + }); + return res; +} + +HashtablezInfo* Register(HashtablezSampler* s, size_t size) { + auto* info = s->Register(); + assert(info != nullptr); + info->size.store(size); + return info; +} + +TEST(HashtablezInfoTest, PrepareForSampling) { + absl::Time test_start = absl::Now(); + HashtablezInfo info; + absl::MutexLock l(&info.init_mu); + info.PrepareForSampling(); + + EXPECT_EQ(info.capacity.load(), 0); + EXPECT_EQ(info.size.load(), 0); + EXPECT_EQ(info.num_erases.load(), 0); + EXPECT_EQ(info.max_probe_length.load(), 0); + EXPECT_EQ(info.total_probe_length.load(), 0); + EXPECT_EQ(info.hashes_bitwise_or.load(), 0); + EXPECT_EQ(info.hashes_bitwise_and.load(), ~size_t{}); + EXPECT_GE(info.create_time, test_start); + + info.capacity.store(1, std::memory_order_relaxed); + info.size.store(1, std::memory_order_relaxed); + info.num_erases.store(1, std::memory_order_relaxed); + info.max_probe_length.store(1, std::memory_order_relaxed); + info.total_probe_length.store(1, std::memory_order_relaxed); + info.hashes_bitwise_or.store(1, std::memory_order_relaxed); + info.hashes_bitwise_and.store(1, std::memory_order_relaxed); + info.create_time = test_start - absl::Hours(20); + + info.PrepareForSampling(); + EXPECT_EQ(info.capacity.load(), 0); + EXPECT_EQ(info.size.load(), 0); + EXPECT_EQ(info.num_erases.load(), 0); + EXPECT_EQ(info.max_probe_length.load(), 0); + EXPECT_EQ(info.total_probe_length.load(), 0); + EXPECT_EQ(info.hashes_bitwise_or.load(), 0); + EXPECT_EQ(info.hashes_bitwise_and.load(), ~size_t{}); + EXPECT_GE(info.create_time, test_start); +} + +TEST(HashtablezInfoTest, RecordStorageChanged) { + HashtablezInfo info; + absl::MutexLock l(&info.init_mu); + info.PrepareForSampling(); + RecordStorageChangedSlow(&info, 17, 47); + EXPECT_EQ(info.size.load(), 17); + EXPECT_EQ(info.capacity.load(), 47); + RecordStorageChangedSlow(&info, 20, 20); + EXPECT_EQ(info.size.load(), 20); + EXPECT_EQ(info.capacity.load(), 20); +} + +TEST(HashtablezInfoTest, RecordInsert) { + HashtablezInfo info; + absl::MutexLock l(&info.init_mu); + info.PrepareForSampling(); + EXPECT_EQ(info.max_probe_length.load(), 0); + RecordInsertSlow(&info, 0x0000FF00, 6 * kProbeLength); + EXPECT_EQ(info.max_probe_length.load(), 6); + EXPECT_EQ(info.hashes_bitwise_and.load(), 0x0000FF00); + EXPECT_EQ(info.hashes_bitwise_or.load(), 0x0000FF00); + RecordInsertSlow(&info, 0x000FF000, 4 * kProbeLength); + EXPECT_EQ(info.max_probe_length.load(), 6); + EXPECT_EQ(info.hashes_bitwise_and.load(), 0x0000F000); + EXPECT_EQ(info.hashes_bitwise_or.load(), 0x000FFF00); + RecordInsertSlow(&info, 0x00FF0000, 12 * kProbeLength); + EXPECT_EQ(info.max_probe_length.load(), 12); + EXPECT_EQ(info.hashes_bitwise_and.load(), 0x00000000); + EXPECT_EQ(info.hashes_bitwise_or.load(), 0x00FFFF00); +} + +TEST(HashtablezInfoTest, RecordErase) { + HashtablezInfo info; + absl::MutexLock l(&info.init_mu); + info.PrepareForSampling(); + EXPECT_EQ(info.num_erases.load(), 0); + EXPECT_EQ(info.size.load(), 0); + RecordInsertSlow(&info, 0x0000FF00, 6 * kProbeLength); + EXPECT_EQ(info.size.load(), 1); + RecordEraseSlow(&info); + EXPECT_EQ(info.size.load(), 0); + EXPECT_EQ(info.num_erases.load(), 1); +} + +TEST(HashtablezInfoTest, RecordRehash) { + HashtablezInfo info; + absl::MutexLock l(&info.init_mu); + info.PrepareForSampling(); + RecordInsertSlow(&info, 0x1, 0); + RecordInsertSlow(&info, 0x2, kProbeLength); + RecordInsertSlow(&info, 0x4, kProbeLength); + RecordInsertSlow(&info, 0x8, 2 * kProbeLength); + EXPECT_EQ(info.size.load(), 4); + EXPECT_EQ(info.total_probe_length.load(), 4); + + RecordEraseSlow(&info); + RecordEraseSlow(&info); + EXPECT_EQ(info.size.load(), 2); + EXPECT_EQ(info.total_probe_length.load(), 4); + EXPECT_EQ(info.num_erases.load(), 2); + + RecordRehashSlow(&info, 3 * kProbeLength); + EXPECT_EQ(info.size.load(), 2); + EXPECT_EQ(info.total_probe_length.load(), 3); + EXPECT_EQ(info.num_erases.load(), 0); +} + +#if defined(ABSL_HASHTABLEZ_SAMPLE) +TEST(HashtablezSamplerTest, SmallSampleParameter) { + SetHashtablezEnabled(true); + SetHashtablezSampleParameter(100); + + for (int i = 0; i < 1000; ++i) { + int64_t next_sample = 0; + HashtablezInfo* sample = SampleSlow(&next_sample); + EXPECT_GT(next_sample, 0); + EXPECT_NE(sample, nullptr); + UnsampleSlow(sample); + } +} + +TEST(HashtablezSamplerTest, LargeSampleParameter) { + SetHashtablezEnabled(true); + SetHashtablezSampleParameter(std::numeric_limits<int32_t>::max()); + + for (int i = 0; i < 1000; ++i) { + int64_t next_sample = 0; + HashtablezInfo* sample = SampleSlow(&next_sample); + EXPECT_GT(next_sample, 0); + EXPECT_NE(sample, nullptr); + UnsampleSlow(sample); + } +} + +TEST(HashtablezSamplerTest, Sample) { + SetHashtablezEnabled(true); + SetHashtablezSampleParameter(100); + int64_t num_sampled = 0; + int64_t total = 0; + double sample_rate = 0.0; + for (int i = 0; i < 1000000; ++i) { + HashtablezInfoHandle h = Sample(); + ++total; + if (HashtablezInfoHandlePeer::IsSampled(h)) { + ++num_sampled; + } + sample_rate = static_cast<double>(num_sampled) / total; + if (0.005 < sample_rate && sample_rate < 0.015) break; + } + EXPECT_NEAR(sample_rate, 0.01, 0.005); +} +#endif + +TEST(HashtablezSamplerTest, Handle) { + auto& sampler = HashtablezSampler::Global(); + HashtablezInfoHandle h(sampler.Register()); + auto* info = HashtablezInfoHandlePeer::GetInfo(&h); + info->hashes_bitwise_and.store(0x12345678, std::memory_order_relaxed); + + bool found = false; + sampler.Iterate([&](const HashtablezInfo& h) { + if (&h == info) { + EXPECT_EQ(h.hashes_bitwise_and.load(), 0x12345678); + found = true; + } + }); + EXPECT_TRUE(found); + + h = HashtablezInfoHandle(); + found = false; + sampler.Iterate([&](const HashtablezInfo& h) { + if (&h == info) { + // this will only happen if some other thread has resurrected the info + // the old handle was using. + if (h.hashes_bitwise_and.load() == 0x12345678) { + found = true; + } + } + }); + EXPECT_FALSE(found); +} + +TEST(HashtablezSamplerTest, Registration) { + HashtablezSampler sampler; + auto* info1 = Register(&sampler, 1); + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(1)); + + auto* info2 = Register(&sampler, 2); + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(1, 2)); + info1->size.store(3); + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(3, 2)); + + sampler.Unregister(info1); + sampler.Unregister(info2); +} + +TEST(HashtablezSamplerTest, Unregistration) { + HashtablezSampler sampler; + std::vector<HashtablezInfo*> infos; + for (size_t i = 0; i < 3; ++i) { + infos.push_back(Register(&sampler, i)); + } + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(0, 1, 2)); + + sampler.Unregister(infos[1]); + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(0, 2)); + + infos.push_back(Register(&sampler, 3)); + infos.push_back(Register(&sampler, 4)); + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(0, 2, 3, 4)); + sampler.Unregister(infos[3]); + EXPECT_THAT(GetSizes(&sampler), UnorderedElementsAre(0, 2, 4)); + + sampler.Unregister(infos[0]); + sampler.Unregister(infos[2]); + sampler.Unregister(infos[4]); + EXPECT_THAT(GetSizes(&sampler), IsEmpty()); +} + +TEST(HashtablezSamplerTest, MultiThreaded) { + HashtablezSampler sampler; + Notification stop; + ThreadPool pool(10); + + for (int i = 0; i < 10; ++i) { + pool.Schedule([&sampler, &stop]() { + std::random_device rd; + std::mt19937 gen(rd()); + + std::vector<HashtablezInfo*> infoz; + while (!stop.HasBeenNotified()) { + if (infoz.empty()) { + infoz.push_back(sampler.Register()); + } + switch (std::uniform_int_distribution<>(0, 2)(gen)) { + case 0: { + infoz.push_back(sampler.Register()); + break; + } + case 1: { + size_t p = + std::uniform_int_distribution<>(0, infoz.size() - 1)(gen); + HashtablezInfo* info = infoz[p]; + infoz[p] = infoz.back(); + infoz.pop_back(); + sampler.Unregister(info); + break; + } + case 2: { + absl::Duration oldest = absl::ZeroDuration(); + sampler.Iterate([&](const HashtablezInfo& info) { + oldest = std::max(oldest, absl::Now() - info.create_time); + }); + ASSERT_GE(oldest, absl::ZeroDuration()); + break; + } + } + } + }); + } + // The threads will hammer away. Give it a little bit of time for tsan to + // spot errors. + absl::SleepFor(absl::Seconds(3)); + stop.Notify(); +} + +TEST(HashtablezSamplerTest, Callback) { + HashtablezSampler sampler; + + auto* info1 = Register(&sampler, 1); + auto* info2 = Register(&sampler, 2); + + static const HashtablezInfo* expected; + + auto callback = [](const HashtablezInfo& info) { + // We can't use `info` outside of this callback because the object will be + // disposed as soon as we return from here. + EXPECT_EQ(&info, expected); + }; + + // Set the callback. + EXPECT_EQ(sampler.SetDisposeCallback(callback), nullptr); + expected = info1; + sampler.Unregister(info1); + + // Unset the callback. + EXPECT_EQ(callback, sampler.SetDisposeCallback(nullptr)); + expected = nullptr; // no more calls. + sampler.Unregister(info2); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/have_sse.h b/third_party/abseil_cpp/absl/container/internal/have_sse.h new file mode 100644 index 0000000000..e75e1a16d3 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/have_sse.h @@ -0,0 +1,50 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Shared config probing for SSE instructions used in Swiss tables. +#ifndef ABSL_CONTAINER_INTERNAL_HAVE_SSE_H_ +#define ABSL_CONTAINER_INTERNAL_HAVE_SSE_H_ + +#ifndef ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 +#if defined(__SSE2__) || \ + (defined(_MSC_VER) && \ + (defined(_M_X64) || (defined(_M_IX86) && _M_IX86_FP >= 2))) +#define ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 1 +#else +#define ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 0 +#endif +#endif + +#ifndef ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 +#ifdef __SSSE3__ +#define ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 1 +#else +#define ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 0 +#endif +#endif + +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 && \ + !ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 +#error "Bad configuration!" +#endif + +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 +#include <emmintrin.h> +#endif + +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 +#include <tmmintrin.h> +#endif + +#endif // ABSL_CONTAINER_INTERNAL_HAVE_SSE_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/inlined_vector.h b/third_party/abseil_cpp/absl/container/internal/inlined_vector.h new file mode 100644 index 0000000000..4d80b727bf --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/inlined_vector.h @@ -0,0 +1,892 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_INLINED_VECTOR_INTERNAL_H_ +#define ABSL_CONTAINER_INTERNAL_INLINED_VECTOR_INTERNAL_H_ + +#include <algorithm> +#include <cstddef> +#include <cstring> +#include <iterator> +#include <limits> +#include <memory> +#include <utility> + +#include "absl/base/macros.h" +#include "absl/container/internal/compressed_tuple.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace inlined_vector_internal { + +template <typename Iterator> +using IsAtLeastForwardIterator = std::is_convertible< + typename std::iterator_traits<Iterator>::iterator_category, + std::forward_iterator_tag>; + +template <typename AllocatorType, + typename ValueType = + typename absl::allocator_traits<AllocatorType>::value_type> +using IsMemcpyOk = + absl::conjunction<std::is_same<AllocatorType, std::allocator<ValueType>>, + absl::is_trivially_copy_constructible<ValueType>, + absl::is_trivially_copy_assignable<ValueType>, + absl::is_trivially_destructible<ValueType>>; + +template <typename AllocatorType, typename Pointer, typename SizeType> +void DestroyElements(AllocatorType* alloc_ptr, Pointer destroy_first, + SizeType destroy_size) { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + + if (destroy_first != nullptr) { + for (auto i = destroy_size; i != 0;) { + --i; + AllocatorTraits::destroy(*alloc_ptr, destroy_first + i); + } + +#if !defined(NDEBUG) + { + using ValueType = typename AllocatorTraits::value_type; + + // Overwrite unused memory with `0xab` so we can catch uninitialized + // usage. + // + // Cast to `void*` to tell the compiler that we don't care that we might + // be scribbling on a vtable pointer. + void* memory_ptr = destroy_first; + auto memory_size = destroy_size * sizeof(ValueType); + std::memset(memory_ptr, 0xab, memory_size); + } +#endif // !defined(NDEBUG) + } +} + +template <typename AllocatorType, typename Pointer, typename ValueAdapter, + typename SizeType> +void ConstructElements(AllocatorType* alloc_ptr, Pointer construct_first, + ValueAdapter* values_ptr, SizeType construct_size) { + for (SizeType i = 0; i < construct_size; ++i) { + ABSL_INTERNAL_TRY { + values_ptr->ConstructNext(alloc_ptr, construct_first + i); + } + ABSL_INTERNAL_CATCH_ANY { + inlined_vector_internal::DestroyElements(alloc_ptr, construct_first, i); + ABSL_INTERNAL_RETHROW; + } + } +} + +template <typename Pointer, typename ValueAdapter, typename SizeType> +void AssignElements(Pointer assign_first, ValueAdapter* values_ptr, + SizeType assign_size) { + for (SizeType i = 0; i < assign_size; ++i) { + values_ptr->AssignNext(assign_first + i); + } +} + +template <typename AllocatorType> +struct StorageView { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + using Pointer = typename AllocatorTraits::pointer; + using SizeType = typename AllocatorTraits::size_type; + + Pointer data; + SizeType size; + SizeType capacity; +}; + +template <typename AllocatorType, typename Iterator> +class IteratorValueAdapter { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + using Pointer = typename AllocatorTraits::pointer; + + public: + explicit IteratorValueAdapter(const Iterator& it) : it_(it) {} + + void ConstructNext(AllocatorType* alloc_ptr, Pointer construct_at) { + AllocatorTraits::construct(*alloc_ptr, construct_at, *it_); + ++it_; + } + + void AssignNext(Pointer assign_at) { + *assign_at = *it_; + ++it_; + } + + private: + Iterator it_; +}; + +template <typename AllocatorType> +class CopyValueAdapter { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + using ValueType = typename AllocatorTraits::value_type; + using Pointer = typename AllocatorTraits::pointer; + using ConstPointer = typename AllocatorTraits::const_pointer; + + public: + explicit CopyValueAdapter(const ValueType& v) : ptr_(std::addressof(v)) {} + + void ConstructNext(AllocatorType* alloc_ptr, Pointer construct_at) { + AllocatorTraits::construct(*alloc_ptr, construct_at, *ptr_); + } + + void AssignNext(Pointer assign_at) { *assign_at = *ptr_; } + + private: + ConstPointer ptr_; +}; + +template <typename AllocatorType> +class DefaultValueAdapter { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + using ValueType = typename AllocatorTraits::value_type; + using Pointer = typename AllocatorTraits::pointer; + + public: + explicit DefaultValueAdapter() {} + + void ConstructNext(AllocatorType* alloc_ptr, Pointer construct_at) { + AllocatorTraits::construct(*alloc_ptr, construct_at); + } + + void AssignNext(Pointer assign_at) { *assign_at = ValueType(); } +}; + +template <typename AllocatorType> +class AllocationTransaction { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + using Pointer = typename AllocatorTraits::pointer; + using SizeType = typename AllocatorTraits::size_type; + + public: + explicit AllocationTransaction(AllocatorType* alloc_ptr) + : alloc_data_(*alloc_ptr, nullptr) {} + + ~AllocationTransaction() { + if (DidAllocate()) { + AllocatorTraits::deallocate(GetAllocator(), GetData(), GetCapacity()); + } + } + + AllocationTransaction(const AllocationTransaction&) = delete; + void operator=(const AllocationTransaction&) = delete; + + AllocatorType& GetAllocator() { return alloc_data_.template get<0>(); } + Pointer& GetData() { return alloc_data_.template get<1>(); } + SizeType& GetCapacity() { return capacity_; } + + bool DidAllocate() { return GetData() != nullptr; } + Pointer Allocate(SizeType capacity) { + GetData() = AllocatorTraits::allocate(GetAllocator(), capacity); + GetCapacity() = capacity; + return GetData(); + } + + void Reset() { + GetData() = nullptr; + GetCapacity() = 0; + } + + private: + container_internal::CompressedTuple<AllocatorType, Pointer> alloc_data_; + SizeType capacity_ = 0; +}; + +template <typename AllocatorType> +class ConstructionTransaction { + using AllocatorTraits = absl::allocator_traits<AllocatorType>; + using Pointer = typename AllocatorTraits::pointer; + using SizeType = typename AllocatorTraits::size_type; + + public: + explicit ConstructionTransaction(AllocatorType* alloc_ptr) + : alloc_data_(*alloc_ptr, nullptr) {} + + ~ConstructionTransaction() { + if (DidConstruct()) { + inlined_vector_internal::DestroyElements(std::addressof(GetAllocator()), + GetData(), GetSize()); + } + } + + ConstructionTransaction(const ConstructionTransaction&) = delete; + void operator=(const ConstructionTransaction&) = delete; + + AllocatorType& GetAllocator() { return alloc_data_.template get<0>(); } + Pointer& GetData() { return alloc_data_.template get<1>(); } + SizeType& GetSize() { return size_; } + + bool DidConstruct() { return GetData() != nullptr; } + template <typename ValueAdapter> + void Construct(Pointer data, ValueAdapter* values_ptr, SizeType size) { + inlined_vector_internal::ConstructElements(std::addressof(GetAllocator()), + data, values_ptr, size); + GetData() = data; + GetSize() = size; + } + void Commit() { + GetData() = nullptr; + GetSize() = 0; + } + + private: + container_internal::CompressedTuple<AllocatorType, Pointer> alloc_data_; + SizeType size_ = 0; +}; + +template <typename T, size_t N, typename A> +class Storage { + public: + using AllocatorTraits = absl::allocator_traits<A>; + using allocator_type = typename AllocatorTraits::allocator_type; + using value_type = typename AllocatorTraits::value_type; + using pointer = typename AllocatorTraits::pointer; + using const_pointer = typename AllocatorTraits::const_pointer; + using size_type = typename AllocatorTraits::size_type; + using difference_type = typename AllocatorTraits::difference_type; + + using reference = value_type&; + using const_reference = const value_type&; + using RValueReference = value_type&&; + using iterator = pointer; + using const_iterator = const_pointer; + using reverse_iterator = std::reverse_iterator<iterator>; + using const_reverse_iterator = std::reverse_iterator<const_iterator>; + using MoveIterator = std::move_iterator<iterator>; + using IsMemcpyOk = inlined_vector_internal::IsMemcpyOk<allocator_type>; + + using StorageView = inlined_vector_internal::StorageView<allocator_type>; + + template <typename Iterator> + using IteratorValueAdapter = + inlined_vector_internal::IteratorValueAdapter<allocator_type, Iterator>; + using CopyValueAdapter = + inlined_vector_internal::CopyValueAdapter<allocator_type>; + using DefaultValueAdapter = + inlined_vector_internal::DefaultValueAdapter<allocator_type>; + + using AllocationTransaction = + inlined_vector_internal::AllocationTransaction<allocator_type>; + using ConstructionTransaction = + inlined_vector_internal::ConstructionTransaction<allocator_type>; + + static size_type NextCapacity(size_type current_capacity) { + return current_capacity * 2; + } + + static size_type ComputeCapacity(size_type current_capacity, + size_type requested_capacity) { + return (std::max)(NextCapacity(current_capacity), requested_capacity); + } + + // --------------------------------------------------------------------------- + // Storage Constructors and Destructor + // --------------------------------------------------------------------------- + + Storage() : metadata_() {} + + explicit Storage(const allocator_type& alloc) : metadata_(alloc, {}) {} + + ~Storage() { + pointer data = GetIsAllocated() ? GetAllocatedData() : GetInlinedData(); + inlined_vector_internal::DestroyElements(GetAllocPtr(), data, GetSize()); + DeallocateIfAllocated(); + } + + // --------------------------------------------------------------------------- + // Storage Member Accessors + // --------------------------------------------------------------------------- + + size_type& GetSizeAndIsAllocated() { return metadata_.template get<1>(); } + + const size_type& GetSizeAndIsAllocated() const { + return metadata_.template get<1>(); + } + + size_type GetSize() const { return GetSizeAndIsAllocated() >> 1; } + + bool GetIsAllocated() const { return GetSizeAndIsAllocated() & 1; } + + pointer GetAllocatedData() { return data_.allocated.allocated_data; } + + const_pointer GetAllocatedData() const { + return data_.allocated.allocated_data; + } + + pointer GetInlinedData() { + return reinterpret_cast<pointer>( + std::addressof(data_.inlined.inlined_data[0])); + } + + const_pointer GetInlinedData() const { + return reinterpret_cast<const_pointer>( + std::addressof(data_.inlined.inlined_data[0])); + } + + size_type GetAllocatedCapacity() const { + return data_.allocated.allocated_capacity; + } + + size_type GetInlinedCapacity() const { return static_cast<size_type>(N); } + + StorageView MakeStorageView() { + return GetIsAllocated() + ? StorageView{GetAllocatedData(), GetSize(), + GetAllocatedCapacity()} + : StorageView{GetInlinedData(), GetSize(), GetInlinedCapacity()}; + } + + allocator_type* GetAllocPtr() { + return std::addressof(metadata_.template get<0>()); + } + + const allocator_type* GetAllocPtr() const { + return std::addressof(metadata_.template get<0>()); + } + + // --------------------------------------------------------------------------- + // Storage Member Mutators + // --------------------------------------------------------------------------- + + template <typename ValueAdapter> + void Initialize(ValueAdapter values, size_type new_size); + + template <typename ValueAdapter> + void Assign(ValueAdapter values, size_type new_size); + + template <typename ValueAdapter> + void Resize(ValueAdapter values, size_type new_size); + + template <typename ValueAdapter> + iterator Insert(const_iterator pos, ValueAdapter values, + size_type insert_count); + + template <typename... Args> + reference EmplaceBack(Args&&... args); + + iterator Erase(const_iterator from, const_iterator to); + + void Reserve(size_type requested_capacity); + + void ShrinkToFit(); + + void Swap(Storage* other_storage_ptr); + + void SetIsAllocated() { + GetSizeAndIsAllocated() |= static_cast<size_type>(1); + } + + void UnsetIsAllocated() { + GetSizeAndIsAllocated() &= ((std::numeric_limits<size_type>::max)() - 1); + } + + void SetSize(size_type size) { + GetSizeAndIsAllocated() = + (size << 1) | static_cast<size_type>(GetIsAllocated()); + } + + void SetAllocatedSize(size_type size) { + GetSizeAndIsAllocated() = (size << 1) | static_cast<size_type>(1); + } + + void SetInlinedSize(size_type size) { + GetSizeAndIsAllocated() = size << static_cast<size_type>(1); + } + + void AddSize(size_type count) { + GetSizeAndIsAllocated() += count << static_cast<size_type>(1); + } + + void SubtractSize(size_type count) { + assert(count <= GetSize()); + + GetSizeAndIsAllocated() -= count << static_cast<size_type>(1); + } + + void SetAllocatedData(pointer data, size_type capacity) { + data_.allocated.allocated_data = data; + data_.allocated.allocated_capacity = capacity; + } + + void AcquireAllocatedData(AllocationTransaction* allocation_tx_ptr) { + SetAllocatedData(allocation_tx_ptr->GetData(), + allocation_tx_ptr->GetCapacity()); + + allocation_tx_ptr->Reset(); + } + + void MemcpyFrom(const Storage& other_storage) { + assert(IsMemcpyOk::value || other_storage.GetIsAllocated()); + + GetSizeAndIsAllocated() = other_storage.GetSizeAndIsAllocated(); + data_ = other_storage.data_; + } + + void DeallocateIfAllocated() { + if (GetIsAllocated()) { + AllocatorTraits::deallocate(*GetAllocPtr(), GetAllocatedData(), + GetAllocatedCapacity()); + } + } + + private: + using Metadata = + container_internal::CompressedTuple<allocator_type, size_type>; + + struct Allocated { + pointer allocated_data; + size_type allocated_capacity; + }; + + struct Inlined { + alignas(value_type) char inlined_data[sizeof(value_type[N])]; + }; + + union Data { + Allocated allocated; + Inlined inlined; + }; + + Metadata metadata_; + Data data_; +}; + +template <typename T, size_t N, typename A> +template <typename ValueAdapter> +auto Storage<T, N, A>::Initialize(ValueAdapter values, size_type new_size) + -> void { + // Only callable from constructors! + assert(!GetIsAllocated()); + assert(GetSize() == 0); + + pointer construct_data; + if (new_size > GetInlinedCapacity()) { + // Because this is only called from the `InlinedVector` constructors, it's + // safe to take on the allocation with size `0`. If `ConstructElements(...)` + // throws, deallocation will be automatically handled by `~Storage()`. + size_type new_capacity = ComputeCapacity(GetInlinedCapacity(), new_size); + construct_data = AllocatorTraits::allocate(*GetAllocPtr(), new_capacity); + SetAllocatedData(construct_data, new_capacity); + SetIsAllocated(); + } else { + construct_data = GetInlinedData(); + } + + inlined_vector_internal::ConstructElements(GetAllocPtr(), construct_data, + &values, new_size); + + // Since the initial size was guaranteed to be `0` and the allocated bit is + // already correct for either case, *adding* `new_size` gives us the correct + // result faster than setting it directly. + AddSize(new_size); +} + +template <typename T, size_t N, typename A> +template <typename ValueAdapter> +auto Storage<T, N, A>::Assign(ValueAdapter values, size_type new_size) -> void { + StorageView storage_view = MakeStorageView(); + + AllocationTransaction allocation_tx(GetAllocPtr()); + + absl::Span<value_type> assign_loop; + absl::Span<value_type> construct_loop; + absl::Span<value_type> destroy_loop; + + if (new_size > storage_view.capacity) { + size_type new_capacity = ComputeCapacity(storage_view.capacity, new_size); + construct_loop = {allocation_tx.Allocate(new_capacity), new_size}; + destroy_loop = {storage_view.data, storage_view.size}; + } else if (new_size > storage_view.size) { + assign_loop = {storage_view.data, storage_view.size}; + construct_loop = {storage_view.data + storage_view.size, + new_size - storage_view.size}; + } else { + assign_loop = {storage_view.data, new_size}; + destroy_loop = {storage_view.data + new_size, storage_view.size - new_size}; + } + + inlined_vector_internal::AssignElements(assign_loop.data(), &values, + assign_loop.size()); + + inlined_vector_internal::ConstructElements( + GetAllocPtr(), construct_loop.data(), &values, construct_loop.size()); + + inlined_vector_internal::DestroyElements(GetAllocPtr(), destroy_loop.data(), + destroy_loop.size()); + + if (allocation_tx.DidAllocate()) { + DeallocateIfAllocated(); + AcquireAllocatedData(&allocation_tx); + SetIsAllocated(); + } + + SetSize(new_size); +} + +template <typename T, size_t N, typename A> +template <typename ValueAdapter> +auto Storage<T, N, A>::Resize(ValueAdapter values, size_type new_size) -> void { + StorageView storage_view = MakeStorageView(); + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(storage_view.data)); + + AllocationTransaction allocation_tx(GetAllocPtr()); + ConstructionTransaction construction_tx(GetAllocPtr()); + + absl::Span<value_type> construct_loop; + absl::Span<value_type> move_construct_loop; + absl::Span<value_type> destroy_loop; + + if (new_size > storage_view.capacity) { + size_type new_capacity = ComputeCapacity(storage_view.capacity, new_size); + pointer new_data = allocation_tx.Allocate(new_capacity); + construct_loop = {new_data + storage_view.size, + new_size - storage_view.size}; + move_construct_loop = {new_data, storage_view.size}; + destroy_loop = {storage_view.data, storage_view.size}; + } else if (new_size > storage_view.size) { + construct_loop = {storage_view.data + storage_view.size, + new_size - storage_view.size}; + } else { + destroy_loop = {storage_view.data + new_size, storage_view.size - new_size}; + } + + construction_tx.Construct(construct_loop.data(), &values, + construct_loop.size()); + + inlined_vector_internal::ConstructElements( + GetAllocPtr(), move_construct_loop.data(), &move_values, + move_construct_loop.size()); + + inlined_vector_internal::DestroyElements(GetAllocPtr(), destroy_loop.data(), + destroy_loop.size()); + + construction_tx.Commit(); + if (allocation_tx.DidAllocate()) { + DeallocateIfAllocated(); + AcquireAllocatedData(&allocation_tx); + SetIsAllocated(); + } + + SetSize(new_size); +} + +template <typename T, size_t N, typename A> +template <typename ValueAdapter> +auto Storage<T, N, A>::Insert(const_iterator pos, ValueAdapter values, + size_type insert_count) -> iterator { + StorageView storage_view = MakeStorageView(); + + size_type insert_index = + std::distance(const_iterator(storage_view.data), pos); + size_type insert_end_index = insert_index + insert_count; + size_type new_size = storage_view.size + insert_count; + + if (new_size > storage_view.capacity) { + AllocationTransaction allocation_tx(GetAllocPtr()); + ConstructionTransaction construction_tx(GetAllocPtr()); + ConstructionTransaction move_construciton_tx(GetAllocPtr()); + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(storage_view.data)); + + size_type new_capacity = ComputeCapacity(storage_view.capacity, new_size); + pointer new_data = allocation_tx.Allocate(new_capacity); + + construction_tx.Construct(new_data + insert_index, &values, insert_count); + + move_construciton_tx.Construct(new_data, &move_values, insert_index); + + inlined_vector_internal::ConstructElements( + GetAllocPtr(), new_data + insert_end_index, &move_values, + storage_view.size - insert_index); + + inlined_vector_internal::DestroyElements(GetAllocPtr(), storage_view.data, + storage_view.size); + + construction_tx.Commit(); + move_construciton_tx.Commit(); + DeallocateIfAllocated(); + AcquireAllocatedData(&allocation_tx); + + SetAllocatedSize(new_size); + return iterator(new_data + insert_index); + } else { + size_type move_construction_destination_index = + (std::max)(insert_end_index, storage_view.size); + + ConstructionTransaction move_construction_tx(GetAllocPtr()); + + IteratorValueAdapter<MoveIterator> move_construction_values( + MoveIterator(storage_view.data + + (move_construction_destination_index - insert_count))); + absl::Span<value_type> move_construction = { + storage_view.data + move_construction_destination_index, + new_size - move_construction_destination_index}; + + pointer move_assignment_values = storage_view.data + insert_index; + absl::Span<value_type> move_assignment = { + storage_view.data + insert_end_index, + move_construction_destination_index - insert_end_index}; + + absl::Span<value_type> insert_assignment = {move_assignment_values, + move_construction.size()}; + + absl::Span<value_type> insert_construction = { + insert_assignment.data() + insert_assignment.size(), + insert_count - insert_assignment.size()}; + + move_construction_tx.Construct(move_construction.data(), + &move_construction_values, + move_construction.size()); + + for (pointer destination = move_assignment.data() + move_assignment.size(), + last_destination = move_assignment.data(), + source = move_assignment_values + move_assignment.size(); + ;) { + --destination; + --source; + if (destination < last_destination) break; + *destination = std::move(*source); + } + + inlined_vector_internal::AssignElements(insert_assignment.data(), &values, + insert_assignment.size()); + + inlined_vector_internal::ConstructElements( + GetAllocPtr(), insert_construction.data(), &values, + insert_construction.size()); + + move_construction_tx.Commit(); + + AddSize(insert_count); + return iterator(storage_view.data + insert_index); + } +} + +template <typename T, size_t N, typename A> +template <typename... Args> +auto Storage<T, N, A>::EmplaceBack(Args&&... args) -> reference { + StorageView storage_view = MakeStorageView(); + + AllocationTransaction allocation_tx(GetAllocPtr()); + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(storage_view.data)); + + pointer construct_data; + if (storage_view.size == storage_view.capacity) { + size_type new_capacity = NextCapacity(storage_view.capacity); + construct_data = allocation_tx.Allocate(new_capacity); + } else { + construct_data = storage_view.data; + } + + pointer last_ptr = construct_data + storage_view.size; + + AllocatorTraits::construct(*GetAllocPtr(), last_ptr, + std::forward<Args>(args)...); + + if (allocation_tx.DidAllocate()) { + ABSL_INTERNAL_TRY { + inlined_vector_internal::ConstructElements( + GetAllocPtr(), allocation_tx.GetData(), &move_values, + storage_view.size); + } + ABSL_INTERNAL_CATCH_ANY { + AllocatorTraits::destroy(*GetAllocPtr(), last_ptr); + ABSL_INTERNAL_RETHROW; + } + + inlined_vector_internal::DestroyElements(GetAllocPtr(), storage_view.data, + storage_view.size); + + DeallocateIfAllocated(); + AcquireAllocatedData(&allocation_tx); + SetIsAllocated(); + } + + AddSize(1); + return *last_ptr; +} + +template <typename T, size_t N, typename A> +auto Storage<T, N, A>::Erase(const_iterator from, const_iterator to) + -> iterator { + StorageView storage_view = MakeStorageView(); + + size_type erase_size = std::distance(from, to); + size_type erase_index = + std::distance(const_iterator(storage_view.data), from); + size_type erase_end_index = erase_index + erase_size; + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(storage_view.data + erase_end_index)); + + inlined_vector_internal::AssignElements(storage_view.data + erase_index, + &move_values, + storage_view.size - erase_end_index); + + inlined_vector_internal::DestroyElements( + GetAllocPtr(), storage_view.data + (storage_view.size - erase_size), + erase_size); + + SubtractSize(erase_size); + return iterator(storage_view.data + erase_index); +} + +template <typename T, size_t N, typename A> +auto Storage<T, N, A>::Reserve(size_type requested_capacity) -> void { + StorageView storage_view = MakeStorageView(); + + if (ABSL_PREDICT_FALSE(requested_capacity <= storage_view.capacity)) return; + + AllocationTransaction allocation_tx(GetAllocPtr()); + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(storage_view.data)); + + size_type new_capacity = + ComputeCapacity(storage_view.capacity, requested_capacity); + pointer new_data = allocation_tx.Allocate(new_capacity); + + inlined_vector_internal::ConstructElements(GetAllocPtr(), new_data, + &move_values, storage_view.size); + + inlined_vector_internal::DestroyElements(GetAllocPtr(), storage_view.data, + storage_view.size); + + DeallocateIfAllocated(); + AcquireAllocatedData(&allocation_tx); + SetIsAllocated(); +} + +template <typename T, size_t N, typename A> +auto Storage<T, N, A>::ShrinkToFit() -> void { + // May only be called on allocated instances! + assert(GetIsAllocated()); + + StorageView storage_view{GetAllocatedData(), GetSize(), + GetAllocatedCapacity()}; + + if (ABSL_PREDICT_FALSE(storage_view.size == storage_view.capacity)) return; + + AllocationTransaction allocation_tx(GetAllocPtr()); + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(storage_view.data)); + + pointer construct_data; + if (storage_view.size > GetInlinedCapacity()) { + size_type new_capacity = storage_view.size; + construct_data = allocation_tx.Allocate(new_capacity); + } else { + construct_data = GetInlinedData(); + } + + ABSL_INTERNAL_TRY { + inlined_vector_internal::ConstructElements(GetAllocPtr(), construct_data, + &move_values, storage_view.size); + } + ABSL_INTERNAL_CATCH_ANY { + SetAllocatedData(storage_view.data, storage_view.capacity); + ABSL_INTERNAL_RETHROW; + } + + inlined_vector_internal::DestroyElements(GetAllocPtr(), storage_view.data, + storage_view.size); + + AllocatorTraits::deallocate(*GetAllocPtr(), storage_view.data, + storage_view.capacity); + + if (allocation_tx.DidAllocate()) { + AcquireAllocatedData(&allocation_tx); + } else { + UnsetIsAllocated(); + } +} + +template <typename T, size_t N, typename A> +auto Storage<T, N, A>::Swap(Storage* other_storage_ptr) -> void { + using std::swap; + assert(this != other_storage_ptr); + + if (GetIsAllocated() && other_storage_ptr->GetIsAllocated()) { + swap(data_.allocated, other_storage_ptr->data_.allocated); + } else if (!GetIsAllocated() && !other_storage_ptr->GetIsAllocated()) { + Storage* small_ptr = this; + Storage* large_ptr = other_storage_ptr; + if (small_ptr->GetSize() > large_ptr->GetSize()) swap(small_ptr, large_ptr); + + for (size_type i = 0; i < small_ptr->GetSize(); ++i) { + swap(small_ptr->GetInlinedData()[i], large_ptr->GetInlinedData()[i]); + } + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(large_ptr->GetInlinedData() + small_ptr->GetSize())); + + inlined_vector_internal::ConstructElements( + large_ptr->GetAllocPtr(), + small_ptr->GetInlinedData() + small_ptr->GetSize(), &move_values, + large_ptr->GetSize() - small_ptr->GetSize()); + + inlined_vector_internal::DestroyElements( + large_ptr->GetAllocPtr(), + large_ptr->GetInlinedData() + small_ptr->GetSize(), + large_ptr->GetSize() - small_ptr->GetSize()); + } else { + Storage* allocated_ptr = this; + Storage* inlined_ptr = other_storage_ptr; + if (!allocated_ptr->GetIsAllocated()) swap(allocated_ptr, inlined_ptr); + + StorageView allocated_storage_view{allocated_ptr->GetAllocatedData(), + allocated_ptr->GetSize(), + allocated_ptr->GetAllocatedCapacity()}; + + IteratorValueAdapter<MoveIterator> move_values( + MoveIterator(inlined_ptr->GetInlinedData())); + + ABSL_INTERNAL_TRY { + inlined_vector_internal::ConstructElements( + inlined_ptr->GetAllocPtr(), allocated_ptr->GetInlinedData(), + &move_values, inlined_ptr->GetSize()); + } + ABSL_INTERNAL_CATCH_ANY { + allocated_ptr->SetAllocatedData(allocated_storage_view.data, + allocated_storage_view.capacity); + ABSL_INTERNAL_RETHROW; + } + + inlined_vector_internal::DestroyElements(inlined_ptr->GetAllocPtr(), + inlined_ptr->GetInlinedData(), + inlined_ptr->GetSize()); + + inlined_ptr->SetAllocatedData(allocated_storage_view.data, + allocated_storage_view.capacity); + } + + swap(GetSizeAndIsAllocated(), other_storage_ptr->GetSizeAndIsAllocated()); + swap(*GetAllocPtr(), *other_storage_ptr->GetAllocPtr()); +} + +} // namespace inlined_vector_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_INLINED_VECTOR_INTERNAL_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/layout.h b/third_party/abseil_cpp/absl/container/internal/layout.h new file mode 100644 index 0000000000..69cc85dd66 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/layout.h @@ -0,0 +1,741 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// MOTIVATION AND TUTORIAL +// +// If you want to put in a single heap allocation N doubles followed by M ints, +// it's easy if N and M are known at compile time. +// +// struct S { +// double a[N]; +// int b[M]; +// }; +// +// S* p = new S; +// +// But what if N and M are known only in run time? Class template Layout to the +// rescue! It's a portable generalization of the technique known as struct hack. +// +// // This object will tell us everything we need to know about the memory +// // layout of double[N] followed by int[M]. It's structurally identical to +// // size_t[2] that stores N and M. It's very cheap to create. +// const Layout<double, int> layout(N, M); +// +// // Allocate enough memory for both arrays. `AllocSize()` tells us how much +// // memory is needed. We are free to use any allocation function we want as +// // long as it returns aligned memory. +// std::unique_ptr<unsigned char[]> p(new unsigned char[layout.AllocSize()]); +// +// // Obtain the pointer to the array of doubles. +// // Equivalent to `reinterpret_cast<double*>(p.get())`. +// // +// // We could have written layout.Pointer<0>(p) instead. If all the types are +// // unique you can use either form, but if some types are repeated you must +// // use the index form. +// double* a = layout.Pointer<double>(p.get()); +// +// // Obtain the pointer to the array of ints. +// // Equivalent to `reinterpret_cast<int*>(p.get() + N * 8)`. +// int* b = layout.Pointer<int>(p); +// +// If we are unable to specify sizes of all fields, we can pass as many sizes as +// we can to `Partial()`. In return, it'll allow us to access the fields whose +// locations and sizes can be computed from the provided information. +// `Partial()` comes in handy when the array sizes are embedded into the +// allocation. +// +// // size_t[1] containing N, size_t[1] containing M, double[N], int[M]. +// using L = Layout<size_t, size_t, double, int>; +// +// unsigned char* Allocate(size_t n, size_t m) { +// const L layout(1, 1, n, m); +// unsigned char* p = new unsigned char[layout.AllocSize()]; +// *layout.Pointer<0>(p) = n; +// *layout.Pointer<1>(p) = m; +// return p; +// } +// +// void Use(unsigned char* p) { +// // First, extract N and M. +// // Specify that the first array has only one element. Using `prefix` we +// // can access the first two arrays but not more. +// constexpr auto prefix = L::Partial(1); +// size_t n = *prefix.Pointer<0>(p); +// size_t m = *prefix.Pointer<1>(p); +// +// // Now we can get pointers to the payload. +// const L layout(1, 1, n, m); +// double* a = layout.Pointer<double>(p); +// int* b = layout.Pointer<int>(p); +// } +// +// The layout we used above combines fixed-size with dynamically-sized fields. +// This is quite common. Layout is optimized for this use case and generates +// optimal code. All computations that can be performed at compile time are +// indeed performed at compile time. +// +// Efficiency tip: The order of fields matters. In `Layout<T1, ..., TN>` try to +// ensure that `alignof(T1) >= ... >= alignof(TN)`. This way you'll have no +// padding in between arrays. +// +// You can manually override the alignment of an array by wrapping the type in +// `Aligned<T, N>`. `Layout<..., Aligned<T, N>, ...>` has exactly the same API +// and behavior as `Layout<..., T, ...>` except that the first element of the +// array of `T` is aligned to `N` (the rest of the elements follow without +// padding). `N` cannot be less than `alignof(T)`. +// +// `AllocSize()` and `Pointer()` are the most basic methods for dealing with +// memory layouts. Check out the reference or code below to discover more. +// +// EXAMPLE +// +// // Immutable move-only string with sizeof equal to sizeof(void*). The +// // string size and the characters are kept in the same heap allocation. +// class CompactString { +// public: +// CompactString(const char* s = "") { +// const size_t size = strlen(s); +// // size_t[1] followed by char[size + 1]. +// const L layout(1, size + 1); +// p_.reset(new unsigned char[layout.AllocSize()]); +// // If running under ASAN, mark the padding bytes, if any, to catch +// // memory errors. +// layout.PoisonPadding(p_.get()); +// // Store the size in the allocation. +// *layout.Pointer<size_t>(p_.get()) = size; +// // Store the characters in the allocation. +// memcpy(layout.Pointer<char>(p_.get()), s, size + 1); +// } +// +// size_t size() const { +// // Equivalent to reinterpret_cast<size_t&>(*p). +// return *L::Partial().Pointer<size_t>(p_.get()); +// } +// +// const char* c_str() const { +// // Equivalent to reinterpret_cast<char*>(p.get() + sizeof(size_t)). +// // The argument in Partial(1) specifies that we have size_t[1] in front +// // of the characters. +// return L::Partial(1).Pointer<char>(p_.get()); +// } +// +// private: +// // Our heap allocation contains a size_t followed by an array of chars. +// using L = Layout<size_t, char>; +// std::unique_ptr<unsigned char[]> p_; +// }; +// +// int main() { +// CompactString s = "hello"; +// assert(s.size() == 5); +// assert(strcmp(s.c_str(), "hello") == 0); +// } +// +// DOCUMENTATION +// +// The interface exported by this file consists of: +// - class `Layout<>` and its public members. +// - The public members of class `internal_layout::LayoutImpl<>`. That class +// isn't intended to be used directly, and its name and template parameter +// list are internal implementation details, but the class itself provides +// most of the functionality in this file. See comments on its members for +// detailed documentation. +// +// `Layout<T1,... Tn>::Partial(count1,..., countm)` (where `m` <= `n`) returns a +// `LayoutImpl<>` object. `Layout<T1,..., Tn> layout(count1,..., countn)` +// creates a `Layout` object, which exposes the same functionality by inheriting +// from `LayoutImpl<>`. + +#ifndef ABSL_CONTAINER_INTERNAL_LAYOUT_H_ +#define ABSL_CONTAINER_INTERNAL_LAYOUT_H_ + +#include <assert.h> +#include <stddef.h> +#include <stdint.h> +#include <ostream> +#include <string> +#include <tuple> +#include <type_traits> +#include <typeinfo> +#include <utility> + +#ifdef ADDRESS_SANITIZER +#include <sanitizer/asan_interface.h> +#endif + +#include "absl/meta/type_traits.h" +#include "absl/strings/str_cat.h" +#include "absl/types/span.h" +#include "absl/utility/utility.h" + +#if defined(__GXX_RTTI) +#define ABSL_INTERNAL_HAS_CXA_DEMANGLE +#endif + +#ifdef ABSL_INTERNAL_HAS_CXA_DEMANGLE +#include <cxxabi.h> +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// A type wrapper that instructs `Layout` to use the specific alignment for the +// array. `Layout<..., Aligned<T, N>, ...>` has exactly the same API +// and behavior as `Layout<..., T, ...>` except that the first element of the +// array of `T` is aligned to `N` (the rest of the elements follow without +// padding). +// +// Requires: `N >= alignof(T)` and `N` is a power of 2. +template <class T, size_t N> +struct Aligned; + +namespace internal_layout { + +template <class T> +struct NotAligned {}; + +template <class T, size_t N> +struct NotAligned<const Aligned<T, N>> { + static_assert(sizeof(T) == 0, "Aligned<T, N> cannot be const-qualified"); +}; + +template <size_t> +using IntToSize = size_t; + +template <class> +using TypeToSize = size_t; + +template <class T> +struct Type : NotAligned<T> { + using type = T; +}; + +template <class T, size_t N> +struct Type<Aligned<T, N>> { + using type = T; +}; + +template <class T> +struct SizeOf : NotAligned<T>, std::integral_constant<size_t, sizeof(T)> {}; + +template <class T, size_t N> +struct SizeOf<Aligned<T, N>> : std::integral_constant<size_t, sizeof(T)> {}; + +// Note: workaround for https://gcc.gnu.org/PR88115 +template <class T> +struct AlignOf : NotAligned<T> { + static constexpr size_t value = alignof(T); +}; + +template <class T, size_t N> +struct AlignOf<Aligned<T, N>> { + static_assert(N % alignof(T) == 0, + "Custom alignment can't be lower than the type's alignment"); + static constexpr size_t value = N; +}; + +// Does `Ts...` contain `T`? +template <class T, class... Ts> +using Contains = absl::disjunction<std::is_same<T, Ts>...>; + +template <class From, class To> +using CopyConst = + typename std::conditional<std::is_const<From>::value, const To, To>::type; + +// Note: We're not qualifying this with absl:: because it doesn't compile under +// MSVC. +template <class T> +using SliceType = Span<T>; + +// This namespace contains no types. It prevents functions defined in it from +// being found by ADL. +namespace adl_barrier { + +template <class Needle, class... Ts> +constexpr size_t Find(Needle, Needle, Ts...) { + static_assert(!Contains<Needle, Ts...>(), "Duplicate element type"); + return 0; +} + +template <class Needle, class T, class... Ts> +constexpr size_t Find(Needle, T, Ts...) { + return adl_barrier::Find(Needle(), Ts()...) + 1; +} + +constexpr bool IsPow2(size_t n) { return !(n & (n - 1)); } + +// Returns `q * m` for the smallest `q` such that `q * m >= n`. +// Requires: `m` is a power of two. It's enforced by IsLegalElementType below. +constexpr size_t Align(size_t n, size_t m) { return (n + m - 1) & ~(m - 1); } + +constexpr size_t Min(size_t a, size_t b) { return b < a ? b : a; } + +constexpr size_t Max(size_t a) { return a; } + +template <class... Ts> +constexpr size_t Max(size_t a, size_t b, Ts... rest) { + return adl_barrier::Max(b < a ? a : b, rest...); +} + +template <class T> +std::string TypeName() { + std::string out; + int status = 0; + char* demangled = nullptr; +#ifdef ABSL_INTERNAL_HAS_CXA_DEMANGLE + demangled = abi::__cxa_demangle(typeid(T).name(), nullptr, nullptr, &status); +#endif + if (status == 0 && demangled != nullptr) { // Demangling succeeded. + absl::StrAppend(&out, "<", demangled, ">"); + free(demangled); + } else { +#if defined(__GXX_RTTI) || defined(_CPPRTTI) + absl::StrAppend(&out, "<", typeid(T).name(), ">"); +#endif + } + return out; +} + +} // namespace adl_barrier + +template <bool C> +using EnableIf = typename std::enable_if<C, int>::type; + +// Can `T` be a template argument of `Layout`? +template <class T> +using IsLegalElementType = std::integral_constant< + bool, !std::is_reference<T>::value && !std::is_volatile<T>::value && + !std::is_reference<typename Type<T>::type>::value && + !std::is_volatile<typename Type<T>::type>::value && + adl_barrier::IsPow2(AlignOf<T>::value)>; + +template <class Elements, class SizeSeq, class OffsetSeq> +class LayoutImpl; + +// Public base class of `Layout` and the result type of `Layout::Partial()`. +// +// `Elements...` contains all template arguments of `Layout` that created this +// instance. +// +// `SizeSeq...` is `[0, NumSizes)` where `NumSizes` is the number of arguments +// passed to `Layout::Partial()` or `Layout::Layout()`. +// +// `OffsetSeq...` is `[0, NumOffsets)` where `NumOffsets` is +// `Min(sizeof...(Elements), NumSizes + 1)` (the number of arrays for which we +// can compute offsets). +template <class... Elements, size_t... SizeSeq, size_t... OffsetSeq> +class LayoutImpl<std::tuple<Elements...>, absl::index_sequence<SizeSeq...>, + absl::index_sequence<OffsetSeq...>> { + private: + static_assert(sizeof...(Elements) > 0, "At least one field is required"); + static_assert(absl::conjunction<IsLegalElementType<Elements>...>::value, + "Invalid element type (see IsLegalElementType)"); + + enum { + NumTypes = sizeof...(Elements), + NumSizes = sizeof...(SizeSeq), + NumOffsets = sizeof...(OffsetSeq), + }; + + // These are guaranteed by `Layout`. + static_assert(NumOffsets == adl_barrier::Min(NumTypes, NumSizes + 1), + "Internal error"); + static_assert(NumTypes > 0, "Internal error"); + + // Returns the index of `T` in `Elements...`. Results in a compilation error + // if `Elements...` doesn't contain exactly one instance of `T`. + template <class T> + static constexpr size_t ElementIndex() { + static_assert(Contains<Type<T>, Type<typename Type<Elements>::type>...>(), + "Type not found"); + return adl_barrier::Find(Type<T>(), + Type<typename Type<Elements>::type>()...); + } + + template <size_t N> + using ElementAlignment = + AlignOf<typename std::tuple_element<N, std::tuple<Elements...>>::type>; + + public: + // Element types of all arrays packed in a tuple. + using ElementTypes = std::tuple<typename Type<Elements>::type...>; + + // Element type of the Nth array. + template <size_t N> + using ElementType = typename std::tuple_element<N, ElementTypes>::type; + + constexpr explicit LayoutImpl(IntToSize<SizeSeq>... sizes) + : size_{sizes...} {} + + // Alignment of the layout, equal to the strictest alignment of all elements. + // All pointers passed to the methods of layout must be aligned to this value. + static constexpr size_t Alignment() { + return adl_barrier::Max(AlignOf<Elements>::value...); + } + + // Offset in bytes of the Nth array. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // assert(x.Offset<0>() == 0); // The ints starts from 0. + // assert(x.Offset<1>() == 16); // The doubles starts from 16. + // + // Requires: `N <= NumSizes && N < sizeof...(Ts)`. + template <size_t N, EnableIf<N == 0> = 0> + constexpr size_t Offset() const { + return 0; + } + + template <size_t N, EnableIf<N != 0> = 0> + constexpr size_t Offset() const { + static_assert(N < NumOffsets, "Index out of bounds"); + return adl_barrier::Align( + Offset<N - 1>() + SizeOf<ElementType<N - 1>>() * size_[N - 1], + ElementAlignment<N>::value); + } + + // Offset in bytes of the array with the specified element type. There must + // be exactly one such array and its zero-based index must be at most + // `NumSizes`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // assert(x.Offset<int>() == 0); // The ints starts from 0. + // assert(x.Offset<double>() == 16); // The doubles starts from 16. + template <class T> + constexpr size_t Offset() const { + return Offset<ElementIndex<T>()>(); + } + + // Offsets in bytes of all arrays for which the offsets are known. + constexpr std::array<size_t, NumOffsets> Offsets() const { + return {{Offset<OffsetSeq>()...}}; + } + + // The number of elements in the Nth array. This is the Nth argument of + // `Layout::Partial()` or `Layout::Layout()` (zero-based). + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // assert(x.Size<0>() == 3); + // assert(x.Size<1>() == 4); + // + // Requires: `N < NumSizes`. + template <size_t N> + constexpr size_t Size() const { + static_assert(N < NumSizes, "Index out of bounds"); + return size_[N]; + } + + // The number of elements in the array with the specified element type. + // There must be exactly one such array and its zero-based index must be + // at most `NumSizes`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // assert(x.Size<int>() == 3); + // assert(x.Size<double>() == 4); + template <class T> + constexpr size_t Size() const { + return Size<ElementIndex<T>()>(); + } + + // The number of elements of all arrays for which they are known. + constexpr std::array<size_t, NumSizes> Sizes() const { + return {{Size<SizeSeq>()...}}; + } + + // Pointer to the beginning of the Nth array. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; + // int* ints = x.Pointer<0>(p); + // double* doubles = x.Pointer<1>(p); + // + // Requires: `N <= NumSizes && N < sizeof...(Ts)`. + // Requires: `p` is aligned to `Alignment()`. + template <size_t N, class Char> + CopyConst<Char, ElementType<N>>* Pointer(Char* p) const { + using C = typename std::remove_const<Char>::type; + static_assert( + std::is_same<C, char>() || std::is_same<C, unsigned char>() || + std::is_same<C, signed char>(), + "The argument must be a pointer to [const] [signed|unsigned] char"); + constexpr size_t alignment = Alignment(); + (void)alignment; + assert(reinterpret_cast<uintptr_t>(p) % alignment == 0); + return reinterpret_cast<CopyConst<Char, ElementType<N>>*>(p + Offset<N>()); + } + + // Pointer to the beginning of the array with the specified element type. + // There must be exactly one such array and its zero-based index must be at + // most `NumSizes`. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; + // int* ints = x.Pointer<int>(p); + // double* doubles = x.Pointer<double>(p); + // + // Requires: `p` is aligned to `Alignment()`. + template <class T, class Char> + CopyConst<Char, T>* Pointer(Char* p) const { + return Pointer<ElementIndex<T>()>(p); + } + + // Pointers to all arrays for which pointers are known. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; + // + // int* ints; + // double* doubles; + // std::tie(ints, doubles) = x.Pointers(p); + // + // Requires: `p` is aligned to `Alignment()`. + // + // Note: We're not using ElementType alias here because it does not compile + // under MSVC. + template <class Char> + std::tuple<CopyConst< + Char, typename std::tuple_element<OffsetSeq, ElementTypes>::type>*...> + Pointers(Char* p) const { + return std::tuple<CopyConst<Char, ElementType<OffsetSeq>>*...>( + Pointer<OffsetSeq>(p)...); + } + + // The Nth array. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; + // Span<int> ints = x.Slice<0>(p); + // Span<double> doubles = x.Slice<1>(p); + // + // Requires: `N < NumSizes`. + // Requires: `p` is aligned to `Alignment()`. + template <size_t N, class Char> + SliceType<CopyConst<Char, ElementType<N>>> Slice(Char* p) const { + return SliceType<CopyConst<Char, ElementType<N>>>(Pointer<N>(p), Size<N>()); + } + + // The array with the specified element type. There must be exactly one + // such array and its zero-based index must be less than `NumSizes`. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; + // Span<int> ints = x.Slice<int>(p); + // Span<double> doubles = x.Slice<double>(p); + // + // Requires: `p` is aligned to `Alignment()`. + template <class T, class Char> + SliceType<CopyConst<Char, T>> Slice(Char* p) const { + return Slice<ElementIndex<T>()>(p); + } + + // All arrays with known sizes. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; + // + // Span<int> ints; + // Span<double> doubles; + // std::tie(ints, doubles) = x.Slices(p); + // + // Requires: `p` is aligned to `Alignment()`. + // + // Note: We're not using ElementType alias here because it does not compile + // under MSVC. + template <class Char> + std::tuple<SliceType<CopyConst< + Char, typename std::tuple_element<SizeSeq, ElementTypes>::type>>...> + Slices(Char* p) const { + // Workaround for https://gcc.gnu.org/bugzilla/show_bug.cgi?id=63875 (fixed + // in 6.1). + (void)p; + return std::tuple<SliceType<CopyConst<Char, ElementType<SizeSeq>>>...>( + Slice<SizeSeq>(p)...); + } + + // The size of the allocation that fits all arrays. + // + // // int[3], 4 bytes of padding, double[4]. + // Layout<int, double> x(3, 4); + // unsigned char* p = new unsigned char[x.AllocSize()]; // 48 bytes + // + // Requires: `NumSizes == sizeof...(Ts)`. + constexpr size_t AllocSize() const { + static_assert(NumTypes == NumSizes, "You must specify sizes of all fields"); + return Offset<NumTypes - 1>() + + SizeOf<ElementType<NumTypes - 1>>() * size_[NumTypes - 1]; + } + + // If built with --config=asan, poisons padding bytes (if any) in the + // allocation. The pointer must point to a memory block at least + // `AllocSize()` bytes in length. + // + // `Char` must be `[const] [signed|unsigned] char`. + // + // Requires: `p` is aligned to `Alignment()`. + template <class Char, size_t N = NumOffsets - 1, EnableIf<N == 0> = 0> + void PoisonPadding(const Char* p) const { + Pointer<0>(p); // verify the requirements on `Char` and `p` + } + + template <class Char, size_t N = NumOffsets - 1, EnableIf<N != 0> = 0> + void PoisonPadding(const Char* p) const { + static_assert(N < NumOffsets, "Index out of bounds"); + (void)p; +#ifdef ADDRESS_SANITIZER + PoisonPadding<Char, N - 1>(p); + // The `if` is an optimization. It doesn't affect the observable behaviour. + if (ElementAlignment<N - 1>::value % ElementAlignment<N>::value) { + size_t start = + Offset<N - 1>() + SizeOf<ElementType<N - 1>>() * size_[N - 1]; + ASAN_POISON_MEMORY_REGION(p + start, Offset<N>() - start); + } +#endif + } + + // Human-readable description of the memory layout. Useful for debugging. + // Slow. + // + // // char[5], 3 bytes of padding, int[3], 4 bytes of padding, followed + // // by an unknown number of doubles. + // auto x = Layout<char, int, double>::Partial(5, 3); + // assert(x.DebugString() == + // "@0<char>(1)[5]; @8<int>(4)[3]; @24<double>(8)"); + // + // Each field is in the following format: @offset<type>(sizeof)[size] (<type> + // may be missing depending on the target platform). For example, + // @8<int>(4)[3] means that at offset 8 we have an array of ints, where each + // int is 4 bytes, and we have 3 of those ints. The size of the last field may + // be missing (as in the example above). Only fields with known offsets are + // described. Type names may differ across platforms: one compiler might + // produce "unsigned*" where another produces "unsigned int *". + std::string DebugString() const { + const auto offsets = Offsets(); + const size_t sizes[] = {SizeOf<ElementType<OffsetSeq>>()...}; + const std::string types[] = { + adl_barrier::TypeName<ElementType<OffsetSeq>>()...}; + std::string res = absl::StrCat("@0", types[0], "(", sizes[0], ")"); + for (size_t i = 0; i != NumOffsets - 1; ++i) { + absl::StrAppend(&res, "[", size_[i], "]; @", offsets[i + 1], types[i + 1], + "(", sizes[i + 1], ")"); + } + // NumSizes is a constant that may be zero. Some compilers cannot see that + // inside the if statement "size_[NumSizes - 1]" must be valid. + int last = static_cast<int>(NumSizes) - 1; + if (NumTypes == NumSizes && last >= 0) { + absl::StrAppend(&res, "[", size_[last], "]"); + } + return res; + } + + private: + // Arguments of `Layout::Partial()` or `Layout::Layout()`. + size_t size_[NumSizes > 0 ? NumSizes : 1]; +}; + +template <size_t NumSizes, class... Ts> +using LayoutType = LayoutImpl< + std::tuple<Ts...>, absl::make_index_sequence<NumSizes>, + absl::make_index_sequence<adl_barrier::Min(sizeof...(Ts), NumSizes + 1)>>; + +} // namespace internal_layout + +// Descriptor of arrays of various types and sizes laid out in memory one after +// another. See the top of the file for documentation. +// +// Check out the public API of internal_layout::LayoutImpl above. The type is +// internal to the library but its methods are public, and they are inherited +// by `Layout`. +template <class... Ts> +class Layout : public internal_layout::LayoutType<sizeof...(Ts), Ts...> { + public: + static_assert(sizeof...(Ts) > 0, "At least one field is required"); + static_assert( + absl::conjunction<internal_layout::IsLegalElementType<Ts>...>::value, + "Invalid element type (see IsLegalElementType)"); + + // The result type of `Partial()` with `NumSizes` arguments. + template <size_t NumSizes> + using PartialType = internal_layout::LayoutType<NumSizes, Ts...>; + + // `Layout` knows the element types of the arrays we want to lay out in + // memory but not the number of elements in each array. + // `Partial(size1, ..., sizeN)` allows us to specify the latter. The + // resulting immutable object can be used to obtain pointers to the + // individual arrays. + // + // It's allowed to pass fewer array sizes than the number of arrays. E.g., + // if all you need is to the offset of the second array, you only need to + // pass one argument -- the number of elements in the first array. + // + // // int[3] followed by 4 bytes of padding and an unknown number of + // // doubles. + // auto x = Layout<int, double>::Partial(3); + // // doubles start at byte 16. + // assert(x.Offset<1>() == 16); + // + // If you know the number of elements in all arrays, you can still call + // `Partial()` but it's more convenient to use the constructor of `Layout`. + // + // Layout<int, double> x(3, 5); + // + // Note: The sizes of the arrays must be specified in number of elements, + // not in bytes. + // + // Requires: `sizeof...(Sizes) <= sizeof...(Ts)`. + // Requires: all arguments are convertible to `size_t`. + template <class... Sizes> + static constexpr PartialType<sizeof...(Sizes)> Partial(Sizes&&... sizes) { + static_assert(sizeof...(Sizes) <= sizeof...(Ts), ""); + return PartialType<sizeof...(Sizes)>(absl::forward<Sizes>(sizes)...); + } + + // Creates a layout with the sizes of all arrays specified. If you know + // only the sizes of the first N arrays (where N can be zero), you can use + // `Partial()` defined above. The constructor is essentially equivalent to + // calling `Partial()` and passing in all array sizes; the constructor is + // provided as a convenient abbreviation. + // + // Note: The sizes of the arrays must be specified in number of elements, + // not in bytes. + constexpr explicit Layout(internal_layout::TypeToSize<Ts>... sizes) + : internal_layout::LayoutType<sizeof...(Ts), Ts...>(sizes...) {} +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_LAYOUT_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/layout_test.cc b/third_party/abseil_cpp/absl/container/internal/layout_test.cc new file mode 100644 index 0000000000..8f3628a1f1 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/layout_test.cc @@ -0,0 +1,1567 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/layout.h" + +// We need ::max_align_t because some libstdc++ versions don't provide +// std::max_align_t +#include <stddef.h> +#include <cstdint> +#include <memory> +#include <sstream> +#include <type_traits> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::absl::Span; +using ::testing::ElementsAre; + +size_t Distance(const void* from, const void* to) { + ABSL_RAW_CHECK(from <= to, "Distance must be non-negative"); + return static_cast<const char*>(to) - static_cast<const char*>(from); +} + +template <class Expected, class Actual> +Expected Type(Actual val) { + static_assert(std::is_same<Expected, Actual>(), ""); + return val; +} + +// Helper classes to test different size and alignments. +struct alignas(8) Int128 { + uint64_t a, b; + friend bool operator==(Int128 lhs, Int128 rhs) { + return std::tie(lhs.a, lhs.b) == std::tie(rhs.a, rhs.b); + } + + static std::string Name() { + return internal_layout::adl_barrier::TypeName<Int128>(); + } +}; + +// int64_t is *not* 8-byte aligned on all platforms! +struct alignas(8) Int64 { + int64_t a; + friend bool operator==(Int64 lhs, Int64 rhs) { + return lhs.a == rhs.a; + } +}; + +// Properties of types that this test relies on. +static_assert(sizeof(int8_t) == 1, ""); +static_assert(alignof(int8_t) == 1, ""); +static_assert(sizeof(int16_t) == 2, ""); +static_assert(alignof(int16_t) == 2, ""); +static_assert(sizeof(int32_t) == 4, ""); +static_assert(alignof(int32_t) == 4, ""); +static_assert(sizeof(Int64) == 8, ""); +static_assert(alignof(Int64) == 8, ""); +static_assert(sizeof(Int128) == 16, ""); +static_assert(alignof(Int128) == 8, ""); + +template <class Expected, class Actual> +void SameType() { + static_assert(std::is_same<Expected, Actual>(), ""); +} + +TEST(Layout, ElementType) { + { + using L = Layout<int32_t>; + SameType<int32_t, L::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial())::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial(0))::ElementType<0>>(); + } + { + using L = Layout<int32_t, int32_t>; + SameType<int32_t, L::ElementType<0>>(); + SameType<int32_t, L::ElementType<1>>(); + SameType<int32_t, decltype(L::Partial())::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial())::ElementType<1>>(); + SameType<int32_t, decltype(L::Partial(0))::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial(0))::ElementType<1>>(); + } + { + using L = Layout<int8_t, int32_t, Int128>; + SameType<int8_t, L::ElementType<0>>(); + SameType<int32_t, L::ElementType<1>>(); + SameType<Int128, L::ElementType<2>>(); + SameType<int8_t, decltype(L::Partial())::ElementType<0>>(); + SameType<int8_t, decltype(L::Partial(0))::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial(0))::ElementType<1>>(); + SameType<int8_t, decltype(L::Partial(0, 0))::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial(0, 0))::ElementType<1>>(); + SameType<Int128, decltype(L::Partial(0, 0))::ElementType<2>>(); + SameType<int8_t, decltype(L::Partial(0, 0, 0))::ElementType<0>>(); + SameType<int32_t, decltype(L::Partial(0, 0, 0))::ElementType<1>>(); + SameType<Int128, decltype(L::Partial(0, 0, 0))::ElementType<2>>(); + } +} + +TEST(Layout, ElementTypes) { + { + using L = Layout<int32_t>; + SameType<std::tuple<int32_t>, L::ElementTypes>(); + SameType<std::tuple<int32_t>, decltype(L::Partial())::ElementTypes>(); + SameType<std::tuple<int32_t>, decltype(L::Partial(0))::ElementTypes>(); + } + { + using L = Layout<int32_t, int32_t>; + SameType<std::tuple<int32_t, int32_t>, L::ElementTypes>(); + SameType<std::tuple<int32_t, int32_t>, decltype(L::Partial())::ElementTypes>(); + SameType<std::tuple<int32_t, int32_t>, decltype(L::Partial(0))::ElementTypes>(); + } + { + using L = Layout<int8_t, int32_t, Int128>; + SameType<std::tuple<int8_t, int32_t, Int128>, L::ElementTypes>(); + SameType<std::tuple<int8_t, int32_t, Int128>, + decltype(L::Partial())::ElementTypes>(); + SameType<std::tuple<int8_t, int32_t, Int128>, + decltype(L::Partial(0))::ElementTypes>(); + SameType<std::tuple<int8_t, int32_t, Int128>, + decltype(L::Partial(0, 0))::ElementTypes>(); + SameType<std::tuple<int8_t, int32_t, Int128>, + decltype(L::Partial(0, 0, 0))::ElementTypes>(); + } +} + +TEST(Layout, OffsetByIndex) { + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial().Offset<0>()); + EXPECT_EQ(0, L::Partial(3).Offset<0>()); + EXPECT_EQ(0, L(3).Offset<0>()); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(0, L::Partial().Offset<0>()); + EXPECT_EQ(0, L::Partial(3).Offset<0>()); + EXPECT_EQ(12, L::Partial(3).Offset<1>()); + EXPECT_EQ(0, L::Partial(3, 5).Offset<0>()); + EXPECT_EQ(12, L::Partial(3, 5).Offset<1>()); + EXPECT_EQ(0, L(3, 5).Offset<0>()); + EXPECT_EQ(12, L(3, 5).Offset<1>()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, L::Partial().Offset<0>()); + EXPECT_EQ(0, L::Partial(0).Offset<0>()); + EXPECT_EQ(0, L::Partial(0).Offset<1>()); + EXPECT_EQ(0, L::Partial(1).Offset<0>()); + EXPECT_EQ(4, L::Partial(1).Offset<1>()); + EXPECT_EQ(0, L::Partial(5).Offset<0>()); + EXPECT_EQ(8, L::Partial(5).Offset<1>()); + EXPECT_EQ(0, L::Partial(0, 0).Offset<0>()); + EXPECT_EQ(0, L::Partial(0, 0).Offset<1>()); + EXPECT_EQ(0, L::Partial(0, 0).Offset<2>()); + EXPECT_EQ(0, L::Partial(1, 0).Offset<0>()); + EXPECT_EQ(4, L::Partial(1, 0).Offset<1>()); + EXPECT_EQ(8, L::Partial(1, 0).Offset<2>()); + EXPECT_EQ(0, L::Partial(5, 3).Offset<0>()); + EXPECT_EQ(8, L::Partial(5, 3).Offset<1>()); + EXPECT_EQ(24, L::Partial(5, 3).Offset<2>()); + EXPECT_EQ(0, L::Partial(0, 0, 0).Offset<0>()); + EXPECT_EQ(0, L::Partial(0, 0, 0).Offset<1>()); + EXPECT_EQ(0, L::Partial(0, 0, 0).Offset<2>()); + EXPECT_EQ(0, L::Partial(1, 0, 0).Offset<0>()); + EXPECT_EQ(4, L::Partial(1, 0, 0).Offset<1>()); + EXPECT_EQ(8, L::Partial(1, 0, 0).Offset<2>()); + EXPECT_EQ(0, L::Partial(5, 3, 1).Offset<0>()); + EXPECT_EQ(24, L::Partial(5, 3, 1).Offset<2>()); + EXPECT_EQ(8, L::Partial(5, 3, 1).Offset<1>()); + EXPECT_EQ(0, L(5, 3, 1).Offset<0>()); + EXPECT_EQ(24, L(5, 3, 1).Offset<2>()); + EXPECT_EQ(8, L(5, 3, 1).Offset<1>()); + } +} + +TEST(Layout, OffsetByType) { + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial().Offset<int32_t>()); + EXPECT_EQ(0, L::Partial(3).Offset<int32_t>()); + EXPECT_EQ(0, L(3).Offset<int32_t>()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, L::Partial().Offset<int8_t>()); + EXPECT_EQ(0, L::Partial(0).Offset<int8_t>()); + EXPECT_EQ(0, L::Partial(0).Offset<int32_t>()); + EXPECT_EQ(0, L::Partial(1).Offset<int8_t>()); + EXPECT_EQ(4, L::Partial(1).Offset<int32_t>()); + EXPECT_EQ(0, L::Partial(5).Offset<int8_t>()); + EXPECT_EQ(8, L::Partial(5).Offset<int32_t>()); + EXPECT_EQ(0, L::Partial(0, 0).Offset<int8_t>()); + EXPECT_EQ(0, L::Partial(0, 0).Offset<int32_t>()); + EXPECT_EQ(0, L::Partial(0, 0).Offset<Int128>()); + EXPECT_EQ(0, L::Partial(1, 0).Offset<int8_t>()); + EXPECT_EQ(4, L::Partial(1, 0).Offset<int32_t>()); + EXPECT_EQ(8, L::Partial(1, 0).Offset<Int128>()); + EXPECT_EQ(0, L::Partial(5, 3).Offset<int8_t>()); + EXPECT_EQ(8, L::Partial(5, 3).Offset<int32_t>()); + EXPECT_EQ(24, L::Partial(5, 3).Offset<Int128>()); + EXPECT_EQ(0, L::Partial(0, 0, 0).Offset<int8_t>()); + EXPECT_EQ(0, L::Partial(0, 0, 0).Offset<int32_t>()); + EXPECT_EQ(0, L::Partial(0, 0, 0).Offset<Int128>()); + EXPECT_EQ(0, L::Partial(1, 0, 0).Offset<int8_t>()); + EXPECT_EQ(4, L::Partial(1, 0, 0).Offset<int32_t>()); + EXPECT_EQ(8, L::Partial(1, 0, 0).Offset<Int128>()); + EXPECT_EQ(0, L::Partial(5, 3, 1).Offset<int8_t>()); + EXPECT_EQ(24, L::Partial(5, 3, 1).Offset<Int128>()); + EXPECT_EQ(8, L::Partial(5, 3, 1).Offset<int32_t>()); + EXPECT_EQ(0, L(5, 3, 1).Offset<int8_t>()); + EXPECT_EQ(24, L(5, 3, 1).Offset<Int128>()); + EXPECT_EQ(8, L(5, 3, 1).Offset<int32_t>()); + } +} + +TEST(Layout, Offsets) { + { + using L = Layout<int32_t>; + EXPECT_THAT(L::Partial().Offsets(), ElementsAre(0)); + EXPECT_THAT(L::Partial(3).Offsets(), ElementsAre(0)); + EXPECT_THAT(L(3).Offsets(), ElementsAre(0)); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_THAT(L::Partial().Offsets(), ElementsAre(0)); + EXPECT_THAT(L::Partial(3).Offsets(), ElementsAre(0, 12)); + EXPECT_THAT(L::Partial(3, 5).Offsets(), ElementsAre(0, 12)); + EXPECT_THAT(L(3, 5).Offsets(), ElementsAre(0, 12)); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_THAT(L::Partial().Offsets(), ElementsAre(0)); + EXPECT_THAT(L::Partial(1).Offsets(), ElementsAre(0, 4)); + EXPECT_THAT(L::Partial(5).Offsets(), ElementsAre(0, 8)); + EXPECT_THAT(L::Partial(0, 0).Offsets(), ElementsAre(0, 0, 0)); + EXPECT_THAT(L::Partial(1, 0).Offsets(), ElementsAre(0, 4, 8)); + EXPECT_THAT(L::Partial(5, 3).Offsets(), ElementsAre(0, 8, 24)); + EXPECT_THAT(L::Partial(0, 0, 0).Offsets(), ElementsAre(0, 0, 0)); + EXPECT_THAT(L::Partial(1, 0, 0).Offsets(), ElementsAre(0, 4, 8)); + EXPECT_THAT(L::Partial(5, 3, 1).Offsets(), ElementsAre(0, 8, 24)); + EXPECT_THAT(L(5, 3, 1).Offsets(), ElementsAre(0, 8, 24)); + } +} + +TEST(Layout, AllocSize) { + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).AllocSize()); + EXPECT_EQ(12, L::Partial(3).AllocSize()); + EXPECT_EQ(12, L(3).AllocSize()); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(32, L::Partial(3, 5).AllocSize()); + EXPECT_EQ(32, L(3, 5).AllocSize()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, L::Partial(0, 0, 0).AllocSize()); + EXPECT_EQ(8, L::Partial(1, 0, 0).AllocSize()); + EXPECT_EQ(8, L::Partial(0, 1, 0).AllocSize()); + EXPECT_EQ(16, L::Partial(0, 0, 1).AllocSize()); + EXPECT_EQ(24, L::Partial(1, 1, 1).AllocSize()); + EXPECT_EQ(136, L::Partial(3, 5, 7).AllocSize()); + EXPECT_EQ(136, L(3, 5, 7).AllocSize()); + } +} + +TEST(Layout, SizeByIndex) { + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).Size<0>()); + EXPECT_EQ(3, L::Partial(3).Size<0>()); + EXPECT_EQ(3, L(3).Size<0>()); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(0, L::Partial(0).Size<0>()); + EXPECT_EQ(3, L::Partial(3).Size<0>()); + EXPECT_EQ(3, L::Partial(3, 5).Size<0>()); + EXPECT_EQ(5, L::Partial(3, 5).Size<1>()); + EXPECT_EQ(3, L(3, 5).Size<0>()); + EXPECT_EQ(5, L(3, 5).Size<1>()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(3, L::Partial(3).Size<0>()); + EXPECT_EQ(3, L::Partial(3, 5).Size<0>()); + EXPECT_EQ(5, L::Partial(3, 5).Size<1>()); + EXPECT_EQ(3, L::Partial(3, 5, 7).Size<0>()); + EXPECT_EQ(5, L::Partial(3, 5, 7).Size<1>()); + EXPECT_EQ(7, L::Partial(3, 5, 7).Size<2>()); + EXPECT_EQ(3, L(3, 5, 7).Size<0>()); + EXPECT_EQ(5, L(3, 5, 7).Size<1>()); + EXPECT_EQ(7, L(3, 5, 7).Size<2>()); + } +} + +TEST(Layout, SizeByType) { + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).Size<int32_t>()); + EXPECT_EQ(3, L::Partial(3).Size<int32_t>()); + EXPECT_EQ(3, L(3).Size<int32_t>()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(3, L::Partial(3).Size<int8_t>()); + EXPECT_EQ(3, L::Partial(3, 5).Size<int8_t>()); + EXPECT_EQ(5, L::Partial(3, 5).Size<int32_t>()); + EXPECT_EQ(3, L::Partial(3, 5, 7).Size<int8_t>()); + EXPECT_EQ(5, L::Partial(3, 5, 7).Size<int32_t>()); + EXPECT_EQ(7, L::Partial(3, 5, 7).Size<Int128>()); + EXPECT_EQ(3, L(3, 5, 7).Size<int8_t>()); + EXPECT_EQ(5, L(3, 5, 7).Size<int32_t>()); + EXPECT_EQ(7, L(3, 5, 7).Size<Int128>()); + } +} + +TEST(Layout, Sizes) { + { + using L = Layout<int32_t>; + EXPECT_THAT(L::Partial().Sizes(), ElementsAre()); + EXPECT_THAT(L::Partial(3).Sizes(), ElementsAre(3)); + EXPECT_THAT(L(3).Sizes(), ElementsAre(3)); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_THAT(L::Partial().Sizes(), ElementsAre()); + EXPECT_THAT(L::Partial(3).Sizes(), ElementsAre(3)); + EXPECT_THAT(L::Partial(3, 5).Sizes(), ElementsAre(3, 5)); + EXPECT_THAT(L(3, 5).Sizes(), ElementsAre(3, 5)); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_THAT(L::Partial().Sizes(), ElementsAre()); + EXPECT_THAT(L::Partial(3).Sizes(), ElementsAre(3)); + EXPECT_THAT(L::Partial(3, 5).Sizes(), ElementsAre(3, 5)); + EXPECT_THAT(L::Partial(3, 5, 7).Sizes(), ElementsAre(3, 5, 7)); + EXPECT_THAT(L(3, 5, 7).Sizes(), ElementsAre(3, 5, 7)); + } +} + +TEST(Layout, PointerByIndex) { + alignas(max_align_t) const unsigned char p[100] = {}; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L::Partial().Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L::Partial(3).Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L(3).Pointer<0>(p)))); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L::Partial().Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L::Partial(3).Pointer<0>(p)))); + EXPECT_EQ(12, Distance(p, Type<const int32_t*>(L::Partial(3).Pointer<1>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int32_t*>(L::Partial(3, 5).Pointer<0>(p)))); + EXPECT_EQ(12, + Distance(p, Type<const int32_t*>(L::Partial(3, 5).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L(3, 5).Pointer<0>(p)))); + EXPECT_EQ(12, Distance(p, Type<const int32_t*>(L(3, 5).Pointer<1>(p)))); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, Distance(p, Type<const int8_t*>(L::Partial().Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int8_t*>(L::Partial(0).Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L::Partial(0).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int8_t*>(L::Partial(1).Pointer<0>(p)))); + EXPECT_EQ(4, Distance(p, Type<const int32_t*>(L::Partial(1).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int8_t*>(L::Partial(5).Pointer<0>(p)))); + EXPECT_EQ(8, Distance(p, Type<const int32_t*>(L::Partial(5).Pointer<1>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int8_t*>(L::Partial(0, 0).Pointer<0>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int32_t*>(L::Partial(0, 0).Pointer<1>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const Int128*>(L::Partial(0, 0).Pointer<2>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int8_t*>(L::Partial(1, 0).Pointer<0>(p)))); + EXPECT_EQ(4, + Distance(p, Type<const int32_t*>(L::Partial(1, 0).Pointer<1>(p)))); + EXPECT_EQ(8, + Distance(p, Type<const Int128*>(L::Partial(1, 0).Pointer<2>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int8_t*>(L::Partial(5, 3).Pointer<0>(p)))); + EXPECT_EQ(8, + Distance(p, Type<const int32_t*>(L::Partial(5, 3).Pointer<1>(p)))); + EXPECT_EQ(24, + Distance(p, Type<const Int128*>(L::Partial(5, 3).Pointer<2>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int8_t*>(L::Partial(0, 0, 0).Pointer<0>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int32_t*>(L::Partial(0, 0, 0).Pointer<1>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const Int128*>(L::Partial(0, 0, 0).Pointer<2>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int8_t*>(L::Partial(1, 0, 0).Pointer<0>(p)))); + EXPECT_EQ( + 4, Distance(p, Type<const int32_t*>(L::Partial(1, 0, 0).Pointer<1>(p)))); + EXPECT_EQ( + 8, Distance(p, Type<const Int128*>(L::Partial(1, 0, 0).Pointer<2>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int8_t*>(L::Partial(5, 3, 1).Pointer<0>(p)))); + EXPECT_EQ( + 24, + Distance(p, Type<const Int128*>(L::Partial(5, 3, 1).Pointer<2>(p)))); + EXPECT_EQ( + 8, Distance(p, Type<const int32_t*>(L::Partial(5, 3, 1).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int8_t*>(L(5, 3, 1).Pointer<0>(p)))); + EXPECT_EQ(24, Distance(p, Type<const Int128*>(L(5, 3, 1).Pointer<2>(p)))); + EXPECT_EQ(8, Distance(p, Type<const int32_t*>(L(5, 3, 1).Pointer<1>(p)))); + } +} + +TEST(Layout, PointerByType) { + alignas(max_align_t) const unsigned char p[100] = {}; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, + Distance(p, Type<const int32_t*>(L::Partial().Pointer<int32_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int32_t*>(L::Partial(3).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<const int32_t*>(L(3).Pointer<int32_t>(p)))); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, Distance(p, Type<const int8_t*>(L::Partial().Pointer<int8_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int8_t*>(L::Partial(0).Pointer<int8_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int32_t*>(L::Partial(0).Pointer<int32_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int8_t*>(L::Partial(1).Pointer<int8_t>(p)))); + EXPECT_EQ(4, + Distance(p, Type<const int32_t*>(L::Partial(1).Pointer<int32_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<const int8_t*>(L::Partial(5).Pointer<int8_t>(p)))); + EXPECT_EQ(8, + Distance(p, Type<const int32_t*>(L::Partial(5).Pointer<int32_t>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int8_t*>(L::Partial(0, 0).Pointer<int8_t>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int32_t*>(L::Partial(0, 0).Pointer<int32_t>(p)))); + EXPECT_EQ( + 0, + Distance(p, Type<const Int128*>(L::Partial(0, 0).Pointer<Int128>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int8_t*>(L::Partial(1, 0).Pointer<int8_t>(p)))); + EXPECT_EQ( + 4, Distance(p, Type<const int32_t*>(L::Partial(1, 0).Pointer<int32_t>(p)))); + EXPECT_EQ( + 8, + Distance(p, Type<const Int128*>(L::Partial(1, 0).Pointer<Int128>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<const int8_t*>(L::Partial(5, 3).Pointer<int8_t>(p)))); + EXPECT_EQ( + 8, Distance(p, Type<const int32_t*>(L::Partial(5, 3).Pointer<int32_t>(p)))); + EXPECT_EQ( + 24, + Distance(p, Type<const Int128*>(L::Partial(5, 3).Pointer<Int128>(p)))); + EXPECT_EQ( + 0, + Distance(p, Type<const int8_t*>(L::Partial(0, 0, 0).Pointer<int8_t>(p)))); + EXPECT_EQ( + 0, + Distance(p, Type<const int32_t*>(L::Partial(0, 0, 0).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<const Int128*>( + L::Partial(0, 0, 0).Pointer<Int128>(p)))); + EXPECT_EQ( + 0, + Distance(p, Type<const int8_t*>(L::Partial(1, 0, 0).Pointer<int8_t>(p)))); + EXPECT_EQ( + 4, + Distance(p, Type<const int32_t*>(L::Partial(1, 0, 0).Pointer<int32_t>(p)))); + EXPECT_EQ(8, Distance(p, Type<const Int128*>( + L::Partial(1, 0, 0).Pointer<Int128>(p)))); + EXPECT_EQ( + 0, + Distance(p, Type<const int8_t*>(L::Partial(5, 3, 1).Pointer<int8_t>(p)))); + EXPECT_EQ(24, Distance(p, Type<const Int128*>( + L::Partial(5, 3, 1).Pointer<Int128>(p)))); + EXPECT_EQ( + 8, + Distance(p, Type<const int32_t*>(L::Partial(5, 3, 1).Pointer<int32_t>(p)))); + EXPECT_EQ(24, + Distance(p, Type<const Int128*>(L(5, 3, 1).Pointer<Int128>(p)))); + EXPECT_EQ(8, Distance(p, Type<const int32_t*>(L(5, 3, 1).Pointer<int32_t>(p)))); + } +} + +TEST(Layout, MutablePointerByIndex) { + alignas(max_align_t) unsigned char p[100]; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial().Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(3).Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L(3).Pointer<0>(p)))); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial().Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(3).Pointer<0>(p)))); + EXPECT_EQ(12, Distance(p, Type<int32_t*>(L::Partial(3).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(3, 5).Pointer<0>(p)))); + EXPECT_EQ(12, Distance(p, Type<int32_t*>(L::Partial(3, 5).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L(3, 5).Pointer<0>(p)))); + EXPECT_EQ(12, Distance(p, Type<int32_t*>(L(3, 5).Pointer<1>(p)))); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial().Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(0).Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(0).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(1).Pointer<0>(p)))); + EXPECT_EQ(4, Distance(p, Type<int32_t*>(L::Partial(1).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(5).Pointer<0>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L::Partial(5).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(0, 0).Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(0, 0).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<Int128*>(L::Partial(0, 0).Pointer<2>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(1, 0).Pointer<0>(p)))); + EXPECT_EQ(4, Distance(p, Type<int32_t*>(L::Partial(1, 0).Pointer<1>(p)))); + EXPECT_EQ(8, Distance(p, Type<Int128*>(L::Partial(1, 0).Pointer<2>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(5, 3).Pointer<0>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L::Partial(5, 3).Pointer<1>(p)))); + EXPECT_EQ(24, Distance(p, Type<Int128*>(L::Partial(5, 3).Pointer<2>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(0, 0, 0).Pointer<0>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(0, 0, 0).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<Int128*>(L::Partial(0, 0, 0).Pointer<2>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(1, 0, 0).Pointer<0>(p)))); + EXPECT_EQ(4, Distance(p, Type<int32_t*>(L::Partial(1, 0, 0).Pointer<1>(p)))); + EXPECT_EQ(8, Distance(p, Type<Int128*>(L::Partial(1, 0, 0).Pointer<2>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(5, 3, 1).Pointer<0>(p)))); + EXPECT_EQ(24, + Distance(p, Type<Int128*>(L::Partial(5, 3, 1).Pointer<2>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L::Partial(5, 3, 1).Pointer<1>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L(5, 3, 1).Pointer<0>(p)))); + EXPECT_EQ(24, Distance(p, Type<Int128*>(L(5, 3, 1).Pointer<2>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L(5, 3, 1).Pointer<1>(p)))); + } +} + +TEST(Layout, MutablePointerByType) { + alignas(max_align_t) unsigned char p[100]; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial().Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(3).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L(3).Pointer<int32_t>(p)))); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial().Pointer<int8_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(0).Pointer<int8_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(0).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(1).Pointer<int8_t>(p)))); + EXPECT_EQ(4, Distance(p, Type<int32_t*>(L::Partial(1).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(5).Pointer<int8_t>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L::Partial(5).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(0, 0).Pointer<int8_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int32_t*>(L::Partial(0, 0).Pointer<int32_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<Int128*>(L::Partial(0, 0).Pointer<Int128>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(1, 0).Pointer<int8_t>(p)))); + EXPECT_EQ(4, Distance(p, Type<int32_t*>(L::Partial(1, 0).Pointer<int32_t>(p)))); + EXPECT_EQ(8, + Distance(p, Type<Int128*>(L::Partial(1, 0).Pointer<Int128>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L::Partial(5, 3).Pointer<int8_t>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L::Partial(5, 3).Pointer<int32_t>(p)))); + EXPECT_EQ(24, + Distance(p, Type<Int128*>(L::Partial(5, 3).Pointer<Int128>(p)))); + EXPECT_EQ(0, + Distance(p, Type<int8_t*>(L::Partial(0, 0, 0).Pointer<int8_t>(p)))); + EXPECT_EQ(0, + Distance(p, Type<int32_t*>(L::Partial(0, 0, 0).Pointer<int32_t>(p)))); + EXPECT_EQ( + 0, Distance(p, Type<Int128*>(L::Partial(0, 0, 0).Pointer<Int128>(p)))); + EXPECT_EQ(0, + Distance(p, Type<int8_t*>(L::Partial(1, 0, 0).Pointer<int8_t>(p)))); + EXPECT_EQ(4, + Distance(p, Type<int32_t*>(L::Partial(1, 0, 0).Pointer<int32_t>(p)))); + EXPECT_EQ( + 8, Distance(p, Type<Int128*>(L::Partial(1, 0, 0).Pointer<Int128>(p)))); + EXPECT_EQ(0, + Distance(p, Type<int8_t*>(L::Partial(5, 3, 1).Pointer<int8_t>(p)))); + EXPECT_EQ( + 24, Distance(p, Type<Int128*>(L::Partial(5, 3, 1).Pointer<Int128>(p)))); + EXPECT_EQ(8, + Distance(p, Type<int32_t*>(L::Partial(5, 3, 1).Pointer<int32_t>(p)))); + EXPECT_EQ(0, Distance(p, Type<int8_t*>(L(5, 3, 1).Pointer<int8_t>(p)))); + EXPECT_EQ(24, Distance(p, Type<Int128*>(L(5, 3, 1).Pointer<Int128>(p)))); + EXPECT_EQ(8, Distance(p, Type<int32_t*>(L(5, 3, 1).Pointer<int32_t>(p)))); + } +} + +TEST(Layout, Pointers) { + alignas(max_align_t) const unsigned char p[100] = {}; + using L = Layout<int8_t, int8_t, Int128>; + { + const auto x = L::Partial(); + EXPECT_EQ(std::make_tuple(x.Pointer<0>(p)), + Type<std::tuple<const int8_t*>>(x.Pointers(p))); + } + { + const auto x = L::Partial(1); + EXPECT_EQ(std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p)), + (Type<std::tuple<const int8_t*, const int8_t*>>(x.Pointers(p)))); + } + { + const auto x = L::Partial(1, 2); + EXPECT_EQ( + std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p), x.Pointer<2>(p)), + (Type<std::tuple<const int8_t*, const int8_t*, const Int128*>>( + x.Pointers(p)))); + } + { + const auto x = L::Partial(1, 2, 3); + EXPECT_EQ( + std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p), x.Pointer<2>(p)), + (Type<std::tuple<const int8_t*, const int8_t*, const Int128*>>( + x.Pointers(p)))); + } + { + const L x(1, 2, 3); + EXPECT_EQ( + std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p), x.Pointer<2>(p)), + (Type<std::tuple<const int8_t*, const int8_t*, const Int128*>>( + x.Pointers(p)))); + } +} + +TEST(Layout, MutablePointers) { + alignas(max_align_t) unsigned char p[100]; + using L = Layout<int8_t, int8_t, Int128>; + { + const auto x = L::Partial(); + EXPECT_EQ(std::make_tuple(x.Pointer<0>(p)), + Type<std::tuple<int8_t*>>(x.Pointers(p))); + } + { + const auto x = L::Partial(1); + EXPECT_EQ(std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p)), + (Type<std::tuple<int8_t*, int8_t*>>(x.Pointers(p)))); + } + { + const auto x = L::Partial(1, 2); + EXPECT_EQ( + std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p), x.Pointer<2>(p)), + (Type<std::tuple<int8_t*, int8_t*, Int128*>>(x.Pointers(p)))); + } + { + const auto x = L::Partial(1, 2, 3); + EXPECT_EQ( + std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p), x.Pointer<2>(p)), + (Type<std::tuple<int8_t*, int8_t*, Int128*>>(x.Pointers(p)))); + } + { + const L x(1, 2, 3); + EXPECT_EQ( + std::make_tuple(x.Pointer<0>(p), x.Pointer<1>(p), x.Pointer<2>(p)), + (Type<std::tuple<int8_t*, int8_t*, Int128*>>(x.Pointers(p)))); + } +} + +TEST(Layout, SliceByIndexSize) { + alignas(max_align_t) const unsigned char p[100] = {}; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).Slice<0>(p).size()); + EXPECT_EQ(3, L::Partial(3).Slice<0>(p).size()); + EXPECT_EQ(3, L(3).Slice<0>(p).size()); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(3, L::Partial(3).Slice<0>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5).Slice<1>(p).size()); + EXPECT_EQ(5, L(3, 5).Slice<1>(p).size()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(3, L::Partial(3).Slice<0>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5).Slice<0>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5).Slice<1>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5, 7).Slice<0>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5, 7).Slice<1>(p).size()); + EXPECT_EQ(7, L::Partial(3, 5, 7).Slice<2>(p).size()); + EXPECT_EQ(3, L(3, 5, 7).Slice<0>(p).size()); + EXPECT_EQ(5, L(3, 5, 7).Slice<1>(p).size()); + EXPECT_EQ(7, L(3, 5, 7).Slice<2>(p).size()); + } +} + +TEST(Layout, SliceByTypeSize) { + alignas(max_align_t) const unsigned char p[100] = {}; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).Slice<int32_t>(p).size()); + EXPECT_EQ(3, L::Partial(3).Slice<int32_t>(p).size()); + EXPECT_EQ(3, L(3).Slice<int32_t>(p).size()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(3, L::Partial(3).Slice<int8_t>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5).Slice<int8_t>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5).Slice<int32_t>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5, 7).Slice<int8_t>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5, 7).Slice<int32_t>(p).size()); + EXPECT_EQ(7, L::Partial(3, 5, 7).Slice<Int128>(p).size()); + EXPECT_EQ(3, L(3, 5, 7).Slice<int8_t>(p).size()); + EXPECT_EQ(5, L(3, 5, 7).Slice<int32_t>(p).size()); + EXPECT_EQ(7, L(3, 5, 7).Slice<Int128>(p).size()); + } +} + +TEST(Layout, MutableSliceByIndexSize) { + alignas(max_align_t) unsigned char p[100]; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).Slice<0>(p).size()); + EXPECT_EQ(3, L::Partial(3).Slice<0>(p).size()); + EXPECT_EQ(3, L(3).Slice<0>(p).size()); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(3, L::Partial(3).Slice<0>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5).Slice<1>(p).size()); + EXPECT_EQ(5, L(3, 5).Slice<1>(p).size()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(3, L::Partial(3).Slice<0>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5).Slice<0>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5).Slice<1>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5, 7).Slice<0>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5, 7).Slice<1>(p).size()); + EXPECT_EQ(7, L::Partial(3, 5, 7).Slice<2>(p).size()); + EXPECT_EQ(3, L(3, 5, 7).Slice<0>(p).size()); + EXPECT_EQ(5, L(3, 5, 7).Slice<1>(p).size()); + EXPECT_EQ(7, L(3, 5, 7).Slice<2>(p).size()); + } +} + +TEST(Layout, MutableSliceByTypeSize) { + alignas(max_align_t) unsigned char p[100]; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, L::Partial(0).Slice<int32_t>(p).size()); + EXPECT_EQ(3, L::Partial(3).Slice<int32_t>(p).size()); + EXPECT_EQ(3, L(3).Slice<int32_t>(p).size()); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(3, L::Partial(3).Slice<int8_t>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5).Slice<int8_t>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5).Slice<int32_t>(p).size()); + EXPECT_EQ(3, L::Partial(3, 5, 7).Slice<int8_t>(p).size()); + EXPECT_EQ(5, L::Partial(3, 5, 7).Slice<int32_t>(p).size()); + EXPECT_EQ(7, L::Partial(3, 5, 7).Slice<Int128>(p).size()); + EXPECT_EQ(3, L(3, 5, 7).Slice<int8_t>(p).size()); + EXPECT_EQ(5, L(3, 5, 7).Slice<int32_t>(p).size()); + EXPECT_EQ(7, L(3, 5, 7).Slice<Int128>(p).size()); + } +} + +TEST(Layout, SliceByIndexData) { + alignas(max_align_t) const unsigned char p[100] = {}; + { + using L = Layout<int32_t>; + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int32_t>>(L::Partial(0).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int32_t>>(L::Partial(3).Slice<0>(p)).data())); + EXPECT_EQ(0, Distance(p, Type<Span<const int32_t>>(L(3).Slice<0>(p)).data())); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int32_t>>(L::Partial(3).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, + Type<Span<const int32_t>>(L::Partial(3, 5).Slice<0>(p)).data())); + EXPECT_EQ( + 12, + Distance(p, + Type<Span<const int32_t>>(L::Partial(3, 5).Slice<1>(p)).data())); + EXPECT_EQ(0, + Distance(p, Type<Span<const int32_t>>(L(3, 5).Slice<0>(p)).data())); + EXPECT_EQ(12, + Distance(p, Type<Span<const int32_t>>(L(3, 5).Slice<1>(p)).data())); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int8_t>>(L::Partial(0).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int8_t>>(L::Partial(1).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int8_t>>(L::Partial(5).Slice<0>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<const int8_t>>(L::Partial(0, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, + Type<Span<const int32_t>>(L::Partial(0, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<const int8_t>>(L::Partial(1, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 4, + Distance(p, + Type<Span<const int32_t>>(L::Partial(1, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<const int8_t>>(L::Partial(5, 3).Slice<0>(p)).data())); + EXPECT_EQ( + 8, + Distance(p, + Type<Span<const int32_t>>(L::Partial(5, 3).Slice<1>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int8_t>>(L::Partial(0, 0, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<const int32_t>>(L::Partial(0, 0, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<const Int128>>(L::Partial(0, 0, 0).Slice<2>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int8_t>>(L::Partial(1, 0, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 4, + Distance( + p, + Type<Span<const int32_t>>(L::Partial(1, 0, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 8, + Distance( + p, + Type<Span<const Int128>>(L::Partial(1, 0, 0).Slice<2>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int8_t>>(L::Partial(5, 3, 1).Slice<0>(p)).data())); + EXPECT_EQ( + 24, + Distance( + p, + Type<Span<const Int128>>(L::Partial(5, 3, 1).Slice<2>(p)).data())); + EXPECT_EQ( + 8, + Distance( + p, + Type<Span<const int32_t>>(L::Partial(5, 3, 1).Slice<1>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<const int8_t>>(L(5, 3, 1).Slice<0>(p)).data())); + EXPECT_EQ( + 24, + Distance(p, Type<Span<const Int128>>(L(5, 3, 1).Slice<2>(p)).data())); + EXPECT_EQ( + 8, Distance(p, Type<Span<const int32_t>>(L(5, 3, 1).Slice<1>(p)).data())); + } +} + +TEST(Layout, SliceByTypeData) { + alignas(max_align_t) const unsigned char p[100] = {}; + { + using L = Layout<int32_t>; + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int32_t>>(L::Partial(0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int32_t>>(L::Partial(3).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<const int32_t>>(L(3).Slice<int32_t>(p)).data())); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ( + 0, Distance( + p, Type<Span<const int8_t>>(L::Partial(0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<const int8_t>>(L::Partial(1).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<const int8_t>>(L::Partial(5).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int8_t>>(L::Partial(0, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<const int32_t>>(L::Partial(0, 0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int8_t>>(L::Partial(1, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 4, + Distance( + p, + Type<Span<const int32_t>>(L::Partial(1, 0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<const int8_t>>(L::Partial(5, 3).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 8, + Distance( + p, + Type<Span<const int32_t>>(L::Partial(5, 3).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<const int8_t>>(L::Partial(0, 0, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int32_t>>(L::Partial(0, 0, 0).Slice<int32_t>(p)) + .data())); + EXPECT_EQ(0, Distance(p, Type<Span<const Int128>>( + L::Partial(0, 0, 0).Slice<Int128>(p)) + .data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<const int8_t>>(L::Partial(1, 0, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 4, + Distance(p, Type<Span<const int32_t>>(L::Partial(1, 0, 0).Slice<int32_t>(p)) + .data())); + EXPECT_EQ(8, Distance(p, Type<Span<const Int128>>( + L::Partial(1, 0, 0).Slice<Int128>(p)) + .data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<const int8_t>>(L::Partial(5, 3, 1).Slice<int8_t>(p)).data())); + EXPECT_EQ(24, Distance(p, Type<Span<const Int128>>( + L::Partial(5, 3, 1).Slice<Int128>(p)) + .data())); + EXPECT_EQ( + 8, + Distance(p, Type<Span<const int32_t>>(L::Partial(5, 3, 1).Slice<int32_t>(p)) + .data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<const int8_t>>(L(5, 3, 1).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 24, + Distance(p, + Type<Span<const Int128>>(L(5, 3, 1).Slice<Int128>(p)).data())); + EXPECT_EQ( + 8, Distance( + p, Type<Span<const int32_t>>(L(5, 3, 1).Slice<int32_t>(p)).data())); + } +} + +TEST(Layout, MutableSliceByIndexData) { + alignas(max_align_t) unsigned char p[100]; + { + using L = Layout<int32_t>; + EXPECT_EQ(0, + Distance(p, Type<Span<int32_t>>(L::Partial(0).Slice<0>(p)).data())); + EXPECT_EQ(0, + Distance(p, Type<Span<int32_t>>(L::Partial(3).Slice<0>(p)).data())); + EXPECT_EQ(0, Distance(p, Type<Span<int32_t>>(L(3).Slice<0>(p)).data())); + } + { + using L = Layout<int32_t, int32_t>; + EXPECT_EQ(0, + Distance(p, Type<Span<int32_t>>(L::Partial(3).Slice<0>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int32_t>>(L::Partial(3, 5).Slice<0>(p)).data())); + EXPECT_EQ( + 12, + Distance(p, Type<Span<int32_t>>(L::Partial(3, 5).Slice<1>(p)).data())); + EXPECT_EQ(0, Distance(p, Type<Span<int32_t>>(L(3, 5).Slice<0>(p)).data())); + EXPECT_EQ(12, Distance(p, Type<Span<int32_t>>(L(3, 5).Slice<1>(p)).data())); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ(0, + Distance(p, Type<Span<int8_t>>(L::Partial(0).Slice<0>(p)).data())); + EXPECT_EQ(0, + Distance(p, Type<Span<int8_t>>(L::Partial(1).Slice<0>(p)).data())); + EXPECT_EQ(0, + Distance(p, Type<Span<int8_t>>(L::Partial(5).Slice<0>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int8_t>>(L::Partial(0, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int32_t>>(L::Partial(0, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int8_t>>(L::Partial(1, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 4, Distance(p, Type<Span<int32_t>>(L::Partial(1, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int8_t>>(L::Partial(5, 3).Slice<0>(p)).data())); + EXPECT_EQ( + 8, Distance(p, Type<Span<int32_t>>(L::Partial(5, 3).Slice<1>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int8_t>>(L::Partial(0, 0, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int32_t>>(L::Partial(0, 0, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<Int128>>(L::Partial(0, 0, 0).Slice<2>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int8_t>>(L::Partial(1, 0, 0).Slice<0>(p)).data())); + EXPECT_EQ( + 4, + Distance(p, Type<Span<int32_t>>(L::Partial(1, 0, 0).Slice<1>(p)).data())); + EXPECT_EQ( + 8, Distance( + p, Type<Span<Int128>>(L::Partial(1, 0, 0).Slice<2>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int8_t>>(L::Partial(5, 3, 1).Slice<0>(p)).data())); + EXPECT_EQ( + 24, Distance( + p, Type<Span<Int128>>(L::Partial(5, 3, 1).Slice<2>(p)).data())); + EXPECT_EQ( + 8, + Distance(p, Type<Span<int32_t>>(L::Partial(5, 3, 1).Slice<1>(p)).data())); + EXPECT_EQ(0, Distance(p, Type<Span<int8_t>>(L(5, 3, 1).Slice<0>(p)).data())); + EXPECT_EQ(24, + Distance(p, Type<Span<Int128>>(L(5, 3, 1).Slice<2>(p)).data())); + EXPECT_EQ(8, Distance(p, Type<Span<int32_t>>(L(5, 3, 1).Slice<1>(p)).data())); + } +} + +TEST(Layout, MutableSliceByTypeData) { + alignas(max_align_t) unsigned char p[100]; + { + using L = Layout<int32_t>; + EXPECT_EQ( + 0, + Distance(p, Type<Span<int32_t>>(L::Partial(0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int32_t>>(L::Partial(3).Slice<int32_t>(p)).data())); + EXPECT_EQ(0, Distance(p, Type<Span<int32_t>>(L(3).Slice<int32_t>(p)).data())); + } + { + using L = Layout<int8_t, int32_t, Int128>; + EXPECT_EQ( + 0, Distance(p, Type<Span<int8_t>>(L::Partial(0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int8_t>>(L::Partial(1).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, Distance(p, Type<Span<int8_t>>(L::Partial(5).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int8_t>>(L::Partial(0, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<int32_t>>(L::Partial(0, 0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int8_t>>(L::Partial(1, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 4, Distance( + p, Type<Span<int32_t>>(L::Partial(1, 0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance(p, Type<Span<int8_t>>(L::Partial(5, 3).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 8, Distance( + p, Type<Span<int32_t>>(L::Partial(5, 3).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<int8_t>>(L::Partial(0, 0, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, Type<Span<int32_t>>(L::Partial(0, 0, 0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 0, + Distance( + p, + Type<Span<Int128>>(L::Partial(0, 0, 0).Slice<Int128>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<int8_t>>(L::Partial(1, 0, 0).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 4, + Distance( + p, Type<Span<int32_t>>(L::Partial(1, 0, 0).Slice<int32_t>(p)).data())); + EXPECT_EQ( + 8, + Distance( + p, + Type<Span<Int128>>(L::Partial(1, 0, 0).Slice<Int128>(p)).data())); + EXPECT_EQ( + 0, Distance( + p, Type<Span<int8_t>>(L::Partial(5, 3, 1).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 24, + Distance( + p, + Type<Span<Int128>>(L::Partial(5, 3, 1).Slice<Int128>(p)).data())); + EXPECT_EQ( + 8, + Distance( + p, Type<Span<int32_t>>(L::Partial(5, 3, 1).Slice<int32_t>(p)).data())); + EXPECT_EQ(0, + Distance(p, Type<Span<int8_t>>(L(5, 3, 1).Slice<int8_t>(p)).data())); + EXPECT_EQ( + 24, + Distance(p, Type<Span<Int128>>(L(5, 3, 1).Slice<Int128>(p)).data())); + EXPECT_EQ( + 8, Distance(p, Type<Span<int32_t>>(L(5, 3, 1).Slice<int32_t>(p)).data())); + } +} + +MATCHER_P(IsSameSlice, slice, "") { + return arg.size() == slice.size() && arg.data() == slice.data(); +} + +template <typename... M> +class TupleMatcher { + public: + explicit TupleMatcher(M... matchers) : matchers_(std::move(matchers)...) {} + + template <typename Tuple> + bool MatchAndExplain(const Tuple& p, + testing::MatchResultListener* /* listener */) const { + static_assert(std::tuple_size<Tuple>::value == sizeof...(M), ""); + return MatchAndExplainImpl( + p, absl::make_index_sequence<std::tuple_size<Tuple>::value>{}); + } + + // For the matcher concept. Left empty as we don't really need the diagnostics + // right now. + void DescribeTo(::std::ostream* os) const {} + void DescribeNegationTo(::std::ostream* os) const {} + + private: + template <typename Tuple, size_t... Is> + bool MatchAndExplainImpl(const Tuple& p, absl::index_sequence<Is...>) const { + // Using std::min as a simple variadic "and". + return std::min( + {true, testing::SafeMatcherCast< + const typename std::tuple_element<Is, Tuple>::type&>( + std::get<Is>(matchers_)) + .Matches(std::get<Is>(p))...}); + } + + std::tuple<M...> matchers_; +}; + +template <typename... M> +testing::PolymorphicMatcher<TupleMatcher<M...>> Tuple(M... matchers) { + return testing::MakePolymorphicMatcher( + TupleMatcher<M...>(std::move(matchers)...)); +} + +TEST(Layout, Slices) { + alignas(max_align_t) const unsigned char p[100] = {}; + using L = Layout<int8_t, int8_t, Int128>; + { + const auto x = L::Partial(); + EXPECT_THAT(Type<std::tuple<>>(x.Slices(p)), Tuple()); + } + { + const auto x = L::Partial(1); + EXPECT_THAT(Type<std::tuple<Span<const int8_t>>>(x.Slices(p)), + Tuple(IsSameSlice(x.Slice<0>(p)))); + } + { + const auto x = L::Partial(1, 2); + EXPECT_THAT( + (Type<std::tuple<Span<const int8_t>, Span<const int8_t>>>(x.Slices(p))), + Tuple(IsSameSlice(x.Slice<0>(p)), IsSameSlice(x.Slice<1>(p)))); + } + { + const auto x = L::Partial(1, 2, 3); + EXPECT_THAT((Type<std::tuple<Span<const int8_t>, Span<const int8_t>, + Span<const Int128>>>(x.Slices(p))), + Tuple(IsSameSlice(x.Slice<0>(p)), IsSameSlice(x.Slice<1>(p)), + IsSameSlice(x.Slice<2>(p)))); + } + { + const L x(1, 2, 3); + EXPECT_THAT((Type<std::tuple<Span<const int8_t>, Span<const int8_t>, + Span<const Int128>>>(x.Slices(p))), + Tuple(IsSameSlice(x.Slice<0>(p)), IsSameSlice(x.Slice<1>(p)), + IsSameSlice(x.Slice<2>(p)))); + } +} + +TEST(Layout, MutableSlices) { + alignas(max_align_t) unsigned char p[100] = {}; + using L = Layout<int8_t, int8_t, Int128>; + { + const auto x = L::Partial(); + EXPECT_THAT(Type<std::tuple<>>(x.Slices(p)), Tuple()); + } + { + const auto x = L::Partial(1); + EXPECT_THAT(Type<std::tuple<Span<int8_t>>>(x.Slices(p)), + Tuple(IsSameSlice(x.Slice<0>(p)))); + } + { + const auto x = L::Partial(1, 2); + EXPECT_THAT((Type<std::tuple<Span<int8_t>, Span<int8_t>>>(x.Slices(p))), + Tuple(IsSameSlice(x.Slice<0>(p)), IsSameSlice(x.Slice<1>(p)))); + } + { + const auto x = L::Partial(1, 2, 3); + EXPECT_THAT( + (Type<std::tuple<Span<int8_t>, Span<int8_t>, Span<Int128>>>(x.Slices(p))), + Tuple(IsSameSlice(x.Slice<0>(p)), IsSameSlice(x.Slice<1>(p)), + IsSameSlice(x.Slice<2>(p)))); + } + { + const L x(1, 2, 3); + EXPECT_THAT( + (Type<std::tuple<Span<int8_t>, Span<int8_t>, Span<Int128>>>(x.Slices(p))), + Tuple(IsSameSlice(x.Slice<0>(p)), IsSameSlice(x.Slice<1>(p)), + IsSameSlice(x.Slice<2>(p)))); + } +} + +TEST(Layout, UnalignedTypes) { + constexpr Layout<unsigned char, unsigned char, unsigned char> x(1, 2, 3); + alignas(max_align_t) unsigned char p[x.AllocSize() + 1]; + EXPECT_THAT(x.Pointers(p + 1), Tuple(p + 1, p + 2, p + 4)); +} + +TEST(Layout, CustomAlignment) { + constexpr Layout<unsigned char, Aligned<unsigned char, 8>> x(1, 2); + alignas(max_align_t) unsigned char p[x.AllocSize()]; + EXPECT_EQ(10, x.AllocSize()); + EXPECT_THAT(x.Pointers(p), Tuple(p + 0, p + 8)); +} + +TEST(Layout, OverAligned) { + constexpr size_t M = alignof(max_align_t); + constexpr Layout<unsigned char, Aligned<unsigned char, 2 * M>> x(1, 3); + alignas(2 * M) unsigned char p[x.AllocSize()]; + EXPECT_EQ(2 * M + 3, x.AllocSize()); + EXPECT_THAT(x.Pointers(p), Tuple(p + 0, p + 2 * M)); +} + +TEST(Layout, Alignment) { + static_assert(Layout<int8_t>::Alignment() == 1, ""); + static_assert(Layout<int32_t>::Alignment() == 4, ""); + static_assert(Layout<Int64>::Alignment() == 8, ""); + static_assert(Layout<Aligned<int8_t, 64>>::Alignment() == 64, ""); + static_assert(Layout<int8_t, int32_t, Int64>::Alignment() == 8, ""); + static_assert(Layout<int8_t, Int64, int32_t>::Alignment() == 8, ""); + static_assert(Layout<int32_t, int8_t, Int64>::Alignment() == 8, ""); + static_assert(Layout<int32_t, Int64, int8_t>::Alignment() == 8, ""); + static_assert(Layout<Int64, int8_t, int32_t>::Alignment() == 8, ""); + static_assert(Layout<Int64, int32_t, int8_t>::Alignment() == 8, ""); +} + +TEST(Layout, ConstexprPartial) { + constexpr size_t M = alignof(max_align_t); + constexpr Layout<unsigned char, Aligned<unsigned char, 2 * M>> x(1, 3); + static_assert(x.Partial(1).template Offset<1>() == 2 * M, ""); +} +// [from, to) +struct Region { + size_t from; + size_t to; +}; + +void ExpectRegionPoisoned(const unsigned char* p, size_t n, bool poisoned) { +#ifdef ADDRESS_SANITIZER + for (size_t i = 0; i != n; ++i) { + EXPECT_EQ(poisoned, __asan_address_is_poisoned(p + i)); + } +#endif +} + +template <size_t N> +void ExpectPoisoned(const unsigned char (&buf)[N], + std::initializer_list<Region> reg) { + size_t prev = 0; + for (const Region& r : reg) { + ExpectRegionPoisoned(buf + prev, r.from - prev, false); + ExpectRegionPoisoned(buf + r.from, r.to - r.from, true); + prev = r.to; + } + ExpectRegionPoisoned(buf + prev, N - prev, false); +} + +TEST(Layout, PoisonPadding) { + using L = Layout<int8_t, Int64, int32_t, Int128>; + + constexpr size_t n = L::Partial(1, 2, 3, 4).AllocSize(); + { + constexpr auto x = L::Partial(); + alignas(max_align_t) const unsigned char c[n] = {}; + x.PoisonPadding(c); + EXPECT_EQ(x.Slices(c), x.Slices(c)); + ExpectPoisoned(c, {}); + } + { + constexpr auto x = L::Partial(1); + alignas(max_align_t) const unsigned char c[n] = {}; + x.PoisonPadding(c); + EXPECT_EQ(x.Slices(c), x.Slices(c)); + ExpectPoisoned(c, {{1, 8}}); + } + { + constexpr auto x = L::Partial(1, 2); + alignas(max_align_t) const unsigned char c[n] = {}; + x.PoisonPadding(c); + EXPECT_EQ(x.Slices(c), x.Slices(c)); + ExpectPoisoned(c, {{1, 8}}); + } + { + constexpr auto x = L::Partial(1, 2, 3); + alignas(max_align_t) const unsigned char c[n] = {}; + x.PoisonPadding(c); + EXPECT_EQ(x.Slices(c), x.Slices(c)); + ExpectPoisoned(c, {{1, 8}, {36, 40}}); + } + { + constexpr auto x = L::Partial(1, 2, 3, 4); + alignas(max_align_t) const unsigned char c[n] = {}; + x.PoisonPadding(c); + EXPECT_EQ(x.Slices(c), x.Slices(c)); + ExpectPoisoned(c, {{1, 8}, {36, 40}}); + } + { + constexpr L x(1, 2, 3, 4); + alignas(max_align_t) const unsigned char c[n] = {}; + x.PoisonPadding(c); + EXPECT_EQ(x.Slices(c), x.Slices(c)); + ExpectPoisoned(c, {{1, 8}, {36, 40}}); + } +} + +TEST(Layout, DebugString) { + { + constexpr auto x = Layout<int8_t, int32_t, int8_t, Int128>::Partial(); + EXPECT_EQ("@0<signed char>(1)", x.DebugString()); + } + { + constexpr auto x = Layout<int8_t, int32_t, int8_t, Int128>::Partial(1); + EXPECT_EQ("@0<signed char>(1)[1]; @4<int>(4)", x.DebugString()); + } + { + constexpr auto x = Layout<int8_t, int32_t, int8_t, Int128>::Partial(1, 2); + EXPECT_EQ("@0<signed char>(1)[1]; @4<int>(4)[2]; @12<signed char>(1)", + x.DebugString()); + } + { + constexpr auto x = Layout<int8_t, int32_t, int8_t, Int128>::Partial(1, 2, 3); + EXPECT_EQ( + "@0<signed char>(1)[1]; @4<int>(4)[2]; @12<signed char>(1)[3]; " + "@16" + + Int128::Name() + "(16)", + x.DebugString()); + } + { + constexpr auto x = Layout<int8_t, int32_t, int8_t, Int128>::Partial(1, 2, 3, 4); + EXPECT_EQ( + "@0<signed char>(1)[1]; @4<int>(4)[2]; @12<signed char>(1)[3]; " + "@16" + + Int128::Name() + "(16)[4]", + x.DebugString()); + } + { + constexpr Layout<int8_t, int32_t, int8_t, Int128> x(1, 2, 3, 4); + EXPECT_EQ( + "@0<signed char>(1)[1]; @4<int>(4)[2]; @12<signed char>(1)[3]; " + "@16" + + Int128::Name() + "(16)[4]", + x.DebugString()); + } +} + +TEST(Layout, CharTypes) { + constexpr Layout<int32_t> x(1); + alignas(max_align_t) char c[x.AllocSize()] = {}; + alignas(max_align_t) unsigned char uc[x.AllocSize()] = {}; + alignas(max_align_t) signed char sc[x.AllocSize()] = {}; + alignas(max_align_t) const char cc[x.AllocSize()] = {}; + alignas(max_align_t) const unsigned char cuc[x.AllocSize()] = {}; + alignas(max_align_t) const signed char csc[x.AllocSize()] = {}; + + Type<int32_t*>(x.Pointer<0>(c)); + Type<int32_t*>(x.Pointer<0>(uc)); + Type<int32_t*>(x.Pointer<0>(sc)); + Type<const int32_t*>(x.Pointer<0>(cc)); + Type<const int32_t*>(x.Pointer<0>(cuc)); + Type<const int32_t*>(x.Pointer<0>(csc)); + + Type<int32_t*>(x.Pointer<int32_t>(c)); + Type<int32_t*>(x.Pointer<int32_t>(uc)); + Type<int32_t*>(x.Pointer<int32_t>(sc)); + Type<const int32_t*>(x.Pointer<int32_t>(cc)); + Type<const int32_t*>(x.Pointer<int32_t>(cuc)); + Type<const int32_t*>(x.Pointer<int32_t>(csc)); + + Type<std::tuple<int32_t*>>(x.Pointers(c)); + Type<std::tuple<int32_t*>>(x.Pointers(uc)); + Type<std::tuple<int32_t*>>(x.Pointers(sc)); + Type<std::tuple<const int32_t*>>(x.Pointers(cc)); + Type<std::tuple<const int32_t*>>(x.Pointers(cuc)); + Type<std::tuple<const int32_t*>>(x.Pointers(csc)); + + Type<Span<int32_t>>(x.Slice<0>(c)); + Type<Span<int32_t>>(x.Slice<0>(uc)); + Type<Span<int32_t>>(x.Slice<0>(sc)); + Type<Span<const int32_t>>(x.Slice<0>(cc)); + Type<Span<const int32_t>>(x.Slice<0>(cuc)); + Type<Span<const int32_t>>(x.Slice<0>(csc)); + + Type<std::tuple<Span<int32_t>>>(x.Slices(c)); + Type<std::tuple<Span<int32_t>>>(x.Slices(uc)); + Type<std::tuple<Span<int32_t>>>(x.Slices(sc)); + Type<std::tuple<Span<const int32_t>>>(x.Slices(cc)); + Type<std::tuple<Span<const int32_t>>>(x.Slices(cuc)); + Type<std::tuple<Span<const int32_t>>>(x.Slices(csc)); +} + +TEST(Layout, ConstElementType) { + constexpr Layout<const int32_t> x(1); + alignas(int32_t) char c[x.AllocSize()] = {}; + const char* cc = c; + const int32_t* p = reinterpret_cast<const int32_t*>(cc); + + EXPECT_EQ(alignof(int32_t), x.Alignment()); + + EXPECT_EQ(0, x.Offset<0>()); + EXPECT_EQ(0, x.Offset<const int32_t>()); + + EXPECT_THAT(x.Offsets(), ElementsAre(0)); + + EXPECT_EQ(1, x.Size<0>()); + EXPECT_EQ(1, x.Size<const int32_t>()); + + EXPECT_THAT(x.Sizes(), ElementsAre(1)); + + EXPECT_EQ(sizeof(int32_t), x.AllocSize()); + + EXPECT_EQ(p, Type<const int32_t*>(x.Pointer<0>(c))); + EXPECT_EQ(p, Type<const int32_t*>(x.Pointer<0>(cc))); + + EXPECT_EQ(p, Type<const int32_t*>(x.Pointer<const int32_t>(c))); + EXPECT_EQ(p, Type<const int32_t*>(x.Pointer<const int32_t>(cc))); + + EXPECT_THAT(Type<std::tuple<const int32_t*>>(x.Pointers(c)), Tuple(p)); + EXPECT_THAT(Type<std::tuple<const int32_t*>>(x.Pointers(cc)), Tuple(p)); + + EXPECT_THAT(Type<Span<const int32_t>>(x.Slice<0>(c)), + IsSameSlice(Span<const int32_t>(p, 1))); + EXPECT_THAT(Type<Span<const int32_t>>(x.Slice<0>(cc)), + IsSameSlice(Span<const int32_t>(p, 1))); + + EXPECT_THAT(Type<Span<const int32_t>>(x.Slice<const int32_t>(c)), + IsSameSlice(Span<const int32_t>(p, 1))); + EXPECT_THAT(Type<Span<const int32_t>>(x.Slice<const int32_t>(cc)), + IsSameSlice(Span<const int32_t>(p, 1))); + + EXPECT_THAT(Type<std::tuple<Span<const int32_t>>>(x.Slices(c)), + Tuple(IsSameSlice(Span<const int32_t>(p, 1)))); + EXPECT_THAT(Type<std::tuple<Span<const int32_t>>>(x.Slices(cc)), + Tuple(IsSameSlice(Span<const int32_t>(p, 1)))); +} + +namespace example { + +// Immutable move-only string with sizeof equal to sizeof(void*). The string +// size and the characters are kept in the same heap allocation. +class CompactString { + public: + CompactString(const char* s = "") { // NOLINT + const size_t size = strlen(s); + // size_t[1], followed by char[size + 1]. + // This statement doesn't allocate memory. + const L layout(1, size + 1); + // AllocSize() tells us how much memory we need to allocate for all our + // data. + p_.reset(new unsigned char[layout.AllocSize()]); + // If running under ASAN, mark the padding bytes, if any, to catch memory + // errors. + layout.PoisonPadding(p_.get()); + // Store the size in the allocation. + // Pointer<size_t>() is a synonym for Pointer<0>(). + *layout.Pointer<size_t>(p_.get()) = size; + // Store the characters in the allocation. + memcpy(layout.Pointer<char>(p_.get()), s, size + 1); + } + + size_t size() const { + // Equivalent to reinterpret_cast<size_t&>(*p). + return *L::Partial().Pointer<size_t>(p_.get()); + } + + const char* c_str() const { + // Equivalent to reinterpret_cast<char*>(p.get() + sizeof(size_t)). + // The argument in Partial(1) specifies that we have size_t[1] in front of + // the characters. + return L::Partial(1).Pointer<char>(p_.get()); + } + + private: + // Our heap allocation contains a size_t followed by an array of chars. + using L = Layout<size_t, char>; + std::unique_ptr<unsigned char[]> p_; +}; + +TEST(CompactString, Works) { + CompactString s = "hello"; + EXPECT_EQ(5, s.size()); + EXPECT_STREQ("hello", s.c_str()); +} + +} // namespace example + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/node_hash_policy.h b/third_party/abseil_cpp/absl/container/internal/node_hash_policy.h new file mode 100644 index 0000000000..4617162f0b --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/node_hash_policy.h @@ -0,0 +1,92 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Adapts a policy for nodes. +// +// The node policy should model: +// +// struct Policy { +// // Returns a new node allocated and constructed using the allocator, using +// // the specified arguments. +// template <class Alloc, class... Args> +// value_type* new_element(Alloc* alloc, Args&&... args) const; +// +// // Destroys and deallocates node using the allocator. +// template <class Alloc> +// void delete_element(Alloc* alloc, value_type* node) const; +// }; +// +// It may also optionally define `value()` and `apply()`. For documentation on +// these, see hash_policy_traits.h. + +#ifndef ABSL_CONTAINER_INTERNAL_NODE_HASH_POLICY_H_ +#define ABSL_CONTAINER_INTERNAL_NODE_HASH_POLICY_H_ + +#include <cassert> +#include <cstddef> +#include <memory> +#include <type_traits> +#include <utility> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class Reference, class Policy> +struct node_hash_policy { + static_assert(std::is_lvalue_reference<Reference>::value, ""); + + using slot_type = typename std::remove_cv< + typename std::remove_reference<Reference>::type>::type*; + + template <class Alloc, class... Args> + static void construct(Alloc* alloc, slot_type* slot, Args&&... args) { + *slot = Policy::new_element(alloc, std::forward<Args>(args)...); + } + + template <class Alloc> + static void destroy(Alloc* alloc, slot_type* slot) { + Policy::delete_element(alloc, *slot); + } + + template <class Alloc> + static void transfer(Alloc*, slot_type* new_slot, slot_type* old_slot) { + *new_slot = *old_slot; + } + + static size_t space_used(const slot_type* slot) { + if (slot == nullptr) return Policy::element_space_used(nullptr); + return Policy::element_space_used(*slot); + } + + static Reference element(slot_type* slot) { return **slot; } + + template <class T, class P = Policy> + static auto value(T* elem) -> decltype(P::value(elem)) { + return P::value(elem); + } + + template <class... Ts, class P = Policy> + static auto apply(Ts&&... ts) -> decltype(P::apply(std::forward<Ts>(ts)...)) { + return P::apply(std::forward<Ts>(ts)...); + } +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_NODE_HASH_POLICY_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/node_hash_policy_test.cc b/third_party/abseil_cpp/absl/container/internal/node_hash_policy_test.cc new file mode 100644 index 0000000000..84aabba968 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/node_hash_policy_test.cc @@ -0,0 +1,69 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/node_hash_policy.h" + +#include <memory> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_policy_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::testing::Pointee; + +struct Policy : node_hash_policy<int&, Policy> { + using key_type = int; + using init_type = int; + + template <class Alloc> + static int* new_element(Alloc* alloc, int value) { + return new int(value); + } + + template <class Alloc> + static void delete_element(Alloc* alloc, int* elem) { + delete elem; + } +}; + +using NodePolicy = hash_policy_traits<Policy>; + +struct NodeTest : ::testing::Test { + std::allocator<int> alloc; + int n = 53; + int* a = &n; +}; + +TEST_F(NodeTest, ConstructDestroy) { + NodePolicy::construct(&alloc, &a, 42); + EXPECT_THAT(a, Pointee(42)); + NodePolicy::destroy(&alloc, &a); +} + +TEST_F(NodeTest, transfer) { + int s = 42; + int* b = &s; + NodePolicy::transfer(&alloc, &a, &b); + EXPECT_EQ(&s, a); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/raw_hash_map.h b/third_party/abseil_cpp/absl/container/internal/raw_hash_map.h new file mode 100644 index 0000000000..0a02757ddf --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/raw_hash_map.h @@ -0,0 +1,197 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_RAW_HASH_MAP_H_ +#define ABSL_CONTAINER_INTERNAL_RAW_HASH_MAP_H_ + +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/throw_delegate.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/raw_hash_set.h" // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class Policy, class Hash, class Eq, class Alloc> +class raw_hash_map : public raw_hash_set<Policy, Hash, Eq, Alloc> { + // P is Policy. It's passed as a template argument to support maps that have + // incomplete types as values, as in unordered_map<K, IncompleteType>. + // MappedReference<> may be a non-reference type. + template <class P> + using MappedReference = decltype(P::value( + std::addressof(std::declval<typename raw_hash_map::reference>()))); + + // MappedConstReference<> may be a non-reference type. + template <class P> + using MappedConstReference = decltype(P::value( + std::addressof(std::declval<typename raw_hash_map::const_reference>()))); + + using KeyArgImpl = + KeyArg<IsTransparent<Eq>::value && IsTransparent<Hash>::value>; + + public: + using key_type = typename Policy::key_type; + using mapped_type = typename Policy::mapped_type; + template <class K> + using key_arg = typename KeyArgImpl::template type<K, key_type>; + + static_assert(!std::is_reference<key_type>::value, ""); + // TODO(alkis): remove this assertion and verify that reference mapped_type is + // supported. + static_assert(!std::is_reference<mapped_type>::value, ""); + + using iterator = typename raw_hash_map::raw_hash_set::iterator; + using const_iterator = typename raw_hash_map::raw_hash_set::const_iterator; + + raw_hash_map() {} + using raw_hash_map::raw_hash_set::raw_hash_set; + + // The last two template parameters ensure that both arguments are rvalues + // (lvalue arguments are handled by the overloads below). This is necessary + // for supporting bitfield arguments. + // + // union { int n : 1; }; + // flat_hash_map<int, int> m; + // m.insert_or_assign(n, n); + template <class K = key_type, class V = mapped_type, K* = nullptr, + V* = nullptr> + std::pair<iterator, bool> insert_or_assign(key_arg<K>&& k, V&& v) { + return insert_or_assign_impl(std::forward<K>(k), std::forward<V>(v)); + } + + template <class K = key_type, class V = mapped_type, K* = nullptr> + std::pair<iterator, bool> insert_or_assign(key_arg<K>&& k, const V& v) { + return insert_or_assign_impl(std::forward<K>(k), v); + } + + template <class K = key_type, class V = mapped_type, V* = nullptr> + std::pair<iterator, bool> insert_or_assign(const key_arg<K>& k, V&& v) { + return insert_or_assign_impl(k, std::forward<V>(v)); + } + + template <class K = key_type, class V = mapped_type> + std::pair<iterator, bool> insert_or_assign(const key_arg<K>& k, const V& v) { + return insert_or_assign_impl(k, v); + } + + template <class K = key_type, class V = mapped_type, K* = nullptr, + V* = nullptr> + iterator insert_or_assign(const_iterator, key_arg<K>&& k, V&& v) { + return insert_or_assign(std::forward<K>(k), std::forward<V>(v)).first; + } + + template <class K = key_type, class V = mapped_type, K* = nullptr> + iterator insert_or_assign(const_iterator, key_arg<K>&& k, const V& v) { + return insert_or_assign(std::forward<K>(k), v).first; + } + + template <class K = key_type, class V = mapped_type, V* = nullptr> + iterator insert_or_assign(const_iterator, const key_arg<K>& k, V&& v) { + return insert_or_assign(k, std::forward<V>(v)).first; + } + + template <class K = key_type, class V = mapped_type> + iterator insert_or_assign(const_iterator, const key_arg<K>& k, const V& v) { + return insert_or_assign(k, v).first; + } + + // All `try_emplace()` overloads make the same guarantees regarding rvalue + // arguments as `std::unordered_map::try_emplace()`, namely that these + // functions will not move from rvalue arguments if insertions do not happen. + template <class K = key_type, class... Args, + typename std::enable_if< + !std::is_convertible<K, const_iterator>::value, int>::type = 0, + K* = nullptr> + std::pair<iterator, bool> try_emplace(key_arg<K>&& k, Args&&... args) { + return try_emplace_impl(std::forward<K>(k), std::forward<Args>(args)...); + } + + template <class K = key_type, class... Args, + typename std::enable_if< + !std::is_convertible<K, const_iterator>::value, int>::type = 0> + std::pair<iterator, bool> try_emplace(const key_arg<K>& k, Args&&... args) { + return try_emplace_impl(k, std::forward<Args>(args)...); + } + + template <class K = key_type, class... Args, K* = nullptr> + iterator try_emplace(const_iterator, key_arg<K>&& k, Args&&... args) { + return try_emplace(std::forward<K>(k), std::forward<Args>(args)...).first; + } + + template <class K = key_type, class... Args> + iterator try_emplace(const_iterator, const key_arg<K>& k, Args&&... args) { + return try_emplace(k, std::forward<Args>(args)...).first; + } + + template <class K = key_type, class P = Policy> + MappedReference<P> at(const key_arg<K>& key) { + auto it = this->find(key); + if (it == this->end()) { + base_internal::ThrowStdOutOfRange( + "absl::container_internal::raw_hash_map<>::at"); + } + return Policy::value(&*it); + } + + template <class K = key_type, class P = Policy> + MappedConstReference<P> at(const key_arg<K>& key) const { + auto it = this->find(key); + if (it == this->end()) { + base_internal::ThrowStdOutOfRange( + "absl::container_internal::raw_hash_map<>::at"); + } + return Policy::value(&*it); + } + + template <class K = key_type, class P = Policy, K* = nullptr> + MappedReference<P> operator[](key_arg<K>&& key) { + return Policy::value(&*try_emplace(std::forward<K>(key)).first); + } + + template <class K = key_type, class P = Policy> + MappedReference<P> operator[](const key_arg<K>& key) { + return Policy::value(&*try_emplace(key).first); + } + + private: + template <class K, class V> + std::pair<iterator, bool> insert_or_assign_impl(K&& k, V&& v) { + auto res = this->find_or_prepare_insert(k); + if (res.second) + this->emplace_at(res.first, std::forward<K>(k), std::forward<V>(v)); + else + Policy::value(&*this->iterator_at(res.first)) = std::forward<V>(v); + return {this->iterator_at(res.first), res.second}; + } + + template <class K = key_type, class... Args> + std::pair<iterator, bool> try_emplace_impl(K&& k, Args&&... args) { + auto res = this->find_or_prepare_insert(k); + if (res.second) + this->emplace_at(res.first, std::piecewise_construct, + std::forward_as_tuple(std::forward<K>(k)), + std::forward_as_tuple(std::forward<Args>(args)...)); + return {this->iterator_at(res.first), res.second}; + } +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_RAW_HASH_MAP_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/raw_hash_set.cc b/third_party/abseil_cpp/absl/container/internal/raw_hash_set.cc new file mode 100644 index 0000000000..919ac07405 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/raw_hash_set.cc @@ -0,0 +1,48 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/raw_hash_set.h" + +#include <atomic> +#include <cstddef> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +constexpr size_t Group::kWidth; + +// Returns "random" seed. +inline size_t RandomSeed() { +#if ABSL_HAVE_THREAD_LOCAL + static thread_local size_t counter = 0; + size_t value = ++counter; +#else // ABSL_HAVE_THREAD_LOCAL + static std::atomic<size_t> counter(0); + size_t value = counter.fetch_add(1, std::memory_order_relaxed); +#endif // ABSL_HAVE_THREAD_LOCAL + return value ^ static_cast<size_t>(reinterpret_cast<uintptr_t>(&counter)); +} + +bool ShouldInsertBackwards(size_t hash, ctrl_t* ctrl) { + // To avoid problems with weak hashes and single bit tests, we use % 13. + // TODO(kfm,sbenza): revisit after we do unconditional mixing + return (H1(hash, ctrl) ^ RandomSeed()) % 13 > 6; +} + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/raw_hash_set.h b/third_party/abseil_cpp/absl/container/internal/raw_hash_set.h new file mode 100644 index 0000000000..df0f2b2b54 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/raw_hash_set.h @@ -0,0 +1,1885 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// An open-addressing +// hashtable with quadratic probing. +// +// This is a low level hashtable on top of which different interfaces can be +// implemented, like flat_hash_set, node_hash_set, string_hash_set, etc. +// +// The table interface is similar to that of std::unordered_set. Notable +// differences are that most member functions support heterogeneous keys when +// BOTH the hash and eq functions are marked as transparent. They do so by +// providing a typedef called `is_transparent`. +// +// When heterogeneous lookup is enabled, functions that take key_type act as if +// they have an overload set like: +// +// iterator find(const key_type& key); +// template <class K> +// iterator find(const K& key); +// +// size_type erase(const key_type& key); +// template <class K> +// size_type erase(const K& key); +// +// std::pair<iterator, iterator> equal_range(const key_type& key); +// template <class K> +// std::pair<iterator, iterator> equal_range(const K& key); +// +// When heterogeneous lookup is disabled, only the explicit `key_type` overloads +// exist. +// +// find() also supports passing the hash explicitly: +// +// iterator find(const key_type& key, size_t hash); +// template <class U> +// iterator find(const U& key, size_t hash); +// +// In addition the pointer to element and iterator stability guarantees are +// weaker: all iterators and pointers are invalidated after a new element is +// inserted. +// +// IMPLEMENTATION DETAILS +// +// The table stores elements inline in a slot array. In addition to the slot +// array the table maintains some control state per slot. The extra state is one +// byte per slot and stores empty or deleted marks, or alternatively 7 bits from +// the hash of an occupied slot. The table is split into logical groups of +// slots, like so: +// +// Group 1 Group 2 Group 3 +// +---------------+---------------+---------------+ +// | | | | | | | | | | | | | | | | | | | | | | | | | +// +---------------+---------------+---------------+ +// +// On lookup the hash is split into two parts: +// - H2: 7 bits (those stored in the control bytes) +// - H1: the rest of the bits +// The groups are probed using H1. For each group the slots are matched to H2 in +// parallel. Because H2 is 7 bits (128 states) and the number of slots per group +// is low (8 or 16) in almost all cases a match in H2 is also a lookup hit. +// +// On insert, once the right group is found (as in lookup), its slots are +// filled in order. +// +// On erase a slot is cleared. In case the group did not have any empty slots +// before the erase, the erased slot is marked as deleted. +// +// Groups without empty slots (but maybe with deleted slots) extend the probe +// sequence. The probing algorithm is quadratic. Given N the number of groups, +// the probing function for the i'th probe is: +// +// P(0) = H1 % N +// +// P(i) = (P(i - 1) + i) % N +// +// This probing function guarantees that after N probes, all the groups of the +// table will be probed exactly once. + +#ifndef ABSL_CONTAINER_INTERNAL_RAW_HASH_SET_H_ +#define ABSL_CONTAINER_INTERNAL_RAW_HASH_SET_H_ + +#include <algorithm> +#include <cmath> +#include <cstdint> +#include <cstring> +#include <iterator> +#include <limits> +#include <memory> +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/bits.h" +#include "absl/base/internal/endian.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" +#include "absl/container/internal/common.h" +#include "absl/container/internal/compressed_tuple.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/hash_policy_traits.h" +#include "absl/container/internal/hashtable_debug_hooks.h" +#include "absl/container/internal/hashtablez_sampler.h" +#include "absl/container/internal/have_sse.h" +#include "absl/container/internal/layout.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <size_t Width> +class probe_seq { + public: + probe_seq(size_t hash, size_t mask) { + assert(((mask + 1) & mask) == 0 && "not a mask"); + mask_ = mask; + offset_ = hash & mask_; + } + size_t offset() const { return offset_; } + size_t offset(size_t i) const { return (offset_ + i) & mask_; } + + void next() { + index_ += Width; + offset_ += index_; + offset_ &= mask_; + } + // 0-based probe index. The i-th probe in the probe sequence. + size_t index() const { return index_; } + + private: + size_t mask_; + size_t offset_; + size_t index_ = 0; +}; + +template <class ContainerKey, class Hash, class Eq> +struct RequireUsableKey { + template <class PassedKey, class... Args> + std::pair< + decltype(std::declval<const Hash&>()(std::declval<const PassedKey&>())), + decltype(std::declval<const Eq&>()(std::declval<const ContainerKey&>(), + std::declval<const PassedKey&>()))>* + operator()(const PassedKey&, const Args&...) const; +}; + +template <class E, class Policy, class Hash, class Eq, class... Ts> +struct IsDecomposable : std::false_type {}; + +template <class Policy, class Hash, class Eq, class... Ts> +struct IsDecomposable< + absl::void_t<decltype( + Policy::apply(RequireUsableKey<typename Policy::key_type, Hash, Eq>(), + std::declval<Ts>()...))>, + Policy, Hash, Eq, Ts...> : std::true_type {}; + +// TODO(alkis): Switch to std::is_nothrow_swappable when gcc/clang supports it. +template <class T> +constexpr bool IsNoThrowSwappable() { + using std::swap; + return noexcept(swap(std::declval<T&>(), std::declval<T&>())); +} + +template <typename T> +int TrailingZeros(T x) { + return sizeof(T) == 8 ? base_internal::CountTrailingZerosNonZero64( + static_cast<uint64_t>(x)) + : base_internal::CountTrailingZerosNonZero32( + static_cast<uint32_t>(x)); +} + +template <typename T> +int LeadingZeros(T x) { + return sizeof(T) == 8 + ? base_internal::CountLeadingZeros64(static_cast<uint64_t>(x)) + : base_internal::CountLeadingZeros32(static_cast<uint32_t>(x)); +} + +// An abstraction over a bitmask. It provides an easy way to iterate through the +// indexes of the set bits of a bitmask. When Shift=0 (platforms with SSE), +// this is a true bitmask. On non-SSE, platforms the arithematic used to +// emulate the SSE behavior works in bytes (Shift=3) and leaves each bytes as +// either 0x00 or 0x80. +// +// For example: +// for (int i : BitMask<uint32_t, 16>(0x5)) -> yields 0, 2 +// for (int i : BitMask<uint64_t, 8, 3>(0x0000000080800000)) -> yields 2, 3 +template <class T, int SignificantBits, int Shift = 0> +class BitMask { + static_assert(std::is_unsigned<T>::value, ""); + static_assert(Shift == 0 || Shift == 3, ""); + + public: + // These are useful for unit tests (gunit). + using value_type = int; + using iterator = BitMask; + using const_iterator = BitMask; + + explicit BitMask(T mask) : mask_(mask) {} + BitMask& operator++() { + mask_ &= (mask_ - 1); + return *this; + } + explicit operator bool() const { return mask_ != 0; } + int operator*() const { return LowestBitSet(); } + int LowestBitSet() const { + return container_internal::TrailingZeros(mask_) >> Shift; + } + int HighestBitSet() const { + return (sizeof(T) * CHAR_BIT - container_internal::LeadingZeros(mask_) - + 1) >> + Shift; + } + + BitMask begin() const { return *this; } + BitMask end() const { return BitMask(0); } + + int TrailingZeros() const { + return container_internal::TrailingZeros(mask_) >> Shift; + } + + int LeadingZeros() const { + constexpr int total_significant_bits = SignificantBits << Shift; + constexpr int extra_bits = sizeof(T) * 8 - total_significant_bits; + return container_internal::LeadingZeros(mask_ << extra_bits) >> Shift; + } + + private: + friend bool operator==(const BitMask& a, const BitMask& b) { + return a.mask_ == b.mask_; + } + friend bool operator!=(const BitMask& a, const BitMask& b) { + return a.mask_ != b.mask_; + } + + T mask_; +}; + +using ctrl_t = signed char; +using h2_t = uint8_t; + +// The values here are selected for maximum performance. See the static asserts +// below for details. +enum Ctrl : ctrl_t { + kEmpty = -128, // 0b10000000 + kDeleted = -2, // 0b11111110 + kSentinel = -1, // 0b11111111 +}; +static_assert( + kEmpty & kDeleted & kSentinel & 0x80, + "Special markers need to have the MSB to make checking for them efficient"); +static_assert(kEmpty < kSentinel && kDeleted < kSentinel, + "kEmpty and kDeleted must be smaller than kSentinel to make the " + "SIMD test of IsEmptyOrDeleted() efficient"); +static_assert(kSentinel == -1, + "kSentinel must be -1 to elide loading it from memory into SIMD " + "registers (pcmpeqd xmm, xmm)"); +static_assert(kEmpty == -128, + "kEmpty must be -128 to make the SIMD check for its " + "existence efficient (psignb xmm, xmm)"); +static_assert(~kEmpty & ~kDeleted & kSentinel & 0x7F, + "kEmpty and kDeleted must share an unset bit that is not shared " + "by kSentinel to make the scalar test for MatchEmptyOrDeleted() " + "efficient"); +static_assert(kDeleted == -2, + "kDeleted must be -2 to make the implementation of " + "ConvertSpecialToEmptyAndFullToDeleted efficient"); + +// A single block of empty control bytes for tables without any slots allocated. +// This enables removing a branch in the hot path of find(). +inline ctrl_t* EmptyGroup() { + alignas(16) static constexpr ctrl_t empty_group[] = { + kSentinel, kEmpty, kEmpty, kEmpty, kEmpty, kEmpty, kEmpty, kEmpty, + kEmpty, kEmpty, kEmpty, kEmpty, kEmpty, kEmpty, kEmpty, kEmpty}; + return const_cast<ctrl_t*>(empty_group); +} + +// Mixes a randomly generated per-process seed with `hash` and `ctrl` to +// randomize insertion order within groups. +bool ShouldInsertBackwards(size_t hash, ctrl_t* ctrl); + +// Returns a hash seed. +// +// The seed consists of the ctrl_ pointer, which adds enough entropy to ensure +// non-determinism of iteration order in most cases. +inline size_t HashSeed(const ctrl_t* ctrl) { + // The low bits of the pointer have little or no entropy because of + // alignment. We shift the pointer to try to use higher entropy bits. A + // good number seems to be 12 bits, because that aligns with page size. + return reinterpret_cast<uintptr_t>(ctrl) >> 12; +} + +inline size_t H1(size_t hash, const ctrl_t* ctrl) { + return (hash >> 7) ^ HashSeed(ctrl); +} +inline ctrl_t H2(size_t hash) { return hash & 0x7F; } + +inline bool IsEmpty(ctrl_t c) { return c == kEmpty; } +inline bool IsFull(ctrl_t c) { return c >= 0; } +inline bool IsDeleted(ctrl_t c) { return c == kDeleted; } +inline bool IsEmptyOrDeleted(ctrl_t c) { return c < kSentinel; } + +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 + +// https://github.com/abseil/abseil-cpp/issues/209 +// https://gcc.gnu.org/bugzilla/show_bug.cgi?id=87853 +// _mm_cmpgt_epi8 is broken under GCC with -funsigned-char +// Work around this by using the portable implementation of Group +// when using -funsigned-char under GCC. +inline __m128i _mm_cmpgt_epi8_fixed(__m128i a, __m128i b) { +#if defined(__GNUC__) && !defined(__clang__) + if (std::is_unsigned<char>::value) { + const __m128i mask = _mm_set1_epi8(0x80); + const __m128i diff = _mm_subs_epi8(b, a); + return _mm_cmpeq_epi8(_mm_and_si128(diff, mask), mask); + } +#endif + return _mm_cmpgt_epi8(a, b); +} + +struct GroupSse2Impl { + static constexpr size_t kWidth = 16; // the number of slots per group + + explicit GroupSse2Impl(const ctrl_t* pos) { + ctrl = _mm_loadu_si128(reinterpret_cast<const __m128i*>(pos)); + } + + // Returns a bitmask representing the positions of slots that match hash. + BitMask<uint32_t, kWidth> Match(h2_t hash) const { + auto match = _mm_set1_epi8(hash); + return BitMask<uint32_t, kWidth>( + _mm_movemask_epi8(_mm_cmpeq_epi8(match, ctrl))); + } + + // Returns a bitmask representing the positions of empty slots. + BitMask<uint32_t, kWidth> MatchEmpty() const { +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 + // This only works because kEmpty is -128. + return BitMask<uint32_t, kWidth>( + _mm_movemask_epi8(_mm_sign_epi8(ctrl, ctrl))); +#else + return Match(static_cast<h2_t>(kEmpty)); +#endif + } + + // Returns a bitmask representing the positions of empty or deleted slots. + BitMask<uint32_t, kWidth> MatchEmptyOrDeleted() const { + auto special = _mm_set1_epi8(kSentinel); + return BitMask<uint32_t, kWidth>( + _mm_movemask_epi8(_mm_cmpgt_epi8_fixed(special, ctrl))); + } + + // Returns the number of trailing empty or deleted elements in the group. + uint32_t CountLeadingEmptyOrDeleted() const { + auto special = _mm_set1_epi8(kSentinel); + return TrailingZeros( + _mm_movemask_epi8(_mm_cmpgt_epi8_fixed(special, ctrl)) + 1); + } + + void ConvertSpecialToEmptyAndFullToDeleted(ctrl_t* dst) const { + auto msbs = _mm_set1_epi8(static_cast<char>(-128)); + auto x126 = _mm_set1_epi8(126); +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSSE3 + auto res = _mm_or_si128(_mm_shuffle_epi8(x126, ctrl), msbs); +#else + auto zero = _mm_setzero_si128(); + auto special_mask = _mm_cmpgt_epi8_fixed(zero, ctrl); + auto res = _mm_or_si128(msbs, _mm_andnot_si128(special_mask, x126)); +#endif + _mm_storeu_si128(reinterpret_cast<__m128i*>(dst), res); + } + + __m128i ctrl; +}; +#endif // ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 + +struct GroupPortableImpl { + static constexpr size_t kWidth = 8; + + explicit GroupPortableImpl(const ctrl_t* pos) + : ctrl(little_endian::Load64(pos)) {} + + BitMask<uint64_t, kWidth, 3> Match(h2_t hash) const { + // For the technique, see: + // http://graphics.stanford.edu/~seander/bithacks.html##ValueInWord + // (Determine if a word has a byte equal to n). + // + // Caveat: there are false positives but: + // - they only occur if there is a real match + // - they never occur on kEmpty, kDeleted, kSentinel + // - they will be handled gracefully by subsequent checks in code + // + // Example: + // v = 0x1716151413121110 + // hash = 0x12 + // retval = (v - lsbs) & ~v & msbs = 0x0000000080800000 + constexpr uint64_t msbs = 0x8080808080808080ULL; + constexpr uint64_t lsbs = 0x0101010101010101ULL; + auto x = ctrl ^ (lsbs * hash); + return BitMask<uint64_t, kWidth, 3>((x - lsbs) & ~x & msbs); + } + + BitMask<uint64_t, kWidth, 3> MatchEmpty() const { + constexpr uint64_t msbs = 0x8080808080808080ULL; + return BitMask<uint64_t, kWidth, 3>((ctrl & (~ctrl << 6)) & msbs); + } + + BitMask<uint64_t, kWidth, 3> MatchEmptyOrDeleted() const { + constexpr uint64_t msbs = 0x8080808080808080ULL; + return BitMask<uint64_t, kWidth, 3>((ctrl & (~ctrl << 7)) & msbs); + } + + uint32_t CountLeadingEmptyOrDeleted() const { + constexpr uint64_t gaps = 0x00FEFEFEFEFEFEFEULL; + return (TrailingZeros(((~ctrl & (ctrl >> 7)) | gaps) + 1) + 7) >> 3; + } + + void ConvertSpecialToEmptyAndFullToDeleted(ctrl_t* dst) const { + constexpr uint64_t msbs = 0x8080808080808080ULL; + constexpr uint64_t lsbs = 0x0101010101010101ULL; + auto x = ctrl & msbs; + auto res = (~x + (x >> 7)) & ~lsbs; + little_endian::Store64(dst, res); + } + + uint64_t ctrl; +}; + +#if ABSL_INTERNAL_RAW_HASH_SET_HAVE_SSE2 +using Group = GroupSse2Impl; +#else +using Group = GroupPortableImpl; +#endif + +template <class Policy, class Hash, class Eq, class Alloc> +class raw_hash_set; + +inline bool IsValidCapacity(size_t n) { return ((n + 1) & n) == 0 && n > 0; } + +// PRECONDITION: +// IsValidCapacity(capacity) +// ctrl[capacity] == kSentinel +// ctrl[i] != kSentinel for all i < capacity +// Applies mapping for every byte in ctrl: +// DELETED -> EMPTY +// EMPTY -> EMPTY +// FULL -> DELETED +inline void ConvertDeletedToEmptyAndFullToDeleted( + ctrl_t* ctrl, size_t capacity) { + assert(ctrl[capacity] == kSentinel); + assert(IsValidCapacity(capacity)); + for (ctrl_t* pos = ctrl; pos != ctrl + capacity + 1; pos += Group::kWidth) { + Group{pos}.ConvertSpecialToEmptyAndFullToDeleted(pos); + } + // Copy the cloned ctrl bytes. + std::memcpy(ctrl + capacity + 1, ctrl, Group::kWidth); + ctrl[capacity] = kSentinel; +} + +// Rounds up the capacity to the next power of 2 minus 1, with a minimum of 1. +inline size_t NormalizeCapacity(size_t n) { + return n ? ~size_t{} >> LeadingZeros(n) : 1; +} + +// We use 7/8th as maximum load factor. +// For 16-wide groups, that gives an average of two empty slots per group. +inline size_t CapacityToGrowth(size_t capacity) { + assert(IsValidCapacity(capacity)); + // `capacity*7/8` + if (Group::kWidth == 8 && capacity == 7) { + // x-x/8 does not work when x==7. + return 6; + } + return capacity - capacity / 8; +} +// From desired "growth" to a lowerbound of the necessary capacity. +// Might not be a valid one and required NormalizeCapacity(). +inline size_t GrowthToLowerboundCapacity(size_t growth) { + // `growth*8/7` + if (Group::kWidth == 8 && growth == 7) { + // x+(x-1)/7 does not work when x==7. + return 8; + } + return growth + static_cast<size_t>((static_cast<int64_t>(growth) - 1) / 7); +} + +// Policy: a policy defines how to perform different operations on +// the slots of the hashtable (see hash_policy_traits.h for the full interface +// of policy). +// +// Hash: a (possibly polymorphic) functor that hashes keys of the hashtable. The +// functor should accept a key and return size_t as hash. For best performance +// it is important that the hash function provides high entropy across all bits +// of the hash. +// +// Eq: a (possibly polymorphic) functor that compares two keys for equality. It +// should accept two (of possibly different type) keys and return a bool: true +// if they are equal, false if they are not. If two keys compare equal, then +// their hash values as defined by Hash MUST be equal. +// +// Allocator: an Allocator [https://devdocs.io/cpp/concept/allocator] with which +// the storage of the hashtable will be allocated and the elements will be +// constructed and destroyed. +template <class Policy, class Hash, class Eq, class Alloc> +class raw_hash_set { + using PolicyTraits = hash_policy_traits<Policy>; + using KeyArgImpl = + KeyArg<IsTransparent<Eq>::value && IsTransparent<Hash>::value>; + + public: + using init_type = typename PolicyTraits::init_type; + using key_type = typename PolicyTraits::key_type; + // TODO(sbenza): Hide slot_type as it is an implementation detail. Needs user + // code fixes! + using slot_type = typename PolicyTraits::slot_type; + using allocator_type = Alloc; + using size_type = size_t; + using difference_type = ptrdiff_t; + using hasher = Hash; + using key_equal = Eq; + using policy_type = Policy; + using value_type = typename PolicyTraits::value_type; + using reference = value_type&; + using const_reference = const value_type&; + using pointer = typename absl::allocator_traits< + allocator_type>::template rebind_traits<value_type>::pointer; + using const_pointer = typename absl::allocator_traits< + allocator_type>::template rebind_traits<value_type>::const_pointer; + + // Alias used for heterogeneous lookup functions. + // `key_arg<K>` evaluates to `K` when the functors are transparent and to + // `key_type` otherwise. It permits template argument deduction on `K` for the + // transparent case. + template <class K> + using key_arg = typename KeyArgImpl::template type<K, key_type>; + + private: + // Give an early error when key_type is not hashable/eq. + auto KeyTypeCanBeHashed(const Hash& h, const key_type& k) -> decltype(h(k)); + auto KeyTypeCanBeEq(const Eq& eq, const key_type& k) -> decltype(eq(k, k)); + + using Layout = absl::container_internal::Layout<ctrl_t, slot_type>; + + static Layout MakeLayout(size_t capacity) { + assert(IsValidCapacity(capacity)); + return Layout(capacity + Group::kWidth + 1, capacity); + } + + using AllocTraits = absl::allocator_traits<allocator_type>; + using SlotAlloc = typename absl::allocator_traits< + allocator_type>::template rebind_alloc<slot_type>; + using SlotAllocTraits = typename absl::allocator_traits< + allocator_type>::template rebind_traits<slot_type>; + + static_assert(std::is_lvalue_reference<reference>::value, + "Policy::element() must return a reference"); + + template <typename T> + struct SameAsElementReference + : std::is_same<typename std::remove_cv< + typename std::remove_reference<reference>::type>::type, + typename std::remove_cv< + typename std::remove_reference<T>::type>::type> {}; + + // An enabler for insert(T&&): T must be convertible to init_type or be the + // same as [cv] value_type [ref]. + // Note: we separate SameAsElementReference into its own type to avoid using + // reference unless we need to. MSVC doesn't seem to like it in some + // cases. + template <class T> + using RequiresInsertable = typename std::enable_if< + absl::disjunction<std::is_convertible<T, init_type>, + SameAsElementReference<T>>::value, + int>::type; + + // RequiresNotInit is a workaround for gcc prior to 7.1. + // See https://godbolt.org/g/Y4xsUh. + template <class T> + using RequiresNotInit = + typename std::enable_if<!std::is_same<T, init_type>::value, int>::type; + + template <class... Ts> + using IsDecomposable = IsDecomposable<void, PolicyTraits, Hash, Eq, Ts...>; + + public: + static_assert(std::is_same<pointer, value_type*>::value, + "Allocators with custom pointer types are not supported"); + static_assert(std::is_same<const_pointer, const value_type*>::value, + "Allocators with custom pointer types are not supported"); + + class iterator { + friend class raw_hash_set; + + public: + using iterator_category = std::forward_iterator_tag; + using value_type = typename raw_hash_set::value_type; + using reference = + absl::conditional_t<PolicyTraits::constant_iterators::value, + const value_type&, value_type&>; + using pointer = absl::remove_reference_t<reference>*; + using difference_type = typename raw_hash_set::difference_type; + + iterator() {} + + // PRECONDITION: not an end() iterator. + reference operator*() const { + assert_is_full(); + return PolicyTraits::element(slot_); + } + + // PRECONDITION: not an end() iterator. + pointer operator->() const { return &operator*(); } + + // PRECONDITION: not an end() iterator. + iterator& operator++() { + assert_is_full(); + ++ctrl_; + ++slot_; + skip_empty_or_deleted(); + return *this; + } + // PRECONDITION: not an end() iterator. + iterator operator++(int) { + auto tmp = *this; + ++*this; + return tmp; + } + + friend bool operator==(const iterator& a, const iterator& b) { + a.assert_is_valid(); + b.assert_is_valid(); + return a.ctrl_ == b.ctrl_; + } + friend bool operator!=(const iterator& a, const iterator& b) { + return !(a == b); + } + + private: + iterator(ctrl_t* ctrl, slot_type* slot) : ctrl_(ctrl), slot_(slot) { + // This assumption helps the compiler know that any non-end iterator is + // not equal to any end iterator. + ABSL_INTERNAL_ASSUME(ctrl != nullptr); + } + + void assert_is_full() const { + ABSL_HARDENING_ASSERT(ctrl_ != nullptr && IsFull(*ctrl_)); + } + void assert_is_valid() const { + ABSL_HARDENING_ASSERT(ctrl_ == nullptr || IsFull(*ctrl_)); + } + + void skip_empty_or_deleted() { + while (IsEmptyOrDeleted(*ctrl_)) { + uint32_t shift = Group{ctrl_}.CountLeadingEmptyOrDeleted(); + ctrl_ += shift; + slot_ += shift; + } + if (ABSL_PREDICT_FALSE(*ctrl_ == kSentinel)) ctrl_ = nullptr; + } + + ctrl_t* ctrl_ = nullptr; + // To avoid uninitialized member warnings, put slot_ in an anonymous union. + // The member is not initialized on singleton and end iterators. + union { + slot_type* slot_; + }; + }; + + class const_iterator { + friend class raw_hash_set; + + public: + using iterator_category = typename iterator::iterator_category; + using value_type = typename raw_hash_set::value_type; + using reference = typename raw_hash_set::const_reference; + using pointer = typename raw_hash_set::const_pointer; + using difference_type = typename raw_hash_set::difference_type; + + const_iterator() {} + // Implicit construction from iterator. + const_iterator(iterator i) : inner_(std::move(i)) {} + + reference operator*() const { return *inner_; } + pointer operator->() const { return inner_.operator->(); } + + const_iterator& operator++() { + ++inner_; + return *this; + } + const_iterator operator++(int) { return inner_++; } + + friend bool operator==(const const_iterator& a, const const_iterator& b) { + return a.inner_ == b.inner_; + } + friend bool operator!=(const const_iterator& a, const const_iterator& b) { + return !(a == b); + } + + private: + const_iterator(const ctrl_t* ctrl, const slot_type* slot) + : inner_(const_cast<ctrl_t*>(ctrl), const_cast<slot_type*>(slot)) {} + + iterator inner_; + }; + + using node_type = node_handle<Policy, hash_policy_traits<Policy>, Alloc>; + using insert_return_type = InsertReturnType<iterator, node_type>; + + raw_hash_set() noexcept( + std::is_nothrow_default_constructible<hasher>::value&& + std::is_nothrow_default_constructible<key_equal>::value&& + std::is_nothrow_default_constructible<allocator_type>::value) {} + + explicit raw_hash_set(size_t bucket_count, const hasher& hash = hasher(), + const key_equal& eq = key_equal(), + const allocator_type& alloc = allocator_type()) + : ctrl_(EmptyGroup()), settings_(0, hash, eq, alloc) { + if (bucket_count) { + capacity_ = NormalizeCapacity(bucket_count); + reset_growth_left(); + initialize_slots(); + } + } + + raw_hash_set(size_t bucket_count, const hasher& hash, + const allocator_type& alloc) + : raw_hash_set(bucket_count, hash, key_equal(), alloc) {} + + raw_hash_set(size_t bucket_count, const allocator_type& alloc) + : raw_hash_set(bucket_count, hasher(), key_equal(), alloc) {} + + explicit raw_hash_set(const allocator_type& alloc) + : raw_hash_set(0, hasher(), key_equal(), alloc) {} + + template <class InputIter> + raw_hash_set(InputIter first, InputIter last, size_t bucket_count = 0, + const hasher& hash = hasher(), const key_equal& eq = key_equal(), + const allocator_type& alloc = allocator_type()) + : raw_hash_set(bucket_count, hash, eq, alloc) { + insert(first, last); + } + + template <class InputIter> + raw_hash_set(InputIter first, InputIter last, size_t bucket_count, + const hasher& hash, const allocator_type& alloc) + : raw_hash_set(first, last, bucket_count, hash, key_equal(), alloc) {} + + template <class InputIter> + raw_hash_set(InputIter first, InputIter last, size_t bucket_count, + const allocator_type& alloc) + : raw_hash_set(first, last, bucket_count, hasher(), key_equal(), alloc) {} + + template <class InputIter> + raw_hash_set(InputIter first, InputIter last, const allocator_type& alloc) + : raw_hash_set(first, last, 0, hasher(), key_equal(), alloc) {} + + // Instead of accepting std::initializer_list<value_type> as the first + // argument like std::unordered_set<value_type> does, we have two overloads + // that accept std::initializer_list<T> and std::initializer_list<init_type>. + // This is advantageous for performance. + // + // // Turns {"abc", "def"} into std::initializer_list<std::string>, then + // // copies the strings into the set. + // std::unordered_set<std::string> s = {"abc", "def"}; + // + // // Turns {"abc", "def"} into std::initializer_list<const char*>, then + // // copies the strings into the set. + // absl::flat_hash_set<std::string> s = {"abc", "def"}; + // + // The same trick is used in insert(). + // + // The enabler is necessary to prevent this constructor from triggering where + // the copy constructor is meant to be called. + // + // absl::flat_hash_set<int> a, b{a}; + // + // RequiresNotInit<T> is a workaround for gcc prior to 7.1. + template <class T, RequiresNotInit<T> = 0, RequiresInsertable<T> = 0> + raw_hash_set(std::initializer_list<T> init, size_t bucket_count = 0, + const hasher& hash = hasher(), const key_equal& eq = key_equal(), + const allocator_type& alloc = allocator_type()) + : raw_hash_set(init.begin(), init.end(), bucket_count, hash, eq, alloc) {} + + raw_hash_set(std::initializer_list<init_type> init, size_t bucket_count = 0, + const hasher& hash = hasher(), const key_equal& eq = key_equal(), + const allocator_type& alloc = allocator_type()) + : raw_hash_set(init.begin(), init.end(), bucket_count, hash, eq, alloc) {} + + template <class T, RequiresNotInit<T> = 0, RequiresInsertable<T> = 0> + raw_hash_set(std::initializer_list<T> init, size_t bucket_count, + const hasher& hash, const allocator_type& alloc) + : raw_hash_set(init, bucket_count, hash, key_equal(), alloc) {} + + raw_hash_set(std::initializer_list<init_type> init, size_t bucket_count, + const hasher& hash, const allocator_type& alloc) + : raw_hash_set(init, bucket_count, hash, key_equal(), alloc) {} + + template <class T, RequiresNotInit<T> = 0, RequiresInsertable<T> = 0> + raw_hash_set(std::initializer_list<T> init, size_t bucket_count, + const allocator_type& alloc) + : raw_hash_set(init, bucket_count, hasher(), key_equal(), alloc) {} + + raw_hash_set(std::initializer_list<init_type> init, size_t bucket_count, + const allocator_type& alloc) + : raw_hash_set(init, bucket_count, hasher(), key_equal(), alloc) {} + + template <class T, RequiresNotInit<T> = 0, RequiresInsertable<T> = 0> + raw_hash_set(std::initializer_list<T> init, const allocator_type& alloc) + : raw_hash_set(init, 0, hasher(), key_equal(), alloc) {} + + raw_hash_set(std::initializer_list<init_type> init, + const allocator_type& alloc) + : raw_hash_set(init, 0, hasher(), key_equal(), alloc) {} + + raw_hash_set(const raw_hash_set& that) + : raw_hash_set(that, AllocTraits::select_on_container_copy_construction( + that.alloc_ref())) {} + + raw_hash_set(const raw_hash_set& that, const allocator_type& a) + : raw_hash_set(0, that.hash_ref(), that.eq_ref(), a) { + reserve(that.size()); + // Because the table is guaranteed to be empty, we can do something faster + // than a full `insert`. + for (const auto& v : that) { + const size_t hash = PolicyTraits::apply(HashElement{hash_ref()}, v); + auto target = find_first_non_full(hash); + set_ctrl(target.offset, H2(hash)); + emplace_at(target.offset, v); + infoz_.RecordInsert(hash, target.probe_length); + } + size_ = that.size(); + growth_left() -= that.size(); + } + + raw_hash_set(raw_hash_set&& that) noexcept( + std::is_nothrow_copy_constructible<hasher>::value&& + std::is_nothrow_copy_constructible<key_equal>::value&& + std::is_nothrow_copy_constructible<allocator_type>::value) + : ctrl_(absl::exchange(that.ctrl_, EmptyGroup())), + slots_(absl::exchange(that.slots_, nullptr)), + size_(absl::exchange(that.size_, 0)), + capacity_(absl::exchange(that.capacity_, 0)), + infoz_(absl::exchange(that.infoz_, HashtablezInfoHandle())), + // Hash, equality and allocator are copied instead of moved because + // `that` must be left valid. If Hash is std::function<Key>, moving it + // would create a nullptr functor that cannot be called. + settings_(that.settings_) { + // growth_left was copied above, reset the one from `that`. + that.growth_left() = 0; + } + + raw_hash_set(raw_hash_set&& that, const allocator_type& a) + : ctrl_(EmptyGroup()), + slots_(nullptr), + size_(0), + capacity_(0), + settings_(0, that.hash_ref(), that.eq_ref(), a) { + if (a == that.alloc_ref()) { + std::swap(ctrl_, that.ctrl_); + std::swap(slots_, that.slots_); + std::swap(size_, that.size_); + std::swap(capacity_, that.capacity_); + std::swap(growth_left(), that.growth_left()); + std::swap(infoz_, that.infoz_); + } else { + reserve(that.size()); + // Note: this will copy elements of dense_set and unordered_set instead of + // moving them. This can be fixed if it ever becomes an issue. + for (auto& elem : that) insert(std::move(elem)); + } + } + + raw_hash_set& operator=(const raw_hash_set& that) { + raw_hash_set tmp(that, + AllocTraits::propagate_on_container_copy_assignment::value + ? that.alloc_ref() + : alloc_ref()); + swap(tmp); + return *this; + } + + raw_hash_set& operator=(raw_hash_set&& that) noexcept( + absl::allocator_traits<allocator_type>::is_always_equal::value&& + std::is_nothrow_move_assignable<hasher>::value&& + std::is_nothrow_move_assignable<key_equal>::value) { + // TODO(sbenza): We should only use the operations from the noexcept clause + // to make sure we actually adhere to that contract. + return move_assign( + std::move(that), + typename AllocTraits::propagate_on_container_move_assignment()); + } + + ~raw_hash_set() { destroy_slots(); } + + iterator begin() { + auto it = iterator_at(0); + it.skip_empty_or_deleted(); + return it; + } + iterator end() { return {}; } + + const_iterator begin() const { + return const_cast<raw_hash_set*>(this)->begin(); + } + const_iterator end() const { return {}; } + const_iterator cbegin() const { return begin(); } + const_iterator cend() const { return end(); } + + bool empty() const { return !size(); } + size_t size() const { return size_; } + size_t capacity() const { return capacity_; } + size_t max_size() const { return (std::numeric_limits<size_t>::max)(); } + + ABSL_ATTRIBUTE_REINITIALIZES void clear() { + // Iterating over this container is O(bucket_count()). When bucket_count() + // is much greater than size(), iteration becomes prohibitively expensive. + // For clear() it is more important to reuse the allocated array when the + // container is small because allocation takes comparatively long time + // compared to destruction of the elements of the container. So we pick the + // largest bucket_count() threshold for which iteration is still fast and + // past that we simply deallocate the array. + if (capacity_ > 127) { + destroy_slots(); + } else if (capacity_) { + for (size_t i = 0; i != capacity_; ++i) { + if (IsFull(ctrl_[i])) { + PolicyTraits::destroy(&alloc_ref(), slots_ + i); + } + } + size_ = 0; + reset_ctrl(); + reset_growth_left(); + } + assert(empty()); + infoz_.RecordStorageChanged(0, capacity_); + } + + // This overload kicks in when the argument is an rvalue of insertable and + // decomposable type other than init_type. + // + // flat_hash_map<std::string, int> m; + // m.insert(std::make_pair("abc", 42)); + // TODO(cheshire): A type alias T2 is introduced as a workaround for the nvcc + // bug. + template <class T, RequiresInsertable<T> = 0, + class T2 = T, + typename std::enable_if<IsDecomposable<T2>::value, int>::type = 0, + T* = nullptr> + std::pair<iterator, bool> insert(T&& value) { + return emplace(std::forward<T>(value)); + } + + // This overload kicks in when the argument is a bitfield or an lvalue of + // insertable and decomposable type. + // + // union { int n : 1; }; + // flat_hash_set<int> s; + // s.insert(n); + // + // flat_hash_set<std::string> s; + // const char* p = "hello"; + // s.insert(p); + // + // TODO(romanp): Once we stop supporting gcc 5.1 and below, replace + // RequiresInsertable<T> with RequiresInsertable<const T&>. + // We are hitting this bug: https://godbolt.org/g/1Vht4f. + template < + class T, RequiresInsertable<T> = 0, + typename std::enable_if<IsDecomposable<const T&>::value, int>::type = 0> + std::pair<iterator, bool> insert(const T& value) { + return emplace(value); + } + + // This overload kicks in when the argument is an rvalue of init_type. Its + // purpose is to handle brace-init-list arguments. + // + // flat_hash_map<std::string, int> s; + // s.insert({"abc", 42}); + std::pair<iterator, bool> insert(init_type&& value) { + return emplace(std::move(value)); + } + + // TODO(cheshire): A type alias T2 is introduced as a workaround for the nvcc + // bug. + template <class T, RequiresInsertable<T> = 0, class T2 = T, + typename std::enable_if<IsDecomposable<T2>::value, int>::type = 0, + T* = nullptr> + iterator insert(const_iterator, T&& value) { + return insert(std::forward<T>(value)).first; + } + + // TODO(romanp): Once we stop supporting gcc 5.1 and below, replace + // RequiresInsertable<T> with RequiresInsertable<const T&>. + // We are hitting this bug: https://godbolt.org/g/1Vht4f. + template < + class T, RequiresInsertable<T> = 0, + typename std::enable_if<IsDecomposable<const T&>::value, int>::type = 0> + iterator insert(const_iterator, const T& value) { + return insert(value).first; + } + + iterator insert(const_iterator, init_type&& value) { + return insert(std::move(value)).first; + } + + template <class InputIt> + void insert(InputIt first, InputIt last) { + for (; first != last; ++first) insert(*first); + } + + template <class T, RequiresNotInit<T> = 0, RequiresInsertable<const T&> = 0> + void insert(std::initializer_list<T> ilist) { + insert(ilist.begin(), ilist.end()); + } + + void insert(std::initializer_list<init_type> ilist) { + insert(ilist.begin(), ilist.end()); + } + + insert_return_type insert(node_type&& node) { + if (!node) return {end(), false, node_type()}; + const auto& elem = PolicyTraits::element(CommonAccess::GetSlot(node)); + auto res = PolicyTraits::apply( + InsertSlot<false>{*this, std::move(*CommonAccess::GetSlot(node))}, + elem); + if (res.second) { + CommonAccess::Reset(&node); + return {res.first, true, node_type()}; + } else { + return {res.first, false, std::move(node)}; + } + } + + iterator insert(const_iterator, node_type&& node) { + return insert(std::move(node)).first; + } + + // This overload kicks in if we can deduce the key from args. This enables us + // to avoid constructing value_type if an entry with the same key already + // exists. + // + // For example: + // + // flat_hash_map<std::string, std::string> m = {{"abc", "def"}}; + // // Creates no std::string copies and makes no heap allocations. + // m.emplace("abc", "xyz"); + template <class... Args, typename std::enable_if< + IsDecomposable<Args...>::value, int>::type = 0> + std::pair<iterator, bool> emplace(Args&&... args) { + return PolicyTraits::apply(EmplaceDecomposable{*this}, + std::forward<Args>(args)...); + } + + // This overload kicks in if we cannot deduce the key from args. It constructs + // value_type unconditionally and then either moves it into the table or + // destroys. + template <class... Args, typename std::enable_if< + !IsDecomposable<Args...>::value, int>::type = 0> + std::pair<iterator, bool> emplace(Args&&... args) { + alignas(slot_type) unsigned char raw[sizeof(slot_type)]; + slot_type* slot = reinterpret_cast<slot_type*>(&raw); + + PolicyTraits::construct(&alloc_ref(), slot, std::forward<Args>(args)...); + const auto& elem = PolicyTraits::element(slot); + return PolicyTraits::apply(InsertSlot<true>{*this, std::move(*slot)}, elem); + } + + template <class... Args> + iterator emplace_hint(const_iterator, Args&&... args) { + return emplace(std::forward<Args>(args)...).first; + } + + // Extension API: support for lazy emplace. + // + // Looks up key in the table. If found, returns the iterator to the element. + // Otherwise calls `f` with one argument of type `raw_hash_set::constructor`. + // + // `f` must abide by several restrictions: + // - it MUST call `raw_hash_set::constructor` with arguments as if a + // `raw_hash_set::value_type` is constructed, + // - it MUST NOT access the container before the call to + // `raw_hash_set::constructor`, and + // - it MUST NOT erase the lazily emplaced element. + // Doing any of these is undefined behavior. + // + // For example: + // + // std::unordered_set<ArenaString> s; + // // Makes ArenaStr even if "abc" is in the map. + // s.insert(ArenaString(&arena, "abc")); + // + // flat_hash_set<ArenaStr> s; + // // Makes ArenaStr only if "abc" is not in the map. + // s.lazy_emplace("abc", [&](const constructor& ctor) { + // ctor(&arena, "abc"); + // }); + // + // WARNING: This API is currently experimental. If there is a way to implement + // the same thing with the rest of the API, prefer that. + class constructor { + friend class raw_hash_set; + + public: + template <class... Args> + void operator()(Args&&... args) const { + assert(*slot_); + PolicyTraits::construct(alloc_, *slot_, std::forward<Args>(args)...); + *slot_ = nullptr; + } + + private: + constructor(allocator_type* a, slot_type** slot) : alloc_(a), slot_(slot) {} + + allocator_type* alloc_; + slot_type** slot_; + }; + + template <class K = key_type, class F> + iterator lazy_emplace(const key_arg<K>& key, F&& f) { + auto res = find_or_prepare_insert(key); + if (res.second) { + slot_type* slot = slots_ + res.first; + std::forward<F>(f)(constructor(&alloc_ref(), &slot)); + assert(!slot); + } + return iterator_at(res.first); + } + + // Extension API: support for heterogeneous keys. + // + // std::unordered_set<std::string> s; + // // Turns "abc" into std::string. + // s.erase("abc"); + // + // flat_hash_set<std::string> s; + // // Uses "abc" directly without copying it into std::string. + // s.erase("abc"); + template <class K = key_type> + size_type erase(const key_arg<K>& key) { + auto it = find(key); + if (it == end()) return 0; + erase(it); + return 1; + } + + // Erases the element pointed to by `it`. Unlike `std::unordered_set::erase`, + // this method returns void to reduce algorithmic complexity to O(1). The + // iterator is invalidated, so any increment should be done before calling + // erase. In order to erase while iterating across a map, use the following + // idiom (which also works for standard containers): + // + // for (auto it = m.begin(), end = m.end(); it != end;) { + // // `erase()` will invalidate `it`, so advance `it` first. + // auto copy_it = it++; + // if (<pred>) { + // m.erase(copy_it); + // } + // } + void erase(const_iterator cit) { erase(cit.inner_); } + + // This overload is necessary because otherwise erase<K>(const K&) would be + // a better match if non-const iterator is passed as an argument. + void erase(iterator it) { + it.assert_is_full(); + PolicyTraits::destroy(&alloc_ref(), it.slot_); + erase_meta_only(it); + } + + iterator erase(const_iterator first, const_iterator last) { + while (first != last) { + erase(first++); + } + return last.inner_; + } + + // Moves elements from `src` into `this`. + // If the element already exists in `this`, it is left unmodified in `src`. + template <typename H, typename E> + void merge(raw_hash_set<Policy, H, E, Alloc>& src) { // NOLINT + assert(this != &src); + for (auto it = src.begin(), e = src.end(); it != e;) { + auto next = std::next(it); + if (PolicyTraits::apply(InsertSlot<false>{*this, std::move(*it.slot_)}, + PolicyTraits::element(it.slot_)) + .second) { + src.erase_meta_only(it); + } + it = next; + } + } + + template <typename H, typename E> + void merge(raw_hash_set<Policy, H, E, Alloc>&& src) { + merge(src); + } + + node_type extract(const_iterator position) { + position.inner_.assert_is_full(); + auto node = + CommonAccess::Transfer<node_type>(alloc_ref(), position.inner_.slot_); + erase_meta_only(position); + return node; + } + + template < + class K = key_type, + typename std::enable_if<!std::is_same<K, iterator>::value, int>::type = 0> + node_type extract(const key_arg<K>& key) { + auto it = find(key); + return it == end() ? node_type() : extract(const_iterator{it}); + } + + void swap(raw_hash_set& that) noexcept( + IsNoThrowSwappable<hasher>() && IsNoThrowSwappable<key_equal>() && + (!AllocTraits::propagate_on_container_swap::value || + IsNoThrowSwappable<allocator_type>())) { + using std::swap; + swap(ctrl_, that.ctrl_); + swap(slots_, that.slots_); + swap(size_, that.size_); + swap(capacity_, that.capacity_); + swap(growth_left(), that.growth_left()); + swap(hash_ref(), that.hash_ref()); + swap(eq_ref(), that.eq_ref()); + swap(infoz_, that.infoz_); + if (AllocTraits::propagate_on_container_swap::value) { + swap(alloc_ref(), that.alloc_ref()); + } else { + // If the allocators do not compare equal it is officially undefined + // behavior. We choose to do nothing. + } + } + + void rehash(size_t n) { + if (n == 0 && capacity_ == 0) return; + if (n == 0 && size_ == 0) { + destroy_slots(); + infoz_.RecordStorageChanged(0, 0); + return; + } + // bitor is a faster way of doing `max` here. We will round up to the next + // power-of-2-minus-1, so bitor is good enough. + auto m = NormalizeCapacity(n | GrowthToLowerboundCapacity(size())); + // n == 0 unconditionally rehashes as per the standard. + if (n == 0 || m > capacity_) { + resize(m); + } + } + + void reserve(size_t n) { rehash(GrowthToLowerboundCapacity(n)); } + + // Extension API: support for heterogeneous keys. + // + // std::unordered_set<std::string> s; + // // Turns "abc" into std::string. + // s.count("abc"); + // + // ch_set<std::string> s; + // // Uses "abc" directly without copying it into std::string. + // s.count("abc"); + template <class K = key_type> + size_t count(const key_arg<K>& key) const { + return find(key) == end() ? 0 : 1; + } + + // Issues CPU prefetch instructions for the memory needed to find or insert + // a key. Like all lookup functions, this support heterogeneous keys. + // + // NOTE: This is a very low level operation and should not be used without + // specific benchmarks indicating its importance. + template <class K = key_type> + void prefetch(const key_arg<K>& key) const { + (void)key; +#if defined(__GNUC__) + auto seq = probe(hash_ref()(key)); + __builtin_prefetch(static_cast<const void*>(ctrl_ + seq.offset())); + __builtin_prefetch(static_cast<const void*>(slots_ + seq.offset())); +#endif // __GNUC__ + } + + // The API of find() has two extensions. + // + // 1. The hash can be passed by the user. It must be equal to the hash of the + // key. + // + // 2. The type of the key argument doesn't have to be key_type. This is so + // called heterogeneous key support. + template <class K = key_type> + iterator find(const key_arg<K>& key, size_t hash) { + auto seq = probe(hash); + while (true) { + Group g{ctrl_ + seq.offset()}; + for (int i : g.Match(H2(hash))) { + if (ABSL_PREDICT_TRUE(PolicyTraits::apply( + EqualElement<K>{key, eq_ref()}, + PolicyTraits::element(slots_ + seq.offset(i))))) + return iterator_at(seq.offset(i)); + } + if (ABSL_PREDICT_TRUE(g.MatchEmpty())) return end(); + seq.next(); + } + } + template <class K = key_type> + iterator find(const key_arg<K>& key) { + return find(key, hash_ref()(key)); + } + + template <class K = key_type> + const_iterator find(const key_arg<K>& key, size_t hash) const { + return const_cast<raw_hash_set*>(this)->find(key, hash); + } + template <class K = key_type> + const_iterator find(const key_arg<K>& key) const { + return find(key, hash_ref()(key)); + } + + template <class K = key_type> + bool contains(const key_arg<K>& key) const { + return find(key) != end(); + } + + template <class K = key_type> + std::pair<iterator, iterator> equal_range(const key_arg<K>& key) { + auto it = find(key); + if (it != end()) return {it, std::next(it)}; + return {it, it}; + } + template <class K = key_type> + std::pair<const_iterator, const_iterator> equal_range( + const key_arg<K>& key) const { + auto it = find(key); + if (it != end()) return {it, std::next(it)}; + return {it, it}; + } + + size_t bucket_count() const { return capacity_; } + float load_factor() const { + return capacity_ ? static_cast<double>(size()) / capacity_ : 0.0; + } + float max_load_factor() const { return 1.0f; } + void max_load_factor(float) { + // Does nothing. + } + + hasher hash_function() const { return hash_ref(); } + key_equal key_eq() const { return eq_ref(); } + allocator_type get_allocator() const { return alloc_ref(); } + + friend bool operator==(const raw_hash_set& a, const raw_hash_set& b) { + if (a.size() != b.size()) return false; + const raw_hash_set* outer = &a; + const raw_hash_set* inner = &b; + if (outer->capacity() > inner->capacity()) std::swap(outer, inner); + for (const value_type& elem : *outer) + if (!inner->has_element(elem)) return false; + return true; + } + + friend bool operator!=(const raw_hash_set& a, const raw_hash_set& b) { + return !(a == b); + } + + friend void swap(raw_hash_set& a, + raw_hash_set& b) noexcept(noexcept(a.swap(b))) { + a.swap(b); + } + + private: + template <class Container, typename Enabler> + friend struct absl::container_internal::hashtable_debug_internal:: + HashtableDebugAccess; + + struct FindElement { + template <class K, class... Args> + const_iterator operator()(const K& key, Args&&...) const { + return s.find(key); + } + const raw_hash_set& s; + }; + + struct HashElement { + template <class K, class... Args> + size_t operator()(const K& key, Args&&...) const { + return h(key); + } + const hasher& h; + }; + + template <class K1> + struct EqualElement { + template <class K2, class... Args> + bool operator()(const K2& lhs, Args&&...) const { + return eq(lhs, rhs); + } + const K1& rhs; + const key_equal& eq; + }; + + struct EmplaceDecomposable { + template <class K, class... Args> + std::pair<iterator, bool> operator()(const K& key, Args&&... args) const { + auto res = s.find_or_prepare_insert(key); + if (res.second) { + s.emplace_at(res.first, std::forward<Args>(args)...); + } + return {s.iterator_at(res.first), res.second}; + } + raw_hash_set& s; + }; + + template <bool do_destroy> + struct InsertSlot { + template <class K, class... Args> + std::pair<iterator, bool> operator()(const K& key, Args&&...) && { + auto res = s.find_or_prepare_insert(key); + if (res.second) { + PolicyTraits::transfer(&s.alloc_ref(), s.slots_ + res.first, &slot); + } else if (do_destroy) { + PolicyTraits::destroy(&s.alloc_ref(), &slot); + } + return {s.iterator_at(res.first), res.second}; + } + raw_hash_set& s; + // Constructed slot. Either moved into place or destroyed. + slot_type&& slot; + }; + + // "erases" the object from the container, except that it doesn't actually + // destroy the object. It only updates all the metadata of the class. + // This can be used in conjunction with Policy::transfer to move the object to + // another place. + void erase_meta_only(const_iterator it) { + assert(IsFull(*it.inner_.ctrl_) && "erasing a dangling iterator"); + --size_; + const size_t index = it.inner_.ctrl_ - ctrl_; + const size_t index_before = (index - Group::kWidth) & capacity_; + const auto empty_after = Group(it.inner_.ctrl_).MatchEmpty(); + const auto empty_before = Group(ctrl_ + index_before).MatchEmpty(); + + // We count how many consecutive non empties we have to the right and to the + // left of `it`. If the sum is >= kWidth then there is at least one probe + // window that might have seen a full group. + bool was_never_full = + empty_before && empty_after && + static_cast<size_t>(empty_after.TrailingZeros() + + empty_before.LeadingZeros()) < Group::kWidth; + + set_ctrl(index, was_never_full ? kEmpty : kDeleted); + growth_left() += was_never_full; + infoz_.RecordErase(); + } + + void initialize_slots() { + assert(capacity_); + // Folks with custom allocators often make unwarranted assumptions about the + // behavior of their classes vis-a-vis trivial destructability and what + // calls they will or wont make. Avoid sampling for people with custom + // allocators to get us out of this mess. This is not a hard guarantee but + // a workaround while we plan the exact guarantee we want to provide. + // + // People are often sloppy with the exact type of their allocator (sometimes + // it has an extra const or is missing the pair, but rebinds made it work + // anyway). To avoid the ambiguity, we work off SlotAlloc which we have + // bound more carefully. + if (std::is_same<SlotAlloc, std::allocator<slot_type>>::value && + slots_ == nullptr) { + infoz_ = Sample(); + } + + auto layout = MakeLayout(capacity_); + char* mem = static_cast<char*>( + Allocate<Layout::Alignment()>(&alloc_ref(), layout.AllocSize())); + ctrl_ = reinterpret_cast<ctrl_t*>(layout.template Pointer<0>(mem)); + slots_ = layout.template Pointer<1>(mem); + reset_ctrl(); + reset_growth_left(); + infoz_.RecordStorageChanged(size_, capacity_); + } + + void destroy_slots() { + if (!capacity_) return; + for (size_t i = 0; i != capacity_; ++i) { + if (IsFull(ctrl_[i])) { + PolicyTraits::destroy(&alloc_ref(), slots_ + i); + } + } + auto layout = MakeLayout(capacity_); + // Unpoison before returning the memory to the allocator. + SanitizerUnpoisonMemoryRegion(slots_, sizeof(slot_type) * capacity_); + Deallocate<Layout::Alignment()>(&alloc_ref(), ctrl_, layout.AllocSize()); + ctrl_ = EmptyGroup(); + slots_ = nullptr; + size_ = 0; + capacity_ = 0; + growth_left() = 0; + } + + void resize(size_t new_capacity) { + assert(IsValidCapacity(new_capacity)); + auto* old_ctrl = ctrl_; + auto* old_slots = slots_; + const size_t old_capacity = capacity_; + capacity_ = new_capacity; + initialize_slots(); + + size_t total_probe_length = 0; + for (size_t i = 0; i != old_capacity; ++i) { + if (IsFull(old_ctrl[i])) { + size_t hash = PolicyTraits::apply(HashElement{hash_ref()}, + PolicyTraits::element(old_slots + i)); + auto target = find_first_non_full(hash); + size_t new_i = target.offset; + total_probe_length += target.probe_length; + set_ctrl(new_i, H2(hash)); + PolicyTraits::transfer(&alloc_ref(), slots_ + new_i, old_slots + i); + } + } + if (old_capacity) { + SanitizerUnpoisonMemoryRegion(old_slots, + sizeof(slot_type) * old_capacity); + auto layout = MakeLayout(old_capacity); + Deallocate<Layout::Alignment()>(&alloc_ref(), old_ctrl, + layout.AllocSize()); + } + infoz_.RecordRehash(total_probe_length); + } + + void drop_deletes_without_resize() ABSL_ATTRIBUTE_NOINLINE { + assert(IsValidCapacity(capacity_)); + assert(!is_small()); + // Algorithm: + // - mark all DELETED slots as EMPTY + // - mark all FULL slots as DELETED + // - for each slot marked as DELETED + // hash = Hash(element) + // target = find_first_non_full(hash) + // if target is in the same group + // mark slot as FULL + // else if target is EMPTY + // transfer element to target + // mark slot as EMPTY + // mark target as FULL + // else if target is DELETED + // swap current element with target element + // mark target as FULL + // repeat procedure for current slot with moved from element (target) + ConvertDeletedToEmptyAndFullToDeleted(ctrl_, capacity_); + alignas(slot_type) unsigned char raw[sizeof(slot_type)]; + size_t total_probe_length = 0; + slot_type* slot = reinterpret_cast<slot_type*>(&raw); + for (size_t i = 0; i != capacity_; ++i) { + if (!IsDeleted(ctrl_[i])) continue; + size_t hash = PolicyTraits::apply(HashElement{hash_ref()}, + PolicyTraits::element(slots_ + i)); + auto target = find_first_non_full(hash); + size_t new_i = target.offset; + total_probe_length += target.probe_length; + + // Verify if the old and new i fall within the same group wrt the hash. + // If they do, we don't need to move the object as it falls already in the + // best probe we can. + const auto probe_index = [&](size_t pos) { + return ((pos - probe(hash).offset()) & capacity_) / Group::kWidth; + }; + + // Element doesn't move. + if (ABSL_PREDICT_TRUE(probe_index(new_i) == probe_index(i))) { + set_ctrl(i, H2(hash)); + continue; + } + if (IsEmpty(ctrl_[new_i])) { + // Transfer element to the empty spot. + // set_ctrl poisons/unpoisons the slots so we have to call it at the + // right time. + set_ctrl(new_i, H2(hash)); + PolicyTraits::transfer(&alloc_ref(), slots_ + new_i, slots_ + i); + set_ctrl(i, kEmpty); + } else { + assert(IsDeleted(ctrl_[new_i])); + set_ctrl(new_i, H2(hash)); + // Until we are done rehashing, DELETED marks previously FULL slots. + // Swap i and new_i elements. + PolicyTraits::transfer(&alloc_ref(), slot, slots_ + i); + PolicyTraits::transfer(&alloc_ref(), slots_ + i, slots_ + new_i); + PolicyTraits::transfer(&alloc_ref(), slots_ + new_i, slot); + --i; // repeat + } + } + reset_growth_left(); + infoz_.RecordRehash(total_probe_length); + } + + void rehash_and_grow_if_necessary() { + if (capacity_ == 0) { + resize(1); + } else if (size() <= CapacityToGrowth(capacity()) / 2) { + // Squash DELETED without growing if there is enough capacity. + drop_deletes_without_resize(); + } else { + // Otherwise grow the container. + resize(capacity_ * 2 + 1); + } + } + + bool has_element(const value_type& elem) const { + size_t hash = PolicyTraits::apply(HashElement{hash_ref()}, elem); + auto seq = probe(hash); + while (true) { + Group g{ctrl_ + seq.offset()}; + for (int i : g.Match(H2(hash))) { + if (ABSL_PREDICT_TRUE(PolicyTraits::element(slots_ + seq.offset(i)) == + elem)) + return true; + } + if (ABSL_PREDICT_TRUE(g.MatchEmpty())) return false; + seq.next(); + assert(seq.index() < capacity_ && "full table!"); + } + return false; + } + + // Probes the raw_hash_set with the probe sequence for hash and returns the + // pointer to the first empty or deleted slot. + // NOTE: this function must work with tables having both kEmpty and kDelete + // in one group. Such tables appears during drop_deletes_without_resize. + // + // This function is very useful when insertions happen and: + // - the input is already a set + // - there are enough slots + // - the element with the hash is not in the table + struct FindInfo { + size_t offset; + size_t probe_length; + }; + FindInfo find_first_non_full(size_t hash) { + auto seq = probe(hash); + while (true) { + Group g{ctrl_ + seq.offset()}; + auto mask = g.MatchEmptyOrDeleted(); + if (mask) { +#if !defined(NDEBUG) + // We want to add entropy even when ASLR is not enabled. + // In debug build we will randomly insert in either the front or back of + // the group. + // TODO(kfm,sbenza): revisit after we do unconditional mixing + if (!is_small() && ShouldInsertBackwards(hash, ctrl_)) { + return {seq.offset(mask.HighestBitSet()), seq.index()}; + } +#endif + return {seq.offset(mask.LowestBitSet()), seq.index()}; + } + assert(seq.index() < capacity_ && "full table!"); + seq.next(); + } + } + + // TODO(alkis): Optimize this assuming *this and that don't overlap. + raw_hash_set& move_assign(raw_hash_set&& that, std::true_type) { + raw_hash_set tmp(std::move(that)); + swap(tmp); + return *this; + } + raw_hash_set& move_assign(raw_hash_set&& that, std::false_type) { + raw_hash_set tmp(std::move(that), alloc_ref()); + swap(tmp); + return *this; + } + + protected: + template <class K> + std::pair<size_t, bool> find_or_prepare_insert(const K& key) { + auto hash = hash_ref()(key); + auto seq = probe(hash); + while (true) { + Group g{ctrl_ + seq.offset()}; + for (int i : g.Match(H2(hash))) { + if (ABSL_PREDICT_TRUE(PolicyTraits::apply( + EqualElement<K>{key, eq_ref()}, + PolicyTraits::element(slots_ + seq.offset(i))))) + return {seq.offset(i), false}; + } + if (ABSL_PREDICT_TRUE(g.MatchEmpty())) break; + seq.next(); + } + return {prepare_insert(hash), true}; + } + + size_t prepare_insert(size_t hash) ABSL_ATTRIBUTE_NOINLINE { + auto target = find_first_non_full(hash); + if (ABSL_PREDICT_FALSE(growth_left() == 0 && + !IsDeleted(ctrl_[target.offset]))) { + rehash_and_grow_if_necessary(); + target = find_first_non_full(hash); + } + ++size_; + growth_left() -= IsEmpty(ctrl_[target.offset]); + set_ctrl(target.offset, H2(hash)); + infoz_.RecordInsert(hash, target.probe_length); + return target.offset; + } + + // Constructs the value in the space pointed by the iterator. This only works + // after an unsuccessful find_or_prepare_insert() and before any other + // modifications happen in the raw_hash_set. + // + // PRECONDITION: i is an index returned from find_or_prepare_insert(k), where + // k is the key decomposed from `forward<Args>(args)...`, and the bool + // returned by find_or_prepare_insert(k) was true. + // POSTCONDITION: *m.iterator_at(i) == value_type(forward<Args>(args)...). + template <class... Args> + void emplace_at(size_t i, Args&&... args) { + PolicyTraits::construct(&alloc_ref(), slots_ + i, + std::forward<Args>(args)...); + + assert(PolicyTraits::apply(FindElement{*this}, *iterator_at(i)) == + iterator_at(i) && + "constructed value does not match the lookup key"); + } + + iterator iterator_at(size_t i) { return {ctrl_ + i, slots_ + i}; } + const_iterator iterator_at(size_t i) const { return {ctrl_ + i, slots_ + i}; } + + private: + friend struct RawHashSetTestOnlyAccess; + + probe_seq<Group::kWidth> probe(size_t hash) const { + return probe_seq<Group::kWidth>(H1(hash, ctrl_), capacity_); + } + + // Reset all ctrl bytes back to kEmpty, except the sentinel. + void reset_ctrl() { + std::memset(ctrl_, kEmpty, capacity_ + Group::kWidth); + ctrl_[capacity_] = kSentinel; + SanitizerPoisonMemoryRegion(slots_, sizeof(slot_type) * capacity_); + } + + void reset_growth_left() { + growth_left() = CapacityToGrowth(capacity()) - size_; + } + + // Sets the control byte, and if `i < Group::kWidth`, set the cloned byte at + // the end too. + void set_ctrl(size_t i, ctrl_t h) { + assert(i < capacity_); + + if (IsFull(h)) { + SanitizerUnpoisonObject(slots_ + i); + } else { + SanitizerPoisonObject(slots_ + i); + } + + ctrl_[i] = h; + ctrl_[((i - Group::kWidth) & capacity_) + 1 + + ((Group::kWidth - 1) & capacity_)] = h; + } + + size_t& growth_left() { return settings_.template get<0>(); } + + // The representation of the object has two modes: + // - small: For capacities < kWidth-1 + // - large: For the rest. + // + // Differences: + // - In small mode we are able to use the whole capacity. The extra control + // bytes give us at least one "empty" control byte to stop the iteration. + // This is important to make 1 a valid capacity. + // + // - In small mode only the first `capacity()` control bytes after the + // sentinel are valid. The rest contain dummy kEmpty values that do not + // represent a real slot. This is important to take into account on + // find_first_non_full(), where we never try ShouldInsertBackwards() for + // small tables. + bool is_small() const { return capacity_ < Group::kWidth - 1; } + + hasher& hash_ref() { return settings_.template get<1>(); } + const hasher& hash_ref() const { return settings_.template get<1>(); } + key_equal& eq_ref() { return settings_.template get<2>(); } + const key_equal& eq_ref() const { return settings_.template get<2>(); } + allocator_type& alloc_ref() { return settings_.template get<3>(); } + const allocator_type& alloc_ref() const { + return settings_.template get<3>(); + } + + // TODO(alkis): Investigate removing some of these fields: + // - ctrl/slots can be derived from each other + // - size can be moved into the slot array + ctrl_t* ctrl_ = EmptyGroup(); // [(capacity + 1) * ctrl_t] + slot_type* slots_ = nullptr; // [capacity * slot_type] + size_t size_ = 0; // number of full slots + size_t capacity_ = 0; // total number of slots + HashtablezInfoHandle infoz_; + absl::container_internal::CompressedTuple<size_t /* growth_left */, hasher, + key_equal, allocator_type> + settings_{0, hasher{}, key_equal{}, allocator_type{}}; +}; + +// Erases all elements that satisfy the predicate `pred` from the container `c`. +template <typename P, typename H, typename E, typename A, typename Predicate> +void EraseIf(Predicate pred, raw_hash_set<P, H, E, A>* c) { + for (auto it = c->begin(), last = c->end(); it != last;) { + auto copy_it = it++; + if (pred(*copy_it)) { + c->erase(copy_it); + } + } +} + +namespace hashtable_debug_internal { +template <typename Set> +struct HashtableDebugAccess<Set, absl::void_t<typename Set::raw_hash_set>> { + using Traits = typename Set::PolicyTraits; + using Slot = typename Traits::slot_type; + + static size_t GetNumProbes(const Set& set, + const typename Set::key_type& key) { + size_t num_probes = 0; + size_t hash = set.hash_ref()(key); + auto seq = set.probe(hash); + while (true) { + container_internal::Group g{set.ctrl_ + seq.offset()}; + for (int i : g.Match(container_internal::H2(hash))) { + if (Traits::apply( + typename Set::template EqualElement<typename Set::key_type>{ + key, set.eq_ref()}, + Traits::element(set.slots_ + seq.offset(i)))) + return num_probes; + ++num_probes; + } + if (g.MatchEmpty()) return num_probes; + seq.next(); + ++num_probes; + } + } + + static size_t AllocatedByteSize(const Set& c) { + size_t capacity = c.capacity_; + if (capacity == 0) return 0; + auto layout = Set::MakeLayout(capacity); + size_t m = layout.AllocSize(); + + size_t per_slot = Traits::space_used(static_cast<const Slot*>(nullptr)); + if (per_slot != ~size_t{}) { + m += per_slot * c.size(); + } else { + for (size_t i = 0; i != capacity; ++i) { + if (container_internal::IsFull(c.ctrl_[i])) { + m += Traits::space_used(c.slots_ + i); + } + } + } + return m; + } + + static size_t LowerBoundAllocatedByteSize(size_t size) { + size_t capacity = GrowthToLowerboundCapacity(size); + if (capacity == 0) return 0; + auto layout = Set::MakeLayout(NormalizeCapacity(capacity)); + size_t m = layout.AllocSize(); + size_t per_slot = Traits::space_used(static_cast<const Slot*>(nullptr)); + if (per_slot != ~size_t{}) { + m += per_slot * size; + } + return m; + } +}; + +} // namespace hashtable_debug_internal +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_RAW_HASH_SET_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/raw_hash_set_allocator_test.cc b/third_party/abseil_cpp/absl/container/internal/raw_hash_set_allocator_test.cc new file mode 100644 index 0000000000..7ac4b9f7df --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/raw_hash_set_allocator_test.cc @@ -0,0 +1,430 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <limits> +#include <scoped_allocator> + +#include "gtest/gtest.h" +#include "absl/container/internal/raw_hash_set.h" +#include "absl/container/internal/tracked.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +enum AllocSpec { + kPropagateOnCopy = 1, + kPropagateOnMove = 2, + kPropagateOnSwap = 4, +}; + +struct AllocState { + size_t num_allocs = 0; + std::set<void*> owned; +}; + +template <class T, + int Spec = kPropagateOnCopy | kPropagateOnMove | kPropagateOnSwap> +class CheckedAlloc { + public: + template <class, int> + friend class CheckedAlloc; + + using value_type = T; + + CheckedAlloc() {} + explicit CheckedAlloc(size_t id) : id_(id) {} + CheckedAlloc(const CheckedAlloc&) = default; + CheckedAlloc& operator=(const CheckedAlloc&) = default; + + template <class U> + CheckedAlloc(const CheckedAlloc<U, Spec>& that) + : id_(that.id_), state_(that.state_) {} + + template <class U> + struct rebind { + using other = CheckedAlloc<U, Spec>; + }; + + using propagate_on_container_copy_assignment = + std::integral_constant<bool, (Spec & kPropagateOnCopy) != 0>; + + using propagate_on_container_move_assignment = + std::integral_constant<bool, (Spec & kPropagateOnMove) != 0>; + + using propagate_on_container_swap = + std::integral_constant<bool, (Spec & kPropagateOnSwap) != 0>; + + CheckedAlloc select_on_container_copy_construction() const { + if (Spec & kPropagateOnCopy) return *this; + return {}; + } + + T* allocate(size_t n) { + T* ptr = std::allocator<T>().allocate(n); + track_alloc(ptr); + return ptr; + } + void deallocate(T* ptr, size_t n) { + memset(ptr, 0, n * sizeof(T)); // The freed memory must be unpoisoned. + track_dealloc(ptr); + return std::allocator<T>().deallocate(ptr, n); + } + + friend bool operator==(const CheckedAlloc& a, const CheckedAlloc& b) { + return a.id_ == b.id_; + } + friend bool operator!=(const CheckedAlloc& a, const CheckedAlloc& b) { + return !(a == b); + } + + size_t num_allocs() const { return state_->num_allocs; } + + void swap(CheckedAlloc& that) { + using std::swap; + swap(id_, that.id_); + swap(state_, that.state_); + } + + friend void swap(CheckedAlloc& a, CheckedAlloc& b) { a.swap(b); } + + friend std::ostream& operator<<(std::ostream& o, const CheckedAlloc& a) { + return o << "alloc(" << a.id_ << ")"; + } + + private: + void track_alloc(void* ptr) { + AllocState* state = state_.get(); + ++state->num_allocs; + if (!state->owned.insert(ptr).second) + ADD_FAILURE() << *this << " got previously allocated memory: " << ptr; + } + void track_dealloc(void* ptr) { + if (state_->owned.erase(ptr) != 1) + ADD_FAILURE() << *this + << " deleting memory owned by another allocator: " << ptr; + } + + size_t id_ = std::numeric_limits<size_t>::max(); + + std::shared_ptr<AllocState> state_ = std::make_shared<AllocState>(); +}; + +struct Identity { + int32_t operator()(int32_t v) const { return v; } +}; + +struct Policy { + using slot_type = Tracked<int32_t>; + using init_type = Tracked<int32_t>; + using key_type = int32_t; + + template <class allocator_type, class... Args> + static void construct(allocator_type* alloc, slot_type* slot, + Args&&... args) { + std::allocator_traits<allocator_type>::construct( + *alloc, slot, std::forward<Args>(args)...); + } + + template <class allocator_type> + static void destroy(allocator_type* alloc, slot_type* slot) { + std::allocator_traits<allocator_type>::destroy(*alloc, slot); + } + + template <class allocator_type> + static void transfer(allocator_type* alloc, slot_type* new_slot, + slot_type* old_slot) { + construct(alloc, new_slot, std::move(*old_slot)); + destroy(alloc, old_slot); + } + + template <class F> + static auto apply(F&& f, int32_t v) -> decltype(std::forward<F>(f)(v, v)) { + return std::forward<F>(f)(v, v); + } + + template <class F> + static auto apply(F&& f, const slot_type& v) + -> decltype(std::forward<F>(f)(v.val(), v)) { + return std::forward<F>(f)(v.val(), v); + } + + template <class F> + static auto apply(F&& f, slot_type&& v) + -> decltype(std::forward<F>(f)(v.val(), std::move(v))) { + return std::forward<F>(f)(v.val(), std::move(v)); + } + + static slot_type& element(slot_type* slot) { return *slot; } +}; + +template <int Spec> +struct PropagateTest : public ::testing::Test { + using Alloc = CheckedAlloc<Tracked<int32_t>, Spec>; + + using Table = raw_hash_set<Policy, Identity, std::equal_to<int32_t>, Alloc>; + + PropagateTest() { + EXPECT_EQ(a1, t1.get_allocator()); + EXPECT_NE(a2, t1.get_allocator()); + } + + Alloc a1 = Alloc(1); + Table t1 = Table(0, a1); + Alloc a2 = Alloc(2); +}; + +using PropagateOnAll = + PropagateTest<kPropagateOnCopy | kPropagateOnMove | kPropagateOnSwap>; +using NoPropagateOnCopy = PropagateTest<kPropagateOnMove | kPropagateOnSwap>; +using NoPropagateOnMove = PropagateTest<kPropagateOnCopy | kPropagateOnSwap>; + +TEST_F(PropagateOnAll, Empty) { EXPECT_EQ(0, a1.num_allocs()); } + +TEST_F(PropagateOnAll, InsertAllocates) { + auto it = t1.insert(0).first; + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, InsertDecomposes) { + auto it = t1.insert(0).first; + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); + + EXPECT_FALSE(t1.insert(0).second); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, RehashMoves) { + auto it = t1.insert(0).first; + EXPECT_EQ(0, it->num_moves()); + t1.rehash(2 * t1.capacity()); + EXPECT_EQ(2, a1.num_allocs()); + it = t1.find(0); + EXPECT_EQ(1, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, CopyConstructor) { + auto it = t1.insert(0).first; + Table u(t1); + EXPECT_EQ(2, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(NoPropagateOnCopy, CopyConstructor) { + auto it = t1.insert(0).first; + Table u(t1); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, u.get_allocator().num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(PropagateOnAll, CopyConstructorWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(t1, a1); + EXPECT_EQ(2, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(NoPropagateOnCopy, CopyConstructorWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(t1, a1); + EXPECT_EQ(2, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(PropagateOnAll, CopyConstructorWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(t1, a2); + EXPECT_EQ(a2, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, a2.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(NoPropagateOnCopy, CopyConstructorWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(t1, a2); + EXPECT_EQ(a2, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, a2.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(PropagateOnAll, MoveConstructor) { + auto it = t1.insert(0).first; + Table u(std::move(t1)); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(NoPropagateOnMove, MoveConstructor) { + auto it = t1.insert(0).first; + Table u(std::move(t1)); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, MoveConstructorWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(std::move(t1), a1); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(NoPropagateOnMove, MoveConstructorWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(std::move(t1), a1); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, MoveConstructorWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(std::move(t1), a2); + it = u.find(0); + EXPECT_EQ(a2, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, a2.num_allocs()); + EXPECT_EQ(1, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(NoPropagateOnMove, MoveConstructorWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(std::move(t1), a2); + it = u.find(0); + EXPECT_EQ(a2, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, a2.num_allocs()); + EXPECT_EQ(1, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, CopyAssignmentWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(0, a1); + u = t1; + EXPECT_EQ(2, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(NoPropagateOnCopy, CopyAssignmentWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(0, a1); + u = t1; + EXPECT_EQ(2, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(PropagateOnAll, CopyAssignmentWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(0, a2); + u = t1; + EXPECT_EQ(a1, u.get_allocator()); + EXPECT_EQ(2, a1.num_allocs()); + EXPECT_EQ(0, a2.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(NoPropagateOnCopy, CopyAssignmentWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(0, a2); + u = t1; + EXPECT_EQ(a2, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, a2.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(1, it->num_copies()); +} + +TEST_F(PropagateOnAll, MoveAssignmentWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(0, a1); + u = std::move(t1); + EXPECT_EQ(a1, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(NoPropagateOnMove, MoveAssignmentWithSameAlloc) { + auto it = t1.insert(0).first; + Table u(0, a1); + u = std::move(t1); + EXPECT_EQ(a1, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, MoveAssignmentWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(0, a2); + u = std::move(t1); + EXPECT_EQ(a1, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, a2.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(NoPropagateOnMove, MoveAssignmentWithDifferentAlloc) { + auto it = t1.insert(0).first; + Table u(0, a2); + u = std::move(t1); + it = u.find(0); + EXPECT_EQ(a2, u.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(1, a2.num_allocs()); + EXPECT_EQ(1, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +TEST_F(PropagateOnAll, Swap) { + auto it = t1.insert(0).first; + Table u(0, a2); + u.swap(t1); + EXPECT_EQ(a1, u.get_allocator()); + EXPECT_EQ(a2, t1.get_allocator()); + EXPECT_EQ(1, a1.num_allocs()); + EXPECT_EQ(0, a2.num_allocs()); + EXPECT_EQ(0, it->num_moves()); + EXPECT_EQ(0, it->num_copies()); +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/raw_hash_set_test.cc b/third_party/abseil_cpp/absl/container/internal/raw_hash_set_test.cc new file mode 100644 index 0000000000..2fc85591ca --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/raw_hash_set_test.cc @@ -0,0 +1,1871 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/raw_hash_set.h" + +#include <cmath> +#include <cstdint> +#include <deque> +#include <functional> +#include <memory> +#include <numeric> +#include <random> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/cycleclock.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/hash_function_defaults.h" +#include "absl/container/internal/hash_policy_testing.h" +#include "absl/container/internal/hashtable_debug.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +struct RawHashSetTestOnlyAccess { + template <typename C> + static auto GetSlots(const C& c) -> decltype(c.slots_) { + return c.slots_; + } +}; + +namespace { + +using ::testing::DoubleNear; +using ::testing::ElementsAre; +using ::testing::Ge; +using ::testing::Lt; +using ::testing::Optional; +using ::testing::Pair; +using ::testing::UnorderedElementsAre; + +TEST(Util, NormalizeCapacity) { + EXPECT_EQ(1, NormalizeCapacity(0)); + EXPECT_EQ(1, NormalizeCapacity(1)); + EXPECT_EQ(3, NormalizeCapacity(2)); + EXPECT_EQ(3, NormalizeCapacity(3)); + EXPECT_EQ(7, NormalizeCapacity(4)); + EXPECT_EQ(7, NormalizeCapacity(7)); + EXPECT_EQ(15, NormalizeCapacity(8)); + EXPECT_EQ(15, NormalizeCapacity(15)); + EXPECT_EQ(15 * 2 + 1, NormalizeCapacity(15 + 1)); + EXPECT_EQ(15 * 2 + 1, NormalizeCapacity(15 + 2)); +} + +TEST(Util, GrowthAndCapacity) { + // Verify that GrowthToCapacity gives the minimum capacity that has enough + // growth. + for (size_t growth = 0; growth < 10000; ++growth) { + SCOPED_TRACE(growth); + size_t capacity = NormalizeCapacity(GrowthToLowerboundCapacity(growth)); + // The capacity is large enough for `growth` + EXPECT_THAT(CapacityToGrowth(capacity), Ge(growth)); + if (growth != 0 && capacity > 1) { + // There is no smaller capacity that works. + EXPECT_THAT(CapacityToGrowth(capacity / 2), Lt(growth)); + } + } + + for (size_t capacity = Group::kWidth - 1; capacity < 10000; + capacity = 2 * capacity + 1) { + SCOPED_TRACE(capacity); + size_t growth = CapacityToGrowth(capacity); + EXPECT_THAT(growth, Lt(capacity)); + EXPECT_LE(GrowthToLowerboundCapacity(growth), capacity); + EXPECT_EQ(NormalizeCapacity(GrowthToLowerboundCapacity(growth)), capacity); + } +} + +TEST(Util, probe_seq) { + probe_seq<16> seq(0, 127); + auto gen = [&]() { + size_t res = seq.offset(); + seq.next(); + return res; + }; + std::vector<size_t> offsets(8); + std::generate_n(offsets.begin(), 8, gen); + EXPECT_THAT(offsets, ElementsAre(0, 16, 48, 96, 32, 112, 80, 64)); + seq = probe_seq<16>(128, 127); + std::generate_n(offsets.begin(), 8, gen); + EXPECT_THAT(offsets, ElementsAre(0, 16, 48, 96, 32, 112, 80, 64)); +} + +TEST(BitMask, Smoke) { + EXPECT_FALSE((BitMask<uint8_t, 8>(0))); + EXPECT_TRUE((BitMask<uint8_t, 8>(5))); + + EXPECT_THAT((BitMask<uint8_t, 8>(0)), ElementsAre()); + EXPECT_THAT((BitMask<uint8_t, 8>(0x1)), ElementsAre(0)); + EXPECT_THAT((BitMask<uint8_t, 8>(0x2)), ElementsAre(1)); + EXPECT_THAT((BitMask<uint8_t, 8>(0x3)), ElementsAre(0, 1)); + EXPECT_THAT((BitMask<uint8_t, 8>(0x4)), ElementsAre(2)); + EXPECT_THAT((BitMask<uint8_t, 8>(0x5)), ElementsAre(0, 2)); + EXPECT_THAT((BitMask<uint8_t, 8>(0x55)), ElementsAre(0, 2, 4, 6)); + EXPECT_THAT((BitMask<uint8_t, 8>(0xAA)), ElementsAre(1, 3, 5, 7)); +} + +TEST(BitMask, WithShift) { + // See the non-SSE version of Group for details on what this math is for. + uint64_t ctrl = 0x1716151413121110; + uint64_t hash = 0x12; + constexpr uint64_t msbs = 0x8080808080808080ULL; + constexpr uint64_t lsbs = 0x0101010101010101ULL; + auto x = ctrl ^ (lsbs * hash); + uint64_t mask = (x - lsbs) & ~x & msbs; + EXPECT_EQ(0x0000000080800000, mask); + + BitMask<uint64_t, 8, 3> b(mask); + EXPECT_EQ(*b, 2); +} + +TEST(BitMask, LeadingTrailing) { + EXPECT_EQ((BitMask<uint32_t, 16>(0x00001a40).LeadingZeros()), 3); + EXPECT_EQ((BitMask<uint32_t, 16>(0x00001a40).TrailingZeros()), 6); + + EXPECT_EQ((BitMask<uint32_t, 16>(0x00000001).LeadingZeros()), 15); + EXPECT_EQ((BitMask<uint32_t, 16>(0x00000001).TrailingZeros()), 0); + + EXPECT_EQ((BitMask<uint32_t, 16>(0x00008000).LeadingZeros()), 0); + EXPECT_EQ((BitMask<uint32_t, 16>(0x00008000).TrailingZeros()), 15); + + EXPECT_EQ((BitMask<uint64_t, 8, 3>(0x0000008080808000).LeadingZeros()), 3); + EXPECT_EQ((BitMask<uint64_t, 8, 3>(0x0000008080808000).TrailingZeros()), 1); + + EXPECT_EQ((BitMask<uint64_t, 8, 3>(0x0000000000000080).LeadingZeros()), 7); + EXPECT_EQ((BitMask<uint64_t, 8, 3>(0x0000000000000080).TrailingZeros()), 0); + + EXPECT_EQ((BitMask<uint64_t, 8, 3>(0x8000000000000000).LeadingZeros()), 0); + EXPECT_EQ((BitMask<uint64_t, 8, 3>(0x8000000000000000).TrailingZeros()), 7); +} + +TEST(Group, EmptyGroup) { + for (h2_t h = 0; h != 128; ++h) EXPECT_FALSE(Group{EmptyGroup()}.Match(h)); +} + +TEST(Group, Match) { + if (Group::kWidth == 16) { + ctrl_t group[] = {kEmpty, 1, kDeleted, 3, kEmpty, 5, kSentinel, 7, + 7, 5, 3, 1, 1, 1, 1, 1}; + EXPECT_THAT(Group{group}.Match(0), ElementsAre()); + EXPECT_THAT(Group{group}.Match(1), ElementsAre(1, 11, 12, 13, 14, 15)); + EXPECT_THAT(Group{group}.Match(3), ElementsAre(3, 10)); + EXPECT_THAT(Group{group}.Match(5), ElementsAre(5, 9)); + EXPECT_THAT(Group{group}.Match(7), ElementsAre(7, 8)); + } else if (Group::kWidth == 8) { + ctrl_t group[] = {kEmpty, 1, 2, kDeleted, 2, 1, kSentinel, 1}; + EXPECT_THAT(Group{group}.Match(0), ElementsAre()); + EXPECT_THAT(Group{group}.Match(1), ElementsAre(1, 5, 7)); + EXPECT_THAT(Group{group}.Match(2), ElementsAre(2, 4)); + } else { + FAIL() << "No test coverage for Group::kWidth==" << Group::kWidth; + } +} + +TEST(Group, MatchEmpty) { + if (Group::kWidth == 16) { + ctrl_t group[] = {kEmpty, 1, kDeleted, 3, kEmpty, 5, kSentinel, 7, + 7, 5, 3, 1, 1, 1, 1, 1}; + EXPECT_THAT(Group{group}.MatchEmpty(), ElementsAre(0, 4)); + } else if (Group::kWidth == 8) { + ctrl_t group[] = {kEmpty, 1, 2, kDeleted, 2, 1, kSentinel, 1}; + EXPECT_THAT(Group{group}.MatchEmpty(), ElementsAre(0)); + } else { + FAIL() << "No test coverage for Group::kWidth==" << Group::kWidth; + } +} + +TEST(Group, MatchEmptyOrDeleted) { + if (Group::kWidth == 16) { + ctrl_t group[] = {kEmpty, 1, kDeleted, 3, kEmpty, 5, kSentinel, 7, + 7, 5, 3, 1, 1, 1, 1, 1}; + EXPECT_THAT(Group{group}.MatchEmptyOrDeleted(), ElementsAre(0, 2, 4)); + } else if (Group::kWidth == 8) { + ctrl_t group[] = {kEmpty, 1, 2, kDeleted, 2, 1, kSentinel, 1}; + EXPECT_THAT(Group{group}.MatchEmptyOrDeleted(), ElementsAre(0, 3)); + } else { + FAIL() << "No test coverage for Group::kWidth==" << Group::kWidth; + } +} + +TEST(Batch, DropDeletes) { + constexpr size_t kCapacity = 63; + constexpr size_t kGroupWidth = container_internal::Group::kWidth; + std::vector<ctrl_t> ctrl(kCapacity + 1 + kGroupWidth); + ctrl[kCapacity] = kSentinel; + std::vector<ctrl_t> pattern = {kEmpty, 2, kDeleted, 2, kEmpty, 1, kDeleted}; + for (size_t i = 0; i != kCapacity; ++i) { + ctrl[i] = pattern[i % pattern.size()]; + if (i < kGroupWidth - 1) + ctrl[i + kCapacity + 1] = pattern[i % pattern.size()]; + } + ConvertDeletedToEmptyAndFullToDeleted(ctrl.data(), kCapacity); + ASSERT_EQ(ctrl[kCapacity], kSentinel); + for (size_t i = 0; i < kCapacity + 1 + kGroupWidth; ++i) { + ctrl_t expected = pattern[i % (kCapacity + 1) % pattern.size()]; + if (i == kCapacity) expected = kSentinel; + if (expected == kDeleted) expected = kEmpty; + if (IsFull(expected)) expected = kDeleted; + EXPECT_EQ(ctrl[i], expected) + << i << " " << int{pattern[i % pattern.size()]}; + } +} + +TEST(Group, CountLeadingEmptyOrDeleted) { + const std::vector<ctrl_t> empty_examples = {kEmpty, kDeleted}; + const std::vector<ctrl_t> full_examples = {0, 1, 2, 3, 5, 9, 127, kSentinel}; + + for (ctrl_t empty : empty_examples) { + std::vector<ctrl_t> e(Group::kWidth, empty); + EXPECT_EQ(Group::kWidth, Group{e.data()}.CountLeadingEmptyOrDeleted()); + for (ctrl_t full : full_examples) { + for (size_t i = 0; i != Group::kWidth; ++i) { + std::vector<ctrl_t> f(Group::kWidth, empty); + f[i] = full; + EXPECT_EQ(i, Group{f.data()}.CountLeadingEmptyOrDeleted()); + } + std::vector<ctrl_t> f(Group::kWidth, empty); + f[Group::kWidth * 2 / 3] = full; + f[Group::kWidth / 2] = full; + EXPECT_EQ( + Group::kWidth / 2, Group{f.data()}.CountLeadingEmptyOrDeleted()); + } + } +} + +struct IntPolicy { + using slot_type = int64_t; + using key_type = int64_t; + using init_type = int64_t; + + static void construct(void*, int64_t* slot, int64_t v) { *slot = v; } + static void destroy(void*, int64_t*) {} + static void transfer(void*, int64_t* new_slot, int64_t* old_slot) { + *new_slot = *old_slot; + } + + static int64_t& element(slot_type* slot) { return *slot; } + + template <class F> + static auto apply(F&& f, int64_t x) -> decltype(std::forward<F>(f)(x, x)) { + return std::forward<F>(f)(x, x); + } +}; + +class StringPolicy { + template <class F, class K, class V, + class = typename std::enable_if< + std::is_convertible<const K&, absl::string_view>::value>::type> + decltype(std::declval<F>()( + std::declval<const absl::string_view&>(), std::piecewise_construct, + std::declval<std::tuple<K>>(), + std::declval<V>())) static apply_impl(F&& f, + std::pair<std::tuple<K>, V> p) { + const absl::string_view& key = std::get<0>(p.first); + return std::forward<F>(f)(key, std::piecewise_construct, std::move(p.first), + std::move(p.second)); + } + + public: + struct slot_type { + struct ctor {}; + + template <class... Ts> + slot_type(ctor, Ts&&... ts) : pair(std::forward<Ts>(ts)...) {} + + std::pair<std::string, std::string> pair; + }; + + using key_type = std::string; + using init_type = std::pair<std::string, std::string>; + + template <class allocator_type, class... Args> + static void construct(allocator_type* alloc, slot_type* slot, Args... args) { + std::allocator_traits<allocator_type>::construct( + *alloc, slot, typename slot_type::ctor(), std::forward<Args>(args)...); + } + + template <class allocator_type> + static void destroy(allocator_type* alloc, slot_type* slot) { + std::allocator_traits<allocator_type>::destroy(*alloc, slot); + } + + template <class allocator_type> + static void transfer(allocator_type* alloc, slot_type* new_slot, + slot_type* old_slot) { + construct(alloc, new_slot, std::move(old_slot->pair)); + destroy(alloc, old_slot); + } + + static std::pair<std::string, std::string>& element(slot_type* slot) { + return slot->pair; + } + + template <class F, class... Args> + static auto apply(F&& f, Args&&... args) + -> decltype(apply_impl(std::forward<F>(f), + PairArgs(std::forward<Args>(args)...))) { + return apply_impl(std::forward<F>(f), + PairArgs(std::forward<Args>(args)...)); + } +}; + +struct StringHash : absl::Hash<absl::string_view> { + using is_transparent = void; +}; +struct StringEq : std::equal_to<absl::string_view> { + using is_transparent = void; +}; + +struct StringTable + : raw_hash_set<StringPolicy, StringHash, StringEq, std::allocator<int>> { + using Base = typename StringTable::raw_hash_set; + StringTable() {} + using Base::Base; +}; + +struct IntTable + : raw_hash_set<IntPolicy, container_internal::hash_default_hash<int64_t>, + std::equal_to<int64_t>, std::allocator<int64_t>> { + using Base = typename IntTable::raw_hash_set; + using Base::Base; +}; + +template <typename T> +struct CustomAlloc : std::allocator<T> { + CustomAlloc() {} + + template <typename U> + CustomAlloc(const CustomAlloc<U>& other) {} + + template<class U> struct rebind { + using other = CustomAlloc<U>; + }; +}; + +struct CustomAllocIntTable + : raw_hash_set<IntPolicy, container_internal::hash_default_hash<int64_t>, + std::equal_to<int64_t>, CustomAlloc<int64_t>> { + using Base = typename CustomAllocIntTable::raw_hash_set; + using Base::Base; +}; + +struct BadFastHash { + template <class T> + size_t operator()(const T&) const { + return 0; + } +}; + +struct BadTable : raw_hash_set<IntPolicy, BadFastHash, std::equal_to<int>, + std::allocator<int>> { + using Base = typename BadTable::raw_hash_set; + BadTable() {} + using Base::Base; +}; + +TEST(Table, EmptyFunctorOptimization) { + static_assert(std::is_empty<std::equal_to<absl::string_view>>::value, ""); + static_assert(std::is_empty<std::allocator<int>>::value, ""); + + struct MockTable { + void* ctrl; + void* slots; + size_t size; + size_t capacity; + size_t growth_left; + void* infoz; + }; + struct StatelessHash { + size_t operator()(absl::string_view) const { return 0; } + }; + struct StatefulHash : StatelessHash { + size_t dummy; + }; + + EXPECT_EQ( + sizeof(MockTable), + sizeof( + raw_hash_set<StringPolicy, StatelessHash, + std::equal_to<absl::string_view>, std::allocator<int>>)); + + EXPECT_EQ( + sizeof(MockTable) + sizeof(StatefulHash), + sizeof( + raw_hash_set<StringPolicy, StatefulHash, + std::equal_to<absl::string_view>, std::allocator<int>>)); +} + +TEST(Table, Empty) { + IntTable t; + EXPECT_EQ(0, t.size()); + EXPECT_TRUE(t.empty()); +} + +TEST(Table, LookupEmpty) { + IntTable t; + auto it = t.find(0); + EXPECT_TRUE(it == t.end()); +} + +TEST(Table, Insert1) { + IntTable t; + EXPECT_TRUE(t.find(0) == t.end()); + auto res = t.emplace(0); + EXPECT_TRUE(res.second); + EXPECT_THAT(*res.first, 0); + EXPECT_EQ(1, t.size()); + EXPECT_THAT(*t.find(0), 0); +} + +TEST(Table, Insert2) { + IntTable t; + EXPECT_TRUE(t.find(0) == t.end()); + auto res = t.emplace(0); + EXPECT_TRUE(res.second); + EXPECT_THAT(*res.first, 0); + EXPECT_EQ(1, t.size()); + EXPECT_TRUE(t.find(1) == t.end()); + res = t.emplace(1); + EXPECT_TRUE(res.second); + EXPECT_THAT(*res.first, 1); + EXPECT_EQ(2, t.size()); + EXPECT_THAT(*t.find(0), 0); + EXPECT_THAT(*t.find(1), 1); +} + +TEST(Table, InsertCollision) { + BadTable t; + EXPECT_TRUE(t.find(1) == t.end()); + auto res = t.emplace(1); + EXPECT_TRUE(res.second); + EXPECT_THAT(*res.first, 1); + EXPECT_EQ(1, t.size()); + + EXPECT_TRUE(t.find(2) == t.end()); + res = t.emplace(2); + EXPECT_THAT(*res.first, 2); + EXPECT_TRUE(res.second); + EXPECT_EQ(2, t.size()); + + EXPECT_THAT(*t.find(1), 1); + EXPECT_THAT(*t.find(2), 2); +} + +// Test that we do not add existent element in case we need to search through +// many groups with deleted elements +TEST(Table, InsertCollisionAndFindAfterDelete) { + BadTable t; // all elements go to the same group. + // Have at least 2 groups with Group::kWidth collisions + // plus some extra collisions in the last group. + constexpr size_t kNumInserts = Group::kWidth * 2 + 5; + for (size_t i = 0; i < kNumInserts; ++i) { + auto res = t.emplace(i); + EXPECT_TRUE(res.second); + EXPECT_THAT(*res.first, i); + EXPECT_EQ(i + 1, t.size()); + } + + // Remove elements one by one and check + // that we still can find all other elements. + for (size_t i = 0; i < kNumInserts; ++i) { + EXPECT_EQ(1, t.erase(i)) << i; + for (size_t j = i + 1; j < kNumInserts; ++j) { + EXPECT_THAT(*t.find(j), j); + auto res = t.emplace(j); + EXPECT_FALSE(res.second) << i << " " << j; + EXPECT_THAT(*res.first, j); + EXPECT_EQ(kNumInserts - i - 1, t.size()); + } + } + EXPECT_TRUE(t.empty()); +} + +TEST(Table, LazyEmplace) { + StringTable t; + bool called = false; + auto it = t.lazy_emplace("abc", [&](const StringTable::constructor& f) { + called = true; + f("abc", "ABC"); + }); + EXPECT_TRUE(called); + EXPECT_THAT(*it, Pair("abc", "ABC")); + called = false; + it = t.lazy_emplace("abc", [&](const StringTable::constructor& f) { + called = true; + f("abc", "DEF"); + }); + EXPECT_FALSE(called); + EXPECT_THAT(*it, Pair("abc", "ABC")); +} + +TEST(Table, ContainsEmpty) { + IntTable t; + + EXPECT_FALSE(t.contains(0)); +} + +TEST(Table, Contains1) { + IntTable t; + + EXPECT_TRUE(t.insert(0).second); + EXPECT_TRUE(t.contains(0)); + EXPECT_FALSE(t.contains(1)); + + EXPECT_EQ(1, t.erase(0)); + EXPECT_FALSE(t.contains(0)); +} + +TEST(Table, Contains2) { + IntTable t; + + EXPECT_TRUE(t.insert(0).second); + EXPECT_TRUE(t.contains(0)); + EXPECT_FALSE(t.contains(1)); + + t.clear(); + EXPECT_FALSE(t.contains(0)); +} + +int decompose_constructed; +struct DecomposeType { + DecomposeType(int i) : i(i) { // NOLINT + ++decompose_constructed; + } + + explicit DecomposeType(const char* d) : DecomposeType(*d) {} + + int i; +}; + +struct DecomposeHash { + using is_transparent = void; + size_t operator()(DecomposeType a) const { return a.i; } + size_t operator()(int a) const { return a; } + size_t operator()(const char* a) const { return *a; } +}; + +struct DecomposeEq { + using is_transparent = void; + bool operator()(DecomposeType a, DecomposeType b) const { return a.i == b.i; } + bool operator()(DecomposeType a, int b) const { return a.i == b; } + bool operator()(DecomposeType a, const char* b) const { return a.i == *b; } +}; + +struct DecomposePolicy { + using slot_type = DecomposeType; + using key_type = DecomposeType; + using init_type = DecomposeType; + + template <typename T> + static void construct(void*, DecomposeType* slot, T&& v) { + *slot = DecomposeType(std::forward<T>(v)); + } + static void destroy(void*, DecomposeType*) {} + static DecomposeType& element(slot_type* slot) { return *slot; } + + template <class F, class T> + static auto apply(F&& f, const T& x) -> decltype(std::forward<F>(f)(x, x)) { + return std::forward<F>(f)(x, x); + } +}; + +template <typename Hash, typename Eq> +void TestDecompose(bool construct_three) { + DecomposeType elem{0}; + const int one = 1; + const char* three_p = "3"; + const auto& three = three_p; + + raw_hash_set<DecomposePolicy, Hash, Eq, std::allocator<int>> set1; + + decompose_constructed = 0; + int expected_constructed = 0; + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.insert(elem); + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.insert(1); + EXPECT_EQ(++expected_constructed, decompose_constructed); + set1.emplace("3"); + EXPECT_EQ(++expected_constructed, decompose_constructed); + EXPECT_EQ(expected_constructed, decompose_constructed); + + { // insert(T&&) + set1.insert(1); + EXPECT_EQ(expected_constructed, decompose_constructed); + } + + { // insert(const T&) + set1.insert(one); + EXPECT_EQ(expected_constructed, decompose_constructed); + } + + { // insert(hint, T&&) + set1.insert(set1.begin(), 1); + EXPECT_EQ(expected_constructed, decompose_constructed); + } + + { // insert(hint, const T&) + set1.insert(set1.begin(), one); + EXPECT_EQ(expected_constructed, decompose_constructed); + } + + { // emplace(...) + set1.emplace(1); + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.emplace("3"); + expected_constructed += construct_three; + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.emplace(one); + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.emplace(three); + expected_constructed += construct_three; + EXPECT_EQ(expected_constructed, decompose_constructed); + } + + { // emplace_hint(...) + set1.emplace_hint(set1.begin(), 1); + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.emplace_hint(set1.begin(), "3"); + expected_constructed += construct_three; + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.emplace_hint(set1.begin(), one); + EXPECT_EQ(expected_constructed, decompose_constructed); + set1.emplace_hint(set1.begin(), three); + expected_constructed += construct_three; + EXPECT_EQ(expected_constructed, decompose_constructed); + } +} + +TEST(Table, Decompose) { + TestDecompose<DecomposeHash, DecomposeEq>(false); + + struct TransparentHashIntOverload { + size_t operator()(DecomposeType a) const { return a.i; } + size_t operator()(int a) const { return a; } + }; + struct TransparentEqIntOverload { + bool operator()(DecomposeType a, DecomposeType b) const { + return a.i == b.i; + } + bool operator()(DecomposeType a, int b) const { return a.i == b; } + }; + TestDecompose<TransparentHashIntOverload, DecomposeEq>(true); + TestDecompose<TransparentHashIntOverload, TransparentEqIntOverload>(true); + TestDecompose<DecomposeHash, TransparentEqIntOverload>(true); +} + +// Returns the largest m such that a table with m elements has the same number +// of buckets as a table with n elements. +size_t MaxDensitySize(size_t n) { + IntTable t; + t.reserve(n); + for (size_t i = 0; i != n; ++i) t.emplace(i); + const size_t c = t.bucket_count(); + while (c == t.bucket_count()) t.emplace(n++); + return t.size() - 1; +} + +struct Modulo1000Hash { + size_t operator()(int x) const { return x % 1000; } +}; + +struct Modulo1000HashTable + : public raw_hash_set<IntPolicy, Modulo1000Hash, std::equal_to<int>, + std::allocator<int>> {}; + +// Test that rehash with no resize happen in case of many deleted slots. +TEST(Table, RehashWithNoResize) { + Modulo1000HashTable t; + // Adding the same length (and the same hash) strings + // to have at least kMinFullGroups groups + // with Group::kWidth collisions. Then fill up to MaxDensitySize; + const size_t kMinFullGroups = 7; + std::vector<int> keys; + for (size_t i = 0; i < MaxDensitySize(Group::kWidth * kMinFullGroups); ++i) { + int k = i * 1000; + t.emplace(k); + keys.push_back(k); + } + const size_t capacity = t.capacity(); + + // Remove elements from all groups except the first and the last one. + // All elements removed from full groups will be marked as kDeleted. + const size_t erase_begin = Group::kWidth / 2; + const size_t erase_end = (t.size() / Group::kWidth - 1) * Group::kWidth; + for (size_t i = erase_begin; i < erase_end; ++i) { + EXPECT_EQ(1, t.erase(keys[i])) << i; + } + keys.erase(keys.begin() + erase_begin, keys.begin() + erase_end); + + auto last_key = keys.back(); + size_t last_key_num_probes = GetHashtableDebugNumProbes(t, last_key); + + // Make sure that we have to make a lot of probes for last key. + ASSERT_GT(last_key_num_probes, kMinFullGroups); + + int x = 1; + // Insert and erase one element, before inplace rehash happen. + while (last_key_num_probes == GetHashtableDebugNumProbes(t, last_key)) { + t.emplace(x); + ASSERT_EQ(capacity, t.capacity()); + // All elements should be there. + ASSERT_TRUE(t.find(x) != t.end()) << x; + for (const auto& k : keys) { + ASSERT_TRUE(t.find(k) != t.end()) << k; + } + t.erase(x); + ++x; + } +} + +TEST(Table, InsertEraseStressTest) { + IntTable t; + const size_t kMinElementCount = 250; + std::deque<int> keys; + size_t i = 0; + for (; i < MaxDensitySize(kMinElementCount); ++i) { + t.emplace(i); + keys.push_back(i); + } + const size_t kNumIterations = 1000000; + for (; i < kNumIterations; ++i) { + ASSERT_EQ(1, t.erase(keys.front())); + keys.pop_front(); + t.emplace(i); + keys.push_back(i); + } +} + +TEST(Table, InsertOverloads) { + StringTable t; + // These should all trigger the insert(init_type) overload. + t.insert({{}, {}}); + t.insert({"ABC", {}}); + t.insert({"DEF", "!!!"}); + + EXPECT_THAT(t, UnorderedElementsAre(Pair("", ""), Pair("ABC", ""), + Pair("DEF", "!!!"))); +} + +TEST(Table, LargeTable) { + IntTable t; + for (int64_t i = 0; i != 100000; ++i) t.emplace(i << 40); + for (int64_t i = 0; i != 100000; ++i) ASSERT_EQ(i << 40, *t.find(i << 40)); +} + +// Timeout if copy is quadratic as it was in Rust. +TEST(Table, EnsureNonQuadraticAsInRust) { + static const size_t kLargeSize = 1 << 15; + + IntTable t; + for (size_t i = 0; i != kLargeSize; ++i) { + t.insert(i); + } + + // If this is quadratic, the test will timeout. + IntTable t2; + for (const auto& entry : t) t2.insert(entry); +} + +TEST(Table, ClearBug) { + IntTable t; + constexpr size_t capacity = container_internal::Group::kWidth - 1; + constexpr size_t max_size = capacity / 2 + 1; + for (size_t i = 0; i < max_size; ++i) { + t.insert(i); + } + ASSERT_EQ(capacity, t.capacity()); + intptr_t original = reinterpret_cast<intptr_t>(&*t.find(2)); + t.clear(); + ASSERT_EQ(capacity, t.capacity()); + for (size_t i = 0; i < max_size; ++i) { + t.insert(i); + } + ASSERT_EQ(capacity, t.capacity()); + intptr_t second = reinterpret_cast<intptr_t>(&*t.find(2)); + // We are checking that original and second are close enough to each other + // that they are probably still in the same group. This is not strictly + // guaranteed. + EXPECT_LT(std::abs(original - second), + capacity * sizeof(IntTable::value_type)); +} + +TEST(Table, Erase) { + IntTable t; + EXPECT_TRUE(t.find(0) == t.end()); + auto res = t.emplace(0); + EXPECT_TRUE(res.second); + EXPECT_EQ(1, t.size()); + t.erase(res.first); + EXPECT_EQ(0, t.size()); + EXPECT_TRUE(t.find(0) == t.end()); +} + +TEST(Table, EraseMaintainsValidIterator) { + IntTable t; + const int kNumElements = 100; + for (int i = 0; i < kNumElements; i ++) { + EXPECT_TRUE(t.emplace(i).second); + } + EXPECT_EQ(t.size(), kNumElements); + + int num_erase_calls = 0; + auto it = t.begin(); + while (it != t.end()) { + t.erase(it++); + num_erase_calls++; + } + + EXPECT_TRUE(t.empty()); + EXPECT_EQ(num_erase_calls, kNumElements); +} + +// Collect N bad keys by following algorithm: +// 1. Create an empty table and reserve it to 2 * N. +// 2. Insert N random elements. +// 3. Take first Group::kWidth - 1 to bad_keys array. +// 4. Clear the table without resize. +// 5. Go to point 2 while N keys not collected +std::vector<int64_t> CollectBadMergeKeys(size_t N) { + static constexpr int kGroupSize = Group::kWidth - 1; + + auto topk_range = [](size_t b, size_t e, IntTable* t) -> std::vector<int64_t> { + for (size_t i = b; i != e; ++i) { + t->emplace(i); + } + std::vector<int64_t> res; + res.reserve(kGroupSize); + auto it = t->begin(); + for (size_t i = b; i != e && i != b + kGroupSize; ++i, ++it) { + res.push_back(*it); + } + return res; + }; + + std::vector<int64_t> bad_keys; + bad_keys.reserve(N); + IntTable t; + t.reserve(N * 2); + + for (size_t b = 0; bad_keys.size() < N; b += N) { + auto keys = topk_range(b, b + N, &t); + bad_keys.insert(bad_keys.end(), keys.begin(), keys.end()); + t.erase(t.begin(), t.end()); + EXPECT_TRUE(t.empty()); + } + return bad_keys; +} + +struct ProbeStats { + // Number of elements with specific probe length over all tested tables. + std::vector<size_t> all_probes_histogram; + // Ratios total_probe_length/size for every tested table. + std::vector<double> single_table_ratios; + + friend ProbeStats operator+(const ProbeStats& a, const ProbeStats& b) { + ProbeStats res = a; + res.all_probes_histogram.resize(std::max(res.all_probes_histogram.size(), + b.all_probes_histogram.size())); + std::transform(b.all_probes_histogram.begin(), b.all_probes_histogram.end(), + res.all_probes_histogram.begin(), + res.all_probes_histogram.begin(), std::plus<size_t>()); + res.single_table_ratios.insert(res.single_table_ratios.end(), + b.single_table_ratios.begin(), + b.single_table_ratios.end()); + return res; + } + + // Average ratio total_probe_length/size over tables. + double AvgRatio() const { + return std::accumulate(single_table_ratios.begin(), + single_table_ratios.end(), 0.0) / + single_table_ratios.size(); + } + + // Maximum ratio total_probe_length/size over tables. + double MaxRatio() const { + return *std::max_element(single_table_ratios.begin(), + single_table_ratios.end()); + } + + // Percentile ratio total_probe_length/size over tables. + double PercentileRatio(double Percentile = 0.95) const { + auto r = single_table_ratios; + auto mid = r.begin() + static_cast<size_t>(r.size() * Percentile); + if (mid != r.end()) { + std::nth_element(r.begin(), mid, r.end()); + return *mid; + } else { + return MaxRatio(); + } + } + + // Maximum probe length over all elements and all tables. + size_t MaxProbe() const { return all_probes_histogram.size(); } + + // Fraction of elements with specified probe length. + std::vector<double> ProbeNormalizedHistogram() const { + double total_elements = std::accumulate(all_probes_histogram.begin(), + all_probes_histogram.end(), 0ull); + std::vector<double> res; + for (size_t p : all_probes_histogram) { + res.push_back(p / total_elements); + } + return res; + } + + size_t PercentileProbe(double Percentile = 0.99) const { + size_t idx = 0; + for (double p : ProbeNormalizedHistogram()) { + if (Percentile > p) { + Percentile -= p; + ++idx; + } else { + return idx; + } + } + return idx; + } + + friend std::ostream& operator<<(std::ostream& out, const ProbeStats& s) { + out << "{AvgRatio:" << s.AvgRatio() << ", MaxRatio:" << s.MaxRatio() + << ", PercentileRatio:" << s.PercentileRatio() + << ", MaxProbe:" << s.MaxProbe() << ", Probes=["; + for (double p : s.ProbeNormalizedHistogram()) { + out << p << ","; + } + out << "]}"; + + return out; + } +}; + +struct ExpectedStats { + double avg_ratio; + double max_ratio; + std::vector<std::pair<double, double>> pecentile_ratios; + std::vector<std::pair<double, double>> pecentile_probes; + + friend std::ostream& operator<<(std::ostream& out, const ExpectedStats& s) { + out << "{AvgRatio:" << s.avg_ratio << ", MaxRatio:" << s.max_ratio + << ", PercentileRatios: ["; + for (auto el : s.pecentile_ratios) { + out << el.first << ":" << el.second << ", "; + } + out << "], PercentileProbes: ["; + for (auto el : s.pecentile_probes) { + out << el.first << ":" << el.second << ", "; + } + out << "]}"; + + return out; + } +}; + +void VerifyStats(size_t size, const ExpectedStats& exp, + const ProbeStats& stats) { + EXPECT_LT(stats.AvgRatio(), exp.avg_ratio) << size << " " << stats; + EXPECT_LT(stats.MaxRatio(), exp.max_ratio) << size << " " << stats; + for (auto pr : exp.pecentile_ratios) { + EXPECT_LE(stats.PercentileRatio(pr.first), pr.second) + << size << " " << pr.first << " " << stats; + } + + for (auto pr : exp.pecentile_probes) { + EXPECT_LE(stats.PercentileProbe(pr.first), pr.second) + << size << " " << pr.first << " " << stats; + } +} + +using ProbeStatsPerSize = std::map<size_t, ProbeStats>; + +// Collect total ProbeStats on num_iters iterations of the following algorithm: +// 1. Create new table and reserve it to keys.size() * 2 +// 2. Insert all keys xored with seed +// 3. Collect ProbeStats from final table. +ProbeStats CollectProbeStatsOnKeysXoredWithSeed(const std::vector<int64_t>& keys, + size_t num_iters) { + const size_t reserve_size = keys.size() * 2; + + ProbeStats stats; + + int64_t seed = 0x71b1a19b907d6e33; + while (num_iters--) { + seed = static_cast<int64_t>(static_cast<uint64_t>(seed) * 17 + 13); + IntTable t1; + t1.reserve(reserve_size); + for (const auto& key : keys) { + t1.emplace(key ^ seed); + } + + auto probe_histogram = GetHashtableDebugNumProbesHistogram(t1); + stats.all_probes_histogram.resize( + std::max(stats.all_probes_histogram.size(), probe_histogram.size())); + std::transform(probe_histogram.begin(), probe_histogram.end(), + stats.all_probes_histogram.begin(), + stats.all_probes_histogram.begin(), std::plus<size_t>()); + + size_t total_probe_seq_length = 0; + for (size_t i = 0; i < probe_histogram.size(); ++i) { + total_probe_seq_length += i * probe_histogram[i]; + } + stats.single_table_ratios.push_back(total_probe_seq_length * 1.0 / + keys.size()); + t1.erase(t1.begin(), t1.end()); + } + return stats; +} + +ExpectedStats XorSeedExpectedStats() { + constexpr bool kRandomizesInserts = +#ifdef NDEBUG + false; +#else // NDEBUG + true; +#endif // NDEBUG + + // The effective load factor is larger in non-opt mode because we insert + // elements out of order. + switch (container_internal::Group::kWidth) { + case 8: + if (kRandomizesInserts) { + return {0.05, + 1.0, + {{0.95, 0.5}}, + {{0.95, 0}, {0.99, 2}, {0.999, 4}, {0.9999, 10}}}; + } else { + return {0.05, + 2.0, + {{0.95, 0.1}}, + {{0.95, 0}, {0.99, 2}, {0.999, 4}, {0.9999, 10}}}; + } + case 16: + if (kRandomizesInserts) { + return {0.1, + 1.0, + {{0.95, 0.1}}, + {{0.95, 0}, {0.99, 1}, {0.999, 8}, {0.9999, 15}}}; + } else { + return {0.05, + 1.0, + {{0.95, 0.05}}, + {{0.95, 0}, {0.99, 1}, {0.999, 4}, {0.9999, 10}}}; + } + } + ABSL_RAW_LOG(FATAL, "%s", "Unknown Group width"); + return {}; +} + +TEST(Table, DISABLED_EnsureNonQuadraticTopNXorSeedByProbeSeqLength) { + ProbeStatsPerSize stats; + std::vector<size_t> sizes = {Group::kWidth << 5, Group::kWidth << 10}; + for (size_t size : sizes) { + stats[size] = + CollectProbeStatsOnKeysXoredWithSeed(CollectBadMergeKeys(size), 200); + } + auto expected = XorSeedExpectedStats(); + for (size_t size : sizes) { + auto& stat = stats[size]; + VerifyStats(size, expected, stat); + } +} + +// Collect total ProbeStats on num_iters iterations of the following algorithm: +// 1. Create new table +// 2. Select 10% of keys and insert 10 elements key * 17 + j * 13 +// 3. Collect ProbeStats from final table +ProbeStats CollectProbeStatsOnLinearlyTransformedKeys( + const std::vector<int64_t>& keys, size_t num_iters) { + ProbeStats stats; + + std::random_device rd; + std::mt19937 rng(rd()); + auto linear_transform = [](size_t x, size_t y) { return x * 17 + y * 13; }; + std::uniform_int_distribution<size_t> dist(0, keys.size()-1); + while (num_iters--) { + IntTable t1; + size_t num_keys = keys.size() / 10; + size_t start = dist(rng); + for (size_t i = 0; i != num_keys; ++i) { + for (size_t j = 0; j != 10; ++j) { + t1.emplace(linear_transform(keys[(i + start) % keys.size()], j)); + } + } + + auto probe_histogram = GetHashtableDebugNumProbesHistogram(t1); + stats.all_probes_histogram.resize( + std::max(stats.all_probes_histogram.size(), probe_histogram.size())); + std::transform(probe_histogram.begin(), probe_histogram.end(), + stats.all_probes_histogram.begin(), + stats.all_probes_histogram.begin(), std::plus<size_t>()); + + size_t total_probe_seq_length = 0; + for (size_t i = 0; i < probe_histogram.size(); ++i) { + total_probe_seq_length += i * probe_histogram[i]; + } + stats.single_table_ratios.push_back(total_probe_seq_length * 1.0 / + t1.size()); + t1.erase(t1.begin(), t1.end()); + } + return stats; +} + +ExpectedStats LinearTransformExpectedStats() { + constexpr bool kRandomizesInserts = +#ifdef NDEBUG + false; +#else // NDEBUG + true; +#endif // NDEBUG + + // The effective load factor is larger in non-opt mode because we insert + // elements out of order. + switch (container_internal::Group::kWidth) { + case 8: + if (kRandomizesInserts) { + return {0.1, + 0.5, + {{0.95, 0.3}}, + {{0.95, 0}, {0.99, 1}, {0.999, 8}, {0.9999, 15}}}; + } else { + return {0.15, + 0.5, + {{0.95, 0.3}}, + {{0.95, 0}, {0.99, 3}, {0.999, 15}, {0.9999, 25}}}; + } + case 16: + if (kRandomizesInserts) { + return {0.1, + 0.4, + {{0.95, 0.3}}, + {{0.95, 0}, {0.99, 1}, {0.999, 8}, {0.9999, 15}}}; + } else { + return {0.05, + 0.2, + {{0.95, 0.1}}, + {{0.95, 0}, {0.99, 1}, {0.999, 6}, {0.9999, 10}}}; + } + } + ABSL_RAW_LOG(FATAL, "%s", "Unknown Group width"); + return {}; +} + +TEST(Table, DISABLED_EnsureNonQuadraticTopNLinearTransformByProbeSeqLength) { + ProbeStatsPerSize stats; + std::vector<size_t> sizes = {Group::kWidth << 5, Group::kWidth << 10}; + for (size_t size : sizes) { + stats[size] = CollectProbeStatsOnLinearlyTransformedKeys( + CollectBadMergeKeys(size), 300); + } + auto expected = LinearTransformExpectedStats(); + for (size_t size : sizes) { + auto& stat = stats[size]; + VerifyStats(size, expected, stat); + } +} + +TEST(Table, EraseCollision) { + BadTable t; + + // 1 2 3 + t.emplace(1); + t.emplace(2); + t.emplace(3); + EXPECT_THAT(*t.find(1), 1); + EXPECT_THAT(*t.find(2), 2); + EXPECT_THAT(*t.find(3), 3); + EXPECT_EQ(3, t.size()); + + // 1 DELETED 3 + t.erase(t.find(2)); + EXPECT_THAT(*t.find(1), 1); + EXPECT_TRUE(t.find(2) == t.end()); + EXPECT_THAT(*t.find(3), 3); + EXPECT_EQ(2, t.size()); + + // DELETED DELETED 3 + t.erase(t.find(1)); + EXPECT_TRUE(t.find(1) == t.end()); + EXPECT_TRUE(t.find(2) == t.end()); + EXPECT_THAT(*t.find(3), 3); + EXPECT_EQ(1, t.size()); + + // DELETED DELETED DELETED + t.erase(t.find(3)); + EXPECT_TRUE(t.find(1) == t.end()); + EXPECT_TRUE(t.find(2) == t.end()); + EXPECT_TRUE(t.find(3) == t.end()); + EXPECT_EQ(0, t.size()); +} + +TEST(Table, EraseInsertProbing) { + BadTable t(100); + + // 1 2 3 4 + t.emplace(1); + t.emplace(2); + t.emplace(3); + t.emplace(4); + + // 1 DELETED 3 DELETED + t.erase(t.find(2)); + t.erase(t.find(4)); + + // 1 10 3 11 12 + t.emplace(10); + t.emplace(11); + t.emplace(12); + + EXPECT_EQ(5, t.size()); + EXPECT_THAT(t, UnorderedElementsAre(1, 10, 3, 11, 12)); +} + +TEST(Table, Clear) { + IntTable t; + EXPECT_TRUE(t.find(0) == t.end()); + t.clear(); + EXPECT_TRUE(t.find(0) == t.end()); + auto res = t.emplace(0); + EXPECT_TRUE(res.second); + EXPECT_EQ(1, t.size()); + t.clear(); + EXPECT_EQ(0, t.size()); + EXPECT_TRUE(t.find(0) == t.end()); +} + +TEST(Table, Swap) { + IntTable t; + EXPECT_TRUE(t.find(0) == t.end()); + auto res = t.emplace(0); + EXPECT_TRUE(res.second); + EXPECT_EQ(1, t.size()); + IntTable u; + t.swap(u); + EXPECT_EQ(0, t.size()); + EXPECT_EQ(1, u.size()); + EXPECT_TRUE(t.find(0) == t.end()); + EXPECT_THAT(*u.find(0), 0); +} + +TEST(Table, Rehash) { + IntTable t; + EXPECT_TRUE(t.find(0) == t.end()); + t.emplace(0); + t.emplace(1); + EXPECT_EQ(2, t.size()); + t.rehash(128); + EXPECT_EQ(2, t.size()); + EXPECT_THAT(*t.find(0), 0); + EXPECT_THAT(*t.find(1), 1); +} + +TEST(Table, RehashDoesNotRehashWhenNotNecessary) { + IntTable t; + t.emplace(0); + t.emplace(1); + auto* p = &*t.find(0); + t.rehash(1); + EXPECT_EQ(p, &*t.find(0)); +} + +TEST(Table, RehashZeroDoesNotAllocateOnEmptyTable) { + IntTable t; + t.rehash(0); + EXPECT_EQ(0, t.bucket_count()); +} + +TEST(Table, RehashZeroDeallocatesEmptyTable) { + IntTable t; + t.emplace(0); + t.clear(); + EXPECT_NE(0, t.bucket_count()); + t.rehash(0); + EXPECT_EQ(0, t.bucket_count()); +} + +TEST(Table, RehashZeroForcesRehash) { + IntTable t; + t.emplace(0); + t.emplace(1); + auto* p = &*t.find(0); + t.rehash(0); + EXPECT_NE(p, &*t.find(0)); +} + +TEST(Table, ConstructFromInitList) { + using P = std::pair<std::string, std::string>; + struct Q { + operator P() const { return {}; } + }; + StringTable t = {P(), Q(), {}, {{}, {}}}; +} + +TEST(Table, CopyConstruct) { + IntTable t; + t.emplace(0); + EXPECT_EQ(1, t.size()); + { + IntTable u(t); + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find(0), 0); + } + { + IntTable u{t}; + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find(0), 0); + } + { + IntTable u = t; + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find(0), 0); + } +} + +TEST(Table, CopyConstructWithAlloc) { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + StringTable u(t, Alloc<std::pair<std::string, std::string>>()); + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); +} + +struct ExplicitAllocIntTable + : raw_hash_set<IntPolicy, container_internal::hash_default_hash<int64_t>, + std::equal_to<int64_t>, Alloc<int64_t>> { + ExplicitAllocIntTable() {} +}; + +TEST(Table, AllocWithExplicitCtor) { + ExplicitAllocIntTable t; + EXPECT_EQ(0, t.size()); +} + +TEST(Table, MoveConstruct) { + { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + + StringTable u(std::move(t)); + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); + } + { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + + StringTable u{std::move(t)}; + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); + } + { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + + StringTable u = std::move(t); + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); + } +} + +TEST(Table, MoveConstructWithAlloc) { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + StringTable u(std::move(t), Alloc<std::pair<std::string, std::string>>()); + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); +} + +TEST(Table, CopyAssign) { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + StringTable u; + u = t; + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); +} + +TEST(Table, CopySelfAssign) { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + t = *&t; + EXPECT_EQ(1, t.size()); + EXPECT_THAT(*t.find("a"), Pair("a", "b")); +} + +TEST(Table, MoveAssign) { + StringTable t; + t.emplace("a", "b"); + EXPECT_EQ(1, t.size()); + StringTable u; + u = std::move(t); + EXPECT_EQ(1, u.size()); + EXPECT_THAT(*u.find("a"), Pair("a", "b")); +} + +TEST(Table, Equality) { + StringTable t; + std::vector<std::pair<std::string, std::string>> v = {{"a", "b"}, + {"aa", "bb"}}; + t.insert(std::begin(v), std::end(v)); + StringTable u = t; + EXPECT_EQ(u, t); +} + +TEST(Table, Equality2) { + StringTable t; + std::vector<std::pair<std::string, std::string>> v1 = {{"a", "b"}, + {"aa", "bb"}}; + t.insert(std::begin(v1), std::end(v1)); + StringTable u; + std::vector<std::pair<std::string, std::string>> v2 = {{"a", "a"}, + {"aa", "aa"}}; + u.insert(std::begin(v2), std::end(v2)); + EXPECT_NE(u, t); +} + +TEST(Table, Equality3) { + StringTable t; + std::vector<std::pair<std::string, std::string>> v1 = {{"b", "b"}, + {"bb", "bb"}}; + t.insert(std::begin(v1), std::end(v1)); + StringTable u; + std::vector<std::pair<std::string, std::string>> v2 = {{"a", "a"}, + {"aa", "aa"}}; + u.insert(std::begin(v2), std::end(v2)); + EXPECT_NE(u, t); +} + +TEST(Table, NumDeletedRegression) { + IntTable t; + t.emplace(0); + t.erase(t.find(0)); + // construct over a deleted slot. + t.emplace(0); + t.clear(); +} + +TEST(Table, FindFullDeletedRegression) { + IntTable t; + for (int i = 0; i < 1000; ++i) { + t.emplace(i); + t.erase(t.find(i)); + } + EXPECT_EQ(0, t.size()); +} + +TEST(Table, ReplacingDeletedSlotDoesNotRehash) { + size_t n; + { + // Compute n such that n is the maximum number of elements before rehash. + IntTable t; + t.emplace(0); + size_t c = t.bucket_count(); + for (n = 1; c == t.bucket_count(); ++n) t.emplace(n); + --n; + } + IntTable t; + t.rehash(n); + const size_t c = t.bucket_count(); + for (size_t i = 0; i != n; ++i) t.emplace(i); + EXPECT_EQ(c, t.bucket_count()) << "rehashing threshold = " << n; + t.erase(0); + t.emplace(0); + EXPECT_EQ(c, t.bucket_count()) << "rehashing threshold = " << n; +} + +TEST(Table, NoThrowMoveConstruct) { + ASSERT_TRUE( + std::is_nothrow_copy_constructible<absl::Hash<absl::string_view>>::value); + ASSERT_TRUE(std::is_nothrow_copy_constructible< + std::equal_to<absl::string_view>>::value); + ASSERT_TRUE(std::is_nothrow_copy_constructible<std::allocator<int>>::value); + EXPECT_TRUE(std::is_nothrow_move_constructible<StringTable>::value); +} + +TEST(Table, NoThrowMoveAssign) { + ASSERT_TRUE( + std::is_nothrow_move_assignable<absl::Hash<absl::string_view>>::value); + ASSERT_TRUE( + std::is_nothrow_move_assignable<std::equal_to<absl::string_view>>::value); + ASSERT_TRUE(std::is_nothrow_move_assignable<std::allocator<int>>::value); + ASSERT_TRUE( + absl::allocator_traits<std::allocator<int>>::is_always_equal::value); + EXPECT_TRUE(std::is_nothrow_move_assignable<StringTable>::value); +} + +TEST(Table, NoThrowSwappable) { + ASSERT_TRUE( + container_internal::IsNoThrowSwappable<absl::Hash<absl::string_view>>()); + ASSERT_TRUE(container_internal::IsNoThrowSwappable< + std::equal_to<absl::string_view>>()); + ASSERT_TRUE(container_internal::IsNoThrowSwappable<std::allocator<int>>()); + EXPECT_TRUE(container_internal::IsNoThrowSwappable<StringTable>()); +} + +TEST(Table, HeterogeneousLookup) { + struct Hash { + size_t operator()(int64_t i) const { return i; } + size_t operator()(double i) const { + ADD_FAILURE(); + return i; + } + }; + struct Eq { + bool operator()(int64_t a, int64_t b) const { return a == b; } + bool operator()(double a, int64_t b) const { + ADD_FAILURE(); + return a == b; + } + bool operator()(int64_t a, double b) const { + ADD_FAILURE(); + return a == b; + } + bool operator()(double a, double b) const { + ADD_FAILURE(); + return a == b; + } + }; + + struct THash { + using is_transparent = void; + size_t operator()(int64_t i) const { return i; } + size_t operator()(double i) const { return i; } + }; + struct TEq { + using is_transparent = void; + bool operator()(int64_t a, int64_t b) const { return a == b; } + bool operator()(double a, int64_t b) const { return a == b; } + bool operator()(int64_t a, double b) const { return a == b; } + bool operator()(double a, double b) const { return a == b; } + }; + + raw_hash_set<IntPolicy, Hash, Eq, Alloc<int64_t>> s{0, 1, 2}; + // It will convert to int64_t before the query. + EXPECT_EQ(1, *s.find(double{1.1})); + + raw_hash_set<IntPolicy, THash, TEq, Alloc<int64_t>> ts{0, 1, 2}; + // It will try to use the double, and fail to find the object. + EXPECT_TRUE(ts.find(1.1) == ts.end()); +} + +template <class Table> +using CallFind = decltype(std::declval<Table&>().find(17)); + +template <class Table> +using CallErase = decltype(std::declval<Table&>().erase(17)); + +template <class Table> +using CallExtract = decltype(std::declval<Table&>().extract(17)); + +template <class Table> +using CallPrefetch = decltype(std::declval<Table&>().prefetch(17)); + +template <class Table> +using CallCount = decltype(std::declval<Table&>().count(17)); + +template <template <typename> class C, class Table, class = void> +struct VerifyResultOf : std::false_type {}; + +template <template <typename> class C, class Table> +struct VerifyResultOf<C, Table, absl::void_t<C<Table>>> : std::true_type {}; + +TEST(Table, HeterogeneousLookupOverloads) { + using NonTransparentTable = + raw_hash_set<StringPolicy, absl::Hash<absl::string_view>, + std::equal_to<absl::string_view>, std::allocator<int>>; + + EXPECT_FALSE((VerifyResultOf<CallFind, NonTransparentTable>())); + EXPECT_FALSE((VerifyResultOf<CallErase, NonTransparentTable>())); + EXPECT_FALSE((VerifyResultOf<CallExtract, NonTransparentTable>())); + EXPECT_FALSE((VerifyResultOf<CallPrefetch, NonTransparentTable>())); + EXPECT_FALSE((VerifyResultOf<CallCount, NonTransparentTable>())); + + using TransparentTable = raw_hash_set< + StringPolicy, + absl::container_internal::hash_default_hash<absl::string_view>, + absl::container_internal::hash_default_eq<absl::string_view>, + std::allocator<int>>; + + EXPECT_TRUE((VerifyResultOf<CallFind, TransparentTable>())); + EXPECT_TRUE((VerifyResultOf<CallErase, TransparentTable>())); + EXPECT_TRUE((VerifyResultOf<CallExtract, TransparentTable>())); + EXPECT_TRUE((VerifyResultOf<CallPrefetch, TransparentTable>())); + EXPECT_TRUE((VerifyResultOf<CallCount, TransparentTable>())); +} + +// TODO(alkis): Expand iterator tests. +TEST(Iterator, IsDefaultConstructible) { + StringTable::iterator i; + EXPECT_TRUE(i == StringTable::iterator()); +} + +TEST(ConstIterator, IsDefaultConstructible) { + StringTable::const_iterator i; + EXPECT_TRUE(i == StringTable::const_iterator()); +} + +TEST(Iterator, ConvertsToConstIterator) { + StringTable::iterator i; + EXPECT_TRUE(i == StringTable::const_iterator()); +} + +TEST(Iterator, Iterates) { + IntTable t; + for (size_t i = 3; i != 6; ++i) EXPECT_TRUE(t.emplace(i).second); + EXPECT_THAT(t, UnorderedElementsAre(3, 4, 5)); +} + +TEST(Table, Merge) { + StringTable t1, t2; + t1.emplace("0", "-0"); + t1.emplace("1", "-1"); + t2.emplace("0", "~0"); + t2.emplace("2", "~2"); + + EXPECT_THAT(t1, UnorderedElementsAre(Pair("0", "-0"), Pair("1", "-1"))); + EXPECT_THAT(t2, UnorderedElementsAre(Pair("0", "~0"), Pair("2", "~2"))); + + t1.merge(t2); + EXPECT_THAT(t1, UnorderedElementsAre(Pair("0", "-0"), Pair("1", "-1"), + Pair("2", "~2"))); + EXPECT_THAT(t2, UnorderedElementsAre(Pair("0", "~0"))); +} + +TEST(Nodes, EmptyNodeType) { + using node_type = StringTable::node_type; + node_type n; + EXPECT_FALSE(n); + EXPECT_TRUE(n.empty()); + + EXPECT_TRUE((std::is_same<node_type::allocator_type, + StringTable::allocator_type>::value)); +} + +TEST(Nodes, ExtractInsert) { + constexpr char k0[] = "Very long string zero."; + constexpr char k1[] = "Very long string one."; + constexpr char k2[] = "Very long string two."; + StringTable t = {{k0, ""}, {k1, ""}, {k2, ""}}; + EXPECT_THAT(t, + UnorderedElementsAre(Pair(k0, ""), Pair(k1, ""), Pair(k2, ""))); + + auto node = t.extract(k0); + EXPECT_THAT(t, UnorderedElementsAre(Pair(k1, ""), Pair(k2, ""))); + EXPECT_TRUE(node); + EXPECT_FALSE(node.empty()); + + StringTable t2; + StringTable::insert_return_type res = t2.insert(std::move(node)); + EXPECT_TRUE(res.inserted); + EXPECT_THAT(*res.position, Pair(k0, "")); + EXPECT_FALSE(res.node); + EXPECT_THAT(t2, UnorderedElementsAre(Pair(k0, ""))); + + // Not there. + EXPECT_THAT(t, UnorderedElementsAre(Pair(k1, ""), Pair(k2, ""))); + node = t.extract("Not there!"); + EXPECT_THAT(t, UnorderedElementsAre(Pair(k1, ""), Pair(k2, ""))); + EXPECT_FALSE(node); + + // Inserting nothing. + res = t2.insert(std::move(node)); + EXPECT_FALSE(res.inserted); + EXPECT_EQ(res.position, t2.end()); + EXPECT_FALSE(res.node); + EXPECT_THAT(t2, UnorderedElementsAre(Pair(k0, ""))); + + t.emplace(k0, "1"); + node = t.extract(k0); + + // Insert duplicate. + res = t2.insert(std::move(node)); + EXPECT_FALSE(res.inserted); + EXPECT_THAT(*res.position, Pair(k0, "")); + EXPECT_TRUE(res.node); + EXPECT_FALSE(node); +} + +IntTable MakeSimpleTable(size_t size) { + IntTable t; + while (t.size() < size) t.insert(t.size()); + return t; +} + +std::vector<int> OrderOfIteration(const IntTable& t) { + return {t.begin(), t.end()}; +} + +// These IterationOrderChanges tests depend on non-deterministic behavior. +// We are injecting non-determinism from the pointer of the table, but do so in +// a way that only the page matters. We have to retry enough times to make sure +// we are touching different memory pages to cause the ordering to change. +// We also need to keep the old tables around to avoid getting the same memory +// blocks over and over. +TEST(Table, IterationOrderChangesByInstance) { + for (size_t size : {2, 6, 12, 20}) { + const auto reference_table = MakeSimpleTable(size); + const auto reference = OrderOfIteration(reference_table); + + std::vector<IntTable> tables; + bool found_difference = false; + for (int i = 0; !found_difference && i < 5000; ++i) { + tables.push_back(MakeSimpleTable(size)); + found_difference = OrderOfIteration(tables.back()) != reference; + } + if (!found_difference) { + FAIL() + << "Iteration order remained the same across many attempts with size " + << size; + } + } +} + +TEST(Table, IterationOrderChangesOnRehash) { + std::vector<IntTable> garbage; + for (int i = 0; i < 5000; ++i) { + auto t = MakeSimpleTable(20); + const auto reference = OrderOfIteration(t); + // Force rehash to the same size. + t.rehash(0); + auto trial = OrderOfIteration(t); + if (trial != reference) { + // We are done. + return; + } + garbage.push_back(std::move(t)); + } + FAIL() << "Iteration order remained the same across many attempts."; +} + +// Verify that pointers are invalidated as soon as a second element is inserted. +// This prevents dependency on pointer stability on small tables. +TEST(Table, UnstablePointers) { + IntTable table; + + const auto addr = [&](int i) { + return reinterpret_cast<uintptr_t>(&*table.find(i)); + }; + + table.insert(0); + const uintptr_t old_ptr = addr(0); + + // This causes a rehash. + table.insert(1); + + EXPECT_NE(old_ptr, addr(0)); +} + +// Confirm that we assert if we try to erase() end(). +TEST(TableDeathTest, EraseOfEndAsserts) { + // Use an assert with side-effects to figure out if they are actually enabled. + bool assert_enabled = false; + assert([&]() { + assert_enabled = true; + return true; + }()); + if (!assert_enabled) return; + + IntTable t; + // Extra simple "regexp" as regexp support is highly varied across platforms. + constexpr char kDeathMsg[] = "IsFull"; + EXPECT_DEATH_IF_SUPPORTED(t.erase(t.end()), kDeathMsg); +} + +#if defined(ABSL_HASHTABLEZ_SAMPLE) +TEST(RawHashSamplerTest, Sample) { + // Enable the feature even if the prod default is off. + SetHashtablezEnabled(true); + SetHashtablezSampleParameter(100); + + auto& sampler = HashtablezSampler::Global(); + size_t start_size = 0; + start_size += sampler.Iterate([&](const HashtablezInfo&) { ++start_size; }); + + std::vector<IntTable> tables; + for (int i = 0; i < 1000000; ++i) { + tables.emplace_back(); + tables.back().insert(1); + } + size_t end_size = 0; + end_size += sampler.Iterate([&](const HashtablezInfo&) { ++end_size; }); + + EXPECT_NEAR((end_size - start_size) / static_cast<double>(tables.size()), + 0.01, 0.005); +} +#endif // ABSL_HASHTABLEZ_SAMPLER + +TEST(RawHashSamplerTest, DoNotSampleCustomAllocators) { + // Enable the feature even if the prod default is off. + SetHashtablezEnabled(true); + SetHashtablezSampleParameter(100); + + auto& sampler = HashtablezSampler::Global(); + size_t start_size = 0; + start_size += sampler.Iterate([&](const HashtablezInfo&) { ++start_size; }); + + std::vector<CustomAllocIntTable> tables; + for (int i = 0; i < 1000000; ++i) { + tables.emplace_back(); + tables.back().insert(1); + } + size_t end_size = 0; + end_size += sampler.Iterate([&](const HashtablezInfo&) { ++end_size; }); + + EXPECT_NEAR((end_size - start_size) / static_cast<double>(tables.size()), + 0.00, 0.001); +} + +#ifdef ADDRESS_SANITIZER +TEST(Sanitizer, PoisoningUnused) { + IntTable t; + t.reserve(5); + // Insert something to force an allocation. + int64_t& v1 = *t.insert(0).first; + + // Make sure there is something to test. + ASSERT_GT(t.capacity(), 1); + + int64_t* slots = RawHashSetTestOnlyAccess::GetSlots(t); + for (size_t i = 0; i < t.capacity(); ++i) { + EXPECT_EQ(slots + i != &v1, __asan_address_is_poisoned(slots + i)); + } +} + +TEST(Sanitizer, PoisoningOnErase) { + IntTable t; + int64_t& v = *t.insert(0).first; + + EXPECT_FALSE(__asan_address_is_poisoned(&v)); + t.erase(0); + EXPECT_TRUE(__asan_address_is_poisoned(&v)); +} +#endif // ADDRESS_SANITIZER + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/test_instance_tracker.cc b/third_party/abseil_cpp/absl/container/internal/test_instance_tracker.cc new file mode 100644 index 0000000000..f9947f0475 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/test_instance_tracker.cc @@ -0,0 +1,29 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/test_instance_tracker.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace test_internal { +int BaseCountedInstance::num_instances_ = 0; +int BaseCountedInstance::num_live_instances_ = 0; +int BaseCountedInstance::num_moves_ = 0; +int BaseCountedInstance::num_copies_ = 0; +int BaseCountedInstance::num_swaps_ = 0; +int BaseCountedInstance::num_comparisons_ = 0; + +} // namespace test_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/test_instance_tracker.h b/third_party/abseil_cpp/absl/container/internal/test_instance_tracker.h new file mode 100644 index 0000000000..5ff6fd714e --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/test_instance_tracker.h @@ -0,0 +1,274 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_TEST_INSTANCE_TRACKER_H_ +#define ABSL_CONTAINER_INTERNAL_TEST_INSTANCE_TRACKER_H_ + +#include <cstdlib> +#include <ostream> + +#include "absl/types/compare.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace test_internal { + +// A type that counts number of occurrences of the type, the live occurrences of +// the type, as well as the number of copies, moves, swaps, and comparisons that +// have occurred on the type. This is used as a base class for the copyable, +// copyable+movable, and movable types below that are used in actual tests. Use +// InstanceTracker in tests to track the number of instances. +class BaseCountedInstance { + public: + explicit BaseCountedInstance(int x) : value_(x) { + ++num_instances_; + ++num_live_instances_; + } + BaseCountedInstance(const BaseCountedInstance& x) + : value_(x.value_), is_live_(x.is_live_) { + ++num_instances_; + if (is_live_) ++num_live_instances_; + ++num_copies_; + } + BaseCountedInstance(BaseCountedInstance&& x) + : value_(x.value_), is_live_(x.is_live_) { + x.is_live_ = false; + ++num_instances_; + ++num_moves_; + } + ~BaseCountedInstance() { + --num_instances_; + if (is_live_) --num_live_instances_; + } + + BaseCountedInstance& operator=(const BaseCountedInstance& x) { + value_ = x.value_; + if (is_live_) --num_live_instances_; + is_live_ = x.is_live_; + if (is_live_) ++num_live_instances_; + ++num_copies_; + return *this; + } + BaseCountedInstance& operator=(BaseCountedInstance&& x) { + value_ = x.value_; + if (is_live_) --num_live_instances_; + is_live_ = x.is_live_; + x.is_live_ = false; + ++num_moves_; + return *this; + } + + bool operator==(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ == x.value_; + } + + bool operator!=(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ != x.value_; + } + + bool operator<(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ < x.value_; + } + + bool operator>(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ > x.value_; + } + + bool operator<=(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ <= x.value_; + } + + bool operator>=(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ >= x.value_; + } + + absl::weak_ordering compare(const BaseCountedInstance& x) const { + ++num_comparisons_; + return value_ < x.value_ + ? absl::weak_ordering::less + : value_ == x.value_ ? absl::weak_ordering::equivalent + : absl::weak_ordering::greater; + } + + int value() const { + if (!is_live_) std::abort(); + return value_; + } + + friend std::ostream& operator<<(std::ostream& o, + const BaseCountedInstance& v) { + return o << "[value:" << v.value() << "]"; + } + + // Implementation of efficient swap() that counts swaps. + static void SwapImpl( + BaseCountedInstance& lhs, // NOLINT(runtime/references) + BaseCountedInstance& rhs) { // NOLINT(runtime/references) + using std::swap; + swap(lhs.value_, rhs.value_); + swap(lhs.is_live_, rhs.is_live_); + ++BaseCountedInstance::num_swaps_; + } + + private: + friend class InstanceTracker; + + int value_; + + // Indicates if the value is live, ie it hasn't been moved away from. + bool is_live_ = true; + + // Number of instances. + static int num_instances_; + + // Number of live instances (those that have not been moved away from.) + static int num_live_instances_; + + // Number of times that BaseCountedInstance objects were moved. + static int num_moves_; + + // Number of times that BaseCountedInstance objects were copied. + static int num_copies_; + + // Number of times that BaseCountedInstance objects were swapped. + static int num_swaps_; + + // Number of times that BaseCountedInstance objects were compared. + static int num_comparisons_; +}; + +// Helper to track the BaseCountedInstance instance counters. Expects that the +// number of instances and live_instances are the same when it is constructed +// and when it is destructed. +class InstanceTracker { + public: + InstanceTracker() + : start_instances_(BaseCountedInstance::num_instances_), + start_live_instances_(BaseCountedInstance::num_live_instances_) { + ResetCopiesMovesSwaps(); + } + ~InstanceTracker() { + if (instances() != 0) std::abort(); + if (live_instances() != 0) std::abort(); + } + + // Returns the number of BaseCountedInstance instances both containing valid + // values and those moved away from compared to when the InstanceTracker was + // constructed + int instances() const { + return BaseCountedInstance::num_instances_ - start_instances_; + } + + // Returns the number of live BaseCountedInstance instances compared to when + // the InstanceTracker was constructed + int live_instances() const { + return BaseCountedInstance::num_live_instances_ - start_live_instances_; + } + + // Returns the number of moves on BaseCountedInstance objects since + // construction or since the last call to ResetCopiesMovesSwaps(). + int moves() const { return BaseCountedInstance::num_moves_ - start_moves_; } + + // Returns the number of copies on BaseCountedInstance objects since + // construction or the last call to ResetCopiesMovesSwaps(). + int copies() const { + return BaseCountedInstance::num_copies_ - start_copies_; + } + + // Returns the number of swaps on BaseCountedInstance objects since + // construction or the last call to ResetCopiesMovesSwaps(). + int swaps() const { return BaseCountedInstance::num_swaps_ - start_swaps_; } + + // Returns the number of comparisons on BaseCountedInstance objects since + // construction or the last call to ResetCopiesMovesSwaps(). + int comparisons() const { + return BaseCountedInstance::num_comparisons_ - start_comparisons_; + } + + // Resets the base values for moves, copies, comparisons, and swaps to the + // current values, so that subsequent Get*() calls for moves, copies, + // comparisons, and swaps will compare to the situation at the point of this + // call. + void ResetCopiesMovesSwaps() { + start_moves_ = BaseCountedInstance::num_moves_; + start_copies_ = BaseCountedInstance::num_copies_; + start_swaps_ = BaseCountedInstance::num_swaps_; + start_comparisons_ = BaseCountedInstance::num_comparisons_; + } + + private: + int start_instances_; + int start_live_instances_; + int start_moves_; + int start_copies_; + int start_swaps_; + int start_comparisons_; +}; + +// Copyable, not movable. +class CopyableOnlyInstance : public BaseCountedInstance { + public: + explicit CopyableOnlyInstance(int x) : BaseCountedInstance(x) {} + CopyableOnlyInstance(const CopyableOnlyInstance& rhs) = default; + CopyableOnlyInstance& operator=(const CopyableOnlyInstance& rhs) = default; + + friend void swap(CopyableOnlyInstance& lhs, CopyableOnlyInstance& rhs) { + BaseCountedInstance::SwapImpl(lhs, rhs); + } + + static bool supports_move() { return false; } +}; + +// Copyable and movable. +class CopyableMovableInstance : public BaseCountedInstance { + public: + explicit CopyableMovableInstance(int x) : BaseCountedInstance(x) {} + CopyableMovableInstance(const CopyableMovableInstance& rhs) = default; + CopyableMovableInstance(CopyableMovableInstance&& rhs) = default; + CopyableMovableInstance& operator=(const CopyableMovableInstance& rhs) = + default; + CopyableMovableInstance& operator=(CopyableMovableInstance&& rhs) = default; + + friend void swap(CopyableMovableInstance& lhs, CopyableMovableInstance& rhs) { + BaseCountedInstance::SwapImpl(lhs, rhs); + } + + static bool supports_move() { return true; } +}; + +// Only movable, not default-constructible. +class MovableOnlyInstance : public BaseCountedInstance { + public: + explicit MovableOnlyInstance(int x) : BaseCountedInstance(x) {} + MovableOnlyInstance(MovableOnlyInstance&& other) = default; + MovableOnlyInstance& operator=(MovableOnlyInstance&& other) = default; + + friend void swap(MovableOnlyInstance& lhs, MovableOnlyInstance& rhs) { + BaseCountedInstance::SwapImpl(lhs, rhs); + } + + static bool supports_move() { return true; } +}; + +} // namespace test_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_TEST_INSTANCE_TRACKER_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/test_instance_tracker_test.cc b/third_party/abseil_cpp/absl/container/internal/test_instance_tracker_test.cc new file mode 100644 index 0000000000..1c6a4fa715 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/test_instance_tracker_test.cc @@ -0,0 +1,184 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/internal/test_instance_tracker.h" + +#include "gtest/gtest.h" + +namespace { + +using absl::test_internal::CopyableMovableInstance; +using absl::test_internal::CopyableOnlyInstance; +using absl::test_internal::InstanceTracker; +using absl::test_internal::MovableOnlyInstance; + +TEST(TestInstanceTracker, CopyableMovable) { + InstanceTracker tracker; + CopyableMovableInstance src(1); + EXPECT_EQ(1, src.value()) << src; + CopyableMovableInstance copy(src); + CopyableMovableInstance move(std::move(src)); + EXPECT_EQ(1, tracker.copies()); + EXPECT_EQ(1, tracker.moves()); + EXPECT_EQ(0, tracker.swaps()); + EXPECT_EQ(3, tracker.instances()); + EXPECT_EQ(2, tracker.live_instances()); + tracker.ResetCopiesMovesSwaps(); + + CopyableMovableInstance copy_assign(1); + copy_assign = copy; + CopyableMovableInstance move_assign(1); + move_assign = std::move(move); + EXPECT_EQ(1, tracker.copies()); + EXPECT_EQ(1, tracker.moves()); + EXPECT_EQ(0, tracker.swaps()); + EXPECT_EQ(5, tracker.instances()); + EXPECT_EQ(3, tracker.live_instances()); + tracker.ResetCopiesMovesSwaps(); + + { + using std::swap; + swap(move_assign, copy); + swap(copy, move_assign); + EXPECT_EQ(2, tracker.swaps()); + EXPECT_EQ(0, tracker.copies()); + EXPECT_EQ(0, tracker.moves()); + EXPECT_EQ(5, tracker.instances()); + EXPECT_EQ(3, tracker.live_instances()); + } +} + +TEST(TestInstanceTracker, CopyableOnly) { + InstanceTracker tracker; + CopyableOnlyInstance src(1); + EXPECT_EQ(1, src.value()) << src; + CopyableOnlyInstance copy(src); + CopyableOnlyInstance copy2(std::move(src)); // NOLINT + EXPECT_EQ(2, tracker.copies()); + EXPECT_EQ(0, tracker.moves()); + EXPECT_EQ(3, tracker.instances()); + EXPECT_EQ(3, tracker.live_instances()); + tracker.ResetCopiesMovesSwaps(); + + CopyableOnlyInstance copy_assign(1); + copy_assign = copy; + CopyableOnlyInstance copy_assign2(1); + copy_assign2 = std::move(copy2); // NOLINT + EXPECT_EQ(2, tracker.copies()); + EXPECT_EQ(0, tracker.moves()); + EXPECT_EQ(5, tracker.instances()); + EXPECT_EQ(5, tracker.live_instances()); + tracker.ResetCopiesMovesSwaps(); + + { + using std::swap; + swap(src, copy); + swap(copy, src); + EXPECT_EQ(2, tracker.swaps()); + EXPECT_EQ(0, tracker.copies()); + EXPECT_EQ(0, tracker.moves()); + EXPECT_EQ(5, tracker.instances()); + EXPECT_EQ(5, tracker.live_instances()); + } +} + +TEST(TestInstanceTracker, MovableOnly) { + InstanceTracker tracker; + MovableOnlyInstance src(1); + EXPECT_EQ(1, src.value()) << src; + MovableOnlyInstance move(std::move(src)); + MovableOnlyInstance move_assign(2); + move_assign = std::move(move); + EXPECT_EQ(3, tracker.instances()); + EXPECT_EQ(1, tracker.live_instances()); + EXPECT_EQ(2, tracker.moves()); + EXPECT_EQ(0, tracker.copies()); + tracker.ResetCopiesMovesSwaps(); + + { + using std::swap; + MovableOnlyInstance other(2); + swap(move_assign, other); + swap(other, move_assign); + EXPECT_EQ(2, tracker.swaps()); + EXPECT_EQ(0, tracker.copies()); + EXPECT_EQ(0, tracker.moves()); + EXPECT_EQ(4, tracker.instances()); + EXPECT_EQ(2, tracker.live_instances()); + } +} + +TEST(TestInstanceTracker, ExistingInstances) { + CopyableMovableInstance uncounted_instance(1); + CopyableMovableInstance uncounted_live_instance( + std::move(uncounted_instance)); + InstanceTracker tracker; + EXPECT_EQ(0, tracker.instances()); + EXPECT_EQ(0, tracker.live_instances()); + EXPECT_EQ(0, tracker.copies()); + { + CopyableMovableInstance instance1(1); + EXPECT_EQ(1, tracker.instances()); + EXPECT_EQ(1, tracker.live_instances()); + EXPECT_EQ(0, tracker.copies()); + EXPECT_EQ(0, tracker.moves()); + { + InstanceTracker tracker2; + CopyableMovableInstance instance2(instance1); + CopyableMovableInstance instance3(std::move(instance2)); + EXPECT_EQ(3, tracker.instances()); + EXPECT_EQ(2, tracker.live_instances()); + EXPECT_EQ(1, tracker.copies()); + EXPECT_EQ(1, tracker.moves()); + EXPECT_EQ(2, tracker2.instances()); + EXPECT_EQ(1, tracker2.live_instances()); + EXPECT_EQ(1, tracker2.copies()); + EXPECT_EQ(1, tracker2.moves()); + } + EXPECT_EQ(1, tracker.instances()); + EXPECT_EQ(1, tracker.live_instances()); + EXPECT_EQ(1, tracker.copies()); + EXPECT_EQ(1, tracker.moves()); + } + EXPECT_EQ(0, tracker.instances()); + EXPECT_EQ(0, tracker.live_instances()); + EXPECT_EQ(1, tracker.copies()); + EXPECT_EQ(1, tracker.moves()); +} + +TEST(TestInstanceTracker, Comparisons) { + InstanceTracker tracker; + MovableOnlyInstance one(1), two(2); + + EXPECT_EQ(0, tracker.comparisons()); + EXPECT_FALSE(one == two); + EXPECT_EQ(1, tracker.comparisons()); + EXPECT_TRUE(one != two); + EXPECT_EQ(2, tracker.comparisons()); + EXPECT_TRUE(one < two); + EXPECT_EQ(3, tracker.comparisons()); + EXPECT_FALSE(one > two); + EXPECT_EQ(4, tracker.comparisons()); + EXPECT_TRUE(one <= two); + EXPECT_EQ(5, tracker.comparisons()); + EXPECT_FALSE(one >= two); + EXPECT_EQ(6, tracker.comparisons()); + EXPECT_TRUE(one.compare(two) < 0); // NOLINT + EXPECT_EQ(7, tracker.comparisons()); + + tracker.ResetCopiesMovesSwaps(); + EXPECT_EQ(0, tracker.comparisons()); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/container/internal/tracked.h b/third_party/abseil_cpp/absl/container/internal/tracked.h new file mode 100644 index 0000000000..29f5829f71 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/tracked.h @@ -0,0 +1,83 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_TRACKED_H_ +#define ABSL_CONTAINER_INTERNAL_TRACKED_H_ + +#include <stddef.h> + +#include <memory> +#include <utility> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +// A class that tracks its copies and moves so that it can be queried in tests. +template <class T> +class Tracked { + public: + Tracked() {} + // NOLINTNEXTLINE(runtime/explicit) + Tracked(const T& val) : val_(val) {} + Tracked(const Tracked& that) + : val_(that.val_), + num_moves_(that.num_moves_), + num_copies_(that.num_copies_) { + ++(*num_copies_); + } + Tracked(Tracked&& that) + : val_(std::move(that.val_)), + num_moves_(std::move(that.num_moves_)), + num_copies_(std::move(that.num_copies_)) { + ++(*num_moves_); + } + Tracked& operator=(const Tracked& that) { + val_ = that.val_; + num_moves_ = that.num_moves_; + num_copies_ = that.num_copies_; + ++(*num_copies_); + } + Tracked& operator=(Tracked&& that) { + val_ = std::move(that.val_); + num_moves_ = std::move(that.num_moves_); + num_copies_ = std::move(that.num_copies_); + ++(*num_moves_); + } + + const T& val() const { return val_; } + + friend bool operator==(const Tracked& a, const Tracked& b) { + return a.val_ == b.val_; + } + friend bool operator!=(const Tracked& a, const Tracked& b) { + return !(a == b); + } + + size_t num_copies() { return *num_copies_; } + size_t num_moves() { return *num_moves_; } + + private: + T val_; + std::shared_ptr<size_t> num_moves_ = std::make_shared<size_t>(0); + std::shared_ptr<size_t> num_copies_ = std::make_shared<size_t>(0); +}; + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_TRACKED_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_map_constructor_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_map_constructor_test.h new file mode 100644 index 0000000000..76ee95e6ab --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_map_constructor_test.h @@ -0,0 +1,489 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_CONSTRUCTOR_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_CONSTRUCTOR_TEST_H_ + +#include <algorithm> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/hash_policy_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordMap> +class ConstructorTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(ConstructorTest); + +TYPED_TEST_P(ConstructorTest, NoArgs) { + TypeParam m; + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); +} + +TYPED_TEST_P(ConstructorTest, BucketCount) { + TypeParam m(123); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHash) { + using H = typename TypeParam::hasher; + H hasher; + TypeParam m(123, hasher); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHashEqual) { + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + H hasher; + E equal; + TypeParam m(123, hasher, equal); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHashEqualAlloc) { + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +template <typename T> +struct is_std_unordered_map : std::false_type {}; + +template <typename... T> +struct is_std_unordered_map<std::unordered_map<T...>> : std::true_type {}; + +#if defined(UNORDERED_MAP_CXX14) || defined(UNORDERED_MAP_CXX17) +using has_cxx14_std_apis = std::true_type; +#else +using has_cxx14_std_apis = std::false_type; +#endif + +template <typename T> +using expect_cxx14_apis = + absl::disjunction<absl::negation<is_std_unordered_map<T>>, + has_cxx14_std_apis>; + +template <typename TypeParam> +void BucketCountAllocTest(std::false_type) {} + +template <typename TypeParam> +void BucketCountAllocTest(std::true_type) { + using A = typename TypeParam::allocator_type; + A alloc(0); + TypeParam m(123, alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountAlloc) { + BucketCountAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +template <typename TypeParam> +void BucketCountHashAllocTest(std::false_type) {} + +template <typename TypeParam> +void BucketCountHashAllocTest(std::true_type) { + using H = typename TypeParam::hasher; + using A = typename TypeParam::allocator_type; + H hasher; + A alloc(0); + TypeParam m(123, hasher, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHashAlloc) { + BucketCountHashAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +#if ABSL_UNORDERED_SUPPORTS_ALLOC_CTORS +using has_alloc_std_constructors = std::true_type; +#else +using has_alloc_std_constructors = std::false_type; +#endif + +template <typename T> +using expect_alloc_constructors = + absl::disjunction<absl::negation<is_std_unordered_map<T>>, + has_alloc_std_constructors>; + +template <typename TypeParam> +void AllocTest(std::false_type) {} + +template <typename TypeParam> +void AllocTest(std::true_type) { + using A = typename TypeParam::allocator_type; + A alloc(0); + TypeParam m(alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(m, ::testing::UnorderedElementsAre()); +} + +TYPED_TEST_P(ConstructorTest, Alloc) { + AllocTest<TypeParam>(expect_alloc_constructors<TypeParam>()); +} + +TYPED_TEST_P(ConstructorTest, InputIteratorBucketHashEqualAlloc) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end(), 123, hasher, equal, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +template <typename TypeParam> +void InputIteratorBucketAllocTest(std::false_type) {} + +template <typename TypeParam> +void InputIteratorBucketAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using A = typename TypeParam::allocator_type; + A alloc(0); + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end(), 123, alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InputIteratorBucketAlloc) { + InputIteratorBucketAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +template <typename TypeParam> +void InputIteratorBucketHashAllocTest(std::false_type) {} + +template <typename TypeParam> +void InputIteratorBucketHashAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using A = typename TypeParam::allocator_type; + H hasher; + A alloc(0); + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end(), 123, hasher, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InputIteratorBucketHashAlloc) { + InputIteratorBucketHashAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +TYPED_TEST_P(ConstructorTest, CopyConstructor) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam n(m); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +template <typename TypeParam> +void CopyConstructorAllocTest(std::false_type) {} + +template <typename TypeParam> +void CopyConstructorAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam n(m, A(11)); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_NE(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, CopyConstructorAlloc) { + CopyConstructorAllocTest<TypeParam>(expect_alloc_constructors<TypeParam>()); +} + +// TODO(alkis): Test non-propagating allocators on copy constructors. + +TYPED_TEST_P(ConstructorTest, MoveConstructor) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam t(m); + TypeParam n(std::move(t)); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +template <typename TypeParam> +void MoveConstructorAllocTest(std::false_type) {} + +template <typename TypeParam> +void MoveConstructorAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam t(m); + TypeParam n(std::move(t), A(1)); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_NE(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, MoveConstructorAlloc) { + MoveConstructorAllocTest<TypeParam>(expect_alloc_constructors<TypeParam>()); +} + +// TODO(alkis): Test non-propagating allocators on move constructors. + +TYPED_TEST_P(ConstructorTest, InitializerListBucketHashEqualAlloc) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(values, 123, hasher, equal, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +template <typename TypeParam> +void InitializerListBucketAllocTest(std::false_type) {} + +template <typename TypeParam> +void InitializerListBucketAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using A = typename TypeParam::allocator_type; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + A alloc(0); + TypeParam m(values, 123, alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InitializerListBucketAlloc) { + InitializerListBucketAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +template <typename TypeParam> +void InitializerListBucketHashAllocTest(std::false_type) {} + +template <typename TypeParam> +void InitializerListBucketHashAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using A = typename TypeParam::allocator_type; + H hasher; + A alloc(0); + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m(values, 123, hasher, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InitializerListBucketHashAlloc) { + InitializerListBucketHashAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +TYPED_TEST_P(ConstructorTest, Assignment) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}, 123, hasher, equal, alloc); + TypeParam n; + n = m; + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m, n); +} + +// TODO(alkis): Test [non-]propagating allocators on move/copy assignments +// (it depends on traits). + +TYPED_TEST_P(ConstructorTest, MoveAssignment) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}, 123, hasher, equal, alloc); + TypeParam t(m); + TypeParam n; + n = std::move(t); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, AssignmentFromInitializerList) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m; + m = values; + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); +} + +TYPED_TEST_P(ConstructorTest, AssignmentOverwritesExisting) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}); + TypeParam n({gen()}); + n = m; + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, MoveAssignmentOverwritesExisting) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}); + TypeParam t(m); + TypeParam n({gen()}); + n = std::move(t); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, AssignmentFromInitializerListOverwritesExisting) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m; + m = values; + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); +} + +TYPED_TEST_P(ConstructorTest, AssignmentOnSelf) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m(values); + m = *&m; // Avoid -Wself-assign + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); +} + +// We cannot test self move as standard states that it leaves standard +// containers in unspecified state (and in practice in causes memory-leak +// according to heap-checker!). + +REGISTER_TYPED_TEST_CASE_P( + ConstructorTest, NoArgs, BucketCount, BucketCountHash, BucketCountHashEqual, + BucketCountHashEqualAlloc, BucketCountAlloc, BucketCountHashAlloc, Alloc, + InputIteratorBucketHashEqualAlloc, InputIteratorBucketAlloc, + InputIteratorBucketHashAlloc, CopyConstructor, CopyConstructorAlloc, + MoveConstructor, MoveConstructorAlloc, InitializerListBucketHashEqualAlloc, + InitializerListBucketAlloc, InitializerListBucketHashAlloc, Assignment, + MoveAssignment, AssignmentFromInitializerList, AssignmentOverwritesExisting, + MoveAssignmentOverwritesExisting, + AssignmentFromInitializerListOverwritesExisting, AssignmentOnSelf); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_CONSTRUCTOR_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_map_lookup_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_map_lookup_test.h new file mode 100644 index 0000000000..e76421e508 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_map_lookup_test.h @@ -0,0 +1,117 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_LOOKUP_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_LOOKUP_TEST_H_ + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/hash_policy_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordMap> +class LookupTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(LookupTest); + +TYPED_TEST_P(LookupTest, At) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + for (const auto& p : values) { + const auto& val = m.at(p.first); + EXPECT_EQ(p.second, val) << ::testing::PrintToString(p.first); + } +} + +TYPED_TEST_P(LookupTest, OperatorBracket) { + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& p : values) { + auto& val = m[p.first]; + EXPECT_EQ(V(), val) << ::testing::PrintToString(p.first); + val = p.second; + } + for (const auto& p : values) + EXPECT_EQ(p.second, m[p.first]) << ::testing::PrintToString(p.first); +} + +TYPED_TEST_P(LookupTest, Count) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& p : values) + EXPECT_EQ(0, m.count(p.first)) << ::testing::PrintToString(p.first); + m.insert(values.begin(), values.end()); + for (const auto& p : values) + EXPECT_EQ(1, m.count(p.first)) << ::testing::PrintToString(p.first); +} + +TYPED_TEST_P(LookupTest, Find) { + using std::get; + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& p : values) + EXPECT_TRUE(m.end() == m.find(p.first)) + << ::testing::PrintToString(p.first); + m.insert(values.begin(), values.end()); + for (const auto& p : values) { + auto it = m.find(p.first); + EXPECT_TRUE(m.end() != it) << ::testing::PrintToString(p.first); + EXPECT_EQ(p.second, get<1>(*it)) << ::testing::PrintToString(p.first); + } +} + +TYPED_TEST_P(LookupTest, EqualRange) { + using std::get; + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& p : values) { + auto r = m.equal_range(p.first); + ASSERT_EQ(0, std::distance(r.first, r.second)); + } + m.insert(values.begin(), values.end()); + for (const auto& p : values) { + auto r = m.equal_range(p.first); + ASSERT_EQ(1, std::distance(r.first, r.second)); + EXPECT_EQ(p.second, get<1>(*r.first)) << ::testing::PrintToString(p.first); + } +} + +REGISTER_TYPED_TEST_CASE_P(LookupTest, At, OperatorBracket, Count, Find, + EqualRange); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_LOOKUP_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_map_members_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_map_members_test.h new file mode 100644 index 0000000000..7d48cdb890 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_map_members_test.h @@ -0,0 +1,87 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_MEMBERS_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_MEMBERS_TEST_H_ + +#include <type_traits> +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordMap> +class MembersTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(MembersTest); + +template <typename T> +void UseType() {} + +TYPED_TEST_P(MembersTest, Typedefs) { + EXPECT_TRUE((std::is_same<std::pair<const typename TypeParam::key_type, + typename TypeParam::mapped_type>, + typename TypeParam::value_type>())); + EXPECT_TRUE((absl::conjunction< + absl::negation<std::is_signed<typename TypeParam::size_type>>, + std::is_integral<typename TypeParam::size_type>>())); + EXPECT_TRUE((absl::conjunction< + std::is_signed<typename TypeParam::difference_type>, + std::is_integral<typename TypeParam::difference_type>>())); + EXPECT_TRUE((std::is_convertible< + decltype(std::declval<const typename TypeParam::hasher&>()( + std::declval<const typename TypeParam::key_type&>())), + size_t>())); + EXPECT_TRUE((std::is_convertible< + decltype(std::declval<const typename TypeParam::key_equal&>()( + std::declval<const typename TypeParam::key_type&>(), + std::declval<const typename TypeParam::key_type&>())), + bool>())); + EXPECT_TRUE((std::is_same<typename TypeParam::allocator_type::value_type, + typename TypeParam::value_type>())); + EXPECT_TRUE((std::is_same<typename TypeParam::value_type&, + typename TypeParam::reference>())); + EXPECT_TRUE((std::is_same<const typename TypeParam::value_type&, + typename TypeParam::const_reference>())); + EXPECT_TRUE((std::is_same<typename std::allocator_traits< + typename TypeParam::allocator_type>::pointer, + typename TypeParam::pointer>())); + EXPECT_TRUE( + (std::is_same<typename std::allocator_traits< + typename TypeParam::allocator_type>::const_pointer, + typename TypeParam::const_pointer>())); +} + +TYPED_TEST_P(MembersTest, SimpleFunctions) { + EXPECT_GT(TypeParam().max_size(), 0); +} + +TYPED_TEST_P(MembersTest, BeginEnd) { + TypeParam t = {typename TypeParam::value_type{}}; + EXPECT_EQ(t.begin(), t.cbegin()); + EXPECT_EQ(t.end(), t.cend()); + EXPECT_NE(t.begin(), t.end()); + EXPECT_NE(t.cbegin(), t.cend()); +} + +REGISTER_TYPED_TEST_SUITE_P(MembersTest, Typedefs, SimpleFunctions, BeginEnd); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_MEMBERS_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_map_modifiers_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_map_modifiers_test.h new file mode 100644 index 0000000000..b8c513f157 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_map_modifiers_test.h @@ -0,0 +1,316 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_MODIFIERS_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_MODIFIERS_TEST_H_ + +#include <memory> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/hash_policy_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordMap> +class ModifiersTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(ModifiersTest); + +TYPED_TEST_P(ModifiersTest, Clear) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + m.clear(); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAre()); + EXPECT_TRUE(m.empty()); +} + +TYPED_TEST_P(ModifiersTest, Insert) { + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + auto p = m.insert(val); + EXPECT_TRUE(p.second); + EXPECT_EQ(val, *p.first); + T val2 = {val.first, hash_internal::Generator<V>()()}; + p = m.insert(val2); + EXPECT_FALSE(p.second); + EXPECT_EQ(val, *p.first); +} + +TYPED_TEST_P(ModifiersTest, InsertHint) { + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + auto it = m.insert(m.end(), val); + EXPECT_TRUE(it != m.end()); + EXPECT_EQ(val, *it); + T val2 = {val.first, hash_internal::Generator<V>()()}; + it = m.insert(it, val2); + EXPECT_TRUE(it != m.end()); + EXPECT_EQ(val, *it); +} + +TYPED_TEST_P(ModifiersTest, InsertRange) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + m.insert(values.begin(), values.end()); + ASSERT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); +} + +TYPED_TEST_P(ModifiersTest, InsertOrAssign) { +#ifdef UNORDERED_MAP_CXX17 + using std::get; + using K = typename TypeParam::key_type; + using V = typename TypeParam::mapped_type; + K k = hash_internal::Generator<K>()(); + V val = hash_internal::Generator<V>()(); + TypeParam m; + auto p = m.insert_or_assign(k, val); + EXPECT_TRUE(p.second); + EXPECT_EQ(k, get<0>(*p.first)); + EXPECT_EQ(val, get<1>(*p.first)); + V val2 = hash_internal::Generator<V>()(); + p = m.insert_or_assign(k, val2); + EXPECT_FALSE(p.second); + EXPECT_EQ(k, get<0>(*p.first)); + EXPECT_EQ(val2, get<1>(*p.first)); +#endif +} + +TYPED_TEST_P(ModifiersTest, InsertOrAssignHint) { +#ifdef UNORDERED_MAP_CXX17 + using std::get; + using K = typename TypeParam::key_type; + using V = typename TypeParam::mapped_type; + K k = hash_internal::Generator<K>()(); + V val = hash_internal::Generator<V>()(); + TypeParam m; + auto it = m.insert_or_assign(m.end(), k, val); + EXPECT_TRUE(it != m.end()); + EXPECT_EQ(k, get<0>(*it)); + EXPECT_EQ(val, get<1>(*it)); + V val2 = hash_internal::Generator<V>()(); + it = m.insert_or_assign(it, k, val2); + EXPECT_EQ(k, get<0>(*it)); + EXPECT_EQ(val2, get<1>(*it)); +#endif +} + +TYPED_TEST_P(ModifiersTest, Emplace) { + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + // TODO(alkis): We need a way to run emplace in a more meaningful way. Perhaps + // with test traits/policy. + auto p = m.emplace(val); + EXPECT_TRUE(p.second); + EXPECT_EQ(val, *p.first); + T val2 = {val.first, hash_internal::Generator<V>()()}; + p = m.emplace(val2); + EXPECT_FALSE(p.second); + EXPECT_EQ(val, *p.first); +} + +TYPED_TEST_P(ModifiersTest, EmplaceHint) { + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + // TODO(alkis): We need a way to run emplace in a more meaningful way. Perhaps + // with test traits/policy. + auto it = m.emplace_hint(m.end(), val); + EXPECT_EQ(val, *it); + T val2 = {val.first, hash_internal::Generator<V>()()}; + it = m.emplace_hint(it, val2); + EXPECT_EQ(val, *it); +} + +TYPED_TEST_P(ModifiersTest, TryEmplace) { +#ifdef UNORDERED_MAP_CXX17 + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + // TODO(alkis): We need a way to run emplace in a more meaningful way. Perhaps + // with test traits/policy. + auto p = m.try_emplace(val.first, val.second); + EXPECT_TRUE(p.second); + EXPECT_EQ(val, *p.first); + T val2 = {val.first, hash_internal::Generator<V>()()}; + p = m.try_emplace(val2.first, val2.second); + EXPECT_FALSE(p.second); + EXPECT_EQ(val, *p.first); +#endif +} + +TYPED_TEST_P(ModifiersTest, TryEmplaceHint) { +#ifdef UNORDERED_MAP_CXX17 + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + // TODO(alkis): We need a way to run emplace in a more meaningful way. Perhaps + // with test traits/policy. + auto it = m.try_emplace(m.end(), val.first, val.second); + EXPECT_EQ(val, *it); + T val2 = {val.first, hash_internal::Generator<V>()()}; + it = m.try_emplace(it, val2.first, val2.second); + EXPECT_EQ(val, *it); +#endif +} + +template <class V> +using IfNotVoid = typename std::enable_if<!std::is_void<V>::value, V>::type; + +// In openmap we chose not to return the iterator from erase because that's +// more expensive. As such we adapt erase to return an iterator here. +struct EraseFirst { + template <class Map> + auto operator()(Map* m, int) const + -> IfNotVoid<decltype(m->erase(m->begin()))> { + return m->erase(m->begin()); + } + template <class Map> + typename Map::iterator operator()(Map* m, ...) const { + auto it = m->begin(); + m->erase(it++); + return it; + } +}; + +TYPED_TEST_P(ModifiersTest, Erase) { + using T = hash_internal::GeneratedType<TypeParam>; + using std::get; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + auto& first = *m.begin(); + std::vector<T> values2; + for (const auto& val : values) + if (get<0>(val) != get<0>(first)) values2.push_back(val); + auto it = EraseFirst()(&m, 0); + ASSERT_TRUE(it != m.end()); + EXPECT_EQ(1, std::count(values2.begin(), values2.end(), *it)); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values2.begin(), + values2.end())); +} + +TYPED_TEST_P(ModifiersTest, EraseRange) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + auto it = m.erase(m.begin(), m.end()); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAre()); + EXPECT_TRUE(it == m.end()); +} + +TYPED_TEST_P(ModifiersTest, EraseKey) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(items(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_EQ(1, m.erase(values[0].first)); + EXPECT_EQ(0, std::count(m.begin(), m.end(), values[0])); + EXPECT_THAT(items(m), ::testing::UnorderedElementsAreArray(values.begin() + 1, + values.end())); +} + +TYPED_TEST_P(ModifiersTest, Swap) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> v1; + std::vector<T> v2; + std::generate_n(std::back_inserter(v1), 5, hash_internal::Generator<T>()); + std::generate_n(std::back_inserter(v2), 5, hash_internal::Generator<T>()); + TypeParam m1(v1.begin(), v1.end()); + TypeParam m2(v2.begin(), v2.end()); + EXPECT_THAT(items(m1), ::testing::UnorderedElementsAreArray(v1)); + EXPECT_THAT(items(m2), ::testing::UnorderedElementsAreArray(v2)); + m1.swap(m2); + EXPECT_THAT(items(m1), ::testing::UnorderedElementsAreArray(v2)); + EXPECT_THAT(items(m2), ::testing::UnorderedElementsAreArray(v1)); +} + +// TODO(alkis): Write tests for extract. +// TODO(alkis): Write tests for merge. + +REGISTER_TYPED_TEST_CASE_P(ModifiersTest, Clear, Insert, InsertHint, + InsertRange, InsertOrAssign, InsertOrAssignHint, + Emplace, EmplaceHint, TryEmplace, TryEmplaceHint, + Erase, EraseRange, EraseKey, Swap); + +template <typename Type> +struct is_unique_ptr : std::false_type {}; + +template <typename Type> +struct is_unique_ptr<std::unique_ptr<Type>> : std::true_type {}; + +template <class UnordMap> +class UniquePtrModifiersTest : public ::testing::Test { + protected: + UniquePtrModifiersTest() { + static_assert(is_unique_ptr<typename UnordMap::mapped_type>::value, + "UniquePtrModifiersTyest may only be called with a " + "std::unique_ptr value type."); + } +}; + +TYPED_TEST_SUITE_P(UniquePtrModifiersTest); + +// Test that we do not move from rvalue arguments if an insertion does not +// happen. +TYPED_TEST_P(UniquePtrModifiersTest, TryEmplace) { +#ifdef UNORDERED_MAP_CXX17 + using T = hash_internal::GeneratedType<TypeParam>; + using V = typename TypeParam::mapped_type; + T val = hash_internal::Generator<T>()(); + TypeParam m; + auto p = m.try_emplace(val.first, std::move(val.second)); + EXPECT_TRUE(p.second); + // A moved from std::unique_ptr is guaranteed to be nullptr. + EXPECT_EQ(val.second, nullptr); + T val2 = {val.first, hash_internal::Generator<V>()()}; + p = m.try_emplace(val2.first, std::move(val2.second)); + EXPECT_FALSE(p.second); + EXPECT_NE(val2.second, nullptr); +#endif +} + +REGISTER_TYPED_TEST_SUITE_P(UniquePtrModifiersTest, TryEmplace); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_MAP_MODIFIERS_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_map_test.cc b/third_party/abseil_cpp/absl/container/internal/unordered_map_test.cc new file mode 100644 index 0000000000..9cbf512f32 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_map_test.cc @@ -0,0 +1,50 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <memory> +#include <unordered_map> + +#include "absl/container/internal/unordered_map_constructor_test.h" +#include "absl/container/internal/unordered_map_lookup_test.h" +#include "absl/container/internal/unordered_map_members_test.h" +#include "absl/container/internal/unordered_map_modifiers_test.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using MapTypes = ::testing::Types< + std::unordered_map<int, int, StatefulTestingHash, StatefulTestingEqual, + Alloc<std::pair<const int, int>>>, + std::unordered_map<std::string, std::string, StatefulTestingHash, + StatefulTestingEqual, + Alloc<std::pair<const std::string, std::string>>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedMap, ConstructorTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedMap, LookupTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedMap, MembersTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedMap, ModifiersTest, MapTypes); + +using UniquePtrMapTypes = ::testing::Types<std::unordered_map< + int, std::unique_ptr<int>, StatefulTestingHash, StatefulTestingEqual, + Alloc<std::pair<const int, std::unique_ptr<int>>>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedMap, UniquePtrModifiersTest, + UniquePtrMapTypes); + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_set_constructor_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_set_constructor_test.h new file mode 100644 index 0000000000..41165b05e9 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_set_constructor_test.h @@ -0,0 +1,496 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_SET_CONSTRUCTOR_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_SET_CONSTRUCTOR_TEST_H_ + +#include <algorithm> +#include <unordered_set> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/hash_policy_testing.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordMap> +class ConstructorTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(ConstructorTest); + +TYPED_TEST_P(ConstructorTest, NoArgs) { + TypeParam m; + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); +} + +TYPED_TEST_P(ConstructorTest, BucketCount) { + TypeParam m(123); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHash) { + using H = typename TypeParam::hasher; + H hasher; + TypeParam m(123, hasher); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHashEqual) { + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + H hasher; + E equal; + TypeParam m(123, hasher, equal); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHashEqualAlloc) { + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); + + const auto& cm = m; + EXPECT_EQ(cm.hash_function(), hasher); + EXPECT_EQ(cm.key_eq(), equal); + EXPECT_EQ(cm.get_allocator(), alloc); + EXPECT_TRUE(cm.empty()); + EXPECT_THAT(keys(cm), ::testing::UnorderedElementsAre()); + EXPECT_GE(cm.bucket_count(), 123); +} + +template <typename T> +struct is_std_unordered_set : std::false_type {}; + +template <typename... T> +struct is_std_unordered_set<std::unordered_set<T...>> : std::true_type {}; + +#if defined(UNORDERED_SET_CXX14) || defined(UNORDERED_SET_CXX17) +using has_cxx14_std_apis = std::true_type; +#else +using has_cxx14_std_apis = std::false_type; +#endif + +template <typename T> +using expect_cxx14_apis = + absl::disjunction<absl::negation<is_std_unordered_set<T>>, + has_cxx14_std_apis>; + +template <typename TypeParam> +void BucketCountAllocTest(std::false_type) {} + +template <typename TypeParam> +void BucketCountAllocTest(std::true_type) { + using A = typename TypeParam::allocator_type; + A alloc(0); + TypeParam m(123, alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountAlloc) { + BucketCountAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +template <typename TypeParam> +void BucketCountHashAllocTest(std::false_type) {} + +template <typename TypeParam> +void BucketCountHashAllocTest(std::true_type) { + using H = typename TypeParam::hasher; + using A = typename TypeParam::allocator_type; + H hasher; + A alloc(0); + TypeParam m(123, hasher, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, BucketCountHashAlloc) { + BucketCountHashAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +#if ABSL_UNORDERED_SUPPORTS_ALLOC_CTORS +using has_alloc_std_constructors = std::true_type; +#else +using has_alloc_std_constructors = std::false_type; +#endif + +template <typename T> +using expect_alloc_constructors = + absl::disjunction<absl::negation<is_std_unordered_set<T>>, + has_alloc_std_constructors>; + +template <typename TypeParam> +void AllocTest(std::false_type) {} + +template <typename TypeParam> +void AllocTest(std::true_type) { + using A = typename TypeParam::allocator_type; + A alloc(0); + TypeParam m(alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_TRUE(m.empty()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); +} + +TYPED_TEST_P(ConstructorTest, Alloc) { + AllocTest<TypeParam>(expect_alloc_constructors<TypeParam>()); +} + +TYPED_TEST_P(ConstructorTest, InputIteratorBucketHashEqualAlloc) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + std::vector<T> values; + for (size_t i = 0; i != 10; ++i) + values.push_back(hash_internal::Generator<T>()()); + TypeParam m(values.begin(), values.end(), 123, hasher, equal, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +template <typename TypeParam> +void InputIteratorBucketAllocTest(std::false_type) {} + +template <typename TypeParam> +void InputIteratorBucketAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using A = typename TypeParam::allocator_type; + A alloc(0); + std::vector<T> values; + for (size_t i = 0; i != 10; ++i) + values.push_back(hash_internal::Generator<T>()()); + TypeParam m(values.begin(), values.end(), 123, alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InputIteratorBucketAlloc) { + InputIteratorBucketAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +template <typename TypeParam> +void InputIteratorBucketHashAllocTest(std::false_type) {} + +template <typename TypeParam> +void InputIteratorBucketHashAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using A = typename TypeParam::allocator_type; + H hasher; + A alloc(0); + std::vector<T> values; + for (size_t i = 0; i != 10; ++i) + values.push_back(hash_internal::Generator<T>()()); + TypeParam m(values.begin(), values.end(), 123, hasher, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InputIteratorBucketHashAlloc) { + InputIteratorBucketHashAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +TYPED_TEST_P(ConstructorTest, CopyConstructor) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam n(m); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); + EXPECT_NE(TypeParam(0, hasher, equal, alloc), n); +} + +template <typename TypeParam> +void CopyConstructorAllocTest(std::false_type) {} + +template <typename TypeParam> +void CopyConstructorAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam n(m, A(11)); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_NE(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, CopyConstructorAlloc) { + CopyConstructorAllocTest<TypeParam>(expect_alloc_constructors<TypeParam>()); +} + +// TODO(alkis): Test non-propagating allocators on copy constructors. + +TYPED_TEST_P(ConstructorTest, MoveConstructor) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam t(m); + TypeParam n(std::move(t)); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +template <typename TypeParam> +void MoveConstructorAllocTest(std::false_type) {} + +template <typename TypeParam> +void MoveConstructorAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(123, hasher, equal, alloc); + for (size_t i = 0; i != 10; ++i) m.insert(hash_internal::Generator<T>()()); + TypeParam t(m); + TypeParam n(std::move(t), A(1)); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_NE(m.get_allocator(), n.get_allocator()); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, MoveConstructorAlloc) { + MoveConstructorAllocTest<TypeParam>(expect_alloc_constructors<TypeParam>()); +} + +// TODO(alkis): Test non-propagating allocators on move constructors. + +TYPED_TEST_P(ConstructorTest, InitializerListBucketHashEqualAlloc) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + TypeParam m(values, 123, hasher, equal, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.key_eq(), equal); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +template <typename TypeParam> +void InitializerListBucketAllocTest(std::false_type) {} + +template <typename TypeParam> +void InitializerListBucketAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using A = typename TypeParam::allocator_type; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + A alloc(0); + TypeParam m(values, 123, alloc); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InitializerListBucketAlloc) { + InitializerListBucketAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +template <typename TypeParam> +void InitializerListBucketHashAllocTest(std::false_type) {} + +template <typename TypeParam> +void InitializerListBucketHashAllocTest(std::true_type) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using A = typename TypeParam::allocator_type; + H hasher; + A alloc(0); + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m(values, 123, hasher, alloc); + EXPECT_EQ(m.hash_function(), hasher); + EXPECT_EQ(m.get_allocator(), alloc); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_GE(m.bucket_count(), 123); +} + +TYPED_TEST_P(ConstructorTest, InitializerListBucketHashAlloc) { + InitializerListBucketHashAllocTest<TypeParam>(expect_cxx14_apis<TypeParam>()); +} + +TYPED_TEST_P(ConstructorTest, CopyAssignment) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}, 123, hasher, equal, alloc); + TypeParam n; + n = m; + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m, n); +} + +// TODO(alkis): Test [non-]propagating allocators on move/copy assignments +// (it depends on traits). + +TYPED_TEST_P(ConstructorTest, MoveAssignment) { + using T = hash_internal::GeneratedType<TypeParam>; + using H = typename TypeParam::hasher; + using E = typename TypeParam::key_equal; + using A = typename TypeParam::allocator_type; + H hasher; + E equal; + A alloc(0); + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}, 123, hasher, equal, alloc); + TypeParam t(m); + TypeParam n; + n = std::move(t); + EXPECT_EQ(m.hash_function(), n.hash_function()); + EXPECT_EQ(m.key_eq(), n.key_eq()); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, AssignmentFromInitializerList) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m; + m = values; + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); +} + +TYPED_TEST_P(ConstructorTest, AssignmentOverwritesExisting) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}); + TypeParam n({gen()}); + n = m; + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, MoveAssignmentOverwritesExisting) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + TypeParam m({gen(), gen(), gen()}); + TypeParam t(m); + TypeParam n({gen()}); + n = std::move(t); + EXPECT_EQ(m, n); +} + +TYPED_TEST_P(ConstructorTest, AssignmentFromInitializerListOverwritesExisting) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m; + m = values; + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); +} + +TYPED_TEST_P(ConstructorTest, AssignmentOnSelf) { + using T = hash_internal::GeneratedType<TypeParam>; + hash_internal::Generator<T> gen; + std::initializer_list<T> values = {gen(), gen(), gen(), gen(), gen()}; + TypeParam m(values); + m = *&m; // Avoid -Wself-assign. + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); +} + +REGISTER_TYPED_TEST_CASE_P( + ConstructorTest, NoArgs, BucketCount, BucketCountHash, BucketCountHashEqual, + BucketCountHashEqualAlloc, BucketCountAlloc, BucketCountHashAlloc, Alloc, + InputIteratorBucketHashEqualAlloc, InputIteratorBucketAlloc, + InputIteratorBucketHashAlloc, CopyConstructor, CopyConstructorAlloc, + MoveConstructor, MoveConstructorAlloc, InitializerListBucketHashEqualAlloc, + InitializerListBucketAlloc, InitializerListBucketHashAlloc, CopyAssignment, + MoveAssignment, AssignmentFromInitializerList, AssignmentOverwritesExisting, + MoveAssignmentOverwritesExisting, + AssignmentFromInitializerListOverwritesExisting, AssignmentOnSelf); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_SET_CONSTRUCTOR_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_set_lookup_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_set_lookup_test.h new file mode 100644 index 0000000000..8f2f4b207e --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_set_lookup_test.h @@ -0,0 +1,91 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_SET_LOOKUP_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_SET_LOOKUP_TEST_H_ + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/hash_policy_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordSet> +class LookupTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(LookupTest); + +TYPED_TEST_P(LookupTest, Count) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& v : values) + EXPECT_EQ(0, m.count(v)) << ::testing::PrintToString(v); + m.insert(values.begin(), values.end()); + for (const auto& v : values) + EXPECT_EQ(1, m.count(v)) << ::testing::PrintToString(v); +} + +TYPED_TEST_P(LookupTest, Find) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& v : values) + EXPECT_TRUE(m.end() == m.find(v)) << ::testing::PrintToString(v); + m.insert(values.begin(), values.end()); + for (const auto& v : values) { + typename TypeParam::iterator it = m.find(v); + static_assert(std::is_same<const typename TypeParam::value_type&, + decltype(*it)>::value, + ""); + static_assert(std::is_same<const typename TypeParam::value_type*, + decltype(it.operator->())>::value, + ""); + EXPECT_TRUE(m.end() != it) << ::testing::PrintToString(v); + EXPECT_EQ(v, *it) << ::testing::PrintToString(v); + } +} + +TYPED_TEST_P(LookupTest, EqualRange) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + for (const auto& v : values) { + auto r = m.equal_range(v); + ASSERT_EQ(0, std::distance(r.first, r.second)); + } + m.insert(values.begin(), values.end()); + for (const auto& v : values) { + auto r = m.equal_range(v); + ASSERT_EQ(1, std::distance(r.first, r.second)); + EXPECT_EQ(v, *r.first); + } +} + +REGISTER_TYPED_TEST_CASE_P(LookupTest, Count, Find, EqualRange); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_SET_LOOKUP_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_set_members_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_set_members_test.h new file mode 100644 index 0000000000..4c5e104af2 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_set_members_test.h @@ -0,0 +1,86 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_SET_MEMBERS_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_SET_MEMBERS_TEST_H_ + +#include <type_traits> +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordSet> +class MembersTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(MembersTest); + +template <typename T> +void UseType() {} + +TYPED_TEST_P(MembersTest, Typedefs) { + EXPECT_TRUE((std::is_same<typename TypeParam::key_type, + typename TypeParam::value_type>())); + EXPECT_TRUE((absl::conjunction< + absl::negation<std::is_signed<typename TypeParam::size_type>>, + std::is_integral<typename TypeParam::size_type>>())); + EXPECT_TRUE((absl::conjunction< + std::is_signed<typename TypeParam::difference_type>, + std::is_integral<typename TypeParam::difference_type>>())); + EXPECT_TRUE((std::is_convertible< + decltype(std::declval<const typename TypeParam::hasher&>()( + std::declval<const typename TypeParam::key_type&>())), + size_t>())); + EXPECT_TRUE((std::is_convertible< + decltype(std::declval<const typename TypeParam::key_equal&>()( + std::declval<const typename TypeParam::key_type&>(), + std::declval<const typename TypeParam::key_type&>())), + bool>())); + EXPECT_TRUE((std::is_same<typename TypeParam::allocator_type::value_type, + typename TypeParam::value_type>())); + EXPECT_TRUE((std::is_same<typename TypeParam::value_type&, + typename TypeParam::reference>())); + EXPECT_TRUE((std::is_same<const typename TypeParam::value_type&, + typename TypeParam::const_reference>())); + EXPECT_TRUE((std::is_same<typename std::allocator_traits< + typename TypeParam::allocator_type>::pointer, + typename TypeParam::pointer>())); + EXPECT_TRUE( + (std::is_same<typename std::allocator_traits< + typename TypeParam::allocator_type>::const_pointer, + typename TypeParam::const_pointer>())); +} + +TYPED_TEST_P(MembersTest, SimpleFunctions) { + EXPECT_GT(TypeParam().max_size(), 0); +} + +TYPED_TEST_P(MembersTest, BeginEnd) { + TypeParam t = {typename TypeParam::value_type{}}; + EXPECT_EQ(t.begin(), t.cbegin()); + EXPECT_EQ(t.end(), t.cend()); + EXPECT_NE(t.begin(), t.end()); + EXPECT_NE(t.cbegin(), t.cend()); +} + +REGISTER_TYPED_TEST_SUITE_P(MembersTest, Typedefs, SimpleFunctions, BeginEnd); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_SET_MEMBERS_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_set_modifiers_test.h b/third_party/abseil_cpp/absl/container/internal/unordered_set_modifiers_test.h new file mode 100644 index 0000000000..26be58d99f --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_set_modifiers_test.h @@ -0,0 +1,190 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_CONTAINER_INTERNAL_UNORDERED_SET_MODIFIERS_TEST_H_ +#define ABSL_CONTAINER_INTERNAL_UNORDERED_SET_MODIFIERS_TEST_H_ + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/hash_generator_testing.h" +#include "absl/container/internal/hash_policy_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { + +template <class UnordSet> +class ModifiersTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(ModifiersTest); + +TYPED_TEST_P(ModifiersTest, Clear) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + m.clear(); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_TRUE(m.empty()); +} + +TYPED_TEST_P(ModifiersTest, Insert) { + using T = hash_internal::GeneratedType<TypeParam>; + T val = hash_internal::Generator<T>()(); + TypeParam m; + auto p = m.insert(val); + EXPECT_TRUE(p.second); + EXPECT_EQ(val, *p.first); + p = m.insert(val); + EXPECT_FALSE(p.second); +} + +TYPED_TEST_P(ModifiersTest, InsertHint) { + using T = hash_internal::GeneratedType<TypeParam>; + T val = hash_internal::Generator<T>()(); + TypeParam m; + auto it = m.insert(m.end(), val); + EXPECT_TRUE(it != m.end()); + EXPECT_EQ(val, *it); + it = m.insert(it, val); + EXPECT_TRUE(it != m.end()); + EXPECT_EQ(val, *it); +} + +TYPED_TEST_P(ModifiersTest, InsertRange) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m; + m.insert(values.begin(), values.end()); + ASSERT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); +} + +TYPED_TEST_P(ModifiersTest, Emplace) { + using T = hash_internal::GeneratedType<TypeParam>; + T val = hash_internal::Generator<T>()(); + TypeParam m; + // TODO(alkis): We need a way to run emplace in a more meaningful way. Perhaps + // with test traits/policy. + auto p = m.emplace(val); + EXPECT_TRUE(p.second); + EXPECT_EQ(val, *p.first); + p = m.emplace(val); + EXPECT_FALSE(p.second); + EXPECT_EQ(val, *p.first); +} + +TYPED_TEST_P(ModifiersTest, EmplaceHint) { + using T = hash_internal::GeneratedType<TypeParam>; + T val = hash_internal::Generator<T>()(); + TypeParam m; + // TODO(alkis): We need a way to run emplace in a more meaningful way. Perhaps + // with test traits/policy. + auto it = m.emplace_hint(m.end(), val); + EXPECT_EQ(val, *it); + it = m.emplace_hint(it, val); + EXPECT_EQ(val, *it); +} + +template <class V> +using IfNotVoid = typename std::enable_if<!std::is_void<V>::value, V>::type; + +// In openmap we chose not to return the iterator from erase because that's +// more expensive. As such we adapt erase to return an iterator here. +struct EraseFirst { + template <class Map> + auto operator()(Map* m, int) const + -> IfNotVoid<decltype(m->erase(m->begin()))> { + return m->erase(m->begin()); + } + template <class Map> + typename Map::iterator operator()(Map* m, ...) const { + auto it = m->begin(); + m->erase(it++); + return it; + } +}; + +TYPED_TEST_P(ModifiersTest, Erase) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + std::vector<T> values2; + for (const auto& val : values) + if (val != *m.begin()) values2.push_back(val); + auto it = EraseFirst()(&m, 0); + ASSERT_TRUE(it != m.end()); + EXPECT_EQ(1, std::count(values2.begin(), values2.end(), *it)); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values2.begin(), + values2.end())); +} + +TYPED_TEST_P(ModifiersTest, EraseRange) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + auto it = m.erase(m.begin(), m.end()); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAre()); + EXPECT_TRUE(it == m.end()); +} + +TYPED_TEST_P(ModifiersTest, EraseKey) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> values; + std::generate_n(std::back_inserter(values), 10, + hash_internal::Generator<T>()); + TypeParam m(values.begin(), values.end()); + ASSERT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values)); + EXPECT_EQ(1, m.erase(values[0])); + EXPECT_EQ(0, std::count(m.begin(), m.end(), values[0])); + EXPECT_THAT(keys(m), ::testing::UnorderedElementsAreArray(values.begin() + 1, + values.end())); +} + +TYPED_TEST_P(ModifiersTest, Swap) { + using T = hash_internal::GeneratedType<TypeParam>; + std::vector<T> v1; + std::vector<T> v2; + std::generate_n(std::back_inserter(v1), 5, hash_internal::Generator<T>()); + std::generate_n(std::back_inserter(v2), 5, hash_internal::Generator<T>()); + TypeParam m1(v1.begin(), v1.end()); + TypeParam m2(v2.begin(), v2.end()); + EXPECT_THAT(keys(m1), ::testing::UnorderedElementsAreArray(v1)); + EXPECT_THAT(keys(m2), ::testing::UnorderedElementsAreArray(v2)); + m1.swap(m2); + EXPECT_THAT(keys(m1), ::testing::UnorderedElementsAreArray(v2)); + EXPECT_THAT(keys(m2), ::testing::UnorderedElementsAreArray(v1)); +} + +// TODO(alkis): Write tests for extract. +// TODO(alkis): Write tests for merge. + +REGISTER_TYPED_TEST_CASE_P(ModifiersTest, Clear, Insert, InsertHint, + InsertRange, Emplace, EmplaceHint, Erase, EraseRange, + EraseKey, Swap); + +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_INTERNAL_UNORDERED_SET_MODIFIERS_TEST_H_ diff --git a/third_party/abseil_cpp/absl/container/internal/unordered_set_test.cc b/third_party/abseil_cpp/absl/container/internal/unordered_set_test.cc new file mode 100644 index 0000000000..a134b53984 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/internal/unordered_set_test.cc @@ -0,0 +1,41 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <unordered_set> + +#include "absl/container/internal/unordered_set_constructor_test.h" +#include "absl/container/internal/unordered_set_lookup_test.h" +#include "absl/container/internal/unordered_set_members_test.h" +#include "absl/container/internal/unordered_set_modifiers_test.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using SetTypes = ::testing::Types< + std::unordered_set<int, StatefulTestingHash, StatefulTestingEqual, + Alloc<int>>, + std::unordered_set<std::string, StatefulTestingHash, StatefulTestingEqual, + Alloc<std::string>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedSet, ConstructorTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedSet, LookupTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedSet, MembersTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(UnorderedSet, ModifiersTest, SetTypes); + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/node_hash_map.h b/third_party/abseil_cpp/absl/container/node_hash_map.h new file mode 100644 index 0000000000..174b971e99 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/node_hash_map.h @@ -0,0 +1,591 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: node_hash_map.h +// ----------------------------------------------------------------------------- +// +// An `absl::node_hash_map<K, V>` is an unordered associative container of +// unique keys and associated values designed to be a more efficient replacement +// for `std::unordered_map`. Like `unordered_map`, search, insertion, and +// deletion of map elements can be done as an `O(1)` operation. However, +// `node_hash_map` (and other unordered associative containers known as the +// collection of Abseil "Swiss tables") contain other optimizations that result +// in both memory and computation advantages. +// +// In most cases, your default choice for a hash map should be a map of type +// `flat_hash_map`. However, if you need pointer stability and cannot store +// a `flat_hash_map` with `unique_ptr` elements, a `node_hash_map` may be a +// valid alternative. As well, if you are migrating your code from using +// `std::unordered_map`, a `node_hash_map` provides a more straightforward +// migration, because it guarantees pointer stability. Consider migrating to +// `node_hash_map` and perhaps converting to a more efficient `flat_hash_map` +// upon further review. + +#ifndef ABSL_CONTAINER_NODE_HASH_MAP_H_ +#define ABSL_CONTAINER_NODE_HASH_MAP_H_ + +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/algorithm/container.h" +#include "absl/container/internal/container_memory.h" +#include "absl/container/internal/hash_function_defaults.h" // IWYU pragma: export +#include "absl/container/internal/node_hash_policy.h" +#include "absl/container/internal/raw_hash_map.h" // IWYU pragma: export +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +template <class Key, class Value> +class NodeHashMapPolicy; +} // namespace container_internal + +// ----------------------------------------------------------------------------- +// absl::node_hash_map +// ----------------------------------------------------------------------------- +// +// An `absl::node_hash_map<K, V>` is an unordered associative container which +// has been optimized for both speed and memory footprint in most common use +// cases. Its interface is similar to that of `std::unordered_map<K, V>` with +// the following notable differences: +// +// * Supports heterogeneous lookup, through `find()`, `operator[]()` and +// `insert()`, provided that the map is provided a compatible heterogeneous +// hashing function and equality operator. +// * Contains a `capacity()` member function indicating the number of element +// slots (open, deleted, and empty) within the hash map. +// * Returns `void` from the `erase(iterator)` overload. +// +// By default, `node_hash_map` uses the `absl::Hash` hashing framework. +// All fundamental and Abseil types that support the `absl::Hash` framework have +// a compatible equality operator for comparing insertions into `node_hash_map`. +// If your type is not yet supported by the `absl::Hash` framework, see +// absl/hash/hash.h for information on extending Abseil hashing to user-defined +// types. +// +// Example: +// +// // Create a node hash map of three strings (that map to strings) +// absl::node_hash_map<std::string, std::string> ducks = +// {{"a", "huey"}, {"b", "dewey"}, {"c", "louie"}}; +// +// // Insert a new element into the node hash map +// ducks.insert({"d", "donald"}}; +// +// // Force a rehash of the node hash map +// ducks.rehash(0); +// +// // Find the element with the key "b" +// std::string search_key = "b"; +// auto result = ducks.find(search_key); +// if (result != ducks.end()) { +// std::cout << "Result: " << result->second << std::endl; +// } +template <class Key, class Value, + class Hash = absl::container_internal::hash_default_hash<Key>, + class Eq = absl::container_internal::hash_default_eq<Key>, + class Alloc = std::allocator<std::pair<const Key, Value>>> +class node_hash_map + : public absl::container_internal::raw_hash_map< + absl::container_internal::NodeHashMapPolicy<Key, Value>, Hash, Eq, + Alloc> { + using Base = typename node_hash_map::raw_hash_map; + + public: + // Constructors and Assignment Operators + // + // A node_hash_map supports the same overload set as `std::unordered_map` + // for construction and assignment: + // + // * Default constructor + // + // // No allocation for the table's elements is made. + // absl::node_hash_map<int, std::string> map1; + // + // * Initializer List constructor + // + // absl::node_hash_map<int, std::string> map2 = + // {{1, "huey"}, {2, "dewey"}, {3, "louie"},}; + // + // * Copy constructor + // + // absl::node_hash_map<int, std::string> map3(map2); + // + // * Copy assignment operator + // + // // Hash functor and Comparator are copied as well + // absl::node_hash_map<int, std::string> map4; + // map4 = map3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::node_hash_map<int, std::string> map5(std::move(map4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::node_hash_map<int, std::string> map6; + // map6 = std::move(map5); + // + // * Range constructor + // + // std::vector<std::pair<int, std::string>> v = {{1, "a"}, {2, "b"}}; + // absl::node_hash_map<int, std::string> map7(v.begin(), v.end()); + node_hash_map() {} + using Base::Base; + + // node_hash_map::begin() + // + // Returns an iterator to the beginning of the `node_hash_map`. + using Base::begin; + + // node_hash_map::cbegin() + // + // Returns a const iterator to the beginning of the `node_hash_map`. + using Base::cbegin; + + // node_hash_map::cend() + // + // Returns a const iterator to the end of the `node_hash_map`. + using Base::cend; + + // node_hash_map::end() + // + // Returns an iterator to the end of the `node_hash_map`. + using Base::end; + + // node_hash_map::capacity() + // + // Returns the number of element slots (assigned, deleted, and empty) + // available within the `node_hash_map`. + // + // NOTE: this member function is particular to `absl::node_hash_map` and is + // not provided in the `std::unordered_map` API. + using Base::capacity; + + // node_hash_map::empty() + // + // Returns whether or not the `node_hash_map` is empty. + using Base::empty; + + // node_hash_map::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `node_hash_map` under current memory constraints. This value can be thought + // of as the largest value of `std::distance(begin(), end())` for a + // `node_hash_map<K, V>`. + using Base::max_size; + + // node_hash_map::size() + // + // Returns the number of elements currently within the `node_hash_map`. + using Base::size; + + // node_hash_map::clear() + // + // Removes all elements from the `node_hash_map`. Invalidates any references, + // pointers, or iterators referring to contained elements. + // + // NOTE: this operation may shrink the underlying buffer. To avoid shrinking + // the underlying buffer call `erase(begin(), end())`. + using Base::clear; + + // node_hash_map::erase() + // + // Erases elements within the `node_hash_map`. Erasing does not trigger a + // rehash. Overloads are listed below. + // + // void erase(const_iterator pos): + // + // Erases the element at `position` of the `node_hash_map`, returning + // `void`. + // + // NOTE: this return behavior is different than that of STL containers in + // general and `std::unordered_map` in particular. + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning an + // iterator pointing to `last`. + // + // size_type erase(const key_type& key): + // + // Erases the element with the matching key, if it exists. + using Base::erase; + + // node_hash_map::insert() + // + // Inserts an element of the specified value into the `node_hash_map`, + // returning an iterator pointing to the newly inserted element, provided that + // an element with the given key does not already exist. If rehashing occurs + // due to the insertion, all iterators are invalidated. Overloads are listed + // below. + // + // std::pair<iterator,bool> insert(const init_type& value): + // + // Inserts a value into the `node_hash_map`. Returns a pair consisting of an + // iterator to the inserted element (or to the element that prevented the + // insertion) and a `bool` denoting whether the insertion took place. + // + // std::pair<iterator,bool> insert(T&& value): + // std::pair<iterator,bool> insert(init_type&& value): + // + // Inserts a moveable value into the `node_hash_map`. Returns a `std::pair` + // consisting of an iterator to the inserted element (or to the element that + // prevented the insertion) and a `bool` denoting whether the insertion took + // place. + // + // iterator insert(const_iterator hint, const init_type& value): + // iterator insert(const_iterator hint, T&& value): + // iterator insert(const_iterator hint, init_type&& value); + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element, or to the existing element that prevented the + // insertion. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently, for `node_hash_map` we guarantee the + // first match is inserted. + // + // void insert(std::initializer_list<init_type> ilist): + // + // Inserts the elements within the initializer list `ilist`. + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently within the initializer list, for + // `node_hash_map` we guarantee the first match is inserted. + using Base::insert; + + // node_hash_map::insert_or_assign() + // + // Inserts an element of the specified value into the `node_hash_map` provided + // that a value with the given key does not already exist, or replaces it with + // the element value if a key for that value already exists, returning an + // iterator pointing to the newly inserted element. If rehashing occurs due to + // the insertion, all iterators are invalidated. Overloads are listed + // below. + // + // std::pair<iterator, bool> insert_or_assign(const init_type& k, T&& obj): + // std::pair<iterator, bool> insert_or_assign(init_type&& k, T&& obj): + // + // Inserts/Assigns (or moves) the element of the specified key into the + // `node_hash_map`. + // + // iterator insert_or_assign(const_iterator hint, + // const init_type& k, T&& obj): + // iterator insert_or_assign(const_iterator hint, init_type&& k, T&& obj): + // + // Inserts/Assigns (or moves) the element of the specified key into the + // `node_hash_map` using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. + using Base::insert_or_assign; + + // node_hash_map::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `node_hash_map`, provided that no element with the given key + // already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. Prefer `try_emplace()` unless your key is not + // copyable or moveable. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace; + + // node_hash_map::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `node_hash_map`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search, and only inserts + // provided that no element with the given key already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. Prefer `try_emplace()` unless your key is not + // copyable or moveable. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace_hint; + + // node_hash_map::try_emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `node_hash_map`, provided that no element with the given key + // already exists. Unlike `emplace()`, if an element with the given key + // already exists, we guarantee that no element is constructed. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + // Overloads are listed below. + // + // std::pair<iterator, bool> try_emplace(const key_type& k, Args&&... args): + // std::pair<iterator, bool> try_emplace(key_type&& k, Args&&... args): + // + // Inserts (via copy or move) the element of the specified key into the + // `node_hash_map`. + // + // iterator try_emplace(const_iterator hint, + // const init_type& k, Args&&... args): + // iterator try_emplace(const_iterator hint, init_type&& k, Args&&... args): + // + // Inserts (via copy or move) the element of the specified key into the + // `node_hash_map` using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. + // + // All `try_emplace()` overloads make the same guarantees regarding rvalue + // arguments as `std::unordered_map::try_emplace()`, namely that these + // functions will not move from rvalue arguments if insertions do not happen. + using Base::try_emplace; + + // node_hash_map::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the key,value pair of the element at the indicated position and + // returns a node handle owning that extracted data. + // + // node_type extract(const key_type& x): + // + // Extracts the key,value pair of the element with a key matching the passed + // key value and returns a node handle owning that extracted data. If the + // `node_hash_map` does not contain an element with a matching key, this + // function returns an empty node handle. + using Base::extract; + + // node_hash_map::merge() + // + // Extracts elements from a given `source` node hash map into this + // `node_hash_map`. If the destination `node_hash_map` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // node_hash_map::swap(node_hash_map& other) + // + // Exchanges the contents of this `node_hash_map` with those of the `other` + // node hash map, avoiding invocation of any move, copy, or swap operations on + // individual elements. + // + // All iterators and references on the `node_hash_map` remain valid, excepting + // for the past-the-end iterator, which is invalidated. + // + // `swap()` requires that the node hash map's hashing and key equivalence + // functions be Swappable, and are exchaged using unqualified calls to + // non-member `swap()`. If the map's allocator has + // `std::allocator_traits<allocator_type>::propagate_on_container_swap::value` + // set to `true`, the allocators are also exchanged using an unqualified call + // to non-member `swap()`; otherwise, the allocators are not swapped. + using Base::swap; + + // node_hash_map::rehash(count) + // + // Rehashes the `node_hash_map`, setting the number of slots to be at least + // the passed value. If the new number of slots increases the load factor more + // than the current maximum load factor + // (`count` < `size()` / `max_load_factor()`), then the new number of slots + // will be at least `size()` / `max_load_factor()`. + // + // To force a rehash, pass rehash(0). + using Base::rehash; + + // node_hash_map::reserve(count) + // + // Sets the number of slots in the `node_hash_map` to the number needed to + // accommodate at least `count` total elements without exceeding the current + // maximum load factor, and may rehash the container if needed. + using Base::reserve; + + // node_hash_map::at() + // + // Returns a reference to the mapped value of the element with key equivalent + // to the passed key. + using Base::at; + + // node_hash_map::contains() + // + // Determines whether an element with a key comparing equal to the given `key` + // exists within the `node_hash_map`, returning `true` if so or `false` + // otherwise. + using Base::contains; + + // node_hash_map::count(const Key& key) const + // + // Returns the number of elements with a key comparing equal to the given + // `key` within the `node_hash_map`. note that this function will return + // either `1` or `0` since duplicate keys are not allowed within a + // `node_hash_map`. + using Base::count; + + // node_hash_map::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `node_hash_map`. + using Base::equal_range; + + // node_hash_map::find() + // + // Finds an element with the passed `key` within the `node_hash_map`. + using Base::find; + + // node_hash_map::operator[]() + // + // Returns a reference to the value mapped to the passed key within the + // `node_hash_map`, performing an `insert()` if the key does not already + // exist. If an insertion occurs and results in a rehashing of the container, + // all iterators are invalidated. Otherwise iterators are not affected and + // references are not invalidated. Overloads are listed below. + // + // T& operator[](const Key& key): + // + // Inserts an init_type object constructed in-place if the element with the + // given key does not exist. + // + // T& operator[](Key&& key): + // + // Inserts an init_type object constructed in-place provided that an element + // with the given key does not exist. + using Base::operator[]; + + // node_hash_map::bucket_count() + // + // Returns the number of "buckets" within the `node_hash_map`. + using Base::bucket_count; + + // node_hash_map::load_factor() + // + // Returns the current load factor of the `node_hash_map` (the average number + // of slots occupied with a value within the hash map). + using Base::load_factor; + + // node_hash_map::max_load_factor() + // + // Manages the maximum load factor of the `node_hash_map`. Overloads are + // listed below. + // + // float node_hash_map::max_load_factor() + // + // Returns the current maximum load factor of the `node_hash_map`. + // + // void node_hash_map::max_load_factor(float ml) + // + // Sets the maximum load factor of the `node_hash_map` to the passed value. + // + // NOTE: This overload is provided only for API compatibility with the STL; + // `node_hash_map` will ignore any set load factor and manage its rehashing + // internally as an implementation detail. + using Base::max_load_factor; + + // node_hash_map::get_allocator() + // + // Returns the allocator function associated with this `node_hash_map`. + using Base::get_allocator; + + // node_hash_map::hash_function() + // + // Returns the hashing function used to hash the keys within this + // `node_hash_map`. + using Base::hash_function; + + // node_hash_map::key_eq() + // + // Returns the function used for comparing keys equality. + using Base::key_eq; +}; + +// erase_if(node_hash_map<>, Pred) +// +// Erases all elements that satisfy the predicate `pred` from the container `c`. +template <typename K, typename V, typename H, typename E, typename A, + typename Predicate> +void erase_if(node_hash_map<K, V, H, E, A>& c, Predicate pred) { + container_internal::EraseIf(pred, &c); +} + +namespace container_internal { + +template <class Key, class Value> +class NodeHashMapPolicy + : public absl::container_internal::node_hash_policy< + std::pair<const Key, Value>&, NodeHashMapPolicy<Key, Value>> { + using value_type = std::pair<const Key, Value>; + + public: + using key_type = Key; + using mapped_type = Value; + using init_type = std::pair</*non const*/ key_type, mapped_type>; + + template <class Allocator, class... Args> + static value_type* new_element(Allocator* alloc, Args&&... args) { + using PairAlloc = typename absl::allocator_traits< + Allocator>::template rebind_alloc<value_type>; + PairAlloc pair_alloc(*alloc); + value_type* res = + absl::allocator_traits<PairAlloc>::allocate(pair_alloc, 1); + absl::allocator_traits<PairAlloc>::construct(pair_alloc, res, + std::forward<Args>(args)...); + return res; + } + + template <class Allocator> + static void delete_element(Allocator* alloc, value_type* pair) { + using PairAlloc = typename absl::allocator_traits< + Allocator>::template rebind_alloc<value_type>; + PairAlloc pair_alloc(*alloc); + absl::allocator_traits<PairAlloc>::destroy(pair_alloc, pair); + absl::allocator_traits<PairAlloc>::deallocate(pair_alloc, pair, 1); + } + + template <class F, class... Args> + static decltype(absl::container_internal::DecomposePair( + std::declval<F>(), std::declval<Args>()...)) + apply(F&& f, Args&&... args) { + return absl::container_internal::DecomposePair(std::forward<F>(f), + std::forward<Args>(args)...); + } + + static size_t element_space_used(const value_type*) { + return sizeof(value_type); + } + + static Value& value(value_type* elem) { return elem->second; } + static const Value& value(const value_type* elem) { return elem->second; } +}; +} // namespace container_internal + +namespace container_algorithm_internal { + +// Specialization of trait in absl/algorithm/container.h +template <class Key, class T, class Hash, class KeyEqual, class Allocator> +struct IsUnorderedContainer< + absl::node_hash_map<Key, T, Hash, KeyEqual, Allocator>> : std::true_type {}; + +} // namespace container_algorithm_internal + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_NODE_HASH_MAP_H_ diff --git a/third_party/abseil_cpp/absl/container/node_hash_map_test.cc b/third_party/abseil_cpp/absl/container/node_hash_map_test.cc new file mode 100644 index 0000000000..5d74b814b5 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/node_hash_map_test.cc @@ -0,0 +1,260 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/node_hash_map.h" + +#include "absl/container/internal/tracked.h" +#include "absl/container/internal/unordered_map_constructor_test.h" +#include "absl/container/internal/unordered_map_lookup_test.h" +#include "absl/container/internal/unordered_map_members_test.h" +#include "absl/container/internal/unordered_map_modifiers_test.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { + +using ::testing::Field; +using ::testing::IsEmpty; +using ::testing::Pair; +using ::testing::UnorderedElementsAre; + +using MapTypes = ::testing::Types< + absl::node_hash_map<int, int, StatefulTestingHash, StatefulTestingEqual, + Alloc<std::pair<const int, int>>>, + absl::node_hash_map<std::string, std::string, StatefulTestingHash, + StatefulTestingEqual, + Alloc<std::pair<const std::string, std::string>>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashMap, ConstructorTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashMap, LookupTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashMap, MembersTest, MapTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashMap, ModifiersTest, MapTypes); + +using M = absl::node_hash_map<std::string, Tracked<int>>; + +TEST(NodeHashMap, Emplace) { + M m; + Tracked<int> t(53); + m.emplace("a", t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(1, t.num_copies()); + + m.emplace(std::string("a"), t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(1, t.num_copies()); + + std::string a("a"); + m.emplace(a, t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(1, t.num_copies()); + + const std::string ca("a"); + m.emplace(a, t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(1, t.num_copies()); + + m.emplace(std::make_pair("a", t)); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(2, t.num_copies()); + + m.emplace(std::make_pair(std::string("a"), t)); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(3, t.num_copies()); + + std::pair<std::string, Tracked<int>> p("a", t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(4, t.num_copies()); + m.emplace(p); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(4, t.num_copies()); + + const std::pair<std::string, Tracked<int>> cp("a", t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(5, t.num_copies()); + m.emplace(cp); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(5, t.num_copies()); + + std::pair<const std::string, Tracked<int>> pc("a", t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(6, t.num_copies()); + m.emplace(pc); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(6, t.num_copies()); + + const std::pair<const std::string, Tracked<int>> cpc("a", t); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(7, t.num_copies()); + m.emplace(cpc); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(7, t.num_copies()); + + m.emplace(std::piecewise_construct, std::forward_as_tuple("a"), + std::forward_as_tuple(t)); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(7, t.num_copies()); + + m.emplace(std::piecewise_construct, std::forward_as_tuple(std::string("a")), + std::forward_as_tuple(t)); + ASSERT_EQ(0, t.num_moves()); + ASSERT_EQ(7, t.num_copies()); +} + +TEST(NodeHashMap, AssignRecursive) { + struct Tree { + // Verify that unordered_map<K, IncompleteType> can be instantiated. + absl::node_hash_map<int, Tree> children; + }; + Tree root; + const Tree& child = root.children.emplace().first->second; + // Verify that `lhs = rhs` doesn't read rhs after clearing lhs. + root = child; +} + +TEST(FlatHashMap, MoveOnlyKey) { + struct Key { + Key() = default; + Key(Key&&) = default; + Key& operator=(Key&&) = default; + }; + struct Eq { + bool operator()(const Key&, const Key&) const { return true; } + }; + struct Hash { + size_t operator()(const Key&) const { return 0; } + }; + absl::node_hash_map<Key, int, Hash, Eq> m; + m[Key()]; +} + +struct NonMovableKey { + explicit NonMovableKey(int i) : i(i) {} + NonMovableKey(NonMovableKey&&) = delete; + int i; +}; +struct NonMovableKeyHash { + using is_transparent = void; + size_t operator()(const NonMovableKey& k) const { return k.i; } + size_t operator()(int k) const { return k; } +}; +struct NonMovableKeyEq { + using is_transparent = void; + bool operator()(const NonMovableKey& a, const NonMovableKey& b) const { + return a.i == b.i; + } + bool operator()(const NonMovableKey& a, int b) const { return a.i == b; } +}; + +TEST(NodeHashMap, MergeExtractInsert) { + absl::node_hash_map<NonMovableKey, int, NonMovableKeyHash, NonMovableKeyEq> + set1, set2; + set1.emplace(std::piecewise_construct, std::make_tuple(7), + std::make_tuple(-7)); + set1.emplace(std::piecewise_construct, std::make_tuple(17), + std::make_tuple(-17)); + + set2.emplace(std::piecewise_construct, std::make_tuple(7), + std::make_tuple(-70)); + set2.emplace(std::piecewise_construct, std::make_tuple(19), + std::make_tuple(-190)); + + auto Elem = [](int key, int value) { + return Pair(Field(&NonMovableKey::i, key), value); + }; + + EXPECT_THAT(set1, UnorderedElementsAre(Elem(7, -7), Elem(17, -17))); + EXPECT_THAT(set2, UnorderedElementsAre(Elem(7, -70), Elem(19, -190))); + + // NonMovableKey is neither copyable nor movable. We should still be able to + // move nodes around. + static_assert(!std::is_move_constructible<NonMovableKey>::value, ""); + set1.merge(set2); + + EXPECT_THAT(set1, + UnorderedElementsAre(Elem(7, -7), Elem(17, -17), Elem(19, -190))); + EXPECT_THAT(set2, UnorderedElementsAre(Elem(7, -70))); + + auto node = set1.extract(7); + EXPECT_TRUE(node); + EXPECT_EQ(node.key().i, 7); + EXPECT_EQ(node.mapped(), -7); + EXPECT_THAT(set1, UnorderedElementsAre(Elem(17, -17), Elem(19, -190))); + + auto insert_result = set2.insert(std::move(node)); + EXPECT_FALSE(node); + EXPECT_FALSE(insert_result.inserted); + EXPECT_TRUE(insert_result.node); + EXPECT_EQ(insert_result.node.key().i, 7); + EXPECT_EQ(insert_result.node.mapped(), -7); + EXPECT_THAT(*insert_result.position, Elem(7, -70)); + EXPECT_THAT(set2, UnorderedElementsAre(Elem(7, -70))); + + node = set1.extract(17); + EXPECT_TRUE(node); + EXPECT_EQ(node.key().i, 17); + EXPECT_EQ(node.mapped(), -17); + EXPECT_THAT(set1, UnorderedElementsAre(Elem(19, -190))); + + node.mapped() = 23; + + insert_result = set2.insert(std::move(node)); + EXPECT_FALSE(node); + EXPECT_TRUE(insert_result.inserted); + EXPECT_FALSE(insert_result.node); + EXPECT_THAT(*insert_result.position, Elem(17, 23)); + EXPECT_THAT(set2, UnorderedElementsAre(Elem(7, -70), Elem(17, 23))); +} + +bool FirstIsEven(std::pair<const int, int> p) { return p.first % 2 == 0; } + +TEST(NodeHashMap, EraseIf) { + // Erase all elements. + { + node_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, [](std::pair<const int, int>) { return true; }); + EXPECT_THAT(s, IsEmpty()); + } + // Erase no elements. + { + node_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, [](std::pair<const int, int>) { return false; }); + EXPECT_THAT(s, UnorderedElementsAre(Pair(1, 1), Pair(2, 2), Pair(3, 3), + Pair(4, 4), Pair(5, 5))); + } + // Erase specific elements. + { + node_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, + [](std::pair<const int, int> kvp) { return kvp.first % 2 == 1; }); + EXPECT_THAT(s, UnorderedElementsAre(Pair(2, 2), Pair(4, 4))); + } + // Predicate is function reference. + { + node_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, FirstIsEven); + EXPECT_THAT(s, UnorderedElementsAre(Pair(1, 1), Pair(3, 3), Pair(5, 5))); + } + // Predicate is function pointer. + { + node_hash_map<int, int> s = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 5}}; + erase_if(s, &FirstIsEven); + EXPECT_THAT(s, UnorderedElementsAre(Pair(1, 1), Pair(3, 3), Pair(5, 5))); + } +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/container/node_hash_set.h b/third_party/abseil_cpp/absl/container/node_hash_set.h new file mode 100644 index 0000000000..56bab5c2c0 --- /dev/null +++ b/third_party/abseil_cpp/absl/container/node_hash_set.h @@ -0,0 +1,492 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: node_hash_set.h +// ----------------------------------------------------------------------------- +// +// An `absl::node_hash_set<T>` is an unordered associative container designed to +// be a more efficient replacement for `std::unordered_set`. Like +// `unordered_set`, search, insertion, and deletion of map elements can be done +// as an `O(1)` operation. However, `node_hash_set` (and other unordered +// associative containers known as the collection of Abseil "Swiss tables") +// contain other optimizations that result in both memory and computation +// advantages. +// +// In most cases, your default choice for a hash table should be a map of type +// `flat_hash_map` or a set of type `flat_hash_set`. However, if you need +// pointer stability, a `node_hash_set` should be your preferred choice. As +// well, if you are migrating your code from using `std::unordered_set`, a +// `node_hash_set` should be an easy migration. Consider migrating to +// `node_hash_set` and perhaps converting to a more efficient `flat_hash_set` +// upon further review. + +#ifndef ABSL_CONTAINER_NODE_HASH_SET_H_ +#define ABSL_CONTAINER_NODE_HASH_SET_H_ + +#include <type_traits> + +#include "absl/algorithm/container.h" +#include "absl/container/internal/hash_function_defaults.h" // IWYU pragma: export +#include "absl/container/internal/node_hash_policy.h" +#include "absl/container/internal/raw_hash_set.h" // IWYU pragma: export +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +template <typename T> +struct NodeHashSetPolicy; +} // namespace container_internal + +// ----------------------------------------------------------------------------- +// absl::node_hash_set +// ----------------------------------------------------------------------------- +// +// An `absl::node_hash_set<T>` is an unordered associative container which +// has been optimized for both speed and memory footprint in most common use +// cases. Its interface is similar to that of `std::unordered_set<T>` with the +// following notable differences: +// +// * Supports heterogeneous lookup, through `find()`, `operator[]()` and +// `insert()`, provided that the map is provided a compatible heterogeneous +// hashing function and equality operator. +// * Contains a `capacity()` member function indicating the number of element +// slots (open, deleted, and empty) within the hash set. +// * Returns `void` from the `erase(iterator)` overload. +// +// By default, `node_hash_set` uses the `absl::Hash` hashing framework. +// All fundamental and Abseil types that support the `absl::Hash` framework have +// a compatible equality operator for comparing insertions into `node_hash_set`. +// If your type is not yet supported by the `absl::Hash` framework, see +// absl/hash/hash.h for information on extending Abseil hashing to user-defined +// types. +// +// Example: +// +// // Create a node hash set of three strings +// absl::node_hash_map<std::string, std::string> ducks = +// {"huey", "dewey", "louie"}; +// +// // Insert a new element into the node hash map +// ducks.insert("donald"}; +// +// // Force a rehash of the node hash map +// ducks.rehash(0); +// +// // See if "dewey" is present +// if (ducks.contains("dewey")) { +// std::cout << "We found dewey!" << std::endl; +// } +template <class T, class Hash = absl::container_internal::hash_default_hash<T>, + class Eq = absl::container_internal::hash_default_eq<T>, + class Alloc = std::allocator<T>> +class node_hash_set + : public absl::container_internal::raw_hash_set< + absl::container_internal::NodeHashSetPolicy<T>, Hash, Eq, Alloc> { + using Base = typename node_hash_set::raw_hash_set; + + public: + // Constructors and Assignment Operators + // + // A node_hash_set supports the same overload set as `std::unordered_map` + // for construction and assignment: + // + // * Default constructor + // + // // No allocation for the table's elements is made. + // absl::node_hash_set<std::string> set1; + // + // * Initializer List constructor + // + // absl::node_hash_set<std::string> set2 = + // {{"huey"}, {"dewey"}, {"louie"}}; + // + // * Copy constructor + // + // absl::node_hash_set<std::string> set3(set2); + // + // * Copy assignment operator + // + // // Hash functor and Comparator are copied as well + // absl::node_hash_set<std::string> set4; + // set4 = set3; + // + // * Move constructor + // + // // Move is guaranteed efficient + // absl::node_hash_set<std::string> set5(std::move(set4)); + // + // * Move assignment operator + // + // // May be efficient if allocators are compatible + // absl::node_hash_set<std::string> set6; + // set6 = std::move(set5); + // + // * Range constructor + // + // std::vector<std::string> v = {"a", "b"}; + // absl::node_hash_set<std::string> set7(v.begin(), v.end()); + node_hash_set() {} + using Base::Base; + + // node_hash_set::begin() + // + // Returns an iterator to the beginning of the `node_hash_set`. + using Base::begin; + + // node_hash_set::cbegin() + // + // Returns a const iterator to the beginning of the `node_hash_set`. + using Base::cbegin; + + // node_hash_set::cend() + // + // Returns a const iterator to the end of the `node_hash_set`. + using Base::cend; + + // node_hash_set::end() + // + // Returns an iterator to the end of the `node_hash_set`. + using Base::end; + + // node_hash_set::capacity() + // + // Returns the number of element slots (assigned, deleted, and empty) + // available within the `node_hash_set`. + // + // NOTE: this member function is particular to `absl::node_hash_set` and is + // not provided in the `std::unordered_map` API. + using Base::capacity; + + // node_hash_set::empty() + // + // Returns whether or not the `node_hash_set` is empty. + using Base::empty; + + // node_hash_set::max_size() + // + // Returns the largest theoretical possible number of elements within a + // `node_hash_set` under current memory constraints. This value can be thought + // of the largest value of `std::distance(begin(), end())` for a + // `node_hash_set<T>`. + using Base::max_size; + + // node_hash_set::size() + // + // Returns the number of elements currently within the `node_hash_set`. + using Base::size; + + // node_hash_set::clear() + // + // Removes all elements from the `node_hash_set`. Invalidates any references, + // pointers, or iterators referring to contained elements. + // + // NOTE: this operation may shrink the underlying buffer. To avoid shrinking + // the underlying buffer call `erase(begin(), end())`. + using Base::clear; + + // node_hash_set::erase() + // + // Erases elements within the `node_hash_set`. Erasing does not trigger a + // rehash. Overloads are listed below. + // + // void erase(const_iterator pos): + // + // Erases the element at `position` of the `node_hash_set`, returning + // `void`. + // + // NOTE: this return behavior is different than that of STL containers in + // general and `std::unordered_map` in particular. + // + // iterator erase(const_iterator first, const_iterator last): + // + // Erases the elements in the open interval [`first`, `last`), returning an + // iterator pointing to `last`. + // + // size_type erase(const key_type& key): + // + // Erases the element with the matching key, if it exists. + using Base::erase; + + // node_hash_set::insert() + // + // Inserts an element of the specified value into the `node_hash_set`, + // returning an iterator pointing to the newly inserted element, provided that + // an element with the given key does not already exist. If rehashing occurs + // due to the insertion, all iterators are invalidated. Overloads are listed + // below. + // + // std::pair<iterator,bool> insert(const T& value): + // + // Inserts a value into the `node_hash_set`. Returns a pair consisting of an + // iterator to the inserted element (or to the element that prevented the + // insertion) and a bool denoting whether the insertion took place. + // + // std::pair<iterator,bool> insert(T&& value): + // + // Inserts a moveable value into the `node_hash_set`. Returns a pair + // consisting of an iterator to the inserted element (or to the element that + // prevented the insertion) and a bool denoting whether the insertion took + // place. + // + // iterator insert(const_iterator hint, const T& value): + // iterator insert(const_iterator hint, T&& value): + // + // Inserts a value, using the position of `hint` as a non-binding suggestion + // for where to begin the insertion search. Returns an iterator to the + // inserted element, or to the existing element that prevented the + // insertion. + // + // void insert(InputIterator first, InputIterator last): + // + // Inserts a range of values [`first`, `last`). + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently, for `node_hash_set` we guarantee the + // first match is inserted. + // + // void insert(std::initializer_list<T> ilist): + // + // Inserts the elements within the initializer list `ilist`. + // + // NOTE: Although the STL does not specify which element may be inserted if + // multiple keys compare equivalently within the initializer list, for + // `node_hash_set` we guarantee the first match is inserted. + using Base::insert; + + // node_hash_set::emplace() + // + // Inserts an element of the specified value by constructing it in-place + // within the `node_hash_set`, provided that no element with the given key + // already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace; + + // node_hash_set::emplace_hint() + // + // Inserts an element of the specified value by constructing it in-place + // within the `node_hash_set`, using the position of `hint` as a non-binding + // suggestion for where to begin the insertion search, and only inserts + // provided that no element with the given key already exists. + // + // The element may be constructed even if there already is an element with the + // key in the container, in which case the newly constructed element will be + // destroyed immediately. + // + // If rehashing occurs due to the insertion, all iterators are invalidated. + using Base::emplace_hint; + + // node_hash_set::extract() + // + // Extracts the indicated element, erasing it in the process, and returns it + // as a C++17-compatible node handle. Overloads are listed below. + // + // node_type extract(const_iterator position): + // + // Extracts the element at the indicated position and returns a node handle + // owning that extracted data. + // + // node_type extract(const key_type& x): + // + // Extracts the element with the key matching the passed key value and + // returns a node handle owning that extracted data. If the `node_hash_set` + // does not contain an element with a matching key, this function returns an + // empty node handle. + using Base::extract; + + // node_hash_set::merge() + // + // Extracts elements from a given `source` flat hash map into this + // `node_hash_set`. If the destination `node_hash_set` already contains an + // element with an equivalent key, that element is not extracted. + using Base::merge; + + // node_hash_set::swap(node_hash_set& other) + // + // Exchanges the contents of this `node_hash_set` with those of the `other` + // flat hash map, avoiding invocation of any move, copy, or swap operations on + // individual elements. + // + // All iterators and references on the `node_hash_set` remain valid, excepting + // for the past-the-end iterator, which is invalidated. + // + // `swap()` requires that the flat hash set's hashing and key equivalence + // functions be Swappable, and are exchaged using unqualified calls to + // non-member `swap()`. If the map's allocator has + // `std::allocator_traits<allocator_type>::propagate_on_container_swap::value` + // set to `true`, the allocators are also exchanged using an unqualified call + // to non-member `swap()`; otherwise, the allocators are not swapped. + using Base::swap; + + // node_hash_set::rehash(count) + // + // Rehashes the `node_hash_set`, setting the number of slots to be at least + // the passed value. If the new number of slots increases the load factor more + // than the current maximum load factor + // (`count` < `size()` / `max_load_factor()`), then the new number of slots + // will be at least `size()` / `max_load_factor()`. + // + // To force a rehash, pass rehash(0). + // + // NOTE: unlike behavior in `std::unordered_set`, references are also + // invalidated upon a `rehash()`. + using Base::rehash; + + // node_hash_set::reserve(count) + // + // Sets the number of slots in the `node_hash_set` to the number needed to + // accommodate at least `count` total elements without exceeding the current + // maximum load factor, and may rehash the container if needed. + using Base::reserve; + + // node_hash_set::contains() + // + // Determines whether an element comparing equal to the given `key` exists + // within the `node_hash_set`, returning `true` if so or `false` otherwise. + using Base::contains; + + // node_hash_set::count(const Key& key) const + // + // Returns the number of elements comparing equal to the given `key` within + // the `node_hash_set`. note that this function will return either `1` or `0` + // since duplicate elements are not allowed within a `node_hash_set`. + using Base::count; + + // node_hash_set::equal_range() + // + // Returns a closed range [first, last], defined by a `std::pair` of two + // iterators, containing all elements with the passed key in the + // `node_hash_set`. + using Base::equal_range; + + // node_hash_set::find() + // + // Finds an element with the passed `key` within the `node_hash_set`. + using Base::find; + + // node_hash_set::bucket_count() + // + // Returns the number of "buckets" within the `node_hash_set`. Note that + // because a flat hash map contains all elements within its internal storage, + // this value simply equals the current capacity of the `node_hash_set`. + using Base::bucket_count; + + // node_hash_set::load_factor() + // + // Returns the current load factor of the `node_hash_set` (the average number + // of slots occupied with a value within the hash map). + using Base::load_factor; + + // node_hash_set::max_load_factor() + // + // Manages the maximum load factor of the `node_hash_set`. Overloads are + // listed below. + // + // float node_hash_set::max_load_factor() + // + // Returns the current maximum load factor of the `node_hash_set`. + // + // void node_hash_set::max_load_factor(float ml) + // + // Sets the maximum load factor of the `node_hash_set` to the passed value. + // + // NOTE: This overload is provided only for API compatibility with the STL; + // `node_hash_set` will ignore any set load factor and manage its rehashing + // internally as an implementation detail. + using Base::max_load_factor; + + // node_hash_set::get_allocator() + // + // Returns the allocator function associated with this `node_hash_set`. + using Base::get_allocator; + + // node_hash_set::hash_function() + // + // Returns the hashing function used to hash the keys within this + // `node_hash_set`. + using Base::hash_function; + + // node_hash_set::key_eq() + // + // Returns the function used for comparing keys equality. + using Base::key_eq; +}; + +// erase_if(node_hash_set<>, Pred) +// +// Erases all elements that satisfy the predicate `pred` from the container `c`. +template <typename T, typename H, typename E, typename A, typename Predicate> +void erase_if(node_hash_set<T, H, E, A>& c, Predicate pred) { + container_internal::EraseIf(pred, &c); +} + +namespace container_internal { + +template <class T> +struct NodeHashSetPolicy + : absl::container_internal::node_hash_policy<T&, NodeHashSetPolicy<T>> { + using key_type = T; + using init_type = T; + using constant_iterators = std::true_type; + + template <class Allocator, class... Args> + static T* new_element(Allocator* alloc, Args&&... args) { + using ValueAlloc = + typename absl::allocator_traits<Allocator>::template rebind_alloc<T>; + ValueAlloc value_alloc(*alloc); + T* res = absl::allocator_traits<ValueAlloc>::allocate(value_alloc, 1); + absl::allocator_traits<ValueAlloc>::construct(value_alloc, res, + std::forward<Args>(args)...); + return res; + } + + template <class Allocator> + static void delete_element(Allocator* alloc, T* elem) { + using ValueAlloc = + typename absl::allocator_traits<Allocator>::template rebind_alloc<T>; + ValueAlloc value_alloc(*alloc); + absl::allocator_traits<ValueAlloc>::destroy(value_alloc, elem); + absl::allocator_traits<ValueAlloc>::deallocate(value_alloc, elem, 1); + } + + template <class F, class... Args> + static decltype(absl::container_internal::DecomposeValue( + std::declval<F>(), std::declval<Args>()...)) + apply(F&& f, Args&&... args) { + return absl::container_internal::DecomposeValue( + std::forward<F>(f), std::forward<Args>(args)...); + } + + static size_t element_space_used(const T*) { return sizeof(T); } +}; +} // namespace container_internal + +namespace container_algorithm_internal { + +// Specialization of trait in absl/algorithm/container.h +template <class Key, class Hash, class KeyEqual, class Allocator> +struct IsUnorderedContainer<absl::node_hash_set<Key, Hash, KeyEqual, Allocator>> + : std::true_type {}; + +} // namespace container_algorithm_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_CONTAINER_NODE_HASH_SET_H_ diff --git a/third_party/abseil_cpp/absl/container/node_hash_set_test.cc b/third_party/abseil_cpp/absl/container/node_hash_set_test.cc new file mode 100644 index 0000000000..7ddad2021d --- /dev/null +++ b/third_party/abseil_cpp/absl/container/node_hash_set_test.cc @@ -0,0 +1,143 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/container/node_hash_set.h" + +#include "absl/container/internal/unordered_set_constructor_test.h" +#include "absl/container/internal/unordered_set_lookup_test.h" +#include "absl/container/internal/unordered_set_members_test.h" +#include "absl/container/internal/unordered_set_modifiers_test.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace container_internal { +namespace { +using ::absl::container_internal::hash_internal::Enum; +using ::absl::container_internal::hash_internal::EnumClass; +using ::testing::IsEmpty; +using ::testing::Pointee; +using ::testing::UnorderedElementsAre; + +using SetTypes = ::testing::Types< + node_hash_set<int, StatefulTestingHash, StatefulTestingEqual, Alloc<int>>, + node_hash_set<std::string, StatefulTestingHash, StatefulTestingEqual, + Alloc<std::string>>, + node_hash_set<Enum, StatefulTestingHash, StatefulTestingEqual, Alloc<Enum>>, + node_hash_set<EnumClass, StatefulTestingHash, StatefulTestingEqual, + Alloc<EnumClass>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashSet, ConstructorTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashSet, LookupTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashSet, MembersTest, SetTypes); +INSTANTIATE_TYPED_TEST_SUITE_P(NodeHashSet, ModifiersTest, SetTypes); + +TEST(NodeHashSet, MoveableNotCopyableCompiles) { + node_hash_set<std::unique_ptr<void*>> t; + node_hash_set<std::unique_ptr<void*>> u; + u = std::move(t); +} + +TEST(NodeHashSet, MergeExtractInsert) { + struct Hash { + size_t operator()(const std::unique_ptr<int>& p) const { return *p; } + }; + struct Eq { + bool operator()(const std::unique_ptr<int>& a, + const std::unique_ptr<int>& b) const { + return *a == *b; + } + }; + absl::node_hash_set<std::unique_ptr<int>, Hash, Eq> set1, set2; + set1.insert(absl::make_unique<int>(7)); + set1.insert(absl::make_unique<int>(17)); + + set2.insert(absl::make_unique<int>(7)); + set2.insert(absl::make_unique<int>(19)); + + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(7), Pointee(17))); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7), Pointee(19))); + + set1.merge(set2); + + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(7), Pointee(17), Pointee(19))); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7))); + + auto node = set1.extract(absl::make_unique<int>(7)); + EXPECT_TRUE(node); + EXPECT_THAT(node.value(), Pointee(7)); + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(17), Pointee(19))); + + auto insert_result = set2.insert(std::move(node)); + EXPECT_FALSE(node); + EXPECT_FALSE(insert_result.inserted); + EXPECT_TRUE(insert_result.node); + EXPECT_THAT(insert_result.node.value(), Pointee(7)); + EXPECT_EQ(**insert_result.position, 7); + EXPECT_NE(insert_result.position->get(), insert_result.node.value().get()); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7))); + + node = set1.extract(absl::make_unique<int>(17)); + EXPECT_TRUE(node); + EXPECT_THAT(node.value(), Pointee(17)); + EXPECT_THAT(set1, UnorderedElementsAre(Pointee(19))); + + node.value() = absl::make_unique<int>(23); + + insert_result = set2.insert(std::move(node)); + EXPECT_FALSE(node); + EXPECT_TRUE(insert_result.inserted); + EXPECT_FALSE(insert_result.node); + EXPECT_EQ(**insert_result.position, 23); + EXPECT_THAT(set2, UnorderedElementsAre(Pointee(7), Pointee(23))); +} + +bool IsEven(int k) { return k % 2 == 0; } + +TEST(NodeHashSet, EraseIf) { + // Erase all elements. + { + node_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, [](int) { return true; }); + EXPECT_THAT(s, IsEmpty()); + } + // Erase no elements. + { + node_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, [](int) { return false; }); + EXPECT_THAT(s, UnorderedElementsAre(1, 2, 3, 4, 5)); + } + // Erase specific elements. + { + node_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, [](int k) { return k % 2 == 1; }); + EXPECT_THAT(s, UnorderedElementsAre(2, 4)); + } + // Predicate is function reference. + { + node_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, IsEven); + EXPECT_THAT(s, UnorderedElementsAre(1, 3, 5)); + } + // Predicate is function pointer. + { + node_hash_set<int> s = {1, 2, 3, 4, 5}; + erase_if(s, &IsEven); + EXPECT_THAT(s, UnorderedElementsAre(1, 3, 5)); + } +} + +} // namespace +} // namespace container_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/copts/AbseilConfigureCopts.cmake b/third_party/abseil_cpp/absl/copts/AbseilConfigureCopts.cmake new file mode 100644 index 0000000000..acd46d04aa --- /dev/null +++ b/third_party/abseil_cpp/absl/copts/AbseilConfigureCopts.cmake @@ -0,0 +1,67 @@ +# See absl/copts/copts.py and absl/copts/generate_copts.py +include(GENERATED_AbseilCopts) + +set(ABSL_LSAN_LINKOPTS "") +set(ABSL_HAVE_LSAN OFF) +set(ABSL_DEFAULT_LINKOPTS "") + +if (BUILD_SHARED_LIBS AND MSVC) + set(ABSL_BUILD_DLL TRUE) + set(CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS ON) +else() + set(ABSL_BUILD_DLL FALSE) +endif() + +if("${CMAKE_SYSTEM_PROCESSOR}" MATCHES "x86_64|amd64|AMD64") + if (MSVC) + set(ABSL_RANDOM_RANDEN_COPTS "${ABSL_RANDOM_HWAES_MSVC_X64_FLAGS}") + else() + set(ABSL_RANDOM_RANDEN_COPTS "${ABSL_RANDOM_HWAES_X64_FLAGS}") + endif() +elseif("${CMAKE_SYSTEM_PROCESSOR}" MATCHES "arm.*|aarch64") + if ("${CMAKE_SIZEOF_VOID_P}" STREQUAL "8") + set(ABSL_RANDOM_RANDEN_COPTS "${ABSL_RANDOM_HWAES_ARM64_FLAGS}") + elseif("${CMAKE_SIZEOF_VOID_P}" STREQUAL "4") + set(ABSL_RANDOM_RANDEN_COPTS "${ABSL_RANDOM_HWAES_ARM32_FLAGS}") + else() + message(WARNING "Value of CMAKE_SIZEOF_VOID_P (${CMAKE_SIZEOF_VOID_P}) is not supported.") + endif() +else() + message(WARNING "Value of CMAKE_SYSTEM_PROCESSOR (${CMAKE_SYSTEM_PROCESSOR}) is unknown and cannot be used to set ABSL_RANDOM_RANDEN_COPTS") + set(ABSL_RANDOM_RANDEN_COPTS "") +endif() + + +if("${CMAKE_CXX_COMPILER_ID}" STREQUAL "GNU") + set(ABSL_DEFAULT_COPTS "${ABSL_GCC_FLAGS}") + set(ABSL_TEST_COPTS "${ABSL_GCC_FLAGS};${ABSL_GCC_TEST_FLAGS}") +elseif("${CMAKE_CXX_COMPILER_ID}" MATCHES "Clang") + # MATCHES so we get both Clang and AppleClang + if(MSVC) + # clang-cl is half MSVC, half LLVM + set(ABSL_DEFAULT_COPTS "${ABSL_CLANG_CL_FLAGS}") + set(ABSL_TEST_COPTS "${ABSL_CLANG_CL_FLAGS};${ABSL_CLANG_CL_TEST_FLAGS}") + set(ABSL_DEFAULT_LINKOPTS "${ABSL_MSVC_LINKOPTS}") + else() + set(ABSL_DEFAULT_COPTS "${ABSL_LLVM_FLAGS}") + set(ABSL_TEST_COPTS "${ABSL_LLVM_FLAGS};${ABSL_LLVM_TEST_FLAGS}") + if("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Clang") + # AppleClang doesn't have lsan + # https://developer.apple.com/documentation/code_diagnostics + if(NOT CMAKE_CXX_COMPILER_VERSION VERSION_LESS 3.5) + set(ABSL_LSAN_LINKOPTS "-fsanitize=leak") + set(ABSL_HAVE_LSAN ON) + endif() + endif() + endif() +elseif("${CMAKE_CXX_COMPILER_ID}" STREQUAL "MSVC") + set(ABSL_DEFAULT_COPTS "${ABSL_MSVC_FLAGS}") + set(ABSL_TEST_COPTS "${ABSL_MSVC_FLAGS};${ABSL_MSVC_TEST_FLAGS}") + set(ABSL_DEFAULT_LINKOPTS "${ABSL_MSVC_LINKOPTS}") +else() + message(WARNING "Unknown compiler: ${CMAKE_CXX_COMPILER}. Building with no default flags") + set(ABSL_DEFAULT_COPTS "") + set(ABSL_TEST_COPTS "") +endif() + +set(ABSL_CXX_STANDARD "${CMAKE_CXX_STANDARD}") diff --git a/third_party/abseil_cpp/absl/copts/GENERATED_AbseilCopts.cmake b/third_party/abseil_cpp/absl/copts/GENERATED_AbseilCopts.cmake new file mode 100644 index 0000000000..7ef6339be2 --- /dev/null +++ b/third_party/abseil_cpp/absl/copts/GENERATED_AbseilCopts.cmake @@ -0,0 +1,213 @@ +# GENERATED! DO NOT MANUALLY EDIT THIS FILE. +# +# (1) Edit absl/copts/copts.py. +# (2) Run `python <path_to_absl>/copts/generate_copts.py`. + +list(APPEND ABSL_CLANG_CL_FLAGS + "/W3" + "-Wno-c++98-compat-pedantic" + "-Wno-conversion" + "-Wno-covered-switch-default" + "-Wno-deprecated" + "-Wno-disabled-macro-expansion" + "-Wno-double-promotion" + "-Wno-comma" + "-Wno-extra-semi" + "-Wno-extra-semi-stmt" + "-Wno-packed" + "-Wno-padded" + "-Wno-sign-compare" + "-Wno-float-conversion" + "-Wno-float-equal" + "-Wno-format-nonliteral" + "-Wno-gcc-compat" + "-Wno-global-constructors" + "-Wno-exit-time-destructors" + "-Wno-non-modular-include-in-module" + "-Wno-old-style-cast" + "-Wno-range-loop-analysis" + "-Wno-reserved-id-macro" + "-Wno-shorten-64-to-32" + "-Wno-switch-enum" + "-Wno-thread-safety-negative" + "-Wno-unknown-warning-option" + "-Wno-unreachable-code" + "-Wno-unused-macros" + "-Wno-weak-vtables" + "-Wno-zero-as-null-pointer-constant" + "-Wbitfield-enum-conversion" + "-Wbool-conversion" + "-Wconstant-conversion" + "-Wenum-conversion" + "-Wint-conversion" + "-Wliteral-conversion" + "-Wnon-literal-null-conversion" + "-Wnull-conversion" + "-Wobjc-literal-conversion" + "-Wno-sign-conversion" + "-Wstring-conversion" + "/DNOMINMAX" + "/DWIN32_LEAN_AND_MEAN" + "/D_CRT_SECURE_NO_WARNINGS" + "/D_SCL_SECURE_NO_WARNINGS" + "/D_ENABLE_EXTENDED_ALIGNED_STORAGE" +) + +list(APPEND ABSL_CLANG_CL_TEST_FLAGS + "-Wno-c99-extensions" + "-Wno-deprecated-declarations" + "-Wno-missing-noreturn" + "-Wno-missing-prototypes" + "-Wno-missing-variable-declarations" + "-Wno-null-conversion" + "-Wno-shadow" + "-Wno-shift-sign-overflow" + "-Wno-sign-compare" + "-Wno-unused-function" + "-Wno-unused-member-function" + "-Wno-unused-parameter" + "-Wno-unused-private-field" + "-Wno-unused-template" + "-Wno-used-but-marked-unused" + "-Wno-zero-as-null-pointer-constant" + "-Wno-gnu-zero-variadic-macro-arguments" +) + +list(APPEND ABSL_GCC_FLAGS + "-Wall" + "-Wextra" + "-Wcast-qual" + "-Wconversion-null" + "-Wmissing-declarations" + "-Woverlength-strings" + "-Wpointer-arith" + "-Wunused-local-typedefs" + "-Wunused-result" + "-Wvarargs" + "-Wvla" + "-Wwrite-strings" + "-Wno-missing-field-initializers" + "-Wno-sign-compare" +) + +list(APPEND ABSL_GCC_TEST_FLAGS + "-Wno-conversion-null" + "-Wno-deprecated-declarations" + "-Wno-missing-declarations" + "-Wno-sign-compare" + "-Wno-unused-function" + "-Wno-unused-parameter" + "-Wno-unused-private-field" +) + +list(APPEND ABSL_LLVM_FLAGS + "-Wall" + "-Wextra" + "-Weverything" + "-Wno-c++98-compat-pedantic" + "-Wno-conversion" + "-Wno-covered-switch-default" + "-Wno-deprecated" + "-Wno-disabled-macro-expansion" + "-Wno-double-promotion" + "-Wno-comma" + "-Wno-extra-semi" + "-Wno-extra-semi-stmt" + "-Wno-packed" + "-Wno-padded" + "-Wno-sign-compare" + "-Wno-float-conversion" + "-Wno-float-equal" + "-Wno-format-nonliteral" + "-Wno-gcc-compat" + "-Wno-global-constructors" + "-Wno-exit-time-destructors" + "-Wno-non-modular-include-in-module" + "-Wno-old-style-cast" + "-Wno-range-loop-analysis" + "-Wno-reserved-id-macro" + "-Wno-shorten-64-to-32" + "-Wno-switch-enum" + "-Wno-thread-safety-negative" + "-Wno-unknown-warning-option" + "-Wno-unreachable-code" + "-Wno-unused-macros" + "-Wno-weak-vtables" + "-Wno-zero-as-null-pointer-constant" + "-Wbitfield-enum-conversion" + "-Wbool-conversion" + "-Wconstant-conversion" + "-Wenum-conversion" + "-Wint-conversion" + "-Wliteral-conversion" + "-Wnon-literal-null-conversion" + "-Wnull-conversion" + "-Wobjc-literal-conversion" + "-Wno-sign-conversion" + "-Wstring-conversion" +) + +list(APPEND ABSL_LLVM_TEST_FLAGS + "-Wno-c99-extensions" + "-Wno-deprecated-declarations" + "-Wno-missing-noreturn" + "-Wno-missing-prototypes" + "-Wno-missing-variable-declarations" + "-Wno-null-conversion" + "-Wno-shadow" + "-Wno-shift-sign-overflow" + "-Wno-sign-compare" + "-Wno-unused-function" + "-Wno-unused-member-function" + "-Wno-unused-parameter" + "-Wno-unused-private-field" + "-Wno-unused-template" + "-Wno-used-but-marked-unused" + "-Wno-zero-as-null-pointer-constant" + "-Wno-gnu-zero-variadic-macro-arguments" +) + +list(APPEND ABSL_MSVC_FLAGS + "/W3" + "/DNOMINMAX" + "/DWIN32_LEAN_AND_MEAN" + "/D_CRT_SECURE_NO_WARNINGS" + "/D_SCL_SECURE_NO_WARNINGS" + "/D_ENABLE_EXTENDED_ALIGNED_STORAGE" + "/bigobj" + "/wd4005" + "/wd4068" + "/wd4180" + "/wd4244" + "/wd4267" + "/wd4503" + "/wd4800" +) + +list(APPEND ABSL_MSVC_LINKOPTS + "-ignore:4221" +) + +list(APPEND ABSL_MSVC_TEST_FLAGS + "/wd4018" + "/wd4101" + "/wd4503" + "/wd4996" + "/DNOMINMAX" +) + +list(APPEND ABSL_RANDOM_HWAES_ARM32_FLAGS + "-mfpu=neon" +) + +list(APPEND ABSL_RANDOM_HWAES_ARM64_FLAGS + "-march=armv8-a+crypto" +) + +list(APPEND ABSL_RANDOM_HWAES_MSVC_X64_FLAGS +) + +list(APPEND ABSL_RANDOM_HWAES_X64_FLAGS + "-maes" + "-msse4.1" +) diff --git a/third_party/abseil_cpp/absl/copts/GENERATED_copts.bzl b/third_party/abseil_cpp/absl/copts/GENERATED_copts.bzl new file mode 100644 index 0000000000..3cc487845c --- /dev/null +++ b/third_party/abseil_cpp/absl/copts/GENERATED_copts.bzl @@ -0,0 +1,214 @@ +"""GENERATED! DO NOT MANUALLY EDIT THIS FILE. + +(1) Edit absl/copts/copts.py. +(2) Run `python <path_to_absl>/copts/generate_copts.py`. +""" + +ABSL_CLANG_CL_FLAGS = [ + "/W3", + "-Wno-c++98-compat-pedantic", + "-Wno-conversion", + "-Wno-covered-switch-default", + "-Wno-deprecated", + "-Wno-disabled-macro-expansion", + "-Wno-double-promotion", + "-Wno-comma", + "-Wno-extra-semi", + "-Wno-extra-semi-stmt", + "-Wno-packed", + "-Wno-padded", + "-Wno-sign-compare", + "-Wno-float-conversion", + "-Wno-float-equal", + "-Wno-format-nonliteral", + "-Wno-gcc-compat", + "-Wno-global-constructors", + "-Wno-exit-time-destructors", + "-Wno-non-modular-include-in-module", + "-Wno-old-style-cast", + "-Wno-range-loop-analysis", + "-Wno-reserved-id-macro", + "-Wno-shorten-64-to-32", + "-Wno-switch-enum", + "-Wno-thread-safety-negative", + "-Wno-unknown-warning-option", + "-Wno-unreachable-code", + "-Wno-unused-macros", + "-Wno-weak-vtables", + "-Wno-zero-as-null-pointer-constant", + "-Wbitfield-enum-conversion", + "-Wbool-conversion", + "-Wconstant-conversion", + "-Wenum-conversion", + "-Wint-conversion", + "-Wliteral-conversion", + "-Wnon-literal-null-conversion", + "-Wnull-conversion", + "-Wobjc-literal-conversion", + "-Wno-sign-conversion", + "-Wstring-conversion", + "/DNOMINMAX", + "/DWIN32_LEAN_AND_MEAN", + "/D_CRT_SECURE_NO_WARNINGS", + "/D_SCL_SECURE_NO_WARNINGS", + "/D_ENABLE_EXTENDED_ALIGNED_STORAGE", +] + +ABSL_CLANG_CL_TEST_FLAGS = [ + "-Wno-c99-extensions", + "-Wno-deprecated-declarations", + "-Wno-missing-noreturn", + "-Wno-missing-prototypes", + "-Wno-missing-variable-declarations", + "-Wno-null-conversion", + "-Wno-shadow", + "-Wno-shift-sign-overflow", + "-Wno-sign-compare", + "-Wno-unused-function", + "-Wno-unused-member-function", + "-Wno-unused-parameter", + "-Wno-unused-private-field", + "-Wno-unused-template", + "-Wno-used-but-marked-unused", + "-Wno-zero-as-null-pointer-constant", + "-Wno-gnu-zero-variadic-macro-arguments", +] + +ABSL_GCC_FLAGS = [ + "-Wall", + "-Wextra", + "-Wcast-qual", + "-Wconversion-null", + "-Wmissing-declarations", + "-Woverlength-strings", + "-Wpointer-arith", + "-Wunused-local-typedefs", + "-Wunused-result", + "-Wvarargs", + "-Wvla", + "-Wwrite-strings", + "-Wno-missing-field-initializers", + "-Wno-sign-compare", +] + +ABSL_GCC_TEST_FLAGS = [ + "-Wno-conversion-null", + "-Wno-deprecated-declarations", + "-Wno-missing-declarations", + "-Wno-sign-compare", + "-Wno-unused-function", + "-Wno-unused-parameter", + "-Wno-unused-private-field", +] + +ABSL_LLVM_FLAGS = [ + "-Wall", + "-Wextra", + "-Weverything", + "-Wno-c++98-compat-pedantic", + "-Wno-conversion", + "-Wno-covered-switch-default", + "-Wno-deprecated", + "-Wno-disabled-macro-expansion", + "-Wno-double-promotion", + "-Wno-comma", + "-Wno-extra-semi", + "-Wno-extra-semi-stmt", + "-Wno-packed", + "-Wno-padded", + "-Wno-sign-compare", + "-Wno-float-conversion", + "-Wno-float-equal", + "-Wno-format-nonliteral", + "-Wno-gcc-compat", + "-Wno-global-constructors", + "-Wno-exit-time-destructors", + "-Wno-non-modular-include-in-module", + "-Wno-old-style-cast", + "-Wno-range-loop-analysis", + "-Wno-reserved-id-macro", + "-Wno-shorten-64-to-32", + "-Wno-switch-enum", + "-Wno-thread-safety-negative", + "-Wno-unknown-warning-option", + "-Wno-unreachable-code", + "-Wno-unused-macros", + "-Wno-weak-vtables", + "-Wno-zero-as-null-pointer-constant", + "-Wbitfield-enum-conversion", + "-Wbool-conversion", + "-Wconstant-conversion", + "-Wenum-conversion", + "-Wint-conversion", + "-Wliteral-conversion", + "-Wnon-literal-null-conversion", + "-Wnull-conversion", + "-Wobjc-literal-conversion", + "-Wno-sign-conversion", + "-Wstring-conversion", +] + +ABSL_LLVM_TEST_FLAGS = [ + "-Wno-c99-extensions", + "-Wno-deprecated-declarations", + "-Wno-missing-noreturn", + "-Wno-missing-prototypes", + "-Wno-missing-variable-declarations", + "-Wno-null-conversion", + "-Wno-shadow", + "-Wno-shift-sign-overflow", + "-Wno-sign-compare", + "-Wno-unused-function", + "-Wno-unused-member-function", + "-Wno-unused-parameter", + "-Wno-unused-private-field", + "-Wno-unused-template", + "-Wno-used-but-marked-unused", + "-Wno-zero-as-null-pointer-constant", + "-Wno-gnu-zero-variadic-macro-arguments", +] + +ABSL_MSVC_FLAGS = [ + "/W3", + "/DNOMINMAX", + "/DWIN32_LEAN_AND_MEAN", + "/D_CRT_SECURE_NO_WARNINGS", + "/D_SCL_SECURE_NO_WARNINGS", + "/D_ENABLE_EXTENDED_ALIGNED_STORAGE", + "/bigobj", + "/wd4005", + "/wd4068", + "/wd4180", + "/wd4244", + "/wd4267", + "/wd4503", + "/wd4800", +] + +ABSL_MSVC_LINKOPTS = [ + "-ignore:4221", +] + +ABSL_MSVC_TEST_FLAGS = [ + "/wd4018", + "/wd4101", + "/wd4503", + "/wd4996", + "/DNOMINMAX", +] + +ABSL_RANDOM_HWAES_ARM32_FLAGS = [ + "-mfpu=neon", +] + +ABSL_RANDOM_HWAES_ARM64_FLAGS = [ + "-march=armv8-a+crypto", +] + +ABSL_RANDOM_HWAES_MSVC_X64_FLAGS = [ +] + +ABSL_RANDOM_HWAES_X64_FLAGS = [ + "-maes", + "-msse4.1", +] diff --git a/third_party/abseil_cpp/absl/copts/configure_copts.bzl b/third_party/abseil_cpp/absl/copts/configure_copts.bzl new file mode 100644 index 0000000000..ff9a5ea9f4 --- /dev/null +++ b/third_party/abseil_cpp/absl/copts/configure_copts.bzl @@ -0,0 +1,78 @@ +"""absl specific copts. + +This file simply selects the correct options from the generated files. To +change Abseil copts, edit absl/copts/copts.py +""" + +load( + "//absl:copts/GENERATED_copts.bzl", + "ABSL_CLANG_CL_FLAGS", + "ABSL_CLANG_CL_TEST_FLAGS", + "ABSL_GCC_FLAGS", + "ABSL_GCC_TEST_FLAGS", + "ABSL_LLVM_FLAGS", + "ABSL_LLVM_TEST_FLAGS", + "ABSL_MSVC_FLAGS", + "ABSL_MSVC_LINKOPTS", + "ABSL_MSVC_TEST_FLAGS", + "ABSL_RANDOM_HWAES_ARM32_FLAGS", + "ABSL_RANDOM_HWAES_ARM64_FLAGS", + "ABSL_RANDOM_HWAES_MSVC_X64_FLAGS", + "ABSL_RANDOM_HWAES_X64_FLAGS", +) + +ABSL_DEFAULT_COPTS = select({ + "//absl:windows": ABSL_MSVC_FLAGS, + "//absl:llvm_compiler": ABSL_LLVM_FLAGS, + "//conditions:default": ABSL_GCC_FLAGS, +}) + +# in absence of modules (--compiler=gcc or -c opt), cc_tests leak their copts +# to their (included header) dependencies and fail to build outside absl +ABSL_TEST_COPTS = ABSL_DEFAULT_COPTS + select({ + "//absl:windows": ABSL_MSVC_TEST_FLAGS, + "//absl:llvm_compiler": ABSL_LLVM_TEST_FLAGS, + "//conditions:default": ABSL_GCC_TEST_FLAGS, +}) + +ABSL_DEFAULT_LINKOPTS = select({ + "//absl:windows": ABSL_MSVC_LINKOPTS, + "//conditions:default": [], +}) + +# ABSL_RANDOM_RANDEN_COPTS blaze copts flags which are required by each +# environment to build an accelerated RandenHwAes library. +ABSL_RANDOM_RANDEN_COPTS = select({ + # APPLE + ":cpu_darwin_x86_64": ABSL_RANDOM_HWAES_X64_FLAGS, + ":cpu_darwin": ABSL_RANDOM_HWAES_X64_FLAGS, + ":cpu_x64_windows_msvc": ABSL_RANDOM_HWAES_MSVC_X64_FLAGS, + ":cpu_x64_windows": ABSL_RANDOM_HWAES_MSVC_X64_FLAGS, + ":cpu_k8": ABSL_RANDOM_HWAES_X64_FLAGS, + ":cpu_ppc": ["-mcrypto"], + + # Supported by default or unsupported. + "//conditions:default": [], +}) + +# absl_random_randen_copts_init: +# Initialize the config targets based on cpu, os, etc. used to select +# the required values for ABSL_RANDOM_RANDEN_COPTS +def absl_random_randen_copts_init(): + """Initialize the config_settings used by ABSL_RANDOM_RANDEN_COPTS.""" + + # CPU configs. + # These configs have consistent flags to enable HWAES intsructions. + cpu_configs = [ + "ppc", + "k8", + "darwin_x86_64", + "darwin", + "x64_windows_msvc", + "x64_windows", + ] + for cpu in cpu_configs: + native.config_setting( + name = "cpu_%s" % cpu, + values = {"cpu": cpu}, + ) diff --git a/third_party/abseil_cpp/absl/copts/copts.py b/third_party/abseil_cpp/absl/copts/copts.py new file mode 100644 index 0000000000..704ef23450 --- /dev/null +++ b/third_party/abseil_cpp/absl/copts/copts.py @@ -0,0 +1,200 @@ +"""Abseil compiler options. + +This is the source of truth for Abseil compiler options. To modify Abseil +compilation options: + + (1) Edit the appropriate list in this file based on the platform the flag is + needed on. + (2) Run `<path_to_absl>/copts/generate_copts.py`. + +The generated copts are consumed by configure_copts.bzl and +AbseilConfigureCopts.cmake. +""" + +# /Wall with msvc includes unhelpful warnings such as C4711, C4710, ... +MSVC_BIG_WARNING_FLAGS = [ + "/W3", +] + +LLVM_BIG_WARNING_FLAGS = [ + "-Wall", + "-Wextra", + "-Weverything", +] + +# Docs on single flags is preceded by a comment. +# Docs on groups of flags is preceded by ###. +LLVM_DISABLE_WARNINGS_FLAGS = [ + # Abseil does not support C++98 + "-Wno-c++98-compat-pedantic", + # Turns off all implicit conversion warnings. Most are re-enabled below. + "-Wno-conversion", + "-Wno-covered-switch-default", + "-Wno-deprecated", + "-Wno-disabled-macro-expansion", + "-Wno-double-promotion", + ### + # Turned off as they include valid C++ code. + "-Wno-comma", + "-Wno-extra-semi", + "-Wno-extra-semi-stmt", + "-Wno-packed", + "-Wno-padded", + ### + # Google style does not use unsigned integers, though STL containers + # have unsigned types. + "-Wno-sign-compare", + ### + "-Wno-float-conversion", + "-Wno-float-equal", + "-Wno-format-nonliteral", + # Too aggressive: warns on Clang extensions enclosed in Clang-only + # compilation paths. + "-Wno-gcc-compat", + ### + # Some internal globals are necessary. Don't do this at home. + "-Wno-global-constructors", + "-Wno-exit-time-destructors", + ### + "-Wno-non-modular-include-in-module", + "-Wno-old-style-cast", + # Warns on preferred usage of non-POD types such as string_view + "-Wno-range-loop-analysis", + "-Wno-reserved-id-macro", + "-Wno-shorten-64-to-32", + "-Wno-switch-enum", + "-Wno-thread-safety-negative", + "-Wno-unknown-warning-option", + "-Wno-unreachable-code", + # Causes warnings on include guards + "-Wno-unused-macros", + "-Wno-weak-vtables", + # Causes warnings on usage of types/compare.h comparison operators. + "-Wno-zero-as-null-pointer-constant", + ### + # Implicit conversion warnings turned off by -Wno-conversion + # which are re-enabled below. + "-Wbitfield-enum-conversion", + "-Wbool-conversion", + "-Wconstant-conversion", + "-Wenum-conversion", + "-Wint-conversion", + "-Wliteral-conversion", + "-Wnon-literal-null-conversion", + "-Wnull-conversion", + "-Wobjc-literal-conversion", + "-Wno-sign-conversion", + "-Wstring-conversion", +] + +LLVM_TEST_DISABLE_WARNINGS_FLAGS = [ + "-Wno-c99-extensions", + "-Wno-deprecated-declarations", + "-Wno-missing-noreturn", + "-Wno-missing-prototypes", + "-Wno-missing-variable-declarations", + "-Wno-null-conversion", + "-Wno-shadow", + "-Wno-shift-sign-overflow", + "-Wno-sign-compare", + "-Wno-unused-function", + "-Wno-unused-member-function", + "-Wno-unused-parameter", + "-Wno-unused-private-field", + "-Wno-unused-template", + "-Wno-used-but-marked-unused", + "-Wno-zero-as-null-pointer-constant", + # gtest depends on this GNU extension being offered. + "-Wno-gnu-zero-variadic-macro-arguments", +] + +MSVC_DEFINES = [ + "/DNOMINMAX", # Don't define min and max macros (windows.h) + # Don't bloat namespace with incompatible winsock versions. + "/DWIN32_LEAN_AND_MEAN", + # Don't warn about usage of insecure C functions. + "/D_CRT_SECURE_NO_WARNINGS", + "/D_SCL_SECURE_NO_WARNINGS", + # Introduced in VS 2017 15.8, allow overaligned types in aligned_storage + "/D_ENABLE_EXTENDED_ALIGNED_STORAGE", +] + +COPT_VARS = { + "ABSL_GCC_FLAGS": [ + "-Wall", + "-Wextra", + "-Wcast-qual", + "-Wconversion-null", + "-Wmissing-declarations", + "-Woverlength-strings", + "-Wpointer-arith", + "-Wunused-local-typedefs", + "-Wunused-result", + "-Wvarargs", + "-Wvla", # variable-length array + "-Wwrite-strings", + # gcc-4.x has spurious missing field initializer warnings. + # https://gcc.gnu.org/bugzilla/show_bug.cgi?id=36750 + # Remove when gcc-4.x is no longer supported. + "-Wno-missing-field-initializers", + # Google style does not use unsigned integers, though STL containers + # have unsigned types. + "-Wno-sign-compare", + ], + "ABSL_GCC_TEST_FLAGS": [ + "-Wno-conversion-null", + "-Wno-deprecated-declarations", + "-Wno-missing-declarations", + "-Wno-sign-compare", + "-Wno-unused-function", + "-Wno-unused-parameter", + "-Wno-unused-private-field", + ], + "ABSL_LLVM_FLAGS": + LLVM_BIG_WARNING_FLAGS + LLVM_DISABLE_WARNINGS_FLAGS, + "ABSL_LLVM_TEST_FLAGS": + LLVM_TEST_DISABLE_WARNINGS_FLAGS, + "ABSL_CLANG_CL_FLAGS": + (MSVC_BIG_WARNING_FLAGS + LLVM_DISABLE_WARNINGS_FLAGS + MSVC_DEFINES), + "ABSL_CLANG_CL_TEST_FLAGS": + LLVM_TEST_DISABLE_WARNINGS_FLAGS, + "ABSL_MSVC_FLAGS": + MSVC_BIG_WARNING_FLAGS + MSVC_DEFINES + [ + # Increase the number of sections available in object files + "/bigobj", + "/wd4005", # macro-redefinition + "/wd4068", # unknown pragma + # qualifier applied to function type has no meaning; ignored + "/wd4180", + # conversion from 'type1' to 'type2', possible loss of data + "/wd4244", + # conversion from 'size_t' to 'type', possible loss of data + "/wd4267", + # The decorated name was longer than the compiler limit + "/wd4503", + # forcing value to bool 'true' or 'false' (performance warning) + "/wd4800", + ], + "ABSL_MSVC_TEST_FLAGS": [ + "/wd4018", # signed/unsigned mismatch + "/wd4101", # unreferenced local variable + "/wd4503", # decorated name length exceeded, name was truncated + "/wd4996", # use of deprecated symbol + "/DNOMINMAX", # disable the min() and max() macros from <windows.h> + ], + "ABSL_MSVC_LINKOPTS": [ + # Object file doesn't export any previously undefined symbols + "-ignore:4221", + ], + # "HWAES" is an abbreviation for "hardware AES" (AES - Advanced Encryption + # Standard). These flags are used for detecting whether or not the target + # architecture has hardware support for AES instructions which can be used + # to improve performance of some random bit generators. + "ABSL_RANDOM_HWAES_ARM64_FLAGS": ["-march=armv8-a+crypto"], + "ABSL_RANDOM_HWAES_ARM32_FLAGS": ["-mfpu=neon"], + "ABSL_RANDOM_HWAES_X64_FLAGS": [ + "-maes", + "-msse4.1", + ], + "ABSL_RANDOM_HWAES_MSVC_X64_FLAGS": [], +} diff --git a/third_party/abseil_cpp/absl/copts/generate_copts.py b/third_party/abseil_cpp/absl/copts/generate_copts.py new file mode 100755 index 0000000000..0e5dc9fad2 --- /dev/null +++ b/third_party/abseil_cpp/absl/copts/generate_copts.py @@ -0,0 +1,109 @@ +#!/usr/bin/python +"""Generate Abseil compile compile option configs. + +Usage: <path_to_absl>/copts/generate_copts.py + +The configs are generated from copts.py. +""" + +from os import path +import sys +from copts import COPT_VARS + + +# Helper functions +def file_header_lines(): + return [ + "GENERATED! DO NOT MANUALLY EDIT THIS FILE.", "", + "(1) Edit absl/copts/copts.py.", + "(2) Run `python <path_to_absl>/copts/generate_copts.py`." + ] + + +def flatten(*lists): + return [item for sublist in lists for item in sublist] + + +def relative_filename(filename): + return path.join(path.dirname(__file__), filename) + + +# Style classes. These contain all the syntactic styling needed to generate a +# copt file for different build tools. +class CMakeStyle(object): + """Style object for CMake copts file.""" + + def separator(self): + return "" + + def list_introducer(self, name): + return "list(APPEND " + name + + def list_closer(self): + return ")\n" + + def docstring(self): + return "\n".join((("# " + line).strip() for line in file_header_lines())) + + def filename(self): + return "GENERATED_AbseilCopts.cmake" + + +class StarlarkStyle(object): + """Style object for Starlark copts file.""" + + def separator(self): + return "," + + def list_introducer(self, name): + return name + " = [" + + def list_closer(self): + return "]\n" + + def docstring(self): + docstring_quotes = "\"\"\"" + return docstring_quotes + "\n".join( + flatten(file_header_lines(), [docstring_quotes])) + + def filename(self): + return "GENERATED_copts.bzl" + + +def copt_list(name, arg_list, style): + """Copt file generation.""" + + make_line = lambda s: " \"" + s + "\"" + style.separator() + external_str_list = [make_line(s) for s in arg_list] + + return "\n".join( + flatten( + [style.list_introducer(name)], + external_str_list, + [style.list_closer()])) + + +def generate_copt_file(style): + """Creates a generated copt file using the given style object. + + Args: + style: either StarlarkStyle() or CMakeStyle() + """ + with open(relative_filename(style.filename()), "w") as f: + f.write(style.docstring()) + f.write("\n") + for var_name, arg_list in sorted(COPT_VARS.items()): + f.write("\n") + f.write(copt_list(var_name, arg_list, style)) + + +def main(argv): + if len(argv) > 1: + raise RuntimeError("generate_copts needs no command line args") + + generate_copt_file(StarlarkStyle()) + generate_copt_file(CMakeStyle()) + + +if __name__ == "__main__": + main(sys.argv) diff --git a/third_party/abseil_cpp/absl/debugging/BUILD.bazel b/third_party/abseil_cpp/absl/debugging/BUILD.bazel new file mode 100644 index 0000000000..8f521bec46 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/BUILD.bazel @@ -0,0 +1,341 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package( + default_visibility = ["//visibility:public"], +) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "stacktrace", + srcs = [ + "internal/stacktrace_aarch64-inl.inc", + "internal/stacktrace_arm-inl.inc", + "internal/stacktrace_config.h", + "internal/stacktrace_generic-inl.inc", + "internal/stacktrace_powerpc-inl.inc", + "internal/stacktrace_unimplemented-inl.inc", + "internal/stacktrace_win32-inl.inc", + "internal/stacktrace_x86-inl.inc", + "stacktrace.cc", + ], + hdrs = ["stacktrace.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":debugging_internal", + "//absl/base:config", + "//absl/base:core_headers", + ], +) + +cc_library( + name = "symbolize", + srcs = [ + "symbolize.cc", + "symbolize_elf.inc", + "symbolize_unimplemented.inc", + "symbolize_win32.inc", + ], + hdrs = [ + "internal/symbolize.h", + "symbolize.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS + select({ + "//absl:windows": ["-DEFAULTLIB:dbghelp.lib"], + "//conditions:default": [], + }), + deps = [ + ":debugging_internal", + ":demangle_internal", + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:dynamic_annotations", + "//absl/base:malloc_internal", + "//absl/base:raw_logging_internal", + ], +) + +cc_test( + name = "symbolize_test", + srcs = ["symbolize_test.cc"], + copts = ABSL_TEST_COPTS + select({ + "//absl:windows": ["/Z7"], + "//conditions:default": [], + }), + linkopts = ABSL_DEFAULT_LINKOPTS + select({ + "//absl:windows": ["/DEBUG"], + "//conditions:default": [], + }), + deps = [ + ":stack_consumption", + ":symbolize", + "//absl/base", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/memory", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "examine_stack", + srcs = [ + "internal/examine_stack.cc", + ], + hdrs = [ + "internal/examine_stack.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + ":stacktrace", + ":symbolize", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + ], +) + +cc_library( + name = "failure_signal_handler", + srcs = ["failure_signal_handler.cc"], + hdrs = ["failure_signal_handler.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":examine_stack", + ":stacktrace", + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:errno_saver", + "//absl/base:raw_logging_internal", + ], +) + +cc_test( + name = "failure_signal_handler_test", + srcs = ["failure_signal_handler_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = select({ + "//absl:windows": [], + "//conditions:default": ["-pthread"], + }) + ABSL_DEFAULT_LINKOPTS, + deps = [ + ":failure_signal_handler", + ":stacktrace", + ":symbolize", + "//absl/base:raw_logging_internal", + "//absl/strings", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "debugging_internal", + srcs = [ + "internal/address_is_readable.cc", + "internal/elf_mem_image.cc", + "internal/vdso_support.cc", + ], + hdrs = [ + "internal/address_is_readable.h", + "internal/elf_mem_image.h", + "internal/vdso_support.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:dynamic_annotations", + "//absl/base:errno_saver", + "//absl/base:raw_logging_internal", + ], +) + +cc_library( + name = "demangle_internal", + srcs = ["internal/demangle.cc"], + hdrs = ["internal/demangle.h"], + copts = ABSL_DEFAULT_COPTS, + deps = [ + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + ], +) + +cc_test( + name = "demangle_test", + srcs = ["internal/demangle_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":demangle_internal", + ":stack_consumption", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "leak_check", + srcs = ["leak_check.cc"], + hdrs = ["leak_check.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + ], +) + +# Adding a dependency to leak_check_disable will disable +# sanitizer leak checking (asan/lsan) in a test without +# the need to mess around with build features. +cc_library( + name = "leak_check_disable", + srcs = ["leak_check_disable.cc"], + linkopts = ABSL_DEFAULT_LINKOPTS, + linkstatic = 1, + deps = ["//absl/base:config"], + alwayslink = 1, +) + +# These targets exists for use in tests only, explicitly configuring the +# LEAK_SANITIZER macro. It must be linked with -fsanitize=leak for lsan. +ABSL_LSAN_LINKOPTS = select({ + "//absl:llvm_compiler": ["-fsanitize=leak"], + "//conditions:default": [], +}) + +cc_library( + name = "leak_check_api_enabled_for_testing", + testonly = 1, + srcs = ["leak_check.cc"], + hdrs = ["leak_check.h"], + copts = select({ + "//absl:llvm_compiler": ["-DLEAK_SANITIZER"], + "//conditions:default": [], + }), + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + "//absl/base:config", + ], +) + +cc_library( + name = "leak_check_api_disabled_for_testing", + testonly = 1, + srcs = ["leak_check.cc"], + hdrs = ["leak_check.h"], + copts = ["-ULEAK_SANITIZER"], + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + "//absl/base:config", + ], +) + +cc_test( + name = "leak_check_test", + srcs = ["leak_check_test.cc"], + copts = select({ + "//absl:llvm_compiler": ["-DABSL_EXPECT_LEAK_SANITIZER"], + "//conditions:default": [], + }), + linkopts = ABSL_LSAN_LINKOPTS + ABSL_DEFAULT_LINKOPTS, + tags = ["notsan"], + deps = [ + ":leak_check_api_enabled_for_testing", + "//absl/base", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "leak_check_no_lsan_test", + srcs = ["leak_check_test.cc"], + copts = ["-UABSL_EXPECT_LEAK_SANITIZER"], + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["noasan"], + deps = [ + ":leak_check_api_disabled_for_testing", + "//absl/base", # for raw_logging + "@com_google_googletest//:gtest_main", + ], +) + +# Test that leak checking is skipped when lsan is enabled but +# ":leak_check_disable" is linked in. +# +# This test should fail in the absence of a dependency on ":leak_check_disable" +cc_test( + name = "disabled_leak_check_test", + srcs = ["leak_check_fail_test.cc"], + linkopts = ABSL_LSAN_LINKOPTS + ABSL_DEFAULT_LINKOPTS, + tags = ["notsan"], + deps = [ + ":leak_check_api_enabled_for_testing", + ":leak_check_disable", + "//absl/base", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "stack_consumption", + testonly = 1, + srcs = ["internal/stack_consumption.cc"], + hdrs = ["internal/stack_consumption.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + ], +) + +cc_test( + name = "stack_consumption_test", + srcs = ["internal/stack_consumption_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":stack_consumption", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/debugging/CMakeLists.txt b/third_party/abseil_cpp/absl/debugging/CMakeLists.txt new file mode 100644 index 0000000000..7733615939 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/CMakeLists.txt @@ -0,0 +1,333 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + stacktrace + HDRS + "stacktrace.h" + "internal/stacktrace_aarch64-inl.inc" + "internal/stacktrace_arm-inl.inc" + "internal/stacktrace_config.h" + "internal/stacktrace_generic-inl.inc" + "internal/stacktrace_powerpc-inl.inc" + "internal/stacktrace_unimplemented-inl.inc" + "internal/stacktrace_win32-inl.inc" + "internal/stacktrace_x86-inl.inc" + SRCS + "stacktrace.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::debugging_internal + absl::config + absl::core_headers + PUBLIC +) + +absl_cc_library( + NAME + symbolize + HDRS + "symbolize.h" + "internal/symbolize.h" + SRCS + "symbolize.cc" + "symbolize_elf.inc" + "symbolize_unimplemented.inc" + "symbolize_win32.inc" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + $<$<BOOL:${MINGW}>:"dbghelp"> + DEPS + absl::debugging_internal + absl::demangle_internal + absl::base + absl::config + absl::core_headers + absl::dynamic_annotations + absl::malloc_internal + absl::raw_logging_internal + PUBLIC +) + +absl_cc_test( + NAME + symbolize_test + SRCS + "symbolize_test.cc" + COPTS + ${ABSL_TEST_COPTS} + $<$<BOOL:${MSVC}>:-Z7> + LINKOPTS + $<$<BOOL:${MSVC}>:-DEBUG> + DEPS + absl::stack_consumption + absl::symbolize + absl::base + absl::core_headers + absl::memory + absl::raw_logging_internal + gmock +) + +absl_cc_library( + NAME + examine_stack + HDRS + "internal/examine_stack.h" + SRCS + "internal/examine_stack.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::stacktrace + absl::symbolize + absl::config + absl::core_headers + absl::raw_logging_internal +) + +absl_cc_library( + NAME + failure_signal_handler + HDRS + "failure_signal_handler.h" + SRCS + "failure_signal_handler.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::examine_stack + absl::stacktrace + absl::base + absl::config + absl::core_headers + absl::errno_saver + absl::raw_logging_internal + PUBLIC +) + +absl_cc_test( + NAME + failure_signal_handler_test + SRCS + "failure_signal_handler_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::failure_signal_handler + absl::stacktrace + absl::symbolize + absl::strings + absl::raw_logging_internal + Threads::Threads + gmock +) + +absl_cc_library( + NAME + debugging_internal + HDRS + "internal/address_is_readable.h" + "internal/elf_mem_image.h" + "internal/vdso_support.h" + SRCS + "internal/address_is_readable.cc" + "internal/elf_mem_image.cc" + "internal/vdso_support.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::config + absl::dynamic_annotations + absl::errno_saver + absl::raw_logging_internal +) + +absl_cc_library( + NAME + demangle_internal + HDRS + "internal/demangle.h" + SRCS + "internal/demangle.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base + absl::core_headers + PUBLIC +) + +absl_cc_test( + NAME + demangle_test + SRCS + "internal/demangle_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::demangle_internal + absl::stack_consumption + absl::core_headers + absl::memory + absl::raw_logging_internal + gmock_main +) + +absl_cc_library( + NAME + leak_check + HDRS + "leak_check.h" + SRCS + "leak_check.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers + PUBLIC +) + +absl_cc_library( + NAME + leak_check_disable + SRCS + "leak_check_disable.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + PUBLIC +) + +absl_cc_library( + NAME + leak_check_api_enabled_for_testing + HDRS + "leak_check.h" + SRCS + "leak_check.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + $<$<BOOL:${ABSL_HAVE_LSAN}>:-DLEAK_SANITIZER> + TESTONLY +) + +absl_cc_library( + NAME + leak_check_api_disabled_for_testing + HDRS + "leak_check.h" + SRCS + "leak_check.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + "-ULEAK_SANITIZER" + TESTONLY +) + +absl_cc_test( + NAME + leak_check_test + SRCS + "leak_check_test.cc" + COPTS + ${ABSL_TEST_COPTS} + "$<$<BOOL:${ABSL_HAVE_LSAN}>:-DABSL_EXPECT_LEAK_SANITIZER>" + LINKOPTS + "${ABSL_LSAN_LINKOPTS}" + DEPS + absl::leak_check_api_enabled_for_testing + absl::base + gmock_main +) + +absl_cc_test( + NAME + leak_check_no_lsan_test + SRCS + "leak_check_test.cc" + COPTS + ${ABSL_TEST_COPTS} + "-UABSL_EXPECT_LEAK_SANITIZER" + DEPS + absl::leak_check_api_disabled_for_testing + absl::base + gmock_main +) + +absl_cc_test( + NAME + disabled_leak_check_test + SRCS + "leak_check_fail_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + "${ABSL_LSAN_LINKOPTS}" + DEPS + absl::leak_check_api_enabled_for_testing + absl::leak_check_disable + absl::base + absl::raw_logging_internal + gmock_main +) + +absl_cc_library( + NAME + stack_consumption + HDRS + "internal/stack_consumption.h" + SRCS + "internal/stack_consumption.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers + absl::raw_logging_internal + TESTONLY +) + +absl_cc_test( + NAME + stack_consumption_test + SRCS + "internal/stack_consumption_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::stack_consumption + absl::core_headers + absl::raw_logging_internal + gmock_main +) + +# component target +absl_cc_library( + NAME + debugging + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::stacktrace + absl::leak_check + PUBLIC +) diff --git a/third_party/abseil_cpp/absl/debugging/failure_signal_handler.cc b/third_party/abseil_cpp/absl/debugging/failure_signal_handler.cc new file mode 100644 index 0000000000..1f69bfa84d --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/failure_signal_handler.cc @@ -0,0 +1,370 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#include "absl/debugging/failure_signal_handler.h" + +#include "absl/base/config.h" + +#ifdef _WIN32 +#include <windows.h> +#else +#include <unistd.h> +#endif + +#ifdef __APPLE__ +#include <TargetConditionals.h> +#endif + +#ifdef ABSL_HAVE_MMAP +#include <sys/mman.h> +#endif + +#include <algorithm> +#include <atomic> +#include <cerrno> +#include <csignal> +#include <cstdio> +#include <cstring> +#include <ctime> + +#include "absl/base/attributes.h" +#include "absl/base/internal/errno_saver.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/sysinfo.h" +#include "absl/debugging/internal/examine_stack.h" +#include "absl/debugging/stacktrace.h" + +#ifndef _WIN32 +#define ABSL_HAVE_SIGACTION +// Apple WatchOS and TVOS don't allow sigaltstack +#if !(defined(TARGET_OS_WATCH) && TARGET_OS_WATCH) && \ + !(defined(TARGET_OS_TV) && TARGET_OS_TV) +#define ABSL_HAVE_SIGALTSTACK +#endif +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN + +ABSL_CONST_INIT static FailureSignalHandlerOptions fsh_options; + +// Resets the signal handler for signo to the default action for that +// signal, then raises the signal. +static void RaiseToDefaultHandler(int signo) { + signal(signo, SIG_DFL); + raise(signo); +} + +struct FailureSignalData { + const int signo; + const char* const as_string; +#ifdef ABSL_HAVE_SIGACTION + struct sigaction previous_action; + // StructSigaction is used to silence -Wmissing-field-initializers. + using StructSigaction = struct sigaction; + #define FSD_PREVIOUS_INIT FailureSignalData::StructSigaction() +#else + void (*previous_handler)(int); + #define FSD_PREVIOUS_INIT SIG_DFL +#endif +}; + +ABSL_CONST_INIT static FailureSignalData failure_signal_data[] = { + {SIGSEGV, "SIGSEGV", FSD_PREVIOUS_INIT}, + {SIGILL, "SIGILL", FSD_PREVIOUS_INIT}, + {SIGFPE, "SIGFPE", FSD_PREVIOUS_INIT}, + {SIGABRT, "SIGABRT", FSD_PREVIOUS_INIT}, + {SIGTERM, "SIGTERM", FSD_PREVIOUS_INIT}, +#ifndef _WIN32 + {SIGBUS, "SIGBUS", FSD_PREVIOUS_INIT}, + {SIGTRAP, "SIGTRAP", FSD_PREVIOUS_INIT}, +#endif +}; + +#undef FSD_PREVIOUS_INIT + +static void RaiseToPreviousHandler(int signo) { + // Search for the previous handler. + for (const auto& it : failure_signal_data) { + if (it.signo == signo) { +#ifdef ABSL_HAVE_SIGACTION + sigaction(signo, &it.previous_action, nullptr); +#else + signal(signo, it.previous_handler); +#endif + raise(signo); + return; + } + } + + // Not found, use the default handler. + RaiseToDefaultHandler(signo); +} + +namespace debugging_internal { + +const char* FailureSignalToString(int signo) { + for (const auto& it : failure_signal_data) { + if (it.signo == signo) { + return it.as_string; + } + } + return ""; +} + +} // namespace debugging_internal + +#ifdef ABSL_HAVE_SIGALTSTACK + +static bool SetupAlternateStackOnce() { +#if defined(__wasm__) || defined (__asjms__) + const size_t page_mask = getpagesize() - 1; +#else + const size_t page_mask = sysconf(_SC_PAGESIZE) - 1; +#endif + size_t stack_size = (std::max(SIGSTKSZ, 65536) + page_mask) & ~page_mask; +#if defined(ADDRESS_SANITIZER) || defined(MEMORY_SANITIZER) || \ + defined(THREAD_SANITIZER) + // Account for sanitizer instrumentation requiring additional stack space. + stack_size *= 5; +#endif + + stack_t sigstk; + memset(&sigstk, 0, sizeof(sigstk)); + sigstk.ss_size = stack_size; + +#ifdef ABSL_HAVE_MMAP +#ifndef MAP_STACK +#define MAP_STACK 0 +#endif +#if defined(MAP_ANON) && !defined(MAP_ANONYMOUS) +#define MAP_ANONYMOUS MAP_ANON +#endif + sigstk.ss_sp = mmap(nullptr, sigstk.ss_size, PROT_READ | PROT_WRITE, + MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0); + if (sigstk.ss_sp == MAP_FAILED) { + ABSL_RAW_LOG(FATAL, "mmap() for alternate signal stack failed"); + } +#else + sigstk.ss_sp = malloc(sigstk.ss_size); + if (sigstk.ss_sp == nullptr) { + ABSL_RAW_LOG(FATAL, "malloc() for alternate signal stack failed"); + } +#endif + + if (sigaltstack(&sigstk, nullptr) != 0) { + ABSL_RAW_LOG(FATAL, "sigaltstack() failed with errno=%d", errno); + } + return true; +} + +#endif + +#ifdef ABSL_HAVE_SIGACTION + +// Sets up an alternate stack for signal handlers once. +// Returns the appropriate flag for sig_action.sa_flags +// if the system supports using an alternate stack. +static int MaybeSetupAlternateStack() { +#ifdef ABSL_HAVE_SIGALTSTACK + ABSL_ATTRIBUTE_UNUSED static const bool kOnce = SetupAlternateStackOnce(); + return SA_ONSTACK; +#else + return 0; +#endif +} + +static void InstallOneFailureHandler(FailureSignalData* data, + void (*handler)(int, siginfo_t*, void*)) { + struct sigaction act; + memset(&act, 0, sizeof(act)); + sigemptyset(&act.sa_mask); + act.sa_flags |= SA_SIGINFO; + // SA_NODEFER is required to handle SIGABRT from + // ImmediateAbortSignalHandler(). + act.sa_flags |= SA_NODEFER; + if (fsh_options.use_alternate_stack) { + act.sa_flags |= MaybeSetupAlternateStack(); + } + act.sa_sigaction = handler; + ABSL_RAW_CHECK(sigaction(data->signo, &act, &data->previous_action) == 0, + "sigaction() failed"); +} + +#else + +static void InstallOneFailureHandler(FailureSignalData* data, + void (*handler)(int)) { + data->previous_handler = signal(data->signo, handler); + ABSL_RAW_CHECK(data->previous_handler != SIG_ERR, "signal() failed"); +} + +#endif + +static void WriteToStderr(const char* data) { + absl::base_internal::ErrnoSaver errno_saver; + absl::raw_logging_internal::SafeWriteToStderr(data, strlen(data)); +} + +static void WriteSignalMessage(int signo, void (*writerfn)(const char*)) { + char buf[64]; + const char* const signal_string = + debugging_internal::FailureSignalToString(signo); + if (signal_string != nullptr && signal_string[0] != '\0') { + snprintf(buf, sizeof(buf), "*** %s received at time=%ld ***\n", + signal_string, + static_cast<long>(time(nullptr))); // NOLINT(runtime/int) + } else { + snprintf(buf, sizeof(buf), "*** Signal %d received at time=%ld ***\n", + signo, static_cast<long>(time(nullptr))); // NOLINT(runtime/int) + } + writerfn(buf); +} + +// `void*` might not be big enough to store `void(*)(const char*)`. +struct WriterFnStruct { + void (*writerfn)(const char*); +}; + +// Many of the absl::debugging_internal::Dump* functions in +// examine_stack.h take a writer function pointer that has a void* arg +// for historical reasons. failure_signal_handler_writer only takes a +// data pointer. This function converts between these types. +static void WriterFnWrapper(const char* data, void* arg) { + static_cast<WriterFnStruct*>(arg)->writerfn(data); +} + +// Convenient wrapper around DumpPCAndFrameSizesAndStackTrace() for signal +// handlers. "noinline" so that GetStackFrames() skips the top-most stack +// frame for this function. +ABSL_ATTRIBUTE_NOINLINE static void WriteStackTrace( + void* ucontext, bool symbolize_stacktrace, + void (*writerfn)(const char*, void*), void* writerfn_arg) { + constexpr int kNumStackFrames = 32; + void* stack[kNumStackFrames]; + int frame_sizes[kNumStackFrames]; + int min_dropped_frames; + int depth = absl::GetStackFramesWithContext( + stack, frame_sizes, kNumStackFrames, + 1, // Do not include this function in stack trace. + ucontext, &min_dropped_frames); + absl::debugging_internal::DumpPCAndFrameSizesAndStackTrace( + absl::debugging_internal::GetProgramCounter(ucontext), stack, frame_sizes, + depth, min_dropped_frames, symbolize_stacktrace, writerfn, writerfn_arg); +} + +// Called by AbslFailureSignalHandler() to write the failure info. It is +// called once with writerfn set to WriteToStderr() and then possibly +// with writerfn set to the user provided function. +static void WriteFailureInfo(int signo, void* ucontext, + void (*writerfn)(const char*)) { + WriterFnStruct writerfn_struct{writerfn}; + WriteSignalMessage(signo, writerfn); + WriteStackTrace(ucontext, fsh_options.symbolize_stacktrace, WriterFnWrapper, + &writerfn_struct); +} + +// absl::SleepFor() can't be used here since AbslInternalSleepFor() +// may be overridden to do something that isn't async-signal-safe on +// some platforms. +static void PortableSleepForSeconds(int seconds) { +#ifdef _WIN32 + Sleep(seconds * 1000); +#else + struct timespec sleep_time; + sleep_time.tv_sec = seconds; + sleep_time.tv_nsec = 0; + while (nanosleep(&sleep_time, &sleep_time) != 0 && errno == EINTR) {} +#endif +} + +#ifdef ABSL_HAVE_ALARM +// AbslFailureSignalHandler() installs this as a signal handler for +// SIGALRM, then sets an alarm to be delivered to the program after a +// set amount of time. If AbslFailureSignalHandler() hangs for more than +// the alarm timeout, ImmediateAbortSignalHandler() will abort the +// program. +static void ImmediateAbortSignalHandler(int) { + RaiseToDefaultHandler(SIGABRT); +} +#endif + +// absl::base_internal::GetTID() returns pid_t on most platforms, but +// returns absl::base_internal::pid_t on Windows. +using GetTidType = decltype(absl::base_internal::GetTID()); +ABSL_CONST_INIT static std::atomic<GetTidType> failed_tid(0); + +#ifndef ABSL_HAVE_SIGACTION +static void AbslFailureSignalHandler(int signo) { + void* ucontext = nullptr; +#else +static void AbslFailureSignalHandler(int signo, siginfo_t*, void* ucontext) { +#endif + + const GetTidType this_tid = absl::base_internal::GetTID(); + GetTidType previous_failed_tid = 0; + if (!failed_tid.compare_exchange_strong( + previous_failed_tid, static_cast<intptr_t>(this_tid), + std::memory_order_acq_rel, std::memory_order_relaxed)) { + ABSL_RAW_LOG( + ERROR, + "Signal %d raised at PC=%p while already in AbslFailureSignalHandler()", + signo, absl::debugging_internal::GetProgramCounter(ucontext)); + if (this_tid != previous_failed_tid) { + // Another thread is already in AbslFailureSignalHandler(), so wait + // a bit for it to finish. If the other thread doesn't kill us, + // we do so after sleeping. + PortableSleepForSeconds(3); + RaiseToDefaultHandler(signo); + // The recursively raised signal may be blocked until we return. + return; + } + } + +#ifdef ABSL_HAVE_ALARM + // Set an alarm to abort the program in case this code hangs or deadlocks. + if (fsh_options.alarm_on_failure_secs > 0) { + alarm(0); // Cancel any existing alarms. + signal(SIGALRM, ImmediateAbortSignalHandler); + alarm(fsh_options.alarm_on_failure_secs); + } +#endif + + // First write to stderr. + WriteFailureInfo(signo, ucontext, WriteToStderr); + + // Riskier code (because it is less likely to be async-signal-safe) + // goes after this point. + if (fsh_options.writerfn != nullptr) { + WriteFailureInfo(signo, ucontext, fsh_options.writerfn); + } + + if (fsh_options.call_previous_handler) { + RaiseToPreviousHandler(signo); + } else { + RaiseToDefaultHandler(signo); + } +} + +void InstallFailureSignalHandler(const FailureSignalHandlerOptions& options) { + fsh_options = options; + for (auto& it : failure_signal_data) { + InstallOneFailureHandler(&it, AbslFailureSignalHandler); + } +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/failure_signal_handler.h b/third_party/abseil_cpp/absl/debugging/failure_signal_handler.h new file mode 100644 index 0000000000..0c0f585d0f --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/failure_signal_handler.h @@ -0,0 +1,121 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: failure_signal_handler.h +// ----------------------------------------------------------------------------- +// +// This file configures the Abseil *failure signal handler* to capture and dump +// useful debugging information (such as a stacktrace) upon program failure. +// +// To use the failure signal handler, call `absl::InstallFailureSignalHandler()` +// very early in your program, usually in the first few lines of main(): +// +// int main(int argc, char** argv) { +// // Initialize the symbolizer to get a human-readable stack trace +// absl::InitializeSymbolizer(argv[0]); +// +// absl::FailureSignalHandlerOptions options; +// absl::InstallFailureSignalHandler(options); +// DoSomethingInteresting(); +// return 0; +// } +// +// Any program that raises a fatal signal (such as `SIGSEGV`, `SIGILL`, +// `SIGFPE`, `SIGABRT`, `SIGTERM`, `SIGBUG`, and `SIGTRAP`) will call the +// installed failure signal handler and provide debugging information to stderr. +// +// Note that you should *not* install the Abseil failure signal handler more +// than once. You may, of course, have another (non-Abseil) failure signal +// handler installed (which would be triggered if Abseil's failure signal +// handler sets `call_previous_handler` to `true`). + +#ifndef ABSL_DEBUGGING_FAILURE_SIGNAL_HANDLER_H_ +#define ABSL_DEBUGGING_FAILURE_SIGNAL_HANDLER_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// FailureSignalHandlerOptions +// +// Struct for holding `absl::InstallFailureSignalHandler()` configuration +// options. +struct FailureSignalHandlerOptions { + // If true, try to symbolize the stacktrace emitted on failure, provided that + // you have initialized a symbolizer for that purpose. (See symbolize.h for + // more information.) + bool symbolize_stacktrace = true; + + // If true, try to run signal handlers on an alternate stack (if supported on + // the given platform). An alternate stack is useful for program crashes due + // to a stack overflow; by running on a alternate stack, the signal handler + // may run even when normal stack space has been exausted. The downside of + // using an alternate stack is that extra memory for the alternate stack needs + // to be pre-allocated. + bool use_alternate_stack = true; + + // If positive, indicates the number of seconds after which the failure signal + // handler is invoked to abort the program. Setting such an alarm is useful in + // cases where the failure signal handler itself may become hung or + // deadlocked. + int alarm_on_failure_secs = 3; + + // If true, call the previously registered signal handler for the signal that + // was received (if one was registered) after the existing signal handler + // runs. This mechanism can be used to chain signal handlers together. + // + // If false, the signal is raised to the default handler for that signal + // (which normally terminates the program). + // + // IMPORTANT: If true, the chained fatal signal handlers must not try to + // recover from the fatal signal. Instead, they should terminate the program + // via some mechanism, like raising the default handler for the signal, or by + // calling `_exit()`. Note that the failure signal handler may put parts of + // the Abseil library into a state from which they cannot recover. + bool call_previous_handler = false; + + // If non-null, indicates a pointer to a callback function that will be called + // upon failure, with a string argument containing failure data. This function + // may be used as a hook to write failure data to a secondary location, such + // as a log file. This function may also be called with null data, as a hint + // to flush any buffered data before the program may be terminated. Consider + // flushing any buffered data in all calls to this function. + // + // Since this function runs within a signal handler, it should be + // async-signal-safe if possible. + // See http://man7.org/linux/man-pages/man7/signal-safety.7.html + void (*writerfn)(const char*) = nullptr; +}; + +// InstallFailureSignalHandler() +// +// Installs a signal handler for the common failure signals `SIGSEGV`, `SIGILL`, +// `SIGFPE`, `SIGABRT`, `SIGTERM`, `SIGBUG`, and `SIGTRAP` (provided they exist +// on the given platform). The failure signal handler dumps program failure data +// useful for debugging in an unspecified format to stderr. This data may +// include the program counter, a stacktrace, and register information on some +// systems; do not rely on an exact format for the output, as it is subject to +// change. +void InstallFailureSignalHandler(const FailureSignalHandlerOptions& options); + +namespace debugging_internal { +const char* FailureSignalToString(int signo); +} // namespace debugging_internal + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_FAILURE_SIGNAL_HANDLER_H_ diff --git a/third_party/abseil_cpp/absl/debugging/failure_signal_handler_test.cc b/third_party/abseil_cpp/absl/debugging/failure_signal_handler_test.cc new file mode 100644 index 0000000000..d8283b2f47 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/failure_signal_handler_test.cc @@ -0,0 +1,159 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#include "absl/debugging/failure_signal_handler.h" + +#include <csignal> +#include <cstdio> +#include <cstdlib> +#include <cstring> +#include <fstream> + +#include "gtest/gtest.h" +#include "gmock/gmock.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/debugging/stacktrace.h" +#include "absl/debugging/symbolize.h" +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" + +namespace { + +using testing::StartsWith; + +#if GTEST_HAS_DEATH_TEST + +// For the parameterized death tests. GetParam() returns the signal number. +using FailureSignalHandlerDeathTest = ::testing::TestWithParam<int>; + +// This function runs in a fork()ed process on most systems. +void InstallHandlerAndRaise(int signo) { + absl::InstallFailureSignalHandler(absl::FailureSignalHandlerOptions()); + raise(signo); +} + +TEST_P(FailureSignalHandlerDeathTest, AbslFailureSignal) { + const int signo = GetParam(); + std::string exit_regex = absl::StrCat( + "\\*\\*\\* ", absl::debugging_internal::FailureSignalToString(signo), + " received at time="); +#ifndef _WIN32 + EXPECT_EXIT(InstallHandlerAndRaise(signo), testing::KilledBySignal(signo), + exit_regex); +#else + // Windows doesn't have testing::KilledBySignal(). + EXPECT_DEATH_IF_SUPPORTED(InstallHandlerAndRaise(signo), exit_regex); +#endif +} + +ABSL_CONST_INIT FILE* error_file = nullptr; + +void WriteToErrorFile(const char* msg) { + if (msg != nullptr) { + ABSL_RAW_CHECK(fwrite(msg, strlen(msg), 1, error_file) == 1, + "fwrite() failed"); + } + ABSL_RAW_CHECK(fflush(error_file) == 0, "fflush() failed"); +} + +std::string GetTmpDir() { + // TEST_TMPDIR is set by Bazel. Try the others when not running under Bazel. + static const char* const kTmpEnvVars[] = {"TEST_TMPDIR", "TMPDIR", "TEMP", + "TEMPDIR", "TMP"}; + for (const char* const var : kTmpEnvVars) { + const char* tmp_dir = std::getenv(var); + if (tmp_dir != nullptr) { + return tmp_dir; + } + } + + // Try something reasonable. + return "/tmp"; +} + +// This function runs in a fork()ed process on most systems. +void InstallHandlerWithWriteToFileAndRaise(const char* file, int signo) { + error_file = fopen(file, "w"); + ABSL_RAW_CHECK(error_file != nullptr, "Failed create error_file"); + absl::FailureSignalHandlerOptions options; + options.writerfn = WriteToErrorFile; + absl::InstallFailureSignalHandler(options); + raise(signo); +} + +TEST_P(FailureSignalHandlerDeathTest, AbslFatalSignalsWithWriterFn) { + const int signo = GetParam(); + std::string tmp_dir = GetTmpDir(); + std::string file = absl::StrCat(tmp_dir, "/signo_", signo); + + std::string exit_regex = absl::StrCat( + "\\*\\*\\* ", absl::debugging_internal::FailureSignalToString(signo), + " received at time="); +#ifndef _WIN32 + EXPECT_EXIT(InstallHandlerWithWriteToFileAndRaise(file.c_str(), signo), + testing::KilledBySignal(signo), exit_regex); +#else + // Windows doesn't have testing::KilledBySignal(). + EXPECT_DEATH_IF_SUPPORTED( + InstallHandlerWithWriteToFileAndRaise(file.c_str(), signo), exit_regex); +#endif + + // Open the file in this process and check its contents. + std::fstream error_output(file); + ASSERT_TRUE(error_output.is_open()) << file; + std::string error_line; + std::getline(error_output, error_line); + EXPECT_THAT( + error_line, + StartsWith(absl::StrCat( + "*** ", absl::debugging_internal::FailureSignalToString(signo), + " received at "))); + + if (absl::debugging_internal::StackTraceWorksForTest()) { + std::getline(error_output, error_line); + EXPECT_THAT(error_line, StartsWith("PC: ")); + } +} + +constexpr int kFailureSignals[] = { + SIGSEGV, SIGILL, SIGFPE, SIGABRT, SIGTERM, +#ifndef _WIN32 + SIGBUS, SIGTRAP, +#endif +}; + +std::string SignalParamToString(const ::testing::TestParamInfo<int>& info) { + std::string result = + absl::debugging_internal::FailureSignalToString(info.param); + if (result.empty()) { + result = absl::StrCat(info.param); + } + return result; +} + +INSTANTIATE_TEST_SUITE_P(AbslDeathTest, FailureSignalHandlerDeathTest, + ::testing::ValuesIn(kFailureSignals), + SignalParamToString); + +#endif // GTEST_HAS_DEATH_TEST + +} // namespace + +int main(int argc, char** argv) { + absl::InitializeSymbolizer(argv[0]); + testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/third_party/abseil_cpp/absl/debugging/internal/address_is_readable.cc b/third_party/abseil_cpp/absl/debugging/internal/address_is_readable.cc new file mode 100644 index 0000000000..6537606366 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/address_is_readable.cc @@ -0,0 +1,138 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// base::AddressIsReadable() probes an address to see whether it is readable, +// without faulting. + +#include "absl/debugging/internal/address_is_readable.h" + +#if !defined(__linux__) || defined(__ANDROID__) + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// On platforms other than Linux, just return true. +bool AddressIsReadable(const void* /* addr */) { return true; } + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#else + +#include <fcntl.h> +#include <sys/syscall.h> +#include <unistd.h> + +#include <atomic> +#include <cerrno> +#include <cstdint> + +#include "absl/base/internal/errno_saver.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Pack a pid and two file descriptors into a 64-bit word, +// using 16, 24, and 24 bits for each respectively. +static uint64_t Pack(uint64_t pid, uint64_t read_fd, uint64_t write_fd) { + ABSL_RAW_CHECK((read_fd >> 24) == 0 && (write_fd >> 24) == 0, + "fd out of range"); + return (pid << 48) | ((read_fd & 0xffffff) << 24) | (write_fd & 0xffffff); +} + +// Unpack x into a pid and two file descriptors, where x was created with +// Pack(). +static void Unpack(uint64_t x, int *pid, int *read_fd, int *write_fd) { + *pid = x >> 48; + *read_fd = (x >> 24) & 0xffffff; + *write_fd = x & 0xffffff; +} + +// Return whether the byte at *addr is readable, without faulting. +// Save and restores errno. Returns true on systems where +// unimplemented. +// This is a namespace-scoped variable for correct zero-initialization. +static std::atomic<uint64_t> pid_and_fds; // initially 0, an invalid pid. +bool AddressIsReadable(const void *addr) { + absl::base_internal::ErrnoSaver errno_saver; + // We test whether a byte is readable by using write(). Normally, this would + // be done via a cached file descriptor to /dev/null, but linux fails to + // check whether the byte is readable when the destination is /dev/null, so + // we use a cached pipe. We store the pid of the process that created the + // pipe to handle the case where a process forks, and the child closes all + // the file descriptors and then calls this routine. This is not perfect: + // the child could use the routine, then close all file descriptors and then + // use this routine again. But the likely use of this routine is when + // crashing, to test the validity of pages when dumping the stack. Beware + // that we may leak file descriptors, but we're unlikely to leak many. + int bytes_written; + int current_pid = getpid() & 0xffff; // we use only the low order 16 bits + do { // until we do not get EBADF trying to use file descriptors + int pid; + int read_fd; + int write_fd; + uint64_t local_pid_and_fds = pid_and_fds.load(std::memory_order_relaxed); + Unpack(local_pid_and_fds, &pid, &read_fd, &write_fd); + while (current_pid != pid) { + int p[2]; + // new pipe + if (pipe(p) != 0) { + ABSL_RAW_LOG(FATAL, "Failed to create pipe, errno=%d", errno); + } + fcntl(p[0], F_SETFD, FD_CLOEXEC); + fcntl(p[1], F_SETFD, FD_CLOEXEC); + uint64_t new_pid_and_fds = Pack(current_pid, p[0], p[1]); + if (pid_and_fds.compare_exchange_strong( + local_pid_and_fds, new_pid_and_fds, std::memory_order_relaxed, + std::memory_order_relaxed)) { + local_pid_and_fds = new_pid_and_fds; // fds exposed to other threads + } else { // fds not exposed to other threads; we can close them. + close(p[0]); + close(p[1]); + local_pid_and_fds = pid_and_fds.load(std::memory_order_relaxed); + } + Unpack(local_pid_and_fds, &pid, &read_fd, &write_fd); + } + errno = 0; + // Use syscall(SYS_write, ...) instead of write() to prevent ASAN + // and other checkers from complaining about accesses to arbitrary + // memory. + do { + bytes_written = syscall(SYS_write, write_fd, addr, 1); + } while (bytes_written == -1 && errno == EINTR); + if (bytes_written == 1) { // remove the byte from the pipe + char c; + while (read(read_fd, &c, 1) == -1 && errno == EINTR) { + } + } + if (errno == EBADF) { // Descriptors invalid. + // If pid_and_fds contains the problematic file descriptors we just used, + // this call will forget them, and the loop will try again. + pid_and_fds.compare_exchange_strong(local_pid_and_fds, 0, + std::memory_order_relaxed, + std::memory_order_relaxed); + } + } while (errno == EBADF); + return bytes_written == 1; +} + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif diff --git a/third_party/abseil_cpp/absl/debugging/internal/address_is_readable.h b/third_party/abseil_cpp/absl/debugging/internal/address_is_readable.h new file mode 100644 index 0000000000..4bbaf4d69b --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/address_is_readable.h @@ -0,0 +1,32 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_DEBUGGING_INTERNAL_ADDRESS_IS_READABLE_H_ +#define ABSL_DEBUGGING_INTERNAL_ADDRESS_IS_READABLE_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Return whether the byte at *addr is readable, without faulting. +// Save and restores errno. +bool AddressIsReadable(const void *addr); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_ADDRESS_IS_READABLE_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/demangle.cc b/third_party/abseil_cpp/absl/debugging/internal/demangle.cc new file mode 100644 index 0000000000..fc262e50ae --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/demangle.cc @@ -0,0 +1,1895 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// For reference check out: +// https://itanium-cxx-abi.github.io/cxx-abi/abi.html#mangling +// +// Note that we only have partial C++11 support yet. + +#include "absl/debugging/internal/demangle.h" + +#include <cstdint> +#include <cstdio> +#include <limits> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +typedef struct { + const char *abbrev; + const char *real_name; + // Number of arguments in <expression> context, or 0 if disallowed. + int arity; +} AbbrevPair; + +// List of operators from Itanium C++ ABI. +static const AbbrevPair kOperatorList[] = { + // New has special syntax (not currently supported). + {"nw", "new", 0}, + {"na", "new[]", 0}, + + // Works except that the 'gs' prefix is not supported. + {"dl", "delete", 1}, + {"da", "delete[]", 1}, + + {"ps", "+", 1}, // "positive" + {"ng", "-", 1}, // "negative" + {"ad", "&", 1}, // "address-of" + {"de", "*", 1}, // "dereference" + {"co", "~", 1}, + + {"pl", "+", 2}, + {"mi", "-", 2}, + {"ml", "*", 2}, + {"dv", "/", 2}, + {"rm", "%", 2}, + {"an", "&", 2}, + {"or", "|", 2}, + {"eo", "^", 2}, + {"aS", "=", 2}, + {"pL", "+=", 2}, + {"mI", "-=", 2}, + {"mL", "*=", 2}, + {"dV", "/=", 2}, + {"rM", "%=", 2}, + {"aN", "&=", 2}, + {"oR", "|=", 2}, + {"eO", "^=", 2}, + {"ls", "<<", 2}, + {"rs", ">>", 2}, + {"lS", "<<=", 2}, + {"rS", ">>=", 2}, + {"eq", "==", 2}, + {"ne", "!=", 2}, + {"lt", "<", 2}, + {"gt", ">", 2}, + {"le", "<=", 2}, + {"ge", ">=", 2}, + {"nt", "!", 1}, + {"aa", "&&", 2}, + {"oo", "||", 2}, + {"pp", "++", 1}, + {"mm", "--", 1}, + {"cm", ",", 2}, + {"pm", "->*", 2}, + {"pt", "->", 0}, // Special syntax + {"cl", "()", 0}, // Special syntax + {"ix", "[]", 2}, + {"qu", "?", 3}, + {"st", "sizeof", 0}, // Special syntax + {"sz", "sizeof", 1}, // Not a real operator name, but used in expressions. + {nullptr, nullptr, 0}, +}; + +// List of builtin types from Itanium C++ ABI. +// +// Invariant: only one- or two-character type abbreviations here. +static const AbbrevPair kBuiltinTypeList[] = { + {"v", "void", 0}, + {"w", "wchar_t", 0}, + {"b", "bool", 0}, + {"c", "char", 0}, + {"a", "signed char", 0}, + {"h", "unsigned char", 0}, + {"s", "short", 0}, + {"t", "unsigned short", 0}, + {"i", "int", 0}, + {"j", "unsigned int", 0}, + {"l", "long", 0}, + {"m", "unsigned long", 0}, + {"x", "long long", 0}, + {"y", "unsigned long long", 0}, + {"n", "__int128", 0}, + {"o", "unsigned __int128", 0}, + {"f", "float", 0}, + {"d", "double", 0}, + {"e", "long double", 0}, + {"g", "__float128", 0}, + {"z", "ellipsis", 0}, + + {"De", "decimal128", 0}, // IEEE 754r decimal floating point (128 bits) + {"Dd", "decimal64", 0}, // IEEE 754r decimal floating point (64 bits) + {"Dc", "decltype(auto)", 0}, + {"Da", "auto", 0}, + {"Dn", "std::nullptr_t", 0}, // i.e., decltype(nullptr) + {"Df", "decimal32", 0}, // IEEE 754r decimal floating point (32 bits) + {"Di", "char32_t", 0}, + {"Ds", "char16_t", 0}, + {"Dh", "float16", 0}, // IEEE 754r half-precision float (16 bits) + {nullptr, nullptr, 0}, +}; + +// List of substitutions Itanium C++ ABI. +static const AbbrevPair kSubstitutionList[] = { + {"St", "", 0}, + {"Sa", "allocator", 0}, + {"Sb", "basic_string", 0}, + // std::basic_string<char, std::char_traits<char>,std::allocator<char> > + {"Ss", "string", 0}, + // std::basic_istream<char, std::char_traits<char> > + {"Si", "istream", 0}, + // std::basic_ostream<char, std::char_traits<char> > + {"So", "ostream", 0}, + // std::basic_iostream<char, std::char_traits<char> > + {"Sd", "iostream", 0}, + {nullptr, nullptr, 0}, +}; + +// State needed for demangling. This struct is copied in almost every stack +// frame, so every byte counts. +typedef struct { + int mangled_idx; // Cursor of mangled name. + int out_cur_idx; // Cursor of output string. + int prev_name_idx; // For constructors/destructors. + signed int prev_name_length : 16; // For constructors/destructors. + signed int nest_level : 15; // For nested names. + unsigned int append : 1; // Append flag. + // Note: for some reason MSVC can't pack "bool append : 1" into the same int + // with the above two fields, so we use an int instead. Amusingly it can pack + // "signed bool" as expected, but relying on that to continue to be a legal + // type seems ill-advised (as it's illegal in at least clang). +} ParseState; + +static_assert(sizeof(ParseState) == 4 * sizeof(int), + "unexpected size of ParseState"); + +// One-off state for demangling that's not subject to backtracking -- either +// constant data, data that's intentionally immune to backtracking (steps), or +// data that would never be changed by backtracking anyway (recursion_depth). +// +// Only one copy of this exists for each call to Demangle, so the size of this +// struct is nearly inconsequential. +typedef struct { + const char *mangled_begin; // Beginning of input string. + char *out; // Beginning of output string. + int out_end_idx; // One past last allowed output character. + int recursion_depth; // For stack exhaustion prevention. + int steps; // Cap how much work we'll do, regardless of depth. + ParseState parse_state; // Backtrackable state copied for most frames. +} State; + +namespace { +// Prevent deep recursion / stack exhaustion. +// Also prevent unbounded handling of complex inputs. +class ComplexityGuard { + public: + explicit ComplexityGuard(State *state) : state_(state) { + ++state->recursion_depth; + ++state->steps; + } + ~ComplexityGuard() { --state_->recursion_depth; } + + // 256 levels of recursion seems like a reasonable upper limit on depth. + // 128 is not enough to demagle synthetic tests from demangle_unittest.txt: + // "_ZaaZZZZ..." and "_ZaaZcvZcvZ..." + static constexpr int kRecursionDepthLimit = 256; + + // We're trying to pick a charitable upper-limit on how many parse steps are + // necessary to handle something that a human could actually make use of. + // This is mostly in place as a bound on how much work we'll do if we are + // asked to demangle an mangled name from an untrusted source, so it should be + // much larger than the largest expected symbol, but much smaller than the + // amount of work we can do in, e.g., a second. + // + // Some real-world symbols from an arbitrary binary started failing between + // 2^12 and 2^13, so we multiply the latter by an extra factor of 16 to set + // the limit. + // + // Spending one second on 2^17 parse steps would require each step to take + // 7.6us, or ~30000 clock cycles, so it's safe to say this can be done in + // under a second. + static constexpr int kParseStepsLimit = 1 << 17; + + bool IsTooComplex() const { + return state_->recursion_depth > kRecursionDepthLimit || + state_->steps > kParseStepsLimit; + } + + private: + State *state_; +}; +} // namespace + +// We don't use strlen() in libc since it's not guaranteed to be async +// signal safe. +static size_t StrLen(const char *str) { + size_t len = 0; + while (*str != '\0') { + ++str; + ++len; + } + return len; +} + +// Returns true if "str" has at least "n" characters remaining. +static bool AtLeastNumCharsRemaining(const char *str, int n) { + for (int i = 0; i < n; ++i) { + if (str[i] == '\0') { + return false; + } + } + return true; +} + +// Returns true if "str" has "prefix" as a prefix. +static bool StrPrefix(const char *str, const char *prefix) { + size_t i = 0; + while (str[i] != '\0' && prefix[i] != '\0' && str[i] == prefix[i]) { + ++i; + } + return prefix[i] == '\0'; // Consumed everything in "prefix". +} + +static void InitState(State *state, const char *mangled, char *out, + int out_size) { + state->mangled_begin = mangled; + state->out = out; + state->out_end_idx = out_size; + state->recursion_depth = 0; + state->steps = 0; + + state->parse_state.mangled_idx = 0; + state->parse_state.out_cur_idx = 0; + state->parse_state.prev_name_idx = 0; + state->parse_state.prev_name_length = -1; + state->parse_state.nest_level = -1; + state->parse_state.append = true; +} + +static inline const char *RemainingInput(State *state) { + return &state->mangled_begin[state->parse_state.mangled_idx]; +} + +// Returns true and advances "mangled_idx" if we find "one_char_token" +// at "mangled_idx" position. It is assumed that "one_char_token" does +// not contain '\0'. +static bool ParseOneCharToken(State *state, const char one_char_token) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (RemainingInput(state)[0] == one_char_token) { + ++state->parse_state.mangled_idx; + return true; + } + return false; +} + +// Returns true and advances "mangled_cur" if we find "two_char_token" +// at "mangled_cur" position. It is assumed that "two_char_token" does +// not contain '\0'. +static bool ParseTwoCharToken(State *state, const char *two_char_token) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (RemainingInput(state)[0] == two_char_token[0] && + RemainingInput(state)[1] == two_char_token[1]) { + state->parse_state.mangled_idx += 2; + return true; + } + return false; +} + +// Returns true and advances "mangled_cur" if we find any character in +// "char_class" at "mangled_cur" position. +static bool ParseCharClass(State *state, const char *char_class) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (RemainingInput(state)[0] == '\0') { + return false; + } + const char *p = char_class; + for (; *p != '\0'; ++p) { + if (RemainingInput(state)[0] == *p) { + ++state->parse_state.mangled_idx; + return true; + } + } + return false; +} + +static bool ParseDigit(State *state, int *digit) { + char c = RemainingInput(state)[0]; + if (ParseCharClass(state, "0123456789")) { + if (digit != nullptr) { + *digit = c - '0'; + } + return true; + } + return false; +} + +// This function is used for handling an optional non-terminal. +static bool Optional(bool /*status*/) { return true; } + +// This function is used for handling <non-terminal>+ syntax. +typedef bool (*ParseFunc)(State *); +static bool OneOrMore(ParseFunc parse_func, State *state) { + if (parse_func(state)) { + while (parse_func(state)) { + } + return true; + } + return false; +} + +// This function is used for handling <non-terminal>* syntax. The function +// always returns true and must be followed by a termination token or a +// terminating sequence not handled by parse_func (e.g. +// ParseOneCharToken(state, 'E')). +static bool ZeroOrMore(ParseFunc parse_func, State *state) { + while (parse_func(state)) { + } + return true; +} + +// Append "str" at "out_cur_idx". If there is an overflow, out_cur_idx is +// set to out_end_idx+1. The output string is ensured to +// always terminate with '\0' as long as there is no overflow. +static void Append(State *state, const char *const str, const int length) { + for (int i = 0; i < length; ++i) { + if (state->parse_state.out_cur_idx + 1 < + state->out_end_idx) { // +1 for '\0' + state->out[state->parse_state.out_cur_idx++] = str[i]; + } else { + // signal overflow + state->parse_state.out_cur_idx = state->out_end_idx + 1; + break; + } + } + if (state->parse_state.out_cur_idx < state->out_end_idx) { + state->out[state->parse_state.out_cur_idx] = + '\0'; // Terminate it with '\0' + } +} + +// We don't use equivalents in libc to avoid locale issues. +static bool IsLower(char c) { return c >= 'a' && c <= 'z'; } + +static bool IsAlpha(char c) { + return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z'); +} + +static bool IsDigit(char c) { return c >= '0' && c <= '9'; } + +// Returns true if "str" is a function clone suffix. These suffixes are used +// by GCC 4.5.x and later versions (and our locally-modified version of GCC +// 4.4.x) to indicate functions which have been cloned during optimization. +// We treat any sequence (.<alpha>+.<digit>+)+ as a function clone suffix. +static bool IsFunctionCloneSuffix(const char *str) { + size_t i = 0; + while (str[i] != '\0') { + // Consume a single .<alpha>+.<digit>+ sequence. + if (str[i] != '.' || !IsAlpha(str[i + 1])) { + return false; + } + i += 2; + while (IsAlpha(str[i])) { + ++i; + } + if (str[i] != '.' || !IsDigit(str[i + 1])) { + return false; + } + i += 2; + while (IsDigit(str[i])) { + ++i; + } + } + return true; // Consumed everything in "str". +} + +static bool EndsWith(State *state, const char chr) { + return state->parse_state.out_cur_idx > 0 && + chr == state->out[state->parse_state.out_cur_idx - 1]; +} + +// Append "str" with some tweaks, iff "append" state is true. +static void MaybeAppendWithLength(State *state, const char *const str, + const int length) { + if (state->parse_state.append && length > 0) { + // Append a space if the output buffer ends with '<' and "str" + // starts with '<' to avoid <<<. + if (str[0] == '<' && EndsWith(state, '<')) { + Append(state, " ", 1); + } + // Remember the last identifier name for ctors/dtors. + if (IsAlpha(str[0]) || str[0] == '_') { + state->parse_state.prev_name_idx = state->parse_state.out_cur_idx; + state->parse_state.prev_name_length = length; + } + Append(state, str, length); + } +} + +// Appends a positive decimal number to the output if appending is enabled. +static bool MaybeAppendDecimal(State *state, unsigned int val) { + // Max {32-64}-bit unsigned int is 20 digits. + constexpr size_t kMaxLength = 20; + char buf[kMaxLength]; + + // We can't use itoa or sprintf as neither is specified to be + // async-signal-safe. + if (state->parse_state.append) { + // We can't have a one-before-the-beginning pointer, so instead start with + // one-past-the-end and manipulate one character before the pointer. + char *p = &buf[kMaxLength]; + do { // val=0 is the only input that should write a leading zero digit. + *--p = (val % 10) + '0'; + val /= 10; + } while (p > buf && val != 0); + + // 'p' landed on the last character we set. How convenient. + Append(state, p, kMaxLength - (p - buf)); + } + + return true; +} + +// A convenient wrapper around MaybeAppendWithLength(). +// Returns true so that it can be placed in "if" conditions. +static bool MaybeAppend(State *state, const char *const str) { + if (state->parse_state.append) { + int length = StrLen(str); + MaybeAppendWithLength(state, str, length); + } + return true; +} + +// This function is used for handling nested names. +static bool EnterNestedName(State *state) { + state->parse_state.nest_level = 0; + return true; +} + +// This function is used for handling nested names. +static bool LeaveNestedName(State *state, int16_t prev_value) { + state->parse_state.nest_level = prev_value; + return true; +} + +// Disable the append mode not to print function parameters, etc. +static bool DisableAppend(State *state) { + state->parse_state.append = false; + return true; +} + +// Restore the append mode to the previous state. +static bool RestoreAppend(State *state, bool prev_value) { + state->parse_state.append = prev_value; + return true; +} + +// Increase the nest level for nested names. +static void MaybeIncreaseNestLevel(State *state) { + if (state->parse_state.nest_level > -1) { + ++state->parse_state.nest_level; + } +} + +// Appends :: for nested names if necessary. +static void MaybeAppendSeparator(State *state) { + if (state->parse_state.nest_level >= 1) { + MaybeAppend(state, "::"); + } +} + +// Cancel the last separator if necessary. +static void MaybeCancelLastSeparator(State *state) { + if (state->parse_state.nest_level >= 1 && state->parse_state.append && + state->parse_state.out_cur_idx >= 2) { + state->parse_state.out_cur_idx -= 2; + state->out[state->parse_state.out_cur_idx] = '\0'; + } +} + +// Returns true if the identifier of the given length pointed to by +// "mangled_cur" is anonymous namespace. +static bool IdentifierIsAnonymousNamespace(State *state, int length) { + // Returns true if "anon_prefix" is a proper prefix of "mangled_cur". + static const char anon_prefix[] = "_GLOBAL__N_"; + return (length > static_cast<int>(sizeof(anon_prefix) - 1) && + StrPrefix(RemainingInput(state), anon_prefix)); +} + +// Forward declarations of our parsing functions. +static bool ParseMangledName(State *state); +static bool ParseEncoding(State *state); +static bool ParseName(State *state); +static bool ParseUnscopedName(State *state); +static bool ParseNestedName(State *state); +static bool ParsePrefix(State *state); +static bool ParseUnqualifiedName(State *state); +static bool ParseSourceName(State *state); +static bool ParseLocalSourceName(State *state); +static bool ParseUnnamedTypeName(State *state); +static bool ParseNumber(State *state, int *number_out); +static bool ParseFloatNumber(State *state); +static bool ParseSeqId(State *state); +static bool ParseIdentifier(State *state, int length); +static bool ParseOperatorName(State *state, int *arity); +static bool ParseSpecialName(State *state); +static bool ParseCallOffset(State *state); +static bool ParseNVOffset(State *state); +static bool ParseVOffset(State *state); +static bool ParseCtorDtorName(State *state); +static bool ParseDecltype(State *state); +static bool ParseType(State *state); +static bool ParseCVQualifiers(State *state); +static bool ParseBuiltinType(State *state); +static bool ParseFunctionType(State *state); +static bool ParseBareFunctionType(State *state); +static bool ParseClassEnumType(State *state); +static bool ParseArrayType(State *state); +static bool ParsePointerToMemberType(State *state); +static bool ParseTemplateParam(State *state); +static bool ParseTemplateTemplateParam(State *state); +static bool ParseTemplateArgs(State *state); +static bool ParseTemplateArg(State *state); +static bool ParseBaseUnresolvedName(State *state); +static bool ParseUnresolvedName(State *state); +static bool ParseExpression(State *state); +static bool ParseExprPrimary(State *state); +static bool ParseExprCastValue(State *state); +static bool ParseLocalName(State *state); +static bool ParseLocalNameSuffix(State *state); +static bool ParseDiscriminator(State *state); +static bool ParseSubstitution(State *state, bool accept_std); + +// Implementation note: the following code is a straightforward +// translation of the Itanium C++ ABI defined in BNF with a couple of +// exceptions. +// +// - Support GNU extensions not defined in the Itanium C++ ABI +// - <prefix> and <template-prefix> are combined to avoid infinite loop +// - Reorder patterns to shorten the code +// - Reorder patterns to give greedier functions precedence +// We'll mark "Less greedy than" for these cases in the code +// +// Each parsing function changes the parse state and returns true on +// success, or returns false and doesn't change the parse state (note: +// the parse-steps counter increases regardless of success or failure). +// To ensure that the parse state isn't changed in the latter case, we +// save the original state before we call multiple parsing functions +// consecutively with &&, and restore it if unsuccessful. See +// ParseEncoding() as an example of this convention. We follow the +// convention throughout the code. +// +// Originally we tried to do demangling without following the full ABI +// syntax but it turned out we needed to follow the full syntax to +// parse complicated cases like nested template arguments. Note that +// implementing a full-fledged demangler isn't trivial (libiberty's +// cp-demangle.c has +4300 lines). +// +// Note that (foo) in <(foo) ...> is a modifier to be ignored. +// +// Reference: +// - Itanium C++ ABI +// <https://mentorembedded.github.io/cxx-abi/abi.html#mangling> + +// <mangled-name> ::= _Z <encoding> +static bool ParseMangledName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + return ParseTwoCharToken(state, "_Z") && ParseEncoding(state); +} + +// <encoding> ::= <(function) name> <bare-function-type> +// ::= <(data) name> +// ::= <special-name> +static bool ParseEncoding(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + // Implementing the first two productions together as <name> + // [<bare-function-type>] avoids exponential blowup of backtracking. + // + // Since Optional(...) can't fail, there's no need to copy the state for + // backtracking. + if (ParseName(state) && Optional(ParseBareFunctionType(state))) { + return true; + } + + if (ParseSpecialName(state)) { + return true; + } + return false; +} + +// <name> ::= <nested-name> +// ::= <unscoped-template-name> <template-args> +// ::= <unscoped-name> +// ::= <local-name> +static bool ParseName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (ParseNestedName(state) || ParseLocalName(state)) { + return true; + } + + // We reorganize the productions to avoid re-parsing unscoped names. + // - Inline <unscoped-template-name> productions: + // <name> ::= <substitution> <template-args> + // ::= <unscoped-name> <template-args> + // ::= <unscoped-name> + // - Merge the two productions that start with unscoped-name: + // <name> ::= <unscoped-name> [<template-args>] + + ParseState copy = state->parse_state; + // "std<...>" isn't a valid name. + if (ParseSubstitution(state, /*accept_std=*/false) && + ParseTemplateArgs(state)) { + return true; + } + state->parse_state = copy; + + // Note there's no need to restore state after this since only the first + // subparser can fail. + return ParseUnscopedName(state) && Optional(ParseTemplateArgs(state)); +} + +// <unscoped-name> ::= <unqualified-name> +// ::= St <unqualified-name> +static bool ParseUnscopedName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (ParseUnqualifiedName(state)) { + return true; + } + + ParseState copy = state->parse_state; + if (ParseTwoCharToken(state, "St") && MaybeAppend(state, "std::") && + ParseUnqualifiedName(state)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <ref-qualifer> ::= R // lvalue method reference qualifier +// ::= O // rvalue method reference qualifier +static inline bool ParseRefQualifier(State *state) { + return ParseCharClass(state, "OR"); +} + +// <nested-name> ::= N [<CV-qualifiers>] [<ref-qualifier>] <prefix> +// <unqualified-name> E +// ::= N [<CV-qualifiers>] [<ref-qualifier>] <template-prefix> +// <template-args> E +static bool ParseNestedName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'N') && EnterNestedName(state) && + Optional(ParseCVQualifiers(state)) && + Optional(ParseRefQualifier(state)) && ParsePrefix(state) && + LeaveNestedName(state, copy.nest_level) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + return false; +} + +// This part is tricky. If we literally translate them to code, we'll +// end up infinite loop. Hence we merge them to avoid the case. +// +// <prefix> ::= <prefix> <unqualified-name> +// ::= <template-prefix> <template-args> +// ::= <template-param> +// ::= <substitution> +// ::= # empty +// <template-prefix> ::= <prefix> <(template) unqualified-name> +// ::= <template-param> +// ::= <substitution> +static bool ParsePrefix(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + bool has_something = false; + while (true) { + MaybeAppendSeparator(state); + if (ParseTemplateParam(state) || + ParseSubstitution(state, /*accept_std=*/true) || + ParseUnscopedName(state) || + (ParseOneCharToken(state, 'M') && ParseUnnamedTypeName(state))) { + has_something = true; + MaybeIncreaseNestLevel(state); + continue; + } + MaybeCancelLastSeparator(state); + if (has_something && ParseTemplateArgs(state)) { + return ParsePrefix(state); + } else { + break; + } + } + return true; +} + +// <unqualified-name> ::= <operator-name> +// ::= <ctor-dtor-name> +// ::= <source-name> +// ::= <local-source-name> // GCC extension; see below. +// ::= <unnamed-type-name> +static bool ParseUnqualifiedName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + return (ParseOperatorName(state, nullptr) || ParseCtorDtorName(state) || + ParseSourceName(state) || ParseLocalSourceName(state) || + ParseUnnamedTypeName(state)); +} + +// <source-name> ::= <positive length number> <identifier> +static bool ParseSourceName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + int length = -1; + if (ParseNumber(state, &length) && ParseIdentifier(state, length)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <local-source-name> ::= L <source-name> [<discriminator>] +// +// References: +// https://gcc.gnu.org/bugzilla/show_bug.cgi?id=31775 +// https://gcc.gnu.org/viewcvs?view=rev&revision=124467 +static bool ParseLocalSourceName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'L') && ParseSourceName(state) && + Optional(ParseDiscriminator(state))) { + return true; + } + state->parse_state = copy; + return false; +} + +// <unnamed-type-name> ::= Ut [<(nonnegative) number>] _ +// ::= <closure-type-name> +// <closure-type-name> ::= Ul <lambda-sig> E [<(nonnegative) number>] _ +// <lambda-sig> ::= <(parameter) type>+ +static bool ParseUnnamedTypeName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + // Type's 1-based index n is encoded as { "", n == 1; itoa(n-2), otherwise }. + // Optionally parse the encoded value into 'which' and add 2 to get the index. + int which = -1; + + // Unnamed type local to function or class. + if (ParseTwoCharToken(state, "Ut") && Optional(ParseNumber(state, &which)) && + which <= std::numeric_limits<int>::max() - 2 && // Don't overflow. + ParseOneCharToken(state, '_')) { + MaybeAppend(state, "{unnamed type#"); + MaybeAppendDecimal(state, 2 + which); + MaybeAppend(state, "}"); + return true; + } + state->parse_state = copy; + + // Closure type. + which = -1; + if (ParseTwoCharToken(state, "Ul") && DisableAppend(state) && + OneOrMore(ParseType, state) && RestoreAppend(state, copy.append) && + ParseOneCharToken(state, 'E') && Optional(ParseNumber(state, &which)) && + which <= std::numeric_limits<int>::max() - 2 && // Don't overflow. + ParseOneCharToken(state, '_')) { + MaybeAppend(state, "{lambda()#"); + MaybeAppendDecimal(state, 2 + which); + MaybeAppend(state, "}"); + return true; + } + state->parse_state = copy; + + return false; +} + +// <number> ::= [n] <non-negative decimal integer> +// If "number_out" is non-null, then *number_out is set to the value of the +// parsed number on success. +static bool ParseNumber(State *state, int *number_out) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + bool negative = false; + if (ParseOneCharToken(state, 'n')) { + negative = true; + } + const char *p = RemainingInput(state); + uint64_t number = 0; + for (; *p != '\0'; ++p) { + if (IsDigit(*p)) { + number = number * 10 + (*p - '0'); + } else { + break; + } + } + // Apply the sign with uint64_t arithmetic so overflows aren't UB. Gives + // "incorrect" results for out-of-range inputs, but negative values only + // appear for literals, which aren't printed. + if (negative) { + number = ~number + 1; + } + if (p != RemainingInput(state)) { // Conversion succeeded. + state->parse_state.mangled_idx += p - RemainingInput(state); + if (number_out != nullptr) { + // Note: possibly truncate "number". + *number_out = number; + } + return true; + } + return false; +} + +// Floating-point literals are encoded using a fixed-length lowercase +// hexadecimal string. +static bool ParseFloatNumber(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + const char *p = RemainingInput(state); + for (; *p != '\0'; ++p) { + if (!IsDigit(*p) && !(*p >= 'a' && *p <= 'f')) { + break; + } + } + if (p != RemainingInput(state)) { // Conversion succeeded. + state->parse_state.mangled_idx += p - RemainingInput(state); + return true; + } + return false; +} + +// The <seq-id> is a sequence number in base 36, +// using digits and upper case letters +static bool ParseSeqId(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + const char *p = RemainingInput(state); + for (; *p != '\0'; ++p) { + if (!IsDigit(*p) && !(*p >= 'A' && *p <= 'Z')) { + break; + } + } + if (p != RemainingInput(state)) { // Conversion succeeded. + state->parse_state.mangled_idx += p - RemainingInput(state); + return true; + } + return false; +} + +// <identifier> ::= <unqualified source code identifier> (of given length) +static bool ParseIdentifier(State *state, int length) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (length < 0 || !AtLeastNumCharsRemaining(RemainingInput(state), length)) { + return false; + } + if (IdentifierIsAnonymousNamespace(state, length)) { + MaybeAppend(state, "(anonymous namespace)"); + } else { + MaybeAppendWithLength(state, RemainingInput(state), length); + } + state->parse_state.mangled_idx += length; + return true; +} + +// <operator-name> ::= nw, and other two letters cases +// ::= cv <type> # (cast) +// ::= v <digit> <source-name> # vendor extended operator +static bool ParseOperatorName(State *state, int *arity) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (!AtLeastNumCharsRemaining(RemainingInput(state), 2)) { + return false; + } + // First check with "cv" (cast) case. + ParseState copy = state->parse_state; + if (ParseTwoCharToken(state, "cv") && MaybeAppend(state, "operator ") && + EnterNestedName(state) && ParseType(state) && + LeaveNestedName(state, copy.nest_level)) { + if (arity != nullptr) { + *arity = 1; + } + return true; + } + state->parse_state = copy; + + // Then vendor extended operators. + if (ParseOneCharToken(state, 'v') && ParseDigit(state, arity) && + ParseSourceName(state)) { + return true; + } + state->parse_state = copy; + + // Other operator names should start with a lower alphabet followed + // by a lower/upper alphabet. + if (!(IsLower(RemainingInput(state)[0]) && + IsAlpha(RemainingInput(state)[1]))) { + return false; + } + // We may want to perform a binary search if we really need speed. + const AbbrevPair *p; + for (p = kOperatorList; p->abbrev != nullptr; ++p) { + if (RemainingInput(state)[0] == p->abbrev[0] && + RemainingInput(state)[1] == p->abbrev[1]) { + if (arity != nullptr) { + *arity = p->arity; + } + MaybeAppend(state, "operator"); + if (IsLower(*p->real_name)) { // new, delete, etc. + MaybeAppend(state, " "); + } + MaybeAppend(state, p->real_name); + state->parse_state.mangled_idx += 2; + return true; + } + } + return false; +} + +// <special-name> ::= TV <type> +// ::= TT <type> +// ::= TI <type> +// ::= TS <type> +// ::= Tc <call-offset> <call-offset> <(base) encoding> +// ::= GV <(object) name> +// ::= T <call-offset> <(base) encoding> +// G++ extensions: +// ::= TC <type> <(offset) number> _ <(base) type> +// ::= TF <type> +// ::= TJ <type> +// ::= GR <name> +// ::= GA <encoding> +// ::= Th <call-offset> <(base) encoding> +// ::= Tv <call-offset> <(base) encoding> +// +// Note: we don't care much about them since they don't appear in +// stack traces. The are special data. +static bool ParseSpecialName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'T') && ParseCharClass(state, "VTIS") && + ParseType(state)) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "Tc") && ParseCallOffset(state) && + ParseCallOffset(state) && ParseEncoding(state)) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "GV") && ParseName(state)) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'T') && ParseCallOffset(state) && + ParseEncoding(state)) { + return true; + } + state->parse_state = copy; + + // G++ extensions + if (ParseTwoCharToken(state, "TC") && ParseType(state) && + ParseNumber(state, nullptr) && ParseOneCharToken(state, '_') && + DisableAppend(state) && ParseType(state)) { + RestoreAppend(state, copy.append); + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'T') && ParseCharClass(state, "FJ") && + ParseType(state)) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "GR") && ParseName(state)) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "GA") && ParseEncoding(state)) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'T') && ParseCharClass(state, "hv") && + ParseCallOffset(state) && ParseEncoding(state)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <call-offset> ::= h <nv-offset> _ +// ::= v <v-offset> _ +static bool ParseCallOffset(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'h') && ParseNVOffset(state) && + ParseOneCharToken(state, '_')) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'v') && ParseVOffset(state) && + ParseOneCharToken(state, '_')) { + return true; + } + state->parse_state = copy; + + return false; +} + +// <nv-offset> ::= <(offset) number> +static bool ParseNVOffset(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + return ParseNumber(state, nullptr); +} + +// <v-offset> ::= <(offset) number> _ <(virtual offset) number> +static bool ParseVOffset(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseNumber(state, nullptr) && ParseOneCharToken(state, '_') && + ParseNumber(state, nullptr)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <ctor-dtor-name> ::= C1 | C2 | C3 +// ::= D0 | D1 | D2 +// # GCC extensions: "unified" constructor/destructor. See +// # https://github.com/gcc-mirror/gcc/blob/7ad17b583c3643bd4557f29b8391ca7ef08391f5/gcc/cp/mangle.c#L1847 +// ::= C4 | D4 +static bool ParseCtorDtorName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'C') && ParseCharClass(state, "1234")) { + const char *const prev_name = state->out + state->parse_state.prev_name_idx; + MaybeAppendWithLength(state, prev_name, + state->parse_state.prev_name_length); + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'D') && ParseCharClass(state, "0124")) { + const char *const prev_name = state->out + state->parse_state.prev_name_idx; + MaybeAppend(state, "~"); + MaybeAppendWithLength(state, prev_name, + state->parse_state.prev_name_length); + return true; + } + state->parse_state = copy; + return false; +} + +// <decltype> ::= Dt <expression> E # decltype of an id-expression or class +// # member access (C++0x) +// ::= DT <expression> E # decltype of an expression (C++0x) +static bool ParseDecltype(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'D') && ParseCharClass(state, "tT") && + ParseExpression(state) && ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + + return false; +} + +// <type> ::= <CV-qualifiers> <type> +// ::= P <type> # pointer-to +// ::= R <type> # reference-to +// ::= O <type> # rvalue reference-to (C++0x) +// ::= C <type> # complex pair (C 2000) +// ::= G <type> # imaginary (C 2000) +// ::= U <source-name> <type> # vendor extended type qualifier +// ::= <builtin-type> +// ::= <function-type> +// ::= <class-enum-type> # note: just an alias for <name> +// ::= <array-type> +// ::= <pointer-to-member-type> +// ::= <template-template-param> <template-args> +// ::= <template-param> +// ::= <decltype> +// ::= <substitution> +// ::= Dp <type> # pack expansion of (C++0x) +// +static bool ParseType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + + // We should check CV-qualifers, and PRGC things first. + // + // CV-qualifiers overlap with some operator names, but an operator name is not + // valid as a type. To avoid an ambiguity that can lead to exponential time + // complexity, refuse to backtrack the CV-qualifiers. + // + // _Z4aoeuIrMvvE + // => _Z 4aoeuI rM v v E + // aoeu<operator%=, void, void> + // => _Z 4aoeuI r Mv v E + // aoeu<void void::* restrict> + // + // By consuming the CV-qualifiers first, the former parse is disabled. + if (ParseCVQualifiers(state)) { + const bool result = ParseType(state); + if (!result) state->parse_state = copy; + return result; + } + state->parse_state = copy; + + // Similarly, these tag characters can overlap with other <name>s resulting in + // two different parse prefixes that land on <template-args> in the same + // place, such as "C3r1xI...". So, disable the "ctor-name = C3" parse by + // refusing to backtrack the tag characters. + if (ParseCharClass(state, "OPRCG")) { + const bool result = ParseType(state); + if (!result) state->parse_state = copy; + return result; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "Dp") && ParseType(state)) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'U') && ParseSourceName(state) && + ParseType(state)) { + return true; + } + state->parse_state = copy; + + if (ParseBuiltinType(state) || ParseFunctionType(state) || + ParseClassEnumType(state) || ParseArrayType(state) || + ParsePointerToMemberType(state) || ParseDecltype(state) || + // "std" on its own isn't a type. + ParseSubstitution(state, /*accept_std=*/false)) { + return true; + } + + if (ParseTemplateTemplateParam(state) && ParseTemplateArgs(state)) { + return true; + } + state->parse_state = copy; + + // Less greedy than <template-template-param> <template-args>. + if (ParseTemplateParam(state)) { + return true; + } + + return false; +} + +// <CV-qualifiers> ::= [r] [V] [K] +// We don't allow empty <CV-qualifiers> to avoid infinite loop in +// ParseType(). +static bool ParseCVQualifiers(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + int num_cv_qualifiers = 0; + num_cv_qualifiers += ParseOneCharToken(state, 'r'); + num_cv_qualifiers += ParseOneCharToken(state, 'V'); + num_cv_qualifiers += ParseOneCharToken(state, 'K'); + return num_cv_qualifiers > 0; +} + +// <builtin-type> ::= v, etc. # single-character builtin types +// ::= u <source-name> +// ::= Dd, etc. # two-character builtin types +// +// Not supported: +// ::= DF <number> _ # _FloatN (N bits) +// +static bool ParseBuiltinType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + const AbbrevPair *p; + for (p = kBuiltinTypeList; p->abbrev != nullptr; ++p) { + // Guaranteed only 1- or 2-character strings in kBuiltinTypeList. + if (p->abbrev[1] == '\0') { + if (ParseOneCharToken(state, p->abbrev[0])) { + MaybeAppend(state, p->real_name); + return true; + } + } else if (p->abbrev[2] == '\0' && ParseTwoCharToken(state, p->abbrev)) { + MaybeAppend(state, p->real_name); + return true; + } + } + + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'u') && ParseSourceName(state)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <function-type> ::= F [Y] <bare-function-type> E +static bool ParseFunctionType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'F') && + Optional(ParseOneCharToken(state, 'Y')) && ParseBareFunctionType(state) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + return false; +} + +// <bare-function-type> ::= <(signature) type>+ +static bool ParseBareFunctionType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + DisableAppend(state); + if (OneOrMore(ParseType, state)) { + RestoreAppend(state, copy.append); + MaybeAppend(state, "()"); + return true; + } + state->parse_state = copy; + return false; +} + +// <class-enum-type> ::= <name> +static bool ParseClassEnumType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + return ParseName(state); +} + +// <array-type> ::= A <(positive dimension) number> _ <(element) type> +// ::= A [<(dimension) expression>] _ <(element) type> +static bool ParseArrayType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'A') && ParseNumber(state, nullptr) && + ParseOneCharToken(state, '_') && ParseType(state)) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'A') && Optional(ParseExpression(state)) && + ParseOneCharToken(state, '_') && ParseType(state)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <pointer-to-member-type> ::= M <(class) type> <(member) type> +static bool ParsePointerToMemberType(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'M') && ParseType(state) && ParseType(state)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <template-param> ::= T_ +// ::= T <parameter-2 non-negative number> _ +static bool ParseTemplateParam(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (ParseTwoCharToken(state, "T_")) { + MaybeAppend(state, "?"); // We don't support template substitutions. + return true; + } + + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'T') && ParseNumber(state, nullptr) && + ParseOneCharToken(state, '_')) { + MaybeAppend(state, "?"); // We don't support template substitutions. + return true; + } + state->parse_state = copy; + return false; +} + +// <template-template-param> ::= <template-param> +// ::= <substitution> +static bool ParseTemplateTemplateParam(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + return (ParseTemplateParam(state) || + // "std" on its own isn't a template. + ParseSubstitution(state, /*accept_std=*/false)); +} + +// <template-args> ::= I <template-arg>+ E +static bool ParseTemplateArgs(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + DisableAppend(state); + if (ParseOneCharToken(state, 'I') && OneOrMore(ParseTemplateArg, state) && + ParseOneCharToken(state, 'E')) { + RestoreAppend(state, copy.append); + MaybeAppend(state, "<>"); + return true; + } + state->parse_state = copy; + return false; +} + +// <template-arg> ::= <type> +// ::= <expr-primary> +// ::= J <template-arg>* E # argument pack +// ::= X <expression> E +static bool ParseTemplateArg(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'J') && ZeroOrMore(ParseTemplateArg, state) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + + // There can be significant overlap between the following leading to + // exponential backtracking: + // + // <expr-primary> ::= L <type> <expr-cast-value> E + // e.g. L 2xxIvE 1 E + // <type> ==> <local-source-name> <template-args> + // e.g. L 2xx IvE + // + // This means parsing an entire <type> twice, and <type> can contain + // <template-arg>, so this can generate exponential backtracking. There is + // only overlap when the remaining input starts with "L <source-name>", so + // parse all cases that can start this way jointly to share the common prefix. + // + // We have: + // + // <template-arg> ::= <type> + // ::= <expr-primary> + // + // First, drop all the productions of <type> that must start with something + // other than 'L'. All that's left is <class-enum-type>; inline it. + // + // <type> ::= <nested-name> # starts with 'N' + // ::= <unscoped-name> + // ::= <unscoped-template-name> <template-args> + // ::= <local-name> # starts with 'Z' + // + // Drop and inline again: + // + // <type> ::= <unscoped-name> + // ::= <unscoped-name> <template-args> + // ::= <substitution> <template-args> # starts with 'S' + // + // Merge the first two, inline <unscoped-name>, drop last: + // + // <type> ::= <unqualified-name> [<template-args>] + // ::= St <unqualified-name> [<template-args>] # starts with 'S' + // + // Drop and inline: + // + // <type> ::= <operator-name> [<template-args>] # starts with lowercase + // ::= <ctor-dtor-name> [<template-args>] # starts with 'C' or 'D' + // ::= <source-name> [<template-args>] # starts with digit + // ::= <local-source-name> [<template-args>] + // ::= <unnamed-type-name> [<template-args>] # starts with 'U' + // + // One more time: + // + // <type> ::= L <source-name> [<template-args>] + // + // Likewise with <expr-primary>: + // + // <expr-primary> ::= L <type> <expr-cast-value> E + // ::= LZ <encoding> E # cannot overlap; drop + // ::= L <mangled_name> E # cannot overlap; drop + // + // By similar reasoning as shown above, the only <type>s starting with + // <source-name> are "<source-name> [<template-args>]". Inline this. + // + // <expr-primary> ::= L <source-name> [<template-args>] <expr-cast-value> E + // + // Now inline both of these into <template-arg>: + // + // <template-arg> ::= L <source-name> [<template-args>] + // ::= L <source-name> [<template-args>] <expr-cast-value> E + // + // Merge them and we're done: + // <template-arg> + // ::= L <source-name> [<template-args>] [<expr-cast-value> E] + if (ParseLocalSourceName(state) && Optional(ParseTemplateArgs(state))) { + copy = state->parse_state; + if (ParseExprCastValue(state) && ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + return true; + } + + // Now that the overlapping cases can't reach this code, we can safely call + // both of these. + if (ParseType(state) || ParseExprPrimary(state)) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'X') && ParseExpression(state) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + return false; +} + +// <unresolved-type> ::= <template-param> [<template-args>] +// ::= <decltype> +// ::= <substitution> +static inline bool ParseUnresolvedType(State *state) { + // No ComplexityGuard because we don't copy the state in this stack frame. + return (ParseTemplateParam(state) && Optional(ParseTemplateArgs(state))) || + ParseDecltype(state) || ParseSubstitution(state, /*accept_std=*/false); +} + +// <simple-id> ::= <source-name> [<template-args>] +static inline bool ParseSimpleId(State *state) { + // No ComplexityGuard because we don't copy the state in this stack frame. + + // Note: <simple-id> cannot be followed by a parameter pack; see comment in + // ParseUnresolvedType. + return ParseSourceName(state) && Optional(ParseTemplateArgs(state)); +} + +// <base-unresolved-name> ::= <source-name> [<template-args>] +// ::= on <operator-name> [<template-args>] +// ::= dn <destructor-name> +static bool ParseBaseUnresolvedName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + + if (ParseSimpleId(state)) { + return true; + } + + ParseState copy = state->parse_state; + if (ParseTwoCharToken(state, "on") && ParseOperatorName(state, nullptr) && + Optional(ParseTemplateArgs(state))) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "dn") && + (ParseUnresolvedType(state) || ParseSimpleId(state))) { + return true; + } + state->parse_state = copy; + + return false; +} + +// <unresolved-name> ::= [gs] <base-unresolved-name> +// ::= sr <unresolved-type> <base-unresolved-name> +// ::= srN <unresolved-type> <unresolved-qualifier-level>+ E +// <base-unresolved-name> +// ::= [gs] sr <unresolved-qualifier-level>+ E +// <base-unresolved-name> +static bool ParseUnresolvedName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + + ParseState copy = state->parse_state; + if (Optional(ParseTwoCharToken(state, "gs")) && + ParseBaseUnresolvedName(state)) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "sr") && ParseUnresolvedType(state) && + ParseBaseUnresolvedName(state)) { + return true; + } + state->parse_state = copy; + + if (ParseTwoCharToken(state, "sr") && ParseOneCharToken(state, 'N') && + ParseUnresolvedType(state) && + OneOrMore(/* <unresolved-qualifier-level> ::= */ ParseSimpleId, state) && + ParseOneCharToken(state, 'E') && ParseBaseUnresolvedName(state)) { + return true; + } + state->parse_state = copy; + + if (Optional(ParseTwoCharToken(state, "gs")) && + ParseTwoCharToken(state, "sr") && + OneOrMore(/* <unresolved-qualifier-level> ::= */ ParseSimpleId, state) && + ParseOneCharToken(state, 'E') && ParseBaseUnresolvedName(state)) { + return true; + } + state->parse_state = copy; + + return false; +} + +// <expression> ::= <1-ary operator-name> <expression> +// ::= <2-ary operator-name> <expression> <expression> +// ::= <3-ary operator-name> <expression> <expression> <expression> +// ::= cl <expression>+ E +// ::= cv <type> <expression> # type (expression) +// ::= cv <type> _ <expression>* E # type (expr-list) +// ::= st <type> +// ::= <template-param> +// ::= <function-param> +// ::= <expr-primary> +// ::= dt <expression> <unresolved-name> # expr.name +// ::= pt <expression> <unresolved-name> # expr->name +// ::= sp <expression> # argument pack expansion +// ::= sr <type> <unqualified-name> <template-args> +// ::= sr <type> <unqualified-name> +// <function-param> ::= fp <(top-level) CV-qualifiers> _ +// ::= fp <(top-level) CV-qualifiers> <number> _ +// ::= fL <number> p <(top-level) CV-qualifiers> _ +// ::= fL <number> p <(top-level) CV-qualifiers> <number> _ +static bool ParseExpression(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (ParseTemplateParam(state) || ParseExprPrimary(state)) { + return true; + } + + // Object/function call expression. + ParseState copy = state->parse_state; + if (ParseTwoCharToken(state, "cl") && OneOrMore(ParseExpression, state) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + + // Function-param expression (level 0). + if (ParseTwoCharToken(state, "fp") && Optional(ParseCVQualifiers(state)) && + Optional(ParseNumber(state, nullptr)) && ParseOneCharToken(state, '_')) { + return true; + } + state->parse_state = copy; + + // Function-param expression (level 1+). + if (ParseTwoCharToken(state, "fL") && Optional(ParseNumber(state, nullptr)) && + ParseOneCharToken(state, 'p') && Optional(ParseCVQualifiers(state)) && + Optional(ParseNumber(state, nullptr)) && ParseOneCharToken(state, '_')) { + return true; + } + state->parse_state = copy; + + // Parse the conversion expressions jointly to avoid re-parsing the <type> in + // their common prefix. Parsed as: + // <expression> ::= cv <type> <conversion-args> + // <conversion-args> ::= _ <expression>* E + // ::= <expression> + // + // Also don't try ParseOperatorName after seeing "cv", since ParseOperatorName + // also needs to accept "cv <type>" in other contexts. + if (ParseTwoCharToken(state, "cv")) { + if (ParseType(state)) { + ParseState copy2 = state->parse_state; + if (ParseOneCharToken(state, '_') && ZeroOrMore(ParseExpression, state) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy2; + if (ParseExpression(state)) { + return true; + } + } + } else { + // Parse unary, binary, and ternary operator expressions jointly, taking + // care not to re-parse subexpressions repeatedly. Parse like: + // <expression> ::= <operator-name> <expression> + // [<one-to-two-expressions>] + // <one-to-two-expressions> ::= <expression> [<expression>] + int arity = -1; + if (ParseOperatorName(state, &arity) && + arity > 0 && // 0 arity => disabled. + (arity < 3 || ParseExpression(state)) && + (arity < 2 || ParseExpression(state)) && + (arity < 1 || ParseExpression(state))) { + return true; + } + } + state->parse_state = copy; + + // sizeof type + if (ParseTwoCharToken(state, "st") && ParseType(state)) { + return true; + } + state->parse_state = copy; + + // Object and pointer member access expressions. + if ((ParseTwoCharToken(state, "dt") || ParseTwoCharToken(state, "pt")) && + ParseExpression(state) && ParseType(state)) { + return true; + } + state->parse_state = copy; + + // Pointer-to-member access expressions. This parses the same as a binary + // operator, but it's implemented separately because "ds" shouldn't be + // accepted in other contexts that parse an operator name. + if (ParseTwoCharToken(state, "ds") && ParseExpression(state) && + ParseExpression(state)) { + return true; + } + state->parse_state = copy; + + // Parameter pack expansion + if (ParseTwoCharToken(state, "sp") && ParseExpression(state)) { + return true; + } + state->parse_state = copy; + + return ParseUnresolvedName(state); +} + +// <expr-primary> ::= L <type> <(value) number> E +// ::= L <type> <(value) float> E +// ::= L <mangled-name> E +// // A bug in g++'s C++ ABI version 2 (-fabi-version=2). +// ::= LZ <encoding> E +// +// Warning, subtle: the "bug" LZ production above is ambiguous with the first +// production where <type> starts with <local-name>, which can lead to +// exponential backtracking in two scenarios: +// +// - When whatever follows the E in the <local-name> in the first production is +// not a name, we backtrack the whole <encoding> and re-parse the whole thing. +// +// - When whatever follows the <local-name> in the first production is not a +// number and this <expr-primary> may be followed by a name, we backtrack the +// <name> and re-parse it. +// +// Moreover this ambiguity isn't always resolved -- for example, the following +// has two different parses: +// +// _ZaaILZ4aoeuE1x1EvE +// => operator&&<aoeu, x, E, void> +// => operator&&<(aoeu::x)(1), void> +// +// To resolve this, we just do what GCC's demangler does, and refuse to parse +// casts to <local-name> types. +static bool ParseExprPrimary(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + + // The "LZ" special case: if we see LZ, we commit to accept "LZ <encoding> E" + // or fail, no backtracking. + if (ParseTwoCharToken(state, "LZ")) { + if (ParseEncoding(state) && ParseOneCharToken(state, 'E')) { + return true; + } + + state->parse_state = copy; + return false; + } + + // The merged cast production. + if (ParseOneCharToken(state, 'L') && ParseType(state) && + ParseExprCastValue(state)) { + return true; + } + state->parse_state = copy; + + if (ParseOneCharToken(state, 'L') && ParseMangledName(state) && + ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + + return false; +} + +// <number> or <float>, followed by 'E', as described above ParseExprPrimary. +static bool ParseExprCastValue(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + // We have to be able to backtrack after accepting a number because we could + // have e.g. "7fffE", which will accept "7" as a number but then fail to find + // the 'E'. + ParseState copy = state->parse_state; + if (ParseNumber(state, nullptr) && ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + + if (ParseFloatNumber(state) && ParseOneCharToken(state, 'E')) { + return true; + } + state->parse_state = copy; + + return false; +} + +// <local-name> ::= Z <(function) encoding> E <(entity) name> [<discriminator>] +// ::= Z <(function) encoding> E s [<discriminator>] +// +// Parsing a common prefix of these two productions together avoids an +// exponential blowup of backtracking. Parse like: +// <local-name> := Z <encoding> E <local-name-suffix> +// <local-name-suffix> ::= s [<discriminator>] +// ::= <name> [<discriminator>] + +static bool ParseLocalNameSuffix(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + + if (MaybeAppend(state, "::") && ParseName(state) && + Optional(ParseDiscriminator(state))) { + return true; + } + + // Since we're not going to overwrite the above "::" by re-parsing the + // <encoding> (whose trailing '\0' byte was in the byte now holding the + // first ':'), we have to rollback the "::" if the <name> parse failed. + if (state->parse_state.append) { + state->out[state->parse_state.out_cur_idx - 2] = '\0'; + } + + return ParseOneCharToken(state, 's') && Optional(ParseDiscriminator(state)); +} + +static bool ParseLocalName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'Z') && ParseEncoding(state) && + ParseOneCharToken(state, 'E') && ParseLocalNameSuffix(state)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <discriminator> := _ <(non-negative) number> +static bool ParseDiscriminator(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, '_') && ParseNumber(state, nullptr)) { + return true; + } + state->parse_state = copy; + return false; +} + +// <substitution> ::= S_ +// ::= S <seq-id> _ +// ::= St, etc. +// +// "St" is special in that it's not valid as a standalone name, and it *is* +// allowed to precede a name without being wrapped in "N...E". This means that +// if we accept it on its own, we can accept "St1a" and try to parse +// template-args, then fail and backtrack, accept "St" on its own, then "1a" as +// an unqualified name and re-parse the same template-args. To block this +// exponential backtracking, we disable it with 'accept_std=false' in +// problematic contexts. +static bool ParseSubstitution(State *state, bool accept_std) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (ParseTwoCharToken(state, "S_")) { + MaybeAppend(state, "?"); // We don't support substitutions. + return true; + } + + ParseState copy = state->parse_state; + if (ParseOneCharToken(state, 'S') && ParseSeqId(state) && + ParseOneCharToken(state, '_')) { + MaybeAppend(state, "?"); // We don't support substitutions. + return true; + } + state->parse_state = copy; + + // Expand abbreviations like "St" => "std". + if (ParseOneCharToken(state, 'S')) { + const AbbrevPair *p; + for (p = kSubstitutionList; p->abbrev != nullptr; ++p) { + if (RemainingInput(state)[0] == p->abbrev[1] && + (accept_std || p->abbrev[1] != 't')) { + MaybeAppend(state, "std"); + if (p->real_name[0] != '\0') { + MaybeAppend(state, "::"); + MaybeAppend(state, p->real_name); + } + ++state->parse_state.mangled_idx; + return true; + } + } + } + state->parse_state = copy; + return false; +} + +// Parse <mangled-name>, optionally followed by either a function-clone suffix +// or version suffix. Returns true only if all of "mangled_cur" was consumed. +static bool ParseTopLevelMangledName(State *state) { + ComplexityGuard guard(state); + if (guard.IsTooComplex()) return false; + if (ParseMangledName(state)) { + if (RemainingInput(state)[0] != '\0') { + // Drop trailing function clone suffix, if any. + if (IsFunctionCloneSuffix(RemainingInput(state))) { + return true; + } + // Append trailing version suffix if any. + // ex. _Z3foo@@GLIBCXX_3.4 + if (RemainingInput(state)[0] == '@') { + MaybeAppend(state, RemainingInput(state)); + return true; + } + return false; // Unconsumed suffix. + } + return true; + } + return false; +} + +static bool Overflowed(const State *state) { + return state->parse_state.out_cur_idx >= state->out_end_idx; +} + +// The demangler entry point. +bool Demangle(const char *mangled, char *out, int out_size) { + State state; + InitState(&state, mangled, out, out_size); + return ParseTopLevelMangledName(&state) && !Overflowed(&state); +} + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/internal/demangle.h b/third_party/abseil_cpp/absl/debugging/internal/demangle.h new file mode 100644 index 0000000000..c314d9bc23 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/demangle.h @@ -0,0 +1,71 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// An async-signal-safe and thread-safe demangler for Itanium C++ ABI +// (aka G++ V3 ABI). +// +// The demangler is implemented to be used in async signal handlers to +// symbolize stack traces. We cannot use libstdc++'s +// abi::__cxa_demangle() in such signal handlers since it's not async +// signal safe (it uses malloc() internally). +// +// Note that this demangler doesn't support full demangling. More +// specifically, it doesn't print types of function parameters and +// types of template arguments. It just skips them. However, it's +// still very useful to extract basic information such as class, +// function, constructor, destructor, and operator names. +// +// See the implementation note in demangle.cc if you are interested. +// +// Example: +// +// | Mangled Name | The Demangler | abi::__cxa_demangle() +// |---------------|---------------|----------------------- +// | _Z1fv | f() | f() +// | _Z1fi | f() | f(int) +// | _Z3foo3bar | foo() | foo(bar) +// | _Z1fIiEvi | f<>() | void f<int>(int) +// | _ZN1N1fE | N::f | N::f +// | _ZN3Foo3BarEv | Foo::Bar() | Foo::Bar() +// | _Zrm1XS_" | operator%() | operator%(X, X) +// | _ZN3FooC1Ev | Foo::Foo() | Foo::Foo() +// | _Z1fSs | f() | f(std::basic_string<char, +// | | | std::char_traits<char>, +// | | | std::allocator<char> >) +// +// See the unit test for more examples. +// +// Note: we might want to write demanglers for ABIs other than Itanium +// C++ ABI in the future. +// + +#ifndef ABSL_DEBUGGING_INTERNAL_DEMANGLE_H_ +#define ABSL_DEBUGGING_INTERNAL_DEMANGLE_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Demangle `mangled`. On success, return true and write the +// demangled symbol name to `out`. Otherwise, return false. +// `out` is modified even if demangling is unsuccessful. +bool Demangle(const char *mangled, char *out, int out_size); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_DEMANGLE_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/demangle_test.cc b/third_party/abseil_cpp/absl/debugging/internal/demangle_test.cc new file mode 100644 index 0000000000..c6f1ce184c --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/demangle_test.cc @@ -0,0 +1,195 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/debugging/internal/demangle.h" + +#include <cstdlib> +#include <string> + +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/debugging/internal/stack_consumption.h" +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +namespace { + +// A wrapper function for Demangle() to make the unit test simple. +static const char *DemangleIt(const char * const mangled) { + static char demangled[4096]; + if (Demangle(mangled, demangled, sizeof(demangled))) { + return demangled; + } else { + return mangled; + } +} + +// Test corner cases of bounary conditions. +TEST(Demangle, CornerCases) { + char tmp[10]; + EXPECT_TRUE(Demangle("_Z6foobarv", tmp, sizeof(tmp))); + // sizeof("foobar()") == 9 + EXPECT_STREQ("foobar()", tmp); + EXPECT_TRUE(Demangle("_Z6foobarv", tmp, 9)); + EXPECT_STREQ("foobar()", tmp); + EXPECT_FALSE(Demangle("_Z6foobarv", tmp, 8)); // Not enough. + EXPECT_FALSE(Demangle("_Z6foobarv", tmp, 1)); + EXPECT_FALSE(Demangle("_Z6foobarv", tmp, 0)); + EXPECT_FALSE(Demangle("_Z6foobarv", nullptr, 0)); // Should not cause SEGV. + EXPECT_FALSE(Demangle("_Z1000000", tmp, 9)); +} + +// Test handling of functions suffixed with .clone.N, which is used +// by GCC 4.5.x (and our locally-modified version of GCC 4.4.x), and +// .constprop.N and .isra.N, which are used by GCC 4.6.x. These +// suffixes are used to indicate functions which have been cloned +// during optimization. We ignore these suffixes. +TEST(Demangle, Clones) { + char tmp[20]; + EXPECT_TRUE(Demangle("_ZL3Foov", tmp, sizeof(tmp))); + EXPECT_STREQ("Foo()", tmp); + EXPECT_TRUE(Demangle("_ZL3Foov.clone.3", tmp, sizeof(tmp))); + EXPECT_STREQ("Foo()", tmp); + EXPECT_TRUE(Demangle("_ZL3Foov.constprop.80", tmp, sizeof(tmp))); + EXPECT_STREQ("Foo()", tmp); + EXPECT_TRUE(Demangle("_ZL3Foov.isra.18", tmp, sizeof(tmp))); + EXPECT_STREQ("Foo()", tmp); + EXPECT_TRUE(Demangle("_ZL3Foov.isra.2.constprop.18", tmp, sizeof(tmp))); + EXPECT_STREQ("Foo()", tmp); + // Invalid (truncated), should not demangle. + EXPECT_FALSE(Demangle("_ZL3Foov.clo", tmp, sizeof(tmp))); + // Invalid (.clone. not followed by number), should not demangle. + EXPECT_FALSE(Demangle("_ZL3Foov.clone.", tmp, sizeof(tmp))); + // Invalid (.clone. followed by non-number), should not demangle. + EXPECT_FALSE(Demangle("_ZL3Foov.clone.foo", tmp, sizeof(tmp))); + // Invalid (.constprop. not followed by number), should not demangle. + EXPECT_FALSE(Demangle("_ZL3Foov.isra.2.constprop.", tmp, sizeof(tmp))); +} + +// Tests that verify that Demangle footprint is within some limit. +// They are not to be run under sanitizers as the sanitizers increase +// stack consumption by about 4x. +#if defined(ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION) && \ + !defined(ADDRESS_SANITIZER) && !defined(MEMORY_SANITIZER) && \ + !defined(THREAD_SANITIZER) + +static const char *g_mangled; +static char g_demangle_buffer[4096]; +static char *g_demangle_result; + +static void DemangleSignalHandler(int signo) { + if (Demangle(g_mangled, g_demangle_buffer, sizeof(g_demangle_buffer))) { + g_demangle_result = g_demangle_buffer; + } else { + g_demangle_result = nullptr; + } +} + +// Call Demangle and figure out the stack footprint of this call. +static const char *DemangleStackConsumption(const char *mangled, + int *stack_consumed) { + g_mangled = mangled; + *stack_consumed = GetSignalHandlerStackConsumption(DemangleSignalHandler); + ABSL_RAW_LOG(INFO, "Stack consumption of Demangle: %d", *stack_consumed); + return g_demangle_result; +} + +// Demangle stack consumption should be within 8kB for simple mangled names +// with some level of nesting. With alternate signal stack we have 64K, +// but some signal handlers run on thread stack, and could have arbitrarily +// little space left (so we don't want to make this number too large). +const int kStackConsumptionUpperLimit = 8192; + +// Returns a mangled name nested to the given depth. +static std::string NestedMangledName(int depth) { + std::string mangled_name = "_Z1a"; + if (depth > 0) { + mangled_name += "IXL"; + mangled_name += NestedMangledName(depth - 1); + mangled_name += "EEE"; + } + return mangled_name; +} + +TEST(Demangle, DemangleStackConsumption) { + // Measure stack consumption of Demangle for nested mangled names of varying + // depth. Since Demangle is implemented as a recursive descent parser, + // stack consumption will grow as the nesting depth increases. By measuring + // the stack consumption for increasing depths, we can see the growing + // impact of any stack-saving changes made to the code for Demangle. + int stack_consumed = 0; + + const char *demangled = + DemangleStackConsumption("_Z6foobarv", &stack_consumed); + EXPECT_STREQ("foobar()", demangled); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, kStackConsumptionUpperLimit); + + const std::string nested_mangled_name0 = NestedMangledName(0); + demangled = DemangleStackConsumption(nested_mangled_name0.c_str(), + &stack_consumed); + EXPECT_STREQ("a", demangled); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, kStackConsumptionUpperLimit); + + const std::string nested_mangled_name1 = NestedMangledName(1); + demangled = DemangleStackConsumption(nested_mangled_name1.c_str(), + &stack_consumed); + EXPECT_STREQ("a<>", demangled); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, kStackConsumptionUpperLimit); + + const std::string nested_mangled_name2 = NestedMangledName(2); + demangled = DemangleStackConsumption(nested_mangled_name2.c_str(), + &stack_consumed); + EXPECT_STREQ("a<>", demangled); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, kStackConsumptionUpperLimit); + + const std::string nested_mangled_name3 = NestedMangledName(3); + demangled = DemangleStackConsumption(nested_mangled_name3.c_str(), + &stack_consumed); + EXPECT_STREQ("a<>", demangled); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, kStackConsumptionUpperLimit); +} + +#endif // Stack consumption tests + +static void TestOnInput(const char* input) { + static const int kOutSize = 1048576; + auto out = absl::make_unique<char[]>(kOutSize); + Demangle(input, out.get(), kOutSize); +} + +TEST(DemangleRegression, NegativeLength) { + TestOnInput("_ZZn4"); +} + +TEST(DemangleRegression, DeeplyNestedArrayType) { + const int depth = 100000; + std::string data = "_ZStI"; + data.reserve(data.size() + 3 * depth + 1); + for (int i = 0; i < depth; i++) { + data += "A1_"; + } + TestOnInput(data.c_str()); +} + +} // namespace +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/internal/elf_mem_image.cc b/third_party/abseil_cpp/absl/debugging/internal/elf_mem_image.cc new file mode 100644 index 0000000000..24cc01302d --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/elf_mem_image.cc @@ -0,0 +1,382 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Allow dynamic symbol lookup in an in-memory Elf image. +// + +#include "absl/debugging/internal/elf_mem_image.h" + +#ifdef ABSL_HAVE_ELF_MEM_IMAGE // defined in elf_mem_image.h + +#include <string.h> +#include <cassert> +#include <cstddef> +#include "absl/base/internal/raw_logging.h" + +// From binutils/include/elf/common.h (this doesn't appear to be documented +// anywhere else). +// +// /* This flag appears in a Versym structure. It means that the symbol +// is hidden, and is only visible with an explicit version number. +// This is a GNU extension. */ +// #define VERSYM_HIDDEN 0x8000 +// +// /* This is the mask for the rest of the Versym information. */ +// #define VERSYM_VERSION 0x7fff + +#define VERSYM_VERSION 0x7fff + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +namespace { + +#if __WORDSIZE == 32 +const int kElfClass = ELFCLASS32; +int ElfBind(const ElfW(Sym) *symbol) { return ELF32_ST_BIND(symbol->st_info); } +int ElfType(const ElfW(Sym) *symbol) { return ELF32_ST_TYPE(symbol->st_info); } +#elif __WORDSIZE == 64 +const int kElfClass = ELFCLASS64; +int ElfBind(const ElfW(Sym) *symbol) { return ELF64_ST_BIND(symbol->st_info); } +int ElfType(const ElfW(Sym) *symbol) { return ELF64_ST_TYPE(symbol->st_info); } +#else +const int kElfClass = -1; +int ElfBind(const ElfW(Sym) *) { + ABSL_RAW_LOG(FATAL, "Unexpected word size"); + return 0; +} +int ElfType(const ElfW(Sym) *) { + ABSL_RAW_LOG(FATAL, "Unexpected word size"); + return 0; +} +#endif + +// Extract an element from one of the ELF tables, cast it to desired type. +// This is just a simple arithmetic and a glorified cast. +// Callers are responsible for bounds checking. +template <typename T> +const T *GetTableElement(const ElfW(Ehdr) * ehdr, ElfW(Off) table_offset, + ElfW(Word) element_size, size_t index) { + return reinterpret_cast<const T*>(reinterpret_cast<const char *>(ehdr) + + table_offset + + index * element_size); +} + +} // namespace + +// The value of this variable doesn't matter; it's used only for its +// unique address. +const int ElfMemImage::kInvalidBaseSentinel = 0; + +ElfMemImage::ElfMemImage(const void *base) { + ABSL_RAW_CHECK(base != kInvalidBase, "bad pointer"); + Init(base); +} + +int ElfMemImage::GetNumSymbols() const { + if (!hash_) { + return 0; + } + // See http://www.caldera.com/developers/gabi/latest/ch5.dynamic.html#hash + return hash_[1]; +} + +const ElfW(Sym) *ElfMemImage::GetDynsym(int index) const { + ABSL_RAW_CHECK(index < GetNumSymbols(), "index out of range"); + return dynsym_ + index; +} + +const ElfW(Versym) *ElfMemImage::GetVersym(int index) const { + ABSL_RAW_CHECK(index < GetNumSymbols(), "index out of range"); + return versym_ + index; +} + +const ElfW(Phdr) *ElfMemImage::GetPhdr(int index) const { + ABSL_RAW_CHECK(index < ehdr_->e_phnum, "index out of range"); + return GetTableElement<ElfW(Phdr)>(ehdr_, + ehdr_->e_phoff, + ehdr_->e_phentsize, + index); +} + +const char *ElfMemImage::GetDynstr(ElfW(Word) offset) const { + ABSL_RAW_CHECK(offset < strsize_, "offset out of range"); + return dynstr_ + offset; +} + +const void *ElfMemImage::GetSymAddr(const ElfW(Sym) *sym) const { + if (sym->st_shndx == SHN_UNDEF || sym->st_shndx >= SHN_LORESERVE) { + // Symbol corresponds to "special" (e.g. SHN_ABS) section. + return reinterpret_cast<const void *>(sym->st_value); + } + ABSL_RAW_CHECK(link_base_ < sym->st_value, "symbol out of range"); + return GetTableElement<char>(ehdr_, 0, 1, sym->st_value - link_base_); +} + +const ElfW(Verdef) *ElfMemImage::GetVerdef(int index) const { + ABSL_RAW_CHECK(0 <= index && static_cast<size_t>(index) <= verdefnum_, + "index out of range"); + const ElfW(Verdef) *version_definition = verdef_; + while (version_definition->vd_ndx < index && version_definition->vd_next) { + const char *const version_definition_as_char = + reinterpret_cast<const char *>(version_definition); + version_definition = + reinterpret_cast<const ElfW(Verdef) *>(version_definition_as_char + + version_definition->vd_next); + } + return version_definition->vd_ndx == index ? version_definition : nullptr; +} + +const ElfW(Verdaux) *ElfMemImage::GetVerdefAux( + const ElfW(Verdef) *verdef) const { + return reinterpret_cast<const ElfW(Verdaux) *>(verdef+1); +} + +const char *ElfMemImage::GetVerstr(ElfW(Word) offset) const { + ABSL_RAW_CHECK(offset < strsize_, "offset out of range"); + return dynstr_ + offset; +} + +void ElfMemImage::Init(const void *base) { + ehdr_ = nullptr; + dynsym_ = nullptr; + dynstr_ = nullptr; + versym_ = nullptr; + verdef_ = nullptr; + hash_ = nullptr; + strsize_ = 0; + verdefnum_ = 0; + link_base_ = ~0L; // Sentinel: PT_LOAD .p_vaddr can't possibly be this. + if (!base) { + return; + } + const char *const base_as_char = reinterpret_cast<const char *>(base); + if (base_as_char[EI_MAG0] != ELFMAG0 || base_as_char[EI_MAG1] != ELFMAG1 || + base_as_char[EI_MAG2] != ELFMAG2 || base_as_char[EI_MAG3] != ELFMAG3) { + assert(false); + return; + } + int elf_class = base_as_char[EI_CLASS]; + if (elf_class != kElfClass) { + assert(false); + return; + } + switch (base_as_char[EI_DATA]) { + case ELFDATA2LSB: { + if (__LITTLE_ENDIAN != __BYTE_ORDER) { + assert(false); + return; + } + break; + } + case ELFDATA2MSB: { + if (__BIG_ENDIAN != __BYTE_ORDER) { + assert(false); + return; + } + break; + } + default: { + assert(false); + return; + } + } + + ehdr_ = reinterpret_cast<const ElfW(Ehdr) *>(base); + const ElfW(Phdr) *dynamic_program_header = nullptr; + for (int i = 0; i < ehdr_->e_phnum; ++i) { + const ElfW(Phdr) *const program_header = GetPhdr(i); + switch (program_header->p_type) { + case PT_LOAD: + if (!~link_base_) { + link_base_ = program_header->p_vaddr; + } + break; + case PT_DYNAMIC: + dynamic_program_header = program_header; + break; + } + } + if (!~link_base_ || !dynamic_program_header) { + assert(false); + // Mark this image as not present. Can not recur infinitely. + Init(nullptr); + return; + } + ptrdiff_t relocation = + base_as_char - reinterpret_cast<const char *>(link_base_); + ElfW(Dyn) *dynamic_entry = + reinterpret_cast<ElfW(Dyn) *>(dynamic_program_header->p_vaddr + + relocation); + for (; dynamic_entry->d_tag != DT_NULL; ++dynamic_entry) { + const ElfW(Xword) value = dynamic_entry->d_un.d_val + relocation; + switch (dynamic_entry->d_tag) { + case DT_HASH: + hash_ = reinterpret_cast<ElfW(Word) *>(value); + break; + case DT_SYMTAB: + dynsym_ = reinterpret_cast<ElfW(Sym) *>(value); + break; + case DT_STRTAB: + dynstr_ = reinterpret_cast<const char *>(value); + break; + case DT_VERSYM: + versym_ = reinterpret_cast<ElfW(Versym) *>(value); + break; + case DT_VERDEF: + verdef_ = reinterpret_cast<ElfW(Verdef) *>(value); + break; + case DT_VERDEFNUM: + verdefnum_ = dynamic_entry->d_un.d_val; + break; + case DT_STRSZ: + strsize_ = dynamic_entry->d_un.d_val; + break; + default: + // Unrecognized entries explicitly ignored. + break; + } + } + if (!hash_ || !dynsym_ || !dynstr_ || !versym_ || + !verdef_ || !verdefnum_ || !strsize_) { + assert(false); // invalid VDSO + // Mark this image as not present. Can not recur infinitely. + Init(nullptr); + return; + } +} + +bool ElfMemImage::LookupSymbol(const char *name, + const char *version, + int type, + SymbolInfo *info_out) const { + for (const SymbolInfo& info : *this) { + if (strcmp(info.name, name) == 0 && strcmp(info.version, version) == 0 && + ElfType(info.symbol) == type) { + if (info_out) { + *info_out = info; + } + return true; + } + } + return false; +} + +bool ElfMemImage::LookupSymbolByAddress(const void *address, + SymbolInfo *info_out) const { + for (const SymbolInfo& info : *this) { + const char *const symbol_start = + reinterpret_cast<const char *>(info.address); + const char *const symbol_end = symbol_start + info.symbol->st_size; + if (symbol_start <= address && address < symbol_end) { + if (info_out) { + // Client wants to know details for that symbol (the usual case). + if (ElfBind(info.symbol) == STB_GLOBAL) { + // Strong symbol; just return it. + *info_out = info; + return true; + } else { + // Weak or local. Record it, but keep looking for a strong one. + *info_out = info; + } + } else { + // Client only cares if there is an overlapping symbol. + return true; + } + } + } + return false; +} + +ElfMemImage::SymbolIterator::SymbolIterator(const void *const image, int index) + : index_(index), image_(image) { +} + +const ElfMemImage::SymbolInfo *ElfMemImage::SymbolIterator::operator->() const { + return &info_; +} + +const ElfMemImage::SymbolInfo& ElfMemImage::SymbolIterator::operator*() const { + return info_; +} + +bool ElfMemImage::SymbolIterator::operator==(const SymbolIterator &rhs) const { + return this->image_ == rhs.image_ && this->index_ == rhs.index_; +} + +bool ElfMemImage::SymbolIterator::operator!=(const SymbolIterator &rhs) const { + return !(*this == rhs); +} + +ElfMemImage::SymbolIterator &ElfMemImage::SymbolIterator::operator++() { + this->Update(1); + return *this; +} + +ElfMemImage::SymbolIterator ElfMemImage::begin() const { + SymbolIterator it(this, 0); + it.Update(0); + return it; +} + +ElfMemImage::SymbolIterator ElfMemImage::end() const { + return SymbolIterator(this, GetNumSymbols()); +} + +void ElfMemImage::SymbolIterator::Update(int increment) { + const ElfMemImage *image = reinterpret_cast<const ElfMemImage *>(image_); + ABSL_RAW_CHECK(image->IsPresent() || increment == 0, ""); + if (!image->IsPresent()) { + return; + } + index_ += increment; + if (index_ >= image->GetNumSymbols()) { + index_ = image->GetNumSymbols(); + return; + } + const ElfW(Sym) *symbol = image->GetDynsym(index_); + const ElfW(Versym) *version_symbol = image->GetVersym(index_); + ABSL_RAW_CHECK(symbol && version_symbol, ""); + const char *const symbol_name = image->GetDynstr(symbol->st_name); + const ElfW(Versym) version_index = version_symbol[0] & VERSYM_VERSION; + const ElfW(Verdef) *version_definition = nullptr; + const char *version_name = ""; + if (symbol->st_shndx == SHN_UNDEF) { + // Undefined symbols reference DT_VERNEED, not DT_VERDEF, and + // version_index could well be greater than verdefnum_, so calling + // GetVerdef(version_index) may trigger assertion. + } else { + version_definition = image->GetVerdef(version_index); + } + if (version_definition) { + // I am expecting 1 or 2 auxiliary entries: 1 for the version itself, + // optional 2nd if the version has a parent. + ABSL_RAW_CHECK( + version_definition->vd_cnt == 1 || version_definition->vd_cnt == 2, + "wrong number of entries"); + const ElfW(Verdaux) *version_aux = image->GetVerdefAux(version_definition); + version_name = image->GetVerstr(version_aux->vda_name); + } + info_.name = symbol_name; + info_.version = version_name; + info_.address = image->GetSymAddr(symbol); + info_.symbol = symbol; +} + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HAVE_ELF_MEM_IMAGE diff --git a/third_party/abseil_cpp/absl/debugging/internal/elf_mem_image.h b/third_party/abseil_cpp/absl/debugging/internal/elf_mem_image.h new file mode 100644 index 0000000000..46bfade350 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/elf_mem_image.h @@ -0,0 +1,134 @@ +/* + * Copyright 2017 The Abseil Authors. + * + * Licensed under the Apache License, Version 2.0 (the "License"); + * you may not use this file except in compliance with the License. + * You may obtain a copy of the License at + * + * https://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +// Allow dynamic symbol lookup for in-memory Elf images. + +#ifndef ABSL_DEBUGGING_INTERNAL_ELF_MEM_IMAGE_H_ +#define ABSL_DEBUGGING_INTERNAL_ELF_MEM_IMAGE_H_ + +// Including this will define the __GLIBC__ macro if glibc is being +// used. +#include <climits> + +#include "absl/base/config.h" + +// Maybe one day we can rewrite this file not to require the elf +// symbol extensions in glibc, but for right now we need them. +#ifdef ABSL_HAVE_ELF_MEM_IMAGE +#error ABSL_HAVE_ELF_MEM_IMAGE cannot be directly set +#endif + +#if defined(__ELF__) && defined(__GLIBC__) && !defined(__native_client__) && \ + !defined(__asmjs__) && !defined(__wasm__) +#define ABSL_HAVE_ELF_MEM_IMAGE 1 +#endif + +#ifdef ABSL_HAVE_ELF_MEM_IMAGE + +#include <link.h> // for ElfW + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// An in-memory ELF image (may not exist on disk). +class ElfMemImage { + private: + // Sentinel: there could never be an elf image at &kInvalidBaseSentinel. + static const int kInvalidBaseSentinel; + + public: + // Sentinel: there could never be an elf image at this address. + static constexpr const void *const kInvalidBase = + static_cast<const void*>(&kInvalidBaseSentinel); + + // Information about a single vdso symbol. + // All pointers are into .dynsym, .dynstr, or .text of the VDSO. + // Do not free() them or modify through them. + struct SymbolInfo { + const char *name; // E.g. "__vdso_getcpu" + const char *version; // E.g. "LINUX_2.6", could be "" + // for unversioned symbol. + const void *address; // Relocated symbol address. + const ElfW(Sym) *symbol; // Symbol in the dynamic symbol table. + }; + + // Supports iteration over all dynamic symbols. + class SymbolIterator { + public: + friend class ElfMemImage; + const SymbolInfo *operator->() const; + const SymbolInfo &operator*() const; + SymbolIterator& operator++(); + bool operator!=(const SymbolIterator &rhs) const; + bool operator==(const SymbolIterator &rhs) const; + private: + SymbolIterator(const void *const image, int index); + void Update(int incr); + SymbolInfo info_; + int index_; + const void *const image_; + }; + + + explicit ElfMemImage(const void *base); + void Init(const void *base); + bool IsPresent() const { return ehdr_ != nullptr; } + const ElfW(Phdr)* GetPhdr(int index) const; + const ElfW(Sym)* GetDynsym(int index) const; + const ElfW(Versym)* GetVersym(int index) const; + const ElfW(Verdef)* GetVerdef(int index) const; + const ElfW(Verdaux)* GetVerdefAux(const ElfW(Verdef) *verdef) const; + const char* GetDynstr(ElfW(Word) offset) const; + const void* GetSymAddr(const ElfW(Sym) *sym) const; + const char* GetVerstr(ElfW(Word) offset) const; + int GetNumSymbols() const; + + SymbolIterator begin() const; + SymbolIterator end() const; + + // Look up versioned dynamic symbol in the image. + // Returns false if image is not present, or doesn't contain given + // symbol/version/type combination. + // If info_out is non-null, additional details are filled in. + bool LookupSymbol(const char *name, const char *version, + int symbol_type, SymbolInfo *info_out) const; + + // Find info about symbol (if any) which overlaps given address. + // Returns true if symbol was found; false if image isn't present + // or doesn't have a symbol overlapping given address. + // If info_out is non-null, additional details are filled in. + bool LookupSymbolByAddress(const void *address, SymbolInfo *info_out) const; + + private: + const ElfW(Ehdr) *ehdr_; + const ElfW(Sym) *dynsym_; + const ElfW(Versym) *versym_; + const ElfW(Verdef) *verdef_; + const ElfW(Word) *hash_; + const char *dynstr_; + size_t strsize_; + size_t verdefnum_; + ElfW(Addr) link_base_; // Link-time base (p_vaddr of first PT_LOAD). +}; + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HAVE_ELF_MEM_IMAGE + +#endif // ABSL_DEBUGGING_INTERNAL_ELF_MEM_IMAGE_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/examine_stack.cc b/third_party/abseil_cpp/absl/debugging/internal/examine_stack.cc new file mode 100644 index 0000000000..a3dd893a9d --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/examine_stack.cc @@ -0,0 +1,157 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#include "absl/debugging/internal/examine_stack.h" + +#ifndef _WIN32 +#include <unistd.h> +#endif + +#include <csignal> +#include <cstdio> + +#include "absl/base/attributes.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/debugging/stacktrace.h" +#include "absl/debugging/symbolize.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Returns the program counter from signal context, nullptr if +// unknown. vuc is a ucontext_t*. We use void* to avoid the use of +// ucontext_t on non-POSIX systems. +void* GetProgramCounter(void* vuc) { +#ifdef __linux__ + if (vuc != nullptr) { + ucontext_t* context = reinterpret_cast<ucontext_t*>(vuc); +#if defined(__aarch64__) + return reinterpret_cast<void*>(context->uc_mcontext.pc); +#elif defined(__arm__) + return reinterpret_cast<void*>(context->uc_mcontext.arm_pc); +#elif defined(__i386__) + if (14 < ABSL_ARRAYSIZE(context->uc_mcontext.gregs)) + return reinterpret_cast<void*>(context->uc_mcontext.gregs[14]); +#elif defined(__mips__) + return reinterpret_cast<void*>(context->uc_mcontext.pc); +#elif defined(__powerpc64__) + return reinterpret_cast<void*>(context->uc_mcontext.gp_regs[32]); +#elif defined(__powerpc__) + return reinterpret_cast<void*>(context->uc_mcontext.regs->nip); +#elif defined(__riscv) + return reinterpret_cast<void*>(context->uc_mcontext.__gregs[REG_PC]); +#elif defined(__s390__) && !defined(__s390x__) + return reinterpret_cast<void*>(context->uc_mcontext.psw.addr & 0x7fffffff); +#elif defined(__s390__) && defined(__s390x__) + return reinterpret_cast<void*>(context->uc_mcontext.psw.addr); +#elif defined(__x86_64__) + if (16 < ABSL_ARRAYSIZE(context->uc_mcontext.gregs)) + return reinterpret_cast<void*>(context->uc_mcontext.gregs[16]); +#else +#error "Undefined Architecture." +#endif + } +#elif defined(__akaros__) + auto* ctx = reinterpret_cast<struct user_context*>(vuc); + return reinterpret_cast<void*>(get_user_ctx_pc(ctx)); +#endif + static_cast<void>(vuc); + return nullptr; +} + +// The %p field width for printf() functions is two characters per byte, +// and two extra for the leading "0x". +static constexpr int kPrintfPointerFieldWidth = 2 + 2 * sizeof(void*); + +// Print a program counter, its stack frame size, and its symbol name. +// Note that there is a separate symbolize_pc argument. Return addresses may be +// at the end of the function, and this allows the caller to back up from pc if +// appropriate. +static void DumpPCAndFrameSizeAndSymbol(void (*writerfn)(const char*, void*), + void* writerfn_arg, void* pc, + void* symbolize_pc, int framesize, + const char* const prefix) { + char tmp[1024]; + const char* symbol = "(unknown)"; + if (absl::Symbolize(symbolize_pc, tmp, sizeof(tmp))) { + symbol = tmp; + } + char buf[1024]; + if (framesize <= 0) { + snprintf(buf, sizeof(buf), "%s@ %*p (unknown) %s\n", prefix, + kPrintfPointerFieldWidth, pc, symbol); + } else { + snprintf(buf, sizeof(buf), "%s@ %*p %9d %s\n", prefix, + kPrintfPointerFieldWidth, pc, framesize, symbol); + } + writerfn(buf, writerfn_arg); +} + +// Print a program counter and the corresponding stack frame size. +static void DumpPCAndFrameSize(void (*writerfn)(const char*, void*), + void* writerfn_arg, void* pc, int framesize, + const char* const prefix) { + char buf[100]; + if (framesize <= 0) { + snprintf(buf, sizeof(buf), "%s@ %*p (unknown)\n", prefix, + kPrintfPointerFieldWidth, pc); + } else { + snprintf(buf, sizeof(buf), "%s@ %*p %9d\n", prefix, + kPrintfPointerFieldWidth, pc, framesize); + } + writerfn(buf, writerfn_arg); +} + +void DumpPCAndFrameSizesAndStackTrace( + void* pc, void* const stack[], int frame_sizes[], int depth, + int min_dropped_frames, bool symbolize_stacktrace, + void (*writerfn)(const char*, void*), void* writerfn_arg) { + if (pc != nullptr) { + // We don't know the stack frame size for PC, use 0. + if (symbolize_stacktrace) { + DumpPCAndFrameSizeAndSymbol(writerfn, writerfn_arg, pc, pc, 0, "PC: "); + } else { + DumpPCAndFrameSize(writerfn, writerfn_arg, pc, 0, "PC: "); + } + } + for (int i = 0; i < depth; i++) { + if (symbolize_stacktrace) { + // Pass the previous address of pc as the symbol address because pc is a + // return address, and an overrun may occur when the function ends with a + // call to a function annotated noreturn (e.g. CHECK). Note that we don't + // do this for pc above, as the adjustment is only correct for return + // addresses. + DumpPCAndFrameSizeAndSymbol(writerfn, writerfn_arg, stack[i], + reinterpret_cast<char*>(stack[i]) - 1, + frame_sizes[i], " "); + } else { + DumpPCAndFrameSize(writerfn, writerfn_arg, stack[i], frame_sizes[i], + " "); + } + } + if (min_dropped_frames > 0) { + char buf[100]; + snprintf(buf, sizeof(buf), " @ ... and at least %d more frames\n", + min_dropped_frames); + writerfn(buf, writerfn_arg); + } +} + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/internal/examine_stack.h b/third_party/abseil_cpp/absl/debugging/internal/examine_stack.h new file mode 100644 index 0000000000..393369131f --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/examine_stack.h @@ -0,0 +1,42 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_DEBUGGING_INTERNAL_EXAMINE_STACK_H_ +#define ABSL_DEBUGGING_INTERNAL_EXAMINE_STACK_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Returns the program counter from signal context, or nullptr if +// unknown. `vuc` is a ucontext_t*. We use void* to avoid the use of +// ucontext_t on non-POSIX systems. +void* GetProgramCounter(void* vuc); + +// Uses `writerfn` to dump the program counter, stack trace, and stack +// frame sizes. +void DumpPCAndFrameSizesAndStackTrace( + void* pc, void* const stack[], int frame_sizes[], int depth, + int min_dropped_frames, bool symbolize_stacktrace, + void (*writerfn)(const char*, void*), void* writerfn_arg); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_EXAMINE_STACK_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stack_consumption.cc b/third_party/abseil_cpp/absl/debugging/internal/stack_consumption.cc new file mode 100644 index 0000000000..875ca6d91f --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stack_consumption.cc @@ -0,0 +1,184 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/debugging/internal/stack_consumption.h" + +#ifdef ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION + +#include <signal.h> +#include <sys/mman.h> +#include <unistd.h> + +#include <string.h> + +#include "absl/base/attributes.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +namespace { + +// This code requires that we know the direction in which the stack +// grows. It is commonly believed that this can be detected by putting +// a variable on the stack and then passing its address to a function +// that compares the address of this variable to the address of a +// variable on the function's own stack. However, this is unspecified +// behavior in C++: If two pointers p and q of the same type point to +// different objects that are not members of the same object or +// elements of the same array or to different functions, or if only +// one of them is null, the results of p<q, p>q, p<=q, and p>=q are +// unspecified. Therefore, instead we hardcode the direction of the +// stack on platforms we know about. +#if defined(__i386__) || defined(__x86_64__) || defined(__ppc__) +constexpr bool kStackGrowsDown = true; +#else +#error Need to define kStackGrowsDown +#endif + +// To measure the stack footprint of some code, we create a signal handler +// (for SIGUSR2 say) that exercises this code on an alternate stack. This +// alternate stack is initialized to some known pattern (0x55, 0x55, 0x55, +// ...). We then self-send this signal, and after the signal handler returns, +// look at the alternate stack buffer to see what portion has been touched. +// +// This trick gives us the the stack footprint of the signal handler. But the +// signal handler, even before the code for it is exercised, consumes some +// stack already. We however only want the stack usage of the code inside the +// signal handler. To measure this accurately, we install two signal handlers: +// one that does nothing and just returns, and the user-provided signal +// handler. The difference between the stack consumption of these two signals +// handlers should give us the stack foorprint of interest. + +void EmptySignalHandler(int) {} + +// This is arbitrary value, and could be increase further, at the cost of +// memset()ting it all to known sentinel value. +constexpr int kAlternateStackSize = 64 << 10; // 64KiB + +constexpr int kSafetyMargin = 32; +constexpr char kAlternateStackFillValue = 0x55; + +// These helper functions look at the alternate stack buffer, and figure +// out what portion of this buffer has been touched - this is the stack +// consumption of the signal handler running on this alternate stack. +// This function will return -1 if the alternate stack buffer has not been +// touched. It will abort the program if the buffer has overflowed or is about +// to overflow. +int GetStackConsumption(const void* const altstack) { + const char* begin; + int increment; + if (kStackGrowsDown) { + begin = reinterpret_cast<const char*>(altstack); + increment = 1; + } else { + begin = reinterpret_cast<const char*>(altstack) + kAlternateStackSize - 1; + increment = -1; + } + + for (int usage_count = kAlternateStackSize; usage_count > 0; --usage_count) { + if (*begin != kAlternateStackFillValue) { + ABSL_RAW_CHECK(usage_count <= kAlternateStackSize - kSafetyMargin, + "Buffer has overflowed or is about to overflow"); + return usage_count; + } + begin += increment; + } + + ABSL_RAW_LOG(FATAL, "Unreachable code"); + return -1; +} + +} // namespace + +int GetSignalHandlerStackConsumption(void (*signal_handler)(int)) { + // The alt-signal-stack cannot be heap allocated because there is a + // bug in glibc-2.2 where some signal handler setup code looks at the + // current stack pointer to figure out what thread is currently running. + // Therefore, the alternate stack must be allocated from the main stack + // itself. + void* altstack = mmap(nullptr, kAlternateStackSize, PROT_READ | PROT_WRITE, + MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); + ABSL_RAW_CHECK(altstack != MAP_FAILED, "mmap() failed"); + + // Set up the alt-signal-stack (and save the older one). + stack_t sigstk; + memset(&sigstk, 0, sizeof(sigstk)); + sigstk.ss_sp = altstack; + sigstk.ss_size = kAlternateStackSize; + sigstk.ss_flags = 0; + stack_t old_sigstk; + memset(&old_sigstk, 0, sizeof(old_sigstk)); + ABSL_RAW_CHECK(sigaltstack(&sigstk, &old_sigstk) == 0, + "sigaltstack() failed"); + + // Set up SIGUSR1 and SIGUSR2 signal handlers (and save the older ones). + struct sigaction sa; + memset(&sa, 0, sizeof(sa)); + struct sigaction old_sa1, old_sa2; + sigemptyset(&sa.sa_mask); + sa.sa_flags = SA_ONSTACK; + + // SIGUSR1 maps to EmptySignalHandler. + sa.sa_handler = EmptySignalHandler; + ABSL_RAW_CHECK(sigaction(SIGUSR1, &sa, &old_sa1) == 0, "sigaction() failed"); + + // SIGUSR2 maps to signal_handler. + sa.sa_handler = signal_handler; + ABSL_RAW_CHECK(sigaction(SIGUSR2, &sa, &old_sa2) == 0, "sigaction() failed"); + + // Send SIGUSR1 signal and measure the stack consumption of the empty + // signal handler. + // The first signal might use more stack space. Run once and ignore the + // results to get that out of the way. + ABSL_RAW_CHECK(kill(getpid(), SIGUSR1) == 0, "kill() failed"); + + memset(altstack, kAlternateStackFillValue, kAlternateStackSize); + ABSL_RAW_CHECK(kill(getpid(), SIGUSR1) == 0, "kill() failed"); + int base_stack_consumption = GetStackConsumption(altstack); + + // Send SIGUSR2 signal and measure the stack consumption of signal_handler. + ABSL_RAW_CHECK(kill(getpid(), SIGUSR2) == 0, "kill() failed"); + int signal_handler_stack_consumption = GetStackConsumption(altstack); + + // Now restore the old alt-signal-stack and signal handlers. + if (old_sigstk.ss_sp == nullptr && old_sigstk.ss_size == 0 && + (old_sigstk.ss_flags & SS_DISABLE)) { + // https://git.musl-libc.org/cgit/musl/commit/src/signal/sigaltstack.c?id=7829f42a2c8944555439380498ab8b924d0f2070 + // The original stack has ss_size==0 and ss_flags==SS_DISABLE, but some + // versions of musl have a bug that rejects ss_size==0. Work around this by + // setting ss_size to MINSIGSTKSZ, which should be ignored by the kernel + // when SS_DISABLE is set. + old_sigstk.ss_size = MINSIGSTKSZ; + } + ABSL_RAW_CHECK(sigaltstack(&old_sigstk, nullptr) == 0, + "sigaltstack() failed"); + ABSL_RAW_CHECK(sigaction(SIGUSR1, &old_sa1, nullptr) == 0, + "sigaction() failed"); + ABSL_RAW_CHECK(sigaction(SIGUSR2, &old_sa2, nullptr) == 0, + "sigaction() failed"); + + ABSL_RAW_CHECK(munmap(altstack, kAlternateStackSize) == 0, "munmap() failed"); + if (signal_handler_stack_consumption != -1 && base_stack_consumption != -1) { + return signal_handler_stack_consumption - base_stack_consumption; + } + return -1; +} + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION diff --git a/third_party/abseil_cpp/absl/debugging/internal/stack_consumption.h b/third_party/abseil_cpp/absl/debugging/internal/stack_consumption.h new file mode 100644 index 0000000000..5e60ec4229 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stack_consumption.h @@ -0,0 +1,49 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Helper function for measuring stack consumption of signal handlers. + +#ifndef ABSL_DEBUGGING_INTERNAL_STACK_CONSUMPTION_H_ +#define ABSL_DEBUGGING_INTERNAL_STACK_CONSUMPTION_H_ + +#include "absl/base/config.h" + +// The code in this module is not portable. +// Use this feature test macro to detect its availability. +#ifdef ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION +#error ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION cannot be set directly +#elif !defined(__APPLE__) && !defined(_WIN32) && \ + (defined(__i386__) || defined(__x86_64__) || defined(__ppc__)) +#define ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION 1 + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Returns the stack consumption in bytes for the code exercised by +// signal_handler. To measure stack consumption, signal_handler is registered +// as a signal handler, so the code that it exercises must be async-signal +// safe. The argument of signal_handler is an implementation detail of signal +// handlers and should ignored by the code for signal_handler. Use global +// variables to pass information between your test code and signal_handler. +int GetSignalHandlerStackConsumption(void (*signal_handler)(int)); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION + +#endif // ABSL_DEBUGGING_INTERNAL_STACK_CONSUMPTION_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stack_consumption_test.cc b/third_party/abseil_cpp/absl/debugging/internal/stack_consumption_test.cc new file mode 100644 index 0000000000..80445bf43a --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stack_consumption_test.cc @@ -0,0 +1,50 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/debugging/internal/stack_consumption.h" + +#ifdef ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION + +#include <string.h> + +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +namespace { + +static void SimpleSignalHandler(int signo) { + char buf[100]; + memset(buf, 'a', sizeof(buf)); + + // Never true, but prevents compiler from optimizing buf out. + if (signo == 0) { + ABSL_RAW_LOG(INFO, "%p", static_cast<void*>(buf)); + } +} + +TEST(SignalHandlerStackConsumptionTest, MeasuresStackConsumption) { + // Our handler should consume reasonable number of bytes. + EXPECT_GE(GetSignalHandlerStackConsumption(SimpleSignalHandler), 100); +} + +} // namespace +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_aarch64-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_aarch64-inl.inc new file mode 100644 index 0000000000..14a76f1eb5 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_aarch64-inl.inc @@ -0,0 +1,196 @@ +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_AARCH64_INL_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_AARCH64_INL_H_ + +// Generate stack tracer for aarch64 + +#if defined(__linux__) +#include <sys/mman.h> +#include <ucontext.h> +#include <unistd.h> +#endif + +#include <atomic> +#include <cassert> +#include <cstdint> +#include <iostream> + +#include "absl/base/attributes.h" +#include "absl/debugging/internal/address_is_readable.h" +#include "absl/debugging/internal/vdso_support.h" // a no-op on non-elf or non-glibc systems +#include "absl/debugging/stacktrace.h" + +static const uintptr_t kUnknownFrameSize = 0; + +#if defined(__linux__) +// Returns the address of the VDSO __kernel_rt_sigreturn function, if present. +static const unsigned char* GetKernelRtSigreturnAddress() { + constexpr uintptr_t kImpossibleAddress = 1; + ABSL_CONST_INIT static std::atomic<uintptr_t> memoized{kImpossibleAddress}; + uintptr_t address = memoized.load(std::memory_order_relaxed); + if (address != kImpossibleAddress) { + return reinterpret_cast<const unsigned char*>(address); + } + + address = reinterpret_cast<uintptr_t>(nullptr); + +#ifdef ABSL_HAVE_VDSO_SUPPORT + absl::debugging_internal::VDSOSupport vdso; + if (vdso.IsPresent()) { + absl::debugging_internal::VDSOSupport::SymbolInfo symbol_info; + if (!vdso.LookupSymbol("__kernel_rt_sigreturn", "LINUX_2.6.39", STT_FUNC, + &symbol_info) || + symbol_info.address == nullptr) { + // Unexpected: VDSO is present, yet the expected symbol is missing + // or null. + assert(false && "VDSO is present, but doesn't have expected symbol"); + } else { + if (reinterpret_cast<uintptr_t>(symbol_info.address) != + kImpossibleAddress) { + address = reinterpret_cast<uintptr_t>(symbol_info.address); + } else { + assert(false && "VDSO returned invalid address"); + } + } + } +#endif + + memoized.store(address, std::memory_order_relaxed); + return reinterpret_cast<const unsigned char*>(address); +} +#endif // __linux__ + +// Compute the size of a stack frame in [low..high). We assume that +// low < high. Return size of kUnknownFrameSize. +template<typename T> +static inline uintptr_t ComputeStackFrameSize(const T* low, + const T* high) { + const char* low_char_ptr = reinterpret_cast<const char *>(low); + const char* high_char_ptr = reinterpret_cast<const char *>(high); + return low < high ? high_char_ptr - low_char_ptr : kUnknownFrameSize; +} + +// Given a pointer to a stack frame, locate and return the calling +// stackframe, or return null if no stackframe can be found. Perform sanity +// checks (the strictness of which is controlled by the boolean parameter +// "STRICT_UNWINDING") to reduce the chance that a bad pointer is returned. +template<bool STRICT_UNWINDING, bool WITH_CONTEXT> +ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS // May read random elements from stack. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY // May read random elements from stack. +static void **NextStackFrame(void **old_frame_pointer, const void *uc) { + void **new_frame_pointer = reinterpret_cast<void**>(*old_frame_pointer); + bool check_frame_size = true; + +#if defined(__linux__) + if (WITH_CONTEXT && uc != nullptr) { + // Check to see if next frame's return address is __kernel_rt_sigreturn. + if (old_frame_pointer[1] == GetKernelRtSigreturnAddress()) { + const ucontext_t *ucv = static_cast<const ucontext_t *>(uc); + // old_frame_pointer[0] is not suitable for unwinding, look at + // ucontext to discover frame pointer before signal. + void **const pre_signal_frame_pointer = + reinterpret_cast<void **>(ucv->uc_mcontext.regs[29]); + + // Check that alleged frame pointer is actually readable. This is to + // prevent "double fault" in case we hit the first fault due to e.g. + // stack corruption. + if (!absl::debugging_internal::AddressIsReadable( + pre_signal_frame_pointer)) + return nullptr; + + // Alleged frame pointer is readable, use it for further unwinding. + new_frame_pointer = pre_signal_frame_pointer; + + // Skip frame size check if we return from a signal. We may be using a + // an alternate stack for signals. + check_frame_size = false; + } + } +#endif + + // aarch64 ABI requires stack pointer to be 16-byte-aligned. + if ((reinterpret_cast<uintptr_t>(new_frame_pointer) & 15) != 0) + return nullptr; + + // Check frame size. In strict mode, we assume frames to be under + // 100,000 bytes. In non-strict mode, we relax the limit to 1MB. + if (check_frame_size) { + const uintptr_t max_size = STRICT_UNWINDING ? 100000 : 1000000; + const uintptr_t frame_size = + ComputeStackFrameSize(old_frame_pointer, new_frame_pointer); + if (frame_size == kUnknownFrameSize || frame_size > max_size) + return nullptr; + } + + return new_frame_pointer; +} + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS // May read random elements from stack. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY // May read random elements from stack. +static int UnwindImpl(void** result, int* sizes, int max_depth, int skip_count, + const void *ucp, int *min_dropped_frames) { +#ifdef __GNUC__ + void **frame_pointer = reinterpret_cast<void**>(__builtin_frame_address(0)); +#else +# error reading stack point not yet supported on this platform. +#endif + + skip_count++; // Skip the frame for this function. + int n = 0; + + // The frame pointer points to low address of a frame. The first 64-bit + // word of a frame points to the next frame up the call chain, which normally + // is just after the high address of the current frame. The second word of + // a frame contains return adress of to the caller. To find a pc value + // associated with the current frame, we need to go down a level in the call + // chain. So we remember return the address of the last frame seen. This + // does not work for the first stack frame, which belongs to UnwindImp() but + // we skip the frame for UnwindImp() anyway. + void* prev_return_address = nullptr; + + while (frame_pointer && n < max_depth) { + // The absl::GetStackFrames routine is called when we are in some + // informational context (the failure signal handler for example). + // Use the non-strict unwinding rules to produce a stack trace + // that is as complete as possible (even if it contains a few bogus + // entries in some rare cases). + void **next_frame_pointer = + NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(frame_pointer, ucp); + + if (skip_count > 0) { + skip_count--; + } else { + result[n] = prev_return_address; + if (IS_STACK_FRAMES) { + sizes[n] = ComputeStackFrameSize(frame_pointer, next_frame_pointer); + } + n++; + } + prev_return_address = frame_pointer[1]; + frame_pointer = next_frame_pointer; + } + if (min_dropped_frames != nullptr) { + // Implementation detail: we clamp the max of frames we are willing to + // count, so as not to spend too much time in the loop below. + const int kMaxUnwind = 200; + int j = 0; + for (; frame_pointer != nullptr && j < kMaxUnwind; j++) { + frame_pointer = + NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(frame_pointer, ucp); + } + *min_dropped_frames = j; + } + return n; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return true; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_AARCH64_INL_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_arm-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_arm-inl.inc new file mode 100644 index 0000000000..2a1bf2e886 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_arm-inl.inc @@ -0,0 +1,134 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This is inspired by Craig Silverstein's PowerPC stacktrace code. + +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_ARM_INL_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_ARM_INL_H_ + +#include <cstdint> + +#include "absl/debugging/stacktrace.h" + +// WARNING: +// This only works if all your code is in either ARM or THUMB mode. With +// interworking, the frame pointer of the caller can either be in r11 (ARM +// mode) or r7 (THUMB mode). A callee only saves the frame pointer of its +// mode in a fixed location on its stack frame. If the caller is a different +// mode, there is no easy way to find the frame pointer. It can either be +// still in the designated register or saved on stack along with other callee +// saved registers. + +// Given a pointer to a stack frame, locate and return the calling +// stackframe, or return nullptr if no stackframe can be found. Perform sanity +// checks (the strictness of which is controlled by the boolean parameter +// "STRICT_UNWINDING") to reduce the chance that a bad pointer is returned. +template<bool STRICT_UNWINDING> +static void **NextStackFrame(void **old_sp) { + void **new_sp = (void**) old_sp[-1]; + + // Check that the transition from frame pointer old_sp to frame + // pointer new_sp isn't clearly bogus + if (STRICT_UNWINDING) { + // With the stack growing downwards, older stack frame must be + // at a greater address that the current one. + if (new_sp <= old_sp) return nullptr; + // Assume stack frames larger than 100,000 bytes are bogus. + if ((uintptr_t)new_sp - (uintptr_t)old_sp > 100000) return nullptr; + } else { + // In the non-strict mode, allow discontiguous stack frames. + // (alternate-signal-stacks for example). + if (new_sp == old_sp) return nullptr; + // And allow frames upto about 1MB. + if ((new_sp > old_sp) + && ((uintptr_t)new_sp - (uintptr_t)old_sp > 1000000)) return nullptr; + } + if ((uintptr_t)new_sp & (sizeof(void *) - 1)) return nullptr; + return new_sp; +} + +// This ensures that absl::GetStackTrace sets up the Link Register properly. +#ifdef __GNUC__ +void StacktraceArmDummyFunction() __attribute__((noinline)); +void StacktraceArmDummyFunction() { __asm__ volatile(""); } +#else +# error StacktraceArmDummyFunction() needs to be ported to this platform. +#endif + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +static int UnwindImpl(void** result, int* sizes, int max_depth, int skip_count, + const void * /* ucp */, int *min_dropped_frames) { +#ifdef __GNUC__ + void **sp = reinterpret_cast<void**>(__builtin_frame_address(0)); +#else +# error reading stack point not yet supported on this platform. +#endif + + // On ARM, the return address is stored in the link register (r14). + // This is not saved on the stack frame of a leaf function. To + // simplify code that reads return addresses, we call a dummy + // function so that the return address of this function is also + // stored in the stack frame. This works at least for gcc. + StacktraceArmDummyFunction(); + + int n = 0; + while (sp && n < max_depth) { + // The absl::GetStackFrames routine is called when we are in some + // informational context (the failure signal handler for example). + // Use the non-strict unwinding rules to produce a stack trace + // that is as complete as possible (even if it contains a few bogus + // entries in some rare cases). + void **next_sp = NextStackFrame<!IS_STACK_FRAMES>(sp); + + if (skip_count > 0) { + skip_count--; + } else { + result[n] = *sp; + + if (IS_STACK_FRAMES) { + if (next_sp > sp) { + sizes[n] = (uintptr_t)next_sp - (uintptr_t)sp; + } else { + // A frame-size of 0 is used to indicate unknown frame size. + sizes[n] = 0; + } + } + n++; + } + sp = next_sp; + } + if (min_dropped_frames != nullptr) { + // Implementation detail: we clamp the max of frames we are willing to + // count, so as not to spend too much time in the loop below. + const int kMaxUnwind = 200; + int j = 0; + for (; sp != nullptr && j < kMaxUnwind; j++) { + sp = NextStackFrame<!IS_STACK_FRAMES>(sp); + } + *min_dropped_frames = j; + } + return n; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return false; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_ARM_INL_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_config.h b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_config.h new file mode 100644 index 0000000000..d4e8480a8e --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_config.h @@ -0,0 +1,70 @@ +/* + * Copyright 2017 The Abseil Authors. + * + * Licensed under the Apache License, Version 2.0 (the "License"); + * you may not use this file except in compliance with the License. + * You may obtain a copy of the License at + * + * https://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + + * Defines ABSL_STACKTRACE_INL_HEADER to the *-inl.h containing + * actual unwinder implementation. + * This header is "private" to stacktrace.cc. + * DO NOT include it into any other files. +*/ +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_CONFIG_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_CONFIG_H_ + +#if defined(ABSL_STACKTRACE_INL_HEADER) +#error ABSL_STACKTRACE_INL_HEADER cannot be directly set + +#elif defined(_WIN32) +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_win32-inl.inc" + +#elif defined(__linux__) && !defined(__ANDROID__) + +#if !defined(NO_FRAME_POINTER) +# if defined(__i386__) || defined(__x86_64__) +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_x86-inl.inc" +# elif defined(__ppc__) || defined(__PPC__) +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_powerpc-inl.inc" +# elif defined(__aarch64__) +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_aarch64-inl.inc" +# elif defined(__arm__) +// Note: When using glibc this may require -funwind-tables to function properly. +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_generic-inl.inc" +# else +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_unimplemented-inl.inc" +# endif +#else // defined(NO_FRAME_POINTER) +# if defined(__i386__) || defined(__x86_64__) || defined(__aarch64__) +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_generic-inl.inc" +# elif defined(__ppc__) || defined(__PPC__) +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_generic-inl.inc" +# else +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_unimplemented-inl.inc" +# endif +#endif // NO_FRAME_POINTER + +#else +#define ABSL_STACKTRACE_INL_HEADER \ + "absl/debugging/internal/stacktrace_unimplemented-inl.inc" + +#endif + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_CONFIG_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_generic-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_generic-inl.inc new file mode 100644 index 0000000000..b2792a1f3a --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_generic-inl.inc @@ -0,0 +1,108 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Portable implementation - just use glibc +// +// Note: The glibc implementation may cause a call to malloc. +// This can cause a deadlock in HeapProfiler. + +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_GENERIC_INL_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_GENERIC_INL_H_ + +#include <execinfo.h> +#include <atomic> +#include <cstring> + +#include "absl/debugging/stacktrace.h" +#include "absl/base/attributes.h" + +// Sometimes, we can try to get a stack trace from within a stack +// trace, because we don't block signals inside this code (which would be too +// expensive: the two extra system calls per stack trace do matter here). +// That can cause a self-deadlock. +// Protect against such reentrant call by failing to get a stack trace. +// +// We use __thread here because the code here is extremely low level -- it is +// called while collecting stack traces from within malloc and mmap, and thus +// can not call anything which might call malloc or mmap itself. +static __thread int recursive = 0; + +// The stack trace function might be invoked very early in the program's +// execution (e.g. from the very first malloc if using tcmalloc). Also, the +// glibc implementation itself will trigger malloc the first time it is called. +// As such, we suppress usage of backtrace during this early stage of execution. +static std::atomic<bool> disable_stacktraces(true); // Disabled until healthy. +// Waiting until static initializers run seems to be late enough. +// This file is included into stacktrace.cc so this will only run once. +ABSL_ATTRIBUTE_UNUSED static int stacktraces_enabler = []() { + void* unused_stack[1]; + // Force the first backtrace to happen early to get the one-time shared lib + // loading (allocation) out of the way. After the first call it is much safer + // to use backtrace from a signal handler if we crash somewhere later. + backtrace(unused_stack, 1); + disable_stacktraces.store(false, std::memory_order_relaxed); + return 0; +}(); + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +static int UnwindImpl(void** result, int* sizes, int max_depth, int skip_count, + const void *ucp, int *min_dropped_frames) { + if (recursive || disable_stacktraces.load(std::memory_order_relaxed)) { + return 0; + } + ++recursive; + + static_cast<void>(ucp); // Unused. + static const int kStackLength = 64; + void * stack[kStackLength]; + int size; + + size = backtrace(stack, kStackLength); + skip_count++; // we want to skip the current frame as well + int result_count = size - skip_count; + if (result_count < 0) + result_count = 0; + if (result_count > max_depth) + result_count = max_depth; + for (int i = 0; i < result_count; i++) + result[i] = stack[i + skip_count]; + + if (IS_STACK_FRAMES) { + // No implementation for finding out the stack frame sizes yet. + memset(sizes, 0, sizeof(*sizes) * result_count); + } + if (min_dropped_frames != nullptr) { + if (size - skip_count - max_depth > 0) { + *min_dropped_frames = size - skip_count - max_depth; + } else { + *min_dropped_frames = 0; + } + } + + --recursive; + + return result_count; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return true; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_GENERIC_INL_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_powerpc-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_powerpc-inl.inc new file mode 100644 index 0000000000..2e7c2f404f --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_powerpc-inl.inc @@ -0,0 +1,248 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Produce stack trace. I'm guessing (hoping!) the code is much like +// for x86. For apple machines, at least, it seems to be; see +// https://developer.apple.com/documentation/mac/runtimehtml/RTArch-59.html +// https://www.linux-foundation.org/spec/ELF/ppc64/PPC-elf64abi-1.9.html#STACK +// Linux has similar code: http://patchwork.ozlabs.org/linuxppc/patch?id=8882 + +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_POWERPC_INL_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_POWERPC_INL_H_ + +#if defined(__linux__) +#include <asm/ptrace.h> // for PT_NIP. +#include <ucontext.h> // for ucontext_t +#endif + +#include <unistd.h> +#include <cassert> +#include <cstdint> +#include <cstdio> + +#include "absl/base/attributes.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" +#include "absl/debugging/stacktrace.h" +#include "absl/debugging/internal/address_is_readable.h" +#include "absl/debugging/internal/vdso_support.h" // a no-op on non-elf or non-glibc systems + +// Given a stack pointer, return the saved link register value. +// Note that this is the link register for a callee. +static inline void *StacktracePowerPCGetLR(void **sp) { + // PowerPC has 3 main ABIs, which say where in the stack the + // Link Register is. For DARWIN and AIX (used by apple and + // linux ppc64), it's in sp[2]. For SYSV (used by linux ppc), + // it's in sp[1]. +#if defined(_CALL_AIX) || defined(_CALL_DARWIN) + return *(sp+2); +#elif defined(_CALL_SYSV) + return *(sp+1); +#elif defined(__APPLE__) || defined(__FreeBSD__) || \ + (defined(__linux__) && defined(__PPC64__)) + // This check is in case the compiler doesn't define _CALL_AIX/etc. + return *(sp+2); +#elif defined(__linux) + // This check is in case the compiler doesn't define _CALL_SYSV. + return *(sp+1); +#else +#error Need to specify the PPC ABI for your archiecture. +#endif +} + +// Given a pointer to a stack frame, locate and return the calling +// stackframe, or return null if no stackframe can be found. Perform sanity +// checks (the strictness of which is controlled by the boolean parameter +// "STRICT_UNWINDING") to reduce the chance that a bad pointer is returned. +template<bool STRICT_UNWINDING, bool IS_WITH_CONTEXT> +ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS // May read random elements from stack. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY // May read random elements from stack. +static void **NextStackFrame(void **old_sp, const void *uc) { + void **new_sp = (void **) *old_sp; + enum { kStackAlignment = 16 }; + + // Check that the transition from frame pointer old_sp to frame + // pointer new_sp isn't clearly bogus + if (STRICT_UNWINDING) { + // With the stack growing downwards, older stack frame must be + // at a greater address that the current one. + if (new_sp <= old_sp) return nullptr; + // Assume stack frames larger than 100,000 bytes are bogus. + if ((uintptr_t)new_sp - (uintptr_t)old_sp > 100000) return nullptr; + } else { + // In the non-strict mode, allow discontiguous stack frames. + // (alternate-signal-stacks for example). + if (new_sp == old_sp) return nullptr; + // And allow frames upto about 1MB. + if ((new_sp > old_sp) + && ((uintptr_t)new_sp - (uintptr_t)old_sp > 1000000)) return nullptr; + } + if ((uintptr_t)new_sp % kStackAlignment != 0) return nullptr; + +#if defined(__linux__) + enum StackTraceKernelSymbolStatus { + kNotInitialized = 0, kAddressValid, kAddressInvalid }; + + if (IS_WITH_CONTEXT && uc != nullptr) { + static StackTraceKernelSymbolStatus kernel_symbol_status = + kNotInitialized; // Sentinel: not computed yet. + // Initialize with sentinel value: __kernel_rt_sigtramp_rt64 can not + // possibly be there. + static const unsigned char *kernel_sigtramp_rt64_address = nullptr; + if (kernel_symbol_status == kNotInitialized) { + absl::debugging_internal::VDSOSupport vdso; + if (vdso.IsPresent()) { + absl::debugging_internal::VDSOSupport::SymbolInfo + sigtramp_rt64_symbol_info; + if (!vdso.LookupSymbol( + "__kernel_sigtramp_rt64", "LINUX_2.6.15", + absl::debugging_internal::VDSOSupport::kVDSOSymbolType, + &sigtramp_rt64_symbol_info) || + sigtramp_rt64_symbol_info.address == nullptr) { + // Unexpected: VDSO is present, yet the expected symbol is missing + // or null. + assert(false && "VDSO is present, but doesn't have expected symbol"); + kernel_symbol_status = kAddressInvalid; + } else { + kernel_sigtramp_rt64_address = + reinterpret_cast<const unsigned char *>( + sigtramp_rt64_symbol_info.address); + kernel_symbol_status = kAddressValid; + } + } else { + kernel_symbol_status = kAddressInvalid; + } + } + + if (new_sp != nullptr && + kernel_symbol_status == kAddressValid && + StacktracePowerPCGetLR(new_sp) == kernel_sigtramp_rt64_address) { + const ucontext_t* signal_context = + reinterpret_cast<const ucontext_t*>(uc); + void **const sp_before_signal = + reinterpret_cast<void**>(signal_context->uc_mcontext.gp_regs[PT_R1]); + // Check that alleged sp before signal is nonnull and is reasonably + // aligned. + if (sp_before_signal != nullptr && + ((uintptr_t)sp_before_signal % kStackAlignment) == 0) { + // Check that alleged stack pointer is actually readable. This is to + // prevent a "double fault" in case we hit the first fault due to e.g. + // a stack corruption. + if (absl::debugging_internal::AddressIsReadable(sp_before_signal)) { + // Alleged stack pointer is readable, use it for further unwinding. + new_sp = sp_before_signal; + } + } + } + } +#endif + + return new_sp; +} + +// This ensures that absl::GetStackTrace sets up the Link Register properly. +ABSL_ATTRIBUTE_NOINLINE static void AbslStacktracePowerPCDummyFunction() { + ABSL_BLOCK_TAIL_CALL_OPTIMIZATION(); +} + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS // May read random elements from stack. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY // May read random elements from stack. +static int UnwindImpl(void** result, int* sizes, int max_depth, int skip_count, + const void *ucp, int *min_dropped_frames) { + void **sp; + // Apple macOS uses an old version of gnu as -- both Darwin 7.9.0 (Panther) + // and Darwin 8.8.1 (Tiger) use as 1.38. This means we have to use a + // different asm syntax. I don't know quite the best way to discriminate + // systems using the old as from the new one; I've gone with __APPLE__. +#ifdef __APPLE__ + __asm__ volatile ("mr %0,r1" : "=r" (sp)); +#else + __asm__ volatile ("mr %0,1" : "=r" (sp)); +#endif + + // On PowerPC, the "Link Register" or "Link Record" (LR), is a stack + // entry that holds the return address of the subroutine call (what + // instruction we run after our function finishes). This is the + // same as the stack-pointer of our parent routine, which is what we + // want here. While the compiler will always(?) set up LR for + // subroutine calls, it may not for leaf functions (such as this one). + // This routine forces the compiler (at least gcc) to push it anyway. + AbslStacktracePowerPCDummyFunction(); + + // The LR save area is used by the callee, so the top entry is bogus. + skip_count++; + + int n = 0; + + // Unlike ABIs of X86 and ARM, PowerPC ABIs say that return address (in + // the link register) of a function call is stored in the caller's stack + // frame instead of the callee's. When we look for the return address + // associated with a stack frame, we need to make sure that there is a + // caller frame before it. So we call NextStackFrame before entering the + // loop below and check next_sp instead of sp for loop termination. + // The outermost frame is set up by runtimes and it does not have a + // caller frame, so it is skipped. + + // The absl::GetStackFrames routine is called when we are in some + // informational context (the failure signal handler for example). + // Use the non-strict unwinding rules to produce a stack trace + // that is as complete as possible (even if it contains a few + // bogus entries in some rare cases). + void **next_sp = NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(sp, ucp); + + while (next_sp && n < max_depth) { + if (skip_count > 0) { + skip_count--; + } else { + result[n] = StacktracePowerPCGetLR(sp); + if (IS_STACK_FRAMES) { + if (next_sp > sp) { + sizes[n] = (uintptr_t)next_sp - (uintptr_t)sp; + } else { + // A frame-size of 0 is used to indicate unknown frame size. + sizes[n] = 0; + } + } + n++; + } + + sp = next_sp; + next_sp = NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(sp, ucp); + } + + if (min_dropped_frames != nullptr) { + // Implementation detail: we clamp the max of frames we are willing to + // count, so as not to spend too much time in the loop below. + const int kMaxUnwind = 1000; + int j = 0; + for (; next_sp != nullptr && j < kMaxUnwind; j++) { + next_sp = NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(next_sp, ucp); + } + *min_dropped_frames = j; + } + return n; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return true; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_POWERPC_INL_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_unimplemented-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_unimplemented-inl.inc new file mode 100644 index 0000000000..5b8fb191b6 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_unimplemented-inl.inc @@ -0,0 +1,24 @@ +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_UNIMPLEMENTED_INL_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_UNIMPLEMENTED_INL_H_ + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +static int UnwindImpl(void** /* result */, int* /* sizes */, + int /* max_depth */, int /* skip_count */, + const void* /* ucp */, int *min_dropped_frames) { + if (min_dropped_frames != nullptr) { + *min_dropped_frames = 0; + } + return 0; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return false; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_UNIMPLEMENTED_INL_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_win32-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_win32-inl.inc new file mode 100644 index 0000000000..1c666c8b56 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_win32-inl.inc @@ -0,0 +1,93 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Produces a stack trace for Windows. Normally, one could use +// stacktrace_x86-inl.h or stacktrace_x86_64-inl.h -- and indeed, that +// should work for binaries compiled using MSVC in "debug" mode. +// However, in "release" mode, Windows uses frame-pointer +// optimization, which makes getting a stack trace very difficult. +// +// There are several approaches one can take. One is to use Windows +// intrinsics like StackWalk64. These can work, but have restrictions +// on how successful they can be. Another attempt is to write a +// version of stacktrace_x86-inl.h that has heuristic support for +// dealing with FPO, similar to what WinDbg does (see +// http://www.nynaeve.net/?p=97). There are (non-working) examples of +// these approaches, complete with TODOs, in stacktrace_win32-inl.h#1 +// +// The solution we've ended up doing is to call the undocumented +// windows function RtlCaptureStackBackTrace, which probably doesn't +// work with FPO but at least is fast, and doesn't require a symbol +// server. +// +// This code is inspired by a patch from David Vitek: +// https://code.google.com/p/google-perftools/issues/detail?id=83 + +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_WIN32_INL_H_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_WIN32_INL_H_ + +#include <windows.h> // for GetProcAddress and GetModuleHandle +#include <cassert> + +typedef USHORT NTAPI RtlCaptureStackBackTrace_Function( + IN ULONG frames_to_skip, + IN ULONG frames_to_capture, + OUT PVOID *backtrace, + OUT PULONG backtrace_hash); + +// It is not possible to load RtlCaptureStackBackTrace at static init time in +// UWP. CaptureStackBackTrace is the public version of RtlCaptureStackBackTrace +#if WINAPI_FAMILY_PARTITION(WINAPI_PARTITION_APP) && \ + !WINAPI_FAMILY_PARTITION(WINAPI_PARTITION_DESKTOP) +static RtlCaptureStackBackTrace_Function* const RtlCaptureStackBackTrace_fn = + &::CaptureStackBackTrace; +#else +// Load the function we need at static init time, where we don't have +// to worry about someone else holding the loader's lock. +static RtlCaptureStackBackTrace_Function* const RtlCaptureStackBackTrace_fn = + (RtlCaptureStackBackTrace_Function*)GetProcAddress( + GetModuleHandleA("ntdll.dll"), "RtlCaptureStackBackTrace"); +#endif // WINAPI_PARTITION_APP && !WINAPI_PARTITION_DESKTOP + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +static int UnwindImpl(void** result, int* sizes, int max_depth, int skip_count, + const void*, int* min_dropped_frames) { + int n = 0; + if (!RtlCaptureStackBackTrace_fn) { + // can't find a stacktrace with no function to call + } else { + n = (int)RtlCaptureStackBackTrace_fn(skip_count + 2, max_depth, result, 0); + } + if (IS_STACK_FRAMES) { + // No implementation for finding out the stack frame sizes yet. + memset(sizes, 0, sizeof(*sizes) * n); + } + if (min_dropped_frames != nullptr) { + // Not implemented. + *min_dropped_frames = 0; + } + return n; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return false; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_WIN32_INL_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/stacktrace_x86-inl.inc b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_x86-inl.inc new file mode 100644 index 0000000000..bc320ff75b --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/stacktrace_x86-inl.inc @@ -0,0 +1,346 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Produce stack trace + +#ifndef ABSL_DEBUGGING_INTERNAL_STACKTRACE_X86_INL_INC_ +#define ABSL_DEBUGGING_INTERNAL_STACKTRACE_X86_INL_INC_ + +#if defined(__linux__) && (defined(__i386__) || defined(__x86_64__)) +#include <ucontext.h> // for ucontext_t +#endif + +#if !defined(_WIN32) +#include <unistd.h> +#endif + +#include <cassert> +#include <cstdint> + +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/debugging/internal/address_is_readable.h" +#include "absl/debugging/internal/vdso_support.h" // a no-op on non-elf or non-glibc systems +#include "absl/debugging/stacktrace.h" + +#include "absl/base/internal/raw_logging.h" + +using absl::debugging_internal::AddressIsReadable; + +#if defined(__linux__) && defined(__i386__) +// Count "push %reg" instructions in VDSO __kernel_vsyscall(), +// preceeding "syscall" or "sysenter". +// If __kernel_vsyscall uses frame pointer, answer 0. +// +// kMaxBytes tells how many instruction bytes of __kernel_vsyscall +// to analyze before giving up. Up to kMaxBytes+1 bytes of +// instructions could be accessed. +// +// Here are known __kernel_vsyscall instruction sequences: +// +// SYSENTER (linux-2.6.26/arch/x86/vdso/vdso32/sysenter.S). +// Used on Intel. +// 0xffffe400 <__kernel_vsyscall+0>: push %ecx +// 0xffffe401 <__kernel_vsyscall+1>: push %edx +// 0xffffe402 <__kernel_vsyscall+2>: push %ebp +// 0xffffe403 <__kernel_vsyscall+3>: mov %esp,%ebp +// 0xffffe405 <__kernel_vsyscall+5>: sysenter +// +// SYSCALL (see linux-2.6.26/arch/x86/vdso/vdso32/syscall.S). +// Used on AMD. +// 0xffffe400 <__kernel_vsyscall+0>: push %ebp +// 0xffffe401 <__kernel_vsyscall+1>: mov %ecx,%ebp +// 0xffffe403 <__kernel_vsyscall+3>: syscall +// + +// The sequence below isn't actually expected in Google fleet, +// here only for completeness. Remove this comment from OSS release. + +// i386 (see linux-2.6.26/arch/x86/vdso/vdso32/int80.S) +// 0xffffe400 <__kernel_vsyscall+0>: int $0x80 +// 0xffffe401 <__kernel_vsyscall+1>: ret +// +static const int kMaxBytes = 10; + +// We use assert()s instead of DCHECK()s -- this is too low level +// for DCHECK(). + +static int CountPushInstructions(const unsigned char *const addr) { + int result = 0; + for (int i = 0; i < kMaxBytes; ++i) { + if (addr[i] == 0x89) { + // "mov reg,reg" + if (addr[i + 1] == 0xE5) { + // Found "mov %esp,%ebp". + return 0; + } + ++i; // Skip register encoding byte. + } else if (addr[i] == 0x0F && + (addr[i + 1] == 0x34 || addr[i + 1] == 0x05)) { + // Found "sysenter" or "syscall". + return result; + } else if ((addr[i] & 0xF0) == 0x50) { + // Found "push %reg". + ++result; + } else if (addr[i] == 0xCD && addr[i + 1] == 0x80) { + // Found "int $0x80" + assert(result == 0); + return 0; + } else { + // Unexpected instruction. + assert(false && "unexpected instruction in __kernel_vsyscall"); + return 0; + } + } + // Unexpected: didn't find SYSENTER or SYSCALL in + // [__kernel_vsyscall, __kernel_vsyscall + kMaxBytes) interval. + assert(false && "did not find SYSENTER or SYSCALL in __kernel_vsyscall"); + return 0; +} +#endif + +// Assume stack frames larger than 100,000 bytes are bogus. +static const int kMaxFrameBytes = 100000; + +// Returns the stack frame pointer from signal context, 0 if unknown. +// vuc is a ucontext_t *. We use void* to avoid the use +// of ucontext_t on non-POSIX systems. +static uintptr_t GetFP(const void *vuc) { +#if !defined(__linux__) + static_cast<void>(vuc); // Avoid an unused argument compiler warning. +#else + if (vuc != nullptr) { + auto *uc = reinterpret_cast<const ucontext_t *>(vuc); +#if defined(__i386__) + const auto bp = uc->uc_mcontext.gregs[REG_EBP]; + const auto sp = uc->uc_mcontext.gregs[REG_ESP]; +#elif defined(__x86_64__) + const auto bp = uc->uc_mcontext.gregs[REG_RBP]; + const auto sp = uc->uc_mcontext.gregs[REG_RSP]; +#else + const uintptr_t bp = 0; + const uintptr_t sp = 0; +#endif + // Sanity-check that the base pointer is valid. It should be as long as + // SHRINK_WRAP_FRAME_POINTER is not set, but it's possible that some code in + // the process is compiled with --copt=-fomit-frame-pointer or + // --copt=-momit-leaf-frame-pointer. + // + // TODO(bcmills): -momit-leaf-frame-pointer is currently the default + // behavior when building with clang. Talk to the C++ toolchain team about + // fixing that. + if (bp >= sp && bp - sp <= kMaxFrameBytes) return bp; + + // If bp isn't a plausible frame pointer, return the stack pointer instead. + // If we're lucky, it points to the start of a stack frame; otherwise, we'll + // get one frame of garbage in the stack trace and fail the sanity check on + // the next iteration. + return sp; + } +#endif + return 0; +} + +// Given a pointer to a stack frame, locate and return the calling +// stackframe, or return null if no stackframe can be found. Perform sanity +// checks (the strictness of which is controlled by the boolean parameter +// "STRICT_UNWINDING") to reduce the chance that a bad pointer is returned. +template <bool STRICT_UNWINDING, bool WITH_CONTEXT> +ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS // May read random elements from stack. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY // May read random elements from stack. +static void **NextStackFrame(void **old_fp, const void *uc) { + void **new_fp = (void **)*old_fp; + +#if defined(__linux__) && defined(__i386__) + if (WITH_CONTEXT && uc != nullptr) { + // How many "push %reg" instructions are there at __kernel_vsyscall? + // This is constant for a given kernel and processor, so compute + // it only once. + static int num_push_instructions = -1; // Sentinel: not computed yet. + // Initialize with sentinel value: __kernel_rt_sigreturn can not possibly + // be there. + static const unsigned char *kernel_rt_sigreturn_address = nullptr; + static const unsigned char *kernel_vsyscall_address = nullptr; + if (num_push_instructions == -1) { +#ifdef ABSL_HAVE_VDSO_SUPPORT + absl::debugging_internal::VDSOSupport vdso; + if (vdso.IsPresent()) { + absl::debugging_internal::VDSOSupport::SymbolInfo + rt_sigreturn_symbol_info; + absl::debugging_internal::VDSOSupport::SymbolInfo vsyscall_symbol_info; + if (!vdso.LookupSymbol("__kernel_rt_sigreturn", "LINUX_2.5", STT_FUNC, + &rt_sigreturn_symbol_info) || + !vdso.LookupSymbol("__kernel_vsyscall", "LINUX_2.5", STT_FUNC, + &vsyscall_symbol_info) || + rt_sigreturn_symbol_info.address == nullptr || + vsyscall_symbol_info.address == nullptr) { + // Unexpected: 32-bit VDSO is present, yet one of the expected + // symbols is missing or null. + assert(false && "VDSO is present, but doesn't have expected symbols"); + num_push_instructions = 0; + } else { + kernel_rt_sigreturn_address = + reinterpret_cast<const unsigned char *>( + rt_sigreturn_symbol_info.address); + kernel_vsyscall_address = + reinterpret_cast<const unsigned char *>( + vsyscall_symbol_info.address); + num_push_instructions = + CountPushInstructions(kernel_vsyscall_address); + } + } else { + num_push_instructions = 0; + } +#else // ABSL_HAVE_VDSO_SUPPORT + num_push_instructions = 0; +#endif // ABSL_HAVE_VDSO_SUPPORT + } + if (num_push_instructions != 0 && kernel_rt_sigreturn_address != nullptr && + old_fp[1] == kernel_rt_sigreturn_address) { + const ucontext_t *ucv = static_cast<const ucontext_t *>(uc); + // This kernel does not use frame pointer in its VDSO code, + // and so %ebp is not suitable for unwinding. + void **const reg_ebp = + reinterpret_cast<void **>(ucv->uc_mcontext.gregs[REG_EBP]); + const unsigned char *const reg_eip = + reinterpret_cast<unsigned char *>(ucv->uc_mcontext.gregs[REG_EIP]); + if (new_fp == reg_ebp && kernel_vsyscall_address <= reg_eip && + reg_eip - kernel_vsyscall_address < kMaxBytes) { + // We "stepped up" to __kernel_vsyscall, but %ebp is not usable. + // Restore from 'ucv' instead. + void **const reg_esp = + reinterpret_cast<void **>(ucv->uc_mcontext.gregs[REG_ESP]); + // Check that alleged %esp is not null and is reasonably aligned. + if (reg_esp && + ((uintptr_t)reg_esp & (sizeof(reg_esp) - 1)) == 0) { + // Check that alleged %esp is actually readable. This is to prevent + // "double fault" in case we hit the first fault due to e.g. stack + // corruption. + void *const reg_esp2 = reg_esp[num_push_instructions - 1]; + if (AddressIsReadable(reg_esp2)) { + // Alleged %esp is readable, use it for further unwinding. + new_fp = reinterpret_cast<void **>(reg_esp2); + } + } + } + } + } +#endif + + const uintptr_t old_fp_u = reinterpret_cast<uintptr_t>(old_fp); + const uintptr_t new_fp_u = reinterpret_cast<uintptr_t>(new_fp); + + // Check that the transition from frame pointer old_fp to frame + // pointer new_fp isn't clearly bogus. Skip the checks if new_fp + // matches the signal context, so that we don't skip out early when + // using an alternate signal stack. + // + // TODO(bcmills): The GetFP call should be completely unnecessary when + // SHRINK_WRAP_FRAME_POINTER is set (because we should be back in the thread's + // stack by this point), but it is empirically still needed (e.g. when the + // stack includes a call to abort). unw_get_reg returns UNW_EBADREG for some + // frames. Figure out why GetValidFrameAddr and/or libunwind isn't doing what + // it's supposed to. + if (STRICT_UNWINDING && + (!WITH_CONTEXT || uc == nullptr || new_fp_u != GetFP(uc))) { + // With the stack growing downwards, older stack frame must be + // at a greater address that the current one. + if (new_fp_u <= old_fp_u) return nullptr; + if (new_fp_u - old_fp_u > kMaxFrameBytes) return nullptr; + } else { + if (new_fp == nullptr) return nullptr; // skip AddressIsReadable() below + // In the non-strict mode, allow discontiguous stack frames. + // (alternate-signal-stacks for example). + if (new_fp == old_fp) return nullptr; + } + + if (new_fp_u & (sizeof(void *) - 1)) return nullptr; +#ifdef __i386__ + // On 32-bit machines, the stack pointer can be very close to + // 0xffffffff, so we explicitly check for a pointer into the + // last two pages in the address space + if (new_fp_u >= 0xffffe000) return nullptr; +#endif +#if !defined(_WIN32) + if (!STRICT_UNWINDING) { + // Lax sanity checks cause a crash in 32-bit tcmalloc/crash_reason_test + // on AMD-based machines with VDSO-enabled kernels. + // Make an extra sanity check to insure new_fp is readable. + // Note: NextStackFrame<false>() is only called while the program + // is already on its last leg, so it's ok to be slow here. + + if (!AddressIsReadable(new_fp)) { + return nullptr; + } + } +#endif + return new_fp; +} + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +ABSL_ATTRIBUTE_NO_SANITIZE_ADDRESS // May read random elements from stack. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY // May read random elements from stack. +ABSL_ATTRIBUTE_NOINLINE +static int UnwindImpl(void **result, int *sizes, int max_depth, int skip_count, + const void *ucp, int *min_dropped_frames) { + int n = 0; + void **fp = reinterpret_cast<void **>(__builtin_frame_address(0)); + + while (fp && n < max_depth) { + if (*(fp + 1) == reinterpret_cast<void *>(0)) { + // In 64-bit code, we often see a frame that + // points to itself and has a return address of 0. + break; + } + void **next_fp = NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(fp, ucp); + if (skip_count > 0) { + skip_count--; + } else { + result[n] = *(fp + 1); + if (IS_STACK_FRAMES) { + if (next_fp > fp) { + sizes[n] = (uintptr_t)next_fp - (uintptr_t)fp; + } else { + // A frame-size of 0 is used to indicate unknown frame size. + sizes[n] = 0; + } + } + n++; + } + fp = next_fp; + } + if (min_dropped_frames != nullptr) { + // Implementation detail: we clamp the max of frames we are willing to + // count, so as not to spend too much time in the loop below. + const int kMaxUnwind = 1000; + int j = 0; + for (; fp != nullptr && j < kMaxUnwind; j++) { + fp = NextStackFrame<!IS_STACK_FRAMES, IS_WITH_CONTEXT>(fp, ucp); + } + *min_dropped_frames = j; + } + return n; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { +bool StackTraceWorksForTest() { + return true; +} +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_STACKTRACE_X86_INL_INC_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/symbolize.h b/third_party/abseil_cpp/absl/debugging/internal/symbolize.h new file mode 100644 index 0000000000..5d0858b5c7 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/symbolize.h @@ -0,0 +1,128 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file contains internal parts of the Abseil symbolizer. +// Do not depend on the anything in this file, it may change at anytime. + +#ifndef ABSL_DEBUGGING_INTERNAL_SYMBOLIZE_H_ +#define ABSL_DEBUGGING_INTERNAL_SYMBOLIZE_H_ + +#include <cstddef> +#include <cstdint> + +#include "absl/base/config.h" + +#ifdef ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE +#error ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE cannot be directly set +#elif defined(__ELF__) && defined(__GLIBC__) && !defined(__native_client__) && \ + !defined(__asmjs__) && !defined(__wasm__) +#define ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE 1 + +#include <elf.h> +#include <link.h> // For ElfW() macro. +#include <functional> +#include <string> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// Iterates over all sections, invoking callback on each with the section name +// and the section header. +// +// Returns true on success; otherwise returns false in case of errors. +// +// This is not async-signal-safe. +bool ForEachSection(int fd, + const std::function<bool(const std::string& name, + const ElfW(Shdr) &)>& callback); + +// Gets the section header for the given name, if it exists. Returns true on +// success. Otherwise, returns false. +bool GetSectionHeaderByName(int fd, const char *name, size_t name_len, + ElfW(Shdr) *out); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +struct SymbolDecoratorArgs { + // The program counter we are getting symbolic name for. + const void *pc; + // 0 for main executable, load address for shared libraries. + ptrdiff_t relocation; + // Read-only file descriptor for ELF image covering "pc", + // or -1 if no such ELF image exists in /proc/self/maps. + int fd; + // Output buffer, size. + // Note: the buffer may not be empty -- default symbolizer may have already + // produced some output, and earlier decorators may have adorned it in + // some way. You are free to replace or augment the contents (within the + // symbol_buf_size limit). + char *const symbol_buf; + size_t symbol_buf_size; + // Temporary scratch space, size. + // Use that space in preference to allocating your own stack buffer to + // conserve stack. + char *const tmp_buf; + size_t tmp_buf_size; + // User-provided argument + void* arg; +}; +using SymbolDecorator = void (*)(const SymbolDecoratorArgs *); + +// Installs a function-pointer as a decorator. Returns a value less than zero +// if the system cannot install the decorator. Otherwise, returns a unique +// identifier corresponding to the decorator. This identifier can be used to +// uninstall the decorator - See RemoveSymbolDecorator() below. +int InstallSymbolDecorator(SymbolDecorator decorator, void* arg); + +// Removes a previously installed function-pointer decorator. Parameter "ticket" +// is the return-value from calling InstallSymbolDecorator(). +bool RemoveSymbolDecorator(int ticket); + +// Remove all installed decorators. Returns true if successful, false if +// symbolization is currently in progress. +bool RemoveAllSymbolDecorators(void); + +// Registers an address range to a file mapping. +// +// Preconditions: +// start <= end +// filename != nullptr +// +// Returns true if the file was successfully registered. +bool RegisterFileMappingHint( + const void* start, const void* end, uint64_t offset, const char* filename); + +// Looks up the file mapping registered by RegisterFileMappingHint for an +// address range. If there is one, the file name is stored in *filename and +// *start and *end are modified to reflect the registered mapping. Returns +// whether any hint was found. +bool GetFileMappingHint(const void** start, + const void** end, + uint64_t * offset, + const char** filename); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_INTERNAL_SYMBOLIZE_H_ diff --git a/third_party/abseil_cpp/absl/debugging/internal/vdso_support.cc b/third_party/abseil_cpp/absl/debugging/internal/vdso_support.cc new file mode 100644 index 0000000000..1e8a78ac9c --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/vdso_support.cc @@ -0,0 +1,194 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Allow dynamic symbol lookup in the kernel VDSO page. +// +// VDSOSupport -- a class representing kernel VDSO (if present). + +#include "absl/debugging/internal/vdso_support.h" + +#ifdef ABSL_HAVE_VDSO_SUPPORT // defined in vdso_support.h + +#include <errno.h> +#include <fcntl.h> +#include <sys/syscall.h> +#include <unistd.h> + +#if __GLIBC_PREREQ(2, 16) // GLIBC-2.16 implements getauxval. +#include <sys/auxv.h> +#endif + +#include "absl/base/dynamic_annotations.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/port.h" + +#ifndef AT_SYSINFO_EHDR +#define AT_SYSINFO_EHDR 33 // for crosstoolv10 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +ABSL_CONST_INIT +std::atomic<const void *> VDSOSupport::vdso_base_( + debugging_internal::ElfMemImage::kInvalidBase); + +std::atomic<VDSOSupport::GetCpuFn> VDSOSupport::getcpu_fn_(&InitAndGetCPU); +VDSOSupport::VDSOSupport() + // If vdso_base_ is still set to kInvalidBase, we got here + // before VDSOSupport::Init has been called. Call it now. + : image_(vdso_base_.load(std::memory_order_relaxed) == + debugging_internal::ElfMemImage::kInvalidBase + ? Init() + : vdso_base_.load(std::memory_order_relaxed)) {} + +// NOTE: we can't use GoogleOnceInit() below, because we can be +// called by tcmalloc, and none of the *once* stuff may be functional yet. +// +// In addition, we hope that the VDSOSupportHelper constructor +// causes this code to run before there are any threads, and before +// InitGoogle() has executed any chroot or setuid calls. +// +// Finally, even if there is a race here, it is harmless, because +// the operation should be idempotent. +const void *VDSOSupport::Init() { + const auto kInvalidBase = debugging_internal::ElfMemImage::kInvalidBase; +#if __GLIBC_PREREQ(2, 16) + if (vdso_base_.load(std::memory_order_relaxed) == kInvalidBase) { + errno = 0; + const void *const sysinfo_ehdr = + reinterpret_cast<const void *>(getauxval(AT_SYSINFO_EHDR)); + if (errno == 0) { + vdso_base_.store(sysinfo_ehdr, std::memory_order_relaxed); + } + } +#endif // __GLIBC_PREREQ(2, 16) + if (vdso_base_.load(std::memory_order_relaxed) == kInvalidBase) { + // Valgrind zaps AT_SYSINFO_EHDR and friends from the auxv[] + // on stack, and so glibc works as if VDSO was not present. + // But going directly to kernel via /proc/self/auxv below bypasses + // Valgrind zapping. So we check for Valgrind separately. + if (RunningOnValgrind()) { + vdso_base_.store(nullptr, std::memory_order_relaxed); + getcpu_fn_.store(&GetCPUViaSyscall, std::memory_order_relaxed); + return nullptr; + } + int fd = open("/proc/self/auxv", O_RDONLY); + if (fd == -1) { + // Kernel too old to have a VDSO. + vdso_base_.store(nullptr, std::memory_order_relaxed); + getcpu_fn_.store(&GetCPUViaSyscall, std::memory_order_relaxed); + return nullptr; + } + ElfW(auxv_t) aux; + while (read(fd, &aux, sizeof(aux)) == sizeof(aux)) { + if (aux.a_type == AT_SYSINFO_EHDR) { + vdso_base_.store(reinterpret_cast<void *>(aux.a_un.a_val), + std::memory_order_relaxed); + break; + } + } + close(fd); + if (vdso_base_.load(std::memory_order_relaxed) == kInvalidBase) { + // Didn't find AT_SYSINFO_EHDR in auxv[]. + vdso_base_.store(nullptr, std::memory_order_relaxed); + } + } + GetCpuFn fn = &GetCPUViaSyscall; // default if VDSO not present. + if (vdso_base_.load(std::memory_order_relaxed)) { + VDSOSupport vdso; + SymbolInfo info; + if (vdso.LookupSymbol("__vdso_getcpu", "LINUX_2.6", STT_FUNC, &info)) { + fn = reinterpret_cast<GetCpuFn>(const_cast<void *>(info.address)); + } + } + // Subtle: this code runs outside of any locks; prevent compiler + // from assigning to getcpu_fn_ more than once. + getcpu_fn_.store(fn, std::memory_order_relaxed); + return vdso_base_.load(std::memory_order_relaxed); +} + +const void *VDSOSupport::SetBase(const void *base) { + ABSL_RAW_CHECK(base != debugging_internal::ElfMemImage::kInvalidBase, + "internal error"); + const void *old_base = vdso_base_.load(std::memory_order_relaxed); + vdso_base_.store(base, std::memory_order_relaxed); + image_.Init(base); + // Also reset getcpu_fn_, so GetCPU could be tested with simulated VDSO. + getcpu_fn_.store(&InitAndGetCPU, std::memory_order_relaxed); + return old_base; +} + +bool VDSOSupport::LookupSymbol(const char *name, + const char *version, + int type, + SymbolInfo *info) const { + return image_.LookupSymbol(name, version, type, info); +} + +bool VDSOSupport::LookupSymbolByAddress(const void *address, + SymbolInfo *info_out) const { + return image_.LookupSymbolByAddress(address, info_out); +} + +// NOLINT on 'long' because this routine mimics kernel api. +long VDSOSupport::GetCPUViaSyscall(unsigned *cpu, // NOLINT(runtime/int) + void *, void *) { +#ifdef SYS_getcpu + return syscall(SYS_getcpu, cpu, nullptr, nullptr); +#else + // x86_64 never implemented sys_getcpu(), except as a VDSO call. + static_cast<void>(cpu); // Avoid an unused argument compiler warning. + errno = ENOSYS; + return -1; +#endif +} + +// Use fast __vdso_getcpu if available. +long VDSOSupport::InitAndGetCPU(unsigned *cpu, // NOLINT(runtime/int) + void *x, void *y) { + Init(); + GetCpuFn fn = getcpu_fn_.load(std::memory_order_relaxed); + ABSL_RAW_CHECK(fn != &InitAndGetCPU, "Init() did not set getcpu_fn_"); + return (*fn)(cpu, x, y); +} + +// This function must be very fast, and may be called from very +// low level (e.g. tcmalloc). Hence I avoid things like +// GoogleOnceInit() and ::operator new. +ABSL_ATTRIBUTE_NO_SANITIZE_MEMORY +int GetCPU() { + unsigned cpu; + int ret_code = (*VDSOSupport::getcpu_fn_)(&cpu, nullptr, nullptr); + return ret_code == 0 ? cpu : ret_code; +} + +// We need to make sure VDSOSupport::Init() is called before +// InitGoogle() does any setuid or chroot calls. If VDSOSupport +// is used in any global constructor, this will happen, since +// VDSOSupport's constructor calls Init. But if not, we need to +// ensure it here, with a global constructor of our own. This +// is an allowed exception to the normal rule against non-trivial +// global constructors. +static class VDSOInitHelper { + public: + VDSOInitHelper() { VDSOSupport::Init(); } +} vdso_init_helper; + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HAVE_VDSO_SUPPORT diff --git a/third_party/abseil_cpp/absl/debugging/internal/vdso_support.h b/third_party/abseil_cpp/absl/debugging/internal/vdso_support.h new file mode 100644 index 0000000000..6562c6c235 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/internal/vdso_support.h @@ -0,0 +1,158 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// Allow dynamic symbol lookup in the kernel VDSO page. +// +// VDSO stands for "Virtual Dynamic Shared Object" -- a page of +// executable code, which looks like a shared library, but doesn't +// necessarily exist anywhere on disk, and which gets mmap()ed into +// every process by kernels which support VDSO, such as 2.6.x for 32-bit +// executables, and 2.6.24 and above for 64-bit executables. +// +// More details could be found here: +// http://www.trilithium.com/johan/2005/08/linux-gate/ +// +// VDSOSupport -- a class representing kernel VDSO (if present). +// +// Example usage: +// VDSOSupport vdso; +// VDSOSupport::SymbolInfo info; +// typedef (*FN)(unsigned *, void *, void *); +// FN fn = nullptr; +// if (vdso.LookupSymbol("__vdso_getcpu", "LINUX_2.6", STT_FUNC, &info)) { +// fn = reinterpret_cast<FN>(info.address); +// } + +#ifndef ABSL_DEBUGGING_INTERNAL_VDSO_SUPPORT_H_ +#define ABSL_DEBUGGING_INTERNAL_VDSO_SUPPORT_H_ + +#include <atomic> + +#include "absl/base/attributes.h" +#include "absl/debugging/internal/elf_mem_image.h" + +#ifdef ABSL_HAVE_ELF_MEM_IMAGE + +#ifdef ABSL_HAVE_VDSO_SUPPORT +#error ABSL_HAVE_VDSO_SUPPORT cannot be directly set +#else +#define ABSL_HAVE_VDSO_SUPPORT 1 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace debugging_internal { + +// NOTE: this class may be used from within tcmalloc, and can not +// use any memory allocation routines. +class VDSOSupport { + public: + VDSOSupport(); + + typedef ElfMemImage::SymbolInfo SymbolInfo; + typedef ElfMemImage::SymbolIterator SymbolIterator; + + // On PowerPC64 VDSO symbols can either be of type STT_FUNC or STT_NOTYPE + // depending on how the kernel is built. The kernel is normally built with + // STT_NOTYPE type VDSO symbols. Let's make things simpler first by using a + // compile-time constant. +#ifdef __powerpc64__ + enum { kVDSOSymbolType = STT_NOTYPE }; +#else + enum { kVDSOSymbolType = STT_FUNC }; +#endif + + // Answers whether we have a vdso at all. + bool IsPresent() const { return image_.IsPresent(); } + + // Allow to iterate over all VDSO symbols. + SymbolIterator begin() const { return image_.begin(); } + SymbolIterator end() const { return image_.end(); } + + // Look up versioned dynamic symbol in the kernel VDSO. + // Returns false if VDSO is not present, or doesn't contain given + // symbol/version/type combination. + // If info_out != nullptr, additional details are filled in. + bool LookupSymbol(const char *name, const char *version, + int symbol_type, SymbolInfo *info_out) const; + + // Find info about symbol (if any) which overlaps given address. + // Returns true if symbol was found; false if VDSO isn't present + // or doesn't have a symbol overlapping given address. + // If info_out != nullptr, additional details are filled in. + bool LookupSymbolByAddress(const void *address, SymbolInfo *info_out) const; + + // Used only for testing. Replace real VDSO base with a mock. + // Returns previous value of vdso_base_. After you are done testing, + // you are expected to call SetBase() with previous value, in order to + // reset state to the way it was. + const void *SetBase(const void *s); + + // Computes vdso_base_ and returns it. Should be called as early as + // possible; before any thread creation, chroot or setuid. + static const void *Init(); + + private: + // image_ represents VDSO ELF image in memory. + // image_.ehdr_ == nullptr implies there is no VDSO. + ElfMemImage image_; + + // Cached value of auxv AT_SYSINFO_EHDR, computed once. + // This is a tri-state: + // kInvalidBase => value hasn't been determined yet. + // 0 => there is no VDSO. + // else => vma of VDSO Elf{32,64}_Ehdr. + // + // When testing with mock VDSO, low bit is set. + // The low bit is always available because vdso_base_ is + // page-aligned. + static std::atomic<const void *> vdso_base_; + + // NOLINT on 'long' because these routines mimic kernel api. + // The 'cache' parameter may be used by some versions of the kernel, + // and should be nullptr or point to a static buffer containing at + // least two 'long's. + static long InitAndGetCPU(unsigned *cpu, void *cache, // NOLINT 'long'. + void *unused); + static long GetCPUViaSyscall(unsigned *cpu, void *cache, // NOLINT 'long'. + void *unused); + typedef long (*GetCpuFn)(unsigned *cpu, void *cache, // NOLINT 'long'. + void *unused); + + // This function pointer may point to InitAndGetCPU, + // GetCPUViaSyscall, or __vdso_getcpu at different stages of initialization. + ABSL_CONST_INIT static std::atomic<GetCpuFn> getcpu_fn_; + + friend int GetCPU(void); // Needs access to getcpu_fn_. + + VDSOSupport(const VDSOSupport&) = delete; + VDSOSupport& operator=(const VDSOSupport&) = delete; +}; + +// Same as sched_getcpu() on later glibc versions. +// Return current CPU, using (fast) __vdso_getcpu@LINUX_2.6 if present, +// otherwise use syscall(SYS_getcpu,...). +// May return -1 with errno == ENOSYS if the kernel doesn't +// support SYS_getcpu. +int GetCPU(); + +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HAVE_ELF_MEM_IMAGE + +#endif // ABSL_DEBUGGING_INTERNAL_VDSO_SUPPORT_H_ diff --git a/third_party/abseil_cpp/absl/debugging/leak_check.cc b/third_party/abseil_cpp/absl/debugging/leak_check.cc new file mode 100644 index 0000000000..ff9049559d --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/leak_check.cc @@ -0,0 +1,53 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Wrappers around lsan_interface functions. +// When lsan is not linked in, these functions are not available, +// therefore Abseil code which depends on these functions is conditioned on the +// definition of LEAK_SANITIZER. +#include "absl/debugging/leak_check.h" + +#ifndef LEAK_SANITIZER + +namespace absl { +ABSL_NAMESPACE_BEGIN +bool HaveLeakSanitizer() { return false; } +void DoIgnoreLeak(const void*) { } +void RegisterLivePointers(const void*, size_t) { } +void UnRegisterLivePointers(const void*, size_t) { } +LeakCheckDisabler::LeakCheckDisabler() { } +LeakCheckDisabler::~LeakCheckDisabler() { } +ABSL_NAMESPACE_END +} // namespace absl + +#else + +#include <sanitizer/lsan_interface.h> + +namespace absl { +ABSL_NAMESPACE_BEGIN +bool HaveLeakSanitizer() { return true; } +void DoIgnoreLeak(const void* ptr) { __lsan_ignore_object(ptr); } +void RegisterLivePointers(const void* ptr, size_t size) { + __lsan_register_root_region(ptr, size); +} +void UnRegisterLivePointers(const void* ptr, size_t size) { + __lsan_unregister_root_region(ptr, size); +} +LeakCheckDisabler::LeakCheckDisabler() { __lsan_disable(); } +LeakCheckDisabler::~LeakCheckDisabler() { __lsan_enable(); } +ABSL_NAMESPACE_END +} // namespace absl + +#endif // LEAK_SANITIZER diff --git a/third_party/abseil_cpp/absl/debugging/leak_check.h b/third_party/abseil_cpp/absl/debugging/leak_check.h new file mode 100644 index 0000000000..7a5a22dd1c --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/leak_check.h @@ -0,0 +1,113 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: leak_check.h +// ----------------------------------------------------------------------------- +// +// This file contains functions that affect leak checking behavior within +// targets built with the LeakSanitizer (LSan), a memory leak detector that is +// integrated within the AddressSanitizer (ASan) as an additional component, or +// which can be used standalone. LSan and ASan are included (or can be provided) +// as additional components for most compilers such as Clang, gcc and MSVC. +// Note: this leak checking API is not yet supported in MSVC. +// Leak checking is enabled by default in all ASan builds. +// +// See https://github.com/google/sanitizers/wiki/AddressSanitizerLeakSanitizer +// +// ----------------------------------------------------------------------------- +#ifndef ABSL_DEBUGGING_LEAK_CHECK_H_ +#define ABSL_DEBUGGING_LEAK_CHECK_H_ + +#include <cstddef> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// HaveLeakSanitizer() +// +// Returns true if a leak-checking sanitizer (either ASan or standalone LSan) is +// currently built into this target. +bool HaveLeakSanitizer(); + +// DoIgnoreLeak() +// +// Implements `IgnoreLeak()` below. This function should usually +// not be called directly; calling `IgnoreLeak()` is preferred. +void DoIgnoreLeak(const void* ptr); + +// IgnoreLeak() +// +// Instruct the leak sanitizer to ignore leak warnings on the object referenced +// by the passed pointer, as well as all heap objects transitively referenced +// by it. The passed object pointer can point to either the beginning of the +// object or anywhere within it. +// +// Example: +// +// static T* obj = IgnoreLeak(new T(...)); +// +// If the passed `ptr` does not point to an actively allocated object at the +// time `IgnoreLeak()` is called, the call is a no-op; if it is actively +// allocated, the object must not get deallocated later. +// +template <typename T> +T* IgnoreLeak(T* ptr) { + DoIgnoreLeak(ptr); + return ptr; +} + +// LeakCheckDisabler +// +// This helper class indicates that any heap allocations done in the code block +// covered by the scoped object, which should be allocated on the stack, will +// not be reported as leaks. Leak check disabling will occur within the code +// block and any nested function calls within the code block. +// +// Example: +// +// void Foo() { +// LeakCheckDisabler disabler; +// ... code that allocates objects whose leaks should be ignored ... +// } +// +// REQUIRES: Destructor runs in same thread as constructor +class LeakCheckDisabler { + public: + LeakCheckDisabler(); + LeakCheckDisabler(const LeakCheckDisabler&) = delete; + LeakCheckDisabler& operator=(const LeakCheckDisabler&) = delete; + ~LeakCheckDisabler(); +}; + +// RegisterLivePointers() +// +// Registers `ptr[0,size-1]` as pointers to memory that is still actively being +// referenced and for which leak checking should be ignored. This function is +// useful if you store pointers in mapped memory, for memory ranges that we know +// are correct but for which normal analysis would flag as leaked code. +void RegisterLivePointers(const void* ptr, size_t size); + +// UnRegisterLivePointers() +// +// Deregisters the pointers previously marked as active in +// `RegisterLivePointers()`, enabling leak checking of those pointers. +void UnRegisterLivePointers(const void* ptr, size_t size); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_LEAK_CHECK_H_ diff --git a/third_party/abseil_cpp/absl/debugging/leak_check_disable.cc b/third_party/abseil_cpp/absl/debugging/leak_check_disable.cc new file mode 100644 index 0000000000..924d6e3d54 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/leak_check_disable.cc @@ -0,0 +1,20 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Disable LeakSanitizer when this file is linked in. +// This function overrides __lsan_is_turned_off from sanitizer/lsan_interface.h +extern "C" int __lsan_is_turned_off(); +extern "C" int __lsan_is_turned_off() { + return 1; +} diff --git a/third_party/abseil_cpp/absl/debugging/leak_check_fail_test.cc b/third_party/abseil_cpp/absl/debugging/leak_check_fail_test.cc new file mode 100644 index 0000000000..c49b81a9d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/leak_check_fail_test.cc @@ -0,0 +1,41 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <memory> +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/debugging/leak_check.h" + +namespace { + +TEST(LeakCheckTest, LeakMemory) { + // This test is expected to cause lsan failures on program exit. Therefore the + // test will be run only by leak_check_test.sh, which will verify a + // failed exit code. + + char* foo = strdup("lsan should complain about this leaked string"); + ABSL_RAW_LOG(INFO, "Should detect leaked string %s", foo); +} + +TEST(LeakCheckTest, LeakMemoryAfterDisablerScope) { + // This test is expected to cause lsan failures on program exit. Therefore the + // test will be run only by external_leak_check_test.sh, which will verify a + // failed exit code. + { absl::LeakCheckDisabler disabler; } + char* foo = strdup("lsan should also complain about this leaked string"); + ABSL_RAW_LOG(INFO, "Re-enabled leak detection.Should detect leaked string %s", + foo); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/debugging/leak_check_test.cc b/third_party/abseil_cpp/absl/debugging/leak_check_test.cc new file mode 100644 index 0000000000..b5cc487488 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/leak_check_test.cc @@ -0,0 +1,42 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <string> + +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/debugging/leak_check.h" + +namespace { + +TEST(LeakCheckTest, DetectLeakSanitizer) { +#ifdef ABSL_EXPECT_LEAK_SANITIZER + EXPECT_TRUE(absl::HaveLeakSanitizer()); +#else + EXPECT_FALSE(absl::HaveLeakSanitizer()); +#endif +} + +TEST(LeakCheckTest, IgnoreLeakSuppressesLeakedMemoryErrors) { + auto foo = absl::IgnoreLeak(new std::string("some ignored leaked string")); + ABSL_RAW_LOG(INFO, "Ignoring leaked string %s", foo->c_str()); +} + +TEST(LeakCheckTest, LeakCheckDisablerIgnoresLeak) { + absl::LeakCheckDisabler disabler; + auto foo = new std::string("some string leaked while checks are disabled"); + ABSL_RAW_LOG(INFO, "Ignoring leaked string %s", foo->c_str()); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/debugging/stacktrace.cc b/third_party/abseil_cpp/absl/debugging/stacktrace.cc new file mode 100644 index 0000000000..1f7c7d82b2 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/stacktrace.cc @@ -0,0 +1,140 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Produce stack trace. +// +// There are three different ways we can try to get the stack trace: +// +// 1) Our hand-coded stack-unwinder. This depends on a certain stack +// layout, which is used by gcc (and those systems using a +// gcc-compatible ABI) on x86 systems, at least since gcc 2.95. +// It uses the frame pointer to do its work. +// +// 2) The libunwind library. This is still in development, and as a +// separate library adds a new dependency, but doesn't need a frame +// pointer. It also doesn't call malloc. +// +// 3) The gdb unwinder -- also the one used by the c++ exception code. +// It's obviously well-tested, but has a fatal flaw: it can call +// malloc() from the unwinder. This is a problem because we're +// trying to use the unwinder to instrument malloc(). +// +// Note: if you add a new implementation here, make sure it works +// correctly when absl::GetStackTrace() is called with max_depth == 0. +// Some code may do that. + +#include "absl/debugging/stacktrace.h" + +#include <atomic> + +#include "absl/base/attributes.h" +#include "absl/base/port.h" +#include "absl/debugging/internal/stacktrace_config.h" + +#if defined(ABSL_STACKTRACE_INL_HEADER) +#include ABSL_STACKTRACE_INL_HEADER +#else +# error Cannot calculate stack trace: will need to write for your environment + +# include "absl/debugging/internal/stacktrace_aarch64-inl.inc" +# include "absl/debugging/internal/stacktrace_arm-inl.inc" +# include "absl/debugging/internal/stacktrace_generic-inl.inc" +# include "absl/debugging/internal/stacktrace_powerpc-inl.inc" +# include "absl/debugging/internal/stacktrace_unimplemented-inl.inc" +# include "absl/debugging/internal/stacktrace_win32-inl.inc" +# include "absl/debugging/internal/stacktrace_x86-inl.inc" +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +typedef int (*Unwinder)(void**, int*, int, int, const void*, int*); +std::atomic<Unwinder> custom; + +template <bool IS_STACK_FRAMES, bool IS_WITH_CONTEXT> +ABSL_ATTRIBUTE_ALWAYS_INLINE inline int Unwind(void** result, int* sizes, + int max_depth, int skip_count, + const void* uc, + int* min_dropped_frames) { + Unwinder f = &UnwindImpl<IS_STACK_FRAMES, IS_WITH_CONTEXT>; + Unwinder g = custom.load(std::memory_order_acquire); + if (g != nullptr) f = g; + + // Add 1 to skip count for the unwinder function itself + int size = (*f)(result, sizes, max_depth, skip_count + 1, uc, + min_dropped_frames); + // To disable tail call to (*f)(...) + ABSL_BLOCK_TAIL_CALL_OPTIMIZATION(); + return size; +} + +} // anonymous namespace + +ABSL_ATTRIBUTE_NOINLINE ABSL_ATTRIBUTE_NO_TAIL_CALL int GetStackFrames( + void** result, int* sizes, int max_depth, int skip_count) { + return Unwind<true, false>(result, sizes, max_depth, skip_count, nullptr, + nullptr); +} + +ABSL_ATTRIBUTE_NOINLINE ABSL_ATTRIBUTE_NO_TAIL_CALL int +GetStackFramesWithContext(void** result, int* sizes, int max_depth, + int skip_count, const void* uc, + int* min_dropped_frames) { + return Unwind<true, true>(result, sizes, max_depth, skip_count, uc, + min_dropped_frames); +} + +ABSL_ATTRIBUTE_NOINLINE ABSL_ATTRIBUTE_NO_TAIL_CALL int GetStackTrace( + void** result, int max_depth, int skip_count) { + return Unwind<false, false>(result, nullptr, max_depth, skip_count, nullptr, + nullptr); +} + +ABSL_ATTRIBUTE_NOINLINE ABSL_ATTRIBUTE_NO_TAIL_CALL int +GetStackTraceWithContext(void** result, int max_depth, int skip_count, + const void* uc, int* min_dropped_frames) { + return Unwind<false, true>(result, nullptr, max_depth, skip_count, uc, + min_dropped_frames); +} + +void SetStackUnwinder(Unwinder w) { + custom.store(w, std::memory_order_release); +} + +int DefaultStackUnwinder(void** pcs, int* sizes, int depth, int skip, + const void* uc, int* min_dropped_frames) { + skip++; // For this function + Unwinder f = nullptr; + if (sizes == nullptr) { + if (uc == nullptr) { + f = &UnwindImpl<false, false>; + } else { + f = &UnwindImpl<false, true>; + } + } else { + if (uc == nullptr) { + f = &UnwindImpl<true, false>; + } else { + f = &UnwindImpl<true, true>; + } + } + volatile int x = 0; + int n = (*f)(pcs, sizes, depth, skip, uc, min_dropped_frames); + x = 1; (void) x; // To disable tail call to (*f)(...) + return n; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/stacktrace.h b/third_party/abseil_cpp/absl/debugging/stacktrace.h new file mode 100644 index 0000000000..0ec0ffdabd --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/stacktrace.h @@ -0,0 +1,231 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: stacktrace.h +// ----------------------------------------------------------------------------- +// +// This file contains routines to extract the current stack trace and associated +// stack frames. These functions are thread-safe and async-signal-safe. +// +// Note that stack trace functionality is platform dependent and requires +// additional support from the compiler/build system in most cases. (That is, +// this functionality generally only works on platforms/builds that have been +// specifically configured to support it.) +// +// Note: stack traces in Abseil that do not utilize a symbolizer will result in +// frames consisting of function addresses rather than human-readable function +// names. (See symbolize.h for information on symbolizing these values.) + +#ifndef ABSL_DEBUGGING_STACKTRACE_H_ +#define ABSL_DEBUGGING_STACKTRACE_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// GetStackFrames() +// +// Records program counter values for up to `max_depth` frames, skipping the +// most recent `skip_count` stack frames, stores their corresponding values +// and sizes in `results` and `sizes` buffers, and returns the number of frames +// stored. (Note that the frame generated for the `absl::GetStackFrames()` +// routine itself is also skipped.) +// +// Example: +// +// main() { foo(); } +// foo() { bar(); } +// bar() { +// void* result[10]; +// int sizes[10]; +// int depth = absl::GetStackFrames(result, sizes, 10, 1); +// } +// +// The current stack frame would consist of three function calls: `bar()`, +// `foo()`, and then `main()`; however, since the `GetStackFrames()` call sets +// `skip_count` to `1`, it will skip the frame for `bar()`, the most recently +// invoked function call. It will therefore return 2 and fill `result` with +// program counters within the following functions: +// +// result[0] foo() +// result[1] main() +// +// (Note: in practice, a few more entries after `main()` may be added to account +// for startup processes.) +// +// Corresponding stack frame sizes will also be recorded: +// +// sizes[0] 16 +// sizes[1] 16 +// +// (Stack frame sizes of `16` above are just for illustration purposes.) +// +// Stack frame sizes of 0 or less indicate that those frame sizes couldn't +// be identified. +// +// This routine may return fewer stack frame entries than are +// available. Also note that `result` and `sizes` must both be non-null. +extern int GetStackFrames(void** result, int* sizes, int max_depth, + int skip_count); + +// GetStackFramesWithContext() +// +// Records program counter values obtained from a signal handler. Records +// program counter values for up to `max_depth` frames, skipping the most recent +// `skip_count` stack frames, stores their corresponding values and sizes in +// `results` and `sizes` buffers, and returns the number of frames stored. (Note +// that the frame generated for the `absl::GetStackFramesWithContext()` routine +// itself is also skipped.) +// +// The `uc` parameter, if non-null, should be a pointer to a `ucontext_t` value +// passed to a signal handler registered via the `sa_sigaction` field of a +// `sigaction` struct. (See +// http://man7.org/linux/man-pages/man2/sigaction.2.html.) The `uc` value may +// help a stack unwinder to provide a better stack trace under certain +// conditions. `uc` may safely be null. +// +// The `min_dropped_frames` output parameter, if non-null, points to the +// location to note any dropped stack frames, if any, due to buffer limitations +// or other reasons. (This value will be set to `0` if no frames were dropped.) +// The number of total stack frames is guaranteed to be >= skip_count + +// max_depth + *min_dropped_frames. +extern int GetStackFramesWithContext(void** result, int* sizes, int max_depth, + int skip_count, const void* uc, + int* min_dropped_frames); + +// GetStackTrace() +// +// Records program counter values for up to `max_depth` frames, skipping the +// most recent `skip_count` stack frames, stores their corresponding values +// in `results`, and returns the number of frames +// stored. Note that this function is similar to `absl::GetStackFrames()` +// except that it returns the stack trace only, and not stack frame sizes. +// +// Example: +// +// main() { foo(); } +// foo() { bar(); } +// bar() { +// void* result[10]; +// int depth = absl::GetStackTrace(result, 10, 1); +// } +// +// This produces: +// +// result[0] foo +// result[1] main +// .... ... +// +// `result` must not be null. +extern int GetStackTrace(void** result, int max_depth, int skip_count); + +// GetStackTraceWithContext() +// +// Records program counter values obtained from a signal handler. Records +// program counter values for up to `max_depth` frames, skipping the most recent +// `skip_count` stack frames, stores their corresponding values in `results`, +// and returns the number of frames stored. (Note that the frame generated for +// the `absl::GetStackFramesWithContext()` routine itself is also skipped.) +// +// The `uc` parameter, if non-null, should be a pointer to a `ucontext_t` value +// passed to a signal handler registered via the `sa_sigaction` field of a +// `sigaction` struct. (See +// http://man7.org/linux/man-pages/man2/sigaction.2.html.) The `uc` value may +// help a stack unwinder to provide a better stack trace under certain +// conditions. `uc` may safely be null. +// +// The `min_dropped_frames` output parameter, if non-null, points to the +// location to note any dropped stack frames, if any, due to buffer limitations +// or other reasons. (This value will be set to `0` if no frames were dropped.) +// The number of total stack frames is guaranteed to be >= skip_count + +// max_depth + *min_dropped_frames. +extern int GetStackTraceWithContext(void** result, int max_depth, + int skip_count, const void* uc, + int* min_dropped_frames); + +// SetStackUnwinder() +// +// Provides a custom function for unwinding stack frames that will be used in +// place of the default stack unwinder when invoking the static +// GetStack{Frames,Trace}{,WithContext}() functions above. +// +// The arguments passed to the unwinder function will match the +// arguments passed to `absl::GetStackFramesWithContext()` except that sizes +// will be non-null iff the caller is interested in frame sizes. +// +// If unwinder is set to null, we revert to the default stack-tracing behavior. +// +// ***************************************************************************** +// WARNING +// ***************************************************************************** +// +// absl::SetStackUnwinder is not suitable for general purpose use. It is +// provided for custom runtimes. +// Some things to watch out for when calling `absl::SetStackUnwinder()`: +// +// (a) The unwinder may be called from within signal handlers and +// therefore must be async-signal-safe. +// +// (b) Even after a custom stack unwinder has been unregistered, other +// threads may still be in the process of using that unwinder. +// Therefore do not clean up any state that may be needed by an old +// unwinder. +// ***************************************************************************** +extern void SetStackUnwinder(int (*unwinder)(void** pcs, int* sizes, + int max_depth, int skip_count, + const void* uc, + int* min_dropped_frames)); + +// DefaultStackUnwinder() +// +// Records program counter values of up to `max_depth` frames, skipping the most +// recent `skip_count` stack frames, and stores their corresponding values in +// `pcs`. (Note that the frame generated for this call itself is also skipped.) +// This function acts as a generic stack-unwinder; prefer usage of the more +// specific `GetStack{Trace,Frames}{,WithContext}()` functions above. +// +// If you have set your own stack unwinder (with the `SetStackUnwinder()` +// function above, you can still get the default stack unwinder by calling +// `DefaultStackUnwinder()`, which will ignore any previously set stack unwinder +// and use the default one instead. +// +// Because this function is generic, only `pcs` is guaranteed to be non-null +// upon return. It is legal for `sizes`, `uc`, and `min_dropped_frames` to all +// be null when called. +// +// The semantics are the same as the corresponding `GetStack*()` function in the +// case where `absl::SetStackUnwinder()` was never called. Equivalents are: +// +// null sizes | non-nullptr sizes +// |==========================================================| +// null uc | GetStackTrace() | GetStackFrames() | +// non-null uc | GetStackTraceWithContext() | GetStackFramesWithContext() | +// |==========================================================| +extern int DefaultStackUnwinder(void** pcs, int* sizes, int max_depth, + int skip_count, const void* uc, + int* min_dropped_frames); + +namespace debugging_internal { +// Returns true for platforms which are expected to have functioning stack trace +// implementations. Intended to be used for tests which want to exclude +// verification of logic known to be broken because stack traces are not +// working. +extern bool StackTraceWorksForTest(); +} // namespace debugging_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_STACKTRACE_H_ diff --git a/third_party/abseil_cpp/absl/debugging/symbolize.cc b/third_party/abseil_cpp/absl/debugging/symbolize.cc new file mode 100644 index 0000000000..54ed97002a --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/symbolize.cc @@ -0,0 +1,25 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/debugging/symbolize.h" + +#if defined(ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE) +#include "absl/debugging/symbolize_elf.inc" +#elif defined(_WIN32) +// The Windows Symbolizer only works if PDB files containing the debug info +// are available to the program at runtime. +#include "absl/debugging/symbolize_win32.inc" +#else +#include "absl/debugging/symbolize_unimplemented.inc" +#endif diff --git a/third_party/abseil_cpp/absl/debugging/symbolize.h b/third_party/abseil_cpp/absl/debugging/symbolize.h new file mode 100644 index 0000000000..43d93a8682 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/symbolize.h @@ -0,0 +1,99 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: symbolize.h +// ----------------------------------------------------------------------------- +// +// This file configures the Abseil symbolizer for use in converting instruction +// pointer addresses (program counters) into human-readable names (function +// calls, etc.) within Abseil code. +// +// The symbolizer may be invoked from several sources: +// +// * Implicitly, through the installation of an Abseil failure signal handler. +// (See failure_signal_handler.h for more information.) +// * By calling `Symbolize()` directly on a program counter you obtain through +// `absl::GetStackTrace()` or `absl::GetStackFrames()`. (See stacktrace.h +// for more information. +// * By calling `Symbolize()` directly on a program counter you obtain through +// other means (which would be platform-dependent). +// +// In all of the above cases, the symbolizer must first be initialized before +// any program counter values can be symbolized. If you are installing a failure +// signal handler, initialize the symbolizer before you do so. +// +// Example: +// +// int main(int argc, char** argv) { +// // Initialize the Symbolizer before installing the failure signal handler +// absl::InitializeSymbolizer(argv[0]); +// +// // Now you may install the failure signal handler +// absl::FailureSignalHandlerOptions options; +// absl::InstallFailureSignalHandler(options); +// +// // Start running your main program +// ... +// return 0; +// } +// +#ifndef ABSL_DEBUGGING_SYMBOLIZE_H_ +#define ABSL_DEBUGGING_SYMBOLIZE_H_ + +#include "absl/debugging/internal/symbolize.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// InitializeSymbolizer() +// +// Initializes the program counter symbolizer, given the path of the program +// (typically obtained through `main()`s `argv[0]`). The Abseil symbolizer +// allows you to read program counters (instruction pointer values) using their +// human-readable names within output such as stack traces. +// +// Example: +// +// int main(int argc, char *argv[]) { +// absl::InitializeSymbolizer(argv[0]); +// // Now you can use the symbolizer +// } +void InitializeSymbolizer(const char* argv0); +// +// Symbolize() +// +// Symbolizes a program counter (instruction pointer value) `pc` and, on +// success, writes the name to `out`. The symbol name is demangled, if possible. +// Note that the symbolized name may be truncated and will be NUL-terminated. +// Demangling is supported for symbols generated by GCC 3.x or newer). Returns +// `false` on failure. +// +// Example: +// +// // Print a program counter and its symbol name. +// static void DumpPCAndSymbol(void *pc) { +// char tmp[1024]; +// const char *symbol = "(unknown)"; +// if (absl::Symbolize(pc, tmp, sizeof(tmp))) { +// symbol = tmp; +// } +// absl::PrintF("%p %s\n", pc, symbol); +// } +bool Symbolize(const void *pc, char *out, int out_size); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_DEBUGGING_SYMBOLIZE_H_ diff --git a/third_party/abseil_cpp/absl/debugging/symbolize_elf.inc b/third_party/abseil_cpp/absl/debugging/symbolize_elf.inc new file mode 100644 index 0000000000..ec86f9a933 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/symbolize_elf.inc @@ -0,0 +1,1482 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This library provides Symbolize() function that symbolizes program +// counters to their corresponding symbol names on linux platforms. +// This library has a minimal implementation of an ELF symbol table +// reader (i.e. it doesn't depend on libelf, etc.). +// +// The algorithm used in Symbolize() is as follows. +// +// 1. Go through a list of maps in /proc/self/maps and find the map +// containing the program counter. +// +// 2. Open the mapped file and find a regular symbol table inside. +// Iterate over symbols in the symbol table and look for the symbol +// containing the program counter. If such a symbol is found, +// obtain the symbol name, and demangle the symbol if possible. +// If the symbol isn't found in the regular symbol table (binary is +// stripped), try the same thing with a dynamic symbol table. +// +// Note that Symbolize() is originally implemented to be used in +// signal handlers, hence it doesn't use malloc() and other unsafe +// operations. It should be both thread-safe and async-signal-safe. +// +// Implementation note: +// +// We don't use heaps but only use stacks. We want to reduce the +// stack consumption so that the symbolizer can run on small stacks. +// +// Here are some numbers collected with GCC 4.1.0 on x86: +// - sizeof(Elf32_Sym) = 16 +// - sizeof(Elf32_Shdr) = 40 +// - sizeof(Elf64_Sym) = 24 +// - sizeof(Elf64_Shdr) = 64 +// +// This implementation is intended to be async-signal-safe but uses some +// functions which are not guaranteed to be so, such as memchr() and +// memmove(). We assume they are async-signal-safe. + +#include <dlfcn.h> +#include <elf.h> +#include <fcntl.h> +#include <link.h> // For ElfW() macro. +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include <algorithm> +#include <atomic> +#include <cerrno> +#include <cinttypes> +#include <climits> +#include <cstdint> +#include <cstdio> +#include <cstdlib> +#include <cstring> + +#include "absl/base/casts.h" +#include "absl/base/dynamic_annotations.h" +#include "absl/base/internal/low_level_alloc.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/port.h" +#include "absl/debugging/internal/demangle.h" +#include "absl/debugging/internal/vdso_support.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Value of argv[0]. Used by MaybeInitializeObjFile(). +static char *argv0_value = nullptr; + +void InitializeSymbolizer(const char *argv0) { + if (argv0_value != nullptr) { + free(argv0_value); + argv0_value = nullptr; + } + if (argv0 != nullptr && argv0[0] != '\0') { + argv0_value = strdup(argv0); + } +} + +namespace debugging_internal { +namespace { + +// Re-runs fn until it doesn't cause EINTR. +#define NO_INTR(fn) \ + do { \ + } while ((fn) < 0 && errno == EINTR) + +// On Linux, ELF_ST_* are defined in <linux/elf.h>. To make this portable +// we define our own ELF_ST_BIND and ELF_ST_TYPE if not available. +#ifndef ELF_ST_BIND +#define ELF_ST_BIND(info) (((unsigned char)(info)) >> 4) +#endif + +#ifndef ELF_ST_TYPE +#define ELF_ST_TYPE(info) (((unsigned char)(info)) & 0xF) +#endif + +// Some platforms use a special .opd section to store function pointers. +const char kOpdSectionName[] = ".opd"; + +#if (defined(__powerpc__) && !(_CALL_ELF > 1)) || defined(__ia64) +// Use opd section for function descriptors on these platforms, the function +// address is the first word of the descriptor. +enum { kPlatformUsesOPDSections = 1 }; +#else // not PPC or IA64 +enum { kPlatformUsesOPDSections = 0 }; +#endif + +// This works for PowerPC & IA64 only. A function descriptor consist of two +// pointers and the first one is the function's entry. +const size_t kFunctionDescriptorSize = sizeof(void *) * 2; + +const int kMaxDecorators = 10; // Seems like a reasonable upper limit. + +struct InstalledSymbolDecorator { + SymbolDecorator fn; + void *arg; + int ticket; +}; + +int g_num_decorators; +InstalledSymbolDecorator g_decorators[kMaxDecorators]; + +struct FileMappingHint { + const void *start; + const void *end; + uint64_t offset; + const char *filename; +}; + +// Protects g_decorators. +// We are using SpinLock and not a Mutex here, because we may be called +// from inside Mutex::Lock itself, and it prohibits recursive calls. +// This happens in e.g. base/stacktrace_syscall_unittest. +// Moreover, we are using only TryLock(), if the decorator list +// is being modified (is busy), we skip all decorators, and possibly +// loose some info. Sorry, that's the best we could do. +ABSL_CONST_INIT absl::base_internal::SpinLock g_decorators_mu( + absl::kConstInit, absl::base_internal::SCHEDULE_KERNEL_ONLY); + +const int kMaxFileMappingHints = 8; +int g_num_file_mapping_hints; +FileMappingHint g_file_mapping_hints[kMaxFileMappingHints]; +// Protects g_file_mapping_hints. +ABSL_CONST_INIT absl::base_internal::SpinLock g_file_mapping_mu( + absl::kConstInit, absl::base_internal::SCHEDULE_KERNEL_ONLY); + +// Async-signal-safe function to zero a buffer. +// memset() is not guaranteed to be async-signal-safe. +static void SafeMemZero(void* p, size_t size) { + unsigned char *c = static_cast<unsigned char *>(p); + while (size--) { + *c++ = 0; + } +} + +struct ObjFile { + ObjFile() + : filename(nullptr), + start_addr(nullptr), + end_addr(nullptr), + offset(0), + fd(-1), + elf_type(-1) { + SafeMemZero(&elf_header, sizeof(elf_header)); + } + + char *filename; + const void *start_addr; + const void *end_addr; + uint64_t offset; + + // The following fields are initialized on the first access to the + // object file. + int fd; + int elf_type; + ElfW(Ehdr) elf_header; +}; + +// Build 4-way associative cache for symbols. Within each cache line, symbols +// are replaced in LRU order. +enum { + ASSOCIATIVITY = 4, +}; +struct SymbolCacheLine { + const void *pc[ASSOCIATIVITY]; + char *name[ASSOCIATIVITY]; + + // age[i] is incremented when a line is accessed. it's reset to zero if the + // i'th entry is read. + uint32_t age[ASSOCIATIVITY]; +}; + +// --------------------------------------------------------------- +// An async-signal-safe arena for LowLevelAlloc +static std::atomic<base_internal::LowLevelAlloc::Arena *> g_sig_safe_arena; + +static base_internal::LowLevelAlloc::Arena *SigSafeArena() { + return g_sig_safe_arena.load(std::memory_order_acquire); +} + +static void InitSigSafeArena() { + if (SigSafeArena() == nullptr) { + base_internal::LowLevelAlloc::Arena *new_arena = + base_internal::LowLevelAlloc::NewArena( + base_internal::LowLevelAlloc::kAsyncSignalSafe); + base_internal::LowLevelAlloc::Arena *old_value = nullptr; + if (!g_sig_safe_arena.compare_exchange_strong(old_value, new_arena, + std::memory_order_release, + std::memory_order_relaxed)) { + // We lost a race to allocate an arena; deallocate. + base_internal::LowLevelAlloc::DeleteArena(new_arena); + } + } +} + +// --------------------------------------------------------------- +// An AddrMap is a vector of ObjFile, using SigSafeArena() for allocation. + +class AddrMap { + public: + AddrMap() : size_(0), allocated_(0), obj_(nullptr) {} + ~AddrMap() { base_internal::LowLevelAlloc::Free(obj_); } + int Size() const { return size_; } + ObjFile *At(int i) { return &obj_[i]; } + ObjFile *Add(); + void Clear(); + + private: + int size_; // count of valid elements (<= allocated_) + int allocated_; // count of allocated elements + ObjFile *obj_; // array of allocated_ elements + AddrMap(const AddrMap &) = delete; + AddrMap &operator=(const AddrMap &) = delete; +}; + +void AddrMap::Clear() { + for (int i = 0; i != size_; i++) { + At(i)->~ObjFile(); + } + size_ = 0; +} + +ObjFile *AddrMap::Add() { + if (size_ == allocated_) { + int new_allocated = allocated_ * 2 + 50; + ObjFile *new_obj_ = + static_cast<ObjFile *>(base_internal::LowLevelAlloc::AllocWithArena( + new_allocated * sizeof(*new_obj_), SigSafeArena())); + if (obj_) { + memcpy(new_obj_, obj_, allocated_ * sizeof(*new_obj_)); + base_internal::LowLevelAlloc::Free(obj_); + } + obj_ = new_obj_; + allocated_ = new_allocated; + } + return new (&obj_[size_++]) ObjFile; +} + +// --------------------------------------------------------------- + +enum FindSymbolResult { SYMBOL_NOT_FOUND = 1, SYMBOL_TRUNCATED, SYMBOL_FOUND }; + +class Symbolizer { + public: + Symbolizer(); + ~Symbolizer(); + const char *GetSymbol(const void *const pc); + + private: + char *CopyString(const char *s) { + int len = strlen(s); + char *dst = static_cast<char *>( + base_internal::LowLevelAlloc::AllocWithArena(len + 1, SigSafeArena())); + ABSL_RAW_CHECK(dst != nullptr, "out of memory"); + memcpy(dst, s, len + 1); + return dst; + } + ObjFile *FindObjFile(const void *const start, + size_t size) ABSL_ATTRIBUTE_NOINLINE; + static bool RegisterObjFile(const char *filename, + const void *const start_addr, + const void *const end_addr, uint64_t offset, + void *arg); + SymbolCacheLine *GetCacheLine(const void *const pc); + const char *FindSymbolInCache(const void *const pc); + const char *InsertSymbolInCache(const void *const pc, const char *name); + void AgeSymbols(SymbolCacheLine *line); + void ClearAddrMap(); + FindSymbolResult GetSymbolFromObjectFile(const ObjFile &obj, + const void *const pc, + const ptrdiff_t relocation, + char *out, int out_size, + char *tmp_buf, int tmp_buf_size); + + enum { + SYMBOL_BUF_SIZE = 3072, + TMP_BUF_SIZE = 1024, + SYMBOL_CACHE_LINES = 128, + }; + + AddrMap addr_map_; + + bool ok_; + bool addr_map_read_; + + char symbol_buf_[SYMBOL_BUF_SIZE]; + + // tmp_buf_ will be used to store arrays of ElfW(Shdr) and ElfW(Sym) + // so we ensure that tmp_buf_ is properly aligned to store either. + alignas(16) char tmp_buf_[TMP_BUF_SIZE]; + static_assert(alignof(ElfW(Shdr)) <= 16, + "alignment of tmp buf too small for Shdr"); + static_assert(alignof(ElfW(Sym)) <= 16, + "alignment of tmp buf too small for Sym"); + + SymbolCacheLine symbol_cache_[SYMBOL_CACHE_LINES]; +}; + +static std::atomic<Symbolizer *> g_cached_symbolizer; + +} // namespace + +static int SymbolizerSize() { +#if defined(__wasm__) || defined(__asmjs__) + int pagesize = getpagesize(); +#else + int pagesize = sysconf(_SC_PAGESIZE); +#endif + return ((sizeof(Symbolizer) - 1) / pagesize + 1) * pagesize; +} + +// Return (and set null) g_cached_symbolized_state if it is not null. +// Otherwise return a new symbolizer. +static Symbolizer *AllocateSymbolizer() { + InitSigSafeArena(); + Symbolizer *symbolizer = + g_cached_symbolizer.exchange(nullptr, std::memory_order_acquire); + if (symbolizer != nullptr) { + return symbolizer; + } + return new (base_internal::LowLevelAlloc::AllocWithArena( + SymbolizerSize(), SigSafeArena())) Symbolizer(); +} + +// Set g_cached_symbolize_state to s if it is null, otherwise +// delete s. +static void FreeSymbolizer(Symbolizer *s) { + Symbolizer *old_cached_symbolizer = nullptr; + if (!g_cached_symbolizer.compare_exchange_strong(old_cached_symbolizer, s, + std::memory_order_release, + std::memory_order_relaxed)) { + s->~Symbolizer(); + base_internal::LowLevelAlloc::Free(s); + } +} + +Symbolizer::Symbolizer() : ok_(true), addr_map_read_(false) { + for (SymbolCacheLine &symbol_cache_line : symbol_cache_) { + for (size_t j = 0; j < ABSL_ARRAYSIZE(symbol_cache_line.name); ++j) { + symbol_cache_line.pc[j] = nullptr; + symbol_cache_line.name[j] = nullptr; + symbol_cache_line.age[j] = 0; + } + } +} + +Symbolizer::~Symbolizer() { + for (SymbolCacheLine &symbol_cache_line : symbol_cache_) { + for (char *s : symbol_cache_line.name) { + base_internal::LowLevelAlloc::Free(s); + } + } + ClearAddrMap(); +} + +// We don't use assert() since it's not guaranteed to be +// async-signal-safe. Instead we define a minimal assertion +// macro. So far, we don't need pretty printing for __FILE__, etc. +#define SAFE_ASSERT(expr) ((expr) ? static_cast<void>(0) : abort()) + +// Read up to "count" bytes from file descriptor "fd" into the buffer +// starting at "buf" while handling short reads and EINTR. On +// success, return the number of bytes read. Otherwise, return -1. +static ssize_t ReadPersistent(int fd, void *buf, size_t count) { + SAFE_ASSERT(fd >= 0); + SAFE_ASSERT(count <= SSIZE_MAX); + char *buf0 = reinterpret_cast<char *>(buf); + size_t num_bytes = 0; + while (num_bytes < count) { + ssize_t len; + NO_INTR(len = read(fd, buf0 + num_bytes, count - num_bytes)); + if (len < 0) { // There was an error other than EINTR. + ABSL_RAW_LOG(WARNING, "read failed: errno=%d", errno); + return -1; + } + if (len == 0) { // Reached EOF. + break; + } + num_bytes += len; + } + SAFE_ASSERT(num_bytes <= count); + return static_cast<ssize_t>(num_bytes); +} + +// Read up to "count" bytes from "offset" in the file pointed by file +// descriptor "fd" into the buffer starting at "buf". On success, +// return the number of bytes read. Otherwise, return -1. +static ssize_t ReadFromOffset(const int fd, void *buf, const size_t count, + const off_t offset) { + off_t off = lseek(fd, offset, SEEK_SET); + if (off == (off_t)-1) { + ABSL_RAW_LOG(WARNING, "lseek(%d, %ju, SEEK_SET) failed: errno=%d", fd, + static_cast<uintmax_t>(offset), errno); + return -1; + } + return ReadPersistent(fd, buf, count); +} + +// Try reading exactly "count" bytes from "offset" bytes in a file +// pointed by "fd" into the buffer starting at "buf" while handling +// short reads and EINTR. On success, return true. Otherwise, return +// false. +static bool ReadFromOffsetExact(const int fd, void *buf, const size_t count, + const off_t offset) { + ssize_t len = ReadFromOffset(fd, buf, count, offset); + return len >= 0 && static_cast<size_t>(len) == count; +} + +// Returns elf_header.e_type if the file pointed by fd is an ELF binary. +static int FileGetElfType(const int fd) { + ElfW(Ehdr) elf_header; + if (!ReadFromOffsetExact(fd, &elf_header, sizeof(elf_header), 0)) { + return -1; + } + if (memcmp(elf_header.e_ident, ELFMAG, SELFMAG) != 0) { + return -1; + } + return elf_header.e_type; +} + +// Read the section headers in the given ELF binary, and if a section +// of the specified type is found, set the output to this section header +// and return true. Otherwise, return false. +// To keep stack consumption low, we would like this function to not get +// inlined. +static ABSL_ATTRIBUTE_NOINLINE bool GetSectionHeaderByType( + const int fd, ElfW(Half) sh_num, const off_t sh_offset, ElfW(Word) type, + ElfW(Shdr) * out, char *tmp_buf, int tmp_buf_size) { + ElfW(Shdr) *buf = reinterpret_cast<ElfW(Shdr) *>(tmp_buf); + const int buf_entries = tmp_buf_size / sizeof(buf[0]); + const int buf_bytes = buf_entries * sizeof(buf[0]); + + for (int i = 0; i < sh_num;) { + const ssize_t num_bytes_left = (sh_num - i) * sizeof(buf[0]); + const ssize_t num_bytes_to_read = + (buf_bytes > num_bytes_left) ? num_bytes_left : buf_bytes; + const off_t offset = sh_offset + i * sizeof(buf[0]); + const ssize_t len = ReadFromOffset(fd, buf, num_bytes_to_read, offset); + if (len % sizeof(buf[0]) != 0) { + ABSL_RAW_LOG( + WARNING, + "Reading %zd bytes from offset %ju returned %zd which is not a " + "multiple of %zu.", + num_bytes_to_read, static_cast<uintmax_t>(offset), len, + sizeof(buf[0])); + return false; + } + const ssize_t num_headers_in_buf = len / sizeof(buf[0]); + SAFE_ASSERT(num_headers_in_buf <= buf_entries); + for (int j = 0; j < num_headers_in_buf; ++j) { + if (buf[j].sh_type == type) { + *out = buf[j]; + return true; + } + } + i += num_headers_in_buf; + } + return false; +} + +// There is no particular reason to limit section name to 63 characters, +// but there has (as yet) been no need for anything longer either. +const int kMaxSectionNameLen = 64; + +bool ForEachSection(int fd, + const std::function<bool(const std::string &name, + const ElfW(Shdr) &)> &callback) { + ElfW(Ehdr) elf_header; + if (!ReadFromOffsetExact(fd, &elf_header, sizeof(elf_header), 0)) { + return false; + } + + ElfW(Shdr) shstrtab; + off_t shstrtab_offset = + (elf_header.e_shoff + elf_header.e_shentsize * elf_header.e_shstrndx); + if (!ReadFromOffsetExact(fd, &shstrtab, sizeof(shstrtab), shstrtab_offset)) { + return false; + } + + for (int i = 0; i < elf_header.e_shnum; ++i) { + ElfW(Shdr) out; + off_t section_header_offset = + (elf_header.e_shoff + elf_header.e_shentsize * i); + if (!ReadFromOffsetExact(fd, &out, sizeof(out), section_header_offset)) { + return false; + } + off_t name_offset = shstrtab.sh_offset + out.sh_name; + char header_name[kMaxSectionNameLen + 1]; + ssize_t n_read = + ReadFromOffset(fd, &header_name, kMaxSectionNameLen, name_offset); + if (n_read == -1) { + return false; + } else if (n_read > kMaxSectionNameLen) { + // Long read? + return false; + } + header_name[n_read] = '\0'; + + std::string name(header_name); + if (!callback(name, out)) { + break; + } + } + return true; +} + +// name_len should include terminating '\0'. +bool GetSectionHeaderByName(int fd, const char *name, size_t name_len, + ElfW(Shdr) * out) { + char header_name[kMaxSectionNameLen]; + if (sizeof(header_name) < name_len) { + ABSL_RAW_LOG(WARNING, + "Section name '%s' is too long (%zu); " + "section will not be found (even if present).", + name, name_len); + // No point in even trying. + return false; + } + + ElfW(Ehdr) elf_header; + if (!ReadFromOffsetExact(fd, &elf_header, sizeof(elf_header), 0)) { + return false; + } + + ElfW(Shdr) shstrtab; + off_t shstrtab_offset = + (elf_header.e_shoff + elf_header.e_shentsize * elf_header.e_shstrndx); + if (!ReadFromOffsetExact(fd, &shstrtab, sizeof(shstrtab), shstrtab_offset)) { + return false; + } + + for (int i = 0; i < elf_header.e_shnum; ++i) { + off_t section_header_offset = + (elf_header.e_shoff + elf_header.e_shentsize * i); + if (!ReadFromOffsetExact(fd, out, sizeof(*out), section_header_offset)) { + return false; + } + off_t name_offset = shstrtab.sh_offset + out->sh_name; + ssize_t n_read = ReadFromOffset(fd, &header_name, name_len, name_offset); + if (n_read < 0) { + return false; + } else if (static_cast<size_t>(n_read) != name_len) { + // Short read -- name could be at end of file. + continue; + } + if (memcmp(header_name, name, name_len) == 0) { + return true; + } + } + return false; +} + +// Compare symbols at in the same address. +// Return true if we should pick symbol1. +static bool ShouldPickFirstSymbol(const ElfW(Sym) & symbol1, + const ElfW(Sym) & symbol2) { + // If one of the symbols is weak and the other is not, pick the one + // this is not a weak symbol. + char bind1 = ELF_ST_BIND(symbol1.st_info); + char bind2 = ELF_ST_BIND(symbol1.st_info); + if (bind1 == STB_WEAK && bind2 != STB_WEAK) return false; + if (bind2 == STB_WEAK && bind1 != STB_WEAK) return true; + + // If one of the symbols has zero size and the other is not, pick the + // one that has non-zero size. + if (symbol1.st_size != 0 && symbol2.st_size == 0) { + return true; + } + if (symbol1.st_size == 0 && symbol2.st_size != 0) { + return false; + } + + // If one of the symbols has no type and the other is not, pick the + // one that has a type. + char type1 = ELF_ST_TYPE(symbol1.st_info); + char type2 = ELF_ST_TYPE(symbol1.st_info); + if (type1 != STT_NOTYPE && type2 == STT_NOTYPE) { + return true; + } + if (type1 == STT_NOTYPE && type2 != STT_NOTYPE) { + return false; + } + + // Pick the first one, if we still cannot decide. + return true; +} + +// Return true if an address is inside a section. +static bool InSection(const void *address, const ElfW(Shdr) * section) { + const char *start = reinterpret_cast<const char *>(section->sh_addr); + size_t size = static_cast<size_t>(section->sh_size); + return start <= address && address < (start + size); +} + +static const char *ComputeOffset(const char *base, ptrdiff_t offset) { + // Note: cast to uintptr_t to avoid undefined behavior when base evaluates to + // zero and offset is non-zero. + return reinterpret_cast<const char *>( + reinterpret_cast<uintptr_t>(base) + offset); +} + +// Read a symbol table and look for the symbol containing the +// pc. Iterate over symbols in a symbol table and look for the symbol +// containing "pc". If the symbol is found, and its name fits in +// out_size, the name is written into out and SYMBOL_FOUND is returned. +// If the name does not fit, truncated name is written into out, +// and SYMBOL_TRUNCATED is returned. Out is NUL-terminated. +// If the symbol is not found, SYMBOL_NOT_FOUND is returned; +// To keep stack consumption low, we would like this function to not get +// inlined. +static ABSL_ATTRIBUTE_NOINLINE FindSymbolResult FindSymbol( + const void *const pc, const int fd, char *out, int out_size, + ptrdiff_t relocation, const ElfW(Shdr) * strtab, const ElfW(Shdr) * symtab, + const ElfW(Shdr) * opd, char *tmp_buf, int tmp_buf_size) { + if (symtab == nullptr) { + return SYMBOL_NOT_FOUND; + } + + // Read multiple symbols at once to save read() calls. + ElfW(Sym) *buf = reinterpret_cast<ElfW(Sym) *>(tmp_buf); + const int buf_entries = tmp_buf_size / sizeof(buf[0]); + + const int num_symbols = symtab->sh_size / symtab->sh_entsize; + + // On platforms using an .opd section (PowerPC & IA64), a function symbol + // has the address of a function descriptor, which contains the real + // starting address. However, we do not always want to use the real + // starting address because we sometimes want to symbolize a function + // pointer into the .opd section, e.g. FindSymbol(&foo,...). + const bool pc_in_opd = + kPlatformUsesOPDSections && opd != nullptr && InSection(pc, opd); + const bool deref_function_descriptor_pointer = + kPlatformUsesOPDSections && opd != nullptr && !pc_in_opd; + + ElfW(Sym) best_match; + SafeMemZero(&best_match, sizeof(best_match)); + bool found_match = false; + for (int i = 0; i < num_symbols;) { + off_t offset = symtab->sh_offset + i * symtab->sh_entsize; + const int num_remaining_symbols = num_symbols - i; + const int entries_in_chunk = std::min(num_remaining_symbols, buf_entries); + const int bytes_in_chunk = entries_in_chunk * sizeof(buf[0]); + const ssize_t len = ReadFromOffset(fd, buf, bytes_in_chunk, offset); + SAFE_ASSERT(len % sizeof(buf[0]) == 0); + const ssize_t num_symbols_in_buf = len / sizeof(buf[0]); + SAFE_ASSERT(num_symbols_in_buf <= entries_in_chunk); + for (int j = 0; j < num_symbols_in_buf; ++j) { + const ElfW(Sym) &symbol = buf[j]; + + // For a DSO, a symbol address is relocated by the loading address. + // We keep the original address for opd redirection below. + const char *const original_start_address = + reinterpret_cast<const char *>(symbol.st_value); + const char *start_address = + ComputeOffset(original_start_address, relocation); + + if (deref_function_descriptor_pointer && + InSection(original_start_address, opd)) { + // The opd section is mapped into memory. Just dereference + // start_address to get the first double word, which points to the + // function entry. + start_address = *reinterpret_cast<const char *const *>(start_address); + } + + // If pc is inside the .opd section, it points to a function descriptor. + const size_t size = pc_in_opd ? kFunctionDescriptorSize : symbol.st_size; + const void *const end_address = ComputeOffset(start_address, size); + if (symbol.st_value != 0 && // Skip null value symbols. + symbol.st_shndx != 0 && // Skip undefined symbols. +#ifdef STT_TLS + ELF_ST_TYPE(symbol.st_info) != STT_TLS && // Skip thread-local data. +#endif // STT_TLS + ((start_address <= pc && pc < end_address) || + (start_address == pc && pc == end_address))) { + if (!found_match || ShouldPickFirstSymbol(symbol, best_match)) { + found_match = true; + best_match = symbol; + } + } + } + i += num_symbols_in_buf; + } + + if (found_match) { + const size_t off = strtab->sh_offset + best_match.st_name; + const ssize_t n_read = ReadFromOffset(fd, out, out_size, off); + if (n_read <= 0) { + // This should never happen. + ABSL_RAW_LOG(WARNING, + "Unable to read from fd %d at offset %zu: n_read = %zd", fd, + off, n_read); + return SYMBOL_NOT_FOUND; + } + ABSL_RAW_CHECK(n_read <= out_size, "ReadFromOffset read too much data."); + + // strtab->sh_offset points into .strtab-like section that contains + // NUL-terminated strings: '\0foo\0barbaz\0...". + // + // sh_offset+st_name points to the start of symbol name, but we don't know + // how long the symbol is, so we try to read as much as we have space for, + // and usually over-read (i.e. there is a NUL somewhere before n_read). + if (memchr(out, '\0', n_read) == nullptr) { + // Either out_size was too small (n_read == out_size and no NUL), or + // we tried to read past the EOF (n_read < out_size) and .strtab is + // corrupt (missing terminating NUL; should never happen for valid ELF). + out[n_read - 1] = '\0'; + return SYMBOL_TRUNCATED; + } + return SYMBOL_FOUND; + } + + return SYMBOL_NOT_FOUND; +} + +// Get the symbol name of "pc" from the file pointed by "fd". Process +// both regular and dynamic symbol tables if necessary. +// See FindSymbol() comment for description of return value. +FindSymbolResult Symbolizer::GetSymbolFromObjectFile( + const ObjFile &obj, const void *const pc, const ptrdiff_t relocation, + char *out, int out_size, char *tmp_buf, int tmp_buf_size) { + ElfW(Shdr) symtab; + ElfW(Shdr) strtab; + ElfW(Shdr) opd; + ElfW(Shdr) *opd_ptr = nullptr; + + // On platforms using an .opd sections for function descriptor, read + // the section header. The .opd section is in data segment and should be + // loaded but we check that it is mapped just to be extra careful. + if (kPlatformUsesOPDSections) { + if (GetSectionHeaderByName(obj.fd, kOpdSectionName, + sizeof(kOpdSectionName) - 1, &opd) && + FindObjFile(reinterpret_cast<const char *>(opd.sh_addr) + relocation, + opd.sh_size) != nullptr) { + opd_ptr = &opd; + } else { + return SYMBOL_NOT_FOUND; + } + } + + // Consult a regular symbol table, then fall back to the dynamic symbol table. + for (const auto symbol_table_type : {SHT_SYMTAB, SHT_DYNSYM}) { + if (!GetSectionHeaderByType(obj.fd, obj.elf_header.e_shnum, + obj.elf_header.e_shoff, symbol_table_type, + &symtab, tmp_buf, tmp_buf_size)) { + continue; + } + if (!ReadFromOffsetExact( + obj.fd, &strtab, sizeof(strtab), + obj.elf_header.e_shoff + symtab.sh_link * sizeof(symtab))) { + continue; + } + const FindSymbolResult rc = + FindSymbol(pc, obj.fd, out, out_size, relocation, &strtab, &symtab, + opd_ptr, tmp_buf, tmp_buf_size); + if (rc != SYMBOL_NOT_FOUND) { + return rc; + } + } + + return SYMBOL_NOT_FOUND; +} + +namespace { +// Thin wrapper around a file descriptor so that the file descriptor +// gets closed for sure. +class FileDescriptor { + public: + explicit FileDescriptor(int fd) : fd_(fd) {} + FileDescriptor(const FileDescriptor &) = delete; + FileDescriptor &operator=(const FileDescriptor &) = delete; + + ~FileDescriptor() { + if (fd_ >= 0) { + NO_INTR(close(fd_)); + } + } + + int get() const { return fd_; } + + private: + const int fd_; +}; + +// Helper class for reading lines from file. +// +// Note: we don't use ProcMapsIterator since the object is big (it has +// a 5k array member) and uses async-unsafe functions such as sscanf() +// and snprintf(). +class LineReader { + public: + explicit LineReader(int fd, char *buf, int buf_len) + : fd_(fd), + buf_len_(buf_len), + buf_(buf), + bol_(buf), + eol_(buf), + eod_(buf) {} + + LineReader(const LineReader &) = delete; + LineReader &operator=(const LineReader &) = delete; + + // Read '\n'-terminated line from file. On success, modify "bol" + // and "eol", then return true. Otherwise, return false. + // + // Note: if the last line doesn't end with '\n', the line will be + // dropped. It's an intentional behavior to make the code simple. + bool ReadLine(const char **bol, const char **eol) { + if (BufferIsEmpty()) { // First time. + const ssize_t num_bytes = ReadPersistent(fd_, buf_, buf_len_); + if (num_bytes <= 0) { // EOF or error. + return false; + } + eod_ = buf_ + num_bytes; + bol_ = buf_; + } else { + bol_ = eol_ + 1; // Advance to the next line in the buffer. + SAFE_ASSERT(bol_ <= eod_); // "bol_" can point to "eod_". + if (!HasCompleteLine()) { + const int incomplete_line_length = eod_ - bol_; + // Move the trailing incomplete line to the beginning. + memmove(buf_, bol_, incomplete_line_length); + // Read text from file and append it. + char *const append_pos = buf_ + incomplete_line_length; + const int capacity_left = buf_len_ - incomplete_line_length; + const ssize_t num_bytes = + ReadPersistent(fd_, append_pos, capacity_left); + if (num_bytes <= 0) { // EOF or error. + return false; + } + eod_ = append_pos + num_bytes; + bol_ = buf_; + } + } + eol_ = FindLineFeed(); + if (eol_ == nullptr) { // '\n' not found. Malformed line. + return false; + } + *eol_ = '\0'; // Replace '\n' with '\0'. + + *bol = bol_; + *eol = eol_; + return true; + } + + private: + char *FindLineFeed() const { + return reinterpret_cast<char *>(memchr(bol_, '\n', eod_ - bol_)); + } + + bool BufferIsEmpty() const { return buf_ == eod_; } + + bool HasCompleteLine() const { + return !BufferIsEmpty() && FindLineFeed() != nullptr; + } + + const int fd_; + const int buf_len_; + char *const buf_; + char *bol_; + char *eol_; + const char *eod_; // End of data in "buf_". +}; +} // namespace + +// Place the hex number read from "start" into "*hex". The pointer to +// the first non-hex character or "end" is returned. +static const char *GetHex(const char *start, const char *end, + uint64_t *const value) { + uint64_t hex = 0; + const char *p; + for (p = start; p < end; ++p) { + int ch = *p; + if ((ch >= '0' && ch <= '9') || (ch >= 'A' && ch <= 'F') || + (ch >= 'a' && ch <= 'f')) { + hex = (hex << 4) | (ch < 'A' ? ch - '0' : (ch & 0xF) + 9); + } else { // Encountered the first non-hex character. + break; + } + } + SAFE_ASSERT(p <= end); + *value = hex; + return p; +} + +static const char *GetHex(const char *start, const char *end, + const void **const addr) { + uint64_t hex = 0; + const char *p = GetHex(start, end, &hex); + *addr = reinterpret_cast<void *>(hex); + return p; +} + +// Normally we are only interested in "r?x" maps. +// On the PowerPC, function pointers point to descriptors in the .opd +// section. The descriptors themselves are not executable code, so +// we need to relax the check below to "r??". +static bool ShouldUseMapping(const char *const flags) { + return flags[0] == 'r' && (kPlatformUsesOPDSections || flags[2] == 'x'); +} + +// Read /proc/self/maps and run "callback" for each mmapped file found. If +// "callback" returns false, stop scanning and return true. Else continue +// scanning /proc/self/maps. Return true if no parse error is found. +static ABSL_ATTRIBUTE_NOINLINE bool ReadAddrMap( + bool (*callback)(const char *filename, const void *const start_addr, + const void *const end_addr, uint64_t offset, void *arg), + void *arg, void *tmp_buf, int tmp_buf_size) { + // Use /proc/self/task/<pid>/maps instead of /proc/self/maps. The latter + // requires kernel to stop all threads, and is significantly slower when there + // are 1000s of threads. + char maps_path[80]; + snprintf(maps_path, sizeof(maps_path), "/proc/self/task/%d/maps", getpid()); + + int maps_fd; + NO_INTR(maps_fd = open(maps_path, O_RDONLY)); + FileDescriptor wrapped_maps_fd(maps_fd); + if (wrapped_maps_fd.get() < 0) { + ABSL_RAW_LOG(WARNING, "%s: errno=%d", maps_path, errno); + return false; + } + + // Iterate over maps and look for the map containing the pc. Then + // look into the symbol tables inside. + LineReader reader(wrapped_maps_fd.get(), static_cast<char *>(tmp_buf), + tmp_buf_size); + while (true) { + const char *cursor; + const char *eol; + if (!reader.ReadLine(&cursor, &eol)) { // EOF or malformed line. + break; + } + + const char *line = cursor; + const void *start_address; + // Start parsing line in /proc/self/maps. Here is an example: + // + // 08048000-0804c000 r-xp 00000000 08:01 2142121 /bin/cat + // + // We want start address (08048000), end address (0804c000), flags + // (r-xp) and file name (/bin/cat). + + // Read start address. + cursor = GetHex(cursor, eol, &start_address); + if (cursor == eol || *cursor != '-') { + ABSL_RAW_LOG(WARNING, "Corrupt /proc/self/maps line: %s", line); + return false; + } + ++cursor; // Skip '-'. + + // Read end address. + const void *end_address; + cursor = GetHex(cursor, eol, &end_address); + if (cursor == eol || *cursor != ' ') { + ABSL_RAW_LOG(WARNING, "Corrupt /proc/self/maps line: %s", line); + return false; + } + ++cursor; // Skip ' '. + + // Read flags. Skip flags until we encounter a space or eol. + const char *const flags_start = cursor; + while (cursor < eol && *cursor != ' ') { + ++cursor; + } + // We expect at least four letters for flags (ex. "r-xp"). + if (cursor == eol || cursor < flags_start + 4) { + ABSL_RAW_LOG(WARNING, "Corrupt /proc/self/maps: %s", line); + return false; + } + + // Check flags. + if (!ShouldUseMapping(flags_start)) { + continue; // We skip this map. + } + ++cursor; // Skip ' '. + + // Read file offset. + uint64_t offset; + cursor = GetHex(cursor, eol, &offset); + ++cursor; // Skip ' '. + + // Skip to file name. "cursor" now points to dev. We need to skip at least + // two spaces for dev and inode. + int num_spaces = 0; + while (cursor < eol) { + if (*cursor == ' ') { + ++num_spaces; + } else if (num_spaces >= 2) { + // The first non-space character after skipping two spaces + // is the beginning of the file name. + break; + } + ++cursor; + } + + // Check whether this entry corresponds to our hint table for the true + // filename. + bool hinted = + GetFileMappingHint(&start_address, &end_address, &offset, &cursor); + if (!hinted && (cursor == eol || cursor[0] == '[')) { + // not an object file, typically [vdso] or [vsyscall] + continue; + } + if (!callback(cursor, start_address, end_address, offset, arg)) break; + } + return true; +} + +// Find the objfile mapped in address region containing [addr, addr + len). +ObjFile *Symbolizer::FindObjFile(const void *const addr, size_t len) { + for (int i = 0; i < 2; ++i) { + if (!ok_) return nullptr; + + // Read /proc/self/maps if necessary + if (!addr_map_read_) { + addr_map_read_ = true; + if (!ReadAddrMap(RegisterObjFile, this, tmp_buf_, TMP_BUF_SIZE)) { + ok_ = false; + return nullptr; + } + } + + int lo = 0; + int hi = addr_map_.Size(); + while (lo < hi) { + int mid = (lo + hi) / 2; + if (addr < addr_map_.At(mid)->end_addr) { + hi = mid; + } else { + lo = mid + 1; + } + } + if (lo != addr_map_.Size()) { + ObjFile *obj = addr_map_.At(lo); + SAFE_ASSERT(obj->end_addr > addr); + if (addr >= obj->start_addr && + reinterpret_cast<const char *>(addr) + len <= obj->end_addr) + return obj; + } + + // The address mapping may have changed since it was last read. Retry. + ClearAddrMap(); + } + return nullptr; +} + +void Symbolizer::ClearAddrMap() { + for (int i = 0; i != addr_map_.Size(); i++) { + ObjFile *o = addr_map_.At(i); + base_internal::LowLevelAlloc::Free(o->filename); + if (o->fd >= 0) { + NO_INTR(close(o->fd)); + } + } + addr_map_.Clear(); + addr_map_read_ = false; +} + +// Callback for ReadAddrMap to register objfiles in an in-memory table. +bool Symbolizer::RegisterObjFile(const char *filename, + const void *const start_addr, + const void *const end_addr, uint64_t offset, + void *arg) { + Symbolizer *impl = static_cast<Symbolizer *>(arg); + + // Files are supposed to be added in the increasing address order. Make + // sure that's the case. + int addr_map_size = impl->addr_map_.Size(); + if (addr_map_size != 0) { + ObjFile *old = impl->addr_map_.At(addr_map_size - 1); + if (old->end_addr > end_addr) { + ABSL_RAW_LOG(ERROR, + "Unsorted addr map entry: 0x%" PRIxPTR ": %s <-> 0x%" PRIxPTR + ": %s", + reinterpret_cast<uintptr_t>(end_addr), filename, + reinterpret_cast<uintptr_t>(old->end_addr), old->filename); + return true; + } else if (old->end_addr == end_addr) { + // The same entry appears twice. This sometimes happens for [vdso]. + if (old->start_addr != start_addr || + strcmp(old->filename, filename) != 0) { + ABSL_RAW_LOG(ERROR, + "Duplicate addr 0x%" PRIxPTR ": %s <-> 0x%" PRIxPTR ": %s", + reinterpret_cast<uintptr_t>(end_addr), filename, + reinterpret_cast<uintptr_t>(old->end_addr), old->filename); + } + return true; + } + } + ObjFile *obj = impl->addr_map_.Add(); + obj->filename = impl->CopyString(filename); + obj->start_addr = start_addr; + obj->end_addr = end_addr; + obj->offset = offset; + obj->elf_type = -1; // filled on demand + obj->fd = -1; // opened on demand + return true; +} + +// This function wraps the Demangle function to provide an interface +// where the input symbol is demangled in-place. +// To keep stack consumption low, we would like this function to not +// get inlined. +static ABSL_ATTRIBUTE_NOINLINE void DemangleInplace(char *out, int out_size, + char *tmp_buf, + int tmp_buf_size) { + if (Demangle(out, tmp_buf, tmp_buf_size)) { + // Demangling succeeded. Copy to out if the space allows. + int len = strlen(tmp_buf); + if (len + 1 <= out_size) { // +1 for '\0'. + SAFE_ASSERT(len < tmp_buf_size); + memmove(out, tmp_buf, len + 1); + } + } +} + +SymbolCacheLine *Symbolizer::GetCacheLine(const void *const pc) { + uintptr_t pc0 = reinterpret_cast<uintptr_t>(pc); + pc0 >>= 3; // drop the low 3 bits + + // Shuffle bits. + pc0 ^= (pc0 >> 6) ^ (pc0 >> 12) ^ (pc0 >> 18); + return &symbol_cache_[pc0 % SYMBOL_CACHE_LINES]; +} + +void Symbolizer::AgeSymbols(SymbolCacheLine *line) { + for (uint32_t &age : line->age) { + ++age; + } +} + +const char *Symbolizer::FindSymbolInCache(const void *const pc) { + if (pc == nullptr) return nullptr; + + SymbolCacheLine *line = GetCacheLine(pc); + for (size_t i = 0; i < ABSL_ARRAYSIZE(line->pc); ++i) { + if (line->pc[i] == pc) { + AgeSymbols(line); + line->age[i] = 0; + return line->name[i]; + } + } + return nullptr; +} + +const char *Symbolizer::InsertSymbolInCache(const void *const pc, + const char *name) { + SAFE_ASSERT(pc != nullptr); + + SymbolCacheLine *line = GetCacheLine(pc); + uint32_t max_age = 0; + int oldest_index = -1; + for (size_t i = 0; i < ABSL_ARRAYSIZE(line->pc); ++i) { + if (line->pc[i] == nullptr) { + AgeSymbols(line); + line->pc[i] = pc; + line->name[i] = CopyString(name); + line->age[i] = 0; + return line->name[i]; + } + if (line->age[i] >= max_age) { + max_age = line->age[i]; + oldest_index = i; + } + } + + AgeSymbols(line); + ABSL_RAW_CHECK(oldest_index >= 0, "Corrupt cache"); + base_internal::LowLevelAlloc::Free(line->name[oldest_index]); + line->pc[oldest_index] = pc; + line->name[oldest_index] = CopyString(name); + line->age[oldest_index] = 0; + return line->name[oldest_index]; +} + +static void MaybeOpenFdFromSelfExe(ObjFile *obj) { + if (memcmp(obj->start_addr, ELFMAG, SELFMAG) != 0) { + return; + } + int fd = open("/proc/self/exe", O_RDONLY); + if (fd == -1) { + return; + } + // Verify that contents of /proc/self/exe matches in-memory image of + // the binary. This can fail if the "deleted" binary is in fact not + // the main executable, or for binaries that have the first PT_LOAD + // segment smaller than 4K. We do it in four steps so that the + // buffer is smaller and we don't consume too much stack space. + const char *mem = reinterpret_cast<const char *>(obj->start_addr); + for (int i = 0; i < 4; ++i) { + char buf[1024]; + ssize_t n = read(fd, buf, sizeof(buf)); + if (n != sizeof(buf) || memcmp(buf, mem, sizeof(buf)) != 0) { + close(fd); + return; + } + mem += sizeof(buf); + } + obj->fd = fd; +} + +static bool MaybeInitializeObjFile(ObjFile *obj) { + if (obj->fd < 0) { + obj->fd = open(obj->filename, O_RDONLY); + + if (obj->fd < 0) { + // Getting /proc/self/exe here means that we were hinted. + if (strcmp(obj->filename, "/proc/self/exe") == 0) { + // /proc/self/exe may be inaccessible (due to setuid, etc.), so try + // accessing the binary via argv0. + if (argv0_value != nullptr) { + obj->fd = open(argv0_value, O_RDONLY); + } + } else { + MaybeOpenFdFromSelfExe(obj); + } + } + + if (obj->fd < 0) { + ABSL_RAW_LOG(WARNING, "%s: open failed: errno=%d", obj->filename, errno); + return false; + } + obj->elf_type = FileGetElfType(obj->fd); + if (obj->elf_type < 0) { + ABSL_RAW_LOG(WARNING, "%s: wrong elf type: %d", obj->filename, + obj->elf_type); + return false; + } + + if (!ReadFromOffsetExact(obj->fd, &obj->elf_header, sizeof(obj->elf_header), + 0)) { + ABSL_RAW_LOG(WARNING, "%s: failed to read elf header", obj->filename); + return false; + } + } + return true; +} + +// The implementation of our symbolization routine. If it +// successfully finds the symbol containing "pc" and obtains the +// symbol name, returns pointer to that symbol. Otherwise, returns nullptr. +// If any symbol decorators have been installed via InstallSymbolDecorator(), +// they are called here as well. +// To keep stack consumption low, we would like this function to not +// get inlined. +const char *Symbolizer::GetSymbol(const void *const pc) { + const char *entry = FindSymbolInCache(pc); + if (entry != nullptr) { + return entry; + } + symbol_buf_[0] = '\0'; + + ObjFile *const obj = FindObjFile(pc, 1); + ptrdiff_t relocation = 0; + int fd = -1; + if (obj != nullptr) { + if (MaybeInitializeObjFile(obj)) { + if (obj->elf_type == ET_DYN && + reinterpret_cast<uint64_t>(obj->start_addr) >= obj->offset) { + // This object was relocated. + // + // For obj->offset > 0, adjust the relocation since a mapping at offset + // X in the file will have a start address of [true relocation]+X. + relocation = reinterpret_cast<ptrdiff_t>(obj->start_addr) - obj->offset; + } + + fd = obj->fd; + } + if (GetSymbolFromObjectFile(*obj, pc, relocation, symbol_buf_, + sizeof(symbol_buf_), tmp_buf_, + sizeof(tmp_buf_)) == SYMBOL_FOUND) { + // Only try to demangle the symbol name if it fit into symbol_buf_. + DemangleInplace(symbol_buf_, sizeof(symbol_buf_), tmp_buf_, + sizeof(tmp_buf_)); + } + } else { +#if ABSL_HAVE_VDSO_SUPPORT + VDSOSupport vdso; + if (vdso.IsPresent()) { + VDSOSupport::SymbolInfo symbol_info; + if (vdso.LookupSymbolByAddress(pc, &symbol_info)) { + // All VDSO symbols are known to be short. + size_t len = strlen(symbol_info.name); + ABSL_RAW_CHECK(len + 1 < sizeof(symbol_buf_), + "VDSO symbol unexpectedly long"); + memcpy(symbol_buf_, symbol_info.name, len + 1); + } + } +#endif + } + + if (g_decorators_mu.TryLock()) { + if (g_num_decorators > 0) { + SymbolDecoratorArgs decorator_args = { + pc, relocation, fd, symbol_buf_, sizeof(symbol_buf_), + tmp_buf_, sizeof(tmp_buf_), nullptr}; + for (int i = 0; i < g_num_decorators; ++i) { + decorator_args.arg = g_decorators[i].arg; + g_decorators[i].fn(&decorator_args); + } + } + g_decorators_mu.Unlock(); + } + if (symbol_buf_[0] == '\0') { + return nullptr; + } + symbol_buf_[sizeof(symbol_buf_) - 1] = '\0'; // Paranoia. + return InsertSymbolInCache(pc, symbol_buf_); +} + +bool RemoveAllSymbolDecorators(void) { + if (!g_decorators_mu.TryLock()) { + // Someone else is using decorators. Get out. + return false; + } + g_num_decorators = 0; + g_decorators_mu.Unlock(); + return true; +} + +bool RemoveSymbolDecorator(int ticket) { + if (!g_decorators_mu.TryLock()) { + // Someone else is using decorators. Get out. + return false; + } + for (int i = 0; i < g_num_decorators; ++i) { + if (g_decorators[i].ticket == ticket) { + while (i < g_num_decorators - 1) { + g_decorators[i] = g_decorators[i + 1]; + ++i; + } + g_num_decorators = i; + break; + } + } + g_decorators_mu.Unlock(); + return true; // Decorator is known to be removed. +} + +int InstallSymbolDecorator(SymbolDecorator decorator, void *arg) { + static int ticket = 0; + + if (!g_decorators_mu.TryLock()) { + // Someone else is using decorators. Get out. + return false; + } + int ret = ticket; + if (g_num_decorators >= kMaxDecorators) { + ret = -1; + } else { + g_decorators[g_num_decorators] = {decorator, arg, ticket++}; + ++g_num_decorators; + } + g_decorators_mu.Unlock(); + return ret; +} + +bool RegisterFileMappingHint(const void *start, const void *end, uint64_t offset, + const char *filename) { + SAFE_ASSERT(start <= end); + SAFE_ASSERT(filename != nullptr); + + InitSigSafeArena(); + + if (!g_file_mapping_mu.TryLock()) { + return false; + } + + bool ret = true; + if (g_num_file_mapping_hints >= kMaxFileMappingHints) { + ret = false; + } else { + // TODO(ckennelly): Move this into a string copy routine. + int len = strlen(filename); + char *dst = static_cast<char *>( + base_internal::LowLevelAlloc::AllocWithArena(len + 1, SigSafeArena())); + ABSL_RAW_CHECK(dst != nullptr, "out of memory"); + memcpy(dst, filename, len + 1); + + auto &hint = g_file_mapping_hints[g_num_file_mapping_hints++]; + hint.start = start; + hint.end = end; + hint.offset = offset; + hint.filename = dst; + } + + g_file_mapping_mu.Unlock(); + return ret; +} + +bool GetFileMappingHint(const void **start, const void **end, uint64_t *offset, + const char **filename) { + if (!g_file_mapping_mu.TryLock()) { + return false; + } + bool found = false; + for (int i = 0; i < g_num_file_mapping_hints; i++) { + if (g_file_mapping_hints[i].start <= *start && + *end <= g_file_mapping_hints[i].end) { + // We assume that the start_address for the mapping is the base + // address of the ELF section, but when [start_address,end_address) is + // not strictly equal to [hint.start, hint.end), that assumption is + // invalid. + // + // This uses the hint's start address (even though hint.start is not + // necessarily equal to start_address) to ensure the correct + // relocation is computed later. + *start = g_file_mapping_hints[i].start; + *end = g_file_mapping_hints[i].end; + *offset = g_file_mapping_hints[i].offset; + *filename = g_file_mapping_hints[i].filename; + found = true; + break; + } + } + g_file_mapping_mu.Unlock(); + return found; +} + +} // namespace debugging_internal + +bool Symbolize(const void *pc, char *out, int out_size) { + // Symbolization is very slow under tsan. + ANNOTATE_IGNORE_READS_AND_WRITES_BEGIN(); + SAFE_ASSERT(out_size >= 0); + debugging_internal::Symbolizer *s = debugging_internal::AllocateSymbolizer(); + const char *name = s->GetSymbol(pc); + bool ok = false; + if (name != nullptr && out_size > 0) { + strncpy(out, name, out_size); + ok = true; + if (out[out_size - 1] != '\0') { + // strncpy() does not '\0' terminate when it truncates. Do so, with + // trailing ellipsis. + static constexpr char kEllipsis[] = "..."; + int ellipsis_size = + std::min(implicit_cast<int>(strlen(kEllipsis)), out_size - 1); + memcpy(out + out_size - ellipsis_size - 1, kEllipsis, ellipsis_size); + out[out_size - 1] = '\0'; + } + } + debugging_internal::FreeSymbolizer(s); + ANNOTATE_IGNORE_READS_AND_WRITES_END(); + return ok; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/symbolize_test.cc b/third_party/abseil_cpp/absl/debugging/symbolize_test.cc new file mode 100644 index 0000000000..a1d03aab53 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/symbolize_test.cc @@ -0,0 +1,551 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/debugging/symbolize.h" + +#ifndef _WIN32 +#include <fcntl.h> +#include <sys/mman.h> +#endif + +#include <cstring> +#include <iostream> +#include <memory> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/casts.h" +#include "absl/base/internal/per_thread_tls.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/optimization.h" +#include "absl/debugging/internal/stack_consumption.h" +#include "absl/memory/memory.h" + +using testing::Contains; + +#ifdef _WIN32 +#define ABSL_SYMBOLIZE_TEST_NOINLINE __declspec(noinline) +#else +#define ABSL_SYMBOLIZE_TEST_NOINLINE ABSL_ATTRIBUTE_NOINLINE +#endif + +// Functions to symbolize. Use C linkage to avoid mangled names. +extern "C" { +ABSL_SYMBOLIZE_TEST_NOINLINE void nonstatic_func() { + // The next line makes this a unique function to prevent the compiler from + // folding identical functions together. + volatile int x = __LINE__; + static_cast<void>(x); + ABSL_BLOCK_TAIL_CALL_OPTIMIZATION(); +} + +ABSL_SYMBOLIZE_TEST_NOINLINE static void static_func() { + // The next line makes this a unique function to prevent the compiler from + // folding identical functions together. + volatile int x = __LINE__; + static_cast<void>(x); + ABSL_BLOCK_TAIL_CALL_OPTIMIZATION(); +} +} // extern "C" + +struct Foo { + static void func(int x); +}; + +// A C++ method that should have a mangled name. +ABSL_SYMBOLIZE_TEST_NOINLINE void Foo::func(int) { + // The next line makes this a unique function to prevent the compiler from + // folding identical functions together. + volatile int x = __LINE__; + static_cast<void>(x); + ABSL_BLOCK_TAIL_CALL_OPTIMIZATION(); +} + +// Create functions that will remain in different text sections in the +// final binary when linker option "-z,keep-text-section-prefix" is used. +int ABSL_ATTRIBUTE_SECTION_VARIABLE(.text.unlikely) unlikely_func() { + return 0; +} + +int ABSL_ATTRIBUTE_SECTION_VARIABLE(.text.hot) hot_func() { + return 0; +} + +int ABSL_ATTRIBUTE_SECTION_VARIABLE(.text.startup) startup_func() { + return 0; +} + +int ABSL_ATTRIBUTE_SECTION_VARIABLE(.text.exit) exit_func() { + return 0; +} + +int /*ABSL_ATTRIBUTE_SECTION_VARIABLE(.text)*/ regular_func() { + return 0; +} + +// Thread-local data may confuse the symbolizer, ensure that it does not. +// Variable sizes and order are important. +#if ABSL_PER_THREAD_TLS +static ABSL_PER_THREAD_TLS_KEYWORD char symbolize_test_thread_small[1]; +static ABSL_PER_THREAD_TLS_KEYWORD char + symbolize_test_thread_big[2 * 1024 * 1024]; +#endif + +#if !defined(__EMSCRIPTEN__) +// Used below to hopefully inhibit some compiler/linker optimizations +// that may remove kHpageTextPadding, kPadding0, and kPadding1 from +// the binary. +static volatile bool volatile_bool = false; + +// Force the binary to be large enough that a THP .text remap will succeed. +static constexpr size_t kHpageSize = 1 << 21; +const char kHpageTextPadding[kHpageSize * 4] ABSL_ATTRIBUTE_SECTION_VARIABLE( + .text) = ""; +#endif // !defined(__EMSCRIPTEN__) + +static char try_symbolize_buffer[4096]; + +// A wrapper function for absl::Symbolize() to make the unit test simple. The +// limit must be < sizeof(try_symbolize_buffer). Returns null if +// absl::Symbolize() returns false, otherwise returns try_symbolize_buffer with +// the result of absl::Symbolize(). +static const char *TrySymbolizeWithLimit(void *pc, int limit) { + ABSL_RAW_CHECK(limit <= sizeof(try_symbolize_buffer), + "try_symbolize_buffer is too small"); + + // Use the heap to facilitate heap and buffer sanitizer tools. + auto heap_buffer = absl::make_unique<char[]>(sizeof(try_symbolize_buffer)); + bool found = absl::Symbolize(pc, heap_buffer.get(), limit); + if (found) { + ABSL_RAW_CHECK(strnlen(heap_buffer.get(), limit) < limit, + "absl::Symbolize() did not properly terminate the string"); + strncpy(try_symbolize_buffer, heap_buffer.get(), + sizeof(try_symbolize_buffer) - 1); + try_symbolize_buffer[sizeof(try_symbolize_buffer) - 1] = '\0'; + } + + return found ? try_symbolize_buffer : nullptr; +} + +// A wrapper for TrySymbolizeWithLimit(), with a large limit. +static const char *TrySymbolize(void *pc) { + return TrySymbolizeWithLimit(pc, sizeof(try_symbolize_buffer)); +} + +#ifdef ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE + +TEST(Symbolize, Cached) { + // Compilers should give us pointers to them. + EXPECT_STREQ("nonstatic_func", TrySymbolize((void *)(&nonstatic_func))); + + // The name of an internal linkage symbol is not specified; allow either a + // mangled or an unmangled name here. + const char *static_func_symbol = TrySymbolize((void *)(&static_func)); + EXPECT_TRUE(strcmp("static_func", static_func_symbol) == 0 || + strcmp("static_func()", static_func_symbol) == 0); + + EXPECT_TRUE(nullptr == TrySymbolize(nullptr)); +} + +TEST(Symbolize, Truncation) { + constexpr char kNonStaticFunc[] = "nonstatic_func"; + EXPECT_STREQ("nonstatic_func", + TrySymbolizeWithLimit((void *)(&nonstatic_func), + strlen(kNonStaticFunc) + 1)); + EXPECT_STREQ("nonstatic_...", + TrySymbolizeWithLimit((void *)(&nonstatic_func), + strlen(kNonStaticFunc) + 0)); + EXPECT_STREQ("nonstatic...", + TrySymbolizeWithLimit((void *)(&nonstatic_func), + strlen(kNonStaticFunc) - 1)); + EXPECT_STREQ("n...", TrySymbolizeWithLimit((void *)(&nonstatic_func), 5)); + EXPECT_STREQ("...", TrySymbolizeWithLimit((void *)(&nonstatic_func), 4)); + EXPECT_STREQ("..", TrySymbolizeWithLimit((void *)(&nonstatic_func), 3)); + EXPECT_STREQ(".", TrySymbolizeWithLimit((void *)(&nonstatic_func), 2)); + EXPECT_STREQ("", TrySymbolizeWithLimit((void *)(&nonstatic_func), 1)); + EXPECT_EQ(nullptr, TrySymbolizeWithLimit((void *)(&nonstatic_func), 0)); +} + +TEST(Symbolize, SymbolizeWithDemangling) { + Foo::func(100); + EXPECT_STREQ("Foo::func()", TrySymbolize((void *)(&Foo::func))); +} + +TEST(Symbolize, SymbolizeSplitTextSections) { + EXPECT_STREQ("unlikely_func()", TrySymbolize((void *)(&unlikely_func))); + EXPECT_STREQ("hot_func()", TrySymbolize((void *)(&hot_func))); + EXPECT_STREQ("startup_func()", TrySymbolize((void *)(&startup_func))); + EXPECT_STREQ("exit_func()", TrySymbolize((void *)(&exit_func))); + EXPECT_STREQ("regular_func()", TrySymbolize((void *)(®ular_func))); +} + +// Tests that verify that Symbolize stack footprint is within some limit. +#ifdef ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION + +static void *g_pc_to_symbolize; +static char g_symbolize_buffer[4096]; +static char *g_symbolize_result; + +static void SymbolizeSignalHandler(int signo) { + if (absl::Symbolize(g_pc_to_symbolize, g_symbolize_buffer, + sizeof(g_symbolize_buffer))) { + g_symbolize_result = g_symbolize_buffer; + } else { + g_symbolize_result = nullptr; + } +} + +// Call Symbolize and figure out the stack footprint of this call. +static const char *SymbolizeStackConsumption(void *pc, int *stack_consumed) { + g_pc_to_symbolize = pc; + *stack_consumed = absl::debugging_internal::GetSignalHandlerStackConsumption( + SymbolizeSignalHandler); + return g_symbolize_result; +} + +static int GetStackConsumptionUpperLimit() { + // Symbolize stack consumption should be within 2kB. + int stack_consumption_upper_limit = 2048; +#if defined(ADDRESS_SANITIZER) || defined(MEMORY_SANITIZER) || \ + defined(THREAD_SANITIZER) + // Account for sanitizer instrumentation requiring additional stack space. + stack_consumption_upper_limit *= 5; +#endif + return stack_consumption_upper_limit; +} + +TEST(Symbolize, SymbolizeStackConsumption) { + int stack_consumed = 0; + + const char *symbol = + SymbolizeStackConsumption((void *)(&nonstatic_func), &stack_consumed); + EXPECT_STREQ("nonstatic_func", symbol); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, GetStackConsumptionUpperLimit()); + + // The name of an internal linkage symbol is not specified; allow either a + // mangled or an unmangled name here. + symbol = SymbolizeStackConsumption((void *)(&static_func), &stack_consumed); + EXPECT_TRUE(strcmp("static_func", symbol) == 0 || + strcmp("static_func()", symbol) == 0); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, GetStackConsumptionUpperLimit()); +} + +TEST(Symbolize, SymbolizeWithDemanglingStackConsumption) { + Foo::func(100); + int stack_consumed = 0; + + const char *symbol = + SymbolizeStackConsumption((void *)(&Foo::func), &stack_consumed); + + EXPECT_STREQ("Foo::func()", symbol); + EXPECT_GT(stack_consumed, 0); + EXPECT_LT(stack_consumed, GetStackConsumptionUpperLimit()); +} + +#endif // ABSL_INTERNAL_HAVE_DEBUGGING_STACK_CONSUMPTION + +// Use a 64K page size for PPC. +const size_t kPageSize = 64 << 10; +// We place a read-only symbols into the .text section and verify that we can +// symbolize them and other symbols after remapping them. +const char kPadding0[kPageSize * 4] ABSL_ATTRIBUTE_SECTION_VARIABLE(.text) = + ""; +const char kPadding1[kPageSize * 4] ABSL_ATTRIBUTE_SECTION_VARIABLE(.text) = + ""; + +static int FilterElfHeader(struct dl_phdr_info *info, size_t size, void *data) { + for (int i = 0; i < info->dlpi_phnum; i++) { + if (info->dlpi_phdr[i].p_type == PT_LOAD && + info->dlpi_phdr[i].p_flags == (PF_R | PF_X)) { + const void *const vaddr = + absl::bit_cast<void *>(info->dlpi_addr + info->dlpi_phdr[i].p_vaddr); + const auto segsize = info->dlpi_phdr[i].p_memsz; + + const char *self_exe; + if (info->dlpi_name != nullptr && info->dlpi_name[0] != '\0') { + self_exe = info->dlpi_name; + } else { + self_exe = "/proc/self/exe"; + } + + absl::debugging_internal::RegisterFileMappingHint( + vaddr, reinterpret_cast<const char *>(vaddr) + segsize, + info->dlpi_phdr[i].p_offset, self_exe); + + return 1; + } + } + + return 1; +} + +TEST(Symbolize, SymbolizeWithMultipleMaps) { + // Force kPadding0 and kPadding1 to be linked in. + if (volatile_bool) { + ABSL_RAW_LOG(INFO, "%s", kPadding0); + ABSL_RAW_LOG(INFO, "%s", kPadding1); + } + + // Verify we can symbolize everything. + char buf[512]; + memset(buf, 0, sizeof(buf)); + absl::Symbolize(kPadding0, buf, sizeof(buf)); + EXPECT_STREQ("kPadding0", buf); + + memset(buf, 0, sizeof(buf)); + absl::Symbolize(kPadding1, buf, sizeof(buf)); + EXPECT_STREQ("kPadding1", buf); + + // Specify a hint for the executable segment. + dl_iterate_phdr(FilterElfHeader, nullptr); + + // Reload at least one page out of kPadding0, kPadding1 + const char *ptrs[] = {kPadding0, kPadding1}; + + for (const char *ptr : ptrs) { + const int kMapFlags = MAP_ANONYMOUS | MAP_PRIVATE; + void *addr = mmap(nullptr, kPageSize, PROT_READ, kMapFlags, 0, 0); + ASSERT_NE(addr, MAP_FAILED); + + // kPadding[0-1] is full of zeroes, so we can remap anywhere within it, but + // we ensure there is at least a full page of padding. + void *remapped = reinterpret_cast<void *>( + reinterpret_cast<uintptr_t>(ptr + kPageSize) & ~(kPageSize - 1ULL)); + + const int kMremapFlags = (MREMAP_MAYMOVE | MREMAP_FIXED); + void *ret = mremap(addr, kPageSize, kPageSize, kMremapFlags, remapped); + ASSERT_NE(ret, MAP_FAILED); + } + + // Invalidate the symbolization cache so we are forced to rely on the hint. + absl::Symbolize(nullptr, buf, sizeof(buf)); + + // Verify we can still symbolize. + const char *expected[] = {"kPadding0", "kPadding1"}; + const size_t offsets[] = {0, kPageSize, 2 * kPageSize, 3 * kPageSize}; + + for (int i = 0; i < 2; i++) { + for (size_t offset : offsets) { + memset(buf, 0, sizeof(buf)); + absl::Symbolize(ptrs[i] + offset, buf, sizeof(buf)); + EXPECT_STREQ(expected[i], buf); + } + } +} + +// Appends string(*args->arg) to args->symbol_buf. +static void DummySymbolDecorator( + const absl::debugging_internal::SymbolDecoratorArgs *args) { + std::string *message = static_cast<std::string *>(args->arg); + strncat(args->symbol_buf, message->c_str(), + args->symbol_buf_size - strlen(args->symbol_buf) - 1); +} + +TEST(Symbolize, InstallAndRemoveSymbolDecorators) { + int ticket_a; + std::string a_message("a"); + EXPECT_GE(ticket_a = absl::debugging_internal::InstallSymbolDecorator( + DummySymbolDecorator, &a_message), + 0); + + int ticket_b; + std::string b_message("b"); + EXPECT_GE(ticket_b = absl::debugging_internal::InstallSymbolDecorator( + DummySymbolDecorator, &b_message), + 0); + + int ticket_c; + std::string c_message("c"); + EXPECT_GE(ticket_c = absl::debugging_internal::InstallSymbolDecorator( + DummySymbolDecorator, &c_message), + 0); + + char *address = reinterpret_cast<char *>(1); + EXPECT_STREQ("abc", TrySymbolize(address++)); + + EXPECT_TRUE(absl::debugging_internal::RemoveSymbolDecorator(ticket_b)); + + EXPECT_STREQ("ac", TrySymbolize(address++)); + + // Cleanup: remove all remaining decorators so other stack traces don't + // get mystery "ac" decoration. + EXPECT_TRUE(absl::debugging_internal::RemoveSymbolDecorator(ticket_a)); + EXPECT_TRUE(absl::debugging_internal::RemoveSymbolDecorator(ticket_c)); +} + +// Some versions of Clang with optimizations enabled seem to be able +// to optimize away the .data section if no variables live in the +// section. This variable should get placed in the .data section, and +// the test below checks for the existence of a .data section. +static int in_data_section = 1; + +TEST(Symbolize, ForEachSection) { + int fd = TEMP_FAILURE_RETRY(open("/proc/self/exe", O_RDONLY)); + ASSERT_NE(fd, -1); + + std::vector<std::string> sections; + ASSERT_TRUE(absl::debugging_internal::ForEachSection( + fd, [§ions](const std::string &name, const ElfW(Shdr) &) { + sections.push_back(name); + return true; + })); + + // Check for the presence of common section names. + EXPECT_THAT(sections, Contains(".text")); + EXPECT_THAT(sections, Contains(".rodata")); + EXPECT_THAT(sections, Contains(".bss")); + ++in_data_section; + EXPECT_THAT(sections, Contains(".data")); + + close(fd); +} + +// x86 specific tests. Uses some inline assembler. +extern "C" { +inline void *ABSL_ATTRIBUTE_ALWAYS_INLINE inline_func() { + void *pc = nullptr; +#if defined(__i386__) + __asm__ __volatile__("call 1f;\n 1: pop %[PC]" : [ PC ] "=r"(pc)); +#elif defined(__x86_64__) + __asm__ __volatile__("leaq 0(%%rip),%[PC];\n" : [ PC ] "=r"(pc)); +#endif + return pc; +} + +void *ABSL_ATTRIBUTE_NOINLINE non_inline_func() { + void *pc = nullptr; +#if defined(__i386__) + __asm__ __volatile__("call 1f;\n 1: pop %[PC]" : [ PC ] "=r"(pc)); +#elif defined(__x86_64__) + __asm__ __volatile__("leaq 0(%%rip),%[PC];\n" : [ PC ] "=r"(pc)); +#endif + return pc; +} + +void ABSL_ATTRIBUTE_NOINLINE TestWithPCInsideNonInlineFunction() { +#if defined(ABSL_HAVE_ATTRIBUTE_NOINLINE) && \ + (defined(__i386__) || defined(__x86_64__)) + void *pc = non_inline_func(); + const char *symbol = TrySymbolize(pc); + ABSL_RAW_CHECK(symbol != nullptr, "TestWithPCInsideNonInlineFunction failed"); + ABSL_RAW_CHECK(strcmp(symbol, "non_inline_func") == 0, + "TestWithPCInsideNonInlineFunction failed"); + std::cout << "TestWithPCInsideNonInlineFunction passed" << std::endl; +#endif +} + +void ABSL_ATTRIBUTE_NOINLINE TestWithPCInsideInlineFunction() { +#if defined(ABSL_HAVE_ATTRIBUTE_ALWAYS_INLINE) && \ + (defined(__i386__) || defined(__x86_64__)) + void *pc = inline_func(); // Must be inlined. + const char *symbol = TrySymbolize(pc); + ABSL_RAW_CHECK(symbol != nullptr, "TestWithPCInsideInlineFunction failed"); + ABSL_RAW_CHECK(strcmp(symbol, __FUNCTION__) == 0, + "TestWithPCInsideInlineFunction failed"); + std::cout << "TestWithPCInsideInlineFunction passed" << std::endl; +#endif +} +} + +// Test with a return address. +void ABSL_ATTRIBUTE_NOINLINE TestWithReturnAddress() { +#if defined(ABSL_HAVE_ATTRIBUTE_NOINLINE) + void *return_address = __builtin_return_address(0); + const char *symbol = TrySymbolize(return_address); + ABSL_RAW_CHECK(symbol != nullptr, "TestWithReturnAddress failed"); + ABSL_RAW_CHECK(strcmp(symbol, "main") == 0, "TestWithReturnAddress failed"); + std::cout << "TestWithReturnAddress passed" << std::endl; +#endif +} + +#elif defined(_WIN32) +#if !defined(ABSL_CONSUME_DLL) + +TEST(Symbolize, Basics) { + EXPECT_STREQ("nonstatic_func", TrySymbolize((void *)(&nonstatic_func))); + + // The name of an internal linkage symbol is not specified; allow either a + // mangled or an unmangled name here. + const char *static_func_symbol = TrySymbolize((void *)(&static_func)); + ASSERT_TRUE(static_func_symbol != nullptr); + EXPECT_TRUE(strstr(static_func_symbol, "static_func") != nullptr); + + EXPECT_TRUE(nullptr == TrySymbolize(nullptr)); +} + +TEST(Symbolize, Truncation) { + constexpr char kNonStaticFunc[] = "nonstatic_func"; + EXPECT_STREQ("nonstatic_func", + TrySymbolizeWithLimit((void *)(&nonstatic_func), + strlen(kNonStaticFunc) + 1)); + EXPECT_STREQ("nonstatic_...", + TrySymbolizeWithLimit((void *)(&nonstatic_func), + strlen(kNonStaticFunc) + 0)); + EXPECT_STREQ("nonstatic...", + TrySymbolizeWithLimit((void *)(&nonstatic_func), + strlen(kNonStaticFunc) - 1)); + EXPECT_STREQ("n...", TrySymbolizeWithLimit((void *)(&nonstatic_func), 5)); + EXPECT_STREQ("...", TrySymbolizeWithLimit((void *)(&nonstatic_func), 4)); + EXPECT_STREQ("..", TrySymbolizeWithLimit((void *)(&nonstatic_func), 3)); + EXPECT_STREQ(".", TrySymbolizeWithLimit((void *)(&nonstatic_func), 2)); + EXPECT_STREQ("", TrySymbolizeWithLimit((void *)(&nonstatic_func), 1)); + EXPECT_EQ(nullptr, TrySymbolizeWithLimit((void *)(&nonstatic_func), 0)); +} + +TEST(Symbolize, SymbolizeWithDemangling) { + const char *result = TrySymbolize((void *)(&Foo::func)); + ASSERT_TRUE(result != nullptr); + EXPECT_TRUE(strstr(result, "Foo::func") != nullptr) << result; +} + +#endif // !defined(ABSL_CONSUME_DLL) +#else // Symbolizer unimplemented + +TEST(Symbolize, Unimplemented) { + char buf[64]; + EXPECT_FALSE(absl::Symbolize((void *)(&nonstatic_func), buf, sizeof(buf))); + EXPECT_FALSE(absl::Symbolize((void *)(&static_func), buf, sizeof(buf))); + EXPECT_FALSE(absl::Symbolize((void *)(&Foo::func), buf, sizeof(buf))); +} + +#endif + +int main(int argc, char **argv) { +#if !defined(__EMSCRIPTEN__) + // Make sure kHpageTextPadding is linked into the binary. + if (volatile_bool) { + ABSL_RAW_LOG(INFO, "%s", kHpageTextPadding); + } +#endif // !defined(__EMSCRIPTEN__) + +#if ABSL_PER_THREAD_TLS + // Touch the per-thread variables. + symbolize_test_thread_small[0] = 0; + symbolize_test_thread_big[0] = 0; +#endif + + absl::InitializeSymbolizer(argv[0]); + testing::InitGoogleTest(&argc, argv); + +#ifdef ABSL_INTERNAL_HAVE_ELF_SYMBOLIZE + TestWithPCInsideInlineFunction(); + TestWithPCInsideNonInlineFunction(); + TestWithReturnAddress(); +#endif + + return RUN_ALL_TESTS(); +} diff --git a/third_party/abseil_cpp/absl/debugging/symbolize_unimplemented.inc b/third_party/abseil_cpp/absl/debugging/symbolize_unimplemented.inc new file mode 100644 index 0000000000..db24456b0a --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/symbolize_unimplemented.inc @@ -0,0 +1,40 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdint> + +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace debugging_internal { + +int InstallSymbolDecorator(SymbolDecorator, void*) { return -1; } +bool RemoveSymbolDecorator(int) { return false; } +bool RemoveAllSymbolDecorators(void) { return false; } +bool RegisterFileMappingHint(const void *, const void *, uint64_t, const char *) { + return false; +} +bool GetFileMappingHint(const void **, const void **, uint64_t *, const char **) { + return false; +} + +} // namespace debugging_internal + +void InitializeSymbolizer(const char*) {} +bool Symbolize(const void *, char *, int) { return false; } + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/debugging/symbolize_win32.inc b/third_party/abseil_cpp/absl/debugging/symbolize_win32.inc new file mode 100644 index 0000000000..c3df46f606 --- /dev/null +++ b/third_party/abseil_cpp/absl/debugging/symbolize_win32.inc @@ -0,0 +1,81 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// See "Retrieving Symbol Information by Address": +// https://msdn.microsoft.com/en-us/library/windows/desktop/ms680578(v=vs.85).aspx + +#include <windows.h> + +// MSVC header dbghelp.h has a warning for an ignored typedef. +#pragma warning(push) +#pragma warning(disable:4091) +#include <dbghelp.h> +#pragma warning(pop) + +#pragma comment(lib, "dbghelp.lib") + +#include <algorithm> +#include <cstring> + +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +static HANDLE process = NULL; + +void InitializeSymbolizer(const char*) { + if (process != nullptr) { + return; + } + process = GetCurrentProcess(); + + // Symbols are not loaded until a reference is made requiring the + // symbols be loaded. This is the fastest, most efficient way to use + // the symbol handler. + SymSetOptions(SYMOPT_DEFERRED_LOADS | SYMOPT_UNDNAME); + if (!SymInitialize(process, nullptr, true)) { + // GetLastError() returns a Win32 DWORD, but we assign to + // unsigned long long to simplify the ABSL_RAW_LOG case below. The uniform + // initialization guarantees this is not a narrowing conversion. + const unsigned long long error{GetLastError()}; // NOLINT(runtime/int) + ABSL_RAW_LOG(FATAL, "SymInitialize() failed: %llu", error); + } +} + +bool Symbolize(const void* pc, char* out, int out_size) { + if (out_size <= 0) { + return false; + } + alignas(SYMBOL_INFO) char buf[sizeof(SYMBOL_INFO) + MAX_SYM_NAME]; + SYMBOL_INFO* symbol = reinterpret_cast<SYMBOL_INFO*>(buf); + symbol->SizeOfStruct = sizeof(SYMBOL_INFO); + symbol->MaxNameLen = MAX_SYM_NAME; + if (!SymFromAddr(process, reinterpret_cast<DWORD64>(pc), nullptr, symbol)) { + return false; + } + strncpy(out, symbol->Name, out_size); + if (out[out_size - 1] != '\0') { + // strncpy() does not '\0' terminate when it truncates. + static constexpr char kEllipsis[] = "..."; + int ellipsis_size = + std::min<int>(sizeof(kEllipsis) - 1, out_size - 1); + memcpy(out + out_size - ellipsis_size - 1, kEllipsis, ellipsis_size); + out[out_size - 1] = '\0'; + } + return true; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/BUILD.bazel b/third_party/abseil_cpp/absl/flags/BUILD.bazel new file mode 100644 index 0000000000..3681082527 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/BUILD.bazel @@ -0,0 +1,491 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "flag_internal", + srcs = [ + "internal/flag.cc", + ], + hdrs = [ + "internal/flag.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//absl/base:__subpackages__"], + deps = [ + ":config", + ":handle", + ":marshalling", + ":registry", + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/synchronization", + ], +) + +cc_library( + name = "program_name", + srcs = [ + "internal/program_name.cc", + ], + hdrs = [ + "internal/program_name.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/flags:__pkg__", + ], + deps = [ + ":path_util", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/strings", + "//absl/synchronization", + ], +) + +cc_library( + name = "path_util", + hdrs = [ + "internal/path_util.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/flags:__pkg__", + ], + deps = [ + "//absl/base:config", + "//absl/strings", + ], +) + +cc_library( + name = "config", + srcs = [ + "usage_config.cc", + ], + hdrs = [ + "config.h", + "usage_config.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":path_util", + ":program_name", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/strings", + "//absl/synchronization", + ], +) + +cc_library( + name = "marshalling", + srcs = [ + "marshalling.cc", + ], + hdrs = [ + "marshalling.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:log_severity", + "//absl/strings", + "//absl/strings:str_format", + ], +) + +cc_library( + name = "handle", + srcs = [ + "internal/commandlineflag.cc", + ], + hdrs = [ + "internal/commandlineflag.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/flags:__pkg__", + ], + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:fast_type_id", + "//absl/strings", + "//absl/types:optional", + ], +) + +cc_library( + name = "private_handle_accessor", + srcs = [ + "internal/private_handle_accessor.cc", + ], + hdrs = [ + "internal/private_handle_accessor.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/flags:__pkg__", + ], + deps = [":handle"], +) + +cc_library( + name = "registry", + srcs = [ + "internal/registry.cc", + "internal/type_erased.cc", + ], + hdrs = [ + "internal/registry.h", + "internal/type_erased.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/flags:__pkg__", + ], + deps = [ + ":config", + ":handle", + ":private_handle_accessor", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/strings", + "//absl/synchronization", + ], +) + +cc_library( + name = "flag", + srcs = [ + "flag.cc", + ], + hdrs = [ + "declare.h", + "flag.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":flag_internal", + ":handle", + ":marshalling", + ":registry", + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/strings", + ], +) + +cc_library( + name = "usage_internal", + srcs = [ + "internal/usage.cc", + ], + hdrs = [ + "internal/usage.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/flags:__pkg__", + ], + deps = [ + ":config", + ":flag", + ":flag_internal", + ":handle", + ":path_util", + ":private_handle_accessor", + ":program_name", + ":registry", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/strings", + ], +) + +cc_library( + name = "usage", + srcs = [ + "usage.cc", + ], + hdrs = [ + "usage.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":usage_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/strings", + "//absl/synchronization", + ], +) + +cc_library( + name = "parse", + srcs = ["parse.cc"], + hdrs = [ + "internal/parse.h", + "parse.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":flag", + ":flag_internal", + ":handle", + ":private_handle_accessor", + ":program_name", + ":registry", + ":usage", + ":usage_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/strings", + "//absl/synchronization", + ], +) + +############################################################################ +# Unit tests in alphabetical order. + +cc_test( + name = "commandlineflag_test", + size = "small", + srcs = [ + "internal/commandlineflag_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":flag", + ":handle", + ":private_handle_accessor", + ":registry", + "//absl/memory", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "config_test", + size = "small", + srcs = [ + "config_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "flag_test", + size = "small", + srcs = [ + "flag_test.cc", + "flag_test_defs.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":flag", + ":flag_internal", + ":handle", + ":registry", + "//absl/base:core_headers", + "//absl/base:malloc_internal", + "//absl/strings", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_binary( + name = "flag_benchmark", + testonly = 1, + srcs = [ + "flag_benchmark.cc", + ], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":flag", + "//absl/time", + "//absl/types:optional", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "marshalling_test", + size = "small", + srcs = [ + "marshalling_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":marshalling", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "path_util_test", + size = "small", + srcs = [ + "internal/path_util_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":path_util", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "parse_test", + size = "small", + srcs = [ + "parse_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":flag", + ":parse", + ":registry", + "//absl/base:raw_logging_internal", + "//absl/base:scoped_set_env", + "//absl/strings", + "//absl/types:span", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "program_name_test", + size = "small", + srcs = [ + "internal/program_name_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":program_name", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "type_erased_test", + size = "small", + srcs = [ + "internal/type_erased_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":flag", + ":handle", + ":marshalling", + ":registry", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "usage_config_test", + size = "small", + srcs = [ + "usage_config_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":path_util", + ":program_name", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "usage_test", + size = "small", + srcs = [ + "internal/usage_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":config", + ":flag", + ":parse", + ":path_util", + ":program_name", + ":registry", + ":usage", + ":usage_internal", + "//absl/memory", + "//absl/strings", + "@com_google_googletest//:gtest", + ], +) diff --git a/third_party/abseil_cpp/absl/flags/CMakeLists.txt b/third_party/abseil_cpp/absl/flags/CMakeLists.txt new file mode 100644 index 0000000000..e6b17c9b04 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/CMakeLists.txt @@ -0,0 +1,435 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_internal + SRCS + "internal/flag.cc" + HDRS + "internal/flag.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::base + absl::config + absl::flags_config + absl::flags_handle + absl::flags_marshalling + absl::flags_registry + absl::synchronization + absl::meta + PUBLIC +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_program_name + SRCS + "internal/program_name.cc" + HDRS + "internal/program_name.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::core_headers + absl::flags_path_util + absl::strings + absl::synchronization + PUBLIC +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_path_util + HDRS + "internal/path_util.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::strings + PUBLIC +) + +absl_cc_library( + NAME + flags_config + SRCS + "usage_config.cc" + HDRS + "config.h" + "usage_config.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::flags_path_util + absl::flags_program_name + absl::core_headers + absl::strings + absl::synchronization +) + +absl_cc_library( + NAME + flags_marshalling + SRCS + "marshalling.cc" + HDRS + "marshalling.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::core_headers + absl::log_severity + absl::strings + absl::str_format +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_handle + SRCS + "internal/commandlineflag.cc" + HDRS + "internal/commandlineflag.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::fast_type_id + absl::core_headers + absl::optional + absl::raw_logging_internal + absl::strings + absl::synchronization +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_private_handle_accessor + SRCS + "internal/private_handle_accessor.cc" + HDRS + "internal/private_handle_accessor.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::flags_handle +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_registry + SRCS + "internal/registry.cc" + "internal/type_erased.cc" + HDRS + "internal/registry.h" + "internal/type_erased.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::flags_config + absl::flags_handle + absl::flags_private_handle_accessor + absl::core_headers + absl::raw_logging_internal + absl::strings + absl::synchronization +) + +absl_cc_library( + NAME + flags + SRCS + "flag.cc" + HDRS + "declare.h" + "flag.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::flags_config + absl::flags_handle + absl::flags_internal + absl::flags_marshalling + absl::flags_registry + absl::base + absl::core_headers + absl::strings +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + flags_usage_internal + SRCS + "internal/usage.cc" + HDRS + "internal/usage.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::flags_config + absl::flags + absl::flags_handle + absl::flags_private_handle_accessor + absl::flags_internal + absl::flags_path_util + absl::flags_program_name + absl::flags_registry + absl::strings + absl::synchronization +) + +absl_cc_library( + NAME + flags_usage + SRCS + "usage.cc" + HDRS + "usage.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::core_headers + absl::flags_usage_internal + absl::strings + absl::synchronization +) + +absl_cc_library( + NAME + flags_parse + SRCS + "parse.cc" + HDRS + "internal/parse.h" + "parse.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::core_headers + absl::flags_config + absl::flags + absl::flags_handle + absl::flags_private_handle_accessor + absl::flags_internal + absl::flags_program_name + absl::flags_registry + absl::flags_usage + absl::strings + absl::synchronization +) + +############################################################################ +# Unit tests in alpahabetical order. + +absl_cc_test( + NAME + flags_commandlineflag_test + SRCS + "internal/commandlineflag_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags + absl::flags_config + absl::flags_handle + absl::flags_private_handle_accessor + absl::flags_registry + absl::memory + absl::strings + gtest_main +) + +absl_cc_test( + NAME + flags_config_test + SRCS + "config_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags_config + gtest_main +) + +absl_cc_test( + NAME + flags_flag_test + SRCS + "flag_test.cc" + "flag_test_defs.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::core_headers + absl::flags + absl::flags_config + absl::flags_handle + absl::flags_internal + absl::flags_registry + absl::strings + absl::time + gtest_main +) + +absl_cc_test( + NAME + flags_marshalling_test + SRCS + "marshalling_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags_marshalling + gtest_main +) + +absl_cc_test( + NAME + flags_parse_test + SRCS + "parse_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags + absl::flags_parse + absl::flags_registry + absl::raw_logging_internal + absl::scoped_set_env + absl::span + absl::strings + gmock_main +) + +absl_cc_test( + NAME + flags_path_util_test + SRCS + "internal/path_util_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags_path_util + gtest_main +) + +absl_cc_test( + NAME + flags_program_name_test + SRCS + "internal/program_name_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags_program_name + absl::strings + gtest_main +) + +absl_cc_test( + NAME + flags_type_erased_test + SRCS + "internal/type_erased_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags + absl::flags_handle + absl::flags_marshalling + absl::flags_registry + absl::memory + absl::strings + gtest_main +) + +absl_cc_test( + NAME + flags_usage_config_test + SRCS + "usage_config_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags_config + absl::flags_path_util + absl::flags_program_name + absl::strings + gtest_main +) + +absl_cc_test( + NAME + flags_usage_test + SRCS + "internal/usage_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::flags_config + absl::flags + absl::flags_path_util + absl::flags_program_name + absl::flags_parse + absl::flags_registry + absl::flags_usage + absl::memory + absl::strings + gtest +) diff --git a/third_party/abseil_cpp/absl/flags/config.h b/third_party/abseil_cpp/absl/flags/config.h new file mode 100644 index 0000000000..813a925700 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/config.h @@ -0,0 +1,87 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_CONFIG_H_ +#define ABSL_FLAGS_CONFIG_H_ + +// Determine if we should strip string literals from the Flag objects. +// By default we strip string literals on mobile platforms. +#if !defined(ABSL_FLAGS_STRIP_NAMES) + +#if defined(__ANDROID__) +#define ABSL_FLAGS_STRIP_NAMES 1 + +#elif defined(__APPLE__) +#include <TargetConditionals.h> +#if defined(TARGET_OS_IPHONE) && TARGET_OS_IPHONE +#define ABSL_FLAGS_STRIP_NAMES 1 +#elif defined(TARGET_OS_EMBEDDED) && TARGET_OS_EMBEDDED +#define ABSL_FLAGS_STRIP_NAMES 1 +#endif // TARGET_OS_* +#endif + +#endif // !defined(ABSL_FLAGS_STRIP_NAMES) + +#if !defined(ABSL_FLAGS_STRIP_NAMES) +// If ABSL_FLAGS_STRIP_NAMES wasn't set on the command line or above, +// the default is not to strip. +#define ABSL_FLAGS_STRIP_NAMES 0 +#endif + +#if !defined(ABSL_FLAGS_STRIP_HELP) +// By default, if we strip names, we also strip help. +#define ABSL_FLAGS_STRIP_HELP ABSL_FLAGS_STRIP_NAMES +#endif + +// ABSL_FLAGS_INTERNAL_ATOMIC_DOUBLE_WORD macro is used for using atomics with +// double words, e.g. absl::Duration. +// For reasons in bug https://gcc.gnu.org/bugzilla/show_bug.cgi?id=80878, modern +// versions of GCC do not support cmpxchg16b instruction in standard atomics. +#ifdef ABSL_FLAGS_INTERNAL_ATOMIC_DOUBLE_WORD +#error "ABSL_FLAGS_INTERNAL_ATOMIC_DOUBLE_WORD should not be defined." +#elif defined(__clang__) && defined(__x86_64__) && \ + defined(__GCC_HAVE_SYNC_COMPARE_AND_SWAP_16) +#define ABSL_FLAGS_INTERNAL_ATOMIC_DOUBLE_WORD 1 +#endif + +// ABSL_FLAGS_INTERNAL_HAS_RTTI macro is used for selecting if we can use RTTI +// for flag type identification. +#ifdef ABSL_FLAGS_INTERNAL_HAS_RTTI +#error ABSL_FLAGS_INTERNAL_HAS_RTTI cannot be directly set +#elif !defined(__GNUC__) || defined(__GXX_RTTI) +#define ABSL_FLAGS_INTERNAL_HAS_RTTI 1 +#endif // !defined(__GNUC__) || defined(__GXX_RTTI) + +// These macros represent the "source of truth" for the list of supported +// built-in types. +#define ABSL_FLAGS_INTERNAL_BUILTIN_TYPES(A) \ + A(bool, bool) \ + A(short, short) \ + A(unsigned short, unsigned_short) \ + A(int, int) \ + A(unsigned int, unsigned_int) \ + A(long, long) \ + A(unsigned long, unsigned_long) \ + A(long long, long_long) \ + A(unsigned long long, unsigned_long_long) \ + A(double, double) \ + A(float, float) + +#define ABSL_FLAGS_INTERNAL_SUPPORTED_TYPES(A) \ + ABSL_FLAGS_INTERNAL_BUILTIN_TYPES(A) \ + A(std::string, std_string) \ + A(std::vector<std::string>, std_vector_of_string) + +#endif // ABSL_FLAGS_CONFIG_H_ diff --git a/third_party/abseil_cpp/absl/flags/config_test.cc b/third_party/abseil_cpp/absl/flags/config_test.cc new file mode 100644 index 0000000000..638998667e --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/config_test.cc @@ -0,0 +1,61 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/config.h" + +#ifdef __APPLE__ +#include <TargetConditionals.h> +#endif + +#include "gtest/gtest.h" + +#ifndef ABSL_FLAGS_STRIP_NAMES +#error ABSL_FLAGS_STRIP_NAMES is not defined +#endif + +#ifndef ABSL_FLAGS_STRIP_HELP +#error ABSL_FLAGS_STRIP_HELP is not defined +#endif + +namespace { + +// Test that ABSL_FLAGS_STRIP_NAMES and ABSL_FLAGS_STRIP_HELP are configured how +// we expect them to be configured by default. If you override this +// configuration, this test will fail, but the code should still be safe to use. +TEST(FlagsConfigTest, Test) { +#if defined(__ANDROID__) + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 1); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 1); +#elif defined(__myriad2__) + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 0); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 0); +#elif defined(TARGET_OS_IPHONE) && TARGET_OS_IPHONE + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 1); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 1); +#elif defined(TARGET_OS_EMBEDDED) && TARGET_OS_EMBEDDED + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 1); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 1); +#elif defined(__APPLE__) + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 0); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 0); +#elif defined(_WIN32) + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 0); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 0); +#elif defined(__linux__) + EXPECT_EQ(ABSL_FLAGS_STRIP_NAMES, 0); + EXPECT_EQ(ABSL_FLAGS_STRIP_HELP, 0); +#endif +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/declare.h b/third_party/abseil_cpp/absl/flags/declare.h new file mode 100644 index 0000000000..0f8cc6a599 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/declare.h @@ -0,0 +1,66 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: declare.h +// ----------------------------------------------------------------------------- +// +// This file defines the ABSL_DECLARE_FLAG macro, allowing you to declare an +// `absl::Flag` for use within a translation unit. You should place this +// declaration within the header file associated with the .cc file that defines +// and owns the `Flag`. + +#ifndef ABSL_FLAGS_DECLARE_H_ +#define ABSL_FLAGS_DECLARE_H_ + +#include "absl/base/config.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// absl::Flag<T> represents a flag of type 'T' created by ABSL_FLAG. +template <typename T> +class Flag; + +} // namespace flags_internal + +// Flag +// +// Forward declaration of the `absl::Flag` type for use in defining the macro. +#if defined(_MSC_VER) && !defined(__clang__) +template <typename T> +class Flag; +#else +template <typename T> +using Flag = flags_internal::Flag<T>; +#endif + +ABSL_NAMESPACE_END +} // namespace absl + +// ABSL_DECLARE_FLAG() +// +// This macro is a convenience for declaring use of an `absl::Flag` within a +// translation unit. This macro should be used within a header file to +// declare usage of the flag within any .cc file including that header file. +// +// The ABSL_DECLARE_FLAG(type, name) macro expands to: +// +// extern absl::Flag<type> FLAGS_name; +#define ABSL_DECLARE_FLAG(type, name) extern ::absl::Flag<type> FLAGS_##name + +#endif // ABSL_FLAGS_DECLARE_H_ diff --git a/third_party/abseil_cpp/absl/flags/flag.cc b/third_party/abseil_cpp/absl/flags/flag.cc new file mode 100644 index 0000000000..f7a457bf0c --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/flag.cc @@ -0,0 +1,40 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/flag.h" + +#include "absl/base/config.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/flag.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// This global mutex protects on-demand construction of flag objects in MSVC +// builds. +#if defined(_MSC_VER) && !defined(__clang__) + +namespace flags_internal { + +ABSL_CONST_INIT static absl::Mutex construction_guard(absl::kConstInit); + +absl::Mutex* GetGlobalConstructionGuard() { return &construction_guard; } + +} // namespace flags_internal + +#endif + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/flag.h b/third_party/abseil_cpp/absl/flags/flag.h new file mode 100644 index 0000000000..ca7d581fce --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/flag.h @@ -0,0 +1,381 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: flag.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::Flag<T>` type for holding command-line +// flag data, and abstractions to create, get and set such flag data. +// +// It is important to note that this type is **unspecified** (an implementation +// detail) and you do not construct or manipulate actual `absl::Flag<T>` +// instances. Instead, you define and declare flags using the +// `ABSL_FLAG()` and `ABSL_DECLARE_FLAG()` macros, and get and set flag values +// using the `absl::GetFlag()` and `absl::SetFlag()` functions. + +#ifndef ABSL_FLAGS_FLAG_H_ +#define ABSL_FLAGS_FLAG_H_ + +#include <string> +#include <type_traits> + +#include "absl/base/attributes.h" +#include "absl/base/casts.h" +#include "absl/base/config.h" +#include "absl/flags/config.h" +#include "absl/flags/declare.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/flag.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/marshalling.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Flag +// +// An `absl::Flag` holds a command-line flag value, providing a runtime +// parameter to a binary. Such flags should be defined in the global namespace +// and (preferably) in the module containing the binary's `main()` function. +// +// You should not construct and cannot use the `absl::Flag` type directly; +// instead, you should declare flags using the `ABSL_DECLARE_FLAG()` macro +// within a header file, and define your flag using `ABSL_FLAG()` within your +// header's associated `.cc` file. Such flags will be named `FLAGS_name`. +// +// Example: +// +// .h file +// +// // Declares usage of a flag named "FLAGS_count" +// ABSL_DECLARE_FLAG(int, count); +// +// .cc file +// +// // Defines a flag named "FLAGS_count" with a default `int` value of 0. +// ABSL_FLAG(int, count, 0, "Count of items to process"); +// +// No public methods of `absl::Flag<T>` are part of the Abseil Flags API. +#if !defined(_MSC_VER) || defined(__clang__) +template <typename T> +using Flag = flags_internal::Flag<T>; +#else +// MSVC debug builds do not implement initialization with constexpr constructors +// correctly. To work around this we add a level of indirection, so that the +// class `absl::Flag` contains an `internal::Flag*` (instead of being an alias +// to that class) and dynamically allocates an instance when necessary. We also +// forward all calls to internal::Flag methods via trampoline methods. In this +// setup the `absl::Flag` class does not have constructor and virtual methods, +// all the data members are public and thus MSVC is able to initialize it at +// link time. To deal with multiple threads accessing the flag for the first +// time concurrently we use an atomic boolean indicating if flag object is +// initialized. We also employ the double-checked locking pattern where the +// second level of protection is a global Mutex, so if two threads attempt to +// construct the flag concurrently only one wins. +// This solution is based on a recomendation here: +// https://developercommunity.visualstudio.com/content/problem/336946/class-with-constexpr-constructor-not-using-static.html?childToView=648454#comment-648454 + +namespace flags_internal { +absl::Mutex* GetGlobalConstructionGuard(); +} // namespace flags_internal + +template <typename T> +class Flag { + public: + // No constructor and destructor to ensure this is an aggregate type. + // Visual Studio 2015 still requires the constructor for class to be + // constexpr initializable. +#if _MSC_VER <= 1900 + constexpr Flag(const char* name, const char* filename, + const flags_internal::HelpGenFunc help_gen, + const flags_internal::FlagDfltGenFunc default_value_gen) + : name_(name), + filename_(filename), + help_gen_(help_gen), + default_value_gen_(default_value_gen), + inited_(false), + impl_(nullptr) {} +#endif + + flags_internal::Flag<T>* GetImpl() const { + if (!inited_.load(std::memory_order_acquire)) { + absl::MutexLock l(flags_internal::GetGlobalConstructionGuard()); + + if (inited_.load(std::memory_order_acquire)) { + return impl_; + } + + impl_ = new flags_internal::Flag<T>( + name_, filename_, + {flags_internal::FlagHelpMsg(help_gen_), + flags_internal::FlagHelpKind::kGenFunc}, + {flags_internal::FlagDefaultSrc(default_value_gen_), + flags_internal::FlagDefaultKind::kGenFunc}); + inited_.store(true, std::memory_order_release); + } + + return impl_; + } + + // Public methods of `absl::Flag<T>` are NOT part of the Abseil Flags API. + // See https://abseil.io/docs/cpp/guides/flags + bool IsRetired() const { return GetImpl()->IsRetired(); } + absl::string_view Name() const { return GetImpl()->Name(); } + std::string Help() const { return GetImpl()->Help(); } + bool IsModified() const { return GetImpl()->IsModified(); } + bool IsSpecifiedOnCommandLine() const { + return GetImpl()->IsSpecifiedOnCommandLine(); + } + std::string Filename() const { return GetImpl()->Filename(); } + std::string DefaultValue() const { return GetImpl()->DefaultValue(); } + std::string CurrentValue() const { return GetImpl()->CurrentValue(); } + template <typename U> + inline bool IsOfType() const { + return GetImpl()->template IsOfType<U>(); + } + T Get() const { return GetImpl()->Get(); } + void Set(const T& v) { GetImpl()->Set(v); } + void InvokeCallback() { GetImpl()->InvokeCallback(); } + + // The data members are logically private, but they need to be public for + // this to be an aggregate type. + const char* name_; + const char* filename_; + const flags_internal::HelpGenFunc help_gen_; + const flags_internal::FlagDfltGenFunc default_value_gen_; + + mutable std::atomic<bool> inited_; + mutable flags_internal::Flag<T>* impl_; +}; +#endif + +// GetFlag() +// +// Returns the value (of type `T`) of an `absl::Flag<T>` instance, by value. Do +// not construct an `absl::Flag<T>` directly and call `absl::GetFlag()`; +// instead, refer to flag's constructed variable name (e.g. `FLAGS_name`). +// Because this function returns by value and not by reference, it is +// thread-safe, but note that the operation may be expensive; as a result, avoid +// `absl::GetFlag()` within any tight loops. +// +// Example: +// +// // FLAGS_count is a Flag of type `int` +// int my_count = absl::GetFlag(FLAGS_count); +// +// // FLAGS_firstname is a Flag of type `std::string` +// std::string first_name = absl::GetFlag(FLAGS_firstname); +template <typename T> +ABSL_MUST_USE_RESULT T GetFlag(const absl::Flag<T>& flag) { + return flag.Get(); +} + +// SetFlag() +// +// Sets the value of an `absl::Flag` to the value `v`. Do not construct an +// `absl::Flag<T>` directly and call `absl::SetFlag()`; instead, use the +// flag's variable name (e.g. `FLAGS_name`). This function is +// thread-safe, but is potentially expensive. Avoid setting flags in general, +// but especially within performance-critical code. +template <typename T> +void SetFlag(absl::Flag<T>* flag, const T& v) { + flag->Set(v); +} + +// Overload of `SetFlag()` to allow callers to pass in a value that is +// convertible to `T`. E.g., use this overload to pass a "const char*" when `T` +// is `std::string`. +template <typename T, typename V> +void SetFlag(absl::Flag<T>* flag, const V& v) { + T value(v); + flag->Set(value); +} + +ABSL_NAMESPACE_END +} // namespace absl + + +// ABSL_FLAG() +// +// This macro defines an `absl::Flag<T>` instance of a specified type `T`: +// +// ABSL_FLAG(T, name, default_value, help); +// +// where: +// +// * `T` is a supported flag type (see the list of types in `marshalling.h`), +// * `name` designates the name of the flag (as a global variable +// `FLAGS_name`), +// * `default_value` is an expression holding the default value for this flag +// (which must be implicitly convertible to `T`), +// * `help` is the help text, which can also be an expression. +// +// This macro expands to a flag named 'FLAGS_name' of type 'T': +// +// absl::Flag<T> FLAGS_name = ...; +// +// Note that all such instances are created as global variables. +// +// For `ABSL_FLAG()` values that you wish to expose to other translation units, +// it is recommended to define those flags within the `.cc` file associated with +// the header where the flag is declared. +// +// Note: do not construct objects of type `absl::Flag<T>` directly. Only use the +// `ABSL_FLAG()` macro for such construction. +#define ABSL_FLAG(Type, name, default_value, help) \ + ABSL_FLAG_IMPL(Type, name, default_value, help) + +// ABSL_FLAG().OnUpdate() +// +// Defines a flag of type `T` with a callback attached: +// +// ABSL_FLAG(T, name, default_value, help).OnUpdate(callback); +// +// After any setting of the flag value, the callback will be called at least +// once. A rapid sequence of changes may be merged together into the same +// callback. No concurrent calls to the callback will be made for the same +// flag. Callbacks are allowed to read the current value of the flag but must +// not mutate that flag. +// +// The update mechanism guarantees "eventual consistency"; if the callback +// derives an auxiliary data structure from the flag value, it is guaranteed +// that eventually the flag value and the derived data structure will be +// consistent. +// +// Note: ABSL_FLAG.OnUpdate() does not have a public definition. Hence, this +// comment serves as its API documentation. + + +// ----------------------------------------------------------------------------- +// Implementation details below this section +// ----------------------------------------------------------------------------- + +// ABSL_FLAG_IMPL macro definition conditional on ABSL_FLAGS_STRIP_NAMES + +#if ABSL_FLAGS_STRIP_NAMES +#define ABSL_FLAG_IMPL_FLAGNAME(txt) "" +#define ABSL_FLAG_IMPL_FILENAME() "" +#if !defined(_MSC_VER) || defined(__clang__) +#define ABSL_FLAG_IMPL_REGISTRAR(T, flag) \ + absl::flags_internal::FlagRegistrar<T, false>(&flag) +#else +#define ABSL_FLAG_IMPL_REGISTRAR(T, flag) \ + absl::flags_internal::FlagRegistrar<T, false>(flag.GetImpl()) +#endif +#else +#define ABSL_FLAG_IMPL_FLAGNAME(txt) txt +#define ABSL_FLAG_IMPL_FILENAME() __FILE__ +#if !defined(_MSC_VER) || defined(__clang__) +#define ABSL_FLAG_IMPL_REGISTRAR(T, flag) \ + absl::flags_internal::FlagRegistrar<T, true>(&flag) +#else +#define ABSL_FLAG_IMPL_REGISTRAR(T, flag) \ + absl::flags_internal::FlagRegistrar<T, true>(flag.GetImpl()) +#endif +#endif + +// ABSL_FLAG_IMPL macro definition conditional on ABSL_FLAGS_STRIP_HELP + +#if ABSL_FLAGS_STRIP_HELP +#define ABSL_FLAG_IMPL_FLAGHELP(txt) absl::flags_internal::kStrippedFlagHelp +#else +#define ABSL_FLAG_IMPL_FLAGHELP(txt) txt +#endif + +// AbslFlagHelpGenFor##name is used to encapsulate both immediate (method Const) +// and lazy (method NonConst) evaluation of help message expression. We choose +// between the two via the call to HelpArg in absl::Flag instantiation below. +// If help message expression is constexpr evaluable compiler will optimize +// away this whole struct. +#define ABSL_FLAG_IMPL_DECLARE_HELP_WRAPPER(name, txt) \ + struct AbslFlagHelpGenFor##name { \ + template <typename T = void> \ + static constexpr const char* Const() { \ + return absl::flags_internal::HelpConstexprWrap( \ + ABSL_FLAG_IMPL_FLAGHELP(txt)); \ + } \ + static std::string NonConst() { return ABSL_FLAG_IMPL_FLAGHELP(txt); } \ + } + +#define ABSL_FLAG_IMPL_DECLARE_DEF_VAL_WRAPPER(name, Type, default_value) \ + struct AbslFlagDefaultGenFor##name { \ + Type value = absl::flags_internal::InitDefaultValue<Type>(default_value); \ + static void Gen(void* p) { \ + new (p) Type(AbslFlagDefaultGenFor##name{}.value); \ + } \ + } + +// ABSL_FLAG_IMPL +// +// Note: Name of registrar object is not arbitrary. It is used to "grab" +// global name for FLAGS_no<flag_name> symbol, thus preventing the possibility +// of defining two flags with names foo and nofoo. +#if !defined(_MSC_VER) || defined(__clang__) + +#define ABSL_FLAG_IMPL(Type, name, default_value, help) \ + namespace absl /* block flags in namespaces */ {} \ + ABSL_FLAG_IMPL_DECLARE_DEF_VAL_WRAPPER(name, Type, default_value); \ + ABSL_FLAG_IMPL_DECLARE_HELP_WRAPPER(name, help); \ + ABSL_CONST_INIT absl::Flag<Type> FLAGS_##name{ \ + ABSL_FLAG_IMPL_FLAGNAME(#name), ABSL_FLAG_IMPL_FILENAME(), \ + absl::flags_internal::HelpArg<AbslFlagHelpGenFor##name>(0), \ + absl::flags_internal::DefaultArg<Type, AbslFlagDefaultGenFor##name>(0)}; \ + extern absl::flags_internal::FlagRegistrarEmpty FLAGS_no##name; \ + absl::flags_internal::FlagRegistrarEmpty FLAGS_no##name = \ + ABSL_FLAG_IMPL_REGISTRAR(Type, FLAGS_##name) +#else +// MSVC version uses aggregate initialization. We also do not try to +// optimize away help wrapper. +#define ABSL_FLAG_IMPL(Type, name, default_value, help) \ + namespace absl /* block flags in namespaces */ {} \ + ABSL_FLAG_IMPL_DECLARE_DEF_VAL_WRAPPER(name, Type, default_value); \ + ABSL_FLAG_IMPL_DECLARE_HELP_WRAPPER(name, help); \ + ABSL_CONST_INIT absl::Flag<Type> FLAGS_##name{ \ + ABSL_FLAG_IMPL_FLAGNAME(#name), ABSL_FLAG_IMPL_FILENAME(), \ + &AbslFlagHelpGenFor##name::NonConst, &AbslFlagDefaultGenFor##name::Gen}; \ + extern absl::flags_internal::FlagRegistrarEmpty FLAGS_no##name; \ + absl::flags_internal::FlagRegistrarEmpty FLAGS_no##name = \ + ABSL_FLAG_IMPL_REGISTRAR(Type, FLAGS_##name) +#endif + +// ABSL_RETIRED_FLAG +// +// Designates the flag (which is usually pre-existing) as "retired." A retired +// flag is a flag that is now unused by the program, but may still be passed on +// the command line, usually by production scripts. A retired flag is ignored +// and code can't access it at runtime. +// +// This macro registers a retired flag with given name and type, with a name +// identical to the name of the original flag you are retiring. The retired +// flag's type can change over time, so that you can retire code to support a +// custom flag type. +// +// This macro has the same signature as `ABSL_FLAG`. To retire a flag, simply +// replace an `ABSL_FLAG` definition with `ABSL_RETIRED_FLAG`, leaving the +// arguments unchanged (unless of course you actually want to retire the flag +// type at this time as well). +// +// `default_value` is only used as a double check on the type. `explanation` is +// unused. +// TODO(rogeeff): Return an anonymous struct instead of bool, and place it into +// the unnamed namespace. +#define ABSL_RETIRED_FLAG(type, flagname, default_value, explanation) \ + ABSL_ATTRIBUTE_UNUSED static const bool ignored_##flagname = \ + ([] { return type(default_value); }, \ + absl::flags_internal::RetiredFlag<type>(#flagname)) + +#endif // ABSL_FLAGS_FLAG_H_ diff --git a/third_party/abseil_cpp/absl/flags/flag_benchmark.cc b/third_party/abseil_cpp/absl/flags/flag_benchmark.cc new file mode 100644 index 0000000000..ff95bb5d7b --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/flag_benchmark.cc @@ -0,0 +1,119 @@ +// +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/flag.h" +#include "absl/time/time.h" +#include "absl/types/optional.h" +#include "benchmark/benchmark.h" + +namespace { +using String = std::string; +using VectorOfStrings = std::vector<std::string>; +using AbslDuration = absl::Duration; + +// We do not want to take over marshalling for the types absl::optional<int>, +// absl::optional<std::string> which we do not own. Instead we introduce unique +// "aliases" to these types, which we do. +using AbslOptionalInt = absl::optional<int>; +struct OptionalInt : AbslOptionalInt { + using AbslOptionalInt::AbslOptionalInt; +}; +// Next two functions represent Abseil Flags marshalling for OptionalInt. +bool AbslParseFlag(absl::string_view src, OptionalInt* flag, + std::string* error) { + int val; + if (src.empty()) + flag->reset(); + else if (!absl::ParseFlag(src, &val, error)) + return false; + *flag = val; + return true; +} +std::string AbslUnparseFlag(const OptionalInt& flag) { + return !flag ? "" : absl::UnparseFlag(*flag); +} + +using AbslOptionalString = absl::optional<std::string>; +struct OptionalString : AbslOptionalString { + using AbslOptionalString::AbslOptionalString; +}; +// Next two functions represent Abseil Flags marshalling for OptionalString. +bool AbslParseFlag(absl::string_view src, OptionalString* flag, + std::string* error) { + std::string val; + if (src.empty()) + flag->reset(); + else if (!absl::ParseFlag(src, &val, error)) + return false; + *flag = val; + return true; +} +std::string AbslUnparseFlag(const OptionalString& flag) { + return !flag ? "" : absl::UnparseFlag(*flag); +} + +struct UDT { + UDT() = default; + UDT(const UDT&) {} + UDT& operator=(const UDT&) { return *this; } +}; +// Next two functions represent Abseil Flags marshalling for UDT. +bool AbslParseFlag(absl::string_view, UDT*, std::string*) { return true; } +std::string AbslUnparseFlag(const UDT&) { return ""; } + +} // namespace + +#define BENCHMARKED_TYPES(A) \ + A(bool) \ + A(int16_t) \ + A(uint16_t) \ + A(int32_t) \ + A(uint32_t) \ + A(int64_t) \ + A(uint64_t) \ + A(double) \ + A(float) \ + A(String) \ + A(VectorOfStrings) \ + A(OptionalInt) \ + A(OptionalString) \ + A(AbslDuration) \ + A(UDT) + +#define FLAG_DEF(T) ABSL_FLAG(T, T##_flag, {}, ""); + +BENCHMARKED_TYPES(FLAG_DEF) + +namespace { + +#define BM_GetFlag(T) \ + void BM_GetFlag_##T(benchmark::State& state) { \ + for (auto _ : state) { \ + benchmark::DoNotOptimize(absl::GetFlag(FLAGS_##T##_flag)); \ + } \ + } \ + BENCHMARK(BM_GetFlag_##T); + +BENCHMARKED_TYPES(BM_GetFlag) + +} // namespace + +#define InvokeGetFlag(T) \ + T AbslInvokeGetFlag##T() { return absl::GetFlag(FLAGS_##T##_flag); } \ + int odr##T = (benchmark::DoNotOptimize(AbslInvokeGetFlag##T), 1); + +BENCHMARKED_TYPES(InvokeGetFlag) + +// To veiw disassembly use: gdb ${BINARY} -batch -ex "disassemble /s $FUNC" diff --git a/third_party/abseil_cpp/absl/flags/flag_test.cc b/third_party/abseil_cpp/absl/flags/flag_test.cc new file mode 100644 index 0000000000..416a31e523 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/flag_test.cc @@ -0,0 +1,783 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/flag.h" + +#include <stdint.h> + +#include <cmath> +#include <string> +#include <thread> // NOLINT +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/flags/config.h" +#include "absl/flags/declare.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/flag.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/usage_config.h" +#include "absl/strings/match.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" +#include "absl/time/time.h" + +ABSL_DECLARE_FLAG(int64_t, mistyped_int_flag); +ABSL_DECLARE_FLAG(std::vector<std::string>, mistyped_string_flag); + +namespace { + +namespace flags = absl::flags_internal; + +std::string TestHelpMsg() { return "dynamic help"; } +template <typename T> +void TestMakeDflt(void* dst) { + new (dst) T{}; +} +void TestCallback() {} + +struct UDT { + UDT() = default; + UDT(const UDT&) = default; +}; +bool AbslParseFlag(absl::string_view, UDT*, std::string*) { return true; } +std::string AbslUnparseFlag(const UDT&) { return ""; } + +class FlagTest : public testing::Test { + protected: + static void SetUpTestSuite() { + // Install a function to normalize filenames before this test is run. + absl::FlagsUsageConfig default_config; + default_config.normalize_filename = &FlagTest::NormalizeFileName; + absl::SetFlagsUsageConfig(default_config); + } + + private: + static std::string NormalizeFileName(absl::string_view fname) { +#ifdef _WIN32 + std::string normalized(fname); + std::replace(normalized.begin(), normalized.end(), '\\', '/'); + fname = normalized; +#endif + return std::string(fname); + } + flags::FlagSaver flag_saver_; +}; + +struct S1 { + S1() = default; + S1(const S1&) = default; + int32_t f1; + int64_t f2; +}; + +struct S2 { + S2() = default; + S2(const S2&) = default; + int64_t f1; + double f2; +}; + +TEST_F(FlagTest, Traits) { + EXPECT_EQ(flags::StorageKind<int>(), + flags::FlagValueStorageKind::kOneWordAtomic); + EXPECT_EQ(flags::StorageKind<bool>(), + flags::FlagValueStorageKind::kOneWordAtomic); + EXPECT_EQ(flags::StorageKind<double>(), + flags::FlagValueStorageKind::kOneWordAtomic); + EXPECT_EQ(flags::StorageKind<int64_t>(), + flags::FlagValueStorageKind::kOneWordAtomic); + +#if defined(ABSL_FLAGS_INTERNAL_ATOMIC_DOUBLE_WORD) + EXPECT_EQ(flags::StorageKind<S1>(), + flags::FlagValueStorageKind::kTwoWordsAtomic); + EXPECT_EQ(flags::StorageKind<S2>(), + flags::FlagValueStorageKind::kTwoWordsAtomic); +#else + EXPECT_EQ(flags::StorageKind<S1>(), + flags::FlagValueStorageKind::kAlignedBuffer); + EXPECT_EQ(flags::StorageKind<S2>(), + flags::FlagValueStorageKind::kAlignedBuffer); +#endif + + EXPECT_EQ(flags::StorageKind<std::string>(), + flags::FlagValueStorageKind::kAlignedBuffer); + EXPECT_EQ(flags::StorageKind<std::vector<std::string>>(), + flags::FlagValueStorageKind::kAlignedBuffer); +} + +// -------------------------------------------------------------------- + +constexpr flags::FlagHelpArg help_arg{flags::FlagHelpMsg("literal help"), + flags::FlagHelpKind::kLiteral}; + +using String = std::string; + +#define DEFINE_CONSTRUCTED_FLAG(T, dflt, dflt_kind) \ + constexpr flags::FlagDefaultArg f1default##T{ \ + flags::FlagDefaultSrc{dflt}, flags::FlagDefaultKind::dflt_kind}; \ + constexpr flags::Flag<T> f1##T("f1", "file", help_arg, f1default##T); \ + ABSL_CONST_INIT flags::Flag<T> f2##T( \ + "f2", "file", \ + {flags::FlagHelpMsg(&TestHelpMsg), flags::FlagHelpKind::kGenFunc}, \ + flags::FlagDefaultArg{flags::FlagDefaultSrc(&TestMakeDflt<T>), \ + flags::FlagDefaultKind::kGenFunc}) + +DEFINE_CONSTRUCTED_FLAG(bool, true, kOneWord); +DEFINE_CONSTRUCTED_FLAG(int16_t, 1, kOneWord); +DEFINE_CONSTRUCTED_FLAG(uint16_t, 2, kOneWord); +DEFINE_CONSTRUCTED_FLAG(int32_t, 3, kOneWord); +DEFINE_CONSTRUCTED_FLAG(uint32_t, 4, kOneWord); +DEFINE_CONSTRUCTED_FLAG(int64_t, 5, kOneWord); +DEFINE_CONSTRUCTED_FLAG(uint64_t, 6, kOneWord); +DEFINE_CONSTRUCTED_FLAG(float, 7.8, kOneWord); +DEFINE_CONSTRUCTED_FLAG(double, 9.10, kOneWord); +DEFINE_CONSTRUCTED_FLAG(String, &TestMakeDflt<String>, kGenFunc); +DEFINE_CONSTRUCTED_FLAG(UDT, &TestMakeDflt<UDT>, kGenFunc); + +template <typename T> +bool TestConstructionFor(const flags::Flag<T>& f1, flags::Flag<T>* f2) { + EXPECT_EQ(f1.Name(), "f1"); + EXPECT_EQ(f1.Help(), "literal help"); + EXPECT_EQ(f1.Filename(), "file"); + + flags::FlagRegistrar<T, false>(f2).OnUpdate(TestCallback); + + EXPECT_EQ(f2->Name(), "f2"); + EXPECT_EQ(f2->Help(), "dynamic help"); + EXPECT_EQ(f2->Filename(), "file"); + + return true; +} + +#define TEST_CONSTRUCTED_FLAG(T) TestConstructionFor(f1##T, &f2##T); + +TEST_F(FlagTest, TestConstruction) { + TEST_CONSTRUCTED_FLAG(bool); + TEST_CONSTRUCTED_FLAG(int16_t); + TEST_CONSTRUCTED_FLAG(uint16_t); + TEST_CONSTRUCTED_FLAG(int32_t); + TEST_CONSTRUCTED_FLAG(uint32_t); + TEST_CONSTRUCTED_FLAG(int64_t); + TEST_CONSTRUCTED_FLAG(uint64_t); + TEST_CONSTRUCTED_FLAG(float); + TEST_CONSTRUCTED_FLAG(double); + TEST_CONSTRUCTED_FLAG(String); + TEST_CONSTRUCTED_FLAG(UDT); +} + +// -------------------------------------------------------------------- + +} // namespace + +ABSL_DECLARE_FLAG(bool, test_flag_01); +ABSL_DECLARE_FLAG(int, test_flag_02); +ABSL_DECLARE_FLAG(int16_t, test_flag_03); +ABSL_DECLARE_FLAG(uint16_t, test_flag_04); +ABSL_DECLARE_FLAG(int32_t, test_flag_05); +ABSL_DECLARE_FLAG(uint32_t, test_flag_06); +ABSL_DECLARE_FLAG(int64_t, test_flag_07); +ABSL_DECLARE_FLAG(uint64_t, test_flag_08); +ABSL_DECLARE_FLAG(double, test_flag_09); +ABSL_DECLARE_FLAG(float, test_flag_10); +ABSL_DECLARE_FLAG(std::string, test_flag_11); +ABSL_DECLARE_FLAG(absl::Duration, test_flag_12); + +namespace { + +#if !ABSL_FLAGS_STRIP_NAMES + +TEST_F(FlagTest, TestFlagDeclaration) { + // test that we can access flag objects. + EXPECT_EQ(FLAGS_test_flag_01.Name(), "test_flag_01"); + EXPECT_EQ(FLAGS_test_flag_02.Name(), "test_flag_02"); + EXPECT_EQ(FLAGS_test_flag_03.Name(), "test_flag_03"); + EXPECT_EQ(FLAGS_test_flag_04.Name(), "test_flag_04"); + EXPECT_EQ(FLAGS_test_flag_05.Name(), "test_flag_05"); + EXPECT_EQ(FLAGS_test_flag_06.Name(), "test_flag_06"); + EXPECT_EQ(FLAGS_test_flag_07.Name(), "test_flag_07"); + EXPECT_EQ(FLAGS_test_flag_08.Name(), "test_flag_08"); + EXPECT_EQ(FLAGS_test_flag_09.Name(), "test_flag_09"); + EXPECT_EQ(FLAGS_test_flag_10.Name(), "test_flag_10"); + EXPECT_EQ(FLAGS_test_flag_11.Name(), "test_flag_11"); + EXPECT_EQ(FLAGS_test_flag_12.Name(), "test_flag_12"); +} +#endif // !ABSL_FLAGS_STRIP_NAMES + +// -------------------------------------------------------------------- + +} // namespace + +ABSL_FLAG(bool, test_flag_01, true, "test flag 01"); +ABSL_FLAG(int, test_flag_02, 1234, "test flag 02"); +ABSL_FLAG(int16_t, test_flag_03, -34, "test flag 03"); +ABSL_FLAG(uint16_t, test_flag_04, 189, "test flag 04"); +ABSL_FLAG(int32_t, test_flag_05, 10765, "test flag 05"); +ABSL_FLAG(uint32_t, test_flag_06, 40000, "test flag 06"); +ABSL_FLAG(int64_t, test_flag_07, -1234567, "test flag 07"); +ABSL_FLAG(uint64_t, test_flag_08, 9876543, "test flag 08"); +ABSL_FLAG(double, test_flag_09, -9.876e-50, "test flag 09"); +ABSL_FLAG(float, test_flag_10, 1.234e12f, "test flag 10"); +ABSL_FLAG(std::string, test_flag_11, "", "test flag 11"); +ABSL_FLAG(absl::Duration, test_flag_12, absl::Minutes(10), "test flag 12"); + +namespace { + +#if !ABSL_FLAGS_STRIP_NAMES +TEST_F(FlagTest, TestFlagDefinition) { + absl::string_view expected_file_name = "absl/flags/flag_test.cc"; + + EXPECT_EQ(FLAGS_test_flag_01.Name(), "test_flag_01"); + EXPECT_EQ(FLAGS_test_flag_01.Help(), "test flag 01"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_01.Filename(), expected_file_name)) + << FLAGS_test_flag_01.Filename(); + + EXPECT_EQ(FLAGS_test_flag_02.Name(), "test_flag_02"); + EXPECT_EQ(FLAGS_test_flag_02.Help(), "test flag 02"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_02.Filename(), expected_file_name)) + << FLAGS_test_flag_02.Filename(); + + EXPECT_EQ(FLAGS_test_flag_03.Name(), "test_flag_03"); + EXPECT_EQ(FLAGS_test_flag_03.Help(), "test flag 03"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_03.Filename(), expected_file_name)) + << FLAGS_test_flag_03.Filename(); + + EXPECT_EQ(FLAGS_test_flag_04.Name(), "test_flag_04"); + EXPECT_EQ(FLAGS_test_flag_04.Help(), "test flag 04"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_04.Filename(), expected_file_name)) + << FLAGS_test_flag_04.Filename(); + + EXPECT_EQ(FLAGS_test_flag_05.Name(), "test_flag_05"); + EXPECT_EQ(FLAGS_test_flag_05.Help(), "test flag 05"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_05.Filename(), expected_file_name)) + << FLAGS_test_flag_05.Filename(); + + EXPECT_EQ(FLAGS_test_flag_06.Name(), "test_flag_06"); + EXPECT_EQ(FLAGS_test_flag_06.Help(), "test flag 06"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_06.Filename(), expected_file_name)) + << FLAGS_test_flag_06.Filename(); + + EXPECT_EQ(FLAGS_test_flag_07.Name(), "test_flag_07"); + EXPECT_EQ(FLAGS_test_flag_07.Help(), "test flag 07"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_07.Filename(), expected_file_name)) + << FLAGS_test_flag_07.Filename(); + + EXPECT_EQ(FLAGS_test_flag_08.Name(), "test_flag_08"); + EXPECT_EQ(FLAGS_test_flag_08.Help(), "test flag 08"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_08.Filename(), expected_file_name)) + << FLAGS_test_flag_08.Filename(); + + EXPECT_EQ(FLAGS_test_flag_09.Name(), "test_flag_09"); + EXPECT_EQ(FLAGS_test_flag_09.Help(), "test flag 09"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_09.Filename(), expected_file_name)) + << FLAGS_test_flag_09.Filename(); + + EXPECT_EQ(FLAGS_test_flag_10.Name(), "test_flag_10"); + EXPECT_EQ(FLAGS_test_flag_10.Help(), "test flag 10"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_10.Filename(), expected_file_name)) + << FLAGS_test_flag_10.Filename(); + + EXPECT_EQ(FLAGS_test_flag_11.Name(), "test_flag_11"); + EXPECT_EQ(FLAGS_test_flag_11.Help(), "test flag 11"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_11.Filename(), expected_file_name)) + << FLAGS_test_flag_11.Filename(); + + EXPECT_EQ(FLAGS_test_flag_12.Name(), "test_flag_12"); + EXPECT_EQ(FLAGS_test_flag_12.Help(), "test flag 12"); + EXPECT_TRUE(absl::EndsWith(FLAGS_test_flag_12.Filename(), expected_file_name)) + << FLAGS_test_flag_12.Filename(); +} +#endif // !ABSL_FLAGS_STRIP_NAMES + +// -------------------------------------------------------------------- + +TEST_F(FlagTest, TestDefault) { + EXPECT_EQ(FLAGS_test_flag_01.DefaultValue(), "true"); + EXPECT_EQ(FLAGS_test_flag_02.DefaultValue(), "1234"); + EXPECT_EQ(FLAGS_test_flag_03.DefaultValue(), "-34"); + EXPECT_EQ(FLAGS_test_flag_04.DefaultValue(), "189"); + EXPECT_EQ(FLAGS_test_flag_05.DefaultValue(), "10765"); + EXPECT_EQ(FLAGS_test_flag_06.DefaultValue(), "40000"); + EXPECT_EQ(FLAGS_test_flag_07.DefaultValue(), "-1234567"); + EXPECT_EQ(FLAGS_test_flag_08.DefaultValue(), "9876543"); + EXPECT_EQ(FLAGS_test_flag_09.DefaultValue(), "-9.876e-50"); + EXPECT_EQ(FLAGS_test_flag_10.DefaultValue(), "1.234e+12"); + EXPECT_EQ(FLAGS_test_flag_11.DefaultValue(), ""); + EXPECT_EQ(FLAGS_test_flag_12.DefaultValue(), "10m"); + + EXPECT_EQ(FLAGS_test_flag_01.CurrentValue(), "true"); + EXPECT_EQ(FLAGS_test_flag_02.CurrentValue(), "1234"); + EXPECT_EQ(FLAGS_test_flag_03.CurrentValue(), "-34"); + EXPECT_EQ(FLAGS_test_flag_04.CurrentValue(), "189"); + EXPECT_EQ(FLAGS_test_flag_05.CurrentValue(), "10765"); + EXPECT_EQ(FLAGS_test_flag_06.CurrentValue(), "40000"); + EXPECT_EQ(FLAGS_test_flag_07.CurrentValue(), "-1234567"); + EXPECT_EQ(FLAGS_test_flag_08.CurrentValue(), "9876543"); + EXPECT_EQ(FLAGS_test_flag_09.CurrentValue(), "-9.876e-50"); + EXPECT_EQ(FLAGS_test_flag_10.CurrentValue(), "1.234e+12"); + EXPECT_EQ(FLAGS_test_flag_11.CurrentValue(), ""); + EXPECT_EQ(FLAGS_test_flag_12.CurrentValue(), "10m"); + + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_01), true); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_02), 1234); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_03), -34); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_04), 189); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_05), 10765); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_06), 40000); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_07), -1234567); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_08), 9876543); + EXPECT_NEAR(absl::GetFlag(FLAGS_test_flag_09), -9.876e-50, 1e-55); + EXPECT_NEAR(absl::GetFlag(FLAGS_test_flag_10), 1.234e12f, 1e5f); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_11), ""); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_12), absl::Minutes(10)); +} + +// -------------------------------------------------------------------- + +struct NonTriviallyCopyableAggregate { + NonTriviallyCopyableAggregate() = default; + NonTriviallyCopyableAggregate(const NonTriviallyCopyableAggregate& rhs) + : value(rhs.value) {} + NonTriviallyCopyableAggregate& operator=( + const NonTriviallyCopyableAggregate& rhs) { + value = rhs.value; + return *this; + } + + int value; +}; +bool AbslParseFlag(absl::string_view src, NonTriviallyCopyableAggregate* f, + std::string* e) { + return absl::ParseFlag(src, &f->value, e); +} +std::string AbslUnparseFlag(const NonTriviallyCopyableAggregate& ntc) { + return absl::StrCat(ntc.value); +} + +bool operator==(const NonTriviallyCopyableAggregate& ntc1, + const NonTriviallyCopyableAggregate& ntc2) { + return ntc1.value == ntc2.value; +} + +} // namespace + +ABSL_FLAG(bool, test_flag_eb_01, {}, ""); +ABSL_FLAG(int32_t, test_flag_eb_02, {}, ""); +ABSL_FLAG(int64_t, test_flag_eb_03, {}, ""); +ABSL_FLAG(double, test_flag_eb_04, {}, ""); +ABSL_FLAG(std::string, test_flag_eb_05, {}, ""); +ABSL_FLAG(NonTriviallyCopyableAggregate, test_flag_eb_06, {}, ""); + +namespace { + +TEST_F(FlagTest, TestEmptyBracesDefault) { + EXPECT_EQ(FLAGS_test_flag_eb_01.DefaultValue(), "false"); + EXPECT_EQ(FLAGS_test_flag_eb_02.DefaultValue(), "0"); + EXPECT_EQ(FLAGS_test_flag_eb_03.DefaultValue(), "0"); + EXPECT_EQ(FLAGS_test_flag_eb_04.DefaultValue(), "0"); + EXPECT_EQ(FLAGS_test_flag_eb_05.DefaultValue(), ""); + EXPECT_EQ(FLAGS_test_flag_eb_06.DefaultValue(), "0"); + + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_eb_01), false); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_eb_02), 0); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_eb_03), 0); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_eb_04), 0.0); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_eb_05), ""); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_eb_06), + NonTriviallyCopyableAggregate{}); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagTest, TestGetSet) { + absl::SetFlag(&FLAGS_test_flag_01, false); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_01), false); + + absl::SetFlag(&FLAGS_test_flag_02, 321); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_02), 321); + + absl::SetFlag(&FLAGS_test_flag_03, 67); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_03), 67); + + absl::SetFlag(&FLAGS_test_flag_04, 1); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_04), 1); + + absl::SetFlag(&FLAGS_test_flag_05, -908); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_05), -908); + + absl::SetFlag(&FLAGS_test_flag_06, 4001); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_06), 4001); + + absl::SetFlag(&FLAGS_test_flag_07, -23456); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_07), -23456); + + absl::SetFlag(&FLAGS_test_flag_08, 975310); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_08), 975310); + + absl::SetFlag(&FLAGS_test_flag_09, 1.00001); + EXPECT_NEAR(absl::GetFlag(FLAGS_test_flag_09), 1.00001, 1e-10); + + absl::SetFlag(&FLAGS_test_flag_10, -3.54f); + EXPECT_NEAR(absl::GetFlag(FLAGS_test_flag_10), -3.54f, 1e-6f); + + absl::SetFlag(&FLAGS_test_flag_11, "asdf"); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_11), "asdf"); + + absl::SetFlag(&FLAGS_test_flag_12, absl::Seconds(110)); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_12), absl::Seconds(110)); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagTest, TestGetViaReflection) { + auto* handle = flags::FindCommandLineFlag("test_flag_01"); + EXPECT_EQ(*handle->TryGet<bool>(), true); + handle = flags::FindCommandLineFlag("test_flag_02"); + EXPECT_EQ(*handle->TryGet<int>(), 1234); + handle = flags::FindCommandLineFlag("test_flag_03"); + EXPECT_EQ(*handle->TryGet<int16_t>(), -34); + handle = flags::FindCommandLineFlag("test_flag_04"); + EXPECT_EQ(*handle->TryGet<uint16_t>(), 189); + handle = flags::FindCommandLineFlag("test_flag_05"); + EXPECT_EQ(*handle->TryGet<int32_t>(), 10765); + handle = flags::FindCommandLineFlag("test_flag_06"); + EXPECT_EQ(*handle->TryGet<uint32_t>(), 40000); + handle = flags::FindCommandLineFlag("test_flag_07"); + EXPECT_EQ(*handle->TryGet<int64_t>(), -1234567); + handle = flags::FindCommandLineFlag("test_flag_08"); + EXPECT_EQ(*handle->TryGet<uint64_t>(), 9876543); + handle = flags::FindCommandLineFlag("test_flag_09"); + EXPECT_NEAR(*handle->TryGet<double>(), -9.876e-50, 1e-55); + handle = flags::FindCommandLineFlag("test_flag_10"); + EXPECT_NEAR(*handle->TryGet<float>(), 1.234e12f, 1e5f); + handle = flags::FindCommandLineFlag("test_flag_11"); + EXPECT_EQ(*handle->TryGet<std::string>(), ""); + handle = flags::FindCommandLineFlag("test_flag_12"); + EXPECT_EQ(*handle->TryGet<absl::Duration>(), absl::Minutes(10)); +} + +// -------------------------------------------------------------------- + +int GetDflt1() { return 1; } + +} // namespace + +ABSL_FLAG(int, test_int_flag_with_non_const_default, GetDflt1(), + "test int flag non const default"); +ABSL_FLAG(std::string, test_string_flag_with_non_const_default, + absl::StrCat("AAA", "BBB"), "test string flag non const default"); + +namespace { + +TEST_F(FlagTest, TestNonConstexprDefault) { + EXPECT_EQ(absl::GetFlag(FLAGS_test_int_flag_with_non_const_default), 1); + EXPECT_EQ(absl::GetFlag(FLAGS_test_string_flag_with_non_const_default), + "AAABBB"); +} + +// -------------------------------------------------------------------- + +} // namespace + +ABSL_FLAG(bool, test_flag_with_non_const_help, true, + absl::StrCat("test ", "flag ", "non const help")); + +namespace { + +#if !ABSL_FLAGS_STRIP_HELP +TEST_F(FlagTest, TestNonConstexprHelp) { + EXPECT_EQ(FLAGS_test_flag_with_non_const_help.Help(), + "test flag non const help"); +} +#endif //! ABSL_FLAGS_STRIP_HELP + +// -------------------------------------------------------------------- + +int cb_test_value = -1; +void TestFlagCB(); + +} // namespace + +ABSL_FLAG(int, test_flag_with_cb, 100, "").OnUpdate(TestFlagCB); + +ABSL_FLAG(int, test_flag_with_lambda_cb, 200, "").OnUpdate([]() { + cb_test_value = absl::GetFlag(FLAGS_test_flag_with_lambda_cb) + + absl::GetFlag(FLAGS_test_flag_with_cb); +}); + +namespace { + +void TestFlagCB() { cb_test_value = absl::GetFlag(FLAGS_test_flag_with_cb); } + +// Tests side-effects of callback invocation. +TEST_F(FlagTest, CallbackInvocation) { + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_with_cb), 100); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_with_lambda_cb), 200); + EXPECT_EQ(cb_test_value, 300); + + absl::SetFlag(&FLAGS_test_flag_with_cb, 1); + EXPECT_EQ(cb_test_value, 1); + + absl::SetFlag(&FLAGS_test_flag_with_lambda_cb, 3); + EXPECT_EQ(cb_test_value, 4); +} + +// -------------------------------------------------------------------- + +struct CustomUDT { + CustomUDT() : a(1), b(1) {} + CustomUDT(int a_, int b_) : a(a_), b(b_) {} + + friend bool operator==(const CustomUDT& f1, const CustomUDT& f2) { + return f1.a == f2.a && f1.b == f2.b; + } + + int a; + int b; +}; +bool AbslParseFlag(absl::string_view in, CustomUDT* f, std::string*) { + std::vector<absl::string_view> parts = + absl::StrSplit(in, ':', absl::SkipWhitespace()); + + if (parts.size() != 2) return false; + + if (!absl::SimpleAtoi(parts[0], &f->a)) return false; + + if (!absl::SimpleAtoi(parts[1], &f->b)) return false; + + return true; +} +std::string AbslUnparseFlag(const CustomUDT& f) { + return absl::StrCat(f.a, ":", f.b); +} + +} // namespace + +ABSL_FLAG(CustomUDT, test_flag_custom_udt, CustomUDT(), "test flag custom UDT"); + +namespace { + +TEST_F(FlagTest, TestCustomUDT) { + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_custom_udt), CustomUDT(1, 1)); + absl::SetFlag(&FLAGS_test_flag_custom_udt, CustomUDT(2, 3)); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_custom_udt), CustomUDT(2, 3)); +} + +// MSVC produces link error on the type mismatch. +// Linux does not have build errors and validations work as expected. +#if !defined(_WIN32) && GTEST_HAS_DEATH_TEST + +using FlagDeathTest = FlagTest; + +TEST_F(FlagDeathTest, TestTypeMismatchValidations) { +#if !defined(NDEBUG) + EXPECT_DEATH_IF_SUPPORTED( + static_cast<void>(absl::GetFlag(FLAGS_mistyped_int_flag)), + "Flag 'mistyped_int_flag' is defined as one type and declared " + "as another"); + EXPECT_DEATH_IF_SUPPORTED( + static_cast<void>(absl::GetFlag(FLAGS_mistyped_string_flag)), + "Flag 'mistyped_string_flag' is defined as one type and " + "declared as another"); +#endif + + EXPECT_DEATH_IF_SUPPORTED( + absl::SetFlag(&FLAGS_mistyped_int_flag, 1), + "Flag 'mistyped_int_flag' is defined as one type and declared " + "as another"); + EXPECT_DEATH_IF_SUPPORTED( + absl::SetFlag(&FLAGS_mistyped_string_flag, std::vector<std::string>{}), + "Flag 'mistyped_string_flag' is defined as one type and declared as " + "another"); +} + +#endif + +// -------------------------------------------------------------------- + +// A contrived type that offers implicit and explicit conversion from specific +// source types. +struct ConversionTestVal { + ConversionTestVal() = default; + explicit ConversionTestVal(int a_in) : a(a_in) {} + + enum class ViaImplicitConv { kTen = 10, kEleven }; + // NOLINTNEXTLINE + ConversionTestVal(ViaImplicitConv from) : a(static_cast<int>(from)) {} + + int a; +}; + +bool AbslParseFlag(absl::string_view in, ConversionTestVal* val_out, + std::string*) { + if (!absl::SimpleAtoi(in, &val_out->a)) { + return false; + } + return true; +} +std::string AbslUnparseFlag(const ConversionTestVal& val) { + return absl::StrCat(val.a); +} + +} // namespace + +// Flag default values can be specified with a value that converts to the flag +// value type implicitly. +ABSL_FLAG(ConversionTestVal, test_flag_implicit_conv, + ConversionTestVal::ViaImplicitConv::kTen, + "test flag init via implicit conversion"); + +namespace { + +TEST_F(FlagTest, CanSetViaImplicitConversion) { + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_implicit_conv).a, 10); + absl::SetFlag(&FLAGS_test_flag_implicit_conv, + ConversionTestVal::ViaImplicitConv::kEleven); + EXPECT_EQ(absl::GetFlag(FLAGS_test_flag_implicit_conv).a, 11); +} + +// -------------------------------------------------------------------- + +struct NonDfltConstructible { + public: + // This constructor tests that we can initialize the flag with int value + NonDfltConstructible(int i) : value(i) {} // NOLINT + + // This constructor tests that we can't initialize the flag with char value + // but can with explicitly constructed NonDfltConstructible. + explicit NonDfltConstructible(char c) : value(100 + static_cast<int>(c)) {} + + int value; +}; + +bool AbslParseFlag(absl::string_view in, NonDfltConstructible* ndc_out, + std::string*) { + return absl::SimpleAtoi(in, &ndc_out->value); +} +std::string AbslUnparseFlag(const NonDfltConstructible& ndc) { + return absl::StrCat(ndc.value); +} + +} // namespace + +ABSL_FLAG(NonDfltConstructible, ndc_flag1, NonDfltConstructible('1'), + "Flag with non default constructible type"); +ABSL_FLAG(NonDfltConstructible, ndc_flag2, 0, + "Flag with non default constructible type"); + +namespace { + +TEST_F(FlagTest, TestNonDefaultConstructibleType) { + EXPECT_EQ(absl::GetFlag(FLAGS_ndc_flag1).value, '1' + 100); + EXPECT_EQ(absl::GetFlag(FLAGS_ndc_flag2).value, 0); + + absl::SetFlag(&FLAGS_ndc_flag1, NonDfltConstructible('A')); + absl::SetFlag(&FLAGS_ndc_flag2, 25); + + EXPECT_EQ(absl::GetFlag(FLAGS_ndc_flag1).value, 'A' + 100); + EXPECT_EQ(absl::GetFlag(FLAGS_ndc_flag2).value, 25); +} + +} // namespace + +// -------------------------------------------------------------------- + +ABSL_RETIRED_FLAG(bool, old_bool_flag, true, "old descr"); +ABSL_RETIRED_FLAG(int, old_int_flag, (int)std::sqrt(10), "old descr"); +ABSL_RETIRED_FLAG(std::string, old_str_flag, "", absl::StrCat("old ", "descr")); + +namespace { + +TEST_F(FlagTest, TestRetiredFlagRegistration) { + bool is_bool = false; + EXPECT_TRUE(flags::IsRetiredFlag("old_bool_flag", &is_bool)); + EXPECT_TRUE(is_bool); + EXPECT_TRUE(flags::IsRetiredFlag("old_int_flag", &is_bool)); + EXPECT_FALSE(is_bool); + EXPECT_TRUE(flags::IsRetiredFlag("old_str_flag", &is_bool)); + EXPECT_FALSE(is_bool); + EXPECT_FALSE(flags::IsRetiredFlag("some_other_flag", &is_bool)); +} + +} // namespace + +// -------------------------------------------------------------------- + +namespace { + +// User-defined type with small alignment, but size exceeding 16. +struct SmallAlignUDT { + SmallAlignUDT() : c('A'), s(12) {} + char c; + int16_t s; + char bytes[14]; +}; + +bool AbslParseFlag(absl::string_view, SmallAlignUDT*, std::string*) { + return true; +} +std::string AbslUnparseFlag(const SmallAlignUDT&) { return ""; } + +// User-defined type with small size, but not trivially copyable. +struct NonTriviallyCopyableUDT { + NonTriviallyCopyableUDT() : c('A') {} + NonTriviallyCopyableUDT(const NonTriviallyCopyableUDT& rhs) : c(rhs.c) {} + NonTriviallyCopyableUDT& operator=(const NonTriviallyCopyableUDT& rhs) { + c = rhs.c; + return *this; + } + + char c; +}; + +bool AbslParseFlag(absl::string_view, NonTriviallyCopyableUDT*, std::string*) { + return true; +} +std::string AbslUnparseFlag(const NonTriviallyCopyableUDT&) { return ""; } + +} // namespace + +ABSL_FLAG(SmallAlignUDT, test_flag_sa_udt, {}, "help"); +ABSL_FLAG(NonTriviallyCopyableUDT, test_flag_ntc_udt, {}, "help"); + +namespace { + +TEST_F(FlagTest, TestSmallAlignUDT) { + SmallAlignUDT value = absl::GetFlag(FLAGS_test_flag_sa_udt); + EXPECT_EQ(value.c, 'A'); + EXPECT_EQ(value.s, 12); + + value.c = 'B'; + value.s = 45; + absl::SetFlag(&FLAGS_test_flag_sa_udt, value); + value = absl::GetFlag(FLAGS_test_flag_sa_udt); + EXPECT_EQ(value.c, 'B'); + EXPECT_EQ(value.s, 45); +} + +TEST_F(FlagTest, TestNonTriviallyCopyableUDT) { + NonTriviallyCopyableUDT value = absl::GetFlag(FLAGS_test_flag_ntc_udt); + EXPECT_EQ(value.c, 'A'); + + value.c = 'B'; + absl::SetFlag(&FLAGS_test_flag_ntc_udt, value); + value = absl::GetFlag(FLAGS_test_flag_ntc_udt); + EXPECT_EQ(value.c, 'B'); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/flag_test_defs.cc b/third_party/abseil_cpp/absl/flags/flag_test_defs.cc new file mode 100644 index 0000000000..49f91dee39 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/flag_test_defs.cc @@ -0,0 +1,24 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file is used to test the mismatch of the flag type between definition +// and declaration. These are definitions. flag_test.cc contains declarations. +#include <string> +#include "absl/flags/flag.h" + +ABSL_FLAG(int, mistyped_int_flag, 0, ""); +ABSL_FLAG(std::string, mistyped_string_flag, "", ""); +ABSL_RETIRED_FLAG(bool, old_bool_flag, true, + "repetition of retired flag definition"); diff --git a/third_party/abseil_cpp/absl/flags/internal/commandlineflag.cc b/third_party/abseil_cpp/absl/flags/internal/commandlineflag.cc new file mode 100644 index 0000000000..84112437d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/commandlineflag.cc @@ -0,0 +1,34 @@ +// +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/commandlineflag.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +FlagStateInterface::~FlagStateInterface() {} + +bool CommandLineFlag::IsRetired() const { return false; } + +bool CommandLineFlag::ParseFrom(absl::string_view value, std::string* error) { + return ParseFrom(value, flags_internal::SET_FLAGS_VALUE, + flags_internal::kProgrammaticChange, error); +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + diff --git a/third_party/abseil_cpp/absl/flags/internal/commandlineflag.h b/third_party/abseil_cpp/absl/flags/internal/commandlineflag.h new file mode 100644 index 0000000000..fa050209b0 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/commandlineflag.h @@ -0,0 +1,185 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_COMMANDLINEFLAG_H_ +#define ABSL_FLAGS_INTERNAL_COMMANDLINEFLAG_H_ + +#include <memory> +#include <string> + +#include "absl/base/config.h" +#include "absl/base/internal/fast_type_id.h" +#include "absl/base/macros.h" +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// An alias for flag fast type id. This value identifies the flag value type +// simialarly to typeid(T), without relying on RTTI being available. In most +// cases this id is enough to uniquely identify the flag's value type. In a few +// cases we'll have to resort to using actual RTTI implementation if it is +// available. +using FlagFastTypeId = base_internal::FastTypeIdType; + +// Options that control SetCommandLineOptionWithMode. +enum FlagSettingMode { + // update the flag's value unconditionally (can call this multiple times). + SET_FLAGS_VALUE, + // update the flag's value, but *only if* it has not yet been updated + // with SET_FLAGS_VALUE, SET_FLAG_IF_DEFAULT, or "FLAGS_xxx = nondef". + SET_FLAG_IF_DEFAULT, + // set the flag's default value to this. If the flag has not been updated + // yet (via SET_FLAGS_VALUE, SET_FLAG_IF_DEFAULT, or "FLAGS_xxx = nondef") + // change the flag's current value to the new default value as well. + SET_FLAGS_DEFAULT +}; + +// Options that control ParseFrom: Source of a value. +enum ValueSource { + // Flag is being set by value specified on a command line. + kCommandLine, + // Flag is being set by value specified in the code. + kProgrammaticChange, +}; + +// Handle to FlagState objects. Specific flag state objects will restore state +// of a flag produced this flag state from method CommandLineFlag::SaveState(). +class FlagStateInterface { + public: + virtual ~FlagStateInterface(); + + // Restores the flag originated this object to the saved state. + virtual void Restore() const = 0; +}; + +// Holds all information for a flag. +class CommandLineFlag { + public: + constexpr CommandLineFlag() = default; + + // Not copyable/assignable. + CommandLineFlag(const CommandLineFlag&) = delete; + CommandLineFlag& operator=(const CommandLineFlag&) = delete; + + // Non-polymorphic access methods. + + // Return true iff flag has type T. + template <typename T> + inline bool IsOfType() const { + return TypeId() == base_internal::FastTypeId<T>(); + } + + // Attempts to retrieve the flag value. Returns value on success, + // absl::nullopt otherwise. + template <typename T> + absl::optional<T> TryGet() const { + if (IsRetired() || !IsOfType<T>()) { + return absl::nullopt; + } + + // Implementation notes: + // + // We are wrapping a union around the value of `T` to serve three purposes: + // + // 1. `U.value` has correct size and alignment for a value of type `T` + // 2. The `U.value` constructor is not invoked since U's constructor does + // not do it explicitly. + // 3. The `U.value` destructor is invoked since U's destructor does it + // explicitly. This makes `U` a kind of RAII wrapper around non default + // constructible value of T, which is destructed when we leave the + // scope. We do need to destroy U.value, which is constructed by + // CommandLineFlag::Read even though we left it in a moved-from state + // after std::move. + // + // All of this serves to avoid requiring `T` being default constructible. + union U { + T value; + U() {} + ~U() { value.~T(); } + }; + U u; + + Read(&u.value); + return std::move(u.value); + } + + // Polymorphic access methods + + // Returns name of this flag. + virtual absl::string_view Name() const = 0; + // Returns name of the file where this flag is defined. + virtual std::string Filename() const = 0; + // Returns help message associated with this flag. + virtual std::string Help() const = 0; + // Returns true iff this object corresponds to retired flag. + virtual bool IsRetired() const; + virtual std::string DefaultValue() const = 0; + virtual std::string CurrentValue() const = 0; + + // Sets the value of the flag based on specified string `value`. If the flag + // was successfully set to new value, it returns true. Otherwise, sets `error` + // to indicate the error, leaves the flag unchanged, and returns false. + bool ParseFrom(absl::string_view value, std::string* error); + + protected: + ~CommandLineFlag() = default; + + private: + friend class PrivateHandleAccessor; + + // Sets the value of the flag based on specified string `value`. If the flag + // was successfully set to new value, it returns true. Otherwise, sets `error` + // to indicate the error, leaves the flag unchanged, and returns false. There + // are three ways to set the flag's value: + // * Update the current flag value + // * Update the flag's default value + // * Update the current flag value if it was never set before + // The mode is selected based on `set_mode` parameter. + virtual bool ParseFrom(absl::string_view value, + flags_internal::FlagSettingMode set_mode, + flags_internal::ValueSource source, + std::string* error) = 0; + + // Returns id of the flag's value type. + virtual FlagFastTypeId TypeId() const = 0; + + // Interface to save flag to some persistent state. Returns current flag state + // or nullptr if flag does not support saving and restoring a state. + virtual std::unique_ptr<FlagStateInterface> SaveState() = 0; + + // Copy-construct a new value of the flag's type in a memory referenced by + // the dst based on the current flag's value. + virtual void Read(void* dst) const = 0; + + // To be deleted. Used to return true if flag's current value originated from + // command line. + virtual bool IsSpecifiedOnCommandLine() const = 0; + + // Validates supplied value usign validator or parseflag routine + virtual bool ValidateInputValue(absl::string_view value) const = 0; + + // Checks that flags default value can be converted to string and back to the + // flag's value type. + virtual void CheckDefaultValueParsingRoundtrip() const = 0; +}; + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_COMMANDLINEFLAG_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/commandlineflag_test.cc b/third_party/abseil_cpp/absl/flags/internal/commandlineflag_test.cc new file mode 100644 index 0000000000..0b5aea3792 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/commandlineflag_test.cc @@ -0,0 +1,233 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/commandlineflag.h" + +#include <memory> +#include <string> + +#include "gtest/gtest.h" +#include "absl/flags/flag.h" +#include "absl/flags/internal/private_handle_accessor.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/usage_config.h" +#include "absl/memory/memory.h" +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" + +ABSL_FLAG(int, int_flag, 201, "int_flag help"); +ABSL_FLAG(std::string, string_flag, "dflt", + absl::StrCat("string_flag", " help")); +ABSL_RETIRED_FLAG(bool, bool_retired_flag, false, "bool_retired_flag help"); + +namespace { + +namespace flags = absl::flags_internal; + +class CommandLineFlagTest : public testing::Test { + protected: + static void SetUpTestSuite() { + // Install a function to normalize filenames before this test is run. + absl::FlagsUsageConfig default_config; + default_config.normalize_filename = &CommandLineFlagTest::NormalizeFileName; + absl::SetFlagsUsageConfig(default_config); + } + + void SetUp() override { flag_saver_ = absl::make_unique<flags::FlagSaver>(); } + void TearDown() override { flag_saver_.reset(); } + + private: + static std::string NormalizeFileName(absl::string_view fname) { +#ifdef _WIN32 + std::string normalized(fname); + std::replace(normalized.begin(), normalized.end(), '\\', '/'); + fname = normalized; +#endif + return std::string(fname); + } + + std::unique_ptr<flags::FlagSaver> flag_saver_; +}; + +TEST_F(CommandLineFlagTest, TestAttributesAccessMethods) { + auto* flag_01 = flags::FindCommandLineFlag("int_flag"); + + ASSERT_TRUE(flag_01); + EXPECT_EQ(flag_01->Name(), "int_flag"); + EXPECT_EQ(flag_01->Help(), "int_flag help"); + EXPECT_TRUE(!flag_01->IsRetired()); + EXPECT_TRUE(flag_01->IsOfType<int>()); + EXPECT_TRUE( + absl::EndsWith(flag_01->Filename(), + "absl/flags/internal/commandlineflag_test.cc")) + << flag_01->Filename(); + + auto* flag_02 = flags::FindCommandLineFlag("string_flag"); + + ASSERT_TRUE(flag_02); + EXPECT_EQ(flag_02->Name(), "string_flag"); + EXPECT_EQ(flag_02->Help(), "string_flag help"); + EXPECT_TRUE(!flag_02->IsRetired()); + EXPECT_TRUE(flag_02->IsOfType<std::string>()); + EXPECT_TRUE( + absl::EndsWith(flag_02->Filename(), + "absl/flags/internal/commandlineflag_test.cc")) + << flag_02->Filename(); + + auto* flag_03 = flags::FindRetiredFlag("bool_retired_flag"); + + ASSERT_TRUE(flag_03); + EXPECT_EQ(flag_03->Name(), "bool_retired_flag"); + EXPECT_EQ(flag_03->Help(), ""); + EXPECT_TRUE(flag_03->IsRetired()); + EXPECT_TRUE(flag_03->IsOfType<bool>()); + EXPECT_EQ(flag_03->Filename(), "RETIRED"); +} + +// -------------------------------------------------------------------- + +TEST_F(CommandLineFlagTest, TestValueAccessMethods) { + absl::SetFlag(&FLAGS_int_flag, 301); + auto* flag_01 = flags::FindCommandLineFlag("int_flag"); + + ASSERT_TRUE(flag_01); + EXPECT_EQ(flag_01->CurrentValue(), "301"); + EXPECT_EQ(flag_01->DefaultValue(), "201"); + + absl::SetFlag(&FLAGS_string_flag, "new_str_value"); + auto* flag_02 = flags::FindCommandLineFlag("string_flag"); + + ASSERT_TRUE(flag_02); + EXPECT_EQ(flag_02->CurrentValue(), "new_str_value"); + EXPECT_EQ(flag_02->DefaultValue(), "dflt"); +} + +// -------------------------------------------------------------------- + +TEST_F(CommandLineFlagTest, TestParseFromCurrentValue) { + std::string err; + + auto* flag_01 = flags::FindCommandLineFlag("int_flag"); + EXPECT_FALSE( + flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "11", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 11); + EXPECT_FALSE( + flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "-123", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), -123); + EXPECT_FALSE( + flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(!flags::PrivateHandleAccessor::ParseFrom( + flag_01, "xyz", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), -123); + EXPECT_EQ(err, "Illegal value 'xyz' specified for flag 'int_flag'"); + EXPECT_FALSE( + flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(!flags::PrivateHandleAccessor::ParseFrom( + flag_01, "A1", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), -123); + EXPECT_EQ(err, "Illegal value 'A1' specified for flag 'int_flag'"); + EXPECT_FALSE( + flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "0x10", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 16); + EXPECT_FALSE( + flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "011", flags::SET_FLAGS_VALUE, flags::kCommandLine, &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 11); + EXPECT_TRUE(flags::PrivateHandleAccessor::IsSpecifiedOnCommandLine(*flag_01)); + + EXPECT_TRUE(!flags::PrivateHandleAccessor::ParseFrom( + flag_01, "", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, &err)); + EXPECT_EQ(err, "Illegal value '' specified for flag 'int_flag'"); + + auto* flag_02 = flags::FindCommandLineFlag("string_flag"); + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_02, "xyz", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), "xyz"); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_02, "", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), ""); +} + +// -------------------------------------------------------------------- + +TEST_F(CommandLineFlagTest, TestParseFromDefaultValue) { + std::string err; + + auto* flag_01 = flags::FindCommandLineFlag("int_flag"); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "111", flags::SET_FLAGS_DEFAULT, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(flag_01->DefaultValue(), "111"); + + auto* flag_02 = flags::FindCommandLineFlag("string_flag"); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_02, "abc", flags::SET_FLAGS_DEFAULT, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(flag_02->DefaultValue(), "abc"); +} + +// -------------------------------------------------------------------- + +TEST_F(CommandLineFlagTest, TestParseFromIfDefault) { + std::string err; + + auto* flag_01 = flags::FindCommandLineFlag("int_flag"); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "22", flags::SET_FLAG_IF_DEFAULT, flags::kProgrammaticChange, + &err)) + << err; + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 22); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "33", flags::SET_FLAG_IF_DEFAULT, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 22); + // EXPECT_EQ(err, "ERROR: int_flag is already set to 22"); + + // Reset back to default value + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "201", flags::SET_FLAGS_VALUE, flags::kProgrammaticChange, + &err)); + + EXPECT_TRUE(flags::PrivateHandleAccessor::ParseFrom( + flag_01, "33", flags::SET_FLAG_IF_DEFAULT, flags::kProgrammaticChange, + &err)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 201); + // EXPECT_EQ(err, "ERROR: int_flag is already set to 201"); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/internal/flag.cc b/third_party/abseil_cpp/absl/flags/internal/flag.cc new file mode 100644 index 0000000000..96c026dcb5 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/flag.cc @@ -0,0 +1,564 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/flag.h" + +#include <stddef.h> +#include <stdint.h> +#include <string.h> + +#include <atomic> +#include <memory> +#include <string> +#include <vector> + +#include "absl/base/attributes.h" +#include "absl/base/casts.h" +#include "absl/base/config.h" +#include "absl/base/const_init.h" +#include "absl/base/optimization.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/usage_config.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// The help message indicating that the commandline flag has been +// 'stripped'. It will not show up when doing "-help" and its +// variants. The flag is stripped if ABSL_FLAGS_STRIP_HELP is set to 1 +// before including absl/flags/flag.h +const char kStrippedFlagHelp[] = "\001\002\003\004 (unknown) \004\003\002\001"; + +namespace { + +// Currently we only validate flag values for user-defined flag types. +bool ShouldValidateFlagValue(FlagFastTypeId flag_type_id) { +#define DONT_VALIDATE(T, _) \ + if (flag_type_id == base_internal::FastTypeId<T>()) return false; + ABSL_FLAGS_INTERNAL_SUPPORTED_TYPES(DONT_VALIDATE) +#undef DONT_VALIDATE + + return true; +} + +// RAII helper used to temporarily unlock and relock `absl::Mutex`. +// This is used when we need to ensure that locks are released while +// invoking user supplied callbacks and then reacquired, since callbacks may +// need to acquire these locks themselves. +class MutexRelock { + public: + explicit MutexRelock(absl::Mutex* mu) : mu_(mu) { mu_->Unlock(); } + ~MutexRelock() { mu_->Lock(); } + + MutexRelock(const MutexRelock&) = delete; + MutexRelock& operator=(const MutexRelock&) = delete; + + private: + absl::Mutex* mu_; +}; + +} // namespace + +/////////////////////////////////////////////////////////////////////////////// +// Persistent state of the flag data. + +class FlagImpl; + +class FlagState : public flags_internal::FlagStateInterface { + public: + template <typename V> + FlagState(FlagImpl* flag_impl, const V& v, bool modified, + bool on_command_line, int64_t counter) + : flag_impl_(flag_impl), + value_(v), + modified_(modified), + on_command_line_(on_command_line), + counter_(counter) {} + + ~FlagState() override { + if (flag_impl_->ValueStorageKind() != FlagValueStorageKind::kAlignedBuffer) + return; + flags_internal::Delete(flag_impl_->op_, value_.heap_allocated); + } + + private: + friend class FlagImpl; + + // Restores the flag to the saved state. + void Restore() const override { + if (!flag_impl_->RestoreState(*this)) return; + + ABSL_INTERNAL_LOG( + INFO, absl::StrCat("Restore saved value of ", flag_impl_->Name(), + " to: ", flag_impl_->CurrentValue())); + } + + // Flag and saved flag data. + FlagImpl* flag_impl_; + union SavedValue { + explicit SavedValue(void* v) : heap_allocated(v) {} + explicit SavedValue(int64_t v) : one_word(v) {} + explicit SavedValue(flags_internal::AlignedTwoWords v) : two_words(v) {} + + void* heap_allocated; + int64_t one_word; + flags_internal::AlignedTwoWords two_words; + } value_; + bool modified_; + bool on_command_line_; + int64_t counter_; +}; + +/////////////////////////////////////////////////////////////////////////////// +// Flag implementation, which does not depend on flag value type. + +DynValueDeleter::DynValueDeleter(FlagOpFn op_arg) : op(op_arg) {} + +void DynValueDeleter::operator()(void* ptr) const { + if (op == nullptr) return; + + Delete(op, ptr); +} + +void FlagImpl::Init() { + new (&data_guard_) absl::Mutex; + + auto def_kind = static_cast<FlagDefaultKind>(def_kind_); + + switch (ValueStorageKind()) { + case FlagValueStorageKind::kAlignedBuffer: + // For this storage kind the default_value_ always points to gen_func + // during initialization. + assert(def_kind == FlagDefaultKind::kGenFunc); + (*default_value_.gen_func)(AlignedBufferValue()); + break; + case FlagValueStorageKind::kOneWordAtomic: { + alignas(int64_t) std::array<char, sizeof(int64_t)> buf{}; + if (def_kind == FlagDefaultKind::kGenFunc) { + (*default_value_.gen_func)(buf.data()); + } else { + assert(def_kind != FlagDefaultKind::kDynamicValue); + std::memcpy(buf.data(), &default_value_, Sizeof(op_)); + } + OneWordValue().store(absl::bit_cast<int64_t>(buf), + std::memory_order_release); + break; + } + case FlagValueStorageKind::kTwoWordsAtomic: { + // For this storage kind the default_value_ always points to gen_func + // during initialization. + assert(def_kind == FlagDefaultKind::kGenFunc); + alignas(AlignedTwoWords) std::array<char, sizeof(AlignedTwoWords)> buf{}; + (*default_value_.gen_func)(buf.data()); + auto atomic_value = absl::bit_cast<AlignedTwoWords>(buf); + TwoWordsValue().store(atomic_value, std::memory_order_release); + break; + } + } +} + +absl::Mutex* FlagImpl::DataGuard() const { + absl::call_once(const_cast<FlagImpl*>(this)->init_control_, &FlagImpl::Init, + const_cast<FlagImpl*>(this)); + + // data_guard_ is initialized inside Init. + return reinterpret_cast<absl::Mutex*>(&data_guard_); +} + +void FlagImpl::AssertValidType(FlagFastTypeId rhs_type_id, + const std::type_info* (*gen_rtti)()) const { + FlagFastTypeId lhs_type_id = flags_internal::FastTypeId(op_); + + // `rhs_type_id` is the fast type id corresponding to the declaration + // visibile at the call site. `lhs_type_id` is the fast type id + // corresponding to the type specified in flag definition. They must match + // for this operation to be well-defined. + if (ABSL_PREDICT_TRUE(lhs_type_id == rhs_type_id)) return; + + const std::type_info* lhs_runtime_type_id = + flags_internal::RuntimeTypeId(op_); + const std::type_info* rhs_runtime_type_id = (*gen_rtti)(); + + if (lhs_runtime_type_id == rhs_runtime_type_id) return; + +#if defined(ABSL_FLAGS_INTERNAL_HAS_RTTI) + if (*lhs_runtime_type_id == *rhs_runtime_type_id) return; +#endif + + ABSL_INTERNAL_LOG( + FATAL, absl::StrCat("Flag '", Name(), + "' is defined as one type and declared as another")); +} + +std::unique_ptr<void, DynValueDeleter> FlagImpl::MakeInitValue() const { + void* res = nullptr; + switch (DefaultKind()) { + case FlagDefaultKind::kDynamicValue: + res = flags_internal::Clone(op_, default_value_.dynamic_value); + break; + case FlagDefaultKind::kGenFunc: + res = flags_internal::Alloc(op_); + (*default_value_.gen_func)(res); + break; + default: + res = flags_internal::Clone(op_, &default_value_); + break; + } + return {res, DynValueDeleter{op_}}; +} + +void FlagImpl::StoreValue(const void* src) { + switch (ValueStorageKind()) { + case FlagValueStorageKind::kAlignedBuffer: + Copy(op_, src, AlignedBufferValue()); + break; + case FlagValueStorageKind::kOneWordAtomic: { + int64_t one_word_val = 0; + std::memcpy(&one_word_val, src, Sizeof(op_)); + OneWordValue().store(one_word_val, std::memory_order_release); + break; + } + case FlagValueStorageKind::kTwoWordsAtomic: { + AlignedTwoWords two_words_val{0, 0}; + std::memcpy(&two_words_val, src, Sizeof(op_)); + TwoWordsValue().store(two_words_val, std::memory_order_release); + break; + } + } + + modified_ = true; + ++counter_; + InvokeCallback(); +} + +absl::string_view FlagImpl::Name() const { return name_; } + +std::string FlagImpl::Filename() const { + return flags_internal::GetUsageConfig().normalize_filename(filename_); +} + +std::string FlagImpl::Help() const { + return HelpSourceKind() == FlagHelpKind::kLiteral ? help_.literal + : help_.gen_func(); +} + +FlagFastTypeId FlagImpl::TypeId() const { + return flags_internal::FastTypeId(op_); +} + +bool FlagImpl::IsSpecifiedOnCommandLine() const { + absl::MutexLock l(DataGuard()); + return on_command_line_; +} + +std::string FlagImpl::DefaultValue() const { + absl::MutexLock l(DataGuard()); + + auto obj = MakeInitValue(); + return flags_internal::Unparse(op_, obj.get()); +} + +std::string FlagImpl::CurrentValue() const { + auto* guard = DataGuard(); // Make sure flag initialized + switch (ValueStorageKind()) { + case FlagValueStorageKind::kAlignedBuffer: { + absl::MutexLock l(guard); + return flags_internal::Unparse(op_, AlignedBufferValue()); + } + case FlagValueStorageKind::kOneWordAtomic: { + const auto one_word_val = + absl::bit_cast<std::array<char, sizeof(int64_t)>>( + OneWordValue().load(std::memory_order_acquire)); + return flags_internal::Unparse(op_, one_word_val.data()); + } + case FlagValueStorageKind::kTwoWordsAtomic: { + const auto two_words_val = + absl::bit_cast<std::array<char, sizeof(AlignedTwoWords)>>( + TwoWordsValue().load(std::memory_order_acquire)); + return flags_internal::Unparse(op_, two_words_val.data()); + } + } + + return ""; +} + +void FlagImpl::SetCallback(const FlagCallbackFunc mutation_callback) { + absl::MutexLock l(DataGuard()); + + if (callback_ == nullptr) { + callback_ = new FlagCallback; + } + callback_->func = mutation_callback; + + InvokeCallback(); +} + +void FlagImpl::InvokeCallback() const { + if (!callback_) return; + + // Make a copy of the C-style function pointer that we are about to invoke + // before we release the lock guarding it. + FlagCallbackFunc cb = callback_->func; + + // If the flag has a mutation callback this function invokes it. While the + // callback is being invoked the primary flag's mutex is unlocked and it is + // re-locked back after call to callback is completed. Callback invocation is + // guarded by flag's secondary mutex instead which prevents concurrent + // callback invocation. Note that it is possible for other thread to grab the + // primary lock and update flag's value at any time during the callback + // invocation. This is by design. Callback can get a value of the flag if + // necessary, but it might be different from the value initiated the callback + // and it also can be different by the time the callback invocation is + // completed. Requires that *primary_lock be held in exclusive mode; it may be + // released and reacquired by the implementation. + MutexRelock relock(DataGuard()); + absl::MutexLock lock(&callback_->guard); + cb(); +} + +std::unique_ptr<FlagStateInterface> FlagImpl::SaveState() { + absl::MutexLock l(DataGuard()); + + bool modified = modified_; + bool on_command_line = on_command_line_; + switch (ValueStorageKind()) { + case FlagValueStorageKind::kAlignedBuffer: { + return absl::make_unique<FlagState>( + this, flags_internal::Clone(op_, AlignedBufferValue()), modified, + on_command_line, counter_); + } + case FlagValueStorageKind::kOneWordAtomic: { + return absl::make_unique<FlagState>( + this, OneWordValue().load(std::memory_order_acquire), modified, + on_command_line, counter_); + } + case FlagValueStorageKind::kTwoWordsAtomic: { + return absl::make_unique<FlagState>( + this, TwoWordsValue().load(std::memory_order_acquire), modified, + on_command_line, counter_); + } + } + return nullptr; +} + +bool FlagImpl::RestoreState(const FlagState& flag_state) { + absl::MutexLock l(DataGuard()); + + if (flag_state.counter_ == counter_) { + return false; + } + + switch (ValueStorageKind()) { + case FlagValueStorageKind::kAlignedBuffer: + StoreValue(flag_state.value_.heap_allocated); + break; + case FlagValueStorageKind::kOneWordAtomic: + StoreValue(&flag_state.value_.one_word); + break; + case FlagValueStorageKind::kTwoWordsAtomic: + StoreValue(&flag_state.value_.two_words); + break; + } + + modified_ = flag_state.modified_; + on_command_line_ = flag_state.on_command_line_; + + return true; +} + +template <typename StorageT> +StorageT* FlagImpl::OffsetValue() const { + char* p = reinterpret_cast<char*>(const_cast<FlagImpl*>(this)); + // The offset is deduced via Flag value type specific op_. + size_t offset = flags_internal::ValueOffset(op_); + + return reinterpret_cast<StorageT*>(p + offset); +} + +void* FlagImpl::AlignedBufferValue() const { + assert(ValueStorageKind() == FlagValueStorageKind::kAlignedBuffer); + return OffsetValue<void>(); +} + +std::atomic<int64_t>& FlagImpl::OneWordValue() const { + assert(ValueStorageKind() == FlagValueStorageKind::kOneWordAtomic); + return OffsetValue<FlagOneWordValue>()->value; +} + +std::atomic<AlignedTwoWords>& FlagImpl::TwoWordsValue() const { + assert(ValueStorageKind() == FlagValueStorageKind::kTwoWordsAtomic); + return OffsetValue<FlagTwoWordsValue>()->value; +} + +// Attempts to parse supplied `value` string using parsing routine in the `flag` +// argument. If parsing successful, this function replaces the dst with newly +// parsed value. In case if any error is encountered in either step, the error +// message is stored in 'err' +std::unique_ptr<void, DynValueDeleter> FlagImpl::TryParse( + absl::string_view value, std::string* err) const { + std::unique_ptr<void, DynValueDeleter> tentative_value = MakeInitValue(); + + std::string parse_err; + if (!flags_internal::Parse(op_, value, tentative_value.get(), &parse_err)) { + absl::string_view err_sep = parse_err.empty() ? "" : "; "; + *err = absl::StrCat("Illegal value '", value, "' specified for flag '", + Name(), "'", err_sep, parse_err); + return nullptr; + } + + return tentative_value; +} + +void FlagImpl::Read(void* dst) const { + auto* guard = DataGuard(); // Make sure flag initialized + switch (ValueStorageKind()) { + case FlagValueStorageKind::kAlignedBuffer: { + absl::MutexLock l(guard); + flags_internal::CopyConstruct(op_, AlignedBufferValue(), dst); + break; + } + case FlagValueStorageKind::kOneWordAtomic: { + const int64_t one_word_val = + OneWordValue().load(std::memory_order_acquire); + std::memcpy(dst, &one_word_val, Sizeof(op_)); + break; + } + case FlagValueStorageKind::kTwoWordsAtomic: { + const AlignedTwoWords two_words_val = + TwoWordsValue().load(std::memory_order_acquire); + std::memcpy(dst, &two_words_val, Sizeof(op_)); + break; + } + } +} + +void FlagImpl::Write(const void* src) { + absl::MutexLock l(DataGuard()); + + if (ShouldValidateFlagValue(flags_internal::FastTypeId(op_))) { + std::unique_ptr<void, DynValueDeleter> obj{flags_internal::Clone(op_, src), + DynValueDeleter{op_}}; + std::string ignored_error; + std::string src_as_str = flags_internal::Unparse(op_, src); + if (!flags_internal::Parse(op_, src_as_str, obj.get(), &ignored_error)) { + ABSL_INTERNAL_LOG(ERROR, absl::StrCat("Attempt to set flag '", Name(), + "' to invalid value ", src_as_str)); + } + } + + StoreValue(src); +} + +// Sets the value of the flag based on specified string `value`. If the flag +// was successfully set to new value, it returns true. Otherwise, sets `err` +// to indicate the error, leaves the flag unchanged, and returns false. There +// are three ways to set the flag's value: +// * Update the current flag value +// * Update the flag's default value +// * Update the current flag value if it was never set before +// The mode is selected based on 'set_mode' parameter. +bool FlagImpl::ParseFrom(absl::string_view value, FlagSettingMode set_mode, + ValueSource source, std::string* err) { + absl::MutexLock l(DataGuard()); + + switch (set_mode) { + case SET_FLAGS_VALUE: { + // set or modify the flag's value + auto tentative_value = TryParse(value, err); + if (!tentative_value) return false; + + StoreValue(tentative_value.get()); + + if (source == kCommandLine) { + on_command_line_ = true; + } + break; + } + case SET_FLAG_IF_DEFAULT: { + // set the flag's value, but only if it hasn't been set by someone else + if (modified_) { + // TODO(rogeeff): review and fix this semantic. Currently we do not fail + // in this case if flag is modified. This is misleading since the flag's + // value is not updated even though we return true. + // *err = absl::StrCat(Name(), " is already set to ", + // CurrentValue(), "\n"); + // return false; + return true; + } + auto tentative_value = TryParse(value, err); + if (!tentative_value) return false; + + StoreValue(tentative_value.get()); + break; + } + case SET_FLAGS_DEFAULT: { + auto tentative_value = TryParse(value, err); + if (!tentative_value) return false; + + if (DefaultKind() == FlagDefaultKind::kDynamicValue) { + void* old_value = default_value_.dynamic_value; + default_value_.dynamic_value = tentative_value.release(); + tentative_value.reset(old_value); + } else { + default_value_.dynamic_value = tentative_value.release(); + def_kind_ = static_cast<uint8_t>(FlagDefaultKind::kDynamicValue); + } + + if (!modified_) { + // Need to set both default value *and* current, in this case. + StoreValue(default_value_.dynamic_value); + modified_ = false; + } + break; + } + } + + return true; +} + +void FlagImpl::CheckDefaultValueParsingRoundtrip() const { + std::string v = DefaultValue(); + + absl::MutexLock lock(DataGuard()); + + auto dst = MakeInitValue(); + std::string error; + if (!flags_internal::Parse(op_, v, dst.get(), &error)) { + ABSL_INTERNAL_LOG( + FATAL, + absl::StrCat("Flag ", Name(), " (from ", Filename(), + "): string form of default value '", v, + "' could not be parsed; error=", error)); + } + + // We do not compare dst to def since parsing/unparsing may make + // small changes, e.g., precision loss for floating point types. +} + +bool FlagImpl::ValidateInputValue(absl::string_view value) const { + absl::MutexLock l(DataGuard()); + + auto obj = MakeInitValue(); + std::string ignored_error; + return flags_internal::Parse(op_, value, obj.get(), &ignored_error); +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/internal/flag.h b/third_party/abseil_cpp/absl/flags/internal/flag.h new file mode 100644 index 0000000000..e374ecde3d --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/flag.h @@ -0,0 +1,745 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_FLAG_H_ +#define ABSL_FLAGS_INTERNAL_FLAG_H_ + +#include <stdint.h> + +#include <atomic> +#include <cstring> +#include <memory> +#include <string> +#include <type_traits> +#include <typeinfo> + +#include "absl/base/call_once.h" +#include "absl/base/config.h" +#include "absl/base/thread_annotations.h" +#include "absl/flags/config.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/marshalling.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Forward declaration of absl::Flag<T> public API. +namespace flags_internal { +template <typename T> +class Flag; +} // namespace flags_internal + +#if defined(_MSC_VER) && !defined(__clang__) +template <typename T> +class Flag; +#else +template <typename T> +using Flag = flags_internal::Flag<T>; +#endif + +template <typename T> +ABSL_MUST_USE_RESULT T GetFlag(const absl::Flag<T>& flag); + +template <typename T> +void SetFlag(absl::Flag<T>* flag, const T& v); + +template <typename T, typename V> +void SetFlag(absl::Flag<T>* flag, const V& v); + +namespace flags_internal { + +/////////////////////////////////////////////////////////////////////////////// +// Flag value type operations, eg., parsing, copying, etc. are provided +// by function specific to that type with a signature matching FlagOpFn. + +enum class FlagOp { + kAlloc, + kDelete, + kCopy, + kCopyConstruct, + kSizeof, + kFastTypeId, + kRuntimeTypeId, + kParse, + kUnparse, + kValueOffset, +}; +using FlagOpFn = void* (*)(FlagOp, const void*, void*, void*); + +// Forward declaration for Flag value specific operations. +template <typename T> +void* FlagOps(FlagOp op, const void* v1, void* v2, void* v3); + +// Allocate aligned memory for a flag value. +inline void* Alloc(FlagOpFn op) { + return op(FlagOp::kAlloc, nullptr, nullptr, nullptr); +} +// Deletes memory interpreting obj as flag value type pointer. +inline void Delete(FlagOpFn op, void* obj) { + op(FlagOp::kDelete, nullptr, obj, nullptr); +} +// Copies src to dst interpreting as flag value type pointers. +inline void Copy(FlagOpFn op, const void* src, void* dst) { + op(FlagOp::kCopy, src, dst, nullptr); +} +// Construct a copy of flag value in a location pointed by dst +// based on src - pointer to the flag's value. +inline void CopyConstruct(FlagOpFn op, const void* src, void* dst) { + op(FlagOp::kCopyConstruct, src, dst, nullptr); +} +// Makes a copy of flag value pointed by obj. +inline void* Clone(FlagOpFn op, const void* obj) { + void* res = flags_internal::Alloc(op); + flags_internal::CopyConstruct(op, obj, res); + return res; +} +// Returns true if parsing of input text is successfull. +inline bool Parse(FlagOpFn op, absl::string_view text, void* dst, + std::string* error) { + return op(FlagOp::kParse, &text, dst, error) != nullptr; +} +// Returns string representing supplied value. +inline std::string Unparse(FlagOpFn op, const void* val) { + std::string result; + op(FlagOp::kUnparse, val, &result, nullptr); + return result; +} +// Returns size of flag value type. +inline size_t Sizeof(FlagOpFn op) { + // This sequence of casts reverses the sequence from + // `flags_internal::FlagOps()` + return static_cast<size_t>(reinterpret_cast<intptr_t>( + op(FlagOp::kSizeof, nullptr, nullptr, nullptr))); +} +// Returns fast type id coresponding to the value type. +inline FlagFastTypeId FastTypeId(FlagOpFn op) { + return reinterpret_cast<FlagFastTypeId>( + op(FlagOp::kFastTypeId, nullptr, nullptr, nullptr)); +} +// Returns fast type id coresponding to the value type. +inline const std::type_info* RuntimeTypeId(FlagOpFn op) { + return reinterpret_cast<const std::type_info*>( + op(FlagOp::kRuntimeTypeId, nullptr, nullptr, nullptr)); +} +// Returns offset of the field value_ from the field impl_ inside of +// absl::Flag<T> data. Given FlagImpl pointer p you can get the +// location of the corresponding value as: +// reinterpret_cast<char*>(p) + ValueOffset(). +inline ptrdiff_t ValueOffset(FlagOpFn op) { + // This sequence of casts reverses the sequence from + // `flags_internal::FlagOps()` + return static_cast<ptrdiff_t>(reinterpret_cast<intptr_t>( + op(FlagOp::kValueOffset, nullptr, nullptr, nullptr))); +} + +// Returns an address of RTTI's typeid(T). +template <typename T> +inline const std::type_info* GenRuntimeTypeId() { +#if defined(ABSL_FLAGS_INTERNAL_HAS_RTTI) + return &typeid(T); +#else + return nullptr; +#endif +} + +/////////////////////////////////////////////////////////////////////////////// +// Flag help auxiliary structs. + +// This is help argument for absl::Flag encapsulating the string literal pointer +// or pointer to function generating it as well as enum descriminating two +// cases. +using HelpGenFunc = std::string (*)(); + +union FlagHelpMsg { + constexpr explicit FlagHelpMsg(const char* help_msg) : literal(help_msg) {} + constexpr explicit FlagHelpMsg(HelpGenFunc help_gen) : gen_func(help_gen) {} + + const char* literal; + HelpGenFunc gen_func; +}; + +enum class FlagHelpKind : uint8_t { kLiteral = 0, kGenFunc = 1 }; + +struct FlagHelpArg { + FlagHelpMsg source; + FlagHelpKind kind; +}; + +extern const char kStrippedFlagHelp[]; + +// HelpConstexprWrap is used by struct AbslFlagHelpGenFor##name generated by +// ABSL_FLAG macro. It is only used to silence the compiler in the case where +// help message expression is not constexpr and does not have type const char*. +// If help message expression is indeed constexpr const char* HelpConstexprWrap +// is just a trivial identity function. +template <typename T> +const char* HelpConstexprWrap(const T&) { + return nullptr; +} +constexpr const char* HelpConstexprWrap(const char* p) { return p; } +constexpr const char* HelpConstexprWrap(char* p) { return p; } + +// These two HelpArg overloads allows us to select at compile time one of two +// way to pass Help argument to absl::Flag. We'll be passing +// AbslFlagHelpGenFor##name as T and integer 0 as a single argument to prefer +// first overload if possible. If T::Const is evaluatable on constexpr +// context (see non template int parameter below) we'll choose first overload. +// In this case the help message expression is immediately evaluated and is used +// to construct the absl::Flag. No additionl code is generated by ABSL_FLAG. +// Otherwise SFINAE kicks in and first overload is dropped from the +// consideration, in which case the second overload will be used. The second +// overload does not attempt to evaluate the help message expression +// immediately and instead delays the evaluation by returing the function +// pointer (&T::NonConst) genering the help message when necessary. This is +// evaluatable in constexpr context, but the cost is an extra function being +// generated in the ABSL_FLAG code. +template <typename T, int = (T::Const(), 1)> +constexpr FlagHelpArg HelpArg(int) { + return {FlagHelpMsg(T::Const()), FlagHelpKind::kLiteral}; +} + +template <typename T> +constexpr FlagHelpArg HelpArg(char) { + return {FlagHelpMsg(&T::NonConst), FlagHelpKind::kGenFunc}; +} + +/////////////////////////////////////////////////////////////////////////////// +// Flag default value auxiliary structs. + +// Signature for the function generating the initial flag value (usually +// based on default value supplied in flag's definition) +using FlagDfltGenFunc = void (*)(void*); + +union FlagDefaultSrc { + constexpr explicit FlagDefaultSrc(FlagDfltGenFunc gen_func_arg) + : gen_func(gen_func_arg) {} + +#define ABSL_FLAGS_INTERNAL_DFLT_FOR_TYPE(T, name) \ + T name##_value; \ + constexpr explicit FlagDefaultSrc(T value) : name##_value(value) {} // NOLINT + ABSL_FLAGS_INTERNAL_BUILTIN_TYPES(ABSL_FLAGS_INTERNAL_DFLT_FOR_TYPE) +#undef ABSL_FLAGS_INTERNAL_DFLT_FOR_TYPE + + void* dynamic_value; + FlagDfltGenFunc gen_func; +}; + +enum class FlagDefaultKind : uint8_t { + kDynamicValue = 0, + kGenFunc = 1, + kOneWord = 2 // for default values UP to one word in size +}; + +struct FlagDefaultArg { + FlagDefaultSrc source; + FlagDefaultKind kind; +}; + +// This struct and corresponding overload to InitDefaultValue are used to +// facilitate usage of {} as default value in ABSL_FLAG macro. +// TODO(rogeeff): Fix handling types with explicit constructors. +struct EmptyBraces {}; + +template <typename T> +constexpr T InitDefaultValue(T t) { + return t; +} + +template <typename T> +constexpr T InitDefaultValue(EmptyBraces) { + return T{}; +} + +template <typename ValueT, typename GenT, + typename std::enable_if<std::is_integral<ValueT>::value, int>::type = + (GenT{}, 0)> +constexpr FlagDefaultArg DefaultArg(int) { + return {FlagDefaultSrc(GenT{}.value), FlagDefaultKind::kOneWord}; +} + +template <typename ValueT, typename GenT> +constexpr FlagDefaultArg DefaultArg(char) { + return {FlagDefaultSrc(&GenT::Gen), FlagDefaultKind::kGenFunc}; +} + +/////////////////////////////////////////////////////////////////////////////// +// Flag current value auxiliary structs. + +constexpr int64_t UninitializedFlagValue() { return 0xababababababababll; } + +template <typename T> +using FlagUseOneWordStorage = std::integral_constant< + bool, absl::type_traits_internal::is_trivially_copyable<T>::value && + (sizeof(T) <= 8)>; + +#if defined(ABSL_FLAGS_INTERNAL_ATOMIC_DOUBLE_WORD) +// Clang does not always produce cmpxchg16b instruction when alignment of a 16 +// bytes type is not 16. +struct alignas(16) AlignedTwoWords { + int64_t first; + int64_t second; + + bool IsInitialized() const { + return first != flags_internal::UninitializedFlagValue(); + } +}; + +template <typename T> +using FlagUseTwoWordsStorage = std::integral_constant< + bool, absl::type_traits_internal::is_trivially_copyable<T>::value && + (sizeof(T) > 8) && (sizeof(T) <= 16)>; +#else +// This is actually unused and only here to avoid ifdefs in other palces. +struct AlignedTwoWords { + constexpr AlignedTwoWords() noexcept : dummy() {} + constexpr AlignedTwoWords(int64_t, int64_t) noexcept : dummy() {} + char dummy; + + bool IsInitialized() const { + std::abort(); + return true; + } +}; + +// This trait should be type dependent, otherwise SFINAE below will fail +template <typename T> +using FlagUseTwoWordsStorage = + std::integral_constant<bool, sizeof(T) != sizeof(T)>; +#endif + +template <typename T> +using FlagUseBufferStorage = + std::integral_constant<bool, !FlagUseOneWordStorage<T>::value && + !FlagUseTwoWordsStorage<T>::value>; + +enum class FlagValueStorageKind : uint8_t { + kAlignedBuffer = 0, + kOneWordAtomic = 1, + kTwoWordsAtomic = 2 +}; + +template <typename T> +static constexpr FlagValueStorageKind StorageKind() { + return FlagUseBufferStorage<T>::value + ? FlagValueStorageKind::kAlignedBuffer + : FlagUseOneWordStorage<T>::value + ? FlagValueStorageKind::kOneWordAtomic + : FlagValueStorageKind::kTwoWordsAtomic; +} + +struct FlagOneWordValue { + constexpr FlagOneWordValue() : value(UninitializedFlagValue()) {} + + std::atomic<int64_t> value; +}; + +struct FlagTwoWordsValue { + constexpr FlagTwoWordsValue() + : value(AlignedTwoWords{UninitializedFlagValue(), 0}) {} + + std::atomic<AlignedTwoWords> value; +}; + +template <typename T, + FlagValueStorageKind Kind = flags_internal::StorageKind<T>()> +struct FlagValue; + +template <typename T> +struct FlagValue<T, FlagValueStorageKind::kAlignedBuffer> { + bool Get(T*) const { return false; } + + alignas(T) char value[sizeof(T)]; +}; + +template <typename T> +struct FlagValue<T, FlagValueStorageKind::kOneWordAtomic> : FlagOneWordValue { + bool Get(T* dst) const { + int64_t one_word_val = value.load(std::memory_order_acquire); + if (ABSL_PREDICT_FALSE(one_word_val == UninitializedFlagValue())) { + return false; + } + std::memcpy(dst, static_cast<const void*>(&one_word_val), sizeof(T)); + return true; + } +}; + +template <typename T> +struct FlagValue<T, FlagValueStorageKind::kTwoWordsAtomic> : FlagTwoWordsValue { + bool Get(T* dst) const { + AlignedTwoWords two_words_val = value.load(std::memory_order_acquire); + if (ABSL_PREDICT_FALSE(!two_words_val.IsInitialized())) { + return false; + } + std::memcpy(dst, static_cast<const void*>(&two_words_val), sizeof(T)); + return true; + } +}; + +/////////////////////////////////////////////////////////////////////////////// +// Flag callback auxiliary structs. + +// Signature for the mutation callback used by watched Flags +// The callback is noexcept. +// TODO(rogeeff): add noexcept after C++17 support is added. +using FlagCallbackFunc = void (*)(); + +struct FlagCallback { + FlagCallbackFunc func; + absl::Mutex guard; // Guard for concurrent callback invocations. +}; + +/////////////////////////////////////////////////////////////////////////////// +// Flag implementation, which does not depend on flag value type. +// The class encapsulates the Flag's data and access to it. + +struct DynValueDeleter { + explicit DynValueDeleter(FlagOpFn op_arg = nullptr); + void operator()(void* ptr) const; + + FlagOpFn op; +}; + +class FlagState; + +class FlagImpl final : public flags_internal::CommandLineFlag { + public: + constexpr FlagImpl(const char* name, const char* filename, FlagOpFn op, + FlagHelpArg help, FlagValueStorageKind value_kind, + FlagDefaultArg default_arg) + : name_(name), + filename_(filename), + op_(op), + help_(help.source), + help_source_kind_(static_cast<uint8_t>(help.kind)), + value_storage_kind_(static_cast<uint8_t>(value_kind)), + def_kind_(static_cast<uint8_t>(default_arg.kind)), + modified_(false), + on_command_line_(false), + counter_(0), + callback_(nullptr), + default_value_(default_arg.source), + data_guard_{} {} + + // Constant access methods + void Read(void* dst) const override ABSL_LOCKS_EXCLUDED(*DataGuard()); + + // Mutating access methods + void Write(const void* src) ABSL_LOCKS_EXCLUDED(*DataGuard()); + + // Interfaces to operate on callbacks. + void SetCallback(const FlagCallbackFunc mutation_callback) + ABSL_LOCKS_EXCLUDED(*DataGuard()); + void InvokeCallback() const ABSL_EXCLUSIVE_LOCKS_REQUIRED(*DataGuard()); + + // Used in read/write operations to validate source/target has correct type. + // For example if flag is declared as absl::Flag<int> FLAGS_foo, a call to + // absl::GetFlag(FLAGS_foo) validates that the type of FLAGS_foo is indeed + // int. To do that we pass the "assumed" type id (which is deduced from type + // int) as an argument `type_id`, which is in turn is validated against the + // type id stored in flag object by flag definition statement. + void AssertValidType(FlagFastTypeId type_id, + const std::type_info* (*gen_rtti)()) const; + + private: + template <typename T> + friend class Flag; + friend class FlagState; + + // Ensures that `data_guard_` is initialized and returns it. + absl::Mutex* DataGuard() const ABSL_LOCK_RETURNED((absl::Mutex*)&data_guard_); + // Returns heap allocated value of type T initialized with default value. + std::unique_ptr<void, DynValueDeleter> MakeInitValue() const + ABSL_EXCLUSIVE_LOCKS_REQUIRED(*DataGuard()); + // Flag initialization called via absl::call_once. + void Init(); + + // Offset value access methods. One per storage kind. These methods to not + // respect const correctness, so be very carefull using them. + + // This is a shared helper routine which encapsulates most of the magic. Since + // it is only used inside the three routines below, which are defined in + // flag.cc, we can define it in that file as well. + template <typename StorageT> + StorageT* OffsetValue() const; + // This is an accessor for a value stored in an aligned buffer storage. + // Returns a mutable pointer to the start of a buffer. + void* AlignedBufferValue() const; + // This is an accessor for a value stored as one word atomic. Returns a + // mutable reference to an atomic value. + std::atomic<int64_t>& OneWordValue() const; + // This is an accessor for a value stored as two words atomic. Returns a + // mutable reference to an atomic value. + std::atomic<AlignedTwoWords>& TwoWordsValue() const; + + // Attempts to parse supplied `value` string. If parsing is successful, + // returns new value. Otherwise returns nullptr. + std::unique_ptr<void, DynValueDeleter> TryParse(absl::string_view value, + std::string* err) const + ABSL_EXCLUSIVE_LOCKS_REQUIRED(*DataGuard()); + // Stores the flag value based on the pointer to the source. + void StoreValue(const void* src) ABSL_EXCLUSIVE_LOCKS_REQUIRED(*DataGuard()); + + FlagHelpKind HelpSourceKind() const { + return static_cast<FlagHelpKind>(help_source_kind_); + } + FlagValueStorageKind ValueStorageKind() const { + return static_cast<FlagValueStorageKind>(value_storage_kind_); + } + FlagDefaultKind DefaultKind() const + ABSL_EXCLUSIVE_LOCKS_REQUIRED(*DataGuard()) { + return static_cast<FlagDefaultKind>(def_kind_); + } + + // CommandLineFlag interface implementation + absl::string_view Name() const override; + std::string Filename() const override; + std::string Help() const override; + FlagFastTypeId TypeId() const override; + bool IsSpecifiedOnCommandLine() const override + ABSL_LOCKS_EXCLUDED(*DataGuard()); + std::string DefaultValue() const override ABSL_LOCKS_EXCLUDED(*DataGuard()); + std::string CurrentValue() const override ABSL_LOCKS_EXCLUDED(*DataGuard()); + bool ValidateInputValue(absl::string_view value) const override + ABSL_LOCKS_EXCLUDED(*DataGuard()); + void CheckDefaultValueParsingRoundtrip() const override + ABSL_LOCKS_EXCLUDED(*DataGuard()); + + // Interfaces to save and restore flags to/from persistent state. + // Returns current flag state or nullptr if flag does not support + // saving and restoring a state. + std::unique_ptr<FlagStateInterface> SaveState() override + ABSL_LOCKS_EXCLUDED(*DataGuard()); + + // Restores the flag state to the supplied state object. If there is + // nothing to restore returns false. Otherwise returns true. + bool RestoreState(const FlagState& flag_state) + ABSL_LOCKS_EXCLUDED(*DataGuard()); + + bool ParseFrom(absl::string_view value, FlagSettingMode set_mode, + ValueSource source, std::string* error) override + ABSL_LOCKS_EXCLUDED(*DataGuard()); + + // Immutable flag's state. + + // Flags name passed to ABSL_FLAG as second arg. + const char* const name_; + // The file name where ABSL_FLAG resides. + const char* const filename_; + // Type-specific operations "vtable". + const FlagOpFn op_; + // Help message literal or function to generate it. + const FlagHelpMsg help_; + // Indicates if help message was supplied as literal or generator func. + const uint8_t help_source_kind_ : 1; + // Kind of storage this flag is using for the flag's value. + const uint8_t value_storage_kind_ : 2; + + uint8_t : 0; // The bytes containing the const bitfields must not be + // shared with bytes containing the mutable bitfields. + + // Mutable flag's state (guarded by `data_guard_`). + + // def_kind_ is not guard by DataGuard() since it is accessed in Init without + // locks. + uint8_t def_kind_ : 2; + // Has this flag's value been modified? + bool modified_ : 1 ABSL_GUARDED_BY(*DataGuard()); + // Has this flag been specified on command line. + bool on_command_line_ : 1 ABSL_GUARDED_BY(*DataGuard()); + + // Unique tag for absl::call_once call to initialize this flag. + absl::once_flag init_control_; + + // Mutation counter + int64_t counter_ ABSL_GUARDED_BY(*DataGuard()); + // Optional flag's callback and absl::Mutex to guard the invocations. + FlagCallback* callback_ ABSL_GUARDED_BY(*DataGuard()); + // Either a pointer to the function generating the default value based on the + // value specified in ABSL_FLAG or pointer to the dynamically set default + // value via SetCommandLineOptionWithMode. def_kind_ is used to distinguish + // these two cases. + FlagDefaultSrc default_value_; + + // This is reserved space for an absl::Mutex to guard flag data. It will be + // initialized in FlagImpl::Init via placement new. + // We can't use "absl::Mutex data_guard_", since this class is not literal. + // We do not want to use "absl::Mutex* data_guard_", since this would require + // heap allocation during initialization, which is both slows program startup + // and can fail. Using reserved space + placement new allows us to avoid both + // problems. + alignas(absl::Mutex) mutable char data_guard_[sizeof(absl::Mutex)]; +}; + +/////////////////////////////////////////////////////////////////////////////// +// The Flag object parameterized by the flag's value type. This class implements +// flag reflection handle interface. + +template <typename T> +class Flag { + public: + constexpr Flag(const char* name, const char* filename, FlagHelpArg help, + const FlagDefaultArg default_arg) + : impl_(name, filename, &FlagOps<T>, help, + flags_internal::StorageKind<T>(), default_arg), + value_() {} + + // CommandLineFlag interface + absl::string_view Name() const { return impl_.Name(); } + std::string Filename() const { return impl_.Filename(); } + std::string Help() const { return impl_.Help(); } + // Do not use. To be removed. + bool IsSpecifiedOnCommandLine() const { + return impl_.IsSpecifiedOnCommandLine(); + } + std::string DefaultValue() const { return impl_.DefaultValue(); } + std::string CurrentValue() const { return impl_.CurrentValue(); } + + private: + template <typename U, bool do_register> + friend class FlagRegistrar; + +#if !defined(_MSC_VER) || defined(__clang__) + template <typename U> + friend U absl::GetFlag(const flags_internal::Flag<U>& flag); + template <typename U> + friend void absl::SetFlag(flags_internal::Flag<U>* flag, const U& v); + template <typename U, typename V> + friend void absl::SetFlag(flags_internal::Flag<U>* flag, const V& v); +#else + template <typename U> + friend class absl::Flag; +#endif + + T Get() const { + // See implementation notes in CommandLineFlag::Get(). + union U { + T value; + U() {} + ~U() { value.~T(); } + }; + U u; + +#if !defined(NDEBUG) + impl_.AssertValidType(base_internal::FastTypeId<T>(), &GenRuntimeTypeId<T>); +#endif + + if (!value_.Get(&u.value)) impl_.Read(&u.value); + return std::move(u.value); + } + void Set(const T& v) { + impl_.AssertValidType(base_internal::FastTypeId<T>(), &GenRuntimeTypeId<T>); + impl_.Write(&v); + } + + // Flag's data + // The implementation depends on value_ field to be placed exactly after the + // impl_ field, so that impl_ can figure out the offset to the value and + // access it. + FlagImpl impl_; + FlagValue<T> value_; +}; + +/////////////////////////////////////////////////////////////////////////////// +// Implementation of Flag value specific operations routine. +template <typename T> +void* FlagOps(FlagOp op, const void* v1, void* v2, void* v3) { + switch (op) { + case FlagOp::kAlloc: { + std::allocator<T> alloc; + return std::allocator_traits<std::allocator<T>>::allocate(alloc, 1); + } + case FlagOp::kDelete: { + T* p = static_cast<T*>(v2); + p->~T(); + std::allocator<T> alloc; + std::allocator_traits<std::allocator<T>>::deallocate(alloc, p, 1); + return nullptr; + } + case FlagOp::kCopy: + *static_cast<T*>(v2) = *static_cast<const T*>(v1); + return nullptr; + case FlagOp::kCopyConstruct: + new (v2) T(*static_cast<const T*>(v1)); + return nullptr; + case FlagOp::kSizeof: + return reinterpret_cast<void*>(static_cast<uintptr_t>(sizeof(T))); + case FlagOp::kFastTypeId: + return const_cast<void*>(base_internal::FastTypeId<T>()); + case FlagOp::kRuntimeTypeId: + return const_cast<std::type_info*>(GenRuntimeTypeId<T>()); + case FlagOp::kParse: { + // Initialize the temporary instance of type T based on current value in + // destination (which is going to be flag's default value). + T temp(*static_cast<T*>(v2)); + if (!absl::ParseFlag<T>(*static_cast<const absl::string_view*>(v1), &temp, + static_cast<std::string*>(v3))) { + return nullptr; + } + *static_cast<T*>(v2) = std::move(temp); + return v2; + } + case FlagOp::kUnparse: + *static_cast<std::string*>(v2) = + absl::UnparseFlag<T>(*static_cast<const T*>(v1)); + return nullptr; + case FlagOp::kValueOffset: { + // Round sizeof(FlagImp) to a multiple of alignof(FlagValue<T>) to get the + // offset of the data. + ptrdiff_t round_to = alignof(FlagValue<T>); + ptrdiff_t offset = + (sizeof(FlagImpl) + round_to - 1) / round_to * round_to; + return reinterpret_cast<void*>(offset); + } + } + return nullptr; +} + +/////////////////////////////////////////////////////////////////////////////// +// This class facilitates Flag object registration and tail expression-based +// flag definition, for example: +// ABSL_FLAG(int, foo, 42, "Foo help").OnUpdate(NotifyFooWatcher); +struct FlagRegistrarEmpty {}; +template <typename T, bool do_register> +class FlagRegistrar { + public: + explicit FlagRegistrar(Flag<T>* flag) : flag_(flag) { + if (do_register) flags_internal::RegisterCommandLineFlag(&flag_->impl_); + } + + FlagRegistrar OnUpdate(FlagCallbackFunc cb) && { + flag_->impl_.SetCallback(cb); + return *this; + } + + // Make the registrar "die" gracefully as an empty struct on a line where + // registration happens. Registrar objects are intended to live only as + // temporary. + operator FlagRegistrarEmpty() const { return {}; } // NOLINT + + private: + Flag<T>* flag_; // Flag being registered (not owned). +}; + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_FLAG_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/parse.h b/third_party/abseil_cpp/absl/flags/internal/parse.h new file mode 100644 index 0000000000..d259be733c --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/parse.h @@ -0,0 +1,58 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_PARSE_H_ +#define ABSL_FLAGS_INTERNAL_PARSE_H_ + +#include <string> +#include <vector> + +#include "absl/base/config.h" +#include "absl/flags/declare.h" + +ABSL_DECLARE_FLAG(std::vector<std::string>, flagfile); +ABSL_DECLARE_FLAG(std::vector<std::string>, fromenv); +ABSL_DECLARE_FLAG(std::vector<std::string>, tryfromenv); +ABSL_DECLARE_FLAG(std::vector<std::string>, undefok); + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +enum class ArgvListAction { kRemoveParsedArgs, kKeepParsedArgs }; +enum class UsageFlagsAction { kHandleUsage, kIgnoreUsage }; +enum class OnUndefinedFlag { + kIgnoreUndefined, + kReportUndefined, + kAbortIfUndefined +}; + +std::vector<char*> ParseCommandLineImpl(int argc, char* argv[], + ArgvListAction arg_list_act, + UsageFlagsAction usage_flag_act, + OnUndefinedFlag on_undef_flag); + +// -------------------------------------------------------------------- +// Inspect original command line + +// Returns true if flag with specified name was either present on the original +// command line or specified in flag file present on the original command line. +bool WasPresentOnCommandLine(absl::string_view flag_name); + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_PARSE_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/path_util.h b/third_party/abseil_cpp/absl/flags/internal/path_util.h new file mode 100644 index 0000000000..365c830522 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/path_util.h @@ -0,0 +1,63 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_PATH_UTIL_H_ +#define ABSL_FLAGS_INTERNAL_PATH_UTIL_H_ + +#include "absl/base/config.h" +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// A portable interface that returns the basename of the filename passed as an +// argument. It is similar to basename(3) +// <https://linux.die.net/man/3/basename>. +// For example: +// flags_internal::Basename("a/b/prog/file.cc") +// returns "file.cc" +// flags_internal::Basename("file.cc") +// returns "file.cc" +inline absl::string_view Basename(absl::string_view filename) { + auto last_slash_pos = filename.find_last_of("/\\"); + + return last_slash_pos == absl::string_view::npos + ? filename + : filename.substr(last_slash_pos + 1); +} + +// A portable interface that returns the directory name of the filename +// passed as an argument, including the trailing slash. +// Returns the empty string if a slash is not found in the input file name. +// For example: +// flags_internal::Package("a/b/prog/file.cc") +// returns "a/b/prog/" +// flags_internal::Package("file.cc") +// returns "" +inline absl::string_view Package(absl::string_view filename) { + auto last_slash_pos = filename.find_last_of("/\\"); + + return last_slash_pos == absl::string_view::npos + ? absl::string_view() + : filename.substr(0, last_slash_pos + 1); +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_PATH_UTIL_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/path_util_test.cc b/third_party/abseil_cpp/absl/flags/internal/path_util_test.cc new file mode 100644 index 0000000000..2091373c88 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/path_util_test.cc @@ -0,0 +1,46 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/path_util.h" + +#include "gtest/gtest.h" + +namespace { + +namespace flags = absl::flags_internal; + +TEST(FlagsPathUtilTest, TestBasename) { + EXPECT_EQ(flags::Basename(""), ""); + EXPECT_EQ(flags::Basename("a.cc"), "a.cc"); + EXPECT_EQ(flags::Basename("dir/a.cc"), "a.cc"); + EXPECT_EQ(flags::Basename("dir1/dir2/a.cc"), "a.cc"); + EXPECT_EQ(flags::Basename("../dir1/dir2/a.cc"), "a.cc"); + EXPECT_EQ(flags::Basename("/dir1/dir2/a.cc"), "a.cc"); + EXPECT_EQ(flags::Basename("/dir1/dir2/../dir3/a.cc"), "a.cc"); +} + +// -------------------------------------------------------------------- + +TEST(FlagsPathUtilTest, TestPackage) { + EXPECT_EQ(flags::Package(""), ""); + EXPECT_EQ(flags::Package("a.cc"), ""); + EXPECT_EQ(flags::Package("dir/a.cc"), "dir/"); + EXPECT_EQ(flags::Package("dir1/dir2/a.cc"), "dir1/dir2/"); + EXPECT_EQ(flags::Package("../dir1/dir2/a.cc"), "../dir1/dir2/"); + EXPECT_EQ(flags::Package("/dir1/dir2/a.cc"), "/dir1/dir2/"); + EXPECT_EQ(flags::Package("/dir1/dir2/../dir3/a.cc"), "/dir1/dir2/../dir3/"); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/internal/private_handle_accessor.cc b/third_party/abseil_cpp/absl/flags/internal/private_handle_accessor.cc new file mode 100644 index 0000000000..64fe31663a --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/private_handle_accessor.cc @@ -0,0 +1,57 @@ +// +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/private_handle_accessor.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +FlagFastTypeId PrivateHandleAccessor::TypeId(const CommandLineFlag& flag) { + return flag.TypeId(); +} + +std::unique_ptr<FlagStateInterface> PrivateHandleAccessor::SaveState( + CommandLineFlag* flag) { + return flag->SaveState(); +} + +bool PrivateHandleAccessor::IsSpecifiedOnCommandLine( + const CommandLineFlag& flag) { + return flag.IsSpecifiedOnCommandLine(); +} + +bool PrivateHandleAccessor::ValidateInputValue(const CommandLineFlag& flag, + absl::string_view value) { + return flag.ValidateInputValue(value); +} + +void PrivateHandleAccessor::CheckDefaultValueParsingRoundtrip( + const CommandLineFlag& flag) { + flag.CheckDefaultValueParsingRoundtrip(); +} + +bool PrivateHandleAccessor::ParseFrom(CommandLineFlag* flag, + absl::string_view value, + flags_internal::FlagSettingMode set_mode, + flags_internal::ValueSource source, + std::string* error) { + return flag->ParseFrom(value, set_mode, source, error); +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + diff --git a/third_party/abseil_cpp/absl/flags/internal/private_handle_accessor.h b/third_party/abseil_cpp/absl/flags/internal/private_handle_accessor.h new file mode 100644 index 0000000000..40591de447 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/private_handle_accessor.h @@ -0,0 +1,55 @@ +// +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_PRIVATE_HANDLE_ACCESSOR_H_ +#define ABSL_FLAGS_INTERNAL_PRIVATE_HANDLE_ACCESSOR_H_ + +#include "absl/flags/internal/commandlineflag.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// This class serves as a trampoline to access private methods of +// CommandLineFlag. This class is intended for use exclusively internally inside +// of the Abseil Flags implementation. +class PrivateHandleAccessor { + public: + // Access to CommandLineFlag::TypeId. + static FlagFastTypeId TypeId(const CommandLineFlag& flag); + + // Access to CommandLineFlag::SaveState. + static std::unique_ptr<FlagStateInterface> SaveState(CommandLineFlag* flag); + + // Access to CommandLineFlag::IsSpecifiedOnCommandLine. + static bool IsSpecifiedOnCommandLine(const CommandLineFlag& flag); + + // Access to CommandLineFlag::ValidateInputValue. + static bool ValidateInputValue(const CommandLineFlag& flag, + absl::string_view value); + + // Access to CommandLineFlag::CheckDefaultValueParsingRoundtrip. + static void CheckDefaultValueParsingRoundtrip(const CommandLineFlag& flag); + + static bool ParseFrom(CommandLineFlag* flag, absl::string_view value, + flags_internal::FlagSettingMode set_mode, + flags_internal::ValueSource source, std::string* error); +}; + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_PRIVATE_HANDLE_ACCESSOR_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/program_name.cc b/third_party/abseil_cpp/absl/flags/internal/program_name.cc new file mode 100644 index 0000000000..51d698da8b --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/program_name.cc @@ -0,0 +1,60 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/program_name.h" + +#include <string> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/const_init.h" +#include "absl/base/thread_annotations.h" +#include "absl/flags/internal/path_util.h" +#include "absl/strings/string_view.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +ABSL_CONST_INIT static absl::Mutex program_name_guard(absl::kConstInit); +ABSL_CONST_INIT static std::string* program_name + ABSL_GUARDED_BY(program_name_guard) = nullptr; + +std::string ProgramInvocationName() { + absl::MutexLock l(&program_name_guard); + + return program_name ? *program_name : "UNKNOWN"; +} + +std::string ShortProgramInvocationName() { + absl::MutexLock l(&program_name_guard); + + return program_name ? std::string(flags_internal::Basename(*program_name)) + : "UNKNOWN"; +} + +void SetProgramInvocationName(absl::string_view prog_name_str) { + absl::MutexLock l(&program_name_guard); + + if (!program_name) + program_name = new std::string(prog_name_str); + else + program_name->assign(prog_name_str.data(), prog_name_str.size()); +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/internal/program_name.h b/third_party/abseil_cpp/absl/flags/internal/program_name.h new file mode 100644 index 0000000000..b99b94fe18 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/program_name.h @@ -0,0 +1,50 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_PROGRAM_NAME_H_ +#define ABSL_FLAGS_INTERNAL_PROGRAM_NAME_H_ + +#include <string> + +#include "absl/base/config.h" +#include "absl/strings/string_view.h" + +// -------------------------------------------------------------------- +// Program name + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// Returns program invocation name or "UNKNOWN" if `SetProgramInvocationName()` +// is never called. At the moment this is always set to argv[0] as part of +// library initialization. +std::string ProgramInvocationName(); + +// Returns base name for program invocation name. For example, if +// ProgramInvocationName() == "a/b/mybinary" +// then +// ShortProgramInvocationName() == "mybinary" +std::string ShortProgramInvocationName(); + +// Sets program invocation name to a new value. Should only be called once +// during program initialization, before any threads are spawned. +void SetProgramInvocationName(absl::string_view prog_name_str); + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_PROGRAM_NAME_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/program_name_test.cc b/third_party/abseil_cpp/absl/flags/internal/program_name_test.cc new file mode 100644 index 0000000000..269142f225 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/program_name_test.cc @@ -0,0 +1,63 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/program_name.h" + +#include <string> + +#include "gtest/gtest.h" +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" + +namespace { + +namespace flags = absl::flags_internal; + +TEST(FlagsPathUtilTest, TestInitialProgamName) { + flags::SetProgramInvocationName("absl/flags/program_name_test"); + std::string program_name = flags::ProgramInvocationName(); + for (char& c : program_name) + if (c == '\\') c = '/'; + +#if !defined(__wasm__) && !defined(__asmjs__) + const std::string expect_name = "absl/flags/program_name_test"; + const std::string expect_basename = "program_name_test"; +#else + // For targets that generate javascript or webassembly the invocation name + // has the special value below. + const std::string expect_name = "this.program"; + const std::string expect_basename = "this.program"; +#endif + + EXPECT_TRUE(absl::EndsWith(program_name, expect_name)) << program_name; + EXPECT_EQ(flags::ShortProgramInvocationName(), expect_basename); +} + +TEST(FlagsPathUtilTest, TestProgamNameInterfaces) { + flags::SetProgramInvocationName("a/my_test"); + + EXPECT_EQ(flags::ProgramInvocationName(), "a/my_test"); + EXPECT_EQ(flags::ShortProgramInvocationName(), "my_test"); + + absl::string_view not_null_terminated("absl/aaa/bbb"); + not_null_terminated = not_null_terminated.substr(1, 10); + + flags::SetProgramInvocationName(not_null_terminated); + + EXPECT_EQ(flags::ProgramInvocationName(), "bsl/aaa/bb"); + EXPECT_EQ(flags::ShortProgramInvocationName(), "bb"); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/internal/registry.cc b/third_party/abseil_cpp/absl/flags/internal/registry.cc new file mode 100644 index 0000000000..3b941f04c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/registry.cc @@ -0,0 +1,350 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/registry.h" + +#include <assert.h> +#include <stdlib.h> + +#include <functional> +#include <map> +#include <memory> +#include <string> +#include <utility> +#include <vector> + +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/thread_annotations.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/private_handle_accessor.h" +#include "absl/flags/usage_config.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/synchronization/mutex.h" + +// -------------------------------------------------------------------- +// FlagRegistry implementation +// A FlagRegistry holds all flag objects indexed +// by their names so that if you know a flag's name you can access or +// set it. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// -------------------------------------------------------------------- +// FlagRegistry +// A FlagRegistry singleton object holds all flag objects indexed +// by their names so that if you know a flag's name (as a C +// string), you can access or set it. If the function is named +// FooLocked(), you must own the registry lock before calling +// the function; otherwise, you should *not* hold the lock, and +// the function will acquire it itself if needed. +// -------------------------------------------------------------------- + +class FlagRegistry { + public: + FlagRegistry() = default; + ~FlagRegistry() = default; + + // Store a flag in this registry. Takes ownership of *flag. + void RegisterFlag(CommandLineFlag* flag); + + void Lock() ABSL_EXCLUSIVE_LOCK_FUNCTION(lock_) { lock_.Lock(); } + void Unlock() ABSL_UNLOCK_FUNCTION(lock_) { lock_.Unlock(); } + + // Returns the flag object for the specified name, or nullptr if not found. + // Will emit a warning if a 'retired' flag is specified. + CommandLineFlag* FindFlagLocked(absl::string_view name); + + // Returns the retired flag object for the specified name, or nullptr if not + // found or not retired. Does not emit a warning. + CommandLineFlag* FindRetiredFlagLocked(absl::string_view name); + + static FlagRegistry* GlobalRegistry(); // returns a singleton registry + + private: + friend class FlagSaverImpl; // reads all the flags in order to copy them + friend void ForEachFlagUnlocked( + std::function<void(CommandLineFlag*)> visitor); + + // The map from name to flag, for FindFlagLocked(). + using FlagMap = std::map<absl::string_view, CommandLineFlag*>; + using FlagIterator = FlagMap::iterator; + using FlagConstIterator = FlagMap::const_iterator; + FlagMap flags_; + + absl::Mutex lock_; + + // Disallow + FlagRegistry(const FlagRegistry&); + FlagRegistry& operator=(const FlagRegistry&); +}; + +FlagRegistry* FlagRegistry::GlobalRegistry() { + static FlagRegistry* global_registry = new FlagRegistry; + return global_registry; +} + +namespace { + +class FlagRegistryLock { + public: + explicit FlagRegistryLock(FlagRegistry* fr) : fr_(fr) { fr_->Lock(); } + ~FlagRegistryLock() { fr_->Unlock(); } + + private: + FlagRegistry* const fr_; +}; + +void DestroyRetiredFlag(CommandLineFlag* flag); +} // namespace + +void FlagRegistry::RegisterFlag(CommandLineFlag* flag) { + FlagRegistryLock registry_lock(this); + std::pair<FlagIterator, bool> ins = + flags_.insert(FlagMap::value_type(flag->Name(), flag)); + if (ins.second == false) { // means the name was already in the map + CommandLineFlag* old_flag = ins.first->second; + if (flag->IsRetired() != old_flag->IsRetired()) { + // All registrations must agree on the 'retired' flag. + flags_internal::ReportUsageError( + absl::StrCat( + "Retired flag '", flag->Name(), + "' was defined normally in file '", + (flag->IsRetired() ? old_flag->Filename() : flag->Filename()), + "'."), + true); + } else if (flags_internal::PrivateHandleAccessor::TypeId(*flag) != + flags_internal::PrivateHandleAccessor::TypeId(*old_flag)) { + flags_internal::ReportUsageError( + absl::StrCat("Flag '", flag->Name(), + "' was defined more than once but with " + "differing types. Defined in files '", + old_flag->Filename(), "' and '", flag->Filename(), "'."), + true); + } else if (old_flag->IsRetired()) { + // Retired flag can just be deleted. + DestroyRetiredFlag(flag); + return; + } else if (old_flag->Filename() != flag->Filename()) { + flags_internal::ReportUsageError( + absl::StrCat("Flag '", flag->Name(), + "' was defined more than once (in files '", + old_flag->Filename(), "' and '", flag->Filename(), + "')."), + true); + } else { + flags_internal::ReportUsageError( + absl::StrCat( + "Something wrong with flag '", flag->Name(), "' in file '", + flag->Filename(), "'. One possibility: file '", flag->Filename(), + "' is being linked both statically and dynamically into this " + "executable. e.g. some files listed as srcs to a test and also " + "listed as srcs of some shared lib deps of the same test."), + true); + } + // All cases above are fatal, except for the retired flags. + std::exit(1); + } +} + +CommandLineFlag* FlagRegistry::FindFlagLocked(absl::string_view name) { + FlagConstIterator i = flags_.find(name); + if (i == flags_.end()) { + return nullptr; + } + + if (i->second->IsRetired()) { + flags_internal::ReportUsageError( + absl::StrCat("Accessing retired flag '", name, "'"), false); + } + + return i->second; +} + +CommandLineFlag* FlagRegistry::FindRetiredFlagLocked(absl::string_view name) { + FlagConstIterator i = flags_.find(name); + if (i == flags_.end() || !i->second->IsRetired()) { + return nullptr; + } + + return i->second; +} + +// -------------------------------------------------------------------- +// FlagSaver +// FlagSaverImpl +// This class stores the states of all flags at construct time, +// and restores all flags to that state at destruct time. +// Its major implementation challenge is that it never modifies +// pointers in the 'main' registry, so global FLAG_* vars always +// point to the right place. +// -------------------------------------------------------------------- + +class FlagSaverImpl { + public: + FlagSaverImpl() = default; + FlagSaverImpl(const FlagSaverImpl&) = delete; + void operator=(const FlagSaverImpl&) = delete; + + // Saves the flag states from the flag registry into this object. + // It's an error to call this more than once. + void SaveFromRegistry() { + assert(backup_registry_.empty()); // call only once! + flags_internal::ForEachFlag([&](flags_internal::CommandLineFlag* flag) { + if (auto flag_state = + flags_internal::PrivateHandleAccessor::SaveState(flag)) { + backup_registry_.emplace_back(std::move(flag_state)); + } + }); + } + + // Restores the saved flag states into the flag registry. + void RestoreToRegistry() { + for (const auto& flag_state : backup_registry_) { + flag_state->Restore(); + } + } + + private: + std::vector<std::unique_ptr<flags_internal::FlagStateInterface>> + backup_registry_; +}; + +FlagSaver::FlagSaver() : impl_(new FlagSaverImpl) { impl_->SaveFromRegistry(); } + +void FlagSaver::Ignore() { + delete impl_; + impl_ = nullptr; +} + +FlagSaver::~FlagSaver() { + if (!impl_) return; + + impl_->RestoreToRegistry(); + delete impl_; +} + +// -------------------------------------------------------------------- + +CommandLineFlag* FindCommandLineFlag(absl::string_view name) { + if (name.empty()) return nullptr; + FlagRegistry* const registry = FlagRegistry::GlobalRegistry(); + FlagRegistryLock frl(registry); + + return registry->FindFlagLocked(name); +} + +CommandLineFlag* FindRetiredFlag(absl::string_view name) { + FlagRegistry* const registry = FlagRegistry::GlobalRegistry(); + FlagRegistryLock frl(registry); + + return registry->FindRetiredFlagLocked(name); +} + +// -------------------------------------------------------------------- + +void ForEachFlagUnlocked(std::function<void(CommandLineFlag*)> visitor) { + FlagRegistry* const registry = FlagRegistry::GlobalRegistry(); + for (FlagRegistry::FlagConstIterator i = registry->flags_.begin(); + i != registry->flags_.end(); ++i) { + visitor(i->second); + } +} + +void ForEachFlag(std::function<void(CommandLineFlag*)> visitor) { + FlagRegistry* const registry = FlagRegistry::GlobalRegistry(); + FlagRegistryLock frl(registry); + ForEachFlagUnlocked(visitor); +} + +// -------------------------------------------------------------------- + +bool RegisterCommandLineFlag(CommandLineFlag* flag) { + FlagRegistry::GlobalRegistry()->RegisterFlag(flag); + return true; +} + +// -------------------------------------------------------------------- + +namespace { + +class RetiredFlagObj final : public flags_internal::CommandLineFlag { + public: + constexpr RetiredFlagObj(const char* name, FlagFastTypeId type_id) + : name_(name), type_id_(type_id) {} + + private: + absl::string_view Name() const override { return name_; } + std::string Filename() const override { return "RETIRED"; } + FlagFastTypeId TypeId() const override { return type_id_; } + std::string Help() const override { return ""; } + bool IsRetired() const override { return true; } + bool IsSpecifiedOnCommandLine() const override { return false; } + std::string DefaultValue() const override { return ""; } + std::string CurrentValue() const override { return ""; } + + // Any input is valid + bool ValidateInputValue(absl::string_view) const override { return true; } + + std::unique_ptr<flags_internal::FlagStateInterface> SaveState() override { + return nullptr; + } + + bool ParseFrom(absl::string_view, flags_internal::FlagSettingMode, + flags_internal::ValueSource, std::string*) override { + return false; + } + + void CheckDefaultValueParsingRoundtrip() const override {} + + void Read(void*) const override {} + + // Data members + const char* const name_; + const FlagFastTypeId type_id_; +}; + +void DestroyRetiredFlag(flags_internal::CommandLineFlag* flag) { + assert(flag->IsRetired()); + delete static_cast<RetiredFlagObj*>(flag); +} + +} // namespace + +bool Retire(const char* name, FlagFastTypeId type_id) { + auto* flag = new flags_internal::RetiredFlagObj(name, type_id); + FlagRegistry::GlobalRegistry()->RegisterFlag(flag); + return true; +} + +// -------------------------------------------------------------------- + +bool IsRetiredFlag(absl::string_view name, bool* type_is_bool) { + assert(!name.empty()); + CommandLineFlag* flag = flags_internal::FindRetiredFlag(name); + if (flag == nullptr) { + return false; + } + assert(type_is_bool); + *type_is_bool = flag->IsOfType<bool>(); + return true; +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/internal/registry.h b/third_party/abseil_cpp/absl/flags/internal/registry.h new file mode 100644 index 0000000000..af8ed6b99b --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/registry.h @@ -0,0 +1,124 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_REGISTRY_H_ +#define ABSL_FLAGS_INTERNAL_REGISTRY_H_ + +#include <functional> +#include <map> +#include <string> + +#include "absl/base/config.h" +#include "absl/base/macros.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/strings/string_view.h" + +// -------------------------------------------------------------------- +// Global flags registry API. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +CommandLineFlag* FindCommandLineFlag(absl::string_view name); +CommandLineFlag* FindRetiredFlag(absl::string_view name); + +// Executes specified visitor for each non-retired flag in the registry. +// Requires the caller hold the registry lock. +void ForEachFlagUnlocked(std::function<void(CommandLineFlag*)> visitor); +// Executes specified visitor for each non-retired flag in the registry. While +// callback are executed, the registry is locked and can't be changed. +void ForEachFlag(std::function<void(CommandLineFlag*)> visitor); + +//----------------------------------------------------------------------------- + +bool RegisterCommandLineFlag(CommandLineFlag*); + +//----------------------------------------------------------------------------- +// Retired registrations: +// +// Retired flag registrations are treated specially. A 'retired' flag is +// provided only for compatibility with automated invocations that still +// name it. A 'retired' flag: +// - is not bound to a C++ FLAGS_ reference. +// - has a type and a value, but that value is intentionally inaccessible. +// - does not appear in --help messages. +// - is fully supported by _all_ flag parsing routines. +// - consumes args normally, and complains about type mismatches in its +// argument. +// - emits a complaint but does not die (e.g. LOG(ERROR)) if it is +// accessed by name through the flags API for parsing or otherwise. +// +// The registrations for a flag happen in an unspecified order as the +// initializers for the namespace-scope objects of a program are run. +// Any number of weak registrations for a flag can weakly define the flag. +// One non-weak registration will upgrade the flag from weak to non-weak. +// Further weak registrations of a non-weak flag are ignored. +// +// This mechanism is designed to support moving dead flags into a +// 'graveyard' library. An example migration: +// +// 0: Remove references to this FLAGS_flagname in the C++ codebase. +// 1: Register as 'retired' in old_lib. +// 2: Make old_lib depend on graveyard. +// 3: Add a redundant 'retired' registration to graveyard. +// 4: Remove the old_lib 'retired' registration. +// 5: Eventually delete the graveyard registration entirely. +// + +// Retire flag with name "name" and type indicated by ops. +bool Retire(const char* name, FlagFastTypeId type_id); + +// Registered a retired flag with name 'flag_name' and type 'T'. +template <typename T> +inline bool RetiredFlag(const char* flag_name) { + return flags_internal::Retire(flag_name, base_internal::FastTypeId<T>()); +} + +// If the flag is retired, returns true and indicates in |*type_is_bool| +// whether the type of the retired flag is a bool. +// Only to be called by code that needs to explicitly ignore retired flags. +bool IsRetiredFlag(absl::string_view name, bool* type_is_bool); + +//----------------------------------------------------------------------------- +// Saves the states (value, default value, whether the user has set +// the flag, registered validators, etc) of all flags, and restores +// them when the FlagSaver is destroyed. +// +// This class is thread-safe. However, its destructor writes to +// exactly the set of flags that have changed value during its +// lifetime, so concurrent _direct_ access to those flags +// (i.e. FLAGS_foo instead of {Get,Set}CommandLineOption()) is unsafe. + +class FlagSaver { + public: + FlagSaver(); + ~FlagSaver(); + + FlagSaver(const FlagSaver&) = delete; + void operator=(const FlagSaver&) = delete; + + // Prevents saver from restoring the saved state of flags. + void Ignore(); + + private: + class FlagSaverImpl* impl_; // we use pimpl here to keep API steady +}; + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_REGISTRY_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/type_erased.cc b/third_party/abseil_cpp/absl/flags/internal/type_erased.cc new file mode 100644 index 0000000000..c13fb9b0d4 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/type_erased.cc @@ -0,0 +1,86 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/type_erased.h" + +#include <assert.h> + +#include <string> + +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/private_handle_accessor.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/usage_config.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +bool GetCommandLineOption(absl::string_view name, std::string* value) { + if (name.empty()) return false; + assert(value); + + CommandLineFlag* flag = flags_internal::FindCommandLineFlag(name); + if (flag == nullptr || flag->IsRetired()) { + return false; + } + + *value = flag->CurrentValue(); + return true; +} + +bool SetCommandLineOption(absl::string_view name, absl::string_view value) { + return SetCommandLineOptionWithMode(name, value, + flags_internal::SET_FLAGS_VALUE); +} + +bool SetCommandLineOptionWithMode(absl::string_view name, + absl::string_view value, + FlagSettingMode set_mode) { + CommandLineFlag* flag = flags_internal::FindCommandLineFlag(name); + + if (!flag || flag->IsRetired()) return false; + + std::string error; + if (!flags_internal::PrivateHandleAccessor::ParseFrom( + flag, value, set_mode, kProgrammaticChange, &error)) { + // Errors here are all of the form: the provided name was a recognized + // flag, but the value was invalid (bad type, or validation failed). + flags_internal::ReportUsageError(error, false); + return false; + } + + return true; +} + +// -------------------------------------------------------------------- + +bool IsValidFlagValue(absl::string_view name, absl::string_view value) { + CommandLineFlag* flag = flags_internal::FindCommandLineFlag(name); + + return flag != nullptr && + (flag->IsRetired() || + flags_internal::PrivateHandleAccessor::ValidateInputValue(*flag, + value)); +} + +// -------------------------------------------------------------------- + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/internal/type_erased.h b/third_party/abseil_cpp/absl/flags/internal/type_erased.h new file mode 100644 index 0000000000..b43a0ff7be --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/type_erased.h @@ -0,0 +1,79 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_TYPE_ERASED_H_ +#define ABSL_FLAGS_INTERNAL_TYPE_ERASED_H_ + +#include <string> + +#include "absl/base/config.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/registry.h" +#include "absl/strings/string_view.h" + +// -------------------------------------------------------------------- +// Registry interfaces operating on type erased handles. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// If a flag named "name" exists, store its current value in *OUTPUT +// and return true. Else return false without changing *OUTPUT. +// Thread-safe. +bool GetCommandLineOption(absl::string_view name, std::string* value); + +// Set the value of the flag named "name" to value. If successful, +// returns true. If not successful (e.g., the flag was not found or +// the value is not a valid value), returns false. +// Thread-safe. +bool SetCommandLineOption(absl::string_view name, absl::string_view value); + +bool SetCommandLineOptionWithMode(absl::string_view name, + absl::string_view value, + FlagSettingMode set_mode); + +//----------------------------------------------------------------------------- + +// Returns true iff all of the following conditions are true: +// (a) "name" names a registered flag +// (b) "value" can be parsed succesfully according to the type of the flag +// (c) parsed value passes any validator associated with the flag +bool IsValidFlagValue(absl::string_view name, absl::string_view value); + +//----------------------------------------------------------------------------- + +// If a flag with specified "name" exists and has type T, store +// its current value in *dst and return true. Else return false +// without touching *dst. T must obey all of the requirements for +// types passed to DEFINE_FLAG. +template <typename T> +inline bool GetByName(absl::string_view name, T* dst) { + CommandLineFlag* flag = flags_internal::FindCommandLineFlag(name); + if (!flag) return false; + + if (auto val = flag->TryGet<T>()) { + *dst = *val; + return true; + } + + return false; +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_INTERNAL_TYPE_ERASED_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/type_erased_test.cc b/third_party/abseil_cpp/absl/flags/internal/type_erased_test.cc new file mode 100644 index 0000000000..4ce5981047 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/type_erased_test.cc @@ -0,0 +1,157 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/type_erased.h" + +#include <memory> +#include <string> + +#include "gtest/gtest.h" +#include "absl/flags/flag.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/marshalling.h" +#include "absl/memory/memory.h" + +ABSL_FLAG(int, int_flag, 1, "int_flag help"); +ABSL_FLAG(std::string, string_flag, "dflt", "string_flag help"); +ABSL_RETIRED_FLAG(bool, bool_retired_flag, false, "bool_retired_flag help"); + +namespace { + +namespace flags = absl::flags_internal; + +class TypeErasedTest : public testing::Test { + protected: + void SetUp() override { flag_saver_ = absl::make_unique<flags::FlagSaver>(); } + void TearDown() override { flag_saver_.reset(); } + + private: + std::unique_ptr<flags::FlagSaver> flag_saver_; +}; + +// -------------------------------------------------------------------- + +TEST_F(TypeErasedTest, TestGetCommandLineOption) { + std::string value; + EXPECT_TRUE(flags::GetCommandLineOption("int_flag", &value)); + EXPECT_EQ(value, "1"); + + EXPECT_TRUE(flags::GetCommandLineOption("string_flag", &value)); + EXPECT_EQ(value, "dflt"); + + EXPECT_FALSE(flags::GetCommandLineOption("bool_retired_flag", &value)); + + EXPECT_FALSE(flags::GetCommandLineOption("unknown_flag", &value)); +} + +// -------------------------------------------------------------------- + +TEST_F(TypeErasedTest, TestSetCommandLineOption) { + EXPECT_TRUE(flags::SetCommandLineOption("int_flag", "101")); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 101); + + EXPECT_TRUE(flags::SetCommandLineOption("string_flag", "asdfgh")); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), "asdfgh"); + + EXPECT_FALSE(flags::SetCommandLineOption("bool_retired_flag", "true")); + + EXPECT_FALSE(flags::SetCommandLineOption("unknown_flag", "true")); +} + +// -------------------------------------------------------------------- + +TEST_F(TypeErasedTest, TestSetCommandLineOptionWithMode_SET_FLAGS_VALUE) { + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "101", + flags::SET_FLAGS_VALUE)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 101); + + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("string_flag", "asdfgh", + flags::SET_FLAGS_VALUE)); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), "asdfgh"); + + EXPECT_FALSE(flags::SetCommandLineOptionWithMode("bool_retired_flag", "true", + flags::SET_FLAGS_VALUE)); + + EXPECT_FALSE(flags::SetCommandLineOptionWithMode("unknown_flag", "true", + flags::SET_FLAGS_VALUE)); +} + +// -------------------------------------------------------------------- + +TEST_F(TypeErasedTest, TestSetCommandLineOptionWithMode_SET_FLAG_IF_DEFAULT) { + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "101", + flags::SET_FLAG_IF_DEFAULT)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 101); + + // This semantic is broken. We return true instead of false. Value is not + // updated. + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "202", + flags::SET_FLAG_IF_DEFAULT)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 101); + + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("string_flag", "asdfgh", + flags::SET_FLAG_IF_DEFAULT)); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), "asdfgh"); + + EXPECT_FALSE(flags::SetCommandLineOptionWithMode("bool_retired_flag", "true", + flags::SET_FLAG_IF_DEFAULT)); + + EXPECT_FALSE(flags::SetCommandLineOptionWithMode("unknown_flag", "true", + flags::SET_FLAG_IF_DEFAULT)); +} + +// -------------------------------------------------------------------- + +TEST_F(TypeErasedTest, TestSetCommandLineOptionWithMode_SET_FLAGS_DEFAULT) { + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "101", + flags::SET_FLAGS_DEFAULT)); + + // Set it again to ensure that resetting logic is covered. + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "102", + flags::SET_FLAGS_DEFAULT)); + + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "103", + flags::SET_FLAGS_DEFAULT)); + + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("string_flag", "asdfgh", + flags::SET_FLAGS_DEFAULT)); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), "asdfgh"); + + EXPECT_FALSE(flags::SetCommandLineOptionWithMode("bool_retired_flag", "true", + flags::SET_FLAGS_DEFAULT)); + + EXPECT_FALSE(flags::SetCommandLineOptionWithMode("unknown_flag", "true", + flags::SET_FLAGS_DEFAULT)); + + // This should be successfull, since flag is still is not set + EXPECT_TRUE(flags::SetCommandLineOptionWithMode("int_flag", "202", + flags::SET_FLAG_IF_DEFAULT)); + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 202); +} + +// -------------------------------------------------------------------- + +TEST_F(TypeErasedTest, TestIsValidFlagValue) { + EXPECT_TRUE(flags::IsValidFlagValue("int_flag", "57")); + EXPECT_TRUE(flags::IsValidFlagValue("int_flag", "-101")); + EXPECT_FALSE(flags::IsValidFlagValue("int_flag", "1.1")); + + EXPECT_TRUE(flags::IsValidFlagValue("string_flag", "#%^#%^$%DGHDG$W%adsf")); + + EXPECT_TRUE(flags::IsValidFlagValue("bool_retired_flag", "true")); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/internal/usage.cc b/third_party/abseil_cpp/absl/flags/internal/usage.cc new file mode 100644 index 0000000000..10accc46f3 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/usage.cc @@ -0,0 +1,392 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/usage.h" + +#include <functional> +#include <map> +#include <ostream> +#include <string> +#include <utility> +#include <vector> + +#include "absl/base/config.h" +#include "absl/flags/flag.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/flag.h" +#include "absl/flags/internal/path_util.h" +#include "absl/flags/internal/private_handle_accessor.h" +#include "absl/flags/internal/program_name.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/usage_config.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" + +ABSL_FLAG(bool, help, false, + "show help on important flags for this binary [tip: all flags can " + "have two dashes]"); +ABSL_FLAG(bool, helpfull, false, "show help on all flags"); +ABSL_FLAG(bool, helpshort, false, + "show help on only the main module for this program"); +ABSL_FLAG(bool, helppackage, false, + "show help on all modules in the main package"); +ABSL_FLAG(bool, version, false, "show version and build info and exit"); +ABSL_FLAG(bool, only_check_args, false, "exit after checking all flags"); +ABSL_FLAG(std::string, helpon, "", + "show help on the modules named by this flag value"); +ABSL_FLAG(std::string, helpmatch, "", + "show help on modules whose name contains the specified substr"); + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { +namespace { + +// This class is used to emit an XML element with `tag` and `text`. +// It adds opening and closing tags and escapes special characters in the text. +// For example: +// std::cout << XMLElement("title", "Milk & Cookies"); +// prints "<title>Milk & Cookies</title>" +class XMLElement { + public: + XMLElement(absl::string_view tag, absl::string_view txt) + : tag_(tag), txt_(txt) {} + + friend std::ostream& operator<<(std::ostream& out, + const XMLElement& xml_elem) { + out << "<" << xml_elem.tag_ << ">"; + + for (auto c : xml_elem.txt_) { + switch (c) { + case '"': + out << """; + break; + case '\'': + out << "'"; + break; + case '&': + out << "&"; + break; + case '<': + out << "<"; + break; + case '>': + out << ">"; + break; + default: + out << c; + break; + } + } + + return out << "</" << xml_elem.tag_ << ">"; + } + + private: + absl::string_view tag_; + absl::string_view txt_; +}; + +// -------------------------------------------------------------------- +// Helper class to pretty-print info about a flag. + +class FlagHelpPrettyPrinter { + public: + // Pretty printer holds on to the std::ostream& reference to direct an output + // to that stream. + FlagHelpPrettyPrinter(int max_line_len, std::ostream* out) + : out_(*out), + max_line_len_(max_line_len), + line_len_(0), + first_line_(true) {} + + void Write(absl::string_view str, bool wrap_line = false) { + // Empty string - do nothing. + if (str.empty()) return; + + std::vector<absl::string_view> tokens; + if (wrap_line) { + for (auto line : absl::StrSplit(str, absl::ByAnyChar("\n\r"))) { + if (!tokens.empty()) { + // Keep line separators in the input string. + tokens.push_back("\n"); + } + for (auto token : + absl::StrSplit(line, absl::ByAnyChar(" \t"), absl::SkipEmpty())) { + tokens.push_back(token); + } + } + } else { + tokens.push_back(str); + } + + for (auto token : tokens) { + bool new_line = (line_len_ == 0); + + // Respect line separators in the input string. + if (token == "\n") { + EndLine(); + continue; + } + + // Write the token, ending the string first if necessary/possible. + if (!new_line && (line_len_ + token.size() >= max_line_len_)) { + EndLine(); + new_line = true; + } + + if (new_line) { + StartLine(); + } else { + out_ << ' '; + ++line_len_; + } + + out_ << token; + line_len_ += token.size(); + } + } + + void StartLine() { + if (first_line_) { + out_ << " "; + line_len_ = 4; + first_line_ = false; + } else { + out_ << " "; + line_len_ = 6; + } + } + void EndLine() { + out_ << '\n'; + line_len_ = 0; + } + + private: + std::ostream& out_; + const int max_line_len_; + int line_len_; + bool first_line_; +}; + +void FlagHelpHumanReadable(const flags_internal::CommandLineFlag& flag, + std::ostream* out) { + FlagHelpPrettyPrinter printer(80, out); // Max line length is 80. + + // Flag name. + printer.Write(absl::StrCat("--", flag.Name())); + + // Flag help. + printer.Write(absl::StrCat("(", flag.Help(), ");"), /*wrap_line=*/true); + + // The listed default value will be the actual default from the flag + // definition in the originating source file, unless the value has + // subsequently been modified using SetCommandLineOption() with mode + // SET_FLAGS_DEFAULT. + std::string dflt_val = flag.DefaultValue(); + std::string curr_val = flag.CurrentValue(); + bool is_modified = curr_val != dflt_val; + + if (flag.IsOfType<std::string>()) { + dflt_val = absl::StrCat("\"", dflt_val, "\""); + } + printer.Write(absl::StrCat("default: ", dflt_val, ";")); + + if (is_modified) { + if (flag.IsOfType<std::string>()) { + curr_val = absl::StrCat("\"", curr_val, "\""); + } + printer.Write(absl::StrCat("currently: ", curr_val, ";")); + } + + printer.EndLine(); +} + +// Shows help for every filename which matches any of the filters +// If filters are empty, shows help for every file. +// If a flag's help message has been stripped (e.g. by adding '#define +// STRIP_FLAG_HELP 1' then this flag will not be displayed by '--help' +// and its variants. +void FlagsHelpImpl(std::ostream& out, flags_internal::FlagKindFilter filter_cb, + HelpFormat format, absl::string_view program_usage_message) { + if (format == HelpFormat::kHumanReadable) { + out << flags_internal::ShortProgramInvocationName() << ": " + << program_usage_message << "\n\n"; + } else { + // XML schema is not a part of our public API for now. + out << "<?xml version=\"1.0\"?>\n" + << "<!-- This output should be used with care. We do not report type " + "names for flags with user defined types -->\n" + << "<!-- Prefer flag only_check_args for validating flag inputs -->\n" + // The document. + << "<AllFlags>\n" + // The program name and usage. + << XMLElement("program", flags_internal::ShortProgramInvocationName()) + << '\n' + << XMLElement("usage", program_usage_message) << '\n'; + } + + // Map of package name to + // map of file name to + // vector of flags in the file. + // This map is used to output matching flags grouped by package and file + // name. + std::map<std::string, + std::map<std::string, + std::vector<const flags_internal::CommandLineFlag*>>> + matching_flags; + + flags_internal::ForEachFlag([&](flags_internal::CommandLineFlag* flag) { + std::string flag_filename = flag->Filename(); + + // Ignore retired flags. + if (flag->IsRetired()) return; + + // If the flag has been stripped, pretend that it doesn't exist. + if (flag->Help() == flags_internal::kStrippedFlagHelp) return; + + // Make sure flag satisfies the filter + if (!filter_cb || !filter_cb(flag_filename)) return; + + matching_flags[std::string(flags_internal::Package(flag_filename))] + [flag_filename] + .push_back(flag); + }); + + absl::string_view + package_separator; // controls blank lines between packages. + absl::string_view file_separator; // controls blank lines between files. + for (const auto& package : matching_flags) { + if (format == HelpFormat::kHumanReadable) { + out << package_separator; + package_separator = "\n\n"; + } + + file_separator = ""; + for (const auto& flags_in_file : package.second) { + if (format == HelpFormat::kHumanReadable) { + out << file_separator << " Flags from " << flags_in_file.first + << ":\n"; + file_separator = "\n"; + } + + for (const auto* flag : flags_in_file.second) { + flags_internal::FlagHelp(out, *flag, format); + } + } + } + + if (format == HelpFormat::kHumanReadable) { + if (filter_cb && matching_flags.empty()) { + out << " No modules matched: use -helpfull\n"; + } + } else { + // The end of the document. + out << "</AllFlags>\n"; + } +} + +} // namespace + +// -------------------------------------------------------------------- +// Produces the help message describing specific flag. +void FlagHelp(std::ostream& out, const flags_internal::CommandLineFlag& flag, + HelpFormat format) { + if (format == HelpFormat::kHumanReadable) + flags_internal::FlagHelpHumanReadable(flag, &out); +} + +// -------------------------------------------------------------------- +// Produces the help messages for all flags matching the filter. +// If filter is empty produces help messages for all flags. +void FlagsHelp(std::ostream& out, absl::string_view filter, HelpFormat format, + absl::string_view program_usage_message) { + flags_internal::FlagKindFilter filter_cb = [&](absl::string_view filename) { + return filter.empty() || filename.find(filter) != absl::string_view::npos; + }; + flags_internal::FlagsHelpImpl(out, filter_cb, format, program_usage_message); +} + +// -------------------------------------------------------------------- +// Checks all the 'usage' command line flags to see if any have been set. +// If so, handles them appropriately. +int HandleUsageFlags(std::ostream& out, + absl::string_view program_usage_message) { + if (absl::GetFlag(FLAGS_helpshort)) { + flags_internal::FlagsHelpImpl( + out, flags_internal::GetUsageConfig().contains_helpshort_flags, + HelpFormat::kHumanReadable, program_usage_message); + return 1; + } + + if (absl::GetFlag(FLAGS_helpfull)) { + // show all options + flags_internal::FlagsHelp(out, "", HelpFormat::kHumanReadable, + program_usage_message); + return 1; + } + + if (!absl::GetFlag(FLAGS_helpon).empty()) { + flags_internal::FlagsHelp( + out, absl::StrCat("/", absl::GetFlag(FLAGS_helpon), "."), + HelpFormat::kHumanReadable, program_usage_message); + return 1; + } + + if (!absl::GetFlag(FLAGS_helpmatch).empty()) { + flags_internal::FlagsHelp(out, absl::GetFlag(FLAGS_helpmatch), + HelpFormat::kHumanReadable, + program_usage_message); + return 1; + } + + if (absl::GetFlag(FLAGS_help)) { + flags_internal::FlagsHelpImpl( + out, flags_internal::GetUsageConfig().contains_help_flags, + HelpFormat::kHumanReadable, program_usage_message); + + out << "\nTry --helpfull to get a list of all flags.\n"; + + return 1; + } + + if (absl::GetFlag(FLAGS_helppackage)) { + flags_internal::FlagsHelpImpl( + out, flags_internal::GetUsageConfig().contains_helppackage_flags, + HelpFormat::kHumanReadable, program_usage_message); + + out << "\nTry --helpfull to get a list of all flags.\n"; + + return 1; + } + + if (absl::GetFlag(FLAGS_version)) { + if (flags_internal::GetUsageConfig().version_string) + out << flags_internal::GetUsageConfig().version_string(); + // Unlike help, we may be asking for version in a script, so return 0 + return 0; + } + + if (absl::GetFlag(FLAGS_only_check_args)) { + return 0; + } + + return -1; +} + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/internal/usage.h b/third_party/abseil_cpp/absl/flags/internal/usage.h new file mode 100644 index 0000000000..6b080fd1ee --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/usage.h @@ -0,0 +1,81 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_INTERNAL_USAGE_H_ +#define ABSL_FLAGS_INTERNAL_USAGE_H_ + +#include <iosfwd> +#include <string> + +#include "absl/base/config.h" +#include "absl/flags/declare.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/strings/string_view.h" + +// -------------------------------------------------------------------- +// Usage reporting interfaces + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// The format to report the help messages in. +enum class HelpFormat { + kHumanReadable, +}; + +// Outputs the help message describing specific flag. +void FlagHelp(std::ostream& out, const flags_internal::CommandLineFlag& flag, + HelpFormat format = HelpFormat::kHumanReadable); + +// Produces the help messages for all flags matching the filter. A flag matches +// the filter if it is defined in a file with a filename which includes +// filter string as a substring. You can use '/' and '.' to restrict the +// matching to a specific file names. For example: +// FlagsHelp(out, "/path/to/file."); +// restricts help to only flags which resides in files named like: +// .../path/to/file.<ext> +// for any extension 'ext'. If the filter is empty this function produces help +// messages for all flags. +void FlagsHelp(std::ostream& out, absl::string_view filter, + HelpFormat format, absl::string_view program_usage_message); + +// -------------------------------------------------------------------- + +// If any of the 'usage' related command line flags (listed on the bottom of +// this file) has been set this routine produces corresponding help message in +// the specified output stream and returns: +// 0 - if "version" or "only_check_flags" flags were set and handled. +// 1 - if some other 'usage' related flag was set and handled. +// -1 - if no usage flags were set on a commmand line. +// Non negative return values are expected to be used as an exit code for a +// binary. +int HandleUsageFlags(std::ostream& out, + absl::string_view program_usage_message); + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +ABSL_DECLARE_FLAG(bool, help); +ABSL_DECLARE_FLAG(bool, helpfull); +ABSL_DECLARE_FLAG(bool, helpshort); +ABSL_DECLARE_FLAG(bool, helppackage); +ABSL_DECLARE_FLAG(bool, version); +ABSL_DECLARE_FLAG(bool, only_check_args); +ABSL_DECLARE_FLAG(std::string, helpon); +ABSL_DECLARE_FLAG(std::string, helpmatch); + +#endif // ABSL_FLAGS_INTERNAL_USAGE_H_ diff --git a/third_party/abseil_cpp/absl/flags/internal/usage_test.cc b/third_party/abseil_cpp/absl/flags/internal/usage_test.cc new file mode 100644 index 0000000000..8dd3532e6d --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/internal/usage_test.cc @@ -0,0 +1,411 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/internal/usage.h" + +#include <stdint.h> + +#include <sstream> +#include <string> + +#include "gtest/gtest.h" +#include "absl/flags/declare.h" +#include "absl/flags/flag.h" +#include "absl/flags/internal/parse.h" +#include "absl/flags/internal/path_util.h" +#include "absl/flags/internal/program_name.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/usage.h" +#include "absl/flags/usage_config.h" +#include "absl/memory/memory.h" +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" + +ABSL_FLAG(int, usage_reporting_test_flag_01, 101, + "usage_reporting_test_flag_01 help message"); +ABSL_FLAG(bool, usage_reporting_test_flag_02, false, + "usage_reporting_test_flag_02 help message"); +ABSL_FLAG(double, usage_reporting_test_flag_03, 1.03, + "usage_reporting_test_flag_03 help message"); +ABSL_FLAG(int64_t, usage_reporting_test_flag_04, 1000000000000004L, + "usage_reporting_test_flag_04 help message"); + +static const char kTestUsageMessage[] = "Custom usage message"; + +struct UDT { + UDT() = default; + UDT(const UDT&) = default; +}; +bool AbslParseFlag(absl::string_view, UDT*, std::string*) { return true; } +std::string AbslUnparseFlag(const UDT&) { return "UDT{}"; } + +ABSL_FLAG(UDT, usage_reporting_test_flag_05, {}, + "usage_reporting_test_flag_05 help message"); + +ABSL_FLAG( + std::string, usage_reporting_test_flag_06, {}, + "usage_reporting_test_flag_06 help message.\n" + "\n" + "Some more help.\n" + "Even more long long long long long long long long long long long long " + "help message."); + +namespace { + +namespace flags = absl::flags_internal; + +static std::string NormalizeFileName(absl::string_view fname) { +#ifdef _WIN32 + std::string normalized(fname); + std::replace(normalized.begin(), normalized.end(), '\\', '/'); + fname = normalized; +#endif + + auto absl_pos = fname.rfind("absl/"); + if (absl_pos != absl::string_view::npos) { + fname = fname.substr(absl_pos); + } + return std::string(fname); +} + +class UsageReportingTest : public testing::Test { + protected: + UsageReportingTest() { + // Install default config for the use on this unit test. + // Binary may install a custom config before tests are run. + absl::FlagsUsageConfig default_config; + default_config.normalize_filename = &NormalizeFileName; + absl::SetFlagsUsageConfig(default_config); + } + + private: + flags::FlagSaver flag_saver_; +}; + +// -------------------------------------------------------------------- + +using UsageReportingDeathTest = UsageReportingTest; + +TEST_F(UsageReportingDeathTest, TestSetProgramUsageMessage) { + EXPECT_EQ(absl::ProgramUsageMessage(), kTestUsageMessage); + +#ifndef _WIN32 + // TODO(rogeeff): figure out why this does not work on Windows. + EXPECT_DEATH_IF_SUPPORTED( + absl::SetProgramUsageMessage("custom usage message"), + ".*SetProgramUsageMessage\\(\\) called twice.*"); +#endif +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestFlagHelpHRF_on_flag_01) { + const auto* flag = flags::FindCommandLineFlag("usage_reporting_test_flag_01"); + std::stringstream test_buf; + + flags::FlagHelp(test_buf, *flag, flags::HelpFormat::kHumanReadable); + EXPECT_EQ( + test_buf.str(), + R"( --usage_reporting_test_flag_01 (usage_reporting_test_flag_01 help message); + default: 101; +)"); +} + +TEST_F(UsageReportingTest, TestFlagHelpHRF_on_flag_02) { + const auto* flag = flags::FindCommandLineFlag("usage_reporting_test_flag_02"); + std::stringstream test_buf; + + flags::FlagHelp(test_buf, *flag, flags::HelpFormat::kHumanReadable); + EXPECT_EQ( + test_buf.str(), + R"( --usage_reporting_test_flag_02 (usage_reporting_test_flag_02 help message); + default: false; +)"); +} + +TEST_F(UsageReportingTest, TestFlagHelpHRF_on_flag_03) { + const auto* flag = flags::FindCommandLineFlag("usage_reporting_test_flag_03"); + std::stringstream test_buf; + + flags::FlagHelp(test_buf, *flag, flags::HelpFormat::kHumanReadable); + EXPECT_EQ( + test_buf.str(), + R"( --usage_reporting_test_flag_03 (usage_reporting_test_flag_03 help message); + default: 1.03; +)"); +} + +TEST_F(UsageReportingTest, TestFlagHelpHRF_on_flag_04) { + const auto* flag = flags::FindCommandLineFlag("usage_reporting_test_flag_04"); + std::stringstream test_buf; + + flags::FlagHelp(test_buf, *flag, flags::HelpFormat::kHumanReadable); + EXPECT_EQ( + test_buf.str(), + R"( --usage_reporting_test_flag_04 (usage_reporting_test_flag_04 help message); + default: 1000000000000004; +)"); +} + +TEST_F(UsageReportingTest, TestFlagHelpHRF_on_flag_05) { + const auto* flag = flags::FindCommandLineFlag("usage_reporting_test_flag_05"); + std::stringstream test_buf; + + flags::FlagHelp(test_buf, *flag, flags::HelpFormat::kHumanReadable); + EXPECT_EQ( + test_buf.str(), + R"( --usage_reporting_test_flag_05 (usage_reporting_test_flag_05 help message); + default: UDT{}; +)"); +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestFlagsHelpHRF) { + std::string usage_test_flags_out = + R"(usage_test: Custom usage message + + Flags from absl/flags/internal/usage_test.cc: + --usage_reporting_test_flag_01 (usage_reporting_test_flag_01 help message); + default: 101; + --usage_reporting_test_flag_02 (usage_reporting_test_flag_02 help message); + default: false; + --usage_reporting_test_flag_03 (usage_reporting_test_flag_03 help message); + default: 1.03; + --usage_reporting_test_flag_04 (usage_reporting_test_flag_04 help message); + default: 1000000000000004; + --usage_reporting_test_flag_05 (usage_reporting_test_flag_05 help message); + default: UDT{}; + --usage_reporting_test_flag_06 (usage_reporting_test_flag_06 help message. + + Some more help. + Even more long long long long long long long long long long long long help + message.); default: ""; +)"; + + std::stringstream test_buf_01; + flags::FlagsHelp(test_buf_01, "usage_test.cc", + flags::HelpFormat::kHumanReadable, kTestUsageMessage); + EXPECT_EQ(test_buf_01.str(), usage_test_flags_out); + + std::stringstream test_buf_02; + flags::FlagsHelp(test_buf_02, "flags/internal/usage_test.cc", + flags::HelpFormat::kHumanReadable, kTestUsageMessage); + EXPECT_EQ(test_buf_02.str(), usage_test_flags_out); + + std::stringstream test_buf_03; + flags::FlagsHelp(test_buf_03, "usage_test", flags::HelpFormat::kHumanReadable, + kTestUsageMessage); + EXPECT_EQ(test_buf_03.str(), usage_test_flags_out); + + std::stringstream test_buf_04; + flags::FlagsHelp(test_buf_04, "flags/invalid_file_name.cc", + flags::HelpFormat::kHumanReadable, kTestUsageMessage); + EXPECT_EQ(test_buf_04.str(), + R"(usage_test: Custom usage message + + No modules matched: use -helpfull +)"); + + std::stringstream test_buf_05; + flags::FlagsHelp(test_buf_05, "", flags::HelpFormat::kHumanReadable, + kTestUsageMessage); + std::string test_out = test_buf_05.str(); + absl::string_view test_out_str(test_out); + EXPECT_TRUE( + absl::StartsWith(test_out_str, "usage_test: Custom usage message")); + EXPECT_TRUE(absl::StrContains( + test_out_str, "Flags from absl/flags/internal/usage_test.cc:")); + EXPECT_TRUE(absl::StrContains(test_out_str, + "Flags from absl/flags/internal/usage.cc:")); + EXPECT_TRUE( + absl::StrContains(test_out_str, "-usage_reporting_test_flag_01 ")); + EXPECT_TRUE(absl::StrContains(test_out_str, "-help (show help")) + << test_out_str; +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestNoUsageFlags) { + std::stringstream test_buf; + EXPECT_EQ(flags::HandleUsageFlags(test_buf, kTestUsageMessage), -1); +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestUsageFlag_helpshort) { + absl::SetFlag(&FLAGS_helpshort, true); + + std::stringstream test_buf; + EXPECT_EQ(flags::HandleUsageFlags(test_buf, kTestUsageMessage), 1); + EXPECT_EQ(test_buf.str(), + R"(usage_test: Custom usage message + + Flags from absl/flags/internal/usage_test.cc: + --usage_reporting_test_flag_01 (usage_reporting_test_flag_01 help message); + default: 101; + --usage_reporting_test_flag_02 (usage_reporting_test_flag_02 help message); + default: false; + --usage_reporting_test_flag_03 (usage_reporting_test_flag_03 help message); + default: 1.03; + --usage_reporting_test_flag_04 (usage_reporting_test_flag_04 help message); + default: 1000000000000004; + --usage_reporting_test_flag_05 (usage_reporting_test_flag_05 help message); + default: UDT{}; + --usage_reporting_test_flag_06 (usage_reporting_test_flag_06 help message. + + Some more help. + Even more long long long long long long long long long long long long help + message.); default: ""; +)"); +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestUsageFlag_help) { + absl::SetFlag(&FLAGS_help, true); + + std::stringstream test_buf; + EXPECT_EQ(flags::HandleUsageFlags(test_buf, kTestUsageMessage), 1); + EXPECT_EQ(test_buf.str(), + R"(usage_test: Custom usage message + + Flags from absl/flags/internal/usage_test.cc: + --usage_reporting_test_flag_01 (usage_reporting_test_flag_01 help message); + default: 101; + --usage_reporting_test_flag_02 (usage_reporting_test_flag_02 help message); + default: false; + --usage_reporting_test_flag_03 (usage_reporting_test_flag_03 help message); + default: 1.03; + --usage_reporting_test_flag_04 (usage_reporting_test_flag_04 help message); + default: 1000000000000004; + --usage_reporting_test_flag_05 (usage_reporting_test_flag_05 help message); + default: UDT{}; + --usage_reporting_test_flag_06 (usage_reporting_test_flag_06 help message. + + Some more help. + Even more long long long long long long long long long long long long help + message.); default: ""; + +Try --helpfull to get a list of all flags. +)"); +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestUsageFlag_helppackage) { + absl::SetFlag(&FLAGS_helppackage, true); + + std::stringstream test_buf; + EXPECT_EQ(flags::HandleUsageFlags(test_buf, kTestUsageMessage), 1); + EXPECT_EQ(test_buf.str(), + R"(usage_test: Custom usage message + + Flags from absl/flags/internal/usage_test.cc: + --usage_reporting_test_flag_01 (usage_reporting_test_flag_01 help message); + default: 101; + --usage_reporting_test_flag_02 (usage_reporting_test_flag_02 help message); + default: false; + --usage_reporting_test_flag_03 (usage_reporting_test_flag_03 help message); + default: 1.03; + --usage_reporting_test_flag_04 (usage_reporting_test_flag_04 help message); + default: 1000000000000004; + --usage_reporting_test_flag_05 (usage_reporting_test_flag_05 help message); + default: UDT{}; + --usage_reporting_test_flag_06 (usage_reporting_test_flag_06 help message. + + Some more help. + Even more long long long long long long long long long long long long help + message.); default: ""; + +Try --helpfull to get a list of all flags. +)"); +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestUsageFlag_version) { + absl::SetFlag(&FLAGS_version, true); + + std::stringstream test_buf; + EXPECT_EQ(flags::HandleUsageFlags(test_buf, kTestUsageMessage), 0); +#ifndef NDEBUG + EXPECT_EQ(test_buf.str(), "usage_test\nDebug build (NDEBUG not #defined)\n"); +#else + EXPECT_EQ(test_buf.str(), "usage_test\n"); +#endif +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestUsageFlag_only_check_args) { + absl::SetFlag(&FLAGS_only_check_args, true); + + std::stringstream test_buf; + EXPECT_EQ(flags::HandleUsageFlags(test_buf, kTestUsageMessage), 0); + EXPECT_EQ(test_buf.str(), ""); +} + +// -------------------------------------------------------------------- + +TEST_F(UsageReportingTest, TestUsageFlag_helpon) { + absl::SetFlag(&FLAGS_helpon, "bla-bla"); + + std::stringstream test_buf_01; + EXPECT_EQ(flags::HandleUsageFlags(test_buf_01, kTestUsageMessage), 1); + EXPECT_EQ(test_buf_01.str(), + R"(usage_test: Custom usage message + + No modules matched: use -helpfull +)"); + + absl::SetFlag(&FLAGS_helpon, "usage_test"); + + std::stringstream test_buf_02; + EXPECT_EQ(flags::HandleUsageFlags(test_buf_02, kTestUsageMessage), 1); + EXPECT_EQ(test_buf_02.str(), + R"(usage_test: Custom usage message + + Flags from absl/flags/internal/usage_test.cc: + --usage_reporting_test_flag_01 (usage_reporting_test_flag_01 help message); + default: 101; + --usage_reporting_test_flag_02 (usage_reporting_test_flag_02 help message); + default: false; + --usage_reporting_test_flag_03 (usage_reporting_test_flag_03 help message); + default: 1.03; + --usage_reporting_test_flag_04 (usage_reporting_test_flag_04 help message); + default: 1000000000000004; + --usage_reporting_test_flag_05 (usage_reporting_test_flag_05 help message); + default: UDT{}; + --usage_reporting_test_flag_06 (usage_reporting_test_flag_06 help message. + + Some more help. + Even more long long long long long long long long long long long long help + message.); default: ""; +)"); +} + +// -------------------------------------------------------------------- + +} // namespace + +int main(int argc, char* argv[]) { + (void)absl::GetFlag(FLAGS_undefok); // Force linking of parse.cc + flags::SetProgramInvocationName("usage_test"); + absl::SetProgramUsageMessage(kTestUsageMessage); + ::testing::InitGoogleTest(&argc, argv); + + return RUN_ALL_TESTS(); +} diff --git a/third_party/abseil_cpp/absl/flags/marshalling.cc b/third_party/abseil_cpp/absl/flags/marshalling.cc new file mode 100644 index 0000000000..09baae88cd --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/marshalling.cc @@ -0,0 +1,240 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/marshalling.h" + +#include <stddef.h> + +#include <cmath> +#include <limits> +#include <string> +#include <type_traits> +#include <vector> + +#include "absl/base/config.h" +#include "absl/base/log_severity.h" +#include "absl/base/macros.h" +#include "absl/strings/ascii.h" +#include "absl/strings/match.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// -------------------------------------------------------------------- +// AbslParseFlag specializations for boolean type. + +bool AbslParseFlag(absl::string_view text, bool* dst, std::string*) { + const char* kTrue[] = {"1", "t", "true", "y", "yes"}; + const char* kFalse[] = {"0", "f", "false", "n", "no"}; + static_assert(sizeof(kTrue) == sizeof(kFalse), "true_false_equal"); + + text = absl::StripAsciiWhitespace(text); + + for (size_t i = 0; i < ABSL_ARRAYSIZE(kTrue); ++i) { + if (absl::EqualsIgnoreCase(text, kTrue[i])) { + *dst = true; + return true; + } else if (absl::EqualsIgnoreCase(text, kFalse[i])) { + *dst = false; + return true; + } + } + return false; // didn't match a legal input +} + +// -------------------------------------------------------------------- +// AbslParseFlag for integral types. + +// Return the base to use for parsing text as an integer. Leading 0x +// puts us in base 16. But leading 0 does not put us in base 8. It +// caused too many bugs when we had that behavior. +static int NumericBase(absl::string_view text) { + const bool hex = (text.size() >= 2 && text[0] == '0' && + (text[1] == 'x' || text[1] == 'X')); + return hex ? 16 : 10; +} + +template <typename IntType> +inline bool ParseFlagImpl(absl::string_view text, IntType* dst) { + text = absl::StripAsciiWhitespace(text); + + return absl::numbers_internal::safe_strtoi_base(text, dst, NumericBase(text)); +} + +bool AbslParseFlag(absl::string_view text, short* dst, std::string*) { + int val; + if (!ParseFlagImpl(text, &val)) return false; + if (static_cast<short>(val) != val) // worked, but number out of range + return false; + *dst = static_cast<short>(val); + return true; +} + +bool AbslParseFlag(absl::string_view text, unsigned short* dst, std::string*) { + unsigned int val; + if (!ParseFlagImpl(text, &val)) return false; + if (static_cast<unsigned short>(val) != + val) // worked, but number out of range + return false; + *dst = static_cast<unsigned short>(val); + return true; +} + +bool AbslParseFlag(absl::string_view text, int* dst, std::string*) { + return ParseFlagImpl(text, dst); +} + +bool AbslParseFlag(absl::string_view text, unsigned int* dst, std::string*) { + return ParseFlagImpl(text, dst); +} + +bool AbslParseFlag(absl::string_view text, long* dst, std::string*) { + return ParseFlagImpl(text, dst); +} + +bool AbslParseFlag(absl::string_view text, unsigned long* dst, std::string*) { + return ParseFlagImpl(text, dst); +} + +bool AbslParseFlag(absl::string_view text, long long* dst, std::string*) { + return ParseFlagImpl(text, dst); +} + +bool AbslParseFlag(absl::string_view text, unsigned long long* dst, + std::string*) { + return ParseFlagImpl(text, dst); +} + +// -------------------------------------------------------------------- +// AbslParseFlag for floating point types. + +bool AbslParseFlag(absl::string_view text, float* dst, std::string*) { + return absl::SimpleAtof(text, dst); +} + +bool AbslParseFlag(absl::string_view text, double* dst, std::string*) { + return absl::SimpleAtod(text, dst); +} + +// -------------------------------------------------------------------- +// AbslParseFlag for strings. + +bool AbslParseFlag(absl::string_view text, std::string* dst, std::string*) { + dst->assign(text.data(), text.size()); + return true; +} + +// -------------------------------------------------------------------- +// AbslParseFlag for vector of strings. + +bool AbslParseFlag(absl::string_view text, std::vector<std::string>* dst, + std::string*) { + // An empty flag value corresponds to an empty vector, not a vector + // with a single, empty std::string. + if (text.empty()) { + dst->clear(); + return true; + } + *dst = absl::StrSplit(text, ',', absl::AllowEmpty()); + return true; +} + +// -------------------------------------------------------------------- +// AbslUnparseFlag specializations for various builtin flag types. + +std::string Unparse(bool v) { return v ? "true" : "false"; } +std::string Unparse(short v) { return absl::StrCat(v); } +std::string Unparse(unsigned short v) { return absl::StrCat(v); } +std::string Unparse(int v) { return absl::StrCat(v); } +std::string Unparse(unsigned int v) { return absl::StrCat(v); } +std::string Unparse(long v) { return absl::StrCat(v); } +std::string Unparse(unsigned long v) { return absl::StrCat(v); } +std::string Unparse(long long v) { return absl::StrCat(v); } +std::string Unparse(unsigned long long v) { return absl::StrCat(v); } +template <typename T> +std::string UnparseFloatingPointVal(T v) { + // digits10 is guaranteed to roundtrip correctly in string -> value -> string + // conversions, but may not be enough to represent all the values correctly. + std::string digit10_str = + absl::StrFormat("%.*g", std::numeric_limits<T>::digits10, v); + if (std::isnan(v) || std::isinf(v)) return digit10_str; + + T roundtrip_val = 0; + std::string err; + if (absl::ParseFlag(digit10_str, &roundtrip_val, &err) && + roundtrip_val == v) { + return digit10_str; + } + + // max_digits10 is the number of base-10 digits that are necessary to uniquely + // represent all distinct values. + return absl::StrFormat("%.*g", std::numeric_limits<T>::max_digits10, v); +} +std::string Unparse(float v) { return UnparseFloatingPointVal(v); } +std::string Unparse(double v) { return UnparseFloatingPointVal(v); } +std::string AbslUnparseFlag(absl::string_view v) { return std::string(v); } +std::string AbslUnparseFlag(const std::vector<std::string>& v) { + return absl::StrJoin(v, ","); +} + +} // namespace flags_internal + +bool AbslParseFlag(absl::string_view text, absl::LogSeverity* dst, + std::string* err) { + text = absl::StripAsciiWhitespace(text); + if (text.empty()) { + *err = "no value provided"; + return false; + } + if (text.front() == 'k' || text.front() == 'K') text.remove_prefix(1); + if (absl::EqualsIgnoreCase(text, "info")) { + *dst = absl::LogSeverity::kInfo; + return true; + } + if (absl::EqualsIgnoreCase(text, "warning")) { + *dst = absl::LogSeverity::kWarning; + return true; + } + if (absl::EqualsIgnoreCase(text, "error")) { + *dst = absl::LogSeverity::kError; + return true; + } + if (absl::EqualsIgnoreCase(text, "fatal")) { + *dst = absl::LogSeverity::kFatal; + return true; + } + std::underlying_type<absl::LogSeverity>::type numeric_value; + if (absl::ParseFlag(text, &numeric_value, err)) { + *dst = static_cast<absl::LogSeverity>(numeric_value); + return true; + } + *err = "only integers and absl::LogSeverity enumerators are accepted"; + return false; +} + +std::string AbslUnparseFlag(absl::LogSeverity v) { + if (v == absl::NormalizeLogSeverity(v)) return absl::LogSeverityName(v); + return absl::UnparseFlag(static_cast<int>(v)); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/marshalling.h b/third_party/abseil_cpp/absl/flags/marshalling.h new file mode 100644 index 0000000000..0b5033547e --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/marshalling.h @@ -0,0 +1,264 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: marshalling.h +// ----------------------------------------------------------------------------- +// +// This header file defines the API for extending Abseil flag support to +// custom types, and defines the set of overloads for fundamental types. +// +// Out of the box, the Abseil flags library supports the following types: +// +// * `bool` +// * `int16_t` +// * `uint16_t` +// * `int32_t` +// * `uint32_t` +// * `int64_t` +// * `uint64_t` +// * `float` +// * `double` +// * `std::string` +// * `std::vector<std::string>` +// * `absl::LogSeverity` (provided natively for layering reasons) +// +// Note that support for integral types is implemented using overloads for +// variable-width fundamental types (`short`, `int`, `long`, etc.). However, +// you should prefer the fixed-width integral types (`int32_t`, `uint64_t`, +// etc.) we've noted above within flag definitions. +// +// In addition, several Abseil libraries provide their own custom support for +// Abseil flags. Documentation for these formats is provided in the type's +// `AbslParseFlag()` definition. +// +// The Abseil time library provides the following support for civil time values: +// +// * `absl::CivilSecond` +// * `absl::CivilMinute` +// * `absl::CivilHour` +// * `absl::CivilDay` +// * `absl::CivilMonth` +// * `absl::CivilYear` +// +// and also provides support for the following absolute time values: +// +// * `absl::Duration` +// * `absl::Time` +// +// Additional support for Abseil types will be noted here as it is added. +// +// You can also provide your own custom flags by adding overloads for +// `AbslParseFlag()` and `AbslUnparseFlag()` to your type definitions. (See +// below.) +// +// ----------------------------------------------------------------------------- +// Adding Type Support for Abseil Flags +// ----------------------------------------------------------------------------- +// +// To add support for your user-defined type, add overloads of `AbslParseFlag()` +// and `AbslUnparseFlag()` as free (non-member) functions to your type. If `T` +// is a class type, these functions can be friend function definitions. These +// overloads must be added to the same namespace where the type is defined, so +// that they can be discovered by Argument-Dependent Lookup (ADL). +// +// Example: +// +// namespace foo { +// +// enum OutputMode { kPlainText, kHtml }; +// +// // AbslParseFlag converts from a string to OutputMode. +// // Must be in same namespace as OutputMode. +// +// // Parses an OutputMode from the command line flag value `text. Returns +// // `true` and sets `*mode` on success; returns `false` and sets `*error` +// // on failure. +// bool AbslParseFlag(absl::string_view text, +// OutputMode* mode, +// std::string* error) { +// if (text == "plaintext") { +// *mode = kPlainText; +// return true; +// } +// if (text == "html") { +// *mode = kHtml; +// return true; +// } +// *error = "unknown value for enumeration"; +// return false; +// } +// +// // AbslUnparseFlag converts from an OutputMode to a string. +// // Must be in same namespace as OutputMode. +// +// // Returns a textual flag value corresponding to the OutputMode `mode`. +// std::string AbslUnparseFlag(OutputMode mode) { +// switch (mode) { +// case kPlainText: return "plaintext"; +// case kHtml: return "html"; +// } +// return absl::StrCat(mode); +// } +// +// Notice that neither `AbslParseFlag()` nor `AbslUnparseFlag()` are class +// members, but free functions. `AbslParseFlag/AbslUnparseFlag()` overloads +// for a type should only be declared in the same file and namespace as said +// type. The proper `AbslParseFlag/AbslUnparseFlag()` implementations for a +// given type will be discovered via Argument-Dependent Lookup (ADL). +// +// `AbslParseFlag()` may need, in turn, to parse simpler constituent types +// using `absl::ParseFlag()`. For example, a custom struct `MyFlagType` +// consisting of a `std::pair<int, std::string>` would add an `AbslParseFlag()` +// overload for its `MyFlagType` like so: +// +// Example: +// +// namespace my_flag_type { +// +// struct MyFlagType { +// std::pair<int, std::string> my_flag_data; +// }; +// +// bool AbslParseFlag(absl::string_view text, MyFlagType* flag, +// std::string* err); +// +// std::string AbslUnparseFlag(const MyFlagType&); +// +// // Within the implementation, `AbslParseFlag()` will, in turn invoke +// // `absl::ParseFlag()` on its constituent `int` and `std::string` types +// // (which have built-in Abseil flag support. +// +// bool AbslParseFlag(absl::string_view text, MyFlagType* flag, +// std::string* err) { +// std::pair<absl::string_view, absl::string_view> tokens = +// absl::StrSplit(text, ','); +// if (!absl::ParseFlag(tokens.first, &flag->my_flag_data.first, err)) +// return false; +// if (!absl::ParseFlag(tokens.second, &flag->my_flag_data.second, err)) +// return false; +// return true; +// } +// +// // Similarly, for unparsing, we can simply invoke `absl::UnparseFlag()` on +// // the constituent types. +// std::string AbslUnparseFlag(const MyFlagType& flag) { +// return absl::StrCat(absl::UnparseFlag(flag.my_flag_data.first), +// ",", +// absl::UnparseFlag(flag.my_flag_data.second)); +// } +#ifndef ABSL_FLAGS_MARSHALLING_H_ +#define ABSL_FLAGS_MARSHALLING_H_ + +#include <string> +#include <vector> + +#include "absl/base/config.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +// Overloads of `AbslParseFlag()` and `AbslUnparseFlag()` for fundamental types. +bool AbslParseFlag(absl::string_view, bool*, std::string*); +bool AbslParseFlag(absl::string_view, short*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, unsigned short*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, int*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, unsigned int*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, long*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, unsigned long*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, long long*, std::string*); // NOLINT +bool AbslParseFlag(absl::string_view, unsigned long long*, // NOLINT + std::string*); +bool AbslParseFlag(absl::string_view, float*, std::string*); +bool AbslParseFlag(absl::string_view, double*, std::string*); +bool AbslParseFlag(absl::string_view, std::string*, std::string*); +bool AbslParseFlag(absl::string_view, std::vector<std::string>*, std::string*); + +template <typename T> +bool InvokeParseFlag(absl::string_view input, T* dst, std::string* err) { + // Comment on next line provides a good compiler error message if T + // does not have AbslParseFlag(absl::string_view, T*, std::string*). + return AbslParseFlag(input, dst, err); // Is T missing AbslParseFlag? +} + +// Strings and std:: containers do not have the same overload resolution +// considerations as fundamental types. Naming these 'AbslUnparseFlag' means we +// can avoid the need for additional specializations of Unparse (below). +std::string AbslUnparseFlag(absl::string_view v); +std::string AbslUnparseFlag(const std::vector<std::string>&); + +template <typename T> +std::string Unparse(const T& v) { + // Comment on next line provides a good compiler error message if T does not + // have UnparseFlag. + return AbslUnparseFlag(v); // Is T missing AbslUnparseFlag? +} + +// Overloads for builtin types. +std::string Unparse(bool v); +std::string Unparse(short v); // NOLINT +std::string Unparse(unsigned short v); // NOLINT +std::string Unparse(int v); // NOLINT +std::string Unparse(unsigned int v); // NOLINT +std::string Unparse(long v); // NOLINT +std::string Unparse(unsigned long v); // NOLINT +std::string Unparse(long long v); // NOLINT +std::string Unparse(unsigned long long v); // NOLINT +std::string Unparse(float v); +std::string Unparse(double v); + +} // namespace flags_internal + +// ParseFlag() +// +// Parses a string value into a flag value of type `T`. Do not add overloads of +// this function for your type directly; instead, add an `AbslParseFlag()` +// free function as documented above. +// +// Some implementations of `AbslParseFlag()` for types which consist of other, +// constituent types which already have Abseil flag support, may need to call +// `absl::ParseFlag()` on those consituent string values. (See above.) +template <typename T> +inline bool ParseFlag(absl::string_view input, T* dst, std::string* error) { + return flags_internal::InvokeParseFlag(input, dst, error); +} + +// UnparseFlag() +// +// Unparses a flag value of type `T` into a string value. Do not add overloads +// of this function for your type directly; instead, add an `AbslUnparseFlag()` +// free function as documented above. +// +// Some implementations of `AbslUnparseFlag()` for types which consist of other, +// constituent types which already have Abseil flag support, may want to call +// `absl::UnparseFlag()` on those constituent types. (See above.) +template <typename T> +inline std::string UnparseFlag(const T& v) { + return flags_internal::Unparse(v); +} + +// Overloads for `absl::LogSeverity` can't (easily) appear alongside that type's +// definition because it is layered below flags. See proper documentation in +// base/log_severity.h. +enum class LogSeverity : int; +bool AbslParseFlag(absl::string_view, absl::LogSeverity*, std::string*); +std::string AbslUnparseFlag(absl::LogSeverity); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_MARSHALLING_H_ diff --git a/third_party/abseil_cpp/absl/flags/marshalling_test.cc b/third_party/abseil_cpp/absl/flags/marshalling_test.cc new file mode 100644 index 0000000000..4a64ce11a1 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/marshalling_test.cc @@ -0,0 +1,904 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/marshalling.h" + +#include <stdint.h> + +#include <cmath> +#include <limits> +#include <string> +#include <vector> + +#include "gtest/gtest.h" + +namespace { + +TEST(MarshallingTest, TestBoolParsing) { + std::string err; + bool value; + + // True values. + EXPECT_TRUE(absl::ParseFlag("True", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("true", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("TRUE", &value, &err)); + EXPECT_TRUE(value); + + EXPECT_TRUE(absl::ParseFlag("Yes", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("yes", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("YES", &value, &err)); + EXPECT_TRUE(value); + + EXPECT_TRUE(absl::ParseFlag("t", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("T", &value, &err)); + EXPECT_TRUE(value); + + EXPECT_TRUE(absl::ParseFlag("y", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("Y", &value, &err)); + EXPECT_TRUE(value); + + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_TRUE(value); + + // False values. + EXPECT_TRUE(absl::ParseFlag("False", &value, &err)); + EXPECT_FALSE(value); + EXPECT_TRUE(absl::ParseFlag("false", &value, &err)); + EXPECT_FALSE(value); + EXPECT_TRUE(absl::ParseFlag("FALSE", &value, &err)); + EXPECT_FALSE(value); + + EXPECT_TRUE(absl::ParseFlag("No", &value, &err)); + EXPECT_FALSE(value); + EXPECT_TRUE(absl::ParseFlag("no", &value, &err)); + EXPECT_FALSE(value); + EXPECT_TRUE(absl::ParseFlag("NO", &value, &err)); + EXPECT_FALSE(value); + + EXPECT_TRUE(absl::ParseFlag("f", &value, &err)); + EXPECT_FALSE(value); + EXPECT_TRUE(absl::ParseFlag("F", &value, &err)); + EXPECT_FALSE(value); + + EXPECT_TRUE(absl::ParseFlag("n", &value, &err)); + EXPECT_FALSE(value); + EXPECT_TRUE(absl::ParseFlag("N", &value, &err)); + EXPECT_FALSE(value); + + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_FALSE(value); + + // Whitespace handling. + EXPECT_TRUE(absl::ParseFlag(" true", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag("true ", &value, &err)); + EXPECT_TRUE(value); + EXPECT_TRUE(absl::ParseFlag(" true ", &value, &err)); + EXPECT_TRUE(value); + + // Invalid input. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("11", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("tt", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestInt16Parsing) { + std::string err; + int16_t value; + + // Decimal values. + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("-1", &value, &err)); + EXPECT_EQ(value, -1); + EXPECT_TRUE(absl::ParseFlag("123", &value, &err)); + EXPECT_EQ(value, 123); + EXPECT_TRUE(absl::ParseFlag("-18765", &value, &err)); + EXPECT_EQ(value, -18765); + EXPECT_TRUE(absl::ParseFlag("+3", &value, &err)); + EXPECT_EQ(value, 3); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("-001", &value, &err)); + EXPECT_EQ(value, -1); + EXPECT_TRUE(absl::ParseFlag("0000100", &value, &err)); + EXPECT_EQ(value, 100); + + // Hex values. + EXPECT_TRUE(absl::ParseFlag("0x10", &value, &err)); + EXPECT_EQ(value, 16); + EXPECT_TRUE(absl::ParseFlag("0X234", &value, &err)); + EXPECT_EQ(value, 564); + // TODO(rogeeff): fix below validations + EXPECT_FALSE(absl::ParseFlag("-0x7FFD", &value, &err)); + EXPECT_NE(value, -3); + EXPECT_FALSE(absl::ParseFlag("+0x31", &value, &err)); + EXPECT_NE(value, 49); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10 ", &value, &err)); + EXPECT_EQ(value, 10); + EXPECT_TRUE(absl::ParseFlag(" 11", &value, &err)); + EXPECT_EQ(value, 11); + EXPECT_TRUE(absl::ParseFlag(" 012 ", &value, &err)); + EXPECT_EQ(value, 12); + EXPECT_TRUE(absl::ParseFlag(" 0x22 ", &value, &err)); + EXPECT_EQ(value, 34); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("40000", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2U", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("FFF", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestUint16Parsing) { + std::string err; + uint16_t value; + + // Decimal values. + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("123", &value, &err)); + EXPECT_EQ(value, 123); + EXPECT_TRUE(absl::ParseFlag("+3", &value, &err)); + EXPECT_EQ(value, 3); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("001", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0000100", &value, &err)); + EXPECT_EQ(value, 100); + + // Hex values. + EXPECT_TRUE(absl::ParseFlag("0x10", &value, &err)); + EXPECT_EQ(value, 16); + EXPECT_TRUE(absl::ParseFlag("0X234", &value, &err)); + EXPECT_EQ(value, 564); + // TODO(rogeeff): fix below validations + EXPECT_FALSE(absl::ParseFlag("+0x31", &value, &err)); + EXPECT_NE(value, 49); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10 ", &value, &err)); + EXPECT_EQ(value, 10); + EXPECT_TRUE(absl::ParseFlag(" 11", &value, &err)); + EXPECT_EQ(value, 11); + EXPECT_TRUE(absl::ParseFlag(" 012 ", &value, &err)); + EXPECT_EQ(value, 12); + EXPECT_TRUE(absl::ParseFlag(" 0x22 ", &value, &err)); + EXPECT_EQ(value, 34); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("70000", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("-1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2U", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("FFF", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestInt32Parsing) { + std::string err; + int32_t value; + + // Decimal values. + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("-1", &value, &err)); + EXPECT_EQ(value, -1); + EXPECT_TRUE(absl::ParseFlag("123", &value, &err)); + EXPECT_EQ(value, 123); + EXPECT_TRUE(absl::ParseFlag("-98765", &value, &err)); + EXPECT_EQ(value, -98765); + EXPECT_TRUE(absl::ParseFlag("+3", &value, &err)); + EXPECT_EQ(value, 3); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("-001", &value, &err)); + EXPECT_EQ(value, -1); + EXPECT_TRUE(absl::ParseFlag("0000100", &value, &err)); + EXPECT_EQ(value, 100); + + // Hex values. + EXPECT_TRUE(absl::ParseFlag("0x10", &value, &err)); + EXPECT_EQ(value, 16); + EXPECT_TRUE(absl::ParseFlag("0X234", &value, &err)); + EXPECT_EQ(value, 564); + // TODO(rogeeff): fix below validations + EXPECT_FALSE(absl::ParseFlag("-0x7FFFFFFD", &value, &err)); + EXPECT_NE(value, -3); + EXPECT_FALSE(absl::ParseFlag("+0x31", &value, &err)); + EXPECT_NE(value, 49); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10 ", &value, &err)); + EXPECT_EQ(value, 10); + EXPECT_TRUE(absl::ParseFlag(" 11", &value, &err)); + EXPECT_EQ(value, 11); + EXPECT_TRUE(absl::ParseFlag(" 012 ", &value, &err)); + EXPECT_EQ(value, 12); + EXPECT_TRUE(absl::ParseFlag(" 0x22 ", &value, &err)); + EXPECT_EQ(value, 34); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("70000000000", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2U", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("FFF", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestUint32Parsing) { + std::string err; + uint32_t value; + + // Decimal values. + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("123", &value, &err)); + EXPECT_EQ(value, 123); + EXPECT_TRUE(absl::ParseFlag("+3", &value, &err)); + EXPECT_EQ(value, 3); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0000100", &value, &err)); + EXPECT_EQ(value, 100); + + // Hex values. + EXPECT_TRUE(absl::ParseFlag("0x10", &value, &err)); + EXPECT_EQ(value, 16); + EXPECT_TRUE(absl::ParseFlag("0X234", &value, &err)); + EXPECT_EQ(value, 564); + EXPECT_TRUE(absl::ParseFlag("0xFFFFFFFD", &value, &err)); + EXPECT_EQ(value, 4294967293); + // TODO(rogeeff): fix below validations + EXPECT_FALSE(absl::ParseFlag("+0x31", &value, &err)); + EXPECT_NE(value, 49); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10 ", &value, &err)); + EXPECT_EQ(value, 10); + EXPECT_TRUE(absl::ParseFlag(" 11", &value, &err)); + EXPECT_EQ(value, 11); + EXPECT_TRUE(absl::ParseFlag(" 012 ", &value, &err)); + EXPECT_EQ(value, 12); + EXPECT_TRUE(absl::ParseFlag(" 0x22 ", &value, &err)); + EXPECT_EQ(value, 34); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("140000000000", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("-1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2U", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("FFF", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestInt64Parsing) { + std::string err; + int64_t value; + + // Decimal values. + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("-1", &value, &err)); + EXPECT_EQ(value, -1); + EXPECT_TRUE(absl::ParseFlag("123", &value, &err)); + EXPECT_EQ(value, 123); + EXPECT_TRUE(absl::ParseFlag("-98765", &value, &err)); + EXPECT_EQ(value, -98765); + EXPECT_TRUE(absl::ParseFlag("+3", &value, &err)); + EXPECT_EQ(value, 3); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("001", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0000100", &value, &err)); + EXPECT_EQ(value, 100); + + // Hex values. + EXPECT_TRUE(absl::ParseFlag("0x10", &value, &err)); + EXPECT_EQ(value, 16); + EXPECT_TRUE(absl::ParseFlag("0XFFFAAABBBCCCDDD", &value, &err)); + EXPECT_EQ(value, 1152827684197027293); + // TODO(rogeeff): fix below validation + EXPECT_FALSE(absl::ParseFlag("-0x7FFFFFFFFFFFFFFE", &value, &err)); + EXPECT_NE(value, -2); + EXPECT_FALSE(absl::ParseFlag("+0x31", &value, &err)); + EXPECT_NE(value, 49); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10 ", &value, &err)); + EXPECT_EQ(value, 10); + EXPECT_TRUE(absl::ParseFlag(" 11", &value, &err)); + EXPECT_EQ(value, 11); + EXPECT_TRUE(absl::ParseFlag(" 012 ", &value, &err)); + EXPECT_EQ(value, 12); + EXPECT_TRUE(absl::ParseFlag(" 0x7F ", &value, &err)); + EXPECT_EQ(value, 127); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("0xFFFFFFFFFFFFFFFFFF", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2U", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("FFF", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestUInt64Parsing) { + std::string err; + uint64_t value; + + // Decimal values. + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0", &value, &err)); + EXPECT_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("123", &value, &err)); + EXPECT_EQ(value, 123); + EXPECT_TRUE(absl::ParseFlag("+13", &value, &err)); + EXPECT_EQ(value, 13); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("001", &value, &err)); + EXPECT_EQ(value, 1); + EXPECT_TRUE(absl::ParseFlag("0000300", &value, &err)); + EXPECT_EQ(value, 300); + + // Hex values. + EXPECT_TRUE(absl::ParseFlag("0x10", &value, &err)); + EXPECT_EQ(value, 16); + EXPECT_TRUE(absl::ParseFlag("0XFFFF", &value, &err)); + EXPECT_EQ(value, 65535); + // TODO(rogeeff): fix below validation + EXPECT_FALSE(absl::ParseFlag("+0x31", &value, &err)); + EXPECT_NE(value, 49); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10 ", &value, &err)); + EXPECT_EQ(value, 10); + EXPECT_TRUE(absl::ParseFlag(" 11", &value, &err)); + EXPECT_EQ(value, 11); + EXPECT_TRUE(absl::ParseFlag(" 012 ", &value, &err)); + EXPECT_EQ(value, 12); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("0xFFFFFFFFFFFFFFFFFF", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("-1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2U", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("FFF", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestFloatParsing) { + std::string err; + float value; + + // Ordinary values. + EXPECT_TRUE(absl::ParseFlag("1.3", &value, &err)); + EXPECT_FLOAT_EQ(value, 1.3f); + EXPECT_TRUE(absl::ParseFlag("-0.1", &value, &err)); + EXPECT_DOUBLE_EQ(value, -0.1f); + EXPECT_TRUE(absl::ParseFlag("+0.01", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.01f); + + // Scientific values. + EXPECT_TRUE(absl::ParseFlag("1.2e3", &value, &err)); + EXPECT_DOUBLE_EQ(value, 1.2e3f); + EXPECT_TRUE(absl::ParseFlag("9.8765402e-37", &value, &err)); + EXPECT_DOUBLE_EQ(value, 9.8765402e-37f); + EXPECT_TRUE(absl::ParseFlag("0.11e+3", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.11e+3f); + EXPECT_TRUE(absl::ParseFlag("1.e-2300", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.f); + EXPECT_TRUE(absl::ParseFlag("1.e+2300", &value, &err)); + EXPECT_TRUE(std::isinf(value)); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01.6", &value, &err)); + EXPECT_DOUBLE_EQ(value, 1.6f); + EXPECT_TRUE(absl::ParseFlag("000.0001", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.0001f); + + // Trailing zero values. + EXPECT_TRUE(absl::ParseFlag("-5.1000", &value, &err)); + EXPECT_DOUBLE_EQ(value, -5.1f); + + // Exceptional values. + EXPECT_TRUE(absl::ParseFlag("NaN", &value, &err)); + EXPECT_TRUE(std::isnan(value)); + EXPECT_TRUE(absl::ParseFlag("Inf", &value, &err)); + EXPECT_TRUE(std::isinf(value)); + + // Hex values + EXPECT_TRUE(absl::ParseFlag("0x10.23p12", &value, &err)); + EXPECT_DOUBLE_EQ(value, 66096.f); + EXPECT_TRUE(absl::ParseFlag("-0xF1.A3p-2", &value, &err)); + EXPECT_NEAR(value, -60.4092f, 5e-5f); + EXPECT_TRUE(absl::ParseFlag("+0x0.0AAp-12", &value, &err)); + EXPECT_NEAR(value, 1.01328e-05f, 5e-11f); + EXPECT_TRUE(absl::ParseFlag("0x.01p1", &value, &err)); + EXPECT_NEAR(value, 0.0078125f, 5e-8f); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10.1 ", &value, &err)); + EXPECT_DOUBLE_EQ(value, 10.1f); + EXPECT_TRUE(absl::ParseFlag(" 2.34", &value, &err)); + EXPECT_DOUBLE_EQ(value, 2.34f); + EXPECT_TRUE(absl::ParseFlag(" 5.7 ", &value, &err)); + EXPECT_DOUBLE_EQ(value, 5.7f); + EXPECT_TRUE(absl::ParseFlag(" -0xE0.F3p01 ", &value, &err)); + EXPECT_NEAR(value, -449.8984375f, 5e-8f); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2.3xxx", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("0x0.1pAA", &value, &err)); + // TODO(rogeeff): below assertion should fail + EXPECT_TRUE(absl::ParseFlag("0x0.1", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestDoubleParsing) { + std::string err; + double value; + + // Ordinary values. + EXPECT_TRUE(absl::ParseFlag("1.3", &value, &err)); + EXPECT_DOUBLE_EQ(value, 1.3); + EXPECT_TRUE(absl::ParseFlag("-0.1", &value, &err)); + EXPECT_DOUBLE_EQ(value, -0.1); + EXPECT_TRUE(absl::ParseFlag("+0.01", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.01); + + // Scientific values. + EXPECT_TRUE(absl::ParseFlag("1.2e3", &value, &err)); + EXPECT_DOUBLE_EQ(value, 1.2e3); + EXPECT_TRUE(absl::ParseFlag("9.00000002e-123", &value, &err)); + EXPECT_DOUBLE_EQ(value, 9.00000002e-123); + EXPECT_TRUE(absl::ParseFlag("0.11e+3", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.11e+3); + EXPECT_TRUE(absl::ParseFlag("1.e-2300", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0); + EXPECT_TRUE(absl::ParseFlag("1.e+2300", &value, &err)); + EXPECT_TRUE(std::isinf(value)); + + // Leading zero values. + EXPECT_TRUE(absl::ParseFlag("01.6", &value, &err)); + EXPECT_DOUBLE_EQ(value, 1.6); + EXPECT_TRUE(absl::ParseFlag("000.0001", &value, &err)); + EXPECT_DOUBLE_EQ(value, 0.0001); + + // Trailing zero values. + EXPECT_TRUE(absl::ParseFlag("-5.1000", &value, &err)); + EXPECT_DOUBLE_EQ(value, -5.1); + + // Exceptional values. + EXPECT_TRUE(absl::ParseFlag("NaN", &value, &err)); + EXPECT_TRUE(std::isnan(value)); + EXPECT_TRUE(absl::ParseFlag("nan", &value, &err)); + EXPECT_TRUE(std::isnan(value)); + EXPECT_TRUE(absl::ParseFlag("Inf", &value, &err)); + EXPECT_TRUE(std::isinf(value)); + EXPECT_TRUE(absl::ParseFlag("inf", &value, &err)); + EXPECT_TRUE(std::isinf(value)); + + // Hex values + EXPECT_TRUE(absl::ParseFlag("0x10.23p12", &value, &err)); + EXPECT_DOUBLE_EQ(value, 66096); + EXPECT_TRUE(absl::ParseFlag("-0xF1.A3p-2", &value, &err)); + EXPECT_NEAR(value, -60.4092, 5e-5); + EXPECT_TRUE(absl::ParseFlag("+0x0.0AAp-12", &value, &err)); + EXPECT_NEAR(value, 1.01328e-05, 5e-11); + EXPECT_TRUE(absl::ParseFlag("0x.01p1", &value, &err)); + EXPECT_NEAR(value, 0.0078125, 5e-8); + + // Whitespace handling + EXPECT_TRUE(absl::ParseFlag("10.1 ", &value, &err)); + EXPECT_DOUBLE_EQ(value, 10.1); + EXPECT_TRUE(absl::ParseFlag(" 2.34", &value, &err)); + EXPECT_DOUBLE_EQ(value, 2.34); + EXPECT_TRUE(absl::ParseFlag(" 5.7 ", &value, &err)); + EXPECT_DOUBLE_EQ(value, 5.7); + EXPECT_TRUE(absl::ParseFlag(" -0xE0.F3p01 ", &value, &err)); + EXPECT_NEAR(value, -449.8984375, 5e-8); + + // Invalid values. + EXPECT_FALSE(absl::ParseFlag("", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag(" ", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("--1", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\n", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("\t", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("2.3xxx", &value, &err)); + EXPECT_FALSE(absl::ParseFlag("0x0.1pAA", &value, &err)); + // TODO(rogeeff): below assertion should fail + EXPECT_TRUE(absl::ParseFlag("0x0.1", &value, &err)); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestStringParsing) { + std::string err; + std::string value; + + EXPECT_TRUE(absl::ParseFlag("", &value, &err)); + EXPECT_EQ(value, ""); + EXPECT_TRUE(absl::ParseFlag(" ", &value, &err)); + EXPECT_EQ(value, " "); + EXPECT_TRUE(absl::ParseFlag(" ", &value, &err)); + EXPECT_EQ(value, " "); + EXPECT_TRUE(absl::ParseFlag("\n", &value, &err)); + EXPECT_EQ(value, "\n"); + EXPECT_TRUE(absl::ParseFlag("\t", &value, &err)); + EXPECT_EQ(value, "\t"); + EXPECT_TRUE(absl::ParseFlag("asdfg", &value, &err)); + EXPECT_EQ(value, "asdfg"); + EXPECT_TRUE(absl::ParseFlag("asdf ghjk", &value, &err)); + EXPECT_EQ(value, "asdf ghjk"); + EXPECT_TRUE(absl::ParseFlag("a\nb\nc", &value, &err)); + EXPECT_EQ(value, "a\nb\nc"); + EXPECT_TRUE(absl::ParseFlag("asd\0fgh", &value, &err)); + EXPECT_EQ(value, "asd"); + EXPECT_TRUE(absl::ParseFlag("\\\\", &value, &err)); + EXPECT_EQ(value, "\\\\"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestVectorOfStringParsing) { + std::string err; + std::vector<std::string> value; + + EXPECT_TRUE(absl::ParseFlag("", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>{}); + EXPECT_TRUE(absl::ParseFlag("1", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>({"1"})); + EXPECT_TRUE(absl::ParseFlag("a,b", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>({"a", "b"})); + EXPECT_TRUE(absl::ParseFlag("a,b,c,", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>({"a", "b", "c", ""})); + EXPECT_TRUE(absl::ParseFlag("a,,", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>({"a", "", ""})); + EXPECT_TRUE(absl::ParseFlag(",", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>({"", ""})); + EXPECT_TRUE(absl::ParseFlag("a, b,c ", &value, &err)); + EXPECT_EQ(value, std::vector<std::string>({"a", " b", "c "})); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestBoolUnparsing) { + EXPECT_EQ(absl::UnparseFlag(true), "true"); + EXPECT_EQ(absl::UnparseFlag(false), "false"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestInt16Unparsing) { + int16_t value; + + value = 1; + EXPECT_EQ(absl::UnparseFlag(value), "1"); + value = 0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = -1; + EXPECT_EQ(absl::UnparseFlag(value), "-1"); + value = 9876; + EXPECT_EQ(absl::UnparseFlag(value), "9876"); + value = -987; + EXPECT_EQ(absl::UnparseFlag(value), "-987"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestUint16Unparsing) { + uint16_t value; + + value = 1; + EXPECT_EQ(absl::UnparseFlag(value), "1"); + value = 0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = 19876; + EXPECT_EQ(absl::UnparseFlag(value), "19876"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestInt32Unparsing) { + int32_t value; + + value = 1; + EXPECT_EQ(absl::UnparseFlag(value), "1"); + value = 0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = -1; + EXPECT_EQ(absl::UnparseFlag(value), "-1"); + value = 12345; + EXPECT_EQ(absl::UnparseFlag(value), "12345"); + value = -987; + EXPECT_EQ(absl::UnparseFlag(value), "-987"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestUint32Unparsing) { + uint32_t value; + + value = 1; + EXPECT_EQ(absl::UnparseFlag(value), "1"); + value = 0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = 1234500; + EXPECT_EQ(absl::UnparseFlag(value), "1234500"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestInt64Unparsing) { + int64_t value; + + value = 1; + EXPECT_EQ(absl::UnparseFlag(value), "1"); + value = 0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = -1; + EXPECT_EQ(absl::UnparseFlag(value), "-1"); + value = 123456789L; + EXPECT_EQ(absl::UnparseFlag(value), "123456789"); + value = -987654321L; + EXPECT_EQ(absl::UnparseFlag(value), "-987654321"); + value = 0x7FFFFFFFFFFFFFFF; + EXPECT_EQ(absl::UnparseFlag(value), "9223372036854775807"); + value = 0xFFFFFFFFFFFFFFFF; + EXPECT_EQ(absl::UnparseFlag(value), "-1"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestUint64Unparsing) { + uint64_t value; + + value = 1; + EXPECT_EQ(absl::UnparseFlag(value), "1"); + value = 0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = 123456789L; + EXPECT_EQ(absl::UnparseFlag(value), "123456789"); + value = 0xFFFFFFFFFFFFFFFF; + EXPECT_EQ(absl::UnparseFlag(value), "18446744073709551615"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestFloatUnparsing) { + float value; + + value = 1.1f; + EXPECT_EQ(absl::UnparseFlag(value), "1.1"); + value = 0.01f; + EXPECT_EQ(absl::UnparseFlag(value), "0.01"); + value = 1.23e-2f; + EXPECT_EQ(absl::UnparseFlag(value), "0.0123"); + value = -0.71f; + EXPECT_EQ(absl::UnparseFlag(value), "-0.71"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestDoubleUnparsing) { + double value; + + value = 1.1; + EXPECT_EQ(absl::UnparseFlag(value), "1.1"); + value = 0.01; + EXPECT_EQ(absl::UnparseFlag(value), "0.01"); + value = 1.23e-2; + EXPECT_EQ(absl::UnparseFlag(value), "0.0123"); + value = -0.71; + EXPECT_EQ(absl::UnparseFlag(value), "-0.71"); + value = -0; + EXPECT_EQ(absl::UnparseFlag(value), "0"); + value = std::nan(""); + EXPECT_EQ(absl::UnparseFlag(value), "nan"); + value = std::numeric_limits<double>::infinity(); + EXPECT_EQ(absl::UnparseFlag(value), "inf"); +} + +// -------------------------------------------------------------------- + +TEST(MarshallingTest, TestStringUnparsing) { + EXPECT_EQ(absl::UnparseFlag(""), ""); + EXPECT_EQ(absl::UnparseFlag(" "), " "); + EXPECT_EQ(absl::UnparseFlag("qwerty"), "qwerty"); + EXPECT_EQ(absl::UnparseFlag("ASDFGH"), "ASDFGH"); + EXPECT_EQ(absl::UnparseFlag("\n\t "), "\n\t "); +} + +// -------------------------------------------------------------------- + +template <typename T> +void TestRoundtrip(T v) { + T new_v; + std::string err; + EXPECT_TRUE(absl::ParseFlag(absl::UnparseFlag(v), &new_v, &err)); + EXPECT_EQ(new_v, v); +} + +TEST(MarshallingTest, TestFloatRoundTrip) { + TestRoundtrip(0.1f); + TestRoundtrip(0.12f); + TestRoundtrip(0.123f); + TestRoundtrip(0.1234f); + TestRoundtrip(0.12345f); + TestRoundtrip(0.123456f); + TestRoundtrip(0.1234567f); + TestRoundtrip(0.12345678f); + + TestRoundtrip(0.1e20f); + TestRoundtrip(0.12e20f); + TestRoundtrip(0.123e20f); + TestRoundtrip(0.1234e20f); + TestRoundtrip(0.12345e20f); + TestRoundtrip(0.123456e20f); + TestRoundtrip(0.1234567e20f); + TestRoundtrip(0.12345678e20f); + + TestRoundtrip(0.1e-20f); + TestRoundtrip(0.12e-20f); + TestRoundtrip(0.123e-20f); + TestRoundtrip(0.1234e-20f); + TestRoundtrip(0.12345e-20f); + TestRoundtrip(0.123456e-20f); + TestRoundtrip(0.1234567e-20f); + TestRoundtrip(0.12345678e-20f); +} + +TEST(MarshallingTest, TestDoubleRoundTrip) { + TestRoundtrip(0.1); + TestRoundtrip(0.12); + TestRoundtrip(0.123); + TestRoundtrip(0.1234); + TestRoundtrip(0.12345); + TestRoundtrip(0.123456); + TestRoundtrip(0.1234567); + TestRoundtrip(0.12345678); + TestRoundtrip(0.123456789); + TestRoundtrip(0.1234567891); + TestRoundtrip(0.12345678912); + TestRoundtrip(0.123456789123); + TestRoundtrip(0.1234567891234); + TestRoundtrip(0.12345678912345); + TestRoundtrip(0.123456789123456); + TestRoundtrip(0.1234567891234567); + TestRoundtrip(0.12345678912345678); + + TestRoundtrip(0.1e50); + TestRoundtrip(0.12e50); + TestRoundtrip(0.123e50); + TestRoundtrip(0.1234e50); + TestRoundtrip(0.12345e50); + TestRoundtrip(0.123456e50); + TestRoundtrip(0.1234567e50); + TestRoundtrip(0.12345678e50); + TestRoundtrip(0.123456789e50); + TestRoundtrip(0.1234567891e50); + TestRoundtrip(0.12345678912e50); + TestRoundtrip(0.123456789123e50); + TestRoundtrip(0.1234567891234e50); + TestRoundtrip(0.12345678912345e50); + TestRoundtrip(0.123456789123456e50); + TestRoundtrip(0.1234567891234567e50); + TestRoundtrip(0.12345678912345678e50); + + TestRoundtrip(0.1e-50); + TestRoundtrip(0.12e-50); + TestRoundtrip(0.123e-50); + TestRoundtrip(0.1234e-50); + TestRoundtrip(0.12345e-50); + TestRoundtrip(0.123456e-50); + TestRoundtrip(0.1234567e-50); + TestRoundtrip(0.12345678e-50); + TestRoundtrip(0.123456789e-50); + TestRoundtrip(0.1234567891e-50); + TestRoundtrip(0.12345678912e-50); + TestRoundtrip(0.123456789123e-50); + TestRoundtrip(0.1234567891234e-50); + TestRoundtrip(0.12345678912345e-50); + TestRoundtrip(0.123456789123456e-50); + TestRoundtrip(0.1234567891234567e-50); + TestRoundtrip(0.12345678912345678e-50); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/parse.cc b/third_party/abseil_cpp/absl/flags/parse.cc new file mode 100644 index 0000000000..fbf4267512 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/parse.cc @@ -0,0 +1,811 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/parse.h" + +#include <stdlib.h> + +#include <algorithm> +#include <fstream> +#include <iostream> +#include <iterator> +#include <string> +#include <tuple> +#include <utility> +#include <vector> + +#ifdef _WIN32 +#include <windows.h> +#endif + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/const_init.h" +#include "absl/base/thread_annotations.h" +#include "absl/flags/config.h" +#include "absl/flags/flag.h" +#include "absl/flags/internal/commandlineflag.h" +#include "absl/flags/internal/flag.h" +#include "absl/flags/internal/parse.h" +#include "absl/flags/internal/private_handle_accessor.h" +#include "absl/flags/internal/program_name.h" +#include "absl/flags/internal/registry.h" +#include "absl/flags/internal/usage.h" +#include "absl/flags/usage.h" +#include "absl/flags/usage_config.h" +#include "absl/strings/ascii.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" +#include "absl/synchronization/mutex.h" + +// -------------------------------------------------------------------- + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { +namespace { + +ABSL_CONST_INIT absl::Mutex processing_checks_guard(absl::kConstInit); + +ABSL_CONST_INIT bool flagfile_needs_processing + ABSL_GUARDED_BY(processing_checks_guard) = false; +ABSL_CONST_INIT bool fromenv_needs_processing + ABSL_GUARDED_BY(processing_checks_guard) = false; +ABSL_CONST_INIT bool tryfromenv_needs_processing + ABSL_GUARDED_BY(processing_checks_guard) = false; + +ABSL_CONST_INIT absl::Mutex specified_flags_guard(absl::kConstInit); +ABSL_CONST_INIT std::vector<const CommandLineFlag*>* specified_flags + ABSL_GUARDED_BY(specified_flags_guard) = nullptr; + +struct SpecifiedFlagsCompare { + bool operator()(const CommandLineFlag* a, const CommandLineFlag* b) const { + return a->Name() < b->Name(); + } + bool operator()(const CommandLineFlag* a, absl::string_view b) const { + return a->Name() < b; + } + bool operator()(absl::string_view a, const CommandLineFlag* b) const { + return a < b->Name(); + } +}; + +} // namespace +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +ABSL_FLAG(std::vector<std::string>, flagfile, {}, + "comma-separated list of files to load flags from") + .OnUpdate([]() { + if (absl::GetFlag(FLAGS_flagfile).empty()) return; + + absl::MutexLock l(&absl::flags_internal::processing_checks_guard); + + // Setting this flag twice before it is handled most likely an internal + // error and should be reviewed by developers. + if (absl::flags_internal::flagfile_needs_processing) { + ABSL_INTERNAL_LOG(WARNING, "flagfile set twice before it is handled"); + } + + absl::flags_internal::flagfile_needs_processing = true; + }); +ABSL_FLAG(std::vector<std::string>, fromenv, {}, + "comma-separated list of flags to set from the environment" + " [use 'export FLAGS_flag1=value']") + .OnUpdate([]() { + if (absl::GetFlag(FLAGS_fromenv).empty()) return; + + absl::MutexLock l(&absl::flags_internal::processing_checks_guard); + + // Setting this flag twice before it is handled most likely an internal + // error and should be reviewed by developers. + if (absl::flags_internal::fromenv_needs_processing) { + ABSL_INTERNAL_LOG(WARNING, "fromenv set twice before it is handled."); + } + + absl::flags_internal::fromenv_needs_processing = true; + }); +ABSL_FLAG(std::vector<std::string>, tryfromenv, {}, + "comma-separated list of flags to try to set from the environment if " + "present") + .OnUpdate([]() { + if (absl::GetFlag(FLAGS_tryfromenv).empty()) return; + + absl::MutexLock l(&absl::flags_internal::processing_checks_guard); + + // Setting this flag twice before it is handled most likely an internal + // error and should be reviewed by developers. + if (absl::flags_internal::tryfromenv_needs_processing) { + ABSL_INTERNAL_LOG(WARNING, + "tryfromenv set twice before it is handled."); + } + + absl::flags_internal::tryfromenv_needs_processing = true; + }); + +ABSL_FLAG(std::vector<std::string>, undefok, {}, + "comma-separated list of flag names that it is okay to specify " + "on the command line even if the program does not define a flag " + "with that name"); + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +namespace { + +class ArgsList { + public: + ArgsList() : next_arg_(0) {} + ArgsList(int argc, char* argv[]) : args_(argv, argv + argc), next_arg_(0) {} + explicit ArgsList(const std::vector<std::string>& args) + : args_(args), next_arg_(0) {} + + // Returns success status: true if parsing successful, false otherwise. + bool ReadFromFlagfile(const std::string& flag_file_name); + + int Size() const { return args_.size() - next_arg_; } + int FrontIndex() const { return next_arg_; } + absl::string_view Front() const { return args_[next_arg_]; } + void PopFront() { next_arg_++; } + + private: + std::vector<std::string> args_; + int next_arg_; +}; + +bool ArgsList::ReadFromFlagfile(const std::string& flag_file_name) { + std::ifstream flag_file(flag_file_name); + + if (!flag_file) { + flags_internal::ReportUsageError( + absl::StrCat("Can't open flagfile ", flag_file_name), true); + + return false; + } + + // This argument represents fake argv[0], which should be present in all arg + // lists. + args_.push_back(""); + + std::string line; + bool success = true; + + while (std::getline(flag_file, line)) { + absl::string_view stripped = absl::StripLeadingAsciiWhitespace(line); + + if (stripped.empty() || stripped[0] == '#') { + // Comment or empty line; just ignore. + continue; + } + + if (stripped[0] == '-') { + if (stripped == "--") { + flags_internal::ReportUsageError( + "Flagfile can't contain position arguments or --", true); + + success = false; + break; + } + + args_.push_back(std::string(stripped)); + continue; + } + + flags_internal::ReportUsageError( + absl::StrCat("Unexpected line in the flagfile ", flag_file_name, ": ", + line), + true); + + success = false; + } + + return success; +} + +// -------------------------------------------------------------------- + +// Reads the environment variable with name `name` and stores results in +// `value`. If variable is not present in environment returns false, otherwise +// returns true. +bool GetEnvVar(const char* var_name, std::string* var_value) { +#ifdef _WIN32 + char buf[1024]; + auto get_res = GetEnvironmentVariableA(var_name, buf, sizeof(buf)); + if (get_res >= sizeof(buf)) { + return false; + } + + if (get_res == 0) { + return false; + } + + *var_value = std::string(buf, get_res); +#else + const char* val = ::getenv(var_name); + if (val == nullptr) { + return false; + } + + *var_value = val; +#endif + + return true; +} + +// -------------------------------------------------------------------- + +// Returns: +// Flag name or empty if arg= -- +// Flag value after = in --flag=value (empty if --foo) +// "Is empty value" status. True if arg= --foo=, false otherwise. This is +// required to separate --foo from --foo=. +// For example: +// arg return values +// "--foo=bar" -> {"foo", "bar", false}. +// "--foo" -> {"foo", "", false}. +// "--foo=" -> {"foo", "", true}. +std::tuple<absl::string_view, absl::string_view, bool> SplitNameAndValue( + absl::string_view arg) { + // Allow -foo and --foo + absl::ConsumePrefix(&arg, "-"); + + if (arg.empty()) { + return std::make_tuple("", "", false); + } + + auto equal_sign_pos = arg.find("="); + + absl::string_view flag_name = arg.substr(0, equal_sign_pos); + + absl::string_view value; + bool is_empty_value = false; + + if (equal_sign_pos != absl::string_view::npos) { + value = arg.substr(equal_sign_pos + 1); + is_empty_value = value.empty(); + } + + return std::make_tuple(flag_name, value, is_empty_value); +} + +// -------------------------------------------------------------------- + +// Returns: +// found flag or nullptr +// is negative in case of --nofoo +std::tuple<CommandLineFlag*, bool> LocateFlag(absl::string_view flag_name) { + CommandLineFlag* flag = flags_internal::FindCommandLineFlag(flag_name); + bool is_negative = false; + + if (!flag && absl::ConsumePrefix(&flag_name, "no")) { + flag = flags_internal::FindCommandLineFlag(flag_name); + is_negative = true; + } + + return std::make_tuple(flag, is_negative); +} + +// -------------------------------------------------------------------- + +// Verify that default values of typed flags must be convertible to string and +// back. +void CheckDefaultValuesParsingRoundtrip() { +#ifndef NDEBUG + flags_internal::ForEachFlag([&](CommandLineFlag* flag) { + if (flag->IsRetired()) return; + +#define ABSL_FLAGS_INTERNAL_IGNORE_TYPE(T, _) \ + if (flag->IsOfType<T>()) return; + + ABSL_FLAGS_INTERNAL_SUPPORTED_TYPES(ABSL_FLAGS_INTERNAL_IGNORE_TYPE) +#undef ABSL_FLAGS_INTERNAL_IGNORE_TYPE + + flags_internal::PrivateHandleAccessor::CheckDefaultValueParsingRoundtrip( + *flag); + }); +#endif +} + +// -------------------------------------------------------------------- + +// Returns success status, which is true if we successfully read all flag files, +// in which case new ArgLists are appended to the input_args in a reverse order +// of file names in the input flagfiles list. This order ensures that flags from +// the first flagfile in the input list are processed before the second flagfile +// etc. +bool ReadFlagfiles(const std::vector<std::string>& flagfiles, + std::vector<ArgsList>* input_args) { + bool success = true; + for (auto it = flagfiles.rbegin(); it != flagfiles.rend(); ++it) { + ArgsList al; + + if (al.ReadFromFlagfile(*it)) { + input_args->push_back(al); + } else { + success = false; + } + } + + return success; +} + +// Returns success status, which is true if were able to locate all environment +// variables correctly or if fail_on_absent_in_env is false. The environment +// variable names are expected to be of the form `FLAGS_<flag_name>`, where +// `flag_name` is a string from the input flag_names list. If successful we +// append a single ArgList at the end of the input_args. +bool ReadFlagsFromEnv(const std::vector<std::string>& flag_names, + std::vector<ArgsList>* input_args, + bool fail_on_absent_in_env) { + bool success = true; + std::vector<std::string> args; + + // This argument represents fake argv[0], which should be present in all arg + // lists. + args.push_back(""); + + for (const auto& flag_name : flag_names) { + // Avoid infinite recursion. + if (flag_name == "fromenv" || flag_name == "tryfromenv") { + flags_internal::ReportUsageError( + absl::StrCat("Infinite recursion on flag ", flag_name), true); + + success = false; + continue; + } + + const std::string envname = absl::StrCat("FLAGS_", flag_name); + std::string envval; + if (!GetEnvVar(envname.c_str(), &envval)) { + if (fail_on_absent_in_env) { + flags_internal::ReportUsageError( + absl::StrCat(envname, " not found in environment"), true); + + success = false; + } + + continue; + } + + args.push_back(absl::StrCat("--", flag_name, "=", envval)); + } + + if (success) { + input_args->emplace_back(args); + } + + return success; +} + +// -------------------------------------------------------------------- + +// Returns success status, which is true if were able to handle all generator +// flags (flagfile, fromenv, tryfromemv) successfully. +bool HandleGeneratorFlags(std::vector<ArgsList>* input_args, + std::vector<std::string>* flagfile_value) { + bool success = true; + + absl::MutexLock l(&flags_internal::processing_checks_guard); + + // flagfile could have been set either on a command line or + // programmatically before invoking ParseCommandLine. Note that we do not + // actually process arguments specified in the flagfile, but instead + // create a secondary arguments list to be processed along with the rest + // of the comamnd line arguments. Since we always the process most recently + // created list of arguments first, this will result in flagfile argument + // being processed before any other argument in the command line. If + // FLAGS_flagfile contains more than one file name we create multiple new + // levels of arguments in a reverse order of file names. Thus we always + // process arguments from first file before arguments containing in a + // second file, etc. If flagfile contains another + // --flagfile inside of it, it will produce new level of arguments and + // processed before the rest of the flagfile. We are also collecting all + // flagfiles set on original command line. Unlike the rest of the flags, + // this flag can be set multiple times and is expected to be handled + // multiple times. We are collecting them all into a single list and set + // the value of FLAGS_flagfile to that value at the end of the parsing. + if (flags_internal::flagfile_needs_processing) { + auto flagfiles = absl::GetFlag(FLAGS_flagfile); + + if (input_args->size() == 1) { + flagfile_value->insert(flagfile_value->end(), flagfiles.begin(), + flagfiles.end()); + } + + success &= ReadFlagfiles(flagfiles, input_args); + + flags_internal::flagfile_needs_processing = false; + } + + // Similar to flagfile fromenv/tryfromemv can be set both + // programmatically and at runtime on a command line. Unlike flagfile these + // can't be recursive. + if (flags_internal::fromenv_needs_processing) { + auto flags_list = absl::GetFlag(FLAGS_fromenv); + + success &= ReadFlagsFromEnv(flags_list, input_args, true); + + flags_internal::fromenv_needs_processing = false; + } + + if (flags_internal::tryfromenv_needs_processing) { + auto flags_list = absl::GetFlag(FLAGS_tryfromenv); + + success &= ReadFlagsFromEnv(flags_list, input_args, false); + + flags_internal::tryfromenv_needs_processing = false; + } + + return success; +} + +// -------------------------------------------------------------------- + +void ResetGeneratorFlags(const std::vector<std::string>& flagfile_value) { + // Setting flagfile to the value which collates all the values set on a + // command line and programmatically. So if command line looked like + // --flagfile=f1 --flagfile=f2 the final value of the FLAGS_flagfile flag is + // going to be {"f1", "f2"} + if (!flagfile_value.empty()) { + absl::SetFlag(&FLAGS_flagfile, flagfile_value); + absl::MutexLock l(&flags_internal::processing_checks_guard); + flags_internal::flagfile_needs_processing = false; + } + + // fromenv/tryfromenv are set to <undefined> value. + if (!absl::GetFlag(FLAGS_fromenv).empty()) { + absl::SetFlag(&FLAGS_fromenv, {}); + } + if (!absl::GetFlag(FLAGS_tryfromenv).empty()) { + absl::SetFlag(&FLAGS_tryfromenv, {}); + } + + absl::MutexLock l(&flags_internal::processing_checks_guard); + flags_internal::fromenv_needs_processing = false; + flags_internal::tryfromenv_needs_processing = false; +} + +// -------------------------------------------------------------------- + +// Returns: +// success status +// deduced value +// We are also mutating curr_list in case if we need to get a hold of next +// argument in the input. +std::tuple<bool, absl::string_view> DeduceFlagValue(const CommandLineFlag& flag, + absl::string_view value, + bool is_negative, + bool is_empty_value, + ArgsList* curr_list) { + // Value is either an argument suffix after `=` in "--foo=<value>" + // or separate argument in case of "--foo" "<value>". + + // boolean flags have these forms: + // --foo + // --nofoo + // --foo=true + // --foo=false + // --nofoo=<value> is not supported + // --foo <value> is not supported + + // non boolean flags have these forms: + // --foo=<value> + // --foo <value> + // --nofoo is not supported + + if (flag.IsOfType<bool>()) { + if (value.empty()) { + if (is_empty_value) { + // "--bool_flag=" case + flags_internal::ReportUsageError( + absl::StrCat( + "Missing the value after assignment for the boolean flag '", + flag.Name(), "'"), + true); + return std::make_tuple(false, ""); + } + + // "--bool_flag" case + value = is_negative ? "0" : "1"; + } else if (is_negative) { + // "--nobool_flag=Y" case + flags_internal::ReportUsageError( + absl::StrCat("Negative form with assignment is not valid for the " + "boolean flag '", + flag.Name(), "'"), + true); + return std::make_tuple(false, ""); + } + } else if (is_negative) { + // "--noint_flag=1" case + flags_internal::ReportUsageError( + absl::StrCat("Negative form is not valid for the flag '", flag.Name(), + "'"), + true); + return std::make_tuple(false, ""); + } else if (value.empty() && (!is_empty_value)) { + if (curr_list->Size() == 1) { + // "--int_flag" case + flags_internal::ReportUsageError( + absl::StrCat("Missing the value for the flag '", flag.Name(), "'"), + true); + return std::make_tuple(false, ""); + } + + // "--int_flag" "10" case + curr_list->PopFront(); + value = curr_list->Front(); + + // Heuristic to detect the case where someone treats a string arg + // like a bool or just forgets to pass a value: + // --my_string_var --foo=bar + // We look for a flag of string type, whose value begins with a + // dash and corresponds to known flag or standalone --. + if (!value.empty() && value[0] == '-' && flag.IsOfType<std::string>()) { + auto maybe_flag_name = std::get<0>(SplitNameAndValue(value.substr(1))); + + if (maybe_flag_name.empty() || + std::get<0>(LocateFlag(maybe_flag_name)) != nullptr) { + // "--string_flag" "--known_flag" case + ABSL_INTERNAL_LOG( + WARNING, + absl::StrCat("Did you really mean to set flag '", flag.Name(), + "' to the value '", value, "'?")); + } + } + } + + return std::make_tuple(true, value); +} + +// -------------------------------------------------------------------- + +bool CanIgnoreUndefinedFlag(absl::string_view flag_name) { + auto undefok = absl::GetFlag(FLAGS_undefok); + if (std::find(undefok.begin(), undefok.end(), flag_name) != undefok.end()) { + return true; + } + + if (absl::ConsumePrefix(&flag_name, "no") && + std::find(undefok.begin(), undefok.end(), flag_name) != undefok.end()) { + return true; + } + + return false; +} + +} // namespace + +// -------------------------------------------------------------------- + +bool WasPresentOnCommandLine(absl::string_view flag_name) { + absl::MutexLock l(&specified_flags_guard); + ABSL_INTERNAL_CHECK(specified_flags != nullptr, + "ParseCommandLine is not invoked yet"); + + return std::binary_search(specified_flags->begin(), specified_flags->end(), + flag_name, SpecifiedFlagsCompare{}); +} + +// -------------------------------------------------------------------- + +std::vector<char*> ParseCommandLineImpl(int argc, char* argv[], + ArgvListAction arg_list_act, + UsageFlagsAction usage_flag_act, + OnUndefinedFlag on_undef_flag) { + ABSL_INTERNAL_CHECK(argc > 0, "Missing argv[0]"); + + // This routine does not return anything since we abort on failure. + CheckDefaultValuesParsingRoundtrip(); + + std::vector<std::string> flagfile_value; + + std::vector<ArgsList> input_args; + input_args.push_back(ArgsList(argc, argv)); + + std::vector<char*> output_args; + std::vector<char*> positional_args; + output_args.reserve(argc); + + // This is the list of undefined flags. The element of the list is the pair + // consisting of boolean indicating if flag came from command line (vs from + // some flag file we've read) and flag name. + // TODO(rogeeff): Eliminate the first element in the pair after cleanup. + std::vector<std::pair<bool, std::string>> undefined_flag_names; + + // Set program invocation name if it is not set before. + if (ProgramInvocationName() == "UNKNOWN") { + flags_internal::SetProgramInvocationName(argv[0]); + } + output_args.push_back(argv[0]); + + absl::MutexLock l(&specified_flags_guard); + if (specified_flags == nullptr) { + specified_flags = new std::vector<const CommandLineFlag*>; + } else { + specified_flags->clear(); + } + + // Iterate through the list of the input arguments. First level are arguments + // originated from argc/argv. Following levels are arguments originated from + // recursive parsing of flagfile(s). + bool success = true; + while (!input_args.empty()) { + // 10. First we process the built-in generator flags. + success &= HandleGeneratorFlags(&input_args, &flagfile_value); + + // 30. Select top-most (most recent) arguments list. If it is empty drop it + // and re-try. + ArgsList& curr_list = input_args.back(); + + curr_list.PopFront(); + + if (curr_list.Size() == 0) { + input_args.pop_back(); + continue; + } + + // 40. Pick up the front remaining argument in the current list. If current + // stack of argument lists contains only one element - we are processing an + // argument from the original argv. + absl::string_view arg(curr_list.Front()); + bool arg_from_argv = input_args.size() == 1; + + // 50. If argument does not start with - or is just "-" - this is + // positional argument. + if (!absl::ConsumePrefix(&arg, "-") || arg.empty()) { + ABSL_INTERNAL_CHECK(arg_from_argv, + "Flagfile cannot contain positional argument"); + + positional_args.push_back(argv[curr_list.FrontIndex()]); + continue; + } + + if (arg_from_argv && (arg_list_act == ArgvListAction::kKeepParsedArgs)) { + output_args.push_back(argv[curr_list.FrontIndex()]); + } + + // 60. Split the current argument on '=' to figure out the argument + // name and value. If flag name is empty it means we've got "--". value + // can be empty either if there were no '=' in argument string at all or + // an argument looked like "--foo=". In a latter case is_empty_value is + // true. + absl::string_view flag_name; + absl::string_view value; + bool is_empty_value = false; + + std::tie(flag_name, value, is_empty_value) = SplitNameAndValue(arg); + + // 70. "--" alone means what it does for GNU: stop flags parsing. We do + // not support positional arguments in flagfiles, so we just drop them. + if (flag_name.empty()) { + ABSL_INTERNAL_CHECK(arg_from_argv, + "Flagfile cannot contain positional argument"); + + curr_list.PopFront(); + break; + } + + // 80. Locate the flag based on flag name. Handle both --foo and --nofoo + CommandLineFlag* flag = nullptr; + bool is_negative = false; + std::tie(flag, is_negative) = LocateFlag(flag_name); + + if (flag == nullptr) { + if (on_undef_flag != OnUndefinedFlag::kIgnoreUndefined) { + undefined_flag_names.emplace_back(arg_from_argv, + std::string(flag_name)); + } + continue; + } + + // 90. Deduce flag's value (from this or next argument) + auto curr_index = curr_list.FrontIndex(); + bool value_success = true; + std::tie(value_success, value) = + DeduceFlagValue(*flag, value, is_negative, is_empty_value, &curr_list); + success &= value_success; + + // If above call consumed an argument, it was a standalone value + if (arg_from_argv && (arg_list_act == ArgvListAction::kKeepParsedArgs) && + (curr_index != curr_list.FrontIndex())) { + output_args.push_back(argv[curr_list.FrontIndex()]); + } + + // 100. Set the located flag to a new new value, unless it is retired. + // Setting retired flag fails, but we ignoring it here. + if (flag->IsRetired()) continue; + + std::string error; + if (!flags_internal::PrivateHandleAccessor::ParseFrom( + flag, value, SET_FLAGS_VALUE, kCommandLine, &error)) { + flags_internal::ReportUsageError(error, true); + success = false; + } else { + specified_flags->push_back(flag); + } + } + + for (const auto& flag_name : undefined_flag_names) { + if (CanIgnoreUndefinedFlag(flag_name.second)) continue; + + flags_internal::ReportUsageError( + absl::StrCat("Unknown command line flag '", flag_name.second, "'"), + true); + + success = false; + } + +#if ABSL_FLAGS_STRIP_NAMES + if (!success) { + flags_internal::ReportUsageError( + "NOTE: command line flags are disabled in this build", true); + } +#endif + + if (!success) { + flags_internal::HandleUsageFlags(std::cout, + ProgramUsageMessage()); + std::exit(1); + } + + if (usage_flag_act == UsageFlagsAction::kHandleUsage) { + int exit_code = flags_internal::HandleUsageFlags( + std::cout, ProgramUsageMessage()); + + if (exit_code != -1) { + std::exit(exit_code); + } + } + + ResetGeneratorFlags(flagfile_value); + + // Reinstate positional args which were intermixed with flags in the arguments + // list. + for (auto arg : positional_args) { + output_args.push_back(arg); + } + + // All the remaining arguments are positional. + if (!input_args.empty()) { + for (int arg_index = input_args.back().FrontIndex(); arg_index < argc; + ++arg_index) { + output_args.push_back(argv[arg_index]); + } + } + + // Trim and sort the vector. + specified_flags->shrink_to_fit(); + std::sort(specified_flags->begin(), specified_flags->end(), + SpecifiedFlagsCompare{}); + return output_args; +} + +} // namespace flags_internal + +// -------------------------------------------------------------------- + +std::vector<char*> ParseCommandLine(int argc, char* argv[]) { + return flags_internal::ParseCommandLineImpl( + argc, argv, flags_internal::ArgvListAction::kRemoveParsedArgs, + flags_internal::UsageFlagsAction::kHandleUsage, + flags_internal::OnUndefinedFlag::kAbortIfUndefined); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/parse.h b/third_party/abseil_cpp/absl/flags/parse.h new file mode 100644 index 0000000000..f37b0602e6 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/parse.h @@ -0,0 +1,61 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: parse.h +// ----------------------------------------------------------------------------- +// +// This file defines the main parsing function for Abseil flags: +// `absl::ParseCommandLine()`. + +#ifndef ABSL_FLAGS_PARSE_H_ +#define ABSL_FLAGS_PARSE_H_ + +#include <string> +#include <vector> + +#include "absl/base/config.h" +#include "absl/flags/internal/parse.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ParseCommandLine() +// +// Parses the set of command-line arguments passed in the `argc` (argument +// count) and `argv[]` (argument vector) parameters from `main()`, assigning +// values to any defined Abseil flags. (Any arguments passed after the +// flag-terminating delimiter (`--`) are treated as positional arguments and +// ignored.) +// +// Any command-line flags (and arguments to those flags) are parsed into Abseil +// Flag values, if those flags are defined. Any undefined flags will either +// return an error, or be ignored if that flag is designated using `undefok` to +// indicate "undefined is OK." +// +// Any command-line positional arguments not part of any command-line flag (or +// arguments to a flag) are returned in a vector, with the program invocation +// name at position 0 of that vector. (Note that this includes positional +// arguments after the flag-terminating delimiter `--`.) +// +// After all flags and flag arguments are parsed, this function looks for any +// built-in usage flags (e.g. `--help`), and if any were specified, it reports +// help messages and then exits the program. +std::vector<char*> ParseCommandLine(int argc, char* argv[]); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_PARSE_H_ diff --git a/third_party/abseil_cpp/absl/flags/parse_test.cc b/third_party/abseil_cpp/absl/flags/parse_test.cc new file mode 100644 index 0000000000..e6a53ae6cb --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/parse_test.cc @@ -0,0 +1,894 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/parse.h" + +#include <stdlib.h> + +#include <fstream> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/scoped_set_env.h" +#include "absl/flags/declare.h" +#include "absl/flags/flag.h" +#include "absl/flags/internal/parse.h" +#include "absl/flags/internal/registry.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/strings/substitute.h" +#include "absl/types/span.h" + +#ifdef _WIN32 +#include <windows.h> +#endif + +namespace { + +using absl::base_internal::ScopedSetEnv; + +struct UDT { + UDT() = default; + UDT(const UDT&) = default; + UDT(int v) : value(v) {} // NOLINT + + int value; +}; + +bool AbslParseFlag(absl::string_view in, UDT* udt, std::string* err) { + if (in == "A") { + udt->value = 1; + return true; + } + if (in == "AAA") { + udt->value = 10; + return true; + } + + *err = "Use values A, AAA instead"; + return false; +} +std::string AbslUnparseFlag(const UDT& udt) { + return udt.value == 1 ? "A" : "AAA"; +} + +std::string GetTestTmpDirEnvVar(const char* const env_var_name) { +#ifdef _WIN32 + char buf[MAX_PATH]; + auto get_res = GetEnvironmentVariableA(env_var_name, buf, sizeof(buf)); + if (get_res >= sizeof(buf) || get_res == 0) { + return ""; + } + + return std::string(buf, get_res); +#else + const char* val = ::getenv(env_var_name); + if (val == nullptr) { + return ""; + } + + return val; +#endif +} + +const std::string& GetTestTempDir() { + static std::string* temp_dir_name = []() -> std::string* { + std::string* res = new std::string(GetTestTmpDirEnvVar("TEST_TMPDIR")); + + if (res->empty()) { + *res = GetTestTmpDirEnvVar("TMPDIR"); + } + + if (res->empty()) { +#ifdef _WIN32 + char temp_path_buffer[MAX_PATH]; + + auto len = GetTempPathA(MAX_PATH, temp_path_buffer); + if (len < MAX_PATH && len != 0) { + std::string temp_dir_name = temp_path_buffer; + if (!absl::EndsWith(temp_dir_name, "\\")) { + temp_dir_name.push_back('\\'); + } + absl::StrAppend(&temp_dir_name, "parse_test.", GetCurrentProcessId()); + if (CreateDirectoryA(temp_dir_name.c_str(), nullptr)) { + *res = temp_dir_name; + } + } +#else + char temp_dir_template[] = "/tmp/parse_test.XXXXXX"; + if (auto* unique_name = ::mkdtemp(temp_dir_template)) { + *res = unique_name; + } +#endif + } + + if (res->empty()) { + ABSL_INTERNAL_LOG(FATAL, + "Failed to make temporary directory for data files"); + } + +#ifdef _WIN32 + *res += "\\"; +#else + *res += "/"; +#endif + + return res; + }(); + + return *temp_dir_name; +} + +struct FlagfileData { + const absl::string_view file_name; + const absl::Span<const char* const> file_lines; +}; + +// clang-format off +constexpr const char* const ff1_data[] = { + "# comment ", + " # comment ", + "", + " ", + "--int_flag=-1", + " --string_flag=q2w2 ", + " ## ", + " --double_flag=0.1", + "--bool_flag=Y " +}; + +constexpr const char* const ff2_data[] = { + "# Setting legacy flag", + "--legacy_int=1111", + "--legacy_bool", + "--nobool_flag", + "--legacy_str=aqsw", + "--int_flag=100", + " ## =============" +}; +// clang-format on + +// Builds flagfile flag in the flagfile_flag buffer and returns it. This +// function also creates a temporary flagfile based on FlagfileData input. +// We create a flagfile in a temporary directory with the name specified in +// FlagfileData and populate it with lines specifed in FlagfileData. If $0 is +// referenced in any of the lines in FlagfileData they are replaced with +// temporary directory location. This way we can test inclusion of one flagfile +// from another flagfile. +const char* GetFlagfileFlag(const std::vector<FlagfileData>& ffd, + std::string* flagfile_flag) { + *flagfile_flag = "--flagfile="; + absl::string_view separator; + for (const auto& flagfile_data : ffd) { + std::string flagfile_name = + absl::StrCat(GetTestTempDir(), flagfile_data.file_name); + + std::ofstream flagfile_out(flagfile_name); + for (auto line : flagfile_data.file_lines) { + flagfile_out << absl::Substitute(line, GetTestTempDir()) << "\n"; + } + + absl::StrAppend(flagfile_flag, separator, flagfile_name); + separator = ","; + } + + return flagfile_flag->c_str(); +} + +} // namespace + +ABSL_FLAG(int, int_flag, 1, ""); +ABSL_FLAG(double, double_flag, 1.1, ""); +ABSL_FLAG(std::string, string_flag, "a", ""); +ABSL_FLAG(bool, bool_flag, false, ""); +ABSL_FLAG(UDT, udt_flag, -1, ""); +ABSL_RETIRED_FLAG(int, legacy_int, 1, ""); +ABSL_RETIRED_FLAG(bool, legacy_bool, false, ""); +ABSL_RETIRED_FLAG(std::string, legacy_str, "l", ""); + +namespace { + +namespace flags = absl::flags_internal; +using testing::ElementsAreArray; + +class ParseTest : public testing::Test { + private: + flags::FlagSaver flag_saver_; +}; + +// -------------------------------------------------------------------- + +template <int N> +std::vector<char*> InvokeParse(const char* (&in_argv)[N]) { + return absl::ParseCommandLine(N, const_cast<char**>(in_argv)); +} + +// -------------------------------------------------------------------- + +template <int N> +void TestParse(const char* (&in_argv)[N], int int_flag_value, + double double_flag_val, absl::string_view string_flag_val, + bool bool_flag_val, int exp_position_args = 0) { + auto out_args = InvokeParse(in_argv); + + EXPECT_EQ(out_args.size(), 1 + exp_position_args); + EXPECT_STREQ(out_args[0], "testbin"); + + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), int_flag_value); + EXPECT_NEAR(absl::GetFlag(FLAGS_double_flag), double_flag_val, 0.0001); + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), string_flag_val); + EXPECT_EQ(absl::GetFlag(FLAGS_bool_flag), bool_flag_val); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestEmptyArgv) { + const char* in_argv[] = {"testbin"}; + + auto out_args = InvokeParse(in_argv); + + EXPECT_EQ(out_args.size(), 1); + EXPECT_STREQ(out_args[0], "testbin"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidIntArg) { + const char* in_args1[] = { + "testbin", + "--int_flag=10", + }; + TestParse(in_args1, 10, 1.1, "a", false); + + const char* in_args2[] = { + "testbin", + "-int_flag=020", + }; + TestParse(in_args2, 20, 1.1, "a", false); + + const char* in_args3[] = { + "testbin", + "--int_flag", + "-30", + }; + TestParse(in_args3, -30, 1.1, "a", false); + + const char* in_args4[] = { + "testbin", + "-int_flag", + "0x21", + }; + TestParse(in_args4, 33, 1.1, "a", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidDoubleArg) { + const char* in_args1[] = { + "testbin", + "--double_flag=2.3", + }; + TestParse(in_args1, 1, 2.3, "a", false); + + const char* in_args2[] = { + "testbin", + "--double_flag=0x1.2", + }; + TestParse(in_args2, 1, 1.125, "a", false); + + const char* in_args3[] = { + "testbin", + "--double_flag", + "99.7", + }; + TestParse(in_args3, 1, 99.7, "a", false); + + const char* in_args4[] = { + "testbin", + "--double_flag", + "0x20.1", + }; + TestParse(in_args4, 1, 32.0625, "a", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidStringArg) { + const char* in_args1[] = { + "testbin", + "--string_flag=aqswde", + }; + TestParse(in_args1, 1, 1.1, "aqswde", false); + + const char* in_args2[] = { + "testbin", + "-string_flag=a=b=c", + }; + TestParse(in_args2, 1, 1.1, "a=b=c", false); + + const char* in_args3[] = { + "testbin", + "--string_flag", + "zaxscd", + }; + TestParse(in_args3, 1, 1.1, "zaxscd", false); + + const char* in_args4[] = { + "testbin", + "-string_flag", + "--int_flag", + }; + TestParse(in_args4, 1, 1.1, "--int_flag", false); + + const char* in_args5[] = { + "testbin", + "--string_flag", + "--no_a_flag=11", + }; + TestParse(in_args5, 1, 1.1, "--no_a_flag=11", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidBoolArg) { + const char* in_args1[] = { + "testbin", + "--bool_flag", + }; + TestParse(in_args1, 1, 1.1, "a", true); + + const char* in_args2[] = { + "testbin", + "--nobool_flag", + }; + TestParse(in_args2, 1, 1.1, "a", false); + + const char* in_args3[] = { + "testbin", + "--bool_flag=true", + }; + TestParse(in_args3, 1, 1.1, "a", true); + + const char* in_args4[] = { + "testbin", + "-bool_flag=false", + }; + TestParse(in_args4, 1, 1.1, "a", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidUDTArg) { + const char* in_args1[] = { + "testbin", + "--udt_flag=A", + }; + InvokeParse(in_args1); + + EXPECT_EQ(absl::GetFlag(FLAGS_udt_flag).value, 1); + + const char* in_args2[] = {"testbin", "--udt_flag", "AAA"}; + InvokeParse(in_args2); + + EXPECT_EQ(absl::GetFlag(FLAGS_udt_flag).value, 10); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidMultipleArg) { + const char* in_args1[] = { + "testbin", "--bool_flag", "--int_flag=2", + "--double_flag=0.1", "--string_flag=asd", + }; + TestParse(in_args1, 2, 0.1, "asd", true); + + const char* in_args2[] = { + "testbin", "--string_flag=", "--nobool_flag", "--int_flag", + "-011", "--double_flag", "-1e-2", + }; + TestParse(in_args2, -11, -0.01, "", false); + + const char* in_args3[] = { + "testbin", "--int_flag", "-0", "--string_flag", "\"\"", + "--bool_flag=true", "--double_flag=1e18", + }; + TestParse(in_args3, 0, 1e18, "\"\"", true); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestPositionalArgs) { + const char* in_args1[] = { + "testbin", + "p1", + "p2", + }; + TestParse(in_args1, 1, 1.1, "a", false, 2); + + auto out_args1 = InvokeParse(in_args1); + + EXPECT_STREQ(out_args1[1], "p1"); + EXPECT_STREQ(out_args1[2], "p2"); + + const char* in_args2[] = { + "testbin", + "--int_flag=2", + "p1", + }; + TestParse(in_args2, 2, 1.1, "a", false, 1); + + auto out_args2 = InvokeParse(in_args2); + + EXPECT_STREQ(out_args2[1], "p1"); + + const char* in_args3[] = {"testbin", "p1", "--int_flag=3", + "p2", "--bool_flag", "true"}; + TestParse(in_args3, 3, 1.1, "a", true, 3); + + auto out_args3 = InvokeParse(in_args3); + + EXPECT_STREQ(out_args3[1], "p1"); + EXPECT_STREQ(out_args3[2], "p2"); + EXPECT_STREQ(out_args3[3], "true"); + + const char* in_args4[] = { + "testbin", + "--", + "p1", + "p2", + }; + TestParse(in_args4, 3, 1.1, "a", true, 2); + + auto out_args4 = InvokeParse(in_args4); + + EXPECT_STREQ(out_args4[1], "p1"); + EXPECT_STREQ(out_args4[2], "p2"); + + const char* in_args5[] = { + "testbin", "p1", "--int_flag=4", "--", "--bool_flag", "false", "p2", + }; + TestParse(in_args5, 4, 1.1, "a", true, 4); + + auto out_args5 = InvokeParse(in_args5); + + EXPECT_STREQ(out_args5[1], "p1"); + EXPECT_STREQ(out_args5[2], "--bool_flag"); + EXPECT_STREQ(out_args5[3], "false"); + EXPECT_STREQ(out_args5[4], "p2"); +} + +// -------------------------------------------------------------------- + +using ParseDeathTest = ParseTest; + +TEST_F(ParseDeathTest, TestUndefinedArg) { + const char* in_args1[] = { + "testbin", + "--undefined_flag", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args1), + "Unknown command line flag 'undefined_flag'"); + + const char* in_args2[] = { + "testbin", + "--noprefixed_flag", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args2), + "Unknown command line flag 'noprefixed_flag'"); + + const char* in_args3[] = { + "testbin", + "--Int_flag=1", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args3), + "Unknown command line flag 'Int_flag'"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestInvalidBoolFlagFormat) { + const char* in_args1[] = { + "testbin", + "--bool_flag=", + }; + EXPECT_DEATH_IF_SUPPORTED( + InvokeParse(in_args1), + "Missing the value after assignment for the boolean flag 'bool_flag'"); + + const char* in_args2[] = { + "testbin", + "--nobool_flag=true", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args2), + "Negative form with assignment is not valid for the boolean " + "flag 'bool_flag'"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestInvalidNonBoolFlagFormat) { + const char* in_args1[] = { + "testbin", + "--nostring_flag", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args1), + "Negative form is not valid for the flag 'string_flag'"); + + const char* in_args2[] = { + "testbin", + "--int_flag", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args2), + "Missing the value for the flag 'int_flag'"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestInvalidUDTFlagFormat) { + const char* in_args1[] = { + "testbin", + "--udt_flag=1", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args1), + "Illegal value '1' specified for flag 'udt_flag'; Use values A, " + "AAA instead"); + + const char* in_args2[] = { + "testbin", + "--udt_flag", + "AA", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args2), + "Illegal value 'AA' specified for flag 'udt_flag'; Use values " + "A, AAA instead"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestLegacyFlags) { + const char* in_args1[] = { + "testbin", + "--legacy_int=11", + }; + TestParse(in_args1, 1, 1.1, "a", false); + + const char* in_args2[] = { + "testbin", + "--legacy_bool", + }; + TestParse(in_args2, 1, 1.1, "a", false); + + const char* in_args3[] = { + "testbin", "--legacy_int", "22", "--int_flag=2", + "--legacy_bool", "true", "--legacy_str", "--string_flag=qwe", + }; + TestParse(in_args3, 2, 1.1, "a", false, 1); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestSimpleValidFlagfile) { + std::string flagfile_flag; + + const char* in_args1[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff1", absl::MakeConstSpan(ff1_data)}}, + &flagfile_flag), + }; + TestParse(in_args1, -1, 0.1, "q2w2 ", true); + + const char* in_args2[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff2", absl::MakeConstSpan(ff2_data)}}, + &flagfile_flag), + }; + TestParse(in_args2, 100, 0.1, "q2w2 ", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestValidMultiFlagfile) { + std::string flagfile_flag; + + const char* in_args1[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff2", absl::MakeConstSpan(ff2_data)}, + {"parse_test.ff1", absl::MakeConstSpan(ff1_data)}}, + &flagfile_flag), + }; + TestParse(in_args1, -1, 0.1, "q2w2 ", true); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestFlagfileMixedWithRegularFlags) { + std::string flagfile_flag; + + const char* in_args1[] = { + "testbin", "--int_flag=3", + GetFlagfileFlag({{"parse_test.ff1", absl::MakeConstSpan(ff1_data)}}, + &flagfile_flag), + "-double_flag=0.2"}; + TestParse(in_args1, -1, 0.2, "q2w2 ", true); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestFlagfileInFlagfile) { + std::string flagfile_flag; + + constexpr const char* const ff3_data[] = { + "--flagfile=$0/parse_test.ff1", + "--flagfile=$0/parse_test.ff2", + }; + + const char* in_args1[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff3", absl::MakeConstSpan(ff3_data)}}, + &flagfile_flag), + }; + TestParse(in_args1, 100, 0.1, "q2w2 ", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestInvalidFlagfiles) { + std::string flagfile_flag; + + constexpr const char* const ff4_data[] = { + "--unknown_flag=10" + }; + + const char* in_args1[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff4", + absl::MakeConstSpan(ff4_data)}}, &flagfile_flag), + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args1), + "Unknown command line flag 'unknown_flag'"); + + constexpr const char* const ff5_data[] = { + "--int_flag 10", + }; + + const char* in_args2[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff5", + absl::MakeConstSpan(ff5_data)}}, &flagfile_flag), + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args2), + "Unknown command line flag 'int_flag 10'"); + + constexpr const char* const ff6_data[] = { + "--int_flag=10", "--", "arg1", "arg2", "arg3", + }; + + const char* in_args3[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff6", absl::MakeConstSpan(ff6_data)}}, + &flagfile_flag), + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args3), + "Flagfile can't contain position arguments or --"); + + const char* in_args4[] = { + "testbin", + "--flagfile=invalid_flag_file", + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args4), + "Can't open flagfile invalid_flag_file"); + + constexpr const char* const ff7_data[] = { + "--int_flag=10", + "*bin*", + "--str_flag=aqsw", + }; + + const char* in_args5[] = { + "testbin", + GetFlagfileFlag({{"parse_test.ff7", absl::MakeConstSpan(ff7_data)}}, + &flagfile_flag), + }; + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args5), + "Unexpected line in the flagfile .*: \\*bin\\*"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestReadingRequiredFlagsFromEnv) { + const char* in_args1[] = {"testbin", + "--fromenv=int_flag,bool_flag,string_flag"}; + + ScopedSetEnv set_int_flag("FLAGS_int_flag", "33"); + ScopedSetEnv set_bool_flag("FLAGS_bool_flag", "True"); + ScopedSetEnv set_string_flag("FLAGS_string_flag", "AQ12"); + + TestParse(in_args1, 33, 1.1, "AQ12", true); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestReadingUnsetRequiredFlagsFromEnv) { + const char* in_args1[] = {"testbin", "--fromenv=int_flag"}; + + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args1), + "FLAGS_int_flag not found in environment"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestRecursiveFlagsFromEnv) { + const char* in_args1[] = {"testbin", "--fromenv=tryfromenv"}; + + ScopedSetEnv set_tryfromenv("FLAGS_tryfromenv", "int_flag"); + + EXPECT_DEATH_IF_SUPPORTED(InvokeParse(in_args1), + "Infinite recursion on flag tryfromenv"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestReadingOptionalFlagsFromEnv) { + const char* in_args1[] = { + "testbin", "--tryfromenv=int_flag,bool_flag,string_flag,other_flag"}; + + ScopedSetEnv set_int_flag("FLAGS_int_flag", "17"); + ScopedSetEnv set_bool_flag("FLAGS_bool_flag", "Y"); + + TestParse(in_args1, 17, 1.1, "a", true); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestReadingFlagsFromEnvMoxedWithRegularFlags) { + const char* in_args1[] = { + "testbin", + "--bool_flag=T", + "--tryfromenv=int_flag,bool_flag", + "--int_flag=-21", + }; + + ScopedSetEnv set_int_flag("FLAGS_int_flag", "-15"); + ScopedSetEnv set_bool_flag("FLAGS_bool_flag", "F"); + + TestParse(in_args1, -21, 1.1, "a", false); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestKeepParsedArgs) { + const char* in_args1[] = { + "testbin", "arg1", "--bool_flag", + "--int_flag=211", "arg2", "--double_flag=1.1", + "--string_flag", "asd", "--", + "arg3", "arg4", + }; + + auto out_args1 = InvokeParse(in_args1); + + EXPECT_THAT( + out_args1, + ElementsAreArray({absl::string_view("testbin"), absl::string_view("arg1"), + absl::string_view("arg2"), absl::string_view("arg3"), + absl::string_view("arg4")})); + + auto out_args2 = flags::ParseCommandLineImpl( + 11, const_cast<char**>(in_args1), flags::ArgvListAction::kKeepParsedArgs, + flags::UsageFlagsAction::kHandleUsage, + flags::OnUndefinedFlag::kAbortIfUndefined); + + EXPECT_THAT( + out_args2, + ElementsAreArray({absl::string_view("testbin"), + absl::string_view("--bool_flag"), + absl::string_view("--int_flag=211"), + absl::string_view("--double_flag=1.1"), + absl::string_view("--string_flag"), + absl::string_view("asd"), absl::string_view("--"), + absl::string_view("arg1"), absl::string_view("arg2"), + absl::string_view("arg3"), absl::string_view("arg4")})); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, TestIgnoreUndefinedFlags) { + const char* in_args1[] = { + "testbin", + "arg1", + "--undef_flag=aa", + "--int_flag=21", + }; + + auto out_args1 = flags::ParseCommandLineImpl( + 4, const_cast<char**>(in_args1), flags::ArgvListAction::kRemoveParsedArgs, + flags::UsageFlagsAction::kHandleUsage, + flags::OnUndefinedFlag::kIgnoreUndefined); + + EXPECT_THAT(out_args1, ElementsAreArray({absl::string_view("testbin"), + absl::string_view("arg1")})); + + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 21); + + const char* in_args2[] = { + "testbin", + "arg1", + "--undef_flag=aa", + "--string_flag=AA", + }; + + auto out_args2 = flags::ParseCommandLineImpl( + 4, const_cast<char**>(in_args2), flags::ArgvListAction::kKeepParsedArgs, + flags::UsageFlagsAction::kHandleUsage, + flags::OnUndefinedFlag::kIgnoreUndefined); + + EXPECT_THAT( + out_args2, + ElementsAreArray( + {absl::string_view("testbin"), absl::string_view("--undef_flag=aa"), + absl::string_view("--string_flag=AA"), absl::string_view("arg1")})); + + EXPECT_EQ(absl::GetFlag(FLAGS_string_flag), "AA"); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseDeathTest, TestHelpFlagHandling) { + const char* in_args1[] = { + "testbin", + "--help", + }; + + EXPECT_EXIT(InvokeParse(in_args1), testing::ExitedWithCode(1), ""); + + const char* in_args2[] = { + "testbin", + "--help", + "--int_flag=3", + }; + + auto out_args2 = flags::ParseCommandLineImpl( + 3, const_cast<char**>(in_args2), flags::ArgvListAction::kRemoveParsedArgs, + flags::UsageFlagsAction::kIgnoreUsage, + flags::OnUndefinedFlag::kAbortIfUndefined); + + EXPECT_EQ(absl::GetFlag(FLAGS_int_flag), 3); +} + +// -------------------------------------------------------------------- + +TEST_F(ParseTest, WasPresentOnCommandLine) { + const char* in_args1[] = { + "testbin", "arg1", "--bool_flag", + "--int_flag=211", "arg2", "--double_flag=1.1", + "--string_flag", "asd", "--", + "--some_flag", "arg4", + }; + + InvokeParse(in_args1); + + EXPECT_TRUE(flags::WasPresentOnCommandLine("bool_flag")); + EXPECT_TRUE(flags::WasPresentOnCommandLine("int_flag")); + EXPECT_TRUE(flags::WasPresentOnCommandLine("double_flag")); + EXPECT_TRUE(flags::WasPresentOnCommandLine("string_flag")); + EXPECT_FALSE(flags::WasPresentOnCommandLine("some_flag")); + EXPECT_FALSE(flags::WasPresentOnCommandLine("another_flag")); +} + +// -------------------------------------------------------------------- + +} // namespace diff --git a/third_party/abseil_cpp/absl/flags/usage.cc b/third_party/abseil_cpp/absl/flags/usage.cc new file mode 100644 index 0000000000..452f667512 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/usage.cc @@ -0,0 +1,65 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +#include "absl/flags/usage.h" + +#include <stdlib.h> + +#include <string> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/const_init.h" +#include "absl/base/thread_annotations.h" +#include "absl/flags/internal/usage.h" +#include "absl/strings/string_view.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { +namespace { +ABSL_CONST_INIT absl::Mutex usage_message_guard(absl::kConstInit); +ABSL_CONST_INIT std::string* program_usage_message + ABSL_GUARDED_BY(usage_message_guard) = nullptr; +} // namespace +} // namespace flags_internal + +// -------------------------------------------------------------------- +// Sets the "usage" message to be used by help reporting routines. +void SetProgramUsageMessage(absl::string_view new_usage_message) { + absl::MutexLock l(&flags_internal::usage_message_guard); + + if (flags_internal::program_usage_message != nullptr) { + ABSL_INTERNAL_LOG(FATAL, "SetProgramUsageMessage() called twice."); + std::exit(1); + } + + flags_internal::program_usage_message = new std::string(new_usage_message); +} + +// -------------------------------------------------------------------- +// Returns the usage message set by SetProgramUsageMessage(). +// Note: We able to return string_view here only because calling +// SetProgramUsageMessage twice is prohibited. +absl::string_view ProgramUsageMessage() { + absl::MutexLock l(&flags_internal::usage_message_guard); + + return flags_internal::program_usage_message != nullptr + ? absl::string_view(*flags_internal::program_usage_message) + : "Warning: SetProgramUsageMessage() never called"; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/usage.h b/third_party/abseil_cpp/absl/flags/usage.h new file mode 100644 index 0000000000..ad12ab7ad9 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/usage.h @@ -0,0 +1,43 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FLAGS_USAGE_H_ +#define ABSL_FLAGS_USAGE_H_ + +#include "absl/base/config.h" +#include "absl/strings/string_view.h" + +// -------------------------------------------------------------------- +// Usage reporting interfaces + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Sets the "usage" message to be used by help reporting routines. +// For example: +// absl::SetProgramUsageMessage( +// absl::StrCat("This program does nothing. Sample usage:\n", argv[0], +// " <uselessarg1> <uselessarg2>")); +// Do not include commandline flags in the usage: we do that for you! +// Note: Calling SetProgramUsageMessage twice will trigger a call to std::exit. +void SetProgramUsageMessage(absl::string_view new_usage_message); + +// Returns the usage message set by SetProgramUsageMessage(). +absl::string_view ProgramUsageMessage(); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FLAGS_USAGE_H_ diff --git a/third_party/abseil_cpp/absl/flags/usage_config.cc b/third_party/abseil_cpp/absl/flags/usage_config.cc new file mode 100644 index 0000000000..0d21bce6a9 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/usage_config.cc @@ -0,0 +1,163 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/usage_config.h" + +#include <iostream> +#include <string> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/const_init.h" +#include "absl/base/thread_annotations.h" +#include "absl/flags/internal/path_util.h" +#include "absl/flags/internal/program_name.h" +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" +#include "absl/synchronization/mutex.h" + +extern "C" { + +// Additional report of fatal usage error message before we std::exit. Error is +// fatal if is_fatal argument to ReportUsageError is true. +ABSL_ATTRIBUTE_WEAK void AbslInternalReportFatalUsageError(absl::string_view) {} + +} // extern "C" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace flags_internal { + +namespace { + +// -------------------------------------------------------------------- +// Returns true if flags defined in the filename should be reported with +// -helpshort flag. + +bool ContainsHelpshortFlags(absl::string_view filename) { + // By default we only want flags in binary's main. We expect the main + // routine to reside in <program>.cc or <program>-main.cc or + // <program>_main.cc, where the <program> is the name of the binary + // (without .exe on Windows). + auto suffix = flags_internal::Basename(filename); + auto program_name = flags_internal::ShortProgramInvocationName(); + absl::string_view program_name_ref = program_name; +#if defined(_WIN32) + absl::ConsumeSuffix(&program_name_ref, ".exe"); +#endif + if (!absl::ConsumePrefix(&suffix, program_name_ref)) + return false; + return absl::StartsWith(suffix, ".") || absl::StartsWith(suffix, "-main.") || + absl::StartsWith(suffix, "_main."); +} + +// -------------------------------------------------------------------- +// Returns true if flags defined in the filename should be reported with +// -helppackage flag. + +bool ContainsHelppackageFlags(absl::string_view filename) { + // TODO(rogeeff): implement properly when registry is available. + return ContainsHelpshortFlags(filename); +} + +// -------------------------------------------------------------------- +// Generates program version information into supplied output. + +std::string VersionString() { + std::string version_str(flags_internal::ShortProgramInvocationName()); + + version_str += "\n"; + +#if !defined(NDEBUG) + version_str += "Debug build (NDEBUG not #defined)\n"; +#endif + + return version_str; +} + +// -------------------------------------------------------------------- +// Normalizes the filename specific to the build system/filesystem used. + +std::string NormalizeFilename(absl::string_view filename) { + // Skip any leading slashes + auto pos = filename.find_first_not_of("\\/"); + if (pos == absl::string_view::npos) return ""; + + filename.remove_prefix(pos); + return std::string(filename); +} + +// -------------------------------------------------------------------- + +ABSL_CONST_INIT absl::Mutex custom_usage_config_guard(absl::kConstInit); +ABSL_CONST_INIT FlagsUsageConfig* custom_usage_config + ABSL_GUARDED_BY(custom_usage_config_guard) = nullptr; + +} // namespace + +FlagsUsageConfig GetUsageConfig() { + absl::MutexLock l(&custom_usage_config_guard); + + if (custom_usage_config) return *custom_usage_config; + + FlagsUsageConfig default_config; + default_config.contains_helpshort_flags = &ContainsHelpshortFlags; + default_config.contains_help_flags = &ContainsHelppackageFlags; + default_config.contains_helppackage_flags = &ContainsHelppackageFlags; + default_config.version_string = &VersionString; + default_config.normalize_filename = &NormalizeFilename; + + return default_config; +} + +void ReportUsageError(absl::string_view msg, bool is_fatal) { + std::cerr << "ERROR: " << msg << std::endl; + + if (is_fatal) { + AbslInternalReportFatalUsageError(msg); + } +} + +} // namespace flags_internal + +void SetFlagsUsageConfig(FlagsUsageConfig usage_config) { + absl::MutexLock l(&flags_internal::custom_usage_config_guard); + + if (!usage_config.contains_helpshort_flags) + usage_config.contains_helpshort_flags = + flags_internal::ContainsHelpshortFlags; + + if (!usage_config.contains_help_flags) + usage_config.contains_help_flags = flags_internal::ContainsHelppackageFlags; + + if (!usage_config.contains_helppackage_flags) + usage_config.contains_helppackage_flags = + flags_internal::ContainsHelppackageFlags; + + if (!usage_config.version_string) + usage_config.version_string = flags_internal::VersionString; + + if (!usage_config.normalize_filename) + usage_config.normalize_filename = flags_internal::NormalizeFilename; + + if (flags_internal::custom_usage_config) + *flags_internal::custom_usage_config = usage_config; + else + flags_internal::custom_usage_config = new FlagsUsageConfig(usage_config); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/flags/usage_config.h b/third_party/abseil_cpp/absl/flags/usage_config.h new file mode 100644 index 0000000000..96eecea231 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/usage_config.h @@ -0,0 +1,134 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: usage_config.h +// ----------------------------------------------------------------------------- +// +// This file defines the main usage reporting configuration interfaces and +// documents Abseil's supported built-in usage flags. If these flags are found +// when parsing a command-line, Abseil will exit the program and display +// appropriate help messages. +#ifndef ABSL_FLAGS_USAGE_CONFIG_H_ +#define ABSL_FLAGS_USAGE_CONFIG_H_ + +#include <functional> +#include <string> + +#include "absl/base/config.h" +#include "absl/strings/string_view.h" + +// ----------------------------------------------------------------------------- +// Built-in Usage Flags +// ----------------------------------------------------------------------------- +// +// Abseil supports the following built-in usage flags. When passed, these flags +// exit the program and : +// +// * --help +// Shows help on important flags for this binary +// * --helpfull +// Shows help on all flags +// * --helpshort +// Shows help on only the main module for this program +// * --helppackage +// Shows help on all modules in the main package +// * --version +// Shows the version and build info for this binary and exits +// * --only_check_args +// Exits after checking all flags +// * --helpon +// Shows help on the modules named by this flag value +// * --helpmatch +// Shows help on modules whose name contains the specified substring + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace flags_internal { +using FlagKindFilter = std::function<bool (absl::string_view)>; +} // namespace flags_internal + +// FlagsUsageConfig +// +// This structure contains the collection of callbacks for changing the behavior +// of the usage reporting routines in Abseil Flags. +struct FlagsUsageConfig { + // Returns true if flags defined in the given source code file should be + // reported with --helpshort flag. For example, if the file + // "path/to/my/code.cc" defines the flag "--my_flag", and + // contains_helpshort_flags("path/to/my/code.cc") returns true, invoking the + // program with --helpshort will include information about --my_flag in the + // program output. + flags_internal::FlagKindFilter contains_helpshort_flags; + + // Returns true if flags defined in the filename should be reported with + // --help flag. For example, if the file + // "path/to/my/code.cc" defines the flag "--my_flag", and + // contains_help_flags("path/to/my/code.cc") returns true, invoking the + // program with --help will include information about --my_flag in the + // program output. + flags_internal::FlagKindFilter contains_help_flags; + + // Returns true if flags defined in the filename should be reported with + // --helppackage flag. For example, if the file + // "path/to/my/code.cc" defines the flag "--my_flag", and + // contains_helppackage_flags("path/to/my/code.cc") returns true, invoking the + // program with --helppackage will include information about --my_flag in the + // program output. + flags_internal::FlagKindFilter contains_helppackage_flags; + + // Generates string containing program version. This is the string reported + // when user specifies --version in a command line. + std::function<std::string()> version_string; + + // Normalizes the filename specific to the build system/filesystem used. This + // routine is used when we report the information about the flag definition + // location. For instance, if your build resides at some location you do not + // want to expose in the usage output, you can trim it to show only relevant + // part. + // For example: + // normalize_filename("/my_company/some_long_path/src/project/file.cc") + // might produce + // "project/file.cc". + std::function<std::string(absl::string_view)> normalize_filename; +}; + +// SetFlagsUsageConfig() +// +// Sets the usage reporting configuration callbacks. If any of the callbacks are +// not set in usage_config instance, then the default value of the callback is +// used. +void SetFlagsUsageConfig(FlagsUsageConfig usage_config); + +namespace flags_internal { + +FlagsUsageConfig GetUsageConfig(); + +void ReportUsageError(absl::string_view msg, bool is_fatal); + +} // namespace flags_internal +ABSL_NAMESPACE_END +} // namespace absl + +extern "C" { + +// Additional report of fatal usage error message before we std::exit. Error is +// fatal if is_fatal argument to ReportUsageError is true. +void AbslInternalReportFatalUsageError(absl::string_view); + +} // extern "C" + +#endif // ABSL_FLAGS_USAGE_CONFIG_H_ diff --git a/third_party/abseil_cpp/absl/flags/usage_config_test.cc b/third_party/abseil_cpp/absl/flags/usage_config_test.cc new file mode 100644 index 0000000000..e57a8832f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/flags/usage_config_test.cc @@ -0,0 +1,205 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/flags/usage_config.h" + +#include <string> + +#include "gtest/gtest.h" +#include "absl/flags/internal/path_util.h" +#include "absl/flags/internal/program_name.h" +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" + +namespace { + +class FlagsUsageConfigTest : public testing::Test { + protected: + void SetUp() override { + // Install Default config for the use on this unit test. + // Binary may install a custom config before tests are run. + absl::FlagsUsageConfig default_config; + absl::SetFlagsUsageConfig(default_config); + } +}; + +namespace flags = absl::flags_internal; + +bool TstContainsHelpshortFlags(absl::string_view f) { + return absl::StartsWith(flags::Basename(f), "progname."); +} + +bool TstContainsHelppackageFlags(absl::string_view f) { + return absl::EndsWith(flags::Package(f), "aaa/"); +} + +bool TstContainsHelpFlags(absl::string_view f) { + return absl::EndsWith(flags::Package(f), "zzz/"); +} + +std::string TstVersionString() { return "program 1.0.0"; } + +std::string TstNormalizeFilename(absl::string_view filename) { + return std::string(filename.substr(2)); +} + +void TstReportUsageMessage(absl::string_view msg) {} + +// -------------------------------------------------------------------- + +TEST_F(FlagsUsageConfigTest, TestGetSetFlagsUsageConfig) { + EXPECT_TRUE(flags::GetUsageConfig().contains_helpshort_flags); + EXPECT_TRUE(flags::GetUsageConfig().contains_help_flags); + EXPECT_TRUE(flags::GetUsageConfig().contains_helppackage_flags); + EXPECT_TRUE(flags::GetUsageConfig().version_string); + EXPECT_TRUE(flags::GetUsageConfig().normalize_filename); + + absl::FlagsUsageConfig empty_config; + empty_config.contains_helpshort_flags = &TstContainsHelpshortFlags; + empty_config.contains_help_flags = &TstContainsHelpFlags; + empty_config.contains_helppackage_flags = &TstContainsHelppackageFlags; + empty_config.version_string = &TstVersionString; + empty_config.normalize_filename = &TstNormalizeFilename; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_TRUE(flags::GetUsageConfig().contains_helpshort_flags); + EXPECT_TRUE(flags::GetUsageConfig().contains_help_flags); + EXPECT_TRUE(flags::GetUsageConfig().contains_helppackage_flags); + EXPECT_TRUE(flags::GetUsageConfig().version_string); + EXPECT_TRUE(flags::GetUsageConfig().normalize_filename); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagsUsageConfigTest, TestContainsHelpshortFlags) { +#if defined(_WIN32) + flags::SetProgramInvocationName("usage_config_test.exe"); +#else + flags::SetProgramInvocationName("usage_config_test"); +#endif + + auto config = flags::GetUsageConfig(); + EXPECT_TRUE(config.contains_helpshort_flags("adir/cd/usage_config_test.cc")); + EXPECT_TRUE( + config.contains_helpshort_flags("aaaa/usage_config_test-main.cc")); + EXPECT_TRUE(config.contains_helpshort_flags("abc/usage_config_test_main.cc")); + EXPECT_FALSE(config.contains_helpshort_flags("usage_config_main.cc")); + + absl::FlagsUsageConfig empty_config; + empty_config.contains_helpshort_flags = &TstContainsHelpshortFlags; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_TRUE( + flags::GetUsageConfig().contains_helpshort_flags("aaa/progname.cpp")); + EXPECT_FALSE( + flags::GetUsageConfig().contains_helpshort_flags("aaa/progmane.cpp")); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagsUsageConfigTest, TestContainsHelpFlags) { + flags::SetProgramInvocationName("usage_config_test"); + + auto config = flags::GetUsageConfig(); + EXPECT_TRUE(config.contains_help_flags("zzz/usage_config_test.cc")); + EXPECT_TRUE( + config.contains_help_flags("bdir/a/zzz/usage_config_test-main.cc")); + EXPECT_TRUE( + config.contains_help_flags("//aqse/zzz/usage_config_test_main.cc")); + EXPECT_FALSE(config.contains_help_flags("zzz/aa/usage_config_main.cc")); + + absl::FlagsUsageConfig empty_config; + empty_config.contains_help_flags = &TstContainsHelpFlags; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_TRUE(flags::GetUsageConfig().contains_help_flags("zzz/main-body.c")); + EXPECT_FALSE( + flags::GetUsageConfig().contains_help_flags("zzz/dir/main-body.c")); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagsUsageConfigTest, TestContainsHelppackageFlags) { + flags::SetProgramInvocationName("usage_config_test"); + + auto config = flags::GetUsageConfig(); + EXPECT_TRUE(config.contains_helppackage_flags("aaa/usage_config_test.cc")); + EXPECT_TRUE( + config.contains_helppackage_flags("bbdir/aaa/usage_config_test-main.cc")); + EXPECT_TRUE(config.contains_helppackage_flags( + "//aqswde/aaa/usage_config_test_main.cc")); + EXPECT_FALSE(config.contains_helppackage_flags("aadir/usage_config_main.cc")); + + absl::FlagsUsageConfig empty_config; + empty_config.contains_helppackage_flags = &TstContainsHelppackageFlags; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_TRUE( + flags::GetUsageConfig().contains_helppackage_flags("aaa/main-body.c")); + EXPECT_FALSE( + flags::GetUsageConfig().contains_helppackage_flags("aadir/main-body.c")); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagsUsageConfigTest, TestVersionString) { + flags::SetProgramInvocationName("usage_config_test"); + +#ifdef NDEBUG + std::string expected_output = "usage_config_test\n"; +#else + std::string expected_output = + "usage_config_test\nDebug build (NDEBUG not #defined)\n"; +#endif + + EXPECT_EQ(flags::GetUsageConfig().version_string(), expected_output); + + absl::FlagsUsageConfig empty_config; + empty_config.version_string = &TstVersionString; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_EQ(flags::GetUsageConfig().version_string(), "program 1.0.0"); +} + +// -------------------------------------------------------------------- + +TEST_F(FlagsUsageConfigTest, TestNormalizeFilename) { + // This tests the default implementation. + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("a/a.cc"), "a/a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("/a/a.cc"), "a/a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("///a/a.cc"), "a/a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("/"), ""); + + // This tests that the custom implementation is called. + absl::FlagsUsageConfig empty_config; + empty_config.normalize_filename = &TstNormalizeFilename; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("a/a.cc"), "a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("aaa/a.cc"), "a/a.cc"); + + // This tests that the default implementation is called. + empty_config.normalize_filename = nullptr; + absl::SetFlagsUsageConfig(empty_config); + + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("a/a.cc"), "a/a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("/a/a.cc"), "a/a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("///a/a.cc"), "a/a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("\\a\\a.cc"), "a\\a.cc"); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("//"), ""); + EXPECT_EQ(flags::GetUsageConfig().normalize_filename("\\\\"), ""); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/functional/BUILD.bazel b/third_party/abseil_cpp/absl/functional/BUILD.bazel new file mode 100644 index 0000000000..432546ce0c --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/BUILD.bazel @@ -0,0 +1,93 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "bind_front", + srcs = ["internal/front_binder.h"], + hdrs = ["bind_front.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:base_internal", + "//absl/container:compressed_tuple", + "//absl/meta:type_traits", + "//absl/utility", + ], +) + +cc_test( + name = "bind_front_test", + srcs = ["bind_front_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bind_front", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "function_ref", + srcs = ["internal/function_ref.h"], + hdrs = ["function_ref.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:base_internal", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "function_ref_test", + size = "small", + srcs = ["function_ref_test.cc"], + copts = ABSL_TEST_COPTS, + deps = [ + ":function_ref", + "//absl/container:test_instance_tracker", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "function_ref_benchmark", + srcs = [ + "function_ref_benchmark.cc", + ], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":function_ref", + "//absl/base:core_headers", + "@com_github_google_benchmark//:benchmark_main", + ], +) diff --git a/third_party/abseil_cpp/absl/functional/CMakeLists.txt b/third_party/abseil_cpp/absl/functional/CMakeLists.txt new file mode 100644 index 0000000000..cda914f2cd --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/CMakeLists.txt @@ -0,0 +1,72 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + bind_front + SRCS + "internal/front_binder.h" + HDRS + "bind_front.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base_internal + absl::compressed_tuple + PUBLIC +) + +absl_cc_test( + NAME + bind_front_test + SRCS + "bind_front_test.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bind_front + absl::memory + gmock_main +) + +absl_cc_library( + NAME + function_ref + SRCS + "internal/function_ref.h" + HDRS + "function_ref.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base_internal + absl::meta + PUBLIC +) + +absl_cc_test( + NAME + function_ref_test + SRCS + "function_ref_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::function_ref + absl::memory + absl::test_instance_tracker + gmock_main +) diff --git a/third_party/abseil_cpp/absl/functional/bind_front.h b/third_party/abseil_cpp/absl/functional/bind_front.h new file mode 100644 index 0000000000..5b47970e35 --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/bind_front.h @@ -0,0 +1,184 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: bind_front.h +// ----------------------------------------------------------------------------- +// +// `absl::bind_front()` returns a functor by binding a number of arguments to +// the front of a provided (usually more generic) functor. Unlike `std::bind`, +// it does not require the use of argument placeholders. The simpler syntax of +// `absl::bind_front()` allows you to avoid known misuses with `std::bind()`. +// +// `absl::bind_front()` is meant as a drop-in replacement for C++20's upcoming +// `std::bind_front()`, which similarly resolves these issues with +// `std::bind()`. Both `bind_front()` alternatives, unlike `std::bind()`, allow +// partial function application. (See +// https://en.wikipedia.org/wiki/Partial_application). + +#ifndef ABSL_FUNCTIONAL_BIND_FRONT_H_ +#define ABSL_FUNCTIONAL_BIND_FRONT_H_ + +#include "absl/functional/internal/front_binder.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// bind_front() +// +// Binds the first N arguments of an invocable object and stores them by value. +// +// Like `std::bind()`, `absl::bind_front()` is implicitly convertible to +// `std::function`. In particular, it may be used as a simpler replacement for +// `std::bind()` in most cases, as it does not require placeholders to be +// specified. More importantly, it provides more reliable correctness guarantees +// than `std::bind()`; while `std::bind()` will silently ignore passing more +// parameters than expected, for example, `absl::bind_front()` will report such +// mis-uses as errors. +// +// absl::bind_front(a...) can be seen as storing the results of +// std::make_tuple(a...). +// +// Example: Binding a free function. +// +// int Minus(int a, int b) { return a - b; } +// +// assert(absl::bind_front(Minus)(3, 2) == 3 - 2); +// assert(absl::bind_front(Minus, 3)(2) == 3 - 2); +// assert(absl::bind_front(Minus, 3, 2)() == 3 - 2); +// +// Example: Binding a member function. +// +// struct Math { +// int Double(int a) const { return 2 * a; } +// }; +// +// Math math; +// +// assert(absl::bind_front(&Math::Double)(&math, 3) == 2 * 3); +// // Stores a pointer to math inside the functor. +// assert(absl::bind_front(&Math::Double, &math)(3) == 2 * 3); +// // Stores a copy of math inside the functor. +// assert(absl::bind_front(&Math::Double, math)(3) == 2 * 3); +// // Stores std::unique_ptr<Math> inside the functor. +// assert(absl::bind_front(&Math::Double, +// std::unique_ptr<Math>(new Math))(3) == 2 * 3); +// +// Example: Using `absl::bind_front()`, instead of `std::bind()`, with +// `std::function`. +// +// class FileReader { +// public: +// void ReadFileAsync(const std::string& filename, std::string* content, +// const std::function<void()>& done) { +// // Calls Executor::Schedule(std::function<void()>). +// Executor::DefaultExecutor()->Schedule( +// absl::bind_front(&FileReader::BlockingRead, this, +// filename, content, done)); +// } +// +// private: +// void BlockingRead(const std::string& filename, std::string* content, +// const std::function<void()>& done) { +// CHECK_OK(file::GetContents(filename, content, {})); +// done(); +// } +// }; +// +// `absl::bind_front()` stores bound arguments explicitly using the type passed +// rather than implicitly based on the type accepted by its functor. +// +// Example: Binding arguments explicitly. +// +// void LogStringView(absl::string_view sv) { +// LOG(INFO) << sv; +// } +// +// Executor* e = Executor::DefaultExecutor(); +// std::string s = "hello"; +// absl::string_view sv = s; +// +// // absl::bind_front(LogStringView, arg) makes a copy of arg and stores it. +// e->Schedule(absl::bind_front(LogStringView, sv)); // ERROR: dangling +// // string_view. +// +// e->Schedule(absl::bind_front(LogStringView, s)); // OK: stores a copy of +// // s. +// +// To store some of the arguments passed to `absl::bind_front()` by reference, +// use std::ref()` and `std::cref()`. +// +// Example: Storing some of the bound arguments by reference. +// +// class Service { +// public: +// void Serve(const Request& req, std::function<void()>* done) { +// // The request protocol buffer won't be deleted until done is called. +// // It's safe to store a reference to it inside the functor. +// Executor::DefaultExecutor()->Schedule( +// absl::bind_front(&Service::BlockingServe, this, std::cref(req), +// done)); +// } +// +// private: +// void BlockingServe(const Request& req, std::function<void()>* done); +// }; +// +// Example: Storing bound arguments by reference. +// +// void Print(const std::string& a, const std::string& b) { +// std::cerr << a << b; +// } +// +// std::string hi = "Hello, "; +// std::vector<std::string> names = {"Chuk", "Gek"}; +// // Doesn't copy hi. +// for_each(names.begin(), names.end(), +// absl::bind_front(Print, std::ref(hi))); +// +// // DO NOT DO THIS: the functor may outlive "hi", resulting in +// // dangling references. +// foo->DoInFuture(absl::bind_front(Print, std::ref(hi), "Guest")); // BAD! +// auto f = absl::bind_front(Print, std::ref(hi), "Guest"); // BAD! +// +// Example: Storing reference-like types. +// +// void Print(absl::string_view a, const std::string& b) { +// std::cerr << a << b; +// } +// +// std::string hi = "Hello, "; +// // Copies "hi". +// absl::bind_front(Print, hi)("Chuk"); +// +// // Compile error: std::reference_wrapper<const string> is not implicitly +// // convertible to string_view. +// // absl::bind_front(Print, std::cref(hi))("Chuk"); +// +// // Doesn't copy "hi". +// absl::bind_front(Print, absl::string_view(hi))("Chuk"); +// +template <class F, class... BoundArgs> +constexpr functional_internal::bind_front_t<F, BoundArgs...> bind_front( + F&& func, BoundArgs&&... args) { + return functional_internal::bind_front_t<F, BoundArgs...>( + absl::in_place, absl::forward<F>(func), + absl::forward<BoundArgs>(args)...); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FUNCTIONAL_BIND_FRONT_H_ diff --git a/third_party/abseil_cpp/absl/functional/bind_front_test.cc b/third_party/abseil_cpp/absl/functional/bind_front_test.cc new file mode 100644 index 0000000000..4801a81caf --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/bind_front_test.cc @@ -0,0 +1,231 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/functional/bind_front.h" + +#include <stddef.h> + +#include <functional> +#include <memory> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/memory/memory.h" + +namespace { + +char CharAt(const char* s, size_t index) { return s[index]; } + +TEST(BindTest, Basics) { + EXPECT_EQ('C', absl::bind_front(CharAt)("ABC", 2)); + EXPECT_EQ('C', absl::bind_front(CharAt, "ABC")(2)); + EXPECT_EQ('C', absl::bind_front(CharAt, "ABC", 2)()); +} + +TEST(BindTest, Lambda) { + auto lambda = [](int x, int y, int z) { return x + y + z; }; + EXPECT_EQ(6, absl::bind_front(lambda)(1, 2, 3)); + EXPECT_EQ(6, absl::bind_front(lambda, 1)(2, 3)); + EXPECT_EQ(6, absl::bind_front(lambda, 1, 2)(3)); + EXPECT_EQ(6, absl::bind_front(lambda, 1, 2, 3)()); +} + +struct Functor { + std::string operator()() & { return "&"; } + std::string operator()() const& { return "const&"; } + std::string operator()() && { return "&&"; } + std::string operator()() const&& { return "const&&"; } +}; + +TEST(BindTest, PerfectForwardingOfBoundArgs) { + auto f = absl::bind_front(Functor()); + const auto& cf = f; + EXPECT_EQ("&", f()); + EXPECT_EQ("const&", cf()); + EXPECT_EQ("&&", std::move(f)()); + EXPECT_EQ("const&&", std::move(cf)()); +} + +struct ArgDescribe { + std::string operator()(int&) const { return "&"; } // NOLINT + std::string operator()(const int&) const { return "const&"; } // NOLINT + std::string operator()(int&&) const { return "&&"; } + std::string operator()(const int&&) const { return "const&&"; } +}; + +TEST(BindTest, PerfectForwardingOfFreeArgs) { + ArgDescribe f; + int i; + EXPECT_EQ("&", absl::bind_front(f)(static_cast<int&>(i))); + EXPECT_EQ("const&", absl::bind_front(f)(static_cast<const int&>(i))); + EXPECT_EQ("&&", absl::bind_front(f)(static_cast<int&&>(i))); + EXPECT_EQ("const&&", absl::bind_front(f)(static_cast<const int&&>(i))); +} + +struct NonCopyableFunctor { + NonCopyableFunctor() = default; + NonCopyableFunctor(const NonCopyableFunctor&) = delete; + NonCopyableFunctor& operator=(const NonCopyableFunctor&) = delete; + const NonCopyableFunctor* operator()() const { return this; } +}; + +TEST(BindTest, RefToFunctor) { + // It won't copy/move the functor and use the original object. + NonCopyableFunctor ncf; + auto bound_ncf = absl::bind_front(std::ref(ncf)); + auto bound_ncf_copy = bound_ncf; + EXPECT_EQ(&ncf, bound_ncf_copy()); +} + +struct Struct { + std::string value; +}; + +TEST(BindTest, StoreByCopy) { + Struct s = {"hello"}; + auto f = absl::bind_front(&Struct::value, s); + auto g = f; + EXPECT_EQ("hello", f()); + EXPECT_EQ("hello", g()); + EXPECT_NE(&s.value, &f()); + EXPECT_NE(&s.value, &g()); + EXPECT_NE(&g(), &f()); +} + +struct NonCopyable { + explicit NonCopyable(const std::string& s) : value(s) {} + NonCopyable(const NonCopyable&) = delete; + NonCopyable& operator=(const NonCopyable&) = delete; + + std::string value; +}; + +const std::string& GetNonCopyableValue(const NonCopyable& n) { return n.value; } + +TEST(BindTest, StoreByRef) { + NonCopyable s("hello"); + auto f = absl::bind_front(&GetNonCopyableValue, std::ref(s)); + EXPECT_EQ("hello", f()); + EXPECT_EQ(&s.value, &f()); + auto g = std::move(f); // NOLINT + EXPECT_EQ("hello", g()); + EXPECT_EQ(&s.value, &g()); + s.value = "goodbye"; + EXPECT_EQ("goodbye", g()); +} + +TEST(BindTest, StoreByCRef) { + NonCopyable s("hello"); + auto f = absl::bind_front(&GetNonCopyableValue, std::cref(s)); + EXPECT_EQ("hello", f()); + EXPECT_EQ(&s.value, &f()); + auto g = std::move(f); // NOLINT + EXPECT_EQ("hello", g()); + EXPECT_EQ(&s.value, &g()); + s.value = "goodbye"; + EXPECT_EQ("goodbye", g()); +} + +const std::string& GetNonCopyableValueByWrapper( + std::reference_wrapper<NonCopyable> n) { + return n.get().value; +} + +TEST(BindTest, StoreByRefInvokeByWrapper) { + NonCopyable s("hello"); + auto f = absl::bind_front(GetNonCopyableValueByWrapper, std::ref(s)); + EXPECT_EQ("hello", f()); + EXPECT_EQ(&s.value, &f()); + auto g = std::move(f); + EXPECT_EQ("hello", g()); + EXPECT_EQ(&s.value, &g()); + s.value = "goodbye"; + EXPECT_EQ("goodbye", g()); +} + +TEST(BindTest, StoreByPointer) { + NonCopyable s("hello"); + auto f = absl::bind_front(&NonCopyable::value, &s); + EXPECT_EQ("hello", f()); + EXPECT_EQ(&s.value, &f()); + auto g = std::move(f); + EXPECT_EQ("hello", g()); + EXPECT_EQ(&s.value, &g()); +} + +int Sink(std::unique_ptr<int> p) { + return *p; +} + +std::unique_ptr<int> Factory(int n) { return absl::make_unique<int>(n); } + +TEST(BindTest, NonCopyableArg) { + EXPECT_EQ(42, absl::bind_front(Sink)(absl::make_unique<int>(42))); + EXPECT_EQ(42, absl::bind_front(Sink, absl::make_unique<int>(42))()); +} + +TEST(BindTest, NonCopyableResult) { + EXPECT_THAT(absl::bind_front(Factory)(42), ::testing::Pointee(42)); + EXPECT_THAT(absl::bind_front(Factory, 42)(), ::testing::Pointee(42)); +} + +// is_copy_constructible<FalseCopyable<unique_ptr<T>> is true but an attempt to +// instantiate the copy constructor leads to a compile error. This is similar +// to how standard containers behave. +template <class T> +struct FalseCopyable { + FalseCopyable() {} + FalseCopyable(const FalseCopyable& other) : m(other.m) {} + FalseCopyable(FalseCopyable&& other) : m(std::move(other.m)) {} + T m; +}; + +int GetMember(FalseCopyable<std::unique_ptr<int>> x) { return *x.m; } + +TEST(BindTest, WrappedMoveOnly) { + FalseCopyable<std::unique_ptr<int>> x; + x.m = absl::make_unique<int>(42); + auto f = absl::bind_front(&GetMember, std::move(x)); + EXPECT_EQ(42, std::move(f)()); +} + +int Plus(int a, int b) { return a + b; } + +TEST(BindTest, ConstExpr) { + constexpr auto f = absl::bind_front(CharAt); + EXPECT_EQ(f("ABC", 1), 'B'); + static constexpr int five = 5; + constexpr auto plus5 = absl::bind_front(Plus, five); + EXPECT_EQ(plus5(1), 6); + + // There seems to be a bug in MSVC dealing constexpr construction of + // char[]. Notice 'plus5' above; 'int' works just fine. +#if !(defined(_MSC_VER) && _MSC_VER < 1910) + static constexpr char data[] = "DEF"; + constexpr auto g = absl::bind_front(CharAt, data); + EXPECT_EQ(g(1), 'E'); +#endif +} + +struct ManglingCall { + int operator()(int, double, std::string) const { return 0; } +}; + +TEST(BindTest, Mangling) { + // We just want to generate a particular instantiation to see its mangling. + absl::bind_front(ManglingCall{}, 1, 3.3)("A"); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/functional/function_ref.h b/third_party/abseil_cpp/absl/functional/function_ref.h new file mode 100644 index 0000000000..370acc55b0 --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/function_ref.h @@ -0,0 +1,139 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: function_ref.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::FunctionRef` type for holding a +// non-owning reference to an object of any invocable type. This function +// reference is typically most useful as a type-erased argument type for +// accepting function types that neither take ownership nor copy the type; using +// the reference type in this case avoids a copy and an allocation. Best +// practices of other non-owning reference-like objects (such as +// `absl::string_view`) apply here. +// +// An `absl::FunctionRef` is similar in usage to a `std::function` but has the +// following differences: +// +// * It doesn't own the underlying object. +// * It doesn't have a null or empty state. +// * It never performs deep copies or allocations. +// * It's much faster and cheaper to construct. +// * It's trivially copyable and destructable. +// +// Generally, `absl::FunctionRef` should not be used as a return value, data +// member, or to initialize a `std::function`. Such usages will often lead to +// problematic lifetime issues. Once you convert something to an +// `absl::FunctionRef` you cannot make a deep copy later. +// +// This class is suitable for use wherever a "const std::function<>&" +// would be used without making a copy. ForEach functions and other versions of +// the visitor pattern are a good example of when this class should be used. +// +// This class is trivial to copy and should be passed by value. +#ifndef ABSL_FUNCTIONAL_FUNCTION_REF_H_ +#define ABSL_FUNCTIONAL_FUNCTION_REF_H_ + +#include <cassert> +#include <functional> +#include <type_traits> + +#include "absl/functional/internal/function_ref.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// FunctionRef +// +// Dummy class declaration to allow the partial specialization based on function +// types below. +template <typename T> +class FunctionRef; + +// FunctionRef +// +// An `absl::FunctionRef` is a lightweight wrapper to any invokable object with +// a compatible signature. Generally, an `absl::FunctionRef` should only be used +// as an argument type and should be preferred as an argument over a const +// reference to a `std::function`. +// +// Example: +// +// // The following function takes a function callback by const reference +// bool Visitor(const std::function<void(my_proto&, +// absl::string_view)>& callback); +// +// // Assuming that the function is not stored or otherwise copied, it can be +// // replaced by an `absl::FunctionRef`: +// bool Visitor(absl::FunctionRef<void(my_proto&, absl::string_view)> +// callback); +// +// Note: the assignment operator within an `absl::FunctionRef` is intentionally +// deleted to prevent misuse; because the `absl::FunctionRef` does not own the +// underlying type, assignment likely indicates misuse. +template <typename R, typename... Args> +class FunctionRef<R(Args...)> { + private: + // Used to disable constructors for objects that are not compatible with the + // signature of this FunctionRef. + template <typename F, + typename FR = absl::base_internal::InvokeT<F, Args&&...>> + using EnableIfCompatible = + typename std::enable_if<std::is_void<R>::value || + std::is_convertible<FR, R>::value>::type; + + public: + // Constructs a FunctionRef from any invokable type. + template <typename F, typename = EnableIfCompatible<const F&>> + FunctionRef(const F& f) // NOLINT(runtime/explicit) + : invoker_(&absl::functional_internal::InvokeObject<F, R, Args...>) { + absl::functional_internal::AssertNonNull(f); + ptr_.obj = &f; + } + + // Overload for function pointers. This eliminates a level of indirection that + // would happen if the above overload was used (it lets us store the pointer + // instead of a pointer to a pointer). + // + // This overload is also used for references to functions, since references to + // functions can decay to function pointers implicitly. + template < + typename F, typename = EnableIfCompatible<F*>, + absl::functional_internal::EnableIf<absl::is_function<F>::value> = 0> + FunctionRef(F* f) // NOLINT(runtime/explicit) + : invoker_(&absl::functional_internal::InvokeFunction<F*, R, Args...>) { + assert(f != nullptr); + ptr_.fun = reinterpret_cast<decltype(ptr_.fun)>(f); + } + + // To help prevent subtle lifetime bugs, FunctionRef is not assignable. + // Typically, it should only be used as an argument type. + FunctionRef& operator=(const FunctionRef& rhs) = delete; + + // Call the underlying object. + R operator()(Args... args) const { + return invoker_(ptr_, std::forward<Args>(args)...); + } + + private: + absl::functional_internal::VoidPtr ptr_; + absl::functional_internal::Invoker<R, Args...> invoker_; +}; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FUNCTIONAL_FUNCTION_REF_H_ diff --git a/third_party/abseil_cpp/absl/functional/function_ref_benchmark.cc b/third_party/abseil_cpp/absl/functional/function_ref_benchmark.cc new file mode 100644 index 0000000000..045305bfef --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/function_ref_benchmark.cc @@ -0,0 +1,142 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/functional/function_ref.h" + +#include <memory> + +#include "benchmark/benchmark.h" +#include "absl/base/attributes.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +int dummy = 0; + +void FreeFunction() { benchmark::DoNotOptimize(dummy); } + +struct TrivialFunctor { + void operator()() const { benchmark::DoNotOptimize(dummy); } +}; + +struct LargeFunctor { + void operator()() const { benchmark::DoNotOptimize(this); } + std::string a, b, c; +}; + +template <typename Function, typename... Args> +void ABSL_ATTRIBUTE_NOINLINE CallFunction(Function f, Args&&... args) { + f(std::forward<Args>(args)...); +} + +template <typename Function, typename Callable, typename... Args> +void ConstructAndCallFunctionBenchmark(benchmark::State& state, + const Callable& c, Args&&... args) { + for (auto _ : state) { + CallFunction<Function>(c, std::forward<Args>(args)...); + } +} + +void BM_TrivialStdFunction(benchmark::State& state) { + ConstructAndCallFunctionBenchmark<std::function<void()>>(state, + TrivialFunctor{}); +} +BENCHMARK(BM_TrivialStdFunction); + +void BM_TrivialFunctionRef(benchmark::State& state) { + ConstructAndCallFunctionBenchmark<FunctionRef<void()>>(state, + TrivialFunctor{}); +} +BENCHMARK(BM_TrivialFunctionRef); + +void BM_LargeStdFunction(benchmark::State& state) { + ConstructAndCallFunctionBenchmark<std::function<void()>>(state, + LargeFunctor{}); +} +BENCHMARK(BM_LargeStdFunction); + +void BM_LargeFunctionRef(benchmark::State& state) { + ConstructAndCallFunctionBenchmark<FunctionRef<void()>>(state, LargeFunctor{}); +} +BENCHMARK(BM_LargeFunctionRef); + +void BM_FunPtrStdFunction(benchmark::State& state) { + ConstructAndCallFunctionBenchmark<std::function<void()>>(state, FreeFunction); +} +BENCHMARK(BM_FunPtrStdFunction); + +void BM_FunPtrFunctionRef(benchmark::State& state) { + ConstructAndCallFunctionBenchmark<FunctionRef<void()>>(state, FreeFunction); +} +BENCHMARK(BM_FunPtrFunctionRef); + +// Doesn't include construction or copy overhead in the loop. +template <typename Function, typename Callable, typename... Args> +void CallFunctionBenchmark(benchmark::State& state, const Callable& c, + Args... args) { + Function f = c; + for (auto _ : state) { + benchmark::DoNotOptimize(&f); + f(args...); + } +} + +struct FunctorWithTrivialArgs { + void operator()(int a, int b, int c) const { + benchmark::DoNotOptimize(a); + benchmark::DoNotOptimize(b); + benchmark::DoNotOptimize(c); + } +}; + +void BM_TrivialArgsStdFunction(benchmark::State& state) { + CallFunctionBenchmark<std::function<void(int, int, int)>>( + state, FunctorWithTrivialArgs{}, 1, 2, 3); +} +BENCHMARK(BM_TrivialArgsStdFunction); + +void BM_TrivialArgsFunctionRef(benchmark::State& state) { + CallFunctionBenchmark<FunctionRef<void(int, int, int)>>( + state, FunctorWithTrivialArgs{}, 1, 2, 3); +} +BENCHMARK(BM_TrivialArgsFunctionRef); + +struct FunctorWithNonTrivialArgs { + void operator()(std::string a, std::string b, std::string c) const { + benchmark::DoNotOptimize(&a); + benchmark::DoNotOptimize(&b); + benchmark::DoNotOptimize(&c); + } +}; + +void BM_NonTrivialArgsStdFunction(benchmark::State& state) { + std::string a, b, c; + CallFunctionBenchmark< + std::function<void(std::string, std::string, std::string)>>( + state, FunctorWithNonTrivialArgs{}, a, b, c); +} +BENCHMARK(BM_NonTrivialArgsStdFunction); + +void BM_NonTrivialArgsFunctionRef(benchmark::State& state) { + std::string a, b, c; + CallFunctionBenchmark< + FunctionRef<void(std::string, std::string, std::string)>>( + state, FunctorWithNonTrivialArgs{}, a, b, c); +} +BENCHMARK(BM_NonTrivialArgsFunctionRef); + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/functional/function_ref_test.cc b/third_party/abseil_cpp/absl/functional/function_ref_test.cc new file mode 100644 index 0000000000..3aa5974587 --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/function_ref_test.cc @@ -0,0 +1,257 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/functional/function_ref.h" + +#include <memory> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/internal/test_instance_tracker.h" +#include "absl/memory/memory.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +void RunFun(FunctionRef<void()> f) { f(); } + +TEST(FunctionRefTest, Lambda) { + bool ran = false; + RunFun([&] { ran = true; }); + EXPECT_TRUE(ran); +} + +int Function() { return 1337; } + +TEST(FunctionRefTest, Function1) { + FunctionRef<int()> ref(&Function); + EXPECT_EQ(1337, ref()); +} + +TEST(FunctionRefTest, Function2) { + FunctionRef<int()> ref(Function); + EXPECT_EQ(1337, ref()); +} + +int NoExceptFunction() noexcept { return 1337; } + +// TODO(jdennett): Add a test for noexcept member functions. +TEST(FunctionRefTest, NoExceptFunction) { + FunctionRef<int()> ref(NoExceptFunction); + EXPECT_EQ(1337, ref()); +} + +TEST(FunctionRefTest, ForwardsArgs) { + auto l = [](std::unique_ptr<int> i) { return *i; }; + FunctionRef<int(std::unique_ptr<int>)> ref(l); + EXPECT_EQ(42, ref(absl::make_unique<int>(42))); +} + +TEST(FunctionRef, ReturnMoveOnly) { + auto l = [] { return absl::make_unique<int>(29); }; + FunctionRef<std::unique_ptr<int>()> ref(l); + EXPECT_EQ(29, *ref()); +} + +TEST(FunctionRef, ManyArgs) { + auto l = [](int a, int b, int c) { return a + b + c; }; + FunctionRef<int(int, int, int)> ref(l); + EXPECT_EQ(6, ref(1, 2, 3)); +} + +TEST(FunctionRef, VoidResultFromNonVoidFunctor) { + bool ran = false; + auto l = [&]() -> int { + ran = true; + return 2; + }; + FunctionRef<void()> ref(l); + ref(); + EXPECT_TRUE(ran); +} + +TEST(FunctionRef, CastFromDerived) { + struct Base {}; + struct Derived : public Base {}; + + Derived d; + auto l1 = [&](Base* b) { EXPECT_EQ(&d, b); }; + FunctionRef<void(Derived*)> ref1(l1); + ref1(&d); + + auto l2 = [&]() -> Derived* { return &d; }; + FunctionRef<Base*()> ref2(l2); + EXPECT_EQ(&d, ref2()); +} + +TEST(FunctionRef, VoidResultFromNonVoidFuncton) { + FunctionRef<void()> ref(Function); + ref(); +} + +TEST(FunctionRef, MemberPtr) { + struct S { + int i; + }; + + S s{1100111}; + auto mem_ptr = &S::i; + FunctionRef<int(const S& s)> ref(mem_ptr); + EXPECT_EQ(1100111, ref(s)); +} + +TEST(FunctionRef, MemberFun) { + struct S { + int i; + int get_i() const { return i; } + }; + + S s{22}; + auto mem_fun_ptr = &S::get_i; + FunctionRef<int(const S& s)> ref(mem_fun_ptr); + EXPECT_EQ(22, ref(s)); +} + +TEST(FunctionRef, MemberFunRefqualified) { + struct S { + int i; + int get_i() && { return i; } + }; + auto mem_fun_ptr = &S::get_i; + S s{22}; + FunctionRef<int(S && s)> ref(mem_fun_ptr); + EXPECT_EQ(22, ref(std::move(s))); +} + +#if !defined(_WIN32) && defined(GTEST_HAS_DEATH_TEST) + +TEST(FunctionRef, MemberFunRefqualifiedNull) { + struct S { + int i; + int get_i() && { return i; } + }; + auto mem_fun_ptr = &S::get_i; + mem_fun_ptr = nullptr; + EXPECT_DEBUG_DEATH({ FunctionRef<int(S && s)> ref(mem_fun_ptr); }, ""); +} + +TEST(FunctionRef, NullMemberPtrAssertFails) { + struct S { + int i; + }; + using MemberPtr = int S::*; + MemberPtr mem_ptr = nullptr; + EXPECT_DEBUG_DEATH({ FunctionRef<int(const S& s)> ref(mem_ptr); }, ""); +} + +#endif // GTEST_HAS_DEATH_TEST + +TEST(FunctionRef, CopiesAndMovesPerPassByValue) { + absl::test_internal::InstanceTracker tracker; + absl::test_internal::CopyableMovableInstance instance(0); + auto l = [](absl::test_internal::CopyableMovableInstance) {}; + FunctionRef<void(absl::test_internal::CopyableMovableInstance)> ref(l); + ref(instance); + EXPECT_EQ(tracker.copies(), 1); + EXPECT_EQ(tracker.moves(), 1); +} + +TEST(FunctionRef, CopiesAndMovesPerPassByRef) { + absl::test_internal::InstanceTracker tracker; + absl::test_internal::CopyableMovableInstance instance(0); + auto l = [](const absl::test_internal::CopyableMovableInstance&) {}; + FunctionRef<void(const absl::test_internal::CopyableMovableInstance&)> ref(l); + ref(instance); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 0); +} + +TEST(FunctionRef, CopiesAndMovesPerPassByValueCallByMove) { + absl::test_internal::InstanceTracker tracker; + absl::test_internal::CopyableMovableInstance instance(0); + auto l = [](absl::test_internal::CopyableMovableInstance) {}; + FunctionRef<void(absl::test_internal::CopyableMovableInstance)> ref(l); + ref(std::move(instance)); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 2); +} + +TEST(FunctionRef, CopiesAndMovesPerPassByValueToRef) { + absl::test_internal::InstanceTracker tracker; + absl::test_internal::CopyableMovableInstance instance(0); + auto l = [](const absl::test_internal::CopyableMovableInstance&) {}; + FunctionRef<void(absl::test_internal::CopyableMovableInstance)> ref(l); + ref(std::move(instance)); + EXPECT_EQ(tracker.copies(), 0); + EXPECT_EQ(tracker.moves(), 1); +} + +TEST(FunctionRef, PassByValueTypes) { + using absl::functional_internal::Invoker; + using absl::functional_internal::VoidPtr; + using absl::test_internal::CopyableMovableInstance; + struct Trivial { + void* p[2]; + }; + struct LargeTrivial { + void* p[3]; + }; + + static_assert(std::is_same<Invoker<void, int>, void (*)(VoidPtr, int)>::value, + "Scalar types should be passed by value"); + static_assert( + std::is_same<Invoker<void, Trivial>, void (*)(VoidPtr, Trivial)>::value, + "Small trivial types should be passed by value"); + static_assert(std::is_same<Invoker<void, LargeTrivial>, + void (*)(VoidPtr, LargeTrivial &&)>::value, + "Large trivial types should be passed by rvalue reference"); + static_assert( + std::is_same<Invoker<void, CopyableMovableInstance>, + void (*)(VoidPtr, CopyableMovableInstance &&)>::value, + "Types with copy/move ctor should be passed by rvalue reference"); + + // References are passed as references. + static_assert( + std::is_same<Invoker<void, int&>, void (*)(VoidPtr, int&)>::value, + "Reference types should be preserved"); + static_assert( + std::is_same<Invoker<void, CopyableMovableInstance&>, + void (*)(VoidPtr, CopyableMovableInstance&)>::value, + "Reference types should be preserved"); + static_assert( + std::is_same<Invoker<void, CopyableMovableInstance&&>, + void (*)(VoidPtr, CopyableMovableInstance &&)>::value, + "Reference types should be preserved"); + + // Make sure the address of an object received by reference is the same as the + // addess of the object passed by the caller. + { + LargeTrivial obj; + auto test = [&obj](LargeTrivial& input) { ASSERT_EQ(&input, &obj); }; + absl::FunctionRef<void(LargeTrivial&)> ref(test); + ref(obj); + } + + { + Trivial obj; + auto test = [&obj](Trivial& input) { ASSERT_EQ(&input, &obj); }; + absl::FunctionRef<void(Trivial&)> ref(test); + ref(obj); + } +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/functional/internal/front_binder.h b/third_party/abseil_cpp/absl/functional/internal/front_binder.h new file mode 100644 index 0000000000..a4d95da44a --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/internal/front_binder.h @@ -0,0 +1,95 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Implementation details for `absl::bind_front()`. + +#ifndef ABSL_FUNCTIONAL_INTERNAL_FRONT_BINDER_H_ +#define ABSL_FUNCTIONAL_INTERNAL_FRONT_BINDER_H_ + +#include <cstddef> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/invoke.h" +#include "absl/container/internal/compressed_tuple.h" +#include "absl/meta/type_traits.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace functional_internal { + +// Invoke the method, expanding the tuple of bound arguments. +template <class R, class Tuple, size_t... Idx, class... Args> +R Apply(Tuple&& bound, absl::index_sequence<Idx...>, Args&&... free) { + return base_internal::Invoke( + absl::forward<Tuple>(bound).template get<Idx>()..., + absl::forward<Args>(free)...); +} + +template <class F, class... BoundArgs> +class FrontBinder { + using BoundArgsT = absl::container_internal::CompressedTuple<F, BoundArgs...>; + using Idx = absl::make_index_sequence<sizeof...(BoundArgs) + 1>; + + BoundArgsT bound_args_; + + public: + template <class... Ts> + constexpr explicit FrontBinder(absl::in_place_t, Ts&&... ts) + : bound_args_(absl::forward<Ts>(ts)...) {} + + template <class... FreeArgs, + class R = base_internal::InvokeT<F&, BoundArgs&..., FreeArgs&&...>> + R operator()(FreeArgs&&... free_args) & { + return functional_internal::Apply<R>(bound_args_, Idx(), + absl::forward<FreeArgs>(free_args)...); + } + + template <class... FreeArgs, + class R = base_internal::InvokeT<const F&, const BoundArgs&..., + FreeArgs&&...>> + R operator()(FreeArgs&&... free_args) const& { + return functional_internal::Apply<R>(bound_args_, Idx(), + absl::forward<FreeArgs>(free_args)...); + } + + template <class... FreeArgs, class R = base_internal::InvokeT< + F&&, BoundArgs&&..., FreeArgs&&...>> + R operator()(FreeArgs&&... free_args) && { + // This overload is called when *this is an rvalue. If some of the bound + // arguments are stored by value or rvalue reference, we move them. + return functional_internal::Apply<R>(absl::move(bound_args_), Idx(), + absl::forward<FreeArgs>(free_args)...); + } + + template <class... FreeArgs, + class R = base_internal::InvokeT<const F&&, const BoundArgs&&..., + FreeArgs&&...>> + R operator()(FreeArgs&&... free_args) const&& { + // This overload is called when *this is an rvalue. If some of the bound + // arguments are stored by value or rvalue reference, we move them. + return functional_internal::Apply<R>(absl::move(bound_args_), Idx(), + absl::forward<FreeArgs>(free_args)...); + } +}; + +template <class F, class... BoundArgs> +using bind_front_t = FrontBinder<decay_t<F>, absl::decay_t<BoundArgs>...>; + +} // namespace functional_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FUNCTIONAL_INTERNAL_FRONT_BINDER_H_ diff --git a/third_party/abseil_cpp/absl/functional/internal/function_ref.h b/third_party/abseil_cpp/absl/functional/internal/function_ref.h new file mode 100644 index 0000000000..d1575054ea --- /dev/null +++ b/third_party/abseil_cpp/absl/functional/internal/function_ref.h @@ -0,0 +1,106 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_FUNCTIONAL_INTERNAL_FUNCTION_REF_H_ +#define ABSL_FUNCTIONAL_INTERNAL_FUNCTION_REF_H_ + +#include <cassert> +#include <functional> +#include <type_traits> + +#include "absl/base/internal/invoke.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace functional_internal { + +// Like a void* that can handle function pointers as well. The standard does not +// allow function pointers to round-trip through void*, but void(*)() is fine. +// +// Note: It's important that this class remains trivial and is the same size as +// a pointer, since this allows the compiler to perform tail-call optimizations +// when the underlying function is a callable object with a matching signature. +union VoidPtr { + const void* obj; + void (*fun)(); +}; + +// Chooses the best type for passing T as an argument. +// Attempt to be close to SystemV AMD64 ABI. Objects with trivial copy ctor are +// passed by value. +template <typename T> +constexpr bool PassByValue() { + return !std::is_lvalue_reference<T>::value && + absl::is_trivially_copy_constructible<T>::value && + absl::is_trivially_copy_assignable< + typename std::remove_cv<T>::type>::value && + std::is_trivially_destructible<T>::value && + sizeof(T) <= 2 * sizeof(void*); +} + +template <typename T> +struct ForwardT : std::conditional<PassByValue<T>(), T, T&&> {}; + +// An Invoker takes a pointer to the type-erased invokable object, followed by +// the arguments that the invokable object expects. +// +// Note: The order of arguments here is an optimization, since member functions +// have an implicit "this" pointer as their first argument, putting VoidPtr +// first allows the compiler to perform tail-call optimization in many cases. +template <typename R, typename... Args> +using Invoker = R (*)(VoidPtr, typename ForwardT<Args>::type...); + +// +// InvokeObject and InvokeFunction provide static "Invoke" functions that can be +// used as Invokers for objects or functions respectively. +// +// static_cast<R> handles the case the return type is void. +template <typename Obj, typename R, typename... Args> +R InvokeObject(VoidPtr ptr, typename ForwardT<Args>::type... args) { + auto o = static_cast<const Obj*>(ptr.obj); + return static_cast<R>( + absl::base_internal::Invoke(*o, std::forward<Args>(args)...)); +} + +template <typename Fun, typename R, typename... Args> +R InvokeFunction(VoidPtr ptr, typename ForwardT<Args>::type... args) { + auto f = reinterpret_cast<Fun>(ptr.fun); + return static_cast<R>( + absl::base_internal::Invoke(f, std::forward<Args>(args)...)); +} + +template <typename Sig> +void AssertNonNull(const std::function<Sig>& f) { + assert(f != nullptr); + (void)f; +} + +template <typename F> +void AssertNonNull(const F&) {} + +template <typename F, typename C> +void AssertNonNull(F C::*f) { + assert(f != nullptr); + (void)f; +} + +template <bool C> +using EnableIf = typename ::std::enable_if<C, int>::type; + +} // namespace functional_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_FUNCTIONAL_INTERNAL_FUNCTION_REF_H_ diff --git a/third_party/abseil_cpp/absl/hash/BUILD.bazel b/third_party/abseil_cpp/absl/hash/BUILD.bazel new file mode 100644 index 0000000000..6c77f1a135 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/BUILD.bazel @@ -0,0 +1,122 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "hash", + srcs = [ + "internal/hash.cc", + "internal/hash.h", + ], + hdrs = ["hash.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":city", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/container:fixed_array", + "//absl/meta:type_traits", + "//absl/numeric:int128", + "//absl/strings", + "//absl/types:optional", + "//absl/types:variant", + "//absl/utility", + ], +) + +cc_library( + name = "hash_testing", + testonly = 1, + hdrs = ["hash_testing.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":spy_hash_state", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/types:variant", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "hash_test", + srcs = ["hash_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":hash", + ":hash_testing", + ":spy_hash_state", + "//absl/base:core_headers", + "//absl/container:flat_hash_set", + "//absl/meta:type_traits", + "//absl/numeric:int128", + "//absl/strings:cord_test_helpers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "spy_hash_state", + testonly = 1, + hdrs = ["internal/spy_hash_state.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + ":hash", + "//absl/strings", + "//absl/strings:str_format", + ], +) + +cc_library( + name = "city", + srcs = ["internal/city.cc"], + hdrs = [ + "internal/city.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:endian", + ], +) + +cc_test( + name = "city_test", + srcs = ["internal/city_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":city", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/hash/CMakeLists.txt b/third_party/abseil_cpp/absl/hash/CMakeLists.txt new file mode 100644 index 0000000000..61365e9bb5 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/CMakeLists.txt @@ -0,0 +1,116 @@ +# +# Copyright 2018 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + hash + HDRS + "hash.h" + SRCS + "internal/hash.cc" + "internal/hash.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::endian + absl::fixed_array + absl::meta + absl::int128 + absl::strings + absl::optional + absl::variant + absl::utility + absl::city + PUBLIC +) + +absl_cc_library( + NAME + hash_testing + HDRS + "hash_testing.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::spy_hash_state + absl::meta + absl::strings + absl::variant + gmock + TESTONLY +) + +absl_cc_test( + NAME + hash_test + SRCS + "hash_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::cord_test_helpers + absl::hash + absl::hash_testing + absl::core_headers + absl::flat_hash_set + absl::spy_hash_state + absl::meta + absl::int128 + gmock_main +) + +absl_cc_library( + NAME + spy_hash_state + HDRS + "internal/spy_hash_state.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::hash + absl::strings + absl::str_format + TESTONLY +) + +absl_cc_library( + NAME + city + HDRS + "internal/city.h" + SRCS + "internal/city.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers + absl::endian +) + +absl_cc_test( + NAME + city_test + SRCS + "internal/city_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::city + gmock_main +) + diff --git a/third_party/abseil_cpp/absl/hash/hash.h b/third_party/abseil_cpp/absl/hash/hash.h new file mode 100644 index 0000000000..d7386f6ce6 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/hash.h @@ -0,0 +1,328 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: hash.h +// ----------------------------------------------------------------------------- +// +// This header file defines the Abseil `hash` library and the Abseil hashing +// framework. This framework consists of the following: +// +// * The `absl::Hash` functor, which is used to invoke the hasher within the +// Abseil hashing framework. `absl::Hash<T>` supports most basic types and +// a number of Abseil types out of the box. +// * `AbslHashValue`, an extension point that allows you to extend types to +// support Abseil hashing without requiring you to define a hashing +// algorithm. +// * `HashState`, a type-erased class which implements the manipulation of the +// hash state (H) itself, contains member functions `combine()` and +// `combine_contiguous()`, which you can use to contribute to an existing +// hash state when hashing your types. +// +// Unlike `std::hash` or other hashing frameworks, the Abseil hashing framework +// provides most of its utility by abstracting away the hash algorithm (and its +// implementation) entirely. Instead, a type invokes the Abseil hashing +// framework by simply combining its state with the state of known, hashable +// types. Hashing of that combined state is separately done by `absl::Hash`. +// +// One should assume that a hash algorithm is chosen randomly at the start of +// each process. E.g., `absl::Hash<int>{}(9)` in one process and +// `absl::Hash<int>{}(9)` in another process are likely to differ. +// +// `absl::Hash` is intended to strongly mix input bits with a target of passing +// an [Avalanche Test](https://en.wikipedia.org/wiki/Avalanche_effect). +// +// Example: +// +// // Suppose we have a class `Circle` for which we want to add hashing: +// class Circle { +// public: +// ... +// private: +// std::pair<int, int> center_; +// int radius_; +// }; +// +// // To add hashing support to `Circle`, we simply need to add a free +// // (non-member) function `AbslHashValue()`, and return the combined hash +// // state of the existing hash state and the class state. You can add such a +// // free function using a friend declaration within the body of the class: +// class Circle { +// public: +// ... +// template <typename H> +// friend H AbslHashValue(H h, const Circle& c) { +// return H::combine(std::move(h), c.center_, c.radius_); +// } +// ... +// }; +// +// For more information, see Adding Type Support to `absl::Hash` below. +// +#ifndef ABSL_HASH_HASH_H_ +#define ABSL_HASH_HASH_H_ + +#include "absl/hash/internal/hash.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// `absl::Hash` +// ----------------------------------------------------------------------------- +// +// `absl::Hash<T>` is a convenient general-purpose hash functor for any type `T` +// satisfying any of the following conditions (in order): +// +// * T is an arithmetic or pointer type +// * T defines an overload for `AbslHashValue(H, const T&)` for an arbitrary +// hash state `H`. +// - T defines a specialization of `HASH_NAMESPACE::hash<T>` +// - T defines a specialization of `std::hash<T>` +// +// `absl::Hash` intrinsically supports the following types: +// +// * All integral types (including bool) +// * All enum types +// * All floating-point types (although hashing them is discouraged) +// * All pointer types, including nullptr_t +// * std::pair<T1, T2>, if T1 and T2 are hashable +// * std::tuple<Ts...>, if all the Ts... are hashable +// * std::unique_ptr and std::shared_ptr +// * All string-like types including: +// * absl::Cord +// * std::string +// * std::string_view (as well as any instance of std::basic_string that +// uses char and std::char_traits) +// * All the standard sequence containers (provided the elements are hashable) +// * All the standard ordered associative containers (provided the elements are +// hashable) +// * absl types such as the following: +// * absl::string_view +// * absl::InlinedVector +// * absl::FixedArray +// * absl::uint128 +// * absl::Time, absl::Duration, and absl::TimeZone +// +// Note: the list above is not meant to be exhaustive. Additional type support +// may be added, in which case the above list will be updated. +// +// ----------------------------------------------------------------------------- +// absl::Hash Invocation Evaluation +// ----------------------------------------------------------------------------- +// +// When invoked, `absl::Hash<T>` searches for supplied hash functions in the +// following order: +// +// * Natively supported types out of the box (see above) +// * Types for which an `AbslHashValue()` overload is provided (such as +// user-defined types). See "Adding Type Support to `absl::Hash`" below. +// * Types which define a `HASH_NAMESPACE::hash<T>` specialization (aka +// `__gnu_cxx::hash<T>` for gcc/Clang or `stdext::hash<T>` for MSVC) +// * Types which define a `std::hash<T>` specialization +// +// The fallback to legacy hash functions exists mainly for backwards +// compatibility. If you have a choice, prefer defining an `AbslHashValue` +// overload instead of specializing any legacy hash functors. +// +// ----------------------------------------------------------------------------- +// The Hash State Concept, and using `HashState` for Type Erasure +// ----------------------------------------------------------------------------- +// +// The `absl::Hash` framework relies on the Concept of a "hash state." Such a +// hash state is used in several places: +// +// * Within existing implementations of `absl::Hash<T>` to store the hashed +// state of an object. Note that it is up to the implementation how it stores +// such state. A hash table, for example, may mix the state to produce an +// integer value; a testing framework may simply hold a vector of that state. +// * Within implementations of `AbslHashValue()` used to extend user-defined +// types. (See "Adding Type Support to absl::Hash" below.) +// * Inside a `HashState`, providing type erasure for the concept of a hash +// state, which you can use to extend the `absl::Hash` framework for types +// that are otherwise difficult to extend using `AbslHashValue()`. (See the +// `HashState` class below.) +// +// The "hash state" concept contains two member functions for mixing hash state: +// +// * `H::combine(state, values...)` +// +// Combines an arbitrary number of values into a hash state, returning the +// updated state. Note that the existing hash state is move-only and must be +// passed by value. +// +// Each of the value types T must be hashable by H. +// +// NOTE: +// +// state = H::combine(std::move(state), value1, value2, value3); +// +// must be guaranteed to produce the same hash expansion as +// +// state = H::combine(std::move(state), value1); +// state = H::combine(std::move(state), value2); +// state = H::combine(std::move(state), value3); +// +// * `H::combine_contiguous(state, data, size)` +// +// Combines a contiguous array of `size` elements into a hash state, +// returning the updated state. Note that the existing hash state is +// move-only and must be passed by value. +// +// NOTE: +// +// state = H::combine_contiguous(std::move(state), data, size); +// +// need NOT be guaranteed to produce the same hash expansion as a loop +// (it may perform internal optimizations). If you need this guarantee, use a +// loop instead. +// +// ----------------------------------------------------------------------------- +// Adding Type Support to `absl::Hash` +// ----------------------------------------------------------------------------- +// +// To add support for your user-defined type, add a proper `AbslHashValue()` +// overload as a free (non-member) function. The overload will take an +// existing hash state and should combine that state with state from the type. +// +// Example: +// +// template <typename H> +// H AbslHashValue(H state, const MyType& v) { +// return H::combine(std::move(state), v.field1, ..., v.fieldN); +// } +// +// where `(field1, ..., fieldN)` are the members you would use on your +// `operator==` to define equality. +// +// Notice that `AbslHashValue` is not a class member, but an ordinary function. +// An `AbslHashValue` overload for a type should only be declared in the same +// file and namespace as said type. The proper `AbslHashValue` implementation +// for a given type will be discovered via ADL. +// +// Note: unlike `std::hash', `absl::Hash` should never be specialized. It must +// only be extended by adding `AbslHashValue()` overloads. +// +template <typename T> +using Hash = absl::hash_internal::Hash<T>; + +// HashState +// +// A type erased version of the hash state concept, for use in user-defined +// `AbslHashValue` implementations that can't use templates (such as PImpl +// classes, virtual functions, etc.). The type erasure adds overhead so it +// should be avoided unless necessary. +// +// Note: This wrapper will only erase calls to: +// combine_contiguous(H, const unsigned char*, size_t) +// +// All other calls will be handled internally and will not invoke overloads +// provided by the wrapped class. +// +// Users of this class should still define a template `AbslHashValue` function, +// but can use `absl::HashState::Create(&state)` to erase the type of the hash +// state and dispatch to their private hashing logic. +// +// This state can be used like any other hash state. In particular, you can call +// `HashState::combine()` and `HashState::combine_contiguous()` on it. +// +// Example: +// +// class Interface { +// public: +// template <typename H> +// friend H AbslHashValue(H state, const Interface& value) { +// state = H::combine(std::move(state), std::type_index(typeid(*this))); +// value.HashValue(absl::HashState::Create(&state)); +// return state; +// } +// private: +// virtual void HashValue(absl::HashState state) const = 0; +// }; +// +// class Impl : Interface { +// private: +// void HashValue(absl::HashState state) const override { +// absl::HashState::combine(std::move(state), v1_, v2_); +// } +// int v1_; +// std::string v2_; +// }; +class HashState : public hash_internal::HashStateBase<HashState> { + public: + // HashState::Create() + // + // Create a new `HashState` instance that wraps `state`. All calls to + // `combine()` and `combine_contiguous()` on the new instance will be + // redirected to the original `state` object. The `state` object must outlive + // the `HashState` instance. + template <typename T> + static HashState Create(T* state) { + HashState s; + s.Init(state); + return s; + } + + HashState(const HashState&) = delete; + HashState& operator=(const HashState&) = delete; + HashState(HashState&&) = default; + HashState& operator=(HashState&&) = default; + + // HashState::combine() + // + // Combines an arbitrary number of values into a hash state, returning the + // updated state. + using HashState::HashStateBase::combine; + + // HashState::combine_contiguous() + // + // Combines a contiguous array of `size` elements into a hash state, returning + // the updated state. + static HashState combine_contiguous(HashState hash_state, + const unsigned char* first, size_t size) { + hash_state.combine_contiguous_(hash_state.state_, first, size); + return hash_state; + } + using HashState::HashStateBase::combine_contiguous; + + private: + HashState() = default; + + template <typename T> + static void CombineContiguousImpl(void* p, const unsigned char* first, + size_t size) { + T& state = *static_cast<T*>(p); + state = T::combine_contiguous(std::move(state), first, size); + } + + template <typename T> + void Init(T* state) { + state_ = state; + combine_contiguous_ = &CombineContiguousImpl<T>; + } + + // Do not erase an already erased state. + void Init(HashState* state) { + state_ = state->state_; + combine_contiguous_ = state->combine_contiguous_; + } + + void* state_; + void (*combine_contiguous_)(void*, const unsigned char*, size_t); +}; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HASH_HASH_H_ diff --git a/third_party/abseil_cpp/absl/hash/hash_test.cc b/third_party/abseil_cpp/absl/hash/hash_test.cc new file mode 100644 index 0000000000..39ba24a85a --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/hash_test.cc @@ -0,0 +1,976 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/hash/hash.h" + +#include <array> +#include <bitset> +#include <cstring> +#include <deque> +#include <forward_list> +#include <functional> +#include <iterator> +#include <limits> +#include <list> +#include <map> +#include <memory> +#include <numeric> +#include <random> +#include <set> +#include <string> +#include <tuple> +#include <type_traits> +#include <unordered_map> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/flat_hash_set.h" +#include "absl/hash/hash_testing.h" +#include "absl/hash/internal/spy_hash_state.h" +#include "absl/meta/type_traits.h" +#include "absl/numeric/int128.h" +#include "absl/strings/cord_test_helpers.h" + +namespace { + +using absl::Hash; +using absl::hash_internal::SpyHashState; + +template <typename T> +class HashValueIntTest : public testing::Test { +}; +TYPED_TEST_SUITE_P(HashValueIntTest); + +template <typename T> +SpyHashState SpyHash(const T& value) { + return SpyHashState::combine(SpyHashState(), value); +} + +// Helper trait to verify if T is hashable. We use absl::Hash's poison status to +// detect it. +template <typename T> +using is_hashable = std::is_default_constructible<absl::Hash<T>>; + +TYPED_TEST_P(HashValueIntTest, BasicUsage) { + EXPECT_TRUE((is_hashable<TypeParam>::value)); + + TypeParam n = 42; + EXPECT_EQ(SpyHash(n), SpyHash(TypeParam{42})); + EXPECT_NE(SpyHash(n), SpyHash(TypeParam{0})); + EXPECT_NE(SpyHash(std::numeric_limits<TypeParam>::max()), + SpyHash(std::numeric_limits<TypeParam>::min())); +} + +TYPED_TEST_P(HashValueIntTest, FastPath) { + // Test the fast-path to make sure the values are the same. + TypeParam n = 42; + EXPECT_EQ(absl::Hash<TypeParam>{}(n), + absl::Hash<std::tuple<TypeParam>>{}(std::tuple<TypeParam>(n))); +} + +REGISTER_TYPED_TEST_CASE_P(HashValueIntTest, BasicUsage, FastPath); +using IntTypes = testing::Types<unsigned char, char, int, int32_t, int64_t, uint32_t, + uint64_t, size_t>; +INSTANTIATE_TYPED_TEST_CASE_P(My, HashValueIntTest, IntTypes); + +enum LegacyEnum { kValue1, kValue2, kValue3 }; + +enum class EnumClass { kValue4, kValue5, kValue6 }; + +TEST(HashValueTest, EnumAndBool) { + EXPECT_TRUE((is_hashable<LegacyEnum>::value)); + EXPECT_TRUE((is_hashable<EnumClass>::value)); + EXPECT_TRUE((is_hashable<bool>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + LegacyEnum::kValue1, LegacyEnum::kValue2, LegacyEnum::kValue3))); + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + EnumClass::kValue4, EnumClass::kValue5, EnumClass::kValue6))); + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(true, false))); +} + +TEST(HashValueTest, FloatingPoint) { + EXPECT_TRUE((is_hashable<float>::value)); + EXPECT_TRUE((is_hashable<double>::value)); + EXPECT_TRUE((is_hashable<long double>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(42.f, 0.f, -0.f, std::numeric_limits<float>::infinity(), + -std::numeric_limits<float>::infinity()))); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(42., 0., -0., std::numeric_limits<double>::infinity(), + -std::numeric_limits<double>::infinity()))); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + // Add some values with small exponent to test that NORMAL values also + // append their category. + .5L, 1.L, 2.L, 4.L, 42.L, 0.L, -0.L, + 17 * static_cast<long double>(std::numeric_limits<double>::max()), + std::numeric_limits<long double>::infinity(), + -std::numeric_limits<long double>::infinity()))); +} + +TEST(HashValueTest, Pointer) { + EXPECT_TRUE((is_hashable<int*>::value)); + + int i; + int* ptr = &i; + int* n = nullptr; + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(&i, ptr, nullptr, ptr + 1, n))); +} + +TEST(HashValueTest, PointerAlignment) { + // We want to make sure that pointer alignment will not cause bits to be + // stuck. + + constexpr size_t kTotalSize = 1 << 20; + std::unique_ptr<char[]> data(new char[kTotalSize]); + constexpr size_t kLog2NumValues = 5; + constexpr size_t kNumValues = 1 << kLog2NumValues; + + for (size_t align = 1; align < kTotalSize / kNumValues; + align < 8 ? align += 1 : align < 1024 ? align += 8 : align += 32) { + SCOPED_TRACE(align); + ASSERT_LE(align * kNumValues, kTotalSize); + + size_t bits_or = 0; + size_t bits_and = ~size_t{}; + + for (size_t i = 0; i < kNumValues; ++i) { + size_t hash = absl::Hash<void*>()(data.get() + i * align); + bits_or |= hash; + bits_and &= hash; + } + + // Limit the scope to the bits we would be using for Swisstable. + constexpr size_t kMask = (1 << (kLog2NumValues + 7)) - 1; + size_t stuck_bits = (~bits_or | bits_and) & kMask; + EXPECT_EQ(stuck_bits, 0) << "0x" << std::hex << stuck_bits; + } +} + +TEST(HashValueTest, PairAndTuple) { + EXPECT_TRUE((is_hashable<std::pair<int, int>>::value)); + EXPECT_TRUE((is_hashable<std::pair<const int&, const int&>>::value)); + EXPECT_TRUE((is_hashable<std::tuple<int&, int&>>::value)); + EXPECT_TRUE((is_hashable<std::tuple<int&&, int&&>>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + std::make_pair(0, 42), std::make_pair(0, 42), std::make_pair(42, 0), + std::make_pair(0, 0), std::make_pair(42, 42), std::make_pair(1, 42)))); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(std::make_tuple(0, 0, 0), std::make_tuple(0, 0, 42), + std::make_tuple(0, 23, 0), std::make_tuple(17, 0, 0), + std::make_tuple(42, 0, 0), std::make_tuple(3, 9, 9), + std::make_tuple(0, 0, -42)))); + + // Test that tuples of lvalue references work (so we need a few lvalues): + int a = 0, b = 1, c = 17, d = 23; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + std::tie(a, a), std::tie(a, b), std::tie(b, c), std::tie(c, d)))); + + // Test that tuples of rvalue references work: + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + std::forward_as_tuple(0, 0, 0), std::forward_as_tuple(0, 0, 42), + std::forward_as_tuple(0, 23, 0), std::forward_as_tuple(17, 0, 0), + std::forward_as_tuple(42, 0, 0), std::forward_as_tuple(3, 9, 9), + std::forward_as_tuple(0, 0, -42)))); +} + +TEST(HashValueTest, CombineContiguousWorks) { + std::vector<std::tuple<int>> v1 = {std::make_tuple(1), std::make_tuple(3)}; + std::vector<std::tuple<int>> v2 = {std::make_tuple(1), std::make_tuple(2)}; + + auto vh1 = SpyHash(v1); + auto vh2 = SpyHash(v2); + EXPECT_NE(vh1, vh2); +} + +struct DummyDeleter { + template <typename T> + void operator() (T* ptr) {} +}; + +struct SmartPointerEq { + template <typename T, typename U> + bool operator()(const T& t, const U& u) const { + return GetPtr(t) == GetPtr(u); + } + + template <typename T> + static auto GetPtr(const T& t) -> decltype(&*t) { + return t ? &*t : nullptr; + } + + static std::nullptr_t GetPtr(std::nullptr_t) { return nullptr; } +}; + +TEST(HashValueTest, SmartPointers) { + EXPECT_TRUE((is_hashable<std::unique_ptr<int>>::value)); + EXPECT_TRUE((is_hashable<std::unique_ptr<int, DummyDeleter>>::value)); + EXPECT_TRUE((is_hashable<std::shared_ptr<int>>::value)); + + int i, j; + std::unique_ptr<int, DummyDeleter> unique1(&i); + std::unique_ptr<int, DummyDeleter> unique2(&i); + std::unique_ptr<int, DummyDeleter> unique_other(&j); + std::unique_ptr<int, DummyDeleter> unique_null; + + std::shared_ptr<int> shared1(&i, DummyDeleter()); + std::shared_ptr<int> shared2(&i, DummyDeleter()); + std::shared_ptr<int> shared_other(&j, DummyDeleter()); + std::shared_ptr<int> shared_null; + + // Sanity check of the Eq function. + ASSERT_TRUE(SmartPointerEq{}(unique1, shared1)); + ASSERT_FALSE(SmartPointerEq{}(unique1, shared_other)); + ASSERT_TRUE(SmartPointerEq{}(unique_null, nullptr)); + ASSERT_FALSE(SmartPointerEq{}(shared2, nullptr)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::forward_as_tuple(&i, nullptr, // + unique1, unique2, unique_null, // + absl::make_unique<int>(), // + shared1, shared2, shared_null, // + std::make_shared<int>()), + SmartPointerEq{})); +} + +TEST(HashValueTest, FunctionPointer) { + using Func = int (*)(); + EXPECT_TRUE(is_hashable<Func>::value); + + Func p1 = [] { return 2; }, p2 = [] { return 1; }; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(p1, p2, nullptr))); +} + +struct WrapInTuple { + template <typename T> + std::tuple<int, T, size_t> operator()(const T& t) const { + return std::make_tuple(7, t, 0xdeadbeef); + } +}; + +absl::Cord FlatCord(absl::string_view sv) { + absl::Cord c(sv); + c.Flatten(); + return c; +} + +absl::Cord FragmentedCord(absl::string_view sv) { + if (sv.size() < 2) { + return absl::Cord(sv); + } + size_t halfway = sv.size() / 2; + std::vector<absl::string_view> parts = {sv.substr(0, halfway), + sv.substr(halfway)}; + return absl::MakeFragmentedCord(parts); +} + +TEST(HashValueTest, Strings) { + EXPECT_TRUE((is_hashable<std::string>::value)); + + const std::string small = "foo"; + const std::string dup = "foofoo"; + const std::string large = std::string(2048, 'x'); // multiple of chunk size + const std::string huge = std::string(5000, 'a'); // not a multiple + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( // + std::string(), absl::string_view(), absl::Cord(), // + std::string(""), absl::string_view(""), absl::Cord(""), // + std::string(small), absl::string_view(small), absl::Cord(small), // + std::string(dup), absl::string_view(dup), absl::Cord(dup), // + std::string(large), absl::string_view(large), absl::Cord(large), // + std::string(huge), absl::string_view(huge), FlatCord(huge), // + FragmentedCord(huge)))); + + // Also check that nested types maintain the same hash. + const WrapInTuple t{}; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( // + t(std::string()), t(absl::string_view()), t(absl::Cord()), // + t(std::string("")), t(absl::string_view("")), t(absl::Cord("")), // + t(std::string(small)), t(absl::string_view(small)), // + t(absl::Cord(small)), // + t(std::string(dup)), t(absl::string_view(dup)), t(absl::Cord(dup)), // + t(std::string(large)), t(absl::string_view(large)), // + t(absl::Cord(large)), // + t(std::string(huge)), t(absl::string_view(huge)), // + t(FlatCord(huge)), t(FragmentedCord(huge))))); + + // Make sure that hashing a `const char*` does not use its string-value. + EXPECT_NE(SpyHash(static_cast<const char*>("ABC")), + SpyHash(absl::string_view("ABC"))); +} + +TEST(HashValueTest, WString) { + EXPECT_TRUE((is_hashable<std::wstring>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + std::wstring(), std::wstring(L"ABC"), std::wstring(L"ABC"), + std::wstring(L"Some other different string"), + std::wstring(L"Iñtërnâtiônàlizætiøn")))); +} + +TEST(HashValueTest, U16String) { + EXPECT_TRUE((is_hashable<std::u16string>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + std::u16string(), std::u16string(u"ABC"), std::u16string(u"ABC"), + std::u16string(u"Some other different string"), + std::u16string(u"Iñtërnâtiônàlizætiøn")))); +} + +TEST(HashValueTest, U32String) { + EXPECT_TRUE((is_hashable<std::u32string>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + std::u32string(), std::u32string(U"ABC"), std::u32string(U"ABC"), + std::u32string(U"Some other different string"), + std::u32string(U"Iñtërnâtiônàlizætiøn")))); +} + +TEST(HashValueTest, StdArray) { + EXPECT_TRUE((is_hashable<std::array<int, 3>>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(std::array<int, 3>{}, std::array<int, 3>{{0, 23, 42}}))); +} + +TEST(HashValueTest, StdBitset) { + EXPECT_TRUE((is_hashable<std::bitset<257>>::value)); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + {std::bitset<2>("00"), std::bitset<2>("01"), std::bitset<2>("10"), + std::bitset<2>("11")})); + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + {std::bitset<5>("10101"), std::bitset<5>("10001"), std::bitset<5>()})); + + constexpr int kNumBits = 256; + std::array<std::string, 6> bit_strings; + bit_strings.fill(std::string(kNumBits, '1')); + bit_strings[1][0] = '0'; + bit_strings[2][1] = '0'; + bit_strings[3][kNumBits / 3] = '0'; + bit_strings[4][kNumBits - 2] = '0'; + bit_strings[5][kNumBits - 1] = '0'; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + {std::bitset<kNumBits>(bit_strings[0].c_str()), + std::bitset<kNumBits>(bit_strings[1].c_str()), + std::bitset<kNumBits>(bit_strings[2].c_str()), + std::bitset<kNumBits>(bit_strings[3].c_str()), + std::bitset<kNumBits>(bit_strings[4].c_str()), + std::bitset<kNumBits>(bit_strings[5].c_str())})); +} // namespace + +template <typename T> +class HashValueSequenceTest : public testing::Test { +}; +TYPED_TEST_SUITE_P(HashValueSequenceTest); + +TYPED_TEST_P(HashValueSequenceTest, BasicUsage) { + EXPECT_TRUE((is_hashable<TypeParam>::value)); + + using ValueType = typename TypeParam::value_type; + auto a = static_cast<ValueType>(0); + auto b = static_cast<ValueType>(23); + auto c = static_cast<ValueType>(42); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(TypeParam(), TypeParam{}, TypeParam{a, b, c}, + TypeParam{a, b}, TypeParam{b, c}))); +} + +REGISTER_TYPED_TEST_CASE_P(HashValueSequenceTest, BasicUsage); +using IntSequenceTypes = + testing::Types<std::deque<int>, std::forward_list<int>, std::list<int>, + std::vector<int>, std::vector<bool>, std::set<int>, + std::multiset<int>>; +INSTANTIATE_TYPED_TEST_CASE_P(My, HashValueSequenceTest, IntSequenceTypes); + +// Private type that only supports AbslHashValue to make sure our chosen hash +// implementation is recursive within absl::Hash. +// It uses std::abs() on the value to provide different bitwise representations +// of the same logical value. +struct Private { + int i; + template <typename H> + friend H AbslHashValue(H h, Private p) { + return H::combine(std::move(h), std::abs(p.i)); + } + + friend bool operator==(Private a, Private b) { + return std::abs(a.i) == std::abs(b.i); + } + + friend std::ostream& operator<<(std::ostream& o, Private p) { + return o << p.i; + } +}; + +// Test helper for combine_piecewise_buffer. It holds a string_view to the +// buffer-to-be-hashed. Its AbslHashValue specialization will split up its +// contents at the character offsets requested. +class PiecewiseHashTester { + public: + // Create a hash view of a buffer to be hashed contiguously. + explicit PiecewiseHashTester(absl::string_view buf) + : buf_(buf), piecewise_(false), split_locations_() {} + + // Create a hash view of a buffer to be hashed piecewise, with breaks at the + // given locations. + PiecewiseHashTester(absl::string_view buf, std::set<size_t> split_locations) + : buf_(buf), + piecewise_(true), + split_locations_(std::move(split_locations)) {} + + template <typename H> + friend H AbslHashValue(H h, const PiecewiseHashTester& p) { + if (!p.piecewise_) { + return H::combine_contiguous(std::move(h), p.buf_.data(), p.buf_.size()); + } + absl::hash_internal::PiecewiseCombiner combiner; + if (p.split_locations_.empty()) { + h = combiner.add_buffer(std::move(h), p.buf_.data(), p.buf_.size()); + return combiner.finalize(std::move(h)); + } + size_t begin = 0; + for (size_t next : p.split_locations_) { + absl::string_view chunk = p.buf_.substr(begin, next - begin); + h = combiner.add_buffer(std::move(h), chunk.data(), chunk.size()); + begin = next; + } + absl::string_view last_chunk = p.buf_.substr(begin); + if (!last_chunk.empty()) { + h = combiner.add_buffer(std::move(h), last_chunk.data(), + last_chunk.size()); + } + return combiner.finalize(std::move(h)); + } + + private: + absl::string_view buf_; + bool piecewise_; + std::set<size_t> split_locations_; +}; + +// Dummy object that hashes as two distinct contiguous buffers, "foo" followed +// by "bar" +struct DummyFooBar { + template <typename H> + friend H AbslHashValue(H h, const DummyFooBar&) { + const char* foo = "foo"; + const char* bar = "bar"; + h = H::combine_contiguous(std::move(h), foo, 3); + h = H::combine_contiguous(std::move(h), bar, 3); + return h; + } +}; + +TEST(HashValueTest, CombinePiecewiseBuffer) { + absl::Hash<PiecewiseHashTester> hash; + + // Check that hashing an empty buffer through the piecewise API works. + EXPECT_EQ(hash(PiecewiseHashTester("")), hash(PiecewiseHashTester("", {}))); + + // Similarly, small buffers should give consistent results + EXPECT_EQ(hash(PiecewiseHashTester("foobar")), + hash(PiecewiseHashTester("foobar", {}))); + EXPECT_EQ(hash(PiecewiseHashTester("foobar")), + hash(PiecewiseHashTester("foobar", {3}))); + + // But hashing "foobar" in pieces gives a different answer than hashing "foo" + // contiguously, then "bar" contiguously. + EXPECT_NE(hash(PiecewiseHashTester("foobar", {3})), + absl::Hash<DummyFooBar>()(DummyFooBar{})); + + // Test hashing a large buffer incrementally, broken up in several different + // ways. Arrange for breaks on and near the stride boundaries to look for + // off-by-one errors in the implementation. + // + // This test is run on a buffer that is a multiple of the stride size, and one + // that isn't. + for (size_t big_buffer_size : {1024 * 2 + 512, 1024 * 3}) { + SCOPED_TRACE(big_buffer_size); + std::string big_buffer; + for (int i = 0; i < big_buffer_size; ++i) { + // Arbitrary string + big_buffer.push_back(32 + (i * (i / 3)) % 64); + } + auto big_buffer_hash = hash(PiecewiseHashTester(big_buffer)); + + const int possible_breaks = 9; + size_t breaks[possible_breaks] = {1, 512, 1023, 1024, 1025, + 1536, 2047, 2048, 2049}; + for (unsigned test_mask = 0; test_mask < (1u << possible_breaks); + ++test_mask) { + SCOPED_TRACE(test_mask); + std::set<size_t> break_locations; + for (int j = 0; j < possible_breaks; ++j) { + if (test_mask & (1u << j)) { + break_locations.insert(breaks[j]); + } + } + EXPECT_EQ( + hash(PiecewiseHashTester(big_buffer, std::move(break_locations))), + big_buffer_hash); + } + } +} + +TEST(HashValueTest, PrivateSanity) { + // Sanity check that Private is working as the tests below expect it to work. + EXPECT_TRUE(is_hashable<Private>::value); + EXPECT_NE(SpyHash(Private{0}), SpyHash(Private{1})); + EXPECT_EQ(SpyHash(Private{1}), SpyHash(Private{1})); +} + +TEST(HashValueTest, Optional) { + EXPECT_TRUE(is_hashable<absl::optional<Private>>::value); + + using O = absl::optional<Private>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(O{}, O{{1}}, O{{-1}}, O{{10}}))); +} + +TEST(HashValueTest, Variant) { + using V = absl::variant<Private, std::string>; + EXPECT_TRUE(is_hashable<V>::value); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + V(Private{1}), V(Private{-1}), V(Private{2}), V("ABC"), V("BCD")))); + +#if ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + struct S {}; + EXPECT_FALSE(is_hashable<absl::variant<S>>::value); +#endif +} + +TEST(HashValueTest, Maps) { + EXPECT_TRUE((is_hashable<std::map<int, std::string>>::value)); + + using M = std::map<int, std::string>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + M{}, M{{0, "foo"}}, M{{1, "foo"}}, M{{0, "bar"}}, M{{1, "bar"}}, + M{{0, "foo"}, {42, "bar"}}, M{{1, "foo"}, {42, "bar"}}, + M{{1, "foo"}, {43, "bar"}}, M{{1, "foo"}, {43, "baz"}}))); + + using MM = std::multimap<int, std::string>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + MM{}, MM{{0, "foo"}}, MM{{1, "foo"}}, MM{{0, "bar"}}, MM{{1, "bar"}}, + MM{{0, "foo"}, {0, "bar"}}, MM{{0, "bar"}, {0, "foo"}}, + MM{{0, "foo"}, {42, "bar"}}, MM{{1, "foo"}, {42, "bar"}}, + MM{{1, "foo"}, {1, "foo"}, {43, "bar"}}, MM{{1, "foo"}, {43, "baz"}}))); +} + +TEST(HashValueTest, ReferenceWrapper) { + EXPECT_TRUE(is_hashable<std::reference_wrapper<Private>>::value); + + Private p1{1}, p10{10}; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + p1, p10, std::ref(p1), std::ref(p10), std::cref(p1), std::cref(p10)))); + + EXPECT_TRUE(is_hashable<std::reference_wrapper<int>>::value); + int one = 1, ten = 10; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(std::make_tuple( + one, ten, std::ref(one), std::ref(ten), std::cref(one), std::cref(ten)))); + + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + std::make_tuple(std::tuple<std::reference_wrapper<int>>(std::ref(one)), + std::tuple<std::reference_wrapper<int>>(std::ref(ten)), + std::tuple<int>(one), std::tuple<int>(ten)))); +} + +template <typename T, typename = void> +struct IsHashCallable : std::false_type {}; + +template <typename T> +struct IsHashCallable<T, absl::void_t<decltype(std::declval<absl::Hash<T>>()( + std::declval<const T&>()))>> : std::true_type {}; + +template <typename T, typename = void> +struct IsAggregateInitializable : std::false_type {}; + +template <typename T> +struct IsAggregateInitializable<T, absl::void_t<decltype(T{})>> + : std::true_type {}; + +TEST(IsHashableTest, ValidHash) { + EXPECT_TRUE((is_hashable<int>::value)); + EXPECT_TRUE(std::is_default_constructible<absl::Hash<int>>::value); + EXPECT_TRUE(std::is_copy_constructible<absl::Hash<int>>::value); + EXPECT_TRUE(std::is_move_constructible<absl::Hash<int>>::value); + EXPECT_TRUE(absl::is_copy_assignable<absl::Hash<int>>::value); + EXPECT_TRUE(absl::is_move_assignable<absl::Hash<int>>::value); + EXPECT_TRUE(IsHashCallable<int>::value); + EXPECT_TRUE(IsAggregateInitializable<absl::Hash<int>>::value); +} + +#if ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ +TEST(IsHashableTest, PoisonHash) { + struct X {}; + EXPECT_FALSE((is_hashable<X>::value)); + EXPECT_FALSE(std::is_default_constructible<absl::Hash<X>>::value); + EXPECT_FALSE(std::is_copy_constructible<absl::Hash<X>>::value); + EXPECT_FALSE(std::is_move_constructible<absl::Hash<X>>::value); + EXPECT_FALSE(absl::is_copy_assignable<absl::Hash<X>>::value); + EXPECT_FALSE(absl::is_move_assignable<absl::Hash<X>>::value); + EXPECT_FALSE(IsHashCallable<X>::value); +#if !defined(__GNUC__) || __GNUC__ < 9 + // This doesn't compile on GCC 9. + EXPECT_FALSE(IsAggregateInitializable<absl::Hash<X>>::value); +#endif +} +#endif // ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + +// Hashable types +// +// These types exist simply to exercise various AbslHashValue behaviors, so +// they are named by what their AbslHashValue overload does. +struct NoOp { + template <typename HashCode> + friend HashCode AbslHashValue(HashCode h, NoOp n) { + return h; + } +}; + +struct EmptyCombine { + template <typename HashCode> + friend HashCode AbslHashValue(HashCode h, EmptyCombine e) { + return HashCode::combine(std::move(h)); + } +}; + +template <typename Int> +struct CombineIterative { + template <typename HashCode> + friend HashCode AbslHashValue(HashCode h, CombineIterative c) { + for (int i = 0; i < 5; ++i) { + h = HashCode::combine(std::move(h), Int(i)); + } + return h; + } +}; + +template <typename Int> +struct CombineVariadic { + template <typename HashCode> + friend HashCode AbslHashValue(HashCode h, CombineVariadic c) { + return HashCode::combine(std::move(h), Int(0), Int(1), Int(2), Int(3), + Int(4)); + } +}; +enum class InvokeTag { + kUniquelyRepresented, + kHashValue, +#if ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ + kLegacyHash, +#endif // ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ + kStdHash, + kNone +}; + +template <InvokeTag T> +using InvokeTagConstant = std::integral_constant<InvokeTag, T>; + +template <InvokeTag... Tags> +struct MinTag; + +template <InvokeTag a, InvokeTag b, InvokeTag... Tags> +struct MinTag<a, b, Tags...> : MinTag<(a < b ? a : b), Tags...> {}; + +template <InvokeTag a> +struct MinTag<a> : InvokeTagConstant<a> {}; + +template <InvokeTag... Tags> +struct CustomHashType { + explicit CustomHashType(size_t val) : value(val) {} + size_t value; +}; + +template <InvokeTag allowed, InvokeTag... tags> +struct EnableIfContained + : std::enable_if<absl::disjunction< + std::integral_constant<bool, allowed == tags>...>::value> {}; + +template < + typename H, InvokeTag... Tags, + typename = typename EnableIfContained<InvokeTag::kHashValue, Tags...>::type> +H AbslHashValue(H state, CustomHashType<Tags...> t) { + static_assert(MinTag<Tags...>::value == InvokeTag::kHashValue, ""); + return H::combine(std::move(state), + t.value + static_cast<int>(InvokeTag::kHashValue)); +} + +} // namespace + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { +template <InvokeTag... Tags> +struct is_uniquely_represented< + CustomHashType<Tags...>, + typename EnableIfContained<InvokeTag::kUniquelyRepresented, Tags...>::type> + : std::true_type {}; +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl + +#if ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ +namespace ABSL_INTERNAL_LEGACY_HASH_NAMESPACE { +template <InvokeTag... Tags> +struct hash<CustomHashType<Tags...>> { + template <InvokeTag... TagsIn, typename = typename EnableIfContained< + InvokeTag::kLegacyHash, TagsIn...>::type> + size_t operator()(CustomHashType<TagsIn...> t) const { + static_assert(MinTag<Tags...>::value == InvokeTag::kLegacyHash, ""); + return t.value + static_cast<int>(InvokeTag::kLegacyHash); + } +}; +} // namespace ABSL_INTERNAL_LEGACY_HASH_NAMESPACE +#endif // ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ + +namespace std { +template <InvokeTag... Tags> // NOLINT +struct hash<CustomHashType<Tags...>> { + template <InvokeTag... TagsIn, typename = typename EnableIfContained< + InvokeTag::kStdHash, TagsIn...>::type> + size_t operator()(CustomHashType<TagsIn...> t) const { + static_assert(MinTag<Tags...>::value == InvokeTag::kStdHash, ""); + return t.value + static_cast<int>(InvokeTag::kStdHash); + } +}; +} // namespace std + +namespace { + +template <typename... T> +void TestCustomHashType(InvokeTagConstant<InvokeTag::kNone>, T...) { + using type = CustomHashType<T::value...>; + SCOPED_TRACE(testing::PrintToString(std::vector<InvokeTag>{T::value...})); + EXPECT_TRUE(is_hashable<type>()); + EXPECT_TRUE(is_hashable<const type>()); + EXPECT_TRUE(is_hashable<const type&>()); + + const size_t offset = static_cast<int>(std::min({T::value...})); + EXPECT_EQ(SpyHash(type(7)), SpyHash(size_t{7 + offset})); +} + +void TestCustomHashType(InvokeTagConstant<InvokeTag::kNone>) { +#if ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + // is_hashable is false if we don't support any of the hooks. + using type = CustomHashType<>; + EXPECT_FALSE(is_hashable<type>()); + EXPECT_FALSE(is_hashable<const type>()); + EXPECT_FALSE(is_hashable<const type&>()); +#endif // ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ +} + +template <InvokeTag Tag, typename... T> +void TestCustomHashType(InvokeTagConstant<Tag> tag, T... t) { + constexpr auto next = static_cast<InvokeTag>(static_cast<int>(Tag) + 1); + TestCustomHashType(InvokeTagConstant<next>(), tag, t...); + TestCustomHashType(InvokeTagConstant<next>(), t...); +} + +TEST(HashTest, CustomHashType) { + TestCustomHashType(InvokeTagConstant<InvokeTag{}>()); +} + +TEST(HashTest, NoOpsAreEquivalent) { + EXPECT_EQ(Hash<NoOp>()({}), Hash<NoOp>()({})); + EXPECT_EQ(Hash<NoOp>()({}), Hash<EmptyCombine>()({})); +} + +template <typename T> +class HashIntTest : public testing::Test { +}; +TYPED_TEST_SUITE_P(HashIntTest); + +TYPED_TEST_P(HashIntTest, BasicUsage) { + EXPECT_NE(Hash<NoOp>()({}), Hash<TypeParam>()(0)); + EXPECT_NE(Hash<NoOp>()({}), + Hash<TypeParam>()(std::numeric_limits<TypeParam>::max())); + if (std::numeric_limits<TypeParam>::min() != 0) { + EXPECT_NE(Hash<NoOp>()({}), + Hash<TypeParam>()(std::numeric_limits<TypeParam>::min())); + } + + EXPECT_EQ(Hash<CombineIterative<TypeParam>>()({}), + Hash<CombineVariadic<TypeParam>>()({})); +} + +REGISTER_TYPED_TEST_CASE_P(HashIntTest, BasicUsage); +using IntTypes = testing::Types<unsigned char, char, int, int32_t, int64_t, uint32_t, + uint64_t, size_t>; +INSTANTIATE_TYPED_TEST_CASE_P(My, HashIntTest, IntTypes); + +struct StructWithPadding { + char c; + int i; + + template <typename H> + friend H AbslHashValue(H hash_state, const StructWithPadding& s) { + return H::combine(std::move(hash_state), s.c, s.i); + } +}; + +static_assert(sizeof(StructWithPadding) > sizeof(char) + sizeof(int), + "StructWithPadding doesn't have padding"); +static_assert(std::is_standard_layout<StructWithPadding>::value, ""); + +// This check has to be disabled because libstdc++ doesn't support it. +// static_assert(std::is_trivially_constructible<StructWithPadding>::value, ""); + +template <typename T> +struct ArraySlice { + T* begin; + T* end; + + template <typename H> + friend H AbslHashValue(H hash_state, const ArraySlice& slice) { + for (auto t = slice.begin; t != slice.end; ++t) { + hash_state = H::combine(std::move(hash_state), *t); + } + return hash_state; + } +}; + +TEST(HashTest, HashNonUniquelyRepresentedType) { + // Create equal StructWithPadding objects that are known to have non-equal + // padding bytes. + static const size_t kNumStructs = 10; + unsigned char buffer1[kNumStructs * sizeof(StructWithPadding)]; + std::memset(buffer1, 0, sizeof(buffer1)); + auto* s1 = reinterpret_cast<StructWithPadding*>(buffer1); + + unsigned char buffer2[kNumStructs * sizeof(StructWithPadding)]; + std::memset(buffer2, 255, sizeof(buffer2)); + auto* s2 = reinterpret_cast<StructWithPadding*>(buffer2); + for (int i = 0; i < kNumStructs; ++i) { + SCOPED_TRACE(i); + s1[i].c = s2[i].c = '0' + i; + s1[i].i = s2[i].i = i; + ASSERT_FALSE(memcmp(buffer1 + i * sizeof(StructWithPadding), + buffer2 + i * sizeof(StructWithPadding), + sizeof(StructWithPadding)) == 0) + << "Bug in test code: objects do not have unequal" + << " object representations"; + } + + EXPECT_EQ(Hash<StructWithPadding>()(s1[0]), Hash<StructWithPadding>()(s2[0])); + EXPECT_EQ(Hash<ArraySlice<StructWithPadding>>()({s1, s1 + kNumStructs}), + Hash<ArraySlice<StructWithPadding>>()({s2, s2 + kNumStructs})); +} + +TEST(HashTest, StandardHashContainerUsage) { + std::unordered_map<int, std::string, Hash<int>> map = {{0, "foo"}, + {42, "bar"}}; + + EXPECT_NE(map.find(0), map.end()); + EXPECT_EQ(map.find(1), map.end()); + EXPECT_NE(map.find(0u), map.end()); +} + +struct ConvertibleFromNoOp { + ConvertibleFromNoOp(NoOp) {} // NOLINT(runtime/explicit) + + template <typename H> + friend H AbslHashValue(H hash_state, ConvertibleFromNoOp) { + return H::combine(std::move(hash_state), 1); + } +}; + +TEST(HashTest, HeterogeneousCall) { + EXPECT_NE(Hash<ConvertibleFromNoOp>()(NoOp()), + Hash<NoOp>()(NoOp())); +} + +TEST(IsUniquelyRepresentedTest, SanityTest) { + using absl::hash_internal::is_uniquely_represented; + + EXPECT_TRUE(is_uniquely_represented<unsigned char>::value); + EXPECT_TRUE(is_uniquely_represented<int>::value); + EXPECT_FALSE(is_uniquely_represented<bool>::value); + EXPECT_FALSE(is_uniquely_represented<int*>::value); +} + +struct IntAndString { + int i; + std::string s; + + template <typename H> + friend H AbslHashValue(H hash_state, IntAndString int_and_string) { + return H::combine(std::move(hash_state), int_and_string.s, + int_and_string.i); + } +}; + +TEST(HashTest, SmallValueOn64ByteBoundary) { + Hash<IntAndString>()(IntAndString{0, std::string(63, '0')}); +} + +struct TypeErased { + size_t n; + + template <typename H> + friend H AbslHashValue(H hash_state, const TypeErased& v) { + v.HashValue(absl::HashState::Create(&hash_state)); + return hash_state; + } + + void HashValue(absl::HashState state) const { + absl::HashState::combine(std::move(state), n); + } +}; + +TEST(HashTest, TypeErased) { + EXPECT_TRUE((is_hashable<TypeErased>::value)); + EXPECT_TRUE((is_hashable<std::pair<TypeErased, int>>::value)); + + EXPECT_EQ(SpyHash(TypeErased{7}), SpyHash(size_t{7})); + EXPECT_NE(SpyHash(TypeErased{7}), SpyHash(size_t{13})); + + EXPECT_EQ(SpyHash(std::make_pair(TypeErased{7}, 17)), + SpyHash(std::make_pair(size_t{7}, 17))); +} + +struct ValueWithBoolConversion { + operator bool() const { return false; } + int i; +}; + +} // namespace +namespace std { +template <> +struct hash<ValueWithBoolConversion> { + size_t operator()(ValueWithBoolConversion v) { return v.i; } +}; +} // namespace std + +namespace { + +TEST(HashTest, DoesNotUseImplicitConversionsToBool) { + EXPECT_NE(absl::Hash<ValueWithBoolConversion>()(ValueWithBoolConversion{0}), + absl::Hash<ValueWithBoolConversion>()(ValueWithBoolConversion{1})); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/hash/hash_testing.h b/third_party/abseil_cpp/absl/hash/hash_testing.h new file mode 100644 index 0000000000..1e1c574149 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/hash_testing.h @@ -0,0 +1,378 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_HASH_HASH_TESTING_H_ +#define ABSL_HASH_HASH_TESTING_H_ + +#include <initializer_list> +#include <tuple> +#include <type_traits> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/hash/internal/spy_hash_state.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/str_cat.h" +#include "absl/types/variant.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Run the absl::Hash algorithm over all the elements passed in and verify that +// their hash expansion is congruent with their `==` operator. +// +// It is used in conjunction with EXPECT_TRUE. Failures will output information +// on what requirement failed and on which objects. +// +// Users should pass a collection of types as either an initializer list or a +// container of cases. +// +// EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( +// {v1, v2, ..., vN})); +// +// std::vector<MyType> cases; +// // Fill cases... +// EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly(cases)); +// +// Users can pass a variety of types for testing heterogeneous lookup with +// `std::make_tuple`: +// +// EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( +// std::make_tuple(v1, v2, ..., vN))); +// +// +// Ideally, the values passed should provide enough coverage of the `==` +// operator and the AbslHashValue implementations. +// For dynamically sized types, the empty state should usually be included in +// the values. +// +// The function accepts an optional comparator function, in case that `==` is +// not enough for the values provided. +// +// Usage: +// +// EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( +// std::make_tuple(v1, v2, ..., vN), MyCustomEq{})); +// +// It checks the following requirements: +// 1. The expansion for a value is deterministic. +// 2. For any two objects `a` and `b` in the sequence, if `a == b` evaluates +// to true, then their hash expansion must be equal. +// 3. If `a == b` evaluates to false their hash expansion must be unequal. +// 4. If `a == b` evaluates to false neither hash expansion can be a +// suffix of the other. +// 5. AbslHashValue overloads should not be called by the user. They are only +// meant to be called by the framework. Users should call H::combine() and +// H::combine_contiguous(). +// 6. No moved-from instance of the hash state is used in the implementation +// of AbslHashValue. +// +// The values do not have to have the same type. This can be useful for +// equivalent types that support heterogeneous lookup. +// +// A possible reason for breaking (2) is combining state in the hash expansion +// that was not used in `==`. +// For example: +// +// struct Bad2 { +// int a, b; +// template <typename H> +// friend H AbslHashValue(H state, Bad2 x) { +// // Uses a and b. +// return H::combine(std::move(state), x.a, x.b); +// } +// friend bool operator==(Bad2 x, Bad2 y) { +// // Only uses a. +// return x.a == y.a; +// } +// }; +// +// As for (3), breaking this usually means that there is state being passed to +// the `==` operator that is not used in the hash expansion. +// For example: +// +// struct Bad3 { +// int a, b; +// template <typename H> +// friend H AbslHashValue(H state, Bad3 x) { +// // Only uses a. +// return H::combine(std::move(state), x.a); +// } +// friend bool operator==(Bad3 x, Bad3 y) { +// // Uses a and b. +// return x.a == y.a && x.b == y.b; +// } +// }; +// +// Finally, a common way to break 4 is by combining dynamic ranges without +// combining the size of the range. +// For example: +// +// struct Bad4 { +// int *p, size; +// template <typename H> +// friend H AbslHashValue(H state, Bad4 x) { +// return H::combine_contiguous(std::move(state), x.p, x.p + x.size); +// } +// friend bool operator==(Bad4 x, Bad4 y) { +// // Compare two ranges for equality. C++14 code can instead use std::equal. +// return absl::equal(x.p, x.p + x.size, y.p, y.p + y.size); +// } +// }; +// +// An easy solution to this is to combine the size after combining the range, +// like so: +// template <typename H> +// friend H AbslHashValue(H state, Bad4 x) { +// return H::combine( +// H::combine_contiguous(std::move(state), x.p, x.p + x.size), x.size); +// } +// +template <int&... ExplicitBarrier, typename Container> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(const Container& values); + +template <int&... ExplicitBarrier, typename Container, typename Eq> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(const Container& values, Eq equals); + +template <int&..., typename T> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(std::initializer_list<T> values); + +template <int&..., typename T, typename Eq> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(std::initializer_list<T> values, + Eq equals); + +namespace hash_internal { + +struct PrintVisitor { + size_t index; + template <typename T> + std::string operator()(const T* value) const { + return absl::StrCat("#", index, "(", testing::PrintToString(*value), ")"); + } +}; + +template <typename Eq> +struct EqVisitor { + Eq eq; + template <typename T, typename U> + bool operator()(const T* t, const U* u) const { + return eq(*t, *u); + } +}; + +struct ExpandVisitor { + template <typename T> + SpyHashState operator()(const T* value) const { + return SpyHashState::combine(SpyHashState(), *value); + } +}; + +template <typename Container, typename Eq> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(const Container& values, Eq equals) { + using V = typename Container::value_type; + + struct Info { + const V& value; + size_t index; + std::string ToString() const { + return absl::visit(PrintVisitor{index}, value); + } + SpyHashState expand() const { return absl::visit(ExpandVisitor{}, value); } + }; + + using EqClass = std::vector<Info>; + std::vector<EqClass> classes; + + // Gather the values in equivalence classes. + size_t i = 0; + for (const auto& value : values) { + EqClass* c = nullptr; + for (auto& eqclass : classes) { + if (absl::visit(EqVisitor<Eq>{equals}, value, eqclass[0].value)) { + c = &eqclass; + break; + } + } + if (c == nullptr) { + classes.emplace_back(); + c = &classes.back(); + } + c->push_back({value, i}); + ++i; + + // Verify potential errors captured by SpyHashState. + if (auto error = c->back().expand().error()) { + return testing::AssertionFailure() << *error; + } + } + + if (classes.size() < 2) { + return testing::AssertionFailure() + << "At least two equivalence classes are expected."; + } + + // We assume that equality is correctly implemented. + // Now we verify that AbslHashValue is also correctly implemented. + + for (const auto& c : classes) { + // All elements of the equivalence class must have the same hash + // expansion. + const SpyHashState expected = c[0].expand(); + for (const Info& v : c) { + if (v.expand() != v.expand()) { + return testing::AssertionFailure() + << "Hash expansion for " << v.ToString() + << " is non-deterministic."; + } + if (v.expand() != expected) { + return testing::AssertionFailure() + << "Values " << c[0].ToString() << " and " << v.ToString() + << " evaluate as equal but have an unequal hash expansion."; + } + } + + // Elements from other classes must have different hash expansion. + for (const auto& c2 : classes) { + if (&c == &c2) continue; + const SpyHashState c2_hash = c2[0].expand(); + switch (SpyHashState::Compare(expected, c2_hash)) { + case SpyHashState::CompareResult::kEqual: + return testing::AssertionFailure() + << "Values " << c[0].ToString() << " and " << c2[0].ToString() + << " evaluate as unequal but have an equal hash expansion."; + case SpyHashState::CompareResult::kBSuffixA: + return testing::AssertionFailure() + << "Hash expansion of " << c2[0].ToString() + << " is a suffix of the hash expansion of " << c[0].ToString() + << "."; + case SpyHashState::CompareResult::kASuffixB: + return testing::AssertionFailure() + << "Hash expansion of " << c[0].ToString() + << " is a suffix of the hash expansion of " << c2[0].ToString() + << "."; + case SpyHashState::CompareResult::kUnequal: + break; + } + } + } + return testing::AssertionSuccess(); +} + +template <typename... T> +struct TypeSet { + template <typename U, bool = disjunction<std::is_same<T, U>...>::value> + struct Insert { + using type = TypeSet<U, T...>; + }; + template <typename U> + struct Insert<U, true> { + using type = TypeSet; + }; + + template <template <typename...> class C> + using apply = C<T...>; +}; + +template <typename... T> +struct MakeTypeSet : TypeSet<> {}; +template <typename T, typename... Ts> +struct MakeTypeSet<T, Ts...> : MakeTypeSet<Ts...>::template Insert<T>::type {}; + +template <typename... T> +using VariantForTypes = typename MakeTypeSet< + const typename std::decay<T>::type*...>::template apply<absl::variant>; + +template <typename Container> +struct ContainerAsVector { + using V = absl::variant<const typename Container::value_type*>; + using Out = std::vector<V>; + + static Out Do(const Container& values) { + Out out; + for (const auto& v : values) out.push_back(&v); + return out; + } +}; + +template <typename... T> +struct ContainerAsVector<std::tuple<T...>> { + using V = VariantForTypes<T...>; + using Out = std::vector<V>; + + template <size_t... I> + static Out DoImpl(const std::tuple<T...>& tuple, absl::index_sequence<I...>) { + return Out{&std::get<I>(tuple)...}; + } + + static Out Do(const std::tuple<T...>& values) { + return DoImpl(values, absl::index_sequence_for<T...>()); + } +}; + +template <> +struct ContainerAsVector<std::tuple<>> { + static std::vector<VariantForTypes<int>> Do(std::tuple<>) { return {}; } +}; + +struct DefaultEquals { + template <typename T, typename U> + bool operator()(const T& t, const U& u) const { + return t == u; + } +}; + +} // namespace hash_internal + +template <int&..., typename Container> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(const Container& values) { + return hash_internal::VerifyTypeImplementsAbslHashCorrectly( + hash_internal::ContainerAsVector<Container>::Do(values), + hash_internal::DefaultEquals{}); +} + +template <int&..., typename Container, typename Eq> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(const Container& values, Eq equals) { + return hash_internal::VerifyTypeImplementsAbslHashCorrectly( + hash_internal::ContainerAsVector<Container>::Do(values), equals); +} + +template <int&..., typename T> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(std::initializer_list<T> values) { + return hash_internal::VerifyTypeImplementsAbslHashCorrectly( + hash_internal::ContainerAsVector<std::initializer_list<T>>::Do(values), + hash_internal::DefaultEquals{}); +} + +template <int&..., typename T, typename Eq> +ABSL_MUST_USE_RESULT testing::AssertionResult +VerifyTypeImplementsAbslHashCorrectly(std::initializer_list<T> values, + Eq equals) { + return hash_internal::VerifyTypeImplementsAbslHashCorrectly( + hash_internal::ContainerAsVector<std::initializer_list<T>>::Do(values), + equals); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HASH_HASH_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/hash/internal/city.cc b/third_party/abseil_cpp/absl/hash/internal/city.cc new file mode 100644 index 0000000000..e122c184b6 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/city.cc @@ -0,0 +1,346 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file provides CityHash64() and related functions. +// +// It's probably possible to create even faster hash functions by +// writing a program that systematically explores some of the space of +// possible hash functions, by using SIMD instructions, or by +// compromising on hash quality. + +#include "absl/hash/internal/city.h" + +#include <string.h> // for memcpy and memset +#include <algorithm> + +#include "absl/base/config.h" +#include "absl/base/internal/endian.h" +#include "absl/base/internal/unaligned_access.h" +#include "absl/base/optimization.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { + +#ifdef ABSL_IS_BIG_ENDIAN +#define uint32_in_expected_order(x) (absl::gbswap_32(x)) +#define uint64_in_expected_order(x) (absl::gbswap_64(x)) +#else +#define uint32_in_expected_order(x) (x) +#define uint64_in_expected_order(x) (x) +#endif + +static uint64_t Fetch64(const char *p) { + return uint64_in_expected_order(ABSL_INTERNAL_UNALIGNED_LOAD64(p)); +} + +static uint32_t Fetch32(const char *p) { + return uint32_in_expected_order(ABSL_INTERNAL_UNALIGNED_LOAD32(p)); +} + +// Some primes between 2^63 and 2^64 for various uses. +static const uint64_t k0 = 0xc3a5c85c97cb3127ULL; +static const uint64_t k1 = 0xb492b66fbe98f273ULL; +static const uint64_t k2 = 0x9ae16a3b2f90404fULL; + +// Magic numbers for 32-bit hashing. Copied from Murmur3. +static const uint32_t c1 = 0xcc9e2d51; +static const uint32_t c2 = 0x1b873593; + +// A 32-bit to 32-bit integer hash copied from Murmur3. +static uint32_t fmix(uint32_t h) { + h ^= h >> 16; + h *= 0x85ebca6b; + h ^= h >> 13; + h *= 0xc2b2ae35; + h ^= h >> 16; + return h; +} + +static uint32_t Rotate32(uint32_t val, int shift) { + // Avoid shifting by 32: doing so yields an undefined result. + return shift == 0 ? val : ((val >> shift) | (val << (32 - shift))); +} + +#undef PERMUTE3 +#define PERMUTE3(a, b, c) \ + do { \ + std::swap(a, b); \ + std::swap(a, c); \ + } while (0) + +static uint32_t Mur(uint32_t a, uint32_t h) { + // Helper from Murmur3 for combining two 32-bit values. + a *= c1; + a = Rotate32(a, 17); + a *= c2; + h ^= a; + h = Rotate32(h, 19); + return h * 5 + 0xe6546b64; +} + +static uint32_t Hash32Len13to24(const char *s, size_t len) { + uint32_t a = Fetch32(s - 4 + (len >> 1)); + uint32_t b = Fetch32(s + 4); + uint32_t c = Fetch32(s + len - 8); + uint32_t d = Fetch32(s + (len >> 1)); + uint32_t e = Fetch32(s); + uint32_t f = Fetch32(s + len - 4); + uint32_t h = len; + + return fmix(Mur(f, Mur(e, Mur(d, Mur(c, Mur(b, Mur(a, h))))))); +} + +static uint32_t Hash32Len0to4(const char *s, size_t len) { + uint32_t b = 0; + uint32_t c = 9; + for (size_t i = 0; i < len; i++) { + signed char v = s[i]; + b = b * c1 + v; + c ^= b; + } + return fmix(Mur(b, Mur(len, c))); +} + +static uint32_t Hash32Len5to12(const char *s, size_t len) { + uint32_t a = len, b = len * 5, c = 9, d = b; + a += Fetch32(s); + b += Fetch32(s + len - 4); + c += Fetch32(s + ((len >> 1) & 4)); + return fmix(Mur(c, Mur(b, Mur(a, d)))); +} + +uint32_t CityHash32(const char *s, size_t len) { + if (len <= 24) { + return len <= 12 + ? (len <= 4 ? Hash32Len0to4(s, len) : Hash32Len5to12(s, len)) + : Hash32Len13to24(s, len); + } + + // len > 24 + uint32_t h = len, g = c1 * len, f = g; + + uint32_t a0 = Rotate32(Fetch32(s + len - 4) * c1, 17) * c2; + uint32_t a1 = Rotate32(Fetch32(s + len - 8) * c1, 17) * c2; + uint32_t a2 = Rotate32(Fetch32(s + len - 16) * c1, 17) * c2; + uint32_t a3 = Rotate32(Fetch32(s + len - 12) * c1, 17) * c2; + uint32_t a4 = Rotate32(Fetch32(s + len - 20) * c1, 17) * c2; + h ^= a0; + h = Rotate32(h, 19); + h = h * 5 + 0xe6546b64; + h ^= a2; + h = Rotate32(h, 19); + h = h * 5 + 0xe6546b64; + g ^= a1; + g = Rotate32(g, 19); + g = g * 5 + 0xe6546b64; + g ^= a3; + g = Rotate32(g, 19); + g = g * 5 + 0xe6546b64; + f += a4; + f = Rotate32(f, 19); + f = f * 5 + 0xe6546b64; + size_t iters = (len - 1) / 20; + do { + uint32_t b0 = Rotate32(Fetch32(s) * c1, 17) * c2; + uint32_t b1 = Fetch32(s + 4); + uint32_t b2 = Rotate32(Fetch32(s + 8) * c1, 17) * c2; + uint32_t b3 = Rotate32(Fetch32(s + 12) * c1, 17) * c2; + uint32_t b4 = Fetch32(s + 16); + h ^= b0; + h = Rotate32(h, 18); + h = h * 5 + 0xe6546b64; + f += b1; + f = Rotate32(f, 19); + f = f * c1; + g += b2; + g = Rotate32(g, 18); + g = g * 5 + 0xe6546b64; + h ^= b3 + b1; + h = Rotate32(h, 19); + h = h * 5 + 0xe6546b64; + g ^= b4; + g = absl::gbswap_32(g) * 5; + h += b4 * 5; + h = absl::gbswap_32(h); + f += b0; + PERMUTE3(f, h, g); + s += 20; + } while (--iters != 0); + g = Rotate32(g, 11) * c1; + g = Rotate32(g, 17) * c1; + f = Rotate32(f, 11) * c1; + f = Rotate32(f, 17) * c1; + h = Rotate32(h + g, 19); + h = h * 5 + 0xe6546b64; + h = Rotate32(h, 17) * c1; + h = Rotate32(h + f, 19); + h = h * 5 + 0xe6546b64; + h = Rotate32(h, 17) * c1; + return h; +} + +// Bitwise right rotate. Normally this will compile to a single +// instruction, especially if the shift is a manifest constant. +static uint64_t Rotate(uint64_t val, int shift) { + // Avoid shifting by 64: doing so yields an undefined result. + return shift == 0 ? val : ((val >> shift) | (val << (64 - shift))); +} + +static uint64_t ShiftMix(uint64_t val) { return val ^ (val >> 47); } + +static uint64_t HashLen16(uint64_t u, uint64_t v) { + return Hash128to64(uint128(u, v)); +} + +static uint64_t HashLen16(uint64_t u, uint64_t v, uint64_t mul) { + // Murmur-inspired hashing. + uint64_t a = (u ^ v) * mul; + a ^= (a >> 47); + uint64_t b = (v ^ a) * mul; + b ^= (b >> 47); + b *= mul; + return b; +} + +static uint64_t HashLen0to16(const char *s, size_t len) { + if (len >= 8) { + uint64_t mul = k2 + len * 2; + uint64_t a = Fetch64(s) + k2; + uint64_t b = Fetch64(s + len - 8); + uint64_t c = Rotate(b, 37) * mul + a; + uint64_t d = (Rotate(a, 25) + b) * mul; + return HashLen16(c, d, mul); + } + if (len >= 4) { + uint64_t mul = k2 + len * 2; + uint64_t a = Fetch32(s); + return HashLen16(len + (a << 3), Fetch32(s + len - 4), mul); + } + if (len > 0) { + uint8_t a = s[0]; + uint8_t b = s[len >> 1]; + uint8_t c = s[len - 1]; + uint32_t y = static_cast<uint32_t>(a) + (static_cast<uint32_t>(b) << 8); + uint32_t z = len + (static_cast<uint32_t>(c) << 2); + return ShiftMix(y * k2 ^ z * k0) * k2; + } + return k2; +} + +// This probably works well for 16-byte strings as well, but it may be overkill +// in that case. +static uint64_t HashLen17to32(const char *s, size_t len) { + uint64_t mul = k2 + len * 2; + uint64_t a = Fetch64(s) * k1; + uint64_t b = Fetch64(s + 8); + uint64_t c = Fetch64(s + len - 8) * mul; + uint64_t d = Fetch64(s + len - 16) * k2; + return HashLen16(Rotate(a + b, 43) + Rotate(c, 30) + d, + a + Rotate(b + k2, 18) + c, mul); +} + +// Return a 16-byte hash for 48 bytes. Quick and dirty. +// Callers do best to use "random-looking" values for a and b. +static std::pair<uint64_t, uint64_t> WeakHashLen32WithSeeds(uint64_t w, uint64_t x, + uint64_t y, uint64_t z, + uint64_t a, uint64_t b) { + a += w; + b = Rotate(b + a + z, 21); + uint64_t c = a; + a += x; + a += y; + b += Rotate(a, 44); + return std::make_pair(a + z, b + c); +} + +// Return a 16-byte hash for s[0] ... s[31], a, and b. Quick and dirty. +static std::pair<uint64_t, uint64_t> WeakHashLen32WithSeeds(const char *s, uint64_t a, + uint64_t b) { + return WeakHashLen32WithSeeds(Fetch64(s), Fetch64(s + 8), Fetch64(s + 16), + Fetch64(s + 24), a, b); +} + +// Return an 8-byte hash for 33 to 64 bytes. +static uint64_t HashLen33to64(const char *s, size_t len) { + uint64_t mul = k2 + len * 2; + uint64_t a = Fetch64(s) * k2; + uint64_t b = Fetch64(s + 8); + uint64_t c = Fetch64(s + len - 24); + uint64_t d = Fetch64(s + len - 32); + uint64_t e = Fetch64(s + 16) * k2; + uint64_t f = Fetch64(s + 24) * 9; + uint64_t g = Fetch64(s + len - 8); + uint64_t h = Fetch64(s + len - 16) * mul; + uint64_t u = Rotate(a + g, 43) + (Rotate(b, 30) + c) * 9; + uint64_t v = ((a + g) ^ d) + f + 1; + uint64_t w = absl::gbswap_64((u + v) * mul) + h; + uint64_t x = Rotate(e + f, 42) + c; + uint64_t y = (absl::gbswap_64((v + w) * mul) + g) * mul; + uint64_t z = e + f + c; + a = absl::gbswap_64((x + z) * mul + y) + b; + b = ShiftMix((z + a) * mul + d + h) * mul; + return b + x; +} + +uint64_t CityHash64(const char *s, size_t len) { + if (len <= 32) { + if (len <= 16) { + return HashLen0to16(s, len); + } else { + return HashLen17to32(s, len); + } + } else if (len <= 64) { + return HashLen33to64(s, len); + } + + // For strings over 64 bytes we hash the end first, and then as we + // loop we keep 56 bytes of state: v, w, x, y, and z. + uint64_t x = Fetch64(s + len - 40); + uint64_t y = Fetch64(s + len - 16) + Fetch64(s + len - 56); + uint64_t z = HashLen16(Fetch64(s + len - 48) + len, Fetch64(s + len - 24)); + std::pair<uint64_t, uint64_t> v = WeakHashLen32WithSeeds(s + len - 64, len, z); + std::pair<uint64_t, uint64_t> w = WeakHashLen32WithSeeds(s + len - 32, y + k1, x); + x = x * k1 + Fetch64(s); + + // Decrease len to the nearest multiple of 64, and operate on 64-byte chunks. + len = (len - 1) & ~static_cast<size_t>(63); + do { + x = Rotate(x + y + v.first + Fetch64(s + 8), 37) * k1; + y = Rotate(y + v.second + Fetch64(s + 48), 42) * k1; + x ^= w.second; + y += v.first + Fetch64(s + 40); + z = Rotate(z + w.first, 33) * k1; + v = WeakHashLen32WithSeeds(s, v.second * k1, x + w.first); + w = WeakHashLen32WithSeeds(s + 32, z + w.second, y + Fetch64(s + 16)); + std::swap(z, x); + s += 64; + len -= 64; + } while (len != 0); + return HashLen16(HashLen16(v.first, w.first) + ShiftMix(y) * k1 + z, + HashLen16(v.second, w.second) + x); +} + +uint64_t CityHash64WithSeed(const char *s, size_t len, uint64_t seed) { + return CityHash64WithSeeds(s, len, k2, seed); +} + +uint64_t CityHash64WithSeeds(const char *s, size_t len, uint64_t seed0, + uint64_t seed1) { + return HashLen16(CityHash64(s, len) - seed0, seed1); +} + +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/hash/internal/city.h b/third_party/abseil_cpp/absl/hash/internal/city.h new file mode 100644 index 0000000000..161c7748ec --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/city.h @@ -0,0 +1,96 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// https://code.google.com/p/cityhash/ +// +// This file provides a few functions for hashing strings. All of them are +// high-quality functions in the sense that they pass standard tests such +// as Austin Appleby's SMHasher. They are also fast. +// +// For 64-bit x86 code, on short strings, we don't know of anything faster than +// CityHash64 that is of comparable quality. We believe our nearest competitor +// is Murmur3. For 64-bit x86 code, CityHash64 is an excellent choice for hash +// tables and most other hashing (excluding cryptography). +// +// For 32-bit x86 code, we don't know of anything faster than CityHash32 that +// is of comparable quality. We believe our nearest competitor is Murmur3A. +// (On 64-bit CPUs, it is typically faster to use the other CityHash variants.) +// +// Functions in the CityHash family are not suitable for cryptography. +// +// Please see CityHash's README file for more details on our performance +// measurements and so on. +// +// WARNING: This code has been only lightly tested on big-endian platforms! +// It is known to work well on little-endian platforms that have a small penalty +// for unaligned reads, such as current Intel and AMD moderate-to-high-end CPUs. +// It should work on all 32-bit and 64-bit platforms that allow unaligned reads; +// bug reports are welcome. +// +// By the way, for some hash functions, given strings a and b, the hash +// of a+b is easily derived from the hashes of a and b. This property +// doesn't hold for any hash functions in this file. + +#ifndef ABSL_HASH_INTERNAL_CITY_H_ +#define ABSL_HASH_INTERNAL_CITY_H_ + +#include <stdint.h> +#include <stdlib.h> // for size_t. + +#include <utility> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { + +typedef std::pair<uint64_t, uint64_t> uint128; + +inline uint64_t Uint128Low64(const uint128 &x) { return x.first; } +inline uint64_t Uint128High64(const uint128 &x) { return x.second; } + +// Hash function for a byte array. +uint64_t CityHash64(const char *s, size_t len); + +// Hash function for a byte array. For convenience, a 64-bit seed is also +// hashed into the result. +uint64_t CityHash64WithSeed(const char *s, size_t len, uint64_t seed); + +// Hash function for a byte array. For convenience, two seeds are also +// hashed into the result. +uint64_t CityHash64WithSeeds(const char *s, size_t len, uint64_t seed0, + uint64_t seed1); + +// Hash function for a byte array. Most useful in 32-bit binaries. +uint32_t CityHash32(const char *s, size_t len); + +// Hash 128 input bits down to 64 bits of output. +// This is intended to be a reasonably good hash function. +inline uint64_t Hash128to64(const uint128 &x) { + // Murmur-inspired hashing. + const uint64_t kMul = 0x9ddfea08eb382d69ULL; + uint64_t a = (Uint128Low64(x) ^ Uint128High64(x)) * kMul; + a ^= (a >> 47); + uint64_t b = (Uint128High64(x) ^ a) * kMul; + b ^= (b >> 47); + b *= kMul; + return b; +} + +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HASH_INTERNAL_CITY_H_ diff --git a/third_party/abseil_cpp/absl/hash/internal/city_test.cc b/third_party/abseil_cpp/absl/hash/internal/city_test.cc new file mode 100644 index 0000000000..251d381d73 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/city_test.cc @@ -0,0 +1,595 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/hash/internal/city.h" + +#include <string.h> +#include <cstdio> +#include <iostream> +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { + +static const uint64_t k0 = 0xc3a5c85c97cb3127ULL; +static const uint64_t kSeed0 = 1234567; +static const uint64_t kSeed1 = k0; +static const int kDataSize = 1 << 20; +static const int kTestSize = 300; + +static char data[kDataSize]; + +// Initialize data to pseudorandom values. +void setup() { + uint64_t a = 9; + uint64_t b = 777; + for (int i = 0; i < kDataSize; i++) { + a += b; + b += a; + a = (a ^ (a >> 41)) * k0; + b = (b ^ (b >> 41)) * k0 + i; + uint8_t u = b >> 37; + memcpy(data + i, &u, 1); // uint8_t -> char + } +} + +#define C(x) 0x##x##ULL +static const uint64_t testdata[kTestSize][4] = { + {C(9ae16a3b2f90404f), C(75106db890237a4a), C(3feac5f636039766), + C(dc56d17a)}, + {C(541150e87f415e96), C(1aef0d24b3148a1a), C(bacc300e1e82345a), + C(99929334)}, + {C(f3786a4b25827c1), C(34ee1a2bf767bd1c), C(2f15ca2ebfb631f2), C(4252edb7)}, + {C(ef923a7a1af78eab), C(79163b1e1e9a9b18), C(df3b2aca6e1e4a30), + C(ebc34f3c)}, + {C(11df592596f41d88), C(843ec0bce9042f9c), C(cce2ea1e08b1eb30), + C(26f2b463)}, + {C(831f448bdc5600b3), C(62a24be3120a6919), C(1b44098a41e010da), + C(b042c047)}, + {C(3eca803e70304894), C(d80de767e4a920a), C(a51cfbb292efd53d), C(e73bb0a8)}, + {C(1b5a063fb4c7f9f1), C(318dbc24af66dee9), C(10ef7b32d5c719af), + C(91dfdd75)}, + {C(a0f10149a0e538d6), C(69d008c20f87419f), C(41b36376185b3e9e), + C(c87f95de)}, + {C(fb8d9c70660b910b), C(a45b0cc3476bff1b), C(b28d1996144f0207), + C(3f5538ef)}, + {C(236827beae282a46), C(e43970221139c946), C(4f3ac6faa837a3aa), + C(70eb1a1f)}, + {C(c385e435136ecf7c), C(d9d17368ff6c4a08), C(1b31eed4e5251a67), + C(cfd63b83)}, + {C(e3f6828b6017086d), C(21b4d1900554b3b0), C(bef38be1809e24f1), + C(894a52ef)}, + {C(851fff285561dca0), C(4d1277d73cdf416f), C(28ccffa61010ebe2), + C(9cde6a54)}, + {C(61152a63595a96d9), C(d1a3a91ef3a7ba45), C(443b6bb4a493ad0c), + C(6c4898d5)}, + {C(44473e03be306c88), C(30097761f872472a), C(9fd1b669bfad82d7), + C(13e1978e)}, + {C(3ead5f21d344056), C(fb6420393cfb05c3), C(407932394cbbd303), C(51b4ba8)}, + {C(6abbfde37ee03b5b), C(83febf188d2cc113), C(cda7b62d94d5b8ee), + C(b6b06e40)}, + {C(943e7ed63b3c080), C(1ef207e9444ef7f8), C(ef4a9f9f8c6f9b4a), C(240a2f2)}, + {C(d72ce05171ef8a1a), C(c6bd6bd869203894), C(c760e6396455d23a), + C(5dcefc30)}, + {C(4182832b52d63735), C(337097e123eea414), C(b5a72ca0456df910), + C(7a48b105)}, + {C(d6cdae892584a2cb), C(58de0fa4eca17dcd), C(43df30b8f5f1cb00), + C(fd55007b)}, + {C(5c8e90bc267c5ee4), C(e9ae044075d992d9), C(f234cbfd1f0a1e59), + C(6b95894c)}, + {C(bbd7f30ac310a6f3), C(b23b570d2666685f), C(fb13fb08c9814fe7), + C(3360e827)}, + {C(36a097aa49519d97), C(8204380a73c4065), C(77c2004bdd9e276a), C(45177e0b)}, + {C(dc78cb032c49217), C(112464083f83e03a), C(96ae53e28170c0f5), C(7c6fffe4)}, + {C(441593e0da922dfe), C(936ef46061469b32), C(204a1921197ddd87), + C(bbc78da4)}, + {C(2ba3883d71cc2133), C(72f2bbb32bed1a3c), C(27e1bd96d4843251), + C(c5c25d39)}, + {C(f2b6d2adf8423600), C(7514e2f016a48722), C(43045743a50396ba), + C(b6e5d06e)}, + {C(38fffe7f3680d63c), C(d513325255a7a6d1), C(31ed47790f6ca62f), + C(6178504e)}, + {C(b7477bf0b9ce37c6), C(63b1c580a7fd02a4), C(f6433b9f10a5dac), C(bd4c3637)}, + {C(55bdb0e71e3edebd), C(c7ab562bcf0568bc), C(43166332f9ee684f), + C(6e7ac474)}, + {C(782fa1b08b475e7), C(fb7138951c61b23b), C(9829105e234fb11e), C(1fb4b518)}, + {C(c5dc19b876d37a80), C(15ffcff666cfd710), C(e8c30c72003103e2), + C(31d13d6d)}, + {C(5e1141711d2d6706), C(b537f6dee8de6933), C(3af0a1fbbe027c54), + C(26fa72e3)}, + {C(782edf6da001234f), C(f48cbd5c66c48f3), C(808754d1e64e2a32), C(6a7433bf)}, + {C(d26285842ff04d44), C(8f38d71341eacca9), C(5ca436f4db7a883c), + C(4e6df758)}, + {C(c6ab830865a6bae6), C(6aa8e8dd4b98815c), C(efe3846713c371e5), + C(d57f63ea)}, + {C(44b3a1929232892), C(61dca0e914fc217), C(a607cc142096b964), C(52ef73b3)}, + {C(4b603d7932a8de4f), C(fae64c464b8a8f45), C(8fafab75661d602a), C(3cb36c3)}, + {C(4ec0b54cf1566aff), C(30d2c7269b206bf4), C(77c22e82295e1061), + C(72c39bea)}, + {C(ed8b7a4b34954ff7), C(56432de31f4ee757), C(85bd3abaa572b155), + C(a65aa25c)}, + {C(5d28b43694176c26), C(714cc8bc12d060ae), C(3437726273a83fe6), + C(74740539)}, + {C(6a1ef3639e1d202e), C(919bc1bd145ad928), C(30f3f7e48c28a773), + C(c3ae3c26)}, + {C(159f4d9e0307b111), C(3e17914a5675a0c), C(af849bd425047b51), C(f29db8a2)}, + {C(cc0a840725a7e25b), C(57c69454396e193a), C(976eaf7eee0b4540), + C(1ef4cbf4)}, + {C(a2b27ee22f63c3f1), C(9ebde0ce1b3976b2), C(2fe6a92a257af308), + C(a9be6c41)}, + {C(d8f2f234899bcab3), C(b10b037297c3a168), C(debea2c510ceda7f), C(fa31801)}, + {C(584f28543864844f), C(d7cee9fc2d46f20d), C(a38dca5657387205), + C(8331c5d8)}, + {C(a94be46dd9aa41af), C(a57e5b7723d3f9bd), C(34bf845a52fd2f), C(e9876db8)}, + {C(9a87bea227491d20), C(a468657e2b9c43e7), C(af9ba60db8d89ef7), + C(27b0604e)}, + {C(27688c24958d1a5c), C(e3b4a1c9429cf253), C(48a95811f70d64bc), + C(dcec07f2)}, + {C(5d1d37790a1873ad), C(ed9cd4bcc5fa1090), C(ce51cde05d8cd96a), + C(cff0a82a)}, + {C(1f03fd18b711eea9), C(566d89b1946d381a), C(6e96e83fc92563ab), + C(fec83621)}, + {C(f0316f286cf527b6), C(f84c29538de1aa5a), C(7612ed3c923d4a71), C(743d8dc)}, + {C(297008bcb3e3401d), C(61a8e407f82b0c69), C(a4a35bff0524fa0e), + C(64d41d26)}, + {C(43c6252411ee3be), C(b4ca1b8077777168), C(2746dc3f7da1737f), C(acd90c81)}, + {C(ce38a9a54fad6599), C(6d6f4a90b9e8755e), C(c3ecc79ff105de3f), + C(7c746a4b)}, + {C(270a9305fef70cf), C(600193999d884f3a), C(f4d49eae09ed8a1), C(b1047e99)}, + {C(e71be7c28e84d119), C(eb6ace59932736e6), C(70c4397807ba12c5), + C(d1fd1068)}, + {C(b5b58c24b53aaa19), C(d2a6ab0773dd897f), C(ef762fe01ecb5b97), + C(56486077)}, + {C(44dd59bd301995cf), C(3ccabd76493ada1a), C(540db4c87d55ef23), + C(6069be80)}, + {C(b4d4789eb6f2630b), C(bf6973263ce8ef0e), C(d1c75c50844b9d3), C(2078359b)}, + {C(12807833c463737c), C(58e927ea3b3776b4), C(72dd20ef1c2f8ad0), + C(9ea21004)}, + {C(e88419922b87176f), C(bcf32f41a7ddbf6f), C(d6ebefd8085c1a0f), + C(9c9cfe88)}, + {C(105191e0ec8f7f60), C(5918dbfcca971e79), C(6b285c8a944767b9), + C(b70a6ddd)}, + {C(a5b88bf7399a9f07), C(fca3ddfd96461cc4), C(ebe738fdc0282fc6), + C(dea37298)}, + {C(d08c3f5747d84f50), C(4e708b27d1b6f8ac), C(70f70fd734888606), + C(8f480819)}, + {C(2f72d12a40044b4b), C(889689352fec53de), C(f03e6ad87eb2f36), C(30b3b16)}, + {C(aa1f61fdc5c2e11e), C(c2c56cd11277ab27), C(a1e73069fdf1f94f), + C(f31bc4e8)}, + {C(9489b36fe2246244), C(3355367033be74b8), C(5f57c2277cbce516), + C(419f953b)}, + {C(358d7c0476a044cd), C(e0b7b47bcbd8854f), C(ffb42ec696705519), + C(20e9e76d)}, + {C(b0c48df14275265a), C(9da4448975905efa), C(d716618e414ceb6d), + C(646f0ff8)}, + {C(daa70bb300956588), C(410ea6883a240c6d), C(f5c8239fb5673eb3), + C(eeb7eca8)}, + {C(4ec97a20b6c4c7c2), C(5913b1cd454f29fd), C(a9629f9daf06d685), C(8112bb9)}, + {C(5c3323628435a2e8), C(1bea45ce9e72a6e3), C(904f0a7027ddb52e), + C(85a6d477)}, + {C(c1ef26bea260abdb), C(6ee423f2137f9280), C(df2118b946ed0b43), + C(56f76c84)}, + {C(6be7381b115d653a), C(ed046190758ea511), C(de6a45ffc3ed1159), + C(9af45d55)}, + {C(ae3eece1711b2105), C(14fd3f4027f81a4a), C(abb7e45177d151db), + C(d1c33760)}, + {C(376c28588b8fb389), C(6b045e84d8491ed2), C(4e857effb7d4e7dc), + C(c56bbf69)}, + {C(58d943503bb6748f), C(419c6c8e88ac70f6), C(586760cbf3d3d368), + C(abecfb9b)}, + {C(dfff5989f5cfd9a1), C(bcee2e7ea3a96f83), C(681c7874adb29017), + C(8de13255)}, + {C(7fb19eb1a496e8f5), C(d49e5dfdb5c0833f), C(c0d5d7b2f7c48dc7), + C(a98ee299)}, + {C(5dba5b0dadccdbaa), C(4ba8da8ded87fcdc), C(f693fdd25badf2f0), + C(3015f556)}, + {C(688bef4b135a6829), C(8d31d82abcd54e8e), C(f95f8a30d55036d7), + C(5a430e29)}, + {C(d8323be05433a412), C(8d48fa2b2b76141d), C(3d346f23978336a5), + C(2797add0)}, + {C(3b5404278a55a7fc), C(23ca0b327c2d0a81), C(a6d65329571c892c), + C(27d55016)}, + {C(2a96a3f96c5e9bbc), C(8caf8566e212dda8), C(904de559ca16e45e), + C(84945a82)}, + {C(22bebfdcc26d18ff), C(4b4d8dcb10807ba1), C(40265eee30c6b896), + C(3ef7e224)}, + {C(627a2249ec6bbcc2), C(c0578b462a46735a), C(4974b8ee1c2d4f1f), + C(35ed8dc8)}, + {C(3abaf1667ba2f3e0), C(ee78476b5eeadc1), C(7e56ac0a6ca4f3f4), C(6a75e43d)}, + {C(3931ac68c5f1b2c9), C(efe3892363ab0fb0), C(40b707268337cd36), + C(235d9805)}, + {C(b98fb0606f416754), C(46a6e5547ba99c1e), C(c909d82112a8ed2), C(f7d69572)}, + {C(7f7729a33e58fcc4), C(2e4bc1e7a023ead4), C(e707008ea7ca6222), + C(bacd0199)}, + {C(42a0aa9ce82848b3), C(57232730e6bee175), C(f89bb3f370782031), + C(e428f50e)}, + {C(6b2c6d38408a4889), C(de3ef6f68fb25885), C(20754f456c203361), + C(81eaaad3)}, + {C(930380a3741e862a), C(348d28638dc71658), C(89dedcfd1654ea0d), + C(addbd3e3)}, + {C(94808b5d2aa25f9a), C(cec72968128195e0), C(d9f4da2bdc1e130f), + C(e66dbca0)}, + {C(b31abb08ae6e3d38), C(9eb9a95cbd9e8223), C(8019e79b7ee94ea9), + C(afe11fd5)}, + {C(dccb5534a893ea1a), C(ce71c398708c6131), C(fe2396315457c164), + C(a71a406f)}, + {C(6369163565814de6), C(8feb86fb38d08c2f), C(4976933485cc9a20), + C(9d90eaf5)}, + {C(edee4ff253d9f9b3), C(96ef76fb279ef0ad), C(a4d204d179db2460), + C(6665db10)}, + {C(941993df6e633214), C(929bc1beca5b72c6), C(141fc52b8d55572d), + C(9c977cbf)}, + {C(859838293f64cd4c), C(484403b39d44ad79), C(bf674e64d64b9339), + C(ee83ddd4)}, + {C(c19b5648e0d9f555), C(328e47b2b7562993), C(e756b92ba4bd6a51), C(26519cc)}, + {C(f963b63b9006c248), C(9e9bf727ffaa00bc), C(c73bacc75b917e3a), + C(a485a53f)}, + {C(6a8aa0852a8c1f3b), C(c8f1e5e206a21016), C(2aa554aed1ebb524), + C(f62bc412)}, + {C(740428b4d45e5fb8), C(4c95a4ce922cb0a5), C(e99c3ba78feae796), + C(8975a436)}, + {C(658b883b3a872b86), C(2f0e303f0f64827a), C(975337e23dc45e1), C(94ff7f41)}, + {C(6df0a977da5d27d4), C(891dd0e7cb19508), C(fd65434a0b71e680), C(760aa031)}, + {C(a900275464ae07ef), C(11f2cfda34beb4a3), C(9abf91e5a1c38e4), C(3bda76df)}, + {C(810bc8aa0c40bcb0), C(448a019568d01441), C(f60ec52f60d3aeae), + C(498e2e65)}, + {C(22036327deb59ed7), C(adc05ceb97026a02), C(48bff0654262672b), + C(d38deb48)}, + {C(7d14dfa9772b00c8), C(595735efc7eeaed7), C(29872854f94c3507), + C(82b3fb6b)}, + {C(2d777cddb912675d), C(278d7b10722a13f9), C(f5c02bfb7cc078af), + C(e500e25f)}, + {C(f2ec98824e8aa613), C(5eb7e3fb53fe3bed), C(12c22860466e1dd4), + C(bd2bb07c)}, + {C(5e763988e21f487f), C(24189de8065d8dc5), C(d1519d2403b62aa0), + C(3a2b431d)}, + {C(48949dc327bb96ad), C(e1fd21636c5c50b4), C(3f6eb7f13a8712b4), + C(7322a83d)}, + {C(b7c4209fb24a85c5), C(b35feb319c79ce10), C(f0d3de191833b922), + C(a645ca1c)}, + {C(9c9e5be0943d4b05), C(b73dc69e45201cbb), C(aab17180bfe5083d), + C(8909a45a)}, + {C(3898bca4dfd6638d), C(f911ff35efef0167), C(24bdf69e5091fc88), + C(bd30074c)}, + {C(5b5d2557400e68e7), C(98d610033574cee), C(dfd08772ce385deb), C(c17cf001)}, + {C(a927ed8b2bf09bb6), C(606e52f10ae94eca), C(71c2203feb35a9ee), + C(26ffd25a)}, + {C(8d25746414aedf28), C(34b1629d28b33d3a), C(4d5394aea5f82d7b), + C(f1d8ce3c)}, + {C(b5bbdb73458712f2), C(1ff887b3c2a35137), C(7f7231f702d0ace9), + C(3ee8fb17)}, + {C(3d32a26e3ab9d254), C(fc4070574dc30d3a), C(f02629579c2b27c9), + C(a77acc2a)}, + {C(9371d3c35fa5e9a5), C(42967cf4d01f30), C(652d1eeae704145c), C(f4556dee)}, + {C(cbaa3cb8f64f54e0), C(76c3b48ee5c08417), C(9f7d24e87e61ce9), C(de287a64)}, + {C(b2e23e8116c2ba9f), C(7e4d9c0060101151), C(3310da5e5028f367), + C(878e55b9)}, + {C(8aa77f52d7868eb9), C(4d55bd587584e6e2), C(d2db37041f495f5), C(7648486)}, + {C(858fea922c7fe0c3), C(cfe8326bf733bc6f), C(4e5e2018cf8f7dfc), + C(57ac0fb1)}, + {C(46ef25fdec8392b1), C(e48d7b6d42a5cd35), C(56a6fe1c175299ca), + C(d01967ca)}, + {C(8d078f726b2df464), C(b50ee71cdcabb299), C(f4af300106f9c7ba), + C(96ecdf74)}, + {C(35ea86e6960ca950), C(34fe1fe234fc5c76), C(a00207a3dc2a72b7), + C(779f5506)}, + {C(8aee9edbc15dd011), C(51f5839dc8462695), C(b2213e17c37dca2d), + C(3c94c2de)}, + {C(c3e142ba98432dda), C(911d060cab126188), C(b753fbfa8365b844), + C(39f98faf)}, + {C(123ba6b99c8cd8db), C(448e582672ee07c4), C(cebe379292db9e65), + C(7af31199)}, + {C(ba87acef79d14f53), C(b3e0fcae63a11558), C(d5ac313a593a9f45), + C(e341a9d6)}, + {C(bcd3957d5717dc3), C(2da746741b03a007), C(873816f4b1ece472), C(ca24aeeb)}, + {C(61442ff55609168e), C(6447c5fc76e8c9cf), C(6a846de83ae15728), + C(b2252b57)}, + {C(dbe4b1b2d174757f), C(506512da18712656), C(6857f3e0b8dd95f), C(72c81da1)}, + {C(531e8e77b363161c), C(eece0b43e2dae030), C(8294b82c78f34ed1), + C(6b9fce95)}, + {C(f71e9c926d711e2b), C(d77af2853a4ceaa1), C(9aa0d6d76a36fae7), + C(19399857)}, + {C(cb20ac28f52df368), C(e6705ee7880996de), C(9b665cc3ec6972f2), + C(3c57a994)}, + {C(e4a794b4acb94b55), C(89795358057b661b), C(9c4cdcec176d7a70), + C(c053e729)}, + {C(cb942e91443e7208), C(e335de8125567c2a), C(d4d74d268b86df1f), + C(51cbbba7)}, + {C(ecca7563c203f7ba), C(177ae2423ef34bb2), C(f60b7243400c5731), + C(1acde79a)}, + {C(1652cb940177c8b5), C(8c4fe7d85d2a6d6d), C(f6216ad097e54e72), + C(2d160d13)}, + {C(31fed0fc04c13ce8), C(3d5d03dbf7ff240a), C(727c5c9b51581203), + C(787f5801)}, + {C(e7b668947590b9b3), C(baa41ad32938d3fa), C(abcbc8d4ca4b39e4), + C(c9629828)}, + {C(1de2119923e8ef3c), C(6ab27c096cf2fe14), C(8c3658edca958891), + C(be139231)}, + {C(1269df1e69e14fa7), C(992f9d58ac5041b7), C(e97fcf695a7cbbb4), + C(7df699ef)}, + {C(820826d7aba567ff), C(1f73d28e036a52f3), C(41c4c5a73f3b0893), + C(8ce6b96d)}, + {C(ffe0547e4923cef9), C(3534ed49b9da5b02), C(548a273700fba03d), + C(6f9ed99c)}, + {C(72da8d1b11d8bc8b), C(ba94b56b91b681c6), C(4e8cc51bd9b0fc8c), + C(e0244796)}, + {C(d62ab4e3f88fc797), C(ea86c7aeb6283ae4), C(b5b93e09a7fe465), C(4ccf7e75)}, + {C(d0f06c28c7b36823), C(1008cb0874de4bb8), C(d6c7ff816c7a737b), + C(915cef86)}, + {C(99b7042460d72ec6), C(2a53e5e2b8e795c2), C(53a78132d9e1b3e3), + C(5cb59482)}, + {C(4f4dfcfc0ec2bae5), C(841233148268a1b8), C(9248a76ab8be0d3), C(6ca3f532)}, + {C(fe86bf9d4422b9ae), C(ebce89c90641ef9c), C(1c84e2292c0b5659), + C(e24f3859)}, + {C(a90d81060932dbb0), C(8acfaa88c5fbe92b), C(7c6f3447e90f7f3f), + C(adf5a9c7)}, + {C(17938a1b0e7f5952), C(22cadd2f56f8a4be), C(84b0d1183d5ed7c1), + C(32264b75)}, + {C(de9e0cb0e16f6e6d), C(238e6283aa4f6594), C(4fb9c914c2f0a13b), + C(a64b3376)}, + {C(6d4b876d9b146d1a), C(aab2d64ce8f26739), C(d315f93600e83fe5), C(d33890e)}, + {C(e698fa3f54e6ea22), C(bd28e20e7455358c), C(9ace161f6ea76e66), + C(926d4b63)}, + {C(7bc0deed4fb349f7), C(1771aff25dc722fa), C(19ff0644d9681917), + C(d51ba539)}, + {C(db4b15e88533f622), C(256d6d2419b41ce9), C(9d7c5378396765d5), + C(7f37636d)}, + {C(922834735e86ecb2), C(363382685b88328e), C(e9c92960d7144630), + C(b98026c0)}, + {C(30f1d72c812f1eb8), C(b567cd4a69cd8989), C(820b6c992a51f0bc), + C(b877767e)}, + {C(168884267f3817e9), C(5b376e050f637645), C(1c18314abd34497a), C(aefae77)}, + {C(82e78596ee3e56a7), C(25697d9c87f30d98), C(7600a8342834924d), C(f686911)}, + {C(aa2d6cf22e3cc252), C(9b4dec4f5e179f16), C(76fb0fba1d99a99a), + C(3deadf12)}, + {C(7bf5ffd7f69385c7), C(fc077b1d8bc82879), C(9c04e36f9ed83a24), + C(ccf02a4e)}, + {C(e89c8ff9f9c6e34b), C(f54c0f669a49f6c4), C(fc3e46f5d846adef), + C(176c1722)}, + {C(a18fbcdccd11e1f4), C(8248216751dfd65e), C(40c089f208d89d7c), C(26f82ad)}, + {C(2d54f40cc4088b17), C(59d15633b0cd1399), C(a8cc04bb1bffd15b), + C(b5244f42)}, + {C(69276946cb4e87c7), C(62bdbe6183be6fa9), C(3ba9773dac442a1a), + C(49a689e5)}, + {C(668174a3f443df1d), C(407299392da1ce86), C(c2a3f7d7f2c5be28), C(59fcdd3)}, + {C(5e29be847bd5046), C(b561c7f19c8f80c3), C(5e5abd5021ccaeaf), C(4f4b04e9)}, + {C(cd0d79f2164da014), C(4c386bb5c5d6ca0c), C(8e771b03647c3b63), + C(8b00f891)}, + {C(e0e6fc0b1628af1d), C(29be5fb4c27a2949), C(1c3f781a604d3630), + C(16e114f3)}, + {C(2058927664adfd93), C(6e8f968c7963baa5), C(af3dced6fff7c394), + C(d6b6dadc)}, + {C(dc107285fd8e1af7), C(a8641a0609321f3f), C(db06e89ffdc54466), + C(897e20ac)}, + {C(fbba1afe2e3280f1), C(755a5f392f07fce), C(9e44a9a15402809a), C(f996e05d)}, + {C(bfa10785ddc1011b), C(b6e1c4d2f670f7de), C(517d95604e4fcc1f), + C(c4306af6)}, + {C(534cc35f0ee1eb4e), C(b703820f1f3b3dce), C(884aa164cf22363), C(6dcad433)}, + {C(7ca6e3933995dac), C(fd118c77daa8188), C(3aceb7b5e7da6545), C(3c07374d)}, + {C(f0d6044f6efd7598), C(e044d6ba4369856e), C(91968e4f8c8a1a4c), + C(f0f4602c)}, + {C(3d69e52049879d61), C(76610636ea9f74fe), C(e9bf5602f89310c0), + C(3e1ea071)}, + {C(79da242a16acae31), C(183c5f438e29d40), C(6d351710ae92f3de), C(67580f0c)}, + {C(461c82656a74fb57), C(d84b491b275aa0f7), C(8f262cb29a6eb8b2), + C(4e109454)}, + {C(53c1a66d0b13003), C(731f060e6fe797fc), C(daa56811791371e3), C(88a474a7)}, + {C(d3a2efec0f047e9), C(1cabce58853e58ea), C(7a17b2eae3256be4), C(5b5bedd)}, + {C(43c64d7484f7f9b2), C(5da002b64aafaeb7), C(b576c1e45800a716), + C(1aaddfa7)}, + {C(a7dec6ad81cf7fa1), C(180c1ab708683063), C(95e0fd7008d67cff), + C(5be07fd8)}, + {C(5408a1df99d4aff), C(b9565e588740f6bd), C(abf241813b08006e), C(cbca8606)}, + {C(a8b27a6bcaeeed4b), C(aec1eeded6a87e39), C(9daf246d6fed8326), + C(bde64d01)}, + {C(9a952a8246fdc269), C(d0dcfcac74ef278c), C(250f7139836f0f1f), + C(ee90cf33)}, + {C(c930841d1d88684f), C(5eb66eb18b7f9672), C(e455d413008a2546), + C(4305c3ce)}, + {C(94dc6971e3cf071a), C(994c7003b73b2b34), C(ea16e85978694e5), C(4b3a1d76)}, + {C(7fc98006e25cac9), C(77fee0484cda86a7), C(376ec3d447060456), C(a8bb6d80)}, + {C(bd781c4454103f6), C(612197322f49c931), C(b9cf17fd7e5462d5), C(1f9fa607)}, + {C(da60e6b14479f9df), C(3bdccf69ece16792), C(18ebf45c4fecfdc9), + C(8d0e4ed2)}, + {C(4ca56a348b6c4d3), C(60618537c3872514), C(2fbb9f0e65871b09), C(1bf31347)}, + {C(ebd22d4b70946401), C(6863602bf7139017), C(c0b1ac4e11b00666), + C(1ae3fc5b)}, + {C(3cc4693d6cbcb0c), C(501689ea1c70ffa), C(10a4353e9c89e364), C(459c3930)}, + {C(38908e43f7ba5ef0), C(1ab035d4e7781e76), C(41d133e8c0a68ff7), + C(e00c4184)}, + {C(34983ccc6aa40205), C(21802cad34e72bc4), C(1943e8fb3c17bb8), C(ffc7a781)}, + {C(86215c45dcac9905), C(ea546afe851cae4b), C(d85b6457e489e374), + C(6a125480)}, + {C(420fc255c38db175), C(d503cd0f3c1208d1), C(d4684e74c825a0bc), + C(88a1512b)}, + {C(1d7a31f5bc8fe2f9), C(4763991092dcf836), C(ed695f55b97416f4), + C(549bbbe5)}, + {C(94129a84c376a26e), C(c245e859dc231933), C(1b8f74fecf917453), + C(c133d38c)}, + {C(1d3a9809dab05c8d), C(adddeb4f71c93e8), C(ef342eb36631edb), C(fcace348)}, + {C(90fa3ccbd60848da), C(dfa6e0595b569e11), C(e585d067a1f5135d), + C(ed7b6f9a)}, + {C(2dbb4fc71b554514), C(9650e04b86be0f82), C(60f2304fba9274d3), + C(6d907dda)}, + {C(b98bf4274d18374a), C(1b669fd4c7f9a19a), C(b1f5972b88ba2b7a), + C(7a4d48d5)}, + {C(d6781d0b5e18eb68), C(b992913cae09b533), C(58f6021caaee3a40), + C(e686f3db)}, + {C(226651cf18f4884c), C(595052a874f0f51c), C(c9b75162b23bab42), C(cce7c55)}, + {C(a734fb047d3162d6), C(e523170d240ba3a5), C(125a6972809730e8), C(f58b96b)}, + {C(c6df6364a24f75a3), C(c294e2c84c4f5df8), C(a88df65c6a89313b), + C(1bbf6f60)}, + {C(d8d1364c1fbcd10), C(2d7cc7f54832deaa), C(4e22c876a7c57625), C(ce5e0cc2)}, + {C(aae06f9146db885f), C(3598736441e280d9), C(fba339b117083e55), + C(584cfd6f)}, + {C(8955ef07631e3bcc), C(7d70965ea3926f83), C(39aed4134f8b2db6), + C(8f9bbc33)}, + {C(ad611c609cfbe412), C(d3c00b18bf253877), C(90b2172e1f3d0bfd), + C(d7640d95)}, + {C(d5339adc295d5d69), C(b633cc1dcb8b586a), C(ee84184cf5b1aeaf), C(3d12a2b)}, + {C(40d0aeff521375a8), C(77ba1ad7ecebd506), C(547c6f1a7d9df427), + C(aaeafed0)}, + {C(8b2d54ae1a3df769), C(11e7adaee3216679), C(3483781efc563e03), + C(95b9b814)}, + {C(99c175819b4eae28), C(932e8ff9f7a40043), C(ec78dcab07ca9f7c), + C(45fbe66e)}, + {C(2a418335779b82fc), C(af0295987849a76b), C(c12bc5ff0213f46e), + C(b4baa7a8)}, + {C(3b1fc6a3d279e67d), C(70ea1e49c226396), C(25505adcf104697c), C(83e962fe)}, + {C(d97eacdf10f1c3c9), C(b54f4654043a36e0), C(b128f6eb09d1234), C(aac3531c)}, + {C(293a5c1c4e203cd4), C(6b3329f1c130cefe), C(f2e32f8ec76aac91), + C(2b1db7cc)}, + {C(4290e018ffaedde7), C(a14948545418eb5e), C(72d851b202284636), + C(cf00cd31)}, + {C(f919a59cbde8bf2f), C(a56d04203b2dc5a5), C(38b06753ac871e48), + C(7d3c43b8)}, + {C(1d70a3f5521d7fa4), C(fb97b3fdc5891965), C(299d49bbbe3535af), + C(cbd5fac6)}, + {C(6af98d7b656d0d7c), C(d2e99ae96d6b5c0c), C(f63bd1603ef80627), + C(76d0fec4)}, + {C(395b7a8adb96ab75), C(582df7165b20f4a), C(e52bd30e9ff657f9), C(405e3402)}, + {C(3822dd82c7df012f), C(b9029b40bd9f122b), C(fd25b988468266c4), + C(c732c481)}, + {C(79f7efe4a80b951a), C(dd3a3fddfc6c9c41), C(ab4c812f9e27aa40), + C(a8d123c9)}, + {C(ae6e59f5f055921a), C(e9d9b7bf68e82), C(5ce4e4a5b269cc59), C(1e80ad7d)}, + {C(8959dbbf07387d36), C(b4658afce48ea35d), C(8f3f82437d8cb8d6), + C(52aeb863)}, + {C(4739613234278a49), C(99ea5bcd340bf663), C(258640912e712b12), + C(ef7c0c18)}, + {C(420e6c926bc54841), C(96dbbf6f4e7c75cd), C(d8d40fa70c3c67bb), + C(b6ad4b68)}, + {C(c8601bab561bc1b7), C(72b26272a0ff869a), C(56fdfc986d6bc3c4), + C(c1e46b17)}, + {C(b2d294931a0e20eb), C(284ffd9a0815bc38), C(1f8a103aac9bbe6), C(57b8df25)}, + {C(7966f53c37b6c6d7), C(8e6abcfb3aa2b88f), C(7f2e5e0724e5f345), + C(e9fa36d6)}, + {C(be9bb0abd03b7368), C(13bca93a3031be55), C(e864f4f52b55b472), + C(8f8daefc)}, + {C(a08d128c5f1649be), C(a8166c3dbbe19aad), C(cb9f914f829ec62c), C(6e1bb7e)}, + {C(7c386f0ffe0465ac), C(530419c9d843dbf3), C(7450e3a4f72b8d8c), + C(fd0076f0)}, + {C(bb362094e7ef4f8), C(ff3c2a48966f9725), C(55152803acd4a7fe), C(899b17b6)}, + {C(cd80dea24321eea4), C(52b4fdc8130c2b15), C(f3ea100b154bfb82), + C(e3e84e31)}, + {C(d599a04125372c3a), C(313136c56a56f363), C(1e993c3677625832), + C(eef79b6b)}, + {C(dbbf541e9dfda0a), C(1479fceb6db4f844), C(31ab576b59062534), C(868e3315)}, + {C(c2ee3288be4fe2bf), C(c65d2f5ddf32b92), C(af6ecdf121ba5485), C(4639a426)}, + {C(d86603ced1ed4730), C(f9de718aaada7709), C(db8b9755194c6535), + C(f3213646)}, + {C(915263c671b28809), C(a815378e7ad762fd), C(abec6dc9b669f559), + C(17f148e9)}, + {C(2b67cdd38c307a5e), C(cb1d45bb5c9fe1c), C(800baf2a02ec18ad), C(bfd94880)}, + {C(2d107419073b9cd0), C(a96db0740cef8f54), C(ec41ee91b3ecdc1b), + C(bb1fa7f3)}, + {C(f3e9487ec0e26dfc), C(1ab1f63224e837fa), C(119983bb5a8125d8), C(88816b1)}, + {C(1160987c8fe86f7d), C(879e6db1481eb91b), C(d7dcb802bfe6885d), + C(5c2faeb3)}, + {C(eab8112c560b967b), C(97f550b58e89dbae), C(846ed506d304051f), + C(51b5fc6f)}, + {C(1addcf0386d35351), C(b5f436561f8f1484), C(85d38e22181c9bb1), + C(33d94752)}, + {C(d445ba84bf803e09), C(1216c2497038f804), C(2293216ea2237207), + C(b0c92948)}, + {C(37235a096a8be435), C(d9b73130493589c2), C(3b1024f59378d3be), + C(c7171590)}, + {C(763ad6ea2fe1c99d), C(cf7af5368ac1e26b), C(4d5e451b3bb8d3d4), + C(240a67fb)}, + {C(ea627fc84cd1b857), C(85e372494520071f), C(69ec61800845780b), + C(e1843cd5)}, + {C(1f2ffd79f2cdc0c8), C(726a1bc31b337aaa), C(678b7f275ef96434), + C(fda1452b)}, + {C(39a9e146ec4b3210), C(f63f75802a78b1ac), C(e2e22539c94741c3), + C(a2cad330)}, + {C(74cba303e2dd9d6d), C(692699b83289fad1), C(dfb9aa7874678480), + C(53467e16)}, + {C(4cbc2b73a43071e0), C(56c5db4c4ca4e0b7), C(1b275a162f46bd3d), + C(da14a8d0)}, + {C(875638b9715d2221), C(d9ba0615c0c58740), C(616d4be2dfe825aa), + C(67333551)}, + {C(fb686b2782994a8d), C(edee60693756bb48), C(e6bc3cae0ded2ef5), + C(a0ebd66e)}, + {C(ab21d81a911e6723), C(4c31b07354852f59), C(835da384c9384744), + C(4b769593)}, + {C(33d013cc0cd46ecf), C(3de726423aea122c), C(116af51117fe21a9), + C(6aa75624)}, + {C(8ca92c7cd39fae5d), C(317e620e1bf20f1), C(4f0b33bf2194b97f), C(602a3f96)}, + {C(fdde3b03f018f43e), C(38f932946c78660), C(c84084ce946851ee), C(cd183c4d)}, + {C(9c8502050e9c9458), C(d6d2a1a69964beb9), C(1675766f480229b5), + C(960a4d07)}, + {C(348176ca2fa2fdd2), C(3a89c514cc360c2d), C(9f90b8afb318d6d0), + C(9ae998c4)}, + {C(4a3d3dfbbaea130b), C(4e221c920f61ed01), C(553fd6cd1304531f), + C(74e2179d)}, + {C(b371f768cdf4edb9), C(bdef2ace6d2de0f0), C(e05b4100f7f1baec), + C(ee9bae25)}, + {C(7a1d2e96934f61f), C(eb1760ae6af7d961), C(887eb0da063005df), C(b66edf10)}, + {C(8be53d466d4728f2), C(86a5ac8e0d416640), C(984aa464cdb5c8bb), + C(d6209737)}, + {C(829677eb03abf042), C(43cad004b6bc2c0), C(f2f224756803971a), C(b994a88)}, + {C(754435bae3496fc), C(5707fc006f094dcf), C(8951c86ab19d8e40), C(a05d43c0)}, + {C(fda9877ea8e3805f), C(31e868b6ffd521b7), C(b08c90681fb6a0fd), + C(c79f73a8)}, + {C(2e36f523ca8f5eb5), C(8b22932f89b27513), C(331cd6ecbfadc1bb), + C(a490aff5)}, + {C(21a378ef76828208), C(a5c13037fa841da2), C(506d22a53fbe9812), + C(dfad65b4)}, + {C(ccdd5600054b16ca), C(f78846e84204cb7b), C(1f9faec82c24eac9), C(1d07dfb)}, + {C(7854468f4e0cabd0), C(3a3f6b4f098d0692), C(ae2423ec7799d30d), + C(416df9a0)}, + {C(7f88db5346d8f997), C(88eac9aacc653798), C(68a4d0295f8eefa1), + C(1f8fb9cc)}, + {C(bb3fb5fb01d60fcf), C(1b7cc0847a215eb6), C(1246c994437990a1), + C(7abf48e3)}, + {C(2e783e1761acd84d), C(39158042bac975a0), C(1cd21c5a8071188d), + C(dea4e3dd)}, + {C(392058251cf22acc), C(944ec4475ead4620), C(b330a10b5cb94166), + C(c6064f22)}, + {C(adf5c1e5d6419947), C(2a9747bc659d28aa), C(95c5b8cb1f5d62c), C(743bed9c)}, + {C(6bc1db2c2bee5aba), C(e63b0ed635307398), C(7b2eca111f30dbbc), + C(fce254d5)}, + {C(b00f898229efa508), C(83b7590ad7f6985c), C(2780e70a0592e41d), + C(e47ec9d1)}, + {C(b56eb769ce0d9a8c), C(ce196117bfbcaf04), C(b26c3c3797d66165), + C(334a145c)}, + {C(70c0637675b94150), C(259e1669305b0a15), C(46e1dd9fd387a58d), + C(adec1e3c)}, + {C(74c0b8a6821faafe), C(abac39d7491370e7), C(faf0b2a48a4e6aed), + C(f6a9fbf8)}, + {C(5fb5e48ac7b7fa4f), C(a96170f08f5acbc7), C(bbf5c63d4f52a1e5), + C(5398210c)}, +}; + +void TestUnchanging(const uint64_t* expected, int offset, int len) { + EXPECT_EQ(expected[0], CityHash64(data + offset, len)); + EXPECT_EQ(expected[3], CityHash32(data + offset, len)); + EXPECT_EQ(expected[1], CityHash64WithSeed(data + offset, len, kSeed0)); + EXPECT_EQ(expected[2], + CityHash64WithSeeds(data + offset, len, kSeed0, kSeed1)); +} + +TEST(CityHashTest, Unchanging) { + setup(); + int i = 0; + for (; i < kTestSize - 1; i++) { + TestUnchanging(testdata[i], i * i, i); + } + TestUnchanging(testdata[i], 0, kDataSize); +} + +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/hash/internal/hash.cc b/third_party/abseil_cpp/absl/hash/internal/hash.cc new file mode 100644 index 0000000000..b44ecb3a6b --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/hash.cc @@ -0,0 +1,55 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/hash/internal/hash.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { + +uint64_t CityHashState::CombineLargeContiguousImpl32(uint64_t state, + const unsigned char* first, + size_t len) { + while (len >= PiecewiseChunkSize()) { + state = + Mix(state, absl::hash_internal::CityHash32(reinterpret_cast<const char*>(first), + PiecewiseChunkSize())); + len -= PiecewiseChunkSize(); + first += PiecewiseChunkSize(); + } + // Handle the remainder. + return CombineContiguousImpl(state, first, len, + std::integral_constant<int, 4>{}); +} + +uint64_t CityHashState::CombineLargeContiguousImpl64(uint64_t state, + const unsigned char* first, + size_t len) { + while (len >= PiecewiseChunkSize()) { + state = + Mix(state, absl::hash_internal::CityHash64(reinterpret_cast<const char*>(first), + PiecewiseChunkSize())); + len -= PiecewiseChunkSize(); + first += PiecewiseChunkSize(); + } + // Handle the remainder. + return CombineContiguousImpl(state, first, len, + std::integral_constant<int, 8>{}); +} + +ABSL_CONST_INIT const void* const CityHashState::kSeed = &kSeed; + +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/hash/internal/hash.h b/third_party/abseil_cpp/absl/hash/internal/hash.h new file mode 100644 index 0000000000..9e608f7c3c --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/hash.h @@ -0,0 +1,996 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: hash.h +// ----------------------------------------------------------------------------- +// +#ifndef ABSL_HASH_INTERNAL_HASH_H_ +#define ABSL_HASH_INTERNAL_HASH_H_ + +#include <algorithm> +#include <array> +#include <cmath> +#include <cstring> +#include <deque> +#include <forward_list> +#include <functional> +#include <iterator> +#include <limits> +#include <list> +#include <map> +#include <memory> +#include <set> +#include <string> +#include <tuple> +#include <type_traits> +#include <utility> +#include <vector> + +#include "absl/base/internal/endian.h" +#include "absl/base/port.h" +#include "absl/container/fixed_array.h" +#include "absl/meta/type_traits.h" +#include "absl/numeric/int128.h" +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" +#include "absl/types/variant.h" +#include "absl/utility/utility.h" +#include "absl/hash/internal/city.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { + +// Internal detail: Large buffers are hashed in smaller chunks. This function +// returns the size of these chunks. +constexpr size_t PiecewiseChunkSize() { return 1024; } + +// PiecewiseCombiner +// +// PiecewiseCombiner is an internal-only helper class for hashing a piecewise +// buffer of `char` or `unsigned char` as though it were contiguous. This class +// provides two methods: +// +// H add_buffer(state, data, size) +// H finalize(state) +// +// `add_buffer` can be called zero or more times, followed by a single call to +// `finalize`. This will produce the same hash expansion as concatenating each +// buffer piece into a single contiguous buffer, and passing this to +// `H::combine_contiguous`. +// +// Example usage: +// PiecewiseCombiner combiner; +// for (const auto& piece : pieces) { +// state = combiner.add_buffer(std::move(state), piece.data, piece.size); +// } +// return combiner.finalize(std::move(state)); +class PiecewiseCombiner { + public: + PiecewiseCombiner() : position_(0) {} + PiecewiseCombiner(const PiecewiseCombiner&) = delete; + PiecewiseCombiner& operator=(const PiecewiseCombiner&) = delete; + + // PiecewiseCombiner::add_buffer() + // + // Appends the given range of bytes to the sequence to be hashed, which may + // modify the provided hash state. + template <typename H> + H add_buffer(H state, const unsigned char* data, size_t size); + template <typename H> + H add_buffer(H state, const char* data, size_t size) { + return add_buffer(std::move(state), + reinterpret_cast<const unsigned char*>(data), size); + } + + // PiecewiseCombiner::finalize() + // + // Finishes combining the hash sequence, which may may modify the provided + // hash state. + // + // Once finalize() is called, add_buffer() may no longer be called. The + // resulting hash state will be the same as if the pieces passed to + // add_buffer() were concatenated into a single flat buffer, and then provided + // to H::combine_contiguous(). + template <typename H> + H finalize(H state); + + private: + unsigned char buf_[PiecewiseChunkSize()]; + size_t position_; +}; + +// HashStateBase +// +// A hash state object represents an intermediate state in the computation +// of an unspecified hash algorithm. `HashStateBase` provides a CRTP style +// base class for hash state implementations. Developers adding type support +// for `absl::Hash` should not rely on any parts of the state object other than +// the following member functions: +// +// * HashStateBase::combine() +// * HashStateBase::combine_contiguous() +// +// A derived hash state class of type `H` must provide a static member function +// with a signature similar to the following: +// +// `static H combine_contiguous(H state, const unsigned char*, size_t)`. +// +// `HashStateBase` will provide a complete implementation for a hash state +// object in terms of this method. +// +// Example: +// +// // Use CRTP to define your derived class. +// struct MyHashState : HashStateBase<MyHashState> { +// static H combine_contiguous(H state, const unsigned char*, size_t); +// using MyHashState::HashStateBase::combine; +// using MyHashState::HashStateBase::combine_contiguous; +// }; +template <typename H> +class HashStateBase { + public: + // HashStateBase::combine() + // + // Combines an arbitrary number of values into a hash state, returning the + // updated state. + // + // Each of the value types `T` must be separately hashable by the Abseil + // hashing framework. + // + // NOTE: + // + // state = H::combine(std::move(state), value1, value2, value3); + // + // is guaranteed to produce the same hash expansion as: + // + // state = H::combine(std::move(state), value1); + // state = H::combine(std::move(state), value2); + // state = H::combine(std::move(state), value3); + template <typename T, typename... Ts> + static H combine(H state, const T& value, const Ts&... values); + static H combine(H state) { return state; } + + // HashStateBase::combine_contiguous() + // + // Combines a contiguous array of `size` elements into a hash state, returning + // the updated state. + // + // NOTE: + // + // state = H::combine_contiguous(std::move(state), data, size); + // + // is NOT guaranteed to produce the same hash expansion as a for-loop (it may + // perform internal optimizations). If you need this guarantee, use the + // for-loop instead. + template <typename T> + static H combine_contiguous(H state, const T* data, size_t size); + + using AbslInternalPiecewiseCombiner = PiecewiseCombiner; +}; + +// is_uniquely_represented +// +// `is_uniquely_represented<T>` is a trait class that indicates whether `T` +// is uniquely represented. +// +// A type is "uniquely represented" if two equal values of that type are +// guaranteed to have the same bytes in their underlying storage. In other +// words, if `a == b`, then `memcmp(&a, &b, sizeof(T))` is guaranteed to be +// zero. This property cannot be detected automatically, so this trait is false +// by default, but can be specialized by types that wish to assert that they are +// uniquely represented. This makes them eligible for certain optimizations. +// +// If you have any doubt whatsoever, do not specialize this template. +// The default is completely safe, and merely disables some optimizations +// that will not matter for most types. Specializing this template, +// on the other hand, can be very hazardous. +// +// To be uniquely represented, a type must not have multiple ways of +// representing the same value; for example, float and double are not +// uniquely represented, because they have distinct representations for +// +0 and -0. Furthermore, the type's byte representation must consist +// solely of user-controlled data, with no padding bits and no compiler- +// controlled data such as vptrs or sanitizer metadata. This is usually +// very difficult to guarantee, because in most cases the compiler can +// insert data and padding bits at its own discretion. +// +// If you specialize this template for a type `T`, you must do so in the file +// that defines that type (or in this file). If you define that specialization +// anywhere else, `is_uniquely_represented<T>` could have different meanings +// in different places. +// +// The Enable parameter is meaningless; it is provided as a convenience, +// to support certain SFINAE techniques when defining specializations. +template <typename T, typename Enable = void> +struct is_uniquely_represented : std::false_type {}; + +// is_uniquely_represented<unsigned char> +// +// unsigned char is a synonym for "byte", so it is guaranteed to be +// uniquely represented. +template <> +struct is_uniquely_represented<unsigned char> : std::true_type {}; + +// is_uniquely_represented for non-standard integral types +// +// Integral types other than bool should be uniquely represented on any +// platform that this will plausibly be ported to. +template <typename Integral> +struct is_uniquely_represented< + Integral, typename std::enable_if<std::is_integral<Integral>::value>::type> + : std::true_type {}; + +// is_uniquely_represented<bool> +// +// +template <> +struct is_uniquely_represented<bool> : std::false_type {}; + +// hash_bytes() +// +// Convenience function that combines `hash_state` with the byte representation +// of `value`. +template <typename H, typename T> +H hash_bytes(H hash_state, const T& value) { + const unsigned char* start = reinterpret_cast<const unsigned char*>(&value); + return H::combine_contiguous(std::move(hash_state), start, sizeof(value)); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Basic Types +// ----------------------------------------------------------------------------- + +// Note: Default `AbslHashValue` implementations live in `hash_internal`. This +// allows us to block lexical scope lookup when doing an unqualified call to +// `AbslHashValue` below. User-defined implementations of `AbslHashValue` can +// only be found via ADL. + +// AbslHashValue() for hashing bool values +// +// We use SFINAE to ensure that this overload only accepts bool, not types that +// are convertible to bool. +template <typename H, typename B> +typename std::enable_if<std::is_same<B, bool>::value, H>::type AbslHashValue( + H hash_state, B value) { + return H::combine(std::move(hash_state), + static_cast<unsigned char>(value ? 1 : 0)); +} + +// AbslHashValue() for hashing enum values +template <typename H, typename Enum> +typename std::enable_if<std::is_enum<Enum>::value, H>::type AbslHashValue( + H hash_state, Enum e) { + // In practice, we could almost certainly just invoke hash_bytes directly, + // but it's possible that a sanitizer might one day want to + // store data in the unused bits of an enum. To avoid that risk, we + // convert to the underlying type before hashing. Hopefully this will get + // optimized away; if not, we can reopen discussion with c-toolchain-team. + return H::combine(std::move(hash_state), + static_cast<typename std::underlying_type<Enum>::type>(e)); +} +// AbslHashValue() for hashing floating-point values +template <typename H, typename Float> +typename std::enable_if<std::is_same<Float, float>::value || + std::is_same<Float, double>::value, + H>::type +AbslHashValue(H hash_state, Float value) { + return hash_internal::hash_bytes(std::move(hash_state), + value == 0 ? 0 : value); +} + +// Long double has the property that it might have extra unused bytes in it. +// For example, in x86 sizeof(long double)==16 but it only really uses 80-bits +// of it. This means we can't use hash_bytes on a long double and have to +// convert it to something else first. +template <typename H, typename LongDouble> +typename std::enable_if<std::is_same<LongDouble, long double>::value, H>::type +AbslHashValue(H hash_state, LongDouble value) { + const int category = std::fpclassify(value); + switch (category) { + case FP_INFINITE: + // Add the sign bit to differentiate between +Inf and -Inf + hash_state = H::combine(std::move(hash_state), std::signbit(value)); + break; + + case FP_NAN: + case FP_ZERO: + default: + // Category is enough for these. + break; + + case FP_NORMAL: + case FP_SUBNORMAL: + // We can't convert `value` directly to double because this would have + // undefined behavior if the value is out of range. + // std::frexp gives us a value in the range (-1, -.5] or [.5, 1) that is + // guaranteed to be in range for `double`. The truncation is + // implementation defined, but that works as long as it is deterministic. + int exp; + auto mantissa = static_cast<double>(std::frexp(value, &exp)); + hash_state = H::combine(std::move(hash_state), mantissa, exp); + } + + return H::combine(std::move(hash_state), category); +} + +// AbslHashValue() for hashing pointers +template <typename H, typename T> +H AbslHashValue(H hash_state, T* ptr) { + auto v = reinterpret_cast<uintptr_t>(ptr); + // Due to alignment, pointers tend to have low bits as zero, and the next few + // bits follow a pattern since they are also multiples of some base value. + // Mixing the pointer twice helps prevent stuck low bits for certain alignment + // values. + return H::combine(std::move(hash_state), v, v); +} + +// AbslHashValue() for hashing nullptr_t +template <typename H> +H AbslHashValue(H hash_state, std::nullptr_t) { + return H::combine(std::move(hash_state), static_cast<void*>(nullptr)); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Composite Types +// ----------------------------------------------------------------------------- + +// is_hashable() +// +// Trait class which returns true if T is hashable by the absl::Hash framework. +// Used for the AbslHashValue implementations for composite types below. +template <typename T> +struct is_hashable; + +// AbslHashValue() for hashing pairs +template <typename H, typename T1, typename T2> +typename std::enable_if<is_hashable<T1>::value && is_hashable<T2>::value, + H>::type +AbslHashValue(H hash_state, const std::pair<T1, T2>& p) { + return H::combine(std::move(hash_state), p.first, p.second); +} + +// hash_tuple() +// +// Helper function for hashing a tuple. The third argument should +// be an index_sequence running from 0 to tuple_size<Tuple> - 1. +template <typename H, typename Tuple, size_t... Is> +H hash_tuple(H hash_state, const Tuple& t, absl::index_sequence<Is...>) { + return H::combine(std::move(hash_state), std::get<Is>(t)...); +} + +// AbslHashValue for hashing tuples +template <typename H, typename... Ts> +#if defined(_MSC_VER) +// This SFINAE gets MSVC confused under some conditions. Let's just disable it +// for now. +H +#else // _MSC_VER +typename std::enable_if<absl::conjunction<is_hashable<Ts>...>::value, H>::type +#endif // _MSC_VER +AbslHashValue(H hash_state, const std::tuple<Ts...>& t) { + return hash_internal::hash_tuple(std::move(hash_state), t, + absl::make_index_sequence<sizeof...(Ts)>()); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Pointers +// ----------------------------------------------------------------------------- + +// AbslHashValue for hashing unique_ptr +template <typename H, typename T, typename D> +H AbslHashValue(H hash_state, const std::unique_ptr<T, D>& ptr) { + return H::combine(std::move(hash_state), ptr.get()); +} + +// AbslHashValue for hashing shared_ptr +template <typename H, typename T> +H AbslHashValue(H hash_state, const std::shared_ptr<T>& ptr) { + return H::combine(std::move(hash_state), ptr.get()); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for String-Like Types +// ----------------------------------------------------------------------------- + +// AbslHashValue for hashing strings +// +// All the string-like types supported here provide the same hash expansion for +// the same character sequence. These types are: +// +// - `absl::Cord` +// - `std::string` (and std::basic_string<char, std::char_traits<char>, A> for +// any allocator A) +// - `absl::string_view` and `std::string_view` +// +// For simplicity, we currently support only `char` strings. This support may +// be broadened, if necessary, but with some caution - this overload would +// misbehave in cases where the traits' `eq()` member isn't equivalent to `==` +// on the underlying character type. +template <typename H> +H AbslHashValue(H hash_state, absl::string_view str) { + return H::combine( + H::combine_contiguous(std::move(hash_state), str.data(), str.size()), + str.size()); +} + +// Support std::wstring, std::u16string and std::u32string. +template <typename Char, typename Alloc, typename H, + typename = absl::enable_if_t<std::is_same<Char, wchar_t>::value || + std::is_same<Char, char16_t>::value || + std::is_same<Char, char32_t>::value>> +H AbslHashValue( + H hash_state, + const std::basic_string<Char, std::char_traits<Char>, Alloc>& str) { + return H::combine( + H::combine_contiguous(std::move(hash_state), str.data(), str.size()), + str.size()); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Sequence Containers +// ----------------------------------------------------------------------------- + +// AbslHashValue for hashing std::array +template <typename H, typename T, size_t N> +typename std::enable_if<is_hashable<T>::value, H>::type AbslHashValue( + H hash_state, const std::array<T, N>& array) { + return H::combine_contiguous(std::move(hash_state), array.data(), + array.size()); +} + +// AbslHashValue for hashing std::deque +template <typename H, typename T, typename Allocator> +typename std::enable_if<is_hashable<T>::value, H>::type AbslHashValue( + H hash_state, const std::deque<T, Allocator>& deque) { + // TODO(gromer): investigate a more efficient implementation taking + // advantage of the chunk structure. + for (const auto& t : deque) { + hash_state = H::combine(std::move(hash_state), t); + } + return H::combine(std::move(hash_state), deque.size()); +} + +// AbslHashValue for hashing std::forward_list +template <typename H, typename T, typename Allocator> +typename std::enable_if<is_hashable<T>::value, H>::type AbslHashValue( + H hash_state, const std::forward_list<T, Allocator>& list) { + size_t size = 0; + for (const T& t : list) { + hash_state = H::combine(std::move(hash_state), t); + ++size; + } + return H::combine(std::move(hash_state), size); +} + +// AbslHashValue for hashing std::list +template <typename H, typename T, typename Allocator> +typename std::enable_if<is_hashable<T>::value, H>::type AbslHashValue( + H hash_state, const std::list<T, Allocator>& list) { + for (const auto& t : list) { + hash_state = H::combine(std::move(hash_state), t); + } + return H::combine(std::move(hash_state), list.size()); +} + +// AbslHashValue for hashing std::vector +// +// Do not use this for vector<bool>. It does not have a .data(), and a fallback +// for std::hash<> is most likely faster. +template <typename H, typename T, typename Allocator> +typename std::enable_if<is_hashable<T>::value && !std::is_same<T, bool>::value, + H>::type +AbslHashValue(H hash_state, const std::vector<T, Allocator>& vector) { + return H::combine(H::combine_contiguous(std::move(hash_state), vector.data(), + vector.size()), + vector.size()); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Ordered Associative Containers +// ----------------------------------------------------------------------------- + +// AbslHashValue for hashing std::map +template <typename H, typename Key, typename T, typename Compare, + typename Allocator> +typename std::enable_if<is_hashable<Key>::value && is_hashable<T>::value, + H>::type +AbslHashValue(H hash_state, const std::map<Key, T, Compare, Allocator>& map) { + for (const auto& t : map) { + hash_state = H::combine(std::move(hash_state), t); + } + return H::combine(std::move(hash_state), map.size()); +} + +// AbslHashValue for hashing std::multimap +template <typename H, typename Key, typename T, typename Compare, + typename Allocator> +typename std::enable_if<is_hashable<Key>::value && is_hashable<T>::value, + H>::type +AbslHashValue(H hash_state, + const std::multimap<Key, T, Compare, Allocator>& map) { + for (const auto& t : map) { + hash_state = H::combine(std::move(hash_state), t); + } + return H::combine(std::move(hash_state), map.size()); +} + +// AbslHashValue for hashing std::set +template <typename H, typename Key, typename Compare, typename Allocator> +typename std::enable_if<is_hashable<Key>::value, H>::type AbslHashValue( + H hash_state, const std::set<Key, Compare, Allocator>& set) { + for (const auto& t : set) { + hash_state = H::combine(std::move(hash_state), t); + } + return H::combine(std::move(hash_state), set.size()); +} + +// AbslHashValue for hashing std::multiset +template <typename H, typename Key, typename Compare, typename Allocator> +typename std::enable_if<is_hashable<Key>::value, H>::type AbslHashValue( + H hash_state, const std::multiset<Key, Compare, Allocator>& set) { + for (const auto& t : set) { + hash_state = H::combine(std::move(hash_state), t); + } + return H::combine(std::move(hash_state), set.size()); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Wrapper Types +// ----------------------------------------------------------------------------- + +// AbslHashValue for hashing std::reference_wrapper +template <typename H, typename T> +typename std::enable_if<is_hashable<T>::value, H>::type AbslHashValue( + H hash_state, std::reference_wrapper<T> opt) { + return H::combine(std::move(hash_state), opt.get()); +} + +// AbslHashValue for hashing absl::optional +template <typename H, typename T> +typename std::enable_if<is_hashable<T>::value, H>::type AbslHashValue( + H hash_state, const absl::optional<T>& opt) { + if (opt) hash_state = H::combine(std::move(hash_state), *opt); + return H::combine(std::move(hash_state), opt.has_value()); +} + +// VariantVisitor +template <typename H> +struct VariantVisitor { + H&& hash_state; + template <typename T> + H operator()(const T& t) const { + return H::combine(std::move(hash_state), t); + } +}; + +// AbslHashValue for hashing absl::variant +template <typename H, typename... T> +typename std::enable_if<conjunction<is_hashable<T>...>::value, H>::type +AbslHashValue(H hash_state, const absl::variant<T...>& v) { + if (!v.valueless_by_exception()) { + hash_state = absl::visit(VariantVisitor<H>{std::move(hash_state)}, v); + } + return H::combine(std::move(hash_state), v.index()); +} + +// ----------------------------------------------------------------------------- +// AbslHashValue for Other Types +// ----------------------------------------------------------------------------- + +// AbslHashValue for hashing std::bitset is not defined, for the same reason as +// for vector<bool> (see std::vector above): It does not expose the raw bytes, +// and a fallback to std::hash<> is most likely faster. + +// ----------------------------------------------------------------------------- + +// hash_range_or_bytes() +// +// Mixes all values in the range [data, data+size) into the hash state. +// This overload accepts only uniquely-represented types, and hashes them by +// hashing the entire range of bytes. +template <typename H, typename T> +typename std::enable_if<is_uniquely_represented<T>::value, H>::type +hash_range_or_bytes(H hash_state, const T* data, size_t size) { + const auto* bytes = reinterpret_cast<const unsigned char*>(data); + return H::combine_contiguous(std::move(hash_state), bytes, sizeof(T) * size); +} + +// hash_range_or_bytes() +template <typename H, typename T> +typename std::enable_if<!is_uniquely_represented<T>::value, H>::type +hash_range_or_bytes(H hash_state, const T* data, size_t size) { + for (const auto end = data + size; data < end; ++data) { + hash_state = H::combine(std::move(hash_state), *data); + } + return hash_state; +} + +#if defined(ABSL_INTERNAL_LEGACY_HASH_NAMESPACE) && \ + ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ +#define ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ 1 +#else +#define ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ 0 +#endif + +// HashSelect +// +// Type trait to select the appropriate hash implementation to use. +// HashSelect::type<T> will give the proper hash implementation, to be invoked +// as: +// HashSelect::type<T>::Invoke(state, value) +// Also, HashSelect::type<T>::value is a boolean equal to `true` if there is a +// valid `Invoke` function. Types that are not hashable will have a ::value of +// `false`. +struct HashSelect { + private: + struct State : HashStateBase<State> { + static State combine_contiguous(State hash_state, const unsigned char*, + size_t); + using State::HashStateBase::combine_contiguous; + }; + + struct UniquelyRepresentedProbe { + template <typename H, typename T> + static auto Invoke(H state, const T& value) + -> absl::enable_if_t<is_uniquely_represented<T>::value, H> { + return hash_internal::hash_bytes(std::move(state), value); + } + }; + + struct HashValueProbe { + template <typename H, typename T> + static auto Invoke(H state, const T& value) -> absl::enable_if_t< + std::is_same<H, + decltype(AbslHashValue(std::move(state), value))>::value, + H> { + return AbslHashValue(std::move(state), value); + } + }; + + struct LegacyHashProbe { +#if ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ + template <typename H, typename T> + static auto Invoke(H state, const T& value) -> absl::enable_if_t< + std::is_convertible< + decltype(ABSL_INTERNAL_LEGACY_HASH_NAMESPACE::hash<T>()(value)), + size_t>::value, + H> { + return hash_internal::hash_bytes( + std::move(state), + ABSL_INTERNAL_LEGACY_HASH_NAMESPACE::hash<T>{}(value)); + } +#endif // ABSL_HASH_INTERNAL_SUPPORT_LEGACY_HASH_ + }; + + struct StdHashProbe { + template <typename H, typename T> + static auto Invoke(H state, const T& value) + -> absl::enable_if_t<type_traits_internal::IsHashable<T>::value, H> { + return hash_internal::hash_bytes(std::move(state), std::hash<T>{}(value)); + } + }; + + template <typename Hash, typename T> + struct Probe : Hash { + private: + template <typename H, typename = decltype(H::Invoke( + std::declval<State>(), std::declval<const T&>()))> + static std::true_type Test(int); + template <typename U> + static std::false_type Test(char); + + public: + static constexpr bool value = decltype(Test<Hash>(0))::value; + }; + + public: + // Probe each implementation in order. + // disjunction provides short circuiting wrt instantiation. + template <typename T> + using Apply = absl::disjunction< // + Probe<UniquelyRepresentedProbe, T>, // + Probe<HashValueProbe, T>, // + Probe<LegacyHashProbe, T>, // + Probe<StdHashProbe, T>, // + std::false_type>; +}; + +template <typename T> +struct is_hashable + : std::integral_constant<bool, HashSelect::template Apply<T>::value> {}; + +// CityHashState +class ABSL_DLL CityHashState + : public HashStateBase<CityHashState> { + // absl::uint128 is not an alias or a thin wrapper around the intrinsic. + // We use the intrinsic when available to improve performance. +#ifdef ABSL_HAVE_INTRINSIC_INT128 + using uint128 = __uint128_t; +#else // ABSL_HAVE_INTRINSIC_INT128 + using uint128 = absl::uint128; +#endif // ABSL_HAVE_INTRINSIC_INT128 + + static constexpr uint64_t kMul = + sizeof(size_t) == 4 ? uint64_t{0xcc9e2d51} + : uint64_t{0x9ddfea08eb382d69}; + + template <typename T> + using IntegralFastPath = + conjunction<std::is_integral<T>, is_uniquely_represented<T>>; + + public: + // Move only + CityHashState(CityHashState&&) = default; + CityHashState& operator=(CityHashState&&) = default; + + // CityHashState::combine_contiguous() + // + // Fundamental base case for hash recursion: mixes the given range of bytes + // into the hash state. + static CityHashState combine_contiguous(CityHashState hash_state, + const unsigned char* first, + size_t size) { + return CityHashState( + CombineContiguousImpl(hash_state.state_, first, size, + std::integral_constant<int, sizeof(size_t)>{})); + } + using CityHashState::HashStateBase::combine_contiguous; + + // CityHashState::hash() + // + // For performance reasons in non-opt mode, we specialize this for + // integral types. + // Otherwise we would be instantiating and calling dozens of functions for + // something that is just one multiplication and a couple xor's. + // The result should be the same as running the whole algorithm, but faster. + template <typename T, absl::enable_if_t<IntegralFastPath<T>::value, int> = 0> + static size_t hash(T value) { + return static_cast<size_t>(Mix(Seed(), static_cast<uint64_t>(value))); + } + + // Overload of CityHashState::hash() + template <typename T, absl::enable_if_t<!IntegralFastPath<T>::value, int> = 0> + static size_t hash(const T& value) { + return static_cast<size_t>(combine(CityHashState{}, value).state_); + } + + private: + // Invoked only once for a given argument; that plus the fact that this is + // move-only ensures that there is only one non-moved-from object. + CityHashState() : state_(Seed()) {} + + // Workaround for MSVC bug. + // We make the type copyable to fix the calling convention, even though we + // never actually copy it. Keep it private to not affect the public API of the + // type. + CityHashState(const CityHashState&) = default; + + explicit CityHashState(uint64_t state) : state_(state) {} + + // Implementation of the base case for combine_contiguous where we actually + // mix the bytes into the state. + // Dispatch to different implementations of the combine_contiguous depending + // on the value of `sizeof(size_t)`. + static uint64_t CombineContiguousImpl(uint64_t state, + const unsigned char* first, size_t len, + std::integral_constant<int, 4> + /* sizeof_size_t */); + static uint64_t CombineContiguousImpl(uint64_t state, + const unsigned char* first, size_t len, + std::integral_constant<int, 8> + /* sizeof_size_t*/); + + // Slow dispatch path for calls to CombineContiguousImpl with a size argument + // larger than PiecewiseChunkSize(). Has the same effect as calling + // CombineContiguousImpl() repeatedly with the chunk stride size. + static uint64_t CombineLargeContiguousImpl32(uint64_t state, + const unsigned char* first, + size_t len); + static uint64_t CombineLargeContiguousImpl64(uint64_t state, + const unsigned char* first, + size_t len); + + // Reads 9 to 16 bytes from p. + // The first 8 bytes are in .first, the rest (zero padded) bytes are in + // .second. + static std::pair<uint64_t, uint64_t> Read9To16(const unsigned char* p, + size_t len) { + uint64_t high = little_endian::Load64(p + len - 8); + return {little_endian::Load64(p), high >> (128 - len * 8)}; + } + + // Reads 4 to 8 bytes from p. Zero pads to fill uint64_t. + static uint64_t Read4To8(const unsigned char* p, size_t len) { + return (static_cast<uint64_t>(little_endian::Load32(p + len - 4)) + << (len - 4) * 8) | + little_endian::Load32(p); + } + + // Reads 1 to 3 bytes from p. Zero pads to fill uint32_t. + static uint32_t Read1To3(const unsigned char* p, size_t len) { + return static_cast<uint32_t>((p[0]) | // + (p[len / 2] << (len / 2 * 8)) | // + (p[len - 1] << ((len - 1) * 8))); + } + + ABSL_ATTRIBUTE_ALWAYS_INLINE static uint64_t Mix(uint64_t state, uint64_t v) { + using MultType = + absl::conditional_t<sizeof(size_t) == 4, uint64_t, uint128>; + // We do the addition in 64-bit space to make sure the 128-bit + // multiplication is fast. If we were to do it as MultType the compiler has + // to assume that the high word is non-zero and needs to perform 2 + // multiplications instead of one. + MultType m = state + v; + m *= kMul; + return static_cast<uint64_t>(m ^ (m >> (sizeof(m) * 8 / 2))); + } + + // Seed() + // + // A non-deterministic seed. + // + // The current purpose of this seed is to generate non-deterministic results + // and prevent having users depend on the particular hash values. + // It is not meant as a security feature right now, but it leaves the door + // open to upgrade it to a true per-process random seed. A true random seed + // costs more and we don't need to pay for that right now. + // + // On platforms with ASLR, we take advantage of it to make a per-process + // random value. + // See https://en.wikipedia.org/wiki/Address_space_layout_randomization + // + // On other platforms this is still going to be non-deterministic but most + // probably per-build and not per-process. + ABSL_ATTRIBUTE_ALWAYS_INLINE static uint64_t Seed() { + return static_cast<uint64_t>(reinterpret_cast<uintptr_t>(kSeed)); + } + static const void* const kSeed; + + uint64_t state_; +}; + +// CityHashState::CombineContiguousImpl() +inline uint64_t CityHashState::CombineContiguousImpl( + uint64_t state, const unsigned char* first, size_t len, + std::integral_constant<int, 4> /* sizeof_size_t */) { + // For large values we use CityHash, for small ones we just use a + // multiplicative hash. + uint64_t v; + if (len > 8) { + if (ABSL_PREDICT_FALSE(len > PiecewiseChunkSize())) { + return CombineLargeContiguousImpl32(state, first, len); + } + v = absl::hash_internal::CityHash32(reinterpret_cast<const char*>(first), len); + } else if (len >= 4) { + v = Read4To8(first, len); + } else if (len > 0) { + v = Read1To3(first, len); + } else { + // Empty ranges have no effect. + return state; + } + return Mix(state, v); +} + +// Overload of CityHashState::CombineContiguousImpl() +inline uint64_t CityHashState::CombineContiguousImpl( + uint64_t state, const unsigned char* first, size_t len, + std::integral_constant<int, 8> /* sizeof_size_t */) { + // For large values we use CityHash, for small ones we just use a + // multiplicative hash. + uint64_t v; + if (len > 16) { + if (ABSL_PREDICT_FALSE(len > PiecewiseChunkSize())) { + return CombineLargeContiguousImpl64(state, first, len); + } + v = absl::hash_internal::CityHash64(reinterpret_cast<const char*>(first), len); + } else if (len > 8) { + auto p = Read9To16(first, len); + state = Mix(state, p.first); + v = p.second; + } else if (len >= 4) { + v = Read4To8(first, len); + } else if (len > 0) { + v = Read1To3(first, len); + } else { + // Empty ranges have no effect. + return state; + } + return Mix(state, v); +} + +struct AggregateBarrier {}; + +// HashImpl + +// Add a private base class to make sure this type is not an aggregate. +// Aggregates can be aggregate initialized even if the default constructor is +// deleted. +struct PoisonedHash : private AggregateBarrier { + PoisonedHash() = delete; + PoisonedHash(const PoisonedHash&) = delete; + PoisonedHash& operator=(const PoisonedHash&) = delete; +}; + +template <typename T> +struct HashImpl { + size_t operator()(const T& value) const { return CityHashState::hash(value); } +}; + +template <typename T> +struct Hash + : absl::conditional_t<is_hashable<T>::value, HashImpl<T>, PoisonedHash> {}; + +template <typename H> +template <typename T, typename... Ts> +H HashStateBase<H>::combine(H state, const T& value, const Ts&... values) { + return H::combine(hash_internal::HashSelect::template Apply<T>::Invoke( + std::move(state), value), + values...); +} + +// HashStateBase::combine_contiguous() +template <typename H> +template <typename T> +H HashStateBase<H>::combine_contiguous(H state, const T* data, size_t size) { + return hash_internal::hash_range_or_bytes(std::move(state), data, size); +} + +// HashStateBase::PiecewiseCombiner::add_buffer() +template <typename H> +H PiecewiseCombiner::add_buffer(H state, const unsigned char* data, + size_t size) { + if (position_ + size < PiecewiseChunkSize()) { + // This partial chunk does not fill our existing buffer + memcpy(buf_ + position_, data, size); + position_ += size; + return state; + } + + // If the buffer is partially filled we need to complete the buffer + // and hash it. + if (position_ != 0) { + const size_t bytes_needed = PiecewiseChunkSize() - position_; + memcpy(buf_ + position_, data, bytes_needed); + state = H::combine_contiguous(std::move(state), buf_, PiecewiseChunkSize()); + data += bytes_needed; + size -= bytes_needed; + } + + // Hash whatever chunks we can without copying + while (size >= PiecewiseChunkSize()) { + state = H::combine_contiguous(std::move(state), data, PiecewiseChunkSize()); + data += PiecewiseChunkSize(); + size -= PiecewiseChunkSize(); + } + // Fill the buffer with the remainder + memcpy(buf_, data, size); + position_ = size; + return state; +} + +// HashStateBase::PiecewiseCombiner::finalize() +template <typename H> +H PiecewiseCombiner::finalize(H state) { + // Hash the remainder left in the buffer, which may be empty + return H::combine_contiguous(std::move(state), buf_, position_); +} + +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HASH_INTERNAL_HASH_H_ diff --git a/third_party/abseil_cpp/absl/hash/internal/print_hash_of.cc b/third_party/abseil_cpp/absl/hash/internal/print_hash_of.cc new file mode 100644 index 0000000000..c392125a69 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/print_hash_of.cc @@ -0,0 +1,23 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdlib> + +#include "absl/hash/hash.h" + +// Prints the hash of argv[1]. +int main(int argc, char** argv) { + if (argc < 2) return 1; + printf("%zu\n", absl::Hash<int>{}(std::atoi(argv[1]))); // NOLINT +} diff --git a/third_party/abseil_cpp/absl/hash/internal/spy_hash_state.h b/third_party/abseil_cpp/absl/hash/internal/spy_hash_state.h new file mode 100644 index 0000000000..c083120811 --- /dev/null +++ b/third_party/abseil_cpp/absl/hash/internal/spy_hash_state.h @@ -0,0 +1,231 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_HASH_INTERNAL_SPY_HASH_STATE_H_ +#define ABSL_HASH_INTERNAL_SPY_HASH_STATE_H_ + +#include <ostream> +#include <string> +#include <vector> + +#include "absl/hash/hash.h" +#include "absl/strings/match.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace hash_internal { + +// SpyHashState is an implementation of the HashState API that simply +// accumulates all input bytes in an internal buffer. This makes it useful +// for testing AbslHashValue overloads (so long as they are templated on the +// HashState parameter), since it can report the exact hash representation +// that the AbslHashValue overload produces. +// +// Sample usage: +// EXPECT_EQ(SpyHashState::combine(SpyHashState(), foo), +// SpyHashState::combine(SpyHashState(), bar)); +template <typename T> +class SpyHashStateImpl : public HashStateBase<SpyHashStateImpl<T>> { + public: + SpyHashStateImpl() : error_(std::make_shared<absl::optional<std::string>>()) { + static_assert(std::is_void<T>::value, ""); + } + + // Move-only + SpyHashStateImpl(const SpyHashStateImpl&) = delete; + SpyHashStateImpl& operator=(const SpyHashStateImpl&) = delete; + + SpyHashStateImpl(SpyHashStateImpl&& other) noexcept { + *this = std::move(other); + } + + SpyHashStateImpl& operator=(SpyHashStateImpl&& other) noexcept { + hash_representation_ = std::move(other.hash_representation_); + error_ = other.error_; + moved_from_ = other.moved_from_; + other.moved_from_ = true; + return *this; + } + + template <typename U> + SpyHashStateImpl(SpyHashStateImpl<U>&& other) { // NOLINT + hash_representation_ = std::move(other.hash_representation_); + error_ = other.error_; + moved_from_ = other.moved_from_; + other.moved_from_ = true; + } + + template <typename A, typename... Args> + static SpyHashStateImpl combine(SpyHashStateImpl s, const A& a, + const Args&... args) { + // Pass an instance of SpyHashStateImpl<A> when trying to combine `A`. This + // allows us to test that the user only uses this instance for combine calls + // and does not call AbslHashValue directly. + // See AbslHashValue implementation at the bottom. + s = SpyHashStateImpl<A>::HashStateBase::combine(std::move(s), a); + return SpyHashStateImpl::combine(std::move(s), args...); + } + static SpyHashStateImpl combine(SpyHashStateImpl s) { + if (direct_absl_hash_value_error_) { + *s.error_ = "AbslHashValue should not be invoked directly."; + } else if (s.moved_from_) { + *s.error_ = "Used moved-from instance of the hash state object."; + } + return s; + } + + static void SetDirectAbslHashValueError() { + direct_absl_hash_value_error_ = true; + } + + // Two SpyHashStateImpl objects are equal if they hold equal hash + // representations. + friend bool operator==(const SpyHashStateImpl& lhs, + const SpyHashStateImpl& rhs) { + return lhs.hash_representation_ == rhs.hash_representation_; + } + + friend bool operator!=(const SpyHashStateImpl& lhs, + const SpyHashStateImpl& rhs) { + return !(lhs == rhs); + } + + enum class CompareResult { + kEqual, + kASuffixB, + kBSuffixA, + kUnequal, + }; + + static CompareResult Compare(const SpyHashStateImpl& a, + const SpyHashStateImpl& b) { + const std::string a_flat = absl::StrJoin(a.hash_representation_, ""); + const std::string b_flat = absl::StrJoin(b.hash_representation_, ""); + if (a_flat == b_flat) return CompareResult::kEqual; + if (absl::EndsWith(a_flat, b_flat)) return CompareResult::kBSuffixA; + if (absl::EndsWith(b_flat, a_flat)) return CompareResult::kASuffixB; + return CompareResult::kUnequal; + } + + // operator<< prints the hash representation as a hex and ASCII dump, to + // facilitate debugging. + friend std::ostream& operator<<(std::ostream& out, + const SpyHashStateImpl& hash_state) { + out << "[\n"; + for (auto& s : hash_state.hash_representation_) { + size_t offset = 0; + for (char c : s) { + if (offset % 16 == 0) { + out << absl::StreamFormat("\n0x%04x: ", offset); + } + if (offset % 2 == 0) { + out << " "; + } + out << absl::StreamFormat("%02x", c); + ++offset; + } + out << "\n"; + } + return out << "]"; + } + + // The base case of the combine recursion, which writes raw bytes into the + // internal buffer. + static SpyHashStateImpl combine_contiguous(SpyHashStateImpl hash_state, + const unsigned char* begin, + size_t size) { + const size_t large_chunk_stride = PiecewiseChunkSize(); + if (size > large_chunk_stride) { + // Combining a large contiguous buffer must have the same effect as + // doing it piecewise by the stride length, followed by the (possibly + // empty) remainder. + while (size >= large_chunk_stride) { + hash_state = SpyHashStateImpl::combine_contiguous( + std::move(hash_state), begin, large_chunk_stride); + begin += large_chunk_stride; + size -= large_chunk_stride; + } + } + + hash_state.hash_representation_.emplace_back( + reinterpret_cast<const char*>(begin), size); + return hash_state; + } + + using SpyHashStateImpl::HashStateBase::combine_contiguous; + + absl::optional<std::string> error() const { + if (moved_from_) { + return "Returned a moved-from instance of the hash state object."; + } + return *error_; + } + + private: + template <typename U> + friend class SpyHashStateImpl; + + // This is true if SpyHashStateImpl<T> has been passed to a call of + // AbslHashValue with the wrong type. This detects that the user called + // AbslHashValue directly (because the hash state type does not match). + static bool direct_absl_hash_value_error_; + + std::vector<std::string> hash_representation_; + // This is a shared_ptr because we want all instances of the particular + // SpyHashState run to share the field. This way we can set the error for + // use-after-move and all the copies will see it. + std::shared_ptr<absl::optional<std::string>> error_; + bool moved_from_ = false; +}; + +template <typename T> +bool SpyHashStateImpl<T>::direct_absl_hash_value_error_; + +template <bool& B> +struct OdrUse { + constexpr OdrUse() {} + bool& b = B; +}; + +template <void (*)()> +struct RunOnStartup { + static bool run; + static constexpr OdrUse<run> kOdrUse{}; +}; + +template <void (*f)()> +bool RunOnStartup<f>::run = (f(), true); + +template < + typename T, typename U, + // Only trigger for when (T != U), + typename = absl::enable_if_t<!std::is_same<T, U>::value>, + // This statement works in two ways: + // - First, it instantiates RunOnStartup and forces the initialization of + // `run`, which set the global variable. + // - Second, it triggers a SFINAE error disabling the overload to prevent + // compile time errors. If we didn't disable the overload we would get + // ambiguous overload errors, which we don't want. + int = RunOnStartup<SpyHashStateImpl<T>::SetDirectAbslHashValueError>::run> +void AbslHashValue(SpyHashStateImpl<T>, const U&); + +using SpyHashState = SpyHashStateImpl<void>; + +} // namespace hash_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HASH_INTERNAL_SPY_HASH_STATE_H_ diff --git a/third_party/abseil_cpp/absl/memory/BUILD.bazel b/third_party/abseil_cpp/absl/memory/BUILD.bazel new file mode 100644 index 0000000000..2ba9d7cb98 --- /dev/null +++ b/third_party/abseil_cpp/absl/memory/BUILD.bazel @@ -0,0 +1,65 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "memory", + hdrs = ["memory.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:core_headers", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "memory_test", + srcs = ["memory_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":memory", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "memory_exception_safety_test", + srcs = [ + "memory_exception_safety_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":memory", + "//absl/base:config", + "//absl/base:exception_safety_testing", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/memory/CMakeLists.txt b/third_party/abseil_cpp/absl/memory/CMakeLists.txt new file mode 100644 index 0000000000..78fb7e1b31 --- /dev/null +++ b/third_party/abseil_cpp/absl/memory/CMakeLists.txt @@ -0,0 +1,55 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + memory + HDRS + "memory.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::meta + PUBLIC +) + +absl_cc_test( + NAME + memory_test + SRCS + "memory_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::memory + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + memory_exception_safety_test + SRCS + "memory_exception_safety_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::memory + absl::config + absl::exception_safety_testing + gmock_main +) diff --git a/third_party/abseil_cpp/absl/memory/memory.h b/third_party/abseil_cpp/absl/memory/memory.h new file mode 100644 index 0000000000..513f7103a0 --- /dev/null +++ b/third_party/abseil_cpp/absl/memory/memory.h @@ -0,0 +1,695 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: memory.h +// ----------------------------------------------------------------------------- +// +// This header file contains utility functions for managing the creation and +// conversion of smart pointers. This file is an extension to the C++ +// standard <memory> library header file. + +#ifndef ABSL_MEMORY_MEMORY_H_ +#define ABSL_MEMORY_MEMORY_H_ + +#include <cstddef> +#include <limits> +#include <memory> +#include <new> +#include <type_traits> +#include <utility> + +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// Function Template: WrapUnique() +// ----------------------------------------------------------------------------- +// +// Adopts ownership from a raw pointer and transfers it to the returned +// `std::unique_ptr`, whose type is deduced. Because of this deduction, *do not* +// specify the template type `T` when calling `WrapUnique`. +// +// Example: +// X* NewX(int, int); +// auto x = WrapUnique(NewX(1, 2)); // 'x' is std::unique_ptr<X>. +// +// Do not call WrapUnique with an explicit type, as in +// `WrapUnique<X>(NewX(1, 2))`. The purpose of WrapUnique is to automatically +// deduce the pointer type. If you wish to make the type explicit, just use +// `std::unique_ptr` directly. +// +// auto x = std::unique_ptr<X>(NewX(1, 2)); +// - or - +// std::unique_ptr<X> x(NewX(1, 2)); +// +// While `absl::WrapUnique` is useful for capturing the output of a raw +// pointer factory, prefer 'absl::make_unique<T>(args...)' over +// 'absl::WrapUnique(new T(args...))'. +// +// auto x = WrapUnique(new X(1, 2)); // works, but nonideal. +// auto x = make_unique<X>(1, 2); // safer, standard, avoids raw 'new'. +// +// Note that `absl::WrapUnique(p)` is valid only if `delete p` is a valid +// expression. In particular, `absl::WrapUnique()` cannot wrap pointers to +// arrays, functions or void, and it must not be used to capture pointers +// obtained from array-new expressions (even though that would compile!). +template <typename T> +std::unique_ptr<T> WrapUnique(T* ptr) { + static_assert(!std::is_array<T>::value, "array types are unsupported"); + static_assert(std::is_object<T>::value, "non-object types are unsupported"); + return std::unique_ptr<T>(ptr); +} + +namespace memory_internal { + +// Traits to select proper overload and return type for `absl::make_unique<>`. +template <typename T> +struct MakeUniqueResult { + using scalar = std::unique_ptr<T>; +}; +template <typename T> +struct MakeUniqueResult<T[]> { + using array = std::unique_ptr<T[]>; +}; +template <typename T, size_t N> +struct MakeUniqueResult<T[N]> { + using invalid = void; +}; + +} // namespace memory_internal + +// gcc 4.8 has __cplusplus at 201301 but the libstdc++ shipped with it doesn't +// define make_unique. Other supported compilers either just define __cplusplus +// as 201103 but have make_unique (msvc), or have make_unique whenever +// __cplusplus > 201103 (clang). +#if (__cplusplus > 201103L || defined(_MSC_VER)) && \ + !(defined(__GLIBCXX__) && !defined(__cpp_lib_make_unique)) +using std::make_unique; +#else +// ----------------------------------------------------------------------------- +// Function Template: make_unique<T>() +// ----------------------------------------------------------------------------- +// +// Creates a `std::unique_ptr<>`, while avoiding issues creating temporaries +// during the construction process. `absl::make_unique<>` also avoids redundant +// type declarations, by avoiding the need to explicitly use the `new` operator. +// +// This implementation of `absl::make_unique<>` is designed for C++11 code and +// will be replaced in C++14 by the equivalent `std::make_unique<>` abstraction. +// `absl::make_unique<>` is designed to be 100% compatible with +// `std::make_unique<>` so that the eventual migration will involve a simple +// rename operation. +// +// For more background on why `std::unique_ptr<T>(new T(a,b))` is problematic, +// see Herb Sutter's explanation on +// (Exception-Safe Function Calls)[https://herbsutter.com/gotw/_102/]. +// (In general, reviewers should treat `new T(a,b)` with scrutiny.) +// +// Example usage: +// +// auto p = make_unique<X>(args...); // 'p' is a std::unique_ptr<X> +// auto pa = make_unique<X[]>(5); // 'pa' is a std::unique_ptr<X[]> +// +// Three overloads of `absl::make_unique` are required: +// +// - For non-array T: +// +// Allocates a T with `new T(std::forward<Args> args...)`, +// forwarding all `args` to T's constructor. +// Returns a `std::unique_ptr<T>` owning that object. +// +// - For an array of unknown bounds T[]: +// +// `absl::make_unique<>` will allocate an array T of type U[] with +// `new U[n]()` and return a `std::unique_ptr<U[]>` owning that array. +// +// Note that 'U[n]()' is different from 'U[n]', and elements will be +// value-initialized. Note as well that `std::unique_ptr` will perform its +// own destruction of the array elements upon leaving scope, even though +// the array [] does not have a default destructor. +// +// NOTE: an array of unknown bounds T[] may still be (and often will be) +// initialized to have a size, and will still use this overload. E.g: +// +// auto my_array = absl::make_unique<int[]>(10); +// +// - For an array of known bounds T[N]: +// +// `absl::make_unique<>` is deleted (like with `std::make_unique<>`) as +// this overload is not useful. +// +// NOTE: an array of known bounds T[N] is not considered a useful +// construction, and may cause undefined behavior in templates. E.g: +// +// auto my_array = absl::make_unique<int[10]>(); +// +// In those cases, of course, you can still use the overload above and +// simply initialize it to its desired size: +// +// auto my_array = absl::make_unique<int[]>(10); + +// `absl::make_unique` overload for non-array types. +template <typename T, typename... Args> +typename memory_internal::MakeUniqueResult<T>::scalar make_unique( + Args&&... args) { + return std::unique_ptr<T>(new T(std::forward<Args>(args)...)); +} + +// `absl::make_unique` overload for an array T[] of unknown bounds. +// The array allocation needs to use the `new T[size]` form and cannot take +// element constructor arguments. The `std::unique_ptr` will manage destructing +// these array elements. +template <typename T> +typename memory_internal::MakeUniqueResult<T>::array make_unique(size_t n) { + return std::unique_ptr<T>(new typename absl::remove_extent_t<T>[n]()); +} + +// `absl::make_unique` overload for an array T[N] of known bounds. +// This construction will be rejected. +template <typename T, typename... Args> +typename memory_internal::MakeUniqueResult<T>::invalid make_unique( + Args&&... /* args */) = delete; +#endif + +// ----------------------------------------------------------------------------- +// Function Template: RawPtr() +// ----------------------------------------------------------------------------- +// +// Extracts the raw pointer from a pointer-like value `ptr`. `absl::RawPtr` is +// useful within templates that need to handle a complement of raw pointers, +// `std::nullptr_t`, and smart pointers. +template <typename T> +auto RawPtr(T&& ptr) -> decltype(std::addressof(*ptr)) { + // ptr is a forwarding reference to support Ts with non-const operators. + return (ptr != nullptr) ? std::addressof(*ptr) : nullptr; +} +inline std::nullptr_t RawPtr(std::nullptr_t) { return nullptr; } + +// ----------------------------------------------------------------------------- +// Function Template: ShareUniquePtr() +// ----------------------------------------------------------------------------- +// +// Adopts a `std::unique_ptr` rvalue and returns a `std::shared_ptr` of deduced +// type. Ownership (if any) of the held value is transferred to the returned +// shared pointer. +// +// Example: +// +// auto up = absl::make_unique<int>(10); +// auto sp = absl::ShareUniquePtr(std::move(up)); // shared_ptr<int> +// CHECK_EQ(*sp, 10); +// CHECK(up == nullptr); +// +// Note that this conversion is correct even when T is an array type, and more +// generally it works for *any* deleter of the `unique_ptr` (single-object +// deleter, array deleter, or any custom deleter), since the deleter is adopted +// by the shared pointer as well. The deleter is copied (unless it is a +// reference). +// +// Implements the resolution of [LWG 2415](http://wg21.link/lwg2415), by which a +// null shared pointer does not attempt to call the deleter. +template <typename T, typename D> +std::shared_ptr<T> ShareUniquePtr(std::unique_ptr<T, D>&& ptr) { + return ptr ? std::shared_ptr<T>(std::move(ptr)) : std::shared_ptr<T>(); +} + +// ----------------------------------------------------------------------------- +// Function Template: WeakenPtr() +// ----------------------------------------------------------------------------- +// +// Creates a weak pointer associated with a given shared pointer. The returned +// value is a `std::weak_ptr` of deduced type. +// +// Example: +// +// auto sp = std::make_shared<int>(10); +// auto wp = absl::WeakenPtr(sp); +// CHECK_EQ(sp.get(), wp.lock().get()); +// sp.reset(); +// CHECK(wp.lock() == nullptr); +// +template <typename T> +std::weak_ptr<T> WeakenPtr(const std::shared_ptr<T>& ptr) { + return std::weak_ptr<T>(ptr); +} + +namespace memory_internal { + +// ExtractOr<E, O, D>::type evaluates to E<O> if possible. Otherwise, D. +template <template <typename> class Extract, typename Obj, typename Default, + typename> +struct ExtractOr { + using type = Default; +}; + +template <template <typename> class Extract, typename Obj, typename Default> +struct ExtractOr<Extract, Obj, Default, void_t<Extract<Obj>>> { + using type = Extract<Obj>; +}; + +template <template <typename> class Extract, typename Obj, typename Default> +using ExtractOrT = typename ExtractOr<Extract, Obj, Default, void>::type; + +// Extractors for the features of allocators. +template <typename T> +using GetPointer = typename T::pointer; + +template <typename T> +using GetConstPointer = typename T::const_pointer; + +template <typename T> +using GetVoidPointer = typename T::void_pointer; + +template <typename T> +using GetConstVoidPointer = typename T::const_void_pointer; + +template <typename T> +using GetDifferenceType = typename T::difference_type; + +template <typename T> +using GetSizeType = typename T::size_type; + +template <typename T> +using GetPropagateOnContainerCopyAssignment = + typename T::propagate_on_container_copy_assignment; + +template <typename T> +using GetPropagateOnContainerMoveAssignment = + typename T::propagate_on_container_move_assignment; + +template <typename T> +using GetPropagateOnContainerSwap = typename T::propagate_on_container_swap; + +template <typename T> +using GetIsAlwaysEqual = typename T::is_always_equal; + +template <typename T> +struct GetFirstArg; + +template <template <typename...> class Class, typename T, typename... Args> +struct GetFirstArg<Class<T, Args...>> { + using type = T; +}; + +template <typename Ptr, typename = void> +struct ElementType { + using type = typename GetFirstArg<Ptr>::type; +}; + +template <typename T> +struct ElementType<T, void_t<typename T::element_type>> { + using type = typename T::element_type; +}; + +template <typename T, typename U> +struct RebindFirstArg; + +template <template <typename...> class Class, typename T, typename... Args, + typename U> +struct RebindFirstArg<Class<T, Args...>, U> { + using type = Class<U, Args...>; +}; + +template <typename T, typename U, typename = void> +struct RebindPtr { + using type = typename RebindFirstArg<T, U>::type; +}; + +template <typename T, typename U> +struct RebindPtr<T, U, void_t<typename T::template rebind<U>>> { + using type = typename T::template rebind<U>; +}; + +template <typename T, typename U> +constexpr bool HasRebindAlloc(...) { + return false; +} + +template <typename T, typename U> +constexpr bool HasRebindAlloc(typename T::template rebind<U>::other*) { + return true; +} + +template <typename T, typename U, bool = HasRebindAlloc<T, U>(nullptr)> +struct RebindAlloc { + using type = typename RebindFirstArg<T, U>::type; +}; + +template <typename T, typename U> +struct RebindAlloc<T, U, true> { + using type = typename T::template rebind<U>::other; +}; + +} // namespace memory_internal + +// ----------------------------------------------------------------------------- +// Class Template: pointer_traits +// ----------------------------------------------------------------------------- +// +// An implementation of C++11's std::pointer_traits. +// +// Provided for portability on toolchains that have a working C++11 compiler, +// but the standard library is lacking in C++11 support. For example, some +// version of the Android NDK. +// + +template <typename Ptr> +struct pointer_traits { + using pointer = Ptr; + + // element_type: + // Ptr::element_type if present. Otherwise T if Ptr is a template + // instantiation Template<T, Args...> + using element_type = typename memory_internal::ElementType<Ptr>::type; + + // difference_type: + // Ptr::difference_type if present, otherwise std::ptrdiff_t + using difference_type = + memory_internal::ExtractOrT<memory_internal::GetDifferenceType, Ptr, + std::ptrdiff_t>; + + // rebind: + // Ptr::rebind<U> if exists, otherwise Template<U, Args...> if Ptr is a + // template instantiation Template<T, Args...> + template <typename U> + using rebind = typename memory_internal::RebindPtr<Ptr, U>::type; + + // pointer_to: + // Calls Ptr::pointer_to(r) + static pointer pointer_to(element_type& r) { // NOLINT(runtime/references) + return Ptr::pointer_to(r); + } +}; + +// Specialization for T*. +template <typename T> +struct pointer_traits<T*> { + using pointer = T*; + using element_type = T; + using difference_type = std::ptrdiff_t; + + template <typename U> + using rebind = U*; + + // pointer_to: + // Calls std::addressof(r) + static pointer pointer_to( + element_type& r) noexcept { // NOLINT(runtime/references) + return std::addressof(r); + } +}; + +// ----------------------------------------------------------------------------- +// Class Template: allocator_traits +// ----------------------------------------------------------------------------- +// +// A C++11 compatible implementation of C++17's std::allocator_traits. +// +template <typename Alloc> +struct allocator_traits { + using allocator_type = Alloc; + + // value_type: + // Alloc::value_type + using value_type = typename Alloc::value_type; + + // pointer: + // Alloc::pointer if present, otherwise value_type* + using pointer = memory_internal::ExtractOrT<memory_internal::GetPointer, + Alloc, value_type*>; + + // const_pointer: + // Alloc::const_pointer if present, otherwise + // absl::pointer_traits<pointer>::rebind<const value_type> + using const_pointer = + memory_internal::ExtractOrT<memory_internal::GetConstPointer, Alloc, + typename absl::pointer_traits<pointer>:: + template rebind<const value_type>>; + + // void_pointer: + // Alloc::void_pointer if present, otherwise + // absl::pointer_traits<pointer>::rebind<void> + using void_pointer = memory_internal::ExtractOrT< + memory_internal::GetVoidPointer, Alloc, + typename absl::pointer_traits<pointer>::template rebind<void>>; + + // const_void_pointer: + // Alloc::const_void_pointer if present, otherwise + // absl::pointer_traits<pointer>::rebind<const void> + using const_void_pointer = memory_internal::ExtractOrT< + memory_internal::GetConstVoidPointer, Alloc, + typename absl::pointer_traits<pointer>::template rebind<const void>>; + + // difference_type: + // Alloc::difference_type if present, otherwise + // absl::pointer_traits<pointer>::difference_type + using difference_type = memory_internal::ExtractOrT< + memory_internal::GetDifferenceType, Alloc, + typename absl::pointer_traits<pointer>::difference_type>; + + // size_type: + // Alloc::size_type if present, otherwise + // std::make_unsigned<difference_type>::type + using size_type = memory_internal::ExtractOrT< + memory_internal::GetSizeType, Alloc, + typename std::make_unsigned<difference_type>::type>; + + // propagate_on_container_copy_assignment: + // Alloc::propagate_on_container_copy_assignment if present, otherwise + // std::false_type + using propagate_on_container_copy_assignment = memory_internal::ExtractOrT< + memory_internal::GetPropagateOnContainerCopyAssignment, Alloc, + std::false_type>; + + // propagate_on_container_move_assignment: + // Alloc::propagate_on_container_move_assignment if present, otherwise + // std::false_type + using propagate_on_container_move_assignment = memory_internal::ExtractOrT< + memory_internal::GetPropagateOnContainerMoveAssignment, Alloc, + std::false_type>; + + // propagate_on_container_swap: + // Alloc::propagate_on_container_swap if present, otherwise std::false_type + using propagate_on_container_swap = + memory_internal::ExtractOrT<memory_internal::GetPropagateOnContainerSwap, + Alloc, std::false_type>; + + // is_always_equal: + // Alloc::is_always_equal if present, otherwise std::is_empty<Alloc>::type + using is_always_equal = + memory_internal::ExtractOrT<memory_internal::GetIsAlwaysEqual, Alloc, + typename std::is_empty<Alloc>::type>; + + // rebind_alloc: + // Alloc::rebind<T>::other if present, otherwise Alloc<T, Args> if this Alloc + // is Alloc<U, Args> + template <typename T> + using rebind_alloc = typename memory_internal::RebindAlloc<Alloc, T>::type; + + // rebind_traits: + // absl::allocator_traits<rebind_alloc<T>> + template <typename T> + using rebind_traits = absl::allocator_traits<rebind_alloc<T>>; + + // allocate(Alloc& a, size_type n): + // Calls a.allocate(n) + static pointer allocate(Alloc& a, // NOLINT(runtime/references) + size_type n) { + return a.allocate(n); + } + + // allocate(Alloc& a, size_type n, const_void_pointer hint): + // Calls a.allocate(n, hint) if possible. + // If not possible, calls a.allocate(n) + static pointer allocate(Alloc& a, size_type n, // NOLINT(runtime/references) + const_void_pointer hint) { + return allocate_impl(0, a, n, hint); + } + + // deallocate(Alloc& a, pointer p, size_type n): + // Calls a.deallocate(p, n) + static void deallocate(Alloc& a, pointer p, // NOLINT(runtime/references) + size_type n) { + a.deallocate(p, n); + } + + // construct(Alloc& a, T* p, Args&&... args): + // Calls a.construct(p, std::forward<Args>(args)...) if possible. + // If not possible, calls + // ::new (static_cast<void*>(p)) T(std::forward<Args>(args)...) + template <typename T, typename... Args> + static void construct(Alloc& a, T* p, // NOLINT(runtime/references) + Args&&... args) { + construct_impl(0, a, p, std::forward<Args>(args)...); + } + + // destroy(Alloc& a, T* p): + // Calls a.destroy(p) if possible. If not possible, calls p->~T(). + template <typename T> + static void destroy(Alloc& a, T* p) { // NOLINT(runtime/references) + destroy_impl(0, a, p); + } + + // max_size(const Alloc& a): + // Returns a.max_size() if possible. If not possible, returns + // std::numeric_limits<size_type>::max() / sizeof(value_type) + static size_type max_size(const Alloc& a) { return max_size_impl(0, a); } + + // select_on_container_copy_construction(const Alloc& a): + // Returns a.select_on_container_copy_construction() if possible. + // If not possible, returns a. + static Alloc select_on_container_copy_construction(const Alloc& a) { + return select_on_container_copy_construction_impl(0, a); + } + + private: + template <typename A> + static auto allocate_impl(int, A& a, // NOLINT(runtime/references) + size_type n, const_void_pointer hint) + -> decltype(a.allocate(n, hint)) { + return a.allocate(n, hint); + } + static pointer allocate_impl(char, Alloc& a, // NOLINT(runtime/references) + size_type n, const_void_pointer) { + return a.allocate(n); + } + + template <typename A, typename... Args> + static auto construct_impl(int, A& a, // NOLINT(runtime/references) + Args&&... args) + -> decltype(a.construct(std::forward<Args>(args)...)) { + a.construct(std::forward<Args>(args)...); + } + + template <typename T, typename... Args> + static void construct_impl(char, Alloc&, T* p, Args&&... args) { + ::new (static_cast<void*>(p)) T(std::forward<Args>(args)...); + } + + template <typename A, typename T> + static auto destroy_impl(int, A& a, // NOLINT(runtime/references) + T* p) -> decltype(a.destroy(p)) { + a.destroy(p); + } + template <typename T> + static void destroy_impl(char, Alloc&, T* p) { + p->~T(); + } + + template <typename A> + static auto max_size_impl(int, const A& a) -> decltype(a.max_size()) { + return a.max_size(); + } + static size_type max_size_impl(char, const Alloc&) { + return (std::numeric_limits<size_type>::max)() / sizeof(value_type); + } + + template <typename A> + static auto select_on_container_copy_construction_impl(int, const A& a) + -> decltype(a.select_on_container_copy_construction()) { + return a.select_on_container_copy_construction(); + } + static Alloc select_on_container_copy_construction_impl(char, + const Alloc& a) { + return a; + } +}; + +namespace memory_internal { + +// This template alias transforms Alloc::is_nothrow into a metafunction with +// Alloc as a parameter so it can be used with ExtractOrT<>. +template <typename Alloc> +using GetIsNothrow = typename Alloc::is_nothrow; + +} // namespace memory_internal + +// ABSL_ALLOCATOR_NOTHROW is a build time configuration macro for user to +// specify whether the default allocation function can throw or never throws. +// If the allocation function never throws, user should define it to a non-zero +// value (e.g. via `-DABSL_ALLOCATOR_NOTHROW`). +// If the allocation function can throw, user should leave it undefined or +// define it to zero. +// +// allocator_is_nothrow<Alloc> is a traits class that derives from +// Alloc::is_nothrow if present, otherwise std::false_type. It's specialized +// for Alloc = std::allocator<T> for any type T according to the state of +// ABSL_ALLOCATOR_NOTHROW. +// +// default_allocator_is_nothrow is a class that derives from std::true_type +// when the default allocator (global operator new) never throws, and +// std::false_type when it can throw. It is a convenience shorthand for writing +// allocator_is_nothrow<std::allocator<T>> (T can be any type). +// NOTE: allocator_is_nothrow<std::allocator<T>> is guaranteed to derive from +// the same type for all T, because users should specialize neither +// allocator_is_nothrow nor std::allocator. +template <typename Alloc> +struct allocator_is_nothrow + : memory_internal::ExtractOrT<memory_internal::GetIsNothrow, Alloc, + std::false_type> {}; + +#if defined(ABSL_ALLOCATOR_NOTHROW) && ABSL_ALLOCATOR_NOTHROW +template <typename T> +struct allocator_is_nothrow<std::allocator<T>> : std::true_type {}; +struct default_allocator_is_nothrow : std::true_type {}; +#else +struct default_allocator_is_nothrow : std::false_type {}; +#endif + +namespace memory_internal { +template <typename Allocator, typename Iterator, typename... Args> +void ConstructRange(Allocator& alloc, Iterator first, Iterator last, + const Args&... args) { + for (Iterator cur = first; cur != last; ++cur) { + ABSL_INTERNAL_TRY { + std::allocator_traits<Allocator>::construct(alloc, std::addressof(*cur), + args...); + } + ABSL_INTERNAL_CATCH_ANY { + while (cur != first) { + --cur; + std::allocator_traits<Allocator>::destroy(alloc, std::addressof(*cur)); + } + ABSL_INTERNAL_RETHROW; + } + } +} + +template <typename Allocator, typename Iterator, typename InputIterator> +void CopyRange(Allocator& alloc, Iterator destination, InputIterator first, + InputIterator last) { + for (Iterator cur = destination; first != last; + static_cast<void>(++cur), static_cast<void>(++first)) { + ABSL_INTERNAL_TRY { + std::allocator_traits<Allocator>::construct(alloc, std::addressof(*cur), + *first); + } + ABSL_INTERNAL_CATCH_ANY { + while (cur != destination) { + --cur; + std::allocator_traits<Allocator>::destroy(alloc, std::addressof(*cur)); + } + ABSL_INTERNAL_RETHROW; + } + } +} +} // namespace memory_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_MEMORY_MEMORY_H_ diff --git a/third_party/abseil_cpp/absl/memory/memory_exception_safety_test.cc b/third_party/abseil_cpp/absl/memory/memory_exception_safety_test.cc new file mode 100644 index 0000000000..1df72614c0 --- /dev/null +++ b/third_party/abseil_cpp/absl/memory/memory_exception_safety_test.cc @@ -0,0 +1,57 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/memory/memory.h" + +#include "absl/base/config.h" + +#ifdef ABSL_HAVE_EXCEPTIONS + +#include "gtest/gtest.h" +#include "absl/base/internal/exception_safety_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +constexpr int kLength = 50; +using Thrower = testing::ThrowingValue<testing::TypeSpec::kEverythingThrows>; + +TEST(MakeUnique, CheckForLeaks) { + constexpr int kValue = 321; + auto tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(Thrower(kValue)) + // Ensures make_unique does not modify the input. The real + // test, though, is ConstructorTracker checking for leaks. + .WithContracts(testing::strong_guarantee); + + EXPECT_TRUE(tester.Test([](Thrower* thrower) { + static_cast<void>(absl::make_unique<Thrower>(*thrower)); + })); + + EXPECT_TRUE(tester.Test([](Thrower* thrower) { + static_cast<void>(absl::make_unique<Thrower>(std::move(*thrower))); + })); + + // Test T[n] overload + EXPECT_TRUE(tester.Test([&](Thrower*) { + static_cast<void>(absl::make_unique<Thrower[]>(kLength)); + })); +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_HAVE_EXCEPTIONS diff --git a/third_party/abseil_cpp/absl/memory/memory_test.cc b/third_party/abseil_cpp/absl/memory/memory_test.cc new file mode 100644 index 0000000000..c47820e54a --- /dev/null +++ b/third_party/abseil_cpp/absl/memory/memory_test.cc @@ -0,0 +1,652 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Tests for pointer utilities. + +#include "absl/memory/memory.h" + +#include <sys/types.h> +#include <cstddef> +#include <memory> +#include <string> +#include <type_traits> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" + +namespace { + +using ::testing::ElementsAre; +using ::testing::Return; + +// This class creates observable behavior to verify that a destructor has +// been called, via the instance_count variable. +class DestructorVerifier { + public: + DestructorVerifier() { ++instance_count_; } + DestructorVerifier(const DestructorVerifier&) = delete; + DestructorVerifier& operator=(const DestructorVerifier&) = delete; + ~DestructorVerifier() { --instance_count_; } + + // The number of instances of this class currently active. + static int instance_count() { return instance_count_; } + + private: + // The number of instances of this class currently active. + static int instance_count_; +}; + +int DestructorVerifier::instance_count_ = 0; + +TEST(WrapUniqueTest, WrapUnique) { + // Test that the unique_ptr is constructed properly by verifying that the + // destructor for its payload gets called at the proper time. + { + auto dv = new DestructorVerifier; + EXPECT_EQ(1, DestructorVerifier::instance_count()); + std::unique_ptr<DestructorVerifier> ptr = absl::WrapUnique(dv); + EXPECT_EQ(1, DestructorVerifier::instance_count()); + } + EXPECT_EQ(0, DestructorVerifier::instance_count()); +} +TEST(MakeUniqueTest, Basic) { + std::unique_ptr<std::string> p = absl::make_unique<std::string>(); + EXPECT_EQ("", *p); + p = absl::make_unique<std::string>("hi"); + EXPECT_EQ("hi", *p); +} + +// InitializationVerifier fills in a pattern when allocated so we can +// distinguish between its default and value initialized states (without +// accessing truly uninitialized memory). +struct InitializationVerifier { + static constexpr int kDefaultScalar = 0x43; + static constexpr int kDefaultArray = 0x4B; + + static void* operator new(size_t n) { + void* ret = ::operator new(n); + memset(ret, kDefaultScalar, n); + return ret; + } + + static void* operator new[](size_t n) { + void* ret = ::operator new[](n); + memset(ret, kDefaultArray, n); + return ret; + } + + int a; + int b; +}; + +TEST(Initialization, MakeUnique) { + auto p = absl::make_unique<InitializationVerifier>(); + + EXPECT_EQ(0, p->a); + EXPECT_EQ(0, p->b); +} + +TEST(Initialization, MakeUniqueArray) { + auto p = absl::make_unique<InitializationVerifier[]>(2); + + EXPECT_EQ(0, p[0].a); + EXPECT_EQ(0, p[0].b); + EXPECT_EQ(0, p[1].a); + EXPECT_EQ(0, p[1].b); +} + +struct MoveOnly { + MoveOnly() = default; + explicit MoveOnly(int i1) : ip1{new int{i1}} {} + MoveOnly(int i1, int i2) : ip1{new int{i1}}, ip2{new int{i2}} {} + std::unique_ptr<int> ip1; + std::unique_ptr<int> ip2; +}; + +struct AcceptMoveOnly { + explicit AcceptMoveOnly(MoveOnly m) : m_(std::move(m)) {} + MoveOnly m_; +}; + +TEST(MakeUniqueTest, MoveOnlyTypeAndValue) { + using ExpectedType = std::unique_ptr<MoveOnly>; + { + auto p = absl::make_unique<MoveOnly>(); + static_assert(std::is_same<decltype(p), ExpectedType>::value, + "unexpected return type"); + EXPECT_TRUE(!p->ip1); + EXPECT_TRUE(!p->ip2); + } + { + auto p = absl::make_unique<MoveOnly>(1); + static_assert(std::is_same<decltype(p), ExpectedType>::value, + "unexpected return type"); + EXPECT_TRUE(p->ip1 && *p->ip1 == 1); + EXPECT_TRUE(!p->ip2); + } + { + auto p = absl::make_unique<MoveOnly>(1, 2); + static_assert(std::is_same<decltype(p), ExpectedType>::value, + "unexpected return type"); + EXPECT_TRUE(p->ip1 && *p->ip1 == 1); + EXPECT_TRUE(p->ip2 && *p->ip2 == 2); + } +} + +TEST(MakeUniqueTest, AcceptMoveOnly) { + auto p = absl::make_unique<AcceptMoveOnly>(MoveOnly()); + p = std::unique_ptr<AcceptMoveOnly>(new AcceptMoveOnly(MoveOnly())); +} + +struct ArrayWatch { + void* operator new[](size_t n) { + allocs().push_back(n); + return ::operator new[](n); + } + void operator delete[](void* p) { + return ::operator delete[](p); + } + static std::vector<size_t>& allocs() { + static auto& v = *new std::vector<size_t>; + return v; + } +}; + +TEST(Make_UniqueTest, Array) { + // Ensure state is clean before we start so that these tests + // are order-agnostic. + ArrayWatch::allocs().clear(); + + auto p = absl::make_unique<ArrayWatch[]>(5); + static_assert(std::is_same<decltype(p), + std::unique_ptr<ArrayWatch[]>>::value, + "unexpected return type"); + EXPECT_THAT(ArrayWatch::allocs(), ElementsAre(5 * sizeof(ArrayWatch))); +} + +TEST(Make_UniqueTest, NotAmbiguousWithStdMakeUnique) { + // Ensure that absl::make_unique is not ambiguous with std::make_unique. + // In C++14 mode, the below call to make_unique has both types as candidates. + struct TakesStdType { + explicit TakesStdType(const std::vector<int> &vec) {} + }; + using absl::make_unique; + (void)make_unique<TakesStdType>(std::vector<int>()); +} + +#if 0 +// These tests shouldn't compile. +TEST(MakeUniqueTestNC, AcceptMoveOnlyLvalue) { + auto m = MoveOnly(); + auto p = absl::make_unique<AcceptMoveOnly>(m); +} +TEST(MakeUniqueTestNC, KnownBoundArray) { + auto p = absl::make_unique<ArrayWatch[5]>(); +} +#endif + +TEST(RawPtrTest, RawPointer) { + int i = 5; + EXPECT_EQ(&i, absl::RawPtr(&i)); +} + +TEST(RawPtrTest, SmartPointer) { + int* o = new int(5); + std::unique_ptr<int> p(o); + EXPECT_EQ(o, absl::RawPtr(p)); +} + +class IntPointerNonConstDeref { + public: + explicit IntPointerNonConstDeref(int* p) : p_(p) {} + friend bool operator!=(const IntPointerNonConstDeref& a, std::nullptr_t) { + return a.p_ != nullptr; + } + int& operator*() { return *p_; } + + private: + std::unique_ptr<int> p_; +}; + +TEST(RawPtrTest, SmartPointerNonConstDereference) { + int* o = new int(5); + IntPointerNonConstDeref p(o); + EXPECT_EQ(o, absl::RawPtr(p)); +} + +TEST(RawPtrTest, NullValuedRawPointer) { + int* p = nullptr; + EXPECT_EQ(nullptr, absl::RawPtr(p)); +} + +TEST(RawPtrTest, NullValuedSmartPointer) { + std::unique_ptr<int> p; + EXPECT_EQ(nullptr, absl::RawPtr(p)); +} + +TEST(RawPtrTest, Nullptr) { + auto p = absl::RawPtr(nullptr); + EXPECT_TRUE((std::is_same<std::nullptr_t, decltype(p)>::value)); + EXPECT_EQ(nullptr, p); +} + +TEST(RawPtrTest, Null) { + auto p = absl::RawPtr(nullptr); + EXPECT_TRUE((std::is_same<std::nullptr_t, decltype(p)>::value)); + EXPECT_EQ(nullptr, p); +} + +TEST(RawPtrTest, Zero) { + auto p = absl::RawPtr(nullptr); + EXPECT_TRUE((std::is_same<std::nullptr_t, decltype(p)>::value)); + EXPECT_EQ(nullptr, p); +} + +TEST(ShareUniquePtrTest, Share) { + auto up = absl::make_unique<int>(); + int* rp = up.get(); + auto sp = absl::ShareUniquePtr(std::move(up)); + EXPECT_EQ(sp.get(), rp); +} + +TEST(ShareUniquePtrTest, ShareNull) { + struct NeverDie { + using pointer = void*; + void operator()(pointer) { + ASSERT_TRUE(false) << "Deleter should not have been called."; + } + }; + + std::unique_ptr<void, NeverDie> up; + auto sp = absl::ShareUniquePtr(std::move(up)); +} + +TEST(WeakenPtrTest, Weak) { + auto sp = std::make_shared<int>(); + auto wp = absl::WeakenPtr(sp); + EXPECT_EQ(sp.get(), wp.lock().get()); + sp.reset(); + EXPECT_TRUE(wp.expired()); +} + +// Should not compile. +/* +TEST(RawPtrTest, NotAPointer) { + absl::RawPtr(1.5); +} +*/ + +template <typename T> +struct SmartPointer { + using difference_type = char; +}; + +struct PointerWith { + using element_type = int32_t; + using difference_type = int16_t; + template <typename U> + using rebind = SmartPointer<U>; + + static PointerWith pointer_to( + element_type& r) { // NOLINT(runtime/references) + return PointerWith{&r}; + } + + element_type* ptr; +}; + +template <typename... Args> +struct PointerWithout {}; + +TEST(PointerTraits, Types) { + using TraitsWith = absl::pointer_traits<PointerWith>; + EXPECT_TRUE((std::is_same<TraitsWith::pointer, PointerWith>::value)); + EXPECT_TRUE((std::is_same<TraitsWith::element_type, int32_t>::value)); + EXPECT_TRUE((std::is_same<TraitsWith::difference_type, int16_t>::value)); + EXPECT_TRUE(( + std::is_same<TraitsWith::rebind<int64_t>, SmartPointer<int64_t>>::value)); + + using TraitsWithout = absl::pointer_traits<PointerWithout<double, int>>; + EXPECT_TRUE((std::is_same<TraitsWithout::pointer, + PointerWithout<double, int>>::value)); + EXPECT_TRUE((std::is_same<TraitsWithout::element_type, double>::value)); + EXPECT_TRUE( + (std::is_same<TraitsWithout ::difference_type, std::ptrdiff_t>::value)); + EXPECT_TRUE((std::is_same<TraitsWithout::rebind<int64_t>, + PointerWithout<int64_t, int>>::value)); + + using TraitsRawPtr = absl::pointer_traits<char*>; + EXPECT_TRUE((std::is_same<TraitsRawPtr::pointer, char*>::value)); + EXPECT_TRUE((std::is_same<TraitsRawPtr::element_type, char>::value)); + EXPECT_TRUE( + (std::is_same<TraitsRawPtr::difference_type, std::ptrdiff_t>::value)); + EXPECT_TRUE((std::is_same<TraitsRawPtr::rebind<int64_t>, int64_t*>::value)); +} + +TEST(PointerTraits, Functions) { + int i; + EXPECT_EQ(&i, absl::pointer_traits<PointerWith>::pointer_to(i).ptr); + EXPECT_EQ(&i, absl::pointer_traits<int*>::pointer_to(i)); +} + +TEST(AllocatorTraits, Typedefs) { + struct A { + struct value_type {}; + }; + EXPECT_TRUE(( + std::is_same<A, + typename absl::allocator_traits<A>::allocator_type>::value)); + EXPECT_TRUE( + (std::is_same<A::value_type, + typename absl::allocator_traits<A>::value_type>::value)); + + struct X {}; + struct HasPointer { + using value_type = X; + using pointer = SmartPointer<X>; + }; + EXPECT_TRUE((std::is_same<SmartPointer<X>, typename absl::allocator_traits< + HasPointer>::pointer>::value)); + EXPECT_TRUE( + (std::is_same<A::value_type*, + typename absl::allocator_traits<A>::pointer>::value)); + + EXPECT_TRUE( + (std::is_same< + SmartPointer<const X>, + typename absl::allocator_traits<HasPointer>::const_pointer>::value)); + EXPECT_TRUE( + (std::is_same<const A::value_type*, + typename absl::allocator_traits<A>::const_pointer>::value)); + + struct HasVoidPointer { + using value_type = X; + struct void_pointer {}; + }; + + EXPECT_TRUE((std::is_same<HasVoidPointer::void_pointer, + typename absl::allocator_traits< + HasVoidPointer>::void_pointer>::value)); + EXPECT_TRUE( + (std::is_same<SmartPointer<void>, typename absl::allocator_traits< + HasPointer>::void_pointer>::value)); + + struct HasConstVoidPointer { + using value_type = X; + struct const_void_pointer {}; + }; + + EXPECT_TRUE( + (std::is_same<HasConstVoidPointer::const_void_pointer, + typename absl::allocator_traits< + HasConstVoidPointer>::const_void_pointer>::value)); + EXPECT_TRUE((std::is_same<SmartPointer<const void>, + typename absl::allocator_traits< + HasPointer>::const_void_pointer>::value)); + + struct HasDifferenceType { + using value_type = X; + using difference_type = int; + }; + EXPECT_TRUE( + (std::is_same<int, typename absl::allocator_traits< + HasDifferenceType>::difference_type>::value)); + EXPECT_TRUE((std::is_same<char, typename absl::allocator_traits< + HasPointer>::difference_type>::value)); + + struct HasSizeType { + using value_type = X; + using size_type = unsigned int; + }; + EXPECT_TRUE((std::is_same<unsigned int, typename absl::allocator_traits< + HasSizeType>::size_type>::value)); + EXPECT_TRUE((std::is_same<unsigned char, typename absl::allocator_traits< + HasPointer>::size_type>::value)); + + struct HasPropagateOnCopy { + using value_type = X; + struct propagate_on_container_copy_assignment {}; + }; + + EXPECT_TRUE( + (std::is_same<HasPropagateOnCopy::propagate_on_container_copy_assignment, + typename absl::allocator_traits<HasPropagateOnCopy>:: + propagate_on_container_copy_assignment>::value)); + EXPECT_TRUE( + (std::is_same<std::false_type, + typename absl::allocator_traits< + A>::propagate_on_container_copy_assignment>::value)); + + struct HasPropagateOnMove { + using value_type = X; + struct propagate_on_container_move_assignment {}; + }; + + EXPECT_TRUE( + (std::is_same<HasPropagateOnMove::propagate_on_container_move_assignment, + typename absl::allocator_traits<HasPropagateOnMove>:: + propagate_on_container_move_assignment>::value)); + EXPECT_TRUE( + (std::is_same<std::false_type, + typename absl::allocator_traits< + A>::propagate_on_container_move_assignment>::value)); + + struct HasPropagateOnSwap { + using value_type = X; + struct propagate_on_container_swap {}; + }; + + EXPECT_TRUE( + (std::is_same<HasPropagateOnSwap::propagate_on_container_swap, + typename absl::allocator_traits<HasPropagateOnSwap>:: + propagate_on_container_swap>::value)); + EXPECT_TRUE( + (std::is_same<std::false_type, typename absl::allocator_traits<A>:: + propagate_on_container_swap>::value)); + + struct HasIsAlwaysEqual { + using value_type = X; + struct is_always_equal {}; + }; + + EXPECT_TRUE((std::is_same<HasIsAlwaysEqual::is_always_equal, + typename absl::allocator_traits< + HasIsAlwaysEqual>::is_always_equal>::value)); + EXPECT_TRUE((std::is_same<std::true_type, typename absl::allocator_traits< + A>::is_always_equal>::value)); + struct NonEmpty { + using value_type = X; + int i; + }; + EXPECT_TRUE( + (std::is_same<std::false_type, + absl::allocator_traits<NonEmpty>::is_always_equal>::value)); +} + +template <typename T> +struct AllocWithPrivateInheritance : private std::allocator<T> { + using value_type = T; +}; + +TEST(AllocatorTraits, RebindWithPrivateInheritance) { + // Regression test for some versions of gcc that do not like the sfinae we + // used in combination with private inheritance. + EXPECT_TRUE( + (std::is_same<AllocWithPrivateInheritance<int>, + absl::allocator_traits<AllocWithPrivateInheritance<char>>:: + rebind_alloc<int>>::value)); +} + +template <typename T> +struct Rebound {}; + +struct AllocWithRebind { + using value_type = int; + template <typename T> + struct rebind { + using other = Rebound<T>; + }; +}; + +template <typename T, typename U> +struct AllocWithoutRebind { + using value_type = int; +}; + +TEST(AllocatorTraits, Rebind) { + EXPECT_TRUE( + (std::is_same<Rebound<int>, + typename absl::allocator_traits< + AllocWithRebind>::template rebind_alloc<int>>::value)); + EXPECT_TRUE( + (std::is_same<absl::allocator_traits<Rebound<int>>, + typename absl::allocator_traits< + AllocWithRebind>::template rebind_traits<int>>::value)); + + EXPECT_TRUE( + (std::is_same<AllocWithoutRebind<double, char>, + typename absl::allocator_traits<AllocWithoutRebind< + int, char>>::template rebind_alloc<double>>::value)); + EXPECT_TRUE( + (std::is_same<absl::allocator_traits<AllocWithoutRebind<double, char>>, + typename absl::allocator_traits<AllocWithoutRebind< + int, char>>::template rebind_traits<double>>::value)); +} + +struct TestValue { + TestValue() {} + explicit TestValue(int* trace) : trace(trace) { ++*trace; } + ~TestValue() { + if (trace) --*trace; + } + int* trace = nullptr; +}; + +struct MinimalMockAllocator { + MinimalMockAllocator() : value(0) {} + explicit MinimalMockAllocator(int value) : value(value) {} + MinimalMockAllocator(const MinimalMockAllocator& other) + : value(other.value) {} + using value_type = TestValue; + MOCK_METHOD1(allocate, value_type*(size_t)); + MOCK_METHOD2(deallocate, void(value_type*, size_t)); + + int value; +}; + +TEST(AllocatorTraits, FunctionsMinimal) { + int trace = 0; + int hint; + TestValue x(&trace); + MinimalMockAllocator mock; + using Traits = absl::allocator_traits<MinimalMockAllocator>; + EXPECT_CALL(mock, allocate(7)).WillRepeatedly(Return(&x)); + EXPECT_CALL(mock, deallocate(&x, 7)); + + EXPECT_EQ(&x, Traits::allocate(mock, 7)); + Traits::allocate(mock, 7, static_cast<const void*>(&hint)); + EXPECT_EQ(&x, Traits::allocate(mock, 7, static_cast<const void*>(&hint))); + Traits::deallocate(mock, &x, 7); + + EXPECT_EQ(1, trace); + Traits::construct(mock, &x, &trace); + EXPECT_EQ(2, trace); + Traits::destroy(mock, &x); + EXPECT_EQ(1, trace); + + EXPECT_EQ(std::numeric_limits<size_t>::max() / sizeof(TestValue), + Traits::max_size(mock)); + + EXPECT_EQ(0, mock.value); + EXPECT_EQ(0, Traits::select_on_container_copy_construction(mock).value); +} + +struct FullMockAllocator { + FullMockAllocator() : value(0) {} + explicit FullMockAllocator(int value) : value(value) {} + FullMockAllocator(const FullMockAllocator& other) : value(other.value) {} + using value_type = TestValue; + MOCK_METHOD1(allocate, value_type*(size_t)); + MOCK_METHOD2(allocate, value_type*(size_t, const void*)); + MOCK_METHOD2(construct, void(value_type*, int*)); + MOCK_METHOD1(destroy, void(value_type*)); + MOCK_CONST_METHOD0(max_size, size_t()); + MOCK_CONST_METHOD0(select_on_container_copy_construction, + FullMockAllocator()); + + int value; +}; + +TEST(AllocatorTraits, FunctionsFull) { + int trace = 0; + int hint; + TestValue x(&trace), y; + FullMockAllocator mock; + using Traits = absl::allocator_traits<FullMockAllocator>; + EXPECT_CALL(mock, allocate(7)).WillRepeatedly(Return(&x)); + EXPECT_CALL(mock, allocate(13, &hint)).WillRepeatedly(Return(&y)); + EXPECT_CALL(mock, construct(&x, &trace)); + EXPECT_CALL(mock, destroy(&x)); + EXPECT_CALL(mock, max_size()).WillRepeatedly(Return(17)); + EXPECT_CALL(mock, select_on_container_copy_construction()) + .WillRepeatedly(Return(FullMockAllocator(23))); + + EXPECT_EQ(&x, Traits::allocate(mock, 7)); + EXPECT_EQ(&y, Traits::allocate(mock, 13, static_cast<const void*>(&hint))); + + EXPECT_EQ(1, trace); + Traits::construct(mock, &x, &trace); + EXPECT_EQ(1, trace); + Traits::destroy(mock, &x); + EXPECT_EQ(1, trace); + + EXPECT_EQ(17, Traits::max_size(mock)); + + EXPECT_EQ(0, mock.value); + EXPECT_EQ(23, Traits::select_on_container_copy_construction(mock).value); +} + +TEST(AllocatorNoThrowTest, DefaultAllocator) { +#if defined(ABSL_ALLOCATOR_NOTHROW) && ABSL_ALLOCATOR_NOTHROW + EXPECT_TRUE(absl::default_allocator_is_nothrow::value); +#else + EXPECT_FALSE(absl::default_allocator_is_nothrow::value); +#endif +} + +TEST(AllocatorNoThrowTest, StdAllocator) { +#if defined(ABSL_ALLOCATOR_NOTHROW) && ABSL_ALLOCATOR_NOTHROW + EXPECT_TRUE(absl::allocator_is_nothrow<std::allocator<int>>::value); +#else + EXPECT_FALSE(absl::allocator_is_nothrow<std::allocator<int>>::value); +#endif +} + +TEST(AllocatorNoThrowTest, CustomAllocator) { + struct NoThrowAllocator { + using is_nothrow = std::true_type; + }; + struct CanThrowAllocator { + using is_nothrow = std::false_type; + }; + struct UnspecifiedAllocator { + }; + EXPECT_TRUE(absl::allocator_is_nothrow<NoThrowAllocator>::value); + EXPECT_FALSE(absl::allocator_is_nothrow<CanThrowAllocator>::value); + EXPECT_FALSE(absl::allocator_is_nothrow<UnspecifiedAllocator>::value); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/meta/BUILD.bazel b/third_party/abseil_cpp/absl/meta/BUILD.bazel new file mode 100644 index 0000000000..c06d2d9708 --- /dev/null +++ b/third_party/abseil_cpp/absl/meta/BUILD.bazel @@ -0,0 +1,48 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "type_traits", + hdrs = ["type_traits.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + ], +) + +cc_test( + name = "type_traits_test", + srcs = ["type_traits_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":type_traits", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/meta/CMakeLists.txt b/third_party/abseil_cpp/absl/meta/CMakeLists.txt new file mode 100644 index 0000000000..672ead2fd0 --- /dev/null +++ b/third_party/abseil_cpp/absl/meta/CMakeLists.txt @@ -0,0 +1,50 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + type_traits + HDRS + "type_traits.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + PUBLIC +) + +absl_cc_test( + NAME + type_traits_test + SRCS + "type_traits_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::type_traits + gmock_main +) + +# component target +absl_cc_library( + NAME + meta + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::type_traits + PUBLIC +) diff --git a/third_party/abseil_cpp/absl/meta/type_traits.h b/third_party/abseil_cpp/absl/meta/type_traits.h new file mode 100644 index 0000000000..ba87d2f0ed --- /dev/null +++ b/third_party/abseil_cpp/absl/meta/type_traits.h @@ -0,0 +1,759 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// type_traits.h +// ----------------------------------------------------------------------------- +// +// This file contains C++11-compatible versions of standard <type_traits> API +// functions for determining the characteristics of types. Such traits can +// support type inference, classification, and transformation, as well as +// make it easier to write templates based on generic type behavior. +// +// See https://en.cppreference.com/w/cpp/header/type_traits +// +// WARNING: use of many of the constructs in this header will count as "complex +// template metaprogramming", so before proceeding, please carefully consider +// https://google.github.io/styleguide/cppguide.html#Template_metaprogramming +// +// WARNING: using template metaprogramming to detect or depend on API +// features is brittle and not guaranteed. Neither the standard library nor +// Abseil provides any guarantee that APIs are stable in the face of template +// metaprogramming. Use with caution. +#ifndef ABSL_META_TYPE_TRAITS_H_ +#define ABSL_META_TYPE_TRAITS_H_ + +#include <stddef.h> +#include <functional> +#include <type_traits> + +#include "absl/base/config.h" + +// MSVC constructibility traits do not detect destructor properties and so our +// implementations should not use them as a source-of-truth. +#if defined(_MSC_VER) && !defined(__clang__) && !defined(__GNUC__) +#define ABSL_META_INTERNAL_STD_CONSTRUCTION_TRAITS_DONT_CHECK_DESTRUCTION 1 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Defined and documented later on in this file. +template <typename T> +struct is_trivially_destructible; + +// Defined and documented later on in this file. +template <typename T> +struct is_trivially_move_assignable; + +namespace type_traits_internal { + +// Silence MSVC warnings about the destructor being defined as deleted. +#if defined(_MSC_VER) && !defined(__GNUC__) +#pragma warning(push) +#pragma warning(disable : 4624) +#endif // defined(_MSC_VER) && !defined(__GNUC__) + +template <class T> +union SingleMemberUnion { + T t; +}; + +// Restore the state of the destructor warning that was silenced above. +#if defined(_MSC_VER) && !defined(__GNUC__) +#pragma warning(pop) +#endif // defined(_MSC_VER) && !defined(__GNUC__) + +template <class T> +struct IsTriviallyMoveConstructibleObject + : std::integral_constant< + bool, std::is_move_constructible< + type_traits_internal::SingleMemberUnion<T>>::value && + absl::is_trivially_destructible<T>::value> {}; + +template <class T> +struct IsTriviallyCopyConstructibleObject + : std::integral_constant< + bool, std::is_copy_constructible< + type_traits_internal::SingleMemberUnion<T>>::value && + absl::is_trivially_destructible<T>::value> {}; + +template <class T> +struct IsTriviallyMoveAssignableReference : std::false_type {}; + +template <class T> +struct IsTriviallyMoveAssignableReference<T&> + : absl::is_trivially_move_assignable<T>::type {}; + +template <class T> +struct IsTriviallyMoveAssignableReference<T&&> + : absl::is_trivially_move_assignable<T>::type {}; + +template <typename... Ts> +struct VoidTImpl { + using type = void; +}; + +// This trick to retrieve a default alignment is necessary for our +// implementation of aligned_storage_t to be consistent with any implementation +// of std::aligned_storage. +template <size_t Len, typename T = std::aligned_storage<Len>> +struct default_alignment_of_aligned_storage; + +template <size_t Len, size_t Align> +struct default_alignment_of_aligned_storage<Len, + std::aligned_storage<Len, Align>> { + static constexpr size_t value = Align; +}; + +//////////////////////////////// +// Library Fundamentals V2 TS // +//////////////////////////////// + +// NOTE: The `is_detected` family of templates here differ from the library +// fundamentals specification in that for library fundamentals, `Op<Args...>` is +// evaluated as soon as the type `is_detected<Op, Args...>` undergoes +// substitution, regardless of whether or not the `::value` is accessed. That +// is inconsistent with all other standard traits and prevents lazy evaluation +// in larger contexts (such as if the `is_detected` check is a trailing argument +// of a `conjunction`. This implementation opts to instead be lazy in the same +// way that the standard traits are (this "defect" of the detection idiom +// specifications has been reported). + +template <class Enabler, template <class...> class Op, class... Args> +struct is_detected_impl { + using type = std::false_type; +}; + +template <template <class...> class Op, class... Args> +struct is_detected_impl<typename VoidTImpl<Op<Args...>>::type, Op, Args...> { + using type = std::true_type; +}; + +template <template <class...> class Op, class... Args> +struct is_detected : is_detected_impl<void, Op, Args...>::type {}; + +template <class Enabler, class To, template <class...> class Op, class... Args> +struct is_detected_convertible_impl { + using type = std::false_type; +}; + +template <class To, template <class...> class Op, class... Args> +struct is_detected_convertible_impl< + typename std::enable_if<std::is_convertible<Op<Args...>, To>::value>::type, + To, Op, Args...> { + using type = std::true_type; +}; + +template <class To, template <class...> class Op, class... Args> +struct is_detected_convertible + : is_detected_convertible_impl<void, To, Op, Args...>::type {}; + +template <typename T> +using IsCopyAssignableImpl = + decltype(std::declval<T&>() = std::declval<const T&>()); + +template <typename T> +using IsMoveAssignableImpl = decltype(std::declval<T&>() = std::declval<T&&>()); + +} // namespace type_traits_internal + +// MSVC 19.20 has a regression that causes our workarounds to fail, but their +// std forms now appear to be compliant. +#if defined(_MSC_VER) && !defined(__clang__) && (_MSC_VER >= 1920) + +template <typename T> +using is_copy_assignable = std::is_copy_assignable<T>; + +template <typename T> +using is_move_assignable = std::is_move_assignable<T>; + +#else + +template <typename T> +struct is_copy_assignable : type_traits_internal::is_detected< + type_traits_internal::IsCopyAssignableImpl, T> { +}; + +template <typename T> +struct is_move_assignable : type_traits_internal::is_detected< + type_traits_internal::IsMoveAssignableImpl, T> { +}; + +#endif + +// void_t() +// +// Ignores the type of any its arguments and returns `void`. In general, this +// metafunction allows you to create a general case that maps to `void` while +// allowing specializations that map to specific types. +// +// This metafunction is designed to be a drop-in replacement for the C++17 +// `std::void_t` metafunction. +// +// NOTE: `absl::void_t` does not use the standard-specified implementation so +// that it can remain compatible with gcc < 5.1. This can introduce slightly +// different behavior, such as when ordering partial specializations. +template <typename... Ts> +using void_t = typename type_traits_internal::VoidTImpl<Ts...>::type; + +// conjunction +// +// Performs a compile-time logical AND operation on the passed types (which +// must have `::value` members convertible to `bool`. Short-circuits if it +// encounters any `false` members (and does not compare the `::value` members +// of any remaining arguments). +// +// This metafunction is designed to be a drop-in replacement for the C++17 +// `std::conjunction` metafunction. +template <typename... Ts> +struct conjunction; + +template <typename T, typename... Ts> +struct conjunction<T, Ts...> + : std::conditional<T::value, conjunction<Ts...>, T>::type {}; + +template <typename T> +struct conjunction<T> : T {}; + +template <> +struct conjunction<> : std::true_type {}; + +// disjunction +// +// Performs a compile-time logical OR operation on the passed types (which +// must have `::value` members convertible to `bool`. Short-circuits if it +// encounters any `true` members (and does not compare the `::value` members +// of any remaining arguments). +// +// This metafunction is designed to be a drop-in replacement for the C++17 +// `std::disjunction` metafunction. +template <typename... Ts> +struct disjunction; + +template <typename T, typename... Ts> +struct disjunction<T, Ts...> : + std::conditional<T::value, T, disjunction<Ts...>>::type {}; + +template <typename T> +struct disjunction<T> : T {}; + +template <> +struct disjunction<> : std::false_type {}; + +// negation +// +// Performs a compile-time logical NOT operation on the passed type (which +// must have `::value` members convertible to `bool`. +// +// This metafunction is designed to be a drop-in replacement for the C++17 +// `std::negation` metafunction. +template <typename T> +struct negation : std::integral_constant<bool, !T::value> {}; + +// is_function() +// +// Determines whether the passed type `T` is a function type. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_function()` metafunction for platforms that have incomplete C++11 +// support (such as libstdc++ 4.x). +// +// This metafunction works because appending `const` to a type does nothing to +// function types and reference types (and forms a const-qualified type +// otherwise). +template <typename T> +struct is_function + : std::integral_constant< + bool, !(std::is_reference<T>::value || + std::is_const<typename std::add_const<T>::type>::value)> {}; + +// is_trivially_destructible() +// +// Determines whether the passed type `T` is trivially destructible. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_destructible()` metafunction for platforms that have +// incomplete C++11 support (such as libstdc++ 4.x). On any platforms that do +// fully support C++11, we check whether this yields the same result as the std +// implementation. +// +// NOTE: the extensions (__has_trivial_xxx) are implemented in gcc (version >= +// 4.3) and clang. Since we are supporting libstdc++ > 4.7, they should always +// be present. These extensions are documented at +// https://gcc.gnu.org/onlinedocs/gcc/Type-Traits.html#Type-Traits. +template <typename T> +struct is_trivially_destructible + : std::integral_constant<bool, __has_trivial_destructor(T) && + std::is_destructible<T>::value> { +#ifdef ABSL_HAVE_STD_IS_TRIVIALLY_DESTRUCTIBLE + private: + static constexpr bool compliant = std::is_trivially_destructible<T>::value == + is_trivially_destructible::value; + static_assert(compliant || std::is_trivially_destructible<T>::value, + "Not compliant with std::is_trivially_destructible; " + "Standard: false, Implementation: true"); + static_assert(compliant || !std::is_trivially_destructible<T>::value, + "Not compliant with std::is_trivially_destructible; " + "Standard: true, Implementation: false"); +#endif // ABSL_HAVE_STD_IS_TRIVIALLY_DESTRUCTIBLE +}; + +// is_trivially_default_constructible() +// +// Determines whether the passed type `T` is trivially default constructible. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_default_constructible()` metafunction for platforms that +// have incomplete C++11 support (such as libstdc++ 4.x). On any platforms that +// do fully support C++11, we check whether this yields the same result as the +// std implementation. +// +// NOTE: according to the C++ standard, Section: 20.15.4.3 [meta.unary.prop] +// "The predicate condition for a template specialization is_constructible<T, +// Args...> shall be satisfied if and only if the following variable +// definition would be well-formed for some invented variable t: +// +// T t(declval<Args>()...); +// +// is_trivially_constructible<T, Args...> additionally requires that the +// variable definition does not call any operation that is not trivial. +// For the purposes of this check, the call to std::declval is considered +// trivial." +// +// Notes from https://en.cppreference.com/w/cpp/types/is_constructible: +// In many implementations, is_nothrow_constructible also checks if the +// destructor throws because it is effectively noexcept(T(arg)). Same +// applies to is_trivially_constructible, which, in these implementations, also +// requires that the destructor is trivial. +// GCC bug 51452: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=51452 +// LWG issue 2116: http://cplusplus.github.io/LWG/lwg-active.html#2116. +// +// "T obj();" need to be well-formed and not call any nontrivial operation. +// Nontrivially destructible types will cause the expression to be nontrivial. +template <typename T> +struct is_trivially_default_constructible + : std::integral_constant<bool, __has_trivial_constructor(T) && + std::is_default_constructible<T>::value && + is_trivially_destructible<T>::value> { +#if defined(ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE) && \ + !defined( \ + ABSL_META_INTERNAL_STD_CONSTRUCTION_TRAITS_DONT_CHECK_DESTRUCTION) + private: + static constexpr bool compliant = + std::is_trivially_default_constructible<T>::value == + is_trivially_default_constructible::value; + static_assert(compliant || std::is_trivially_default_constructible<T>::value, + "Not compliant with std::is_trivially_default_constructible; " + "Standard: false, Implementation: true"); + static_assert(compliant || !std::is_trivially_default_constructible<T>::value, + "Not compliant with std::is_trivially_default_constructible; " + "Standard: true, Implementation: false"); +#endif // ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE +}; + +// is_trivially_move_constructible() +// +// Determines whether the passed type `T` is trivially move constructible. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_move_constructible()` metafunction for platforms that have +// incomplete C++11 support (such as libstdc++ 4.x). On any platforms that do +// fully support C++11, we check whether this yields the same result as the std +// implementation. +// +// NOTE: `T obj(declval<T>());` needs to be well-formed and not call any +// nontrivial operation. Nontrivially destructible types will cause the +// expression to be nontrivial. +template <typename T> +struct is_trivially_move_constructible + : std::conditional< + std::is_object<T>::value && !std::is_array<T>::value, + type_traits_internal::IsTriviallyMoveConstructibleObject<T>, + std::is_reference<T>>::type::type { +#if defined(ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE) && \ + !defined( \ + ABSL_META_INTERNAL_STD_CONSTRUCTION_TRAITS_DONT_CHECK_DESTRUCTION) + private: + static constexpr bool compliant = + std::is_trivially_move_constructible<T>::value == + is_trivially_move_constructible::value; + static_assert(compliant || std::is_trivially_move_constructible<T>::value, + "Not compliant with std::is_trivially_move_constructible; " + "Standard: false, Implementation: true"); + static_assert(compliant || !std::is_trivially_move_constructible<T>::value, + "Not compliant with std::is_trivially_move_constructible; " + "Standard: true, Implementation: false"); +#endif // ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE +}; + +// is_trivially_copy_constructible() +// +// Determines whether the passed type `T` is trivially copy constructible. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_copy_constructible()` metafunction for platforms that have +// incomplete C++11 support (such as libstdc++ 4.x). On any platforms that do +// fully support C++11, we check whether this yields the same result as the std +// implementation. +// +// NOTE: `T obj(declval<const T&>());` needs to be well-formed and not call any +// nontrivial operation. Nontrivially destructible types will cause the +// expression to be nontrivial. +template <typename T> +struct is_trivially_copy_constructible + : std::conditional< + std::is_object<T>::value && !std::is_array<T>::value, + type_traits_internal::IsTriviallyCopyConstructibleObject<T>, + std::is_lvalue_reference<T>>::type::type { +#if defined(ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE) && \ + !defined( \ + ABSL_META_INTERNAL_STD_CONSTRUCTION_TRAITS_DONT_CHECK_DESTRUCTION) + private: + static constexpr bool compliant = + std::is_trivially_copy_constructible<T>::value == + is_trivially_copy_constructible::value; + static_assert(compliant || std::is_trivially_copy_constructible<T>::value, + "Not compliant with std::is_trivially_copy_constructible; " + "Standard: false, Implementation: true"); + static_assert(compliant || !std::is_trivially_copy_constructible<T>::value, + "Not compliant with std::is_trivially_copy_constructible; " + "Standard: true, Implementation: false"); +#endif // ABSL_HAVE_STD_IS_TRIVIALLY_CONSTRUCTIBLE +}; + +// is_trivially_move_assignable() +// +// Determines whether the passed type `T` is trivially move assignable. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_move_assignable()` metafunction for platforms that have +// incomplete C++11 support (such as libstdc++ 4.x). On any platforms that do +// fully support C++11, we check whether this yields the same result as the std +// implementation. +// +// NOTE: `is_assignable<T, U>::value` is `true` if the expression +// `declval<T>() = declval<U>()` is well-formed when treated as an unevaluated +// operand. `is_trivially_assignable<T, U>` requires the assignment to call no +// operation that is not trivial. `is_trivially_copy_assignable<T>` is simply +// `is_trivially_assignable<T&, T>`. +template <typename T> +struct is_trivially_move_assignable + : std::conditional< + std::is_object<T>::value && !std::is_array<T>::value && + std::is_move_assignable<T>::value, + std::is_move_assignable<type_traits_internal::SingleMemberUnion<T>>, + type_traits_internal::IsTriviallyMoveAssignableReference<T>>::type:: + type { +#ifdef ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE + private: + static constexpr bool compliant = + std::is_trivially_move_assignable<T>::value == + is_trivially_move_assignable::value; + static_assert(compliant || std::is_trivially_move_assignable<T>::value, + "Not compliant with std::is_trivially_move_assignable; " + "Standard: false, Implementation: true"); + static_assert(compliant || !std::is_trivially_move_assignable<T>::value, + "Not compliant with std::is_trivially_move_assignable; " + "Standard: true, Implementation: false"); +#endif // ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE +}; + +// is_trivially_copy_assignable() +// +// Determines whether the passed type `T` is trivially copy assignable. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_copy_assignable()` metafunction for platforms that have +// incomplete C++11 support (such as libstdc++ 4.x). On any platforms that do +// fully support C++11, we check whether this yields the same result as the std +// implementation. +// +// NOTE: `is_assignable<T, U>::value` is `true` if the expression +// `declval<T>() = declval<U>()` is well-formed when treated as an unevaluated +// operand. `is_trivially_assignable<T, U>` requires the assignment to call no +// operation that is not trivial. `is_trivially_copy_assignable<T>` is simply +// `is_trivially_assignable<T&, const T&>`. +template <typename T> +struct is_trivially_copy_assignable + : std::integral_constant< + bool, __has_trivial_assign(typename std::remove_reference<T>::type) && + absl::is_copy_assignable<T>::value> { +#ifdef ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE + private: + static constexpr bool compliant = + std::is_trivially_copy_assignable<T>::value == + is_trivially_copy_assignable::value; + static_assert(compliant || std::is_trivially_copy_assignable<T>::value, + "Not compliant with std::is_trivially_copy_assignable; " + "Standard: false, Implementation: true"); + static_assert(compliant || !std::is_trivially_copy_assignable<T>::value, + "Not compliant with std::is_trivially_copy_assignable; " + "Standard: true, Implementation: false"); +#endif // ABSL_HAVE_STD_IS_TRIVIALLY_ASSIGNABLE +}; + +namespace type_traits_internal { +// is_trivially_copyable() +// +// Determines whether the passed type `T` is trivially copyable. +// +// This metafunction is designed to be a drop-in replacement for the C++11 +// `std::is_trivially_copyable()` metafunction for platforms that have +// incomplete C++11 support (such as libstdc++ 4.x). We use the C++17 definition +// of TriviallyCopyable. +// +// NOTE: `is_trivially_copyable<T>::value` is `true` if all of T's copy/move +// constructors/assignment operators are trivial or deleted, T has at least +// one non-deleted copy/move constructor/assignment operator, and T is trivially +// destructible. Arrays of trivially copyable types are trivially copyable. +// +// We expose this metafunction only for internal use within absl. +template <typename T> +class is_trivially_copyable_impl { + using ExtentsRemoved = typename std::remove_all_extents<T>::type; + static constexpr bool kIsCopyOrMoveConstructible = + std::is_copy_constructible<ExtentsRemoved>::value || + std::is_move_constructible<ExtentsRemoved>::value; + static constexpr bool kIsCopyOrMoveAssignable = + absl::is_copy_assignable<ExtentsRemoved>::value || + absl::is_move_assignable<ExtentsRemoved>::value; + + public: + static constexpr bool kValue = + (__has_trivial_copy(ExtentsRemoved) || !kIsCopyOrMoveConstructible) && + (__has_trivial_assign(ExtentsRemoved) || !kIsCopyOrMoveAssignable) && + (kIsCopyOrMoveConstructible || kIsCopyOrMoveAssignable) && + is_trivially_destructible<ExtentsRemoved>::value && + // We need to check for this explicitly because otherwise we'll say + // references are trivial copyable when compiled by MSVC. + !std::is_reference<ExtentsRemoved>::value; +}; + +template <typename T> +struct is_trivially_copyable + : std::integral_constant< + bool, type_traits_internal::is_trivially_copyable_impl<T>::kValue> {}; +} // namespace type_traits_internal + +// ----------------------------------------------------------------------------- +// C++14 "_t" trait aliases +// ----------------------------------------------------------------------------- + +template <typename T> +using remove_cv_t = typename std::remove_cv<T>::type; + +template <typename T> +using remove_const_t = typename std::remove_const<T>::type; + +template <typename T> +using remove_volatile_t = typename std::remove_volatile<T>::type; + +template <typename T> +using add_cv_t = typename std::add_cv<T>::type; + +template <typename T> +using add_const_t = typename std::add_const<T>::type; + +template <typename T> +using add_volatile_t = typename std::add_volatile<T>::type; + +template <typename T> +using remove_reference_t = typename std::remove_reference<T>::type; + +template <typename T> +using add_lvalue_reference_t = typename std::add_lvalue_reference<T>::type; + +template <typename T> +using add_rvalue_reference_t = typename std::add_rvalue_reference<T>::type; + +template <typename T> +using remove_pointer_t = typename std::remove_pointer<T>::type; + +template <typename T> +using add_pointer_t = typename std::add_pointer<T>::type; + +template <typename T> +using make_signed_t = typename std::make_signed<T>::type; + +template <typename T> +using make_unsigned_t = typename std::make_unsigned<T>::type; + +template <typename T> +using remove_extent_t = typename std::remove_extent<T>::type; + +template <typename T> +using remove_all_extents_t = typename std::remove_all_extents<T>::type; + +template <size_t Len, size_t Align = type_traits_internal:: + default_alignment_of_aligned_storage<Len>::value> +using aligned_storage_t = typename std::aligned_storage<Len, Align>::type; + +template <typename T> +using decay_t = typename std::decay<T>::type; + +template <bool B, typename T = void> +using enable_if_t = typename std::enable_if<B, T>::type; + +template <bool B, typename T, typename F> +using conditional_t = typename std::conditional<B, T, F>::type; + +template <typename... T> +using common_type_t = typename std::common_type<T...>::type; + +template <typename T> +using underlying_type_t = typename std::underlying_type<T>::type; + +template <typename T> +using result_of_t = typename std::result_of<T>::type; + +namespace type_traits_internal { +// In MSVC we can't probe std::hash or stdext::hash because it triggers a +// static_assert instead of failing substitution. Libc++ prior to 4.0 +// also used a static_assert. +// +#if defined(_MSC_VER) || (defined(_LIBCPP_VERSION) && \ + _LIBCPP_VERSION < 4000 && _LIBCPP_STD_VER > 11) +#define ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ 0 +#else +#define ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ 1 +#endif + +#if !ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ +template <typename Key, typename = size_t> +struct IsHashable : std::true_type {}; +#else // ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ +template <typename Key, typename = void> +struct IsHashable : std::false_type {}; + +template <typename Key> +struct IsHashable< + Key, + absl::enable_if_t<std::is_convertible< + decltype(std::declval<std::hash<Key>&>()(std::declval<Key const&>())), + std::size_t>::value>> : std::true_type {}; +#endif // !ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + +struct AssertHashEnabledHelper { + private: + static void Sink(...) {} + struct NAT {}; + + template <class Key> + static auto GetReturnType(int) + -> decltype(std::declval<std::hash<Key>>()(std::declval<Key const&>())); + template <class Key> + static NAT GetReturnType(...); + + template <class Key> + static std::nullptr_t DoIt() { + static_assert(IsHashable<Key>::value, + "std::hash<Key> does not provide a call operator"); + static_assert( + std::is_default_constructible<std::hash<Key>>::value, + "std::hash<Key> must be default constructible when it is enabled"); + static_assert( + std::is_copy_constructible<std::hash<Key>>::value, + "std::hash<Key> must be copy constructible when it is enabled"); + static_assert(absl::is_copy_assignable<std::hash<Key>>::value, + "std::hash<Key> must be copy assignable when it is enabled"); + // is_destructible is unchecked as it's implied by each of the + // is_constructible checks. + using ReturnType = decltype(GetReturnType<Key>(0)); + static_assert(std::is_same<ReturnType, NAT>::value || + std::is_same<ReturnType, size_t>::value, + "std::hash<Key> must return size_t"); + return nullptr; + } + + template <class... Ts> + friend void AssertHashEnabled(); +}; + +template <class... Ts> +inline void AssertHashEnabled() { + using Helper = AssertHashEnabledHelper; + Helper::Sink(Helper::DoIt<Ts>()...); +} + +} // namespace type_traits_internal + +// An internal namespace that is required to implement the C++17 swap traits. +// It is not further nested in type_traits_internal to avoid long symbol names. +namespace swap_internal { + +// Necessary for the traits. +using std::swap; + +// This declaration prevents global `swap` and `absl::swap` overloads from being +// considered unless ADL picks them up. +void swap(); + +template <class T> +using IsSwappableImpl = decltype(swap(std::declval<T&>(), std::declval<T&>())); + +// NOTE: This dance with the default template parameter is for MSVC. +template <class T, + class IsNoexcept = std::integral_constant< + bool, noexcept(swap(std::declval<T&>(), std::declval<T&>()))>> +using IsNothrowSwappableImpl = typename std::enable_if<IsNoexcept::value>::type; + +// IsSwappable +// +// Determines whether the standard swap idiom is a valid expression for +// arguments of type `T`. +template <class T> +struct IsSwappable + : absl::type_traits_internal::is_detected<IsSwappableImpl, T> {}; + +// IsNothrowSwappable +// +// Determines whether the standard swap idiom is a valid expression for +// arguments of type `T` and is noexcept. +template <class T> +struct IsNothrowSwappable + : absl::type_traits_internal::is_detected<IsNothrowSwappableImpl, T> {}; + +// Swap() +// +// Performs the swap idiom from a namespace where valid candidates may only be +// found in `std` or via ADL. +template <class T, absl::enable_if_t<IsSwappable<T>::value, int> = 0> +void Swap(T& lhs, T& rhs) noexcept(IsNothrowSwappable<T>::value) { + swap(lhs, rhs); +} + +// StdSwapIsUnconstrained +// +// Some standard library implementations are broken in that they do not +// constrain `std::swap`. This will effectively tell us if we are dealing with +// one of those implementations. +using StdSwapIsUnconstrained = IsSwappable<void()>; + +} // namespace swap_internal + +namespace type_traits_internal { + +// Make the swap-related traits/function accessible from this namespace. +using swap_internal::IsNothrowSwappable; +using swap_internal::IsSwappable; +using swap_internal::Swap; +using swap_internal::StdSwapIsUnconstrained; + +} // namespace type_traits_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_META_TYPE_TRAITS_H_ diff --git a/third_party/abseil_cpp/absl/meta/type_traits_test.cc b/third_party/abseil_cpp/absl/meta/type_traits_test.cc new file mode 100644 index 0000000000..1aafd0d49a --- /dev/null +++ b/third_party/abseil_cpp/absl/meta/type_traits_test.cc @@ -0,0 +1,1368 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/meta/type_traits.h" + +#include <cstdint> +#include <string> +#include <type_traits> +#include <utility> +#include <vector> + +#include "gtest/gtest.h" + +namespace { + +using ::testing::StaticAssertTypeEq; + +template <class T, class U> +struct simple_pair { + T first; + U second; +}; + +struct Dummy {}; + +struct ReturnType {}; +struct ConvertibleToReturnType { + operator ReturnType() const; // NOLINT +}; + +// Unique types used as parameter types for testing the detection idiom. +struct StructA {}; +struct StructB {}; +struct StructC {}; + +struct TypeWithBarFunction { + template <class T, + absl::enable_if_t<std::is_same<T&&, StructA&>::value, int> = 0> + ReturnType bar(T&&, const StructB&, StructC&&) &&; // NOLINT +}; + +struct TypeWithBarFunctionAndConvertibleReturnType { + template <class T, + absl::enable_if_t<std::is_same<T&&, StructA&>::value, int> = 0> + ConvertibleToReturnType bar(T&&, const StructB&, StructC&&) &&; // NOLINT +}; + +template <class Class, class... Ts> +using BarIsCallableImpl = + decltype(std::declval<Class>().bar(std::declval<Ts>()...)); + +template <class Class, class... T> +using BarIsCallable = + absl::type_traits_internal::is_detected<BarIsCallableImpl, Class, T...>; + +template <class Class, class... T> +using BarIsCallableConv = absl::type_traits_internal::is_detected_convertible< + ReturnType, BarIsCallableImpl, Class, T...>; + +// NOTE: Test of detail type_traits_internal::is_detected. +TEST(IsDetectedTest, BasicUsage) { + EXPECT_TRUE((BarIsCallable<TypeWithBarFunction, StructA&, const StructB&, + StructC>::value)); + EXPECT_TRUE( + (BarIsCallable<TypeWithBarFunction, StructA&, StructB&, StructC>::value)); + EXPECT_TRUE( + (BarIsCallable<TypeWithBarFunction, StructA&, StructB, StructC>::value)); + + EXPECT_FALSE((BarIsCallable<int, StructA&, const StructB&, StructC>::value)); + EXPECT_FALSE((BarIsCallable<TypeWithBarFunction&, StructA&, const StructB&, + StructC>::value)); + EXPECT_FALSE((BarIsCallable<TypeWithBarFunction, StructA, const StructB&, + StructC>::value)); +} + +// NOTE: Test of detail type_traits_internal::is_detected_convertible. +TEST(IsDetectedConvertibleTest, BasicUsage) { + EXPECT_TRUE((BarIsCallableConv<TypeWithBarFunction, StructA&, const StructB&, + StructC>::value)); + EXPECT_TRUE((BarIsCallableConv<TypeWithBarFunction, StructA&, StructB&, + StructC>::value)); + EXPECT_TRUE((BarIsCallableConv<TypeWithBarFunction, StructA&, StructB, + StructC>::value)); + EXPECT_TRUE((BarIsCallableConv<TypeWithBarFunctionAndConvertibleReturnType, + StructA&, const StructB&, StructC>::value)); + EXPECT_TRUE((BarIsCallableConv<TypeWithBarFunctionAndConvertibleReturnType, + StructA&, StructB&, StructC>::value)); + EXPECT_TRUE((BarIsCallableConv<TypeWithBarFunctionAndConvertibleReturnType, + StructA&, StructB, StructC>::value)); + + EXPECT_FALSE( + (BarIsCallableConv<int, StructA&, const StructB&, StructC>::value)); + EXPECT_FALSE((BarIsCallableConv<TypeWithBarFunction&, StructA&, + const StructB&, StructC>::value)); + EXPECT_FALSE((BarIsCallableConv<TypeWithBarFunction, StructA, const StructB&, + StructC>::value)); + EXPECT_FALSE((BarIsCallableConv<TypeWithBarFunctionAndConvertibleReturnType&, + StructA&, const StructB&, StructC>::value)); + EXPECT_FALSE((BarIsCallableConv<TypeWithBarFunctionAndConvertibleReturnType, + StructA, const StructB&, StructC>::value)); +} + +TEST(VoidTTest, BasicUsage) { + StaticAssertTypeEq<void, absl::void_t<Dummy>>(); + StaticAssertTypeEq<void, absl::void_t<Dummy, Dummy, Dummy>>(); +} + +TEST(ConjunctionTest, BasicBooleanLogic) { + EXPECT_TRUE(absl::conjunction<>::value); + EXPECT_TRUE(absl::conjunction<std::true_type>::value); + EXPECT_TRUE((absl::conjunction<std::true_type, std::true_type>::value)); + EXPECT_FALSE((absl::conjunction<std::true_type, std::false_type>::value)); + EXPECT_FALSE((absl::conjunction<std::false_type, std::true_type>::value)); + EXPECT_FALSE((absl::conjunction<std::false_type, std::false_type>::value)); +} + +struct MyTrueType { + static constexpr bool value = true; +}; + +struct MyFalseType { + static constexpr bool value = false; +}; + +TEST(ConjunctionTest, ShortCircuiting) { + EXPECT_FALSE( + (absl::conjunction<std::true_type, std::false_type, Dummy>::value)); + EXPECT_TRUE((std::is_base_of<MyFalseType, + absl::conjunction<std::true_type, MyFalseType, + std::false_type>>::value)); + EXPECT_TRUE( + (std::is_base_of<MyTrueType, + absl::conjunction<std::true_type, MyTrueType>>::value)); +} + +TEST(DisjunctionTest, BasicBooleanLogic) { + EXPECT_FALSE(absl::disjunction<>::value); + EXPECT_FALSE(absl::disjunction<std::false_type>::value); + EXPECT_TRUE((absl::disjunction<std::true_type, std::true_type>::value)); + EXPECT_TRUE((absl::disjunction<std::true_type, std::false_type>::value)); + EXPECT_TRUE((absl::disjunction<std::false_type, std::true_type>::value)); + EXPECT_FALSE((absl::disjunction<std::false_type, std::false_type>::value)); +} + +TEST(DisjunctionTest, ShortCircuiting) { + EXPECT_TRUE( + (absl::disjunction<std::false_type, std::true_type, Dummy>::value)); + EXPECT_TRUE(( + std::is_base_of<MyTrueType, absl::disjunction<std::false_type, MyTrueType, + std::true_type>>::value)); + EXPECT_TRUE(( + std::is_base_of<MyFalseType, + absl::disjunction<std::false_type, MyFalseType>>::value)); +} + +TEST(NegationTest, BasicBooleanLogic) { + EXPECT_FALSE(absl::negation<std::true_type>::value); + EXPECT_FALSE(absl::negation<MyTrueType>::value); + EXPECT_TRUE(absl::negation<std::false_type>::value); + EXPECT_TRUE(absl::negation<MyFalseType>::value); +} + +// all member functions are trivial +class Trivial { + int n_; +}; + +struct TrivialDestructor { + ~TrivialDestructor() = default; +}; + +struct NontrivialDestructor { + ~NontrivialDestructor() {} +}; + +struct DeletedDestructor { + ~DeletedDestructor() = delete; +}; + +class TrivialDefaultCtor { + public: + TrivialDefaultCtor() = default; + explicit TrivialDefaultCtor(int n) : n_(n) {} + + private: + int n_; +}; + +class NontrivialDefaultCtor { + public: + NontrivialDefaultCtor() : n_(1) {} + + private: + int n_; +}; + +class DeletedDefaultCtor { + public: + DeletedDefaultCtor() = delete; + explicit DeletedDefaultCtor(int n) : n_(n) {} + + private: + int n_; +}; + +class TrivialMoveCtor { + public: + explicit TrivialMoveCtor(int n) : n_(n) {} + TrivialMoveCtor(TrivialMoveCtor&&) = default; + TrivialMoveCtor& operator=(const TrivialMoveCtor& t) { + n_ = t.n_; + return *this; + } + + private: + int n_; +}; + +class NontrivialMoveCtor { + public: + explicit NontrivialMoveCtor(int n) : n_(n) {} + NontrivialMoveCtor(NontrivialMoveCtor&& t) noexcept : n_(t.n_) {} + NontrivialMoveCtor& operator=(const NontrivialMoveCtor&) = default; + + private: + int n_; +}; + +class TrivialCopyCtor { + public: + explicit TrivialCopyCtor(int n) : n_(n) {} + TrivialCopyCtor(const TrivialCopyCtor&) = default; + TrivialCopyCtor& operator=(const TrivialCopyCtor& t) { + n_ = t.n_; + return *this; + } + + private: + int n_; +}; + +class NontrivialCopyCtor { + public: + explicit NontrivialCopyCtor(int n) : n_(n) {} + NontrivialCopyCtor(const NontrivialCopyCtor& t) : n_(t.n_) {} + NontrivialCopyCtor& operator=(const NontrivialCopyCtor&) = default; + + private: + int n_; +}; + +class DeletedCopyCtor { + public: + explicit DeletedCopyCtor(int n) : n_(n) {} + DeletedCopyCtor(const DeletedCopyCtor&) = delete; + DeletedCopyCtor& operator=(const DeletedCopyCtor&) = default; + + private: + int n_; +}; + +class TrivialMoveAssign { + public: + explicit TrivialMoveAssign(int n) : n_(n) {} + TrivialMoveAssign(const TrivialMoveAssign& t) : n_(t.n_) {} + TrivialMoveAssign& operator=(TrivialMoveAssign&&) = default; + ~TrivialMoveAssign() {} // can have nontrivial destructor + private: + int n_; +}; + +class NontrivialMoveAssign { + public: + explicit NontrivialMoveAssign(int n) : n_(n) {} + NontrivialMoveAssign(const NontrivialMoveAssign&) = default; + NontrivialMoveAssign& operator=(NontrivialMoveAssign&& t) noexcept { + n_ = t.n_; + return *this; + } + + private: + int n_; +}; + +class TrivialCopyAssign { + public: + explicit TrivialCopyAssign(int n) : n_(n) {} + TrivialCopyAssign(const TrivialCopyAssign& t) : n_(t.n_) {} + TrivialCopyAssign& operator=(const TrivialCopyAssign& t) = default; + ~TrivialCopyAssign() {} // can have nontrivial destructor + private: + int n_; +}; + +class NontrivialCopyAssign { + public: + explicit NontrivialCopyAssign(int n) : n_(n) {} + NontrivialCopyAssign(const NontrivialCopyAssign&) = default; + NontrivialCopyAssign& operator=(const NontrivialCopyAssign& t) { + n_ = t.n_; + return *this; + } + + private: + int n_; +}; + +class DeletedCopyAssign { + public: + explicit DeletedCopyAssign(int n) : n_(n) {} + DeletedCopyAssign(const DeletedCopyAssign&) = default; + DeletedCopyAssign& operator=(const DeletedCopyAssign&) = delete; + + private: + int n_; +}; + +struct MovableNonCopyable { + MovableNonCopyable() = default; + MovableNonCopyable(const MovableNonCopyable&) = delete; + MovableNonCopyable(MovableNonCopyable&&) = default; + MovableNonCopyable& operator=(const MovableNonCopyable&) = delete; + MovableNonCopyable& operator=(MovableNonCopyable&&) = default; +}; + +struct NonCopyableOrMovable { + NonCopyableOrMovable() = default; + NonCopyableOrMovable(const NonCopyableOrMovable&) = delete; + NonCopyableOrMovable(NonCopyableOrMovable&&) = delete; + NonCopyableOrMovable& operator=(const NonCopyableOrMovable&) = delete; + NonCopyableOrMovable& operator=(NonCopyableOrMovable&&) = delete; +}; + +class Base { + public: + virtual ~Base() {} +}; + +// Old versions of libc++, around Clang 3.5 to 3.6, consider deleted destructors +// as also being trivial. With the resolution of CWG 1928 and CWG 1734, this +// is no longer considered true and has thus been amended. +// Compiler Explorer: https://godbolt.org/g/zT59ZL +// CWG issue 1734: http://open-std.org/JTC1/SC22/WG21/docs/cwg_defects.html#1734 +// CWG issue 1928: http://open-std.org/JTC1/SC22/WG21/docs/cwg_closed.html#1928 +#if !defined(_LIBCPP_VERSION) || _LIBCPP_VERSION >= 3700 +#define ABSL_TRIVIALLY_DESTRUCTIBLE_CONSIDER_DELETED_DESTRUCTOR_NOT_TRIVIAL 1 +#endif + +// As of the moment, GCC versions >5.1 have a problem compiling for +// std::is_trivially_default_constructible<NontrivialDestructor[10]>, where +// NontrivialDestructor is a struct with a custom nontrivial destructor. Note +// that this problem only occurs for arrays of a known size, so something like +// std::is_trivially_default_constructible<NontrivialDestructor[]> does not +// have any problems. +// Compiler Explorer: https://godbolt.org/g/dXRbdK +// GCC bug 83689: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=83689 +#if defined(__clang__) || defined(_MSC_VER) || \ + (defined(__GNUC__) && __GNUC__ < 5) +#define ABSL_GCC_BUG_TRIVIALLY_CONSTRUCTIBLE_ON_ARRAY_OF_NONTRIVIAL 1 +#endif + +TEST(TypeTraitsTest, TestIsFunction) { + struct Callable { + void operator()() {} + }; + EXPECT_TRUE(absl::is_function<void()>::value); + EXPECT_TRUE(absl::is_function<void()&>::value); + EXPECT_TRUE(absl::is_function<void() const>::value); + EXPECT_TRUE(absl::is_function<void() noexcept>::value); + EXPECT_TRUE(absl::is_function<void(...) noexcept>::value); + + EXPECT_FALSE(absl::is_function<void(*)()>::value); + EXPECT_FALSE(absl::is_function<void(&)()>::value); + EXPECT_FALSE(absl::is_function<int>::value); + EXPECT_FALSE(absl::is_function<Callable>::value); +} + +TEST(TypeTraitsTest, TestTrivialDestructor) { + // Verify that arithmetic types and pointers have trivial destructors. + EXPECT_TRUE(absl::is_trivially_destructible<bool>::value); + EXPECT_TRUE(absl::is_trivially_destructible<char>::value); + EXPECT_TRUE(absl::is_trivially_destructible<unsigned char>::value); + EXPECT_TRUE(absl::is_trivially_destructible<signed char>::value); + EXPECT_TRUE(absl::is_trivially_destructible<wchar_t>::value); + EXPECT_TRUE(absl::is_trivially_destructible<int>::value); + EXPECT_TRUE(absl::is_trivially_destructible<unsigned int>::value); + EXPECT_TRUE(absl::is_trivially_destructible<int16_t>::value); + EXPECT_TRUE(absl::is_trivially_destructible<uint16_t>::value); + EXPECT_TRUE(absl::is_trivially_destructible<int64_t>::value); + EXPECT_TRUE(absl::is_trivially_destructible<uint64_t>::value); + EXPECT_TRUE(absl::is_trivially_destructible<float>::value); + EXPECT_TRUE(absl::is_trivially_destructible<double>::value); + EXPECT_TRUE(absl::is_trivially_destructible<long double>::value); + EXPECT_TRUE(absl::is_trivially_destructible<std::string*>::value); + EXPECT_TRUE(absl::is_trivially_destructible<Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_destructible<const std::string*>::value); + EXPECT_TRUE(absl::is_trivially_destructible<const Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_destructible<std::string**>::value); + EXPECT_TRUE(absl::is_trivially_destructible<Trivial**>::value); + + // classes with destructors + EXPECT_TRUE(absl::is_trivially_destructible<Trivial>::value); + EXPECT_TRUE(absl::is_trivially_destructible<TrivialDestructor>::value); + + // Verify that types with a nontrivial or deleted destructor + // are marked as such. + EXPECT_FALSE(absl::is_trivially_destructible<NontrivialDestructor>::value); +#ifdef ABSL_TRIVIALLY_DESTRUCTIBLE_CONSIDER_DELETED_DESTRUCTOR_NOT_TRIVIAL + EXPECT_FALSE(absl::is_trivially_destructible<DeletedDestructor>::value); +#endif + + // simple_pair of such types is trivial + EXPECT_TRUE((absl::is_trivially_destructible<simple_pair<int, int>>::value)); + EXPECT_TRUE((absl::is_trivially_destructible< + simple_pair<Trivial, TrivialDestructor>>::value)); + + // Verify that types without trivial destructors are correctly marked as such. + EXPECT_FALSE(absl::is_trivially_destructible<std::string>::value); + EXPECT_FALSE(absl::is_trivially_destructible<std::vector<int>>::value); + + // Verify that simple_pairs of types without trivial destructors + // are not marked as trivial. + EXPECT_FALSE((absl::is_trivially_destructible< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::is_trivially_destructible< + simple_pair<std::string, int>>::value)); + + // array of such types is trivial + using int10 = int[10]; + EXPECT_TRUE(absl::is_trivially_destructible<int10>::value); + using Trivial10 = Trivial[10]; + EXPECT_TRUE(absl::is_trivially_destructible<Trivial10>::value); + using TrivialDestructor10 = TrivialDestructor[10]; + EXPECT_TRUE(absl::is_trivially_destructible<TrivialDestructor10>::value); + + // Conversely, the opposite also holds. + using NontrivialDestructor10 = NontrivialDestructor[10]; + EXPECT_FALSE(absl::is_trivially_destructible<NontrivialDestructor10>::value); +} + +TEST(TypeTraitsTest, TestTrivialDefaultCtor) { + // arithmetic types and pointers have trivial default constructors. + EXPECT_TRUE(absl::is_trivially_default_constructible<bool>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<char>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<unsigned char>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<signed char>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<wchar_t>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<int>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<unsigned int>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<int16_t>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<uint16_t>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<int64_t>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<uint64_t>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<float>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<double>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<long double>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<std::string*>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<Trivial*>::value); + EXPECT_TRUE( + absl::is_trivially_default_constructible<const std::string*>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<const Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<std::string**>::value); + EXPECT_TRUE(absl::is_trivially_default_constructible<Trivial**>::value); + + // types with compiler generated default ctors + EXPECT_TRUE(absl::is_trivially_default_constructible<Trivial>::value); + EXPECT_TRUE( + absl::is_trivially_default_constructible<TrivialDefaultCtor>::value); + + // Verify that types without them are not. + EXPECT_FALSE( + absl::is_trivially_default_constructible<NontrivialDefaultCtor>::value); + EXPECT_FALSE( + absl::is_trivially_default_constructible<DeletedDefaultCtor>::value); + + // types with nontrivial destructor are nontrivial + EXPECT_FALSE( + absl::is_trivially_default_constructible<NontrivialDestructor>::value); + + // types with vtables + EXPECT_FALSE(absl::is_trivially_default_constructible<Base>::value); + + // Verify that simple_pair has trivial constructors where applicable. + EXPECT_TRUE((absl::is_trivially_default_constructible< + simple_pair<int, char*>>::value)); + EXPECT_TRUE((absl::is_trivially_default_constructible< + simple_pair<int, Trivial>>::value)); + EXPECT_TRUE((absl::is_trivially_default_constructible< + simple_pair<int, TrivialDefaultCtor>>::value)); + + // Verify that types without trivial constructors are + // correctly marked as such. + EXPECT_FALSE(absl::is_trivially_default_constructible<std::string>::value); + EXPECT_FALSE( + absl::is_trivially_default_constructible<std::vector<int>>::value); + + // Verify that simple_pairs of types without trivial constructors + // are not marked as trivial. + EXPECT_FALSE((absl::is_trivially_default_constructible< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::is_trivially_default_constructible< + simple_pair<std::string, int>>::value)); + + // Verify that arrays of such types are trivially default constructible + using int10 = int[10]; + EXPECT_TRUE(absl::is_trivially_default_constructible<int10>::value); + using Trivial10 = Trivial[10]; + EXPECT_TRUE(absl::is_trivially_default_constructible<Trivial10>::value); + using TrivialDefaultCtor10 = TrivialDefaultCtor[10]; + EXPECT_TRUE( + absl::is_trivially_default_constructible<TrivialDefaultCtor10>::value); + + // Conversely, the opposite also holds. +#ifdef ABSL_GCC_BUG_TRIVIALLY_CONSTRUCTIBLE_ON_ARRAY_OF_NONTRIVIAL + using NontrivialDefaultCtor10 = NontrivialDefaultCtor[10]; + EXPECT_FALSE( + absl::is_trivially_default_constructible<NontrivialDefaultCtor10>::value); +#endif +} + +// GCC prior to 7.4 had a bug in its trivially-constructible traits +// (https://gcc.gnu.org/bugzilla/show_bug.cgi?id=80654). +// This test makes sure that we do not depend on the trait in these cases when +// implementing absl triviality traits. + +template <class T> +struct BadConstructors { + BadConstructors() { static_assert(T::value, ""); } + + BadConstructors(BadConstructors&&) { static_assert(T::value, ""); } + + BadConstructors(const BadConstructors&) { static_assert(T::value, ""); } +}; + +TEST(TypeTraitsTest, TestTrivialityBadConstructors) { + using BadType = BadConstructors<int>; + + EXPECT_FALSE(absl::is_trivially_default_constructible<BadType>::value); + EXPECT_FALSE(absl::is_trivially_move_constructible<BadType>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<BadType>::value); +} + +TEST(TypeTraitsTest, TestTrivialMoveCtor) { + // Verify that arithmetic types and pointers have trivial move + // constructors. + EXPECT_TRUE(absl::is_trivially_move_constructible<bool>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<char>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<unsigned char>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<signed char>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<wchar_t>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<int>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<unsigned int>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<int16_t>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<uint16_t>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<int64_t>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<uint64_t>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<float>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<double>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<long double>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<std::string*>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<const std::string*>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<const Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<std::string**>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<Trivial**>::value); + + // Reference types + EXPECT_TRUE(absl::is_trivially_move_constructible<int&>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<int&&>::value); + + // types with compiler generated move ctors + EXPECT_TRUE(absl::is_trivially_move_constructible<Trivial>::value); + EXPECT_TRUE(absl::is_trivially_move_constructible<TrivialMoveCtor>::value); + + // Verify that types without them (i.e. nontrivial or deleted) are not. + EXPECT_FALSE( + absl::is_trivially_move_constructible<NontrivialCopyCtor>::value); + EXPECT_FALSE(absl::is_trivially_move_constructible<DeletedCopyCtor>::value); + EXPECT_FALSE( + absl::is_trivially_move_constructible<NonCopyableOrMovable>::value); + + // type with nontrivial destructor are nontrivial move construbtible + EXPECT_FALSE( + absl::is_trivially_move_constructible<NontrivialDestructor>::value); + + // types with vtables + EXPECT_FALSE(absl::is_trivially_move_constructible<Base>::value); + + // Verify that simple_pair of such types is trivially move constructible + EXPECT_TRUE( + (absl::is_trivially_move_constructible<simple_pair<int, char*>>::value)); + EXPECT_TRUE(( + absl::is_trivially_move_constructible<simple_pair<int, Trivial>>::value)); + EXPECT_TRUE((absl::is_trivially_move_constructible< + simple_pair<int, TrivialMoveCtor>>::value)); + + // Verify that types without trivial move constructors are + // correctly marked as such. + EXPECT_FALSE(absl::is_trivially_move_constructible<std::string>::value); + EXPECT_FALSE(absl::is_trivially_move_constructible<std::vector<int>>::value); + + // Verify that simple_pairs of types without trivial move constructors + // are not marked as trivial. + EXPECT_FALSE((absl::is_trivially_move_constructible< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::is_trivially_move_constructible< + simple_pair<std::string, int>>::value)); + + // Verify that arrays are not + using int10 = int[10]; + EXPECT_FALSE(absl::is_trivially_move_constructible<int10>::value); +} + +TEST(TypeTraitsTest, TestTrivialCopyCtor) { + // Verify that arithmetic types and pointers have trivial copy + // constructors. + EXPECT_TRUE(absl::is_trivially_copy_constructible<bool>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<char>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<unsigned char>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<signed char>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<wchar_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<int>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<unsigned int>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<int16_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<uint16_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<int64_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<uint64_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<float>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<double>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<long double>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<std::string*>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<const std::string*>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<const Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<std::string**>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<Trivial**>::value); + + // Reference types + EXPECT_TRUE(absl::is_trivially_copy_constructible<int&>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<int&&>::value); + + // types with compiler generated copy ctors + EXPECT_TRUE(absl::is_trivially_copy_constructible<Trivial>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<TrivialCopyCtor>::value); + + // Verify that types without them (i.e. nontrivial or deleted) are not. + EXPECT_FALSE( + absl::is_trivially_copy_constructible<NontrivialCopyCtor>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<DeletedCopyCtor>::value); + EXPECT_FALSE( + absl::is_trivially_copy_constructible<MovableNonCopyable>::value); + EXPECT_FALSE( + absl::is_trivially_copy_constructible<NonCopyableOrMovable>::value); + + // type with nontrivial destructor are nontrivial copy construbtible + EXPECT_FALSE( + absl::is_trivially_copy_constructible<NontrivialDestructor>::value); + + // types with vtables + EXPECT_FALSE(absl::is_trivially_copy_constructible<Base>::value); + + // Verify that simple_pair of such types is trivially copy constructible + EXPECT_TRUE( + (absl::is_trivially_copy_constructible<simple_pair<int, char*>>::value)); + EXPECT_TRUE(( + absl::is_trivially_copy_constructible<simple_pair<int, Trivial>>::value)); + EXPECT_TRUE((absl::is_trivially_copy_constructible< + simple_pair<int, TrivialCopyCtor>>::value)); + + // Verify that types without trivial copy constructors are + // correctly marked as such. + EXPECT_FALSE(absl::is_trivially_copy_constructible<std::string>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<std::vector<int>>::value); + + // Verify that simple_pairs of types without trivial copy constructors + // are not marked as trivial. + EXPECT_FALSE((absl::is_trivially_copy_constructible< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::is_trivially_copy_constructible< + simple_pair<std::string, int>>::value)); + + // Verify that arrays are not + using int10 = int[10]; + EXPECT_FALSE(absl::is_trivially_copy_constructible<int10>::value); +} + +TEST(TypeTraitsTest, TestTrivialMoveAssign) { + // Verify that arithmetic types and pointers have trivial move + // assignment operators. + EXPECT_TRUE(absl::is_trivially_move_assignable<bool>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<char>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<unsigned char>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<signed char>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<wchar_t>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<int>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<unsigned int>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<int16_t>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<uint16_t>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<int64_t>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<uint64_t>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<float>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<double>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<long double>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<std::string*>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<const std::string*>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<const Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<std::string**>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<Trivial**>::value); + + // const qualified types are not assignable + EXPECT_FALSE(absl::is_trivially_move_assignable<const int>::value); + + // types with compiler generated move assignment + EXPECT_TRUE(absl::is_trivially_move_assignable<Trivial>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<TrivialMoveAssign>::value); + + // Verify that types without them (i.e. nontrivial or deleted) are not. + EXPECT_FALSE(absl::is_trivially_move_assignable<NontrivialCopyAssign>::value); + EXPECT_FALSE(absl::is_trivially_move_assignable<DeletedCopyAssign>::value); + EXPECT_FALSE(absl::is_trivially_move_assignable<NonCopyableOrMovable>::value); + + // types with vtables + EXPECT_FALSE(absl::is_trivially_move_assignable<Base>::value); + + // Verify that simple_pair is trivially assignable + EXPECT_TRUE( + (absl::is_trivially_move_assignable<simple_pair<int, char*>>::value)); + EXPECT_TRUE( + (absl::is_trivially_move_assignable<simple_pair<int, Trivial>>::value)); + EXPECT_TRUE((absl::is_trivially_move_assignable< + simple_pair<int, TrivialMoveAssign>>::value)); + + // Verify that types not trivially move assignable are + // correctly marked as such. + EXPECT_FALSE(absl::is_trivially_move_assignable<std::string>::value); + EXPECT_FALSE(absl::is_trivially_move_assignable<std::vector<int>>::value); + + // Verify that simple_pairs of types not trivially move assignable + // are not marked as trivial. + EXPECT_FALSE((absl::is_trivially_move_assignable< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::is_trivially_move_assignable< + simple_pair<std::string, int>>::value)); + + // Verify that arrays are not trivially move assignable + using int10 = int[10]; + EXPECT_FALSE(absl::is_trivially_move_assignable<int10>::value); + + // Verify that references are handled correctly + EXPECT_TRUE(absl::is_trivially_move_assignable<Trivial&&>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<Trivial&>::value); +} + +TEST(TypeTraitsTest, TestTrivialCopyAssign) { + // Verify that arithmetic types and pointers have trivial copy + // assignment operators. + EXPECT_TRUE(absl::is_trivially_copy_assignable<bool>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<char>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<unsigned char>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<signed char>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<wchar_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<int>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<unsigned int>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<int16_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<uint16_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<int64_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<uint64_t>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<float>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<double>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<long double>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<std::string*>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<const std::string*>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<const Trivial*>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<std::string**>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<Trivial**>::value); + + // const qualified types are not assignable + EXPECT_FALSE(absl::is_trivially_copy_assignable<const int>::value); + + // types with compiler generated copy assignment + EXPECT_TRUE(absl::is_trivially_copy_assignable<Trivial>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<TrivialCopyAssign>::value); + + // Verify that types without them (i.e. nontrivial or deleted) are not. + EXPECT_FALSE(absl::is_trivially_copy_assignable<NontrivialCopyAssign>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<DeletedCopyAssign>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<MovableNonCopyable>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<NonCopyableOrMovable>::value); + + // types with vtables + EXPECT_FALSE(absl::is_trivially_copy_assignable<Base>::value); + + // Verify that simple_pair is trivially assignable + EXPECT_TRUE( + (absl::is_trivially_copy_assignable<simple_pair<int, char*>>::value)); + EXPECT_TRUE( + (absl::is_trivially_copy_assignable<simple_pair<int, Trivial>>::value)); + EXPECT_TRUE((absl::is_trivially_copy_assignable< + simple_pair<int, TrivialCopyAssign>>::value)); + + // Verify that types not trivially copy assignable are + // correctly marked as such. + EXPECT_FALSE(absl::is_trivially_copy_assignable<std::string>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<std::vector<int>>::value); + + // Verify that simple_pairs of types not trivially copy assignable + // are not marked as trivial. + EXPECT_FALSE((absl::is_trivially_copy_assignable< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::is_trivially_copy_assignable< + simple_pair<std::string, int>>::value)); + + // Verify that arrays are not trivially copy assignable + using int10 = int[10]; + EXPECT_FALSE(absl::is_trivially_copy_assignable<int10>::value); + + // Verify that references are handled correctly + EXPECT_TRUE(absl::is_trivially_copy_assignable<Trivial&&>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<Trivial&>::value); +} + +TEST(TypeTraitsTest, TestTriviallyCopyable) { + // Verify that arithmetic types and pointers are trivially copyable. + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable<bool>::value); + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable<char>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<unsigned char>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<signed char>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<wchar_t>::value); + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable<int>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<unsigned int>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<int16_t>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<uint16_t>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<int64_t>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<uint64_t>::value); + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable<float>::value); + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable<double>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<long double>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<std::string*>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<Trivial*>::value); + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable< + const std::string*>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<const Trivial*>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<std::string**>::value); + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<Trivial**>::value); + + // const qualified types are not assignable but are constructible + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<const int>::value); + + // Trivial copy constructor/assignment and destructor. + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<Trivial>::value); + // Trivial copy assignment, but non-trivial copy constructor/destructor. + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable< + TrivialCopyAssign>::value); + // Trivial copy constructor, but non-trivial assignment. + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable< + TrivialCopyCtor>::value); + + // Types with a non-trivial copy constructor/assignment + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable< + NontrivialCopyCtor>::value); + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable< + NontrivialCopyAssign>::value); + + // Types without copy constructor/assignment, but with move + // MSVC disagrees with other compilers about this: + // EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable< + // MovableNonCopyable>::value); + + // Types without copy/move constructor/assignment + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable< + NonCopyableOrMovable>::value); + + // No copy assign, but has trivial copy constructor. + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable< + DeletedCopyAssign>::value); + + // types with vtables + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable<Base>::value); + + // Verify that simple_pair is trivially copyable if members are + EXPECT_TRUE((absl::type_traits_internal::is_trivially_copyable< + simple_pair<int, char*>>::value)); + EXPECT_TRUE((absl::type_traits_internal::is_trivially_copyable< + simple_pair<int, Trivial>>::value)); + + // Verify that types not trivially copyable are + // correctly marked as such. + EXPECT_FALSE( + absl::type_traits_internal::is_trivially_copyable<std::string>::value); + EXPECT_FALSE(absl::type_traits_internal::is_trivially_copyable< + std::vector<int>>::value); + + // Verify that simple_pairs of types not trivially copyable + // are not marked as trivial. + EXPECT_FALSE((absl::type_traits_internal::is_trivially_copyable< + simple_pair<int, std::string>>::value)); + EXPECT_FALSE((absl::type_traits_internal::is_trivially_copyable< + simple_pair<std::string, int>>::value)); + EXPECT_FALSE((absl::type_traits_internal::is_trivially_copyable< + simple_pair<int, TrivialCopyAssign>>::value)); + + // Verify that arrays of trivially copyable types are trivially copyable + using int10 = int[10]; + EXPECT_TRUE(absl::type_traits_internal::is_trivially_copyable<int10>::value); + using int10x10 = int[10][10]; + EXPECT_TRUE( + absl::type_traits_internal::is_trivially_copyable<int10x10>::value); + + // Verify that references are handled correctly + EXPECT_FALSE( + absl::type_traits_internal::is_trivially_copyable<Trivial&&>::value); + EXPECT_FALSE( + absl::type_traits_internal::is_trivially_copyable<Trivial&>::value); +} + +#define ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(trait_name, ...) \ + EXPECT_TRUE((std::is_same<typename std::trait_name<__VA_ARGS__>::type, \ + absl::trait_name##_t<__VA_ARGS__>>::value)) + +TEST(TypeTraitsTest, TestRemoveCVAliases) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_cv, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_cv, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_cv, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_cv, const volatile int); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_const, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_const, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_const, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_const, const volatile int); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_volatile, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_volatile, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_volatile, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_volatile, const volatile int); +} + +TEST(TypeTraitsTest, TestAddCVAliases) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_cv, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_cv, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_cv, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_cv, const volatile int); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_const, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_const, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_const, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_const, const volatile int); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_volatile, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_volatile, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_volatile, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_volatile, const volatile int); +} + +TEST(TypeTraitsTest, TestReferenceAliases) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_reference, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_reference, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_reference, int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_reference, volatile int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_reference, int&&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_reference, volatile int&&); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_lvalue_reference, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_lvalue_reference, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_lvalue_reference, int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_lvalue_reference, volatile int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_lvalue_reference, int&&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_lvalue_reference, volatile int&&); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_rvalue_reference, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_rvalue_reference, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_rvalue_reference, int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_rvalue_reference, volatile int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_rvalue_reference, int&&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_rvalue_reference, volatile int&&); +} + +TEST(TypeTraitsTest, TestPointerAliases) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_pointer, int*); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_pointer, volatile int*); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_pointer, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(add_pointer, volatile int); +} + +TEST(TypeTraitsTest, TestSignednessAliases) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_signed, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_signed, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_signed, unsigned); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_signed, volatile unsigned); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_unsigned, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_unsigned, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_unsigned, unsigned); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(make_unsigned, volatile unsigned); +} + +TEST(TypeTraitsTest, TestExtentAliases) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_extent, int[]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_extent, int[1]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_extent, int[1][1]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_extent, int[][1]); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_all_extents, int[]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_all_extents, int[1]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_all_extents, int[1][1]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(remove_all_extents, int[][1]); +} + +TEST(TypeTraitsTest, TestAlignedStorageAlias) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 1); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 2); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 3); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 4); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 5); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 6); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 7); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 8); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 9); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 10); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 11); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 12); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 13); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 14); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 15); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 16); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 17); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 18); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 19); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 20); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 21); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 22); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 23); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 24); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 25); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 26); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 27); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 28); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 29); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 30); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 31); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 32); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 33); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 1, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 2, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 3, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 4, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 5, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 6, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 7, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 8, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 9, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 10, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 11, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 12, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 13, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 14, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 15, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 16, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 17, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 18, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 19, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 20, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 21, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 22, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 23, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 24, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 25, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 26, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 27, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 28, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 29, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 30, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 31, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 32, 128); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(aligned_storage, 33, 128); +} + +TEST(TypeTraitsTest, TestDecay) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, const int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, volatile int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, const volatile int); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, const int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, volatile int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, const volatile int&); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, const int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, volatile int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, const volatile int&); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int[1]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int[1][1]); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int[][1]); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int()); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int(float)); // NOLINT + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(decay, int(char, ...)); // NOLINT +} + +struct TypeA {}; +struct TypeB {}; +struct TypeC {}; +struct TypeD {}; + +template <typename T> +struct Wrap {}; + +enum class TypeEnum { A, B, C, D }; + +struct GetTypeT { + template <typename T, + absl::enable_if_t<std::is_same<T, TypeA>::value, int> = 0> + TypeEnum operator()(Wrap<T>) const { + return TypeEnum::A; + } + + template <typename T, + absl::enable_if_t<std::is_same<T, TypeB>::value, int> = 0> + TypeEnum operator()(Wrap<T>) const { + return TypeEnum::B; + } + + template <typename T, + absl::enable_if_t<std::is_same<T, TypeC>::value, int> = 0> + TypeEnum operator()(Wrap<T>) const { + return TypeEnum::C; + } + + // NOTE: TypeD is intentionally not handled +} constexpr GetType = {}; + +TEST(TypeTraitsTest, TestEnableIf) { + EXPECT_EQ(TypeEnum::A, GetType(Wrap<TypeA>())); + EXPECT_EQ(TypeEnum::B, GetType(Wrap<TypeB>())); + EXPECT_EQ(TypeEnum::C, GetType(Wrap<TypeC>())); +} + +TEST(TypeTraitsTest, TestConditional) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(conditional, true, int, char); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(conditional, false, int, char); +} + +// TODO(calabrese) Check with specialized std::common_type +TEST(TypeTraitsTest, TestCommonType) { + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(common_type, int); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(common_type, int, char); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(common_type, int, char, int); + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(common_type, int&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(common_type, int, char&); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(common_type, int, char, int&); +} + +TEST(TypeTraitsTest, TestUnderlyingType) { + enum class enum_char : char {}; + enum class enum_long_long : long long {}; // NOLINT(runtime/int) + + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(underlying_type, enum_char); + ABSL_INTERNAL_EXPECT_ALIAS_EQUIVALENCE(underlying_type, enum_long_long); +} + +struct GetTypeExtT { + template <typename T> + absl::result_of_t<const GetTypeT&(T)> operator()(T&& arg) const { + return GetType(std::forward<T>(arg)); + } + + TypeEnum operator()(Wrap<TypeD>) const { return TypeEnum::D; } +} constexpr GetTypeExt = {}; + +TEST(TypeTraitsTest, TestResultOf) { + EXPECT_EQ(TypeEnum::A, GetTypeExt(Wrap<TypeA>())); + EXPECT_EQ(TypeEnum::B, GetTypeExt(Wrap<TypeB>())); + EXPECT_EQ(TypeEnum::C, GetTypeExt(Wrap<TypeC>())); + EXPECT_EQ(TypeEnum::D, GetTypeExt(Wrap<TypeD>())); +} + +template <typename T> +bool TestCopyAssign() { + return absl::is_copy_assignable<T>::value == + std::is_copy_assignable<T>::value; +} + +TEST(TypeTraitsTest, IsCopyAssignable) { + EXPECT_TRUE(TestCopyAssign<int>()); + EXPECT_TRUE(TestCopyAssign<int&>()); + EXPECT_TRUE(TestCopyAssign<int&&>()); + + struct S {}; + EXPECT_TRUE(TestCopyAssign<S>()); + EXPECT_TRUE(TestCopyAssign<S&>()); + EXPECT_TRUE(TestCopyAssign<S&&>()); + + class C { + public: + explicit C(C* c) : c_(c) {} + ~C() { delete c_; } + + private: + C* c_; + }; + EXPECT_TRUE(TestCopyAssign<C>()); + EXPECT_TRUE(TestCopyAssign<C&>()); + EXPECT_TRUE(TestCopyAssign<C&&>()); + + // Reason for ifndef: add_lvalue_reference<T> in libc++ breaks for these cases +#ifndef _LIBCPP_VERSION + EXPECT_TRUE(TestCopyAssign<int()>()); + EXPECT_TRUE(TestCopyAssign<int(int) const>()); + EXPECT_TRUE(TestCopyAssign<int(...) volatile&>()); + EXPECT_TRUE(TestCopyAssign<int(int, ...) const volatile&&>()); +#endif // _LIBCPP_VERSION +} + +template <typename T> +bool TestMoveAssign() { + return absl::is_move_assignable<T>::value == + std::is_move_assignable<T>::value; +} + +TEST(TypeTraitsTest, IsMoveAssignable) { + EXPECT_TRUE(TestMoveAssign<int>()); + EXPECT_TRUE(TestMoveAssign<int&>()); + EXPECT_TRUE(TestMoveAssign<int&&>()); + + struct S {}; + EXPECT_TRUE(TestMoveAssign<S>()); + EXPECT_TRUE(TestMoveAssign<S&>()); + EXPECT_TRUE(TestMoveAssign<S&&>()); + + class C { + public: + explicit C(C* c) : c_(c) {} + ~C() { delete c_; } + void operator=(const C&) = delete; + void operator=(C&&) = delete; + + private: + C* c_; + }; + EXPECT_TRUE(TestMoveAssign<C>()); + EXPECT_TRUE(TestMoveAssign<C&>()); + EXPECT_TRUE(TestMoveAssign<C&&>()); + + // Reason for ifndef: add_lvalue_reference<T> in libc++ breaks for these cases +#ifndef _LIBCPP_VERSION + EXPECT_TRUE(TestMoveAssign<int()>()); + EXPECT_TRUE(TestMoveAssign<int(int) const>()); + EXPECT_TRUE(TestMoveAssign<int(...) volatile&>()); + EXPECT_TRUE(TestMoveAssign<int(int, ...) const volatile&&>()); +#endif // _LIBCPP_VERSION +} + +namespace adl_namespace { + +struct DeletedSwap { +}; + +void swap(DeletedSwap&, DeletedSwap&) = delete; + +struct SpecialNoexceptSwap { + SpecialNoexceptSwap(SpecialNoexceptSwap&&) {} + SpecialNoexceptSwap& operator=(SpecialNoexceptSwap&&) { return *this; } + ~SpecialNoexceptSwap() = default; +}; + +void swap(SpecialNoexceptSwap&, SpecialNoexceptSwap&) noexcept {} + +} // namespace adl_namespace + +TEST(TypeTraitsTest, IsSwappable) { + using absl::type_traits_internal::IsSwappable; + using absl::type_traits_internal::StdSwapIsUnconstrained; + + EXPECT_TRUE(IsSwappable<int>::value); + + struct S {}; + EXPECT_TRUE(IsSwappable<S>::value); + + struct NoConstruct { + NoConstruct(NoConstruct&&) = delete; + NoConstruct& operator=(NoConstruct&&) { return *this; } + ~NoConstruct() = default; + }; + + EXPECT_EQ(IsSwappable<NoConstruct>::value, StdSwapIsUnconstrained::value); + struct NoAssign { + NoAssign(NoAssign&&) {} + NoAssign& operator=(NoAssign&&) = delete; + ~NoAssign() = default; + }; + + EXPECT_EQ(IsSwappable<NoAssign>::value, StdSwapIsUnconstrained::value); + + EXPECT_FALSE(IsSwappable<adl_namespace::DeletedSwap>::value); + + EXPECT_TRUE(IsSwappable<adl_namespace::SpecialNoexceptSwap>::value); +} + +TEST(TypeTraitsTest, IsNothrowSwappable) { + using absl::type_traits_internal::IsNothrowSwappable; + using absl::type_traits_internal::StdSwapIsUnconstrained; + + EXPECT_TRUE(IsNothrowSwappable<int>::value); + + struct NonNoexceptMoves { + NonNoexceptMoves(NonNoexceptMoves&&) {} + NonNoexceptMoves& operator=(NonNoexceptMoves&&) { return *this; } + ~NonNoexceptMoves() = default; + }; + + EXPECT_FALSE(IsNothrowSwappable<NonNoexceptMoves>::value); + + struct NoConstruct { + NoConstruct(NoConstruct&&) = delete; + NoConstruct& operator=(NoConstruct&&) { return *this; } + ~NoConstruct() = default; + }; + + EXPECT_FALSE(IsNothrowSwappable<NoConstruct>::value); + + struct NoAssign { + NoAssign(NoAssign&&) {} + NoAssign& operator=(NoAssign&&) = delete; + ~NoAssign() = default; + }; + + EXPECT_FALSE(IsNothrowSwappable<NoAssign>::value); + + EXPECT_FALSE(IsNothrowSwappable<adl_namespace::DeletedSwap>::value); + + EXPECT_TRUE(IsNothrowSwappable<adl_namespace::SpecialNoexceptSwap>::value); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/numeric/BUILD.bazel b/third_party/abseil_cpp/absl/numeric/BUILD.bazel new file mode 100644 index 0000000000..e09e52d21f --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/BUILD.bazel @@ -0,0 +1,73 @@ +# Copyright 2018 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "int128", + srcs = [ + "int128.cc", + "int128_have_intrinsic.inc", + "int128_no_intrinsic.inc", + ], + hdrs = ["int128.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + ], +) + +cc_test( + name = "int128_test", + size = "small", + srcs = [ + "int128_stream_test.cc", + "int128_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":int128", + "//absl/base", + "//absl/base:core_headers", + "//absl/hash:hash_testing", + "//absl/meta:type_traits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "int128_benchmark", + srcs = ["int128_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + deps = [ + ":int128", + "//absl/base:config", + "@com_github_google_benchmark//:benchmark_main", + ], +) diff --git a/third_party/abseil_cpp/absl/numeric/CMakeLists.txt b/third_party/abseil_cpp/absl/numeric/CMakeLists.txt new file mode 100644 index 0000000000..242889f088 --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/CMakeLists.txt @@ -0,0 +1,60 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + int128 + HDRS + "int128.h" + SRCS + "int128.cc" + "int128_have_intrinsic.inc" + "int128_no_intrinsic.inc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers + PUBLIC +) + +absl_cc_test( + NAME + int128_test + SRCS + "int128_stream_test.cc" + "int128_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::int128 + absl::base + absl::core_headers + absl::hash_testing + absl::type_traits + gmock_main +) + +# component target +absl_cc_library( + NAME + numeric + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::int128 + PUBLIC +) diff --git a/third_party/abseil_cpp/absl/numeric/int128.cc b/third_party/abseil_cpp/absl/numeric/int128.cc new file mode 100644 index 0000000000..b605a87042 --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128.cc @@ -0,0 +1,404 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/numeric/int128.h" + +#include <stddef.h> +#include <cassert> +#include <iomanip> +#include <ostream> // NOLINT(readability/streams) +#include <sstream> +#include <string> +#include <type_traits> + +namespace absl { +ABSL_NAMESPACE_BEGIN + +ABSL_DLL const uint128 kuint128max = MakeUint128( + std::numeric_limits<uint64_t>::max(), std::numeric_limits<uint64_t>::max()); + +namespace { + +// Returns the 0-based position of the last set bit (i.e., most significant bit) +// in the given uint64_t. The argument may not be 0. +// +// For example: +// Given: 5 (decimal) == 101 (binary) +// Returns: 2 +#define STEP(T, n, pos, sh) \ + do { \ + if ((n) >= (static_cast<T>(1) << (sh))) { \ + (n) = (n) >> (sh); \ + (pos) |= (sh); \ + } \ + } while (0) +static inline int Fls64(uint64_t n) { + assert(n != 0); + int pos = 0; + STEP(uint64_t, n, pos, 0x20); + uint32_t n32 = static_cast<uint32_t>(n); + STEP(uint32_t, n32, pos, 0x10); + STEP(uint32_t, n32, pos, 0x08); + STEP(uint32_t, n32, pos, 0x04); + return pos + ((uint64_t{0x3333333322221100} >> (n32 << 2)) & 0x3); +} +#undef STEP + +// Like Fls64() above, but returns the 0-based position of the last set bit +// (i.e., most significant bit) in the given uint128. The argument may not be 0. +static inline int Fls128(uint128 n) { + if (uint64_t hi = Uint128High64(n)) { + return Fls64(hi) + 64; + } + return Fls64(Uint128Low64(n)); +} + +// Long division/modulo for uint128 implemented using the shift-subtract +// division algorithm adapted from: +// https://stackoverflow.com/questions/5386377/division-without-using +void DivModImpl(uint128 dividend, uint128 divisor, uint128* quotient_ret, + uint128* remainder_ret) { + assert(divisor != 0); + + if (divisor > dividend) { + *quotient_ret = 0; + *remainder_ret = dividend; + return; + } + + if (divisor == dividend) { + *quotient_ret = 1; + *remainder_ret = 0; + return; + } + + uint128 denominator = divisor; + uint128 quotient = 0; + + // Left aligns the MSB of the denominator and the dividend. + const int shift = Fls128(dividend) - Fls128(denominator); + denominator <<= shift; + + // Uses shift-subtract algorithm to divide dividend by denominator. The + // remainder will be left in dividend. + for (int i = 0; i <= shift; ++i) { + quotient <<= 1; + if (dividend >= denominator) { + dividend -= denominator; + quotient |= 1; + } + denominator >>= 1; + } + + *quotient_ret = quotient; + *remainder_ret = dividend; +} + +template <typename T> +uint128 MakeUint128FromFloat(T v) { + static_assert(std::is_floating_point<T>::value, ""); + + // Rounding behavior is towards zero, same as for built-in types. + + // Undefined behavior if v is NaN or cannot fit into uint128. + assert(std::isfinite(v) && v > -1 && + (std::numeric_limits<T>::max_exponent <= 128 || + v < std::ldexp(static_cast<T>(1), 128))); + + if (v >= std::ldexp(static_cast<T>(1), 64)) { + uint64_t hi = static_cast<uint64_t>(std::ldexp(v, -64)); + uint64_t lo = static_cast<uint64_t>(v - std::ldexp(static_cast<T>(hi), 64)); + return MakeUint128(hi, lo); + } + + return MakeUint128(0, static_cast<uint64_t>(v)); +} + +#if defined(__clang__) && !defined(__SSE3__) +// Workaround for clang bug: https://bugs.llvm.org/show_bug.cgi?id=38289 +// Casting from long double to uint64_t is miscompiled and drops bits. +// It is more work, so only use when we need the workaround. +uint128 MakeUint128FromFloat(long double v) { + // Go 50 bits at a time, that fits in a double + static_assert(std::numeric_limits<double>::digits >= 50, ""); + static_assert(std::numeric_limits<long double>::digits <= 150, ""); + // Undefined behavior if v is not finite or cannot fit into uint128. + assert(std::isfinite(v) && v > -1 && v < std::ldexp(1.0L, 128)); + + v = std::ldexp(v, -100); + uint64_t w0 = static_cast<uint64_t>(static_cast<double>(std::trunc(v))); + v = std::ldexp(v - static_cast<double>(w0), 50); + uint64_t w1 = static_cast<uint64_t>(static_cast<double>(std::trunc(v))); + v = std::ldexp(v - static_cast<double>(w1), 50); + uint64_t w2 = static_cast<uint64_t>(static_cast<double>(std::trunc(v))); + return (static_cast<uint128>(w0) << 100) | (static_cast<uint128>(w1) << 50) | + static_cast<uint128>(w2); +} +#endif // __clang__ && !__SSE3__ +} // namespace + +uint128::uint128(float v) : uint128(MakeUint128FromFloat(v)) {} +uint128::uint128(double v) : uint128(MakeUint128FromFloat(v)) {} +uint128::uint128(long double v) : uint128(MakeUint128FromFloat(v)) {} + +uint128 operator/(uint128 lhs, uint128 rhs) { +#if defined(ABSL_HAVE_INTRINSIC_INT128) + return static_cast<unsigned __int128>(lhs) / + static_cast<unsigned __int128>(rhs); +#else // ABSL_HAVE_INTRINSIC_INT128 + uint128 quotient = 0; + uint128 remainder = 0; + DivModImpl(lhs, rhs, "ient, &remainder); + return quotient; +#endif // ABSL_HAVE_INTRINSIC_INT128 +} +uint128 operator%(uint128 lhs, uint128 rhs) { +#if defined(ABSL_HAVE_INTRINSIC_INT128) + return static_cast<unsigned __int128>(lhs) % + static_cast<unsigned __int128>(rhs); +#else // ABSL_HAVE_INTRINSIC_INT128 + uint128 quotient = 0; + uint128 remainder = 0; + DivModImpl(lhs, rhs, "ient, &remainder); + return remainder; +#endif // ABSL_HAVE_INTRINSIC_INT128 +} + +namespace { + +std::string Uint128ToFormattedString(uint128 v, std::ios_base::fmtflags flags) { + // Select a divisor which is the largest power of the base < 2^64. + uint128 div; + int div_base_log; + switch (flags & std::ios::basefield) { + case std::ios::hex: + div = 0x1000000000000000; // 16^15 + div_base_log = 15; + break; + case std::ios::oct: + div = 01000000000000000000000; // 8^21 + div_base_log = 21; + break; + default: // std::ios::dec + div = 10000000000000000000u; // 10^19 + div_base_log = 19; + break; + } + + // Now piece together the uint128 representation from three chunks of the + // original value, each less than "div" and therefore representable as a + // uint64_t. + std::ostringstream os; + std::ios_base::fmtflags copy_mask = + std::ios::basefield | std::ios::showbase | std::ios::uppercase; + os.setf(flags & copy_mask, copy_mask); + uint128 high = v; + uint128 low; + DivModImpl(high, div, &high, &low); + uint128 mid; + DivModImpl(high, div, &high, &mid); + if (Uint128Low64(high) != 0) { + os << Uint128Low64(high); + os << std::noshowbase << std::setfill('0') << std::setw(div_base_log); + os << Uint128Low64(mid); + os << std::setw(div_base_log); + } else if (Uint128Low64(mid) != 0) { + os << Uint128Low64(mid); + os << std::noshowbase << std::setfill('0') << std::setw(div_base_log); + } + os << Uint128Low64(low); + return os.str(); +} + +} // namespace + +std::ostream& operator<<(std::ostream& os, uint128 v) { + std::ios_base::fmtflags flags = os.flags(); + std::string rep = Uint128ToFormattedString(v, flags); + + // Add the requisite padding. + std::streamsize width = os.width(0); + if (static_cast<size_t>(width) > rep.size()) { + std::ios::fmtflags adjustfield = flags & std::ios::adjustfield; + if (adjustfield == std::ios::left) { + rep.append(width - rep.size(), os.fill()); + } else if (adjustfield == std::ios::internal && + (flags & std::ios::showbase) && + (flags & std::ios::basefield) == std::ios::hex && v != 0) { + rep.insert(2, width - rep.size(), os.fill()); + } else { + rep.insert(0, width - rep.size(), os.fill()); + } + } + + return os << rep; +} + +namespace { + +uint128 UnsignedAbsoluteValue(int128 v) { + // Cast to uint128 before possibly negating because -Int128Min() is undefined. + return Int128High64(v) < 0 ? -uint128(v) : uint128(v); +} + +} // namespace + +#if !defined(ABSL_HAVE_INTRINSIC_INT128) +namespace { + +template <typename T> +int128 MakeInt128FromFloat(T v) { + // Conversion when v is NaN or cannot fit into int128 would be undefined + // behavior if using an intrinsic 128-bit integer. + assert(std::isfinite(v) && (std::numeric_limits<T>::max_exponent <= 127 || + (v >= -std::ldexp(static_cast<T>(1), 127) && + v < std::ldexp(static_cast<T>(1), 127)))); + + // We must convert the absolute value and then negate as needed, because + // floating point types are typically sign-magnitude. Otherwise, the + // difference between the high and low 64 bits when interpreted as two's + // complement overwhelms the precision of the mantissa. + uint128 result = v < 0 ? -MakeUint128FromFloat(-v) : MakeUint128FromFloat(v); + return MakeInt128(int128_internal::BitCastToSigned(Uint128High64(result)), + Uint128Low64(result)); +} + +} // namespace + +int128::int128(float v) : int128(MakeInt128FromFloat(v)) {} +int128::int128(double v) : int128(MakeInt128FromFloat(v)) {} +int128::int128(long double v) : int128(MakeInt128FromFloat(v)) {} + +int128 operator/(int128 lhs, int128 rhs) { + assert(lhs != Int128Min() || rhs != -1); // UB on two's complement. + + uint128 quotient = 0; + uint128 remainder = 0; + DivModImpl(UnsignedAbsoluteValue(lhs), UnsignedAbsoluteValue(rhs), + "ient, &remainder); + if ((Int128High64(lhs) < 0) != (Int128High64(rhs) < 0)) quotient = -quotient; + return MakeInt128(int128_internal::BitCastToSigned(Uint128High64(quotient)), + Uint128Low64(quotient)); +} + +int128 operator%(int128 lhs, int128 rhs) { + assert(lhs != Int128Min() || rhs != -1); // UB on two's complement. + + uint128 quotient = 0; + uint128 remainder = 0; + DivModImpl(UnsignedAbsoluteValue(lhs), UnsignedAbsoluteValue(rhs), + "ient, &remainder); + if (Int128High64(lhs) < 0) remainder = -remainder; + return MakeInt128(int128_internal::BitCastToSigned(Uint128High64(remainder)), + Uint128Low64(remainder)); +} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +std::ostream& operator<<(std::ostream& os, int128 v) { + std::ios_base::fmtflags flags = os.flags(); + std::string rep; + + // Add the sign if needed. + bool print_as_decimal = + (flags & std::ios::basefield) == std::ios::dec || + (flags & std::ios::basefield) == std::ios_base::fmtflags(); + if (print_as_decimal) { + if (Int128High64(v) < 0) { + rep = "-"; + } else if (flags & std::ios::showpos) { + rep = "+"; + } + } + + rep.append(Uint128ToFormattedString( + print_as_decimal ? UnsignedAbsoluteValue(v) : uint128(v), os.flags())); + + // Add the requisite padding. + std::streamsize width = os.width(0); + if (static_cast<size_t>(width) > rep.size()) { + switch (flags & std::ios::adjustfield) { + case std::ios::left: + rep.append(width - rep.size(), os.fill()); + break; + case std::ios::internal: + if (print_as_decimal && (rep[0] == '+' || rep[0] == '-')) { + rep.insert(1, width - rep.size(), os.fill()); + } else if ((flags & std::ios::basefield) == std::ios::hex && + (flags & std::ios::showbase) && v != 0) { + rep.insert(2, width - rep.size(), os.fill()); + } else { + rep.insert(0, width - rep.size(), os.fill()); + } + break; + default: // std::ios::right + rep.insert(0, width - rep.size(), os.fill()); + break; + } + } + + return os << rep; +} + +ABSL_NAMESPACE_END +} // namespace absl + +namespace std { +constexpr bool numeric_limits<absl::uint128>::is_specialized; +constexpr bool numeric_limits<absl::uint128>::is_signed; +constexpr bool numeric_limits<absl::uint128>::is_integer; +constexpr bool numeric_limits<absl::uint128>::is_exact; +constexpr bool numeric_limits<absl::uint128>::has_infinity; +constexpr bool numeric_limits<absl::uint128>::has_quiet_NaN; +constexpr bool numeric_limits<absl::uint128>::has_signaling_NaN; +constexpr float_denorm_style numeric_limits<absl::uint128>::has_denorm; +constexpr bool numeric_limits<absl::uint128>::has_denorm_loss; +constexpr float_round_style numeric_limits<absl::uint128>::round_style; +constexpr bool numeric_limits<absl::uint128>::is_iec559; +constexpr bool numeric_limits<absl::uint128>::is_bounded; +constexpr bool numeric_limits<absl::uint128>::is_modulo; +constexpr int numeric_limits<absl::uint128>::digits; +constexpr int numeric_limits<absl::uint128>::digits10; +constexpr int numeric_limits<absl::uint128>::max_digits10; +constexpr int numeric_limits<absl::uint128>::radix; +constexpr int numeric_limits<absl::uint128>::min_exponent; +constexpr int numeric_limits<absl::uint128>::min_exponent10; +constexpr int numeric_limits<absl::uint128>::max_exponent; +constexpr int numeric_limits<absl::uint128>::max_exponent10; +constexpr bool numeric_limits<absl::uint128>::traps; +constexpr bool numeric_limits<absl::uint128>::tinyness_before; + +constexpr bool numeric_limits<absl::int128>::is_specialized; +constexpr bool numeric_limits<absl::int128>::is_signed; +constexpr bool numeric_limits<absl::int128>::is_integer; +constexpr bool numeric_limits<absl::int128>::is_exact; +constexpr bool numeric_limits<absl::int128>::has_infinity; +constexpr bool numeric_limits<absl::int128>::has_quiet_NaN; +constexpr bool numeric_limits<absl::int128>::has_signaling_NaN; +constexpr float_denorm_style numeric_limits<absl::int128>::has_denorm; +constexpr bool numeric_limits<absl::int128>::has_denorm_loss; +constexpr float_round_style numeric_limits<absl::int128>::round_style; +constexpr bool numeric_limits<absl::int128>::is_iec559; +constexpr bool numeric_limits<absl::int128>::is_bounded; +constexpr bool numeric_limits<absl::int128>::is_modulo; +constexpr int numeric_limits<absl::int128>::digits; +constexpr int numeric_limits<absl::int128>::digits10; +constexpr int numeric_limits<absl::int128>::max_digits10; +constexpr int numeric_limits<absl::int128>::radix; +constexpr int numeric_limits<absl::int128>::min_exponent; +constexpr int numeric_limits<absl::int128>::min_exponent10; +constexpr int numeric_limits<absl::int128>::max_exponent; +constexpr int numeric_limits<absl::int128>::max_exponent10; +constexpr bool numeric_limits<absl::int128>::traps; +constexpr bool numeric_limits<absl::int128>::tinyness_before; +} // namespace std diff --git a/third_party/abseil_cpp/absl/numeric/int128.h b/third_party/abseil_cpp/absl/numeric/int128.h new file mode 100644 index 0000000000..0dd814a890 --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128.h @@ -0,0 +1,1092 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: int128.h +// ----------------------------------------------------------------------------- +// +// This header file defines 128-bit integer types, `uint128` and `int128`. + +#ifndef ABSL_NUMERIC_INT128_H_ +#define ABSL_NUMERIC_INT128_H_ + +#include <cassert> +#include <cmath> +#include <cstdint> +#include <cstring> +#include <iosfwd> +#include <limits> +#include <utility> + +#include "absl/base/config.h" +#include "absl/base/macros.h" +#include "absl/base/port.h" + +#if defined(_MSC_VER) +// In very old versions of MSVC and when the /Zc:wchar_t flag is off, wchar_t is +// a typedef for unsigned short. Otherwise wchar_t is mapped to the __wchar_t +// builtin type. We need to make sure not to define operator wchar_t() +// alongside operator unsigned short() in these instances. +#define ABSL_INTERNAL_WCHAR_T __wchar_t +#if defined(_M_X64) +#include <intrin.h> +#pragma intrinsic(_umul128) +#endif // defined(_M_X64) +#else // defined(_MSC_VER) +#define ABSL_INTERNAL_WCHAR_T wchar_t +#endif // defined(_MSC_VER) + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class int128; + +// uint128 +// +// An unsigned 128-bit integer type. The API is meant to mimic an intrinsic type +// as closely as is practical, including exhibiting undefined behavior in +// analogous cases (e.g. division by zero). This type is intended to be a +// drop-in replacement once C++ supports an intrinsic `uint128_t` type; when +// that occurs, existing well-behaved uses of `uint128` will continue to work +// using that new type. +// +// Note: code written with this type will continue to compile once `uint128_t` +// is introduced, provided the replacement helper functions +// `Uint128(Low|High)64()` and `MakeUint128()` are made. +// +// A `uint128` supports the following: +// +// * Implicit construction from integral types +// * Explicit conversion to integral types +// +// Additionally, if your compiler supports `__int128`, `uint128` is +// interoperable with that type. (Abseil checks for this compatibility through +// the `ABSL_HAVE_INTRINSIC_INT128` macro.) +// +// However, a `uint128` differs from intrinsic integral types in the following +// ways: +// +// * Errors on implicit conversions that do not preserve value (such as +// loss of precision when converting to float values). +// * Requires explicit construction from and conversion to floating point +// types. +// * Conversion to integral types requires an explicit static_cast() to +// mimic use of the `-Wnarrowing` compiler flag. +// * The alignment requirement of `uint128` may differ from that of an +// intrinsic 128-bit integer type depending on platform and build +// configuration. +// +// Example: +// +// float y = absl::Uint128Max(); // Error. uint128 cannot be implicitly +// // converted to float. +// +// absl::uint128 v; +// uint64_t i = v; // Error +// uint64_t i = static_cast<uint64_t>(v); // OK +// +class +#if defined(ABSL_HAVE_INTRINSIC_INT128) + alignas(unsigned __int128) +#endif // ABSL_HAVE_INTRINSIC_INT128 + uint128 { + public: + uint128() = default; + + // Constructors from arithmetic types + constexpr uint128(int v); // NOLINT(runtime/explicit) + constexpr uint128(unsigned int v); // NOLINT(runtime/explicit) + constexpr uint128(long v); // NOLINT(runtime/int) + constexpr uint128(unsigned long v); // NOLINT(runtime/int) + constexpr uint128(long long v); // NOLINT(runtime/int) + constexpr uint128(unsigned long long v); // NOLINT(runtime/int) +#ifdef ABSL_HAVE_INTRINSIC_INT128 + constexpr uint128(__int128 v); // NOLINT(runtime/explicit) + constexpr uint128(unsigned __int128 v); // NOLINT(runtime/explicit) +#endif // ABSL_HAVE_INTRINSIC_INT128 + constexpr uint128(int128 v); // NOLINT(runtime/explicit) + explicit uint128(float v); + explicit uint128(double v); + explicit uint128(long double v); + + // Assignment operators from arithmetic types + uint128& operator=(int v); + uint128& operator=(unsigned int v); + uint128& operator=(long v); // NOLINT(runtime/int) + uint128& operator=(unsigned long v); // NOLINT(runtime/int) + uint128& operator=(long long v); // NOLINT(runtime/int) + uint128& operator=(unsigned long long v); // NOLINT(runtime/int) +#ifdef ABSL_HAVE_INTRINSIC_INT128 + uint128& operator=(__int128 v); + uint128& operator=(unsigned __int128 v); +#endif // ABSL_HAVE_INTRINSIC_INT128 + uint128& operator=(int128 v); + + // Conversion operators to other arithmetic types + constexpr explicit operator bool() const; + constexpr explicit operator char() const; + constexpr explicit operator signed char() const; + constexpr explicit operator unsigned char() const; + constexpr explicit operator char16_t() const; + constexpr explicit operator char32_t() const; + constexpr explicit operator ABSL_INTERNAL_WCHAR_T() const; + constexpr explicit operator short() const; // NOLINT(runtime/int) + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator unsigned short() const; + constexpr explicit operator int() const; + constexpr explicit operator unsigned int() const; + constexpr explicit operator long() const; // NOLINT(runtime/int) + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator unsigned long() const; + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator long long() const; + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator unsigned long long() const; +#ifdef ABSL_HAVE_INTRINSIC_INT128 + constexpr explicit operator __int128() const; + constexpr explicit operator unsigned __int128() const; +#endif // ABSL_HAVE_INTRINSIC_INT128 + explicit operator float() const; + explicit operator double() const; + explicit operator long double() const; + + // Trivial copy constructor, assignment operator and destructor. + + // Arithmetic operators. + uint128& operator+=(uint128 other); + uint128& operator-=(uint128 other); + uint128& operator*=(uint128 other); + // Long division/modulo for uint128. + uint128& operator/=(uint128 other); + uint128& operator%=(uint128 other); + uint128 operator++(int); + uint128 operator--(int); + uint128& operator<<=(int); + uint128& operator>>=(int); + uint128& operator&=(uint128 other); + uint128& operator|=(uint128 other); + uint128& operator^=(uint128 other); + uint128& operator++(); + uint128& operator--(); + + // Uint128Low64() + // + // Returns the lower 64-bit value of a `uint128` value. + friend constexpr uint64_t Uint128Low64(uint128 v); + + // Uint128High64() + // + // Returns the higher 64-bit value of a `uint128` value. + friend constexpr uint64_t Uint128High64(uint128 v); + + // MakeUInt128() + // + // Constructs a `uint128` numeric value from two 64-bit unsigned integers. + // Note that this factory function is the only way to construct a `uint128` + // from integer values greater than 2^64. + // + // Example: + // + // absl::uint128 big = absl::MakeUint128(1, 0); + friend constexpr uint128 MakeUint128(uint64_t high, uint64_t low); + + // Uint128Max() + // + // Returns the highest value for a 128-bit unsigned integer. + friend constexpr uint128 Uint128Max(); + + // Support for absl::Hash. + template <typename H> + friend H AbslHashValue(H h, uint128 v) { + return H::combine(std::move(h), Uint128High64(v), Uint128Low64(v)); + } + + private: + constexpr uint128(uint64_t high, uint64_t low); + + // TODO(strel) Update implementation to use __int128 once all users of + // uint128 are fixed to not depend on alignof(uint128) == 8. Also add + // alignas(16) to class definition to keep alignment consistent across + // platforms. +#if defined(ABSL_IS_LITTLE_ENDIAN) + uint64_t lo_; + uint64_t hi_; +#elif defined(ABSL_IS_BIG_ENDIAN) + uint64_t hi_; + uint64_t lo_; +#else // byte order +#error "Unsupported byte order: must be little-endian or big-endian." +#endif // byte order +}; + +// Prefer to use the constexpr `Uint128Max()`. +// +// TODO(absl-team) deprecate kuint128max once migration tool is released. +ABSL_DLL extern const uint128 kuint128max; + +// allow uint128 to be logged +std::ostream& operator<<(std::ostream& os, uint128 v); + +// TODO(strel) add operator>>(std::istream&, uint128) + +constexpr uint128 Uint128Max() { + return uint128((std::numeric_limits<uint64_t>::max)(), + (std::numeric_limits<uint64_t>::max)()); +} + +ABSL_NAMESPACE_END +} // namespace absl + +// Specialized numeric_limits for uint128. +namespace std { +template <> +class numeric_limits<absl::uint128> { + public: + static constexpr bool is_specialized = true; + static constexpr bool is_signed = false; + static constexpr bool is_integer = true; + static constexpr bool is_exact = true; + static constexpr bool has_infinity = false; + static constexpr bool has_quiet_NaN = false; + static constexpr bool has_signaling_NaN = false; + static constexpr float_denorm_style has_denorm = denorm_absent; + static constexpr bool has_denorm_loss = false; + static constexpr float_round_style round_style = round_toward_zero; + static constexpr bool is_iec559 = false; + static constexpr bool is_bounded = true; + static constexpr bool is_modulo = true; + static constexpr int digits = 128; + static constexpr int digits10 = 38; + static constexpr int max_digits10 = 0; + static constexpr int radix = 2; + static constexpr int min_exponent = 0; + static constexpr int min_exponent10 = 0; + static constexpr int max_exponent = 0; + static constexpr int max_exponent10 = 0; +#ifdef ABSL_HAVE_INTRINSIC_INT128 + static constexpr bool traps = numeric_limits<unsigned __int128>::traps; +#else // ABSL_HAVE_INTRINSIC_INT128 + static constexpr bool traps = numeric_limits<uint64_t>::traps; +#endif // ABSL_HAVE_INTRINSIC_INT128 + static constexpr bool tinyness_before = false; + + static constexpr absl::uint128 (min)() { return 0; } + static constexpr absl::uint128 lowest() { return 0; } + static constexpr absl::uint128 (max)() { return absl::Uint128Max(); } + static constexpr absl::uint128 epsilon() { return 0; } + static constexpr absl::uint128 round_error() { return 0; } + static constexpr absl::uint128 infinity() { return 0; } + static constexpr absl::uint128 quiet_NaN() { return 0; } + static constexpr absl::uint128 signaling_NaN() { return 0; } + static constexpr absl::uint128 denorm_min() { return 0; } +}; +} // namespace std + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// int128 +// +// A signed 128-bit integer type. The API is meant to mimic an intrinsic +// integral type as closely as is practical, including exhibiting undefined +// behavior in analogous cases (e.g. division by zero). +// +// An `int128` supports the following: +// +// * Implicit construction from integral types +// * Explicit conversion to integral types +// +// However, an `int128` differs from intrinsic integral types in the following +// ways: +// +// * It is not implicitly convertible to other integral types. +// * Requires explicit construction from and conversion to floating point +// types. + +// Additionally, if your compiler supports `__int128`, `int128` is +// interoperable with that type. (Abseil checks for this compatibility through +// the `ABSL_HAVE_INTRINSIC_INT128` macro.) +// +// The design goal for `int128` is that it will be compatible with a future +// `int128_t`, if that type becomes a part of the standard. +// +// Example: +// +// float y = absl::int128(17); // Error. int128 cannot be implicitly +// // converted to float. +// +// absl::int128 v; +// int64_t i = v; // Error +// int64_t i = static_cast<int64_t>(v); // OK +// +class int128 { + public: + int128() = default; + + // Constructors from arithmetic types + constexpr int128(int v); // NOLINT(runtime/explicit) + constexpr int128(unsigned int v); // NOLINT(runtime/explicit) + constexpr int128(long v); // NOLINT(runtime/int) + constexpr int128(unsigned long v); // NOLINT(runtime/int) + constexpr int128(long long v); // NOLINT(runtime/int) + constexpr int128(unsigned long long v); // NOLINT(runtime/int) +#ifdef ABSL_HAVE_INTRINSIC_INT128 + constexpr int128(__int128 v); // NOLINT(runtime/explicit) + constexpr explicit int128(unsigned __int128 v); +#endif // ABSL_HAVE_INTRINSIC_INT128 + constexpr explicit int128(uint128 v); + explicit int128(float v); + explicit int128(double v); + explicit int128(long double v); + + // Assignment operators from arithmetic types + int128& operator=(int v); + int128& operator=(unsigned int v); + int128& operator=(long v); // NOLINT(runtime/int) + int128& operator=(unsigned long v); // NOLINT(runtime/int) + int128& operator=(long long v); // NOLINT(runtime/int) + int128& operator=(unsigned long long v); // NOLINT(runtime/int) +#ifdef ABSL_HAVE_INTRINSIC_INT128 + int128& operator=(__int128 v); +#endif // ABSL_HAVE_INTRINSIC_INT128 + + // Conversion operators to other arithmetic types + constexpr explicit operator bool() const; + constexpr explicit operator char() const; + constexpr explicit operator signed char() const; + constexpr explicit operator unsigned char() const; + constexpr explicit operator char16_t() const; + constexpr explicit operator char32_t() const; + constexpr explicit operator ABSL_INTERNAL_WCHAR_T() const; + constexpr explicit operator short() const; // NOLINT(runtime/int) + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator unsigned short() const; + constexpr explicit operator int() const; + constexpr explicit operator unsigned int() const; + constexpr explicit operator long() const; // NOLINT(runtime/int) + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator unsigned long() const; + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator long long() const; + // NOLINTNEXTLINE(runtime/int) + constexpr explicit operator unsigned long long() const; +#ifdef ABSL_HAVE_INTRINSIC_INT128 + constexpr explicit operator __int128() const; + constexpr explicit operator unsigned __int128() const; +#endif // ABSL_HAVE_INTRINSIC_INT128 + explicit operator float() const; + explicit operator double() const; + explicit operator long double() const; + + // Trivial copy constructor, assignment operator and destructor. + + // Arithmetic operators + int128& operator+=(int128 other); + int128& operator-=(int128 other); + int128& operator*=(int128 other); + int128& operator/=(int128 other); + int128& operator%=(int128 other); + int128 operator++(int); // postfix increment: i++ + int128 operator--(int); // postfix decrement: i-- + int128& operator++(); // prefix increment: ++i + int128& operator--(); // prefix decrement: --i + int128& operator&=(int128 other); + int128& operator|=(int128 other); + int128& operator^=(int128 other); + int128& operator<<=(int amount); + int128& operator>>=(int amount); + + // Int128Low64() + // + // Returns the lower 64-bit value of a `int128` value. + friend constexpr uint64_t Int128Low64(int128 v); + + // Int128High64() + // + // Returns the higher 64-bit value of a `int128` value. + friend constexpr int64_t Int128High64(int128 v); + + // MakeInt128() + // + // Constructs a `int128` numeric value from two 64-bit integers. Note that + // signedness is conveyed in the upper `high` value. + // + // (absl::int128(1) << 64) * high + low + // + // Note that this factory function is the only way to construct a `int128` + // from integer values greater than 2^64 or less than -2^64. + // + // Example: + // + // absl::int128 big = absl::MakeInt128(1, 0); + // absl::int128 big_n = absl::MakeInt128(-1, 0); + friend constexpr int128 MakeInt128(int64_t high, uint64_t low); + + // Int128Max() + // + // Returns the maximum value for a 128-bit signed integer. + friend constexpr int128 Int128Max(); + + // Int128Min() + // + // Returns the minimum value for a 128-bit signed integer. + friend constexpr int128 Int128Min(); + + // Support for absl::Hash. + template <typename H> + friend H AbslHashValue(H h, int128 v) { + return H::combine(std::move(h), Int128High64(v), Int128Low64(v)); + } + + private: + constexpr int128(int64_t high, uint64_t low); + +#if defined(ABSL_HAVE_INTRINSIC_INT128) + __int128 v_; +#else // ABSL_HAVE_INTRINSIC_INT128 +#if defined(ABSL_IS_LITTLE_ENDIAN) + uint64_t lo_; + int64_t hi_; +#elif defined(ABSL_IS_BIG_ENDIAN) + int64_t hi_; + uint64_t lo_; +#else // byte order +#error "Unsupported byte order: must be little-endian or big-endian." +#endif // byte order +#endif // ABSL_HAVE_INTRINSIC_INT128 +}; + +std::ostream& operator<<(std::ostream& os, int128 v); + +// TODO(absl-team) add operator>>(std::istream&, int128) + +constexpr int128 Int128Max() { + return int128((std::numeric_limits<int64_t>::max)(), + (std::numeric_limits<uint64_t>::max)()); +} + +constexpr int128 Int128Min() { + return int128((std::numeric_limits<int64_t>::min)(), 0); +} + +ABSL_NAMESPACE_END +} // namespace absl + +// Specialized numeric_limits for int128. +namespace std { +template <> +class numeric_limits<absl::int128> { + public: + static constexpr bool is_specialized = true; + static constexpr bool is_signed = true; + static constexpr bool is_integer = true; + static constexpr bool is_exact = true; + static constexpr bool has_infinity = false; + static constexpr bool has_quiet_NaN = false; + static constexpr bool has_signaling_NaN = false; + static constexpr float_denorm_style has_denorm = denorm_absent; + static constexpr bool has_denorm_loss = false; + static constexpr float_round_style round_style = round_toward_zero; + static constexpr bool is_iec559 = false; + static constexpr bool is_bounded = true; + static constexpr bool is_modulo = false; + static constexpr int digits = 127; + static constexpr int digits10 = 38; + static constexpr int max_digits10 = 0; + static constexpr int radix = 2; + static constexpr int min_exponent = 0; + static constexpr int min_exponent10 = 0; + static constexpr int max_exponent = 0; + static constexpr int max_exponent10 = 0; +#ifdef ABSL_HAVE_INTRINSIC_INT128 + static constexpr bool traps = numeric_limits<__int128>::traps; +#else // ABSL_HAVE_INTRINSIC_INT128 + static constexpr bool traps = numeric_limits<uint64_t>::traps; +#endif // ABSL_HAVE_INTRINSIC_INT128 + static constexpr bool tinyness_before = false; + + static constexpr absl::int128 (min)() { return absl::Int128Min(); } + static constexpr absl::int128 lowest() { return absl::Int128Min(); } + static constexpr absl::int128 (max)() { return absl::Int128Max(); } + static constexpr absl::int128 epsilon() { return 0; } + static constexpr absl::int128 round_error() { return 0; } + static constexpr absl::int128 infinity() { return 0; } + static constexpr absl::int128 quiet_NaN() { return 0; } + static constexpr absl::int128 signaling_NaN() { return 0; } + static constexpr absl::int128 denorm_min() { return 0; } +}; +} // namespace std + +// -------------------------------------------------------------------------- +// Implementation details follow +// -------------------------------------------------------------------------- +namespace absl { +ABSL_NAMESPACE_BEGIN + +constexpr uint128 MakeUint128(uint64_t high, uint64_t low) { + return uint128(high, low); +} + +// Assignment from integer types. + +inline uint128& uint128::operator=(int v) { return *this = uint128(v); } + +inline uint128& uint128::operator=(unsigned int v) { + return *this = uint128(v); +} + +inline uint128& uint128::operator=(long v) { // NOLINT(runtime/int) + return *this = uint128(v); +} + +// NOLINTNEXTLINE(runtime/int) +inline uint128& uint128::operator=(unsigned long v) { + return *this = uint128(v); +} + +// NOLINTNEXTLINE(runtime/int) +inline uint128& uint128::operator=(long long v) { + return *this = uint128(v); +} + +// NOLINTNEXTLINE(runtime/int) +inline uint128& uint128::operator=(unsigned long long v) { + return *this = uint128(v); +} + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +inline uint128& uint128::operator=(__int128 v) { + return *this = uint128(v); +} + +inline uint128& uint128::operator=(unsigned __int128 v) { + return *this = uint128(v); +} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +inline uint128& uint128::operator=(int128 v) { + return *this = uint128(v); +} + +// Arithmetic operators. + +uint128 operator<<(uint128 lhs, int amount); +uint128 operator>>(uint128 lhs, int amount); +uint128 operator+(uint128 lhs, uint128 rhs); +uint128 operator-(uint128 lhs, uint128 rhs); +uint128 operator*(uint128 lhs, uint128 rhs); +uint128 operator/(uint128 lhs, uint128 rhs); +uint128 operator%(uint128 lhs, uint128 rhs); + +inline uint128& uint128::operator<<=(int amount) { + *this = *this << amount; + return *this; +} + +inline uint128& uint128::operator>>=(int amount) { + *this = *this >> amount; + return *this; +} + +inline uint128& uint128::operator+=(uint128 other) { + *this = *this + other; + return *this; +} + +inline uint128& uint128::operator-=(uint128 other) { + *this = *this - other; + return *this; +} + +inline uint128& uint128::operator*=(uint128 other) { + *this = *this * other; + return *this; +} + +inline uint128& uint128::operator/=(uint128 other) { + *this = *this / other; + return *this; +} + +inline uint128& uint128::operator%=(uint128 other) { + *this = *this % other; + return *this; +} + +constexpr uint64_t Uint128Low64(uint128 v) { return v.lo_; } + +constexpr uint64_t Uint128High64(uint128 v) { return v.hi_; } + +// Constructors from integer types. + +#if defined(ABSL_IS_LITTLE_ENDIAN) + +constexpr uint128::uint128(uint64_t high, uint64_t low) + : lo_{low}, hi_{high} {} + +constexpr uint128::uint128(int v) + : lo_{static_cast<uint64_t>(v)}, + hi_{v < 0 ? (std::numeric_limits<uint64_t>::max)() : 0} {} +constexpr uint128::uint128(long v) // NOLINT(runtime/int) + : lo_{static_cast<uint64_t>(v)}, + hi_{v < 0 ? (std::numeric_limits<uint64_t>::max)() : 0} {} +constexpr uint128::uint128(long long v) // NOLINT(runtime/int) + : lo_{static_cast<uint64_t>(v)}, + hi_{v < 0 ? (std::numeric_limits<uint64_t>::max)() : 0} {} + +constexpr uint128::uint128(unsigned int v) : lo_{v}, hi_{0} {} +// NOLINTNEXTLINE(runtime/int) +constexpr uint128::uint128(unsigned long v) : lo_{v}, hi_{0} {} +// NOLINTNEXTLINE(runtime/int) +constexpr uint128::uint128(unsigned long long v) : lo_{v}, hi_{0} {} + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +constexpr uint128::uint128(__int128 v) + : lo_{static_cast<uint64_t>(v & ~uint64_t{0})}, + hi_{static_cast<uint64_t>(static_cast<unsigned __int128>(v) >> 64)} {} +constexpr uint128::uint128(unsigned __int128 v) + : lo_{static_cast<uint64_t>(v & ~uint64_t{0})}, + hi_{static_cast<uint64_t>(v >> 64)} {} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +constexpr uint128::uint128(int128 v) + : lo_{Int128Low64(v)}, hi_{static_cast<uint64_t>(Int128High64(v))} {} + +#elif defined(ABSL_IS_BIG_ENDIAN) + +constexpr uint128::uint128(uint64_t high, uint64_t low) + : hi_{high}, lo_{low} {} + +constexpr uint128::uint128(int v) + : hi_{v < 0 ? (std::numeric_limits<uint64_t>::max)() : 0}, + lo_{static_cast<uint64_t>(v)} {} +constexpr uint128::uint128(long v) // NOLINT(runtime/int) + : hi_{v < 0 ? (std::numeric_limits<uint64_t>::max)() : 0}, + lo_{static_cast<uint64_t>(v)} {} +constexpr uint128::uint128(long long v) // NOLINT(runtime/int) + : hi_{v < 0 ? (std::numeric_limits<uint64_t>::max)() : 0}, + lo_{static_cast<uint64_t>(v)} {} + +constexpr uint128::uint128(unsigned int v) : hi_{0}, lo_{v} {} +// NOLINTNEXTLINE(runtime/int) +constexpr uint128::uint128(unsigned long v) : hi_{0}, lo_{v} {} +// NOLINTNEXTLINE(runtime/int) +constexpr uint128::uint128(unsigned long long v) : hi_{0}, lo_{v} {} + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +constexpr uint128::uint128(__int128 v) + : hi_{static_cast<uint64_t>(static_cast<unsigned __int128>(v) >> 64)}, + lo_{static_cast<uint64_t>(v & ~uint64_t{0})} {} +constexpr uint128::uint128(unsigned __int128 v) + : hi_{static_cast<uint64_t>(v >> 64)}, + lo_{static_cast<uint64_t>(v & ~uint64_t{0})} {} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +constexpr uint128::uint128(int128 v) + : hi_{static_cast<uint64_t>(Int128High64(v))}, lo_{Int128Low64(v)} {} + +#else // byte order +#error "Unsupported byte order: must be little-endian or big-endian." +#endif // byte order + +// Conversion operators to integer types. + +constexpr uint128::operator bool() const { return lo_ || hi_; } + +constexpr uint128::operator char() const { return static_cast<char>(lo_); } + +constexpr uint128::operator signed char() const { + return static_cast<signed char>(lo_); +} + +constexpr uint128::operator unsigned char() const { + return static_cast<unsigned char>(lo_); +} + +constexpr uint128::operator char16_t() const { + return static_cast<char16_t>(lo_); +} + +constexpr uint128::operator char32_t() const { + return static_cast<char32_t>(lo_); +} + +constexpr uint128::operator ABSL_INTERNAL_WCHAR_T() const { + return static_cast<ABSL_INTERNAL_WCHAR_T>(lo_); +} + +// NOLINTNEXTLINE(runtime/int) +constexpr uint128::operator short() const { return static_cast<short>(lo_); } + +constexpr uint128::operator unsigned short() const { // NOLINT(runtime/int) + return static_cast<unsigned short>(lo_); // NOLINT(runtime/int) +} + +constexpr uint128::operator int() const { return static_cast<int>(lo_); } + +constexpr uint128::operator unsigned int() const { + return static_cast<unsigned int>(lo_); +} + +// NOLINTNEXTLINE(runtime/int) +constexpr uint128::operator long() const { return static_cast<long>(lo_); } + +constexpr uint128::operator unsigned long() const { // NOLINT(runtime/int) + return static_cast<unsigned long>(lo_); // NOLINT(runtime/int) +} + +constexpr uint128::operator long long() const { // NOLINT(runtime/int) + return static_cast<long long>(lo_); // NOLINT(runtime/int) +} + +constexpr uint128::operator unsigned long long() const { // NOLINT(runtime/int) + return static_cast<unsigned long long>(lo_); // NOLINT(runtime/int) +} + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +constexpr uint128::operator __int128() const { + return (static_cast<__int128>(hi_) << 64) + lo_; +} + +constexpr uint128::operator unsigned __int128() const { + return (static_cast<unsigned __int128>(hi_) << 64) + lo_; +} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +// Conversion operators to floating point types. + +inline uint128::operator float() const { + return static_cast<float>(lo_) + std::ldexp(static_cast<float>(hi_), 64); +} + +inline uint128::operator double() const { + return static_cast<double>(lo_) + std::ldexp(static_cast<double>(hi_), 64); +} + +inline uint128::operator long double() const { + return static_cast<long double>(lo_) + + std::ldexp(static_cast<long double>(hi_), 64); +} + +// Comparison operators. + +inline bool operator==(uint128 lhs, uint128 rhs) { + return (Uint128Low64(lhs) == Uint128Low64(rhs) && + Uint128High64(lhs) == Uint128High64(rhs)); +} + +inline bool operator!=(uint128 lhs, uint128 rhs) { + return !(lhs == rhs); +} + +inline bool operator<(uint128 lhs, uint128 rhs) { +#ifdef ABSL_HAVE_INTRINSIC_INT128 + return static_cast<unsigned __int128>(lhs) < + static_cast<unsigned __int128>(rhs); +#else + return (Uint128High64(lhs) == Uint128High64(rhs)) + ? (Uint128Low64(lhs) < Uint128Low64(rhs)) + : (Uint128High64(lhs) < Uint128High64(rhs)); +#endif +} + +inline bool operator>(uint128 lhs, uint128 rhs) { return rhs < lhs; } + +inline bool operator<=(uint128 lhs, uint128 rhs) { return !(rhs < lhs); } + +inline bool operator>=(uint128 lhs, uint128 rhs) { return !(lhs < rhs); } + +// Unary operators. + +inline uint128 operator-(uint128 val) { + uint64_t hi = ~Uint128High64(val); + uint64_t lo = ~Uint128Low64(val) + 1; + if (lo == 0) ++hi; // carry + return MakeUint128(hi, lo); +} + +inline bool operator!(uint128 val) { + return !Uint128High64(val) && !Uint128Low64(val); +} + +// Logical operators. + +inline uint128 operator~(uint128 val) { + return MakeUint128(~Uint128High64(val), ~Uint128Low64(val)); +} + +inline uint128 operator|(uint128 lhs, uint128 rhs) { + return MakeUint128(Uint128High64(lhs) | Uint128High64(rhs), + Uint128Low64(lhs) | Uint128Low64(rhs)); +} + +inline uint128 operator&(uint128 lhs, uint128 rhs) { + return MakeUint128(Uint128High64(lhs) & Uint128High64(rhs), + Uint128Low64(lhs) & Uint128Low64(rhs)); +} + +inline uint128 operator^(uint128 lhs, uint128 rhs) { + return MakeUint128(Uint128High64(lhs) ^ Uint128High64(rhs), + Uint128Low64(lhs) ^ Uint128Low64(rhs)); +} + +inline uint128& uint128::operator|=(uint128 other) { + hi_ |= other.hi_; + lo_ |= other.lo_; + return *this; +} + +inline uint128& uint128::operator&=(uint128 other) { + hi_ &= other.hi_; + lo_ &= other.lo_; + return *this; +} + +inline uint128& uint128::operator^=(uint128 other) { + hi_ ^= other.hi_; + lo_ ^= other.lo_; + return *this; +} + +// Arithmetic operators. + +inline uint128 operator<<(uint128 lhs, int amount) { +#ifdef ABSL_HAVE_INTRINSIC_INT128 + return static_cast<unsigned __int128>(lhs) << amount; +#else + // uint64_t shifts of >= 64 are undefined, so we will need some + // special-casing. + if (amount < 64) { + if (amount != 0) { + return MakeUint128( + (Uint128High64(lhs) << amount) | (Uint128Low64(lhs) >> (64 - amount)), + Uint128Low64(lhs) << amount); + } + return lhs; + } + return MakeUint128(Uint128Low64(lhs) << (amount - 64), 0); +#endif +} + +inline uint128 operator>>(uint128 lhs, int amount) { +#ifdef ABSL_HAVE_INTRINSIC_INT128 + return static_cast<unsigned __int128>(lhs) >> amount; +#else + // uint64_t shifts of >= 64 are undefined, so we will need some + // special-casing. + if (amount < 64) { + if (amount != 0) { + return MakeUint128(Uint128High64(lhs) >> amount, + (Uint128Low64(lhs) >> amount) | + (Uint128High64(lhs) << (64 - amount))); + } + return lhs; + } + return MakeUint128(0, Uint128High64(lhs) >> (amount - 64)); +#endif +} + +inline uint128 operator+(uint128 lhs, uint128 rhs) { + uint128 result = MakeUint128(Uint128High64(lhs) + Uint128High64(rhs), + Uint128Low64(lhs) + Uint128Low64(rhs)); + if (Uint128Low64(result) < Uint128Low64(lhs)) { // check for carry + return MakeUint128(Uint128High64(result) + 1, Uint128Low64(result)); + } + return result; +} + +inline uint128 operator-(uint128 lhs, uint128 rhs) { + uint128 result = MakeUint128(Uint128High64(lhs) - Uint128High64(rhs), + Uint128Low64(lhs) - Uint128Low64(rhs)); + if (Uint128Low64(lhs) < Uint128Low64(rhs)) { // check for carry + return MakeUint128(Uint128High64(result) - 1, Uint128Low64(result)); + } + return result; +} + +inline uint128 operator*(uint128 lhs, uint128 rhs) { +#if defined(ABSL_HAVE_INTRINSIC_INT128) + // TODO(strel) Remove once alignment issues are resolved and unsigned __int128 + // can be used for uint128 storage. + return static_cast<unsigned __int128>(lhs) * + static_cast<unsigned __int128>(rhs); +#elif defined(_MSC_VER) && defined(_M_X64) + uint64_t carry; + uint64_t low = _umul128(Uint128Low64(lhs), Uint128Low64(rhs), &carry); + return MakeUint128(Uint128Low64(lhs) * Uint128High64(rhs) + + Uint128High64(lhs) * Uint128Low64(rhs) + carry, + low); +#else // ABSL_HAVE_INTRINSIC128 + uint64_t a32 = Uint128Low64(lhs) >> 32; + uint64_t a00 = Uint128Low64(lhs) & 0xffffffff; + uint64_t b32 = Uint128Low64(rhs) >> 32; + uint64_t b00 = Uint128Low64(rhs) & 0xffffffff; + uint128 result = + MakeUint128(Uint128High64(lhs) * Uint128Low64(rhs) + + Uint128Low64(lhs) * Uint128High64(rhs) + a32 * b32, + a00 * b00); + result += uint128(a32 * b00) << 32; + result += uint128(a00 * b32) << 32; + return result; +#endif // ABSL_HAVE_INTRINSIC128 +} + +// Increment/decrement operators. + +inline uint128 uint128::operator++(int) { + uint128 tmp(*this); + *this += 1; + return tmp; +} + +inline uint128 uint128::operator--(int) { + uint128 tmp(*this); + *this -= 1; + return tmp; +} + +inline uint128& uint128::operator++() { + *this += 1; + return *this; +} + +inline uint128& uint128::operator--() { + *this -= 1; + return *this; +} + +constexpr int128 MakeInt128(int64_t high, uint64_t low) { + return int128(high, low); +} + +// Assignment from integer types. +inline int128& int128::operator=(int v) { + return *this = int128(v); +} + +inline int128& int128::operator=(unsigned int v) { + return *this = int128(v); +} + +inline int128& int128::operator=(long v) { // NOLINT(runtime/int) + return *this = int128(v); +} + +// NOLINTNEXTLINE(runtime/int) +inline int128& int128::operator=(unsigned long v) { + return *this = int128(v); +} + +// NOLINTNEXTLINE(runtime/int) +inline int128& int128::operator=(long long v) { + return *this = int128(v); +} + +// NOLINTNEXTLINE(runtime/int) +inline int128& int128::operator=(unsigned long long v) { + return *this = int128(v); +} + +// Arithmetic operators. + +int128 operator+(int128 lhs, int128 rhs); +int128 operator-(int128 lhs, int128 rhs); +int128 operator*(int128 lhs, int128 rhs); +int128 operator/(int128 lhs, int128 rhs); +int128 operator%(int128 lhs, int128 rhs); +int128 operator|(int128 lhs, int128 rhs); +int128 operator&(int128 lhs, int128 rhs); +int128 operator^(int128 lhs, int128 rhs); +int128 operator<<(int128 lhs, int amount); +int128 operator>>(int128 lhs, int amount); + +inline int128& int128::operator+=(int128 other) { + *this = *this + other; + return *this; +} + +inline int128& int128::operator-=(int128 other) { + *this = *this - other; + return *this; +} + +inline int128& int128::operator*=(int128 other) { + *this = *this * other; + return *this; +} + +inline int128& int128::operator/=(int128 other) { + *this = *this / other; + return *this; +} + +inline int128& int128::operator%=(int128 other) { + *this = *this % other; + return *this; +} + +inline int128& int128::operator|=(int128 other) { + *this = *this | other; + return *this; +} + +inline int128& int128::operator&=(int128 other) { + *this = *this & other; + return *this; +} + +inline int128& int128::operator^=(int128 other) { + *this = *this ^ other; + return *this; +} + +inline int128& int128::operator<<=(int amount) { + *this = *this << amount; + return *this; +} + +inline int128& int128::operator>>=(int amount) { + *this = *this >> amount; + return *this; +} + +namespace int128_internal { + +// Casts from unsigned to signed while preserving the underlying binary +// representation. +constexpr int64_t BitCastToSigned(uint64_t v) { + // Casting an unsigned integer to a signed integer of the same + // width is implementation defined behavior if the source value would not fit + // in the destination type. We step around it with a roundtrip bitwise not + // operation to make sure this function remains constexpr. Clang, GCC, and + // MSVC optimize this to a no-op on x86-64. + return v & (uint64_t{1} << 63) ? ~static_cast<int64_t>(~v) + : static_cast<int64_t>(v); +} + +} // namespace int128_internal + +#if defined(ABSL_HAVE_INTRINSIC_INT128) +#include "absl/numeric/int128_have_intrinsic.inc" // IWYU pragma: export +#else // ABSL_HAVE_INTRINSIC_INT128 +#include "absl/numeric/int128_no_intrinsic.inc" // IWYU pragma: export +#endif // ABSL_HAVE_INTRINSIC_INT128 + +ABSL_NAMESPACE_END +} // namespace absl + +#undef ABSL_INTERNAL_WCHAR_T + +#endif // ABSL_NUMERIC_INT128_H_ diff --git a/third_party/abseil_cpp/absl/numeric/int128_benchmark.cc b/third_party/abseil_cpp/absl/numeric/int128_benchmark.cc new file mode 100644 index 0000000000..a5502d927c --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128_benchmark.cc @@ -0,0 +1,221 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/numeric/int128.h" + +#include <algorithm> +#include <cstdint> +#include <random> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/base/config.h" + +namespace { + +constexpr size_t kSampleSize = 1000000; + +std::mt19937 MakeRandomEngine() { + std::random_device r; + std::seed_seq seed({r(), r(), r(), r(), r(), r(), r(), r()}); + return std::mt19937(seed); +} + +std::vector<std::pair<absl::uint128, absl::uint128>> +GetRandomClass128SampleUniformDivisor() { + std::vector<std::pair<absl::uint128, absl::uint128>> values; + std::mt19937 random = MakeRandomEngine(); + std::uniform_int_distribution<uint64_t> uniform_uint64; + values.reserve(kSampleSize); + for (size_t i = 0; i < kSampleSize; ++i) { + absl::uint128 a = + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random)); + absl::uint128 b = + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random)); + values.emplace_back(std::max(a, b), + std::max(absl::uint128(2), std::min(a, b))); + } + return values; +} + +void BM_DivideClass128UniformDivisor(benchmark::State& state) { + auto values = GetRandomClass128SampleUniformDivisor(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first / pair.second); + } + } +} +BENCHMARK(BM_DivideClass128UniformDivisor); + +std::vector<std::pair<absl::uint128, uint64_t>> +GetRandomClass128SampleSmallDivisor() { + std::vector<std::pair<absl::uint128, uint64_t>> values; + std::mt19937 random = MakeRandomEngine(); + std::uniform_int_distribution<uint64_t> uniform_uint64; + values.reserve(kSampleSize); + for (size_t i = 0; i < kSampleSize; ++i) { + absl::uint128 a = + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random)); + uint64_t b = std::max(uint64_t{2}, uniform_uint64(random)); + values.emplace_back(std::max(a, absl::uint128(b)), b); + } + return values; +} + +void BM_DivideClass128SmallDivisor(benchmark::State& state) { + auto values = GetRandomClass128SampleSmallDivisor(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first / pair.second); + } + } +} +BENCHMARK(BM_DivideClass128SmallDivisor); + +std::vector<std::pair<absl::uint128, absl::uint128>> GetRandomClass128Sample() { + std::vector<std::pair<absl::uint128, absl::uint128>> values; + std::mt19937 random = MakeRandomEngine(); + std::uniform_int_distribution<uint64_t> uniform_uint64; + values.reserve(kSampleSize); + for (size_t i = 0; i < kSampleSize; ++i) { + values.emplace_back( + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random)), + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random))); + } + return values; +} + +void BM_MultiplyClass128(benchmark::State& state) { + auto values = GetRandomClass128Sample(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first * pair.second); + } + } +} +BENCHMARK(BM_MultiplyClass128); + +void BM_AddClass128(benchmark::State& state) { + auto values = GetRandomClass128Sample(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first + pair.second); + } + } +} +BENCHMARK(BM_AddClass128); + +#ifdef ABSL_HAVE_INTRINSIC_INT128 + +// Some implementations of <random> do not support __int128 when it is +// available, so we make our own uniform_int_distribution-like type. +class UniformIntDistribution128 { + public: + // NOLINTNEXTLINE: mimicking std::uniform_int_distribution API + unsigned __int128 operator()(std::mt19937& generator) { + return (static_cast<unsigned __int128>(dist64_(generator)) << 64) | + dist64_(generator); + } + + private: + std::uniform_int_distribution<uint64_t> dist64_; +}; + +std::vector<std::pair<unsigned __int128, unsigned __int128>> +GetRandomIntrinsic128SampleUniformDivisor() { + std::vector<std::pair<unsigned __int128, unsigned __int128>> values; + std::mt19937 random = MakeRandomEngine(); + UniformIntDistribution128 uniform_uint128; + values.reserve(kSampleSize); + for (size_t i = 0; i < kSampleSize; ++i) { + unsigned __int128 a = uniform_uint128(random); + unsigned __int128 b = uniform_uint128(random); + values.emplace_back( + std::max(a, b), + std::max(static_cast<unsigned __int128>(2), std::min(a, b))); + } + return values; +} + +void BM_DivideIntrinsic128UniformDivisor(benchmark::State& state) { + auto values = GetRandomIntrinsic128SampleUniformDivisor(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first / pair.second); + } + } +} +BENCHMARK(BM_DivideIntrinsic128UniformDivisor); + +std::vector<std::pair<unsigned __int128, uint64_t>> +GetRandomIntrinsic128SampleSmallDivisor() { + std::vector<std::pair<unsigned __int128, uint64_t>> values; + std::mt19937 random = MakeRandomEngine(); + UniformIntDistribution128 uniform_uint128; + std::uniform_int_distribution<uint64_t> uniform_uint64; + values.reserve(kSampleSize); + for (size_t i = 0; i < kSampleSize; ++i) { + unsigned __int128 a = uniform_uint128(random); + uint64_t b = std::max(uint64_t{2}, uniform_uint64(random)); + values.emplace_back(std::max(a, static_cast<unsigned __int128>(b)), b); + } + return values; +} + +void BM_DivideIntrinsic128SmallDivisor(benchmark::State& state) { + auto values = GetRandomIntrinsic128SampleSmallDivisor(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first / pair.second); + } + } +} +BENCHMARK(BM_DivideIntrinsic128SmallDivisor); + +std::vector<std::pair<unsigned __int128, unsigned __int128>> + GetRandomIntrinsic128Sample() { + std::vector<std::pair<unsigned __int128, unsigned __int128>> values; + std::mt19937 random = MakeRandomEngine(); + UniformIntDistribution128 uniform_uint128; + values.reserve(kSampleSize); + for (size_t i = 0; i < kSampleSize; ++i) { + values.emplace_back(uniform_uint128(random), uniform_uint128(random)); + } + return values; +} + +void BM_MultiplyIntrinsic128(benchmark::State& state) { + auto values = GetRandomIntrinsic128Sample(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first * pair.second); + } + } +} +BENCHMARK(BM_MultiplyIntrinsic128); + +void BM_AddIntrinsic128(benchmark::State& state) { + auto values = GetRandomIntrinsic128Sample(); + while (state.KeepRunningBatch(values.size())) { + for (const auto& pair : values) { + benchmark::DoNotOptimize(pair.first + pair.second); + } + } +} +BENCHMARK(BM_AddIntrinsic128); + +#endif // ABSL_HAVE_INTRINSIC_INT128 + +} // namespace diff --git a/third_party/abseil_cpp/absl/numeric/int128_have_intrinsic.inc b/third_party/abseil_cpp/absl/numeric/int128_have_intrinsic.inc new file mode 100644 index 0000000000..d6c76dd320 --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128_have_intrinsic.inc @@ -0,0 +1,302 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file contains :int128 implementation details that depend on internal +// representation when ABSL_HAVE_INTRINSIC_INT128 is defined. This file is +// included by int128.h and relies on ABSL_INTERNAL_WCHAR_T being defined. + +namespace int128_internal { + +// Casts from unsigned to signed while preserving the underlying binary +// representation. +constexpr __int128 BitCastToSigned(unsigned __int128 v) { + // Casting an unsigned integer to a signed integer of the same + // width is implementation defined behavior if the source value would not fit + // in the destination type. We step around it with a roundtrip bitwise not + // operation to make sure this function remains constexpr. Clang and GCC + // optimize this to a no-op on x86-64. + return v & (static_cast<unsigned __int128>(1) << 127) + ? ~static_cast<__int128>(~v) + : static_cast<__int128>(v); +} + +} // namespace int128_internal + +inline int128& int128::operator=(__int128 v) { + v_ = v; + return *this; +} + +constexpr uint64_t Int128Low64(int128 v) { + return static_cast<uint64_t>(v.v_ & ~uint64_t{0}); +} + +constexpr int64_t Int128High64(int128 v) { + // Initially cast to unsigned to prevent a right shift on a negative value. + return int128_internal::BitCastToSigned( + static_cast<uint64_t>(static_cast<unsigned __int128>(v.v_) >> 64)); +} + +constexpr int128::int128(int64_t high, uint64_t low) + // Initially cast to unsigned to prevent a left shift that overflows. + : v_(int128_internal::BitCastToSigned(static_cast<unsigned __int128>(high) + << 64) | + low) {} + + +constexpr int128::int128(int v) : v_{v} {} + +constexpr int128::int128(long v) : v_{v} {} // NOLINT(runtime/int) + +constexpr int128::int128(long long v) : v_{v} {} // NOLINT(runtime/int) + +constexpr int128::int128(__int128 v) : v_{v} {} + +constexpr int128::int128(unsigned int v) : v_{v} {} + +constexpr int128::int128(unsigned long v) : v_{v} {} // NOLINT(runtime/int) + +// NOLINTNEXTLINE(runtime/int) +constexpr int128::int128(unsigned long long v) : v_{v} {} + +constexpr int128::int128(unsigned __int128 v) : v_{static_cast<__int128>(v)} {} + +inline int128::int128(float v) { + v_ = static_cast<__int128>(v); +} + +inline int128::int128(double v) { + v_ = static_cast<__int128>(v); +} + +inline int128::int128(long double v) { + v_ = static_cast<__int128>(v); +} + +constexpr int128::int128(uint128 v) : v_{static_cast<__int128>(v)} {} + +constexpr int128::operator bool() const { return static_cast<bool>(v_); } + +constexpr int128::operator char() const { return static_cast<char>(v_); } + +constexpr int128::operator signed char() const { + return static_cast<signed char>(v_); +} + +constexpr int128::operator unsigned char() const { + return static_cast<unsigned char>(v_); +} + +constexpr int128::operator char16_t() const { + return static_cast<char16_t>(v_); +} + +constexpr int128::operator char32_t() const { + return static_cast<char32_t>(v_); +} + +constexpr int128::operator ABSL_INTERNAL_WCHAR_T() const { + return static_cast<ABSL_INTERNAL_WCHAR_T>(v_); +} + +constexpr int128::operator short() const { // NOLINT(runtime/int) + return static_cast<short>(v_); // NOLINT(runtime/int) +} + +constexpr int128::operator unsigned short() const { // NOLINT(runtime/int) + return static_cast<unsigned short>(v_); // NOLINT(runtime/int) +} + +constexpr int128::operator int() const { + return static_cast<int>(v_); +} + +constexpr int128::operator unsigned int() const { + return static_cast<unsigned int>(v_); +} + +constexpr int128::operator long() const { // NOLINT(runtime/int) + return static_cast<long>(v_); // NOLINT(runtime/int) +} + +constexpr int128::operator unsigned long() const { // NOLINT(runtime/int) + return static_cast<unsigned long>(v_); // NOLINT(runtime/int) +} + +constexpr int128::operator long long() const { // NOLINT(runtime/int) + return static_cast<long long>(v_); // NOLINT(runtime/int) +} + +constexpr int128::operator unsigned long long() const { // NOLINT(runtime/int) + return static_cast<unsigned long long>(v_); // NOLINT(runtime/int) +} + +constexpr int128::operator __int128() const { return v_; } + +constexpr int128::operator unsigned __int128() const { + return static_cast<unsigned __int128>(v_); +} + +// Clang on PowerPC sometimes produces incorrect __int128 to floating point +// conversions. In that case, we do the conversion with a similar implementation +// to the conversion operators in int128_no_intrinsic.inc. +#if defined(__clang__) && !defined(__ppc64__) +inline int128::operator float() const { return static_cast<float>(v_); } + +inline int128::operator double () const { return static_cast<double>(v_); } + +inline int128::operator long double() const { + return static_cast<long double>(v_); +} + +#else // Clang on PowerPC +// Forward declaration for conversion operators to floating point types. +int128 operator-(int128 v); +bool operator!=(int128 lhs, int128 rhs); + +inline int128::operator float() const { + // We must convert the absolute value and then negate as needed, because + // floating point types are typically sign-magnitude. Otherwise, the + // difference between the high and low 64 bits when interpreted as two's + // complement overwhelms the precision of the mantissa. + // + // Also check to make sure we don't negate Int128Min() + return v_ < 0 && *this != Int128Min() + ? -static_cast<float>(-*this) + : static_cast<float>(Int128Low64(*this)) + + std::ldexp(static_cast<float>(Int128High64(*this)), 64); +} + +inline int128::operator double() const { + // See comment in int128::operator float() above. + return v_ < 0 && *this != Int128Min() + ? -static_cast<double>(-*this) + : static_cast<double>(Int128Low64(*this)) + + std::ldexp(static_cast<double>(Int128High64(*this)), 64); +} + +inline int128::operator long double() const { + // See comment in int128::operator float() above. + return v_ < 0 && *this != Int128Min() + ? -static_cast<long double>(-*this) + : static_cast<long double>(Int128Low64(*this)) + + std::ldexp(static_cast<long double>(Int128High64(*this)), + 64); +} +#endif // Clang on PowerPC + +// Comparison operators. + +inline bool operator==(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) == static_cast<__int128>(rhs); +} + +inline bool operator!=(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) != static_cast<__int128>(rhs); +} + +inline bool operator<(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) < static_cast<__int128>(rhs); +} + +inline bool operator>(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) > static_cast<__int128>(rhs); +} + +inline bool operator<=(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) <= static_cast<__int128>(rhs); +} + +inline bool operator>=(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) >= static_cast<__int128>(rhs); +} + +// Unary operators. + +inline int128 operator-(int128 v) { + return -static_cast<__int128>(v); +} + +inline bool operator!(int128 v) { + return !static_cast<__int128>(v); +} + +inline int128 operator~(int128 val) { + return ~static_cast<__int128>(val); +} + +// Arithmetic operators. + +inline int128 operator+(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) + static_cast<__int128>(rhs); +} + +inline int128 operator-(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) - static_cast<__int128>(rhs); +} + +inline int128 operator*(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) * static_cast<__int128>(rhs); +} + +inline int128 operator/(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) / static_cast<__int128>(rhs); +} + +inline int128 operator%(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) % static_cast<__int128>(rhs); +} + +inline int128 int128::operator++(int) { + int128 tmp(*this); + ++v_; + return tmp; +} + +inline int128 int128::operator--(int) { + int128 tmp(*this); + --v_; + return tmp; +} + +inline int128& int128::operator++() { + ++v_; + return *this; +} + +inline int128& int128::operator--() { + --v_; + return *this; +} + +inline int128 operator|(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) | static_cast<__int128>(rhs); +} + +inline int128 operator&(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) & static_cast<__int128>(rhs); +} + +inline int128 operator^(int128 lhs, int128 rhs) { + return static_cast<__int128>(lhs) ^ static_cast<__int128>(rhs); +} + +inline int128 operator<<(int128 lhs, int amount) { + return static_cast<__int128>(lhs) << amount; +} + +inline int128 operator>>(int128 lhs, int amount) { + return static_cast<__int128>(lhs) >> amount; +} diff --git a/third_party/abseil_cpp/absl/numeric/int128_no_intrinsic.inc b/third_party/abseil_cpp/absl/numeric/int128_no_intrinsic.inc new file mode 100644 index 0000000000..c753771ae7 --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128_no_intrinsic.inc @@ -0,0 +1,308 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file contains :int128 implementation details that depend on internal +// representation when ABSL_HAVE_INTRINSIC_INT128 is *not* defined. This file +// is included by int128.h and relies on ABSL_INTERNAL_WCHAR_T being defined. + +constexpr uint64_t Int128Low64(int128 v) { return v.lo_; } + +constexpr int64_t Int128High64(int128 v) { return v.hi_; } + +#if defined(ABSL_IS_LITTLE_ENDIAN) + +constexpr int128::int128(int64_t high, uint64_t low) : + lo_(low), hi_(high) {} + +constexpr int128::int128(int v) + : lo_{static_cast<uint64_t>(v)}, hi_{v < 0 ? ~int64_t{0} : 0} {} +constexpr int128::int128(long v) // NOLINT(runtime/int) + : lo_{static_cast<uint64_t>(v)}, hi_{v < 0 ? ~int64_t{0} : 0} {} +constexpr int128::int128(long long v) // NOLINT(runtime/int) + : lo_{static_cast<uint64_t>(v)}, hi_{v < 0 ? ~int64_t{0} : 0} {} + +constexpr int128::int128(unsigned int v) : lo_{v}, hi_{0} {} +// NOLINTNEXTLINE(runtime/int) +constexpr int128::int128(unsigned long v) : lo_{v}, hi_{0} {} +// NOLINTNEXTLINE(runtime/int) +constexpr int128::int128(unsigned long long v) : lo_{v}, hi_{0} {} + +constexpr int128::int128(uint128 v) + : lo_{Uint128Low64(v)}, hi_{static_cast<int64_t>(Uint128High64(v))} {} + +#elif defined(ABSL_IS_BIG_ENDIAN) + +constexpr int128::int128(int64_t high, uint64_t low) : + hi_{high}, lo_{low} {} + +constexpr int128::int128(int v) + : hi_{v < 0 ? ~int64_t{0} : 0}, lo_{static_cast<uint64_t>(v)} {} +constexpr int128::int128(long v) // NOLINT(runtime/int) + : hi_{v < 0 ? ~int64_t{0} : 0}, lo_{static_cast<uint64_t>(v)} {} +constexpr int128::int128(long long v) // NOLINT(runtime/int) + : hi_{v < 0 ? ~int64_t{0} : 0}, lo_{static_cast<uint64_t>(v)} {} + +constexpr int128::int128(unsigned int v) : hi_{0}, lo_{v} {} +// NOLINTNEXTLINE(runtime/int) +constexpr int128::int128(unsigned long v) : hi_{0}, lo_{v} {} +// NOLINTNEXTLINE(runtime/int) +constexpr int128::int128(unsigned long long v) : hi_{0}, lo_{v} {} + +constexpr int128::int128(uint128 v) + : hi_{static_cast<int64_t>(Uint128High64(v))}, lo_{Uint128Low64(v)} {} + +#else // byte order +#error "Unsupported byte order: must be little-endian or big-endian." +#endif // byte order + +constexpr int128::operator bool() const { return lo_ || hi_; } + +constexpr int128::operator char() const { + // NOLINTNEXTLINE(runtime/int) + return static_cast<char>(static_cast<long long>(*this)); +} + +constexpr int128::operator signed char() const { + // NOLINTNEXTLINE(runtime/int) + return static_cast<signed char>(static_cast<long long>(*this)); +} + +constexpr int128::operator unsigned char() const { + return static_cast<unsigned char>(lo_); +} + +constexpr int128::operator char16_t() const { + return static_cast<char16_t>(lo_); +} + +constexpr int128::operator char32_t() const { + return static_cast<char32_t>(lo_); +} + +constexpr int128::operator ABSL_INTERNAL_WCHAR_T() const { + // NOLINTNEXTLINE(runtime/int) + return static_cast<ABSL_INTERNAL_WCHAR_T>(static_cast<long long>(*this)); +} + +constexpr int128::operator short() const { // NOLINT(runtime/int) + // NOLINTNEXTLINE(runtime/int) + return static_cast<short>(static_cast<long long>(*this)); +} + +constexpr int128::operator unsigned short() const { // NOLINT(runtime/int) + return static_cast<unsigned short>(lo_); // NOLINT(runtime/int) +} + +constexpr int128::operator int() const { + // NOLINTNEXTLINE(runtime/int) + return static_cast<int>(static_cast<long long>(*this)); +} + +constexpr int128::operator unsigned int() const { + return static_cast<unsigned int>(lo_); +} + +constexpr int128::operator long() const { // NOLINT(runtime/int) + // NOLINTNEXTLINE(runtime/int) + return static_cast<long>(static_cast<long long>(*this)); +} + +constexpr int128::operator unsigned long() const { // NOLINT(runtime/int) + return static_cast<unsigned long>(lo_); // NOLINT(runtime/int) +} + +constexpr int128::operator long long() const { // NOLINT(runtime/int) + // We don't bother checking the value of hi_. If *this < 0, lo_'s high bit + // must be set in order for the value to fit into a long long. Conversely, if + // lo_'s high bit is set, *this must be < 0 for the value to fit. + return int128_internal::BitCastToSigned(lo_); +} + +constexpr int128::operator unsigned long long() const { // NOLINT(runtime/int) + return static_cast<unsigned long long>(lo_); // NOLINT(runtime/int) +} + +// Forward declaration for conversion operators to floating point types. +int128 operator-(int128 v); +bool operator!=(int128 lhs, int128 rhs); + +inline int128::operator float() const { + // We must convert the absolute value and then negate as needed, because + // floating point types are typically sign-magnitude. Otherwise, the + // difference between the high and low 64 bits when interpreted as two's + // complement overwhelms the precision of the mantissa. + // + // Also check to make sure we don't negate Int128Min() + return hi_ < 0 && *this != Int128Min() + ? -static_cast<float>(-*this) + : static_cast<float>(lo_) + + std::ldexp(static_cast<float>(hi_), 64); +} + +inline int128::operator double() const { + // See comment in int128::operator float() above. + return hi_ < 0 && *this != Int128Min() + ? -static_cast<double>(-*this) + : static_cast<double>(lo_) + + std::ldexp(static_cast<double>(hi_), 64); +} + +inline int128::operator long double() const { + // See comment in int128::operator float() above. + return hi_ < 0 && *this != Int128Min() + ? -static_cast<long double>(-*this) + : static_cast<long double>(lo_) + + std::ldexp(static_cast<long double>(hi_), 64); +} + +// Comparison operators. + +inline bool operator==(int128 lhs, int128 rhs) { + return (Int128Low64(lhs) == Int128Low64(rhs) && + Int128High64(lhs) == Int128High64(rhs)); +} + +inline bool operator!=(int128 lhs, int128 rhs) { + return !(lhs == rhs); +} + +inline bool operator<(int128 lhs, int128 rhs) { + return (Int128High64(lhs) == Int128High64(rhs)) + ? (Int128Low64(lhs) < Int128Low64(rhs)) + : (Int128High64(lhs) < Int128High64(rhs)); +} + +inline bool operator>(int128 lhs, int128 rhs) { + return (Int128High64(lhs) == Int128High64(rhs)) + ? (Int128Low64(lhs) > Int128Low64(rhs)) + : (Int128High64(lhs) > Int128High64(rhs)); +} + +inline bool operator<=(int128 lhs, int128 rhs) { + return !(lhs > rhs); +} + +inline bool operator>=(int128 lhs, int128 rhs) { + return !(lhs < rhs); +} + +// Unary operators. + +inline int128 operator-(int128 v) { + int64_t hi = ~Int128High64(v); + uint64_t lo = ~Int128Low64(v) + 1; + if (lo == 0) ++hi; // carry + return MakeInt128(hi, lo); +} + +inline bool operator!(int128 v) { + return !Int128Low64(v) && !Int128High64(v); +} + +inline int128 operator~(int128 val) { + return MakeInt128(~Int128High64(val), ~Int128Low64(val)); +} + +// Arithmetic operators. + +inline int128 operator+(int128 lhs, int128 rhs) { + int128 result = MakeInt128(Int128High64(lhs) + Int128High64(rhs), + Int128Low64(lhs) + Int128Low64(rhs)); + if (Int128Low64(result) < Int128Low64(lhs)) { // check for carry + return MakeInt128(Int128High64(result) + 1, Int128Low64(result)); + } + return result; +} + +inline int128 operator-(int128 lhs, int128 rhs) { + int128 result = MakeInt128(Int128High64(lhs) - Int128High64(rhs), + Int128Low64(lhs) - Int128Low64(rhs)); + if (Int128Low64(lhs) < Int128Low64(rhs)) { // check for carry + return MakeInt128(Int128High64(result) - 1, Int128Low64(result)); + } + return result; +} + +inline int128 operator*(int128 lhs, int128 rhs) { + uint128 result = uint128(lhs) * rhs; + return MakeInt128(int128_internal::BitCastToSigned(Uint128High64(result)), + Uint128Low64(result)); +} + +inline int128 int128::operator++(int) { + int128 tmp(*this); + *this += 1; + return tmp; +} + +inline int128 int128::operator--(int) { + int128 tmp(*this); + *this -= 1; + return tmp; +} + +inline int128& int128::operator++() { + *this += 1; + return *this; +} + +inline int128& int128::operator--() { + *this -= 1; + return *this; +} + +inline int128 operator|(int128 lhs, int128 rhs) { + return MakeInt128(Int128High64(lhs) | Int128High64(rhs), + Int128Low64(lhs) | Int128Low64(rhs)); +} + +inline int128 operator&(int128 lhs, int128 rhs) { + return MakeInt128(Int128High64(lhs) & Int128High64(rhs), + Int128Low64(lhs) & Int128Low64(rhs)); +} + +inline int128 operator^(int128 lhs, int128 rhs) { + return MakeInt128(Int128High64(lhs) ^ Int128High64(rhs), + Int128Low64(lhs) ^ Int128Low64(rhs)); +} + +inline int128 operator<<(int128 lhs, int amount) { + // uint64_t shifts of >= 64 are undefined, so we need some special-casing. + if (amount < 64) { + if (amount != 0) { + return MakeInt128( + (Int128High64(lhs) << amount) | + static_cast<int64_t>(Int128Low64(lhs) >> (64 - amount)), + Int128Low64(lhs) << amount); + } + return lhs; + } + return MakeInt128(static_cast<int64_t>(Int128Low64(lhs) << (amount - 64)), 0); +} + +inline int128 operator>>(int128 lhs, int amount) { + // uint64_t shifts of >= 64 are undefined, so we need some special-casing. + if (amount < 64) { + if (amount != 0) { + return MakeInt128( + Int128High64(lhs) >> amount, + (Int128Low64(lhs) >> amount) | + (static_cast<uint64_t>(Int128High64(lhs)) << (64 - amount))); + } + return lhs; + } + return MakeInt128(0, + static_cast<uint64_t>(Int128High64(lhs) >> (amount - 64))); +} diff --git a/third_party/abseil_cpp/absl/numeric/int128_stream_test.cc b/third_party/abseil_cpp/absl/numeric/int128_stream_test.cc new file mode 100644 index 0000000000..479ad66cf4 --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128_stream_test.cc @@ -0,0 +1,1395 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/numeric/int128.h" + +#include <sstream> +#include <string> + +#include "gtest/gtest.h" + +namespace { + +struct Uint128TestCase { + absl::uint128 value; + std::ios_base::fmtflags flags; + std::streamsize width; + const char* expected; +}; + +constexpr char kFill = '_'; + +std::string StreamFormatToString(std::ios_base::fmtflags flags, + std::streamsize width) { + std::vector<const char*> flagstr; + switch (flags & std::ios::basefield) { + case std::ios::dec: + flagstr.push_back("std::ios::dec"); + break; + case std::ios::oct: + flagstr.push_back("std::ios::oct"); + break; + case std::ios::hex: + flagstr.push_back("std::ios::hex"); + break; + default: // basefield not specified + break; + } + switch (flags & std::ios::adjustfield) { + case std::ios::left: + flagstr.push_back("std::ios::left"); + break; + case std::ios::internal: + flagstr.push_back("std::ios::internal"); + break; + case std::ios::right: + flagstr.push_back("std::ios::right"); + break; + default: // adjustfield not specified + break; + } + if (flags & std::ios::uppercase) flagstr.push_back("std::ios::uppercase"); + if (flags & std::ios::showbase) flagstr.push_back("std::ios::showbase"); + if (flags & std::ios::showpos) flagstr.push_back("std::ios::showpos"); + + std::ostringstream msg; + msg << "\n StreamFormatToString(test_case.flags, test_case.width)\n " + "flags: "; + if (!flagstr.empty()) { + for (size_t i = 0; i < flagstr.size() - 1; ++i) msg << flagstr[i] << " | "; + msg << flagstr.back(); + } else { + msg << "(default)"; + } + msg << "\n width: " << width << "\n fill: '" << kFill << "'"; + return msg.str(); +} + +void CheckUint128Case(const Uint128TestCase& test_case) { + std::ostringstream os; + os.flags(test_case.flags); + os.width(test_case.width); + os.fill(kFill); + os << test_case.value; + SCOPED_TRACE(StreamFormatToString(test_case.flags, test_case.width)); + EXPECT_EQ(test_case.expected, os.str()); +} + +constexpr std::ios::fmtflags kDec = std::ios::dec; +constexpr std::ios::fmtflags kOct = std::ios::oct; +constexpr std::ios::fmtflags kHex = std::ios::hex; +constexpr std::ios::fmtflags kLeft = std::ios::left; +constexpr std::ios::fmtflags kInt = std::ios::internal; +constexpr std::ios::fmtflags kRight = std::ios::right; +constexpr std::ios::fmtflags kUpper = std::ios::uppercase; +constexpr std::ios::fmtflags kBase = std::ios::showbase; +constexpr std::ios::fmtflags kPos = std::ios::showpos; + +TEST(Uint128, OStreamValueTest) { + CheckUint128Case({1, kDec, /*width = */ 0, "1"}); + CheckUint128Case({1, kOct, /*width = */ 0, "1"}); + CheckUint128Case({1, kHex, /*width = */ 0, "1"}); + CheckUint128Case({9, kDec, /*width = */ 0, "9"}); + CheckUint128Case({9, kOct, /*width = */ 0, "11"}); + CheckUint128Case({9, kHex, /*width = */ 0, "9"}); + CheckUint128Case({12345, kDec, /*width = */ 0, "12345"}); + CheckUint128Case({12345, kOct, /*width = */ 0, "30071"}); + CheckUint128Case({12345, kHex, /*width = */ 0, "3039"}); + CheckUint128Case( + {0x8000000000000000, kDec, /*width = */ 0, "9223372036854775808"}); + CheckUint128Case( + {0x8000000000000000, kOct, /*width = */ 0, "1000000000000000000000"}); + CheckUint128Case( + {0x8000000000000000, kHex, /*width = */ 0, "8000000000000000"}); + CheckUint128Case({std::numeric_limits<uint64_t>::max(), kDec, + /*width = */ 0, "18446744073709551615"}); + CheckUint128Case({std::numeric_limits<uint64_t>::max(), kOct, + /*width = */ 0, "1777777777777777777777"}); + CheckUint128Case({std::numeric_limits<uint64_t>::max(), kHex, + /*width = */ 0, "ffffffffffffffff"}); + CheckUint128Case( + {absl::MakeUint128(1, 0), kDec, /*width = */ 0, "18446744073709551616"}); + CheckUint128Case({absl::MakeUint128(1, 0), kOct, /*width = */ 0, + "2000000000000000000000"}); + CheckUint128Case( + {absl::MakeUint128(1, 0), kHex, /*width = */ 0, "10000000000000000"}); + CheckUint128Case({absl::MakeUint128(0x8000000000000000, 0), kDec, + /*width = */ 0, "170141183460469231731687303715884105728"}); + CheckUint128Case({absl::MakeUint128(0x8000000000000000, 0), kOct, + /*width = */ 0, + "2000000000000000000000000000000000000000000"}); + CheckUint128Case({absl::MakeUint128(0x8000000000000000, 0), kHex, + /*width = */ 0, "80000000000000000000000000000000"}); + CheckUint128Case({absl::kuint128max, kDec, /*width = */ 0, + "340282366920938463463374607431768211455"}); + CheckUint128Case({absl::kuint128max, kOct, /*width = */ 0, + "3777777777777777777777777777777777777777777"}); + CheckUint128Case({absl::kuint128max, kHex, /*width = */ 0, + "ffffffffffffffffffffffffffffffff"}); +} + +std::vector<Uint128TestCase> GetUint128FormatCases(); + +TEST(Uint128, OStreamFormatTest) { + for (const Uint128TestCase& test_case : GetUint128FormatCases()) { + CheckUint128Case(test_case); + } +} + +struct Int128TestCase { + absl::int128 value; + std::ios_base::fmtflags flags; + std::streamsize width; + const char* expected; +}; + +void CheckInt128Case(const Int128TestCase& test_case) { + std::ostringstream os; + os.flags(test_case.flags); + os.width(test_case.width); + os.fill(kFill); + os << test_case.value; + SCOPED_TRACE(StreamFormatToString(test_case.flags, test_case.width)); + EXPECT_EQ(test_case.expected, os.str()); +} + +TEST(Int128, OStreamValueTest) { + CheckInt128Case({1, kDec, /*width = */ 0, "1"}); + CheckInt128Case({1, kOct, /*width = */ 0, "1"}); + CheckInt128Case({1, kHex, /*width = */ 0, "1"}); + CheckInt128Case({9, kDec, /*width = */ 0, "9"}); + CheckInt128Case({9, kOct, /*width = */ 0, "11"}); + CheckInt128Case({9, kHex, /*width = */ 0, "9"}); + CheckInt128Case({12345, kDec, /*width = */ 0, "12345"}); + CheckInt128Case({12345, kOct, /*width = */ 0, "30071"}); + CheckInt128Case({12345, kHex, /*width = */ 0, "3039"}); + CheckInt128Case( + {0x8000000000000000, kDec, /*width = */ 0, "9223372036854775808"}); + CheckInt128Case( + {0x8000000000000000, kOct, /*width = */ 0, "1000000000000000000000"}); + CheckInt128Case( + {0x8000000000000000, kHex, /*width = */ 0, "8000000000000000"}); + CheckInt128Case({std::numeric_limits<uint64_t>::max(), kDec, + /*width = */ 0, "18446744073709551615"}); + CheckInt128Case({std::numeric_limits<uint64_t>::max(), kOct, + /*width = */ 0, "1777777777777777777777"}); + CheckInt128Case({std::numeric_limits<uint64_t>::max(), kHex, + /*width = */ 0, "ffffffffffffffff"}); + CheckInt128Case( + {absl::MakeInt128(1, 0), kDec, /*width = */ 0, "18446744073709551616"}); + CheckInt128Case( + {absl::MakeInt128(1, 0), kOct, /*width = */ 0, "2000000000000000000000"}); + CheckInt128Case( + {absl::MakeInt128(1, 0), kHex, /*width = */ 0, "10000000000000000"}); + CheckInt128Case({absl::MakeInt128(std::numeric_limits<int64_t>::max(), + std::numeric_limits<uint64_t>::max()), + std::ios::dec, /*width = */ 0, + "170141183460469231731687303715884105727"}); + CheckInt128Case({absl::MakeInt128(std::numeric_limits<int64_t>::max(), + std::numeric_limits<uint64_t>::max()), + std::ios::oct, /*width = */ 0, + "1777777777777777777777777777777777777777777"}); + CheckInt128Case({absl::MakeInt128(std::numeric_limits<int64_t>::max(), + std::numeric_limits<uint64_t>::max()), + std::ios::hex, /*width = */ 0, + "7fffffffffffffffffffffffffffffff"}); + CheckInt128Case({absl::MakeInt128(std::numeric_limits<int64_t>::min(), 0), + std::ios::dec, /*width = */ 0, + "-170141183460469231731687303715884105728"}); + CheckInt128Case({absl::MakeInt128(std::numeric_limits<int64_t>::min(), 0), + std::ios::oct, /*width = */ 0, + "2000000000000000000000000000000000000000000"}); + CheckInt128Case({absl::MakeInt128(std::numeric_limits<int64_t>::min(), 0), + std::ios::hex, /*width = */ 0, + "80000000000000000000000000000000"}); + CheckInt128Case({-1, std::ios::dec, /*width = */ 0, "-1"}); + CheckInt128Case({-1, std::ios::oct, /*width = */ 0, + "3777777777777777777777777777777777777777777"}); + CheckInt128Case( + {-1, std::ios::hex, /*width = */ 0, "ffffffffffffffffffffffffffffffff"}); + CheckInt128Case({-12345, std::ios::dec, /*width = */ 0, "-12345"}); + CheckInt128Case({-12345, std::ios::oct, /*width = */ 0, + "3777777777777777777777777777777777777747707"}); + CheckInt128Case({-12345, std::ios::hex, /*width = */ 0, + "ffffffffffffffffffffffffffffcfc7"}); +} + +std::vector<Int128TestCase> GetInt128FormatCases(); +TEST(Int128, OStreamFormatTest) { + for (const Int128TestCase& test_case : GetInt128FormatCases()) { + CheckInt128Case(test_case); + } +} + +std::vector<Int128TestCase> GetInt128FormatCases() { + return { + {0, std::ios_base::fmtflags(), /*width = */ 0, "0"}, + {0, std::ios_base::fmtflags(), /*width = */ 6, "_____0"}, + {0, kPos, /*width = */ 0, "+0"}, + {0, kPos, /*width = */ 6, "____+0"}, + {0, kBase, /*width = */ 0, "0"}, + {0, kBase, /*width = */ 6, "_____0"}, + {0, kBase | kPos, /*width = */ 0, "+0"}, + {0, kBase | kPos, /*width = */ 6, "____+0"}, + {0, kUpper, /*width = */ 0, "0"}, + {0, kUpper, /*width = */ 6, "_____0"}, + {0, kUpper | kPos, /*width = */ 0, "+0"}, + {0, kUpper | kPos, /*width = */ 6, "____+0"}, + {0, kUpper | kBase, /*width = */ 0, "0"}, + {0, kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kUpper | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kLeft, /*width = */ 0, "0"}, + {0, kLeft, /*width = */ 6, "0_____"}, + {0, kLeft | kPos, /*width = */ 0, "+0"}, + {0, kLeft | kPos, /*width = */ 6, "+0____"}, + {0, kLeft | kBase, /*width = */ 0, "0"}, + {0, kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kLeft | kBase | kPos, /*width = */ 0, "+0"}, + {0, kLeft | kBase | kPos, /*width = */ 6, "+0____"}, + {0, kLeft | kUpper, /*width = */ 0, "0"}, + {0, kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kLeft | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kLeft | kUpper | kPos, /*width = */ 6, "+0____"}, + {0, kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kLeft | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kLeft | kUpper | kBase | kPos, /*width = */ 6, "+0____"}, + {0, kInt, /*width = */ 0, "0"}, + {0, kInt, /*width = */ 6, "_____0"}, + {0, kInt | kPos, /*width = */ 0, "+0"}, + {0, kInt | kPos, /*width = */ 6, "+____0"}, + {0, kInt | kBase, /*width = */ 0, "0"}, + {0, kInt | kBase, /*width = */ 6, "_____0"}, + {0, kInt | kBase | kPos, /*width = */ 0, "+0"}, + {0, kInt | kBase | kPos, /*width = */ 6, "+____0"}, + {0, kInt | kUpper, /*width = */ 0, "0"}, + {0, kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kInt | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kInt | kUpper | kPos, /*width = */ 6, "+____0"}, + {0, kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kInt | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kInt | kUpper | kBase | kPos, /*width = */ 6, "+____0"}, + {0, kRight, /*width = */ 0, "0"}, + {0, kRight, /*width = */ 6, "_____0"}, + {0, kRight | kPos, /*width = */ 0, "+0"}, + {0, kRight | kPos, /*width = */ 6, "____+0"}, + {0, kRight | kBase, /*width = */ 0, "0"}, + {0, kRight | kBase, /*width = */ 6, "_____0"}, + {0, kRight | kBase | kPos, /*width = */ 0, "+0"}, + {0, kRight | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kRight | kUpper, /*width = */ 0, "0"}, + {0, kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kRight | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kRight | kUpper | kPos, /*width = */ 6, "____+0"}, + {0, kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kRight | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kRight | kUpper | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kDec, /*width = */ 0, "0"}, + {0, kDec, /*width = */ 6, "_____0"}, + {0, kDec | kPos, /*width = */ 0, "+0"}, + {0, kDec | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kBase, /*width = */ 0, "0"}, + {0, kDec | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kUpper, /*width = */ 0, "0"}, + {0, kDec | kUpper, /*width = */ 6, "_____0"}, + {0, kDec | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kDec | kUpper | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kUpper | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kLeft, /*width = */ 0, "0"}, + {0, kDec | kLeft, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kPos, /*width = */ 0, "+0"}, + {0, kDec | kLeft | kPos, /*width = */ 6, "+0____"}, + {0, kDec | kLeft | kBase, /*width = */ 0, "0"}, + {0, kDec | kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kLeft | kBase | kPos, /*width = */ 6, "+0____"}, + {0, kDec | kLeft | kUpper, /*width = */ 0, "0"}, + {0, kDec | kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kDec | kLeft | kUpper | kPos, /*width = */ 6, "+0____"}, + {0, kDec | kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 6, "+0____"}, + {0, kDec | kInt, /*width = */ 0, "0"}, + {0, kDec | kInt, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kPos, /*width = */ 0, "+0"}, + {0, kDec | kInt | kPos, /*width = */ 6, "+____0"}, + {0, kDec | kInt | kBase, /*width = */ 0, "0"}, + {0, kDec | kInt | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kInt | kBase | kPos, /*width = */ 6, "+____0"}, + {0, kDec | kInt | kUpper, /*width = */ 0, "0"}, + {0, kDec | kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kDec | kInt | kUpper | kPos, /*width = */ 6, "+____0"}, + {0, kDec | kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kInt | kUpper | kBase | kPos, /*width = */ 6, "+____0"}, + {0, kDec | kRight, /*width = */ 0, "0"}, + {0, kDec | kRight, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kPos, /*width = */ 0, "+0"}, + {0, kDec | kRight | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kRight | kBase, /*width = */ 0, "0"}, + {0, kDec | kRight | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kRight | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kRight | kUpper, /*width = */ 0, "0"}, + {0, kDec | kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kUpper | kPos, /*width = */ 0, "+0"}, + {0, kDec | kRight | kUpper | kPos, /*width = */ 6, "____+0"}, + {0, kDec | kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kUpper | kBase | kPos, /*width = */ 0, "+0"}, + {0, kDec | kRight | kUpper | kBase | kPos, /*width = */ 6, "____+0"}, + {0, kOct, /*width = */ 0, "0"}, + {0, kOct, /*width = */ 6, "_____0"}, + {0, kOct | kPos, /*width = */ 0, "0"}, + {0, kOct | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kBase, /*width = */ 0, "0"}, + {0, kOct | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kUpper, /*width = */ 0, "0"}, + {0, kOct | kUpper, /*width = */ 6, "_____0"}, + {0, kOct | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kLeft, /*width = */ 0, "0"}, + {0, kOct | kLeft, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kBase, /*width = */ 0, "0"}, + {0, kOct | kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kInt, /*width = */ 0, "0"}, + {0, kOct | kInt, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kBase, /*width = */ 0, "0"}, + {0, kOct | kInt | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight, /*width = */ 0, "0"}, + {0, kOct | kRight, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kBase, /*width = */ 0, "0"}, + {0, kOct | kRight | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex, /*width = */ 0, "0"}, + {0, kHex, /*width = */ 6, "_____0"}, + {0, kHex | kPos, /*width = */ 0, "0"}, + {0, kHex | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kBase, /*width = */ 0, "0"}, + {0, kHex | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kUpper, /*width = */ 0, "0"}, + {0, kHex | kUpper, /*width = */ 6, "_____0"}, + {0, kHex | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kLeft, /*width = */ 0, "0"}, + {0, kHex | kLeft, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kBase, /*width = */ 0, "0"}, + {0, kHex | kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kInt, /*width = */ 0, "0"}, + {0, kHex | kInt, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kBase, /*width = */ 0, "0"}, + {0, kHex | kInt | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight, /*width = */ 0, "0"}, + {0, kHex | kRight, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kBase, /*width = */ 0, "0"}, + {0, kHex | kRight | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {42, std::ios_base::fmtflags(), /*width = */ 0, "42"}, + {42, std::ios_base::fmtflags(), /*width = */ 6, "____42"}, + {42, kPos, /*width = */ 0, "+42"}, + {42, kPos, /*width = */ 6, "___+42"}, + {42, kBase, /*width = */ 0, "42"}, + {42, kBase, /*width = */ 6, "____42"}, + {42, kBase | kPos, /*width = */ 0, "+42"}, + {42, kBase | kPos, /*width = */ 6, "___+42"}, + {42, kUpper, /*width = */ 0, "42"}, + {42, kUpper, /*width = */ 6, "____42"}, + {42, kUpper | kPos, /*width = */ 0, "+42"}, + {42, kUpper | kPos, /*width = */ 6, "___+42"}, + {42, kUpper | kBase, /*width = */ 0, "42"}, + {42, kUpper | kBase, /*width = */ 6, "____42"}, + {42, kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kUpper | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kLeft, /*width = */ 0, "42"}, + {42, kLeft, /*width = */ 6, "42____"}, + {42, kLeft | kPos, /*width = */ 0, "+42"}, + {42, kLeft | kPos, /*width = */ 6, "+42___"}, + {42, kLeft | kBase, /*width = */ 0, "42"}, + {42, kLeft | kBase, /*width = */ 6, "42____"}, + {42, kLeft | kBase | kPos, /*width = */ 0, "+42"}, + {42, kLeft | kBase | kPos, /*width = */ 6, "+42___"}, + {42, kLeft | kUpper, /*width = */ 0, "42"}, + {42, kLeft | kUpper, /*width = */ 6, "42____"}, + {42, kLeft | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kLeft | kUpper | kPos, /*width = */ 6, "+42___"}, + {42, kLeft | kUpper | kBase, /*width = */ 0, "42"}, + {42, kLeft | kUpper | kBase, /*width = */ 6, "42____"}, + {42, kLeft | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kLeft | kUpper | kBase | kPos, /*width = */ 6, "+42___"}, + {42, kInt, /*width = */ 0, "42"}, + {42, kInt, /*width = */ 6, "____42"}, + {42, kInt | kPos, /*width = */ 0, "+42"}, + {42, kInt | kPos, /*width = */ 6, "+___42"}, + {42, kInt | kBase, /*width = */ 0, "42"}, + {42, kInt | kBase, /*width = */ 6, "____42"}, + {42, kInt | kBase | kPos, /*width = */ 0, "+42"}, + {42, kInt | kBase | kPos, /*width = */ 6, "+___42"}, + {42, kInt | kUpper, /*width = */ 0, "42"}, + {42, kInt | kUpper, /*width = */ 6, "____42"}, + {42, kInt | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kInt | kUpper | kPos, /*width = */ 6, "+___42"}, + {42, kInt | kUpper | kBase, /*width = */ 0, "42"}, + {42, kInt | kUpper | kBase, /*width = */ 6, "____42"}, + {42, kInt | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kInt | kUpper | kBase | kPos, /*width = */ 6, "+___42"}, + {42, kRight, /*width = */ 0, "42"}, + {42, kRight, /*width = */ 6, "____42"}, + {42, kRight | kPos, /*width = */ 0, "+42"}, + {42, kRight | kPos, /*width = */ 6, "___+42"}, + {42, kRight | kBase, /*width = */ 0, "42"}, + {42, kRight | kBase, /*width = */ 6, "____42"}, + {42, kRight | kBase | kPos, /*width = */ 0, "+42"}, + {42, kRight | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kRight | kUpper, /*width = */ 0, "42"}, + {42, kRight | kUpper, /*width = */ 6, "____42"}, + {42, kRight | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kRight | kUpper | kPos, /*width = */ 6, "___+42"}, + {42, kRight | kUpper | kBase, /*width = */ 0, "42"}, + {42, kRight | kUpper | kBase, /*width = */ 6, "____42"}, + {42, kRight | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kRight | kUpper | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kDec, /*width = */ 0, "42"}, + {42, kDec, /*width = */ 6, "____42"}, + {42, kDec | kPos, /*width = */ 0, "+42"}, + {42, kDec | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kBase, /*width = */ 0, "42"}, + {42, kDec | kBase, /*width = */ 6, "____42"}, + {42, kDec | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kUpper, /*width = */ 0, "42"}, + {42, kDec | kUpper, /*width = */ 6, "____42"}, + {42, kDec | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kDec | kUpper | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kUpper | kBase, /*width = */ 0, "42"}, + {42, kDec | kUpper | kBase, /*width = */ 6, "____42"}, + {42, kDec | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kUpper | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kLeft, /*width = */ 0, "42"}, + {42, kDec | kLeft, /*width = */ 6, "42____"}, + {42, kDec | kLeft | kPos, /*width = */ 0, "+42"}, + {42, kDec | kLeft | kPos, /*width = */ 6, "+42___"}, + {42, kDec | kLeft | kBase, /*width = */ 0, "42"}, + {42, kDec | kLeft | kBase, /*width = */ 6, "42____"}, + {42, kDec | kLeft | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kLeft | kBase | kPos, /*width = */ 6, "+42___"}, + {42, kDec | kLeft | kUpper, /*width = */ 0, "42"}, + {42, kDec | kLeft | kUpper, /*width = */ 6, "42____"}, + {42, kDec | kLeft | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kDec | kLeft | kUpper | kPos, /*width = */ 6, "+42___"}, + {42, kDec | kLeft | kUpper | kBase, /*width = */ 0, "42"}, + {42, kDec | kLeft | kUpper | kBase, /*width = */ 6, "42____"}, + {42, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 6, "+42___"}, + {42, kDec | kInt, /*width = */ 0, "42"}, + {42, kDec | kInt, /*width = */ 6, "____42"}, + {42, kDec | kInt | kPos, /*width = */ 0, "+42"}, + {42, kDec | kInt | kPos, /*width = */ 6, "+___42"}, + {42, kDec | kInt | kBase, /*width = */ 0, "42"}, + {42, kDec | kInt | kBase, /*width = */ 6, "____42"}, + {42, kDec | kInt | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kInt | kBase | kPos, /*width = */ 6, "+___42"}, + {42, kDec | kInt | kUpper, /*width = */ 0, "42"}, + {42, kDec | kInt | kUpper, /*width = */ 6, "____42"}, + {42, kDec | kInt | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kDec | kInt | kUpper | kPos, /*width = */ 6, "+___42"}, + {42, kDec | kInt | kUpper | kBase, /*width = */ 0, "42"}, + {42, kDec | kInt | kUpper | kBase, /*width = */ 6, "____42"}, + {42, kDec | kInt | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kInt | kUpper | kBase | kPos, /*width = */ 6, "+___42"}, + {42, kDec | kRight, /*width = */ 0, "42"}, + {42, kDec | kRight, /*width = */ 6, "____42"}, + {42, kDec | kRight | kPos, /*width = */ 0, "+42"}, + {42, kDec | kRight | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kRight | kBase, /*width = */ 0, "42"}, + {42, kDec | kRight | kBase, /*width = */ 6, "____42"}, + {42, kDec | kRight | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kRight | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kRight | kUpper, /*width = */ 0, "42"}, + {42, kDec | kRight | kUpper, /*width = */ 6, "____42"}, + {42, kDec | kRight | kUpper | kPos, /*width = */ 0, "+42"}, + {42, kDec | kRight | kUpper | kPos, /*width = */ 6, "___+42"}, + {42, kDec | kRight | kUpper | kBase, /*width = */ 0, "42"}, + {42, kDec | kRight | kUpper | kBase, /*width = */ 6, "____42"}, + {42, kDec | kRight | kUpper | kBase | kPos, /*width = */ 0, "+42"}, + {42, kDec | kRight | kUpper | kBase | kPos, /*width = */ 6, "___+42"}, + {42, kOct, /*width = */ 0, "52"}, + {42, kOct, /*width = */ 6, "____52"}, + {42, kOct | kPos, /*width = */ 0, "52"}, + {42, kOct | kPos, /*width = */ 6, "____52"}, + {42, kOct | kBase, /*width = */ 0, "052"}, + {42, kOct | kBase, /*width = */ 6, "___052"}, + {42, kOct | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kBase | kPos, /*width = */ 6, "___052"}, + {42, kOct | kUpper, /*width = */ 0, "52"}, + {42, kOct | kUpper, /*width = */ 6, "____52"}, + {42, kOct | kUpper | kPos, /*width = */ 0, "52"}, + {42, kOct | kUpper | kPos, /*width = */ 6, "____52"}, + {42, kOct | kUpper | kBase, /*width = */ 0, "052"}, + {42, kOct | kUpper | kBase, /*width = */ 6, "___052"}, + {42, kOct | kUpper | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kUpper | kBase | kPos, /*width = */ 6, "___052"}, + {42, kOct | kLeft, /*width = */ 0, "52"}, + {42, kOct | kLeft, /*width = */ 6, "52____"}, + {42, kOct | kLeft | kPos, /*width = */ 0, "52"}, + {42, kOct | kLeft | kPos, /*width = */ 6, "52____"}, + {42, kOct | kLeft | kBase, /*width = */ 0, "052"}, + {42, kOct | kLeft | kBase, /*width = */ 6, "052___"}, + {42, kOct | kLeft | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kLeft | kBase | kPos, /*width = */ 6, "052___"}, + {42, kOct | kLeft | kUpper, /*width = */ 0, "52"}, + {42, kOct | kLeft | kUpper, /*width = */ 6, "52____"}, + {42, kOct | kLeft | kUpper | kPos, /*width = */ 0, "52"}, + {42, kOct | kLeft | kUpper | kPos, /*width = */ 6, "52____"}, + {42, kOct | kLeft | kUpper | kBase, /*width = */ 0, "052"}, + {42, kOct | kLeft | kUpper | kBase, /*width = */ 6, "052___"}, + {42, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 6, "052___"}, + {42, kOct | kInt, /*width = */ 0, "52"}, + {42, kOct | kInt, /*width = */ 6, "____52"}, + {42, kOct | kInt | kPos, /*width = */ 0, "52"}, + {42, kOct | kInt | kPos, /*width = */ 6, "____52"}, + {42, kOct | kInt | kBase, /*width = */ 0, "052"}, + {42, kOct | kInt | kBase, /*width = */ 6, "___052"}, + {42, kOct | kInt | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kInt | kBase | kPos, /*width = */ 6, "___052"}, + {42, kOct | kInt | kUpper, /*width = */ 0, "52"}, + {42, kOct | kInt | kUpper, /*width = */ 6, "____52"}, + {42, kOct | kInt | kUpper | kPos, /*width = */ 0, "52"}, + {42, kOct | kInt | kUpper | kPos, /*width = */ 6, "____52"}, + {42, kOct | kInt | kUpper | kBase, /*width = */ 0, "052"}, + {42, kOct | kInt | kUpper | kBase, /*width = */ 6, "___052"}, + {42, kOct | kInt | kUpper | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kInt | kUpper | kBase | kPos, /*width = */ 6, "___052"}, + {42, kOct | kRight, /*width = */ 0, "52"}, + {42, kOct | kRight, /*width = */ 6, "____52"}, + {42, kOct | kRight | kPos, /*width = */ 0, "52"}, + {42, kOct | kRight | kPos, /*width = */ 6, "____52"}, + {42, kOct | kRight | kBase, /*width = */ 0, "052"}, + {42, kOct | kRight | kBase, /*width = */ 6, "___052"}, + {42, kOct | kRight | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kRight | kBase | kPos, /*width = */ 6, "___052"}, + {42, kOct | kRight | kUpper, /*width = */ 0, "52"}, + {42, kOct | kRight | kUpper, /*width = */ 6, "____52"}, + {42, kOct | kRight | kUpper | kPos, /*width = */ 0, "52"}, + {42, kOct | kRight | kUpper | kPos, /*width = */ 6, "____52"}, + {42, kOct | kRight | kUpper | kBase, /*width = */ 0, "052"}, + {42, kOct | kRight | kUpper | kBase, /*width = */ 6, "___052"}, + {42, kOct | kRight | kUpper | kBase | kPos, /*width = */ 0, "052"}, + {42, kOct | kRight | kUpper | kBase | kPos, /*width = */ 6, "___052"}, + {42, kHex, /*width = */ 0, "2a"}, + {42, kHex, /*width = */ 6, "____2a"}, + {42, kHex | kPos, /*width = */ 0, "2a"}, + {42, kHex | kPos, /*width = */ 6, "____2a"}, + {42, kHex | kBase, /*width = */ 0, "0x2a"}, + {42, kHex | kBase, /*width = */ 6, "__0x2a"}, + {42, kHex | kBase | kPos, /*width = */ 0, "0x2a"}, + {42, kHex | kBase | kPos, /*width = */ 6, "__0x2a"}, + {42, kHex | kUpper, /*width = */ 0, "2A"}, + {42, kHex | kUpper, /*width = */ 6, "____2A"}, + {42, kHex | kUpper | kPos, /*width = */ 0, "2A"}, + {42, kHex | kUpper | kPos, /*width = */ 6, "____2A"}, + {42, kHex | kUpper | kBase, /*width = */ 0, "0X2A"}, + {42, kHex | kUpper | kBase, /*width = */ 6, "__0X2A"}, + {42, kHex | kUpper | kBase | kPos, /*width = */ 0, "0X2A"}, + {42, kHex | kUpper | kBase | kPos, /*width = */ 6, "__0X2A"}, + {42, kHex | kLeft, /*width = */ 0, "2a"}, + {42, kHex | kLeft, /*width = */ 6, "2a____"}, + {42, kHex | kLeft | kPos, /*width = */ 0, "2a"}, + {42, kHex | kLeft | kPos, /*width = */ 6, "2a____"}, + {42, kHex | kLeft | kBase, /*width = */ 0, "0x2a"}, + {42, kHex | kLeft | kBase, /*width = */ 6, "0x2a__"}, + {42, kHex | kLeft | kBase | kPos, /*width = */ 0, "0x2a"}, + {42, kHex | kLeft | kBase | kPos, /*width = */ 6, "0x2a__"}, + {42, kHex | kLeft | kUpper, /*width = */ 0, "2A"}, + {42, kHex | kLeft | kUpper, /*width = */ 6, "2A____"}, + {42, kHex | kLeft | kUpper | kPos, /*width = */ 0, "2A"}, + {42, kHex | kLeft | kUpper | kPos, /*width = */ 6, "2A____"}, + {42, kHex | kLeft | kUpper | kBase, /*width = */ 0, "0X2A"}, + {42, kHex | kLeft | kUpper | kBase, /*width = */ 6, "0X2A__"}, + {42, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0X2A"}, + {42, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0X2A__"}, + {42, kHex | kInt, /*width = */ 0, "2a"}, + {42, kHex | kInt, /*width = */ 6, "____2a"}, + {42, kHex | kInt | kPos, /*width = */ 0, "2a"}, + {42, kHex | kInt | kPos, /*width = */ 6, "____2a"}, + {42, kHex | kInt | kBase, /*width = */ 0, "0x2a"}, + {42, kHex | kInt | kBase, /*width = */ 6, "0x__2a"}, + {42, kHex | kInt | kBase | kPos, /*width = */ 0, "0x2a"}, + {42, kHex | kInt | kBase | kPos, /*width = */ 6, "0x__2a"}, + {42, kHex | kInt | kUpper, /*width = */ 0, "2A"}, + {42, kHex | kInt | kUpper, /*width = */ 6, "____2A"}, + {42, kHex | kInt | kUpper | kPos, /*width = */ 0, "2A"}, + {42, kHex | kInt | kUpper | kPos, /*width = */ 6, "____2A"}, + {42, kHex | kInt | kUpper | kBase, /*width = */ 0, "0X2A"}, + {42, kHex | kInt | kUpper | kBase, /*width = */ 6, "0X__2A"}, + {42, kHex | kInt | kUpper | kBase | kPos, /*width = */ 0, "0X2A"}, + {42, kHex | kInt | kUpper | kBase | kPos, /*width = */ 6, "0X__2A"}, + {42, kHex | kRight, /*width = */ 0, "2a"}, + {42, kHex | kRight, /*width = */ 6, "____2a"}, + {42, kHex | kRight | kPos, /*width = */ 0, "2a"}, + {42, kHex | kRight | kPos, /*width = */ 6, "____2a"}, + {42, kHex | kRight | kBase, /*width = */ 0, "0x2a"}, + {42, kHex | kRight | kBase, /*width = */ 6, "__0x2a"}, + {42, kHex | kRight | kBase | kPos, /*width = */ 0, "0x2a"}, + {42, kHex | kRight | kBase | kPos, /*width = */ 6, "__0x2a"}, + {42, kHex | kRight | kUpper, /*width = */ 0, "2A"}, + {42, kHex | kRight | kUpper, /*width = */ 6, "____2A"}, + {42, kHex | kRight | kUpper | kPos, /*width = */ 0, "2A"}, + {42, kHex | kRight | kUpper | kPos, /*width = */ 6, "____2A"}, + {42, kHex | kRight | kUpper | kBase, /*width = */ 0, "0X2A"}, + {42, kHex | kRight | kUpper | kBase, /*width = */ 6, "__0X2A"}, + {42, kHex | kRight | kUpper | kBase | kPos, /*width = */ 0, "0X2A"}, + {42, kHex | kRight | kUpper | kBase | kPos, /*width = */ 6, "__0X2A"}, + {-321, std::ios_base::fmtflags(), /*width = */ 0, "-321"}, + {-321, std::ios_base::fmtflags(), /*width = */ 6, "__-321"}, + {-321, kPos, /*width = */ 0, "-321"}, + {-321, kPos, /*width = */ 6, "__-321"}, + {-321, kBase, /*width = */ 0, "-321"}, + {-321, kBase, /*width = */ 6, "__-321"}, + {-321, kBase | kPos, /*width = */ 0, "-321"}, + {-321, kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kUpper, /*width = */ 0, "-321"}, + {-321, kUpper, /*width = */ 6, "__-321"}, + {-321, kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kUpper | kPos, /*width = */ 6, "__-321"}, + {-321, kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kUpper | kBase, /*width = */ 6, "__-321"}, + {-321, kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kUpper | kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kLeft, /*width = */ 0, "-321"}, + {-321, kLeft, /*width = */ 6, "-321__"}, + {-321, kLeft | kPos, /*width = */ 0, "-321"}, + {-321, kLeft | kPos, /*width = */ 6, "-321__"}, + {-321, kLeft | kBase, /*width = */ 0, "-321"}, + {-321, kLeft | kBase, /*width = */ 6, "-321__"}, + {-321, kLeft | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kLeft | kBase | kPos, /*width = */ 6, "-321__"}, + {-321, kLeft | kUpper, /*width = */ 0, "-321"}, + {-321, kLeft | kUpper, /*width = */ 6, "-321__"}, + {-321, kLeft | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kLeft | kUpper | kPos, /*width = */ 6, "-321__"}, + {-321, kLeft | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kLeft | kUpper | kBase, /*width = */ 6, "-321__"}, + {-321, kLeft | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kLeft | kUpper | kBase | kPos, /*width = */ 6, "-321__"}, + {-321, kInt, /*width = */ 0, "-321"}, + {-321, kInt, /*width = */ 6, "-__321"}, + {-321, kInt | kPos, /*width = */ 0, "-321"}, + {-321, kInt | kPos, /*width = */ 6, "-__321"}, + {-321, kInt | kBase, /*width = */ 0, "-321"}, + {-321, kInt | kBase, /*width = */ 6, "-__321"}, + {-321, kInt | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kInt | kBase | kPos, /*width = */ 6, "-__321"}, + {-321, kInt | kUpper, /*width = */ 0, "-321"}, + {-321, kInt | kUpper, /*width = */ 6, "-__321"}, + {-321, kInt | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kInt | kUpper | kPos, /*width = */ 6, "-__321"}, + {-321, kInt | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kInt | kUpper | kBase, /*width = */ 6, "-__321"}, + {-321, kInt | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kInt | kUpper | kBase | kPos, /*width = */ 6, "-__321"}, + {-321, kRight, /*width = */ 0, "-321"}, + {-321, kRight, /*width = */ 6, "__-321"}, + {-321, kRight | kPos, /*width = */ 0, "-321"}, + {-321, kRight | kPos, /*width = */ 6, "__-321"}, + {-321, kRight | kBase, /*width = */ 0, "-321"}, + {-321, kRight | kBase, /*width = */ 6, "__-321"}, + {-321, kRight | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kRight | kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kRight | kUpper, /*width = */ 0, "-321"}, + {-321, kRight | kUpper, /*width = */ 6, "__-321"}, + {-321, kRight | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kRight | kUpper | kPos, /*width = */ 6, "__-321"}, + {-321, kRight | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kRight | kUpper | kBase, /*width = */ 6, "__-321"}, + {-321, kRight | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kRight | kUpper | kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kDec, /*width = */ 0, "-321"}, + {-321, kDec, /*width = */ 6, "__-321"}, + {-321, kDec | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kBase, /*width = */ 6, "__-321"}, + {-321, kDec | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kUpper, /*width = */ 0, "-321"}, + {-321, kDec | kUpper, /*width = */ 6, "__-321"}, + {-321, kDec | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kUpper | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kUpper | kBase, /*width = */ 6, "__-321"}, + {-321, kDec | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kUpper | kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kLeft, /*width = */ 0, "-321"}, + {-321, kDec | kLeft, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kPos, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kBase, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kBase | kPos, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kUpper, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kUpper, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kUpper | kPos, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kUpper | kBase, /*width = */ 6, "-321__"}, + {-321, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 6, "-321__"}, + {-321, kDec | kInt, /*width = */ 0, "-321"}, + {-321, kDec | kInt, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kPos, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kBase, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kBase | kPos, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kUpper, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kUpper, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kUpper | kPos, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kUpper | kBase, /*width = */ 6, "-__321"}, + {-321, kDec | kInt | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kInt | kUpper | kBase | kPos, /*width = */ 6, "-__321"}, + {-321, kDec | kRight, /*width = */ 0, "-321"}, + {-321, kDec | kRight, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kBase, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kBase | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kUpper, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kUpper, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kUpper | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kUpper | kPos, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kUpper | kBase, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kUpper | kBase, /*width = */ 6, "__-321"}, + {-321, kDec | kRight | kUpper | kBase | kPos, /*width = */ 0, "-321"}, + {-321, kDec | kRight | kUpper | kBase | kPos, /*width = */ 6, "__-321"}}; +} + +std::vector<Uint128TestCase> GetUint128FormatCases() { + return { + {0, std::ios_base::fmtflags(), /*width = */ 0, "0"}, + {0, std::ios_base::fmtflags(), /*width = */ 6, "_____0"}, + {0, kPos, /*width = */ 0, "0"}, + {0, kPos, /*width = */ 6, "_____0"}, + {0, kBase, /*width = */ 0, "0"}, + {0, kBase, /*width = */ 6, "_____0"}, + {0, kBase | kPos, /*width = */ 0, "0"}, + {0, kBase | kPos, /*width = */ 6, "_____0"}, + {0, kUpper, /*width = */ 0, "0"}, + {0, kUpper, /*width = */ 6, "_____0"}, + {0, kUpper | kPos, /*width = */ 0, "0"}, + {0, kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kUpper | kBase, /*width = */ 0, "0"}, + {0, kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kLeft, /*width = */ 0, "0"}, + {0, kLeft, /*width = */ 6, "0_____"}, + {0, kLeft | kPos, /*width = */ 0, "0"}, + {0, kLeft | kPos, /*width = */ 6, "0_____"}, + {0, kLeft | kBase, /*width = */ 0, "0"}, + {0, kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kLeft | kBase | kPos, /*width = */ 0, "0"}, + {0, kLeft | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kLeft | kUpper, /*width = */ 0, "0"}, + {0, kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kLeft | kUpper | kPos, /*width = */ 0, "0"}, + {0, kLeft | kUpper | kPos, /*width = */ 6, "0_____"}, + {0, kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kLeft | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kLeft | kUpper | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kInt, /*width = */ 0, "0"}, + {0, kInt, /*width = */ 6, "_____0"}, + {0, kInt | kPos, /*width = */ 0, "0"}, + {0, kInt | kPos, /*width = */ 6, "_____0"}, + {0, kInt | kBase, /*width = */ 0, "0"}, + {0, kInt | kBase, /*width = */ 6, "_____0"}, + {0, kInt | kBase | kPos, /*width = */ 0, "0"}, + {0, kInt | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kInt | kUpper, /*width = */ 0, "0"}, + {0, kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kInt | kUpper | kPos, /*width = */ 0, "0"}, + {0, kInt | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kInt | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kInt | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kRight, /*width = */ 0, "0"}, + {0, kRight, /*width = */ 6, "_____0"}, + {0, kRight | kPos, /*width = */ 0, "0"}, + {0, kRight | kPos, /*width = */ 6, "_____0"}, + {0, kRight | kBase, /*width = */ 0, "0"}, + {0, kRight | kBase, /*width = */ 6, "_____0"}, + {0, kRight | kBase | kPos, /*width = */ 0, "0"}, + {0, kRight | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kRight | kUpper, /*width = */ 0, "0"}, + {0, kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kRight | kUpper | kPos, /*width = */ 0, "0"}, + {0, kRight | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kRight | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kRight | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kDec, /*width = */ 0, "0"}, + {0, kDec, /*width = */ 6, "_____0"}, + {0, kDec | kPos, /*width = */ 0, "0"}, + {0, kDec | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kBase, /*width = */ 0, "0"}, + {0, kDec | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kUpper, /*width = */ 0, "0"}, + {0, kDec | kUpper, /*width = */ 6, "_____0"}, + {0, kDec | kUpper | kPos, /*width = */ 0, "0"}, + {0, kDec | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kLeft, /*width = */ 0, "0"}, + {0, kDec | kLeft, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kPos, /*width = */ 0, "0"}, + {0, kDec | kLeft | kPos, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kBase, /*width = */ 0, "0"}, + {0, kDec | kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kLeft | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kUpper, /*width = */ 0, "0"}, + {0, kDec | kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kUpper | kPos, /*width = */ 0, "0"}, + {0, kDec | kLeft | kUpper | kPos, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kDec | kInt, /*width = */ 0, "0"}, + {0, kDec | kInt, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kPos, /*width = */ 0, "0"}, + {0, kDec | kInt | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kBase, /*width = */ 0, "0"}, + {0, kDec | kInt | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kInt | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kUpper, /*width = */ 0, "0"}, + {0, kDec | kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kUpper | kPos, /*width = */ 0, "0"}, + {0, kDec | kInt | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kInt | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kInt | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kRight, /*width = */ 0, "0"}, + {0, kDec | kRight, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kPos, /*width = */ 0, "0"}, + {0, kDec | kRight | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kBase, /*width = */ 0, "0"}, + {0, kDec | kRight | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kRight | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kUpper, /*width = */ 0, "0"}, + {0, kDec | kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kUpper | kPos, /*width = */ 0, "0"}, + {0, kDec | kRight | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kDec | kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kDec | kRight | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kDec | kRight | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct, /*width = */ 0, "0"}, + {0, kOct, /*width = */ 6, "_____0"}, + {0, kOct | kPos, /*width = */ 0, "0"}, + {0, kOct | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kBase, /*width = */ 0, "0"}, + {0, kOct | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kUpper, /*width = */ 0, "0"}, + {0, kOct | kUpper, /*width = */ 6, "_____0"}, + {0, kOct | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kLeft, /*width = */ 0, "0"}, + {0, kOct | kLeft, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kBase, /*width = */ 0, "0"}, + {0, kOct | kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kOct | kInt, /*width = */ 0, "0"}, + {0, kOct | kInt, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kBase, /*width = */ 0, "0"}, + {0, kOct | kInt | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kInt | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kInt | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight, /*width = */ 0, "0"}, + {0, kOct | kRight, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kBase, /*width = */ 0, "0"}, + {0, kOct | kRight | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kOct | kRight | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kOct | kRight | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex, /*width = */ 0, "0"}, + {0, kHex, /*width = */ 6, "_____0"}, + {0, kHex | kPos, /*width = */ 0, "0"}, + {0, kHex | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kBase, /*width = */ 0, "0"}, + {0, kHex | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kUpper, /*width = */ 0, "0"}, + {0, kHex | kUpper, /*width = */ 6, "_____0"}, + {0, kHex | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kLeft, /*width = */ 0, "0"}, + {0, kHex | kLeft, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kBase, /*width = */ 0, "0"}, + {0, kHex | kLeft | kBase, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper | kBase, /*width = */ 6, "0_____"}, + {0, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0_____"}, + {0, kHex | kInt, /*width = */ 0, "0"}, + {0, kHex | kInt, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kBase, /*width = */ 0, "0"}, + {0, kHex | kInt | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kInt | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kInt | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight, /*width = */ 0, "0"}, + {0, kHex | kRight, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kBase, /*width = */ 0, "0"}, + {0, kHex | kRight | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kBase | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper | kPos, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper | kBase, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper | kBase, /*width = */ 6, "_____0"}, + {0, kHex | kRight | kUpper | kBase | kPos, /*width = */ 0, "0"}, + {0, kHex | kRight | kUpper | kBase | kPos, /*width = */ 6, "_____0"}, + {37, std::ios_base::fmtflags(), /*width = */ 0, "37"}, + {37, std::ios_base::fmtflags(), /*width = */ 6, "____37"}, + {37, kPos, /*width = */ 0, "37"}, + {37, kPos, /*width = */ 6, "____37"}, + {37, kBase, /*width = */ 0, "37"}, + {37, kBase, /*width = */ 6, "____37"}, + {37, kBase | kPos, /*width = */ 0, "37"}, + {37, kBase | kPos, /*width = */ 6, "____37"}, + {37, kUpper, /*width = */ 0, "37"}, + {37, kUpper, /*width = */ 6, "____37"}, + {37, kUpper | kPos, /*width = */ 0, "37"}, + {37, kUpper | kPos, /*width = */ 6, "____37"}, + {37, kUpper | kBase, /*width = */ 0, "37"}, + {37, kUpper | kBase, /*width = */ 6, "____37"}, + {37, kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kUpper | kBase | kPos, /*width = */ 6, "____37"}, + {37, kLeft, /*width = */ 0, "37"}, + {37, kLeft, /*width = */ 6, "37____"}, + {37, kLeft | kPos, /*width = */ 0, "37"}, + {37, kLeft | kPos, /*width = */ 6, "37____"}, + {37, kLeft | kBase, /*width = */ 0, "37"}, + {37, kLeft | kBase, /*width = */ 6, "37____"}, + {37, kLeft | kBase | kPos, /*width = */ 0, "37"}, + {37, kLeft | kBase | kPos, /*width = */ 6, "37____"}, + {37, kLeft | kUpper, /*width = */ 0, "37"}, + {37, kLeft | kUpper, /*width = */ 6, "37____"}, + {37, kLeft | kUpper | kPos, /*width = */ 0, "37"}, + {37, kLeft | kUpper | kPos, /*width = */ 6, "37____"}, + {37, kLeft | kUpper | kBase, /*width = */ 0, "37"}, + {37, kLeft | kUpper | kBase, /*width = */ 6, "37____"}, + {37, kLeft | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kLeft | kUpper | kBase | kPos, /*width = */ 6, "37____"}, + {37, kInt, /*width = */ 0, "37"}, + {37, kInt, /*width = */ 6, "____37"}, + {37, kInt | kPos, /*width = */ 0, "37"}, + {37, kInt | kPos, /*width = */ 6, "____37"}, + {37, kInt | kBase, /*width = */ 0, "37"}, + {37, kInt | kBase, /*width = */ 6, "____37"}, + {37, kInt | kBase | kPos, /*width = */ 0, "37"}, + {37, kInt | kBase | kPos, /*width = */ 6, "____37"}, + {37, kInt | kUpper, /*width = */ 0, "37"}, + {37, kInt | kUpper, /*width = */ 6, "____37"}, + {37, kInt | kUpper | kPos, /*width = */ 0, "37"}, + {37, kInt | kUpper | kPos, /*width = */ 6, "____37"}, + {37, kInt | kUpper | kBase, /*width = */ 0, "37"}, + {37, kInt | kUpper | kBase, /*width = */ 6, "____37"}, + {37, kInt | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kInt | kUpper | kBase | kPos, /*width = */ 6, "____37"}, + {37, kRight, /*width = */ 0, "37"}, + {37, kRight, /*width = */ 6, "____37"}, + {37, kRight | kPos, /*width = */ 0, "37"}, + {37, kRight | kPos, /*width = */ 6, "____37"}, + {37, kRight | kBase, /*width = */ 0, "37"}, + {37, kRight | kBase, /*width = */ 6, "____37"}, + {37, kRight | kBase | kPos, /*width = */ 0, "37"}, + {37, kRight | kBase | kPos, /*width = */ 6, "____37"}, + {37, kRight | kUpper, /*width = */ 0, "37"}, + {37, kRight | kUpper, /*width = */ 6, "____37"}, + {37, kRight | kUpper | kPos, /*width = */ 0, "37"}, + {37, kRight | kUpper | kPos, /*width = */ 6, "____37"}, + {37, kRight | kUpper | kBase, /*width = */ 0, "37"}, + {37, kRight | kUpper | kBase, /*width = */ 6, "____37"}, + {37, kRight | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kRight | kUpper | kBase | kPos, /*width = */ 6, "____37"}, + {37, kDec, /*width = */ 0, "37"}, + {37, kDec, /*width = */ 6, "____37"}, + {37, kDec | kPos, /*width = */ 0, "37"}, + {37, kDec | kPos, /*width = */ 6, "____37"}, + {37, kDec | kBase, /*width = */ 0, "37"}, + {37, kDec | kBase, /*width = */ 6, "____37"}, + {37, kDec | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kBase | kPos, /*width = */ 6, "____37"}, + {37, kDec | kUpper, /*width = */ 0, "37"}, + {37, kDec | kUpper, /*width = */ 6, "____37"}, + {37, kDec | kUpper | kPos, /*width = */ 0, "37"}, + {37, kDec | kUpper | kPos, /*width = */ 6, "____37"}, + {37, kDec | kUpper | kBase, /*width = */ 0, "37"}, + {37, kDec | kUpper | kBase, /*width = */ 6, "____37"}, + {37, kDec | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kUpper | kBase | kPos, /*width = */ 6, "____37"}, + {37, kDec | kLeft, /*width = */ 0, "37"}, + {37, kDec | kLeft, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kPos, /*width = */ 0, "37"}, + {37, kDec | kLeft | kPos, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kBase, /*width = */ 0, "37"}, + {37, kDec | kLeft | kBase, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kLeft | kBase | kPos, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kUpper, /*width = */ 0, "37"}, + {37, kDec | kLeft | kUpper, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kUpper | kPos, /*width = */ 0, "37"}, + {37, kDec | kLeft | kUpper | kPos, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kUpper | kBase, /*width = */ 0, "37"}, + {37, kDec | kLeft | kUpper | kBase, /*width = */ 6, "37____"}, + {37, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kLeft | kUpper | kBase | kPos, /*width = */ 6, "37____"}, + {37, kDec | kInt, /*width = */ 0, "37"}, + {37, kDec | kInt, /*width = */ 6, "____37"}, + {37, kDec | kInt | kPos, /*width = */ 0, "37"}, + {37, kDec | kInt | kPos, /*width = */ 6, "____37"}, + {37, kDec | kInt | kBase, /*width = */ 0, "37"}, + {37, kDec | kInt | kBase, /*width = */ 6, "____37"}, + {37, kDec | kInt | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kInt | kBase | kPos, /*width = */ 6, "____37"}, + {37, kDec | kInt | kUpper, /*width = */ 0, "37"}, + {37, kDec | kInt | kUpper, /*width = */ 6, "____37"}, + {37, kDec | kInt | kUpper | kPos, /*width = */ 0, "37"}, + {37, kDec | kInt | kUpper | kPos, /*width = */ 6, "____37"}, + {37, kDec | kInt | kUpper | kBase, /*width = */ 0, "37"}, + {37, kDec | kInt | kUpper | kBase, /*width = */ 6, "____37"}, + {37, kDec | kInt | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kInt | kUpper | kBase | kPos, /*width = */ 6, "____37"}, + {37, kDec | kRight, /*width = */ 0, "37"}, + {37, kDec | kRight, /*width = */ 6, "____37"}, + {37, kDec | kRight | kPos, /*width = */ 0, "37"}, + {37, kDec | kRight | kPos, /*width = */ 6, "____37"}, + {37, kDec | kRight | kBase, /*width = */ 0, "37"}, + {37, kDec | kRight | kBase, /*width = */ 6, "____37"}, + {37, kDec | kRight | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kRight | kBase | kPos, /*width = */ 6, "____37"}, + {37, kDec | kRight | kUpper, /*width = */ 0, "37"}, + {37, kDec | kRight | kUpper, /*width = */ 6, "____37"}, + {37, kDec | kRight | kUpper | kPos, /*width = */ 0, "37"}, + {37, kDec | kRight | kUpper | kPos, /*width = */ 6, "____37"}, + {37, kDec | kRight | kUpper | kBase, /*width = */ 0, "37"}, + {37, kDec | kRight | kUpper | kBase, /*width = */ 6, "____37"}, + {37, kDec | kRight | kUpper | kBase | kPos, /*width = */ 0, "37"}, + {37, kDec | kRight | kUpper | kBase | kPos, /*width = */ 6, "____37"}, + {37, kOct, /*width = */ 0, "45"}, + {37, kOct, /*width = */ 6, "____45"}, + {37, kOct | kPos, /*width = */ 0, "45"}, + {37, kOct | kPos, /*width = */ 6, "____45"}, + {37, kOct | kBase, /*width = */ 0, "045"}, + {37, kOct | kBase, /*width = */ 6, "___045"}, + {37, kOct | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kBase | kPos, /*width = */ 6, "___045"}, + {37, kOct | kUpper, /*width = */ 0, "45"}, + {37, kOct | kUpper, /*width = */ 6, "____45"}, + {37, kOct | kUpper | kPos, /*width = */ 0, "45"}, + {37, kOct | kUpper | kPos, /*width = */ 6, "____45"}, + {37, kOct | kUpper | kBase, /*width = */ 0, "045"}, + {37, kOct | kUpper | kBase, /*width = */ 6, "___045"}, + {37, kOct | kUpper | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kUpper | kBase | kPos, /*width = */ 6, "___045"}, + {37, kOct | kLeft, /*width = */ 0, "45"}, + {37, kOct | kLeft, /*width = */ 6, "45____"}, + {37, kOct | kLeft | kPos, /*width = */ 0, "45"}, + {37, kOct | kLeft | kPos, /*width = */ 6, "45____"}, + {37, kOct | kLeft | kBase, /*width = */ 0, "045"}, + {37, kOct | kLeft | kBase, /*width = */ 6, "045___"}, + {37, kOct | kLeft | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kLeft | kBase | kPos, /*width = */ 6, "045___"}, + {37, kOct | kLeft | kUpper, /*width = */ 0, "45"}, + {37, kOct | kLeft | kUpper, /*width = */ 6, "45____"}, + {37, kOct | kLeft | kUpper | kPos, /*width = */ 0, "45"}, + {37, kOct | kLeft | kUpper | kPos, /*width = */ 6, "45____"}, + {37, kOct | kLeft | kUpper | kBase, /*width = */ 0, "045"}, + {37, kOct | kLeft | kUpper | kBase, /*width = */ 6, "045___"}, + {37, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kLeft | kUpper | kBase | kPos, /*width = */ 6, "045___"}, + {37, kOct | kInt, /*width = */ 0, "45"}, + {37, kOct | kInt, /*width = */ 6, "____45"}, + {37, kOct | kInt | kPos, /*width = */ 0, "45"}, + {37, kOct | kInt | kPos, /*width = */ 6, "____45"}, + {37, kOct | kInt | kBase, /*width = */ 0, "045"}, + {37, kOct | kInt | kBase, /*width = */ 6, "___045"}, + {37, kOct | kInt | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kInt | kBase | kPos, /*width = */ 6, "___045"}, + {37, kOct | kInt | kUpper, /*width = */ 0, "45"}, + {37, kOct | kInt | kUpper, /*width = */ 6, "____45"}, + {37, kOct | kInt | kUpper | kPos, /*width = */ 0, "45"}, + {37, kOct | kInt | kUpper | kPos, /*width = */ 6, "____45"}, + {37, kOct | kInt | kUpper | kBase, /*width = */ 0, "045"}, + {37, kOct | kInt | kUpper | kBase, /*width = */ 6, "___045"}, + {37, kOct | kInt | kUpper | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kInt | kUpper | kBase | kPos, /*width = */ 6, "___045"}, + {37, kOct | kRight, /*width = */ 0, "45"}, + {37, kOct | kRight, /*width = */ 6, "____45"}, + {37, kOct | kRight | kPos, /*width = */ 0, "45"}, + {37, kOct | kRight | kPos, /*width = */ 6, "____45"}, + {37, kOct | kRight | kBase, /*width = */ 0, "045"}, + {37, kOct | kRight | kBase, /*width = */ 6, "___045"}, + {37, kOct | kRight | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kRight | kBase | kPos, /*width = */ 6, "___045"}, + {37, kOct | kRight | kUpper, /*width = */ 0, "45"}, + {37, kOct | kRight | kUpper, /*width = */ 6, "____45"}, + {37, kOct | kRight | kUpper | kPos, /*width = */ 0, "45"}, + {37, kOct | kRight | kUpper | kPos, /*width = */ 6, "____45"}, + {37, kOct | kRight | kUpper | kBase, /*width = */ 0, "045"}, + {37, kOct | kRight | kUpper | kBase, /*width = */ 6, "___045"}, + {37, kOct | kRight | kUpper | kBase | kPos, /*width = */ 0, "045"}, + {37, kOct | kRight | kUpper | kBase | kPos, /*width = */ 6, "___045"}, + {37, kHex, /*width = */ 0, "25"}, + {37, kHex, /*width = */ 6, "____25"}, + {37, kHex | kPos, /*width = */ 0, "25"}, + {37, kHex | kPos, /*width = */ 6, "____25"}, + {37, kHex | kBase, /*width = */ 0, "0x25"}, + {37, kHex | kBase, /*width = */ 6, "__0x25"}, + {37, kHex | kBase | kPos, /*width = */ 0, "0x25"}, + {37, kHex | kBase | kPos, /*width = */ 6, "__0x25"}, + {37, kHex | kUpper, /*width = */ 0, "25"}, + {37, kHex | kUpper, /*width = */ 6, "____25"}, + {37, kHex | kUpper | kPos, /*width = */ 0, "25"}, + {37, kHex | kUpper | kPos, /*width = */ 6, "____25"}, + {37, kHex | kUpper | kBase, /*width = */ 0, "0X25"}, + {37, kHex | kUpper | kBase, /*width = */ 6, "__0X25"}, + {37, kHex | kUpper | kBase | kPos, /*width = */ 0, "0X25"}, + {37, kHex | kUpper | kBase | kPos, /*width = */ 6, "__0X25"}, + {37, kHex | kLeft, /*width = */ 0, "25"}, + {37, kHex | kLeft, /*width = */ 6, "25____"}, + {37, kHex | kLeft | kPos, /*width = */ 0, "25"}, + {37, kHex | kLeft | kPos, /*width = */ 6, "25____"}, + {37, kHex | kLeft | kBase, /*width = */ 0, "0x25"}, + {37, kHex | kLeft | kBase, /*width = */ 6, "0x25__"}, + {37, kHex | kLeft | kBase | kPos, /*width = */ 0, "0x25"}, + {37, kHex | kLeft | kBase | kPos, /*width = */ 6, "0x25__"}, + {37, kHex | kLeft | kUpper, /*width = */ 0, "25"}, + {37, kHex | kLeft | kUpper, /*width = */ 6, "25____"}, + {37, kHex | kLeft | kUpper | kPos, /*width = */ 0, "25"}, + {37, kHex | kLeft | kUpper | kPos, /*width = */ 6, "25____"}, + {37, kHex | kLeft | kUpper | kBase, /*width = */ 0, "0X25"}, + {37, kHex | kLeft | kUpper | kBase, /*width = */ 6, "0X25__"}, + {37, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 0, "0X25"}, + {37, kHex | kLeft | kUpper | kBase | kPos, /*width = */ 6, "0X25__"}, + {37, kHex | kInt, /*width = */ 0, "25"}, + {37, kHex | kInt, /*width = */ 6, "____25"}, + {37, kHex | kInt | kPos, /*width = */ 0, "25"}, + {37, kHex | kInt | kPos, /*width = */ 6, "____25"}, + {37, kHex | kInt | kBase, /*width = */ 0, "0x25"}, + {37, kHex | kInt | kBase, /*width = */ 6, "0x__25"}, + {37, kHex | kInt | kBase | kPos, /*width = */ 0, "0x25"}, + {37, kHex | kInt | kBase | kPos, /*width = */ 6, "0x__25"}, + {37, kHex | kInt | kUpper, /*width = */ 0, "25"}, + {37, kHex | kInt | kUpper, /*width = */ 6, "____25"}, + {37, kHex | kInt | kUpper | kPos, /*width = */ 0, "25"}, + {37, kHex | kInt | kUpper | kPos, /*width = */ 6, "____25"}, + {37, kHex | kInt | kUpper | kBase, /*width = */ 0, "0X25"}, + {37, kHex | kInt | kUpper | kBase, /*width = */ 6, "0X__25"}, + {37, kHex | kInt | kUpper | kBase | kPos, /*width = */ 0, "0X25"}, + {37, kHex | kInt | kUpper | kBase | kPos, /*width = */ 6, "0X__25"}, + {37, kHex | kRight, /*width = */ 0, "25"}, + {37, kHex | kRight, /*width = */ 6, "____25"}, + {37, kHex | kRight | kPos, /*width = */ 0, "25"}, + {37, kHex | kRight | kPos, /*width = */ 6, "____25"}, + {37, kHex | kRight | kBase, /*width = */ 0, "0x25"}, + {37, kHex | kRight | kBase, /*width = */ 6, "__0x25"}, + {37, kHex | kRight | kBase | kPos, /*width = */ 0, "0x25"}, + {37, kHex | kRight | kBase | kPos, /*width = */ 6, "__0x25"}, + {37, kHex | kRight | kUpper, /*width = */ 0, "25"}, + {37, kHex | kRight | kUpper, /*width = */ 6, "____25"}, + {37, kHex | kRight | kUpper | kPos, /*width = */ 0, "25"}, + {37, kHex | kRight | kUpper | kPos, /*width = */ 6, "____25"}, + {37, kHex | kRight | kUpper | kBase, /*width = */ 0, "0X25"}, + {37, kHex | kRight | kUpper | kBase, /*width = */ 6, "__0X25"}, + {37, kHex | kRight | kUpper | kBase | kPos, /*width = */ 0, "0X25"}, + {37, kHex | kRight | kUpper | kBase | kPos, /*width = */ 6, "__0X25"}}; +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/numeric/int128_test.cc b/third_party/abseil_cpp/absl/numeric/int128_test.cc new file mode 100644 index 0000000000..bc86c714ac --- /dev/null +++ b/third_party/abseil_cpp/absl/numeric/int128_test.cc @@ -0,0 +1,1225 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/numeric/int128.h" + +#include <algorithm> +#include <limits> +#include <random> +#include <type_traits> +#include <utility> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/internal/cycleclock.h" +#include "absl/hash/hash_testing.h" +#include "absl/meta/type_traits.h" + +#if defined(_MSC_VER) && _MSC_VER == 1900 +// Disable "unary minus operator applied to unsigned type" warnings in Microsoft +// Visual C++ 14 (2015). +#pragma warning(disable:4146) +#endif + +namespace { + +template <typename T> +class Uint128IntegerTraitsTest : public ::testing::Test {}; +typedef ::testing::Types<bool, char, signed char, unsigned char, char16_t, + char32_t, wchar_t, + short, // NOLINT(runtime/int) + unsigned short, // NOLINT(runtime/int) + int, unsigned int, + long, // NOLINT(runtime/int) + unsigned long, // NOLINT(runtime/int) + long long, // NOLINT(runtime/int) + unsigned long long> // NOLINT(runtime/int) + IntegerTypes; + +template <typename T> +class Uint128FloatTraitsTest : public ::testing::Test {}; +typedef ::testing::Types<float, double, long double> FloatingPointTypes; + +TYPED_TEST_SUITE(Uint128IntegerTraitsTest, IntegerTypes); + +TYPED_TEST(Uint128IntegerTraitsTest, ConstructAssignTest) { + static_assert(std::is_constructible<absl::uint128, TypeParam>::value, + "absl::uint128 must be constructible from TypeParam"); + static_assert(std::is_assignable<absl::uint128&, TypeParam>::value, + "absl::uint128 must be assignable from TypeParam"); + static_assert(!std::is_assignable<TypeParam&, absl::uint128>::value, + "TypeParam must not be assignable from absl::uint128"); +} + +TYPED_TEST_SUITE(Uint128FloatTraitsTest, FloatingPointTypes); + +TYPED_TEST(Uint128FloatTraitsTest, ConstructAssignTest) { + static_assert(std::is_constructible<absl::uint128, TypeParam>::value, + "absl::uint128 must be constructible from TypeParam"); + static_assert(!std::is_assignable<absl::uint128&, TypeParam>::value, + "absl::uint128 must not be assignable from TypeParam"); + static_assert(!std::is_assignable<TypeParam&, absl::uint128>::value, + "TypeParam must not be assignable from absl::uint128"); +} + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +// These type traits done separately as TYPED_TEST requires typeinfo, and not +// all platforms have this for __int128 even though they define the type. +TEST(Uint128, IntrinsicTypeTraitsTest) { + static_assert(std::is_constructible<absl::uint128, __int128>::value, + "absl::uint128 must be constructible from __int128"); + static_assert(std::is_assignable<absl::uint128&, __int128>::value, + "absl::uint128 must be assignable from __int128"); + static_assert(!std::is_assignable<__int128&, absl::uint128>::value, + "__int128 must not be assignable from absl::uint128"); + + static_assert(std::is_constructible<absl::uint128, unsigned __int128>::value, + "absl::uint128 must be constructible from unsigned __int128"); + static_assert(std::is_assignable<absl::uint128&, unsigned __int128>::value, + "absl::uint128 must be assignable from unsigned __int128"); + static_assert(!std::is_assignable<unsigned __int128&, absl::uint128>::value, + "unsigned __int128 must not be assignable from absl::uint128"); +} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +TEST(Uint128, TrivialTraitsTest) { + static_assert(absl::is_trivially_default_constructible<absl::uint128>::value, + ""); + static_assert(absl::is_trivially_copy_constructible<absl::uint128>::value, + ""); + static_assert(absl::is_trivially_copy_assignable<absl::uint128>::value, ""); + static_assert(std::is_trivially_destructible<absl::uint128>::value, ""); +} + +TEST(Uint128, AllTests) { + absl::uint128 zero = 0; + absl::uint128 one = 1; + absl::uint128 one_2arg = absl::MakeUint128(0, 1); + absl::uint128 two = 2; + absl::uint128 three = 3; + absl::uint128 big = absl::MakeUint128(2000, 2); + absl::uint128 big_minus_one = absl::MakeUint128(2000, 1); + absl::uint128 bigger = absl::MakeUint128(2001, 1); + absl::uint128 biggest = absl::Uint128Max(); + absl::uint128 high_low = absl::MakeUint128(1, 0); + absl::uint128 low_high = + absl::MakeUint128(0, std::numeric_limits<uint64_t>::max()); + EXPECT_LT(one, two); + EXPECT_GT(two, one); + EXPECT_LT(one, big); + EXPECT_LT(one, big); + EXPECT_EQ(one, one_2arg); + EXPECT_NE(one, two); + EXPECT_GT(big, one); + EXPECT_GE(big, two); + EXPECT_GE(big, big_minus_one); + EXPECT_GT(big, big_minus_one); + EXPECT_LT(big_minus_one, big); + EXPECT_LE(big_minus_one, big); + EXPECT_NE(big_minus_one, big); + EXPECT_LT(big, biggest); + EXPECT_LE(big, biggest); + EXPECT_GT(biggest, big); + EXPECT_GE(biggest, big); + EXPECT_EQ(big, ~~big); + EXPECT_EQ(one, one | one); + EXPECT_EQ(big, big | big); + EXPECT_EQ(one, one | zero); + EXPECT_EQ(one, one & one); + EXPECT_EQ(big, big & big); + EXPECT_EQ(zero, one & zero); + EXPECT_EQ(zero, big & ~big); + EXPECT_EQ(zero, one ^ one); + EXPECT_EQ(zero, big ^ big); + EXPECT_EQ(one, one ^ zero); + + // Shift operators. + EXPECT_EQ(big, big << 0); + EXPECT_EQ(big, big >> 0); + EXPECT_GT(big << 1, big); + EXPECT_LT(big >> 1, big); + EXPECT_EQ(big, (big << 10) >> 10); + EXPECT_EQ(big, (big >> 1) << 1); + EXPECT_EQ(one, (one << 80) >> 80); + EXPECT_EQ(zero, (one >> 80) << 80); + + // Shift assignments. + absl::uint128 big_copy = big; + EXPECT_EQ(big << 0, big_copy <<= 0); + big_copy = big; + EXPECT_EQ(big >> 0, big_copy >>= 0); + big_copy = big; + EXPECT_EQ(big << 1, big_copy <<= 1); + big_copy = big; + EXPECT_EQ(big >> 1, big_copy >>= 1); + big_copy = big; + EXPECT_EQ(big << 10, big_copy <<= 10); + big_copy = big; + EXPECT_EQ(big >> 10, big_copy >>= 10); + big_copy = big; + EXPECT_EQ(big << 64, big_copy <<= 64); + big_copy = big; + EXPECT_EQ(big >> 64, big_copy >>= 64); + big_copy = big; + EXPECT_EQ(big << 73, big_copy <<= 73); + big_copy = big; + EXPECT_EQ(big >> 73, big_copy >>= 73); + + EXPECT_EQ(absl::Uint128High64(biggest), std::numeric_limits<uint64_t>::max()); + EXPECT_EQ(absl::Uint128Low64(biggest), std::numeric_limits<uint64_t>::max()); + EXPECT_EQ(zero + one, one); + EXPECT_EQ(one + one, two); + EXPECT_EQ(big_minus_one + one, big); + EXPECT_EQ(one - one, zero); + EXPECT_EQ(one - zero, one); + EXPECT_EQ(zero - one, biggest); + EXPECT_EQ(big - big, zero); + EXPECT_EQ(big - one, big_minus_one); + EXPECT_EQ(big + std::numeric_limits<uint64_t>::max(), bigger); + EXPECT_EQ(biggest + 1, zero); + EXPECT_EQ(zero - 1, biggest); + EXPECT_EQ(high_low - one, low_high); + EXPECT_EQ(low_high + one, high_low); + EXPECT_EQ(absl::Uint128High64((absl::uint128(1) << 64) - 1), 0); + EXPECT_EQ(absl::Uint128Low64((absl::uint128(1) << 64) - 1), + std::numeric_limits<uint64_t>::max()); + EXPECT_TRUE(!!one); + EXPECT_TRUE(!!high_low); + EXPECT_FALSE(!!zero); + EXPECT_FALSE(!one); + EXPECT_FALSE(!high_low); + EXPECT_TRUE(!zero); + EXPECT_TRUE(zero == 0); // NOLINT(readability/check) + EXPECT_FALSE(zero != 0); // NOLINT(readability/check) + EXPECT_FALSE(one == 0); // NOLINT(readability/check) + EXPECT_TRUE(one != 0); // NOLINT(readability/check) + EXPECT_FALSE(high_low == 0); // NOLINT(readability/check) + EXPECT_TRUE(high_low != 0); // NOLINT(readability/check) + + absl::uint128 test = zero; + EXPECT_EQ(++test, one); + EXPECT_EQ(test, one); + EXPECT_EQ(test++, one); + EXPECT_EQ(test, two); + EXPECT_EQ(test -= 2, zero); + EXPECT_EQ(test, zero); + EXPECT_EQ(test += 2, two); + EXPECT_EQ(test, two); + EXPECT_EQ(--test, one); + EXPECT_EQ(test, one); + EXPECT_EQ(test--, one); + EXPECT_EQ(test, zero); + EXPECT_EQ(test |= three, three); + EXPECT_EQ(test &= one, one); + EXPECT_EQ(test ^= three, two); + EXPECT_EQ(test >>= 1, one); + EXPECT_EQ(test <<= 1, two); + + EXPECT_EQ(big, -(-big)); + EXPECT_EQ(two, -((-one) - 1)); + EXPECT_EQ(absl::Uint128Max(), -one); + EXPECT_EQ(zero, -zero); + + EXPECT_EQ(absl::Uint128Max(), absl::kuint128max); +} + +TEST(Uint128, ConversionTests) { + EXPECT_TRUE(absl::MakeUint128(1, 0)); + +#ifdef ABSL_HAVE_INTRINSIC_INT128 + unsigned __int128 intrinsic = + (static_cast<unsigned __int128>(0x3a5b76c209de76f6) << 64) + + 0x1f25e1d63a2b46c5; + absl::uint128 custom = + absl::MakeUint128(0x3a5b76c209de76f6, 0x1f25e1d63a2b46c5); + + EXPECT_EQ(custom, absl::uint128(intrinsic)); + EXPECT_EQ(custom, absl::uint128(static_cast<__int128>(intrinsic))); + EXPECT_EQ(intrinsic, static_cast<unsigned __int128>(custom)); + EXPECT_EQ(intrinsic, static_cast<__int128>(custom)); +#endif // ABSL_HAVE_INTRINSIC_INT128 + + // verify that an integer greater than 2**64 that can be stored precisely + // inside a double is converted to a absl::uint128 without loss of + // information. + double precise_double = 0x530e * std::pow(2.0, 64.0) + 0xda74000000000000; + absl::uint128 from_precise_double(precise_double); + absl::uint128 from_precise_ints = + absl::MakeUint128(0x530e, 0xda74000000000000); + EXPECT_EQ(from_precise_double, from_precise_ints); + EXPECT_DOUBLE_EQ(static_cast<double>(from_precise_ints), precise_double); + + double approx_double = 0xffffeeeeddddcccc * std::pow(2.0, 64.0) + + 0xbbbbaaaa99998888; + absl::uint128 from_approx_double(approx_double); + EXPECT_DOUBLE_EQ(static_cast<double>(from_approx_double), approx_double); + + double round_to_zero = 0.7; + double round_to_five = 5.8; + double round_to_nine = 9.3; + EXPECT_EQ(static_cast<absl::uint128>(round_to_zero), 0); + EXPECT_EQ(static_cast<absl::uint128>(round_to_five), 5); + EXPECT_EQ(static_cast<absl::uint128>(round_to_nine), 9); + + absl::uint128 highest_precision_in_long_double = + ~absl::uint128{} >> (128 - std::numeric_limits<long double>::digits); + EXPECT_EQ(highest_precision_in_long_double, + static_cast<absl::uint128>( + static_cast<long double>(highest_precision_in_long_double))); + // Apply a mask just to make sure all the bits are the right place. + const absl::uint128 arbitrary_mask = + absl::MakeUint128(0xa29f622677ded751, 0xf8ca66add076f468); + EXPECT_EQ(highest_precision_in_long_double & arbitrary_mask, + static_cast<absl::uint128>(static_cast<long double>( + highest_precision_in_long_double & arbitrary_mask))); + + EXPECT_EQ(static_cast<absl::uint128>(-0.1L), 0); +} + +TEST(Uint128, OperatorAssignReturnRef) { + absl::uint128 v(1); + (v += 4) -= 3; + EXPECT_EQ(2, v); +} + +TEST(Uint128, Multiply) { + absl::uint128 a, b, c; + + // Zero test. + a = 0; + b = 0; + c = a * b; + EXPECT_EQ(0, c); + + // Max carries. + a = absl::uint128(0) - 1; + b = absl::uint128(0) - 1; + c = a * b; + EXPECT_EQ(1, c); + + // Self-operation with max carries. + c = absl::uint128(0) - 1; + c *= c; + EXPECT_EQ(1, c); + + // 1-bit x 1-bit. + for (int i = 0; i < 64; ++i) { + for (int j = 0; j < 64; ++j) { + a = absl::uint128(1) << i; + b = absl::uint128(1) << j; + c = a * b; + EXPECT_EQ(absl::uint128(1) << (i + j), c); + } + } + + // Verified with dc. + a = absl::MakeUint128(0xffffeeeeddddcccc, 0xbbbbaaaa99998888); + b = absl::MakeUint128(0x7777666655554444, 0x3333222211110000); + c = a * b; + EXPECT_EQ(absl::MakeUint128(0x530EDA741C71D4C3, 0xBF25975319080000), c); + EXPECT_EQ(0, c - b * a); + EXPECT_EQ(a*a - b*b, (a+b) * (a-b)); + + // Verified with dc. + a = absl::MakeUint128(0x0123456789abcdef, 0xfedcba9876543210); + b = absl::MakeUint128(0x02468ace13579bdf, 0xfdb97531eca86420); + c = a * b; + EXPECT_EQ(absl::MakeUint128(0x97a87f4f261ba3f2, 0x342d0bbf48948200), c); + EXPECT_EQ(0, c - b * a); + EXPECT_EQ(a*a - b*b, (a+b) * (a-b)); +} + +TEST(Uint128, AliasTests) { + absl::uint128 x1 = absl::MakeUint128(1, 2); + absl::uint128 x2 = absl::MakeUint128(2, 4); + x1 += x1; + EXPECT_EQ(x2, x1); + + absl::uint128 x3 = absl::MakeUint128(1, static_cast<uint64_t>(1) << 63); + absl::uint128 x4 = absl::MakeUint128(3, 0); + x3 += x3; + EXPECT_EQ(x4, x3); +} + +TEST(Uint128, DivideAndMod) { + using std::swap; + + // a := q * b + r + absl::uint128 a, b, q, r; + + // Zero test. + a = 0; + b = 123; + q = a / b; + r = a % b; + EXPECT_EQ(0, q); + EXPECT_EQ(0, r); + + a = absl::MakeUint128(0x530eda741c71d4c3, 0xbf25975319080000); + q = absl::MakeUint128(0x4de2cab081, 0x14c34ab4676e4bab); + b = absl::uint128(0x1110001); + r = absl::uint128(0x3eb455); + ASSERT_EQ(a, q * b + r); // Sanity-check. + + absl::uint128 result_q, result_r; + result_q = a / b; + result_r = a % b; + EXPECT_EQ(q, result_q); + EXPECT_EQ(r, result_r); + + // Try the other way around. + swap(q, b); + result_q = a / b; + result_r = a % b; + EXPECT_EQ(q, result_q); + EXPECT_EQ(r, result_r); + // Restore. + swap(b, q); + + // Dividend < divisor; result should be q:0 r:<dividend>. + swap(a, b); + result_q = a / b; + result_r = a % b; + EXPECT_EQ(0, result_q); + EXPECT_EQ(a, result_r); + // Try the other way around. + swap(a, q); + result_q = a / b; + result_r = a % b; + EXPECT_EQ(0, result_q); + EXPECT_EQ(a, result_r); + // Restore. + swap(q, a); + swap(b, a); + + // Try a large remainder. + b = a / 2 + 1; + absl::uint128 expected_r = + absl::MakeUint128(0x29876d3a0e38ea61, 0xdf92cba98c83ffff); + // Sanity checks. + ASSERT_EQ(a / 2 - 1, expected_r); + ASSERT_EQ(a, b + expected_r); + result_q = a / b; + result_r = a % b; + EXPECT_EQ(1, result_q); + EXPECT_EQ(expected_r, result_r); +} + +TEST(Uint128, DivideAndModRandomInputs) { + const int kNumIters = 1 << 18; + std::minstd_rand random(testing::UnitTest::GetInstance()->random_seed()); + std::uniform_int_distribution<uint64_t> uniform_uint64; + for (int i = 0; i < kNumIters; ++i) { + const absl::uint128 a = + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random)); + const absl::uint128 b = + absl::MakeUint128(uniform_uint64(random), uniform_uint64(random)); + if (b == 0) { + continue; // Avoid a div-by-zero. + } + const absl::uint128 q = a / b; + const absl::uint128 r = a % b; + ASSERT_EQ(a, b * q + r); + } +} + +TEST(Uint128, ConstexprTest) { + constexpr absl::uint128 zero = absl::uint128(); + constexpr absl::uint128 one = 1; + constexpr absl::uint128 minus_two = -2; + EXPECT_EQ(zero, absl::uint128(0)); + EXPECT_EQ(one, absl::uint128(1)); + EXPECT_EQ(minus_two, absl::MakeUint128(-1, -2)); +} + +TEST(Uint128, NumericLimitsTest) { + static_assert(std::numeric_limits<absl::uint128>::is_specialized, ""); + static_assert(!std::numeric_limits<absl::uint128>::is_signed, ""); + static_assert(std::numeric_limits<absl::uint128>::is_integer, ""); + EXPECT_EQ(static_cast<int>(128 * std::log10(2)), + std::numeric_limits<absl::uint128>::digits10); + EXPECT_EQ(0, std::numeric_limits<absl::uint128>::min()); + EXPECT_EQ(0, std::numeric_limits<absl::uint128>::lowest()); + EXPECT_EQ(absl::Uint128Max(), std::numeric_limits<absl::uint128>::max()); +} + +TEST(Uint128, Hash) { + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly({ + // Some simple values + absl::uint128{0}, + absl::uint128{1}, + ~absl::uint128{}, + // 64 bit limits + absl::uint128{std::numeric_limits<int64_t>::max()}, + absl::uint128{std::numeric_limits<uint64_t>::max()} + 0, + absl::uint128{std::numeric_limits<uint64_t>::max()} + 1, + absl::uint128{std::numeric_limits<uint64_t>::max()} + 2, + // Keeping high same + absl::uint128{1} << 62, + absl::uint128{1} << 63, + // Keeping low same + absl::uint128{1} << 64, + absl::uint128{1} << 65, + // 128 bit limits + std::numeric_limits<absl::uint128>::max(), + std::numeric_limits<absl::uint128>::max() - 1, + std::numeric_limits<absl::uint128>::min() + 1, + std::numeric_limits<absl::uint128>::min(), + })); +} + + +TEST(Int128Uint128, ConversionTest) { + absl::int128 nonnegative_signed_values[] = { + 0, + 1, + 0xffeeddccbbaa9988, + absl::MakeInt128(0x7766554433221100, 0), + absl::MakeInt128(0x1234567890abcdef, 0xfedcba0987654321), + absl::Int128Max()}; + for (absl::int128 value : nonnegative_signed_values) { + EXPECT_EQ(value, absl::int128(absl::uint128(value))); + + absl::uint128 assigned_value; + assigned_value = value; + EXPECT_EQ(value, absl::int128(assigned_value)); + } + + absl::int128 negative_values[] = { + -1, -0x1234567890abcdef, + absl::MakeInt128(-0x5544332211ffeedd, 0), + -absl::MakeInt128(0x76543210fedcba98, 0xabcdef0123456789)}; + for (absl::int128 value : negative_values) { + EXPECT_EQ(absl::uint128(-value), -absl::uint128(value)); + + absl::uint128 assigned_value; + assigned_value = value; + EXPECT_EQ(absl::uint128(-value), -assigned_value); + } +} + +template <typename T> +class Int128IntegerTraitsTest : public ::testing::Test {}; + +TYPED_TEST_SUITE(Int128IntegerTraitsTest, IntegerTypes); + +TYPED_TEST(Int128IntegerTraitsTest, ConstructAssignTest) { + static_assert(std::is_constructible<absl::int128, TypeParam>::value, + "absl::int128 must be constructible from TypeParam"); + static_assert(std::is_assignable<absl::int128&, TypeParam>::value, + "absl::int128 must be assignable from TypeParam"); + static_assert(!std::is_assignable<TypeParam&, absl::int128>::value, + "TypeParam must not be assignable from absl::int128"); +} + +template <typename T> +class Int128FloatTraitsTest : public ::testing::Test {}; + +TYPED_TEST_SUITE(Int128FloatTraitsTest, FloatingPointTypes); + +TYPED_TEST(Int128FloatTraitsTest, ConstructAssignTest) { + static_assert(std::is_constructible<absl::int128, TypeParam>::value, + "absl::int128 must be constructible from TypeParam"); + static_assert(!std::is_assignable<absl::int128&, TypeParam>::value, + "absl::int128 must not be assignable from TypeParam"); + static_assert(!std::is_assignable<TypeParam&, absl::int128>::value, + "TypeParam must not be assignable from absl::int128"); +} + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +// These type traits done separately as TYPED_TEST requires typeinfo, and not +// all platforms have this for __int128 even though they define the type. +TEST(Int128, IntrinsicTypeTraitsTest) { + static_assert(std::is_constructible<absl::int128, __int128>::value, + "absl::int128 must be constructible from __int128"); + static_assert(std::is_assignable<absl::int128&, __int128>::value, + "absl::int128 must be assignable from __int128"); + static_assert(!std::is_assignable<__int128&, absl::int128>::value, + "__int128 must not be assignable from absl::int128"); + + static_assert(std::is_constructible<absl::int128, unsigned __int128>::value, + "absl::int128 must be constructible from unsigned __int128"); + static_assert(!std::is_assignable<absl::int128&, unsigned __int128>::value, + "absl::int128 must be assignable from unsigned __int128"); + static_assert(!std::is_assignable<unsigned __int128&, absl::int128>::value, + "unsigned __int128 must not be assignable from absl::int128"); +} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +TEST(Int128, TrivialTraitsTest) { + static_assert(absl::is_trivially_default_constructible<absl::int128>::value, + ""); + static_assert(absl::is_trivially_copy_constructible<absl::int128>::value, ""); + static_assert(absl::is_trivially_copy_assignable<absl::int128>::value, ""); + static_assert(std::is_trivially_destructible<absl::int128>::value, ""); +} + +TEST(Int128, BoolConversionTest) { + EXPECT_FALSE(absl::int128(0)); + for (int i = 0; i < 64; ++i) { + EXPECT_TRUE(absl::MakeInt128(0, uint64_t{1} << i)); + } + for (int i = 0; i < 63; ++i) { + EXPECT_TRUE(absl::MakeInt128(int64_t{1} << i, 0)); + } + EXPECT_TRUE(absl::Int128Min()); + + EXPECT_EQ(absl::int128(1), absl::int128(true)); + EXPECT_EQ(absl::int128(0), absl::int128(false)); +} + +template <typename T> +class Int128IntegerConversionTest : public ::testing::Test {}; + +TYPED_TEST_SUITE(Int128IntegerConversionTest, IntegerTypes); + +TYPED_TEST(Int128IntegerConversionTest, RoundTripTest) { + EXPECT_EQ(TypeParam{0}, static_cast<TypeParam>(absl::int128(0))); + EXPECT_EQ(std::numeric_limits<TypeParam>::min(), + static_cast<TypeParam>( + absl::int128(std::numeric_limits<TypeParam>::min()))); + EXPECT_EQ(std::numeric_limits<TypeParam>::max(), + static_cast<TypeParam>( + absl::int128(std::numeric_limits<TypeParam>::max()))); +} + +template <typename T> +class Int128FloatConversionTest : public ::testing::Test {}; + +TYPED_TEST_SUITE(Int128FloatConversionTest, FloatingPointTypes); + +TYPED_TEST(Int128FloatConversionTest, ConstructAndCastTest) { + // Conversions where the floating point values should be exactly the same. + // 0x9f5b is a randomly chosen small value. + for (int i = 0; i < 110; ++i) { // 110 = 126 - #bits in 0x9f5b + SCOPED_TRACE(::testing::Message() << "i = " << i); + + TypeParam float_value = std::ldexp(static_cast<TypeParam>(0x9f5b), i); + absl::int128 int_value = absl::int128(0x9f5b) << i; + + EXPECT_EQ(float_value, static_cast<TypeParam>(int_value)); + EXPECT_EQ(-float_value, static_cast<TypeParam>(-int_value)); + EXPECT_EQ(int_value, absl::int128(float_value)); + EXPECT_EQ(-int_value, absl::int128(-float_value)); + } + + // Round trip conversions with a small sample of randomly generated uint64_t + // values (less than int64_t max so that value * 2^64 fits into int128). + uint64_t values[] = {0x6d4492c24fb86199, 0x26ead65e4cb359b5, + 0x2c43407433ba3fd1, 0x3b574ec668df6b55, + 0x1c750e55a29f4f0f}; + for (uint64_t value : values) { + for (int i = 0; i <= 64; ++i) { + SCOPED_TRACE(::testing::Message() + << "value = " << value << "; i = " << i); + + TypeParam fvalue = std::ldexp(static_cast<TypeParam>(value), i); + EXPECT_DOUBLE_EQ(fvalue, static_cast<TypeParam>(absl::int128(fvalue))); + EXPECT_DOUBLE_EQ(-fvalue, static_cast<TypeParam>(-absl::int128(fvalue))); + EXPECT_DOUBLE_EQ(-fvalue, static_cast<TypeParam>(absl::int128(-fvalue))); + EXPECT_DOUBLE_EQ(fvalue, static_cast<TypeParam>(-absl::int128(-fvalue))); + } + } + + // Round trip conversions with a small sample of random large positive values. + absl::int128 large_values[] = { + absl::MakeInt128(0x5b0640d96c7b3d9f, 0xb7a7189e51d18622), + absl::MakeInt128(0x34bed042c6f65270, 0x73b236570669a089), + absl::MakeInt128(0x43deba9e6da12724, 0xf7f0f83da686797d), + absl::MakeInt128(0x71e8d383be4e5589, 0x75c3f96fb00752b6)}; + for (absl::int128 value : large_values) { + // Make value have as many significant bits as can be represented by + // the mantissa, also making sure the highest and lowest bit in the range + // are set. + value >>= (127 - std::numeric_limits<TypeParam>::digits); + value |= absl::int128(1) << (std::numeric_limits<TypeParam>::digits - 1); + value |= 1; + for (int i = 0; i < 127 - std::numeric_limits<TypeParam>::digits; ++i) { + absl::int128 int_value = value << i; + EXPECT_EQ(int_value, + static_cast<absl::int128>(static_cast<TypeParam>(int_value))); + EXPECT_EQ(-int_value, + static_cast<absl::int128>(static_cast<TypeParam>(-int_value))); + } + } + + // Small sample of checks that rounding is toward zero + EXPECT_EQ(0, absl::int128(TypeParam(0.1))); + EXPECT_EQ(17, absl::int128(TypeParam(17.8))); + EXPECT_EQ(0, absl::int128(TypeParam(-0.8))); + EXPECT_EQ(-53, absl::int128(TypeParam(-53.1))); + EXPECT_EQ(0, absl::int128(TypeParam(0.5))); + EXPECT_EQ(0, absl::int128(TypeParam(-0.5))); + TypeParam just_lt_one = std::nexttoward(TypeParam(1), TypeParam(0)); + EXPECT_EQ(0, absl::int128(just_lt_one)); + TypeParam just_gt_minus_one = std::nexttoward(TypeParam(-1), TypeParam(0)); + EXPECT_EQ(0, absl::int128(just_gt_minus_one)); + + // Check limits + EXPECT_DOUBLE_EQ(std::ldexp(static_cast<TypeParam>(1), 127), + static_cast<TypeParam>(absl::Int128Max())); + EXPECT_DOUBLE_EQ(-std::ldexp(static_cast<TypeParam>(1), 127), + static_cast<TypeParam>(absl::Int128Min())); +} + +TEST(Int128, FactoryTest) { + EXPECT_EQ(absl::int128(-1), absl::MakeInt128(-1, -1)); + EXPECT_EQ(absl::int128(-31), absl::MakeInt128(-1, -31)); + EXPECT_EQ(absl::int128(std::numeric_limits<int64_t>::min()), + absl::MakeInt128(-1, std::numeric_limits<int64_t>::min())); + EXPECT_EQ(absl::int128(0), absl::MakeInt128(0, 0)); + EXPECT_EQ(absl::int128(1), absl::MakeInt128(0, 1)); + EXPECT_EQ(absl::int128(std::numeric_limits<int64_t>::max()), + absl::MakeInt128(0, std::numeric_limits<int64_t>::max())); +} + +TEST(Int128, HighLowTest) { + struct HighLowPair { + int64_t high; + uint64_t low; + }; + HighLowPair values[]{{0, 0}, {0, 1}, {1, 0}, {123, 456}, {-654, 321}}; + for (const HighLowPair& pair : values) { + absl::int128 value = absl::MakeInt128(pair.high, pair.low); + EXPECT_EQ(pair.low, absl::Int128Low64(value)); + EXPECT_EQ(pair.high, absl::Int128High64(value)); + } +} + +TEST(Int128, LimitsTest) { + EXPECT_EQ(absl::MakeInt128(0x7fffffffffffffff, 0xffffffffffffffff), + absl::Int128Max()); + EXPECT_EQ(absl::Int128Max(), ~absl::Int128Min()); +} + +#if defined(ABSL_HAVE_INTRINSIC_INT128) +TEST(Int128, IntrinsicConversionTest) { + __int128 intrinsic = + (static_cast<__int128>(0x3a5b76c209de76f6) << 64) + 0x1f25e1d63a2b46c5; + absl::int128 custom = + absl::MakeInt128(0x3a5b76c209de76f6, 0x1f25e1d63a2b46c5); + + EXPECT_EQ(custom, absl::int128(intrinsic)); + EXPECT_EQ(intrinsic, static_cast<__int128>(custom)); +} +#endif // ABSL_HAVE_INTRINSIC_INT128 + +TEST(Int128, ConstexprTest) { + constexpr absl::int128 zero = absl::int128(); + constexpr absl::int128 one = 1; + constexpr absl::int128 minus_two = -2; + constexpr absl::int128 min = absl::Int128Min(); + constexpr absl::int128 max = absl::Int128Max(); + EXPECT_EQ(zero, absl::int128(0)); + EXPECT_EQ(one, absl::int128(1)); + EXPECT_EQ(minus_two, absl::MakeInt128(-1, -2)); + EXPECT_GT(max, one); + EXPECT_LT(min, minus_two); +} + +TEST(Int128, ComparisonTest) { + struct TestCase { + absl::int128 smaller; + absl::int128 larger; + }; + TestCase cases[] = { + {absl::int128(0), absl::int128(123)}, + {absl::MakeInt128(-12, 34), absl::MakeInt128(12, 34)}, + {absl::MakeInt128(1, 1000), absl::MakeInt128(1000, 1)}, + {absl::MakeInt128(-1000, 1000), absl::MakeInt128(-1, 1)}, + }; + for (const TestCase& pair : cases) { + SCOPED_TRACE(::testing::Message() << "pair.smaller = " << pair.smaller + << "; pair.larger = " << pair.larger); + + EXPECT_TRUE(pair.smaller == pair.smaller); // NOLINT(readability/check) + EXPECT_TRUE(pair.larger == pair.larger); // NOLINT(readability/check) + EXPECT_FALSE(pair.smaller == pair.larger); // NOLINT(readability/check) + + EXPECT_TRUE(pair.smaller != pair.larger); // NOLINT(readability/check) + EXPECT_FALSE(pair.smaller != pair.smaller); // NOLINT(readability/check) + EXPECT_FALSE(pair.larger != pair.larger); // NOLINT(readability/check) + + EXPECT_TRUE(pair.smaller < pair.larger); // NOLINT(readability/check) + EXPECT_FALSE(pair.larger < pair.smaller); // NOLINT(readability/check) + + EXPECT_TRUE(pair.larger > pair.smaller); // NOLINT(readability/check) + EXPECT_FALSE(pair.smaller > pair.larger); // NOLINT(readability/check) + + EXPECT_TRUE(pair.smaller <= pair.larger); // NOLINT(readability/check) + EXPECT_FALSE(pair.larger <= pair.smaller); // NOLINT(readability/check) + EXPECT_TRUE(pair.smaller <= pair.smaller); // NOLINT(readability/check) + EXPECT_TRUE(pair.larger <= pair.larger); // NOLINT(readability/check) + + EXPECT_TRUE(pair.larger >= pair.smaller); // NOLINT(readability/check) + EXPECT_FALSE(pair.smaller >= pair.larger); // NOLINT(readability/check) + EXPECT_TRUE(pair.smaller >= pair.smaller); // NOLINT(readability/check) + EXPECT_TRUE(pair.larger >= pair.larger); // NOLINT(readability/check) + } +} + +TEST(Int128, UnaryNegationTest) { + int64_t values64[] = {0, 1, 12345, 0x4000000000000000, + std::numeric_limits<int64_t>::max()}; + for (int64_t value : values64) { + SCOPED_TRACE(::testing::Message() << "value = " << value); + + EXPECT_EQ(absl::int128(-value), -absl::int128(value)); + EXPECT_EQ(absl::int128(value), -absl::int128(-value)); + EXPECT_EQ(absl::MakeInt128(-value, 0), -absl::MakeInt128(value, 0)); + EXPECT_EQ(absl::MakeInt128(value, 0), -absl::MakeInt128(-value, 0)); + } +} + +TEST(Int128, LogicalNotTest) { + EXPECT_TRUE(!absl::int128(0)); + for (int i = 0; i < 64; ++i) { + EXPECT_FALSE(!absl::MakeInt128(0, uint64_t{1} << i)); + } + for (int i = 0; i < 63; ++i) { + EXPECT_FALSE(!absl::MakeInt128(int64_t{1} << i, 0)); + } +} + +TEST(Int128, AdditionSubtractionTest) { + // 64 bit pairs that will not cause overflow / underflow. These test negative + // carry; positive carry must be checked separately. + std::pair<int64_t, int64_t> cases[]{ + {0, 0}, // 0, 0 + {0, 2945781290834}, // 0, + + {1908357619234, 0}, // +, 0 + {0, -1204895918245}, // 0, - + {-2957928523560, 0}, // -, 0 + {89023982312461, 98346012567134}, // +, + + {-63454234568239, -23456235230773}, // -, - + {98263457263502, -21428561935925}, // +, - + {-88235237438467, 15923659234573}, // -, + + }; + for (const auto& pair : cases) { + SCOPED_TRACE(::testing::Message() + << "pair = {" << pair.first << ", " << pair.second << '}'); + + EXPECT_EQ(absl::int128(pair.first + pair.second), + absl::int128(pair.first) + absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.second + pair.first), + absl::int128(pair.second) += absl::int128(pair.first)); + + EXPECT_EQ(absl::int128(pair.first - pair.second), + absl::int128(pair.first) - absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.second - pair.first), + absl::int128(pair.second) -= absl::int128(pair.first)); + + EXPECT_EQ( + absl::MakeInt128(pair.second + pair.first, 0), + absl::MakeInt128(pair.second, 0) + absl::MakeInt128(pair.first, 0)); + EXPECT_EQ( + absl::MakeInt128(pair.first + pair.second, 0), + absl::MakeInt128(pair.first, 0) += absl::MakeInt128(pair.second, 0)); + + EXPECT_EQ( + absl::MakeInt128(pair.second - pair.first, 0), + absl::MakeInt128(pair.second, 0) - absl::MakeInt128(pair.first, 0)); + EXPECT_EQ( + absl::MakeInt128(pair.first - pair.second, 0), + absl::MakeInt128(pair.first, 0) -= absl::MakeInt128(pair.second, 0)); + } + + // check positive carry + EXPECT_EQ(absl::MakeInt128(31, 0), + absl::MakeInt128(20, 1) + + absl::MakeInt128(10, std::numeric_limits<uint64_t>::max())); +} + +TEST(Int128, IncrementDecrementTest) { + absl::int128 value = 0; + EXPECT_EQ(0, value++); + EXPECT_EQ(1, value); + EXPECT_EQ(1, value--); + EXPECT_EQ(0, value); + EXPECT_EQ(-1, --value); + EXPECT_EQ(-1, value); + EXPECT_EQ(0, ++value); + EXPECT_EQ(0, value); +} + +TEST(Int128, MultiplicationTest) { + // 1 bit x 1 bit, and negative combinations + for (int i = 0; i < 64; ++i) { + for (int j = 0; j < 127 - i; ++j) { + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + absl::int128 a = absl::int128(1) << i; + absl::int128 b = absl::int128(1) << j; + absl::int128 c = absl::int128(1) << (i + j); + + EXPECT_EQ(c, a * b); + EXPECT_EQ(-c, -a * b); + EXPECT_EQ(-c, a * -b); + EXPECT_EQ(c, -a * -b); + + EXPECT_EQ(c, absl::int128(a) *= b); + EXPECT_EQ(-c, absl::int128(-a) *= b); + EXPECT_EQ(-c, absl::int128(a) *= -b); + EXPECT_EQ(c, absl::int128(-a) *= -b); + } + } + + // Pairs of random values that will not overflow signed 64-bit multiplication + std::pair<int64_t, int64_t> small_values[] = { + {0x5e61, 0xf29f79ca14b4}, // +, + + {0x3e033b, -0x612c0ee549}, // +, - + {-0x052ce7e8, 0x7c728f0f}, // -, + + {-0x3af7054626, -0xfb1e1d}, // -, - + }; + for (const std::pair<int64_t, int64_t>& pair : small_values) { + SCOPED_TRACE(::testing::Message() + << "pair = {" << pair.first << ", " << pair.second << '}'); + + EXPECT_EQ(absl::int128(pair.first * pair.second), + absl::int128(pair.first) * absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.first * pair.second), + absl::int128(pair.first) *= absl::int128(pair.second)); + + EXPECT_EQ(absl::MakeInt128(pair.first * pair.second, 0), + absl::MakeInt128(pair.first, 0) * absl::int128(pair.second)); + EXPECT_EQ(absl::MakeInt128(pair.first * pair.second, 0), + absl::MakeInt128(pair.first, 0) *= absl::int128(pair.second)); + } + + // Pairs of positive random values that will not overflow 64-bit + // multiplication and can be left shifted by 32 without overflow + std::pair<int64_t, int64_t> small_values2[] = { + {0x1bb0a110, 0x31487671}, + {0x4792784e, 0x28add7d7}, + {0x7b66553a, 0x11dff8ef}, + }; + for (const std::pair<int64_t, int64_t>& pair : small_values2) { + SCOPED_TRACE(::testing::Message() + << "pair = {" << pair.first << ", " << pair.second << '}'); + + absl::int128 a = absl::int128(pair.first << 32); + absl::int128 b = absl::int128(pair.second << 32); + absl::int128 c = absl::MakeInt128(pair.first * pair.second, 0); + + EXPECT_EQ(c, a * b); + EXPECT_EQ(-c, -a * b); + EXPECT_EQ(-c, a * -b); + EXPECT_EQ(c, -a * -b); + + EXPECT_EQ(c, absl::int128(a) *= b); + EXPECT_EQ(-c, absl::int128(-a) *= b); + EXPECT_EQ(-c, absl::int128(a) *= -b); + EXPECT_EQ(c, absl::int128(-a) *= -b); + } + + // check 0, 1, and -1 behavior with large values + absl::int128 large_values[] = { + {absl::MakeInt128(0xd66f061af02d0408, 0x727d2846cb475b53)}, + {absl::MakeInt128(0x27b8d5ed6104452d, 0x03f8a33b0ee1df4f)}, + {-absl::MakeInt128(0x621b6626b9e8d042, 0x27311ac99df00938)}, + {-absl::MakeInt128(0x34e0656f1e95fb60, 0x4281cfd731257a47)}, + }; + for (absl::int128 value : large_values) { + EXPECT_EQ(0, 0 * value); + EXPECT_EQ(0, value * 0); + EXPECT_EQ(0, absl::int128(0) *= value); + EXPECT_EQ(0, value *= 0); + + EXPECT_EQ(value, 1 * value); + EXPECT_EQ(value, value * 1); + EXPECT_EQ(value, absl::int128(1) *= value); + EXPECT_EQ(value, value *= 1); + + EXPECT_EQ(-value, -1 * value); + EXPECT_EQ(-value, value * -1); + EXPECT_EQ(-value, absl::int128(-1) *= value); + EXPECT_EQ(-value, value *= -1); + } + + // Manually calculated random large value cases + EXPECT_EQ(absl::MakeInt128(0xcd0efd3442219bb, 0xde47c05bcd9df6e1), + absl::MakeInt128(0x7c6448, 0x3bc4285c47a9d253) * 0x1a6037537b); + EXPECT_EQ(-absl::MakeInt128(0x1f8f149850b1e5e6, 0x1e50d6b52d272c3e), + -absl::MakeInt128(0x23, 0x2e68a513ca1b8859) * 0xe5a434cd14866e); + EXPECT_EQ(-absl::MakeInt128(0x55cae732029d1fce, 0xca6474b6423263e4), + 0xa9b98a8ddf66bc * -absl::MakeInt128(0x81, 0x672e58231e2469d7)); + EXPECT_EQ(absl::MakeInt128(0x19c8b7620b507dc4, 0xfec042b71a5f29a4), + -0x3e39341147 * -absl::MakeInt128(0x6a14b2, 0x5ed34cca42327b3c)); + + EXPECT_EQ(absl::MakeInt128(0xcd0efd3442219bb, 0xde47c05bcd9df6e1), + absl::MakeInt128(0x7c6448, 0x3bc4285c47a9d253) *= 0x1a6037537b); + EXPECT_EQ(-absl::MakeInt128(0x1f8f149850b1e5e6, 0x1e50d6b52d272c3e), + -absl::MakeInt128(0x23, 0x2e68a513ca1b8859) *= 0xe5a434cd14866e); + EXPECT_EQ(-absl::MakeInt128(0x55cae732029d1fce, 0xca6474b6423263e4), + absl::int128(0xa9b98a8ddf66bc) *= + -absl::MakeInt128(0x81, 0x672e58231e2469d7)); + EXPECT_EQ(absl::MakeInt128(0x19c8b7620b507dc4, 0xfec042b71a5f29a4), + absl::int128(-0x3e39341147) *= + -absl::MakeInt128(0x6a14b2, 0x5ed34cca42327b3c)); +} + +TEST(Int128, DivisionAndModuloTest) { + // Check against 64 bit division and modulo operators with a sample of + // randomly generated pairs. + std::pair<int64_t, int64_t> small_pairs[] = { + {0x15f2a64138, 0x67da05}, {0x5e56d194af43045f, 0xcf1543fb99}, + {0x15e61ed052036a, -0xc8e6}, {0x88125a341e85, -0xd23fb77683}, + {-0xc06e20, 0x5a}, {-0x4f100219aea3e85d, 0xdcc56cb4efe993}, + {-0x168d629105, -0xa7}, {-0x7b44e92f03ab2375, -0x6516}, + }; + for (const std::pair<int64_t, int64_t>& pair : small_pairs) { + SCOPED_TRACE(::testing::Message() + << "pair = {" << pair.first << ", " << pair.second << '}'); + + absl::int128 dividend = pair.first; + absl::int128 divisor = pair.second; + int64_t quotient = pair.first / pair.second; + int64_t remainder = pair.first % pair.second; + + EXPECT_EQ(quotient, dividend / divisor); + EXPECT_EQ(quotient, absl::int128(dividend) /= divisor); + EXPECT_EQ(remainder, dividend % divisor); + EXPECT_EQ(remainder, absl::int128(dividend) %= divisor); + } + + // Test behavior with 0, 1, and -1 with a sample of randomly generated large + // values. + absl::int128 values[] = { + absl::MakeInt128(0x63d26ee688a962b2, 0x9e1411abda5c1d70), + absl::MakeInt128(0x152f385159d6f986, 0xbf8d48ef63da395d), + -absl::MakeInt128(0x3098d7567030038c, 0x14e7a8a098dc2164), + -absl::MakeInt128(0x49a037aca35c809f, 0xa6a87525480ef330), + }; + for (absl::int128 value : values) { + SCOPED_TRACE(::testing::Message() << "value = " << value); + + EXPECT_EQ(0, 0 / value); + EXPECT_EQ(0, absl::int128(0) /= value); + EXPECT_EQ(0, 0 % value); + EXPECT_EQ(0, absl::int128(0) %= value); + + EXPECT_EQ(value, value / 1); + EXPECT_EQ(value, absl::int128(value) /= 1); + EXPECT_EQ(0, value % 1); + EXPECT_EQ(0, absl::int128(value) %= 1); + + EXPECT_EQ(-value, value / -1); + EXPECT_EQ(-value, absl::int128(value) /= -1); + EXPECT_EQ(0, value % -1); + EXPECT_EQ(0, absl::int128(value) %= -1); + } + + // Min and max values + EXPECT_EQ(0, absl::Int128Max() / absl::Int128Min()); + EXPECT_EQ(absl::Int128Max(), absl::Int128Max() % absl::Int128Min()); + EXPECT_EQ(-1, absl::Int128Min() / absl::Int128Max()); + EXPECT_EQ(-1, absl::Int128Min() % absl::Int128Max()); + + // Power of two division and modulo of random large dividends + absl::int128 positive_values[] = { + absl::MakeInt128(0x21e1a1cc69574620, 0xe7ac447fab2fc869), + absl::MakeInt128(0x32c2ff3ab89e66e8, 0x03379a613fd1ce74), + absl::MakeInt128(0x6f32ca786184dcaf, 0x046f9c9ecb3a9ce1), + absl::MakeInt128(0x1aeb469dd990e0ee, 0xda2740f243cd37eb), + }; + for (absl::int128 value : positive_values) { + for (int i = 0; i < 127; ++i) { + SCOPED_TRACE(::testing::Message() + << "value = " << value << "; i = " << i); + absl::int128 power_of_two = absl::int128(1) << i; + + EXPECT_EQ(value >> i, value / power_of_two); + EXPECT_EQ(value >> i, absl::int128(value) /= power_of_two); + EXPECT_EQ(value & (power_of_two - 1), value % power_of_two); + EXPECT_EQ(value & (power_of_two - 1), + absl::int128(value) %= power_of_two); + } + } + + // Manually calculated cases with random large dividends + struct DivisionModCase { + absl::int128 dividend; + absl::int128 divisor; + absl::int128 quotient; + absl::int128 remainder; + }; + DivisionModCase manual_cases[] = { + {absl::MakeInt128(0x6ada48d489007966, 0x3c9c5c98150d5d69), + absl::MakeInt128(0x8bc308fb, 0x8cb9cc9a3b803344), 0xc3b87e08, + absl::MakeInt128(0x1b7db5e1, 0xd9eca34b7af04b49)}, + {absl::MakeInt128(0xd6946511b5b, 0x4886c5c96546bf5f), + -absl::MakeInt128(0x263b, 0xfd516279efcfe2dc), -0x59cbabf0, + absl::MakeInt128(0x622, 0xf462909155651d1f)}, + {-absl::MakeInt128(0x33db734f9e8d1399, 0x8447ac92482bca4d), 0x37495078240, + -absl::MakeInt128(0xf01f1, 0xbc0368bf9a77eae8), -0x21a508f404d}, + {-absl::MakeInt128(0x13f837b409a07e7d, 0x7fc8e248a7d73560), -0x1b9f, + absl::MakeInt128(0xb9157556d724, 0xb14f635714d7563e), -0x1ade}, + }; + for (const DivisionModCase test_case : manual_cases) { + EXPECT_EQ(test_case.quotient, test_case.dividend / test_case.divisor); + EXPECT_EQ(test_case.quotient, + absl::int128(test_case.dividend) /= test_case.divisor); + EXPECT_EQ(test_case.remainder, test_case.dividend % test_case.divisor); + EXPECT_EQ(test_case.remainder, + absl::int128(test_case.dividend) %= test_case.divisor); + } +} + +TEST(Int128, BitwiseLogicTest) { + EXPECT_EQ(absl::int128(-1), ~absl::int128(0)); + + absl::int128 values[]{ + 0, -1, 0xde400bee05c3ff6b, absl::MakeInt128(0x7f32178dd81d634a, 0), + absl::MakeInt128(0xaf539057055613a9, 0x7d104d7d946c2e4d)}; + for (absl::int128 value : values) { + EXPECT_EQ(value, ~~value); + + EXPECT_EQ(value, value | value); + EXPECT_EQ(value, value & value); + EXPECT_EQ(0, value ^ value); + + EXPECT_EQ(value, absl::int128(value) |= value); + EXPECT_EQ(value, absl::int128(value) &= value); + EXPECT_EQ(0, absl::int128(value) ^= value); + + EXPECT_EQ(value, value | 0); + EXPECT_EQ(0, value & 0); + EXPECT_EQ(value, value ^ 0); + + EXPECT_EQ(absl::int128(-1), value | absl::int128(-1)); + EXPECT_EQ(value, value & absl::int128(-1)); + EXPECT_EQ(~value, value ^ absl::int128(-1)); + } + + // small sample of randomly generated int64_t's + std::pair<int64_t, int64_t> pairs64[]{ + {0x7f86797f5e991af4, 0x1ee30494fb007c97}, + {0x0b278282bacf01af, 0x58780e0a57a49e86}, + {0x059f266ccb93a666, 0x3d5b731bae9286f5}, + {0x63c0c4820f12108c, 0x58166713c12e1c3a}, + {0x381488bb2ed2a66e, 0x2220a3eb76a3698c}, + {0x2a0a0dfb81e06f21, 0x4b60585927f5523c}, + {0x555b1c3a03698537, 0x25478cd19d8e53cb}, + {0x4750f6f27d779225, 0x16397553c6ff05fc}, + }; + for (const std::pair<int64_t, int64_t>& pair : pairs64) { + SCOPED_TRACE(::testing::Message() + << "pair = {" << pair.first << ", " << pair.second << '}'); + + EXPECT_EQ(absl::MakeInt128(~pair.first, ~pair.second), + ~absl::MakeInt128(pair.first, pair.second)); + + EXPECT_EQ(absl::int128(pair.first & pair.second), + absl::int128(pair.first) & absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.first | pair.second), + absl::int128(pair.first) | absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.first ^ pair.second), + absl::int128(pair.first) ^ absl::int128(pair.second)); + + EXPECT_EQ(absl::int128(pair.first & pair.second), + absl::int128(pair.first) &= absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.first | pair.second), + absl::int128(pair.first) |= absl::int128(pair.second)); + EXPECT_EQ(absl::int128(pair.first ^ pair.second), + absl::int128(pair.first) ^= absl::int128(pair.second)); + + EXPECT_EQ( + absl::MakeInt128(pair.first & pair.second, 0), + absl::MakeInt128(pair.first, 0) & absl::MakeInt128(pair.second, 0)); + EXPECT_EQ( + absl::MakeInt128(pair.first | pair.second, 0), + absl::MakeInt128(pair.first, 0) | absl::MakeInt128(pair.second, 0)); + EXPECT_EQ( + absl::MakeInt128(pair.first ^ pair.second, 0), + absl::MakeInt128(pair.first, 0) ^ absl::MakeInt128(pair.second, 0)); + + EXPECT_EQ( + absl::MakeInt128(pair.first & pair.second, 0), + absl::MakeInt128(pair.first, 0) &= absl::MakeInt128(pair.second, 0)); + EXPECT_EQ( + absl::MakeInt128(pair.first | pair.second, 0), + absl::MakeInt128(pair.first, 0) |= absl::MakeInt128(pair.second, 0)); + EXPECT_EQ( + absl::MakeInt128(pair.first ^ pair.second, 0), + absl::MakeInt128(pair.first, 0) ^= absl::MakeInt128(pair.second, 0)); + } +} + +TEST(Int128, BitwiseShiftTest) { + for (int i = 0; i < 64; ++i) { + for (int j = 0; j <= i; ++j) { + // Left shift from j-th bit to i-th bit. + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + EXPECT_EQ(uint64_t{1} << i, absl::int128(uint64_t{1} << j) << (i - j)); + EXPECT_EQ(uint64_t{1} << i, absl::int128(uint64_t{1} << j) <<= (i - j)); + } + } + for (int i = 0; i < 63; ++i) { + for (int j = 0; j < 64; ++j) { + // Left shift from j-th bit to (i + 64)-th bit. + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + EXPECT_EQ(absl::MakeInt128(uint64_t{1} << i, 0), + absl::int128(uint64_t{1} << j) << (i + 64 - j)); + EXPECT_EQ(absl::MakeInt128(uint64_t{1} << i, 0), + absl::int128(uint64_t{1} << j) <<= (i + 64 - j)); + } + for (int j = 0; j <= i; ++j) { + // Left shift from (j + 64)-th bit to (i + 64)-th bit. + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + EXPECT_EQ(absl::MakeInt128(uint64_t{1} << i, 0), + absl::MakeInt128(uint64_t{1} << j, 0) << (i - j)); + EXPECT_EQ(absl::MakeInt128(uint64_t{1} << i, 0), + absl::MakeInt128(uint64_t{1} << j, 0) <<= (i - j)); + } + } + + for (int i = 0; i < 64; ++i) { + for (int j = i; j < 64; ++j) { + // Right shift from j-th bit to i-th bit. + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + EXPECT_EQ(uint64_t{1} << i, absl::int128(uint64_t{1} << j) >> (j - i)); + EXPECT_EQ(uint64_t{1} << i, absl::int128(uint64_t{1} << j) >>= (j - i)); + } + for (int j = 0; j < 63; ++j) { + // Right shift from (j + 64)-th bit to i-th bit. + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + EXPECT_EQ(uint64_t{1} << i, + absl::MakeInt128(uint64_t{1} << j, 0) >> (j + 64 - i)); + EXPECT_EQ(uint64_t{1} << i, + absl::MakeInt128(uint64_t{1} << j, 0) >>= (j + 64 - i)); + } + } + for (int i = 0; i < 63; ++i) { + for (int j = i; j < 63; ++j) { + // Right shift from (j + 64)-th bit to (i + 64)-th bit. + SCOPED_TRACE(::testing::Message() << "i = " << i << "; j = " << j); + EXPECT_EQ(absl::MakeInt128(uint64_t{1} << i, 0), + absl::MakeInt128(uint64_t{1} << j, 0) >> (j - i)); + EXPECT_EQ(absl::MakeInt128(uint64_t{1} << i, 0), + absl::MakeInt128(uint64_t{1} << j, 0) >>= (j - i)); + } + } +} + +TEST(Int128, NumericLimitsTest) { + static_assert(std::numeric_limits<absl::int128>::is_specialized, ""); + static_assert(std::numeric_limits<absl::int128>::is_signed, ""); + static_assert(std::numeric_limits<absl::int128>::is_integer, ""); + EXPECT_EQ(static_cast<int>(127 * std::log10(2)), + std::numeric_limits<absl::int128>::digits10); + EXPECT_EQ(absl::Int128Min(), std::numeric_limits<absl::int128>::min()); + EXPECT_EQ(absl::Int128Min(), std::numeric_limits<absl::int128>::lowest()); + EXPECT_EQ(absl::Int128Max(), std::numeric_limits<absl::int128>::max()); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/BUILD.bazel b/third_party/abseil_cpp/absl/random/BUILD.bazel new file mode 100644 index 0000000000..9ba75b5236 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/BUILD.bazel @@ -0,0 +1,506 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +# ABSL random-number generation libraries. + +load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) + +cc_library( + name = "random", + hdrs = ["random.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":seed_sequences", + "//absl/random/internal:nonsecure_base", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:pool_urbg", + "//absl/random/internal:randen_engine", + ], +) + +cc_library( + name = "distributions", + srcs = [ + "discrete_distribution.cc", + "gaussian_distribution.cc", + ], + hdrs = [ + "bernoulli_distribution.h", + "beta_distribution.h", + "discrete_distribution.h", + "distributions.h", + "exponential_distribution.h", + "gaussian_distribution.h", + "log_uniform_int_distribution.h", + "poisson_distribution.h", + "uniform_int_distribution.h", + "uniform_real_distribution.h", + "zipf_distribution.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:base_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/meta:type_traits", + "//absl/random/internal:distributions", + "//absl/random/internal:fast_uniform_bits", + "//absl/random/internal:fastmath", + "//absl/random/internal:generate_real", + "//absl/random/internal:iostream_state_saver", + "//absl/random/internal:traits", + "//absl/random/internal:uniform_helper", + "//absl/random/internal:wide_multiply", + "//absl/strings", + "//absl/types:span", + ], +) + +cc_library( + name = "seed_gen_exception", + srcs = ["seed_gen_exception.cc"], + hdrs = ["seed_gen_exception.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_library( + name = "seed_sequences", + srcs = ["seed_sequences.cc"], + hdrs = [ + "seed_sequences.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":seed_gen_exception", + "//absl/container:inlined_vector", + "//absl/random/internal:nonsecure_base", + "//absl/random/internal:pool_urbg", + "//absl/random/internal:salted_seed_seq", + "//absl/random/internal:seed_material", + "//absl/types:span", + ], +) + +cc_library( + name = "bit_gen_ref", + hdrs = ["bit_gen_ref.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:core_headers", + "//absl/meta:type_traits", + "//absl/random/internal:distribution_caller", + "//absl/random/internal:fast_uniform_bits", + "//absl/random/internal:mocking_bit_gen_base", + ], +) + +cc_library( + name = "mock_distributions", + testonly = 1, + hdrs = ["mock_distributions.h"], + deps = [ + ":distributions", + ":mocking_bit_gen", + "//absl/meta:type_traits", + "//absl/random/internal:mock_overload_set", + "@com_google_googletest//:gtest", + ], +) + +cc_library( + name = "mocking_bit_gen", + testonly = 1, + hdrs = [ + "mocking_bit_gen.h", + ], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + "//absl/container:flat_hash_map", + "//absl/meta:type_traits", + "//absl/random/internal:distribution_caller", + "//absl/random/internal:mocking_bit_gen_base", + "//absl/strings", + "//absl/types:span", + "//absl/types:variant", + "//absl/utility", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "bernoulli_distribution_test", + size = "small", + timeout = "eternal", # Android can take a very long time + srcs = ["bernoulli_distribution_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "beta_distribution_test", + size = "small", + timeout = "eternal", # Android can take a very long time + srcs = ["beta_distribution_test.cc"], + copts = ABSL_TEST_COPTS, + flaky = 1, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "distributions_test", + size = "small", + srcs = [ + "distributions_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/random/internal:distribution_test_util", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "generators_test", + size = "small", + srcs = ["generators_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "log_uniform_int_distribution_test", + size = "medium", + srcs = [ + "log_uniform_int_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "discrete_distribution_test", + size = "medium", + srcs = [ + "discrete_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "poisson_distribution_test", + size = "small", + timeout = "eternal", # Android can take a very long time + srcs = [ + "poisson_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = [ + # Too Slow. + "no_test_android_arm", + "no_test_loonix", + ], + deps = [ + ":distributions", + ":random", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/container:flat_hash_map", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "exponential_distribution_test", + size = "small", + srcs = ["exponential_distribution_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "gaussian_distribution_test", + size = "small", + timeout = "eternal", # Android can take a very long time + srcs = [ + "gaussian_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "//absl/strings:str_format", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "uniform_int_distribution_test", + size = "medium", + timeout = "long", + srcs = [ + "uniform_int_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "uniform_real_distribution_test", + size = "medium", + srcs = [ + "uniform_real_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = [ + "no_test_android_arm", + "no_test_android_arm64", + "no_test_android_x86", + ], + deps = [ + ":distributions", + ":random", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "zipf_distribution_test", + size = "medium", + srcs = [ + "zipf_distribution_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distributions", + ":random", + "//absl/base:raw_logging_internal", + "//absl/random/internal:distribution_test_util", + "//absl/random/internal:pcg_engine", + "//absl/random/internal:sequence_urbg", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "bit_gen_ref_test", + size = "small", + srcs = ["bit_gen_ref_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bit_gen_ref", + ":random", + "//absl/random/internal:sequence_urbg", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "mocking_bit_gen_test", + size = "small", + srcs = ["mocking_bit_gen_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bit_gen_ref", + ":mock_distributions", + ":mocking_bit_gen", + ":random", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "mock_distributions_test", + size = "small", + srcs = ["mock_distributions_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":mock_distributions", + ":mocking_bit_gen", + ":random", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "examples_test", + size = "small", + srcs = ["examples_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":random", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "seed_sequences_test", + size = "small", + srcs = ["seed_sequences_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":random", + ":seed_sequences", + "//absl/random/internal:nonsecure_base", + "@com_google_googletest//:gtest_main", + ], +) + +BENCHMARK_TAGS = [ + "benchmark", + "no_test_android_arm", + "no_test_android_arm64", + "no_test_android_x86", + "no_test_darwin_x86_64", + "no_test_ios_x86_64", + "no_test_loonix", + "no_test_msvc_x64", + "no_test_wasm", +] + +# Benchmarks for various methods / test utilities +cc_binary( + name = "benchmarks", + testonly = 1, + srcs = [ + "benchmarks.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = BENCHMARK_TAGS, + deps = [ + ":distributions", + ":random", + ":seed_sequences", + "//absl/base:core_headers", + "//absl/meta:type_traits", + "//absl/random/internal:fast_uniform_bits", + "//absl/random/internal:randen_engine", + "@com_github_google_benchmark//:benchmark_main", + ], +) diff --git a/third_party/abseil_cpp/absl/random/CMakeLists.txt b/third_party/abseil_cpp/absl/random/CMakeLists.txt new file mode 100644 index 0000000000..ec616dd952 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/CMakeLists.txt @@ -0,0 +1,1214 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + random_random + HDRS + "random.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_internal_nonsecure_base + absl::random_internal_pcg_engine + absl::random_internal_pool_urbg + absl::random_internal_randen_engine + absl::random_seed_sequences +) + +absl_cc_library( + NAME + random_bit_gen_ref + HDRS + "bit_gen_ref.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::core_headers + absl::random_internal_distribution_caller + absl::random_internal_fast_uniform_bits + absl::random_internal_mocking_bit_gen_base + absl::type_traits +) + +absl_cc_test( + NAME + random_bit_gen_ref_test + SRCS + "bit_gen_ref_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_bit_gen_ref + absl::random_random + absl::random_internal_sequence_urbg + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_mocking_bit_gen_base + HDRS + "internal/mocking_bit_gen_base.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_random + absl::strings +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_mock_overload_set + HDRS + "internal/mock_overload_set.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_mocking_bit_gen + TESTONLY +) + +absl_cc_library( + NAME + random_mocking_bit_gen + HDRS + "mock_distributions.h" + "mocking_bit_gen.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::flat_hash_map + absl::raw_logging_internal + absl::random_distributions + absl::random_internal_distribution_caller + absl::random_internal_mocking_bit_gen_base + absl::random_internal_mock_overload_set + absl::strings + absl::span + absl::type_traits + absl::utility + absl::variant + gmock + gtest + TESTONLY +) + +absl_cc_test( + NAME + random_mock_distributions_test + SRCS + "mock_distributions_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_mocking_bit_gen + absl::random_random + gmock + gtest_main +) + +absl_cc_test( + NAME + random_mocking_bit_gen_test + SRCS + "mocking_bit_gen_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_bit_gen_ref + absl::random_mocking_bit_gen + absl::random_random + gmock + gtest_main +) + +absl_cc_library( + NAME + random_distributions + SRCS + "discrete_distribution.cc" + "gaussian_distribution.cc" + HDRS + "bernoulli_distribution.h" + "beta_distribution.h" + "discrete_distribution.h" + "distributions.h" + "exponential_distribution.h" + "gaussian_distribution.h" + "log_uniform_int_distribution.h" + "poisson_distribution.h" + "uniform_int_distribution.h" + "uniform_real_distribution.h" + "zipf_distribution.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::base_internal + absl::config + absl::core_headers + absl::random_internal_generate_real + absl::random_internal_distributions + absl::random_internal_fast_uniform_bits + absl::random_internal_fastmath + absl::random_internal_iostream_state_saver + absl::random_internal_traits + absl::random_internal_uniform_helper + absl::random_internal_wide_multiply + absl::strings + absl::span + absl::type_traits +) + +absl_cc_library( + NAME + random_seed_gen_exception + SRCS + "seed_gen_exception.cc" + HDRS + "seed_gen_exception.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config +) + +absl_cc_library( + NAME + random_seed_sequences + SRCS + "seed_sequences.cc" + HDRS + "seed_sequences.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::inlined_vector + absl::random_internal_nonsecure_base + absl::random_internal_pool_urbg + absl::random_internal_salted_seed_seq + absl::random_internal_seed_material + absl::random_seed_gen_exception + absl::span +) + +absl_cc_test( + NAME + random_bernoulli_distribution_test + SRCS + "bernoulli_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_random + absl::random_internal_sequence_urbg + absl::random_internal_pcg_engine + gmock + gtest_main +) + +absl_cc_test( + NAME + random_beta_distribution_test + SRCS + "beta_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_random + absl::random_internal_distribution_test_util + absl::random_internal_sequence_urbg + absl::random_internal_pcg_engine + absl::raw_logging_internal + absl::strings + absl::str_format + gmock + gtest_main +) + +absl_cc_test( + NAME + random_distributions_test + SRCS + "distributions_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_random + absl::random_internal_distribution_test_util + gmock + gtest_main +) + +absl_cc_test( + NAME + random_generators_test + SRCS + "generators_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + absl::random_distributions + absl::random_random + absl::raw_logging_internal + gmock + gtest_main +) + +absl_cc_test( + NAME + random_log_uniform_int_distribution_test + SRCS + "log_uniform_int_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::random_random + absl::raw_logging_internal + absl::strings + absl::str_format + gmock + gtest_main +) + +absl_cc_test( + NAME + random_discrete_distribution_test + SRCS + "discrete_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::random_random + absl::raw_logging_internal + absl::strings + gmock + gtest_main +) + +absl_cc_test( + NAME + random_poisson_distribution_test + SRCS + "poisson_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_random + absl::core_headers + absl::flat_hash_map + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::raw_logging_internal + absl::strings + absl::str_format + gmock + gtest_main +) + +absl_cc_test( + NAME + random_exponential_distribution_test + SRCS + "exponential_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::core_headers + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::random_random + absl::raw_logging_internal + absl::strings + absl::str_format + gmock + gtest_main +) + +absl_cc_test( + NAME + random_gaussian_distribution_test + SRCS + "gaussian_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::core_headers + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_sequence_urbg + absl::random_random + absl::raw_logging_internal + absl::strings + absl::str_format + gmock + gtest_main +) + +absl_cc_test( + NAME + random_uniform_int_distribution_test + SRCS + "uniform_int_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::random_random + absl::raw_logging_internal + absl::strings + gmock + gtest_main +) + +absl_cc_test( + NAME + random_uniform_real_distribution_test + SRCS + "uniform_real_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::random_random + absl::strings + gmock + gtest_main +) + +absl_cc_test( + NAME + random_zipf_distribution_test + SRCS + "zipf_distribution_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_distributions + absl::random_internal_distribution_test_util + absl::random_internal_pcg_engine + absl::random_internal_sequence_urbg + absl::random_random + absl::raw_logging_internal + absl::strings + gmock + gtest_main +) + +absl_cc_test( + NAME + random_examples_test + SRCS + "examples_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_random + gtest_main +) + +absl_cc_test( + NAME + random_seed_sequences_test + SRCS + "seed_sequences_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_seed_sequences + absl::random_internal_nonsecure_base + absl::random_random + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_traits + HDRS + "internal/traits.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_distribution_caller + HDRS + "internal/distribution_caller.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_distributions + HDRS + "internal/distributions.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_distribution_caller + absl::random_internal_fast_uniform_bits + absl::random_internal_fastmath + absl::random_internal_traits + absl::random_internal_uniform_helper + absl::span + absl::strings + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_fast_uniform_bits + HDRS + "internal/fast_uniform_bits.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_seed_material + SRCS + "internal/seed_material.cc" + HDRS + "internal/seed_material.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + $<$<BOOL:${MINGW}>:"bcrypt"> + DEPS + absl::core_headers + absl::optional + absl::random_internal_fast_uniform_bits + absl::raw_logging_internal + absl::span + absl::strings +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_pool_urbg + SRCS + "internal/pool_urbg.cc" + HDRS + "internal/pool_urbg.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::base + absl::config + absl::core_headers + absl::endian + absl::random_internal_randen + absl::random_internal_seed_material + absl::random_internal_traits + absl::random_seed_gen_exception + absl::raw_logging_internal + absl::span +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_explicit_seed_seq + HDRS + "internal/random_internal_explicit_seed_seq.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + TESTONLY +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_sequence_urbg + HDRS + "internal/sequence_urbg.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + TESTONLY +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_salted_seed_seq + HDRS + "internal/salted_seed_seq.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::inlined_vector + absl::optional + absl::span + absl::random_internal_seed_material + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_iostream_state_saver + HDRS + "internal/iostream_state_saver.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::int128 + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_generate_real + HDRS + "internal/generate_real.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::bits + absl::random_internal_fastmath + absl::random_internal_traits + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_wide_multiply + HDRS + "internal/wide_multiply.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::bits + absl::config + absl::int128 +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_fastmath + HDRS + "internal/fastmath.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::bits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_nonsecure_base + HDRS + "internal/nonsecure_base.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::core_headers + absl::optional + absl::random_internal_pool_urbg + absl::random_internal_salted_seed_seq + absl::random_internal_seed_material + absl::span + absl::strings + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_pcg_engine + HDRS + "internal/pcg_engine.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::int128 + absl::random_internal_fastmath + absl::random_internal_iostream_state_saver + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_randen_engine + HDRS + "internal/randen_engine.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_iostream_state_saver + absl::random_internal_randen + absl::raw_logging_internal + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_platform + HDRS + "internal/randen_traits.h" + "internal/platform.h" + SRCS + "internal/randen_round_keys.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_randen + SRCS + "internal/randen.cc" + HDRS + "internal/randen.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_platform + absl::random_internal_randen_hwaes + absl::random_internal_randen_slow +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_randen_slow + SRCS + "internal/randen_slow.cc" + HDRS + "internal/randen_slow.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_platform + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_randen_hwaes + SRCS + "internal/randen_detect.cc" + HDRS + "internal/randen_detect.h" + "internal/randen_hwaes.h" + COPTS + ${ABSL_DEFAULT_COPTS} + ${ABSL_RANDOM_RANDEN_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_platform + absl::random_internal_randen_hwaes_impl + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_randen_hwaes_impl + SRCS + "internal/randen_hwaes.cc" + "internal/randen_hwaes.h" + COPTS + ${ABSL_DEFAULT_COPTS} + ${ABSL_RANDOM_RANDEN_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_platform + absl::config +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_distribution_test_util + SRCS + "internal/chi_square.cc" + "internal/distribution_test_util.cc" + HDRS + "internal/chi_square.h" + "internal/distribution_test_util.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::config + absl::core_headers + absl::raw_logging_internal + absl::strings + absl::str_format + absl::span +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_traits_test + SRCS + "internal/traits_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_traits + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_generate_real_test + SRCS + "internal/generate_real_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::bits + absl::flags + absl::random_internal_generate_real + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_distribution_test_util_test + SRCS + "internal/distribution_test_util_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_distribution_test_util + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_fastmath_test + SRCS + "internal/fastmath_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_fastmath + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_explicit_seed_seq_test + SRCS + "internal/explicit_seed_seq_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_explicit_seed_seq + absl::random_seed_sequences + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_salted_seed_seq_test + SRCS + "internal/salted_seed_seq_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_salted_seed_seq + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_chi_square_test + SRCS + "internal/chi_square_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::core_headers + absl::random_internal_distribution_test_util + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_fast_uniform_bits_test + SRCS + "internal/fast_uniform_bits_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_fast_uniform_bits + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_nonsecure_base_test + SRCS + "internal/nonsecure_base_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_nonsecure_base + absl::random_random + absl::random_distributions + absl::random_seed_sequences + absl::strings + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_seed_material_test + SRCS + "internal/seed_material_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_seed_material + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_pool_urbg_test + SRCS + "internal/pool_urbg_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_pool_urbg + absl::span + absl::type_traits + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_pcg_engine_test + SRCS + "internal/pcg_engine_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_explicit_seed_seq + absl::random_internal_pcg_engine + absl::time + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_randen_engine_test + SRCS + "internal/randen_engine_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_explicit_seed_seq + absl::random_internal_randen_engine + absl::raw_logging_internal + absl::strings + absl::time + gmock + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_randen_test + SRCS + "internal/randen_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_randen + absl::type_traits + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_randen_slow_test + SRCS + "internal/randen_slow_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_randen_slow + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_randen_hwaes_test + SRCS + "internal/randen_hwaes_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_platform + absl::random_internal_randen_hwaes + absl::random_internal_randen_hwaes_impl + absl::raw_logging_internal + absl::str_format + gmock + gtest +) + +# Internal-only target, do not depend on directly. +absl_cc_library( + NAME + random_internal_uniform_helper + HDRS + "internal/uniform_helper.h" + COPTS + ${ABSL_DEFAULT_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::core_headers + absl::random_internal_fast_uniform_bits + absl::random_internal_iostream_state_saver + absl::random_internal_traits + absl::type_traits +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_iostream_state_saver_test + SRCS + "internal/iostream_state_saver_test.cc" + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_iostream_state_saver + gtest_main +) + +# Internal-only target, do not depend on directly. +absl_cc_test( + NAME + random_internal_wide_multiply_test + SRCS + internal/wide_multiply_test.cc + COPTS + ${ABSL_TEST_COPTS} + LINKOPTS + ${ABSL_DEFAULT_LINKOPTS} + DEPS + absl::random_internal_wide_multiply + absl::bits + absl::int128 + gtest_main +) diff --git a/third_party/abseil_cpp/absl/random/benchmarks.cc b/third_party/abseil_cpp/absl/random/benchmarks.cc new file mode 100644 index 0000000000..87bbb9810a --- /dev/null +++ b/third_party/abseil_cpp/absl/random/benchmarks.cc @@ -0,0 +1,383 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Benchmarks for absl random distributions as well as a selection of the +// C++ standard library random distributions. + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <initializer_list> +#include <iterator> +#include <limits> +#include <random> +#include <type_traits> +#include <vector> + +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" +#include "absl/random/bernoulli_distribution.h" +#include "absl/random/beta_distribution.h" +#include "absl/random/exponential_distribution.h" +#include "absl/random/gaussian_distribution.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/randen_engine.h" +#include "absl/random/log_uniform_int_distribution.h" +#include "absl/random/poisson_distribution.h" +#include "absl/random/random.h" +#include "absl/random/uniform_int_distribution.h" +#include "absl/random/uniform_real_distribution.h" +#include "absl/random/zipf_distribution.h" +#include "benchmark/benchmark.h" + +namespace { + +// Seed data to avoid reading random_device() for benchmarks. +uint32_t kSeedData[] = { + 0x1B510052, 0x9A532915, 0xD60F573F, 0xBC9BC6E4, 0x2B60A476, 0x81E67400, + 0x08BA6FB5, 0x571BE91F, 0xF296EC6B, 0x2A0DD915, 0xB6636521, 0xE7B9F9B6, + 0xFF34052E, 0xC5855664, 0x53B02D5D, 0xA99F8FA1, 0x08BA4799, 0x6E85076A, + 0x4B7A70E9, 0xB5B32944, 0xDB75092E, 0xC4192623, 0xAD6EA6B0, 0x49A7DF7D, + 0x9CEE60B8, 0x8FEDB266, 0xECAA8C71, 0x699A18FF, 0x5664526C, 0xC2B19EE1, + 0x193602A5, 0x75094C29, 0xA0591340, 0xE4183A3E, 0x3F54989A, 0x5B429D65, + 0x6B8FE4D6, 0x99F73FD6, 0xA1D29C07, 0xEFE830F5, 0x4D2D38E6, 0xF0255DC1, + 0x4CDD2086, 0x8470EB26, 0x6382E9C6, 0x021ECC5E, 0x09686B3F, 0x3EBAEFC9, + 0x3C971814, 0x6B6A70A1, 0x687F3584, 0x52A0E286, 0x13198A2E, 0x03707344, +}; + +// PrecompiledSeedSeq provides kSeedData to a conforming +// random engine to speed initialization in the benchmarks. +class PrecompiledSeedSeq { + public: + using result_type = uint32_t; + + PrecompiledSeedSeq() {} + + template <typename Iterator> + PrecompiledSeedSeq(Iterator begin, Iterator end) {} + + template <typename T> + PrecompiledSeedSeq(std::initializer_list<T> il) {} + + template <typename OutIterator> + void generate(OutIterator begin, OutIterator end) { + static size_t idx = 0; + for (; begin != end; begin++) { + *begin = kSeedData[idx++]; + if (idx >= ABSL_ARRAYSIZE(kSeedData)) { + idx = 0; + } + } + } + + size_t size() const { return ABSL_ARRAYSIZE(kSeedData); } + + template <typename OutIterator> + void param(OutIterator out) const { + std::copy(std::begin(kSeedData), std::end(kSeedData), out); + } +}; + +// use_default_initialization<T> indicates whether the random engine +// T must be default initialized, or whether we may initialize it using +// a seed sequence. This is used because some engines do not accept seed +// sequence-based initialization. +template <typename E> +using use_default_initialization = std::false_type; + +// make_engine<T, SSeq> returns a random_engine which is initialized, +// either via the default constructor, when use_default_initialization<T> +// is true, or via the indicated seed sequence, SSeq. +template <typename Engine, typename SSeq = PrecompiledSeedSeq> +typename absl::enable_if_t<!use_default_initialization<Engine>::value, Engine> +make_engine() { + // Initialize the random engine using the seed sequence SSeq, which + // is constructed from the precompiled seed data. + SSeq seq(std::begin(kSeedData), std::end(kSeedData)); + return Engine(seq); +} + +template <typename Engine, typename SSeq = PrecompiledSeedSeq> +typename absl::enable_if_t<use_default_initialization<Engine>::value, Engine> +make_engine() { + // Initialize the random engine using the default constructor. + return Engine(); +} + +template <typename Engine, typename SSeq> +void BM_Construct(benchmark::State& state) { + for (auto _ : state) { + auto rng = make_engine<Engine, SSeq>(); + benchmark::DoNotOptimize(rng()); + } +} + +template <typename Engine> +void BM_Direct(benchmark::State& state) { + using value_type = typename Engine::result_type; + // Direct use of the URBG. + auto rng = make_engine<Engine>(); + for (auto _ : state) { + benchmark::DoNotOptimize(rng()); + } + state.SetBytesProcessed(sizeof(value_type) * state.iterations()); +} + +template <typename Engine> +void BM_Generate(benchmark::State& state) { + // std::generate makes a copy of the RNG; thus this tests the + // copy-constructor efficiency. + using value_type = typename Engine::result_type; + std::vector<value_type> v(64); + auto rng = make_engine<Engine>(); + while (state.KeepRunningBatch(64)) { + std::generate(std::begin(v), std::end(v), rng); + } +} + +template <typename Engine, size_t elems> +void BM_Shuffle(benchmark::State& state) { + // Direct use of the Engine. + std::vector<uint32_t> v(elems); + while (state.KeepRunningBatch(elems)) { + auto rng = make_engine<Engine>(); + std::shuffle(std::begin(v), std::end(v), rng); + } +} + +template <typename Engine, size_t elems> +void BM_ShuffleReuse(benchmark::State& state) { + // Direct use of the Engine. + std::vector<uint32_t> v(elems); + auto rng = make_engine<Engine>(); + while (state.KeepRunningBatch(elems)) { + std::shuffle(std::begin(v), std::end(v), rng); + } +} + +template <typename Engine, typename Dist, typename... Args> +void BM_Dist(benchmark::State& state, Args&&... args) { + using value_type = typename Dist::result_type; + auto rng = make_engine<Engine>(); + Dist dis{std::forward<Args>(args)...}; + // Compare the following loop performance: + for (auto _ : state) { + benchmark::DoNotOptimize(dis(rng)); + } + state.SetBytesProcessed(sizeof(value_type) * state.iterations()); +} + +template <typename Engine, typename Dist> +void BM_Large(benchmark::State& state) { + using value_type = typename Dist::result_type; + volatile value_type kMin = 0; + volatile value_type kMax = std::numeric_limits<value_type>::max() / 2 + 1; + BM_Dist<Engine, Dist>(state, kMin, kMax); +} + +template <typename Engine, typename Dist> +void BM_Small(benchmark::State& state) { + using value_type = typename Dist::result_type; + volatile value_type kMin = 0; + volatile value_type kMax = std::numeric_limits<value_type>::max() / 64 + 1; + BM_Dist<Engine, Dist>(state, kMin, kMax); +} + +template <typename Engine, typename Dist, int A> +void BM_Bernoulli(benchmark::State& state) { + volatile double a = static_cast<double>(A) / 1000000; + BM_Dist<Engine, Dist>(state, a); +} + +template <typename Engine, typename Dist, int A, int B> +void BM_Beta(benchmark::State& state) { + using value_type = typename Dist::result_type; + volatile value_type a = static_cast<value_type>(A) / 100; + volatile value_type b = static_cast<value_type>(B) / 100; + BM_Dist<Engine, Dist>(state, a, b); +} + +template <typename Engine, typename Dist, int A> +void BM_Gamma(benchmark::State& state) { + using value_type = typename Dist::result_type; + volatile value_type a = static_cast<value_type>(A) / 100; + BM_Dist<Engine, Dist>(state, a); +} + +template <typename Engine, typename Dist, int A = 100> +void BM_Poisson(benchmark::State& state) { + volatile double a = static_cast<double>(A) / 100; + BM_Dist<Engine, Dist>(state, a); +} + +template <typename Engine, typename Dist, int Q = 2, int V = 1> +void BM_Zipf(benchmark::State& state) { + using value_type = typename Dist::result_type; + volatile double q = Q; + volatile double v = V; + BM_Dist<Engine, Dist>(state, std::numeric_limits<value_type>::max(), q, v); +} + +template <typename Engine, typename Dist> +void BM_Thread(benchmark::State& state) { + using value_type = typename Dist::result_type; + auto rng = make_engine<Engine>(); + Dist dis{}; + for (auto _ : state) { + benchmark::DoNotOptimize(dis(rng)); + } + state.SetBytesProcessed(sizeof(value_type) * state.iterations()); +} + +// NOTES: +// +// std::geometric_distribution is similar to the zipf distributions. +// The algorithm for the geometric_distribution is, basically, +// floor(log(1-X) / log(1-p)) + +// Normal benchmark suite +#define BM_BASIC(Engine) \ + BENCHMARK_TEMPLATE(BM_Construct, Engine, PrecompiledSeedSeq); \ + BENCHMARK_TEMPLATE(BM_Construct, Engine, std::seed_seq); \ + BENCHMARK_TEMPLATE(BM_Direct, Engine); \ + BENCHMARK_TEMPLATE(BM_Shuffle, Engine, 10); \ + BENCHMARK_TEMPLATE(BM_Shuffle, Engine, 100); \ + BENCHMARK_TEMPLATE(BM_Shuffle, Engine, 1000); \ + BENCHMARK_TEMPLATE(BM_ShuffleReuse, Engine, 100); \ + BENCHMARK_TEMPLATE(BM_ShuffleReuse, Engine, 1000); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, \ + absl::random_internal::FastUniformBits<uint32_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, \ + absl::random_internal::FastUniformBits<uint64_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, \ + absl::uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, \ + absl::uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Large, Engine, \ + std::uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Large, Engine, \ + std::uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Large, Engine, \ + absl::uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Large, Engine, \ + absl::uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::uniform_real_distribution<float>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::uniform_real_distribution<double>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, absl::uniform_real_distribution<float>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, absl::uniform_real_distribution<double>) + +#define BM_COPY(Engine) BENCHMARK_TEMPLATE(BM_Generate, Engine) + +#define BM_THREAD(Engine) \ + BENCHMARK_TEMPLATE(BM_Thread, Engine, \ + absl::uniform_int_distribution<int64_t>) \ + ->ThreadPerCpu(); \ + BENCHMARK_TEMPLATE(BM_Thread, Engine, \ + absl::uniform_real_distribution<double>) \ + ->ThreadPerCpu(); \ + BENCHMARK_TEMPLATE(BM_Shuffle, Engine, 100)->ThreadPerCpu(); \ + BENCHMARK_TEMPLATE(BM_Shuffle, Engine, 1000)->ThreadPerCpu(); \ + BENCHMARK_TEMPLATE(BM_ShuffleReuse, Engine, 100)->ThreadPerCpu(); \ + BENCHMARK_TEMPLATE(BM_ShuffleReuse, Engine, 1000)->ThreadPerCpu(); + +#define BM_EXTENDED(Engine) \ + /* -------------- Extended Uniform -----------------------*/ \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + std::uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + std::uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + absl::uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + absl::uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, std::uniform_real_distribution<float>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + std::uniform_real_distribution<double>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + absl::uniform_real_distribution<float>); \ + BENCHMARK_TEMPLATE(BM_Small, Engine, \ + absl::uniform_real_distribution<double>); \ + /* -------------- Other -----------------------*/ \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::normal_distribution<double>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, absl::gaussian_distribution<double>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::exponential_distribution<double>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, absl::exponential_distribution<double>); \ + BENCHMARK_TEMPLATE(BM_Poisson, Engine, std::poisson_distribution<int64_t>, \ + 100); \ + BENCHMARK_TEMPLATE(BM_Poisson, Engine, absl::poisson_distribution<int64_t>, \ + 100); \ + BENCHMARK_TEMPLATE(BM_Poisson, Engine, std::poisson_distribution<int64_t>, \ + 10 * 100); \ + BENCHMARK_TEMPLATE(BM_Poisson, Engine, absl::poisson_distribution<int64_t>, \ + 10 * 100); \ + BENCHMARK_TEMPLATE(BM_Poisson, Engine, std::poisson_distribution<int64_t>, \ + 13 * 100); \ + BENCHMARK_TEMPLATE(BM_Poisson, Engine, absl::poisson_distribution<int64_t>, \ + 13 * 100); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, \ + absl::log_uniform_int_distribution<int32_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, \ + absl::log_uniform_int_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Dist, Engine, std::geometric_distribution<int64_t>); \ + BENCHMARK_TEMPLATE(BM_Zipf, Engine, absl::zipf_distribution<uint64_t>); \ + BENCHMARK_TEMPLATE(BM_Zipf, Engine, absl::zipf_distribution<uint64_t>, 2, \ + 3); \ + BENCHMARK_TEMPLATE(BM_Bernoulli, Engine, std::bernoulli_distribution, \ + 257305); \ + BENCHMARK_TEMPLATE(BM_Bernoulli, Engine, absl::bernoulli_distribution, \ + 257305); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<double>, 65, \ + 41); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<double>, 99, \ + 330); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<double>, 150, \ + 150); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<double>, 410, \ + 580); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<float>, 65, 41); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<float>, 99, \ + 330); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<float>, 150, \ + 150); \ + BENCHMARK_TEMPLATE(BM_Beta, Engine, absl::beta_distribution<float>, 410, \ + 580); \ + BENCHMARK_TEMPLATE(BM_Gamma, Engine, std::gamma_distribution<float>, 199); \ + BENCHMARK_TEMPLATE(BM_Gamma, Engine, std::gamma_distribution<double>, 199); + +// ABSL Recommended interfaces. +BM_BASIC(absl::InsecureBitGen); // === pcg64_2018_engine +BM_BASIC(absl::BitGen); // === randen_engine<uint64_t>. +BM_THREAD(absl::BitGen); +BM_EXTENDED(absl::BitGen); + +// Instantiate benchmarks for multiple engines. +using randen_engine_64 = absl::random_internal::randen_engine<uint64_t>; +using randen_engine_32 = absl::random_internal::randen_engine<uint32_t>; + +// Comparison interfaces. +BM_BASIC(std::mt19937_64); +BM_COPY(std::mt19937_64); +BM_EXTENDED(std::mt19937_64); +BM_BASIC(randen_engine_64); +BM_COPY(randen_engine_64); +BM_EXTENDED(randen_engine_64); + +BM_BASIC(std::mt19937); +BM_COPY(std::mt19937); +BM_BASIC(randen_engine_32); +BM_COPY(randen_engine_32); + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/bernoulli_distribution.h b/third_party/abseil_cpp/absl/random/bernoulli_distribution.h new file mode 100644 index 0000000000..25bd0d5ca4 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/bernoulli_distribution.h @@ -0,0 +1,200 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_BERNOULLI_DISTRIBUTION_H_ +#define ABSL_RANDOM_BERNOULLI_DISTRIBUTION_H_ + +#include <cstdint> +#include <istream> +#include <limits> + +#include "absl/base/optimization.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::bernoulli_distribution is a drop in replacement for +// std::bernoulli_distribution. It guarantees that (given a perfect +// UniformRandomBitGenerator) the acceptance probability is *exactly* equal to +// the given double. +// +// The implementation assumes that double is IEEE754 +class bernoulli_distribution { + public: + using result_type = bool; + + class param_type { + public: + using distribution_type = bernoulli_distribution; + + explicit param_type(double p = 0.5) : prob_(p) { + assert(p >= 0.0 && p <= 1.0); + } + + double p() const { return prob_; } + + friend bool operator==(const param_type& p1, const param_type& p2) { + return p1.p() == p2.p(); + } + friend bool operator!=(const param_type& p1, const param_type& p2) { + return p1.p() != p2.p(); + } + + private: + double prob_; + }; + + bernoulli_distribution() : bernoulli_distribution(0.5) {} + + explicit bernoulli_distribution(double p) : param_(p) {} + + explicit bernoulli_distribution(param_type p) : param_(p) {} + + // no-op + void reset() {} + + template <typename URBG> + bool operator()(URBG& g) { // NOLINT(runtime/references) + return Generate(param_.p(), g); + } + + template <typename URBG> + bool operator()(URBG& g, // NOLINT(runtime/references) + const param_type& param) { + return Generate(param.p(), g); + } + + param_type param() const { return param_; } + void param(const param_type& param) { param_ = param; } + + double p() const { return param_.p(); } + + result_type(min)() const { return false; } + result_type(max)() const { return true; } + + friend bool operator==(const bernoulli_distribution& d1, + const bernoulli_distribution& d2) { + return d1.param_ == d2.param_; + } + + friend bool operator!=(const bernoulli_distribution& d1, + const bernoulli_distribution& d2) { + return d1.param_ != d2.param_; + } + + private: + static constexpr uint64_t kP32 = static_cast<uint64_t>(1) << 32; + + template <typename URBG> + static bool Generate(double p, URBG& g); // NOLINT(runtime/references) + + param_type param_; +}; + +template <typename CharT, typename Traits> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const bernoulli_distribution& x) { + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<double>::kPrecision); + os << x.p(); + return os; +} + +template <typename CharT, typename Traits> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + bernoulli_distribution& x) { // NOLINT(runtime/references) + auto saver = random_internal::make_istream_state_saver(is); + auto p = random_internal::read_floating_point<double>(is); + if (!is.fail()) { + x.param(bernoulli_distribution::param_type(p)); + } + return is; +} + +template <typename URBG> +bool bernoulli_distribution::Generate(double p, + URBG& g) { // NOLINT(runtime/references) + random_internal::FastUniformBits<uint32_t> fast_u32; + + while (true) { + // There are two aspects of the definition of `c` below that are worth + // commenting on. First, because `p` is in the range [0, 1], `c` is in the + // range [0, 2^32] which does not fit in a uint32_t and therefore requires + // 64 bits. + // + // Second, `c` is constructed by first casting explicitly to a signed + // integer and then converting implicitly to an unsigned integer of the same + // size. This is done because the hardware conversion instructions produce + // signed integers from double; if taken as a uint64_t the conversion would + // be wrong for doubles greater than 2^63 (not relevant in this use-case). + // If converted directly to an unsigned integer, the compiler would end up + // emitting code to handle such large values that are not relevant due to + // the known bounds on `c`. To avoid these extra instructions this + // implementation converts first to the signed type and then use the + // implicit conversion to unsigned (which is a no-op). + const uint64_t c = static_cast<int64_t>(p * kP32); + const uint32_t v = fast_u32(g); + // FAST PATH: this path fails with probability 1/2^32. Note that simply + // returning v <= c would approximate P very well (up to an absolute error + // of 1/2^32); the slow path (taken in that range of possible error, in the + // case of equality) eliminates the remaining error. + if (ABSL_PREDICT_TRUE(v != c)) return v < c; + + // It is guaranteed that `q` is strictly less than 1, because if `q` were + // greater than or equal to 1, the same would be true for `p`. Certainly `p` + // cannot be greater than 1, and if `p == 1`, then the fast path would + // necessary have been taken already. + const double q = static_cast<double>(c) / kP32; + + // The probability of acceptance on the fast path is `q` and so the + // probability of acceptance here should be `p - q`. + // + // Note that `q` is obtained from `p` via some shifts and conversions, the + // upshot of which is that `q` is simply `p` with some of the + // least-significant bits of its mantissa set to zero. This means that the + // difference `p - q` will not have any rounding errors. To see why, pretend + // that double has 10 bits of resolution and q is obtained from `p` in such + // a way that the 4 least-significant bits of its mantissa are set to zero. + // For example: + // p = 1.1100111011 * 2^-1 + // q = 1.1100110000 * 2^-1 + // p - q = 1.011 * 2^-8 + // The difference `p - q` has exactly the nonzero mantissa bits that were + // "lost" in `q` producing a number which is certainly representable in a + // double. + const double left = p - q; + + // By construction, the probability of being on this slow path is 1/2^32, so + // P(accept in slow path) = P(accept| in slow path) * P(slow path), + // which means the probability of acceptance here is `1 / (left * kP32)`: + const double here = left * kP32; + + // The simplest way to compute the result of this trial is to repeat the + // whole algorithm with the new probability. This terminates because even + // given arbitrarily unfriendly "random" bits, each iteration either + // multiplies a tiny probability by 2^32 (if c == 0) or strips off some + // number of nonzero mantissa bits. That process is bounded. + if (here == 0) return false; + p = here; + } +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_BERNOULLI_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/bernoulli_distribution_test.cc b/third_party/abseil_cpp/absl/random/bernoulli_distribution_test.cc new file mode 100644 index 0000000000..b250f8787c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/bernoulli_distribution_test.cc @@ -0,0 +1,217 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/bernoulli_distribution.h" + +#include <cmath> +#include <cstddef> +#include <random> +#include <sstream> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" + +namespace { + +class BernoulliTest : public testing::TestWithParam<std::pair<double, size_t>> { +}; + +TEST_P(BernoulliTest, Serialize) { + const double d = GetParam().first; + absl::bernoulli_distribution before(d); + + { + absl::bernoulli_distribution via_param{ + absl::bernoulli_distribution::param_type(d)}; + EXPECT_EQ(via_param, before); + } + + std::stringstream ss; + ss << before; + absl::bernoulli_distribution after(0.6789); + + EXPECT_NE(before.p(), after.p()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before.p(), after.p()); + EXPECT_EQ(before.param(), after.param()); + EXPECT_EQ(before, after); +} + +TEST_P(BernoulliTest, Accuracy) { + // Sadly, the claim to fame for this implementation is precise accuracy, which + // is very, very hard to measure, the improvements come as trials approach the + // limit of double accuracy; thus the outcome differs from the + // std::bernoulli_distribution with a probability of approximately 1 in 2^-53. + const std::pair<double, size_t> para = GetParam(); + size_t trials = para.second; + double p = para.first; + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng(0x2B7E151628AED2A6); + + size_t yes = 0; + absl::bernoulli_distribution dist(p); + for (size_t i = 0; i < trials; ++i) { + if (dist(rng)) yes++; + } + + // Compute the distribution parameters for a binomial test, using a normal + // approximation for the confidence interval, as there are a sufficiently + // large number of trials that the central limit theorem applies. + const double stddev_p = std::sqrt((p * (1.0 - p)) / trials); + const double expected = trials * p; + const double stddev = trials * stddev_p; + + // 5 sigma, approved by Richard Feynman + EXPECT_NEAR(yes, expected, 5 * stddev) + << "@" << p << ", " + << std::abs(static_cast<double>(yes) - expected) / stddev << " stddev"; +} + +// There must be many more trials to make the mean approximately normal for `p` +// closes to 0 or 1. +INSTANTIATE_TEST_SUITE_P( + All, BernoulliTest, + ::testing::Values( + // Typical values. + std::make_pair(0, 30000), std::make_pair(1e-3, 30000000), + std::make_pair(0.1, 3000000), std::make_pair(0.5, 3000000), + std::make_pair(0.9, 30000000), std::make_pair(0.999, 30000000), + std::make_pair(1, 30000), + // Boundary cases. + std::make_pair(std::nextafter(1.0, 0.0), 1), // ~1 - epsilon + std::make_pair(std::numeric_limits<double>::epsilon(), 1), + std::make_pair(std::nextafter(std::numeric_limits<double>::min(), + 1.0), // min + epsilon + 1), + std::make_pair(std::numeric_limits<double>::min(), // smallest normal + 1), + std::make_pair( + std::numeric_limits<double>::denorm_min(), // smallest denorm + 1), + std::make_pair(std::numeric_limits<double>::min() / 2, 1), // denorm + std::make_pair(std::nextafter(std::numeric_limits<double>::min(), + 0.0), // denorm_max + 1))); + +// NOTE: absl::bernoulli_distribution is not guaranteed to be stable. +TEST(BernoulliTest, StabilityTest) { + // absl::bernoulli_distribution stability relies on FastUniformBits and + // integer arithmetic. + absl::random_internal::sequence_urbg urbg({ + 0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull, + 0x4864f22c059bf29eull, 0x247856d8b862665cull, 0xe46e86e9a1337e10ull, + 0xd8c8541f3519b133ull, 0xe75b5162c567b9e4ull, 0xf732e5ded7009c5bull, + 0xb170b98353121eacull, 0x1ec2e8986d2362caull, 0x814c8e35fe9a961aull, + 0x0c3cd59c9b638a02ull, 0xcb3bb6478a07715cull, 0x1224e62c978bbc7full, + 0x671ef2cb04e81f6eull, 0x3c1cbd811eaf1808ull, 0x1bbc23cfa8fac721ull, + 0xa4c2cda65e596a51ull, 0xb77216fad37adf91ull, 0x836d794457c08849ull, + 0xe083df03475f49d7ull, 0xbc9feb512e6b0d6cull, 0xb12d74fdd718c8c5ull, + 0x12ff09653bfbe4caull, 0x8dd03a105bc4ee7eull, 0x5738341045ba0d85ull, + 0xe3fd722dc65ad09eull, 0x5a14fd21ea2a5705ull, 0x14e6ea4d6edb0c73ull, + 0x275b0dc7e0a18acfull, 0x36cebe0d2653682eull, 0x0361e9b23861596bull, + }); + + // Generate a string of '0' and '1' for the distribution output. + auto generate = [&urbg](absl::bernoulli_distribution& dist) { + std::string output; + output.reserve(36); + urbg.reset(); + for (int i = 0; i < 35; i++) { + output.append(dist(urbg) ? "1" : "0"); + } + return output; + }; + + const double kP = 0.0331289862362; + { + absl::bernoulli_distribution dist(kP); + auto v = generate(dist); + EXPECT_EQ(35, urbg.invocations()); + EXPECT_EQ(v, "00000000000010000000000010000000000") << dist; + } + { + absl::bernoulli_distribution dist(kP * 10.0); + auto v = generate(dist); + EXPECT_EQ(35, urbg.invocations()); + EXPECT_EQ(v, "00000100010010010010000011000011010") << dist; + } + { + absl::bernoulli_distribution dist(kP * 20.0); + auto v = generate(dist); + EXPECT_EQ(35, urbg.invocations()); + EXPECT_EQ(v, "00011110010110110011011111110111011") << dist; + } + { + absl::bernoulli_distribution dist(1.0 - kP); + auto v = generate(dist); + EXPECT_EQ(35, urbg.invocations()); + EXPECT_EQ(v, "11111111111111111111011111111111111") << dist; + } +} + +TEST(BernoulliTest, StabilityTest2) { + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + // Generate a string of '0' and '1' for the distribution output. + auto generate = [&urbg](absl::bernoulli_distribution& dist) { + std::string output; + output.reserve(13); + urbg.reset(); + for (int i = 0; i < 12; i++) { + output.append(dist(urbg) ? "1" : "0"); + } + return output; + }; + + constexpr double b0 = 1.0 / 13.0 / 0.2; + constexpr double b1 = 2.0 / 13.0 / 0.2; + constexpr double b3 = (5.0 / 13.0 / 0.2) - ((1 - b0) + (1 - b1) + (1 - b1)); + { + absl::bernoulli_distribution dist(b0); + auto v = generate(dist); + EXPECT_EQ(12, urbg.invocations()); + EXPECT_EQ(v, "000011100101") << dist; + } + { + absl::bernoulli_distribution dist(b1); + auto v = generate(dist); + EXPECT_EQ(12, urbg.invocations()); + EXPECT_EQ(v, "001111101101") << dist; + } + { + absl::bernoulli_distribution dist(b3); + auto v = generate(dist); + EXPECT_EQ(12, urbg.invocations()); + EXPECT_EQ(v, "001111101111") << dist; + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/beta_distribution.h b/third_party/abseil_cpp/absl/random/beta_distribution.h new file mode 100644 index 0000000000..c154066fb8 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/beta_distribution.h @@ -0,0 +1,427 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_BETA_DISTRIBUTION_H_ +#define ABSL_RANDOM_BETA_DISTRIBUTION_H_ + +#include <cassert> +#include <cmath> +#include <istream> +#include <limits> +#include <ostream> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/fastmath.h" +#include "absl/random/internal/generate_real.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::beta_distribution: +// Generate a floating-point variate conforming to a Beta distribution: +// pdf(x) \propto x^(alpha-1) * (1-x)^(beta-1), +// where the params alpha and beta are both strictly positive real values. +// +// The support is the open interval (0, 1), but the return value might be equal +// to 0 or 1, due to numerical errors when alpha and beta are very different. +// +// Usage note: One usage is that alpha and beta are counts of number of +// successes and failures. When the total number of trials are large, consider +// approximating a beta distribution with a Gaussian distribution with the same +// mean and variance. One could use the skewness, which depends only on the +// smaller of alpha and beta when the number of trials are sufficiently large, +// to quantify how far a beta distribution is from the normal distribution. +template <typename RealType = double> +class beta_distribution { + public: + using result_type = RealType; + + class param_type { + public: + using distribution_type = beta_distribution; + + explicit param_type(result_type alpha, result_type beta) + : alpha_(alpha), beta_(beta) { + assert(alpha >= 0); + assert(beta >= 0); + assert(alpha <= (std::numeric_limits<result_type>::max)()); + assert(beta <= (std::numeric_limits<result_type>::max)()); + if (alpha == 0 || beta == 0) { + method_ = DEGENERATE_SMALL; + x_ = (alpha >= beta) ? 1 : 0; + return; + } + // a_ = min(beta, alpha), b_ = max(beta, alpha). + if (beta < alpha) { + inverted_ = true; + a_ = beta; + b_ = alpha; + } else { + inverted_ = false; + a_ = alpha; + b_ = beta; + } + if (a_ <= 1 && b_ >= ThresholdForLargeA()) { + method_ = DEGENERATE_SMALL; + x_ = inverted_ ? result_type(1) : result_type(0); + return; + } + // For threshold values, see also: + // Evaluation of Beta Generation Algorithms, Ying-Chao Hung, et. al. + // February, 2009. + if ((b_ < 1.0 && a_ + b_ <= 1.2) || a_ <= ThresholdForSmallA()) { + // Choose Joehnk over Cheng when it's faster or when Cheng encounters + // numerical issues. + method_ = JOEHNK; + a_ = result_type(1) / alpha_; + b_ = result_type(1) / beta_; + if (std::isinf(a_) || std::isinf(b_)) { + method_ = DEGENERATE_SMALL; + x_ = inverted_ ? result_type(1) : result_type(0); + } + return; + } + if (a_ >= ThresholdForLargeA()) { + method_ = DEGENERATE_LARGE; + // Note: on PPC for long double, evaluating + // `std::numeric_limits::max() / ThresholdForLargeA` results in NaN. + result_type r = a_ / b_; + x_ = (inverted_ ? result_type(1) : r) / (1 + r); + return; + } + x_ = a_ + b_; + log_x_ = std::log(x_); + if (a_ <= 1) { + method_ = CHENG_BA; + y_ = result_type(1) / a_; + gamma_ = a_ + a_; + return; + } + method_ = CHENG_BB; + result_type r = (a_ - 1) / (b_ - 1); + y_ = std::sqrt((1 + r) / (b_ * r * 2 - r + 1)); + gamma_ = a_ + result_type(1) / y_; + } + + result_type alpha() const { return alpha_; } + result_type beta() const { return beta_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.alpha_ == b.alpha_ && a.beta_ == b.beta_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class beta_distribution; + +#ifdef _MSC_VER + // MSVC does not have constexpr implementations for std::log and std::exp + // so they are computed at runtime. +#define ABSL_RANDOM_INTERNAL_LOG_EXP_CONSTEXPR +#else +#define ABSL_RANDOM_INTERNAL_LOG_EXP_CONSTEXPR constexpr +#endif + + // The threshold for whether std::exp(1/a) is finite. + // Note that this value is quite large, and a smaller a_ is NOT abnormal. + static ABSL_RANDOM_INTERNAL_LOG_EXP_CONSTEXPR result_type + ThresholdForSmallA() { + return result_type(1) / + std::log((std::numeric_limits<result_type>::max)()); + } + + // The threshold for whether a * std::log(a) is finite. + static ABSL_RANDOM_INTERNAL_LOG_EXP_CONSTEXPR result_type + ThresholdForLargeA() { + return std::exp( + std::log((std::numeric_limits<result_type>::max)()) - + std::log(std::log((std::numeric_limits<result_type>::max)())) - + ThresholdPadding()); + } + +#undef ABSL_RANDOM_INTERNAL_LOG_EXP_CONSTEXPR + + // Pad the threshold for large A for long double on PPC. This is done via a + // template specialization below. + static constexpr result_type ThresholdPadding() { return 0; } + + enum Method { + JOEHNK, // Uses algorithm Joehnk + CHENG_BA, // Uses algorithm BA in Cheng + CHENG_BB, // Uses algorithm BB in Cheng + + // Note: See also: + // Hung et al. Evaluation of beta generation algorithms. Communications + // in Statistics-Simulation and Computation 38.4 (2009): 750-770. + // especially: + // Zechner, Heinz, and Ernst Stadlober. Generating beta variates via + // patchwork rejection. Computing 50.1 (1993): 1-18. + + DEGENERATE_SMALL, // a_ is abnormally small. + DEGENERATE_LARGE, // a_ is abnormally large. + }; + + result_type alpha_; + result_type beta_; + + result_type a_; // the smaller of {alpha, beta}, or 1.0/alpha_ in JOEHNK + result_type b_; // the larger of {alpha, beta}, or 1.0/beta_ in JOEHNK + result_type x_; // alpha + beta, or the result in degenerate cases + result_type log_x_; // log(x_) + result_type y_; // "beta" in Cheng + result_type gamma_; // "gamma" in Cheng + + Method method_; + + // Placing this last for optimal alignment. + // Whether alpha_ != a_, i.e. true iff alpha_ > beta_. + bool inverted_; + + static_assert(std::is_floating_point<RealType>::value, + "Class-template absl::beta_distribution<> must be " + "parameterized using a floating-point type."); + }; + + beta_distribution() : beta_distribution(1) {} + + explicit beta_distribution(result_type alpha, result_type beta = 1) + : param_(alpha, beta) {} + + explicit beta_distribution(const param_type& p) : param_(p) {} + + void reset() {} + + // Generating functions + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + param_type param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + result_type(min)() const { return 0; } + result_type(max)() const { return 1; } + + result_type alpha() const { return param_.alpha(); } + result_type beta() const { return param_.beta(); } + + friend bool operator==(const beta_distribution& a, + const beta_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const beta_distribution& a, + const beta_distribution& b) { + return a.param_ != b.param_; + } + + private: + template <typename URBG> + result_type AlgorithmJoehnk(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + template <typename URBG> + result_type AlgorithmCheng(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + template <typename URBG> + result_type DegenerateCase(URBG& g, // NOLINT(runtime/references) + const param_type& p) { + if (p.method_ == param_type::DEGENERATE_SMALL && p.alpha_ == p.beta_) { + // Returns 0 or 1 with equal probability. + random_internal::FastUniformBits<uint8_t> fast_u8; + return static_cast<result_type>((fast_u8(g) & 0x10) != + 0); // pick any single bit. + } + return p.x_; + } + + param_type param_; + random_internal::FastUniformBits<uint64_t> fast_u64_; +}; + +#if defined(__powerpc64__) || defined(__PPC64__) || defined(__powerpc__) || \ + defined(__ppc__) || defined(__PPC__) +// PPC needs a more stringent boundary for long double. +template <> +constexpr long double +beta_distribution<long double>::param_type::ThresholdPadding() { + return 10; +} +#endif + +template <typename RealType> +template <typename URBG> +typename beta_distribution<RealType>::result_type +beta_distribution<RealType>::AlgorithmJoehnk( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + using random_internal::GeneratePositiveTag; + using random_internal::GenerateRealFromBits; + using real_type = + absl::conditional_t<std::is_same<RealType, float>::value, float, double>; + + // Based on Joehnk, M. D. Erzeugung von betaverteilten und gammaverteilten + // Zufallszahlen. Metrika 8.1 (1964): 5-15. + // This method is described in Knuth, Vol 2 (Third Edition), pp 134. + + result_type u, v, x, y, z; + for (;;) { + u = GenerateRealFromBits<real_type, GeneratePositiveTag, false>( + fast_u64_(g)); + v = GenerateRealFromBits<real_type, GeneratePositiveTag, false>( + fast_u64_(g)); + + // Direct method. std::pow is slow for float, so rely on the optimizer to + // remove the std::pow() path for that case. + if (!std::is_same<float, result_type>::value) { + x = std::pow(u, p.a_); + y = std::pow(v, p.b_); + z = x + y; + if (z > 1) { + // Reject if and only if `x + y > 1.0` + continue; + } + if (z > 0) { + // When both alpha and beta are small, x and y are both close to 0, so + // divide by (x+y) directly may result in nan. + return x / z; + } + } + + // Log transform. + // x = log( pow(u, p.a_) ), y = log( pow(v, p.b_) ) + // since u, v <= 1.0, x, y < 0. + x = std::log(u) * p.a_; + y = std::log(v) * p.b_; + if (!std::isfinite(x) || !std::isfinite(y)) { + continue; + } + // z = log( pow(u, a) + pow(v, b) ) + z = x > y ? (x + std::log(1 + std::exp(y - x))) + : (y + std::log(1 + std::exp(x - y))); + // Reject iff log(x+y) > 0. + if (z > 0) { + continue; + } + return std::exp(x - z); + } +} + +template <typename RealType> +template <typename URBG> +typename beta_distribution<RealType>::result_type +beta_distribution<RealType>::AlgorithmCheng( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + using random_internal::GeneratePositiveTag; + using random_internal::GenerateRealFromBits; + using real_type = + absl::conditional_t<std::is_same<RealType, float>::value, float, double>; + + // Based on Cheng, Russell CH. Generating beta variates with nonintegral + // shape parameters. Communications of the ACM 21.4 (1978): 317-322. + // (https://dl.acm.org/citation.cfm?id=359482). + static constexpr result_type kLogFour = + result_type(1.3862943611198906188344642429163531361); // log(4) + static constexpr result_type kS = + result_type(2.6094379124341003746007593332261876); // 1+log(5) + + const bool use_algorithm_ba = (p.method_ == param_type::CHENG_BA); + result_type u1, u2, v, w, z, r, s, t, bw_inv, lhs; + for (;;) { + u1 = GenerateRealFromBits<real_type, GeneratePositiveTag, false>( + fast_u64_(g)); + u2 = GenerateRealFromBits<real_type, GeneratePositiveTag, false>( + fast_u64_(g)); + v = p.y_ * std::log(u1 / (1 - u1)); + w = p.a_ * std::exp(v); + bw_inv = result_type(1) / (p.b_ + w); + r = p.gamma_ * v - kLogFour; + s = p.a_ + r - w; + z = u1 * u1 * u2; + if (!use_algorithm_ba && s + kS >= 5 * z) { + break; + } + t = std::log(z); + if (!use_algorithm_ba && s >= t) { + break; + } + lhs = p.x_ * (p.log_x_ + std::log(bw_inv)) + r; + if (lhs >= t) { + break; + } + } + return p.inverted_ ? (1 - w * bw_inv) : w * bw_inv; +} + +template <typename RealType> +template <typename URBG> +typename beta_distribution<RealType>::result_type +beta_distribution<RealType>::operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p) { + switch (p.method_) { + case param_type::JOEHNK: + return AlgorithmJoehnk(g, p); + case param_type::CHENG_BA: + ABSL_FALLTHROUGH_INTENDED; + case param_type::CHENG_BB: + return AlgorithmCheng(g, p); + default: + return DegenerateCase(g, p); + } +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const beta_distribution<RealType>& x) { + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<RealType>::kPrecision); + os << x.alpha() << os.fill() << x.beta(); + return os; +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + beta_distribution<RealType>& x) { // NOLINT(runtime/references) + using result_type = typename beta_distribution<RealType>::result_type; + using param_type = typename beta_distribution<RealType>::param_type; + result_type alpha, beta; + + auto saver = random_internal::make_istream_state_saver(is); + alpha = random_internal::read_floating_point<result_type>(is); + if (is.fail()) return is; + beta = random_internal::read_floating_point<result_type>(is); + if (!is.fail()) { + x.param(param_type(alpha, beta)); + } + return is; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_BETA_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/beta_distribution_test.cc b/third_party/abseil_cpp/absl/random/beta_distribution_test.cc new file mode 100644 index 0000000000..277e4dc6ee --- /dev/null +++ b/third_party/abseil_cpp/absl/random/beta_distribution_test.cc @@ -0,0 +1,619 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/beta_distribution.h" + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <random> +#include <sstream> +#include <string> +#include <unordered_map> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_replace.h" +#include "absl/strings/strip.h" + +namespace { + +template <typename IntType> +class BetaDistributionInterfaceTest : public ::testing::Test {}; + +using RealTypes = ::testing::Types<float, double, long double>; +TYPED_TEST_CASE(BetaDistributionInterfaceTest, RealTypes); + +TYPED_TEST(BetaDistributionInterfaceTest, SerializeTest) { + // The threshold for whether std::exp(1/a) is finite. + const TypeParam kSmallA = + 1.0f / std::log((std::numeric_limits<TypeParam>::max)()); + // The threshold for whether a * std::log(a) is finite. + const TypeParam kLargeA = + std::exp(std::log((std::numeric_limits<TypeParam>::max)()) - + std::log(std::log((std::numeric_limits<TypeParam>::max)()))); + const TypeParam kLargeAPPC = std::exp( + std::log((std::numeric_limits<TypeParam>::max)()) - + std::log(std::log((std::numeric_limits<TypeParam>::max)())) - 10.0f); + using param_type = typename absl::beta_distribution<TypeParam>::param_type; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + const TypeParam kValues[] = { + TypeParam(1e-20), TypeParam(1e-12), TypeParam(1e-8), TypeParam(1e-4), + TypeParam(1e-3), TypeParam(0.1), TypeParam(0.25), + std::nextafter(TypeParam(0.5), TypeParam(0)), // 0.5 - epsilon + std::nextafter(TypeParam(0.5), TypeParam(1)), // 0.5 + epsilon + TypeParam(0.5), TypeParam(1.0), // + std::nextafter(TypeParam(1), TypeParam(0)), // 1 - epsilon + std::nextafter(TypeParam(1), TypeParam(2)), // 1 + epsilon + TypeParam(12.5), TypeParam(1e2), TypeParam(1e8), TypeParam(1e12), + TypeParam(1e20), // + kSmallA, // + std::nextafter(kSmallA, TypeParam(0)), // + std::nextafter(kSmallA, TypeParam(1)), // + kLargeA, // + std::nextafter(kLargeA, TypeParam(0)), // + std::nextafter(kLargeA, std::numeric_limits<TypeParam>::max()), + kLargeAPPC, // + std::nextafter(kLargeAPPC, TypeParam(0)), + std::nextafter(kLargeAPPC, std::numeric_limits<TypeParam>::max()), + // Boundary cases. + std::numeric_limits<TypeParam>::max(), + std::numeric_limits<TypeParam>::epsilon(), + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(1)), // min + epsilon + std::numeric_limits<TypeParam>::min(), // smallest normal + std::numeric_limits<TypeParam>::denorm_min(), // smallest denorm + std::numeric_limits<TypeParam>::min() / 2, // denorm + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(0)), // denorm_max + }; + for (TypeParam alpha : kValues) { + for (TypeParam beta : kValues) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("Smoke test for Beta(%a, %a)", alpha, beta)); + + param_type param(alpha, beta); + absl::beta_distribution<TypeParam> before(alpha, beta); + EXPECT_EQ(before.alpha(), param.alpha()); + EXPECT_EQ(before.beta(), param.beta()); + + { + absl::beta_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + EXPECT_EQ(via_param.param(), before.param()); + } + + // Smoke test. + for (int i = 0; i < kCount; ++i) { + auto sample = before(gen); + EXPECT_TRUE(std::isfinite(sample)); + EXPECT_GE(sample, before.min()); + EXPECT_LE(sample, before.max()); + } + + // Validate stream serialization. + std::stringstream ss; + ss << before; + absl::beta_distribution<TypeParam> after(3.8f, 1.43f); + EXPECT_NE(before.alpha(), after.alpha()); + EXPECT_NE(before.beta(), after.beta()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + +#if defined(__powerpc64__) || defined(__PPC64__) || defined(__powerpc__) || \ + defined(__ppc__) || defined(__PPC__) + if (std::is_same<TypeParam, long double>::value) { + // Roundtripping floating point values requires sufficient precision + // to reconstruct the exact value. It turns out that long double + // has some errors doing this on ppc. + if (alpha <= std::numeric_limits<double>::max() && + alpha >= std::numeric_limits<double>::lowest()) { + EXPECT_EQ(static_cast<double>(before.alpha()), + static_cast<double>(after.alpha())) + << ss.str(); + } + if (beta <= std::numeric_limits<double>::max() && + beta >= std::numeric_limits<double>::lowest()) { + EXPECT_EQ(static_cast<double>(before.beta()), + static_cast<double>(after.beta())) + << ss.str(); + } + continue; + } +#endif + + EXPECT_EQ(before.alpha(), after.alpha()); + EXPECT_EQ(before.beta(), after.beta()); + EXPECT_EQ(before, after) // + << ss.str() << " " // + << (ss.good() ? "good " : "") // + << (ss.bad() ? "bad " : "") // + << (ss.eof() ? "eof " : "") // + << (ss.fail() ? "fail " : ""); + } + } +} + +TYPED_TEST(BetaDistributionInterfaceTest, DegenerateCases) { + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng(0x2B7E151628AED2A6); + + // Extreme cases when the params are abnormal. + constexpr int kCount = 1000; + const TypeParam kSmallValues[] = { + std::numeric_limits<TypeParam>::min(), + std::numeric_limits<TypeParam>::denorm_min(), + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(0)), // denorm_max + std::numeric_limits<TypeParam>::epsilon(), + }; + const TypeParam kLargeValues[] = { + std::numeric_limits<TypeParam>::max() * static_cast<TypeParam>(0.9999), + std::numeric_limits<TypeParam>::max() - 1, + std::numeric_limits<TypeParam>::max(), + }; + { + // Small alpha and beta. + // Useful WolframAlpha plots: + // * plot InverseBetaRegularized[x, 0.0001, 0.0001] from 0.495 to 0.505 + // * Beta[1.0, 0.0000001, 0.0000001] + // * Beta[0.9999, 0.0000001, 0.0000001] + for (TypeParam alpha : kSmallValues) { + for (TypeParam beta : kSmallValues) { + int zeros = 0; + int ones = 0; + absl::beta_distribution<TypeParam> d(alpha, beta); + for (int i = 0; i < kCount; ++i) { + TypeParam x = d(rng); + if (x == 0.0) { + zeros++; + } else if (x == 1.0) { + ones++; + } + } + EXPECT_EQ(ones + zeros, kCount); + if (alpha == beta) { + EXPECT_NE(ones, 0); + EXPECT_NE(zeros, 0); + } + } + } + } + { + // Small alpha, large beta. + // Useful WolframAlpha plots: + // * plot InverseBetaRegularized[x, 0.0001, 10000] from 0.995 to 1 + // * Beta[0, 0.0000001, 1000000] + // * Beta[0.001, 0.0000001, 1000000] + // * Beta[1, 0.0000001, 1000000] + for (TypeParam alpha : kSmallValues) { + for (TypeParam beta : kLargeValues) { + absl::beta_distribution<TypeParam> d(alpha, beta); + for (int i = 0; i < kCount; ++i) { + EXPECT_EQ(d(rng), 0.0); + } + } + } + } + { + // Large alpha, small beta. + // Useful WolframAlpha plots: + // * plot InverseBetaRegularized[x, 10000, 0.0001] from 0 to 0.001 + // * Beta[0.99, 1000000, 0.0000001] + // * Beta[1, 1000000, 0.0000001] + for (TypeParam alpha : kLargeValues) { + for (TypeParam beta : kSmallValues) { + absl::beta_distribution<TypeParam> d(alpha, beta); + for (int i = 0; i < kCount; ++i) { + EXPECT_EQ(d(rng), 1.0); + } + } + } + } + { + // Large alpha and beta. + absl::beta_distribution<TypeParam> d(std::numeric_limits<TypeParam>::max(), + std::numeric_limits<TypeParam>::max()); + for (int i = 0; i < kCount; ++i) { + EXPECT_EQ(d(rng), 0.5); + } + } + { + // Large alpha and beta but unequal. + absl::beta_distribution<TypeParam> d( + std::numeric_limits<TypeParam>::max(), + std::numeric_limits<TypeParam>::max() * 0.9999); + for (int i = 0; i < kCount; ++i) { + TypeParam x = d(rng); + EXPECT_NE(x, 0.5f); + EXPECT_FLOAT_EQ(x, 0.500025f); + } + } +} + +class BetaDistributionModel { + public: + explicit BetaDistributionModel(::testing::tuple<double, double> p) + : alpha_(::testing::get<0>(p)), beta_(::testing::get<1>(p)) {} + + double Mean() const { return alpha_ / (alpha_ + beta_); } + + double Variance() const { + return alpha_ * beta_ / (alpha_ + beta_ + 1) / (alpha_ + beta_) / + (alpha_ + beta_); + } + + double Kurtosis() const { + return 3 + 6 * + ((alpha_ - beta_) * (alpha_ - beta_) * (alpha_ + beta_ + 1) - + alpha_ * beta_ * (2 + alpha_ + beta_)) / + alpha_ / beta_ / (alpha_ + beta_ + 2) / (alpha_ + beta_ + 3); + } + + protected: + const double alpha_; + const double beta_; +}; + +class BetaDistributionTest + : public ::testing::TestWithParam<::testing::tuple<double, double>>, + public BetaDistributionModel { + public: + BetaDistributionTest() : BetaDistributionModel(GetParam()) {} + + protected: + template <class D> + bool SingleZTestOnMeanAndVariance(double p, size_t samples); + + template <class D> + bool SingleChiSquaredTest(double p, size_t samples, size_t buckets); + + absl::InsecureBitGen rng_; +}; + +template <class D> +bool BetaDistributionTest::SingleZTestOnMeanAndVariance(double p, + size_t samples) { + D dis(alpha_, beta_); + + std::vector<double> data; + data.reserve(samples); + for (size_t i = 0; i < samples; i++) { + const double variate = dis(rng_); + EXPECT_FALSE(std::isnan(variate)); + // Note that equality is allowed on both sides. + EXPECT_GE(variate, 0.0); + EXPECT_LE(variate, 1.0); + data.push_back(variate); + } + + // We validate that the sample mean and sample variance are indeed from a + // Beta distribution with the given shape parameters. + const auto m = absl::random_internal::ComputeDistributionMoments(data); + + // The variance of the sample mean is variance / n. + const double mean_stddev = std::sqrt(Variance() / static_cast<double>(m.n)); + + // The variance of the sample variance is (approximately): + // (kurtosis - 1) * variance^2 / n + const double variance_stddev = std::sqrt( + (Kurtosis() - 1) * Variance() * Variance() / static_cast<double>(m.n)); + // z score for the sample variance. + const double z_variance = (m.variance - Variance()) / variance_stddev; + + const double max_err = absl::random_internal::MaxErrorTolerance(p); + const double z_mean = absl::random_internal::ZScore(Mean(), m); + const bool pass = + absl::random_internal::Near("z", z_mean, 0.0, max_err) && + absl::random_internal::Near("z_variance", z_variance, 0.0, max_err); + if (!pass) { + ABSL_INTERNAL_LOG( + INFO, + absl::StrFormat( + "Beta(%f, %f), " + "mean: sample %f, expect %f, which is %f stddevs away, " + "variance: sample %f, expect %f, which is %f stddevs away.", + alpha_, beta_, m.mean, Mean(), + std::abs(m.mean - Mean()) / mean_stddev, m.variance, Variance(), + std::abs(m.variance - Variance()) / variance_stddev)); + } + return pass; +} + +template <class D> +bool BetaDistributionTest::SingleChiSquaredTest(double p, size_t samples, + size_t buckets) { + constexpr double kErr = 1e-7; + std::vector<double> cutoffs, expected; + const double bucket_width = 1.0 / static_cast<double>(buckets); + int i = 1; + int unmerged_buckets = 0; + for (; i < buckets; ++i) { + const double p = bucket_width * static_cast<double>(i); + const double boundary = + absl::random_internal::BetaIncompleteInv(alpha_, beta_, p); + // The intention is to add `boundary` to the list of `cutoffs`. It becomes + // problematic, however, when the boundary values are not monotone, due to + // numerical issues when computing the inverse regularized incomplete + // Beta function. In these cases, we merge that bucket with its previous + // neighbor and merge their expected counts. + if ((cutoffs.empty() && boundary < kErr) || + (!cutoffs.empty() && boundary <= cutoffs.back())) { + unmerged_buckets++; + continue; + } + if (boundary >= 1.0 - 1e-10) { + break; + } + cutoffs.push_back(boundary); + expected.push_back(static_cast<double>(1 + unmerged_buckets) * + bucket_width * static_cast<double>(samples)); + unmerged_buckets = 0; + } + cutoffs.push_back(std::numeric_limits<double>::infinity()); + // Merge all remaining buckets. + expected.push_back(static_cast<double>(buckets - i + 1) * bucket_width * + static_cast<double>(samples)); + // Make sure that we don't merge all the buckets, making this test + // meaningless. + EXPECT_GE(cutoffs.size(), 3) << alpha_ << ", " << beta_; + + D dis(alpha_, beta_); + + std::vector<int32_t> counts(cutoffs.size(), 0); + for (int i = 0; i < samples; i++) { + const double x = dis(rng_); + auto it = std::upper_bound(cutoffs.begin(), cutoffs.end(), x); + counts[std::distance(cutoffs.begin(), it)]++; + } + + // Null-hypothesis is that the distribution is beta distributed with the + // provided alpha, beta params (not estimated from the data). + const int dof = cutoffs.size() - 1; + + const double chi_square = absl::random_internal::ChiSquare( + counts.begin(), counts.end(), expected.begin(), expected.end()); + const bool pass = + (absl::random_internal::ChiSquarePValue(chi_square, dof) >= p); + if (!pass) { + for (int i = 0; i < cutoffs.size(); i++) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("cutoff[%d] = %f, actual count %d, expected %d", + i, cutoffs[i], counts[i], + static_cast<int>(expected[i]))); + } + + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat( + "Beta(%f, %f) %s %f, p = %f", alpha_, beta_, + absl::random_internal::kChiSquared, chi_square, + absl::random_internal::ChiSquarePValue(chi_square, dof))); + } + return pass; +} + +TEST_P(BetaDistributionTest, TestSampleStatistics) { + static constexpr int kRuns = 20; + static constexpr double kPFail = 0.02; + const double p = + absl::random_internal::RequiredSuccessProbability(kPFail, kRuns); + static constexpr int kSampleCount = 10000; + static constexpr int kBucketCount = 100; + int failed = 0; + for (int i = 0; i < kRuns; ++i) { + if (!SingleZTestOnMeanAndVariance<absl::beta_distribution<double>>( + p, kSampleCount)) { + failed++; + } + if (!SingleChiSquaredTest<absl::beta_distribution<double>>( + 0.005, kSampleCount, kBucketCount)) { + failed++; + } + } + // Set so that the test is not flaky at --runs_per_test=10000 + EXPECT_LE(failed, 5); +} + +std::string ParamName( + const ::testing::TestParamInfo<::testing::tuple<double, double>>& info) { + std::string name = absl::StrCat("alpha_", ::testing::get<0>(info.param), + "__beta_", ::testing::get<1>(info.param)); + return absl::StrReplaceAll(name, {{"+", "_"}, {"-", "_"}, {".", "_"}}); +} + +INSTANTIATE_TEST_CASE_P( + TestSampleStatisticsCombinations, BetaDistributionTest, + ::testing::Combine(::testing::Values(0.1, 0.2, 0.9, 1.1, 2.5, 10.0, 123.4), + ::testing::Values(0.1, 0.2, 0.9, 1.1, 2.5, 10.0, 123.4)), + ParamName); + +INSTANTIATE_TEST_CASE_P( + TestSampleStatistics_SelectedPairs, BetaDistributionTest, + ::testing::Values(std::make_pair(0.5, 1000), std::make_pair(1000, 0.5), + std::make_pair(900, 1000), std::make_pair(10000, 20000), + std::make_pair(4e5, 2e7), std::make_pair(1e7, 1e5)), + ParamName); + +// NOTE: absl::beta_distribution is not guaranteed to be stable. +TEST(BetaDistributionTest, StabilityTest) { + // absl::beta_distribution stability relies on the stability of + // absl::random_interna::RandU64ToDouble, std::exp, std::log, std::pow, + // and std::sqrt. + // + // This test also depends on the stability of std::frexp. + using testing::ElementsAre; + absl::random_internal::sequence_urbg urbg({ + 0xffff00000000e6c8ull, 0xffff0000000006c8ull, 0x800003766295CFA9ull, + 0x11C819684E734A41ull, 0x832603766295CFA9ull, 0x7fbe76c8b4395800ull, + 0xB3472DCA7B14A94Aull, 0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, + 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, 0x00035C904C70A239ull, + 0x00009E0BCBAADE14ull, 0x0000000000622CA7ull, 0x4864f22c059bf29eull, + 0x247856d8b862665cull, 0xe46e86e9a1337e10ull, 0xd8c8541f3519b133ull, + 0xffe75b52c567b9e4ull, 0xfffff732e5709c5bull, 0xff1f7f0b983532acull, + 0x1ec2e8986d2362caull, 0xC332DDEFBE6C5AA5ull, 0x6558218568AB9702ull, + 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, 0xECDD4775619F1510ull, + 0x814c8e35fe9a961aull, 0x0c3cd59c9b638a02ull, 0xcb3bb6478a07715cull, + 0x1224e62c978bbc7full, 0x671ef2cb04e81f6eull, 0x3c1cbd811eaf1808ull, + 0x1bbc23cfa8fac721ull, 0xa4c2cda65e596a51ull, 0xb77216fad37adf91ull, + 0x836d794457c08849ull, 0xe083df03475f49d7ull, 0xbc9feb512e6b0d6cull, + 0xb12d74fdd718c8c5ull, 0x12ff09653bfbe4caull, 0x8dd03a105bc4ee7eull, + 0x5738341045ba0d85ull, 0xf3fd722dc65ad09eull, 0xfa14fd21ea2a5705ull, + 0xffe6ea4d6edb0c73ull, 0xD07E9EFE2BF11FB4ull, 0x95DBDA4DAE909198ull, + 0xEAAD8E716B93D5A0ull, 0xD08ED1D0AFC725E0ull, 0x8E3C5B2F8E7594B7ull, + 0x8FF6E2FBF2122B64ull, 0x8888B812900DF01Cull, 0x4FAD5EA0688FC31Cull, + 0xD1CFF191B3A8C1ADull, 0x2F2F2218BE0E1777ull, 0xEA752DFE8B021FA1ull, + }); + + // Convert the real-valued result into a unit64 where we compare + // 5 (float) or 10 (double) decimal digits plus the base-2 exponent. + auto float_to_u64 = [](float d) { + int exp = 0; + auto f = std::frexp(d, &exp); + return (static_cast<uint64_t>(1e5 * f) * 10000) + std::abs(exp); + }; + auto double_to_u64 = [](double d) { + int exp = 0; + auto f = std::frexp(d, &exp); + return (static_cast<uint64_t>(1e10 * f) * 10000) + std::abs(exp); + }; + + std::vector<uint64_t> output(20); + { + // Algorithm Joehnk (float) + absl::beta_distribution<float> dist(0.1f, 0.2f); + std::generate(std::begin(output), std::end(output), + [&] { return float_to_u64(dist(urbg)); }); + EXPECT_EQ(44, urbg.invocations()); + EXPECT_THAT(output, // + testing::ElementsAre( + 998340000, 619030004, 500000001, 999990000, 996280000, + 500000001, 844740004, 847210001, 999970000, 872320000, + 585480007, 933280000, 869080042, 647670031, 528240004, + 969980004, 626050008, 915930002, 833440033, 878040015)); + } + + urbg.reset(); + { + // Algorithm Joehnk (double) + absl::beta_distribution<double> dist(0.1, 0.2); + std::generate(std::begin(output), std::end(output), + [&] { return double_to_u64(dist(urbg)); }); + EXPECT_EQ(44, urbg.invocations()); + EXPECT_THAT( + output, // + testing::ElementsAre( + 99834713000000, 61903356870004, 50000000000001, 99999721170000, + 99628374770000, 99999999990000, 84474397860004, 84721276240001, + 99997407490000, 87232528120000, 58548364780007, 93328932910000, + 86908237770042, 64767917930031, 52824581970004, 96998544140004, + 62605946270008, 91593604380002, 83345031740033, 87804397230015)); + } + + urbg.reset(); + { + // Algorithm Cheng 1 + absl::beta_distribution<double> dist(0.9, 2.0); + std::generate(std::begin(output), std::end(output), + [&] { return double_to_u64(dist(urbg)); }); + EXPECT_EQ(62, urbg.invocations()); + EXPECT_THAT( + output, // + testing::ElementsAre( + 62069004780001, 64433204450001, 53607416560000, 89644295430008, + 61434586310019, 55172615890002, 62187161490000, 56433684810003, + 80454622050005, 86418558710003, 92920514700001, 64645184680001, + 58549183380000, 84881283650005, 71078728590002, 69949694970000, + 73157461710001, 68592191300001, 70747623900000, 78584696930005)); + } + + urbg.reset(); + { + // Algorithm Cheng 2 + absl::beta_distribution<double> dist(1.5, 2.5); + std::generate(std::begin(output), std::end(output), + [&] { return double_to_u64(dist(urbg)); }); + EXPECT_EQ(54, urbg.invocations()); + EXPECT_THAT( + output, // + testing::ElementsAre( + 75000029250001, 76751482860001, 53264575220000, 69193133650005, + 78028324470013, 91573587560002, 59167523770000, 60658618560002, + 80075870540000, 94141320460004, 63196592770003, 78883906300002, + 96797992590001, 76907587800001, 56645167560000, 65408302280003, + 53401156320001, 64731238570000, 83065573750001, 79788333820001)); + } +} + +// This is an implementation-specific test. If any part of the implementation +// changes, then it is likely that this test will change as well. Also, if +// dependencies of the distribution change, such as RandU64ToDouble, then this +// is also likely to change. +TEST(BetaDistributionTest, AlgorithmBounds) { + { + absl::random_internal::sequence_urbg urbg( + {0x7fbe76c8b4395800ull, 0x8000000000000000ull}); + // u=0.499, v=0.5 + absl::beta_distribution<double> dist(1e-4, 1e-4); + double a = dist(urbg); + EXPECT_EQ(a, 2.0202860861567108529e-09); + EXPECT_EQ(2, urbg.invocations()); + } + + // Test that both the float & double algorithms appropriately reject the + // initial draw. + { + // 1/alpha = 1/beta = 2. + absl::beta_distribution<float> dist(0.5, 0.5); + + // first two outputs are close to 1.0 - epsilon, + // thus: (u ^ 2 + v ^ 2) > 1.0 + absl::random_internal::sequence_urbg urbg( + {0xffff00000006e6c8ull, 0xffff00000007c7c8ull, 0x800003766295CFA9ull, + 0x11C819684E734A41ull}); + { + double y = absl::beta_distribution<double>(0.5, 0.5)(urbg); + EXPECT_EQ(4, urbg.invocations()); + EXPECT_EQ(y, 0.9810668952633862) << y; + } + + // ...and: log(u) * a ~= log(v) * b ~= -0.02 + // thus z ~= -0.02 + log(1 + e(~0)) + // ~= -0.02 + 0.69 + // thus z > 0 + urbg.reset(); + { + float x = absl::beta_distribution<float>(0.5, 0.5)(urbg); + EXPECT_EQ(4, urbg.invocations()); + EXPECT_NEAR(0.98106688261032104, x, 0.0000005) << x << "f"; + } + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/bit_gen_ref.h b/third_party/abseil_cpp/absl/random/bit_gen_ref.h new file mode 100644 index 0000000000..59591a479d --- /dev/null +++ b/third_party/abseil_cpp/absl/random/bit_gen_ref.h @@ -0,0 +1,152 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: bit_gen_ref.h +// ----------------------------------------------------------------------------- +// +// This header defines a bit generator "reference" class, for use in interfaces +// that take both Abseil (e.g. `absl::BitGen`) and standard library (e.g. +// `std::mt19937`) bit generators. + +#ifndef ABSL_RANDOM_BIT_GEN_REF_H_ +#define ABSL_RANDOM_BIT_GEN_REF_H_ + +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" +#include "absl/random/internal/distribution_caller.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/mocking_bit_gen_base.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +template <typename URBG, typename = void, typename = void, typename = void> +struct is_urbg : std::false_type {}; + +template <typename URBG> +struct is_urbg< + URBG, + absl::enable_if_t<std::is_same< + typename URBG::result_type, + typename std::decay<decltype((URBG::min)())>::type>::value>, + absl::enable_if_t<std::is_same< + typename URBG::result_type, + typename std::decay<decltype((URBG::max)())>::type>::value>, + absl::enable_if_t<std::is_same< + typename URBG::result_type, + typename std::decay<decltype(std::declval<URBG>()())>::type>::value>> + : std::true_type {}; + +} // namespace random_internal + +// ----------------------------------------------------------------------------- +// absl::BitGenRef +// ----------------------------------------------------------------------------- +// +// `absl::BitGenRef` is a type-erasing class that provides a generator-agnostic +// non-owning "reference" interface for use in place of any specific uniform +// random bit generator (URBG). This class may be used for both Abseil +// (e.g. `absl::BitGen`, `absl::InsecureBitGen`) and Standard library (e.g +// `std::mt19937`, `std::minstd_rand`) bit generators. +// +// Like other reference classes, `absl::BitGenRef` does not own the +// underlying bit generator, and the underlying instance must outlive the +// `absl::BitGenRef`. +// +// `absl::BitGenRef` is particularly useful when used with an +// `absl::MockingBitGen` to test specific paths in functions which use random +// values. +// +// Example: +// void TakesBitGenRef(absl::BitGenRef gen) { +// int x = absl::Uniform<int>(gen, 0, 1000); +// } +// +class BitGenRef { + public: + using result_type = uint64_t; + + BitGenRef(const absl::BitGenRef&) = default; + BitGenRef(absl::BitGenRef&&) = default; + BitGenRef& operator=(const absl::BitGenRef&) = default; + BitGenRef& operator=(absl::BitGenRef&&) = default; + + template <typename URBG, + typename absl::enable_if_t< + (!std::is_same<URBG, BitGenRef>::value && + random_internal::is_urbg<URBG>::value)>* = nullptr> + BitGenRef(URBG& gen) // NOLINT + : mocked_gen_ptr_(MakeMockPointer(&gen)), + t_erased_gen_ptr_(reinterpret_cast<uintptr_t>(&gen)), + generate_impl_fn_(ImplFn<URBG>) { + } + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + result_type operator()() { return generate_impl_fn_(t_erased_gen_ptr_); } + + private: + friend struct absl::random_internal::DistributionCaller<absl::BitGenRef>; + using impl_fn = result_type (*)(uintptr_t); + using mocker_base_t = absl::random_internal::MockingBitGenBase; + + // Convert an arbitrary URBG pointer into either a valid mocker_base_t + // pointer or a nullptr. + static inline mocker_base_t* MakeMockPointer(mocker_base_t* t) { return t; } + static inline mocker_base_t* MakeMockPointer(void*) { return nullptr; } + + template <typename URBG> + static result_type ImplFn(uintptr_t ptr) { + // Ensure that the return values from operator() fill the entire + // range promised by result_type, min() and max(). + absl::random_internal::FastUniformBits<result_type> fast_uniform_bits; + return fast_uniform_bits(*reinterpret_cast<URBG*>(ptr)); + } + + mocker_base_t* mocked_gen_ptr_; + uintptr_t t_erased_gen_ptr_; + impl_fn generate_impl_fn_; +}; + +namespace random_internal { + +template <> +struct DistributionCaller<absl::BitGenRef> { + template <typename DistrT, typename... Args> + static typename DistrT::result_type Call(absl::BitGenRef* gen_ref, + Args&&... args) { + auto* mock_ptr = gen_ref->mocked_gen_ptr_; + if (mock_ptr == nullptr) { + DistrT dist(std::forward<Args>(args)...); + return dist(*gen_ref); + } else { + return mock_ptr->template Call<DistrT>(std::forward<Args>(args)...); + } + } +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_BIT_GEN_REF_H_ diff --git a/third_party/abseil_cpp/absl/random/bit_gen_ref_test.cc b/third_party/abseil_cpp/absl/random/bit_gen_ref_test.cc new file mode 100644 index 0000000000..ca0e4d7072 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/bit_gen_ref_test.cc @@ -0,0 +1,101 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#include "absl/random/bit_gen_ref.h" + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class ConstBitGen : public absl::random_internal::MockingBitGenBase { + bool CallImpl(const std::type_info&, void*, void* result) override { + *static_cast<int*>(result) = 42; + return true; + } +}; + +namespace random_internal { +template <> +struct DistributionCaller<ConstBitGen> { + template <typename DistrT, typename FormatT, typename... Args> + static typename DistrT::result_type Call(ConstBitGen* gen, Args&&... args) { + return gen->template Call<DistrT, FormatT>(std::forward<Args>(args)...); + } +}; +} // namespace random_internal + +namespace { +int FnTest(absl::BitGenRef gen_ref) { return absl::Uniform(gen_ref, 1, 7); } + +template <typename T> +class BitGenRefTest : public testing::Test {}; + +using BitGenTypes = + ::testing::Types<absl::BitGen, absl::InsecureBitGen, std::mt19937, + std::mt19937_64, std::minstd_rand>; +TYPED_TEST_SUITE(BitGenRefTest, BitGenTypes); + +TYPED_TEST(BitGenRefTest, BasicTest) { + TypeParam gen; + auto x = FnTest(gen); + EXPECT_NEAR(x, 4, 3); +} + +TYPED_TEST(BitGenRefTest, Copyable) { + TypeParam gen; + absl::BitGenRef gen_ref(gen); + FnTest(gen_ref); // Copy +} + +TEST(BitGenRefTest, PassThroughEquivalence) { + // sequence_urbg returns 64-bit results. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<uint64_t> output(12); + + { + absl::BitGenRef view(urbg); + for (auto& v : output) { + v = view(); + } + } + + std::vector<uint64_t> expected( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + EXPECT_THAT(output, testing::Eq(expected)); +} + +TEST(BitGenRefTest, MockingBitGenBaseOverrides) { + ConstBitGen const_gen; + EXPECT_EQ(FnTest(const_gen), 42); + + absl::BitGenRef gen_ref(const_gen); + EXPECT_EQ(FnTest(gen_ref), 42); // Copy +} +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/discrete_distribution.cc b/third_party/abseil_cpp/absl/random/discrete_distribution.cc new file mode 100644 index 0000000000..081accee52 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/discrete_distribution.cc @@ -0,0 +1,98 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/discrete_distribution.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Initializes the distribution table for Walker's Aliasing algorithm, described +// in Knuth, Vol 2. as well as in https://en.wikipedia.org/wiki/Alias_method +std::vector<std::pair<double, size_t>> InitDiscreteDistribution( + std::vector<double>* probabilities) { + // The empty-case should already be handled by the constructor. + assert(probabilities); + assert(!probabilities->empty()); + + // Step 1. Normalize the input probabilities to 1.0. + double sum = std::accumulate(std::begin(*probabilities), + std::end(*probabilities), 0.0); + if (std::fabs(sum - 1.0) > 1e-6) { + // Scale `probabilities` only when the sum is too far from 1.0. Scaling + // unconditionally will alter the probabilities slightly. + for (double& item : *probabilities) { + item = item / sum; + } + } + + // Step 2. At this point `probabilities` is set to the conditional + // probabilities of each element which sum to 1.0, to within reasonable error. + // These values are used to construct the proportional probability tables for + // the selection phases of Walker's Aliasing algorithm. + // + // To construct the table, pick an element which is under-full (i.e., an + // element for which `(*probabilities)[i] < 1.0/n`), and pair it with an + // element which is over-full (i.e., an element for which + // `(*probabilities)[i] > 1.0/n`). The smaller value can always be retired. + // The larger may still be greater than 1.0/n, or may now be less than 1.0/n, + // and put back onto the appropriate collection. + const size_t n = probabilities->size(); + std::vector<std::pair<double, size_t>> q; + q.reserve(n); + + std::vector<size_t> over; + std::vector<size_t> under; + size_t idx = 0; + for (const double item : *probabilities) { + assert(item >= 0); + const double v = item * n; + q.emplace_back(v, 0); + if (v < 1.0) { + under.push_back(idx++); + } else { + over.push_back(idx++); + } + } + while (!over.empty() && !under.empty()) { + auto lo = under.back(); + under.pop_back(); + auto hi = over.back(); + over.pop_back(); + + q[lo].second = hi; + const double r = q[hi].first - (1.0 - q[lo].first); + q[hi].first = r; + if (r < 1.0) { + under.push_back(hi); + } else { + over.push_back(hi); + } + } + + // Due to rounding errors, there may be un-paired elements in either + // collection; these should all be values near 1.0. For these values, set `q` + // to 1.0 and set the alternate to the identity. + for (auto i : over) { + q[i] = {1.0, i}; + } + for (auto i : under) { + q[i] = {1.0, i}; + } + return q; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/discrete_distribution.h b/third_party/abseil_cpp/absl/random/discrete_distribution.h new file mode 100644 index 0000000000..171aa11a1e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/discrete_distribution.h @@ -0,0 +1,247 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_DISCRETE_DISTRIBUTION_H_ +#define ABSL_RANDOM_DISCRETE_DISTRIBUTION_H_ + +#include <cassert> +#include <cmath> +#include <istream> +#include <limits> +#include <numeric> +#include <type_traits> +#include <utility> +#include <vector> + +#include "absl/random/bernoulli_distribution.h" +#include "absl/random/internal/iostream_state_saver.h" +#include "absl/random/uniform_int_distribution.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::discrete_distribution +// +// A discrete distribution produces random integers i, where 0 <= i < n +// distributed according to the discrete probability function: +// +// P(i|p0,...,pn−1)=pi +// +// This class is an implementation of discrete_distribution (see +// [rand.dist.samp.discrete]). +// +// The algorithm used is Walker's Aliasing algorithm, described in Knuth, Vol 2. +// absl::discrete_distribution takes O(N) time to precompute the probabilities +// (where N is the number of possible outcomes in the distribution) at +// construction, and then takes O(1) time for each variate generation. Many +// other implementations also take O(N) time to construct an ordered sequence of +// partial sums, plus O(log N) time per variate to binary search. +// +template <typename IntType = int> +class discrete_distribution { + public: + using result_type = IntType; + + class param_type { + public: + using distribution_type = discrete_distribution; + + param_type() { init(); } + + template <typename InputIterator> + explicit param_type(InputIterator begin, InputIterator end) + : p_(begin, end) { + init(); + } + + explicit param_type(std::initializer_list<double> weights) : p_(weights) { + init(); + } + + template <class UnaryOperation> + explicit param_type(size_t nw, double xmin, double xmax, + UnaryOperation fw) { + if (nw > 0) { + p_.reserve(nw); + double delta = (xmax - xmin) / static_cast<double>(nw); + assert(delta > 0); + double t = delta * 0.5; + for (size_t i = 0; i < nw; ++i) { + p_.push_back(fw(xmin + i * delta + t)); + } + } + init(); + } + + const std::vector<double>& probabilities() const { return p_; } + size_t n() const { return p_.size() - 1; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.probabilities() == b.probabilities(); + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class discrete_distribution; + + void init(); + + std::vector<double> p_; // normalized probabilities + std::vector<std::pair<double, size_t>> q_; // (acceptance, alternate) pairs + + static_assert(std::is_integral<result_type>::value, + "Class-template absl::discrete_distribution<> must be " + "parameterized using an integral type."); + }; + + discrete_distribution() : param_() {} + + explicit discrete_distribution(const param_type& p) : param_(p) {} + + template <typename InputIterator> + explicit discrete_distribution(InputIterator begin, InputIterator end) + : param_(begin, end) {} + + explicit discrete_distribution(std::initializer_list<double> weights) + : param_(weights) {} + + template <class UnaryOperation> + explicit discrete_distribution(size_t nw, double xmin, double xmax, + UnaryOperation fw) + : param_(nw, xmin, xmax, std::move(fw)) {} + + void reset() {} + + // generating functions + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + const param_type& param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + result_type(min)() const { return 0; } + result_type(max)() const { + return static_cast<result_type>(param_.n()); + } // inclusive + + // NOTE [rand.dist.sample.discrete] returns a std::vector<double> not a + // const std::vector<double>&. + const std::vector<double>& probabilities() const { + return param_.probabilities(); + } + + friend bool operator==(const discrete_distribution& a, + const discrete_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const discrete_distribution& a, + const discrete_distribution& b) { + return a.param_ != b.param_; + } + + private: + param_type param_; +}; + +// -------------------------------------------------------------------------- +// Implementation details only below +// -------------------------------------------------------------------------- + +namespace random_internal { + +// Using the vector `*probabilities`, whose values are the weights or +// probabilities of an element being selected, constructs the proportional +// probabilities used by the discrete distribution. `*probabilities` will be +// scaled, if necessary, so that its entries sum to a value sufficiently close +// to 1.0. +std::vector<std::pair<double, size_t>> InitDiscreteDistribution( + std::vector<double>* probabilities); + +} // namespace random_internal + +template <typename IntType> +void discrete_distribution<IntType>::param_type::init() { + if (p_.empty()) { + p_.push_back(1.0); + q_.emplace_back(1.0, 0); + } else { + assert(n() <= (std::numeric_limits<IntType>::max)()); + q_ = random_internal::InitDiscreteDistribution(&p_); + } +} + +template <typename IntType> +template <typename URBG> +typename discrete_distribution<IntType>::result_type +discrete_distribution<IntType>::operator()( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + const auto idx = absl::uniform_int_distribution<result_type>(0, p.n())(g); + const auto& q = p.q_[idx]; + const bool selected = absl::bernoulli_distribution(q.first)(g); + return selected ? idx : static_cast<result_type>(q.second); +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const discrete_distribution<IntType>& x) { + auto saver = random_internal::make_ostream_state_saver(os); + const auto& probabilities = x.param().probabilities(); + os << probabilities.size(); + + os.precision(random_internal::stream_precision_helper<double>::kPrecision); + for (const auto& p : probabilities) { + os << os.fill() << p; + } + return os; +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + discrete_distribution<IntType>& x) { // NOLINT(runtime/references) + using param_type = typename discrete_distribution<IntType>::param_type; + auto saver = random_internal::make_istream_state_saver(is); + + size_t n; + std::vector<double> p; + + is >> n; + if (is.fail()) return is; + if (n > 0) { + p.reserve(n); + for (IntType i = 0; i < n && !is.fail(); ++i) { + auto tmp = random_internal::read_floating_point<double>(is); + if (is.fail()) return is; + p.push_back(tmp); + } + } + x.param(param_type(p.begin(), p.end())); + return is; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_DISCRETE_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/discrete_distribution_test.cc b/third_party/abseil_cpp/absl/random/discrete_distribution_test.cc new file mode 100644 index 0000000000..6d007006ef --- /dev/null +++ b/third_party/abseil_cpp/absl/random/discrete_distribution_test.cc @@ -0,0 +1,250 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/discrete_distribution.h" + +#include <cmath> +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <numeric> +#include <random> +#include <sstream> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/strip.h" + +namespace { + +template <typename IntType> +class DiscreteDistributionTypeTest : public ::testing::Test {}; + +using IntTypes = ::testing::Types<int8_t, uint8_t, int16_t, uint16_t, int32_t, + uint32_t, int64_t, uint64_t>; +TYPED_TEST_SUITE(DiscreteDistributionTypeTest, IntTypes); + +TYPED_TEST(DiscreteDistributionTypeTest, ParamSerializeTest) { + using param_type = + typename absl::discrete_distribution<TypeParam>::param_type; + + absl::discrete_distribution<TypeParam> empty; + EXPECT_THAT(empty.probabilities(), testing::ElementsAre(1.0)); + + absl::discrete_distribution<TypeParam> before({1.0, 2.0, 1.0}); + + // Validate that the probabilities sum to 1.0. We picked values which + // can be represented exactly to avoid floating-point roundoff error. + double s = 0; + for (const auto& x : before.probabilities()) { + s += x; + } + EXPECT_EQ(s, 1.0); + EXPECT_THAT(before.probabilities(), testing::ElementsAre(0.25, 0.5, 0.25)); + + // Validate the same data via an initializer list. + { + std::vector<double> data({1.0, 2.0, 1.0}); + + absl::discrete_distribution<TypeParam> via_param{ + param_type(std::begin(data), std::end(data))}; + + EXPECT_EQ(via_param, before); + } + + std::stringstream ss; + ss << before; + absl::discrete_distribution<TypeParam> after; + + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before, after); +} + +TYPED_TEST(DiscreteDistributionTypeTest, Constructor) { + auto fn = [](double x) { return x; }; + { + absl::discrete_distribution<int> unary(0, 1.0, 9.0, fn); + EXPECT_THAT(unary.probabilities(), testing::ElementsAre(1.0)); + } + + { + absl::discrete_distribution<int> unary(2, 1.0, 9.0, fn); + // => fn(1.0 + 0 * 4 + 2) => 3 + // => fn(1.0 + 1 * 4 + 2) => 7 + EXPECT_THAT(unary.probabilities(), testing::ElementsAre(0.3, 0.7)); + } +} + +TEST(DiscreteDistributionTest, InitDiscreteDistribution) { + using testing::Pair; + + { + std::vector<double> p({1.0, 2.0, 3.0}); + std::vector<std::pair<double, size_t>> q = + absl::random_internal::InitDiscreteDistribution(&p); + + EXPECT_THAT(p, testing::ElementsAre(1 / 6.0, 2 / 6.0, 3 / 6.0)); + + // Each bucket is p=1/3, so bucket 0 will send half it's traffic + // to bucket 2, while the rest will retain all of their traffic. + EXPECT_THAT(q, testing::ElementsAre(Pair(0.5, 2), // + Pair(1.0, 1), // + Pair(1.0, 2))); + } + + { + std::vector<double> p({1.0, 2.0, 3.0, 5.0, 2.0}); + + std::vector<std::pair<double, size_t>> q = + absl::random_internal::InitDiscreteDistribution(&p); + + EXPECT_THAT(p, testing::ElementsAre(1 / 13.0, 2 / 13.0, 3 / 13.0, 5 / 13.0, + 2 / 13.0)); + + // A more complex bucketing solution: Each bucket has p=0.2 + // So buckets 0, 1, 4 will send their alternate traffic elsewhere, which + // happens to be bucket 3. + // However, summing up that alternate traffic gives bucket 3 too much + // traffic, so it will send some traffic to bucket 2. + constexpr double b0 = 1.0 / 13.0 / 0.2; + constexpr double b1 = 2.0 / 13.0 / 0.2; + constexpr double b3 = (5.0 / 13.0 / 0.2) - ((1 - b0) + (1 - b1) + (1 - b1)); + + EXPECT_THAT(q, testing::ElementsAre(Pair(b0, 3), // + Pair(b1, 3), // + Pair(1.0, 2), // + Pair(b3, 2), // + Pair(b1, 3))); + } +} + +TEST(DiscreteDistributionTest, ChiSquaredTest50) { + using absl::random_internal::kChiSquared; + + constexpr size_t kTrials = 10000; + constexpr int kBuckets = 50; // inclusive, so actally +1 + + // 1-in-100000 threshold, but remember, there are about 8 tests + // in this file. And the test could fail for other reasons. + // Empirically validated with --runs_per_test=10000. + const int kThreshold = + absl::random_internal::ChiSquareValue(kBuckets, 0.99999); + + std::vector<double> weights(kBuckets, 0); + std::iota(std::begin(weights), std::end(weights), 1); + absl::discrete_distribution<int> dist(std::begin(weights), std::end(weights)); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng(0x2B7E151628AED2A6); + + std::vector<int32_t> counts(kBuckets, 0); + for (size_t i = 0; i < kTrials; i++) { + auto x = dist(rng); + counts[x]++; + } + + // Scale weights. + double sum = 0; + for (double x : weights) { + sum += x; + } + for (double& x : weights) { + x = kTrials * (x / sum); + } + + double chi_square = + absl::random_internal::ChiSquare(std::begin(counts), std::end(counts), + std::begin(weights), std::end(weights)); + + if (chi_square > kThreshold) { + double p_value = + absl::random_internal::ChiSquarePValue(chi_square, kBuckets); + + // Chi-squared test failed. Output does not appear to be uniform. + std::string msg; + for (size_t i = 0; i < counts.size(); i++) { + absl::StrAppend(&msg, i, ": ", counts[i], " vs ", weights[i], "\n"); + } + absl::StrAppend(&msg, kChiSquared, " p-value ", p_value, "\n"); + absl::StrAppend(&msg, "High ", kChiSquared, " value: ", chi_square, " > ", + kThreshold); + ABSL_RAW_LOG(INFO, "%s", msg.c_str()); + FAIL() << msg; + } +} + +TEST(DiscreteDistributionTest, StabilityTest) { + // absl::discrete_distribution stabilitiy relies on + // absl::uniform_int_distribution and absl::bernoulli_distribution. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(6); + + { + absl::discrete_distribution<int32_t> dist({1.0, 2.0, 3.0, 5.0, 2.0}); + EXPECT_EQ(0, dist.min()); + EXPECT_EQ(4, dist.max()); + for (auto& v : output) { + v = dist(urbg); + } + EXPECT_EQ(12, urbg.invocations()); + } + + // With 12 calls to urbg, each call into discrete_distribution consumes + // precisely 2 values: one for the uniform call, and a second for the + // bernoulli. + // + // Given the alt mapping: 0=>3, 1=>3, 2=>2, 3=>2, 4=>3, we can + // + // uniform: 443210143131 + // bernoulli: b0 000011100101 + // bernoulli: b1 001111101101 + // bernoulli: b2 111111111111 + // bernoulli: b3 001111101111 + // bernoulli: b4 001111101101 + // ... + EXPECT_THAT(output, testing::ElementsAre(3, 3, 1, 3, 3, 3)); + + { + urbg.reset(); + absl::discrete_distribution<int64_t> dist({1.0, 2.0, 3.0, 5.0, 2.0}); + EXPECT_EQ(0, dist.min()); + EXPECT_EQ(4, dist.max()); + for (auto& v : output) { + v = dist(urbg); + } + EXPECT_EQ(12, urbg.invocations()); + } + EXPECT_THAT(output, testing::ElementsAre(3, 3, 0, 3, 0, 4)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/distributions.h b/third_party/abseil_cpp/absl/random/distributions.h new file mode 100644 index 0000000000..8680f6a66f --- /dev/null +++ b/third_party/abseil_cpp/absl/random/distributions.h @@ -0,0 +1,452 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: distributions.h +// ----------------------------------------------------------------------------- +// +// This header defines functions representing distributions, which you use in +// combination with an Abseil random bit generator to produce random values +// according to the rules of that distribution. +// +// The Abseil random library defines the following distributions within this +// file: +// +// * `absl::Uniform` for uniform (constant) distributions having constant +// probability +// * `absl::Bernoulli` for discrete distributions having exactly two outcomes +// * `absl::Beta` for continuous distributions parameterized through two +// free parameters +// * `absl::Exponential` for discrete distributions of events occurring +// continuously and independently at a constant average rate +// * `absl::Gaussian` (also known as "normal distributions") for continuous +// distributions using an associated quadratic function +// * `absl::LogUniform` for continuous uniform distributions where the log +// to the given base of all values is uniform +// * `absl::Poisson` for discrete probability distributions that express the +// probability of a given number of events occurring within a fixed interval +// * `absl::Zipf` for discrete probability distributions commonly used for +// modelling of rare events +// +// Prefer use of these distribution function classes over manual construction of +// your own distribution classes, as it allows library maintainers greater +// flexibility to change the underlying implementation in the future. + +#ifndef ABSL_RANDOM_DISTRIBUTIONS_H_ +#define ABSL_RANDOM_DISTRIBUTIONS_H_ + +#include <algorithm> +#include <cmath> +#include <limits> +#include <random> +#include <type_traits> + +#include "absl/base/internal/inline_variable.h" +#include "absl/random/bernoulli_distribution.h" +#include "absl/random/beta_distribution.h" +#include "absl/random/exponential_distribution.h" +#include "absl/random/gaussian_distribution.h" +#include "absl/random/internal/distributions.h" // IWYU pragma: export +#include "absl/random/internal/uniform_helper.h" // IWYU pragma: export +#include "absl/random/log_uniform_int_distribution.h" +#include "absl/random/poisson_distribution.h" +#include "absl/random/uniform_int_distribution.h" +#include "absl/random/uniform_real_distribution.h" +#include "absl/random/zipf_distribution.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +ABSL_INTERNAL_INLINE_CONSTEXPR(IntervalClosedClosedTag, IntervalClosedClosed, + {}); +ABSL_INTERNAL_INLINE_CONSTEXPR(IntervalClosedClosedTag, IntervalClosed, {}); +ABSL_INTERNAL_INLINE_CONSTEXPR(IntervalClosedOpenTag, IntervalClosedOpen, {}); +ABSL_INTERNAL_INLINE_CONSTEXPR(IntervalOpenOpenTag, IntervalOpenOpen, {}); +ABSL_INTERNAL_INLINE_CONSTEXPR(IntervalOpenOpenTag, IntervalOpen, {}); +ABSL_INTERNAL_INLINE_CONSTEXPR(IntervalOpenClosedTag, IntervalOpenClosed, {}); + +// ----------------------------------------------------------------------------- +// absl::Uniform<T>(tag, bitgen, lo, hi) +// ----------------------------------------------------------------------------- +// +// `absl::Uniform()` produces random values of type `T` uniformly distributed in +// a defined interval {lo, hi}. The interval `tag` defines the type of interval +// which should be one of the following possible values: +// +// * `absl::IntervalOpenOpen` +// * `absl::IntervalOpenClosed` +// * `absl::IntervalClosedOpen` +// * `absl::IntervalClosedClosed` +// +// where "open" refers to an exclusive value (excluded) from the output, while +// "closed" refers to an inclusive value (included) from the output. +// +// In the absence of an explicit return type `T`, `absl::Uniform()` will deduce +// the return type based on the provided endpoint arguments {A lo, B hi}. +// Given these endpoints, one of {A, B} will be chosen as the return type, if +// a type can be implicitly converted into the other in a lossless way. The +// lack of any such implicit conversion between {A, B} will produce a +// compile-time error +// +// See https://en.wikipedia.org/wiki/Uniform_distribution_(continuous) +// +// Example: +// +// absl::BitGen bitgen; +// +// // Produce a random float value between 0.0 and 1.0, inclusive +// auto x = absl::Uniform(absl::IntervalClosedClosed, bitgen, 0.0f, 1.0f); +// +// // The most common interval of `absl::IntervalClosedOpen` is available by +// // default: +// +// auto x = absl::Uniform(bitgen, 0.0f, 1.0f); +// +// // Return-types are typically inferred from the arguments, however callers +// // can optionally provide an explicit return-type to the template. +// +// auto x = absl::Uniform<float>(bitgen, 0, 1); +// +template <typename R = void, typename TagType, typename URBG> +typename absl::enable_if_t<!std::is_same<R, void>::value, R> // +Uniform(TagType tag, + URBG&& urbg, // NOLINT(runtime/references) + R lo, R hi) { + using gen_t = absl::decay_t<URBG>; + using distribution_t = random_internal::UniformDistributionWrapper<R>; + + auto a = random_internal::uniform_lower_bound(tag, lo, hi); + auto b = random_internal::uniform_upper_bound(tag, lo, hi); + if (a > b) return a; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, tag, lo, hi); +} + +// absl::Uniform<T>(bitgen, lo, hi) +// +// Overload of `Uniform()` using the default closed-open interval of [lo, hi), +// and returning values of type `T` +template <typename R = void, typename URBG> +typename absl::enable_if_t<!std::is_same<R, void>::value, R> // +Uniform(URBG&& urbg, // NOLINT(runtime/references) + R lo, R hi) { + using gen_t = absl::decay_t<URBG>; + using distribution_t = random_internal::UniformDistributionWrapper<R>; + + constexpr auto tag = absl::IntervalClosedOpen; + auto a = random_internal::uniform_lower_bound(tag, lo, hi); + auto b = random_internal::uniform_upper_bound(tag, lo, hi); + if (a > b) return a; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, lo, hi); +} + +// absl::Uniform(tag, bitgen, lo, hi) +// +// Overload of `Uniform()` using different (but compatible) lo, hi types. Note +// that a compile-error will result if the return type cannot be deduced +// correctly from the passed types. +template <typename R = void, typename TagType, typename URBG, typename A, + typename B> +typename absl::enable_if_t<std::is_same<R, void>::value, + random_internal::uniform_inferred_return_t<A, B>> +Uniform(TagType tag, + URBG&& urbg, // NOLINT(runtime/references) + A lo, B hi) { + using gen_t = absl::decay_t<URBG>; + using return_t = typename random_internal::uniform_inferred_return_t<A, B>; + using distribution_t = random_internal::UniformDistributionWrapper<return_t>; + + auto a = random_internal::uniform_lower_bound<return_t>(tag, lo, hi); + auto b = random_internal::uniform_upper_bound<return_t>(tag, lo, hi); + if (a > b) return a; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, tag, static_cast<return_t>(lo), + static_cast<return_t>(hi)); +} + +// absl::Uniform(bitgen, lo, hi) +// +// Overload of `Uniform()` using different (but compatible) lo, hi types and the +// default closed-open interval of [lo, hi). Note that a compile-error will +// result if the return type cannot be deduced correctly from the passed types. +template <typename R = void, typename URBG, typename A, typename B> +typename absl::enable_if_t<std::is_same<R, void>::value, + random_internal::uniform_inferred_return_t<A, B>> +Uniform(URBG&& urbg, // NOLINT(runtime/references) + A lo, B hi) { + using gen_t = absl::decay_t<URBG>; + using return_t = typename random_internal::uniform_inferred_return_t<A, B>; + using distribution_t = random_internal::UniformDistributionWrapper<return_t>; + + constexpr auto tag = absl::IntervalClosedOpen; + auto a = random_internal::uniform_lower_bound<return_t>(tag, lo, hi); + auto b = random_internal::uniform_upper_bound<return_t>(tag, lo, hi); + if (a > b) return a; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, static_cast<return_t>(lo), + static_cast<return_t>(hi)); +} + +// absl::Uniform<unsigned T>(bitgen) +// +// Overload of Uniform() using the minimum and maximum values of a given type +// `T` (which must be unsigned), returning a value of type `unsigned T` +template <typename R, typename URBG> +typename absl::enable_if_t<!std::is_signed<R>::value, R> // +Uniform(URBG&& urbg) { // NOLINT(runtime/references) + using gen_t = absl::decay_t<URBG>; + using distribution_t = random_internal::UniformDistributionWrapper<R>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg); +} + +// ----------------------------------------------------------------------------- +// absl::Bernoulli(bitgen, p) +// ----------------------------------------------------------------------------- +// +// `absl::Bernoulli` produces a random boolean value, with probability `p` +// (where 0.0 <= p <= 1.0) equaling `true`. +// +// Prefer `absl::Bernoulli` to produce boolean values over other alternatives +// such as comparing an `absl::Uniform()` value to a specific output. +// +// See https://en.wikipedia.org/wiki/Bernoulli_distribution +// +// Example: +// +// absl::BitGen bitgen; +// ... +// if (absl::Bernoulli(bitgen, 1.0/3721.0)) { +// std::cout << "Asteroid field navigation successful."; +// } +// +template <typename URBG> +bool Bernoulli(URBG&& urbg, // NOLINT(runtime/references) + double p) { + using gen_t = absl::decay_t<URBG>; + using distribution_t = absl::bernoulli_distribution; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, p); +} + +// ----------------------------------------------------------------------------- +// absl::Beta<T>(bitgen, alpha, beta) +// ----------------------------------------------------------------------------- +// +// `absl::Beta` produces a floating point number distributed in the closed +// interval [0,1] and parameterized by two values `alpha` and `beta` as per a +// Beta distribution. `T` must be a floating point type, but may be inferred +// from the types of `alpha` and `beta`. +// +// See https://en.wikipedia.org/wiki/Beta_distribution. +// +// Example: +// +// absl::BitGen bitgen; +// ... +// double sample = absl::Beta(bitgen, 3.0, 2.0); +// +template <typename RealType, typename URBG> +RealType Beta(URBG&& urbg, // NOLINT(runtime/references) + RealType alpha, RealType beta) { + static_assert( + std::is_floating_point<RealType>::value, + "Template-argument 'RealType' must be a floating-point type, in " + "absl::Beta<RealType, URBG>(...)"); + + using gen_t = absl::decay_t<URBG>; + using distribution_t = typename absl::beta_distribution<RealType>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, alpha, beta); +} + +// ----------------------------------------------------------------------------- +// absl::Exponential<T>(bitgen, lambda = 1) +// ----------------------------------------------------------------------------- +// +// `absl::Exponential` produces a floating point number representing the +// distance (time) between two consecutive events in a point process of events +// occurring continuously and independently at a constant average rate. `T` must +// be a floating point type, but may be inferred from the type of `lambda`. +// +// See https://en.wikipedia.org/wiki/Exponential_distribution. +// +// Example: +// +// absl::BitGen bitgen; +// ... +// double call_length = absl::Exponential(bitgen, 7.0); +// +template <typename RealType, typename URBG> +RealType Exponential(URBG&& urbg, // NOLINT(runtime/references) + RealType lambda = 1) { + static_assert( + std::is_floating_point<RealType>::value, + "Template-argument 'RealType' must be a floating-point type, in " + "absl::Exponential<RealType, URBG>(...)"); + + using gen_t = absl::decay_t<URBG>; + using distribution_t = typename absl::exponential_distribution<RealType>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, lambda); +} + +// ----------------------------------------------------------------------------- +// absl::Gaussian<T>(bitgen, mean = 0, stddev = 1) +// ----------------------------------------------------------------------------- +// +// `absl::Gaussian` produces a floating point number selected from the Gaussian +// (ie. "Normal") distribution. `T` must be a floating point type, but may be +// inferred from the types of `mean` and `stddev`. +// +// See https://en.wikipedia.org/wiki/Normal_distribution +// +// Example: +// +// absl::BitGen bitgen; +// ... +// double giraffe_height = absl::Gaussian(bitgen, 16.3, 3.3); +// +template <typename RealType, typename URBG> +RealType Gaussian(URBG&& urbg, // NOLINT(runtime/references) + RealType mean = 0, RealType stddev = 1) { + static_assert( + std::is_floating_point<RealType>::value, + "Template-argument 'RealType' must be a floating-point type, in " + "absl::Gaussian<RealType, URBG>(...)"); + + using gen_t = absl::decay_t<URBG>; + using distribution_t = typename absl::gaussian_distribution<RealType>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, mean, stddev); +} + +// ----------------------------------------------------------------------------- +// absl::LogUniform<T>(bitgen, lo, hi, base = 2) +// ----------------------------------------------------------------------------- +// +// `absl::LogUniform` produces random values distributed where the log to a +// given base of all values is uniform in a closed interval [lo, hi]. `T` must +// be an integral type, but may be inferred from the types of `lo` and `hi`. +// +// I.e., `LogUniform(0, n, b)` is uniformly distributed across buckets +// [0], [1, b-1], [b, b^2-1] .. [b^(k-1), (b^k)-1] .. [b^floor(log(n, b)), n] +// and is uniformly distributed within each bucket. +// +// The resulting probability density is inversely related to bucket size, though +// values in the final bucket may be more likely than previous values. (In the +// extreme case where n = b^i the final value will be tied with zero as the most +// probable result. +// +// If `lo` is nonzero then this distribution is shifted to the desired interval, +// so LogUniform(lo, hi, b) is equivalent to LogUniform(0, hi-lo, b)+lo. +// +// See http://ecolego.facilia.se/ecolego/show/Log-Uniform%20Distribution +// +// Example: +// +// absl::BitGen bitgen; +// ... +// int v = absl::LogUniform(bitgen, 0, 1000); +// +template <typename IntType, typename URBG> +IntType LogUniform(URBG&& urbg, // NOLINT(runtime/references) + IntType lo, IntType hi, IntType base = 2) { + static_assert(std::is_integral<IntType>::value, + "Template-argument 'IntType' must be an integral type, in " + "absl::LogUniform<IntType, URBG>(...)"); + + using gen_t = absl::decay_t<URBG>; + using distribution_t = typename absl::log_uniform_int_distribution<IntType>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, lo, hi, base); +} + +// ----------------------------------------------------------------------------- +// absl::Poisson<T>(bitgen, mean = 1) +// ----------------------------------------------------------------------------- +// +// `absl::Poisson` produces discrete probabilities for a given number of events +// occurring within a fixed interval within the closed interval [0, max]. `T` +// must be an integral type. +// +// See https://en.wikipedia.org/wiki/Poisson_distribution +// +// Example: +// +// absl::BitGen bitgen; +// ... +// int requests_per_minute = absl::Poisson<int>(bitgen, 3.2); +// +template <typename IntType, typename URBG> +IntType Poisson(URBG&& urbg, // NOLINT(runtime/references) + double mean = 1.0) { + static_assert(std::is_integral<IntType>::value, + "Template-argument 'IntType' must be an integral type, in " + "absl::Poisson<IntType, URBG>(...)"); + + using gen_t = absl::decay_t<URBG>; + using distribution_t = typename absl::poisson_distribution<IntType>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, mean); +} + +// ----------------------------------------------------------------------------- +// absl::Zipf<T>(bitgen, hi = max, q = 2, v = 1) +// ----------------------------------------------------------------------------- +// +// `absl::Zipf` produces discrete probabilities commonly used for modelling of +// rare events over the closed interval [0, hi]. The parameters `v` and `q` +// determine the skew of the distribution. `T` must be an integral type, but +// may be inferred from the type of `hi`. +// +// See http://mathworld.wolfram.com/ZipfDistribution.html +// +// Example: +// +// absl::BitGen bitgen; +// ... +// int term_rank = absl::Zipf<int>(bitgen); +// +template <typename IntType, typename URBG> +IntType Zipf(URBG&& urbg, // NOLINT(runtime/references) + IntType hi = (std::numeric_limits<IntType>::max)(), double q = 2.0, + double v = 1.0) { + static_assert(std::is_integral<IntType>::value, + "Template-argument 'IntType' must be an integral type, in " + "absl::Zipf<IntType, URBG>(...)"); + + using gen_t = absl::decay_t<URBG>; + using distribution_t = typename absl::zipf_distribution<IntType>; + + return random_internal::DistributionCaller<gen_t>::template Call< + distribution_t>(&urbg, hi, q, v); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_DISTRIBUTIONS_H_ diff --git a/third_party/abseil_cpp/absl/random/distributions_test.cc b/third_party/abseil_cpp/absl/random/distributions_test.cc new file mode 100644 index 0000000000..2d92723ad2 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/distributions_test.cc @@ -0,0 +1,489 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/distributions.h" + +#include <cmath> +#include <cstdint> +#include <random> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/random.h" + +namespace { + +constexpr int kSize = 400000; + +class RandomDistributionsTest : public testing::Test {}; + +TEST_F(RandomDistributionsTest, UniformBoundFunctions) { + using absl::IntervalClosedClosed; + using absl::IntervalClosedOpen; + using absl::IntervalOpenClosed; + using absl::IntervalOpenOpen; + using absl::random_internal::uniform_lower_bound; + using absl::random_internal::uniform_upper_bound; + + // absl::uniform_int_distribution natively assumes IntervalClosedClosed + // absl::uniform_real_distribution natively assumes IntervalClosedOpen + + EXPECT_EQ(uniform_lower_bound(IntervalOpenClosed, 0, 100), 1); + EXPECT_EQ(uniform_lower_bound(IntervalOpenOpen, 0, 100), 1); + EXPECT_GT(uniform_lower_bound<float>(IntervalOpenClosed, 0, 1.0), 0); + EXPECT_GT(uniform_lower_bound<float>(IntervalOpenOpen, 0, 1.0), 0); + EXPECT_GT(uniform_lower_bound<double>(IntervalOpenClosed, 0, 1.0), 0); + EXPECT_GT(uniform_lower_bound<double>(IntervalOpenOpen, 0, 1.0), 0); + + EXPECT_EQ(uniform_lower_bound(IntervalClosedClosed, 0, 100), 0); + EXPECT_EQ(uniform_lower_bound(IntervalClosedOpen, 0, 100), 0); + EXPECT_EQ(uniform_lower_bound<float>(IntervalClosedClosed, 0, 1.0), 0); + EXPECT_EQ(uniform_lower_bound<float>(IntervalClosedOpen, 0, 1.0), 0); + EXPECT_EQ(uniform_lower_bound<double>(IntervalClosedClosed, 0, 1.0), 0); + EXPECT_EQ(uniform_lower_bound<double>(IntervalClosedOpen, 0, 1.0), 0); + + EXPECT_EQ(uniform_upper_bound(IntervalOpenOpen, 0, 100), 99); + EXPECT_EQ(uniform_upper_bound(IntervalClosedOpen, 0, 100), 99); + EXPECT_EQ(uniform_upper_bound<float>(IntervalOpenOpen, 0, 1.0), 1.0); + EXPECT_EQ(uniform_upper_bound<float>(IntervalClosedOpen, 0, 1.0), 1.0); + EXPECT_EQ(uniform_upper_bound<double>(IntervalOpenOpen, 0, 1.0), 1.0); + EXPECT_EQ(uniform_upper_bound<double>(IntervalClosedOpen, 0, 1.0), 1.0); + + EXPECT_EQ(uniform_upper_bound(IntervalOpenClosed, 0, 100), 100); + EXPECT_EQ(uniform_upper_bound(IntervalClosedClosed, 0, 100), 100); + EXPECT_GT(uniform_upper_bound<float>(IntervalOpenClosed, 0, 1.0), 1.0); + EXPECT_GT(uniform_upper_bound<float>(IntervalClosedClosed, 0, 1.0), 1.0); + EXPECT_GT(uniform_upper_bound<double>(IntervalOpenClosed, 0, 1.0), 1.0); + EXPECT_GT(uniform_upper_bound<double>(IntervalClosedClosed, 0, 1.0), 1.0); + + // Negative value tests + EXPECT_EQ(uniform_lower_bound(IntervalOpenClosed, -100, -1), -99); + EXPECT_EQ(uniform_lower_bound(IntervalOpenOpen, -100, -1), -99); + EXPECT_GT(uniform_lower_bound<float>(IntervalOpenClosed, -2.0, -1.0), -2.0); + EXPECT_GT(uniform_lower_bound<float>(IntervalOpenOpen, -2.0, -1.0), -2.0); + EXPECT_GT(uniform_lower_bound<double>(IntervalOpenClosed, -2.0, -1.0), -2.0); + EXPECT_GT(uniform_lower_bound<double>(IntervalOpenOpen, -2.0, -1.0), -2.0); + + EXPECT_EQ(uniform_lower_bound(IntervalClosedClosed, -100, -1), -100); + EXPECT_EQ(uniform_lower_bound(IntervalClosedOpen, -100, -1), -100); + EXPECT_EQ(uniform_lower_bound<float>(IntervalClosedClosed, -2.0, -1.0), -2.0); + EXPECT_EQ(uniform_lower_bound<float>(IntervalClosedOpen, -2.0, -1.0), -2.0); + EXPECT_EQ(uniform_lower_bound<double>(IntervalClosedClosed, -2.0, -1.0), + -2.0); + EXPECT_EQ(uniform_lower_bound<double>(IntervalClosedOpen, -2.0, -1.0), -2.0); + + EXPECT_EQ(uniform_upper_bound(IntervalOpenOpen, -100, -1), -2); + EXPECT_EQ(uniform_upper_bound(IntervalClosedOpen, -100, -1), -2); + EXPECT_EQ(uniform_upper_bound<float>(IntervalOpenOpen, -2.0, -1.0), -1.0); + EXPECT_EQ(uniform_upper_bound<float>(IntervalClosedOpen, -2.0, -1.0), -1.0); + EXPECT_EQ(uniform_upper_bound<double>(IntervalOpenOpen, -2.0, -1.0), -1.0); + EXPECT_EQ(uniform_upper_bound<double>(IntervalClosedOpen, -2.0, -1.0), -1.0); + + EXPECT_EQ(uniform_upper_bound(IntervalOpenClosed, -100, -1), -1); + EXPECT_EQ(uniform_upper_bound(IntervalClosedClosed, -100, -1), -1); + EXPECT_GT(uniform_upper_bound<float>(IntervalOpenClosed, -2.0, -1.0), -1.0); + EXPECT_GT(uniform_upper_bound<float>(IntervalClosedClosed, -2.0, -1.0), -1.0); + EXPECT_GT(uniform_upper_bound<double>(IntervalOpenClosed, -2.0, -1.0), -1.0); + EXPECT_GT(uniform_upper_bound<double>(IntervalClosedClosed, -2.0, -1.0), + -1.0); + + // Edge cases: the next value toward itself is itself. + const double d = 1.0; + const float f = 1.0; + EXPECT_EQ(uniform_lower_bound(IntervalOpenClosed, d, d), d); + EXPECT_EQ(uniform_lower_bound(IntervalOpenClosed, f, f), f); + + EXPECT_GT(uniform_lower_bound(IntervalOpenClosed, 1.0, 2.0), 1.0); + EXPECT_LT(uniform_lower_bound(IntervalOpenClosed, 1.0, +0.0), 1.0); + EXPECT_LT(uniform_lower_bound(IntervalOpenClosed, 1.0, -0.0), 1.0); + EXPECT_LT(uniform_lower_bound(IntervalOpenClosed, 1.0, -1.0), 1.0); + + EXPECT_EQ(uniform_upper_bound(IntervalClosedClosed, 0.0f, + std::numeric_limits<float>::max()), + std::numeric_limits<float>::max()); + EXPECT_EQ(uniform_upper_bound(IntervalClosedClosed, 0.0, + std::numeric_limits<double>::max()), + std::numeric_limits<double>::max()); +} + +struct Invalid {}; + +template <typename A, typename B> +auto InferredUniformReturnT(int) + -> decltype(absl::Uniform(std::declval<absl::InsecureBitGen&>(), + std::declval<A>(), std::declval<B>())); + +template <typename, typename> +Invalid InferredUniformReturnT(...); + +template <typename TagType, typename A, typename B> +auto InferredTaggedUniformReturnT(int) + -> decltype(absl::Uniform(std::declval<TagType>(), + std::declval<absl::InsecureBitGen&>(), + std::declval<A>(), std::declval<B>())); + +template <typename, typename, typename> +Invalid InferredTaggedUniformReturnT(...); + +// Given types <A, B, Expect>, CheckArgsInferType() verifies that +// +// absl::Uniform(gen, A{}, B{}) +// +// returns the type "Expect". +// +// This interface can also be used to assert that a given absl::Uniform() +// overload does not exist / will not compile. Given types <A, B>, the +// expression +// +// decltype(absl::Uniform(..., std::declval<A>(), std::declval<B>())) +// +// will not compile, leaving the definition of InferredUniformReturnT<A, B> to +// resolve (via SFINAE) to the overload which returns type "Invalid". This +// allows tests to assert that an invocation such as +// +// absl::Uniform(gen, 1.23f, std::numeric_limits<int>::max() - 1) +// +// should not compile, since neither type, float nor int, can precisely +// represent both endpoint-values. Writing: +// +// CheckArgsInferType<float, int, Invalid>() +// +// will assert that this overload does not exist. +template <typename A, typename B, typename Expect> +void CheckArgsInferType() { + static_assert( + absl::conjunction< + std::is_same<Expect, decltype(InferredUniformReturnT<A, B>(0))>, + std::is_same<Expect, + decltype(InferredUniformReturnT<B, A>(0))>>::value, + ""); + static_assert( + absl::conjunction< + std::is_same<Expect, decltype(InferredTaggedUniformReturnT< + absl::IntervalOpenOpenTag, A, B>(0))>, + std::is_same<Expect, + decltype(InferredTaggedUniformReturnT< + absl::IntervalOpenOpenTag, B, A>(0))>>::value, + ""); +} + +template <typename A, typename B, typename ExplicitRet> +auto ExplicitUniformReturnT(int) -> decltype( + absl::Uniform<ExplicitRet>(*std::declval<absl::InsecureBitGen*>(), + std::declval<A>(), std::declval<B>())); + +template <typename, typename, typename ExplicitRet> +Invalid ExplicitUniformReturnT(...); + +template <typename TagType, typename A, typename B, typename ExplicitRet> +auto ExplicitTaggedUniformReturnT(int) -> decltype(absl::Uniform<ExplicitRet>( + std::declval<TagType>(), *std::declval<absl::InsecureBitGen*>(), + std::declval<A>(), std::declval<B>())); + +template <typename, typename, typename, typename ExplicitRet> +Invalid ExplicitTaggedUniformReturnT(...); + +// Given types <A, B, Expect>, CheckArgsReturnExpectedType() verifies that +// +// absl::Uniform<Expect>(gen, A{}, B{}) +// +// returns the type "Expect", and that the function-overload has the signature +// +// Expect(URBG&, Expect, Expect) +template <typename A, typename B, typename Expect> +void CheckArgsReturnExpectedType() { + static_assert( + absl::conjunction< + std::is_same<Expect, + decltype(ExplicitUniformReturnT<A, B, Expect>(0))>, + std::is_same<Expect, decltype(ExplicitUniformReturnT<B, A, Expect>( + 0))>>::value, + ""); + static_assert( + absl::conjunction< + std::is_same<Expect, + decltype(ExplicitTaggedUniformReturnT< + absl::IntervalOpenOpenTag, A, B, Expect>(0))>, + std::is_same<Expect, decltype(ExplicitTaggedUniformReturnT< + absl::IntervalOpenOpenTag, B, A, + Expect>(0))>>::value, + ""); +} + +TEST_F(RandomDistributionsTest, UniformTypeInference) { + // Infers common types. + CheckArgsInferType<uint16_t, uint16_t, uint16_t>(); + CheckArgsInferType<uint32_t, uint32_t, uint32_t>(); + CheckArgsInferType<uint64_t, uint64_t, uint64_t>(); + CheckArgsInferType<int16_t, int16_t, int16_t>(); + CheckArgsInferType<int32_t, int32_t, int32_t>(); + CheckArgsInferType<int64_t, int64_t, int64_t>(); + CheckArgsInferType<float, float, float>(); + CheckArgsInferType<double, double, double>(); + + // Explicitly-specified return-values override inferences. + CheckArgsReturnExpectedType<int16_t, int16_t, int32_t>(); + CheckArgsReturnExpectedType<uint16_t, uint16_t, int32_t>(); + CheckArgsReturnExpectedType<int16_t, int16_t, int64_t>(); + CheckArgsReturnExpectedType<int16_t, int32_t, int64_t>(); + CheckArgsReturnExpectedType<int16_t, int32_t, double>(); + CheckArgsReturnExpectedType<float, float, double>(); + CheckArgsReturnExpectedType<int, int, int16_t>(); + + // Properly promotes uint16_t. + CheckArgsInferType<uint16_t, uint32_t, uint32_t>(); + CheckArgsInferType<uint16_t, uint64_t, uint64_t>(); + CheckArgsInferType<uint16_t, int32_t, int32_t>(); + CheckArgsInferType<uint16_t, int64_t, int64_t>(); + CheckArgsInferType<uint16_t, float, float>(); + CheckArgsInferType<uint16_t, double, double>(); + + // Properly promotes int16_t. + CheckArgsInferType<int16_t, int32_t, int32_t>(); + CheckArgsInferType<int16_t, int64_t, int64_t>(); + CheckArgsInferType<int16_t, float, float>(); + CheckArgsInferType<int16_t, double, double>(); + + // Invalid (u)int16_t-pairings do not compile. + // See "CheckArgsInferType" comments above, for how this is achieved. + CheckArgsInferType<uint16_t, int16_t, Invalid>(); + CheckArgsInferType<int16_t, uint32_t, Invalid>(); + CheckArgsInferType<int16_t, uint64_t, Invalid>(); + + // Properly promotes uint32_t. + CheckArgsInferType<uint32_t, uint64_t, uint64_t>(); + CheckArgsInferType<uint32_t, int64_t, int64_t>(); + CheckArgsInferType<uint32_t, double, double>(); + + // Properly promotes int32_t. + CheckArgsInferType<int32_t, int64_t, int64_t>(); + CheckArgsInferType<int32_t, double, double>(); + + // Invalid (u)int32_t-pairings do not compile. + CheckArgsInferType<uint32_t, int32_t, Invalid>(); + CheckArgsInferType<int32_t, uint64_t, Invalid>(); + CheckArgsInferType<int32_t, float, Invalid>(); + CheckArgsInferType<uint32_t, float, Invalid>(); + + // Invalid (u)int64_t-pairings do not compile. + CheckArgsInferType<uint64_t, int64_t, Invalid>(); + CheckArgsInferType<int64_t, float, Invalid>(); + CheckArgsInferType<int64_t, double, Invalid>(); + + // Properly promotes float. + CheckArgsInferType<float, double, double>(); + + // Examples. + absl::InsecureBitGen gen; + EXPECT_NE(1, absl::Uniform(gen, static_cast<uint16_t>(0), 1.0f)); + EXPECT_NE(1, absl::Uniform(gen, 0, 1.0)); + EXPECT_NE(1, absl::Uniform(absl::IntervalOpenOpen, gen, + static_cast<uint16_t>(0), 1.0f)); + EXPECT_NE(1, absl::Uniform(absl::IntervalOpenOpen, gen, 0, 1.0)); + EXPECT_NE(1, absl::Uniform(absl::IntervalOpenOpen, gen, -1, 1.0)); + EXPECT_NE(1, absl::Uniform<double>(absl::IntervalOpenOpen, gen, -1, 1)); + EXPECT_NE(1, absl::Uniform<float>(absl::IntervalOpenOpen, gen, 0, 1)); + EXPECT_NE(1, absl::Uniform<float>(gen, 0, 1)); +} + +TEST_F(RandomDistributionsTest, UniformNoBounds) { + absl::InsecureBitGen gen; + + absl::Uniform<uint8_t>(gen); + absl::Uniform<uint16_t>(gen); + absl::Uniform<uint32_t>(gen); + absl::Uniform<uint64_t>(gen); +} + +// TODO(lar): Validate properties of non-default interval-semantics. +TEST_F(RandomDistributionsTest, UniformReal) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Uniform(gen, 0, 1.0); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(0.5, moments.mean, 0.02); + EXPECT_NEAR(1 / 12.0, moments.variance, 0.02); + EXPECT_NEAR(0.0, moments.skewness, 0.02); + EXPECT_NEAR(9 / 5.0, moments.kurtosis, 0.02); +} + +TEST_F(RandomDistributionsTest, UniformInt) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + const int64_t kMax = 1000000000000ll; + int64_t j = absl::Uniform(absl::IntervalClosedClosed, gen, 0, kMax); + // convert to double. + values[i] = static_cast<double>(j) / static_cast<double>(kMax); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(0.5, moments.mean, 0.02); + EXPECT_NEAR(1 / 12.0, moments.variance, 0.02); + EXPECT_NEAR(0.0, moments.skewness, 0.02); + EXPECT_NEAR(9 / 5.0, moments.kurtosis, 0.02); + + /* + // NOTE: These are not supported by absl::Uniform, which is specialized + // on integer and real valued types. + + enum E { E0, E1 }; // enum + enum S : int { S0, S1 }; // signed enum + enum U : unsigned int { U0, U1 }; // unsigned enum + + absl::Uniform(gen, E0, E1); + absl::Uniform(gen, S0, S1); + absl::Uniform(gen, U0, U1); + */ +} + +TEST_F(RandomDistributionsTest, Exponential) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Exponential<double>(gen); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(1.0, moments.mean, 0.02); + EXPECT_NEAR(1.0, moments.variance, 0.025); + EXPECT_NEAR(2.0, moments.skewness, 0.1); + EXPECT_LT(5.0, moments.kurtosis); +} + +TEST_F(RandomDistributionsTest, PoissonDefault) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Poisson<int64_t>(gen); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(1.0, moments.mean, 0.02); + EXPECT_NEAR(1.0, moments.variance, 0.02); + EXPECT_NEAR(1.0, moments.skewness, 0.025); + EXPECT_LT(2.0, moments.kurtosis); +} + +TEST_F(RandomDistributionsTest, PoissonLarge) { + constexpr double kMean = 100000000.0; + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Poisson<int64_t>(gen, kMean); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(kMean, moments.mean, kMean * 0.015); + EXPECT_NEAR(kMean, moments.variance, kMean * 0.015); + EXPECT_NEAR(std::sqrt(kMean), moments.skewness, kMean * 0.02); + EXPECT_LT(2.0, moments.kurtosis); +} + +TEST_F(RandomDistributionsTest, Bernoulli) { + constexpr double kP = 0.5151515151; + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Bernoulli(gen, kP); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(kP, moments.mean, 0.01); +} + +TEST_F(RandomDistributionsTest, Beta) { + constexpr double kAlpha = 2.0; + constexpr double kBeta = 3.0; + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Beta(gen, kAlpha, kBeta); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(0.4, moments.mean, 0.01); +} + +TEST_F(RandomDistributionsTest, Zipf) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Zipf<int64_t>(gen, 100); + } + + // The mean of a zipf distribution is: H(N, s-1) / H(N,s). + // Given the parameter v = 1, this gives the following function: + // (Hn(100, 1) - Hn(1,1)) / (Hn(100,2) - Hn(1,2)) = 6.5944 + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(6.5944, moments.mean, 2000) << moments; +} + +TEST_F(RandomDistributionsTest, Gaussian) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::Gaussian<double>(gen); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(0.0, moments.mean, 0.02); + EXPECT_NEAR(1.0, moments.variance, 0.04); + EXPECT_NEAR(0, moments.skewness, 0.2); + EXPECT_NEAR(3.0, moments.kurtosis, 0.5); +} + +TEST_F(RandomDistributionsTest, LogUniform) { + std::vector<double> values(kSize); + + absl::InsecureBitGen gen; + for (int i = 0; i < kSize; i++) { + values[i] = absl::LogUniform<int64_t>(gen, 0, (1 << 10) - 1); + } + + // The mean is the sum of the fractional means of the uniform distributions: + // [0..0][1..1][2..3][4..7][8..15][16..31][32..63] + // [64..127][128..255][256..511][512..1023] + const double mean = (0 + 1 + 1 + 2 + 3 + 4 + 7 + 8 + 15 + 16 + 31 + 32 + 63 + + 64 + 127 + 128 + 255 + 256 + 511 + 512 + 1023) / + (2.0 * 11.0); + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(mean, moments.mean, 2) << moments; +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/examples_test.cc b/third_party/abseil_cpp/absl/random/examples_test.cc new file mode 100644 index 0000000000..1dcb5146f3 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/examples_test.cc @@ -0,0 +1,99 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cinttypes> +#include <random> +#include <sstream> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/random/random.h" + +template <typename T> +void Use(T) {} + +TEST(Examples, Basic) { + absl::BitGen gen; + std::vector<int> objs = {10, 20, 30, 40, 50}; + + // Choose an element from a set. + auto elem = objs[absl::Uniform(gen, 0u, objs.size())]; + Use(elem); + + // Generate a uniform value between 1 and 6. + auto dice_roll = absl::Uniform<int>(absl::IntervalClosedClosed, gen, 1, 6); + Use(dice_roll); + + // Generate a random byte. + auto byte = absl::Uniform<uint8_t>(gen); + Use(byte); + + // Generate a fractional value from [0f, 1f). + auto fraction = absl::Uniform<float>(gen, 0, 1); + Use(fraction); + + // Toss a fair coin; 50/50 probability. + bool coin_toss = absl::Bernoulli(gen, 0.5); + Use(coin_toss); + + // Select a file size between 1k and 10MB, biased towards smaller file sizes. + auto file_size = absl::LogUniform<size_t>(gen, 1000, 10 * 1000 * 1000); + Use(file_size); + + // Randomize (shuffle) a collection. + std::shuffle(std::begin(objs), std::end(objs), gen); +} + +TEST(Examples, CreateingCorrelatedVariateSequences) { + // Unexpected PRNG correlation is often a source of bugs, + // so when using absl::BitGen it must be an intentional choice. + // NOTE: All of these only exhibit process-level stability. + + // Create a correlated sequence from system entropy. + { + auto my_seed = absl::MakeSeedSeq(); + + absl::BitGen gen_1(my_seed); + absl::BitGen gen_2(my_seed); // Produces same variates as gen_1. + + EXPECT_EQ(absl::Bernoulli(gen_1, 0.5), absl::Bernoulli(gen_2, 0.5)); + EXPECT_EQ(absl::Uniform<uint32_t>(gen_1), absl::Uniform<uint32_t>(gen_2)); + } + + // Create a correlated sequence from an existing URBG. + { + absl::BitGen gen; + + auto my_seed = absl::CreateSeedSeqFrom(&gen); + absl::BitGen gen_1(my_seed); + absl::BitGen gen_2(my_seed); + + EXPECT_EQ(absl::Bernoulli(gen_1, 0.5), absl::Bernoulli(gen_2, 0.5)); + EXPECT_EQ(absl::Uniform<uint32_t>(gen_1), absl::Uniform<uint32_t>(gen_2)); + } + + // An alternate construction which uses user-supplied data + // instead of a random seed. + { + const char kData[] = "A simple seed string"; + std::seed_seq my_seed(std::begin(kData), std::end(kData)); + + absl::BitGen gen_1(my_seed); + absl::BitGen gen_2(my_seed); + + EXPECT_EQ(absl::Bernoulli(gen_1, 0.5), absl::Bernoulli(gen_2, 0.5)); + EXPECT_EQ(absl::Uniform<uint32_t>(gen_1), absl::Uniform<uint32_t>(gen_2)); + } +} + diff --git a/third_party/abseil_cpp/absl/random/exponential_distribution.h b/third_party/abseil_cpp/absl/random/exponential_distribution.h new file mode 100644 index 0000000000..b5caf8a1e1 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/exponential_distribution.h @@ -0,0 +1,165 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_EXPONENTIAL_DISTRIBUTION_H_ +#define ABSL_RANDOM_EXPONENTIAL_DISTRIBUTION_H_ + +#include <cassert> +#include <cmath> +#include <istream> +#include <limits> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/generate_real.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::exponential_distribution: +// Generates a number conforming to an exponential distribution and is +// equivalent to the standard [rand.dist.pois.exp] distribution. +template <typename RealType = double> +class exponential_distribution { + public: + using result_type = RealType; + + class param_type { + public: + using distribution_type = exponential_distribution; + + explicit param_type(result_type lambda = 1) : lambda_(lambda) { + assert(lambda > 0); + neg_inv_lambda_ = -result_type(1) / lambda_; + } + + result_type lambda() const { return lambda_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.lambda_ == b.lambda_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class exponential_distribution; + + result_type lambda_; + result_type neg_inv_lambda_; + + static_assert( + std::is_floating_point<RealType>::value, + "Class-template absl::exponential_distribution<> must be parameterized " + "using a floating-point type."); + }; + + exponential_distribution() : exponential_distribution(1) {} + + explicit exponential_distribution(result_type lambda) : param_(lambda) {} + + explicit exponential_distribution(const param_type& p) : param_(p) {} + + void reset() {} + + // Generating functions + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + param_type param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + result_type(min)() const { return 0; } + result_type(max)() const { + return std::numeric_limits<result_type>::infinity(); + } + + result_type lambda() const { return param_.lambda(); } + + friend bool operator==(const exponential_distribution& a, + const exponential_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const exponential_distribution& a, + const exponential_distribution& b) { + return a.param_ != b.param_; + } + + private: + param_type param_; + random_internal::FastUniformBits<uint64_t> fast_u64_; +}; + +// -------------------------------------------------------------------------- +// Implementation details follow +// -------------------------------------------------------------------------- + +template <typename RealType> +template <typename URBG> +typename exponential_distribution<RealType>::result_type +exponential_distribution<RealType>::operator()( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + using random_internal::GenerateNegativeTag; + using random_internal::GenerateRealFromBits; + using real_type = + absl::conditional_t<std::is_same<RealType, float>::value, float, double>; + + const result_type u = GenerateRealFromBits<real_type, GenerateNegativeTag, + false>(fast_u64_(g)); // U(-1, 0) + + // log1p(-x) is mathematically equivalent to log(1 - x) but has more + // accuracy for x near zero. + return p.neg_inv_lambda_ * std::log1p(u); +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const exponential_distribution<RealType>& x) { + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<RealType>::kPrecision); + os << x.lambda(); + return os; +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + exponential_distribution<RealType>& x) { // NOLINT(runtime/references) + using result_type = typename exponential_distribution<RealType>::result_type; + using param_type = typename exponential_distribution<RealType>::param_type; + result_type lambda; + + auto saver = random_internal::make_istream_state_saver(is); + lambda = random_internal::read_floating_point<result_type>(is); + if (!is.fail()) { + x.param(param_type(lambda)); + } + return is; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_EXPONENTIAL_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/exponential_distribution_test.cc b/third_party/abseil_cpp/absl/random/exponential_distribution_test.cc new file mode 100644 index 0000000000..8e9e69b64b --- /dev/null +++ b/third_party/abseil_cpp/absl/random/exponential_distribution_test.cc @@ -0,0 +1,430 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/exponential_distribution.h" + +#include <algorithm> +#include <cmath> +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <limits> +#include <random> +#include <sstream> +#include <string> +#include <type_traits> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_replace.h" +#include "absl/strings/strip.h" + +namespace { + +using absl::random_internal::kChiSquared; + +template <typename RealType> +class ExponentialDistributionTypedTest : public ::testing::Test {}; + +#if defined(__EMSCRIPTEN__) +using RealTypes = ::testing::Types<float, double>; +#else +using RealTypes = ::testing::Types<float, double, long double>; +#endif // defined(__EMSCRIPTEN__) +TYPED_TEST_CASE(ExponentialDistributionTypedTest, RealTypes); + +TYPED_TEST(ExponentialDistributionTypedTest, SerializeTest) { + using param_type = + typename absl::exponential_distribution<TypeParam>::param_type; + + const TypeParam kParams[] = { + // Cases around 1. + 1, // + std::nextafter(TypeParam(1), TypeParam(0)), // 1 - epsilon + std::nextafter(TypeParam(1), TypeParam(2)), // 1 + epsilon + // Typical cases. + TypeParam(1e-8), TypeParam(1e-4), TypeParam(1), TypeParam(2), + TypeParam(1e4), TypeParam(1e8), TypeParam(1e20), TypeParam(2.5), + // Boundary cases. + std::numeric_limits<TypeParam>::max(), + std::numeric_limits<TypeParam>::epsilon(), + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(1)), // min + epsilon + std::numeric_limits<TypeParam>::min(), // smallest normal + // There are some errors dealing with denorms on apple platforms. + std::numeric_limits<TypeParam>::denorm_min(), // smallest denorm + std::numeric_limits<TypeParam>::min() / 2, // denorm + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(0)), // denorm_max + }; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + + for (const TypeParam lambda : kParams) { + // Some values may be invalid; skip those. + if (!std::isfinite(lambda)) continue; + ABSL_ASSERT(lambda > 0); + + const param_type param(lambda); + + absl::exponential_distribution<TypeParam> before(lambda); + EXPECT_EQ(before.lambda(), param.lambda()); + + { + absl::exponential_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + EXPECT_EQ(via_param.param(), before.param()); + } + + // Smoke test. + auto sample_min = before.max(); + auto sample_max = before.min(); + for (int i = 0; i < kCount; i++) { + auto sample = before(gen); + EXPECT_GE(sample, before.min()) << before; + EXPECT_LE(sample, before.max()) << before; + if (sample > sample_max) sample_max = sample; + if (sample < sample_min) sample_min = sample; + } + if (!std::is_same<TypeParam, long double>::value) { + ABSL_INTERNAL_LOG(INFO, + absl::StrFormat("Range {%f}: %f, %f, lambda=%f", lambda, + sample_min, sample_max, lambda)); + } + + std::stringstream ss; + ss << before; + + if (!std::isfinite(lambda)) { + // Streams do not deserialize inf/nan correctly. + continue; + } + // Validate stream serialization. + absl::exponential_distribution<TypeParam> after(34.56f); + + EXPECT_NE(before.lambda(), after.lambda()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + +#if defined(__powerpc64__) || defined(__PPC64__) || defined(__powerpc__) || \ + defined(__ppc__) || defined(__PPC__) + if (std::is_same<TypeParam, long double>::value) { + // Roundtripping floating point values requires sufficient precision to + // reconstruct the exact value. It turns out that long double has some + // errors doing this on ppc, particularly for values + // near {1.0 +/- epsilon}. + if (lambda <= std::numeric_limits<double>::max() && + lambda >= std::numeric_limits<double>::lowest()) { + EXPECT_EQ(static_cast<double>(before.lambda()), + static_cast<double>(after.lambda())) + << ss.str(); + } + continue; + } +#endif + + EXPECT_EQ(before.lambda(), after.lambda()) // + << ss.str() << " " // + << (ss.good() ? "good " : "") // + << (ss.bad() ? "bad " : "") // + << (ss.eof() ? "eof " : "") // + << (ss.fail() ? "fail " : ""); + } +} + +// http://www.itl.nist.gov/div898/handbook/eda/section3/eda3667.htm + +class ExponentialModel { + public: + explicit ExponentialModel(double lambda) + : lambda_(lambda), beta_(1.0 / lambda) {} + + double lambda() const { return lambda_; } + + double mean() const { return beta_; } + double variance() const { return beta_ * beta_; } + double stddev() const { return std::sqrt(variance()); } + double skew() const { return 2; } + double kurtosis() const { return 6.0; } + + double CDF(double x) { return 1.0 - std::exp(-lambda_ * x); } + + // The inverse CDF, or PercentPoint function of the distribution + double InverseCDF(double p) { + ABSL_ASSERT(p >= 0.0); + ABSL_ASSERT(p < 1.0); + return -beta_ * std::log(1.0 - p); + } + + private: + const double lambda_; + const double beta_; +}; + +struct Param { + double lambda; + double p_fail; + int trials; +}; + +class ExponentialDistributionTests : public testing::TestWithParam<Param>, + public ExponentialModel { + public: + ExponentialDistributionTests() : ExponentialModel(GetParam().lambda) {} + + // SingleZTest provides a basic z-squared test of the mean vs. expected + // mean for data generated by the poisson distribution. + template <typename D> + bool SingleZTest(const double p, const size_t samples); + + // SingleChiSquaredTest provides a basic chi-squared test of the normal + // distribution. + template <typename D> + double SingleChiSquaredTest(); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng_{0x2B7E151628AED2A6}; +}; + +template <typename D> +bool ExponentialDistributionTests::SingleZTest(const double p, + const size_t samples) { + D dis(lambda()); + + std::vector<double> data; + data.reserve(samples); + for (size_t i = 0; i < samples; i++) { + const double x = dis(rng_); + data.push_back(x); + } + + const auto m = absl::random_internal::ComputeDistributionMoments(data); + const double max_err = absl::random_internal::MaxErrorTolerance(p); + const double z = absl::random_internal::ZScore(mean(), m); + const bool pass = absl::random_internal::Near("z", z, 0.0, max_err); + + if (!pass) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("p=%f max_err=%f\n" + " lambda=%f\n" + " mean=%f vs. %f\n" + " stddev=%f vs. %f\n" + " skewness=%f vs. %f\n" + " kurtosis=%f vs. %f\n" + " z=%f vs. 0", + p, max_err, lambda(), m.mean, mean(), + std::sqrt(m.variance), stddev(), m.skewness, + skew(), m.kurtosis, kurtosis(), z)); + } + return pass; +} + +template <typename D> +double ExponentialDistributionTests::SingleChiSquaredTest() { + const size_t kSamples = 10000; + const int kBuckets = 50; + + // The InverseCDF is the percent point function of the distribution, and can + // be used to assign buckets roughly uniformly. + std::vector<double> cutoffs; + const double kInc = 1.0 / static_cast<double>(kBuckets); + for (double p = kInc; p < 1.0; p += kInc) { + cutoffs.push_back(InverseCDF(p)); + } + if (cutoffs.back() != std::numeric_limits<double>::infinity()) { + cutoffs.push_back(std::numeric_limits<double>::infinity()); + } + + D dis(lambda()); + + std::vector<int32_t> counts(cutoffs.size(), 0); + for (int j = 0; j < kSamples; j++) { + const double x = dis(rng_); + auto it = std::upper_bound(cutoffs.begin(), cutoffs.end(), x); + counts[std::distance(cutoffs.begin(), it)]++; + } + + // Null-hypothesis is that the distribution is exponentially distributed + // with the provided lambda (not estimated from the data). + const int dof = static_cast<int>(counts.size()) - 1; + + // Our threshold for logging is 1-in-50. + const double threshold = absl::random_internal::ChiSquareValue(dof, 0.98); + + const double expected = + static_cast<double>(kSamples) / static_cast<double>(counts.size()); + + double chi_square = absl::random_internal::ChiSquareWithExpected( + std::begin(counts), std::end(counts), expected); + double p = absl::random_internal::ChiSquarePValue(chi_square, dof); + + if (chi_square > threshold) { + for (int i = 0; i < cutoffs.size(); i++) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("%d : (%f) = %d", i, cutoffs[i], counts[i])); + } + + ABSL_INTERNAL_LOG(INFO, + absl::StrCat("lambda ", lambda(), "\n", // + " expected ", expected, "\n", // + kChiSquared, " ", chi_square, " (", p, ")\n", + kChiSquared, " @ 0.98 = ", threshold)); + } + return p; +} + +TEST_P(ExponentialDistributionTests, ZTest) { + const size_t kSamples = 10000; + const auto& param = GetParam(); + const int expected_failures = + std::max(1, static_cast<int>(std::ceil(param.trials * param.p_fail))); + const double p = absl::random_internal::RequiredSuccessProbability( + param.p_fail, param.trials); + + int failures = 0; + for (int i = 0; i < param.trials; i++) { + failures += SingleZTest<absl::exponential_distribution<double>>(p, kSamples) + ? 0 + : 1; + } + EXPECT_LE(failures, expected_failures); +} + +TEST_P(ExponentialDistributionTests, ChiSquaredTest) { + const int kTrials = 20; + int failures = 0; + + for (int i = 0; i < kTrials; i++) { + double p_value = + SingleChiSquaredTest<absl::exponential_distribution<double>>(); + if (p_value < 0.005) { // 1/200 + failures++; + } + } + + // There is a 0.10% chance of producing at least one failure, so raise the + // failure threshold high enough to allow for a flake rate < 10,000. + EXPECT_LE(failures, 4); +} + +std::vector<Param> GenParams() { + return { + Param{1.0, 0.02, 100}, + Param{2.5, 0.02, 100}, + Param{10, 0.02, 100}, + // large + Param{1e4, 0.02, 100}, + Param{1e9, 0.02, 100}, + // small + Param{0.1, 0.02, 100}, + Param{1e-3, 0.02, 100}, + Param{1e-5, 0.02, 100}, + }; +} + +std::string ParamName(const ::testing::TestParamInfo<Param>& info) { + const auto& p = info.param; + std::string name = absl::StrCat("lambda_", absl::SixDigits(p.lambda)); + return absl::StrReplaceAll(name, {{"+", "_"}, {"-", "_"}, {".", "_"}}); +} + +INSTANTIATE_TEST_CASE_P(All, ExponentialDistributionTests, + ::testing::ValuesIn(GenParams()), ParamName); + +// NOTE: absl::exponential_distribution is not guaranteed to be stable. +TEST(ExponentialDistributionTest, StabilityTest) { + // absl::exponential_distribution stability relies on std::log1p and + // absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(14); + + { + absl::exponential_distribution<double> dist; + std::generate(std::begin(output), std::end(output), + [&] { return static_cast<int>(10000.0 * dist(urbg)); }); + + EXPECT_EQ(14, urbg.invocations()); + EXPECT_THAT(output, + testing::ElementsAre(0, 71913, 14375, 5039, 1835, 861, 25936, + 804, 126, 12337, 17984, 27002, 0, 71913)); + } + + urbg.reset(); + { + absl::exponential_distribution<float> dist; + std::generate(std::begin(output), std::end(output), + [&] { return static_cast<int>(10000.0f * dist(urbg)); }); + + EXPECT_EQ(14, urbg.invocations()); + EXPECT_THAT(output, + testing::ElementsAre(0, 71913, 14375, 5039, 1835, 861, 25936, + 804, 126, 12337, 17984, 27002, 0, 71913)); + } +} + +TEST(ExponentialDistributionTest, AlgorithmBounds) { + // Relies on absl::uniform_real_distribution, so some of these comments + // reference that. + absl::exponential_distribution<double> dist; + + { + // This returns the smallest value >0 from absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg({0x0000000000000001ull}); + double a = dist(urbg); + EXPECT_EQ(a, 5.42101086242752217004e-20); + } + + { + // This returns a value very near 0.5 from absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg({0x7fffffffffffffefull}); + double a = dist(urbg); + EXPECT_EQ(a, 0.693147180559945175204); + } + + { + // This returns the largest value <1 from absl::uniform_real_distribution. + // WolframAlpha: ~39.1439465808987766283058547296341915292187253 + absl::random_internal::sequence_urbg urbg({0xFFFFFFFFFFFFFFeFull}); + double a = dist(urbg); + EXPECT_EQ(a, 36.7368005696771007251); + } + { + // This *ALSO* returns the largest value <1. + absl::random_internal::sequence_urbg urbg({0xFFFFFFFFFFFFFFFFull}); + double a = dist(urbg); + EXPECT_EQ(a, 36.7368005696771007251); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/gaussian_distribution.cc b/third_party/abseil_cpp/absl/random/gaussian_distribution.cc new file mode 100644 index 0000000000..c7a72cb2f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/gaussian_distribution.cc @@ -0,0 +1,104 @@ +// BEGIN GENERATED CODE; DO NOT EDIT +// clang-format off + +#include "absl/random/gaussian_distribution.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +const gaussian_distribution_base::Tables + gaussian_distribution_base::zg_ = { + {3.7130862467425505, 3.442619855899000214, 3.223084984581141565, + 3.083228858216868318, 2.978696252647779819, 2.894344007021528942, + 2.82312535054891045, 2.761169372387176857, 2.706113573121819549, + 2.656406411261359679, 2.610972248431847387, 2.56903362592493778, + 2.530009672388827457, 2.493454522095372106, 2.459018177411830486, + 2.426420645533749809, 2.395434278011062457, 2.365871370117638595, + 2.337575241339236776, 2.310413683698762988, 2.284274059677471769, + 2.25905957386919809, 2.234686395590979036, 2.21108140887870297, + 2.188180432076048731, 2.165926793748921497, 2.144270182360394905, + 2.123165708673976138, 2.102573135189237608, 2.082456237992015957, + 2.062782274508307978, 2.043521536655067194, 2.02464697337738464, + 2.006133869963471206, 1.987959574127619033, 1.970103260854325633, + 1.952545729553555764, 1.935269228296621957, 1.918257300864508963, + 1.901494653105150423, 1.884967035707758143, 1.868661140994487768, + 1.852564511728090002, 1.836665460258444904, 1.820952996596124418, + 1.805416764219227366, 1.790046982599857506, 1.77483439558606837, + 1.759770224899592339, 1.744846128113799244, 1.730054160563729182, + 1.71538674071366648, 1.700836618569915748, 1.686396846779167014, + 1.6720607540975998, 1.657821920954023254, 1.643674156862867441, + 1.629611479470633562, 1.615628095043159629, 1.601718380221376581, + 1.587876864890574558, 1.574098216022999264, 1.560377222366167382, + 1.546708779859908844, 1.533087877674041755, 1.519509584765938559, + 1.505969036863201937, 1.492461423781352714, 1.478981976989922842, + 1.465525957342709296, 1.452088642889222792, 1.438665316684561546, + 1.425251254514058319, 1.411841712447055919, 1.398431914131003539, + 1.385017037732650058, 1.371592202427340812, 1.358152454330141534, + 1.34469275175354519, 1.331207949665625279, 1.317692783209412299, + 1.304141850128615054, 1.290549591926194894, 1.27691027356015363, + 1.263217961454619287, 1.249466499573066436, 1.23564948326336066, + 1.221760230539994385, 1.207791750415947662, 1.193736707833126465, + 1.17958738466398616, 1.165335636164750222, 1.150972842148865416, + 1.136489852013158774, 1.121876922582540237, 1.107123647534034028, + 1.092218876907275371, 1.077150624892893482, 1.061905963694822042, + 1.046470900764042922, 1.030830236068192907, 1.014967395251327842, + 0.9988642334929808131, 0.9825008035154263464, 0.9658550794011470098, + 0.9489026255113034436, 0.9316161966151479401, 0.9139652510230292792, + 0.8959153525809346874, 0.8774274291129204872, 0.8584568431938099931, + 0.8389522142975741614, 0.8188539067003538507, 0.7980920606440534693, + 0.7765839878947563557, 0.7542306644540520688, 0.7309119106424850631, + 0.7064796113354325779, 0.6807479186691505202, 0.6534786387399710295, + 0.6243585973360461505, 0.5929629424714434327, 0.5586921784081798625, + 0.5206560387620546848, 0.4774378372966830431, 0.4265479863554152429, + 0.3628714310970211909, 0.2723208648139477384, 0}, + {0.001014352564120377413, 0.002669629083880922793, 0.005548995220771345792, + 0.008624484412859888607, 0.01183947865788486861, 0.01516729801054656976, + 0.01859210273701129151, 0.02210330461592709475, 0.02569329193593428151, + 0.02935631744000685023, 0.03308788614622575758, 0.03688438878665621645, + 0.04074286807444417458, 0.04466086220049143157, 0.04863629585986780496, + 0.05266740190305100461, 0.05675266348104984759, 0.06089077034804041277, + 0.06508058521306804567, 0.06932111739357792179, 0.07361150188411341722, + 0.07795098251397346301, 0.08233889824223575293, 0.08677467189478028919, + 0.09125780082683036809, 0.095787849121731522, 0.1003644410286559929, + 0.1049872554094214289, 0.1096560210148404546, 0.1143705124488661323, + 0.1191305467076509556, 0.1239359802028679736, 0.1287867061959434012, + 0.1336826525834396151, 0.1386237799845948804, 0.1436100800906280339, + 0.1486415742423425057, 0.1537183122081819397, 0.1588403711394795748, + 0.1640078546834206341, 0.1692208922373653057, 0.1744796383307898324, + 0.1797842721232958407, 0.1851349970089926078, 0.1905320403191375633, + 0.1959756531162781534, 0.2014661100743140865, 0.2070037094399269362, + 0.2125887730717307134, 0.2182216465543058426, 0.2239026993850088965, + 0.229632325232116602, 0.2354109422634795556, 0.2412389935454402889, + 0.2471169475123218551, 0.2530452985073261551, 0.2590245673962052742, + 0.2650553022555897087, 0.271138079138385224, 0.2772735029191887857, + 0.2834622082232336471, 0.2897048604429605656, 0.2960021568469337061, + 0.3023548277864842593, 0.3087636380061818397, 0.3152293880650116065, + 0.3217529158759855901, 0.3283350983728509642, 0.3349768533135899506, + 0.3416791412315512977, 0.3484429675463274756, 0.355269384847918035, + 0.3621594953693184626, 0.3691144536644731522, 0.376135469510563536, + 0.3832238110559021416, 0.3903808082373155797, 0.3976078564938743676, + 0.404906420807223999, 0.4122780401026620578, 0.4197243320495753771, + 0.4272469983049970721, 0.4348478302499918513, 0.4425287152754694975, + 0.4502916436820402768, 0.458138716267873114, 0.4660721526894572309, + 0.4740943006930180559, 0.4822076463294863724, 0.4904148252838453348, + 0.4987186354709807201, 0.5071220510755701794, 0.5156282382440030565, + 0.5242405726729852944, 0.5329626593838373561, 0.5417983550254266145, + 0.5507517931146057588, 0.5598274127040882009, 0.5690299910679523787, + 0.5783646811197646898, 0.5878370544347081283, 0.5974531509445183408, + 0.6072195366251219584, 0.6171433708188825973, 0.6272324852499290282, + 0.6374954773350440806, 0.6479418211102242475, 0.6585820000500898219, + 0.6694276673488921414, 0.6804918409973358395, 0.6917891434366769676, + 0.7033360990161600101, 0.7151515074105005976, 0.7272569183441868201, + 0.7396772436726493094, 0.7524415591746134169, 0.7655841738977066102, + 0.7791460859296898134, 0.7931770117713072832, 0.8077382946829627652, + 0.8229072113814113187, 0.8387836052959920519, 0.8555006078694531446, + 0.873243048910072206, 0.8922816507840289901, 0.9130436479717434217, + 0.9362826816850632339, 0.9635996931270905952, 1}}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +// clang-format on +// END GENERATED CODE diff --git a/third_party/abseil_cpp/absl/random/gaussian_distribution.h b/third_party/abseil_cpp/absl/random/gaussian_distribution.h new file mode 100644 index 0000000000..4b07a5c0af --- /dev/null +++ b/third_party/abseil_cpp/absl/random/gaussian_distribution.h @@ -0,0 +1,275 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_GAUSSIAN_DISTRIBUTION_H_ +#define ABSL_RANDOM_GAUSSIAN_DISTRIBUTION_H_ + +// absl::gaussian_distribution implements the Ziggurat algorithm +// for generating random gaussian numbers. +// +// Implementation based on "The Ziggurat Method for Generating Random Variables" +// by George Marsaglia and Wai Wan Tsang: http://www.jstatsoft.org/v05/i08/ +// + +#include <cmath> +#include <cstdint> +#include <istream> +#include <limits> +#include <type_traits> + +#include "absl/base/config.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/generate_real.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// absl::gaussian_distribution_base implements the underlying ziggurat algorithm +// using the ziggurat tables generated by the gaussian_distribution_gentables +// binary. +// +// The specific algorithm has some of the improvements suggested by the +// 2005 paper, "An Improved Ziggurat Method to Generate Normal Random Samples", +// Jurgen A Doornik. (https://www.doornik.com/research/ziggurat.pdf) +class ABSL_DLL gaussian_distribution_base { + public: + template <typename URBG> + inline double zignor(URBG& g); // NOLINT(runtime/references) + + private: + friend class TableGenerator; + + template <typename URBG> + inline double zignor_fallback(URBG& g, // NOLINT(runtime/references) + bool neg); + + // Constants used for the gaussian distribution. + static constexpr double kR = 3.442619855899; // Start of the tail. + static constexpr double kRInv = 0.29047645161474317; // ~= (1.0 / kR) . + static constexpr double kV = 9.91256303526217e-3; + static constexpr uint64_t kMask = 0x07f; + + // The ziggurat tables store the pdf(f) and inverse-pdf(x) for equal-area + // points on one-half of the normal distribution, where the pdf function, + // pdf = e ^ (-1/2 *x^2), assumes that the mean = 0 & stddev = 1. + // + // These tables are just over 2kb in size; larger tables might improve the + // distributions, but also lead to more cache pollution. + // + // x = {3.71308, 3.44261, 3.22308, ..., 0} + // f = {0.00101, 0.00266, 0.00554, ..., 1} + struct Tables { + double x[kMask + 2]; + double f[kMask + 2]; + }; + static const Tables zg_; + random_internal::FastUniformBits<uint64_t> fast_u64_; +}; + +} // namespace random_internal + +// absl::gaussian_distribution: +// Generates a number conforming to a Gaussian distribution. +template <typename RealType = double> +class gaussian_distribution : random_internal::gaussian_distribution_base { + public: + using result_type = RealType; + + class param_type { + public: + using distribution_type = gaussian_distribution; + + explicit param_type(result_type mean = 0, result_type stddev = 1) + : mean_(mean), stddev_(stddev) {} + + // Returns the mean distribution parameter. The mean specifies the location + // of the peak. The default value is 0.0. + result_type mean() const { return mean_; } + + // Returns the deviation distribution parameter. The default value is 1.0. + result_type stddev() const { return stddev_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.mean_ == b.mean_ && a.stddev_ == b.stddev_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + result_type mean_; + result_type stddev_; + + static_assert( + std::is_floating_point<RealType>::value, + "Class-template absl::gaussian_distribution<> must be parameterized " + "using a floating-point type."); + }; + + gaussian_distribution() : gaussian_distribution(0) {} + + explicit gaussian_distribution(result_type mean, result_type stddev = 1) + : param_(mean, stddev) {} + + explicit gaussian_distribution(const param_type& p) : param_(p) {} + + void reset() {} + + // Generating functions + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + param_type param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + result_type(min)() const { + return -std::numeric_limits<result_type>::infinity(); + } + result_type(max)() const { + return std::numeric_limits<result_type>::infinity(); + } + + result_type mean() const { return param_.mean(); } + result_type stddev() const { return param_.stddev(); } + + friend bool operator==(const gaussian_distribution& a, + const gaussian_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const gaussian_distribution& a, + const gaussian_distribution& b) { + return a.param_ != b.param_; + } + + private: + param_type param_; +}; + +// -------------------------------------------------------------------------- +// Implementation details only below +// -------------------------------------------------------------------------- + +template <typename RealType> +template <typename URBG> +typename gaussian_distribution<RealType>::result_type +gaussian_distribution<RealType>::operator()( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + return p.mean() + p.stddev() * static_cast<result_type>(zignor(g)); +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const gaussian_distribution<RealType>& x) { + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<RealType>::kPrecision); + os << x.mean() << os.fill() << x.stddev(); + return os; +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + gaussian_distribution<RealType>& x) { // NOLINT(runtime/references) + using result_type = typename gaussian_distribution<RealType>::result_type; + using param_type = typename gaussian_distribution<RealType>::param_type; + + auto saver = random_internal::make_istream_state_saver(is); + auto mean = random_internal::read_floating_point<result_type>(is); + if (is.fail()) return is; + auto stddev = random_internal::read_floating_point<result_type>(is); + if (!is.fail()) { + x.param(param_type(mean, stddev)); + } + return is; +} + +namespace random_internal { + +template <typename URBG> +inline double gaussian_distribution_base::zignor_fallback(URBG& g, bool neg) { + using random_internal::GeneratePositiveTag; + using random_internal::GenerateRealFromBits; + + // This fallback path happens approximately 0.05% of the time. + double x, y; + do { + // kRInv = 1/r, U(0, 1) + x = kRInv * + std::log(GenerateRealFromBits<double, GeneratePositiveTag, false>( + fast_u64_(g))); + y = -std::log( + GenerateRealFromBits<double, GeneratePositiveTag, false>(fast_u64_(g))); + } while ((y + y) < (x * x)); + return neg ? (x - kR) : (kR - x); +} + +template <typename URBG> +inline double gaussian_distribution_base::zignor( + URBG& g) { // NOLINT(runtime/references) + using random_internal::GeneratePositiveTag; + using random_internal::GenerateRealFromBits; + using random_internal::GenerateSignedTag; + + while (true) { + // We use a single uint64_t to generate both a double and a strip. + // These bits are unused when the generated double is > 1/2^5. + // This may introduce some bias from the duplicated low bits of small + // values (those smaller than 1/2^5, which all end up on the left tail). + uint64_t bits = fast_u64_(g); + int i = static_cast<int>(bits & kMask); // pick a random strip + double j = GenerateRealFromBits<double, GenerateSignedTag, false>( + bits); // U(-1, 1) + const double x = j * zg_.x[i]; + + // Retangular box. Handles >97% of all cases. + // For any given box, this handles between 75% and 99% of values. + // Equivalent to U(01) < (x[i+1] / x[i]), and when i == 0, ~93.5% + if (std::abs(x) < zg_.x[i + 1]) { + return x; + } + + // i == 0: Base box. Sample using a ratio of uniforms. + if (i == 0) { + // This path happens about 0.05% of the time. + return zignor_fallback(g, j < 0); + } + + // i > 0: Wedge samples using precomputed values. + double v = GenerateRealFromBits<double, GeneratePositiveTag, false>( + fast_u64_(g)); // U(0, 1) + if ((zg_.f[i + 1] + v * (zg_.f[i] - zg_.f[i + 1])) < + std::exp(-0.5 * x * x)) { + return x; + } + + // The wedge was missed; reject the value and try again. + } +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_GAUSSIAN_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/gaussian_distribution_test.cc b/third_party/abseil_cpp/absl/random/gaussian_distribution_test.cc new file mode 100644 index 0000000000..02ac578a5c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/gaussian_distribution_test.cc @@ -0,0 +1,579 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/gaussian_distribution.h" + +#include <algorithm> +#include <cmath> +#include <cstddef> +#include <ios> +#include <iterator> +#include <random> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_replace.h" +#include "absl/strings/strip.h" + +namespace { + +using absl::random_internal::kChiSquared; + +template <typename RealType> +class GaussianDistributionInterfaceTest : public ::testing::Test {}; + +using RealTypes = ::testing::Types<float, double, long double>; +TYPED_TEST_CASE(GaussianDistributionInterfaceTest, RealTypes); + +TYPED_TEST(GaussianDistributionInterfaceTest, SerializeTest) { + using param_type = + typename absl::gaussian_distribution<TypeParam>::param_type; + + const TypeParam kParams[] = { + // Cases around 1. + 1, // + std::nextafter(TypeParam(1), TypeParam(0)), // 1 - epsilon + std::nextafter(TypeParam(1), TypeParam(2)), // 1 + epsilon + // Arbitrary values. + TypeParam(1e-8), TypeParam(1e-4), TypeParam(2), TypeParam(1e4), + TypeParam(1e8), TypeParam(1e20), TypeParam(2.5), + // Boundary cases. + std::numeric_limits<TypeParam>::infinity(), + std::numeric_limits<TypeParam>::max(), + std::numeric_limits<TypeParam>::epsilon(), + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(1)), // min + epsilon + std::numeric_limits<TypeParam>::min(), // smallest normal + // There are some errors dealing with denorms on apple platforms. + std::numeric_limits<TypeParam>::denorm_min(), // smallest denorm + std::numeric_limits<TypeParam>::min() / 2, + std::nextafter(std::numeric_limits<TypeParam>::min(), + TypeParam(0)), // denorm_max + }; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + + // Use a loop to generate the combinations of {+/-x, +/-y}, and assign x, y to + // all values in kParams, + for (const auto mod : {0, 1, 2, 3}) { + for (const auto x : kParams) { + if (!std::isfinite(x)) continue; + for (const auto y : kParams) { + const TypeParam mean = (mod & 0x1) ? -x : x; + const TypeParam stddev = (mod & 0x2) ? -y : y; + const param_type param(mean, stddev); + + absl::gaussian_distribution<TypeParam> before(mean, stddev); + EXPECT_EQ(before.mean(), param.mean()); + EXPECT_EQ(before.stddev(), param.stddev()); + + { + absl::gaussian_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + EXPECT_EQ(via_param.param(), before.param()); + } + + // Smoke test. + auto sample_min = before.max(); + auto sample_max = before.min(); + for (int i = 0; i < kCount; i++) { + auto sample = before(gen); + if (sample > sample_max) sample_max = sample; + if (sample < sample_min) sample_min = sample; + EXPECT_GE(sample, before.min()) << before; + EXPECT_LE(sample, before.max()) << before; + } + if (!std::is_same<TypeParam, long double>::value) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("Range{%f, %f}: %f, %f", mean, stddev, + sample_min, sample_max)); + } + + std::stringstream ss; + ss << before; + + if (!std::isfinite(mean) || !std::isfinite(stddev)) { + // Streams do not parse inf/nan. + continue; + } + + // Validate stream serialization. + absl::gaussian_distribution<TypeParam> after(-0.53f, 2.3456f); + + EXPECT_NE(before.mean(), after.mean()); + EXPECT_NE(before.stddev(), after.stddev()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + +#if defined(__powerpc64__) || defined(__PPC64__) || defined(__powerpc__) || \ + defined(__ppc__) || defined(__PPC__) || defined(__EMSCRIPTEN__) + if (std::is_same<TypeParam, long double>::value) { + // Roundtripping floating point values requires sufficient precision + // to reconstruct the exact value. It turns out that long double + // has some errors doing this on ppc, particularly for values + // near {1.0 +/- epsilon}. + // + // Emscripten is even worse, implementing long double as a 128-bit + // type, but shipping with a strtold() that doesn't support that. + if (mean <= std::numeric_limits<double>::max() && + mean >= std::numeric_limits<double>::lowest()) { + EXPECT_EQ(static_cast<double>(before.mean()), + static_cast<double>(after.mean())) + << ss.str(); + } + if (stddev <= std::numeric_limits<double>::max() && + stddev >= std::numeric_limits<double>::lowest()) { + EXPECT_EQ(static_cast<double>(before.stddev()), + static_cast<double>(after.stddev())) + << ss.str(); + } + continue; + } +#endif + + EXPECT_EQ(before.mean(), after.mean()); + EXPECT_EQ(before.stddev(), after.stddev()) // + << ss.str() << " " // + << (ss.good() ? "good " : "") // + << (ss.bad() ? "bad " : "") // + << (ss.eof() ? "eof " : "") // + << (ss.fail() ? "fail " : ""); + } + } + } +} + +// http://www.itl.nist.gov/div898/handbook/eda/section3/eda3661.htm + +class GaussianModel { + public: + GaussianModel(double mean, double stddev) : mean_(mean), stddev_(stddev) {} + + double mean() const { return mean_; } + double variance() const { return stddev() * stddev(); } + double stddev() const { return stddev_; } + double skew() const { return 0; } + double kurtosis() const { return 3.0; } + + // The inverse CDF, or PercentPoint function. + double InverseCDF(double p) { + ABSL_ASSERT(p >= 0.0); + ABSL_ASSERT(p < 1.0); + return mean() + stddev() * -absl::random_internal::InverseNormalSurvival(p); + } + + private: + const double mean_; + const double stddev_; +}; + +struct Param { + double mean; + double stddev; + double p_fail; // Z-Test probability of failure. + int trials; // Z-Test trials. +}; + +// GaussianDistributionTests implements a z-test for the gaussian +// distribution. +class GaussianDistributionTests : public testing::TestWithParam<Param>, + public GaussianModel { + public: + GaussianDistributionTests() + : GaussianModel(GetParam().mean, GetParam().stddev) {} + + // SingleZTest provides a basic z-squared test of the mean vs. expected + // mean for data generated by the poisson distribution. + template <typename D> + bool SingleZTest(const double p, const size_t samples); + + // SingleChiSquaredTest provides a basic chi-squared test of the normal + // distribution. + template <typename D> + double SingleChiSquaredTest(); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng_{0x2B7E151628AED2A6}; +}; + +template <typename D> +bool GaussianDistributionTests::SingleZTest(const double p, + const size_t samples) { + D dis(mean(), stddev()); + + std::vector<double> data; + data.reserve(samples); + for (size_t i = 0; i < samples; i++) { + const double x = dis(rng_); + data.push_back(x); + } + + const double max_err = absl::random_internal::MaxErrorTolerance(p); + const auto m = absl::random_internal::ComputeDistributionMoments(data); + const double z = absl::random_internal::ZScore(mean(), m); + const bool pass = absl::random_internal::Near("z", z, 0.0, max_err); + + // NOTE: Informational statistical test: + // + // Compute the Jarque-Bera test statistic given the excess skewness + // and kurtosis. The statistic is drawn from a chi-square(2) distribution. + // https://en.wikipedia.org/wiki/Jarque%E2%80%93Bera_test + // + // The null-hypothesis (normal distribution) is rejected when + // (p = 0.05 => jb > 5.99) + // (p = 0.01 => jb > 9.21) + // NOTE: JB has a large type-I error rate, so it will reject the + // null-hypothesis even when it is true more often than the z-test. + // + const double jb = + static_cast<double>(m.n) / 6.0 * + (std::pow(m.skewness, 2.0) + std::pow(m.kurtosis - 3.0, 2.0) / 4.0); + + if (!pass || jb > 9.21) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("p=%f max_err=%f\n" + " mean=%f vs. %f\n" + " stddev=%f vs. %f\n" + " skewness=%f vs. %f\n" + " kurtosis=%f vs. %f\n" + " z=%f vs. 0\n" + " jb=%f vs. 9.21", + p, max_err, m.mean, mean(), std::sqrt(m.variance), + stddev(), m.skewness, skew(), m.kurtosis, + kurtosis(), z, jb)); + } + return pass; +} + +template <typename D> +double GaussianDistributionTests::SingleChiSquaredTest() { + const size_t kSamples = 10000; + const int kBuckets = 50; + + // The InverseCDF is the percent point function of the + // distribution, and can be used to assign buckets + // roughly uniformly. + std::vector<double> cutoffs; + const double kInc = 1.0 / static_cast<double>(kBuckets); + for (double p = kInc; p < 1.0; p += kInc) { + cutoffs.push_back(InverseCDF(p)); + } + if (cutoffs.back() != std::numeric_limits<double>::infinity()) { + cutoffs.push_back(std::numeric_limits<double>::infinity()); + } + + D dis(mean(), stddev()); + + std::vector<int32_t> counts(cutoffs.size(), 0); + for (int j = 0; j < kSamples; j++) { + const double x = dis(rng_); + auto it = std::upper_bound(cutoffs.begin(), cutoffs.end(), x); + counts[std::distance(cutoffs.begin(), it)]++; + } + + // Null-hypothesis is that the distribution is a gaussian distribution + // with the provided mean and stddev (not estimated from the data). + const int dof = static_cast<int>(counts.size()) - 1; + + // Our threshold for logging is 1-in-50. + const double threshold = absl::random_internal::ChiSquareValue(dof, 0.98); + + const double expected = + static_cast<double>(kSamples) / static_cast<double>(counts.size()); + + double chi_square = absl::random_internal::ChiSquareWithExpected( + std::begin(counts), std::end(counts), expected); + double p = absl::random_internal::ChiSquarePValue(chi_square, dof); + + // Log if the chi_square value is above the threshold. + if (chi_square > threshold) { + for (int i = 0; i < cutoffs.size(); i++) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("%d : (%f) = %d", i, cutoffs[i], counts[i])); + } + + ABSL_INTERNAL_LOG( + INFO, absl::StrCat("mean=", mean(), " stddev=", stddev(), "\n", // + " expected ", expected, "\n", // + kChiSquared, " ", chi_square, " (", p, ")\n", // + kChiSquared, " @ 0.98 = ", threshold)); + } + return p; +} + +TEST_P(GaussianDistributionTests, ZTest) { + // TODO(absl-team): Run these tests against std::normal_distribution<double> + // to validate outcomes are similar. + const size_t kSamples = 10000; + const auto& param = GetParam(); + const int expected_failures = + std::max(1, static_cast<int>(std::ceil(param.trials * param.p_fail))); + const double p = absl::random_internal::RequiredSuccessProbability( + param.p_fail, param.trials); + + int failures = 0; + for (int i = 0; i < param.trials; i++) { + failures += + SingleZTest<absl::gaussian_distribution<double>>(p, kSamples) ? 0 : 1; + } + EXPECT_LE(failures, expected_failures); +} + +TEST_P(GaussianDistributionTests, ChiSquaredTest) { + const int kTrials = 20; + int failures = 0; + + for (int i = 0; i < kTrials; i++) { + double p_value = + SingleChiSquaredTest<absl::gaussian_distribution<double>>(); + if (p_value < 0.0025) { // 1/400 + failures++; + } + } + // There is a 0.05% chance of producing at least one failure, so raise the + // failure threshold high enough to allow for a flake rate of less than one in + // 10,000. + EXPECT_LE(failures, 4); +} + +std::vector<Param> GenParams() { + return { + // Mean around 0. + Param{0.0, 1.0, 0.01, 100}, + Param{0.0, 1e2, 0.01, 100}, + Param{0.0, 1e4, 0.01, 100}, + Param{0.0, 1e8, 0.01, 100}, + Param{0.0, 1e16, 0.01, 100}, + Param{0.0, 1e-3, 0.01, 100}, + Param{0.0, 1e-5, 0.01, 100}, + Param{0.0, 1e-9, 0.01, 100}, + Param{0.0, 1e-17, 0.01, 100}, + + // Mean around 1. + Param{1.0, 1.0, 0.01, 100}, + Param{1.0, 1e2, 0.01, 100}, + Param{1.0, 1e-2, 0.01, 100}, + + // Mean around 100 / -100 + Param{1e2, 1.0, 0.01, 100}, + Param{-1e2, 1.0, 0.01, 100}, + Param{1e2, 1e6, 0.01, 100}, + Param{-1e2, 1e6, 0.01, 100}, + + // More extreme + Param{1e4, 1e4, 0.01, 100}, + Param{1e8, 1e4, 0.01, 100}, + Param{1e12, 1e4, 0.01, 100}, + }; +} + +std::string ParamName(const ::testing::TestParamInfo<Param>& info) { + const auto& p = info.param; + std::string name = absl::StrCat("mean_", absl::SixDigits(p.mean), "__stddev_", + absl::SixDigits(p.stddev)); + return absl::StrReplaceAll(name, {{"+", "_"}, {"-", "_"}, {".", "_"}}); +} + +INSTANTIATE_TEST_SUITE_P(All, GaussianDistributionTests, + ::testing::ValuesIn(GenParams()), ParamName); + +// NOTE: absl::gaussian_distribution is not guaranteed to be stable. +TEST(GaussianDistributionTest, StabilityTest) { + // absl::gaussian_distribution stability relies on the underlying zignor + // data, absl::random_interna::RandU64ToDouble, std::exp, std::log, and + // std::abs. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(11); + + { + absl::gaussian_distribution<double> dist; + std::generate(std::begin(output), std::end(output), + [&] { return static_cast<int>(10000000.0 * dist(urbg)); }); + + EXPECT_EQ(13, urbg.invocations()); + EXPECT_THAT(output, // + testing::ElementsAre(1494, 25518841, 9991550, 1351856, + -20373238, 3456682, 333530, -6804981, + -15279580, -16459654, 1494)); + } + + urbg.reset(); + { + absl::gaussian_distribution<float> dist; + std::generate(std::begin(output), std::end(output), + [&] { return static_cast<int>(1000000.0f * dist(urbg)); }); + + EXPECT_EQ(13, urbg.invocations()); + EXPECT_THAT( + output, // + testing::ElementsAre(149, 2551884, 999155, 135185, -2037323, 345668, + 33353, -680498, -1527958, -1645965, 149)); + } +} + +// This is an implementation-specific test. If any part of the implementation +// changes, then it is likely that this test will change as well. +// Also, if dependencies of the distribution change, such as RandU64ToDouble, +// then this is also likely to change. +TEST(GaussianDistributionTest, AlgorithmBounds) { + absl::gaussian_distribution<double> dist; + + // In ~95% of cases, a single value is used to generate the output. + // for all inputs where |x| < 0.750461021389 this should be the case. + // + // The exact constraints are based on the ziggurat tables, and any + // changes to the ziggurat tables may require adjusting these bounds. + // + // for i in range(0, len(X)-1): + // print i, X[i+1]/X[i], (X[i+1]/X[i] > 0.984375) + // + // 0.125 <= |values| <= 0.75 + const uint64_t kValues[] = { + 0x1000000000000100ull, 0x2000000000000100ull, 0x3000000000000100ull, + 0x4000000000000100ull, 0x5000000000000100ull, 0x6000000000000100ull, + // negative values + 0x9000000000000100ull, 0xa000000000000100ull, 0xb000000000000100ull, + 0xc000000000000100ull, 0xd000000000000100ull, 0xe000000000000100ull}; + + // 0.875 <= |values| <= 0.984375 + const uint64_t kExtraValues[] = { + 0x7000000000000100ull, 0x7800000000000100ull, // + 0x7c00000000000100ull, 0x7e00000000000100ull, // + // negative values + 0xf000000000000100ull, 0xf800000000000100ull, // + 0xfc00000000000100ull, 0xfe00000000000100ull}; + + auto make_box = [](uint64_t v, uint64_t box) { + return (v & 0xffffffffffffff80ull) | box; + }; + + // The box is the lower 7 bits of the value. When the box == 0, then + // the algorithm uses an escape hatch to select the result for large + // outputs. + for (uint64_t box = 0; box < 0x7f; box++) { + for (const uint64_t v : kValues) { + // Extra values are added to the sequence to attempt to avoid + // infinite loops from rejection sampling on bugs/errors. + absl::random_internal::sequence_urbg urbg( + {make_box(v, box), 0x0003eb76f6f7f755ull, 0x5FCEA50FDB2F953Bull}); + + auto a = dist(urbg); + EXPECT_EQ(1, urbg.invocations()) << box << " " << std::hex << v; + if (v & 0x8000000000000000ull) { + EXPECT_LT(a, 0.0) << box << " " << std::hex << v; + } else { + EXPECT_GT(a, 0.0) << box << " " << std::hex << v; + } + } + if (box > 10 && box < 100) { + // The center boxes use the fast algorithm for more + // than 98.4375% of values. + for (const uint64_t v : kExtraValues) { + absl::random_internal::sequence_urbg urbg( + {make_box(v, box), 0x0003eb76f6f7f755ull, 0x5FCEA50FDB2F953Bull}); + + auto a = dist(urbg); + EXPECT_EQ(1, urbg.invocations()) << box << " " << std::hex << v; + if (v & 0x8000000000000000ull) { + EXPECT_LT(a, 0.0) << box << " " << std::hex << v; + } else { + EXPECT_GT(a, 0.0) << box << " " << std::hex << v; + } + } + } + } + + // When the box == 0, the fallback algorithm uses a ratio of uniforms, + // which consumes 2 additional values from the urbg. + // Fallback also requires that the initial value be > 0.9271586026096681. + auto make_fallback = [](uint64_t v) { return (v & 0xffffffffffffff80ull); }; + + double tail[2]; + { + // 0.9375 + absl::random_internal::sequence_urbg urbg( + {make_fallback(0x7800000000000000ull), 0x13CCA830EB61BD96ull, + 0x00000076f6f7f755ull}); + tail[0] = dist(urbg); + EXPECT_EQ(3, urbg.invocations()); + EXPECT_GT(tail[0], 0); + } + { + // -0.9375 + absl::random_internal::sequence_urbg urbg( + {make_fallback(0xf800000000000000ull), 0x13CCA830EB61BD96ull, + 0x00000076f6f7f755ull}); + tail[1] = dist(urbg); + EXPECT_EQ(3, urbg.invocations()); + EXPECT_LT(tail[1], 0); + } + EXPECT_EQ(tail[0], -tail[1]); + EXPECT_EQ(418610, static_cast<int64_t>(tail[0] * 100000.0)); + + // When the box != 0, the fallback algorithm computes a wedge function. + // Depending on the box, the threshold for varies as high as + // 0.991522480228. + { + // 0.9921875, 0.875 + absl::random_internal::sequence_urbg urbg( + {make_box(0x7f00000000000000ull, 120), 0xe000000000000001ull, + 0x13CCA830EB61BD96ull}); + tail[0] = dist(urbg); + EXPECT_EQ(2, urbg.invocations()); + EXPECT_GT(tail[0], 0); + } + { + // -0.9921875, 0.875 + absl::random_internal::sequence_urbg urbg( + {make_box(0xff00000000000000ull, 120), 0xe000000000000001ull, + 0x13CCA830EB61BD96ull}); + tail[1] = dist(urbg); + EXPECT_EQ(2, urbg.invocations()); + EXPECT_LT(tail[1], 0); + } + EXPECT_EQ(tail[0], -tail[1]); + EXPECT_EQ(61948, static_cast<int64_t>(tail[0] * 100000.0)); + + // Fallback rejected, try again. + { + // -0.9921875, 0.0625 + absl::random_internal::sequence_urbg urbg( + {make_box(0xff00000000000000ull, 120), 0x1000000000000001, + make_box(0x1000000000000100ull, 50), 0x13CCA830EB61BD96ull}); + dist(urbg); + EXPECT_EQ(3, urbg.invocations()); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/generators_test.cc b/third_party/abseil_cpp/absl/random/generators_test.cc new file mode 100644 index 0000000000..41725f139c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/generators_test.cc @@ -0,0 +1,179 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstddef> +#include <cstdint> +#include <random> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/random/distributions.h" +#include "absl/random/random.h" + +namespace { + +template <typename URBG> +void TestUniform(URBG* gen) { + // [a, b) default-semantics, inferred types. + absl::Uniform(*gen, 0, 100); // int + absl::Uniform(*gen, 0, 1.0); // Promoted to double + absl::Uniform(*gen, 0.0f, 1.0); // Promoted to double + absl::Uniform(*gen, 0.0, 1.0); // double + absl::Uniform(*gen, -1, 1L); // Promoted to long + + // Roll a die. + absl::Uniform(absl::IntervalClosedClosed, *gen, 1, 6); + + // Get a fraction. + absl::Uniform(absl::IntervalOpenOpen, *gen, 0.0, 1.0); + + // Assign a value to a random element. + std::vector<int> elems = {10, 20, 30, 40, 50}; + elems[absl::Uniform(*gen, 0u, elems.size())] = 5; + elems[absl::Uniform<size_t>(*gen, 0, elems.size())] = 3; + + // Choose some epsilon around zero. + absl::Uniform(absl::IntervalOpenOpen, *gen, -1.0, 1.0); + + // (a, b) semantics, inferred types. + absl::Uniform(absl::IntervalOpenOpen, *gen, 0, 1.0); // Promoted to double + + // Explict overriding of types. + absl::Uniform<int>(*gen, 0, 100); + absl::Uniform<int8_t>(*gen, 0, 100); + absl::Uniform<int16_t>(*gen, 0, 100); + absl::Uniform<uint16_t>(*gen, 0, 100); + absl::Uniform<int32_t>(*gen, 0, 1 << 10); + absl::Uniform<uint32_t>(*gen, 0, 1 << 10); + absl::Uniform<int64_t>(*gen, 0, 1 << 10); + absl::Uniform<uint64_t>(*gen, 0, 1 << 10); + + absl::Uniform<float>(*gen, 0.0, 1.0); + absl::Uniform<float>(*gen, 0, 1); + absl::Uniform<float>(*gen, -1, 1); + absl::Uniform<double>(*gen, 0.0, 1.0); + + absl::Uniform<float>(*gen, -1.0, 0); + absl::Uniform<double>(*gen, -1.0, 0); + + // Tagged + absl::Uniform<double>(absl::IntervalClosedClosed, *gen, 0, 1); + absl::Uniform<double>(absl::IntervalClosedOpen, *gen, 0, 1); + absl::Uniform<double>(absl::IntervalOpenOpen, *gen, 0, 1); + absl::Uniform<double>(absl::IntervalOpenClosed, *gen, 0, 1); + absl::Uniform<double>(absl::IntervalClosedClosed, *gen, 0, 1); + absl::Uniform<double>(absl::IntervalOpenOpen, *gen, 0, 1); + + absl::Uniform<int>(absl::IntervalClosedClosed, *gen, 0, 100); + absl::Uniform<int>(absl::IntervalClosedOpen, *gen, 0, 100); + absl::Uniform<int>(absl::IntervalOpenOpen, *gen, 0, 100); + absl::Uniform<int>(absl::IntervalOpenClosed, *gen, 0, 100); + absl::Uniform<int>(absl::IntervalClosedClosed, *gen, 0, 100); + absl::Uniform<int>(absl::IntervalOpenOpen, *gen, 0, 100); + + // With *generator as an R-value reference. + absl::Uniform<int>(URBG(), 0, 100); + absl::Uniform<double>(URBG(), 0.0, 1.0); +} + +template <typename URBG> +void TestExponential(URBG* gen) { + absl::Exponential<float>(*gen); + absl::Exponential<double>(*gen); + absl::Exponential<double>(URBG()); +} + +template <typename URBG> +void TestPoisson(URBG* gen) { + // [rand.dist.pois] Indicates that the std::poisson_distribution + // is parameterized by IntType, however MSVC does not allow 8-bit + // types. + absl::Poisson<int>(*gen); + absl::Poisson<int16_t>(*gen); + absl::Poisson<uint16_t>(*gen); + absl::Poisson<int32_t>(*gen); + absl::Poisson<uint32_t>(*gen); + absl::Poisson<int64_t>(*gen); + absl::Poisson<uint64_t>(*gen); + absl::Poisson<uint64_t>(URBG()); +} + +template <typename URBG> +void TestBernoulli(URBG* gen) { + absl::Bernoulli(*gen, 0.5); + absl::Bernoulli(*gen, 0.5); +} + +template <typename URBG> +void TestZipf(URBG* gen) { + absl::Zipf<int>(*gen, 100); + absl::Zipf<int8_t>(*gen, 100); + absl::Zipf<int16_t>(*gen, 100); + absl::Zipf<uint16_t>(*gen, 100); + absl::Zipf<int32_t>(*gen, 1 << 10); + absl::Zipf<uint32_t>(*gen, 1 << 10); + absl::Zipf<int64_t>(*gen, 1 << 10); + absl::Zipf<uint64_t>(*gen, 1 << 10); + absl::Zipf<uint64_t>(URBG(), 1 << 10); +} + +template <typename URBG> +void TestGaussian(URBG* gen) { + absl::Gaussian<float>(*gen, 1.0, 1.0); + absl::Gaussian<double>(*gen, 1.0, 1.0); + absl::Gaussian<double>(URBG(), 1.0, 1.0); +} + +template <typename URBG> +void TestLogNormal(URBG* gen) { + absl::LogUniform<int>(*gen, 0, 100); + absl::LogUniform<int8_t>(*gen, 0, 100); + absl::LogUniform<int16_t>(*gen, 0, 100); + absl::LogUniform<uint16_t>(*gen, 0, 100); + absl::LogUniform<int32_t>(*gen, 0, 1 << 10); + absl::LogUniform<uint32_t>(*gen, 0, 1 << 10); + absl::LogUniform<int64_t>(*gen, 0, 1 << 10); + absl::LogUniform<uint64_t>(*gen, 0, 1 << 10); + absl::LogUniform<uint64_t>(URBG(), 0, 1 << 10); +} + +template <typename URBG> +void CompatibilityTest() { + URBG gen; + + TestUniform(&gen); + TestExponential(&gen); + TestPoisson(&gen); + TestBernoulli(&gen); + TestZipf(&gen); + TestGaussian(&gen); + TestLogNormal(&gen); +} + +TEST(std_mt19937_64, Compatibility) { + // Validate with std::mt19937_64 + CompatibilityTest<std::mt19937_64>(); +} + +TEST(BitGen, Compatibility) { + // Validate with absl::BitGen + CompatibilityTest<absl::BitGen>(); +} + +TEST(InsecureBitGen, Compatibility) { + // Validate with absl::InsecureBitGen + CompatibilityTest<absl::InsecureBitGen>(); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/BUILD.bazel b/third_party/abseil_cpp/absl/random/internal/BUILD.bazel new file mode 100644 index 0000000000..85d1fb81d2 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/BUILD.bazel @@ -0,0 +1,728 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library", "cc_test") + +# Internal-only implementation classes for Abseil Random +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_RANDOM_RANDEN_COPTS", + "ABSL_TEST_COPTS", + "absl_random_randen_copts_init", +) + +package(default_visibility = [ + "//absl/random:__pkg__", +]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "traits", + hdrs = ["traits.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_library( + name = "distribution_caller", + hdrs = ["distribution_caller.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_library( + name = "distributions", + hdrs = ["distributions.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distribution_caller", + ":traits", + ":uniform_helper", + "//absl/base", + "//absl/meta:type_traits", + "//absl/strings", + ], +) + +cc_library( + name = "fast_uniform_bits", + hdrs = [ + "fast_uniform_bits.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_library( + name = "seed_material", + srcs = [ + "seed_material.cc", + ], + hdrs = [ + "seed_material.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS + select({ + "//absl:windows": ["-DEFAULTLIB:bcrypt.lib"], + "//conditions:default": [], + }), + deps = [ + ":fast_uniform_bits", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/strings", + "//absl/types:optional", + "//absl/types:span", + ], +) + +cc_library( + name = "pool_urbg", + srcs = [ + "pool_urbg.cc", + ], + hdrs = [ + "pool_urbg.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = select({ + "//absl:windows": [], + "//conditions:default": ["-pthread"], + }) + ABSL_DEFAULT_LINKOPTS, + deps = [ + ":randen", + ":seed_material", + ":traits", + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/base:raw_logging_internal", + "//absl/random:seed_gen_exception", + "//absl/types:span", + ], +) + +cc_library( + name = "explicit_seed_seq", + testonly = 1, + hdrs = [ + "explicit_seed_seq.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_library( + name = "sequence_urbg", + testonly = 1, + hdrs = [ + "sequence_urbg.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:config"], +) + +cc_library( + name = "salted_seed_seq", + hdrs = [ + "salted_seed_seq.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":seed_material", + "//absl/container:inlined_vector", + "//absl/meta:type_traits", + "//absl/types:optional", + "//absl/types:span", + ], +) + +cc_library( + name = "iostream_state_saver", + hdrs = ["iostream_state_saver.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/meta:type_traits", + "//absl/numeric:int128", + ], +) + +cc_library( + name = "generate_real", + hdrs = [ + "generate_real.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":fastmath", + ":traits", + "//absl/base:bits", + "//absl/meta:type_traits", + ], +) + +cc_library( + name = "fastmath", + hdrs = [ + "fastmath.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = ["//absl/base:bits"], +) + +cc_library( + name = "wide_multiply", + hdrs = ["wide_multiply.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":traits", + "//absl/base:bits", + "//absl/base:config", + "//absl/numeric:int128", + ], +) + +cc_library( + name = "nonsecure_base", + hdrs = ["nonsecure_base.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":pool_urbg", + ":salted_seed_seq", + ":seed_material", + "//absl/base:core_headers", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/types:optional", + "//absl/types:span", + ], +) + +cc_library( + name = "pcg_engine", + hdrs = ["pcg_engine.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":fastmath", + ":iostream_state_saver", + "//absl/base:config", + "//absl/meta:type_traits", + "//absl/numeric:int128", + ], +) + +cc_library( + name = "randen_engine", + hdrs = ["randen_engine.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":iostream_state_saver", + ":randen", + "//absl/meta:type_traits", + ], +) + +cc_library( + name = "platform", + srcs = [ + "randen_round_keys.cc", + ], + hdrs = [ + "randen_traits.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + textual_hdrs = [ + "platform.h", + ], + deps = ["//absl/base:config"], +) + +cc_library( + name = "randen", + srcs = [ + "randen.cc", + ], + hdrs = [ + "randen.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":platform", + ":randen_hwaes", + ":randen_slow", + "//absl/base:raw_logging_internal", + ], +) + +cc_library( + name = "randen_slow", + srcs = ["randen_slow.cc"], + hdrs = ["randen_slow.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":platform", + "//absl/base:config", + "//absl/base:core_headers", + ], +) + +absl_random_randen_copts_init() + +cc_library( + name = "randen_hwaes", + srcs = [ + "randen_detect.cc", + ], + hdrs = [ + "randen_detect.h", + "randen_hwaes.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":platform", + ":randen_hwaes_impl", + "//absl/base:config", + ], +) + +# build with --save_temps to see assembly language output. +cc_library( + name = "randen_hwaes_impl", + srcs = [ + "randen_hwaes.cc", + "randen_hwaes.h", + ], + copts = ABSL_DEFAULT_COPTS + ABSL_RANDOM_RANDEN_COPTS + select({ + "//absl:windows": [], + "//conditions:default": ["-Wno-pass-failed"], + }), + # copts in RANDEN_HWAES_COPTS can make this target unusable as a module + # leading to a Clang diagnostic. Furthermore, it only has a private header + # anyway and thus there wouldn't be any gain from using it as a module. + features = ["-header_modules"], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":platform", + "//absl/base:config", + "//absl/base:core_headers", + ], +) + +cc_binary( + name = "gaussian_distribution_gentables", + srcs = [ + "gaussian_distribution_gentables.cc", + ], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:core_headers", + "//absl/random:distributions", + ], +) + +cc_library( + name = "distribution_test_util", + testonly = 1, + srcs = [ + "chi_square.cc", + "distribution_test_util.cc", + ], + hdrs = [ + "chi_square.h", + "distribution_test_util.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/strings", + "//absl/strings:str_format", + "//absl/types:span", + ], +) + +# Common tags for tests, etc. +ABSL_RANDOM_NONPORTABLE_TAGS = [ + "no_test_android_arm", + "no_test_android_arm64", + "no_test_android_x86", + "no_test_darwin_x86_64", + "no_test_ios_x86_64", + "no_test_loonix", + "no_test_msvc_x64", + "no_test_wasm", +] + +cc_test( + name = "traits_test", + size = "small", + srcs = ["traits_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":traits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "generate_real_test", + size = "small", + srcs = [ + "generate_real_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":generate_real", + "//absl/base:bits", + "//absl/flags:flag", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "distribution_test_util_test", + size = "small", + srcs = ["distribution_test_util_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distribution_test_util", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "fastmath_test", + size = "small", + srcs = ["fastmath_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":fastmath", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "explicit_seed_seq_test", + size = "small", + srcs = ["explicit_seed_seq_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":explicit_seed_seq", + "//absl/random:seed_sequences", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "salted_seed_seq_test", + size = "small", + srcs = ["salted_seed_seq_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":salted_seed_seq", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "chi_square_test", + size = "small", + srcs = [ + "chi_square_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":distribution_test_util", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "fast_uniform_bits_test", + size = "small", + srcs = [ + "fast_uniform_bits_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":fast_uniform_bits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "mocking_bit_gen_base", + hdrs = ["mocking_bit_gen_base.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/random", + "//absl/strings", + ], +) + +cc_library( + name = "mock_overload_set", + testonly = 1, + hdrs = ["mock_overload_set.h"], + deps = [ + "//absl/random:mocking_bit_gen", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "nonsecure_base_test", + size = "small", + srcs = [ + "nonsecure_base_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":nonsecure_base", + "//absl/random", + "//absl/random:distributions", + "//absl/random:seed_sequences", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "seed_material_test", + size = "small", + srcs = ["seed_material_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":seed_material", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "pool_urbg_test", + size = "small", + srcs = [ + "pool_urbg_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":pool_urbg", + "//absl/meta:type_traits", + "//absl/types:span", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "pcg_engine_test", + size = "medium", # Trying to measure accuracy. + srcs = ["pcg_engine_test.cc"], + copts = ABSL_TEST_COPTS, + flaky = 1, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":explicit_seed_seq", + ":pcg_engine", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "randen_engine_test", + size = "medium", + srcs = [ + "randen_engine_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":explicit_seed_seq", + ":randen_engine", + "//absl/base:raw_logging_internal", + "//absl/strings", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "randen_test", + size = "small", + srcs = ["randen_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":randen", + "//absl/meta:type_traits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "randen_slow_test", + size = "small", + srcs = ["randen_slow_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":platform", + ":randen_slow", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "randen_hwaes_test", + size = "small", + srcs = ["randen_hwaes_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ABSL_RANDOM_NONPORTABLE_TAGS, + deps = [ + ":platform", + ":randen_hwaes", + ":randen_hwaes_impl", # build_cleaner: keep + "//absl/base:raw_logging_internal", + "//absl/strings:str_format", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "wide_multiply_test", + size = "small", + srcs = ["wide_multiply_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":wide_multiply", + "//absl/base:bits", + "//absl/numeric:int128", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "nanobenchmark", + srcs = ["nanobenchmark.cc"], + linkopts = ABSL_DEFAULT_LINKOPTS, + textual_hdrs = ["nanobenchmark.h"], + deps = [ + ":platform", + ":randen_engine", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + ], +) + +cc_library( + name = "uniform_helper", + hdrs = ["uniform_helper.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "nanobenchmark_test", + size = "small", + srcs = ["nanobenchmark_test.cc"], + flaky = 1, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = [ + "benchmark", + "no_test_ios_x86_64", + "no_test_loonix", # Crashing. + ], + deps = [ + ":nanobenchmark", + "//absl/base:raw_logging_internal", + "//absl/strings", + ], +) + +cc_test( + name = "randen_benchmarks", + size = "medium", + timeout = "long", + srcs = ["randen_benchmarks.cc"], + copts = ABSL_TEST_COPTS + ABSL_RANDOM_RANDEN_COPTS, + flaky = 1, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ABSL_RANDOM_NONPORTABLE_TAGS + ["benchmark"], + deps = [ + ":nanobenchmark", + ":platform", + ":randen", + ":randen_engine", + ":randen_hwaes", + ":randen_hwaes_impl", + ":randen_slow", + "//absl/base:raw_logging_internal", + "//absl/strings", + ], +) + +cc_test( + name = "iostream_state_saver_test", + size = "small", + srcs = ["iostream_state_saver_test.cc"], + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":iostream_state_saver", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/random/internal/chi_square.cc b/third_party/abseil_cpp/absl/random/internal/chi_square.cc new file mode 100644 index 0000000000..640d48cea6 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/chi_square.cc @@ -0,0 +1,232 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/chi_square.h" + +#include <cmath> + +#include "absl/random/internal/distribution_test_util.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +#if defined(__EMSCRIPTEN__) +// Workaround __EMSCRIPTEN__ error: llvm_fma_f64 not found. +inline double fma(double x, double y, double z) { + return (x * y) + z; +} +#endif + +// Use Horner's method to evaluate a polynomial. +template <typename T, unsigned N> +inline T EvaluatePolynomial(T x, const T (&poly)[N]) { +#if !defined(__EMSCRIPTEN__) + using std::fma; +#endif + T p = poly[N - 1]; + for (unsigned i = 2; i <= N; i++) { + p = fma(p, x, poly[N - i]); + } + return p; +} + +static constexpr int kLargeDOF = 150; + +// Returns the probability of a normal z-value. +// +// Adapted from the POZ function in: +// Ibbetson D, Algorithm 209 +// Collected Algorithms of the CACM 1963 p. 616 +// +double POZ(double z) { + static constexpr double kP1[] = { + 0.797884560593, -0.531923007300, 0.319152932694, + -0.151968751364, 0.059054035642, -0.019198292004, + 0.005198775019, -0.001075204047, 0.000124818987, + }; + static constexpr double kP2[] = { + 0.999936657524, 0.000535310849, -0.002141268741, 0.005353579108, + -0.009279453341, 0.011630447319, -0.010557625006, 0.006549791214, + -0.002034254874, -0.000794620820, 0.001390604284, -0.000676904986, + -0.000019538132, 0.000152529290, -0.000045255659, + }; + + const double kZMax = 6.0; // Maximum meaningful z-value. + if (z == 0.0) { + return 0.5; + } + double x; + double y = 0.5 * std::fabs(z); + if (y >= (kZMax * 0.5)) { + x = 1.0; + } else if (y < 1.0) { + double w = y * y; + x = EvaluatePolynomial(w, kP1) * y * 2.0; + } else { + y -= 2.0; + x = EvaluatePolynomial(y, kP2); + } + return z > 0.0 ? ((x + 1.0) * 0.5) : ((1.0 - x) * 0.5); +} + +// Approximates the survival function of the normal distribution. +// +// Algorithm 26.2.18, from: +// [Abramowitz and Stegun, Handbook of Mathematical Functions,p.932] +// http://people.math.sfu.ca/~cbm/aands/abramowitz_and_stegun.pdf +// +double normal_survival(double z) { + // Maybe replace with the alternate formulation. + // 0.5 * erfc((x - mean)/(sqrt(2) * sigma)) + static constexpr double kR[] = { + 1.0, 0.196854, 0.115194, 0.000344, 0.019527, + }; + double r = EvaluatePolynomial(z, kR); + r *= r; + return 0.5 / (r * r); +} + +} // namespace + +// Calculates the critical chi-square value given degrees-of-freedom and a +// p-value, usually using bisection. Also known by the name CRITCHI. +double ChiSquareValue(int dof, double p) { + static constexpr double kChiEpsilon = + 0.000001; // Accuracy of the approximation. + static constexpr double kChiMax = + 99999.0; // Maximum chi-squared value. + + const double p_value = 1.0 - p; + if (dof < 1 || p_value > 1.0) { + return 0.0; + } + + if (dof > kLargeDOF) { + // For large degrees of freedom, use the normal approximation by + // Wilson, E. B. and Hilferty, M. M. (1931) + // chi^2 - mean + // Z = -------------- + // stddev + const double z = InverseNormalSurvival(p_value); + const double mean = 1 - 2.0 / (9 * dof); + const double variance = 2.0 / (9 * dof); + // Cannot use this method if the variance is 0. + if (variance != 0) { + return std::pow(z * std::sqrt(variance) + mean, 3.0) * dof; + } + } + + if (p_value <= 0.0) return kChiMax; + + // Otherwise search for the p value by bisection + double min_chisq = 0.0; + double max_chisq = kChiMax; + double current = dof / std::sqrt(p_value); + while ((max_chisq - min_chisq) > kChiEpsilon) { + if (ChiSquarePValue(current, dof) < p_value) { + max_chisq = current; + } else { + min_chisq = current; + } + current = (max_chisq + min_chisq) * 0.5; + } + return current; +} + +// Calculates the p-value (probability) of a given chi-square value +// and degrees of freedom. +// +// Adapted from the POCHISQ function from: +// Hill, I. D. and Pike, M. C. Algorithm 299 +// Collected Algorithms of the CACM 1963 p. 243 +// +double ChiSquarePValue(double chi_square, int dof) { + static constexpr double kLogSqrtPi = + 0.5723649429247000870717135; // Log[Sqrt[Pi]] + static constexpr double kInverseSqrtPi = + 0.5641895835477562869480795; // 1/(Sqrt[Pi]) + + // For large degrees of freedom, use the normal approximation by + // Wilson, E. B. and Hilferty, M. M. (1931) + // Via Wikipedia: + // By the Central Limit Theorem, because the chi-square distribution is the + // sum of k independent random variables with finite mean and variance, it + // converges to a normal distribution for large k. + if (dof > kLargeDOF) { + // Re-scale everything. + const double chi_square_scaled = std::pow(chi_square / dof, 1.0 / 3); + const double mean = 1 - 2.0 / (9 * dof); + const double variance = 2.0 / (9 * dof); + // If variance is 0, this method cannot be used. + if (variance != 0) { + const double z = (chi_square_scaled - mean) / std::sqrt(variance); + if (z > 0) { + return normal_survival(z); + } else if (z < 0) { + return 1.0 - normal_survival(-z); + } else { + return 0.5; + } + } + } + + // The chi square function is >= 0 for any degrees of freedom. + // In other words, probability that the chi square function >= 0 is 1. + if (chi_square <= 0.0) return 1.0; + + // If the degrees of freedom is zero, the chi square function is always 0 by + // definition. In other words, the probability that the chi square function + // is > 0 is zero (chi square values <= 0 have been filtered above). + if (dof < 1) return 0; + + auto capped_exp = [](double x) { return x < -20 ? 0.0 : std::exp(x); }; + static constexpr double kBigX = 20; + + double a = 0.5 * chi_square; + const bool even = !(dof & 1); // True if dof is an even number. + const double y = capped_exp(-a); + double s = even ? y : (2.0 * POZ(-std::sqrt(chi_square))); + + if (dof <= 2) { + return s; + } + + chi_square = 0.5 * (dof - 1.0); + double z = (even ? 1.0 : 0.5); + if (a > kBigX) { + double e = (even ? 0.0 : kLogSqrtPi); + double c = std::log(a); + while (z <= chi_square) { + e = std::log(z) + e; + s += capped_exp(c * z - a - e); + z += 1.0; + } + return s; + } + + double e = (even ? 1.0 : (kInverseSqrtPi / std::sqrt(a))); + double c = 0.0; + while (z <= chi_square) { + e = e * (a / z); + c = c + e; + z += 1.0; + } + return c * y + s; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/chi_square.h b/third_party/abseil_cpp/absl/random/internal/chi_square.h new file mode 100644 index 0000000000..07f4fbe522 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/chi_square.h @@ -0,0 +1,89 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_CHI_SQUARE_H_ +#define ABSL_RANDOM_INTERNAL_CHI_SQUARE_H_ + +// The chi-square statistic. +// +// Useful for evaluating if `D` independent random variables are behaving as +// expected, or if two distributions are similar. (`D` is the degrees of +// freedom). +// +// Each bucket should have an expected count of 10 or more for the chi square to +// be meaningful. + +#include <cassert> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +constexpr const char kChiSquared[] = "chi-squared"; + +// Returns the measured chi square value, using a single expected value. This +// assumes that the values in [begin, end) are uniformly distributed. +template <typename Iterator> +double ChiSquareWithExpected(Iterator begin, Iterator end, double expected) { + // Compute the sum and the number of buckets. + assert(expected >= 10); // require at least 10 samples per bucket. + double chi_square = 0; + for (auto it = begin; it != end; it++) { + double d = static_cast<double>(*it) - expected; + chi_square += d * d; + } + chi_square = chi_square / expected; + return chi_square; +} + +// Returns the measured chi square value, taking the actual value of each bucket +// from the first set of iterators, and the expected value of each bucket from +// the second set of iterators. +template <typename Iterator, typename Expected> +double ChiSquare(Iterator it, Iterator end, Expected eit, Expected eend) { + double chi_square = 0; + for (; it != end && eit != eend; ++it, ++eit) { + if (*it > 0) { + assert(*eit > 0); + } + double e = static_cast<double>(*eit); + double d = static_cast<double>(*it - *eit); + if (d != 0) { + assert(e > 0); + chi_square += (d * d) / e; + } + } + assert(it == end && eit == eend); + return chi_square; +} + +// ====================================================================== +// The following methods can be used for an arbitrary significance level. +// + +// Calculates critical chi-square values to produce the given p-value using a +// bisection search for a value within epsilon, relying on the monotonicity of +// ChiSquarePValue(). +double ChiSquareValue(int dof, double p); + +// Calculates the p-value (probability) of a given chi-square value. +double ChiSquarePValue(double chi_square, int dof); + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_CHI_SQUARE_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/chi_square_test.cc b/third_party/abseil_cpp/absl/random/internal/chi_square_test.cc new file mode 100644 index 0000000000..5025defac1 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/chi_square_test.cc @@ -0,0 +1,365 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/chi_square.h" + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <numeric> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/macros.h" + +using absl::random_internal::ChiSquare; +using absl::random_internal::ChiSquarePValue; +using absl::random_internal::ChiSquareValue; +using absl::random_internal::ChiSquareWithExpected; + +namespace { + +TEST(ChiSquare, Value) { + struct { + int line; + double chi_square; + int df; + double confidence; + } const specs[] = { + // Testing lookup at 1% confidence + {__LINE__, 0, 0, 0.01}, + {__LINE__, 0.00016, 1, 0.01}, + {__LINE__, 1.64650, 8, 0.01}, + {__LINE__, 5.81221, 16, 0.01}, + {__LINE__, 156.4319, 200, 0.01}, + {__LINE__, 1121.3784, 1234, 0.01}, + {__LINE__, 53557.1629, 54321, 0.01}, + {__LINE__, 651662.6647, 654321, 0.01}, + + // Testing lookup at 99% confidence + {__LINE__, 0, 0, 0.99}, + {__LINE__, 6.635, 1, 0.99}, + {__LINE__, 20.090, 8, 0.99}, + {__LINE__, 32.000, 16, 0.99}, + {__LINE__, 249.4456, 200, 0.99}, + {__LINE__, 1131.1573, 1023, 0.99}, + {__LINE__, 1352.5038, 1234, 0.99}, + {__LINE__, 55090.7356, 54321, 0.99}, + {__LINE__, 656985.1514, 654321, 0.99}, + + // Testing lookup at 99.9% confidence + {__LINE__, 16.2659, 3, 0.999}, + {__LINE__, 22.4580, 6, 0.999}, + {__LINE__, 267.5409, 200, 0.999}, + {__LINE__, 1168.5033, 1023, 0.999}, + {__LINE__, 55345.1741, 54321, 0.999}, + {__LINE__, 657861.7284, 654321, 0.999}, + {__LINE__, 51.1772, 24, 0.999}, + {__LINE__, 59.7003, 30, 0.999}, + {__LINE__, 37.6984, 15, 0.999}, + {__LINE__, 29.5898, 10, 0.999}, + {__LINE__, 27.8776, 9, 0.999}, + + // Testing lookup at random confidences + {__LINE__, 0.000157088, 1, 0.01}, + {__LINE__, 5.31852, 2, 0.93}, + {__LINE__, 1.92256, 4, 0.25}, + {__LINE__, 10.7709, 13, 0.37}, + {__LINE__, 26.2514, 17, 0.93}, + {__LINE__, 36.4799, 29, 0.84}, + {__LINE__, 25.818, 31, 0.27}, + {__LINE__, 63.3346, 64, 0.50}, + {__LINE__, 196.211, 128, 0.9999}, + {__LINE__, 215.21, 243, 0.10}, + {__LINE__, 285.393, 256, 0.90}, + {__LINE__, 984.504, 1024, 0.1923}, + {__LINE__, 2043.85, 2048, 0.4783}, + {__LINE__, 48004.6, 48273, 0.194}, + }; + for (const auto& spec : specs) { + SCOPED_TRACE(spec.line); + // Verify all values are have at most a 1% relative error. + const double val = ChiSquareValue(spec.df, spec.confidence); + const double err = std::max(5e-6, spec.chi_square / 5e3); // 1 part in 5000 + EXPECT_NEAR(spec.chi_square, val, err) << spec.line; + } + + // Relaxed test for extreme values, from + // http://www.ciphersbyritter.com/JAVASCRP/NORMCHIK.HTM#ChiSquare + EXPECT_NEAR(49.2680, ChiSquareValue(100, 1e-6), 5); // 0.000'005 mark + EXPECT_NEAR(123.499, ChiSquareValue(200, 1e-6), 5); // 0.000'005 mark + + EXPECT_NEAR(149.449, ChiSquareValue(100, 0.999), 0.01); + EXPECT_NEAR(161.318, ChiSquareValue(100, 0.9999), 0.01); + EXPECT_NEAR(172.098, ChiSquareValue(100, 0.99999), 0.01); + + EXPECT_NEAR(381.426, ChiSquareValue(300, 0.999), 0.05); + EXPECT_NEAR(399.756, ChiSquareValue(300, 0.9999), 0.1); + EXPECT_NEAR(416.126, ChiSquareValue(300, 0.99999), 0.2); +} + +TEST(ChiSquareTest, PValue) { + struct { + int line; + double pval; + double chi_square; + int df; + } static const specs[] = { + {__LINE__, 1, 0, 0}, + {__LINE__, 0, 0.001, 0}, + {__LINE__, 1.000, 0, 453}, + {__LINE__, 0.134471, 7972.52, 7834}, + {__LINE__, 0.203922, 28.32, 23}, + {__LINE__, 0.737171, 48274, 48472}, + {__LINE__, 0.444146, 583.1234, 579}, + {__LINE__, 0.294814, 138.2, 130}, + {__LINE__, 0.0816532, 12.63, 7}, + {__LINE__, 0, 682.32, 67}, + {__LINE__, 0.49405, 999, 999}, + {__LINE__, 1.000, 0, 9999}, + {__LINE__, 0.997477, 0.00001, 1}, + {__LINE__, 0, 5823.21, 5040}, + }; + for (const auto& spec : specs) { + SCOPED_TRACE(spec.line); + const double pval = ChiSquarePValue(spec.chi_square, spec.df); + EXPECT_NEAR(spec.pval, pval, 1e-3); + } +} + +TEST(ChiSquareTest, CalcChiSquare) { + struct { + int line; + std::vector<int> expected; + std::vector<int> actual; + } const specs[] = { + {__LINE__, + {56, 234, 76, 1, 546, 1, 87, 345, 1, 234}, + {2, 132, 4, 43, 234, 8, 345, 8, 236, 56}}, + {__LINE__, + {123, 36, 234, 367, 345, 2, 456, 567, 234, 567}, + {123, 56, 2345, 8, 345, 8, 2345, 23, 48, 267}}, + {__LINE__, + {123, 234, 345, 456, 567, 678, 789, 890, 98, 76}, + {123, 234, 345, 456, 567, 678, 789, 890, 98, 76}}, + {__LINE__, {3, 675, 23, 86, 2, 8, 2}, {456, 675, 23, 86, 23, 65, 2}}, + {__LINE__, {1}, {23}}, + }; + for (const auto& spec : specs) { + SCOPED_TRACE(spec.line); + double chi_square = 0; + for (int i = 0; i < spec.expected.size(); ++i) { + const double diff = spec.actual[i] - spec.expected[i]; + chi_square += (diff * diff) / spec.expected[i]; + } + EXPECT_NEAR(chi_square, + ChiSquare(std::begin(spec.actual), std::end(spec.actual), + std::begin(spec.expected), std::end(spec.expected)), + 1e-5); + } +} + +TEST(ChiSquareTest, CalcChiSquareInt64) { + const int64_t data[3] = {910293487, 910292491, 910216780}; + // $ python -c "import scipy.stats + // > print scipy.stats.chisquare([910293487, 910292491, 910216780])[0]" + // 4.25410123524 + double sum = std::accumulate(std::begin(data), std::end(data), double{0}); + size_t n = std::distance(std::begin(data), std::end(data)); + double a = ChiSquareWithExpected(std::begin(data), std::end(data), sum / n); + EXPECT_NEAR(4.254101, a, 1e-6); + + // ... Or with known values. + double b = + ChiSquareWithExpected(std::begin(data), std::end(data), 910267586.0); + EXPECT_NEAR(4.254101, b, 1e-6); +} + +TEST(ChiSquareTest, TableData) { + // Test data from + // http://www.itl.nist.gov/div898/handbook/eda/section3/eda3674.htm + // 0.90 0.95 0.975 0.99 0.999 + const double data[100][5] = { + /* 1*/ {2.706, 3.841, 5.024, 6.635, 10.828}, + /* 2*/ {4.605, 5.991, 7.378, 9.210, 13.816}, + /* 3*/ {6.251, 7.815, 9.348, 11.345, 16.266}, + /* 4*/ {7.779, 9.488, 11.143, 13.277, 18.467}, + /* 5*/ {9.236, 11.070, 12.833, 15.086, 20.515}, + /* 6*/ {10.645, 12.592, 14.449, 16.812, 22.458}, + /* 7*/ {12.017, 14.067, 16.013, 18.475, 24.322}, + /* 8*/ {13.362, 15.507, 17.535, 20.090, 26.125}, + /* 9*/ {14.684, 16.919, 19.023, 21.666, 27.877}, + /*10*/ {15.987, 18.307, 20.483, 23.209, 29.588}, + /*11*/ {17.275, 19.675, 21.920, 24.725, 31.264}, + /*12*/ {18.549, 21.026, 23.337, 26.217, 32.910}, + /*13*/ {19.812, 22.362, 24.736, 27.688, 34.528}, + /*14*/ {21.064, 23.685, 26.119, 29.141, 36.123}, + /*15*/ {22.307, 24.996, 27.488, 30.578, 37.697}, + /*16*/ {23.542, 26.296, 28.845, 32.000, 39.252}, + /*17*/ {24.769, 27.587, 30.191, 33.409, 40.790}, + /*18*/ {25.989, 28.869, 31.526, 34.805, 42.312}, + /*19*/ {27.204, 30.144, 32.852, 36.191, 43.820}, + /*20*/ {28.412, 31.410, 34.170, 37.566, 45.315}, + /*21*/ {29.615, 32.671, 35.479, 38.932, 46.797}, + /*22*/ {30.813, 33.924, 36.781, 40.289, 48.268}, + /*23*/ {32.007, 35.172, 38.076, 41.638, 49.728}, + /*24*/ {33.196, 36.415, 39.364, 42.980, 51.179}, + /*25*/ {34.382, 37.652, 40.646, 44.314, 52.620}, + /*26*/ {35.563, 38.885, 41.923, 45.642, 54.052}, + /*27*/ {36.741, 40.113, 43.195, 46.963, 55.476}, + /*28*/ {37.916, 41.337, 44.461, 48.278, 56.892}, + /*29*/ {39.087, 42.557, 45.722, 49.588, 58.301}, + /*30*/ {40.256, 43.773, 46.979, 50.892, 59.703}, + /*31*/ {41.422, 44.985, 48.232, 52.191, 61.098}, + /*32*/ {42.585, 46.194, 49.480, 53.486, 62.487}, + /*33*/ {43.745, 47.400, 50.725, 54.776, 63.870}, + /*34*/ {44.903, 48.602, 51.966, 56.061, 65.247}, + /*35*/ {46.059, 49.802, 53.203, 57.342, 66.619}, + /*36*/ {47.212, 50.998, 54.437, 58.619, 67.985}, + /*37*/ {48.363, 52.192, 55.668, 59.893, 69.347}, + /*38*/ {49.513, 53.384, 56.896, 61.162, 70.703}, + /*39*/ {50.660, 54.572, 58.120, 62.428, 72.055}, + /*40*/ {51.805, 55.758, 59.342, 63.691, 73.402}, + /*41*/ {52.949, 56.942, 60.561, 64.950, 74.745}, + /*42*/ {54.090, 58.124, 61.777, 66.206, 76.084}, + /*43*/ {55.230, 59.304, 62.990, 67.459, 77.419}, + /*44*/ {56.369, 60.481, 64.201, 68.710, 78.750}, + /*45*/ {57.505, 61.656, 65.410, 69.957, 80.077}, + /*46*/ {58.641, 62.830, 66.617, 71.201, 81.400}, + /*47*/ {59.774, 64.001, 67.821, 72.443, 82.720}, + /*48*/ {60.907, 65.171, 69.023, 73.683, 84.037}, + /*49*/ {62.038, 66.339, 70.222, 74.919, 85.351}, + /*50*/ {63.167, 67.505, 71.420, 76.154, 86.661}, + /*51*/ {64.295, 68.669, 72.616, 77.386, 87.968}, + /*52*/ {65.422, 69.832, 73.810, 78.616, 89.272}, + /*53*/ {66.548, 70.993, 75.002, 79.843, 90.573}, + /*54*/ {67.673, 72.153, 76.192, 81.069, 91.872}, + /*55*/ {68.796, 73.311, 77.380, 82.292, 93.168}, + /*56*/ {69.919, 74.468, 78.567, 83.513, 94.461}, + /*57*/ {71.040, 75.624, 79.752, 84.733, 95.751}, + /*58*/ {72.160, 76.778, 80.936, 85.950, 97.039}, + /*59*/ {73.279, 77.931, 82.117, 87.166, 98.324}, + /*60*/ {74.397, 79.082, 83.298, 88.379, 99.607}, + /*61*/ {75.514, 80.232, 84.476, 89.591, 100.888}, + /*62*/ {76.630, 81.381, 85.654, 90.802, 102.166}, + /*63*/ {77.745, 82.529, 86.830, 92.010, 103.442}, + /*64*/ {78.860, 83.675, 88.004, 93.217, 104.716}, + /*65*/ {79.973, 84.821, 89.177, 94.422, 105.988}, + /*66*/ {81.085, 85.965, 90.349, 95.626, 107.258}, + /*67*/ {82.197, 87.108, 91.519, 96.828, 108.526}, + /*68*/ {83.308, 88.250, 92.689, 98.028, 109.791}, + /*69*/ {84.418, 89.391, 93.856, 99.228, 111.055}, + /*70*/ {85.527, 90.531, 95.023, 100.425, 112.317}, + /*71*/ {86.635, 91.670, 96.189, 101.621, 113.577}, + /*72*/ {87.743, 92.808, 97.353, 102.816, 114.835}, + /*73*/ {88.850, 93.945, 98.516, 104.010, 116.092}, + /*74*/ {89.956, 95.081, 99.678, 105.202, 117.346}, + /*75*/ {91.061, 96.217, 100.839, 106.393, 118.599}, + /*76*/ {92.166, 97.351, 101.999, 107.583, 119.850}, + /*77*/ {93.270, 98.484, 103.158, 108.771, 121.100}, + /*78*/ {94.374, 99.617, 104.316, 109.958, 122.348}, + /*79*/ {95.476, 100.749, 105.473, 111.144, 123.594}, + /*80*/ {96.578, 101.879, 106.629, 112.329, 124.839}, + /*81*/ {97.680, 103.010, 107.783, 113.512, 126.083}, + /*82*/ {98.780, 104.139, 108.937, 114.695, 127.324}, + /*83*/ {99.880, 105.267, 110.090, 115.876, 128.565}, + /*84*/ {100.980, 106.395, 111.242, 117.057, 129.804}, + /*85*/ {102.079, 107.522, 112.393, 118.236, 131.041}, + /*86*/ {103.177, 108.648, 113.544, 119.414, 132.277}, + /*87*/ {104.275, 109.773, 114.693, 120.591, 133.512}, + /*88*/ {105.372, 110.898, 115.841, 121.767, 134.746}, + /*89*/ {106.469, 112.022, 116.989, 122.942, 135.978}, + /*90*/ {107.565, 113.145, 118.136, 124.116, 137.208}, + /*91*/ {108.661, 114.268, 119.282, 125.289, 138.438}, + /*92*/ {109.756, 115.390, 120.427, 126.462, 139.666}, + /*93*/ {110.850, 116.511, 121.571, 127.633, 140.893}, + /*94*/ {111.944, 117.632, 122.715, 128.803, 142.119}, + /*95*/ {113.038, 118.752, 123.858, 129.973, 143.344}, + /*96*/ {114.131, 119.871, 125.000, 131.141, 144.567}, + /*97*/ {115.223, 120.990, 126.141, 132.309, 145.789}, + /*98*/ {116.315, 122.108, 127.282, 133.476, 147.010}, + /*99*/ {117.407, 123.225, 128.422, 134.642, 148.230}, + /*100*/ {118.498, 124.342, 129.561, 135.807, 149.449} + /**/}; + + // 0.90 0.95 0.975 0.99 0.999 + for (int i = 0; i < ABSL_ARRAYSIZE(data); i++) { + const double E = 0.0001; + EXPECT_NEAR(ChiSquarePValue(data[i][0], i + 1), 0.10, E) + << i << " " << data[i][0]; + EXPECT_NEAR(ChiSquarePValue(data[i][1], i + 1), 0.05, E) + << i << " " << data[i][1]; + EXPECT_NEAR(ChiSquarePValue(data[i][2], i + 1), 0.025, E) + << i << " " << data[i][2]; + EXPECT_NEAR(ChiSquarePValue(data[i][3], i + 1), 0.01, E) + << i << " " << data[i][3]; + EXPECT_NEAR(ChiSquarePValue(data[i][4], i + 1), 0.001, E) + << i << " " << data[i][4]; + + const double F = 0.1; + EXPECT_NEAR(ChiSquareValue(i + 1, 0.90), data[i][0], F) << i; + EXPECT_NEAR(ChiSquareValue(i + 1, 0.95), data[i][1], F) << i; + EXPECT_NEAR(ChiSquareValue(i + 1, 0.975), data[i][2], F) << i; + EXPECT_NEAR(ChiSquareValue(i + 1, 0.99), data[i][3], F) << i; + EXPECT_NEAR(ChiSquareValue(i + 1, 0.999), data[i][4], F) << i; + } +} + +TEST(ChiSquareTest, ChiSquareTwoIterator) { + // Test data from http://www.stat.yale.edu/Courses/1997-98/101/chigf.htm + // Null-hypothesis: This data is normally distributed. + const int counts[10] = {6, 6, 18, 33, 38, 38, 28, 21, 9, 3}; + const double expected[10] = {4.6, 8.8, 18.4, 30.0, 38.2, + 38.2, 30.0, 18.4, 8.8, 4.6}; + double chi_square = ChiSquare(std::begin(counts), std::end(counts), + std::begin(expected), std::end(expected)); + EXPECT_NEAR(chi_square, 2.69, 0.001); + + // Degrees of freedom: 10 bins. two estimated parameters. = 10 - 2 - 1. + const int dof = 7; + // The critical value of 7, 95% => 14.067 (see above test) + double p_value_05 = ChiSquarePValue(14.067, dof); + EXPECT_NEAR(p_value_05, 0.05, 0.001); // 95%-ile p-value + + double p_actual = ChiSquarePValue(chi_square, dof); + EXPECT_GT(p_actual, 0.05); // Accept the null hypothesis. +} + +TEST(ChiSquareTest, DiceRolls) { + // Assume we are testing 102 fair dice rolls. + // Null-hypothesis: This data is fairly distributed. + // + // The dof value of 4, @95% = 9.488 (see above test) + // The dof value of 5, @95% = 11.070 + const int rolls[6] = {22, 11, 17, 14, 20, 18}; + double sum = std::accumulate(std::begin(rolls), std::end(rolls), double{0}); + size_t n = std::distance(std::begin(rolls), std::end(rolls)); + + double a = ChiSquareWithExpected(std::begin(rolls), std::end(rolls), sum / n); + EXPECT_NEAR(a, 4.70588, 1e-5); + EXPECT_LT(a, ChiSquareValue(4, 0.95)); + + double p_a = ChiSquarePValue(a, 4); + EXPECT_NEAR(p_a, 0.318828, 1e-5); // Accept the null hypothesis. + + double b = ChiSquareWithExpected(std::begin(rolls), std::end(rolls), 17.0); + EXPECT_NEAR(b, 4.70588, 1e-5); + EXPECT_LT(b, ChiSquareValue(5, 0.95)); + + double p_b = ChiSquarePValue(b, 5); + EXPECT_NEAR(p_b, 0.4528180, 1e-5); // Accept the null hypothesis. +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/distribution_caller.h b/third_party/abseil_cpp/absl/random/internal/distribution_caller.h new file mode 100644 index 0000000000..4e0724440c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/distribution_caller.h @@ -0,0 +1,47 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_RANDOM_INTERNAL_DISTRIBUTION_CALLER_H_ +#define ABSL_RANDOM_INTERNAL_DISTRIBUTION_CALLER_H_ + +#include <utility> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// DistributionCaller provides an opportunity to overload the general +// mechanism for calling a distribution, allowing for mock-RNG classes +// to intercept such calls. +template <typename URBG> +struct DistributionCaller { + // Call the provided distribution type. The parameters are expected + // to be explicitly specified. + // DistrT is the distribution type. + template <typename DistrT, typename... Args> + static typename DistrT::result_type Call(URBG* urbg, Args&&... args) { + DistrT dist(std::forward<Args>(args)...); + return dist(*urbg); + } +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_DISTRIBUTION_CALLER_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/distribution_test_util.cc b/third_party/abseil_cpp/absl/random/internal/distribution_test_util.cc new file mode 100644 index 0000000000..e9005658c0 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/distribution_test_util.cc @@ -0,0 +1,418 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/distribution_test_util.h" + +#include <cassert> +#include <cmath> +#include <string> +#include <vector> + +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +#if defined(__EMSCRIPTEN__) +// Workaround __EMSCRIPTEN__ error: llvm_fma_f64 not found. +inline double fma(double x, double y, double z) { return (x * y) + z; } +#endif + +} // namespace + +DistributionMoments ComputeDistributionMoments( + absl::Span<const double> data_points) { + DistributionMoments result; + + // Compute m1 + for (double x : data_points) { + result.n++; + result.mean += x; + } + result.mean /= static_cast<double>(result.n); + + // Compute m2, m3, m4 + for (double x : data_points) { + double v = x - result.mean; + result.variance += v * v; + result.skewness += v * v * v; + result.kurtosis += v * v * v * v; + } + result.variance /= static_cast<double>(result.n - 1); + + result.skewness /= static_cast<double>(result.n); + result.skewness /= std::pow(result.variance, 1.5); + + result.kurtosis /= static_cast<double>(result.n); + result.kurtosis /= std::pow(result.variance, 2.0); + return result; + + // When validating the min/max count, the following confidence intervals may + // be of use: + // 3.291 * stddev = 99.9% CI + // 2.576 * stddev = 99% CI + // 1.96 * stddev = 95% CI + // 1.65 * stddev = 90% CI +} + +std::ostream& operator<<(std::ostream& os, const DistributionMoments& moments) { + return os << absl::StrFormat("mean=%f, stddev=%f, skewness=%f, kurtosis=%f", + moments.mean, std::sqrt(moments.variance), + moments.skewness, moments.kurtosis); +} + +double InverseNormalSurvival(double x) { + // inv_sf(u) = -sqrt(2) * erfinv(2u-1) + static constexpr double kSqrt2 = 1.4142135623730950488; + return -kSqrt2 * absl::random_internal::erfinv(2 * x - 1.0); +} + +bool Near(absl::string_view msg, double actual, double expected, double bound) { + assert(bound > 0.0); + double delta = fabs(expected - actual); + if (delta < bound) { + return true; + } + + std::string formatted = absl::StrCat( + msg, " actual=", actual, " expected=", expected, " err=", delta / bound); + ABSL_RAW_LOG(INFO, "%s", formatted.c_str()); + return false; +} + +// TODO(absl-team): Replace with an "ABSL_HAVE_SPECIAL_MATH" and try +// to use std::beta(). As of this writing P0226R1 is not implemented +// in libc++: http://libcxx.llvm.org/cxx1z_status.html +double beta(double p, double q) { + // Beta(x, y) = Gamma(x) * Gamma(y) / Gamma(x+y) + double lbeta = std::lgamma(p) + std::lgamma(q) - std::lgamma(p + q); + return std::exp(lbeta); +} + +// Approximation to inverse of the Error Function in double precision. +// (http://people.maths.ox.ac.uk/gilesm/files/gems_erfinv.pdf) +double erfinv(double x) { +#if !defined(__EMSCRIPTEN__) + using std::fma; +#endif + + double w = 0.0; + double p = 0.0; + w = -std::log((1.0 - x) * (1.0 + x)); + if (w < 6.250000) { + w = w - 3.125000; + p = -3.6444120640178196996e-21; + p = fma(p, w, -1.685059138182016589e-19); + p = fma(p, w, 1.2858480715256400167e-18); + p = fma(p, w, 1.115787767802518096e-17); + p = fma(p, w, -1.333171662854620906e-16); + p = fma(p, w, 2.0972767875968561637e-17); + p = fma(p, w, 6.6376381343583238325e-15); + p = fma(p, w, -4.0545662729752068639e-14); + p = fma(p, w, -8.1519341976054721522e-14); + p = fma(p, w, 2.6335093153082322977e-12); + p = fma(p, w, -1.2975133253453532498e-11); + p = fma(p, w, -5.4154120542946279317e-11); + p = fma(p, w, 1.051212273321532285e-09); + p = fma(p, w, -4.1126339803469836976e-09); + p = fma(p, w, -2.9070369957882005086e-08); + p = fma(p, w, 4.2347877827932403518e-07); + p = fma(p, w, -1.3654692000834678645e-06); + p = fma(p, w, -1.3882523362786468719e-05); + p = fma(p, w, 0.0001867342080340571352); + p = fma(p, w, -0.00074070253416626697512); + p = fma(p, w, -0.0060336708714301490533); + p = fma(p, w, 0.24015818242558961693); + p = fma(p, w, 1.6536545626831027356); + } else if (w < 16.000000) { + w = std::sqrt(w) - 3.250000; + p = 2.2137376921775787049e-09; + p = fma(p, w, 9.0756561938885390979e-08); + p = fma(p, w, -2.7517406297064545428e-07); + p = fma(p, w, 1.8239629214389227755e-08); + p = fma(p, w, 1.5027403968909827627e-06); + p = fma(p, w, -4.013867526981545969e-06); + p = fma(p, w, 2.9234449089955446044e-06); + p = fma(p, w, 1.2475304481671778723e-05); + p = fma(p, w, -4.7318229009055733981e-05); + p = fma(p, w, 6.8284851459573175448e-05); + p = fma(p, w, 2.4031110387097893999e-05); + p = fma(p, w, -0.0003550375203628474796); + p = fma(p, w, 0.00095328937973738049703); + p = fma(p, w, -0.0016882755560235047313); + p = fma(p, w, 0.0024914420961078508066); + p = fma(p, w, -0.0037512085075692412107); + p = fma(p, w, 0.005370914553590063617); + p = fma(p, w, 1.0052589676941592334); + p = fma(p, w, 3.0838856104922207635); + } else { + w = std::sqrt(w) - 5.000000; + p = -2.7109920616438573243e-11; + p = fma(p, w, -2.5556418169965252055e-10); + p = fma(p, w, 1.5076572693500548083e-09); + p = fma(p, w, -3.7894654401267369937e-09); + p = fma(p, w, 7.6157012080783393804e-09); + p = fma(p, w, -1.4960026627149240478e-08); + p = fma(p, w, 2.9147953450901080826e-08); + p = fma(p, w, -6.7711997758452339498e-08); + p = fma(p, w, 2.2900482228026654717e-07); + p = fma(p, w, -9.9298272942317002539e-07); + p = fma(p, w, 4.5260625972231537039e-06); + p = fma(p, w, -1.9681778105531670567e-05); + p = fma(p, w, 7.5995277030017761139e-05); + p = fma(p, w, -0.00021503011930044477347); + p = fma(p, w, -0.00013871931833623122026); + p = fma(p, w, 1.0103004648645343977); + p = fma(p, w, 4.8499064014085844221); + } + return p * x; +} + +namespace { + +// Direct implementation of AS63, BETAIN() +// https://www.jstor.org/stable/2346797?seq=3#page_scan_tab_contents. +// +// BETAIN(x, p, q, beta) +// x: the value of the upper limit x. +// p: the value of the parameter p. +// q: the value of the parameter q. +// beta: the value of ln B(p, q) +// +double BetaIncompleteImpl(const double x, const double p, const double q, + const double beta) { + if (p < (p + q) * x) { + // Incomplete beta function is symmetrical, so return the complement. + return 1. - BetaIncompleteImpl(1.0 - x, q, p, beta); + } + + double psq = p + q; + const double kErr = 1e-14; + const double xc = 1. - x; + const double pre = + std::exp(p * std::log(x) + (q - 1.) * std::log(xc) - beta) / p; + + double term = 1.; + double ai = 1.; + double result = 1.; + int ns = static_cast<int>(q + xc * psq); + + // Use the soper reduction forumla. + double rx = (ns == 0) ? x : x / xc; + double temp = q - ai; + for (;;) { + term = term * temp * rx / (p + ai); + result = result + term; + temp = std::fabs(term); + if (temp < kErr && temp < kErr * result) { + return result * pre; + } + ai = ai + 1.; + --ns; + if (ns >= 0) { + temp = q - ai; + if (ns == 0) { + rx = x; + } + } else { + temp = psq; + psq = psq + 1.; + } + } + + // NOTE: See also TOMS Alogrithm 708. + // http://www.netlib.org/toms/index.html + // + // NOTE: The NWSC library also includes BRATIO / ISUBX (p87) + // https://archive.org/details/DTIC_ADA261511/page/n75 +} + +// Direct implementation of AS109, XINBTA(p, q, beta, alpha) +// https://www.jstor.org/stable/2346798?read-now=1&seq=4#page_scan_tab_contents +// https://www.jstor.org/stable/2346887?seq=1#page_scan_tab_contents +// +// XINBTA(p, q, beta, alhpa) +// p: the value of the parameter p. +// q: the value of the parameter q. +// beta: the value of ln B(p, q) +// alpha: the value of the lower tail area. +// +double BetaIncompleteInvImpl(const double p, const double q, const double beta, + const double alpha) { + if (alpha < 0.5) { + // Inverse Incomplete beta function is symmetrical, return the complement. + return 1. - BetaIncompleteInvImpl(q, p, beta, 1. - alpha); + } + const double kErr = 1e-14; + double value = kErr; + + // Compute the initial estimate. + { + double r = std::sqrt(-std::log(alpha * alpha)); + double y = + r - fma(r, 0.27061, 2.30753) / fma(r, fma(r, 0.04481, 0.99229), 1.0); + if (p > 1. && q > 1.) { + r = (y * y - 3.) / 6.; + double s = 1. / (p + p - 1.); + double t = 1. / (q + q - 1.); + double h = 2. / s + t; + double w = + y * std::sqrt(h + r) / h - (t - s) * (r + 5. / 6. - t / (3. * h)); + value = p / (p + q * std::exp(w + w)); + } else { + r = q + q; + double t = 1.0 / (9. * q); + double u = 1.0 - t + y * std::sqrt(t); + t = r * (u * u * u); + if (t <= 0) { + value = 1.0 - std::exp((std::log((1.0 - alpha) * q) + beta) / q); + } else { + t = (4.0 * p + r - 2.0) / t; + if (t <= 1) { + value = std::exp((std::log(alpha * p) + beta) / p); + } else { + value = 1.0 - 2.0 / (t + 1.0); + } + } + } + } + + // Solve for x using a modified newton-raphson method using the function + // BetaIncomplete. + { + value = std::max(value, kErr); + value = std::min(value, 1.0 - kErr); + + const double r = 1.0 - p; + const double t = 1.0 - q; + double y; + double yprev = 0; + double sq = 1; + double prev = 1; + for (;;) { + if (value < 0 || value > 1.0) { + // Error case; value went infinite. + return std::numeric_limits<double>::infinity(); + } else if (value == 0 || value == 1) { + y = value; + } else { + y = BetaIncompleteImpl(value, p, q, beta); + if (!std::isfinite(y)) { + return y; + } + } + y = (y - alpha) * + std::exp(beta + r * std::log(value) + t * std::log(1.0 - value)); + if (y * yprev <= 0) { + prev = std::max(sq, std::numeric_limits<double>::min()); + } + double g = 1.0; + for (;;) { + const double adj = g * y; + const double adj_sq = adj * adj; + if (adj_sq >= prev) { + g = g / 3.0; + continue; + } + const double tx = value - adj; + if (tx < 0 || tx > 1) { + g = g / 3.0; + continue; + } + if (prev < kErr) { + return value; + } + if (y * y < kErr) { + return value; + } + if (tx == value) { + return value; + } + if (tx == 0 || tx == 1) { + g = g / 3.0; + continue; + } + value = tx; + yprev = y; + break; + } + } + } + + // NOTES: See also: Asymptotic inversion of the incomplete beta function. + // https://core.ac.uk/download/pdf/82140723.pdf + // + // NOTE: See the Boost library documentation as well: + // https://www.boost.org/doc/libs/1_52_0/libs/math/doc/sf_and_dist/html/math_toolkit/special/sf_beta/ibeta_function.html +} + +} // namespace + +double BetaIncomplete(const double x, const double p, const double q) { + // Error cases. + if (p < 0 || q < 0 || x < 0 || x > 1.0) { + return std::numeric_limits<double>::infinity(); + } + if (x == 0 || x == 1) { + return x; + } + // ln(Beta(p, q)) + double beta = std::lgamma(p) + std::lgamma(q) - std::lgamma(p + q); + return BetaIncompleteImpl(x, p, q, beta); +} + +double BetaIncompleteInv(const double p, const double q, const double alpha) { + // Error cases. + if (p < 0 || q < 0 || alpha < 0 || alpha > 1.0) { + return std::numeric_limits<double>::infinity(); + } + if (alpha == 0 || alpha == 1) { + return alpha; + } + // ln(Beta(p, q)) + double beta = std::lgamma(p) + std::lgamma(q) - std::lgamma(p + q); + return BetaIncompleteInvImpl(p, q, beta, alpha); +} + +// Given `num_trials` trials each with probability `p` of success, the +// probability of no failures is `p^k`. To ensure the probability of a failure +// is no more than `p_fail`, it must be that `p^k == 1 - p_fail`. This function +// computes `p` from that equation. +double RequiredSuccessProbability(const double p_fail, const int num_trials) { + double p = std::exp(std::log(1.0 - p_fail) / static_cast<double>(num_trials)); + ABSL_ASSERT(p > 0); + return p; +} + +double ZScore(double expected_mean, const DistributionMoments& moments) { + return (moments.mean - expected_mean) / + (std::sqrt(moments.variance) / + std::sqrt(static_cast<double>(moments.n))); +} + +double MaxErrorTolerance(double acceptance_probability) { + double one_sided_pvalue = 0.5 * (1.0 - acceptance_probability); + const double max_err = InverseNormalSurvival(one_sided_pvalue); + ABSL_ASSERT(max_err > 0); + return max_err; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/distribution_test_util.h b/third_party/abseil_cpp/absl/random/internal/distribution_test_util.h new file mode 100644 index 0000000000..6d94cf6c97 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/distribution_test_util.h @@ -0,0 +1,113 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_DISTRIBUTION_TEST_UTIL_H_ +#define ABSL_RANDOM_INTERNAL_DISTRIBUTION_TEST_UTIL_H_ + +#include <cstddef> +#include <iostream> +#include <vector> + +#include "absl/strings/string_view.h" +#include "absl/types/span.h" + +// NOTE: The functions in this file are test only, and are should not be used in +// non-test code. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// http://webspace.ship.edu/pgmarr/Geo441/Lectures/Lec%205%20-%20Normality%20Testing.pdf + +// Compute the 1st to 4th standard moments: +// mean, variance, skewness, and kurtosis. +// http://www.itl.nist.gov/div898/handbook/eda/section3/eda35b.htm +struct DistributionMoments { + size_t n = 0; + double mean = 0.0; + double variance = 0.0; + double skewness = 0.0; + double kurtosis = 0.0; +}; +DistributionMoments ComputeDistributionMoments( + absl::Span<const double> data_points); + +std::ostream& operator<<(std::ostream& os, const DistributionMoments& moments); + +// Computes the Z-score for a set of data with the given distribution moments +// compared against `expected_mean`. +double ZScore(double expected_mean, const DistributionMoments& moments); + +// Returns the probability of success required for a single trial to ensure that +// after `num_trials` trials, the probability of at least one failure is no more +// than `p_fail`. +double RequiredSuccessProbability(double p_fail, int num_trials); + +// Computes the maximum distance from the mean tolerable, for Z-Tests that are +// expected to pass with `acceptance_probability`. Will terminate if the +// resulting tolerance is zero (due to passing in 0.0 for +// `acceptance_probability` or rounding errors). +// +// For example, +// MaxErrorTolerance(0.001) = 0.0 +// MaxErrorTolerance(0.5) = ~0.47 +// MaxErrorTolerance(1.0) = inf +double MaxErrorTolerance(double acceptance_probability); + +// Approximation to inverse of the Error Function in double precision. +// (http://people.maths.ox.ac.uk/gilesm/files/gems_erfinv.pdf) +double erfinv(double x); + +// Beta(p, q) = Gamma(p) * Gamma(q) / Gamma(p+q) +double beta(double p, double q); + +// The inverse of the normal survival function. +double InverseNormalSurvival(double x); + +// Returns whether actual is "near" expected, based on the bound. +bool Near(absl::string_view msg, double actual, double expected, double bound); + +// Implements the incomplete regularized beta function, AS63, BETAIN. +// https://www.jstor.org/stable/2346797 +// +// BetaIncomplete(x, p, q), where +// `x` is the value of the upper limit +// `p` is beta parameter p, `q` is beta parameter q. +// +// NOTE: This is a test-only function which is only accurate to within, at most, +// 1e-13 of the actual value. +// +double BetaIncomplete(double x, double p, double q); + +// Implements the inverse of the incomplete regularized beta function, AS109, +// XINBTA. +// https://www.jstor.org/stable/2346798 +// https://www.jstor.org/stable/2346887 +// +// BetaIncompleteInv(p, q, beta, alhpa) +// `p` is beta parameter p, `q` is beta parameter q. +// `alpha` is the value of the lower tail area. +// +// NOTE: This is a test-only function and, when successful, is only accurate to +// within ~1e-6 of the actual value; there are some cases where it diverges from +// the actual value by much more than that. The function uses Newton's method, +// and thus the runtime is highly variable. +double BetaIncompleteInv(double p, double q, double alpha); + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_DISTRIBUTION_TEST_UTIL_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/distribution_test_util_test.cc b/third_party/abseil_cpp/absl/random/internal/distribution_test_util_test.cc new file mode 100644 index 0000000000..c49d44fb47 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/distribution_test_util_test.cc @@ -0,0 +1,193 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/distribution_test_util.h" + +#include "gtest/gtest.h" + +namespace { + +TEST(TestUtil, InverseErf) { + const struct { + const double z; + const double value; + } kErfInvTable[] = { + {0.0000001, 8.86227e-8}, + {0.00001, 8.86227e-6}, + {0.5, 0.4769362762044}, + {0.6, 0.5951160814499}, + {0.99999, 3.1234132743}, + {0.9999999, 3.7665625816}, + {0.999999944, 3.8403850690566985}, // = log((1-x) * (1+x)) =~ 16.004 + {0.999999999, 4.3200053849134452}, + }; + + for (const auto& data : kErfInvTable) { + auto value = absl::random_internal::erfinv(data.z); + + // Log using the Wolfram-alpha function name & parameters. + EXPECT_NEAR(value, data.value, 1e-8) + << " InverseErf[" << data.z << "] (expected=" << data.value << ") -> " + << value; + } +} + +const struct { + const double p; + const double q; + const double x; + const double alpha; +} kBetaTable[] = { + {0.5, 0.5, 0.01, 0.06376856085851985}, + {0.5, 0.5, 0.1, 0.2048327646991335}, + {0.5, 0.5, 1, 1}, + {1, 0.5, 0, 0}, + {1, 0.5, 0.01, 0.005012562893380045}, + {1, 0.5, 0.1, 0.0513167019494862}, + {1, 0.5, 0.5, 0.2928932188134525}, + {1, 1, 0.5, 0.5}, + {2, 2, 0.1, 0.028}, + {2, 2, 0.2, 0.104}, + {2, 2, 0.3, 0.216}, + {2, 2, 0.4, 0.352}, + {2, 2, 0.5, 0.5}, + {2, 2, 0.6, 0.648}, + {2, 2, 0.7, 0.784}, + {2, 2, 0.8, 0.896}, + {2, 2, 0.9, 0.972}, + {5.5, 5, 0.5, 0.4361908850559777}, + {10, 0.5, 0.9, 0.1516409096346979}, + {10, 5, 0.5, 0.08978271484375}, + {10, 5, 1, 1}, + {10, 10, 0.5, 0.5}, + {20, 5, 0.8, 0.4598773297575791}, + {20, 10, 0.6, 0.2146816102371739}, + {20, 10, 0.8, 0.9507364826957875}, + {20, 20, 0.5, 0.5}, + {20, 20, 0.6, 0.8979413687105918}, + {30, 10, 0.7, 0.2241297491808366}, + {30, 10, 0.8, 0.7586405487192086}, + {40, 20, 0.7, 0.7001783247477069}, + {1, 0.5, 0.1, 0.0513167019494862}, + {1, 0.5, 0.2, 0.1055728090000841}, + {1, 0.5, 0.3, 0.1633399734659245}, + {1, 0.5, 0.4, 0.2254033307585166}, + {1, 2, 0.2, 0.36}, + {1, 3, 0.2, 0.488}, + {1, 4, 0.2, 0.5904}, + {1, 5, 0.2, 0.67232}, + {2, 2, 0.3, 0.216}, + {3, 2, 0.3, 0.0837}, + {4, 2, 0.3, 0.03078}, + {5, 2, 0.3, 0.010935}, + + // These values test small & large points along the range of the Beta + // function. + // + // When selecting test points, remember that if BetaIncomplete(x, p, q) + // returns the same value to within the limits of precision over a large + // domain of the input, x, then BetaIncompleteInv(alpha, p, q) may return an + // essentially arbitrary value where BetaIncomplete(x, p, q) =~ alpha. + + // BetaRegularized[x, 0.00001, 0.00001], + // For x in {~0.001 ... ~0.999}, => ~0.5 + {1e-5, 1e-5, 1e-5, 0.4999424388184638311}, + {1e-5, 1e-5, (1.0 - 1e-8), 0.5000920948389232964}, + + // BetaRegularized[x, 0.00001, 10000]. + // For x in {~epsilon ... 1.0}, => ~1 + {1e-5, 1e5, 1e-6, 0.9999817708130066936}, + {1e-5, 1e5, (1.0 - 1e-7), 1.0}, + + // BetaRegularized[x, 10000, 0.00001]. + // For x in {0 .. 1-epsilon}, => ~0 + {1e5, 1e-5, 1e-6, 0}, + {1e5, 1e-5, (1.0 - 1e-6), 1.8229186993306369e-5}, +}; + +TEST(BetaTest, BetaIncomplete) { + for (const auto& data : kBetaTable) { + auto value = absl::random_internal::BetaIncomplete(data.x, data.p, data.q); + + // Log using the Wolfram-alpha function name & parameters. + EXPECT_NEAR(value, data.alpha, 1e-12) + << " BetaRegularized[" << data.x << ", " << data.p << ", " << data.q + << "] (expected=" << data.alpha << ") -> " << value; + } +} + +TEST(BetaTest, BetaIncompleteInv) { + for (const auto& data : kBetaTable) { + auto value = + absl::random_internal::BetaIncompleteInv(data.p, data.q, data.alpha); + + // Log using the Wolfram-alpha function name & parameters. + EXPECT_NEAR(value, data.x, 1e-6) + << " InverseBetaRegularized[" << data.alpha << ", " << data.p << ", " + << data.q << "] (expected=" << data.x << ") -> " << value; + } +} + +TEST(MaxErrorTolerance, MaxErrorTolerance) { + std::vector<std::pair<double, double>> cases = { + {0.0000001, 8.86227e-8 * 1.41421356237}, + {0.00001, 8.86227e-6 * 1.41421356237}, + {0.5, 0.4769362762044 * 1.41421356237}, + {0.6, 0.5951160814499 * 1.41421356237}, + {0.99999, 3.1234132743 * 1.41421356237}, + {0.9999999, 3.7665625816 * 1.41421356237}, + {0.999999944, 3.8403850690566985 * 1.41421356237}, + {0.999999999, 4.3200053849134452 * 1.41421356237}}; + for (auto entry : cases) { + EXPECT_NEAR(absl::random_internal::MaxErrorTolerance(entry.first), + entry.second, 1e-8); + } +} + +TEST(ZScore, WithSameMean) { + absl::random_internal::DistributionMoments m; + m.n = 100; + m.mean = 5; + m.variance = 1; + EXPECT_NEAR(absl::random_internal::ZScore(5, m), 0, 1e-12); + + m.n = 1; + m.mean = 0; + m.variance = 1; + EXPECT_NEAR(absl::random_internal::ZScore(0, m), 0, 1e-12); + + m.n = 10000; + m.mean = -5; + m.variance = 100; + EXPECT_NEAR(absl::random_internal::ZScore(-5, m), 0, 1e-12); +} + +TEST(ZScore, DifferentMean) { + absl::random_internal::DistributionMoments m; + m.n = 100; + m.mean = 5; + m.variance = 1; + EXPECT_NEAR(absl::random_internal::ZScore(4, m), 10, 1e-12); + + m.n = 1; + m.mean = 0; + m.variance = 1; + EXPECT_NEAR(absl::random_internal::ZScore(-1, m), 1, 1e-12); + + m.n = 10000; + m.mean = -5; + m.variance = 100; + EXPECT_NEAR(absl::random_internal::ZScore(-4, m), -10, 1e-12); +} +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/distributions.h b/third_party/abseil_cpp/absl/random/internal/distributions.h new file mode 100644 index 0000000000..d7e3c0161f --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/distributions.h @@ -0,0 +1,52 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_DISTRIBUTIONS_H_ +#define ABSL_RANDOM_INTERNAL_DISTRIBUTIONS_H_ + +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/random/internal/distribution_caller.h" +#include "absl/random/internal/traits.h" +#include "absl/random/internal/uniform_helper.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// In the absence of an explicitly provided return-type, the template +// "uniform_inferred_return_t<A, B>" is used to derive a suitable type, based on +// the data-types of the endpoint-arguments {A lo, B hi}. +// +// Given endpoints {A lo, B hi}, one of {A, B} will be chosen as the +// return-type, if one type can be implicitly converted into the other, in a +// lossless way. The template "is_widening_convertible" implements the +// compile-time logic for deciding if such a conversion is possible. +// +// If no such conversion between {A, B} exists, then the overload for +// absl::Uniform() will be discarded, and the call will be ill-formed. +// Return-type for absl::Uniform() when the return-type is inferred. +template <typename A, typename B> +using uniform_inferred_return_t = + absl::enable_if_t<absl::disjunction<is_widening_convertible<A, B>, + is_widening_convertible<B, A>>::value, + typename std::conditional< + is_widening_convertible<A, B>::value, B, A>::type>; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_DISTRIBUTIONS_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/explicit_seed_seq.h b/third_party/abseil_cpp/absl/random/internal/explicit_seed_seq.h new file mode 100644 index 0000000000..6a743eaf46 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/explicit_seed_seq.h @@ -0,0 +1,91 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_EXPLICIT_SEED_SEQ_H_ +#define ABSL_RANDOM_INTERNAL_EXPLICIT_SEED_SEQ_H_ + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <initializer_list> +#include <iterator> +#include <vector> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// This class conforms to the C++ Standard "Seed Sequence" concept +// [rand.req.seedseq]. +// +// An "ExplicitSeedSeq" is meant to provide a conformant interface for +// forwarding pre-computed seed material to the constructor of a class +// conforming to the "Uniform Random Bit Generator" concept. This class makes no +// attempt to mutate the state provided by its constructor, and returns it +// directly via ExplicitSeedSeq::generate(). +// +// If this class is asked to generate more seed material than was provided to +// the constructor, then the remaining bytes will be filled with deterministic, +// nonrandom data. +class ExplicitSeedSeq { + public: + using result_type = uint32_t; + + ExplicitSeedSeq() : state_() {} + + // Copy and move both allowed. + ExplicitSeedSeq(const ExplicitSeedSeq& other) = default; + ExplicitSeedSeq& operator=(const ExplicitSeedSeq& other) = default; + ExplicitSeedSeq(ExplicitSeedSeq&& other) = default; + ExplicitSeedSeq& operator=(ExplicitSeedSeq&& other) = default; + + template <typename Iterator> + ExplicitSeedSeq(Iterator begin, Iterator end) { + for (auto it = begin; it != end; it++) { + state_.push_back(*it & 0xffffffff); + } + } + + template <typename T> + ExplicitSeedSeq(std::initializer_list<T> il) + : ExplicitSeedSeq(il.begin(), il.end()) {} + + size_t size() const { return state_.size(); } + + template <typename OutIterator> + void param(OutIterator out) const { + std::copy(std::begin(state_), std::end(state_), out); + } + + template <typename OutIterator> + void generate(OutIterator begin, OutIterator end) { + for (size_t index = 0; begin != end; begin++) { + *begin = state_.empty() ? 0 : state_[index++]; + if (index >= state_.size()) { + index = 0; + } + } + } + + protected: + std::vector<uint32_t> state_; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_EXPLICIT_SEED_SEQ_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/explicit_seed_seq_test.cc b/third_party/abseil_cpp/absl/random/internal/explicit_seed_seq_test.cc new file mode 100644 index 0000000000..a55ad73948 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/explicit_seed_seq_test.cc @@ -0,0 +1,204 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/explicit_seed_seq.h" + +#include <iterator> +#include <random> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/random/seed_sequences.h" + +namespace { + +template <typename Sseq> +bool ConformsToInterface() { + // Check that the SeedSequence can be default-constructed. + { Sseq default_constructed_seq; } + // Check that the SeedSequence can be constructed with two iterators. + { + uint32_t init_array[] = {1, 3, 5, 7, 9}; + Sseq iterator_constructed_seq(init_array, &init_array[5]); + } + // Check that the SeedSequence can be std::initializer_list-constructed. + { Sseq list_constructed_seq = {1, 3, 5, 7, 9, 11, 13}; } + // Check that param() and size() return state provided to constructor. + { + uint32_t init_array[] = {1, 2, 3, 4, 5}; + Sseq seq(init_array, &init_array[ABSL_ARRAYSIZE(init_array)]); + EXPECT_EQ(seq.size(), ABSL_ARRAYSIZE(init_array)); + + uint32_t state_array[ABSL_ARRAYSIZE(init_array)]; + seq.param(state_array); + + for (int i = 0; i < ABSL_ARRAYSIZE(state_array); i++) { + EXPECT_EQ(state_array[i], i + 1); + } + } + // Check for presence of generate() method. + { + Sseq seq; + uint32_t seeds[5]; + + seq.generate(seeds, &seeds[ABSL_ARRAYSIZE(seeds)]); + } + return true; +} +} // namespace + +TEST(SeedSequences, CheckInterfaces) { + // Control case + EXPECT_TRUE(ConformsToInterface<std::seed_seq>()); + + // Abseil classes + EXPECT_TRUE(ConformsToInterface<absl::random_internal::ExplicitSeedSeq>()); +} + +TEST(ExplicitSeedSeq, DefaultConstructorGeneratesZeros) { + const size_t kNumBlocks = 128; + + uint32_t outputs[kNumBlocks]; + absl::random_internal::ExplicitSeedSeq seq; + seq.generate(outputs, &outputs[kNumBlocks]); + + for (uint32_t& seed : outputs) { + EXPECT_EQ(seed, 0); + } +} + +TEST(ExplicitSeeqSeq, SeedMaterialIsForwardedIdentically) { + const size_t kNumBlocks = 128; + + uint32_t seed_material[kNumBlocks]; + std::random_device urandom{"/dev/urandom"}; + for (uint32_t& seed : seed_material) { + seed = urandom(); + } + absl::random_internal::ExplicitSeedSeq seq(seed_material, + &seed_material[kNumBlocks]); + + // Check that output is same as seed-material provided to constructor. + { + const size_t kNumGenerated = kNumBlocks / 2; + uint32_t outputs[kNumGenerated]; + seq.generate(outputs, &outputs[kNumGenerated]); + for (size_t i = 0; i < kNumGenerated; i++) { + EXPECT_EQ(outputs[i], seed_material[i]); + } + } + // Check that SeedSequence is stateless between invocations: Despite the last + // invocation of generate() only consuming half of the input-entropy, the same + // entropy will be recycled for the next invocation. + { + const size_t kNumGenerated = kNumBlocks; + uint32_t outputs[kNumGenerated]; + seq.generate(outputs, &outputs[kNumGenerated]); + for (size_t i = 0; i < kNumGenerated; i++) { + EXPECT_EQ(outputs[i], seed_material[i]); + } + } + // Check that when more seed-material is asked for than is provided, nonzero + // values are still written. + { + const size_t kNumGenerated = kNumBlocks * 2; + uint32_t outputs[kNumGenerated]; + seq.generate(outputs, &outputs[kNumGenerated]); + for (size_t i = 0; i < kNumGenerated; i++) { + EXPECT_EQ(outputs[i], seed_material[i % kNumBlocks]); + } + } +} + +TEST(ExplicitSeedSeq, CopyAndMoveConstructors) { + using testing::Each; + using testing::Eq; + using testing::Not; + using testing::Pointwise; + + uint32_t entropy[4]; + std::random_device urandom("/dev/urandom"); + for (uint32_t& entry : entropy) { + entry = urandom(); + } + absl::random_internal::ExplicitSeedSeq seq_from_entropy(std::begin(entropy), + std::end(entropy)); + // Copy constructor. + { + absl::random_internal::ExplicitSeedSeq seq_copy(seq_from_entropy); + EXPECT_EQ(seq_copy.size(), seq_from_entropy.size()); + + std::vector<uint32_t> seeds_1; + seeds_1.resize(1000, 0); + std::vector<uint32_t> seeds_2; + seeds_2.resize(1000, 1); + + seq_from_entropy.generate(seeds_1.begin(), seeds_1.end()); + seq_copy.generate(seeds_2.begin(), seeds_2.end()); + + EXPECT_THAT(seeds_1, Pointwise(Eq(), seeds_2)); + } + // Assignment operator. + { + for (uint32_t& entry : entropy) { + entry = urandom(); + } + absl::random_internal::ExplicitSeedSeq another_seq(std::begin(entropy), + std::end(entropy)); + + std::vector<uint32_t> seeds_1; + seeds_1.resize(1000, 0); + std::vector<uint32_t> seeds_2; + seeds_2.resize(1000, 0); + + seq_from_entropy.generate(seeds_1.begin(), seeds_1.end()); + another_seq.generate(seeds_2.begin(), seeds_2.end()); + + // Assert precondition: Sequences generated by seed-sequences are not equal. + EXPECT_THAT(seeds_1, Not(Pointwise(Eq(), seeds_2))); + + // Apply the assignment-operator. + another_seq = seq_from_entropy; + + // Re-generate seeds. + seq_from_entropy.generate(seeds_1.begin(), seeds_1.end()); + another_seq.generate(seeds_2.begin(), seeds_2.end()); + + // Seeds generated by seed-sequences should now be equal. + EXPECT_THAT(seeds_1, Pointwise(Eq(), seeds_2)); + } + // Move constructor. + { + // Get seeds from seed-sequence constructed from entropy. + std::vector<uint32_t> seeds_1; + seeds_1.resize(1000, 0); + seq_from_entropy.generate(seeds_1.begin(), seeds_1.end()); + + // Apply move-constructor move the sequence to another instance. + absl::random_internal::ExplicitSeedSeq moved_seq( + std::move(seq_from_entropy)); + std::vector<uint32_t> seeds_2; + seeds_2.resize(1000, 1); + moved_seq.generate(seeds_2.begin(), seeds_2.end()); + // Verify that seeds produced by moved-instance are the same as original. + EXPECT_THAT(seeds_1, Pointwise(Eq(), seeds_2)); + + // Verify that the moved-from instance now behaves like a + // default-constructed instance. + EXPECT_EQ(seq_from_entropy.size(), 0); + seq_from_entropy.generate(seeds_1.begin(), seeds_1.end()); + EXPECT_THAT(seeds_1, Each(Eq(0))); + } +} diff --git a/third_party/abseil_cpp/absl/random/internal/fast_uniform_bits.h b/third_party/abseil_cpp/absl/random/internal/fast_uniform_bits.h new file mode 100644 index 0000000000..f13c8729f7 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/fast_uniform_bits.h @@ -0,0 +1,264 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_FAST_UNIFORM_BITS_H_ +#define ABSL_RANDOM_INTERNAL_FAST_UNIFORM_BITS_H_ + +#include <cstddef> +#include <cstdint> +#include <limits> +#include <type_traits> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +// Returns true if the input value is zero or a power of two. Useful for +// determining if the range of output values in a URBG +template <typename UIntType> +constexpr bool IsPowerOfTwoOrZero(UIntType n) { + return (n == 0) || ((n & (n - 1)) == 0); +} + +// Computes the length of the range of values producible by the URBG, or returns +// zero if that would encompass the entire range of representable values in +// URBG::result_type. +template <typename URBG> +constexpr typename URBG::result_type RangeSize() { + using result_type = typename URBG::result_type; + return ((URBG::max)() == (std::numeric_limits<result_type>::max)() && + (URBG::min)() == std::numeric_limits<result_type>::lowest()) + ? result_type{0} + : (URBG::max)() - (URBG::min)() + result_type{1}; +} + +template <typename UIntType> +constexpr UIntType LargestPowerOfTwoLessThanOrEqualTo(UIntType n) { + return n < 2 ? n : 2 * LargestPowerOfTwoLessThanOrEqualTo(n / 2); +} + +// Given a URBG generating values in the closed interval [Lo, Hi], returns the +// largest power of two less than or equal to `Hi - Lo + 1`. +template <typename URBG> +constexpr typename URBG::result_type PowerOfTwoSubRangeSize() { + return LargestPowerOfTwoLessThanOrEqualTo(RangeSize<URBG>()); +} + +// Computes the floor of the log. (i.e., std::floor(std::log2(N)); +template <typename UIntType> +constexpr UIntType IntegerLog2(UIntType n) { + return (n <= 1) ? 0 : 1 + IntegerLog2(n / 2); +} + +// Returns the number of bits of randomness returned through +// `PowerOfTwoVariate(urbg)`. +template <typename URBG> +constexpr size_t NumBits() { + return RangeSize<URBG>() == 0 + ? std::numeric_limits<typename URBG::result_type>::digits + : IntegerLog2(PowerOfTwoSubRangeSize<URBG>()); +} + +// Given a shift value `n`, constructs a mask with exactly the low `n` bits set. +// If `n == 0`, all bits are set. +template <typename UIntType> +constexpr UIntType MaskFromShift(UIntType n) { + return ((n % std::numeric_limits<UIntType>::digits) == 0) + ? ~UIntType{0} + : (UIntType{1} << n) - UIntType{1}; +} + +// FastUniformBits implements a fast path to acquire uniform independent bits +// from a type which conforms to the [rand.req.urbg] concept. +// Parameterized by: +// `UIntType`: the result (output) type +// +// The std::independent_bits_engine [rand.adapt.ibits] adaptor can be +// instantiated from an existing generator through a copy or a move. It does +// not, however, facilitate the production of pseudorandom bits from an un-owned +// generator that will outlive the std::independent_bits_engine instance. +template <typename UIntType = uint64_t> +class FastUniformBits { + public: + using result_type = UIntType; + + static constexpr result_type(min)() { return 0; } + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + template <typename URBG> + result_type operator()(URBG& g); // NOLINT(runtime/references) + + private: + static_assert(std::is_unsigned<UIntType>::value, + "Class-template FastUniformBits<> must be parameterized using " + "an unsigned type."); + + // PowerOfTwoVariate() generates a single random variate, always returning a + // value in the half-open interval `[0, PowerOfTwoSubRangeSize<URBG>())`. If + // the URBG already generates values in a power-of-two range, the generator + // itself is used. Otherwise, we use rejection sampling on the largest + // possible power-of-two-sized subrange. + struct PowerOfTwoTag {}; + struct RejectionSamplingTag {}; + template <typename URBG> + static typename URBG::result_type PowerOfTwoVariate( + URBG& g) { // NOLINT(runtime/references) + using tag = + typename std::conditional<IsPowerOfTwoOrZero(RangeSize<URBG>()), + PowerOfTwoTag, RejectionSamplingTag>::type; + return PowerOfTwoVariate(g, tag{}); + } + + template <typename URBG> + static typename URBG::result_type PowerOfTwoVariate( + URBG& g, // NOLINT(runtime/references) + PowerOfTwoTag) { + return g() - (URBG::min)(); + } + + template <typename URBG> + static typename URBG::result_type PowerOfTwoVariate( + URBG& g, // NOLINT(runtime/references) + RejectionSamplingTag) { + // Use rejection sampling to ensure uniformity across the range. + typename URBG::result_type u; + do { + u = g() - (URBG::min)(); + } while (u >= PowerOfTwoSubRangeSize<URBG>()); + return u; + } + + // Generate() generates a random value, dispatched on whether + // the underlying URBG must loop over multiple calls or not. + template <typename URBG> + result_type Generate(URBG& g, // NOLINT(runtime/references) + std::true_type /* avoid_looping */); + + template <typename URBG> + result_type Generate(URBG& g, // NOLINT(runtime/references) + std::false_type /* avoid_looping */); +}; + +template <typename UIntType> +template <typename URBG> +typename FastUniformBits<UIntType>::result_type +FastUniformBits<UIntType>::operator()(URBG& g) { // NOLINT(runtime/references) + // kRangeMask is the mask used when sampling variates from the URBG when the + // width of the URBG range is not a power of 2. + // Y = (2 ^ kRange) - 1 + static_assert((URBG::max)() > (URBG::min)(), + "URBG::max and URBG::min may not be equal."); + using urbg_result_type = typename URBG::result_type; + constexpr urbg_result_type kRangeMask = + RangeSize<URBG>() == 0 + ? (std::numeric_limits<urbg_result_type>::max)() + : static_cast<urbg_result_type>(PowerOfTwoSubRangeSize<URBG>() - 1); + return Generate(g, std::integral_constant<bool, (kRangeMask >= (max)())>{}); +} + +template <typename UIntType> +template <typename URBG> +typename FastUniformBits<UIntType>::result_type +FastUniformBits<UIntType>::Generate(URBG& g, // NOLINT(runtime/references) + std::true_type /* avoid_looping */) { + // The width of the result_type is less than than the width of the random bits + // provided by URBG. Thus, generate a single value and then simply mask off + // the required bits. + + return PowerOfTwoVariate(g) & (max)(); +} + +template <typename UIntType> +template <typename URBG> +typename FastUniformBits<UIntType>::result_type +FastUniformBits<UIntType>::Generate(URBG& g, // NOLINT(runtime/references) + std::false_type /* avoid_looping */) { + // See [rand.adapt.ibits] for more details on the constants calculated below. + // + // It is preferable to use roughly the same number of bits from each generator + // call, however this is only possible when the number of bits provided by the + // URBG is a divisor of the number of bits in `result_type`. In all other + // cases, the number of bits used cannot always be the same, but it can be + // guaranteed to be off by at most 1. Thus we run two loops, one with a + // smaller bit-width size (`kSmallWidth`) and one with a larger width size + // (satisfying `kLargeWidth == kSmallWidth + 1`). The loops are run + // `kSmallIters` and `kLargeIters` times respectively such + // that + // + // `kTotalWidth == kSmallIters * kSmallWidth + // + kLargeIters * kLargeWidth` + // + // where `kTotalWidth` is the total number of bits in `result_type`. + // + constexpr size_t kTotalWidth = std::numeric_limits<result_type>::digits; + constexpr size_t kUrbgWidth = NumBits<URBG>(); + constexpr size_t kTotalIters = + kTotalWidth / kUrbgWidth + (kTotalWidth % kUrbgWidth != 0); + constexpr size_t kSmallWidth = kTotalWidth / kTotalIters; + constexpr size_t kLargeWidth = kSmallWidth + 1; + // + // Because `kLargeWidth == kSmallWidth + 1`, it follows that + // + // `kTotalWidth == kTotalIters * kSmallWidth + kLargeIters` + // + // and therefore + // + // `kLargeIters == kTotalWidth % kSmallWidth` + // + // Intuitively, each iteration with the large width accounts for one unit + // of the remainder when `kTotalWidth` is divided by `kSmallWidth`. As + // mentioned above, if the URBG width is a divisor of `kTotalWidth`, then + // there would be no need for any large iterations (i.e., one loop would + // suffice), and indeed, in this case, `kLargeIters` would be zero. + constexpr size_t kLargeIters = kTotalWidth % kSmallWidth; + constexpr size_t kSmallIters = + (kTotalWidth - (kLargeWidth * kLargeIters)) / kSmallWidth; + + static_assert( + kTotalWidth == kSmallIters * kSmallWidth + kLargeIters * kLargeWidth, + "Error in looping constant calculations."); + + result_type s = 0; + + constexpr size_t kSmallShift = kSmallWidth % kTotalWidth; + constexpr result_type kSmallMask = MaskFromShift(result_type{kSmallShift}); + for (size_t n = 0; n < kSmallIters; ++n) { + s = (s << kSmallShift) + + (static_cast<result_type>(PowerOfTwoVariate(g)) & kSmallMask); + } + + constexpr size_t kLargeShift = kLargeWidth % kTotalWidth; + constexpr result_type kLargeMask = MaskFromShift(result_type{kLargeShift}); + for (size_t n = 0; n < kLargeIters; ++n) { + s = (s << kLargeShift) + + (static_cast<result_type>(PowerOfTwoVariate(g)) & kLargeMask); + } + + static_assert( + kLargeShift == kSmallShift + 1 || + (kLargeShift == 0 && + kSmallShift == std::numeric_limits<result_type>::digits - 1), + "Error in looping constant calculations"); + + return s; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_FAST_UNIFORM_BITS_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/fast_uniform_bits_test.cc b/third_party/abseil_cpp/absl/random/internal/fast_uniform_bits_test.cc new file mode 100644 index 0000000000..f5b837e586 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/fast_uniform_bits_test.cc @@ -0,0 +1,274 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/fast_uniform_bits.h" + +#include <random> + +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +template <typename IntType> +class FastUniformBitsTypedTest : public ::testing::Test {}; + +using IntTypes = ::testing::Types<uint8_t, uint16_t, uint32_t, uint64_t>; + +TYPED_TEST_SUITE(FastUniformBitsTypedTest, IntTypes); + +TYPED_TEST(FastUniformBitsTypedTest, BasicTest) { + using Limits = std::numeric_limits<TypeParam>; + using FastBits = FastUniformBits<TypeParam>; + + EXPECT_EQ(0, FastBits::min()); + EXPECT_EQ(Limits::max(), FastBits::max()); + + constexpr int kIters = 10000; + std::random_device rd; + std::mt19937 gen(rd()); + FastBits fast; + for (int i = 0; i < kIters; i++) { + const auto v = fast(gen); + EXPECT_LE(v, FastBits::max()); + EXPECT_GE(v, FastBits::min()); + } +} + +template <typename UIntType, UIntType Lo, UIntType Hi, UIntType Val = Lo> +struct FakeUrbg { + using result_type = UIntType; + + static constexpr result_type(max)() { return Hi; } + static constexpr result_type(min)() { return Lo; } + result_type operator()() { return Val; } +}; + +using UrngOddbits = FakeUrbg<uint8_t, 1, 0xfe, 0x73>; +using Urng4bits = FakeUrbg<uint8_t, 1, 0x10, 2>; +using Urng31bits = FakeUrbg<uint32_t, 1, 0xfffffffe, 0x60070f03>; +using Urng32bits = FakeUrbg<uint32_t, 0, 0xffffffff, 0x74010f01>; + +TEST(FastUniformBitsTest, IsPowerOfTwoOrZero) { + EXPECT_TRUE(IsPowerOfTwoOrZero(uint8_t{0})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint8_t{1})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint8_t{2})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint8_t{3})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint8_t{16})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint8_t{17})); + EXPECT_FALSE(IsPowerOfTwoOrZero((std::numeric_limits<uint8_t>::max)())); + + EXPECT_TRUE(IsPowerOfTwoOrZero(uint16_t{0})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint16_t{1})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint16_t{2})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint16_t{3})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint16_t{16})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint16_t{17})); + EXPECT_FALSE(IsPowerOfTwoOrZero((std::numeric_limits<uint16_t>::max)())); + + EXPECT_TRUE(IsPowerOfTwoOrZero(uint32_t{0})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint32_t{1})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint32_t{2})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint32_t{3})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint32_t{32})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint32_t{17})); + EXPECT_FALSE(IsPowerOfTwoOrZero((std::numeric_limits<uint32_t>::max)())); + + EXPECT_TRUE(IsPowerOfTwoOrZero(uint64_t{0})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint64_t{1})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint64_t{2})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint64_t{3})); + EXPECT_TRUE(IsPowerOfTwoOrZero(uint64_t{64})); + EXPECT_FALSE(IsPowerOfTwoOrZero(uint64_t{17})); + EXPECT_FALSE(IsPowerOfTwoOrZero((std::numeric_limits<uint64_t>::max)())); +} + +TEST(FastUniformBitsTest, IntegerLog2) { + EXPECT_EQ(IntegerLog2(uint16_t{0}), 0); + EXPECT_EQ(IntegerLog2(uint16_t{1}), 0); + EXPECT_EQ(IntegerLog2(uint16_t{2}), 1); + EXPECT_EQ(IntegerLog2(uint16_t{3}), 1); + EXPECT_EQ(IntegerLog2(uint16_t{4}), 2); + EXPECT_EQ(IntegerLog2(uint16_t{5}), 2); + EXPECT_EQ(IntegerLog2(std::numeric_limits<uint64_t>::max()), 63); +} + +TEST(FastUniformBitsTest, RangeSize) { + EXPECT_EQ((RangeSize<FakeUrbg<uint8_t, 0, 3>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint8_t, 2, 2>>()), 1); + EXPECT_EQ((RangeSize<FakeUrbg<uint8_t, 2, 5>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint8_t, 2, 6>>()), 5); + EXPECT_EQ((RangeSize<FakeUrbg<uint8_t, 2, 10>>()), 9); + EXPECT_EQ( + (RangeSize<FakeUrbg<uint8_t, 0, std::numeric_limits<uint8_t>::max()>>()), + 0); + + EXPECT_EQ((RangeSize<FakeUrbg<uint16_t, 0, 3>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint16_t, 2, 2>>()), 1); + EXPECT_EQ((RangeSize<FakeUrbg<uint16_t, 2, 5>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint16_t, 2, 6>>()), 5); + EXPECT_EQ((RangeSize<FakeUrbg<uint16_t, 1000, 1017>>()), 18); + EXPECT_EQ((RangeSize< + FakeUrbg<uint16_t, 0, std::numeric_limits<uint16_t>::max()>>()), + 0); + + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 0, 3>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 2, 2>>()), 1); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 2, 5>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 2, 6>>()), 5); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 1000, 1017>>()), 18); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 0, 0xffffffff>>()), 0); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 1, 0xffffffff>>()), 0xffffffff); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 1, 0xfffffffe>>()), 0xfffffffe); + EXPECT_EQ((RangeSize<FakeUrbg<uint32_t, 2, 0xfffffffe>>()), 0xfffffffd); + EXPECT_EQ((RangeSize< + FakeUrbg<uint32_t, 0, std::numeric_limits<uint32_t>::max()>>()), + 0); + + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 0, 3>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 2, 2>>()), 1); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 2, 5>>()), 4); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 2, 6>>()), 5); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 1000, 1017>>()), 18); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 0, 0xffffffff>>()), 0x100000000ull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 1, 0xffffffff>>()), 0xffffffffull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 1, 0xfffffffe>>()), 0xfffffffeull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 2, 0xfffffffe>>()), 0xfffffffdull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 0, 0xffffffffffffffffull>>()), 0ull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 1, 0xffffffffffffffffull>>()), + 0xffffffffffffffffull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 1, 0xfffffffffffffffeull>>()), + 0xfffffffffffffffeull); + EXPECT_EQ((RangeSize<FakeUrbg<uint64_t, 2, 0xfffffffffffffffeull>>()), + 0xfffffffffffffffdull); + EXPECT_EQ((RangeSize< + FakeUrbg<uint64_t, 0, std::numeric_limits<uint64_t>::max()>>()), + 0); +} + +TEST(FastUniformBitsTest, PowerOfTwoSubRangeSize) { + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint8_t, 0, 3>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint8_t, 2, 2>>()), 1); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint8_t, 2, 5>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint8_t, 2, 6>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint8_t, 2, 10>>()), 8); + EXPECT_EQ((PowerOfTwoSubRangeSize< + FakeUrbg<uint8_t, 0, std::numeric_limits<uint8_t>::max()>>()), + 0); + + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint16_t, 0, 3>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint16_t, 2, 2>>()), 1); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint16_t, 2, 5>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint16_t, 2, 6>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint16_t, 1000, 1017>>()), 16); + EXPECT_EQ((PowerOfTwoSubRangeSize< + FakeUrbg<uint16_t, 0, std::numeric_limits<uint16_t>::max()>>()), + 0); + + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 0, 3>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 2, 2>>()), 1); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 2, 5>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 2, 6>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 1000, 1017>>()), 16); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 0, 0xffffffff>>()), 0); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 1, 0xffffffff>>()), + 0x80000000); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint32_t, 1, 0xfffffffe>>()), + 0x80000000); + EXPECT_EQ((PowerOfTwoSubRangeSize< + FakeUrbg<uint32_t, 0, std::numeric_limits<uint32_t>::max()>>()), + 0); + + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 0, 3>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 2, 2>>()), 1); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 2, 5>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 2, 6>>()), 4); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 1000, 1017>>()), 16); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 0, 0xffffffff>>()), + 0x100000000ull); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 1, 0xffffffff>>()), + 0x80000000ull); + EXPECT_EQ((PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 1, 0xfffffffe>>()), + 0x80000000ull); + EXPECT_EQ( + (PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 0, 0xffffffffffffffffull>>()), + 0); + EXPECT_EQ( + (PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 1, 0xffffffffffffffffull>>()), + 0x8000000000000000ull); + EXPECT_EQ( + (PowerOfTwoSubRangeSize<FakeUrbg<uint64_t, 1, 0xfffffffffffffffeull>>()), + 0x8000000000000000ull); + EXPECT_EQ((PowerOfTwoSubRangeSize< + FakeUrbg<uint64_t, 0, std::numeric_limits<uint64_t>::max()>>()), + 0); +} + +TEST(FastUniformBitsTest, Urng4_VariousOutputs) { + // Tests that how values are composed; the single-bit deltas should be spread + // across each invocation. + Urng4bits urng4; + Urng31bits urng31; + Urng32bits urng32; + + // 8-bit types + { + FastUniformBits<uint8_t> fast8; + EXPECT_EQ(0x11, fast8(urng4)); + EXPECT_EQ(0x2, fast8(urng31)); + EXPECT_EQ(0x1, fast8(urng32)); + } + + // 16-bit types + { + FastUniformBits<uint16_t> fast16; + EXPECT_EQ(0x1111, fast16(urng4)); + EXPECT_EQ(0xf02, fast16(urng31)); + EXPECT_EQ(0xf01, fast16(urng32)); + } + + // 32-bit types + { + FastUniformBits<uint32_t> fast32; + EXPECT_EQ(0x11111111, fast32(urng4)); + EXPECT_EQ(0x0f020f02, fast32(urng31)); + EXPECT_EQ(0x74010f01, fast32(urng32)); + } + + // 64-bit types + { + FastUniformBits<uint64_t> fast64; + EXPECT_EQ(0x1111111111111111, fast64(urng4)); + EXPECT_EQ(0x387811c3c0870f02, fast64(urng31)); + EXPECT_EQ(0x74010f0174010f01, fast64(urng32)); + } +} + +TEST(FastUniformBitsTest, URBG32bitRegression) { + // Validate with deterministic 32-bit std::minstd_rand + // to ensure that operator() performs as expected. + std::minstd_rand gen(1); + FastUniformBits<uint64_t> fast64; + + EXPECT_EQ(0x05e47095f847c122ull, fast64(gen)); + EXPECT_EQ(0x8f82c1ba30b64d22ull, fast64(gen)); + EXPECT_EQ(0x3b971a3558155039ull, fast64(gen)); +} + +} // namespace +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/fastmath.h b/third_party/abseil_cpp/absl/random/internal/fastmath.h new file mode 100644 index 0000000000..6baeb5a7c9 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/fastmath.h @@ -0,0 +1,74 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_FASTMATH_H_ +#define ABSL_RANDOM_INTERNAL_FASTMATH_H_ + +// This file contains fast math functions (bitwise ops as well as some others) +// which are implementation details of various absl random number distributions. + +#include <cassert> +#include <cmath> +#include <cstdint> + +#include "absl/base/internal/bits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Returns the position of the first bit set. +inline int LeadingSetBit(uint64_t n) { + return 64 - base_internal::CountLeadingZeros64(n); +} + +// Compute log2(n) using integer operations. +// While std::log2 is more accurate than std::log(n) / std::log(2), for +// very large numbers--those close to std::numeric_limits<uint64_t>::max() - 2, +// for instance--std::log2 rounds up rather than down, which introduces +// definite skew in the results. +inline int IntLog2Floor(uint64_t n) { + return (n <= 1) ? 0 : (63 - base_internal::CountLeadingZeros64(n)); +} +inline int IntLog2Ceil(uint64_t n) { + return (n <= 1) ? 0 : (64 - base_internal::CountLeadingZeros64(n - 1)); +} + +inline double StirlingLogFactorial(double n) { + assert(n >= 1); + // Using Stirling's approximation. + constexpr double kLog2PI = 1.83787706640934548356; + const double logn = std::log(n); + const double ninv = 1.0 / static_cast<double>(n); + return n * logn - n + 0.5 * (kLog2PI + logn) + (1.0 / 12.0) * ninv - + (1.0 / 360.0) * ninv * ninv * ninv; +} + +// Rotate value right. +// +// We only implement the uint32_t / uint64_t versions because +// 1) those are the only ones we use, and +// 2) those are the only ones where clang detects the rotate idiom correctly. +inline constexpr uint32_t rotr(uint32_t value, uint8_t bits) { + return (value >> (bits & 31)) | (value << ((-bits) & 31)); +} +inline constexpr uint64_t rotr(uint64_t value, uint8_t bits) { + return (value >> (bits & 63)) | (value << ((-bits) & 63)); +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_FASTMATH_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/fastmath_test.cc b/third_party/abseil_cpp/absl/random/internal/fastmath_test.cc new file mode 100644 index 0000000000..65859c25de --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/fastmath_test.cc @@ -0,0 +1,110 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/fastmath.h" + +#include "gtest/gtest.h" + +#if defined(__native_client__) || defined(__EMSCRIPTEN__) +// NACL has a less accurate implementation of std::log2 than most of +// the other platforms. For some values which should have integral results, +// sometimes NACL returns slightly larger values. +// +// The MUSL libc used by emscripten also has a similar bug. +#define ABSL_RANDOM_INACCURATE_LOG2 +#endif + +namespace { + +TEST(DistributionImplTest, LeadingSetBit) { + using absl::random_internal::LeadingSetBit; + constexpr uint64_t kZero = 0; + EXPECT_EQ(0, LeadingSetBit(kZero)); + EXPECT_EQ(64, LeadingSetBit(~kZero)); + + for (int index = 0; index < 64; index++) { + uint64_t x = static_cast<uint64_t>(1) << index; + EXPECT_EQ(index + 1, LeadingSetBit(x)) << index; + EXPECT_EQ(index + 1, LeadingSetBit(x + x - 1)) << index; + } +} + +TEST(FastMathTest, IntLog2FloorTest) { + using absl::random_internal::IntLog2Floor; + constexpr uint64_t kZero = 0; + EXPECT_EQ(0, IntLog2Floor(0)); // boundary. return 0. + EXPECT_EQ(0, IntLog2Floor(1)); + EXPECT_EQ(1, IntLog2Floor(2)); + EXPECT_EQ(63, IntLog2Floor(~kZero)); + + // A boundary case: Converting 0xffffffffffffffff requires > 53 + // bits of precision, so the conversion to double rounds up, + // and the result of std::log2(x) > IntLog2Floor(x). + EXPECT_LT(IntLog2Floor(~kZero), static_cast<int>(std::log2(~kZero))); + + for (int i = 0; i < 64; i++) { + const uint64_t i_pow_2 = static_cast<uint64_t>(1) << i; + EXPECT_EQ(i, IntLog2Floor(i_pow_2)); + EXPECT_EQ(i, static_cast<int>(std::log2(i_pow_2))); + + uint64_t y = i_pow_2; + for (int j = i - 1; j > 0; --j) { + y = y | (i_pow_2 >> j); + EXPECT_EQ(i, IntLog2Floor(y)); + } + } +} + +TEST(FastMathTest, IntLog2CeilTest) { + using absl::random_internal::IntLog2Ceil; + constexpr uint64_t kZero = 0; + EXPECT_EQ(0, IntLog2Ceil(0)); // boundary. return 0. + EXPECT_EQ(0, IntLog2Ceil(1)); + EXPECT_EQ(1, IntLog2Ceil(2)); + EXPECT_EQ(64, IntLog2Ceil(~kZero)); + + // A boundary case: Converting 0xffffffffffffffff requires > 53 + // bits of precision, so the conversion to double rounds up, + // and the result of std::log2(x) > IntLog2Floor(x). + EXPECT_LE(IntLog2Ceil(~kZero), static_cast<int>(std::log2(~kZero))); + + for (int i = 0; i < 64; i++) { + const uint64_t i_pow_2 = static_cast<uint64_t>(1) << i; + EXPECT_EQ(i, IntLog2Ceil(i_pow_2)); +#ifndef ABSL_RANDOM_INACCURATE_LOG2 + EXPECT_EQ(i, static_cast<int>(std::ceil(std::log2(i_pow_2)))); +#endif + + uint64_t y = i_pow_2; + for (int j = i - 1; j > 0; --j) { + y = y | (i_pow_2 >> j); + EXPECT_EQ(i + 1, IntLog2Ceil(y)); + } + } +} + +TEST(FastMathTest, StirlingLogFactorial) { + using absl::random_internal::StirlingLogFactorial; + + EXPECT_NEAR(StirlingLogFactorial(1.0), 0, 1e-3); + EXPECT_NEAR(StirlingLogFactorial(1.50), 0.284683, 1e-3); + EXPECT_NEAR(StirlingLogFactorial(2.0), 0.69314718056, 1e-4); + + for (int i = 2; i < 50; i++) { + double d = static_cast<double>(i); + EXPECT_NEAR(StirlingLogFactorial(d), std::lgamma(d + 1), 3e-5); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/gaussian_distribution_gentables.cc b/third_party/abseil_cpp/absl/random/internal/gaussian_distribution_gentables.cc new file mode 100644 index 0000000000..a2bf03940f --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/gaussian_distribution_gentables.cc @@ -0,0 +1,147 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Generates gaussian_distribution.cc +// +// $ blaze run :gaussian_distribution_gentables > gaussian_distribution.cc +// +#include "absl/random/gaussian_distribution.h" + +#include <cmath> +#include <cstddef> +#include <iostream> +#include <limits> +#include <string> + +#include "absl/base/macros.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +template <typename T, size_t N> +void FormatArrayContents(std::ostream* os, T (&data)[N]) { + if (!std::numeric_limits<T>::is_exact) { + // Note: T is either an integer or a float. + // float requires higher precision to ensure that values are + // reproduced exactly. + // Trivia: C99 has hexadecimal floating point literals, but C++11 does not. + // Using them would remove all concern of precision loss. + os->precision(std::numeric_limits<T>::max_digits10 + 2); + } + *os << " {"; + std::string separator = ""; + for (size_t i = 0; i < N; ++i) { + *os << separator << data[i]; + if ((i + 1) % 3 != 0) { + separator = ", "; + } else { + separator = ",\n "; + } + } + *os << "}"; +} + +} // namespace + +class TableGenerator : public gaussian_distribution_base { + public: + TableGenerator(); + void Print(std::ostream* os); + + using gaussian_distribution_base::kMask; + using gaussian_distribution_base::kR; + using gaussian_distribution_base::kV; + + private: + Tables tables_; +}; + +// Ziggurat gaussian initialization. For an explanation of the algorithm, see +// the Marsaglia paper, "The Ziggurat Method for Generating Random Variables". +// http://www.jstatsoft.org/v05/i08/ +// +// Further details are available in the Doornik paper +// https://www.doornik.com/research/ziggurat.pdf +// +TableGenerator::TableGenerator() { + // The constants here should match the values in gaussian_distribution.h + static constexpr int kC = kMask + 1; + + static_assert((ABSL_ARRAYSIZE(tables_.x) == kC + 1), + "xArray must be length kMask + 2"); + + static_assert((ABSL_ARRAYSIZE(tables_.x) == ABSL_ARRAYSIZE(tables_.f)), + "fx and x arrays must be identical length"); + + auto f = [](double x) { return std::exp(-0.5 * x * x); }; + auto f_inv = [](double x) { return std::sqrt(-2.0 * std::log(x)); }; + + tables_.x[0] = kV / f(kR); + tables_.f[0] = f(tables_.x[0]); + + tables_.x[1] = kR; + tables_.f[1] = f(tables_.x[1]); + + tables_.x[kC] = 0.0; + tables_.f[kC] = f(tables_.x[kC]); // 1.0 + + for (int i = 2; i < kC; i++) { + double v = (kV / tables_.x[i - 1]) + tables_.f[i - 1]; + tables_.x[i] = f_inv(v); + tables_.f[i] = v; + } +} + +void TableGenerator::Print(std::ostream* os) { + *os << "// BEGIN GENERATED CODE; DO NOT EDIT\n" + "// clang-format off\n" + "\n" + "#include \"absl/random/gaussian_distribution.h\"\n" + "\n" + // "namespace " and "absl" are broken apart so as not to conflict with + // script that adds the LTS inline namespace. + "namespace " + "absl {\n" + "namespace " + "random_internal {\n" + "\n" + "const gaussian_distribution_base::Tables\n" + " gaussian_distribution_base::zg_ = {\n"; + FormatArrayContents(os, tables_.x); + *os << ",\n"; + FormatArrayContents(os, tables_.f); + *os << "};\n" + "\n" + "} // namespace " + "random_internal\n" + "} // namespace " + "absl\n" + "\n" + "// clang-format on\n" + "// END GENERATED CODE"; + *os << std::endl; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +int main(int, char**) { + std::cerr << "\nCopy the output to gaussian_distribution.cc" << std::endl; + absl::random_internal::TableGenerator generator; + generator.Print(&std::cout); + return 0; +} diff --git a/third_party/abseil_cpp/absl/random/internal/generate_real.h b/third_party/abseil_cpp/absl/random/internal/generate_real.h new file mode 100644 index 0000000000..20f6d20807 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/generate_real.h @@ -0,0 +1,146 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_GENERATE_REAL_H_ +#define ABSL_RANDOM_INTERNAL_GENERATE_REAL_H_ + +// This file contains some implementation details which are used by one or more +// of the absl random number distributions. + +#include <cstdint> +#include <cstring> +#include <limits> +#include <type_traits> + +#include "absl/base/internal/bits.h" +#include "absl/meta/type_traits.h" +#include "absl/random/internal/fastmath.h" +#include "absl/random/internal/traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Tristate tag types controlling the output of GenerateRealFromBits. +struct GeneratePositiveTag {}; +struct GenerateNegativeTag {}; +struct GenerateSignedTag {}; + +// GenerateRealFromBits generates a single real value from a single 64-bit +// `bits` with template fields controlling the output. +// +// The `SignedTag` parameter controls whether positive, negative, +// or either signed/unsigned may be returned. +// When SignedTag == GeneratePositiveTag, range is U(0, 1) +// When SignedTag == GenerateNegativeTag, range is U(-1, 0) +// When SignedTag == GenerateSignedTag, range is U(-1, 1) +// +// When the `IncludeZero` parameter is true, the function may return 0 for some +// inputs, otherwise it never returns 0. +// +// When a value in U(0,1) is required, use: +// Uniform64ToReal<double, PositiveValueT, true>; +// +// When a value in U(-1,1) is required, use: +// Uniform64ToReal<double, SignedValueT, false>; +// +// This generates more distinct values than the mathematical equivalent +// `U(0, 1) * 2.0 - 1.0`. +// +// Scaling the result by powers of 2 (and avoiding a multiply) is also possible: +// GenerateRealFromBits<double>(..., -1); => U(0, 0.5) +// GenerateRealFromBits<double>(..., 1); => U(0, 2) +// +template <typename RealType, // Real type, either float or double. + typename SignedTag = GeneratePositiveTag, // Whether a positive, + // negative, or signed + // value is generated. + bool IncludeZero = true> +inline RealType GenerateRealFromBits(uint64_t bits, int exp_bias = 0) { + using real_type = RealType; + using uint_type = absl::conditional_t<std::is_same<real_type, float>::value, + uint32_t, uint64_t>; + + static_assert( + (std::is_same<double, real_type>::value || + std::is_same<float, real_type>::value), + "GenerateRealFromBits must be parameterized by either float or double."); + + static_assert(sizeof(uint_type) == sizeof(real_type), + "Mismatched unsinged and real types."); + + static_assert((std::numeric_limits<real_type>::is_iec559 && + std::numeric_limits<real_type>::radix == 2), + "RealType representation is not IEEE 754 binary."); + + static_assert((std::is_same<SignedTag, GeneratePositiveTag>::value || + std::is_same<SignedTag, GenerateNegativeTag>::value || + std::is_same<SignedTag, GenerateSignedTag>::value), + ""); + + static constexpr int kExp = std::numeric_limits<real_type>::digits - 1; + static constexpr uint_type kMask = (static_cast<uint_type>(1) << kExp) - 1u; + static constexpr int kUintBits = sizeof(uint_type) * 8; + + int exp = exp_bias + int{std::numeric_limits<real_type>::max_exponent - 2}; + + // Determine the sign bit. + // Depending on the SignedTag, this may use the left-most bit + // or it may be a constant value. + uint_type sign = std::is_same<SignedTag, GenerateNegativeTag>::value + ? (static_cast<uint_type>(1) << (kUintBits - 1)) + : 0; + if (std::is_same<SignedTag, GenerateSignedTag>::value) { + if (std::is_same<uint_type, uint64_t>::value) { + sign = bits & uint64_t{0x8000000000000000}; + } + if (std::is_same<uint_type, uint32_t>::value) { + const uint64_t tmp = bits & uint64_t{0x8000000000000000}; + sign = static_cast<uint32_t>(tmp >> 32); + } + // adjust the bits and the exponent to account for removing + // the leading bit. + bits = bits & uint64_t{0x7FFFFFFFFFFFFFFF}; + exp++; + } + if (IncludeZero) { + if (bits == 0u) return 0; + } + + // Number of leading zeros is mapped to the exponent: 2^-clz + // bits is 0..01xxxxxx. After shifting, we're left with 1xxx...0..0 + int clz = base_internal::CountLeadingZeros64(bits); + bits <<= (IncludeZero ? clz : (clz & 63)); // remove 0-bits. + exp -= clz; // set the exponent. + bits >>= (63 - kExp); + + // Construct the 32-bit or 64-bit IEEE 754 floating-point value from + // the individual fields: sign, exp, mantissa(bits). + uint_type val = + (std::is_same<SignedTag, GeneratePositiveTag>::value ? 0u : sign) | + (static_cast<uint_type>(exp) << kExp) | + (static_cast<uint_type>(bits) & kMask); + + // bit_cast to the output-type + real_type result; + memcpy(static_cast<void*>(&result), static_cast<const void*>(&val), + sizeof(result)); + return result; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_GENERATE_REAL_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/generate_real_test.cc b/third_party/abseil_cpp/absl/random/internal/generate_real_test.cc new file mode 100644 index 0000000000..aa02f0c2c1 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/generate_real_test.cc @@ -0,0 +1,497 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/generate_real.h" + +#include <cfloat> +#include <cstddef> +#include <cstdint> +#include <string> + +#include "gtest/gtest.h" +#include "absl/base/internal/bits.h" +#include "absl/flags/flag.h" + +ABSL_FLAG(int64_t, absl_random_test_trials, 50000, + "Number of trials for the probability tests."); + +using absl::random_internal::GenerateNegativeTag; +using absl::random_internal::GeneratePositiveTag; +using absl::random_internal::GenerateRealFromBits; +using absl::random_internal::GenerateSignedTag; + +namespace { + +TEST(GenerateRealTest, U64ToFloat_Positive_NoZero_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GeneratePositiveTag, false>(a); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), 2.710505431e-20f); + EXPECT_EQ(ToFloat(0x0000000000000001), 5.421010862e-20f); + EXPECT_EQ(ToFloat(0x8000000000000000), 0.5); + EXPECT_EQ(ToFloat(0x8000000000000001), 0.5); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), 0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloat_Positive_Zero_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GeneratePositiveTag, true>(a); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), 0.0); + EXPECT_EQ(ToFloat(0x0000000000000001), 5.421010862e-20f); + EXPECT_EQ(ToFloat(0x8000000000000000), 0.5); + EXPECT_EQ(ToFloat(0x8000000000000001), 0.5); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), 0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloat_Negative_NoZero_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GenerateNegativeTag, false>(a); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), -2.710505431e-20f); + EXPECT_EQ(ToFloat(0x0000000000000001), -5.421010862e-20f); + EXPECT_EQ(ToFloat(0x8000000000000000), -0.5); + EXPECT_EQ(ToFloat(0x8000000000000001), -0.5); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), -0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloat_Negative_Zero_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GenerateNegativeTag, true>(a); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), 0.0); + EXPECT_EQ(ToFloat(0x0000000000000001), -5.421010862e-20f); + EXPECT_EQ(ToFloat(0x8000000000000000), -0.5); + EXPECT_EQ(ToFloat(0x8000000000000001), -0.5); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), -0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloat_Signed_NoZero_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GenerateSignedTag, false>(a); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), 5.421010862e-20f); + EXPECT_EQ(ToFloat(0x0000000000000001), 1.084202172e-19f); + EXPECT_EQ(ToFloat(0x7FFFFFFFFFFFFFFF), 0.9999999404f); + EXPECT_EQ(ToFloat(0x8000000000000000), -5.421010862e-20f); + EXPECT_EQ(ToFloat(0x8000000000000001), -1.084202172e-19f); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), -0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloat_Signed_Zero_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GenerateSignedTag, true>(a); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), 0); + EXPECT_EQ(ToFloat(0x0000000000000001), 1.084202172e-19f); + EXPECT_EQ(ToFloat(0x7FFFFFFFFFFFFFFF), 0.9999999404f); + EXPECT_EQ(ToFloat(0x8000000000000000), 0); + EXPECT_EQ(ToFloat(0x8000000000000001), -1.084202172e-19f); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), -0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloat_Signed_Bias_Test) { + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GenerateSignedTag, true>(a, 1); + }; + EXPECT_EQ(ToFloat(0x0000000000000000), 0); + EXPECT_EQ(ToFloat(0x0000000000000001), 2 * 1.084202172e-19f); + EXPECT_EQ(ToFloat(0x7FFFFFFFFFFFFFFF), 2 * 0.9999999404f); + EXPECT_EQ(ToFloat(0x8000000000000000), 0); + EXPECT_EQ(ToFloat(0x8000000000000001), 2 * -1.084202172e-19f); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), 2 * -0.9999999404f); +} + +TEST(GenerateRealTest, U64ToFloatTest) { + auto ToFloat = [](uint64_t a) -> float { + return GenerateRealFromBits<float, GeneratePositiveTag, true>(a); + }; + + EXPECT_EQ(ToFloat(0x0000000000000000), 0.0f); + + EXPECT_EQ(ToFloat(0x8000000000000000), 0.5f); + EXPECT_EQ(ToFloat(0x8000000000000001), 0.5f); + EXPECT_EQ(ToFloat(0x800000FFFFFFFFFF), 0.5f); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), 0.9999999404f); + + EXPECT_GT(ToFloat(0x0000000000000001), 0.0f); + + EXPECT_NE(ToFloat(0x7FFFFF0000000000), ToFloat(0x7FFFFEFFFFFFFFFF)); + + EXPECT_LT(ToFloat(0xFFFFFFFFFFFFFFFF), 1.0f); + int32_t two_to_24 = 1 << 24; + EXPECT_EQ(static_cast<int32_t>(ToFloat(0xFFFFFFFFFFFFFFFF) * two_to_24), + two_to_24 - 1); + EXPECT_NE(static_cast<int32_t>(ToFloat(0xFFFFFFFFFFFFFFFF) * two_to_24 * 2), + two_to_24 * 2 - 1); + EXPECT_EQ(ToFloat(0xFFFFFFFFFFFFFFFF), ToFloat(0xFFFFFF0000000000)); + EXPECT_NE(ToFloat(0xFFFFFFFFFFFFFFFF), ToFloat(0xFFFFFEFFFFFFFFFF)); + EXPECT_EQ(ToFloat(0x7FFFFFFFFFFFFFFF), ToFloat(0x7FFFFF8000000000)); + EXPECT_NE(ToFloat(0x7FFFFFFFFFFFFFFF), ToFloat(0x7FFFFF7FFFFFFFFF)); + EXPECT_EQ(ToFloat(0x3FFFFFFFFFFFFFFF), ToFloat(0x3FFFFFC000000000)); + EXPECT_NE(ToFloat(0x3FFFFFFFFFFFFFFF), ToFloat(0x3FFFFFBFFFFFFFFF)); + + // For values where every bit counts, the values scale as multiples of the + // input. + for (int i = 0; i < 100; ++i) { + EXPECT_EQ(i * ToFloat(0x0000000000000001), ToFloat(i)); + } + + // For each i: value generated from (1 << i). + float exp_values[64]; + exp_values[63] = 0.5f; + for (int i = 62; i >= 0; --i) exp_values[i] = 0.5f * exp_values[i + 1]; + constexpr uint64_t one = 1; + for (int i = 0; i < 64; ++i) { + EXPECT_EQ(ToFloat(one << i), exp_values[i]); + for (int j = 1; j < FLT_MANT_DIG && i - j >= 0; ++j) { + EXPECT_NE(exp_values[i] + exp_values[i - j], exp_values[i]); + EXPECT_EQ(ToFloat((one << i) + (one << (i - j))), + exp_values[i] + exp_values[i - j]); + } + for (int j = FLT_MANT_DIG; i - j >= 0; ++j) { + EXPECT_EQ(exp_values[i] + exp_values[i - j], exp_values[i]); + EXPECT_EQ(ToFloat((one << i) + (one << (i - j))), exp_values[i]); + } + } +} + +TEST(GenerateRealTest, U64ToDouble_Positive_NoZero_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GeneratePositiveTag, false>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), 2.710505431213761085e-20); + EXPECT_EQ(ToDouble(0x0000000000000001), 5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x0000000000000002), 1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0x8000000000000000), 0.5); + EXPECT_EQ(ToDouble(0x8000000000000001), 0.5); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), 0.999999999999999888978); +} + +TEST(GenerateRealTest, U64ToDouble_Positive_Zero_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GeneratePositiveTag, true>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), 0.0); + EXPECT_EQ(ToDouble(0x0000000000000001), 5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x8000000000000000), 0.5); + EXPECT_EQ(ToDouble(0x8000000000000001), 0.5); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), 0.999999999999999888978); +} + +TEST(GenerateRealTest, U64ToDouble_Negative_NoZero_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GenerateNegativeTag, false>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), -2.710505431213761085e-20); + EXPECT_EQ(ToDouble(0x0000000000000001), -5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x0000000000000002), -1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0x8000000000000000), -0.5); + EXPECT_EQ(ToDouble(0x8000000000000001), -0.5); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), -0.999999999999999888978); +} + +TEST(GenerateRealTest, U64ToDouble_Negative_Zero_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GenerateNegativeTag, true>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), 0.0); + EXPECT_EQ(ToDouble(0x0000000000000001), -5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x0000000000000002), -1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0x8000000000000000), -0.5); + EXPECT_EQ(ToDouble(0x8000000000000001), -0.5); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), -0.999999999999999888978); +} + +TEST(GenerateRealTest, U64ToDouble_Signed_NoZero_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GenerateSignedTag, false>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), 5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x0000000000000001), 1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0x7FFFFFFFFFFFFFFF), 0.999999999999999888978); + EXPECT_EQ(ToDouble(0x8000000000000000), -5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x8000000000000001), -1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), -0.999999999999999888978); +} + +TEST(GenerateRealTest, U64ToDouble_Signed_Zero_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GenerateSignedTag, true>(a); + }; + EXPECT_EQ(ToDouble(0x0000000000000000), 0); + EXPECT_EQ(ToDouble(0x0000000000000001), 1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0x7FFFFFFFFFFFFFFF), 0.999999999999999888978); + EXPECT_EQ(ToDouble(0x8000000000000000), 0); + EXPECT_EQ(ToDouble(0x8000000000000001), -1.084202172485504434e-19); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), -0.999999999999999888978); +} + +TEST(GenerateRealTest, U64ToDouble_GenerateSignedTag_Bias_Test) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GenerateSignedTag, true>(a, -1); + }; + EXPECT_EQ(ToDouble(0x0000000000000000), 0); + EXPECT_EQ(ToDouble(0x0000000000000001), 1.084202172485504434e-19 / 2); + EXPECT_EQ(ToDouble(0x7FFFFFFFFFFFFFFF), 0.999999999999999888978 / 2); + EXPECT_EQ(ToDouble(0x8000000000000000), 0); + EXPECT_EQ(ToDouble(0x8000000000000001), -1.084202172485504434e-19 / 2); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), -0.999999999999999888978 / 2); +} + +TEST(GenerateRealTest, U64ToDoubleTest) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GeneratePositiveTag, true>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), 0.0); + EXPECT_EQ(ToDouble(0x0000000000000000), 0.0); + + EXPECT_EQ(ToDouble(0x0000000000000001), 5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x7fffffffffffffef), 0.499999999999999944489); + EXPECT_EQ(ToDouble(0x8000000000000000), 0.5); + + // For values > 0.5, RandU64ToDouble discards up to 11 bits. (64-53). + EXPECT_EQ(ToDouble(0x8000000000000001), 0.5); + EXPECT_EQ(ToDouble(0x80000000000007FF), 0.5); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), 0.999999999999999888978); + EXPECT_NE(ToDouble(0x7FFFFFFFFFFFF800), ToDouble(0x7FFFFFFFFFFFF7FF)); + + EXPECT_LT(ToDouble(0xFFFFFFFFFFFFFFFF), 1.0); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFF), ToDouble(0xFFFFFFFFFFFFF800)); + EXPECT_NE(ToDouble(0xFFFFFFFFFFFFFFFF), ToDouble(0xFFFFFFFFFFFFF7FF)); + EXPECT_EQ(ToDouble(0x7FFFFFFFFFFFFFFF), ToDouble(0x7FFFFFFFFFFFFC00)); + EXPECT_NE(ToDouble(0x7FFFFFFFFFFFFFFF), ToDouble(0x7FFFFFFFFFFFFBFF)); + EXPECT_EQ(ToDouble(0x3FFFFFFFFFFFFFFF), ToDouble(0x3FFFFFFFFFFFFE00)); + EXPECT_NE(ToDouble(0x3FFFFFFFFFFFFFFF), ToDouble(0x3FFFFFFFFFFFFDFF)); + + EXPECT_EQ(ToDouble(0x1000000000000001), 0.0625); + EXPECT_EQ(ToDouble(0x2000000000000001), 0.125); + EXPECT_EQ(ToDouble(0x3000000000000001), 0.1875); + EXPECT_EQ(ToDouble(0x4000000000000001), 0.25); + EXPECT_EQ(ToDouble(0x5000000000000001), 0.3125); + EXPECT_EQ(ToDouble(0x6000000000000001), 0.375); + EXPECT_EQ(ToDouble(0x7000000000000001), 0.4375); + EXPECT_EQ(ToDouble(0x8000000000000001), 0.5); + EXPECT_EQ(ToDouble(0x9000000000000001), 0.5625); + EXPECT_EQ(ToDouble(0xa000000000000001), 0.625); + EXPECT_EQ(ToDouble(0xb000000000000001), 0.6875); + EXPECT_EQ(ToDouble(0xc000000000000001), 0.75); + EXPECT_EQ(ToDouble(0xd000000000000001), 0.8125); + EXPECT_EQ(ToDouble(0xe000000000000001), 0.875); + EXPECT_EQ(ToDouble(0xf000000000000001), 0.9375); + + // Large powers of 2. + int64_t two_to_53 = int64_t{1} << 53; + EXPECT_EQ(static_cast<int64_t>(ToDouble(0xFFFFFFFFFFFFFFFF) * two_to_53), + two_to_53 - 1); + EXPECT_NE(static_cast<int64_t>(ToDouble(0xFFFFFFFFFFFFFFFF) * two_to_53 * 2), + two_to_53 * 2 - 1); + + // For values where every bit counts, the values scale as multiples of the + // input. + for (int i = 0; i < 100; ++i) { + EXPECT_EQ(i * ToDouble(0x0000000000000001), ToDouble(i)); + } + + // For each i: value generated from (1 << i). + double exp_values[64]; + exp_values[63] = 0.5; + for (int i = 62; i >= 0; --i) exp_values[i] = 0.5 * exp_values[i + 1]; + constexpr uint64_t one = 1; + for (int i = 0; i < 64; ++i) { + EXPECT_EQ(ToDouble(one << i), exp_values[i]); + for (int j = 1; j < DBL_MANT_DIG && i - j >= 0; ++j) { + EXPECT_NE(exp_values[i] + exp_values[i - j], exp_values[i]); + EXPECT_EQ(ToDouble((one << i) + (one << (i - j))), + exp_values[i] + exp_values[i - j]); + } + for (int j = DBL_MANT_DIG; i - j >= 0; ++j) { + EXPECT_EQ(exp_values[i] + exp_values[i - j], exp_values[i]); + EXPECT_EQ(ToDouble((one << i) + (one << (i - j))), exp_values[i]); + } + } +} + +TEST(GenerateRealTest, U64ToDoubleSignedTest) { + auto ToDouble = [](uint64_t a) { + return GenerateRealFromBits<double, GenerateSignedTag, false>(a); + }; + + EXPECT_EQ(ToDouble(0x0000000000000000), 5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x0000000000000001), 1.084202172485504434e-19); + + EXPECT_EQ(ToDouble(0x8000000000000000), -5.42101086242752217004e-20); + EXPECT_EQ(ToDouble(0x8000000000000001), -1.084202172485504434e-19); + + const double e_plus = ToDouble(0x0000000000000001); + const double e_minus = ToDouble(0x8000000000000001); + EXPECT_EQ(e_plus, 1.084202172485504434e-19); + EXPECT_EQ(e_minus, -1.084202172485504434e-19); + + EXPECT_EQ(ToDouble(0x3fffffffffffffef), 0.499999999999999944489); + EXPECT_EQ(ToDouble(0xbfffffffffffffef), -0.499999999999999944489); + + // For values > 0.5, RandU64ToDouble discards up to 10 bits. (63-53). + EXPECT_EQ(ToDouble(0x4000000000000000), 0.5); + EXPECT_EQ(ToDouble(0x4000000000000001), 0.5); + EXPECT_EQ(ToDouble(0x40000000000003FF), 0.5); + + EXPECT_EQ(ToDouble(0xC000000000000000), -0.5); + EXPECT_EQ(ToDouble(0xC000000000000001), -0.5); + EXPECT_EQ(ToDouble(0xC0000000000003FF), -0.5); + + EXPECT_EQ(ToDouble(0x7FFFFFFFFFFFFFFe), 0.999999999999999888978); + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFe), -0.999999999999999888978); + + EXPECT_NE(ToDouble(0x7FFFFFFFFFFFF800), ToDouble(0x7FFFFFFFFFFFF7FF)); + + EXPECT_LT(ToDouble(0x7FFFFFFFFFFFFFFF), 1.0); + EXPECT_GT(ToDouble(0x7FFFFFFFFFFFFFFF), 0.9999999999); + + EXPECT_GT(ToDouble(0xFFFFFFFFFFFFFFFe), -1.0); + EXPECT_LT(ToDouble(0xFFFFFFFFFFFFFFFe), -0.999999999); + + EXPECT_EQ(ToDouble(0xFFFFFFFFFFFFFFFe), ToDouble(0xFFFFFFFFFFFFFC00)); + EXPECT_EQ(ToDouble(0x7FFFFFFFFFFFFFFF), ToDouble(0x7FFFFFFFFFFFFC00)); + EXPECT_NE(ToDouble(0xFFFFFFFFFFFFFFFe), ToDouble(0xFFFFFFFFFFFFF3FF)); + EXPECT_NE(ToDouble(0x7FFFFFFFFFFFFFFF), ToDouble(0x7FFFFFFFFFFFF3FF)); + + EXPECT_EQ(ToDouble(0x1000000000000001), 0.125); + EXPECT_EQ(ToDouble(0x2000000000000001), 0.25); + EXPECT_EQ(ToDouble(0x3000000000000001), 0.375); + EXPECT_EQ(ToDouble(0x4000000000000001), 0.5); + EXPECT_EQ(ToDouble(0x5000000000000001), 0.625); + EXPECT_EQ(ToDouble(0x6000000000000001), 0.75); + EXPECT_EQ(ToDouble(0x7000000000000001), 0.875); + EXPECT_EQ(ToDouble(0x7800000000000001), 0.9375); + EXPECT_EQ(ToDouble(0x7c00000000000001), 0.96875); + EXPECT_EQ(ToDouble(0x7e00000000000001), 0.984375); + EXPECT_EQ(ToDouble(0x7f00000000000001), 0.9921875); + + // 0x8000000000000000 ~= 0 + EXPECT_EQ(ToDouble(0x9000000000000001), -0.125); + EXPECT_EQ(ToDouble(0xa000000000000001), -0.25); + EXPECT_EQ(ToDouble(0xb000000000000001), -0.375); + EXPECT_EQ(ToDouble(0xc000000000000001), -0.5); + EXPECT_EQ(ToDouble(0xd000000000000001), -0.625); + EXPECT_EQ(ToDouble(0xe000000000000001), -0.75); + EXPECT_EQ(ToDouble(0xf000000000000001), -0.875); + + // Large powers of 2. + int64_t two_to_53 = int64_t{1} << 53; + EXPECT_EQ(static_cast<int64_t>(ToDouble(0x7FFFFFFFFFFFFFFF) * two_to_53), + two_to_53 - 1); + EXPECT_EQ(static_cast<int64_t>(ToDouble(0xFFFFFFFFFFFFFFFF) * two_to_53), + -(two_to_53 - 1)); + + EXPECT_NE(static_cast<int64_t>(ToDouble(0x7FFFFFFFFFFFFFFF) * two_to_53 * 2), + two_to_53 * 2 - 1); + + // For values where every bit counts, the values scale as multiples of the + // input. + for (int i = 1; i < 100; ++i) { + EXPECT_EQ(i * e_plus, ToDouble(i)) << i; + EXPECT_EQ(i * e_minus, ToDouble(0x8000000000000000 | i)) << i; + } +} + +TEST(GenerateRealTest, ExhaustiveFloat) { + using absl::base_internal::CountLeadingZeros64; + auto ToFloat = [](uint64_t a) { + return GenerateRealFromBits<float, GeneratePositiveTag, true>(a); + }; + + // Rely on RandU64ToFloat generating values from greatest to least when + // supplied with uint64_t values from greatest (0xfff...) to least (0x0). Thus, + // this algorithm stores the previous value, and if the new value is at + // greater than or equal to the previous value, then there is a collision in + // the generation algorithm. + // + // Use the computation below to convert the random value into a result: + // double res = a() * (1.0f - sample) + b() * sample; + float last_f = 1.0, last_g = 2.0; + uint64_t f_collisions = 0, g_collisions = 0; + uint64_t f_unique = 0, g_unique = 0; + uint64_t total = 0; + auto count = [&](const float r) { + total++; + // `f` is mapped to the range [0, 1) (default) + const float f = 0.0f * (1.0f - r) + 1.0f * r; + if (f >= last_f) { + f_collisions++; + } else { + f_unique++; + last_f = f; + } + // `g` is mapped to the range [1, 2) + const float g = 1.0f * (1.0f - r) + 2.0f * r; + if (g >= last_g) { + g_collisions++; + } else { + g_unique++; + last_g = g; + } + }; + + size_t limit = absl::GetFlag(FLAGS_absl_random_test_trials); + + // Generate all uint64_t which have unique floating point values. + // Counting down from 0xFFFFFFFFFFFFFFFFu ... 0x0u + uint64_t x = ~uint64_t(0); + for (; x != 0 && limit > 0;) { + constexpr int kDig = (64 - FLT_MANT_DIG); + // Set a decrement value & the next point at which to change + // the decrement value. By default these are 1, 0. + uint64_t dec = 1; + uint64_t chk = 0; + + // Adjust decrement and check value based on how many leading 0 + // bits are set in the current value. + const int clz = CountLeadingZeros64(x); + if (clz < kDig) { + dec <<= (kDig - clz); + chk = (~uint64_t(0)) >> (clz + 1); + } + for (; x > chk && limit > 0; x -= dec) { + count(ToFloat(x)); + --limit; + } + } + + static_assert(FLT_MANT_DIG == 24, + "The float type is expected to have a 24 bit mantissa."); + + if (limit != 0) { + // There are between 2^28 and 2^29 unique values in the range [0, 1). For + // the low values of x, there are 2^24 -1 unique values. Once x > 2^24, + // there are 40 * 2^24 unique values. Thus: + // (2 + 4 + 8 ... + 2^23) + 40 * 2^23 + EXPECT_LT(1 << 28, f_unique); + EXPECT_EQ((1 << 24) + 40 * (1 << 23) - 1, f_unique); + EXPECT_EQ(total, f_unique); + EXPECT_EQ(0, f_collisions); + + // Expect at least 2^23 unique values for the range [1, 2) + EXPECT_LE(1 << 23, g_unique); + EXPECT_EQ(total - g_unique, g_collisions); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/iostream_state_saver.h b/third_party/abseil_cpp/absl/random/internal/iostream_state_saver.h new file mode 100644 index 0000000000..e6e242ee1e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/iostream_state_saver.h @@ -0,0 +1,245 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_IOSTREAM_STATE_SAVER_H_ +#define ABSL_RANDOM_INTERNAL_IOSTREAM_STATE_SAVER_H_ + +#include <cmath> +#include <iostream> +#include <limits> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/numeric/int128.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// The null_state_saver does nothing. +template <typename T> +class null_state_saver { + public: + using stream_type = T; + using flags_type = std::ios_base::fmtflags; + + null_state_saver(T&, flags_type) {} + ~null_state_saver() {} +}; + +// ostream_state_saver is a RAII object to save and restore the common +// basic_ostream flags used when implementing `operator <<()` on any of +// the absl random distributions. +template <typename OStream> +class ostream_state_saver { + public: + using ostream_type = OStream; + using flags_type = std::ios_base::fmtflags; + using fill_type = typename ostream_type::char_type; + using precision_type = std::streamsize; + + ostream_state_saver(ostream_type& os, // NOLINT(runtime/references) + flags_type flags, fill_type fill) + : os_(os), + flags_(os.flags(flags)), + fill_(os.fill(fill)), + precision_(os.precision()) { + // Save state in initialized variables. + } + + ~ostream_state_saver() { + // Restore saved state. + os_.precision(precision_); + os_.fill(fill_); + os_.flags(flags_); + } + + private: + ostream_type& os_; + const flags_type flags_; + const fill_type fill_; + const precision_type precision_; +}; + +#if defined(__NDK_MAJOR__) && __NDK_MAJOR__ < 16 +#define ABSL_RANDOM_INTERNAL_IOSTREAM_HEXFLOAT 1 +#else +#define ABSL_RANDOM_INTERNAL_IOSTREAM_HEXFLOAT 0 +#endif + +template <typename CharT, typename Traits> +ostream_state_saver<std::basic_ostream<CharT, Traits>> make_ostream_state_saver( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + std::ios_base::fmtflags flags = std::ios_base::dec | std::ios_base::left | +#if ABSL_RANDOM_INTERNAL_IOSTREAM_HEXFLOAT + std::ios_base::fixed | +#endif + std::ios_base::scientific) { + using result_type = ostream_state_saver<std::basic_ostream<CharT, Traits>>; + return result_type(os, flags, os.widen(' ')); +} + +template <typename T> +typename absl::enable_if_t<!std::is_base_of<std::ios_base, T>::value, + null_state_saver<T>> +make_ostream_state_saver(T& is, // NOLINT(runtime/references) + std::ios_base::fmtflags flags = std::ios_base::dec) { + std::cerr << "null_state_saver"; + using result_type = null_state_saver<T>; + return result_type(is, flags); +} + +// stream_precision_helper<type>::kPrecision returns the base 10 precision +// required to stream and reconstruct a real type exact binary value through +// a binary->decimal->binary transition. +template <typename T> +struct stream_precision_helper { + // max_digits10 may be 0 on MSVC; if so, use digits10 + 3. + static constexpr int kPrecision = + (std::numeric_limits<T>::max_digits10 > std::numeric_limits<T>::digits10) + ? std::numeric_limits<T>::max_digits10 + : (std::numeric_limits<T>::digits10 + 3); +}; + +template <> +struct stream_precision_helper<float> { + static constexpr int kPrecision = 9; +}; +template <> +struct stream_precision_helper<double> { + static constexpr int kPrecision = 17; +}; +template <> +struct stream_precision_helper<long double> { + static constexpr int kPrecision = 36; // assuming fp128 +}; + +// istream_state_saver is a RAII object to save and restore the common +// std::basic_istream<> flags used when implementing `operator >>()` on any of +// the absl random distributions. +template <typename IStream> +class istream_state_saver { + public: + using istream_type = IStream; + using flags_type = std::ios_base::fmtflags; + + istream_state_saver(istream_type& is, // NOLINT(runtime/references) + flags_type flags) + : is_(is), flags_(is.flags(flags)) {} + + ~istream_state_saver() { is_.flags(flags_); } + + private: + istream_type& is_; + flags_type flags_; +}; + +template <typename CharT, typename Traits> +istream_state_saver<std::basic_istream<CharT, Traits>> make_istream_state_saver( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + std::ios_base::fmtflags flags = std::ios_base::dec | + std::ios_base::scientific | + std::ios_base::skipws) { + using result_type = istream_state_saver<std::basic_istream<CharT, Traits>>; + return result_type(is, flags); +} + +template <typename T> +typename absl::enable_if_t<!std::is_base_of<std::ios_base, T>::value, + null_state_saver<T>> +make_istream_state_saver(T& is, // NOLINT(runtime/references) + std::ios_base::fmtflags flags = std::ios_base::dec) { + using result_type = null_state_saver<T>; + return result_type(is, flags); +} + +// stream_format_type<T> is a helper struct to convert types which +// basic_iostream cannot output as decimal numbers into types which +// basic_iostream can output as decimal numbers. Specifically: +// * signed/unsigned char-width types are converted to int. +// * TODO(lar): __int128 => uint128, except there is no operator << yet. +// +template <typename T> +struct stream_format_type + : public std::conditional<(sizeof(T) == sizeof(char)), int, T> {}; + +// stream_u128_helper allows us to write out either absl::uint128 or +// __uint128_t types in the same way, which enables their use as internal +// state of PRNG engines. +template <typename T> +struct stream_u128_helper; + +template <> +struct stream_u128_helper<absl::uint128> { + template <typename IStream> + inline absl::uint128 read(IStream& in) { + uint64_t h = 0; + uint64_t l = 0; + in >> h >> l; + return absl::MakeUint128(h, l); + } + + template <typename OStream> + inline void write(absl::uint128 val, OStream& out) { + uint64_t h = absl::Uint128High64(val); + uint64_t l = absl::Uint128Low64(val); + out << h << out.fill() << l; + } +}; + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +template <> +struct stream_u128_helper<__uint128_t> { + template <typename IStream> + inline __uint128_t read(IStream& in) { + uint64_t h = 0; + uint64_t l = 0; + in >> h >> l; + return (static_cast<__uint128_t>(h) << 64) | l; + } + + template <typename OStream> + inline void write(__uint128_t val, OStream& out) { + uint64_t h = static_cast<uint64_t>(val >> 64u); + uint64_t l = static_cast<uint64_t>(val); + out << h << out.fill() << l; + } +}; +#endif + +template <typename FloatType, typename IStream> +inline FloatType read_floating_point(IStream& is) { + static_assert(std::is_floating_point<FloatType>::value, ""); + FloatType dest; + is >> dest; + // Parsing a double value may report a subnormal value as an error + // despite being able to represent it. + // See https://stackoverflow.com/q/52410931/3286653 + // It may also report an underflow when parsing DOUBLE_MIN as an + // ERANGE error, as the parsed value may be smaller than DOUBLE_MIN + // and rounded up. + // See: https://stackoverflow.com/q/42005462 + if (is.fail() && + (std::fabs(dest) == (std::numeric_limits<FloatType>::min)() || + std::fpclassify(dest) == FP_SUBNORMAL)) { + is.clear(is.rdstate() & (~std::ios_base::failbit)); + } + return dest; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_IOSTREAM_STATE_SAVER_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/iostream_state_saver_test.cc b/third_party/abseil_cpp/absl/random/internal/iostream_state_saver_test.cc new file mode 100644 index 0000000000..7bb8ad959c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/iostream_state_saver_test.cc @@ -0,0 +1,371 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/iostream_state_saver.h" + +#include <sstream> +#include <string> + +#include "gtest/gtest.h" + +namespace { + +using absl::random_internal::make_istream_state_saver; +using absl::random_internal::make_ostream_state_saver; +using absl::random_internal::stream_precision_helper; + +template <typename T> +typename absl::enable_if_t<std::is_integral<T>::value, T> // +StreamRoundTrip(T t) { + std::stringstream ss; + { + auto saver = make_ostream_state_saver(ss); + ss.precision(stream_precision_helper<T>::kPrecision); + ss << t; + } + T result = 0; + { + auto saver = make_istream_state_saver(ss); + ss >> result; + } + EXPECT_FALSE(ss.fail()) // + << ss.str() << " " // + << (ss.good() ? "good " : "") // + << (ss.bad() ? "bad " : "") // + << (ss.eof() ? "eof " : "") // + << (ss.fail() ? "fail " : ""); + + return result; +} + +template <typename T> +typename absl::enable_if_t<std::is_floating_point<T>::value, T> // +StreamRoundTrip(T t) { + std::stringstream ss; + { + auto saver = make_ostream_state_saver(ss); + ss.precision(stream_precision_helper<T>::kPrecision); + ss << t; + } + T result = 0; + { + auto saver = make_istream_state_saver(ss); + result = absl::random_internal::read_floating_point<T>(ss); + } + EXPECT_FALSE(ss.fail()) // + << ss.str() << " " // + << (ss.good() ? "good " : "") // + << (ss.bad() ? "bad " : "") // + << (ss.eof() ? "eof " : "") // + << (ss.fail() ? "fail " : ""); + + return result; +} + +TEST(IOStreamStateSaver, BasicSaverState) { + std::stringstream ss; + ss.precision(2); + ss.fill('x'); + ss.flags(std::ios_base::dec | std::ios_base::right); + + { + auto saver = make_ostream_state_saver(ss); + ss.precision(10); + EXPECT_NE('x', ss.fill()); + EXPECT_EQ(10, ss.precision()); + EXPECT_NE(std::ios_base::dec | std::ios_base::right, ss.flags()); + + ss << 1.23; + } + + EXPECT_EQ('x', ss.fill()); + EXPECT_EQ(2, ss.precision()); + EXPECT_EQ(std::ios_base::dec | std::ios_base::right, ss.flags()); +} + +TEST(IOStreamStateSaver, RoundTripInts) { + const uint64_t kUintValues[] = { + 0, + 1, + static_cast<uint64_t>(-1), + 2, + static_cast<uint64_t>(-2), + + 1 << 7, + 1 << 8, + 1 << 16, + 1ull << 32, + 1ull << 50, + 1ull << 62, + 1ull << 63, + + (1 << 7) - 1, + (1 << 8) - 1, + (1 << 16) - 1, + (1ull << 32) - 1, + (1ull << 50) - 1, + (1ull << 62) - 1, + (1ull << 63) - 1, + + static_cast<uint64_t>(-(1 << 8)), + static_cast<uint64_t>(-(1 << 16)), + static_cast<uint64_t>(-(1ll << 32)), + static_cast<uint64_t>(-(1ll << 50)), + static_cast<uint64_t>(-(1ll << 62)), + + static_cast<uint64_t>(-(1 << 8) - 1), + static_cast<uint64_t>(-(1 << 16) - 1), + static_cast<uint64_t>(-(1ll << 32) - 1), + static_cast<uint64_t>(-(1ll << 50) - 1), + static_cast<uint64_t>(-(1ll << 62) - 1), + }; + + for (const uint64_t u : kUintValues) { + EXPECT_EQ(u, StreamRoundTrip<uint64_t>(u)); + + int64_t x = static_cast<int64_t>(u); + EXPECT_EQ(x, StreamRoundTrip<int64_t>(x)); + + double d = static_cast<double>(x); + EXPECT_EQ(d, StreamRoundTrip<double>(d)); + + float f = d; + EXPECT_EQ(f, StreamRoundTrip<float>(f)); + } +} + +TEST(IOStreamStateSaver, RoundTripFloats) { + static_assert( + stream_precision_helper<float>::kPrecision >= 9, + "stream_precision_helper<float>::kPrecision should be at least 9"); + + const float kValues[] = { + 1, + std::nextafter(1.0f, 0.0f), // 1 - epsilon + std::nextafter(1.0f, 2.0f), // 1 + epsilon + + 1.0e+1f, + 1.0e-1f, + 1.0e+2f, + 1.0e-2f, + 1.0e+10f, + 1.0e-10f, + + 0.00000051110000111311111111f, + -0.00000051110000111211111111f, + + 1.234678912345678912345e+6f, + 1.234678912345678912345e-6f, + 1.234678912345678912345e+30f, + 1.234678912345678912345e-30f, + 1.234678912345678912345e+38f, + 1.0234678912345678912345e-38f, + + // Boundary cases. + std::numeric_limits<float>::max(), + std::numeric_limits<float>::lowest(), + std::numeric_limits<float>::epsilon(), + std::nextafter(std::numeric_limits<float>::min(), + 1.0f), // min + epsilon + std::numeric_limits<float>::min(), // smallest normal + // There are some errors dealing with denorms on apple platforms. + std::numeric_limits<float>::denorm_min(), // smallest denorm + std::numeric_limits<float>::min() / 2, + std::nextafter(std::numeric_limits<float>::min(), + 0.0f), // denorm_max + std::nextafter(std::numeric_limits<float>::denorm_min(), 1.0f), + }; + + for (const float f : kValues) { + EXPECT_EQ(f, StreamRoundTrip<float>(f)); + EXPECT_EQ(-f, StreamRoundTrip<float>(-f)); + + double d = f; + EXPECT_EQ(d, StreamRoundTrip<double>(d)); + EXPECT_EQ(-d, StreamRoundTrip<double>(-d)); + + // Avoid undefined behavior (overflow/underflow). + if (f <= static_cast<float>(std::numeric_limits<int64_t>::max()) && + f >= static_cast<float>(std::numeric_limits<int64_t>::lowest())) { + int64_t x = static_cast<int64_t>(f); + EXPECT_EQ(x, StreamRoundTrip<int64_t>(x)); + } + } +} + +TEST(IOStreamStateSaver, RoundTripDoubles) { + static_assert( + stream_precision_helper<double>::kPrecision >= 17, + "stream_precision_helper<double>::kPrecision should be at least 17"); + + const double kValues[] = { + 1, + std::nextafter(1.0, 0.0), // 1 - epsilon + std::nextafter(1.0, 2.0), // 1 + epsilon + + 1.0e+1, + 1.0e-1, + 1.0e+2, + 1.0e-2, + 1.0e+10, + 1.0e-10, + + 0.00000051110000111311111111, + -0.00000051110000111211111111, + + 1.234678912345678912345e+6, + 1.234678912345678912345e-6, + 1.234678912345678912345e+30, + 1.234678912345678912345e-30, + 1.234678912345678912345e+38, + 1.0234678912345678912345e-38, + + 1.0e+100, + 1.0e-100, + 1.234678912345678912345e+308, + 1.0234678912345678912345e-308, + 2.22507385850720138e-308, + + // Boundary cases. + std::numeric_limits<double>::max(), + std::numeric_limits<double>::lowest(), + std::numeric_limits<double>::epsilon(), + std::nextafter(std::numeric_limits<double>::min(), + 1.0), // min + epsilon + std::numeric_limits<double>::min(), // smallest normal + // There are some errors dealing with denorms on apple platforms. + std::numeric_limits<double>::denorm_min(), // smallest denorm + std::numeric_limits<double>::min() / 2, + std::nextafter(std::numeric_limits<double>::min(), + 0.0), // denorm_max + std::nextafter(std::numeric_limits<double>::denorm_min(), 1.0f), + }; + + for (const double d : kValues) { + EXPECT_EQ(d, StreamRoundTrip<double>(d)); + EXPECT_EQ(-d, StreamRoundTrip<double>(-d)); + + // Avoid undefined behavior (overflow/underflow). + if (d <= std::numeric_limits<float>::max() && + d >= std::numeric_limits<float>::lowest()) { + float f = static_cast<float>(d); + EXPECT_EQ(f, StreamRoundTrip<float>(f)); + } + + // Avoid undefined behavior (overflow/underflow). + if (d <= static_cast<double>(std::numeric_limits<int64_t>::max()) && + d >= static_cast<double>(std::numeric_limits<int64_t>::lowest())) { + int64_t x = static_cast<int64_t>(d); + EXPECT_EQ(x, StreamRoundTrip<int64_t>(x)); + } + } +} + +#if !defined(__EMSCRIPTEN__) +TEST(IOStreamStateSaver, RoundTripLongDoubles) { + // Technically, C++ only guarantees that long double is at least as large as a + // double. Practically it varies from 64-bits to 128-bits. + // + // So it is best to consider long double a best-effort extended precision + // type. + + static_assert( + stream_precision_helper<long double>::kPrecision >= 36, + "stream_precision_helper<long double>::kPrecision should be at least 36"); + + using real_type = long double; + const real_type kValues[] = { + 1, + std::nextafter(1.0, 0.0), // 1 - epsilon + std::nextafter(1.0, 2.0), // 1 + epsilon + + 1.0e+1, + 1.0e-1, + 1.0e+2, + 1.0e-2, + 1.0e+10, + 1.0e-10, + + 0.00000051110000111311111111, + -0.00000051110000111211111111, + + 1.2346789123456789123456789123456789e+6, + 1.2346789123456789123456789123456789e-6, + 1.2346789123456789123456789123456789e+30, + 1.2346789123456789123456789123456789e-30, + 1.2346789123456789123456789123456789e+38, + 1.2346789123456789123456789123456789e-38, + 1.2346789123456789123456789123456789e+308, + 1.2346789123456789123456789123456789e-308, + + 1.0e+100, + 1.0e-100, + 1.234678912345678912345e+308, + 1.0234678912345678912345e-308, + + // Boundary cases. + std::numeric_limits<real_type>::max(), + std::numeric_limits<real_type>::lowest(), + std::numeric_limits<real_type>::epsilon(), + std::nextafter(std::numeric_limits<real_type>::min(), + real_type(1)), // min + epsilon + std::numeric_limits<real_type>::min(), // smallest normal + // There are some errors dealing with denorms on apple platforms. + std::numeric_limits<real_type>::denorm_min(), // smallest denorm + std::numeric_limits<real_type>::min() / 2, + std::nextafter(std::numeric_limits<real_type>::min(), + 0.0), // denorm_max + std::nextafter(std::numeric_limits<real_type>::denorm_min(), 1.0f), + }; + + int index = -1; + for (const long double dd : kValues) { + index++; + EXPECT_EQ(dd, StreamRoundTrip<real_type>(dd)) << index; + EXPECT_EQ(-dd, StreamRoundTrip<real_type>(-dd)) << index; + + // Avoid undefined behavior (overflow/underflow). + if (dd <= std::numeric_limits<double>::max() && + dd >= std::numeric_limits<double>::lowest()) { + double d = static_cast<double>(dd); + EXPECT_EQ(d, StreamRoundTrip<double>(d)); + } + + // Avoid undefined behavior (overflow/underflow). + if (dd <= std::numeric_limits<int64_t>::max() && + dd >= std::numeric_limits<int64_t>::lowest()) { + int64_t x = static_cast<int64_t>(dd); + EXPECT_EQ(x, StreamRoundTrip<int64_t>(x)); + } + } +} +#endif // !defined(__EMSCRIPTEN__) + +TEST(StrToDTest, DoubleMin) { + const char kV[] = "2.22507385850720138e-308"; + char* end; + double x = std::strtod(kV, &end); + EXPECT_EQ(std::numeric_limits<double>::min(), x); + // errno may equal ERANGE. +} + +TEST(StrToDTest, DoubleDenormMin) { + const char kV[] = "4.94065645841246544e-324"; + char* end; + double x = std::strtod(kV, &end); + EXPECT_EQ(std::numeric_limits<double>::denorm_min(), x); + // errno may equal ERANGE. +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/mock_overload_set.h b/third_party/abseil_cpp/absl/random/internal/mock_overload_set.h new file mode 100644 index 0000000000..c2a30d89d5 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/mock_overload_set.h @@ -0,0 +1,91 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_MOCK_OVERLOAD_SET_H_ +#define ABSL_RANDOM_INTERNAL_MOCK_OVERLOAD_SET_H_ + +#include <type_traits> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/random/mocking_bit_gen.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +template <typename DistrT, typename Fn> +struct MockSingleOverload; + +// MockSingleOverload +// +// MockSingleOverload hooks in to gMock's `ON_CALL` and `EXPECT_CALL` macros. +// EXPECT_CALL(mock_single_overload, Call(...))` will expand to a call to +// `mock_single_overload.gmock_Call(...)`. Because expectations are stored on +// the MockingBitGen (an argument passed inside `Call(...)`), this forwards to +// arguments to Mocking::Register. +template <typename DistrT, typename Ret, typename... Args> +struct MockSingleOverload<DistrT, Ret(MockingBitGen&, Args...)> { + static_assert(std::is_same<typename DistrT::result_type, Ret>::value, + "Overload signature must have return type matching the " + "distributions result type."); + auto gmock_Call( + absl::MockingBitGen& gen, // NOLINT(google-runtime-references) + const ::testing::Matcher<Args>&... args) + -> decltype(gen.Register<DistrT, Args...>(args...)) { + return gen.Register<DistrT, Args...>(args...); + } +}; + +template <typename DistrT, typename Ret, typename Arg, typename... Args> +struct MockSingleOverload<DistrT, Ret(Arg, MockingBitGen&, Args...)> { + static_assert(std::is_same<typename DistrT::result_type, Ret>::value, + "Overload signature must have return type matching the " + "distributions result type."); + auto gmock_Call( + const ::testing::Matcher<Arg>& arg, + absl::MockingBitGen& gen, // NOLINT(google-runtime-references) + const ::testing::Matcher<Args>&... args) + -> decltype(gen.Register<DistrT, Arg, Args...>(arg, args...)) { + return gen.Register<DistrT, Arg, Args...>(arg, args...); + } +}; + +// MockOverloadSet +// +// MockOverloadSet takes a distribution and a collection of signatures and +// performs overload resolution amongst all the overloads. This makes +// `EXPECT_CALL(mock_overload_set, Call(...))` expand and do overload resolution +// correctly. +template <typename DistrT, typename... Signatures> +struct MockOverloadSet; + +template <typename DistrT, typename Sig> +struct MockOverloadSet<DistrT, Sig> : public MockSingleOverload<DistrT, Sig> { + using MockSingleOverload<DistrT, Sig>::gmock_Call; +}; + +template <typename DistrT, typename FirstSig, typename... Rest> +struct MockOverloadSet<DistrT, FirstSig, Rest...> + : public MockSingleOverload<DistrT, FirstSig>, + public MockOverloadSet<DistrT, Rest...> { + using MockSingleOverload<DistrT, FirstSig>::gmock_Call; + using MockOverloadSet<DistrT, Rest...>::gmock_Call; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_RANDOM_INTERNAL_MOCK_OVERLOAD_SET_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/mocking_bit_gen_base.h b/third_party/abseil_cpp/absl/random/internal/mocking_bit_gen_base.h new file mode 100644 index 0000000000..23ecaf6c7e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/mocking_bit_gen_base.h @@ -0,0 +1,85 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#ifndef ABSL_RANDOM_INTERNAL_MOCKING_BIT_GEN_BASE_H_ +#define ABSL_RANDOM_INTERNAL_MOCKING_BIT_GEN_BASE_H_ + +#include <string> +#include <typeinfo> + +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +class MockingBitGenBase { + template <typename> + friend struct DistributionCaller; + using generator_type = absl::BitGen; + + public: + // URBG interface + using result_type = generator_type::result_type; + static constexpr result_type(min)() { return (generator_type::min)(); } + static constexpr result_type(max)() { return (generator_type::max)(); } + result_type operator()() { return gen_(); } + + virtual ~MockingBitGenBase() = default; + + protected: + // CallImpl is the type-erased virtual dispatch. + // The type of dist is always distribution<T>, + // The type of result is always distribution<T>::result_type. + virtual bool CallImpl(const std::type_info& distr_type, void* dist_args, + void* result) = 0; + + template <typename DistrT, typename ArgTupleT> + static const std::type_info& GetTypeId() { + return typeid(std::pair<absl::decay_t<DistrT>, absl::decay_t<ArgTupleT>>); + } + + // Call the generating distribution function. + // Invoked by DistributionCaller<>::Call<DistT>. + // DistT is the distribution type. + template <typename DistrT, typename... Args> + typename DistrT::result_type Call(Args&&... args) { + using distr_result_type = typename DistrT::result_type; + using ArgTupleT = std::tuple<absl::decay_t<Args>...>; + + ArgTupleT arg_tuple(std::forward<Args>(args)...); + auto dist = absl::make_from_tuple<DistrT>(arg_tuple); + + distr_result_type result{}; + bool found_match = + CallImpl(GetTypeId<DistrT, ArgTupleT>(), &arg_tuple, &result); + + if (!found_match) { + result = dist(gen_); + } + + return result; + } + + private: + generator_type gen_; +}; // namespace random_internal + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_MOCKING_BIT_GEN_BASE_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/nanobenchmark.cc b/third_party/abseil_cpp/absl/random/internal/nanobenchmark.cc new file mode 100644 index 0000000000..c9181813f7 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/nanobenchmark.cc @@ -0,0 +1,804 @@ +// Copyright 2017 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/nanobenchmark.h" + +#include <sys/types.h> + +#include <algorithm> // sort +#include <atomic> +#include <cstddef> +#include <cstdint> +#include <cstdlib> +#include <cstring> // memcpy +#include <limits> +#include <string> +#include <utility> +#include <vector> + +#include "absl/base/attributes.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/platform.h" +#include "absl/random/internal/randen_engine.h" + +// OS +#if defined(_WIN32) || defined(_WIN64) +#define ABSL_OS_WIN +#include <windows.h> // NOLINT + +#elif defined(__ANDROID__) +#define ABSL_OS_ANDROID + +#elif defined(__linux__) +#define ABSL_OS_LINUX +#include <sched.h> // NOLINT +#include <sys/syscall.h> // NOLINT +#endif + +#if defined(ABSL_ARCH_X86_64) && !defined(ABSL_OS_WIN) +#include <cpuid.h> // NOLINT +#endif + +// __ppc_get_timebase_freq +#if defined(ABSL_ARCH_PPC) +#include <sys/platform/ppc.h> // NOLINT +#endif + +// clock_gettime +#if defined(ABSL_ARCH_ARM) || defined(ABSL_ARCH_AARCH64) +#include <time.h> // NOLINT +#endif + +// ABSL_RANDOM_INTERNAL_ATTRIBUTE_NEVER_INLINE prevents inlining of the method. +#if ABSL_HAVE_ATTRIBUTE(noinline) || (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_RANDOM_INTERNAL_ATTRIBUTE_NEVER_INLINE __attribute__((noinline)) +#elif defined(_MSC_VER) +#define ABSL_RANDOM_INTERNAL_ATTRIBUTE_NEVER_INLINE __declspec(noinline) +#else +#define ABSL_RANDOM_INTERNAL_ATTRIBUTE_NEVER_INLINE +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal_nanobenchmark { +namespace { + +// For code folding. +namespace platform { +#if defined(ABSL_ARCH_X86_64) + +// TODO(janwas): Merge with the one in randen_hwaes.cc? +void Cpuid(const uint32_t level, const uint32_t count, + uint32_t* ABSL_RANDOM_INTERNAL_RESTRICT abcd) { +#if defined(ABSL_OS_WIN) + int regs[4]; + __cpuidex(regs, level, count); + for (int i = 0; i < 4; ++i) { + abcd[i] = regs[i]; + } +#else + uint32_t a, b, c, d; + __cpuid_count(level, count, a, b, c, d); + abcd[0] = a; + abcd[1] = b; + abcd[2] = c; + abcd[3] = d; +#endif +} + +std::string BrandString() { + char brand_string[49]; + uint32_t abcd[4]; + + // Check if brand string is supported (it is on all reasonable Intel/AMD) + Cpuid(0x80000000U, 0, abcd); + if (abcd[0] < 0x80000004U) { + return std::string(); + } + + for (int i = 0; i < 3; ++i) { + Cpuid(0x80000002U + i, 0, abcd); + memcpy(brand_string + i * 16, &abcd, sizeof(abcd)); + } + brand_string[48] = 0; + return brand_string; +} + +// Returns the frequency quoted inside the brand string. This does not +// account for throttling nor Turbo Boost. +double NominalClockRate() { + const std::string& brand_string = BrandString(); + // Brand strings include the maximum configured frequency. These prefixes are + // defined by Intel CPUID documentation. + const char* prefixes[3] = {"MHz", "GHz", "THz"}; + const double multipliers[3] = {1E6, 1E9, 1E12}; + for (size_t i = 0; i < 3; ++i) { + const size_t pos_prefix = brand_string.find(prefixes[i]); + if (pos_prefix != std::string::npos) { + const size_t pos_space = brand_string.rfind(' ', pos_prefix - 1); + if (pos_space != std::string::npos) { + const std::string digits = + brand_string.substr(pos_space + 1, pos_prefix - pos_space - 1); + return std::stod(digits) * multipliers[i]; + } + } + } + + return 0.0; +} + +#endif // ABSL_ARCH_X86_64 +} // namespace platform + +// Prevents the compiler from eliding the computations that led to "output". +template <class T> +inline void PreventElision(T&& output) { +#ifndef ABSL_OS_WIN + // Works by indicating to the compiler that "output" is being read and + // modified. The +r constraint avoids unnecessary writes to memory, but only + // works for built-in types (typically FuncOutput). + asm volatile("" : "+r"(output) : : "memory"); +#else + // MSVC does not support inline assembly anymore (and never supported GCC's + // RTL constraints). Self-assignment with #pragma optimize("off") might be + // expected to prevent elision, but it does not with MSVC 2015. Type-punning + // with volatile pointers generates inefficient code on MSVC 2017. + static std::atomic<T> dummy(T{}); + dummy.store(output, std::memory_order_relaxed); +#endif +} + +namespace timer { + +// Start/Stop return absolute timestamps and must be placed immediately before +// and after the region to measure. We provide separate Start/Stop functions +// because they use different fences. +// +// Background: RDTSC is not 'serializing'; earlier instructions may complete +// after it, and/or later instructions may complete before it. 'Fences' ensure +// regions' elapsed times are independent of such reordering. The only +// documented unprivileged serializing instruction is CPUID, which acts as a +// full fence (no reordering across it in either direction). Unfortunately +// the latency of CPUID varies wildly (perhaps made worse by not initializing +// its EAX input). Because it cannot reliably be deducted from the region's +// elapsed time, it must not be included in the region to measure (i.e. +// between the two RDTSC). +// +// The newer RDTSCP is sometimes described as serializing, but it actually +// only serves as a half-fence with release semantics. Although all +// instructions in the region will complete before the final timestamp is +// captured, subsequent instructions may leak into the region and increase the +// elapsed time. Inserting another fence after the final RDTSCP would prevent +// such reordering without affecting the measured region. +// +// Fortunately, such a fence exists. The LFENCE instruction is only documented +// to delay later loads until earlier loads are visible. However, Intel's +// reference manual says it acts as a full fence (waiting until all earlier +// instructions have completed, and delaying later instructions until it +// completes). AMD assigns the same behavior to MFENCE. +// +// We need a fence before the initial RDTSC to prevent earlier instructions +// from leaking into the region, and arguably another after RDTSC to avoid +// region instructions from completing before the timestamp is recorded. +// When surrounded by fences, the additional RDTSCP half-fence provides no +// benefit, so the initial timestamp can be recorded via RDTSC, which has +// lower overhead than RDTSCP because it does not read TSC_AUX. In summary, +// we define Start = LFENCE/RDTSC/LFENCE; Stop = RDTSCP/LFENCE. +// +// Using Start+Start leads to higher variance and overhead than Stop+Stop. +// However, Stop+Stop includes an LFENCE in the region measurements, which +// adds a delay dependent on earlier loads. The combination of Start+Stop +// is faster than Start+Start and more consistent than Stop+Stop because +// the first LFENCE already delayed subsequent loads before the measured +// region. This combination seems not to have been considered in prior work: +// http://akaros.cs.berkeley.edu/lxr/akaros/kern/arch/x86/rdtsc_test.c +// +// Note: performance counters can measure 'exact' instructions-retired or +// (unhalted) cycle counts. The RDPMC instruction is not serializing and also +// requires fences. Unfortunately, it is not accessible on all OSes and we +// prefer to avoid kernel-mode drivers. Performance counters are also affected +// by several under/over-count errata, so we use the TSC instead. + +// Returns a 64-bit timestamp in unit of 'ticks'; to convert to seconds, +// divide by InvariantTicksPerSecond. +inline uint64_t Start64() { + uint64_t t; +#if defined(ABSL_ARCH_PPC) + asm volatile("mfspr %0, %1" : "=r"(t) : "i"(268)); +#elif defined(ABSL_ARCH_X86_64) +#if defined(ABSL_OS_WIN) + _ReadWriteBarrier(); + _mm_lfence(); + _ReadWriteBarrier(); + t = __rdtsc(); + _ReadWriteBarrier(); + _mm_lfence(); + _ReadWriteBarrier(); +#else + asm volatile( + "lfence\n\t" + "rdtsc\n\t" + "shl $32, %%rdx\n\t" + "or %%rdx, %0\n\t" + "lfence" + : "=a"(t) + : + // "memory" avoids reordering. rdx = TSC >> 32. + // "cc" = flags modified by SHL. + : "rdx", "memory", "cc"); +#endif +#else + // Fall back to OS - unsure how to reliably query cntvct_el0 frequency. + timespec ts; + clock_gettime(CLOCK_REALTIME, &ts); + t = ts.tv_sec * 1000000000LL + ts.tv_nsec; +#endif + return t; +} + +inline uint64_t Stop64() { + uint64_t t; +#if defined(ABSL_ARCH_X86_64) +#if defined(ABSL_OS_WIN) + _ReadWriteBarrier(); + unsigned aux; + t = __rdtscp(&aux); + _ReadWriteBarrier(); + _mm_lfence(); + _ReadWriteBarrier(); +#else + // Use inline asm because __rdtscp generates code to store TSC_AUX (ecx). + asm volatile( + "rdtscp\n\t" + "shl $32, %%rdx\n\t" + "or %%rdx, %0\n\t" + "lfence" + : "=a"(t) + : + // "memory" avoids reordering. rcx = TSC_AUX. rdx = TSC >> 32. + // "cc" = flags modified by SHL. + : "rcx", "rdx", "memory", "cc"); +#endif +#else + t = Start64(); +#endif + return t; +} + +// Returns a 32-bit timestamp with about 4 cycles less overhead than +// Start64. Only suitable for measuring very short regions because the +// timestamp overflows about once a second. +inline uint32_t Start32() { + uint32_t t; +#if defined(ABSL_ARCH_X86_64) +#if defined(ABSL_OS_WIN) + _ReadWriteBarrier(); + _mm_lfence(); + _ReadWriteBarrier(); + t = static_cast<uint32_t>(__rdtsc()); + _ReadWriteBarrier(); + _mm_lfence(); + _ReadWriteBarrier(); +#else + asm volatile( + "lfence\n\t" + "rdtsc\n\t" + "lfence" + : "=a"(t) + : + // "memory" avoids reordering. rdx = TSC >> 32. + : "rdx", "memory"); +#endif +#else + t = static_cast<uint32_t>(Start64()); +#endif + return t; +} + +inline uint32_t Stop32() { + uint32_t t; +#if defined(ABSL_ARCH_X86_64) +#if defined(ABSL_OS_WIN) + _ReadWriteBarrier(); + unsigned aux; + t = static_cast<uint32_t>(__rdtscp(&aux)); + _ReadWriteBarrier(); + _mm_lfence(); + _ReadWriteBarrier(); +#else + // Use inline asm because __rdtscp generates code to store TSC_AUX (ecx). + asm volatile( + "rdtscp\n\t" + "lfence" + : "=a"(t) + : + // "memory" avoids reordering. rcx = TSC_AUX. rdx = TSC >> 32. + : "rcx", "rdx", "memory"); +#endif +#else + t = static_cast<uint32_t>(Stop64()); +#endif + return t; +} + +} // namespace timer + +namespace robust_statistics { + +// Sorts integral values in ascending order (e.g. for Mode). About 3x faster +// than std::sort for input distributions with very few unique values. +template <class T> +void CountingSort(T* values, size_t num_values) { + // Unique values and their frequency (similar to flat_map). + using Unique = std::pair<T, int>; + std::vector<Unique> unique; + for (size_t i = 0; i < num_values; ++i) { + const T value = values[i]; + const auto pos = + std::find_if(unique.begin(), unique.end(), + [value](const Unique u) { return u.first == value; }); + if (pos == unique.end()) { + unique.push_back(std::make_pair(value, 1)); + } else { + ++pos->second; + } + } + + // Sort in ascending order of value (pair.first). + std::sort(unique.begin(), unique.end()); + + // Write that many copies of each unique value to the array. + T* ABSL_RANDOM_INTERNAL_RESTRICT p = values; + for (const auto& value_count : unique) { + std::fill(p, p + value_count.second, value_count.first); + p += value_count.second; + } + ABSL_RAW_CHECK(p == values + num_values, "Did not produce enough output"); +} + +// @return i in [idx_begin, idx_begin + half_count) that minimizes +// sorted[i + half_count] - sorted[i]. +template <typename T> +size_t MinRange(const T* const ABSL_RANDOM_INTERNAL_RESTRICT sorted, + const size_t idx_begin, const size_t half_count) { + T min_range = (std::numeric_limits<T>::max)(); + size_t min_idx = 0; + + for (size_t idx = idx_begin; idx < idx_begin + half_count; ++idx) { + ABSL_RAW_CHECK(sorted[idx] <= sorted[idx + half_count], "Not sorted"); + const T range = sorted[idx + half_count] - sorted[idx]; + if (range < min_range) { + min_range = range; + min_idx = idx; + } + } + + return min_idx; +} + +// Returns an estimate of the mode by calling MinRange on successively +// halved intervals. "sorted" must be in ascending order. This is the +// Half Sample Mode estimator proposed by Bickel in "On a fast, robust +// estimator of the mode", with complexity O(N log N). The mode is less +// affected by outliers in highly-skewed distributions than the median. +// The averaging operation below assumes "T" is an unsigned integer type. +template <typename T> +T ModeOfSorted(const T* const ABSL_RANDOM_INTERNAL_RESTRICT sorted, + const size_t num_values) { + size_t idx_begin = 0; + size_t half_count = num_values / 2; + while (half_count > 1) { + idx_begin = MinRange(sorted, idx_begin, half_count); + half_count >>= 1; + } + + const T x = sorted[idx_begin + 0]; + if (half_count == 0) { + return x; + } + ABSL_RAW_CHECK(half_count == 1, "Should stop at half_count=1"); + const T average = (x + sorted[idx_begin + 1] + 1) / 2; + return average; +} + +// Returns the mode. Side effect: sorts "values". +template <typename T> +T Mode(T* values, const size_t num_values) { + CountingSort(values, num_values); + return ModeOfSorted(values, num_values); +} + +template <typename T, size_t N> +T Mode(T (&values)[N]) { + return Mode(&values[0], N); +} + +// Returns the median value. Side effect: sorts "values". +template <typename T> +T Median(T* values, const size_t num_values) { + ABSL_RAW_CHECK(num_values != 0, "Empty input"); + std::sort(values, values + num_values); + const size_t half = num_values / 2; + // Odd count: return middle + if (num_values % 2) { + return values[half]; + } + // Even count: return average of middle two. + return (values[half] + values[half - 1] + 1) / 2; +} + +// Returns a robust measure of variability. +template <typename T> +T MedianAbsoluteDeviation(const T* values, const size_t num_values, + const T median) { + ABSL_RAW_CHECK(num_values != 0, "Empty input"); + std::vector<T> abs_deviations; + abs_deviations.reserve(num_values); + for (size_t i = 0; i < num_values; ++i) { + const int64_t abs = std::abs(int64_t(values[i]) - int64_t(median)); + abs_deviations.push_back(static_cast<T>(abs)); + } + return Median(abs_deviations.data(), num_values); +} + +} // namespace robust_statistics + +// Ticks := platform-specific timer values (CPU cycles on x86). Must be +// unsigned to guarantee wraparound on overflow. 32 bit timers are faster to +// read than 64 bit. +using Ticks = uint32_t; + +// Returns timer overhead / minimum measurable difference. +Ticks TimerResolution() { + // Nested loop avoids exceeding stack/L1 capacity. + Ticks repetitions[Params::kTimerSamples]; + for (size_t rep = 0; rep < Params::kTimerSamples; ++rep) { + Ticks samples[Params::kTimerSamples]; + for (size_t i = 0; i < Params::kTimerSamples; ++i) { + const Ticks t0 = timer::Start32(); + const Ticks t1 = timer::Stop32(); + samples[i] = t1 - t0; + } + repetitions[rep] = robust_statistics::Mode(samples); + } + return robust_statistics::Mode(repetitions); +} + +static const Ticks timer_resolution = TimerResolution(); + +// Estimates the expected value of "lambda" values with a variable number of +// samples until the variability "rel_mad" is less than "max_rel_mad". +template <class Lambda> +Ticks SampleUntilStable(const double max_rel_mad, double* rel_mad, + const Params& p, const Lambda& lambda) { + auto measure_duration = [&lambda]() -> Ticks { + const Ticks t0 = timer::Start32(); + lambda(); + const Ticks t1 = timer::Stop32(); + return t1 - t0; + }; + + // Choose initial samples_per_eval based on a single estimated duration. + Ticks est = measure_duration(); + static const double ticks_per_second = InvariantTicksPerSecond(); + const size_t ticks_per_eval = ticks_per_second * p.seconds_per_eval; + size_t samples_per_eval = ticks_per_eval / est; + samples_per_eval = (std::max)(samples_per_eval, p.min_samples_per_eval); + + std::vector<Ticks> samples; + samples.reserve(1 + samples_per_eval); + samples.push_back(est); + + // Percentage is too strict for tiny differences, so also allow a small + // absolute "median absolute deviation". + const Ticks max_abs_mad = (timer_resolution + 99) / 100; + *rel_mad = 0.0; // ensure initialized + + for (size_t eval = 0; eval < p.max_evals; ++eval, samples_per_eval *= 2) { + samples.reserve(samples.size() + samples_per_eval); + for (size_t i = 0; i < samples_per_eval; ++i) { + const Ticks r = measure_duration(); + samples.push_back(r); + } + + if (samples.size() >= p.min_mode_samples) { + est = robust_statistics::Mode(samples.data(), samples.size()); + } else { + // For "few" (depends also on the variance) samples, Median is safer. + est = robust_statistics::Median(samples.data(), samples.size()); + } + ABSL_RAW_CHECK(est != 0, "Estimator returned zero duration"); + + // Median absolute deviation (mad) is a robust measure of 'variability'. + const Ticks abs_mad = robust_statistics::MedianAbsoluteDeviation( + samples.data(), samples.size(), est); + *rel_mad = static_cast<double>(static_cast<int>(abs_mad)) / est; + + if (*rel_mad <= max_rel_mad || abs_mad <= max_abs_mad) { + if (p.verbose) { + ABSL_RAW_LOG(INFO, + "%6zu samples => %5u (abs_mad=%4u, rel_mad=%4.2f%%)\n", + samples.size(), est, abs_mad, *rel_mad * 100.0); + } + return est; + } + } + + if (p.verbose) { + ABSL_RAW_LOG(WARNING, + "rel_mad=%4.2f%% still exceeds %4.2f%% after %6zu samples.\n", + *rel_mad * 100.0, max_rel_mad * 100.0, samples.size()); + } + return est; +} + +using InputVec = std::vector<FuncInput>; + +// Returns vector of unique input values. +InputVec UniqueInputs(const FuncInput* inputs, const size_t num_inputs) { + InputVec unique(inputs, inputs + num_inputs); + std::sort(unique.begin(), unique.end()); + unique.erase(std::unique(unique.begin(), unique.end()), unique.end()); + return unique; +} + +// Returns how often we need to call func for sufficient precision, or zero +// on failure (e.g. the elapsed time is too long for a 32-bit tick count). +size_t NumSkip(const Func func, const void* arg, const InputVec& unique, + const Params& p) { + // Min elapsed ticks for any input. + Ticks min_duration = ~0u; + + for (const FuncInput input : unique) { + // Make sure a 32-bit timer is sufficient. + const uint64_t t0 = timer::Start64(); + PreventElision(func(arg, input)); + const uint64_t t1 = timer::Stop64(); + const uint64_t elapsed = t1 - t0; + if (elapsed >= (1ULL << 30)) { + ABSL_RAW_LOG(WARNING, + "Measurement failed: need 64-bit timer for input=%zu\n", + static_cast<size_t>(input)); + return 0; + } + + double rel_mad; + const Ticks total = SampleUntilStable( + p.target_rel_mad, &rel_mad, p, + [func, arg, input]() { PreventElision(func(arg, input)); }); + min_duration = (std::min)(min_duration, total - timer_resolution); + } + + // Number of repetitions required to reach the target resolution. + const size_t max_skip = p.precision_divisor; + // Number of repetitions given the estimated duration. + const size_t num_skip = + min_duration == 0 ? 0 : (max_skip + min_duration - 1) / min_duration; + if (p.verbose) { + ABSL_RAW_LOG(INFO, "res=%u max_skip=%zu min_dur=%u num_skip=%zu\n", + timer_resolution, max_skip, min_duration, num_skip); + } + return num_skip; +} + +// Replicates inputs until we can omit "num_skip" occurrences of an input. +InputVec ReplicateInputs(const FuncInput* inputs, const size_t num_inputs, + const size_t num_unique, const size_t num_skip, + const Params& p) { + InputVec full; + if (num_unique == 1) { + full.assign(p.subset_ratio * num_skip, inputs[0]); + return full; + } + + full.reserve(p.subset_ratio * num_skip * num_inputs); + for (size_t i = 0; i < p.subset_ratio * num_skip; ++i) { + full.insert(full.end(), inputs, inputs + num_inputs); + } + absl::random_internal::randen_engine<uint32_t> rng; + std::shuffle(full.begin(), full.end(), rng); + return full; +} + +// Copies the "full" to "subset" in the same order, but with "num_skip" +// randomly selected occurrences of "input_to_skip" removed. +void FillSubset(const InputVec& full, const FuncInput input_to_skip, + const size_t num_skip, InputVec* subset) { + const size_t count = std::count(full.begin(), full.end(), input_to_skip); + // Generate num_skip random indices: which occurrence to skip. + std::vector<uint32_t> omit; + // Replacement for std::iota, not yet available in MSVC builds. + omit.reserve(count); + for (size_t i = 0; i < count; ++i) { + omit.push_back(i); + } + // omit[] is the same on every call, but that's OK because they identify the + // Nth instance of input_to_skip, so the position within full[] differs. + absl::random_internal::randen_engine<uint32_t> rng; + std::shuffle(omit.begin(), omit.end(), rng); + omit.resize(num_skip); + std::sort(omit.begin(), omit.end()); + + uint32_t occurrence = ~0u; // 0 after preincrement + size_t idx_omit = 0; // cursor within omit[] + size_t idx_subset = 0; // cursor within *subset + for (const FuncInput next : full) { + if (next == input_to_skip) { + ++occurrence; + // Haven't removed enough already + if (idx_omit < num_skip) { + // This one is up for removal + if (occurrence == omit[idx_omit]) { + ++idx_omit; + continue; + } + } + } + if (idx_subset < subset->size()) { + (*subset)[idx_subset++] = next; + } + } + ABSL_RAW_CHECK(idx_subset == subset->size(), "idx_subset not at end"); + ABSL_RAW_CHECK(idx_omit == omit.size(), "idx_omit not at end"); + ABSL_RAW_CHECK(occurrence == count - 1, "occurrence not at end"); +} + +// Returns total ticks elapsed for all inputs. +Ticks TotalDuration(const Func func, const void* arg, const InputVec* inputs, + const Params& p, double* max_rel_mad) { + double rel_mad; + const Ticks duration = + SampleUntilStable(p.target_rel_mad, &rel_mad, p, [func, arg, inputs]() { + for (const FuncInput input : *inputs) { + PreventElision(func(arg, input)); + } + }); + *max_rel_mad = (std::max)(*max_rel_mad, rel_mad); + return duration; +} + +// (Nearly) empty Func for measuring timer overhead/resolution. +ABSL_RANDOM_INTERNAL_ATTRIBUTE_NEVER_INLINE FuncOutput +EmptyFunc(const void* arg, const FuncInput input) { + return input; +} + +// Returns overhead of accessing inputs[] and calling a function; this will +// be deducted from future TotalDuration return values. +Ticks Overhead(const void* arg, const InputVec* inputs, const Params& p) { + double rel_mad; + // Zero tolerance because repeatability is crucial and EmptyFunc is fast. + return SampleUntilStable(0.0, &rel_mad, p, [arg, inputs]() { + for (const FuncInput input : *inputs) { + PreventElision(EmptyFunc(arg, input)); + } + }); +} + +} // namespace + +void PinThreadToCPU(int cpu) { + // We might migrate to another CPU before pinning below, but at least cpu + // will be one of the CPUs on which this thread ran. +#if defined(ABSL_OS_WIN) + if (cpu < 0) { + cpu = static_cast<int>(GetCurrentProcessorNumber()); + ABSL_RAW_CHECK(cpu >= 0, "PinThreadToCPU detect failed"); + if (cpu >= 64) { + // NOTE: On wine, at least, GetCurrentProcessorNumber() sometimes returns + // a value > 64, which is out of range. When this happens, log a message + // and don't set a cpu affinity. + ABSL_RAW_LOG(ERROR, "Invalid CPU number: %d", cpu); + return; + } + } else if (cpu >= 64) { + // User specified an explicit CPU affinity > the valid range. + ABSL_RAW_LOG(FATAL, "Invalid CPU number: %d", cpu); + } + const DWORD_PTR prev = SetThreadAffinityMask(GetCurrentThread(), 1ULL << cpu); + ABSL_RAW_CHECK(prev != 0, "SetAffinity failed"); +#elif defined(ABSL_OS_LINUX) && !defined(ABSL_OS_ANDROID) + if (cpu < 0) { + cpu = sched_getcpu(); + ABSL_RAW_CHECK(cpu >= 0, "PinThreadToCPU detect failed"); + } + const pid_t pid = 0; // current thread + cpu_set_t set; + CPU_ZERO(&set); + CPU_SET(cpu, &set); + const int err = sched_setaffinity(pid, sizeof(set), &set); + ABSL_RAW_CHECK(err == 0, "SetAffinity failed"); +#endif +} + +// Returns tick rate. Invariant means the tick counter frequency is independent +// of CPU throttling or sleep. May be expensive, caller should cache the result. +double InvariantTicksPerSecond() { +#if defined(ABSL_ARCH_PPC) + return __ppc_get_timebase_freq(); +#elif defined(ABSL_ARCH_X86_64) + // We assume the TSC is invariant; it is on all recent Intel/AMD CPUs. + return platform::NominalClockRate(); +#else + // Fall back to clock_gettime nanoseconds. + return 1E9; +#endif +} + +size_t MeasureImpl(const Func func, const void* arg, const size_t num_skip, + const InputVec& unique, const InputVec& full, + const Params& p, Result* results) { + const float mul = 1.0f / static_cast<int>(num_skip); + + InputVec subset(full.size() - num_skip); + const Ticks overhead = Overhead(arg, &full, p); + const Ticks overhead_skip = Overhead(arg, &subset, p); + if (overhead < overhead_skip) { + ABSL_RAW_LOG(WARNING, "Measurement failed: overhead %u < %u\n", overhead, + overhead_skip); + return 0; + } + + if (p.verbose) { + ABSL_RAW_LOG(INFO, "#inputs=%5zu,%5zu overhead=%5u,%5u\n", full.size(), + subset.size(), overhead, overhead_skip); + } + + double max_rel_mad = 0.0; + const Ticks total = TotalDuration(func, arg, &full, p, &max_rel_mad); + + for (size_t i = 0; i < unique.size(); ++i) { + FillSubset(full, unique[i], num_skip, &subset); + const Ticks total_skip = TotalDuration(func, arg, &subset, p, &max_rel_mad); + + if (total < total_skip) { + ABSL_RAW_LOG(WARNING, "Measurement failed: total %u < %u\n", total, + total_skip); + return 0; + } + + const Ticks duration = (total - overhead) - (total_skip - overhead_skip); + results[i].input = unique[i]; + results[i].ticks = duration * mul; + results[i].variability = max_rel_mad; + } + + return unique.size(); +} + +size_t Measure(const Func func, const void* arg, const FuncInput* inputs, + const size_t num_inputs, Result* results, const Params& p) { + ABSL_RAW_CHECK(num_inputs != 0, "No inputs"); + + const InputVec unique = UniqueInputs(inputs, num_inputs); + const size_t num_skip = NumSkip(func, arg, unique, p); // never 0 + if (num_skip == 0) return 0; // NumSkip already printed error message + + const InputVec full = + ReplicateInputs(inputs, num_inputs, unique.size(), num_skip, p); + + // MeasureImpl may fail up to p.max_measure_retries times. + for (size_t i = 0; i < p.max_measure_retries; i++) { + auto result = MeasureImpl(func, arg, num_skip, unique, full, p, results); + if (result != 0) { + return result; + } + } + // All retries failed. (Unusual) + return 0; +} + +} // namespace random_internal_nanobenchmark +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/nanobenchmark.h b/third_party/abseil_cpp/absl/random/internal/nanobenchmark.h new file mode 100644 index 0000000000..a5097ba27b --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/nanobenchmark.h @@ -0,0 +1,172 @@ +// Copyright 2017 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_NANOBENCHMARK_H_ +#define ABSL_RANDOM_INTERNAL_NANOBENCHMARK_H_ + +// Benchmarks functions of a single integer argument with realistic branch +// prediction hit rates. Uses a robust estimator to summarize the measurements. +// The precision is about 0.2%. +// +// Examples: see nanobenchmark_test.cc. +// +// Background: Microbenchmarks such as http://github.com/google/benchmark +// can measure elapsed times on the order of a microsecond. Shorter functions +// are typically measured by repeating them thousands of times and dividing +// the total elapsed time by this count. Unfortunately, repetition (especially +// with the same input parameter!) influences the runtime. In time-critical +// code, it is reasonable to expect warm instruction/data caches and TLBs, +// but a perfect record of which branches will be taken is unrealistic. +// Unless the application also repeatedly invokes the measured function with +// the same parameter, the benchmark is measuring something very different - +// a best-case result, almost as if the parameter were made a compile-time +// constant. This may lead to erroneous conclusions about branch-heavy +// algorithms outperforming branch-free alternatives. +// +// Our approach differs in three ways. Adding fences to the timer functions +// reduces variability due to instruction reordering, improving the timer +// resolution to about 40 CPU cycles. However, shorter functions must still +// be invoked repeatedly. For more realistic branch prediction performance, +// we vary the input parameter according to a user-specified distribution. +// Thus, instead of VaryInputs(Measure(Repeat(func))), we change the +// loop nesting to Measure(Repeat(VaryInputs(func))). We also estimate the +// central tendency of the measurement samples with the "half sample mode", +// which is more robust to outliers and skewed data than the mean or median. + +// NOTE: for compatibility with multiple translation units compiled with +// distinct flags, avoid #including headers that define functions. + +#include <stddef.h> +#include <stdint.h> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal_nanobenchmark { + +// Input influencing the function being measured (e.g. number of bytes to copy). +using FuncInput = size_t; + +// "Proof of work" returned by Func to ensure the compiler does not elide it. +using FuncOutput = uint64_t; + +// Function to measure: either 1) a captureless lambda or function with two +// arguments or 2) a lambda with capture, in which case the first argument +// is reserved for use by MeasureClosure. +using Func = FuncOutput (*)(const void*, FuncInput); + +// Internal parameters that determine precision/resolution/measuring time. +struct Params { + // For measuring timer overhead/resolution. Used in a nested loop => + // quadratic time, acceptable because we know timer overhead is "low". + // constexpr because this is used to define array bounds. + static constexpr size_t kTimerSamples = 256; + + // Best-case precision, expressed as a divisor of the timer resolution. + // Larger => more calls to Func and higher precision. + size_t precision_divisor = 1024; + + // Ratio between full and subset input distribution sizes. Cannot be less + // than 2; larger values increase measurement time but more faithfully + // model the given input distribution. + size_t subset_ratio = 2; + + // Together with the estimated Func duration, determines how many times to + // call Func before checking the sample variability. Larger values increase + // measurement time, memory/cache use and precision. + double seconds_per_eval = 4E-3; + + // The minimum number of samples before estimating the central tendency. + size_t min_samples_per_eval = 7; + + // The mode is better than median for estimating the central tendency of + // skewed/fat-tailed distributions, but it requires sufficient samples + // relative to the width of half-ranges. + size_t min_mode_samples = 64; + + // Maximum permissible variability (= median absolute deviation / center). + double target_rel_mad = 0.002; + + // Abort after this many evals without reaching target_rel_mad. This + // prevents infinite loops. + size_t max_evals = 9; + + // Retry the measure loop up to this many times. + size_t max_measure_retries = 2; + + // Whether to print additional statistics to stdout. + bool verbose = true; +}; + +// Measurement result for each unique input. +struct Result { + FuncInput input; + + // Robust estimate (mode or median) of duration. + float ticks; + + // Measure of variability (median absolute deviation relative to "ticks"). + float variability; +}; + +// Ensures the thread is running on the specified cpu, and no others. +// Reduces noise due to desynchronized socket RDTSC and context switches. +// If "cpu" is negative, pin to the currently running core. +void PinThreadToCPU(const int cpu = -1); + +// Returns tick rate, useful for converting measurements to seconds. Invariant +// means the tick counter frequency is independent of CPU throttling or sleep. +// This call may be expensive, callers should cache the result. +double InvariantTicksPerSecond(); + +// Precisely measures the number of ticks elapsed when calling "func" with the +// given inputs, shuffled to ensure realistic branch prediction hit rates. +// +// "func" returns a 'proof of work' to ensure its computations are not elided. +// "arg" is passed to Func, or reserved for internal use by MeasureClosure. +// "inputs" is an array of "num_inputs" (not necessarily unique) arguments to +// "func". The values should be chosen to maximize coverage of "func". This +// represents a distribution, so a value's frequency should reflect its +// probability in the real application. Order does not matter; for example, a +// uniform distribution over [0, 4) could be represented as {3,0,2,1}. +// Returns how many Result were written to "results": one per unique input, or +// zero if the measurement failed (an error message goes to stderr). +size_t Measure(const Func func, const void* arg, const FuncInput* inputs, + const size_t num_inputs, Result* results, + const Params& p = Params()); + +// Calls operator() of the given closure (lambda function). +template <class Closure> +static FuncOutput CallClosure(const void* f, const FuncInput input) { + return (*reinterpret_cast<const Closure*>(f))(input); +} + +// Same as Measure, except "closure" is typically a lambda function of +// FuncInput -> FuncOutput with a capture list. +template <class Closure> +static inline size_t MeasureClosure(const Closure& closure, + const FuncInput* inputs, + const size_t num_inputs, Result* results, + const Params& p = Params()) { + return Measure(reinterpret_cast<Func>(&CallClosure<Closure>), + reinterpret_cast<const void*>(&closure), inputs, num_inputs, + results, p); +} + +} // namespace random_internal_nanobenchmark +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_NANOBENCHMARK_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/nanobenchmark_test.cc b/third_party/abseil_cpp/absl/random/internal/nanobenchmark_test.cc new file mode 100644 index 0000000000..f1571e269f --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/nanobenchmark_test.cc @@ -0,0 +1,77 @@ +// Copyright 2017 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/nanobenchmark.h" + +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/numbers.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal_nanobenchmark { +namespace { + +uint64_t Div(const void*, FuncInput in) { + // Here we're measuring the throughput because benchmark invocations are + // independent. + const int64_t d1 = 0xFFFFFFFFFFll / int64_t(in); // IDIV + return d1; +} + +template <size_t N> +void MeasureDiv(const FuncInput (&inputs)[N]) { + Result results[N]; + Params params; + params.max_evals = 6; // avoid test timeout + const size_t num_results = Measure(&Div, nullptr, inputs, N, results, params); + if (num_results == 0) { + ABSL_RAW_LOG( + WARNING, + "WARNING: Measurement failed, should not happen when using " + "PinThreadToCPU unless the region to measure takes > 1 second.\n"); + return; + } + for (size_t i = 0; i < num_results; ++i) { + ABSL_RAW_LOG(INFO, "%5zu: %6.2f ticks; MAD=%4.2f%%\n", results[i].input, + results[i].ticks, results[i].variability * 100.0); + ABSL_RAW_CHECK(results[i].ticks != 0.0f, "Zero duration"); + } +} + +void RunAll(const int argc, char* argv[]) { + // Avoid migrating between cores - important on multi-socket systems. + int cpu = -1; + if (argc == 2) { + if (!absl::SimpleAtoi(argv[1], &cpu)) { + ABSL_RAW_LOG(FATAL, "The optional argument must be a CPU number >= 0.\n"); + } + } + PinThreadToCPU(cpu); + + // unpredictable == 1 but the compiler doesn't know that. + const FuncInput unpredictable = argc != 999; + static const FuncInput inputs[] = {unpredictable * 10, unpredictable * 100}; + + MeasureDiv(inputs); +} + +} // namespace +} // namespace random_internal_nanobenchmark +ABSL_NAMESPACE_END +} // namespace absl + +int main(int argc, char* argv[]) { + absl::random_internal_nanobenchmark::RunAll(argc, argv); + return 0; +} diff --git a/third_party/abseil_cpp/absl/random/internal/nonsecure_base.h b/third_party/abseil_cpp/absl/random/internal/nonsecure_base.h new file mode 100644 index 0000000000..730fa2ea12 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/nonsecure_base.h @@ -0,0 +1,150 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_NONSECURE_BASE_H_ +#define ABSL_RANDOM_INTERNAL_NONSECURE_BASE_H_ + +#include <algorithm> +#include <cstdint> +#include <iostream> +#include <iterator> +#include <random> +#include <string> +#include <type_traits> +#include <vector> + +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" +#include "absl/random/internal/pool_urbg.h" +#include "absl/random/internal/salted_seed_seq.h" +#include "absl/random/internal/seed_material.h" +#include "absl/types/optional.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Each instance of NonsecureURBGBase<URBG> will be seeded by variates produced +// by a thread-unique URBG-instance. +template <typename URBG> +class NonsecureURBGBase { + public: + using result_type = typename URBG::result_type; + + // Default constructor + NonsecureURBGBase() : urbg_(ConstructURBG()) {} + + // Copy disallowed, move allowed. + NonsecureURBGBase(const NonsecureURBGBase&) = delete; + NonsecureURBGBase& operator=(const NonsecureURBGBase&) = delete; + NonsecureURBGBase(NonsecureURBGBase&&) = default; + NonsecureURBGBase& operator=(NonsecureURBGBase&&) = default; + + // Constructor using a seed + template <class SSeq, typename = typename absl::enable_if_t< + !std::is_same<SSeq, NonsecureURBGBase>::value>> + explicit NonsecureURBGBase(SSeq&& seq) + : urbg_(ConstructURBG(std::forward<SSeq>(seq))) {} + + // Note: on MSVC, min() or max() can be interpreted as MIN() or MAX(), so we + // enclose min() or max() in parens as (min)() and (max)(). + // Additionally, clang-format requires no space before this construction. + + // NonsecureURBGBase::min() + static constexpr result_type(min)() { return (URBG::min)(); } + + // NonsecureURBGBase::max() + static constexpr result_type(max)() { return (URBG::max)(); } + + // NonsecureURBGBase::operator()() + result_type operator()() { return urbg_(); } + + // NonsecureURBGBase::discard() + void discard(unsigned long long values) { // NOLINT(runtime/int) + urbg_.discard(values); + } + + bool operator==(const NonsecureURBGBase& other) const { + return urbg_ == other.urbg_; + } + + bool operator!=(const NonsecureURBGBase& other) const { + return !(urbg_ == other.urbg_); + } + + private: + // Seeder is a custom seed sequence type where generate() fills the provided + // buffer via the RandenPool entropy source. + struct Seeder { + using result_type = uint32_t; + + size_t size() { return 0; } + + template <typename OutIterator> + void param(OutIterator) const {} + + template <typename RandomAccessIterator> + void generate(RandomAccessIterator begin, RandomAccessIterator end) { + if (begin != end) { + // begin, end must be random access iterators assignable from uint32_t. + generate_impl( + std::integral_constant<bool, sizeof(*begin) == sizeof(uint32_t)>{}, + begin, end); + } + } + + // Commonly, generate is invoked with a pointer to a buffer which + // can be cast to a uint32_t. + template <typename RandomAccessIterator> + void generate_impl(std::integral_constant<bool, true>, + RandomAccessIterator begin, RandomAccessIterator end) { + auto buffer = absl::MakeSpan(begin, end); + auto target = absl::MakeSpan(reinterpret_cast<uint32_t*>(buffer.data()), + buffer.size()); + RandenPool<uint32_t>::Fill(target); + } + + // The non-uint32_t case should be uncommon, and involves an extra copy, + // filling the uint32_t buffer and then mixing into the output. + template <typename RandomAccessIterator> + void generate_impl(std::integral_constant<bool, false>, + RandomAccessIterator begin, RandomAccessIterator end) { + const size_t n = std::distance(begin, end); + absl::InlinedVector<uint32_t, 8> data(n, 0); + RandenPool<uint32_t>::Fill(absl::MakeSpan(data.begin(), data.end())); + std::copy(std::begin(data), std::end(data), begin); + } + }; + + static URBG ConstructURBG() { + Seeder seeder; + return URBG(seeder); + } + + template <typename SSeq> + static URBG ConstructURBG(SSeq&& seq) { // NOLINT(runtime/references) + auto salted_seq = + random_internal::MakeSaltedSeedSeq(std::forward<SSeq>(seq)); + return URBG(salted_seq); + } + + URBG urbg_; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_NONSECURE_BASE_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/nonsecure_base_test.cc b/third_party/abseil_cpp/absl/random/internal/nonsecure_base_test.cc new file mode 100644 index 0000000000..698027fc6e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/nonsecure_base_test.cc @@ -0,0 +1,245 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/nonsecure_base.h" + +#include <algorithm> +#include <iostream> +#include <memory> +#include <random> +#include <sstream> + +#include "gtest/gtest.h" +#include "absl/random/distributions.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" + +namespace { + +using ExampleNonsecureURBG = + absl::random_internal::NonsecureURBGBase<std::mt19937>; + +template <typename T> +void Use(const T&) {} + +} // namespace + +TEST(NonsecureURBGBase, DefaultConstructorIsValid) { + ExampleNonsecureURBG urbg; +} + +// Ensure that the recommended template-instantiations are valid. +TEST(RecommendedTemplates, CanBeConstructed) { + absl::BitGen default_generator; + absl::InsecureBitGen insecure_generator; +} + +TEST(RecommendedTemplates, CanDiscardValues) { + absl::BitGen default_generator; + absl::InsecureBitGen insecure_generator; + + default_generator.discard(5); + insecure_generator.discard(5); +} + +TEST(NonsecureURBGBase, StandardInterface) { + // Names after definition of [rand.req.urbg] in C++ standard. + // e us a value of E + // v is a lvalue of E + // x, y are possibly const values of E + // s is a value of T + // q is a value satisfying requirements of seed_sequence + // z is a value of type unsigned long long + // os is a some specialization of basic_ostream + // is is a some specialization of basic_istream + + using E = absl::random_internal::NonsecureURBGBase<std::minstd_rand>; + + using T = typename E::result_type; + + static_assert(!std::is_copy_constructible<E>::value, + "NonsecureURBGBase should not be copy constructible"); + + static_assert(!absl::is_copy_assignable<E>::value, + "NonsecureURBGBase should not be copy assignable"); + + static_assert(std::is_move_constructible<E>::value, + "NonsecureURBGBase should be move constructible"); + + static_assert(absl::is_move_assignable<E>::value, + "NonsecureURBGBase should be move assignable"); + + static_assert(std::is_same<decltype(std::declval<E>()()), T>::value, + "return type of operator() must be result_type"); + + { + const E x, y; + Use(x); + Use(y); + + static_assert(std::is_same<decltype(x == y), bool>::value, + "return type of operator== must be bool"); + + static_assert(std::is_same<decltype(x != y), bool>::value, + "return type of operator== must be bool"); + } + + E e; + std::seed_seq q{1, 2, 3}; + + E{}; + E{q}; + + // Copy constructor not supported. + // E{x}; + + // result_type seed constructor not supported. + // E{T{1}}; + + // Move constructors are supported. + { + E tmp(q); + E m = std::move(tmp); + E n(std::move(m)); + EXPECT_TRUE(e != n); + } + + // Comparisons work. + { + // MSVC emits error 2718 when using EXPECT_EQ(e, x) + // * actual parameter with __declspec(align('#')) won't be aligned + E a(q); + E b(q); + + EXPECT_TRUE(a != e); + EXPECT_TRUE(a == b); + + a(); + EXPECT_TRUE(a != b); + } + + // e.seed(s) not supported. + + // [rand.req.eng] specifies the parameter as 'unsigned long long' + // e.discard(unsigned long long) is supported. + unsigned long long z = 1; // NOLINT(runtime/int) + e.discard(z); +} + +TEST(NonsecureURBGBase, SeedSeqConstructorIsValid) { + std::seed_seq seq; + ExampleNonsecureURBG rbg(seq); +} + +TEST(NonsecureURBGBase, CompatibleWithDistributionUtils) { + ExampleNonsecureURBG rbg; + + absl::Uniform(rbg, 0, 100); + absl::Uniform(rbg, 0.5, 0.7); + absl::Poisson<uint32_t>(rbg); + absl::Exponential<float>(rbg); +} + +TEST(NonsecureURBGBase, CompatibleWithStdDistributions) { + ExampleNonsecureURBG rbg; + + // Cast to void to suppress [[nodiscard]] warnings + static_cast<void>(std::uniform_int_distribution<uint32_t>(0, 100)(rbg)); + static_cast<void>(std::uniform_real_distribution<float>()(rbg)); + static_cast<void>(std::bernoulli_distribution(0.2)(rbg)); +} + +TEST(NonsecureURBGBase, ConsecutiveDefaultInstancesYieldUniqueVariates) { + const size_t kNumSamples = 128; + + ExampleNonsecureURBG rbg1; + ExampleNonsecureURBG rbg2; + + for (size_t i = 0; i < kNumSamples; i++) { + EXPECT_NE(rbg1(), rbg2()); + } +} + +TEST(NonsecureURBGBase, EqualSeedSequencesYieldEqualVariates) { + std::seed_seq seq; + + ExampleNonsecureURBG rbg1(seq); + ExampleNonsecureURBG rbg2(seq); + + // ExampleNonsecureURBG rbg3({1, 2, 3}); // Should not compile. + + for (uint32_t i = 0; i < 1000; i++) { + EXPECT_EQ(rbg1(), rbg2()); + } + + rbg1.discard(100); + rbg2.discard(100); + + // The sequences should continue after discarding + for (uint32_t i = 0; i < 1000; i++) { + EXPECT_EQ(rbg1(), rbg2()); + } +} + +// This is a PRNG-compatible type specifically designed to test +// that NonsecureURBGBase::Seeder can correctly handle iterators +// to arbitrary non-uint32_t size types. +template <typename T> +struct SeederTestEngine { + using result_type = T; + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + template <class SeedSequence, + typename = typename absl::enable_if_t< + !std::is_same<SeedSequence, SeederTestEngine>::value>> + explicit SeederTestEngine(SeedSequence&& seq) { + seed(seq); + } + + SeederTestEngine(const SeederTestEngine&) = default; + SeederTestEngine& operator=(const SeederTestEngine&) = default; + SeederTestEngine(SeederTestEngine&&) = default; + SeederTestEngine& operator=(SeederTestEngine&&) = default; + + result_type operator()() { return state[0]; } + + template <class SeedSequence> + void seed(SeedSequence&& seq) { + std::fill(std::begin(state), std::end(state), T(0)); + seq.generate(std::begin(state), std::end(state)); + } + + T state[2]; +}; + +TEST(NonsecureURBGBase, SeederWorksForU32) { + using U32 = + absl::random_internal::NonsecureURBGBase<SeederTestEngine<uint32_t>>; + U32 x; + EXPECT_NE(0, x()); +} + +TEST(NonsecureURBGBase, SeederWorksForU64) { + using U64 = + absl::random_internal::NonsecureURBGBase<SeederTestEngine<uint64_t>>; + + U64 x; + EXPECT_NE(0, x()); +} diff --git a/third_party/abseil_cpp/absl/random/internal/pcg_engine.h b/third_party/abseil_cpp/absl/random/internal/pcg_engine.h new file mode 100644 index 0000000000..53c23fe1b4 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/pcg_engine.h @@ -0,0 +1,307 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_PCG_ENGINE_H_ +#define ABSL_RANDOM_INTERNAL_PCG_ENGINE_H_ + +#include <type_traits> + +#include "absl/base/config.h" +#include "absl/meta/type_traits.h" +#include "absl/numeric/int128.h" +#include "absl/random/internal/fastmath.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// pcg_engine is a simplified implementation of Melissa O'Neil's PCG engine in +// C++. PCG combines a linear congruential generator (LCG) with output state +// mixing functions to generate each random variate. pcg_engine supports only a +// single sequence (oneseq), and does not support streams. +// +// pcg_engine is parameterized by two types: +// Params, which provides the multiplier and increment values; +// Mix, which mixes the state into the result. +// +template <typename Params, typename Mix> +class pcg_engine { + static_assert(std::is_same<typename Params::state_type, + typename Mix::state_type>::value, + "Class-template absl::pcg_engine must be parameterized by " + "Params and Mix with identical state_type"); + + static_assert(std::is_unsigned<typename Mix::result_type>::value, + "Class-template absl::pcg_engine must be parameterized by " + "an unsigned Mix::result_type"); + + using params_type = Params; + using mix_type = Mix; + using state_type = typename Mix::state_type; + + public: + // C++11 URBG interface: + using result_type = typename Mix::result_type; + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + explicit pcg_engine(uint64_t seed_value = 0) { seed(seed_value); } + + template <class SeedSequence, + typename = typename absl::enable_if_t< + !std::is_same<SeedSequence, pcg_engine>::value>> + explicit pcg_engine(SeedSequence&& seq) { + seed(seq); + } + + pcg_engine(const pcg_engine&) = default; + pcg_engine& operator=(const pcg_engine&) = default; + pcg_engine(pcg_engine&&) = default; + pcg_engine& operator=(pcg_engine&&) = default; + + result_type operator()() { + // Advance the LCG state, always using the new value to generate the output. + state_ = lcg(state_); + return Mix{}(state_); + } + + void seed(uint64_t seed_value = 0) { + state_type tmp = seed_value; + state_ = lcg(tmp + Params::increment()); + } + + template <class SeedSequence> + typename absl::enable_if_t< + !std::is_convertible<SeedSequence, uint64_t>::value, void> + seed(SeedSequence&& seq) { + reseed(seq); + } + + void discard(uint64_t count) { state_ = advance(state_, count); } + + bool operator==(const pcg_engine& other) const { + return state_ == other.state_; + } + + bool operator!=(const pcg_engine& other) const { return !(*this == other); } + + template <class CharT, class Traits> + friend typename absl::enable_if_t<(sizeof(state_type) == 16), + std::basic_ostream<CharT, Traits>&> + operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const pcg_engine& engine) { + auto saver = random_internal::make_ostream_state_saver(os); + random_internal::stream_u128_helper<state_type> helper; + helper.write(pcg_engine::params_type::multiplier(), os); + os << os.fill(); + helper.write(pcg_engine::params_type::increment(), os); + os << os.fill(); + helper.write(engine.state_, os); + return os; + } + + template <class CharT, class Traits> + friend typename absl::enable_if_t<(sizeof(state_type) <= 8), + std::basic_ostream<CharT, Traits>&> + operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const pcg_engine& engine) { + auto saver = random_internal::make_ostream_state_saver(os); + os << pcg_engine::params_type::multiplier() << os.fill(); + os << pcg_engine::params_type::increment() << os.fill(); + os << engine.state_; + return os; + } + + template <class CharT, class Traits> + friend typename absl::enable_if_t<(sizeof(state_type) == 16), + std::basic_istream<CharT, Traits>&> + operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + pcg_engine& engine) { // NOLINT(runtime/references) + random_internal::stream_u128_helper<state_type> helper; + auto mult = helper.read(is); + auto inc = helper.read(is); + auto tmp = helper.read(is); + if (mult != pcg_engine::params_type::multiplier() || + inc != pcg_engine::params_type::increment()) { + // signal failure by setting the failbit. + is.setstate(is.rdstate() | std::ios_base::failbit); + } + if (!is.fail()) { + engine.state_ = tmp; + } + return is; + } + + template <class CharT, class Traits> + friend typename absl::enable_if_t<(sizeof(state_type) <= 8), + std::basic_istream<CharT, Traits>&> + operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + pcg_engine& engine) { // NOLINT(runtime/references) + state_type mult{}, inc{}, tmp{}; + is >> mult >> inc >> tmp; + if (mult != pcg_engine::params_type::multiplier() || + inc != pcg_engine::params_type::increment()) { + // signal failure by setting the failbit. + is.setstate(is.rdstate() | std::ios_base::failbit); + } + if (!is.fail()) { + engine.state_ = tmp; + } + return is; + } + + private: + state_type state_; + + // Returns the linear-congruential generator next state. + static inline constexpr state_type lcg(state_type s) { + return s * Params::multiplier() + Params::increment(); + } + + // Returns the linear-congruential arbitrary seek state. + inline state_type advance(state_type s, uint64_t n) const { + state_type mult = Params::multiplier(); + state_type inc = Params::increment(); + state_type m = 1; + state_type i = 0; + while (n > 0) { + if (n & 1) { + m *= mult; + i = i * mult + inc; + } + inc = (mult + 1) * inc; + mult *= mult; + n >>= 1; + } + return m * s + i; + } + + template <class SeedSequence> + void reseed(SeedSequence& seq) { + using sequence_result_type = typename SeedSequence::result_type; + constexpr size_t kBufferSize = + sizeof(state_type) / sizeof(sequence_result_type); + sequence_result_type buffer[kBufferSize]; + seq.generate(std::begin(buffer), std::end(buffer)); + // Convert the seed output to a single state value. + state_type tmp = buffer[0]; + for (size_t i = 1; i < kBufferSize; i++) { + tmp <<= (sizeof(sequence_result_type) * 8); + tmp |= buffer[i]; + } + state_ = lcg(tmp + params_type::increment()); + } +}; + +// Parameterized implementation of the PCG 128-bit oneseq state. +// This provides state_type, multiplier, and increment for pcg_engine. +template <uint64_t kMultA, uint64_t kMultB, uint64_t kIncA, uint64_t kIncB> +class pcg128_params { + public: +#if ABSL_HAVE_INTRINSIC_INT128 + using state_type = __uint128_t; + static inline constexpr state_type make_u128(uint64_t a, uint64_t b) { + return (static_cast<__uint128_t>(a) << 64) | b; + } +#else + using state_type = absl::uint128; + static inline constexpr state_type make_u128(uint64_t a, uint64_t b) { + return absl::MakeUint128(a, b); + } +#endif + + static inline constexpr state_type multiplier() { + return make_u128(kMultA, kMultB); + } + static inline constexpr state_type increment() { + return make_u128(kIncA, kIncB); + } +}; + +// Implementation of the PCG xsl_rr_128_64 128-bit mixing function, which +// accepts an input of state_type and mixes it into an output of result_type. +struct pcg_xsl_rr_128_64 { +#if ABSL_HAVE_INTRINSIC_INT128 + using state_type = __uint128_t; +#else + using state_type = absl::uint128; +#endif + using result_type = uint64_t; + + inline uint64_t operator()(state_type state) { + // This is equivalent to the xsl_rr_128_64 mixing function. +#if ABSL_HAVE_INTRINSIC_INT128 + uint64_t rotate = static_cast<uint64_t>(state >> 122u); + state ^= state >> 64; + uint64_t s = static_cast<uint64_t>(state); +#else + uint64_t h = Uint128High64(state); + uint64_t rotate = h >> 58u; + uint64_t s = Uint128Low64(state) ^ h; +#endif + return random_internal::rotr(s, rotate); + } +}; + +// Parameterized implementation of the PCG 64-bit oneseq state. +// This provides state_type, multiplier, and increment for pcg_engine. +template <uint64_t kMult, uint64_t kInc> +class pcg64_params { + public: + using state_type = uint64_t; + static inline constexpr state_type multiplier() { return kMult; } + static inline constexpr state_type increment() { return kInc; } +}; + +// Implementation of the PCG xsh_rr_64_32 64-bit mixing function, which accepts +// an input of state_type and mixes it into an output of result_type. +struct pcg_xsh_rr_64_32 { + using state_type = uint64_t; + using result_type = uint32_t; + inline uint32_t operator()(uint64_t state) { + return random_internal::rotr( + static_cast<uint32_t>(((state >> 18) ^ state) >> 27), state >> 59); + } +}; + +// Stable pcg_engine implementations: +// This is a 64-bit generator using 128-bits of state. +// The output sequence is equivalent to Melissa O'Neil's pcg64_oneseq. +using pcg64_2018_engine = pcg_engine< + random_internal::pcg128_params<0x2360ed051fc65da4ull, 0x4385df649fccf645ull, + 0x5851f42d4c957f2d, 0x14057b7ef767814f>, + random_internal::pcg_xsl_rr_128_64>; + +// This is a 32-bit generator using 64-bits of state. +// This is equivalent to Melissa O'Neil's pcg32_oneseq. +using pcg32_2018_engine = pcg_engine< + random_internal::pcg64_params<0x5851f42d4c957f2dull, 0x14057b7ef767814full>, + random_internal::pcg_xsh_rr_64_32>; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_PCG_ENGINE_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/pcg_engine_test.cc b/third_party/abseil_cpp/absl/random/internal/pcg_engine_test.cc new file mode 100644 index 0000000000..4d763e89eb --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/pcg_engine_test.cc @@ -0,0 +1,638 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/pcg_engine.h" + +#include <algorithm> +#include <bitset> +#include <random> +#include <sstream> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/random/internal/explicit_seed_seq.h" +#include "absl/time/clock.h" + +#define UPDATE_GOLDEN 0 + +namespace { + +using absl::random_internal::ExplicitSeedSeq; +using absl::random_internal::pcg32_2018_engine; +using absl::random_internal::pcg64_2018_engine; + +template <typename EngineType> +class PCGEngineTest : public ::testing::Test {}; + +using EngineTypes = ::testing::Types<pcg64_2018_engine, pcg32_2018_engine>; + +TYPED_TEST_SUITE(PCGEngineTest, EngineTypes); + +TYPED_TEST(PCGEngineTest, VerifyReseedChangesAllValues) { + using engine_type = TypeParam; + using result_type = typename engine_type::result_type; + + const size_t kNumOutputs = 16; + engine_type engine; + + // MSVC emits error 2719 without the use of std::ref below. + // * formal parameter with __declspec(align('#')) won't be aligned + + { + std::seed_seq seq1{1, 2, 3, 4, 5, 6, 7}; + engine.seed(seq1); + } + result_type a[kNumOutputs]; + std::generate(std::begin(a), std::end(a), std::ref(engine)); + + { + std::random_device rd; + std::seed_seq seq2{rd(), rd(), rd()}; + engine.seed(seq2); + } + result_type b[kNumOutputs]; + std::generate(std::begin(b), std::end(b), std::ref(engine)); + + // Verify that two uncorrelated values have ~50% of there bits in common. Use + // a 10% margin-of-error to reduce flakiness. + size_t changed_bits = 0; + size_t unchanged_bits = 0; + size_t total_set = 0; + size_t total_bits = 0; + size_t equal_count = 0; + for (size_t i = 0; i < kNumOutputs; ++i) { + equal_count += (a[i] == b[i]) ? 1 : 0; + std::bitset<sizeof(result_type) * 8> bitset(a[i] ^ b[i]); + changed_bits += bitset.count(); + unchanged_bits += bitset.size() - bitset.count(); + + std::bitset<sizeof(result_type) * 8> a_set(a[i]); + std::bitset<sizeof(result_type) * 8> b_set(b[i]); + total_set += a_set.count() + b_set.count(); + total_bits += 2 * 8 * sizeof(result_type); + } + // On average, half the bits are changed between two calls. + EXPECT_LE(changed_bits, 0.60 * (changed_bits + unchanged_bits)); + EXPECT_GE(changed_bits, 0.40 * (changed_bits + unchanged_bits)); + + // verify using a quick normal-approximation to the binomial. + EXPECT_NEAR(total_set, total_bits * 0.5, 4 * std::sqrt(total_bits)) + << "@" << total_set / static_cast<double>(total_bits); + + // Also, A[i] == B[i] with probability (1/range) * N. + // Give this a pretty wide latitude, though. + const double kExpected = kNumOutputs / (1.0 * sizeof(result_type) * 8); + EXPECT_LE(equal_count, 1.0 + kExpected); +} + +// Number of values that needs to be consumed to clean two sizes of buffer +// and trigger third refresh. (slightly overestimates the actual state size). +constexpr size_t kTwoBufferValues = 16; + +TYPED_TEST(PCGEngineTest, VerifyDiscard) { + using engine_type = TypeParam; + + for (size_t num_used = 0; num_used < kTwoBufferValues; ++num_used) { + engine_type engine_used; + for (size_t i = 0; i < num_used; ++i) { + engine_used(); + } + + for (size_t num_discard = 0; num_discard < kTwoBufferValues; + ++num_discard) { + engine_type engine1 = engine_used; + engine_type engine2 = engine_used; + for (size_t i = 0; i < num_discard; ++i) { + engine1(); + } + engine2.discard(num_discard); + for (size_t i = 0; i < kTwoBufferValues; ++i) { + const auto r1 = engine1(); + const auto r2 = engine2(); + ASSERT_EQ(r1, r2) << "used=" << num_used << " discard=" << num_discard; + } + } + } +} + +TYPED_TEST(PCGEngineTest, StreamOperatorsResult) { + using engine_type = TypeParam; + + std::wostringstream os; + std::wistringstream is; + engine_type engine; + + EXPECT_EQ(&(os << engine), &os); + EXPECT_EQ(&(is >> engine), &is); +} + +TYPED_TEST(PCGEngineTest, StreamSerialization) { + using engine_type = TypeParam; + + for (size_t discard = 0; discard < kTwoBufferValues; ++discard) { + ExplicitSeedSeq seed_sequence{12, 34, 56}; + engine_type engine(seed_sequence); + engine.discard(discard); + + std::stringstream stream; + stream << engine; + + engine_type new_engine; + stream >> new_engine; + for (size_t i = 0; i < 64; ++i) { + EXPECT_EQ(engine(), new_engine()) << " " << i; + } + } +} + +constexpr size_t kNumGoldenOutputs = 127; + +// This test is checking if randen_engine is meets interface requirements +// defined in [rand.req.urbg]. +TYPED_TEST(PCGEngineTest, RandomNumberEngineInterface) { + using engine_type = TypeParam; + + using E = engine_type; + using T = typename E::result_type; + + static_assert(std::is_copy_constructible<E>::value, + "engine_type must be copy constructible"); + + static_assert(absl::is_copy_assignable<E>::value, + "engine_type must be copy assignable"); + + static_assert(std::is_move_constructible<E>::value, + "engine_type must be move constructible"); + + static_assert(absl::is_move_assignable<E>::value, + "engine_type must be move assignable"); + + static_assert(std::is_same<decltype(std::declval<E>()()), T>::value, + "return type of operator() must be result_type"); + + // Names after definition of [rand.req.urbg] in C++ standard. + // e us a value of E + // v is a lvalue of E + // x, y are possibly const values of E + // s is a value of T + // q is a value satisfying requirements of seed_sequence + // z is a value of type unsigned long long + // os is a some specialization of basic_ostream + // is is a some specialization of basic_istream + + E e, v; + const E x, y; + T s = 1; + std::seed_seq q{1, 2, 3}; + unsigned long long z = 1; // NOLINT(runtime/int) + std::wostringstream os; + std::wistringstream is; + + E{}; + E{x}; + E{s}; + E{q}; + + e.seed(); + + // MSVC emits error 2718 when using EXPECT_EQ(e, x) + // * actual parameter with __declspec(align('#')) won't be aligned + EXPECT_TRUE(e == x); + + e.seed(q); + { + E tmp(q); + EXPECT_TRUE(e == tmp); + } + + e(); + { + E tmp(q); + EXPECT_TRUE(e != tmp); + } + + e.discard(z); + + static_assert(std::is_same<decltype(x == y), bool>::value, + "return type of operator== must be bool"); + + static_assert(std::is_same<decltype(x != y), bool>::value, + "return type of operator== must be bool"); +} + +TYPED_TEST(PCGEngineTest, RandenEngineSFINAETest) { + using engine_type = TypeParam; + using result_type = typename engine_type::result_type; + + { + engine_type engine(result_type(1)); + engine.seed(result_type(1)); + } + + { + result_type n = 1; + engine_type engine(n); + engine.seed(n); + } + + { + engine_type engine(1); + engine.seed(1); + } + + { + int n = 1; + engine_type engine(n); + engine.seed(n); + } + + { + std::seed_seq seed_seq; + engine_type engine(seed_seq); + engine.seed(seed_seq); + } + + { + engine_type engine{std::seed_seq()}; + engine.seed(std::seed_seq()); + } +} + +// ------------------------------------------------------------------ +// Stability tests for pcg64_2018_engine +// ------------------------------------------------------------------ +TEST(PCG642018EngineTest, VerifyGolden) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0x01070196e695f8f1, 0x703ec840c59f4493, 0xe54954914b3a44fa, + 0x96130ff204b9285e, 0x7d9fdef535ceb21a, 0x666feed42e1219a0, + 0x981f685721c8326f, 0xad80710d6eab4dda, 0xe202c480b037a029, + 0x5d3390eaedd907e2, 0x0756befb39c6b8aa, 0x1fb44ba6634d62a3, + 0x8d20423662426642, 0x34ea910167a39fb4, 0x93010b43a80d0ab6, + 0x663db08a98fc568a, 0x720b0a1335956fae, 0x2c35483e31e1d3ba, + 0x429f39776337409d, 0xb46d99e638687344, 0x105370b96aedcaee, + 0x3999e92f811cff71, 0xd230f8bcb591cfc9, 0x0dce3db2ba7bdea5, + 0xcf2f52c91eec99af, 0x2bc7c24a8b998a39, 0xbd8af1b0d599a19c, + 0x56bc45abc66059f5, 0x170a46dc170f7f1e, 0xc25daf5277b85fad, + 0xe629c2e0c948eadb, 0x1720a796915542ed, 0x22fb0caa4f909951, + 0x7e0c0f4175acd83d, 0xd9fcab37ff2a860c, 0xab2280fb2054bad1, + 0x58e8a06f37fa9e99, 0xc3a52a30b06528c7, 0x0175f773a13fc1bd, + 0x731cfc584b00e840, 0x404cc7b2648069cb, 0x5bc29153b0b7f783, + 0x771310a38cc999d1, 0x766a572f0a71a916, 0x90f450fb4fc48348, + 0xf080ea3e1c7b1a0d, 0x15471a4507d66a44, 0x7d58e55a78f3df69, + 0x0130a094576ac99c, 0x46669cb2d04b1d87, 0x17ab5bed20191840, + 0x95b177d260adff3e, 0x025fb624b6ee4c07, 0xb35de4330154a95f, + 0xe8510fff67e24c79, 0x132c3cbcd76ed2d3, 0x35e7cc145a093904, + 0x9f5b5b5f81583b79, 0x3ee749a533966233, 0x4af85886cdeda8cd, + 0x0ca5380ecb3ef3aa, 0x4f674eb7661d3192, 0x88a29aad00cd7733, + 0x70b627ca045ffac6, 0x5912b43ea887623d, 0x95dc9fc6f62cf221, + 0x926081a12a5c905b, 0x9c57d4cd7dfce651, 0x85ab2cbf23e3bb5d, + 0xc5cd669f63023152, 0x3067be0fad5d898e, 0x12b56f444cb53d05, + 0xbc2e5a640c3434fc, 0x9280bff0e4613fe1, 0x98819094c528743e, + 0x999d1c98d829df33, 0x9ff82a012dc89242, 0xf99183ed39c8be94, + 0xf0f59161cd421c55, 0x3c705730c2f6c48d, 0x66ad85c6e9278a61, + 0x2a3428e4a428d5d0, 0x79207d68fd04940d, 0xea7f2b402edc8430, + 0xa06b419ac857f63b, 0xcb1dd0e6fbc47e1c, 0x4f55229200ada6a4, + 0x9647b5e6359c927f, 0x30bf8f9197c7efe5, 0xa79519529cc384d0, + 0xbb22c4f339ad6497, 0xd7b9782f59d14175, 0x0dff12fff2ec0118, + 0xa331ad8305343a7c, 0x48dad7e3f17e0862, 0x324c6fb3fd3c9665, + 0xf0e4350e7933dfc4, 0x7ccda2f30b8b03b6, 0xa0afc6179005de40, + 0xee65da6d063b3a30, 0xb9506f42f2bfe87a, 0xc9a2e26b0ef5baa0, + 0x39fa9d4f495011d6, 0xbecc21a45d023948, 0x6bf484c6593f737f, + 0x8065e0070cadc3b7, 0x9ef617ed8d419799, 0xac692cf8c233dd15, + 0xd2ed87583c4ebb98, 0xad95ba1bebfedc62, 0x9b60b160a8264e43, + 0x0bc8c45f71fcf25b, 0x4a78035cdf1c9931, 0x4602dc106667e029, + 0xb335a3c250498ac8, 0x0256ebc4df20cab8, 0x0c61efd153f0c8d9, + 0xe5d0150a4f806f88, 0x99d6521d351e7d87, 0x8d4888c9f80f4325, + 0x106c5735c1ba868d, 0x73414881b880a878, 0x808a9a58a3064751, + 0x339a29f3746de3d5, 0x5410d7fa4f873896, 0xd84623c81d7b8a03, + 0x1f7c7e7a7f47f462, + }; + + pcg64_2018_engine engine(0); +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%016lx, ", engine()); + if (i % 3 == 2) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(PCG642018EngineTest, VerifyGoldenSeeded) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0xb03988f1e39691ee, 0xbd2a1eb5ac31e97a, 0x8f00d6d433634d02, + 0x1823c28d483d5776, 0x000c3ee3e1aeb74a, 0xfa82ef27a4f3df9c, + 0xc6f382308654e454, 0x414afb1a238996c2, 0x4703a4bc252eb411, + 0x99d64f62c8f7f654, 0xbb07ebe11a34fa44, 0x79eb06a363c06131, + 0xf66ad3756f1c6b21, 0x130c01d5e869f457, 0x5ca2b9963aecbc81, + 0xfef7bebc1de27e6c, 0x1d174faa5ed2cdbf, 0xd75b7a773f2bb889, + 0xc35c872327a170a5, 0x46da6d88646a42fe, 0x4622985e0442dae2, + 0xbe3cbd67297f1f9b, 0xe7c37b4a4798bfd1, 0x173d5dfad15a25c3, + 0x0eb6849ba2961522, 0xb0ff7246e6700d73, 0x88cb9c42d3afa577, + 0xb609731dbd94d917, 0xd3941cda04b40081, 0x28d140f7409bea3a, + 0x3c96699a920a124a, 0xdb28be521958b2fd, 0x0a3f44db3d4c5124, + 0x7ac8e60ba13b70d2, 0x75f03a41ded5195a, 0xaed10ac7c4e4825d, + 0xb92a3b18aadb7adc, 0xda45e0081f2bca46, 0x74d39ab3753143fc, + 0xb686038018fac9ca, 0x4cc309fe99542dbb, 0xf3e1a4fcb311097c, + 0x58763d6fa698d69d, 0xd11c365dbecd8d60, 0x2c15d55725b1dee7, + 0x89805f254d85658c, 0x2374c44dfc62158b, 0x9a8350fa7995328d, + 0x198f838970cf91da, 0x96aff569562c0e53, 0xd76c8c52b7ec6e3f, + 0x23a01cd9ae4baa81, 0x3adb366b6d02a893, 0xb3313e2a4c5b333f, + 0x04c11230b96a5425, 0x1f7f7af04787d571, 0xaddb019365275ec7, + 0x5c960468ccb09f42, 0x8438db698c69a44a, 0x492be1e46111637e, + 0x9c6c01e18100c610, 0xbfe48e75b7d0aceb, 0xb5e0b89ec1ce6a00, + 0x9d280ecbc2fe8997, 0x290d9e991ba5fcab, 0xeec5bec7d9d2a4f0, + 0x726e81488f19150e, 0x1a6df7955a7e462c, 0x37a12d174ba46bb5, + 0x3cdcdffd96b1b5c5, 0x2c5d5ac10661a26e, 0xa742ed18f22e50c4, + 0x00e0ed88ff0d8a35, 0x3d3c1718cb1efc0b, 0x1d70c51ffbccbf11, + 0xfbbb895132a4092f, 0x619d27f2fb095f24, 0x69af68200985e5c4, + 0xbee4885f57373f8d, 0x10b7a6bfe0587e40, 0xa885e6cf2f7e5f0a, + 0x59f879464f767550, 0x24e805d69056990d, 0x860970b911095891, + 0xca3189954f84170d, 0x6652a5edd4590134, 0x5e1008cef76174bf, + 0xcbd417881f2bcfe5, 0xfd49fc9d706ecd17, 0xeebf540221ebd066, + 0x46af7679464504cb, 0xd4028486946956f1, 0xd4f41864b86c2103, + 0x7af090e751583372, 0x98cdaa09278cb642, 0xffd42b921215602f, + 0x1d05bec8466b1740, 0xf036fa78a0132044, 0x787880589d1ecc78, + 0x5644552cfef33230, 0x0a97e275fe06884b, 0x96d1b13333d470b5, + 0xc8b3cdad52d3b034, 0x091357b9db7376fd, 0xa5fe4232555edf8c, + 0x3371bc3b6ada76b5, 0x7deeb2300477c995, 0x6fc6d4244f2849c1, + 0x750e8cc797ca340a, 0x81728613cd79899f, 0x3467f4ee6f9aeb93, + 0x5ef0a905f58c640f, 0x432db85e5101c98a, 0x6488e96f46ac80c2, + 0x22fddb282625048c, 0x15b287a0bc2d4c5d, 0xa7e2343ef1f28bce, + 0xc87ee1aa89bed09e, 0x220610107812c5e9, 0xcbdab6fcd640f586, + 0x8d41047970928784, 0x1aa431509ec1ade0, 0xac3f0be53f518ddc, + 0x16f4428ad81d0cbb, 0x675b13c2736fc4bb, 0x6db073afdd87e32d, + 0x572f3ca2f1a078c6, + }; + + ExplicitSeedSeq seed_sequence{12, 34, 56}; + pcg64_2018_engine engine(seed_sequence); +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%016lx, ", engine()); + if (i % 3 == 2) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(seed_sequence); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(PCG642018EngineTest, VerifyGoldenFromDeserializedEngine) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0xdd425b47b4113dea, 0x1b07176479d444b0, 0x6b391027586f2e42, + 0xa166f2b15f4a2143, 0xffb6dbd7a179ee97, 0xb2c00035365bf0b1, + 0x8fbb518b45855521, 0xfc789a55ddf87c3b, 0x429531f0f17ff355, + 0xbe708560d603d283, 0x5bff415175c5cb6b, 0xe813491f4ad45394, + 0xa853f4506d55880d, 0x7e538453e568172e, 0xe101f1e098ddd0ec, + 0x6ee31266ee4c766d, 0xa8786d92d66b39d7, 0xfee622a2acf5e5b0, + 0x5fe8e82c102fa7b3, 0x01f10be4cdb53c9d, 0xbe0545366f857022, + 0x12e74f010a339bca, 0xb10d85ca40d5ce34, 0xe80d6feba5054875, + 0x2b7c1ee6d567d4ee, 0x2a9cd043bfd03b66, 0x5cfc531bd239f3f1, + 0x1c4734e4647d70f5, 0x85a8f60f006b5760, 0x6a4239ce76dca387, + 0x8da0f86d7339335c, 0xf055b0468551374d, 0x486e8567e9bea9a0, + 0x4cb531b8405192dd, 0xf813b1ee3157110b, 0x214c2a664a875d8e, + 0x74531237b29b35f7, 0xa6f0267bb77a771e, 0x64b552bff54184a4, + 0xa2d6f7af2d75b6fc, 0x460a10018e03b5ab, 0x76fd1fdcb81d0800, + 0x76f5f81805070d9d, 0x1fb75cb1a70b289a, 0x9dfd25a022c4b27f, + 0x9a31a14a80528e9e, 0x910dc565ddc25820, 0xd6aef8e2b0936c10, + 0xe1773c507fe70225, 0xe027fd7aadd632bc, 0xc1fecb427089c8b8, + 0xb5c74c69fa9dbf26, 0x71bf9b0e4670227d, 0x25f48fad205dcfdd, + 0x905248ec4d689c56, 0x5c2b7631b0de5c9d, 0x9f2ee0f8f485036c, + 0xfd6ce4ebb90bf7ea, 0xd435d20046085574, 0x6b7eadcb0625f986, + 0x679d7d44b48be89e, 0x49683b8e1cdc49de, 0x4366cf76e9a2f4ca, + 0x54026ec1cdad7bed, 0xa9a04385207f28d3, 0xc8e66de4eba074b2, + 0x40b08c42de0f4cc0, 0x1d4c5e0e93c5bbc0, 0x19b80792e470ae2d, + 0x6fcaaeaa4c2a5bd9, 0xa92cb07c4238438e, 0x8bb5c918a007e298, + 0x7cd671e944874cf4, 0x88166470b1ba3cac, 0xd013d476eaeeade6, + 0xcee416947189b3c3, 0x5d7c16ab0dce6088, 0xd3578a5c32b13d27, + 0x3875db5adc9cc973, 0xfbdaba01c5b5dc56, 0xffc4fdd391b231c3, + 0x2334520ecb164fec, 0x361c115e7b6de1fa, 0xeee58106cc3563d7, + 0x8b7f35a8db25ebb8, 0xb29d00211e2cafa6, 0x22a39fe4614b646b, + 0x92ca6de8b998506d, 0x40922fe3d388d1db, 0x9da47f1e540f802a, + 0x811dceebf16a25db, 0xf6524ae22e0e53a9, 0x52d9e780a16eb99d, + 0x4f504286bb830207, 0xf6654d4786bd5cc3, 0x00bd98316003a7e1, + 0xefda054a6ab8f5f3, 0x46cfb0f4c1872827, 0xc22b316965c0f3b2, + 0xd1a28087c7e7562a, 0xaa4f6a094b7f5cff, 0xfe2bc853a041f7da, + 0xe9d531402a83c3ba, 0xe545d8663d3ce4dd, 0xfa2dcd7d91a13fa8, + 0xda1a080e52a127b8, 0x19c98f1f809c3d84, 0x2cef109af4678c88, + 0x53462accab3b9132, 0x176b13a80415394e, 0xea70047ef6bc178b, + 0x57bca80506d6dcdf, 0xd853ba09ff09f5c4, 0x75f4df3a7ddd4775, + 0x209c367ade62f4fe, 0xa9a0bbc74d5f4682, 0x5dfe34bada86c21a, + 0xc2c05bbcd38566d1, 0x6de8088e348c916a, 0x6a7001c6000c2196, + 0xd9fb51865fc4a367, 0x12f320e444ece8ff, 0x6d56f7f793d65035, + 0x138f31b7a865f8aa, 0x58fc68b4026b9adf, 0xcd48954b79fb6436, + 0x27dfce4a0232af87, + }; + +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + std::seed_seq seed_sequence{1, 2, 3}; + pcg64_2018_engine engine(seed_sequence); + std::ostringstream stream; + stream << engine; + auto str = stream.str(); + printf("%s\n\n", str.c_str()); + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%016lx, ", engine()); + if (i % 3 == 2) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + pcg64_2018_engine engine; + std::istringstream stream( + "2549297995355413924 4865540595714422341 6364136223846793005 " + "1442695040888963407 18088519957565336995 4845369368158826708"); + stream >> engine; + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +// ------------------------------------------------------------------ +// Stability tests for pcg32_2018_engine +// ------------------------------------------------------------------ +TEST(PCG322018EngineTest, VerifyGolden) { + constexpr uint32_t kGolden[kNumGoldenOutputs] = { + 0x7a7ecbd9, 0x89fd6c06, 0xae646aa8, 0xcd3cf945, 0x6204b303, 0x198c8585, + 0x49fce611, 0xd1e9297a, 0x142d9440, 0xee75f56b, 0x473a9117, 0xe3a45903, + 0xbce807a1, 0xe54e5f4d, 0x497d6c51, 0x61829166, 0xa740474b, 0x031912a8, + 0x9de3defa, 0xd266dbf1, 0x0f38bebb, 0xec3c4f65, 0x07c5057d, 0xbbce03c8, + 0xfd2ac7a8, 0xffcf4773, 0x5b10affb, 0xede1c842, 0xe22b01b7, 0xda133c8c, + 0xaf89b0f4, 0x25d1b8bc, 0x9f625482, 0x7bfd6882, 0x2e2210c0, 0x2c8fb9a6, + 0x42cb3b83, 0x40ce0dab, 0x644a3510, 0x36230ef2, 0xe2cb6d43, 0x1012b343, + 0x746c6c9f, 0x36714cf8, 0xed1f5026, 0x8bbbf83e, 0xe98710f4, 0x8a2afa36, + 0x09035349, 0x6dc1a487, 0x682b634b, 0xc106794f, 0x7dd78beb, 0x628c262b, + 0x852fb232, 0xb153ac4c, 0x4f169d1b, 0xa69ab774, 0x4bd4b6f2, 0xdc351dd3, + 0x93ff3c8c, 0xa30819ab, 0xff07758c, 0x5ab13c62, 0xd16d7fb5, 0xc4950ffa, + 0xd309ae49, 0xb9677a87, 0x4464e317, 0x90dc44f1, 0xc694c1d4, 0x1d5e1168, + 0xadf37a2d, 0xda38990d, 0x1ec4bd33, 0x36ca25ce, 0xfa0dc76a, 0x968a9d43, + 0x6950ac39, 0xdd3276bc, 0x06d5a71e, 0x1f6f282d, 0x5c626c62, 0xdde3fc31, + 0x152194ce, 0xc35ed14c, 0xb1f7224e, 0x47f76bb8, 0xb34fdd08, 0x7011395e, + 0x162d2a49, 0x0d1bf09f, 0x9428a952, 0x03c5c344, 0xd3525616, 0x7816fff3, + 0x6bceb8a8, 0x8345a081, 0x366420fd, 0x182abeda, 0x70f82745, 0xaf15ded8, + 0xc7f52ca2, 0xa98db9c5, 0x919d99ba, 0x9c376c1c, 0xed8d34c2, 0x716ae9f5, + 0xef062fa5, 0xee3b6c56, 0x52325658, 0x61afa9c3, 0xfdaf02f0, 0x961cf3ab, + 0x9f291565, 0x4fbf3045, 0x0590c899, 0xde901385, 0x45005ffb, 0x509db162, + 0x262fa941, 0x4c421653, 0x4b17c21e, 0xea0d1530, 0xde803845, 0x61bfd515, + 0x438523ef, + }; + + pcg32_2018_engine engine(0); +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%08x, ", engine()); + if (i % 6 == 5) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(PCG322018EngineTest, VerifyGoldenSeeded) { + constexpr uint32_t kGolden[kNumGoldenOutputs] = { + 0x60b5a64c, 0x978502f9, 0x80a75f60, 0x241f1158, 0xa4cd1dbb, 0xe7284017, + 0x3b678da5, 0x5223ec99, 0xe4bdd5d9, 0x72190e6d, 0xe6e702c9, 0xff80c768, + 0xcf126ed3, 0x1fbd20ab, 0x60980489, 0xbc72bf89, 0x407ac6c0, 0x00bf3c51, + 0xf9087897, 0x172e4eb6, 0xe9e4f443, 0x1a6098bf, 0xbf44f8c2, 0xdd84a0e5, + 0xd9a52364, 0xc0e2e786, 0x061ae2ba, 0x9facb8e3, 0x6109432d, 0xd4e0a013, + 0xbd8eb9a6, 0x7e86c3b6, 0x629c0e68, 0x05337430, 0xb495b9f4, 0x11ccd65d, + 0xb578db25, 0x66f1246d, 0x6ef20a7f, 0x5e429812, 0x11772130, 0xb944b5c2, + 0x01624128, 0xa2385ab7, 0xd3e10d35, 0xbe570ec3, 0xc951656f, 0xbe8944a0, + 0x7be41062, 0x5709f919, 0xd745feda, 0x9870b9ae, 0xb44b8168, 0x19e7683b, + 0xded8017f, 0xc6e4d544, 0x91ae4225, 0xd6745fba, 0xb992f284, 0x65b12b33, + 0xa9d5fdb4, 0xf105ce1a, 0x35ca1a6e, 0x2ff70dd0, 0xd8335e49, 0xfb71ddf2, + 0xcaeabb89, 0x5c6f5f84, 0x9a811a7d, 0xbcecbbd1, 0x0f661ba0, 0x9ad93b9d, + 0xedd23e0b, 0x42062f48, 0xd38dd7e4, 0x6cd63c9c, 0x640b98ae, 0x4bff5653, + 0x12626371, 0x13266017, 0xe7a698d8, 0x39c74667, 0xe8fdf2e3, 0x52803bf8, + 0x2af6895b, 0x91335b7b, 0x699e4961, 0x00a40fff, 0x253ff2b6, 0x4a6cf672, + 0x9584e85f, 0xf2a5000c, 0x4d58aba8, 0xb8513e6a, 0x767fad65, 0x8e326f9e, + 0x182f15a1, 0x163dab52, 0xdf99c780, 0x047282a1, 0xee4f90dd, 0xd50394ae, + 0x6c9fd5f0, 0xb06a9194, 0x387e3840, 0x04a9487b, 0xf678a4c2, 0xd0a78810, + 0xd502c97e, 0xd6a9b12a, 0x4accc5dc, 0x416ed53e, 0x50411536, 0xeeb89c24, + 0x813a7902, 0x034ebca6, 0xffa52e7c, 0x7ecd3d0e, 0xfa37a0d2, 0xb1fbe2c1, + 0xb7efc6d1, 0xefa4ccee, 0xf6f80424, 0x2283f3d9, 0x68732284, 0x94f3b5c8, + 0xbbdeceb9, + }; + + ExplicitSeedSeq seed_sequence{12, 34, 56}; + pcg32_2018_engine engine(seed_sequence); +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%08x, ", engine()); + if (i % 6 == 5) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(seed_sequence); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(PCG322018EngineTest, VerifyGoldenFromDeserializedEngine) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0x780f7042, 0xba137215, 0x43ab6f22, 0x0cb55f46, 0x44b2627d, 0x835597af, + 0xea973ea1, 0x0d2abd35, 0x4fdd601c, 0xac4342fe, 0x7db7e93c, 0xe56ebcaf, + 0x3596470a, 0x7770a9ad, 0x9b893320, 0x57db3415, 0xb432de54, 0xa02baf71, + 0xa256aadb, 0x88921fc7, 0xa35fa6b3, 0xde3eca46, 0x605739a7, 0xa890b82b, + 0xe457b7ad, 0x335fb903, 0xeb06790c, 0xb3c54bf6, 0x6141e442, 0xa599a482, + 0xb78987cc, 0xc61dfe9d, 0x0f1d6ace, 0x17460594, 0x8f6a5061, 0x083dc354, + 0xe9c337fb, 0xcfd105f7, 0x926764b6, 0x638d24dc, 0xeaac650a, 0x67d2cb9c, + 0xd807733c, 0x205fc52e, 0xf5399e2e, 0x6c46ddcc, 0xb603e875, 0xce113a25, + 0x3c8d4813, 0xfb584db8, 0xf6d255ff, 0xea80954f, 0x42e8be85, 0xb2feee72, + 0x62bd8d16, 0x1be4a142, 0x97dca1a4, 0xdd6e7333, 0xb2caa20e, 0xa12b1588, + 0xeb3a5a1a, 0x6fa5ba89, 0x077ea931, 0x8ddb1713, 0x0dd03079, 0x2c2ba965, + 0xa77fac17, 0xc8325742, 0x8bb893bf, 0xc2315741, 0xeaceee92, 0x81dd2ee2, + 0xe5214216, 0x1b9b8fb2, 0x01646d03, 0x24facc25, 0xd8c0e0bb, 0xa33fe106, + 0xf34fe976, 0xb3b4b44e, 0x65618fed, 0x032c6192, 0xa9dd72ce, 0xf391887b, + 0xf41c6a6e, 0x05c4bd6d, 0x37fa260e, 0x46b05659, 0xb5f6348a, 0x62d26d89, + 0x39f6452d, 0xb17b30a2, 0xbdd82743, 0x38ecae3b, 0xfe90f0a2, 0xcb2d226d, + 0xcf8a0b1c, 0x0eed3d4d, 0xa1f69cfc, 0xd7ac3ba5, 0xce9d9a6b, 0x121deb4c, + 0x4a0d03f3, 0xc1821ed1, 0x59c249ac, 0xc0abb474, 0x28149985, 0xfd9a82ba, + 0x5960c3b2, 0xeff00cba, 0x6073aa17, 0x25dc0919, 0x9976626e, 0xdd2ccc33, + 0x39ecb6ec, 0xc6e15d13, 0xfac94cfd, 0x28cfd34f, 0xf2d2c32d, 0x51c23d08, + 0x4fdb2f48, 0x97baa807, 0xf2c1004c, 0xc4ae8136, 0x71f31c94, 0x8c92d601, + 0x36caf5cd, + }; + +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + std::seed_seq seed_sequence{1, 2, 3}; + pcg32_2018_engine engine(seed_sequence); + std::ostringstream stream; + stream << engine; + auto str = stream.str(); + printf("%s\n\n", str.c_str()); + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%08x, ", engine()); + if (i % 6 == 5) { + printf("\n"); + } + } + printf("\n\n\n"); + + EXPECT_FALSE(true); +#else + pcg32_2018_engine engine; + std::istringstream stream( + "6364136223846793005 1442695040888963407 6537028157270659894"); + stream >> engine; + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/platform.h b/third_party/abseil_cpp/absl/random/internal/platform.h new file mode 100644 index 0000000000..bbdb4e6208 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/platform.h @@ -0,0 +1,171 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_PLATFORM_H_ +#define ABSL_RANDOM_INTERNAL_PLATFORM_H_ + +// HERMETIC NOTE: The randen_hwaes target must not introduce duplicate +// symbols from arbitrary system and other headers, since it may be built +// with different flags from other targets, using different levels of +// optimization, potentially introducing ODR violations. + +// ----------------------------------------------------------------------------- +// Platform Feature Checks +// ----------------------------------------------------------------------------- + +// Currently supported operating systems and associated preprocessor +// symbols: +// +// Linux and Linux-derived __linux__ +// Android __ANDROID__ (implies __linux__) +// Linux (non-Android) __linux__ && !__ANDROID__ +// Darwin (macOS and iOS) __APPLE__ +// Akaros (http://akaros.org) __ros__ +// Windows _WIN32 +// NaCL __native_client__ +// AsmJS __asmjs__ +// WebAssembly __wasm__ +// Fuchsia __Fuchsia__ +// +// Note that since Android defines both __ANDROID__ and __linux__, one +// may probe for either Linux or Android by simply testing for __linux__. +// +// NOTE: For __APPLE__ platforms, we use #include <TargetConditionals.h> +// to distinguish os variants. +// +// http://nadeausoftware.com/articles/2012/01/c_c_tip_how_use_compiler_predefined_macros_detect_operating_system + +#if defined(__APPLE__) +#include <TargetConditionals.h> +#endif + +// ----------------------------------------------------------------------------- +// Architecture Checks +// ----------------------------------------------------------------------------- + +// These preprocessor directives are trying to determine CPU architecture, +// including necessary headers to support hardware AES. +// +// ABSL_ARCH_{X86/PPC/ARM} macros determine the platform. +#if defined(__x86_64__) || defined(__x86_64) || defined(_M_AMD64) || \ + defined(_M_X64) +#define ABSL_ARCH_X86_64 +#elif defined(__i386) || defined(_M_IX86) +#define ABSL_ARCH_X86_32 +#elif defined(__aarch64__) || defined(__arm64__) || defined(_M_ARM64) +#define ABSL_ARCH_AARCH64 +#elif defined(__arm__) || defined(__ARMEL__) || defined(_M_ARM) +#define ABSL_ARCH_ARM +#elif defined(__powerpc64__) || defined(__PPC64__) || defined(__powerpc__) || \ + defined(__ppc__) || defined(__PPC__) +#define ABSL_ARCH_PPC +#else +// Unsupported architecture. +// * https://sourceforge.net/p/predef/wiki/Architectures/ +// * https://msdn.microsoft.com/en-us/library/b0084kay.aspx +// * for gcc, clang: "echo | gcc -E -dM -" +#endif + +// ----------------------------------------------------------------------------- +// Attribute Checks +// ----------------------------------------------------------------------------- + +// ABSL_RANDOM_INTERNAL_RESTRICT annotates whether pointers may be considered +// to be unaliased. +#if defined(__clang__) || defined(__GNUC__) +#define ABSL_RANDOM_INTERNAL_RESTRICT __restrict__ +#elif defined(_MSC_VER) +#define ABSL_RANDOM_INTERNAL_RESTRICT __restrict +#else +#define ABSL_RANDOM_INTERNAL_RESTRICT +#endif + +// ABSL_HAVE_ACCELERATED_AES indicates whether the currently active compiler +// flags (e.g. -maes) allow using hardware accelerated AES instructions, which +// implies us assuming that the target platform supports them. +#define ABSL_HAVE_ACCELERATED_AES 0 + +#if defined(ABSL_ARCH_X86_64) + +#if defined(__AES__) || defined(__AVX__) +#undef ABSL_HAVE_ACCELERATED_AES +#define ABSL_HAVE_ACCELERATED_AES 1 +#endif + +#elif defined(ABSL_ARCH_PPC) + +// Rely on VSX and CRYPTO extensions for vcipher on PowerPC. +#if (defined(__VEC__) || defined(__ALTIVEC__)) && defined(__VSX__) && \ + defined(__CRYPTO__) +#undef ABSL_HAVE_ACCELERATED_AES +#define ABSL_HAVE_ACCELERATED_AES 1 +#endif + +#elif defined(ABSL_ARCH_ARM) || defined(ABSL_ARCH_AARCH64) + +// http://infocenter.arm.com/help/topic/com.arm.doc.ihi0053c/IHI0053C_acle_2_0.pdf +// Rely on NEON+CRYPTO extensions for ARM. +#if defined(__ARM_NEON) && defined(__ARM_FEATURE_CRYPTO) +#undef ABSL_HAVE_ACCELERATED_AES +#define ABSL_HAVE_ACCELERATED_AES 1 +#endif + +#endif + +// NaCl does not allow AES. +#if defined(__native_client__) +#undef ABSL_HAVE_ACCELERATED_AES +#define ABSL_HAVE_ACCELERATED_AES 0 +#endif + +// ABSL_RANDOM_INTERNAL_AES_DISPATCH indicates whether the currently active +// platform has, or should use run-time dispatch for selecting the +// acclerated Randen implementation. +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 0 + +#if defined(ABSL_ARCH_X86_64) +// Dispatch is available on x86_64 +#undef ABSL_RANDOM_INTERNAL_AES_DISPATCH +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 1 +#elif defined(__linux__) && defined(ABSL_ARCH_PPC) +// Or when running linux PPC +#undef ABSL_RANDOM_INTERNAL_AES_DISPATCH +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 1 +#elif defined(__linux__) && defined(ABSL_ARCH_AARCH64) +// Or when running linux AArch64 +#undef ABSL_RANDOM_INTERNAL_AES_DISPATCH +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 1 +#elif defined(__linux__) && defined(ABSL_ARCH_ARM) && (__ARM_ARCH >= 8) +// Or when running linux ARM v8 or higher. +// (This captures a lot of Android configurations.) +#undef ABSL_RANDOM_INTERNAL_AES_DISPATCH +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 1 +#endif + +// NaCl does not allow dispatch. +#if defined(__native_client__) +#undef ABSL_RANDOM_INTERNAL_AES_DISPATCH +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 0 +#endif + +// iOS does not support dispatch, even on x86, since applications +// should be bundled as fat binaries, with a different build tailored for +// each specific supported platform/architecture. +#if (defined(TARGET_OS_IPHONE) && TARGET_OS_IPHONE) || \ + (defined(TARGET_OS_IPHONE_SIMULATOR) && TARGET_OS_IPHONE_SIMULATOR) +#undef ABSL_RANDOM_INTERNAL_AES_DISPATCH +#define ABSL_RANDOM_INTERNAL_AES_DISPATCH 0 +#endif + +#endif // ABSL_RANDOM_INTERNAL_PLATFORM_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/pool_urbg.cc b/third_party/abseil_cpp/absl/random/internal/pool_urbg.cc new file mode 100644 index 0000000000..5bee530770 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/pool_urbg.cc @@ -0,0 +1,254 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/pool_urbg.h" + +#include <algorithm> +#include <atomic> +#include <cstdint> +#include <cstring> +#include <iterator> + +#include "absl/base/attributes.h" +#include "absl/base/call_once.h" +#include "absl/base/config.h" +#include "absl/base/internal/endian.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/internal/sysinfo.h" +#include "absl/base/internal/unaligned_access.h" +#include "absl/base/optimization.h" +#include "absl/random/internal/randen.h" +#include "absl/random/internal/seed_material.h" +#include "absl/random/seed_gen_exception.h" + +using absl::base_internal::SpinLock; +using absl::base_internal::SpinLockHolder; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +// RandenPoolEntry is a thread-safe pseudorandom bit generator, implementing a +// single generator within a RandenPool<T>. It is an internal implementation +// detail, and does not aim to conform to [rand.req.urng]. +// +// NOTE: There are alignment issues when used on ARM, for instance. +// See the allocation code in PoolAlignedAlloc(). +class RandenPoolEntry { + public: + static constexpr size_t kState = RandenTraits::kStateBytes / sizeof(uint32_t); + static constexpr size_t kCapacity = + RandenTraits::kCapacityBytes / sizeof(uint32_t); + + void Init(absl::Span<const uint32_t> data) { + SpinLockHolder l(&mu_); // Always uncontested. + std::copy(data.begin(), data.end(), std::begin(state_)); + next_ = kState; + } + + // Copy bytes into out. + void Fill(uint8_t* out, size_t bytes) ABSL_LOCKS_EXCLUDED(mu_); + + // Returns random bits from the buffer in units of T. + template <typename T> + inline T Generate() ABSL_LOCKS_EXCLUDED(mu_); + + inline void MaybeRefill() ABSL_EXCLUSIVE_LOCKS_REQUIRED(mu_) { + if (next_ >= kState) { + next_ = kCapacity; + impl_.Generate(state_); + } + } + + private: + // Randen URBG state. + uint32_t state_[kState] ABSL_GUARDED_BY(mu_); // First to satisfy alignment. + SpinLock mu_; + const Randen impl_; + size_t next_ ABSL_GUARDED_BY(mu_); +}; + +template <> +inline uint8_t RandenPoolEntry::Generate<uint8_t>() { + SpinLockHolder l(&mu_); + MaybeRefill(); + return static_cast<uint8_t>(state_[next_++]); +} + +template <> +inline uint16_t RandenPoolEntry::Generate<uint16_t>() { + SpinLockHolder l(&mu_); + MaybeRefill(); + return static_cast<uint16_t>(state_[next_++]); +} + +template <> +inline uint32_t RandenPoolEntry::Generate<uint32_t>() { + SpinLockHolder l(&mu_); + MaybeRefill(); + return state_[next_++]; +} + +template <> +inline uint64_t RandenPoolEntry::Generate<uint64_t>() { + SpinLockHolder l(&mu_); + if (next_ >= kState - 1) { + next_ = kCapacity; + impl_.Generate(state_); + } + auto p = state_ + next_; + next_ += 2; + + uint64_t result; + std::memcpy(&result, p, sizeof(result)); + return result; +} + +void RandenPoolEntry::Fill(uint8_t* out, size_t bytes) { + SpinLockHolder l(&mu_); + while (bytes > 0) { + MaybeRefill(); + size_t remaining = (kState - next_) * sizeof(state_[0]); + size_t to_copy = std::min(bytes, remaining); + std::memcpy(out, &state_[next_], to_copy); + out += to_copy; + bytes -= to_copy; + next_ += (to_copy + sizeof(state_[0]) - 1) / sizeof(state_[0]); + } +} + +// Number of pooled urbg entries. +static constexpr int kPoolSize = 8; + +// Shared pool entries. +static absl::once_flag pool_once; +ABSL_CACHELINE_ALIGNED static RandenPoolEntry* shared_pools[kPoolSize]; + +// Returns an id in the range [0 ... kPoolSize), which indexes into the +// pool of random engines. +// +// Each thread to access the pool is assigned a sequential ID (without reuse) +// from the pool-id space; the id is cached in a thread_local variable. +// This id is assigned based on the arrival-order of the thread to the +// GetPoolID call; this has no binary, CL, or runtime stability because +// on subsequent runs the order within the same program may be significantly +// different. However, as other thread IDs are not assigned sequentially, +// this is not expected to matter. +int GetPoolID() { + static_assert(kPoolSize >= 1, + "At least one urbg instance is required for PoolURBG"); + + ABSL_CONST_INIT static std::atomic<int64_t> sequence{0}; + +#ifdef ABSL_HAVE_THREAD_LOCAL + static thread_local int my_pool_id = -1; + if (ABSL_PREDICT_FALSE(my_pool_id < 0)) { + my_pool_id = (sequence++ % kPoolSize); + } + return my_pool_id; +#else + static pthread_key_t tid_key = [] { + pthread_key_t tmp_key; + int err = pthread_key_create(&tmp_key, nullptr); + if (err) { + ABSL_RAW_LOG(FATAL, "pthread_key_create failed with %d", err); + } + return tmp_key; + }(); + + // Store the value in the pthread_{get/set}specific. However an uninitialized + // value is 0, so add +1 to distinguish from the null value. + intptr_t my_pool_id = + reinterpret_cast<intptr_t>(pthread_getspecific(tid_key)); + if (ABSL_PREDICT_FALSE(my_pool_id == 0)) { + // No allocated ID, allocate the next value, cache it, and return. + my_pool_id = (sequence++ % kPoolSize) + 1; + int err = pthread_setspecific(tid_key, reinterpret_cast<void*>(my_pool_id)); + if (err) { + ABSL_RAW_LOG(FATAL, "pthread_setspecific failed with %d", err); + } + } + return my_pool_id - 1; +#endif +} + +// Allocate a RandenPoolEntry with at least 32-byte alignment, which is required +// by ARM platform code. +RandenPoolEntry* PoolAlignedAlloc() { + constexpr size_t kAlignment = + ABSL_CACHELINE_SIZE > 32 ? ABSL_CACHELINE_SIZE : 32; + + // Not all the platforms that we build for have std::aligned_alloc, however + // since we never free these objects, we can over allocate and munge the + // pointers to the correct alignment. + void* memory = std::malloc(sizeof(RandenPoolEntry) + kAlignment); + auto x = reinterpret_cast<intptr_t>(memory); + auto y = x % kAlignment; + void* aligned = + (y == 0) ? memory : reinterpret_cast<void*>(x + kAlignment - y); + return new (aligned) RandenPoolEntry(); +} + +// Allocate and initialize kPoolSize objects of type RandenPoolEntry. +// +// The initialization strategy is to initialize one object directly from +// OS entropy, then to use that object to seed all of the individual +// pool instances. +void InitPoolURBG() { + static constexpr size_t kSeedSize = + RandenTraits::kStateBytes / sizeof(uint32_t); + // Read the seed data from OS entropy once. + uint32_t seed_material[kPoolSize * kSeedSize]; + if (!random_internal::ReadSeedMaterialFromOSEntropy( + absl::MakeSpan(seed_material))) { + random_internal::ThrowSeedGenException(); + } + for (int i = 0; i < kPoolSize; i++) { + shared_pools[i] = PoolAlignedAlloc(); + shared_pools[i]->Init( + absl::MakeSpan(&seed_material[i * kSeedSize], kSeedSize)); + } +} + +// Returns the pool entry for the current thread. +RandenPoolEntry* GetPoolForCurrentThread() { + absl::call_once(pool_once, InitPoolURBG); + return shared_pools[GetPoolID()]; +} + +} // namespace + +template <typename T> +typename RandenPool<T>::result_type RandenPool<T>::Generate() { + auto* pool = GetPoolForCurrentThread(); + return pool->Generate<T>(); +} + +template <typename T> +void RandenPool<T>::Fill(absl::Span<result_type> data) { + auto* pool = GetPoolForCurrentThread(); + pool->Fill(reinterpret_cast<uint8_t*>(data.data()), + data.size() * sizeof(result_type)); +} + +template class RandenPool<uint8_t>; +template class RandenPool<uint16_t>; +template class RandenPool<uint32_t>; +template class RandenPool<uint64_t>; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/pool_urbg.h b/third_party/abseil_cpp/absl/random/internal/pool_urbg.h new file mode 100644 index 0000000000..05721929f5 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/pool_urbg.h @@ -0,0 +1,131 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_POOL_URBG_H_ +#define ABSL_RANDOM_INTERNAL_POOL_URBG_H_ + +#include <cinttypes> +#include <limits> + +#include "absl/random/internal/traits.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// RandenPool is a thread-safe random number generator [random.req.urbg] that +// uses an underlying pool of Randen generators to generate values. Each thread +// has affinity to one instance of the underlying pool generators. Concurrent +// access is guarded by a spin-lock. +template <typename T> +class RandenPool { + public: + using result_type = T; + static_assert(std::is_unsigned<result_type>::value, + "RandenPool template argument must be a built-in unsigned " + "integer type"); + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + RandenPool() {} + + // Returns a single value. + inline result_type operator()() { return Generate(); } + + // Fill data with random values. + static void Fill(absl::Span<result_type> data); + + protected: + // Generate returns a single value. + static result_type Generate(); +}; + +extern template class RandenPool<uint8_t>; +extern template class RandenPool<uint16_t>; +extern template class RandenPool<uint32_t>; +extern template class RandenPool<uint64_t>; + +// PoolURBG uses an underlying pool of random generators to implement a +// thread-compatible [random.req.urbg] interface with an internal cache of +// values. +template <typename T, size_t kBufferSize> +class PoolURBG { + // Inheritance to access the protected static members of RandenPool. + using unsigned_type = typename make_unsigned_bits<T>::type; + using PoolType = RandenPool<unsigned_type>; + using SpanType = absl::Span<unsigned_type>; + + static constexpr size_t kInitialBuffer = kBufferSize + 1; + static constexpr size_t kHalfBuffer = kBufferSize / 2; + + public: + using result_type = T; + + static_assert(std::is_unsigned<result_type>::value, + "PoolURBG must be parameterized by an unsigned integer type"); + + static_assert(kBufferSize > 1, + "PoolURBG must be parameterized by a buffer-size > 1"); + + static_assert(kBufferSize <= 256, + "PoolURBG must be parameterized by a buffer-size <= 256"); + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + PoolURBG() : next_(kInitialBuffer) {} + + // copy-constructor does not copy cache. + PoolURBG(const PoolURBG&) : next_(kInitialBuffer) {} + const PoolURBG& operator=(const PoolURBG&) { + next_ = kInitialBuffer; + return *this; + } + + // move-constructor does move cache. + PoolURBG(PoolURBG&&) = default; + PoolURBG& operator=(PoolURBG&&) = default; + + inline result_type operator()() { + if (next_ >= kBufferSize) { + next_ = (kBufferSize > 2 && next_ > kBufferSize) ? kHalfBuffer : 0; + PoolType::Fill(SpanType(reinterpret_cast<unsigned_type*>(state_ + next_), + kBufferSize - next_)); + } + return state_[next_++]; + } + + private: + // Buffer size. + size_t next_; // index within state_ + result_type state_[kBufferSize]; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_POOL_URBG_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/pool_urbg_test.cc b/third_party/abseil_cpp/absl/random/internal/pool_urbg_test.cc new file mode 100644 index 0000000000..53f4eacf16 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/pool_urbg_test.cc @@ -0,0 +1,182 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/pool_urbg.h" + +#include <algorithm> +#include <bitset> +#include <cmath> +#include <cstdint> +#include <iterator> + +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" +#include "absl/types/span.h" + +using absl::random_internal::PoolURBG; +using absl::random_internal::RandenPool; + +namespace { + +// is_randen_pool trait is true when parameterized by an RandenPool +template <typename T> +using is_randen_pool = typename absl::disjunction< // + std::is_same<T, RandenPool<uint8_t>>, // + std::is_same<T, RandenPool<uint16_t>>, // + std::is_same<T, RandenPool<uint32_t>>, // + std::is_same<T, RandenPool<uint64_t>>>; // + +// MyFill either calls RandenPool::Fill() or std::generate(..., rng) +template <typename T, typename V> +typename absl::enable_if_t<absl::negation<is_randen_pool<T>>::value, void> // +MyFill(T& rng, absl::Span<V> data) { // NOLINT(runtime/references) + std::generate(std::begin(data), std::end(data), rng); +} + +template <typename T, typename V> +typename absl::enable_if_t<is_randen_pool<T>::value, void> // +MyFill(T& rng, absl::Span<V> data) { // NOLINT(runtime/references) + rng.Fill(data); +} + +template <typename EngineType> +class PoolURBGTypedTest : public ::testing::Test {}; + +using EngineTypes = ::testing::Types< // + RandenPool<uint8_t>, // + RandenPool<uint16_t>, // + RandenPool<uint32_t>, // + RandenPool<uint64_t>, // + PoolURBG<uint8_t, 2>, // + PoolURBG<uint16_t, 2>, // + PoolURBG<uint32_t, 2>, // + PoolURBG<uint64_t, 2>, // + PoolURBG<unsigned int, 8>, // NOLINT(runtime/int) + PoolURBG<unsigned long, 8>, // NOLINT(runtime/int) + PoolURBG<unsigned long int, 4>, // NOLINT(runtime/int) + PoolURBG<unsigned long long, 4>>; // NOLINT(runtime/int) + +TYPED_TEST_SUITE(PoolURBGTypedTest, EngineTypes); + +// This test is checks that the engines meet the URBG interface requirements +// defined in [rand.req.urbg]. +TYPED_TEST(PoolURBGTypedTest, URBGInterface) { + using E = TypeParam; + using T = typename E::result_type; + + static_assert(std::is_copy_constructible<E>::value, + "engine must be copy constructible"); + + static_assert(absl::is_copy_assignable<E>::value, + "engine must be copy assignable"); + + E e; + const E x; + + e(); + + static_assert(std::is_same<decltype(e()), T>::value, + "return type of operator() must be result_type"); + + E u0(x); + u0(); + + E u1 = e; + u1(); +} + +// This validates that sequences are independent. +TYPED_TEST(PoolURBGTypedTest, VerifySequences) { + using E = TypeParam; + using result_type = typename E::result_type; + + E rng; + (void)rng(); // Discard one value. + + constexpr int kNumOutputs = 64; + result_type a[kNumOutputs]; + result_type b[kNumOutputs]; + std::fill(std::begin(b), std::end(b), 0); + + // Fill a using Fill or generate, depending on the engine type. + { + E x = rng; + MyFill(x, absl::MakeSpan(a)); + } + + // Fill b using std::generate(). + { + E x = rng; + std::generate(std::begin(b), std::end(b), x); + } + + // Test that generated sequence changed as sequence of bits, i.e. if about + // half of the bites were flipped between two non-correlated values. + size_t changed_bits = 0; + size_t unchanged_bits = 0; + size_t total_set = 0; + size_t total_bits = 0; + size_t equal_count = 0; + for (size_t i = 0; i < kNumOutputs; ++i) { + equal_count += (a[i] == b[i]) ? 1 : 0; + std::bitset<sizeof(result_type) * 8> bitset(a[i] ^ b[i]); + changed_bits += bitset.count(); + unchanged_bits += bitset.size() - bitset.count(); + + std::bitset<sizeof(result_type) * 8> a_set(a[i]); + std::bitset<sizeof(result_type) * 8> b_set(b[i]); + total_set += a_set.count() + b_set.count(); + total_bits += 2 * 8 * sizeof(result_type); + } + // On average, half the bits are changed between two calls. + EXPECT_LE(changed_bits, 0.60 * (changed_bits + unchanged_bits)); + EXPECT_GE(changed_bits, 0.40 * (changed_bits + unchanged_bits)); + + // verify using a quick normal-approximation to the binomial. + EXPECT_NEAR(total_set, total_bits * 0.5, 4 * std::sqrt(total_bits)) + << "@" << total_set / static_cast<double>(total_bits); + + // Also, A[i] == B[i] with probability (1/range) * N. + // Give this a pretty wide latitude, though. + const double kExpected = kNumOutputs / (1.0 * sizeof(result_type) * 8); + EXPECT_LE(equal_count, 1.0 + kExpected); +} + +} // namespace + +/* +$ nanobenchmarks 1 RandenPool construct +$ nanobenchmarks 1 PoolURBG construct + +RandenPool<uint32_t> | 1 | 1000 | 48482.00 ticks | 48.48 ticks | 13.9 ns +RandenPool<uint32_t> | 10 | 2000 | 1028795.00 ticks | 51.44 ticks | 14.7 ns +RandenPool<uint32_t> | 100 | 1000 | 5119968.00 ticks | 51.20 ticks | 14.6 ns +RandenPool<uint32_t> | 1000 | 500 | 25867936.00 ticks | 51.74 ticks | 14.8 ns + +RandenPool<uint64_t> | 1 | 1000 | 49921.00 ticks | 49.92 ticks | 14.3 ns +RandenPool<uint64_t> | 10 | 2000 | 1208269.00 ticks | 60.41 ticks | 17.3 ns +RandenPool<uint64_t> | 100 | 1000 | 5844955.00 ticks | 58.45 ticks | 16.7 ns +RandenPool<uint64_t> | 1000 | 500 | 28767404.00 ticks | 57.53 ticks | 16.4 ns + +PoolURBG<uint32_t,8> | 1 | 1000 | 86431.00 ticks | 86.43 ticks | 24.7 ns +PoolURBG<uint32_t,8> | 10 | 1000 | 206191.00 ticks | 20.62 ticks | 5.9 ns +PoolURBG<uint32_t,8> | 100 | 1000 | 1516049.00 ticks | 15.16 ticks | 4.3 ns +PoolURBG<uint32_t,8> | 1000 | 500 | 7613936.00 ticks | 15.23 ticks | 4.4 ns + +PoolURBG<uint64_t,4> | 1 | 1000 | 96668.00 ticks | 96.67 ticks | 27.6 ns +PoolURBG<uint64_t,4> | 10 | 1000 | 282423.00 ticks | 28.24 ticks | 8.1 ns +PoolURBG<uint64_t,4> | 100 | 1000 | 2609587.00 ticks | 26.10 ticks | 7.5 ns +PoolURBG<uint64_t,4> | 1000 | 500 | 12408757.00 ticks | 24.82 ticks | 7.1 ns + +*/ diff --git a/third_party/abseil_cpp/absl/random/internal/randen.cc b/third_party/abseil_cpp/absl/random/internal/randen.cc new file mode 100644 index 0000000000..78a1e00c08 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen.cc @@ -0,0 +1,91 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen.h" + +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/randen_detect.h" + +// RANDen = RANDom generator or beetroots in Swiss German. +// 'Strong' (well-distributed, unpredictable, backtracking-resistant) random +// generator, faster in some benchmarks than std::mt19937_64 and pcg64_c32. +// +// High-level summary: +// 1) Reverie (see "A Robust and Sponge-Like PRNG with Improved Efficiency") is +// a sponge-like random generator that requires a cryptographic permutation. +// It improves upon "Provably Robust Sponge-Based PRNGs and KDFs" by +// achieving backtracking resistance with only one Permute() per buffer. +// +// 2) "Simpira v2: A Family of Efficient Permutations Using the AES Round +// Function" constructs up to 1024-bit permutations using an improved +// Generalized Feistel network with 2-round AES-128 functions. This Feistel +// block shuffle achieves diffusion faster and is less vulnerable to +// sliced-biclique attacks than the Type-2 cyclic shuffle. +// +// 3) "Improving the Generalized Feistel" and "New criterion for diffusion +// property" extends the same kind of improved Feistel block shuffle to 16 +// branches, which enables a 2048-bit permutation. +// +// We combine these three ideas and also change Simpira's subround keys from +// structured/low-entropy counters to digits of Pi. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +struct RandenState { + const void* keys; + bool has_crypto; +}; + +RandenState GetRandenState() { + static const RandenState state = []() { + RandenState tmp; +#if ABSL_RANDOM_INTERNAL_AES_DISPATCH + // HW AES Dispatch. + if (HasRandenHwAesImplementation() && CPUSupportsRandenHwAes()) { + tmp.has_crypto = true; + tmp.keys = RandenHwAes::GetKeys(); + } else { + tmp.has_crypto = false; + tmp.keys = RandenSlow::GetKeys(); + } +#elif ABSL_HAVE_ACCELERATED_AES + // HW AES is enabled. + tmp.has_crypto = true; + tmp.keys = RandenHwAes::GetKeys(); +#else + // HW AES is disabled. + tmp.has_crypto = false; + tmp.keys = RandenSlow::GetKeys(); +#endif + return tmp; + }(); + return state; +} + +} // namespace + +Randen::Randen() { + auto tmp = GetRandenState(); + keys_ = tmp.keys; +#if ABSL_RANDOM_INTERNAL_AES_DISPATCH + has_crypto_ = tmp.has_crypto; +#endif +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/randen.h b/third_party/abseil_cpp/absl/random/internal/randen.h new file mode 100644 index 0000000000..c2834aaf3d --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen.h @@ -0,0 +1,102 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_RANDEN_H_ +#define ABSL_RANDOM_INTERNAL_RANDEN_H_ + +#include <cstddef> + +#include "absl/random/internal/platform.h" +#include "absl/random/internal/randen_hwaes.h" +#include "absl/random/internal/randen_slow.h" +#include "absl/random/internal/randen_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// RANDen = RANDom generator or beetroots in Swiss German. +// 'Strong' (well-distributed, unpredictable, backtracking-resistant) random +// generator, faster in some benchmarks than std::mt19937_64 and pcg64_c32. +// +// Randen implements the basic state manipulation methods. +class Randen { + public: + static constexpr size_t kStateBytes = RandenTraits::kStateBytes; + static constexpr size_t kCapacityBytes = RandenTraits::kCapacityBytes; + static constexpr size_t kSeedBytes = RandenTraits::kSeedBytes; + + ~Randen() = default; + + Randen(); + + // Generate updates the randen sponge. The outer portion of the sponge + // (kCapacityBytes .. kStateBytes) may be consumed as PRNG state. + template <typename T, size_t N> + void Generate(T (&state)[N]) const { + static_assert(N * sizeof(T) == kStateBytes, + "Randen::Generate() requires kStateBytes of state"); +#if ABSL_RANDOM_INTERNAL_AES_DISPATCH + // HW AES Dispatch. + if (has_crypto_) { + RandenHwAes::Generate(keys_, state); + } else { + RandenSlow::Generate(keys_, state); + } +#elif ABSL_HAVE_ACCELERATED_AES + // HW AES is enabled. + RandenHwAes::Generate(keys_, state); +#else + // HW AES is disabled. + RandenSlow::Generate(keys_, state); +#endif + } + + // Absorb incorporates additional seed material into the randen sponge. After + // absorb returns, Generate must be called before the state may be consumed. + template <typename S, size_t M, typename T, size_t N> + void Absorb(const S (&seed)[M], T (&state)[N]) const { + static_assert(M * sizeof(S) == RandenTraits::kSeedBytes, + "Randen::Absorb() requires kSeedBytes of seed"); + + static_assert(N * sizeof(T) == RandenTraits::kStateBytes, + "Randen::Absorb() requires kStateBytes of state"); +#if ABSL_RANDOM_INTERNAL_AES_DISPATCH + // HW AES Dispatch. + if (has_crypto_) { + RandenHwAes::Absorb(seed, state); + } else { + RandenSlow::Absorb(seed, state); + } +#elif ABSL_HAVE_ACCELERATED_AES + // HW AES is enabled. + RandenHwAes::Absorb(seed, state); +#else + // HW AES is disabled. + RandenSlow::Absorb(seed, state); +#endif + } + + private: + const void* keys_; +#if ABSL_RANDOM_INTERNAL_AES_DISPATCH + bool has_crypto_; +#endif +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_RANDEN_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/randen_benchmarks.cc b/third_party/abseil_cpp/absl/random/internal/randen_benchmarks.cc new file mode 100644 index 0000000000..f589172c04 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_benchmarks.cc @@ -0,0 +1,174 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#include "absl/random/internal/randen.h" + +#include <cstdint> +#include <cstdio> +#include <cstring> + +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/nanobenchmark.h" +#include "absl/random/internal/platform.h" +#include "absl/random/internal/randen_engine.h" +#include "absl/random/internal/randen_hwaes.h" +#include "absl/random/internal/randen_slow.h" +#include "absl/strings/numbers.h" + +namespace { + +using absl::random_internal::Randen; +using absl::random_internal::RandenHwAes; +using absl::random_internal::RandenSlow; + +using absl::random_internal_nanobenchmark::FuncInput; +using absl::random_internal_nanobenchmark::FuncOutput; +using absl::random_internal_nanobenchmark::InvariantTicksPerSecond; +using absl::random_internal_nanobenchmark::MeasureClosure; +using absl::random_internal_nanobenchmark::Params; +using absl::random_internal_nanobenchmark::PinThreadToCPU; +using absl::random_internal_nanobenchmark::Result; + +// Local state parameters. +static constexpr size_t kStateSizeT = Randen::kStateBytes / sizeof(uint64_t); +static constexpr size_t kSeedSizeT = Randen::kSeedBytes / sizeof(uint32_t); + +// Randen implementation benchmarks. +template <typename T> +struct AbsorbFn : public T { + mutable uint64_t state[kStateSizeT] = {}; + mutable uint32_t seed[kSeedSizeT] = {}; + + static constexpr size_t bytes() { return sizeof(seed); } + + FuncOutput operator()(const FuncInput num_iters) const { + for (size_t i = 0; i < num_iters; ++i) { + this->Absorb(seed, state); + } + return state[0]; + } +}; + +template <typename T> +struct GenerateFn : public T { + mutable uint64_t state[kStateSizeT]; + GenerateFn() { std::memset(state, 0, sizeof(state)); } + + static constexpr size_t bytes() { return sizeof(state); } + + FuncOutput operator()(const FuncInput num_iters) const { + const auto* keys = this->GetKeys(); + for (size_t i = 0; i < num_iters; ++i) { + this->Generate(keys, state); + } + return state[0]; + } +}; + +template <typename UInt> +struct Engine { + mutable absl::random_internal::randen_engine<UInt> rng; + + static constexpr size_t bytes() { return sizeof(UInt); } + + FuncOutput operator()(const FuncInput num_iters) const { + for (size_t i = 0; i < num_iters - 1; ++i) { + rng(); + } + return rng(); + } +}; + +template <size_t N> +void Print(const char* name, const size_t n, const Result (&results)[N], + const size_t bytes) { + if (n == 0) { + ABSL_RAW_LOG( + WARNING, + "WARNING: Measurement failed, should not happen when using " + "PinThreadToCPU unless the region to measure takes > 1 second.\n"); + return; + } + + static const double ns_per_tick = 1e9 / InvariantTicksPerSecond(); + static constexpr const double kNsPerS = 1e9; // ns/s + static constexpr const double kMBPerByte = 1.0 / 1048576.0; // Mb / b + static auto header = [] { + return printf("%20s %8s: %12s ticks; %9s (%9s) %8s\n", "Name", "Count", + "Total", "Variance", "Time", "bytes/s"); + }(); + (void)header; + + for (size_t i = 0; i < n; ++i) { + const double ticks_per_call = results[i].ticks / results[i].input; + const double ns_per_call = ns_per_tick * ticks_per_call; + const double bytes_per_ns = bytes / ns_per_call; + const double mb_per_s = bytes_per_ns * kNsPerS * kMBPerByte; + // Output + printf("%20s %8zu: %12.2f ticks; MAD=%4.2f%% (%6.1f ns) %8.1f Mb/s\n", + name, results[i].input, results[i].ticks, + results[i].variability * 100.0, ns_per_call, mb_per_s); + } +} + +// Fails here +template <typename Op, size_t N> +void Measure(const char* name, const FuncInput (&inputs)[N]) { + Op op; + + Result results[N]; + Params params; + params.verbose = false; + params.max_evals = 6; // avoid test timeout + const size_t num_results = MeasureClosure(op, inputs, N, results, params); + Print(name, num_results, results, op.bytes()); +} + +// unpredictable == 1 but the compiler does not know that. +void RunAll(const int argc, char* argv[]) { + if (argc == 2) { + int cpu = -1; + if (!absl::SimpleAtoi(argv[1], &cpu)) { + ABSL_RAW_LOG(FATAL, "The optional argument must be a CPU number >= 0.\n"); + } + PinThreadToCPU(cpu); + } + + // The compiler cannot reduce this to a constant. + const FuncInput unpredictable = (argc != 999); + static const FuncInput inputs[] = {unpredictable * 100, unpredictable * 1000}; + +#if !defined(ABSL_INTERNAL_DISABLE_AES) && ABSL_HAVE_ACCELERATED_AES + Measure<AbsorbFn<RandenHwAes>>("Absorb (HwAes)", inputs); +#endif + Measure<AbsorbFn<RandenSlow>>("Absorb (Slow)", inputs); + +#if !defined(ABSL_INTERNAL_DISABLE_AES) && ABSL_HAVE_ACCELERATED_AES + Measure<GenerateFn<RandenHwAes>>("Generate (HwAes)", inputs); +#endif + Measure<GenerateFn<RandenSlow>>("Generate (Slow)", inputs); + + // Measure the production engine. + static const FuncInput inputs1[] = {unpredictable * 1000, + unpredictable * 10000}; + Measure<Engine<uint64_t>>("randen_engine<uint64_t>", inputs1); + Measure<Engine<uint32_t>>("randen_engine<uint32_t>", inputs1); +} + +} // namespace + +int main(int argc, char* argv[]) { + RunAll(argc, argv); + return 0; +} diff --git a/third_party/abseil_cpp/absl/random/internal/randen_detect.cc b/third_party/abseil_cpp/absl/random/internal/randen_detect.cc new file mode 100644 index 0000000000..d63230c255 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_detect.cc @@ -0,0 +1,221 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the"License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an"AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// HERMETIC NOTE: The randen_hwaes target must not introduce duplicate +// symbols from arbitrary system and other headers, since it may be built +// with different flags from other targets, using different levels of +// optimization, potentially introducing ODR violations. + +#include "absl/random/internal/randen_detect.h" + +#include <cstdint> +#include <cstring> + +#include "absl/random/internal/platform.h" + +#if defined(ABSL_ARCH_X86_64) +#define ABSL_INTERNAL_USE_X86_CPUID +#elif defined(ABSL_ARCH_PPC) || defined(ABSL_ARCH_ARM) || \ + defined(ABSL_ARCH_AARCH64) +#if defined(__ANDROID__) +#define ABSL_INTERNAL_USE_ANDROID_GETAUXVAL +#define ABSL_INTERNAL_USE_GETAUXVAL +#elif defined(__linux__) +#define ABSL_INTERNAL_USE_LINUX_GETAUXVAL +#define ABSL_INTERNAL_USE_GETAUXVAL +#endif +#endif + +#if defined(ABSL_INTERNAL_USE_X86_CPUID) +#if defined(_WIN32) || defined(_WIN64) +#include <intrin.h> // NOLINT(build/include_order) +#pragma intrinsic(__cpuid) +#else +// MSVC-equivalent __cpuid intrinsic function. +static void __cpuid(int cpu_info[4], int info_type) { + __asm__ volatile("cpuid \n\t" + : "=a"(cpu_info[0]), "=b"(cpu_info[1]), "=c"(cpu_info[2]), + "=d"(cpu_info[3]) + : "a"(info_type), "c"(0)); +} +#endif +#endif // ABSL_INTERNAL_USE_X86_CPUID + +// On linux, just use the c-library getauxval call. +#if defined(ABSL_INTERNAL_USE_LINUX_GETAUXVAL) + +extern "C" unsigned long getauxval(unsigned long type); // NOLINT(runtime/int) + +static uint32_t GetAuxval(uint32_t hwcap_type) { + return static_cast<uint32_t>(getauxval(hwcap_type)); +} + +#endif + +// On android, probe the system's C library for getauxval(). +// This is the same technique used by the android NDK cpu features library +// as well as the google open-source cpu_features library. +// +// TODO(absl-team): Consider implementing a fallback of directly reading +// /proc/self/auxval. +#if defined(ABSL_INTERNAL_USE_ANDROID_GETAUXVAL) +#include <dlfcn.h> + +static uint32_t GetAuxval(uint32_t hwcap_type) { + // NOLINTNEXTLINE(runtime/int) + typedef unsigned long (*getauxval_func_t)(unsigned long); + + dlerror(); // Cleaning error state before calling dlopen. + void* libc_handle = dlopen("libc.so", RTLD_NOW); + if (!libc_handle) { + return 0; + } + uint32_t result = 0; + void* sym = dlsym(libc_handle, "getauxval"); + if (sym) { + getauxval_func_t func; + memcpy(&func, &sym, sizeof(func)); + result = static_cast<uint32_t>((*func)(hwcap_type)); + } + dlclose(libc_handle); + return result; +} + +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// The default return at the end of the function might be unreachable depending +// on the configuration. Ignore that warning. +#if defined(__clang__) +#pragma clang diagnostic push +#pragma clang diagnostic ignored "-Wunreachable-code-return" +#endif + +// CPUSupportsRandenHwAes returns whether the CPU is a microarchitecture +// which supports the crpyto/aes instructions or extensions necessary to use the +// accelerated RandenHwAes implementation. +// +// 1. For x86 it is sufficient to use the CPUID instruction to detect whether +// the cpu supports AES instructions. Done. +// +// Fon non-x86 it is much more complicated. +// +// 2. When ABSL_INTERNAL_USE_GETAUXVAL is defined, use getauxval() (either +// the direct c-library version, or the android probing version which loads +// libc), and read the hardware capability bits. +// This is based on the technique used by boringssl uses to detect +// cpu capabilities, and should allow us to enable crypto in the android +// builds where it is supported. +// +// 3. Use the default for the compiler architecture. +// + +bool CPUSupportsRandenHwAes() { +#if defined(ABSL_INTERNAL_USE_X86_CPUID) + // 1. For x86: Use CPUID to detect the required AES instruction set. + int regs[4]; + __cpuid(reinterpret_cast<int*>(regs), 1); + return regs[2] & (1 << 25); // AES + +#elif defined(ABSL_INTERNAL_USE_GETAUXVAL) + // 2. Use getauxval() to read the hardware bits and determine + // cpu capabilities. + +#define AT_HWCAP 16 +#define AT_HWCAP2 26 +#if defined(ABSL_ARCH_PPC) + // For Power / PPC: Expect that the cpu supports VCRYPTO + // See https://members.openpowerfoundation.org/document/dl/576 + // VCRYPTO should be present in POWER8 >= 2.07. + // Uses Linux kernel constants from arch/powerpc/include/uapi/asm/cputable.h + static const uint32_t kVCRYPTO = 0x02000000; + const uint32_t hwcap = GetAuxval(AT_HWCAP2); + return (hwcap & kVCRYPTO) != 0; + +#elif defined(ABSL_ARCH_ARM) + // For ARM: Require crypto+neon + // http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0500f/CIHBIBBA.html + // Uses Linux kernel constants from arch/arm64/include/asm/hwcap.h + static const uint32_t kNEON = 1 << 12; + uint32_t hwcap = GetAuxval(AT_HWCAP); + if ((hwcap & kNEON) == 0) { + return false; + } + + // And use it again to detect AES. + static const uint32_t kAES = 1 << 0; + const uint32_t hwcap2 = GetAuxval(AT_HWCAP2); + return (hwcap2 & kAES) != 0; + +#elif defined(ABSL_ARCH_AARCH64) + // For AARCH64: Require crypto+neon + // http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0500f/CIHBIBBA.html + static const uint32_t kNEON = 1 << 1; + static const uint32_t kAES = 1 << 3; + const uint32_t hwcap = GetAuxval(AT_HWCAP); + return ((hwcap & kNEON) != 0) && ((hwcap & kAES) != 0); +#endif + +#else // ABSL_INTERNAL_USE_GETAUXVAL + // 3. By default, assume that the compiler default. + return ABSL_HAVE_ACCELERATED_AES ? true : false; + +#endif + // NOTE: There are some other techniques that may be worth trying: + // + // * Use an environment variable: ABSL_RANDOM_USE_HWAES + // + // * Rely on compiler-generated target-based dispatch. + // Using x86/gcc it might look something like this: + // + // int __attribute__((target("aes"))) HasAes() { return 1; } + // int __attribute__((target("default"))) HasAes() { return 0; } + // + // This does not work on all architecture/compiler combinations. + // + // * On Linux consider reading /proc/cpuinfo and/or /proc/self/auxv. + // These files have lines which are easy to parse; for ARM/AARCH64 it is quite + // easy to find the Features: line and extract aes / neon. Likewise for + // PPC. + // + // * Fork a process and test for SIGILL: + // + // * Many architectures have instructions to read the ISA. Unfortunately + // most of those require that the code is running in ring 0 / + // protected-mode. + // + // There are several examples. e.g. Valgrind detects PPC ISA 2.07: + // https://github.com/lu-zero/valgrind/blob/master/none/tests/ppc64/test_isa_2_07_part1.c + // + // MRS <Xt>, ID_AA64ISAR0_EL1 ; Read ID_AA64ISAR0_EL1 into Xt + // + // uint64_t val; + // __asm __volatile("mrs %0, id_aa64isar0_el1" :"=&r" (val)); + // + // * Use a CPUID-style heuristic database. + // + // * On Apple (__APPLE__), AES is available on Arm v8. + // https://stackoverflow.com/questions/45637888/how-to-determine-armv8-features-at-runtime-on-ios +} + +#if defined(__clang__) +#pragma clang diagnostic pop +#endif + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/randen_detect.h b/third_party/abseil_cpp/absl/random/internal/randen_detect.h new file mode 100644 index 0000000000..f283f43226 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_detect.h @@ -0,0 +1,33 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_RANDEN_DETECT_H_ +#define ABSL_RANDOM_INTERNAL_RANDEN_DETECT_H_ + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Returns whether the current CPU supports RandenHwAes implementation. +// This typically involves supporting cryptographic extensions on whichever +// platform is currently running. +bool CPUSupportsRandenHwAes(); + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_RANDEN_DETECT_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/randen_engine.h b/third_party/abseil_cpp/absl/random/internal/randen_engine.h new file mode 100644 index 0000000000..6b33731336 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_engine.h @@ -0,0 +1,230 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_RANDEN_ENGINE_H_ +#define ABSL_RANDOM_INTERNAL_RANDEN_ENGINE_H_ + +#include <algorithm> +#include <cinttypes> +#include <cstdlib> +#include <iostream> +#include <iterator> +#include <limits> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/random/internal/iostream_state_saver.h" +#include "absl/random/internal/randen.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Deterministic pseudorandom byte generator with backtracking resistance +// (leaking the state does not compromise prior outputs). Based on Reverie +// (see "A Robust and Sponge-Like PRNG with Improved Efficiency") instantiated +// with an improved Simpira-like permutation. +// Returns values of type "T" (must be a built-in unsigned integer type). +// +// RANDen = RANDom generator or beetroots in Swiss High German. +// 'Strong' (well-distributed, unpredictable, backtracking-resistant) random +// generator, faster in some benchmarks than std::mt19937_64 and pcg64_c32. +template <typename T> +class alignas(16) randen_engine { + public: + // C++11 URBG interface: + using result_type = T; + static_assert(std::is_unsigned<result_type>::value, + "randen_engine template argument must be a built-in unsigned " + "integer type"); + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + explicit randen_engine(result_type seed_value = 0) { seed(seed_value); } + + template <class SeedSequence, + typename = typename absl::enable_if_t< + !std::is_same<SeedSequence, randen_engine>::value>> + explicit randen_engine(SeedSequence&& seq) { + seed(seq); + } + + randen_engine(const randen_engine&) = default; + + // Returns random bits from the buffer in units of result_type. + result_type operator()() { + // Refill the buffer if needed (unlikely). + if (next_ >= kStateSizeT) { + next_ = kCapacityT; + impl_.Generate(state_); + } + + return state_[next_++]; + } + + template <class SeedSequence> + typename absl::enable_if_t< + !std::is_convertible<SeedSequence, result_type>::value> + seed(SeedSequence&& seq) { + // Zeroes the state. + seed(); + reseed(seq); + } + + void seed(result_type seed_value = 0) { + next_ = kStateSizeT; + // Zeroes the inner state and fills the outer state with seed_value to + // mimics behaviour of reseed + std::fill(std::begin(state_), std::begin(state_) + kCapacityT, 0); + std::fill(std::begin(state_) + kCapacityT, std::end(state_), seed_value); + } + + // Inserts entropy into (part of) the state. Calling this periodically with + // sufficient entropy ensures prediction resistance (attackers cannot predict + // future outputs even if state is compromised). + template <class SeedSequence> + void reseed(SeedSequence& seq) { + using sequence_result_type = typename SeedSequence::result_type; + static_assert(sizeof(sequence_result_type) == 4, + "SeedSequence::result_type must be 32-bit"); + + constexpr size_t kBufferSize = + Randen::kSeedBytes / sizeof(sequence_result_type); + alignas(16) sequence_result_type buffer[kBufferSize]; + + // Randen::Absorb XORs the seed into state, which is then mixed by a call + // to Randen::Generate. Seeding with only the provided entropy is preferred + // to using an arbitrary generate() call, so use [rand.req.seed_seq] + // size as a proxy for the number of entropy units that can be generated + // without relying on seed sequence mixing... + const size_t entropy_size = seq.size(); + if (entropy_size < kBufferSize) { + // ... and only request that many values, or 256-bits, when unspecified. + const size_t requested_entropy = (entropy_size == 0) ? 8u : entropy_size; + std::fill(std::begin(buffer) + requested_entropy, std::end(buffer), 0); + seq.generate(std::begin(buffer), std::begin(buffer) + requested_entropy); + // The Randen paper suggests preferentially initializing even-numbered + // 128-bit vectors of the randen state (there are 16 such vectors). + // The seed data is merged into the state offset by 128-bits, which + // implies prefering seed bytes [16..31, ..., 208..223]. Since the + // buffer is 32-bit values, we swap the corresponding buffer positions in + // 128-bit chunks. + size_t dst = kBufferSize; + while (dst > 7) { + // leave the odd bucket as-is. + dst -= 4; + size_t src = dst >> 1; + // swap 128-bits into the even bucket + std::swap(buffer[--dst], buffer[--src]); + std::swap(buffer[--dst], buffer[--src]); + std::swap(buffer[--dst], buffer[--src]); + std::swap(buffer[--dst], buffer[--src]); + } + } else { + seq.generate(std::begin(buffer), std::end(buffer)); + } + impl_.Absorb(buffer, state_); + + // Generate will be called when operator() is called + next_ = kStateSizeT; + } + + void discard(uint64_t count) { + uint64_t step = std::min<uint64_t>(kStateSizeT - next_, count); + count -= step; + + constexpr uint64_t kRateT = kStateSizeT - kCapacityT; + while (count > 0) { + next_ = kCapacityT; + impl_.Generate(state_); + step = std::min<uint64_t>(kRateT, count); + count -= step; + } + next_ += step; + } + + bool operator==(const randen_engine& other) const { + return next_ == other.next_ && + std::equal(std::begin(state_), std::end(state_), + std::begin(other.state_)); + } + + bool operator!=(const randen_engine& other) const { + return !(*this == other); + } + + template <class CharT, class Traits> + friend std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const randen_engine<T>& engine) { // NOLINT(runtime/references) + using numeric_type = + typename random_internal::stream_format_type<result_type>::type; + auto saver = random_internal::make_ostream_state_saver(os); + for (const auto& elem : engine.state_) { + // In the case that `elem` is `uint8_t`, it must be cast to something + // larger so that it prints as an integer rather than a character. For + // simplicity, apply the cast all circumstances. + os << static_cast<numeric_type>(elem) << os.fill(); + } + os << engine.next_; + return os; + } + + template <class CharT, class Traits> + friend std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + randen_engine<T>& engine) { // NOLINT(runtime/references) + using numeric_type = + typename random_internal::stream_format_type<result_type>::type; + result_type state[kStateSizeT]; + size_t next; + for (auto& elem : state) { + // It is not possible to read uint8_t from wide streams, so it is + // necessary to read a wider type and then cast it to uint8_t. + numeric_type value; + is >> value; + elem = static_cast<result_type>(value); + } + is >> next; + if (is.fail()) { + return is; + } + std::memcpy(engine.state_, state, sizeof(engine.state_)); + engine.next_ = next; + return is; + } + + private: + static constexpr size_t kStateSizeT = + Randen::kStateBytes / sizeof(result_type); + static constexpr size_t kCapacityT = + Randen::kCapacityBytes / sizeof(result_type); + + // First kCapacityT are `inner', the others are accessible random bits. + alignas(16) result_type state_[kStateSizeT]; + size_t next_; // index within state_ + Randen impl_; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_RANDEN_ENGINE_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/randen_engine_test.cc b/third_party/abseil_cpp/absl/random/internal/randen_engine_test.cc new file mode 100644 index 0000000000..c8e7685bdd --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_engine_test.cc @@ -0,0 +1,656 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen_engine.h" + +#include <algorithm> +#include <bitset> +#include <random> +#include <sstream> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/explicit_seed_seq.h" +#include "absl/strings/str_cat.h" +#include "absl/time/clock.h" + +#define UPDATE_GOLDEN 0 + +using randen_u64 = absl::random_internal::randen_engine<uint64_t>; +using randen_u32 = absl::random_internal::randen_engine<uint32_t>; +using absl::random_internal::ExplicitSeedSeq; + +namespace { + +template <typename UIntType> +class RandenEngineTypedTest : public ::testing::Test {}; + +using UIntTypes = ::testing::Types<uint8_t, uint16_t, uint32_t, uint64_t>; + +TYPED_TEST_SUITE(RandenEngineTypedTest, UIntTypes); + +TYPED_TEST(RandenEngineTypedTest, VerifyReseedChangesAllValues) { + using randen = typename absl::random_internal::randen_engine<TypeParam>; + using result_type = typename randen::result_type; + + const size_t kNumOutputs = (sizeof(randen) * 2 / sizeof(TypeParam)) + 1; + randen engine; + + // MSVC emits error 2719 without the use of std::ref below. + // * formal parameter with __declspec(align('#')) won't be aligned + + { + std::seed_seq seq1{1, 2, 3, 4, 5, 6, 7}; + engine.seed(seq1); + } + result_type a[kNumOutputs]; + std::generate(std::begin(a), std::end(a), std::ref(engine)); + + { + std::random_device rd; + std::seed_seq seq2{rd(), rd(), rd()}; + engine.seed(seq2); + } + result_type b[kNumOutputs]; + std::generate(std::begin(b), std::end(b), std::ref(engine)); + + // Test that generated sequence changed as sequence of bits, i.e. if about + // half of the bites were flipped between two non-correlated values. + size_t changed_bits = 0; + size_t unchanged_bits = 0; + size_t total_set = 0; + size_t total_bits = 0; + size_t equal_count = 0; + for (size_t i = 0; i < kNumOutputs; ++i) { + equal_count += (a[i] == b[i]) ? 1 : 0; + std::bitset<sizeof(result_type) * 8> bitset(a[i] ^ b[i]); + changed_bits += bitset.count(); + unchanged_bits += bitset.size() - bitset.count(); + + std::bitset<sizeof(result_type) * 8> a_set(a[i]); + std::bitset<sizeof(result_type) * 8> b_set(b[i]); + total_set += a_set.count() + b_set.count(); + total_bits += 2 * 8 * sizeof(result_type); + } + // On average, half the bits are changed between two calls. + EXPECT_LE(changed_bits, 0.60 * (changed_bits + unchanged_bits)); + EXPECT_GE(changed_bits, 0.40 * (changed_bits + unchanged_bits)); + + // Verify using a quick normal-approximation to the binomial. + EXPECT_NEAR(total_set, total_bits * 0.5, 4 * std::sqrt(total_bits)) + << "@" << total_set / static_cast<double>(total_bits); + + // Also, A[i] == B[i] with probability (1/range) * N. + // Give this a pretty wide latitude, though. + const double kExpected = kNumOutputs / (1.0 * sizeof(result_type) * 8); + EXPECT_LE(equal_count, 1.0 + kExpected); +} + +// Number of values that needs to be consumed to clean two sizes of buffer +// and trigger third refresh. (slightly overestimates the actual state size). +constexpr size_t kTwoBufferValues = sizeof(randen_u64) / sizeof(uint16_t) + 1; + +TYPED_TEST(RandenEngineTypedTest, VerifyDiscard) { + using randen = typename absl::random_internal::randen_engine<TypeParam>; + + for (size_t num_used = 0; num_used < kTwoBufferValues; ++num_used) { + randen engine_used; + for (size_t i = 0; i < num_used; ++i) { + engine_used(); + } + + for (size_t num_discard = 0; num_discard < kTwoBufferValues; + ++num_discard) { + randen engine1 = engine_used; + randen engine2 = engine_used; + for (size_t i = 0; i < num_discard; ++i) { + engine1(); + } + engine2.discard(num_discard); + for (size_t i = 0; i < kTwoBufferValues; ++i) { + const auto r1 = engine1(); + const auto r2 = engine2(); + ASSERT_EQ(r1, r2) << "used=" << num_used << " discard=" << num_discard; + } + } + } +} + +TYPED_TEST(RandenEngineTypedTest, StreamOperatorsResult) { + using randen = typename absl::random_internal::randen_engine<TypeParam>; + std::wostringstream os; + std::wistringstream is; + randen engine; + + EXPECT_EQ(&(os << engine), &os); + EXPECT_EQ(&(is >> engine), &is); +} + +TYPED_TEST(RandenEngineTypedTest, StreamSerialization) { + using randen = typename absl::random_internal::randen_engine<TypeParam>; + + for (size_t discard = 0; discard < kTwoBufferValues; ++discard) { + ExplicitSeedSeq seed_sequence{12, 34, 56}; + randen engine(seed_sequence); + engine.discard(discard); + + std::stringstream stream; + stream << engine; + + randen new_engine; + stream >> new_engine; + for (size_t i = 0; i < 64; ++i) { + EXPECT_EQ(engine(), new_engine()) << " " << i; + } + } +} + +constexpr size_t kNumGoldenOutputs = 127; + +// This test is checking if randen_engine is meets interface requirements +// defined in [rand.req.urbg]. +TYPED_TEST(RandenEngineTypedTest, RandomNumberEngineInterface) { + using randen = typename absl::random_internal::randen_engine<TypeParam>; + + using E = randen; + using T = typename E::result_type; + + static_assert(std::is_copy_constructible<E>::value, + "randen_engine must be copy constructible"); + + static_assert(absl::is_copy_assignable<E>::value, + "randen_engine must be copy assignable"); + + static_assert(std::is_move_constructible<E>::value, + "randen_engine must be move constructible"); + + static_assert(absl::is_move_assignable<E>::value, + "randen_engine must be move assignable"); + + static_assert(std::is_same<decltype(std::declval<E>()()), T>::value, + "return type of operator() must be result_type"); + + // Names after definition of [rand.req.urbg] in C++ standard. + // e us a value of E + // v is a lvalue of E + // x, y are possibly const values of E + // s is a value of T + // q is a value satisfying requirements of seed_sequence + // z is a value of type unsigned long long + // os is a some specialization of basic_ostream + // is is a some specialization of basic_istream + + E e, v; + const E x, y; + T s = 1; + std::seed_seq q{1, 2, 3}; + unsigned long long z = 1; // NOLINT(runtime/int) + std::wostringstream os; + std::wistringstream is; + + E{}; + E{x}; + E{s}; + E{q}; + + e.seed(); + + // MSVC emits error 2718 when using EXPECT_EQ(e, x) + // * actual parameter with __declspec(align('#')) won't be aligned + EXPECT_TRUE(e == x); + + e.seed(q); + { + E tmp(q); + EXPECT_TRUE(e == tmp); + } + + e(); + { + E tmp(q); + EXPECT_TRUE(e != tmp); + } + + e.discard(z); + + static_assert(std::is_same<decltype(x == y), bool>::value, + "return type of operator== must be bool"); + + static_assert(std::is_same<decltype(x != y), bool>::value, + "return type of operator== must be bool"); +} + +TYPED_TEST(RandenEngineTypedTest, RandenEngineSFINAETest) { + using randen = typename absl::random_internal::randen_engine<TypeParam>; + using result_type = typename randen::result_type; + + { + randen engine(result_type(1)); + engine.seed(result_type(1)); + } + + { + result_type n = 1; + randen engine(n); + engine.seed(n); + } + + { + randen engine(1); + engine.seed(1); + } + + { + int n = 1; + randen engine(n); + engine.seed(n); + } + + { + std::seed_seq seed_seq; + randen engine(seed_seq); + engine.seed(seed_seq); + } + + { + randen engine{std::seed_seq()}; + engine.seed(std::seed_seq()); + } +} + +TEST(RandenTest, VerifyGoldenRanden64Default) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0xc3c14f134e433977, 0xdda9f47cd90410ee, 0x887bf3087fd8ca10, + 0xf0b780f545c72912, 0x15dbb1d37696599f, 0x30ec63baff3c6d59, + 0xb29f73606f7f20a6, 0x02808a316f49a54c, 0x3b8feaf9d5c8e50e, + 0x9cbf605e3fd9de8a, 0xc970ae1a78183bbb, 0xd8b2ffd356301ed5, + 0xf4b327fe0fc73c37, 0xcdfd8d76eb8f9a19, 0xc3a506eb91420c9d, + 0xd5af05dd3eff9556, 0x48db1bb78f83c4a1, 0x7023920e0d6bfe8c, + 0x58d3575834956d42, 0xed1ef4c26b87b840, 0x8eef32a23e0b2df3, + 0x497cabf3431154fc, 0x4e24370570029a8b, 0xd88b5749f090e5ea, + 0xc651a582a970692f, 0x78fcec2cbb6342f5, 0x463cb745612f55db, + 0x352ee4ad1816afe3, 0x026ff374c101da7e, 0x811ef0821c3de851, + 0x6f7e616704c4fa59, 0xa0660379992d58fc, 0x04b0a374a3b795c7, + 0x915f3445685da798, 0x26802a8ac76571ce, 0x4663352533ce1882, + 0xb9fdefb4a24dc738, 0x5588ba3a4d6e6c51, 0xa2101a42d35f1956, + 0x607195a5e200f5fd, 0x7e100308f3290764, 0xe1e5e03c759c0709, + 0x082572cc5da6606f, 0xcbcf585399e432f1, 0xe8a2be4f8335d8f1, + 0x0904469acbfee8f2, 0xf08bd31b6daecd51, 0x08e8a1f1a69da69a, + 0x6542a20aad57bff5, 0x2e9705bb053d6b46, 0xda2fc9db0713c391, + 0x78e3a810213b6ffb, 0xdc16a59cdd85f8a6, 0xc0932718cd55781f, + 0xb9bfb29c2b20bfe5, 0xb97289c1be0f2f9c, 0xc0a2a0e403a892d4, + 0x5524bb834771435b, 0x8265da3d39d1a750, 0xff4af3ab8d1b78c5, + 0xf0ec5f424bcad77f, 0x66e455f627495189, 0xc82d3120b57e3270, + 0x3424e47dc22596e3, 0xbc0c95129ccedcdd, 0xc191c595afc4dcbf, + 0x120392bd2bb70939, 0x7f90650ea6cd6ab4, 0x7287491832695ad3, + 0xa7c8fac5a7917eb0, 0xd088cb9418be0361, 0x7c1bf9839c7c1ce5, + 0xe2e991fa58e1e79e, 0x78565cdefd28c4ad, 0x7351b9fef98bafad, + 0x2a9eac28b08c96bf, 0x6c4f179696cb2225, 0x13a685861bab87e0, + 0x64c6de5aa0501971, 0x30537425cac70991, 0x01590d9dc6c532b7, + 0x7e05e3aa8ec720dc, 0x74a07d9c54e3e63f, 0x738184388f3bc1d2, + 0x26ffdc5067be3acb, 0x6bcdf185561f255f, 0xa0eaf2e1cf99b1c6, + 0x171df81934f68604, 0x7ea5a21665683e5a, 0x5d1cb02075ba1cea, + 0x957f38cbd2123fdf, 0xba6364eff80de02f, 0x606e0a0e41d452ee, + 0x892d8317de82f7a2, 0xe707b1db50f7b43e, 0x4eb28826766fcf5b, + 0x5a362d56e80a0951, 0x6ee217df16527d78, 0xf6737962ba6b23dd, + 0x443e63857d4076ca, 0x790d9a5f048adfeb, 0xd796b052151ee94d, + 0x033ed95c12b04a03, 0x8b833ff84893da5d, 0x3d6724b1bb15eab9, + 0x9877c4225061ca76, 0xd68d6810adf74fb3, 0x42e5352fe30ce989, + 0x265b565a7431fde7, 0x3cdbf7e358df4b8b, 0x2922a47f6d3e8779, + 0x52d2242f65b37f88, 0x5d836d6e2958d6b5, 0x29d40f00566d5e26, + 0x288db0e1124b14a0, 0x6c056608b7d9c1b6, 0x0b9471bdb8f19d32, + 0x8fb946504faa6c9d, 0x8943a9464540251c, 0xfd1fe27d144a09e0, + 0xea6ac458da141bda, 0x8048f217633fce36, 0xfeda1384ade74d31, + 0x4334b8b02ff7612f, 0xdbc8441f5227e216, 0x096d119a3605c85b, + 0x2b72b31c21b7d7d0}; + + randen_u64 engine; +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%016lx, ", engine()); + if (i % 3 == 2) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(RandenTest, VerifyGoldenRanden64Seeded) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0x83a9e58f94d3dcd5, 0x70bbdff3d97949fb, 0x0438481f7471c1b4, + 0x34fdc58ee5fb5930, 0xceee4f2d2a937d17, 0xb5a26a68e432aea9, + 0x8b64774a3fb51740, 0xd89ac1fc74249c74, 0x03910d1d23fc3fdf, + 0xd38f630878aa897f, 0x0ee8f0f5615f7e44, 0x98f5a53df8279d52, + 0xb403f52c25938d0e, 0x240072996ea6e838, 0xd3a791246190fa61, + 0xaaedd3df7a7b4f80, 0xc6eacabe05deaf6e, 0xb7967dd8790edf4d, + 0x9a0a8e67e049d279, 0x0494f606aebc23e7, 0x598dcd687bc3e0ee, + 0x010ac81802d452a1, 0x6407c87160aa2842, 0x5a56e276486f93a0, + 0xc887a399d46a8f02, 0x9e1e6100fe93b740, 0x12d02e330f8901f6, + 0xc39ca52b47e790b7, 0xb0b0a2fa11e82e61, 0x1542d841a303806a, + 0x1fe659fd7d6e9d86, 0xb8c90d80746541ac, 0x239d56a5669ddc94, + 0xd40db57c8123d13c, 0x3abc2414153a0db0, 0x9bad665630cb8d61, + 0x0bd1fb90ee3f4bbc, 0x8f0b4d7e079b4e42, 0xfa0fb0e0ee59e793, + 0x51080b283e071100, 0x2c4b9e715081cc15, 0xbe10ed49de4941df, + 0xf8eaac9d4b1b0d37, 0x4bcce4b54605e139, 0xa64722b76765dda6, + 0xb9377d738ca28ab5, 0x779fad81a8ccc1af, 0x65cb3ee61ffd3ba7, + 0xd74e79087862836f, 0xd05b9c584c3f25bf, 0x2ba93a4693579827, + 0xd81530aff05420ce, 0xec06cea215478621, 0x4b1798a6796d65ad, + 0xf142f3fb3a6f6fa6, 0x002b7bf7e237b560, 0xf47f2605ef65b4f8, + 0x9804ec5517effc18, 0xaed3d7f8b7d481cd, 0x5651c24c1ce338d1, + 0x3e7a38208bf0a3c6, 0x6796a7b614534aed, 0x0d0f3b848358460f, + 0x0fa5fe7600b19524, 0x2b0cf38253faaedc, 0x10df9188233a9fd6, + 0x3a10033880138b59, 0x5fb0b0d23948e80f, 0x9e76f7b02fbf5350, + 0x0816052304b1a985, 0x30c9880db41fd218, 0x14aa399b65e20f28, + 0xe1454a8cace787b4, 0x325ac971b6c6f0f5, 0x716b1aa2784f3d36, + 0x3d5ce14accfd144f, 0x6c0c97710f651792, 0xbc5b0f59fb333532, + 0x2a90a7d2140470bc, 0x8da269f55c1e1c8d, 0xcfc37143895792ca, + 0xbe21eab1f30b238f, 0x8c47229dee4d65fd, 0x5743614ed1ed7d54, + 0x351372a99e9c476e, 0x2bd5ea15e5db085f, 0x6925fde46e0af4ca, + 0xed3eda2bdc1f45bd, 0xdef68c68d460fa6e, 0xe42a0de76253e2b5, + 0x4e5176dcbc29c305, 0xbfd85fba9f810f6e, 0x76a5a2a9beb815c6, + 0x01edc4ddceaf414c, 0xa4e98904b4bb3b4b, 0x00bd63ac7d2f1ddd, + 0xb8491fe6e998ddbb, 0xb386a3463dda6800, 0x0081887688871619, + 0x33d394b3344e9a38, 0x815dba65a3a8baf9, 0x4232f6ec02c2fd1a, + 0xb5cff603edd20834, 0x580189243f687663, 0xa8d5a2cbdc27fe99, + 0x725d881693fa0131, 0xa2be2c13db2c7ac5, 0x7b6a9614b509fd78, + 0xb6b136d71e717636, 0x660f1a71aff046ea, 0x0ba10ae346c8ec9e, + 0xe66dde53e3145b41, 0x3b18288c88c26be6, 0x4d9d9d2ff02db933, + 0x4167da8c70f46e8a, 0xf183beef8c6318b4, 0x4d889e1e71eeeef1, + 0x7175c71ad6689b6b, 0xfb9e42beacd1b7dd, 0xc33d0e91b29b5e0d, + 0xd39b83291ce47922, 0xc4d570fb8493d12e, 0x23d5a5724f424ae6, + 0x5245f161876b6616, 0x38d77dbd21ab578d, 0x9c3423311f4ecbfe, + 0x76fe31389bacd9d5, + }; + + ExplicitSeedSeq seed_sequence{12, 34, 56}; + randen_u64 engine(seed_sequence); +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%016lx, ", engine()); + if (i % 3 == 2) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(seed_sequence); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(RandenTest, VerifyGoldenRanden32Default) { + constexpr uint64_t kGolden[2 * kNumGoldenOutputs] = { + 0x4e433977, 0xc3c14f13, 0xd90410ee, 0xdda9f47c, 0x7fd8ca10, 0x887bf308, + 0x45c72912, 0xf0b780f5, 0x7696599f, 0x15dbb1d3, 0xff3c6d59, 0x30ec63ba, + 0x6f7f20a6, 0xb29f7360, 0x6f49a54c, 0x02808a31, 0xd5c8e50e, 0x3b8feaf9, + 0x3fd9de8a, 0x9cbf605e, 0x78183bbb, 0xc970ae1a, 0x56301ed5, 0xd8b2ffd3, + 0x0fc73c37, 0xf4b327fe, 0xeb8f9a19, 0xcdfd8d76, 0x91420c9d, 0xc3a506eb, + 0x3eff9556, 0xd5af05dd, 0x8f83c4a1, 0x48db1bb7, 0x0d6bfe8c, 0x7023920e, + 0x34956d42, 0x58d35758, 0x6b87b840, 0xed1ef4c2, 0x3e0b2df3, 0x8eef32a2, + 0x431154fc, 0x497cabf3, 0x70029a8b, 0x4e243705, 0xf090e5ea, 0xd88b5749, + 0xa970692f, 0xc651a582, 0xbb6342f5, 0x78fcec2c, 0x612f55db, 0x463cb745, + 0x1816afe3, 0x352ee4ad, 0xc101da7e, 0x026ff374, 0x1c3de851, 0x811ef082, + 0x04c4fa59, 0x6f7e6167, 0x992d58fc, 0xa0660379, 0xa3b795c7, 0x04b0a374, + 0x685da798, 0x915f3445, 0xc76571ce, 0x26802a8a, 0x33ce1882, 0x46633525, + 0xa24dc738, 0xb9fdefb4, 0x4d6e6c51, 0x5588ba3a, 0xd35f1956, 0xa2101a42, + 0xe200f5fd, 0x607195a5, 0xf3290764, 0x7e100308, 0x759c0709, 0xe1e5e03c, + 0x5da6606f, 0x082572cc, 0x99e432f1, 0xcbcf5853, 0x8335d8f1, 0xe8a2be4f, + 0xcbfee8f2, 0x0904469a, 0x6daecd51, 0xf08bd31b, 0xa69da69a, 0x08e8a1f1, + 0xad57bff5, 0x6542a20a, 0x053d6b46, 0x2e9705bb, 0x0713c391, 0xda2fc9db, + 0x213b6ffb, 0x78e3a810, 0xdd85f8a6, 0xdc16a59c, 0xcd55781f, 0xc0932718, + 0x2b20bfe5, 0xb9bfb29c, 0xbe0f2f9c, 0xb97289c1, 0x03a892d4, 0xc0a2a0e4, + 0x4771435b, 0x5524bb83, 0x39d1a750, 0x8265da3d, 0x8d1b78c5, 0xff4af3ab, + 0x4bcad77f, 0xf0ec5f42, 0x27495189, 0x66e455f6, 0xb57e3270, 0xc82d3120, + 0xc22596e3, 0x3424e47d, 0x9ccedcdd, 0xbc0c9512, 0xafc4dcbf, 0xc191c595, + 0x2bb70939, 0x120392bd, 0xa6cd6ab4, 0x7f90650e, 0x32695ad3, 0x72874918, + 0xa7917eb0, 0xa7c8fac5, 0x18be0361, 0xd088cb94, 0x9c7c1ce5, 0x7c1bf983, + 0x58e1e79e, 0xe2e991fa, 0xfd28c4ad, 0x78565cde, 0xf98bafad, 0x7351b9fe, + 0xb08c96bf, 0x2a9eac28, 0x96cb2225, 0x6c4f1796, 0x1bab87e0, 0x13a68586, + 0xa0501971, 0x64c6de5a, 0xcac70991, 0x30537425, 0xc6c532b7, 0x01590d9d, + 0x8ec720dc, 0x7e05e3aa, 0x54e3e63f, 0x74a07d9c, 0x8f3bc1d2, 0x73818438, + 0x67be3acb, 0x26ffdc50, 0x561f255f, 0x6bcdf185, 0xcf99b1c6, 0xa0eaf2e1, + 0x34f68604, 0x171df819, 0x65683e5a, 0x7ea5a216, 0x75ba1cea, 0x5d1cb020, + 0xd2123fdf, 0x957f38cb, 0xf80de02f, 0xba6364ef, 0x41d452ee, 0x606e0a0e, + 0xde82f7a2, 0x892d8317, 0x50f7b43e, 0xe707b1db, 0x766fcf5b, 0x4eb28826, + 0xe80a0951, 0x5a362d56, 0x16527d78, 0x6ee217df, 0xba6b23dd, 0xf6737962, + 0x7d4076ca, 0x443e6385, 0x048adfeb, 0x790d9a5f, 0x151ee94d, 0xd796b052, + 0x12b04a03, 0x033ed95c, 0x4893da5d, 0x8b833ff8, 0xbb15eab9, 0x3d6724b1, + 0x5061ca76, 0x9877c422, 0xadf74fb3, 0xd68d6810, 0xe30ce989, 0x42e5352f, + 0x7431fde7, 0x265b565a, 0x58df4b8b, 0x3cdbf7e3, 0x6d3e8779, 0x2922a47f, + 0x65b37f88, 0x52d2242f, 0x2958d6b5, 0x5d836d6e, 0x566d5e26, 0x29d40f00, + 0x124b14a0, 0x288db0e1, 0xb7d9c1b6, 0x6c056608, 0xb8f19d32, 0x0b9471bd, + 0x4faa6c9d, 0x8fb94650, 0x4540251c, 0x8943a946, 0x144a09e0, 0xfd1fe27d, + 0xda141bda, 0xea6ac458, 0x633fce36, 0x8048f217, 0xade74d31, 0xfeda1384, + 0x2ff7612f, 0x4334b8b0, 0x5227e216, 0xdbc8441f, 0x3605c85b, 0x096d119a, + 0x21b7d7d0, 0x2b72b31c}; + + randen_u32 engine; +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < 2 * kNumGoldenOutputs; ++i) { + printf("0x%08x, ", engine()); + if (i % 6 == 5) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(RandenTest, VerifyGoldenRanden32Seeded) { + constexpr uint64_t kGolden[2 * kNumGoldenOutputs] = { + 0x94d3dcd5, 0x83a9e58f, 0xd97949fb, 0x70bbdff3, 0x7471c1b4, 0x0438481f, + 0xe5fb5930, 0x34fdc58e, 0x2a937d17, 0xceee4f2d, 0xe432aea9, 0xb5a26a68, + 0x3fb51740, 0x8b64774a, 0x74249c74, 0xd89ac1fc, 0x23fc3fdf, 0x03910d1d, + 0x78aa897f, 0xd38f6308, 0x615f7e44, 0x0ee8f0f5, 0xf8279d52, 0x98f5a53d, + 0x25938d0e, 0xb403f52c, 0x6ea6e838, 0x24007299, 0x6190fa61, 0xd3a79124, + 0x7a7b4f80, 0xaaedd3df, 0x05deaf6e, 0xc6eacabe, 0x790edf4d, 0xb7967dd8, + 0xe049d279, 0x9a0a8e67, 0xaebc23e7, 0x0494f606, 0x7bc3e0ee, 0x598dcd68, + 0x02d452a1, 0x010ac818, 0x60aa2842, 0x6407c871, 0x486f93a0, 0x5a56e276, + 0xd46a8f02, 0xc887a399, 0xfe93b740, 0x9e1e6100, 0x0f8901f6, 0x12d02e33, + 0x47e790b7, 0xc39ca52b, 0x11e82e61, 0xb0b0a2fa, 0xa303806a, 0x1542d841, + 0x7d6e9d86, 0x1fe659fd, 0x746541ac, 0xb8c90d80, 0x669ddc94, 0x239d56a5, + 0x8123d13c, 0xd40db57c, 0x153a0db0, 0x3abc2414, 0x30cb8d61, 0x9bad6656, + 0xee3f4bbc, 0x0bd1fb90, 0x079b4e42, 0x8f0b4d7e, 0xee59e793, 0xfa0fb0e0, + 0x3e071100, 0x51080b28, 0x5081cc15, 0x2c4b9e71, 0xde4941df, 0xbe10ed49, + 0x4b1b0d37, 0xf8eaac9d, 0x4605e139, 0x4bcce4b5, 0x6765dda6, 0xa64722b7, + 0x8ca28ab5, 0xb9377d73, 0xa8ccc1af, 0x779fad81, 0x1ffd3ba7, 0x65cb3ee6, + 0x7862836f, 0xd74e7908, 0x4c3f25bf, 0xd05b9c58, 0x93579827, 0x2ba93a46, + 0xf05420ce, 0xd81530af, 0x15478621, 0xec06cea2, 0x796d65ad, 0x4b1798a6, + 0x3a6f6fa6, 0xf142f3fb, 0xe237b560, 0x002b7bf7, 0xef65b4f8, 0xf47f2605, + 0x17effc18, 0x9804ec55, 0xb7d481cd, 0xaed3d7f8, 0x1ce338d1, 0x5651c24c, + 0x8bf0a3c6, 0x3e7a3820, 0x14534aed, 0x6796a7b6, 0x8358460f, 0x0d0f3b84, + 0x00b19524, 0x0fa5fe76, 0x53faaedc, 0x2b0cf382, 0x233a9fd6, 0x10df9188, + 0x80138b59, 0x3a100338, 0x3948e80f, 0x5fb0b0d2, 0x2fbf5350, 0x9e76f7b0, + 0x04b1a985, 0x08160523, 0xb41fd218, 0x30c9880d, 0x65e20f28, 0x14aa399b, + 0xace787b4, 0xe1454a8c, 0xb6c6f0f5, 0x325ac971, 0x784f3d36, 0x716b1aa2, + 0xccfd144f, 0x3d5ce14a, 0x0f651792, 0x6c0c9771, 0xfb333532, 0xbc5b0f59, + 0x140470bc, 0x2a90a7d2, 0x5c1e1c8d, 0x8da269f5, 0x895792ca, 0xcfc37143, + 0xf30b238f, 0xbe21eab1, 0xee4d65fd, 0x8c47229d, 0xd1ed7d54, 0x5743614e, + 0x9e9c476e, 0x351372a9, 0xe5db085f, 0x2bd5ea15, 0x6e0af4ca, 0x6925fde4, + 0xdc1f45bd, 0xed3eda2b, 0xd460fa6e, 0xdef68c68, 0x6253e2b5, 0xe42a0de7, + 0xbc29c305, 0x4e5176dc, 0x9f810f6e, 0xbfd85fba, 0xbeb815c6, 0x76a5a2a9, + 0xceaf414c, 0x01edc4dd, 0xb4bb3b4b, 0xa4e98904, 0x7d2f1ddd, 0x00bd63ac, + 0xe998ddbb, 0xb8491fe6, 0x3dda6800, 0xb386a346, 0x88871619, 0x00818876, + 0x344e9a38, 0x33d394b3, 0xa3a8baf9, 0x815dba65, 0x02c2fd1a, 0x4232f6ec, + 0xedd20834, 0xb5cff603, 0x3f687663, 0x58018924, 0xdc27fe99, 0xa8d5a2cb, + 0x93fa0131, 0x725d8816, 0xdb2c7ac5, 0xa2be2c13, 0xb509fd78, 0x7b6a9614, + 0x1e717636, 0xb6b136d7, 0xaff046ea, 0x660f1a71, 0x46c8ec9e, 0x0ba10ae3, + 0xe3145b41, 0xe66dde53, 0x88c26be6, 0x3b18288c, 0xf02db933, 0x4d9d9d2f, + 0x70f46e8a, 0x4167da8c, 0x8c6318b4, 0xf183beef, 0x71eeeef1, 0x4d889e1e, + 0xd6689b6b, 0x7175c71a, 0xacd1b7dd, 0xfb9e42be, 0xb29b5e0d, 0xc33d0e91, + 0x1ce47922, 0xd39b8329, 0x8493d12e, 0xc4d570fb, 0x4f424ae6, 0x23d5a572, + 0x876b6616, 0x5245f161, 0x21ab578d, 0x38d77dbd, 0x1f4ecbfe, 0x9c342331, + 0x9bacd9d5, 0x76fe3138, + }; + + ExplicitSeedSeq seed_sequence{12, 34, 56}; + randen_u32 engine(seed_sequence); +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + for (size_t i = 0; i < 2 * kNumGoldenOutputs; ++i) { + printf("0x%08x, ", engine()); + if (i % 6 == 5) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } + engine.seed(seed_sequence); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(RandenTest, VerifyGoldenFromDeserializedEngine) { + constexpr uint64_t kGolden[kNumGoldenOutputs] = { + 0x067f9f9ab919657a, 0x0534605912988583, 0x8a303f72feaa673f, + 0x77b7fd747909185c, 0xd9af90403c56d891, 0xd939c6cb204d14b5, + 0x7fbe6b954a47b483, 0x8b31a47cc34c768d, 0x3a9e546da2701a9c, + 0x5246539046253e71, 0x417191ffb2a848a1, 0x7b1c7bf5a5001d09, + 0x9489b15d194f2361, 0xfcebdeea3bcd2461, 0xd643027c854cec97, + 0x5885397f91e0d21c, 0x53173b0efae30d58, 0x1c9c71168449fac1, + 0xe358202b711ed8aa, 0x94e3918ed1d8227c, 0x5bb4e251450144cf, + 0xb5c7a519b489af3b, 0x6f8b560b1f7b3469, 0xfde11dd4a1c74eef, + 0x33383d2f76457dcf, 0x3060c0ec6db9fce1, 0x18f451fcddeec766, + 0xe73c5d6b9f26da2a, 0x8d4cc566671b32a4, 0xb8189b73776bc9ff, + 0x497a70f9caf0bc23, 0x23afcc509791dcea, 0x18af70dc4b27d306, + 0xd3853f955a0ce5b9, 0x441db6c01a0afb17, 0xd0136c3fb8e1f13f, + 0x5e4fd6fc2f33783c, 0xe0d24548adb5da51, 0x0f4d8362a7d3485a, + 0x9f572d68270fa563, 0x6351fbc823024393, 0xa66dbfc61810e9ab, + 0x0ff17fc14b651af8, 0xd74c55dafb99e623, 0x36303bc1ad85c6c2, + 0x4920cd6a2af7e897, 0x0b8848addc30fecd, 0x9e1562eda6488e93, + 0x197553807d607828, 0xbef5eaeda5e21235, 0x18d91d2616aca527, + 0xb7821937f5c873cd, 0x2cd4ae5650dbeefc, 0xb35a64376f75ffdf, + 0x9226d414d647fe07, 0x663f3db455bbb35e, 0xa829eead6ae93247, + 0x7fd69c204dd0d25f, 0xbe1411f891c9acb1, 0xd476f34a506d5f11, + 0xf423d2831649c5ca, 0x1e503962951abd75, 0xeccc9e8b1e34b537, + 0xb11a147294044854, 0xc4cf27f0abf4929d, 0xe9193abf6fa24c8c, + 0xa94a259e3aba8808, 0x21dc414197deffa3, 0xa2ae211d1ff622ae, + 0xfe3995c46be5a4f4, 0xe9984c284bf11128, 0xcb1ce9d2f0851a80, + 0x42fee17971d87cd8, 0xac76a98d177adc88, 0xa0973b3dedc4af6f, + 0xdf56d6bbcb1b8e86, 0xf1e6485f407b11c9, 0x2c63de4deccb15c0, + 0x6fe69db32ed4fad7, 0xaa51a65f84bca1f1, 0x242f2ee81d608afc, + 0x8eb88b2b69fc153b, 0x22c20098baf73fd1, 0x57759466f576488c, + 0x075ca562cea1be9d, 0x9a74814d73d28891, 0x73d1555fc02f4d3d, + 0xc17f8f210ee89337, 0x46cca7999eaeafd4, 0x5db8d6a327a0d8ac, + 0xb79b4f93c738d7a1, 0x9994512f0036ded1, 0xd3883026f38747f4, + 0xf31f7458078d097c, 0x736ce4d480680669, 0x7a496f4c7e1033e3, + 0xecf85bf297fbc68c, 0x9e37e1d0f24f3c4e, 0x15b6e067ca0746fc, + 0xdd4a39905c5db81c, 0xb5dfafa7bcfdf7da, 0xca6646fb6f92a276, + 0x1c6b35f363ef0efd, 0x6a33d06037ad9f76, 0x45544241afd8f80f, + 0x83f8d83f859c90c5, 0x22aea9c5365e8c19, 0xfac35b11f20b6a6a, + 0xd1acf49d1a27dd2f, 0xf281cd09c4fed405, 0x076000a42cd38e4f, + 0x6ace300565070445, 0x463a62781bddc4db, 0x1477126b46b569ac, + 0x127f2bb15035fbb8, 0xdfa30946049c04a8, 0x89072a586ba8dd3e, + 0x62c809582bb7e74d, 0x22c0c3641406c28b, 0x9b66e36c47ff004d, + 0xb9cd2c7519653330, 0x18608d79cd7a598d, 0x92c0bd1323e53e32, + 0x887ff00de8524aa5, 0xa074410b787abd10, 0x18ab41b8057a2063, + 0x1560abf26bc5f987}; + +#if UPDATE_GOLDEN + (void)kGolden; // Silence warning. + std::seed_seq seed_sequence{1, 2, 3, 4, 5}; + randen_u64 engine(seed_sequence); + std::ostringstream stream; + stream << engine; + auto str = stream.str(); + printf("%s\n\n", str.c_str()); + for (size_t i = 0; i < kNumGoldenOutputs; ++i) { + printf("0x%016lx, ", engine()); + if (i % 3 == 2) { + printf("\n"); + } + } + printf("\n\n\n"); +#else + randen_u64 engine; + std::istringstream stream( + "0 0 9824501439887287479 3242284395352394785 243836530774933777 " + "4047941804708365596 17165468127298385802 949276103645889255 " + "10659970394998657921 1657570836810929787 11697746266668051452 " + "9967209969299905230 14140390331161524430 7383014124183271684 " + "13146719127702337852 13983155220295807171 11121125587542359264 " + "195757810993252695 17138580243103178492 11326030747260920501 " + "8585097322474965590 18342582839328350995 15052982824209724634 " + "7321861343874683609 1806786911778767826 10100850842665572955 " + "9249328950653985078 13600624835326909759 11137960060943860251 " + "10208781341792329629 9282723971471525577 16373271619486811032 32"); + stream >> engine; + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, engine()); + } +#endif +} + +TEST(RandenTest, IsFastOrSlow) { + // randen_engine typically costs ~5ns per value for the optimized code paths, + // and the ~1000ns per value for slow code paths. However when running under + // msan, asan, etc. it can take much longer. + // + // The estimated operation time is something like: + // + // linux, optimized ~5ns + // ppc, optimized ~7ns + // nacl (slow), ~1100ns + // + // `kCount` is chosen below so that, in debug builds and without hardware + // acceleration, the test (assuming ~1us per call) should finish in ~0.1s + static constexpr size_t kCount = 100000; + randen_u64 engine; + randen_u64::result_type sum = 0; + auto start = absl::GetCurrentTimeNanos(); + for (int i = 0; i < kCount; i++) { + sum += engine(); + } + auto duration = absl::GetCurrentTimeNanos() - start; + + ABSL_INTERNAL_LOG(INFO, absl::StrCat(static_cast<double>(duration) / + static_cast<double>(kCount), + "ns")); + + EXPECT_GT(sum, 0); + EXPECT_GE(duration, kCount); // Should be slower than 1ns per call. +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/randen_hwaes.cc b/third_party/abseil_cpp/absl/random/internal/randen_hwaes.cc new file mode 100644 index 0000000000..9966486fde --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_hwaes.cc @@ -0,0 +1,572 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// HERMETIC NOTE: The randen_hwaes target must not introduce duplicate +// symbols from arbitrary system and other headers, since it may be built +// with different flags from other targets, using different levels of +// optimization, potentially introducing ODR violations. + +#include "absl/random/internal/randen_hwaes.h" + +#include <cstdint> +#include <cstring> + +#include "absl/base/attributes.h" +#include "absl/random/internal/platform.h" +#include "absl/random/internal/randen_traits.h" + +// ABSL_RANDEN_HWAES_IMPL indicates whether this file will contain +// a hardware accelerated implementation of randen, or whether it +// will contain stubs that exit the process. +#if defined(ABSL_ARCH_X86_64) || defined(ABSL_ARCH_X86_32) +// The platform.h directives are sufficient to indicate whether +// we should build accelerated implementations for x86. +#if (ABSL_HAVE_ACCELERATED_AES || ABSL_RANDOM_INTERNAL_AES_DISPATCH) +#define ABSL_RANDEN_HWAES_IMPL 1 +#endif +#elif defined(ABSL_ARCH_PPC) +// The platform.h directives are sufficient to indicate whether +// we should build accelerated implementations for PPC. +// +// NOTE: This has mostly been tested on 64-bit Power variants, +// and not embedded cpus such as powerpc32-8540 +#if ABSL_HAVE_ACCELERATED_AES +#define ABSL_RANDEN_HWAES_IMPL 1 +#endif +#elif defined(ABSL_ARCH_ARM) || defined(ABSL_ARCH_AARCH64) +// ARM is somewhat more complicated. We might support crypto natively... +#if ABSL_HAVE_ACCELERATED_AES || \ + (defined(__ARM_NEON) && defined(__ARM_FEATURE_CRYPTO)) +#define ABSL_RANDEN_HWAES_IMPL 1 + +#elif ABSL_RANDOM_INTERNAL_AES_DISPATCH && !defined(__APPLE__) && \ + (defined(__GNUC__) && __GNUC__ > 4 || __GNUC__ == 4 && __GNUC_MINOR__ > 9) +// ...or, on GCC, we can use an ASM directive to +// instruct the assember to allow crypto instructions. +#define ABSL_RANDEN_HWAES_IMPL 1 +#define ABSL_RANDEN_HWAES_IMPL_CRYPTO_DIRECTIVE 1 +#endif +#else +// HWAES is unsupported by these architectures / platforms: +// __myriad2__ +// __mips__ +// +// Other architectures / platforms are unknown. +// +// See the Abseil documentation on supported macros at: +// https://abseil.io/docs/cpp/platforms/macros +#endif + +#if !defined(ABSL_RANDEN_HWAES_IMPL) +// No accelerated implementation is supported. +// The RandenHwAes functions are stubs that print an error and exit. + +#include <cstdio> +#include <cstdlib> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// No accelerated implementation. +bool HasRandenHwAesImplementation() { return false; } + +// NOLINTNEXTLINE +const void* RandenHwAes::GetKeys() { + // Attempted to dispatch to an unsupported dispatch target. + const int d = ABSL_RANDOM_INTERNAL_AES_DISPATCH; + fprintf(stderr, "AES Hardware detection failed (%d).\n", d); + exit(1); + return nullptr; +} + +// NOLINTNEXTLINE +void RandenHwAes::Absorb(const void*, void*) { + // Attempted to dispatch to an unsupported dispatch target. + const int d = ABSL_RANDOM_INTERNAL_AES_DISPATCH; + fprintf(stderr, "AES Hardware detection failed (%d).\n", d); + exit(1); +} + +// NOLINTNEXTLINE +void RandenHwAes::Generate(const void*, void*) { + // Attempted to dispatch to an unsupported dispatch target. + const int d = ABSL_RANDOM_INTERNAL_AES_DISPATCH; + fprintf(stderr, "AES Hardware detection failed (%d).\n", d); + exit(1); +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#else // defined(ABSL_RANDEN_HWAES_IMPL) +// +// Accelerated implementations are supported. +// We need the per-architecture includes and defines. +// +namespace { + +using absl::random_internal::RandenTraits; + +// Randen operates on 128-bit vectors. +struct alignas(16) u64x2 { + uint64_t data[2]; +}; + +} // namespace + +// TARGET_CRYPTO defines a crypto attribute for each architecture. +// +// NOTE: Evaluate whether we should eliminate ABSL_TARGET_CRYPTO. +#if (defined(__clang__) || defined(__GNUC__)) +#if defined(ABSL_ARCH_X86_64) || defined(ABSL_ARCH_X86_32) +#define ABSL_TARGET_CRYPTO __attribute__((target("aes"))) +#elif defined(ABSL_ARCH_PPC) +#define ABSL_TARGET_CRYPTO __attribute__((target("crypto"))) +#else +#define ABSL_TARGET_CRYPTO +#endif +#else +#define ABSL_TARGET_CRYPTO +#endif + +#if defined(ABSL_ARCH_PPC) +// NOTE: Keep in mind that PPC can operate in little-endian or big-endian mode, +// however the PPC altivec vector registers (and thus the AES instructions) +// always operate in big-endian mode. + +#include <altivec.h> +// <altivec.h> #defines vector __vector; in C++, this is bad form. +#undef vector + +// Rely on the PowerPC AltiVec vector operations for accelerated AES +// instructions. GCC support of the PPC vector types is described in: +// https://gcc.gnu.org/onlinedocs/gcc-4.9.0/gcc/PowerPC-AltiVec_002fVSX-Built-in-Functions.html +// +// Already provides operator^=. +using Vector128 = __vector unsigned long long; // NOLINT(runtime/int) + +namespace { +inline ABSL_TARGET_CRYPTO Vector128 ReverseBytes(const Vector128& v) { + // Reverses the bytes of the vector. + const __vector unsigned char perm = {15, 14, 13, 12, 11, 10, 9, 8, + 7, 6, 5, 4, 3, 2, 1, 0}; + return vec_perm(v, v, perm); +} + +// WARNING: these load/store in native byte order. It is OK to load and then +// store an unchanged vector, but interpreting the bits as a number or input +// to AES will have undefined results. +inline ABSL_TARGET_CRYPTO Vector128 Vector128Load(const void* from) { + return vec_vsx_ld(0, reinterpret_cast<const Vector128*>(from)); +} + +inline ABSL_TARGET_CRYPTO void Vector128Store(const Vector128& v, void* to) { + vec_vsx_st(v, 0, reinterpret_cast<Vector128*>(to)); +} + +// One round of AES. "round_key" is a public constant for breaking the +// symmetry of AES (ensures previously equal columns differ afterwards). +inline ABSL_TARGET_CRYPTO Vector128 AesRound(const Vector128& state, + const Vector128& round_key) { + return Vector128(__builtin_crypto_vcipher(state, round_key)); +} + +// Enables native loads in the round loop by pre-swapping. +inline ABSL_TARGET_CRYPTO void SwapEndian(u64x2* state) { + for (uint32_t block = 0; block < RandenTraits::kFeistelBlocks; ++block) { + Vector128Store(ReverseBytes(Vector128Load(state + block)), state + block); + } +} + +} // namespace + +#elif defined(ABSL_ARCH_ARM) || defined(ABSL_ARCH_AARCH64) + +// This asm directive will cause the file to be compiled with crypto extensions +// whether or not the cpu-architecture supports it. +#if ABSL_RANDEN_HWAES_IMPL_CRYPTO_DIRECTIVE +asm(".arch_extension crypto\n"); + +// Override missing defines. +#if !defined(__ARM_NEON) +#define __ARM_NEON 1 +#endif + +#if !defined(__ARM_FEATURE_CRYPTO) +#define __ARM_FEATURE_CRYPTO 1 +#endif + +#endif + +// Rely on the ARM NEON+Crypto advanced simd types, defined in <arm_neon.h>. +// uint8x16_t is the user alias for underlying __simd128_uint8_t type. +// http://infocenter.arm.com/help/topic/com.arm.doc.ihi0073a/IHI0073A_arm_neon_intrinsics_ref.pdf +// +// <arm_neon> defines the following +// +// typedef __attribute__((neon_vector_type(16))) uint8_t uint8x16_t; +// typedef __attribute__((neon_vector_type(16))) int8_t int8x16_t; +// typedef __attribute__((neon_polyvector_type(16))) int8_t poly8x16_t; +// +// vld1q_v +// vst1q_v +// vaeseq_v +// vaesmcq_v +#include <arm_neon.h> + +// Already provides operator^=. +using Vector128 = uint8x16_t; + +namespace { + +inline ABSL_TARGET_CRYPTO Vector128 Vector128Load(const void* from) { + return vld1q_u8(reinterpret_cast<const uint8_t*>(from)); +} + +inline ABSL_TARGET_CRYPTO void Vector128Store(const Vector128& v, void* to) { + vst1q_u8(reinterpret_cast<uint8_t*>(to), v); +} + +// One round of AES. "round_key" is a public constant for breaking the +// symmetry of AES (ensures previously equal columns differ afterwards). +inline ABSL_TARGET_CRYPTO Vector128 AesRound(const Vector128& state, + const Vector128& round_key) { + // It is important to always use the full round function - omitting the + // final MixColumns reduces security [https://eprint.iacr.org/2010/041.pdf] + // and does not help because we never decrypt. + // + // Note that ARM divides AES instructions differently than x86 / PPC, + // And we need to skip the first AddRoundKey step and add an extra + // AddRoundKey step to the end. Lucky for us this is just XOR. + return vaesmcq_u8(vaeseq_u8(state, uint8x16_t{})) ^ round_key; +} + +inline ABSL_TARGET_CRYPTO void SwapEndian(void*) {} + +} // namespace + +#elif defined(ABSL_ARCH_X86_64) || defined(ABSL_ARCH_X86_32) +// On x86 we rely on the aesni instructions +#include <wmmintrin.h> + +namespace { + +// Vector128 class is only wrapper for __m128i, benchmark indicates that it's +// faster than using __m128i directly. +class Vector128 { + public: + // Convert from/to intrinsics. + inline explicit Vector128(const __m128i& Vector128) : data_(Vector128) {} + + inline __m128i data() const { return data_; } + + inline Vector128& operator^=(const Vector128& other) { + data_ = _mm_xor_si128(data_, other.data()); + return *this; + } + + private: + __m128i data_; +}; + +inline ABSL_TARGET_CRYPTO Vector128 Vector128Load(const void* from) { + return Vector128(_mm_load_si128(reinterpret_cast<const __m128i*>(from))); +} + +inline ABSL_TARGET_CRYPTO void Vector128Store(const Vector128& v, void* to) { + _mm_store_si128(reinterpret_cast<__m128i*>(to), v.data()); +} + +// One round of AES. "round_key" is a public constant for breaking the +// symmetry of AES (ensures previously equal columns differ afterwards). +inline ABSL_TARGET_CRYPTO Vector128 AesRound(const Vector128& state, + const Vector128& round_key) { + // It is important to always use the full round function - omitting the + // final MixColumns reduces security [https://eprint.iacr.org/2010/041.pdf] + // and does not help because we never decrypt. + return Vector128(_mm_aesenc_si128(state.data(), round_key.data())); +} + +inline ABSL_TARGET_CRYPTO void SwapEndian(void*) {} + +} // namespace + +#endif + +#ifdef __clang__ +#pragma clang diagnostic push +#pragma clang diagnostic ignored "-Wunknown-pragmas" +#endif + +// At this point, all of the platform-specific features have been defined / +// implemented. +// +// REQUIRES: using Vector128 = ... +// REQUIRES: Vector128 Vector128Load(void*) {...} +// REQUIRES: void Vector128Store(Vector128, void*) {...} +// REQUIRES: Vector128 AesRound(Vector128, Vector128) {...} +// REQUIRES: void SwapEndian(uint64_t*) {...} +// +// PROVIDES: absl::random_internal::RandenHwAes::Absorb +// PROVIDES: absl::random_internal::RandenHwAes::Generate +namespace { + +// Block shuffles applies a shuffle to the entire state between AES rounds. +// Improved odd-even shuffle from "New criterion for diffusion property". +inline ABSL_TARGET_CRYPTO void BlockShuffle(u64x2* state) { + static_assert(RandenTraits::kFeistelBlocks == 16, + "Expecting 16 FeistelBlocks."); + + constexpr size_t shuffle[RandenTraits::kFeistelBlocks] = { + 7, 2, 13, 4, 11, 8, 3, 6, 15, 0, 9, 10, 1, 14, 5, 12}; + + const Vector128 v0 = Vector128Load(state + shuffle[0]); + const Vector128 v1 = Vector128Load(state + shuffle[1]); + const Vector128 v2 = Vector128Load(state + shuffle[2]); + const Vector128 v3 = Vector128Load(state + shuffle[3]); + const Vector128 v4 = Vector128Load(state + shuffle[4]); + const Vector128 v5 = Vector128Load(state + shuffle[5]); + const Vector128 v6 = Vector128Load(state + shuffle[6]); + const Vector128 v7 = Vector128Load(state + shuffle[7]); + const Vector128 w0 = Vector128Load(state + shuffle[8]); + const Vector128 w1 = Vector128Load(state + shuffle[9]); + const Vector128 w2 = Vector128Load(state + shuffle[10]); + const Vector128 w3 = Vector128Load(state + shuffle[11]); + const Vector128 w4 = Vector128Load(state + shuffle[12]); + const Vector128 w5 = Vector128Load(state + shuffle[13]); + const Vector128 w6 = Vector128Load(state + shuffle[14]); + const Vector128 w7 = Vector128Load(state + shuffle[15]); + + Vector128Store(v0, state + 0); + Vector128Store(v1, state + 1); + Vector128Store(v2, state + 2); + Vector128Store(v3, state + 3); + Vector128Store(v4, state + 4); + Vector128Store(v5, state + 5); + Vector128Store(v6, state + 6); + Vector128Store(v7, state + 7); + Vector128Store(w0, state + 8); + Vector128Store(w1, state + 9); + Vector128Store(w2, state + 10); + Vector128Store(w3, state + 11); + Vector128Store(w4, state + 12); + Vector128Store(w5, state + 13); + Vector128Store(w6, state + 14); + Vector128Store(w7, state + 15); +} + +// Feistel round function using two AES subrounds. Very similar to F() +// from Simpira v2, but with independent subround keys. Uses 17 AES rounds +// per 16 bytes (vs. 10 for AES-CTR). Computing eight round functions in +// parallel hides the 7-cycle AESNI latency on HSW. Note that the Feistel +// XORs are 'free' (included in the second AES instruction). +inline ABSL_TARGET_CRYPTO const u64x2* FeistelRound( + u64x2* state, const u64x2* ABSL_RANDOM_INTERNAL_RESTRICT keys) { + static_assert(RandenTraits::kFeistelBlocks == 16, + "Expecting 16 FeistelBlocks."); + + // MSVC does a horrible job at unrolling loops. + // So we unroll the loop by hand to improve the performance. + const Vector128 s0 = Vector128Load(state + 0); + const Vector128 s1 = Vector128Load(state + 1); + const Vector128 s2 = Vector128Load(state + 2); + const Vector128 s3 = Vector128Load(state + 3); + const Vector128 s4 = Vector128Load(state + 4); + const Vector128 s5 = Vector128Load(state + 5); + const Vector128 s6 = Vector128Load(state + 6); + const Vector128 s7 = Vector128Load(state + 7); + const Vector128 s8 = Vector128Load(state + 8); + const Vector128 s9 = Vector128Load(state + 9); + const Vector128 s10 = Vector128Load(state + 10); + const Vector128 s11 = Vector128Load(state + 11); + const Vector128 s12 = Vector128Load(state + 12); + const Vector128 s13 = Vector128Load(state + 13); + const Vector128 s14 = Vector128Load(state + 14); + const Vector128 s15 = Vector128Load(state + 15); + + // Encode even blocks with keys. + const Vector128 e0 = AesRound(s0, Vector128Load(keys + 0)); + const Vector128 e2 = AesRound(s2, Vector128Load(keys + 1)); + const Vector128 e4 = AesRound(s4, Vector128Load(keys + 2)); + const Vector128 e6 = AesRound(s6, Vector128Load(keys + 3)); + const Vector128 e8 = AesRound(s8, Vector128Load(keys + 4)); + const Vector128 e10 = AesRound(s10, Vector128Load(keys + 5)); + const Vector128 e12 = AesRound(s12, Vector128Load(keys + 6)); + const Vector128 e14 = AesRound(s14, Vector128Load(keys + 7)); + + // Encode odd blocks with even output from above. + const Vector128 o1 = AesRound(e0, s1); + const Vector128 o3 = AesRound(e2, s3); + const Vector128 o5 = AesRound(e4, s5); + const Vector128 o7 = AesRound(e6, s7); + const Vector128 o9 = AesRound(e8, s9); + const Vector128 o11 = AesRound(e10, s11); + const Vector128 o13 = AesRound(e12, s13); + const Vector128 o15 = AesRound(e14, s15); + + // Store odd blocks. (These will be shuffled later). + Vector128Store(o1, state + 1); + Vector128Store(o3, state + 3); + Vector128Store(o5, state + 5); + Vector128Store(o7, state + 7); + Vector128Store(o9, state + 9); + Vector128Store(o11, state + 11); + Vector128Store(o13, state + 13); + Vector128Store(o15, state + 15); + + return keys + 8; +} + +// Cryptographic permutation based via type-2 Generalized Feistel Network. +// Indistinguishable from ideal by chosen-ciphertext adversaries using less than +// 2^64 queries if the round function is a PRF. This is similar to the b=8 case +// of Simpira v2, but more efficient than its generic construction for b=16. +inline ABSL_TARGET_CRYPTO void Permute( + u64x2* state, const u64x2* ABSL_RANDOM_INTERNAL_RESTRICT keys) { + // (Successfully unrolled; the first iteration jumps into the second half) +#ifdef __clang__ +#pragma clang loop unroll_count(2) +#endif + for (size_t round = 0; round < RandenTraits::kFeistelRounds; ++round) { + keys = FeistelRound(state, keys); + BlockShuffle(state); + } +} + +} // namespace + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +bool HasRandenHwAesImplementation() { return true; } + +const void* ABSL_TARGET_CRYPTO RandenHwAes::GetKeys() { + // Round keys for one AES per Feistel round and branch. + // The canonical implementation uses first digits of Pi. +#if defined(ABSL_ARCH_PPC) + return kRandenRoundKeysBE; +#else + return kRandenRoundKeys; +#endif +} + +// NOLINTNEXTLINE +void ABSL_TARGET_CRYPTO RandenHwAes::Absorb(const void* seed_void, + void* state_void) { + static_assert(RandenTraits::kCapacityBytes / sizeof(Vector128) == 1, + "Unexpected Randen kCapacityBlocks"); + static_assert(RandenTraits::kStateBytes / sizeof(Vector128) == 16, + "Unexpected Randen kStateBlocks"); + + auto* state = + reinterpret_cast<u64x2 * ABSL_RANDOM_INTERNAL_RESTRICT>(state_void); + const auto* seed = + reinterpret_cast<const u64x2 * ABSL_RANDOM_INTERNAL_RESTRICT>(seed_void); + + Vector128 b1 = Vector128Load(state + 1); + b1 ^= Vector128Load(seed + 0); + Vector128Store(b1, state + 1); + + Vector128 b2 = Vector128Load(state + 2); + b2 ^= Vector128Load(seed + 1); + Vector128Store(b2, state + 2); + + Vector128 b3 = Vector128Load(state + 3); + b3 ^= Vector128Load(seed + 2); + Vector128Store(b3, state + 3); + + Vector128 b4 = Vector128Load(state + 4); + b4 ^= Vector128Load(seed + 3); + Vector128Store(b4, state + 4); + + Vector128 b5 = Vector128Load(state + 5); + b5 ^= Vector128Load(seed + 4); + Vector128Store(b5, state + 5); + + Vector128 b6 = Vector128Load(state + 6); + b6 ^= Vector128Load(seed + 5); + Vector128Store(b6, state + 6); + + Vector128 b7 = Vector128Load(state + 7); + b7 ^= Vector128Load(seed + 6); + Vector128Store(b7, state + 7); + + Vector128 b8 = Vector128Load(state + 8); + b8 ^= Vector128Load(seed + 7); + Vector128Store(b8, state + 8); + + Vector128 b9 = Vector128Load(state + 9); + b9 ^= Vector128Load(seed + 8); + Vector128Store(b9, state + 9); + + Vector128 b10 = Vector128Load(state + 10); + b10 ^= Vector128Load(seed + 9); + Vector128Store(b10, state + 10); + + Vector128 b11 = Vector128Load(state + 11); + b11 ^= Vector128Load(seed + 10); + Vector128Store(b11, state + 11); + + Vector128 b12 = Vector128Load(state + 12); + b12 ^= Vector128Load(seed + 11); + Vector128Store(b12, state + 12); + + Vector128 b13 = Vector128Load(state + 13); + b13 ^= Vector128Load(seed + 12); + Vector128Store(b13, state + 13); + + Vector128 b14 = Vector128Load(state + 14); + b14 ^= Vector128Load(seed + 13); + Vector128Store(b14, state + 14); + + Vector128 b15 = Vector128Load(state + 15); + b15 ^= Vector128Load(seed + 14); + Vector128Store(b15, state + 15); +} + +// NOLINTNEXTLINE +void ABSL_TARGET_CRYPTO RandenHwAes::Generate(const void* keys_void, + void* state_void) { + static_assert(RandenTraits::kCapacityBytes == sizeof(Vector128), + "Capacity mismatch"); + + auto* state = reinterpret_cast<u64x2*>(state_void); + const auto* keys = reinterpret_cast<const u64x2*>(keys_void); + + const Vector128 prev_inner = Vector128Load(state); + + SwapEndian(state); + + Permute(state, keys); + + SwapEndian(state); + + // Ensure backtracking resistance. + Vector128 inner = Vector128Load(state); + inner ^= prev_inner; + Vector128Store(inner, state); +} + +#ifdef __clang__ +#pragma clang diagnostic pop +#endif + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // (ABSL_RANDEN_HWAES_IMPL) diff --git a/third_party/abseil_cpp/absl/random/internal/randen_hwaes.h b/third_party/abseil_cpp/absl/random/internal/randen_hwaes.h new file mode 100644 index 0000000000..bce36b5226 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_hwaes.h @@ -0,0 +1,50 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_RANDEN_HWAES_H_ +#define ABSL_RANDOM_INTERNAL_RANDEN_HWAES_H_ + +#include "absl/base/config.h" + +// HERMETIC NOTE: The randen_hwaes target must not introduce duplicate +// symbols from arbitrary system and other headers, since it may be built +// with different flags from other targets, using different levels of +// optimization, potentially introducing ODR violations. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// RANDen = RANDom generator or beetroots in Swiss German. +// 'Strong' (well-distributed, unpredictable, backtracking-resistant) random +// generator, faster in some benchmarks than std::mt19937_64 and pcg64_c32. +// +// RandenHwAes implements the basic state manipulation methods. +class RandenHwAes { + public: + static void Generate(const void* keys, void* state_void); + static void Absorb(const void* seed_void, void* state_void); + static const void* GetKeys(); +}; + +// HasRandenHwAesImplementation returns true when there is an accelerated +// implementation, and false otherwise. If there is no implementation, +// then attempting to use it will abort the program. +bool HasRandenHwAesImplementation(); + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_RANDEN_HWAES_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/randen_hwaes_test.cc b/third_party/abseil_cpp/absl/random/internal/randen_hwaes_test.cc new file mode 100644 index 0000000000..66ddb43fd6 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_hwaes_test.cc @@ -0,0 +1,104 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen_hwaes.h" + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/platform.h" +#include "absl/random/internal/randen_detect.h" +#include "absl/random/internal/randen_traits.h" +#include "absl/strings/str_format.h" + +namespace { + +using absl::random_internal::RandenHwAes; +using absl::random_internal::RandenTraits; + +// Local state parameters. +constexpr size_t kSeedBytes = + RandenTraits::kStateBytes - RandenTraits::kCapacityBytes; +constexpr size_t kStateSizeT = RandenTraits::kStateBytes / sizeof(uint64_t); +constexpr size_t kSeedSizeT = kSeedBytes / sizeof(uint32_t); + +struct alignas(16) randen { + uint64_t state[kStateSizeT]; + uint32_t seed[kSeedSizeT]; +}; + +TEST(RandenHwAesTest, Default) { + EXPECT_TRUE(absl::random_internal::CPUSupportsRandenHwAes()); + + constexpr uint64_t kGolden[] = { + 0x6c6534090ee6d3ee, 0x044e2b9b9d5333c6, 0xc3c14f134e433977, + 0xdda9f47cd90410ee, 0x887bf3087fd8ca10, 0xf0b780f545c72912, + 0x15dbb1d37696599f, 0x30ec63baff3c6d59, 0xb29f73606f7f20a6, + 0x02808a316f49a54c, 0x3b8feaf9d5c8e50e, 0x9cbf605e3fd9de8a, + 0xc970ae1a78183bbb, 0xd8b2ffd356301ed5, 0xf4b327fe0fc73c37, + 0xcdfd8d76eb8f9a19, 0xc3a506eb91420c9d, 0xd5af05dd3eff9556, + 0x48db1bb78f83c4a1, 0x7023920e0d6bfe8c, 0x58d3575834956d42, + 0xed1ef4c26b87b840, 0x8eef32a23e0b2df3, 0x497cabf3431154fc, + 0x4e24370570029a8b, 0xd88b5749f090e5ea, 0xc651a582a970692f, + 0x78fcec2cbb6342f5, 0x463cb745612f55db, 0x352ee4ad1816afe3, + 0x026ff374c101da7e, 0x811ef0821c3de851, + }; + + alignas(16) randen d; + memset(d.state, 0, sizeof(d.state)); + RandenHwAes::Generate(RandenHwAes::GetKeys(), d.state); + + uint64_t* id = d.state; + for (const auto& elem : kGolden) { + auto a = absl::StrFormat("%#x", elem); + auto b = absl::StrFormat("%#x", *id++); + EXPECT_EQ(a, b); + } +} + +} // namespace + +int main(int argc, char* argv[]) { + testing::InitGoogleTest(&argc, argv); + + ABSL_RAW_LOG(INFO, "ABSL_HAVE_ACCELERATED_AES=%d", ABSL_HAVE_ACCELERATED_AES); + ABSL_RAW_LOG(INFO, "ABSL_RANDOM_INTERNAL_AES_DISPATCH=%d", + ABSL_RANDOM_INTERNAL_AES_DISPATCH); + +#if defined(ABSL_ARCH_X86_64) + ABSL_RAW_LOG(INFO, "ABSL_ARCH_X86_64"); +#elif defined(ABSL_ARCH_X86_32) + ABSL_RAW_LOG(INFO, "ABSL_ARCH_X86_32"); +#elif defined(ABSL_ARCH_AARCH64) + ABSL_RAW_LOG(INFO, "ABSL_ARCH_AARCH64"); +#elif defined(ABSL_ARCH_ARM) + ABSL_RAW_LOG(INFO, "ABSL_ARCH_ARM"); +#elif defined(ABSL_ARCH_PPC) + ABSL_RAW_LOG(INFO, "ABSL_ARCH_PPC"); +#else + ABSL_RAW_LOG(INFO, "ARCH Unknown"); +#endif + + int x = absl::random_internal::HasRandenHwAesImplementation(); + ABSL_RAW_LOG(INFO, "HasRandenHwAesImplementation = %d", x); + + int y = absl::random_internal::CPUSupportsRandenHwAes(); + ABSL_RAW_LOG(INFO, "CPUSupportsRandenHwAes = %d", x); + + if (!x || !y) { + ABSL_RAW_LOG(INFO, "Skipping Randen HWAES tests."); + return 0; + } + return RUN_ALL_TESTS(); +} diff --git a/third_party/abseil_cpp/absl/random/internal/randen_round_keys.cc b/third_party/abseil_cpp/absl/random/internal/randen_round_keys.cc new file mode 100644 index 0000000000..5fb3ca556d --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_round_keys.cc @@ -0,0 +1,462 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen_traits.h" + +// This file contains only the round keys for randen. +// +// "Nothing up my sleeve" numbers from the first hex digits of Pi, obtained +// from http://hexpi.sourceforge.net/. The array was generated by following +// Python script: + +/* +python >tmp.cc << EOF +"""Generates Randen round keys array from pi-hex.62500.txt file.""" +import binascii + +KEYS = 17 * 8 + +def chunks(l, n): + """Yield successive n-sized chunks from l.""" + for i in range(0, len(l), n): + yield l[i:i + n] + +def pairwise(t): + """Transforms sequence into sequence of pairs.""" + it = iter(t) + return zip(it,it) + +def digits_from_pi(): + """Reads digits from hexpi.sourceforge.net file.""" + with open("pi-hex.62500.txt") as file: + return file.read() + +def digits_from_urandom(): + """Reads digits from /dev/urandom.""" + with open("/dev/urandom") as file: + return binascii.hexlify(file.read(KEYS * 16)) + +def print_row(b) + print(" 0x{0}, 0x{1}, 0x{2}, 0x{3}, 0x{4}, 0x{5}, 0x{6}, 0x{7}, 0x{8}, 0x{9}, +0x{10}, 0x{11}, 0x{12}, 0x{13}, 0x{14}, 0x{15},".format(*b)) + + +digits = digits_from_pi() +#digits = digits_from_urandom() + +print("namespace {") +print("static constexpr size_t kKeyBytes = {0};\n".format(KEYS * 16)) +print("}") + +print("alignas(16) const unsigned char kRandenRoundKeysBE[kKeyBytes] = {") + +for i, u16 in zip(range(KEYS), chunks(digits, 32)): + b = list(chunks(u16, 2)) + print_row(b) + +print("};") + +print("alignas(16) const unsigned char kRandenRoundKeys[kKeyBytes] = {") + +for i, u16 in zip(range(KEYS), chunks(digits, 32)): + b = list(chunks(u16, 2)) + b.reverse() + print_row(b) + +print("};") + +EOF + +*/ + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { +static constexpr size_t kKeyBytes = 2176; +} + +alignas(16) const unsigned char kRandenRoundKeysBE[kKeyBytes] = { + 0x24, 0x3F, 0x6A, 0x88, 0x85, 0xA3, 0x08, 0xD3, 0x13, 0x19, 0x8A, 0x2E, + 0x03, 0x70, 0x73, 0x44, 0xA4, 0x09, 0x38, 0x22, 0x29, 0x9F, 0x31, 0xD0, + 0x08, 0x2E, 0xFA, 0x98, 0xEC, 0x4E, 0x6C, 0x89, 0x45, 0x28, 0x21, 0xE6, + 0x38, 0xD0, 0x13, 0x77, 0xBE, 0x54, 0x66, 0xCF, 0x34, 0xE9, 0x0C, 0x6C, + 0xC0, 0xAC, 0x29, 0xB7, 0xC9, 0x7C, 0x50, 0xDD, 0x3F, 0x84, 0xD5, 0xB5, + 0xB5, 0x47, 0x09, 0x17, 0x92, 0x16, 0xD5, 0xD9, 0x89, 0x79, 0xFB, 0x1B, + 0xD1, 0x31, 0x0B, 0xA6, 0x98, 0xDF, 0xB5, 0xAC, 0x2F, 0xFD, 0x72, 0xDB, + 0xD0, 0x1A, 0xDF, 0xB7, 0xB8, 0xE1, 0xAF, 0xED, 0x6A, 0x26, 0x7E, 0x96, + 0xBA, 0x7C, 0x90, 0x45, 0xF1, 0x2C, 0x7F, 0x99, 0x24, 0xA1, 0x99, 0x47, + 0xB3, 0x91, 0x6C, 0xF7, 0x08, 0x01, 0xF2, 0xE2, 0x85, 0x8E, 0xFC, 0x16, + 0x63, 0x69, 0x20, 0xD8, 0x71, 0x57, 0x4E, 0x69, 0xA4, 0x58, 0xFE, 0xA3, + 0xF4, 0x93, 0x3D, 0x7E, 0x0D, 0x95, 0x74, 0x8F, 0x72, 0x8E, 0xB6, 0x58, + 0x71, 0x8B, 0xCD, 0x58, 0x82, 0x15, 0x4A, 0xEE, 0x7B, 0x54, 0xA4, 0x1D, + 0xC2, 0x5A, 0x59, 0xB5, 0x9C, 0x30, 0xD5, 0x39, 0x2A, 0xF2, 0x60, 0x13, + 0xC5, 0xD1, 0xB0, 0x23, 0x28, 0x60, 0x85, 0xF0, 0xCA, 0x41, 0x79, 0x18, + 0xB8, 0xDB, 0x38, 0xEF, 0x8E, 0x79, 0xDC, 0xB0, 0x60, 0x3A, 0x18, 0x0E, + 0x6C, 0x9E, 0x0E, 0x8B, 0xB0, 0x1E, 0x8A, 0x3E, 0xD7, 0x15, 0x77, 0xC1, + 0xBD, 0x31, 0x4B, 0x27, 0x78, 0xAF, 0x2F, 0xDA, 0x55, 0x60, 0x5C, 0x60, + 0xE6, 0x55, 0x25, 0xF3, 0xAA, 0x55, 0xAB, 0x94, 0x57, 0x48, 0x98, 0x62, + 0x63, 0xE8, 0x14, 0x40, 0x55, 0xCA, 0x39, 0x6A, 0x2A, 0xAB, 0x10, 0xB6, + 0xB4, 0xCC, 0x5C, 0x34, 0x11, 0x41, 0xE8, 0xCE, 0xA1, 0x54, 0x86, 0xAF, + 0x7C, 0x72, 0xE9, 0x93, 0xB3, 0xEE, 0x14, 0x11, 0x63, 0x6F, 0xBC, 0x2A, + 0x2B, 0xA9, 0xC5, 0x5D, 0x74, 0x18, 0x31, 0xF6, 0xCE, 0x5C, 0x3E, 0x16, + 0x9B, 0x87, 0x93, 0x1E, 0xAF, 0xD6, 0xBA, 0x33, 0x6C, 0x24, 0xCF, 0x5C, + 0x7A, 0x32, 0x53, 0x81, 0x28, 0x95, 0x86, 0x77, 0x3B, 0x8F, 0x48, 0x98, + 0x6B, 0x4B, 0xB9, 0xAF, 0xC4, 0xBF, 0xE8, 0x1B, 0x66, 0x28, 0x21, 0x93, + 0x61, 0xD8, 0x09, 0xCC, 0xFB, 0x21, 0xA9, 0x91, 0x48, 0x7C, 0xAC, 0x60, + 0x5D, 0xEC, 0x80, 0x32, 0xEF, 0x84, 0x5D, 0x5D, 0xE9, 0x85, 0x75, 0xB1, + 0xDC, 0x26, 0x23, 0x02, 0xEB, 0x65, 0x1B, 0x88, 0x23, 0x89, 0x3E, 0x81, + 0xD3, 0x96, 0xAC, 0xC5, 0x0F, 0x6D, 0x6F, 0xF3, 0x83, 0xF4, 0x42, 0x39, + 0x2E, 0x0B, 0x44, 0x82, 0xA4, 0x84, 0x20, 0x04, 0x69, 0xC8, 0xF0, 0x4A, + 0x9E, 0x1F, 0x9B, 0x5E, 0x21, 0xC6, 0x68, 0x42, 0xF6, 0xE9, 0x6C, 0x9A, + 0x67, 0x0C, 0x9C, 0x61, 0xAB, 0xD3, 0x88, 0xF0, 0x6A, 0x51, 0xA0, 0xD2, + 0xD8, 0x54, 0x2F, 0x68, 0x96, 0x0F, 0xA7, 0x28, 0xAB, 0x51, 0x33, 0xA3, + 0x6E, 0xEF, 0x0B, 0x6C, 0x13, 0x7A, 0x3B, 0xE4, 0xBA, 0x3B, 0xF0, 0x50, + 0x7E, 0xFB, 0x2A, 0x98, 0xA1, 0xF1, 0x65, 0x1D, 0x39, 0xAF, 0x01, 0x76, + 0x66, 0xCA, 0x59, 0x3E, 0x82, 0x43, 0x0E, 0x88, 0x8C, 0xEE, 0x86, 0x19, + 0x45, 0x6F, 0x9F, 0xB4, 0x7D, 0x84, 0xA5, 0xC3, 0x3B, 0x8B, 0x5E, 0xBE, + 0xE0, 0x6F, 0x75, 0xD8, 0x85, 0xC1, 0x20, 0x73, 0x40, 0x1A, 0x44, 0x9F, + 0x56, 0xC1, 0x6A, 0xA6, 0x4E, 0xD3, 0xAA, 0x62, 0x36, 0x3F, 0x77, 0x06, + 0x1B, 0xFE, 0xDF, 0x72, 0x42, 0x9B, 0x02, 0x3D, 0x37, 0xD0, 0xD7, 0x24, + 0xD0, 0x0A, 0x12, 0x48, 0xDB, 0x0F, 0xEA, 0xD3, 0x49, 0xF1, 0xC0, 0x9B, + 0x07, 0x53, 0x72, 0xC9, 0x80, 0x99, 0x1B, 0x7B, 0x25, 0xD4, 0x79, 0xD8, + 0xF6, 0xE8, 0xDE, 0xF7, 0xE3, 0xFE, 0x50, 0x1A, 0xB6, 0x79, 0x4C, 0x3B, + 0x97, 0x6C, 0xE0, 0xBD, 0x04, 0xC0, 0x06, 0xBA, 0xC1, 0xA9, 0x4F, 0xB6, + 0x40, 0x9F, 0x60, 0xC4, 0x5E, 0x5C, 0x9E, 0xC2, 0x19, 0x6A, 0x24, 0x63, + 0x68, 0xFB, 0x6F, 0xAF, 0x3E, 0x6C, 0x53, 0xB5, 0x13, 0x39, 0xB2, 0xEB, + 0x3B, 0x52, 0xEC, 0x6F, 0x6D, 0xFC, 0x51, 0x1F, 0x9B, 0x30, 0x95, 0x2C, + 0xCC, 0x81, 0x45, 0x44, 0xAF, 0x5E, 0xBD, 0x09, 0xBE, 0xE3, 0xD0, 0x04, + 0xDE, 0x33, 0x4A, 0xFD, 0x66, 0x0F, 0x28, 0x07, 0x19, 0x2E, 0x4B, 0xB3, + 0xC0, 0xCB, 0xA8, 0x57, 0x45, 0xC8, 0x74, 0x0F, 0xD2, 0x0B, 0x5F, 0x39, + 0xB9, 0xD3, 0xFB, 0xDB, 0x55, 0x79, 0xC0, 0xBD, 0x1A, 0x60, 0x32, 0x0A, + 0xD6, 0xA1, 0x00, 0xC6, 0x40, 0x2C, 0x72, 0x79, 0x67, 0x9F, 0x25, 0xFE, + 0xFB, 0x1F, 0xA3, 0xCC, 0x8E, 0xA5, 0xE9, 0xF8, 0xDB, 0x32, 0x22, 0xF8, + 0x3C, 0x75, 0x16, 0xDF, 0xFD, 0x61, 0x6B, 0x15, 0x2F, 0x50, 0x1E, 0xC8, + 0xAD, 0x05, 0x52, 0xAB, 0x32, 0x3D, 0xB5, 0xFA, 0xFD, 0x23, 0x87, 0x60, + 0x53, 0x31, 0x7B, 0x48, 0x3E, 0x00, 0xDF, 0x82, 0x9E, 0x5C, 0x57, 0xBB, + 0xCA, 0x6F, 0x8C, 0xA0, 0x1A, 0x87, 0x56, 0x2E, 0xDF, 0x17, 0x69, 0xDB, + 0xD5, 0x42, 0xA8, 0xF6, 0x28, 0x7E, 0xFF, 0xC3, 0xAC, 0x67, 0x32, 0xC6, + 0x8C, 0x4F, 0x55, 0x73, 0x69, 0x5B, 0x27, 0xB0, 0xBB, 0xCA, 0x58, 0xC8, + 0xE1, 0xFF, 0xA3, 0x5D, 0xB8, 0xF0, 0x11, 0xA0, 0x10, 0xFA, 0x3D, 0x98, + 0xFD, 0x21, 0x83, 0xB8, 0x4A, 0xFC, 0xB5, 0x6C, 0x2D, 0xD1, 0xD3, 0x5B, + 0x9A, 0x53, 0xE4, 0x79, 0xB6, 0xF8, 0x45, 0x65, 0xD2, 0x8E, 0x49, 0xBC, + 0x4B, 0xFB, 0x97, 0x90, 0xE1, 0xDD, 0xF2, 0xDA, 0xA4, 0xCB, 0x7E, 0x33, + 0x62, 0xFB, 0x13, 0x41, 0xCE, 0xE4, 0xC6, 0xE8, 0xEF, 0x20, 0xCA, 0xDA, + 0x36, 0x77, 0x4C, 0x01, 0xD0, 0x7E, 0x9E, 0xFE, 0x2B, 0xF1, 0x1F, 0xB4, + 0x95, 0xDB, 0xDA, 0x4D, 0xAE, 0x90, 0x91, 0x98, 0xEA, 0xAD, 0x8E, 0x71, + 0x6B, 0x93, 0xD5, 0xA0, 0xD0, 0x8E, 0xD1, 0xD0, 0xAF, 0xC7, 0x25, 0xE0, + 0x8E, 0x3C, 0x5B, 0x2F, 0x8E, 0x75, 0x94, 0xB7, 0x8F, 0xF6, 0xE2, 0xFB, + 0xF2, 0x12, 0x2B, 0x64, 0x88, 0x88, 0xB8, 0x12, 0x90, 0x0D, 0xF0, 0x1C, + 0x4F, 0xAD, 0x5E, 0xA0, 0x68, 0x8F, 0xC3, 0x1C, 0xD1, 0xCF, 0xF1, 0x91, + 0xB3, 0xA8, 0xC1, 0xAD, 0x2F, 0x2F, 0x22, 0x18, 0xBE, 0x0E, 0x17, 0x77, + 0xEA, 0x75, 0x2D, 0xFE, 0x8B, 0x02, 0x1F, 0xA1, 0xE5, 0xA0, 0xCC, 0x0F, + 0xB5, 0x6F, 0x74, 0xE8, 0x18, 0xAC, 0xF3, 0xD6, 0xCE, 0x89, 0xE2, 0x99, + 0xB4, 0xA8, 0x4F, 0xE0, 0xFD, 0x13, 0xE0, 0xB7, 0x7C, 0xC4, 0x3B, 0x81, + 0xD2, 0xAD, 0xA8, 0xD9, 0x16, 0x5F, 0xA2, 0x66, 0x80, 0x95, 0x77, 0x05, + 0x93, 0xCC, 0x73, 0x14, 0x21, 0x1A, 0x14, 0x77, 0xE6, 0xAD, 0x20, 0x65, + 0x77, 0xB5, 0xFA, 0x86, 0xC7, 0x54, 0x42, 0xF5, 0xFB, 0x9D, 0x35, 0xCF, + 0xEB, 0xCD, 0xAF, 0x0C, 0x7B, 0x3E, 0x89, 0xA0, 0xD6, 0x41, 0x1B, 0xD3, + 0xAE, 0x1E, 0x7E, 0x49, 0x00, 0x25, 0x0E, 0x2D, 0x20, 0x71, 0xB3, 0x5E, + 0x22, 0x68, 0x00, 0xBB, 0x57, 0xB8, 0xE0, 0xAF, 0x24, 0x64, 0x36, 0x9B, + 0xF0, 0x09, 0xB9, 0x1E, 0x55, 0x63, 0x91, 0x1D, 0x59, 0xDF, 0xA6, 0xAA, + 0x78, 0xC1, 0x43, 0x89, 0xD9, 0x5A, 0x53, 0x7F, 0x20, 0x7D, 0x5B, 0xA2, + 0x02, 0xE5, 0xB9, 0xC5, 0x83, 0x26, 0x03, 0x76, 0x62, 0x95, 0xCF, 0xA9, + 0x11, 0xC8, 0x19, 0x68, 0x4E, 0x73, 0x4A, 0x41, 0xB3, 0x47, 0x2D, 0xCA, + 0x7B, 0x14, 0xA9, 0x4A, 0x1B, 0x51, 0x00, 0x52, 0x9A, 0x53, 0x29, 0x15, + 0xD6, 0x0F, 0x57, 0x3F, 0xBC, 0x9B, 0xC6, 0xE4, 0x2B, 0x60, 0xA4, 0x76, + 0x81, 0xE6, 0x74, 0x00, 0x08, 0xBA, 0x6F, 0xB5, 0x57, 0x1B, 0xE9, 0x1F, + 0xF2, 0x96, 0xEC, 0x6B, 0x2A, 0x0D, 0xD9, 0x15, 0xB6, 0x63, 0x65, 0x21, + 0xE7, 0xB9, 0xF9, 0xB6, 0xFF, 0x34, 0x05, 0x2E, 0xC5, 0x85, 0x56, 0x64, + 0x53, 0xB0, 0x2D, 0x5D, 0xA9, 0x9F, 0x8F, 0xA1, 0x08, 0xBA, 0x47, 0x99, + 0x6E, 0x85, 0x07, 0x6A, 0x4B, 0x7A, 0x70, 0xE9, 0xB5, 0xB3, 0x29, 0x44, + 0xDB, 0x75, 0x09, 0x2E, 0xC4, 0x19, 0x26, 0x23, 0xAD, 0x6E, 0xA6, 0xB0, + 0x49, 0xA7, 0xDF, 0x7D, 0x9C, 0xEE, 0x60, 0xB8, 0x8F, 0xED, 0xB2, 0x66, + 0xEC, 0xAA, 0x8C, 0x71, 0x69, 0x9A, 0x18, 0xFF, 0x56, 0x64, 0x52, 0x6C, + 0xC2, 0xB1, 0x9E, 0xE1, 0x19, 0x36, 0x02, 0xA5, 0x75, 0x09, 0x4C, 0x29, + 0xA0, 0x59, 0x13, 0x40, 0xE4, 0x18, 0x3A, 0x3E, 0x3F, 0x54, 0x98, 0x9A, + 0x5B, 0x42, 0x9D, 0x65, 0x6B, 0x8F, 0xE4, 0xD6, 0x99, 0xF7, 0x3F, 0xD6, + 0xA1, 0xD2, 0x9C, 0x07, 0xEF, 0xE8, 0x30, 0xF5, 0x4D, 0x2D, 0x38, 0xE6, + 0xF0, 0x25, 0x5D, 0xC1, 0x4C, 0xDD, 0x20, 0x86, 0x84, 0x70, 0xEB, 0x26, + 0x63, 0x82, 0xE9, 0xC6, 0x02, 0x1E, 0xCC, 0x5E, 0x09, 0x68, 0x6B, 0x3F, + 0x3E, 0xBA, 0xEF, 0xC9, 0x3C, 0x97, 0x18, 0x14, 0x6B, 0x6A, 0x70, 0xA1, + 0x68, 0x7F, 0x35, 0x84, 0x52, 0xA0, 0xE2, 0x86, 0xB7, 0x9C, 0x53, 0x05, + 0xAA, 0x50, 0x07, 0x37, 0x3E, 0x07, 0x84, 0x1C, 0x7F, 0xDE, 0xAE, 0x5C, + 0x8E, 0x7D, 0x44, 0xEC, 0x57, 0x16, 0xF2, 0xB8, 0xB0, 0x3A, 0xDA, 0x37, + 0xF0, 0x50, 0x0C, 0x0D, 0xF0, 0x1C, 0x1F, 0x04, 0x02, 0x00, 0xB3, 0xFF, + 0xAE, 0x0C, 0xF5, 0x1A, 0x3C, 0xB5, 0x74, 0xB2, 0x25, 0x83, 0x7A, 0x58, + 0xDC, 0x09, 0x21, 0xBD, 0xD1, 0x91, 0x13, 0xF9, 0x7C, 0xA9, 0x2F, 0xF6, + 0x94, 0x32, 0x47, 0x73, 0x22, 0xF5, 0x47, 0x01, 0x3A, 0xE5, 0xE5, 0x81, + 0x37, 0xC2, 0xDA, 0xDC, 0xC8, 0xB5, 0x76, 0x34, 0x9A, 0xF3, 0xDD, 0xA7, + 0xA9, 0x44, 0x61, 0x46, 0x0F, 0xD0, 0x03, 0x0E, 0xEC, 0xC8, 0xC7, 0x3E, + 0xA4, 0x75, 0x1E, 0x41, 0xE2, 0x38, 0xCD, 0x99, 0x3B, 0xEA, 0x0E, 0x2F, + 0x32, 0x80, 0xBB, 0xA1, 0x18, 0x3E, 0xB3, 0x31, 0x4E, 0x54, 0x8B, 0x38, + 0x4F, 0x6D, 0xB9, 0x08, 0x6F, 0x42, 0x0D, 0x03, 0xF6, 0x0A, 0x04, 0xBF, + 0x2C, 0xB8, 0x12, 0x90, 0x24, 0x97, 0x7C, 0x79, 0x56, 0x79, 0xB0, 0x72, + 0xBC, 0xAF, 0x89, 0xAF, 0xDE, 0x9A, 0x77, 0x1F, 0xD9, 0x93, 0x08, 0x10, + 0xB3, 0x8B, 0xAE, 0x12, 0xDC, 0xCF, 0x3F, 0x2E, 0x55, 0x12, 0x72, 0x1F, + 0x2E, 0x6B, 0x71, 0x24, 0x50, 0x1A, 0xDD, 0xE6, 0x9F, 0x84, 0xCD, 0x87, + 0x7A, 0x58, 0x47, 0x18, 0x74, 0x08, 0xDA, 0x17, 0xBC, 0x9F, 0x9A, 0xBC, + 0xE9, 0x4B, 0x7D, 0x8C, 0xEC, 0x7A, 0xEC, 0x3A, 0xDB, 0x85, 0x1D, 0xFA, + 0x63, 0x09, 0x43, 0x66, 0xC4, 0x64, 0xC3, 0xD2, 0xEF, 0x1C, 0x18, 0x47, + 0x32, 0x15, 0xD8, 0x08, 0xDD, 0x43, 0x3B, 0x37, 0x24, 0xC2, 0xBA, 0x16, + 0x12, 0xA1, 0x4D, 0x43, 0x2A, 0x65, 0xC4, 0x51, 0x50, 0x94, 0x00, 0x02, + 0x13, 0x3A, 0xE4, 0xDD, 0x71, 0xDF, 0xF8, 0x9E, 0x10, 0x31, 0x4E, 0x55, + 0x81, 0xAC, 0x77, 0xD6, 0x5F, 0x11, 0x19, 0x9B, 0x04, 0x35, 0x56, 0xF1, + 0xD7, 0xA3, 0xC7, 0x6B, 0x3C, 0x11, 0x18, 0x3B, 0x59, 0x24, 0xA5, 0x09, + 0xF2, 0x8F, 0xE6, 0xED, 0x97, 0xF1, 0xFB, 0xFA, 0x9E, 0xBA, 0xBF, 0x2C, + 0x1E, 0x15, 0x3C, 0x6E, 0x86, 0xE3, 0x45, 0x70, 0xEA, 0xE9, 0x6F, 0xB1, + 0x86, 0x0E, 0x5E, 0x0A, 0x5A, 0x3E, 0x2A, 0xB3, 0x77, 0x1F, 0xE7, 0x1C, + 0x4E, 0x3D, 0x06, 0xFA, 0x29, 0x65, 0xDC, 0xB9, 0x99, 0xE7, 0x1D, 0x0F, + 0x80, 0x3E, 0x89, 0xD6, 0x52, 0x66, 0xC8, 0x25, 0x2E, 0x4C, 0xC9, 0x78, + 0x9C, 0x10, 0xB3, 0x6A, 0xC6, 0x15, 0x0E, 0xBA, 0x94, 0xE2, 0xEA, 0x78, + 0xA6, 0xFC, 0x3C, 0x53, 0x1E, 0x0A, 0x2D, 0xF4, 0xF2, 0xF7, 0x4E, 0xA7, + 0x36, 0x1D, 0x2B, 0x3D, 0x19, 0x39, 0x26, 0x0F, 0x19, 0xC2, 0x79, 0x60, + 0x52, 0x23, 0xA7, 0x08, 0xF7, 0x13, 0x12, 0xB6, 0xEB, 0xAD, 0xFE, 0x6E, + 0xEA, 0xC3, 0x1F, 0x66, 0xE3, 0xBC, 0x45, 0x95, 0xA6, 0x7B, 0xC8, 0x83, + 0xB1, 0x7F, 0x37, 0xD1, 0x01, 0x8C, 0xFF, 0x28, 0xC3, 0x32, 0xDD, 0xEF, + 0xBE, 0x6C, 0x5A, 0xA5, 0x65, 0x58, 0x21, 0x85, 0x68, 0xAB, 0x97, 0x02, + 0xEE, 0xCE, 0xA5, 0x0F, 0xDB, 0x2F, 0x95, 0x3B, 0x2A, 0xEF, 0x7D, 0xAD, + 0x5B, 0x6E, 0x2F, 0x84, 0x15, 0x21, 0xB6, 0x28, 0x29, 0x07, 0x61, 0x70, + 0xEC, 0xDD, 0x47, 0x75, 0x61, 0x9F, 0x15, 0x10, 0x13, 0xCC, 0xA8, 0x30, + 0xEB, 0x61, 0xBD, 0x96, 0x03, 0x34, 0xFE, 0x1E, 0xAA, 0x03, 0x63, 0xCF, + 0xB5, 0x73, 0x5C, 0x90, 0x4C, 0x70, 0xA2, 0x39, 0xD5, 0x9E, 0x9E, 0x0B, + 0xCB, 0xAA, 0xDE, 0x14, 0xEE, 0xCC, 0x86, 0xBC, 0x60, 0x62, 0x2C, 0xA7, + 0x9C, 0xAB, 0x5C, 0xAB, 0xB2, 0xF3, 0x84, 0x6E, 0x64, 0x8B, 0x1E, 0xAF, + 0x19, 0xBD, 0xF0, 0xCA, 0xA0, 0x23, 0x69, 0xB9, 0x65, 0x5A, 0xBB, 0x50, + 0x40, 0x68, 0x5A, 0x32, 0x3C, 0x2A, 0xB4, 0xB3, 0x31, 0x9E, 0xE9, 0xD5, + 0xC0, 0x21, 0xB8, 0xF7, 0x9B, 0x54, 0x0B, 0x19, 0x87, 0x5F, 0xA0, 0x99, + 0x95, 0xF7, 0x99, 0x7E, 0x62, 0x3D, 0x7D, 0xA8, 0xF8, 0x37, 0x88, 0x9A, + 0x97, 0xE3, 0x2D, 0x77, 0x11, 0xED, 0x93, 0x5F, 0x16, 0x68, 0x12, 0x81, + 0x0E, 0x35, 0x88, 0x29, 0xC7, 0xE6, 0x1F, 0xD6, 0x96, 0xDE, 0xDF, 0xA1, + 0x78, 0x58, 0xBA, 0x99, 0x57, 0xF5, 0x84, 0xA5, 0x1B, 0x22, 0x72, 0x63, + 0x9B, 0x83, 0xC3, 0xFF, 0x1A, 0xC2, 0x46, 0x96, 0xCD, 0xB3, 0x0A, 0xEB, + 0x53, 0x2E, 0x30, 0x54, 0x8F, 0xD9, 0x48, 0xE4, 0x6D, 0xBC, 0x31, 0x28, + 0x58, 0xEB, 0xF2, 0xEF, 0x34, 0xC6, 0xFF, 0xEA, 0xFE, 0x28, 0xED, 0x61, + 0xEE, 0x7C, 0x3C, 0x73, 0x5D, 0x4A, 0x14, 0xD9, 0xE8, 0x64, 0xB7, 0xE3, + 0x42, 0x10, 0x5D, 0x14, 0x20, 0x3E, 0x13, 0xE0, 0x45, 0xEE, 0xE2, 0xB6, + 0xA3, 0xAA, 0xAB, 0xEA, 0xDB, 0x6C, 0x4F, 0x15, 0xFA, 0xCB, 0x4F, 0xD0, + 0xC7, 0x42, 0xF4, 0x42, 0xEF, 0x6A, 0xBB, 0xB5, 0x65, 0x4F, 0x3B, 0x1D, + 0x41, 0xCD, 0x21, 0x05, 0xD8, 0x1E, 0x79, 0x9E, 0x86, 0x85, 0x4D, 0xC7, + 0xE4, 0x4B, 0x47, 0x6A, 0x3D, 0x81, 0x62, 0x50, 0xCF, 0x62, 0xA1, 0xF2, + 0x5B, 0x8D, 0x26, 0x46, 0xFC, 0x88, 0x83, 0xA0, 0xC1, 0xC7, 0xB6, 0xA3, + 0x7F, 0x15, 0x24, 0xC3, 0x69, 0xCB, 0x74, 0x92, 0x47, 0x84, 0x8A, 0x0B, + 0x56, 0x92, 0xB2, 0x85, 0x09, 0x5B, 0xBF, 0x00, 0xAD, 0x19, 0x48, 0x9D, + 0x14, 0x62, 0xB1, 0x74, 0x23, 0x82, 0x0D, 0x00, 0x58, 0x42, 0x8D, 0x2A, + 0x0C, 0x55, 0xF5, 0xEA, 0x1D, 0xAD, 0xF4, 0x3E, 0x23, 0x3F, 0x70, 0x61, + 0x33, 0x72, 0xF0, 0x92, 0x8D, 0x93, 0x7E, 0x41, 0xD6, 0x5F, 0xEC, 0xF1, + 0x6C, 0x22, 0x3B, 0xDB, 0x7C, 0xDE, 0x37, 0x59, 0xCB, 0xEE, 0x74, 0x60, + 0x40, 0x85, 0xF2, 0xA7, 0xCE, 0x77, 0x32, 0x6E, 0xA6, 0x07, 0x80, 0x84, + 0x19, 0xF8, 0x50, 0x9E, 0xE8, 0xEF, 0xD8, 0x55, 0x61, 0xD9, 0x97, 0x35, + 0xA9, 0x69, 0xA7, 0xAA, 0xC5, 0x0C, 0x06, 0xC2, 0x5A, 0x04, 0xAB, 0xFC, + 0x80, 0x0B, 0xCA, 0xDC, 0x9E, 0x44, 0x7A, 0x2E, 0xC3, 0x45, 0x34, 0x84, + 0xFD, 0xD5, 0x67, 0x05, 0x0E, 0x1E, 0x9E, 0xC9, 0xDB, 0x73, 0xDB, 0xD3, + 0x10, 0x55, 0x88, 0xCD, 0x67, 0x5F, 0xDA, 0x79, 0xE3, 0x67, 0x43, 0x40, + 0xC5, 0xC4, 0x34, 0x65, 0x71, 0x3E, 0x38, 0xD8, 0x3D, 0x28, 0xF8, 0x9E, + 0xF1, 0x6D, 0xFF, 0x20, 0x15, 0x3E, 0x21, 0xE7, 0x8F, 0xB0, 0x3D, 0x4A, + 0xE6, 0xE3, 0x9F, 0x2B, 0xDB, 0x83, 0xAD, 0xF7, 0xE9, 0x3D, 0x5A, 0x68, + 0x94, 0x81, 0x40, 0xF7, 0xF6, 0x4C, 0x26, 0x1C, 0x94, 0x69, 0x29, 0x34, + 0x41, 0x15, 0x20, 0xF7, 0x76, 0x02, 0xD4, 0xF7, 0xBC, 0xF4, 0x6B, 0x2E, + 0xD4, 0xA1, 0x00, 0x68, 0xD4, 0x08, 0x24, 0x71, 0x33, 0x20, 0xF4, 0x6A, + 0x43, 0xB7, 0xD4, 0xB7, 0x50, 0x00, 0x61, 0xAF, 0x1E, 0x39, 0xF6, 0x2E, + 0x97, 0x24, 0x45, 0x46, +}; + +alignas(16) const unsigned char kRandenRoundKeys[kKeyBytes] = { + 0x44, 0x73, 0x70, 0x03, 0x2E, 0x8A, 0x19, 0x13, 0xD3, 0x08, 0xA3, 0x85, + 0x88, 0x6A, 0x3F, 0x24, 0x89, 0x6C, 0x4E, 0xEC, 0x98, 0xFA, 0x2E, 0x08, + 0xD0, 0x31, 0x9F, 0x29, 0x22, 0x38, 0x09, 0xA4, 0x6C, 0x0C, 0xE9, 0x34, + 0xCF, 0x66, 0x54, 0xBE, 0x77, 0x13, 0xD0, 0x38, 0xE6, 0x21, 0x28, 0x45, + 0x17, 0x09, 0x47, 0xB5, 0xB5, 0xD5, 0x84, 0x3F, 0xDD, 0x50, 0x7C, 0xC9, + 0xB7, 0x29, 0xAC, 0xC0, 0xAC, 0xB5, 0xDF, 0x98, 0xA6, 0x0B, 0x31, 0xD1, + 0x1B, 0xFB, 0x79, 0x89, 0xD9, 0xD5, 0x16, 0x92, 0x96, 0x7E, 0x26, 0x6A, + 0xED, 0xAF, 0xE1, 0xB8, 0xB7, 0xDF, 0x1A, 0xD0, 0xDB, 0x72, 0xFD, 0x2F, + 0xF7, 0x6C, 0x91, 0xB3, 0x47, 0x99, 0xA1, 0x24, 0x99, 0x7F, 0x2C, 0xF1, + 0x45, 0x90, 0x7C, 0xBA, 0x69, 0x4E, 0x57, 0x71, 0xD8, 0x20, 0x69, 0x63, + 0x16, 0xFC, 0x8E, 0x85, 0xE2, 0xF2, 0x01, 0x08, 0x58, 0xB6, 0x8E, 0x72, + 0x8F, 0x74, 0x95, 0x0D, 0x7E, 0x3D, 0x93, 0xF4, 0xA3, 0xFE, 0x58, 0xA4, + 0xB5, 0x59, 0x5A, 0xC2, 0x1D, 0xA4, 0x54, 0x7B, 0xEE, 0x4A, 0x15, 0x82, + 0x58, 0xCD, 0x8B, 0x71, 0xF0, 0x85, 0x60, 0x28, 0x23, 0xB0, 0xD1, 0xC5, + 0x13, 0x60, 0xF2, 0x2A, 0x39, 0xD5, 0x30, 0x9C, 0x0E, 0x18, 0x3A, 0x60, + 0xB0, 0xDC, 0x79, 0x8E, 0xEF, 0x38, 0xDB, 0xB8, 0x18, 0x79, 0x41, 0xCA, + 0x27, 0x4B, 0x31, 0xBD, 0xC1, 0x77, 0x15, 0xD7, 0x3E, 0x8A, 0x1E, 0xB0, + 0x8B, 0x0E, 0x9E, 0x6C, 0x94, 0xAB, 0x55, 0xAA, 0xF3, 0x25, 0x55, 0xE6, + 0x60, 0x5C, 0x60, 0x55, 0xDA, 0x2F, 0xAF, 0x78, 0xB6, 0x10, 0xAB, 0x2A, + 0x6A, 0x39, 0xCA, 0x55, 0x40, 0x14, 0xE8, 0x63, 0x62, 0x98, 0x48, 0x57, + 0x93, 0xE9, 0x72, 0x7C, 0xAF, 0x86, 0x54, 0xA1, 0xCE, 0xE8, 0x41, 0x11, + 0x34, 0x5C, 0xCC, 0xB4, 0xF6, 0x31, 0x18, 0x74, 0x5D, 0xC5, 0xA9, 0x2B, + 0x2A, 0xBC, 0x6F, 0x63, 0x11, 0x14, 0xEE, 0xB3, 0x5C, 0xCF, 0x24, 0x6C, + 0x33, 0xBA, 0xD6, 0xAF, 0x1E, 0x93, 0x87, 0x9B, 0x16, 0x3E, 0x5C, 0xCE, + 0xAF, 0xB9, 0x4B, 0x6B, 0x98, 0x48, 0x8F, 0x3B, 0x77, 0x86, 0x95, 0x28, + 0x81, 0x53, 0x32, 0x7A, 0x91, 0xA9, 0x21, 0xFB, 0xCC, 0x09, 0xD8, 0x61, + 0x93, 0x21, 0x28, 0x66, 0x1B, 0xE8, 0xBF, 0xC4, 0xB1, 0x75, 0x85, 0xE9, + 0x5D, 0x5D, 0x84, 0xEF, 0x32, 0x80, 0xEC, 0x5D, 0x60, 0xAC, 0x7C, 0x48, + 0xC5, 0xAC, 0x96, 0xD3, 0x81, 0x3E, 0x89, 0x23, 0x88, 0x1B, 0x65, 0xEB, + 0x02, 0x23, 0x26, 0xDC, 0x04, 0x20, 0x84, 0xA4, 0x82, 0x44, 0x0B, 0x2E, + 0x39, 0x42, 0xF4, 0x83, 0xF3, 0x6F, 0x6D, 0x0F, 0x9A, 0x6C, 0xE9, 0xF6, + 0x42, 0x68, 0xC6, 0x21, 0x5E, 0x9B, 0x1F, 0x9E, 0x4A, 0xF0, 0xC8, 0x69, + 0x68, 0x2F, 0x54, 0xD8, 0xD2, 0xA0, 0x51, 0x6A, 0xF0, 0x88, 0xD3, 0xAB, + 0x61, 0x9C, 0x0C, 0x67, 0xE4, 0x3B, 0x7A, 0x13, 0x6C, 0x0B, 0xEF, 0x6E, + 0xA3, 0x33, 0x51, 0xAB, 0x28, 0xA7, 0x0F, 0x96, 0x76, 0x01, 0xAF, 0x39, + 0x1D, 0x65, 0xF1, 0xA1, 0x98, 0x2A, 0xFB, 0x7E, 0x50, 0xF0, 0x3B, 0xBA, + 0xB4, 0x9F, 0x6F, 0x45, 0x19, 0x86, 0xEE, 0x8C, 0x88, 0x0E, 0x43, 0x82, + 0x3E, 0x59, 0xCA, 0x66, 0x73, 0x20, 0xC1, 0x85, 0xD8, 0x75, 0x6F, 0xE0, + 0xBE, 0x5E, 0x8B, 0x3B, 0xC3, 0xA5, 0x84, 0x7D, 0x06, 0x77, 0x3F, 0x36, + 0x62, 0xAA, 0xD3, 0x4E, 0xA6, 0x6A, 0xC1, 0x56, 0x9F, 0x44, 0x1A, 0x40, + 0x48, 0x12, 0x0A, 0xD0, 0x24, 0xD7, 0xD0, 0x37, 0x3D, 0x02, 0x9B, 0x42, + 0x72, 0xDF, 0xFE, 0x1B, 0x7B, 0x1B, 0x99, 0x80, 0xC9, 0x72, 0x53, 0x07, + 0x9B, 0xC0, 0xF1, 0x49, 0xD3, 0xEA, 0x0F, 0xDB, 0x3B, 0x4C, 0x79, 0xB6, + 0x1A, 0x50, 0xFE, 0xE3, 0xF7, 0xDE, 0xE8, 0xF6, 0xD8, 0x79, 0xD4, 0x25, + 0xC4, 0x60, 0x9F, 0x40, 0xB6, 0x4F, 0xA9, 0xC1, 0xBA, 0x06, 0xC0, 0x04, + 0xBD, 0xE0, 0x6C, 0x97, 0xB5, 0x53, 0x6C, 0x3E, 0xAF, 0x6F, 0xFB, 0x68, + 0x63, 0x24, 0x6A, 0x19, 0xC2, 0x9E, 0x5C, 0x5E, 0x2C, 0x95, 0x30, 0x9B, + 0x1F, 0x51, 0xFC, 0x6D, 0x6F, 0xEC, 0x52, 0x3B, 0xEB, 0xB2, 0x39, 0x13, + 0xFD, 0x4A, 0x33, 0xDE, 0x04, 0xD0, 0xE3, 0xBE, 0x09, 0xBD, 0x5E, 0xAF, + 0x44, 0x45, 0x81, 0xCC, 0x0F, 0x74, 0xC8, 0x45, 0x57, 0xA8, 0xCB, 0xC0, + 0xB3, 0x4B, 0x2E, 0x19, 0x07, 0x28, 0x0F, 0x66, 0x0A, 0x32, 0x60, 0x1A, + 0xBD, 0xC0, 0x79, 0x55, 0xDB, 0xFB, 0xD3, 0xB9, 0x39, 0x5F, 0x0B, 0xD2, + 0xCC, 0xA3, 0x1F, 0xFB, 0xFE, 0x25, 0x9F, 0x67, 0x79, 0x72, 0x2C, 0x40, + 0xC6, 0x00, 0xA1, 0xD6, 0x15, 0x6B, 0x61, 0xFD, 0xDF, 0x16, 0x75, 0x3C, + 0xF8, 0x22, 0x32, 0xDB, 0xF8, 0xE9, 0xA5, 0x8E, 0x60, 0x87, 0x23, 0xFD, + 0xFA, 0xB5, 0x3D, 0x32, 0xAB, 0x52, 0x05, 0xAD, 0xC8, 0x1E, 0x50, 0x2F, + 0xA0, 0x8C, 0x6F, 0xCA, 0xBB, 0x57, 0x5C, 0x9E, 0x82, 0xDF, 0x00, 0x3E, + 0x48, 0x7B, 0x31, 0x53, 0xC3, 0xFF, 0x7E, 0x28, 0xF6, 0xA8, 0x42, 0xD5, + 0xDB, 0x69, 0x17, 0xDF, 0x2E, 0x56, 0x87, 0x1A, 0xC8, 0x58, 0xCA, 0xBB, + 0xB0, 0x27, 0x5B, 0x69, 0x73, 0x55, 0x4F, 0x8C, 0xC6, 0x32, 0x67, 0xAC, + 0xB8, 0x83, 0x21, 0xFD, 0x98, 0x3D, 0xFA, 0x10, 0xA0, 0x11, 0xF0, 0xB8, + 0x5D, 0xA3, 0xFF, 0xE1, 0x65, 0x45, 0xF8, 0xB6, 0x79, 0xE4, 0x53, 0x9A, + 0x5B, 0xD3, 0xD1, 0x2D, 0x6C, 0xB5, 0xFC, 0x4A, 0x33, 0x7E, 0xCB, 0xA4, + 0xDA, 0xF2, 0xDD, 0xE1, 0x90, 0x97, 0xFB, 0x4B, 0xBC, 0x49, 0x8E, 0xD2, + 0x01, 0x4C, 0x77, 0x36, 0xDA, 0xCA, 0x20, 0xEF, 0xE8, 0xC6, 0xE4, 0xCE, + 0x41, 0x13, 0xFB, 0x62, 0x98, 0x91, 0x90, 0xAE, 0x4D, 0xDA, 0xDB, 0x95, + 0xB4, 0x1F, 0xF1, 0x2B, 0xFE, 0x9E, 0x7E, 0xD0, 0xE0, 0x25, 0xC7, 0xAF, + 0xD0, 0xD1, 0x8E, 0xD0, 0xA0, 0xD5, 0x93, 0x6B, 0x71, 0x8E, 0xAD, 0xEA, + 0x64, 0x2B, 0x12, 0xF2, 0xFB, 0xE2, 0xF6, 0x8F, 0xB7, 0x94, 0x75, 0x8E, + 0x2F, 0x5B, 0x3C, 0x8E, 0x1C, 0xC3, 0x8F, 0x68, 0xA0, 0x5E, 0xAD, 0x4F, + 0x1C, 0xF0, 0x0D, 0x90, 0x12, 0xB8, 0x88, 0x88, 0x77, 0x17, 0x0E, 0xBE, + 0x18, 0x22, 0x2F, 0x2F, 0xAD, 0xC1, 0xA8, 0xB3, 0x91, 0xF1, 0xCF, 0xD1, + 0xE8, 0x74, 0x6F, 0xB5, 0x0F, 0xCC, 0xA0, 0xE5, 0xA1, 0x1F, 0x02, 0x8B, + 0xFE, 0x2D, 0x75, 0xEA, 0xB7, 0xE0, 0x13, 0xFD, 0xE0, 0x4F, 0xA8, 0xB4, + 0x99, 0xE2, 0x89, 0xCE, 0xD6, 0xF3, 0xAC, 0x18, 0x05, 0x77, 0x95, 0x80, + 0x66, 0xA2, 0x5F, 0x16, 0xD9, 0xA8, 0xAD, 0xD2, 0x81, 0x3B, 0xC4, 0x7C, + 0x86, 0xFA, 0xB5, 0x77, 0x65, 0x20, 0xAD, 0xE6, 0x77, 0x14, 0x1A, 0x21, + 0x14, 0x73, 0xCC, 0x93, 0xA0, 0x89, 0x3E, 0x7B, 0x0C, 0xAF, 0xCD, 0xEB, + 0xCF, 0x35, 0x9D, 0xFB, 0xF5, 0x42, 0x54, 0xC7, 0x5E, 0xB3, 0x71, 0x20, + 0x2D, 0x0E, 0x25, 0x00, 0x49, 0x7E, 0x1E, 0xAE, 0xD3, 0x1B, 0x41, 0xD6, + 0x1E, 0xB9, 0x09, 0xF0, 0x9B, 0x36, 0x64, 0x24, 0xAF, 0xE0, 0xB8, 0x57, + 0xBB, 0x00, 0x68, 0x22, 0x7F, 0x53, 0x5A, 0xD9, 0x89, 0x43, 0xC1, 0x78, + 0xAA, 0xA6, 0xDF, 0x59, 0x1D, 0x91, 0x63, 0x55, 0xA9, 0xCF, 0x95, 0x62, + 0x76, 0x03, 0x26, 0x83, 0xC5, 0xB9, 0xE5, 0x02, 0xA2, 0x5B, 0x7D, 0x20, + 0x4A, 0xA9, 0x14, 0x7B, 0xCA, 0x2D, 0x47, 0xB3, 0x41, 0x4A, 0x73, 0x4E, + 0x68, 0x19, 0xC8, 0x11, 0xE4, 0xC6, 0x9B, 0xBC, 0x3F, 0x57, 0x0F, 0xD6, + 0x15, 0x29, 0x53, 0x9A, 0x52, 0x00, 0x51, 0x1B, 0x1F, 0xE9, 0x1B, 0x57, + 0xB5, 0x6F, 0xBA, 0x08, 0x00, 0x74, 0xE6, 0x81, 0x76, 0xA4, 0x60, 0x2B, + 0xB6, 0xF9, 0xB9, 0xE7, 0x21, 0x65, 0x63, 0xB6, 0x15, 0xD9, 0x0D, 0x2A, + 0x6B, 0xEC, 0x96, 0xF2, 0xA1, 0x8F, 0x9F, 0xA9, 0x5D, 0x2D, 0xB0, 0x53, + 0x64, 0x56, 0x85, 0xC5, 0x2E, 0x05, 0x34, 0xFF, 0x44, 0x29, 0xB3, 0xB5, + 0xE9, 0x70, 0x7A, 0x4B, 0x6A, 0x07, 0x85, 0x6E, 0x99, 0x47, 0xBA, 0x08, + 0x7D, 0xDF, 0xA7, 0x49, 0xB0, 0xA6, 0x6E, 0xAD, 0x23, 0x26, 0x19, 0xC4, + 0x2E, 0x09, 0x75, 0xDB, 0xFF, 0x18, 0x9A, 0x69, 0x71, 0x8C, 0xAA, 0xEC, + 0x66, 0xB2, 0xED, 0x8F, 0xB8, 0x60, 0xEE, 0x9C, 0x29, 0x4C, 0x09, 0x75, + 0xA5, 0x02, 0x36, 0x19, 0xE1, 0x9E, 0xB1, 0xC2, 0x6C, 0x52, 0x64, 0x56, + 0x65, 0x9D, 0x42, 0x5B, 0x9A, 0x98, 0x54, 0x3F, 0x3E, 0x3A, 0x18, 0xE4, + 0x40, 0x13, 0x59, 0xA0, 0xF5, 0x30, 0xE8, 0xEF, 0x07, 0x9C, 0xD2, 0xA1, + 0xD6, 0x3F, 0xF7, 0x99, 0xD6, 0xE4, 0x8F, 0x6B, 0x26, 0xEB, 0x70, 0x84, + 0x86, 0x20, 0xDD, 0x4C, 0xC1, 0x5D, 0x25, 0xF0, 0xE6, 0x38, 0x2D, 0x4D, + 0xC9, 0xEF, 0xBA, 0x3E, 0x3F, 0x6B, 0x68, 0x09, 0x5E, 0xCC, 0x1E, 0x02, + 0xC6, 0xE9, 0x82, 0x63, 0x86, 0xE2, 0xA0, 0x52, 0x84, 0x35, 0x7F, 0x68, + 0xA1, 0x70, 0x6A, 0x6B, 0x14, 0x18, 0x97, 0x3C, 0x5C, 0xAE, 0xDE, 0x7F, + 0x1C, 0x84, 0x07, 0x3E, 0x37, 0x07, 0x50, 0xAA, 0x05, 0x53, 0x9C, 0xB7, + 0x0D, 0x0C, 0x50, 0xF0, 0x37, 0xDA, 0x3A, 0xB0, 0xB8, 0xF2, 0x16, 0x57, + 0xEC, 0x44, 0x7D, 0x8E, 0xB2, 0x74, 0xB5, 0x3C, 0x1A, 0xF5, 0x0C, 0xAE, + 0xFF, 0xB3, 0x00, 0x02, 0x04, 0x1F, 0x1C, 0xF0, 0xF6, 0x2F, 0xA9, 0x7C, + 0xF9, 0x13, 0x91, 0xD1, 0xBD, 0x21, 0x09, 0xDC, 0x58, 0x7A, 0x83, 0x25, + 0xDC, 0xDA, 0xC2, 0x37, 0x81, 0xE5, 0xE5, 0x3A, 0x01, 0x47, 0xF5, 0x22, + 0x73, 0x47, 0x32, 0x94, 0x0E, 0x03, 0xD0, 0x0F, 0x46, 0x61, 0x44, 0xA9, + 0xA7, 0xDD, 0xF3, 0x9A, 0x34, 0x76, 0xB5, 0xC8, 0x2F, 0x0E, 0xEA, 0x3B, + 0x99, 0xCD, 0x38, 0xE2, 0x41, 0x1E, 0x75, 0xA4, 0x3E, 0xC7, 0xC8, 0xEC, + 0x08, 0xB9, 0x6D, 0x4F, 0x38, 0x8B, 0x54, 0x4E, 0x31, 0xB3, 0x3E, 0x18, + 0xA1, 0xBB, 0x80, 0x32, 0x79, 0x7C, 0x97, 0x24, 0x90, 0x12, 0xB8, 0x2C, + 0xBF, 0x04, 0x0A, 0xF6, 0x03, 0x0D, 0x42, 0x6F, 0x10, 0x08, 0x93, 0xD9, + 0x1F, 0x77, 0x9A, 0xDE, 0xAF, 0x89, 0xAF, 0xBC, 0x72, 0xB0, 0x79, 0x56, + 0x24, 0x71, 0x6B, 0x2E, 0x1F, 0x72, 0x12, 0x55, 0x2E, 0x3F, 0xCF, 0xDC, + 0x12, 0xAE, 0x8B, 0xB3, 0x17, 0xDA, 0x08, 0x74, 0x18, 0x47, 0x58, 0x7A, + 0x87, 0xCD, 0x84, 0x9F, 0xE6, 0xDD, 0x1A, 0x50, 0xFA, 0x1D, 0x85, 0xDB, + 0x3A, 0xEC, 0x7A, 0xEC, 0x8C, 0x7D, 0x4B, 0xE9, 0xBC, 0x9A, 0x9F, 0xBC, + 0x08, 0xD8, 0x15, 0x32, 0x47, 0x18, 0x1C, 0xEF, 0xD2, 0xC3, 0x64, 0xC4, + 0x66, 0x43, 0x09, 0x63, 0x51, 0xC4, 0x65, 0x2A, 0x43, 0x4D, 0xA1, 0x12, + 0x16, 0xBA, 0xC2, 0x24, 0x37, 0x3B, 0x43, 0xDD, 0x55, 0x4E, 0x31, 0x10, + 0x9E, 0xF8, 0xDF, 0x71, 0xDD, 0xE4, 0x3A, 0x13, 0x02, 0x00, 0x94, 0x50, + 0x6B, 0xC7, 0xA3, 0xD7, 0xF1, 0x56, 0x35, 0x04, 0x9B, 0x19, 0x11, 0x5F, + 0xD6, 0x77, 0xAC, 0x81, 0xFA, 0xFB, 0xF1, 0x97, 0xED, 0xE6, 0x8F, 0xF2, + 0x09, 0xA5, 0x24, 0x59, 0x3B, 0x18, 0x11, 0x3C, 0xB1, 0x6F, 0xE9, 0xEA, + 0x70, 0x45, 0xE3, 0x86, 0x6E, 0x3C, 0x15, 0x1E, 0x2C, 0xBF, 0xBA, 0x9E, + 0xFA, 0x06, 0x3D, 0x4E, 0x1C, 0xE7, 0x1F, 0x77, 0xB3, 0x2A, 0x3E, 0x5A, + 0x0A, 0x5E, 0x0E, 0x86, 0x25, 0xC8, 0x66, 0x52, 0xD6, 0x89, 0x3E, 0x80, + 0x0F, 0x1D, 0xE7, 0x99, 0xB9, 0xDC, 0x65, 0x29, 0x78, 0xEA, 0xE2, 0x94, + 0xBA, 0x0E, 0x15, 0xC6, 0x6A, 0xB3, 0x10, 0x9C, 0x78, 0xC9, 0x4C, 0x2E, + 0x3D, 0x2B, 0x1D, 0x36, 0xA7, 0x4E, 0xF7, 0xF2, 0xF4, 0x2D, 0x0A, 0x1E, + 0x53, 0x3C, 0xFC, 0xA6, 0xB6, 0x12, 0x13, 0xF7, 0x08, 0xA7, 0x23, 0x52, + 0x60, 0x79, 0xC2, 0x19, 0x0F, 0x26, 0x39, 0x19, 0x83, 0xC8, 0x7B, 0xA6, + 0x95, 0x45, 0xBC, 0xE3, 0x66, 0x1F, 0xC3, 0xEA, 0x6E, 0xFE, 0xAD, 0xEB, + 0xA5, 0x5A, 0x6C, 0xBE, 0xEF, 0xDD, 0x32, 0xC3, 0x28, 0xFF, 0x8C, 0x01, + 0xD1, 0x37, 0x7F, 0xB1, 0x3B, 0x95, 0x2F, 0xDB, 0x0F, 0xA5, 0xCE, 0xEE, + 0x02, 0x97, 0xAB, 0x68, 0x85, 0x21, 0x58, 0x65, 0x70, 0x61, 0x07, 0x29, + 0x28, 0xB6, 0x21, 0x15, 0x84, 0x2F, 0x6E, 0x5B, 0xAD, 0x7D, 0xEF, 0x2A, + 0x96, 0xBD, 0x61, 0xEB, 0x30, 0xA8, 0xCC, 0x13, 0x10, 0x15, 0x9F, 0x61, + 0x75, 0x47, 0xDD, 0xEC, 0x39, 0xA2, 0x70, 0x4C, 0x90, 0x5C, 0x73, 0xB5, + 0xCF, 0x63, 0x03, 0xAA, 0x1E, 0xFE, 0x34, 0x03, 0xA7, 0x2C, 0x62, 0x60, + 0xBC, 0x86, 0xCC, 0xEE, 0x14, 0xDE, 0xAA, 0xCB, 0x0B, 0x9E, 0x9E, 0xD5, + 0xCA, 0xF0, 0xBD, 0x19, 0xAF, 0x1E, 0x8B, 0x64, 0x6E, 0x84, 0xF3, 0xB2, + 0xAB, 0x5C, 0xAB, 0x9C, 0xB3, 0xB4, 0x2A, 0x3C, 0x32, 0x5A, 0x68, 0x40, + 0x50, 0xBB, 0x5A, 0x65, 0xB9, 0x69, 0x23, 0xA0, 0x99, 0xA0, 0x5F, 0x87, + 0x19, 0x0B, 0x54, 0x9B, 0xF7, 0xB8, 0x21, 0xC0, 0xD5, 0xE9, 0x9E, 0x31, + 0x77, 0x2D, 0xE3, 0x97, 0x9A, 0x88, 0x37, 0xF8, 0xA8, 0x7D, 0x3D, 0x62, + 0x7E, 0x99, 0xF7, 0x95, 0xD6, 0x1F, 0xE6, 0xC7, 0x29, 0x88, 0x35, 0x0E, + 0x81, 0x12, 0x68, 0x16, 0x5F, 0x93, 0xED, 0x11, 0x63, 0x72, 0x22, 0x1B, + 0xA5, 0x84, 0xF5, 0x57, 0x99, 0xBA, 0x58, 0x78, 0xA1, 0xDF, 0xDE, 0x96, + 0x54, 0x30, 0x2E, 0x53, 0xEB, 0x0A, 0xB3, 0xCD, 0x96, 0x46, 0xC2, 0x1A, + 0xFF, 0xC3, 0x83, 0x9B, 0xEA, 0xFF, 0xC6, 0x34, 0xEF, 0xF2, 0xEB, 0x58, + 0x28, 0x31, 0xBC, 0x6D, 0xE4, 0x48, 0xD9, 0x8F, 0xE3, 0xB7, 0x64, 0xE8, + 0xD9, 0x14, 0x4A, 0x5D, 0x73, 0x3C, 0x7C, 0xEE, 0x61, 0xED, 0x28, 0xFE, + 0xEA, 0xAB, 0xAA, 0xA3, 0xB6, 0xE2, 0xEE, 0x45, 0xE0, 0x13, 0x3E, 0x20, + 0x14, 0x5D, 0x10, 0x42, 0xB5, 0xBB, 0x6A, 0xEF, 0x42, 0xF4, 0x42, 0xC7, + 0xD0, 0x4F, 0xCB, 0xFA, 0x15, 0x4F, 0x6C, 0xDB, 0xC7, 0x4D, 0x85, 0x86, + 0x9E, 0x79, 0x1E, 0xD8, 0x05, 0x21, 0xCD, 0x41, 0x1D, 0x3B, 0x4F, 0x65, + 0x46, 0x26, 0x8D, 0x5B, 0xF2, 0xA1, 0x62, 0xCF, 0x50, 0x62, 0x81, 0x3D, + 0x6A, 0x47, 0x4B, 0xE4, 0x92, 0x74, 0xCB, 0x69, 0xC3, 0x24, 0x15, 0x7F, + 0xA3, 0xB6, 0xC7, 0xC1, 0xA0, 0x83, 0x88, 0xFC, 0x9D, 0x48, 0x19, 0xAD, + 0x00, 0xBF, 0x5B, 0x09, 0x85, 0xB2, 0x92, 0x56, 0x0B, 0x8A, 0x84, 0x47, + 0xEA, 0xF5, 0x55, 0x0C, 0x2A, 0x8D, 0x42, 0x58, 0x00, 0x0D, 0x82, 0x23, + 0x74, 0xB1, 0x62, 0x14, 0x41, 0x7E, 0x93, 0x8D, 0x92, 0xF0, 0x72, 0x33, + 0x61, 0x70, 0x3F, 0x23, 0x3E, 0xF4, 0xAD, 0x1D, 0x60, 0x74, 0xEE, 0xCB, + 0x59, 0x37, 0xDE, 0x7C, 0xDB, 0x3B, 0x22, 0x6C, 0xF1, 0xEC, 0x5F, 0xD6, + 0x9E, 0x50, 0xF8, 0x19, 0x84, 0x80, 0x07, 0xA6, 0x6E, 0x32, 0x77, 0xCE, + 0xA7, 0xF2, 0x85, 0x40, 0xC2, 0x06, 0x0C, 0xC5, 0xAA, 0xA7, 0x69, 0xA9, + 0x35, 0x97, 0xD9, 0x61, 0x55, 0xD8, 0xEF, 0xE8, 0x84, 0x34, 0x45, 0xC3, + 0x2E, 0x7A, 0x44, 0x9E, 0xDC, 0xCA, 0x0B, 0x80, 0xFC, 0xAB, 0x04, 0x5A, + 0xCD, 0x88, 0x55, 0x10, 0xD3, 0xDB, 0x73, 0xDB, 0xC9, 0x9E, 0x1E, 0x0E, + 0x05, 0x67, 0xD5, 0xFD, 0xD8, 0x38, 0x3E, 0x71, 0x65, 0x34, 0xC4, 0xC5, + 0x40, 0x43, 0x67, 0xE3, 0x79, 0xDA, 0x5F, 0x67, 0x4A, 0x3D, 0xB0, 0x8F, + 0xE7, 0x21, 0x3E, 0x15, 0x20, 0xFF, 0x6D, 0xF1, 0x9E, 0xF8, 0x28, 0x3D, + 0xF7, 0x40, 0x81, 0x94, 0x68, 0x5A, 0x3D, 0xE9, 0xF7, 0xAD, 0x83, 0xDB, + 0x2B, 0x9F, 0xE3, 0xE6, 0xF7, 0xD4, 0x02, 0x76, 0xF7, 0x20, 0x15, 0x41, + 0x34, 0x29, 0x69, 0x94, 0x1C, 0x26, 0x4C, 0xF6, 0x6A, 0xF4, 0x20, 0x33, + 0x71, 0x24, 0x08, 0xD4, 0x68, 0x00, 0xA1, 0xD4, 0x2E, 0x6B, 0xF4, 0xBC, + 0x46, 0x45, 0x24, 0x97, 0x2E, 0xF6, 0x39, 0x1E, 0xAF, 0x61, 0x00, 0x50, + 0xB7, 0xD4, 0xB7, 0x43, +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/randen_slow.cc b/third_party/abseil_cpp/absl/random/internal/randen_slow.cc new file mode 100644 index 0000000000..4e5f3dc1c7 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_slow.cc @@ -0,0 +1,457 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen_slow.h" + +#include <cstddef> +#include <cstdint> +#include <cstring> + +#include "absl/base/attributes.h" +#include "absl/random/internal/platform.h" +#include "absl/random/internal/randen_traits.h" + +#if ABSL_HAVE_ATTRIBUTE(always_inline) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE \ + __attribute__((always_inline)) +#elif defined(_MSC_VER) +// We can achieve something similar to attribute((always_inline)) with MSVC by +// using the __forceinline keyword, however this is not perfect. MSVC is +// much less aggressive about inlining, and even with the __forceinline keyword. +#define ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE __forceinline +#else +#define ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE +#endif + +namespace { + +// AES portions based on rijndael-alg-fst.c, +// https://fastcrypto.org/front/misc/rijndael-alg-fst.c +// +// Implementation of +// http://www.csrc.nist.gov/publications/fips/fips197/fips-197.pdf +constexpr uint32_t te0[256] = { + 0xc66363a5, 0xf87c7c84, 0xee777799, 0xf67b7b8d, 0xfff2f20d, 0xd66b6bbd, + 0xde6f6fb1, 0x91c5c554, 0x60303050, 0x02010103, 0xce6767a9, 0x562b2b7d, + 0xe7fefe19, 0xb5d7d762, 0x4dababe6, 0xec76769a, 0x8fcaca45, 0x1f82829d, + 0x89c9c940, 0xfa7d7d87, 0xeffafa15, 0xb25959eb, 0x8e4747c9, 0xfbf0f00b, + 0x41adadec, 0xb3d4d467, 0x5fa2a2fd, 0x45afafea, 0x239c9cbf, 0x53a4a4f7, + 0xe4727296, 0x9bc0c05b, 0x75b7b7c2, 0xe1fdfd1c, 0x3d9393ae, 0x4c26266a, + 0x6c36365a, 0x7e3f3f41, 0xf5f7f702, 0x83cccc4f, 0x6834345c, 0x51a5a5f4, + 0xd1e5e534, 0xf9f1f108, 0xe2717193, 0xabd8d873, 0x62313153, 0x2a15153f, + 0x0804040c, 0x95c7c752, 0x46232365, 0x9dc3c35e, 0x30181828, 0x379696a1, + 0x0a05050f, 0x2f9a9ab5, 0x0e070709, 0x24121236, 0x1b80809b, 0xdfe2e23d, + 0xcdebeb26, 0x4e272769, 0x7fb2b2cd, 0xea75759f, 0x1209091b, 0x1d83839e, + 0x582c2c74, 0x341a1a2e, 0x361b1b2d, 0xdc6e6eb2, 0xb45a5aee, 0x5ba0a0fb, + 0xa45252f6, 0x763b3b4d, 0xb7d6d661, 0x7db3b3ce, 0x5229297b, 0xdde3e33e, + 0x5e2f2f71, 0x13848497, 0xa65353f5, 0xb9d1d168, 0x00000000, 0xc1eded2c, + 0x40202060, 0xe3fcfc1f, 0x79b1b1c8, 0xb65b5bed, 0xd46a6abe, 0x8dcbcb46, + 0x67bebed9, 0x7239394b, 0x944a4ade, 0x984c4cd4, 0xb05858e8, 0x85cfcf4a, + 0xbbd0d06b, 0xc5efef2a, 0x4faaaae5, 0xedfbfb16, 0x864343c5, 0x9a4d4dd7, + 0x66333355, 0x11858594, 0x8a4545cf, 0xe9f9f910, 0x04020206, 0xfe7f7f81, + 0xa05050f0, 0x783c3c44, 0x259f9fba, 0x4ba8a8e3, 0xa25151f3, 0x5da3a3fe, + 0x804040c0, 0x058f8f8a, 0x3f9292ad, 0x219d9dbc, 0x70383848, 0xf1f5f504, + 0x63bcbcdf, 0x77b6b6c1, 0xafdada75, 0x42212163, 0x20101030, 0xe5ffff1a, + 0xfdf3f30e, 0xbfd2d26d, 0x81cdcd4c, 0x180c0c14, 0x26131335, 0xc3ecec2f, + 0xbe5f5fe1, 0x359797a2, 0x884444cc, 0x2e171739, 0x93c4c457, 0x55a7a7f2, + 0xfc7e7e82, 0x7a3d3d47, 0xc86464ac, 0xba5d5de7, 0x3219192b, 0xe6737395, + 0xc06060a0, 0x19818198, 0x9e4f4fd1, 0xa3dcdc7f, 0x44222266, 0x542a2a7e, + 0x3b9090ab, 0x0b888883, 0x8c4646ca, 0xc7eeee29, 0x6bb8b8d3, 0x2814143c, + 0xa7dede79, 0xbc5e5ee2, 0x160b0b1d, 0xaddbdb76, 0xdbe0e03b, 0x64323256, + 0x743a3a4e, 0x140a0a1e, 0x924949db, 0x0c06060a, 0x4824246c, 0xb85c5ce4, + 0x9fc2c25d, 0xbdd3d36e, 0x43acacef, 0xc46262a6, 0x399191a8, 0x319595a4, + 0xd3e4e437, 0xf279798b, 0xd5e7e732, 0x8bc8c843, 0x6e373759, 0xda6d6db7, + 0x018d8d8c, 0xb1d5d564, 0x9c4e4ed2, 0x49a9a9e0, 0xd86c6cb4, 0xac5656fa, + 0xf3f4f407, 0xcfeaea25, 0xca6565af, 0xf47a7a8e, 0x47aeaee9, 0x10080818, + 0x6fbabad5, 0xf0787888, 0x4a25256f, 0x5c2e2e72, 0x381c1c24, 0x57a6a6f1, + 0x73b4b4c7, 0x97c6c651, 0xcbe8e823, 0xa1dddd7c, 0xe874749c, 0x3e1f1f21, + 0x964b4bdd, 0x61bdbddc, 0x0d8b8b86, 0x0f8a8a85, 0xe0707090, 0x7c3e3e42, + 0x71b5b5c4, 0xcc6666aa, 0x904848d8, 0x06030305, 0xf7f6f601, 0x1c0e0e12, + 0xc26161a3, 0x6a35355f, 0xae5757f9, 0x69b9b9d0, 0x17868691, 0x99c1c158, + 0x3a1d1d27, 0x279e9eb9, 0xd9e1e138, 0xebf8f813, 0x2b9898b3, 0x22111133, + 0xd26969bb, 0xa9d9d970, 0x078e8e89, 0x339494a7, 0x2d9b9bb6, 0x3c1e1e22, + 0x15878792, 0xc9e9e920, 0x87cece49, 0xaa5555ff, 0x50282878, 0xa5dfdf7a, + 0x038c8c8f, 0x59a1a1f8, 0x09898980, 0x1a0d0d17, 0x65bfbfda, 0xd7e6e631, + 0x844242c6, 0xd06868b8, 0x824141c3, 0x299999b0, 0x5a2d2d77, 0x1e0f0f11, + 0x7bb0b0cb, 0xa85454fc, 0x6dbbbbd6, 0x2c16163a, +}; + +constexpr uint32_t te1[256] = { + 0xa5c66363, 0x84f87c7c, 0x99ee7777, 0x8df67b7b, 0x0dfff2f2, 0xbdd66b6b, + 0xb1de6f6f, 0x5491c5c5, 0x50603030, 0x03020101, 0xa9ce6767, 0x7d562b2b, + 0x19e7fefe, 0x62b5d7d7, 0xe64dabab, 0x9aec7676, 0x458fcaca, 0x9d1f8282, + 0x4089c9c9, 0x87fa7d7d, 0x15effafa, 0xebb25959, 0xc98e4747, 0x0bfbf0f0, + 0xec41adad, 0x67b3d4d4, 0xfd5fa2a2, 0xea45afaf, 0xbf239c9c, 0xf753a4a4, + 0x96e47272, 0x5b9bc0c0, 0xc275b7b7, 0x1ce1fdfd, 0xae3d9393, 0x6a4c2626, + 0x5a6c3636, 0x417e3f3f, 0x02f5f7f7, 0x4f83cccc, 0x5c683434, 0xf451a5a5, + 0x34d1e5e5, 0x08f9f1f1, 0x93e27171, 0x73abd8d8, 0x53623131, 0x3f2a1515, + 0x0c080404, 0x5295c7c7, 0x65462323, 0x5e9dc3c3, 0x28301818, 0xa1379696, + 0x0f0a0505, 0xb52f9a9a, 0x090e0707, 0x36241212, 0x9b1b8080, 0x3ddfe2e2, + 0x26cdebeb, 0x694e2727, 0xcd7fb2b2, 0x9fea7575, 0x1b120909, 0x9e1d8383, + 0x74582c2c, 0x2e341a1a, 0x2d361b1b, 0xb2dc6e6e, 0xeeb45a5a, 0xfb5ba0a0, + 0xf6a45252, 0x4d763b3b, 0x61b7d6d6, 0xce7db3b3, 0x7b522929, 0x3edde3e3, + 0x715e2f2f, 0x97138484, 0xf5a65353, 0x68b9d1d1, 0x00000000, 0x2cc1eded, + 0x60402020, 0x1fe3fcfc, 0xc879b1b1, 0xedb65b5b, 0xbed46a6a, 0x468dcbcb, + 0xd967bebe, 0x4b723939, 0xde944a4a, 0xd4984c4c, 0xe8b05858, 0x4a85cfcf, + 0x6bbbd0d0, 0x2ac5efef, 0xe54faaaa, 0x16edfbfb, 0xc5864343, 0xd79a4d4d, + 0x55663333, 0x94118585, 0xcf8a4545, 0x10e9f9f9, 0x06040202, 0x81fe7f7f, + 0xf0a05050, 0x44783c3c, 0xba259f9f, 0xe34ba8a8, 0xf3a25151, 0xfe5da3a3, + 0xc0804040, 0x8a058f8f, 0xad3f9292, 0xbc219d9d, 0x48703838, 0x04f1f5f5, + 0xdf63bcbc, 0xc177b6b6, 0x75afdada, 0x63422121, 0x30201010, 0x1ae5ffff, + 0x0efdf3f3, 0x6dbfd2d2, 0x4c81cdcd, 0x14180c0c, 0x35261313, 0x2fc3ecec, + 0xe1be5f5f, 0xa2359797, 0xcc884444, 0x392e1717, 0x5793c4c4, 0xf255a7a7, + 0x82fc7e7e, 0x477a3d3d, 0xacc86464, 0xe7ba5d5d, 0x2b321919, 0x95e67373, + 0xa0c06060, 0x98198181, 0xd19e4f4f, 0x7fa3dcdc, 0x66442222, 0x7e542a2a, + 0xab3b9090, 0x830b8888, 0xca8c4646, 0x29c7eeee, 0xd36bb8b8, 0x3c281414, + 0x79a7dede, 0xe2bc5e5e, 0x1d160b0b, 0x76addbdb, 0x3bdbe0e0, 0x56643232, + 0x4e743a3a, 0x1e140a0a, 0xdb924949, 0x0a0c0606, 0x6c482424, 0xe4b85c5c, + 0x5d9fc2c2, 0x6ebdd3d3, 0xef43acac, 0xa6c46262, 0xa8399191, 0xa4319595, + 0x37d3e4e4, 0x8bf27979, 0x32d5e7e7, 0x438bc8c8, 0x596e3737, 0xb7da6d6d, + 0x8c018d8d, 0x64b1d5d5, 0xd29c4e4e, 0xe049a9a9, 0xb4d86c6c, 0xfaac5656, + 0x07f3f4f4, 0x25cfeaea, 0xafca6565, 0x8ef47a7a, 0xe947aeae, 0x18100808, + 0xd56fbaba, 0x88f07878, 0x6f4a2525, 0x725c2e2e, 0x24381c1c, 0xf157a6a6, + 0xc773b4b4, 0x5197c6c6, 0x23cbe8e8, 0x7ca1dddd, 0x9ce87474, 0x213e1f1f, + 0xdd964b4b, 0xdc61bdbd, 0x860d8b8b, 0x850f8a8a, 0x90e07070, 0x427c3e3e, + 0xc471b5b5, 0xaacc6666, 0xd8904848, 0x05060303, 0x01f7f6f6, 0x121c0e0e, + 0xa3c26161, 0x5f6a3535, 0xf9ae5757, 0xd069b9b9, 0x91178686, 0x5899c1c1, + 0x273a1d1d, 0xb9279e9e, 0x38d9e1e1, 0x13ebf8f8, 0xb32b9898, 0x33221111, + 0xbbd26969, 0x70a9d9d9, 0x89078e8e, 0xa7339494, 0xb62d9b9b, 0x223c1e1e, + 0x92158787, 0x20c9e9e9, 0x4987cece, 0xffaa5555, 0x78502828, 0x7aa5dfdf, + 0x8f038c8c, 0xf859a1a1, 0x80098989, 0x171a0d0d, 0xda65bfbf, 0x31d7e6e6, + 0xc6844242, 0xb8d06868, 0xc3824141, 0xb0299999, 0x775a2d2d, 0x111e0f0f, + 0xcb7bb0b0, 0xfca85454, 0xd66dbbbb, 0x3a2c1616, +}; + +constexpr uint32_t te2[256] = { + 0x63a5c663, 0x7c84f87c, 0x7799ee77, 0x7b8df67b, 0xf20dfff2, 0x6bbdd66b, + 0x6fb1de6f, 0xc55491c5, 0x30506030, 0x01030201, 0x67a9ce67, 0x2b7d562b, + 0xfe19e7fe, 0xd762b5d7, 0xabe64dab, 0x769aec76, 0xca458fca, 0x829d1f82, + 0xc94089c9, 0x7d87fa7d, 0xfa15effa, 0x59ebb259, 0x47c98e47, 0xf00bfbf0, + 0xadec41ad, 0xd467b3d4, 0xa2fd5fa2, 0xafea45af, 0x9cbf239c, 0xa4f753a4, + 0x7296e472, 0xc05b9bc0, 0xb7c275b7, 0xfd1ce1fd, 0x93ae3d93, 0x266a4c26, + 0x365a6c36, 0x3f417e3f, 0xf702f5f7, 0xcc4f83cc, 0x345c6834, 0xa5f451a5, + 0xe534d1e5, 0xf108f9f1, 0x7193e271, 0xd873abd8, 0x31536231, 0x153f2a15, + 0x040c0804, 0xc75295c7, 0x23654623, 0xc35e9dc3, 0x18283018, 0x96a13796, + 0x050f0a05, 0x9ab52f9a, 0x07090e07, 0x12362412, 0x809b1b80, 0xe23ddfe2, + 0xeb26cdeb, 0x27694e27, 0xb2cd7fb2, 0x759fea75, 0x091b1209, 0x839e1d83, + 0x2c74582c, 0x1a2e341a, 0x1b2d361b, 0x6eb2dc6e, 0x5aeeb45a, 0xa0fb5ba0, + 0x52f6a452, 0x3b4d763b, 0xd661b7d6, 0xb3ce7db3, 0x297b5229, 0xe33edde3, + 0x2f715e2f, 0x84971384, 0x53f5a653, 0xd168b9d1, 0x00000000, 0xed2cc1ed, + 0x20604020, 0xfc1fe3fc, 0xb1c879b1, 0x5bedb65b, 0x6abed46a, 0xcb468dcb, + 0xbed967be, 0x394b7239, 0x4ade944a, 0x4cd4984c, 0x58e8b058, 0xcf4a85cf, + 0xd06bbbd0, 0xef2ac5ef, 0xaae54faa, 0xfb16edfb, 0x43c58643, 0x4dd79a4d, + 0x33556633, 0x85941185, 0x45cf8a45, 0xf910e9f9, 0x02060402, 0x7f81fe7f, + 0x50f0a050, 0x3c44783c, 0x9fba259f, 0xa8e34ba8, 0x51f3a251, 0xa3fe5da3, + 0x40c08040, 0x8f8a058f, 0x92ad3f92, 0x9dbc219d, 0x38487038, 0xf504f1f5, + 0xbcdf63bc, 0xb6c177b6, 0xda75afda, 0x21634221, 0x10302010, 0xff1ae5ff, + 0xf30efdf3, 0xd26dbfd2, 0xcd4c81cd, 0x0c14180c, 0x13352613, 0xec2fc3ec, + 0x5fe1be5f, 0x97a23597, 0x44cc8844, 0x17392e17, 0xc45793c4, 0xa7f255a7, + 0x7e82fc7e, 0x3d477a3d, 0x64acc864, 0x5de7ba5d, 0x192b3219, 0x7395e673, + 0x60a0c060, 0x81981981, 0x4fd19e4f, 0xdc7fa3dc, 0x22664422, 0x2a7e542a, + 0x90ab3b90, 0x88830b88, 0x46ca8c46, 0xee29c7ee, 0xb8d36bb8, 0x143c2814, + 0xde79a7de, 0x5ee2bc5e, 0x0b1d160b, 0xdb76addb, 0xe03bdbe0, 0x32566432, + 0x3a4e743a, 0x0a1e140a, 0x49db9249, 0x060a0c06, 0x246c4824, 0x5ce4b85c, + 0xc25d9fc2, 0xd36ebdd3, 0xacef43ac, 0x62a6c462, 0x91a83991, 0x95a43195, + 0xe437d3e4, 0x798bf279, 0xe732d5e7, 0xc8438bc8, 0x37596e37, 0x6db7da6d, + 0x8d8c018d, 0xd564b1d5, 0x4ed29c4e, 0xa9e049a9, 0x6cb4d86c, 0x56faac56, + 0xf407f3f4, 0xea25cfea, 0x65afca65, 0x7a8ef47a, 0xaee947ae, 0x08181008, + 0xbad56fba, 0x7888f078, 0x256f4a25, 0x2e725c2e, 0x1c24381c, 0xa6f157a6, + 0xb4c773b4, 0xc65197c6, 0xe823cbe8, 0xdd7ca1dd, 0x749ce874, 0x1f213e1f, + 0x4bdd964b, 0xbddc61bd, 0x8b860d8b, 0x8a850f8a, 0x7090e070, 0x3e427c3e, + 0xb5c471b5, 0x66aacc66, 0x48d89048, 0x03050603, 0xf601f7f6, 0x0e121c0e, + 0x61a3c261, 0x355f6a35, 0x57f9ae57, 0xb9d069b9, 0x86911786, 0xc15899c1, + 0x1d273a1d, 0x9eb9279e, 0xe138d9e1, 0xf813ebf8, 0x98b32b98, 0x11332211, + 0x69bbd269, 0xd970a9d9, 0x8e89078e, 0x94a73394, 0x9bb62d9b, 0x1e223c1e, + 0x87921587, 0xe920c9e9, 0xce4987ce, 0x55ffaa55, 0x28785028, 0xdf7aa5df, + 0x8c8f038c, 0xa1f859a1, 0x89800989, 0x0d171a0d, 0xbfda65bf, 0xe631d7e6, + 0x42c68442, 0x68b8d068, 0x41c38241, 0x99b02999, 0x2d775a2d, 0x0f111e0f, + 0xb0cb7bb0, 0x54fca854, 0xbbd66dbb, 0x163a2c16, +}; + +constexpr uint32_t te3[256] = { + 0x6363a5c6, 0x7c7c84f8, 0x777799ee, 0x7b7b8df6, 0xf2f20dff, 0x6b6bbdd6, + 0x6f6fb1de, 0xc5c55491, 0x30305060, 0x01010302, 0x6767a9ce, 0x2b2b7d56, + 0xfefe19e7, 0xd7d762b5, 0xababe64d, 0x76769aec, 0xcaca458f, 0x82829d1f, + 0xc9c94089, 0x7d7d87fa, 0xfafa15ef, 0x5959ebb2, 0x4747c98e, 0xf0f00bfb, + 0xadadec41, 0xd4d467b3, 0xa2a2fd5f, 0xafafea45, 0x9c9cbf23, 0xa4a4f753, + 0x727296e4, 0xc0c05b9b, 0xb7b7c275, 0xfdfd1ce1, 0x9393ae3d, 0x26266a4c, + 0x36365a6c, 0x3f3f417e, 0xf7f702f5, 0xcccc4f83, 0x34345c68, 0xa5a5f451, + 0xe5e534d1, 0xf1f108f9, 0x717193e2, 0xd8d873ab, 0x31315362, 0x15153f2a, + 0x04040c08, 0xc7c75295, 0x23236546, 0xc3c35e9d, 0x18182830, 0x9696a137, + 0x05050f0a, 0x9a9ab52f, 0x0707090e, 0x12123624, 0x80809b1b, 0xe2e23ddf, + 0xebeb26cd, 0x2727694e, 0xb2b2cd7f, 0x75759fea, 0x09091b12, 0x83839e1d, + 0x2c2c7458, 0x1a1a2e34, 0x1b1b2d36, 0x6e6eb2dc, 0x5a5aeeb4, 0xa0a0fb5b, + 0x5252f6a4, 0x3b3b4d76, 0xd6d661b7, 0xb3b3ce7d, 0x29297b52, 0xe3e33edd, + 0x2f2f715e, 0x84849713, 0x5353f5a6, 0xd1d168b9, 0x00000000, 0xeded2cc1, + 0x20206040, 0xfcfc1fe3, 0xb1b1c879, 0x5b5bedb6, 0x6a6abed4, 0xcbcb468d, + 0xbebed967, 0x39394b72, 0x4a4ade94, 0x4c4cd498, 0x5858e8b0, 0xcfcf4a85, + 0xd0d06bbb, 0xefef2ac5, 0xaaaae54f, 0xfbfb16ed, 0x4343c586, 0x4d4dd79a, + 0x33335566, 0x85859411, 0x4545cf8a, 0xf9f910e9, 0x02020604, 0x7f7f81fe, + 0x5050f0a0, 0x3c3c4478, 0x9f9fba25, 0xa8a8e34b, 0x5151f3a2, 0xa3a3fe5d, + 0x4040c080, 0x8f8f8a05, 0x9292ad3f, 0x9d9dbc21, 0x38384870, 0xf5f504f1, + 0xbcbcdf63, 0xb6b6c177, 0xdada75af, 0x21216342, 0x10103020, 0xffff1ae5, + 0xf3f30efd, 0xd2d26dbf, 0xcdcd4c81, 0x0c0c1418, 0x13133526, 0xecec2fc3, + 0x5f5fe1be, 0x9797a235, 0x4444cc88, 0x1717392e, 0xc4c45793, 0xa7a7f255, + 0x7e7e82fc, 0x3d3d477a, 0x6464acc8, 0x5d5de7ba, 0x19192b32, 0x737395e6, + 0x6060a0c0, 0x81819819, 0x4f4fd19e, 0xdcdc7fa3, 0x22226644, 0x2a2a7e54, + 0x9090ab3b, 0x8888830b, 0x4646ca8c, 0xeeee29c7, 0xb8b8d36b, 0x14143c28, + 0xdede79a7, 0x5e5ee2bc, 0x0b0b1d16, 0xdbdb76ad, 0xe0e03bdb, 0x32325664, + 0x3a3a4e74, 0x0a0a1e14, 0x4949db92, 0x06060a0c, 0x24246c48, 0x5c5ce4b8, + 0xc2c25d9f, 0xd3d36ebd, 0xacacef43, 0x6262a6c4, 0x9191a839, 0x9595a431, + 0xe4e437d3, 0x79798bf2, 0xe7e732d5, 0xc8c8438b, 0x3737596e, 0x6d6db7da, + 0x8d8d8c01, 0xd5d564b1, 0x4e4ed29c, 0xa9a9e049, 0x6c6cb4d8, 0x5656faac, + 0xf4f407f3, 0xeaea25cf, 0x6565afca, 0x7a7a8ef4, 0xaeaee947, 0x08081810, + 0xbabad56f, 0x787888f0, 0x25256f4a, 0x2e2e725c, 0x1c1c2438, 0xa6a6f157, + 0xb4b4c773, 0xc6c65197, 0xe8e823cb, 0xdddd7ca1, 0x74749ce8, 0x1f1f213e, + 0x4b4bdd96, 0xbdbddc61, 0x8b8b860d, 0x8a8a850f, 0x707090e0, 0x3e3e427c, + 0xb5b5c471, 0x6666aacc, 0x4848d890, 0x03030506, 0xf6f601f7, 0x0e0e121c, + 0x6161a3c2, 0x35355f6a, 0x5757f9ae, 0xb9b9d069, 0x86869117, 0xc1c15899, + 0x1d1d273a, 0x9e9eb927, 0xe1e138d9, 0xf8f813eb, 0x9898b32b, 0x11113322, + 0x6969bbd2, 0xd9d970a9, 0x8e8e8907, 0x9494a733, 0x9b9bb62d, 0x1e1e223c, + 0x87879215, 0xe9e920c9, 0xcece4987, 0x5555ffaa, 0x28287850, 0xdfdf7aa5, + 0x8c8c8f03, 0xa1a1f859, 0x89898009, 0x0d0d171a, 0xbfbfda65, 0xe6e631d7, + 0x4242c684, 0x6868b8d0, 0x4141c382, 0x9999b029, 0x2d2d775a, 0x0f0f111e, + 0xb0b0cb7b, 0x5454fca8, 0xbbbbd66d, 0x16163a2c, +}; + +// Software implementation of the Vector128 class, using uint32_t +// as an underlying vector register. +struct alignas(16) Vector128 { + uint32_t s[4]; +}; + +inline ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE Vector128 +Vector128Load(const void* from) { + Vector128 result; + const uint8_t* src = reinterpret_cast<const uint8_t*>(from); + result.s[0] = static_cast<uint32_t>(src[0]) << 24 | + static_cast<uint32_t>(src[1]) << 16 | + static_cast<uint32_t>(src[2]) << 8 | + static_cast<uint32_t>(src[3]); + result.s[1] = static_cast<uint32_t>(src[4]) << 24 | + static_cast<uint32_t>(src[5]) << 16 | + static_cast<uint32_t>(src[6]) << 8 | + static_cast<uint32_t>(src[7]); + result.s[2] = static_cast<uint32_t>(src[8]) << 24 | + static_cast<uint32_t>(src[9]) << 16 | + static_cast<uint32_t>(src[10]) << 8 | + static_cast<uint32_t>(src[11]); + result.s[3] = static_cast<uint32_t>(src[12]) << 24 | + static_cast<uint32_t>(src[13]) << 16 | + static_cast<uint32_t>(src[14]) << 8 | + static_cast<uint32_t>(src[15]); + return result; +} + +inline ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE void Vector128Store( + const Vector128& v, void* to) { + uint8_t* dst = reinterpret_cast<uint8_t*>(to); + dst[0] = static_cast<uint8_t>(v.s[0] >> 24); + dst[1] = static_cast<uint8_t>(v.s[0] >> 16); + dst[2] = static_cast<uint8_t>(v.s[0] >> 8); + dst[3] = static_cast<uint8_t>(v.s[0]); + dst[4] = static_cast<uint8_t>(v.s[1] >> 24); + dst[5] = static_cast<uint8_t>(v.s[1] >> 16); + dst[6] = static_cast<uint8_t>(v.s[1] >> 8); + dst[7] = static_cast<uint8_t>(v.s[1]); + dst[8] = static_cast<uint8_t>(v.s[2] >> 24); + dst[9] = static_cast<uint8_t>(v.s[2] >> 16); + dst[10] = static_cast<uint8_t>(v.s[2] >> 8); + dst[11] = static_cast<uint8_t>(v.s[2]); + dst[12] = static_cast<uint8_t>(v.s[3] >> 24); + dst[13] = static_cast<uint8_t>(v.s[3] >> 16); + dst[14] = static_cast<uint8_t>(v.s[3] >> 8); + dst[15] = static_cast<uint8_t>(v.s[3]); +} + +// One round of AES. "round_key" is a public constant for breaking the +// symmetry of AES (ensures previously equal columns differ afterwards). +inline ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE Vector128 +AesRound(const Vector128& state, const Vector128& round_key) { + Vector128 result; + result.s[0] = round_key.s[0] ^ // + te0[uint8_t(state.s[0] >> 24)] ^ // + te1[uint8_t(state.s[1] >> 16)] ^ // + te2[uint8_t(state.s[2] >> 8)] ^ // + te3[uint8_t(state.s[3])]; + result.s[1] = round_key.s[1] ^ // + te0[uint8_t(state.s[1] >> 24)] ^ // + te1[uint8_t(state.s[2] >> 16)] ^ // + te2[uint8_t(state.s[3] >> 8)] ^ // + te3[uint8_t(state.s[0])]; + result.s[2] = round_key.s[2] ^ // + te0[uint8_t(state.s[2] >> 24)] ^ // + te1[uint8_t(state.s[3] >> 16)] ^ // + te2[uint8_t(state.s[0] >> 8)] ^ // + te3[uint8_t(state.s[1])]; + result.s[3] = round_key.s[3] ^ // + te0[uint8_t(state.s[3] >> 24)] ^ // + te1[uint8_t(state.s[0] >> 16)] ^ // + te2[uint8_t(state.s[1] >> 8)] ^ // + te3[uint8_t(state.s[2])]; + return result; +} + +using ::absl::random_internal::RandenTraits; + +// Randen operates on 128-bit vectors. +struct alignas(16) u64x2 { + uint64_t data[2]; +}; + +// The improved Feistel block shuffle function for 16 blocks. +inline ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE void BlockShuffle( + u64x2* state) { + static_assert(RandenTraits::kFeistelBlocks == 16, + "Feistel block shuffle only works for 16 blocks."); + + constexpr size_t shuffle[RandenTraits::kFeistelBlocks] = { + 7, 2, 13, 4, 11, 8, 3, 6, 15, 0, 9, 10, 1, 14, 5, 12}; + + // The fully unrolled loop without the memcpy improves the speed by about + // 30% over the equivalent: +#if 0 + u64x2 source[RandenTraits::kFeistelBlocks]; + std::memcpy(source, state, sizeof(source)); + for (size_t i = 0; i < RandenTraits::kFeistelBlocks; i++) { + const u64x2 v0 = source[shuffle[i]]; + state[i] = v0; + } + return; +#endif + + const u64x2 v0 = state[shuffle[0]]; + const u64x2 v1 = state[shuffle[1]]; + const u64x2 v2 = state[shuffle[2]]; + const u64x2 v3 = state[shuffle[3]]; + const u64x2 v4 = state[shuffle[4]]; + const u64x2 v5 = state[shuffle[5]]; + const u64x2 v6 = state[shuffle[6]]; + const u64x2 v7 = state[shuffle[7]]; + const u64x2 w0 = state[shuffle[8]]; + const u64x2 w1 = state[shuffle[9]]; + const u64x2 w2 = state[shuffle[10]]; + const u64x2 w3 = state[shuffle[11]]; + const u64x2 w4 = state[shuffle[12]]; + const u64x2 w5 = state[shuffle[13]]; + const u64x2 w6 = state[shuffle[14]]; + const u64x2 w7 = state[shuffle[15]]; + state[0] = v0; + state[1] = v1; + state[2] = v2; + state[3] = v3; + state[4] = v4; + state[5] = v5; + state[6] = v6; + state[7] = v7; + state[8] = w0; + state[9] = w1; + state[10] = w2; + state[11] = w3; + state[12] = w4; + state[13] = w5; + state[14] = w6; + state[15] = w7; +} + +// Feistel round function using two AES subrounds. Very similar to F() +// from Simpira v2, but with independent subround keys. Uses 17 AES rounds +// per 16 bytes (vs. 10 for AES-CTR). Computing eight round functions in +// parallel hides the 7-cycle AESNI latency on HSW. Note that the Feistel +// XORs are 'free' (included in the second AES instruction). +inline ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE const u64x2* FeistelRound( + u64x2* ABSL_RANDOM_INTERNAL_RESTRICT state, + const u64x2* ABSL_RANDOM_INTERNAL_RESTRICT keys) { + for (size_t branch = 0; branch < RandenTraits::kFeistelBlocks; branch += 4) { + const Vector128 s0 = Vector128Load(state + branch); + const Vector128 s1 = Vector128Load(state + branch + 1); + const Vector128 f0 = AesRound(s0, Vector128Load(keys)); + keys++; + const Vector128 o1 = AesRound(f0, s1); + Vector128Store(o1, state + branch + 1); + + // Manually unroll this loop once. about 10% better than not unrolled. + const Vector128 s2 = Vector128Load(state + branch + 2); + const Vector128 s3 = Vector128Load(state + branch + 3); + const Vector128 f2 = AesRound(s2, Vector128Load(keys)); + keys++; + const Vector128 o3 = AesRound(f2, s3); + Vector128Store(o3, state + branch + 3); + } + return keys; +} + +// Cryptographic permutation based via type-2 Generalized Feistel Network. +// Indistinguishable from ideal by chosen-ciphertext adversaries using less than +// 2^64 queries if the round function is a PRF. This is similar to the b=8 case +// of Simpira v2, but more efficient than its generic construction for b=16. +inline ABSL_RANDOM_INTERNAL_ATTRIBUTE_ALWAYS_INLINE void Permute( + u64x2* state, const u64x2* ABSL_RANDOM_INTERNAL_RESTRICT keys) { + for (size_t round = 0; round < RandenTraits::kFeistelRounds; ++round) { + keys = FeistelRound(state, keys); + BlockShuffle(state); + } +} + +} // namespace + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +const void* RandenSlow::GetKeys() { + // Round keys for one AES per Feistel round and branch. + // The canonical implementation uses first digits of Pi. + return kRandenRoundKeys; +} + +void RandenSlow::Absorb(const void* seed_void, void* state_void) { + auto* state = + reinterpret_cast<uint64_t * ABSL_RANDOM_INTERNAL_RESTRICT>(state_void); + const auto* seed = + reinterpret_cast<const uint64_t * ABSL_RANDOM_INTERNAL_RESTRICT>( + seed_void); + + constexpr size_t kCapacityBlocks = + RandenTraits::kCapacityBytes / sizeof(uint64_t); + static_assert( + kCapacityBlocks * sizeof(uint64_t) == RandenTraits::kCapacityBytes, + "Not i*V"); + + for (size_t i = kCapacityBlocks; + i < RandenTraits::kStateBytes / sizeof(uint64_t); ++i) { + state[i] ^= seed[i - kCapacityBlocks]; + } +} + +void RandenSlow::Generate(const void* keys_void, void* state_void) { + static_assert(RandenTraits::kCapacityBytes == sizeof(u64x2), + "Capacity mismatch"); + + auto* state = reinterpret_cast<u64x2*>(state_void); + const auto* keys = reinterpret_cast<const u64x2*>(keys_void); + + const u64x2 prev_inner = state[0]; + + Permute(state, keys); + + // Ensure backtracking resistance. + state[0].data[0] ^= prev_inner.data[0]; + state[0].data[1] ^= prev_inner.data[1]; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/randen_slow.h b/third_party/abseil_cpp/absl/random/internal/randen_slow.h new file mode 100644 index 0000000000..b6f137eb94 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_slow.h @@ -0,0 +1,40 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_RANDEN_SLOW_H_ +#define ABSL_RANDOM_INTERNAL_RANDEN_SLOW_H_ + +#include <cstddef> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// RANDen = RANDom generator or beetroots in Swiss German. +// RandenSlow implements the basic state manipulation methods for +// architectures lacking AES hardware acceleration intrinsics. +class RandenSlow { + public: + static void Generate(const void* keys, void* state_void); + static void Absorb(const void* seed_void, void* state_void); + static const void* GetKeys(); +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_RANDEN_SLOW_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/randen_slow_test.cc b/third_party/abseil_cpp/absl/random/internal/randen_slow_test.cc new file mode 100644 index 0000000000..4a53583705 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_slow_test.cc @@ -0,0 +1,63 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen_slow.h" + +#include <cstring> + +#include "gtest/gtest.h" +#include "absl/random/internal/randen_traits.h" + +namespace { + +using absl::random_internal::RandenSlow; +using absl::random_internal::RandenTraits; + +// Local state parameters. +constexpr size_t kSeedBytes = + RandenTraits::kStateBytes - RandenTraits::kCapacityBytes; +constexpr size_t kStateSizeT = RandenTraits::kStateBytes / sizeof(uint64_t); +constexpr size_t kSeedSizeT = kSeedBytes / sizeof(uint32_t); + +struct alignas(16) randen { + uint64_t state[kStateSizeT]; + uint32_t seed[kSeedSizeT]; +}; + +TEST(RandenSlowTest, Default) { + constexpr uint64_t kGolden[] = { + 0x6c6534090ee6d3ee, 0x044e2b9b9d5333c6, 0xc3c14f134e433977, + 0xdda9f47cd90410ee, 0x887bf3087fd8ca10, 0xf0b780f545c72912, + 0x15dbb1d37696599f, 0x30ec63baff3c6d59, 0xb29f73606f7f20a6, + 0x02808a316f49a54c, 0x3b8feaf9d5c8e50e, 0x9cbf605e3fd9de8a, + 0xc970ae1a78183bbb, 0xd8b2ffd356301ed5, 0xf4b327fe0fc73c37, + 0xcdfd8d76eb8f9a19, 0xc3a506eb91420c9d, 0xd5af05dd3eff9556, + 0x48db1bb78f83c4a1, 0x7023920e0d6bfe8c, 0x58d3575834956d42, + 0xed1ef4c26b87b840, 0x8eef32a23e0b2df3, 0x497cabf3431154fc, + 0x4e24370570029a8b, 0xd88b5749f090e5ea, 0xc651a582a970692f, + 0x78fcec2cbb6342f5, 0x463cb745612f55db, 0x352ee4ad1816afe3, + 0x026ff374c101da7e, 0x811ef0821c3de851, + }; + + alignas(16) randen d; + std::memset(d.state, 0, sizeof(d.state)); + RandenSlow::Generate(RandenSlow::GetKeys(), d.state); + + uint64_t* id = d.state; + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, *id++); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/randen_test.cc b/third_party/abseil_cpp/absl/random/internal/randen_test.cc new file mode 100644 index 0000000000..c186fe0d68 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_test.cc @@ -0,0 +1,70 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/randen.h" + +#include <cstring> + +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" + +namespace { + +using absl::random_internal::Randen; + +// Local state parameters. +constexpr size_t kStateSizeT = Randen::kStateBytes / sizeof(uint64_t); + +TEST(RandenTest, CopyAndMove) { + static_assert(std::is_copy_constructible<Randen>::value, + "Randen must be copy constructible"); + + static_assert(absl::is_copy_assignable<Randen>::value, + "Randen must be copy assignable"); + + static_assert(std::is_move_constructible<Randen>::value, + "Randen must be move constructible"); + + static_assert(absl::is_move_assignable<Randen>::value, + "Randen must be move assignable"); +} + +TEST(RandenTest, Default) { + constexpr uint64_t kGolden[] = { + 0x6c6534090ee6d3ee, 0x044e2b9b9d5333c6, 0xc3c14f134e433977, + 0xdda9f47cd90410ee, 0x887bf3087fd8ca10, 0xf0b780f545c72912, + 0x15dbb1d37696599f, 0x30ec63baff3c6d59, 0xb29f73606f7f20a6, + 0x02808a316f49a54c, 0x3b8feaf9d5c8e50e, 0x9cbf605e3fd9de8a, + 0xc970ae1a78183bbb, 0xd8b2ffd356301ed5, 0xf4b327fe0fc73c37, + 0xcdfd8d76eb8f9a19, 0xc3a506eb91420c9d, 0xd5af05dd3eff9556, + 0x48db1bb78f83c4a1, 0x7023920e0d6bfe8c, 0x58d3575834956d42, + 0xed1ef4c26b87b840, 0x8eef32a23e0b2df3, 0x497cabf3431154fc, + 0x4e24370570029a8b, 0xd88b5749f090e5ea, 0xc651a582a970692f, + 0x78fcec2cbb6342f5, 0x463cb745612f55db, 0x352ee4ad1816afe3, + 0x026ff374c101da7e, 0x811ef0821c3de851, + }; + + alignas(16) uint64_t state[kStateSizeT]; + std::memset(state, 0, sizeof(state)); + + Randen r; + r.Generate(state); + + auto id = std::begin(state); + for (const auto& elem : kGolden) { + EXPECT_EQ(elem, *id++); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/randen_traits.h b/third_party/abseil_cpp/absl/random/internal/randen_traits.h new file mode 100644 index 0000000000..53caa93614 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/randen_traits.h @@ -0,0 +1,88 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_RANDEN_TRAITS_H_ +#define ABSL_RANDOM_INTERNAL_RANDEN_TRAITS_H_ + +// HERMETIC NOTE: The randen_hwaes target must not introduce duplicate +// symbols from arbitrary system and other headers, since it may be built +// with different flags from other targets, using different levels of +// optimization, potentially introducing ODR violations. + +#include <cstddef> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// RANDen = RANDom generator or beetroots in Swiss German. +// 'Strong' (well-distributed, unpredictable, backtracking-resistant) random +// generator, faster in some benchmarks than std::mt19937_64 and pcg64_c32. +// +// High-level summary: +// 1) Reverie (see "A Robust and Sponge-Like PRNG with Improved Efficiency") is +// a sponge-like random generator that requires a cryptographic permutation. +// It improves upon "Provably Robust Sponge-Based PRNGs and KDFs" by +// achieving backtracking resistance with only one Permute() per buffer. +// +// 2) "Simpira v2: A Family of Efficient Permutations Using the AES Round +// Function" constructs up to 1024-bit permutations using an improved +// Generalized Feistel network with 2-round AES-128 functions. This Feistel +// block shuffle achieves diffusion faster and is less vulnerable to +// sliced-biclique attacks than the Type-2 cyclic shuffle. +// +// 3) "Improving the Generalized Feistel" and "New criterion for diffusion +// property" extends the same kind of improved Feistel block shuffle to 16 +// branches, which enables a 2048-bit permutation. +// +// Combine these three ideas and also change Simpira's subround keys from +// structured/low-entropy counters to digits of Pi (or other random source). + +// RandenTraits contains the basic algorithm traits, such as the size of the +// state, seed, sponge, etc. +struct RandenTraits { + // Size of the entire sponge / state for the randen PRNG. + static constexpr size_t kStateBytes = 256; // 2048-bit + + // Size of the 'inner' (inaccessible) part of the sponge. Larger values would + // require more frequent calls to RandenGenerate. + static constexpr size_t kCapacityBytes = 16; // 128-bit + + // Size of the default seed consumed by the sponge. + static constexpr size_t kSeedBytes = kStateBytes - kCapacityBytes; + + // Assuming 128-bit blocks, the number of blocks in the state. + // Largest size for which security proofs are known. + static constexpr size_t kFeistelBlocks = 16; + + // Ensures SPRP security and two full subblock diffusions. + // Must be > 4 * log2(kFeistelBlocks). + static constexpr size_t kFeistelRounds = 16 + 1; + + // Size of the key. A 128-bit key block is used for every-other + // feistel block (Type-2 generalized Feistel network) in each round. + static constexpr size_t kKeyBytes = 16 * kFeistelRounds * kFeistelBlocks / 2; +}; + +// Randen key arrays. In randen_round_keys.cc +extern const unsigned char kRandenRoundKeys[RandenTraits::kKeyBytes]; +extern const unsigned char kRandenRoundKeysBE[RandenTraits::kKeyBytes]; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_RANDEN_TRAITS_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/salted_seed_seq.h b/third_party/abseil_cpp/absl/random/internal/salted_seed_seq.h new file mode 100644 index 0000000000..5953a090f8 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/salted_seed_seq.h @@ -0,0 +1,167 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_SALTED_SEED_SEQ_H_ +#define ABSL_RANDOM_INTERNAL_SALTED_SEED_SEQ_H_ + +#include <cstdint> +#include <cstdlib> +#include <initializer_list> +#include <iterator> +#include <memory> +#include <type_traits> +#include <utility> + +#include "absl/container/inlined_vector.h" +#include "absl/meta/type_traits.h" +#include "absl/random/internal/seed_material.h" +#include "absl/types/optional.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// This class conforms to the C++ Standard "Seed Sequence" concept +// [rand.req.seedseq]. +// +// A `SaltedSeedSeq` is meant to wrap an existing seed sequence and modify +// generated sequence by mixing with extra entropy. This entropy may be +// build-dependent or process-dependent. The implementation may change to be +// have either or both kinds of entropy. If salt is not available sequence is +// not modified. +template <typename SSeq> +class SaltedSeedSeq { + public: + using inner_sequence_type = SSeq; + using result_type = typename SSeq::result_type; + + SaltedSeedSeq() : seq_(absl::make_unique<SSeq>()) {} + + template <typename Iterator> + SaltedSeedSeq(Iterator begin, Iterator end) + : seq_(absl::make_unique<SSeq>(begin, end)) {} + + template <typename T> + SaltedSeedSeq(std::initializer_list<T> il) + : SaltedSeedSeq(il.begin(), il.end()) {} + + SaltedSeedSeq(const SaltedSeedSeq&) = delete; + SaltedSeedSeq& operator=(const SaltedSeedSeq&) = delete; + + SaltedSeedSeq(SaltedSeedSeq&&) = default; + SaltedSeedSeq& operator=(SaltedSeedSeq&&) = default; + + template <typename RandomAccessIterator> + void generate(RandomAccessIterator begin, RandomAccessIterator end) { + // The common case is that generate is called with ContiguousIterators + // to uint arrays. Such contiguous memory regions may be optimized, + // which we detect here. + using tag = absl::conditional_t< + (std::is_pointer<RandomAccessIterator>::value && + std::is_same<absl::decay_t<decltype(*begin)>, uint32_t>::value), + ContiguousAndUint32Tag, DefaultTag>; + if (begin != end) { + generate_impl(begin, end, tag{}); + } + } + + template <typename OutIterator> + void param(OutIterator out) const { + seq_->param(out); + } + + size_t size() const { return seq_->size(); } + + private: + struct ContiguousAndUint32Tag {}; + struct DefaultTag {}; + + // Generate which requires the iterators are contiguous pointers to uint32_t. + void generate_impl(uint32_t* begin, uint32_t* end, ContiguousAndUint32Tag) { + generate_contiguous(absl::MakeSpan(begin, end)); + } + + // The uncommon case for generate is that it is called with iterators over + // some other buffer type which is assignable from a 32-bit value. In this + // case we allocate a temporary 32-bit buffer and then copy-assign back + // to the initial inputs. + template <typename RandomAccessIterator> + void generate_impl(RandomAccessIterator begin, RandomAccessIterator end, + DefaultTag) { + return generate_and_copy(std::distance(begin, end), begin); + } + + // Fills the initial seed buffer the underlying SSeq::generate() call, + // mixing in the salt material. + void generate_contiguous(absl::Span<uint32_t> buffer) { + seq_->generate(buffer.begin(), buffer.end()); + const uint32_t salt = absl::random_internal::GetSaltMaterial().value_or(0); + MixIntoSeedMaterial(absl::MakeConstSpan(&salt, 1), buffer); + } + + // Allocates a seed buffer of `n` elements, generates the seed, then + // copies the result into the `out` iterator. + template <typename Iterator> + void generate_and_copy(size_t n, Iterator out) { + // Allocate a temporary buffer, generate, and then copy. + absl::InlinedVector<uint32_t, 8> data(n, 0); + generate_contiguous(absl::MakeSpan(data.data(), data.size())); + std::copy(data.begin(), data.end(), out); + } + + // Because [rand.req.seedseq] is not required to be copy-constructible, + // copy-assignable nor movable, we wrap it with unique pointer to be able + // to move SaltedSeedSeq. + std::unique_ptr<SSeq> seq_; +}; + +// is_salted_seed_seq indicates whether the type is a SaltedSeedSeq. +template <typename T, typename = void> +struct is_salted_seed_seq : public std::false_type {}; + +template <typename T> +struct is_salted_seed_seq< + T, typename std::enable_if<std::is_same< + T, SaltedSeedSeq<typename T::inner_sequence_type>>::value>::type> + : public std::true_type {}; + +// MakeSaltedSeedSeq returns a salted variant of the seed sequence. +// When provided with an existing SaltedSeedSeq, returns the input parameter, +// otherwise constructs a new SaltedSeedSeq which embodies the original +// non-salted seed parameters. +template < + typename SSeq, // + typename EnableIf = absl::enable_if_t<is_salted_seed_seq<SSeq>::value>> +SSeq MakeSaltedSeedSeq(SSeq&& seq) { + return SSeq(std::forward<SSeq>(seq)); +} + +template < + typename SSeq, // + typename EnableIf = absl::enable_if_t<!is_salted_seed_seq<SSeq>::value>> +SaltedSeedSeq<typename std::decay<SSeq>::type> MakeSaltedSeedSeq(SSeq&& seq) { + using sseq_type = typename std::decay<SSeq>::type; + using result_type = typename sseq_type::result_type; + + absl::InlinedVector<result_type, 8> data; + seq.param(std::back_inserter(data)); + return SaltedSeedSeq<sseq_type>(data.begin(), data.end()); +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_SALTED_SEED_SEQ_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/salted_seed_seq_test.cc b/third_party/abseil_cpp/absl/random/internal/salted_seed_seq_test.cc new file mode 100644 index 0000000000..0bf19a63ef --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/salted_seed_seq_test.cc @@ -0,0 +1,168 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/salted_seed_seq.h" + +#include <iterator> +#include <random> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" + +using absl::random_internal::GetSaltMaterial; +using absl::random_internal::MakeSaltedSeedSeq; +using absl::random_internal::SaltedSeedSeq; +using testing::Eq; +using testing::Pointwise; + +namespace { + +template <typename Sseq> +void ConformsToInterface() { + // Check that the SeedSequence can be default-constructed. + { Sseq default_constructed_seq; } + // Check that the SeedSequence can be constructed with two iterators. + { + uint32_t init_array[] = {1, 3, 5, 7, 9}; + Sseq iterator_constructed_seq(std::begin(init_array), std::end(init_array)); + } + // Check that the SeedSequence can be std::initializer_list-constructed. + { Sseq list_constructed_seq = {1, 3, 5, 7, 9, 11, 13}; } + // Check that param() and size() return state provided to constructor. + { + uint32_t init_array[] = {1, 2, 3, 4, 5}; + Sseq seq(std::begin(init_array), std::end(init_array)); + EXPECT_EQ(seq.size(), ABSL_ARRAYSIZE(init_array)); + + std::vector<uint32_t> state_vector; + seq.param(std::back_inserter(state_vector)); + + EXPECT_EQ(state_vector.size(), ABSL_ARRAYSIZE(init_array)); + for (int i = 0; i < state_vector.size(); i++) { + EXPECT_EQ(state_vector[i], i + 1); + } + } + // Check for presence of generate() method. + { + Sseq seq; + uint32_t seeds[5]; + + seq.generate(std::begin(seeds), std::end(seeds)); + } +} + +TEST(SaltedSeedSeq, CheckInterfaces) { + // Control case + ConformsToInterface<std::seed_seq>(); + + // Abseil classes + ConformsToInterface<SaltedSeedSeq<std::seed_seq>>(); +} + +TEST(SaltedSeedSeq, CheckConstructingFromOtherSequence) { + std::vector<uint32_t> seed_values(10, 1); + std::seed_seq seq(seed_values.begin(), seed_values.end()); + auto salted_seq = MakeSaltedSeedSeq(std::move(seq)); + + EXPECT_EQ(seq.size(), salted_seq.size()); + + std::vector<uint32_t> param_result; + seq.param(std::back_inserter(param_result)); + + EXPECT_EQ(seed_values, param_result); +} + +TEST(SaltedSeedSeq, SaltedSaltedSeedSeqIsNotDoubleSalted) { + uint32_t init[] = {1, 3, 5, 7, 9}; + + std::seed_seq seq(std::begin(init), std::end(init)); + + // The first salting. + SaltedSeedSeq<std::seed_seq> salted_seq = MakeSaltedSeedSeq(std::move(seq)); + uint32_t a[16]; + salted_seq.generate(std::begin(a), std::end(a)); + + // The second salting. + SaltedSeedSeq<std::seed_seq> salted_salted_seq = + MakeSaltedSeedSeq(std::move(salted_seq)); + uint32_t b[16]; + salted_salted_seq.generate(std::begin(b), std::end(b)); + + // ... both should be equal. + EXPECT_THAT(b, Pointwise(Eq(), a)) << "a[0] " << a[0]; +} + +TEST(SaltedSeedSeq, SeedMaterialIsSalted) { + const size_t kNumBlocks = 16; + + uint32_t seed_material[kNumBlocks]; + std::random_device urandom{"/dev/urandom"}; + for (uint32_t& seed : seed_material) { + seed = urandom(); + } + + std::seed_seq seq(std::begin(seed_material), std::end(seed_material)); + SaltedSeedSeq<std::seed_seq> salted_seq(std::begin(seed_material), + std::end(seed_material)); + + bool salt_is_available = GetSaltMaterial().has_value(); + + // If salt is available generated sequence should be different. + if (salt_is_available) { + uint32_t outputs[kNumBlocks]; + uint32_t salted_outputs[kNumBlocks]; + + seq.generate(std::begin(outputs), std::end(outputs)); + salted_seq.generate(std::begin(salted_outputs), std::end(salted_outputs)); + + EXPECT_THAT(outputs, Pointwise(testing::Ne(), salted_outputs)); + } +} + +TEST(SaltedSeedSeq, GenerateAcceptsDifferentTypes) { + const size_t kNumBlocks = 4; + + SaltedSeedSeq<std::seed_seq> seq({1, 2, 3}); + + uint32_t expected[kNumBlocks]; + seq.generate(std::begin(expected), std::end(expected)); + + // 32-bit outputs + { + unsigned long seed_material[kNumBlocks]; // NOLINT(runtime/int) + seq.generate(std::begin(seed_material), std::end(seed_material)); + EXPECT_THAT(seed_material, Pointwise(Eq(), expected)); + } + { + unsigned int seed_material[kNumBlocks]; // NOLINT(runtime/int) + seq.generate(std::begin(seed_material), std::end(seed_material)); + EXPECT_THAT(seed_material, Pointwise(Eq(), expected)); + } + + // 64-bit outputs. + { + uint64_t seed_material[kNumBlocks]; + seq.generate(std::begin(seed_material), std::end(seed_material)); + EXPECT_THAT(seed_material, Pointwise(Eq(), expected)); + } + { + int64_t seed_material[kNumBlocks]; + seq.generate(std::begin(seed_material), std::end(seed_material)); + EXPECT_THAT(seed_material, Pointwise(Eq(), expected)); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/seed_material.cc b/third_party/abseil_cpp/absl/random/internal/seed_material.cc new file mode 100644 index 0000000000..4d38a57419 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/seed_material.cc @@ -0,0 +1,219 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/seed_material.h" + +#include <fcntl.h> + +#ifndef _WIN32 +#include <unistd.h> +#else +#include <io.h> +#endif + +#include <algorithm> +#include <cerrno> +#include <cstdint> +#include <cstdlib> +#include <cstring> + +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/ascii.h" +#include "absl/strings/escaping.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" + +#if defined(__native_client__) + +#include <nacl/nacl_random.h> +#define ABSL_RANDOM_USE_NACL_SECURE_RANDOM 1 + +#elif defined(_WIN32) + +#include <windows.h> +#define ABSL_RANDOM_USE_BCRYPT 1 +#pragma comment(lib, "bcrypt.lib") + +#elif defined(__Fuchsia__) +#include <zircon/syscalls.h> + +#endif + +#if defined(ABSL_RANDOM_USE_BCRYPT) +#include <bcrypt.h> + +#ifndef BCRYPT_SUCCESS +#define BCRYPT_SUCCESS(Status) (((NTSTATUS)(Status)) >= 0) +#endif +// Also link bcrypt; this can be done via linker options or: +// #pragma comment(lib, "bcrypt.lib") +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { +namespace { + +// Read OS Entropy for random number seeds. +// TODO(absl-team): Possibly place a cap on how much entropy may be read at a +// time. + +#if defined(ABSL_RANDOM_USE_BCRYPT) + +// On Windows potentially use the BCRYPT CNG API to read available entropy. +bool ReadSeedMaterialFromOSEntropyImpl(absl::Span<uint32_t> values) { + BCRYPT_ALG_HANDLE hProvider; + NTSTATUS ret; + ret = BCryptOpenAlgorithmProvider(&hProvider, BCRYPT_RNG_ALGORITHM, + MS_PRIMITIVE_PROVIDER, 0); + if (!(BCRYPT_SUCCESS(ret))) { + ABSL_RAW_LOG(ERROR, "Failed to open crypto provider."); + return false; + } + ret = BCryptGenRandom( + hProvider, // provider + reinterpret_cast<UCHAR*>(values.data()), // buffer + static_cast<ULONG>(sizeof(uint32_t) * values.size()), // bytes + 0); // flags + BCryptCloseAlgorithmProvider(hProvider, 0); + return BCRYPT_SUCCESS(ret); +} + +#elif defined(ABSL_RANDOM_USE_NACL_SECURE_RANDOM) + +// On NaCL use nacl_secure_random to acquire bytes. +bool ReadSeedMaterialFromOSEntropyImpl(absl::Span<uint32_t> values) { + auto buffer = reinterpret_cast<uint8_t*>(values.data()); + size_t buffer_size = sizeof(uint32_t) * values.size(); + + uint8_t* output_ptr = buffer; + while (buffer_size > 0) { + size_t nread = 0; + const int error = nacl_secure_random(output_ptr, buffer_size, &nread); + if (error != 0 || nread > buffer_size) { + ABSL_RAW_LOG(ERROR, "Failed to read secure_random seed data: %d", error); + return false; + } + output_ptr += nread; + buffer_size -= nread; + } + return true; +} + +#elif defined(__Fuchsia__) + +bool ReadSeedMaterialFromOSEntropyImpl(absl::Span<uint32_t> values) { + auto buffer = reinterpret_cast<uint8_t*>(values.data()); + size_t buffer_size = sizeof(uint32_t) * values.size(); + zx_cprng_draw(buffer, buffer_size); + return true; +} + +#else + +// On *nix, read entropy from /dev/urandom. +bool ReadSeedMaterialFromOSEntropyImpl(absl::Span<uint32_t> values) { + const char kEntropyFile[] = "/dev/urandom"; + + auto buffer = reinterpret_cast<uint8_t*>(values.data()); + size_t buffer_size = sizeof(uint32_t) * values.size(); + + int dev_urandom = open(kEntropyFile, O_RDONLY); + bool success = (-1 != dev_urandom); + if (!success) { + return false; + } + + while (success && buffer_size > 0) { + int bytes_read = read(dev_urandom, buffer, buffer_size); + int read_error = errno; + success = (bytes_read > 0); + if (success) { + buffer += bytes_read; + buffer_size -= bytes_read; + } else if (bytes_read == -1 && read_error == EINTR) { + success = true; // Need to try again. + } + } + close(dev_urandom); + return success; +} + +#endif + +} // namespace + +bool ReadSeedMaterialFromOSEntropy(absl::Span<uint32_t> values) { + assert(values.data() != nullptr); + if (values.data() == nullptr) { + return false; + } + if (values.empty()) { + return true; + } + return ReadSeedMaterialFromOSEntropyImpl(values); +} + +void MixIntoSeedMaterial(absl::Span<const uint32_t> sequence, + absl::Span<uint32_t> seed_material) { + // Algorithm is based on code available at + // https://gist.github.com/imneme/540829265469e673d045 + constexpr uint32_t kInitVal = 0x43b0d7e5; + constexpr uint32_t kHashMul = 0x931e8875; + constexpr uint32_t kMixMulL = 0xca01f9dd; + constexpr uint32_t kMixMulR = 0x4973f715; + constexpr uint32_t kShiftSize = sizeof(uint32_t) * 8 / 2; + + uint32_t hash_const = kInitVal; + auto hash = [&](uint32_t value) { + value ^= hash_const; + hash_const *= kHashMul; + value *= hash_const; + value ^= value >> kShiftSize; + return value; + }; + + auto mix = [&](uint32_t x, uint32_t y) { + uint32_t result = kMixMulL * x - kMixMulR * y; + result ^= result >> kShiftSize; + return result; + }; + + for (const auto& seq_val : sequence) { + for (auto& elem : seed_material) { + elem = mix(elem, hash(seq_val)); + } + } +} + +absl::optional<uint32_t> GetSaltMaterial() { + // Salt must be common for all generators within the same process so read it + // only once and store in static variable. + static const auto salt_material = []() -> absl::optional<uint32_t> { + uint32_t salt_value = 0; + + if (random_internal::ReadSeedMaterialFromOSEntropy( + MakeSpan(&salt_value, 1))) { + return salt_value; + } + + return absl::nullopt; + }(); + + return salt_material; +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/internal/seed_material.h b/third_party/abseil_cpp/absl/random/internal/seed_material.h new file mode 100644 index 0000000000..4be10e9256 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/seed_material.h @@ -0,0 +1,104 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_SEED_MATERIAL_H_ +#define ABSL_RANDOM_INTERNAL_SEED_MATERIAL_H_ + +#include <cassert> +#include <cstdint> +#include <cstdlib> +#include <string> +#include <vector> + +#include "absl/base/attributes.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/types/optional.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Returns the number of 32-bit blocks needed to contain the given number of +// bits. +constexpr size_t SeedBitsToBlocks(size_t seed_size) { + return (seed_size + 31) / 32; +} + +// Amount of entropy (measured in bits) used to instantiate a Seed Sequence, +// with which to create a URBG. +constexpr size_t kEntropyBitsNeeded = 256; + +// Amount of entropy (measured in 32-bit blocks) used to instantiate a Seed +// Sequence, with which to create a URBG. +constexpr size_t kEntropyBlocksNeeded = + random_internal::SeedBitsToBlocks(kEntropyBitsNeeded); + +static_assert(kEntropyBlocksNeeded > 0, + "Entropy used to seed URBGs must be nonzero."); + +// Attempts to fill a span of uint32_t-values using an OS-provided source of +// true entropy (eg. /dev/urandom) into an array of uint32_t blocks of data. The +// resulting array may be used to initialize an instance of a class conforming +// to the C++ Standard "Seed Sequence" concept [rand.req.seedseq]. +// +// If values.data() == nullptr, the behavior is undefined. +ABSL_MUST_USE_RESULT +bool ReadSeedMaterialFromOSEntropy(absl::Span<uint32_t> values); + +// Attempts to fill a span of uint32_t-values using variates generated by an +// existing instance of a class conforming to the C++ Standard "Uniform Random +// Bit Generator" concept [rand.req.urng]. The resulting data may be used to +// initialize an instance of a class conforming to the C++ Standard +// "Seed Sequence" concept [rand.req.seedseq]. +// +// If urbg == nullptr or values.data() == nullptr, the behavior is undefined. +template <typename URBG> +ABSL_MUST_USE_RESULT bool ReadSeedMaterialFromURBG( + URBG* urbg, absl::Span<uint32_t> values) { + random_internal::FastUniformBits<uint32_t> distr; + + assert(urbg != nullptr && values.data() != nullptr); + if (urbg == nullptr || values.data() == nullptr) { + return false; + } + + for (uint32_t& seed_value : values) { + seed_value = distr(*urbg); + } + return true; +} + +// Mixes given sequence of values with into given sequence of seed material. +// Time complexity of this function is O(sequence.size() * +// seed_material.size()). +// +// Algorithm is based on code available at +// https://gist.github.com/imneme/540829265469e673d045 +// by Melissa O'Neill. +void MixIntoSeedMaterial(absl::Span<const uint32_t> sequence, + absl::Span<uint32_t> seed_material); + +// Returns salt value. +// +// Salt is obtained only once and stored in static variable. +// +// May return empty value if optaining the salt was not possible. +absl::optional<uint32_t> GetSaltMaterial(); + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_SEED_MATERIAL_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/seed_material_test.cc b/third_party/abseil_cpp/absl/random/internal/seed_material_test.cc new file mode 100644 index 0000000000..6db2820ec7 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/seed_material_test.cc @@ -0,0 +1,202 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/seed_material.h" + +#include <bitset> +#include <cstdlib> +#include <cstring> +#include <random> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" + +#ifdef __ANDROID__ +// Android assert messages only go to system log, so death tests cannot inspect +// the message for matching. +#define ABSL_EXPECT_DEATH_IF_SUPPORTED(statement, regex) \ + EXPECT_DEATH_IF_SUPPORTED(statement, ".*") +#else +#define ABSL_EXPECT_DEATH_IF_SUPPORTED(statement, regex) \ + EXPECT_DEATH_IF_SUPPORTED(statement, regex) +#endif + +namespace { + +using testing::Each; +using testing::ElementsAre; +using testing::Eq; +using testing::Ne; +using testing::Pointwise; + +TEST(SeedBitsToBlocks, VerifyCases) { + EXPECT_EQ(0, absl::random_internal::SeedBitsToBlocks(0)); + EXPECT_EQ(1, absl::random_internal::SeedBitsToBlocks(1)); + EXPECT_EQ(1, absl::random_internal::SeedBitsToBlocks(31)); + EXPECT_EQ(1, absl::random_internal::SeedBitsToBlocks(32)); + EXPECT_EQ(2, absl::random_internal::SeedBitsToBlocks(33)); + EXPECT_EQ(4, absl::random_internal::SeedBitsToBlocks(127)); + EXPECT_EQ(4, absl::random_internal::SeedBitsToBlocks(128)); + EXPECT_EQ(5, absl::random_internal::SeedBitsToBlocks(129)); +} + +TEST(ReadSeedMaterialFromOSEntropy, SuccessiveReadsAreDistinct) { + constexpr size_t kSeedMaterialSize = 64; + uint32_t seed_material_1[kSeedMaterialSize] = {}; + uint32_t seed_material_2[kSeedMaterialSize] = {}; + + EXPECT_TRUE(absl::random_internal::ReadSeedMaterialFromOSEntropy( + absl::Span<uint32_t>(seed_material_1, kSeedMaterialSize))); + EXPECT_TRUE(absl::random_internal::ReadSeedMaterialFromOSEntropy( + absl::Span<uint32_t>(seed_material_2, kSeedMaterialSize))); + + EXPECT_THAT(seed_material_1, Pointwise(Ne(), seed_material_2)); +} + +TEST(ReadSeedMaterialFromOSEntropy, ReadZeroBytesIsNoOp) { + uint32_t seed_material[32] = {}; + std::memset(seed_material, 0xAA, sizeof(seed_material)); + EXPECT_TRUE(absl::random_internal::ReadSeedMaterialFromOSEntropy( + absl::Span<uint32_t>(seed_material, 0))); + + EXPECT_THAT(seed_material, Each(Eq(0xAAAAAAAA))); +} + +TEST(ReadSeedMaterialFromOSEntropy, NullPtrVectorArgument) { +#ifdef NDEBUG + EXPECT_FALSE(absl::random_internal::ReadSeedMaterialFromOSEntropy( + absl::Span<uint32_t>(nullptr, 32))); +#else + bool result; + ABSL_EXPECT_DEATH_IF_SUPPORTED( + result = absl::random_internal::ReadSeedMaterialFromOSEntropy( + absl::Span<uint32_t>(nullptr, 32)), + "!= nullptr"); + (void)result; // suppress unused-variable warning +#endif +} + +TEST(ReadSeedMaterialFromURBG, SeedMaterialEqualsVariateSequence) { + // Two default-constructed instances of std::mt19937_64 are guaranteed to + // produce equal variate-sequences. + std::mt19937 urbg_1; + std::mt19937 urbg_2; + constexpr size_t kSeedMaterialSize = 1024; + uint32_t seed_material[kSeedMaterialSize] = {}; + + EXPECT_TRUE(absl::random_internal::ReadSeedMaterialFromURBG( + &urbg_1, absl::Span<uint32_t>(seed_material, kSeedMaterialSize))); + for (uint32_t seed : seed_material) { + EXPECT_EQ(seed, urbg_2()); + } +} + +TEST(ReadSeedMaterialFromURBG, ReadZeroBytesIsNoOp) { + std::mt19937_64 urbg; + uint32_t seed_material[32]; + std::memset(seed_material, 0xAA, sizeof(seed_material)); + EXPECT_TRUE(absl::random_internal::ReadSeedMaterialFromURBG( + &urbg, absl::Span<uint32_t>(seed_material, 0))); + + EXPECT_THAT(seed_material, Each(Eq(0xAAAAAAAA))); +} + +TEST(ReadSeedMaterialFromURBG, NullUrbgArgument) { + constexpr size_t kSeedMaterialSize = 32; + uint32_t seed_material[kSeedMaterialSize]; +#ifdef NDEBUG + EXPECT_FALSE(absl::random_internal::ReadSeedMaterialFromURBG<std::mt19937_64>( + nullptr, absl::Span<uint32_t>(seed_material, kSeedMaterialSize))); +#else + bool result; + ABSL_EXPECT_DEATH_IF_SUPPORTED( + result = absl::random_internal::ReadSeedMaterialFromURBG<std::mt19937_64>( + nullptr, absl::Span<uint32_t>(seed_material, kSeedMaterialSize)), + "!= nullptr"); + (void)result; // suppress unused-variable warning +#endif +} + +TEST(ReadSeedMaterialFromURBG, NullPtrVectorArgument) { + std::mt19937_64 urbg; +#ifdef NDEBUG + EXPECT_FALSE(absl::random_internal::ReadSeedMaterialFromURBG( + &urbg, absl::Span<uint32_t>(nullptr, 32))); +#else + bool result; + ABSL_EXPECT_DEATH_IF_SUPPORTED( + result = absl::random_internal::ReadSeedMaterialFromURBG( + &urbg, absl::Span<uint32_t>(nullptr, 32)), + "!= nullptr"); + (void)result; // suppress unused-variable warning +#endif +} + +// The avalanche effect is a desirable cryptographic property of hashes in which +// changing a single bit in the input causes each bit of the output to be +// changed with probability near 50%. +// +// https://en.wikipedia.org/wiki/Avalanche_effect + +TEST(MixSequenceIntoSeedMaterial, AvalancheEffectTestOneBitLong) { + std::vector<uint32_t> seed_material = {1, 2, 3, 4, 5, 6, 7, 8}; + + // For every 32-bit number with exactly one bit set, verify the avalanche + // effect holds. In order to reduce flakiness of tests, accept values + // anywhere in the range of 30%-70%. + for (uint32_t v = 1; v != 0; v <<= 1) { + std::vector<uint32_t> seed_material_copy = seed_material; + absl::random_internal::MixIntoSeedMaterial( + absl::Span<uint32_t>(&v, 1), + absl::Span<uint32_t>(seed_material_copy.data(), + seed_material_copy.size())); + + uint32_t changed_bits = 0; + for (size_t i = 0; i < seed_material.size(); i++) { + std::bitset<sizeof(uint32_t) * 8> bitset(seed_material[i] ^ + seed_material_copy[i]); + changed_bits += bitset.count(); + } + + EXPECT_LE(changed_bits, 0.7 * sizeof(uint32_t) * 8 * seed_material.size()); + EXPECT_GE(changed_bits, 0.3 * sizeof(uint32_t) * 8 * seed_material.size()); + } +} + +TEST(MixSequenceIntoSeedMaterial, AvalancheEffectTestOneBitShort) { + std::vector<uint32_t> seed_material = {1}; + + // For every 32-bit number with exactly one bit set, verify the avalanche + // effect holds. In order to reduce flakiness of tests, accept values + // anywhere in the range of 30%-70%. + for (uint32_t v = 1; v != 0; v <<= 1) { + std::vector<uint32_t> seed_material_copy = seed_material; + absl::random_internal::MixIntoSeedMaterial( + absl::Span<uint32_t>(&v, 1), + absl::Span<uint32_t>(seed_material_copy.data(), + seed_material_copy.size())); + + uint32_t changed_bits = 0; + for (size_t i = 0; i < seed_material.size(); i++) { + std::bitset<sizeof(uint32_t) * 8> bitset(seed_material[i] ^ + seed_material_copy[i]); + changed_bits += bitset.count(); + } + + EXPECT_LE(changed_bits, 0.7 * sizeof(uint32_t) * 8 * seed_material.size()); + EXPECT_GE(changed_bits, 0.3 * sizeof(uint32_t) * 8 * seed_material.size()); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/sequence_urbg.h b/third_party/abseil_cpp/absl/random/internal/sequence_urbg.h new file mode 100644 index 0000000000..bc96a12cd2 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/sequence_urbg.h @@ -0,0 +1,60 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_SEQUENCE_URBG_H_ +#define ABSL_RANDOM_INTERNAL_SEQUENCE_URBG_H_ + +#include <cstdint> +#include <cstring> +#include <limits> +#include <type_traits> +#include <vector> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// `sequence_urbg` is a simple random number generator which meets the +// requirements of [rand.req.urbg], and is solely for testing absl +// distributions. +class sequence_urbg { + public: + using result_type = uint64_t; + + static constexpr result_type(min)() { + return (std::numeric_limits<result_type>::min)(); + } + static constexpr result_type(max)() { + return (std::numeric_limits<result_type>::max)(); + } + + sequence_urbg(std::initializer_list<result_type> data) : i_(0), data_(data) {} + void reset() { i_ = 0; } + + result_type operator()() { return data_[i_++ % data_.size()]; } + + size_t invocations() const { return i_; } + + private: + size_t i_; + std::vector<result_type> data_; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_SEQUENCE_URBG_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/traits.h b/third_party/abseil_cpp/absl/random/internal/traits.h new file mode 100644 index 0000000000..75772bd9ab --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/traits.h @@ -0,0 +1,101 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_TRAITS_H_ +#define ABSL_RANDOM_INTERNAL_TRAITS_H_ + +#include <cstdint> +#include <limits> +#include <type_traits> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// random_internal::is_widening_convertible<A, B> +// +// Returns whether a type A is widening-convertible to a type B. +// +// A is widening-convertible to B means: +// A a = <any number>; +// B b = a; +// A c = b; +// EXPECT_EQ(a, c); +template <typename A, typename B> +class is_widening_convertible { + // As long as there are enough bits in the exact part of a number: + // - unsigned can fit in float, signed, unsigned + // - signed can fit in float, signed + // - float can fit in float + // So we define rank to be: + // - rank(float) -> 2 + // - rank(signed) -> 1 + // - rank(unsigned) -> 0 + template <class T> + static constexpr int rank() { + return !std::numeric_limits<T>::is_integer + + std::numeric_limits<T>::is_signed; + } + + public: + // If an arithmetic-type B can represent at least as many digits as a type A, + // and B belongs to a rank no lower than A, then A can be safely represented + // by B through a widening-conversion. + static constexpr bool value = + std::numeric_limits<A>::digits <= std::numeric_limits<B>::digits && + rank<A>() <= rank<B>(); +}; + +// unsigned_bits<N>::type returns the unsigned int type with the indicated +// number of bits. +template <size_t N> +struct unsigned_bits; + +template <> +struct unsigned_bits<8> { + using type = uint8_t; +}; +template <> +struct unsigned_bits<16> { + using type = uint16_t; +}; +template <> +struct unsigned_bits<32> { + using type = uint32_t; +}; +template <> +struct unsigned_bits<64> { + using type = uint64_t; +}; + +#ifdef ABSL_HAVE_INTRINSIC_INT128 +template <> +struct unsigned_bits<128> { + using type = __uint128_t; +}; +#endif + +template <typename IntType> +struct make_unsigned_bits { + using type = typename unsigned_bits<std::numeric_limits< + typename std::make_unsigned<IntType>::type>::digits>::type; +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_TRAITS_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/traits_test.cc b/third_party/abseil_cpp/absl/random/internal/traits_test.cc new file mode 100644 index 0000000000..a844887d3e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/traits_test.cc @@ -0,0 +1,126 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/traits.h" + +#include <cstdint> +#include <type_traits> + +#include "gtest/gtest.h" + +namespace { + +using absl::random_internal::is_widening_convertible; + +// CheckWideningConvertsToSelf<T1, T2, ...>() +// +// For each type T, checks: +// - T IS widening-convertible to itself. +// +template <typename T> +void CheckWideningConvertsToSelf() { + static_assert(is_widening_convertible<T, T>::value, + "Type is not convertible to self!"); +} + +template <typename T, typename Next, typename... Args> +void CheckWideningConvertsToSelf() { + CheckWideningConvertsToSelf<T>(); + CheckWideningConvertsToSelf<Next, Args...>(); +} + +// CheckNotWideningConvertibleWithSigned<T1, T2, ...>() +// +// For each unsigned-type T, checks that: +// - T is NOT widening-convertible to Signed(T) +// - Signed(T) is NOT widening-convertible to T +// +template <typename T> +void CheckNotWideningConvertibleWithSigned() { + using signed_t = typename std::make_signed<T>::type; + + static_assert(!is_widening_convertible<T, signed_t>::value, + "Unsigned type is convertible to same-sized signed-type!"); + static_assert(!is_widening_convertible<signed_t, T>::value, + "Signed type is convertible to same-sized unsigned-type!"); +} + +template <typename T, typename Next, typename... Args> +void CheckNotWideningConvertibleWithSigned() { + CheckNotWideningConvertibleWithSigned<T>(); + CheckWideningConvertsToSelf<Next, Args...>(); +} + +// CheckWideningConvertsToLargerType<T1, T2, ...>() +// +// For each successive unsigned-types {Ti, Ti+1}, checks that: +// - Ti IS widening-convertible to Ti+1 +// - Ti IS widening-convertible to Signed(Ti+1) +// - Signed(Ti) is NOT widening-convertible to Ti +// - Signed(Ti) IS widening-convertible to Ti+1 +template <typename T, typename Higher> +void CheckWideningConvertsToLargerTypes() { + using signed_t = typename std::make_signed<T>::type; + using higher_t = Higher; + using signed_higher_t = typename std::make_signed<Higher>::type; + + static_assert(is_widening_convertible<T, higher_t>::value, + "Type not embeddable into larger type!"); + static_assert(is_widening_convertible<T, signed_higher_t>::value, + "Type not embeddable into larger signed type!"); + static_assert(!is_widening_convertible<signed_t, higher_t>::value, + "Signed type is embeddable into larger unsigned type!"); + static_assert(is_widening_convertible<signed_t, signed_higher_t>::value, + "Signed type not embeddable into larger signed type!"); +} + +template <typename T, typename Higher, typename Next, typename... Args> +void CheckWideningConvertsToLargerTypes() { + CheckWideningConvertsToLargerTypes<T, Higher>(); + CheckWideningConvertsToLargerTypes<Higher, Next, Args...>(); +} + +// CheckWideningConvertsTo<T, U, [expect]> +// +// Checks that T DOES widening-convert to U. +// If "expect" is false, then asserts that T does NOT widening-convert to U. +template <typename T, typename U, bool expect = true> +void CheckWideningConvertsTo() { + static_assert(is_widening_convertible<T, U>::value == expect, + "Unexpected result for is_widening_convertible<T, U>!"); +} + +TEST(TraitsTest, IsWideningConvertibleTest) { + constexpr bool kInvalid = false; + + CheckWideningConvertsToSelf< + uint8_t, uint16_t, uint32_t, uint64_t, + int8_t, int16_t, int32_t, int64_t, + float, double>(); + CheckNotWideningConvertibleWithSigned< + uint8_t, uint16_t, uint32_t, uint64_t>(); + CheckWideningConvertsToLargerTypes< + uint8_t, uint16_t, uint32_t, uint64_t>(); + + CheckWideningConvertsTo<float, double>(); + CheckWideningConvertsTo<uint16_t, float>(); + CheckWideningConvertsTo<uint32_t, double>(); + CheckWideningConvertsTo<uint64_t, double, kInvalid>(); + CheckWideningConvertsTo<double, float, kInvalid>(); + + CheckWideningConvertsTo<bool, int>(); + CheckWideningConvertsTo<bool, float>(); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/internal/uniform_helper.h b/third_party/abseil_cpp/absl/random/internal/uniform_helper.h new file mode 100644 index 0000000000..663107cb3a --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/uniform_helper.h @@ -0,0 +1,180 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#ifndef ABSL_RANDOM_INTERNAL_UNIFORM_HELPER_H_ +#define ABSL_RANDOM_INTERNAL_UNIFORM_HELPER_H_ + +#include <cmath> +#include <limits> +#include <type_traits> + +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +template <typename IntType> +class uniform_int_distribution; + +template <typename RealType> +class uniform_real_distribution; + +// Interval tag types which specify whether the interval is open or closed +// on either boundary. + +namespace random_internal { +template <typename T> +struct TagTypeCompare {}; + +template <typename T> +constexpr bool operator==(TagTypeCompare<T>, TagTypeCompare<T>) { + // Tags are mono-states. They always compare equal. + return true; +} +template <typename T> +constexpr bool operator!=(TagTypeCompare<T>, TagTypeCompare<T>) { + return false; +} + +} // namespace random_internal + +struct IntervalClosedClosedTag + : public random_internal::TagTypeCompare<IntervalClosedClosedTag> {}; +struct IntervalClosedOpenTag + : public random_internal::TagTypeCompare<IntervalClosedOpenTag> {}; +struct IntervalOpenClosedTag + : public random_internal::TagTypeCompare<IntervalOpenClosedTag> {}; +struct IntervalOpenOpenTag + : public random_internal::TagTypeCompare<IntervalOpenOpenTag> {}; + +namespace random_internal { +// The functions +// uniform_lower_bound(tag, a, b) +// and +// uniform_upper_bound(tag, a, b) +// are used as implementation-details for absl::Uniform(). +// +// Conceptually, +// [a, b] == [uniform_lower_bound(IntervalClosedClosed, a, b), +// uniform_upper_bound(IntervalClosedClosed, a, b)] +// (a, b) == [uniform_lower_bound(IntervalOpenOpen, a, b), +// uniform_upper_bound(IntervalOpenOpen, a, b)] +// [a, b) == [uniform_lower_bound(IntervalClosedOpen, a, b), +// uniform_upper_bound(IntervalClosedOpen, a, b)] +// (a, b] == [uniform_lower_bound(IntervalOpenClosed, a, b), +// uniform_upper_bound(IntervalOpenClosed, a, b)] +// +template <typename IntType, typename Tag> +typename absl::enable_if_t< + absl::conjunction< + std::is_integral<IntType>, + absl::disjunction<std::is_same<Tag, IntervalOpenClosedTag>, + std::is_same<Tag, IntervalOpenOpenTag>>>::value, + IntType> +uniform_lower_bound(Tag, IntType a, IntType) { + return a + 1; +} + +template <typename FloatType, typename Tag> +typename absl::enable_if_t< + absl::conjunction< + std::is_floating_point<FloatType>, + absl::disjunction<std::is_same<Tag, IntervalOpenClosedTag>, + std::is_same<Tag, IntervalOpenOpenTag>>>::value, + FloatType> +uniform_lower_bound(Tag, FloatType a, FloatType b) { + return std::nextafter(a, b); +} + +template <typename NumType, typename Tag> +typename absl::enable_if_t< + absl::disjunction<std::is_same<Tag, IntervalClosedClosedTag>, + std::is_same<Tag, IntervalClosedOpenTag>>::value, + NumType> +uniform_lower_bound(Tag, NumType a, NumType) { + return a; +} + +template <typename IntType, typename Tag> +typename absl::enable_if_t< + absl::conjunction< + std::is_integral<IntType>, + absl::disjunction<std::is_same<Tag, IntervalClosedOpenTag>, + std::is_same<Tag, IntervalOpenOpenTag>>>::value, + IntType> +uniform_upper_bound(Tag, IntType, IntType b) { + return b - 1; +} + +template <typename FloatType, typename Tag> +typename absl::enable_if_t< + absl::conjunction< + std::is_floating_point<FloatType>, + absl::disjunction<std::is_same<Tag, IntervalClosedOpenTag>, + std::is_same<Tag, IntervalOpenOpenTag>>>::value, + FloatType> +uniform_upper_bound(Tag, FloatType, FloatType b) { + return b; +} + +template <typename IntType, typename Tag> +typename absl::enable_if_t< + absl::conjunction< + std::is_integral<IntType>, + absl::disjunction<std::is_same<Tag, IntervalClosedClosedTag>, + std::is_same<Tag, IntervalOpenClosedTag>>>::value, + IntType> +uniform_upper_bound(Tag, IntType, IntType b) { + return b; +} + +template <typename FloatType, typename Tag> +typename absl::enable_if_t< + absl::conjunction< + std::is_floating_point<FloatType>, + absl::disjunction<std::is_same<Tag, IntervalClosedClosedTag>, + std::is_same<Tag, IntervalOpenClosedTag>>>::value, + FloatType> +uniform_upper_bound(Tag, FloatType, FloatType b) { + return std::nextafter(b, (std::numeric_limits<FloatType>::max)()); +} + +template <typename NumType> +using UniformDistribution = + typename std::conditional<std::is_integral<NumType>::value, + absl::uniform_int_distribution<NumType>, + absl::uniform_real_distribution<NumType>>::type; + +template <typename NumType> +struct UniformDistributionWrapper : public UniformDistribution<NumType> { + template <typename TagType> + explicit UniformDistributionWrapper(TagType, NumType lo, NumType hi) + : UniformDistribution<NumType>( + uniform_lower_bound<NumType>(TagType{}, lo, hi), + uniform_upper_bound<NumType>(TagType{}, lo, hi)) {} + + explicit UniformDistributionWrapper(NumType lo, NumType hi) + : UniformDistribution<NumType>( + uniform_lower_bound<NumType>(IntervalClosedOpenTag(), lo, hi), + uniform_upper_bound<NumType>(IntervalClosedOpenTag(), lo, hi)) {} + + explicit UniformDistributionWrapper() + : UniformDistribution<NumType>(std::numeric_limits<NumType>::lowest(), + (std::numeric_limits<NumType>::max)()) {} +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_UNIFORM_HELPER_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/wide_multiply.h b/third_party/abseil_cpp/absl/random/internal/wide_multiply.h new file mode 100644 index 0000000000..0afcbe08e2 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/wide_multiply.h @@ -0,0 +1,111 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_INTERNAL_WIDE_MULTIPLY_H_ +#define ABSL_RANDOM_INTERNAL_WIDE_MULTIPLY_H_ + +#include <cstdint> +#include <limits> +#include <type_traits> + +#if (defined(_WIN32) || defined(_WIN64)) && defined(_M_IA64) +#include <intrin.h> // NOLINT(build/include_order) +#pragma intrinsic(_umul128) +#define ABSL_INTERNAL_USE_UMUL128 1 +#endif + +#include "absl/base/config.h" +#include "absl/base/internal/bits.h" +#include "absl/numeric/int128.h" +#include "absl/random/internal/traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace random_internal { + +// Helper object to multiply two 64-bit values to a 128-bit value. +// MultiplyU64ToU128 multiplies two 64-bit values to a 128-bit value. +// If an intrinsic is available, it is used, otherwise use native 32-bit +// multiplies to construct the result. +inline absl::uint128 MultiplyU64ToU128(uint64_t a, uint64_t b) { +#if defined(ABSL_HAVE_INTRINSIC_INT128) + return absl::uint128(static_cast<__uint128_t>(a) * b); +#elif defined(ABSL_INTERNAL_USE_UMUL128) + // uint64_t * uint64_t => uint128 multiply using imul intrinsic on MSVC. + uint64_t high = 0; + const uint64_t low = _umul128(a, b, &high); + return absl::MakeUint128(high, low); +#else + // uint128(a) * uint128(b) in emulated mode computes a full 128-bit x 128-bit + // multiply. However there are many cases where that is not necessary, and it + // is only necessary to support a 64-bit x 64-bit = 128-bit multiply. This is + // for those cases. + const uint64_t a00 = static_cast<uint32_t>(a); + const uint64_t a32 = a >> 32; + const uint64_t b00 = static_cast<uint32_t>(b); + const uint64_t b32 = b >> 32; + + const uint64_t c00 = a00 * b00; + const uint64_t c32a = a00 * b32; + const uint64_t c32b = a32 * b00; + const uint64_t c64 = a32 * b32; + + const uint32_t carry = + static_cast<uint32_t>(((c00 >> 32) + static_cast<uint32_t>(c32a) + + static_cast<uint32_t>(c32b)) >> + 32); + + return absl::MakeUint128(c64 + (c32a >> 32) + (c32b >> 32) + carry, + c00 + (c32a << 32) + (c32b << 32)); +#endif +} + +// wide_multiply<T> multiplies two N-bit values to a 2N-bit result. +template <typename UIntType> +struct wide_multiply { + static constexpr size_t kN = std::numeric_limits<UIntType>::digits; + using input_type = UIntType; + using result_type = typename random_internal::unsigned_bits<kN * 2>::type; + + static result_type multiply(input_type a, input_type b) { + return static_cast<result_type>(a) * b; + } + + static input_type hi(result_type r) { return r >> kN; } + static input_type lo(result_type r) { return r; } + + static_assert(std::is_unsigned<UIntType>::value, + "Class-template wide_multiply<> argument must be unsigned."); +}; + +#ifndef ABSL_HAVE_INTRINSIC_INT128 +template <> +struct wide_multiply<uint64_t> { + using input_type = uint64_t; + using result_type = absl::uint128; + + static result_type multiply(uint64_t a, uint64_t b) { + return MultiplyU64ToU128(a, b); + } + + static uint64_t hi(result_type r) { return absl::Uint128High64(r); } + static uint64_t lo(result_type r) { return absl::Uint128Low64(r); } +}; +#endif + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_INTERNAL_WIDE_MULTIPLY_H_ diff --git a/third_party/abseil_cpp/absl/random/internal/wide_multiply_test.cc b/third_party/abseil_cpp/absl/random/internal/wide_multiply_test.cc new file mode 100644 index 0000000000..ca8ce923b7 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/internal/wide_multiply_test.cc @@ -0,0 +1,66 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/internal/wide_multiply.h" + +#include "gtest/gtest.h" +#include "absl/base/internal/bits.h" +#include "absl/numeric/int128.h" + +using absl::random_internal::MultiplyU64ToU128; + +namespace { + +TEST(WideMultiplyTest, MultiplyU64ToU128Test) { + constexpr uint64_t k1 = 1; + constexpr uint64_t kMax = ~static_cast<uint64_t>(0); + + EXPECT_EQ(absl::uint128(0), MultiplyU64ToU128(0, 0)); + + // Max uint64_t + EXPECT_EQ(MultiplyU64ToU128(kMax, kMax), + absl::MakeUint128(0xfffffffffffffffe, 0x0000000000000001)); + EXPECT_EQ(absl::MakeUint128(0, kMax), MultiplyU64ToU128(kMax, 1)); + EXPECT_EQ(absl::MakeUint128(0, kMax), MultiplyU64ToU128(1, kMax)); + for (int i = 0; i < 64; ++i) { + EXPECT_EQ(absl::MakeUint128(0, kMax) << i, + MultiplyU64ToU128(kMax, k1 << i)); + EXPECT_EQ(absl::MakeUint128(0, kMax) << i, + MultiplyU64ToU128(k1 << i, kMax)); + } + + // 1-bit x 1-bit. + for (int i = 0; i < 64; ++i) { + for (int j = 0; j < 64; ++j) { + EXPECT_EQ(absl::MakeUint128(0, 1) << (i + j), + MultiplyU64ToU128(k1 << i, k1 << j)); + EXPECT_EQ(absl::MakeUint128(0, 1) << (i + j), + MultiplyU64ToU128(k1 << i, k1 << j)); + } + } + + // Verified multiplies + EXPECT_EQ(MultiplyU64ToU128(0xffffeeeeddddcccc, 0xbbbbaaaa99998888), + absl::MakeUint128(0xbbbb9e2692c5dddc, 0xc28f7531048d2c60)); + EXPECT_EQ(MultiplyU64ToU128(0x0123456789abcdef, 0xfedcba9876543210), + absl::MakeUint128(0x0121fa00ad77d742, 0x2236d88fe5618cf0)); + EXPECT_EQ(MultiplyU64ToU128(0x0123456789abcdef, 0xfdb97531eca86420), + absl::MakeUint128(0x0120ae99d26725fc, 0xce197f0ecac319e0)); + EXPECT_EQ(MultiplyU64ToU128(0x97a87f4f261ba3f2, 0xfedcba9876543210), + absl::MakeUint128(0x96fbf1a8ae78d0ba, 0x5a6dd4b71f278320)); + EXPECT_EQ(MultiplyU64ToU128(0xfedcba9876543210, 0xfdb97531eca86420), + absl::MakeUint128(0xfc98c6981a413e22, 0x342d0bbf48948200)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/log_uniform_int_distribution.h b/third_party/abseil_cpp/absl/random/log_uniform_int_distribution.h new file mode 100644 index 0000000000..960816e2f8 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/log_uniform_int_distribution.h @@ -0,0 +1,254 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_LOG_UNIFORM_INT_DISTRIBUTION_H_ +#define ABSL_RANDOM_LOG_UNIFORM_INT_DISTRIBUTION_H_ + +#include <algorithm> +#include <cassert> +#include <cmath> +#include <istream> +#include <limits> +#include <ostream> +#include <type_traits> + +#include "absl/random/internal/fastmath.h" +#include "absl/random/internal/generate_real.h" +#include "absl/random/internal/iostream_state_saver.h" +#include "absl/random/internal/traits.h" +#include "absl/random/uniform_int_distribution.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// log_uniform_int_distribution: +// +// Returns a random variate R in range [min, max] such that +// floor(log(R-min, base)) is uniformly distributed. +// We ensure uniformity by discretization using the +// boundary sets [0, 1, base, base * base, ... min(base*n, max)] +// +template <typename IntType = int> +class log_uniform_int_distribution { + private: + using unsigned_type = + typename random_internal::make_unsigned_bits<IntType>::type; + + public: + using result_type = IntType; + + class param_type { + public: + using distribution_type = log_uniform_int_distribution; + + explicit param_type( + result_type min = 0, + result_type max = (std::numeric_limits<result_type>::max)(), + result_type base = 2) + : min_(min), + max_(max), + base_(base), + range_(static_cast<unsigned_type>(max_) - + static_cast<unsigned_type>(min_)), + log_range_(0) { + assert(max_ >= min_); + assert(base_ > 1); + + if (base_ == 2) { + // Determine where the first set bit is on range(), giving a log2(range) + // value which can be used to construct bounds. + log_range_ = (std::min)(random_internal::LeadingSetBit(range()), + std::numeric_limits<unsigned_type>::digits); + } else { + // NOTE: Computing the logN(x) introduces error from 2 sources: + // 1. Conversion of int to double loses precision for values >= + // 2^53, which may cause some log() computations to operate on + // different values. + // 2. The error introduced by the division will cause the result + // to differ from the expected value. + // + // Thus a result which should equal K may equal K +/- epsilon, + // which can eliminate some values depending on where the bounds fall. + const double inv_log_base = 1.0 / std::log(base_); + const double log_range = std::log(static_cast<double>(range()) + 0.5); + log_range_ = static_cast<int>(std::ceil(inv_log_base * log_range)); + } + } + + result_type(min)() const { return min_; } + result_type(max)() const { return max_; } + result_type base() const { return base_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.min_ == b.min_ && a.max_ == b.max_ && a.base_ == b.base_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class log_uniform_int_distribution; + + int log_range() const { return log_range_; } + unsigned_type range() const { return range_; } + + result_type min_; + result_type max_; + result_type base_; + unsigned_type range_; // max - min + int log_range_; // ceil(logN(range_)) + + static_assert(std::is_integral<IntType>::value, + "Class-template absl::log_uniform_int_distribution<> must be " + "parameterized using an integral type."); + }; + + log_uniform_int_distribution() : log_uniform_int_distribution(0) {} + + explicit log_uniform_int_distribution( + result_type min, + result_type max = (std::numeric_limits<result_type>::max)(), + result_type base = 2) + : param_(min, max, base) {} + + explicit log_uniform_int_distribution(const param_type& p) : param_(p) {} + + void reset() {} + + // generating functions + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p) { + return (p.min)() + Generate(g, p); + } + + result_type(min)() const { return (param_.min)(); } + result_type(max)() const { return (param_.max)(); } + result_type base() const { return param_.base(); } + + param_type param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + friend bool operator==(const log_uniform_int_distribution& a, + const log_uniform_int_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const log_uniform_int_distribution& a, + const log_uniform_int_distribution& b) { + return a.param_ != b.param_; + } + + private: + // Returns a log-uniform variate in the range [0, p.range()]. The caller + // should add min() to shift the result to the correct range. + template <typename URNG> + unsigned_type Generate(URNG& g, // NOLINT(runtime/references) + const param_type& p); + + param_type param_; +}; + +template <typename IntType> +template <typename URBG> +typename log_uniform_int_distribution<IntType>::unsigned_type +log_uniform_int_distribution<IntType>::Generate( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + // sample e over [0, log_range]. Map the results of e to this: + // 0 => 0 + // 1 => [1, b-1] + // 2 => [b, (b^2)-1] + // n => [b^(n-1)..(b^n)-1] + const int e = absl::uniform_int_distribution<int>(0, p.log_range())(g); + if (e == 0) { + return 0; + } + const int d = e - 1; + + unsigned_type base_e, top_e; + if (p.base() == 2) { + base_e = static_cast<unsigned_type>(1) << d; + + top_e = (e >= std::numeric_limits<unsigned_type>::digits) + ? (std::numeric_limits<unsigned_type>::max)() + : (static_cast<unsigned_type>(1) << e) - 1; + } else { + const double r = std::pow(p.base(), d); + const double s = (r * p.base()) - 1.0; + + base_e = + (r > static_cast<double>((std::numeric_limits<unsigned_type>::max)())) + ? (std::numeric_limits<unsigned_type>::max)() + : static_cast<unsigned_type>(r); + + top_e = + (s > static_cast<double>((std::numeric_limits<unsigned_type>::max)())) + ? (std::numeric_limits<unsigned_type>::max)() + : static_cast<unsigned_type>(s); + } + + const unsigned_type lo = (base_e >= p.range()) ? p.range() : base_e; + const unsigned_type hi = (top_e >= p.range()) ? p.range() : top_e; + + // choose uniformly over [lo, hi] + return absl::uniform_int_distribution<result_type>(lo, hi)(g); +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const log_uniform_int_distribution<IntType>& x) { + using stream_type = + typename random_internal::stream_format_type<IntType>::type; + auto saver = random_internal::make_ostream_state_saver(os); + os << static_cast<stream_type>((x.min)()) << os.fill() + << static_cast<stream_type>((x.max)()) << os.fill() + << static_cast<stream_type>(x.base()); + return os; +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + log_uniform_int_distribution<IntType>& x) { // NOLINT(runtime/references) + using param_type = typename log_uniform_int_distribution<IntType>::param_type; + using result_type = + typename log_uniform_int_distribution<IntType>::result_type; + using stream_type = + typename random_internal::stream_format_type<IntType>::type; + + stream_type min; + stream_type max; + stream_type base; + + auto saver = random_internal::make_istream_state_saver(is); + is >> min >> max >> base; + if (!is.fail()) { + x.param(param_type(static_cast<result_type>(min), + static_cast<result_type>(max), + static_cast<result_type>(base))); + } + return is; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_LOG_UNIFORM_INT_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/log_uniform_int_distribution_test.cc b/third_party/abseil_cpp/absl/random/log_uniform_int_distribution_test.cc new file mode 100644 index 0000000000..5e780d96d3 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/log_uniform_int_distribution_test.cc @@ -0,0 +1,280 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/log_uniform_int_distribution.h" + +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <random> +#include <sstream> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_replace.h" +#include "absl/strings/strip.h" + +namespace { + +template <typename IntType> +class LogUniformIntDistributionTypeTest : public ::testing::Test {}; + +using IntTypes = ::testing::Types<int8_t, int16_t, int32_t, int64_t, // + uint8_t, uint16_t, uint32_t, uint64_t>; +TYPED_TEST_CASE(LogUniformIntDistributionTypeTest, IntTypes); + +TYPED_TEST(LogUniformIntDistributionTypeTest, SerializeTest) { + using param_type = + typename absl::log_uniform_int_distribution<TypeParam>::param_type; + using Limits = std::numeric_limits<TypeParam>; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + for (const auto& param : { + param_type(0, 1), // + param_type(0, 2), // + param_type(0, 2, 10), // + param_type(9, 32, 4), // + param_type(1, 101, 10), // + param_type(1, Limits::max() / 2), // + param_type(0, Limits::max() - 1), // + param_type(0, Limits::max(), 2), // + param_type(0, Limits::max(), 10), // + param_type(Limits::min(), 0), // + param_type(Limits::lowest(), Limits::max()), // + param_type(Limits::min(), Limits::max()), // + }) { + // Validate parameters. + const auto min = param.min(); + const auto max = param.max(); + const auto base = param.base(); + absl::log_uniform_int_distribution<TypeParam> before(min, max, base); + EXPECT_EQ(before.min(), param.min()); + EXPECT_EQ(before.max(), param.max()); + EXPECT_EQ(before.base(), param.base()); + + { + absl::log_uniform_int_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + } + + // Validate stream serialization. + std::stringstream ss; + ss << before; + + absl::log_uniform_int_distribution<TypeParam> after(3, 6, 17); + + EXPECT_NE(before.max(), after.max()); + EXPECT_NE(before.base(), after.base()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before.min(), after.min()); + EXPECT_EQ(before.max(), after.max()); + EXPECT_EQ(before.base(), after.base()); + EXPECT_EQ(before.param(), after.param()); + EXPECT_EQ(before, after); + + // Smoke test. + auto sample_min = after.max(); + auto sample_max = after.min(); + for (int i = 0; i < kCount; i++) { + auto sample = after(gen); + EXPECT_GE(sample, after.min()); + EXPECT_LE(sample, after.max()); + if (sample > sample_max) sample_max = sample; + if (sample < sample_min) sample_min = sample; + } + ABSL_INTERNAL_LOG(INFO, + absl::StrCat("Range: ", +sample_min, ", ", +sample_max)); + } +} + +using log_uniform_i32 = absl::log_uniform_int_distribution<int32_t>; + +class LogUniformIntChiSquaredTest + : public testing::TestWithParam<log_uniform_i32::param_type> { + public: + // The ChiSquaredTestImpl provides a chi-squared goodness of fit test for + // data generated by the log-uniform-int distribution. + double ChiSquaredTestImpl(); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng_{0x2B7E151628AED2A6}; +}; + +double LogUniformIntChiSquaredTest::ChiSquaredTestImpl() { + using absl::random_internal::kChiSquared; + + const auto& param = GetParam(); + + // Check the distribution of L=log(log_uniform_int_distribution, base), + // expecting that L is roughly uniformly distributed, that is: + // + // P[L=0] ~= P[L=1] ~= ... ~= P[L=log(max)] + // + // For a total of X entries, each bucket should contain some number of samples + // in the interval [X/k - a, X/k + a]. + // + // Where `a` is approximately sqrt(X/k). This is validated by bucketing + // according to the log function and using a chi-squared test for uniformity. + + const bool is_2 = (param.base() == 2); + const double base_log = 1.0 / std::log(param.base()); + const auto bucket_index = [base_log, is_2, ¶m](int32_t x) { + uint64_t y = static_cast<uint64_t>(x) - param.min(); + return (y == 0) ? 0 + : is_2 ? static_cast<int>(1 + std::log2(y)) + : static_cast<int>(1 + std::log(y) * base_log); + }; + const int max_bucket = bucket_index(param.max()); // inclusive + const size_t trials = 15 + (max_bucket + 1) * 10; + + log_uniform_i32 dist(param); + + std::vector<int64_t> buckets(max_bucket + 1); + for (size_t i = 0; i < trials; ++i) { + const auto sample = dist(rng_); + // Check the bounds. + ABSL_ASSERT(sample <= dist.max()); + ABSL_ASSERT(sample >= dist.min()); + // Convert the output of the generator to one of num_bucket buckets. + int bucket = bucket_index(sample); + ABSL_ASSERT(bucket <= max_bucket); + ++buckets[bucket]; + } + + // The null-hypothesis is that the distribution is uniform with respect to + // log-uniform-int bucketization. + const int dof = buckets.size() - 1; + const double expected = trials / static_cast<double>(buckets.size()); + + const double threshold = absl::random_internal::ChiSquareValue(dof, 0.98); + + double chi_square = absl::random_internal::ChiSquareWithExpected( + std::begin(buckets), std::end(buckets), expected); + + const double p = absl::random_internal::ChiSquarePValue(chi_square, dof); + + if (chi_square > threshold) { + ABSL_INTERNAL_LOG(INFO, "values"); + for (size_t i = 0; i < buckets.size(); i++) { + ABSL_INTERNAL_LOG(INFO, absl::StrCat(i, ": ", buckets[i])); + } + ABSL_INTERNAL_LOG(INFO, + absl::StrFormat("trials=%d\n" + "%s(data, %d) = %f (%f)\n" + "%s @ 0.98 = %f", + trials, kChiSquared, dof, chi_square, p, + kChiSquared, threshold)); + } + return p; +} + +TEST_P(LogUniformIntChiSquaredTest, MultiTest) { + const int kTrials = 5; + int failures = 0; + for (int i = 0; i < kTrials; i++) { + double p_value = ChiSquaredTestImpl(); + if (p_value < 0.005) { + failures++; + } + } + + // There is a 0.10% chance of producing at least one failure, so raise the + // failure threshold high enough to allow for a flake rate < 10,000. + EXPECT_LE(failures, 4); +} + +// Generate the parameters for the test. +std::vector<log_uniform_i32::param_type> GenParams() { + using Param = log_uniform_i32::param_type; + using Limits = std::numeric_limits<int32_t>; + + return std::vector<Param>{ + Param{0, 1, 2}, + Param{1, 1, 2}, + Param{0, 2, 2}, + Param{0, 3, 2}, + Param{0, 4, 2}, + Param{0, 9, 10}, + Param{0, 10, 10}, + Param{0, 11, 10}, + Param{1, 10, 10}, + Param{0, (1 << 8) - 1, 2}, + Param{0, (1 << 8), 2}, + Param{0, (1 << 30) - 1, 2}, + Param{-1000, 1000, 10}, + Param{0, Limits::max(), 2}, + Param{0, Limits::max(), 3}, + Param{0, Limits::max(), 10}, + Param{Limits::min(), 0}, + Param{Limits::min(), Limits::max(), 2}, + }; +} + +std::string ParamName( + const ::testing::TestParamInfo<log_uniform_i32::param_type>& info) { + const auto& p = info.param; + std::string name = + absl::StrCat("min_", p.min(), "__max_", p.max(), "__base_", p.base()); + return absl::StrReplaceAll(name, {{"+", "_"}, {"-", "_"}, {".", "_"}}); +} + +INSTANTIATE_TEST_SUITE_P(All, LogUniformIntChiSquaredTest, + ::testing::ValuesIn(GenParams()), ParamName); + +// NOTE: absl::log_uniform_int_distribution is not guaranteed to be stable. +TEST(LogUniformIntDistributionTest, StabilityTest) { + using testing::ElementsAre; + // absl::uniform_int_distribution stability relies on + // absl::random_internal::LeadingSetBit, std::log, std::pow. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(6); + + { + absl::log_uniform_int_distribution<int32_t> dist(0, 256); + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + EXPECT_THAT(output, ElementsAre(256, 66, 4, 6, 57, 103)); + } + urbg.reset(); + { + absl::log_uniform_int_distribution<int32_t> dist(0, 256, 10); + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + EXPECT_THAT(output, ElementsAre(8, 4, 0, 0, 0, 69)); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/mock_distributions.h b/third_party/abseil_cpp/absl/random/mock_distributions.h new file mode 100644 index 0000000000..d36d5ba03c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/mock_distributions.h @@ -0,0 +1,261 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: mock_distributions.h +// ----------------------------------------------------------------------------- +// +// This file contains mock distribution functions for use alongside an +// `absl::MockingBitGen` object within the Googletest testing framework. Such +// mocks are useful to provide deterministic values as return values within +// (otherwise random) Abseil distribution functions. +// +// The return type of each function is a mock expectation object which +// is used to set the match result. +// +// More information about the Googletest testing framework is available at +// https://github.com/google/googletest +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockUniform<int>(), Call(mock, 1, 1000)) +// .WillRepeatedly(testing::ReturnRoundRobin({20, 40})); +// +// EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000), 20); +// EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000), 40); +// EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000), 20); +// EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000), 40); + +#ifndef ABSL_RANDOM_MOCK_DISTRIBUTIONS_H_ +#define ABSL_RANDOM_MOCK_DISTRIBUTIONS_H_ + +#include <limits> +#include <type_traits> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" +#include "absl/random/distributions.h" +#include "absl/random/internal/mock_overload_set.h" +#include "absl/random/mocking_bit_gen.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// absl::MockUniform +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Uniform. +// +// `absl::MockUniform` is a class template used in conjunction with Googletest's +// `ON_CALL()` and `EXPECT_CALL()` macros. To use it, default-construct an +// instance of it inside `ON_CALL()` or `EXPECT_CALL()`, and use `Call(...)` the +// same way one would define mocks on a Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockUniform<uint32_t>(), Call(mock)) +// .WillOnce(Return(123456)); +// auto x = absl::Uniform<uint32_t>(mock); +// assert(x == 123456) +// +template <typename R> +using MockUniform = random_internal::MockOverloadSet< + random_internal::UniformDistributionWrapper<R>, + R(IntervalClosedOpenTag, MockingBitGen&, R, R), + R(IntervalClosedClosedTag, MockingBitGen&, R, R), + R(IntervalOpenOpenTag, MockingBitGen&, R, R), + R(IntervalOpenClosedTag, MockingBitGen&, R, R), R(MockingBitGen&, R, R), + R(MockingBitGen&)>; + +// ----------------------------------------------------------------------------- +// absl::MockBernoulli +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Bernoulli. +// +// `absl::MockBernoulli` is a class used in conjunction with Googletest's +// `ON_CALL()` and `EXPECT_CALL()` macros. To use it, default-construct an +// instance of it inside `ON_CALL()` or `EXPECT_CALL()`, and use `Call(...)` the +// same way one would define mocks on a Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockBernoulli(), Call(mock, testing::_)) +// .WillOnce(Return(false)); +// assert(absl::Bernoulli(mock, 0.5) == false); +// +using MockBernoulli = + random_internal::MockOverloadSet<absl::bernoulli_distribution, + bool(MockingBitGen&, double)>; + +// ----------------------------------------------------------------------------- +// absl::MockBeta +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Beta. +// +// `absl::MockBeta` is a class used in conjunction with Googletest's `ON_CALL()` +// and `EXPECT_CALL()` macros. To use it, default-construct an instance of it +// inside `ON_CALL()` or `EXPECT_CALL()`, and use `Call(...)` the same way one +// would define mocks on a Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockBeta(), Call(mock, 3.0, 2.0)) +// .WillOnce(Return(0.567)); +// auto x = absl::Beta<double>(mock, 3.0, 2.0); +// assert(x == 0.567); +// +template <typename RealType> +using MockBeta = + random_internal::MockOverloadSet<absl::beta_distribution<RealType>, + RealType(MockingBitGen&, RealType, + RealType)>; + +// ----------------------------------------------------------------------------- +// absl::MockExponential +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Exponential. +// +// `absl::MockExponential` is a class template used in conjunction with +// Googletest's `ON_CALL()` and `EXPECT_CALL()` macros. To use it, +// default-construct an instance of it inside `ON_CALL()` or `EXPECT_CALL()`, +// and use `Call(...)` the same way one would define mocks on a +// Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockExponential<double>(), Call(mock, 0.5)) +// .WillOnce(Return(12.3456789)); +// auto x = absl::Exponential<double>(mock, 0.5); +// assert(x == 12.3456789) +// +template <typename RealType> +using MockExponential = + random_internal::MockOverloadSet<absl::exponential_distribution<RealType>, + RealType(MockingBitGen&, RealType)>; + +// ----------------------------------------------------------------------------- +// absl::MockGaussian +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Gaussian. +// +// `absl::MockGaussian` is a class template used in conjunction with +// Googletest's `ON_CALL()` and `EXPECT_CALL()` macros. To use it, +// default-construct an instance of it inside `ON_CALL()` or `EXPECT_CALL()`, +// and use `Call(...)` the same way one would define mocks on a +// Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockGaussian<double>(), Call(mock, 16.3, 3.3)) +// .WillOnce(Return(12.3456789)); +// auto x = absl::Gaussian<double>(mock, 16.3, 3.3); +// assert(x == 12.3456789) +// +template <typename RealType> +using MockGaussian = + random_internal::MockOverloadSet<absl::gaussian_distribution<RealType>, + RealType(MockingBitGen&, RealType, + RealType)>; + +// ----------------------------------------------------------------------------- +// absl::MockLogUniform +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::LogUniform. +// +// `absl::MockLogUniform` is a class template used in conjunction with +// Googletest's `ON_CALL()` and `EXPECT_CALL()` macros. To use it, +// default-construct an instance of it inside `ON_CALL()` or `EXPECT_CALL()`, +// and use `Call(...)` the same way one would define mocks on a +// Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockLogUniform<int>(), Call(mock, 10, 10000, 10)) +// .WillOnce(Return(1221)); +// auto x = absl::LogUniform<int>(mock, 10, 10000, 10); +// assert(x == 1221) +// +template <typename IntType> +using MockLogUniform = random_internal::MockOverloadSet< + absl::log_uniform_int_distribution<IntType>, + IntType(MockingBitGen&, IntType, IntType, IntType)>; + +// ----------------------------------------------------------------------------- +// absl::MockPoisson +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Poisson. +// +// `absl::MockPoisson` is a class template used in conjunction with Googletest's +// `ON_CALL()` and `EXPECT_CALL()` macros. To use it, default-construct an +// instance of it inside `ON_CALL()` or `EXPECT_CALL()`, and use `Call(...)` the +// same way one would define mocks on a Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockPoisson<int>(), Call(mock, 2.0)) +// .WillOnce(Return(1221)); +// auto x = absl::Poisson<int>(mock, 2.0); +// assert(x == 1221) +// +template <typename IntType> +using MockPoisson = + random_internal::MockOverloadSet<absl::poisson_distribution<IntType>, + IntType(MockingBitGen&, double)>; + +// ----------------------------------------------------------------------------- +// absl::MockZipf +// ----------------------------------------------------------------------------- +// +// Matches calls to absl::Zipf. +// +// `absl::MockZipf` is a class template used in conjunction with Googletest's +// `ON_CALL()` and `EXPECT_CALL()` macros. To use it, default-construct an +// instance of it inside `ON_CALL()` or `EXPECT_CALL()`, and use `Call(...)` the +// same way one would define mocks on a Googletest `MockFunction()`. +// +// Example: +// +// absl::MockingBitGen mock; +// EXPECT_CALL(absl::MockZipf<int>(), Call(mock, 1000000, 2.0, 1.0)) +// .WillOnce(Return(1221)); +// auto x = absl::Zipf<int>(mock, 1000000, 2.0, 1.0); +// assert(x == 1221) +// +template <typename IntType> +using MockZipf = + random_internal::MockOverloadSet<absl::zipf_distribution<IntType>, + IntType(MockingBitGen&, IntType, double, + double)>; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_MOCK_DISTRIBUTIONS_H_ diff --git a/third_party/abseil_cpp/absl/random/mock_distributions_test.cc b/third_party/abseil_cpp/absl/random/mock_distributions_test.cc new file mode 100644 index 0000000000..de23bafe1e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/mock_distributions_test.cc @@ -0,0 +1,72 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/mock_distributions.h" + +#include "gtest/gtest.h" +#include "absl/random/mocking_bit_gen.h" +#include "absl/random/random.h" + +namespace { +using ::testing::Return; + +TEST(MockDistributions, Examples) { + absl::MockingBitGen gen; + + EXPECT_NE(absl::Uniform<int>(gen, 1, 1000000), 20); + EXPECT_CALL(absl::MockUniform<int>(), Call(gen, 1, 1000000)) + .WillOnce(Return(20)); + EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000000), 20); + + EXPECT_NE(absl::Uniform<double>(gen, 0.0, 100.0), 5.0); + EXPECT_CALL(absl::MockUniform<double>(), Call(gen, 0.0, 100.0)) + .WillOnce(Return(5.0)); + EXPECT_EQ(absl::Uniform<double>(gen, 0.0, 100.0), 5.0); + + EXPECT_NE(absl::Exponential<double>(gen, 1.0), 42); + EXPECT_CALL(absl::MockExponential<double>(), Call(gen, 1.0)) + .WillOnce(Return(42)); + EXPECT_EQ(absl::Exponential<double>(gen, 1.0), 42); + + EXPECT_NE(absl::Poisson<int>(gen, 1.0), 500); + EXPECT_CALL(absl::MockPoisson<int>(), Call(gen, 1.0)).WillOnce(Return(500)); + EXPECT_EQ(absl::Poisson<int>(gen, 1.0), 500); + + EXPECT_NE(absl::Bernoulli(gen, 0.000001), true); + EXPECT_CALL(absl::MockBernoulli(), Call(gen, 0.000001)) + .WillOnce(Return(true)); + EXPECT_EQ(absl::Bernoulli(gen, 0.000001), true); + + EXPECT_NE(absl::Beta<double>(gen, 3.0, 2.0), 0.567); + EXPECT_CALL(absl::MockBeta<double>(), Call(gen, 3.0, 2.0)) + .WillOnce(Return(0.567)); + EXPECT_EQ(absl::Beta<double>(gen, 3.0, 2.0), 0.567); + + EXPECT_NE(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + EXPECT_CALL(absl::MockZipf<int>(), Call(gen, 1000000, 2.0, 1.0)) + .WillOnce(Return(1221)); + EXPECT_EQ(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + + EXPECT_NE(absl::Gaussian<double>(gen, 0.0, 1.0), 0.001); + EXPECT_CALL(absl::MockGaussian<double>(), Call(gen, 0.0, 1.0)) + .WillOnce(Return(0.001)); + EXPECT_EQ(absl::Gaussian<double>(gen, 0.0, 1.0), 0.001); + + EXPECT_NE(absl::LogUniform<int>(gen, 0, 1000000, 2), 2040); + EXPECT_CALL(absl::MockLogUniform<int>(), Call(gen, 0, 1000000, 2)) + .WillOnce(Return(2040)); + EXPECT_EQ(absl::LogUniform<int>(gen, 0, 1000000, 2), 2040); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/mocking_bit_gen.h b/third_party/abseil_cpp/absl/random/mocking_bit_gen.h new file mode 100644 index 0000000000..3d8a979e73 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/mocking_bit_gen.h @@ -0,0 +1,198 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// mocking_bit_gen.h +// ----------------------------------------------------------------------------- +// +// This file includes an `absl::MockingBitGen` class to use as a mock within the +// Googletest testing framework. Such a mock is useful to provide deterministic +// values as return values within (otherwise random) Abseil distribution +// functions. Such determinism within a mock is useful within testing frameworks +// to test otherwise indeterminate APIs. +// +// More information about the Googletest testing framework is available at +// https://github.com/google/googletest + +#ifndef ABSL_RANDOM_MOCKING_BIT_GEN_H_ +#define ABSL_RANDOM_MOCKING_BIT_GEN_H_ + +#include <iterator> +#include <limits> +#include <memory> +#include <tuple> +#include <type_traits> +#include <typeindex> +#include <typeinfo> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/flat_hash_map.h" +#include "absl/meta/type_traits.h" +#include "absl/random/distributions.h" +#include "absl/random/internal/distribution_caller.h" +#include "absl/random/internal/mocking_bit_gen_base.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/types/span.h" +#include "absl/types/variant.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace random_internal { + +template <typename, typename> +struct MockSingleOverload; + +} // namespace random_internal + +// MockingBitGen +// +// `absl::MockingBitGen` is a mock Uniform Random Bit Generator (URBG) class +// which can act in place of an `absl::BitGen` URBG within tests using the +// Googletest testing framework. +// +// Usage: +// +// Use an `absl::MockingBitGen` along with a mock distribution object (within +// mock_distributions.h) inside Googletest constructs such as ON_CALL(), +// EXPECT_TRUE(), etc. to produce deterministic results conforming to the +// distribution's API contract. +// +// Example: +// +// // Mock a call to an `absl::Bernoulli` distribution using Googletest +// absl::MockingBitGen bitgen; +// +// ON_CALL(absl::MockBernoulli(), Call(bitgen, 0.5)) +// .WillByDefault(testing::Return(true)); +// EXPECT_TRUE(absl::Bernoulli(bitgen, 0.5)); +// +// // Mock a call to an `absl::Uniform` distribution within Googletest +// absl::MockingBitGen bitgen; +// +// ON_CALL(absl::MockUniform<int>(), Call(bitgen, testing::_, testing::_)) +// .WillByDefault([] (int low, int high) { +// return (low + high) / 2; +// }); +// +// EXPECT_EQ(absl::Uniform<int>(gen, 0, 10), 5); +// EXPECT_EQ(absl::Uniform<int>(gen, 30, 40), 35); +// +// At this time, only mock distributions supplied within the Abseil random +// library are officially supported. +// +class MockingBitGen : public absl::random_internal::MockingBitGenBase { + public: + MockingBitGen() {} + + ~MockingBitGen() override { + for (const auto& del : deleters_) del(); + } + + private: + template <typename DistrT, typename... Args> + using MockFnType = + ::testing::MockFunction<typename DistrT::result_type(Args...)>; + + // MockingBitGen::Register + // + // Register<DistrT, FormatT, ArgTupleT> is the main extension point for + // extending the MockingBitGen framework. It provides a mechanism to install a + // mock expectation for the distribution `distr_t` onto the MockingBitGen + // context. + // + // The returned MockFunction<...> type can be used to setup additional + // distribution parameters of the expectation. + template <typename DistrT, typename... Args, typename... Ms> + decltype(std::declval<MockFnType<DistrT, Args...>>().gmock_Call( + std::declval<Ms>()...)) + Register(Ms&&... matchers) { + auto& mock = + mocks_[std::type_index(GetTypeId<DistrT, std::tuple<Args...>>())]; + + if (!mock.mock_fn) { + auto* mock_fn = new MockFnType<DistrT, Args...>; + mock.mock_fn = mock_fn; + mock.match_impl = &MatchImpl<DistrT, Args...>; + deleters_.emplace_back([mock_fn] { delete mock_fn; }); + } + + return static_cast<MockFnType<DistrT, Args...>*>(mock.mock_fn) + ->gmock_Call(std::forward<Ms>(matchers)...); + } + + mutable std::vector<std::function<void()>> deleters_; + + using match_impl_fn = void (*)(void* mock_fn, void* t_erased_dist_args, + void* t_erased_result); + struct MockData { + void* mock_fn = nullptr; + match_impl_fn match_impl = nullptr; + }; + + mutable absl::flat_hash_map<std::type_index, MockData> mocks_; + + template <typename DistrT, typename... Args> + static void MatchImpl(void* mock_fn, void* dist_args, void* result) { + using result_type = typename DistrT::result_type; + *static_cast<result_type*>(result) = absl::apply( + [mock_fn](Args... args) -> result_type { + return (*static_cast<MockFnType<DistrT, Args...>*>(mock_fn)) + .Call(std::move(args)...); + }, + *static_cast<std::tuple<Args...>*>(dist_args)); + } + + // Looks for an appropriate mock - Returns the mocked result if one is found. + // Otherwise, returns a random value generated by the underlying URBG. + bool CallImpl(const std::type_info& key_type, void* dist_args, + void* result) override { + // Trigger a mock, if there exists one that matches `param`. + auto it = mocks_.find(std::type_index(key_type)); + if (it == mocks_.end()) return false; + auto* mock_data = static_cast<MockData*>(&it->second); + mock_data->match_impl(mock_data->mock_fn, dist_args, result); + return true; + } + + template <typename, typename> + friend struct ::absl::random_internal::MockSingleOverload; + friend struct ::absl::random_internal::DistributionCaller< + absl::MockingBitGen>; +}; + +// ----------------------------------------------------------------------------- +// Implementation Details Only Below +// ----------------------------------------------------------------------------- + +namespace random_internal { + +template <> +struct DistributionCaller<absl::MockingBitGen> { + template <typename DistrT, typename... Args> + static typename DistrT::result_type Call(absl::MockingBitGen* gen, + Args&&... args) { + return gen->template Call<DistrT>(std::forward<Args>(args)...); + } +}; + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_MOCKING_BIT_GEN_H_ diff --git a/third_party/abseil_cpp/absl/random/mocking_bit_gen_test.cc b/third_party/abseil_cpp/absl/random/mocking_bit_gen_test.cc new file mode 100644 index 0000000000..f0ffc9ac92 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/mocking_bit_gen_test.cc @@ -0,0 +1,347 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#include "absl/random/mocking_bit_gen.h" + +#include <numeric> +#include <random> + +#include "gmock/gmock.h" +#include "gtest/gtest-spi.h" +#include "gtest/gtest.h" +#include "absl/random/bit_gen_ref.h" +#include "absl/random/mock_distributions.h" +#include "absl/random/random.h" + +namespace { +using ::testing::Ne; +using ::testing::Return; + +TEST(BasicMocking, AllDistributionsAreOverridable) { + absl::MockingBitGen gen; + + EXPECT_NE(absl::Uniform<int>(gen, 1, 1000000), 20); + EXPECT_CALL(absl::MockUniform<int>(), Call(gen, 1, 1000000)) + .WillOnce(Return(20)); + EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000000), 20); + + EXPECT_NE(absl::Uniform<double>(gen, 0.0, 100.0), 5.0); + EXPECT_CALL(absl::MockUniform<double>(), Call(gen, 0.0, 100.0)) + .WillOnce(Return(5.0)); + EXPECT_EQ(absl::Uniform<double>(gen, 0.0, 100.0), 5.0); + + EXPECT_NE(absl::Exponential<double>(gen, 1.0), 42); + EXPECT_CALL(absl::MockExponential<double>(), Call(gen, 1.0)) + .WillOnce(Return(42)); + EXPECT_EQ(absl::Exponential<double>(gen, 1.0), 42); + + EXPECT_NE(absl::Poisson<int>(gen, 1.0), 500); + EXPECT_CALL(absl::MockPoisson<int>(), Call(gen, 1.0)).WillOnce(Return(500)); + EXPECT_EQ(absl::Poisson<int>(gen, 1.0), 500); + + EXPECT_NE(absl::Bernoulli(gen, 0.000001), true); + EXPECT_CALL(absl::MockBernoulli(), Call(gen, 0.000001)) + .WillOnce(Return(true)); + EXPECT_EQ(absl::Bernoulli(gen, 0.000001), true); + + EXPECT_NE(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + EXPECT_CALL(absl::MockZipf<int>(), Call(gen, 1000000, 2.0, 1.0)) + .WillOnce(Return(1221)); + EXPECT_EQ(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + + EXPECT_NE(absl::Gaussian<double>(gen, 0.0, 1.0), 0.001); + EXPECT_CALL(absl::MockGaussian<double>(), Call(gen, 0.0, 1.0)) + .WillOnce(Return(0.001)); + EXPECT_EQ(absl::Gaussian<double>(gen, 0.0, 1.0), 0.001); + + EXPECT_NE(absl::LogUniform<int>(gen, 0, 1000000, 2), 500000); + EXPECT_CALL(absl::MockLogUniform<int>(), Call(gen, 0, 1000000, 2)) + .WillOnce(Return(500000)); + EXPECT_EQ(absl::LogUniform<int>(gen, 0, 1000000, 2), 500000); +} + +TEST(BasicMocking, OnDistribution) { + absl::MockingBitGen gen; + + EXPECT_NE(absl::Uniform<int>(gen, 1, 1000000), 20); + ON_CALL(absl::MockUniform<int>(), Call(gen, 1, 1000000)) + .WillByDefault(Return(20)); + EXPECT_EQ(absl::Uniform<int>(gen, 1, 1000000), 20); + + EXPECT_NE(absl::Uniform<double>(gen, 0.0, 100.0), 5.0); + ON_CALL(absl::MockUniform<double>(), Call(gen, 0.0, 100.0)) + .WillByDefault(Return(5.0)); + EXPECT_EQ(absl::Uniform<double>(gen, 0.0, 100.0), 5.0); + + EXPECT_NE(absl::Exponential<double>(gen, 1.0), 42); + ON_CALL(absl::MockExponential<double>(), Call(gen, 1.0)) + .WillByDefault(Return(42)); + EXPECT_EQ(absl::Exponential<double>(gen, 1.0), 42); + + EXPECT_NE(absl::Poisson<int>(gen, 1.0), 500); + ON_CALL(absl::MockPoisson<int>(), Call(gen, 1.0)).WillByDefault(Return(500)); + EXPECT_EQ(absl::Poisson<int>(gen, 1.0), 500); + + EXPECT_NE(absl::Bernoulli(gen, 0.000001), true); + ON_CALL(absl::MockBernoulli(), Call(gen, 0.000001)) + .WillByDefault(Return(true)); + EXPECT_EQ(absl::Bernoulli(gen, 0.000001), true); + + EXPECT_NE(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + ON_CALL(absl::MockZipf<int>(), Call(gen, 1000000, 2.0, 1.0)) + .WillByDefault(Return(1221)); + EXPECT_EQ(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + + EXPECT_NE(absl::Gaussian<double>(gen, 0.0, 1.0), 0.001); + ON_CALL(absl::MockGaussian<double>(), Call(gen, 0.0, 1.0)) + .WillByDefault(Return(0.001)); + EXPECT_EQ(absl::Gaussian<double>(gen, 0.0, 1.0), 0.001); + + EXPECT_NE(absl::LogUniform<int>(gen, 0, 1000000, 2), 2040); + ON_CALL(absl::MockLogUniform<int>(), Call(gen, 0, 1000000, 2)) + .WillByDefault(Return(2040)); + EXPECT_EQ(absl::LogUniform<int>(gen, 0, 1000000, 2), 2040); +} + +TEST(BasicMocking, GMockMatchers) { + absl::MockingBitGen gen; + + EXPECT_NE(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); + ON_CALL(absl::MockZipf<int>(), Call(gen, 1000000, 2.0, 1.0)) + .WillByDefault(Return(1221)); + EXPECT_EQ(absl::Zipf<int>(gen, 1000000, 2.0, 1.0), 1221); +} + +TEST(BasicMocking, OverridesWithMultipleGMockExpectations) { + absl::MockingBitGen gen; + + EXPECT_CALL(absl::MockUniform<int>(), Call(gen, 1, 10000)) + .WillOnce(Return(20)) + .WillOnce(Return(40)) + .WillOnce(Return(60)); + EXPECT_EQ(absl::Uniform(gen, 1, 10000), 20); + EXPECT_EQ(absl::Uniform(gen, 1, 10000), 40); + EXPECT_EQ(absl::Uniform(gen, 1, 10000), 60); +} + +TEST(BasicMocking, DefaultArgument) { + absl::MockingBitGen gen; + + ON_CALL(absl::MockExponential<double>(), Call(gen, 1.0)) + .WillByDefault(Return(200)); + + EXPECT_EQ(absl::Exponential<double>(gen), 200); + EXPECT_EQ(absl::Exponential<double>(gen, 1.0), 200); +} + +TEST(BasicMocking, MultipleGenerators) { + auto get_value = [](absl::BitGenRef gen_ref) { + return absl::Uniform(gen_ref, 1, 1000000); + }; + absl::MockingBitGen unmocked_generator; + absl::MockingBitGen mocked_with_3; + absl::MockingBitGen mocked_with_11; + + EXPECT_CALL(absl::MockUniform<int>(), Call(mocked_with_3, 1, 1000000)) + .WillOnce(Return(3)) + .WillRepeatedly(Return(17)); + EXPECT_CALL(absl::MockUniform<int>(), Call(mocked_with_11, 1, 1000000)) + .WillOnce(Return(11)) + .WillRepeatedly(Return(17)); + + // Ensure that unmocked generator generates neither value. + int unmocked_value = get_value(unmocked_generator); + EXPECT_NE(unmocked_value, 3); + EXPECT_NE(unmocked_value, 11); + // Mocked generators should generate their mocked values. + EXPECT_EQ(get_value(mocked_with_3), 3); + EXPECT_EQ(get_value(mocked_with_11), 11); + // Ensure that the mocks have expired. + EXPECT_NE(get_value(mocked_with_3), 3); + EXPECT_NE(get_value(mocked_with_11), 11); +} + +TEST(BasicMocking, MocksNotTrigeredForIncorrectTypes) { + absl::MockingBitGen gen; + EXPECT_CALL(absl::MockUniform<uint32_t>(), Call(gen)).WillOnce(Return(42)); + + EXPECT_NE(absl::Uniform<uint16_t>(gen), 42); // Not mocked + EXPECT_EQ(absl::Uniform<uint32_t>(gen), 42); // Mock triggered +} + +TEST(BasicMocking, FailsOnUnsatisfiedMocks) { + EXPECT_NONFATAL_FAILURE( + []() { + absl::MockingBitGen gen; + EXPECT_CALL(absl::MockExponential<double>(), Call(gen, 1.0)) + .WillOnce(Return(3.0)); + // Does not call absl::Exponential(). + }(), + "unsatisfied and active"); +} + +TEST(OnUniform, RespectsUniformIntervalSemantics) { + absl::MockingBitGen gen; + + EXPECT_CALL(absl::MockUniform<int>(), + Call(absl::IntervalClosed, gen, 1, 1000000)) + .WillOnce(Return(301)); + EXPECT_NE(absl::Uniform(gen, 1, 1000000), 301); // Not mocked + EXPECT_EQ(absl::Uniform(absl::IntervalClosed, gen, 1, 1000000), 301); +} + +TEST(OnUniform, RespectsNoArgUnsignedShorthand) { + absl::MockingBitGen gen; + EXPECT_CALL(absl::MockUniform<uint32_t>(), Call(gen)).WillOnce(Return(42)); + EXPECT_EQ(absl::Uniform<uint32_t>(gen), 42); +} + +TEST(RepeatedlyModifier, ForceSnakeEyesForManyDice) { + auto roll_some_dice = [](absl::BitGenRef gen_ref) { + std::vector<int> results(16); + for (auto& r : results) { + r = absl::Uniform(absl::IntervalClosed, gen_ref, 1, 6); + } + return results; + }; + std::vector<int> results; + absl::MockingBitGen gen; + + // Without any mocked calls, not all dice roll a "6". + results = roll_some_dice(gen); + EXPECT_LT(std::accumulate(std::begin(results), std::end(results), 0), + results.size() * 6); + + // Verify that we can force all "6"-rolls, with mocking. + ON_CALL(absl::MockUniform<int>(), Call(absl::IntervalClosed, gen, 1, 6)) + .WillByDefault(Return(6)); + results = roll_some_dice(gen); + EXPECT_EQ(std::accumulate(std::begin(results), std::end(results), 0), + results.size() * 6); +} + +TEST(WillOnce, DistinctCounters) { + absl::MockingBitGen gen; + EXPECT_CALL(absl::MockUniform<int>(), Call(gen, 1, 1000000)) + .Times(3) + .WillRepeatedly(Return(0)); + EXPECT_CALL(absl::MockUniform<int>(), Call(gen, 1000001, 2000000)) + .Times(3) + .WillRepeatedly(Return(1)); + EXPECT_EQ(absl::Uniform(gen, 1000001, 2000000), 1); + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 0); + EXPECT_EQ(absl::Uniform(gen, 1000001, 2000000), 1); + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 0); + EXPECT_EQ(absl::Uniform(gen, 1000001, 2000000), 1); + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 0); +} + +TEST(TimesModifier, ModifierSaturatesAndExpires) { + EXPECT_NONFATAL_FAILURE( + []() { + absl::MockingBitGen gen; + EXPECT_CALL(absl::MockUniform<int>(), Call(gen, 1, 1000000)) + .Times(3) + .WillRepeatedly(Return(15)) + .RetiresOnSaturation(); + + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 15); + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 15); + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 15); + // Times(3) has expired - Should get a different value now. + + EXPECT_NE(absl::Uniform(gen, 1, 1000000), 15); + }(), + ""); +} + +TEST(TimesModifier, Times0) { + absl::MockingBitGen gen; + EXPECT_CALL(absl::MockBernoulli(), Call(gen, 0.0)).Times(0); + EXPECT_CALL(absl::MockPoisson<int>(), Call(gen, 1.0)).Times(0); +} + +TEST(AnythingMatcher, MatchesAnyArgument) { + using testing::_; + + { + absl::MockingBitGen gen; + ON_CALL(absl::MockUniform<int>(), Call(absl::IntervalClosed, gen, _, 1000)) + .WillByDefault(Return(11)); + ON_CALL(absl::MockUniform<int>(), + Call(absl::IntervalClosed, gen, _, Ne(1000))) + .WillByDefault(Return(99)); + + EXPECT_EQ(absl::Uniform(absl::IntervalClosed, gen, 10, 1000000), 99); + EXPECT_EQ(absl::Uniform(absl::IntervalClosed, gen, 10, 1000), 11); + } + + { + absl::MockingBitGen gen; + ON_CALL(absl::MockUniform<int>(), Call(gen, 1, _)) + .WillByDefault(Return(25)); + ON_CALL(absl::MockUniform<int>(), Call(gen, Ne(1), _)) + .WillByDefault(Return(99)); + EXPECT_EQ(absl::Uniform(gen, 3, 1000000), 99); + EXPECT_EQ(absl::Uniform(gen, 1, 1000000), 25); + } + + { + absl::MockingBitGen gen; + ON_CALL(absl::MockUniform<int>(), Call(gen, _, _)) + .WillByDefault(Return(145)); + EXPECT_EQ(absl::Uniform(gen, 1, 1000), 145); + EXPECT_EQ(absl::Uniform(gen, 10, 1000), 145); + EXPECT_EQ(absl::Uniform(gen, 100, 1000), 145); + } +} + +TEST(AnythingMatcher, WithWillByDefault) { + using testing::_; + absl::MockingBitGen gen; + std::vector<int> values = {11, 22, 33, 44, 55, 66, 77, 88, 99, 1010}; + + ON_CALL(absl::MockUniform<size_t>(), Call(gen, 0, _)) + .WillByDefault(Return(0)); + for (int i = 0; i < 100; i++) { + auto& elem = values[absl::Uniform(gen, 0u, values.size())]; + EXPECT_EQ(elem, 11); + } +} + +TEST(BasicMocking, WillByDefaultWithArgs) { + using testing::_; + + absl::MockingBitGen gen; + ON_CALL(absl::MockPoisson<int>(), Call(gen, _)) + .WillByDefault( + [](double lambda) { return static_cast<int>(lambda * 10); }); + EXPECT_EQ(absl::Poisson<int>(gen, 1.7), 17); + EXPECT_EQ(absl::Poisson<int>(gen, 0.03), 0); +} + +TEST(MockingBitGen, InSequenceSucceedsInOrder) { + absl::MockingBitGen gen; + + testing::InSequence seq; + + EXPECT_CALL(absl::MockPoisson<int>(), Call(gen, 1.0)).WillOnce(Return(3)); + EXPECT_CALL(absl::MockPoisson<int>(), Call(gen, 2.0)).WillOnce(Return(4)); + + EXPECT_EQ(absl::Poisson<int>(gen, 1.0), 3); + EXPECT_EQ(absl::Poisson<int>(gen, 2.0), 4); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/poisson_distribution.h b/third_party/abseil_cpp/absl/random/poisson_distribution.h new file mode 100644 index 0000000000..cb5f5d5d0f --- /dev/null +++ b/third_party/abseil_cpp/absl/random/poisson_distribution.h @@ -0,0 +1,258 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_POISSON_DISTRIBUTION_H_ +#define ABSL_RANDOM_POISSON_DISTRIBUTION_H_ + +#include <cassert> +#include <cmath> +#include <istream> +#include <limits> +#include <ostream> +#include <type_traits> + +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/fastmath.h" +#include "absl/random/internal/generate_real.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::poisson_distribution: +// Generates discrete variates conforming to a Poisson distribution. +// p(n) = (mean^n / n!) exp(-mean) +// +// Depending on the parameter, the distribution selects one of the following +// algorithms: +// * The standard algorithm, attributed to Knuth, extended using a split method +// for larger values +// * The "Ratio of Uniforms as a convenient method for sampling from classical +// discrete distributions", Stadlober, 1989. +// http://www.sciencedirect.com/science/article/pii/0377042790903495 +// +// NOTE: param_type.mean() is a double, which permits values larger than +// poisson_distribution<IntType>::max(), however this should be avoided and +// the distribution results are limited to the max() value. +// +// The goals of this implementation are to provide good performance while still +// beig thread-safe: This limits the implementation to not using lgamma provided +// by <math.h>. +// +template <typename IntType = int> +class poisson_distribution { + public: + using result_type = IntType; + + class param_type { + public: + using distribution_type = poisson_distribution; + explicit param_type(double mean = 1.0); + + double mean() const { return mean_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.mean_ == b.mean_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class poisson_distribution; + + double mean_; + double emu_; // e ^ -mean_ + double lmu_; // ln(mean_) + double s_; + double log_k_; + int split_; + + static_assert(std::is_integral<IntType>::value, + "Class-template absl::poisson_distribution<> must be " + "parameterized using an integral type."); + }; + + poisson_distribution() : poisson_distribution(1.0) {} + + explicit poisson_distribution(double mean) : param_(mean) {} + + explicit poisson_distribution(const param_type& p) : param_(p) {} + + void reset() {} + + // generating functions + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + param_type param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + result_type(min)() const { return 0; } + result_type(max)() const { return (std::numeric_limits<result_type>::max)(); } + + double mean() const { return param_.mean(); } + + friend bool operator==(const poisson_distribution& a, + const poisson_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const poisson_distribution& a, + const poisson_distribution& b) { + return a.param_ != b.param_; + } + + private: + param_type param_; + random_internal::FastUniformBits<uint64_t> fast_u64_; +}; + +// ----------------------------------------------------------------------------- +// Implementation details follow +// ----------------------------------------------------------------------------- + +template <typename IntType> +poisson_distribution<IntType>::param_type::param_type(double mean) + : mean_(mean), split_(0) { + assert(mean >= 0); + assert(mean <= (std::numeric_limits<result_type>::max)()); + // As a defensive measure, avoid large values of the mean. The rejection + // algorithm used does not support very large values well. It my be worth + // changing algorithms to better deal with these cases. + assert(mean <= 1e10); + if (mean_ < 10) { + // For small lambda, use the knuth method. + split_ = 1; + emu_ = std::exp(-mean_); + } else if (mean_ <= 50) { + // Use split-knuth method. + split_ = 1 + static_cast<int>(mean_ / 10.0); + emu_ = std::exp(-mean_ / static_cast<double>(split_)); + } else { + // Use ratio of uniforms method. + constexpr double k2E = 0.7357588823428846; + constexpr double kSA = 0.4494580810294493; + + lmu_ = std::log(mean_); + double a = mean_ + 0.5; + s_ = kSA + std::sqrt(k2E * a); + const double mode = std::ceil(mean_) - 1; + log_k_ = lmu_ * mode - absl::random_internal::StirlingLogFactorial(mode); + } +} + +template <typename IntType> +template <typename URBG> +typename poisson_distribution<IntType>::result_type +poisson_distribution<IntType>::operator()( + URBG& g, // NOLINT(runtime/references) + const param_type& p) { + using random_internal::GeneratePositiveTag; + using random_internal::GenerateRealFromBits; + using random_internal::GenerateSignedTag; + + if (p.split_ != 0) { + // Use Knuth's algorithm with range splitting to avoid floating-point + // errors. Knuth's algorithm is: Ui is a sequence of uniform variates on + // (0,1); return the number of variates required for product(Ui) < + // exp(-lambda). + // + // The expected number of variates required for Knuth's method can be + // computed as follows: + // The expected value of U is 0.5, so solving for 0.5^n < exp(-lambda) gives + // the expected number of uniform variates + // required for a given lambda, which is: + // lambda = [2, 5, 9, 10, 11, 12, 13, 14, 15, 16, 17] + // n = [3, 8, 13, 15, 16, 18, 19, 21, 22, 24, 25] + // + result_type n = 0; + for (int split = p.split_; split > 0; --split) { + double r = 1.0; + do { + r *= GenerateRealFromBits<double, GeneratePositiveTag, true>( + fast_u64_(g)); // U(-1, 0) + ++n; + } while (r > p.emu_); + --n; + } + return n; + } + + // Use ratio of uniforms method. + // + // Let u ~ Uniform(0, 1), v ~ Uniform(-1, 1), + // a = lambda + 1/2, + // s = 1.5 - sqrt(3/e) + sqrt(2(lambda + 1/2)/e), + // x = s * v/u + a. + // P(floor(x) = k | u^2 < f(floor(x))/k), where + // f(m) = lambda^m exp(-lambda)/ m!, for 0 <= m, and f(m) = 0 otherwise, + // and k = max(f). + const double a = p.mean_ + 0.5; + for (;;) { + const double u = GenerateRealFromBits<double, GeneratePositiveTag, false>( + fast_u64_(g)); // U(0, 1) + const double v = GenerateRealFromBits<double, GenerateSignedTag, false>( + fast_u64_(g)); // U(-1, 1) + + const double x = std::floor(p.s_ * v / u + a); + if (x < 0) continue; // f(negative) = 0 + const double rhs = x * p.lmu_; + // clang-format off + double s = (x <= 1.0) ? 0.0 + : (x == 2.0) ? 0.693147180559945 + : absl::random_internal::StirlingLogFactorial(x); + // clang-format on + const double lhs = 2.0 * std::log(u) + p.log_k_ + s; + if (lhs < rhs) { + return x > (max)() ? (max)() + : static_cast<result_type>(x); // f(x)/k >= u^2 + } + } +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const poisson_distribution<IntType>& x) { + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<double>::kPrecision); + os << x.mean(); + return os; +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + poisson_distribution<IntType>& x) { // NOLINT(runtime/references) + using param_type = typename poisson_distribution<IntType>::param_type; + + auto saver = random_internal::make_istream_state_saver(is); + double mean = random_internal::read_floating_point<double>(is); + if (!is.fail()) { + x.param(param_type(mean)); + } + return is; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_POISSON_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/poisson_distribution_test.cc b/third_party/abseil_cpp/absl/random/poisson_distribution_test.cc new file mode 100644 index 0000000000..8baabd1118 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/poisson_distribution_test.cc @@ -0,0 +1,573 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/poisson_distribution.h" + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <random> +#include <sstream> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/container/flat_hash_map.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_replace.h" +#include "absl/strings/strip.h" + +// Notes about generating poisson variates: +// +// It is unlikely that any implementation of std::poisson_distribution +// will be stable over time and across library implementations. For instance +// the three different poisson variate generators listed below all differ: +// +// https://github.com/ampl/gsl/tree/master/randist/poisson.c +// * GSL uses a gamma + binomial + knuth method to compute poisson variates. +// +// https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/random.tcc +// * GCC uses the Devroye rejection algorithm, based on +// Devroye, L. Non-Uniform Random Variates Generation. Springer-Verlag, +// New York, 1986, Ch. X, Sects. 3.3 & 3.4 (+ Errata!), ~p.511 +// http://www.nrbook.com/devroye/ +// +// https://github.com/llvm-mirror/libcxx/blob/master/include/random +// * CLANG uses a different rejection method, which appears to include a +// normal-distribution approximation and an exponential distribution to +// compute the threshold, including a similar factorial approximation to this +// one, but it is unclear where the algorithm comes from, exactly. +// + +namespace { + +using absl::random_internal::kChiSquared; + +// The PoissonDistributionInterfaceTest provides a basic test that +// absl::poisson_distribution conforms to the interface and serialization +// requirements imposed by [rand.req.dist] for the common integer types. + +template <typename IntType> +class PoissonDistributionInterfaceTest : public ::testing::Test {}; + +using IntTypes = ::testing::Types<int, int8_t, int16_t, int32_t, int64_t, + uint8_t, uint16_t, uint32_t, uint64_t>; +TYPED_TEST_CASE(PoissonDistributionInterfaceTest, IntTypes); + +TYPED_TEST(PoissonDistributionInterfaceTest, SerializeTest) { + using param_type = typename absl::poisson_distribution<TypeParam>::param_type; + const double kMax = + std::min(1e10 /* assertion limit */, + static_cast<double>(std::numeric_limits<TypeParam>::max())); + + const double kParams[] = { + // Cases around 1. + 1, // + std::nextafter(1.0, 0.0), // 1 - epsilon + std::nextafter(1.0, 2.0), // 1 + epsilon + // Arbitrary values. + 1e-8, 1e-4, + 0.0000005, // ~7.2e-7 + 0.2, // ~0.2x + 0.5, // 0.72 + 2, // ~2.8 + 20, // 3x ~9.6 + 100, 1e4, 1e8, 1.5e9, 1e20, + // Boundary cases. + std::numeric_limits<double>::max(), + std::numeric_limits<double>::epsilon(), + std::nextafter(std::numeric_limits<double>::min(), + 1.0), // min + epsilon + std::numeric_limits<double>::min(), // smallest normal + std::numeric_limits<double>::denorm_min(), // smallest denorm + std::numeric_limits<double>::min() / 2, // denorm + std::nextafter(std::numeric_limits<double>::min(), + 0.0), // denorm_max + }; + + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + for (const double m : kParams) { + const double mean = std::min(kMax, m); + const param_type param(mean); + + // Validate parameters. + absl::poisson_distribution<TypeParam> before(mean); + EXPECT_EQ(before.mean(), param.mean()); + + { + absl::poisson_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + EXPECT_EQ(via_param.param(), before.param()); + } + + // Smoke test. + auto sample_min = before.max(); + auto sample_max = before.min(); + for (int i = 0; i < kCount; i++) { + auto sample = before(gen); + EXPECT_GE(sample, before.min()); + EXPECT_LE(sample, before.max()); + if (sample > sample_max) sample_max = sample; + if (sample < sample_min) sample_min = sample; + } + + ABSL_INTERNAL_LOG(INFO, absl::StrCat("Range {", param.mean(), "}: ", + +sample_min, ", ", +sample_max)); + + // Validate stream serialization. + std::stringstream ss; + ss << before; + + absl::poisson_distribution<TypeParam> after(3.8); + + EXPECT_NE(before.mean(), after.mean()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before.mean(), after.mean()) // + << ss.str() << " " // + << (ss.good() ? "good " : "") // + << (ss.bad() ? "bad " : "") // + << (ss.eof() ? "eof " : "") // + << (ss.fail() ? "fail " : ""); + } +} + +// See http://www.itl.nist.gov/div898/handbook/eda/section3/eda366j.htm + +class PoissonModel { + public: + explicit PoissonModel(double mean) : mean_(mean) {} + + double mean() const { return mean_; } + double variance() const { return mean_; } + double stddev() const { return std::sqrt(variance()); } + double skew() const { return 1.0 / mean_; } + double kurtosis() const { return 3.0 + 1.0 / mean_; } + + // InitCDF() initializes the CDF for the distribution parameters. + void InitCDF(); + + // The InverseCDF, or the Percent-point function returns x, P(x) < v. + struct CDF { + size_t index; + double pmf; + double cdf; + }; + CDF InverseCDF(double p) { + CDF target{0, 0, p}; + auto it = std::upper_bound( + std::begin(cdf_), std::end(cdf_), target, + [](const CDF& a, const CDF& b) { return a.cdf < b.cdf; }); + return *it; + } + + void LogCDF() { + ABSL_INTERNAL_LOG(INFO, absl::StrCat("CDF (mean = ", mean_, ")")); + for (const auto c : cdf_) { + ABSL_INTERNAL_LOG(INFO, + absl::StrCat(c.index, ": pmf=", c.pmf, " cdf=", c.cdf)); + } + } + + private: + const double mean_; + + std::vector<CDF> cdf_; +}; + +// The goal is to compute an InverseCDF function, or percent point function for +// the poisson distribution, and use that to partition our output into equal +// range buckets. However there is no closed form solution for the inverse cdf +// for poisson distributions (the closest is the incomplete gamma function). +// Instead, `InitCDF` iteratively computes the PMF and the CDF. This enables +// searching for the bucket points. +void PoissonModel::InitCDF() { + if (!cdf_.empty()) { + // State already initialized. + return; + } + ABSL_ASSERT(mean_ < 201.0); + + const size_t max_i = 50 * stddev() + mean(); + const double e_neg_mean = std::exp(-mean()); + ABSL_ASSERT(e_neg_mean > 0); + + double d = 1; + double last_result = e_neg_mean; + double cumulative = e_neg_mean; + if (e_neg_mean > 1e-10) { + cdf_.push_back({0, e_neg_mean, cumulative}); + } + for (size_t i = 1; i < max_i; i++) { + d *= (mean() / i); + double result = e_neg_mean * d; + cumulative += result; + if (result < 1e-10 && result < last_result && cumulative > 0.999999) { + break; + } + if (result > 1e-7) { + cdf_.push_back({i, result, cumulative}); + } + last_result = result; + } + ABSL_ASSERT(!cdf_.empty()); +} + +// PoissonDistributionZTest implements a z-test for the poisson distribution. + +struct ZParam { + double mean; + double p_fail; // Z-Test probability of failure. + int trials; // Z-Test trials. + size_t samples; // Z-Test samples. +}; + +class PoissonDistributionZTest : public testing::TestWithParam<ZParam>, + public PoissonModel { + public: + PoissonDistributionZTest() : PoissonModel(GetParam().mean) {} + + // ZTestImpl provides a basic z-squared test of the mean vs. expected + // mean for data generated by the poisson distribution. + template <typename D> + bool SingleZTest(const double p, const size_t samples); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng_{0x2B7E151628AED2A6}; +}; + +template <typename D> +bool PoissonDistributionZTest::SingleZTest(const double p, + const size_t samples) { + D dis(mean()); + + absl::flat_hash_map<int32_t, int> buckets; + std::vector<double> data; + data.reserve(samples); + for (int j = 0; j < samples; j++) { + const auto x = dis(rng_); + buckets[x]++; + data.push_back(x); + } + + // The null-hypothesis is that the distribution is a poisson distribution with + // the provided mean (not estimated from the data). + const auto m = absl::random_internal::ComputeDistributionMoments(data); + const double max_err = absl::random_internal::MaxErrorTolerance(p); + const double z = absl::random_internal::ZScore(mean(), m); + const bool pass = absl::random_internal::Near("z", z, 0.0, max_err); + + if (!pass) { + ABSL_INTERNAL_LOG( + INFO, absl::StrFormat("p=%f max_err=%f\n" + " mean=%f vs. %f\n" + " stddev=%f vs. %f\n" + " skewness=%f vs. %f\n" + " kurtosis=%f vs. %f\n" + " z=%f", + p, max_err, m.mean, mean(), std::sqrt(m.variance), + stddev(), m.skewness, skew(), m.kurtosis, + kurtosis(), z)); + } + return pass; +} + +TEST_P(PoissonDistributionZTest, AbslPoissonDistribution) { + const auto& param = GetParam(); + const int expected_failures = + std::max(1, static_cast<int>(std::ceil(param.trials * param.p_fail))); + const double p = absl::random_internal::RequiredSuccessProbability( + param.p_fail, param.trials); + + int failures = 0; + for (int i = 0; i < param.trials; i++) { + failures += + SingleZTest<absl::poisson_distribution<int32_t>>(p, param.samples) ? 0 + : 1; + } + EXPECT_LE(failures, expected_failures); +} + +std::vector<ZParam> GetZParams() { + // These values have been adjusted from the "exact" computed values to reduce + // failure rates. + // + // It turns out that the actual values are not as close to the expected values + // as would be ideal. + return std::vector<ZParam>({ + // Knuth method. + ZParam{0.5, 0.01, 100, 1000}, + ZParam{1.0, 0.01, 100, 1000}, + ZParam{10.0, 0.01, 100, 5000}, + // Split-knuth method. + ZParam{20.0, 0.01, 100, 10000}, + ZParam{50.0, 0.01, 100, 10000}, + // Ratio of gaussians method. + ZParam{51.0, 0.01, 100, 10000}, + ZParam{200.0, 0.05, 10, 100000}, + ZParam{100000.0, 0.05, 10, 1000000}, + }); +} + +std::string ZParamName(const ::testing::TestParamInfo<ZParam>& info) { + const auto& p = info.param; + std::string name = absl::StrCat("mean_", absl::SixDigits(p.mean)); + return absl::StrReplaceAll(name, {{"+", "_"}, {"-", "_"}, {".", "_"}}); +} + +INSTANTIATE_TEST_SUITE_P(All, PoissonDistributionZTest, + ::testing::ValuesIn(GetZParams()), ZParamName); + +// The PoissonDistributionChiSquaredTest class provides a basic test framework +// for variates generated by a conforming poisson_distribution. +class PoissonDistributionChiSquaredTest : public testing::TestWithParam<double>, + public PoissonModel { + public: + PoissonDistributionChiSquaredTest() : PoissonModel(GetParam()) {} + + // The ChiSquaredTestImpl provides a chi-squared goodness of fit test for data + // generated by the poisson distribution. + template <typename D> + double ChiSquaredTestImpl(); + + private: + void InitChiSquaredTest(const double buckets); + + std::vector<size_t> cutoffs_; + std::vector<double> expected_; + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng_{0x2B7E151628AED2A6}; +}; + +void PoissonDistributionChiSquaredTest::InitChiSquaredTest( + const double buckets) { + if (!cutoffs_.empty() && !expected_.empty()) { + return; + } + InitCDF(); + + // The code below finds cuttoffs that yield approximately equally-sized + // buckets to the extent that it is possible. However for poisson + // distributions this is particularly challenging for small mean parameters. + // Track the expected proportion of items in each bucket. + double last_cdf = 0; + const double inc = 1.0 / buckets; + for (double p = inc; p <= 1.0; p += inc) { + auto result = InverseCDF(p); + if (!cutoffs_.empty() && cutoffs_.back() == result.index) { + continue; + } + double d = result.cdf - last_cdf; + cutoffs_.push_back(result.index); + expected_.push_back(d); + last_cdf = result.cdf; + } + cutoffs_.push_back(std::numeric_limits<size_t>::max()); + expected_.push_back(std::max(0.0, 1.0 - last_cdf)); +} + +template <typename D> +double PoissonDistributionChiSquaredTest::ChiSquaredTestImpl() { + const int kSamples = 2000; + const int kBuckets = 50; + + // The poisson CDF fails for large mean values, since e^-mean exceeds the + // machine precision. For these cases, using a normal approximation would be + // appropriate. + ABSL_ASSERT(mean() <= 200); + InitChiSquaredTest(kBuckets); + + D dis(mean()); + + std::vector<int32_t> counts(cutoffs_.size(), 0); + for (int j = 0; j < kSamples; j++) { + const size_t x = dis(rng_); + auto it = std::lower_bound(std::begin(cutoffs_), std::end(cutoffs_), x); + counts[std::distance(cutoffs_.begin(), it)]++; + } + + // Normalize the counts. + std::vector<int32_t> e(expected_.size(), 0); + for (int i = 0; i < e.size(); i++) { + e[i] = kSamples * expected_[i]; + } + + // The null-hypothesis is that the distribution is a poisson distribution with + // the provided mean (not estimated from the data). + const int dof = static_cast<int>(counts.size()) - 1; + + // The threshold for logging is 1-in-50. + const double threshold = absl::random_internal::ChiSquareValue(dof, 0.98); + + const double chi_square = absl::random_internal::ChiSquare( + std::begin(counts), std::end(counts), std::begin(e), std::end(e)); + + const double p = absl::random_internal::ChiSquarePValue(chi_square, dof); + + // Log if the chi_squared value is above the threshold. + if (chi_square > threshold) { + LogCDF(); + + ABSL_INTERNAL_LOG(INFO, absl::StrCat("VALUES buckets=", counts.size(), + " samples=", kSamples)); + for (size_t i = 0; i < counts.size(); i++) { + ABSL_INTERNAL_LOG( + INFO, absl::StrCat(cutoffs_[i], ": ", counts[i], " vs. E=", e[i])); + } + + ABSL_INTERNAL_LOG( + INFO, + absl::StrCat(kChiSquared, "(data, dof=", dof, ") = ", chi_square, " (", + p, ")\n", " vs.\n", kChiSquared, " @ 0.98 = ", threshold)); + } + return p; +} + +TEST_P(PoissonDistributionChiSquaredTest, AbslPoissonDistribution) { + const int kTrials = 20; + + // Large values are not yet supported -- this requires estimating the cdf + // using the normal distribution instead of the poisson in this case. + ASSERT_LE(mean(), 200.0); + if (mean() > 200.0) { + return; + } + + int failures = 0; + for (int i = 0; i < kTrials; i++) { + double p_value = ChiSquaredTestImpl<absl::poisson_distribution<int32_t>>(); + if (p_value < 0.005) { + failures++; + } + } + // There is a 0.10% chance of producing at least one failure, so raise the + // failure threshold high enough to allow for a flake rate < 10,000. + EXPECT_LE(failures, 4); +} + +INSTANTIATE_TEST_SUITE_P(All, PoissonDistributionChiSquaredTest, + ::testing::Values(0.5, 1.0, 2.0, 10.0, 50.0, 51.0, + 200.0)); + +// NOTE: absl::poisson_distribution is not guaranteed to be stable. +TEST(PoissonDistributionTest, StabilityTest) { + using testing::ElementsAre; + // absl::poisson_distribution stability relies on stability of + // std::exp, std::log, std::sqrt, std::ceil, std::floor, and + // absl::FastUniformBits, absl::StirlingLogFactorial, absl::RandU64ToDouble. + absl::random_internal::sequence_urbg urbg({ + 0x035b0dc7e0a18acfull, 0x06cebe0d2653682eull, 0x0061e9b23861596bull, + 0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull, + 0x4864f22c059bf29eull, 0x247856d8b862665cull, 0xe46e86e9a1337e10ull, + 0xd8c8541f3519b133ull, 0xe75b5162c567b9e4ull, 0xf732e5ded7009c5bull, + 0xb170b98353121eacull, 0x1ec2e8986d2362caull, 0x814c8e35fe9a961aull, + 0x0c3cd59c9b638a02ull, 0xcb3bb6478a07715cull, 0x1224e62c978bbc7full, + 0x671ef2cb04e81f6eull, 0x3c1cbd811eaf1808ull, 0x1bbc23cfa8fac721ull, + 0xa4c2cda65e596a51ull, 0xb77216fad37adf91ull, 0x836d794457c08849ull, + 0xe083df03475f49d7ull, 0xbc9feb512e6b0d6cull, 0xb12d74fdd718c8c5ull, + 0x12ff09653bfbe4caull, 0x8dd03a105bc4ee7eull, 0x5738341045ba0d85ull, + 0xf3fd722dc65ad09eull, 0xfa14fd21ea2a5705ull, 0xffe6ea4d6edb0c73ull, + 0xD07E9EFE2BF11FB4ull, 0x95DBDA4DAE909198ull, 0xEAAD8E716B93D5A0ull, + 0xD08ED1D0AFC725E0ull, 0x8E3C5B2F8E7594B7ull, 0x8FF6E2FBF2122B64ull, + 0x8888B812900DF01Cull, 0x4FAD5EA0688FC31Cull, 0xD1CFF191B3A8C1ADull, + 0x2F2F2218BE0E1777ull, 0xEA752DFE8B021FA1ull, 0xE5A0CC0FB56F74E8ull, + 0x18ACF3D6CE89E299ull, 0xB4A84FE0FD13E0B7ull, 0x7CC43B81D2ADA8D9ull, + 0x165FA26680957705ull, 0x93CC7314211A1477ull, 0xE6AD206577B5FA86ull, + 0xC75442F5FB9D35CFull, 0xEBCDAF0C7B3E89A0ull, 0xD6411BD3AE1E7E49ull, + 0x00250E2D2071B35Eull, 0x226800BB57B8E0AFull, 0x2464369BF009B91Eull, + 0x5563911D59DFA6AAull, 0x78C14389D95A537Full, 0x207D5BA202E5B9C5ull, + 0x832603766295CFA9ull, 0x11C819684E734A41ull, 0xB3472DCA7B14A94Aull, + }); + + std::vector<int> output(10); + + // Method 1. + { + absl::poisson_distribution<int> dist(5); + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + } + EXPECT_THAT(output, // mean = 4.2 + ElementsAre(1, 0, 0, 4, 2, 10, 3, 3, 7, 12)); + + // Method 2. + { + urbg.reset(); + absl::poisson_distribution<int> dist(25); + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + } + EXPECT_THAT(output, // mean = 19.8 + ElementsAre(9, 35, 18, 10, 35, 18, 10, 35, 18, 10)); + + // Method 3. + { + urbg.reset(); + absl::poisson_distribution<int> dist(121); + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + } + EXPECT_THAT(output, // mean = 124.1 + ElementsAre(161, 122, 129, 124, 112, 112, 117, 120, 130, 114)); +} + +TEST(PoissonDistributionTest, AlgorithmExpectedValue_1) { + // This tests small values of the Knuth method. + // The underlying uniform distribution will generate exactly 0.5. + absl::random_internal::sequence_urbg urbg({0x8000000000000001ull}); + absl::poisson_distribution<int> dist(5); + EXPECT_EQ(7, dist(urbg)); +} + +TEST(PoissonDistributionTest, AlgorithmExpectedValue_2) { + // This tests larger values of the Knuth method. + // The underlying uniform distribution will generate exactly 0.5. + absl::random_internal::sequence_urbg urbg({0x8000000000000001ull}); + absl::poisson_distribution<int> dist(25); + EXPECT_EQ(36, dist(urbg)); +} + +TEST(PoissonDistributionTest, AlgorithmExpectedValue_3) { + // This variant uses the ratio of uniforms method. + absl::random_internal::sequence_urbg urbg( + {0x7fffffffffffffffull, 0x8000000000000000ull}); + + absl::poisson_distribution<int> dist(121); + EXPECT_EQ(121, dist(urbg)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/random.h b/third_party/abseil_cpp/absl/random/random.h new file mode 100644 index 0000000000..71b6309288 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/random.h @@ -0,0 +1,189 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: random.h +// ----------------------------------------------------------------------------- +// +// This header defines the recommended Uniform Random Bit Generator (URBG) +// types for use within the Abseil Random library. These types are not +// suitable for security-related use-cases, but should suffice for most other +// uses of generating random values. +// +// The Abseil random library provides the following URBG types: +// +// * BitGen, a good general-purpose bit generator, optimized for generating +// random (but not cryptographically secure) values +// * InsecureBitGen, a slightly faster, though less random, bit generator, for +// cases where the existing BitGen is a drag on performance. + +#ifndef ABSL_RANDOM_RANDOM_H_ +#define ABSL_RANDOM_RANDOM_H_ + +#include <random> + +#include "absl/random/distributions.h" // IWYU pragma: export +#include "absl/random/internal/nonsecure_base.h" // IWYU pragma: export +#include "absl/random/internal/pcg_engine.h" // IWYU pragma: export +#include "absl/random/internal/pool_urbg.h" +#include "absl/random/internal/randen_engine.h" +#include "absl/random/seed_sequences.h" // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// absl::BitGen +// ----------------------------------------------------------------------------- +// +// `absl::BitGen` is a general-purpose random bit generator for generating +// random values for use within the Abseil random library. Typically, you use a +// bit generator in combination with a distribution to provide random values. +// +// Example: +// +// // Create an absl::BitGen. There is no need to seed this bit generator. +// absl::BitGen gen; +// +// // Generate an integer value in the closed interval [1,6] +// int die_roll = absl::uniform_int_distribution<int>(1, 6)(gen); +// +// `absl::BitGen` is seeded by default with non-deterministic data to produce +// different sequences of random values across different instances, including +// different binary invocations. This behavior is different than the standard +// library bit generators, which use golden values as their seeds. Default +// construction intentionally provides no stability guarantees, to avoid +// accidental dependence on such a property. +// +// `absl::BitGen` may be constructed with an optional seed sequence type, +// conforming to [rand.req.seed_seq], which will be mixed with additional +// non-deterministic data. +// +// Example: +// +// // Create an absl::BitGen using an std::seed_seq seed sequence +// std::seed_seq seq{1,2,3}; +// absl::BitGen gen_with_seed(seq); +// +// // Generate an integer value in the closed interval [1,6] +// int die_roll2 = absl::uniform_int_distribution<int>(1, 6)(gen_with_seed); +// +// `absl::BitGen` meets the requirements of the Uniform Random Bit Generator +// (URBG) concept as per the C++17 standard [rand.req.urng] though differs +// slightly with [rand.req.eng]. Like its standard library equivalents (e.g. +// `std::mersenne_twister_engine`) `absl::BitGen` is not cryptographically +// secure. +// +// Constructing two `absl::BitGen`s with the same seed sequence in the same +// binary will produce the same sequence of variates within the same binary, but +// need not do so across multiple binary invocations. +// +// This type has been optimized to perform better than Mersenne Twister +// (https://en.wikipedia.org/wiki/Mersenne_Twister) and many other complex URBG +// types on modern x86, ARM, and PPC architectures. +// +// This type is thread-compatible, but not thread-safe. + +// --------------------------------------------------------------------------- +// absl::BitGen member functions +// --------------------------------------------------------------------------- + +// absl::BitGen::operator()() +// +// Calls the BitGen, returning a generated value. + +// absl::BitGen::min() +// +// Returns the smallest possible value from this bit generator. + +// absl::BitGen::max() +// +// Returns the largest possible value from this bit generator. + +// absl::BitGen::discard(num) +// +// Advances the internal state of this bit generator by `num` times, and +// discards the intermediate results. +// --------------------------------------------------------------------------- + +using BitGen = random_internal::NonsecureURBGBase< + random_internal::randen_engine<uint64_t>>; + +// ----------------------------------------------------------------------------- +// absl::InsecureBitGen +// ----------------------------------------------------------------------------- +// +// `absl::InsecureBitGen` is an efficient random bit generator for generating +// random values, recommended only for performance-sensitive use cases where +// `absl::BitGen` is not satisfactory when compute-bounded by bit generation +// costs. +// +// Example: +// +// // Create an absl::InsecureBitGen +// absl::InsecureBitGen gen; +// for (size_t i = 0; i < 1000000; i++) { +// +// // Generate a bunch of random values from some complex distribution +// auto my_rnd = some_distribution(gen, 1, 1000); +// } +// +// Like `absl::BitGen`, `absl::InsecureBitGen` is seeded by default with +// non-deterministic data to produce different sequences of random values across +// different instances, including different binary invocations. (This behavior +// is different than the standard library bit generators, which use golden +// values as their seeds.) +// +// `absl::InsecureBitGen` may be constructed with an optional seed sequence +// type, conforming to [rand.req.seed_seq], which will be mixed with additional +// non-deterministic data. (See std_seed_seq.h for more information.) +// +// `absl::InsecureBitGen` meets the requirements of the Uniform Random Bit +// Generator (URBG) concept as per the C++17 standard [rand.req.urng] though +// its implementation differs slightly with [rand.req.eng]. Like its standard +// library equivalents (e.g. `std::mersenne_twister_engine`) +// `absl::InsecureBitGen` is not cryptographically secure. +// +// Prefer `absl::BitGen` over `absl::InsecureBitGen` as the general type is +// often fast enough for the vast majority of applications. + +using InsecureBitGen = + random_internal::NonsecureURBGBase<random_internal::pcg64_2018_engine>; + +// --------------------------------------------------------------------------- +// absl::InsecureBitGen member functions +// --------------------------------------------------------------------------- + +// absl::InsecureBitGen::operator()() +// +// Calls the InsecureBitGen, returning a generated value. + +// absl::InsecureBitGen::min() +// +// Returns the smallest possible value from this bit generator. + +// absl::InsecureBitGen::max() +// +// Returns the largest possible value from this bit generator. + +// absl::InsecureBitGen::discard(num) +// +// Advances the internal state of this bit generator by `num` times, and +// discards the intermediate results. +// --------------------------------------------------------------------------- + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_RANDOM_H_ diff --git a/third_party/abseil_cpp/absl/random/seed_gen_exception.cc b/third_party/abseil_cpp/absl/random/seed_gen_exception.cc new file mode 100644 index 0000000000..fdcb54a86c --- /dev/null +++ b/third_party/abseil_cpp/absl/random/seed_gen_exception.cc @@ -0,0 +1,46 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/seed_gen_exception.h" + +#include <iostream> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +static constexpr const char kExceptionMessage[] = + "Failed generating seed-material for URBG."; + +SeedGenException::~SeedGenException() = default; + +const char* SeedGenException::what() const noexcept { + return kExceptionMessage; +} + +namespace random_internal { + +void ThrowSeedGenException() { +#ifdef ABSL_HAVE_EXCEPTIONS + throw absl::SeedGenException(); +#else + std::cerr << kExceptionMessage << std::endl; + std::terminate(); +#endif +} + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/seed_gen_exception.h b/third_party/abseil_cpp/absl/random/seed_gen_exception.h new file mode 100644 index 0000000000..5353900564 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/seed_gen_exception.h @@ -0,0 +1,55 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: seed_gen_exception.h +// ----------------------------------------------------------------------------- +// +// This header defines an exception class which may be thrown if unpredictable +// events prevent the derivation of suitable seed-material for constructing a +// bit generator conforming to [rand.req.urng] (eg. entropy cannot be read from +// /dev/urandom on a Unix-based system). +// +// Note: if exceptions are disabled, `std::terminate()` is called instead. + +#ifndef ABSL_RANDOM_SEED_GEN_EXCEPTION_H_ +#define ABSL_RANDOM_SEED_GEN_EXCEPTION_H_ + +#include <exception> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +//------------------------------------------------------------------------------ +// SeedGenException +//------------------------------------------------------------------------------ +class SeedGenException : public std::exception { + public: + SeedGenException() = default; + ~SeedGenException() override; + const char* what() const noexcept override; +}; + +namespace random_internal { + +// throw delegator +[[noreturn]] void ThrowSeedGenException(); + +} // namespace random_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_SEED_GEN_EXCEPTION_H_ diff --git a/third_party/abseil_cpp/absl/random/seed_sequences.cc b/third_party/abseil_cpp/absl/random/seed_sequences.cc new file mode 100644 index 0000000000..426eafd3c8 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/seed_sequences.cc @@ -0,0 +1,29 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/seed_sequences.h" + +#include "absl/random/internal/pool_urbg.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +SeedSeq MakeSeedSeq() { + SeedSeq::result_type seed_material[8]; + random_internal::RandenPool<uint32_t>::Fill(absl::MakeSpan(seed_material)); + return SeedSeq(std::begin(seed_material), std::end(seed_material)); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/random/seed_sequences.h b/third_party/abseil_cpp/absl/random/seed_sequences.h new file mode 100644 index 0000000000..ff1340cc8e --- /dev/null +++ b/third_party/abseil_cpp/absl/random/seed_sequences.h @@ -0,0 +1,110 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: seed_sequences.h +// ----------------------------------------------------------------------------- +// +// This header contains utilities for creating and working with seed sequences +// conforming to [rand.req.seedseq]. In general, direct construction of seed +// sequences is discouraged, but use-cases for construction of identical bit +// generators (using the same seed sequence) may be helpful (e.g. replaying a +// simulation whose state is derived from variates of a bit generator). + +#ifndef ABSL_RANDOM_SEED_SEQUENCES_H_ +#define ABSL_RANDOM_SEED_SEQUENCES_H_ + +#include <iterator> +#include <random> + +#include "absl/random/internal/salted_seed_seq.h" +#include "absl/random/internal/seed_material.h" +#include "absl/random/seed_gen_exception.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// absl::SeedSeq +// ----------------------------------------------------------------------------- +// +// `absl::SeedSeq` constructs a seed sequence according to [rand.req.seedseq] +// for use within bit generators. `absl::SeedSeq`, unlike `std::seed_seq` +// additionally salts the generated seeds with extra implementation-defined +// entropy. For that reason, you can use `absl::SeedSeq` in combination with +// standard library bit generators (e.g. `std::mt19937`) to introduce +// non-determinism in your seeds. +// +// Example: +// +// absl::SeedSeq my_seed_seq({a, b, c}); +// std::mt19937 my_bitgen(my_seed_seq); +// +using SeedSeq = random_internal::SaltedSeedSeq<std::seed_seq>; + +// ----------------------------------------------------------------------------- +// absl::CreateSeedSeqFrom(bitgen*) +// ----------------------------------------------------------------------------- +// +// Constructs a seed sequence conforming to [rand.req.seedseq] using variates +// produced by a provided bit generator. +// +// You should generally avoid direct construction of seed sequences, but +// use-cases for reuse of a seed sequence to construct identical bit generators +// may be helpful (eg. replaying a simulation whose state is derived from bit +// generator values). +// +// If bitgen == nullptr, then behavior is undefined. +// +// Example: +// +// absl::BitGen my_bitgen; +// auto seed_seq = absl::CreateSeedSeqFrom(&my_bitgen); +// absl::BitGen new_engine(seed_seq); // derived from my_bitgen, but not +// // correlated. +// +template <typename URBG> +SeedSeq CreateSeedSeqFrom(URBG* urbg) { + SeedSeq::result_type + seed_material[random_internal::kEntropyBlocksNeeded]; + + if (!random_internal::ReadSeedMaterialFromURBG( + urbg, absl::MakeSpan(seed_material))) { + random_internal::ThrowSeedGenException(); + } + return SeedSeq(std::begin(seed_material), std::end(seed_material)); +} + +// ----------------------------------------------------------------------------- +// absl::MakeSeedSeq() +// ----------------------------------------------------------------------------- +// +// Constructs an `absl::SeedSeq` salting the generated values using +// implementation-defined entropy. The returned sequence can be used to create +// equivalent bit generators correlated using this sequence. +// +// Example: +// +// auto my_seed_seq = absl::MakeSeedSeq(); +// std::mt19937 rng1(my_seed_seq); +// std::mt19937 rng2(my_seed_seq); +// EXPECT_EQ(rng1(), rng2()); +// +SeedSeq MakeSeedSeq(); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_SEED_SEQUENCES_H_ diff --git a/third_party/abseil_cpp/absl/random/seed_sequences_test.cc b/third_party/abseil_cpp/absl/random/seed_sequences_test.cc new file mode 100644 index 0000000000..2cc8b0e6f2 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/seed_sequences_test.cc @@ -0,0 +1,127 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/seed_sequences.h" + +#include <iterator> +#include <random> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/random/internal/nonsecure_base.h" +#include "absl/random/random.h" +namespace { + +TEST(SeedSequences, Examples) { + { + absl::SeedSeq seed_seq({1, 2, 3}); + absl::BitGen bitgen(seed_seq); + + EXPECT_NE(0, bitgen()); + } + { + absl::BitGen engine; + auto seed_seq = absl::CreateSeedSeqFrom(&engine); + absl::BitGen bitgen(seed_seq); + + EXPECT_NE(engine(), bitgen()); + } + { + auto seed_seq = absl::MakeSeedSeq(); + std::mt19937 random(seed_seq); + + EXPECT_NE(0, random()); + } +} + +TEST(CreateSeedSeqFrom, CompatibleWithStdTypes) { + using ExampleNonsecureURBG = + absl::random_internal::NonsecureURBGBase<std::minstd_rand0>; + + // Construct a URBG instance. + ExampleNonsecureURBG rng; + + // Construct a Seed Sequence from its variates. + auto seq_from_rng = absl::CreateSeedSeqFrom(&rng); + + // Ensure that another URBG can be validly constructed from the Seed Sequence. + std::mt19937_64{seq_from_rng}; +} + +TEST(CreateSeedSeqFrom, CompatibleWithBitGenerator) { + // Construct a URBG instance. + absl::BitGen rng; + + // Construct a Seed Sequence from its variates. + auto seq_from_rng = absl::CreateSeedSeqFrom(&rng); + + // Ensure that another URBG can be validly constructed from the Seed Sequence. + std::mt19937_64{seq_from_rng}; +} + +TEST(CreateSeedSeqFrom, CompatibleWithInsecureBitGen) { + // Construct a URBG instance. + absl::InsecureBitGen rng; + + // Construct a Seed Sequence from its variates. + auto seq_from_rng = absl::CreateSeedSeqFrom(&rng); + + // Ensure that another URBG can be validly constructed from the Seed Sequence. + std::mt19937_64{seq_from_rng}; +} + +TEST(CreateSeedSeqFrom, CompatibleWithRawURBG) { + // Construct a URBG instance. + std::random_device urandom; + + // Construct a Seed Sequence from its variates, using 64b of seed-material. + auto seq_from_rng = absl::CreateSeedSeqFrom(&urandom); + + // Ensure that another URBG can be validly constructed from the Seed Sequence. + std::mt19937_64{seq_from_rng}; +} + +template <typename URBG> +void TestReproducibleVariateSequencesForNonsecureURBG() { + const size_t kNumVariates = 1000; + + // Master RNG instance. + URBG rng; + // Reused for both RNG instances. + auto reusable_seed = absl::CreateSeedSeqFrom(&rng); + + typename URBG::result_type variates[kNumVariates]; + { + URBG child(reusable_seed); + for (auto& variate : variates) { + variate = child(); + } + } + // Ensure that variate-sequence can be "replayed" by identical RNG. + { + URBG child(reusable_seed); + for (auto& variate : variates) { + ASSERT_EQ(variate, child()); + } + } +} + +TEST(CreateSeedSeqFrom, ReproducesVariateSequencesForInsecureBitGen) { + TestReproducibleVariateSequencesForNonsecureURBG<absl::InsecureBitGen>(); +} + +TEST(CreateSeedSeqFrom, ReproducesVariateSequencesForBitGenerator) { + TestReproducibleVariateSequencesForNonsecureURBG<absl::BitGen>(); +} +} // namespace diff --git a/third_party/abseil_cpp/absl/random/uniform_int_distribution.h b/third_party/abseil_cpp/absl/random/uniform_int_distribution.h new file mode 100644 index 0000000000..da66564a6b --- /dev/null +++ b/third_party/abseil_cpp/absl/random/uniform_int_distribution.h @@ -0,0 +1,275 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: uniform_int_distribution.h +// ----------------------------------------------------------------------------- +// +// This header defines a class for representing a uniform integer distribution +// over the closed (inclusive) interval [a,b]. You use this distribution in +// combination with an Abseil random bit generator to produce random values +// according to the rules of the distribution. +// +// `absl::uniform_int_distribution` is a drop-in replacement for the C++11 +// `std::uniform_int_distribution` [rand.dist.uni.int] but is considerably +// faster than the libstdc++ implementation. + +#ifndef ABSL_RANDOM_UNIFORM_INT_DISTRIBUTION_H_ +#define ABSL_RANDOM_UNIFORM_INT_DISTRIBUTION_H_ + +#include <cassert> +#include <istream> +#include <limits> +#include <type_traits> + +#include "absl/base/optimization.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/iostream_state_saver.h" +#include "absl/random/internal/traits.h" +#include "absl/random/internal/wide_multiply.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::uniform_int_distribution<T> +// +// This distribution produces random integer values uniformly distributed in the +// closed (inclusive) interval [a, b]. +// +// Example: +// +// absl::BitGen gen; +// +// // Use the distribution to produce a value between 1 and 6, inclusive. +// int die_roll = absl::uniform_int_distribution<int>(1, 6)(gen); +// +template <typename IntType = int> +class uniform_int_distribution { + private: + using unsigned_type = + typename random_internal::make_unsigned_bits<IntType>::type; + + public: + using result_type = IntType; + + class param_type { + public: + using distribution_type = uniform_int_distribution; + + explicit param_type( + result_type lo = 0, + result_type hi = (std::numeric_limits<result_type>::max)()) + : lo_(lo), + range_(static_cast<unsigned_type>(hi) - + static_cast<unsigned_type>(lo)) { + // [rand.dist.uni.int] precondition 2 + assert(lo <= hi); + } + + result_type a() const { return lo_; } + result_type b() const { + return static_cast<result_type>(static_cast<unsigned_type>(lo_) + range_); + } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.lo_ == b.lo_ && a.range_ == b.range_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class uniform_int_distribution; + unsigned_type range() const { return range_; } + + result_type lo_; + unsigned_type range_; + + static_assert(std::is_integral<result_type>::value, + "Class-template absl::uniform_int_distribution<> must be " + "parameterized using an integral type."); + }; // param_type + + uniform_int_distribution() : uniform_int_distribution(0) {} + + explicit uniform_int_distribution( + result_type lo, + result_type hi = (std::numeric_limits<result_type>::max)()) + : param_(lo, hi) {} + + explicit uniform_int_distribution(const param_type& param) : param_(param) {} + + // uniform_int_distribution<T>::reset() + // + // Resets the uniform int distribution. Note that this function has no effect + // because the distribution already produces independent values. + void reset() {} + + template <typename URBG> + result_type operator()(URBG& gen) { // NOLINT(runtime/references) + return (*this)(gen, param()); + } + + template <typename URBG> + result_type operator()( + URBG& gen, const param_type& param) { // NOLINT(runtime/references) + return param.a() + Generate(gen, param.range()); + } + + result_type a() const { return param_.a(); } + result_type b() const { return param_.b(); } + + param_type param() const { return param_; } + void param(const param_type& params) { param_ = params; } + + result_type(min)() const { return a(); } + result_type(max)() const { return b(); } + + friend bool operator==(const uniform_int_distribution& a, + const uniform_int_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const uniform_int_distribution& a, + const uniform_int_distribution& b) { + return !(a == b); + } + + private: + // Generates a value in the *closed* interval [0, R] + template <typename URBG> + unsigned_type Generate(URBG& g, // NOLINT(runtime/references) + unsigned_type R); + param_type param_; +}; + +// ----------------------------------------------------------------------------- +// Implementation details follow +// ----------------------------------------------------------------------------- +template <typename CharT, typename Traits, typename IntType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, + const uniform_int_distribution<IntType>& x) { + using stream_type = + typename random_internal::stream_format_type<IntType>::type; + auto saver = random_internal::make_ostream_state_saver(os); + os << static_cast<stream_type>(x.a()) << os.fill() + << static_cast<stream_type>(x.b()); + return os; +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, + uniform_int_distribution<IntType>& x) { + using param_type = typename uniform_int_distribution<IntType>::param_type; + using result_type = typename uniform_int_distribution<IntType>::result_type; + using stream_type = + typename random_internal::stream_format_type<IntType>::type; + + stream_type a; + stream_type b; + + auto saver = random_internal::make_istream_state_saver(is); + is >> a >> b; + if (!is.fail()) { + x.param( + param_type(static_cast<result_type>(a), static_cast<result_type>(b))); + } + return is; +} + +template <typename IntType> +template <typename URBG> +typename random_internal::make_unsigned_bits<IntType>::type +uniform_int_distribution<IntType>::Generate( + URBG& g, // NOLINT(runtime/references) + typename random_internal::make_unsigned_bits<IntType>::type R) { + random_internal::FastUniformBits<unsigned_type> fast_bits; + unsigned_type bits = fast_bits(g); + const unsigned_type Lim = R + 1; + if ((R & Lim) == 0) { + // If the interval's length is a power of two range, just take the low bits. + return bits & R; + } + + // Generates a uniform variate on [0, Lim) using fixed-point multiplication. + // The above fast-path guarantees that Lim is representable in unsigned_type. + // + // Algorithm adapted from + // http://lemire.me/blog/2016/06/30/fast-random-shuffling/, with added + // explanation. + // + // The algorithm creates a uniform variate `bits` in the interval [0, 2^N), + // and treats it as the fractional part of a fixed-point real value in [0, 1), + // multiplied by 2^N. For example, 0.25 would be represented as 2^(N - 2), + // because 2^N * 0.25 == 2^(N - 2). + // + // Next, `bits` and `Lim` are multiplied with a wide-multiply to bring the + // value into the range [0, Lim). The integral part (the high word of the + // multiplication result) is then very nearly the desired result. However, + // this is not quite accurate; viewing the multiplication result as one + // double-width integer, the resulting values for the sample are mapped as + // follows: + // + // If the result lies in this interval: Return this value: + // [0, 2^N) 0 + // [2^N, 2 * 2^N) 1 + // ... ... + // [K * 2^N, (K + 1) * 2^N) K + // ... ... + // [(Lim - 1) * 2^N, Lim * 2^N) Lim - 1 + // + // While all of these intervals have the same size, the result of `bits * Lim` + // must be a multiple of `Lim`, and not all of these intervals contain the + // same number of multiples of `Lim`. In particular, some contain + // `F = floor(2^N / Lim)` and some contain `F + 1 = ceil(2^N / Lim)`. This + // difference produces a small nonuniformity, which is corrected by applying + // rejection sampling to one of the values in the "larger intervals" (i.e., + // the intervals containing `F + 1` multiples of `Lim`. + // + // An interval contains `F + 1` multiples of `Lim` if and only if its smallest + // value modulo 2^N is less than `2^N % Lim`. The unique value satisfying + // this property is used as the one for rejection. That is, a value of + // `bits * Lim` is rejected if `(bit * Lim) % 2^N < (2^N % Lim)`. + + using helper = random_internal::wide_multiply<unsigned_type>; + auto product = helper::multiply(bits, Lim); + + // Two optimizations here: + // * Rejection occurs with some probability less than 1/2, and for reasonable + // ranges considerably less (in particular, less than 1/(F+1)), so + // ABSL_PREDICT_FALSE is apt. + // * `Lim` is an overestimate of `threshold`, and doesn't require a divide. + if (ABSL_PREDICT_FALSE(helper::lo(product) < Lim)) { + // This quantity is exactly equal to `2^N % Lim`, but does not require high + // precision calculations: `2^N % Lim` is congruent to `(2^N - Lim) % Lim`. + // Ideally this could be expressed simply as `-X` rather than `2^N - X`, but + // for types smaller than int, this calculation is incorrect due to integer + // promotion rules. + const unsigned_type threshold = + ((std::numeric_limits<unsigned_type>::max)() - Lim + 1) % Lim; + while (helper::lo(product) < threshold) { + bits = fast_bits(g); + product = helper::multiply(bits, Lim); + } + } + + return helper::hi(product); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_UNIFORM_INT_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/uniform_int_distribution_test.cc b/third_party/abseil_cpp/absl/random/uniform_int_distribution_test.cc new file mode 100644 index 0000000000..276d72ad20 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/uniform_int_distribution_test.cc @@ -0,0 +1,259 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/uniform_int_distribution.h" + +#include <cmath> +#include <cstdint> +#include <iterator> +#include <random> +#include <sstream> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" + +namespace { + +template <typename IntType> +class UniformIntDistributionTest : public ::testing::Test {}; + +using IntTypes = ::testing::Types<int8_t, uint8_t, int16_t, uint16_t, int32_t, + uint32_t, int64_t, uint64_t>; +TYPED_TEST_SUITE(UniformIntDistributionTest, IntTypes); + +TYPED_TEST(UniformIntDistributionTest, ParamSerializeTest) { + // This test essentially ensures that the parameters serialize, + // not that the values generated cover the full range. + using Limits = std::numeric_limits<TypeParam>; + using param_type = + typename absl::uniform_int_distribution<TypeParam>::param_type; + const TypeParam kMin = std::is_unsigned<TypeParam>::value ? 37 : -105; + const TypeParam kNegOneOrZero = std::is_unsigned<TypeParam>::value ? 0 : -1; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + for (const auto& param : { + param_type(), + param_type(2, 2), // Same + param_type(9, 32), + param_type(kMin, 115), + param_type(kNegOneOrZero, Limits::max()), + param_type(Limits::min(), Limits::max()), + param_type(Limits::lowest(), Limits::max()), + param_type(Limits::min() + 1, Limits::max() - 1), + }) { + const auto a = param.a(); + const auto b = param.b(); + absl::uniform_int_distribution<TypeParam> before(a, b); + EXPECT_EQ(before.a(), param.a()); + EXPECT_EQ(before.b(), param.b()); + + { + // Initialize via param_type + absl::uniform_int_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + } + + // Initialize via iostreams + std::stringstream ss; + ss << before; + + absl::uniform_int_distribution<TypeParam> after(Limits::min() + 3, + Limits::max() - 5); + + EXPECT_NE(before.a(), after.a()); + EXPECT_NE(before.b(), after.b()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before.a(), after.a()); + EXPECT_EQ(before.b(), after.b()); + EXPECT_EQ(before.param(), after.param()); + EXPECT_EQ(before, after); + + // Smoke test. + auto sample_min = after.max(); + auto sample_max = after.min(); + for (int i = 0; i < kCount; i++) { + auto sample = after(gen); + EXPECT_GE(sample, after.min()); + EXPECT_LE(sample, after.max()); + if (sample > sample_max) { + sample_max = sample; + } + if (sample < sample_min) { + sample_min = sample; + } + } + std::string msg = absl::StrCat("Range: ", +sample_min, ", ", +sample_max); + ABSL_RAW_LOG(INFO, "%s", msg.c_str()); + } +} + +TYPED_TEST(UniformIntDistributionTest, ViolatesPreconditionsDeathTest) { +#if GTEST_HAS_DEATH_TEST + // Hi < Lo + EXPECT_DEBUG_DEATH({ absl::uniform_int_distribution<TypeParam> dist(10, 1); }, + ""); +#endif // GTEST_HAS_DEATH_TEST +#if defined(NDEBUG) + // opt-mode, for invalid parameters, will generate a garbage value, + // but should not enter an infinite loop. + absl::InsecureBitGen gen; + absl::uniform_int_distribution<TypeParam> dist(10, 1); + auto x = dist(gen); + + // Any value will generate a non-empty string. + EXPECT_FALSE(absl::StrCat(+x).empty()) << x; +#endif // NDEBUG +} + +TYPED_TEST(UniformIntDistributionTest, TestMoments) { + constexpr int kSize = 100000; + using Limits = std::numeric_limits<TypeParam>; + using param_type = + typename absl::uniform_int_distribution<TypeParam>::param_type; + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng{0x2B7E151628AED2A6}; + + std::vector<double> values(kSize); + for (const auto& param : + {param_type(0, Limits::max()), param_type(13, 127)}) { + absl::uniform_int_distribution<TypeParam> dist(param); + for (int i = 0; i < kSize; i++) { + const auto sample = dist(rng); + ASSERT_LE(dist.param().a(), sample); + ASSERT_GE(dist.param().b(), sample); + values[i] = sample; + } + + auto moments = absl::random_internal::ComputeDistributionMoments(values); + const double a = dist.param().a(); + const double b = dist.param().b(); + const double n = (b - a + 1); + const double mean = (a + b) / 2; + const double var = ((b - a + 1) * (b - a + 1) - 1) / 12; + const double kurtosis = 3 - 6 * (n * n + 1) / (5 * (n * n - 1)); + + // TODO(ahh): this is not the right bound + // empirically validated with --runs_per_test=10000. + EXPECT_NEAR(mean, moments.mean, 0.01 * var); + EXPECT_NEAR(var, moments.variance, 0.015 * var); + EXPECT_NEAR(0.0, moments.skewness, 0.025); + EXPECT_NEAR(kurtosis, moments.kurtosis, 0.02 * kurtosis); + } +} + +TYPED_TEST(UniformIntDistributionTest, ChiSquaredTest50) { + using absl::random_internal::kChiSquared; + + constexpr size_t kTrials = 1000; + constexpr int kBuckets = 50; // inclusive, so actally +1 + constexpr double kExpected = + static_cast<double>(kTrials) / static_cast<double>(kBuckets); + + // Empirically validated with --runs_per_test=10000. + const int kThreshold = + absl::random_internal::ChiSquareValue(kBuckets, 0.999999); + + const TypeParam min = std::is_unsigned<TypeParam>::value ? 37 : -37; + const TypeParam max = min + kBuckets; + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng{0x2B7E151628AED2A6}; + + absl::uniform_int_distribution<TypeParam> dist(min, max); + + std::vector<int32_t> counts(kBuckets + 1, 0); + for (size_t i = 0; i < kTrials; i++) { + auto x = dist(rng); + counts[x - min]++; + } + double chi_square = absl::random_internal::ChiSquareWithExpected( + std::begin(counts), std::end(counts), kExpected); + if (chi_square > kThreshold) { + double p_value = + absl::random_internal::ChiSquarePValue(chi_square, kBuckets); + + // Chi-squared test failed. Output does not appear to be uniform. + std::string msg; + for (const auto& a : counts) { + absl::StrAppend(&msg, a, "\n"); + } + absl::StrAppend(&msg, kChiSquared, " p-value ", p_value, "\n"); + absl::StrAppend(&msg, "High ", kChiSquared, " value: ", chi_square, " > ", + kThreshold); + ABSL_RAW_LOG(INFO, "%s", msg.c_str()); + FAIL() << msg; + } +} + +TEST(UniformIntDistributionTest, StabilityTest) { + // absl::uniform_int_distribution stability relies only on integer operations. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(12); + + { + absl::uniform_int_distribution<int32_t> dist(0, 4); + for (auto& v : output) { + v = dist(urbg); + } + } + EXPECT_EQ(12, urbg.invocations()); + EXPECT_THAT(output, testing::ElementsAre(4, 4, 3, 2, 1, 0, 1, 4, 3, 1, 3, 1)); + + { + urbg.reset(); + absl::uniform_int_distribution<int32_t> dist(0, 100); + for (auto& v : output) { + v = dist(urbg); + } + } + EXPECT_EQ(12, urbg.invocations()); + EXPECT_THAT(output, testing::ElementsAre(97, 86, 75, 41, 36, 16, 38, 92, 67, + 30, 80, 38)); + + { + urbg.reset(); + absl::uniform_int_distribution<int32_t> dist(0, 10000); + for (auto& v : output) { + v = dist(urbg); + } + } + EXPECT_EQ(12, urbg.invocations()); + EXPECT_THAT(output, testing::ElementsAre(9648, 8562, 7439, 4089, 3571, 1602, + 3813, 9195, 6641, 2986, 7956, 3765)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/uniform_real_distribution.h b/third_party/abseil_cpp/absl/random/uniform_real_distribution.h new file mode 100644 index 0000000000..5ba17b2341 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/uniform_real_distribution.h @@ -0,0 +1,202 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: uniform_real_distribution.h +// ----------------------------------------------------------------------------- +// +// This header defines a class for representing a uniform floating-point +// distribution over a half-open interval [a,b). You use this distribution in +// combination with an Abseil random bit generator to produce random values +// according to the rules of the distribution. +// +// `absl::uniform_real_distribution` is a drop-in replacement for the C++11 +// `std::uniform_real_distribution` [rand.dist.uni.real] but is considerably +// faster than the libstdc++ implementation. +// +// Note: the standard-library version may occasionally return `1.0` when +// default-initialized. See https://bugs.llvm.org//show_bug.cgi?id=18767 +// `absl::uniform_real_distribution` does not exhibit this behavior. + +#ifndef ABSL_RANDOM_UNIFORM_REAL_DISTRIBUTION_H_ +#define ABSL_RANDOM_UNIFORM_REAL_DISTRIBUTION_H_ + +#include <cassert> +#include <cmath> +#include <cstdint> +#include <istream> +#include <limits> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/random/internal/fast_uniform_bits.h" +#include "absl/random/internal/generate_real.h" +#include "absl/random/internal/iostream_state_saver.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::uniform_real_distribution<T> +// +// This distribution produces random floating-point values uniformly distributed +// over the half-open interval [a, b). +// +// Example: +// +// absl::BitGen gen; +// +// // Use the distribution to produce a value between 0.0 (inclusive) +// // and 1.0 (exclusive). +// double value = absl::uniform_real_distribution<double>(0, 1)(gen); +// +template <typename RealType = double> +class uniform_real_distribution { + public: + using result_type = RealType; + + class param_type { + public: + using distribution_type = uniform_real_distribution; + + explicit param_type(result_type lo = 0, result_type hi = 1) + : lo_(lo), hi_(hi), range_(hi - lo) { + // [rand.dist.uni.real] preconditions 2 & 3 + assert(lo <= hi); + // NOTE: For integral types, we can promote the range to an unsigned type, + // which gives full width of the range. However for real (fp) types, this + // is not possible, so value generation cannot use the full range of the + // real type. + assert(range_ <= (std::numeric_limits<result_type>::max)()); + assert(std::isfinite(range_)); + } + + result_type a() const { return lo_; } + result_type b() const { return hi_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.lo_ == b.lo_ && a.hi_ == b.hi_; + } + + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class uniform_real_distribution; + result_type lo_, hi_, range_; + + static_assert(std::is_floating_point<RealType>::value, + "Class-template absl::uniform_real_distribution<> must be " + "parameterized using a floating-point type."); + }; + + uniform_real_distribution() : uniform_real_distribution(0) {} + + explicit uniform_real_distribution(result_type lo, result_type hi = 1) + : param_(lo, hi) {} + + explicit uniform_real_distribution(const param_type& param) : param_(param) {} + + // uniform_real_distribution<T>::reset() + // + // Resets the uniform real distribution. Note that this function has no effect + // because the distribution already produces independent values. + void reset() {} + + template <typename URBG> + result_type operator()(URBG& gen) { // NOLINT(runtime/references) + return operator()(gen, param_); + } + + template <typename URBG> + result_type operator()(URBG& gen, // NOLINT(runtime/references) + const param_type& p); + + result_type a() const { return param_.a(); } + result_type b() const { return param_.b(); } + + param_type param() const { return param_; } + void param(const param_type& params) { param_ = params; } + + result_type(min)() const { return a(); } + result_type(max)() const { return b(); } + + friend bool operator==(const uniform_real_distribution& a, + const uniform_real_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const uniform_real_distribution& a, + const uniform_real_distribution& b) { + return a.param_ != b.param_; + } + + private: + param_type param_; + random_internal::FastUniformBits<uint64_t> fast_u64_; +}; + +// ----------------------------------------------------------------------------- +// Implementation details follow +// ----------------------------------------------------------------------------- +template <typename RealType> +template <typename URBG> +typename uniform_real_distribution<RealType>::result_type +uniform_real_distribution<RealType>::operator()( + URBG& gen, const param_type& p) { // NOLINT(runtime/references) + using random_internal::GeneratePositiveTag; + using random_internal::GenerateRealFromBits; + using real_type = + absl::conditional_t<std::is_same<RealType, float>::value, float, double>; + + while (true) { + const result_type sample = + GenerateRealFromBits<real_type, GeneratePositiveTag, true>( + fast_u64_(gen)); + const result_type res = p.a() + (sample * p.range_); + if (res < p.b() || p.range_ <= 0 || !std::isfinite(p.range_)) { + return res; + } + // else sample rejected, try again. + } +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const uniform_real_distribution<RealType>& x) { + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<RealType>::kPrecision); + os << x.a() << os.fill() << x.b(); + return os; +} + +template <typename CharT, typename Traits, typename RealType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + uniform_real_distribution<RealType>& x) { // NOLINT(runtime/references) + using param_type = typename uniform_real_distribution<RealType>::param_type; + using result_type = typename uniform_real_distribution<RealType>::result_type; + auto saver = random_internal::make_istream_state_saver(is); + auto a = random_internal::read_floating_point<result_type>(is); + if (is.fail()) return is; + auto b = random_internal::read_floating_point<result_type>(is); + if (!is.fail()) { + x.param(param_type(a, b)); + } + return is; +} +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_UNIFORM_REAL_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/uniform_real_distribution_test.cc b/third_party/abseil_cpp/absl/random/uniform_real_distribution_test.cc new file mode 100644 index 0000000000..be107cdde4 --- /dev/null +++ b/third_party/abseil_cpp/absl/random/uniform_real_distribution_test.cc @@ -0,0 +1,343 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/uniform_real_distribution.h" + +#include <cmath> +#include <cstdint> +#include <iterator> +#include <random> +#include <sstream> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/distribution_test_util.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" + +// NOTES: +// * Some documentation on generating random real values suggests that +// it is possible to use std::nextafter(b, DBL_MAX) to generate a value on +// the closed range [a, b]. Unfortunately, that technique is not universally +// reliable due to floating point quantization. +// +// * absl::uniform_real_distribution<float> generates between 2^28 and 2^29 +// distinct floating point values in the range [0, 1). +// +// * absl::uniform_real_distribution<float> generates at least 2^23 distinct +// floating point values in the range [1, 2). This should be the same as +// any other range covered by a single exponent in IEEE 754. +// +// * absl::uniform_real_distribution<double> generates more than 2^52 distinct +// values in the range [0, 1), and should generate at least 2^52 distinct +// values in the range of [1, 2). +// + +namespace { + +template <typename RealType> +class UniformRealDistributionTest : public ::testing::Test {}; + +#if defined(__EMSCRIPTEN__) +using RealTypes = ::testing::Types<float, double>; +#else +using RealTypes = ::testing::Types<float, double, long double>; +#endif // defined(__EMSCRIPTEN__) + +TYPED_TEST_SUITE(UniformRealDistributionTest, RealTypes); + +TYPED_TEST(UniformRealDistributionTest, ParamSerializeTest) { + using param_type = + typename absl::uniform_real_distribution<TypeParam>::param_type; + + constexpr const TypeParam a{1152921504606846976}; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + for (const auto& param : { + param_type(), + param_type(TypeParam(2.0), TypeParam(2.0)), // Same + param_type(TypeParam(-0.1), TypeParam(0.1)), + param_type(TypeParam(0.05), TypeParam(0.12)), + param_type(TypeParam(-0.05), TypeParam(0.13)), + param_type(TypeParam(-0.05), TypeParam(-0.02)), + // double range = 0 + // 2^60 , 2^60 + 2^6 + param_type(a, TypeParam(1152921504606847040)), + // 2^60 , 2^60 + 2^7 + param_type(a, TypeParam(1152921504606847104)), + // double range = 2^8 + // 2^60 , 2^60 + 2^8 + param_type(a, TypeParam(1152921504606847232)), + // float range = 0 + // 2^60 , 2^60 + 2^36 + param_type(a, TypeParam(1152921573326323712)), + // 2^60 , 2^60 + 2^37 + param_type(a, TypeParam(1152921642045800448)), + // float range = 2^38 + // 2^60 , 2^60 + 2^38 + param_type(a, TypeParam(1152921779484753920)), + // Limits + param_type(0, std::numeric_limits<TypeParam>::max()), + param_type(std::numeric_limits<TypeParam>::lowest(), 0), + param_type(0, std::numeric_limits<TypeParam>::epsilon()), + param_type(-std::numeric_limits<TypeParam>::epsilon(), + std::numeric_limits<TypeParam>::epsilon()), + param_type(std::numeric_limits<TypeParam>::epsilon(), + 2 * std::numeric_limits<TypeParam>::epsilon()), + }) { + // Validate parameters. + const auto a = param.a(); + const auto b = param.b(); + absl::uniform_real_distribution<TypeParam> before(a, b); + EXPECT_EQ(before.a(), param.a()); + EXPECT_EQ(before.b(), param.b()); + + { + absl::uniform_real_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + } + + std::stringstream ss; + ss << before; + absl::uniform_real_distribution<TypeParam> after(TypeParam(1.0), + TypeParam(3.1)); + + EXPECT_NE(before.a(), after.a()); + EXPECT_NE(before.b(), after.b()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before.a(), after.a()); + EXPECT_EQ(before.b(), after.b()); + EXPECT_EQ(before.param(), after.param()); + EXPECT_EQ(before, after); + + // Smoke test. + auto sample_min = after.max(); + auto sample_max = after.min(); + for (int i = 0; i < kCount; i++) { + auto sample = after(gen); + // Failure here indicates a bug in uniform_real_distribution::operator(), + // or bad parameters--range too large, etc. + if (after.min() == after.max()) { + EXPECT_EQ(sample, after.min()); + } else { + EXPECT_GE(sample, after.min()); + EXPECT_LT(sample, after.max()); + } + if (sample > sample_max) { + sample_max = sample; + } + if (sample < sample_min) { + sample_min = sample; + } + } + + if (!std::is_same<TypeParam, long double>::value) { + // static_cast<double>(long double) can overflow. + std::string msg = absl::StrCat("Range: ", static_cast<double>(sample_min), + ", ", static_cast<double>(sample_max)); + ABSL_RAW_LOG(INFO, "%s", msg.c_str()); + } + } +} + +#ifdef _MSC_VER +#pragma warning(push) +#pragma warning(disable:4756) // Constant arithmetic overflow. +#endif +TYPED_TEST(UniformRealDistributionTest, ViolatesPreconditionsDeathTest) { +#if GTEST_HAS_DEATH_TEST + // Hi < Lo + EXPECT_DEBUG_DEATH( + { absl::uniform_real_distribution<TypeParam> dist(10.0, 1.0); }, ""); + + // Hi - Lo > numeric_limits<>::max() + EXPECT_DEBUG_DEATH( + { + absl::uniform_real_distribution<TypeParam> dist( + std::numeric_limits<TypeParam>::lowest(), + std::numeric_limits<TypeParam>::max()); + }, + ""); +#endif // GTEST_HAS_DEATH_TEST +#if defined(NDEBUG) + // opt-mode, for invalid parameters, will generate a garbage value, + // but should not enter an infinite loop. + absl::InsecureBitGen gen; + { + absl::uniform_real_distribution<TypeParam> dist(10.0, 1.0); + auto x = dist(gen); + EXPECT_FALSE(std::isnan(x)) << x; + } + { + absl::uniform_real_distribution<TypeParam> dist( + std::numeric_limits<TypeParam>::lowest(), + std::numeric_limits<TypeParam>::max()); + auto x = dist(gen); + // Infinite result. + EXPECT_FALSE(std::isfinite(x)) << x; + } +#endif // NDEBUG +} +#ifdef _MSC_VER +#pragma warning(pop) // warning(disable:4756) +#endif + +TYPED_TEST(UniformRealDistributionTest, TestMoments) { + constexpr int kSize = 1000000; + std::vector<double> values(kSize); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng{0x2B7E151628AED2A6}; + + absl::uniform_real_distribution<TypeParam> dist; + for (int i = 0; i < kSize; i++) { + values[i] = dist(rng); + } + + const auto moments = + absl::random_internal::ComputeDistributionMoments(values); + EXPECT_NEAR(0.5, moments.mean, 0.01); + EXPECT_NEAR(1 / 12.0, moments.variance, 0.015); + EXPECT_NEAR(0.0, moments.skewness, 0.02); + EXPECT_NEAR(9 / 5.0, moments.kurtosis, 0.015); +} + +TYPED_TEST(UniformRealDistributionTest, ChiSquaredTest50) { + using absl::random_internal::kChiSquared; + using param_type = + typename absl::uniform_real_distribution<TypeParam>::param_type; + + constexpr size_t kTrials = 100000; + constexpr int kBuckets = 50; + constexpr double kExpected = + static_cast<double>(kTrials) / static_cast<double>(kBuckets); + + // 1-in-100000 threshold, but remember, there are about 8 tests + // in this file. And the test could fail for other reasons. + // Empirically validated with --runs_per_test=10000. + const int kThreshold = + absl::random_internal::ChiSquareValue(kBuckets - 1, 0.999999); + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng{0x2B7E151628AED2A6}; + + for (const auto& param : {param_type(0, 1), param_type(5, 12), + param_type(-5, 13), param_type(-5, -2)}) { + const double min_val = param.a(); + const double max_val = param.b(); + const double factor = kBuckets / (max_val - min_val); + + std::vector<int32_t> counts(kBuckets, 0); + absl::uniform_real_distribution<TypeParam> dist(param); + for (size_t i = 0; i < kTrials; i++) { + auto x = dist(rng); + auto bucket = static_cast<size_t>((x - min_val) * factor); + counts[bucket]++; + } + + double chi_square = absl::random_internal::ChiSquareWithExpected( + std::begin(counts), std::end(counts), kExpected); + if (chi_square > kThreshold) { + double p_value = + absl::random_internal::ChiSquarePValue(chi_square, kBuckets); + + // Chi-squared test failed. Output does not appear to be uniform. + std::string msg; + for (const auto& a : counts) { + absl::StrAppend(&msg, a, "\n"); + } + absl::StrAppend(&msg, kChiSquared, " p-value ", p_value, "\n"); + absl::StrAppend(&msg, "High ", kChiSquared, " value: ", chi_square, " > ", + kThreshold); + ABSL_RAW_LOG(INFO, "%s", msg.c_str()); + FAIL() << msg; + } + } +} + +TYPED_TEST(UniformRealDistributionTest, StabilityTest) { + // absl::uniform_real_distribution stability relies only on + // random_internal::RandU64ToDouble and random_internal::RandU64ToFloat. + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(12); + + absl::uniform_real_distribution<TypeParam> dist; + std::generate(std::begin(output), std::end(output), [&] { + return static_cast<int>(TypeParam(1000000) * dist(urbg)); + }); + + EXPECT_THAT( + output, // + testing::ElementsAre(59, 999246, 762494, 395876, 167716, 82545, 925251, + 77341, 12527, 708791, 834451, 932808)); +} + +TEST(UniformRealDistributionTest, AlgorithmBounds) { + absl::uniform_real_distribution<double> dist; + + { + // This returns the smallest value >0 from absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg({0x0000000000000001ull}); + double a = dist(urbg); + EXPECT_EQ(a, 5.42101086242752217004e-20); + } + + { + // This returns a value very near 0.5 from absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg({0x7fffffffffffffefull}); + double a = dist(urbg); + EXPECT_EQ(a, 0.499999999999999944489); + } + { + // This returns a value very near 0.5 from absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg({0x8000000000000000ull}); + double a = dist(urbg); + EXPECT_EQ(a, 0.5); + } + + { + // This returns the largest value <1 from absl::uniform_real_distribution. + absl::random_internal::sequence_urbg urbg({0xFFFFFFFFFFFFFFEFull}); + double a = dist(urbg); + EXPECT_EQ(a, 0.999999999999999888978); + } + { + // This *ALSO* returns the largest value <1. + absl::random_internal::sequence_urbg urbg({0xFFFFFFFFFFFFFFFFull}); + double a = dist(urbg); + EXPECT_EQ(a, 0.999999999999999888978); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/random/zipf_distribution.h b/third_party/abseil_cpp/absl/random/zipf_distribution.h new file mode 100644 index 0000000000..22ebc756cf --- /dev/null +++ b/third_party/abseil_cpp/absl/random/zipf_distribution.h @@ -0,0 +1,271 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_RANDOM_ZIPF_DISTRIBUTION_H_ +#define ABSL_RANDOM_ZIPF_DISTRIBUTION_H_ + +#include <cassert> +#include <cmath> +#include <istream> +#include <limits> +#include <ostream> +#include <type_traits> + +#include "absl/random/internal/iostream_state_saver.h" +#include "absl/random/uniform_real_distribution.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::zipf_distribution produces random integer-values in the range [0, k], +// distributed according to the discrete probability function: +// +// P(x) = (v + x) ^ -q +// +// The parameter `v` must be greater than 0 and the parameter `q` must be +// greater than 1. If either of these parameters take invalid values then the +// behavior is undefined. +// +// IntType is the result_type generated by the generator. It must be of integral +// type; a static_assert ensures this is the case. +// +// The implementation is based on W.Hormann, G.Derflinger: +// +// "Rejection-Inversion to Generate Variates from Monotone Discrete +// Distributions" +// +// http://eeyore.wu-wien.ac.at/papers/96-04-04.wh-der.ps.gz +// +template <typename IntType = int> +class zipf_distribution { + public: + using result_type = IntType; + + class param_type { + public: + using distribution_type = zipf_distribution; + + // Preconditions: k > 0, v > 0, q > 1 + // The precondidtions are validated when NDEBUG is not defined via + // a pair of assert() directives. + // If NDEBUG is defined and either or both of these parameters take invalid + // values, the behavior of the class is undefined. + explicit param_type(result_type k = (std::numeric_limits<IntType>::max)(), + double q = 2.0, double v = 1.0); + + result_type k() const { return k_; } + double q() const { return q_; } + double v() const { return v_; } + + friend bool operator==(const param_type& a, const param_type& b) { + return a.k_ == b.k_ && a.q_ == b.q_ && a.v_ == b.v_; + } + friend bool operator!=(const param_type& a, const param_type& b) { + return !(a == b); + } + + private: + friend class zipf_distribution; + inline double h(double x) const; + inline double hinv(double x) const; + inline double compute_s() const; + inline double pow_negative_q(double x) const; + + // Parameters here are exactly the same as the parameters of Algorithm ZRI + // in the paper. + IntType k_; + double q_; + double v_; + + double one_minus_q_; // 1-q + double s_; + double one_minus_q_inv_; // 1 / 1-q + double hxm_; // h(k + 0.5) + double hx0_minus_hxm_; // h(x0) - h(k + 0.5) + + static_assert(std::is_integral<IntType>::value, + "Class-template absl::zipf_distribution<> must be " + "parameterized using an integral type."); + }; + + zipf_distribution() + : zipf_distribution((std::numeric_limits<IntType>::max)()) {} + + explicit zipf_distribution(result_type k, double q = 2.0, double v = 1.0) + : param_(k, q, v) {} + + explicit zipf_distribution(const param_type& p) : param_(p) {} + + void reset() {} + + template <typename URBG> + result_type operator()(URBG& g) { // NOLINT(runtime/references) + return (*this)(g, param_); + } + + template <typename URBG> + result_type operator()(URBG& g, // NOLINT(runtime/references) + const param_type& p); + + result_type k() const { return param_.k(); } + double q() const { return param_.q(); } + double v() const { return param_.v(); } + + param_type param() const { return param_; } + void param(const param_type& p) { param_ = p; } + + result_type(min)() const { return 0; } + result_type(max)() const { return k(); } + + friend bool operator==(const zipf_distribution& a, + const zipf_distribution& b) { + return a.param_ == b.param_; + } + friend bool operator!=(const zipf_distribution& a, + const zipf_distribution& b) { + return a.param_ != b.param_; + } + + private: + param_type param_; +}; + +// -------------------------------------------------------------------------- +// Implementation details follow +// -------------------------------------------------------------------------- + +template <typename IntType> +zipf_distribution<IntType>::param_type::param_type( + typename zipf_distribution<IntType>::result_type k, double q, double v) + : k_(k), q_(q), v_(v), one_minus_q_(1 - q) { + assert(q > 1); + assert(v > 0); + assert(k > 0); + one_minus_q_inv_ = 1 / one_minus_q_; + + // Setup for the ZRI algorithm (pg 17 of the paper). + // Compute: h(i max) => h(k + 0.5) + constexpr double kMax = 18446744073709549568.0; + double kd = static_cast<double>(k); + // TODO(absl-team): Determine if this check is needed, and if so, add a test + // that fails for k > kMax + if (kd > kMax) { + // Ensure that our maximum value is capped to a value which will + // round-trip back through double. + kd = kMax; + } + hxm_ = h(kd + 0.5); + + // Compute: h(0) + const bool use_precomputed = (v == 1.0 && q == 2.0); + const double h0x5 = use_precomputed ? (-1.0 / 1.5) // exp(-log(1.5)) + : h(0.5); + const double elogv_q = (v_ == 1.0) ? 1 : pow_negative_q(v_); + + // h(0) = h(0.5) - exp(log(v) * -q) + hx0_minus_hxm_ = (h0x5 - elogv_q) - hxm_; + + // And s + s_ = use_precomputed ? 0.46153846153846123 : compute_s(); +} + +template <typename IntType> +double zipf_distribution<IntType>::param_type::h(double x) const { + // std::exp(one_minus_q_ * std::log(v_ + x)) * one_minus_q_inv_; + x += v_; + return (one_minus_q_ == -1.0) + ? (-1.0 / x) // -exp(-log(x)) + : (std::exp(std::log(x) * one_minus_q_) * one_minus_q_inv_); +} + +template <typename IntType> +double zipf_distribution<IntType>::param_type::hinv(double x) const { + // std::exp(one_minus_q_inv_ * std::log(one_minus_q_ * x)) - v_; + return -v_ + ((one_minus_q_ == -1.0) + ? (-1.0 / x) // exp(-log(-x)) + : std::exp(one_minus_q_inv_ * std::log(one_minus_q_ * x))); +} + +template <typename IntType> +double zipf_distribution<IntType>::param_type::compute_s() const { + // 1 - hinv(h(1.5) - std::exp(std::log(v_ + 1) * -q_)); + return 1.0 - hinv(h(1.5) - pow_negative_q(v_ + 1.0)); +} + +template <typename IntType> +double zipf_distribution<IntType>::param_type::pow_negative_q(double x) const { + // std::exp(std::log(x) * -q_); + return q_ == 2.0 ? (1.0 / (x * x)) : std::exp(std::log(x) * -q_); +} + +template <typename IntType> +template <typename URBG> +typename zipf_distribution<IntType>::result_type +zipf_distribution<IntType>::operator()( + URBG& g, const param_type& p) { // NOLINT(runtime/references) + absl::uniform_real_distribution<double> uniform_double; + double k; + for (;;) { + const double v = uniform_double(g); + const double u = p.hxm_ + v * p.hx0_minus_hxm_; + const double x = p.hinv(u); + k = rint(x); // std::floor(x + 0.5); + if (k > p.k()) continue; // reject k > max_k + if (k - x <= p.s_) break; + const double h = p.h(k + 0.5); + const double r = p.pow_negative_q(p.v_ + k); + if (u >= h - r) break; + } + IntType ki = static_cast<IntType>(k); + assert(ki <= p.k_); + return ki; +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_ostream<CharT, Traits>& operator<<( + std::basic_ostream<CharT, Traits>& os, // NOLINT(runtime/references) + const zipf_distribution<IntType>& x) { + using stream_type = + typename random_internal::stream_format_type<IntType>::type; + auto saver = random_internal::make_ostream_state_saver(os); + os.precision(random_internal::stream_precision_helper<double>::kPrecision); + os << static_cast<stream_type>(x.k()) << os.fill() << x.q() << os.fill() + << x.v(); + return os; +} + +template <typename CharT, typename Traits, typename IntType> +std::basic_istream<CharT, Traits>& operator>>( + std::basic_istream<CharT, Traits>& is, // NOLINT(runtime/references) + zipf_distribution<IntType>& x) { // NOLINT(runtime/references) + using result_type = typename zipf_distribution<IntType>::result_type; + using param_type = typename zipf_distribution<IntType>::param_type; + using stream_type = + typename random_internal::stream_format_type<IntType>::type; + stream_type k; + double q; + double v; + + auto saver = random_internal::make_istream_state_saver(is); + is >> k >> q >> v; + if (!is.fail()) { + x.param(param_type(static_cast<result_type>(k), q, v)); + } + return is; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_RANDOM_ZIPF_DISTRIBUTION_H_ diff --git a/third_party/abseil_cpp/absl/random/zipf_distribution_test.cc b/third_party/abseil_cpp/absl/random/zipf_distribution_test.cc new file mode 100644 index 0000000000..f8cf70e0dd --- /dev/null +++ b/third_party/abseil_cpp/absl/random/zipf_distribution_test.cc @@ -0,0 +1,427 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/random/zipf_distribution.h" + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <iterator> +#include <random> +#include <string> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/internal/chi_square.h" +#include "absl/random/internal/pcg_engine.h" +#include "absl/random/internal/sequence_urbg.h" +#include "absl/random/random.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_replace.h" +#include "absl/strings/strip.h" + +namespace { + +using ::absl::random_internal::kChiSquared; +using ::testing::ElementsAre; + +template <typename IntType> +class ZipfDistributionTypedTest : public ::testing::Test {}; + +using IntTypes = ::testing::Types<int, int8_t, int16_t, int32_t, int64_t, + uint8_t, uint16_t, uint32_t, uint64_t>; +TYPED_TEST_CASE(ZipfDistributionTypedTest, IntTypes); + +TYPED_TEST(ZipfDistributionTypedTest, SerializeTest) { + using param_type = typename absl::zipf_distribution<TypeParam>::param_type; + + constexpr int kCount = 1000; + absl::InsecureBitGen gen; + for (const auto& param : { + param_type(), + param_type(32), + param_type(100, 3, 2), + param_type(std::numeric_limits<TypeParam>::max(), 4, 3), + param_type(std::numeric_limits<TypeParam>::max() / 2), + }) { + // Validate parameters. + const auto k = param.k(); + const auto q = param.q(); + const auto v = param.v(); + + absl::zipf_distribution<TypeParam> before(k, q, v); + EXPECT_EQ(before.k(), param.k()); + EXPECT_EQ(before.q(), param.q()); + EXPECT_EQ(before.v(), param.v()); + + { + absl::zipf_distribution<TypeParam> via_param(param); + EXPECT_EQ(via_param, before); + } + + // Validate stream serialization. + std::stringstream ss; + ss << before; + absl::zipf_distribution<TypeParam> after(4, 5.5, 4.4); + + EXPECT_NE(before.k(), after.k()); + EXPECT_NE(before.q(), after.q()); + EXPECT_NE(before.v(), after.v()); + EXPECT_NE(before.param(), after.param()); + EXPECT_NE(before, after); + + ss >> after; + + EXPECT_EQ(before.k(), after.k()); + EXPECT_EQ(before.q(), after.q()); + EXPECT_EQ(before.v(), after.v()); + EXPECT_EQ(before.param(), after.param()); + EXPECT_EQ(before, after); + + // Smoke test. + auto sample_min = after.max(); + auto sample_max = after.min(); + for (int i = 0; i < kCount; i++) { + auto sample = after(gen); + EXPECT_GE(sample, after.min()); + EXPECT_LE(sample, after.max()); + if (sample > sample_max) sample_max = sample; + if (sample < sample_min) sample_min = sample; + } + ABSL_INTERNAL_LOG(INFO, + absl::StrCat("Range: ", +sample_min, ", ", +sample_max)); + } +} + +class ZipfModel { + public: + ZipfModel(size_t k, double q, double v) : k_(k), q_(q), v_(v) {} + + double mean() const { return mean_; } + + // For the other moments of the Zipf distribution, see, for example, + // http://mathworld.wolfram.com/ZipfDistribution.html + + // PMF(k) = (1 / k^s) / H(N,s) + // Returns the probability that any single invocation returns k. + double PMF(size_t i) { return i >= hnq_.size() ? 0.0 : hnq_[i] / sum_hnq_; } + + // CDF = H(k, s) / H(N,s) + double CDF(size_t i) { + if (i >= hnq_.size()) { + return 1.0; + } + auto it = std::begin(hnq_); + double h = 0.0; + for (const auto end = it; it != end; it++) { + h += *it; + } + return h / sum_hnq_; + } + + // The InverseCDF returns the k values which bound p on the upper and lower + // bound. Since there is no closed-form solution, this is implemented as a + // bisction of the cdf. + std::pair<size_t, size_t> InverseCDF(double p) { + size_t min = 0; + size_t max = hnq_.size(); + while (max > min + 1) { + size_t target = (max + min) >> 1; + double x = CDF(target); + if (x > p) { + max = target; + } else { + min = target; + } + } + return {min, max}; + } + + // Compute the probability totals, which are based on the generalized harmonic + // number, H(N,s). + // H(N,s) == SUM(k=1..N, 1 / k^s) + // + // In the limit, H(N,s) == zetac(s) + 1. + // + // NOTE: The mean of a zipf distribution could be computed here as well. + // Mean := H(N, s-1) / H(N,s). + // Given the parameter v = 1, this gives the following function: + // (Hn(100, 1) - Hn(1,1)) / (Hn(100,2) - Hn(1,2)) = 6.5944 + // + void Init() { + if (!hnq_.empty()) { + return; + } + hnq_.clear(); + hnq_.reserve(std::min(k_, size_t{1000})); + + sum_hnq_ = 0; + double qm1 = q_ - 1.0; + double sum_hnq_m1 = 0; + for (size_t i = 0; i < k_; i++) { + // Partial n-th generalized harmonic number + const double x = v_ + i; + + // H(n, q-1) + const double hnqm1 = + (q_ == 2.0) ? (1.0 / x) + : (q_ == 3.0) ? (1.0 / (x * x)) : std::pow(x, -qm1); + sum_hnq_m1 += hnqm1; + + // H(n, q) + const double hnq = + (q_ == 2.0) ? (1.0 / (x * x)) + : (q_ == 3.0) ? (1.0 / (x * x * x)) : std::pow(x, -q_); + sum_hnq_ += hnq; + hnq_.push_back(hnq); + if (i > 1000 && hnq <= 1e-10) { + // The harmonic number is too small. + break; + } + } + assert(sum_hnq_ > 0); + mean_ = sum_hnq_m1 / sum_hnq_; + } + + private: + const size_t k_; + const double q_; + const double v_; + + double mean_; + std::vector<double> hnq_; + double sum_hnq_; +}; + +using zipf_u64 = absl::zipf_distribution<uint64_t>; + +class ZipfTest : public testing::TestWithParam<zipf_u64::param_type>, + public ZipfModel { + public: + ZipfTest() : ZipfModel(GetParam().k(), GetParam().q(), GetParam().v()) {} + + // We use a fixed bit generator for distribution accuracy tests. This allows + // these tests to be deterministic, while still testing the qualify of the + // implementation. + absl::random_internal::pcg64_2018_engine rng_{0x2B7E151628AED2A6}; +}; + +TEST_P(ZipfTest, ChiSquaredTest) { + const auto& param = GetParam(); + Init(); + + size_t trials = 10000; + + // Find the split-points for the buckets. + std::vector<size_t> points; + std::vector<double> expected; + { + double last_cdf = 0.0; + double min_p = 1.0; + for (double p = 0.01; p < 1.0; p += 0.01) { + auto x = InverseCDF(p); + if (points.empty() || points.back() < x.second) { + const double p = CDF(x.second); + points.push_back(x.second); + double q = p - last_cdf; + expected.push_back(q); + last_cdf = p; + if (q < min_p) { + min_p = q; + } + } + } + if (last_cdf < 0.999) { + points.push_back(std::numeric_limits<size_t>::max()); + double q = 1.0 - last_cdf; + expected.push_back(q); + if (q < min_p) { + min_p = q; + } + } else { + points.back() = std::numeric_limits<size_t>::max(); + expected.back() += (1.0 - last_cdf); + } + // The Chi-Squared score is not completely scale-invariant; it works best + // when the small values are in the small digits. + trials = static_cast<size_t>(8.0 / min_p); + } + ASSERT_GT(points.size(), 0); + + // Generate n variates and fill the counts vector with the count of their + // occurrences. + std::vector<int64_t> buckets(points.size(), 0); + double avg = 0; + { + zipf_u64 dis(param); + for (size_t i = 0; i < trials; i++) { + uint64_t x = dis(rng_); + ASSERT_LE(x, dis.max()); + ASSERT_GE(x, dis.min()); + avg += static_cast<double>(x); + auto it = std::upper_bound(std::begin(points), std::end(points), + static_cast<size_t>(x)); + buckets[std::distance(std::begin(points), it)]++; + } + avg = avg / static_cast<double>(trials); + } + + // Validate the output using the Chi-Squared test. + for (auto& e : expected) { + e *= trials; + } + + // The null-hypothesis is that the distribution is a poisson distribution with + // the provided mean (not estimated from the data). + const int dof = static_cast<int>(expected.size()) - 1; + + // NOTE: This test runs about 15x per invocation, so a value of 0.9995 is + // approximately correct for a test suite failure rate of 1 in 100. In + // practice we see failures slightly higher than that. + const double threshold = absl::random_internal::ChiSquareValue(dof, 0.9999); + + const double chi_square = absl::random_internal::ChiSquare( + std::begin(buckets), std::end(buckets), std::begin(expected), + std::end(expected)); + + const double p_actual = + absl::random_internal::ChiSquarePValue(chi_square, dof); + + // Log if the chi_squared value is above the threshold. + if (chi_square > threshold) { + ABSL_INTERNAL_LOG(INFO, "values"); + for (size_t i = 0; i < expected.size(); i++) { + ABSL_INTERNAL_LOG(INFO, absl::StrCat(points[i], ": ", buckets[i], + " vs. E=", expected[i])); + } + ABSL_INTERNAL_LOG(INFO, absl::StrCat("trials ", trials)); + ABSL_INTERNAL_LOG(INFO, + absl::StrCat("mean ", avg, " vs. expected ", mean())); + ABSL_INTERNAL_LOG(INFO, absl::StrCat(kChiSquared, "(data, ", dof, ") = ", + chi_square, " (", p_actual, ")")); + ABSL_INTERNAL_LOG(INFO, + absl::StrCat(kChiSquared, " @ 0.9995 = ", threshold)); + FAIL() << kChiSquared << " value of " << chi_square + << " is above the threshold."; + } +} + +std::vector<zipf_u64::param_type> GenParams() { + using param = zipf_u64::param_type; + const auto k = param().k(); + const auto q = param().q(); + const auto v = param().v(); + const uint64_t k2 = 1 << 10; + return std::vector<zipf_u64::param_type>{ + // Default + param(k, q, v), + // vary K + param(4, q, v), param(1 << 4, q, v), param(k2, q, v), + // vary V + param(k2, q, 0.5), param(k2, q, 1.5), param(k2, q, 2.5), param(k2, q, 10), + // vary Q + param(k2, 1.5, v), param(k2, 3, v), param(k2, 5, v), param(k2, 10, v), + // Vary V & Q + param(k2, 1.5, 0.5), param(k2, 3, 1.5), param(k, 10, 10)}; +} + +std::string ParamName( + const ::testing::TestParamInfo<zipf_u64::param_type>& info) { + const auto& p = info.param; + std::string name = absl::StrCat("k_", p.k(), "__q_", absl::SixDigits(p.q()), + "__v_", absl::SixDigits(p.v())); + return absl::StrReplaceAll(name, {{"+", "_"}, {"-", "_"}, {".", "_"}}); +} + +INSTANTIATE_TEST_SUITE_P(All, ZipfTest, ::testing::ValuesIn(GenParams()), + ParamName); + +// NOTE: absl::zipf_distribution is not guaranteed to be stable. +TEST(ZipfDistributionTest, StabilityTest) { + // absl::zipf_distribution stability relies on + // absl::uniform_real_distribution, std::log, std::exp, std::log1p + absl::random_internal::sequence_urbg urbg( + {0x0003eb76f6f7f755ull, 0xFFCEA50FDB2F953Bull, 0xC332DDEFBE6C5AA5ull, + 0x6558218568AB9702ull, 0x2AEF7DAD5B6E2F84ull, 0x1521B62829076170ull, + 0xECDD4775619F1510ull, 0x13CCA830EB61BD96ull, 0x0334FE1EAA0363CFull, + 0xB5735C904C70A239ull, 0xD59E9E0BCBAADE14ull, 0xEECC86BC60622CA7ull}); + + std::vector<int> output(10); + + { + absl::zipf_distribution<int32_t> dist; + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + EXPECT_THAT(output, ElementsAre(10031, 0, 0, 3, 6, 0, 7, 47, 0, 0)); + } + urbg.reset(); + { + absl::zipf_distribution<int32_t> dist(std::numeric_limits<int32_t>::max(), + 3.3); + std::generate(std::begin(output), std::end(output), + [&] { return dist(urbg); }); + EXPECT_THAT(output, ElementsAre(44, 0, 0, 0, 0, 1, 0, 1, 3, 0)); + } +} + +TEST(ZipfDistributionTest, AlgorithmBounds) { + absl::zipf_distribution<int32_t> dist; + + // Small values from absl::uniform_real_distribution map to larger Zipf + // distribution values. + const std::pair<uint64_t, int32_t> kInputs[] = { + {0xffffffffffffffff, 0x0}, {0x7fffffffffffffff, 0x0}, + {0x3ffffffffffffffb, 0x1}, {0x1ffffffffffffffd, 0x4}, + {0xffffffffffffffe, 0x9}, {0x7ffffffffffffff, 0x12}, + {0x3ffffffffffffff, 0x25}, {0x1ffffffffffffff, 0x4c}, + {0xffffffffffffff, 0x99}, {0x7fffffffffffff, 0x132}, + {0x3fffffffffffff, 0x265}, {0x1fffffffffffff, 0x4cc}, + {0xfffffffffffff, 0x999}, {0x7ffffffffffff, 0x1332}, + {0x3ffffffffffff, 0x2665}, {0x1ffffffffffff, 0x4ccc}, + {0xffffffffffff, 0x9998}, {0x7fffffffffff, 0x1332f}, + {0x3fffffffffff, 0x2665a}, {0x1fffffffffff, 0x4cc9e}, + {0xfffffffffff, 0x998e0}, {0x7ffffffffff, 0x133051}, + {0x3ffffffffff, 0x265ae4}, {0x1ffffffffff, 0x4c9ed3}, + {0xffffffffff, 0x98e223}, {0x7fffffffff, 0x13058c4}, + {0x3fffffffff, 0x25b178e}, {0x1fffffffff, 0x4a062b2}, + {0xfffffffff, 0x8ee23b8}, {0x7ffffffff, 0x10b21642}, + {0x3ffffffff, 0x1d89d89d}, {0x1ffffffff, 0x2fffffff}, + {0xffffffff, 0x45d1745d}, {0x7fffffff, 0x5a5a5a5a}, + {0x3fffffff, 0x69ee5846}, {0x1fffffff, 0x73ecade3}, + {0xfffffff, 0x79a9d260}, {0x7ffffff, 0x7cc0532b}, + {0x3ffffff, 0x7e5ad146}, {0x1ffffff, 0x7f2c0bec}, + {0xffffff, 0x7f95adef}, {0x7fffff, 0x7fcac0da}, + {0x3fffff, 0x7fe55ae2}, {0x1fffff, 0x7ff2ac0e}, + {0xfffff, 0x7ff955ae}, {0x7ffff, 0x7ffcaac1}, + {0x3ffff, 0x7ffe555b}, {0x1ffff, 0x7fff2aac}, + {0xffff, 0x7fff9556}, {0x7fff, 0x7fffcaab}, + {0x3fff, 0x7fffe555}, {0x1fff, 0x7ffff2ab}, + {0xfff, 0x7ffff955}, {0x7ff, 0x7ffffcab}, + {0x3ff, 0x7ffffe55}, {0x1ff, 0x7fffff2b}, + {0xff, 0x7fffff95}, {0x7f, 0x7fffffcb}, + {0x3f, 0x7fffffe5}, {0x1f, 0x7ffffff3}, + {0xf, 0x7ffffff9}, {0x7, 0x7ffffffd}, + {0x3, 0x7ffffffe}, {0x1, 0x7fffffff}, + }; + + for (const auto& instance : kInputs) { + absl::random_internal::sequence_urbg urbg({instance.first}); + EXPECT_EQ(instance.second, dist(urbg)); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/status/BUILD.bazel b/third_party/abseil_cpp/absl/status/BUILD.bazel new file mode 100644 index 0000000000..d164252da9 --- /dev/null +++ b/third_party/abseil_cpp/absl/status/BUILD.bazel @@ -0,0 +1,66 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This package contains `absl::Status`. +# It will expand later to have utilities around `Status` like `StatusOr`, +# `StatusBuilder` and macros. + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "status", + srcs = [ + "status.cc", + "status_payload_printer.cc", + ], + hdrs = [ + "status.h", + "status_payload_printer.h", + ], + copts = ABSL_DEFAULT_COPTS, + deps = [ + "//absl/base:atomic_hook", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/container:inlined_vector", + "//absl/debugging:stacktrace", + "//absl/debugging:symbolize", + "//absl/strings", + "//absl/strings:cord", + "//absl/strings:str_format", + "//absl/types:optional", + ], +) + +cc_test( + name = "status_test", + srcs = ["status_test.cc"], + copts = ABSL_TEST_COPTS, + deps = [ + ":status", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/status/CMakeLists.txt b/third_party/abseil_cpp/absl/status/CMakeLists.txt new file mode 100644 index 0000000000..c041d69517 --- /dev/null +++ b/third_party/abseil_cpp/absl/status/CMakeLists.txt @@ -0,0 +1,53 @@ +# +# Copyright 2020 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +absl_cc_library( + NAME + status + HDRS + "status.h" + SRCS + "status.cc" + "status_payload_printer.h" + "status_payload_printer.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::atomic_hook + absl::config + absl::core_headers + absl::raw_logging_internal + absl::inlined_vector + absl::stacktrace + absl::symbolize + absl::strings + absl::cord + absl::str_format + absl::optional + PUBLIC +) + +absl_cc_test( + NAME + status_test + SRCS + "status_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::status + absl::strings + gmock_main +) diff --git a/third_party/abseil_cpp/absl/status/status.cc b/third_party/abseil_cpp/absl/status/status.cc new file mode 100644 index 0000000000..6d57a6be8d --- /dev/null +++ b/third_party/abseil_cpp/absl/status/status.cc @@ -0,0 +1,447 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +#include "absl/status/status.h" + +#include <cassert> + +#include "absl/base/internal/raw_logging.h" +#include "absl/debugging/stacktrace.h" +#include "absl/debugging/symbolize.h" +#include "absl/status/status_payload_printer.h" +#include "absl/strings/escaping.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_split.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// The implementation was intentionally kept same as util::error::Code_Name() +// to ease the migration. +std::string StatusCodeToString(StatusCode code) { + switch (code) { + case StatusCode::kOk: + return "OK"; + case StatusCode::kCancelled: + return "CANCELLED"; + case StatusCode::kUnknown: + return "UNKNOWN"; + case StatusCode::kInvalidArgument: + return "INVALID_ARGUMENT"; + case StatusCode::kDeadlineExceeded: + return "DEADLINE_EXCEEDED"; + case StatusCode::kNotFound: + return "NOT_FOUND"; + case StatusCode::kAlreadyExists: + return "ALREADY_EXISTS"; + case StatusCode::kPermissionDenied: + return "PERMISSION_DENIED"; + case StatusCode::kUnauthenticated: + return "UNAUTHENTICATED"; + case StatusCode::kResourceExhausted: + return "RESOURCE_EXHAUSTED"; + case StatusCode::kFailedPrecondition: + return "FAILED_PRECONDITION"; + case StatusCode::kAborted: + return "ABORTED"; + case StatusCode::kOutOfRange: + return "OUT_OF_RANGE"; + case StatusCode::kUnimplemented: + return "UNIMPLEMENTED"; + case StatusCode::kInternal: + return "INTERNAL"; + case StatusCode::kUnavailable: + return "UNAVAILABLE"; + case StatusCode::kDataLoss: + return "DATA_LOSS"; + default: + return ""; + } +} + +std::ostream& operator<<(std::ostream& os, StatusCode code) { + return os << StatusCodeToString(code); +} + +namespace status_internal { + +static int FindPayloadIndexByUrl(const Payloads* payloads, + absl::string_view type_url) { + if (payloads == nullptr) return -1; + + for (int i = 0; i < payloads->size(); ++i) { + if ((*payloads)[i].type_url == type_url) return i; + } + + return -1; +} + +// Convert canonical code to a value known to this binary. +absl::StatusCode MapToLocalCode(int value) { + absl::StatusCode code = static_cast<absl::StatusCode>(value); + switch (code) { + case absl::StatusCode::kOk: + case absl::StatusCode::kCancelled: + case absl::StatusCode::kUnknown: + case absl::StatusCode::kInvalidArgument: + case absl::StatusCode::kDeadlineExceeded: + case absl::StatusCode::kNotFound: + case absl::StatusCode::kAlreadyExists: + case absl::StatusCode::kPermissionDenied: + case absl::StatusCode::kResourceExhausted: + case absl::StatusCode::kFailedPrecondition: + case absl::StatusCode::kAborted: + case absl::StatusCode::kOutOfRange: + case absl::StatusCode::kUnimplemented: + case absl::StatusCode::kInternal: + case absl::StatusCode::kUnavailable: + case absl::StatusCode::kDataLoss: + case absl::StatusCode::kUnauthenticated: + return code; + default: + return absl::StatusCode::kUnknown; + } +} +} // namespace status_internal + +absl::optional<absl::Cord> Status::GetPayload( + absl::string_view type_url) const { + const auto* payloads = GetPayloads(); + int index = status_internal::FindPayloadIndexByUrl(payloads, type_url); + if (index != -1) return (*payloads)[index].payload; + + return absl::nullopt; +} + +void Status::SetPayload(absl::string_view type_url, absl::Cord payload) { + if (ok()) return; + + PrepareToModify(); + + status_internal::StatusRep* rep = RepToPointer(rep_); + if (!rep->payloads) { + rep->payloads = absl::make_unique<status_internal::Payloads>(); + } + + int index = + status_internal::FindPayloadIndexByUrl(rep->payloads.get(), type_url); + if (index != -1) { + (*rep->payloads)[index].payload = std::move(payload); + return; + } + + rep->payloads->push_back({std::string(type_url), std::move(payload)}); +} + +bool Status::ErasePayload(absl::string_view type_url) { + int index = status_internal::FindPayloadIndexByUrl(GetPayloads(), type_url); + if (index != -1) { + PrepareToModify(); + GetPayloads()->erase(GetPayloads()->begin() + index); + if (GetPayloads()->empty() && message().empty()) { + // Special case: If this can be represented inlined, it MUST be + // inlined (EqualsSlow depends on this behavior). + StatusCode c = static_cast<StatusCode>(raw_code()); + Unref(rep_); + rep_ = CodeToInlinedRep(c); + } + return true; + } + + return false; +} + +void Status::ForEachPayload( + const std::function<void(absl::string_view, const absl::Cord&)>& visitor) + const { + if (auto* payloads = GetPayloads()) { + bool in_reverse = + payloads->size() > 1 && reinterpret_cast<uintptr_t>(payloads) % 13 > 6; + + for (int index = 0; index < payloads->size(); ++index) { + const auto& elem = + (*payloads)[in_reverse ? payloads->size() - 1 - index : index]; + +#ifdef NDEBUG + visitor(elem.type_url, elem.payload); +#else + // In debug mode invalidate the type url to prevent users from relying on + // this string lifetime. + + // NOLINTNEXTLINE intentional extra conversion to force temporary. + visitor(std::string(elem.type_url), elem.payload); +#endif // NDEBUG + } + } +} + +const std::string* Status::EmptyString() { + static std::string* empty_string = new std::string(); + return empty_string; +} + +constexpr const char Status::kMovedFromString[]; + +const std::string* Status::MovedFromString() { + static std::string* moved_from_string = new std::string(kMovedFromString); + return moved_from_string; +} + +void Status::UnrefNonInlined(uintptr_t rep) { + status_internal::StatusRep* r = RepToPointer(rep); + // Fast path: if ref==1, there is no need for a RefCountDec (since + // this is the only reference and therefore no other thread is + // allowed to be mucking with r). + if (r->ref.load(std::memory_order_acquire) == 1 || + r->ref.fetch_sub(1, std::memory_order_acq_rel) - 1 == 0) { + delete r; + } +} + +uintptr_t Status::NewRep(absl::StatusCode code, absl::string_view msg, + std::unique_ptr<status_internal::Payloads> payloads) { + status_internal::StatusRep* rep = new status_internal::StatusRep; + rep->ref.store(1, std::memory_order_relaxed); + rep->code = code; + rep->message.assign(msg.data(), msg.size()); + rep->payloads = std::move(payloads); + return PointerToRep(rep); +} + +Status::Status(absl::StatusCode code, absl::string_view msg) + : rep_(CodeToInlinedRep(code)) { + if (code != absl::StatusCode::kOk && !msg.empty()) { + rep_ = NewRep(code, msg, nullptr); + } +} + +int Status::raw_code() const { + if (IsInlined(rep_)) { + return static_cast<int>(InlinedRepToCode(rep_)); + } + status_internal::StatusRep* rep = RepToPointer(rep_); + return static_cast<int>(rep->code); +} + +absl::StatusCode Status::code() const { + return status_internal::MapToLocalCode(raw_code()); +} + +void Status::PrepareToModify() { + ABSL_RAW_CHECK(!ok(), "PrepareToModify shouldn't be called on OK status."); + if (IsInlined(rep_)) { + rep_ = NewRep(static_cast<absl::StatusCode>(raw_code()), + absl::string_view(), nullptr); + return; + } + + uintptr_t rep_i = rep_; + status_internal::StatusRep* rep = RepToPointer(rep_); + if (rep->ref.load(std::memory_order_acquire) != 1) { + std::unique_ptr<status_internal::Payloads> payloads; + if (rep->payloads) { + payloads = absl::make_unique<status_internal::Payloads>(*rep->payloads); + } + rep_ = NewRep(rep->code, message(), std::move(payloads)); + UnrefNonInlined(rep_i); + } +} + +bool Status::EqualsSlow(const absl::Status& a, const absl::Status& b) { + if (IsInlined(a.rep_) != IsInlined(b.rep_)) return false; + if (a.message() != b.message()) return false; + if (a.raw_code() != b.raw_code()) return false; + if (a.GetPayloads() == b.GetPayloads()) return true; + + const status_internal::Payloads no_payloads; + const status_internal::Payloads* larger_payloads = + a.GetPayloads() ? a.GetPayloads() : &no_payloads; + const status_internal::Payloads* smaller_payloads = + b.GetPayloads() ? b.GetPayloads() : &no_payloads; + if (larger_payloads->size() < smaller_payloads->size()) { + std::swap(larger_payloads, smaller_payloads); + } + if ((larger_payloads->size() - smaller_payloads->size()) > 1) return false; + // Payloads can be ordered differently, so we can't just compare payload + // vectors. + for (const auto& payload : *larger_payloads) { + + bool found = false; + for (const auto& other_payload : *smaller_payloads) { + if (payload.type_url == other_payload.type_url) { + if (payload.payload != other_payload.payload) { + return false; + } + found = true; + break; + } + } + if (!found) return false; + } + return true; +} + +std::string Status::ToStringSlow() const { + std::string text; + absl::StrAppend(&text, absl::StatusCodeToString(code()), ": ", message()); + status_internal::StatusPayloadPrinter printer = + status_internal::GetStatusPayloadPrinter(); + this->ForEachPayload([&](absl::string_view type_url, + const absl::Cord& payload) { + absl::optional<std::string> result; + if (printer) result = printer(type_url, payload); + absl::StrAppend( + &text, " [", type_url, "='", + result.has_value() ? *result : absl::CHexEscape(std::string(payload)), + "']"); + }); + + return text; +} + +std::ostream& operator<<(std::ostream& os, const Status& x) { + os << x.ToString(); + return os; +} + +Status AbortedError(absl::string_view message) { + return Status(absl::StatusCode::kAborted, message); +} + +Status AlreadyExistsError(absl::string_view message) { + return Status(absl::StatusCode::kAlreadyExists, message); +} + +Status CancelledError(absl::string_view message) { + return Status(absl::StatusCode::kCancelled, message); +} + +Status DataLossError(absl::string_view message) { + return Status(absl::StatusCode::kDataLoss, message); +} + +Status DeadlineExceededError(absl::string_view message) { + return Status(absl::StatusCode::kDeadlineExceeded, message); +} + +Status FailedPreconditionError(absl::string_view message) { + return Status(absl::StatusCode::kFailedPrecondition, message); +} + +Status InternalError(absl::string_view message) { + return Status(absl::StatusCode::kInternal, message); +} + +Status InvalidArgumentError(absl::string_view message) { + return Status(absl::StatusCode::kInvalidArgument, message); +} + +Status NotFoundError(absl::string_view message) { + return Status(absl::StatusCode::kNotFound, message); +} + +Status OutOfRangeError(absl::string_view message) { + return Status(absl::StatusCode::kOutOfRange, message); +} + +Status PermissionDeniedError(absl::string_view message) { + return Status(absl::StatusCode::kPermissionDenied, message); +} + +Status ResourceExhaustedError(absl::string_view message) { + return Status(absl::StatusCode::kResourceExhausted, message); +} + +Status UnauthenticatedError(absl::string_view message) { + return Status(absl::StatusCode::kUnauthenticated, message); +} + +Status UnavailableError(absl::string_view message) { + return Status(absl::StatusCode::kUnavailable, message); +} + +Status UnimplementedError(absl::string_view message) { + return Status(absl::StatusCode::kUnimplemented, message); +} + +Status UnknownError(absl::string_view message) { + return Status(absl::StatusCode::kUnknown, message); +} + +bool IsAborted(const Status& status) { + return status.code() == absl::StatusCode::kAborted; +} + +bool IsAlreadyExists(const Status& status) { + return status.code() == absl::StatusCode::kAlreadyExists; +} + +bool IsCancelled(const Status& status) { + return status.code() == absl::StatusCode::kCancelled; +} + +bool IsDataLoss(const Status& status) { + return status.code() == absl::StatusCode::kDataLoss; +} + +bool IsDeadlineExceeded(const Status& status) { + return status.code() == absl::StatusCode::kDeadlineExceeded; +} + +bool IsFailedPrecondition(const Status& status) { + return status.code() == absl::StatusCode::kFailedPrecondition; +} + +bool IsInternal(const Status& status) { + return status.code() == absl::StatusCode::kInternal; +} + +bool IsInvalidArgument(const Status& status) { + return status.code() == absl::StatusCode::kInvalidArgument; +} + +bool IsNotFound(const Status& status) { + return status.code() == absl::StatusCode::kNotFound; +} + +bool IsOutOfRange(const Status& status) { + return status.code() == absl::StatusCode::kOutOfRange; +} + +bool IsPermissionDenied(const Status& status) { + return status.code() == absl::StatusCode::kPermissionDenied; +} + +bool IsResourceExhausted(const Status& status) { + return status.code() == absl::StatusCode::kResourceExhausted; +} + +bool IsUnauthenticated(const Status& status) { + return status.code() == absl::StatusCode::kUnauthenticated; +} + +bool IsUnavailable(const Status& status) { + return status.code() == absl::StatusCode::kUnavailable; +} + +bool IsUnimplemented(const Status& status) { + return status.code() == absl::StatusCode::kUnimplemented; +} + +bool IsUnknown(const Status& status) { + return status.code() == absl::StatusCode::kUnknown; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/status/status.h b/third_party/abseil_cpp/absl/status/status.h new file mode 100644 index 0000000000..967e60644f --- /dev/null +++ b/third_party/abseil_cpp/absl/status/status.h @@ -0,0 +1,428 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +#ifndef ABSL_STATUS_STATUS_H_ +#define ABSL_STATUS_STATUS_H_ + +#include <iostream> +#include <string> + +#include "absl/container/inlined_vector.h" +#include "absl/strings/cord.h" +#include "absl/types/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +enum class StatusCode : int { + kOk = 0, + kCancelled = 1, + kUnknown = 2, + kInvalidArgument = 3, + kDeadlineExceeded = 4, + kNotFound = 5, + kAlreadyExists = 6, + kPermissionDenied = 7, + kResourceExhausted = 8, + kFailedPrecondition = 9, + kAborted = 10, + kOutOfRange = 11, + kUnimplemented = 12, + kInternal = 13, + kUnavailable = 14, + kDataLoss = 15, + kUnauthenticated = 16, + kDoNotUseReservedForFutureExpansionUseDefaultInSwitchInstead_ = 20 +}; + +// Returns the name for the status code, or "" if it is an unknown value. +std::string StatusCodeToString(StatusCode code); + +// Streams StatusCodeToString(code) to `os`. +std::ostream& operator<<(std::ostream& os, StatusCode code); + +namespace status_internal { + +// Container for status payloads. +struct Payload { + std::string type_url; + absl::Cord payload; +}; + +using Payloads = absl::InlinedVector<Payload, 1>; + +// Reference-counted representation of Status data. +struct StatusRep { + std::atomic<int32_t> ref; + absl::StatusCode code; + std::string message; + std::unique_ptr<status_internal::Payloads> payloads; +}; + +absl::StatusCode MapToLocalCode(int value); +} // namespace status_internal + +class ABSL_MUST_USE_RESULT Status final { + public: + // Creates an OK status with no message or payload. + Status(); + + // Create a status in the canonical error space with the specified code and + // error message. If `code == absl::StatusCode::kOk`, `msg` is ignored and an + // object identical to an OK status is constructed. + // + // `msg` must be in UTF-8. The implementation may complain (e.g., + // by printing a warning) if it is not. + Status(absl::StatusCode code, absl::string_view msg); + + Status(const Status&); + Status& operator=(const Status& x); + + // Move operations. + // The moved-from state is valid but unspecified. + Status(Status&&) noexcept; + Status& operator=(Status&&); + + ~Status(); + + // If `this->ok()`, stores `new_status` into *this. If `!this->ok()`, + // preserves the current data. May, in the future, augment the current status + // with additional information about `new_status`. + // + // Convenient way of keeping track of the first error encountered. + // Instead of: + // if (overall_status.ok()) overall_status = new_status + // Use: + // overall_status.Update(new_status); + // + // Style guide exception for rvalue reference granted in CL 153567220. + void Update(const Status& new_status); + void Update(Status&& new_status); + + // Returns true if the Status is OK. + ABSL_MUST_USE_RESULT bool ok() const; + + // Returns the (canonical) error code. + absl::StatusCode code() const; + + // Returns the raw (canonical) error code which could be out of the range of + // the local `absl::StatusCode` enum. NOTE: This should only be called when + // converting to wire format. Use `code` for error handling. + int raw_code() const; + + // Returns the error message. Note: prefer ToString() for debug logging. + // This message rarely describes the error code. It is not unusual for the + // error message to be the empty string. + absl::string_view message() const; + + friend bool operator==(const Status&, const Status&); + friend bool operator!=(const Status&, const Status&); + + // Returns a combination of the error code name, the message and the payloads. + // You can expect the code name and the message to be substrings of the + // result, and the payloads to be printed by the registered printer extensions + // if they are recognized. + // WARNING: Do not depend on the exact format of the result of `ToString()` + // which is subject to change. + std::string ToString() const; + + // Ignores any errors. This method does nothing except potentially suppress + // complaints from any tools that are checking that errors are not dropped on + // the floor. + void IgnoreError() const; + + // Swap the contents of `a` with `b` + friend void swap(Status& a, Status& b); + + // Payload management APIs + + // Type URL should be unique and follow the naming convention below: + // The idea of type URL comes from `google.protobuf.Any` + // (https://developers.google.com/protocol-buffers/docs/proto3#any). The + // type URL should be globally unique and follow the format of URL + // (https://en.wikipedia.org/wiki/URL). The default type URL for a given + // protobuf message type is "type.googleapis.com/packagename.messagename". For + // other custom wire formats, users should define the format of type URL in a + // similar practice so as to minimize the chance of conflict between type + // URLs. Users should make sure that the type URL can be mapped to a concrete + // C++ type if they want to deserialize the payload and read it effectively. + + // Gets the payload based for `type_url` key, if it is present. + absl::optional<absl::Cord> GetPayload(absl::string_view type_url) const; + + // Sets the payload for `type_url` key for a non-ok status, overwriting any + // existing payload for `type_url`. + // + // NOTE: Does nothing if the Status is ok. + void SetPayload(absl::string_view type_url, absl::Cord payload); + + // Erases the payload corresponding to the `type_url` key. Returns true if + // the payload was present. + bool ErasePayload(absl::string_view type_url); + + // Iterates over the stored payloads and calls `visitor(type_key, payload)` + // for each one. + // + // NOTE: The order of calls to `visitor` is not specified and may change at + // any time. + // + // NOTE: Any mutation on the same 'Status' object during visitation is + // forbidden and could result in undefined behavior. + void ForEachPayload( + const std::function<void(absl::string_view, const absl::Cord&)>& visitor) + const; + + private: + friend Status CancelledError(); + + // Creates a status in the canonical error space with the specified + // code, and an empty error message. + explicit Status(absl::StatusCode code); + + static void UnrefNonInlined(uintptr_t rep); + static void Ref(uintptr_t rep); + static void Unref(uintptr_t rep); + + // REQUIRES: !ok() + // Ensures rep_ is not shared with any other Status. + void PrepareToModify(); + + const status_internal::Payloads* GetPayloads() const; + status_internal::Payloads* GetPayloads(); + + // Takes ownership of payload. + static uintptr_t NewRep(absl::StatusCode code, absl::string_view msg, + std::unique_ptr<status_internal::Payloads> payload); + static bool EqualsSlow(const absl::Status& a, const absl::Status& b); + + // MSVC 14.0 limitation requires the const. + static constexpr const char kMovedFromString[] = + "Status accessed after move."; + + static const std::string* EmptyString(); + static const std::string* MovedFromString(); + + // Returns whether rep contains an inlined representation. + // See rep_ for details. + static bool IsInlined(uintptr_t rep); + + // Indicates whether this Status was the rhs of a move operation. See rep_ + // for details. + static bool IsMovedFrom(uintptr_t rep); + static uintptr_t MovedFromRep(); + + // Convert between error::Code and the inlined uintptr_t representation used + // by rep_. See rep_ for details. + static uintptr_t CodeToInlinedRep(absl::StatusCode code); + static absl::StatusCode InlinedRepToCode(uintptr_t rep); + + // Converts between StatusRep* and the external uintptr_t representation used + // by rep_. See rep_ for details. + static uintptr_t PointerToRep(status_internal::StatusRep* r); + static status_internal::StatusRep* RepToPointer(uintptr_t r); + + // Returns string for non-ok Status. + std::string ToStringSlow() const; + + // Status supports two different representations. + // - When the low bit is off it is an inlined representation. + // It uses the canonical error space, no message or payload. + // The error code is (rep_ >> 2). + // The (rep_ & 2) bit is the "moved from" indicator, used in IsMovedFrom(). + // - When the low bit is on it is an external representation. + // In this case all the data comes from a heap allocated Rep object. + // (rep_ - 1) is a status_internal::StatusRep* pointer to that structure. + uintptr_t rep_; +}; + +// Returns an OK status, equivalent to a default constructed instance. +Status OkStatus(); + +// Prints a human-readable representation of `x` to `os`. +std::ostream& operator<<(std::ostream& os, const Status& x); + +// ----------------------------------------------------------------- +// Implementation details follow + +inline Status::Status() : rep_(CodeToInlinedRep(absl::StatusCode::kOk)) {} + +inline Status::Status(absl::StatusCode code) : rep_(CodeToInlinedRep(code)) {} + +inline Status::Status(const Status& x) : rep_(x.rep_) { Ref(rep_); } + +inline Status& Status::operator=(const Status& x) { + uintptr_t old_rep = rep_; + if (x.rep_ != old_rep) { + Ref(x.rep_); + rep_ = x.rep_; + Unref(old_rep); + } + return *this; +} + +inline Status::Status(Status&& x) noexcept : rep_(x.rep_) { + x.rep_ = MovedFromRep(); +} + +inline Status& Status::operator=(Status&& x) { + uintptr_t old_rep = rep_; + rep_ = x.rep_; + x.rep_ = MovedFromRep(); + Unref(old_rep); + return *this; +} + +inline void Status::Update(const Status& new_status) { + if (ok()) { + *this = new_status; + } +} + +inline void Status::Update(Status&& new_status) { + if (ok()) { + *this = std::move(new_status); + } +} + +inline Status::~Status() { Unref(rep_); } + +inline bool Status::ok() const { + return rep_ == CodeToInlinedRep(absl::StatusCode::kOk); +} + +inline absl::string_view Status::message() const { + return !IsInlined(rep_) + ? RepToPointer(rep_)->message + : (IsMovedFrom(rep_) ? absl::string_view(kMovedFromString) + : absl::string_view()); +} + +inline bool operator==(const Status& lhs, const Status& rhs) { + return lhs.rep_ == rhs.rep_ || Status::EqualsSlow(lhs, rhs); +} + +inline bool operator!=(const Status& lhs, const Status& rhs) { + return !(lhs == rhs); +} + +inline std::string Status::ToString() const { + return ok() ? "OK" : ToStringSlow(); +} + +inline void Status::IgnoreError() const { + // no-op +} + +inline void swap(absl::Status& a, absl::Status& b) { + using std::swap; + swap(a.rep_, b.rep_); +} + +inline const status_internal::Payloads* Status::GetPayloads() const { + return IsInlined(rep_) ? nullptr : RepToPointer(rep_)->payloads.get(); +} + +inline status_internal::Payloads* Status::GetPayloads() { + return IsInlined(rep_) ? nullptr : RepToPointer(rep_)->payloads.get(); +} + +inline bool Status::IsInlined(uintptr_t rep) { return (rep & 1) == 0; } + +inline bool Status::IsMovedFrom(uintptr_t rep) { + return IsInlined(rep) && (rep & 2) != 0; +} + +inline uintptr_t Status::MovedFromRep() { + return CodeToInlinedRep(absl::StatusCode::kInternal) | 2; +} + +inline uintptr_t Status::CodeToInlinedRep(absl::StatusCode code) { + return static_cast<uintptr_t>(code) << 2; +} + +inline absl::StatusCode Status::InlinedRepToCode(uintptr_t rep) { + assert(IsInlined(rep)); + return static_cast<absl::StatusCode>(rep >> 2); +} + +inline status_internal::StatusRep* Status::RepToPointer(uintptr_t rep) { + assert(!IsInlined(rep)); + return reinterpret_cast<status_internal::StatusRep*>(rep - 1); +} + +inline uintptr_t Status::PointerToRep(status_internal::StatusRep* rep) { + return reinterpret_cast<uintptr_t>(rep) + 1; +} + +inline void Status::Ref(uintptr_t rep) { + if (!IsInlined(rep)) { + RepToPointer(rep)->ref.fetch_add(1, std::memory_order_relaxed); + } +} + +inline void Status::Unref(uintptr_t rep) { + if (!IsInlined(rep)) { + UnrefNonInlined(rep); + } +} + +inline Status OkStatus() { return Status(); } + +// Each of the functions below creates a Status object with a particular error +// code and the given message. The error code of the returned status object +// matches the name of the function. +Status AbortedError(absl::string_view message); +Status AlreadyExistsError(absl::string_view message); +Status CancelledError(absl::string_view message); +Status DataLossError(absl::string_view message); +Status DeadlineExceededError(absl::string_view message); +Status FailedPreconditionError(absl::string_view message); +Status InternalError(absl::string_view message); +Status InvalidArgumentError(absl::string_view message); +Status NotFoundError(absl::string_view message); +Status OutOfRangeError(absl::string_view message); +Status PermissionDeniedError(absl::string_view message); +Status ResourceExhaustedError(absl::string_view message); +Status UnauthenticatedError(absl::string_view message); +Status UnavailableError(absl::string_view message); +Status UnimplementedError(absl::string_view message); +Status UnknownError(absl::string_view message); + +// Creates a `Status` object with the `absl::StatusCode::kCancelled` error code +// and an empty message. It is provided only for efficiency, given that +// message-less kCancelled errors are common in the infrastructure. +inline Status CancelledError() { return Status(absl::StatusCode::kCancelled); } + +// Each of the functions below returns true if the given status matches the +// error code implied by the function's name. +ABSL_MUST_USE_RESULT bool IsAborted(const Status& status); +ABSL_MUST_USE_RESULT bool IsAlreadyExists(const Status& status); +ABSL_MUST_USE_RESULT bool IsCancelled(const Status& status); +ABSL_MUST_USE_RESULT bool IsDataLoss(const Status& status); +ABSL_MUST_USE_RESULT bool IsDeadlineExceeded(const Status& status); +ABSL_MUST_USE_RESULT bool IsFailedPrecondition(const Status& status); +ABSL_MUST_USE_RESULT bool IsInternal(const Status& status); +ABSL_MUST_USE_RESULT bool IsInvalidArgument(const Status& status); +ABSL_MUST_USE_RESULT bool IsNotFound(const Status& status); +ABSL_MUST_USE_RESULT bool IsOutOfRange(const Status& status); +ABSL_MUST_USE_RESULT bool IsPermissionDenied(const Status& status); +ABSL_MUST_USE_RESULT bool IsResourceExhausted(const Status& status); +ABSL_MUST_USE_RESULT bool IsUnauthenticated(const Status& status); +ABSL_MUST_USE_RESULT bool IsUnavailable(const Status& status); +ABSL_MUST_USE_RESULT bool IsUnimplemented(const Status& status); +ABSL_MUST_USE_RESULT bool IsUnknown(const Status& status); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STATUS_STATUS_H_ diff --git a/third_party/abseil_cpp/absl/status/status_payload_printer.cc b/third_party/abseil_cpp/absl/status/status_payload_printer.cc new file mode 100644 index 0000000000..a47aea11c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/status/status_payload_printer.cc @@ -0,0 +1,38 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +#include "absl/status/status_payload_printer.h" + +#include <atomic> + +#include "absl/base/attributes.h" +#include "absl/base/internal/atomic_hook.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace status_internal { + +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES +static absl::base_internal::AtomicHook<StatusPayloadPrinter> storage; + +void SetStatusPayloadPrinter(StatusPayloadPrinter printer) { + storage.Store(printer); +} + +StatusPayloadPrinter GetStatusPayloadPrinter() { + return storage.Load(); +} + +} // namespace status_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/status/status_payload_printer.h b/third_party/abseil_cpp/absl/status/status_payload_printer.h new file mode 100644 index 0000000000..5e0937f67d --- /dev/null +++ b/third_party/abseil_cpp/absl/status/status_payload_printer.h @@ -0,0 +1,51 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +#ifndef ABSL_STATUS_STATUS_PAYLOAD_PRINTER_H_ +#define ABSL_STATUS_STATUS_PAYLOAD_PRINTER_H_ + +#include <string> + +#include "absl/strings/cord.h" +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace status_internal { + +// By default, `Status::ToString` and `operator<<(Status)` print a payload by +// dumping the type URL and the raw bytes. To help debugging, we provide an +// extension point, which is a global printer function that can be set by users +// to specify how to print payloads. The function takes the type URL and the +// payload as input, and should return a valid human-readable string on success +// or `absl::nullopt` on failure (in which case it falls back to the default +// approach of printing the raw bytes). +// NOTE: This is an internal API and the design is subject to change in the +// future in a non-backward-compatible way. Since it's only meant for debugging +// purpose, you should not rely on it in any critical logic. +using StatusPayloadPrinter = absl::optional<std::string> (*)(absl::string_view, + const absl::Cord&); + +// Sets the global payload printer. Only one printer should be set per process. +// If multiple printers are set, it's undefined which one will be used. +void SetStatusPayloadPrinter(StatusPayloadPrinter); + +// Returns the global payload printer if previously set, otherwise `nullptr`. +StatusPayloadPrinter GetStatusPayloadPrinter(); + +} // namespace status_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STATUS_STATUS_PAYLOAD_PRINTER_H_ diff --git a/third_party/abseil_cpp/absl/status/status_test.cc b/third_party/abseil_cpp/absl/status/status_test.cc new file mode 100644 index 0000000000..ca9488ad22 --- /dev/null +++ b/third_party/abseil_cpp/absl/status/status_test.cc @@ -0,0 +1,458 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/status/status.h" + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/str_cat.h" + +namespace { + +using ::testing::Eq; +using ::testing::HasSubstr; +using ::testing::Optional; +using ::testing::UnorderedElementsAreArray; + +TEST(StatusCode, InsertionOperator) { + const absl::StatusCode code = absl::StatusCode::kUnknown; + std::ostringstream oss; + oss << code; + EXPECT_EQ(oss.str(), absl::StatusCodeToString(code)); +} + +// This structure holds the details for testing a single error code, +// its creator, and its classifier. +struct ErrorTest { + absl::StatusCode code; + using Creator = absl::Status (*)(absl::string_view); + using Classifier = bool (*)(const absl::Status&); + Creator creator; + Classifier classifier; +}; + +constexpr ErrorTest kErrorTests[]{ + {absl::StatusCode::kCancelled, absl::CancelledError, absl::IsCancelled}, + {absl::StatusCode::kUnknown, absl::UnknownError, absl::IsUnknown}, + {absl::StatusCode::kInvalidArgument, absl::InvalidArgumentError, + absl::IsInvalidArgument}, + {absl::StatusCode::kDeadlineExceeded, absl::DeadlineExceededError, + absl::IsDeadlineExceeded}, + {absl::StatusCode::kNotFound, absl::NotFoundError, absl::IsNotFound}, + {absl::StatusCode::kAlreadyExists, absl::AlreadyExistsError, + absl::IsAlreadyExists}, + {absl::StatusCode::kPermissionDenied, absl::PermissionDeniedError, + absl::IsPermissionDenied}, + {absl::StatusCode::kResourceExhausted, absl::ResourceExhaustedError, + absl::IsResourceExhausted}, + {absl::StatusCode::kFailedPrecondition, absl::FailedPreconditionError, + absl::IsFailedPrecondition}, + {absl::StatusCode::kAborted, absl::AbortedError, absl::IsAborted}, + {absl::StatusCode::kOutOfRange, absl::OutOfRangeError, absl::IsOutOfRange}, + {absl::StatusCode::kUnimplemented, absl::UnimplementedError, + absl::IsUnimplemented}, + {absl::StatusCode::kInternal, absl::InternalError, absl::IsInternal}, + {absl::StatusCode::kUnavailable, absl::UnavailableError, + absl::IsUnavailable}, + {absl::StatusCode::kDataLoss, absl::DataLossError, absl::IsDataLoss}, + {absl::StatusCode::kUnauthenticated, absl::UnauthenticatedError, + absl::IsUnauthenticated}, +}; + +TEST(Status, CreateAndClassify) { + for (const auto& test : kErrorTests) { + SCOPED_TRACE(absl::StatusCodeToString(test.code)); + + // Ensure that the creator does, in fact, create status objects with the + // expected error code and message. + std::string message = + absl::StrCat("error code ", test.code, " test message"); + absl::Status status = test.creator(message); + EXPECT_EQ(test.code, status.code()); + EXPECT_EQ(message, status.message()); + + // Ensure that the classifier returns true for a status produced by the + // creator. + EXPECT_TRUE(test.classifier(status)); + + // Ensure that the classifier returns false for status with a different + // code. + for (const auto& other : kErrorTests) { + if (other.code != test.code) { + EXPECT_FALSE(test.classifier(absl::Status(other.code, ""))) + << " other.code = " << other.code; + } + } + } +} + +TEST(Status, DefaultConstructor) { + absl::Status status; + EXPECT_TRUE(status.ok()); + EXPECT_EQ(absl::StatusCode::kOk, status.code()); + EXPECT_EQ("", status.message()); +} + +TEST(Status, OkStatus) { + absl::Status status = absl::OkStatus(); + EXPECT_TRUE(status.ok()); + EXPECT_EQ(absl::StatusCode::kOk, status.code()); + EXPECT_EQ("", status.message()); +} + +TEST(Status, ConstructorWithCodeMessage) { + { + absl::Status status(absl::StatusCode::kCancelled, ""); + EXPECT_FALSE(status.ok()); + EXPECT_EQ(absl::StatusCode::kCancelled, status.code()); + EXPECT_EQ("", status.message()); + } + { + absl::Status status(absl::StatusCode::kInternal, "message"); + EXPECT_FALSE(status.ok()); + EXPECT_EQ(absl::StatusCode::kInternal, status.code()); + EXPECT_EQ("message", status.message()); + } +} + +TEST(Status, ConstructOutOfRangeCode) { + const int kRawCode = 9999; + absl::Status status(static_cast<absl::StatusCode>(kRawCode), ""); + EXPECT_EQ(absl::StatusCode::kUnknown, status.code()); + EXPECT_EQ(kRawCode, status.raw_code()); +} + +constexpr char kUrl1[] = "url.payload.1"; +constexpr char kUrl2[] = "url.payload.2"; +constexpr char kUrl3[] = "url.payload.3"; +constexpr char kUrl4[] = "url.payload.xx"; + +constexpr char kPayload1[] = "aaaaa"; +constexpr char kPayload2[] = "bbbbb"; +constexpr char kPayload3[] = "ccccc"; + +using PayloadsVec = std::vector<std::pair<std::string, absl::Cord>>; + +TEST(Status, TestGetSetPayload) { + absl::Status ok_status = absl::OkStatus(); + ok_status.SetPayload(kUrl1, absl::Cord(kPayload1)); + ok_status.SetPayload(kUrl2, absl::Cord(kPayload2)); + + EXPECT_FALSE(ok_status.GetPayload(kUrl1)); + EXPECT_FALSE(ok_status.GetPayload(kUrl2)); + + absl::Status bad_status(absl::StatusCode::kInternal, "fail"); + bad_status.SetPayload(kUrl1, absl::Cord(kPayload1)); + bad_status.SetPayload(kUrl2, absl::Cord(kPayload2)); + + EXPECT_THAT(bad_status.GetPayload(kUrl1), Optional(Eq(kPayload1))); + EXPECT_THAT(bad_status.GetPayload(kUrl2), Optional(Eq(kPayload2))); + + EXPECT_FALSE(bad_status.GetPayload(kUrl3)); + + bad_status.SetPayload(kUrl1, absl::Cord(kPayload3)); + EXPECT_THAT(bad_status.GetPayload(kUrl1), Optional(Eq(kPayload3))); + + // Testing dynamically generated type_url + bad_status.SetPayload(absl::StrCat(kUrl1, ".1"), absl::Cord(kPayload1)); + EXPECT_THAT(bad_status.GetPayload(absl::StrCat(kUrl1, ".1")), + Optional(Eq(kPayload1))); +} + +TEST(Status, TestErasePayload) { + absl::Status bad_status(absl::StatusCode::kInternal, "fail"); + bad_status.SetPayload(kUrl1, absl::Cord(kPayload1)); + bad_status.SetPayload(kUrl2, absl::Cord(kPayload2)); + bad_status.SetPayload(kUrl3, absl::Cord(kPayload3)); + + EXPECT_FALSE(bad_status.ErasePayload(kUrl4)); + + EXPECT_TRUE(bad_status.GetPayload(kUrl2)); + EXPECT_TRUE(bad_status.ErasePayload(kUrl2)); + EXPECT_FALSE(bad_status.GetPayload(kUrl2)); + EXPECT_FALSE(bad_status.ErasePayload(kUrl2)); + + EXPECT_TRUE(bad_status.ErasePayload(kUrl1)); + EXPECT_TRUE(bad_status.ErasePayload(kUrl3)); + + bad_status.SetPayload(kUrl1, absl::Cord(kPayload1)); + EXPECT_TRUE(bad_status.ErasePayload(kUrl1)); +} + +TEST(Status, TestComparePayloads) { + absl::Status bad_status1(absl::StatusCode::kInternal, "fail"); + bad_status1.SetPayload(kUrl1, absl::Cord(kPayload1)); + bad_status1.SetPayload(kUrl2, absl::Cord(kPayload2)); + bad_status1.SetPayload(kUrl3, absl::Cord(kPayload3)); + + absl::Status bad_status2(absl::StatusCode::kInternal, "fail"); + bad_status2.SetPayload(kUrl2, absl::Cord(kPayload2)); + bad_status2.SetPayload(kUrl3, absl::Cord(kPayload3)); + bad_status2.SetPayload(kUrl1, absl::Cord(kPayload1)); + + EXPECT_EQ(bad_status1, bad_status2); +} + +TEST(Status, TestComparePayloadsAfterErase) { + absl::Status payload_status(absl::StatusCode::kInternal, ""); + payload_status.SetPayload(kUrl1, absl::Cord(kPayload1)); + payload_status.SetPayload(kUrl2, absl::Cord(kPayload2)); + + absl::Status empty_status(absl::StatusCode::kInternal, ""); + + // Different payloads, not equal + EXPECT_NE(payload_status, empty_status); + EXPECT_TRUE(payload_status.ErasePayload(kUrl1)); + + // Still Different payloads, still not equal. + EXPECT_NE(payload_status, empty_status); + EXPECT_TRUE(payload_status.ErasePayload(kUrl2)); + + // Both empty payloads, should be equal + EXPECT_EQ(payload_status, empty_status); +} + +PayloadsVec AllVisitedPayloads(const absl::Status& s) { + PayloadsVec result; + + s.ForEachPayload([&](absl::string_view type_url, const absl::Cord& payload) { + result.push_back(std::make_pair(std::string(type_url), payload)); + }); + + return result; +} + +TEST(Status, TestForEachPayload) { + absl::Status bad_status(absl::StatusCode::kInternal, "fail"); + bad_status.SetPayload(kUrl1, absl::Cord(kPayload1)); + bad_status.SetPayload(kUrl2, absl::Cord(kPayload2)); + bad_status.SetPayload(kUrl3, absl::Cord(kPayload3)); + + int count = 0; + + bad_status.ForEachPayload( + [&count](absl::string_view, const absl::Cord&) { ++count; }); + + EXPECT_EQ(count, 3); + + PayloadsVec expected_payloads = {{kUrl1, absl::Cord(kPayload1)}, + {kUrl2, absl::Cord(kPayload2)}, + {kUrl3, absl::Cord(kPayload3)}}; + + // Test that we visit all the payloads in the status. + PayloadsVec visited_payloads = AllVisitedPayloads(bad_status); + EXPECT_THAT(visited_payloads, UnorderedElementsAreArray(expected_payloads)); + + // Test that visitation order is not consistent between run. + std::vector<absl::Status> scratch; + while (true) { + scratch.emplace_back(absl::StatusCode::kInternal, "fail"); + + scratch.back().SetPayload(kUrl1, absl::Cord(kPayload1)); + scratch.back().SetPayload(kUrl2, absl::Cord(kPayload2)); + scratch.back().SetPayload(kUrl3, absl::Cord(kPayload3)); + + if (AllVisitedPayloads(scratch.back()) != visited_payloads) { + break; + } + } +} + +TEST(Status, ToString) { + absl::Status s(absl::StatusCode::kInternal, "fail"); + EXPECT_EQ("INTERNAL: fail", s.ToString()); + s.SetPayload("foo", absl::Cord("bar")); + EXPECT_EQ("INTERNAL: fail [foo='bar']", s.ToString()); + s.SetPayload("bar", absl::Cord("\377")); + EXPECT_THAT(s.ToString(), + AllOf(HasSubstr("INTERNAL: fail"), HasSubstr("[foo='bar']"), + HasSubstr("[bar='\\xff']"))); +} + +absl::Status EraseAndReturn(const absl::Status& base) { + absl::Status copy = base; + EXPECT_TRUE(copy.ErasePayload(kUrl1)); + return copy; +} + +TEST(Status, CopyOnWriteForErasePayload) { + { + absl::Status base(absl::StatusCode::kInvalidArgument, "fail"); + base.SetPayload(kUrl1, absl::Cord(kPayload1)); + EXPECT_TRUE(base.GetPayload(kUrl1).has_value()); + absl::Status copy = EraseAndReturn(base); + EXPECT_TRUE(base.GetPayload(kUrl1).has_value()); + EXPECT_FALSE(copy.GetPayload(kUrl1).has_value()); + } + { + absl::Status base(absl::StatusCode::kInvalidArgument, "fail"); + base.SetPayload(kUrl1, absl::Cord(kPayload1)); + absl::Status copy = base; + + EXPECT_TRUE(base.GetPayload(kUrl1).has_value()); + EXPECT_TRUE(copy.GetPayload(kUrl1).has_value()); + + EXPECT_TRUE(base.ErasePayload(kUrl1)); + + EXPECT_FALSE(base.GetPayload(kUrl1).has_value()); + EXPECT_TRUE(copy.GetPayload(kUrl1).has_value()); + } +} + +TEST(Status, CopyConstructor) { + { + absl::Status status; + absl::Status copy(status); + EXPECT_EQ(copy, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + absl::Status copy(status); + EXPECT_EQ(copy, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + status.SetPayload(kUrl1, absl::Cord(kPayload1)); + absl::Status copy(status); + EXPECT_EQ(copy, status); + } +} + +TEST(Status, CopyAssignment) { + absl::Status assignee; + { + absl::Status status; + assignee = status; + EXPECT_EQ(assignee, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + assignee = status; + EXPECT_EQ(assignee, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + status.SetPayload(kUrl1, absl::Cord(kPayload1)); + assignee = status; + EXPECT_EQ(assignee, status); + } +} + +TEST(Status, CopyAssignmentIsNotRef) { + const absl::Status status_orig(absl::StatusCode::kInvalidArgument, "message"); + absl::Status status_copy = status_orig; + EXPECT_EQ(status_orig, status_copy); + status_copy.SetPayload(kUrl1, absl::Cord(kPayload1)); + EXPECT_NE(status_orig, status_copy); +} + +TEST(Status, MoveConstructor) { + { + absl::Status status; + absl::Status copy(absl::Status{}); + EXPECT_EQ(copy, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + absl::Status copy( + absl::Status(absl::StatusCode::kInvalidArgument, "message")); + EXPECT_EQ(copy, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + status.SetPayload(kUrl1, absl::Cord(kPayload1)); + absl::Status copy1(status); + absl::Status copy2(std::move(status)); + EXPECT_EQ(copy1, copy2); + } +} + +TEST(Status, MoveAssignment) { + absl::Status assignee; + { + absl::Status status; + assignee = absl::Status(); + EXPECT_EQ(assignee, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + assignee = absl::Status(absl::StatusCode::kInvalidArgument, "message"); + EXPECT_EQ(assignee, status); + } + { + absl::Status status(absl::StatusCode::kInvalidArgument, "message"); + status.SetPayload(kUrl1, absl::Cord(kPayload1)); + absl::Status copy(status); + assignee = std::move(status); + EXPECT_EQ(assignee, copy); + } +} + +TEST(Status, Update) { + absl::Status s; + s.Update(absl::OkStatus()); + EXPECT_TRUE(s.ok()); + const absl::Status a(absl::StatusCode::kCancelled, "message"); + s.Update(a); + EXPECT_EQ(s, a); + const absl::Status b(absl::StatusCode::kInternal, "other message"); + s.Update(b); + EXPECT_EQ(s, a); + s.Update(absl::OkStatus()); + EXPECT_EQ(s, a); + EXPECT_FALSE(s.ok()); +} + +TEST(Status, Equality) { + absl::Status ok; + absl::Status no_payload = absl::CancelledError("no payload"); + absl::Status one_payload = absl::InvalidArgumentError("one payload"); + one_payload.SetPayload(kUrl1, absl::Cord(kPayload1)); + absl::Status two_payloads = one_payload; + two_payloads.SetPayload(kUrl2, absl::Cord(kPayload2)); + const std::array<absl::Status, 4> status_arr = {ok, no_payload, one_payload, + two_payloads}; + for (int i = 0; i < status_arr.size(); i++) { + for (int j = 0; j < status_arr.size(); j++) { + if (i == j) { + EXPECT_TRUE(status_arr[i] == status_arr[j]); + EXPECT_FALSE(status_arr[i] != status_arr[j]); + } else { + EXPECT_TRUE(status_arr[i] != status_arr[j]); + EXPECT_FALSE(status_arr[i] == status_arr[j]); + } + } + } +} + +TEST(Status, Swap) { + auto test_swap = [](const absl::Status& s1, const absl::Status& s2) { + absl::Status copy1 = s1, copy2 = s2; + swap(copy1, copy2); + EXPECT_EQ(copy1, s2); + EXPECT_EQ(copy2, s1); + }; + const absl::Status ok; + const absl::Status no_payload(absl::StatusCode::kAlreadyExists, "no payload"); + absl::Status with_payload(absl::StatusCode::kInternal, "with payload"); + with_payload.SetPayload(kUrl1, absl::Cord(kPayload1)); + test_swap(ok, no_payload); + test_swap(no_payload, ok); + test_swap(ok, with_payload); + test_swap(with_payload, ok); + test_swap(no_payload, with_payload); + test_swap(with_payload, no_payload); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/BUILD.bazel b/third_party/abseil_cpp/absl/strings/BUILD.bazel new file mode 100644 index 0000000000..8220896d3d --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/BUILD.bazel @@ -0,0 +1,772 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_TEST_COPTS", +) + +package( + default_visibility = ["//visibility:public"], + features = ["parse_headers"], +) + +licenses(["notice"]) + +cc_library( + name = "strings", + srcs = [ + "ascii.cc", + "charconv.cc", + "escaping.cc", + "internal/charconv_bigint.cc", + "internal/charconv_bigint.h", + "internal/charconv_parse.cc", + "internal/charconv_parse.h", + "internal/memutil.cc", + "internal/memutil.h", + "internal/stl_type_traits.h", + "internal/str_join_internal.h", + "internal/str_split_internal.h", + "match.cc", + "numbers.cc", + "str_cat.cc", + "str_replace.cc", + "str_split.cc", + "string_view.cc", + "substitute.cc", + ], + hdrs = [ + "ascii.h", + "charconv.h", + "escaping.h", + "match.h", + "numbers.h", + "str_cat.h", + "str_join.h", + "str_replace.h", + "str_split.h", + "string_view.h", + "strip.h", + "substitute.h", + ], + copts = ABSL_DEFAULT_COPTS, + deps = [ + ":internal", + "//absl/base", + "//absl/base:bits", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/base:raw_logging_internal", + "//absl/base:throw_delegate", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/numeric:int128", + ], +) + +cc_library( + name = "internal", + srcs = [ + "internal/escaping.cc", + "internal/ostringstream.cc", + "internal/utf8.cc", + ], + hdrs = [ + "internal/char_map.h", + "internal/escaping.h", + "internal/ostringstream.h", + "internal/resize_uninitialized.h", + "internal/utf8.h", + ], + copts = ABSL_DEFAULT_COPTS, + deps = [ + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/base:raw_logging_internal", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "match_test", + size = "small", + srcs = ["match_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "escaping_test", + size = "small", + srcs = [ + "escaping_test.cc", + "internal/escaping_test_common.h", + ], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":cord", + ":strings", + "//absl/base:core_headers", + "//absl/container:fixed_array", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "escaping_benchmark", + srcs = [ + "escaping_benchmark.cc", + "internal/escaping_test_common.h", + ], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:raw_logging_internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "ascii_test", + size = "small", + srcs = ["ascii_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "ascii_benchmark", + srcs = ["ascii_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "memutil_benchmark", + srcs = [ + "internal/memutil.h", + "internal/memutil_benchmark.cc", + ], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "memutil_test", + size = "small", + srcs = [ + "internal/memutil.h", + "internal/memutil_test.cc", + ], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "utf8_test", + size = "small", + srcs = [ + "internal/utf8_test.cc", + ], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":internal", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "string_view_benchmark", + srcs = ["string_view_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "string_view_test", + size = "small", + srcs = ["string_view_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:dynamic_annotations", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "cord_internal", + hdrs = ["internal/cord_internal.h"], + copts = ABSL_DEFAULT_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/meta:type_traits", + ], +) + +cc_library( + name = "cord", + srcs = [ + "cord.cc", + ], + hdrs = [ + "cord.h", + ], + copts = ABSL_DEFAULT_COPTS, + deps = [ + ":cord_internal", + ":internal", + ":str_format", + ":strings", + "//absl/base", + "//absl/base:base_internal", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/base:raw_logging_internal", + "//absl/container:fixed_array", + "//absl/container:inlined_vector", + "//absl/functional:function_ref", + "//absl/meta:type_traits", + "//absl/types:optional", + ], +) + +cc_library( + name = "cord_test_helpers", + testonly = 1, + hdrs = [ + "cord_test_helpers.h", + ], + copts = ABSL_DEFAULT_COPTS, + deps = [ + ":cord", + ], +) + +cc_test( + name = "cord_test", + size = "medium", + srcs = ["cord_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":cord", + ":cord_test_helpers", + ":str_format", + ":strings", + "//absl/base", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:endian", + "//absl/base:raw_logging_internal", + "//absl/container:fixed_array", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "substitute_test", + size = "small", + srcs = ["substitute_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_replace_benchmark", + srcs = ["str_replace_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:raw_logging_internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "str_replace_test", + size = "small", + srcs = ["str_replace_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_split_test", + srcs = ["str_split_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "//absl/base:dynamic_annotations", + "//absl/container:flat_hash_map", + "//absl/container:node_hash_map", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_split_benchmark", + srcs = ["str_split_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:raw_logging_internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "ostringstream_test", + size = "small", + srcs = ["internal/ostringstream_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "ostringstream_benchmark", + srcs = ["internal/ostringstream_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "resize_uninitialized_test", + size = "small", + srcs = [ + "internal/resize_uninitialized.h", + "internal/resize_uninitialized_test.cc", + ], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + "//absl/base:core_headers", + "//absl/meta:type_traits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_join_test", + size = "small", + srcs = ["str_join_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_join_benchmark", + srcs = ["str_join_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "str_cat_test", + size = "small", + srcs = ["str_cat_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_cat_benchmark", + srcs = ["str_cat_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "numbers_test", + size = "medium", + srcs = [ + "internal/numbers_test_common.h", + "numbers_test.cc", + ], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":internal", + ":pow10_helper", + ":strings", + "//absl/base:config", + "//absl/base:raw_logging_internal", + "//absl/random", + "//absl/random:distributions", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "numbers_benchmark", + srcs = ["numbers_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:raw_logging_internal", + "//absl/random", + "//absl/random:distributions", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "strip_test", + size = "small", + srcs = ["strip_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "char_map_test", + srcs = ["internal/char_map_test.cc"], + copts = ABSL_TEST_COPTS, + deps = [ + ":internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "char_map_benchmark", + srcs = ["internal/char_map_benchmark.cc"], + copts = ABSL_TEST_COPTS, + tags = ["benchmark"], + deps = [ + ":internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "charconv_test", + srcs = ["charconv_test.cc"], + copts = ABSL_TEST_COPTS, + deps = [ + ":pow10_helper", + ":str_format", + ":strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "charconv_parse_test", + srcs = [ + "internal/charconv_parse.h", + "internal/charconv_parse_test.cc", + ], + copts = ABSL_TEST_COPTS, + deps = [ + ":strings", + "//absl/base:config", + "//absl/base:raw_logging_internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "charconv_bigint_test", + srcs = [ + "internal/charconv_bigint.h", + "internal/charconv_bigint_test.cc", + "internal/charconv_parse.h", + ], + copts = ABSL_TEST_COPTS, + deps = [ + ":strings", + "//absl/base:config", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "charconv_benchmark", + srcs = [ + "charconv_benchmark.cc", + ], + tags = [ + "benchmark", + ], + deps = [ + ":strings", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "str_format", + hdrs = [ + "str_format.h", + ], + copts = ABSL_DEFAULT_COPTS, + deps = [ + ":str_format_internal", + ], +) + +cc_library( + name = "str_format_internal", + srcs = [ + "internal/str_format/arg.cc", + "internal/str_format/bind.cc", + "internal/str_format/extension.cc", + "internal/str_format/float_conversion.cc", + "internal/str_format/output.cc", + "internal/str_format/parser.cc", + ], + hdrs = [ + "internal/str_format/arg.h", + "internal/str_format/bind.h", + "internal/str_format/checker.h", + "internal/str_format/extension.h", + "internal/str_format/float_conversion.h", + "internal/str_format/output.h", + "internal/str_format/parser.h", + ], + copts = ABSL_DEFAULT_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":strings", + "//absl/base:bits", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/functional:function_ref", + "//absl/meta:type_traits", + "//absl/numeric:int128", + "//absl/types:optional", + "//absl/types:span", + ], +) + +cc_test( + name = "str_format_test", + srcs = ["str_format_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":cord", + ":str_format", + ":strings", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_extension_test", + srcs = [ + "internal/str_format/extension_test.cc", + ], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":str_format", + ":str_format_internal", + ":strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_arg_test", + srcs = ["internal/str_format/arg_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":str_format", + ":str_format_internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_bind_test", + srcs = ["internal/str_format/bind_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":str_format_internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_checker_test", + srcs = ["internal/str_format/checker_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":str_format", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_convert_test", + size = "medium", + srcs = ["internal/str_format/convert_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":str_format_internal", + "//absl/base:raw_logging_internal", + "//absl/types:optional", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_output_test", + srcs = ["internal/str_format/output_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":cord", + ":str_format_internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "str_format_parser_test", + srcs = ["internal/str_format/parser_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":str_format_internal", + "//absl/base:core_headers", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "pow10_helper", + testonly = True, + srcs = ["internal/pow10_helper.cc"], + hdrs = ["internal/pow10_helper.h"], + visibility = ["//visibility:private"], + deps = ["//absl/base:config"], +) + +cc_test( + name = "pow10_helper_test", + srcs = ["internal/pow10_helper_test.cc"], + copts = ABSL_TEST_COPTS, + visibility = ["//visibility:private"], + deps = [ + ":pow10_helper", + ":str_format", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/strings/CMakeLists.txt b/third_party/abseil_cpp/absl/strings/CMakeLists.txt new file mode 100644 index 0000000000..c0ea0c8e1d --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/CMakeLists.txt @@ -0,0 +1,593 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + strings + HDRS + "ascii.h" + "charconv.h" + "escaping.h" + "match.h" + "numbers.h" + "str_cat.h" + "str_join.h" + "str_replace.h" + "str_split.h" + "string_view.h" + "strip.h" + "substitute.h" + SRCS + "ascii.cc" + "charconv.cc" + "escaping.cc" + "internal/charconv_bigint.cc" + "internal/charconv_bigint.h" + "internal/charconv_parse.cc" + "internal/charconv_parse.h" + "internal/memutil.cc" + "internal/memutil.h" + "internal/stl_type_traits.h" + "internal/str_join_internal.h" + "internal/str_split_internal.h" + "match.cc" + "numbers.cc" + "str_cat.cc" + "str_replace.cc" + "str_split.cc" + "string_view.cc" + "substitute.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::strings_internal + absl::base + absl::bits + absl::config + absl::core_headers + absl::endian + absl::int128 + absl::memory + absl::raw_logging_internal + absl::throw_delegate + absl::type_traits + PUBLIC +) + +absl_cc_library( + NAME + strings_internal + HDRS + "internal/char_map.h" + "internal/escaping.cc" + "internal/escaping.h" + "internal/ostringstream.h" + "internal/resize_uninitialized.h" + "internal/utf8.h" + SRCS + "internal/ostringstream.cc" + "internal/utf8.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::core_headers + absl::endian + absl::raw_logging_internal + absl::type_traits +) + +absl_cc_test( + NAME + match_test + SRCS + "match_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::base + gmock_main +) + +absl_cc_test( + NAME + escaping_test + SRCS + "escaping_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::core_headers + absl::fixed_array + gmock_main +) + +absl_cc_test( + NAME + ascii_test + SRCS + "ascii_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + memutil_test + SRCS + "internal/memutil.h" + "internal/memutil_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + utf8_test + SRCS + "internal/utf8_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings_internal + absl::base + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + string_view_test + SRCS + "string_view_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::config + absl::core_headers + absl::dynamic_annotations + gmock_main +) + +absl_cc_test( + NAME + substitute_test + SRCS + "substitute_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + str_replace_test + SRCS + "str_replace_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + gmock_main +) + +absl_cc_test( + NAME + str_split_test + SRCS + "str_split_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::base + absl::core_headers + absl::dynamic_annotations + absl::flat_hash_map + absl::node_hash_map + gmock_main +) + +absl_cc_test( + NAME + ostringstream_test + SRCS + "internal/ostringstream_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings_internal + gmock_main +) + +absl_cc_test( + NAME + resize_uninitialized_test + SRCS + "internal/resize_uninitialized.h" + "internal/resize_uninitialized_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::core_headers + absl::type_traits + gmock_main +) + +absl_cc_test( + NAME + str_join_test + SRCS + "str_join_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::base + absl::core_headers + absl::memory + gmock_main +) + +absl_cc_test( + NAME + str_cat_test + SRCS + "str_cat_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + numbers_test + SRCS + "internal/numbers_test_common.h" + "numbers_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::core_headers + absl::pow10_helper + absl::config + absl::raw_logging_internal + absl::random_random + absl::random_distributions + absl::strings_internal + gmock_main +) + +absl_cc_test( + NAME + strip_test + SRCS + "strip_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::base + gmock_main +) + +absl_cc_test( + NAME + char_map_test + SRCS + "internal/char_map_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings_internal + gmock_main +) + +absl_cc_test( + NAME + charconv_test + SRCS + "charconv_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::str_format + absl::pow10_helper + gmock_main +) + +absl_cc_test( + NAME + charconv_parse_test + SRCS + "internal/charconv_parse.h" + "internal/charconv_parse_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::config + absl::raw_logging_internal + gmock_main +) + +absl_cc_test( + NAME + charconv_bigint_test + SRCS + "internal/charconv_bigint.h" + "internal/charconv_bigint_test.cc" + "internal/charconv_parse.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::strings + absl::config + gmock_main +) + +absl_cc_library( + NAME + str_format + HDRS + "str_format.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::str_format_internal + PUBLIC +) + +absl_cc_library( + NAME + str_format_internal + HDRS + "internal/str_format/arg.h" + "internal/str_format/bind.h" + "internal/str_format/checker.h" + "internal/str_format/extension.h" + "internal/str_format/float_conversion.h" + "internal/str_format/output.h" + "internal/str_format/parser.h" + SRCS + "internal/str_format/arg.cc" + "internal/str_format/bind.cc" + "internal/str_format/extension.cc" + "internal/str_format/float_conversion.cc" + "internal/str_format/output.cc" + "internal/str_format/parser.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bits + absl::strings + absl::config + absl::core_headers + absl::type_traits + absl::int128 + absl::span +) + +absl_cc_test( + NAME + str_format_test + SRCS + "str_format_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format + absl::cord + absl::strings + absl::core_headers + gmock_main +) + +absl_cc_test( + NAME + str_format_extension_test + SRCS + "internal/str_format/extension_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format + absl::str_format_internal + absl::strings + gmock_main +) + +absl_cc_test( + NAME + str_format_arg_test + SRCS + "internal/str_format/arg_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format + absl::str_format_internal + gmock_main +) + +absl_cc_test( + NAME + str_format_bind_test + SRCS + "internal/str_format/bind_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format_internal + gmock_main +) + +absl_cc_test( + NAME + str_format_checker_test + SRCS + "internal/str_format/checker_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format + gmock_main +) + +absl_cc_test( + NAME + str_format_convert_test + SRCS + "internal/str_format/convert_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format_internal + absl::raw_logging_internal + absl::int128 + gmock_main +) + +absl_cc_test( + NAME + str_format_output_test + SRCS + "internal/str_format/output_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format_internal + absl::cord + gmock_main +) + +absl_cc_test( + NAME + str_format_parser_test + SRCS + "internal/str_format/parser_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::str_format_internal + absl::core_headers + gmock_main +) + +absl_cc_library( + NAME + pow10_helper + HDRS + "internal/pow10_helper.h" + SRCS + "internal/pow10_helper.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::config + TESTONLY +) + +absl_cc_test( + NAME + pow10_helper_test + SRCS + "internal/pow10_helper_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::pow10_helper + absl::str_format + gmock_main +) + +absl_cc_library( + NAME + cord + HDRS + "cord.h" + SRCS + "cord.cc" + "internal/cord_internal.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base + absl::base_internal + absl::core_headers + absl::endian + absl::fixed_array + absl::function_ref + absl::inlined_vector + absl::optional + absl::raw_logging_internal + absl::strings + absl::strings_internal + absl::type_traits + PUBLIC +) + +absl_cc_library( + NAME + cord_test_helpers + HDRS + "cord_test_helpers.h" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::cord + TESTONLY +) + +absl_cc_test( + NAME + cord_test + SRCS + "cord_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::cord + absl::str_format + absl::strings + absl::base + absl::config + absl::core_headers + absl::endian + absl::raw_logging_internal + absl::fixed_array + gmock_main +) diff --git a/third_party/abseil_cpp/absl/strings/ascii.cc b/third_party/abseil_cpp/absl/strings/ascii.cc new file mode 100644 index 0000000000..93bb03e958 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/ascii.cc @@ -0,0 +1,200 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/ascii.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace ascii_internal { + +// # Table generated by this Python code (bit 0x02 is currently unused): +// TODO(mbar) Move Python code for generation of table to BUILD and link here. + +// NOTE: The kAsciiPropertyBits table used within this code was generated by +// Python code of the following form. (Bit 0x02 is currently unused and +// available.) +// +// def Hex2(n): +// return '0x' + hex(n/16)[2:] + hex(n%16)[2:] +// def IsPunct(ch): +// return (ord(ch) >= 32 and ord(ch) < 127 and +// not ch.isspace() and not ch.isalnum()) +// def IsBlank(ch): +// return ch in ' \t' +// def IsCntrl(ch): +// return ord(ch) < 32 or ord(ch) == 127 +// def IsXDigit(ch): +// return ch.isdigit() or ch.lower() in 'abcdef' +// for i in range(128): +// ch = chr(i) +// mask = ((ch.isalpha() and 0x01 or 0) | +// (ch.isalnum() and 0x04 or 0) | +// (ch.isspace() and 0x08 or 0) | +// (IsPunct(ch) and 0x10 or 0) | +// (IsBlank(ch) and 0x20 or 0) | +// (IsCntrl(ch) and 0x40 or 0) | +// (IsXDigit(ch) and 0x80 or 0)) +// print Hex2(mask) + ',', +// if i % 16 == 7: +// print ' //', Hex2(i & 0x78) +// elif i % 16 == 15: +// print + +// clang-format off +// Array of bitfields holding character information. Each bit value corresponds +// to a particular character feature. For readability, and because the value +// of these bits is tightly coupled to this implementation, the individual bits +// are not named. Note that bitfields for all characters above ASCII 127 are +// zero-initialized. +ABSL_DLL const unsigned char kPropertyBits[256] = { + 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, // 0x00 + 0x40, 0x68, 0x48, 0x48, 0x48, 0x48, 0x40, 0x40, + 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, // 0x10 + 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, 0x40, + 0x28, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, // 0x20 + 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, + 0x84, 0x84, 0x84, 0x84, 0x84, 0x84, 0x84, 0x84, // 0x30 + 0x84, 0x84, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, + 0x10, 0x85, 0x85, 0x85, 0x85, 0x85, 0x85, 0x05, // 0x40 + 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, + 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, // 0x50 + 0x05, 0x05, 0x05, 0x10, 0x10, 0x10, 0x10, 0x10, + 0x10, 0x85, 0x85, 0x85, 0x85, 0x85, 0x85, 0x05, // 0x60 + 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, + 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, 0x05, // 0x70 + 0x05, 0x05, 0x05, 0x10, 0x10, 0x10, 0x10, 0x40, +}; + +// Array of characters for the ascii_tolower() function. For values 'A' +// through 'Z', return the lower-case character; otherwise, return the +// identity of the passed character. +ABSL_DLL const char kToLower[256] = { + '\x00', '\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', + '\x08', '\x09', '\x0a', '\x0b', '\x0c', '\x0d', '\x0e', '\x0f', + '\x10', '\x11', '\x12', '\x13', '\x14', '\x15', '\x16', '\x17', + '\x18', '\x19', '\x1a', '\x1b', '\x1c', '\x1d', '\x1e', '\x1f', + '\x20', '\x21', '\x22', '\x23', '\x24', '\x25', '\x26', '\x27', + '\x28', '\x29', '\x2a', '\x2b', '\x2c', '\x2d', '\x2e', '\x2f', + '\x30', '\x31', '\x32', '\x33', '\x34', '\x35', '\x36', '\x37', + '\x38', '\x39', '\x3a', '\x3b', '\x3c', '\x3d', '\x3e', '\x3f', + '\x40', 'a', 'b', 'c', 'd', 'e', 'f', 'g', + 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', + 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', + 'x', 'y', 'z', '\x5b', '\x5c', '\x5d', '\x5e', '\x5f', + '\x60', '\x61', '\x62', '\x63', '\x64', '\x65', '\x66', '\x67', + '\x68', '\x69', '\x6a', '\x6b', '\x6c', '\x6d', '\x6e', '\x6f', + '\x70', '\x71', '\x72', '\x73', '\x74', '\x75', '\x76', '\x77', + '\x78', '\x79', '\x7a', '\x7b', '\x7c', '\x7d', '\x7e', '\x7f', + '\x80', '\x81', '\x82', '\x83', '\x84', '\x85', '\x86', '\x87', + '\x88', '\x89', '\x8a', '\x8b', '\x8c', '\x8d', '\x8e', '\x8f', + '\x90', '\x91', '\x92', '\x93', '\x94', '\x95', '\x96', '\x97', + '\x98', '\x99', '\x9a', '\x9b', '\x9c', '\x9d', '\x9e', '\x9f', + '\xa0', '\xa1', '\xa2', '\xa3', '\xa4', '\xa5', '\xa6', '\xa7', + '\xa8', '\xa9', '\xaa', '\xab', '\xac', '\xad', '\xae', '\xaf', + '\xb0', '\xb1', '\xb2', '\xb3', '\xb4', '\xb5', '\xb6', '\xb7', + '\xb8', '\xb9', '\xba', '\xbb', '\xbc', '\xbd', '\xbe', '\xbf', + '\xc0', '\xc1', '\xc2', '\xc3', '\xc4', '\xc5', '\xc6', '\xc7', + '\xc8', '\xc9', '\xca', '\xcb', '\xcc', '\xcd', '\xce', '\xcf', + '\xd0', '\xd1', '\xd2', '\xd3', '\xd4', '\xd5', '\xd6', '\xd7', + '\xd8', '\xd9', '\xda', '\xdb', '\xdc', '\xdd', '\xde', '\xdf', + '\xe0', '\xe1', '\xe2', '\xe3', '\xe4', '\xe5', '\xe6', '\xe7', + '\xe8', '\xe9', '\xea', '\xeb', '\xec', '\xed', '\xee', '\xef', + '\xf0', '\xf1', '\xf2', '\xf3', '\xf4', '\xf5', '\xf6', '\xf7', + '\xf8', '\xf9', '\xfa', '\xfb', '\xfc', '\xfd', '\xfe', '\xff', +}; + +// Array of characters for the ascii_toupper() function. For values 'a' +// through 'z', return the upper-case character; otherwise, return the +// identity of the passed character. +ABSL_DLL const char kToUpper[256] = { + '\x00', '\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', + '\x08', '\x09', '\x0a', '\x0b', '\x0c', '\x0d', '\x0e', '\x0f', + '\x10', '\x11', '\x12', '\x13', '\x14', '\x15', '\x16', '\x17', + '\x18', '\x19', '\x1a', '\x1b', '\x1c', '\x1d', '\x1e', '\x1f', + '\x20', '\x21', '\x22', '\x23', '\x24', '\x25', '\x26', '\x27', + '\x28', '\x29', '\x2a', '\x2b', '\x2c', '\x2d', '\x2e', '\x2f', + '\x30', '\x31', '\x32', '\x33', '\x34', '\x35', '\x36', '\x37', + '\x38', '\x39', '\x3a', '\x3b', '\x3c', '\x3d', '\x3e', '\x3f', + '\x40', '\x41', '\x42', '\x43', '\x44', '\x45', '\x46', '\x47', + '\x48', '\x49', '\x4a', '\x4b', '\x4c', '\x4d', '\x4e', '\x4f', + '\x50', '\x51', '\x52', '\x53', '\x54', '\x55', '\x56', '\x57', + '\x58', '\x59', '\x5a', '\x5b', '\x5c', '\x5d', '\x5e', '\x5f', + '\x60', 'A', 'B', 'C', 'D', 'E', 'F', 'G', + 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', + 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', + 'X', 'Y', 'Z', '\x7b', '\x7c', '\x7d', '\x7e', '\x7f', + '\x80', '\x81', '\x82', '\x83', '\x84', '\x85', '\x86', '\x87', + '\x88', '\x89', '\x8a', '\x8b', '\x8c', '\x8d', '\x8e', '\x8f', + '\x90', '\x91', '\x92', '\x93', '\x94', '\x95', '\x96', '\x97', + '\x98', '\x99', '\x9a', '\x9b', '\x9c', '\x9d', '\x9e', '\x9f', + '\xa0', '\xa1', '\xa2', '\xa3', '\xa4', '\xa5', '\xa6', '\xa7', + '\xa8', '\xa9', '\xaa', '\xab', '\xac', '\xad', '\xae', '\xaf', + '\xb0', '\xb1', '\xb2', '\xb3', '\xb4', '\xb5', '\xb6', '\xb7', + '\xb8', '\xb9', '\xba', '\xbb', '\xbc', '\xbd', '\xbe', '\xbf', + '\xc0', '\xc1', '\xc2', '\xc3', '\xc4', '\xc5', '\xc6', '\xc7', + '\xc8', '\xc9', '\xca', '\xcb', '\xcc', '\xcd', '\xce', '\xcf', + '\xd0', '\xd1', '\xd2', '\xd3', '\xd4', '\xd5', '\xd6', '\xd7', + '\xd8', '\xd9', '\xda', '\xdb', '\xdc', '\xdd', '\xde', '\xdf', + '\xe0', '\xe1', '\xe2', '\xe3', '\xe4', '\xe5', '\xe6', '\xe7', + '\xe8', '\xe9', '\xea', '\xeb', '\xec', '\xed', '\xee', '\xef', + '\xf0', '\xf1', '\xf2', '\xf3', '\xf4', '\xf5', '\xf6', '\xf7', + '\xf8', '\xf9', '\xfa', '\xfb', '\xfc', '\xfd', '\xfe', '\xff', +}; +// clang-format on + +} // namespace ascii_internal + +void AsciiStrToLower(std::string* s) { + for (auto& ch : *s) { + ch = absl::ascii_tolower(ch); + } +} + +void AsciiStrToUpper(std::string* s) { + for (auto& ch : *s) { + ch = absl::ascii_toupper(ch); + } +} + +void RemoveExtraAsciiWhitespace(std::string* str) { + auto stripped = StripAsciiWhitespace(*str); + + if (stripped.empty()) { + str->clear(); + return; + } + + auto input_it = stripped.begin(); + auto input_end = stripped.end(); + auto output_it = &(*str)[0]; + bool is_ws = false; + + for (; input_it < input_end; ++input_it) { + if (is_ws) { + // Consecutive whitespace? Keep only the last. + is_ws = absl::ascii_isspace(*input_it); + if (is_ws) --output_it; + } else { + is_ws = absl::ascii_isspace(*input_it); + } + + *output_it = *input_it; + ++output_it; + } + + str->erase(output_it - &(*str)[0]); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/ascii.h b/third_party/abseil_cpp/absl/strings/ascii.h new file mode 100644 index 0000000000..b46bc71f35 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/ascii.h @@ -0,0 +1,242 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: ascii.h +// ----------------------------------------------------------------------------- +// +// This package contains functions operating on characters and strings +// restricted to standard ASCII. These include character classification +// functions analogous to those found in the ANSI C Standard Library <ctype.h> +// header file. +// +// C++ implementations provide <ctype.h> functionality based on their +// C environment locale. In general, reliance on such a locale is not ideal, as +// the locale standard is problematic (and may not return invariant information +// for the same character set, for example). These `ascii_*()` functions are +// hard-wired for standard ASCII, much faster, and guaranteed to behave +// consistently. They will never be overloaded, nor will their function +// signature change. +// +// `ascii_isalnum()`, `ascii_isalpha()`, `ascii_isascii()`, `ascii_isblank()`, +// `ascii_iscntrl()`, `ascii_isdigit()`, `ascii_isgraph()`, `ascii_islower()`, +// `ascii_isprint()`, `ascii_ispunct()`, `ascii_isspace()`, `ascii_isupper()`, +// `ascii_isxdigit()` +// Analogous to the <ctype.h> functions with similar names, these +// functions take an unsigned char and return a bool, based on whether the +// character matches the condition specified. +// +// If the input character has a numerical value greater than 127, these +// functions return `false`. +// +// `ascii_tolower()`, `ascii_toupper()` +// Analogous to the <ctype.h> functions with similar names, these functions +// take an unsigned char and return a char. +// +// If the input character is not an ASCII {lower,upper}-case letter (including +// numerical values greater than 127) then the functions return the same value +// as the input character. + +#ifndef ABSL_STRINGS_ASCII_H_ +#define ABSL_STRINGS_ASCII_H_ + +#include <algorithm> +#include <string> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace ascii_internal { + +// Declaration for an array of bitfields holding character information. +ABSL_DLL extern const unsigned char kPropertyBits[256]; + +// Declaration for the array of characters to upper-case characters. +ABSL_DLL extern const char kToUpper[256]; + +// Declaration for the array of characters to lower-case characters. +ABSL_DLL extern const char kToLower[256]; + +} // namespace ascii_internal + +// ascii_isalpha() +// +// Determines whether the given character is an alphabetic character. +inline bool ascii_isalpha(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x01) != 0; +} + +// ascii_isalnum() +// +// Determines whether the given character is an alphanumeric character. +inline bool ascii_isalnum(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x04) != 0; +} + +// ascii_isspace() +// +// Determines whether the given character is a whitespace character (space, +// tab, vertical tab, formfeed, linefeed, or carriage return). +inline bool ascii_isspace(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x08) != 0; +} + +// ascii_ispunct() +// +// Determines whether the given character is a punctuation character. +inline bool ascii_ispunct(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x10) != 0; +} + +// ascii_isblank() +// +// Determines whether the given character is a blank character (tab or space). +inline bool ascii_isblank(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x20) != 0; +} + +// ascii_iscntrl() +// +// Determines whether the given character is a control character. +inline bool ascii_iscntrl(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x40) != 0; +} + +// ascii_isxdigit() +// +// Determines whether the given character can be represented as a hexadecimal +// digit character (i.e. {0-9} or {A-F}). +inline bool ascii_isxdigit(unsigned char c) { + return (ascii_internal::kPropertyBits[c] & 0x80) != 0; +} + +// ascii_isdigit() +// +// Determines whether the given character can be represented as a decimal +// digit character (i.e. {0-9}). +inline bool ascii_isdigit(unsigned char c) { return c >= '0' && c <= '9'; } + +// ascii_isprint() +// +// Determines whether the given character is printable, including whitespace. +inline bool ascii_isprint(unsigned char c) { return c >= 32 && c < 127; } + +// ascii_isgraph() +// +// Determines whether the given character has a graphical representation. +inline bool ascii_isgraph(unsigned char c) { return c > 32 && c < 127; } + +// ascii_isupper() +// +// Determines whether the given character is uppercase. +inline bool ascii_isupper(unsigned char c) { return c >= 'A' && c <= 'Z'; } + +// ascii_islower() +// +// Determines whether the given character is lowercase. +inline bool ascii_islower(unsigned char c) { return c >= 'a' && c <= 'z'; } + +// ascii_isascii() +// +// Determines whether the given character is ASCII. +inline bool ascii_isascii(unsigned char c) { return c < 128; } + +// ascii_tolower() +// +// Returns an ASCII character, converting to lowercase if uppercase is +// passed. Note that character values > 127 are simply returned. +inline char ascii_tolower(unsigned char c) { + return ascii_internal::kToLower[c]; +} + +// Converts the characters in `s` to lowercase, changing the contents of `s`. +void AsciiStrToLower(std::string* s); + +// Creates a lowercase string from a given absl::string_view. +ABSL_MUST_USE_RESULT inline std::string AsciiStrToLower(absl::string_view s) { + std::string result(s); + absl::AsciiStrToLower(&result); + return result; +} + +// ascii_toupper() +// +// Returns the ASCII character, converting to upper-case if lower-case is +// passed. Note that characters values > 127 are simply returned. +inline char ascii_toupper(unsigned char c) { + return ascii_internal::kToUpper[c]; +} + +// Converts the characters in `s` to uppercase, changing the contents of `s`. +void AsciiStrToUpper(std::string* s); + +// Creates an uppercase string from a given absl::string_view. +ABSL_MUST_USE_RESULT inline std::string AsciiStrToUpper(absl::string_view s) { + std::string result(s); + absl::AsciiStrToUpper(&result); + return result; +} + +// Returns absl::string_view with whitespace stripped from the beginning of the +// given string_view. +ABSL_MUST_USE_RESULT inline absl::string_view StripLeadingAsciiWhitespace( + absl::string_view str) { + auto it = std::find_if_not(str.begin(), str.end(), absl::ascii_isspace); + return str.substr(it - str.begin()); +} + +// Strips in place whitespace from the beginning of the given string. +inline void StripLeadingAsciiWhitespace(std::string* str) { + auto it = std::find_if_not(str->begin(), str->end(), absl::ascii_isspace); + str->erase(str->begin(), it); +} + +// Returns absl::string_view with whitespace stripped from the end of the given +// string_view. +ABSL_MUST_USE_RESULT inline absl::string_view StripTrailingAsciiWhitespace( + absl::string_view str) { + auto it = std::find_if_not(str.rbegin(), str.rend(), absl::ascii_isspace); + return str.substr(0, str.rend() - it); +} + +// Strips in place whitespace from the end of the given string +inline void StripTrailingAsciiWhitespace(std::string* str) { + auto it = std::find_if_not(str->rbegin(), str->rend(), absl::ascii_isspace); + str->erase(str->rend() - it); +} + +// Returns absl::string_view with whitespace stripped from both ends of the +// given string_view. +ABSL_MUST_USE_RESULT inline absl::string_view StripAsciiWhitespace( + absl::string_view str) { + return StripTrailingAsciiWhitespace(StripLeadingAsciiWhitespace(str)); +} + +// Strips in place whitespace from both ends of the given string +inline void StripAsciiWhitespace(std::string* str) { + StripTrailingAsciiWhitespace(str); + StripLeadingAsciiWhitespace(str); +} + +// Removes leading, trailing, and consecutive internal whitespace. +void RemoveExtraAsciiWhitespace(std::string*); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_ASCII_H_ diff --git a/third_party/abseil_cpp/absl/strings/ascii_benchmark.cc b/third_party/abseil_cpp/absl/strings/ascii_benchmark.cc new file mode 100644 index 0000000000..aca458c804 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/ascii_benchmark.cc @@ -0,0 +1,120 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/ascii.h" + +#include <cctype> +#include <string> +#include <array> +#include <random> + +#include "benchmark/benchmark.h" + +namespace { + +std::array<unsigned char, 256> MakeShuffledBytes() { + std::array<unsigned char, 256> bytes; + for (size_t i = 0; i < 256; ++i) bytes[i] = static_cast<unsigned char>(i); + std::random_device rd; + std::seed_seq seed({rd(), rd(), rd(), rd(), rd(), rd(), rd(), rd()}); + std::mt19937 g(seed); + std::shuffle(bytes.begin(), bytes.end(), g); + return bytes; +} + +template <typename Function> +void AsciiBenchmark(benchmark::State& state, Function f) { + std::array<unsigned char, 256> bytes = MakeShuffledBytes(); + size_t sum = 0; + for (auto _ : state) { + for (unsigned char b : bytes) sum += f(b) ? 1 : 0; + } + // Make a copy of `sum` before calling `DoNotOptimize` to make sure that `sum` + // can be put in a CPU register and not degrade performance in the loop above. + size_t sum2 = sum; + benchmark::DoNotOptimize(sum2); + state.SetBytesProcessed(state.iterations() * bytes.size()); +} + +using StdAsciiFunction = int (*)(int); +template <StdAsciiFunction f> +void BM_Ascii(benchmark::State& state) { + AsciiBenchmark(state, f); +} + +using AbslAsciiIsFunction = bool (*)(unsigned char); +template <AbslAsciiIsFunction f> +void BM_Ascii(benchmark::State& state) { + AsciiBenchmark(state, f); +} + +using AbslAsciiToFunction = char (*)(unsigned char); +template <AbslAsciiToFunction f> +void BM_Ascii(benchmark::State& state) { + AsciiBenchmark(state, f); +} + +inline char Noop(unsigned char b) { return static_cast<char>(b); } + +BENCHMARK_TEMPLATE(BM_Ascii, Noop); +BENCHMARK_TEMPLATE(BM_Ascii, std::isalpha); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isalpha); +BENCHMARK_TEMPLATE(BM_Ascii, std::isdigit); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isdigit); +BENCHMARK_TEMPLATE(BM_Ascii, std::isalnum); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isalnum); +BENCHMARK_TEMPLATE(BM_Ascii, std::isspace); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isspace); +BENCHMARK_TEMPLATE(BM_Ascii, std::ispunct); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_ispunct); +BENCHMARK_TEMPLATE(BM_Ascii, std::isblank); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isblank); +BENCHMARK_TEMPLATE(BM_Ascii, std::iscntrl); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_iscntrl); +BENCHMARK_TEMPLATE(BM_Ascii, std::isxdigit); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isxdigit); +BENCHMARK_TEMPLATE(BM_Ascii, std::isprint); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isprint); +BENCHMARK_TEMPLATE(BM_Ascii, std::isgraph); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isgraph); +BENCHMARK_TEMPLATE(BM_Ascii, std::isupper); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isupper); +BENCHMARK_TEMPLATE(BM_Ascii, std::islower); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_islower); +BENCHMARK_TEMPLATE(BM_Ascii, isascii); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_isascii); +BENCHMARK_TEMPLATE(BM_Ascii, std::tolower); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_tolower); +BENCHMARK_TEMPLATE(BM_Ascii, std::toupper); +BENCHMARK_TEMPLATE(BM_Ascii, absl::ascii_toupper); + +static void BM_StrToLower(benchmark::State& state) { + const int size = state.range(0); + std::string s(size, 'X'); + for (auto _ : state) { + benchmark::DoNotOptimize(absl::AsciiStrToLower(s)); + } +} +BENCHMARK(BM_StrToLower)->Range(1, 1 << 20); + +static void BM_StrToUpper(benchmark::State& state) { + const int size = state.range(0); + std::string s(size, 'x'); + for (auto _ : state) { + benchmark::DoNotOptimize(absl::AsciiStrToUpper(s)); + } +} +BENCHMARK(BM_StrToUpper)->Range(1, 1 << 20); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/ascii_test.cc b/third_party/abseil_cpp/absl/strings/ascii_test.cc new file mode 100644 index 0000000000..5ecd23f869 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/ascii_test.cc @@ -0,0 +1,361 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/ascii.h" + +#include <cctype> +#include <clocale> +#include <cstring> +#include <string> + +#include "gtest/gtest.h" +#include "absl/base/macros.h" +#include "absl/base/port.h" + +namespace { + +TEST(AsciiIsFoo, All) { + for (int i = 0; i < 256; i++) { + if ((i >= 'a' && i <= 'z') || (i >= 'A' && i <= 'Z')) + EXPECT_TRUE(absl::ascii_isalpha(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isalpha(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if ((i >= '0' && i <= '9')) + EXPECT_TRUE(absl::ascii_isdigit(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isdigit(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (absl::ascii_isalpha(i) || absl::ascii_isdigit(i)) + EXPECT_TRUE(absl::ascii_isalnum(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isalnum(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i != '\0' && strchr(" \r\n\t\v\f", i)) + EXPECT_TRUE(absl::ascii_isspace(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isspace(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i >= 32 && i < 127) + EXPECT_TRUE(absl::ascii_isprint(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isprint(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (absl::ascii_isprint(i) && !absl::ascii_isspace(i) && + !absl::ascii_isalnum(i)) + EXPECT_TRUE(absl::ascii_ispunct(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_ispunct(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i == ' ' || i == '\t') + EXPECT_TRUE(absl::ascii_isblank(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isblank(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i < 32 || i == 127) + EXPECT_TRUE(absl::ascii_iscntrl(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_iscntrl(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (absl::ascii_isdigit(i) || (i >= 'A' && i <= 'F') || + (i >= 'a' && i <= 'f')) + EXPECT_TRUE(absl::ascii_isxdigit(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isxdigit(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i > 32 && i < 127) + EXPECT_TRUE(absl::ascii_isgraph(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isgraph(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i >= 'A' && i <= 'Z') + EXPECT_TRUE(absl::ascii_isupper(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_isupper(i)) << ": failed on " << i; + } + for (int i = 0; i < 256; i++) { + if (i >= 'a' && i <= 'z') + EXPECT_TRUE(absl::ascii_islower(i)) << ": failed on " << i; + else + EXPECT_TRUE(!absl::ascii_islower(i)) << ": failed on " << i; + } + for (int i = 0; i < 128; i++) { + EXPECT_TRUE(absl::ascii_isascii(i)) << ": failed on " << i; + } + for (int i = 128; i < 256; i++) { + EXPECT_TRUE(!absl::ascii_isascii(i)) << ": failed on " << i; + } + + // The official is* functions don't accept negative signed chars, but + // our absl::ascii_is* functions do. + for (int i = 0; i < 256; i++) { + signed char sc = static_cast<signed char>(static_cast<unsigned char>(i)); + EXPECT_EQ(absl::ascii_isalpha(i), absl::ascii_isalpha(sc)) << i; + EXPECT_EQ(absl::ascii_isdigit(i), absl::ascii_isdigit(sc)) << i; + EXPECT_EQ(absl::ascii_isalnum(i), absl::ascii_isalnum(sc)) << i; + EXPECT_EQ(absl::ascii_isspace(i), absl::ascii_isspace(sc)) << i; + EXPECT_EQ(absl::ascii_ispunct(i), absl::ascii_ispunct(sc)) << i; + EXPECT_EQ(absl::ascii_isblank(i), absl::ascii_isblank(sc)) << i; + EXPECT_EQ(absl::ascii_iscntrl(i), absl::ascii_iscntrl(sc)) << i; + EXPECT_EQ(absl::ascii_isxdigit(i), absl::ascii_isxdigit(sc)) << i; + EXPECT_EQ(absl::ascii_isprint(i), absl::ascii_isprint(sc)) << i; + EXPECT_EQ(absl::ascii_isgraph(i), absl::ascii_isgraph(sc)) << i; + EXPECT_EQ(absl::ascii_isupper(i), absl::ascii_isupper(sc)) << i; + EXPECT_EQ(absl::ascii_islower(i), absl::ascii_islower(sc)) << i; + EXPECT_EQ(absl::ascii_isascii(i), absl::ascii_isascii(sc)) << i; + } +} + +// Checks that absl::ascii_isfoo returns the same value as isfoo in the C +// locale. +TEST(AsciiIsFoo, SameAsIsFoo) { +#ifndef __ANDROID__ + // temporarily change locale to C. It should already be C, but just for safety + const char* old_locale = setlocale(LC_CTYPE, "C"); + ASSERT_TRUE(old_locale != nullptr); +#endif + + for (int i = 0; i < 256; i++) { + EXPECT_EQ(isalpha(i) != 0, absl::ascii_isalpha(i)) << i; + EXPECT_EQ(isdigit(i) != 0, absl::ascii_isdigit(i)) << i; + EXPECT_EQ(isalnum(i) != 0, absl::ascii_isalnum(i)) << i; + EXPECT_EQ(isspace(i) != 0, absl::ascii_isspace(i)) << i; + EXPECT_EQ(ispunct(i) != 0, absl::ascii_ispunct(i)) << i; + EXPECT_EQ(isblank(i) != 0, absl::ascii_isblank(i)) << i; + EXPECT_EQ(iscntrl(i) != 0, absl::ascii_iscntrl(i)) << i; + EXPECT_EQ(isxdigit(i) != 0, absl::ascii_isxdigit(i)) << i; + EXPECT_EQ(isprint(i) != 0, absl::ascii_isprint(i)) << i; + EXPECT_EQ(isgraph(i) != 0, absl::ascii_isgraph(i)) << i; + EXPECT_EQ(isupper(i) != 0, absl::ascii_isupper(i)) << i; + EXPECT_EQ(islower(i) != 0, absl::ascii_islower(i)) << i; + EXPECT_EQ(isascii(i) != 0, absl::ascii_isascii(i)) << i; + } + +#ifndef __ANDROID__ + // restore the old locale. + ASSERT_TRUE(setlocale(LC_CTYPE, old_locale)); +#endif +} + +TEST(AsciiToFoo, All) { +#ifndef __ANDROID__ + // temporarily change locale to C. It should already be C, but just for safety + const char* old_locale = setlocale(LC_CTYPE, "C"); + ASSERT_TRUE(old_locale != nullptr); +#endif + + for (int i = 0; i < 256; i++) { + if (absl::ascii_islower(i)) + EXPECT_EQ(absl::ascii_toupper(i), 'A' + (i - 'a')) << i; + else + EXPECT_EQ(absl::ascii_toupper(i), static_cast<char>(i)) << i; + + if (absl::ascii_isupper(i)) + EXPECT_EQ(absl::ascii_tolower(i), 'a' + (i - 'A')) << i; + else + EXPECT_EQ(absl::ascii_tolower(i), static_cast<char>(i)) << i; + + // These CHECKs only hold in a C locale. + EXPECT_EQ(static_cast<char>(tolower(i)), absl::ascii_tolower(i)) << i; + EXPECT_EQ(static_cast<char>(toupper(i)), absl::ascii_toupper(i)) << i; + + // The official to* functions don't accept negative signed chars, but + // our absl::ascii_to* functions do. + signed char sc = static_cast<signed char>(static_cast<unsigned char>(i)); + EXPECT_EQ(absl::ascii_tolower(i), absl::ascii_tolower(sc)) << i; + EXPECT_EQ(absl::ascii_toupper(i), absl::ascii_toupper(sc)) << i; + } +#ifndef __ANDROID__ + // restore the old locale. + ASSERT_TRUE(setlocale(LC_CTYPE, old_locale)); +#endif +} + +TEST(AsciiStrTo, Lower) { + const char buf[] = "ABCDEF"; + const std::string str("GHIJKL"); + const std::string str2("MNOPQR"); + const absl::string_view sp(str2); + + EXPECT_EQ("abcdef", absl::AsciiStrToLower(buf)); + EXPECT_EQ("ghijkl", absl::AsciiStrToLower(str)); + EXPECT_EQ("mnopqr", absl::AsciiStrToLower(sp)); + + char mutable_buf[] = "Mutable"; + std::transform(mutable_buf, mutable_buf + strlen(mutable_buf), + mutable_buf, absl::ascii_tolower); + EXPECT_STREQ("mutable", mutable_buf); +} + +TEST(AsciiStrTo, Upper) { + const char buf[] = "abcdef"; + const std::string str("ghijkl"); + const std::string str2("mnopqr"); + const absl::string_view sp(str2); + + EXPECT_EQ("ABCDEF", absl::AsciiStrToUpper(buf)); + EXPECT_EQ("GHIJKL", absl::AsciiStrToUpper(str)); + EXPECT_EQ("MNOPQR", absl::AsciiStrToUpper(sp)); + + char mutable_buf[] = "Mutable"; + std::transform(mutable_buf, mutable_buf + strlen(mutable_buf), + mutable_buf, absl::ascii_toupper); + EXPECT_STREQ("MUTABLE", mutable_buf); +} + +TEST(StripLeadingAsciiWhitespace, FromStringView) { + EXPECT_EQ(absl::string_view{}, + absl::StripLeadingAsciiWhitespace(absl::string_view{})); + EXPECT_EQ("foo", absl::StripLeadingAsciiWhitespace({"foo"})); + EXPECT_EQ("foo", absl::StripLeadingAsciiWhitespace({"\t \n\f\r\n\vfoo"})); + EXPECT_EQ("foo foo\n ", + absl::StripLeadingAsciiWhitespace({"\t \n\f\r\n\vfoo foo\n "})); + EXPECT_EQ(absl::string_view{}, absl::StripLeadingAsciiWhitespace( + {"\t \n\f\r\v\n\t \n\f\r\v\n"})); +} + +TEST(StripLeadingAsciiWhitespace, InPlace) { + std::string str; + + absl::StripLeadingAsciiWhitespace(&str); + EXPECT_EQ("", str); + + str = "foo"; + absl::StripLeadingAsciiWhitespace(&str); + EXPECT_EQ("foo", str); + + str = "\t \n\f\r\n\vfoo"; + absl::StripLeadingAsciiWhitespace(&str); + EXPECT_EQ("foo", str); + + str = "\t \n\f\r\n\vfoo foo\n "; + absl::StripLeadingAsciiWhitespace(&str); + EXPECT_EQ("foo foo\n ", str); + + str = "\t \n\f\r\v\n\t \n\f\r\v\n"; + absl::StripLeadingAsciiWhitespace(&str); + EXPECT_EQ(absl::string_view{}, str); +} + +TEST(StripTrailingAsciiWhitespace, FromStringView) { + EXPECT_EQ(absl::string_view{}, + absl::StripTrailingAsciiWhitespace(absl::string_view{})); + EXPECT_EQ("foo", absl::StripTrailingAsciiWhitespace({"foo"})); + EXPECT_EQ("foo", absl::StripTrailingAsciiWhitespace({"foo\t \n\f\r\n\v"})); + EXPECT_EQ(" \nfoo foo", + absl::StripTrailingAsciiWhitespace({" \nfoo foo\t \n\f\r\n\v"})); + EXPECT_EQ(absl::string_view{}, absl::StripTrailingAsciiWhitespace( + {"\t \n\f\r\v\n\t \n\f\r\v\n"})); +} + +TEST(StripTrailingAsciiWhitespace, InPlace) { + std::string str; + + absl::StripTrailingAsciiWhitespace(&str); + EXPECT_EQ("", str); + + str = "foo"; + absl::StripTrailingAsciiWhitespace(&str); + EXPECT_EQ("foo", str); + + str = "foo\t \n\f\r\n\v"; + absl::StripTrailingAsciiWhitespace(&str); + EXPECT_EQ("foo", str); + + str = " \nfoo foo\t \n\f\r\n\v"; + absl::StripTrailingAsciiWhitespace(&str); + EXPECT_EQ(" \nfoo foo", str); + + str = "\t \n\f\r\v\n\t \n\f\r\v\n"; + absl::StripTrailingAsciiWhitespace(&str); + EXPECT_EQ(absl::string_view{}, str); +} + +TEST(StripAsciiWhitespace, FromStringView) { + EXPECT_EQ(absl::string_view{}, + absl::StripAsciiWhitespace(absl::string_view{})); + EXPECT_EQ("foo", absl::StripAsciiWhitespace({"foo"})); + EXPECT_EQ("foo", + absl::StripAsciiWhitespace({"\t \n\f\r\n\vfoo\t \n\f\r\n\v"})); + EXPECT_EQ("foo foo", absl::StripAsciiWhitespace( + {"\t \n\f\r\n\vfoo foo\t \n\f\r\n\v"})); + EXPECT_EQ(absl::string_view{}, + absl::StripAsciiWhitespace({"\t \n\f\r\v\n\t \n\f\r\v\n"})); +} + +TEST(StripAsciiWhitespace, InPlace) { + std::string str; + + absl::StripAsciiWhitespace(&str); + EXPECT_EQ("", str); + + str = "foo"; + absl::StripAsciiWhitespace(&str); + EXPECT_EQ("foo", str); + + str = "\t \n\f\r\n\vfoo\t \n\f\r\n\v"; + absl::StripAsciiWhitespace(&str); + EXPECT_EQ("foo", str); + + str = "\t \n\f\r\n\vfoo foo\t \n\f\r\n\v"; + absl::StripAsciiWhitespace(&str); + EXPECT_EQ("foo foo", str); + + str = "\t \n\f\r\v\n\t \n\f\r\v\n"; + absl::StripAsciiWhitespace(&str); + EXPECT_EQ(absl::string_view{}, str); +} + +TEST(RemoveExtraAsciiWhitespace, InPlace) { + const char* inputs[] = {"No extra space", + " Leading whitespace", + "Trailing whitespace ", + " Leading and trailing ", + " Whitespace \t in\v middle ", + "'Eeeeep! \n Newlines!\n", + "nospaces", + "", + "\n\t a\t\n\nb \t\n"}; + + const char* outputs[] = { + "No extra space", + "Leading whitespace", + "Trailing whitespace", + "Leading and trailing", + "Whitespace in middle", + "'Eeeeep! Newlines!", + "nospaces", + "", + "a\nb", + }; + const int NUM_TESTS = ABSL_ARRAYSIZE(inputs); + + for (int i = 0; i < NUM_TESTS; i++) { + std::string s(inputs[i]); + absl::RemoveExtraAsciiWhitespace(&s); + EXPECT_EQ(outputs[i], s); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/charconv.cc b/third_party/abseil_cpp/absl/strings/charconv.cc new file mode 100644 index 0000000000..3613a65286 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/charconv.cc @@ -0,0 +1,984 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/charconv.h" + +#include <algorithm> +#include <cassert> +#include <cmath> +#include <cstring> + +#include "absl/base/casts.h" +#include "absl/base/internal/bits.h" +#include "absl/numeric/int128.h" +#include "absl/strings/internal/charconv_bigint.h" +#include "absl/strings/internal/charconv_parse.h" + +// The macro ABSL_BIT_PACK_FLOATS is defined on x86-64, where IEEE floating +// point numbers have the same endianness in memory as a bitfield struct +// containing the corresponding parts. +// +// When set, we replace calls to ldexp() with manual bit packing, which is +// faster and is unaffected by floating point environment. +#ifdef ABSL_BIT_PACK_FLOATS +#error ABSL_BIT_PACK_FLOATS cannot be directly set +#elif defined(__x86_64__) || defined(_M_X64) +#define ABSL_BIT_PACK_FLOATS 1 +#endif + +// A note about subnormals: +// +// The code below talks about "normals" and "subnormals". A normal IEEE float +// has a fixed-width mantissa and power of two exponent. For example, a normal +// `double` has a 53-bit mantissa. Because the high bit is always 1, it is not +// stored in the representation. The implicit bit buys an extra bit of +// resolution in the datatype. +// +// The downside of this scheme is that there is a large gap between DBL_MIN and +// zero. (Large, at least, relative to the different between DBL_MIN and the +// next representable number). This gap is softened by the "subnormal" numbers, +// which have the same power-of-two exponent as DBL_MIN, but no implicit 53rd +// bit. An all-bits-zero exponent in the encoding represents subnormals. (Zero +// is represented as a subnormal with an all-bits-zero mantissa.) +// +// The code below, in calculations, represents the mantissa as a uint64_t. The +// end result normally has the 53rd bit set. It represents subnormals by using +// narrower mantissas. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +template <typename FloatType> +struct FloatTraits; + +template <> +struct FloatTraits<double> { + // The number of mantissa bits in the given float type. This includes the + // implied high bit. + static constexpr int kTargetMantissaBits = 53; + + // The largest supported IEEE exponent, in our integral mantissa + // representation. + // + // If `m` is the largest possible int kTargetMantissaBits bits wide, then + // m * 2**kMaxExponent is exactly equal to DBL_MAX. + static constexpr int kMaxExponent = 971; + + // The smallest supported IEEE normal exponent, in our integral mantissa + // representation. + // + // If `m` is the smallest possible int kTargetMantissaBits bits wide, then + // m * 2**kMinNormalExponent is exactly equal to DBL_MIN. + static constexpr int kMinNormalExponent = -1074; + + static double MakeNan(const char* tagp) { + // Support nan no matter which namespace it's in. Some platforms + // incorrectly don't put it in namespace std. + using namespace std; // NOLINT + return nan(tagp); + } + + // Builds a nonzero floating point number out of the provided parts. + // + // This is intended to do the same operation as ldexp(mantissa, exponent), + // but using purely integer math, to avoid -ffastmath and floating + // point environment issues. Using type punning is also faster. We fall back + // to ldexp on a per-platform basis for portability. + // + // `exponent` must be between kMinNormalExponent and kMaxExponent. + // + // `mantissa` must either be exactly kTargetMantissaBits wide, in which case + // a normal value is made, or it must be less narrow than that, in which case + // `exponent` must be exactly kMinNormalExponent, and a subnormal value is + // made. + static double Make(uint64_t mantissa, int exponent, bool sign) { +#ifndef ABSL_BIT_PACK_FLOATS + // Support ldexp no matter which namespace it's in. Some platforms + // incorrectly don't put it in namespace std. + using namespace std; // NOLINT + return sign ? -ldexp(mantissa, exponent) : ldexp(mantissa, exponent); +#else + constexpr uint64_t kMantissaMask = + (uint64_t(1) << (kTargetMantissaBits - 1)) - 1; + uint64_t dbl = static_cast<uint64_t>(sign) << 63; + if (mantissa > kMantissaMask) { + // Normal value. + // Adjust by 1023 for the exponent representation bias, and an additional + // 52 due to the implied decimal point in the IEEE mantissa represenation. + dbl += uint64_t{exponent + 1023u + kTargetMantissaBits - 1} << 52; + mantissa &= kMantissaMask; + } else { + // subnormal value + assert(exponent == kMinNormalExponent); + } + dbl += mantissa; + return absl::bit_cast<double>(dbl); +#endif // ABSL_BIT_PACK_FLOATS + } +}; + +// Specialization of floating point traits for the `float` type. See the +// FloatTraits<double> specialization above for meaning of each of the following +// members and methods. +template <> +struct FloatTraits<float> { + static constexpr int kTargetMantissaBits = 24; + static constexpr int kMaxExponent = 104; + static constexpr int kMinNormalExponent = -149; + static float MakeNan(const char* tagp) { + // Support nanf no matter which namespace it's in. Some platforms + // incorrectly don't put it in namespace std. + using namespace std; // NOLINT + return nanf(tagp); + } + static float Make(uint32_t mantissa, int exponent, bool sign) { +#ifndef ABSL_BIT_PACK_FLOATS + // Support ldexpf no matter which namespace it's in. Some platforms + // incorrectly don't put it in namespace std. + using namespace std; // NOLINT + return sign ? -ldexpf(mantissa, exponent) : ldexpf(mantissa, exponent); +#else + constexpr uint32_t kMantissaMask = + (uint32_t(1) << (kTargetMantissaBits - 1)) - 1; + uint32_t flt = static_cast<uint32_t>(sign) << 31; + if (mantissa > kMantissaMask) { + // Normal value. + // Adjust by 127 for the exponent representation bias, and an additional + // 23 due to the implied decimal point in the IEEE mantissa represenation. + flt += uint32_t{exponent + 127u + kTargetMantissaBits - 1} << 23; + mantissa &= kMantissaMask; + } else { + // subnormal value + assert(exponent == kMinNormalExponent); + } + flt += mantissa; + return absl::bit_cast<float>(flt); +#endif // ABSL_BIT_PACK_FLOATS + } +}; + +// Decimal-to-binary conversions require coercing powers of 10 into a mantissa +// and a power of 2. The two helper functions Power10Mantissa(n) and +// Power10Exponent(n) perform this task. Together, these represent a hand- +// rolled floating point value which is equal to or just less than 10**n. +// +// The return values satisfy two range guarantees: +// +// Power10Mantissa(n) * 2**Power10Exponent(n) <= 10**n +// < (Power10Mantissa(n) + 1) * 2**Power10Exponent(n) +// +// 2**63 <= Power10Mantissa(n) < 2**64. +// +// Lookups into the power-of-10 table must first check the Power10Overflow() and +// Power10Underflow() functions, to avoid out-of-bounds table access. +// +// Indexes into these tables are biased by -kPower10TableMin, and the table has +// values in the range [kPower10TableMin, kPower10TableMax]. +extern const uint64_t kPower10MantissaTable[]; +extern const int16_t kPower10ExponentTable[]; + +// The smallest allowed value for use with the Power10Mantissa() and +// Power10Exponent() functions below. (If a smaller exponent is needed in +// calculations, the end result is guaranteed to underflow.) +constexpr int kPower10TableMin = -342; + +// The largest allowed value for use with the Power10Mantissa() and +// Power10Exponent() functions below. (If a smaller exponent is needed in +// calculations, the end result is guaranteed to overflow.) +constexpr int kPower10TableMax = 308; + +uint64_t Power10Mantissa(int n) { + return kPower10MantissaTable[n - kPower10TableMin]; +} + +int Power10Exponent(int n) { + return kPower10ExponentTable[n - kPower10TableMin]; +} + +// Returns true if n is large enough that 10**n always results in an IEEE +// overflow. +bool Power10Overflow(int n) { return n > kPower10TableMax; } + +// Returns true if n is small enough that 10**n times a ParsedFloat mantissa +// always results in an IEEE underflow. +bool Power10Underflow(int n) { return n < kPower10TableMin; } + +// Returns true if Power10Mantissa(n) * 2**Power10Exponent(n) is exactly equal +// to 10**n numerically. Put another way, this returns true if there is no +// truncation error in Power10Mantissa(n). +bool Power10Exact(int n) { return n >= 0 && n <= 27; } + +// Sentinel exponent values for representing numbers too large or too close to +// zero to represent in a double. +constexpr int kOverflow = 99999; +constexpr int kUnderflow = -99999; + +// Struct representing the calculated conversion result of a positive (nonzero) +// floating point number. +// +// The calculated number is mantissa * 2**exponent (mantissa is treated as an +// integer.) `mantissa` is chosen to be the correct width for the IEEE float +// representation being calculated. (`mantissa` will always have the same bit +// width for normal values, and narrower bit widths for subnormals.) +// +// If the result of conversion was an underflow or overflow, exponent is set +// to kUnderflow or kOverflow. +struct CalculatedFloat { + uint64_t mantissa = 0; + int exponent = 0; +}; + +// Returns the bit width of the given uint128. (Equivalently, returns 128 +// minus the number of leading zero bits.) +int BitWidth(uint128 value) { + if (Uint128High64(value) == 0) { + return 64 - base_internal::CountLeadingZeros64(Uint128Low64(value)); + } + return 128 - base_internal::CountLeadingZeros64(Uint128High64(value)); +} + +// Calculates how far to the right a mantissa needs to be shifted to create a +// properly adjusted mantissa for an IEEE floating point number. +// +// `mantissa_width` is the bit width of the mantissa to be shifted, and +// `binary_exponent` is the exponent of the number before the shift. +// +// This accounts for subnormal values, and will return a larger-than-normal +// shift if binary_exponent would otherwise be too low. +template <typename FloatType> +int NormalizedShiftSize(int mantissa_width, int binary_exponent) { + const int normal_shift = + mantissa_width - FloatTraits<FloatType>::kTargetMantissaBits; + const int minimum_shift = + FloatTraits<FloatType>::kMinNormalExponent - binary_exponent; + return std::max(normal_shift, minimum_shift); +} + +// Right shifts a uint128 so that it has the requested bit width. (The +// resulting value will have 128 - bit_width leading zeroes.) The initial +// `value` must be wider than the requested bit width. +// +// Returns the number of bits shifted. +int TruncateToBitWidth(int bit_width, uint128* value) { + const int current_bit_width = BitWidth(*value); + const int shift = current_bit_width - bit_width; + *value >>= shift; + return shift; +} + +// Checks if the given ParsedFloat represents one of the edge cases that are +// not dependent on number base: zero, infinity, or NaN. If so, sets *value +// the appropriate double, and returns true. +template <typename FloatType> +bool HandleEdgeCase(const strings_internal::ParsedFloat& input, bool negative, + FloatType* value) { + if (input.type == strings_internal::FloatType::kNan) { + // A bug in both clang and gcc would cause the compiler to optimize away the + // buffer we are building below. Declaring the buffer volatile avoids the + // issue, and has no measurable performance impact in microbenchmarks. + // + // https://bugs.llvm.org/show_bug.cgi?id=37778 + // https://gcc.gnu.org/bugzilla/show_bug.cgi?id=86113 + constexpr ptrdiff_t kNanBufferSize = 128; + volatile char n_char_sequence[kNanBufferSize]; + if (input.subrange_begin == nullptr) { + n_char_sequence[0] = '\0'; + } else { + ptrdiff_t nan_size = input.subrange_end - input.subrange_begin; + nan_size = std::min(nan_size, kNanBufferSize - 1); + std::copy_n(input.subrange_begin, nan_size, n_char_sequence); + n_char_sequence[nan_size] = '\0'; + } + char* nan_argument = const_cast<char*>(n_char_sequence); + *value = negative ? -FloatTraits<FloatType>::MakeNan(nan_argument) + : FloatTraits<FloatType>::MakeNan(nan_argument); + return true; + } + if (input.type == strings_internal::FloatType::kInfinity) { + *value = negative ? -std::numeric_limits<FloatType>::infinity() + : std::numeric_limits<FloatType>::infinity(); + return true; + } + if (input.mantissa == 0) { + *value = negative ? -0.0 : 0.0; + return true; + } + return false; +} + +// Given a CalculatedFloat result of a from_chars conversion, generate the +// correct output values. +// +// CalculatedFloat can represent an underflow or overflow, in which case the +// error code in *result is set. Otherwise, the calculated floating point +// number is stored in *value. +template <typename FloatType> +void EncodeResult(const CalculatedFloat& calculated, bool negative, + absl::from_chars_result* result, FloatType* value) { + if (calculated.exponent == kOverflow) { + result->ec = std::errc::result_out_of_range; + *value = negative ? -std::numeric_limits<FloatType>::max() + : std::numeric_limits<FloatType>::max(); + return; + } else if (calculated.mantissa == 0 || calculated.exponent == kUnderflow) { + result->ec = std::errc::result_out_of_range; + *value = negative ? -0.0 : 0.0; + return; + } + *value = FloatTraits<FloatType>::Make(calculated.mantissa, + calculated.exponent, negative); +} + +// Returns the given uint128 shifted to the right by `shift` bits, and rounds +// the remaining bits using round_to_nearest logic. The value is returned as a +// uint64_t, since this is the type used by this library for storing calculated +// floating point mantissas. +// +// It is expected that the width of the input value shifted by `shift` will +// be the correct bit-width for the target mantissa, which is strictly narrower +// than a uint64_t. +// +// If `input_exact` is false, then a nonzero error epsilon is assumed. For +// rounding purposes, the true value being rounded is strictly greater than the +// input value. The error may represent a single lost carry bit. +// +// When input_exact, shifted bits of the form 1000000... represent a tie, which +// is broken by rounding to even -- the rounding direction is chosen so the low +// bit of the returned value is 0. +// +// When !input_exact, shifted bits of the form 10000000... represent a value +// strictly greater than one half (due to the error epsilon), and so ties are +// always broken by rounding up. +// +// When !input_exact, shifted bits of the form 01111111... are uncertain; +// the true value may or may not be greater than 10000000..., due to the +// possible lost carry bit. The correct rounding direction is unknown. In this +// case, the result is rounded down, and `output_exact` is set to false. +// +// Zero and negative values of `shift` are accepted, in which case the word is +// shifted left, as necessary. +uint64_t ShiftRightAndRound(uint128 value, int shift, bool input_exact, + bool* output_exact) { + if (shift <= 0) { + *output_exact = input_exact; + return static_cast<uint64_t>(value << -shift); + } + if (shift >= 128) { + // Exponent is so small that we are shifting away all significant bits. + // Answer will not be representable, even as a subnormal, so return a zero + // mantissa (which represents underflow). + *output_exact = true; + return 0; + } + + *output_exact = true; + const uint128 shift_mask = (uint128(1) << shift) - 1; + const uint128 halfway_point = uint128(1) << (shift - 1); + + const uint128 shifted_bits = value & shift_mask; + value >>= shift; + if (shifted_bits > halfway_point) { + // Shifted bits greater than 10000... require rounding up. + return static_cast<uint64_t>(value + 1); + } + if (shifted_bits == halfway_point) { + // In exact mode, shifted bits of 10000... mean we're exactly halfway + // between two numbers, and we must round to even. So only round up if + // the low bit of `value` is set. + // + // In inexact mode, the nonzero error means the actual value is greater + // than the halfway point and we must alway round up. + if ((value & 1) == 1 || !input_exact) { + ++value; + } + return static_cast<uint64_t>(value); + } + if (!input_exact && shifted_bits == halfway_point - 1) { + // Rounding direction is unclear, due to error. + *output_exact = false; + } + // Otherwise, round down. + return static_cast<uint64_t>(value); +} + +// Checks if a floating point guess needs to be rounded up, using high precision +// math. +// +// `guess_mantissa` and `guess_exponent` represent a candidate guess for the +// number represented by `parsed_decimal`. +// +// The exact number represented by `parsed_decimal` must lie between the two +// numbers: +// A = `guess_mantissa * 2**guess_exponent` +// B = `(guess_mantissa + 1) * 2**guess_exponent` +// +// This function returns false if `A` is the better guess, and true if `B` is +// the better guess, with rounding ties broken by rounding to even. +bool MustRoundUp(uint64_t guess_mantissa, int guess_exponent, + const strings_internal::ParsedFloat& parsed_decimal) { + // 768 is the number of digits needed in the worst case. We could determine a + // better limit dynamically based on the value of parsed_decimal.exponent. + // This would optimize pathological input cases only. (Sane inputs won't have + // hundreds of digits of mantissa.) + absl::strings_internal::BigUnsigned<84> exact_mantissa; + int exact_exponent = exact_mantissa.ReadFloatMantissa(parsed_decimal, 768); + + // Adjust the `guess` arguments to be halfway between A and B. + guess_mantissa = guess_mantissa * 2 + 1; + guess_exponent -= 1; + + // In our comparison: + // lhs = exact = exact_mantissa * 10**exact_exponent + // = exact_mantissa * 5**exact_exponent * 2**exact_exponent + // rhs = guess = guess_mantissa * 2**guess_exponent + // + // Because we are doing integer math, we can't directly deal with negative + // exponents. We instead move these to the other side of the inequality. + absl::strings_internal::BigUnsigned<84>& lhs = exact_mantissa; + int comparison; + if (exact_exponent >= 0) { + lhs.MultiplyByFiveToTheNth(exact_exponent); + absl::strings_internal::BigUnsigned<84> rhs(guess_mantissa); + // There are powers of 2 on both sides of the inequality; reduce this to + // a single bit-shift. + if (exact_exponent > guess_exponent) { + lhs.ShiftLeft(exact_exponent - guess_exponent); + } else { + rhs.ShiftLeft(guess_exponent - exact_exponent); + } + comparison = Compare(lhs, rhs); + } else { + // Move the power of 5 to the other side of the equation, giving us: + // lhs = exact_mantissa * 2**exact_exponent + // rhs = guess_mantissa * 5**(-exact_exponent) * 2**guess_exponent + absl::strings_internal::BigUnsigned<84> rhs = + absl::strings_internal::BigUnsigned<84>::FiveToTheNth(-exact_exponent); + rhs.MultiplyBy(guess_mantissa); + if (exact_exponent > guess_exponent) { + lhs.ShiftLeft(exact_exponent - guess_exponent); + } else { + rhs.ShiftLeft(guess_exponent - exact_exponent); + } + comparison = Compare(lhs, rhs); + } + if (comparison < 0) { + return false; + } else if (comparison > 0) { + return true; + } else { + // When lhs == rhs, the decimal input is exactly between A and B. + // Round towards even -- round up only if the low bit of the initial + // `guess_mantissa` was a 1. We shifted guess_mantissa left 1 bit at + // the beginning of this function, so test the 2nd bit here. + return (guess_mantissa & 2) == 2; + } +} + +// Constructs a CalculatedFloat from a given mantissa and exponent, but +// with the following normalizations applied: +// +// If rounding has caused mantissa to increase just past the allowed bit +// width, shift and adjust exponent. +// +// If exponent is too high, sets kOverflow. +// +// If mantissa is zero (representing a non-zero value not representable, even +// as a subnormal), sets kUnderflow. +template <typename FloatType> +CalculatedFloat CalculatedFloatFromRawValues(uint64_t mantissa, int exponent) { + CalculatedFloat result; + if (mantissa == uint64_t(1) << FloatTraits<FloatType>::kTargetMantissaBits) { + mantissa >>= 1; + exponent += 1; + } + if (exponent > FloatTraits<FloatType>::kMaxExponent) { + result.exponent = kOverflow; + } else if (mantissa == 0) { + result.exponent = kUnderflow; + } else { + result.exponent = exponent; + result.mantissa = mantissa; + } + return result; +} + +template <typename FloatType> +CalculatedFloat CalculateFromParsedHexadecimal( + const strings_internal::ParsedFloat& parsed_hex) { + uint64_t mantissa = parsed_hex.mantissa; + int exponent = parsed_hex.exponent; + int mantissa_width = 64 - base_internal::CountLeadingZeros64(mantissa); + const int shift = NormalizedShiftSize<FloatType>(mantissa_width, exponent); + bool result_exact; + exponent += shift; + mantissa = ShiftRightAndRound(mantissa, shift, + /* input exact= */ true, &result_exact); + // ParseFloat handles rounding in the hexadecimal case, so we don't have to + // check `result_exact` here. + return CalculatedFloatFromRawValues<FloatType>(mantissa, exponent); +} + +template <typename FloatType> +CalculatedFloat CalculateFromParsedDecimal( + const strings_internal::ParsedFloat& parsed_decimal) { + CalculatedFloat result; + + // Large or small enough decimal exponents will always result in overflow + // or underflow. + if (Power10Underflow(parsed_decimal.exponent)) { + result.exponent = kUnderflow; + return result; + } else if (Power10Overflow(parsed_decimal.exponent)) { + result.exponent = kOverflow; + return result; + } + + // Otherwise convert our power of 10 into a power of 2 times an integer + // mantissa, and multiply this by our parsed decimal mantissa. + uint128 wide_binary_mantissa = parsed_decimal.mantissa; + wide_binary_mantissa *= Power10Mantissa(parsed_decimal.exponent); + int binary_exponent = Power10Exponent(parsed_decimal.exponent); + + // Discard bits that are inaccurate due to truncation error. The magic + // `mantissa_width` constants below are justified in + // https://abseil.io/about/design/charconv. They represent the number of bits + // in `wide_binary_mantissa` that are guaranteed to be unaffected by error + // propagation. + bool mantissa_exact; + int mantissa_width; + if (parsed_decimal.subrange_begin) { + // Truncated mantissa + mantissa_width = 58; + mantissa_exact = false; + binary_exponent += + TruncateToBitWidth(mantissa_width, &wide_binary_mantissa); + } else if (!Power10Exact(parsed_decimal.exponent)) { + // Exact mantissa, truncated power of ten + mantissa_width = 63; + mantissa_exact = false; + binary_exponent += + TruncateToBitWidth(mantissa_width, &wide_binary_mantissa); + } else { + // Product is exact + mantissa_width = BitWidth(wide_binary_mantissa); + mantissa_exact = true; + } + + // Shift into an FloatType-sized mantissa, and round to nearest. + const int shift = + NormalizedShiftSize<FloatType>(mantissa_width, binary_exponent); + bool result_exact; + binary_exponent += shift; + uint64_t binary_mantissa = ShiftRightAndRound(wide_binary_mantissa, shift, + mantissa_exact, &result_exact); + if (!result_exact) { + // We could not determine the rounding direction using int128 math. Use + // full resolution math instead. + if (MustRoundUp(binary_mantissa, binary_exponent, parsed_decimal)) { + binary_mantissa += 1; + } + } + + return CalculatedFloatFromRawValues<FloatType>(binary_mantissa, + binary_exponent); +} + +template <typename FloatType> +from_chars_result FromCharsImpl(const char* first, const char* last, + FloatType& value, chars_format fmt_flags) { + from_chars_result result; + result.ptr = first; // overwritten on successful parse + result.ec = std::errc(); + + bool negative = false; + if (first != last && *first == '-') { + ++first; + negative = true; + } + // If the `hex` flag is *not* set, then we will accept a 0x prefix and try + // to parse a hexadecimal float. + if ((fmt_flags & chars_format::hex) == chars_format{} && last - first >= 2 && + *first == '0' && (first[1] == 'x' || first[1] == 'X')) { + const char* hex_first = first + 2; + strings_internal::ParsedFloat hex_parse = + strings_internal::ParseFloat<16>(hex_first, last, fmt_flags); + if (hex_parse.end == nullptr || + hex_parse.type != strings_internal::FloatType::kNumber) { + // Either we failed to parse a hex float after the "0x", or we read + // "0xinf" or "0xnan" which we don't want to match. + // + // However, a string that begins with "0x" also begins with "0", which + // is normally a valid match for the number zero. So we want these + // strings to match zero unless fmt_flags is `scientific`. (This flag + // means an exponent is required, which the string "0" does not have.) + if (fmt_flags == chars_format::scientific) { + result.ec = std::errc::invalid_argument; + } else { + result.ptr = first + 1; + value = negative ? -0.0 : 0.0; + } + return result; + } + // We matched a value. + result.ptr = hex_parse.end; + if (HandleEdgeCase(hex_parse, negative, &value)) { + return result; + } + CalculatedFloat calculated = + CalculateFromParsedHexadecimal<FloatType>(hex_parse); + EncodeResult(calculated, negative, &result, &value); + return result; + } + // Otherwise, we choose the number base based on the flags. + if ((fmt_flags & chars_format::hex) == chars_format::hex) { + strings_internal::ParsedFloat hex_parse = + strings_internal::ParseFloat<16>(first, last, fmt_flags); + if (hex_parse.end == nullptr) { + result.ec = std::errc::invalid_argument; + return result; + } + result.ptr = hex_parse.end; + if (HandleEdgeCase(hex_parse, negative, &value)) { + return result; + } + CalculatedFloat calculated = + CalculateFromParsedHexadecimal<FloatType>(hex_parse); + EncodeResult(calculated, negative, &result, &value); + return result; + } else { + strings_internal::ParsedFloat decimal_parse = + strings_internal::ParseFloat<10>(first, last, fmt_flags); + if (decimal_parse.end == nullptr) { + result.ec = std::errc::invalid_argument; + return result; + } + result.ptr = decimal_parse.end; + if (HandleEdgeCase(decimal_parse, negative, &value)) { + return result; + } + CalculatedFloat calculated = + CalculateFromParsedDecimal<FloatType>(decimal_parse); + EncodeResult(calculated, negative, &result, &value); + return result; + } +} +} // namespace + +from_chars_result from_chars(const char* first, const char* last, double& value, + chars_format fmt) { + return FromCharsImpl(first, last, value, fmt); +} + +from_chars_result from_chars(const char* first, const char* last, float& value, + chars_format fmt) { + return FromCharsImpl(first, last, value, fmt); +} + +namespace { + +// Table of powers of 10, from kPower10TableMin to kPower10TableMax. +// +// kPower10MantissaTable[i - kPower10TableMin] stores the 64-bit mantissa (high +// bit always on), and kPower10ExponentTable[i - kPower10TableMin] stores the +// power-of-two exponent. For a given number i, this gives the unique mantissa +// and exponent such that mantissa * 2**exponent <= 10**i < (mantissa + 1) * +// 2**exponent. + +const uint64_t kPower10MantissaTable[] = { + 0xeef453d6923bd65aU, 0x9558b4661b6565f8U, 0xbaaee17fa23ebf76U, + 0xe95a99df8ace6f53U, 0x91d8a02bb6c10594U, 0xb64ec836a47146f9U, + 0xe3e27a444d8d98b7U, 0x8e6d8c6ab0787f72U, 0xb208ef855c969f4fU, + 0xde8b2b66b3bc4723U, 0x8b16fb203055ac76U, 0xaddcb9e83c6b1793U, + 0xd953e8624b85dd78U, 0x87d4713d6f33aa6bU, 0xa9c98d8ccb009506U, + 0xd43bf0effdc0ba48U, 0x84a57695fe98746dU, 0xa5ced43b7e3e9188U, + 0xcf42894a5dce35eaU, 0x818995ce7aa0e1b2U, 0xa1ebfb4219491a1fU, + 0xca66fa129f9b60a6U, 0xfd00b897478238d0U, 0x9e20735e8cb16382U, + 0xc5a890362fddbc62U, 0xf712b443bbd52b7bU, 0x9a6bb0aa55653b2dU, + 0xc1069cd4eabe89f8U, 0xf148440a256e2c76U, 0x96cd2a865764dbcaU, + 0xbc807527ed3e12bcU, 0xeba09271e88d976bU, 0x93445b8731587ea3U, + 0xb8157268fdae9e4cU, 0xe61acf033d1a45dfU, 0x8fd0c16206306babU, + 0xb3c4f1ba87bc8696U, 0xe0b62e2929aba83cU, 0x8c71dcd9ba0b4925U, + 0xaf8e5410288e1b6fU, 0xdb71e91432b1a24aU, 0x892731ac9faf056eU, + 0xab70fe17c79ac6caU, 0xd64d3d9db981787dU, 0x85f0468293f0eb4eU, + 0xa76c582338ed2621U, 0xd1476e2c07286faaU, 0x82cca4db847945caU, + 0xa37fce126597973cU, 0xcc5fc196fefd7d0cU, 0xff77b1fcbebcdc4fU, + 0x9faacf3df73609b1U, 0xc795830d75038c1dU, 0xf97ae3d0d2446f25U, + 0x9becce62836ac577U, 0xc2e801fb244576d5U, 0xf3a20279ed56d48aU, + 0x9845418c345644d6U, 0xbe5691ef416bd60cU, 0xedec366b11c6cb8fU, + 0x94b3a202eb1c3f39U, 0xb9e08a83a5e34f07U, 0xe858ad248f5c22c9U, + 0x91376c36d99995beU, 0xb58547448ffffb2dU, 0xe2e69915b3fff9f9U, + 0x8dd01fad907ffc3bU, 0xb1442798f49ffb4aU, 0xdd95317f31c7fa1dU, + 0x8a7d3eef7f1cfc52U, 0xad1c8eab5ee43b66U, 0xd863b256369d4a40U, + 0x873e4f75e2224e68U, 0xa90de3535aaae202U, 0xd3515c2831559a83U, + 0x8412d9991ed58091U, 0xa5178fff668ae0b6U, 0xce5d73ff402d98e3U, + 0x80fa687f881c7f8eU, 0xa139029f6a239f72U, 0xc987434744ac874eU, + 0xfbe9141915d7a922U, 0x9d71ac8fada6c9b5U, 0xc4ce17b399107c22U, + 0xf6019da07f549b2bU, 0x99c102844f94e0fbU, 0xc0314325637a1939U, + 0xf03d93eebc589f88U, 0x96267c7535b763b5U, 0xbbb01b9283253ca2U, + 0xea9c227723ee8bcbU, 0x92a1958a7675175fU, 0xb749faed14125d36U, + 0xe51c79a85916f484U, 0x8f31cc0937ae58d2U, 0xb2fe3f0b8599ef07U, + 0xdfbdcece67006ac9U, 0x8bd6a141006042bdU, 0xaecc49914078536dU, + 0xda7f5bf590966848U, 0x888f99797a5e012dU, 0xaab37fd7d8f58178U, + 0xd5605fcdcf32e1d6U, 0x855c3be0a17fcd26U, 0xa6b34ad8c9dfc06fU, + 0xd0601d8efc57b08bU, 0x823c12795db6ce57U, 0xa2cb1717b52481edU, + 0xcb7ddcdda26da268U, 0xfe5d54150b090b02U, 0x9efa548d26e5a6e1U, + 0xc6b8e9b0709f109aU, 0xf867241c8cc6d4c0U, 0x9b407691d7fc44f8U, + 0xc21094364dfb5636U, 0xf294b943e17a2bc4U, 0x979cf3ca6cec5b5aU, + 0xbd8430bd08277231U, 0xece53cec4a314ebdU, 0x940f4613ae5ed136U, + 0xb913179899f68584U, 0xe757dd7ec07426e5U, 0x9096ea6f3848984fU, + 0xb4bca50b065abe63U, 0xe1ebce4dc7f16dfbU, 0x8d3360f09cf6e4bdU, + 0xb080392cc4349decU, 0xdca04777f541c567U, 0x89e42caaf9491b60U, + 0xac5d37d5b79b6239U, 0xd77485cb25823ac7U, 0x86a8d39ef77164bcU, + 0xa8530886b54dbdebU, 0xd267caa862a12d66U, 0x8380dea93da4bc60U, + 0xa46116538d0deb78U, 0xcd795be870516656U, 0x806bd9714632dff6U, + 0xa086cfcd97bf97f3U, 0xc8a883c0fdaf7df0U, 0xfad2a4b13d1b5d6cU, + 0x9cc3a6eec6311a63U, 0xc3f490aa77bd60fcU, 0xf4f1b4d515acb93bU, + 0x991711052d8bf3c5U, 0xbf5cd54678eef0b6U, 0xef340a98172aace4U, + 0x9580869f0e7aac0eU, 0xbae0a846d2195712U, 0xe998d258869facd7U, + 0x91ff83775423cc06U, 0xb67f6455292cbf08U, 0xe41f3d6a7377eecaU, + 0x8e938662882af53eU, 0xb23867fb2a35b28dU, 0xdec681f9f4c31f31U, + 0x8b3c113c38f9f37eU, 0xae0b158b4738705eU, 0xd98ddaee19068c76U, + 0x87f8a8d4cfa417c9U, 0xa9f6d30a038d1dbcU, 0xd47487cc8470652bU, + 0x84c8d4dfd2c63f3bU, 0xa5fb0a17c777cf09U, 0xcf79cc9db955c2ccU, + 0x81ac1fe293d599bfU, 0xa21727db38cb002fU, 0xca9cf1d206fdc03bU, + 0xfd442e4688bd304aU, 0x9e4a9cec15763e2eU, 0xc5dd44271ad3cdbaU, + 0xf7549530e188c128U, 0x9a94dd3e8cf578b9U, 0xc13a148e3032d6e7U, + 0xf18899b1bc3f8ca1U, 0x96f5600f15a7b7e5U, 0xbcb2b812db11a5deU, + 0xebdf661791d60f56U, 0x936b9fcebb25c995U, 0xb84687c269ef3bfbU, + 0xe65829b3046b0afaU, 0x8ff71a0fe2c2e6dcU, 0xb3f4e093db73a093U, + 0xe0f218b8d25088b8U, 0x8c974f7383725573U, 0xafbd2350644eeacfU, + 0xdbac6c247d62a583U, 0x894bc396ce5da772U, 0xab9eb47c81f5114fU, + 0xd686619ba27255a2U, 0x8613fd0145877585U, 0xa798fc4196e952e7U, + 0xd17f3b51fca3a7a0U, 0x82ef85133de648c4U, 0xa3ab66580d5fdaf5U, + 0xcc963fee10b7d1b3U, 0xffbbcfe994e5c61fU, 0x9fd561f1fd0f9bd3U, + 0xc7caba6e7c5382c8U, 0xf9bd690a1b68637bU, 0x9c1661a651213e2dU, + 0xc31bfa0fe5698db8U, 0xf3e2f893dec3f126U, 0x986ddb5c6b3a76b7U, + 0xbe89523386091465U, 0xee2ba6c0678b597fU, 0x94db483840b717efU, + 0xba121a4650e4ddebU, 0xe896a0d7e51e1566U, 0x915e2486ef32cd60U, + 0xb5b5ada8aaff80b8U, 0xe3231912d5bf60e6U, 0x8df5efabc5979c8fU, + 0xb1736b96b6fd83b3U, 0xddd0467c64bce4a0U, 0x8aa22c0dbef60ee4U, + 0xad4ab7112eb3929dU, 0xd89d64d57a607744U, 0x87625f056c7c4a8bU, + 0xa93af6c6c79b5d2dU, 0xd389b47879823479U, 0x843610cb4bf160cbU, + 0xa54394fe1eedb8feU, 0xce947a3da6a9273eU, 0x811ccc668829b887U, + 0xa163ff802a3426a8U, 0xc9bcff6034c13052U, 0xfc2c3f3841f17c67U, + 0x9d9ba7832936edc0U, 0xc5029163f384a931U, 0xf64335bcf065d37dU, + 0x99ea0196163fa42eU, 0xc06481fb9bcf8d39U, 0xf07da27a82c37088U, + 0x964e858c91ba2655U, 0xbbe226efb628afeaU, 0xeadab0aba3b2dbe5U, + 0x92c8ae6b464fc96fU, 0xb77ada0617e3bbcbU, 0xe55990879ddcaabdU, + 0x8f57fa54c2a9eab6U, 0xb32df8e9f3546564U, 0xdff9772470297ebdU, + 0x8bfbea76c619ef36U, 0xaefae51477a06b03U, 0xdab99e59958885c4U, + 0x88b402f7fd75539bU, 0xaae103b5fcd2a881U, 0xd59944a37c0752a2U, + 0x857fcae62d8493a5U, 0xa6dfbd9fb8e5b88eU, 0xd097ad07a71f26b2U, + 0x825ecc24c873782fU, 0xa2f67f2dfa90563bU, 0xcbb41ef979346bcaU, + 0xfea126b7d78186bcU, 0x9f24b832e6b0f436U, 0xc6ede63fa05d3143U, + 0xf8a95fcf88747d94U, 0x9b69dbe1b548ce7cU, 0xc24452da229b021bU, + 0xf2d56790ab41c2a2U, 0x97c560ba6b0919a5U, 0xbdb6b8e905cb600fU, + 0xed246723473e3813U, 0x9436c0760c86e30bU, 0xb94470938fa89bceU, + 0xe7958cb87392c2c2U, 0x90bd77f3483bb9b9U, 0xb4ecd5f01a4aa828U, + 0xe2280b6c20dd5232U, 0x8d590723948a535fU, 0xb0af48ec79ace837U, + 0xdcdb1b2798182244U, 0x8a08f0f8bf0f156bU, 0xac8b2d36eed2dac5U, + 0xd7adf884aa879177U, 0x86ccbb52ea94baeaU, 0xa87fea27a539e9a5U, + 0xd29fe4b18e88640eU, 0x83a3eeeef9153e89U, 0xa48ceaaab75a8e2bU, + 0xcdb02555653131b6U, 0x808e17555f3ebf11U, 0xa0b19d2ab70e6ed6U, + 0xc8de047564d20a8bU, 0xfb158592be068d2eU, 0x9ced737bb6c4183dU, + 0xc428d05aa4751e4cU, 0xf53304714d9265dfU, 0x993fe2c6d07b7fabU, + 0xbf8fdb78849a5f96U, 0xef73d256a5c0f77cU, 0x95a8637627989aadU, + 0xbb127c53b17ec159U, 0xe9d71b689dde71afU, 0x9226712162ab070dU, + 0xb6b00d69bb55c8d1U, 0xe45c10c42a2b3b05U, 0x8eb98a7a9a5b04e3U, + 0xb267ed1940f1c61cU, 0xdf01e85f912e37a3U, 0x8b61313bbabce2c6U, + 0xae397d8aa96c1b77U, 0xd9c7dced53c72255U, 0x881cea14545c7575U, + 0xaa242499697392d2U, 0xd4ad2dbfc3d07787U, 0x84ec3c97da624ab4U, + 0xa6274bbdd0fadd61U, 0xcfb11ead453994baU, 0x81ceb32c4b43fcf4U, + 0xa2425ff75e14fc31U, 0xcad2f7f5359a3b3eU, 0xfd87b5f28300ca0dU, + 0x9e74d1b791e07e48U, 0xc612062576589ddaU, 0xf79687aed3eec551U, + 0x9abe14cd44753b52U, 0xc16d9a0095928a27U, 0xf1c90080baf72cb1U, + 0x971da05074da7beeU, 0xbce5086492111aeaU, 0xec1e4a7db69561a5U, + 0x9392ee8e921d5d07U, 0xb877aa3236a4b449U, 0xe69594bec44de15bU, + 0x901d7cf73ab0acd9U, 0xb424dc35095cd80fU, 0xe12e13424bb40e13U, + 0x8cbccc096f5088cbU, 0xafebff0bcb24aafeU, 0xdbe6fecebdedd5beU, + 0x89705f4136b4a597U, 0xabcc77118461cefcU, 0xd6bf94d5e57a42bcU, + 0x8637bd05af6c69b5U, 0xa7c5ac471b478423U, 0xd1b71758e219652bU, + 0x83126e978d4fdf3bU, 0xa3d70a3d70a3d70aU, 0xccccccccccccccccU, + 0x8000000000000000U, 0xa000000000000000U, 0xc800000000000000U, + 0xfa00000000000000U, 0x9c40000000000000U, 0xc350000000000000U, + 0xf424000000000000U, 0x9896800000000000U, 0xbebc200000000000U, + 0xee6b280000000000U, 0x9502f90000000000U, 0xba43b74000000000U, + 0xe8d4a51000000000U, 0x9184e72a00000000U, 0xb5e620f480000000U, + 0xe35fa931a0000000U, 0x8e1bc9bf04000000U, 0xb1a2bc2ec5000000U, + 0xde0b6b3a76400000U, 0x8ac7230489e80000U, 0xad78ebc5ac620000U, + 0xd8d726b7177a8000U, 0x878678326eac9000U, 0xa968163f0a57b400U, + 0xd3c21bcecceda100U, 0x84595161401484a0U, 0xa56fa5b99019a5c8U, + 0xcecb8f27f4200f3aU, 0x813f3978f8940984U, 0xa18f07d736b90be5U, + 0xc9f2c9cd04674edeU, 0xfc6f7c4045812296U, 0x9dc5ada82b70b59dU, + 0xc5371912364ce305U, 0xf684df56c3e01bc6U, 0x9a130b963a6c115cU, + 0xc097ce7bc90715b3U, 0xf0bdc21abb48db20U, 0x96769950b50d88f4U, + 0xbc143fa4e250eb31U, 0xeb194f8e1ae525fdU, 0x92efd1b8d0cf37beU, + 0xb7abc627050305adU, 0xe596b7b0c643c719U, 0x8f7e32ce7bea5c6fU, + 0xb35dbf821ae4f38bU, 0xe0352f62a19e306eU, 0x8c213d9da502de45U, + 0xaf298d050e4395d6U, 0xdaf3f04651d47b4cU, 0x88d8762bf324cd0fU, + 0xab0e93b6efee0053U, 0xd5d238a4abe98068U, 0x85a36366eb71f041U, + 0xa70c3c40a64e6c51U, 0xd0cf4b50cfe20765U, 0x82818f1281ed449fU, + 0xa321f2d7226895c7U, 0xcbea6f8ceb02bb39U, 0xfee50b7025c36a08U, + 0x9f4f2726179a2245U, 0xc722f0ef9d80aad6U, 0xf8ebad2b84e0d58bU, + 0x9b934c3b330c8577U, 0xc2781f49ffcfa6d5U, 0xf316271c7fc3908aU, + 0x97edd871cfda3a56U, 0xbde94e8e43d0c8ecU, 0xed63a231d4c4fb27U, + 0x945e455f24fb1cf8U, 0xb975d6b6ee39e436U, 0xe7d34c64a9c85d44U, + 0x90e40fbeea1d3a4aU, 0xb51d13aea4a488ddU, 0xe264589a4dcdab14U, + 0x8d7eb76070a08aecU, 0xb0de65388cc8ada8U, 0xdd15fe86affad912U, + 0x8a2dbf142dfcc7abU, 0xacb92ed9397bf996U, 0xd7e77a8f87daf7fbU, + 0x86f0ac99b4e8dafdU, 0xa8acd7c0222311bcU, 0xd2d80db02aabd62bU, + 0x83c7088e1aab65dbU, 0xa4b8cab1a1563f52U, 0xcde6fd5e09abcf26U, + 0x80b05e5ac60b6178U, 0xa0dc75f1778e39d6U, 0xc913936dd571c84cU, + 0xfb5878494ace3a5fU, 0x9d174b2dcec0e47bU, 0xc45d1df942711d9aU, + 0xf5746577930d6500U, 0x9968bf6abbe85f20U, 0xbfc2ef456ae276e8U, + 0xefb3ab16c59b14a2U, 0x95d04aee3b80ece5U, 0xbb445da9ca61281fU, + 0xea1575143cf97226U, 0x924d692ca61be758U, 0xb6e0c377cfa2e12eU, + 0xe498f455c38b997aU, 0x8edf98b59a373fecU, 0xb2977ee300c50fe7U, + 0xdf3d5e9bc0f653e1U, 0x8b865b215899f46cU, 0xae67f1e9aec07187U, + 0xda01ee641a708de9U, 0x884134fe908658b2U, 0xaa51823e34a7eedeU, + 0xd4e5e2cdc1d1ea96U, 0x850fadc09923329eU, 0xa6539930bf6bff45U, + 0xcfe87f7cef46ff16U, 0x81f14fae158c5f6eU, 0xa26da3999aef7749U, + 0xcb090c8001ab551cU, 0xfdcb4fa002162a63U, 0x9e9f11c4014dda7eU, + 0xc646d63501a1511dU, 0xf7d88bc24209a565U, 0x9ae757596946075fU, + 0xc1a12d2fc3978937U, 0xf209787bb47d6b84U, 0x9745eb4d50ce6332U, + 0xbd176620a501fbffU, 0xec5d3fa8ce427affU, 0x93ba47c980e98cdfU, + 0xb8a8d9bbe123f017U, 0xe6d3102ad96cec1dU, 0x9043ea1ac7e41392U, + 0xb454e4a179dd1877U, 0xe16a1dc9d8545e94U, 0x8ce2529e2734bb1dU, + 0xb01ae745b101e9e4U, 0xdc21a1171d42645dU, 0x899504ae72497ebaU, + 0xabfa45da0edbde69U, 0xd6f8d7509292d603U, 0x865b86925b9bc5c2U, + 0xa7f26836f282b732U, 0xd1ef0244af2364ffU, 0x8335616aed761f1fU, + 0xa402b9c5a8d3a6e7U, 0xcd036837130890a1U, 0x802221226be55a64U, + 0xa02aa96b06deb0fdU, 0xc83553c5c8965d3dU, 0xfa42a8b73abbf48cU, + 0x9c69a97284b578d7U, 0xc38413cf25e2d70dU, 0xf46518c2ef5b8cd1U, + 0x98bf2f79d5993802U, 0xbeeefb584aff8603U, 0xeeaaba2e5dbf6784U, + 0x952ab45cfa97a0b2U, 0xba756174393d88dfU, 0xe912b9d1478ceb17U, + 0x91abb422ccb812eeU, 0xb616a12b7fe617aaU, 0xe39c49765fdf9d94U, + 0x8e41ade9fbebc27dU, 0xb1d219647ae6b31cU, 0xde469fbd99a05fe3U, + 0x8aec23d680043beeU, 0xada72ccc20054ae9U, 0xd910f7ff28069da4U, + 0x87aa9aff79042286U, 0xa99541bf57452b28U, 0xd3fa922f2d1675f2U, + 0x847c9b5d7c2e09b7U, 0xa59bc234db398c25U, 0xcf02b2c21207ef2eU, + 0x8161afb94b44f57dU, 0xa1ba1ba79e1632dcU, 0xca28a291859bbf93U, + 0xfcb2cb35e702af78U, 0x9defbf01b061adabU, 0xc56baec21c7a1916U, + 0xf6c69a72a3989f5bU, 0x9a3c2087a63f6399U, 0xc0cb28a98fcf3c7fU, + 0xf0fdf2d3f3c30b9fU, 0x969eb7c47859e743U, 0xbc4665b596706114U, + 0xeb57ff22fc0c7959U, 0x9316ff75dd87cbd8U, 0xb7dcbf5354e9beceU, + 0xe5d3ef282a242e81U, 0x8fa475791a569d10U, 0xb38d92d760ec4455U, + 0xe070f78d3927556aU, 0x8c469ab843b89562U, 0xaf58416654a6babbU, + 0xdb2e51bfe9d0696aU, 0x88fcf317f22241e2U, 0xab3c2fddeeaad25aU, + 0xd60b3bd56a5586f1U, 0x85c7056562757456U, 0xa738c6bebb12d16cU, + 0xd106f86e69d785c7U, 0x82a45b450226b39cU, 0xa34d721642b06084U, + 0xcc20ce9bd35c78a5U, 0xff290242c83396ceU, 0x9f79a169bd203e41U, + 0xc75809c42c684dd1U, 0xf92e0c3537826145U, 0x9bbcc7a142b17ccbU, + 0xc2abf989935ddbfeU, 0xf356f7ebf83552feU, 0x98165af37b2153deU, + 0xbe1bf1b059e9a8d6U, 0xeda2ee1c7064130cU, 0x9485d4d1c63e8be7U, + 0xb9a74a0637ce2ee1U, 0xe8111c87c5c1ba99U, 0x910ab1d4db9914a0U, + 0xb54d5e4a127f59c8U, 0xe2a0b5dc971f303aU, 0x8da471a9de737e24U, + 0xb10d8e1456105dadU, 0xdd50f1996b947518U, 0x8a5296ffe33cc92fU, + 0xace73cbfdc0bfb7bU, 0xd8210befd30efa5aU, 0x8714a775e3e95c78U, + 0xa8d9d1535ce3b396U, 0xd31045a8341ca07cU, 0x83ea2b892091e44dU, + 0xa4e4b66b68b65d60U, 0xce1de40642e3f4b9U, 0x80d2ae83e9ce78f3U, + 0xa1075a24e4421730U, 0xc94930ae1d529cfcU, 0xfb9b7cd9a4a7443cU, + 0x9d412e0806e88aa5U, 0xc491798a08a2ad4eU, 0xf5b5d7ec8acb58a2U, + 0x9991a6f3d6bf1765U, 0xbff610b0cc6edd3fU, 0xeff394dcff8a948eU, + 0x95f83d0a1fb69cd9U, 0xbb764c4ca7a4440fU, 0xea53df5fd18d5513U, + 0x92746b9be2f8552cU, 0xb7118682dbb66a77U, 0xe4d5e82392a40515U, + 0x8f05b1163ba6832dU, 0xb2c71d5bca9023f8U, 0xdf78e4b2bd342cf6U, + 0x8bab8eefb6409c1aU, 0xae9672aba3d0c320U, 0xda3c0f568cc4f3e8U, + 0x8865899617fb1871U, 0xaa7eebfb9df9de8dU, 0xd51ea6fa85785631U, + 0x8533285c936b35deU, 0xa67ff273b8460356U, 0xd01fef10a657842cU, + 0x8213f56a67f6b29bU, 0xa298f2c501f45f42U, 0xcb3f2f7642717713U, + 0xfe0efb53d30dd4d7U, 0x9ec95d1463e8a506U, 0xc67bb4597ce2ce48U, + 0xf81aa16fdc1b81daU, 0x9b10a4e5e9913128U, 0xc1d4ce1f63f57d72U, + 0xf24a01a73cf2dccfU, 0x976e41088617ca01U, 0xbd49d14aa79dbc82U, + 0xec9c459d51852ba2U, 0x93e1ab8252f33b45U, 0xb8da1662e7b00a17U, + 0xe7109bfba19c0c9dU, 0x906a617d450187e2U, 0xb484f9dc9641e9daU, + 0xe1a63853bbd26451U, 0x8d07e33455637eb2U, 0xb049dc016abc5e5fU, + 0xdc5c5301c56b75f7U, 0x89b9b3e11b6329baU, 0xac2820d9623bf429U, + 0xd732290fbacaf133U, 0x867f59a9d4bed6c0U, 0xa81f301449ee8c70U, + 0xd226fc195c6a2f8cU, 0x83585d8fd9c25db7U, 0xa42e74f3d032f525U, + 0xcd3a1230c43fb26fU, 0x80444b5e7aa7cf85U, 0xa0555e361951c366U, + 0xc86ab5c39fa63440U, 0xfa856334878fc150U, 0x9c935e00d4b9d8d2U, + 0xc3b8358109e84f07U, 0xf4a642e14c6262c8U, 0x98e7e9cccfbd7dbdU, + 0xbf21e44003acdd2cU, 0xeeea5d5004981478U, 0x95527a5202df0ccbU, + 0xbaa718e68396cffdU, 0xe950df20247c83fdU, 0x91d28b7416cdd27eU, + 0xb6472e511c81471dU, 0xe3d8f9e563a198e5U, 0x8e679c2f5e44ff8fU, +}; + +const int16_t kPower10ExponentTable[] = { + -1200, -1196, -1193, -1190, -1186, -1183, -1180, -1176, -1173, -1170, -1166, + -1163, -1160, -1156, -1153, -1150, -1146, -1143, -1140, -1136, -1133, -1130, + -1127, -1123, -1120, -1117, -1113, -1110, -1107, -1103, -1100, -1097, -1093, + -1090, -1087, -1083, -1080, -1077, -1073, -1070, -1067, -1063, -1060, -1057, + -1053, -1050, -1047, -1043, -1040, -1037, -1034, -1030, -1027, -1024, -1020, + -1017, -1014, -1010, -1007, -1004, -1000, -997, -994, -990, -987, -984, + -980, -977, -974, -970, -967, -964, -960, -957, -954, -950, -947, + -944, -940, -937, -934, -931, -927, -924, -921, -917, -914, -911, + -907, -904, -901, -897, -894, -891, -887, -884, -881, -877, -874, + -871, -867, -864, -861, -857, -854, -851, -847, -844, -841, -838, + -834, -831, -828, -824, -821, -818, -814, -811, -808, -804, -801, + -798, -794, -791, -788, -784, -781, -778, -774, -771, -768, -764, + -761, -758, -754, -751, -748, -744, -741, -738, -735, -731, -728, + -725, -721, -718, -715, -711, -708, -705, -701, -698, -695, -691, + -688, -685, -681, -678, -675, -671, -668, -665, -661, -658, -655, + -651, -648, -645, -642, -638, -635, -632, -628, -625, -622, -618, + -615, -612, -608, -605, -602, -598, -595, -592, -588, -585, -582, + -578, -575, -572, -568, -565, -562, -558, -555, -552, -549, -545, + -542, -539, -535, -532, -529, -525, -522, -519, -515, -512, -509, + -505, -502, -499, -495, -492, -489, -485, -482, -479, -475, -472, + -469, -465, -462, -459, -455, -452, -449, -446, -442, -439, -436, + -432, -429, -426, -422, -419, -416, -412, -409, -406, -402, -399, + -396, -392, -389, -386, -382, -379, -376, -372, -369, -366, -362, + -359, -356, -353, -349, -346, -343, -339, -336, -333, -329, -326, + -323, -319, -316, -313, -309, -306, -303, -299, -296, -293, -289, + -286, -283, -279, -276, -273, -269, -266, -263, -259, -256, -253, + -250, -246, -243, -240, -236, -233, -230, -226, -223, -220, -216, + -213, -210, -206, -203, -200, -196, -193, -190, -186, -183, -180, + -176, -173, -170, -166, -163, -160, -157, -153, -150, -147, -143, + -140, -137, -133, -130, -127, -123, -120, -117, -113, -110, -107, + -103, -100, -97, -93, -90, -87, -83, -80, -77, -73, -70, + -67, -63, -60, -57, -54, -50, -47, -44, -40, -37, -34, + -30, -27, -24, -20, -17, -14, -10, -7, -4, 0, 3, + 6, 10, 13, 16, 20, 23, 26, 30, 33, 36, 39, + 43, 46, 49, 53, 56, 59, 63, 66, 69, 73, 76, + 79, 83, 86, 89, 93, 96, 99, 103, 106, 109, 113, + 116, 119, 123, 126, 129, 132, 136, 139, 142, 146, 149, + 152, 156, 159, 162, 166, 169, 172, 176, 179, 182, 186, + 189, 192, 196, 199, 202, 206, 209, 212, 216, 219, 222, + 226, 229, 232, 235, 239, 242, 245, 249, 252, 255, 259, + 262, 265, 269, 272, 275, 279, 282, 285, 289, 292, 295, + 299, 302, 305, 309, 312, 315, 319, 322, 325, 328, 332, + 335, 338, 342, 345, 348, 352, 355, 358, 362, 365, 368, + 372, 375, 378, 382, 385, 388, 392, 395, 398, 402, 405, + 408, 412, 415, 418, 422, 425, 428, 431, 435, 438, 441, + 445, 448, 451, 455, 458, 461, 465, 468, 471, 475, 478, + 481, 485, 488, 491, 495, 498, 501, 505, 508, 511, 515, + 518, 521, 524, 528, 531, 534, 538, 541, 544, 548, 551, + 554, 558, 561, 564, 568, 571, 574, 578, 581, 584, 588, + 591, 594, 598, 601, 604, 608, 611, 614, 617, 621, 624, + 627, 631, 634, 637, 641, 644, 647, 651, 654, 657, 661, + 664, 667, 671, 674, 677, 681, 684, 687, 691, 694, 697, + 701, 704, 707, 711, 714, 717, 720, 724, 727, 730, 734, + 737, 740, 744, 747, 750, 754, 757, 760, 764, 767, 770, + 774, 777, 780, 784, 787, 790, 794, 797, 800, 804, 807, + 810, 813, 817, 820, 823, 827, 830, 833, 837, 840, 843, + 847, 850, 853, 857, 860, 863, 867, 870, 873, 877, 880, + 883, 887, 890, 893, 897, 900, 903, 907, 910, 913, 916, + 920, 923, 926, 930, 933, 936, 940, 943, 946, 950, 953, + 956, 960, +}; + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/charconv.h b/third_party/abseil_cpp/absl/strings/charconv.h new file mode 100644 index 0000000000..e04be32f95 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/charconv.h @@ -0,0 +1,119 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_STRINGS_CHARCONV_H_ +#define ABSL_STRINGS_CHARCONV_H_ + +#include <system_error> // NOLINT(build/c++11) + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Workalike compatibilty version of std::chars_format from C++17. +// +// This is an bitfield enumerator which can be passed to absl::from_chars to +// configure the string-to-float conversion. +enum class chars_format { + scientific = 1, + fixed = 2, + hex = 4, + general = fixed | scientific, +}; + +// The return result of a string-to-number conversion. +// +// `ec` will be set to `invalid_argument` if a well-formed number was not found +// at the start of the input range, `result_out_of_range` if a well-formed +// number was found, but it was out of the representable range of the requested +// type, or to std::errc() otherwise. +// +// If a well-formed number was found, `ptr` is set to one past the sequence of +// characters that were successfully parsed. If none was found, `ptr` is set +// to the `first` argument to from_chars. +struct from_chars_result { + const char* ptr; + std::errc ec; +}; + +// Workalike compatibilty version of std::from_chars from C++17. Currently +// this only supports the `double` and `float` types. +// +// This interface incorporates the proposed resolutions for library issues +// DR 3080 and DR 3081. If these are adopted with different wording, +// Abseil's behavior will change to match the standard. (The behavior most +// likely to change is for DR 3081, which says what `value` will be set to in +// the case of overflow and underflow. Code that wants to avoid possible +// breaking changes in this area should not depend on `value` when the returned +// from_chars_result indicates a range error.) +// +// Searches the range [first, last) for the longest matching pattern beginning +// at `first` that represents a floating point number. If one is found, store +// the result in `value`. +// +// The matching pattern format is almost the same as that of strtod(), except +// that C locale is not respected, and an initial '+' character in the input +// range will never be matched. +// +// If `fmt` is set, it must be one of the enumerator values of the chars_format. +// (This is despite the fact that chars_format is a bitmask type.) If set to +// `scientific`, a matching number must contain an exponent. If set to `fixed`, +// then an exponent will never match. (For example, the string "1e5" will be +// parsed as "1".) If set to `hex`, then a hexadecimal float is parsed in the +// format that strtod() accepts, except that a "0x" prefix is NOT matched. +// (In particular, in `hex` mode, the input "0xff" results in the largest +// matching pattern "0".) +absl::from_chars_result from_chars(const char* first, const char* last, + double& value, // NOLINT + chars_format fmt = chars_format::general); + +absl::from_chars_result from_chars(const char* first, const char* last, + float& value, // NOLINT + chars_format fmt = chars_format::general); + +// std::chars_format is specified as a bitmask type, which means the following +// operations must be provided: +inline constexpr chars_format operator&(chars_format lhs, chars_format rhs) { + return static_cast<chars_format>(static_cast<int>(lhs) & + static_cast<int>(rhs)); +} +inline constexpr chars_format operator|(chars_format lhs, chars_format rhs) { + return static_cast<chars_format>(static_cast<int>(lhs) | + static_cast<int>(rhs)); +} +inline constexpr chars_format operator^(chars_format lhs, chars_format rhs) { + return static_cast<chars_format>(static_cast<int>(lhs) ^ + static_cast<int>(rhs)); +} +inline constexpr chars_format operator~(chars_format arg) { + return static_cast<chars_format>(~static_cast<int>(arg)); +} +inline chars_format& operator&=(chars_format& lhs, chars_format rhs) { + lhs = lhs & rhs; + return lhs; +} +inline chars_format& operator|=(chars_format& lhs, chars_format rhs) { + lhs = lhs | rhs; + return lhs; +} +inline chars_format& operator^=(chars_format& lhs, chars_format rhs) { + lhs = lhs ^ rhs; + return lhs; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_CHARCONV_H_ diff --git a/third_party/abseil_cpp/absl/strings/charconv_benchmark.cc b/third_party/abseil_cpp/absl/strings/charconv_benchmark.cc new file mode 100644 index 0000000000..e8c7371d65 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/charconv_benchmark.cc @@ -0,0 +1,204 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/charconv.h" + +#include <cstdlib> +#include <cstring> +#include <string> + +#include "benchmark/benchmark.h" + +namespace { + +void BM_Strtod_Pi(benchmark::State& state) { + const char* pi = "3.14159"; + for (auto s : state) { + benchmark::DoNotOptimize(pi); + benchmark::DoNotOptimize(strtod(pi, nullptr)); + } +} +BENCHMARK(BM_Strtod_Pi); + +void BM_Absl_Pi(benchmark::State& state) { + const char* pi = "3.14159"; + const char* pi_end = pi + strlen(pi); + for (auto s : state) { + benchmark::DoNotOptimize(pi); + double v; + absl::from_chars(pi, pi_end, v); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_Absl_Pi); + +void BM_Strtod_Pi_float(benchmark::State& state) { + const char* pi = "3.14159"; + for (auto s : state) { + benchmark::DoNotOptimize(pi); + benchmark::DoNotOptimize(strtof(pi, nullptr)); + } +} +BENCHMARK(BM_Strtod_Pi_float); + +void BM_Absl_Pi_float(benchmark::State& state) { + const char* pi = "3.14159"; + const char* pi_end = pi + strlen(pi); + for (auto s : state) { + benchmark::DoNotOptimize(pi); + float v; + absl::from_chars(pi, pi_end, v); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_Absl_Pi_float); + +void BM_Strtod_HardLarge(benchmark::State& state) { + const char* num = "272104041512242479.e200"; + for (auto s : state) { + benchmark::DoNotOptimize(num); + benchmark::DoNotOptimize(strtod(num, nullptr)); + } +} +BENCHMARK(BM_Strtod_HardLarge); + +void BM_Absl_HardLarge(benchmark::State& state) { + const char* numstr = "272104041512242479.e200"; + const char* numstr_end = numstr + strlen(numstr); + for (auto s : state) { + benchmark::DoNotOptimize(numstr); + double v; + absl::from_chars(numstr, numstr_end, v); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_Absl_HardLarge); + +void BM_Strtod_HardSmall(benchmark::State& state) { + const char* num = "94080055902682397.e-242"; + for (auto s : state) { + benchmark::DoNotOptimize(num); + benchmark::DoNotOptimize(strtod(num, nullptr)); + } +} +BENCHMARK(BM_Strtod_HardSmall); + +void BM_Absl_HardSmall(benchmark::State& state) { + const char* numstr = "94080055902682397.e-242"; + const char* numstr_end = numstr + strlen(numstr); + for (auto s : state) { + benchmark::DoNotOptimize(numstr); + double v; + absl::from_chars(numstr, numstr_end, v); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_Absl_HardSmall); + +void BM_Strtod_HugeMantissa(benchmark::State& state) { + std::string huge(200, '3'); + const char* num = huge.c_str(); + for (auto s : state) { + benchmark::DoNotOptimize(num); + benchmark::DoNotOptimize(strtod(num, nullptr)); + } +} +BENCHMARK(BM_Strtod_HugeMantissa); + +void BM_Absl_HugeMantissa(benchmark::State& state) { + std::string huge(200, '3'); + const char* num = huge.c_str(); + const char* num_end = num + 200; + for (auto s : state) { + benchmark::DoNotOptimize(num); + double v; + absl::from_chars(num, num_end, v); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_Absl_HugeMantissa); + +std::string MakeHardCase(int length) { + // The number 1.1521...e-297 is exactly halfway between 12345 * 2**-1000 and + // the next larger representable number. The digits of this number are in + // the string below. + const std::string digits = + "1." + "152113937042223790993097181572444900347587985074226836242307364987727724" + "831384300183638649152607195040591791364113930628852279348613864894524591" + "272746490313676832900762939595690019745859128071117417798540258114233761" + "012939937017879509401007964861774960297319002612457273148497158989073482" + "171377406078223015359818300988676687994537274548940612510414856761641652" + "513434981938564294004070500716200446656421722229202383105446378511678258" + "370570631774499359748259931676320916632111681001853983492795053244971606" + "922718923011680846577744433974087653954904214152517799883551075537146316" + "168973685866425605046988661997658648354773076621610279716804960009043764" + "038392994055171112475093876476783502487512538082706095923790634572014823" + "78877699375152587890625" + + std::string(5000, '0'); + // generate the hard cases on either side for the given length. + // Lengths between 3 and 1000 are reasonable. + return digits.substr(0, length) + "1e-297"; +} + +void BM_Strtod_Big_And_Difficult(benchmark::State& state) { + std::string testcase = MakeHardCase(state.range(0)); + const char* begin = testcase.c_str(); + for (auto s : state) { + benchmark::DoNotOptimize(begin); + benchmark::DoNotOptimize(strtod(begin, nullptr)); + } +} +BENCHMARK(BM_Strtod_Big_And_Difficult)->Range(3, 5000); + +void BM_Absl_Big_And_Difficult(benchmark::State& state) { + std::string testcase = MakeHardCase(state.range(0)); + const char* begin = testcase.c_str(); + const char* end = begin + testcase.size(); + for (auto s : state) { + benchmark::DoNotOptimize(begin); + double v; + absl::from_chars(begin, end, v); + benchmark::DoNotOptimize(v); + } +} +BENCHMARK(BM_Absl_Big_And_Difficult)->Range(3, 5000); + +} // namespace + +// ------------------------------------------------------------------------ +// Benchmark Time CPU Iterations +// ------------------------------------------------------------------------ +// BM_Strtod_Pi 96 ns 96 ns 6337454 +// BM_Absl_Pi 35 ns 35 ns 20031996 +// BM_Strtod_Pi_float 91 ns 91 ns 7745851 +// BM_Absl_Pi_float 35 ns 35 ns 20430298 +// BM_Strtod_HardLarge 133 ns 133 ns 5288341 +// BM_Absl_HardLarge 181 ns 181 ns 3855615 +// BM_Strtod_HardSmall 279 ns 279 ns 2517243 +// BM_Absl_HardSmall 287 ns 287 ns 2458744 +// BM_Strtod_HugeMantissa 433 ns 433 ns 1604293 +// BM_Absl_HugeMantissa 160 ns 160 ns 4403671 +// BM_Strtod_Big_And_Difficult/3 236 ns 236 ns 2942496 +// BM_Strtod_Big_And_Difficult/8 232 ns 232 ns 2983796 +// BM_Strtod_Big_And_Difficult/64 437 ns 437 ns 1591951 +// BM_Strtod_Big_And_Difficult/512 1738 ns 1738 ns 402519 +// BM_Strtod_Big_And_Difficult/4096 3943 ns 3943 ns 176128 +// BM_Strtod_Big_And_Difficult/5000 4397 ns 4397 ns 157878 +// BM_Absl_Big_And_Difficult/3 39 ns 39 ns 17799583 +// BM_Absl_Big_And_Difficult/8 43 ns 43 ns 16096859 +// BM_Absl_Big_And_Difficult/64 550 ns 550 ns 1259717 +// BM_Absl_Big_And_Difficult/512 4167 ns 4167 ns 171414 +// BM_Absl_Big_And_Difficult/4096 9160 ns 9159 ns 76297 +// BM_Absl_Big_And_Difficult/5000 9738 ns 9738 ns 70140 diff --git a/third_party/abseil_cpp/absl/strings/charconv_test.cc b/third_party/abseil_cpp/absl/strings/charconv_test.cc new file mode 100644 index 0000000000..9090e9c89c --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/charconv_test.cc @@ -0,0 +1,780 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/charconv.h" + +#include <cstdlib> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/internal/pow10_helper.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" + +#ifdef _MSC_FULL_VER +#define ABSL_COMPILER_DOES_EXACT_ROUNDING 0 +#define ABSL_STRTOD_HANDLES_NAN_CORRECTLY 0 +#else +#define ABSL_COMPILER_DOES_EXACT_ROUNDING 1 +#define ABSL_STRTOD_HANDLES_NAN_CORRECTLY 1 +#endif + +namespace { + +using absl::strings_internal::Pow10; + +#if ABSL_COMPILER_DOES_EXACT_ROUNDING + +// Tests that the given string is accepted by absl::from_chars, and that it +// converts exactly equal to the given number. +void TestDoubleParse(absl::string_view str, double expected_number) { + SCOPED_TRACE(str); + double actual_number = 0.0; + absl::from_chars_result result = + absl::from_chars(str.data(), str.data() + str.length(), actual_number); + EXPECT_EQ(result.ec, std::errc()); + EXPECT_EQ(result.ptr, str.data() + str.length()); + EXPECT_EQ(actual_number, expected_number); +} + +void TestFloatParse(absl::string_view str, float expected_number) { + SCOPED_TRACE(str); + float actual_number = 0.0; + absl::from_chars_result result = + absl::from_chars(str.data(), str.data() + str.length(), actual_number); + EXPECT_EQ(result.ec, std::errc()); + EXPECT_EQ(result.ptr, str.data() + str.length()); + EXPECT_EQ(actual_number, expected_number); +} + +// Tests that the given double or single precision floating point literal is +// parsed correctly by absl::from_chars. +// +// These convenience macros assume that the C++ compiler being used also does +// fully correct decimal-to-binary conversions. +#define FROM_CHARS_TEST_DOUBLE(number) \ + { \ + TestDoubleParse(#number, number); \ + TestDoubleParse("-" #number, -number); \ + } + +#define FROM_CHARS_TEST_FLOAT(number) \ + { \ + TestFloatParse(#number, number##f); \ + TestFloatParse("-" #number, -number##f); \ + } + +TEST(FromChars, NearRoundingCases) { + // Cases from "A Program for Testing IEEE Decimal-Binary Conversion" + // by Vern Paxson. + + // Forms that should round towards zero. (These are the hardest cases for + // each decimal mantissa size.) + FROM_CHARS_TEST_DOUBLE(5.e125); + FROM_CHARS_TEST_DOUBLE(69.e267); + FROM_CHARS_TEST_DOUBLE(999.e-026); + FROM_CHARS_TEST_DOUBLE(7861.e-034); + FROM_CHARS_TEST_DOUBLE(75569.e-254); + FROM_CHARS_TEST_DOUBLE(928609.e-261); + FROM_CHARS_TEST_DOUBLE(9210917.e080); + FROM_CHARS_TEST_DOUBLE(84863171.e114); + FROM_CHARS_TEST_DOUBLE(653777767.e273); + FROM_CHARS_TEST_DOUBLE(5232604057.e-298); + FROM_CHARS_TEST_DOUBLE(27235667517.e-109); + FROM_CHARS_TEST_DOUBLE(653532977297.e-123); + FROM_CHARS_TEST_DOUBLE(3142213164987.e-294); + FROM_CHARS_TEST_DOUBLE(46202199371337.e-072); + FROM_CHARS_TEST_DOUBLE(231010996856685.e-073); + FROM_CHARS_TEST_DOUBLE(9324754620109615.e212); + FROM_CHARS_TEST_DOUBLE(78459735791271921.e049); + FROM_CHARS_TEST_DOUBLE(272104041512242479.e200); + FROM_CHARS_TEST_DOUBLE(6802601037806061975.e198); + FROM_CHARS_TEST_DOUBLE(20505426358836677347.e-221); + FROM_CHARS_TEST_DOUBLE(836168422905420598437.e-234); + FROM_CHARS_TEST_DOUBLE(4891559871276714924261.e222); + FROM_CHARS_TEST_FLOAT(5.e-20); + FROM_CHARS_TEST_FLOAT(67.e14); + FROM_CHARS_TEST_FLOAT(985.e15); + FROM_CHARS_TEST_FLOAT(7693.e-42); + FROM_CHARS_TEST_FLOAT(55895.e-16); + FROM_CHARS_TEST_FLOAT(996622.e-44); + FROM_CHARS_TEST_FLOAT(7038531.e-32); + FROM_CHARS_TEST_FLOAT(60419369.e-46); + FROM_CHARS_TEST_FLOAT(702990899.e-20); + FROM_CHARS_TEST_FLOAT(6930161142.e-48); + FROM_CHARS_TEST_FLOAT(25933168707.e-13); + FROM_CHARS_TEST_FLOAT(596428896559.e20); + + // Similarly, forms that should round away from zero. + FROM_CHARS_TEST_DOUBLE(9.e-265); + FROM_CHARS_TEST_DOUBLE(85.e-037); + FROM_CHARS_TEST_DOUBLE(623.e100); + FROM_CHARS_TEST_DOUBLE(3571.e263); + FROM_CHARS_TEST_DOUBLE(81661.e153); + FROM_CHARS_TEST_DOUBLE(920657.e-023); + FROM_CHARS_TEST_DOUBLE(4603285.e-024); + FROM_CHARS_TEST_DOUBLE(87575437.e-309); + FROM_CHARS_TEST_DOUBLE(245540327.e122); + FROM_CHARS_TEST_DOUBLE(6138508175.e120); + FROM_CHARS_TEST_DOUBLE(83356057653.e193); + FROM_CHARS_TEST_DOUBLE(619534293513.e124); + FROM_CHARS_TEST_DOUBLE(2335141086879.e218); + FROM_CHARS_TEST_DOUBLE(36167929443327.e-159); + FROM_CHARS_TEST_DOUBLE(609610927149051.e-255); + FROM_CHARS_TEST_DOUBLE(3743626360493413.e-165); + FROM_CHARS_TEST_DOUBLE(94080055902682397.e-242); + FROM_CHARS_TEST_DOUBLE(899810892172646163.e283); + FROM_CHARS_TEST_DOUBLE(7120190517612959703.e120); + FROM_CHARS_TEST_DOUBLE(25188282901709339043.e-252); + FROM_CHARS_TEST_DOUBLE(308984926168550152811.e-052); + FROM_CHARS_TEST_DOUBLE(6372891218502368041059.e064); + FROM_CHARS_TEST_FLOAT(3.e-23); + FROM_CHARS_TEST_FLOAT(57.e18); + FROM_CHARS_TEST_FLOAT(789.e-35); + FROM_CHARS_TEST_FLOAT(2539.e-18); + FROM_CHARS_TEST_FLOAT(76173.e28); + FROM_CHARS_TEST_FLOAT(887745.e-11); + FROM_CHARS_TEST_FLOAT(5382571.e-37); + FROM_CHARS_TEST_FLOAT(82381273.e-35); + FROM_CHARS_TEST_FLOAT(750486563.e-38); + FROM_CHARS_TEST_FLOAT(3752432815.e-39); + FROM_CHARS_TEST_FLOAT(75224575729.e-45); + FROM_CHARS_TEST_FLOAT(459926601011.e15); +} + +#undef FROM_CHARS_TEST_DOUBLE +#undef FROM_CHARS_TEST_FLOAT +#endif + +float ToFloat(absl::string_view s) { + float f; + absl::from_chars(s.data(), s.data() + s.size(), f); + return f; +} + +double ToDouble(absl::string_view s) { + double d; + absl::from_chars(s.data(), s.data() + s.size(), d); + return d; +} + +// A duplication of the test cases in "NearRoundingCases" above, but with +// expected values expressed with integers, using ldexp/ldexpf. These test +// cases will work even on compilers that do not accurately round floating point +// literals. +TEST(FromChars, NearRoundingCasesExplicit) { + EXPECT_EQ(ToDouble("5.e125"), ldexp(6653062250012735, 365)); + EXPECT_EQ(ToDouble("69.e267"), ldexp(4705683757438170, 841)); + EXPECT_EQ(ToDouble("999.e-026"), ldexp(6798841691080350, -129)); + EXPECT_EQ(ToDouble("7861.e-034"), ldexp(8975675289889240, -153)); + EXPECT_EQ(ToDouble("75569.e-254"), ldexp(6091718967192243, -880)); + EXPECT_EQ(ToDouble("928609.e-261"), ldexp(7849264900213743, -900)); + EXPECT_EQ(ToDouble("9210917.e080"), ldexp(8341110837370930, 236)); + EXPECT_EQ(ToDouble("84863171.e114"), ldexp(4625202867375927, 353)); + EXPECT_EQ(ToDouble("653777767.e273"), ldexp(5068902999763073, 884)); + EXPECT_EQ(ToDouble("5232604057.e-298"), ldexp(5741343011915040, -1010)); + EXPECT_EQ(ToDouble("27235667517.e-109"), ldexp(6707124626673586, -380)); + EXPECT_EQ(ToDouble("653532977297.e-123"), ldexp(7078246407265384, -422)); + EXPECT_EQ(ToDouble("3142213164987.e-294"), ldexp(8219991337640559, -988)); + EXPECT_EQ(ToDouble("46202199371337.e-072"), ldexp(5224462102115359, -246)); + EXPECT_EQ(ToDouble("231010996856685.e-073"), ldexp(5224462102115359, -247)); + EXPECT_EQ(ToDouble("9324754620109615.e212"), ldexp(5539753864394442, 705)); + EXPECT_EQ(ToDouble("78459735791271921.e049"), ldexp(8388176519442766, 166)); + EXPECT_EQ(ToDouble("272104041512242479.e200"), ldexp(5554409530847367, 670)); + EXPECT_EQ(ToDouble("6802601037806061975.e198"), ldexp(5554409530847367, 668)); + EXPECT_EQ(ToDouble("20505426358836677347.e-221"), + ldexp(4524032052079546, -722)); + EXPECT_EQ(ToDouble("836168422905420598437.e-234"), + ldexp(5070963299887562, -760)); + EXPECT_EQ(ToDouble("4891559871276714924261.e222"), + ldexp(6452687840519111, 757)); + EXPECT_EQ(ToFloat("5.e-20"), ldexpf(15474250, -88)); + EXPECT_EQ(ToFloat("67.e14"), ldexpf(12479722, 29)); + EXPECT_EQ(ToFloat("985.e15"), ldexpf(14333636, 36)); + EXPECT_EQ(ToFloat("7693.e-42"), ldexpf(10979816, -150)); + EXPECT_EQ(ToFloat("55895.e-16"), ldexpf(12888509, -61)); + EXPECT_EQ(ToFloat("996622.e-44"), ldexpf(14224264, -150)); + EXPECT_EQ(ToFloat("7038531.e-32"), ldexpf(11420669, -107)); + EXPECT_EQ(ToFloat("60419369.e-46"), ldexpf(8623340, -150)); + EXPECT_EQ(ToFloat("702990899.e-20"), ldexpf(16209866, -61)); + EXPECT_EQ(ToFloat("6930161142.e-48"), ldexpf(9891056, -150)); + EXPECT_EQ(ToFloat("25933168707.e-13"), ldexpf(11138211, -32)); + EXPECT_EQ(ToFloat("596428896559.e20"), ldexpf(12333860, 82)); + + + EXPECT_EQ(ToDouble("9.e-265"), ldexp(8168427841980010, -930)); + EXPECT_EQ(ToDouble("85.e-037"), ldexp(6360455125664090, -169)); + EXPECT_EQ(ToDouble("623.e100"), ldexp(6263531988747231, 289)); + EXPECT_EQ(ToDouble("3571.e263"), ldexp(6234526311072170, 833)); + EXPECT_EQ(ToDouble("81661.e153"), ldexp(6696636728760206, 472)); + EXPECT_EQ(ToDouble("920657.e-023"), ldexp(5975405561110124, -109)); + EXPECT_EQ(ToDouble("4603285.e-024"), ldexp(5975405561110124, -110)); + EXPECT_EQ(ToDouble("87575437.e-309"), ldexp(8452160731874668, -1053)); + EXPECT_EQ(ToDouble("245540327.e122"), ldexp(4985336549131723, 381)); + EXPECT_EQ(ToDouble("6138508175.e120"), ldexp(4985336549131723, 379)); + EXPECT_EQ(ToDouble("83356057653.e193"), ldexp(5986732817132056, 625)); + EXPECT_EQ(ToDouble("619534293513.e124"), ldexp(4798406992060657, 399)); + EXPECT_EQ(ToDouble("2335141086879.e218"), ldexp(5419088166961646, 713)); + EXPECT_EQ(ToDouble("36167929443327.e-159"), ldexp(8135819834632444, -536)); + EXPECT_EQ(ToDouble("609610927149051.e-255"), ldexp(4576664294594737, -850)); + EXPECT_EQ(ToDouble("3743626360493413.e-165"), ldexp(6898586531774201, -549)); + EXPECT_EQ(ToDouble("94080055902682397.e-242"), ldexp(6273271706052298, -800)); + EXPECT_EQ(ToDouble("899810892172646163.e283"), ldexp(7563892574477827, 947)); + EXPECT_EQ(ToDouble("7120190517612959703.e120"), ldexp(5385467232557565, 409)); + EXPECT_EQ(ToDouble("25188282901709339043.e-252"), + ldexp(5635662608542340, -825)); + EXPECT_EQ(ToDouble("308984926168550152811.e-052"), + ldexp(5644774693823803, -157)); + EXPECT_EQ(ToDouble("6372891218502368041059.e064"), + ldexp(4616868614322430, 233)); + + EXPECT_EQ(ToFloat("3.e-23"), ldexpf(9507380, -98)); + EXPECT_EQ(ToFloat("57.e18"), ldexpf(12960300, 42)); + EXPECT_EQ(ToFloat("789.e-35"), ldexpf(10739312, -130)); + EXPECT_EQ(ToFloat("2539.e-18"), ldexpf(11990089, -72)); + EXPECT_EQ(ToFloat("76173.e28"), ldexpf(9845130, 86)); + EXPECT_EQ(ToFloat("887745.e-11"), ldexpf(9760860, -40)); + EXPECT_EQ(ToFloat("5382571.e-37"), ldexpf(11447463, -124)); + EXPECT_EQ(ToFloat("82381273.e-35"), ldexpf(8554961, -113)); + EXPECT_EQ(ToFloat("750486563.e-38"), ldexpf(9975678, -120)); + EXPECT_EQ(ToFloat("3752432815.e-39"), ldexpf(9975678, -121)); + EXPECT_EQ(ToFloat("75224575729.e-45"), ldexpf(13105970, -137)); + EXPECT_EQ(ToFloat("459926601011.e15"), ldexpf(12466336, 65)); +} + +// Common test logic for converting a string which lies exactly halfway between +// two target floats. +// +// mantissa and exponent represent the precise value between two floating point +// numbers, `expected_low` and `expected_high`. The floating point +// representation to parse in `StrCat(mantissa, "e", exponent)`. +// +// This function checks that an input just slightly less than the exact value +// is rounded down to `expected_low`, and an input just slightly greater than +// the exact value is rounded up to `expected_high`. +// +// The exact value should round to `expected_half`, which must be either +// `expected_low` or `expected_high`. +template <typename FloatType> +void TestHalfwayValue(const std::string& mantissa, int exponent, + FloatType expected_low, FloatType expected_high, + FloatType expected_half) { + std::string low_rep = mantissa; + low_rep[low_rep.size() - 1] -= 1; + absl::StrAppend(&low_rep, std::string(1000, '9'), "e", exponent); + + FloatType actual_low = 0; + absl::from_chars(low_rep.data(), low_rep.data() + low_rep.size(), actual_low); + EXPECT_EQ(expected_low, actual_low); + + std::string high_rep = + absl::StrCat(mantissa, std::string(1000, '0'), "1e", exponent); + FloatType actual_high = 0; + absl::from_chars(high_rep.data(), high_rep.data() + high_rep.size(), + actual_high); + EXPECT_EQ(expected_high, actual_high); + + std::string halfway_rep = absl::StrCat(mantissa, "e", exponent); + FloatType actual_half = 0; + absl::from_chars(halfway_rep.data(), halfway_rep.data() + halfway_rep.size(), + actual_half); + EXPECT_EQ(expected_half, actual_half); +} + +TEST(FromChars, DoubleRounding) { + const double zero = 0.0; + const double first_subnormal = nextafter(zero, 1.0); + const double second_subnormal = nextafter(first_subnormal, 1.0); + + const double first_normal = DBL_MIN; + const double last_subnormal = nextafter(first_normal, 0.0); + const double second_normal = nextafter(first_normal, 1.0); + + const double last_normal = DBL_MAX; + const double penultimate_normal = nextafter(last_normal, 0.0); + + // Various test cases for numbers between two representable floats. Each + // call to TestHalfwayValue tests a number just below and just above the + // halfway point, as well as the number exactly between them. + + // Test between zero and first_subnormal. Round-to-even tie rounds down. + TestHalfwayValue( + "2." + "470328229206232720882843964341106861825299013071623822127928412503377536" + "351043759326499181808179961898982823477228588654633283551779698981993873" + "980053909390631503565951557022639229085839244910518443593180284993653615" + "250031937045767824921936562366986365848075700158576926990370631192827955" + "855133292783433840935197801553124659726357957462276646527282722005637400" + "648549997709659947045402082816622623785739345073633900796776193057750674" + "017632467360096895134053553745851666113422376667860416215968046191446729" + "184030053005753084904876539171138659164623952491262365388187963623937328" + "042389101867234849766823508986338858792562830275599565752445550725518931" + "369083625477918694866799496832404970582102851318545139621383772282614543" + "7693412532098591327667236328125", + -324, zero, first_subnormal, zero); + + // first_subnormal and second_subnormal. Round-to-even tie rounds up. + TestHalfwayValue( + "7." + "410984687618698162648531893023320585475897039214871466383785237510132609" + "053131277979497545424539885696948470431685765963899850655339096945981621" + "940161728171894510697854671067917687257517734731555330779540854980960845" + "750095811137303474765809687100959097544227100475730780971111893578483867" + "565399878350301522805593404659373979179073872386829939581848166016912201" + "945649993128979841136206248449867871357218035220901702390328579173252022" + "052897402080290685402160661237554998340267130003581248647904138574340187" + "552090159017259254714629617513415977493871857473787096164563890871811984" + "127167305601704549300470526959016576377688490826798697257336652176556794" + "107250876433756084600398490497214911746308553955635418864151316847843631" + "3080237596295773983001708984375", + -324, first_subnormal, second_subnormal, second_subnormal); + + // last_subnormal and first_normal. Round-to-even tie rounds up. + TestHalfwayValue( + "2." + "225073858507201136057409796709131975934819546351645648023426109724822222" + "021076945516529523908135087914149158913039621106870086438694594645527657" + "207407820621743379988141063267329253552286881372149012981122451451889849" + "057222307285255133155755015914397476397983411801999323962548289017107081" + "850690630666655994938275772572015763062690663332647565300009245888316433" + "037779791869612049497390377829704905051080609940730262937128958950003583" + "799967207254304360284078895771796150945516748243471030702609144621572289" + "880258182545180325707018860872113128079512233426288368622321503775666622" + "503982534335974568884423900265498198385487948292206894721689831099698365" + "846814022854243330660339850886445804001034933970427567186443383770486037" + "86162277173854562306587467901408672332763671875", + -308, last_subnormal, first_normal, first_normal); + + // first_normal and second_normal. Round-to-even tie rounds down. + TestHalfwayValue( + "2." + "225073858507201630123055637955676152503612414573018013083228724049586647" + "606759446192036794116886953213985520549032000903434781884412325572184367" + "563347617020518175998922941393629966742598285899994830148971433555578567" + "693279306015978183162142425067962460785295885199272493577688320732492479" + "924816869232247165964934329258783950102250973957579510571600738343645738" + "494324192997092179207389919761694314131497173265255020084997973676783743" + "155205818804439163810572367791175177756227497413804253387084478193655533" + "073867420834526162513029462022730109054820067654020201547112002028139700" + "141575259123440177362244273712468151750189745559978653234255886219611516" + "335924167958029604477064946470184777360934300451421683607013647479513962" + "13837722826145437693412532098591327667236328125", + -308, first_normal, second_normal, first_normal); + + // penultimate_normal and last_normal. Round-to-even rounds down. + TestHalfwayValue( + "1." + "797693134862315608353258760581052985162070023416521662616611746258695532" + "672923265745300992879465492467506314903358770175220871059269879629062776" + "047355692132901909191523941804762171253349609463563872612866401980290377" + "995141836029815117562837277714038305214839639239356331336428021390916694" + "57927874464075218944", + 308, penultimate_normal, last_normal, penultimate_normal); +} + +// Same test cases as DoubleRounding, now with new and improved Much Smaller +// Precision! +TEST(FromChars, FloatRounding) { + const float zero = 0.0; + const float first_subnormal = nextafterf(zero, 1.0); + const float second_subnormal = nextafterf(first_subnormal, 1.0); + + const float first_normal = FLT_MIN; + const float last_subnormal = nextafterf(first_normal, 0.0); + const float second_normal = nextafterf(first_normal, 1.0); + + const float last_normal = FLT_MAX; + const float penultimate_normal = nextafterf(last_normal, 0.0); + + // Test between zero and first_subnormal. Round-to-even tie rounds down. + TestHalfwayValue( + "7." + "006492321624085354618647916449580656401309709382578858785341419448955413" + "42930300743319094181060791015625", + -46, zero, first_subnormal, zero); + + // first_subnormal and second_subnormal. Round-to-even tie rounds up. + TestHalfwayValue( + "2." + "101947696487225606385594374934874196920392912814773657635602425834686624" + "028790902229957282543182373046875", + -45, first_subnormal, second_subnormal, second_subnormal); + + // last_subnormal and first_normal. Round-to-even tie rounds up. + TestHalfwayValue( + "1." + "175494280757364291727882991035766513322858992758990427682963118425003064" + "9651730385585324256680905818939208984375", + -38, last_subnormal, first_normal, first_normal); + + // first_normal and second_normal. Round-to-even tie rounds down. + TestHalfwayValue( + "1." + "175494420887210724209590083408724842314472120785184615334540294131831453" + "9442813071445925743319094181060791015625", + -38, first_normal, second_normal, first_normal); + + // penultimate_normal and last_normal. Round-to-even rounds down. + TestHalfwayValue("3.40282336497324057985868971510891282432", 38, + penultimate_normal, last_normal, penultimate_normal); +} + +TEST(FromChars, Underflow) { + // Check that underflow is handled correctly, according to the specification + // in DR 3081. + double d; + float f; + absl::from_chars_result result; + + std::string negative_underflow = "-1e-1000"; + const char* begin = negative_underflow.data(); + const char* end = begin + negative_underflow.size(); + d = 100.0; + result = absl::from_chars(begin, end, d); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_TRUE(std::signbit(d)); // negative + EXPECT_GE(d, -std::numeric_limits<double>::min()); + f = 100.0; + result = absl::from_chars(begin, end, f); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_TRUE(std::signbit(f)); // negative + EXPECT_GE(f, -std::numeric_limits<float>::min()); + + std::string positive_underflow = "1e-1000"; + begin = positive_underflow.data(); + end = begin + positive_underflow.size(); + d = -100.0; + result = absl::from_chars(begin, end, d); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_FALSE(std::signbit(d)); // positive + EXPECT_LE(d, std::numeric_limits<double>::min()); + f = -100.0; + result = absl::from_chars(begin, end, f); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_FALSE(std::signbit(f)); // positive + EXPECT_LE(f, std::numeric_limits<float>::min()); +} + +TEST(FromChars, Overflow) { + // Check that overflow is handled correctly, according to the specification + // in DR 3081. + double d; + float f; + absl::from_chars_result result; + + std::string negative_overflow = "-1e1000"; + const char* begin = negative_overflow.data(); + const char* end = begin + negative_overflow.size(); + d = 100.0; + result = absl::from_chars(begin, end, d); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_TRUE(std::signbit(d)); // negative + EXPECT_EQ(d, -std::numeric_limits<double>::max()); + f = 100.0; + result = absl::from_chars(begin, end, f); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_TRUE(std::signbit(f)); // negative + EXPECT_EQ(f, -std::numeric_limits<float>::max()); + + std::string positive_overflow = "1e1000"; + begin = positive_overflow.data(); + end = begin + positive_overflow.size(); + d = -100.0; + result = absl::from_chars(begin, end, d); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_FALSE(std::signbit(d)); // positive + EXPECT_EQ(d, std::numeric_limits<double>::max()); + f = -100.0; + result = absl::from_chars(begin, end, f); + EXPECT_EQ(result.ptr, end); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_FALSE(std::signbit(f)); // positive + EXPECT_EQ(f, std::numeric_limits<float>::max()); +} + +TEST(FromChars, RegressionTestsFromFuzzer) { + absl::string_view src = "0x21900000p00000000099"; + float f; + auto result = absl::from_chars(src.data(), src.data() + src.size(), f); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); +} + +TEST(FromChars, ReturnValuePtr) { + // Check that `ptr` points one past the number scanned, even if that number + // is not representable. + double d; + absl::from_chars_result result; + + std::string normal = "3.14@#$%@#$%"; + result = absl::from_chars(normal.data(), normal.data() + normal.size(), d); + EXPECT_EQ(result.ec, std::errc()); + EXPECT_EQ(result.ptr - normal.data(), 4); + + std::string overflow = "1e1000@#$%@#$%"; + result = absl::from_chars(overflow.data(), + overflow.data() + overflow.size(), d); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_EQ(result.ptr - overflow.data(), 6); + + std::string garbage = "#$%@#$%"; + result = absl::from_chars(garbage.data(), + garbage.data() + garbage.size(), d); + EXPECT_EQ(result.ec, std::errc::invalid_argument); + EXPECT_EQ(result.ptr - garbage.data(), 0); +} + +// Check for a wide range of inputs that strtod() and absl::from_chars() exactly +// agree on the conversion amount. +// +// This test assumes the platform's strtod() uses perfect round_to_nearest +// rounding. +TEST(FromChars, TestVersusStrtod) { + for (int mantissa = 1000000; mantissa <= 9999999; mantissa += 501) { + for (int exponent = -300; exponent < 300; ++exponent) { + std::string candidate = absl::StrCat(mantissa, "e", exponent); + double strtod_value = strtod(candidate.c_str(), nullptr); + double absl_value = 0; + absl::from_chars(candidate.data(), candidate.data() + candidate.size(), + absl_value); + ASSERT_EQ(strtod_value, absl_value) << candidate; + } + } +} + +// Check for a wide range of inputs that strtof() and absl::from_chars() exactly +// agree on the conversion amount. +// +// This test assumes the platform's strtof() uses perfect round_to_nearest +// rounding. +TEST(FromChars, TestVersusStrtof) { + for (int mantissa = 1000000; mantissa <= 9999999; mantissa += 501) { + for (int exponent = -43; exponent < 32; ++exponent) { + std::string candidate = absl::StrCat(mantissa, "e", exponent); + float strtod_value = strtof(candidate.c_str(), nullptr); + float absl_value = 0; + absl::from_chars(candidate.data(), candidate.data() + candidate.size(), + absl_value); + ASSERT_EQ(strtod_value, absl_value) << candidate; + } + } +} + +// Tests if two floating point values have identical bit layouts. (EXPECT_EQ +// is not suitable for NaN testing, since NaNs are never equal.) +template <typename Float> +bool Identical(Float a, Float b) { + return 0 == memcmp(&a, &b, sizeof(Float)); +} + +// Check that NaNs are parsed correctly. The spec requires that +// std::from_chars on "NaN(123abc)" return the same value as std::nan("123abc"). +// How such an n-char-sequence affects the generated NaN is unspecified, so we +// just test for symmetry with std::nan and strtod here. +// +// (In Linux, this parses the value as a number and stuffs that number into the +// free bits of a quiet NaN.) +TEST(FromChars, NaNDoubles) { + for (std::string n_char_sequence : + {"", "1", "2", "3", "fff", "FFF", "200000", "400000", "4000000000000", + "8000000000000", "abc123", "legal_but_unexpected", + "99999999999999999999999", "_"}) { + std::string input = absl::StrCat("nan(", n_char_sequence, ")"); + SCOPED_TRACE(input); + double from_chars_double; + absl::from_chars(input.data(), input.data() + input.size(), + from_chars_double); + double std_nan_double = std::nan(n_char_sequence.c_str()); + EXPECT_TRUE(Identical(from_chars_double, std_nan_double)); + + // Also check that we match strtod()'s behavior. This test assumes that the + // platform has a compliant strtod(). +#if ABSL_STRTOD_HANDLES_NAN_CORRECTLY + double strtod_double = strtod(input.c_str(), nullptr); + EXPECT_TRUE(Identical(from_chars_double, strtod_double)); +#endif // ABSL_STRTOD_HANDLES_NAN_CORRECTLY + + // Check that we can parse a negative NaN + std::string negative_input = "-" + input; + double negative_from_chars_double; + absl::from_chars(negative_input.data(), + negative_input.data() + negative_input.size(), + negative_from_chars_double); + EXPECT_TRUE(std::signbit(negative_from_chars_double)); + EXPECT_FALSE(Identical(negative_from_chars_double, from_chars_double)); + from_chars_double = std::copysign(from_chars_double, -1.0); + EXPECT_TRUE(Identical(negative_from_chars_double, from_chars_double)); + } +} + +TEST(FromChars, NaNFloats) { + for (std::string n_char_sequence : + {"", "1", "2", "3", "fff", "FFF", "200000", "400000", "4000000000000", + "8000000000000", "abc123", "legal_but_unexpected", + "99999999999999999999999", "_"}) { + std::string input = absl::StrCat("nan(", n_char_sequence, ")"); + SCOPED_TRACE(input); + float from_chars_float; + absl::from_chars(input.data(), input.data() + input.size(), + from_chars_float); + float std_nan_float = std::nanf(n_char_sequence.c_str()); + EXPECT_TRUE(Identical(from_chars_float, std_nan_float)); + + // Also check that we match strtof()'s behavior. This test assumes that the + // platform has a compliant strtof(). +#if ABSL_STRTOD_HANDLES_NAN_CORRECTLY + float strtof_float = strtof(input.c_str(), nullptr); + EXPECT_TRUE(Identical(from_chars_float, strtof_float)); +#endif // ABSL_STRTOD_HANDLES_NAN_CORRECTLY + + // Check that we can parse a negative NaN + std::string negative_input = "-" + input; + float negative_from_chars_float; + absl::from_chars(negative_input.data(), + negative_input.data() + negative_input.size(), + negative_from_chars_float); + EXPECT_TRUE(std::signbit(negative_from_chars_float)); + EXPECT_FALSE(Identical(negative_from_chars_float, from_chars_float)); + from_chars_float = std::copysign(from_chars_float, -1.0); + EXPECT_TRUE(Identical(negative_from_chars_float, from_chars_float)); + } +} + +// Returns an integer larger than step. The values grow exponentially. +int NextStep(int step) { + return step + (step >> 2) + 1; +} + +// Test a conversion on a family of input strings, checking that the calculation +// is correct for in-bounds values, and that overflow and underflow are done +// correctly for out-of-bounds values. +// +// input_generator maps from an integer index to a string to test. +// expected_generator maps from an integer index to an expected Float value. +// from_chars conversion of input_generator(i) should result in +// expected_generator(i). +// +// lower_bound and upper_bound denote the smallest and largest values for which +// the conversion is expected to succeed. +template <typename Float> +void TestOverflowAndUnderflow( + const std::function<std::string(int)>& input_generator, + const std::function<Float(int)>& expected_generator, int lower_bound, + int upper_bound) { + // test legal values near lower_bound + int index, step; + for (index = lower_bound, step = 1; index < upper_bound; + index += step, step = NextStep(step)) { + std::string input = input_generator(index); + SCOPED_TRACE(input); + Float expected = expected_generator(index); + Float actual; + auto result = + absl::from_chars(input.data(), input.data() + input.size(), actual); + EXPECT_EQ(result.ec, std::errc()); + EXPECT_EQ(expected, actual) + << absl::StrFormat("%a vs %a", expected, actual); + } + // test legal values near upper_bound + for (index = upper_bound, step = 1; index > lower_bound; + index -= step, step = NextStep(step)) { + std::string input = input_generator(index); + SCOPED_TRACE(input); + Float expected = expected_generator(index); + Float actual; + auto result = + absl::from_chars(input.data(), input.data() + input.size(), actual); + EXPECT_EQ(result.ec, std::errc()); + EXPECT_EQ(expected, actual) + << absl::StrFormat("%a vs %a", expected, actual); + } + // Test underflow values below lower_bound + for (index = lower_bound - 1, step = 1; index > -1000000; + index -= step, step = NextStep(step)) { + std::string input = input_generator(index); + SCOPED_TRACE(input); + Float actual; + auto result = + absl::from_chars(input.data(), input.data() + input.size(), actual); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_LT(actual, 1.0); // check for underflow + } + // Test overflow values above upper_bound + for (index = upper_bound + 1, step = 1; index < 1000000; + index += step, step = NextStep(step)) { + std::string input = input_generator(index); + SCOPED_TRACE(input); + Float actual; + auto result = + absl::from_chars(input.data(), input.data() + input.size(), actual); + EXPECT_EQ(result.ec, std::errc::result_out_of_range); + EXPECT_GT(actual, 1.0); // check for overflow + } +} + +// Check that overflow and underflow are caught correctly for hex doubles. +// +// The largest representable double is 0x1.fffffffffffffp+1023, and the +// smallest representable subnormal is 0x0.0000000000001p-1022, which equals +// 0x1p-1074. Therefore 1023 and -1074 are the limits of acceptable exponents +// in this test. +TEST(FromChars, HexdecimalDoubleLimits) { + auto input_gen = [](int index) { return absl::StrCat("0x1.0p", index); }; + auto expected_gen = [](int index) { return std::ldexp(1.0, index); }; + TestOverflowAndUnderflow<double>(input_gen, expected_gen, -1074, 1023); +} + +// Check that overflow and underflow are caught correctly for hex floats. +// +// The largest representable float is 0x1.fffffep+127, and the smallest +// representable subnormal is 0x0.000002p-126, which equals 0x1p-149. +// Therefore 127 and -149 are the limits of acceptable exponents in this test. +TEST(FromChars, HexdecimalFloatLimits) { + auto input_gen = [](int index) { return absl::StrCat("0x1.0p", index); }; + auto expected_gen = [](int index) { return std::ldexp(1.0f, index); }; + TestOverflowAndUnderflow<float>(input_gen, expected_gen, -149, 127); +} + +// Check that overflow and underflow are caught correctly for decimal doubles. +// +// The largest representable double is about 1.8e308, and the smallest +// representable subnormal is about 5e-324. '1e-324' therefore rounds away from +// the smallest representable positive value. -323 and 308 are the limits of +// acceptable exponents in this test. +TEST(FromChars, DecimalDoubleLimits) { + auto input_gen = [](int index) { return absl::StrCat("1.0e", index); }; + auto expected_gen = [](int index) { return Pow10(index); }; + TestOverflowAndUnderflow<double>(input_gen, expected_gen, -323, 308); +} + +// Check that overflow and underflow are caught correctly for decimal floats. +// +// The largest representable float is about 3.4e38, and the smallest +// representable subnormal is about 1.45e-45. '1e-45' therefore rounds towards +// the smallest representable positive value. -45 and 38 are the limits of +// acceptable exponents in this test. +TEST(FromChars, DecimalFloatLimits) { + auto input_gen = [](int index) { return absl::StrCat("1.0e", index); }; + auto expected_gen = [](int index) { return Pow10(index); }; + TestOverflowAndUnderflow<float>(input_gen, expected_gen, -45, 38); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/cord.cc b/third_party/abseil_cpp/absl/strings/cord.cc new file mode 100644 index 0000000000..1ddd6aec91 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/cord.cc @@ -0,0 +1,1988 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/cord.h" + +#include <algorithm> +#include <atomic> +#include <cstddef> +#include <cstdio> +#include <cstdlib> +#include <iomanip> +#include <iostream> +#include <limits> +#include <ostream> +#include <sstream> +#include <type_traits> +#include <unordered_set> +#include <vector> + +#include "absl/base/casts.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/container/fixed_array.h" +#include "absl/container/inlined_vector.h" +#include "absl/strings/escaping.h" +#include "absl/strings/internal/cord_internal.h" +#include "absl/strings/internal/resize_uninitialized.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/str_join.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +using ::absl::cord_internal::CordRep; +using ::absl::cord_internal::CordRepConcat; +using ::absl::cord_internal::CordRepExternal; +using ::absl::cord_internal::CordRepSubstring; + +// Various representations that we allow +enum CordRepKind { + CONCAT = 0, + EXTERNAL = 1, + SUBSTRING = 2, + + // We have different tags for different sized flat arrays, + // starting with FLAT + FLAT = 3, +}; + +namespace { + +// Type used with std::allocator for allocating and deallocating +// `CordRepExternal`. std::allocator is used because it opaquely handles the +// different new / delete overloads available on a given platform. +struct alignas(absl::cord_internal::ExternalRepAlignment()) ExternalAllocType { + unsigned char value[absl::cord_internal::ExternalRepAlignment()]; +}; + +// Returns the number of objects to pass in to std::allocator<ExternalAllocType> +// allocate() and deallocate() to create enough room for `CordRepExternal` with +// `releaser_size` bytes on the end. +constexpr size_t GetExternalAllocNumObjects(size_t releaser_size) { + // Be sure to round up since `releaser_size` could be smaller than + // `sizeof(ExternalAllocType)`. + return (sizeof(CordRepExternal) + releaser_size + sizeof(ExternalAllocType) - + 1) / + sizeof(ExternalAllocType); +} + +// Allocates enough memory for `CordRepExternal` and a releaser with size +// `releaser_size` bytes. +void* AllocateExternal(size_t releaser_size) { + return std::allocator<ExternalAllocType>().allocate( + GetExternalAllocNumObjects(releaser_size)); +} + +// Deallocates the memory for a `CordRepExternal` assuming it was allocated with +// a releaser of given size and alignment. +void DeallocateExternal(CordRepExternal* p, size_t releaser_size) { + std::allocator<ExternalAllocType>().deallocate( + reinterpret_cast<ExternalAllocType*>(p), + GetExternalAllocNumObjects(releaser_size)); +} + +// Returns a pointer to the type erased releaser for the given CordRepExternal. +void* GetExternalReleaser(CordRepExternal* rep) { + return rep + 1; +} + +} // namespace + +namespace cord_internal { + +inline CordRepConcat* CordRep::concat() { + assert(tag == CONCAT); + return static_cast<CordRepConcat*>(this); +} + +inline const CordRepConcat* CordRep::concat() const { + assert(tag == CONCAT); + return static_cast<const CordRepConcat*>(this); +} + +inline CordRepSubstring* CordRep::substring() { + assert(tag == SUBSTRING); + return static_cast<CordRepSubstring*>(this); +} + +inline const CordRepSubstring* CordRep::substring() const { + assert(tag == SUBSTRING); + return static_cast<const CordRepSubstring*>(this); +} + +inline CordRepExternal* CordRep::external() { + assert(tag == EXTERNAL); + return static_cast<CordRepExternal*>(this); +} + +inline const CordRepExternal* CordRep::external() const { + assert(tag == EXTERNAL); + return static_cast<const CordRepExternal*>(this); +} + +} // namespace cord_internal + +static const size_t kFlatOverhead = offsetof(CordRep, data); + +// Largest and smallest flat node lengths we are willing to allocate +// Flat allocation size is stored in tag, which currently can encode sizes up +// to 4K, encoded as multiple of either 8 or 32 bytes. +// If we allow for larger sizes, we need to change this to 8/64, 16/128, etc. +static constexpr size_t kMaxFlatSize = 4096; +static constexpr size_t kMaxFlatLength = kMaxFlatSize - kFlatOverhead; +static constexpr size_t kMinFlatLength = 32 - kFlatOverhead; + +// Prefer copying blocks of at most this size, otherwise reference count. +static const size_t kMaxBytesToCopy = 511; + +// Helper functions for rounded div, and rounding to exact sizes. +static size_t DivUp(size_t n, size_t m) { return (n + m - 1) / m; } +static size_t RoundUp(size_t n, size_t m) { return DivUp(n, m) * m; } + +// Returns the size to the nearest equal or larger value that can be +// expressed exactly as a tag value. +static size_t RoundUpForTag(size_t size) { + return RoundUp(size, (size <= 1024) ? 8 : 32); +} + +// Converts the allocated size to a tag, rounding down if the size +// does not exactly match a 'tag expressible' size value. The result is +// undefined if the size exceeds the maximum size that can be encoded in +// a tag, i.e., if size is larger than TagToAllocatedSize(<max tag>). +static uint8_t AllocatedSizeToTag(size_t size) { + const size_t tag = (size <= 1024) ? size / 8 : 128 + size / 32 - 1024 / 32; + assert(tag <= std::numeric_limits<uint8_t>::max()); + return tag; +} + +// Converts the provided tag to the corresponding allocated size +static constexpr size_t TagToAllocatedSize(uint8_t tag) { + return (tag <= 128) ? (tag * 8) : (1024 + (tag - 128) * 32); +} + +// Converts the provided tag to the corresponding available data length +static constexpr size_t TagToLength(uint8_t tag) { + return TagToAllocatedSize(tag) - kFlatOverhead; +} + +// Enforce that kMaxFlatSize maps to a well-known exact tag value. +static_assert(TagToAllocatedSize(224) == kMaxFlatSize, "Bad tag logic"); + +constexpr uint64_t Fibonacci(unsigned char n, uint64_t a = 0, uint64_t b = 1) { + return n == 0 ? a : Fibonacci(n - 1, b, a + b); +} + +static_assert(Fibonacci(63) == 6557470319842, + "Fibonacci values computed incorrectly"); + +// Minimum length required for a given depth tree -- a tree is considered +// balanced if +// length(t) >= min_length[depth(t)] +// The root node depth is allowed to become twice as large to reduce rebalancing +// for larger strings (see IsRootBalanced). +static constexpr uint64_t min_length[] = { + Fibonacci(2), Fibonacci(3), Fibonacci(4), Fibonacci(5), + Fibonacci(6), Fibonacci(7), Fibonacci(8), Fibonacci(9), + Fibonacci(10), Fibonacci(11), Fibonacci(12), Fibonacci(13), + Fibonacci(14), Fibonacci(15), Fibonacci(16), Fibonacci(17), + Fibonacci(18), Fibonacci(19), Fibonacci(20), Fibonacci(21), + Fibonacci(22), Fibonacci(23), Fibonacci(24), Fibonacci(25), + Fibonacci(26), Fibonacci(27), Fibonacci(28), Fibonacci(29), + Fibonacci(30), Fibonacci(31), Fibonacci(32), Fibonacci(33), + Fibonacci(34), Fibonacci(35), Fibonacci(36), Fibonacci(37), + Fibonacci(38), Fibonacci(39), Fibonacci(40), Fibonacci(41), + Fibonacci(42), Fibonacci(43), Fibonacci(44), Fibonacci(45), + Fibonacci(46), Fibonacci(47), + 0xffffffffffffffffull, // Avoid overflow +}; + +static const int kMinLengthSize = ABSL_ARRAYSIZE(min_length); + +// The inlined size to use with absl::InlinedVector. +// +// Note: The InlinedVectors in this file (and in cord.h) do not need to use +// the same value for their inlined size. The fact that they do is historical. +// It may be desirable for each to use a different inlined size optimized for +// that InlinedVector's usage. +// +// TODO(jgm): Benchmark to see if there's a more optimal value than 47 for +// the inlined vector size (47 exists for backward compatibility). +static const int kInlinedVectorSize = 47; + +static inline bool IsRootBalanced(CordRep* node) { + if (node->tag != CONCAT) { + return true; + } else if (node->concat()->depth() <= 15) { + return true; + } else if (node->concat()->depth() > kMinLengthSize) { + return false; + } else { + // Allow depth to become twice as large as implied by fibonacci rule to + // reduce rebalancing for larger strings. + return (node->length >= min_length[node->concat()->depth() / 2]); + } +} + +static CordRep* Rebalance(CordRep* node); +static void DumpNode(CordRep* rep, bool include_data, std::ostream* os); +static bool VerifyNode(CordRep* root, CordRep* start_node, + bool full_validation); + +static inline CordRep* VerifyTree(CordRep* node) { + // Verification is expensive, so only do it in debug mode. + // Even in debug mode we normally do only light validation. + // If you are debugging Cord itself, you should define the + // macro EXTRA_CORD_VALIDATION, e.g. by adding + // --copt=-DEXTRA_CORD_VALIDATION to the blaze line. +#ifdef EXTRA_CORD_VALIDATION + assert(node == nullptr || VerifyNode(node, node, /*full_validation=*/true)); +#else // EXTRA_CORD_VALIDATION + assert(node == nullptr || VerifyNode(node, node, /*full_validation=*/false)); +#endif // EXTRA_CORD_VALIDATION + static_cast<void>(&VerifyNode); + + return node; +} + +// -------------------------------------------------------------------- +// Memory management + +inline CordRep* Ref(CordRep* rep) { + if (rep != nullptr) { + rep->refcount.Increment(); + } + return rep; +} + +// This internal routine is called from the cold path of Unref below. Keeping it +// in a separate routine allows good inlining of Unref into many profitable call +// sites. However, the call to this function can be highly disruptive to the +// register pressure in those callers. To minimize the cost to callers, we use +// a special LLVM calling convention that preserves most registers. This allows +// the call to this routine in cold paths to not disrupt the caller's register +// pressure. This calling convention is not available on all platforms; we +// intentionally allow LLVM to ignore the attribute rather than attempting to +// hardcode the list of supported platforms. +#if defined(__clang__) && !defined(__i386__) +#pragma clang diagnostic push +#pragma clang diagnostic ignored "-Wattributes" +__attribute__((preserve_most)) +#pragma clang diagnostic pop +#endif +static void UnrefInternal(CordRep* rep) { + assert(rep != nullptr); + + absl::InlinedVector<CordRep*, kInlinedVectorSize> pending; + while (true) { + if (rep->tag == CONCAT) { + CordRepConcat* rep_concat = rep->concat(); + CordRep* right = rep_concat->right; + if (!right->refcount.Decrement()) { + pending.push_back(right); + } + CordRep* left = rep_concat->left; + delete rep_concat; + rep = nullptr; + if (!left->refcount.Decrement()) { + rep = left; + continue; + } + } else if (rep->tag == EXTERNAL) { + CordRepExternal* rep_external = rep->external(); + absl::string_view data(rep_external->base, rep->length); + void* releaser = GetExternalReleaser(rep_external); + size_t releaser_size = rep_external->releaser_invoker(releaser, data); + rep_external->~CordRepExternal(); + DeallocateExternal(rep_external, releaser_size); + rep = nullptr; + } else if (rep->tag == SUBSTRING) { + CordRepSubstring* rep_substring = rep->substring(); + CordRep* child = rep_substring->child; + delete rep_substring; + rep = nullptr; + if (!child->refcount.Decrement()) { + rep = child; + continue; + } + } else { + // Flat CordReps are allocated and constructed with raw ::operator new + // and placement new, and must be destructed and deallocated + // accordingly. +#if defined(__cpp_sized_deallocation) + size_t size = TagToAllocatedSize(rep->tag); + rep->~CordRep(); + ::operator delete(rep, size); +#else + rep->~CordRep(); + ::operator delete(rep); +#endif + rep = nullptr; + } + + if (!pending.empty()) { + rep = pending.back(); + pending.pop_back(); + } else { + break; + } + } +} + +inline void Unref(CordRep* rep) { + // Fast-path for two common, hot cases: a null rep and a shared root. + if (ABSL_PREDICT_TRUE(rep == nullptr || + rep->refcount.DecrementExpectHighRefcount())) { + return; + } + + UnrefInternal(rep); +} + +// Return the depth of a node +static int Depth(const CordRep* rep) { + if (rep->tag == CONCAT) { + return rep->concat()->depth(); + } else { + return 0; + } +} + +static void SetConcatChildren(CordRepConcat* concat, CordRep* left, + CordRep* right) { + concat->left = left; + concat->right = right; + + concat->length = left->length + right->length; + concat->set_depth(1 + std::max(Depth(left), Depth(right))); +} + +// Create a concatenation of the specified nodes. +// Does not change the refcounts of "left" and "right". +// The returned node has a refcount of 1. +static CordRep* RawConcat(CordRep* left, CordRep* right) { + // Avoid making degenerate concat nodes (one child is empty) + if (left == nullptr || left->length == 0) { + Unref(left); + return right; + } + if (right == nullptr || right->length == 0) { + Unref(right); + return left; + } + + CordRepConcat* rep = new CordRepConcat(); + rep->tag = CONCAT; + SetConcatChildren(rep, left, right); + + return rep; +} + +static CordRep* Concat(CordRep* left, CordRep* right) { + CordRep* rep = RawConcat(left, right); + if (rep != nullptr && !IsRootBalanced(rep)) { + rep = Rebalance(rep); + } + return VerifyTree(rep); +} + +// Make a balanced tree out of an array of leaf nodes. +static CordRep* MakeBalancedTree(CordRep** reps, size_t n) { + // Make repeated passes over the array, merging adjacent pairs + // until we are left with just a single node. + while (n > 1) { + size_t dst = 0; + for (size_t src = 0; src < n; src += 2) { + if (src + 1 < n) { + reps[dst] = Concat(reps[src], reps[src + 1]); + } else { + reps[dst] = reps[src]; + } + dst++; + } + n = dst; + } + + return reps[0]; +} + +// Create a new flat node. +static CordRep* NewFlat(size_t length_hint) { + if (length_hint <= kMinFlatLength) { + length_hint = kMinFlatLength; + } else if (length_hint > kMaxFlatLength) { + length_hint = kMaxFlatLength; + } + + // Round size up so it matches a size we can exactly express in a tag. + const size_t size = RoundUpForTag(length_hint + kFlatOverhead); + void* const raw_rep = ::operator new(size); + CordRep* rep = new (raw_rep) CordRep(); + rep->tag = AllocatedSizeToTag(size); + return VerifyTree(rep); +} + +// Create a new tree out of the specified array. +// The returned node has a refcount of 1. +static CordRep* NewTree(const char* data, + size_t length, + size_t alloc_hint) { + if (length == 0) return nullptr; + absl::FixedArray<CordRep*> reps((length - 1) / kMaxFlatLength + 1); + size_t n = 0; + do { + const size_t len = std::min(length, kMaxFlatLength); + CordRep* rep = NewFlat(len + alloc_hint); + rep->length = len; + memcpy(rep->data, data, len); + reps[n++] = VerifyTree(rep); + data += len; + length -= len; + } while (length != 0); + return MakeBalancedTree(reps.data(), n); +} + +namespace cord_internal { + +ExternalRepReleaserPair NewExternalWithUninitializedReleaser( + absl::string_view data, ExternalReleaserInvoker invoker, + size_t releaser_size) { + assert(!data.empty()); + + void* raw_rep = AllocateExternal(releaser_size); + auto* rep = new (raw_rep) CordRepExternal(); + rep->length = data.size(); + rep->tag = EXTERNAL; + rep->base = data.data(); + rep->releaser_invoker = invoker; + return {VerifyTree(rep), GetExternalReleaser(rep)}; +} + +} // namespace cord_internal + +static CordRep* NewSubstring(CordRep* child, size_t offset, size_t length) { + // Never create empty substring nodes + if (length == 0) { + Unref(child); + return nullptr; + } else { + CordRepSubstring* rep = new CordRepSubstring(); + assert((offset + length) <= child->length); + rep->length = length; + rep->tag = SUBSTRING; + rep->start = offset; + rep->child = child; + return VerifyTree(rep); + } +} + +// -------------------------------------------------------------------- +// Cord::InlineRep functions + +// This will trigger LNK2005 in MSVC. +#ifndef COMPILER_MSVC +const unsigned char Cord::InlineRep::kMaxInline; +#endif // COMPILER_MSVC + +inline void Cord::InlineRep::set_data(const char* data, size_t n, + bool nullify_tail) { + static_assert(kMaxInline == 15, "set_data is hard-coded for a length of 15"); + + cord_internal::SmallMemmove(data_, data, n, nullify_tail); + data_[kMaxInline] = static_cast<char>(n); +} + +inline char* Cord::InlineRep::set_data(size_t n) { + assert(n <= kMaxInline); + memset(data_, 0, sizeof(data_)); + data_[kMaxInline] = static_cast<char>(n); + return data_; +} + +inline CordRep* Cord::InlineRep::force_tree(size_t extra_hint) { + size_t len = data_[kMaxInline]; + CordRep* result; + if (len > kMaxInline) { + memcpy(&result, data_, sizeof(result)); + } else { + result = NewFlat(len + extra_hint); + result->length = len; + memcpy(result->data, data_, len); + set_tree(result); + } + return result; +} + +inline void Cord::InlineRep::reduce_size(size_t n) { + size_t tag = data_[kMaxInline]; + assert(tag <= kMaxInline); + assert(tag >= n); + tag -= n; + memset(data_ + tag, 0, n); + data_[kMaxInline] = static_cast<char>(tag); +} + +inline void Cord::InlineRep::remove_prefix(size_t n) { + cord_internal::SmallMemmove(data_, data_ + n, data_[kMaxInline] - n); + reduce_size(n); +} + +void Cord::InlineRep::AppendTree(CordRep* tree) { + if (tree == nullptr) return; + size_t len = data_[kMaxInline]; + if (len == 0) { + set_tree(tree); + } else { + set_tree(Concat(force_tree(0), tree)); + } +} + +void Cord::InlineRep::PrependTree(CordRep* tree) { + if (tree == nullptr) return; + size_t len = data_[kMaxInline]; + if (len == 0) { + set_tree(tree); + } else { + set_tree(Concat(tree, force_tree(0))); + } +} + +// Searches for a non-full flat node at the rightmost leaf of the tree. If a +// suitable leaf is found, the function will update the length field for all +// nodes to account for the size increase. The append region address will be +// written to region and the actual size increase will be written to size. +static inline bool PrepareAppendRegion(CordRep* root, char** region, + size_t* size, size_t max_length) { + // Search down the right-hand path for a non-full FLAT node. + CordRep* dst = root; + while (dst->tag == CONCAT && dst->refcount.IsOne()) { + dst = dst->concat()->right; + } + + if (dst->tag < FLAT || !dst->refcount.IsOne()) { + *region = nullptr; + *size = 0; + return false; + } + + const size_t in_use = dst->length; + const size_t capacity = TagToLength(dst->tag); + if (in_use == capacity) { + *region = nullptr; + *size = 0; + return false; + } + + size_t size_increase = std::min(capacity - in_use, max_length); + + // We need to update the length fields for all nodes, including the leaf node. + for (CordRep* rep = root; rep != dst; rep = rep->concat()->right) { + rep->length += size_increase; + } + dst->length += size_increase; + + *region = dst->data + in_use; + *size = size_increase; + return true; +} + +void Cord::InlineRep::GetAppendRegion(char** region, size_t* size, + size_t max_length) { + if (max_length == 0) { + *region = nullptr; + *size = 0; + return; + } + + // Try to fit in the inline buffer if possible. + size_t inline_length = data_[kMaxInline]; + if (inline_length < kMaxInline && max_length <= kMaxInline - inline_length) { + *region = data_ + inline_length; + *size = max_length; + data_[kMaxInline] = static_cast<char>(inline_length + max_length); + return; + } + + CordRep* root = force_tree(max_length); + + if (PrepareAppendRegion(root, region, size, max_length)) { + return; + } + + // Allocate new node. + CordRep* new_node = + NewFlat(std::max(static_cast<size_t>(root->length), max_length)); + new_node->length = + std::min(static_cast<size_t>(TagToLength(new_node->tag)), max_length); + *region = new_node->data; + *size = new_node->length; + replace_tree(Concat(root, new_node)); +} + +void Cord::InlineRep::GetAppendRegion(char** region, size_t* size) { + const size_t max_length = std::numeric_limits<size_t>::max(); + + // Try to fit in the inline buffer if possible. + size_t inline_length = data_[kMaxInline]; + if (inline_length < kMaxInline) { + *region = data_ + inline_length; + *size = kMaxInline - inline_length; + data_[kMaxInline] = kMaxInline; + return; + } + + CordRep* root = force_tree(max_length); + + if (PrepareAppendRegion(root, region, size, max_length)) { + return; + } + + // Allocate new node. + CordRep* new_node = NewFlat(root->length); + new_node->length = TagToLength(new_node->tag); + *region = new_node->data; + *size = new_node->length; + replace_tree(Concat(root, new_node)); +} + +// If the rep is a leaf, this will increment the value at total_mem_usage and +// will return true. +static bool RepMemoryUsageLeaf(const CordRep* rep, size_t* total_mem_usage) { + if (rep->tag >= FLAT) { + *total_mem_usage += TagToAllocatedSize(rep->tag); + return true; + } + if (rep->tag == EXTERNAL) { + *total_mem_usage += sizeof(CordRepConcat) + rep->length; + return true; + } + return false; +} + +void Cord::InlineRep::AssignSlow(const Cord::InlineRep& src) { + ClearSlow(); + + memcpy(data_, src.data_, sizeof(data_)); + if (is_tree()) { + Ref(tree()); + } +} + +void Cord::InlineRep::ClearSlow() { + if (is_tree()) { + Unref(tree()); + } + memset(data_, 0, sizeof(data_)); +} + +// -------------------------------------------------------------------- +// Constructors and destructors + +Cord::Cord(const Cord& src) : contents_(src.contents_) { + Ref(contents_.tree()); // Does nothing if contents_ has embedded data +} + +Cord::Cord(absl::string_view src) { + const size_t n = src.size(); + if (n <= InlineRep::kMaxInline) { + contents_.set_data(src.data(), n, false); + } else { + contents_.set_tree(NewTree(src.data(), n, 0)); + } +} + +// The destruction code is separate so that the compiler can determine +// that it does not need to call the destructor on a moved-from Cord. +void Cord::DestroyCordSlow() { + Unref(VerifyTree(contents_.tree())); +} + +// -------------------------------------------------------------------- +// Mutators + +void Cord::Clear() { + Unref(contents_.clear()); +} + +Cord& Cord::operator=(absl::string_view src) { + + const char* data = src.data(); + size_t length = src.size(); + CordRep* tree = contents_.tree(); + if (length <= InlineRep::kMaxInline) { + // Embed into this->contents_ + contents_.set_data(data, length, true); + Unref(tree); + return *this; + } + if (tree != nullptr && tree->tag >= FLAT && + TagToLength(tree->tag) >= length && tree->refcount.IsOne()) { + // Copy in place if the existing FLAT node is reusable. + memmove(tree->data, data, length); + tree->length = length; + VerifyTree(tree); + return *this; + } + contents_.set_tree(NewTree(data, length, 0)); + Unref(tree); + return *this; +} + +// TODO(sanjay): Move to Cord::InlineRep section of file. For now, +// we keep it here to make diffs easier. +void Cord::InlineRep::AppendArray(const char* src_data, size_t src_size) { + if (src_size == 0) return; // memcpy(_, nullptr, 0) is undefined. + // Try to fit in the inline buffer if possible. + size_t inline_length = data_[kMaxInline]; + if (inline_length < kMaxInline && src_size <= kMaxInline - inline_length) { + // Append new data to embedded array + data_[kMaxInline] = static_cast<char>(inline_length + src_size); + memcpy(data_ + inline_length, src_data, src_size); + return; + } + + CordRep* root = tree(); + + size_t appended = 0; + if (root) { + char* region; + if (PrepareAppendRegion(root, ®ion, &appended, src_size)) { + memcpy(region, src_data, appended); + } + } else { + // It is possible that src_data == data_, but when we transition from an + // InlineRep to a tree we need to assign data_ = root via set_tree. To + // avoid corrupting the source data before we copy it, delay calling + // set_tree until after we've copied data. + // We are going from an inline size to beyond inline size. Make the new size + // either double the inlined size, or the added size + 10%. + const size_t size1 = inline_length * 2 + src_size; + const size_t size2 = inline_length + src_size / 10; + root = NewFlat(std::max<size_t>(size1, size2)); + appended = std::min(src_size, TagToLength(root->tag) - inline_length); + memcpy(root->data, data_, inline_length); + memcpy(root->data + inline_length, src_data, appended); + root->length = inline_length + appended; + set_tree(root); + } + + src_data += appended; + src_size -= appended; + if (src_size == 0) { + return; + } + + // Use new block(s) for any remaining bytes that were not handled above. + // Alloc extra memory only if the right child of the root of the new tree is + // going to be a FLAT node, which will permit further inplace appends. + size_t length = src_size; + if (src_size < kMaxFlatLength) { + // The new length is either + // - old size + 10% + // - old_size + src_size + // This will cause a reasonable conservative step-up in size that is still + // large enough to avoid excessive amounts of small fragments being added. + length = std::max<size_t>(root->length / 10, src_size); + } + set_tree(Concat(root, NewTree(src_data, src_size, length - src_size))); +} + +inline CordRep* Cord::TakeRep() const& { + return Ref(contents_.tree()); +} + +inline CordRep* Cord::TakeRep() && { + CordRep* rep = contents_.tree(); + contents_.clear(); + return rep; +} + +template <typename C> +inline void Cord::AppendImpl(C&& src) { + if (empty()) { + // In case of an empty destination avoid allocating a new node, do not copy + // data. + *this = std::forward<C>(src); + return; + } + + // For short cords, it is faster to copy data if there is room in dst. + const size_t src_size = src.contents_.size(); + if (src_size <= kMaxBytesToCopy) { + CordRep* src_tree = src.contents_.tree(); + if (src_tree == nullptr) { + // src has embedded data. + contents_.AppendArray(src.contents_.data(), src_size); + return; + } + if (src_tree->tag >= FLAT) { + // src tree just has one flat node. + contents_.AppendArray(src_tree->data, src_size); + return; + } + if (&src == this) { + // ChunkIterator below assumes that src is not modified during traversal. + Append(Cord(src)); + return; + } + // TODO(mec): Should we only do this if "dst" has space? + for (absl::string_view chunk : src.Chunks()) { + Append(chunk); + } + return; + } + + contents_.AppendTree(std::forward<C>(src).TakeRep()); +} + +void Cord::Append(const Cord& src) { AppendImpl(src); } + +void Cord::Append(Cord&& src) { AppendImpl(std::move(src)); } + +void Cord::Prepend(const Cord& src) { + CordRep* src_tree = src.contents_.tree(); + if (src_tree != nullptr) { + Ref(src_tree); + contents_.PrependTree(src_tree); + return; + } + + // `src` cord is inlined. + absl::string_view src_contents(src.contents_.data(), src.contents_.size()); + return Prepend(src_contents); +} + +void Cord::Prepend(absl::string_view src) { + if (src.empty()) return; // memcpy(_, nullptr, 0) is undefined. + size_t cur_size = contents_.size(); + if (!contents_.is_tree() && cur_size + src.size() <= InlineRep::kMaxInline) { + // Use embedded storage. + char data[InlineRep::kMaxInline + 1] = {0}; + data[InlineRep::kMaxInline] = cur_size + src.size(); // set size + memcpy(data, src.data(), src.size()); + memcpy(data + src.size(), contents_.data(), cur_size); + memcpy(reinterpret_cast<void*>(&contents_), data, + InlineRep::kMaxInline + 1); + } else { + contents_.PrependTree(NewTree(src.data(), src.size(), 0)); + } +} + +static CordRep* RemovePrefixFrom(CordRep* node, size_t n) { + if (n >= node->length) return nullptr; + if (n == 0) return Ref(node); + absl::InlinedVector<CordRep*, kInlinedVectorSize> rhs_stack; + + while (node->tag == CONCAT) { + assert(n <= node->length); + if (n < node->concat()->left->length) { + // Push right to stack, descend left. + rhs_stack.push_back(node->concat()->right); + node = node->concat()->left; + } else { + // Drop left, descend right. + n -= node->concat()->left->length; + node = node->concat()->right; + } + } + assert(n <= node->length); + + if (n == 0) { + Ref(node); + } else { + size_t start = n; + size_t len = node->length - n; + if (node->tag == SUBSTRING) { + // Consider in-place update of node, similar to in RemoveSuffixFrom(). + start += node->substring()->start; + node = node->substring()->child; + } + node = NewSubstring(Ref(node), start, len); + } + while (!rhs_stack.empty()) { + node = Concat(node, Ref(rhs_stack.back())); + rhs_stack.pop_back(); + } + return node; +} + +// RemoveSuffixFrom() is very similar to RemovePrefixFrom(), with the +// exception that removing a suffix has an optimization where a node may be +// edited in place iff that node and all its ancestors have a refcount of 1. +static CordRep* RemoveSuffixFrom(CordRep* node, size_t n) { + if (n >= node->length) return nullptr; + if (n == 0) return Ref(node); + absl::InlinedVector<CordRep*, kInlinedVectorSize> lhs_stack; + bool inplace_ok = node->refcount.IsOne(); + + while (node->tag == CONCAT) { + assert(n <= node->length); + if (n < node->concat()->right->length) { + // Push left to stack, descend right. + lhs_stack.push_back(node->concat()->left); + node = node->concat()->right; + } else { + // Drop right, descend left. + n -= node->concat()->right->length; + node = node->concat()->left; + } + inplace_ok = inplace_ok && node->refcount.IsOne(); + } + assert(n <= node->length); + + if (n == 0) { + Ref(node); + } else if (inplace_ok && node->tag != EXTERNAL) { + // Consider making a new buffer if the current node capacity is much + // larger than the new length. + Ref(node); + node->length -= n; + } else { + size_t start = 0; + size_t len = node->length - n; + if (node->tag == SUBSTRING) { + start = node->substring()->start; + node = node->substring()->child; + } + node = NewSubstring(Ref(node), start, len); + } + while (!lhs_stack.empty()) { + node = Concat(Ref(lhs_stack.back()), node); + lhs_stack.pop_back(); + } + return node; +} + +void Cord::RemovePrefix(size_t n) { + ABSL_INTERNAL_CHECK(n <= size(), + absl::StrCat("Requested prefix size ", n, + " exceeds Cord's size ", size())); + CordRep* tree = contents_.tree(); + if (tree == nullptr) { + contents_.remove_prefix(n); + } else { + CordRep* newrep = RemovePrefixFrom(tree, n); + Unref(tree); + contents_.replace_tree(VerifyTree(newrep)); + } +} + +void Cord::RemoveSuffix(size_t n) { + ABSL_INTERNAL_CHECK(n <= size(), + absl::StrCat("Requested suffix size ", n, + " exceeds Cord's size ", size())); + CordRep* tree = contents_.tree(); + if (tree == nullptr) { + contents_.reduce_size(n); + } else { + CordRep* newrep = RemoveSuffixFrom(tree, n); + Unref(tree); + contents_.replace_tree(VerifyTree(newrep)); + } +} + +// Work item for NewSubRange(). +struct SubRange { + SubRange(CordRep* a_node, size_t a_pos, size_t a_n) + : node(a_node), pos(a_pos), n(a_n) {} + CordRep* node; // nullptr means concat last 2 results. + size_t pos; + size_t n; +}; + +static CordRep* NewSubRange(CordRep* node, size_t pos, size_t n) { + absl::InlinedVector<CordRep*, kInlinedVectorSize> results; + absl::InlinedVector<SubRange, kInlinedVectorSize> todo; + todo.push_back(SubRange(node, pos, n)); + do { + const SubRange& sr = todo.back(); + node = sr.node; + pos = sr.pos; + n = sr.n; + todo.pop_back(); + + if (node == nullptr) { + assert(results.size() >= 2); + CordRep* right = results.back(); + results.pop_back(); + CordRep* left = results.back(); + results.pop_back(); + results.push_back(Concat(left, right)); + } else if (pos == 0 && n == node->length) { + results.push_back(Ref(node)); + } else if (node->tag != CONCAT) { + if (node->tag == SUBSTRING) { + pos += node->substring()->start; + node = node->substring()->child; + } + results.push_back(NewSubstring(Ref(node), pos, n)); + } else if (pos + n <= node->concat()->left->length) { + todo.push_back(SubRange(node->concat()->left, pos, n)); + } else if (pos >= node->concat()->left->length) { + pos -= node->concat()->left->length; + todo.push_back(SubRange(node->concat()->right, pos, n)); + } else { + size_t left_n = node->concat()->left->length - pos; + todo.push_back(SubRange(nullptr, 0, 0)); // Concat() + todo.push_back(SubRange(node->concat()->right, 0, n - left_n)); + todo.push_back(SubRange(node->concat()->left, pos, left_n)); + } + } while (!todo.empty()); + assert(results.size() == 1); + return results[0]; +} + +Cord Cord::Subcord(size_t pos, size_t new_size) const { + Cord sub_cord; + size_t length = size(); + if (pos > length) pos = length; + if (new_size > length - pos) new_size = length - pos; + CordRep* tree = contents_.tree(); + if (tree == nullptr) { + // sub_cord is newly constructed, no need to re-zero-out the tail of + // contents_ memory. + sub_cord.contents_.set_data(contents_.data() + pos, new_size, false); + } else if (new_size == 0) { + // We want to return empty subcord, so nothing to do. + } else if (new_size <= InlineRep::kMaxInline) { + Cord::ChunkIterator it = chunk_begin(); + it.AdvanceBytes(pos); + char* dest = sub_cord.contents_.data_; + size_t remaining_size = new_size; + while (remaining_size > it->size()) { + cord_internal::SmallMemmove(dest, it->data(), it->size()); + remaining_size -= it->size(); + dest += it->size(); + ++it; + } + cord_internal::SmallMemmove(dest, it->data(), remaining_size); + sub_cord.contents_.data_[InlineRep::kMaxInline] = new_size; + } else { + sub_cord.contents_.set_tree(NewSubRange(tree, pos, new_size)); + } + return sub_cord; +} + +// -------------------------------------------------------------------- +// Balancing + +class CordForest { + public: + explicit CordForest(size_t length) + : root_length_(length), trees_(kMinLengthSize, nullptr) {} + + void Build(CordRep* cord_root) { + std::vector<CordRep*> pending = {cord_root}; + + while (!pending.empty()) { + CordRep* node = pending.back(); + pending.pop_back(); + CheckNode(node); + if (ABSL_PREDICT_FALSE(node->tag != CONCAT)) { + AddNode(node); + continue; + } + + CordRepConcat* concat_node = node->concat(); + if (concat_node->depth() >= kMinLengthSize || + concat_node->length < min_length[concat_node->depth()]) { + pending.push_back(concat_node->right); + pending.push_back(concat_node->left); + + if (concat_node->refcount.IsOne()) { + concat_node->left = concat_freelist_; + concat_freelist_ = concat_node; + } else { + Ref(concat_node->right); + Ref(concat_node->left); + Unref(concat_node); + } + } else { + AddNode(node); + } + } + } + + CordRep* ConcatNodes() { + CordRep* sum = nullptr; + for (auto* node : trees_) { + if (node == nullptr) continue; + + sum = PrependNode(node, sum); + root_length_ -= node->length; + if (root_length_ == 0) break; + } + ABSL_INTERNAL_CHECK(sum != nullptr, "Failed to locate sum node"); + return VerifyTree(sum); + } + + private: + CordRep* AppendNode(CordRep* node, CordRep* sum) { + return (sum == nullptr) ? node : MakeConcat(sum, node); + } + + CordRep* PrependNode(CordRep* node, CordRep* sum) { + return (sum == nullptr) ? node : MakeConcat(node, sum); + } + + void AddNode(CordRep* node) { + CordRep* sum = nullptr; + + // Collect together everything with which we will merge with node + int i = 0; + for (; node->length > min_length[i + 1]; ++i) { + auto& tree_at_i = trees_[i]; + + if (tree_at_i == nullptr) continue; + sum = PrependNode(tree_at_i, sum); + tree_at_i = nullptr; + } + + sum = AppendNode(node, sum); + + // Insert sum into appropriate place in the forest + for (; sum->length >= min_length[i]; ++i) { + auto& tree_at_i = trees_[i]; + if (tree_at_i == nullptr) continue; + + sum = MakeConcat(tree_at_i, sum); + tree_at_i = nullptr; + } + + // min_length[0] == 1, which means sum->length >= min_length[0] + assert(i > 0); + trees_[i - 1] = sum; + } + + // Make concat node trying to resue existing CordRepConcat nodes we + // already collected in the concat_freelist_. + CordRep* MakeConcat(CordRep* left, CordRep* right) { + if (concat_freelist_ == nullptr) return RawConcat(left, right); + + CordRepConcat* rep = concat_freelist_; + if (concat_freelist_->left == nullptr) { + concat_freelist_ = nullptr; + } else { + concat_freelist_ = concat_freelist_->left->concat(); + } + SetConcatChildren(rep, left, right); + + return rep; + } + + static void CheckNode(CordRep* node) { + ABSL_INTERNAL_CHECK(node->length != 0u, ""); + if (node->tag == CONCAT) { + ABSL_INTERNAL_CHECK(node->concat()->left != nullptr, ""); + ABSL_INTERNAL_CHECK(node->concat()->right != nullptr, ""); + ABSL_INTERNAL_CHECK(node->length == (node->concat()->left->length + + node->concat()->right->length), + ""); + } + } + + size_t root_length_; + + // use an inlined vector instead of a flat array to get bounds checking + absl::InlinedVector<CordRep*, kInlinedVectorSize> trees_; + + // List of concat nodes we can re-use for Cord balancing. + CordRepConcat* concat_freelist_ = nullptr; +}; + +static CordRep* Rebalance(CordRep* node) { + VerifyTree(node); + assert(node->tag == CONCAT); + + if (node->length == 0) { + return nullptr; + } + + CordForest forest(node->length); + forest.Build(node); + return forest.ConcatNodes(); +} + +// -------------------------------------------------------------------- +// Comparators + +namespace { + +int ClampResult(int memcmp_res) { + return static_cast<int>(memcmp_res > 0) - static_cast<int>(memcmp_res < 0); +} + +int CompareChunks(absl::string_view* lhs, absl::string_view* rhs, + size_t* size_to_compare) { + size_t compared_size = std::min(lhs->size(), rhs->size()); + assert(*size_to_compare >= compared_size); + *size_to_compare -= compared_size; + + int memcmp_res = ::memcmp(lhs->data(), rhs->data(), compared_size); + if (memcmp_res != 0) return memcmp_res; + + lhs->remove_prefix(compared_size); + rhs->remove_prefix(compared_size); + + return 0; +} + +// This overload set computes comparison results from memcmp result. This +// interface is used inside GenericCompare below. Differet implementations +// are specialized for int and bool. For int we clamp result to {-1, 0, 1} +// set. For bool we just interested in "value == 0". +template <typename ResultType> +ResultType ComputeCompareResult(int memcmp_res) { + return ClampResult(memcmp_res); +} +template <> +bool ComputeCompareResult<bool>(int memcmp_res) { + return memcmp_res == 0; +} + +} // namespace + +// Helper routine. Locates the first flat chunk of the Cord without +// initializing the iterator. +inline absl::string_view Cord::InlineRep::FindFlatStartPiece() const { + size_t n = data_[kMaxInline]; + if (n <= kMaxInline) { + return absl::string_view(data_, n); + } + + CordRep* node = tree(); + if (node->tag >= FLAT) { + return absl::string_view(node->data, node->length); + } + + if (node->tag == EXTERNAL) { + return absl::string_view(node->external()->base, node->length); + } + + // Walk down the left branches until we hit a non-CONCAT node. + while (node->tag == CONCAT) { + node = node->concat()->left; + } + + // Get the child node if we encounter a SUBSTRING. + size_t offset = 0; + size_t length = node->length; + assert(length != 0); + + if (node->tag == SUBSTRING) { + offset = node->substring()->start; + node = node->substring()->child; + } + + if (node->tag >= FLAT) { + return absl::string_view(node->data + offset, length); + } + + assert((node->tag == EXTERNAL) && "Expect FLAT or EXTERNAL node here"); + + return absl::string_view(node->external()->base + offset, length); +} + +inline int Cord::CompareSlowPath(absl::string_view rhs, size_t compared_size, + size_t size_to_compare) const { + auto advance = [](Cord::ChunkIterator* it, absl::string_view* chunk) { + if (!chunk->empty()) return true; + ++*it; + if (it->bytes_remaining_ == 0) return false; + *chunk = **it; + return true; + }; + + Cord::ChunkIterator lhs_it = chunk_begin(); + + // compared_size is inside first chunk. + absl::string_view lhs_chunk = + (lhs_it.bytes_remaining_ != 0) ? *lhs_it : absl::string_view(); + assert(compared_size <= lhs_chunk.size()); + assert(compared_size <= rhs.size()); + lhs_chunk.remove_prefix(compared_size); + rhs.remove_prefix(compared_size); + size_to_compare -= compared_size; // skip already compared size. + + while (advance(&lhs_it, &lhs_chunk) && !rhs.empty()) { + int comparison_result = CompareChunks(&lhs_chunk, &rhs, &size_to_compare); + if (comparison_result != 0) return comparison_result; + if (size_to_compare == 0) return 0; + } + + return static_cast<int>(rhs.empty()) - static_cast<int>(lhs_chunk.empty()); +} + +inline int Cord::CompareSlowPath(const Cord& rhs, size_t compared_size, + size_t size_to_compare) const { + auto advance = [](Cord::ChunkIterator* it, absl::string_view* chunk) { + if (!chunk->empty()) return true; + ++*it; + if (it->bytes_remaining_ == 0) return false; + *chunk = **it; + return true; + }; + + Cord::ChunkIterator lhs_it = chunk_begin(); + Cord::ChunkIterator rhs_it = rhs.chunk_begin(); + + // compared_size is inside both first chunks. + absl::string_view lhs_chunk = + (lhs_it.bytes_remaining_ != 0) ? *lhs_it : absl::string_view(); + absl::string_view rhs_chunk = + (rhs_it.bytes_remaining_ != 0) ? *rhs_it : absl::string_view(); + assert(compared_size <= lhs_chunk.size()); + assert(compared_size <= rhs_chunk.size()); + lhs_chunk.remove_prefix(compared_size); + rhs_chunk.remove_prefix(compared_size); + size_to_compare -= compared_size; // skip already compared size. + + while (advance(&lhs_it, &lhs_chunk) && advance(&rhs_it, &rhs_chunk)) { + int memcmp_res = CompareChunks(&lhs_chunk, &rhs_chunk, &size_to_compare); + if (memcmp_res != 0) return memcmp_res; + if (size_to_compare == 0) return 0; + } + + return static_cast<int>(rhs_chunk.empty()) - + static_cast<int>(lhs_chunk.empty()); +} + +inline absl::string_view Cord::GetFirstChunk(const Cord& c) { + return c.contents_.FindFlatStartPiece(); +} +inline absl::string_view Cord::GetFirstChunk(absl::string_view sv) { + return sv; +} + +// Compares up to 'size_to_compare' bytes of 'lhs' with 'rhs'. It is assumed +// that 'size_to_compare' is greater that size of smallest of first chunks. +template <typename ResultType, typename RHS> +ResultType GenericCompare(const Cord& lhs, const RHS& rhs, + size_t size_to_compare) { + absl::string_view lhs_chunk = Cord::GetFirstChunk(lhs); + absl::string_view rhs_chunk = Cord::GetFirstChunk(rhs); + + size_t compared_size = std::min(lhs_chunk.size(), rhs_chunk.size()); + assert(size_to_compare >= compared_size); + int memcmp_res = ::memcmp(lhs_chunk.data(), rhs_chunk.data(), compared_size); + if (compared_size == size_to_compare || memcmp_res != 0) { + return ComputeCompareResult<ResultType>(memcmp_res); + } + + return ComputeCompareResult<ResultType>( + lhs.CompareSlowPath(rhs, compared_size, size_to_compare)); +} + +bool Cord::EqualsImpl(absl::string_view rhs, size_t size_to_compare) const { + return GenericCompare<bool>(*this, rhs, size_to_compare); +} + +bool Cord::EqualsImpl(const Cord& rhs, size_t size_to_compare) const { + return GenericCompare<bool>(*this, rhs, size_to_compare); +} + +template <typename RHS> +inline int SharedCompareImpl(const Cord& lhs, const RHS& rhs) { + size_t lhs_size = lhs.size(); + size_t rhs_size = rhs.size(); + if (lhs_size == rhs_size) { + return GenericCompare<int>(lhs, rhs, lhs_size); + } + if (lhs_size < rhs_size) { + auto data_comp_res = GenericCompare<int>(lhs, rhs, lhs_size); + return data_comp_res == 0 ? -1 : data_comp_res; + } + + auto data_comp_res = GenericCompare<int>(lhs, rhs, rhs_size); + return data_comp_res == 0 ? +1 : data_comp_res; +} + +int Cord::Compare(absl::string_view rhs) const { + return SharedCompareImpl(*this, rhs); +} + +int Cord::CompareImpl(const Cord& rhs) const { + return SharedCompareImpl(*this, rhs); +} + +bool Cord::EndsWith(absl::string_view rhs) const { + size_t my_size = size(); + size_t rhs_size = rhs.size(); + + if (my_size < rhs_size) return false; + + Cord tmp(*this); + tmp.RemovePrefix(my_size - rhs_size); + return tmp.EqualsImpl(rhs, rhs_size); +} + +bool Cord::EndsWith(const Cord& rhs) const { + size_t my_size = size(); + size_t rhs_size = rhs.size(); + + if (my_size < rhs_size) return false; + + Cord tmp(*this); + tmp.RemovePrefix(my_size - rhs_size); + return tmp.EqualsImpl(rhs, rhs_size); +} + +// -------------------------------------------------------------------- +// Misc. + +Cord::operator std::string() const { + std::string s; + absl::CopyCordToString(*this, &s); + return s; +} + +void CopyCordToString(const Cord& src, std::string* dst) { + if (!src.contents_.is_tree()) { + src.contents_.CopyTo(dst); + } else { + absl::strings_internal::STLStringResizeUninitialized(dst, src.size()); + src.CopyToArraySlowPath(&(*dst)[0]); + } +} + +void Cord::CopyToArraySlowPath(char* dst) const { + assert(contents_.is_tree()); + absl::string_view fragment; + if (GetFlatAux(contents_.tree(), &fragment)) { + memcpy(dst, fragment.data(), fragment.size()); + return; + } + for (absl::string_view chunk : Chunks()) { + memcpy(dst, chunk.data(), chunk.size()); + dst += chunk.size(); + } +} + +Cord::ChunkIterator& Cord::ChunkIterator::operator++() { + ABSL_HARDENING_ASSERT(bytes_remaining_ > 0 && + "Attempted to iterate past `end()`"); + assert(bytes_remaining_ >= current_chunk_.size()); + bytes_remaining_ -= current_chunk_.size(); + + if (stack_of_right_children_.empty()) { + assert(!current_chunk_.empty()); // Called on invalid iterator. + // We have reached the end of the Cord. + return *this; + } + + // Process the next node on the stack. + CordRep* node = stack_of_right_children_.back(); + stack_of_right_children_.pop_back(); + + // Walk down the left branches until we hit a non-CONCAT node. Save the + // right children to the stack for subsequent traversal. + while (node->tag == CONCAT) { + stack_of_right_children_.push_back(node->concat()->right); + node = node->concat()->left; + } + + // Get the child node if we encounter a SUBSTRING. + size_t offset = 0; + size_t length = node->length; + if (node->tag == SUBSTRING) { + offset = node->substring()->start; + node = node->substring()->child; + } + + assert(node->tag == EXTERNAL || node->tag >= FLAT); + assert(length != 0); + const char* data = + node->tag == EXTERNAL ? node->external()->base : node->data; + current_chunk_ = absl::string_view(data + offset, length); + current_leaf_ = node; + return *this; +} + +Cord Cord::ChunkIterator::AdvanceAndReadBytes(size_t n) { + ABSL_HARDENING_ASSERT(bytes_remaining_ >= n && + "Attempted to iterate past `end()`"); + Cord subcord; + + if (n <= InlineRep::kMaxInline) { + // Range to read fits in inline data. Flatten it. + char* data = subcord.contents_.set_data(n); + while (n > current_chunk_.size()) { + memcpy(data, current_chunk_.data(), current_chunk_.size()); + data += current_chunk_.size(); + n -= current_chunk_.size(); + ++*this; + } + memcpy(data, current_chunk_.data(), n); + if (n < current_chunk_.size()) { + RemoveChunkPrefix(n); + } else if (n > 0) { + ++*this; + } + return subcord; + } + if (n < current_chunk_.size()) { + // Range to read is a proper subrange of the current chunk. + assert(current_leaf_ != nullptr); + CordRep* subnode = Ref(current_leaf_); + const char* data = + subnode->tag == EXTERNAL ? subnode->external()->base : subnode->data; + subnode = NewSubstring(subnode, current_chunk_.data() - data, n); + subcord.contents_.set_tree(VerifyTree(subnode)); + RemoveChunkPrefix(n); + return subcord; + } + + // Range to read begins with a proper subrange of the current chunk. + assert(!current_chunk_.empty()); + assert(current_leaf_ != nullptr); + CordRep* subnode = Ref(current_leaf_); + if (current_chunk_.size() < subnode->length) { + const char* data = + subnode->tag == EXTERNAL ? subnode->external()->base : subnode->data; + subnode = NewSubstring(subnode, current_chunk_.data() - data, + current_chunk_.size()); + } + n -= current_chunk_.size(); + bytes_remaining_ -= current_chunk_.size(); + + // Process the next node(s) on the stack, reading whole subtrees depending on + // their length and how many bytes we are advancing. + CordRep* node = nullptr; + while (!stack_of_right_children_.empty()) { + node = stack_of_right_children_.back(); + stack_of_right_children_.pop_back(); + if (node->length > n) break; + // TODO(qrczak): This might unnecessarily recreate existing concat nodes. + // Avoiding that would need pretty complicated logic (instead of + // current_leaf_, keep current_subtree_ which points to the highest node + // such that the current leaf can be found on the path of left children + // starting from current_subtree_; delay creating subnode while node is + // below current_subtree_; find the proper node along the path of left + // children starting from current_subtree_ if this loop exits while staying + // below current_subtree_; etc.; alternatively, push parents instead of + // right children on the stack). + subnode = Concat(subnode, Ref(node)); + n -= node->length; + bytes_remaining_ -= node->length; + node = nullptr; + } + + if (node == nullptr) { + // We have reached the end of the Cord. + assert(bytes_remaining_ == 0); + subcord.contents_.set_tree(VerifyTree(subnode)); + return subcord; + } + + // Walk down the appropriate branches until we hit a non-CONCAT node. Save the + // right children to the stack for subsequent traversal. + while (node->tag == CONCAT) { + if (node->concat()->left->length > n) { + // Push right, descend left. + stack_of_right_children_.push_back(node->concat()->right); + node = node->concat()->left; + } else { + // Read left, descend right. + subnode = Concat(subnode, Ref(node->concat()->left)); + n -= node->concat()->left->length; + bytes_remaining_ -= node->concat()->left->length; + node = node->concat()->right; + } + } + + // Get the child node if we encounter a SUBSTRING. + size_t offset = 0; + size_t length = node->length; + if (node->tag == SUBSTRING) { + offset = node->substring()->start; + node = node->substring()->child; + } + + // Range to read ends with a proper (possibly empty) subrange of the current + // chunk. + assert(node->tag == EXTERNAL || node->tag >= FLAT); + assert(length > n); + if (n > 0) subnode = Concat(subnode, NewSubstring(Ref(node), offset, n)); + const char* data = + node->tag == EXTERNAL ? node->external()->base : node->data; + current_chunk_ = absl::string_view(data + offset + n, length - n); + current_leaf_ = node; + bytes_remaining_ -= n; + subcord.contents_.set_tree(VerifyTree(subnode)); + return subcord; +} + +void Cord::ChunkIterator::AdvanceBytesSlowPath(size_t n) { + assert(bytes_remaining_ >= n && "Attempted to iterate past `end()`"); + assert(n >= current_chunk_.size()); // This should only be called when + // iterating to a new node. + + n -= current_chunk_.size(); + bytes_remaining_ -= current_chunk_.size(); + + // Process the next node(s) on the stack, skipping whole subtrees depending on + // their length and how many bytes we are advancing. + CordRep* node = nullptr; + while (!stack_of_right_children_.empty()) { + node = stack_of_right_children_.back(); + stack_of_right_children_.pop_back(); + if (node->length > n) break; + n -= node->length; + bytes_remaining_ -= node->length; + node = nullptr; + } + + if (node == nullptr) { + // We have reached the end of the Cord. + assert(bytes_remaining_ == 0); + return; + } + + // Walk down the appropriate branches until we hit a non-CONCAT node. Save the + // right children to the stack for subsequent traversal. + while (node->tag == CONCAT) { + if (node->concat()->left->length > n) { + // Push right, descend left. + stack_of_right_children_.push_back(node->concat()->right); + node = node->concat()->left; + } else { + // Skip left, descend right. + n -= node->concat()->left->length; + bytes_remaining_ -= node->concat()->left->length; + node = node->concat()->right; + } + } + + // Get the child node if we encounter a SUBSTRING. + size_t offset = 0; + size_t length = node->length; + if (node->tag == SUBSTRING) { + offset = node->substring()->start; + node = node->substring()->child; + } + + assert(node->tag == EXTERNAL || node->tag >= FLAT); + assert(length > n); + const char* data = + node->tag == EXTERNAL ? node->external()->base : node->data; + current_chunk_ = absl::string_view(data + offset + n, length - n); + current_leaf_ = node; + bytes_remaining_ -= n; +} + +char Cord::operator[](size_t i) const { + ABSL_HARDENING_ASSERT(i < size()); + size_t offset = i; + const CordRep* rep = contents_.tree(); + if (rep == nullptr) { + return contents_.data()[i]; + } + while (true) { + assert(rep != nullptr); + assert(offset < rep->length); + if (rep->tag >= FLAT) { + // Get the "i"th character directly from the flat array. + return rep->data[offset]; + } else if (rep->tag == EXTERNAL) { + // Get the "i"th character from the external array. + return rep->external()->base[offset]; + } else if (rep->tag == CONCAT) { + // Recursively branch to the side of the concatenation that the "i"th + // character is on. + size_t left_length = rep->concat()->left->length; + if (offset < left_length) { + rep = rep->concat()->left; + } else { + offset -= left_length; + rep = rep->concat()->right; + } + } else { + // This must be a substring a node, so bypass it to get to the child. + assert(rep->tag == SUBSTRING); + offset += rep->substring()->start; + rep = rep->substring()->child; + } + } +} + +absl::string_view Cord::FlattenSlowPath() { + size_t total_size = size(); + CordRep* new_rep; + char* new_buffer; + + // Try to put the contents into a new flat rep. If they won't fit in the + // biggest possible flat node, use an external rep instead. + if (total_size <= kMaxFlatLength) { + new_rep = NewFlat(total_size); + new_rep->length = total_size; + new_buffer = new_rep->data; + CopyToArraySlowPath(new_buffer); + } else { + new_buffer = std::allocator<char>().allocate(total_size); + CopyToArraySlowPath(new_buffer); + new_rep = absl::cord_internal::NewExternalRep( + absl::string_view(new_buffer, total_size), [](absl::string_view s) { + std::allocator<char>().deallocate(const_cast<char*>(s.data()), + s.size()); + }); + } + Unref(contents_.tree()); + contents_.set_tree(new_rep); + return absl::string_view(new_buffer, total_size); +} + +/* static */ bool Cord::GetFlatAux(CordRep* rep, absl::string_view* fragment) { + assert(rep != nullptr); + if (rep->tag >= FLAT) { + *fragment = absl::string_view(rep->data, rep->length); + return true; + } else if (rep->tag == EXTERNAL) { + *fragment = absl::string_view(rep->external()->base, rep->length); + return true; + } else if (rep->tag == SUBSTRING) { + CordRep* child = rep->substring()->child; + if (child->tag >= FLAT) { + *fragment = + absl::string_view(child->data + rep->substring()->start, rep->length); + return true; + } else if (child->tag == EXTERNAL) { + *fragment = absl::string_view( + child->external()->base + rep->substring()->start, rep->length); + return true; + } + } + return false; +} + +/* static */ void Cord::ForEachChunkAux( + absl::cord_internal::CordRep* rep, + absl::FunctionRef<void(absl::string_view)> callback) { + assert(rep != nullptr); + int stack_pos = 0; + constexpr int stack_max = 128; + // Stack of right branches for tree traversal + absl::cord_internal::CordRep* stack[stack_max]; + absl::cord_internal::CordRep* current_node = rep; + while (true) { + if (current_node->tag == CONCAT) { + if (stack_pos == stack_max) { + // There's no more room on our stack array to add another right branch, + // and the idea is to avoid allocations, so call this function + // recursively to navigate this subtree further. (This is not something + // we expect to happen in practice). + ForEachChunkAux(current_node, callback); + + // Pop the next right branch and iterate. + current_node = stack[--stack_pos]; + continue; + } else { + // Save the right branch for later traversal and continue down the left + // branch. + stack[stack_pos++] = current_node->concat()->right; + current_node = current_node->concat()->left; + continue; + } + } + // This is a leaf node, so invoke our callback. + absl::string_view chunk; + bool success = GetFlatAux(current_node, &chunk); + assert(success); + if (success) { + callback(chunk); + } + if (stack_pos == 0) { + // end of traversal + return; + } + current_node = stack[--stack_pos]; + } +} + +static void DumpNode(CordRep* rep, bool include_data, std::ostream* os) { + const int kIndentStep = 1; + int indent = 0; + absl::InlinedVector<CordRep*, kInlinedVectorSize> stack; + absl::InlinedVector<int, kInlinedVectorSize> indents; + for (;;) { + *os << std::setw(3) << rep->refcount.Get(); + *os << " " << std::setw(7) << rep->length; + *os << " ["; + if (include_data) *os << static_cast<void*>(rep); + *os << "]"; + *os << " " << (IsRootBalanced(rep) ? 'b' : 'u'); + *os << " " << std::setw(indent) << ""; + if (rep->tag == CONCAT) { + *os << "CONCAT depth=" << Depth(rep) << "\n"; + indent += kIndentStep; + indents.push_back(indent); + stack.push_back(rep->concat()->right); + rep = rep->concat()->left; + } else if (rep->tag == SUBSTRING) { + *os << "SUBSTRING @ " << rep->substring()->start << "\n"; + indent += kIndentStep; + rep = rep->substring()->child; + } else { // Leaf + if (rep->tag == EXTERNAL) { + *os << "EXTERNAL ["; + if (include_data) + *os << absl::CEscape(std::string(rep->external()->base, rep->length)); + *os << "]\n"; + } else { + *os << "FLAT cap=" << TagToLength(rep->tag) << " ["; + if (include_data) + *os << absl::CEscape(std::string(rep->data, rep->length)); + *os << "]\n"; + } + if (stack.empty()) break; + rep = stack.back(); + stack.pop_back(); + indent = indents.back(); + indents.pop_back(); + } + } + ABSL_INTERNAL_CHECK(indents.empty(), ""); +} + +static std::string ReportError(CordRep* root, CordRep* node) { + std::ostringstream buf; + buf << "Error at node " << node << " in:"; + DumpNode(root, true, &buf); + return buf.str(); +} + +static bool VerifyNode(CordRep* root, CordRep* start_node, + bool full_validation) { + absl::InlinedVector<CordRep*, 2> worklist; + worklist.push_back(start_node); + do { + CordRep* node = worklist.back(); + worklist.pop_back(); + + ABSL_INTERNAL_CHECK(node != nullptr, ReportError(root, node)); + if (node != root) { + ABSL_INTERNAL_CHECK(node->length != 0, ReportError(root, node)); + } + + if (node->tag == CONCAT) { + ABSL_INTERNAL_CHECK(node->concat()->left != nullptr, + ReportError(root, node)); + ABSL_INTERNAL_CHECK(node->concat()->right != nullptr, + ReportError(root, node)); + ABSL_INTERNAL_CHECK((node->length == node->concat()->left->length + + node->concat()->right->length), + ReportError(root, node)); + if (full_validation) { + worklist.push_back(node->concat()->right); + worklist.push_back(node->concat()->left); + } + } else if (node->tag >= FLAT) { + ABSL_INTERNAL_CHECK(node->length <= TagToLength(node->tag), + ReportError(root, node)); + } else if (node->tag == EXTERNAL) { + ABSL_INTERNAL_CHECK(node->external()->base != nullptr, + ReportError(root, node)); + } else if (node->tag == SUBSTRING) { + ABSL_INTERNAL_CHECK( + node->substring()->start < node->substring()->child->length, + ReportError(root, node)); + ABSL_INTERNAL_CHECK(node->substring()->start + node->length <= + node->substring()->child->length, + ReportError(root, node)); + } + } while (!worklist.empty()); + return true; +} + +// Traverses the tree and computes the total memory allocated. +/* static */ size_t Cord::MemoryUsageAux(const CordRep* rep) { + size_t total_mem_usage = 0; + + // Allow a quick exit for the common case that the root is a leaf. + if (RepMemoryUsageLeaf(rep, &total_mem_usage)) { + return total_mem_usage; + } + + // Iterate over the tree. cur_node is never a leaf node and leaf nodes will + // never be appended to tree_stack. This reduces overhead from manipulating + // tree_stack. + absl::InlinedVector<const CordRep*, kInlinedVectorSize> tree_stack; + const CordRep* cur_node = rep; + while (true) { + const CordRep* next_node = nullptr; + + if (cur_node->tag == CONCAT) { + total_mem_usage += sizeof(CordRepConcat); + const CordRep* left = cur_node->concat()->left; + if (!RepMemoryUsageLeaf(left, &total_mem_usage)) { + next_node = left; + } + + const CordRep* right = cur_node->concat()->right; + if (!RepMemoryUsageLeaf(right, &total_mem_usage)) { + if (next_node) { + tree_stack.push_back(next_node); + } + next_node = right; + } + } else { + // Since cur_node is not a leaf or a concat node it must be a substring. + assert(cur_node->tag == SUBSTRING); + total_mem_usage += sizeof(CordRepSubstring); + next_node = cur_node->substring()->child; + if (RepMemoryUsageLeaf(next_node, &total_mem_usage)) { + next_node = nullptr; + } + } + + if (!next_node) { + if (tree_stack.empty()) { + return total_mem_usage; + } + next_node = tree_stack.back(); + tree_stack.pop_back(); + } + cur_node = next_node; + } +} + +std::ostream& operator<<(std::ostream& out, const Cord& cord) { + for (absl::string_view chunk : cord.Chunks()) { + out.write(chunk.data(), chunk.size()); + } + return out; +} + +namespace strings_internal { +size_t CordTestAccess::FlatOverhead() { return kFlatOverhead; } +size_t CordTestAccess::MaxFlatLength() { return kMaxFlatLength; } +size_t CordTestAccess::FlatTagToLength(uint8_t tag) { + return TagToLength(tag); +} +uint8_t CordTestAccess::LengthToTag(size_t s) { + ABSL_INTERNAL_CHECK(s <= kMaxFlatLength, absl::StrCat("Invalid length ", s)); + return AllocatedSizeToTag(s + kFlatOverhead); +} +size_t CordTestAccess::SizeofCordRepConcat() { return sizeof(CordRepConcat); } +size_t CordTestAccess::SizeofCordRepExternal() { + return sizeof(CordRepExternal); +} +size_t CordTestAccess::SizeofCordRepSubstring() { + return sizeof(CordRepSubstring); +} +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/cord.h b/third_party/abseil_cpp/absl/strings/cord.h new file mode 100644 index 0000000000..3be8d7d875 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/cord.h @@ -0,0 +1,1338 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: cord.h +// ----------------------------------------------------------------------------- +// +// This file defines the `absl::Cord` data structure and operations on that data +// structure. A Cord is a string-like sequence of characters optimized for +// specific use cases. Unlike a `std::string`, which stores an array of +// contiguous characters, Cord data is stored in a structure consisting of +// separate, reference-counted "chunks." (Currently, this implementation is a +// tree structure, though that implementation may change.) +// +// Because a Cord consists of these chunks, data can be added to or removed from +// a Cord during its lifetime. Chunks may also be shared between Cords. Unlike a +// `std::string`, a Cord can therefore accomodate data that changes over its +// lifetime, though it's not quite "mutable"; it can change only in the +// attachment, detachment, or rearrangement of chunks of its constituent data. +// +// A Cord provides some benefit over `std::string` under the following (albeit +// narrow) circumstances: +// +// * Cord data is designed to grow and shrink over a Cord's lifetime. Cord +// provides efficient insertions and deletions at the start and end of the +// character sequences, avoiding copies in those cases. Static data should +// generally be stored as strings. +// * External memory consisting of string-like data can be directly added to +// a Cord without requiring copies or allocations. +// * Cord data may be shared and copied cheaply. Cord provides a copy-on-write +// implementation and cheap sub-Cord operations. Copying a Cord is an O(1) +// operation. +// +// As a consequence to the above, Cord data is generally large. Small data +// should generally use strings, as construction of a Cord requires some +// overhead. Small Cords (<= 15 bytes) are represented inline, but most small +// Cords are expected to grow over their lifetimes. +// +// Note that because a Cord is made up of separate chunked data, random access +// to character data within a Cord is slower than within a `std::string`. +// +// Thread Safety +// +// Cord has the same thread-safety properties as many other types like +// std::string, std::vector<>, int, etc -- it is thread-compatible. In +// particular, if threads do not call non-const methods, then it is safe to call +// const methods without synchronization. Copying a Cord produces a new instance +// that can be used concurrently with the original in arbitrary ways. + +#ifndef ABSL_STRINGS_CORD_H_ +#define ABSL_STRINGS_CORD_H_ + +#include <algorithm> +#include <cstddef> +#include <cstdint> +#include <cstring> +#include <iosfwd> +#include <iterator> +#include <string> +#include <type_traits> + +#include "absl/base/internal/endian.h" +#include "absl/base/internal/invoke.h" +#include "absl/base/internal/per_thread_tls.h" +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/container/inlined_vector.h" +#include "absl/functional/function_ref.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/internal/cord_internal.h" +#include "absl/strings/internal/resize_uninitialized.h" +#include "absl/strings/string_view.h" +#include "absl/types/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +class Cord; +class CordTestPeer; +template <typename Releaser> +Cord MakeCordFromExternal(absl::string_view, Releaser&&); +void CopyCordToString(const Cord& src, std::string* dst); + +// Cord +// +// A Cord is a sequence of characters, designed to be more efficient than a +// `std::string` in certain circumstances: namely, large string data that needs +// to change over its lifetime or shared, especially when such data is shared +// across API boundaries. +// +// A Cord stores its character data in a structure that allows efficient prepend +// and append operations. This makes a Cord useful for large string data sent +// over in a wire format that may need to be prepended or appended at some point +// during the data exchange (e.g. HTTP, protocol buffers). For example, a +// Cord is useful for storing an HTTP request, and prepending an HTTP header to +// such a request. +// +// Cords should not be used for storing general string data, however. They +// require overhead to construct and are slower than strings for random access. +// +// The Cord API provides the following common API operations: +// +// * Create or assign Cords out of existing string data, memory, or other Cords +// * Append and prepend data to an existing Cord +// * Create new Sub-Cords from existing Cord data +// * Swap Cord data and compare Cord equality +// * Write out Cord data by constructing a `std::string` +// +// Additionally, the API provides iterator utilities to iterate through Cord +// data via chunks or character bytes. +// +class Cord { + private: + template <typename T> + using EnableIfString = + absl::enable_if_t<std::is_same<T, std::string>::value, int>; + + public: + // Cord::Cord() Constructors + + // Creates an empty Cord + constexpr Cord() noexcept; + + // Creates a Cord from an existing Cord. Cord is copyable and efficiently + // movable. The moved-from state is valid but unspecified. + Cord(const Cord& src); + Cord(Cord&& src) noexcept; + Cord& operator=(const Cord& x); + Cord& operator=(Cord&& x) noexcept; + + // Creates a Cord from a `src` string. This constructor is marked explicit to + // prevent implicit Cord constructions from arguments convertible to an + // `absl::string_view`. + explicit Cord(absl::string_view src); + Cord& operator=(absl::string_view src); + + // Creates a Cord from a `std::string&&` rvalue. These constructors are + // templated to avoid ambiguities for types that are convertible to both + // `absl::string_view` and `std::string`, such as `const char*`. + // + // Note that these functions reserve the right to use the `string&&`'s + // memory and that they will do so in the future. + template <typename T, EnableIfString<T> = 0> + explicit Cord(T&& src) : Cord(absl::string_view(src)) {} + template <typename T, EnableIfString<T> = 0> + Cord& operator=(T&& src); + + // Cord::~Cord() + // + // Destructs the Cord + ~Cord() { + if (contents_.is_tree()) DestroyCordSlow(); + } + + // MakeCordFromExternal() + // + // Creates a Cord that takes ownership of external string memory. The + // contents of `data` are not copied to the Cord; instead, the external + // memory is added to the Cord and reference-counted. This data may not be + // changed for the life of the Cord, though it may be prepended or appended + // to. + // + // `MakeCordFromExternal()` takes a callable "releaser" that is invoked when + // the reference count for `data` reaches zero. As noted above, this data must + // remain live until the releaser is invoked. The callable releaser also must: + // + // * be move constructible + // * support `void operator()(absl::string_view) const` or `void operator()` + // * not have alignment requirement greater than what is guaranteed by + // `::operator new`. This alignment is dictated by + // `alignof(std::max_align_t)` (pre-C++17 code) or + // `__STDCPP_DEFAULT_NEW_ALIGNMENT__` (C++17 code). + // + // Example: + // + // Cord MakeCord(BlockPool* pool) { + // Block* block = pool->NewBlock(); + // FillBlock(block); + // return absl::MakeCordFromExternal( + // block->ToStringView(), + // [pool, block](absl::string_view v) { + // pool->FreeBlock(block, v); + // }); + // } + // + // WARNING: Because a Cord can be reference-counted, it's likely a bug if your + // releaser doesn't do anything. For example, consider the following: + // + // void Foo(const char* buffer, int len) { + // auto c = absl::MakeCordFromExternal(absl::string_view(buffer, len), + // [](absl::string_view) {}); + // + // // BUG: If Bar() copies its cord for any reason, including keeping a + // // substring of it, the lifetime of buffer might be extended beyond + // // when Foo() returns. + // Bar(c); + // } + template <typename Releaser> + friend Cord MakeCordFromExternal(absl::string_view data, Releaser&& releaser); + + // Cord::Clear() + // + // Releases the Cord data. Any nodes that share data with other Cords, if + // applicable, will have their reference counts reduced by 1. + void Clear(); + + // Cord::Append() + // + // Appends data to the Cord, which may come from another Cord or other string + // data. + void Append(const Cord& src); + void Append(Cord&& src); + void Append(absl::string_view src); + template <typename T, EnableIfString<T> = 0> + void Append(T&& src); + + // Cord::Prepend() + // + // Prepends data to the Cord, which may come from another Cord or other string + // data. + void Prepend(const Cord& src); + void Prepend(absl::string_view src); + template <typename T, EnableIfString<T> = 0> + void Prepend(T&& src); + + // Cord::RemovePrefix() + // + // Removes the first `n` bytes of a Cord. + void RemovePrefix(size_t n); + void RemoveSuffix(size_t n); + + // Cord::Subcord() + // + // Returns a new Cord representing the subrange [pos, pos + new_size) of + // *this. If pos >= size(), the result is empty(). If + // (pos + new_size) >= size(), the result is the subrange [pos, size()). + Cord Subcord(size_t pos, size_t new_size) const; + + // Cord::swap() + // + // Swaps the contents of the Cord with `other`. + void swap(Cord& other) noexcept; + + // swap() + // + // Swaps the contents of two Cords. + friend void swap(Cord& x, Cord& y) noexcept { + x.swap(y); + } + + // Cord::size() + // + // Returns the size of the Cord. + size_t size() const; + + // Cord::empty() + // + // Determines whether the given Cord is empty, returning `true` is so. + bool empty() const; + + // Cord::EstimatedMemoryUsage() + // + // Returns the *approximate* number of bytes held in full or in part by this + // Cord (which may not remain the same between invocations). Note that Cords + // that share memory could each be "charged" independently for the same shared + // memory. + size_t EstimatedMemoryUsage() const; + + // Cord::Compare() + // + // Compares 'this' Cord with rhs. This function and its relatives treat Cords + // as sequences of unsigned bytes. The comparison is a straightforward + // lexicographic comparison. `Cord::Compare()` returns values as follows: + // + // -1 'this' Cord is smaller + // 0 two Cords are equal + // 1 'this' Cord is larger + int Compare(absl::string_view rhs) const; + int Compare(const Cord& rhs) const; + + // Cord::StartsWith() + // + // Determines whether the Cord starts with the passed string data `rhs`. + bool StartsWith(const Cord& rhs) const; + bool StartsWith(absl::string_view rhs) const; + + // Cord::EndsWidth() + // + // Determines whether the Cord ends with the passed string data `rhs`. + bool EndsWith(absl::string_view rhs) const; + bool EndsWith(const Cord& rhs) const; + + // Cord::operator std::string() + // + // Converts a Cord into a `std::string()`. This operator is marked explicit to + // prevent unintended Cord usage in functions that take a string. + explicit operator std::string() const; + + // CopyCordToString() + // + // Copies the contents of a `src` Cord into a `*dst` string. + // + // This function optimizes the case of reusing the destination string since it + // can reuse previously allocated capacity. However, this function does not + // guarantee that pointers previously returned by `dst->data()` remain valid + // even if `*dst` had enough capacity to hold `src`. If `*dst` is a new + // object, prefer to simply use the conversion operator to `std::string`. + friend void CopyCordToString(const Cord& src, std::string* dst); + + class CharIterator; + + //---------------------------------------------------------------------------- + // Cord::ChunkIterator + //---------------------------------------------------------------------------- + // + // A `Cord::ChunkIterator` allows iteration over the constituent chunks of its + // Cord. Such iteration allows you to perform non-const operatons on the data + // of a Cord without modifying it. + // + // Generally, you do not instantiate a `Cord::ChunkIterator` directly; + // instead, you create one implicitly through use of the `Cord::Chunks()` + // member function. + // + // The `Cord::ChunkIterator` has the following properties: + // + // * The iterator is invalidated after any non-const operation on the + // Cord object over which it iterates. + // * The `string_view` returned by dereferencing a valid, non-`end()` + // iterator is guaranteed to be non-empty. + // * Two `ChunkIterator` objects can be compared equal if and only if they + // remain valid and iterate over the same Cord. + // * The iterator in this case is a proxy iterator; the `string_view` + // returned by the iterator does not live inside the Cord, and its + // lifetime is limited to the lifetime of the iterator itself. To help + // prevent lifetime issues, `ChunkIterator::reference` is not a true + // reference type and is equivalent to `value_type`. + // * The iterator keeps state that can grow for Cords that contain many + // nodes and are imbalanced due to sharing. Prefer to pass this type by + // const reference instead of by value. + class ChunkIterator { + public: + using iterator_category = std::input_iterator_tag; + using value_type = absl::string_view; + using difference_type = ptrdiff_t; + using pointer = const value_type*; + using reference = value_type; + + ChunkIterator() = default; + + ChunkIterator& operator++(); + ChunkIterator operator++(int); + bool operator==(const ChunkIterator& other) const; + bool operator!=(const ChunkIterator& other) const; + reference operator*() const; + pointer operator->() const; + + friend class Cord; + friend class CharIterator; + + private: + // Constructs a `begin()` iterator from `cord`. + explicit ChunkIterator(const Cord* cord); + + // Removes `n` bytes from `current_chunk_`. Expects `n` to be smaller than + // `current_chunk_.size()`. + void RemoveChunkPrefix(size_t n); + Cord AdvanceAndReadBytes(size_t n); + void AdvanceBytes(size_t n); + // Iterates `n` bytes, where `n` is expected to be greater than or equal to + // `current_chunk_.size()`. + void AdvanceBytesSlowPath(size_t n); + + // A view into bytes of the current `CordRep`. It may only be a view to a + // suffix of bytes if this is being used by `CharIterator`. + absl::string_view current_chunk_; + // The current leaf, or `nullptr` if the iterator points to short data. + // If the current chunk is a substring node, current_leaf_ points to the + // underlying flat or external node. + absl::cord_internal::CordRep* current_leaf_ = nullptr; + // The number of bytes left in the `Cord` over which we are iterating. + size_t bytes_remaining_ = 0; + absl::InlinedVector<absl::cord_internal::CordRep*, 4> + stack_of_right_children_; + }; + + // Cord::ChunkIterator::chunk_begin() + // + // Returns an iterator to the first chunk of the `Cord`. + // + // Generally, prefer using `Cord::Chunks()` within a range-based for loop for + // iterating over the chunks of a Cord. This method may be useful for getting + // a `ChunkIterator` where range-based for-loops are not useful. + // + // Example: + // + // absl::Cord::ChunkIterator FindAsChunk(const absl::Cord& c, + // absl::string_view s) { + // return std::find(c.chunk_begin(), c.chunk_end(), s); + // } + ChunkIterator chunk_begin() const; + + // Cord::ChunkItertator::chunk_end() + // + // Returns an iterator one increment past the last chunk of the `Cord`. + // + // Generally, prefer using `Cord::Chunks()` within a range-based for loop for + // iterating over the chunks of a Cord. This method may be useful for getting + // a `ChunkIterator` where range-based for-loops may not be available. + ChunkIterator chunk_end() const; + + //---------------------------------------------------------------------------- + // Cord::ChunkIterator::ChunkRange + //---------------------------------------------------------------------------- + // + // `ChunkRange` is a helper class for iterating over the chunks of the `Cord`, + // producing an iterator which can be used within a range-based for loop. + // Construction of a `ChunkRange` will return an iterator pointing to the + // first chunk of the Cord. Generally, do not construct a `ChunkRange` + // directly; instead, prefer to use the `Cord::Chunks()` method. + // + // Implementation note: `ChunkRange` is simply a convenience wrapper over + // `Cord::chunk_begin()` and `Cord::chunk_end()`. + class ChunkRange { + public: + explicit ChunkRange(const Cord* cord) : cord_(cord) {} + + ChunkIterator begin() const; + ChunkIterator end() const; + + private: + const Cord* cord_; + }; + + // Cord::Chunks() + // + // Returns a `Cord::ChunkIterator::ChunkRange` for iterating over the chunks + // of a `Cord` with a range-based for-loop. For most iteration tasks on a + // Cord, use `Cord::Chunks()` to retrieve this iterator. + // + // Example: + // + // void ProcessChunks(const Cord& cord) { + // for (absl::string_view chunk : cord.Chunks()) { ... } + // } + // + // Note that the ordinary caveats of temporary lifetime extension apply: + // + // void Process() { + // for (absl::string_view chunk : CordFactory().Chunks()) { + // // The temporary Cord returned by CordFactory has been destroyed! + // } + // } + ChunkRange Chunks() const; + + //---------------------------------------------------------------------------- + // Cord::CharIterator + //---------------------------------------------------------------------------- + // + // A `Cord::CharIterator` allows iteration over the constituent characters of + // a `Cord`. + // + // Generally, you do not instantiate a `Cord::CharIterator` directly; instead, + // you create one implicitly through use of the `Cord::Chars()` member + // function. + // + // A `Cord::CharIterator` has the following properties: + // + // * The iterator is invalidated after any non-const operation on the + // Cord object over which it iterates. + // * Two `CharIterator` objects can be compared equal if and only if they + // remain valid and iterate over the same Cord. + // * The iterator keeps state that can grow for Cords that contain many + // nodes and are imbalanced due to sharing. Prefer to pass this type by + // const reference instead of by value. + // * This type cannot act as a forward iterator because a `Cord` can reuse + // sections of memory. This fact violates the requirement for forward + // iterators to compare equal if dereferencing them returns the same + // object. + class CharIterator { + public: + using iterator_category = std::input_iterator_tag; + using value_type = char; + using difference_type = ptrdiff_t; + using pointer = const char*; + using reference = const char&; + + CharIterator() = default; + + CharIterator& operator++(); + CharIterator operator++(int); + bool operator==(const CharIterator& other) const; + bool operator!=(const CharIterator& other) const; + reference operator*() const; + pointer operator->() const; + + friend Cord; + + private: + explicit CharIterator(const Cord* cord) : chunk_iterator_(cord) {} + + ChunkIterator chunk_iterator_; + }; + + // Cord::CharIterator::AdvanceAndRead() + // + // Advances the `Cord::CharIterator` by `n_bytes` and returns the bytes + // advanced as a separate `Cord`. `n_bytes` must be less than or equal to the + // number of bytes within the Cord; otherwise, behavior is undefined. It is + // valid to pass `char_end()` and `0`. + static Cord AdvanceAndRead(CharIterator* it, size_t n_bytes); + + // Cord::CharIterator::Advance() + // + // Advances the `Cord::CharIterator` by `n_bytes`. `n_bytes` must be less than + // or equal to the number of bytes remaining within the Cord; otherwise, + // behavior is undefined. It is valid to pass `char_end()` and `0`. + static void Advance(CharIterator* it, size_t n_bytes); + + // Cord::CharIterator::ChunkRemaining() + // + // Returns the longest contiguous view starting at the iterator's position. + // + // `it` must be dereferenceable. + static absl::string_view ChunkRemaining(const CharIterator& it); + + // Cord::CharIterator::char_begin() + // + // Returns an iterator to the first character of the `Cord`. + // + // Generally, prefer using `Cord::Chars()` within a range-based for loop for + // iterating over the chunks of a Cord. This method may be useful for getting + // a `CharIterator` where range-based for-loops may not be available. + CharIterator char_begin() const; + + // Cord::CharIterator::char_end() + // + // Returns an iterator to one past the last character of the `Cord`. + // + // Generally, prefer using `Cord::Chars()` within a range-based for loop for + // iterating over the chunks of a Cord. This method may be useful for getting + // a `CharIterator` where range-based for-loops are not useful. + CharIterator char_end() const; + + // Cord::CharIterator::CharRange + // + // `CharRange` is a helper class for iterating over the characters of a + // producing an iterator which can be used within a range-based for loop. + // Construction of a `CharRange` will return an iterator pointing to the first + // character of the Cord. Generally, do not construct a `CharRange` directly; + // instead, prefer to use the `Cord::Chars()` method show below. + // + // Implementation note: `CharRange` is simply a convenience wrapper over + // `Cord::char_begin()` and `Cord::char_end()`. + class CharRange { + public: + explicit CharRange(const Cord* cord) : cord_(cord) {} + + CharIterator begin() const; + CharIterator end() const; + + private: + const Cord* cord_; + }; + + // Cord::CharIterator::Chars() + // + // Returns a `Cord::CharIterator` for iterating over the characters of a + // `Cord` with a range-based for-loop. For most character-based iteration + // tasks on a Cord, use `Cord::Chars()` to retrieve this iterator. + // + // Example: + // + // void ProcessCord(const Cord& cord) { + // for (char c : cord.Chars()) { ... } + // } + // + // Note that the ordinary caveats of temporary lifetime extension apply: + // + // void Process() { + // for (char c : CordFactory().Chars()) { + // // The temporary Cord returned by CordFactory has been destroyed! + // } + // } + CharRange Chars() const; + + // Cord::operator[] + // + // Get the "i"th character of the Cord and returns it, provided that + // 0 <= i < Cord.size(). + // + // NOTE: This routine is reasonably efficient. It is roughly + // logarithmic based on the number of chunks that make up the cord. Still, + // if you need to iterate over the contents of a cord, you should + // use a CharIterator/ChunkIterator rather than call operator[] or Get() + // repeatedly in a loop. + char operator[](size_t i) const; + + // Cord::TryFlat() + // + // If this cord's representation is a single flat array, return a + // string_view referencing that array. Otherwise return nullopt. + absl::optional<absl::string_view> TryFlat() const; + + // Cord::Flatten() + // + // Flattens the cord into a single array and returns a view of the data. + // + // If the cord was already flat, the contents are not modified. + absl::string_view Flatten(); + + // Support absl::Cord as a sink object for absl::Format(). + friend void AbslFormatFlush(absl::Cord* cord, absl::string_view part) { + cord->Append(part); + } + + template <typename H> + friend H AbslHashValue(H hash_state, const absl::Cord& c) { + absl::optional<absl::string_view> maybe_flat = c.TryFlat(); + if (maybe_flat.has_value()) { + return H::combine(std::move(hash_state), *maybe_flat); + } + return c.HashFragmented(std::move(hash_state)); + } + + private: + friend class CordTestPeer; + friend bool operator==(const Cord& lhs, const Cord& rhs); + friend bool operator==(const Cord& lhs, absl::string_view rhs); + + // Call the provided function once for each cord chunk, in order. Unlike + // Chunks(), this API will not allocate memory. + void ForEachChunk(absl::FunctionRef<void(absl::string_view)>) const; + + // Allocates new contiguous storage for the contents of the cord. This is + // called by Flatten() when the cord was not already flat. + absl::string_view FlattenSlowPath(); + + // Actual cord contents are hidden inside the following simple + // class so that we can isolate the bulk of cord.cc from changes + // to the representation. + // + // InlineRep holds either a tree pointer, or an array of kMaxInline bytes. + class InlineRep { + public: + static constexpr unsigned char kMaxInline = 15; + static_assert(kMaxInline >= sizeof(absl::cord_internal::CordRep*), ""); + // Tag byte & kMaxInline means we are storing a pointer. + static constexpr unsigned char kTreeFlag = 1 << 4; + // Tag byte & kProfiledFlag means we are profiling the Cord. + static constexpr unsigned char kProfiledFlag = 1 << 5; + + constexpr InlineRep() : data_{} {} + InlineRep(const InlineRep& src); + InlineRep(InlineRep&& src); + InlineRep& operator=(const InlineRep& src); + InlineRep& operator=(InlineRep&& src) noexcept; + + void Swap(InlineRep* rhs); + bool empty() const; + size_t size() const; + const char* data() const; // Returns nullptr if holding pointer + void set_data(const char* data, size_t n, + bool nullify_tail); // Discards pointer, if any + char* set_data(size_t n); // Write data to the result + // Returns nullptr if holding bytes + absl::cord_internal::CordRep* tree() const; + // Discards old pointer, if any + void set_tree(absl::cord_internal::CordRep* rep); + // Replaces a tree with a new root. This is faster than set_tree, but it + // should only be used when it's clear that the old rep was a tree. + void replace_tree(absl::cord_internal::CordRep* rep); + // Returns non-null iff was holding a pointer + absl::cord_internal::CordRep* clear(); + // Convert to pointer if necessary + absl::cord_internal::CordRep* force_tree(size_t extra_hint); + void reduce_size(size_t n); // REQUIRES: holding data + void remove_prefix(size_t n); // REQUIRES: holding data + void AppendArray(const char* src_data, size_t src_size); + absl::string_view FindFlatStartPiece() const; + void AppendTree(absl::cord_internal::CordRep* tree); + void PrependTree(absl::cord_internal::CordRep* tree); + void GetAppendRegion(char** region, size_t* size, size_t max_length); + void GetAppendRegion(char** region, size_t* size); + bool IsSame(const InlineRep& other) const { + return memcmp(data_, other.data_, sizeof(data_)) == 0; + } + int BitwiseCompare(const InlineRep& other) const { + uint64_t x, y; + // Use memcpy to avoid anti-aliasing issues. + memcpy(&x, data_, sizeof(x)); + memcpy(&y, other.data_, sizeof(y)); + if (x == y) { + memcpy(&x, data_ + 8, sizeof(x)); + memcpy(&y, other.data_ + 8, sizeof(y)); + if (x == y) return 0; + } + return absl::big_endian::FromHost64(x) < absl::big_endian::FromHost64(y) + ? -1 + : 1; + } + void CopyTo(std::string* dst) const { + // memcpy is much faster when operating on a known size. On most supported + // platforms, the small string optimization is large enough that resizing + // to 15 bytes does not cause a memory allocation. + absl::strings_internal::STLStringResizeUninitialized(dst, + sizeof(data_) - 1); + memcpy(&(*dst)[0], data_, sizeof(data_) - 1); + // erase is faster than resize because the logic for memory allocation is + // not needed. + dst->erase(data_[kMaxInline]); + } + + // Copies the inline contents into `dst`. Assumes the cord is not empty. + void CopyToArray(char* dst) const; + + bool is_tree() const { return data_[kMaxInline] > kMaxInline; } + + private: + friend class Cord; + + void AssignSlow(const InlineRep& src); + // Unrefs the tree, stops profiling, and zeroes the contents + void ClearSlow(); + + // If the data has length <= kMaxInline, we store it in data_[0..len-1], + // and store the length in data_[kMaxInline]. Else we store it in a tree + // and store a pointer to that tree in data_[0..sizeof(CordRep*)-1]. + alignas(absl::cord_internal::CordRep*) char data_[kMaxInline + 1]; + }; + InlineRep contents_; + + // Helper for MemoryUsage() + static size_t MemoryUsageAux(const absl::cord_internal::CordRep* rep); + + // Helper for GetFlat() and TryFlat() + static bool GetFlatAux(absl::cord_internal::CordRep* rep, + absl::string_view* fragment); + + // Helper for ForEachChunk() + static void ForEachChunkAux( + absl::cord_internal::CordRep* rep, + absl::FunctionRef<void(absl::string_view)> callback); + + // The destructor for non-empty Cords. + void DestroyCordSlow(); + + // Out-of-line implementation of slower parts of logic. + void CopyToArraySlowPath(char* dst) const; + int CompareSlowPath(absl::string_view rhs, size_t compared_size, + size_t size_to_compare) const; + int CompareSlowPath(const Cord& rhs, size_t compared_size, + size_t size_to_compare) const; + bool EqualsImpl(absl::string_view rhs, size_t size_to_compare) const; + bool EqualsImpl(const Cord& rhs, size_t size_to_compare) const; + int CompareImpl(const Cord& rhs) const; + + template <typename ResultType, typename RHS> + friend ResultType GenericCompare(const Cord& lhs, const RHS& rhs, + size_t size_to_compare); + static absl::string_view GetFirstChunk(const Cord& c); + static absl::string_view GetFirstChunk(absl::string_view sv); + + // Returns a new reference to contents_.tree(), or steals an existing + // reference if called on an rvalue. + absl::cord_internal::CordRep* TakeRep() const&; + absl::cord_internal::CordRep* TakeRep() &&; + + // Helper for Append() + template <typename C> + void AppendImpl(C&& src); + + // Helper for AbslHashValue() + template <typename H> + H HashFragmented(H hash_state) const { + typename H::AbslInternalPiecewiseCombiner combiner; + ForEachChunk([&combiner, &hash_state](absl::string_view chunk) { + hash_state = combiner.add_buffer(std::move(hash_state), chunk.data(), + chunk.size()); + }); + return H::combine(combiner.finalize(std::move(hash_state)), size()); + } +}; + +ABSL_NAMESPACE_END +} // namespace absl + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// allow a Cord to be logged +extern std::ostream& operator<<(std::ostream& out, const Cord& cord); + +// ------------------------------------------------------------------ +// Internal details follow. Clients should ignore. + +namespace cord_internal { + +// Fast implementation of memmove for up to 15 bytes. This implementation is +// safe for overlapping regions. If nullify_tail is true, the destination is +// padded with '\0' up to 16 bytes. +inline void SmallMemmove(char* dst, const char* src, size_t n, + bool nullify_tail = false) { + if (n >= 8) { + assert(n <= 16); + uint64_t buf1; + uint64_t buf2; + memcpy(&buf1, src, 8); + memcpy(&buf2, src + n - 8, 8); + if (nullify_tail) { + memset(dst + 8, 0, 8); + } + memcpy(dst, &buf1, 8); + memcpy(dst + n - 8, &buf2, 8); + } else if (n >= 4) { + uint32_t buf1; + uint32_t buf2; + memcpy(&buf1, src, 4); + memcpy(&buf2, src + n - 4, 4); + if (nullify_tail) { + memset(dst + 4, 0, 4); + memset(dst + 8, 0, 8); + } + memcpy(dst, &buf1, 4); + memcpy(dst + n - 4, &buf2, 4); + } else { + if (n != 0) { + dst[0] = src[0]; + dst[n / 2] = src[n / 2]; + dst[n - 1] = src[n - 1]; + } + if (nullify_tail) { + memset(dst + 8, 0, 8); + memset(dst + n, 0, 8); + } + } +} + +struct ExternalRepReleaserPair { + CordRep* rep; + void* releaser_address; +}; + +// Allocates a new external `CordRep` and returns a pointer to it and a pointer +// to `releaser_size` bytes where the desired releaser can be constructed. +// Expects `data` to be non-empty. +ExternalRepReleaserPair NewExternalWithUninitializedReleaser( + absl::string_view data, ExternalReleaserInvoker invoker, + size_t releaser_size); + +struct Rank1 {}; +struct Rank0 : Rank1 {}; + +template <typename Releaser, typename = ::absl::base_internal::InvokeT< + Releaser, absl::string_view>> +void InvokeReleaser(Rank0, Releaser&& releaser, absl::string_view data) { + ::absl::base_internal::Invoke(std::forward<Releaser>(releaser), data); +} + +template <typename Releaser, + typename = ::absl::base_internal::InvokeT<Releaser>> +void InvokeReleaser(Rank1, Releaser&& releaser, absl::string_view) { + ::absl::base_internal::Invoke(std::forward<Releaser>(releaser)); +} + +// Creates a new `CordRep` that owns `data` and `releaser` and returns a pointer +// to it, or `nullptr` if `data` was empty. +template <typename Releaser> +// NOLINTNEXTLINE - suppress clang-tidy raw pointer return. +CordRep* NewExternalRep(absl::string_view data, Releaser&& releaser) { + static_assert( +#if defined(__STDCPP_DEFAULT_NEW_ALIGNMENT__) + alignof(Releaser) <= __STDCPP_DEFAULT_NEW_ALIGNMENT__, +#else + alignof(Releaser) <= alignof(max_align_t), +#endif + "Releasers with alignment requirement greater than what is returned by " + "default `::operator new()` are not supported."); + + using ReleaserType = absl::decay_t<Releaser>; + if (data.empty()) { + // Never create empty external nodes. + InvokeReleaser(Rank0{}, ReleaserType(std::forward<Releaser>(releaser)), + data); + return nullptr; + } + + auto releaser_invoker = [](void* type_erased_releaser, absl::string_view d) { + auto* my_releaser = static_cast<ReleaserType*>(type_erased_releaser); + InvokeReleaser(Rank0{}, std::move(*my_releaser), d); + my_releaser->~ReleaserType(); + return sizeof(Releaser); + }; + + ExternalRepReleaserPair external = NewExternalWithUninitializedReleaser( + data, releaser_invoker, sizeof(releaser)); + ::new (external.releaser_address) + ReleaserType(std::forward<Releaser>(releaser)); + return external.rep; +} + +// Overload for function reference types that dispatches using a function +// pointer because there are no `alignof()` or `sizeof()` a function reference. +// NOLINTNEXTLINE - suppress clang-tidy raw pointer return. +inline CordRep* NewExternalRep(absl::string_view data, + void (&releaser)(absl::string_view)) { + return NewExternalRep(data, &releaser); +} + +} // namespace cord_internal + +template <typename Releaser> +Cord MakeCordFromExternal(absl::string_view data, Releaser&& releaser) { + Cord cord; + cord.contents_.set_tree(::absl::cord_internal::NewExternalRep( + data, std::forward<Releaser>(releaser))); + return cord; +} + +inline Cord::InlineRep::InlineRep(const Cord::InlineRep& src) { + cord_internal::SmallMemmove(data_, src.data_, sizeof(data_)); +} + +inline Cord::InlineRep::InlineRep(Cord::InlineRep&& src) { + memcpy(data_, src.data_, sizeof(data_)); + memset(src.data_, 0, sizeof(data_)); +} + +inline Cord::InlineRep& Cord::InlineRep::operator=(const Cord::InlineRep& src) { + if (this == &src) { + return *this; + } + if (!is_tree() && !src.is_tree()) { + cord_internal::SmallMemmove(data_, src.data_, sizeof(data_)); + return *this; + } + AssignSlow(src); + return *this; +} + +inline Cord::InlineRep& Cord::InlineRep::operator=( + Cord::InlineRep&& src) noexcept { + if (is_tree()) { + ClearSlow(); + } + memcpy(data_, src.data_, sizeof(data_)); + memset(src.data_, 0, sizeof(data_)); + return *this; +} + +inline void Cord::InlineRep::Swap(Cord::InlineRep* rhs) { + if (rhs == this) { + return; + } + + Cord::InlineRep tmp; + cord_internal::SmallMemmove(tmp.data_, data_, sizeof(data_)); + cord_internal::SmallMemmove(data_, rhs->data_, sizeof(data_)); + cord_internal::SmallMemmove(rhs->data_, tmp.data_, sizeof(data_)); +} + +inline const char* Cord::InlineRep::data() const { + return is_tree() ? nullptr : data_; +} + +inline absl::cord_internal::CordRep* Cord::InlineRep::tree() const { + if (is_tree()) { + absl::cord_internal::CordRep* rep; + memcpy(&rep, data_, sizeof(rep)); + return rep; + } else { + return nullptr; + } +} + +inline bool Cord::InlineRep::empty() const { return data_[kMaxInline] == 0; } + +inline size_t Cord::InlineRep::size() const { + const char tag = data_[kMaxInline]; + if (tag <= kMaxInline) return tag; + return static_cast<size_t>(tree()->length); +} + +inline void Cord::InlineRep::set_tree(absl::cord_internal::CordRep* rep) { + if (rep == nullptr) { + memset(data_, 0, sizeof(data_)); + } else { + bool was_tree = is_tree(); + memcpy(data_, &rep, sizeof(rep)); + memset(data_ + sizeof(rep), 0, sizeof(data_) - sizeof(rep) - 1); + if (!was_tree) { + data_[kMaxInline] = kTreeFlag; + } + } +} + +inline void Cord::InlineRep::replace_tree(absl::cord_internal::CordRep* rep) { + ABSL_ASSERT(is_tree()); + if (ABSL_PREDICT_FALSE(rep == nullptr)) { + set_tree(rep); + return; + } + memcpy(data_, &rep, sizeof(rep)); + memset(data_ + sizeof(rep), 0, sizeof(data_) - sizeof(rep) - 1); +} + +inline absl::cord_internal::CordRep* Cord::InlineRep::clear() { + const char tag = data_[kMaxInline]; + absl::cord_internal::CordRep* result = nullptr; + if (tag > kMaxInline) { + memcpy(&result, data_, sizeof(result)); + } + memset(data_, 0, sizeof(data_)); // Clear the cord + return result; +} + +inline void Cord::InlineRep::CopyToArray(char* dst) const { + assert(!is_tree()); + size_t n = data_[kMaxInline]; + assert(n != 0); + cord_internal::SmallMemmove(dst, data_, n); +} + +constexpr inline Cord::Cord() noexcept {} + +inline Cord& Cord::operator=(const Cord& x) { + contents_ = x.contents_; + return *this; +} + +inline Cord::Cord(Cord&& src) noexcept : contents_(std::move(src.contents_)) {} + +inline void Cord::swap(Cord& other) noexcept { + contents_.Swap(&other.contents_); +} + +inline Cord& Cord::operator=(Cord&& x) noexcept { + contents_ = std::move(x.contents_); + return *this; +} + +template <typename T, Cord::EnableIfString<T>> +inline Cord& Cord::operator=(T&& src) { + *this = absl::string_view(src); + return *this; +} + +inline size_t Cord::size() const { + // Length is 1st field in str.rep_ + return contents_.size(); +} + +inline bool Cord::empty() const { return contents_.empty(); } + +inline size_t Cord::EstimatedMemoryUsage() const { + size_t result = sizeof(Cord); + if (const absl::cord_internal::CordRep* rep = contents_.tree()) { + result += MemoryUsageAux(rep); + } + return result; +} + +inline absl::optional<absl::string_view> Cord::TryFlat() const { + absl::cord_internal::CordRep* rep = contents_.tree(); + if (rep == nullptr) { + return absl::string_view(contents_.data(), contents_.size()); + } + absl::string_view fragment; + if (GetFlatAux(rep, &fragment)) { + return fragment; + } + return absl::nullopt; +} + +inline absl::string_view Cord::Flatten() { + absl::cord_internal::CordRep* rep = contents_.tree(); + if (rep == nullptr) { + return absl::string_view(contents_.data(), contents_.size()); + } else { + absl::string_view already_flat_contents; + if (GetFlatAux(rep, &already_flat_contents)) { + return already_flat_contents; + } + } + return FlattenSlowPath(); +} + +inline void Cord::Append(absl::string_view src) { + contents_.AppendArray(src.data(), src.size()); +} + +template <typename T, Cord::EnableIfString<T>> +inline void Cord::Append(T&& src) { + // Note that this function reserves the right to reuse the `string&&`'s + // memory and that it will do so in the future. + Append(absl::string_view(src)); +} + +template <typename T, Cord::EnableIfString<T>> +inline void Cord::Prepend(T&& src) { + // Note that this function reserves the right to reuse the `string&&`'s + // memory and that it will do so in the future. + Prepend(absl::string_view(src)); +} + +inline int Cord::Compare(const Cord& rhs) const { + if (!contents_.is_tree() && !rhs.contents_.is_tree()) { + return contents_.BitwiseCompare(rhs.contents_); + } + + return CompareImpl(rhs); +} + +// Does 'this' cord start/end with rhs +inline bool Cord::StartsWith(const Cord& rhs) const { + if (contents_.IsSame(rhs.contents_)) return true; + size_t rhs_size = rhs.size(); + if (size() < rhs_size) return false; + return EqualsImpl(rhs, rhs_size); +} + +inline bool Cord::StartsWith(absl::string_view rhs) const { + size_t rhs_size = rhs.size(); + if (size() < rhs_size) return false; + return EqualsImpl(rhs, rhs_size); +} + +inline Cord::ChunkIterator::ChunkIterator(const Cord* cord) + : bytes_remaining_(cord->size()) { + if (cord->empty()) return; + if (cord->contents_.is_tree()) { + stack_of_right_children_.push_back(cord->contents_.tree()); + operator++(); + } else { + current_chunk_ = absl::string_view(cord->contents_.data(), cord->size()); + } +} + +inline Cord::ChunkIterator Cord::ChunkIterator::operator++(int) { + ChunkIterator tmp(*this); + operator++(); + return tmp; +} + +inline bool Cord::ChunkIterator::operator==(const ChunkIterator& other) const { + return bytes_remaining_ == other.bytes_remaining_; +} + +inline bool Cord::ChunkIterator::operator!=(const ChunkIterator& other) const { + return !(*this == other); +} + +inline Cord::ChunkIterator::reference Cord::ChunkIterator::operator*() const { + ABSL_HARDENING_ASSERT(bytes_remaining_ != 0); + return current_chunk_; +} + +inline Cord::ChunkIterator::pointer Cord::ChunkIterator::operator->() const { + ABSL_HARDENING_ASSERT(bytes_remaining_ != 0); + return ¤t_chunk_; +} + +inline void Cord::ChunkIterator::RemoveChunkPrefix(size_t n) { + assert(n < current_chunk_.size()); + current_chunk_.remove_prefix(n); + bytes_remaining_ -= n; +} + +inline void Cord::ChunkIterator::AdvanceBytes(size_t n) { + if (ABSL_PREDICT_TRUE(n < current_chunk_.size())) { + RemoveChunkPrefix(n); + } else if (n != 0) { + AdvanceBytesSlowPath(n); + } +} + +inline Cord::ChunkIterator Cord::chunk_begin() const { + return ChunkIterator(this); +} + +inline Cord::ChunkIterator Cord::chunk_end() const { return ChunkIterator(); } + +inline Cord::ChunkIterator Cord::ChunkRange::begin() const { + return cord_->chunk_begin(); +} + +inline Cord::ChunkIterator Cord::ChunkRange::end() const { + return cord_->chunk_end(); +} + +inline Cord::ChunkRange Cord::Chunks() const { return ChunkRange(this); } + +inline Cord::CharIterator& Cord::CharIterator::operator++() { + if (ABSL_PREDICT_TRUE(chunk_iterator_->size() > 1)) { + chunk_iterator_.RemoveChunkPrefix(1); + } else { + ++chunk_iterator_; + } + return *this; +} + +inline Cord::CharIterator Cord::CharIterator::operator++(int) { + CharIterator tmp(*this); + operator++(); + return tmp; +} + +inline bool Cord::CharIterator::operator==(const CharIterator& other) const { + return chunk_iterator_ == other.chunk_iterator_; +} + +inline bool Cord::CharIterator::operator!=(const CharIterator& other) const { + return !(*this == other); +} + +inline Cord::CharIterator::reference Cord::CharIterator::operator*() const { + return *chunk_iterator_->data(); +} + +inline Cord::CharIterator::pointer Cord::CharIterator::operator->() const { + return chunk_iterator_->data(); +} + +inline Cord Cord::AdvanceAndRead(CharIterator* it, size_t n_bytes) { + assert(it != nullptr); + return it->chunk_iterator_.AdvanceAndReadBytes(n_bytes); +} + +inline void Cord::Advance(CharIterator* it, size_t n_bytes) { + assert(it != nullptr); + it->chunk_iterator_.AdvanceBytes(n_bytes); +} + +inline absl::string_view Cord::ChunkRemaining(const CharIterator& it) { + return *it.chunk_iterator_; +} + +inline Cord::CharIterator Cord::char_begin() const { + return CharIterator(this); +} + +inline Cord::CharIterator Cord::char_end() const { return CharIterator(); } + +inline Cord::CharIterator Cord::CharRange::begin() const { + return cord_->char_begin(); +} + +inline Cord::CharIterator Cord::CharRange::end() const { + return cord_->char_end(); +} + +inline Cord::CharRange Cord::Chars() const { return CharRange(this); } + +inline void Cord::ForEachChunk( + absl::FunctionRef<void(absl::string_view)> callback) const { + absl::cord_internal::CordRep* rep = contents_.tree(); + if (rep == nullptr) { + callback(absl::string_view(contents_.data(), contents_.size())); + } else { + return ForEachChunkAux(rep, callback); + } +} + +// Nonmember Cord-to-Cord relational operarators. +inline bool operator==(const Cord& lhs, const Cord& rhs) { + if (lhs.contents_.IsSame(rhs.contents_)) return true; + size_t rhs_size = rhs.size(); + if (lhs.size() != rhs_size) return false; + return lhs.EqualsImpl(rhs, rhs_size); +} + +inline bool operator!=(const Cord& x, const Cord& y) { return !(x == y); } +inline bool operator<(const Cord& x, const Cord& y) { + return x.Compare(y) < 0; +} +inline bool operator>(const Cord& x, const Cord& y) { + return x.Compare(y) > 0; +} +inline bool operator<=(const Cord& x, const Cord& y) { + return x.Compare(y) <= 0; +} +inline bool operator>=(const Cord& x, const Cord& y) { + return x.Compare(y) >= 0; +} + +// Nonmember Cord-to-absl::string_view relational operators. +// +// Due to implicit conversions, these also enable comparisons of Cord with +// with std::string, ::string, and const char*. +inline bool operator==(const Cord& lhs, absl::string_view rhs) { + size_t lhs_size = lhs.size(); + size_t rhs_size = rhs.size(); + if (lhs_size != rhs_size) return false; + return lhs.EqualsImpl(rhs, rhs_size); +} + +inline bool operator==(absl::string_view x, const Cord& y) { return y == x; } +inline bool operator!=(const Cord& x, absl::string_view y) { return !(x == y); } +inline bool operator!=(absl::string_view x, const Cord& y) { return !(x == y); } +inline bool operator<(const Cord& x, absl::string_view y) { + return x.Compare(y) < 0; +} +inline bool operator<(absl::string_view x, const Cord& y) { + return y.Compare(x) > 0; +} +inline bool operator>(const Cord& x, absl::string_view y) { return y < x; } +inline bool operator>(absl::string_view x, const Cord& y) { return y < x; } +inline bool operator<=(const Cord& x, absl::string_view y) { return !(y < x); } +inline bool operator<=(absl::string_view x, const Cord& y) { return !(y < x); } +inline bool operator>=(const Cord& x, absl::string_view y) { return !(x < y); } +inline bool operator>=(absl::string_view x, const Cord& y) { return !(x < y); } + +// Some internals exposed to test code. +namespace strings_internal { +class CordTestAccess { + public: + static size_t FlatOverhead(); + static size_t MaxFlatLength(); + static size_t SizeofCordRepConcat(); + static size_t SizeofCordRepExternal(); + static size_t SizeofCordRepSubstring(); + static size_t FlatTagToLength(uint8_t tag); + static uint8_t LengthToTag(size_t s); +}; +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_CORD_H_ diff --git a/third_party/abseil_cpp/absl/strings/cord_test.cc b/third_party/abseil_cpp/absl/strings/cord_test.cc new file mode 100644 index 0000000000..4443c82896 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/cord_test.cc @@ -0,0 +1,1615 @@ +#include "absl/strings/cord.h" + +#include <algorithm> +#include <climits> +#include <cstdio> +#include <iterator> +#include <map> +#include <numeric> +#include <random> +#include <sstream> +#include <type_traits> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/casts.h" +#include "absl/base/config.h" +#include "absl/base/internal/endian.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/container/fixed_array.h" +#include "absl/strings/cord_test_helpers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_format.h" +#include "absl/strings/string_view.h" + +typedef std::mt19937_64 RandomEngine; + +static std::string RandomLowercaseString(RandomEngine* rng); +static std::string RandomLowercaseString(RandomEngine* rng, size_t length); + +static int GetUniformRandomUpTo(RandomEngine* rng, int upper_bound) { + if (upper_bound > 0) { + std::uniform_int_distribution<int> uniform(0, upper_bound - 1); + return uniform(*rng); + } else { + return 0; + } +} + +static size_t GetUniformRandomUpTo(RandomEngine* rng, size_t upper_bound) { + if (upper_bound > 0) { + std::uniform_int_distribution<size_t> uniform(0, upper_bound - 1); + return uniform(*rng); + } else { + return 0; + } +} + +static int32_t GenerateSkewedRandom(RandomEngine* rng, int max_log) { + const uint32_t base = (*rng)() % (max_log + 1); + const uint32_t mask = ((base < 32) ? (1u << base) : 0u) - 1u; + return (*rng)() & mask; +} + +static std::string RandomLowercaseString(RandomEngine* rng) { + int length; + std::bernoulli_distribution one_in_1k(0.001); + std::bernoulli_distribution one_in_10k(0.0001); + // With low probability, make a large fragment + if (one_in_10k(*rng)) { + length = GetUniformRandomUpTo(rng, 1048576); + } else if (one_in_1k(*rng)) { + length = GetUniformRandomUpTo(rng, 10000); + } else { + length = GenerateSkewedRandom(rng, 10); + } + return RandomLowercaseString(rng, length); +} + +static std::string RandomLowercaseString(RandomEngine* rng, size_t length) { + std::string result(length, '\0'); + std::uniform_int_distribution<int> chars('a', 'z'); + std::generate(result.begin(), result.end(), + [&]() { return static_cast<char>(chars(*rng)); }); + return result; +} + +static void DoNothing(absl::string_view /* data */, void* /* arg */) {} + +static void DeleteExternalString(absl::string_view data, void* arg) { + std::string* s = reinterpret_cast<std::string*>(arg); + EXPECT_EQ(data, *s); + delete s; +} + +// Add "s" to *dst via `MakeCordFromExternal` +static void AddExternalMemory(absl::string_view s, absl::Cord* dst) { + std::string* str = new std::string(s.data(), s.size()); + dst->Append(absl::MakeCordFromExternal(*str, [str](absl::string_view data) { + DeleteExternalString(data, str); + })); +} + +static void DumpGrowth() { + absl::Cord str; + for (int i = 0; i < 1000; i++) { + char c = 'a' + i % 26; + str.Append(absl::string_view(&c, 1)); + } +} + +// Make a Cord with some number of fragments. Return the size (in bytes) +// of the smallest fragment. +static size_t AppendWithFragments(const std::string& s, RandomEngine* rng, + absl::Cord* cord) { + size_t j = 0; + const size_t max_size = s.size() / 5; // Make approx. 10 fragments + size_t min_size = max_size; // size of smallest fragment + while (j < s.size()) { + size_t N = 1 + GetUniformRandomUpTo(rng, max_size); + if (N > (s.size() - j)) { + N = s.size() - j; + } + if (N < min_size) { + min_size = N; + } + + std::bernoulli_distribution coin_flip(0.5); + if (coin_flip(*rng)) { + // Grow by adding an external-memory. + AddExternalMemory(absl::string_view(s.data() + j, N), cord); + } else { + cord->Append(absl::string_view(s.data() + j, N)); + } + j += N; + } + return min_size; +} + +// Add an external memory that contains the specified std::string to cord +static void AddNewStringBlock(const std::string& str, absl::Cord* dst) { + char* data = new char[str.size()]; + memcpy(data, str.data(), str.size()); + dst->Append(absl::MakeCordFromExternal( + absl::string_view(data, str.size()), + [](absl::string_view s) { delete[] s.data(); })); +} + +// Make a Cord out of many different types of nodes. +static absl::Cord MakeComposite() { + absl::Cord cord; + cord.Append("the"); + AddExternalMemory(" quick brown", &cord); + AddExternalMemory(" fox jumped", &cord); + + absl::Cord full(" over"); + AddExternalMemory(" the lazy", &full); + AddNewStringBlock(" dog slept the whole day away", &full); + absl::Cord substring = full.Subcord(0, 18); + + // Make substring long enough to defeat the copying fast path in Append. + substring.Append(std::string(1000, '.')); + cord.Append(substring); + cord = cord.Subcord(0, cord.size() - 998); // Remove most of extra junk + + return cord; +} + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class CordTestPeer { + public: + static void ForEachChunk( + const Cord& c, absl::FunctionRef<void(absl::string_view)> callback) { + c.ForEachChunk(callback); + } +}; + +ABSL_NAMESPACE_END +} // namespace absl + +TEST(Cord, AllFlatSizes) { + using absl::strings_internal::CordTestAccess; + + for (size_t s = 0; s < CordTestAccess::MaxFlatLength(); s++) { + // Make a string of length s. + std::string src; + while (src.size() < s) { + src.push_back('a' + (src.size() % 26)); + } + + absl::Cord dst(src); + EXPECT_EQ(std::string(dst), src) << s; + } +} + +// We create a Cord at least 128GB in size using the fact that Cords can +// internally reference-count; thus the Cord is enormous without actually +// consuming very much memory. +TEST(GigabyteCord, FromExternal) { + const size_t one_gig = 1024U * 1024U * 1024U; + size_t max_size = 2 * one_gig; + if (sizeof(max_size) > 4) max_size = 128 * one_gig; + + size_t length = 128 * 1024; + char* data = new char[length]; + absl::Cord from = absl::MakeCordFromExternal( + absl::string_view(data, length), + [](absl::string_view sv) { delete[] sv.data(); }); + + // This loop may seem odd due to its combination of exponential doubling of + // size and incremental size increases. We do it incrementally to be sure the + // Cord will need rebalancing and will exercise code that, in the past, has + // caused crashes in production. We grow exponentially so that the code will + // execute in a reasonable amount of time. + absl::Cord c; + ABSL_RAW_LOG(INFO, "Made a Cord with %zu bytes!", c.size()); + c.Append(from); + while (c.size() < max_size) { + c.Append(c); + c.Append(from); + c.Append(from); + c.Append(from); + c.Append(from); + } + + for (int i = 0; i < 1024; ++i) { + c.Append(from); + } + ABSL_RAW_LOG(INFO, "Made a Cord with %zu bytes!", c.size()); + // Note: on a 32-bit build, this comes out to 2,818,048,000 bytes. + // Note: on a 64-bit build, this comes out to 171,932,385,280 bytes. +} + +static absl::Cord MakeExternalCord(int size) { + char* buffer = new char[size]; + memset(buffer, 'x', size); + absl::Cord cord; + cord.Append(absl::MakeCordFromExternal( + absl::string_view(buffer, size), + [](absl::string_view s) { delete[] s.data(); })); + return cord; +} + +// Extern to fool clang that this is not constant. Needed to suppress +// a warning of unsafe code we want to test. +extern bool my_unique_true_boolean; +bool my_unique_true_boolean = true; + +TEST(Cord, Assignment) { + absl::Cord x(absl::string_view("hi there")); + absl::Cord y(x); + ASSERT_EQ(std::string(x), "hi there"); + ASSERT_EQ(std::string(y), "hi there"); + ASSERT_TRUE(x == y); + ASSERT_TRUE(x <= y); + ASSERT_TRUE(y <= x); + + x = absl::string_view("foo"); + ASSERT_EQ(std::string(x), "foo"); + ASSERT_EQ(std::string(y), "hi there"); + ASSERT_TRUE(x < y); + ASSERT_TRUE(y > x); + ASSERT_TRUE(x != y); + ASSERT_TRUE(x <= y); + ASSERT_TRUE(y >= x); + + x = "foo"; + ASSERT_EQ(x, "foo"); + + // Test that going from inline rep to tree we don't leak memory. + std::vector<std::pair<absl::string_view, absl::string_view>> + test_string_pairs = {{"hi there", "foo"}, + {"loooooong coooooord", "short cord"}, + {"short cord", "loooooong coooooord"}, + {"loooooong coooooord1", "loooooong coooooord2"}}; + for (std::pair<absl::string_view, absl::string_view> test_strings : + test_string_pairs) { + absl::Cord tmp(test_strings.first); + absl::Cord z(std::move(tmp)); + ASSERT_EQ(std::string(z), test_strings.first); + tmp = test_strings.second; + z = std::move(tmp); + ASSERT_EQ(std::string(z), test_strings.second); + } + { + // Test that self-move assignment doesn't crash/leak. + // Do not write such code! + absl::Cord my_small_cord("foo"); + absl::Cord my_big_cord("loooooong coooooord"); + // Bypass clang's warning on self move-assignment. + absl::Cord* my_small_alias = + my_unique_true_boolean ? &my_small_cord : &my_big_cord; + absl::Cord* my_big_alias = + !my_unique_true_boolean ? &my_small_cord : &my_big_cord; + + *my_small_alias = std::move(my_small_cord); + *my_big_alias = std::move(my_big_cord); + // my_small_cord and my_big_cord are in an unspecified but valid + // state, and will be correctly destroyed here. + } +} + +TEST(Cord, StartsEndsWith) { + absl::Cord x(absl::string_view("abcde")); + absl::Cord empty(""); + + ASSERT_TRUE(x.StartsWith(absl::Cord("abcde"))); + ASSERT_TRUE(x.StartsWith(absl::Cord("abc"))); + ASSERT_TRUE(x.StartsWith(absl::Cord(""))); + ASSERT_TRUE(empty.StartsWith(absl::Cord(""))); + ASSERT_TRUE(x.EndsWith(absl::Cord("abcde"))); + ASSERT_TRUE(x.EndsWith(absl::Cord("cde"))); + ASSERT_TRUE(x.EndsWith(absl::Cord(""))); + ASSERT_TRUE(empty.EndsWith(absl::Cord(""))); + + ASSERT_TRUE(!x.StartsWith(absl::Cord("xyz"))); + ASSERT_TRUE(!empty.StartsWith(absl::Cord("xyz"))); + ASSERT_TRUE(!x.EndsWith(absl::Cord("xyz"))); + ASSERT_TRUE(!empty.EndsWith(absl::Cord("xyz"))); + + ASSERT_TRUE(x.StartsWith("abcde")); + ASSERT_TRUE(x.StartsWith("abc")); + ASSERT_TRUE(x.StartsWith("")); + ASSERT_TRUE(empty.StartsWith("")); + ASSERT_TRUE(x.EndsWith("abcde")); + ASSERT_TRUE(x.EndsWith("cde")); + ASSERT_TRUE(x.EndsWith("")); + ASSERT_TRUE(empty.EndsWith("")); + + ASSERT_TRUE(!x.StartsWith("xyz")); + ASSERT_TRUE(!empty.StartsWith("xyz")); + ASSERT_TRUE(!x.EndsWith("xyz")); + ASSERT_TRUE(!empty.EndsWith("xyz")); +} + +TEST(Cord, Subcord) { + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + const std::string s = RandomLowercaseString(&rng, 1024); + + absl::Cord a; + AppendWithFragments(s, &rng, &a); + ASSERT_EQ(s.size(), a.size()); + + // Check subcords of a, from a variety of interesting points. + std::set<size_t> positions; + for (int i = 0; i <= 32; ++i) { + positions.insert(i); + positions.insert(i * 32 - 1); + positions.insert(i * 32); + positions.insert(i * 32 + 1); + positions.insert(a.size() - i); + } + positions.insert(237); + positions.insert(732); + for (size_t pos : positions) { + if (pos > a.size()) continue; + for (size_t end_pos : positions) { + if (end_pos < pos || end_pos > a.size()) continue; + absl::Cord sa = a.Subcord(pos, end_pos - pos); + EXPECT_EQ(absl::string_view(s).substr(pos, end_pos - pos), + std::string(sa)) + << a; + } + } + + // Do the same thing for an inline cord. + const std::string sh = "short"; + absl::Cord c(sh); + for (size_t pos = 0; pos <= sh.size(); ++pos) { + for (size_t n = 0; n <= sh.size() - pos; ++n) { + absl::Cord sc = c.Subcord(pos, n); + EXPECT_EQ(sh.substr(pos, n), std::string(sc)) << c; + } + } + + // Check subcords of subcords. + absl::Cord sa = a.Subcord(0, a.size()); + std::string ss = s.substr(0, s.size()); + while (sa.size() > 1) { + sa = sa.Subcord(1, sa.size() - 2); + ss = ss.substr(1, ss.size() - 2); + EXPECT_EQ(ss, std::string(sa)) << a; + if (HasFailure()) break; // halt cascade + } + + // It is OK to ask for too much. + sa = a.Subcord(0, a.size() + 1); + EXPECT_EQ(s, std::string(sa)); + + // It is OK to ask for something beyond the end. + sa = a.Subcord(a.size() + 1, 0); + EXPECT_TRUE(sa.empty()); + sa = a.Subcord(a.size() + 1, 1); + EXPECT_TRUE(sa.empty()); +} + +TEST(Cord, Swap) { + absl::string_view a("Dexter"); + absl::string_view b("Mandark"); + absl::Cord x(a); + absl::Cord y(b); + swap(x, y); + ASSERT_EQ(x, absl::Cord(b)); + ASSERT_EQ(y, absl::Cord(a)); + x.swap(y); + ASSERT_EQ(x, absl::Cord(a)); + ASSERT_EQ(y, absl::Cord(b)); +} + +static void VerifyCopyToString(const absl::Cord& cord) { + std::string initially_empty; + absl::CopyCordToString(cord, &initially_empty); + EXPECT_EQ(initially_empty, cord); + + constexpr size_t kInitialLength = 1024; + std::string has_initial_contents(kInitialLength, 'x'); + const char* address_before_copy = has_initial_contents.data(); + absl::CopyCordToString(cord, &has_initial_contents); + EXPECT_EQ(has_initial_contents, cord); + + if (cord.size() <= kInitialLength) { + EXPECT_EQ(has_initial_contents.data(), address_before_copy) + << "CopyCordToString allocated new string storage; " + "has_initial_contents = \"" + << has_initial_contents << "\""; + } +} + +TEST(Cord, CopyToString) { + VerifyCopyToString(absl::Cord()); + VerifyCopyToString(absl::Cord("small cord")); + VerifyCopyToString( + absl::MakeFragmentedCord({"fragmented ", "cord ", "to ", "test ", + "copying ", "to ", "a ", "string."})); +} + +TEST(TryFlat, Empty) { + absl::Cord c; + EXPECT_EQ(c.TryFlat(), ""); +} + +TEST(TryFlat, Flat) { + absl::Cord c("hello"); + EXPECT_EQ(c.TryFlat(), "hello"); +} + +TEST(TryFlat, SubstrInlined) { + absl::Cord c("hello"); + c.RemovePrefix(1); + EXPECT_EQ(c.TryFlat(), "ello"); +} + +TEST(TryFlat, SubstrFlat) { + absl::Cord c("longer than 15 bytes"); + c.RemovePrefix(1); + EXPECT_EQ(c.TryFlat(), "onger than 15 bytes"); +} + +TEST(TryFlat, Concat) { + absl::Cord c = absl::MakeFragmentedCord({"hel", "lo"}); + EXPECT_EQ(c.TryFlat(), absl::nullopt); +} + +TEST(TryFlat, External) { + absl::Cord c = absl::MakeCordFromExternal("hell", [](absl::string_view) {}); + EXPECT_EQ(c.TryFlat(), "hell"); +} + +TEST(TryFlat, SubstrExternal) { + absl::Cord c = absl::MakeCordFromExternal("hell", [](absl::string_view) {}); + c.RemovePrefix(1); + EXPECT_EQ(c.TryFlat(), "ell"); +} + +TEST(TryFlat, SubstrConcat) { + absl::Cord c = absl::MakeFragmentedCord({"hello", " world"}); + c.RemovePrefix(1); + EXPECT_EQ(c.TryFlat(), absl::nullopt); +} + +static bool IsFlat(const absl::Cord& c) { + return c.chunk_begin() == c.chunk_end() || ++c.chunk_begin() == c.chunk_end(); +} + +static void VerifyFlatten(absl::Cord c) { + std::string old_contents(c); + absl::string_view old_flat; + bool already_flat_and_non_empty = IsFlat(c) && !c.empty(); + if (already_flat_and_non_empty) { + old_flat = *c.chunk_begin(); + } + absl::string_view new_flat = c.Flatten(); + + // Verify that the contents of the flattened Cord are correct. + EXPECT_EQ(new_flat, old_contents); + EXPECT_EQ(std::string(c), old_contents); + + // If the Cord contained data and was already flat, verify that the data + // wasn't copied. + if (already_flat_and_non_empty) { + EXPECT_EQ(old_flat.data(), new_flat.data()) + << "Allocated new memory even though the Cord was already flat."; + } + + // Verify that the flattened Cord is in fact flat. + EXPECT_TRUE(IsFlat(c)); +} + +TEST(Cord, Flatten) { + VerifyFlatten(absl::Cord()); + VerifyFlatten(absl::Cord("small cord")); + VerifyFlatten(absl::Cord("larger than small buffer optimization")); + VerifyFlatten(absl::MakeFragmentedCord({"small ", "fragmented ", "cord"})); + + // Test with a cord that is longer than the largest flat buffer + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + VerifyFlatten(absl::Cord(RandomLowercaseString(&rng, 8192))); +} + +// Test data +namespace { +class TestData { + private: + std::vector<std::string> data_; + + // Return a std::string of the specified length. + static std::string MakeString(int length) { + std::string result; + char buf[30]; + snprintf(buf, sizeof(buf), "(%d)", length); + while (result.size() < length) { + result += buf; + } + result.resize(length); + return result; + } + + public: + TestData() { + // short strings increasing in length by one + for (int i = 0; i < 30; i++) { + data_.push_back(MakeString(i)); + } + + // strings around half kMaxFlatLength + static const int kMaxFlatLength = 4096 - 9; + static const int kHalf = kMaxFlatLength / 2; + + for (int i = -10; i <= +10; i++) { + data_.push_back(MakeString(kHalf + i)); + } + + for (int i = -10; i <= +10; i++) { + data_.push_back(MakeString(kMaxFlatLength + i)); + } + } + + size_t size() const { return data_.size(); } + const std::string& data(size_t i) const { return data_[i]; } +}; +} // namespace + +TEST(Cord, MultipleLengths) { + TestData d; + for (size_t i = 0; i < d.size(); i++) { + std::string a = d.data(i); + + { // Construct from Cord + absl::Cord tmp(a); + absl::Cord x(tmp); + EXPECT_EQ(a, std::string(x)) << "'" << a << "'"; + } + + { // Construct from absl::string_view + absl::Cord x(a); + EXPECT_EQ(a, std::string(x)) << "'" << a << "'"; + } + + { // Append cord to self + absl::Cord self(a); + self.Append(self); + EXPECT_EQ(a + a, std::string(self)) << "'" << a << "' + '" << a << "'"; + } + + { // Prepend cord to self + absl::Cord self(a); + self.Prepend(self); + EXPECT_EQ(a + a, std::string(self)) << "'" << a << "' + '" << a << "'"; + } + + // Try to append/prepend others + for (size_t j = 0; j < d.size(); j++) { + std::string b = d.data(j); + + { // CopyFrom Cord + absl::Cord x(a); + absl::Cord y(b); + x = y; + EXPECT_EQ(b, std::string(x)) << "'" << a << "' + '" << b << "'"; + } + + { // CopyFrom absl::string_view + absl::Cord x(a); + x = b; + EXPECT_EQ(b, std::string(x)) << "'" << a << "' + '" << b << "'"; + } + + { // Cord::Append(Cord) + absl::Cord x(a); + absl::Cord y(b); + x.Append(y); + EXPECT_EQ(a + b, std::string(x)) << "'" << a << "' + '" << b << "'"; + } + + { // Cord::Append(absl::string_view) + absl::Cord x(a); + x.Append(b); + EXPECT_EQ(a + b, std::string(x)) << "'" << a << "' + '" << b << "'"; + } + + { // Cord::Prepend(Cord) + absl::Cord x(a); + absl::Cord y(b); + x.Prepend(y); + EXPECT_EQ(b + a, std::string(x)) << "'" << b << "' + '" << a << "'"; + } + + { // Cord::Prepend(absl::string_view) + absl::Cord x(a); + x.Prepend(b); + EXPECT_EQ(b + a, std::string(x)) << "'" << b << "' + '" << a << "'"; + } + } + } +} + +namespace { + +TEST(Cord, RemoveSuffixWithExternalOrSubstring) { + absl::Cord cord = absl::MakeCordFromExternal( + "foo bar baz", [](absl::string_view s) { DoNothing(s, nullptr); }); + + EXPECT_EQ("foo bar baz", std::string(cord)); + + // This RemoveSuffix() will wrap the EXTERNAL node in a SUBSTRING node. + cord.RemoveSuffix(4); + EXPECT_EQ("foo bar", std::string(cord)); + + // This RemoveSuffix() will adjust the SUBSTRING node in-place. + cord.RemoveSuffix(4); + EXPECT_EQ("foo", std::string(cord)); +} + +TEST(Cord, RemoveSuffixMakesZeroLengthNode) { + absl::Cord c; + c.Append(absl::Cord(std::string(100, 'x'))); + absl::Cord other_ref = c; // Prevent inplace appends + c.Append(absl::Cord(std::string(200, 'y'))); + c.RemoveSuffix(200); + EXPECT_EQ(std::string(100, 'x'), std::string(c)); +} + +} // namespace + +// CordSpliceTest contributed by hendrie. +namespace { + +// Create a cord with an external memory block filled with 'z' +absl::Cord CordWithZedBlock(size_t size) { + char* data = new char[size]; + if (size > 0) { + memset(data, 'z', size); + } + absl::Cord cord = absl::MakeCordFromExternal( + absl::string_view(data, size), + [](absl::string_view s) { delete[] s.data(); }); + return cord; +} + +// Establish that ZedBlock does what we think it does. +TEST(CordSpliceTest, ZedBlock) { + absl::Cord blob = CordWithZedBlock(10); + EXPECT_EQ(10, blob.size()); + std::string s; + absl::CopyCordToString(blob, &s); + EXPECT_EQ("zzzzzzzzzz", s); +} + +TEST(CordSpliceTest, ZedBlock0) { + absl::Cord blob = CordWithZedBlock(0); + EXPECT_EQ(0, blob.size()); + std::string s; + absl::CopyCordToString(blob, &s); + EXPECT_EQ("", s); +} + +TEST(CordSpliceTest, ZedBlockSuffix1) { + absl::Cord blob = CordWithZedBlock(10); + EXPECT_EQ(10, blob.size()); + absl::Cord suffix(blob); + suffix.RemovePrefix(9); + EXPECT_EQ(1, suffix.size()); + std::string s; + absl::CopyCordToString(suffix, &s); + EXPECT_EQ("z", s); +} + +// Remove all of a prefix block +TEST(CordSpliceTest, ZedBlockSuffix0) { + absl::Cord blob = CordWithZedBlock(10); + EXPECT_EQ(10, blob.size()); + absl::Cord suffix(blob); + suffix.RemovePrefix(10); + EXPECT_EQ(0, suffix.size()); + std::string s; + absl::CopyCordToString(suffix, &s); + EXPECT_EQ("", s); +} + +absl::Cord BigCord(size_t len, char v) { + std::string s(len, v); + return absl::Cord(s); +} + +// Splice block into cord. +absl::Cord SpliceCord(const absl::Cord& blob, int64_t offset, + const absl::Cord& block) { + ABSL_RAW_CHECK(offset >= 0, ""); + ABSL_RAW_CHECK(offset + block.size() <= blob.size(), ""); + absl::Cord result(blob); + result.RemoveSuffix(blob.size() - offset); + result.Append(block); + absl::Cord suffix(blob); + suffix.RemovePrefix(offset + block.size()); + result.Append(suffix); + ABSL_RAW_CHECK(blob.size() == result.size(), ""); + return result; +} + +// Taking an empty suffix of a block breaks appending. +TEST(CordSpliceTest, RemoveEntireBlock1) { + absl::Cord zero = CordWithZedBlock(10); + absl::Cord suffix(zero); + suffix.RemovePrefix(10); + absl::Cord result; + result.Append(suffix); +} + +TEST(CordSpliceTest, RemoveEntireBlock2) { + absl::Cord zero = CordWithZedBlock(10); + absl::Cord prefix(zero); + prefix.RemoveSuffix(10); + absl::Cord suffix(zero); + suffix.RemovePrefix(10); + absl::Cord result(prefix); + result.Append(suffix); +} + +TEST(CordSpliceTest, RemoveEntireBlock3) { + absl::Cord blob = CordWithZedBlock(10); + absl::Cord block = BigCord(10, 'b'); + blob = SpliceCord(blob, 0, block); +} + +struct CordCompareTestCase { + template <typename LHS, typename RHS> + CordCompareTestCase(const LHS& lhs, const RHS& rhs) + : lhs_cord(lhs), rhs_cord(rhs) {} + + absl::Cord lhs_cord; + absl::Cord rhs_cord; +}; + +const auto sign = [](int x) { return x == 0 ? 0 : (x > 0 ? 1 : -1); }; + +void VerifyComparison(const CordCompareTestCase& test_case) { + std::string lhs_string(test_case.lhs_cord); + std::string rhs_string(test_case.rhs_cord); + int expected = sign(lhs_string.compare(rhs_string)); + EXPECT_EQ(expected, test_case.lhs_cord.Compare(test_case.rhs_cord)) + << "LHS=" << lhs_string << "; RHS=" << rhs_string; + EXPECT_EQ(expected, test_case.lhs_cord.Compare(rhs_string)) + << "LHS=" << lhs_string << "; RHS=" << rhs_string; + EXPECT_EQ(-expected, test_case.rhs_cord.Compare(test_case.lhs_cord)) + << "LHS=" << rhs_string << "; RHS=" << lhs_string; + EXPECT_EQ(-expected, test_case.rhs_cord.Compare(lhs_string)) + << "LHS=" << rhs_string << "; RHS=" << lhs_string; +} + +TEST(Cord, Compare) { + absl::Cord subcord("aaaaaBBBBBcccccDDDDD"); + subcord = subcord.Subcord(3, 10); + + absl::Cord tmp("aaaaaaaaaaaaaaaa"); + tmp.Append("BBBBBBBBBBBBBBBB"); + absl::Cord concat = absl::Cord("cccccccccccccccc"); + concat.Append("DDDDDDDDDDDDDDDD"); + concat.Prepend(tmp); + + absl::Cord concat2("aaaaaaaaaaaaa"); + concat2.Append("aaaBBBBBBBBBBBBBBBBccccc"); + concat2.Append("cccccccccccDDDDDDDDDDDDDD"); + concat2.Append("DD"); + + std::vector<CordCompareTestCase> test_cases = {{ + // Inline cords + {"abcdef", "abcdef"}, + {"abcdef", "abcdee"}, + {"abcdef", "abcdeg"}, + {"bbcdef", "abcdef"}, + {"bbcdef", "abcdeg"}, + {"abcdefa", "abcdef"}, + {"abcdef", "abcdefa"}, + + // Small flat cords + {"aaaaaBBBBBcccccDDDDD", "aaaaaBBBBBcccccDDDDD"}, + {"aaaaaBBBBBcccccDDDDD", "aaaaaBBBBBxccccDDDDD"}, + {"aaaaaBBBBBcxcccDDDDD", "aaaaaBBBBBcccccDDDDD"}, + {"aaaaaBBBBBxccccDDDDD", "aaaaaBBBBBcccccDDDDX"}, + {"aaaaaBBBBBcccccDDDDDa", "aaaaaBBBBBcccccDDDDD"}, + {"aaaaaBBBBBcccccDDDDD", "aaaaaBBBBBcccccDDDDDa"}, + + // Subcords + {subcord, subcord}, + {subcord, "aaBBBBBccc"}, + {subcord, "aaBBBBBccd"}, + {subcord, "aaBBBBBccb"}, + {subcord, "aaBBBBBxcb"}, + {subcord, "aaBBBBBccca"}, + {subcord, "aaBBBBBcc"}, + + // Concats + {concat, concat}, + {concat, + "aaaaaaaaaaaaaaaaBBBBBBBBBBBBBBBBccccccccccccccccDDDDDDDDDDDDDDDD"}, + {concat, + "aaaaaaaaaaaaaaaaBBBBBBBBBBBBBBBBcccccccccccccccxDDDDDDDDDDDDDDDD"}, + {concat, + "aaaaaaaaaaaaaaaaBBBBBBBBBBBBBBBBacccccccccccccccDDDDDDDDDDDDDDDD"}, + {concat, + "aaaaaaaaaaaaaaaaBBBBBBBBBBBBBBBBccccccccccccccccDDDDDDDDDDDDDDD"}, + {concat, + "aaaaaaaaaaaaaaaaBBBBBBBBBBBBBBBBccccccccccccccccDDDDDDDDDDDDDDDDe"}, + + {concat, concat2}, + }}; + + for (const auto& tc : test_cases) { + VerifyComparison(tc); + } +} + +TEST(Cord, CompareAfterAssign) { + absl::Cord a("aaaaaa1111111"); + absl::Cord b("aaaaaa2222222"); + a = "cccccc"; + b = "cccccc"; + EXPECT_EQ(a, b); + EXPECT_FALSE(a < b); + + a = "aaaa"; + b = "bbbbb"; + a = ""; + b = ""; + EXPECT_EQ(a, b); + EXPECT_FALSE(a < b); +} + +// Test CompareTo() and ComparePrefix() against string and substring +// comparison methods from basic_string. +static void TestCompare(const absl::Cord& c, const absl::Cord& d, + RandomEngine* rng) { + typedef std::basic_string<uint8_t> ustring; + ustring cs(reinterpret_cast<const uint8_t*>(std::string(c).data()), c.size()); + ustring ds(reinterpret_cast<const uint8_t*>(std::string(d).data()), d.size()); + // ustring comparison is ideal because we expect Cord comparisons to be + // based on unsigned byte comparisons regardless of whether char is signed. + int expected = sign(cs.compare(ds)); + EXPECT_EQ(expected, sign(c.Compare(d))) << c << ", " << d; +} + +TEST(Compare, ComparisonIsUnsigned) { + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + std::uniform_int_distribution<uint32_t> uniform_uint8(0, 255); + char x = static_cast<char>(uniform_uint8(rng)); + TestCompare( + absl::Cord(std::string(GetUniformRandomUpTo(&rng, 100), x)), + absl::Cord(std::string(GetUniformRandomUpTo(&rng, 100), x ^ 0x80)), &rng); +} + +TEST(Compare, RandomComparisons) { + const int kIters = 5000; + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + + int n = GetUniformRandomUpTo(&rng, 5000); + absl::Cord a[] = {MakeExternalCord(n), + absl::Cord("ant"), + absl::Cord("elephant"), + absl::Cord("giraffe"), + absl::Cord(std::string(GetUniformRandomUpTo(&rng, 100), + GetUniformRandomUpTo(&rng, 100))), + absl::Cord(""), + absl::Cord("x"), + absl::Cord("A"), + absl::Cord("B"), + absl::Cord("C")}; + for (int i = 0; i < kIters; i++) { + absl::Cord c, d; + for (int j = 0; j < (i % 7) + 1; j++) { + c.Append(a[GetUniformRandomUpTo(&rng, ABSL_ARRAYSIZE(a))]); + d.Append(a[GetUniformRandomUpTo(&rng, ABSL_ARRAYSIZE(a))]); + } + std::bernoulli_distribution coin_flip(0.5); + TestCompare(coin_flip(rng) ? c : absl::Cord(std::string(c)), + coin_flip(rng) ? d : absl::Cord(std::string(d)), &rng); + } +} + +template <typename T1, typename T2> +void CompareOperators() { + const T1 a("a"); + const T2 b("b"); + + EXPECT_TRUE(a == a); + // For pointer type (i.e. `const char*`), operator== compares the address + // instead of the string, so `a == const char*("a")` isn't necessarily true. + EXPECT_TRUE(std::is_pointer<T1>::value || a == T1("a")); + EXPECT_TRUE(std::is_pointer<T2>::value || a == T2("a")); + EXPECT_FALSE(a == b); + + EXPECT_TRUE(a != b); + EXPECT_FALSE(a != a); + + EXPECT_TRUE(a < b); + EXPECT_FALSE(b < a); + + EXPECT_TRUE(b > a); + EXPECT_FALSE(a > b); + + EXPECT_TRUE(a >= a); + EXPECT_TRUE(b >= a); + EXPECT_FALSE(a >= b); + + EXPECT_TRUE(a <= a); + EXPECT_TRUE(a <= b); + EXPECT_FALSE(b <= a); +} + +TEST(ComparisonOperators, Cord_Cord) { + CompareOperators<absl::Cord, absl::Cord>(); +} + +TEST(ComparisonOperators, Cord_StringPiece) { + CompareOperators<absl::Cord, absl::string_view>(); +} + +TEST(ComparisonOperators, StringPiece_Cord) { + CompareOperators<absl::string_view, absl::Cord>(); +} + +TEST(ComparisonOperators, Cord_string) { + CompareOperators<absl::Cord, std::string>(); +} + +TEST(ComparisonOperators, string_Cord) { + CompareOperators<std::string, absl::Cord>(); +} + +TEST(ComparisonOperators, stdstring_Cord) { + CompareOperators<std::string, absl::Cord>(); +} + +TEST(ComparisonOperators, Cord_stdstring) { + CompareOperators<absl::Cord, std::string>(); +} + +TEST(ComparisonOperators, charstar_Cord) { + CompareOperators<const char*, absl::Cord>(); +} + +TEST(ComparisonOperators, Cord_charstar) { + CompareOperators<absl::Cord, const char*>(); +} + +TEST(ConstructFromExternal, ReleaserInvoked) { + // Empty external memory means the releaser should be called immediately. + { + bool invoked = false; + auto releaser = [&invoked](absl::string_view) { invoked = true; }; + { + auto c = absl::MakeCordFromExternal("", releaser); + EXPECT_TRUE(invoked); + } + } + + // If the size of the data is small enough, a future constructor + // implementation may copy the bytes and immediately invoke the releaser + // instead of creating an external node. We make a large dummy std::string to + // make this test independent of such an optimization. + std::string large_dummy(2048, 'c'); + { + bool invoked = false; + auto releaser = [&invoked](absl::string_view) { invoked = true; }; + { + auto c = absl::MakeCordFromExternal(large_dummy, releaser); + EXPECT_FALSE(invoked); + } + EXPECT_TRUE(invoked); + } + + { + bool invoked = false; + auto releaser = [&invoked](absl::string_view) { invoked = true; }; + { + absl::Cord copy; + { + auto c = absl::MakeCordFromExternal(large_dummy, releaser); + copy = c; + EXPECT_FALSE(invoked); + } + EXPECT_FALSE(invoked); + } + EXPECT_TRUE(invoked); + } +} + +TEST(ConstructFromExternal, CompareContents) { + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + + for (int length = 1; length <= 2048; length *= 2) { + std::string data = RandomLowercaseString(&rng, length); + auto* external = new std::string(data); + auto cord = + absl::MakeCordFromExternal(*external, [external](absl::string_view sv) { + EXPECT_EQ(external->data(), sv.data()); + EXPECT_EQ(external->size(), sv.size()); + delete external; + }); + EXPECT_EQ(data, cord); + } +} + +TEST(ConstructFromExternal, LargeReleaser) { + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + constexpr size_t kLength = 256; + std::string data = RandomLowercaseString(&rng, kLength); + std::array<char, kLength> data_array; + for (size_t i = 0; i < kLength; ++i) data_array[i] = data[i]; + bool invoked = false; + auto releaser = [data_array, &invoked](absl::string_view data) { + EXPECT_EQ(data, absl::string_view(data_array.data(), data_array.size())); + invoked = true; + }; + (void)absl::MakeCordFromExternal(data, releaser); + EXPECT_TRUE(invoked); +} + +TEST(ConstructFromExternal, FunctionPointerReleaser) { + static absl::string_view data("hello world"); + static bool invoked; + auto* releaser = + static_cast<void (*)(absl::string_view)>([](absl::string_view sv) { + EXPECT_EQ(data, sv); + invoked = true; + }); + invoked = false; + (void)absl::MakeCordFromExternal(data, releaser); + EXPECT_TRUE(invoked); + + invoked = false; + (void)absl::MakeCordFromExternal(data, *releaser); + EXPECT_TRUE(invoked); +} + +TEST(ConstructFromExternal, MoveOnlyReleaser) { + struct Releaser { + explicit Releaser(bool* invoked) : invoked(invoked) {} + Releaser(Releaser&& other) noexcept : invoked(other.invoked) {} + void operator()(absl::string_view) const { *invoked = true; } + + bool* invoked; + }; + + bool invoked = false; + (void)absl::MakeCordFromExternal("dummy", Releaser(&invoked)); + EXPECT_TRUE(invoked); +} + +TEST(ConstructFromExternal, NoArgLambda) { + bool invoked = false; + (void)absl::MakeCordFromExternal("dummy", [&invoked]() { invoked = true; }); + EXPECT_TRUE(invoked); +} + +TEST(ConstructFromExternal, StringViewArgLambda) { + bool invoked = false; + (void)absl::MakeCordFromExternal( + "dummy", [&invoked](absl::string_view) { invoked = true; }); + EXPECT_TRUE(invoked); +} + +TEST(ConstructFromExternal, NonTrivialReleaserDestructor) { + struct Releaser { + explicit Releaser(bool* destroyed) : destroyed(destroyed) {} + ~Releaser() { *destroyed = true; } + void operator()(absl::string_view) const {} + + bool* destroyed; + }; + + bool destroyed = false; + Releaser releaser(&destroyed); + (void)absl::MakeCordFromExternal("dummy", releaser); + EXPECT_TRUE(destroyed); +} + +TEST(ConstructFromExternal, ReferenceQualifierOverloads) { + struct Releaser { + void operator()(absl::string_view) & { *lvalue_invoked = true; } + void operator()(absl::string_view) && { *rvalue_invoked = true; } + + bool* lvalue_invoked; + bool* rvalue_invoked; + }; + + bool lvalue_invoked = false; + bool rvalue_invoked = false; + Releaser releaser = {&lvalue_invoked, &rvalue_invoked}; + (void)absl::MakeCordFromExternal("", releaser); + EXPECT_FALSE(lvalue_invoked); + EXPECT_TRUE(rvalue_invoked); + rvalue_invoked = false; + + (void)absl::MakeCordFromExternal("dummy", releaser); + EXPECT_FALSE(lvalue_invoked); + EXPECT_TRUE(rvalue_invoked); + rvalue_invoked = false; + + // NOLINTNEXTLINE: suppress clang-tidy std::move on trivially copyable type. + (void)absl::MakeCordFromExternal("dummy", std::move(releaser)); + EXPECT_FALSE(lvalue_invoked); + EXPECT_TRUE(rvalue_invoked); +} + +TEST(ExternalMemory, BasicUsage) { + static const char* strings[] = {"", "hello", "there"}; + for (const char* str : strings) { + absl::Cord dst("(prefix)"); + AddExternalMemory(str, &dst); + dst.Append("(suffix)"); + EXPECT_EQ((std::string("(prefix)") + str + std::string("(suffix)")), + std::string(dst)); + } +} + +TEST(ExternalMemory, RemovePrefixSuffix) { + // Exhaustively try all sub-strings. + absl::Cord cord = MakeComposite(); + std::string s = std::string(cord); + for (int offset = 0; offset <= s.size(); offset++) { + for (int length = 0; length <= s.size() - offset; length++) { + absl::Cord result(cord); + result.RemovePrefix(offset); + result.RemoveSuffix(result.size() - length); + EXPECT_EQ(s.substr(offset, length), std::string(result)) + << offset << " " << length; + } + } +} + +TEST(ExternalMemory, Get) { + absl::Cord cord("hello"); + AddExternalMemory(" world!", &cord); + AddExternalMemory(" how are ", &cord); + cord.Append(" you?"); + std::string s = std::string(cord); + for (int i = 0; i < s.size(); i++) { + EXPECT_EQ(s[i], cord[i]); + } +} + +// CordMemoryUsage tests verify the correctness of the EstimatedMemoryUsage() +// These tests take into account that the reported memory usage is approximate +// and non-deterministic. For all tests, We verify that the reported memory +// usage is larger than `size()`, and less than `size() * 1.5` as a cord should +// never reserve more 'extra' capacity than half of its size as it grows. +// Additionally we have some whiteboxed expectations based on our knowledge of +// the layout and size of empty and inlined cords, and flat nodes. + +TEST(CordMemoryUsage, Empty) { + EXPECT_EQ(sizeof(absl::Cord), absl::Cord().EstimatedMemoryUsage()); +} + +TEST(CordMemoryUsage, Embedded) { + absl::Cord a("hello"); + EXPECT_EQ(a.EstimatedMemoryUsage(), sizeof(absl::Cord)); +} + +TEST(CordMemoryUsage, EmbeddedAppend) { + absl::Cord a("a"); + absl::Cord b("bcd"); + EXPECT_EQ(b.EstimatedMemoryUsage(), sizeof(absl::Cord)); + a.Append(b); + EXPECT_EQ(a.EstimatedMemoryUsage(), sizeof(absl::Cord)); +} + +TEST(CordMemoryUsage, ExternalMemory) { + static const int kLength = 1000; + absl::Cord cord; + AddExternalMemory(std::string(kLength, 'x'), &cord); + EXPECT_GT(cord.EstimatedMemoryUsage(), kLength); + EXPECT_LE(cord.EstimatedMemoryUsage(), kLength * 1.5); +} + +TEST(CordMemoryUsage, Flat) { + static const int kLength = 125; + absl::Cord a(std::string(kLength, 'a')); + EXPECT_GT(a.EstimatedMemoryUsage(), kLength); + EXPECT_LE(a.EstimatedMemoryUsage(), kLength * 1.5); +} + +TEST(CordMemoryUsage, AppendFlat) { + using absl::strings_internal::CordTestAccess; + absl::Cord a(std::string(CordTestAccess::MaxFlatLength(), 'a')); + size_t length = a.EstimatedMemoryUsage(); + a.Append(std::string(CordTestAccess::MaxFlatLength(), 'b')); + size_t delta = a.EstimatedMemoryUsage() - length; + EXPECT_GT(delta, CordTestAccess::MaxFlatLength()); + EXPECT_LE(delta, CordTestAccess::MaxFlatLength() * 1.5); +} + +// Regtest for a change that had to be rolled back because it expanded out +// of the InlineRep too soon, which was observable through MemoryUsage(). +TEST(CordMemoryUsage, InlineRep) { + constexpr size_t kMaxInline = 15; // Cord::InlineRep::N + const std::string small_string(kMaxInline, 'x'); + absl::Cord c1(small_string); + + absl::Cord c2; + c2.Append(small_string); + EXPECT_EQ(c1, c2); + EXPECT_EQ(c1.EstimatedMemoryUsage(), c2.EstimatedMemoryUsage()); +} + +} // namespace + +// Regtest for 7510292 (fix a bug introduced by 7465150) +TEST(Cord, Concat_Append) { + // Create a rep of type CONCAT + absl::Cord s1("foobarbarbarbarbar"); + s1.Append("abcdefgabcdefgabcdefgabcdefgabcdefgabcdefgabcdefg"); + size_t size = s1.size(); + + // Create a copy of s1 and append to it. + absl::Cord s2 = s1; + s2.Append("x"); + + // 7465150 modifies s1 when it shouldn't. + EXPECT_EQ(s1.size(), size); + EXPECT_EQ(s2.size(), size + 1); +} + +TEST(MakeFragmentedCord, MakeFragmentedCordFromInitializerList) { + absl::Cord fragmented = + absl::MakeFragmentedCord({"A ", "fragmented ", "Cord"}); + + EXPECT_EQ("A fragmented Cord", fragmented); + + auto chunk_it = fragmented.chunk_begin(); + + ASSERT_TRUE(chunk_it != fragmented.chunk_end()); + EXPECT_EQ("A ", *chunk_it); + + ASSERT_TRUE(++chunk_it != fragmented.chunk_end()); + EXPECT_EQ("fragmented ", *chunk_it); + + ASSERT_TRUE(++chunk_it != fragmented.chunk_end()); + EXPECT_EQ("Cord", *chunk_it); + + ASSERT_TRUE(++chunk_it == fragmented.chunk_end()); +} + +TEST(MakeFragmentedCord, MakeFragmentedCordFromVector) { + std::vector<absl::string_view> chunks = {"A ", "fragmented ", "Cord"}; + absl::Cord fragmented = absl::MakeFragmentedCord(chunks); + + EXPECT_EQ("A fragmented Cord", fragmented); + + auto chunk_it = fragmented.chunk_begin(); + + ASSERT_TRUE(chunk_it != fragmented.chunk_end()); + EXPECT_EQ("A ", *chunk_it); + + ASSERT_TRUE(++chunk_it != fragmented.chunk_end()); + EXPECT_EQ("fragmented ", *chunk_it); + + ASSERT_TRUE(++chunk_it != fragmented.chunk_end()); + EXPECT_EQ("Cord", *chunk_it); + + ASSERT_TRUE(++chunk_it == fragmented.chunk_end()); +} + +TEST(CordChunkIterator, Traits) { + static_assert(std::is_copy_constructible<absl::Cord::ChunkIterator>::value, + ""); + static_assert(std::is_copy_assignable<absl::Cord::ChunkIterator>::value, ""); + + // Move semantics to satisfy swappable via std::swap + static_assert(std::is_move_constructible<absl::Cord::ChunkIterator>::value, + ""); + static_assert(std::is_move_assignable<absl::Cord::ChunkIterator>::value, ""); + + static_assert( + std::is_same< + std::iterator_traits<absl::Cord::ChunkIterator>::iterator_category, + std::input_iterator_tag>::value, + ""); + static_assert( + std::is_same<std::iterator_traits<absl::Cord::ChunkIterator>::value_type, + absl::string_view>::value, + ""); + static_assert( + std::is_same< + std::iterator_traits<absl::Cord::ChunkIterator>::difference_type, + ptrdiff_t>::value, + ""); + static_assert( + std::is_same<std::iterator_traits<absl::Cord::ChunkIterator>::pointer, + const absl::string_view*>::value, + ""); + static_assert( + std::is_same<std::iterator_traits<absl::Cord::ChunkIterator>::reference, + absl::string_view>::value, + ""); +} + +static void VerifyChunkIterator(const absl::Cord& cord, + size_t expected_chunks) { + EXPECT_EQ(cord.chunk_begin() == cord.chunk_end(), cord.empty()) << cord; + EXPECT_EQ(cord.chunk_begin() != cord.chunk_end(), !cord.empty()); + + absl::Cord::ChunkRange range = cord.Chunks(); + EXPECT_EQ(range.begin() == range.end(), cord.empty()); + EXPECT_EQ(range.begin() != range.end(), !cord.empty()); + + std::string content(cord); + size_t pos = 0; + auto pre_iter = cord.chunk_begin(), post_iter = cord.chunk_begin(); + size_t n_chunks = 0; + while (pre_iter != cord.chunk_end() && post_iter != cord.chunk_end()) { + EXPECT_FALSE(pre_iter == cord.chunk_end()); // NOLINT: explicitly test == + EXPECT_FALSE(post_iter == cord.chunk_end()); // NOLINT + + EXPECT_EQ(pre_iter, post_iter); + EXPECT_EQ(*pre_iter, *post_iter); + + EXPECT_EQ(pre_iter->data(), (*pre_iter).data()); + EXPECT_EQ(pre_iter->size(), (*pre_iter).size()); + + absl::string_view chunk = *pre_iter; + EXPECT_FALSE(chunk.empty()); + EXPECT_LE(pos + chunk.size(), content.size()); + EXPECT_EQ(absl::string_view(content.c_str() + pos, chunk.size()), chunk); + + int n_equal_iterators = 0; + for (absl::Cord::ChunkIterator it = range.begin(); it != range.end(); + ++it) { + n_equal_iterators += static_cast<int>(it == pre_iter); + } + EXPECT_EQ(n_equal_iterators, 1); + + ++pre_iter; + EXPECT_EQ(*post_iter++, chunk); + + pos += chunk.size(); + ++n_chunks; + } + EXPECT_EQ(expected_chunks, n_chunks); + EXPECT_EQ(pos, content.size()); + EXPECT_TRUE(pre_iter == cord.chunk_end()); // NOLINT: explicitly test == + EXPECT_TRUE(post_iter == cord.chunk_end()); // NOLINT +} + +TEST(CordChunkIterator, Operations) { + absl::Cord empty_cord; + VerifyChunkIterator(empty_cord, 0); + + absl::Cord small_buffer_cord("small cord"); + VerifyChunkIterator(small_buffer_cord, 1); + + absl::Cord flat_node_cord("larger than small buffer optimization"); + VerifyChunkIterator(flat_node_cord, 1); + + VerifyChunkIterator( + absl::MakeFragmentedCord({"a ", "small ", "fragmented ", "cord ", "for ", + "testing ", "chunk ", "iterations."}), + 8); + + absl::Cord reused_nodes_cord(std::string(40, 'c')); + reused_nodes_cord.Prepend(absl::Cord(std::string(40, 'b'))); + reused_nodes_cord.Prepend(absl::Cord(std::string(40, 'a'))); + size_t expected_chunks = 3; + for (int i = 0; i < 8; ++i) { + reused_nodes_cord.Prepend(reused_nodes_cord); + expected_chunks *= 2; + VerifyChunkIterator(reused_nodes_cord, expected_chunks); + } + + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + absl::Cord flat_cord(RandomLowercaseString(&rng, 256)); + absl::Cord subcords; + for (int i = 0; i < 128; ++i) subcords.Prepend(flat_cord.Subcord(i, 128)); + VerifyChunkIterator(subcords, 128); +} + +TEST(CordCharIterator, Traits) { + static_assert(std::is_copy_constructible<absl::Cord::CharIterator>::value, + ""); + static_assert(std::is_copy_assignable<absl::Cord::CharIterator>::value, ""); + + // Move semantics to satisfy swappable via std::swap + static_assert(std::is_move_constructible<absl::Cord::CharIterator>::value, + ""); + static_assert(std::is_move_assignable<absl::Cord::CharIterator>::value, ""); + + static_assert( + std::is_same< + std::iterator_traits<absl::Cord::CharIterator>::iterator_category, + std::input_iterator_tag>::value, + ""); + static_assert( + std::is_same<std::iterator_traits<absl::Cord::CharIterator>::value_type, + char>::value, + ""); + static_assert( + std::is_same< + std::iterator_traits<absl::Cord::CharIterator>::difference_type, + ptrdiff_t>::value, + ""); + static_assert( + std::is_same<std::iterator_traits<absl::Cord::CharIterator>::pointer, + const char*>::value, + ""); + static_assert( + std::is_same<std::iterator_traits<absl::Cord::CharIterator>::reference, + const char&>::value, + ""); +} + +static void VerifyCharIterator(const absl::Cord& cord) { + EXPECT_EQ(cord.char_begin() == cord.char_end(), cord.empty()); + EXPECT_EQ(cord.char_begin() != cord.char_end(), !cord.empty()); + + absl::Cord::CharRange range = cord.Chars(); + EXPECT_EQ(range.begin() == range.end(), cord.empty()); + EXPECT_EQ(range.begin() != range.end(), !cord.empty()); + + size_t i = 0; + absl::Cord::CharIterator pre_iter = cord.char_begin(); + absl::Cord::CharIterator post_iter = cord.char_begin(); + std::string content(cord); + while (pre_iter != cord.char_end() && post_iter != cord.char_end()) { + EXPECT_FALSE(pre_iter == cord.char_end()); // NOLINT: explicitly test == + EXPECT_FALSE(post_iter == cord.char_end()); // NOLINT + + EXPECT_LT(i, cord.size()); + EXPECT_EQ(content[i], *pre_iter); + + EXPECT_EQ(pre_iter, post_iter); + EXPECT_EQ(*pre_iter, *post_iter); + EXPECT_EQ(&*pre_iter, &*post_iter); + + EXPECT_EQ(&*pre_iter, pre_iter.operator->()); + + const char* character_address = &*pre_iter; + absl::Cord::CharIterator copy = pre_iter; + ++copy; + EXPECT_EQ(character_address, &*pre_iter); + + int n_equal_iterators = 0; + for (absl::Cord::CharIterator it = range.begin(); it != range.end(); ++it) { + n_equal_iterators += static_cast<int>(it == pre_iter); + } + EXPECT_EQ(n_equal_iterators, 1); + + absl::Cord::CharIterator advance_iter = range.begin(); + absl::Cord::Advance(&advance_iter, i); + EXPECT_EQ(pre_iter, advance_iter); + + advance_iter = range.begin(); + EXPECT_EQ(absl::Cord::AdvanceAndRead(&advance_iter, i), cord.Subcord(0, i)); + EXPECT_EQ(pre_iter, advance_iter); + + advance_iter = pre_iter; + absl::Cord::Advance(&advance_iter, cord.size() - i); + EXPECT_EQ(range.end(), advance_iter); + + advance_iter = pre_iter; + EXPECT_EQ(absl::Cord::AdvanceAndRead(&advance_iter, cord.size() - i), + cord.Subcord(i, cord.size() - i)); + EXPECT_EQ(range.end(), advance_iter); + + ++i; + ++pre_iter; + post_iter++; + } + EXPECT_EQ(i, cord.size()); + EXPECT_TRUE(pre_iter == cord.char_end()); // NOLINT: explicitly test == + EXPECT_TRUE(post_iter == cord.char_end()); // NOLINT + + absl::Cord::CharIterator zero_advanced_end = cord.char_end(); + absl::Cord::Advance(&zero_advanced_end, 0); + EXPECT_EQ(zero_advanced_end, cord.char_end()); + + absl::Cord::CharIterator it = cord.char_begin(); + for (absl::string_view chunk : cord.Chunks()) { + while (!chunk.empty()) { + EXPECT_EQ(absl::Cord::ChunkRemaining(it), chunk); + chunk.remove_prefix(1); + ++it; + } + } +} + +TEST(CordCharIterator, Operations) { + absl::Cord empty_cord; + VerifyCharIterator(empty_cord); + + absl::Cord small_buffer_cord("small cord"); + VerifyCharIterator(small_buffer_cord); + + absl::Cord flat_node_cord("larger than small buffer optimization"); + VerifyCharIterator(flat_node_cord); + + VerifyCharIterator( + absl::MakeFragmentedCord({"a ", "small ", "fragmented ", "cord ", "for ", + "testing ", "character ", "iteration."})); + + absl::Cord reused_nodes_cord("ghi"); + reused_nodes_cord.Prepend(absl::Cord("def")); + reused_nodes_cord.Prepend(absl::Cord("abc")); + for (int i = 0; i < 4; ++i) { + reused_nodes_cord.Prepend(reused_nodes_cord); + VerifyCharIterator(reused_nodes_cord); + } + + RandomEngine rng(testing::GTEST_FLAG(random_seed)); + absl::Cord flat_cord(RandomLowercaseString(&rng, 256)); + absl::Cord subcords; + for (int i = 0; i < 4; ++i) subcords.Prepend(flat_cord.Subcord(16 * i, 128)); + VerifyCharIterator(subcords); +} + +TEST(Cord, StreamingOutput) { + absl::Cord c = + absl::MakeFragmentedCord({"A ", "small ", "fragmented ", "Cord", "."}); + std::stringstream output; + output << c; + EXPECT_EQ("A small fragmented Cord.", output.str()); +} + +TEST(Cord, ForEachChunk) { + for (int num_elements : {1, 10, 200}) { + SCOPED_TRACE(num_elements); + std::vector<std::string> cord_chunks; + for (int i = 0; i < num_elements; ++i) { + cord_chunks.push_back(absl::StrCat("[", i, "]")); + } + absl::Cord c = absl::MakeFragmentedCord(cord_chunks); + + std::vector<std::string> iterated_chunks; + absl::CordTestPeer::ForEachChunk(c, + [&iterated_chunks](absl::string_view sv) { + iterated_chunks.emplace_back(sv); + }); + EXPECT_EQ(iterated_chunks, cord_chunks); + } +} + +TEST(Cord, SmallBufferAssignFromOwnData) { + constexpr size_t kMaxInline = 15; + std::string contents = "small buff cord"; + EXPECT_EQ(contents.size(), kMaxInline); + for (size_t pos = 0; pos < contents.size(); ++pos) { + for (size_t count = contents.size() - pos; count > 0; --count) { + absl::Cord c(contents); + absl::string_view flat = c.Flatten(); + c = flat.substr(pos, count); + EXPECT_EQ(c, contents.substr(pos, count)) + << "pos = " << pos << "; count = " << count; + } + } +} + +TEST(Cord, Format) { + absl::Cord c; + absl::Format(&c, "There were %04d little %s.", 3, "pigs"); + EXPECT_EQ(c, "There were 0003 little pigs."); + absl::Format(&c, "And %-3llx bad wolf!", 1); + EXPECT_EQ(c, "There were 0003 little pigs.And 1 bad wolf!"); +} + +TEST(CordDeathTest, Hardening) { + absl::Cord cord("hello"); + // These statement should abort the program in all builds modes. + EXPECT_DEATH_IF_SUPPORTED(cord.RemovePrefix(6), ""); + EXPECT_DEATH_IF_SUPPORTED(cord.RemoveSuffix(6), ""); + + bool test_hardening = false; + ABSL_HARDENING_ASSERT([&]() { + // This only runs when ABSL_HARDENING_ASSERT is active. + test_hardening = true; + return true; + }()); + if (!test_hardening) return; + + EXPECT_DEATH_IF_SUPPORTED(cord[5], ""); + EXPECT_DEATH_IF_SUPPORTED(*cord.chunk_end(), ""); + EXPECT_DEATH_IF_SUPPORTED(static_cast<void>(cord.chunk_end()->empty()), ""); + EXPECT_DEATH_IF_SUPPORTED(++cord.chunk_end(), ""); +} diff --git a/third_party/abseil_cpp/absl/strings/cord_test_helpers.h b/third_party/abseil_cpp/absl/strings/cord_test_helpers.h new file mode 100644 index 0000000000..f1036e3b13 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/cord_test_helpers.h @@ -0,0 +1,60 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_STRINGS_CORD_TEST_HELPERS_H_ +#define ABSL_STRINGS_CORD_TEST_HELPERS_H_ + +#include "absl/strings/cord.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Creates a multi-segment Cord from an iterable container of strings. The +// resulting Cord is guaranteed to have one segment for every string in the +// container. This allows code to be unit tested with multi-segment Cord +// inputs. +// +// Example: +// +// absl::Cord c = absl::MakeFragmentedCord({"A ", "fragmented ", "Cord"}); +// EXPECT_FALSE(c.GetFlat(&unused)); +// +// The mechanism by which this Cord is created is an implementation detail. Any +// implementation that produces a multi-segment Cord may produce a flat Cord in +// the future as new optimizations are added to the Cord class. +// MakeFragmentedCord will, however, always be updated to return a multi-segment +// Cord. +template <typename Container> +Cord MakeFragmentedCord(const Container& c) { + Cord result; + for (const auto& s : c) { + auto* external = new std::string(s); + Cord tmp = absl::MakeCordFromExternal( + *external, [external](absl::string_view) { delete external; }); + tmp.Prepend(result); + result = tmp; + } + return result; +} + +inline Cord MakeFragmentedCord(std::initializer_list<absl::string_view> list) { + return MakeFragmentedCord<std::initializer_list<absl::string_view>>(list); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_CORD_TEST_HELPERS_H_ diff --git a/third_party/abseil_cpp/absl/strings/escaping.cc b/third_party/abseil_cpp/absl/strings/escaping.cc new file mode 100644 index 0000000000..9fceeef0bc --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/escaping.cc @@ -0,0 +1,949 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/escaping.h" + +#include <algorithm> +#include <cassert> +#include <cstdint> +#include <cstring> +#include <iterator> +#include <limits> +#include <string> + +#include "absl/base/internal/endian.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/unaligned_access.h" +#include "absl/strings/internal/char_map.h" +#include "absl/strings/internal/escaping.h" +#include "absl/strings/internal/resize_uninitialized.h" +#include "absl/strings/internal/utf8.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_join.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +// These are used for the leave_nulls_escaped argument to CUnescapeInternal(). +constexpr bool kUnescapeNulls = false; + +inline bool is_octal_digit(char c) { return ('0' <= c) && (c <= '7'); } + +inline int hex_digit_to_int(char c) { + static_assert('0' == 0x30 && 'A' == 0x41 && 'a' == 0x61, + "Character set must be ASCII."); + assert(absl::ascii_isxdigit(c)); + int x = static_cast<unsigned char>(c); + if (x > '9') { + x += 9; + } + return x & 0xf; +} + +inline bool IsSurrogate(char32_t c, absl::string_view src, std::string* error) { + if (c >= 0xD800 && c <= 0xDFFF) { + if (error) { + *error = absl::StrCat("invalid surrogate character (0xD800-DFFF): \\", + src); + } + return true; + } + return false; +} + +// ---------------------------------------------------------------------- +// CUnescapeInternal() +// Implements both CUnescape() and CUnescapeForNullTerminatedString(). +// +// Unescapes C escape sequences and is the reverse of CEscape(). +// +// If 'source' is valid, stores the unescaped string and its size in +// 'dest' and 'dest_len' respectively, and returns true. Otherwise +// returns false and optionally stores the error description in +// 'error'. Set 'error' to nullptr to disable error reporting. +// +// 'dest' should point to a buffer that is at least as big as 'source'. +// 'source' and 'dest' may be the same. +// +// NOTE: any changes to this function must also be reflected in the older +// UnescapeCEscapeSequences(). +// ---------------------------------------------------------------------- +bool CUnescapeInternal(absl::string_view source, bool leave_nulls_escaped, + char* dest, ptrdiff_t* dest_len, std::string* error) { + char* d = dest; + const char* p = source.data(); + const char* end = p + source.size(); + const char* last_byte = end - 1; + + // Small optimization for case where source = dest and there's no escaping + while (p == d && p < end && *p != '\\') p++, d++; + + while (p < end) { + if (*p != '\\') { + *d++ = *p++; + } else { + if (++p > last_byte) { // skip past the '\\' + if (error) *error = "String cannot end with \\"; + return false; + } + switch (*p) { + case 'a': *d++ = '\a'; break; + case 'b': *d++ = '\b'; break; + case 'f': *d++ = '\f'; break; + case 'n': *d++ = '\n'; break; + case 'r': *d++ = '\r'; break; + case 't': *d++ = '\t'; break; + case 'v': *d++ = '\v'; break; + case '\\': *d++ = '\\'; break; + case '?': *d++ = '\?'; break; // \? Who knew? + case '\'': *d++ = '\''; break; + case '"': *d++ = '\"'; break; + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': { + // octal digit: 1 to 3 digits + const char* octal_start = p; + unsigned int ch = *p - '0'; + if (p < last_byte && is_octal_digit(p[1])) ch = ch * 8 + *++p - '0'; + if (p < last_byte && is_octal_digit(p[1])) + ch = ch * 8 + *++p - '0'; // now points at last digit + if (ch > 0xff) { + if (error) { + *error = "Value of \\" + + std::string(octal_start, p + 1 - octal_start) + + " exceeds 0xff"; + } + return false; + } + if ((ch == 0) && leave_nulls_escaped) { + // Copy the escape sequence for the null character + const ptrdiff_t octal_size = p + 1 - octal_start; + *d++ = '\\'; + memcpy(d, octal_start, octal_size); + d += octal_size; + break; + } + *d++ = ch; + break; + } + case 'x': + case 'X': { + if (p >= last_byte) { + if (error) *error = "String cannot end with \\x"; + return false; + } else if (!absl::ascii_isxdigit(p[1])) { + if (error) *error = "\\x cannot be followed by a non-hex digit"; + return false; + } + unsigned int ch = 0; + const char* hex_start = p; + while (p < last_byte && absl::ascii_isxdigit(p[1])) + // Arbitrarily many hex digits + ch = (ch << 4) + hex_digit_to_int(*++p); + if (ch > 0xFF) { + if (error) { + *error = "Value of \\" + + std::string(hex_start, p + 1 - hex_start) + + " exceeds 0xff"; + } + return false; + } + if ((ch == 0) && leave_nulls_escaped) { + // Copy the escape sequence for the null character + const ptrdiff_t hex_size = p + 1 - hex_start; + *d++ = '\\'; + memcpy(d, hex_start, hex_size); + d += hex_size; + break; + } + *d++ = ch; + break; + } + case 'u': { + // \uhhhh => convert 4 hex digits to UTF-8 + char32_t rune = 0; + const char* hex_start = p; + if (p + 4 >= end) { + if (error) { + *error = "\\u must be followed by 4 hex digits: \\" + + std::string(hex_start, p + 1 - hex_start); + } + return false; + } + for (int i = 0; i < 4; ++i) { + // Look one char ahead. + if (absl::ascii_isxdigit(p[1])) { + rune = (rune << 4) + hex_digit_to_int(*++p); // Advance p. + } else { + if (error) { + *error = "\\u must be followed by 4 hex digits: \\" + + std::string(hex_start, p + 1 - hex_start); + } + return false; + } + } + if ((rune == 0) && leave_nulls_escaped) { + // Copy the escape sequence for the null character + *d++ = '\\'; + memcpy(d, hex_start, 5); // u0000 + d += 5; + break; + } + if (IsSurrogate(rune, absl::string_view(hex_start, 5), error)) { + return false; + } + d += strings_internal::EncodeUTF8Char(d, rune); + break; + } + case 'U': { + // \Uhhhhhhhh => convert 8 hex digits to UTF-8 + char32_t rune = 0; + const char* hex_start = p; + if (p + 8 >= end) { + if (error) { + *error = "\\U must be followed by 8 hex digits: \\" + + std::string(hex_start, p + 1 - hex_start); + } + return false; + } + for (int i = 0; i < 8; ++i) { + // Look one char ahead. + if (absl::ascii_isxdigit(p[1])) { + // Don't change rune until we're sure this + // is within the Unicode limit, but do advance p. + uint32_t newrune = (rune << 4) + hex_digit_to_int(*++p); + if (newrune > 0x10FFFF) { + if (error) { + *error = "Value of \\" + + std::string(hex_start, p + 1 - hex_start) + + " exceeds Unicode limit (0x10FFFF)"; + } + return false; + } else { + rune = newrune; + } + } else { + if (error) { + *error = "\\U must be followed by 8 hex digits: \\" + + std::string(hex_start, p + 1 - hex_start); + } + return false; + } + } + if ((rune == 0) && leave_nulls_escaped) { + // Copy the escape sequence for the null character + *d++ = '\\'; + memcpy(d, hex_start, 9); // U00000000 + d += 9; + break; + } + if (IsSurrogate(rune, absl::string_view(hex_start, 9), error)) { + return false; + } + d += strings_internal::EncodeUTF8Char(d, rune); + break; + } + default: { + if (error) *error = std::string("Unknown escape sequence: \\") + *p; + return false; + } + } + p++; // read past letter we escaped + } + } + *dest_len = d - dest; + return true; +} + +// ---------------------------------------------------------------------- +// CUnescapeInternal() +// +// Same as above but uses a std::string for output. 'source' and 'dest' +// may be the same. +// ---------------------------------------------------------------------- +bool CUnescapeInternal(absl::string_view source, bool leave_nulls_escaped, + std::string* dest, std::string* error) { + strings_internal::STLStringResizeUninitialized(dest, source.size()); + + ptrdiff_t dest_size; + if (!CUnescapeInternal(source, + leave_nulls_escaped, + &(*dest)[0], + &dest_size, + error)) { + return false; + } + dest->erase(dest_size); + return true; +} + +// ---------------------------------------------------------------------- +// CEscape() +// CHexEscape() +// Utf8SafeCEscape() +// Utf8SafeCHexEscape() +// Escapes 'src' using C-style escape sequences. This is useful for +// preparing query flags. The 'Hex' version uses hexadecimal rather than +// octal sequences. The 'Utf8Safe' version does not touch UTF-8 bytes. +// +// Escaped chars: \n, \r, \t, ", ', \, and !absl::ascii_isprint(). +// ---------------------------------------------------------------------- +std::string CEscapeInternal(absl::string_view src, bool use_hex, + bool utf8_safe) { + std::string dest; + bool last_hex_escape = false; // true if last output char was \xNN. + + for (unsigned char c : src) { + bool is_hex_escape = false; + switch (c) { + case '\n': dest.append("\\" "n"); break; + case '\r': dest.append("\\" "r"); break; + case '\t': dest.append("\\" "t"); break; + case '\"': dest.append("\\" "\""); break; + case '\'': dest.append("\\" "'"); break; + case '\\': dest.append("\\" "\\"); break; + default: + // Note that if we emit \xNN and the src character after that is a hex + // digit then that digit must be escaped too to prevent it being + // interpreted as part of the character code by C. + if ((!utf8_safe || c < 0x80) && + (!absl::ascii_isprint(c) || + (last_hex_escape && absl::ascii_isxdigit(c)))) { + if (use_hex) { + dest.append("\\" "x"); + dest.push_back(numbers_internal::kHexChar[c / 16]); + dest.push_back(numbers_internal::kHexChar[c % 16]); + is_hex_escape = true; + } else { + dest.append("\\"); + dest.push_back(numbers_internal::kHexChar[c / 64]); + dest.push_back(numbers_internal::kHexChar[(c % 64) / 8]); + dest.push_back(numbers_internal::kHexChar[c % 8]); + } + } else { + dest.push_back(c); + break; + } + } + last_hex_escape = is_hex_escape; + } + + return dest; +} + +/* clang-format off */ +constexpr char c_escaped_len[256] = { + 4, 4, 4, 4, 4, 4, 4, 4, 4, 2, 2, 4, 4, 2, 4, 4, // \t, \n, \r + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, // ", ' + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // '0'..'9' + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 'A'..'O' + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, // 'P'..'Z', '\' + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 'a'..'o' + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 4, // 'p'..'z', DEL + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, + 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, +}; +/* clang-format on */ + +// Calculates the length of the C-style escaped version of 'src'. +// Assumes that non-printable characters are escaped using octal sequences, and +// that UTF-8 bytes are not handled specially. +inline size_t CEscapedLength(absl::string_view src) { + size_t escaped_len = 0; + for (unsigned char c : src) escaped_len += c_escaped_len[c]; + return escaped_len; +} + +void CEscapeAndAppendInternal(absl::string_view src, std::string* dest) { + size_t escaped_len = CEscapedLength(src); + if (escaped_len == src.size()) { + dest->append(src.data(), src.size()); + return; + } + + size_t cur_dest_len = dest->size(); + strings_internal::STLStringResizeUninitialized(dest, + cur_dest_len + escaped_len); + char* append_ptr = &(*dest)[cur_dest_len]; + + for (unsigned char c : src) { + int char_len = c_escaped_len[c]; + if (char_len == 1) { + *append_ptr++ = c; + } else if (char_len == 2) { + switch (c) { + case '\n': + *append_ptr++ = '\\'; + *append_ptr++ = 'n'; + break; + case '\r': + *append_ptr++ = '\\'; + *append_ptr++ = 'r'; + break; + case '\t': + *append_ptr++ = '\\'; + *append_ptr++ = 't'; + break; + case '\"': + *append_ptr++ = '\\'; + *append_ptr++ = '\"'; + break; + case '\'': + *append_ptr++ = '\\'; + *append_ptr++ = '\''; + break; + case '\\': + *append_ptr++ = '\\'; + *append_ptr++ = '\\'; + break; + } + } else { + *append_ptr++ = '\\'; + *append_ptr++ = '0' + c / 64; + *append_ptr++ = '0' + (c % 64) / 8; + *append_ptr++ = '0' + c % 8; + } + } +} + +bool Base64UnescapeInternal(const char* src_param, size_t szsrc, char* dest, + size_t szdest, const signed char* unbase64, + size_t* len) { + static const char kPad64Equals = '='; + static const char kPad64Dot = '.'; + + size_t destidx = 0; + int decode = 0; + int state = 0; + unsigned int ch = 0; + unsigned int temp = 0; + + // If "char" is signed by default, using *src as an array index results in + // accessing negative array elements. Treat the input as a pointer to + // unsigned char to avoid this. + const unsigned char* src = reinterpret_cast<const unsigned char*>(src_param); + + // The GET_INPUT macro gets the next input character, skipping + // over any whitespace, and stopping when we reach the end of the + // string or when we read any non-data character. The arguments are + // an arbitrary identifier (used as a label for goto) and the number + // of data bytes that must remain in the input to avoid aborting the + // loop. +#define GET_INPUT(label, remain) \ + label: \ + --szsrc; \ + ch = *src++; \ + decode = unbase64[ch]; \ + if (decode < 0) { \ + if (absl::ascii_isspace(ch) && szsrc >= remain) goto label; \ + state = 4 - remain; \ + break; \ + } + + // if dest is null, we're just checking to see if it's legal input + // rather than producing output. (I suspect this could just be done + // with a regexp...). We duplicate the loop so this test can be + // outside it instead of in every iteration. + + if (dest) { + // This loop consumes 4 input bytes and produces 3 output bytes + // per iteration. We can't know at the start that there is enough + // data left in the string for a full iteration, so the loop may + // break out in the middle; if so 'state' will be set to the + // number of input bytes read. + + while (szsrc >= 4) { + // We'll start by optimistically assuming that the next four + // bytes of the string (src[0..3]) are four good data bytes + // (that is, no nulls, whitespace, padding chars, or illegal + // chars). We need to test src[0..2] for nulls individually + // before constructing temp to preserve the property that we + // never read past a null in the string (no matter how long + // szsrc claims the string is). + + if (!src[0] || !src[1] || !src[2] || + ((temp = ((unsigned(unbase64[src[0]]) << 18) | + (unsigned(unbase64[src[1]]) << 12) | + (unsigned(unbase64[src[2]]) << 6) | + (unsigned(unbase64[src[3]])))) & + 0x80000000)) { + // Iff any of those four characters was bad (null, illegal, + // whitespace, padding), then temp's high bit will be set + // (because unbase64[] is -1 for all bad characters). + // + // We'll back up and resort to the slower decoder, which knows + // how to handle those cases. + + GET_INPUT(first, 4); + temp = decode; + GET_INPUT(second, 3); + temp = (temp << 6) | decode; + GET_INPUT(third, 2); + temp = (temp << 6) | decode; + GET_INPUT(fourth, 1); + temp = (temp << 6) | decode; + } else { + // We really did have four good data bytes, so advance four + // characters in the string. + + szsrc -= 4; + src += 4; + } + + // temp has 24 bits of input, so write that out as three bytes. + + if (destidx + 3 > szdest) return false; + dest[destidx + 2] = temp; + temp >>= 8; + dest[destidx + 1] = temp; + temp >>= 8; + dest[destidx] = temp; + destidx += 3; + } + } else { + while (szsrc >= 4) { + if (!src[0] || !src[1] || !src[2] || + ((temp = ((unsigned(unbase64[src[0]]) << 18) | + (unsigned(unbase64[src[1]]) << 12) | + (unsigned(unbase64[src[2]]) << 6) | + (unsigned(unbase64[src[3]])))) & + 0x80000000)) { + GET_INPUT(first_no_dest, 4); + GET_INPUT(second_no_dest, 3); + GET_INPUT(third_no_dest, 2); + GET_INPUT(fourth_no_dest, 1); + } else { + szsrc -= 4; + src += 4; + } + destidx += 3; + } + } + +#undef GET_INPUT + + // if the loop terminated because we read a bad character, return + // now. + if (decode < 0 && ch != kPad64Equals && ch != kPad64Dot && + !absl::ascii_isspace(ch)) + return false; + + if (ch == kPad64Equals || ch == kPad64Dot) { + // if we stopped by hitting an '=' or '.', un-read that character -- we'll + // look at it again when we count to check for the proper number of + // equals signs at the end. + ++szsrc; + --src; + } else { + // This loop consumes 1 input byte per iteration. It's used to + // clean up the 0-3 input bytes remaining when the first, faster + // loop finishes. 'temp' contains the data from 'state' input + // characters read by the first loop. + while (szsrc > 0) { + --szsrc; + ch = *src++; + decode = unbase64[ch]; + if (decode < 0) { + if (absl::ascii_isspace(ch)) { + continue; + } else if (ch == kPad64Equals || ch == kPad64Dot) { + // back up one character; we'll read it again when we check + // for the correct number of pad characters at the end. + ++szsrc; + --src; + break; + } else { + return false; + } + } + + // Each input character gives us six bits of output. + temp = (temp << 6) | decode; + ++state; + if (state == 4) { + // If we've accumulated 24 bits of output, write that out as + // three bytes. + if (dest) { + if (destidx + 3 > szdest) return false; + dest[destidx + 2] = temp; + temp >>= 8; + dest[destidx + 1] = temp; + temp >>= 8; + dest[destidx] = temp; + } + destidx += 3; + state = 0; + temp = 0; + } + } + } + + // Process the leftover data contained in 'temp' at the end of the input. + int expected_equals = 0; + switch (state) { + case 0: + // Nothing left over; output is a multiple of 3 bytes. + break; + + case 1: + // Bad input; we have 6 bits left over. + return false; + + case 2: + // Produce one more output byte from the 12 input bits we have left. + if (dest) { + if (destidx + 1 > szdest) return false; + temp >>= 4; + dest[destidx] = temp; + } + ++destidx; + expected_equals = 2; + break; + + case 3: + // Produce two more output bytes from the 18 input bits we have left. + if (dest) { + if (destidx + 2 > szdest) return false; + temp >>= 2; + dest[destidx + 1] = temp; + temp >>= 8; + dest[destidx] = temp; + } + destidx += 2; + expected_equals = 1; + break; + + default: + // state should have no other values at this point. + ABSL_RAW_LOG(FATAL, "This can't happen; base64 decoder state = %d", + state); + } + + // The remainder of the string should be all whitespace, mixed with + // exactly 0 equals signs, or exactly 'expected_equals' equals + // signs. (Always accepting 0 equals signs is an Abseil extension + // not covered in the RFC, as is accepting dot as the pad character.) + + int equals = 0; + while (szsrc > 0) { + if (*src == kPad64Equals || *src == kPad64Dot) + ++equals; + else if (!absl::ascii_isspace(*src)) + return false; + --szsrc; + ++src; + } + + const bool ok = (equals == 0 || equals == expected_equals); + if (ok) *len = destidx; + return ok; +} + +// The arrays below were generated by the following code +// #include <sys/time.h> +// #include <stdlib.h> +// #include <string.h> +// main() +// { +// static const char Base64[] = +// "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; +// char* pos; +// int idx, i, j; +// printf(" "); +// for (i = 0; i < 255; i += 8) { +// for (j = i; j < i + 8; j++) { +// pos = strchr(Base64, j); +// if ((pos == nullptr) || (j == 0)) +// idx = -1; +// else +// idx = pos - Base64; +// if (idx == -1) +// printf(" %2d, ", idx); +// else +// printf(" %2d/*%c*/,", idx, j); +// } +// printf("\n "); +// } +// } +// +// where the value of "Base64[]" was replaced by one of the base-64 conversion +// tables from the functions below. +/* clang-format off */ +constexpr signed char kUnBase64[] = { + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, 62/*+*/, -1, -1, -1, 63/*/ */, + 52/*0*/, 53/*1*/, 54/*2*/, 55/*3*/, 56/*4*/, 57/*5*/, 58/*6*/, 59/*7*/, + 60/*8*/, 61/*9*/, -1, -1, -1, -1, -1, -1, + -1, 0/*A*/, 1/*B*/, 2/*C*/, 3/*D*/, 4/*E*/, 5/*F*/, 6/*G*/, + 07/*H*/, 8/*I*/, 9/*J*/, 10/*K*/, 11/*L*/, 12/*M*/, 13/*N*/, 14/*O*/, + 15/*P*/, 16/*Q*/, 17/*R*/, 18/*S*/, 19/*T*/, 20/*U*/, 21/*V*/, 22/*W*/, + 23/*X*/, 24/*Y*/, 25/*Z*/, -1, -1, -1, -1, -1, + -1, 26/*a*/, 27/*b*/, 28/*c*/, 29/*d*/, 30/*e*/, 31/*f*/, 32/*g*/, + 33/*h*/, 34/*i*/, 35/*j*/, 36/*k*/, 37/*l*/, 38/*m*/, 39/*n*/, 40/*o*/, + 41/*p*/, 42/*q*/, 43/*r*/, 44/*s*/, 45/*t*/, 46/*u*/, 47/*v*/, 48/*w*/, + 49/*x*/, 50/*y*/, 51/*z*/, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1 +}; + +constexpr signed char kUnWebSafeBase64[] = { + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, 62/*-*/, -1, -1, + 52/*0*/, 53/*1*/, 54/*2*/, 55/*3*/, 56/*4*/, 57/*5*/, 58/*6*/, 59/*7*/, + 60/*8*/, 61/*9*/, -1, -1, -1, -1, -1, -1, + -1, 0/*A*/, 1/*B*/, 2/*C*/, 3/*D*/, 4/*E*/, 5/*F*/, 6/*G*/, + 07/*H*/, 8/*I*/, 9/*J*/, 10/*K*/, 11/*L*/, 12/*M*/, 13/*N*/, 14/*O*/, + 15/*P*/, 16/*Q*/, 17/*R*/, 18/*S*/, 19/*T*/, 20/*U*/, 21/*V*/, 22/*W*/, + 23/*X*/, 24/*Y*/, 25/*Z*/, -1, -1, -1, -1, 63/*_*/, + -1, 26/*a*/, 27/*b*/, 28/*c*/, 29/*d*/, 30/*e*/, 31/*f*/, 32/*g*/, + 33/*h*/, 34/*i*/, 35/*j*/, 36/*k*/, 37/*l*/, 38/*m*/, 39/*n*/, 40/*o*/, + 41/*p*/, 42/*q*/, 43/*r*/, 44/*s*/, 45/*t*/, 46/*u*/, 47/*v*/, 48/*w*/, + 49/*x*/, 50/*y*/, 51/*z*/, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1 +}; +/* clang-format on */ + +constexpr char kWebSafeBase64Chars[] = + "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_"; + +template <typename String> +bool Base64UnescapeInternal(const char* src, size_t slen, String* dest, + const signed char* unbase64) { + // Determine the size of the output string. Base64 encodes every 3 bytes into + // 4 characters. any leftover chars are added directly for good measure. + // This is documented in the base64 RFC: http://tools.ietf.org/html/rfc3548 + const size_t dest_len = 3 * (slen / 4) + (slen % 4); + + strings_internal::STLStringResizeUninitialized(dest, dest_len); + + // We are getting the destination buffer by getting the beginning of the + // string and converting it into a char *. + size_t len; + const bool ok = + Base64UnescapeInternal(src, slen, &(*dest)[0], dest_len, unbase64, &len); + if (!ok) { + dest->clear(); + return false; + } + + // could be shorter if there was padding + assert(len <= dest_len); + dest->erase(len); + + return true; +} + +/* clang-format off */ +constexpr char kHexValueLenient[256] = { + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 0, 0, 0, 0, 0, // '0'..'9' + 0, 10, 11, 12, 13, 14, 15, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 'A'..'F' + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 10, 11, 12, 13, 14, 15, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 'a'..'f' + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, +}; + +/* clang-format on */ + +// This is a templated function so that T can be either a char* +// or a string. This works because we use the [] operator to access +// individual characters at a time. +template <typename T> +void HexStringToBytesInternal(const char* from, T to, ptrdiff_t num) { + for (int i = 0; i < num; i++) { + to[i] = (kHexValueLenient[from[i * 2] & 0xFF] << 4) + + (kHexValueLenient[from[i * 2 + 1] & 0xFF]); + } +} + +// This is a templated function so that T can be either a char* or a +// std::string. +template <typename T> +void BytesToHexStringInternal(const unsigned char* src, T dest, ptrdiff_t num) { + auto dest_ptr = &dest[0]; + for (auto src_ptr = src; src_ptr != (src + num); ++src_ptr, dest_ptr += 2) { + const char* hex_p = &numbers_internal::kHexTable[*src_ptr * 2]; + std::copy(hex_p, hex_p + 2, dest_ptr); + } +} + +} // namespace + +// ---------------------------------------------------------------------- +// CUnescape() +// +// See CUnescapeInternal() for implementation details. +// ---------------------------------------------------------------------- +bool CUnescape(absl::string_view source, std::string* dest, + std::string* error) { + return CUnescapeInternal(source, kUnescapeNulls, dest, error); +} + +std::string CEscape(absl::string_view src) { + std::string dest; + CEscapeAndAppendInternal(src, &dest); + return dest; +} + +std::string CHexEscape(absl::string_view src) { + return CEscapeInternal(src, true, false); +} + +std::string Utf8SafeCEscape(absl::string_view src) { + return CEscapeInternal(src, false, true); +} + +std::string Utf8SafeCHexEscape(absl::string_view src) { + return CEscapeInternal(src, true, true); +} + +// ---------------------------------------------------------------------- +// Base64Unescape() - base64 decoder +// Base64Escape() - base64 encoder +// WebSafeBase64Unescape() - Google's variation of base64 decoder +// WebSafeBase64Escape() - Google's variation of base64 encoder +// +// Check out +// http://tools.ietf.org/html/rfc2045 for formal description, but what we +// care about is that... +// Take the encoded stuff in groups of 4 characters and turn each +// character into a code 0 to 63 thus: +// A-Z map to 0 to 25 +// a-z map to 26 to 51 +// 0-9 map to 52 to 61 +// +(- for WebSafe) maps to 62 +// /(_ for WebSafe) maps to 63 +// There will be four numbers, all less than 64 which can be represented +// by a 6 digit binary number (aaaaaa, bbbbbb, cccccc, dddddd respectively). +// Arrange the 6 digit binary numbers into three bytes as such: +// aaaaaabb bbbbcccc ccdddddd +// Equals signs (one or two) are used at the end of the encoded block to +// indicate that the text was not an integer multiple of three bytes long. +// ---------------------------------------------------------------------- + +bool Base64Unescape(absl::string_view src, std::string* dest) { + return Base64UnescapeInternal(src.data(), src.size(), dest, kUnBase64); +} + +bool WebSafeBase64Unescape(absl::string_view src, std::string* dest) { + return Base64UnescapeInternal(src.data(), src.size(), dest, kUnWebSafeBase64); +} + +void Base64Escape(absl::string_view src, std::string* dest) { + strings_internal::Base64EscapeInternal( + reinterpret_cast<const unsigned char*>(src.data()), src.size(), dest, + true, strings_internal::kBase64Chars); +} + +void WebSafeBase64Escape(absl::string_view src, std::string* dest) { + strings_internal::Base64EscapeInternal( + reinterpret_cast<const unsigned char*>(src.data()), src.size(), dest, + false, kWebSafeBase64Chars); +} + +std::string Base64Escape(absl::string_view src) { + std::string dest; + strings_internal::Base64EscapeInternal( + reinterpret_cast<const unsigned char*>(src.data()), src.size(), &dest, + true, strings_internal::kBase64Chars); + return dest; +} + +std::string WebSafeBase64Escape(absl::string_view src) { + std::string dest; + strings_internal::Base64EscapeInternal( + reinterpret_cast<const unsigned char*>(src.data()), src.size(), &dest, + false, kWebSafeBase64Chars); + return dest; +} + +std::string HexStringToBytes(absl::string_view from) { + std::string result; + const auto num = from.size() / 2; + strings_internal::STLStringResizeUninitialized(&result, num); + absl::HexStringToBytesInternal<std::string&>(from.data(), result, num); + return result; +} + +std::string BytesToHexString(absl::string_view from) { + std::string result; + strings_internal::STLStringResizeUninitialized(&result, 2 * from.size()); + absl::BytesToHexStringInternal<std::string&>( + reinterpret_cast<const unsigned char*>(from.data()), result, from.size()); + return result; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/escaping.h b/third_party/abseil_cpp/absl/strings/escaping.h new file mode 100644 index 0000000000..f5ca26c5da --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/escaping.h @@ -0,0 +1,164 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: escaping.h +// ----------------------------------------------------------------------------- +// +// This header file contains string utilities involved in escaping and +// unescaping strings in various ways. + +#ifndef ABSL_STRINGS_ESCAPING_H_ +#define ABSL_STRINGS_ESCAPING_H_ + +#include <cstddef> +#include <string> +#include <vector> + +#include "absl/base/macros.h" +#include "absl/strings/ascii.h" +#include "absl/strings/str_join.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// CUnescape() +// +// Unescapes a `source` string and copies it into `dest`, rewriting C-style +// escape sequences (https://en.cppreference.com/w/cpp/language/escape) into +// their proper code point equivalents, returning `true` if successful. +// +// The following unescape sequences can be handled: +// +// * ASCII escape sequences ('\n','\r','\\', etc.) to their ASCII equivalents +// * Octal escape sequences ('\nnn') to byte nnn. The unescaped value must +// resolve to a single byte or an error will occur. E.g. values greater than +// 0xff will produce an error. +// * Hexadecimal escape sequences ('\xnn') to byte nn. While an arbitrary +// number of following digits are allowed, the unescaped value must resolve +// to a single byte or an error will occur. E.g. '\x0045' is equivalent to +// '\x45', but '\x1234' will produce an error. +// * Unicode escape sequences ('\unnnn' for exactly four hex digits or +// '\Unnnnnnnn' for exactly eight hex digits, which will be encoded in +// UTF-8. (E.g., `\u2019` unescapes to the three bytes 0xE2, 0x80, and +// 0x99). +// +// If any errors are encountered, this function returns `false`, leaving the +// `dest` output parameter in an unspecified state, and stores the first +// encountered error in `error`. To disable error reporting, set `error` to +// `nullptr` or use the overload with no error reporting below. +// +// Example: +// +// std::string s = "foo\\rbar\\nbaz\\t"; +// std::string unescaped_s; +// if (!absl::CUnescape(s, &unescaped_s) { +// ... +// } +// EXPECT_EQ(unescaped_s, "foo\rbar\nbaz\t"); +bool CUnescape(absl::string_view source, std::string* dest, std::string* error); + +// Overload of `CUnescape()` with no error reporting. +inline bool CUnescape(absl::string_view source, std::string* dest) { + return CUnescape(source, dest, nullptr); +} + +// CEscape() +// +// Escapes a 'src' string using C-style escapes sequences +// (https://en.cppreference.com/w/cpp/language/escape), escaping other +// non-printable/non-whitespace bytes as octal sequences (e.g. "\377"). +// +// Example: +// +// std::string s = "foo\rbar\tbaz\010\011\012\013\014\x0d\n"; +// std::string escaped_s = absl::CEscape(s); +// EXPECT_EQ(escaped_s, "foo\\rbar\\tbaz\\010\\t\\n\\013\\014\\r\\n"); +std::string CEscape(absl::string_view src); + +// CHexEscape() +// +// Escapes a 'src' string using C-style escape sequences, escaping +// other non-printable/non-whitespace bytes as hexadecimal sequences (e.g. +// "\xFF"). +// +// Example: +// +// std::string s = "foo\rbar\tbaz\010\011\012\013\014\x0d\n"; +// std::string escaped_s = absl::CHexEscape(s); +// EXPECT_EQ(escaped_s, "foo\\rbar\\tbaz\\x08\\t\\n\\x0b\\x0c\\r\\n"); +std::string CHexEscape(absl::string_view src); + +// Utf8SafeCEscape() +// +// Escapes a 'src' string using C-style escape sequences, escaping bytes as +// octal sequences, and passing through UTF-8 characters without conversion. +// I.e., when encountering any bytes with their high bit set, this function +// will not escape those values, whether or not they are valid UTF-8. +std::string Utf8SafeCEscape(absl::string_view src); + +// Utf8SafeCHexEscape() +// +// Escapes a 'src' string using C-style escape sequences, escaping bytes as +// hexadecimal sequences, and passing through UTF-8 characters without +// conversion. +std::string Utf8SafeCHexEscape(absl::string_view src); + +// Base64Unescape() +// +// Converts a `src` string encoded in Base64 to its binary equivalent, writing +// it to a `dest` buffer, returning `true` on success. If `src` contains invalid +// characters, `dest` is cleared and returns `false`. +bool Base64Unescape(absl::string_view src, std::string* dest); + +// WebSafeBase64Unescape() +// +// Converts a `src` string encoded in Base64 to its binary equivalent, writing +// it to a `dest` buffer, but using '-' instead of '+', and '_' instead of '/'. +// If `src` contains invalid characters, `dest` is cleared and returns `false`. +bool WebSafeBase64Unescape(absl::string_view src, std::string* dest); + +// Base64Escape() +// +// Encodes a `src` string into a base64-encoded string, with padding characters. +// This function conforms with RFC 4648 section 4 (base64). +void Base64Escape(absl::string_view src, std::string* dest); +std::string Base64Escape(absl::string_view src); + +// WebSafeBase64Escape() +// +// Encodes a `src` string into a base64-like string, using '-' instead of '+' +// and '_' instead of '/', and without padding. This function conforms with RFC +// 4648 section 5 (base64url). +void WebSafeBase64Escape(absl::string_view src, std::string* dest); +std::string WebSafeBase64Escape(absl::string_view src); + +// HexStringToBytes() +// +// Converts an ASCII hex string into bytes, returning binary data of length +// `from.size()/2`. +std::string HexStringToBytes(absl::string_view from); + +// BytesToHexString() +// +// Converts binary data into an ASCII text string, returning a string of size +// `2*from.size()`. +std::string BytesToHexString(absl::string_view from); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_ESCAPING_H_ diff --git a/third_party/abseil_cpp/absl/strings/escaping_benchmark.cc b/third_party/abseil_cpp/absl/strings/escaping_benchmark.cc new file mode 100644 index 0000000000..10d5b033c5 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/escaping_benchmark.cc @@ -0,0 +1,94 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/escaping.h" + +#include <cstdio> +#include <cstring> +#include <random> + +#include "benchmark/benchmark.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/internal/escaping_test_common.h" + +namespace { + +void BM_CUnescapeHexString(benchmark::State& state) { + std::string src; + for (int i = 0; i < 50; i++) { + src += "\\x55"; + } + std::string dest; + for (auto _ : state) { + absl::CUnescape(src, &dest); + } +} +BENCHMARK(BM_CUnescapeHexString); + +void BM_WebSafeBase64Escape_string(benchmark::State& state) { + std::string raw; + for (int i = 0; i < 10; ++i) { + for (const auto& test_set : absl::strings_internal::base64_strings()) { + raw += std::string(test_set.plaintext); + } + } + + // The actual benchmark loop is tiny... + std::string escaped; + for (auto _ : state) { + absl::WebSafeBase64Escape(raw, &escaped); + } + + // We want to be sure the compiler doesn't throw away the loop above, + // and the easiest way to ensure that is to round-trip the results and verify + // them. + std::string round_trip; + absl::WebSafeBase64Unescape(escaped, &round_trip); + ABSL_RAW_CHECK(round_trip == raw, ""); +} +BENCHMARK(BM_WebSafeBase64Escape_string); + +// Used for the CEscape benchmarks +const char kStringValueNoEscape[] = "1234567890"; +const char kStringValueSomeEscaped[] = "123\n56789\xA1"; +const char kStringValueMostEscaped[] = "\xA1\xA2\ny\xA4\xA5\xA6z\b\r"; + +void CEscapeBenchmarkHelper(benchmark::State& state, const char* string_value, + int max_len) { + std::string src; + while (src.size() < max_len) { + absl::StrAppend(&src, string_value); + } + + for (auto _ : state) { + absl::CEscape(src); + } +} + +void BM_CEscape_NoEscape(benchmark::State& state) { + CEscapeBenchmarkHelper(state, kStringValueNoEscape, state.range(0)); +} +BENCHMARK(BM_CEscape_NoEscape)->Range(1, 1 << 14); + +void BM_CEscape_SomeEscaped(benchmark::State& state) { + CEscapeBenchmarkHelper(state, kStringValueSomeEscaped, state.range(0)); +} +BENCHMARK(BM_CEscape_SomeEscaped)->Range(1, 1 << 14); + +void BM_CEscape_MostEscaped(benchmark::State& state) { + CEscapeBenchmarkHelper(state, kStringValueMostEscaped, state.range(0)); +} +BENCHMARK(BM_CEscape_MostEscaped)->Range(1, 1 << 14); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/escaping_test.cc b/third_party/abseil_cpp/absl/strings/escaping_test.cc new file mode 100644 index 0000000000..45671a0ed5 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/escaping_test.cc @@ -0,0 +1,664 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/escaping.h" + +#include <array> +#include <cstdio> +#include <cstring> +#include <memory> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/container/fixed_array.h" +#include "absl/strings/str_cat.h" + +#include "absl/strings/internal/escaping_test_common.h" + +namespace { + +struct epair { + std::string escaped; + std::string unescaped; +}; + +TEST(CEscape, EscapeAndUnescape) { + const std::string inputs[] = { + std::string("foo\nxx\r\b\0023"), + std::string(""), + std::string("abc"), + std::string("\1chad_rules"), + std::string("\1arnar_drools"), + std::string("xxxx\r\t'\"\\"), + std::string("\0xx\0", 4), + std::string("\x01\x31"), + std::string("abc\xb\x42\141bc"), + std::string("123\1\x31\x32\x33"), + std::string("\xc1\xca\x1b\x62\x19o\xcc\x04"), + std::string( + "\\\"\xe8\xb0\xb7\xe6\xad\x8c\\\" is Google\\\'s Chinese name"), + }; + // Do this twice, once for octal escapes and once for hex escapes. + for (int kind = 0; kind < 4; kind++) { + for (const std::string& original : inputs) { + std::string escaped; + switch (kind) { + case 0: + escaped = absl::CEscape(original); + break; + case 1: + escaped = absl::CHexEscape(original); + break; + case 2: + escaped = absl::Utf8SafeCEscape(original); + break; + case 3: + escaped = absl::Utf8SafeCHexEscape(original); + break; + } + std::string unescaped_str; + EXPECT_TRUE(absl::CUnescape(escaped, &unescaped_str)); + EXPECT_EQ(unescaped_str, original); + + unescaped_str.erase(); + std::string error; + EXPECT_TRUE(absl::CUnescape(escaped, &unescaped_str, &error)); + EXPECT_EQ(error, ""); + + // Check in-place unescaping + std::string s = escaped; + EXPECT_TRUE(absl::CUnescape(s, &s)); + ASSERT_EQ(s, original); + } + } + // Check that all possible two character strings can be escaped then + // unescaped successfully. + for (int char0 = 0; char0 < 256; char0++) { + for (int char1 = 0; char1 < 256; char1++) { + char chars[2]; + chars[0] = char0; + chars[1] = char1; + std::string s(chars, 2); + std::string escaped = absl::CHexEscape(s); + std::string unescaped; + EXPECT_TRUE(absl::CUnescape(escaped, &unescaped)); + EXPECT_EQ(s, unescaped); + } + } +} + +TEST(CEscape, BasicEscaping) { + epair oct_values[] = { + {"foo\\rbar\\nbaz\\t", "foo\rbar\nbaz\t"}, + {"\\'full of \\\"sound\\\" and \\\"fury\\\"\\'", + "'full of \"sound\" and \"fury\"'"}, + {"signi\\\\fying\\\\ nothing\\\\", "signi\\fying\\ nothing\\"}, + {"\\010\\t\\n\\013\\014\\r", "\010\011\012\013\014\015"} + }; + epair hex_values[] = { + {"ubik\\rubik\\nubik\\t", "ubik\rubik\nubik\t"}, + {"I\\\'ve just seen a \\\"face\\\"", + "I've just seen a \"face\""}, + {"hel\\\\ter\\\\skel\\\\ter\\\\", "hel\\ter\\skel\\ter\\"}, + {"\\x08\\t\\n\\x0b\\x0c\\r", "\010\011\012\013\014\015"} + }; + epair utf8_oct_values[] = { + {"\xe8\xb0\xb7\xe6\xad\x8c\\r\xe8\xb0\xb7\xe6\xad\x8c\\nbaz\\t", + "\xe8\xb0\xb7\xe6\xad\x8c\r\xe8\xb0\xb7\xe6\xad\x8c\nbaz\t"}, + {"\\\"\xe8\xb0\xb7\xe6\xad\x8c\\\" is Google\\\'s Chinese name", + "\"\xe8\xb0\xb7\xe6\xad\x8c\" is Google\'s Chinese name"}, + {"\xe3\x83\xa1\xe3\x83\xbc\xe3\x83\xab\\\\are\\\\Japanese\\\\chars\\\\", + "\xe3\x83\xa1\xe3\x83\xbc\xe3\x83\xab\\are\\Japanese\\chars\\"}, + {"\xed\x81\xac\xeb\xa1\xac\\010\\t\\n\\013\\014\\r", + "\xed\x81\xac\xeb\xa1\xac\010\011\012\013\014\015"} + }; + epair utf8_hex_values[] = { + {"\x20\xe4\xbd\xa0\\t\xe5\xa5\xbd,\\r!\\n", + "\x20\xe4\xbd\xa0\t\xe5\xa5\xbd,\r!\n"}, + {"\xe8\xa9\xa6\xe9\xa8\x93\\\' means \\\"test\\\"", + "\xe8\xa9\xa6\xe9\xa8\x93\' means \"test\""}, + {"\\\\\xe6\x88\x91\\\\:\\\\\xe6\x9d\xa8\xe6\xac\xa2\\\\", + "\\\xe6\x88\x91\\:\\\xe6\x9d\xa8\xe6\xac\xa2\\"}, + {"\xed\x81\xac\xeb\xa1\xac\\x08\\t\\n\\x0b\\x0c\\r", + "\xed\x81\xac\xeb\xa1\xac\010\011\012\013\014\015"} + }; + + for (const epair& val : oct_values) { + std::string escaped = absl::CEscape(val.unescaped); + EXPECT_EQ(escaped, val.escaped); + } + for (const epair& val : hex_values) { + std::string escaped = absl::CHexEscape(val.unescaped); + EXPECT_EQ(escaped, val.escaped); + } + for (const epair& val : utf8_oct_values) { + std::string escaped = absl::Utf8SafeCEscape(val.unescaped); + EXPECT_EQ(escaped, val.escaped); + } + for (const epair& val : utf8_hex_values) { + std::string escaped = absl::Utf8SafeCHexEscape(val.unescaped); + EXPECT_EQ(escaped, val.escaped); + } +} + +TEST(Unescape, BasicFunction) { + epair tests[] = + {{"", ""}, + {"\\u0030", "0"}, + {"\\u00A3", "\xC2\xA3"}, + {"\\u22FD", "\xE2\x8B\xBD"}, + {"\\U00010000", "\xF0\x90\x80\x80"}, + {"\\U0010FFFD", "\xF4\x8F\xBF\xBD"}}; + for (const epair& val : tests) { + std::string out; + EXPECT_TRUE(absl::CUnescape(val.escaped, &out)); + EXPECT_EQ(out, val.unescaped); + } + std::string bad[] = {"\\u1", // too short + "\\U1", // too short + "\\Uffffff", // exceeds 0x10ffff (largest Unicode) + "\\U00110000", // exceeds 0x10ffff (largest Unicode) + "\\uD835", // surrogate character (D800-DFFF) + "\\U0000DD04", // surrogate character (D800-DFFF) + "\\777", // exceeds 0xff + "\\xABCD"}; // exceeds 0xff + for (const std::string& e : bad) { + std::string error; + std::string out; + EXPECT_FALSE(absl::CUnescape(e, &out, &error)); + EXPECT_FALSE(error.empty()); + + out.erase(); + EXPECT_FALSE(absl::CUnescape(e, &out)); + } +} + +class CUnescapeTest : public testing::Test { + protected: + static const char kStringWithMultipleOctalNulls[]; + static const char kStringWithMultipleHexNulls[]; + static const char kStringWithMultipleUnicodeNulls[]; + + std::string result_string_; +}; + +const char CUnescapeTest::kStringWithMultipleOctalNulls[] = + "\\0\\n" // null escape \0 plus newline + "0\\n" // just a number 0 (not a null escape) plus newline + "\\00\\12" // null escape \00 plus octal newline code + "\\000"; // null escape \000 + +// This has the same ingredients as kStringWithMultipleOctalNulls +// but with \x hex escapes instead of octal escapes. +const char CUnescapeTest::kStringWithMultipleHexNulls[] = + "\\x0\\n" + "0\\n" + "\\x00\\xa" + "\\x000"; + +const char CUnescapeTest::kStringWithMultipleUnicodeNulls[] = + "\\u0000\\n" // short-form (4-digit) null escape plus newline + "0\\n" // just a number 0 (not a null escape) plus newline + "\\U00000000"; // long-form (8-digit) null escape + +TEST_F(CUnescapeTest, Unescapes1CharOctalNull) { + std::string original_string = "\\0"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes2CharOctalNull) { + std::string original_string = "\\00"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes3CharOctalNull) { + std::string original_string = "\\000"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes1CharHexNull) { + std::string original_string = "\\x0"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes2CharHexNull) { + std::string original_string = "\\x00"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes3CharHexNull) { + std::string original_string = "\\x000"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes4CharUnicodeNull) { + std::string original_string = "\\u0000"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, Unescapes8CharUnicodeNull) { + std::string original_string = "\\U00000000"; + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0", 1), result_string_); +} + +TEST_F(CUnescapeTest, UnescapesMultipleOctalNulls) { + std::string original_string(kStringWithMultipleOctalNulls); + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + // All escapes, including newlines and null escapes, should have been + // converted to the equivalent characters. + EXPECT_EQ(std::string("\0\n" + "0\n" + "\0\n" + "\0", + 7), + result_string_); +} + + +TEST_F(CUnescapeTest, UnescapesMultipleHexNulls) { + std::string original_string(kStringWithMultipleHexNulls); + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0\n" + "0\n" + "\0\n" + "\0", + 7), + result_string_); +} + +TEST_F(CUnescapeTest, UnescapesMultipleUnicodeNulls) { + std::string original_string(kStringWithMultipleUnicodeNulls); + EXPECT_TRUE(absl::CUnescape(original_string, &result_string_)); + EXPECT_EQ(std::string("\0\n" + "0\n" + "\0", + 5), + result_string_); +} + +static struct { + absl::string_view plaintext; + absl::string_view cyphertext; +} const base64_tests[] = { + // Empty string. + {{"", 0}, {"", 0}}, + {{nullptr, 0}, + {"", 0}}, // if length is zero, plaintext ptr must be ignored! + + // Basic bit patterns; + // values obtained with "echo -n '...' | uuencode -m test" + + {{"\000", 1}, "AA=="}, + {{"\001", 1}, "AQ=="}, + {{"\002", 1}, "Ag=="}, + {{"\004", 1}, "BA=="}, + {{"\010", 1}, "CA=="}, + {{"\020", 1}, "EA=="}, + {{"\040", 1}, "IA=="}, + {{"\100", 1}, "QA=="}, + {{"\200", 1}, "gA=="}, + + {{"\377", 1}, "/w=="}, + {{"\376", 1}, "/g=="}, + {{"\375", 1}, "/Q=="}, + {{"\373", 1}, "+w=="}, + {{"\367", 1}, "9w=="}, + {{"\357", 1}, "7w=="}, + {{"\337", 1}, "3w=="}, + {{"\277", 1}, "vw=="}, + {{"\177", 1}, "fw=="}, + {{"\000\000", 2}, "AAA="}, + {{"\000\001", 2}, "AAE="}, + {{"\000\002", 2}, "AAI="}, + {{"\000\004", 2}, "AAQ="}, + {{"\000\010", 2}, "AAg="}, + {{"\000\020", 2}, "ABA="}, + {{"\000\040", 2}, "ACA="}, + {{"\000\100", 2}, "AEA="}, + {{"\000\200", 2}, "AIA="}, + {{"\001\000", 2}, "AQA="}, + {{"\002\000", 2}, "AgA="}, + {{"\004\000", 2}, "BAA="}, + {{"\010\000", 2}, "CAA="}, + {{"\020\000", 2}, "EAA="}, + {{"\040\000", 2}, "IAA="}, + {{"\100\000", 2}, "QAA="}, + {{"\200\000", 2}, "gAA="}, + + {{"\377\377", 2}, "//8="}, + {{"\377\376", 2}, "//4="}, + {{"\377\375", 2}, "//0="}, + {{"\377\373", 2}, "//s="}, + {{"\377\367", 2}, "//c="}, + {{"\377\357", 2}, "/+8="}, + {{"\377\337", 2}, "/98="}, + {{"\377\277", 2}, "/78="}, + {{"\377\177", 2}, "/38="}, + {{"\376\377", 2}, "/v8="}, + {{"\375\377", 2}, "/f8="}, + {{"\373\377", 2}, "+/8="}, + {{"\367\377", 2}, "9/8="}, + {{"\357\377", 2}, "7/8="}, + {{"\337\377", 2}, "3/8="}, + {{"\277\377", 2}, "v/8="}, + {{"\177\377", 2}, "f/8="}, + + {{"\000\000\000", 3}, "AAAA"}, + {{"\000\000\001", 3}, "AAAB"}, + {{"\000\000\002", 3}, "AAAC"}, + {{"\000\000\004", 3}, "AAAE"}, + {{"\000\000\010", 3}, "AAAI"}, + {{"\000\000\020", 3}, "AAAQ"}, + {{"\000\000\040", 3}, "AAAg"}, + {{"\000\000\100", 3}, "AABA"}, + {{"\000\000\200", 3}, "AACA"}, + {{"\000\001\000", 3}, "AAEA"}, + {{"\000\002\000", 3}, "AAIA"}, + {{"\000\004\000", 3}, "AAQA"}, + {{"\000\010\000", 3}, "AAgA"}, + {{"\000\020\000", 3}, "ABAA"}, + {{"\000\040\000", 3}, "ACAA"}, + {{"\000\100\000", 3}, "AEAA"}, + {{"\000\200\000", 3}, "AIAA"}, + {{"\001\000\000", 3}, "AQAA"}, + {{"\002\000\000", 3}, "AgAA"}, + {{"\004\000\000", 3}, "BAAA"}, + {{"\010\000\000", 3}, "CAAA"}, + {{"\020\000\000", 3}, "EAAA"}, + {{"\040\000\000", 3}, "IAAA"}, + {{"\100\000\000", 3}, "QAAA"}, + {{"\200\000\000", 3}, "gAAA"}, + + {{"\377\377\377", 3}, "////"}, + {{"\377\377\376", 3}, "///+"}, + {{"\377\377\375", 3}, "///9"}, + {{"\377\377\373", 3}, "///7"}, + {{"\377\377\367", 3}, "///3"}, + {{"\377\377\357", 3}, "///v"}, + {{"\377\377\337", 3}, "///f"}, + {{"\377\377\277", 3}, "//+/"}, + {{"\377\377\177", 3}, "//9/"}, + {{"\377\376\377", 3}, "//7/"}, + {{"\377\375\377", 3}, "//3/"}, + {{"\377\373\377", 3}, "//v/"}, + {{"\377\367\377", 3}, "//f/"}, + {{"\377\357\377", 3}, "/+//"}, + {{"\377\337\377", 3}, "/9//"}, + {{"\377\277\377", 3}, "/7//"}, + {{"\377\177\377", 3}, "/3//"}, + {{"\376\377\377", 3}, "/v//"}, + {{"\375\377\377", 3}, "/f//"}, + {{"\373\377\377", 3}, "+///"}, + {{"\367\377\377", 3}, "9///"}, + {{"\357\377\377", 3}, "7///"}, + {{"\337\377\377", 3}, "3///"}, + {{"\277\377\377", 3}, "v///"}, + {{"\177\377\377", 3}, "f///"}, + + // Random numbers: values obtained with + // + // #! /bin/bash + // dd bs=$1 count=1 if=/dev/random of=/tmp/bar.random + // od -N $1 -t o1 /tmp/bar.random + // uuencode -m test < /tmp/bar.random + // + // where $1 is the number of bytes (2, 3) + + {{"\243\361", 2}, "o/E="}, + {{"\024\167", 2}, "FHc="}, + {{"\313\252", 2}, "y6o="}, + {{"\046\041", 2}, "JiE="}, + {{"\145\236", 2}, "ZZ4="}, + {{"\254\325", 2}, "rNU="}, + {{"\061\330", 2}, "Mdg="}, + {{"\245\032", 2}, "pRo="}, + {{"\006\000", 2}, "BgA="}, + {{"\375\131", 2}, "/Vk="}, + {{"\303\210", 2}, "w4g="}, + {{"\040\037", 2}, "IB8="}, + {{"\261\372", 2}, "sfo="}, + {{"\335\014", 2}, "3Qw="}, + {{"\233\217", 2}, "m48="}, + {{"\373\056", 2}, "+y4="}, + {{"\247\232", 2}, "p5o="}, + {{"\107\053", 2}, "Rys="}, + {{"\204\077", 2}, "hD8="}, + {{"\276\211", 2}, "vok="}, + {{"\313\110", 2}, "y0g="}, + {{"\363\376", 2}, "8/4="}, + {{"\251\234", 2}, "qZw="}, + {{"\103\262", 2}, "Q7I="}, + {{"\142\312", 2}, "Yso="}, + {{"\067\211", 2}, "N4k="}, + {{"\220\001", 2}, "kAE="}, + {{"\152\240", 2}, "aqA="}, + {{"\367\061", 2}, "9zE="}, + {{"\133\255", 2}, "W60="}, + {{"\176\035", 2}, "fh0="}, + {{"\032\231", 2}, "Gpk="}, + + {{"\013\007\144", 3}, "Cwdk"}, + {{"\030\112\106", 3}, "GEpG"}, + {{"\047\325\046", 3}, "J9Um"}, + {{"\310\160\022", 3}, "yHAS"}, + {{"\131\100\237", 3}, "WUCf"}, + {{"\064\342\134", 3}, "NOJc"}, + {{"\010\177\004", 3}, "CH8E"}, + {{"\345\147\205", 3}, "5WeF"}, + {{"\300\343\360", 3}, "wOPw"}, + {{"\061\240\201", 3}, "MaCB"}, + {{"\225\333\044", 3}, "ldsk"}, + {{"\215\137\352", 3}, "jV/q"}, + {{"\371\147\160", 3}, "+Wdw"}, + {{"\030\320\051", 3}, "GNAp"}, + {{"\044\174\241", 3}, "JHyh"}, + {{"\260\127\037", 3}, "sFcf"}, + {{"\111\045\033", 3}, "SSUb"}, + {{"\202\114\107", 3}, "gkxH"}, + {{"\057\371\042", 3}, "L/ki"}, + {{"\223\247\244", 3}, "k6ek"}, + {{"\047\216\144", 3}, "J45k"}, + {{"\203\070\327", 3}, "gzjX"}, + {{"\247\140\072", 3}, "p2A6"}, + {{"\124\115\116", 3}, "VE1O"}, + {{"\157\162\050", 3}, "b3Io"}, + {{"\357\223\004", 3}, "75ME"}, + {{"\052\117\156", 3}, "Kk9u"}, + {{"\347\154\000", 3}, "52wA"}, + {{"\303\012\142", 3}, "wwpi"}, + {{"\060\035\362", 3}, "MB3y"}, + {{"\130\226\361", 3}, "WJbx"}, + {{"\173\013\071", 3}, "ews5"}, + {{"\336\004\027", 3}, "3gQX"}, + {{"\357\366\234", 3}, "7/ac"}, + {{"\353\304\111", 3}, "68RJ"}, + {{"\024\264\131", 3}, "FLRZ"}, + {{"\075\114\251", 3}, "PUyp"}, + {{"\315\031\225", 3}, "zRmV"}, + {{"\154\201\276", 3}, "bIG+"}, + {{"\200\066\072", 3}, "gDY6"}, + {{"\142\350\267", 3}, "Yui3"}, + {{"\033\000\166", 3}, "GwB2"}, + {{"\210\055\077", 3}, "iC0/"}, + {{"\341\037\124", 3}, "4R9U"}, + {{"\161\103\152", 3}, "cUNq"}, + {{"\270\142\131", 3}, "uGJZ"}, + {{"\337\076\074", 3}, "3z48"}, + {{"\375\106\362", 3}, "/Uby"}, + {{"\227\301\127", 3}, "l8FX"}, + {{"\340\002\234", 3}, "4AKc"}, + {{"\121\064\033", 3}, "UTQb"}, + {{"\157\134\143", 3}, "b1xj"}, + {{"\247\055\327", 3}, "py3X"}, + {{"\340\142\005", 3}, "4GIF"}, + {{"\060\260\143", 3}, "MLBj"}, + {{"\075\203\170", 3}, "PYN4"}, + {{"\143\160\016", 3}, "Y3AO"}, + {{"\313\013\063", 3}, "ywsz"}, + {{"\174\236\135", 3}, "fJ5d"}, + {{"\103\047\026", 3}, "QycW"}, + {{"\365\005\343", 3}, "9QXj"}, + {{"\271\160\223", 3}, "uXCT"}, + {{"\362\255\172", 3}, "8q16"}, + {{"\113\012\015", 3}, "SwoN"}, + + // various lengths, generated by this python script: + // + // from std::string import lowercase as lc + // for i in range(27): + // print '{ %2d, "%s",%s "%s" },' % (i, lc[:i], ' ' * (26-i), + // lc[:i].encode('base64').strip()) + + {{"", 0}, {"", 0}}, + {"a", "YQ=="}, + {"ab", "YWI="}, + {"abc", "YWJj"}, + {"abcd", "YWJjZA=="}, + {"abcde", "YWJjZGU="}, + {"abcdef", "YWJjZGVm"}, + {"abcdefg", "YWJjZGVmZw=="}, + {"abcdefgh", "YWJjZGVmZ2g="}, + {"abcdefghi", "YWJjZGVmZ2hp"}, + {"abcdefghij", "YWJjZGVmZ2hpag=="}, + {"abcdefghijk", "YWJjZGVmZ2hpams="}, + {"abcdefghijkl", "YWJjZGVmZ2hpamts"}, + {"abcdefghijklm", "YWJjZGVmZ2hpamtsbQ=="}, + {"abcdefghijklmn", "YWJjZGVmZ2hpamtsbW4="}, + {"abcdefghijklmno", "YWJjZGVmZ2hpamtsbW5v"}, + {"abcdefghijklmnop", "YWJjZGVmZ2hpamtsbW5vcA=="}, + {"abcdefghijklmnopq", "YWJjZGVmZ2hpamtsbW5vcHE="}, + {"abcdefghijklmnopqr", "YWJjZGVmZ2hpamtsbW5vcHFy"}, + {"abcdefghijklmnopqrs", "YWJjZGVmZ2hpamtsbW5vcHFycw=="}, + {"abcdefghijklmnopqrst", "YWJjZGVmZ2hpamtsbW5vcHFyc3Q="}, + {"abcdefghijklmnopqrstu", "YWJjZGVmZ2hpamtsbW5vcHFyc3R1"}, + {"abcdefghijklmnopqrstuv", "YWJjZGVmZ2hpamtsbW5vcHFyc3R1dg=="}, + {"abcdefghijklmnopqrstuvw", "YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnc="}, + {"abcdefghijklmnopqrstuvwx", "YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4"}, + {"abcdefghijklmnopqrstuvwxy", "YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eQ=="}, + {"abcdefghijklmnopqrstuvwxyz", "YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXo="}, +}; + +template <typename StringType> +void TestEscapeAndUnescape() { + // Check the short strings; this tests the math (and boundaries) + for (const auto& tc : base64_tests) { + StringType encoded("this junk should be ignored"); + absl::Base64Escape(tc.plaintext, &encoded); + EXPECT_EQ(encoded, tc.cyphertext); + EXPECT_EQ(absl::Base64Escape(tc.plaintext), tc.cyphertext); + + StringType decoded("this junk should be ignored"); + EXPECT_TRUE(absl::Base64Unescape(encoded, &decoded)); + EXPECT_EQ(decoded, tc.plaintext); + + StringType websafe(tc.cyphertext); + for (int c = 0; c < websafe.size(); ++c) { + if ('+' == websafe[c]) websafe[c] = '-'; + if ('/' == websafe[c]) websafe[c] = '_'; + if ('=' == websafe[c]) { + websafe.resize(c); + break; + } + } + + encoded = "this junk should be ignored"; + absl::WebSafeBase64Escape(tc.plaintext, &encoded); + EXPECT_EQ(encoded, websafe); + EXPECT_EQ(absl::WebSafeBase64Escape(tc.plaintext), websafe); + + // Let's try the string version of the decoder + decoded = "this junk should be ignored"; + EXPECT_TRUE(absl::WebSafeBase64Unescape(websafe, &decoded)); + EXPECT_EQ(decoded, tc.plaintext); + } + + // Now try the long strings, this tests the streaming + for (const auto& tc : absl::strings_internal::base64_strings()) { + StringType buffer; + absl::WebSafeBase64Escape(tc.plaintext, &buffer); + EXPECT_EQ(tc.cyphertext, buffer); + EXPECT_EQ(absl::WebSafeBase64Escape(tc.plaintext), tc.cyphertext); + } + + // Verify the behavior when decoding bad data + { + absl::string_view data_set[] = {"ab-/", absl::string_view("\0bcd", 4), + absl::string_view("abc.\0", 5)}; + for (absl::string_view bad_data : data_set) { + StringType buf; + EXPECT_FALSE(absl::Base64Unescape(bad_data, &buf)); + EXPECT_FALSE(absl::WebSafeBase64Unescape(bad_data, &buf)); + EXPECT_TRUE(buf.empty()); + } + } +} + +TEST(Base64, EscapeAndUnescape) { + TestEscapeAndUnescape<std::string>(); +} + +TEST(Base64, DISABLED_HugeData) { + const size_t kSize = size_t(3) * 1000 * 1000 * 1000; + static_assert(kSize % 3 == 0, "kSize must be divisible by 3"); + const std::string huge(kSize, 'x'); + + std::string escaped; + absl::Base64Escape(huge, &escaped); + + // Generates the string that should match a base64 encoded "xxx..." string. + // "xxx" in base64 is "eHh4". + std::string expected_encoding; + expected_encoding.reserve(kSize / 3 * 4); + for (size_t i = 0; i < kSize / 3; ++i) { + expected_encoding.append("eHh4"); + } + EXPECT_EQ(expected_encoding, escaped); + + std::string unescaped; + EXPECT_TRUE(absl::Base64Unescape(escaped, &unescaped)); + EXPECT_EQ(huge, unescaped); +} + +TEST(HexAndBack, HexStringToBytes_and_BytesToHexString) { + std::string hex_mixed = "0123456789abcdefABCDEF"; + std::string bytes_expected = "\x01\x23\x45\x67\x89\xab\xcd\xef\xAB\xCD\xEF"; + std::string hex_only_lower = "0123456789abcdefabcdef"; + + std::string bytes_result = absl::HexStringToBytes(hex_mixed); + EXPECT_EQ(bytes_expected, bytes_result); + + std::string prefix_valid = hex_mixed + "?"; + std::string prefix_valid_result = absl::HexStringToBytes( + absl::string_view(prefix_valid.data(), prefix_valid.size() - 1)); + EXPECT_EQ(bytes_expected, prefix_valid_result); + + std::string infix_valid = "?" + hex_mixed + "???"; + std::string infix_valid_result = absl::HexStringToBytes( + absl::string_view(infix_valid.data() + 1, hex_mixed.size())); + EXPECT_EQ(bytes_expected, infix_valid_result); + + std::string hex_result = absl::BytesToHexString(bytes_expected); + EXPECT_EQ(hex_only_lower, hex_result); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/char_map.h b/third_party/abseil_cpp/absl/strings/internal/char_map.h new file mode 100644 index 0000000000..61484de0b7 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/char_map.h @@ -0,0 +1,156 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Character Map Class +// +// A fast, bit-vector map for 8-bit unsigned characters. +// This class is useful for non-character purposes as well. + +#ifndef ABSL_STRINGS_INTERNAL_CHAR_MAP_H_ +#define ABSL_STRINGS_INTERNAL_CHAR_MAP_H_ + +#include <cstddef> +#include <cstdint> +#include <cstring> + +#include "absl/base/macros.h" +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +class Charmap { + public: + constexpr Charmap() : m_() {} + + // Initializes with a given char*. Note that NUL is not treated as + // a terminator, but rather a char to be flicked. + Charmap(const char* str, int len) : m_() { + while (len--) SetChar(*str++); + } + + // Initializes with a given char*. NUL is treated as a terminator + // and will not be in the charmap. + explicit Charmap(const char* str) : m_() { + while (*str) SetChar(*str++); + } + + constexpr bool contains(unsigned char c) const { + return (m_[c / 64] >> (c % 64)) & 0x1; + } + + // Returns true if and only if a character exists in both maps. + bool IntersectsWith(const Charmap& c) const { + for (size_t i = 0; i < ABSL_ARRAYSIZE(m_); ++i) { + if ((m_[i] & c.m_[i]) != 0) return true; + } + return false; + } + + bool IsZero() const { + for (uint64_t c : m_) { + if (c != 0) return false; + } + return true; + } + + // Containing only a single specified char. + static constexpr Charmap Char(char x) { + return Charmap(CharMaskForWord(x, 0), CharMaskForWord(x, 1), + CharMaskForWord(x, 2), CharMaskForWord(x, 3)); + } + + // Containing all the chars in the C-string 's'. + // Note that this is expensively recursive because of the C++11 constexpr + // formulation. Use only in constexpr initializers. + static constexpr Charmap FromString(const char* s) { + return *s == 0 ? Charmap() : (Char(*s) | FromString(s + 1)); + } + + // Containing all the chars in the closed interval [lo,hi]. + static constexpr Charmap Range(char lo, char hi) { + return Charmap(RangeForWord(lo, hi, 0), RangeForWord(lo, hi, 1), + RangeForWord(lo, hi, 2), RangeForWord(lo, hi, 3)); + } + + friend constexpr Charmap operator&(const Charmap& a, const Charmap& b) { + return Charmap(a.m_[0] & b.m_[0], a.m_[1] & b.m_[1], a.m_[2] & b.m_[2], + a.m_[3] & b.m_[3]); + } + + friend constexpr Charmap operator|(const Charmap& a, const Charmap& b) { + return Charmap(a.m_[0] | b.m_[0], a.m_[1] | b.m_[1], a.m_[2] | b.m_[2], + a.m_[3] | b.m_[3]); + } + + friend constexpr Charmap operator~(const Charmap& a) { + return Charmap(~a.m_[0], ~a.m_[1], ~a.m_[2], ~a.m_[3]); + } + + private: + constexpr Charmap(uint64_t b0, uint64_t b1, uint64_t b2, uint64_t b3) + : m_{b0, b1, b2, b3} {} + + static constexpr uint64_t RangeForWord(unsigned char lo, unsigned char hi, + uint64_t word) { + return OpenRangeFromZeroForWord(hi + 1, word) & + ~OpenRangeFromZeroForWord(lo, word); + } + + // All the chars in the specified word of the range [0, upper). + static constexpr uint64_t OpenRangeFromZeroForWord(uint64_t upper, + uint64_t word) { + return (upper <= 64 * word) + ? 0 + : (upper >= 64 * (word + 1)) + ? ~static_cast<uint64_t>(0) + : (~static_cast<uint64_t>(0) >> (64 - upper % 64)); + } + + static constexpr uint64_t CharMaskForWord(unsigned char x, uint64_t word) { + return (x / 64 == word) ? (static_cast<uint64_t>(1) << (x % 64)) : 0; + } + + private: + void SetChar(unsigned char c) { + m_[c / 64] |= static_cast<uint64_t>(1) << (c % 64); + } + + uint64_t m_[4]; +}; + +// Mirror the char-classifying predicates in <cctype> +constexpr Charmap UpperCharmap() { return Charmap::Range('A', 'Z'); } +constexpr Charmap LowerCharmap() { return Charmap::Range('a', 'z'); } +constexpr Charmap DigitCharmap() { return Charmap::Range('0', '9'); } +constexpr Charmap AlphaCharmap() { return LowerCharmap() | UpperCharmap(); } +constexpr Charmap AlnumCharmap() { return DigitCharmap() | AlphaCharmap(); } +constexpr Charmap XDigitCharmap() { + return DigitCharmap() | Charmap::Range('A', 'F') | Charmap::Range('a', 'f'); +} +constexpr Charmap PrintCharmap() { return Charmap::Range(0x20, 0x7e); } +constexpr Charmap SpaceCharmap() { return Charmap::FromString("\t\n\v\f\r "); } +constexpr Charmap CntrlCharmap() { + return Charmap::Range(0, 0x7f) & ~PrintCharmap(); +} +constexpr Charmap BlankCharmap() { return Charmap::FromString("\t "); } +constexpr Charmap GraphCharmap() { return PrintCharmap() & ~SpaceCharmap(); } +constexpr Charmap PunctCharmap() { return GraphCharmap() & ~AlnumCharmap(); } + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_CHAR_MAP_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/char_map_benchmark.cc b/third_party/abseil_cpp/absl/strings/internal/char_map_benchmark.cc new file mode 100644 index 0000000000..5cef967b30 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/char_map_benchmark.cc @@ -0,0 +1,61 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/char_map.h" + +#include <cstdint> + +#include "benchmark/benchmark.h" + +namespace { + +absl::strings_internal::Charmap MakeBenchmarkMap() { + absl::strings_internal::Charmap m; + uint32_t x[] = {0x0, 0x1, 0x2, 0x3, 0xf, 0xe, 0xd, 0xc}; + for (uint32_t& t : x) t *= static_cast<uint32_t>(0x11111111UL); + for (uint32_t i = 0; i < 256; ++i) { + if ((x[i / 32] >> (i % 32)) & 1) + m = m | absl::strings_internal::Charmap::Char(i); + } + return m; +} + +// Micro-benchmark for Charmap::contains. +void BM_Contains(benchmark::State& state) { + // Loop-body replicated 10 times to increase time per iteration. + // Argument continuously changed to avoid generating common subexpressions. + const absl::strings_internal::Charmap benchmark_map = MakeBenchmarkMap(); + unsigned char c = 0; + int ops = 0; + for (auto _ : state) { + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + ops += benchmark_map.contains(c++); + } + benchmark::DoNotOptimize(ops); +} +BENCHMARK(BM_Contains); + +// We don't bother benchmarking Charmap::IsZero or Charmap::IntersectsWith; +// their running time is data-dependent and it is not worth characterizing +// "typical" data. + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/char_map_test.cc b/third_party/abseil_cpp/absl/strings/internal/char_map_test.cc new file mode 100644 index 0000000000..d3306241a4 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/char_map_test.cc @@ -0,0 +1,172 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/char_map.h" + +#include <cctype> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" + +namespace { + +constexpr absl::strings_internal::Charmap everything_map = + ~absl::strings_internal::Charmap(); +constexpr absl::strings_internal::Charmap nothing_map{}; + +TEST(Charmap, AllTests) { + const absl::strings_internal::Charmap also_nothing_map("", 0); + ASSERT_TRUE(everything_map.contains('\0')); + ASSERT_TRUE(!nothing_map.contains('\0')); + ASSERT_TRUE(!also_nothing_map.contains('\0')); + for (unsigned char ch = 1; ch != 0; ++ch) { + ASSERT_TRUE(everything_map.contains(ch)); + ASSERT_TRUE(!nothing_map.contains(ch)); + ASSERT_TRUE(!also_nothing_map.contains(ch)); + } + + const absl::strings_internal::Charmap symbols("&@#@^!@?", 5); + ASSERT_TRUE(symbols.contains('&')); + ASSERT_TRUE(symbols.contains('@')); + ASSERT_TRUE(symbols.contains('#')); + ASSERT_TRUE(symbols.contains('^')); + ASSERT_TRUE(!symbols.contains('!')); + ASSERT_TRUE(!symbols.contains('?')); + int cnt = 0; + for (unsigned char ch = 1; ch != 0; ++ch) + cnt += symbols.contains(ch); + ASSERT_EQ(cnt, 4); + + const absl::strings_internal::Charmap lets("^abcde", 3); + const absl::strings_internal::Charmap lets2("fghij\0klmnop", 10); + const absl::strings_internal::Charmap lets3("fghij\0klmnop"); + ASSERT_TRUE(lets2.contains('k')); + ASSERT_TRUE(!lets3.contains('k')); + + ASSERT_TRUE(symbols.IntersectsWith(lets)); + ASSERT_TRUE(!lets2.IntersectsWith(lets)); + ASSERT_TRUE(lets.IntersectsWith(symbols)); + ASSERT_TRUE(!lets.IntersectsWith(lets2)); + + ASSERT_TRUE(nothing_map.IsZero()); + ASSERT_TRUE(!lets.IsZero()); +} + +namespace { +std::string Members(const absl::strings_internal::Charmap& m) { + std::string r; + for (size_t i = 0; i < 256; ++i) + if (m.contains(i)) r.push_back(i); + return r; +} + +std::string ClosedRangeString(unsigned char lo, unsigned char hi) { + // Don't depend on lo<hi. Just increment until lo==hi. + std::string s; + while (true) { + s.push_back(lo); + if (lo == hi) break; + ++lo; + } + return s; +} + +} // namespace + +TEST(Charmap, Constexpr) { + constexpr absl::strings_internal::Charmap kEmpty = nothing_map; + EXPECT_THAT(Members(kEmpty), ""); + constexpr absl::strings_internal::Charmap kA = + absl::strings_internal::Charmap::Char('A'); + EXPECT_THAT(Members(kA), "A"); + constexpr absl::strings_internal::Charmap kAZ = + absl::strings_internal::Charmap::Range('A', 'Z'); + EXPECT_THAT(Members(kAZ), "ABCDEFGHIJKLMNOPQRSTUVWXYZ"); + constexpr absl::strings_internal::Charmap kIdentifier = + absl::strings_internal::Charmap::Range('0', '9') | + absl::strings_internal::Charmap::Range('A', 'Z') | + absl::strings_internal::Charmap::Range('a', 'z') | + absl::strings_internal::Charmap::Char('_'); + EXPECT_THAT(Members(kIdentifier), + "0123456789" + "ABCDEFGHIJKLMNOPQRSTUVWXYZ" + "_" + "abcdefghijklmnopqrstuvwxyz"); + constexpr absl::strings_internal::Charmap kAll = everything_map; + for (size_t i = 0; i < 256; ++i) { + EXPECT_TRUE(kAll.contains(i)) << i; + } + constexpr absl::strings_internal::Charmap kHello = + absl::strings_internal::Charmap::FromString("Hello, world!"); + EXPECT_THAT(Members(kHello), " !,Hdelorw"); + + // test negation and intersection + constexpr absl::strings_internal::Charmap kABC = + absl::strings_internal::Charmap::Range('A', 'Z') & + ~absl::strings_internal::Charmap::Range('D', 'Z'); + EXPECT_THAT(Members(kABC), "ABC"); +} + +TEST(Charmap, Range) { + // Exhaustive testing takes too long, so test some of the boundaries that + // are perhaps going to cause trouble. + std::vector<size_t> poi = {0, 1, 2, 3, 4, 7, 8, 9, 15, + 16, 17, 30, 31, 32, 33, 63, 64, 65, + 127, 128, 129, 223, 224, 225, 254, 255}; + for (auto lo = poi.begin(); lo != poi.end(); ++lo) { + SCOPED_TRACE(*lo); + for (auto hi = lo; hi != poi.end(); ++hi) { + SCOPED_TRACE(*hi); + EXPECT_THAT(Members(absl::strings_internal::Charmap::Range(*lo, *hi)), + ClosedRangeString(*lo, *hi)); + } + } +} + +bool AsBool(int x) { return static_cast<bool>(x); } + +TEST(CharmapCtype, Match) { + for (int c = 0; c < 256; ++c) { + SCOPED_TRACE(c); + SCOPED_TRACE(static_cast<char>(c)); + EXPECT_EQ(AsBool(std::isupper(c)), + absl::strings_internal::UpperCharmap().contains(c)); + EXPECT_EQ(AsBool(std::islower(c)), + absl::strings_internal::LowerCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isdigit(c)), + absl::strings_internal::DigitCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isalpha(c)), + absl::strings_internal::AlphaCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isalnum(c)), + absl::strings_internal::AlnumCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isxdigit(c)), + absl::strings_internal::XDigitCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isprint(c)), + absl::strings_internal::PrintCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isspace(c)), + absl::strings_internal::SpaceCharmap().contains(c)); + EXPECT_EQ(AsBool(std::iscntrl(c)), + absl::strings_internal::CntrlCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isblank(c)), + absl::strings_internal::BlankCharmap().contains(c)); + EXPECT_EQ(AsBool(std::isgraph(c)), + absl::strings_internal::GraphCharmap().contains(c)); + EXPECT_EQ(AsBool(std::ispunct(c)), + absl::strings_internal::PunctCharmap().contains(c)); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/charconv_bigint.cc b/third_party/abseil_cpp/absl/strings/internal/charconv_bigint.cc new file mode 100644 index 0000000000..ebf8c0791a --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/charconv_bigint.cc @@ -0,0 +1,359 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/charconv_bigint.h" + +#include <algorithm> +#include <cassert> +#include <string> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +namespace { + +// Table containing some large powers of 5, for fast computation. + +// Constant step size for entries in the kLargePowersOfFive table. Each entry +// is larger than the previous entry by a factor of 5**kLargePowerOfFiveStep +// (or 5**27). +// +// In other words, the Nth entry in the table is 5**(27*N). +// +// 5**27 is the largest power of 5 that fits in 64 bits. +constexpr int kLargePowerOfFiveStep = 27; + +// The largest legal index into the kLargePowersOfFive table. +// +// In other words, the largest precomputed power of 5 is 5**(27*20). +constexpr int kLargestPowerOfFiveIndex = 20; + +// Table of powers of (5**27), up to (5**27)**20 == 5**540. +// +// Used to generate large powers of 5 while limiting the number of repeated +// multiplications required. +// +// clang-format off +const uint32_t kLargePowersOfFive[] = { +// 5**27 (i=1), start=0, end=2 + 0xfa10079dU, 0x6765c793U, +// 5**54 (i=2), start=2, end=6 + 0x97d9f649U, 0x6664242dU, 0x29939b14U, 0x29c30f10U, +// 5**81 (i=3), start=6, end=12 + 0xc4f809c5U, 0x7bf3f22aU, 0x67bdae34U, 0xad340517U, 0x369d1b5fU, 0x10de1593U, +// 5**108 (i=4), start=12, end=20 + 0x92b260d1U, 0x9efff7c7U, 0x81de0ec6U, 0xaeba5d56U, 0x410664a4U, 0x4f40737aU, + 0x20d3846fU, 0x06d00f73U, +// 5**135 (i=5), start=20, end=30 + 0xff1b172dU, 0x13a1d71cU, 0xefa07617U, 0x7f682d3dU, 0xff8c90c0U, 0x3f0131e7U, + 0x3fdcb9feU, 0x917b0177U, 0x16c407a7U, 0x02c06b9dU, +// 5**162 (i=6), start=30, end=42 + 0x960f7199U, 0x056667ecU, 0xe07aefd8U, 0x80f2b9ccU, 0x8273f5e3U, 0xeb9a214aU, + 0x40b38005U, 0x0e477ad4U, 0x277d08e6U, 0xfa28b11eU, 0xd3f7d784U, 0x011c835bU, +// 5**189 (i=7), start=42, end=56 + 0xf723d9d5U, 0x3282d3f3U, 0xe00857d1U, 0x69659d25U, 0x2cf117cfU, 0x24da6d07U, + 0x954d1417U, 0x3e5d8cedU, 0x7a8bb766U, 0xfd785ae6U, 0x645436d2U, 0x40c78b34U, + 0x94151217U, 0x0072e9f7U, +// 5**216 (i=8), start=56, end=72 + 0x2b416aa1U, 0x7893c5a7U, 0xe37dc6d4U, 0x2bad2beaU, 0xf0fc846cU, 0x7575ae4bU, + 0x62587b14U, 0x83b67a34U, 0x02110cdbU, 0xf7992f55U, 0x00deb022U, 0xa4a23becU, + 0x8af5c5cdU, 0xb85b654fU, 0x818df38bU, 0x002e69d2U, +// 5**243 (i=9), start=72, end=90 + 0x3518cbbdU, 0x20b0c15fU, 0x38756c2fU, 0xfb5dc3ddU, 0x22ad2d94U, 0xbf35a952U, + 0xa699192aU, 0x9a613326U, 0xad2a9cedU, 0xd7f48968U, 0xe87dfb54U, 0xc8f05db6U, + 0x5ef67531U, 0x31c1ab49U, 0xe202ac9fU, 0x9b2957b5U, 0xa143f6d3U, 0x0012bf07U, +// 5**270 (i=10), start=90, end=110 + 0x8b971de9U, 0x21aba2e1U, 0x63944362U, 0x57172336U, 0xd9544225U, 0xfb534166U, + 0x08c563eeU, 0x14640ee2U, 0x24e40d31U, 0x02b06537U, 0x03887f14U, 0x0285e533U, + 0xb744ef26U, 0x8be3a6c4U, 0x266979b4U, 0x6761ece2U, 0xd9cb39e4U, 0xe67de319U, + 0x0d39e796U, 0x00079250U, +// 5**297 (i=11), start=110, end=132 + 0x260eb6e5U, 0xf414a796U, 0xee1a7491U, 0xdb9368ebU, 0xf50c105bU, 0x59157750U, + 0x9ed2fb5cU, 0xf6e56d8bU, 0xeaee8d23U, 0x0f319f75U, 0x2aa134d6U, 0xac2908e9U, + 0xd4413298U, 0x02f02a55U, 0x989d5a7aU, 0x70dde184U, 0xba8040a7U, 0x03200981U, + 0xbe03b11cU, 0x3c1c2a18U, 0xd60427a1U, 0x00030ee0U, +// 5**324 (i=12), start=132, end=156 + 0xce566d71U, 0xf1c4aa25U, 0x4e93ca53U, 0xa72283d0U, 0x551a73eaU, 0x3d0538e2U, + 0x8da4303fU, 0x6a58de60U, 0x0e660221U, 0x49cf61a6U, 0x8d058fc1U, 0xb9d1a14cU, + 0x4bab157dU, 0xc85c6932U, 0x518c8b9eU, 0x9b92b8d0U, 0x0d8a0e21U, 0xbd855df9U, + 0xb3ea59a1U, 0x8da29289U, 0x4584d506U, 0x3752d80fU, 0xb72569c6U, 0x00013c33U, +// 5**351 (i=13), start=156, end=182 + 0x190f354dU, 0x83695cfeU, 0xe5a4d0c7U, 0xb60fb7e8U, 0xee5bbcc4U, 0xb922054cU, + 0xbb4f0d85U, 0x48394028U, 0x1d8957dbU, 0x0d7edb14U, 0x4ecc7587U, 0x505e9e02U, + 0x4c87f36bU, 0x99e66bd6U, 0x44b9ed35U, 0x753037d4U, 0xe5fe5f27U, 0x2742c203U, + 0x13b2ed2bU, 0xdc525d2cU, 0xe6fde59aU, 0x77ffb18fU, 0x13c5752cU, 0x08a84bccU, + 0x859a4940U, 0x00007fb6U, +// 5**378 (i=14), start=182, end=210 + 0x4f98cb39U, 0xa60edbbcU, 0x83b5872eU, 0xa501acffU, 0x9cc76f78U, 0xbadd4c73U, + 0x43e989faU, 0xca7acf80U, 0x2e0c824fU, 0xb19f4ffcU, 0x092fd81cU, 0xe4eb645bU, + 0xa1ff84c2U, 0x8a5a83baU, 0xa8a1fae9U, 0x1db43609U, 0xb0fed50bU, 0x0dd7d2bdU, + 0x7d7accd8U, 0x91fa640fU, 0x37dcc6c5U, 0x1c417fd5U, 0xe4d462adU, 0xe8a43399U, + 0x131bf9a5U, 0x8df54d29U, 0x36547dc1U, 0x00003395U, +// 5**405 (i=15), start=210, end=240 + 0x5bd330f5U, 0x77d21967U, 0x1ac481b7U, 0x6be2f7ceU, 0x7f4792a9U, 0xe84c2c52U, + 0x84592228U, 0x9dcaf829U, 0xdab44ce1U, 0x3d0c311bU, 0x532e297dU, 0x4704e8b4U, + 0x9cdc32beU, 0x41e64d9dU, 0x7717bea1U, 0xa824c00dU, 0x08f50b27U, 0x0f198d77U, + 0x49bbfdf0U, 0x025c6c69U, 0xd4e55cd3U, 0xf083602bU, 0xb9f0fecdU, 0xc0864aeaU, + 0x9cb98681U, 0xaaf620e9U, 0xacb6df30U, 0x4faafe66U, 0x8af13c3bU, 0x000014d5U, +// 5**432 (i=16), start=240, end=272 + 0x682bb941U, 0x89a9f297U, 0xcba75d7bU, 0x404217b1U, 0xb4e519e9U, 0xa1bc162bU, + 0xf7f5910aU, 0x98715af5U, 0x2ff53e57U, 0xe3ef118cU, 0x490c4543U, 0xbc9b1734U, + 0x2affbe4dU, 0x4cedcb4cU, 0xfb14e99eU, 0x35e34212U, 0xece39c24U, 0x07673ab3U, + 0xe73115ddU, 0xd15d38e7U, 0x093eed3bU, 0xf8e7eac5U, 0x78a8cc80U, 0x25227aacU, + 0x3f590551U, 0x413da1cbU, 0xdf643a55U, 0xab65ad44U, 0xd70b23d7U, 0xc672cd76U, + 0x3364ea62U, 0x0000086aU, +// 5**459 (i=17), start=272, end=306 + 0x22f163ddU, 0x23cf07acU, 0xbe2af6c2U, 0xf412f6f6U, 0xc3ff541eU, 0x6eeaf7deU, + 0xa47047e0U, 0x408cda92U, 0x0f0eeb08U, 0x56deba9dU, 0xcfc6b090U, 0x8bbbdf04U, + 0x3933cdb3U, 0x9e7bb67dU, 0x9f297035U, 0x38946244U, 0xee1d37bbU, 0xde898174U, + 0x63f3559dU, 0x705b72fbU, 0x138d27d9U, 0xf8603a78U, 0x735eec44U, 0xe30987d5U, + 0xc6d38070U, 0x9cfe548eU, 0x9ff01422U, 0x7c564aa8U, 0x91cc60baU, 0xcbc3565dU, + 0x7550a50bU, 0x6909aeadU, 0x13234c45U, 0x00000366U, +// 5**486 (i=18), start=306, end=342 + 0x17954989U, 0x3a7d7709U, 0x98042de5U, 0xa9011443U, 0x45e723c2U, 0x269ffd6fU, + 0x58852a46U, 0xaaa1042aU, 0x2eee8153U, 0xb2b6c39eU, 0xaf845b65U, 0xf6c365d7U, + 0xe4cffb2bU, 0xc840e90cU, 0xabea8abbU, 0x5c58f8d2U, 0x5c19fa3aU, 0x4670910aU, + 0x4449f21cU, 0xefa645b3U, 0xcc427decU, 0x083c3d73U, 0x467cb413U, 0x6fe10ae4U, + 0x3caffc72U, 0x9f8da55eU, 0x5e5c8ea7U, 0x490594bbU, 0xf0871b0bU, 0xdd89816cU, + 0x8e931df8U, 0xe85ce1c9U, 0xcca090a5U, 0x575fa16bU, 0x6b9f106cU, 0x0000015fU, +// 5**513 (i=19), start=342, end=380 + 0xee20d805U, 0x57bc3c07U, 0xcdea624eU, 0xd3f0f52dU, 0x9924b4f4U, 0xcf968640U, + 0x61d41962U, 0xe87fb464U, 0xeaaf51c7U, 0x564c8b60U, 0xccda4028U, 0x529428bbU, + 0x313a1fa8U, 0x96bd0f94U, 0x7a82ebaaU, 0xad99e7e9U, 0xf2668cd4U, 0xbe33a45eU, + 0xfd0db669U, 0x87ee369fU, 0xd3ec20edU, 0x9c4d7db7U, 0xdedcf0d8U, 0x7cd2ca64U, + 0xe25a6577U, 0x61003fd4U, 0xe56f54ccU, 0x10b7c748U, 0x40526e5eU, 0x7300ae87U, + 0x5c439261U, 0x2c0ff469U, 0xbf723f12U, 0xb2379b61U, 0xbf59b4f5U, 0xc91b1c3fU, + 0xf0046d27U, 0x0000008dU, +// 5**540 (i=20), start=380, end=420 + 0x525c9e11U, 0xf4e0eb41U, 0xebb2895dU, 0x5da512f9U, 0x7d9b29d4U, 0x452f4edcU, + 0x0b90bc37U, 0x341777cbU, 0x63d269afU, 0x1da77929U, 0x0a5c1826U, 0x77991898U, + 0x5aeddf86U, 0xf853a877U, 0x538c31ccU, 0xe84896daU, 0xb7a0010bU, 0x17ef4de5U, + 0xa52a2adeU, 0x029fd81cU, 0x987ce701U, 0x27fefd77U, 0xdb46c66fU, 0x5d301900U, + 0x496998c0U, 0xbb6598b9U, 0x5eebb607U, 0xe547354aU, 0xdf4a2f7eU, 0xf06c4955U, + 0x96242ffaU, 0x1775fb27U, 0xbecc58ceU, 0xebf2a53bU, 0x3eaad82aU, 0xf41137baU, + 0x573e6fbaU, 0xfb4866b8U, 0x54002148U, 0x00000039U, +}; +// clang-format on + +// Returns a pointer to the big integer data for (5**27)**i. i must be +// between 1 and 20, inclusive. +const uint32_t* LargePowerOfFiveData(int i) { + return kLargePowersOfFive + i * (i - 1); +} + +// Returns the size of the big integer data for (5**27)**i, in words. i must be +// between 1 and 20, inclusive. +int LargePowerOfFiveSize(int i) { return 2 * i; } +} // namespace + +ABSL_DLL const uint32_t kFiveToNth[14] = { + 1, 5, 25, 125, 625, 3125, 15625, + 78125, 390625, 1953125, 9765625, 48828125, 244140625, 1220703125, +}; + +ABSL_DLL const uint32_t kTenToNth[10] = { + 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000, 1000000000, +}; + +template <int max_words> +int BigUnsigned<max_words>::ReadFloatMantissa(const ParsedFloat& fp, + int significant_digits) { + SetToZero(); + assert(fp.type == FloatType::kNumber); + + if (fp.subrange_begin == nullptr) { + // We already exactly parsed the mantissa, so no more work is necessary. + words_[0] = fp.mantissa & 0xffffffffu; + words_[1] = fp.mantissa >> 32; + if (words_[1]) { + size_ = 2; + } else if (words_[0]) { + size_ = 1; + } + return fp.exponent; + } + int exponent_adjust = + ReadDigits(fp.subrange_begin, fp.subrange_end, significant_digits); + return fp.literal_exponent + exponent_adjust; +} + +template <int max_words> +int BigUnsigned<max_words>::ReadDigits(const char* begin, const char* end, + int significant_digits) { + assert(significant_digits <= Digits10() + 1); + SetToZero(); + + bool after_decimal_point = false; + // Discard any leading zeroes before the decimal point + while (begin < end && *begin == '0') { + ++begin; + } + int dropped_digits = 0; + // Discard any trailing zeroes. These may or may not be after the decimal + // point. + while (begin < end && *std::prev(end) == '0') { + --end; + ++dropped_digits; + } + if (begin < end && *std::prev(end) == '.') { + // If the string ends in '.', either before or after dropping zeroes, then + // drop the decimal point and look for more digits to drop. + dropped_digits = 0; + --end; + while (begin < end && *std::prev(end) == '0') { + --end; + ++dropped_digits; + } + } else if (dropped_digits) { + // We dropped digits, and aren't sure if they're before or after the decimal + // point. Figure that out now. + const char* dp = std::find(begin, end, '.'); + if (dp != end) { + // The dropped trailing digits were after the decimal point, so don't + // count them. + dropped_digits = 0; + } + } + // Any non-fraction digits we dropped need to be accounted for in our exponent + // adjustment. + int exponent_adjust = dropped_digits; + + uint32_t queued = 0; + int digits_queued = 0; + for (; begin != end && significant_digits > 0; ++begin) { + if (*begin == '.') { + after_decimal_point = true; + continue; + } + if (after_decimal_point) { + // For each fractional digit we emit in our parsed integer, adjust our + // decimal exponent to compensate. + --exponent_adjust; + } + int digit = (*begin - '0'); + --significant_digits; + if (significant_digits == 0 && std::next(begin) != end && + (digit == 0 || digit == 5)) { + // If this is the very last significant digit, but insignificant digits + // remain, we know that the last of those remaining significant digits is + // nonzero. (If it wasn't, we would have stripped it before we got here.) + // So if this final digit is a 0 or 5, adjust it upward by 1. + // + // This adjustment is what allows incredibly large mantissas ending in + // 500000...000000000001 to correctly round up, rather than to nearest. + ++digit; + } + queued = 10 * queued + digit; + ++digits_queued; + if (digits_queued == kMaxSmallPowerOfTen) { + MultiplyBy(kTenToNth[kMaxSmallPowerOfTen]); + AddWithCarry(0, queued); + queued = digits_queued = 0; + } + } + // Encode any remaining digits. + if (digits_queued) { + MultiplyBy(kTenToNth[digits_queued]); + AddWithCarry(0, queued); + } + + // If any insignificant digits remain, we will drop them. But if we have not + // yet read the decimal point, then we have to adjust the exponent to account + // for the dropped digits. + if (begin < end && !after_decimal_point) { + // This call to std::find will result in a pointer either to the decimal + // point, or to the end of our buffer if there was none. + // + // Either way, [begin, decimal_point) will contain the set of dropped digits + // that require an exponent adjustment. + const char* decimal_point = std::find(begin, end, '.'); + exponent_adjust += (decimal_point - begin); + } + return exponent_adjust; +} + +template <int max_words> +/* static */ BigUnsigned<max_words> BigUnsigned<max_words>::FiveToTheNth( + int n) { + BigUnsigned answer(1u); + + // Seed from the table of large powers, if possible. + bool first_pass = true; + while (n >= kLargePowerOfFiveStep) { + int big_power = + std::min(n / kLargePowerOfFiveStep, kLargestPowerOfFiveIndex); + if (first_pass) { + // just copy, rather than multiplying by 1 + std::copy( + LargePowerOfFiveData(big_power), + LargePowerOfFiveData(big_power) + LargePowerOfFiveSize(big_power), + answer.words_); + answer.size_ = LargePowerOfFiveSize(big_power); + first_pass = false; + } else { + answer.MultiplyBy(LargePowerOfFiveSize(big_power), + LargePowerOfFiveData(big_power)); + } + n -= kLargePowerOfFiveStep * big_power; + } + answer.MultiplyByFiveToTheNth(n); + return answer; +} + +template <int max_words> +void BigUnsigned<max_words>::MultiplyStep(int original_size, + const uint32_t* other_words, + int other_size, int step) { + int this_i = std::min(original_size - 1, step); + int other_i = step - this_i; + + uint64_t this_word = 0; + uint64_t carry = 0; + for (; this_i >= 0 && other_i < other_size; --this_i, ++other_i) { + uint64_t product = words_[this_i]; + product *= other_words[other_i]; + this_word += product; + carry += (this_word >> 32); + this_word &= 0xffffffff; + } + AddWithCarry(step + 1, carry); + words_[step] = this_word & 0xffffffff; + if (this_word > 0 && size_ <= step) { + size_ = step + 1; + } +} + +template <int max_words> +std::string BigUnsigned<max_words>::ToString() const { + BigUnsigned<max_words> copy = *this; + std::string result; + // Build result in reverse order + while (copy.size() > 0) { + int next_digit = copy.DivMod<10>(); + result.push_back('0' + next_digit); + } + if (result.empty()) { + result.push_back('0'); + } + std::reverse(result.begin(), result.end()); + return result; +} + +template class BigUnsigned<4>; +template class BigUnsigned<84>; + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/charconv_bigint.h b/third_party/abseil_cpp/absl/strings/internal/charconv_bigint.h new file mode 100644 index 0000000000..8f702976a8 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/charconv_bigint.h @@ -0,0 +1,423 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_STRINGS_INTERNAL_CHARCONV_BIGINT_H_ +#define ABSL_STRINGS_INTERNAL_CHARCONV_BIGINT_H_ + +#include <algorithm> +#include <cstdint> +#include <iostream> +#include <string> + +#include "absl/base/config.h" +#include "absl/strings/ascii.h" +#include "absl/strings/internal/charconv_parse.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// The largest power that 5 that can be raised to, and still fit in a uint32_t. +constexpr int kMaxSmallPowerOfFive = 13; +// The largest power that 10 that can be raised to, and still fit in a uint32_t. +constexpr int kMaxSmallPowerOfTen = 9; + +ABSL_DLL extern const uint32_t + kFiveToNth[kMaxSmallPowerOfFive + 1]; +ABSL_DLL extern const uint32_t kTenToNth[kMaxSmallPowerOfTen + 1]; + +// Large, fixed-width unsigned integer. +// +// Exact rounding for decimal-to-binary floating point conversion requires very +// large integer math, but a design goal of absl::from_chars is to avoid +// allocating memory. The integer precision needed for decimal-to-binary +// conversions is large but bounded, so a huge fixed-width integer class +// suffices. +// +// This is an intentionally limited big integer class. Only needed operations +// are implemented. All storage lives in an array data member, and all +// arithmetic is done in-place, to avoid requiring separate storage for operand +// and result. +// +// This is an internal class. Some methods live in the .cc file, and are +// instantiated only for the values of max_words we need. +template <int max_words> +class BigUnsigned { + public: + static_assert(max_words == 4 || max_words == 84, + "unsupported max_words value"); + + BigUnsigned() : size_(0), words_{} {} + explicit constexpr BigUnsigned(uint64_t v) + : size_((v >> 32) ? 2 : v ? 1 : 0), + words_{static_cast<uint32_t>(v & 0xffffffffu), + static_cast<uint32_t>(v >> 32)} {} + + // Constructs a BigUnsigned from the given string_view containing a decimal + // value. If the input string is not a decimal integer, constructs a 0 + // instead. + explicit BigUnsigned(absl::string_view sv) : size_(0), words_{} { + // Check for valid input, returning a 0 otherwise. This is reasonable + // behavior only because this constructor is for unit tests. + if (std::find_if_not(sv.begin(), sv.end(), ascii_isdigit) != sv.end() || + sv.empty()) { + return; + } + int exponent_adjust = + ReadDigits(sv.data(), sv.data() + sv.size(), Digits10() + 1); + if (exponent_adjust > 0) { + MultiplyByTenToTheNth(exponent_adjust); + } + } + + // Loads the mantissa value of a previously-parsed float. + // + // Returns the associated decimal exponent. The value of the parsed float is + // exactly *this * 10**exponent. + int ReadFloatMantissa(const ParsedFloat& fp, int significant_digits); + + // Returns the number of decimal digits of precision this type provides. All + // numbers with this many decimal digits or fewer are representable by this + // type. + // + // Analagous to std::numeric_limits<BigUnsigned>::digits10. + static constexpr int Digits10() { + // 9975007/1035508 is very slightly less than log10(2**32). + return static_cast<uint64_t>(max_words) * 9975007 / 1035508; + } + + // Shifts left by the given number of bits. + void ShiftLeft(int count) { + if (count > 0) { + const int word_shift = count / 32; + if (word_shift >= max_words) { + SetToZero(); + return; + } + size_ = (std::min)(size_ + word_shift, max_words); + count %= 32; + if (count == 0) { + std::copy_backward(words_, words_ + size_ - word_shift, words_ + size_); + } else { + for (int i = (std::min)(size_, max_words - 1); i > word_shift; --i) { + words_[i] = (words_[i - word_shift] << count) | + (words_[i - word_shift - 1] >> (32 - count)); + } + words_[word_shift] = words_[0] << count; + // Grow size_ if necessary. + if (size_ < max_words && words_[size_]) { + ++size_; + } + } + std::fill(words_, words_ + word_shift, 0u); + } + } + + + // Multiplies by v in-place. + void MultiplyBy(uint32_t v) { + if (size_ == 0 || v == 1) { + return; + } + if (v == 0) { + SetToZero(); + return; + } + const uint64_t factor = v; + uint64_t window = 0; + for (int i = 0; i < size_; ++i) { + window += factor * words_[i]; + words_[i] = window & 0xffffffff; + window >>= 32; + } + // If carry bits remain and there's space for them, grow size_. + if (window && size_ < max_words) { + words_[size_] = window & 0xffffffff; + ++size_; + } + } + + void MultiplyBy(uint64_t v) { + uint32_t words[2]; + words[0] = static_cast<uint32_t>(v); + words[1] = static_cast<uint32_t>(v >> 32); + if (words[1] == 0) { + MultiplyBy(words[0]); + } else { + MultiplyBy(2, words); + } + } + + // Multiplies in place by 5 to the power of n. n must be non-negative. + void MultiplyByFiveToTheNth(int n) { + while (n >= kMaxSmallPowerOfFive) { + MultiplyBy(kFiveToNth[kMaxSmallPowerOfFive]); + n -= kMaxSmallPowerOfFive; + } + if (n > 0) { + MultiplyBy(kFiveToNth[n]); + } + } + + // Multiplies in place by 10 to the power of n. n must be non-negative. + void MultiplyByTenToTheNth(int n) { + if (n > kMaxSmallPowerOfTen) { + // For large n, raise to a power of 5, then shift left by the same amount. + // (10**n == 5**n * 2**n.) This requires fewer multiplications overall. + MultiplyByFiveToTheNth(n); + ShiftLeft(n); + } else if (n > 0) { + // We can do this more quickly for very small N by using a single + // multiplication. + MultiplyBy(kTenToNth[n]); + } + } + + // Returns the value of 5**n, for non-negative n. This implementation uses + // a lookup table, and is faster then seeding a BigUnsigned with 1 and calling + // MultiplyByFiveToTheNth(). + static BigUnsigned FiveToTheNth(int n); + + // Multiplies by another BigUnsigned, in-place. + template <int M> + void MultiplyBy(const BigUnsigned<M>& other) { + MultiplyBy(other.size(), other.words()); + } + + void SetToZero() { + std::fill(words_, words_ + size_, 0u); + size_ = 0; + } + + // Returns the value of the nth word of this BigUnsigned. This is + // range-checked, and returns 0 on out-of-bounds accesses. + uint32_t GetWord(int index) const { + if (index < 0 || index >= size_) { + return 0; + } + return words_[index]; + } + + // Returns this integer as a decimal string. This is not used in the decimal- + // to-binary conversion; it is intended to aid in testing. + std::string ToString() const; + + int size() const { return size_; } + const uint32_t* words() const { return words_; } + + private: + // Reads the number between [begin, end), possibly containing a decimal point, + // into this BigUnsigned. + // + // Callers are required to ensure [begin, end) contains a valid number, with + // one or more decimal digits and at most one decimal point. This routine + // will behave unpredictably if these preconditions are not met. + // + // Only the first `significant_digits` digits are read. Digits beyond this + // limit are "sticky": If the final significant digit is 0 or 5, and if any + // dropped digit is nonzero, then that final significant digit is adjusted up + // to 1 or 6. This adjustment allows for precise rounding. + // + // Returns `exponent_adjustment`, a power-of-ten exponent adjustment to + // account for the decimal point and for dropped significant digits. After + // this function returns, + // actual_value_of_parsed_string ~= *this * 10**exponent_adjustment. + int ReadDigits(const char* begin, const char* end, int significant_digits); + + // Performs a step of big integer multiplication. This computes the full + // (64-bit-wide) values that should be added at the given index (step), and + // adds to that location in-place. + // + // Because our math all occurs in place, we must multiply starting from the + // highest word working downward. (This is a bit more expensive due to the + // extra carries involved.) + // + // This must be called in steps, for each word to be calculated, starting from + // the high end and working down to 0. The first value of `step` should be + // `std::min(original_size + other.size_ - 2, max_words - 1)`. + // The reason for this expression is that multiplying the i'th word from one + // multiplicand and the j'th word of another multiplicand creates a + // two-word-wide value to be stored at the (i+j)'th element. The highest + // word indices we will access are `original_size - 1` from this object, and + // `other.size_ - 1` from our operand. Therefore, + // `original_size + other.size_ - 2` is the first step we should calculate, + // but limited on an upper bound by max_words. + + // Working from high-to-low ensures that we do not overwrite the portions of + // the initial value of *this which are still needed for later steps. + // + // Once called with step == 0, *this contains the result of the + // multiplication. + // + // `original_size` is the size_ of *this before the first call to + // MultiplyStep(). `other_words` and `other_size` are the contents of our + // operand. `step` is the step to perform, as described above. + void MultiplyStep(int original_size, const uint32_t* other_words, + int other_size, int step); + + void MultiplyBy(int other_size, const uint32_t* other_words) { + const int original_size = size_; + const int first_step = + (std::min)(original_size + other_size - 2, max_words - 1); + for (int step = first_step; step >= 0; --step) { + MultiplyStep(original_size, other_words, other_size, step); + } + } + + // Adds a 32-bit value to the index'th word, with carry. + void AddWithCarry(int index, uint32_t value) { + if (value) { + while (index < max_words && value > 0) { + words_[index] += value; + // carry if we overflowed in this word: + if (value > words_[index]) { + value = 1; + ++index; + } else { + value = 0; + } + } + size_ = (std::min)(max_words, (std::max)(index + 1, size_)); + } + } + + void AddWithCarry(int index, uint64_t value) { + if (value && index < max_words) { + uint32_t high = value >> 32; + uint32_t low = value & 0xffffffff; + words_[index] += low; + if (words_[index] < low) { + ++high; + if (high == 0) { + // Carry from the low word caused our high word to overflow. + // Short circuit here to do the right thing. + AddWithCarry(index + 2, static_cast<uint32_t>(1)); + return; + } + } + if (high > 0) { + AddWithCarry(index + 1, high); + } else { + // Normally 32-bit AddWithCarry() sets size_, but since we don't call + // it when `high` is 0, do it ourselves here. + size_ = (std::min)(max_words, (std::max)(index + 1, size_)); + } + } + } + + // Divide this in place by a constant divisor. Returns the remainder of the + // division. + template <uint32_t divisor> + uint32_t DivMod() { + uint64_t accumulator = 0; + for (int i = size_ - 1; i >= 0; --i) { + accumulator <<= 32; + accumulator += words_[i]; + // accumulator / divisor will never overflow an int32_t in this loop + words_[i] = static_cast<uint32_t>(accumulator / divisor); + accumulator = accumulator % divisor; + } + while (size_ > 0 && words_[size_ - 1] == 0) { + --size_; + } + return static_cast<uint32_t>(accumulator); + } + + // The number of elements in words_ that may carry significant values. + // All elements beyond this point are 0. + // + // When size_ is 0, this BigUnsigned stores the value 0. + // When size_ is nonzero, is *not* guaranteed that words_[size_ - 1] is + // nonzero. This can occur due to overflow truncation. + // In particular, x.size_ != y.size_ does *not* imply x != y. + int size_; + uint32_t words_[max_words]; +}; + +// Compares two big integer instances. +// +// Returns -1 if lhs < rhs, 0 if lhs == rhs, and 1 if lhs > rhs. +template <int N, int M> +int Compare(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + int limit = (std::max)(lhs.size(), rhs.size()); + for (int i = limit - 1; i >= 0; --i) { + const uint32_t lhs_word = lhs.GetWord(i); + const uint32_t rhs_word = rhs.GetWord(i); + if (lhs_word < rhs_word) { + return -1; + } else if (lhs_word > rhs_word) { + return 1; + } + } + return 0; +} + +template <int N, int M> +bool operator==(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + int limit = (std::max)(lhs.size(), rhs.size()); + for (int i = 0; i < limit; ++i) { + if (lhs.GetWord(i) != rhs.GetWord(i)) { + return false; + } + } + return true; +} + +template <int N, int M> +bool operator!=(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + return !(lhs == rhs); +} + +template <int N, int M> +bool operator<(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + return Compare(lhs, rhs) == -1; +} + +template <int N, int M> +bool operator>(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + return rhs < lhs; +} +template <int N, int M> +bool operator<=(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + return !(rhs < lhs); +} +template <int N, int M> +bool operator>=(const BigUnsigned<N>& lhs, const BigUnsigned<M>& rhs) { + return !(lhs < rhs); +} + +// Output operator for BigUnsigned, for testing purposes only. +template <int N> +std::ostream& operator<<(std::ostream& os, const BigUnsigned<N>& num) { + return os << num.ToString(); +} + +// Explicit instantiation declarations for the sizes of BigUnsigned that we +// are using. +// +// For now, the choices of 4 and 84 are arbitrary; 4 is a small value that is +// still bigger than an int128, and 84 is a large value we will want to use +// in the from_chars implementation. +// +// Comments justifying the use of 84 belong in the from_chars implementation, +// and will be added in a follow-up CL. +extern template class BigUnsigned<4>; +extern template class BigUnsigned<84>; + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_CHARCONV_BIGINT_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/charconv_bigint_test.cc b/third_party/abseil_cpp/absl/strings/internal/charconv_bigint_test.cc new file mode 100644 index 0000000000..363bcb03d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/charconv_bigint_test.cc @@ -0,0 +1,205 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/charconv_bigint.h" + +#include <string> + +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +TEST(BigUnsigned, ShiftLeft) { + { + // Check that 3 * 2**100 is calculated correctly + BigUnsigned<4> num(3u); + num.ShiftLeft(100); + EXPECT_EQ(num, BigUnsigned<4>("3802951800684688204490109616128")); + } + { + // Test that overflow is truncated properly. + // 15 is 4 bits long, and BigUnsigned<4> is a 128-bit bigint. + // Shifting left by 125 bits should truncate off the high bit, so that + // 15 << 125 == 7 << 125 + // after truncation. + BigUnsigned<4> a(15u); + BigUnsigned<4> b(7u); + BigUnsigned<4> c(3u); + a.ShiftLeft(125); + b.ShiftLeft(125); + c.ShiftLeft(125); + EXPECT_EQ(a, b); + EXPECT_NE(a, c); + } + { + // Same test, larger bigint: + BigUnsigned<84> a(15u); + BigUnsigned<84> b(7u); + BigUnsigned<84> c(3u); + a.ShiftLeft(84 * 32 - 3); + b.ShiftLeft(84 * 32 - 3); + c.ShiftLeft(84 * 32 - 3); + EXPECT_EQ(a, b); + EXPECT_NE(a, c); + } + { + // Check that incrementally shifting has the same result as doing it all at + // once (attempting to capture corner cases.) + const std::string seed = "1234567890123456789012345678901234567890"; + BigUnsigned<84> a(seed); + for (int i = 1; i <= 84 * 32; ++i) { + a.ShiftLeft(1); + BigUnsigned<84> b(seed); + b.ShiftLeft(i); + EXPECT_EQ(a, b); + } + // And we should have fully rotated all bits off by now: + EXPECT_EQ(a, BigUnsigned<84>(0u)); + } +} + +TEST(BigUnsigned, MultiplyByUint32) { + const BigUnsigned<84> factorial_100( + "933262154439441526816992388562667004907159682643816214685929638952175999" + "932299156089414639761565182862536979208272237582511852109168640000000000" + "00000000000000"); + BigUnsigned<84> a(1u); + for (uint32_t i = 1; i <= 100; ++i) { + a.MultiplyBy(i); + } + EXPECT_EQ(a, BigUnsigned<84>(factorial_100)); +} + +TEST(BigUnsigned, MultiplyByBigUnsigned) { + { + // Put the terms of factorial_200 into two bigints, and multiply them + // together. + const BigUnsigned<84> factorial_200( + "7886578673647905035523632139321850622951359776871732632947425332443594" + "4996340334292030428401198462390417721213891963883025764279024263710506" + "1926624952829931113462857270763317237396988943922445621451664240254033" + "2918641312274282948532775242424075739032403212574055795686602260319041" + "7032406235170085879617892222278962370389737472000000000000000000000000" + "0000000000000000000000000"); + BigUnsigned<84> evens(1u); + BigUnsigned<84> odds(1u); + for (uint32_t i = 1; i < 200; i += 2) { + odds.MultiplyBy(i); + evens.MultiplyBy(i + 1); + } + evens.MultiplyBy(odds); + EXPECT_EQ(evens, factorial_200); + } + { + // Multiply various powers of 10 together. + for (int a = 0 ; a < 700; a += 25) { + SCOPED_TRACE(a); + BigUnsigned<84> a_value("3" + std::string(a, '0')); + for (int b = 0; b < (700 - a); b += 25) { + SCOPED_TRACE(b); + BigUnsigned<84> b_value("2" + std::string(b, '0')); + BigUnsigned<84> expected_product("6" + std::string(a + b, '0')); + b_value.MultiplyBy(a_value); + EXPECT_EQ(b_value, expected_product); + } + } + } +} + +TEST(BigUnsigned, MultiplyByOverflow) { + { + // Check that multiplcation overflow predictably truncates. + + // A big int with all bits on. + BigUnsigned<4> all_bits_on("340282366920938463463374607431768211455"); + // Modulo 2**128, this is equal to -1. Therefore the square of this, + // modulo 2**128, should be 1. + all_bits_on.MultiplyBy(all_bits_on); + EXPECT_EQ(all_bits_on, BigUnsigned<4>(1u)); + } + { + // Try multiplying a large bigint by 2**50, and compare the result to + // shifting. + BigUnsigned<4> value_1("12345678901234567890123456789012345678"); + BigUnsigned<4> value_2("12345678901234567890123456789012345678"); + BigUnsigned<4> two_to_fiftieth(1u); + two_to_fiftieth.ShiftLeft(50); + + value_1.ShiftLeft(50); + value_2.MultiplyBy(two_to_fiftieth); + EXPECT_EQ(value_1, value_2); + } +} + +TEST(BigUnsigned, FiveToTheNth) { + { + // Sanity check that MultiplyByFiveToTheNth gives consistent answers, up to + // and including overflow. + for (int i = 0; i < 1160; ++i) { + SCOPED_TRACE(i); + BigUnsigned<84> value_1(123u); + BigUnsigned<84> value_2(123u); + value_1.MultiplyByFiveToTheNth(i); + for (int j = 0; j < i; j++) { + value_2.MultiplyBy(5u); + } + EXPECT_EQ(value_1, value_2); + } + } + { + // Check that the faster, table-lookup-based static method returns the same + // result that multiplying in-place would return, up to and including + // overflow. + for (int i = 0; i < 1160; ++i) { + SCOPED_TRACE(i); + BigUnsigned<84> value_1(1u); + value_1.MultiplyByFiveToTheNth(i); + BigUnsigned<84> value_2 = BigUnsigned<84>::FiveToTheNth(i); + EXPECT_EQ(value_1, value_2); + } + } +} + +TEST(BigUnsigned, TenToTheNth) { + { + // Sanity check MultiplyByTenToTheNth. + for (int i = 0; i < 800; ++i) { + SCOPED_TRACE(i); + BigUnsigned<84> value_1(123u); + BigUnsigned<84> value_2(123u); + value_1.MultiplyByTenToTheNth(i); + for (int j = 0; j < i; j++) { + value_2.MultiplyBy(10u); + } + EXPECT_EQ(value_1, value_2); + } + } + { + // Alternate testing approach, taking advantage of the decimal parser. + for (int i = 0; i < 200; ++i) { + SCOPED_TRACE(i); + BigUnsigned<84> value_1(135u); + value_1.MultiplyByTenToTheNth(i); + BigUnsigned<84> value_2("135" + std::string(i, '0')); + EXPECT_EQ(value_1, value_2); + } + } +} + + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/charconv_parse.cc b/third_party/abseil_cpp/absl/strings/internal/charconv_parse.cc new file mode 100644 index 0000000000..fd6d9480fc --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/charconv_parse.cc @@ -0,0 +1,504 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/charconv_parse.h" +#include "absl/strings/charconv.h" + +#include <cassert> +#include <cstdint> +#include <limits> + +#include "absl/strings/internal/memutil.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +// ParseFloat<10> will read the first 19 significant digits of the mantissa. +// This number was chosen for multiple reasons. +// +// (a) First, for whatever integer type we choose to represent the mantissa, we +// want to choose the largest possible number of decimal digits for that integer +// type. We are using uint64_t, which can express any 19-digit unsigned +// integer. +// +// (b) Second, we need to parse enough digits that the binary value of any +// mantissa we capture has more bits of resolution than the mantissa +// representation in the target float. Our algorithm requires at least 3 bits +// of headway, but 19 decimal digits give a little more than that. +// +// The following static assertions verify the above comments: +constexpr int kDecimalMantissaDigitsMax = 19; + +static_assert(std::numeric_limits<uint64_t>::digits10 == + kDecimalMantissaDigitsMax, + "(a) above"); + +// IEEE doubles, which we assume in Abseil, have 53 binary bits of mantissa. +static_assert(std::numeric_limits<double>::is_iec559, "IEEE double assumed"); +static_assert(std::numeric_limits<double>::radix == 2, "IEEE double fact"); +static_assert(std::numeric_limits<double>::digits == 53, "IEEE double fact"); + +// The lowest valued 19-digit decimal mantissa we can read still contains +// sufficient information to reconstruct a binary mantissa. +static_assert(1000000000000000000u > (uint64_t(1) << (53 + 3)), "(b) above"); + +// ParseFloat<16> will read the first 15 significant digits of the mantissa. +// +// Because a base-16-to-base-2 conversion can be done exactly, we do not need +// to maximize the number of scanned hex digits to improve our conversion. What +// is required is to scan two more bits than the mantissa can represent, so that +// we always round correctly. +// +// (One extra bit does not suffice to perform correct rounding, since a number +// exactly halfway between two representable floats has unique rounding rules, +// so we need to differentiate between a "halfway between" number and a "closer +// to the larger value" number.) +constexpr int kHexadecimalMantissaDigitsMax = 15; + +// The minimum number of significant bits that will be read from +// kHexadecimalMantissaDigitsMax hex digits. We must subtract by three, since +// the most significant digit can be a "1", which only contributes a single +// significant bit. +constexpr int kGuaranteedHexadecimalMantissaBitPrecision = + 4 * kHexadecimalMantissaDigitsMax - 3; + +static_assert(kGuaranteedHexadecimalMantissaBitPrecision > + std::numeric_limits<double>::digits + 2, + "kHexadecimalMantissaDigitsMax too small"); + +// We also impose a limit on the number of significant digits we will read from +// an exponent, to avoid having to deal with integer overflow. We use 9 for +// this purpose. +// +// If we read a 9 digit exponent, the end result of the conversion will +// necessarily be infinity or zero, depending on the sign of the exponent. +// Therefore we can just drop extra digits on the floor without any extra +// logic. +constexpr int kDecimalExponentDigitsMax = 9; +static_assert(std::numeric_limits<int>::digits10 >= kDecimalExponentDigitsMax, + "int type too small"); + +// To avoid incredibly large inputs causing integer overflow for our exponent, +// we impose an arbitrary but very large limit on the number of significant +// digits we will accept. The implementation refuses to match a string with +// more consecutive significant mantissa digits than this. +constexpr int kDecimalDigitLimit = 50000000; + +// Corresponding limit for hexadecimal digit inputs. This is one fourth the +// amount of kDecimalDigitLimit, since each dropped hexadecimal digit requires +// a binary exponent adjustment of 4. +constexpr int kHexadecimalDigitLimit = kDecimalDigitLimit / 4; + +// The largest exponent we can read is 999999999 (per +// kDecimalExponentDigitsMax), and the largest exponent adjustment we can get +// from dropped mantissa digits is 2 * kDecimalDigitLimit, and the sum of these +// comfortably fits in an integer. +// +// We count kDecimalDigitLimit twice because there are independent limits for +// numbers before and after the decimal point. (In the case where there are no +// significant digits before the decimal point, there are independent limits for +// post-decimal-point leading zeroes and for significant digits.) +static_assert(999999999 + 2 * kDecimalDigitLimit < + std::numeric_limits<int>::max(), + "int type too small"); +static_assert(999999999 + 2 * (4 * kHexadecimalDigitLimit) < + std::numeric_limits<int>::max(), + "int type too small"); + +// Returns true if the provided bitfield allows parsing an exponent value +// (e.g., "1.5e100"). +bool AllowExponent(chars_format flags) { + bool fixed = (flags & chars_format::fixed) == chars_format::fixed; + bool scientific = + (flags & chars_format::scientific) == chars_format::scientific; + return scientific || !fixed; +} + +// Returns true if the provided bitfield requires an exponent value be present. +bool RequireExponent(chars_format flags) { + bool fixed = (flags & chars_format::fixed) == chars_format::fixed; + bool scientific = + (flags & chars_format::scientific) == chars_format::scientific; + return scientific && !fixed; +} + +const int8_t kAsciiToInt[256] = { + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, + 9, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, + -1, -1, -1, -1, -1, -1, -1, -1, -1}; + +// Returns true if `ch` is a digit in the given base +template <int base> +bool IsDigit(char ch); + +// Converts a valid `ch` to its digit value in the given base. +template <int base> +unsigned ToDigit(char ch); + +// Returns true if `ch` is the exponent delimiter for the given base. +template <int base> +bool IsExponentCharacter(char ch); + +// Returns the maximum number of significant digits we will read for a float +// in the given base. +template <int base> +constexpr int MantissaDigitsMax(); + +// Returns the largest consecutive run of digits we will accept when parsing a +// number in the given base. +template <int base> +constexpr int DigitLimit(); + +// Returns the amount the exponent must be adjusted by for each dropped digit. +// (For decimal this is 1, since the digits are in base 10 and the exponent base +// is also 10, but for hexadecimal this is 4, since the digits are base 16 but +// the exponent base is 2.) +template <int base> +constexpr int DigitMagnitude(); + +template <> +bool IsDigit<10>(char ch) { + return ch >= '0' && ch <= '9'; +} +template <> +bool IsDigit<16>(char ch) { + return kAsciiToInt[static_cast<unsigned char>(ch)] >= 0; +} + +template <> +unsigned ToDigit<10>(char ch) { + return ch - '0'; +} +template <> +unsigned ToDigit<16>(char ch) { + return kAsciiToInt[static_cast<unsigned char>(ch)]; +} + +template <> +bool IsExponentCharacter<10>(char ch) { + return ch == 'e' || ch == 'E'; +} + +template <> +bool IsExponentCharacter<16>(char ch) { + return ch == 'p' || ch == 'P'; +} + +template <> +constexpr int MantissaDigitsMax<10>() { + return kDecimalMantissaDigitsMax; +} +template <> +constexpr int MantissaDigitsMax<16>() { + return kHexadecimalMantissaDigitsMax; +} + +template <> +constexpr int DigitLimit<10>() { + return kDecimalDigitLimit; +} +template <> +constexpr int DigitLimit<16>() { + return kHexadecimalDigitLimit; +} + +template <> +constexpr int DigitMagnitude<10>() { + return 1; +} +template <> +constexpr int DigitMagnitude<16>() { + return 4; +} + +// Reads decimal digits from [begin, end) into *out. Returns the number of +// digits consumed. +// +// After max_digits has been read, keeps consuming characters, but no longer +// adjusts *out. If a nonzero digit is dropped this way, *dropped_nonzero_digit +// is set; otherwise, it is left unmodified. +// +// If no digits are matched, returns 0 and leaves *out unchanged. +// +// ConsumeDigits does not protect against overflow on *out; max_digits must +// be chosen with respect to type T to avoid the possibility of overflow. +template <int base, typename T> +std::size_t ConsumeDigits(const char* begin, const char* end, int max_digits, + T* out, bool* dropped_nonzero_digit) { + if (base == 10) { + assert(max_digits <= std::numeric_limits<T>::digits10); + } else if (base == 16) { + assert(max_digits * 4 <= std::numeric_limits<T>::digits); + } + const char* const original_begin = begin; + + // Skip leading zeros, but only if *out is zero. + // They don't cause an overflow so we don't have to count them for + // `max_digits`. + while (!*out && end != begin && *begin == '0') ++begin; + + T accumulator = *out; + const char* significant_digits_end = + (end - begin > max_digits) ? begin + max_digits : end; + while (begin < significant_digits_end && IsDigit<base>(*begin)) { + // Do not guard against *out overflow; max_digits was chosen to avoid this. + // Do assert against it, to detect problems in debug builds. + auto digit = static_cast<T>(ToDigit<base>(*begin)); + assert(accumulator * base >= accumulator); + accumulator *= base; + assert(accumulator + digit >= accumulator); + accumulator += digit; + ++begin; + } + bool dropped_nonzero = false; + while (begin < end && IsDigit<base>(*begin)) { + dropped_nonzero = dropped_nonzero || (*begin != '0'); + ++begin; + } + if (dropped_nonzero && dropped_nonzero_digit != nullptr) { + *dropped_nonzero_digit = true; + } + *out = accumulator; + return begin - original_begin; +} + +// Returns true if `v` is one of the chars allowed inside parentheses following +// a NaN. +bool IsNanChar(char v) { + return (v == '_') || (v >= '0' && v <= '9') || (v >= 'a' && v <= 'z') || + (v >= 'A' && v <= 'Z'); +} + +// Checks the range [begin, end) for a strtod()-formatted infinity or NaN. If +// one is found, sets `out` appropriately and returns true. +bool ParseInfinityOrNan(const char* begin, const char* end, + strings_internal::ParsedFloat* out) { + if (end - begin < 3) { + return false; + } + switch (*begin) { + case 'i': + case 'I': { + // An infinity string consists of the characters "inf" or "infinity", + // case insensitive. + if (strings_internal::memcasecmp(begin + 1, "nf", 2) != 0) { + return false; + } + out->type = strings_internal::FloatType::kInfinity; + if (end - begin >= 8 && + strings_internal::memcasecmp(begin + 3, "inity", 5) == 0) { + out->end = begin + 8; + } else { + out->end = begin + 3; + } + return true; + } + case 'n': + case 'N': { + // A NaN consists of the characters "nan", case insensitive, optionally + // followed by a parenthesized sequence of zero or more alphanumeric + // characters and/or underscores. + if (strings_internal::memcasecmp(begin + 1, "an", 2) != 0) { + return false; + } + out->type = strings_internal::FloatType::kNan; + out->end = begin + 3; + // NaN is allowed to be followed by a parenthesized string, consisting of + // only the characters [a-zA-Z0-9_]. Match that if it's present. + begin += 3; + if (begin < end && *begin == '(') { + const char* nan_begin = begin + 1; + while (nan_begin < end && IsNanChar(*nan_begin)) { + ++nan_begin; + } + if (nan_begin < end && *nan_begin == ')') { + // We found an extra NaN specifier range + out->subrange_begin = begin + 1; + out->subrange_end = nan_begin; + out->end = nan_begin + 1; + } + } + return true; + } + default: + return false; + } +} +} // namespace + +namespace strings_internal { + +template <int base> +strings_internal::ParsedFloat ParseFloat(const char* begin, const char* end, + chars_format format_flags) { + strings_internal::ParsedFloat result; + + // Exit early if we're given an empty range. + if (begin == end) return result; + + // Handle the infinity and NaN cases. + if (ParseInfinityOrNan(begin, end, &result)) { + return result; + } + + const char* const mantissa_begin = begin; + while (begin < end && *begin == '0') { + ++begin; // skip leading zeros + } + uint64_t mantissa = 0; + + int exponent_adjustment = 0; + bool mantissa_is_inexact = false; + std::size_t pre_decimal_digits = ConsumeDigits<base>( + begin, end, MantissaDigitsMax<base>(), &mantissa, &mantissa_is_inexact); + begin += pre_decimal_digits; + int digits_left; + if (pre_decimal_digits >= DigitLimit<base>()) { + // refuse to parse pathological inputs + return result; + } else if (pre_decimal_digits > MantissaDigitsMax<base>()) { + // We dropped some non-fraction digits on the floor. Adjust our exponent + // to compensate. + exponent_adjustment = + static_cast<int>(pre_decimal_digits - MantissaDigitsMax<base>()); + digits_left = 0; + } else { + digits_left = + static_cast<int>(MantissaDigitsMax<base>() - pre_decimal_digits); + } + if (begin < end && *begin == '.') { + ++begin; + if (mantissa == 0) { + // If we haven't seen any nonzero digits yet, keep skipping zeros. We + // have to adjust the exponent to reflect the changed place value. + const char* begin_zeros = begin; + while (begin < end && *begin == '0') { + ++begin; + } + std::size_t zeros_skipped = begin - begin_zeros; + if (zeros_skipped >= DigitLimit<base>()) { + // refuse to parse pathological inputs + return result; + } + exponent_adjustment -= static_cast<int>(zeros_skipped); + } + std::size_t post_decimal_digits = ConsumeDigits<base>( + begin, end, digits_left, &mantissa, &mantissa_is_inexact); + begin += post_decimal_digits; + + // Since `mantissa` is an integer, each significant digit we read after + // the decimal point requires an adjustment to the exponent. "1.23e0" will + // be stored as `mantissa` == 123 and `exponent` == -2 (that is, + // "123e-2"). + if (post_decimal_digits >= DigitLimit<base>()) { + // refuse to parse pathological inputs + return result; + } else if (post_decimal_digits > digits_left) { + exponent_adjustment -= digits_left; + } else { + exponent_adjustment -= post_decimal_digits; + } + } + // If we've found no mantissa whatsoever, this isn't a number. + if (mantissa_begin == begin) { + return result; + } + // A bare "." doesn't count as a mantissa either. + if (begin - mantissa_begin == 1 && *mantissa_begin == '.') { + return result; + } + + if (mantissa_is_inexact) { + // We dropped significant digits on the floor. Handle this appropriately. + if (base == 10) { + // If we truncated significant decimal digits, store the full range of the + // mantissa for future big integer math for exact rounding. + result.subrange_begin = mantissa_begin; + result.subrange_end = begin; + } else if (base == 16) { + // If we truncated hex digits, reflect this fact by setting the low + // ("sticky") bit. This allows for correct rounding in all cases. + mantissa |= 1; + } + } + result.mantissa = mantissa; + + const char* const exponent_begin = begin; + result.literal_exponent = 0; + bool found_exponent = false; + if (AllowExponent(format_flags) && begin < end && + IsExponentCharacter<base>(*begin)) { + bool negative_exponent = false; + ++begin; + if (begin < end && *begin == '-') { + negative_exponent = true; + ++begin; + } else if (begin < end && *begin == '+') { + ++begin; + } + const char* const exponent_digits_begin = begin; + // Exponent is always expressed in decimal, even for hexadecimal floats. + begin += ConsumeDigits<10>(begin, end, kDecimalExponentDigitsMax, + &result.literal_exponent, nullptr); + if (begin == exponent_digits_begin) { + // there were no digits where we expected an exponent. We failed to read + // an exponent and should not consume the 'e' after all. Rewind 'begin'. + found_exponent = false; + begin = exponent_begin; + } else { + found_exponent = true; + if (negative_exponent) { + result.literal_exponent = -result.literal_exponent; + } + } + } + + if (!found_exponent && RequireExponent(format_flags)) { + // Provided flags required an exponent, but none was found. This results + // in a failure to scan. + return result; + } + + // Success! + result.type = strings_internal::FloatType::kNumber; + if (result.mantissa > 0) { + result.exponent = result.literal_exponent + + (DigitMagnitude<base>() * exponent_adjustment); + } else { + result.exponent = 0; + } + result.end = begin; + return result; +} + +template ParsedFloat ParseFloat<10>(const char* begin, const char* end, + chars_format format_flags); +template ParsedFloat ParseFloat<16>(const char* begin, const char* end, + chars_format format_flags); + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/charconv_parse.h b/third_party/abseil_cpp/absl/strings/internal/charconv_parse.h new file mode 100644 index 0000000000..505998b539 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/charconv_parse.h @@ -0,0 +1,99 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_STRINGS_INTERNAL_CHARCONV_PARSE_H_ +#define ABSL_STRINGS_INTERNAL_CHARCONV_PARSE_H_ + +#include <cstdint> + +#include "absl/base/config.h" +#include "absl/strings/charconv.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// Enum indicating whether a parsed float is a number or special value. +enum class FloatType { kNumber, kInfinity, kNan }; + +// The decomposed parts of a parsed `float` or `double`. +struct ParsedFloat { + // Representation of the parsed mantissa, with the decimal point adjusted to + // make it an integer. + // + // During decimal scanning, this contains 19 significant digits worth of + // mantissa value. If digits beyond this point are found, they + // are truncated, and if any of these dropped digits are nonzero, then + // `mantissa` is inexact, and the full mantissa is stored in [subrange_begin, + // subrange_end). + // + // During hexadecimal scanning, this contains 15 significant hex digits worth + // of mantissa value. Digits beyond this point are sticky -- they are + // truncated, but if any dropped digits are nonzero, the low bit of mantissa + // will be set. (This allows for precise rounding, and avoids the need + // to store the full mantissa in [subrange_begin, subrange_end).) + uint64_t mantissa = 0; + + // Floating point expontent. This reflects any decimal point adjustments and + // any truncated digits from the mantissa. The absolute value of the parsed + // number is represented by mantissa * (base ** exponent), where base==10 for + // decimal floats, and base==2 for hexadecimal floats. + int exponent = 0; + + // The literal exponent value scanned from the input, or 0 if none was + // present. This does not reflect any adjustments applied to mantissa. + int literal_exponent = 0; + + // The type of number scanned. + FloatType type = FloatType::kNumber; + + // When non-null, [subrange_begin, subrange_end) marks a range of characters + // that require further processing. The meaning is dependent on float type. + // If type == kNumber and this is set, this is a "wide input": the input + // mantissa contained more than 19 digits. The range contains the full + // mantissa. It plus `literal_exponent` need to be examined to find the best + // floating point match. + // If type == kNan and this is set, the range marks the contents of a + // matched parenthesized character region after the NaN. + const char* subrange_begin = nullptr; + const char* subrange_end = nullptr; + + // One-past-the-end of the successfully parsed region, or nullptr if no + // matching pattern was found. + const char* end = nullptr; +}; + +// Read the floating point number in the provided range, and populate +// ParsedFloat accordingly. +// +// format_flags is a bitmask value specifying what patterns this API will match. +// `scientific` and `fixed` are honored per std::from_chars rules +// ([utility.from.chars], C++17): if exactly one of these bits is set, then an +// exponent is required, or dislallowed, respectively. +// +// Template parameter `base` must be either 10 or 16. For base 16, a "0x" is +// *not* consumed. The `hex` bit from format_flags is ignored by ParseFloat. +template <int base> +ParsedFloat ParseFloat(const char* begin, const char* end, + absl::chars_format format_flags); + +extern template ParsedFloat ParseFloat<10>(const char* begin, const char* end, + absl::chars_format format_flags); +extern template ParsedFloat ParseFloat<16>(const char* begin, const char* end, + absl::chars_format format_flags); + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_STRINGS_INTERNAL_CHARCONV_PARSE_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/charconv_parse_test.cc b/third_party/abseil_cpp/absl/strings/internal/charconv_parse_test.cc new file mode 100644 index 0000000000..bc2d111876 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/charconv_parse_test.cc @@ -0,0 +1,357 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/charconv_parse.h" + +#include <string> +#include <utility> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/str_cat.h" + +using absl::chars_format; +using absl::strings_internal::FloatType; +using absl::strings_internal::ParsedFloat; +using absl::strings_internal::ParseFloat; + +namespace { + +// Check that a given string input is parsed to the expected mantissa and +// exponent. +// +// Input string `s` must contain a '$' character. It marks the end of the +// characters that should be consumed by the match. It is stripped from the +// input to ParseFloat. +// +// If input string `s` contains '[' and ']' characters, these mark the region +// of characters that should be marked as the "subrange". For NaNs, this is +// the location of the extended NaN string. For numbers, this is the location +// of the full, over-large mantissa. +template <int base> +void ExpectParsedFloat(std::string s, absl::chars_format format_flags, + FloatType expected_type, uint64_t expected_mantissa, + int expected_exponent, + int expected_literal_exponent = -999) { + SCOPED_TRACE(s); + + int begin_subrange = -1; + int end_subrange = -1; + // If s contains '[' and ']', then strip these characters and set the subrange + // indices appropriately. + std::string::size_type open_bracket_pos = s.find('['); + if (open_bracket_pos != std::string::npos) { + begin_subrange = static_cast<int>(open_bracket_pos); + s.replace(open_bracket_pos, 1, ""); + std::string::size_type close_bracket_pos = s.find(']'); + ABSL_RAW_CHECK(close_bracket_pos != absl::string_view::npos, + "Test input contains [ without matching ]"); + end_subrange = static_cast<int>(close_bracket_pos); + s.replace(close_bracket_pos, 1, ""); + } + const std::string::size_type expected_characters_matched = s.find('$'); + ABSL_RAW_CHECK(expected_characters_matched != std::string::npos, + "Input string must contain $"); + s.replace(expected_characters_matched, 1, ""); + + ParsedFloat parsed = + ParseFloat<base>(s.data(), s.data() + s.size(), format_flags); + + EXPECT_NE(parsed.end, nullptr); + if (parsed.end == nullptr) { + return; // The following tests are not useful if we fully failed to parse + } + EXPECT_EQ(parsed.type, expected_type); + if (begin_subrange == -1) { + EXPECT_EQ(parsed.subrange_begin, nullptr); + EXPECT_EQ(parsed.subrange_end, nullptr); + } else { + EXPECT_EQ(parsed.subrange_begin, s.data() + begin_subrange); + EXPECT_EQ(parsed.subrange_end, s.data() + end_subrange); + } + if (parsed.type == FloatType::kNumber) { + EXPECT_EQ(parsed.mantissa, expected_mantissa); + EXPECT_EQ(parsed.exponent, expected_exponent); + if (expected_literal_exponent != -999) { + EXPECT_EQ(parsed.literal_exponent, expected_literal_exponent); + } + } + auto characters_matched = static_cast<int>(parsed.end - s.data()); + EXPECT_EQ(characters_matched, expected_characters_matched); +} + +// Check that a given string input is parsed to the expected mantissa and +// exponent. +// +// Input string `s` must contain a '$' character. It marks the end of the +// characters that were consumed by the match. +template <int base> +void ExpectNumber(std::string s, absl::chars_format format_flags, + uint64_t expected_mantissa, int expected_exponent, + int expected_literal_exponent = -999) { + ExpectParsedFloat<base>(std::move(s), format_flags, FloatType::kNumber, + expected_mantissa, expected_exponent, + expected_literal_exponent); +} + +// Check that a given string input is parsed to the given special value. +// +// This tests against both number bases, since infinities and NaNs have +// identical representations in both modes. +void ExpectSpecial(const std::string& s, absl::chars_format format_flags, + FloatType type) { + ExpectParsedFloat<10>(s, format_flags, type, 0, 0); + ExpectParsedFloat<16>(s, format_flags, type, 0, 0); +} + +// Check that a given input string is not matched by Float. +template <int base> +void ExpectFailedParse(absl::string_view s, absl::chars_format format_flags) { + ParsedFloat parsed = + ParseFloat<base>(s.data(), s.data() + s.size(), format_flags); + EXPECT_EQ(parsed.end, nullptr); +} + +TEST(ParseFloat, SimpleValue) { + // Test that various forms of floating point numbers all parse correctly. + ExpectNumber<10>("1.23456789e5$", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789e+5$", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789E5$", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789e05$", chars_format::general, 123456789, -3); + ExpectNumber<10>("123.456789e3$", chars_format::general, 123456789, -3); + ExpectNumber<10>("0.000123456789e9$", chars_format::general, 123456789, -3); + ExpectNumber<10>("123456.789$", chars_format::general, 123456789, -3); + ExpectNumber<10>("123456789e-3$", chars_format::general, 123456789, -3); + + ExpectNumber<16>("1.234abcdefp28$", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("1.234abcdefp+28$", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("1.234ABCDEFp28$", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("1.234AbCdEfP0028$", chars_format::general, 0x1234abcdef, + -8); + ExpectNumber<16>("123.4abcdefp20$", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("0.0001234abcdefp44$", chars_format::general, 0x1234abcdef, + -8); + ExpectNumber<16>("1234abcd.ef$", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("1234abcdefp-8$", chars_format::general, 0x1234abcdef, -8); + + // ExpectNumber does not attempt to drop trailing zeroes. + ExpectNumber<10>("0001.2345678900e005$", chars_format::general, 12345678900, + -5); + ExpectNumber<16>("0001.234abcdef000p28$", chars_format::general, + 0x1234abcdef000, -20); + + // Ensure non-matching characters after a number are ignored, even when they + // look like potentially matching characters. + ExpectNumber<10>("1.23456789e5$ ", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789e5$e5e5", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789e5$.25", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789e5$-", chars_format::general, 123456789, -3); + ExpectNumber<10>("1.23456789e5$PUPPERS!!!", chars_format::general, 123456789, + -3); + ExpectNumber<10>("123456.789$efghij", chars_format::general, 123456789, -3); + ExpectNumber<10>("123456.789$e", chars_format::general, 123456789, -3); + ExpectNumber<10>("123456.789$p5", chars_format::general, 123456789, -3); + ExpectNumber<10>("123456.789$.10", chars_format::general, 123456789, -3); + + ExpectNumber<16>("1.234abcdefp28$ ", chars_format::general, 0x1234abcdef, + -8); + ExpectNumber<16>("1.234abcdefp28$p28", chars_format::general, 0x1234abcdef, + -8); + ExpectNumber<16>("1.234abcdefp28$.125", chars_format::general, 0x1234abcdef, + -8); + ExpectNumber<16>("1.234abcdefp28$-", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("1.234abcdefp28$KITTEHS!!!", chars_format::general, + 0x1234abcdef, -8); + ExpectNumber<16>("1234abcd.ef$ghijk", chars_format::general, 0x1234abcdef, + -8); + ExpectNumber<16>("1234abcd.ef$p", chars_format::general, 0x1234abcdef, -8); + ExpectNumber<16>("1234abcd.ef$.10", chars_format::general, 0x1234abcdef, -8); + + // Ensure we can read a full resolution mantissa without overflow. + ExpectNumber<10>("9999999999999999999$", chars_format::general, + 9999999999999999999u, 0); + ExpectNumber<16>("fffffffffffffff$", chars_format::general, + 0xfffffffffffffffu, 0); + + // Check that zero is consistently read. + ExpectNumber<10>("0$", chars_format::general, 0, 0); + ExpectNumber<16>("0$", chars_format::general, 0, 0); + ExpectNumber<10>("000000000000000000000000000000000000000$", + chars_format::general, 0, 0); + ExpectNumber<16>("000000000000000000000000000000000000000$", + chars_format::general, 0, 0); + ExpectNumber<10>("0000000000000000000000.000000000000000000$", + chars_format::general, 0, 0); + ExpectNumber<16>("0000000000000000000000.000000000000000000$", + chars_format::general, 0, 0); + ExpectNumber<10>("0.00000000000000000000000000000000e123456$", + chars_format::general, 0, 0); + ExpectNumber<16>("0.00000000000000000000000000000000p123456$", + chars_format::general, 0, 0); +} + +TEST(ParseFloat, LargeDecimalMantissa) { + // After 19 significant decimal digits in the mantissa, ParsedFloat will + // truncate additional digits. We need to test that: + // 1) the truncation to 19 digits happens + // 2) the returned exponent reflects the dropped significant digits + // 3) a correct literal_exponent is set + // + // If and only if a significant digit is found after 19 digits, then the + // entirety of the mantissa in case the exact value is needed to make a + // rounding decision. The [ and ] characters below denote where such a + // subregion was marked by by ParseFloat. They are not part of the input. + + // Mark a capture group only if a dropped digit is significant (nonzero). + ExpectNumber<10>("100000000000000000000000000$", chars_format::general, + 1000000000000000000, + /* adjusted exponent */ 8); + + ExpectNumber<10>("123456789123456789100000000$", chars_format::general, + 1234567891234567891, + /* adjusted exponent */ 8); + + ExpectNumber<10>("[123456789123456789123456789]$", chars_format::general, + 1234567891234567891, + /* adjusted exponent */ 8, + /* literal exponent */ 0); + + ExpectNumber<10>("[123456789123456789100000009]$", chars_format::general, + 1234567891234567891, + /* adjusted exponent */ 8, + /* literal exponent */ 0); + + ExpectNumber<10>("[123456789123456789120000000]$", chars_format::general, + 1234567891234567891, + /* adjusted exponent */ 8, + /* literal exponent */ 0); + + // Leading zeroes should not count towards the 19 significant digit limit + ExpectNumber<10>("[00000000123456789123456789123456789]$", + chars_format::general, 1234567891234567891, + /* adjusted exponent */ 8, + /* literal exponent */ 0); + + ExpectNumber<10>("00000000123456789123456789100000000$", + chars_format::general, 1234567891234567891, + /* adjusted exponent */ 8); + + // Truncated digits after the decimal point should not cause a further + // exponent adjustment. + ExpectNumber<10>("1.234567891234567891e123$", chars_format::general, + 1234567891234567891, 105); + ExpectNumber<10>("[1.23456789123456789123456789]e123$", chars_format::general, + 1234567891234567891, + /* adjusted exponent */ 105, + /* literal exponent */ 123); + + // Ensure we truncate, and not round. (The from_chars algorithm we use + // depends on our guess missing low, if it misses, so we need the rounding + // error to be downward.) + ExpectNumber<10>("[1999999999999999999999]$", chars_format::general, + 1999999999999999999, + /* adjusted exponent */ 3, + /* literal exponent */ 0); +} + +TEST(ParseFloat, LargeHexadecimalMantissa) { + // After 15 significant hex digits in the mantissa, ParsedFloat will treat + // additional digits as sticky, We need to test that: + // 1) The truncation to 15 digits happens + // 2) The returned exponent reflects the dropped significant digits + // 3) If a nonzero digit is dropped, the low bit of mantissa is set. + + ExpectNumber<16>("123456789abcdef123456789abcdef$", chars_format::general, + 0x123456789abcdef, 60); + + // Leading zeroes should not count towards the 15 significant digit limit + ExpectNumber<16>("000000123456789abcdef123456789abcdef$", + chars_format::general, 0x123456789abcdef, 60); + + // Truncated digits after the radix point should not cause a further + // exponent adjustment. + ExpectNumber<16>("1.23456789abcdefp100$", chars_format::general, + 0x123456789abcdef, 44); + ExpectNumber<16>("1.23456789abcdef123456789abcdefp100$", + chars_format::general, 0x123456789abcdef, 44); + + // test sticky digit behavior. The low bit should be set iff any dropped + // digit is nonzero. + ExpectNumber<16>("123456789abcdee123456789abcdee$", chars_format::general, + 0x123456789abcdef, 60); + ExpectNumber<16>("123456789abcdee000000000000001$", chars_format::general, + 0x123456789abcdef, 60); + ExpectNumber<16>("123456789abcdee000000000000000$", chars_format::general, + 0x123456789abcdee, 60); +} + +TEST(ParseFloat, ScientificVsFixed) { + // In fixed mode, an exponent is never matched (but the remainder of the + // number will be matched.) + ExpectNumber<10>("1.23456789$e5", chars_format::fixed, 123456789, -8); + ExpectNumber<10>("123456.789$", chars_format::fixed, 123456789, -3); + ExpectNumber<16>("1.234abcdef$p28", chars_format::fixed, 0x1234abcdef, -36); + ExpectNumber<16>("1234abcd.ef$", chars_format::fixed, 0x1234abcdef, -8); + + // In scientific mode, numbers don't match *unless* they have an exponent. + ExpectNumber<10>("1.23456789e5$", chars_format::scientific, 123456789, -3); + ExpectFailedParse<10>("-123456.789$", chars_format::scientific); + ExpectNumber<16>("1.234abcdefp28$", chars_format::scientific, 0x1234abcdef, + -8); + ExpectFailedParse<16>("1234abcd.ef$", chars_format::scientific); +} + +TEST(ParseFloat, Infinity) { + ExpectFailedParse<10>("in", chars_format::general); + ExpectFailedParse<16>("in", chars_format::general); + ExpectFailedParse<10>("inx", chars_format::general); + ExpectFailedParse<16>("inx", chars_format::general); + ExpectSpecial("inf$", chars_format::general, FloatType::kInfinity); + ExpectSpecial("Inf$", chars_format::general, FloatType::kInfinity); + ExpectSpecial("INF$", chars_format::general, FloatType::kInfinity); + ExpectSpecial("inf$inite", chars_format::general, FloatType::kInfinity); + ExpectSpecial("iNfInItY$", chars_format::general, FloatType::kInfinity); + ExpectSpecial("infinity$!!!", chars_format::general, FloatType::kInfinity); +} + +TEST(ParseFloat, NaN) { + ExpectFailedParse<10>("na", chars_format::general); + ExpectFailedParse<16>("na", chars_format::general); + ExpectFailedParse<10>("nah", chars_format::general); + ExpectFailedParse<16>("nah", chars_format::general); + ExpectSpecial("nan$", chars_format::general, FloatType::kNan); + ExpectSpecial("NaN$", chars_format::general, FloatType::kNan); + ExpectSpecial("nAn$", chars_format::general, FloatType::kNan); + ExpectSpecial("NAN$", chars_format::general, FloatType::kNan); + ExpectSpecial("NaN$aNaNaNaNaBatman!", chars_format::general, FloatType::kNan); + + // A parenthesized sequence of the characters [a-zA-Z0-9_] is allowed to + // appear after an NaN. Check that this is allowed, and that the correct + // characters are grouped. + // + // (The characters [ and ] in the pattern below delimit the expected matched + // subgroup; they are not part of the input passed to ParseFloat.) + ExpectSpecial("nan([0xabcdef])$", chars_format::general, FloatType::kNan); + ExpectSpecial("nan([0xabcdef])$...", chars_format::general, FloatType::kNan); + ExpectSpecial("nan([0xabcdef])$)...", chars_format::general, FloatType::kNan); + ExpectSpecial("nan([])$", chars_format::general, FloatType::kNan); + ExpectSpecial("nan([aAzZ09_])$", chars_format::general, FloatType::kNan); + // If the subgroup contains illegal characters, don't match it at all. + ExpectSpecial("nan$(bad-char)", chars_format::general, FloatType::kNan); + // Also cope with a missing close paren. + ExpectSpecial("nan$(0xabcdef", chars_format::general, FloatType::kNan); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/cord_internal.h b/third_party/abseil_cpp/absl/strings/internal/cord_internal.h new file mode 100644 index 0000000000..830ceaf473 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/cord_internal.h @@ -0,0 +1,150 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_STRINGS_INTERNAL_CORD_INTERNAL_H_ +#define ABSL_STRINGS_INTERNAL_CORD_INTERNAL_H_ + +#include <atomic> +#include <cassert> +#include <cstddef> +#include <cstdint> +#include <type_traits> + +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace cord_internal { + +// Wraps std::atomic for reference counting. +class Refcount { + public: + Refcount() : count_{1} {} + ~Refcount() {} + + // Increments the reference count by 1. Imposes no memory ordering. + inline void Increment() { count_.fetch_add(1, std::memory_order_relaxed); } + + // Asserts that the current refcount is greater than 0. If the refcount is + // greater than 1, decrements the reference count by 1. + // + // Returns false if there are no references outstanding; true otherwise. + // Inserts barriers to ensure that state written before this method returns + // false will be visible to a thread that just observed this method returning + // false. + inline bool Decrement() { + int32_t refcount = count_.load(std::memory_order_acquire); + assert(refcount > 0); + return refcount != 1 && count_.fetch_sub(1, std::memory_order_acq_rel) != 1; + } + + // Same as Decrement but expect that refcount is greater than 1. + inline bool DecrementExpectHighRefcount() { + int32_t refcount = count_.fetch_sub(1, std::memory_order_acq_rel); + assert(refcount > 0); + return refcount != 1; + } + + // Returns the current reference count using acquire semantics. + inline int32_t Get() const { return count_.load(std::memory_order_acquire); } + + // Returns whether the atomic integer is 1. + // If the reference count is used in the conventional way, a + // reference count of 1 implies that the current thread owns the + // reference and no other thread shares it. + // This call performs the test for a reference count of one, and + // performs the memory barrier needed for the owning thread + // to act on the object, knowing that it has exclusive access to the + // object. + inline bool IsOne() { return count_.load(std::memory_order_acquire) == 1; } + + private: + std::atomic<int32_t> count_; +}; + +// The overhead of a vtable is too much for Cord, so we roll our own subclasses +// using only a single byte to differentiate classes from each other - the "tag" +// byte. Define the subclasses first so we can provide downcasting helper +// functions in the base class. + +struct CordRepConcat; +struct CordRepSubstring; +struct CordRepExternal; + +struct CordRep { + // The following three fields have to be less than 32 bytes since + // that is the smallest supported flat node size. + size_t length; + Refcount refcount; + // If tag < FLAT, it represents CordRepKind and indicates the type of node. + // Otherwise, the node type is CordRepFlat and the tag is the encoded size. + uint8_t tag; + char data[1]; // Starting point for flat array: MUST BE LAST FIELD of CordRep + + inline CordRepConcat* concat(); + inline const CordRepConcat* concat() const; + inline CordRepSubstring* substring(); + inline const CordRepSubstring* substring() const; + inline CordRepExternal* external(); + inline const CordRepExternal* external() const; +}; + +struct CordRepConcat : public CordRep { + CordRep* left; + CordRep* right; + + uint8_t depth() const { return static_cast<uint8_t>(data[0]); } + void set_depth(uint8_t depth) { data[0] = static_cast<char>(depth); } +}; + +struct CordRepSubstring : public CordRep { + size_t start; // Starting offset of substring in child + CordRep* child; +}; + +// TODO(strel): replace the following logic (and related functions in cord.cc) +// with container_internal::Layout. + +// Alignment requirement for CordRepExternal so that the type erased releaser +// will be stored at a suitably aligned address. +constexpr size_t ExternalRepAlignment() { +#if defined(__STDCPP_DEFAULT_NEW_ALIGNMENT__) + return __STDCPP_DEFAULT_NEW_ALIGNMENT__; +#else + return alignof(max_align_t); +#endif +} + +// Type for function pointer that will invoke and destroy the type-erased +// releaser function object. Accepts a pointer to the releaser and the +// `string_view` that were passed in to `NewExternalRep` below. The return value +// is the size of the `Releaser` type. +using ExternalReleaserInvoker = size_t (*)(void*, absl::string_view); + +// External CordReps are allocated together with a type erased releaser. The +// releaser is stored in the memory directly following the CordRepExternal. +struct alignas(ExternalRepAlignment()) CordRepExternal : public CordRep { + const char* base; + // Pointer to function that knows how to call and destroy the releaser. + ExternalReleaserInvoker releaser_invoker; +}; + +// TODO(strel): look into removing, it doesn't seem like anything relies on this +static_assert(sizeof(CordRepConcat) == sizeof(CordRepSubstring), ""); + +} // namespace cord_internal +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_STRINGS_INTERNAL_CORD_INTERNAL_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/escaping.cc b/third_party/abseil_cpp/absl/strings/internal/escaping.cc new file mode 100644 index 0000000000..c5271286ad --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/escaping.cc @@ -0,0 +1,180 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/escaping.h" + +#include "absl/base/internal/endian.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +const char kBase64Chars[] = + "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; + +size_t CalculateBase64EscapedLenInternal(size_t input_len, bool do_padding) { + // Base64 encodes three bytes of input at a time. If the input is not + // divisible by three, we pad as appropriate. + // + // (from https://tools.ietf.org/html/rfc3548) + // Special processing is performed if fewer than 24 bits are available + // at the end of the data being encoded. A full encoding quantum is + // always completed at the end of a quantity. When fewer than 24 input + // bits are available in an input group, zero bits are added (on the + // right) to form an integral number of 6-bit groups. Padding at the + // end of the data is performed using the '=' character. Since all base + // 64 input is an integral number of octets, only the following cases + // can arise: + + // Base64 encodes each three bytes of input into four bytes of output. + size_t len = (input_len / 3) * 4; + + if (input_len % 3 == 0) { + // (from https://tools.ietf.org/html/rfc3548) + // (1) the final quantum of encoding input is an integral multiple of 24 + // bits; here, the final unit of encoded output will be an integral + // multiple of 4 characters with no "=" padding, + } else if (input_len % 3 == 1) { + // (from https://tools.ietf.org/html/rfc3548) + // (2) the final quantum of encoding input is exactly 8 bits; here, the + // final unit of encoded output will be two characters followed by two + // "=" padding characters, or + len += 2; + if (do_padding) { + len += 2; + } + } else { // (input_len % 3 == 2) + // (from https://tools.ietf.org/html/rfc3548) + // (3) the final quantum of encoding input is exactly 16 bits; here, the + // final unit of encoded output will be three characters followed by one + // "=" padding character. + len += 3; + if (do_padding) { + len += 1; + } + } + + assert(len >= input_len); // make sure we didn't overflow + return len; +} + +size_t Base64EscapeInternal(const unsigned char* src, size_t szsrc, char* dest, + size_t szdest, const char* base64, + bool do_padding) { + static const char kPad64 = '='; + + if (szsrc * 4 > szdest * 3) return 0; + + char* cur_dest = dest; + const unsigned char* cur_src = src; + + char* const limit_dest = dest + szdest; + const unsigned char* const limit_src = src + szsrc; + + // Three bytes of data encodes to four characters of cyphertext. + // So we can pump through three-byte chunks atomically. + if (szsrc >= 3) { // "limit_src - 3" is UB if szsrc < 3. + while (cur_src < limit_src - 3) { // While we have >= 32 bits. + uint32_t in = absl::big_endian::Load32(cur_src) >> 8; + + cur_dest[0] = base64[in >> 18]; + in &= 0x3FFFF; + cur_dest[1] = base64[in >> 12]; + in &= 0xFFF; + cur_dest[2] = base64[in >> 6]; + in &= 0x3F; + cur_dest[3] = base64[in]; + + cur_dest += 4; + cur_src += 3; + } + } + // To save time, we didn't update szdest or szsrc in the loop. So do it now. + szdest = limit_dest - cur_dest; + szsrc = limit_src - cur_src; + + /* now deal with the tail (<=3 bytes) */ + switch (szsrc) { + case 0: + // Nothing left; nothing more to do. + break; + case 1: { + // One byte left: this encodes to two characters, and (optionally) + // two pad characters to round out the four-character cypherblock. + if (szdest < 2) return 0; + uint32_t in = cur_src[0]; + cur_dest[0] = base64[in >> 2]; + in &= 0x3; + cur_dest[1] = base64[in << 4]; + cur_dest += 2; + szdest -= 2; + if (do_padding) { + if (szdest < 2) return 0; + cur_dest[0] = kPad64; + cur_dest[1] = kPad64; + cur_dest += 2; + szdest -= 2; + } + break; + } + case 2: { + // Two bytes left: this encodes to three characters, and (optionally) + // one pad character to round out the four-character cypherblock. + if (szdest < 3) return 0; + uint32_t in = absl::big_endian::Load16(cur_src); + cur_dest[0] = base64[in >> 10]; + in &= 0x3FF; + cur_dest[1] = base64[in >> 4]; + in &= 0x00F; + cur_dest[2] = base64[in << 2]; + cur_dest += 3; + szdest -= 3; + if (do_padding) { + if (szdest < 1) return 0; + cur_dest[0] = kPad64; + cur_dest += 1; + szdest -= 1; + } + break; + } + case 3: { + // Three bytes left: same as in the big loop above. We can't do this in + // the loop because the loop above always reads 4 bytes, and the fourth + // byte is past the end of the input. + if (szdest < 4) return 0; + uint32_t in = (cur_src[0] << 16) + absl::big_endian::Load16(cur_src + 1); + cur_dest[0] = base64[in >> 18]; + in &= 0x3FFFF; + cur_dest[1] = base64[in >> 12]; + in &= 0xFFF; + cur_dest[2] = base64[in >> 6]; + in &= 0x3F; + cur_dest[3] = base64[in]; + cur_dest += 4; + szdest -= 4; + break; + } + default: + // Should not be reached: blocks of 4 bytes are handled + // in the while loop before this switch statement. + ABSL_RAW_LOG(FATAL, "Logic problem? szsrc = %zu", szsrc); + break; + } + return (cur_dest - dest); +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/escaping.h b/third_party/abseil_cpp/absl/strings/internal/escaping.h new file mode 100644 index 0000000000..6a9ce602d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/escaping.h @@ -0,0 +1,58 @@ +// Copyright 2020 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_STRINGS_INTERNAL_ESCAPING_H_ +#define ABSL_STRINGS_INTERNAL_ESCAPING_H_ + +#include <cassert> + +#include "absl/strings/internal/resize_uninitialized.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +ABSL_CONST_INIT extern const char kBase64Chars[]; + +// Calculates how long a string will be when it is base64 encoded given its +// length and whether or not the result should be padded. +size_t CalculateBase64EscapedLenInternal(size_t input_len, bool do_padding); + +// Base64-encodes `src` using the alphabet provided in `base64` and writes the +// result to `dest`. If `do_padding` is true, `dest` is padded with '=' chars +// until its length is a multiple of 3. Returns the length of `dest`. +size_t Base64EscapeInternal(const unsigned char* src, size_t szsrc, char* dest, + size_t szdest, const char* base64, bool do_padding); + +// Base64-encodes `src` using the alphabet provided in `base64` and writes the +// result to `dest`. If `do_padding` is true, `dest` is padded with '=' chars +// until its length is a multiple of 3. +template <typename String> +void Base64EscapeInternal(const unsigned char* src, size_t szsrc, String* dest, + bool do_padding, const char* base64_chars) { + const size_t calc_escaped_size = + CalculateBase64EscapedLenInternal(szsrc, do_padding); + STLStringResizeUninitialized(dest, calc_escaped_size); + + const size_t escaped_len = Base64EscapeInternal( + src, szsrc, &(*dest)[0], dest->size(), base64_chars, do_padding); + assert(calc_escaped_size == escaped_len); + dest->erase(escaped_len); +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_ESCAPING_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/escaping_test_common.h b/third_party/abseil_cpp/absl/strings/internal/escaping_test_common.h new file mode 100644 index 0000000000..7b18017a08 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/escaping_test_common.h @@ -0,0 +1,133 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This test contains common things needed by both escaping_test.cc and +// escaping_benchmark.cc. + +#ifndef ABSL_STRINGS_INTERNAL_ESCAPING_TEST_COMMON_H_ +#define ABSL_STRINGS_INTERNAL_ESCAPING_TEST_COMMON_H_ + +#include <array> +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +struct base64_testcase { + absl::string_view plaintext; + absl::string_view cyphertext; +}; + +inline const std::array<base64_testcase, 5>& base64_strings() { + static const std::array<base64_testcase, 5> testcase{{ + // Some google quotes + // Cyphertext created with "uuencode (GNU sharutils) 4.6.3" + // (Note that we're testing the websafe encoding, though, so if + // you add messages, be sure to run "tr -- '+/' '-_'" on the output) + { "I was always good at math and science, and I never realized " + "that was unusual or somehow undesirable. So one of the things " + "I care a lot about is helping to remove that stigma, " + "to show girls that you can be feminine, you can like the things " + "that girls like, but you can also be really good at technology. " + "You can be really good at building things." + " - Marissa Meyer, Newsweek, 2010-12-22" "\n", + + "SSB3YXMgYWx3YXlzIGdvb2QgYXQgbWF0aCBhbmQgc2NpZW5jZSwgYW5kIEkg" + "bmV2ZXIgcmVhbGl6ZWQgdGhhdCB3YXMgdW51c3VhbCBvciBzb21laG93IHVu" + "ZGVzaXJhYmxlLiBTbyBvbmUgb2YgdGhlIHRoaW5ncyBJIGNhcmUgYSBsb3Qg" + "YWJvdXQgaXMgaGVscGluZyB0byByZW1vdmUgdGhhdCBzdGlnbWEsIHRvIHNo" + "b3cgZ2lybHMgdGhhdCB5b3UgY2FuIGJlIGZlbWluaW5lLCB5b3UgY2FuIGxp" + "a2UgdGhlIHRoaW5ncyB0aGF0IGdpcmxzIGxpa2UsIGJ1dCB5b3UgY2FuIGFs" + "c28gYmUgcmVhbGx5IGdvb2QgYXQgdGVjaG5vbG9neS4gWW91IGNhbiBiZSBy" + "ZWFsbHkgZ29vZCBhdCBidWlsZGluZyB0aGluZ3MuIC0gTWFyaXNzYSBNZXll" + "ciwgTmV3c3dlZWssIDIwMTAtMTItMjIK" }, + + { "Typical first year for a new cluster: " + "~0.5 overheating " + "~1 PDU failure " + "~1 rack-move " + "~1 network rewiring " + "~20 rack failures " + "~5 racks go wonky " + "~8 network maintenances " + "~12 router reloads " + "~3 router failures " + "~dozens of minor 30-second blips for dns " + "~1000 individual machine failures " + "~thousands of hard drive failures " + "slow disks, bad memory, misconfigured machines, flaky machines, etc." + " - Jeff Dean, The Joys of Real Hardware" "\n", + + "VHlwaWNhbCBmaXJzdCB5ZWFyIGZvciBhIG5ldyBjbHVzdGVyOiB-MC41IG92" + "ZXJoZWF0aW5nIH4xIFBEVSBmYWlsdXJlIH4xIHJhY2stbW92ZSB-MSBuZXR3" + "b3JrIHJld2lyaW5nIH4yMCByYWNrIGZhaWx1cmVzIH41IHJhY2tzIGdvIHdv" + "bmt5IH44IG5ldHdvcmsgbWFpbnRlbmFuY2VzIH4xMiByb3V0ZXIgcmVsb2Fk" + "cyB-MyByb3V0ZXIgZmFpbHVyZXMgfmRvemVucyBvZiBtaW5vciAzMC1zZWNv" + "bmQgYmxpcHMgZm9yIGRucyB-MTAwMCBpbmRpdmlkdWFsIG1hY2hpbmUgZmFp" + "bHVyZXMgfnRob3VzYW5kcyBvZiBoYXJkIGRyaXZlIGZhaWx1cmVzIHNsb3cg" + "ZGlza3MsIGJhZCBtZW1vcnksIG1pc2NvbmZpZ3VyZWQgbWFjaGluZXMsIGZs" + "YWt5IG1hY2hpbmVzLCBldGMuIC0gSmVmZiBEZWFuLCBUaGUgSm95cyBvZiBS" + "ZWFsIEhhcmR3YXJlCg" }, + + { "I'm the head of the webspam team at Google. " + "That means that if you type your name into Google and get porn back, " + "it's my fault. Unless you're a porn star, in which case porn is a " + "completely reasonable response." + " - Matt Cutts, Google Plus" "\n", + + "SSdtIHRoZSBoZWFkIG9mIHRoZSB3ZWJzcGFtIHRlYW0gYXQgR29vZ2xlLiAg" + "VGhhdCBtZWFucyB0aGF0IGlmIHlvdSB0eXBlIHlvdXIgbmFtZSBpbnRvIEdv" + "b2dsZSBhbmQgZ2V0IHBvcm4gYmFjaywgaXQncyBteSBmYXVsdC4gVW5sZXNz" + "IHlvdSdyZSBhIHBvcm4gc3RhciwgaW4gd2hpY2ggY2FzZSBwb3JuIGlzIGEg" + "Y29tcGxldGVseSByZWFzb25hYmxlIHJlc3BvbnNlLiAtIE1hdHQgQ3V0dHMs" + "IEdvb2dsZSBQbHVzCg" }, + + { "It will still be a long time before machines approach human " + "intelligence. " + "But luckily, machines don't actually have to be intelligent; " + "they just have to fake it. Access to a wealth of information, " + "combined with a rudimentary decision-making capacity, " + "can often be almost as useful. Of course, the results are better yet " + "when coupled with intelligence. A reference librarian with access to " + "a good search engine is a formidable tool." + " - Craig Silverstein, Siemens Pictures of the Future, Spring 2004" + "\n", + + "SXQgd2lsbCBzdGlsbCBiZSBhIGxvbmcgdGltZSBiZWZvcmUgbWFjaGluZXMg" + "YXBwcm9hY2ggaHVtYW4gaW50ZWxsaWdlbmNlLiBCdXQgbHVja2lseSwgbWFj" + "aGluZXMgZG9uJ3QgYWN0dWFsbHkgaGF2ZSB0byBiZSBpbnRlbGxpZ2VudDsg" + "dGhleSBqdXN0IGhhdmUgdG8gZmFrZSBpdC4gQWNjZXNzIHRvIGEgd2VhbHRo" + "IG9mIGluZm9ybWF0aW9uLCBjb21iaW5lZCB3aXRoIGEgcnVkaW1lbnRhcnkg" + "ZGVjaXNpb24tbWFraW5nIGNhcGFjaXR5LCBjYW4gb2Z0ZW4gYmUgYWxtb3N0" + "IGFzIHVzZWZ1bC4gT2YgY291cnNlLCB0aGUgcmVzdWx0cyBhcmUgYmV0dGVy" + "IHlldCB3aGVuIGNvdXBsZWQgd2l0aCBpbnRlbGxpZ2VuY2UuIEEgcmVmZXJl" + "bmNlIGxpYnJhcmlhbiB3aXRoIGFjY2VzcyB0byBhIGdvb2Qgc2VhcmNoIGVu" + "Z2luZSBpcyBhIGZvcm1pZGFibGUgdG9vbC4gLSBDcmFpZyBTaWx2ZXJzdGVp" + "biwgU2llbWVucyBQaWN0dXJlcyBvZiB0aGUgRnV0dXJlLCBTcHJpbmcgMjAw" + "NAo" }, + + // Degenerate edge case + { "", + "" }, + }}; + + return testcase; +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_ESCAPING_TEST_COMMON_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/memutil.cc b/third_party/abseil_cpp/absl/strings/internal/memutil.cc new file mode 100644 index 0000000000..2519c6881e --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/memutil.cc @@ -0,0 +1,112 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/memutil.h" + +#include <cstdlib> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +int memcasecmp(const char* s1, const char* s2, size_t len) { + const unsigned char* us1 = reinterpret_cast<const unsigned char*>(s1); + const unsigned char* us2 = reinterpret_cast<const unsigned char*>(s2); + + for (size_t i = 0; i < len; i++) { + const int diff = + int{static_cast<unsigned char>(absl::ascii_tolower(us1[i]))} - + int{static_cast<unsigned char>(absl::ascii_tolower(us2[i]))}; + if (diff != 0) return diff; + } + return 0; +} + +char* memdup(const char* s, size_t slen) { + void* copy; + if ((copy = malloc(slen)) == nullptr) return nullptr; + memcpy(copy, s, slen); + return reinterpret_cast<char*>(copy); +} + +char* memrchr(const char* s, int c, size_t slen) { + for (const char* e = s + slen - 1; e >= s; e--) { + if (*e == c) return const_cast<char*>(e); + } + return nullptr; +} + +size_t memspn(const char* s, size_t slen, const char* accept) { + const char* p = s; + const char* spanp; + char c, sc; + +cont: + c = *p++; + if (slen-- == 0) return p - 1 - s; + for (spanp = accept; (sc = *spanp++) != '\0';) + if (sc == c) goto cont; + return p - 1 - s; +} + +size_t memcspn(const char* s, size_t slen, const char* reject) { + const char* p = s; + const char* spanp; + char c, sc; + + while (slen-- != 0) { + c = *p++; + for (spanp = reject; (sc = *spanp++) != '\0';) + if (sc == c) return p - 1 - s; + } + return p - s; +} + +char* mempbrk(const char* s, size_t slen, const char* accept) { + const char* scanp; + int sc; + + for (; slen; ++s, --slen) { + for (scanp = accept; (sc = *scanp++) != '\0';) + if (sc == *s) return const_cast<char*>(s); + } + return nullptr; +} + +// This is significantly faster for case-sensitive matches with very +// few possible matches. See unit test for benchmarks. +const char* memmatch(const char* phaystack, size_t haylen, const char* pneedle, + size_t neelen) { + if (0 == neelen) { + return phaystack; // even if haylen is 0 + } + if (haylen < neelen) return nullptr; + + const char* match; + const char* hayend = phaystack + haylen - neelen + 1; + // A static cast is used here to work around the fact that memchr returns + // a void* on Posix-compliant systems and const void* on Windows. + while ((match = static_cast<const char*>( + memchr(phaystack, pneedle[0], hayend - phaystack)))) { + if (memcmp(match, pneedle, neelen) == 0) + return match; + else + phaystack = match + 1; + } + return nullptr; +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/memutil.h b/third_party/abseil_cpp/absl/strings/internal/memutil.h new file mode 100644 index 0000000000..9ad0535808 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/memutil.h @@ -0,0 +1,148 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// These routines provide mem versions of standard C string routines, +// such as strpbrk. They function exactly the same as the str versions, +// so if you wonder what they are, replace the word "mem" by +// "str" and check out the man page. I could return void*, as the +// strutil.h mem*() routines tend to do, but I return char* instead +// since this is by far the most common way these functions are called. +// +// The difference between the mem and str versions is the mem version +// takes a pointer and a length, rather than a '\0'-terminated string. +// The memcase* routines defined here assume the locale is "C" +// (they use absl::ascii_tolower instead of tolower). +// +// These routines are based on the BSD library. +// +// Here's a list of routines from string.h, and their mem analogues. +// Functions in lowercase are defined in string.h; those in UPPERCASE +// are defined here: +// +// strlen -- +// strcat strncat MEMCAT +// strcpy strncpy memcpy +// -- memccpy (very cool function, btw) +// -- memmove +// -- memset +// strcmp strncmp memcmp +// strcasecmp strncasecmp MEMCASECMP +// strchr memchr +// strcoll -- +// strxfrm -- +// strdup strndup MEMDUP +// strrchr MEMRCHR +// strspn MEMSPN +// strcspn MEMCSPN +// strpbrk MEMPBRK +// strstr MEMSTR MEMMEM +// (g)strcasestr MEMCASESTR MEMCASEMEM +// strtok -- +// strprefix MEMPREFIX (strprefix is from strutil.h) +// strcaseprefix MEMCASEPREFIX (strcaseprefix is from strutil.h) +// strsuffix MEMSUFFIX (strsuffix is from strutil.h) +// strcasesuffix MEMCASESUFFIX (strcasesuffix is from strutil.h) +// -- MEMIS +// -- MEMCASEIS +// strcount MEMCOUNT (strcount is from strutil.h) + +#ifndef ABSL_STRINGS_INTERNAL_MEMUTIL_H_ +#define ABSL_STRINGS_INTERNAL_MEMUTIL_H_ + +#include <cstddef> +#include <cstring> + +#include "absl/base/port.h" // disable some warnings on Windows +#include "absl/strings/ascii.h" // for absl::ascii_tolower + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +inline char* memcat(char* dest, size_t destlen, const char* src, + size_t srclen) { + return reinterpret_cast<char*>(memcpy(dest + destlen, src, srclen)); +} + +int memcasecmp(const char* s1, const char* s2, size_t len); +char* memdup(const char* s, size_t slen); +char* memrchr(const char* s, int c, size_t slen); +size_t memspn(const char* s, size_t slen, const char* accept); +size_t memcspn(const char* s, size_t slen, const char* reject); +char* mempbrk(const char* s, size_t slen, const char* accept); + +// This is for internal use only. Don't call this directly +template <bool case_sensitive> +const char* int_memmatch(const char* haystack, size_t haylen, + const char* needle, size_t neelen) { + if (0 == neelen) { + return haystack; // even if haylen is 0 + } + const char* hayend = haystack + haylen; + const char* needlestart = needle; + const char* needleend = needlestart + neelen; + + for (; haystack < hayend; ++haystack) { + char hay = case_sensitive + ? *haystack + : absl::ascii_tolower(static_cast<unsigned char>(*haystack)); + char nee = case_sensitive + ? *needle + : absl::ascii_tolower(static_cast<unsigned char>(*needle)); + if (hay == nee) { + if (++needle == needleend) { + return haystack + 1 - neelen; + } + } else if (needle != needlestart) { + // must back up haystack in case a prefix matched (find "aab" in "aaab") + haystack -= needle - needlestart; // for loop will advance one more + needle = needlestart; + } + } + return nullptr; +} + +// These are the guys you can call directly +inline const char* memstr(const char* phaystack, size_t haylen, + const char* pneedle) { + return int_memmatch<true>(phaystack, haylen, pneedle, strlen(pneedle)); +} + +inline const char* memcasestr(const char* phaystack, size_t haylen, + const char* pneedle) { + return int_memmatch<false>(phaystack, haylen, pneedle, strlen(pneedle)); +} + +inline const char* memmem(const char* phaystack, size_t haylen, + const char* pneedle, size_t needlelen) { + return int_memmatch<true>(phaystack, haylen, pneedle, needlelen); +} + +inline const char* memcasemem(const char* phaystack, size_t haylen, + const char* pneedle, size_t needlelen) { + return int_memmatch<false>(phaystack, haylen, pneedle, needlelen); +} + +// This is significantly faster for case-sensitive matches with very +// few possible matches. See unit test for benchmarks. +const char* memmatch(const char* phaystack, size_t haylen, const char* pneedle, + size_t neelen); + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_MEMUTIL_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/memutil_benchmark.cc b/third_party/abseil_cpp/absl/strings/internal/memutil_benchmark.cc new file mode 100644 index 0000000000..dc95c3e5e5 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/memutil_benchmark.cc @@ -0,0 +1,323 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/memutil.h" + +#include <algorithm> +#include <cstdlib> + +#include "benchmark/benchmark.h" +#include "absl/strings/ascii.h" + +// We fill the haystack with aaaaaaaaaaaaaaaaaa...aaaab. +// That gives us: +// - an easy search: 'b' +// - a medium search: 'ab'. That means every letter is a possible match. +// - a pathological search: 'aaaaaa.......aaaaab' (half as many a's as haytack) +// We benchmark case-sensitive and case-insensitive versions of +// three memmem implementations: +// - memmem() from memutil.h +// - search() from STL +// - memmatch(), a custom implementation using memchr and memcmp. +// Here are sample results: +// +// Run on (12 X 3800 MHz CPU s) +// CPU Caches: +// L1 Data 32K (x6) +// L1 Instruction 32K (x6) +// L2 Unified 256K (x6) +// L3 Unified 15360K (x1) +// ---------------------------------------------------------------- +// Benchmark Time CPU Iterations +// ---------------------------------------------------------------- +// BM_Memmem 3583 ns 3582 ns 196469 2.59966GB/s +// BM_MemmemMedium 13743 ns 13742 ns 50901 693.986MB/s +// BM_MemmemPathological 13695030 ns 13693977 ns 51 713.133kB/s +// BM_Memcasemem 3299 ns 3299 ns 212942 2.82309GB/s +// BM_MemcasememMedium 16407 ns 16406 ns 42170 581.309MB/s +// BM_MemcasememPathological 17267745 ns 17266030 ns 41 565.598kB/s +// BM_Search 1610 ns 1609 ns 431321 5.78672GB/s +// BM_SearchMedium 11111 ns 11110 ns 63001 858.414MB/s +// BM_SearchPathological 12117390 ns 12116397 ns 58 805.984kB/s +// BM_Searchcase 3081 ns 3081 ns 229949 3.02313GB/s +// BM_SearchcaseMedium 16003 ns 16001 ns 44170 595.998MB/s +// BM_SearchcasePathological 15823413 ns 15821909 ns 44 617.222kB/s +// BM_Memmatch 197 ns 197 ns 3584225 47.2951GB/s +// BM_MemmatchMedium 52333 ns 52329 ns 13280 182.244MB/s +// BM_MemmatchPathological 659799 ns 659727 ns 1058 14.4556MB/s +// BM_Memcasematch 5460 ns 5460 ns 127606 1.70586GB/s +// BM_MemcasematchMedium 32861 ns 32857 ns 21258 290.248MB/s +// BM_MemcasematchPathological 15154243 ns 15153089 ns 46 644.464kB/s +// BM_MemmemStartup 5 ns 5 ns 150821500 +// BM_SearchStartup 5 ns 5 ns 150644203 +// BM_MemmatchStartup 7 ns 7 ns 97068802 +// +// Conclusions: +// +// The following recommendations are based on the sample results above. However, +// we have found that the performance of STL search can vary significantly +// depending on compiler and standard library implementation. We recommend you +// run the benchmarks for yourself on relevant platforms. +// +// If you need case-insensitive, STL search is slightly better than memmem for +// all cases. +// +// Case-sensitive is more subtle: +// Custom memmatch is _very_ fast at scanning, so if you have very few possible +// matches in your haystack, that's the way to go. Performance drops +// significantly with more matches. +// +// STL search is slightly faster than memmem in the medium and pathological +// benchmarks. However, the performance of memmem is currently more dependable +// across platforms and build configurations. + +namespace { + +constexpr int kHaystackSize = 10000; +constexpr int64_t kHaystackSize64 = kHaystackSize; +const char* MakeHaystack() { + char* haystack = new char[kHaystackSize]; + for (int i = 0; i < kHaystackSize - 1; ++i) haystack[i] = 'a'; + haystack[kHaystackSize - 1] = 'b'; + return haystack; +} +const char* const kHaystack = MakeHaystack(); + +void BM_Memmem(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::strings_internal::memmem(kHaystack, kHaystackSize, "b", 1)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_Memmem); + +void BM_MemmemMedium(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::strings_internal::memmem(kHaystack, kHaystackSize, "ab", 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemmemMedium); + +void BM_MemmemPathological(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(absl::strings_internal::memmem( + kHaystack, kHaystackSize, kHaystack + kHaystackSize / 2, + kHaystackSize - kHaystackSize / 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemmemPathological); + +void BM_Memcasemem(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::strings_internal::memcasemem(kHaystack, kHaystackSize, "b", 1)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_Memcasemem); + +void BM_MemcasememMedium(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::strings_internal::memcasemem(kHaystack, kHaystackSize, "ab", 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemcasememMedium); + +void BM_MemcasememPathological(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(absl::strings_internal::memcasemem( + kHaystack, kHaystackSize, kHaystack + kHaystackSize / 2, + kHaystackSize - kHaystackSize / 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemcasememPathological); + +bool case_eq(const char a, const char b) { + return absl::ascii_tolower(a) == absl::ascii_tolower(b); +} + +void BM_Search(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::search(kHaystack, kHaystack + kHaystackSize, + kHaystack + kHaystackSize - 1, + kHaystack + kHaystackSize)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_Search); + +void BM_SearchMedium(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::search(kHaystack, kHaystack + kHaystackSize, + kHaystack + kHaystackSize - 2, + kHaystack + kHaystackSize)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_SearchMedium); + +void BM_SearchPathological(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::search(kHaystack, kHaystack + kHaystackSize, + kHaystack + kHaystackSize / 2, + kHaystack + kHaystackSize)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_SearchPathological); + +void BM_Searchcase(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::search(kHaystack, kHaystack + kHaystackSize, + kHaystack + kHaystackSize - 1, + kHaystack + kHaystackSize, case_eq)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_Searchcase); + +void BM_SearchcaseMedium(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::search(kHaystack, kHaystack + kHaystackSize, + kHaystack + kHaystackSize - 2, + kHaystack + kHaystackSize, case_eq)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_SearchcaseMedium); + +void BM_SearchcasePathological(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(std::search(kHaystack, kHaystack + kHaystackSize, + kHaystack + kHaystackSize / 2, + kHaystack + kHaystackSize, case_eq)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_SearchcasePathological); + +char* memcasechr(const char* s, int c, size_t slen) { + c = absl::ascii_tolower(c); + for (; slen; ++s, --slen) { + if (absl::ascii_tolower(*s) == c) return const_cast<char*>(s); + } + return nullptr; +} + +const char* memcasematch(const char* phaystack, size_t haylen, + const char* pneedle, size_t neelen) { + if (0 == neelen) { + return phaystack; // even if haylen is 0 + } + if (haylen < neelen) return nullptr; + + const char* match; + const char* hayend = phaystack + haylen - neelen + 1; + while ((match = static_cast<char*>( + memcasechr(phaystack, pneedle[0], hayend - phaystack)))) { + if (absl::strings_internal::memcasecmp(match, pneedle, neelen) == 0) + return match; + else + phaystack = match + 1; + } + return nullptr; +} + +void BM_Memmatch(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::strings_internal::memmatch(kHaystack, kHaystackSize, "b", 1)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_Memmatch); + +void BM_MemmatchMedium(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::strings_internal::memmatch(kHaystack, kHaystackSize, "ab", 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemmatchMedium); + +void BM_MemmatchPathological(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(absl::strings_internal::memmatch( + kHaystack, kHaystackSize, kHaystack + kHaystackSize / 2, + kHaystackSize - kHaystackSize / 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemmatchPathological); + +void BM_Memcasematch(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(memcasematch(kHaystack, kHaystackSize, "b", 1)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_Memcasematch); + +void BM_MemcasematchMedium(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(memcasematch(kHaystack, kHaystackSize, "ab", 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemcasematchMedium); + +void BM_MemcasematchPathological(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(memcasematch(kHaystack, kHaystackSize, + kHaystack + kHaystackSize / 2, + kHaystackSize - kHaystackSize / 2)); + } + state.SetBytesProcessed(kHaystackSize64 * state.iterations()); +} +BENCHMARK(BM_MemcasematchPathological); + +void BM_MemmemStartup(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(absl::strings_internal::memmem( + kHaystack + kHaystackSize - 10, 10, kHaystack + kHaystackSize - 1, 1)); + } +} +BENCHMARK(BM_MemmemStartup); + +void BM_SearchStartup(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize( + std::search(kHaystack + kHaystackSize - 10, kHaystack + kHaystackSize, + kHaystack + kHaystackSize - 1, kHaystack + kHaystackSize)); + } +} +BENCHMARK(BM_SearchStartup); + +void BM_MemmatchStartup(benchmark::State& state) { + for (auto _ : state) { + benchmark::DoNotOptimize(absl::strings_internal::memmatch( + kHaystack + kHaystackSize - 10, 10, kHaystack + kHaystackSize - 1, 1)); + } +} +BENCHMARK(BM_MemmatchStartup); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/memutil_test.cc b/third_party/abseil_cpp/absl/strings/internal/memutil_test.cc new file mode 100644 index 0000000000..d8681ddf4e --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/memutil_test.cc @@ -0,0 +1,179 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Unit test for memutil.cc + +#include "absl/strings/internal/memutil.h" + +#include <cstdlib> + +#include "gtest/gtest.h" +#include "absl/strings/ascii.h" + +namespace { + +static char* memcasechr(const char* s, int c, size_t slen) { + c = absl::ascii_tolower(c); + for (; slen; ++s, --slen) { + if (absl::ascii_tolower(*s) == c) return const_cast<char*>(s); + } + return nullptr; +} + +static const char* memcasematch(const char* phaystack, size_t haylen, + const char* pneedle, size_t neelen) { + if (0 == neelen) { + return phaystack; // even if haylen is 0 + } + if (haylen < neelen) return nullptr; + + const char* match; + const char* hayend = phaystack + haylen - neelen + 1; + while ((match = static_cast<char*>( + memcasechr(phaystack, pneedle[0], hayend - phaystack)))) { + if (absl::strings_internal::memcasecmp(match, pneedle, neelen) == 0) + return match; + else + phaystack = match + 1; + } + return nullptr; +} + +TEST(MemUtilTest, AllTests) { + // check memutil functions + char a[1000]; + absl::strings_internal::memcat(a, 0, "hello", sizeof("hello") - 1); + absl::strings_internal::memcat(a, 5, " there", sizeof(" there") - 1); + + EXPECT_EQ(absl::strings_internal::memcasecmp(a, "heLLO there", + sizeof("hello there") - 1), + 0); + EXPECT_EQ(absl::strings_internal::memcasecmp(a, "heLLO therf", + sizeof("hello there") - 1), + -1); + EXPECT_EQ(absl::strings_internal::memcasecmp(a, "heLLO therf", + sizeof("hello there") - 2), + 0); + EXPECT_EQ(absl::strings_internal::memcasecmp(a, "whatever", 0), 0); + + char* p = absl::strings_internal::memdup("hello", 5); + free(p); + + p = absl::strings_internal::memrchr("hello there", 'e', + sizeof("hello there") - 1); + EXPECT_TRUE(p && p[-1] == 'r'); + p = absl::strings_internal::memrchr("hello there", 'e', + sizeof("hello there") - 2); + EXPECT_TRUE(p && p[-1] == 'h'); + p = absl::strings_internal::memrchr("hello there", 'u', + sizeof("hello there") - 1); + EXPECT_TRUE(p == nullptr); + + int len = absl::strings_internal::memspn("hello there", + sizeof("hello there") - 1, "hole"); + EXPECT_EQ(len, sizeof("hello") - 1); + len = absl::strings_internal::memspn("hello there", sizeof("hello there") - 1, + "u"); + EXPECT_EQ(len, 0); + len = absl::strings_internal::memspn("hello there", sizeof("hello there") - 1, + ""); + EXPECT_EQ(len, 0); + len = absl::strings_internal::memspn("hello there", sizeof("hello there") - 1, + "trole h"); + EXPECT_EQ(len, sizeof("hello there") - 1); + len = absl::strings_internal::memspn("hello there!", + sizeof("hello there!") - 1, "trole h"); + EXPECT_EQ(len, sizeof("hello there") - 1); + len = absl::strings_internal::memspn("hello there!", + sizeof("hello there!") - 2, "trole h!"); + EXPECT_EQ(len, sizeof("hello there!") - 2); + + len = absl::strings_internal::memcspn("hello there", + sizeof("hello there") - 1, "leho"); + EXPECT_EQ(len, 0); + len = absl::strings_internal::memcspn("hello there", + sizeof("hello there") - 1, "u"); + EXPECT_EQ(len, sizeof("hello there") - 1); + len = absl::strings_internal::memcspn("hello there", + sizeof("hello there") - 1, ""); + EXPECT_EQ(len, sizeof("hello there") - 1); + len = absl::strings_internal::memcspn("hello there", + sizeof("hello there") - 1, " "); + EXPECT_EQ(len, 5); + + p = absl::strings_internal::mempbrk("hello there", sizeof("hello there") - 1, + "leho"); + EXPECT_TRUE(p && p[1] == 'e' && p[2] == 'l'); + p = absl::strings_internal::mempbrk("hello there", sizeof("hello there") - 1, + "nu"); + EXPECT_TRUE(p == nullptr); + p = absl::strings_internal::mempbrk("hello there!", + sizeof("hello there!") - 2, "!"); + EXPECT_TRUE(p == nullptr); + p = absl::strings_internal::mempbrk("hello there", sizeof("hello there") - 1, + " t "); + EXPECT_TRUE(p && p[-1] == 'o' && p[1] == 't'); + + { + const char kHaystack[] = "0123456789"; + EXPECT_EQ(absl::strings_internal::memmem(kHaystack, 0, "", 0), kHaystack); + EXPECT_EQ(absl::strings_internal::memmem(kHaystack, 10, "012", 3), + kHaystack); + EXPECT_EQ(absl::strings_internal::memmem(kHaystack, 10, "0xx", 1), + kHaystack); + EXPECT_EQ(absl::strings_internal::memmem(kHaystack, 10, "789", 3), + kHaystack + 7); + EXPECT_EQ(absl::strings_internal::memmem(kHaystack, 10, "9xx", 1), + kHaystack + 9); + EXPECT_TRUE(absl::strings_internal::memmem(kHaystack, 10, "9xx", 3) == + nullptr); + EXPECT_TRUE(absl::strings_internal::memmem(kHaystack, 10, "xxx", 1) == + nullptr); + } + { + const char kHaystack[] = "aBcDeFgHiJ"; + EXPECT_EQ(absl::strings_internal::memcasemem(kHaystack, 0, "", 0), + kHaystack); + EXPECT_EQ(absl::strings_internal::memcasemem(kHaystack, 10, "Abc", 3), + kHaystack); + EXPECT_EQ(absl::strings_internal::memcasemem(kHaystack, 10, "Axx", 1), + kHaystack); + EXPECT_EQ(absl::strings_internal::memcasemem(kHaystack, 10, "hIj", 3), + kHaystack + 7); + EXPECT_EQ(absl::strings_internal::memcasemem(kHaystack, 10, "jxx", 1), + kHaystack + 9); + EXPECT_TRUE(absl::strings_internal::memcasemem(kHaystack, 10, "jxx", 3) == + nullptr); + EXPECT_TRUE(absl::strings_internal::memcasemem(kHaystack, 10, "xxx", 1) == + nullptr); + } + { + const char kHaystack[] = "0123456789"; + EXPECT_EQ(absl::strings_internal::memmatch(kHaystack, 0, "", 0), kHaystack); + EXPECT_EQ(absl::strings_internal::memmatch(kHaystack, 10, "012", 3), + kHaystack); + EXPECT_EQ(absl::strings_internal::memmatch(kHaystack, 10, "0xx", 1), + kHaystack); + EXPECT_EQ(absl::strings_internal::memmatch(kHaystack, 10, "789", 3), + kHaystack + 7); + EXPECT_EQ(absl::strings_internal::memmatch(kHaystack, 10, "9xx", 1), + kHaystack + 9); + EXPECT_TRUE(absl::strings_internal::memmatch(kHaystack, 10, "9xx", 3) == + nullptr); + EXPECT_TRUE(absl::strings_internal::memmatch(kHaystack, 10, "xxx", 1) == + nullptr); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/numbers_test_common.h b/third_party/abseil_cpp/absl/strings/internal/numbers_test_common.h new file mode 100644 index 0000000000..eaa88a8897 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/numbers_test_common.h @@ -0,0 +1,184 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This file contains common things needed by numbers_test.cc, +// numbers_legacy_test.cc and numbers_benchmark.cc. + +#ifndef ABSL_STRINGS_INTERNAL_NUMBERS_TEST_COMMON_H_ +#define ABSL_STRINGS_INTERNAL_NUMBERS_TEST_COMMON_H_ + +#include <array> +#include <cstdint> +#include <limits> +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +template <typename IntType> +inline bool Itoa(IntType value, int base, std::string* destination) { + destination->clear(); + if (base <= 1 || base > 36) { + return false; + } + + if (value == 0) { + destination->push_back('0'); + return true; + } + + bool negative = value < 0; + while (value != 0) { + const IntType next_value = value / base; + // Can't use std::abs here because of problems when IntType is unsigned. + int remainder = + static_cast<int>(value > next_value * base ? value - next_value * base + : next_value * base - value); + char c = remainder < 10 ? '0' + remainder : 'A' + remainder - 10; + destination->insert(0, 1, c); + value = next_value; + } + + if (negative) { + destination->insert(0, 1, '-'); + } + return true; +} + +struct uint32_test_case { + const char* str; + bool expect_ok; + int base; // base to pass to the conversion function + uint32_t expected; +}; + +inline const std::array<uint32_test_case, 27>& strtouint32_test_cases() { + static const std::array<uint32_test_case, 27> test_cases{{ + {"0xffffffff", true, 16, (std::numeric_limits<uint32_t>::max)()}, + {"0x34234324", true, 16, 0x34234324}, + {"34234324", true, 16, 0x34234324}, + {"0", true, 16, 0}, + {" \t\n 0xffffffff", true, 16, (std::numeric_limits<uint32_t>::max)()}, + {" \f\v 46", true, 10, 46}, // must accept weird whitespace + {" \t\n 72717222", true, 8, 072717222}, + {" \t\n 072717222", true, 8, 072717222}, + {" \t\n 072717228", false, 8, 07271722}, + {"0", true, 0, 0}, + + // Base-10 version. + {"34234324", true, 0, 34234324}, + {"4294967295", true, 0, (std::numeric_limits<uint32_t>::max)()}, + {"34234324 \n\t", true, 10, 34234324}, + + // Unusual base + {"0", true, 3, 0}, + {"2", true, 3, 2}, + {"11", true, 3, 4}, + + // Invalid uints. + {"", false, 0, 0}, + {" ", false, 0, 0}, + {"abc", false, 0, 0}, // would be valid hex, but prefix is missing + {"34234324a", false, 0, 34234324}, + {"34234.3", false, 0, 34234}, + {"-1", false, 0, 0}, + {" -123", false, 0, 0}, + {" \t\n -123", false, 0, 0}, + + // Out of bounds. + {"4294967296", false, 0, (std::numeric_limits<uint32_t>::max)()}, + {"0x100000000", false, 0, (std::numeric_limits<uint32_t>::max)()}, + {nullptr, false, 0, 0}, + }}; + return test_cases; +} + +struct uint64_test_case { + const char* str; + bool expect_ok; + int base; + uint64_t expected; +}; + +inline const std::array<uint64_test_case, 34>& strtouint64_test_cases() { + static const std::array<uint64_test_case, 34> test_cases{{ + {"0x3423432448783446", true, 16, int64_t{0x3423432448783446}}, + {"3423432448783446", true, 16, int64_t{0x3423432448783446}}, + + {"0", true, 16, 0}, + {"000", true, 0, 0}, + {"0", true, 0, 0}, + {" \t\n 0xffffffffffffffff", true, 16, + (std::numeric_limits<uint64_t>::max)()}, + + {"012345670123456701234", true, 8, int64_t{012345670123456701234}}, + {"12345670123456701234", true, 8, int64_t{012345670123456701234}}, + + {"12845670123456701234", false, 8, 0}, + + // Base-10 version. + {"34234324487834466", true, 0, int64_t{34234324487834466}}, + + {" \t\n 18446744073709551615", true, 0, + (std::numeric_limits<uint64_t>::max)()}, + + {"34234324487834466 \n\t ", true, 0, int64_t{34234324487834466}}, + + {" \f\v 46", true, 10, 46}, // must accept weird whitespace + + // Unusual base + {"0", true, 3, 0}, + {"2", true, 3, 2}, + {"11", true, 3, 4}, + + {"0", true, 0, 0}, + + // Invalid uints. + {"", false, 0, 0}, + {" ", false, 0, 0}, + {"abc", false, 0, 0}, + {"34234324487834466a", false, 0, 0}, + {"34234487834466.3", false, 0, 0}, + {"-1", false, 0, 0}, + {" -123", false, 0, 0}, + {" \t\n -123", false, 0, 0}, + + // Out of bounds. + {"18446744073709551616", false, 10, 0}, + {"18446744073709551616", false, 0, 0}, + {"0x10000000000000000", false, 16, + (std::numeric_limits<uint64_t>::max)()}, + {"0X10000000000000000", false, 16, + (std::numeric_limits<uint64_t>::max)()}, // 0X versus 0x. + {"0x10000000000000000", false, 0, (std::numeric_limits<uint64_t>::max)()}, + {"0X10000000000000000", false, 0, + (std::numeric_limits<uint64_t>::max)()}, // 0X versus 0x. + + {"0x1234", true, 16, 0x1234}, + + // Base-10 string version. + {"1234", true, 0, 1234}, + {nullptr, false, 0, 0}, + }}; + return test_cases; +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_NUMBERS_TEST_COMMON_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/ostringstream.cc b/third_party/abseil_cpp/absl/strings/internal/ostringstream.cc new file mode 100644 index 0000000000..05324c780c --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/ostringstream.cc @@ -0,0 +1,36 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/ostringstream.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +OStringStream::Buf::int_type OStringStream::overflow(int c) { + assert(s_); + if (!Buf::traits_type::eq_int_type(c, Buf::traits_type::eof())) + s_->push_back(static_cast<char>(c)); + return 1; +} + +std::streamsize OStringStream::xsputn(const char* s, std::streamsize n) { + assert(s_); + s_->append(s, n); + return n; +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/ostringstream.h b/third_party/abseil_cpp/absl/strings/internal/ostringstream.h new file mode 100644 index 0000000000..d25d60473f --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/ostringstream.h @@ -0,0 +1,89 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_STRINGS_INTERNAL_OSTRINGSTREAM_H_ +#define ABSL_STRINGS_INTERNAL_OSTRINGSTREAM_H_ + +#include <cassert> +#include <ostream> +#include <streambuf> +#include <string> + +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// The same as std::ostringstream but appends to a user-specified std::string, +// and is faster. It is ~70% faster to create, ~50% faster to write to, and +// completely free to extract the result std::string. +// +// std::string s; +// OStringStream strm(&s); +// strm << 42 << ' ' << 3.14; // appends to `s` +// +// The stream object doesn't have to be named. Starting from C++11 operator<< +// works with rvalues of std::ostream. +// +// std::string s; +// OStringStream(&s) << 42 << ' ' << 3.14; // appends to `s` +// +// OStringStream is faster to create than std::ostringstream but it's still +// relatively slow. Avoid creating multiple streams where a single stream will +// do. +// +// Creates unnecessary instances of OStringStream: slow. +// +// std::string s; +// OStringStream(&s) << 42; +// OStringStream(&s) << ' '; +// OStringStream(&s) << 3.14; +// +// Creates a single instance of OStringStream and reuses it: fast. +// +// std::string s; +// OStringStream strm(&s); +// strm << 42; +// strm << ' '; +// strm << 3.14; +// +// Note: flush() has no effect. No reason to call it. +class OStringStream : private std::basic_streambuf<char>, public std::ostream { + public: + // The argument can be null, in which case you'll need to call str(p) with a + // non-null argument before you can write to the stream. + // + // The destructor of OStringStream doesn't use the std::string. It's OK to + // destroy the std::string before the stream. + explicit OStringStream(std::string* s) : std::ostream(this), s_(s) {} + + std::string* str() { return s_; } + const std::string* str() const { return s_; } + void str(std::string* s) { s_ = s; } + + private: + using Buf = std::basic_streambuf<char>; + + Buf::int_type overflow(int c) override; + std::streamsize xsputn(const char* s, std::streamsize n) override; + + std::string* s_; +}; + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_OSTRINGSTREAM_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/ostringstream_benchmark.cc b/third_party/abseil_cpp/absl/strings/internal/ostringstream_benchmark.cc new file mode 100644 index 0000000000..5979f18236 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/ostringstream_benchmark.cc @@ -0,0 +1,106 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/ostringstream.h" + +#include <sstream> +#include <string> + +#include "benchmark/benchmark.h" + +namespace { + +enum StringType { + kNone, + kStdString, +}; + +// Benchmarks for std::ostringstream. +template <StringType kOutput> +void BM_StdStream(benchmark::State& state) { + const int num_writes = state.range(0); + const int bytes_per_write = state.range(1); + const std::string payload(bytes_per_write, 'x'); + for (auto _ : state) { + std::ostringstream strm; + benchmark::DoNotOptimize(strm); + for (int i = 0; i != num_writes; ++i) { + strm << payload; + } + switch (kOutput) { + case kNone: { + break; + } + case kStdString: { + std::string s = strm.str(); + benchmark::DoNotOptimize(s); + break; + } + } + } +} + +// Create the stream, optionally write to it, then destroy it. +BENCHMARK_TEMPLATE(BM_StdStream, kNone) + ->ArgPair(0, 0) + ->ArgPair(1, 16) // 16 bytes is small enough for SSO + ->ArgPair(1, 256) // 256 bytes requires heap allocation + ->ArgPair(1024, 256); +// Create the stream, write to it, get std::string out, then destroy. +BENCHMARK_TEMPLATE(BM_StdStream, kStdString) + ->ArgPair(1, 16) // 16 bytes is small enough for SSO + ->ArgPair(1, 256) // 256 bytes requires heap allocation + ->ArgPair(1024, 256); + +// Benchmarks for OStringStream. +template <StringType kOutput> +void BM_CustomStream(benchmark::State& state) { + const int num_writes = state.range(0); + const int bytes_per_write = state.range(1); + const std::string payload(bytes_per_write, 'x'); + for (auto _ : state) { + std::string out; + absl::strings_internal::OStringStream strm(&out); + benchmark::DoNotOptimize(strm); + for (int i = 0; i != num_writes; ++i) { + strm << payload; + } + switch (kOutput) { + case kNone: { + break; + } + case kStdString: { + std::string s = out; + benchmark::DoNotOptimize(s); + break; + } + } + } +} + +// Create the stream, optionally write to it, then destroy it. +BENCHMARK_TEMPLATE(BM_CustomStream, kNone) + ->ArgPair(0, 0) + ->ArgPair(1, 16) // 16 bytes is small enough for SSO + ->ArgPair(1, 256) // 256 bytes requires heap allocation + ->ArgPair(1024, 256); +// Create the stream, write to it, get std::string out, then destroy. +// It's not useful in practice to extract std::string from OStringStream; we +// measure it for completeness. +BENCHMARK_TEMPLATE(BM_CustomStream, kStdString) + ->ArgPair(1, 16) // 16 bytes is small enough for SSO + ->ArgPair(1, 256) // 256 bytes requires heap allocation + ->ArgPair(1024, 256); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/ostringstream_test.cc b/third_party/abseil_cpp/absl/strings/internal/ostringstream_test.cc new file mode 100644 index 0000000000..2879e50eb3 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/ostringstream_test.cc @@ -0,0 +1,102 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/ostringstream.h" + +#include <memory> +#include <ostream> +#include <string> +#include <type_traits> + +#include "gtest/gtest.h" + +namespace { + +TEST(OStringStream, IsOStream) { + static_assert( + std::is_base_of<std::ostream, absl::strings_internal::OStringStream>(), + ""); +} + +TEST(OStringStream, ConstructDestroy) { + { + absl::strings_internal::OStringStream strm(nullptr); + EXPECT_EQ(nullptr, strm.str()); + } + { + std::string s = "abc"; + { + absl::strings_internal::OStringStream strm(&s); + EXPECT_EQ(&s, strm.str()); + } + EXPECT_EQ("abc", s); + } + { + std::unique_ptr<std::string> s(new std::string); + absl::strings_internal::OStringStream strm(s.get()); + s.reset(); + } +} + +TEST(OStringStream, Str) { + std::string s1; + absl::strings_internal::OStringStream strm(&s1); + const absl::strings_internal::OStringStream& c_strm(strm); + + static_assert(std::is_same<decltype(strm.str()), std::string*>(), ""); + static_assert(std::is_same<decltype(c_strm.str()), const std::string*>(), ""); + + EXPECT_EQ(&s1, strm.str()); + EXPECT_EQ(&s1, c_strm.str()); + + strm.str(&s1); + EXPECT_EQ(&s1, strm.str()); + EXPECT_EQ(&s1, c_strm.str()); + + std::string s2; + strm.str(&s2); + EXPECT_EQ(&s2, strm.str()); + EXPECT_EQ(&s2, c_strm.str()); + + strm.str(nullptr); + EXPECT_EQ(nullptr, strm.str()); + EXPECT_EQ(nullptr, c_strm.str()); +} + +TEST(OStreamStream, WriteToLValue) { + std::string s = "abc"; + { + absl::strings_internal::OStringStream strm(&s); + EXPECT_EQ("abc", s); + strm << ""; + EXPECT_EQ("abc", s); + strm << 42; + EXPECT_EQ("abc42", s); + strm << 'x' << 'y'; + EXPECT_EQ("abc42xy", s); + } + EXPECT_EQ("abc42xy", s); +} + +TEST(OStreamStream, WriteToRValue) { + std::string s = "abc"; + absl::strings_internal::OStringStream(&s) << ""; + EXPECT_EQ("abc", s); + absl::strings_internal::OStringStream(&s) << 42; + EXPECT_EQ("abc42", s); + absl::strings_internal::OStringStream(&s) << 'x' << 'y'; + EXPECT_EQ("abc42xy", s); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/pow10_helper.cc b/third_party/abseil_cpp/absl/strings/internal/pow10_helper.cc new file mode 100644 index 0000000000..42e96c3425 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/pow10_helper.cc @@ -0,0 +1,122 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/pow10_helper.h" + +#include <cmath> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +namespace { + +// The exact value of 1e23 falls precisely halfway between two representable +// doubles. Furthermore, the rounding rules we prefer (break ties by rounding +// to the nearest even) dictate in this case that the number should be rounded +// down, but this is not completely specified for floating-point literals in +// C++. (It just says to use the default rounding mode of the standard +// library.) We ensure the result we want by using a number that has an +// unambiguous correctly rounded answer. +constexpr double k1e23 = 9999999999999999e7; + +constexpr double kPowersOfTen[] = { + 0.0, 1e-323, 1e-322, 1e-321, 1e-320, 1e-319, 1e-318, 1e-317, 1e-316, + 1e-315, 1e-314, 1e-313, 1e-312, 1e-311, 1e-310, 1e-309, 1e-308, 1e-307, + 1e-306, 1e-305, 1e-304, 1e-303, 1e-302, 1e-301, 1e-300, 1e-299, 1e-298, + 1e-297, 1e-296, 1e-295, 1e-294, 1e-293, 1e-292, 1e-291, 1e-290, 1e-289, + 1e-288, 1e-287, 1e-286, 1e-285, 1e-284, 1e-283, 1e-282, 1e-281, 1e-280, + 1e-279, 1e-278, 1e-277, 1e-276, 1e-275, 1e-274, 1e-273, 1e-272, 1e-271, + 1e-270, 1e-269, 1e-268, 1e-267, 1e-266, 1e-265, 1e-264, 1e-263, 1e-262, + 1e-261, 1e-260, 1e-259, 1e-258, 1e-257, 1e-256, 1e-255, 1e-254, 1e-253, + 1e-252, 1e-251, 1e-250, 1e-249, 1e-248, 1e-247, 1e-246, 1e-245, 1e-244, + 1e-243, 1e-242, 1e-241, 1e-240, 1e-239, 1e-238, 1e-237, 1e-236, 1e-235, + 1e-234, 1e-233, 1e-232, 1e-231, 1e-230, 1e-229, 1e-228, 1e-227, 1e-226, + 1e-225, 1e-224, 1e-223, 1e-222, 1e-221, 1e-220, 1e-219, 1e-218, 1e-217, + 1e-216, 1e-215, 1e-214, 1e-213, 1e-212, 1e-211, 1e-210, 1e-209, 1e-208, + 1e-207, 1e-206, 1e-205, 1e-204, 1e-203, 1e-202, 1e-201, 1e-200, 1e-199, + 1e-198, 1e-197, 1e-196, 1e-195, 1e-194, 1e-193, 1e-192, 1e-191, 1e-190, + 1e-189, 1e-188, 1e-187, 1e-186, 1e-185, 1e-184, 1e-183, 1e-182, 1e-181, + 1e-180, 1e-179, 1e-178, 1e-177, 1e-176, 1e-175, 1e-174, 1e-173, 1e-172, + 1e-171, 1e-170, 1e-169, 1e-168, 1e-167, 1e-166, 1e-165, 1e-164, 1e-163, + 1e-162, 1e-161, 1e-160, 1e-159, 1e-158, 1e-157, 1e-156, 1e-155, 1e-154, + 1e-153, 1e-152, 1e-151, 1e-150, 1e-149, 1e-148, 1e-147, 1e-146, 1e-145, + 1e-144, 1e-143, 1e-142, 1e-141, 1e-140, 1e-139, 1e-138, 1e-137, 1e-136, + 1e-135, 1e-134, 1e-133, 1e-132, 1e-131, 1e-130, 1e-129, 1e-128, 1e-127, + 1e-126, 1e-125, 1e-124, 1e-123, 1e-122, 1e-121, 1e-120, 1e-119, 1e-118, + 1e-117, 1e-116, 1e-115, 1e-114, 1e-113, 1e-112, 1e-111, 1e-110, 1e-109, + 1e-108, 1e-107, 1e-106, 1e-105, 1e-104, 1e-103, 1e-102, 1e-101, 1e-100, + 1e-99, 1e-98, 1e-97, 1e-96, 1e-95, 1e-94, 1e-93, 1e-92, 1e-91, + 1e-90, 1e-89, 1e-88, 1e-87, 1e-86, 1e-85, 1e-84, 1e-83, 1e-82, + 1e-81, 1e-80, 1e-79, 1e-78, 1e-77, 1e-76, 1e-75, 1e-74, 1e-73, + 1e-72, 1e-71, 1e-70, 1e-69, 1e-68, 1e-67, 1e-66, 1e-65, 1e-64, + 1e-63, 1e-62, 1e-61, 1e-60, 1e-59, 1e-58, 1e-57, 1e-56, 1e-55, + 1e-54, 1e-53, 1e-52, 1e-51, 1e-50, 1e-49, 1e-48, 1e-47, 1e-46, + 1e-45, 1e-44, 1e-43, 1e-42, 1e-41, 1e-40, 1e-39, 1e-38, 1e-37, + 1e-36, 1e-35, 1e-34, 1e-33, 1e-32, 1e-31, 1e-30, 1e-29, 1e-28, + 1e-27, 1e-26, 1e-25, 1e-24, 1e-23, 1e-22, 1e-21, 1e-20, 1e-19, + 1e-18, 1e-17, 1e-16, 1e-15, 1e-14, 1e-13, 1e-12, 1e-11, 1e-10, + 1e-9, 1e-8, 1e-7, 1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, + 1e+0, 1e+1, 1e+2, 1e+3, 1e+4, 1e+5, 1e+6, 1e+7, 1e+8, + 1e+9, 1e+10, 1e+11, 1e+12, 1e+13, 1e+14, 1e+15, 1e+16, 1e+17, + 1e+18, 1e+19, 1e+20, 1e+21, 1e+22, k1e23, 1e+24, 1e+25, 1e+26, + 1e+27, 1e+28, 1e+29, 1e+30, 1e+31, 1e+32, 1e+33, 1e+34, 1e+35, + 1e+36, 1e+37, 1e+38, 1e+39, 1e+40, 1e+41, 1e+42, 1e+43, 1e+44, + 1e+45, 1e+46, 1e+47, 1e+48, 1e+49, 1e+50, 1e+51, 1e+52, 1e+53, + 1e+54, 1e+55, 1e+56, 1e+57, 1e+58, 1e+59, 1e+60, 1e+61, 1e+62, + 1e+63, 1e+64, 1e+65, 1e+66, 1e+67, 1e+68, 1e+69, 1e+70, 1e+71, + 1e+72, 1e+73, 1e+74, 1e+75, 1e+76, 1e+77, 1e+78, 1e+79, 1e+80, + 1e+81, 1e+82, 1e+83, 1e+84, 1e+85, 1e+86, 1e+87, 1e+88, 1e+89, + 1e+90, 1e+91, 1e+92, 1e+93, 1e+94, 1e+95, 1e+96, 1e+97, 1e+98, + 1e+99, 1e+100, 1e+101, 1e+102, 1e+103, 1e+104, 1e+105, 1e+106, 1e+107, + 1e+108, 1e+109, 1e+110, 1e+111, 1e+112, 1e+113, 1e+114, 1e+115, 1e+116, + 1e+117, 1e+118, 1e+119, 1e+120, 1e+121, 1e+122, 1e+123, 1e+124, 1e+125, + 1e+126, 1e+127, 1e+128, 1e+129, 1e+130, 1e+131, 1e+132, 1e+133, 1e+134, + 1e+135, 1e+136, 1e+137, 1e+138, 1e+139, 1e+140, 1e+141, 1e+142, 1e+143, + 1e+144, 1e+145, 1e+146, 1e+147, 1e+148, 1e+149, 1e+150, 1e+151, 1e+152, + 1e+153, 1e+154, 1e+155, 1e+156, 1e+157, 1e+158, 1e+159, 1e+160, 1e+161, + 1e+162, 1e+163, 1e+164, 1e+165, 1e+166, 1e+167, 1e+168, 1e+169, 1e+170, + 1e+171, 1e+172, 1e+173, 1e+174, 1e+175, 1e+176, 1e+177, 1e+178, 1e+179, + 1e+180, 1e+181, 1e+182, 1e+183, 1e+184, 1e+185, 1e+186, 1e+187, 1e+188, + 1e+189, 1e+190, 1e+191, 1e+192, 1e+193, 1e+194, 1e+195, 1e+196, 1e+197, + 1e+198, 1e+199, 1e+200, 1e+201, 1e+202, 1e+203, 1e+204, 1e+205, 1e+206, + 1e+207, 1e+208, 1e+209, 1e+210, 1e+211, 1e+212, 1e+213, 1e+214, 1e+215, + 1e+216, 1e+217, 1e+218, 1e+219, 1e+220, 1e+221, 1e+222, 1e+223, 1e+224, + 1e+225, 1e+226, 1e+227, 1e+228, 1e+229, 1e+230, 1e+231, 1e+232, 1e+233, + 1e+234, 1e+235, 1e+236, 1e+237, 1e+238, 1e+239, 1e+240, 1e+241, 1e+242, + 1e+243, 1e+244, 1e+245, 1e+246, 1e+247, 1e+248, 1e+249, 1e+250, 1e+251, + 1e+252, 1e+253, 1e+254, 1e+255, 1e+256, 1e+257, 1e+258, 1e+259, 1e+260, + 1e+261, 1e+262, 1e+263, 1e+264, 1e+265, 1e+266, 1e+267, 1e+268, 1e+269, + 1e+270, 1e+271, 1e+272, 1e+273, 1e+274, 1e+275, 1e+276, 1e+277, 1e+278, + 1e+279, 1e+280, 1e+281, 1e+282, 1e+283, 1e+284, 1e+285, 1e+286, 1e+287, + 1e+288, 1e+289, 1e+290, 1e+291, 1e+292, 1e+293, 1e+294, 1e+295, 1e+296, + 1e+297, 1e+298, 1e+299, 1e+300, 1e+301, 1e+302, 1e+303, 1e+304, 1e+305, + 1e+306, 1e+307, 1e+308, +}; + +} // namespace + +double Pow10(int exp) { + if (exp < -324) { + return 0.0; + } else if (exp > 308) { + return INFINITY; + } else { + return kPowersOfTen[exp + 324]; + } +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/pow10_helper.h b/third_party/abseil_cpp/absl/strings/internal/pow10_helper.h new file mode 100644 index 0000000000..c37c2c3ffe --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/pow10_helper.h @@ -0,0 +1,40 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This test helper library contains a table of powers of 10, to guarantee +// precise values are computed across the full range of doubles. We can't rely +// on the pow() function, because not all standard libraries ship a version +// that is precise. +#ifndef ABSL_STRINGS_INTERNAL_POW10_HELPER_H_ +#define ABSL_STRINGS_INTERNAL_POW10_HELPER_H_ + +#include <vector> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// Computes the precise value of 10^exp. (I.e. the nearest representable +// double to the exact value, rounding to nearest-even in the (single) case of +// being exactly halfway between.) +double Pow10(int exp); + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_POW10_HELPER_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/pow10_helper_test.cc b/third_party/abseil_cpp/absl/strings/internal/pow10_helper_test.cc new file mode 100644 index 0000000000..a4ff76d31e --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/pow10_helper_test.cc @@ -0,0 +1,122 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/pow10_helper.h" + +#include <cmath> + +#include "gtest/gtest.h" +#include "absl/strings/str_format.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +namespace { + +struct TestCase { + int power; // Testing Pow10(power) + uint64_t significand; // Raw bits of the expected value + int radix; // significand is adjusted by 2^radix +}; + +TEST(Pow10HelperTest, Works) { + // The logic in pow10_helper.cc is so simple that theoretically we don't even + // need a test. However, we're paranoid and believe that there may be + // compilers that don't round floating-point literals correctly, even though + // it is specified by the standard. We check various edge cases, just to be + // sure. + constexpr TestCase kTestCases[] = { + // Subnormals + {-323, 0x2, -1074}, + {-322, 0x14, -1074}, + {-321, 0xca, -1074}, + {-320, 0x7e8, -1074}, + {-319, 0x4f10, -1074}, + {-318, 0x316a2, -1074}, + {-317, 0x1ee257, -1074}, + {-316, 0x134d761, -1074}, + {-315, 0xc1069cd, -1074}, + {-314, 0x78a42205, -1074}, + {-313, 0x4b6695433, -1074}, + {-312, 0x2f201d49fb, -1074}, + {-311, 0x1d74124e3d1, -1074}, + {-310, 0x12688b70e62b, -1074}, + {-309, 0xb8157268fdaf, -1074}, + {-308, 0x730d67819e8d2, -1074}, + // Values that are very close to rounding the other way. + // Comment shows difference of significand from the true value. + {-307, 0x11fa182c40c60d, -1072}, // -.4588 + {-290, 0x18f2b061aea072, -1016}, // .4854 + {-276, 0x11BA03F5B21000, -969}, // .4709 + {-259, 0x1899C2F6732210, -913}, // .4830 + {-252, 0x1D53844EE47DD1, -890}, // -.4743 + {-227, 0x1E5297287C2F45, -807}, // -.4708 + {-198, 0x1322E220A5B17E, -710}, // -.4714 + {-195, 0x12B010D3E1CF56, -700}, // .4928 + {-192, 0x123FF06EEA847A, -690}, // .4968 + {-163, 0x1708D0F84D3DE7, -594}, // -.4977 + {-145, 0x13FAAC3E3FA1F3, -534}, // -.4785 + {-111, 0x133D4032C2C7F5, -421}, // .4774 + {-106, 0x1D5B561574765B, -405}, // -.4869 + {-104, 0x16EF5B40C2FC77, -398}, // -.4741 + {-88, 0x197683DF2F268D, -345}, // -.4738 + {-86, 0x13E497065CD61F, -338}, // .4736 + {-76, 0x17288E1271F513, -305}, // -.4761 + {-63, 0x1A53FC9631D10D, -262}, // .4929 + {-30, 0x14484BFEEBC2A0, -152}, // .4758 + {-21, 0x12E3B40A0E9B4F, -122}, // -.4916 + {-5, 0x14F8B588E368F1, -69}, // .4829 + {23, 0x152D02C7E14AF6, 24}, // -.5000 (exactly, round-to-even) + {29, 0x1431E0FAE6D721, 44}, // -.4870 + {34, 0x1ED09BEAD87C03, 60}, // -.4721 + {70, 0x172EBAD6DDC73D, 180}, // .4733 + {105, 0x1BE7ABD3781ECA, 296}, // -.4850 + {126, 0x17A2ECC414A03F, 366}, // -.4999 + {130, 0x1CDA62055B2D9E, 379}, // .4855 + {165, 0x115D847AD00087, 496}, // -.4913 + {172, 0x14B378469B6732, 519}, // .4818 + {187, 0x1262DFEEBBB0F9, 569}, // -.4805 + {210, 0x18557F31326BBB, 645}, // -.4992 + {212, 0x1302CB5E6F642A, 652}, // -.4838 + {215, 0x1290BA9A38C7D1, 662}, // -.4881 + {236, 0x1F736F9B3494E9, 731}, // .4707 + {244, 0x176EC98994F489, 758}, // .4924 + {250, 0x1658E3AB795204, 778}, // -.4963 + {252, 0x117571DDF6C814, 785}, // .4873 + {254, 0x1B4781EAD1989E, 791}, // -.4887 + {260, 0x1A03FDE214CAF1, 811}, // .4784 + {284, 0x1585041B2C477F, 891}, // .4798 + {304, 0x1D2A1BE4048F90, 957}, // -.4987 + // Out-of-range values + {-324, 0x0, 0}, + {-325, 0x0, 0}, + {-326, 0x0, 0}, + {309, 1, 2000}, + {310, 1, 2000}, + {311, 1, 2000}, + }; + for (const TestCase& test_case : kTestCases) { + EXPECT_EQ(Pow10(test_case.power), + std::ldexp(test_case.significand, test_case.radix)) + << absl::StrFormat("Failure for Pow10(%d): %a vs %a", test_case.power, + Pow10(test_case.power), + std::ldexp(test_case.significand, test_case.radix)); + } +} + +} // namespace +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/resize_uninitialized.h b/third_party/abseil_cpp/absl/strings/internal/resize_uninitialized.h new file mode 100644 index 0000000000..e42628e394 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/resize_uninitialized.h @@ -0,0 +1,73 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_STRINGS_INTERNAL_RESIZE_UNINITIALIZED_H_ +#define ABSL_STRINGS_INTERNAL_RESIZE_UNINITIALIZED_H_ + +#include <string> +#include <type_traits> +#include <utility> + +#include "absl/base/port.h" +#include "absl/meta/type_traits.h" // for void_t + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// Is a subclass of true_type or false_type, depending on whether or not +// T has a __resize_default_init member. +template <typename string_type, typename = void> +struct ResizeUninitializedTraits { + using HasMember = std::false_type; + static void Resize(string_type* s, size_t new_size) { s->resize(new_size); } +}; + +// __resize_default_init is provided by libc++ >= 8.0 +template <typename string_type> +struct ResizeUninitializedTraits< + string_type, absl::void_t<decltype(std::declval<string_type&>() + .__resize_default_init(237))> > { + using HasMember = std::true_type; + static void Resize(string_type* s, size_t new_size) { + s->__resize_default_init(new_size); + } +}; + +// Returns true if the std::string implementation supports a resize where +// the new characters added to the std::string are left untouched. +// +// (A better name might be "STLStringSupportsUninitializedResize", alluding to +// the previous function.) +template <typename string_type> +inline constexpr bool STLStringSupportsNontrashingResize(string_type*) { + return ResizeUninitializedTraits<string_type>::HasMember::value; +} + +// Like str->resize(new_size), except any new characters added to "*str" as a +// result of resizing may be left uninitialized, rather than being filled with +// '0' bytes. Typically used when code is then going to overwrite the backing +// store of the std::string with known data. +template <typename string_type, typename = void> +inline void STLStringResizeUninitialized(string_type* s, size_t new_size) { + ResizeUninitializedTraits<string_type>::Resize(s, new_size); +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_RESIZE_UNINITIALIZED_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/resize_uninitialized_test.cc b/third_party/abseil_cpp/absl/strings/internal/resize_uninitialized_test.cc new file mode 100644 index 0000000000..0f8b3c2a95 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/resize_uninitialized_test.cc @@ -0,0 +1,82 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/resize_uninitialized.h" + +#include "gtest/gtest.h" + +namespace { + +int resize_call_count = 0; + +// A mock string class whose only purpose is to track how many times its +// resize() method has been called. +struct resizable_string { + size_t size() const { return 0; } + char& operator[](size_t) { + static char c = '\0'; + return c; + } + void resize(size_t) { resize_call_count += 1; } +}; + +int resize_default_init_call_count = 0; + +// A mock string class whose only purpose is to track how many times its +// resize() and __resize_default_init() methods have been called. +struct resize_default_init_string { + size_t size() const { return 0; } + char& operator[](size_t) { + static char c = '\0'; + return c; + } + void resize(size_t) { resize_call_count += 1; } + void __resize_default_init(size_t) { resize_default_init_call_count += 1; } +}; + +TEST(ResizeUninit, WithAndWithout) { + resize_call_count = 0; + resize_default_init_call_count = 0; + { + resizable_string rs; + + EXPECT_EQ(resize_call_count, 0); + EXPECT_EQ(resize_default_init_call_count, 0); + EXPECT_FALSE( + absl::strings_internal::STLStringSupportsNontrashingResize(&rs)); + EXPECT_EQ(resize_call_count, 0); + EXPECT_EQ(resize_default_init_call_count, 0); + absl::strings_internal::STLStringResizeUninitialized(&rs, 237); + EXPECT_EQ(resize_call_count, 1); + EXPECT_EQ(resize_default_init_call_count, 0); + } + + resize_call_count = 0; + resize_default_init_call_count = 0; + { + resize_default_init_string rus; + + EXPECT_EQ(resize_call_count, 0); + EXPECT_EQ(resize_default_init_call_count, 0); + EXPECT_TRUE( + absl::strings_internal::STLStringSupportsNontrashingResize(&rus)); + EXPECT_EQ(resize_call_count, 0); + EXPECT_EQ(resize_default_init_call_count, 0); + absl::strings_internal::STLStringResizeUninitialized(&rus, 237); + EXPECT_EQ(resize_call_count, 0); + EXPECT_EQ(resize_default_init_call_count, 1); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/stl_type_traits.h b/third_party/abseil_cpp/absl/strings/internal/stl_type_traits.h new file mode 100644 index 0000000000..6035ca45cb --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/stl_type_traits.h @@ -0,0 +1,248 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// Thie file provides the IsStrictlyBaseOfAndConvertibleToSTLContainer type +// trait metafunction to assist in working with the _GLIBCXX_DEBUG debug +// wrappers of STL containers. +// +// DO NOT INCLUDE THIS FILE DIRECTLY. Use this file by including +// absl/strings/str_split.h. +// +// IWYU pragma: private, include "absl/strings/str_split.h" + +#ifndef ABSL_STRINGS_INTERNAL_STL_TYPE_TRAITS_H_ +#define ABSL_STRINGS_INTERNAL_STL_TYPE_TRAITS_H_ + +#include <array> +#include <bitset> +#include <deque> +#include <forward_list> +#include <list> +#include <map> +#include <set> +#include <type_traits> +#include <unordered_map> +#include <unordered_set> +#include <vector> + +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +template <typename C, template <typename...> class T> +struct IsSpecializationImpl : std::false_type {}; +template <template <typename...> class T, typename... Args> +struct IsSpecializationImpl<T<Args...>, T> : std::true_type {}; +template <typename C, template <typename...> class T> +using IsSpecialization = IsSpecializationImpl<absl::decay_t<C>, T>; + +template <typename C> +struct IsArrayImpl : std::false_type {}; +template <template <typename, size_t> class A, typename T, size_t N> +struct IsArrayImpl<A<T, N>> : std::is_same<A<T, N>, std::array<T, N>> {}; +template <typename C> +using IsArray = IsArrayImpl<absl::decay_t<C>>; + +template <typename C> +struct IsBitsetImpl : std::false_type {}; +template <template <size_t> class B, size_t N> +struct IsBitsetImpl<B<N>> : std::is_same<B<N>, std::bitset<N>> {}; +template <typename C> +using IsBitset = IsBitsetImpl<absl::decay_t<C>>; + +template <typename C> +struct IsSTLContainer + : absl::disjunction< + IsArray<C>, IsBitset<C>, IsSpecialization<C, std::deque>, + IsSpecialization<C, std::forward_list>, + IsSpecialization<C, std::list>, IsSpecialization<C, std::map>, + IsSpecialization<C, std::multimap>, IsSpecialization<C, std::set>, + IsSpecialization<C, std::multiset>, + IsSpecialization<C, std::unordered_map>, + IsSpecialization<C, std::unordered_multimap>, + IsSpecialization<C, std::unordered_set>, + IsSpecialization<C, std::unordered_multiset>, + IsSpecialization<C, std::vector>> {}; + +template <typename C, template <typename...> class T, typename = void> +struct IsBaseOfSpecializationImpl : std::false_type {}; +// IsBaseOfSpecializationImpl needs multiple partial specializations to SFINAE +// on the existence of container dependent types and plug them into the STL +// template. +template <typename C, template <typename, typename> class T> +struct IsBaseOfSpecializationImpl< + C, T, absl::void_t<typename C::value_type, typename C::allocator_type>> + : std::is_base_of<C, + T<typename C::value_type, typename C::allocator_type>> {}; +template <typename C, template <typename, typename, typename> class T> +struct IsBaseOfSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::key_compare, + typename C::allocator_type>> + : std::is_base_of<C, T<typename C::key_type, typename C::key_compare, + typename C::allocator_type>> {}; +template <typename C, template <typename, typename, typename, typename> class T> +struct IsBaseOfSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::mapped_type, + typename C::key_compare, typename C::allocator_type>> + : std::is_base_of<C, + T<typename C::key_type, typename C::mapped_type, + typename C::key_compare, typename C::allocator_type>> { +}; +template <typename C, template <typename, typename, typename, typename> class T> +struct IsBaseOfSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::hasher, + typename C::key_equal, typename C::allocator_type>> + : std::is_base_of<C, T<typename C::key_type, typename C::hasher, + typename C::key_equal, typename C::allocator_type>> { +}; +template <typename C, + template <typename, typename, typename, typename, typename> class T> +struct IsBaseOfSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::mapped_type, + typename C::hasher, typename C::key_equal, + typename C::allocator_type>> + : std::is_base_of<C, T<typename C::key_type, typename C::mapped_type, + typename C::hasher, typename C::key_equal, + typename C::allocator_type>> {}; +template <typename C, template <typename...> class T> +using IsBaseOfSpecialization = IsBaseOfSpecializationImpl<absl::decay_t<C>, T>; + +template <typename C> +struct IsBaseOfArrayImpl : std::false_type {}; +template <template <typename, size_t> class A, typename T, size_t N> +struct IsBaseOfArrayImpl<A<T, N>> : std::is_base_of<A<T, N>, std::array<T, N>> { +}; +template <typename C> +using IsBaseOfArray = IsBaseOfArrayImpl<absl::decay_t<C>>; + +template <typename C> +struct IsBaseOfBitsetImpl : std::false_type {}; +template <template <size_t> class B, size_t N> +struct IsBaseOfBitsetImpl<B<N>> : std::is_base_of<B<N>, std::bitset<N>> {}; +template <typename C> +using IsBaseOfBitset = IsBaseOfBitsetImpl<absl::decay_t<C>>; + +template <typename C> +struct IsBaseOfSTLContainer + : absl::disjunction<IsBaseOfArray<C>, IsBaseOfBitset<C>, + IsBaseOfSpecialization<C, std::deque>, + IsBaseOfSpecialization<C, std::forward_list>, + IsBaseOfSpecialization<C, std::list>, + IsBaseOfSpecialization<C, std::map>, + IsBaseOfSpecialization<C, std::multimap>, + IsBaseOfSpecialization<C, std::set>, + IsBaseOfSpecialization<C, std::multiset>, + IsBaseOfSpecialization<C, std::unordered_map>, + IsBaseOfSpecialization<C, std::unordered_multimap>, + IsBaseOfSpecialization<C, std::unordered_set>, + IsBaseOfSpecialization<C, std::unordered_multiset>, + IsBaseOfSpecialization<C, std::vector>> {}; + +template <typename C, template <typename...> class T, typename = void> +struct IsConvertibleToSpecializationImpl : std::false_type {}; +// IsConvertibleToSpecializationImpl needs multiple partial specializations to +// SFINAE on the existence of container dependent types and plug them into the +// STL template. +template <typename C, template <typename, typename> class T> +struct IsConvertibleToSpecializationImpl< + C, T, absl::void_t<typename C::value_type, typename C::allocator_type>> + : std::is_convertible< + C, T<typename C::value_type, typename C::allocator_type>> {}; +template <typename C, template <typename, typename, typename> class T> +struct IsConvertibleToSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::key_compare, + typename C::allocator_type>> + : std::is_convertible<C, T<typename C::key_type, typename C::key_compare, + typename C::allocator_type>> {}; +template <typename C, template <typename, typename, typename, typename> class T> +struct IsConvertibleToSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::mapped_type, + typename C::key_compare, typename C::allocator_type>> + : std::is_convertible< + C, T<typename C::key_type, typename C::mapped_type, + typename C::key_compare, typename C::allocator_type>> {}; +template <typename C, template <typename, typename, typename, typename> class T> +struct IsConvertibleToSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::hasher, + typename C::key_equal, typename C::allocator_type>> + : std::is_convertible< + C, T<typename C::key_type, typename C::hasher, typename C::key_equal, + typename C::allocator_type>> {}; +template <typename C, + template <typename, typename, typename, typename, typename> class T> +struct IsConvertibleToSpecializationImpl< + C, T, + absl::void_t<typename C::key_type, typename C::mapped_type, + typename C::hasher, typename C::key_equal, + typename C::allocator_type>> + : std::is_convertible<C, T<typename C::key_type, typename C::mapped_type, + typename C::hasher, typename C::key_equal, + typename C::allocator_type>> {}; +template <typename C, template <typename...> class T> +using IsConvertibleToSpecialization = + IsConvertibleToSpecializationImpl<absl::decay_t<C>, T>; + +template <typename C> +struct IsConvertibleToArrayImpl : std::false_type {}; +template <template <typename, size_t> class A, typename T, size_t N> +struct IsConvertibleToArrayImpl<A<T, N>> + : std::is_convertible<A<T, N>, std::array<T, N>> {}; +template <typename C> +using IsConvertibleToArray = IsConvertibleToArrayImpl<absl::decay_t<C>>; + +template <typename C> +struct IsConvertibleToBitsetImpl : std::false_type {}; +template <template <size_t> class B, size_t N> +struct IsConvertibleToBitsetImpl<B<N>> + : std::is_convertible<B<N>, std::bitset<N>> {}; +template <typename C> +using IsConvertibleToBitset = IsConvertibleToBitsetImpl<absl::decay_t<C>>; + +template <typename C> +struct IsConvertibleToSTLContainer + : absl::disjunction< + IsConvertibleToArray<C>, IsConvertibleToBitset<C>, + IsConvertibleToSpecialization<C, std::deque>, + IsConvertibleToSpecialization<C, std::forward_list>, + IsConvertibleToSpecialization<C, std::list>, + IsConvertibleToSpecialization<C, std::map>, + IsConvertibleToSpecialization<C, std::multimap>, + IsConvertibleToSpecialization<C, std::set>, + IsConvertibleToSpecialization<C, std::multiset>, + IsConvertibleToSpecialization<C, std::unordered_map>, + IsConvertibleToSpecialization<C, std::unordered_multimap>, + IsConvertibleToSpecialization<C, std::unordered_set>, + IsConvertibleToSpecialization<C, std::unordered_multiset>, + IsConvertibleToSpecialization<C, std::vector>> {}; + +template <typename C> +struct IsStrictlyBaseOfAndConvertibleToSTLContainer + : absl::conjunction<absl::negation<IsSTLContainer<C>>, + IsBaseOfSTLContainer<C>, + IsConvertibleToSTLContainer<C>> {}; + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_STRINGS_INTERNAL_STL_TYPE_TRAITS_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/arg.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/arg.cc new file mode 100644 index 0000000000..9feb224879 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/arg.cc @@ -0,0 +1,474 @@ +// +// POSIX spec: +// http://pubs.opengroup.org/onlinepubs/009695399/functions/fprintf.html +// +#include "absl/strings/internal/str_format/arg.h" + +#include <cassert> +#include <cerrno> +#include <cstdlib> +#include <string> +#include <type_traits> + +#include "absl/base/port.h" +#include "absl/strings/internal/str_format/float_conversion.h" +#include "absl/strings/numbers.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { +namespace { + +// Reduce *capacity by s.size(), clipped to a 0 minimum. +void ReducePadding(string_view s, size_t *capacity) { + *capacity = Excess(s.size(), *capacity); +} + +// Reduce *capacity by n, clipped to a 0 minimum. +void ReducePadding(size_t n, size_t *capacity) { + *capacity = Excess(n, *capacity); +} + +template <typename T> +struct MakeUnsigned : std::make_unsigned<T> {}; +template <> +struct MakeUnsigned<absl::int128> { + using type = absl::uint128; +}; +template <> +struct MakeUnsigned<absl::uint128> { + using type = absl::uint128; +}; + +template <typename T> +struct IsSigned : std::is_signed<T> {}; +template <> +struct IsSigned<absl::int128> : std::true_type {}; +template <> +struct IsSigned<absl::uint128> : std::false_type {}; + +// Integral digit printer. +// Call one of the PrintAs* routines after construction once. +// Use with_neg_and_zero/without_neg_or_zero/is_negative to access the results. +class IntDigits { + public: + // Print the unsigned integer as octal. + // Supports unsigned integral types and uint128. + template <typename T> + void PrintAsOct(T v) { + static_assert(!IsSigned<T>::value, ""); + char *p = storage_ + sizeof(storage_); + do { + *--p = static_cast<char>('0' + (static_cast<size_t>(v) & 7)); + v >>= 3; + } while (v); + start_ = p; + size_ = storage_ + sizeof(storage_) - p; + } + + // Print the signed or unsigned integer as decimal. + // Supports all integral types. + template <typename T> + void PrintAsDec(T v) { + static_assert(std::is_integral<T>::value, ""); + start_ = storage_; + size_ = numbers_internal::FastIntToBuffer(v, storage_) - storage_; + } + + void PrintAsDec(int128 v) { + auto u = static_cast<uint128>(v); + bool add_neg = false; + if (v < 0) { + add_neg = true; + u = uint128{} - u; + } + PrintAsDec(u, add_neg); + } + + void PrintAsDec(uint128 v, bool add_neg = false) { + // This function can be sped up if needed. We can call FastIntToBuffer + // twice, or fix FastIntToBuffer to support uint128. + char *p = storage_ + sizeof(storage_); + do { + p -= 2; + numbers_internal::PutTwoDigits(static_cast<size_t>(v % 100), p); + v /= 100; + } while (v); + if (p[0] == '0') { + // We printed one too many hexits. + ++p; + } + if (add_neg) { + *--p = '-'; + } + size_ = storage_ + sizeof(storage_) - p; + start_ = p; + } + + // Print the unsigned integer as hex using lowercase. + // Supports unsigned integral types and uint128. + template <typename T> + void PrintAsHexLower(T v) { + static_assert(!IsSigned<T>::value, ""); + char *p = storage_ + sizeof(storage_); + + do { + p -= 2; + constexpr const char* table = numbers_internal::kHexTable; + std::memcpy(p, table + 2 * (static_cast<size_t>(v) & 0xFF), 2); + if (sizeof(T) == 1) break; + v >>= 8; + } while (v); + if (p[0] == '0') { + // We printed one too many digits. + ++p; + } + start_ = p; + size_ = storage_ + sizeof(storage_) - p; + } + + // Print the unsigned integer as hex using uppercase. + // Supports unsigned integral types and uint128. + template <typename T> + void PrintAsHexUpper(T v) { + static_assert(!IsSigned<T>::value, ""); + char *p = storage_ + sizeof(storage_); + + // kHexTable is only lowercase, so do it manually for uppercase. + do { + *--p = "0123456789ABCDEF"[static_cast<size_t>(v) & 15]; + v >>= 4; + } while (v); + start_ = p; + size_ = storage_ + sizeof(storage_) - p; + } + + // The printed value including the '-' sign if available. + // For inputs of value `0`, this will return "0" + string_view with_neg_and_zero() const { return {start_, size_}; } + + // The printed value not including the '-' sign. + // For inputs of value `0`, this will return "". + string_view without_neg_or_zero() const { + static_assert('-' < '0', "The check below verifies both."); + size_t advance = start_[0] <= '0' ? 1 : 0; + return {start_ + advance, size_ - advance}; + } + + bool is_negative() const { return start_[0] == '-'; } + + private: + const char *start_; + size_t size_; + // Max size: 128 bit value as octal -> 43 digits, plus sign char + char storage_[128 / 3 + 1 + 1]; +}; + +// Note: 'o' conversions do not have a base indicator, it's just that +// the '#' flag is specified to modify the precision for 'o' conversions. +string_view BaseIndicator(const IntDigits &as_digits, + const FormatConversionSpecImpl conv) { + // always show 0x for %p. + bool alt = conv.has_alt_flag() || + conv.conversion_char() == FormatConversionCharInternal::p; + bool hex = (conv.conversion_char() == FormatConversionCharInternal::x || + conv.conversion_char() == FormatConversionCharInternal::X || + conv.conversion_char() == FormatConversionCharInternal::p); + // From the POSIX description of '#' flag: + // "For x or X conversion specifiers, a non-zero result shall have + // 0x (or 0X) prefixed to it." + if (alt && hex && !as_digits.without_neg_or_zero().empty()) { + return conv.conversion_char() == FormatConversionCharInternal::X ? "0X" + : "0x"; + } + return {}; +} + +string_view SignColumn(bool neg, const FormatConversionSpecImpl conv) { + if (conv.conversion_char() == FormatConversionCharInternal::d || + conv.conversion_char() == FormatConversionCharInternal::i) { + if (neg) return "-"; + if (conv.has_show_pos_flag()) return "+"; + if (conv.has_sign_col_flag()) return " "; + } + return {}; +} + +bool ConvertCharImpl(unsigned char v, const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + size_t fill = 0; + if (conv.width() >= 0) fill = conv.width(); + ReducePadding(1, &fill); + if (!conv.has_left_flag()) sink->Append(fill, ' '); + sink->Append(1, v); + if (conv.has_left_flag()) sink->Append(fill, ' '); + return true; +} + +bool ConvertIntImplInnerSlow(const IntDigits &as_digits, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + // Print as a sequence of Substrings: + // [left_spaces][sign][base_indicator][zeroes][formatted][right_spaces] + size_t fill = 0; + if (conv.width() >= 0) fill = conv.width(); + + string_view formatted = as_digits.without_neg_or_zero(); + ReducePadding(formatted, &fill); + + string_view sign = SignColumn(as_digits.is_negative(), conv); + ReducePadding(sign, &fill); + + string_view base_indicator = BaseIndicator(as_digits, conv); + ReducePadding(base_indicator, &fill); + + int precision = conv.precision(); + bool precision_specified = precision >= 0; + if (!precision_specified) + precision = 1; + + if (conv.has_alt_flag() && + conv.conversion_char() == FormatConversionCharInternal::o) { + // From POSIX description of the '#' (alt) flag: + // "For o conversion, it increases the precision (if necessary) to + // force the first digit of the result to be zero." + if (formatted.empty() || *formatted.begin() != '0') { + int needed = static_cast<int>(formatted.size()) + 1; + precision = std::max(precision, needed); + } + } + + size_t num_zeroes = Excess(formatted.size(), precision); + ReducePadding(num_zeroes, &fill); + + size_t num_left_spaces = !conv.has_left_flag() ? fill : 0; + size_t num_right_spaces = conv.has_left_flag() ? fill : 0; + + // From POSIX description of the '0' (zero) flag: + // "For d, i, o, u, x, and X conversion specifiers, if a precision + // is specified, the '0' flag is ignored." + if (!precision_specified && conv.has_zero_flag()) { + num_zeroes += num_left_spaces; + num_left_spaces = 0; + } + + sink->Append(num_left_spaces, ' '); + sink->Append(sign); + sink->Append(base_indicator); + sink->Append(num_zeroes, '0'); + sink->Append(formatted); + sink->Append(num_right_spaces, ' '); + return true; +} + +template <typename T> +bool ConvertIntArg(T v, const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + using U = typename MakeUnsigned<T>::type; + IntDigits as_digits; + + // This odd casting is due to a bug in -Wswitch behavior in gcc49 which causes + // it to complain about a switch/case type mismatch, even though both are + // FormatConverionChar. Likely this is because at this point + // FormatConversionChar is declared, but not defined. + switch (static_cast<uint8_t>(conv.conversion_char())) { + case static_cast<uint8_t>(FormatConversionCharInternal::c): + return ConvertCharImpl(static_cast<unsigned char>(v), conv, sink); + + case static_cast<uint8_t>(FormatConversionCharInternal::o): + as_digits.PrintAsOct(static_cast<U>(v)); + break; + + case static_cast<uint8_t>(FormatConversionCharInternal::x): + as_digits.PrintAsHexLower(static_cast<U>(v)); + break; + case static_cast<uint8_t>(FormatConversionCharInternal::X): + as_digits.PrintAsHexUpper(static_cast<U>(v)); + break; + + case static_cast<uint8_t>(FormatConversionCharInternal::u): + as_digits.PrintAsDec(static_cast<U>(v)); + break; + + case static_cast<uint8_t>(FormatConversionCharInternal::d): + case static_cast<uint8_t>(FormatConversionCharInternal::i): + as_digits.PrintAsDec(v); + break; + + case static_cast<uint8_t>(FormatConversionCharInternal::a): + case static_cast<uint8_t>(FormatConversionCharInternal::e): + case static_cast<uint8_t>(FormatConversionCharInternal::f): + case static_cast<uint8_t>(FormatConversionCharInternal::g): + case static_cast<uint8_t>(FormatConversionCharInternal::A): + case static_cast<uint8_t>(FormatConversionCharInternal::E): + case static_cast<uint8_t>(FormatConversionCharInternal::F): + case static_cast<uint8_t>(FormatConversionCharInternal::G): + return ConvertFloatImpl(static_cast<double>(v), conv, sink); + + default: + ABSL_INTERNAL_ASSUME(false); + } + + if (conv.is_basic()) { + sink->Append(as_digits.with_neg_and_zero()); + return true; + } + return ConvertIntImplInnerSlow(as_digits, conv, sink); +} + +template <typename T> +bool ConvertFloatArg(T v, const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return FormatConversionCharIsFloat(conv.conversion_char()) && + ConvertFloatImpl(v, conv, sink); +} + +inline bool ConvertStringArg(string_view v, const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + if (conv.is_basic()) { + sink->Append(v); + return true; + } + return sink->PutPaddedString(v, conv.width(), conv.precision(), + conv.has_left_flag()); +} + +} // namespace + +// ==================== Strings ==================== +StringConvertResult FormatConvertImpl(const std::string &v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertStringArg(v, conv, sink)}; +} + +StringConvertResult FormatConvertImpl(string_view v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertStringArg(v, conv, sink)}; +} + +ArgConvertResult<FormatConversionCharSetUnion( + FormatConversionCharSetInternal::s, FormatConversionCharSetInternal::p)> +FormatConvertImpl(const char *v, const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + if (conv.conversion_char() == FormatConversionCharInternal::p) + return {FormatConvertImpl(VoidPtr(v), conv, sink).value}; + size_t len; + if (v == nullptr) { + len = 0; + } else if (conv.precision() < 0) { + len = std::strlen(v); + } else { + // If precision is set, we look for the NUL-terminator on the valid range. + len = std::find(v, v + conv.precision(), '\0') - v; + } + return {ConvertStringArg(string_view(v, len), conv, sink)}; +} + +// ==================== Raw pointers ==================== +ArgConvertResult<FormatConversionCharSetInternal::p> FormatConvertImpl( + VoidPtr v, const FormatConversionSpecImpl conv, FormatSinkImpl *sink) { + if (!v.value) { + sink->Append("(nil)"); + return {true}; + } + IntDigits as_digits; + as_digits.PrintAsHexLower(v.value); + return {ConvertIntImplInnerSlow(as_digits, conv, sink)}; +} + +// ==================== Floats ==================== +FloatingConvertResult FormatConvertImpl(float v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertFloatArg(v, conv, sink)}; +} +FloatingConvertResult FormatConvertImpl(double v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertFloatArg(v, conv, sink)}; +} +FloatingConvertResult FormatConvertImpl(long double v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertFloatArg(v, conv, sink)}; +} + +// ==================== Chars ==================== +IntegralConvertResult FormatConvertImpl(char v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(signed char v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(unsigned char v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} + +// ==================== Ints ==================== +IntegralConvertResult FormatConvertImpl(short v, // NOLINT + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(unsigned short v, // NOLINT + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(int v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(unsigned v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(long v, // NOLINT + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(unsigned long v, // NOLINT + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(long long v, // NOLINT + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(unsigned long long v, // NOLINT + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(absl::int128 v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} +IntegralConvertResult FormatConvertImpl(absl::uint128 v, + const FormatConversionSpecImpl conv, + FormatSinkImpl *sink) { + return {ConvertIntArg(v, conv, sink)}; +} + +ABSL_INTERNAL_FORMAT_DISPATCH_OVERLOADS_EXPAND_(); + + + +} // namespace str_format_internal + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/arg.h b/third_party/abseil_cpp/absl/strings/internal/str_format/arg.h new file mode 100644 index 0000000000..d441e87fff --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/arg.h @@ -0,0 +1,474 @@ +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_ARG_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_ARG_H_ + +#include <string.h> +#include <wchar.h> + +#include <cstdio> +#include <iomanip> +#include <limits> +#include <memory> +#include <sstream> +#include <string> +#include <type_traits> + +#include "absl/base/port.h" +#include "absl/meta/type_traits.h" +#include "absl/numeric/int128.h" +#include "absl/strings/internal/str_format/extension.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class Cord; +class FormatCountCapture; +class FormatSink; + +namespace str_format_internal { + +class FormatConversionSpec; + +template <typename T, typename = void> +struct HasUserDefinedConvert : std::false_type {}; + +template <typename T> +struct HasUserDefinedConvert<T, void_t<decltype(AbslFormatConvert( + std::declval<const T&>(), + std::declval<const FormatConversionSpec&>(), + std::declval<FormatSink*>()))>> + : std::true_type {}; + +template <typename T> +class StreamedWrapper; + +// If 'v' can be converted (in the printf sense) according to 'conv', +// then convert it, appending to `sink` and return `true`. +// Otherwise fail and return `false`. + +// Raw pointers. +struct VoidPtr { + VoidPtr() = default; + template <typename T, + decltype(reinterpret_cast<uintptr_t>(std::declval<T*>())) = 0> + VoidPtr(T* ptr) // NOLINT + : value(ptr ? reinterpret_cast<uintptr_t>(ptr) : 0) {} + uintptr_t value; +}; + +template <FormatConversionCharSet C> +struct ArgConvertResult { + bool value; +}; + +template <FormatConversionCharSet C> +constexpr FormatConversionCharSet ExtractCharSet(ArgConvertResult<C>) { + return C; +} + +using StringConvertResult = + ArgConvertResult<FormatConversionCharSetInternal::s>; +ArgConvertResult<FormatConversionCharSetInternal::p> FormatConvertImpl( + VoidPtr v, FormatConversionSpecImpl conv, FormatSinkImpl* sink); + +// Strings. +StringConvertResult FormatConvertImpl(const std::string& v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +StringConvertResult FormatConvertImpl(string_view v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +ArgConvertResult<FormatConversionCharSetUnion( + FormatConversionCharSetInternal::s, FormatConversionCharSetInternal::p)> +FormatConvertImpl(const char* v, const FormatConversionSpecImpl conv, + FormatSinkImpl* sink); + +template <class AbslCord, typename std::enable_if<std::is_same< + AbslCord, absl::Cord>::value>::type* = nullptr> +StringConvertResult FormatConvertImpl(const AbslCord& value, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink) { + bool is_left = conv.has_left_flag(); + size_t space_remaining = 0; + + int width = conv.width(); + if (width >= 0) space_remaining = width; + + size_t to_write = value.size(); + + int precision = conv.precision(); + if (precision >= 0) + to_write = (std::min)(to_write, static_cast<size_t>(precision)); + + space_remaining = Excess(to_write, space_remaining); + + if (space_remaining > 0 && !is_left) sink->Append(space_remaining, ' '); + + for (string_view piece : value.Chunks()) { + if (piece.size() > to_write) { + piece.remove_suffix(piece.size() - to_write); + to_write = 0; + } else { + to_write -= piece.size(); + } + sink->Append(piece); + if (to_write == 0) { + break; + } + } + + if (space_remaining > 0 && is_left) sink->Append(space_remaining, ' '); + return {true}; +} + +using IntegralConvertResult = ArgConvertResult<FormatConversionCharSetUnion( + FormatConversionCharSetInternal::c, + FormatConversionCharSetInternal::kNumeric, + FormatConversionCharSetInternal::kStar)>; +using FloatingConvertResult = + ArgConvertResult<FormatConversionCharSetInternal::kFloating>; + +// Floats. +FloatingConvertResult FormatConvertImpl(float v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +FloatingConvertResult FormatConvertImpl(double v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +FloatingConvertResult FormatConvertImpl(long double v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); + +// Chars. +IntegralConvertResult FormatConvertImpl(char v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(signed char v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(unsigned char v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); + +// Ints. +IntegralConvertResult FormatConvertImpl(short v, // NOLINT + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(unsigned short v, // NOLINT + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(int v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(unsigned v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(long v, // NOLINT + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(unsigned long v, // NOLINT + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(long long v, // NOLINT + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(unsigned long long v, // NOLINT + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(int128 v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +IntegralConvertResult FormatConvertImpl(uint128 v, + FormatConversionSpecImpl conv, + FormatSinkImpl* sink); +template <typename T, enable_if_t<std::is_same<T, bool>::value, int> = 0> +IntegralConvertResult FormatConvertImpl(T v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink) { + return FormatConvertImpl(static_cast<int>(v), conv, sink); +} + +// We provide this function to help the checker, but it is never defined. +// FormatArgImpl will use the underlying Convert functions instead. +template <typename T> +typename std::enable_if<std::is_enum<T>::value && + !HasUserDefinedConvert<T>::value, + IntegralConvertResult>::type +FormatConvertImpl(T v, FormatConversionSpecImpl conv, FormatSinkImpl* sink); + +template <typename T> +StringConvertResult FormatConvertImpl(const StreamedWrapper<T>& v, + FormatConversionSpecImpl conv, + FormatSinkImpl* out) { + std::ostringstream oss; + oss << v.v_; + if (!oss) return {false}; + return str_format_internal::FormatConvertImpl(oss.str(), conv, out); +} + +// Use templates and dependent types to delay evaluation of the function +// until after FormatCountCapture is fully defined. +struct FormatCountCaptureHelper { + template <class T = int> + static ArgConvertResult<FormatConversionCharSetInternal::n> ConvertHelper( + const FormatCountCapture& v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink) { + const absl::enable_if_t<sizeof(T) != 0, FormatCountCapture>& v2 = v; + + if (conv.conversion_char() != + str_format_internal::FormatConversionCharInternal::n) { + return {false}; + } + *v2.p_ = static_cast<int>(sink->size()); + return {true}; + } +}; + +template <class T = int> +ArgConvertResult<FormatConversionCharSetInternal::n> FormatConvertImpl( + const FormatCountCapture& v, FormatConversionSpecImpl conv, + FormatSinkImpl* sink) { + return FormatCountCaptureHelper::ConvertHelper(v, conv, sink); +} + +// Helper friend struct to hide implementation details from the public API of +// FormatArgImpl. +struct FormatArgImplFriend { + template <typename Arg> + static bool ToInt(Arg arg, int* out) { + // A value initialized FormatConversionSpecImpl has a `none` conv, which + // tells the dispatcher to run the `int` conversion. + return arg.dispatcher_(arg.data_, {}, out); + } + + template <typename Arg> + static bool Convert(Arg arg, FormatConversionSpecImpl conv, + FormatSinkImpl* out) { + return arg.dispatcher_(arg.data_, conv, out); + } + + template <typename Arg> + static typename Arg::Dispatcher GetVTablePtrForTest(Arg arg) { + return arg.dispatcher_; + } +}; + +template <typename Arg> +constexpr FormatConversionCharSet ArgumentToConv() { + return absl::str_format_internal::ExtractCharSet( + decltype(str_format_internal::FormatConvertImpl( + std::declval<const Arg&>(), + std::declval<const FormatConversionSpecImpl&>(), + std::declval<FormatSinkImpl*>())){}); +} + +// A type-erased handle to a format argument. +class FormatArgImpl { + private: + enum { kInlinedSpace = 8 }; + + using VoidPtr = str_format_internal::VoidPtr; + + union Data { + const void* ptr; + const volatile void* volatile_ptr; + char buf[kInlinedSpace]; + }; + + using Dispatcher = bool (*)(Data, FormatConversionSpecImpl, void* out); + + template <typename T> + struct store_by_value + : std::integral_constant<bool, (sizeof(T) <= kInlinedSpace) && + (std::is_integral<T>::value || + std::is_floating_point<T>::value || + std::is_pointer<T>::value || + std::is_same<VoidPtr, T>::value)> {}; + + enum StoragePolicy { ByPointer, ByVolatilePointer, ByValue }; + template <typename T> + struct storage_policy + : std::integral_constant<StoragePolicy, + (std::is_volatile<T>::value + ? ByVolatilePointer + : (store_by_value<T>::value ? ByValue + : ByPointer))> { + }; + + // To reduce the number of vtables we will decay values before hand. + // Anything with a user-defined Convert will get its own vtable. + // For everything else: + // - Decay char* and char arrays into `const char*` + // - Decay any other pointer to `const void*` + // - Decay all enums to their underlying type. + // - Decay function pointers to void*. + template <typename T, typename = void> + struct DecayType { + static constexpr bool kHasUserDefined = + str_format_internal::HasUserDefinedConvert<T>::value; + using type = typename std::conditional< + !kHasUserDefined && std::is_convertible<T, const char*>::value, + const char*, + typename std::conditional<!kHasUserDefined && + std::is_convertible<T, VoidPtr>::value, + VoidPtr, const T&>::type>::type; + }; + template <typename T> + struct DecayType<T, + typename std::enable_if< + !str_format_internal::HasUserDefinedConvert<T>::value && + std::is_enum<T>::value>::type> { + using type = typename std::underlying_type<T>::type; + }; + + public: + template <typename T> + explicit FormatArgImpl(const T& value) { + using D = typename DecayType<T>::type; + static_assert( + std::is_same<D, const T&>::value || storage_policy<D>::value == ByValue, + "Decayed types must be stored by value"); + Init(static_cast<D>(value)); + } + + private: + friend struct str_format_internal::FormatArgImplFriend; + template <typename T, StoragePolicy = storage_policy<T>::value> + struct Manager; + + template <typename T> + struct Manager<T, ByPointer> { + static Data SetValue(const T& value) { + Data data; + data.ptr = std::addressof(value); + return data; + } + + static const T& Value(Data arg) { return *static_cast<const T*>(arg.ptr); } + }; + + template <typename T> + struct Manager<T, ByVolatilePointer> { + static Data SetValue(const T& value) { + Data data; + data.volatile_ptr = &value; + return data; + } + + static const T& Value(Data arg) { + return *static_cast<const T*>(arg.volatile_ptr); + } + }; + + template <typename T> + struct Manager<T, ByValue> { + static Data SetValue(const T& value) { + Data data; + memcpy(data.buf, &value, sizeof(value)); + return data; + } + + static T Value(Data arg) { + T value; + memcpy(&value, arg.buf, sizeof(T)); + return value; + } + }; + + template <typename T> + void Init(const T& value) { + data_ = Manager<T>::SetValue(value); + dispatcher_ = &Dispatch<T>; + } + + template <typename T> + static int ToIntVal(const T& val) { + using CommonType = typename std::conditional<std::is_signed<T>::value, + int64_t, uint64_t>::type; + if (static_cast<CommonType>(val) > + static_cast<CommonType>((std::numeric_limits<int>::max)())) { + return (std::numeric_limits<int>::max)(); + } else if (std::is_signed<T>::value && + static_cast<CommonType>(val) < + static_cast<CommonType>((std::numeric_limits<int>::min)())) { + return (std::numeric_limits<int>::min)(); + } + return static_cast<int>(val); + } + + template <typename T> + static bool ToInt(Data arg, int* out, std::true_type /* is_integral */, + std::false_type) { + *out = ToIntVal(Manager<T>::Value(arg)); + return true; + } + + template <typename T> + static bool ToInt(Data arg, int* out, std::false_type, + std::true_type /* is_enum */) { + *out = ToIntVal(static_cast<typename std::underlying_type<T>::type>( + Manager<T>::Value(arg))); + return true; + } + + template <typename T> + static bool ToInt(Data, int*, std::false_type, std::false_type) { + return false; + } + + template <typename T> + static bool Dispatch(Data arg, FormatConversionSpecImpl spec, void* out) { + // A `none` conv indicates that we want the `int` conversion. + if (ABSL_PREDICT_FALSE(spec.conversion_char() == + FormatConversionCharInternal::kNone)) { + return ToInt<T>(arg, static_cast<int*>(out), std::is_integral<T>(), + std::is_enum<T>()); + } + if (ABSL_PREDICT_FALSE(!Contains(ArgumentToConv<T>(), + spec.conversion_char()))) { + return false; + } + return str_format_internal::FormatConvertImpl( + Manager<T>::Value(arg), spec, + static_cast<FormatSinkImpl*>(out)) + .value; + } + + Data data_; + Dispatcher dispatcher_; +}; + +#define ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(T, E) \ + E template bool FormatArgImpl::Dispatch<T>(Data, FormatConversionSpecImpl, \ + void*) + +#define ABSL_INTERNAL_FORMAT_DISPATCH_OVERLOADS_EXPAND_(...) \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(str_format_internal::VoidPtr, \ + __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(bool, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(char, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(signed char, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(unsigned char, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(short, __VA_ARGS__); /* NOLINT */ \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(unsigned short, /* NOLINT */ \ + __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(int, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(unsigned int, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(long, __VA_ARGS__); /* NOLINT */ \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(unsigned long, /* NOLINT */ \ + __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(long long, /* NOLINT */ \ + __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(unsigned long long, /* NOLINT */ \ + __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(int128, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(uint128, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(float, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(double, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(long double, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(const char*, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(std::string, __VA_ARGS__); \ + ABSL_INTERNAL_FORMAT_DISPATCH_INSTANTIATE_(string_view, __VA_ARGS__) + +ABSL_INTERNAL_FORMAT_DISPATCH_OVERLOADS_EXPAND_(extern); + + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_ARG_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/arg_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/arg_test.cc new file mode 100644 index 0000000000..bf3d7e8e37 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/arg_test.cc @@ -0,0 +1,114 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +#include "absl/strings/internal/str_format/arg.h" + +#include <ostream> +#include <string> +#include "gtest/gtest.h" +#include "absl/strings/str_format.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { +namespace { + +class FormatArgImplTest : public ::testing::Test { + public: + enum Color { kRed, kGreen, kBlue }; + + static const char *hi() { return "hi"; } +}; + +TEST_F(FormatArgImplTest, ToInt) { + int out = 0; + EXPECT_TRUE(FormatArgImplFriend::ToInt(FormatArgImpl(1), &out)); + EXPECT_EQ(1, out); + EXPECT_TRUE(FormatArgImplFriend::ToInt(FormatArgImpl(-1), &out)); + EXPECT_EQ(-1, out); + EXPECT_TRUE( + FormatArgImplFriend::ToInt(FormatArgImpl(static_cast<char>(64)), &out)); + EXPECT_EQ(64, out); + EXPECT_TRUE(FormatArgImplFriend::ToInt( + FormatArgImpl(static_cast<unsigned long long>(123456)), &out)); // NOLINT + EXPECT_EQ(123456, out); + EXPECT_TRUE(FormatArgImplFriend::ToInt( + FormatArgImpl(static_cast<unsigned long long>( // NOLINT + std::numeric_limits<int>::max()) + + 1), + &out)); + EXPECT_EQ(std::numeric_limits<int>::max(), out); + EXPECT_TRUE(FormatArgImplFriend::ToInt( + FormatArgImpl(static_cast<long long>( // NOLINT + std::numeric_limits<int>::min()) - + 10), + &out)); + EXPECT_EQ(std::numeric_limits<int>::min(), out); + EXPECT_TRUE(FormatArgImplFriend::ToInt(FormatArgImpl(false), &out)); + EXPECT_EQ(0, out); + EXPECT_TRUE(FormatArgImplFriend::ToInt(FormatArgImpl(true), &out)); + EXPECT_EQ(1, out); + EXPECT_FALSE(FormatArgImplFriend::ToInt(FormatArgImpl(2.2), &out)); + EXPECT_FALSE(FormatArgImplFriend::ToInt(FormatArgImpl(3.2f), &out)); + EXPECT_FALSE(FormatArgImplFriend::ToInt( + FormatArgImpl(static_cast<int *>(nullptr)), &out)); + EXPECT_FALSE(FormatArgImplFriend::ToInt(FormatArgImpl(hi()), &out)); + EXPECT_FALSE(FormatArgImplFriend::ToInt(FormatArgImpl("hi"), &out)); + EXPECT_TRUE(FormatArgImplFriend::ToInt(FormatArgImpl(kBlue), &out)); + EXPECT_EQ(2, out); +} + +extern const char kMyArray[]; + +TEST_F(FormatArgImplTest, CharArraysDecayToCharPtr) { + const char* a = ""; + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(a)), + FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(""))); + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(a)), + FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl("A"))); + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(a)), + FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl("ABC"))); + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(a)), + FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(kMyArray))); +} + +TEST_F(FormatArgImplTest, OtherPtrDecayToVoidPtr) { + auto expected = FormatArgImplFriend::GetVTablePtrForTest( + FormatArgImpl(static_cast<void *>(nullptr))); + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest( + FormatArgImpl(static_cast<int *>(nullptr))), + expected); + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest( + FormatArgImpl(static_cast<volatile int *>(nullptr))), + expected); + + auto p = static_cast<void (*)()>([] {}); + EXPECT_EQ(FormatArgImplFriend::GetVTablePtrForTest(FormatArgImpl(p)), + expected); +} + +TEST_F(FormatArgImplTest, WorksWithCharArraysOfUnknownSize) { + std::string s; + FormatSinkImpl sink(&s); + FormatConversionSpecImpl conv; + FormatConversionSpecImplFriend::SetConversionChar( + FormatConversionCharInternal::s, &conv); + FormatConversionSpecImplFriend::SetFlags(Flags(), &conv); + FormatConversionSpecImplFriend::SetWidth(-1, &conv); + FormatConversionSpecImplFriend::SetPrecision(-1, &conv); + EXPECT_TRUE( + FormatArgImplFriend::Convert(FormatArgImpl(kMyArray), conv, &sink)); + sink.Flush(); + EXPECT_EQ("ABCDE", s); +} +const char kMyArray[] = "ABCDE"; + +} // namespace +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/bind.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/bind.cc new file mode 100644 index 0000000000..6980ed1d8f --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/bind.cc @@ -0,0 +1,245 @@ +#include "absl/strings/internal/str_format/bind.h" + +#include <cerrno> +#include <limits> +#include <sstream> +#include <string> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +namespace { + +inline bool BindFromPosition(int position, int* value, + absl::Span<const FormatArgImpl> pack) { + assert(position > 0); + if (static_cast<size_t>(position) > pack.size()) { + return false; + } + // -1 because positions are 1-based + return FormatArgImplFriend::ToInt(pack[position - 1], value); +} + +class ArgContext { + public: + explicit ArgContext(absl::Span<const FormatArgImpl> pack) : pack_(pack) {} + + // Fill 'bound' with the results of applying the context's argument pack + // to the specified 'unbound'. We synthesize a BoundConversion by + // lining up a UnboundConversion with a user argument. We also + // resolve any '*' specifiers for width and precision, so after + // this call, 'bound' has all the information it needs to be formatted. + // Returns false on failure. + bool Bind(const UnboundConversion* unbound, BoundConversion* bound); + + private: + absl::Span<const FormatArgImpl> pack_; +}; + +inline bool ArgContext::Bind(const UnboundConversion* unbound, + BoundConversion* bound) { + const FormatArgImpl* arg = nullptr; + int arg_position = unbound->arg_position; + if (static_cast<size_t>(arg_position - 1) >= pack_.size()) return false; + arg = &pack_[arg_position - 1]; // 1-based + + if (!unbound->flags.basic) { + int width = unbound->width.value(); + bool force_left = false; + if (unbound->width.is_from_arg()) { + if (!BindFromPosition(unbound->width.get_from_arg(), &width, pack_)) + return false; + if (width < 0) { + // "A negative field width is taken as a '-' flag followed by a + // positive field width." + force_left = true; + // Make sure we don't overflow the width when negating it. + width = -std::max(width, -std::numeric_limits<int>::max()); + } + } + + int precision = unbound->precision.value(); + if (unbound->precision.is_from_arg()) { + if (!BindFromPosition(unbound->precision.get_from_arg(), &precision, + pack_)) + return false; + } + + FormatConversionSpecImplFriend::SetWidth(width, bound); + FormatConversionSpecImplFriend::SetPrecision(precision, bound); + + if (force_left) { + Flags flags = unbound->flags; + flags.left = true; + FormatConversionSpecImplFriend::SetFlags(flags, bound); + } else { + FormatConversionSpecImplFriend::SetFlags(unbound->flags, bound); + } + } else { + FormatConversionSpecImplFriend::SetFlags(unbound->flags, bound); + FormatConversionSpecImplFriend::SetWidth(-1, bound); + FormatConversionSpecImplFriend::SetPrecision(-1, bound); + } + FormatConversionSpecImplFriend::SetConversionChar(unbound->conv, bound); + bound->set_arg(arg); + return true; +} + +template <typename Converter> +class ConverterConsumer { + public: + ConverterConsumer(Converter converter, absl::Span<const FormatArgImpl> pack) + : converter_(converter), arg_context_(pack) {} + + bool Append(string_view s) { + converter_.Append(s); + return true; + } + bool ConvertOne(const UnboundConversion& conv, string_view conv_string) { + BoundConversion bound; + if (!arg_context_.Bind(&conv, &bound)) return false; + return converter_.ConvertOne(bound, conv_string); + } + + private: + Converter converter_; + ArgContext arg_context_; +}; + +template <typename Converter> +bool ConvertAll(const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args, Converter converter) { + if (format.has_parsed_conversion()) { + return format.parsed_conversion()->ProcessFormat( + ConverterConsumer<Converter>(converter, args)); + } else { + return ParseFormatString(format.str(), + ConverterConsumer<Converter>(converter, args)); + } +} + +class DefaultConverter { + public: + explicit DefaultConverter(FormatSinkImpl* sink) : sink_(sink) {} + + void Append(string_view s) const { sink_->Append(s); } + + bool ConvertOne(const BoundConversion& bound, string_view /*conv*/) const { + return FormatArgImplFriend::Convert(*bound.arg(), bound, sink_); + } + + private: + FormatSinkImpl* sink_; +}; + +class SummarizingConverter { + public: + explicit SummarizingConverter(FormatSinkImpl* sink) : sink_(sink) {} + + void Append(string_view s) const { sink_->Append(s); } + + bool ConvertOne(const BoundConversion& bound, string_view /*conv*/) const { + UntypedFormatSpecImpl spec("%d"); + + std::ostringstream ss; + ss << "{" << Streamable(spec, {*bound.arg()}) << ":" + << FormatConversionSpecImplFriend::FlagsToString(bound); + if (bound.width() >= 0) ss << bound.width(); + if (bound.precision() >= 0) ss << "." << bound.precision(); + ss << bound.conversion_char() << "}"; + Append(ss.str()); + return true; + } + + private: + FormatSinkImpl* sink_; +}; + +} // namespace + +bool BindWithPack(const UnboundConversion* props, + absl::Span<const FormatArgImpl> pack, + BoundConversion* bound) { + return ArgContext(pack).Bind(props, bound); +} + +std::string Summarize(const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args) { + typedef SummarizingConverter Converter; + std::string out; + { + // inner block to destroy sink before returning out. It ensures a last + // flush. + FormatSinkImpl sink(&out); + if (!ConvertAll(format, args, Converter(&sink))) { + return ""; + } + } + return out; +} + +bool FormatUntyped(FormatRawSinkImpl raw_sink, + const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args) { + FormatSinkImpl sink(raw_sink); + using Converter = DefaultConverter; + return ConvertAll(format, args, Converter(&sink)); +} + +std::ostream& Streamable::Print(std::ostream& os) const { + if (!FormatUntyped(&os, format_, args_)) os.setstate(std::ios::failbit); + return os; +} + +std::string& AppendPack(std::string* out, const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args) { + size_t orig = out->size(); + if (ABSL_PREDICT_FALSE(!FormatUntyped(out, format, args))) { + out->erase(orig); + } + return *out; +} + +std::string FormatPack(const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args) { + std::string out; + if (ABSL_PREDICT_FALSE(!FormatUntyped(&out, format, args))) { + out.clear(); + } + return out; +} + +int FprintF(std::FILE* output, const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args) { + FILERawSink sink(output); + if (!FormatUntyped(&sink, format, args)) { + errno = EINVAL; + return -1; + } + if (sink.error()) { + errno = sink.error(); + return -1; + } + if (sink.count() > std::numeric_limits<int>::max()) { + errno = EFBIG; + return -1; + } + return static_cast<int>(sink.count()); +} + +int SnprintF(char* output, size_t size, const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args) { + BufferRawSink sink(output, size ? size - 1 : 0); + if (!FormatUntyped(&sink, format, args)) { + errno = EINVAL; + return -1; + } + size_t total = sink.total_written(); + if (size) output[std::min(total, size - 1)] = 0; + return static_cast<int>(total); +} + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/bind.h b/third_party/abseil_cpp/absl/strings/internal/str_format/bind.h new file mode 100644 index 0000000000..585246e77e --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/bind.h @@ -0,0 +1,202 @@ +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_BIND_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_BIND_H_ + +#include <array> +#include <cstdio> +#include <sstream> +#include <string> + +#include "absl/base/port.h" +#include "absl/strings/internal/str_format/arg.h" +#include "absl/strings/internal/str_format/checker.h" +#include "absl/strings/internal/str_format/parser.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class UntypedFormatSpec; + +namespace str_format_internal { + +class BoundConversion : public FormatConversionSpecImpl { + public: + const FormatArgImpl* arg() const { return arg_; } + void set_arg(const FormatArgImpl* a) { arg_ = a; } + + private: + const FormatArgImpl* arg_; +}; + +// This is the type-erased class that the implementation uses. +class UntypedFormatSpecImpl { + public: + UntypedFormatSpecImpl() = delete; + + explicit UntypedFormatSpecImpl(string_view s) + : data_(s.data()), size_(s.size()) {} + explicit UntypedFormatSpecImpl( + const str_format_internal::ParsedFormatBase* pc) + : data_(pc), size_(~size_t{}) {} + + bool has_parsed_conversion() const { return size_ == ~size_t{}; } + + string_view str() const { + assert(!has_parsed_conversion()); + return string_view(static_cast<const char*>(data_), size_); + } + const str_format_internal::ParsedFormatBase* parsed_conversion() const { + assert(has_parsed_conversion()); + return static_cast<const str_format_internal::ParsedFormatBase*>(data_); + } + + template <typename T> + static const UntypedFormatSpecImpl& Extract(const T& s) { + return s.spec_; + } + + private: + const void* data_; + size_t size_; +}; + +template <typename T, FormatConversionCharSet...> +struct MakeDependent { + using type = T; +}; + +// Implicitly convertible from `const char*`, `string_view`, and the +// `ExtendedParsedFormat` type. This abstraction allows all format functions to +// operate on any without providing too many overloads. +template <FormatConversionCharSet... Args> +class FormatSpecTemplate + : public MakeDependent<UntypedFormatSpec, Args...>::type { + using Base = typename MakeDependent<UntypedFormatSpec, Args...>::type; + + public: +#ifdef ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + + // Honeypot overload for when the string is not constexpr. + // We use the 'unavailable' attribute to give a better compiler error than + // just 'method is deleted'. + FormatSpecTemplate(...) // NOLINT + __attribute__((unavailable("Format string is not constexpr."))); + + // Honeypot overload for when the format is constexpr and invalid. + // We use the 'unavailable' attribute to give a better compiler error than + // just 'method is deleted'. + // To avoid checking the format twice, we just check that the format is + // constexpr. If is it valid, then the overload below will kick in. + // We add the template here to make this overload have lower priority. + template <typename = void> + FormatSpecTemplate(const char* s) // NOLINT + __attribute__(( + enable_if(str_format_internal::EnsureConstexpr(s), "constexpr trap"), + unavailable( + "Format specified does not match the arguments passed."))); + + template <typename T = void> + FormatSpecTemplate(string_view s) // NOLINT + __attribute__((enable_if(str_format_internal::EnsureConstexpr(s), + "constexpr trap"))) { + static_assert(sizeof(T*) == 0, + "Format specified does not match the arguments passed."); + } + + // Good format overload. + FormatSpecTemplate(const char* s) // NOLINT + __attribute__((enable_if(ValidFormatImpl<Args...>(s), "bad format trap"))) + : Base(s) {} + + FormatSpecTemplate(string_view s) // NOLINT + __attribute__((enable_if(ValidFormatImpl<Args...>(s), "bad format trap"))) + : Base(s) {} + +#else // ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + + FormatSpecTemplate(const char* s) : Base(s) {} // NOLINT + FormatSpecTemplate(string_view s) : Base(s) {} // NOLINT + +#endif // ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + + template <FormatConversionCharSet... C, + typename = typename std::enable_if< + AllOf(sizeof...(C) == sizeof...(Args), Contains(Args, + C)...)>::type> + FormatSpecTemplate(const ExtendedParsedFormat<C...>& pc) // NOLINT + : Base(&pc) {} +}; + +class Streamable { + public: + Streamable(const UntypedFormatSpecImpl& format, + absl::Span<const FormatArgImpl> args) + : format_(format) { + if (args.size() <= ABSL_ARRAYSIZE(few_args_)) { + for (size_t i = 0; i < args.size(); ++i) { + few_args_[i] = args[i]; + } + args_ = absl::MakeSpan(few_args_, args.size()); + } else { + many_args_.assign(args.begin(), args.end()); + args_ = many_args_; + } + } + + std::ostream& Print(std::ostream& os) const; + + friend std::ostream& operator<<(std::ostream& os, const Streamable& l) { + return l.Print(os); + } + + private: + const UntypedFormatSpecImpl& format_; + absl::Span<const FormatArgImpl> args_; + // if args_.size() is 4 or less: + FormatArgImpl few_args_[4] = {FormatArgImpl(0), FormatArgImpl(0), + FormatArgImpl(0), FormatArgImpl(0)}; + // if args_.size() is more than 4: + std::vector<FormatArgImpl> many_args_; +}; + +// for testing +std::string Summarize(UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args); +bool BindWithPack(const UnboundConversion* props, + absl::Span<const FormatArgImpl> pack, BoundConversion* bound); + +bool FormatUntyped(FormatRawSinkImpl raw_sink, + UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args); + +std::string& AppendPack(std::string* out, UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args); + +std::string FormatPack(const UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args); + +int FprintF(std::FILE* output, UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args); +int SnprintF(char* output, size_t size, UntypedFormatSpecImpl format, + absl::Span<const FormatArgImpl> args); + +// Returned by Streamed(v). Converts via '%s' to the std::string created +// by std::ostream << v. +template <typename T> +class StreamedWrapper { + public: + explicit StreamedWrapper(const T& v) : v_(v) { } + + private: + template <typename S> + friend ArgConvertResult<FormatConversionCharSetInternal::s> FormatConvertImpl( + const StreamedWrapper<S>& v, FormatConversionSpecImpl conv, + FormatSinkImpl* out); + const T& v_; +}; + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_BIND_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/bind_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/bind_test.cc new file mode 100644 index 0000000000..64790a85fd --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/bind_test.cc @@ -0,0 +1,143 @@ +#include "absl/strings/internal/str_format/bind.h" + +#include <string.h> +#include <limits> + +#include "gtest/gtest.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { +namespace { + +class FormatBindTest : public ::testing::Test { + public: + bool Extract(const char *s, UnboundConversion *props, int *next) const { + return ConsumeUnboundConversion(s, s + strlen(s), props, next) == + s + strlen(s); + } +}; + +TEST_F(FormatBindTest, BindSingle) { + struct Expectation { + int line; + const char *fmt; + int ok_phases; + const FormatArgImpl *arg; + int width; + int precision; + int next_arg; + }; + const int no = -1; + const int ia[] = { 10, 20, 30, 40}; + const FormatArgImpl args[] = {FormatArgImpl(ia[0]), FormatArgImpl(ia[1]), + FormatArgImpl(ia[2]), FormatArgImpl(ia[3])}; +#pragma GCC diagnostic push +#pragma GCC diagnostic ignored "-Wmissing-field-initializers" + const Expectation kExpect[] = { + {__LINE__, "d", 2, &args[0], no, no, 2}, + {__LINE__, "4d", 2, &args[0], 4, no, 2}, + {__LINE__, ".5d", 2, &args[0], no, 5, 2}, + {__LINE__, "4.5d", 2, &args[0], 4, 5, 2}, + {__LINE__, "*d", 2, &args[1], 10, no, 3}, + {__LINE__, ".*d", 2, &args[1], no, 10, 3}, + {__LINE__, "*.*d", 2, &args[2], 10, 20, 4}, + {__LINE__, "1$d", 2, &args[0], no, no, 0}, + {__LINE__, "2$d", 2, &args[1], no, no, 0}, + {__LINE__, "3$d", 2, &args[2], no, no, 0}, + {__LINE__, "4$d", 2, &args[3], no, no, 0}, + {__LINE__, "2$*1$d", 2, &args[1], 10, no, 0}, + {__LINE__, "2$*2$d", 2, &args[1], 20, no, 0}, + {__LINE__, "2$*3$d", 2, &args[1], 30, no, 0}, + {__LINE__, "2$.*1$d", 2, &args[1], no, 10, 0}, + {__LINE__, "2$.*2$d", 2, &args[1], no, 20, 0}, + {__LINE__, "2$.*3$d", 2, &args[1], no, 30, 0}, + {__LINE__, "2$*3$.*1$d", 2, &args[1], 30, 10, 0}, + {__LINE__, "2$*2$.*2$d", 2, &args[1], 20, 20, 0}, + {__LINE__, "2$*1$.*3$d", 2, &args[1], 10, 30, 0}, + {__LINE__, "2$*3$.*1$d", 2, &args[1], 30, 10, 0}, + {__LINE__, "1$*d", 0}, // indexed, then positional + {__LINE__, "*2$d", 0}, // positional, then indexed + {__LINE__, "6$d", 1}, // arg position out of bounds + {__LINE__, "1$6$d", 0}, // width position incorrectly specified + {__LINE__, "1$.6$d", 0}, // precision position incorrectly specified + {__LINE__, "1$*6$d", 1}, // width position out of bounds + {__LINE__, "1$.*6$d", 1}, // precision position out of bounds + }; +#pragma GCC diagnostic pop + for (const Expectation &e : kExpect) { + SCOPED_TRACE(e.line); + SCOPED_TRACE(e.fmt); + UnboundConversion props; + BoundConversion bound; + int ok_phases = 0; + int next = 0; + if (Extract(e.fmt, &props, &next)) { + ++ok_phases; + if (BindWithPack(&props, args, &bound)) { + ++ok_phases; + } + } + EXPECT_EQ(e.ok_phases, ok_phases); + if (e.ok_phases < 2) continue; + if (e.arg != nullptr) { + EXPECT_EQ(e.arg, bound.arg()); + } + EXPECT_EQ(e.width, bound.width()); + EXPECT_EQ(e.precision, bound.precision()); + } +} + +TEST_F(FormatBindTest, WidthUnderflowRegression) { + UnboundConversion props; + BoundConversion bound; + int next = 0; + const int args_i[] = {std::numeric_limits<int>::min(), 17}; + const FormatArgImpl args[] = {FormatArgImpl(args_i[0]), + FormatArgImpl(args_i[1])}; + ASSERT_TRUE(Extract("*d", &props, &next)); + ASSERT_TRUE(BindWithPack(&props, args, &bound)); + + EXPECT_EQ(bound.width(), std::numeric_limits<int>::max()); + EXPECT_EQ(bound.arg(), args + 1); +} + +TEST_F(FormatBindTest, FormatPack) { + struct Expectation { + int line; + const char *fmt; + const char *summary; + }; + const int ia[] = { 10, 20, 30, 40, -10 }; + const FormatArgImpl args[] = {FormatArgImpl(ia[0]), FormatArgImpl(ia[1]), + FormatArgImpl(ia[2]), FormatArgImpl(ia[3]), + FormatArgImpl(ia[4])}; + const Expectation kExpect[] = { + {__LINE__, "a%4db%dc", "a{10:4d}b{20:d}c"}, + {__LINE__, "a%.4db%dc", "a{10:.4d}b{20:d}c"}, + {__LINE__, "a%4.5db%dc", "a{10:4.5d}b{20:d}c"}, + {__LINE__, "a%db%4.5dc", "a{10:d}b{20:4.5d}c"}, + {__LINE__, "a%db%*.*dc", "a{10:d}b{40:20.30d}c"}, + {__LINE__, "a%.*fb", "a{20:.10f}b"}, + {__LINE__, "a%1$db%2$*3$.*4$dc", "a{10:d}b{20:30.40d}c"}, + {__LINE__, "a%4$db%3$*2$.*1$dc", "a{40:d}b{30:20.10d}c"}, + {__LINE__, "a%04ldb", "a{10:04d}b"}, + {__LINE__, "a%-#04lldb", "a{10:-#04d}b"}, + {__LINE__, "a%1$*5$db", "a{10:-10d}b"}, + {__LINE__, "a%1$.*5$db", "a{10:d}b"}, + }; + for (const Expectation &e : kExpect) { + absl::string_view fmt = e.fmt; + SCOPED_TRACE(e.line); + SCOPED_TRACE(e.fmt); + UntypedFormatSpecImpl format(fmt); + EXPECT_EQ(e.summary, + str_format_internal::Summarize(format, absl::MakeSpan(args))) + << "line:" << e.line; + } +} + +} // namespace +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/checker.h b/third_party/abseil_cpp/absl/strings/internal/str_format/checker.h new file mode 100644 index 0000000000..424c51f74f --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/checker.h @@ -0,0 +1,319 @@ +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_CHECKER_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_CHECKER_H_ + +#include "absl/base/attributes.h" +#include "absl/strings/internal/str_format/arg.h" +#include "absl/strings/internal/str_format/extension.h" + +// Compile time check support for entry points. + +#ifndef ABSL_INTERNAL_ENABLE_FORMAT_CHECKER +#if ABSL_HAVE_ATTRIBUTE(enable_if) && !defined(__native_client__) +#define ABSL_INTERNAL_ENABLE_FORMAT_CHECKER 1 +#endif // ABSL_HAVE_ATTRIBUTE(enable_if) && !defined(__native_client__) +#endif // ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +constexpr bool AllOf() { return true; } + +template <typename... T> +constexpr bool AllOf(bool b, T... t) { + return b && AllOf(t...); +} + +#ifdef ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + +constexpr bool ContainsChar(const char* chars, char c) { + return *chars == c || (*chars && ContainsChar(chars + 1, c)); +} + +// A constexpr compatible list of Convs. +struct ConvList { + const FormatConversionCharSet* array; + int count; + + // We do the bound check here to avoid having to do it on the callers. + // Returning an empty FormatConversionCharSet has the same effect as + // short circuiting because it will never match any conversion. + constexpr FormatConversionCharSet operator[](int i) const { + return i < count ? array[i] : FormatConversionCharSet{}; + } + + constexpr ConvList without_front() const { + return count != 0 ? ConvList{array + 1, count - 1} : *this; + } +}; + +template <size_t count> +struct ConvListT { + // Make sure the array has size > 0. + FormatConversionCharSet list[count ? count : 1]; +}; + +constexpr char GetChar(string_view str, size_t index) { + return index < str.size() ? str[index] : char{}; +} + +constexpr string_view ConsumeFront(string_view str, size_t len = 1) { + return len <= str.size() ? string_view(str.data() + len, str.size() - len) + : string_view(); +} + +constexpr string_view ConsumeAnyOf(string_view format, const char* chars) { + return ContainsChar(chars, GetChar(format, 0)) + ? ConsumeAnyOf(ConsumeFront(format), chars) + : format; +} + +constexpr bool IsDigit(char c) { return c >= '0' && c <= '9'; } + +// Helper class for the ParseDigits function. +// It encapsulates the two return values we need there. +struct Integer { + string_view format; + int value; + + // If the next character is a '$', consume it. + // Otherwise, make `this` an invalid positional argument. + constexpr Integer ConsumePositionalDollar() const { + return GetChar(format, 0) == '$' ? Integer{ConsumeFront(format), value} + : Integer{format, 0}; + } +}; + +constexpr Integer ParseDigits(string_view format, int value = 0) { + return IsDigit(GetChar(format, 0)) + ? ParseDigits(ConsumeFront(format), + 10 * value + GetChar(format, 0) - '0') + : Integer{format, value}; +} + +// Parse digits for a positional argument. +// The parsing also consumes the '$'. +constexpr Integer ParsePositional(string_view format) { + return ParseDigits(format).ConsumePositionalDollar(); +} + +// Parses a single conversion specifier. +// See ConvParser::Run() for post conditions. +class ConvParser { + constexpr ConvParser SetFormat(string_view format) const { + return ConvParser(format, args_, error_, arg_position_, is_positional_); + } + + constexpr ConvParser SetArgs(ConvList args) const { + return ConvParser(format_, args, error_, arg_position_, is_positional_); + } + + constexpr ConvParser SetError(bool error) const { + return ConvParser(format_, args_, error_ || error, arg_position_, + is_positional_); + } + + constexpr ConvParser SetArgPosition(int arg_position) const { + return ConvParser(format_, args_, error_, arg_position, is_positional_); + } + + // Consumes the next arg and verifies that it matches `conv`. + // `error_` is set if there is no next arg or if it doesn't match `conv`. + constexpr ConvParser ConsumeNextArg(char conv) const { + return SetArgs(args_.without_front()).SetError(!Contains(args_[0], conv)); + } + + // Verify that positional argument `i.value` matches `conv`. + // `error_` is set if `i.value` is not a valid argument or if it doesn't + // match. + constexpr ConvParser VerifyPositional(Integer i, char conv) const { + return SetFormat(i.format).SetError(!Contains(args_[i.value - 1], conv)); + } + + // Parse the position of the arg and store it in `arg_position_`. + constexpr ConvParser ParseArgPosition(Integer arg) const { + return SetFormat(arg.format).SetArgPosition(arg.value); + } + + // Consume the flags. + constexpr ConvParser ParseFlags() const { + return SetFormat(ConsumeAnyOf(format_, "-+ #0")); + } + + // Consume the width. + // If it is '*', we verify that it matches `args_`. `error_` is set if it + // doesn't match. + constexpr ConvParser ParseWidth() const { + return IsDigit(GetChar(format_, 0)) + ? SetFormat(ParseDigits(format_).format) + : GetChar(format_, 0) == '*' + ? is_positional_ + ? VerifyPositional( + ParsePositional(ConsumeFront(format_)), '*') + : SetFormat(ConsumeFront(format_)) + .ConsumeNextArg('*') + : *this; + } + + // Consume the precision. + // If it is '*', we verify that it matches `args_`. `error_` is set if it + // doesn't match. + constexpr ConvParser ParsePrecision() const { + return GetChar(format_, 0) != '.' + ? *this + : GetChar(format_, 1) == '*' + ? is_positional_ + ? VerifyPositional( + ParsePositional(ConsumeFront(format_, 2)), '*') + : SetFormat(ConsumeFront(format_, 2)) + .ConsumeNextArg('*') + : SetFormat(ParseDigits(ConsumeFront(format_)).format); + } + + // Consume the length characters. + constexpr ConvParser ParseLength() const { + return SetFormat(ConsumeAnyOf(format_, "lLhjztq")); + } + + // Consume the conversion character and verify that it matches `args_`. + // `error_` is set if it doesn't match. + constexpr ConvParser ParseConversion() const { + return is_positional_ + ? VerifyPositional({ConsumeFront(format_), arg_position_}, + GetChar(format_, 0)) + : ConsumeNextArg(GetChar(format_, 0)) + .SetFormat(ConsumeFront(format_)); + } + + constexpr ConvParser(string_view format, ConvList args, bool error, + int arg_position, bool is_positional) + : format_(format), + args_(args), + error_(error), + arg_position_(arg_position), + is_positional_(is_positional) {} + + public: + constexpr ConvParser(string_view format, ConvList args, bool is_positional) + : format_(format), + args_(args), + error_(false), + arg_position_(0), + is_positional_(is_positional) {} + + // Consume the whole conversion specifier. + // `format()` will be set to the character after the conversion character. + // `error()` will be set if any of the arguments do not match. + constexpr ConvParser Run() const { + return (is_positional_ ? ParseArgPosition(ParsePositional(format_)) : *this) + .ParseFlags() + .ParseWidth() + .ParsePrecision() + .ParseLength() + .ParseConversion(); + } + + constexpr string_view format() const { return format_; } + constexpr ConvList args() const { return args_; } + constexpr bool error() const { return error_; } + constexpr bool is_positional() const { return is_positional_; } + + private: + string_view format_; + // Current list of arguments. If we are not in positional mode we will consume + // from the front. + ConvList args_; + bool error_; + // Holds the argument position of the conversion character, if we are in + // positional mode. Otherwise, it is unspecified. + int arg_position_; + // Whether we are in positional mode. + // It changes the behavior of '*' and where to find the converted argument. + bool is_positional_; +}; + +// Parses a whole format expression. +// See FormatParser::Run(). +class FormatParser { + static constexpr bool FoundPercent(string_view format) { + return format.empty() || + (GetChar(format, 0) == '%' && GetChar(format, 1) != '%'); + } + + // We use an inner function to increase the recursion limit. + // The inner function consumes up to `limit` characters on every run. + // This increases the limit from 512 to ~512*limit. + static constexpr string_view ConsumeNonPercentInner(string_view format, + int limit = 20) { + return FoundPercent(format) || !limit + ? format + : ConsumeNonPercentInner( + ConsumeFront(format, GetChar(format, 0) == '%' && + GetChar(format, 1) == '%' + ? 2 + : 1), + limit - 1); + } + + // Consume characters until the next conversion spec %. + // It skips %%. + static constexpr string_view ConsumeNonPercent(string_view format) { + return FoundPercent(format) + ? format + : ConsumeNonPercent(ConsumeNonPercentInner(format)); + } + + static constexpr bool IsPositional(string_view format) { + return IsDigit(GetChar(format, 0)) ? IsPositional(ConsumeFront(format)) + : GetChar(format, 0) == '$'; + } + + constexpr bool RunImpl(bool is_positional) const { + // In non-positional mode we require all arguments to be consumed. + // In positional mode just reaching the end of the format without errors is + // enough. + return (format_.empty() && (is_positional || args_.count == 0)) || + (!format_.empty() && + ValidateArg( + ConvParser(ConsumeFront(format_), args_, is_positional).Run())); + } + + constexpr bool ValidateArg(ConvParser conv) const { + return !conv.error() && FormatParser(conv.format(), conv.args()) + .RunImpl(conv.is_positional()); + } + + public: + constexpr FormatParser(string_view format, ConvList args) + : format_(ConsumeNonPercent(format)), args_(args) {} + + // Runs the parser for `format` and `args`. + // It verifies that the format is valid and that all conversion specifiers + // match the arguments passed. + // In non-positional mode it also verfies that all arguments are consumed. + constexpr bool Run() const { + return RunImpl(!format_.empty() && IsPositional(ConsumeFront(format_))); + } + + private: + string_view format_; + // Current list of arguments. + // If we are not in positional mode we will consume from the front and will + // have to be empty in the end. + ConvList args_; +}; + +template <FormatConversionCharSet... C> +constexpr bool ValidFormatImpl(string_view format) { + return FormatParser(format, + {ConvListT<sizeof...(C)>{{C...}}.list, sizeof...(C)}) + .Run(); +} + +#endif // ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_CHECKER_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/checker_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/checker_test.cc new file mode 100644 index 0000000000..a76d70b058 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/checker_test.cc @@ -0,0 +1,156 @@ +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/str_format.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { +namespace { + +std::string ConvToString(FormatConversionCharSet conv) { + std::string out; +#define CONV_SET_CASE(c) \ + if (Contains(conv, FormatConversionCharSetInternal::c)) { \ + out += #c; \ + } + ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(CONV_SET_CASE, ) +#undef CONV_SET_CASE + if (Contains(conv, FormatConversionCharSetInternal::kStar)) { + out += "*"; + } + return out; +} + +TEST(StrFormatChecker, ArgumentToConv) { + FormatConversionCharSet conv = ArgumentToConv<std::string>(); + EXPECT_EQ(ConvToString(conv), "s"); + + conv = ArgumentToConv<const char*>(); + EXPECT_EQ(ConvToString(conv), "sp"); + + conv = ArgumentToConv<double>(); + EXPECT_EQ(ConvToString(conv), "fFeEgGaA"); + + conv = ArgumentToConv<int>(); + EXPECT_EQ(ConvToString(conv), "cdiouxXfFeEgGaA*"); + + conv = ArgumentToConv<std::string*>(); + EXPECT_EQ(ConvToString(conv), "p"); +} + +#ifdef ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + +struct Case { + bool result; + const char* format; +}; + +template <typename... Args> +constexpr Case ValidFormat(const char* format) { + return {ValidFormatImpl<ArgumentToConv<Args>()...>(format), format}; +} + +TEST(StrFormatChecker, ValidFormat) { + // We want to make sure these expressions are constexpr and they have the + // expected value. + // If they are not constexpr the attribute will just ignore them and not give + // a compile time error. + enum e {}; + enum class e2 {}; + constexpr Case trues[] = { + ValidFormat<>("abc"), // + + ValidFormat<e>("%d"), // + ValidFormat<e2>("%d"), // + ValidFormat<int>("%% %d"), // + ValidFormat<int>("%ld"), // + ValidFormat<int>("%lld"), // + ValidFormat<std::string>("%s"), // + ValidFormat<std::string>("%10s"), // + ValidFormat<int>("%.10x"), // + ValidFormat<int, int>("%*.3x"), // + ValidFormat<int>("%1.d"), // + ValidFormat<int>("%.d"), // + ValidFormat<int, double>("%d %g"), // + ValidFormat<int, std::string>("%*s"), // + ValidFormat<int, double>("%.*f"), // + ValidFormat<void (*)(), volatile int*>("%p %p"), // + ValidFormat<string_view, const char*, double, void*>( + "string_view=%s const char*=%s double=%f void*=%p)"), + + ValidFormat<int>("%% %1$d"), // + ValidFormat<int>("%1$ld"), // + ValidFormat<int>("%1$lld"), // + ValidFormat<std::string>("%1$s"), // + ValidFormat<std::string>("%1$10s"), // + ValidFormat<int>("%1$.10x"), // + ValidFormat<int>("%1$*1$.*1$d"), // + ValidFormat<int, int>("%1$*2$.3x"), // + ValidFormat<int>("%1$1.d"), // + ValidFormat<int>("%1$.d"), // + ValidFormat<double, int>("%2$d %1$g"), // + ValidFormat<int, std::string>("%2$*1$s"), // + ValidFormat<int, double>("%2$.*1$f"), // + ValidFormat<void*, string_view, const char*, double>( + "string_view=%2$s const char*=%3$s double=%4$f void*=%1$p " + "repeat=%3$s)")}; + + for (Case c : trues) { + EXPECT_TRUE(c.result) << c.format; + } + + constexpr Case falses[] = { + ValidFormat<int>(""), // + + ValidFormat<e>("%s"), // + ValidFormat<e2>("%s"), // + ValidFormat<>("%s"), // + ValidFormat<>("%r"), // + ValidFormat<int>("%s"), // + ValidFormat<int>("%.1.d"), // + ValidFormat<int>("%*1d"), // + ValidFormat<int>("%1-d"), // + ValidFormat<std::string, int>("%*s"), // + ValidFormat<int>("%*d"), // + ValidFormat<std::string>("%p"), // + ValidFormat<int (*)(int)>("%d"), // + + ValidFormat<>("%3$d"), // + ValidFormat<>("%1$r"), // + ValidFormat<int>("%1$s"), // + ValidFormat<int>("%1$.1.d"), // + ValidFormat<int>("%1$*2$1d"), // + ValidFormat<int>("%1$1-d"), // + ValidFormat<std::string, int>("%2$*1$s"), // + ValidFormat<std::string>("%1$p"), + + ValidFormat<int, int>("%d %2$d"), // + }; + + for (Case c : falses) { + EXPECT_FALSE(c.result) << c.format; + } +} + +TEST(StrFormatChecker, LongFormat) { +#define CHARS_X_40 "1234567890123456789012345678901234567890" +#define CHARS_X_400 \ + CHARS_X_40 CHARS_X_40 CHARS_X_40 CHARS_X_40 CHARS_X_40 CHARS_X_40 CHARS_X_40 \ + CHARS_X_40 CHARS_X_40 CHARS_X_40 +#define CHARS_X_4000 \ + CHARS_X_400 CHARS_X_400 CHARS_X_400 CHARS_X_400 CHARS_X_400 CHARS_X_400 \ + CHARS_X_400 CHARS_X_400 CHARS_X_400 CHARS_X_400 + constexpr char long_format[] = + CHARS_X_4000 "%d" CHARS_X_4000 "%s" CHARS_X_4000; + constexpr bool is_valid = ValidFormat<int, std::string>(long_format).result; + EXPECT_TRUE(is_valid); +} + +#endif // ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + +} // namespace +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/convert_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/convert_test.cc new file mode 100644 index 0000000000..20c6229fcb --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/convert_test.cc @@ -0,0 +1,865 @@ +#include <errno.h> +#include <stdarg.h> +#include <stdio.h> + +#include <cctype> +#include <cmath> +#include <limits> +#include <string> +#include <thread> // NOLINT + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/internal/str_format/bind.h" +#include "absl/types/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { +namespace { + +template <typename T, size_t N> +size_t ArraySize(T (&)[N]) { + return N; +} + +std::string LengthModFor(float) { return ""; } +std::string LengthModFor(double) { return ""; } +std::string LengthModFor(long double) { return "L"; } +std::string LengthModFor(char) { return "hh"; } +std::string LengthModFor(signed char) { return "hh"; } +std::string LengthModFor(unsigned char) { return "hh"; } +std::string LengthModFor(short) { return "h"; } // NOLINT +std::string LengthModFor(unsigned short) { return "h"; } // NOLINT +std::string LengthModFor(int) { return ""; } +std::string LengthModFor(unsigned) { return ""; } +std::string LengthModFor(long) { return "l"; } // NOLINT +std::string LengthModFor(unsigned long) { return "l"; } // NOLINT +std::string LengthModFor(long long) { return "ll"; } // NOLINT +std::string LengthModFor(unsigned long long) { return "ll"; } // NOLINT + +std::string EscCharImpl(int v) { + if (std::isprint(static_cast<unsigned char>(v))) { + return std::string(1, static_cast<char>(v)); + } + char buf[64]; + int n = snprintf(buf, sizeof(buf), "\\%#.2x", + static_cast<unsigned>(v & 0xff)); + assert(n > 0 && n < sizeof(buf)); + return std::string(buf, n); +} + +std::string Esc(char v) { return EscCharImpl(v); } +std::string Esc(signed char v) { return EscCharImpl(v); } +std::string Esc(unsigned char v) { return EscCharImpl(v); } + +template <typename T> +std::string Esc(const T &v) { + std::ostringstream oss; + oss << v; + return oss.str(); +} + +void StrAppendV(std::string *dst, const char *format, va_list ap) { + // First try with a small fixed size buffer + static const int kSpaceLength = 1024; + char space[kSpaceLength]; + + // It's possible for methods that use a va_list to invalidate + // the data in it upon use. The fix is to make a copy + // of the structure before using it and use that copy instead. + va_list backup_ap; + va_copy(backup_ap, ap); + int result = vsnprintf(space, kSpaceLength, format, backup_ap); + va_end(backup_ap); + if (result < kSpaceLength) { + if (result >= 0) { + // Normal case -- everything fit. + dst->append(space, result); + return; + } + if (result < 0) { + // Just an error. + return; + } + } + + // Increase the buffer size to the size requested by vsnprintf, + // plus one for the closing \0. + int length = result + 1; + char *buf = new char[length]; + + // Restore the va_list before we use it again + va_copy(backup_ap, ap); + result = vsnprintf(buf, length, format, backup_ap); + va_end(backup_ap); + + if (result >= 0 && result < length) { + // It fit + dst->append(buf, result); + } + delete[] buf; +} + +void StrAppend(std::string *out, const char *format, ...) { + va_list ap; + va_start(ap, format); + StrAppendV(out, format, ap); + va_end(ap); +} + +std::string StrPrint(const char *format, ...) { + va_list ap; + va_start(ap, format); + std::string result; + StrAppendV(&result, format, ap); + va_end(ap); + return result; +} + +class FormatConvertTest : public ::testing::Test { }; + +template <typename T> +void TestStringConvert(const T& str) { + const FormatArgImpl args[] = {FormatArgImpl(str)}; + struct Expectation { + const char *out; + const char *fmt; + }; + const Expectation kExpect[] = { + {"hello", "%1$s" }, + {"", "%1$.s" }, + {"", "%1$.0s" }, + {"h", "%1$.1s" }, + {"he", "%1$.2s" }, + {"hello", "%1$.10s" }, + {" hello", "%1$6s" }, + {" he", "%1$5.2s" }, + {"he ", "%1$-5.2s" }, + {"hello ", "%1$-6.10s" }, + }; + for (const Expectation &e : kExpect) { + UntypedFormatSpecImpl format(e.fmt); + EXPECT_EQ(e.out, FormatPack(format, absl::MakeSpan(args))); + } +} + +TEST_F(FormatConvertTest, BasicString) { + TestStringConvert("hello"); // As char array. + TestStringConvert(static_cast<const char*>("hello")); + TestStringConvert(std::string("hello")); + TestStringConvert(string_view("hello")); +} + +TEST_F(FormatConvertTest, NullString) { + const char* p = nullptr; + UntypedFormatSpecImpl format("%s"); + EXPECT_EQ("", FormatPack(format, {FormatArgImpl(p)})); +} + +TEST_F(FormatConvertTest, StringPrecision) { + // We cap at the precision. + char c = 'a'; + const char* p = &c; + UntypedFormatSpecImpl format("%.1s"); + EXPECT_EQ("a", FormatPack(format, {FormatArgImpl(p)})); + + // We cap at the NUL-terminator. + p = "ABC"; + UntypedFormatSpecImpl format2("%.10s"); + EXPECT_EQ("ABC", FormatPack(format2, {FormatArgImpl(p)})); +} + +// Pointer formatting is implementation defined. This checks that the argument +// can be matched to `ptr`. +MATCHER_P(MatchesPointerString, ptr, "") { + if (ptr == nullptr && arg == "(nil)") { + return true; + } + void* parsed = nullptr; + if (sscanf(arg.c_str(), "%p", &parsed) != 1) { + ABSL_RAW_LOG(FATAL, "Could not parse %s", arg.c_str()); + } + return ptr == parsed; +} + +TEST_F(FormatConvertTest, Pointer) { + static int x = 0; + const int *xp = &x; + char c = 'h'; + char *mcp = &c; + const char *cp = "hi"; + const char *cnil = nullptr; + const int *inil = nullptr; + using VoidF = void (*)(); + VoidF fp = [] {}, fnil = nullptr; + volatile char vc; + volatile char *vcp = &vc; + volatile char *vcnil = nullptr; + const FormatArgImpl args_array[] = { + FormatArgImpl(xp), FormatArgImpl(cp), FormatArgImpl(inil), + FormatArgImpl(cnil), FormatArgImpl(mcp), FormatArgImpl(fp), + FormatArgImpl(fnil), FormatArgImpl(vcp), FormatArgImpl(vcnil), + }; + auto args = absl::MakeConstSpan(args_array); + + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%20p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%.1p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%.20p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%30.20p"), args), + MatchesPointerString(&x)); + + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%-p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%-20p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%-.1p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%.20p"), args), + MatchesPointerString(&x)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%-30.20p"), args), + MatchesPointerString(&x)); + + // const char* + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%2$p"), args), + MatchesPointerString(cp)); + // null const int* + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%3$p"), args), + MatchesPointerString(nullptr)); + // null const char* + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%4$p"), args), + MatchesPointerString(nullptr)); + // nonconst char* + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%5$p"), args), + MatchesPointerString(mcp)); + + // function pointers + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%6$p"), args), + MatchesPointerString(reinterpret_cast<const void*>(fp))); + EXPECT_THAT( + FormatPack(UntypedFormatSpecImpl("%8$p"), args), + MatchesPointerString(reinterpret_cast<volatile const void *>(vcp))); + + // null function pointers + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%7$p"), args), + MatchesPointerString(nullptr)); + EXPECT_THAT(FormatPack(UntypedFormatSpecImpl("%9$p"), args), + MatchesPointerString(nullptr)); +} + +struct Cardinal { + enum Pos { k1 = 1, k2 = 2, k3 = 3 }; + enum Neg { kM1 = -1, kM2 = -2, kM3 = -3 }; +}; + +TEST_F(FormatConvertTest, Enum) { + const Cardinal::Pos k3 = Cardinal::k3; + const Cardinal::Neg km3 = Cardinal::kM3; + const FormatArgImpl args[] = {FormatArgImpl(k3), FormatArgImpl(km3)}; + UntypedFormatSpecImpl format("%1$d"); + UntypedFormatSpecImpl format2("%2$d"); + EXPECT_EQ("3", FormatPack(format, absl::MakeSpan(args))); + EXPECT_EQ("-3", FormatPack(format2, absl::MakeSpan(args))); +} + +template <typename T> +class TypedFormatConvertTest : public FormatConvertTest { }; + +TYPED_TEST_SUITE_P(TypedFormatConvertTest); + +std::vector<std::string> AllFlagCombinations() { + const char kFlags[] = {'-', '#', '0', '+', ' '}; + std::vector<std::string> result; + for (size_t fsi = 0; fsi < (1ull << ArraySize(kFlags)); ++fsi) { + std::string flag_set; + for (size_t fi = 0; fi < ArraySize(kFlags); ++fi) + if (fsi & (1ull << fi)) + flag_set += kFlags[fi]; + result.push_back(flag_set); + } + return result; +} + +TYPED_TEST_P(TypedFormatConvertTest, AllIntsWithFlags) { + typedef TypeParam T; + typedef typename std::make_unsigned<T>::type UnsignedT; + using remove_volatile_t = typename std::remove_volatile<T>::type; + const T kMin = std::numeric_limits<remove_volatile_t>::min(); + const T kMax = std::numeric_limits<remove_volatile_t>::max(); + const T kVals[] = { + remove_volatile_t(1), + remove_volatile_t(2), + remove_volatile_t(3), + remove_volatile_t(123), + remove_volatile_t(-1), + remove_volatile_t(-2), + remove_volatile_t(-3), + remove_volatile_t(-123), + remove_volatile_t(0), + kMax - remove_volatile_t(1), + kMax, + kMin + remove_volatile_t(1), + kMin, + }; + const char kConvChars[] = {'d', 'i', 'u', 'o', 'x', 'X'}; + const std::string kWid[] = {"", "4", "10"}; + const std::string kPrec[] = {"", ".", ".0", ".4", ".10"}; + + const std::vector<std::string> flag_sets = AllFlagCombinations(); + + for (size_t vi = 0; vi < ArraySize(kVals); ++vi) { + const T val = kVals[vi]; + SCOPED_TRACE(Esc(val)); + const FormatArgImpl args[] = {FormatArgImpl(val)}; + for (size_t ci = 0; ci < ArraySize(kConvChars); ++ci) { + const char conv_char = kConvChars[ci]; + for (size_t fsi = 0; fsi < flag_sets.size(); ++fsi) { + const std::string &flag_set = flag_sets[fsi]; + for (size_t wi = 0; wi < ArraySize(kWid); ++wi) { + const std::string &wid = kWid[wi]; + for (size_t pi = 0; pi < ArraySize(kPrec); ++pi) { + const std::string &prec = kPrec[pi]; + + const bool is_signed_conv = (conv_char == 'd' || conv_char == 'i'); + const bool is_unsigned_to_signed = + !std::is_signed<T>::value && is_signed_conv; + // Don't consider sign-related flags '+' and ' ' when doing + // unsigned to signed conversions. + if (is_unsigned_to_signed && + flag_set.find_first_of("+ ") != std::string::npos) { + continue; + } + + std::string new_fmt("%"); + new_fmt += flag_set; + new_fmt += wid; + new_fmt += prec; + // old and new always agree up to here. + std::string old_fmt = new_fmt; + new_fmt += conv_char; + std::string old_result; + if (is_unsigned_to_signed) { + // don't expect agreement on unsigned formatted as signed, + // as printf can't do that conversion properly. For those + // cases, we do expect agreement with printf with a "%u" + // and the unsigned equivalent of 'val'. + UnsignedT uval = val; + old_fmt += LengthModFor(uval); + old_fmt += "u"; + old_result = StrPrint(old_fmt.c_str(), uval); + } else { + old_fmt += LengthModFor(val); + old_fmt += conv_char; + old_result = StrPrint(old_fmt.c_str(), val); + } + + SCOPED_TRACE(std::string() + " old_fmt: \"" + old_fmt + + "\"'" + " new_fmt: \"" + + new_fmt + "\""); + UntypedFormatSpecImpl format(new_fmt); + EXPECT_EQ(old_result, FormatPack(format, absl::MakeSpan(args))); + } + } + } + } + } +} + +TYPED_TEST_P(TypedFormatConvertTest, Char) { + typedef TypeParam T; + using remove_volatile_t = typename std::remove_volatile<T>::type; + static const T kMin = std::numeric_limits<remove_volatile_t>::min(); + static const T kMax = std::numeric_limits<remove_volatile_t>::max(); + T kVals[] = { + remove_volatile_t(1), remove_volatile_t(2), remove_volatile_t(10), + remove_volatile_t(-1), remove_volatile_t(-2), remove_volatile_t(-10), + remove_volatile_t(0), + kMin + remove_volatile_t(1), kMin, + kMax - remove_volatile_t(1), kMax + }; + for (const T &c : kVals) { + const FormatArgImpl args[] = {FormatArgImpl(c)}; + UntypedFormatSpecImpl format("%c"); + EXPECT_EQ(StrPrint("%c", c), FormatPack(format, absl::MakeSpan(args))); + } +} + +REGISTER_TYPED_TEST_CASE_P(TypedFormatConvertTest, AllIntsWithFlags, Char); + +typedef ::testing::Types< + int, unsigned, volatile int, + short, unsigned short, + long, unsigned long, + long long, unsigned long long, + signed char, unsigned char, char> + AllIntTypes; +INSTANTIATE_TYPED_TEST_CASE_P(TypedFormatConvertTestWithAllIntTypes, + TypedFormatConvertTest, AllIntTypes); +TEST_F(FormatConvertTest, VectorBool) { + // Make sure vector<bool>'s values behave as bools. + std::vector<bool> v = {true, false}; + const std::vector<bool> cv = {true, false}; + EXPECT_EQ("1,0,1,0", + FormatPack(UntypedFormatSpecImpl("%d,%d,%d,%d"), + absl::Span<const FormatArgImpl>( + {FormatArgImpl(v[0]), FormatArgImpl(v[1]), + FormatArgImpl(cv[0]), FormatArgImpl(cv[1])}))); +} + + +TEST_F(FormatConvertTest, Int128) { + absl::int128 positive = static_cast<absl::int128>(0x1234567890abcdef) * 1979; + absl::int128 negative = -positive; + absl::int128 max = absl::Int128Max(), min = absl::Int128Min(); + const FormatArgImpl args[] = {FormatArgImpl(positive), + FormatArgImpl(negative), FormatArgImpl(max), + FormatArgImpl(min)}; + + struct Case { + const char* format; + const char* expected; + } cases[] = { + {"%1$d", "2595989796776606496405"}, + {"%1$30d", " 2595989796776606496405"}, + {"%1$-30d", "2595989796776606496405 "}, + {"%1$u", "2595989796776606496405"}, + {"%1$x", "8cba9876066020f695"}, + {"%2$d", "-2595989796776606496405"}, + {"%2$30d", " -2595989796776606496405"}, + {"%2$-30d", "-2595989796776606496405 "}, + {"%2$u", "340282366920938460867384810655161715051"}, + {"%2$x", "ffffffffffffff73456789f99fdf096b"}, + {"%3$d", "170141183460469231731687303715884105727"}, + {"%3$u", "170141183460469231731687303715884105727"}, + {"%3$x", "7fffffffffffffffffffffffffffffff"}, + {"%4$d", "-170141183460469231731687303715884105728"}, + {"%4$x", "80000000000000000000000000000000"}, + }; + + for (auto c : cases) { + UntypedFormatSpecImpl format(c.format); + EXPECT_EQ(c.expected, FormatPack(format, absl::MakeSpan(args))); + } +} + +TEST_F(FormatConvertTest, Uint128) { + absl::uint128 v = static_cast<absl::uint128>(0x1234567890abcdef) * 1979; + absl::uint128 max = absl::Uint128Max(); + const FormatArgImpl args[] = {FormatArgImpl(v), FormatArgImpl(max)}; + + struct Case { + const char* format; + const char* expected; + } cases[] = { + {"%1$d", "2595989796776606496405"}, + {"%1$30d", " 2595989796776606496405"}, + {"%1$-30d", "2595989796776606496405 "}, + {"%1$u", "2595989796776606496405"}, + {"%1$x", "8cba9876066020f695"}, + {"%2$d", "340282366920938463463374607431768211455"}, + {"%2$u", "340282366920938463463374607431768211455"}, + {"%2$x", "ffffffffffffffffffffffffffffffff"}, + }; + + for (auto c : cases) { + UntypedFormatSpecImpl format(c.format); + EXPECT_EQ(c.expected, FormatPack(format, absl::MakeSpan(args))); + } +} + +TEST_F(FormatConvertTest, Float) { +#ifdef _MSC_VER + // MSVC has a different rounding policy than us so we can't test our + // implementation against the native one there. + return; +#endif // _MSC_VER + + const char *const kFormats[] = { + "%", "%.3", "%8.5", "%500", "%.5000", "%.60", "%.30", "%03", + "%+", "% ", "%-10", "%#15.3", "%#.0", "%.0", "%1$*2$", "%1$.*2$"}; + + std::vector<double> doubles = {0.0, + -0.0, + .99999999999999, + 99999999999999., + std::numeric_limits<double>::max(), + -std::numeric_limits<double>::max(), + std::numeric_limits<double>::min(), + -std::numeric_limits<double>::min(), + std::numeric_limits<double>::lowest(), + -std::numeric_limits<double>::lowest(), + std::numeric_limits<double>::epsilon(), + std::numeric_limits<double>::epsilon() + 1, + std::numeric_limits<double>::infinity(), + -std::numeric_limits<double>::infinity()}; + + // Some regression tests. + doubles.push_back(0.99999999999999989); + + if (std::numeric_limits<double>::has_denorm != std::denorm_absent) { + doubles.push_back(std::numeric_limits<double>::denorm_min()); + doubles.push_back(-std::numeric_limits<double>::denorm_min()); + } + + for (double base : + {1., 12., 123., 1234., 12345., 123456., 1234567., 12345678., 123456789., + 1234567890., 12345678901., 123456789012., 1234567890123.}) { + for (int exp = -123; exp <= 123; ++exp) { + for (int sign : {1, -1}) { + doubles.push_back(sign * std::ldexp(base, exp)); + } + } + } + + // Workaround libc bug. + // https://sourceware.org/bugzilla/show_bug.cgi?id=22142 + const bool gcc_bug_22142 = + StrPrint("%f", std::numeric_limits<double>::max()) != + "1797693134862315708145274237317043567980705675258449965989174768031" + "5726078002853876058955863276687817154045895351438246423432132688946" + "4182768467546703537516986049910576551282076245490090389328944075868" + "5084551339423045832369032229481658085593321233482747978262041447231" + "68738177180919299881250404026184124858368.000000"; + + if (!gcc_bug_22142) { + for (int exp = -300; exp <= 300; ++exp) { + const double all_ones_mantissa = 0x1fffffffffffff; + doubles.push_back(std::ldexp(all_ones_mantissa, exp)); + } + } + + if (gcc_bug_22142) { + for (auto &d : doubles) { + using L = std::numeric_limits<double>; + double d2 = std::abs(d); + if (d2 == L::max() || d2 == L::min() || d2 == L::denorm_min()) { + d = 0; + } + } + } + + // Remove duplicates to speed up the logic below. + std::sort(doubles.begin(), doubles.end()); + doubles.erase(std::unique(doubles.begin(), doubles.end()), doubles.end()); + +#ifndef __APPLE__ + // Apple formats NaN differently (+nan) vs. (nan) + doubles.push_back(std::nan("")); +#endif + + // Reserve the space to ensure we don't allocate memory in the output itself. + std::string str_format_result; + str_format_result.reserve(1 << 20); + std::string string_printf_result; + string_printf_result.reserve(1 << 20); + + for (const char *fmt : kFormats) { + for (char f : {'f', 'F', // + 'g', 'G', // + 'a', 'A', // + 'e', 'E'}) { + std::string fmt_str = std::string(fmt) + f; + + if (fmt == absl::string_view("%.5000") && f != 'f' && f != 'F') { + // This particular test takes way too long with snprintf. + // Disable for the case we are not implementing natively. + continue; + } + + for (double d : doubles) { + int i = -10; + FormatArgImpl args[2] = {FormatArgImpl(d), FormatArgImpl(i)}; + UntypedFormatSpecImpl format(fmt_str); + + string_printf_result.clear(); + StrAppend(&string_printf_result, fmt_str.c_str(), d, i); + str_format_result.clear(); + + { + AppendPack(&str_format_result, format, absl::MakeSpan(args)); + } + + if (string_printf_result != str_format_result) { + // We use ASSERT_EQ here because failures are usually correlated and a + // bug would print way too many failed expectations causing the test + // to time out. + ASSERT_EQ(string_printf_result, str_format_result) + << fmt_str << " " << StrPrint("%.18g", d) << " " + << StrPrint("%a", d) << " " << StrPrint("%.1080f", d); + } + } + } + } +} + +TEST_F(FormatConvertTest, FloatRound) { + std::string s; + const auto format = [&](const char *fmt, double d) -> std::string & { + s.clear(); + FormatArgImpl args[1] = {FormatArgImpl(d)}; + AppendPack(&s, UntypedFormatSpecImpl(fmt), absl::MakeSpan(args)); +#if !defined(_MSC_VER) + // MSVC has a different rounding policy than us so we can't test our + // implementation against the native one there. + EXPECT_EQ(StrPrint(fmt, d), s); +#endif // _MSC_VER + + return s; + }; + // All of these values have to be exactly represented. + // Otherwise we might not be testing what we think we are testing. + + // These values can fit in a 64bit "fast" representation. + const double exact_value = 0.00000000000005684341886080801486968994140625; + assert(exact_value == std::pow(2, -44)); + // Round up at a 5xx. + EXPECT_EQ(format("%.13f", exact_value), "0.0000000000001"); + // Round up at a >5 + EXPECT_EQ(format("%.14f", exact_value), "0.00000000000006"); + // Round down at a <5 + EXPECT_EQ(format("%.16f", exact_value), "0.0000000000000568"); + // Nine handling + EXPECT_EQ(format("%.35f", exact_value), + "0.00000000000005684341886080801486969"); + EXPECT_EQ(format("%.36f", exact_value), + "0.000000000000056843418860808014869690"); + // Round down the last nine. + EXPECT_EQ(format("%.37f", exact_value), + "0.0000000000000568434188608080148696899"); + EXPECT_EQ(format("%.10f", 0.000003814697265625), "0.0000038147"); + // Round up the last nine + EXPECT_EQ(format("%.11f", 0.000003814697265625), "0.00000381470"); + EXPECT_EQ(format("%.12f", 0.000003814697265625), "0.000003814697"); + + // Round to even (down) + EXPECT_EQ(format("%.43f", exact_value), + "0.0000000000000568434188608080148696899414062"); + // Exact + EXPECT_EQ(format("%.44f", exact_value), + "0.00000000000005684341886080801486968994140625"); + // Round to even (up), let make the last digits 75 instead of 25 + EXPECT_EQ(format("%.43f", exact_value + std::pow(2, -43)), + "0.0000000000001705302565824240446090698242188"); + // Exact, just to check. + EXPECT_EQ(format("%.44f", exact_value + std::pow(2, -43)), + "0.00000000000017053025658242404460906982421875"); + + // This value has to be small enough that it won't fit in the uint128 + // representation for printing. + const double small_exact_value = + 0.000000000000000000000000000000000000752316384526264005099991383822237233803945956334136013765601092018187046051025390625; // NOLINT + assert(small_exact_value == std::pow(2, -120)); + // Round up at a 5xx. + EXPECT_EQ(format("%.37f", small_exact_value), + "0.0000000000000000000000000000000000008"); + // Round down at a <5 + EXPECT_EQ(format("%.38f", small_exact_value), + "0.00000000000000000000000000000000000075"); + // Round up at a >5 + EXPECT_EQ(format("%.41f", small_exact_value), + "0.00000000000000000000000000000000000075232"); + // Nine handling + EXPECT_EQ(format("%.55f", small_exact_value), + "0.0000000000000000000000000000000000007523163845262640051"); + EXPECT_EQ(format("%.56f", small_exact_value), + "0.00000000000000000000000000000000000075231638452626400510"); + EXPECT_EQ(format("%.57f", small_exact_value), + "0.000000000000000000000000000000000000752316384526264005100"); + EXPECT_EQ(format("%.58f", small_exact_value), + "0.0000000000000000000000000000000000007523163845262640051000"); + // Round down the last nine + EXPECT_EQ(format("%.59f", small_exact_value), + "0.00000000000000000000000000000000000075231638452626400509999"); + // Round up the last nine + EXPECT_EQ(format("%.79f", small_exact_value), + "0.000000000000000000000000000000000000" + "7523163845262640050999913838222372338039460"); + + // Round to even (down) + EXPECT_EQ(format("%.119f", small_exact_value), + "0.000000000000000000000000000000000000" + "75231638452626400509999138382223723380" + "394595633413601376560109201818704605102539062"); + // Exact + EXPECT_EQ(format("%.120f", small_exact_value), + "0.000000000000000000000000000000000000" + "75231638452626400509999138382223723380" + "3945956334136013765601092018187046051025390625"); + // Round to even (up), let make the last digits 75 instead of 25 + EXPECT_EQ(format("%.119f", small_exact_value + std::pow(2, -119)), + "0.000000000000000000000000000000000002" + "25694915357879201529997415146671170141" + "183786900240804129680327605456113815307617188"); + // Exact, just to check. + EXPECT_EQ(format("%.120f", small_exact_value + std::pow(2, -119)), + "0.000000000000000000000000000000000002" + "25694915357879201529997415146671170141" + "1837869002408041296803276054561138153076171875"); +} + +// We don't actually store the results. This is just to exercise the rest of the +// machinery. +struct NullSink { + friend void AbslFormatFlush(NullSink *sink, string_view str) {} +}; + +template <typename... T> +bool FormatWithNullSink(absl::string_view fmt, const T &... a) { + NullSink sink; + FormatArgImpl args[] = {FormatArgImpl(a)...}; + return FormatUntyped(&sink, UntypedFormatSpecImpl(fmt), absl::MakeSpan(args)); +} + +TEST_F(FormatConvertTest, ExtremeWidthPrecision) { + for (const char *fmt : {"f"}) { + for (double d : {1e-100, 1.0, 1e100}) { + constexpr int max = std::numeric_limits<int>::max(); + EXPECT_TRUE(FormatWithNullSink(std::string("%.*") + fmt, max, d)); + EXPECT_TRUE(FormatWithNullSink(std::string("%1.*") + fmt, max, d)); + EXPECT_TRUE(FormatWithNullSink(std::string("%*") + fmt, max, d)); + EXPECT_TRUE(FormatWithNullSink(std::string("%*.*") + fmt, max, max, d)); + } + } +} + +TEST_F(FormatConvertTest, LongDouble) { +#ifdef _MSC_VER + // MSVC has a different rounding policy than us so we can't test our + // implementation against the native one there. + return; +#endif // _MSC_VER + const char *const kFormats[] = {"%", "%.3", "%8.5", "%9", "%.5000", + "%.60", "%+", "% ", "%-10"}; + + std::vector<long double> doubles = { + 0.0, + -0.0, + std::numeric_limits<long double>::max(), + -std::numeric_limits<long double>::max(), + std::numeric_limits<long double>::min(), + -std::numeric_limits<long double>::min(), + std::numeric_limits<long double>::infinity(), + -std::numeric_limits<long double>::infinity()}; + + for (long double base : {1.L, 12.L, 123.L, 1234.L, 12345.L, 123456.L, + 1234567.L, 12345678.L, 123456789.L, 1234567890.L, + 12345678901.L, 123456789012.L, 1234567890123.L, + // This value is not representable in double, but it + // is in long double that uses the extended format. + // This is to verify that we are not truncating the + // value mistakenly through a double. + 10000000000000000.25L}) { + for (int exp : {-1000, -500, 0, 500, 1000}) { + for (int sign : {1, -1}) { + doubles.push_back(sign * std::ldexp(base, exp)); + doubles.push_back(sign / std::ldexp(base, exp)); + } + } + } + + for (const char *fmt : kFormats) { + for (char f : {'f', 'F', // + 'g', 'G', // + 'a', 'A', // + 'e', 'E'}) { + std::string fmt_str = std::string(fmt) + 'L' + f; + + if (fmt == absl::string_view("%.5000") && f != 'f' && f != 'F') { + // This particular test takes way too long with snprintf. + // Disable for the case we are not implementing natively. + continue; + } + + for (auto d : doubles) { + FormatArgImpl arg(d); + UntypedFormatSpecImpl format(fmt_str); + // We use ASSERT_EQ here because failures are usually correlated and a + // bug would print way too many failed expectations causing the test to + // time out. + ASSERT_EQ(StrPrint(fmt_str.c_str(), d), FormatPack(format, {&arg, 1})) + << fmt_str << " " << StrPrint("%.18Lg", d) << " " + << StrPrint("%La", d) << " " << StrPrint("%.1080Lf", d); + } + } + } +} + +TEST_F(FormatConvertTest, IntAsFloat) { + const int kMin = std::numeric_limits<int>::min(); + const int kMax = std::numeric_limits<int>::max(); + const int ia[] = { + 1, 2, 3, 123, + -1, -2, -3, -123, + 0, kMax - 1, kMax, kMin + 1, kMin }; + for (const int fx : ia) { + SCOPED_TRACE(fx); + const FormatArgImpl args[] = {FormatArgImpl(fx)}; + struct Expectation { + int line; + std::string out; + const char *fmt; + }; + const double dx = static_cast<double>(fx); + const Expectation kExpect[] = { + { __LINE__, StrPrint("%f", dx), "%f" }, + { __LINE__, StrPrint("%12f", dx), "%12f" }, + { __LINE__, StrPrint("%.12f", dx), "%.12f" }, + { __LINE__, StrPrint("%12a", dx), "%12a" }, + { __LINE__, StrPrint("%.12a", dx), "%.12a" }, + }; + for (const Expectation &e : kExpect) { + SCOPED_TRACE(e.line); + SCOPED_TRACE(e.fmt); + UntypedFormatSpecImpl format(e.fmt); + EXPECT_EQ(e.out, FormatPack(format, absl::MakeSpan(args))); + } + } +} + +template <typename T> +bool FormatFails(const char* test_format, T value) { + std::string format_string = std::string("<<") + test_format + ">>"; + UntypedFormatSpecImpl format(format_string); + + int one = 1; + const FormatArgImpl args[] = {FormatArgImpl(value), FormatArgImpl(one)}; + EXPECT_EQ(FormatPack(format, absl::MakeSpan(args)), "") + << "format=" << test_format << " value=" << value; + return FormatPack(format, absl::MakeSpan(args)).empty(); +} + +TEST_F(FormatConvertTest, ExpectedFailures) { + // Int input + EXPECT_TRUE(FormatFails("%p", 1)); + EXPECT_TRUE(FormatFails("%s", 1)); + EXPECT_TRUE(FormatFails("%n", 1)); + + // Double input + EXPECT_TRUE(FormatFails("%p", 1.)); + EXPECT_TRUE(FormatFails("%s", 1.)); + EXPECT_TRUE(FormatFails("%n", 1.)); + EXPECT_TRUE(FormatFails("%c", 1.)); + EXPECT_TRUE(FormatFails("%d", 1.)); + EXPECT_TRUE(FormatFails("%x", 1.)); + EXPECT_TRUE(FormatFails("%*d", 1.)); + + // String input + EXPECT_TRUE(FormatFails("%n", "")); + EXPECT_TRUE(FormatFails("%c", "")); + EXPECT_TRUE(FormatFails("%d", "")); + EXPECT_TRUE(FormatFails("%x", "")); + EXPECT_TRUE(FormatFails("%f", "")); + EXPECT_TRUE(FormatFails("%*d", "")); +} + +} // namespace +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/extension.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/extension.cc new file mode 100644 index 0000000000..94f2b9c209 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/extension.cc @@ -0,0 +1,52 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/str_format/extension.h" + +#include <errno.h> +#include <algorithm> +#include <string> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +std::string Flags::ToString() const { + std::string s; + s.append(left ? "-" : ""); + s.append(show_pos ? "+" : ""); + s.append(sign_col ? " " : ""); + s.append(alt ? "#" : ""); + s.append(zero ? "0" : ""); + return s; +} + +bool FormatSinkImpl::PutPaddedString(string_view value, int width, + int precision, bool left) { + size_t space_remaining = 0; + if (width >= 0) space_remaining = width; + size_t n = value.size(); + if (precision >= 0) n = std::min(n, static_cast<size_t>(precision)); + string_view shown(value.data(), n); + space_remaining = Excess(shown.size(), space_remaining); + if (!left) Append(space_remaining, ' '); + Append(shown); + if (left) Append(space_remaining, ' '); + return true; +} + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/extension.h b/third_party/abseil_cpp/absl/strings/internal/str_format/extension.h new file mode 100644 index 0000000000..6c60c6c3a3 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/extension.h @@ -0,0 +1,429 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_EXTENSION_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_EXTENSION_H_ + +#include <limits.h> + +#include <cstddef> +#include <cstring> +#include <ostream> + +#include "absl/base/config.h" +#include "absl/base/port.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/internal/str_format/output.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace str_format_internal { + +enum class FormatConversionChar : uint8_t; +enum class FormatConversionCharSet : uint64_t; + +class FormatRawSinkImpl { + public: + // Implicitly convert from any type that provides the hook function as + // described above. + template <typename T, decltype(str_format_internal::InvokeFlush( + std::declval<T*>(), string_view()))* = nullptr> + FormatRawSinkImpl(T* raw) // NOLINT + : sink_(raw), write_(&FormatRawSinkImpl::Flush<T>) {} + + void Write(string_view s) { write_(sink_, s); } + + template <typename T> + static FormatRawSinkImpl Extract(T s) { + return s.sink_; + } + + private: + template <typename T> + static void Flush(void* r, string_view s) { + str_format_internal::InvokeFlush(static_cast<T*>(r), s); + } + + void* sink_; + void (*write_)(void*, string_view); +}; + +// An abstraction to which conversions write their string data. +class FormatSinkImpl { + public: + explicit FormatSinkImpl(FormatRawSinkImpl raw) : raw_(raw) {} + + ~FormatSinkImpl() { Flush(); } + + void Flush() { + raw_.Write(string_view(buf_, pos_ - buf_)); + pos_ = buf_; + } + + void Append(size_t n, char c) { + if (n == 0) return; + size_ += n; + auto raw_append = [&](size_t count) { + memset(pos_, c, count); + pos_ += count; + }; + while (n > Avail()) { + n -= Avail(); + if (Avail() > 0) { + raw_append(Avail()); + } + Flush(); + } + raw_append(n); + } + + void Append(string_view v) { + size_t n = v.size(); + if (n == 0) return; + size_ += n; + if (n >= Avail()) { + Flush(); + raw_.Write(v); + return; + } + memcpy(pos_, v.data(), n); + pos_ += n; + } + + size_t size() const { return size_; } + + // Put 'v' to 'sink' with specified width, precision, and left flag. + bool PutPaddedString(string_view v, int width, int precision, bool left); + + template <typename T> + T Wrap() { + return T(this); + } + + template <typename T> + static FormatSinkImpl* Extract(T* s) { + return s->sink_; + } + + private: + size_t Avail() const { return buf_ + sizeof(buf_) - pos_; } + + FormatRawSinkImpl raw_; + size_t size_ = 0; + char* pos_ = buf_; + char buf_[1024]; +}; + +struct Flags { + bool basic : 1; // fastest conversion: no flags, width, or precision + bool left : 1; // "-" + bool show_pos : 1; // "+" + bool sign_col : 1; // " " + bool alt : 1; // "#" + bool zero : 1; // "0" + std::string ToString() const; + friend std::ostream& operator<<(std::ostream& os, const Flags& v) { + return os << v.ToString(); + } +}; + +// clang-format off +#define ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(X_VAL, X_SEP) \ + /* text */ \ + X_VAL(c) X_SEP X_VAL(s) X_SEP \ + /* ints */ \ + X_VAL(d) X_SEP X_VAL(i) X_SEP X_VAL(o) X_SEP \ + X_VAL(u) X_SEP X_VAL(x) X_SEP X_VAL(X) X_SEP \ + /* floats */ \ + X_VAL(f) X_SEP X_VAL(F) X_SEP X_VAL(e) X_SEP X_VAL(E) X_SEP \ + X_VAL(g) X_SEP X_VAL(G) X_SEP X_VAL(a) X_SEP X_VAL(A) X_SEP \ + /* misc */ \ + X_VAL(n) X_SEP X_VAL(p) +// clang-format on + +// This type should not be referenced, it exists only to provide labels +// internally that match the values declared in FormatConversionChar in +// str_format.h. This is meant to allow internal libraries to use the same +// declared interface type as the public interface +// (absl::StrFormatConversionChar) while keeping the definition in a public +// header. +// Internal libraries should use the form +// `FormatConversionCharInternal::c`, `FormatConversionCharInternal::kNone` for +// comparisons. Use in switch statements is not recommended due to a bug in how +// gcc 4.9 -Wswitch handles declared but undefined enums. +struct FormatConversionCharInternal { + FormatConversionCharInternal() = delete; + + private: + // clang-format off + enum class Enum : uint8_t { + c, s, // text + d, i, o, u, x, X, // int + f, F, e, E, g, G, a, A, // float + n, p, // misc + kNone + }; + // clang-format on + public: +#define ABSL_INTERNAL_X_VAL(id) \ + static constexpr FormatConversionChar id = \ + static_cast<FormatConversionChar>(Enum::id); + ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(ABSL_INTERNAL_X_VAL, ) +#undef ABSL_INTERNAL_X_VAL + static constexpr FormatConversionChar kNone = + static_cast<FormatConversionChar>(Enum::kNone); +}; +// clang-format on + +inline FormatConversionChar FormatConversionCharFromChar(char c) { + switch (c) { +#define ABSL_INTERNAL_X_VAL(id) \ + case #id[0]: \ + return FormatConversionCharInternal::id; + ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(ABSL_INTERNAL_X_VAL, ) +#undef ABSL_INTERNAL_X_VAL + } + return FormatConversionCharInternal::kNone; +} + +inline bool FormatConversionCharIsUpper(FormatConversionChar c) { + if (c == FormatConversionCharInternal::X || + c == FormatConversionCharInternal::F || + c == FormatConversionCharInternal::E || + c == FormatConversionCharInternal::G || + c == FormatConversionCharInternal::A) { + return true; + } else { + return false; + } +} + +inline bool FormatConversionCharIsFloat(FormatConversionChar c) { + if (c == FormatConversionCharInternal::a || + c == FormatConversionCharInternal::e || + c == FormatConversionCharInternal::f || + c == FormatConversionCharInternal::g || + c == FormatConversionCharInternal::A || + c == FormatConversionCharInternal::E || + c == FormatConversionCharInternal::F || + c == FormatConversionCharInternal::G) { + return true; + } else { + return false; + } +} + +inline char FormatConversionCharToChar(FormatConversionChar c) { + if (c == FormatConversionCharInternal::kNone) { + return '\0'; + +#define ABSL_INTERNAL_X_VAL(e) \ + } else if (c == FormatConversionCharInternal::e) { \ + return #e[0]; +#define ABSL_INTERNAL_X_SEP + ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(ABSL_INTERNAL_X_VAL, + ABSL_INTERNAL_X_SEP) + } else { + return '\0'; + } + +#undef ABSL_INTERNAL_X_VAL +#undef ABSL_INTERNAL_X_SEP +} + +// The associated char. +inline std::ostream& operator<<(std::ostream& os, FormatConversionChar v) { + char c = FormatConversionCharToChar(v); + if (!c) c = '?'; + return os << c; +} + +struct FormatConversionSpecImplFriend; + +class FormatConversionSpecImpl { + public: + // Width and precison are not specified, no flags are set. + bool is_basic() const { return flags_.basic; } + bool has_left_flag() const { return flags_.left; } + bool has_show_pos_flag() const { return flags_.show_pos; } + bool has_sign_col_flag() const { return flags_.sign_col; } + bool has_alt_flag() const { return flags_.alt; } + bool has_zero_flag() const { return flags_.zero; } + + FormatConversionChar conversion_char() const { + // Keep this field first in the struct . It generates better code when + // accessing it when ConversionSpec is passed by value in registers. + static_assert(offsetof(FormatConversionSpecImpl, conv_) == 0, ""); + return conv_; + } + + // Returns the specified width. If width is unspecfied, it returns a negative + // value. + int width() const { return width_; } + // Returns the specified precision. If precision is unspecfied, it returns a + // negative value. + int precision() const { return precision_; } + + template <typename T> + T Wrap() { + return T(*this); + } + + private: + friend struct str_format_internal::FormatConversionSpecImplFriend; + FormatConversionChar conv_ = FormatConversionCharInternal::kNone; + Flags flags_; + int width_; + int precision_; +}; + +struct FormatConversionSpecImplFriend final { + static void SetFlags(Flags f, FormatConversionSpecImpl* conv) { + conv->flags_ = f; + } + static void SetConversionChar(FormatConversionChar c, + FormatConversionSpecImpl* conv) { + conv->conv_ = c; + } + static void SetWidth(int w, FormatConversionSpecImpl* conv) { + conv->width_ = w; + } + static void SetPrecision(int p, FormatConversionSpecImpl* conv) { + conv->precision_ = p; + } + static std::string FlagsToString(const FormatConversionSpecImpl& spec) { + return spec.flags_.ToString(); + } +}; + +// Type safe OR operator. +// We need this for two reasons: +// 1. operator| on enums makes them decay to integers and the result is an +// integer. We need the result to stay as an enum. +// 2. We use "enum class" which would not work even if we accepted the decay. +constexpr FormatConversionCharSet FormatConversionCharSetUnion( + FormatConversionCharSet a) { + return a; +} + +template <typename... CharSet> +constexpr FormatConversionCharSet FormatConversionCharSetUnion( + FormatConversionCharSet a, CharSet... rest) { + return static_cast<FormatConversionCharSet>( + static_cast<uint64_t>(a) | + static_cast<uint64_t>(FormatConversionCharSetUnion(rest...))); +} + +constexpr uint64_t FormatConversionCharToConvInt(FormatConversionChar c) { + return uint64_t{1} << (1 + static_cast<uint8_t>(c)); +} + +constexpr uint64_t FormatConversionCharToConvInt(char conv) { + return +#define ABSL_INTERNAL_CHAR_SET_CASE(c) \ + conv == #c[0] \ + ? FormatConversionCharToConvInt(FormatConversionCharInternal::c) \ + : + ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(ABSL_INTERNAL_CHAR_SET_CASE, ) +#undef ABSL_INTERNAL_CHAR_SET_CASE + conv == '*' + ? 1 + : 0; +} + +constexpr FormatConversionCharSet FormatConversionCharToConvValue(char conv) { + return static_cast<FormatConversionCharSet>( + FormatConversionCharToConvInt(conv)); +} + +struct FormatConversionCharSetInternal { +#define ABSL_INTERNAL_CHAR_SET_CASE(c) \ + static constexpr FormatConversionCharSet c = \ + FormatConversionCharToConvValue(#c[0]); + ABSL_INTERNAL_CONVERSION_CHARS_EXPAND_(ABSL_INTERNAL_CHAR_SET_CASE, ) +#undef ABSL_INTERNAL_CHAR_SET_CASE + + // Used for width/precision '*' specification. + static constexpr FormatConversionCharSet kStar = + FormatConversionCharToConvValue('*'); + + // Some predefined values (TODO(matthewbr), delete any that are unused). + static constexpr FormatConversionCharSet kIntegral = + FormatConversionCharSetUnion(d, i, u, o, x, X); + static constexpr FormatConversionCharSet kFloating = + FormatConversionCharSetUnion(a, e, f, g, A, E, F, G); + static constexpr FormatConversionCharSet kNumeric = + FormatConversionCharSetUnion(kIntegral, kFloating); + static constexpr FormatConversionCharSet kString = s; + static constexpr FormatConversionCharSet kPointer = p; +}; + +// Type safe OR operator. +// We need this for two reasons: +// 1. operator| on enums makes them decay to integers and the result is an +// integer. We need the result to stay as an enum. +// 2. We use "enum class" which would not work even if we accepted the decay. +constexpr FormatConversionCharSet operator|(FormatConversionCharSet a, + FormatConversionCharSet b) { + return FormatConversionCharSetUnion(a, b); +} + +// Overloaded conversion functions to support absl::ParsedFormat. +// Get a conversion with a single character in it. +constexpr FormatConversionCharSet ToFormatConversionCharSet(char c) { + return static_cast<FormatConversionCharSet>( + FormatConversionCharToConvValue(c)); +} + +// Get a conversion with a single character in it. +constexpr FormatConversionCharSet ToFormatConversionCharSet( + FormatConversionCharSet c) { + return c; +} + +template <typename T> +void ToFormatConversionCharSet(T) = delete; + +// Checks whether `c` exists in `set`. +constexpr bool Contains(FormatConversionCharSet set, char c) { + return (static_cast<uint64_t>(set) & + static_cast<uint64_t>(FormatConversionCharToConvValue(c))) != 0; +} + +// Checks whether all the characters in `c` are contained in `set` +constexpr bool Contains(FormatConversionCharSet set, + FormatConversionCharSet c) { + return (static_cast<uint64_t>(set) & static_cast<uint64_t>(c)) == + static_cast<uint64_t>(c); +} + +// Checks whether all the characters in `c` are contained in `set` +constexpr bool Contains(FormatConversionCharSet set, FormatConversionChar c) { + return (static_cast<uint64_t>(set) & FormatConversionCharToConvInt(c)) != 0; +} + +// Return capacity - used, clipped to a minimum of 0. +inline size_t Excess(size_t used, size_t capacity) { + return used < capacity ? capacity - used : 0; +} + +} // namespace str_format_internal + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_EXTENSION_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/extension_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/extension_test.cc new file mode 100644 index 0000000000..0a023f9c03 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/extension_test.cc @@ -0,0 +1,83 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#include "absl/strings/internal/str_format/extension.h" + +#include <random> +#include <string> + +#include "gtest/gtest.h" +#include "absl/strings/str_format.h" +#include "absl/strings/string_view.h" + +namespace my_namespace { +class UserDefinedType { + public: + UserDefinedType() = default; + + void Append(absl::string_view str) { value_.append(str.data(), str.size()); } + const std::string& Value() const { return value_; } + + friend void AbslFormatFlush(UserDefinedType* x, absl::string_view str) { + x->Append(str); + } + + private: + std::string value_; +}; +} // namespace my_namespace + +namespace { + +std::string MakeRandomString(size_t len) { + std::random_device rd; + std::mt19937 gen(rd()); + std::uniform_int_distribution<> dis('a', 'z'); + std::string s(len, '0'); + for (char& c : s) { + c = dis(gen); + } + return s; +} + +TEST(FormatExtensionTest, SinkAppendSubstring) { + for (size_t chunk_size : {1, 10, 100, 1000, 10000}) { + std::string expected, actual; + absl::str_format_internal::FormatSinkImpl sink(&actual); + for (size_t chunks = 0; chunks < 10; ++chunks) { + std::string rand = MakeRandomString(chunk_size); + expected += rand; + sink.Append(rand); + } + sink.Flush(); + EXPECT_EQ(actual, expected); + } +} + +TEST(FormatExtensionTest, SinkAppendChars) { + for (size_t chunk_size : {1, 10, 100, 1000, 10000}) { + std::string expected, actual; + absl::str_format_internal::FormatSinkImpl sink(&actual); + for (size_t chunks = 0; chunks < 10; ++chunks) { + std::string rand = MakeRandomString(1); + expected.append(chunk_size, rand[0]); + sink.Append(chunk_size, rand[0]); + } + sink.Flush(); + EXPECT_EQ(actual, expected); + } +} +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/float_conversion.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/float_conversion.cc new file mode 100644 index 0000000000..a761a5a5f9 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/float_conversion.cc @@ -0,0 +1,1144 @@ +#include "absl/strings/internal/str_format/float_conversion.h" + +#include <string.h> + +#include <algorithm> +#include <cassert> +#include <cmath> +#include <limits> +#include <string> + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/internal/bits.h" +#include "absl/base/optimization.h" +#include "absl/functional/function_ref.h" +#include "absl/meta/type_traits.h" +#include "absl/numeric/int128.h" +#include "absl/types/optional.h" +#include "absl/types/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +namespace { + +// The code below wants to avoid heap allocations. +// To do so it needs to allocate memory on the stack. +// `StackArray` will allocate memory on the stack in the form of a uint32_t +// array and call the provided callback with said memory. +// It will allocate memory in increments of 512 bytes. We could allocate the +// largest needed unconditionally, but that is more than we need in most of +// cases. This way we use less stack in the common cases. +class StackArray { + using Func = absl::FunctionRef<void(absl::Span<uint32_t>)>; + static constexpr size_t kStep = 512 / sizeof(uint32_t); + // 5 steps is 2560 bytes, which is enough to hold a long double with the + // largest/smallest exponents. + // The operations below will static_assert their particular maximum. + static constexpr size_t kNumSteps = 5; + + // We do not want this function to be inlined. + // Otherwise the caller will allocate the stack space unnecessarily for all + // the variants even though it only calls one. + template <size_t steps> + ABSL_ATTRIBUTE_NOINLINE static void RunWithCapacityImpl(Func f) { + uint32_t values[steps * kStep]{}; + f(absl::MakeSpan(values)); + } + + public: + static constexpr size_t kMaxCapacity = kStep * kNumSteps; + + static void RunWithCapacity(size_t capacity, Func f) { + assert(capacity <= kMaxCapacity); + const size_t step = (capacity + kStep - 1) / kStep; + assert(step <= kNumSteps); + switch (step) { + case 1: + return RunWithCapacityImpl<1>(f); + case 2: + return RunWithCapacityImpl<2>(f); + case 3: + return RunWithCapacityImpl<3>(f); + case 4: + return RunWithCapacityImpl<4>(f); + case 5: + return RunWithCapacityImpl<5>(f); + } + + assert(false && "Invalid capacity"); + } +}; + +// Calculates `10 * (*v) + carry` and stores the result in `*v` and returns +// the carry. +template <typename Int> +inline Int MultiplyBy10WithCarry(Int *v, Int carry) { + using BiggerInt = absl::conditional_t<sizeof(Int) == 4, uint64_t, uint128>; + BiggerInt tmp = 10 * static_cast<BiggerInt>(*v) + carry; + *v = static_cast<Int>(tmp); + return static_cast<Int>(tmp >> (sizeof(Int) * 8)); +} + +// Calculates `(2^64 * carry + *v) / 10`. +// Stores the quotient in `*v` and returns the remainder. +// Requires: `0 <= carry <= 9` +inline uint64_t DivideBy10WithCarry(uint64_t *v, uint64_t carry) { + constexpr uint64_t divisor = 10; + // 2^64 / divisor = chunk_quotient + chunk_remainder / divisor + constexpr uint64_t chunk_quotient = (uint64_t{1} << 63) / (divisor / 2); + constexpr uint64_t chunk_remainder = uint64_t{} - chunk_quotient * divisor; + + const uint64_t mod = *v % divisor; + const uint64_t next_carry = chunk_remainder * carry + mod; + *v = *v / divisor + carry * chunk_quotient + next_carry / divisor; + return next_carry % divisor; +} + +// Generates the decimal representation for an integer of the form `v * 2^exp`, +// where `v` and `exp` are both positive integers. +// It generates the digits from the left (ie the most significant digit first) +// to allow for direct printing into the sink. +// +// Requires `0 <= exp` and `exp <= numeric_limits<long double>::max_exponent`. +class BinaryToDecimal { + static constexpr int ChunksNeeded(int exp) { + // We will left shift a uint128 by `exp` bits, so we need `128+exp` total + // bits. Round up to 32. + // See constructor for details about adding `10%` to the value. + return (128 + exp + 31) / 32 * 11 / 10; + } + + public: + // Run the conversion for `v * 2^exp` and call `f(binary_to_decimal)`. + // This function will allocate enough stack space to perform the conversion. + static void RunConversion(uint128 v, int exp, + absl::FunctionRef<void(BinaryToDecimal)> f) { + assert(exp > 0); + assert(exp <= std::numeric_limits<long double>::max_exponent); + static_assert( + StackArray::kMaxCapacity >= + ChunksNeeded(std::numeric_limits<long double>::max_exponent), + ""); + + StackArray::RunWithCapacity( + ChunksNeeded(exp), + [=](absl::Span<uint32_t> input) { f(BinaryToDecimal(input, v, exp)); }); + } + + int TotalDigits() const { + return static_cast<int>((decimal_end_ - decimal_start_) * kDigitsPerChunk + + CurrentDigits().size()); + } + + // See the current block of digits. + absl::string_view CurrentDigits() const { + return absl::string_view(digits_ + kDigitsPerChunk - size_, size_); + } + + // Advance the current view of digits. + // Returns `false` when no more digits are available. + bool AdvanceDigits() { + if (decimal_start_ >= decimal_end_) return false; + + uint32_t w = data_[decimal_start_++]; + for (size_ = 0; size_ < kDigitsPerChunk; w /= 10) { + digits_[kDigitsPerChunk - ++size_] = w % 10 + '0'; + } + return true; + } + + private: + BinaryToDecimal(absl::Span<uint32_t> data, uint128 v, int exp) : data_(data) { + // We need to print the digits directly into the sink object without + // buffering them all first. To do this we need two things: + // - to know the total number of digits to do padding when necessary + // - to generate the decimal digits from the left. + // + // In order to do this, we do a two pass conversion. + // On the first pass we convert the binary representation of the value into + // a decimal representation in which each uint32_t chunk holds up to 9 + // decimal digits. In the second pass we take each decimal-holding-uint32_t + // value and generate the ascii decimal digits into `digits_`. + // + // The binary and decimal representations actually share the same memory + // region. As we go converting the chunks from binary to decimal we free + // them up and reuse them for the decimal representation. One caveat is that + // the decimal representation is around 7% less efficient in space than the + // binary one. We allocate an extra 10% memory to account for this. See + // ChunksNeeded for this calculation. + int chunk_index = exp / 32; + decimal_start_ = decimal_end_ = ChunksNeeded(exp); + const int offset = exp % 32; + // Left shift v by exp bits. + data_[chunk_index] = static_cast<uint32_t>(v << offset); + for (v >>= (32 - offset); v; v >>= 32) + data_[++chunk_index] = static_cast<uint32_t>(v); + + while (chunk_index >= 0) { + // While we have more than one chunk available, go in steps of 1e9. + // `data_[chunk_index]` holds the highest non-zero binary chunk, so keep + // the variable updated. + uint32_t carry = 0; + for (int i = chunk_index; i >= 0; --i) { + uint64_t tmp = uint64_t{data_[i]} + (uint64_t{carry} << 32); + data_[i] = static_cast<uint32_t>(tmp / uint64_t{1000000000}); + carry = static_cast<uint32_t>(tmp % uint64_t{1000000000}); + } + + // If the highest chunk is now empty, remove it from view. + if (data_[chunk_index] == 0) --chunk_index; + + --decimal_start_; + assert(decimal_start_ != chunk_index); + data_[decimal_start_] = carry; + } + + // Fill the first set of digits. The first chunk might not be complete, so + // handle differently. + for (uint32_t first = data_[decimal_start_++]; first != 0; first /= 10) { + digits_[kDigitsPerChunk - ++size_] = first % 10 + '0'; + } + } + + private: + static constexpr size_t kDigitsPerChunk = 9; + + int decimal_start_; + int decimal_end_; + + char digits_[kDigitsPerChunk]; + int size_ = 0; + + absl::Span<uint32_t> data_; +}; + +// Converts a value of the form `x * 2^-exp` into a sequence of decimal digits. +// Requires `-exp < 0` and +// `-exp >= limits<long double>::min_exponent - limits<long double>::digits`. +class FractionalDigitGenerator { + public: + // Run the conversion for `v * 2^exp` and call `f(generator)`. + // This function will allocate enough stack space to perform the conversion. + static void RunConversion( + uint128 v, int exp, absl::FunctionRef<void(FractionalDigitGenerator)> f) { + assert(-exp < 0); + assert(-exp >= std::numeric_limits<long double>::min_exponent - 128); + static_assert( + StackArray::kMaxCapacity >= + (128 - std::numeric_limits<long double>::min_exponent + 31) / 32, + ""); + StackArray::RunWithCapacity((exp + 31) / 32, + [=](absl::Span<uint32_t> input) { + f(FractionalDigitGenerator(input, v, exp)); + }); + } + + // Returns true if there are any more non-zero digits left. + bool HasMoreDigits() const { return next_digit_ != 0 || chunk_index_ >= 0; } + + // Returns true if the remainder digits are greater than 5000... + bool IsGreaterThanHalf() const { + return next_digit_ > 5 || (next_digit_ == 5 && chunk_index_ >= 0); + } + // Returns true if the remainder digits are exactly 5000... + bool IsExactlyHalf() const { return next_digit_ == 5 && chunk_index_ < 0; } + + struct Digits { + int digit_before_nine; + int num_nines; + }; + + // Get the next set of digits. + // They are composed by a non-9 digit followed by a runs of zero or more 9s. + Digits GetDigits() { + Digits digits{next_digit_, 0}; + + next_digit_ = GetOneDigit(); + while (next_digit_ == 9) { + ++digits.num_nines; + next_digit_ = GetOneDigit(); + } + + return digits; + } + + private: + // Return the next digit. + int GetOneDigit() { + if (chunk_index_ < 0) return 0; + + uint32_t carry = 0; + for (int i = chunk_index_; i >= 0; --i) { + carry = MultiplyBy10WithCarry(&data_[i], carry); + } + // If the lowest chunk is now empty, remove it from view. + if (data_[chunk_index_] == 0) --chunk_index_; + return carry; + } + + FractionalDigitGenerator(absl::Span<uint32_t> data, uint128 v, int exp) + : chunk_index_(exp / 32), data_(data) { + const int offset = exp % 32; + // Right shift `v` by `exp` bits. + data_[chunk_index_] = static_cast<uint32_t>(v << (32 - offset)); + v >>= offset; + // Make sure we don't overflow the data. We already calculated that + // non-zero bits fit, so we might not have space for leading zero bits. + for (int pos = chunk_index_; v; v >>= 32) + data_[--pos] = static_cast<uint32_t>(v); + + // Fill next_digit_, as GetDigits expects it to be populated always. + next_digit_ = GetOneDigit(); + } + + int next_digit_; + int chunk_index_; + absl::Span<uint32_t> data_; +}; + +// Count the number of leading zero bits. +int LeadingZeros(uint64_t v) { return base_internal::CountLeadingZeros64(v); } +int LeadingZeros(uint128 v) { + auto high = static_cast<uint64_t>(v >> 64); + auto low = static_cast<uint64_t>(v); + return high != 0 ? base_internal::CountLeadingZeros64(high) + : 64 + base_internal::CountLeadingZeros64(low); +} + +// Round up the text digits starting at `p`. +// The buffer must have an extra digit that is known to not need rounding. +// This is done below by having an extra '0' digit on the left. +void RoundUp(char *p) { + while (*p == '9' || *p == '.') { + if (*p == '9') *p = '0'; + --p; + } + ++*p; +} + +// Check the previous digit and round up or down to follow the round-to-even +// policy. +void RoundToEven(char *p) { + if (*p == '.') --p; + if (*p % 2 == 1) RoundUp(p); +} + +// Simple integral decimal digit printing for values that fit in 64-bits. +// Returns the pointer to the last written digit. +char *PrintIntegralDigitsFromRightFast(uint64_t v, char *p) { + do { + *--p = DivideBy10WithCarry(&v, 0) + '0'; + } while (v != 0); + return p; +} + +// Simple integral decimal digit printing for values that fit in 128-bits. +// Returns the pointer to the last written digit. +char *PrintIntegralDigitsFromRightFast(uint128 v, char *p) { + auto high = static_cast<uint64_t>(v >> 64); + auto low = static_cast<uint64_t>(v); + + while (high != 0) { + uint64_t carry = DivideBy10WithCarry(&high, 0); + carry = DivideBy10WithCarry(&low, carry); + *--p = carry + '0'; + } + return PrintIntegralDigitsFromRightFast(low, p); +} + +// Simple fractional decimal digit printing for values that fir in 64-bits after +// shifting. +// Performs rounding if necessary to fit within `precision`. +// Returns the pointer to one after the last character written. +char *PrintFractionalDigitsFast(uint64_t v, char *start, int exp, + int precision) { + char *p = start; + v <<= (64 - exp); + while (precision > 0) { + if (!v) return p; + *p++ = MultiplyBy10WithCarry(&v, uint64_t{0}) + '0'; + --precision; + } + + // We need to round. + if (v < 0x8000000000000000) { + // We round down, so nothing to do. + } else if (v > 0x8000000000000000) { + // We round up. + RoundUp(p - 1); + } else { + RoundToEven(p - 1); + } + + assert(precision == 0); + // Precision can only be zero here. + return p; +} + +// Simple fractional decimal digit printing for values that fir in 128-bits +// after shifting. +// Performs rounding if necessary to fit within `precision`. +// Returns the pointer to one after the last character written. +char *PrintFractionalDigitsFast(uint128 v, char *start, int exp, + int precision) { + char *p = start; + v <<= (128 - exp); + auto high = static_cast<uint64_t>(v >> 64); + auto low = static_cast<uint64_t>(v); + + // While we have digits to print and `low` is not empty, do the long + // multiplication. + while (precision > 0 && low != 0) { + uint64_t carry = MultiplyBy10WithCarry(&low, uint64_t{0}); + carry = MultiplyBy10WithCarry(&high, carry); + + *p++ = carry + '0'; + --precision; + } + + // Now `low` is empty, so use a faster approach for the rest of the digits. + // This block is pretty much the same as the main loop for the 64-bit case + // above. + while (precision > 0) { + if (!high) return p; + *p++ = MultiplyBy10WithCarry(&high, uint64_t{0}) + '0'; + --precision; + } + + // We need to round. + if (high < 0x8000000000000000) { + // We round down, so nothing to do. + } else if (high > 0x8000000000000000 || low != 0) { + // We round up. + RoundUp(p - 1); + } else { + RoundToEven(p - 1); + } + + assert(precision == 0); + // Precision can only be zero here. + return p; +} + +struct FormatState { + char sign_char; + int precision; + const FormatConversionSpecImpl &conv; + FormatSinkImpl *sink; + + // In `alt` mode (flag #) we keep the `.` even if there are no fractional + // digits. In non-alt mode, we strip it. + bool ShouldPrintDot() const { return precision != 0 || conv.has_alt_flag(); } +}; + +struct Padding { + int left_spaces; + int zeros; + int right_spaces; +}; + +Padding ExtraWidthToPadding(size_t total_size, const FormatState &state) { + if (state.conv.width() < 0 || state.conv.width() <= total_size) + return {0, 0, 0}; + int missing_chars = state.conv.width() - total_size; + if (state.conv.has_left_flag()) { + return {0, 0, missing_chars}; + } else if (state.conv.has_zero_flag()) { + return {0, missing_chars, 0}; + } else { + return {missing_chars, 0, 0}; + } +} + +void FinalPrint(absl::string_view data, int trailing_zeros, + const FormatState &state) { + if (state.conv.width() < 0) { + // No width specified. Fast-path. + if (state.sign_char != '\0') state.sink->Append(1, state.sign_char); + state.sink->Append(data); + state.sink->Append(trailing_zeros, '0'); + return; + } + + auto padding = + ExtraWidthToPadding((state.sign_char != '\0' ? 1 : 0) + data.size() + + static_cast<size_t>(trailing_zeros), + state); + + state.sink->Append(padding.left_spaces, ' '); + if (state.sign_char != '\0') state.sink->Append(1, state.sign_char); + state.sink->Append(padding.zeros, '0'); + state.sink->Append(data); + state.sink->Append(trailing_zeros, '0'); + state.sink->Append(padding.right_spaces, ' '); +} + +// Fastpath %f formatter for when the shifted value fits in a simple integral +// type. +// Prints `v*2^exp` with the options from `state`. +template <typename Int> +void FormatFFast(Int v, int exp, const FormatState &state) { + constexpr int input_bits = sizeof(Int) * 8; + + static constexpr size_t integral_size = + /* in case we need to round up an extra digit */ 1 + + /* decimal digits for uint128 */ 40 + 1; + char buffer[integral_size + /* . */ 1 + /* max digits uint128 */ 128]; + buffer[integral_size] = '.'; + char *const integral_digits_end = buffer + integral_size; + char *integral_digits_start; + char *const fractional_digits_start = buffer + integral_size + 1; + char *fractional_digits_end = fractional_digits_start; + + if (exp >= 0) { + const int total_bits = input_bits - LeadingZeros(v) + exp; + integral_digits_start = + total_bits <= 64 + ? PrintIntegralDigitsFromRightFast(static_cast<uint64_t>(v) << exp, + integral_digits_end) + : PrintIntegralDigitsFromRightFast(static_cast<uint128>(v) << exp, + integral_digits_end); + } else { + exp = -exp; + + integral_digits_start = PrintIntegralDigitsFromRightFast( + exp < input_bits ? v >> exp : 0, integral_digits_end); + // PrintFractionalDigits may pull a carried 1 all the way up through the + // integral portion. + integral_digits_start[-1] = '0'; + + fractional_digits_end = + exp <= 64 ? PrintFractionalDigitsFast(v, fractional_digits_start, exp, + state.precision) + : PrintFractionalDigitsFast(static_cast<uint128>(v), + fractional_digits_start, exp, + state.precision); + // There was a carry, so include the first digit too. + if (integral_digits_start[-1] != '0') --integral_digits_start; + } + + size_t size = fractional_digits_end - integral_digits_start; + + // In `alt` mode (flag #) we keep the `.` even if there are no fractional + // digits. In non-alt mode, we strip it. + if (!state.ShouldPrintDot()) --size; + FinalPrint(absl::string_view(integral_digits_start, size), + static_cast<int>(state.precision - (fractional_digits_end - + fractional_digits_start)), + state); +} + +// Slow %f formatter for when the shifted value does not fit in a uint128, and +// `exp > 0`. +// Prints `v*2^exp` with the options from `state`. +// This one is guaranteed to not have fractional digits, so we don't have to +// worry about anything after the `.`. +void FormatFPositiveExpSlow(uint128 v, int exp, const FormatState &state) { + BinaryToDecimal::RunConversion(v, exp, [&](BinaryToDecimal btd) { + const size_t total_digits = + btd.TotalDigits() + + (state.ShouldPrintDot() ? static_cast<size_t>(state.precision) + 1 : 0); + + const auto padding = ExtraWidthToPadding( + total_digits + (state.sign_char != '\0' ? 1 : 0), state); + + state.sink->Append(padding.left_spaces, ' '); + if (state.sign_char != '\0') state.sink->Append(1, state.sign_char); + state.sink->Append(padding.zeros, '0'); + + do { + state.sink->Append(btd.CurrentDigits()); + } while (btd.AdvanceDigits()); + + if (state.ShouldPrintDot()) state.sink->Append(1, '.'); + state.sink->Append(state.precision, '0'); + state.sink->Append(padding.right_spaces, ' '); + }); +} + +// Slow %f formatter for when the shifted value does not fit in a uint128, and +// `exp < 0`. +// Prints `v*2^exp` with the options from `state`. +// This one is guaranteed to be < 1.0, so we don't have to worry about integral +// digits. +void FormatFNegativeExpSlow(uint128 v, int exp, const FormatState &state) { + const size_t total_digits = + /* 0 */ 1 + + (state.ShouldPrintDot() ? static_cast<size_t>(state.precision) + 1 : 0); + auto padding = + ExtraWidthToPadding(total_digits + (state.sign_char ? 1 : 0), state); + padding.zeros += 1; + state.sink->Append(padding.left_spaces, ' '); + if (state.sign_char != '\0') state.sink->Append(1, state.sign_char); + state.sink->Append(padding.zeros, '0'); + + if (state.ShouldPrintDot()) state.sink->Append(1, '.'); + + // Print digits + int digits_to_go = state.precision; + + FractionalDigitGenerator::RunConversion( + v, exp, [&](FractionalDigitGenerator digit_gen) { + // There are no digits to print here. + if (state.precision == 0) return; + + // We go one digit at a time, while keeping track of runs of nines. + // The runs of nines are used to perform rounding when necessary. + + while (digits_to_go > 0 && digit_gen.HasMoreDigits()) { + auto digits = digit_gen.GetDigits(); + + // Now we have a digit and a run of nines. + // See if we can print them all. + if (digits.num_nines + 1 < digits_to_go) { + // We don't have to round yet, so print them. + state.sink->Append(1, digits.digit_before_nine + '0'); + state.sink->Append(digits.num_nines, '9'); + digits_to_go -= digits.num_nines + 1; + + } else { + // We can't print all the nines, see where we have to truncate. + + bool round_up = false; + if (digits.num_nines + 1 > digits_to_go) { + // We round up at a nine. No need to print them. + round_up = true; + } else { + // We can fit all the nines, but truncate just after it. + if (digit_gen.IsGreaterThanHalf()) { + round_up = true; + } else if (digit_gen.IsExactlyHalf()) { + // Round to even + round_up = + digits.num_nines != 0 || digits.digit_before_nine % 2 == 1; + } + } + + if (round_up) { + state.sink->Append(1, digits.digit_before_nine + '1'); + --digits_to_go; + // The rest will be zeros. + } else { + state.sink->Append(1, digits.digit_before_nine + '0'); + state.sink->Append(digits_to_go - 1, '9'); + digits_to_go = 0; + } + return; + } + } + }); + + state.sink->Append(digits_to_go, '0'); + state.sink->Append(padding.right_spaces, ' '); +} + +template <typename Int> +void FormatF(Int mantissa, int exp, const FormatState &state) { + if (exp >= 0) { + const int total_bits = sizeof(Int) * 8 - LeadingZeros(mantissa) + exp; + + // Fallback to the slow stack-based approach if we can't do it in a 64 or + // 128 bit state. + if (ABSL_PREDICT_FALSE(total_bits > 128)) { + return FormatFPositiveExpSlow(mantissa, exp, state); + } + } else { + // Fallback to the slow stack-based approach if we can't do it in a 64 or + // 128 bit state. + if (ABSL_PREDICT_FALSE(exp < -128)) { + return FormatFNegativeExpSlow(mantissa, -exp, state); + } + } + return FormatFFast(mantissa, exp, state); +} + +char *CopyStringTo(absl::string_view v, char *out) { + std::memcpy(out, v.data(), v.size()); + return out + v.size(); +} + +template <typename Float> +bool FallbackToSnprintf(const Float v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + int w = conv.width() >= 0 ? conv.width() : 0; + int p = conv.precision() >= 0 ? conv.precision() : -1; + char fmt[32]; + { + char *fp = fmt; + *fp++ = '%'; + fp = CopyStringTo(FormatConversionSpecImplFriend::FlagsToString(conv), fp); + fp = CopyStringTo("*.*", fp); + if (std::is_same<long double, Float>()) { + *fp++ = 'L'; + } + *fp++ = FormatConversionCharToChar(conv.conversion_char()); + *fp = 0; + assert(fp < fmt + sizeof(fmt)); + } + std::string space(512, '\0'); + absl::string_view result; + while (true) { + int n = snprintf(&space[0], space.size(), fmt, w, p, v); + if (n < 0) return false; + if (static_cast<size_t>(n) < space.size()) { + result = absl::string_view(space.data(), n); + break; + } + space.resize(n + 1); + } + sink->Append(result); + return true; +} + +// 128-bits in decimal: ceil(128*log(2)/log(10)) +// or std::numeric_limits<__uint128_t>::digits10 +constexpr int kMaxFixedPrecision = 39; + +constexpr int kBufferLength = /*sign*/ 1 + + /*integer*/ kMaxFixedPrecision + + /*point*/ 1 + + /*fraction*/ kMaxFixedPrecision + + /*exponent e+123*/ 5; + +struct Buffer { + void push_front(char c) { + assert(begin > data); + *--begin = c; + } + void push_back(char c) { + assert(end < data + sizeof(data)); + *end++ = c; + } + void pop_back() { + assert(begin < end); + --end; + } + + char &back() { + assert(begin < end); + return end[-1]; + } + + char last_digit() const { return end[-1] == '.' ? end[-2] : end[-1]; } + + int size() const { return static_cast<int>(end - begin); } + + char data[kBufferLength]; + char *begin; + char *end; +}; + +enum class FormatStyle { Fixed, Precision }; + +// If the value is Inf or Nan, print it and return true. +// Otherwise, return false. +template <typename Float> +bool ConvertNonNumericFloats(char sign_char, Float v, + const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + char text[4], *ptr = text; + if (sign_char != '\0') *ptr++ = sign_char; + if (std::isnan(v)) { + ptr = std::copy_n( + FormatConversionCharIsUpper(conv.conversion_char()) ? "NAN" : "nan", 3, + ptr); + } else if (std::isinf(v)) { + ptr = std::copy_n( + FormatConversionCharIsUpper(conv.conversion_char()) ? "INF" : "inf", 3, + ptr); + } else { + return false; + } + + return sink->PutPaddedString(string_view(text, ptr - text), conv.width(), -1, + conv.has_left_flag()); +} + +// Round up the last digit of the value. +// It will carry over and potentially overflow. 'exp' will be adjusted in that +// case. +template <FormatStyle mode> +void RoundUp(Buffer *buffer, int *exp) { + char *p = &buffer->back(); + while (p >= buffer->begin && (*p == '9' || *p == '.')) { + if (*p == '9') *p = '0'; + --p; + } + + if (p < buffer->begin) { + *p = '1'; + buffer->begin = p; + if (mode == FormatStyle::Precision) { + std::swap(p[1], p[2]); // move the . + ++*exp; + buffer->pop_back(); + } + } else { + ++*p; + } +} + +void PrintExponent(int exp, char e, Buffer *out) { + out->push_back(e); + if (exp < 0) { + out->push_back('-'); + exp = -exp; + } else { + out->push_back('+'); + } + // Exponent digits. + if (exp > 99) { + out->push_back(exp / 100 + '0'); + out->push_back(exp / 10 % 10 + '0'); + out->push_back(exp % 10 + '0'); + } else { + out->push_back(exp / 10 + '0'); + out->push_back(exp % 10 + '0'); + } +} + +template <typename Float, typename Int> +constexpr bool CanFitMantissa() { + return +#if defined(__clang__) && !defined(__SSE3__) + // Workaround for clang bug: https://bugs.llvm.org/show_bug.cgi?id=38289 + // Casting from long double to uint64_t is miscompiled and drops bits. + (!std::is_same<Float, long double>::value || + !std::is_same<Int, uint64_t>::value) && +#endif + std::numeric_limits<Float>::digits <= std::numeric_limits<Int>::digits; +} + +template <typename Float> +struct Decomposed { + using MantissaType = + absl::conditional_t<std::is_same<long double, Float>::value, uint128, + uint64_t>; + static_assert(std::numeric_limits<Float>::digits <= sizeof(MantissaType) * 8, + ""); + MantissaType mantissa; + int exponent; +}; + +// Decompose the double into an integer mantissa and an exponent. +template <typename Float> +Decomposed<Float> Decompose(Float v) { + int exp; + Float m = std::frexp(v, &exp); + m = std::ldexp(m, std::numeric_limits<Float>::digits); + exp -= std::numeric_limits<Float>::digits; + + return {static_cast<typename Decomposed<Float>::MantissaType>(m), exp}; +} + +// Print 'digits' as decimal. +// In Fixed mode, we add a '.' at the end. +// In Precision mode, we add a '.' after the first digit. +template <FormatStyle mode, typename Int> +int PrintIntegralDigits(Int digits, Buffer *out) { + int printed = 0; + if (digits) { + for (; digits; digits /= 10) out->push_front(digits % 10 + '0'); + printed = out->size(); + if (mode == FormatStyle::Precision) { + out->push_front(*out->begin); + out->begin[1] = '.'; + } else { + out->push_back('.'); + } + } else if (mode == FormatStyle::Fixed) { + out->push_front('0'); + out->push_back('.'); + printed = 1; + } + return printed; +} + +// Back out 'extra_digits' digits and round up if necessary. +bool RemoveExtraPrecision(int extra_digits, bool has_leftover_value, + Buffer *out, int *exp_out) { + if (extra_digits <= 0) return false; + + // Back out the extra digits + out->end -= extra_digits; + + bool needs_to_round_up = [&] { + // We look at the digit just past the end. + // There must be 'extra_digits' extra valid digits after end. + if (*out->end > '5') return true; + if (*out->end < '5') return false; + if (has_leftover_value || std::any_of(out->end + 1, out->end + extra_digits, + [](char c) { return c != '0'; })) + return true; + + // Ends in ...50*, round to even. + return out->last_digit() % 2 == 1; + }(); + + if (needs_to_round_up) { + RoundUp<FormatStyle::Precision>(out, exp_out); + } + return true; +} + +// Print the value into the buffer. +// This will not include the exponent, which will be returned in 'exp_out' for +// Precision mode. +template <typename Int, typename Float, FormatStyle mode> +bool FloatToBufferImpl(Int int_mantissa, int exp, int precision, Buffer *out, + int *exp_out) { + assert((CanFitMantissa<Float, Int>())); + + const int int_bits = std::numeric_limits<Int>::digits; + + // In precision mode, we start printing one char to the right because it will + // also include the '.' + // In fixed mode we put the dot afterwards on the right. + out->begin = out->end = + out->data + 1 + kMaxFixedPrecision + (mode == FormatStyle::Precision); + + if (exp >= 0) { + if (std::numeric_limits<Float>::digits + exp > int_bits) { + // The value will overflow the Int + return false; + } + int digits_printed = PrintIntegralDigits<mode>(int_mantissa << exp, out); + int digits_to_zero_pad = precision; + if (mode == FormatStyle::Precision) { + *exp_out = digits_printed - 1; + digits_to_zero_pad -= digits_printed - 1; + if (RemoveExtraPrecision(-digits_to_zero_pad, false, out, exp_out)) { + return true; + } + } + for (; digits_to_zero_pad-- > 0;) out->push_back('0'); + return true; + } + + exp = -exp; + // We need at least 4 empty bits for the next decimal digit. + // We will multiply by 10. + if (exp > int_bits - 4) return false; + + const Int mask = (Int{1} << exp) - 1; + + // Print the integral part first. + int digits_printed = PrintIntegralDigits<mode>(int_mantissa >> exp, out); + int_mantissa &= mask; + + int fractional_count = precision; + if (mode == FormatStyle::Precision) { + if (digits_printed == 0) { + // Find the first non-zero digit, when in Precision mode. + *exp_out = 0; + if (int_mantissa) { + while (int_mantissa <= mask) { + int_mantissa *= 10; + --*exp_out; + } + } + out->push_front(static_cast<char>(int_mantissa >> exp) + '0'); + out->push_back('.'); + int_mantissa &= mask; + } else { + // We already have a digit, and a '.' + *exp_out = digits_printed - 1; + fractional_count -= *exp_out; + if (RemoveExtraPrecision(-fractional_count, int_mantissa != 0, out, + exp_out)) { + // If we had enough digits, return right away. + // The code below will try to round again otherwise. + return true; + } + } + } + + auto get_next_digit = [&] { + int_mantissa *= 10; + int digit = static_cast<int>(int_mantissa >> exp); + int_mantissa &= mask; + return digit; + }; + + // Print fractional_count more digits, if available. + for (; fractional_count > 0; --fractional_count) { + out->push_back(get_next_digit() + '0'); + } + + int next_digit = get_next_digit(); + if (next_digit > 5 || + (next_digit == 5 && (int_mantissa || out->last_digit() % 2 == 1))) { + RoundUp<mode>(out, exp_out); + } + + return true; +} + +template <FormatStyle mode, typename Float> +bool FloatToBuffer(Decomposed<Float> decomposed, int precision, Buffer *out, + int *exp) { + if (precision > kMaxFixedPrecision) return false; + + // Try with uint64_t. + if (CanFitMantissa<Float, std::uint64_t>() && + FloatToBufferImpl<std::uint64_t, Float, mode>( + static_cast<std::uint64_t>(decomposed.mantissa), + static_cast<std::uint64_t>(decomposed.exponent), precision, out, exp)) + return true; + +#if defined(ABSL_HAVE_INTRINSIC_INT128) + // If that is not enough, try with __uint128_t. + return CanFitMantissa<Float, __uint128_t>() && + FloatToBufferImpl<__uint128_t, Float, mode>( + static_cast<__uint128_t>(decomposed.mantissa), + static_cast<__uint128_t>(decomposed.exponent), precision, out, + exp); +#endif + return false; +} + +void WriteBufferToSink(char sign_char, absl::string_view str, + const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + int left_spaces = 0, zeros = 0, right_spaces = 0; + int missing_chars = + conv.width() >= 0 ? std::max(conv.width() - static_cast<int>(str.size()) - + static_cast<int>(sign_char != 0), + 0) + : 0; + if (conv.has_left_flag()) { + right_spaces = missing_chars; + } else if (conv.has_zero_flag()) { + zeros = missing_chars; + } else { + left_spaces = missing_chars; + } + + sink->Append(left_spaces, ' '); + if (sign_char != '\0') sink->Append(1, sign_char); + sink->Append(zeros, '0'); + sink->Append(str); + sink->Append(right_spaces, ' '); +} + +template <typename Float> +bool FloatToSink(const Float v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + // Print the sign or the sign column. + Float abs_v = v; + char sign_char = 0; + if (std::signbit(abs_v)) { + sign_char = '-'; + abs_v = -abs_v; + } else if (conv.has_show_pos_flag()) { + sign_char = '+'; + } else if (conv.has_sign_col_flag()) { + sign_char = ' '; + } + + // Print nan/inf. + if (ConvertNonNumericFloats(sign_char, abs_v, conv, sink)) { + return true; + } + + int precision = conv.precision() < 0 ? 6 : conv.precision(); + + int exp = 0; + + auto decomposed = Decompose(abs_v); + + Buffer buffer; + + FormatConversionChar c = conv.conversion_char(); + + if (c == FormatConversionCharInternal::f || + c == FormatConversionCharInternal::F) { + FormatF(decomposed.mantissa, decomposed.exponent, + {sign_char, precision, conv, sink}); + return true; + } else if (c == FormatConversionCharInternal::e || + c == FormatConversionCharInternal::E) { + if (!FloatToBuffer<FormatStyle::Precision>(decomposed, precision, &buffer, + &exp)) { + return FallbackToSnprintf(v, conv, sink); + } + if (!conv.has_alt_flag() && buffer.back() == '.') buffer.pop_back(); + PrintExponent( + exp, FormatConversionCharIsUpper(conv.conversion_char()) ? 'E' : 'e', + &buffer); + } else if (c == FormatConversionCharInternal::g || + c == FormatConversionCharInternal::G) { + precision = std::max(0, precision - 1); + if (!FloatToBuffer<FormatStyle::Precision>(decomposed, precision, &buffer, + &exp)) { + return FallbackToSnprintf(v, conv, sink); + } + if (precision + 1 > exp && exp >= -4) { + if (exp < 0) { + // Have 1.23456, needs 0.00123456 + // Move the first digit + buffer.begin[1] = *buffer.begin; + // Add some zeros + for (; exp < -1; ++exp) *buffer.begin-- = '0'; + *buffer.begin-- = '.'; + *buffer.begin = '0'; + } else if (exp > 0) { + // Have 1.23456, needs 1234.56 + // Move the '.' exp positions to the right. + std::rotate(buffer.begin + 1, buffer.begin + 2, buffer.begin + exp + 2); + } + exp = 0; + } + if (!conv.has_alt_flag()) { + while (buffer.back() == '0') buffer.pop_back(); + if (buffer.back() == '.') buffer.pop_back(); + } + if (exp) { + PrintExponent( + exp, FormatConversionCharIsUpper(conv.conversion_char()) ? 'E' : 'e', + &buffer); + } + } else if (c == FormatConversionCharInternal::a || + c == FormatConversionCharInternal::A) { + return FallbackToSnprintf(v, conv, sink); + } else { + return false; + } + + WriteBufferToSink(sign_char, + absl::string_view(buffer.begin, buffer.end - buffer.begin), + conv, sink); + + return true; +} + +} // namespace + +bool ConvertFloatImpl(long double v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + if (std::numeric_limits<long double>::digits == + 2 * std::numeric_limits<double>::digits) { + // This is the `double-double` representation of `long double`. + // We do not handle it natively. Fallback to snprintf. + return FallbackToSnprintf(v, conv, sink); + } + + return FloatToSink(v, conv, sink); +} + +bool ConvertFloatImpl(float v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + return FloatToSink(v, conv, sink); +} + +bool ConvertFloatImpl(double v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink) { + return FloatToSink(v, conv, sink); +} + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/float_conversion.h b/third_party/abseil_cpp/absl/strings/internal/str_format/float_conversion.h new file mode 100644 index 0000000000..e78bc19106 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/float_conversion.h @@ -0,0 +1,23 @@ +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_FLOAT_CONVERSION_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_FLOAT_CONVERSION_H_ + +#include "absl/strings/internal/str_format/extension.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +bool ConvertFloatImpl(float v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink); + +bool ConvertFloatImpl(double v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink); + +bool ConvertFloatImpl(long double v, const FormatConversionSpecImpl &conv, + FormatSinkImpl *sink); + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_FLOAT_CONVERSION_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/output.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/output.cc new file mode 100644 index 0000000000..c4b2470613 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/output.cc @@ -0,0 +1,72 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/str_format/output.h" + +#include <errno.h> +#include <cstring> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +namespace { +struct ClearErrnoGuard { + ClearErrnoGuard() : old_value(errno) { errno = 0; } + ~ClearErrnoGuard() { + if (!errno) errno = old_value; + } + int old_value; +}; +} // namespace + +void BufferRawSink::Write(string_view v) { + size_t to_write = std::min(v.size(), size_); + std::memcpy(buffer_, v.data(), to_write); + buffer_ += to_write; + size_ -= to_write; + total_written_ += v.size(); +} + +void FILERawSink::Write(string_view v) { + while (!v.empty() && !error_) { + // Reset errno to zero in case the libc implementation doesn't set errno + // when a failure occurs. + ClearErrnoGuard guard; + + if (size_t result = std::fwrite(v.data(), 1, v.size(), output_)) { + // Some progress was made. + count_ += result; + v.remove_prefix(result); + } else { + if (errno == EINTR) { + continue; + } else if (errno) { + error_ = errno; + } else if (std::ferror(output_)) { + // Non-POSIX compliant libc implementations may not set errno, so we + // have check the streams error indicator. + error_ = EBADF; + } else { + // We're likely on a non-POSIX system that encountered EINTR but had no + // way of reporting it. + continue; + } + } + } +} + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/output.h b/third_party/abseil_cpp/absl/strings/internal/str_format/output.h new file mode 100644 index 0000000000..8030dae00f --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/output.h @@ -0,0 +1,96 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Output extension hooks for the Format library. +// `internal::InvokeFlush` calls the appropriate flush function for the +// specified output argument. +// `BufferRawSink` is a simple output sink for a char buffer. Used by SnprintF. +// `FILERawSink` is a std::FILE* based sink. Used by PrintF and FprintF. + +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_OUTPUT_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_OUTPUT_H_ + +#include <cstdio> +#include <ostream> +#include <string> + +#include "absl/base/port.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +// RawSink implementation that writes into a char* buffer. +// It will not overflow the buffer, but will keep the total count of chars +// that would have been written. +class BufferRawSink { + public: + BufferRawSink(char* buffer, size_t size) : buffer_(buffer), size_(size) {} + + size_t total_written() const { return total_written_; } + void Write(string_view v); + + private: + char* buffer_; + size_t size_; + size_t total_written_ = 0; +}; + +// RawSink implementation that writes into a FILE*. +// It keeps track of the total number of bytes written and any error encountered +// during the writes. +class FILERawSink { + public: + explicit FILERawSink(std::FILE* output) : output_(output) {} + + void Write(string_view v); + + size_t count() const { return count_; } + int error() const { return error_; } + + private: + std::FILE* output_; + int error_ = 0; + size_t count_ = 0; +}; + +// Provide RawSink integration with common types from the STL. +inline void AbslFormatFlush(std::string* out, string_view s) { + out->append(s.data(), s.size()); +} +inline void AbslFormatFlush(std::ostream* out, string_view s) { + out->write(s.data(), s.size()); +} + +inline void AbslFormatFlush(FILERawSink* sink, string_view v) { + sink->Write(v); +} + +inline void AbslFormatFlush(BufferRawSink* sink, string_view v) { + sink->Write(v); +} + +// This is a SFINAE to get a better compiler error message when the type +// is not supported. +template <typename T> +auto InvokeFlush(T* out, string_view s) -> decltype(AbslFormatFlush(out, s)) { + AbslFormatFlush(out, s); +} + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_OUTPUT_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/output_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/output_test.cc new file mode 100644 index 0000000000..ce2e91a0bb --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/output_test.cc @@ -0,0 +1,79 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/str_format/output.h" + +#include <sstream> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/cord.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +TEST(InvokeFlush, String) { + std::string str = "ABC"; + str_format_internal::InvokeFlush(&str, "DEF"); + EXPECT_EQ(str, "ABCDEF"); +} + +TEST(InvokeFlush, Stream) { + std::stringstream str; + str << "ABC"; + str_format_internal::InvokeFlush(&str, "DEF"); + EXPECT_EQ(str.str(), "ABCDEF"); +} + +TEST(InvokeFlush, Cord) { + absl::Cord str("ABC"); + str_format_internal::InvokeFlush(&str, "DEF"); + EXPECT_EQ(str, "ABCDEF"); +} + +TEST(BufferRawSink, Limits) { + char buf[16]; + { + std::fill(std::begin(buf), std::end(buf), 'x'); + str_format_internal::BufferRawSink bufsink(buf, sizeof(buf) - 1); + str_format_internal::InvokeFlush(&bufsink, "Hello World237"); + EXPECT_EQ(std::string(buf, sizeof(buf)), "Hello World237xx"); + } + { + std::fill(std::begin(buf), std::end(buf), 'x'); + str_format_internal::BufferRawSink bufsink(buf, sizeof(buf) - 1); + str_format_internal::InvokeFlush(&bufsink, "Hello World237237"); + EXPECT_EQ(std::string(buf, sizeof(buf)), "Hello World2372x"); + } + { + std::fill(std::begin(buf), std::end(buf), 'x'); + str_format_internal::BufferRawSink bufsink(buf, sizeof(buf) - 1); + str_format_internal::InvokeFlush(&bufsink, "Hello World"); + str_format_internal::InvokeFlush(&bufsink, "237"); + EXPECT_EQ(std::string(buf, sizeof(buf)), "Hello World237xx"); + } + { + std::fill(std::begin(buf), std::end(buf), 'x'); + str_format_internal::BufferRawSink bufsink(buf, sizeof(buf) - 1); + str_format_internal::InvokeFlush(&bufsink, "Hello World"); + str_format_internal::InvokeFlush(&bufsink, "237237"); + EXPECT_EQ(std::string(buf, sizeof(buf)), "Hello World2372x"); + } +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/parser.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/parser.cc new file mode 100644 index 0000000000..cc55dfa9c7 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/parser.cc @@ -0,0 +1,336 @@ +#include "absl/strings/internal/str_format/parser.h" + +#include <assert.h> +#include <string.h> +#include <wchar.h> +#include <cctype> +#include <cstdint> + +#include <algorithm> +#include <initializer_list> +#include <limits> +#include <ostream> +#include <string> +#include <unordered_set> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +using CC = FormatConversionCharInternal; +using LM = LengthMod; + +ABSL_CONST_INIT const ConvTag kTags[256] = { + {}, {}, {}, {}, {}, {}, {}, {}, // 00-07 + {}, {}, {}, {}, {}, {}, {}, {}, // 08-0f + {}, {}, {}, {}, {}, {}, {}, {}, // 10-17 + {}, {}, {}, {}, {}, {}, {}, {}, // 18-1f + {}, {}, {}, {}, {}, {}, {}, {}, // 20-27 + {}, {}, {}, {}, {}, {}, {}, {}, // 28-2f + {}, {}, {}, {}, {}, {}, {}, {}, // 30-37 + {}, {}, {}, {}, {}, {}, {}, {}, // 38-3f + {}, CC::A, {}, {}, {}, CC::E, CC::F, CC::G, // @ABCDEFG + {}, {}, {}, {}, LM::L, {}, {}, {}, // HIJKLMNO + {}, {}, {}, {}, {}, {}, {}, {}, // PQRSTUVW + CC::X, {}, {}, {}, {}, {}, {}, {}, // XYZ[\]^_ + {}, CC::a, {}, CC::c, CC::d, CC::e, CC::f, CC::g, // `abcdefg + LM::h, CC::i, LM::j, {}, LM::l, {}, CC::n, CC::o, // hijklmno + CC::p, LM::q, {}, CC::s, LM::t, CC::u, {}, {}, // pqrstuvw + CC::x, {}, LM::z, {}, {}, {}, {}, {}, // xyz{|}! + {}, {}, {}, {}, {}, {}, {}, {}, // 80-87 + {}, {}, {}, {}, {}, {}, {}, {}, // 88-8f + {}, {}, {}, {}, {}, {}, {}, {}, // 90-97 + {}, {}, {}, {}, {}, {}, {}, {}, // 98-9f + {}, {}, {}, {}, {}, {}, {}, {}, // a0-a7 + {}, {}, {}, {}, {}, {}, {}, {}, // a8-af + {}, {}, {}, {}, {}, {}, {}, {}, // b0-b7 + {}, {}, {}, {}, {}, {}, {}, {}, // b8-bf + {}, {}, {}, {}, {}, {}, {}, {}, // c0-c7 + {}, {}, {}, {}, {}, {}, {}, {}, // c8-cf + {}, {}, {}, {}, {}, {}, {}, {}, // d0-d7 + {}, {}, {}, {}, {}, {}, {}, {}, // d8-df + {}, {}, {}, {}, {}, {}, {}, {}, // e0-e7 + {}, {}, {}, {}, {}, {}, {}, {}, // e8-ef + {}, {}, {}, {}, {}, {}, {}, {}, // f0-f7 + {}, {}, {}, {}, {}, {}, {}, {}, // f8-ff +}; + +namespace { + +bool CheckFastPathSetting(const UnboundConversion& conv) { + bool should_be_basic = !conv.flags.left && // + !conv.flags.show_pos && // + !conv.flags.sign_col && // + !conv.flags.alt && // + !conv.flags.zero && // + (conv.width.value() == -1) && + (conv.precision.value() == -1); + if (should_be_basic != conv.flags.basic) { + fprintf(stderr, + "basic=%d left=%d show_pos=%d sign_col=%d alt=%d zero=%d " + "width=%d precision=%d\n", + conv.flags.basic, conv.flags.left, conv.flags.show_pos, + conv.flags.sign_col, conv.flags.alt, conv.flags.zero, + conv.width.value(), conv.precision.value()); + } + return should_be_basic == conv.flags.basic; +} + +template <bool is_positional> +const char *ConsumeConversion(const char *pos, const char *const end, + UnboundConversion *conv, int *next_arg) { + const char* const original_pos = pos; + char c; + // Read the next char into `c` and update `pos`. Returns false if there are + // no more chars to read. +#define ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR() \ + do { \ + if (ABSL_PREDICT_FALSE(pos == end)) return nullptr; \ + c = *pos++; \ + } while (0) + + const auto parse_digits = [&] { + int digits = c - '0'; + // We do not want to overflow `digits` so we consume at most digits10 + // digits. If there are more digits the parsing will fail later on when the + // digit doesn't match the expected characters. + int num_digits = std::numeric_limits<int>::digits10; + for (;;) { + if (ABSL_PREDICT_FALSE(pos == end)) break; + c = *pos++; + if (!std::isdigit(c)) break; + --num_digits; + if (ABSL_PREDICT_FALSE(!num_digits)) break; + digits = 10 * digits + c - '0'; + } + return digits; + }; + + if (is_positional) { + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + if (ABSL_PREDICT_FALSE(c < '1' || c > '9')) return nullptr; + conv->arg_position = parse_digits(); + assert(conv->arg_position > 0); + if (ABSL_PREDICT_FALSE(c != '$')) return nullptr; + } + + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + + // We should start with the basic flag on. + assert(conv->flags.basic); + + // Any non alpha character makes this conversion not basic. + // This includes flags (-+ #0), width (1-9, *) or precision (.). + // All conversion characters and length modifiers are alpha characters. + if (c < 'A') { + conv->flags.basic = false; + + for (; c <= '0';) { + // FIXME: We might be able to speed this up reusing the lookup table from + // above. It might require changing Flags to be a plain integer where we + // can |= a value. + switch (c) { + case '-': + conv->flags.left = true; + break; + case '+': + conv->flags.show_pos = true; + break; + case ' ': + conv->flags.sign_col = true; + break; + case '#': + conv->flags.alt = true; + break; + case '0': + conv->flags.zero = true; + break; + default: + goto flags_done; + } + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + } +flags_done: + + if (c <= '9') { + if (c >= '0') { + int maybe_width = parse_digits(); + if (!is_positional && c == '$') { + if (ABSL_PREDICT_FALSE(*next_arg != 0)) return nullptr; + // Positional conversion. + *next_arg = -1; + conv->flags = Flags(); + conv->flags.basic = true; + return ConsumeConversion<true>(original_pos, end, conv, next_arg); + } + conv->width.set_value(maybe_width); + } else if (c == '*') { + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + if (is_positional) { + if (ABSL_PREDICT_FALSE(c < '1' || c > '9')) return nullptr; + conv->width.set_from_arg(parse_digits()); + if (ABSL_PREDICT_FALSE(c != '$')) return nullptr; + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + } else { + conv->width.set_from_arg(++*next_arg); + } + } + } + + if (c == '.') { + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + if (std::isdigit(c)) { + conv->precision.set_value(parse_digits()); + } else if (c == '*') { + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + if (is_positional) { + if (ABSL_PREDICT_FALSE(c < '1' || c > '9')) return nullptr; + conv->precision.set_from_arg(parse_digits()); + if (c != '$') return nullptr; + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + } else { + conv->precision.set_from_arg(++*next_arg); + } + } else { + conv->precision.set_value(0); + } + } + } + + auto tag = GetTagForChar(c); + + if (ABSL_PREDICT_FALSE(!tag.is_conv())) { + if (ABSL_PREDICT_FALSE(!tag.is_length())) return nullptr; + + // It is a length modifier. + using str_format_internal::LengthMod; + LengthMod length_mod = tag.as_length(); + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + if (c == 'h' && length_mod == LengthMod::h) { + conv->length_mod = LengthMod::hh; + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + } else if (c == 'l' && length_mod == LengthMod::l) { + conv->length_mod = LengthMod::ll; + ABSL_FORMAT_PARSER_INTERNAL_GET_CHAR(); + } else { + conv->length_mod = length_mod; + } + tag = GetTagForChar(c); + if (ABSL_PREDICT_FALSE(!tag.is_conv())) return nullptr; + } + + assert(CheckFastPathSetting(*conv)); + (void)(&CheckFastPathSetting); + + conv->conv = tag.as_conv(); + if (!is_positional) conv->arg_position = ++*next_arg; + return pos; +} + +} // namespace + +std::string LengthModToString(LengthMod v) { + switch (v) { + case LengthMod::h: + return "h"; + case LengthMod::hh: + return "hh"; + case LengthMod::l: + return "l"; + case LengthMod::ll: + return "ll"; + case LengthMod::L: + return "L"; + case LengthMod::j: + return "j"; + case LengthMod::z: + return "z"; + case LengthMod::t: + return "t"; + case LengthMod::q: + return "q"; + case LengthMod::none: + return ""; + } + return ""; +} + +const char *ConsumeUnboundConversion(const char *p, const char *end, + UnboundConversion *conv, int *next_arg) { + if (*next_arg < 0) return ConsumeConversion<true>(p, end, conv, next_arg); + return ConsumeConversion<false>(p, end, conv, next_arg); +} + +struct ParsedFormatBase::ParsedFormatConsumer { + explicit ParsedFormatConsumer(ParsedFormatBase *parsedformat) + : parsed(parsedformat), data_pos(parsedformat->data_.get()) {} + + bool Append(string_view s) { + if (s.empty()) return true; + + size_t text_end = AppendText(s); + + if (!parsed->items_.empty() && !parsed->items_.back().is_conversion) { + // Let's extend the existing text run. + parsed->items_.back().text_end = text_end; + } else { + // Let's make a new text run. + parsed->items_.push_back({false, text_end, {}}); + } + return true; + } + + bool ConvertOne(const UnboundConversion &conv, string_view s) { + size_t text_end = AppendText(s); + parsed->items_.push_back({true, text_end, conv}); + return true; + } + + size_t AppendText(string_view s) { + memcpy(data_pos, s.data(), s.size()); + data_pos += s.size(); + return static_cast<size_t>(data_pos - parsed->data_.get()); + } + + ParsedFormatBase *parsed; + char* data_pos; +}; + +ParsedFormatBase::ParsedFormatBase( + string_view format, bool allow_ignored, + std::initializer_list<FormatConversionCharSet> convs) + : data_(format.empty() ? nullptr : new char[format.size()]) { + has_error_ = !ParseFormatString(format, ParsedFormatConsumer(this)) || + !MatchesConversions(allow_ignored, convs); +} + +bool ParsedFormatBase::MatchesConversions( + bool allow_ignored, + std::initializer_list<FormatConversionCharSet> convs) const { + std::unordered_set<int> used; + auto add_if_valid_conv = [&](int pos, char c) { + if (static_cast<size_t>(pos) > convs.size() || + !Contains(convs.begin()[pos - 1], c)) + return false; + used.insert(pos); + return true; + }; + for (const ConversionItem &item : items_) { + if (!item.is_conversion) continue; + auto &conv = item.conv; + if (conv.precision.is_from_arg() && + !add_if_valid_conv(conv.precision.get_from_arg(), '*')) + return false; + if (conv.width.is_from_arg() && + !add_if_valid_conv(conv.width.get_from_arg(), '*')) + return false; + if (!add_if_valid_conv(conv.arg_position, + FormatConversionCharToChar(conv.conv))) + return false; + } + return used.size() == convs.size() || allow_ignored; +} + +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/parser.h b/third_party/abseil_cpp/absl/strings/internal/str_format/parser.h new file mode 100644 index 0000000000..fffed04fa0 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/parser.h @@ -0,0 +1,335 @@ +#ifndef ABSL_STRINGS_INTERNAL_STR_FORMAT_PARSER_H_ +#define ABSL_STRINGS_INTERNAL_STR_FORMAT_PARSER_H_ + +#include <limits.h> +#include <stddef.h> +#include <stdlib.h> + +#include <cassert> +#include <cstdint> +#include <initializer_list> +#include <iosfwd> +#include <iterator> +#include <memory> +#include <string> +#include <vector> + +#include "absl/strings/internal/str_format/checker.h" +#include "absl/strings/internal/str_format/extension.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +enum class LengthMod : std::uint8_t { h, hh, l, ll, L, j, z, t, q, none }; + +std::string LengthModToString(LengthMod v); + +// The analyzed properties of a single specified conversion. +struct UnboundConversion { + UnboundConversion() + : flags() /* This is required to zero all the fields of flags. */ { + flags.basic = true; + } + + class InputValue { + public: + void set_value(int value) { + assert(value >= 0); + value_ = value; + } + int value() const { return value_; } + + // Marks the value as "from arg". aka the '*' format. + // Requires `value >= 1`. + // When set, is_from_arg() return true and get_from_arg() returns the + // original value. + // `value()`'s return value is unspecfied in this state. + void set_from_arg(int value) { + assert(value > 0); + value_ = -value - 1; + } + bool is_from_arg() const { return value_ < -1; } + int get_from_arg() const { + assert(is_from_arg()); + return -value_ - 1; + } + + private: + int value_ = -1; + }; + + // No need to initialize. It will always be set in the parser. + int arg_position; + + InputValue width; + InputValue precision; + + Flags flags; + LengthMod length_mod = LengthMod::none; + FormatConversionChar conv = FormatConversionCharInternal::kNone; +}; + +// Consume conversion spec prefix (not including '%') of [p, end) if valid. +// Examples of valid specs would be e.g.: "s", "d", "-12.6f". +// If valid, it returns the first character following the conversion spec, +// and the spec part is broken down and returned in 'conv'. +// If invalid, returns nullptr. +const char* ConsumeUnboundConversion(const char* p, const char* end, + UnboundConversion* conv, int* next_arg); + +// Helper tag class for the table below. +// It allows fast `char -> ConversionChar/LengthMod` checking and +// conversions. +class ConvTag { + public: + constexpr ConvTag(FormatConversionChar conversion_char) // NOLINT + : tag_(static_cast<int8_t>(conversion_char)) {} + // We invert the length modifiers to make them negative so that we can easily + // test for them. + constexpr ConvTag(LengthMod length_mod) // NOLINT + : tag_(~static_cast<std::int8_t>(length_mod)) {} + // Everything else is -128, which is negative to make is_conv() simpler. + constexpr ConvTag() : tag_(-128) {} + + bool is_conv() const { return tag_ >= 0; } + bool is_length() const { return tag_ < 0 && tag_ != -128; } + FormatConversionChar as_conv() const { + assert(is_conv()); + return static_cast<FormatConversionChar>(tag_); + } + LengthMod as_length() const { + assert(is_length()); + return static_cast<LengthMod>(~tag_); + } + + private: + std::int8_t tag_; +}; + +extern const ConvTag kTags[256]; +// Keep a single table for all the conversion chars and length modifiers. +inline ConvTag GetTagForChar(char c) { + return kTags[static_cast<unsigned char>(c)]; +} + +// Parse the format string provided in 'src' and pass the identified items into +// 'consumer'. +// Text runs will be passed by calling +// Consumer::Append(string_view); +// ConversionItems will be passed by calling +// Consumer::ConvertOne(UnboundConversion, string_view); +// In the case of ConvertOne, the string_view that is passed is the +// portion of the format string corresponding to the conversion, not including +// the leading %. On success, it returns true. On failure, it stops and returns +// false. +template <typename Consumer> +bool ParseFormatString(string_view src, Consumer consumer) { + int next_arg = 0; + const char* p = src.data(); + const char* const end = p + src.size(); + while (p != end) { + const char* percent = static_cast<const char*>(memchr(p, '%', end - p)); + if (!percent) { + // We found the last substring. + return consumer.Append(string_view(p, end - p)); + } + // We found a percent, so push the text run then process the percent. + if (ABSL_PREDICT_FALSE(!consumer.Append(string_view(p, percent - p)))) { + return false; + } + if (ABSL_PREDICT_FALSE(percent + 1 >= end)) return false; + + auto tag = GetTagForChar(percent[1]); + if (tag.is_conv()) { + if (ABSL_PREDICT_FALSE(next_arg < 0)) { + // This indicates an error in the format string. + // The only way to get `next_arg < 0` here is to have a positional + // argument first which sets next_arg to -1 and then a non-positional + // argument. + return false; + } + p = percent + 2; + + // Keep this case separate from the one below. + // ConvertOne is more efficient when the compiler can see that the `basic` + // flag is set. + UnboundConversion conv; + conv.conv = tag.as_conv(); + conv.arg_position = ++next_arg; + if (ABSL_PREDICT_FALSE( + !consumer.ConvertOne(conv, string_view(percent + 1, 1)))) { + return false; + } + } else if (percent[1] != '%') { + UnboundConversion conv; + p = ConsumeUnboundConversion(percent + 1, end, &conv, &next_arg); + if (ABSL_PREDICT_FALSE(p == nullptr)) return false; + if (ABSL_PREDICT_FALSE(!consumer.ConvertOne( + conv, string_view(percent + 1, p - (percent + 1))))) { + return false; + } + } else { + if (ABSL_PREDICT_FALSE(!consumer.Append("%"))) return false; + p = percent + 2; + continue; + } + } + return true; +} + +// Always returns true, or fails to compile in a constexpr context if s does not +// point to a constexpr char array. +constexpr bool EnsureConstexpr(string_view s) { + return s.empty() || s[0] == s[0]; +} + +class ParsedFormatBase { + public: + explicit ParsedFormatBase( + string_view format, bool allow_ignored, + std::initializer_list<FormatConversionCharSet> convs); + + ParsedFormatBase(const ParsedFormatBase& other) { *this = other; } + + ParsedFormatBase(ParsedFormatBase&& other) { *this = std::move(other); } + + ParsedFormatBase& operator=(const ParsedFormatBase& other) { + if (this == &other) return *this; + has_error_ = other.has_error_; + items_ = other.items_; + size_t text_size = items_.empty() ? 0 : items_.back().text_end; + data_.reset(new char[text_size]); + memcpy(data_.get(), other.data_.get(), text_size); + return *this; + } + + ParsedFormatBase& operator=(ParsedFormatBase&& other) { + if (this == &other) return *this; + has_error_ = other.has_error_; + data_ = std::move(other.data_); + items_ = std::move(other.items_); + // Reset the vector to make sure the invariants hold. + other.items_.clear(); + return *this; + } + + template <typename Consumer> + bool ProcessFormat(Consumer consumer) const { + const char* const base = data_.get(); + string_view text(base, 0); + for (const auto& item : items_) { + const char* const end = text.data() + text.size(); + text = string_view(end, (base + item.text_end) - end); + if (item.is_conversion) { + if (!consumer.ConvertOne(item.conv, text)) return false; + } else { + if (!consumer.Append(text)) return false; + } + } + return !has_error_; + } + + bool has_error() const { return has_error_; } + + private: + // Returns whether the conversions match and if !allow_ignored it verifies + // that all conversions are used by the format. + bool MatchesConversions( + bool allow_ignored, + std::initializer_list<FormatConversionCharSet> convs) const; + + struct ParsedFormatConsumer; + + struct ConversionItem { + bool is_conversion; + // Points to the past-the-end location of this element in the data_ array. + size_t text_end; + UnboundConversion conv; + }; + + bool has_error_; + std::unique_ptr<char[]> data_; + std::vector<ConversionItem> items_; +}; + + +// A value type representing a preparsed format. These can be created, copied +// around, and reused to speed up formatting loops. +// The user must specify through the template arguments the conversion +// characters used in the format. This will be checked at compile time. +// +// This class uses Conv enum values to specify each argument. +// This allows for more flexibility as you can specify multiple possible +// conversion characters for each argument. +// ParsedFormat<char...> is a simplified alias for when the user only +// needs to specify a single conversion character for each argument. +// +// Example: +// // Extended format supports multiple characters per argument: +// using MyFormat = ExtendedParsedFormat<Conv::d | Conv::x>; +// MyFormat GetFormat(bool use_hex) { +// if (use_hex) return MyFormat("foo %x bar"); +// return MyFormat("foo %d bar"); +// } +// // 'format' can be used with any value that supports 'd' and 'x', +// // like `int`. +// auto format = GetFormat(use_hex); +// value = StringF(format, i); +// +// This class also supports runtime format checking with the ::New() and +// ::NewAllowIgnored() factory functions. +// This is the only API that allows the user to pass a runtime specified format +// string. These factory functions will return NULL if the format does not match +// the conversions requested by the user. +template <FormatConversionCharSet... C> +class ExtendedParsedFormat : public str_format_internal::ParsedFormatBase { + public: + explicit ExtendedParsedFormat(string_view format) +#ifdef ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + __attribute__(( + enable_if(str_format_internal::EnsureConstexpr(format), + "Format string is not constexpr."), + enable_if(str_format_internal::ValidFormatImpl<C...>(format), + "Format specified does not match the template arguments."))) +#endif // ABSL_INTERNAL_ENABLE_FORMAT_CHECKER + : ExtendedParsedFormat(format, false) { + } + + // ExtendedParsedFormat factory function. + // The user still has to specify the conversion characters, but they will not + // be checked at compile time. Instead, it will be checked at runtime. + // This delays the checking to runtime, but allows the user to pass + // dynamically sourced formats. + // It returns NULL if the format does not match the conversion characters. + // The user is responsible for checking the return value before using it. + // + // The 'New' variant will check that all the specified arguments are being + // consumed by the format and return NULL if any argument is being ignored. + // The 'NewAllowIgnored' variant will not verify this and will allow formats + // that ignore arguments. + static std::unique_ptr<ExtendedParsedFormat> New(string_view format) { + return New(format, false); + } + static std::unique_ptr<ExtendedParsedFormat> NewAllowIgnored( + string_view format) { + return New(format, true); + } + + private: + static std::unique_ptr<ExtendedParsedFormat> New(string_view format, + bool allow_ignored) { + std::unique_ptr<ExtendedParsedFormat> conv( + new ExtendedParsedFormat(format, allow_ignored)); + if (conv->has_error()) return nullptr; + return conv; + } + + ExtendedParsedFormat(string_view s, bool allow_ignored) + : ParsedFormatBase(s, allow_ignored, {C...}) {} +}; +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_FORMAT_PARSER_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_format/parser_test.cc b/third_party/abseil_cpp/absl/strings/internal/str_format/parser_test.cc new file mode 100644 index 0000000000..5aced98720 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_format/parser_test.cc @@ -0,0 +1,413 @@ +#include "absl/strings/internal/str_format/parser.h" + +#include <string.h> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/macros.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace str_format_internal { + +namespace { + +using testing::Pair; + +TEST(LengthModTest, Names) { + struct Expectation { + int line; + LengthMod mod; + const char *name; + }; + const Expectation kExpect[] = { + {__LINE__, LengthMod::none, "" }, + {__LINE__, LengthMod::h, "h" }, + {__LINE__, LengthMod::hh, "hh"}, + {__LINE__, LengthMod::l, "l" }, + {__LINE__, LengthMod::ll, "ll"}, + {__LINE__, LengthMod::L, "L" }, + {__LINE__, LengthMod::j, "j" }, + {__LINE__, LengthMod::z, "z" }, + {__LINE__, LengthMod::t, "t" }, + {__LINE__, LengthMod::q, "q" }, + }; + EXPECT_EQ(ABSL_ARRAYSIZE(kExpect), 10); + for (auto e : kExpect) { + SCOPED_TRACE(e.line); + EXPECT_EQ(e.name, LengthModToString(e.mod)); + } +} + +TEST(ConversionCharTest, Names) { + struct Expectation { + FormatConversionChar id; + char name; + }; + // clang-format off + const Expectation kExpect[] = { +#define X(c) {FormatConversionCharInternal::c, #c[0]} + X(c), X(s), // text + X(d), X(i), X(o), X(u), X(x), X(X), // int + X(f), X(F), X(e), X(E), X(g), X(G), X(a), X(A), // float + X(n), X(p), // misc +#undef X + {FormatConversionCharInternal::kNone, '\0'}, + }; + // clang-format on + for (auto e : kExpect) { + SCOPED_TRACE(e.name); + FormatConversionChar v = e.id; + EXPECT_EQ(e.name, FormatConversionCharToChar(v)); + } +} + +class ConsumeUnboundConversionTest : public ::testing::Test { + public: + std::pair<string_view, string_view> Consume(string_view src) { + int next = 0; + o = UnboundConversion(); // refresh + const char* p = ConsumeUnboundConversion( + src.data(), src.data() + src.size(), &o, &next); + if (!p) return {{}, src}; + return {string_view(src.data(), p - src.data()), + string_view(p, src.data() + src.size() - p)}; + } + + bool Run(const char *fmt, bool force_positional = false) { + int next = force_positional ? -1 : 0; + o = UnboundConversion(); // refresh + return ConsumeUnboundConversion(fmt, fmt + strlen(fmt), &o, &next) == + fmt + strlen(fmt); + } + UnboundConversion o; +}; + +TEST_F(ConsumeUnboundConversionTest, ConsumeSpecification) { + struct Expectation { + int line; + string_view src; + string_view out; + string_view src_post; + }; + const Expectation kExpect[] = { + {__LINE__, "", "", "" }, + {__LINE__, "b", "", "b" }, // 'b' is invalid + {__LINE__, "ba", "", "ba"}, // 'b' is invalid + {__LINE__, "l", "", "l" }, // just length mod isn't okay + {__LINE__, "d", "d", "" }, // basic + {__LINE__, "d ", "d", " " }, // leave suffix + {__LINE__, "dd", "d", "d" }, // don't be greedy + {__LINE__, "d9", "d", "9" }, // leave non-space suffix + {__LINE__, "dzz", "d", "zz"}, // length mod as suffix + {__LINE__, "1$*2$d", "1$*2$d", "" }, // arg indexing and * allowed. + {__LINE__, "0-14.3hhd", "0-14.3hhd", ""}, // precision, width + {__LINE__, " 0-+#14.3hhd", " 0-+#14.3hhd", ""}, // flags + }; + for (const auto& e : kExpect) { + SCOPED_TRACE(e.line); + EXPECT_THAT(Consume(e.src), Pair(e.out, e.src_post)); + } +} + +TEST_F(ConsumeUnboundConversionTest, BasicConversion) { + EXPECT_FALSE(Run("")); + EXPECT_FALSE(Run("z")); + + EXPECT_FALSE(Run("dd")); // no excess allowed + + EXPECT_TRUE(Run("d")); + EXPECT_EQ('d', FormatConversionCharToChar(o.conv)); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_LT(o.width.value(), 0); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_LT(o.precision.value(), 0); + EXPECT_EQ(1, o.arg_position); +} + +TEST_F(ConsumeUnboundConversionTest, ArgPosition) { + EXPECT_TRUE(Run("d")); + EXPECT_EQ(1, o.arg_position); + EXPECT_TRUE(Run("3$d")); + EXPECT_EQ(3, o.arg_position); + EXPECT_TRUE(Run("1$d")); + EXPECT_EQ(1, o.arg_position); + EXPECT_TRUE(Run("1$d", true)); + EXPECT_EQ(1, o.arg_position); + EXPECT_TRUE(Run("123$d")); + EXPECT_EQ(123, o.arg_position); + EXPECT_TRUE(Run("123$d", true)); + EXPECT_EQ(123, o.arg_position); + EXPECT_TRUE(Run("10$d")); + EXPECT_EQ(10, o.arg_position); + EXPECT_TRUE(Run("10$d", true)); + EXPECT_EQ(10, o.arg_position); + + // Position can't be zero. + EXPECT_FALSE(Run("0$d")); + EXPECT_FALSE(Run("0$d", true)); + EXPECT_FALSE(Run("1$*0$d")); + EXPECT_FALSE(Run("1$.*0$d")); + + // Position can't start with a zero digit at all. That is not a 'decimal'. + EXPECT_FALSE(Run("01$p")); + EXPECT_FALSE(Run("01$p", true)); + EXPECT_FALSE(Run("1$*01$p")); + EXPECT_FALSE(Run("1$.*01$p")); +} + +TEST_F(ConsumeUnboundConversionTest, WidthAndPrecision) { + EXPECT_TRUE(Run("14d")); + EXPECT_EQ('d', FormatConversionCharToChar(o.conv)); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_EQ(14, o.width.value()); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_LT(o.precision.value(), 0); + + EXPECT_TRUE(Run("14.d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_EQ(14, o.width.value()); + EXPECT_EQ(0, o.precision.value()); + + EXPECT_TRUE(Run(".d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_LT(o.width.value(), 0); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_EQ(0, o.precision.value()); + + EXPECT_TRUE(Run(".5d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_LT(o.width.value(), 0); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_EQ(5, o.precision.value()); + + EXPECT_TRUE(Run(".0d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_LT(o.width.value(), 0); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_EQ(0, o.precision.value()); + + EXPECT_TRUE(Run("14.5d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_EQ(14, o.width.value()); + EXPECT_EQ(5, o.precision.value()); + + EXPECT_TRUE(Run("*.*d")); + EXPECT_TRUE(o.width.is_from_arg()); + EXPECT_EQ(1, o.width.get_from_arg()); + EXPECT_TRUE(o.precision.is_from_arg()); + EXPECT_EQ(2, o.precision.get_from_arg()); + EXPECT_EQ(3, o.arg_position); + + EXPECT_TRUE(Run("*d")); + EXPECT_TRUE(o.width.is_from_arg()); + EXPECT_EQ(1, o.width.get_from_arg()); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_LT(o.precision.value(), 0); + EXPECT_EQ(2, o.arg_position); + + EXPECT_TRUE(Run(".*d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_LT(o.width.value(), 0); + EXPECT_TRUE(o.precision.is_from_arg()); + EXPECT_EQ(1, o.precision.get_from_arg()); + EXPECT_EQ(2, o.arg_position); + + // mixed implicit and explicit: didn't specify arg position. + EXPECT_FALSE(Run("*23$.*34$d")); + + EXPECT_TRUE(Run("12$*23$.*34$d")); + EXPECT_EQ(12, o.arg_position); + EXPECT_TRUE(o.width.is_from_arg()); + EXPECT_EQ(23, o.width.get_from_arg()); + EXPECT_TRUE(o.precision.is_from_arg()); + EXPECT_EQ(34, o.precision.get_from_arg()); + + EXPECT_TRUE(Run("2$*5$.*9$d")); + EXPECT_EQ(2, o.arg_position); + EXPECT_TRUE(o.width.is_from_arg()); + EXPECT_EQ(5, o.width.get_from_arg()); + EXPECT_TRUE(o.precision.is_from_arg()); + EXPECT_EQ(9, o.precision.get_from_arg()); + + EXPECT_FALSE(Run(".*0$d")) << "no arg 0"; + + // Large values + EXPECT_TRUE(Run("999999999.999999999d")); + EXPECT_FALSE(o.width.is_from_arg()); + EXPECT_EQ(999999999, o.width.value()); + EXPECT_FALSE(o.precision.is_from_arg()); + EXPECT_EQ(999999999, o.precision.value()); + + EXPECT_FALSE(Run("1000000000.999999999d")); + EXPECT_FALSE(Run("999999999.1000000000d")); + EXPECT_FALSE(Run("9999999999d")); + EXPECT_FALSE(Run(".9999999999d")); +} + +TEST_F(ConsumeUnboundConversionTest, Flags) { + static const char kAllFlags[] = "-+ #0"; + static const int kNumFlags = ABSL_ARRAYSIZE(kAllFlags) - 1; + for (int rev = 0; rev < 2; ++rev) { + for (int i = 0; i < 1 << kNumFlags; ++i) { + std::string fmt; + for (int k = 0; k < kNumFlags; ++k) + if ((i >> k) & 1) fmt += kAllFlags[k]; + // flag order shouldn't matter + if (rev == 1) { std::reverse(fmt.begin(), fmt.end()); } + fmt += 'd'; + SCOPED_TRACE(fmt); + EXPECT_TRUE(Run(fmt.c_str())); + EXPECT_EQ(fmt.find('-') == std::string::npos, !o.flags.left); + EXPECT_EQ(fmt.find('+') == std::string::npos, !o.flags.show_pos); + EXPECT_EQ(fmt.find(' ') == std::string::npos, !o.flags.sign_col); + EXPECT_EQ(fmt.find('#') == std::string::npos, !o.flags.alt); + EXPECT_EQ(fmt.find('0') == std::string::npos, !o.flags.zero); + } + } +} + +TEST_F(ConsumeUnboundConversionTest, BasicFlag) { + // Flag is on + for (const char* fmt : {"d", "llx", "G", "1$X"}) { + SCOPED_TRACE(fmt); + EXPECT_TRUE(Run(fmt)); + EXPECT_TRUE(o.flags.basic); + } + + // Flag is off + for (const char* fmt : {"3d", ".llx", "-G", "1$#X"}) { + SCOPED_TRACE(fmt); + EXPECT_TRUE(Run(fmt)); + EXPECT_FALSE(o.flags.basic); + } +} + +TEST_F(ConsumeUnboundConversionTest, LengthMod) { + EXPECT_TRUE(Run("d")); + EXPECT_EQ(LengthMod::none, o.length_mod); + EXPECT_TRUE(Run("hd")); + EXPECT_EQ(LengthMod::h, o.length_mod); + EXPECT_TRUE(Run("hhd")); + EXPECT_EQ(LengthMod::hh, o.length_mod); + EXPECT_TRUE(Run("ld")); + EXPECT_EQ(LengthMod::l, o.length_mod); + EXPECT_TRUE(Run("lld")); + EXPECT_EQ(LengthMod::ll, o.length_mod); + EXPECT_TRUE(Run("Lf")); + EXPECT_EQ(LengthMod::L, o.length_mod); + EXPECT_TRUE(Run("qf")); + EXPECT_EQ(LengthMod::q, o.length_mod); + EXPECT_TRUE(Run("jd")); + EXPECT_EQ(LengthMod::j, o.length_mod); + EXPECT_TRUE(Run("zd")); + EXPECT_EQ(LengthMod::z, o.length_mod); + EXPECT_TRUE(Run("td")); + EXPECT_EQ(LengthMod::t, o.length_mod); +} + +struct SummarizeConsumer { + std::string* out; + explicit SummarizeConsumer(std::string* out) : out(out) {} + + bool Append(string_view s) { + *out += "[" + std::string(s) + "]"; + return true; + } + + bool ConvertOne(const UnboundConversion& conv, string_view s) { + *out += "{"; + *out += std::string(s); + *out += ":"; + *out += std::to_string(conv.arg_position) + "$"; + if (conv.width.is_from_arg()) { + *out += std::to_string(conv.width.get_from_arg()) + "$*"; + } + if (conv.precision.is_from_arg()) { + *out += "." + std::to_string(conv.precision.get_from_arg()) + "$*"; + } + *out += FormatConversionCharToChar(conv.conv); + *out += "}"; + return true; + } +}; + +std::string SummarizeParsedFormat(const ParsedFormatBase& pc) { + std::string out; + if (!pc.ProcessFormat(SummarizeConsumer(&out))) out += "!"; + return out; +} + +class ParsedFormatTest : public testing::Test {}; + +TEST_F(ParsedFormatTest, ValueSemantics) { + ParsedFormatBase p1({}, true, {}); // empty format + EXPECT_EQ("", SummarizeParsedFormat(p1)); + + ParsedFormatBase p2 = p1; // copy construct (empty) + EXPECT_EQ(SummarizeParsedFormat(p1), SummarizeParsedFormat(p2)); + + p1 = ParsedFormatBase("hello%s", true, + {FormatConversionCharSetInternal::s}); // move assign + EXPECT_EQ("[hello]{s:1$s}", SummarizeParsedFormat(p1)); + + ParsedFormatBase p3 = p1; // copy construct (nonempty) + EXPECT_EQ(SummarizeParsedFormat(p1), SummarizeParsedFormat(p3)); + + using std::swap; + swap(p1, p2); + EXPECT_EQ("", SummarizeParsedFormat(p1)); + EXPECT_EQ("[hello]{s:1$s}", SummarizeParsedFormat(p2)); + swap(p1, p2); // undo + + p2 = p1; // copy assign + EXPECT_EQ(SummarizeParsedFormat(p1), SummarizeParsedFormat(p2)); +} + +struct ExpectParse { + const char* in; + std::initializer_list<FormatConversionCharSet> conv_set; + const char* out; +}; + +TEST_F(ParsedFormatTest, Parsing) { + // Parse should be equivalent to that obtained by ConversionParseIterator. + // No need to retest the parsing edge cases here. + const ExpectParse kExpect[] = { + {"", {}, ""}, + {"ab", {}, "[ab]"}, + {"a%d", {FormatConversionCharSetInternal::d}, "[a]{d:1$d}"}, + {"a%+d", {FormatConversionCharSetInternal::d}, "[a]{+d:1$d}"}, + {"a% d", {FormatConversionCharSetInternal::d}, "[a]{ d:1$d}"}, + {"a%b %d", {}, "[a]!"}, // stop after error + }; + for (const auto& e : kExpect) { + SCOPED_TRACE(e.in); + EXPECT_EQ(e.out, + SummarizeParsedFormat(ParsedFormatBase(e.in, false, e.conv_set))); + } +} + +TEST_F(ParsedFormatTest, ParsingFlagOrder) { + const ExpectParse kExpect[] = { + {"a%+ 0d", {FormatConversionCharSetInternal::d}, "[a]{+ 0d:1$d}"}, + {"a%+0 d", {FormatConversionCharSetInternal::d}, "[a]{+0 d:1$d}"}, + {"a%0+ d", {FormatConversionCharSetInternal::d}, "[a]{0+ d:1$d}"}, + {"a% +0d", {FormatConversionCharSetInternal::d}, "[a]{ +0d:1$d}"}, + {"a%0 +d", {FormatConversionCharSetInternal::d}, "[a]{0 +d:1$d}"}, + {"a% 0+d", {FormatConversionCharSetInternal::d}, "[a]{ 0+d:1$d}"}, + {"a%+ 0+d", {FormatConversionCharSetInternal::d}, "[a]{+ 0+d:1$d}"}, + }; + for (const auto& e : kExpect) { + SCOPED_TRACE(e.in); + EXPECT_EQ(e.out, + SummarizeParsedFormat(ParsedFormatBase(e.in, false, e.conv_set))); + } +} + +} // namespace +} // namespace str_format_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/str_join_internal.h b/third_party/abseil_cpp/absl/strings/internal/str_join_internal.h new file mode 100644 index 0000000000..31dbf672f0 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_join_internal.h @@ -0,0 +1,314 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// This file declares INTERNAL parts of the Join API that are inlined/templated +// or otherwise need to be available at compile time. The main abstractions +// defined in this file are: +// +// - A handful of default Formatters +// - JoinAlgorithm() overloads +// - JoinRange() overloads +// - JoinTuple() +// +// DO NOT INCLUDE THIS FILE DIRECTLY. Use this file by including +// absl/strings/str_join.h +// +// IWYU pragma: private, include "absl/strings/str_join.h" + +#ifndef ABSL_STRINGS_INTERNAL_STR_JOIN_INTERNAL_H_ +#define ABSL_STRINGS_INTERNAL_STR_JOIN_INTERNAL_H_ + +#include <cstring> +#include <iterator> +#include <memory> +#include <string> +#include <type_traits> +#include <utility> + +#include "absl/strings/internal/ostringstream.h" +#include "absl/strings/internal/resize_uninitialized.h" +#include "absl/strings/str_cat.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// +// Formatter objects +// +// The following are implementation classes for standard Formatter objects. The +// factory functions that users will call to create and use these formatters are +// defined and documented in strings/join.h. +// + +// The default formatter. Converts alpha-numeric types to strings. +struct AlphaNumFormatterImpl { + // This template is needed in order to support passing in a dereferenced + // vector<bool>::iterator + template <typename T> + void operator()(std::string* out, const T& t) const { + StrAppend(out, AlphaNum(t)); + } + + void operator()(std::string* out, const AlphaNum& t) const { + StrAppend(out, t); + } +}; + +// A type that's used to overload the JoinAlgorithm() function (defined below) +// for ranges that do not require additional formatting (e.g., a range of +// strings). + +struct NoFormatter : public AlphaNumFormatterImpl {}; + +// Formats types to strings using the << operator. +class StreamFormatterImpl { + public: + // The method isn't const because it mutates state. Making it const will + // render StreamFormatterImpl thread-hostile. + template <typename T> + void operator()(std::string* out, const T& t) { + // The stream is created lazily to avoid paying the relatively high cost + // of its construction when joining an empty range. + if (strm_) { + strm_->clear(); // clear the bad, fail and eof bits in case they were set + strm_->str(out); + } else { + strm_.reset(new strings_internal::OStringStream(out)); + } + *strm_ << t; + } + + private: + std::unique_ptr<strings_internal::OStringStream> strm_; +}; + +// Formats a std::pair<>. The 'first' member is formatted using f1_ and the +// 'second' member is formatted using f2_. sep_ is the separator. +template <typename F1, typename F2> +class PairFormatterImpl { + public: + PairFormatterImpl(F1 f1, absl::string_view sep, F2 f2) + : f1_(std::move(f1)), sep_(sep), f2_(std::move(f2)) {} + + template <typename T> + void operator()(std::string* out, const T& p) { + f1_(out, p.first); + out->append(sep_); + f2_(out, p.second); + } + + template <typename T> + void operator()(std::string* out, const T& p) const { + f1_(out, p.first); + out->append(sep_); + f2_(out, p.second); + } + + private: + F1 f1_; + std::string sep_; + F2 f2_; +}; + +// Wraps another formatter and dereferences the argument to operator() then +// passes the dereferenced argument to the wrapped formatter. This can be +// useful, for example, to join a std::vector<int*>. +template <typename Formatter> +class DereferenceFormatterImpl { + public: + DereferenceFormatterImpl() : f_() {} + explicit DereferenceFormatterImpl(Formatter&& f) + : f_(std::forward<Formatter>(f)) {} + + template <typename T> + void operator()(std::string* out, const T& t) { + f_(out, *t); + } + + template <typename T> + void operator()(std::string* out, const T& t) const { + f_(out, *t); + } + + private: + Formatter f_; +}; + +// DefaultFormatter<T> is a traits class that selects a default Formatter to use +// for the given type T. The ::Type member names the Formatter to use. This is +// used by the strings::Join() functions that do NOT take a Formatter argument, +// in which case a default Formatter must be chosen. +// +// AlphaNumFormatterImpl is the default in the base template, followed by +// specializations for other types. +template <typename ValueType> +struct DefaultFormatter { + typedef AlphaNumFormatterImpl Type; +}; +template <> +struct DefaultFormatter<const char*> { + typedef AlphaNumFormatterImpl Type; +}; +template <> +struct DefaultFormatter<char*> { + typedef AlphaNumFormatterImpl Type; +}; +template <> +struct DefaultFormatter<std::string> { + typedef NoFormatter Type; +}; +template <> +struct DefaultFormatter<absl::string_view> { + typedef NoFormatter Type; +}; +template <typename ValueType> +struct DefaultFormatter<ValueType*> { + typedef DereferenceFormatterImpl<typename DefaultFormatter<ValueType>::Type> + Type; +}; + +template <typename ValueType> +struct DefaultFormatter<std::unique_ptr<ValueType>> + : public DefaultFormatter<ValueType*> {}; + +// +// JoinAlgorithm() functions +// + +// The main joining algorithm. This simply joins the elements in the given +// iterator range, each separated by the given separator, into an output string, +// and formats each element using the provided Formatter object. +template <typename Iterator, typename Formatter> +std::string JoinAlgorithm(Iterator start, Iterator end, absl::string_view s, + Formatter&& f) { + std::string result; + absl::string_view sep(""); + for (Iterator it = start; it != end; ++it) { + result.append(sep.data(), sep.size()); + f(&result, *it); + sep = s; + } + return result; +} + +// A joining algorithm that's optimized for a forward iterator range of +// string-like objects that do not need any additional formatting. This is to +// optimize the common case of joining, say, a std::vector<string> or a +// std::vector<absl::string_view>. +// +// This is an overload of the previous JoinAlgorithm() function. Here the +// Formatter argument is of type NoFormatter. Since NoFormatter is an internal +// type, this overload is only invoked when strings::Join() is called with a +// range of string-like objects (e.g., std::string, absl::string_view), and an +// explicit Formatter argument was NOT specified. +// +// The optimization is that the needed space will be reserved in the output +// string to avoid the need to resize while appending. To do this, the iterator +// range will be traversed twice: once to calculate the total needed size, and +// then again to copy the elements and delimiters to the output string. +template <typename Iterator, + typename = typename std::enable_if<std::is_convertible< + typename std::iterator_traits<Iterator>::iterator_category, + std::forward_iterator_tag>::value>::type> +std::string JoinAlgorithm(Iterator start, Iterator end, absl::string_view s, + NoFormatter) { + std::string result; + if (start != end) { + // Sums size + size_t result_size = start->size(); + for (Iterator it = start; ++it != end;) { + result_size += s.size(); + result_size += it->size(); + } + + if (result_size > 0) { + STLStringResizeUninitialized(&result, result_size); + + // Joins strings + char* result_buf = &*result.begin(); + memcpy(result_buf, start->data(), start->size()); + result_buf += start->size(); + for (Iterator it = start; ++it != end;) { + memcpy(result_buf, s.data(), s.size()); + result_buf += s.size(); + memcpy(result_buf, it->data(), it->size()); + result_buf += it->size(); + } + } + } + + return result; +} + +// JoinTupleLoop implements a loop over the elements of a std::tuple, which +// are heterogeneous. The primary template matches the tuple interior case. It +// continues the iteration after appending a separator (for nonzero indices) +// and formatting an element of the tuple. The specialization for the I=N case +// matches the end-of-tuple, and terminates the iteration. +template <size_t I, size_t N> +struct JoinTupleLoop { + template <typename Tup, typename Formatter> + void operator()(std::string* out, const Tup& tup, absl::string_view sep, + Formatter&& fmt) { + if (I > 0) out->append(sep.data(), sep.size()); + fmt(out, std::get<I>(tup)); + JoinTupleLoop<I + 1, N>()(out, tup, sep, fmt); + } +}; +template <size_t N> +struct JoinTupleLoop<N, N> { + template <typename Tup, typename Formatter> + void operator()(std::string*, const Tup&, absl::string_view, Formatter&&) {} +}; + +template <typename... T, typename Formatter> +std::string JoinAlgorithm(const std::tuple<T...>& tup, absl::string_view sep, + Formatter&& fmt) { + std::string result; + JoinTupleLoop<0, sizeof...(T)>()(&result, tup, sep, fmt); + return result; +} + +template <typename Iterator> +std::string JoinRange(Iterator first, Iterator last, + absl::string_view separator) { + // No formatter was explicitly given, so a default must be chosen. + typedef typename std::iterator_traits<Iterator>::value_type ValueType; + typedef typename DefaultFormatter<ValueType>::Type Formatter; + return JoinAlgorithm(first, last, separator, Formatter()); +} + +template <typename Range, typename Formatter> +std::string JoinRange(const Range& range, absl::string_view separator, + Formatter&& fmt) { + using std::begin; + using std::end; + return JoinAlgorithm(begin(range), end(range), separator, fmt); +} + +template <typename Range> +std::string JoinRange(const Range& range, absl::string_view separator) { + using std::begin; + using std::end; + return JoinRange(begin(range), end(range), separator); +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_JOIN_INTERNAL_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/str_split_internal.h b/third_party/abseil_cpp/absl/strings/internal/str_split_internal.h new file mode 100644 index 0000000000..6f5bc095fb --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/str_split_internal.h @@ -0,0 +1,455 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// This file declares INTERNAL parts of the Split API that are inline/templated +// or otherwise need to be available at compile time. The main abstractions +// defined in here are +// +// - ConvertibleToStringView +// - SplitIterator<> +// - Splitter<> +// +// DO NOT INCLUDE THIS FILE DIRECTLY. Use this file by including +// absl/strings/str_split.h. +// +// IWYU pragma: private, include "absl/strings/str_split.h" + +#ifndef ABSL_STRINGS_INTERNAL_STR_SPLIT_INTERNAL_H_ +#define ABSL_STRINGS_INTERNAL_STR_SPLIT_INTERNAL_H_ + +#include <array> +#include <initializer_list> +#include <iterator> +#include <map> +#include <type_traits> +#include <utility> +#include <vector> + +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" + +#ifdef _GLIBCXX_DEBUG +#include "absl/strings/internal/stl_type_traits.h" +#endif // _GLIBCXX_DEBUG + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// This class is implicitly constructible from everything that absl::string_view +// is implicitly constructible from. If it's constructed from a temporary +// string, the data is moved into a data member so its lifetime matches that of +// the ConvertibleToStringView instance. +class ConvertibleToStringView { + public: + ConvertibleToStringView(const char* s) // NOLINT(runtime/explicit) + : value_(s) {} + ConvertibleToStringView(char* s) : value_(s) {} // NOLINT(runtime/explicit) + ConvertibleToStringView(absl::string_view s) // NOLINT(runtime/explicit) + : value_(s) {} + ConvertibleToStringView(const std::string& s) // NOLINT(runtime/explicit) + : value_(s) {} + + // Matches rvalue strings and moves their data to a member. + ConvertibleToStringView(std::string&& s) // NOLINT(runtime/explicit) + : copy_(std::move(s)), value_(copy_) {} + + ConvertibleToStringView(const ConvertibleToStringView& other) + : copy_(other.copy_), + value_(other.IsSelfReferential() ? copy_ : other.value_) {} + + ConvertibleToStringView(ConvertibleToStringView&& other) { + StealMembers(std::move(other)); + } + + ConvertibleToStringView& operator=(ConvertibleToStringView other) { + StealMembers(std::move(other)); + return *this; + } + + absl::string_view value() const { return value_; } + + private: + // Returns true if ctsp's value refers to its internal copy_ member. + bool IsSelfReferential() const { return value_.data() == copy_.data(); } + + void StealMembers(ConvertibleToStringView&& other) { + if (other.IsSelfReferential()) { + copy_ = std::move(other.copy_); + value_ = copy_; + other.value_ = other.copy_; + } else { + value_ = other.value_; + } + } + + // Holds the data moved from temporary std::string arguments. Declared first + // so that 'value' can refer to 'copy_'. + std::string copy_; + absl::string_view value_; +}; + +// An iterator that enumerates the parts of a string from a Splitter. The text +// to be split, the Delimiter, and the Predicate are all taken from the given +// Splitter object. Iterators may only be compared if they refer to the same +// Splitter instance. +// +// This class is NOT part of the public splitting API. +template <typename Splitter> +class SplitIterator { + public: + using iterator_category = std::input_iterator_tag; + using value_type = absl::string_view; + using difference_type = ptrdiff_t; + using pointer = const value_type*; + using reference = const value_type&; + + enum State { kInitState, kLastState, kEndState }; + SplitIterator(State state, const Splitter* splitter) + : pos_(0), + state_(state), + splitter_(splitter), + delimiter_(splitter->delimiter()), + predicate_(splitter->predicate()) { + // Hack to maintain backward compatibility. This one block makes it so an + // empty absl::string_view whose .data() happens to be nullptr behaves + // *differently* from an otherwise empty absl::string_view whose .data() is + // not nullptr. This is an undesirable difference in general, but this + // behavior is maintained to avoid breaking existing code that happens to + // depend on this old behavior/bug. Perhaps it will be fixed one day. The + // difference in behavior is as follows: + // Split(absl::string_view(""), '-'); // {""} + // Split(absl::string_view(), '-'); // {} + if (splitter_->text().data() == nullptr) { + state_ = kEndState; + pos_ = splitter_->text().size(); + return; + } + + if (state_ == kEndState) { + pos_ = splitter_->text().size(); + } else { + ++(*this); + } + } + + bool at_end() const { return state_ == kEndState; } + + reference operator*() const { return curr_; } + pointer operator->() const { return &curr_; } + + SplitIterator& operator++() { + do { + if (state_ == kLastState) { + state_ = kEndState; + return *this; + } + const absl::string_view text = splitter_->text(); + const absl::string_view d = delimiter_.Find(text, pos_); + if (d.data() == text.data() + text.size()) state_ = kLastState; + curr_ = text.substr(pos_, d.data() - (text.data() + pos_)); + pos_ += curr_.size() + d.size(); + } while (!predicate_(curr_)); + return *this; + } + + SplitIterator operator++(int) { + SplitIterator old(*this); + ++(*this); + return old; + } + + friend bool operator==(const SplitIterator& a, const SplitIterator& b) { + return a.state_ == b.state_ && a.pos_ == b.pos_; + } + + friend bool operator!=(const SplitIterator& a, const SplitIterator& b) { + return !(a == b); + } + + private: + size_t pos_; + State state_; + absl::string_view curr_; + const Splitter* splitter_; + typename Splitter::DelimiterType delimiter_; + typename Splitter::PredicateType predicate_; +}; + +// HasMappedType<T>::value is true iff there exists a type T::mapped_type. +template <typename T, typename = void> +struct HasMappedType : std::false_type {}; +template <typename T> +struct HasMappedType<T, absl::void_t<typename T::mapped_type>> + : std::true_type {}; + +// HasValueType<T>::value is true iff there exists a type T::value_type. +template <typename T, typename = void> +struct HasValueType : std::false_type {}; +template <typename T> +struct HasValueType<T, absl::void_t<typename T::value_type>> : std::true_type { +}; + +// HasConstIterator<T>::value is true iff there exists a type T::const_iterator. +template <typename T, typename = void> +struct HasConstIterator : std::false_type {}; +template <typename T> +struct HasConstIterator<T, absl::void_t<typename T::const_iterator>> + : std::true_type {}; + +// IsInitializerList<T>::value is true iff T is an std::initializer_list. More +// details below in Splitter<> where this is used. +std::false_type IsInitializerListDispatch(...); // default: No +template <typename T> +std::true_type IsInitializerListDispatch(std::initializer_list<T>*); +template <typename T> +struct IsInitializerList + : decltype(IsInitializerListDispatch(static_cast<T*>(nullptr))) {}; + +// A SplitterIsConvertibleTo<C>::type alias exists iff the specified condition +// is true for type 'C'. +// +// Restricts conversion to container-like types (by testing for the presence of +// a const_iterator member type) and also to disable conversion to an +// std::initializer_list (which also has a const_iterator). Otherwise, code +// compiled in C++11 will get an error due to ambiguous conversion paths (in +// C++11 std::vector<T>::operator= is overloaded to take either a std::vector<T> +// or an std::initializer_list<T>). + +template <typename C, bool has_value_type, bool has_mapped_type> +struct SplitterIsConvertibleToImpl : std::false_type {}; + +template <typename C> +struct SplitterIsConvertibleToImpl<C, true, false> + : std::is_constructible<typename C::value_type, absl::string_view> {}; + +template <typename C> +struct SplitterIsConvertibleToImpl<C, true, true> + : absl::conjunction< + std::is_constructible<typename C::key_type, absl::string_view>, + std::is_constructible<typename C::mapped_type, absl::string_view>> {}; + +template <typename C> +struct SplitterIsConvertibleTo + : SplitterIsConvertibleToImpl< + C, +#ifdef _GLIBCXX_DEBUG + !IsStrictlyBaseOfAndConvertibleToSTLContainer<C>::value && +#endif // _GLIBCXX_DEBUG + !IsInitializerList< + typename std::remove_reference<C>::type>::value && + HasValueType<C>::value && HasConstIterator<C>::value, + HasMappedType<C>::value> { +}; + +// This class implements the range that is returned by absl::StrSplit(). This +// class has templated conversion operators that allow it to be implicitly +// converted to a variety of types that the caller may have specified on the +// left-hand side of an assignment. +// +// The main interface for interacting with this class is through its implicit +// conversion operators. However, this class may also be used like a container +// in that it has .begin() and .end() member functions. It may also be used +// within a range-for loop. +// +// Output containers can be collections of any type that is constructible from +// an absl::string_view. +// +// An Predicate functor may be supplied. This predicate will be used to filter +// the split strings: only strings for which the predicate returns true will be +// kept. A Predicate object is any unary functor that takes an absl::string_view +// and returns bool. +template <typename Delimiter, typename Predicate> +class Splitter { + public: + using DelimiterType = Delimiter; + using PredicateType = Predicate; + using const_iterator = strings_internal::SplitIterator<Splitter>; + using value_type = typename std::iterator_traits<const_iterator>::value_type; + + Splitter(ConvertibleToStringView input_text, Delimiter d, Predicate p) + : text_(std::move(input_text)), + delimiter_(std::move(d)), + predicate_(std::move(p)) {} + + absl::string_view text() const { return text_.value(); } + const Delimiter& delimiter() const { return delimiter_; } + const Predicate& predicate() const { return predicate_; } + + // Range functions that iterate the split substrings as absl::string_view + // objects. These methods enable a Splitter to be used in a range-based for + // loop. + const_iterator begin() const { return {const_iterator::kInitState, this}; } + const_iterator end() const { return {const_iterator::kEndState, this}; } + + // An implicit conversion operator that is restricted to only those containers + // that the splitter is convertible to. + template <typename Container, + typename = typename std::enable_if< + SplitterIsConvertibleTo<Container>::value>::type> + operator Container() const { // NOLINT(runtime/explicit) + return ConvertToContainer<Container, typename Container::value_type, + HasMappedType<Container>::value>()(*this); + } + + // Returns a pair with its .first and .second members set to the first two + // strings returned by the begin() iterator. Either/both of .first and .second + // will be constructed with empty strings if the iterator doesn't have a + // corresponding value. + template <typename First, typename Second> + operator std::pair<First, Second>() const { // NOLINT(runtime/explicit) + absl::string_view first, second; + auto it = begin(); + if (it != end()) { + first = *it; + if (++it != end()) { + second = *it; + } + } + return {First(first), Second(second)}; + } + + private: + // ConvertToContainer is a functor converting a Splitter to the requested + // Container of ValueType. It is specialized below to optimize splitting to + // certain combinations of Container and ValueType. + // + // This base template handles the generic case of storing the split results in + // the requested non-map-like container and converting the split substrings to + // the requested type. + template <typename Container, typename ValueType, bool is_map = false> + struct ConvertToContainer { + Container operator()(const Splitter& splitter) const { + Container c; + auto it = std::inserter(c, c.end()); + for (const auto sp : splitter) { + *it++ = ValueType(sp); + } + return c; + } + }; + + // Partial specialization for a std::vector<absl::string_view>. + // + // Optimized for the common case of splitting to a + // std::vector<absl::string_view>. In this case we first split the results to + // a small array of absl::string_view on the stack, to reduce reallocations. + template <typename A> + struct ConvertToContainer<std::vector<absl::string_view, A>, + absl::string_view, false> { + std::vector<absl::string_view, A> operator()( + const Splitter& splitter) const { + struct raw_view { + const char* data; + size_t size; + operator absl::string_view() const { // NOLINT(runtime/explicit) + return {data, size}; + } + }; + std::vector<absl::string_view, A> v; + std::array<raw_view, 16> ar; + for (auto it = splitter.begin(); !it.at_end();) { + size_t index = 0; + do { + ar[index].data = it->data(); + ar[index].size = it->size(); + ++it; + } while (++index != ar.size() && !it.at_end()); + v.insert(v.end(), ar.begin(), ar.begin() + index); + } + return v; + } + }; + + // Partial specialization for a std::vector<std::string>. + // + // Optimized for the common case of splitting to a std::vector<std::string>. + // In this case we first split the results to a std::vector<absl::string_view> + // so the returned std::vector<std::string> can have space reserved to avoid + // std::string moves. + template <typename A> + struct ConvertToContainer<std::vector<std::string, A>, std::string, false> { + std::vector<std::string, A> operator()(const Splitter& splitter) const { + const std::vector<absl::string_view> v = splitter; + return std::vector<std::string, A>(v.begin(), v.end()); + } + }; + + // Partial specialization for containers of pairs (e.g., maps). + // + // The algorithm is to insert a new pair into the map for each even-numbered + // item, with the even-numbered item as the key with a default-constructed + // value. Each odd-numbered item will then be assigned to the last pair's + // value. + template <typename Container, typename First, typename Second> + struct ConvertToContainer<Container, std::pair<const First, Second>, true> { + Container operator()(const Splitter& splitter) const { + Container m; + typename Container::iterator it; + bool insert = true; + for (const auto sp : splitter) { + if (insert) { + it = Inserter<Container>::Insert(&m, First(sp), Second()); + } else { + it->second = Second(sp); + } + insert = !insert; + } + return m; + } + + // Inserts the key and value into the given map, returning an iterator to + // the inserted item. Specialized for std::map and std::multimap to use + // emplace() and adapt emplace()'s return value. + template <typename Map> + struct Inserter { + using M = Map; + template <typename... Args> + static typename M::iterator Insert(M* m, Args&&... args) { + return m->insert(std::make_pair(std::forward<Args>(args)...)).first; + } + }; + + template <typename... Ts> + struct Inserter<std::map<Ts...>> { + using M = std::map<Ts...>; + template <typename... Args> + static typename M::iterator Insert(M* m, Args&&... args) { + return m->emplace(std::make_pair(std::forward<Args>(args)...)).first; + } + }; + + template <typename... Ts> + struct Inserter<std::multimap<Ts...>> { + using M = std::multimap<Ts...>; + template <typename... Args> + static typename M::iterator Insert(M* m, Args&&... args) { + return m->emplace(std::make_pair(std::forward<Args>(args)...)); + } + }; + }; + + ConvertibleToStringView text_; + Delimiter delimiter_; + Predicate predicate_; +}; + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_STR_SPLIT_INTERNAL_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/utf8.cc b/third_party/abseil_cpp/absl/strings/internal/utf8.cc new file mode 100644 index 0000000000..8fd8edc1ec --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/utf8.cc @@ -0,0 +1,53 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// UTF8 utilities, implemented to reduce dependencies. + +#include "absl/strings/internal/utf8.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +size_t EncodeUTF8Char(char *buffer, char32_t utf8_char) { + if (utf8_char <= 0x7F) { + *buffer = static_cast<char>(utf8_char); + return 1; + } else if (utf8_char <= 0x7FF) { + buffer[1] = 0x80 | (utf8_char & 0x3F); + utf8_char >>= 6; + buffer[0] = 0xC0 | utf8_char; + return 2; + } else if (utf8_char <= 0xFFFF) { + buffer[2] = 0x80 | (utf8_char & 0x3F); + utf8_char >>= 6; + buffer[1] = 0x80 | (utf8_char & 0x3F); + utf8_char >>= 6; + buffer[0] = 0xE0 | utf8_char; + return 3; + } else { + buffer[3] = 0x80 | (utf8_char & 0x3F); + utf8_char >>= 6; + buffer[2] = 0x80 | (utf8_char & 0x3F); + utf8_char >>= 6; + buffer[1] = 0x80 | (utf8_char & 0x3F); + utf8_char >>= 6; + buffer[0] = 0xF0 | utf8_char; + return 4; + } +} + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/internal/utf8.h b/third_party/abseil_cpp/absl/strings/internal/utf8.h new file mode 100644 index 0000000000..32fb1093be --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/utf8.h @@ -0,0 +1,50 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// UTF8 utilities, implemented to reduce dependencies. + +#ifndef ABSL_STRINGS_INTERNAL_UTF8_H_ +#define ABSL_STRINGS_INTERNAL_UTF8_H_ + +#include <cstddef> +#include <cstdint> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +// For Unicode code points 0 through 0x10FFFF, EncodeUTF8Char writes +// out the UTF-8 encoding into buffer, and returns the number of chars +// it wrote. +// +// As described in https://tools.ietf.org/html/rfc3629#section-3 , the encodings +// are: +// 00 - 7F : 0xxxxxxx +// 80 - 7FF : 110xxxxx 10xxxxxx +// 800 - FFFF : 1110xxxx 10xxxxxx 10xxxxxx +// 10000 - 10FFFF : 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx +// +// Values greater than 0x10FFFF are not supported and may or may not write +// characters into buffer, however never will more than kMaxEncodedUTF8Size +// bytes be written, regardless of the value of utf8_char. +enum { kMaxEncodedUTF8Size = 4 }; +size_t EncodeUTF8Char(char *buffer, char32_t utf8_char); + +} // namespace strings_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_INTERNAL_UTF8_H_ diff --git a/third_party/abseil_cpp/absl/strings/internal/utf8_test.cc b/third_party/abseil_cpp/absl/strings/internal/utf8_test.cc new file mode 100644 index 0000000000..88dd5036e3 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/internal/utf8_test.cc @@ -0,0 +1,66 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/internal/utf8.h" + +#include <cstdint> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/base/port.h" + +namespace { + +#if !defined(__cpp_char8_t) +#if defined(__clang__) +#pragma clang diagnostic push +#pragma clang diagnostic ignored "-Wc++2a-compat" +#endif +TEST(EncodeUTF8Char, BasicFunction) { + std::pair<char32_t, std::string> tests[] = {{0x0030, u8"\u0030"}, + {0x00A3, u8"\u00A3"}, + {0x00010000, u8"\U00010000"}, + {0x0000FFFF, u8"\U0000FFFF"}, + {0x0010FFFD, u8"\U0010FFFD"}}; + for (auto &test : tests) { + char buf0[7] = {'\x00', '\x00', '\x00', '\x00', '\x00', '\x00', '\x00'}; + char buf1[7] = {'\xFF', '\xFF', '\xFF', '\xFF', '\xFF', '\xFF', '\xFF'}; + char *buf0_written = + &buf0[absl::strings_internal::EncodeUTF8Char(buf0, test.first)]; + char *buf1_written = + &buf1[absl::strings_internal::EncodeUTF8Char(buf1, test.first)]; + int apparent_length = 7; + while (buf0[apparent_length - 1] == '\x00' && + buf1[apparent_length - 1] == '\xFF') { + if (--apparent_length == 0) break; + } + EXPECT_EQ(apparent_length, buf0_written - buf0); + EXPECT_EQ(apparent_length, buf1_written - buf1); + EXPECT_EQ(apparent_length, test.second.length()); + EXPECT_EQ(std::string(buf0, apparent_length), test.second); + EXPECT_EQ(std::string(buf1, apparent_length), test.second); + } + char buf[32] = "Don't Tread On Me"; + EXPECT_LE(absl::strings_internal::EncodeUTF8Char(buf, 0x00110000), + absl::strings_internal::kMaxEncodedUTF8Size); + char buf2[32] = "Negative is invalid but sane"; + EXPECT_LE(absl::strings_internal::EncodeUTF8Char(buf2, -1), + absl::strings_internal::kMaxEncodedUTF8Size); +} +#if defined(__clang__) +#pragma clang diagnostic pop +#endif +#endif // !defined(__cpp_char8_t) + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/match.cc b/third_party/abseil_cpp/absl/strings/match.cc new file mode 100644 index 0000000000..8127cb0c5e --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/match.cc @@ -0,0 +1,40 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/match.h" + +#include "absl/strings/internal/memutil.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +bool EqualsIgnoreCase(absl::string_view piece1, absl::string_view piece2) { + return (piece1.size() == piece2.size() && + 0 == absl::strings_internal::memcasecmp(piece1.data(), piece2.data(), + piece1.size())); + // memcasecmp uses absl::ascii_tolower(). +} + +bool StartsWithIgnoreCase(absl::string_view text, absl::string_view prefix) { + return (text.size() >= prefix.size()) && + EqualsIgnoreCase(text.substr(0, prefix.size()), prefix); +} + +bool EndsWithIgnoreCase(absl::string_view text, absl::string_view suffix) { + return (text.size() >= suffix.size()) && + EqualsIgnoreCase(text.substr(text.size() - suffix.size()), suffix); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/match.h b/third_party/abseil_cpp/absl/strings/match.h new file mode 100644 index 0000000000..90fca98ad2 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/match.h @@ -0,0 +1,90 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: match.h +// ----------------------------------------------------------------------------- +// +// This file contains simple utilities for performing string matching checks. +// All of these function parameters are specified as `absl::string_view`, +// meaning that these functions can accept `std::string`, `absl::string_view` or +// NUL-terminated C-style strings. +// +// Examples: +// std::string s = "foo"; +// absl::string_view sv = "f"; +// assert(absl::StrContains(s, sv)); +// +// Note: The order of parameters in these functions is designed to mimic the +// order an equivalent member function would exhibit; +// e.g. `s.Contains(x)` ==> `absl::StrContains(s, x). +#ifndef ABSL_STRINGS_MATCH_H_ +#define ABSL_STRINGS_MATCH_H_ + +#include <cstring> + +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// StrContains() +// +// Returns whether a given string `haystack` contains the substring `needle`. +inline bool StrContains(absl::string_view haystack, absl::string_view needle) { + return haystack.find(needle, 0) != haystack.npos; +} + +// StartsWith() +// +// Returns whether a given string `text` begins with `prefix`. +inline bool StartsWith(absl::string_view text, absl::string_view prefix) { + return prefix.empty() || + (text.size() >= prefix.size() && + memcmp(text.data(), prefix.data(), prefix.size()) == 0); +} + +// EndsWith() +// +// Returns whether a given string `text` ends with `suffix`. +inline bool EndsWith(absl::string_view text, absl::string_view suffix) { + return suffix.empty() || + (text.size() >= suffix.size() && + memcmp(text.data() + (text.size() - suffix.size()), suffix.data(), + suffix.size()) == 0); +} + +// EqualsIgnoreCase() +// +// Returns whether given ASCII strings `piece1` and `piece2` are equal, ignoring +// case in the comparison. +bool EqualsIgnoreCase(absl::string_view piece1, absl::string_view piece2); + +// StartsWithIgnoreCase() +// +// Returns whether a given ASCII string `text` starts with `prefix`, +// ignoring case in the comparison. +bool StartsWithIgnoreCase(absl::string_view text, absl::string_view prefix); + +// EndsWithIgnoreCase() +// +// Returns whether a given ASCII string `text` ends with `suffix`, ignoring +// case in the comparison. +bool EndsWithIgnoreCase(absl::string_view text, absl::string_view suffix); + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_MATCH_H_ diff --git a/third_party/abseil_cpp/absl/strings/match_test.cc b/third_party/abseil_cpp/absl/strings/match_test.cc new file mode 100644 index 0000000000..4c313dda14 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/match_test.cc @@ -0,0 +1,110 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/match.h" + +#include "gtest/gtest.h" + +namespace { + +TEST(MatchTest, StartsWith) { + const std::string s1("123\0abc", 7); + const absl::string_view a("foobar"); + const absl::string_view b(s1); + const absl::string_view e; + EXPECT_TRUE(absl::StartsWith(a, a)); + EXPECT_TRUE(absl::StartsWith(a, "foo")); + EXPECT_TRUE(absl::StartsWith(a, e)); + EXPECT_TRUE(absl::StartsWith(b, s1)); + EXPECT_TRUE(absl::StartsWith(b, b)); + EXPECT_TRUE(absl::StartsWith(b, e)); + EXPECT_TRUE(absl::StartsWith(e, "")); + EXPECT_FALSE(absl::StartsWith(a, b)); + EXPECT_FALSE(absl::StartsWith(b, a)); + EXPECT_FALSE(absl::StartsWith(e, a)); +} + +TEST(MatchTest, EndsWith) { + const std::string s1("123\0abc", 7); + const absl::string_view a("foobar"); + const absl::string_view b(s1); + const absl::string_view e; + EXPECT_TRUE(absl::EndsWith(a, a)); + EXPECT_TRUE(absl::EndsWith(a, "bar")); + EXPECT_TRUE(absl::EndsWith(a, e)); + EXPECT_TRUE(absl::EndsWith(b, s1)); + EXPECT_TRUE(absl::EndsWith(b, b)); + EXPECT_TRUE(absl::EndsWith(b, e)); + EXPECT_TRUE(absl::EndsWith(e, "")); + EXPECT_FALSE(absl::EndsWith(a, b)); + EXPECT_FALSE(absl::EndsWith(b, a)); + EXPECT_FALSE(absl::EndsWith(e, a)); +} + +TEST(MatchTest, Contains) { + absl::string_view a("abcdefg"); + absl::string_view b("abcd"); + absl::string_view c("efg"); + absl::string_view d("gh"); + EXPECT_TRUE(absl::StrContains(a, a)); + EXPECT_TRUE(absl::StrContains(a, b)); + EXPECT_TRUE(absl::StrContains(a, c)); + EXPECT_FALSE(absl::StrContains(a, d)); + EXPECT_TRUE(absl::StrContains("", "")); + EXPECT_TRUE(absl::StrContains("abc", "")); + EXPECT_FALSE(absl::StrContains("", "a")); +} + +TEST(MatchTest, ContainsNull) { + const std::string s = "foo"; + const char* cs = "foo"; + const absl::string_view sv("foo"); + const absl::string_view sv2("foo\0bar", 4); + EXPECT_EQ(s, "foo"); + EXPECT_EQ(sv, "foo"); + EXPECT_NE(sv2, "foo"); + EXPECT_TRUE(absl::EndsWith(s, sv)); + EXPECT_TRUE(absl::StartsWith(cs, sv)); + EXPECT_TRUE(absl::StrContains(cs, sv)); + EXPECT_FALSE(absl::StrContains(cs, sv2)); +} + +TEST(MatchTest, EqualsIgnoreCase) { + std::string text = "the"; + absl::string_view data(text); + + EXPECT_TRUE(absl::EqualsIgnoreCase(data, "The")); + EXPECT_TRUE(absl::EqualsIgnoreCase(data, "THE")); + EXPECT_TRUE(absl::EqualsIgnoreCase(data, "the")); + EXPECT_FALSE(absl::EqualsIgnoreCase(data, "Quick")); + EXPECT_FALSE(absl::EqualsIgnoreCase(data, "then")); +} + +TEST(MatchTest, StartsWithIgnoreCase) { + EXPECT_TRUE(absl::StartsWithIgnoreCase("foo", "foo")); + EXPECT_TRUE(absl::StartsWithIgnoreCase("foo", "Fo")); + EXPECT_TRUE(absl::StartsWithIgnoreCase("foo", "")); + EXPECT_FALSE(absl::StartsWithIgnoreCase("foo", "fooo")); + EXPECT_FALSE(absl::StartsWithIgnoreCase("", "fo")); +} + +TEST(MatchTest, EndsWithIgnoreCase) { + EXPECT_TRUE(absl::EndsWithIgnoreCase("foo", "foo")); + EXPECT_TRUE(absl::EndsWithIgnoreCase("foo", "Oo")); + EXPECT_TRUE(absl::EndsWithIgnoreCase("foo", "")); + EXPECT_FALSE(absl::EndsWithIgnoreCase("foo", "fooo")); + EXPECT_FALSE(absl::EndsWithIgnoreCase("", "fo")); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/numbers.cc b/third_party/abseil_cpp/absl/strings/numbers.cc new file mode 100644 index 0000000000..68c26dd6f8 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/numbers.cc @@ -0,0 +1,965 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file contains string processing functions related to +// numeric values. + +#include "absl/strings/numbers.h" + +#include <algorithm> +#include <cassert> +#include <cfloat> // for DBL_DIG and FLT_DIG +#include <cmath> // for HUGE_VAL +#include <cstdint> +#include <cstdio> +#include <cstdlib> +#include <cstring> +#include <iterator> +#include <limits> +#include <memory> +#include <utility> + +#include "absl/base/attributes.h" +#include "absl/base/internal/bits.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/ascii.h" +#include "absl/strings/charconv.h" +#include "absl/strings/escaping.h" +#include "absl/strings/internal/memutil.h" +#include "absl/strings/match.h" +#include "absl/strings/str_cat.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +bool SimpleAtof(absl::string_view str, float* out) { + *out = 0.0; + str = StripAsciiWhitespace(str); + if (!str.empty() && str[0] == '+') { + str.remove_prefix(1); + } + auto result = absl::from_chars(str.data(), str.data() + str.size(), *out); + if (result.ec == std::errc::invalid_argument) { + return false; + } + if (result.ptr != str.data() + str.size()) { + // not all non-whitespace characters consumed + return false; + } + // from_chars() with DR 3081's current wording will return max() on + // overflow. SimpleAtof returns infinity instead. + if (result.ec == std::errc::result_out_of_range) { + if (*out > 1.0) { + *out = std::numeric_limits<float>::infinity(); + } else if (*out < -1.0) { + *out = -std::numeric_limits<float>::infinity(); + } + } + return true; +} + +bool SimpleAtod(absl::string_view str, double* out) { + *out = 0.0; + str = StripAsciiWhitespace(str); + if (!str.empty() && str[0] == '+') { + str.remove_prefix(1); + } + auto result = absl::from_chars(str.data(), str.data() + str.size(), *out); + if (result.ec == std::errc::invalid_argument) { + return false; + } + if (result.ptr != str.data() + str.size()) { + // not all non-whitespace characters consumed + return false; + } + // from_chars() with DR 3081's current wording will return max() on + // overflow. SimpleAtod returns infinity instead. + if (result.ec == std::errc::result_out_of_range) { + if (*out > 1.0) { + *out = std::numeric_limits<double>::infinity(); + } else if (*out < -1.0) { + *out = -std::numeric_limits<double>::infinity(); + } + } + return true; +} + +bool SimpleAtob(absl::string_view str, bool* out) { + ABSL_RAW_CHECK(out != nullptr, "Output pointer must not be nullptr."); + if (EqualsIgnoreCase(str, "true") || EqualsIgnoreCase(str, "t") || + EqualsIgnoreCase(str, "yes") || EqualsIgnoreCase(str, "y") || + EqualsIgnoreCase(str, "1")) { + *out = true; + return true; + } + if (EqualsIgnoreCase(str, "false") || EqualsIgnoreCase(str, "f") || + EqualsIgnoreCase(str, "no") || EqualsIgnoreCase(str, "n") || + EqualsIgnoreCase(str, "0")) { + *out = false; + return true; + } + return false; +} + +// ---------------------------------------------------------------------- +// FastIntToBuffer() overloads +// +// Like the Fast*ToBuffer() functions above, these are intended for speed. +// Unlike the Fast*ToBuffer() functions, however, these functions write +// their output to the beginning of the buffer. The caller is responsible +// for ensuring that the buffer has enough space to hold the output. +// +// Returns a pointer to the end of the string (i.e. the null character +// terminating the string). +// ---------------------------------------------------------------------- + +namespace { + +// Used to optimize printing a decimal number's final digit. +const char one_ASCII_final_digits[10][2] { + {'0', 0}, {'1', 0}, {'2', 0}, {'3', 0}, {'4', 0}, + {'5', 0}, {'6', 0}, {'7', 0}, {'8', 0}, {'9', 0}, +}; + +} // namespace + +char* numbers_internal::FastIntToBuffer(uint32_t i, char* buffer) { + uint32_t digits; + // The idea of this implementation is to trim the number of divides to as few + // as possible, and also reducing memory stores and branches, by going in + // steps of two digits at a time rather than one whenever possible. + // The huge-number case is first, in the hopes that the compiler will output + // that case in one branch-free block of code, and only output conditional + // branches into it from below. + if (i >= 1000000000) { // >= 1,000,000,000 + digits = i / 100000000; // 100,000,000 + i -= digits * 100000000; + PutTwoDigits(digits, buffer); + buffer += 2; + lt100_000_000: + digits = i / 1000000; // 1,000,000 + i -= digits * 1000000; + PutTwoDigits(digits, buffer); + buffer += 2; + lt1_000_000: + digits = i / 10000; // 10,000 + i -= digits * 10000; + PutTwoDigits(digits, buffer); + buffer += 2; + lt10_000: + digits = i / 100; + i -= digits * 100; + PutTwoDigits(digits, buffer); + buffer += 2; + lt100: + digits = i; + PutTwoDigits(digits, buffer); + buffer += 2; + *buffer = 0; + return buffer; + } + + if (i < 100) { + digits = i; + if (i >= 10) goto lt100; + memcpy(buffer, one_ASCII_final_digits[i], 2); + return buffer + 1; + } + if (i < 10000) { // 10,000 + if (i >= 1000) goto lt10_000; + digits = i / 100; + i -= digits * 100; + *buffer++ = '0' + digits; + goto lt100; + } + if (i < 1000000) { // 1,000,000 + if (i >= 100000) goto lt1_000_000; + digits = i / 10000; // 10,000 + i -= digits * 10000; + *buffer++ = '0' + digits; + goto lt10_000; + } + if (i < 100000000) { // 100,000,000 + if (i >= 10000000) goto lt100_000_000; + digits = i / 1000000; // 1,000,000 + i -= digits * 1000000; + *buffer++ = '0' + digits; + goto lt1_000_000; + } + // we already know that i < 1,000,000,000 + digits = i / 100000000; // 100,000,000 + i -= digits * 100000000; + *buffer++ = '0' + digits; + goto lt100_000_000; +} + +char* numbers_internal::FastIntToBuffer(int32_t i, char* buffer) { + uint32_t u = i; + if (i < 0) { + *buffer++ = '-'; + // We need to do the negation in modular (i.e., "unsigned") + // arithmetic; MSVC++ apprently warns for plain "-u", so + // we write the equivalent expression "0 - u" instead. + u = 0 - u; + } + return numbers_internal::FastIntToBuffer(u, buffer); +} + +char* numbers_internal::FastIntToBuffer(uint64_t i, char* buffer) { + uint32_t u32 = static_cast<uint32_t>(i); + if (u32 == i) return numbers_internal::FastIntToBuffer(u32, buffer); + + // Here we know i has at least 10 decimal digits. + uint64_t top_1to11 = i / 1000000000; + u32 = static_cast<uint32_t>(i - top_1to11 * 1000000000); + uint32_t top_1to11_32 = static_cast<uint32_t>(top_1to11); + + if (top_1to11_32 == top_1to11) { + buffer = numbers_internal::FastIntToBuffer(top_1to11_32, buffer); + } else { + // top_1to11 has more than 32 bits too; print it in two steps. + uint32_t top_8to9 = static_cast<uint32_t>(top_1to11 / 100); + uint32_t mid_2 = static_cast<uint32_t>(top_1to11 - top_8to9 * 100); + buffer = numbers_internal::FastIntToBuffer(top_8to9, buffer); + PutTwoDigits(mid_2, buffer); + buffer += 2; + } + + // We have only 9 digits now, again the maximum uint32_t can handle fully. + uint32_t digits = u32 / 10000000; // 10,000,000 + u32 -= digits * 10000000; + PutTwoDigits(digits, buffer); + buffer += 2; + digits = u32 / 100000; // 100,000 + u32 -= digits * 100000; + PutTwoDigits(digits, buffer); + buffer += 2; + digits = u32 / 1000; // 1,000 + u32 -= digits * 1000; + PutTwoDigits(digits, buffer); + buffer += 2; + digits = u32 / 10; + u32 -= digits * 10; + PutTwoDigits(digits, buffer); + buffer += 2; + memcpy(buffer, one_ASCII_final_digits[u32], 2); + return buffer + 1; +} + +char* numbers_internal::FastIntToBuffer(int64_t i, char* buffer) { + uint64_t u = i; + if (i < 0) { + *buffer++ = '-'; + u = 0 - u; + } + return numbers_internal::FastIntToBuffer(u, buffer); +} + +// Given a 128-bit number expressed as a pair of uint64_t, high half first, +// return that number multiplied by the given 32-bit value. If the result is +// too large to fit in a 128-bit number, divide it by 2 until it fits. +static std::pair<uint64_t, uint64_t> Mul32(std::pair<uint64_t, uint64_t> num, + uint32_t mul) { + uint64_t bits0_31 = num.second & 0xFFFFFFFF; + uint64_t bits32_63 = num.second >> 32; + uint64_t bits64_95 = num.first & 0xFFFFFFFF; + uint64_t bits96_127 = num.first >> 32; + + // The picture so far: each of these 64-bit values has only the lower 32 bits + // filled in. + // bits96_127: [ 00000000 xxxxxxxx ] + // bits64_95: [ 00000000 xxxxxxxx ] + // bits32_63: [ 00000000 xxxxxxxx ] + // bits0_31: [ 00000000 xxxxxxxx ] + + bits0_31 *= mul; + bits32_63 *= mul; + bits64_95 *= mul; + bits96_127 *= mul; + + // Now the top halves may also have value, though all 64 of their bits will + // never be set at the same time, since they are a result of a 32x32 bit + // multiply. This makes the carry calculation slightly easier. + // bits96_127: [ mmmmmmmm | mmmmmmmm ] + // bits64_95: [ | mmmmmmmm mmmmmmmm | ] + // bits32_63: | [ mmmmmmmm | mmmmmmmm ] + // bits0_31: | [ | mmmmmmmm mmmmmmmm ] + // eventually: [ bits128_up | ...bits64_127.... | ..bits0_63... ] + + uint64_t bits0_63 = bits0_31 + (bits32_63 << 32); + uint64_t bits64_127 = bits64_95 + (bits96_127 << 32) + (bits32_63 >> 32) + + (bits0_63 < bits0_31); + uint64_t bits128_up = (bits96_127 >> 32) + (bits64_127 < bits64_95); + if (bits128_up == 0) return {bits64_127, bits0_63}; + + int shift = 64 - base_internal::CountLeadingZeros64(bits128_up); + uint64_t lo = (bits0_63 >> shift) + (bits64_127 << (64 - shift)); + uint64_t hi = (bits64_127 >> shift) + (bits128_up << (64 - shift)); + return {hi, lo}; +} + +// Compute num * 5 ^ expfive, and return the first 128 bits of the result, +// where the first bit is always a one. So PowFive(1, 0) starts 0b100000, +// PowFive(1, 1) starts 0b101000, PowFive(1, 2) starts 0b110010, etc. +static std::pair<uint64_t, uint64_t> PowFive(uint64_t num, int expfive) { + std::pair<uint64_t, uint64_t> result = {num, 0}; + while (expfive >= 13) { + // 5^13 is the highest power of five that will fit in a 32-bit integer. + result = Mul32(result, 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5); + expfive -= 13; + } + constexpr int powers_of_five[13] = { + 1, + 5, + 5 * 5, + 5 * 5 * 5, + 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5, + 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5 * 5}; + result = Mul32(result, powers_of_five[expfive & 15]); + int shift = base_internal::CountLeadingZeros64(result.first); + if (shift != 0) { + result.first = (result.first << shift) + (result.second >> (64 - shift)); + result.second = (result.second << shift); + } + return result; +} + +struct ExpDigits { + int32_t exponent; + char digits[6]; +}; + +// SplitToSix converts value, a positive double-precision floating-point number, +// into a base-10 exponent and 6 ASCII digits, where the first digit is never +// zero. For example, SplitToSix(1) returns an exponent of zero and a digits +// array of {'1', '0', '0', '0', '0', '0'}. If value is exactly halfway between +// two possible representations, e.g. value = 100000.5, then "round to even" is +// performed. +static ExpDigits SplitToSix(const double value) { + ExpDigits exp_dig; + int exp = 5; + double d = value; + // First step: calculate a close approximation of the output, where the + // value d will be between 100,000 and 999,999, representing the digits + // in the output ASCII array, and exp is the base-10 exponent. It would be + // faster to use a table here, and to look up the base-2 exponent of value, + // however value is an IEEE-754 64-bit number, so the table would have 2,000 + // entries, which is not cache-friendly. + if (d >= 999999.5) { + if (d >= 1e+261) exp += 256, d *= 1e-256; + if (d >= 1e+133) exp += 128, d *= 1e-128; + if (d >= 1e+69) exp += 64, d *= 1e-64; + if (d >= 1e+37) exp += 32, d *= 1e-32; + if (d >= 1e+21) exp += 16, d *= 1e-16; + if (d >= 1e+13) exp += 8, d *= 1e-8; + if (d >= 1e+9) exp += 4, d *= 1e-4; + if (d >= 1e+7) exp += 2, d *= 1e-2; + if (d >= 1e+6) exp += 1, d *= 1e-1; + } else { + if (d < 1e-250) exp -= 256, d *= 1e256; + if (d < 1e-122) exp -= 128, d *= 1e128; + if (d < 1e-58) exp -= 64, d *= 1e64; + if (d < 1e-26) exp -= 32, d *= 1e32; + if (d < 1e-10) exp -= 16, d *= 1e16; + if (d < 1e-2) exp -= 8, d *= 1e8; + if (d < 1e+2) exp -= 4, d *= 1e4; + if (d < 1e+4) exp -= 2, d *= 1e2; + if (d < 1e+5) exp -= 1, d *= 1e1; + } + // At this point, d is in the range [99999.5..999999.5) and exp is in the + // range [-324..308]. Since we need to round d up, we want to add a half + // and truncate. + // However, the technique above may have lost some precision, due to its + // repeated multiplication by constants that each may be off by half a bit + // of precision. This only matters if we're close to the edge though. + // Since we'd like to know if the fractional part of d is close to a half, + // we multiply it by 65536 and see if the fractional part is close to 32768. + // (The number doesn't have to be a power of two,but powers of two are faster) + uint64_t d64k = d * 65536; + int dddddd; // A 6-digit decimal integer. + if ((d64k % 65536) == 32767 || (d64k % 65536) == 32768) { + // OK, it's fairly likely that precision was lost above, which is + // not a surprise given only 52 mantissa bits are available. Therefore + // redo the calculation using 128-bit numbers. (64 bits are not enough). + + // Start out with digits rounded down; maybe add one below. + dddddd = static_cast<int>(d64k / 65536); + + // mantissa is a 64-bit integer representing M.mmm... * 2^63. The actual + // value we're representing, of course, is M.mmm... * 2^exp2. + int exp2; + double m = std::frexp(value, &exp2); + uint64_t mantissa = m * (32768.0 * 65536.0 * 65536.0 * 65536.0); + // std::frexp returns an m value in the range [0.5, 1.0), however we + // can't multiply it by 2^64 and convert to an integer because some FPUs + // throw an exception when converting an number higher than 2^63 into an + // integer - even an unsigned 64-bit integer! Fortunately it doesn't matter + // since m only has 52 significant bits anyway. + mantissa <<= 1; + exp2 -= 64; // not needed, but nice for debugging + + // OK, we are here to compare: + // (dddddd + 0.5) * 10^(exp-5) vs. mantissa * 2^exp2 + // so we can round up dddddd if appropriate. Those values span the full + // range of 600 orders of magnitude of IEE 64-bit floating-point. + // Fortunately, we already know they are very close, so we don't need to + // track the base-2 exponent of both sides. This greatly simplifies the + // the math since the 2^exp2 calculation is unnecessary and the power-of-10 + // calculation can become a power-of-5 instead. + + std::pair<uint64_t, uint64_t> edge, val; + if (exp >= 6) { + // Compare (dddddd + 0.5) * 5 ^ (exp - 5) to mantissa + // Since we're tossing powers of two, 2 * dddddd + 1 is the + // same as dddddd + 0.5 + edge = PowFive(2 * dddddd + 1, exp - 5); + + val.first = mantissa; + val.second = 0; + } else { + // We can't compare (dddddd + 0.5) * 5 ^ (exp - 5) to mantissa as we did + // above because (exp - 5) is negative. So we compare (dddddd + 0.5) to + // mantissa * 5 ^ (5 - exp) + edge = PowFive(2 * dddddd + 1, 0); + + val = PowFive(mantissa, 5 - exp); + } + // printf("exp=%d %016lx %016lx vs %016lx %016lx\n", exp, val.first, + // val.second, edge.first, edge.second); + if (val > edge) { + dddddd++; + } else if (val == edge) { + dddddd += (dddddd & 1); + } + } else { + // Here, we are not close to the edge. + dddddd = static_cast<int>((d64k + 32768) / 65536); + } + if (dddddd == 1000000) { + dddddd = 100000; + exp += 1; + } + exp_dig.exponent = exp; + + int two_digits = dddddd / 10000; + dddddd -= two_digits * 10000; + numbers_internal::PutTwoDigits(two_digits, &exp_dig.digits[0]); + + two_digits = dddddd / 100; + dddddd -= two_digits * 100; + numbers_internal::PutTwoDigits(two_digits, &exp_dig.digits[2]); + + numbers_internal::PutTwoDigits(dddddd, &exp_dig.digits[4]); + return exp_dig; +} + +// Helper function for fast formatting of floating-point. +// The result is the same as "%g", a.k.a. "%.6g". +size_t numbers_internal::SixDigitsToBuffer(double d, char* const buffer) { + static_assert(std::numeric_limits<float>::is_iec559, + "IEEE-754/IEC-559 support only"); + + char* out = buffer; // we write data to out, incrementing as we go, but + // FloatToBuffer always returns the address of the buffer + // passed in. + + if (std::isnan(d)) { + strcpy(out, "nan"); // NOLINT(runtime/printf) + return 3; + } + if (d == 0) { // +0 and -0 are handled here + if (std::signbit(d)) *out++ = '-'; + *out++ = '0'; + *out = 0; + return out - buffer; + } + if (d < 0) { + *out++ = '-'; + d = -d; + } + if (std::isinf(d)) { + strcpy(out, "inf"); // NOLINT(runtime/printf) + return out + 3 - buffer; + } + + auto exp_dig = SplitToSix(d); + int exp = exp_dig.exponent; + const char* digits = exp_dig.digits; + out[0] = '0'; + out[1] = '.'; + switch (exp) { + case 5: + memcpy(out, &digits[0], 6), out += 6; + *out = 0; + return out - buffer; + case 4: + memcpy(out, &digits[0], 5), out += 5; + if (digits[5] != '0') { + *out++ = '.'; + *out++ = digits[5]; + } + *out = 0; + return out - buffer; + case 3: + memcpy(out, &digits[0], 4), out += 4; + if ((digits[5] | digits[4]) != '0') { + *out++ = '.'; + *out++ = digits[4]; + if (digits[5] != '0') *out++ = digits[5]; + } + *out = 0; + return out - buffer; + case 2: + memcpy(out, &digits[0], 3), out += 3; + *out++ = '.'; + memcpy(out, &digits[3], 3); + out += 3; + while (out[-1] == '0') --out; + if (out[-1] == '.') --out; + *out = 0; + return out - buffer; + case 1: + memcpy(out, &digits[0], 2), out += 2; + *out++ = '.'; + memcpy(out, &digits[2], 4); + out += 4; + while (out[-1] == '0') --out; + if (out[-1] == '.') --out; + *out = 0; + return out - buffer; + case 0: + memcpy(out, &digits[0], 1), out += 1; + *out++ = '.'; + memcpy(out, &digits[1], 5); + out += 5; + while (out[-1] == '0') --out; + if (out[-1] == '.') --out; + *out = 0; + return out - buffer; + case -4: + out[2] = '0'; + ++out; + ABSL_FALLTHROUGH_INTENDED; + case -3: + out[2] = '0'; + ++out; + ABSL_FALLTHROUGH_INTENDED; + case -2: + out[2] = '0'; + ++out; + ABSL_FALLTHROUGH_INTENDED; + case -1: + out += 2; + memcpy(out, &digits[0], 6); + out += 6; + while (out[-1] == '0') --out; + *out = 0; + return out - buffer; + } + assert(exp < -4 || exp >= 6); + out[0] = digits[0]; + assert(out[1] == '.'); + out += 2; + memcpy(out, &digits[1], 5), out += 5; + while (out[-1] == '0') --out; + if (out[-1] == '.') --out; + *out++ = 'e'; + if (exp > 0) { + *out++ = '+'; + } else { + *out++ = '-'; + exp = -exp; + } + if (exp > 99) { + int dig1 = exp / 100; + exp -= dig1 * 100; + *out++ = '0' + dig1; + } + PutTwoDigits(exp, out); + out += 2; + *out = 0; + return out - buffer; +} + +namespace { +// Represents integer values of digits. +// Uses 36 to indicate an invalid character since we support +// bases up to 36. +static const int8_t kAsciiToInt[256] = { + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, // 16 36s. + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 0, 1, 2, 3, 4, 5, + 6, 7, 8, 9, 36, 36, 36, 36, 36, 36, 36, 10, 11, 12, 13, 14, 15, 16, 17, + 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, + 36, 36, 36, 36, 36, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, + 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, + 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36, 36}; + +// Parse the sign and optional hex or oct prefix in text. +inline bool safe_parse_sign_and_base(absl::string_view* text /*inout*/, + int* base_ptr /*inout*/, + bool* negative_ptr /*output*/) { + if (text->data() == nullptr) { + return false; + } + + const char* start = text->data(); + const char* end = start + text->size(); + int base = *base_ptr; + + // Consume whitespace. + while (start < end && absl::ascii_isspace(start[0])) { + ++start; + } + while (start < end && absl::ascii_isspace(end[-1])) { + --end; + } + if (start >= end) { + return false; + } + + // Consume sign. + *negative_ptr = (start[0] == '-'); + if (*negative_ptr || start[0] == '+') { + ++start; + if (start >= end) { + return false; + } + } + + // Consume base-dependent prefix. + // base 0: "0x" -> base 16, "0" -> base 8, default -> base 10 + // base 16: "0x" -> base 16 + // Also validate the base. + if (base == 0) { + if (end - start >= 2 && start[0] == '0' && + (start[1] == 'x' || start[1] == 'X')) { + base = 16; + start += 2; + if (start >= end) { + // "0x" with no digits after is invalid. + return false; + } + } else if (end - start >= 1 && start[0] == '0') { + base = 8; + start += 1; + } else { + base = 10; + } + } else if (base == 16) { + if (end - start >= 2 && start[0] == '0' && + (start[1] == 'x' || start[1] == 'X')) { + start += 2; + if (start >= end) { + // "0x" with no digits after is invalid. + return false; + } + } + } else if (base >= 2 && base <= 36) { + // okay + } else { + return false; + } + *text = absl::string_view(start, end - start); + *base_ptr = base; + return true; +} + +// Consume digits. +// +// The classic loop: +// +// for each digit +// value = value * base + digit +// value *= sign +// +// The classic loop needs overflow checking. It also fails on the most +// negative integer, -2147483648 in 32-bit two's complement representation. +// +// My improved loop: +// +// if (!negative) +// for each digit +// value = value * base +// value = value + digit +// else +// for each digit +// value = value * base +// value = value - digit +// +// Overflow checking becomes simple. + +// Lookup tables per IntType: +// vmax/base and vmin/base are precomputed because division costs at least 8ns. +// TODO(junyer): Doing this per base instead (i.e. an array of structs, not a +// struct of arrays) would probably be better in terms of d-cache for the most +// commonly used bases. +template <typename IntType> +struct LookupTables { + ABSL_CONST_INIT static const IntType kVmaxOverBase[]; + ABSL_CONST_INIT static const IntType kVminOverBase[]; +}; + +// An array initializer macro for X/base where base in [0, 36]. +// However, note that lookups for base in [0, 1] should never happen because +// base has been validated to be in [2, 36] by safe_parse_sign_and_base(). +#define X_OVER_BASE_INITIALIZER(X) \ + { \ + 0, 0, X / 2, X / 3, X / 4, X / 5, X / 6, X / 7, X / 8, X / 9, X / 10, \ + X / 11, X / 12, X / 13, X / 14, X / 15, X / 16, X / 17, X / 18, \ + X / 19, X / 20, X / 21, X / 22, X / 23, X / 24, X / 25, X / 26, \ + X / 27, X / 28, X / 29, X / 30, X / 31, X / 32, X / 33, X / 34, \ + X / 35, X / 36, \ + } + +// uint128& operator/=(uint128) is not constexpr, so hardcode the resulting +// array to avoid a static initializer. +template <> +const uint128 LookupTables<uint128>::kVmaxOverBase[] = { + 0, + 0, + MakeUint128(9223372036854775807u, 18446744073709551615u), + MakeUint128(6148914691236517205u, 6148914691236517205u), + MakeUint128(4611686018427387903u, 18446744073709551615u), + MakeUint128(3689348814741910323u, 3689348814741910323u), + MakeUint128(3074457345618258602u, 12297829382473034410u), + MakeUint128(2635249153387078802u, 5270498306774157604u), + MakeUint128(2305843009213693951u, 18446744073709551615u), + MakeUint128(2049638230412172401u, 14347467612885206812u), + MakeUint128(1844674407370955161u, 11068046444225730969u), + MakeUint128(1676976733973595601u, 8384883669867978007u), + MakeUint128(1537228672809129301u, 6148914691236517205u), + MakeUint128(1418980313362273201u, 4256940940086819603u), + MakeUint128(1317624576693539401u, 2635249153387078802u), + MakeUint128(1229782938247303441u, 1229782938247303441u), + MakeUint128(1152921504606846975u, 18446744073709551615u), + MakeUint128(1085102592571150095u, 1085102592571150095u), + MakeUint128(1024819115206086200u, 16397105843297379214u), + MakeUint128(970881267037344821u, 16504981539634861972u), + MakeUint128(922337203685477580u, 14757395258967641292u), + MakeUint128(878416384462359600u, 14054662151397753612u), + MakeUint128(838488366986797800u, 13415813871788764811u), + MakeUint128(802032351030850070u, 4812194106185100421u), + MakeUint128(768614336404564650u, 12297829382473034410u), + MakeUint128(737869762948382064u, 11805916207174113034u), + MakeUint128(709490156681136600u, 11351842506898185609u), + MakeUint128(683212743470724133u, 17080318586768103348u), + MakeUint128(658812288346769700u, 10540996613548315209u), + MakeUint128(636094623231363848u, 15266270957552732371u), + MakeUint128(614891469123651720u, 9838263505978427528u), + MakeUint128(595056260442243600u, 9520900167075897608u), + MakeUint128(576460752303423487u, 18446744073709551615u), + MakeUint128(558992244657865200u, 8943875914525843207u), + MakeUint128(542551296285575047u, 9765923333140350855u), + MakeUint128(527049830677415760u, 8432797290838652167u), + MakeUint128(512409557603043100u, 8198552921648689607u), +}; + +template <typename IntType> +const IntType LookupTables<IntType>::kVmaxOverBase[] = + X_OVER_BASE_INITIALIZER(std::numeric_limits<IntType>::max()); + +template <typename IntType> +const IntType LookupTables<IntType>::kVminOverBase[] = + X_OVER_BASE_INITIALIZER(std::numeric_limits<IntType>::min()); + +#undef X_OVER_BASE_INITIALIZER + +template <typename IntType> +inline bool safe_parse_positive_int(absl::string_view text, int base, + IntType* value_p) { + IntType value = 0; + const IntType vmax = std::numeric_limits<IntType>::max(); + assert(vmax > 0); + assert(base >= 0); + assert(vmax >= static_cast<IntType>(base)); + const IntType vmax_over_base = LookupTables<IntType>::kVmaxOverBase[base]; + assert(base < 2 || + std::numeric_limits<IntType>::max() / base == vmax_over_base); + const char* start = text.data(); + const char* end = start + text.size(); + // loop over digits + for (; start < end; ++start) { + unsigned char c = static_cast<unsigned char>(start[0]); + int digit = kAsciiToInt[c]; + if (digit >= base) { + *value_p = value; + return false; + } + if (value > vmax_over_base) { + *value_p = vmax; + return false; + } + value *= base; + if (value > vmax - digit) { + *value_p = vmax; + return false; + } + value += digit; + } + *value_p = value; + return true; +} + +template <typename IntType> +inline bool safe_parse_negative_int(absl::string_view text, int base, + IntType* value_p) { + IntType value = 0; + const IntType vmin = std::numeric_limits<IntType>::min(); + assert(vmin < 0); + assert(vmin <= 0 - base); + IntType vmin_over_base = LookupTables<IntType>::kVminOverBase[base]; + assert(base < 2 || + std::numeric_limits<IntType>::min() / base == vmin_over_base); + // 2003 c++ standard [expr.mul] + // "... the sign of the remainder is implementation-defined." + // Although (vmin/base)*base + vmin%base is always vmin. + // 2011 c++ standard tightens the spec but we cannot rely on it. + // TODO(junyer): Handle this in the lookup table generation. + if (vmin % base > 0) { + vmin_over_base += 1; + } + const char* start = text.data(); + const char* end = start + text.size(); + // loop over digits + for (; start < end; ++start) { + unsigned char c = static_cast<unsigned char>(start[0]); + int digit = kAsciiToInt[c]; + if (digit >= base) { + *value_p = value; + return false; + } + if (value < vmin_over_base) { + *value_p = vmin; + return false; + } + value *= base; + if (value < vmin + digit) { + *value_p = vmin; + return false; + } + value -= digit; + } + *value_p = value; + return true; +} + +// Input format based on POSIX.1-2008 strtol +// http://pubs.opengroup.org/onlinepubs/9699919799/functions/strtol.html +template <typename IntType> +inline bool safe_int_internal(absl::string_view text, IntType* value_p, + int base) { + *value_p = 0; + bool negative; + if (!safe_parse_sign_and_base(&text, &base, &negative)) { + return false; + } + if (!negative) { + return safe_parse_positive_int(text, base, value_p); + } else { + return safe_parse_negative_int(text, base, value_p); + } +} + +template <typename IntType> +inline bool safe_uint_internal(absl::string_view text, IntType* value_p, + int base) { + *value_p = 0; + bool negative; + if (!safe_parse_sign_and_base(&text, &base, &negative) || negative) { + return false; + } + return safe_parse_positive_int(text, base, value_p); +} +} // anonymous namespace + +namespace numbers_internal { + +// Digit conversion. +ABSL_CONST_INIT ABSL_DLL const char kHexChar[] = + "0123456789abcdef"; + +ABSL_CONST_INIT ABSL_DLL const char kHexTable[513] = + "000102030405060708090a0b0c0d0e0f" + "101112131415161718191a1b1c1d1e1f" + "202122232425262728292a2b2c2d2e2f" + "303132333435363738393a3b3c3d3e3f" + "404142434445464748494a4b4c4d4e4f" + "505152535455565758595a5b5c5d5e5f" + "606162636465666768696a6b6c6d6e6f" + "707172737475767778797a7b7c7d7e7f" + "808182838485868788898a8b8c8d8e8f" + "909192939495969798999a9b9c9d9e9f" + "a0a1a2a3a4a5a6a7a8a9aaabacadaeaf" + "b0b1b2b3b4b5b6b7b8b9babbbcbdbebf" + "c0c1c2c3c4c5c6c7c8c9cacbcccdcecf" + "d0d1d2d3d4d5d6d7d8d9dadbdcdddedf" + "e0e1e2e3e4e5e6e7e8e9eaebecedeeef" + "f0f1f2f3f4f5f6f7f8f9fafbfcfdfeff"; + +ABSL_CONST_INIT ABSL_DLL const char two_ASCII_digits[100][2] = { + {'0', '0'}, {'0', '1'}, {'0', '2'}, {'0', '3'}, {'0', '4'}, {'0', '5'}, + {'0', '6'}, {'0', '7'}, {'0', '8'}, {'0', '9'}, {'1', '0'}, {'1', '1'}, + {'1', '2'}, {'1', '3'}, {'1', '4'}, {'1', '5'}, {'1', '6'}, {'1', '7'}, + {'1', '8'}, {'1', '9'}, {'2', '0'}, {'2', '1'}, {'2', '2'}, {'2', '3'}, + {'2', '4'}, {'2', '5'}, {'2', '6'}, {'2', '7'}, {'2', '8'}, {'2', '9'}, + {'3', '0'}, {'3', '1'}, {'3', '2'}, {'3', '3'}, {'3', '4'}, {'3', '5'}, + {'3', '6'}, {'3', '7'}, {'3', '8'}, {'3', '9'}, {'4', '0'}, {'4', '1'}, + {'4', '2'}, {'4', '3'}, {'4', '4'}, {'4', '5'}, {'4', '6'}, {'4', '7'}, + {'4', '8'}, {'4', '9'}, {'5', '0'}, {'5', '1'}, {'5', '2'}, {'5', '3'}, + {'5', '4'}, {'5', '5'}, {'5', '6'}, {'5', '7'}, {'5', '8'}, {'5', '9'}, + {'6', '0'}, {'6', '1'}, {'6', '2'}, {'6', '3'}, {'6', '4'}, {'6', '5'}, + {'6', '6'}, {'6', '7'}, {'6', '8'}, {'6', '9'}, {'7', '0'}, {'7', '1'}, + {'7', '2'}, {'7', '3'}, {'7', '4'}, {'7', '5'}, {'7', '6'}, {'7', '7'}, + {'7', '8'}, {'7', '9'}, {'8', '0'}, {'8', '1'}, {'8', '2'}, {'8', '3'}, + {'8', '4'}, {'8', '5'}, {'8', '6'}, {'8', '7'}, {'8', '8'}, {'8', '9'}, + {'9', '0'}, {'9', '1'}, {'9', '2'}, {'9', '3'}, {'9', '4'}, {'9', '5'}, + {'9', '6'}, {'9', '7'}, {'9', '8'}, {'9', '9'}}; + +bool safe_strto32_base(absl::string_view text, int32_t* value, int base) { + return safe_int_internal<int32_t>(text, value, base); +} + +bool safe_strto64_base(absl::string_view text, int64_t* value, int base) { + return safe_int_internal<int64_t>(text, value, base); +} + +bool safe_strtou32_base(absl::string_view text, uint32_t* value, int base) { + return safe_uint_internal<uint32_t>(text, value, base); +} + +bool safe_strtou64_base(absl::string_view text, uint64_t* value, int base) { + return safe_uint_internal<uint64_t>(text, value, base); +} + +bool safe_strtou128_base(absl::string_view text, uint128* value, int base) { + return safe_uint_internal<absl::uint128>(text, value, base); +} + +} // namespace numbers_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/numbers.h b/third_party/abseil_cpp/absl/strings/numbers.h new file mode 100644 index 0000000000..d872cca5dc --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/numbers.h @@ -0,0 +1,266 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: numbers.h +// ----------------------------------------------------------------------------- +// +// This package contains functions for converting strings to numbers. For +// converting numbers to strings, use `StrCat()` or `StrAppend()` in str_cat.h, +// which automatically detect and convert most number values appropriately. + +#ifndef ABSL_STRINGS_NUMBERS_H_ +#define ABSL_STRINGS_NUMBERS_H_ + +#ifdef __SSE4_2__ +#include <x86intrin.h> +#endif + +#include <cstddef> +#include <cstdlib> +#include <cstring> +#include <ctime> +#include <limits> +#include <string> +#include <type_traits> + +#include "absl/base/config.h" +#include "absl/base/internal/bits.h" +#ifdef __SSE4_2__ +// TODO(jorg): Remove this when we figure out the right way +// to swap bytes on SSE 4.2 that works with the compilers +// we claim to support. Also, add tests for the compiler +// that doesn't support the Intel _bswap64 intrinsic but +// does support all the SSE 4.2 intrinsics +#include "absl/base/internal/endian.h" +#endif +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/numeric/int128.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// SimpleAtoi() +// +// Converts the given string (optionally followed or preceded by ASCII +// whitespace) into an integer value, returning `true` if successful. The string +// must reflect a base-10 integer whose value falls within the range of the +// integer type (optionally preceded by a `+` or `-`). If any errors are +// encountered, this function returns `false`, leaving `out` in an unspecified +// state. +template <typename int_type> +ABSL_MUST_USE_RESULT bool SimpleAtoi(absl::string_view str, int_type* out); + +// SimpleAtof() +// +// Converts the given string (optionally followed or preceded by ASCII +// whitespace) into a float, which may be rounded on overflow or underflow, +// returning `true` if successful. +// See https://en.cppreference.com/w/c/string/byte/strtof for details about the +// allowed formats for `str`, except SimpleAtof() is locale-independent and will +// always use the "C" locale. If any errors are encountered, this function +// returns `false`, leaving `out` in an unspecified state. +ABSL_MUST_USE_RESULT bool SimpleAtof(absl::string_view str, float* out); + +// SimpleAtod() +// +// Converts the given string (optionally followed or preceded by ASCII +// whitespace) into a double, which may be rounded on overflow or underflow, +// returning `true` if successful. +// See https://en.cppreference.com/w/c/string/byte/strtof for details about the +// allowed formats for `str`, except SimpleAtod is locale-independent and will +// always use the "C" locale. If any errors are encountered, this function +// returns `false`, leaving `out` in an unspecified state. +ABSL_MUST_USE_RESULT bool SimpleAtod(absl::string_view str, double* out); + +// SimpleAtob() +// +// Converts the given string into a boolean, returning `true` if successful. +// The following case-insensitive strings are interpreted as boolean `true`: +// "true", "t", "yes", "y", "1". The following case-insensitive strings +// are interpreted as boolean `false`: "false", "f", "no", "n", "0". If any +// errors are encountered, this function returns `false`, leaving `out` in an +// unspecified state. +ABSL_MUST_USE_RESULT bool SimpleAtob(absl::string_view str, bool* out); + +ABSL_NAMESPACE_END +} // namespace absl + +// End of public API. Implementation details follow. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace numbers_internal { + +// Digit conversion. +ABSL_DLL extern const char kHexChar[17]; // 0123456789abcdef +ABSL_DLL extern const char + kHexTable[513]; // 000102030405060708090a0b0c0d0e0f1011... +ABSL_DLL extern const char + two_ASCII_digits[100][2]; // 00, 01, 02, 03... + +// Writes a two-character representation of 'i' to 'buf'. 'i' must be in the +// range 0 <= i < 100, and buf must have space for two characters. Example: +// char buf[2]; +// PutTwoDigits(42, buf); +// // buf[0] == '4' +// // buf[1] == '2' +inline void PutTwoDigits(size_t i, char* buf) { + assert(i < 100); + memcpy(buf, two_ASCII_digits[i], 2); +} + +// safe_strto?() functions for implementing SimpleAtoi() +bool safe_strto32_base(absl::string_view text, int32_t* value, int base); +bool safe_strto64_base(absl::string_view text, int64_t* value, int base); +bool safe_strtou32_base(absl::string_view text, uint32_t* value, int base); +bool safe_strtou64_base(absl::string_view text, uint64_t* value, int base); +bool safe_strtou128_base(absl::string_view text, absl::uint128* value, + int base); + +static const int kFastToBufferSize = 32; +static const int kSixDigitsToBufferSize = 16; + +// Helper function for fast formatting of floating-point values. +// The result is the same as printf's "%g", a.k.a. "%.6g"; that is, six +// significant digits are returned, trailing zeros are removed, and numbers +// outside the range 0.0001-999999 are output using scientific notation +// (1.23456e+06). This routine is heavily optimized. +// Required buffer size is `kSixDigitsToBufferSize`. +size_t SixDigitsToBuffer(double d, char* buffer); + +// These functions are intended for speed. All functions take an output buffer +// as an argument and return a pointer to the last byte they wrote, which is the +// terminating '\0'. At most `kFastToBufferSize` bytes are written. +char* FastIntToBuffer(int32_t, char*); +char* FastIntToBuffer(uint32_t, char*); +char* FastIntToBuffer(int64_t, char*); +char* FastIntToBuffer(uint64_t, char*); + +// For enums and integer types that are not an exact match for the types above, +// use templates to call the appropriate one of the four overloads above. +template <typename int_type> +char* FastIntToBuffer(int_type i, char* buffer) { + static_assert(sizeof(i) <= 64 / 8, + "FastIntToBuffer works only with 64-bit-or-less integers."); + // TODO(jorg): This signed-ness check is used because it works correctly + // with enums, and it also serves to check that int_type is not a pointer. + // If one day something like std::is_signed<enum E> works, switch to it. + if (static_cast<int_type>(1) - 2 < 0) { // Signed + if (sizeof(i) > 32 / 8) { // 33-bit to 64-bit + return FastIntToBuffer(static_cast<int64_t>(i), buffer); + } else { // 32-bit or less + return FastIntToBuffer(static_cast<int32_t>(i), buffer); + } + } else { // Unsigned + if (sizeof(i) > 32 / 8) { // 33-bit to 64-bit + return FastIntToBuffer(static_cast<uint64_t>(i), buffer); + } else { // 32-bit or less + return FastIntToBuffer(static_cast<uint32_t>(i), buffer); + } + } +} + +// Implementation of SimpleAtoi, generalized to support arbitrary base (used +// with base different from 10 elsewhere in Abseil implementation). +template <typename int_type> +ABSL_MUST_USE_RESULT bool safe_strtoi_base(absl::string_view s, int_type* out, + int base) { + static_assert(sizeof(*out) == 4 || sizeof(*out) == 8, + "SimpleAtoi works only with 32-bit or 64-bit integers."); + static_assert(!std::is_floating_point<int_type>::value, + "Use SimpleAtof or SimpleAtod instead."); + bool parsed; + // TODO(jorg): This signed-ness check is used because it works correctly + // with enums, and it also serves to check that int_type is not a pointer. + // If one day something like std::is_signed<enum E> works, switch to it. + if (static_cast<int_type>(1) - 2 < 0) { // Signed + if (sizeof(*out) == 64 / 8) { // 64-bit + int64_t val; + parsed = numbers_internal::safe_strto64_base(s, &val, base); + *out = static_cast<int_type>(val); + } else { // 32-bit + int32_t val; + parsed = numbers_internal::safe_strto32_base(s, &val, base); + *out = static_cast<int_type>(val); + } + } else { // Unsigned + if (sizeof(*out) == 64 / 8) { // 64-bit + uint64_t val; + parsed = numbers_internal::safe_strtou64_base(s, &val, base); + *out = static_cast<int_type>(val); + } else { // 32-bit + uint32_t val; + parsed = numbers_internal::safe_strtou32_base(s, &val, base); + *out = static_cast<int_type>(val); + } + } + return parsed; +} + +// FastHexToBufferZeroPad16() +// +// Outputs `val` into `out` as if by `snprintf(out, 17, "%016x", val)` but +// without the terminating null character. Thus `out` must be of length >= 16. +// Returns the number of non-pad digits of the output (it can never be zero +// since 0 has one digit). +inline size_t FastHexToBufferZeroPad16(uint64_t val, char* out) { +#ifdef __SSE4_2__ + uint64_t be = absl::big_endian::FromHost64(val); + const auto kNibbleMask = _mm_set1_epi8(0xf); + const auto kHexDigits = _mm_setr_epi8('0', '1', '2', '3', '4', '5', '6', '7', + '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'); + auto v = _mm_loadl_epi64(reinterpret_cast<__m128i*>(&be)); // load lo dword + auto v4 = _mm_srli_epi64(v, 4); // shift 4 right + auto il = _mm_unpacklo_epi8(v4, v); // interleave bytes + auto m = _mm_and_si128(il, kNibbleMask); // mask out nibbles + auto hexchars = _mm_shuffle_epi8(kHexDigits, m); // hex chars + _mm_storeu_si128(reinterpret_cast<__m128i*>(out), hexchars); +#else + for (int i = 0; i < 8; ++i) { + auto byte = (val >> (56 - 8 * i)) & 0xFF; + auto* hex = &absl::numbers_internal::kHexTable[byte * 2]; + std::memcpy(out + 2 * i, hex, 2); + } +#endif + // | 0x1 so that even 0 has 1 digit. + return 16 - absl::base_internal::CountLeadingZeros64(val | 0x1) / 4; +} + +} // namespace numbers_internal + +// SimpleAtoi() +// +// Converts a string to an integer, using `safe_strto?()` functions for actual +// parsing, returning `true` if successful. The `safe_strto?()` functions apply +// strict checking; the string must be a base-10 integer, optionally followed or +// preceded by ASCII whitespace, with a value in the range of the corresponding +// integer type. +template <typename int_type> +ABSL_MUST_USE_RESULT bool SimpleAtoi(absl::string_view str, int_type* out) { + return numbers_internal::safe_strtoi_base(str, out, 10); +} + +ABSL_MUST_USE_RESULT inline bool SimpleAtoi(absl::string_view str, + absl::uint128* out) { + return numbers_internal::safe_strtou128_base(str, out, 10); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_NUMBERS_H_ diff --git a/third_party/abseil_cpp/absl/strings/numbers_benchmark.cc b/third_party/abseil_cpp/absl/strings/numbers_benchmark.cc new file mode 100644 index 0000000000..6e79b3e811 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/numbers_benchmark.cc @@ -0,0 +1,286 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdint> +#include <random> +#include <string> +#include <type_traits> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/distributions.h" +#include "absl/random/random.h" +#include "absl/strings/numbers.h" + +namespace { + +template <typename T> +void BM_FastIntToBuffer(benchmark::State& state) { + const int inc = state.range(0); + char buf[absl::numbers_internal::kFastToBufferSize]; + // Use the unsigned type to increment to take advantage of well-defined + // modular arithmetic. + typename std::make_unsigned<T>::type x = 0; + for (auto _ : state) { + absl::numbers_internal::FastIntToBuffer(static_cast<T>(x), buf); + x += inc; + } +} +BENCHMARK_TEMPLATE(BM_FastIntToBuffer, int32_t)->Range(0, 1 << 15); +BENCHMARK_TEMPLATE(BM_FastIntToBuffer, int64_t)->Range(0, 1 << 30); + +// Creates an integer that would be printed as `num_digits` repeated 7s in the +// given `base`. `base` must be greater than or equal to 8. +int64_t RepeatedSevens(int num_digits, int base) { + ABSL_RAW_CHECK(base >= 8, ""); + int64_t num = 7; + while (--num_digits) num = base * num + 7; + return num; +} + +void BM_safe_strto32_string(benchmark::State& state) { + const int digits = state.range(0); + const int base = state.range(1); + std::string str(digits, '7'); // valid in octal, decimal and hex + int32_t value = 0; + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::numbers_internal::safe_strto32_base(str, &value, base)); + } + ABSL_RAW_CHECK(value == RepeatedSevens(digits, base), ""); +} +BENCHMARK(BM_safe_strto32_string) + ->ArgPair(1, 8) + ->ArgPair(1, 10) + ->ArgPair(1, 16) + ->ArgPair(2, 8) + ->ArgPair(2, 10) + ->ArgPair(2, 16) + ->ArgPair(4, 8) + ->ArgPair(4, 10) + ->ArgPair(4, 16) + ->ArgPair(8, 8) + ->ArgPair(8, 10) + ->ArgPair(8, 16) + ->ArgPair(10, 8) + ->ArgPair(9, 10); + +void BM_safe_strto64_string(benchmark::State& state) { + const int digits = state.range(0); + const int base = state.range(1); + std::string str(digits, '7'); // valid in octal, decimal and hex + int64_t value = 0; + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::numbers_internal::safe_strto64_base(str, &value, base)); + } + ABSL_RAW_CHECK(value == RepeatedSevens(digits, base), ""); +} +BENCHMARK(BM_safe_strto64_string) + ->ArgPair(1, 8) + ->ArgPair(1, 10) + ->ArgPair(1, 16) + ->ArgPair(2, 8) + ->ArgPair(2, 10) + ->ArgPair(2, 16) + ->ArgPair(4, 8) + ->ArgPair(4, 10) + ->ArgPair(4, 16) + ->ArgPair(8, 8) + ->ArgPair(8, 10) + ->ArgPair(8, 16) + ->ArgPair(16, 8) + ->ArgPair(16, 10) + ->ArgPair(16, 16); + +void BM_safe_strtou32_string(benchmark::State& state) { + const int digits = state.range(0); + const int base = state.range(1); + std::string str(digits, '7'); // valid in octal, decimal and hex + uint32_t value = 0; + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::numbers_internal::safe_strtou32_base(str, &value, base)); + } + ABSL_RAW_CHECK(value == RepeatedSevens(digits, base), ""); +} +BENCHMARK(BM_safe_strtou32_string) + ->ArgPair(1, 8) + ->ArgPair(1, 10) + ->ArgPair(1, 16) + ->ArgPair(2, 8) + ->ArgPair(2, 10) + ->ArgPair(2, 16) + ->ArgPair(4, 8) + ->ArgPair(4, 10) + ->ArgPair(4, 16) + ->ArgPair(8, 8) + ->ArgPair(8, 10) + ->ArgPair(8, 16) + ->ArgPair(10, 8) + ->ArgPair(9, 10); + +void BM_safe_strtou64_string(benchmark::State& state) { + const int digits = state.range(0); + const int base = state.range(1); + std::string str(digits, '7'); // valid in octal, decimal and hex + uint64_t value = 0; + for (auto _ : state) { + benchmark::DoNotOptimize( + absl::numbers_internal::safe_strtou64_base(str, &value, base)); + } + ABSL_RAW_CHECK(value == RepeatedSevens(digits, base), ""); +} +BENCHMARK(BM_safe_strtou64_string) + ->ArgPair(1, 8) + ->ArgPair(1, 10) + ->ArgPair(1, 16) + ->ArgPair(2, 8) + ->ArgPair(2, 10) + ->ArgPair(2, 16) + ->ArgPair(4, 8) + ->ArgPair(4, 10) + ->ArgPair(4, 16) + ->ArgPair(8, 8) + ->ArgPair(8, 10) + ->ArgPair(8, 16) + ->ArgPair(16, 8) + ->ArgPair(16, 10) + ->ArgPair(16, 16); + +// Returns a vector of `num_strings` strings. Each string represents a +// floating point number with `num_digits` digits before the decimal point and +// another `num_digits` digits after. +std::vector<std::string> MakeFloatStrings(int num_strings, int num_digits) { + // For convenience, use a random number generator to generate the test data. + // We don't actually need random properties, so use a fixed seed. + std::minstd_rand0 rng(1); + std::uniform_int_distribution<int> random_digit('0', '9'); + + std::vector<std::string> float_strings(num_strings); + for (std::string& s : float_strings) { + s.reserve(2 * num_digits + 1); + for (int i = 0; i < num_digits; ++i) { + s.push_back(static_cast<char>(random_digit(rng))); + } + s.push_back('.'); + for (int i = 0; i < num_digits; ++i) { + s.push_back(static_cast<char>(random_digit(rng))); + } + } + return float_strings; +} + +template <typename StringType> +StringType GetStringAs(const std::string& s) { + return static_cast<StringType>(s); +} +template <> +const char* GetStringAs<const char*>(const std::string& s) { + return s.c_str(); +} + +template <typename StringType> +std::vector<StringType> GetStringsAs(const std::vector<std::string>& strings) { + std::vector<StringType> result; + result.reserve(strings.size()); + for (const std::string& s : strings) { + result.push_back(GetStringAs<StringType>(s)); + } + return result; +} + +template <typename T> +void BM_SimpleAtof(benchmark::State& state) { + const int num_strings = state.range(0); + const int num_digits = state.range(1); + std::vector<std::string> backing_strings = + MakeFloatStrings(num_strings, num_digits); + std::vector<T> inputs = GetStringsAs<T>(backing_strings); + float value; + for (auto _ : state) { + for (const T& input : inputs) { + benchmark::DoNotOptimize(absl::SimpleAtof(input, &value)); + } + } +} +BENCHMARK_TEMPLATE(BM_SimpleAtof, absl::string_view) + ->ArgPair(10, 1) + ->ArgPair(10, 2) + ->ArgPair(10, 4) + ->ArgPair(10, 8); +BENCHMARK_TEMPLATE(BM_SimpleAtof, const char*) + ->ArgPair(10, 1) + ->ArgPair(10, 2) + ->ArgPair(10, 4) + ->ArgPair(10, 8); +BENCHMARK_TEMPLATE(BM_SimpleAtof, std::string) + ->ArgPair(10, 1) + ->ArgPair(10, 2) + ->ArgPair(10, 4) + ->ArgPair(10, 8); + +template <typename T> +void BM_SimpleAtod(benchmark::State& state) { + const int num_strings = state.range(0); + const int num_digits = state.range(1); + std::vector<std::string> backing_strings = + MakeFloatStrings(num_strings, num_digits); + std::vector<T> inputs = GetStringsAs<T>(backing_strings); + double value; + for (auto _ : state) { + for (const T& input : inputs) { + benchmark::DoNotOptimize(absl::SimpleAtod(input, &value)); + } + } +} +BENCHMARK_TEMPLATE(BM_SimpleAtod, absl::string_view) + ->ArgPair(10, 1) + ->ArgPair(10, 2) + ->ArgPair(10, 4) + ->ArgPair(10, 8); +BENCHMARK_TEMPLATE(BM_SimpleAtod, const char*) + ->ArgPair(10, 1) + ->ArgPair(10, 2) + ->ArgPair(10, 4) + ->ArgPair(10, 8); +BENCHMARK_TEMPLATE(BM_SimpleAtod, std::string) + ->ArgPair(10, 1) + ->ArgPair(10, 2) + ->ArgPair(10, 4) + ->ArgPair(10, 8); + +void BM_FastHexToBufferZeroPad16(benchmark::State& state) { + absl::BitGen rng; + std::vector<uint64_t> nums; + nums.resize(1000); + auto min = std::numeric_limits<uint64_t>::min(); + auto max = std::numeric_limits<uint64_t>::max(); + for (auto& num : nums) { + num = absl::LogUniform(rng, min, max); + } + + char buf[16]; + while (state.KeepRunningBatch(nums.size())) { + for (auto num : nums) { + auto digits = absl::numbers_internal::FastHexToBufferZeroPad16(num, buf); + benchmark::DoNotOptimize(digits); + benchmark::DoNotOptimize(buf); + } + } +} +BENCHMARK(BM_FastHexToBufferZeroPad16); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/numbers_test.cc b/third_party/abseil_cpp/absl/strings/numbers_test.cc new file mode 100644 index 0000000000..7db85e754d --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/numbers_test.cc @@ -0,0 +1,1278 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file tests string processing functions related to numeric values. + +#include "absl/strings/numbers.h" + +#include <sys/types.h> + +#include <cfenv> // NOLINT(build/c++11) +#include <cinttypes> +#include <climits> +#include <cmath> +#include <cstddef> +#include <cstdint> +#include <cstdio> +#include <cstdlib> +#include <cstring> +#include <limits> +#include <numeric> +#include <random> +#include <set> +#include <string> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/random/distributions.h" +#include "absl/random/random.h" +#include "absl/strings/internal/numbers_test_common.h" +#include "absl/strings/internal/ostringstream.h" +#include "absl/strings/internal/pow10_helper.h" +#include "absl/strings/str_cat.h" + +namespace { + +using absl::numbers_internal::kSixDigitsToBufferSize; +using absl::numbers_internal::safe_strto32_base; +using absl::numbers_internal::safe_strto64_base; +using absl::numbers_internal::safe_strtou32_base; +using absl::numbers_internal::safe_strtou64_base; +using absl::numbers_internal::SixDigitsToBuffer; +using absl::strings_internal::Itoa; +using absl::strings_internal::strtouint32_test_cases; +using absl::strings_internal::strtouint64_test_cases; +using absl::SimpleAtoi; +using testing::Eq; +using testing::MatchesRegex; + +// Number of floats to test with. +// 5,000,000 is a reasonable default for a test that only takes a few seconds. +// 1,000,000,000+ triggers checking for all possible mantissa values for +// double-precision tests. 2,000,000,000+ triggers checking for every possible +// single-precision float. +const int kFloatNumCases = 5000000; + +// This is a slow, brute-force routine to compute the exact base-10 +// representation of a double-precision floating-point number. It +// is useful for debugging only. +std::string PerfectDtoa(double d) { + if (d == 0) return "0"; + if (d < 0) return "-" + PerfectDtoa(-d); + + // Basic theory: decompose d into mantissa and exp, where + // d = mantissa * 2^exp, and exp is as close to zero as possible. + int64_t mantissa, exp = 0; + while (d >= 1ULL << 63) ++exp, d *= 0.5; + while ((mantissa = d) != d) --exp, d *= 2.0; + + // Then convert mantissa to ASCII, and either double it (if + // exp > 0) or halve it (if exp < 0) repeatedly. "halve it" + // in this case means multiplying it by five and dividing by 10. + constexpr int maxlen = 1100; // worst case is actually 1030 or so. + char buf[maxlen + 5]; + for (int64_t num = mantissa, pos = maxlen; --pos >= 0;) { + buf[pos] = '0' + (num % 10); + num /= 10; + } + char* begin = &buf[0]; + char* end = buf + maxlen; + for (int i = 0; i != exp; i += (exp > 0) ? 1 : -1) { + int carry = 0; + for (char* p = end; --p != begin;) { + int dig = *p - '0'; + dig = dig * (exp > 0 ? 2 : 5) + carry; + carry = dig / 10; + dig %= 10; + *p = '0' + dig; + } + } + if (exp < 0) { + // "dividing by 10" above means we have to add the decimal point. + memmove(end + 1 + exp, end + exp, 1 - exp); + end[exp] = '.'; + ++end; + } + while (*begin == '0' && begin[1] != '.') ++begin; + return {begin, end}; +} + +TEST(ToString, PerfectDtoa) { + EXPECT_THAT(PerfectDtoa(1), Eq("1")); + EXPECT_THAT(PerfectDtoa(0.1), + Eq("0.1000000000000000055511151231257827021181583404541015625")); + EXPECT_THAT(PerfectDtoa(1e24), Eq("999999999999999983222784")); + EXPECT_THAT(PerfectDtoa(5e-324), MatchesRegex("0.0000.*625")); + for (int i = 0; i < 100; ++i) { + for (double multiplier : + {1e-300, 1e-200, 1e-100, 0.1, 1.0, 10.0, 1e100, 1e300}) { + double d = multiplier * i; + std::string s = PerfectDtoa(d); + EXPECT_DOUBLE_EQ(d, strtod(s.c_str(), nullptr)); + } + } +} + +template <typename integer> +struct MyInteger { + integer i; + explicit constexpr MyInteger(integer i) : i(i) {} + constexpr operator integer() const { return i; } + + constexpr MyInteger operator+(MyInteger other) const { return i + other.i; } + constexpr MyInteger operator-(MyInteger other) const { return i - other.i; } + constexpr MyInteger operator*(MyInteger other) const { return i * other.i; } + constexpr MyInteger operator/(MyInteger other) const { return i / other.i; } + + constexpr bool operator<(MyInteger other) const { return i < other.i; } + constexpr bool operator<=(MyInteger other) const { return i <= other.i; } + constexpr bool operator==(MyInteger other) const { return i == other.i; } + constexpr bool operator>=(MyInteger other) const { return i >= other.i; } + constexpr bool operator>(MyInteger other) const { return i > other.i; } + constexpr bool operator!=(MyInteger other) const { return i != other.i; } + + integer as_integer() const { return i; } +}; + +typedef MyInteger<int64_t> MyInt64; +typedef MyInteger<uint64_t> MyUInt64; + +void CheckInt32(int32_t x) { + char buffer[absl::numbers_internal::kFastToBufferSize]; + char* actual = absl::numbers_internal::FastIntToBuffer(x, buffer); + std::string expected = std::to_string(x); + EXPECT_EQ(expected, std::string(buffer, actual)) << " Input " << x; + + char* generic_actual = absl::numbers_internal::FastIntToBuffer(x, buffer); + EXPECT_EQ(expected, std::string(buffer, generic_actual)) << " Input " << x; +} + +void CheckInt64(int64_t x) { + char buffer[absl::numbers_internal::kFastToBufferSize + 3]; + buffer[0] = '*'; + buffer[23] = '*'; + buffer[24] = '*'; + char* actual = absl::numbers_internal::FastIntToBuffer(x, &buffer[1]); + std::string expected = std::to_string(x); + EXPECT_EQ(expected, std::string(&buffer[1], actual)) << " Input " << x; + EXPECT_EQ(buffer[0], '*'); + EXPECT_EQ(buffer[23], '*'); + EXPECT_EQ(buffer[24], '*'); + + char* my_actual = + absl::numbers_internal::FastIntToBuffer(MyInt64(x), &buffer[1]); + EXPECT_EQ(expected, std::string(&buffer[1], my_actual)) << " Input " << x; +} + +void CheckUInt32(uint32_t x) { + char buffer[absl::numbers_internal::kFastToBufferSize]; + char* actual = absl::numbers_internal::FastIntToBuffer(x, buffer); + std::string expected = std::to_string(x); + EXPECT_EQ(expected, std::string(buffer, actual)) << " Input " << x; + + char* generic_actual = absl::numbers_internal::FastIntToBuffer(x, buffer); + EXPECT_EQ(expected, std::string(buffer, generic_actual)) << " Input " << x; +} + +void CheckUInt64(uint64_t x) { + char buffer[absl::numbers_internal::kFastToBufferSize + 1]; + char* actual = absl::numbers_internal::FastIntToBuffer(x, &buffer[1]); + std::string expected = std::to_string(x); + EXPECT_EQ(expected, std::string(&buffer[1], actual)) << " Input " << x; + + char* generic_actual = absl::numbers_internal::FastIntToBuffer(x, &buffer[1]); + EXPECT_EQ(expected, std::string(&buffer[1], generic_actual)) + << " Input " << x; + + char* my_actual = + absl::numbers_internal::FastIntToBuffer(MyUInt64(x), &buffer[1]); + EXPECT_EQ(expected, std::string(&buffer[1], my_actual)) << " Input " << x; +} + +void CheckHex64(uint64_t v) { + char expected[16 + 1]; + std::string actual = absl::StrCat(absl::Hex(v, absl::kZeroPad16)); + snprintf(expected, sizeof(expected), "%016" PRIx64, static_cast<uint64_t>(v)); + EXPECT_EQ(expected, actual) << " Input " << v; + actual = absl::StrCat(absl::Hex(v, absl::kSpacePad16)); + snprintf(expected, sizeof(expected), "%16" PRIx64, static_cast<uint64_t>(v)); + EXPECT_EQ(expected, actual) << " Input " << v; +} + +TEST(Numbers, TestFastPrints) { + for (int i = -100; i <= 100; i++) { + CheckInt32(i); + CheckInt64(i); + } + for (int i = 0; i <= 100; i++) { + CheckUInt32(i); + CheckUInt64(i); + } + // Test min int to make sure that works + CheckInt32(INT_MIN); + CheckInt32(INT_MAX); + CheckInt64(LONG_MIN); + CheckInt64(uint64_t{1000000000}); + CheckInt64(uint64_t{9999999999}); + CheckInt64(uint64_t{100000000000000}); + CheckInt64(uint64_t{999999999999999}); + CheckInt64(uint64_t{1000000000000000000}); + CheckInt64(uint64_t{1199999999999999999}); + CheckInt64(int64_t{-700000000000000000}); + CheckInt64(LONG_MAX); + CheckUInt32(std::numeric_limits<uint32_t>::max()); + CheckUInt64(uint64_t{1000000000}); + CheckUInt64(uint64_t{9999999999}); + CheckUInt64(uint64_t{100000000000000}); + CheckUInt64(uint64_t{999999999999999}); + CheckUInt64(uint64_t{1000000000000000000}); + CheckUInt64(uint64_t{1199999999999999999}); + CheckUInt64(std::numeric_limits<uint64_t>::max()); + + for (int i = 0; i < 10000; i++) { + CheckHex64(i); + } + CheckHex64(uint64_t{0x123456789abcdef0}); +} + +template <typename int_type, typename in_val_type> +void VerifySimpleAtoiGood(in_val_type in_value, int_type exp_value) { + std::string s; + // uint128 can be streamed but not StrCat'd + absl::strings_internal::OStringStream(&s) << in_value; + int_type x = static_cast<int_type>(~exp_value); + EXPECT_TRUE(SimpleAtoi(s, &x)) + << "in_value=" << in_value << " s=" << s << " x=" << x; + EXPECT_EQ(exp_value, x); + x = static_cast<int_type>(~exp_value); + EXPECT_TRUE(SimpleAtoi(s.c_str(), &x)); + EXPECT_EQ(exp_value, x); +} + +template <typename int_type, typename in_val_type> +void VerifySimpleAtoiBad(in_val_type in_value) { + std::string s = absl::StrCat(in_value); + int_type x; + EXPECT_FALSE(SimpleAtoi(s, &x)); + EXPECT_FALSE(SimpleAtoi(s.c_str(), &x)); +} + +TEST(NumbersTest, Atoi) { + // SimpleAtoi(absl::string_view, int32_t) + VerifySimpleAtoiGood<int32_t>(0, 0); + VerifySimpleAtoiGood<int32_t>(42, 42); + VerifySimpleAtoiGood<int32_t>(-42, -42); + + VerifySimpleAtoiGood<int32_t>(std::numeric_limits<int32_t>::min(), + std::numeric_limits<int32_t>::min()); + VerifySimpleAtoiGood<int32_t>(std::numeric_limits<int32_t>::max(), + std::numeric_limits<int32_t>::max()); + + // SimpleAtoi(absl::string_view, uint32_t) + VerifySimpleAtoiGood<uint32_t>(0, 0); + VerifySimpleAtoiGood<uint32_t>(42, 42); + VerifySimpleAtoiBad<uint32_t>(-42); + + VerifySimpleAtoiBad<uint32_t>(std::numeric_limits<int32_t>::min()); + VerifySimpleAtoiGood<uint32_t>(std::numeric_limits<int32_t>::max(), + std::numeric_limits<int32_t>::max()); + VerifySimpleAtoiGood<uint32_t>(std::numeric_limits<uint32_t>::max(), + std::numeric_limits<uint32_t>::max()); + VerifySimpleAtoiBad<uint32_t>(std::numeric_limits<int64_t>::min()); + VerifySimpleAtoiBad<uint32_t>(std::numeric_limits<int64_t>::max()); + VerifySimpleAtoiBad<uint32_t>(std::numeric_limits<uint64_t>::max()); + + // SimpleAtoi(absl::string_view, int64_t) + VerifySimpleAtoiGood<int64_t>(0, 0); + VerifySimpleAtoiGood<int64_t>(42, 42); + VerifySimpleAtoiGood<int64_t>(-42, -42); + + VerifySimpleAtoiGood<int64_t>(std::numeric_limits<int32_t>::min(), + std::numeric_limits<int32_t>::min()); + VerifySimpleAtoiGood<int64_t>(std::numeric_limits<int32_t>::max(), + std::numeric_limits<int32_t>::max()); + VerifySimpleAtoiGood<int64_t>(std::numeric_limits<uint32_t>::max(), + std::numeric_limits<uint32_t>::max()); + VerifySimpleAtoiGood<int64_t>(std::numeric_limits<int64_t>::min(), + std::numeric_limits<int64_t>::min()); + VerifySimpleAtoiGood<int64_t>(std::numeric_limits<int64_t>::max(), + std::numeric_limits<int64_t>::max()); + VerifySimpleAtoiBad<int64_t>(std::numeric_limits<uint64_t>::max()); + + // SimpleAtoi(absl::string_view, uint64_t) + VerifySimpleAtoiGood<uint64_t>(0, 0); + VerifySimpleAtoiGood<uint64_t>(42, 42); + VerifySimpleAtoiBad<uint64_t>(-42); + + VerifySimpleAtoiBad<uint64_t>(std::numeric_limits<int32_t>::min()); + VerifySimpleAtoiGood<uint64_t>(std::numeric_limits<int32_t>::max(), + std::numeric_limits<int32_t>::max()); + VerifySimpleAtoiGood<uint64_t>(std::numeric_limits<uint32_t>::max(), + std::numeric_limits<uint32_t>::max()); + VerifySimpleAtoiBad<uint64_t>(std::numeric_limits<int64_t>::min()); + VerifySimpleAtoiGood<uint64_t>(std::numeric_limits<int64_t>::max(), + std::numeric_limits<int64_t>::max()); + VerifySimpleAtoiGood<uint64_t>(std::numeric_limits<uint64_t>::max(), + std::numeric_limits<uint64_t>::max()); + + // SimpleAtoi(absl::string_view, absl::uint128) + VerifySimpleAtoiGood<absl::uint128>(0, 0); + VerifySimpleAtoiGood<absl::uint128>(42, 42); + VerifySimpleAtoiBad<absl::uint128>(-42); + + VerifySimpleAtoiBad<absl::uint128>(std::numeric_limits<int32_t>::min()); + VerifySimpleAtoiGood<absl::uint128>(std::numeric_limits<int32_t>::max(), + std::numeric_limits<int32_t>::max()); + VerifySimpleAtoiGood<absl::uint128>(std::numeric_limits<uint32_t>::max(), + std::numeric_limits<uint32_t>::max()); + VerifySimpleAtoiBad<absl::uint128>(std::numeric_limits<int64_t>::min()); + VerifySimpleAtoiGood<absl::uint128>(std::numeric_limits<int64_t>::max(), + std::numeric_limits<int64_t>::max()); + VerifySimpleAtoiGood<absl::uint128>(std::numeric_limits<uint64_t>::max(), + std::numeric_limits<uint64_t>::max()); + VerifySimpleAtoiGood<absl::uint128>( + std::numeric_limits<absl::uint128>::max(), + std::numeric_limits<absl::uint128>::max()); + + // Some other types + VerifySimpleAtoiGood<int>(-42, -42); + VerifySimpleAtoiGood<int32_t>(-42, -42); + VerifySimpleAtoiGood<uint32_t>(42, 42); + VerifySimpleAtoiGood<unsigned int>(42, 42); + VerifySimpleAtoiGood<int64_t>(-42, -42); + VerifySimpleAtoiGood<long>(-42, -42); // NOLINT(runtime/int) + VerifySimpleAtoiGood<uint64_t>(42, 42); + VerifySimpleAtoiGood<size_t>(42, 42); + VerifySimpleAtoiGood<std::string::size_type>(42, 42); +} + +TEST(NumbersTest, Atoenum) { + enum E01 { + E01_zero = 0, + E01_one = 1, + }; + + VerifySimpleAtoiGood<E01>(E01_zero, E01_zero); + VerifySimpleAtoiGood<E01>(E01_one, E01_one); + + enum E_101 { + E_101_minusone = -1, + E_101_zero = 0, + E_101_one = 1, + }; + + VerifySimpleAtoiGood<E_101>(E_101_minusone, E_101_minusone); + VerifySimpleAtoiGood<E_101>(E_101_zero, E_101_zero); + VerifySimpleAtoiGood<E_101>(E_101_one, E_101_one); + + enum E_bigint { + E_bigint_zero = 0, + E_bigint_one = 1, + E_bigint_max31 = static_cast<int32_t>(0x7FFFFFFF), + }; + + VerifySimpleAtoiGood<E_bigint>(E_bigint_zero, E_bigint_zero); + VerifySimpleAtoiGood<E_bigint>(E_bigint_one, E_bigint_one); + VerifySimpleAtoiGood<E_bigint>(E_bigint_max31, E_bigint_max31); + + enum E_fullint { + E_fullint_zero = 0, + E_fullint_one = 1, + E_fullint_max31 = static_cast<int32_t>(0x7FFFFFFF), + E_fullint_min32 = INT32_MIN, + }; + + VerifySimpleAtoiGood<E_fullint>(E_fullint_zero, E_fullint_zero); + VerifySimpleAtoiGood<E_fullint>(E_fullint_one, E_fullint_one); + VerifySimpleAtoiGood<E_fullint>(E_fullint_max31, E_fullint_max31); + VerifySimpleAtoiGood<E_fullint>(E_fullint_min32, E_fullint_min32); + + enum E_biguint { + E_biguint_zero = 0, + E_biguint_one = 1, + E_biguint_max31 = static_cast<uint32_t>(0x7FFFFFFF), + E_biguint_max32 = static_cast<uint32_t>(0xFFFFFFFF), + }; + + VerifySimpleAtoiGood<E_biguint>(E_biguint_zero, E_biguint_zero); + VerifySimpleAtoiGood<E_biguint>(E_biguint_one, E_biguint_one); + VerifySimpleAtoiGood<E_biguint>(E_biguint_max31, E_biguint_max31); + VerifySimpleAtoiGood<E_biguint>(E_biguint_max32, E_biguint_max32); +} + +TEST(stringtest, safe_strto32_base) { + int32_t value; + EXPECT_TRUE(safe_strto32_base("0x34234324", &value, 16)); + EXPECT_EQ(0x34234324, value); + + EXPECT_TRUE(safe_strto32_base("0X34234324", &value, 16)); + EXPECT_EQ(0x34234324, value); + + EXPECT_TRUE(safe_strto32_base("34234324", &value, 16)); + EXPECT_EQ(0x34234324, value); + + EXPECT_TRUE(safe_strto32_base("0", &value, 16)); + EXPECT_EQ(0, value); + + EXPECT_TRUE(safe_strto32_base(" \t\n -0x34234324", &value, 16)); + EXPECT_EQ(-0x34234324, value); + + EXPECT_TRUE(safe_strto32_base(" \t\n -34234324", &value, 16)); + EXPECT_EQ(-0x34234324, value); + + EXPECT_TRUE(safe_strto32_base("7654321", &value, 8)); + EXPECT_EQ(07654321, value); + + EXPECT_TRUE(safe_strto32_base("-01234", &value, 8)); + EXPECT_EQ(-01234, value); + + EXPECT_FALSE(safe_strto32_base("1834", &value, 8)); + + // Autodetect base. + EXPECT_TRUE(safe_strto32_base("0", &value, 0)); + EXPECT_EQ(0, value); + + EXPECT_TRUE(safe_strto32_base("077", &value, 0)); + EXPECT_EQ(077, value); // Octal interpretation + + // Leading zero indicates octal, but then followed by invalid digit. + EXPECT_FALSE(safe_strto32_base("088", &value, 0)); + + // Leading 0x indicated hex, but then followed by invalid digit. + EXPECT_FALSE(safe_strto32_base("0xG", &value, 0)); + + // Base-10 version. + EXPECT_TRUE(safe_strto32_base("34234324", &value, 10)); + EXPECT_EQ(34234324, value); + + EXPECT_TRUE(safe_strto32_base("0", &value, 10)); + EXPECT_EQ(0, value); + + EXPECT_TRUE(safe_strto32_base(" \t\n -34234324", &value, 10)); + EXPECT_EQ(-34234324, value); + + EXPECT_TRUE(safe_strto32_base("34234324 \n\t ", &value, 10)); + EXPECT_EQ(34234324, value); + + // Invalid ints. + EXPECT_FALSE(safe_strto32_base("", &value, 10)); + EXPECT_FALSE(safe_strto32_base(" ", &value, 10)); + EXPECT_FALSE(safe_strto32_base("abc", &value, 10)); + EXPECT_FALSE(safe_strto32_base("34234324a", &value, 10)); + EXPECT_FALSE(safe_strto32_base("34234.3", &value, 10)); + + // Out of bounds. + EXPECT_FALSE(safe_strto32_base("2147483648", &value, 10)); + EXPECT_FALSE(safe_strto32_base("-2147483649", &value, 10)); + + // String version. + EXPECT_TRUE(safe_strto32_base(std::string("0x1234"), &value, 16)); + EXPECT_EQ(0x1234, value); + + // Base-10 string version. + EXPECT_TRUE(safe_strto32_base("1234", &value, 10)); + EXPECT_EQ(1234, value); +} + +TEST(stringtest, safe_strto32_range) { + // These tests verify underflow/overflow behaviour. + int32_t value; + EXPECT_FALSE(safe_strto32_base("2147483648", &value, 10)); + EXPECT_EQ(std::numeric_limits<int32_t>::max(), value); + + EXPECT_TRUE(safe_strto32_base("-2147483648", &value, 10)); + EXPECT_EQ(std::numeric_limits<int32_t>::min(), value); + + EXPECT_FALSE(safe_strto32_base("-2147483649", &value, 10)); + EXPECT_EQ(std::numeric_limits<int32_t>::min(), value); +} + +TEST(stringtest, safe_strto64_range) { + // These tests verify underflow/overflow behaviour. + int64_t value; + EXPECT_FALSE(safe_strto64_base("9223372036854775808", &value, 10)); + EXPECT_EQ(std::numeric_limits<int64_t>::max(), value); + + EXPECT_TRUE(safe_strto64_base("-9223372036854775808", &value, 10)); + EXPECT_EQ(std::numeric_limits<int64_t>::min(), value); + + EXPECT_FALSE(safe_strto64_base("-9223372036854775809", &value, 10)); + EXPECT_EQ(std::numeric_limits<int64_t>::min(), value); +} + +TEST(stringtest, safe_strto32_leading_substring) { + // These tests verify this comment in numbers.h: + // On error, returns false, and sets *value to: [...] + // conversion of leading substring if available ("123@@@" -> 123) + // 0 if no leading substring available + int32_t value; + EXPECT_FALSE(safe_strto32_base("04069@@@", &value, 10)); + EXPECT_EQ(4069, value); + + EXPECT_FALSE(safe_strto32_base("04069@@@", &value, 8)); + EXPECT_EQ(0406, value); + + EXPECT_FALSE(safe_strto32_base("04069balloons", &value, 10)); + EXPECT_EQ(4069, value); + + EXPECT_FALSE(safe_strto32_base("04069balloons", &value, 16)); + EXPECT_EQ(0x4069ba, value); + + EXPECT_FALSE(safe_strto32_base("@@@", &value, 10)); + EXPECT_EQ(0, value); // there was no leading substring +} + +TEST(stringtest, safe_strto64_leading_substring) { + // These tests verify this comment in numbers.h: + // On error, returns false, and sets *value to: [...] + // conversion of leading substring if available ("123@@@" -> 123) + // 0 if no leading substring available + int64_t value; + EXPECT_FALSE(safe_strto64_base("04069@@@", &value, 10)); + EXPECT_EQ(4069, value); + + EXPECT_FALSE(safe_strto64_base("04069@@@", &value, 8)); + EXPECT_EQ(0406, value); + + EXPECT_FALSE(safe_strto64_base("04069balloons", &value, 10)); + EXPECT_EQ(4069, value); + + EXPECT_FALSE(safe_strto64_base("04069balloons", &value, 16)); + EXPECT_EQ(0x4069ba, value); + + EXPECT_FALSE(safe_strto64_base("@@@", &value, 10)); + EXPECT_EQ(0, value); // there was no leading substring +} + +TEST(stringtest, safe_strto64_base) { + int64_t value; + EXPECT_TRUE(safe_strto64_base("0x3423432448783446", &value, 16)); + EXPECT_EQ(int64_t{0x3423432448783446}, value); + + EXPECT_TRUE(safe_strto64_base("3423432448783446", &value, 16)); + EXPECT_EQ(int64_t{0x3423432448783446}, value); + + EXPECT_TRUE(safe_strto64_base("0", &value, 16)); + EXPECT_EQ(0, value); + + EXPECT_TRUE(safe_strto64_base(" \t\n -0x3423432448783446", &value, 16)); + EXPECT_EQ(int64_t{-0x3423432448783446}, value); + + EXPECT_TRUE(safe_strto64_base(" \t\n -3423432448783446", &value, 16)); + EXPECT_EQ(int64_t{-0x3423432448783446}, value); + + EXPECT_TRUE(safe_strto64_base("123456701234567012", &value, 8)); + EXPECT_EQ(int64_t{0123456701234567012}, value); + + EXPECT_TRUE(safe_strto64_base("-017777777777777", &value, 8)); + EXPECT_EQ(int64_t{-017777777777777}, value); + + EXPECT_FALSE(safe_strto64_base("19777777777777", &value, 8)); + + // Autodetect base. + EXPECT_TRUE(safe_strto64_base("0", &value, 0)); + EXPECT_EQ(0, value); + + EXPECT_TRUE(safe_strto64_base("077", &value, 0)); + EXPECT_EQ(077, value); // Octal interpretation + + // Leading zero indicates octal, but then followed by invalid digit. + EXPECT_FALSE(safe_strto64_base("088", &value, 0)); + + // Leading 0x indicated hex, but then followed by invalid digit. + EXPECT_FALSE(safe_strto64_base("0xG", &value, 0)); + + // Base-10 version. + EXPECT_TRUE(safe_strto64_base("34234324487834466", &value, 10)); + EXPECT_EQ(int64_t{34234324487834466}, value); + + EXPECT_TRUE(safe_strto64_base("0", &value, 10)); + EXPECT_EQ(0, value); + + EXPECT_TRUE(safe_strto64_base(" \t\n -34234324487834466", &value, 10)); + EXPECT_EQ(int64_t{-34234324487834466}, value); + + EXPECT_TRUE(safe_strto64_base("34234324487834466 \n\t ", &value, 10)); + EXPECT_EQ(int64_t{34234324487834466}, value); + + // Invalid ints. + EXPECT_FALSE(safe_strto64_base("", &value, 10)); + EXPECT_FALSE(safe_strto64_base(" ", &value, 10)); + EXPECT_FALSE(safe_strto64_base("abc", &value, 10)); + EXPECT_FALSE(safe_strto64_base("34234324487834466a", &value, 10)); + EXPECT_FALSE(safe_strto64_base("34234487834466.3", &value, 10)); + + // Out of bounds. + EXPECT_FALSE(safe_strto64_base("9223372036854775808", &value, 10)); + EXPECT_FALSE(safe_strto64_base("-9223372036854775809", &value, 10)); + + // String version. + EXPECT_TRUE(safe_strto64_base(std::string("0x1234"), &value, 16)); + EXPECT_EQ(0x1234, value); + + // Base-10 string version. + EXPECT_TRUE(safe_strto64_base("1234", &value, 10)); + EXPECT_EQ(1234, value); +} + +const size_t kNumRandomTests = 10000; + +template <typename IntType> +void test_random_integer_parse_base(bool (*parse_func)(absl::string_view, + IntType* value, + int base)) { + using RandomEngine = std::minstd_rand0; + std::random_device rd; + RandomEngine rng(rd()); + std::uniform_int_distribution<IntType> random_int( + std::numeric_limits<IntType>::min()); + std::uniform_int_distribution<int> random_base(2, 35); + for (size_t i = 0; i < kNumRandomTests; i++) { + IntType value = random_int(rng); + int base = random_base(rng); + std::string str_value; + EXPECT_TRUE(Itoa<IntType>(value, base, &str_value)); + IntType parsed_value; + + // Test successful parse + EXPECT_TRUE(parse_func(str_value, &parsed_value, base)); + EXPECT_EQ(parsed_value, value); + + // Test overflow + EXPECT_FALSE( + parse_func(absl::StrCat(std::numeric_limits<IntType>::max(), value), + &parsed_value, base)); + + // Test underflow + if (std::numeric_limits<IntType>::min() < 0) { + EXPECT_FALSE( + parse_func(absl::StrCat(std::numeric_limits<IntType>::min(), value), + &parsed_value, base)); + } else { + EXPECT_FALSE(parse_func(absl::StrCat("-", value), &parsed_value, base)); + } + } +} + +TEST(stringtest, safe_strto32_random) { + test_random_integer_parse_base<int32_t>(&safe_strto32_base); +} +TEST(stringtest, safe_strto64_random) { + test_random_integer_parse_base<int64_t>(&safe_strto64_base); +} +TEST(stringtest, safe_strtou32_random) { + test_random_integer_parse_base<uint32_t>(&safe_strtou32_base); +} +TEST(stringtest, safe_strtou64_random) { + test_random_integer_parse_base<uint64_t>(&safe_strtou64_base); +} +TEST(stringtest, safe_strtou128_random) { + // random number generators don't work for uint128, and + // uint128 can be streamed but not StrCat'd, so this code must be custom + // implemented for uint128, but is generally the same as what's above. + // test_random_integer_parse_base<absl::uint128>( + // &absl::numbers_internal::safe_strtou128_base); + using RandomEngine = std::minstd_rand0; + using IntType = absl::uint128; + constexpr auto parse_func = &absl::numbers_internal::safe_strtou128_base; + + std::random_device rd; + RandomEngine rng(rd()); + std::uniform_int_distribution<uint64_t> random_uint64( + std::numeric_limits<uint64_t>::min()); + std::uniform_int_distribution<int> random_base(2, 35); + + for (size_t i = 0; i < kNumRandomTests; i++) { + IntType value = random_uint64(rng); + value = (value << 64) + random_uint64(rng); + int base = random_base(rng); + std::string str_value; + EXPECT_TRUE(Itoa<IntType>(value, base, &str_value)); + IntType parsed_value; + + // Test successful parse + EXPECT_TRUE(parse_func(str_value, &parsed_value, base)); + EXPECT_EQ(parsed_value, value); + + // Test overflow + std::string s; + absl::strings_internal::OStringStream(&s) + << std::numeric_limits<IntType>::max() << value; + EXPECT_FALSE(parse_func(s, &parsed_value, base)); + + // Test underflow + s.clear(); + absl::strings_internal::OStringStream(&s) << "-" << value; + EXPECT_FALSE(parse_func(s, &parsed_value, base)); + } +} + +TEST(stringtest, safe_strtou32_base) { + for (int i = 0; strtouint32_test_cases()[i].str != nullptr; ++i) { + const auto& e = strtouint32_test_cases()[i]; + uint32_t value; + EXPECT_EQ(e.expect_ok, safe_strtou32_base(e.str, &value, e.base)) + << "str=\"" << e.str << "\" base=" << e.base; + if (e.expect_ok) { + EXPECT_EQ(e.expected, value) << "i=" << i << " str=\"" << e.str + << "\" base=" << e.base; + } + } +} + +TEST(stringtest, safe_strtou32_base_length_delimited) { + for (int i = 0; strtouint32_test_cases()[i].str != nullptr; ++i) { + const auto& e = strtouint32_test_cases()[i]; + std::string tmp(e.str); + tmp.append("12"); // Adds garbage at the end. + + uint32_t value; + EXPECT_EQ(e.expect_ok, + safe_strtou32_base(absl::string_view(tmp.data(), strlen(e.str)), + &value, e.base)) + << "str=\"" << e.str << "\" base=" << e.base; + if (e.expect_ok) { + EXPECT_EQ(e.expected, value) << "i=" << i << " str=" << e.str + << " base=" << e.base; + } + } +} + +TEST(stringtest, safe_strtou64_base) { + for (int i = 0; strtouint64_test_cases()[i].str != nullptr; ++i) { + const auto& e = strtouint64_test_cases()[i]; + uint64_t value; + EXPECT_EQ(e.expect_ok, safe_strtou64_base(e.str, &value, e.base)) + << "str=\"" << e.str << "\" base=" << e.base; + if (e.expect_ok) { + EXPECT_EQ(e.expected, value) << "str=" << e.str << " base=" << e.base; + } + } +} + +TEST(stringtest, safe_strtou64_base_length_delimited) { + for (int i = 0; strtouint64_test_cases()[i].str != nullptr; ++i) { + const auto& e = strtouint64_test_cases()[i]; + std::string tmp(e.str); + tmp.append("12"); // Adds garbage at the end. + + uint64_t value; + EXPECT_EQ(e.expect_ok, + safe_strtou64_base(absl::string_view(tmp.data(), strlen(e.str)), + &value, e.base)) + << "str=\"" << e.str << "\" base=" << e.base; + if (e.expect_ok) { + EXPECT_EQ(e.expected, value) << "str=\"" << e.str << "\" base=" << e.base; + } + } +} + +// feenableexcept() and fedisableexcept() are extensions supported by some libc +// implementations. +#if defined(__GLIBC__) || defined(__BIONIC__) +#define ABSL_HAVE_FEENABLEEXCEPT 1 +#define ABSL_HAVE_FEDISABLEEXCEPT 1 +#endif + +class SimpleDtoaTest : public testing::Test { + protected: + void SetUp() override { + // Store the current floating point env & clear away any pending exceptions. + feholdexcept(&fp_env_); +#ifdef ABSL_HAVE_FEENABLEEXCEPT + // Turn on floating point exceptions. + feenableexcept(FE_DIVBYZERO | FE_INVALID | FE_OVERFLOW); +#endif + } + + void TearDown() override { + // Restore the floating point environment to the original state. + // In theory fedisableexcept is unnecessary; fesetenv will also do it. + // In practice, our toolchains have subtle bugs. +#ifdef ABSL_HAVE_FEDISABLEEXCEPT + fedisableexcept(FE_DIVBYZERO | FE_INVALID | FE_OVERFLOW); +#endif + fesetenv(&fp_env_); + } + + std::string ToNineDigits(double value) { + char buffer[16]; // more than enough for %.9g + snprintf(buffer, sizeof(buffer), "%.9g", value); + return buffer; + } + + fenv_t fp_env_; +}; + +// Run the given runnable functor for "cases" test cases, chosen over the +// available range of float. pi and e and 1/e are seeded, and then all +// available integer powers of 2 and 10 are multiplied against them. In +// addition to trying all those values, we try the next higher and next lower +// float, and then we add additional test cases evenly distributed between them. +// Each test case is passed to runnable as both a positive and negative value. +template <typename R> +void ExhaustiveFloat(uint32_t cases, R&& runnable) { + runnable(0.0f); + runnable(-0.0f); + if (cases >= 2e9) { // more than 2 billion? Might as well run them all. + for (float f = 0; f < std::numeric_limits<float>::max(); ) { + f = nextafterf(f, std::numeric_limits<float>::max()); + runnable(-f); + runnable(f); + } + return; + } + std::set<float> floats = {3.4028234e38f}; + for (float f : {1.0, 3.14159265, 2.718281828, 1 / 2.718281828}) { + for (float testf = f; testf != 0; testf *= 0.1f) floats.insert(testf); + for (float testf = f; testf != 0; testf *= 0.5f) floats.insert(testf); + for (float testf = f; testf < 3e38f / 2; testf *= 2.0f) + floats.insert(testf); + for (float testf = f; testf < 3e38f / 10; testf *= 10) floats.insert(testf); + } + + float last = *floats.begin(); + + runnable(last); + runnable(-last); + int iters_per_float = cases / floats.size(); + if (iters_per_float == 0) iters_per_float = 1; + for (float f : floats) { + if (f == last) continue; + float testf = std::nextafter(last, std::numeric_limits<float>::max()); + runnable(testf); + runnable(-testf); + last = testf; + if (f == last) continue; + double step = (double{f} - last) / iters_per_float; + for (double d = last + step; d < f; d += step) { + testf = d; + if (testf != last) { + runnable(testf); + runnable(-testf); + last = testf; + } + } + testf = std::nextafter(f, 0.0f); + if (testf > last) { + runnable(testf); + runnable(-testf); + last = testf; + } + if (f != last) { + runnable(f); + runnable(-f); + last = f; + } + } +} + +TEST_F(SimpleDtoaTest, ExhaustiveDoubleToSixDigits) { + uint64_t test_count = 0; + std::vector<double> mismatches; + auto checker = [&](double d) { + if (d != d) return; // rule out NaNs + ++test_count; + char sixdigitsbuf[kSixDigitsToBufferSize] = {0}; + SixDigitsToBuffer(d, sixdigitsbuf); + char snprintfbuf[kSixDigitsToBufferSize] = {0}; + snprintf(snprintfbuf, kSixDigitsToBufferSize, "%g", d); + if (strcmp(sixdigitsbuf, snprintfbuf) != 0) { + mismatches.push_back(d); + if (mismatches.size() < 10) { + ABSL_RAW_LOG(ERROR, "%s", + absl::StrCat("Six-digit failure with double. ", "d=", d, + "=", d, " sixdigits=", sixdigitsbuf, + " printf(%g)=", snprintfbuf) + .c_str()); + } + } + }; + // Some quick sanity checks... + checker(5e-324); + checker(1e-308); + checker(1.0); + checker(1.000005); + checker(1.7976931348623157e308); + checker(0.00390625); +#ifndef _MSC_VER + // on MSVC, snprintf() rounds it to 0.00195313. SixDigitsToBuffer() rounds it + // to 0.00195312 (round half to even). + checker(0.001953125); +#endif + checker(0.005859375); + // Some cases where the rounding is very very close + checker(1.089095e-15); + checker(3.274195e-55); + checker(6.534355e-146); + checker(2.920845e+234); + + if (mismatches.empty()) { + test_count = 0; + ExhaustiveFloat(kFloatNumCases, checker); + + test_count = 0; + std::vector<int> digit_testcases{ + 100000, 100001, 100002, 100005, 100010, 100020, 100050, 100100, // misc + 195312, 195313, // 1.953125 is a case where we round down, just barely. + 200000, 500000, 800000, // misc mid-range cases + 585937, 585938, // 5.859375 is a case where we round up, just barely. + 900000, 990000, 999000, 999900, 999990, 999996, 999997, 999998, 999999}; + if (kFloatNumCases >= 1e9) { + // If at least 1 billion test cases were requested, user wants an + // exhaustive test. So let's test all mantissas, too. + constexpr int min_mantissa = 100000, max_mantissa = 999999; + digit_testcases.resize(max_mantissa - min_mantissa + 1); + std::iota(digit_testcases.begin(), digit_testcases.end(), min_mantissa); + } + + for (int exponent = -324; exponent <= 308; ++exponent) { + double powten = absl::strings_internal::Pow10(exponent); + if (powten == 0) powten = 5e-324; + if (kFloatNumCases >= 1e9) { + // The exhaustive test takes a very long time, so log progress. + char buf[kSixDigitsToBufferSize]; + ABSL_RAW_LOG( + INFO, "%s", + absl::StrCat("Exp ", exponent, " powten=", powten, "(", powten, + ") (", + std::string(buf, SixDigitsToBuffer(powten, buf)), ")") + .c_str()); + } + for (int digits : digit_testcases) { + if (exponent == 308 && digits >= 179769) break; // don't overflow! + double digiform = (digits + 0.5) * 0.00001; + double testval = digiform * powten; + double pretestval = nextafter(testval, 0); + double posttestval = nextafter(testval, 1.7976931348623157e308); + checker(testval); + checker(pretestval); + checker(posttestval); + } + } + } else { + EXPECT_EQ(mismatches.size(), 0); + for (size_t i = 0; i < mismatches.size(); ++i) { + if (i > 100) i = mismatches.size() - 1; + double d = mismatches[i]; + char sixdigitsbuf[kSixDigitsToBufferSize] = {0}; + SixDigitsToBuffer(d, sixdigitsbuf); + char snprintfbuf[kSixDigitsToBufferSize] = {0}; + snprintf(snprintfbuf, kSixDigitsToBufferSize, "%g", d); + double before = nextafter(d, 0.0); + double after = nextafter(d, 1.7976931348623157e308); + char b1[32], b2[kSixDigitsToBufferSize]; + ABSL_RAW_LOG( + ERROR, "%s", + absl::StrCat( + "Mismatch #", i, " d=", d, " (", ToNineDigits(d), ")", + " sixdigits='", sixdigitsbuf, "'", " snprintf='", snprintfbuf, + "'", " Before.=", PerfectDtoa(before), " ", + (SixDigitsToBuffer(before, b2), b2), + " vs snprintf=", (snprintf(b1, sizeof(b1), "%g", before), b1), + " Perfect=", PerfectDtoa(d), " ", (SixDigitsToBuffer(d, b2), b2), + " vs snprintf=", (snprintf(b1, sizeof(b1), "%g", d), b1), + " After.=.", PerfectDtoa(after), " ", + (SixDigitsToBuffer(after, b2), b2), + " vs snprintf=", (snprintf(b1, sizeof(b1), "%g", after), b1)) + .c_str()); + } + } +} + +TEST(StrToInt32, Partial) { + struct Int32TestLine { + std::string input; + bool status; + int32_t value; + }; + const int32_t int32_min = std::numeric_limits<int32_t>::min(); + const int32_t int32_max = std::numeric_limits<int32_t>::max(); + Int32TestLine int32_test_line[] = { + {"", false, 0}, + {" ", false, 0}, + {"-", false, 0}, + {"123@@@", false, 123}, + {absl::StrCat(int32_min, int32_max), false, int32_min}, + {absl::StrCat(int32_max, int32_max), false, int32_max}, + }; + + for (const Int32TestLine& test_line : int32_test_line) { + int32_t value = -2; + bool status = safe_strto32_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = -2; + status = safe_strto32_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = -2; + status = safe_strto32_base(absl::string_view(test_line.input), &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + } +} + +TEST(StrToUint32, Partial) { + struct Uint32TestLine { + std::string input; + bool status; + uint32_t value; + }; + const uint32_t uint32_max = std::numeric_limits<uint32_t>::max(); + Uint32TestLine uint32_test_line[] = { + {"", false, 0}, + {" ", false, 0}, + {"-", false, 0}, + {"123@@@", false, 123}, + {absl::StrCat(uint32_max, uint32_max), false, uint32_max}, + }; + + for (const Uint32TestLine& test_line : uint32_test_line) { + uint32_t value = 2; + bool status = safe_strtou32_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = 2; + status = safe_strtou32_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = 2; + status = safe_strtou32_base(absl::string_view(test_line.input), &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + } +} + +TEST(StrToInt64, Partial) { + struct Int64TestLine { + std::string input; + bool status; + int64_t value; + }; + const int64_t int64_min = std::numeric_limits<int64_t>::min(); + const int64_t int64_max = std::numeric_limits<int64_t>::max(); + Int64TestLine int64_test_line[] = { + {"", false, 0}, + {" ", false, 0}, + {"-", false, 0}, + {"123@@@", false, 123}, + {absl::StrCat(int64_min, int64_max), false, int64_min}, + {absl::StrCat(int64_max, int64_max), false, int64_max}, + }; + + for (const Int64TestLine& test_line : int64_test_line) { + int64_t value = -2; + bool status = safe_strto64_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = -2; + status = safe_strto64_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = -2; + status = safe_strto64_base(absl::string_view(test_line.input), &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + } +} + +TEST(StrToUint64, Partial) { + struct Uint64TestLine { + std::string input; + bool status; + uint64_t value; + }; + const uint64_t uint64_max = std::numeric_limits<uint64_t>::max(); + Uint64TestLine uint64_test_line[] = { + {"", false, 0}, + {" ", false, 0}, + {"-", false, 0}, + {"123@@@", false, 123}, + {absl::StrCat(uint64_max, uint64_max), false, uint64_max}, + }; + + for (const Uint64TestLine& test_line : uint64_test_line) { + uint64_t value = 2; + bool status = safe_strtou64_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = 2; + status = safe_strtou64_base(test_line.input, &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + value = 2; + status = safe_strtou64_base(absl::string_view(test_line.input), &value, 10); + EXPECT_EQ(test_line.status, status) << test_line.input; + EXPECT_EQ(test_line.value, value) << test_line.input; + } +} + +TEST(StrToInt32Base, PrefixOnly) { + struct Int32TestLine { + std::string input; + bool status; + int32_t value; + }; + Int32TestLine int32_test_line[] = { + { "", false, 0 }, + { "-", false, 0 }, + { "-0", true, 0 }, + { "0", true, 0 }, + { "0x", false, 0 }, + { "-0x", false, 0 }, + }; + const int base_array[] = { 0, 2, 8, 10, 16 }; + + for (const Int32TestLine& line : int32_test_line) { + for (const int base : base_array) { + int32_t value = 2; + bool status = safe_strto32_base(line.input.c_str(), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strto32_base(line.input, &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strto32_base(absl::string_view(line.input), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + } + } +} + +TEST(StrToUint32Base, PrefixOnly) { + struct Uint32TestLine { + std::string input; + bool status; + uint32_t value; + }; + Uint32TestLine uint32_test_line[] = { + { "", false, 0 }, + { "0", true, 0 }, + { "0x", false, 0 }, + }; + const int base_array[] = { 0, 2, 8, 10, 16 }; + + for (const Uint32TestLine& line : uint32_test_line) { + for (const int base : base_array) { + uint32_t value = 2; + bool status = safe_strtou32_base(line.input.c_str(), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strtou32_base(line.input, &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strtou32_base(absl::string_view(line.input), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + } + } +} + +TEST(StrToInt64Base, PrefixOnly) { + struct Int64TestLine { + std::string input; + bool status; + int64_t value; + }; + Int64TestLine int64_test_line[] = { + { "", false, 0 }, + { "-", false, 0 }, + { "-0", true, 0 }, + { "0", true, 0 }, + { "0x", false, 0 }, + { "-0x", false, 0 }, + }; + const int base_array[] = { 0, 2, 8, 10, 16 }; + + for (const Int64TestLine& line : int64_test_line) { + for (const int base : base_array) { + int64_t value = 2; + bool status = safe_strto64_base(line.input.c_str(), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strto64_base(line.input, &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strto64_base(absl::string_view(line.input), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + } + } +} + +TEST(StrToUint64Base, PrefixOnly) { + struct Uint64TestLine { + std::string input; + bool status; + uint64_t value; + }; + Uint64TestLine uint64_test_line[] = { + { "", false, 0 }, + { "0", true, 0 }, + { "0x", false, 0 }, + }; + const int base_array[] = { 0, 2, 8, 10, 16 }; + + for (const Uint64TestLine& line : uint64_test_line) { + for (const int base : base_array) { + uint64_t value = 2; + bool status = safe_strtou64_base(line.input.c_str(), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strtou64_base(line.input, &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + value = 2; + status = safe_strtou64_base(absl::string_view(line.input), &value, base); + EXPECT_EQ(line.status, status) << line.input << " " << base; + EXPECT_EQ(line.value, value) << line.input << " " << base; + } + } +} + +void TestFastHexToBufferZeroPad16(uint64_t v) { + char buf[16]; + auto digits = absl::numbers_internal::FastHexToBufferZeroPad16(v, buf); + absl::string_view res(buf, 16); + char buf2[17]; + snprintf(buf2, sizeof(buf2), "%016" PRIx64, v); + EXPECT_EQ(res, buf2) << v; + size_t expected_digits = snprintf(buf2, sizeof(buf2), "%" PRIx64, v); + EXPECT_EQ(digits, expected_digits) << v; +} + +TEST(FastHexToBufferZeroPad16, Smoke) { + TestFastHexToBufferZeroPad16(std::numeric_limits<uint64_t>::min()); + TestFastHexToBufferZeroPad16(std::numeric_limits<uint64_t>::max()); + TestFastHexToBufferZeroPad16(std::numeric_limits<int64_t>::min()); + TestFastHexToBufferZeroPad16(std::numeric_limits<int64_t>::max()); + absl::BitGen rng; + for (int i = 0; i < 100000; ++i) { + TestFastHexToBufferZeroPad16( + absl::LogUniform(rng, std::numeric_limits<uint64_t>::min(), + std::numeric_limits<uint64_t>::max())); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_cat.cc b/third_party/abseil_cpp/absl/strings/str_cat.cc new file mode 100644 index 0000000000..d9afe2f385 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_cat.cc @@ -0,0 +1,246 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_cat.h" + +#include <assert.h> + +#include <algorithm> +#include <cstdint> +#include <cstring> + +#include "absl/strings/ascii.h" +#include "absl/strings/internal/resize_uninitialized.h" +#include "absl/strings/numbers.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +AlphaNum::AlphaNum(Hex hex) { + static_assert(numbers_internal::kFastToBufferSize >= 32, + "This function only works when output buffer >= 32 bytes long"); + char* const end = &digits_[numbers_internal::kFastToBufferSize]; + auto real_width = + absl::numbers_internal::FastHexToBufferZeroPad16(hex.value, end - 16); + if (real_width >= hex.width) { + piece_ = absl::string_view(end - real_width, real_width); + } else { + // Pad first 16 chars because FastHexToBufferZeroPad16 pads only to 16 and + // max pad width can be up to 20. + std::memset(end - 32, hex.fill, 16); + // Patch up everything else up to the real_width. + std::memset(end - real_width - 16, hex.fill, 16); + piece_ = absl::string_view(end - hex.width, hex.width); + } +} + +AlphaNum::AlphaNum(Dec dec) { + assert(dec.width <= numbers_internal::kFastToBufferSize); + char* const end = &digits_[numbers_internal::kFastToBufferSize]; + char* const minfill = end - dec.width; + char* writer = end; + uint64_t value = dec.value; + bool neg = dec.neg; + while (value > 9) { + *--writer = '0' + (value % 10); + value /= 10; + } + *--writer = '0' + value; + if (neg) *--writer = '-'; + + ptrdiff_t fillers = writer - minfill; + if (fillers > 0) { + // Tricky: if the fill character is ' ', then it's <fill><+/-><digits> + // But...: if the fill character is '0', then it's <+/-><fill><digits> + bool add_sign_again = false; + if (neg && dec.fill == '0') { // If filling with '0', + ++writer; // ignore the sign we just added + add_sign_again = true; // and re-add the sign later. + } + writer -= fillers; + std::fill_n(writer, fillers, dec.fill); + if (add_sign_again) *--writer = '-'; + } + + piece_ = absl::string_view(writer, end - writer); +} + +// ---------------------------------------------------------------------- +// StrCat() +// This merges the given strings or integers, with no delimiter. This +// is designed to be the fastest possible way to construct a string out +// of a mix of raw C strings, string_views, strings, and integer values. +// ---------------------------------------------------------------------- + +// Append is merely a version of memcpy that returns the address of the byte +// after the area just overwritten. +static char* Append(char* out, const AlphaNum& x) { + // memcpy is allowed to overwrite arbitrary memory, so doing this after the + // call would force an extra fetch of x.size(). + char* after = out + x.size(); + if (x.size() != 0) { + memcpy(out, x.data(), x.size()); + } + return after; +} + +std::string StrCat(const AlphaNum& a, const AlphaNum& b) { + std::string result; + absl::strings_internal::STLStringResizeUninitialized(&result, + a.size() + b.size()); + char* const begin = &result[0]; + char* out = begin; + out = Append(out, a); + out = Append(out, b); + assert(out == begin + result.size()); + return result; +} + +std::string StrCat(const AlphaNum& a, const AlphaNum& b, const AlphaNum& c) { + std::string result; + strings_internal::STLStringResizeUninitialized( + &result, a.size() + b.size() + c.size()); + char* const begin = &result[0]; + char* out = begin; + out = Append(out, a); + out = Append(out, b); + out = Append(out, c); + assert(out == begin + result.size()); + return result; +} + +std::string StrCat(const AlphaNum& a, const AlphaNum& b, const AlphaNum& c, + const AlphaNum& d) { + std::string result; + strings_internal::STLStringResizeUninitialized( + &result, a.size() + b.size() + c.size() + d.size()); + char* const begin = &result[0]; + char* out = begin; + out = Append(out, a); + out = Append(out, b); + out = Append(out, c); + out = Append(out, d); + assert(out == begin + result.size()); + return result; +} + +namespace strings_internal { + +// Do not call directly - these are not part of the public API. +std::string CatPieces(std::initializer_list<absl::string_view> pieces) { + std::string result; + size_t total_size = 0; + for (const absl::string_view piece : pieces) total_size += piece.size(); + strings_internal::STLStringResizeUninitialized(&result, total_size); + + char* const begin = &result[0]; + char* out = begin; + for (const absl::string_view piece : pieces) { + const size_t this_size = piece.size(); + if (this_size != 0) { + memcpy(out, piece.data(), this_size); + out += this_size; + } + } + assert(out == begin + result.size()); + return result; +} + +// It's possible to call StrAppend with an absl::string_view that is itself a +// fragment of the string we're appending to. However the results of this are +// random. Therefore, check for this in debug mode. Use unsigned math so we +// only have to do one comparison. Note, there's an exception case: appending an +// empty string is always allowed. +#define ASSERT_NO_OVERLAP(dest, src) \ + assert(((src).size() == 0) || \ + (uintptr_t((src).data() - (dest).data()) > uintptr_t((dest).size()))) + +void AppendPieces(std::string* dest, + std::initializer_list<absl::string_view> pieces) { + size_t old_size = dest->size(); + size_t total_size = old_size; + for (const absl::string_view piece : pieces) { + ASSERT_NO_OVERLAP(*dest, piece); + total_size += piece.size(); + } + strings_internal::STLStringResizeUninitialized(dest, total_size); + + char* const begin = &(*dest)[0]; + char* out = begin + old_size; + for (const absl::string_view piece : pieces) { + const size_t this_size = piece.size(); + if (this_size != 0) { + memcpy(out, piece.data(), this_size); + out += this_size; + } + } + assert(out == begin + dest->size()); +} + +} // namespace strings_internal + +void StrAppend(std::string* dest, const AlphaNum& a) { + ASSERT_NO_OVERLAP(*dest, a); + dest->append(a.data(), a.size()); +} + +void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b) { + ASSERT_NO_OVERLAP(*dest, a); + ASSERT_NO_OVERLAP(*dest, b); + std::string::size_type old_size = dest->size(); + strings_internal::STLStringResizeUninitialized( + dest, old_size + a.size() + b.size()); + char* const begin = &(*dest)[0]; + char* out = begin + old_size; + out = Append(out, a); + out = Append(out, b); + assert(out == begin + dest->size()); +} + +void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c) { + ASSERT_NO_OVERLAP(*dest, a); + ASSERT_NO_OVERLAP(*dest, b); + ASSERT_NO_OVERLAP(*dest, c); + std::string::size_type old_size = dest->size(); + strings_internal::STLStringResizeUninitialized( + dest, old_size + a.size() + b.size() + c.size()); + char* const begin = &(*dest)[0]; + char* out = begin + old_size; + out = Append(out, a); + out = Append(out, b); + out = Append(out, c); + assert(out == begin + dest->size()); +} + +void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c, const AlphaNum& d) { + ASSERT_NO_OVERLAP(*dest, a); + ASSERT_NO_OVERLAP(*dest, b); + ASSERT_NO_OVERLAP(*dest, c); + ASSERT_NO_OVERLAP(*dest, d); + std::string::size_type old_size = dest->size(); + strings_internal::STLStringResizeUninitialized( + dest, old_size + a.size() + b.size() + c.size() + d.size()); + char* const begin = &(*dest)[0]; + char* out = begin + old_size; + out = Append(out, a); + out = Append(out, b); + out = Append(out, c); + out = Append(out, d); + assert(out == begin + dest->size()); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/str_cat.h b/third_party/abseil_cpp/absl/strings/str_cat.h new file mode 100644 index 0000000000..a8a85c7322 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_cat.h @@ -0,0 +1,408 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: str_cat.h +// ----------------------------------------------------------------------------- +// +// This package contains functions for efficiently concatenating and appending +// strings: `StrCat()` and `StrAppend()`. Most of the work within these routines +// is actually handled through use of a special AlphaNum type, which was +// designed to be used as a parameter type that efficiently manages conversion +// to strings and avoids copies in the above operations. +// +// Any routine accepting either a string or a number may accept `AlphaNum`. +// The basic idea is that by accepting a `const AlphaNum &` as an argument +// to your function, your callers will automagically convert bools, integers, +// and floating point values to strings for you. +// +// NOTE: Use of `AlphaNum` outside of the //absl/strings package is unsupported +// except for the specific case of function parameters of type `AlphaNum` or +// `const AlphaNum &`. In particular, instantiating `AlphaNum` directly as a +// stack variable is not supported. +// +// Conversion from 8-bit values is not accepted because, if it were, then an +// attempt to pass ':' instead of ":" might result in a 58 ending up in your +// result. +// +// Bools convert to "0" or "1". Pointers to types other than `char *` are not +// valid inputs. No output is generated for null `char *` pointers. +// +// Floating point numbers are formatted with six-digit precision, which is +// the default for "std::cout <<" or printf "%g" (the same as "%.6g"). +// +// You can convert to hexadecimal output rather than decimal output using the +// `Hex` type contained here. To do so, pass `Hex(my_int)` as a parameter to +// `StrCat()` or `StrAppend()`. You may specify a minimum hex field width using +// a `PadSpec` enum. +// +// ----------------------------------------------------------------------------- + +#ifndef ABSL_STRINGS_STR_CAT_H_ +#define ABSL_STRINGS_STR_CAT_H_ + +#include <array> +#include <cstdint> +#include <string> +#include <type_traits> +#include <vector> + +#include "absl/base/port.h" +#include "absl/strings/numbers.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace strings_internal { +// AlphaNumBuffer allows a way to pass a string to StrCat without having to do +// memory allocation. It is simply a pair of a fixed-size character array, and +// a size. Please don't use outside of absl, yet. +template <size_t max_size> +struct AlphaNumBuffer { + std::array<char, max_size> data; + size_t size; +}; + +} // namespace strings_internal + +// Enum that specifies the number of significant digits to return in a `Hex` or +// `Dec` conversion and fill character to use. A `kZeroPad2` value, for example, +// would produce hexadecimal strings such as "0a","0f" and a 'kSpacePad5' value +// would produce hexadecimal strings such as " a"," f". +enum PadSpec : uint8_t { + kNoPad = 1, + kZeroPad2, + kZeroPad3, + kZeroPad4, + kZeroPad5, + kZeroPad6, + kZeroPad7, + kZeroPad8, + kZeroPad9, + kZeroPad10, + kZeroPad11, + kZeroPad12, + kZeroPad13, + kZeroPad14, + kZeroPad15, + kZeroPad16, + kZeroPad17, + kZeroPad18, + kZeroPad19, + kZeroPad20, + + kSpacePad2 = kZeroPad2 + 64, + kSpacePad3, + kSpacePad4, + kSpacePad5, + kSpacePad6, + kSpacePad7, + kSpacePad8, + kSpacePad9, + kSpacePad10, + kSpacePad11, + kSpacePad12, + kSpacePad13, + kSpacePad14, + kSpacePad15, + kSpacePad16, + kSpacePad17, + kSpacePad18, + kSpacePad19, + kSpacePad20, +}; + +// ----------------------------------------------------------------------------- +// Hex +// ----------------------------------------------------------------------------- +// +// `Hex` stores a set of hexadecimal string conversion parameters for use +// within `AlphaNum` string conversions. +struct Hex { + uint64_t value; + uint8_t width; + char fill; + + template <typename Int> + explicit Hex( + Int v, PadSpec spec = absl::kNoPad, + typename std::enable_if<sizeof(Int) == 1 && + !std::is_pointer<Int>::value>::type* = nullptr) + : Hex(spec, static_cast<uint8_t>(v)) {} + template <typename Int> + explicit Hex( + Int v, PadSpec spec = absl::kNoPad, + typename std::enable_if<sizeof(Int) == 2 && + !std::is_pointer<Int>::value>::type* = nullptr) + : Hex(spec, static_cast<uint16_t>(v)) {} + template <typename Int> + explicit Hex( + Int v, PadSpec spec = absl::kNoPad, + typename std::enable_if<sizeof(Int) == 4 && + !std::is_pointer<Int>::value>::type* = nullptr) + : Hex(spec, static_cast<uint32_t>(v)) {} + template <typename Int> + explicit Hex( + Int v, PadSpec spec = absl::kNoPad, + typename std::enable_if<sizeof(Int) == 8 && + !std::is_pointer<Int>::value>::type* = nullptr) + : Hex(spec, static_cast<uint64_t>(v)) {} + template <typename Pointee> + explicit Hex(Pointee* v, PadSpec spec = absl::kNoPad) + : Hex(spec, reinterpret_cast<uintptr_t>(v)) {} + + private: + Hex(PadSpec spec, uint64_t v) + : value(v), + width(spec == absl::kNoPad + ? 1 + : spec >= absl::kSpacePad2 ? spec - absl::kSpacePad2 + 2 + : spec - absl::kZeroPad2 + 2), + fill(spec >= absl::kSpacePad2 ? ' ' : '0') {} +}; + +// ----------------------------------------------------------------------------- +// Dec +// ----------------------------------------------------------------------------- +// +// `Dec` stores a set of decimal string conversion parameters for use +// within `AlphaNum` string conversions. Dec is slower than the default +// integer conversion, so use it only if you need padding. +struct Dec { + uint64_t value; + uint8_t width; + char fill; + bool neg; + + template <typename Int> + explicit Dec(Int v, PadSpec spec = absl::kNoPad, + typename std::enable_if<(sizeof(Int) <= 8)>::type* = nullptr) + : value(v >= 0 ? static_cast<uint64_t>(v) + : uint64_t{0} - static_cast<uint64_t>(v)), + width(spec == absl::kNoPad + ? 1 + : spec >= absl::kSpacePad2 ? spec - absl::kSpacePad2 + 2 + : spec - absl::kZeroPad2 + 2), + fill(spec >= absl::kSpacePad2 ? ' ' : '0'), + neg(v < 0) {} +}; + +// ----------------------------------------------------------------------------- +// AlphaNum +// ----------------------------------------------------------------------------- +// +// The `AlphaNum` class acts as the main parameter type for `StrCat()` and +// `StrAppend()`, providing efficient conversion of numeric, boolean, and +// hexadecimal values (through the `Hex` type) into strings. + +class AlphaNum { + public: + // No bool ctor -- bools convert to an integral type. + // A bool ctor would also convert incoming pointers (bletch). + + AlphaNum(int x) // NOLINT(runtime/explicit) + : piece_(digits_, + numbers_internal::FastIntToBuffer(x, digits_) - &digits_[0]) {} + AlphaNum(unsigned int x) // NOLINT(runtime/explicit) + : piece_(digits_, + numbers_internal::FastIntToBuffer(x, digits_) - &digits_[0]) {} + AlphaNum(long x) // NOLINT(*) + : piece_(digits_, + numbers_internal::FastIntToBuffer(x, digits_) - &digits_[0]) {} + AlphaNum(unsigned long x) // NOLINT(*) + : piece_(digits_, + numbers_internal::FastIntToBuffer(x, digits_) - &digits_[0]) {} + AlphaNum(long long x) // NOLINT(*) + : piece_(digits_, + numbers_internal::FastIntToBuffer(x, digits_) - &digits_[0]) {} + AlphaNum(unsigned long long x) // NOLINT(*) + : piece_(digits_, + numbers_internal::FastIntToBuffer(x, digits_) - &digits_[0]) {} + + AlphaNum(float f) // NOLINT(runtime/explicit) + : piece_(digits_, numbers_internal::SixDigitsToBuffer(f, digits_)) {} + AlphaNum(double f) // NOLINT(runtime/explicit) + : piece_(digits_, numbers_internal::SixDigitsToBuffer(f, digits_)) {} + + AlphaNum(Hex hex); // NOLINT(runtime/explicit) + AlphaNum(Dec dec); // NOLINT(runtime/explicit) + + template <size_t size> + AlphaNum( // NOLINT(runtime/explicit) + const strings_internal::AlphaNumBuffer<size>& buf) + : piece_(&buf.data[0], buf.size) {} + + AlphaNum(const char* c_str) : piece_(c_str) {} // NOLINT(runtime/explicit) + AlphaNum(absl::string_view pc) : piece_(pc) {} // NOLINT(runtime/explicit) + + template <typename Allocator> + AlphaNum( // NOLINT(runtime/explicit) + const std::basic_string<char, std::char_traits<char>, Allocator>& str) + : piece_(str) {} + + // Use string literals ":" instead of character literals ':'. + AlphaNum(char c) = delete; // NOLINT(runtime/explicit) + + AlphaNum(const AlphaNum&) = delete; + AlphaNum& operator=(const AlphaNum&) = delete; + + absl::string_view::size_type size() const { return piece_.size(); } + const char* data() const { return piece_.data(); } + absl::string_view Piece() const { return piece_; } + + // Normal enums are already handled by the integer formatters. + // This overload matches only scoped enums. + template <typename T, + typename = typename std::enable_if< + std::is_enum<T>{} && !std::is_convertible<T, int>{}>::type> + AlphaNum(T e) // NOLINT(runtime/explicit) + : AlphaNum(static_cast<typename std::underlying_type<T>::type>(e)) {} + + // vector<bool>::reference and const_reference require special help to + // convert to `AlphaNum` because it requires two user defined conversions. + template < + typename T, + typename std::enable_if< + std::is_class<T>::value && + (std::is_same<T, std::vector<bool>::reference>::value || + std::is_same<T, std::vector<bool>::const_reference>::value)>::type* = + nullptr> + AlphaNum(T e) : AlphaNum(static_cast<bool>(e)) {} // NOLINT(runtime/explicit) + + private: + absl::string_view piece_; + char digits_[numbers_internal::kFastToBufferSize]; +}; + +// ----------------------------------------------------------------------------- +// StrCat() +// ----------------------------------------------------------------------------- +// +// Merges given strings or numbers, using no delimiter(s), returning the merged +// result as a string. +// +// `StrCat()` is designed to be the fastest possible way to construct a string +// out of a mix of raw C strings, string_views, strings, bool values, +// and numeric values. +// +// Don't use `StrCat()` for user-visible strings. The localization process +// works poorly on strings built up out of fragments. +// +// For clarity and performance, don't use `StrCat()` when appending to a +// string. Use `StrAppend()` instead. In particular, avoid using any of these +// (anti-)patterns: +// +// str.append(StrCat(...)) +// str += StrCat(...) +// str = StrCat(str, ...) +// +// The last case is the worst, with a potential to change a loop +// from a linear time operation with O(1) dynamic allocations into a +// quadratic time operation with O(n) dynamic allocations. +// +// See `StrAppend()` below for more information. + +namespace strings_internal { + +// Do not call directly - this is not part of the public API. +std::string CatPieces(std::initializer_list<absl::string_view> pieces); +void AppendPieces(std::string* dest, + std::initializer_list<absl::string_view> pieces); + +} // namespace strings_internal + +ABSL_MUST_USE_RESULT inline std::string StrCat() { return std::string(); } + +ABSL_MUST_USE_RESULT inline std::string StrCat(const AlphaNum& a) { + return std::string(a.data(), a.size()); +} + +ABSL_MUST_USE_RESULT std::string StrCat(const AlphaNum& a, const AlphaNum& b); +ABSL_MUST_USE_RESULT std::string StrCat(const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c); +ABSL_MUST_USE_RESULT std::string StrCat(const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c, const AlphaNum& d); + +// Support 5 or more arguments +template <typename... AV> +ABSL_MUST_USE_RESULT inline std::string StrCat( + const AlphaNum& a, const AlphaNum& b, const AlphaNum& c, const AlphaNum& d, + const AlphaNum& e, const AV&... args) { + return strings_internal::CatPieces( + {a.Piece(), b.Piece(), c.Piece(), d.Piece(), e.Piece(), + static_cast<const AlphaNum&>(args).Piece()...}); +} + +// ----------------------------------------------------------------------------- +// StrAppend() +// ----------------------------------------------------------------------------- +// +// Appends a string or set of strings to an existing string, in a similar +// fashion to `StrCat()`. +// +// WARNING: `StrAppend(&str, a, b, c, ...)` requires that none of the +// a, b, c, parameters be a reference into str. For speed, `StrAppend()` does +// not try to check each of its input arguments to be sure that they are not +// a subset of the string being appended to. That is, while this will work: +// +// std::string s = "foo"; +// s += s; +// +// This output is undefined: +// +// std::string s = "foo"; +// StrAppend(&s, s); +// +// This output is undefined as well, since `absl::string_view` does not own its +// data: +// +// std::string s = "foobar"; +// absl::string_view p = s; +// StrAppend(&s, p); + +inline void StrAppend(std::string*) {} +void StrAppend(std::string* dest, const AlphaNum& a); +void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b); +void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c); +void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c, const AlphaNum& d); + +// Support 5 or more arguments +template <typename... AV> +inline void StrAppend(std::string* dest, const AlphaNum& a, const AlphaNum& b, + const AlphaNum& c, const AlphaNum& d, const AlphaNum& e, + const AV&... args) { + strings_internal::AppendPieces( + dest, {a.Piece(), b.Piece(), c.Piece(), d.Piece(), e.Piece(), + static_cast<const AlphaNum&>(args).Piece()...}); +} + +// Helper function for the future StrCat default floating-point format, %.6g +// This is fast. +inline strings_internal::AlphaNumBuffer< + numbers_internal::kSixDigitsToBufferSize> +SixDigits(double d) { + strings_internal::AlphaNumBuffer<numbers_internal::kSixDigitsToBufferSize> + result; + result.size = numbers_internal::SixDigitsToBuffer(d, &result.data[0]); + return result; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STR_CAT_H_ diff --git a/third_party/abseil_cpp/absl/strings/str_cat_benchmark.cc b/third_party/abseil_cpp/absl/strings/str_cat_benchmark.cc new file mode 100644 index 0000000000..ee4ad112f5 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_cat_benchmark.cc @@ -0,0 +1,140 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_cat.h" + +#include <cstdint> +#include <string> + +#include "benchmark/benchmark.h" +#include "absl/strings/substitute.h" + +namespace { + +const char kStringOne[] = "Once Upon A Time, "; +const char kStringTwo[] = "There was a string benchmark"; + +// We want to include negative numbers in the benchmark, so this function +// is used to count 0, 1, -1, 2, -2, 3, -3, ... +inline int IncrementAlternatingSign(int i) { + return i > 0 ? -i : 1 - i; +} + +void BM_Sum_By_StrCat(benchmark::State& state) { + int i = 0; + char foo[100]; + for (auto _ : state) { + // NOLINTNEXTLINE(runtime/printf) + strcpy(foo, absl::StrCat(kStringOne, i, kStringTwo, i * 65536ULL).c_str()); + int sum = 0; + for (char* f = &foo[0]; *f != 0; ++f) { + sum += *f; + } + benchmark::DoNotOptimize(sum); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_Sum_By_StrCat); + +void BM_StrCat_By_snprintf(benchmark::State& state) { + int i = 0; + char on_stack[1000]; + for (auto _ : state) { + snprintf(on_stack, sizeof(on_stack), "%s %s:%d", kStringOne, kStringTwo, i); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_StrCat_By_snprintf); + +void BM_StrCat_By_Strings(benchmark::State& state) { + int i = 0; + for (auto _ : state) { + std::string result = + std::string(kStringOne) + " " + kStringTwo + ":" + absl::StrCat(i); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_StrCat_By_Strings); + +void BM_StrCat_By_StringOpPlus(benchmark::State& state) { + int i = 0; + for (auto _ : state) { + std::string result = kStringOne; + result += " "; + result += kStringTwo; + result += ":"; + result += absl::StrCat(i); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_StrCat_By_StringOpPlus); + +void BM_StrCat_By_StrCat(benchmark::State& state) { + int i = 0; + for (auto _ : state) { + std::string result = absl::StrCat(kStringOne, " ", kStringTwo, ":", i); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_StrCat_By_StrCat); + +void BM_HexCat_By_StrCat(benchmark::State& state) { + int i = 0; + for (auto _ : state) { + std::string result = + absl::StrCat(kStringOne, " ", absl::Hex(int64_t{i} + 0x10000000)); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_HexCat_By_StrCat); + +void BM_HexCat_By_Substitute(benchmark::State& state) { + int i = 0; + for (auto _ : state) { + std::string result = absl::Substitute( + "$0 $1", kStringOne, reinterpret_cast<void*>(int64_t{i} + 0x10000000)); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_HexCat_By_Substitute); + +void BM_FloatToString_By_StrCat(benchmark::State& state) { + int i = 0; + float foo = 0.0f; + for (auto _ : state) { + std::string result = absl::StrCat(foo += 1.001f, " != ", int64_t{i}); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_FloatToString_By_StrCat); + +void BM_DoubleToString_By_SixDigits(benchmark::State& state) { + int i = 0; + double foo = 0.0; + for (auto _ : state) { + std::string result = + absl::StrCat(absl::SixDigits(foo += 1.001), " != ", int64_t{i}); + benchmark::DoNotOptimize(result); + i = IncrementAlternatingSign(i); + } +} +BENCHMARK(BM_DoubleToString_By_SixDigits); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_cat_test.cc b/third_party/abseil_cpp/absl/strings/str_cat_test.cc new file mode 100644 index 0000000000..f3770dc076 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_cat_test.cc @@ -0,0 +1,610 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Unit tests for all str_cat.h functions + +#include "absl/strings/str_cat.h" + +#include <cstdint> +#include <string> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/strings/substitute.h" + +#ifdef __ANDROID__ +// Android assert messages only go to system log, so death tests cannot inspect +// the message for matching. +#define ABSL_EXPECT_DEBUG_DEATH(statement, regex) \ + EXPECT_DEBUG_DEATH(statement, ".*") +#else +#define ABSL_EXPECT_DEBUG_DEATH(statement, regex) \ + EXPECT_DEBUG_DEATH(statement, regex) +#endif + +namespace { + +// Test absl::StrCat of ints and longs of various sizes and signdedness. +TEST(StrCat, Ints) { + const short s = -1; // NOLINT(runtime/int) + const uint16_t us = 2; + const int i = -3; + const unsigned int ui = 4; + const long l = -5; // NOLINT(runtime/int) + const unsigned long ul = 6; // NOLINT(runtime/int) + const long long ll = -7; // NOLINT(runtime/int) + const unsigned long long ull = 8; // NOLINT(runtime/int) + const ptrdiff_t ptrdiff = -9; + const size_t size = 10; + const intptr_t intptr = -12; + const uintptr_t uintptr = 13; + std::string answer; + answer = absl::StrCat(s, us); + EXPECT_EQ(answer, "-12"); + answer = absl::StrCat(i, ui); + EXPECT_EQ(answer, "-34"); + answer = absl::StrCat(l, ul); + EXPECT_EQ(answer, "-56"); + answer = absl::StrCat(ll, ull); + EXPECT_EQ(answer, "-78"); + answer = absl::StrCat(ptrdiff, size); + EXPECT_EQ(answer, "-910"); + answer = absl::StrCat(ptrdiff, intptr); + EXPECT_EQ(answer, "-9-12"); + answer = absl::StrCat(uintptr, 0); + EXPECT_EQ(answer, "130"); +} + +TEST(StrCat, Enums) { + enum SmallNumbers { One = 1, Ten = 10 } e = Ten; + EXPECT_EQ("10", absl::StrCat(e)); + EXPECT_EQ("-5", absl::StrCat(SmallNumbers(-5))); + + enum class Option { Boxers = 1, Briefs = -1 }; + + EXPECT_EQ("-1", absl::StrCat(Option::Briefs)); + + enum class Airplane : uint64_t { + Airbus = 1, + Boeing = 1000, + Canary = 10000000000 // too big for "int" + }; + + EXPECT_EQ("10000000000", absl::StrCat(Airplane::Canary)); + + enum class TwoGig : int32_t { + TwoToTheZero = 1, + TwoToTheSixteenth = 1 << 16, + TwoToTheThirtyFirst = INT32_MIN + }; + EXPECT_EQ("65536", absl::StrCat(TwoGig::TwoToTheSixteenth)); + EXPECT_EQ("-2147483648", absl::StrCat(TwoGig::TwoToTheThirtyFirst)); + EXPECT_EQ("-1", absl::StrCat(static_cast<TwoGig>(-1))); + + enum class FourGig : uint32_t { + TwoToTheZero = 1, + TwoToTheSixteenth = 1 << 16, + TwoToTheThirtyFirst = 1U << 31 // too big for "int" + }; + EXPECT_EQ("65536", absl::StrCat(FourGig::TwoToTheSixteenth)); + EXPECT_EQ("2147483648", absl::StrCat(FourGig::TwoToTheThirtyFirst)); + EXPECT_EQ("4294967295", absl::StrCat(static_cast<FourGig>(-1))); + + EXPECT_EQ("10000000000", absl::StrCat(Airplane::Canary)); +} + +TEST(StrCat, Basics) { + std::string result; + + std::string strs[] = {"Hello", "Cruel", "World"}; + + std::string stdstrs[] = { + "std::Hello", + "std::Cruel", + "std::World" + }; + + absl::string_view pieces[] = {"Hello", "Cruel", "World"}; + + const char* c_strs[] = { + "Hello", + "Cruel", + "World" + }; + + int32_t i32s[] = {'H', 'C', 'W'}; + uint64_t ui64s[] = {12345678910LL, 10987654321LL}; + + EXPECT_EQ(absl::StrCat(), ""); + + result = absl::StrCat(false, true, 2, 3); + EXPECT_EQ(result, "0123"); + + result = absl::StrCat(-1); + EXPECT_EQ(result, "-1"); + + result = absl::StrCat(absl::SixDigits(0.5)); + EXPECT_EQ(result, "0.5"); + + result = absl::StrCat(strs[1], pieces[2]); + EXPECT_EQ(result, "CruelWorld"); + + result = absl::StrCat(stdstrs[1], " ", stdstrs[2]); + EXPECT_EQ(result, "std::Cruel std::World"); + + result = absl::StrCat(strs[0], ", ", pieces[2]); + EXPECT_EQ(result, "Hello, World"); + + result = absl::StrCat(strs[0], ", ", strs[1], " ", strs[2], "!"); + EXPECT_EQ(result, "Hello, Cruel World!"); + + result = absl::StrCat(pieces[0], ", ", pieces[1], " ", pieces[2]); + EXPECT_EQ(result, "Hello, Cruel World"); + + result = absl::StrCat(c_strs[0], ", ", c_strs[1], " ", c_strs[2]); + EXPECT_EQ(result, "Hello, Cruel World"); + + result = absl::StrCat("ASCII ", i32s[0], ", ", i32s[1], " ", i32s[2], "!"); + EXPECT_EQ(result, "ASCII 72, 67 87!"); + + result = absl::StrCat(ui64s[0], ", ", ui64s[1], "!"); + EXPECT_EQ(result, "12345678910, 10987654321!"); + + std::string one = + "1"; // Actually, it's the size of this string that we want; a + // 64-bit build distinguishes between size_t and uint64_t, + // even though they're both unsigned 64-bit values. + result = absl::StrCat("And a ", one.size(), " and a ", + &result[2] - &result[0], " and a ", one, " 2 3 4", "!"); + EXPECT_EQ(result, "And a 1 and a 2 and a 1 2 3 4!"); + + // result = absl::StrCat("Single chars won't compile", '!'); + // result = absl::StrCat("Neither will nullptrs", nullptr); + result = + absl::StrCat("To output a char by ASCII/numeric value, use +: ", '!' + 0); + EXPECT_EQ(result, "To output a char by ASCII/numeric value, use +: 33"); + + float f = 100000.5; + result = absl::StrCat("A hundred K and a half is ", absl::SixDigits(f)); + EXPECT_EQ(result, "A hundred K and a half is 100000"); + + f = 100001.5; + result = + absl::StrCat("A hundred K and one and a half is ", absl::SixDigits(f)); + EXPECT_EQ(result, "A hundred K and one and a half is 100002"); + + double d = 100000.5; + d *= d; + result = + absl::StrCat("A hundred K and a half squared is ", absl::SixDigits(d)); + EXPECT_EQ(result, "A hundred K and a half squared is 1.00001e+10"); + + result = absl::StrCat(1, 2, 333, 4444, 55555, 666666, 7777777, 88888888, + 999999999); + EXPECT_EQ(result, "12333444455555666666777777788888888999999999"); +} + +TEST(StrCat, CornerCases) { + std::string result; + + result = absl::StrCat(""); // NOLINT + EXPECT_EQ(result, ""); + result = absl::StrCat("", ""); + EXPECT_EQ(result, ""); + result = absl::StrCat("", "", ""); + EXPECT_EQ(result, ""); + result = absl::StrCat("", "", "", ""); + EXPECT_EQ(result, ""); + result = absl::StrCat("", "", "", "", ""); + EXPECT_EQ(result, ""); +} + +// A minimal allocator that uses malloc(). +template <typename T> +struct Mallocator { + typedef T value_type; + typedef size_t size_type; + typedef ptrdiff_t difference_type; + typedef T* pointer; + typedef const T* const_pointer; + typedef T& reference; + typedef const T& const_reference; + + size_type max_size() const { + return size_t(std::numeric_limits<size_type>::max()) / sizeof(value_type); + } + template <typename U> + struct rebind { + typedef Mallocator<U> other; + }; + Mallocator() = default; + template <class U> + Mallocator(const Mallocator<U>&) {} // NOLINT(runtime/explicit) + + T* allocate(size_t n) { return static_cast<T*>(std::malloc(n * sizeof(T))); } + void deallocate(T* p, size_t) { std::free(p); } +}; +template <typename T, typename U> +bool operator==(const Mallocator<T>&, const Mallocator<U>&) { + return true; +} +template <typename T, typename U> +bool operator!=(const Mallocator<T>&, const Mallocator<U>&) { + return false; +} + +TEST(StrCat, CustomAllocator) { + using mstring = + std::basic_string<char, std::char_traits<char>, Mallocator<char>>; + const mstring str1("PARACHUTE OFF A BLIMP INTO MOSCONE!!"); + + const mstring str2("Read this book about coffee tables"); + + std::string result = absl::StrCat(str1, str2); + EXPECT_EQ(result, + "PARACHUTE OFF A BLIMP INTO MOSCONE!!" + "Read this book about coffee tables"); +} + +TEST(StrCat, MaxArgs) { + std::string result; + // Test 10 up to 26 arguments, the old maximum + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a"); + EXPECT_EQ(result, "123456789a"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b"); + EXPECT_EQ(result, "123456789ab"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c"); + EXPECT_EQ(result, "123456789abc"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d"); + EXPECT_EQ(result, "123456789abcd"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e"); + EXPECT_EQ(result, "123456789abcde"); + result = + absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f"); + EXPECT_EQ(result, "123456789abcdef"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g"); + EXPECT_EQ(result, "123456789abcdefg"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h"); + EXPECT_EQ(result, "123456789abcdefgh"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i"); + EXPECT_EQ(result, "123456789abcdefghi"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j"); + EXPECT_EQ(result, "123456789abcdefghij"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k"); + EXPECT_EQ(result, "123456789abcdefghijk"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k", "l"); + EXPECT_EQ(result, "123456789abcdefghijkl"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k", "l", "m"); + EXPECT_EQ(result, "123456789abcdefghijklm"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k", "l", "m", "n"); + EXPECT_EQ(result, "123456789abcdefghijklmn"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k", "l", "m", "n", "o"); + EXPECT_EQ(result, "123456789abcdefghijklmno"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k", "l", "m", "n", "o", "p"); + EXPECT_EQ(result, "123456789abcdefghijklmnop"); + result = absl::StrCat(1, 2, 3, 4, 5, 6, 7, 8, 9, "a", "b", "c", "d", "e", "f", + "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q"); + EXPECT_EQ(result, "123456789abcdefghijklmnopq"); + // No limit thanks to C++11's variadic templates + result = absl::StrCat( + 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, "a", "b", "c", "d", "e", "f", "g", "h", + "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", + "x", "y", "z", "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", + "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"); + EXPECT_EQ(result, + "12345678910abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"); +} + +TEST(StrAppend, Basics) { + std::string result = "existing text"; + + std::string strs[] = {"Hello", "Cruel", "World"}; + + std::string stdstrs[] = { + "std::Hello", + "std::Cruel", + "std::World" + }; + + absl::string_view pieces[] = {"Hello", "Cruel", "World"}; + + const char* c_strs[] = { + "Hello", + "Cruel", + "World" + }; + + int32_t i32s[] = {'H', 'C', 'W'}; + uint64_t ui64s[] = {12345678910LL, 10987654321LL}; + + std::string::size_type old_size = result.size(); + absl::StrAppend(&result); + EXPECT_EQ(result.size(), old_size); + + old_size = result.size(); + absl::StrAppend(&result, strs[0]); + EXPECT_EQ(result.substr(old_size), "Hello"); + + old_size = result.size(); + absl::StrAppend(&result, strs[1], pieces[2]); + EXPECT_EQ(result.substr(old_size), "CruelWorld"); + + old_size = result.size(); + absl::StrAppend(&result, stdstrs[0], ", ", pieces[2]); + EXPECT_EQ(result.substr(old_size), "std::Hello, World"); + + old_size = result.size(); + absl::StrAppend(&result, strs[0], ", ", stdstrs[1], " ", strs[2], "!"); + EXPECT_EQ(result.substr(old_size), "Hello, std::Cruel World!"); + + old_size = result.size(); + absl::StrAppend(&result, pieces[0], ", ", pieces[1], " ", pieces[2]); + EXPECT_EQ(result.substr(old_size), "Hello, Cruel World"); + + old_size = result.size(); + absl::StrAppend(&result, c_strs[0], ", ", c_strs[1], " ", c_strs[2]); + EXPECT_EQ(result.substr(old_size), "Hello, Cruel World"); + + old_size = result.size(); + absl::StrAppend(&result, "ASCII ", i32s[0], ", ", i32s[1], " ", i32s[2], "!"); + EXPECT_EQ(result.substr(old_size), "ASCII 72, 67 87!"); + + old_size = result.size(); + absl::StrAppend(&result, ui64s[0], ", ", ui64s[1], "!"); + EXPECT_EQ(result.substr(old_size), "12345678910, 10987654321!"); + + std::string one = + "1"; // Actually, it's the size of this string that we want; a + // 64-bit build distinguishes between size_t and uint64_t, + // even though they're both unsigned 64-bit values. + old_size = result.size(); + absl::StrAppend(&result, "And a ", one.size(), " and a ", + &result[2] - &result[0], " and a ", one, " 2 3 4", "!"); + EXPECT_EQ(result.substr(old_size), "And a 1 and a 2 and a 1 2 3 4!"); + + // result = absl::StrCat("Single chars won't compile", '!'); + // result = absl::StrCat("Neither will nullptrs", nullptr); + old_size = result.size(); + absl::StrAppend(&result, + "To output a char by ASCII/numeric value, use +: ", '!' + 0); + EXPECT_EQ(result.substr(old_size), + "To output a char by ASCII/numeric value, use +: 33"); + + // Test 9 arguments, the old maximum + old_size = result.size(); + absl::StrAppend(&result, 1, 22, 333, 4444, 55555, 666666, 7777777, 88888888, + 9); + EXPECT_EQ(result.substr(old_size), "1223334444555556666667777777888888889"); + + // No limit thanks to C++11's variadic templates + old_size = result.size(); + absl::StrAppend( + &result, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, // + "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", // + "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", // + "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", // + "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", // + "No limit thanks to C++11's variadic templates"); + EXPECT_EQ(result.substr(old_size), + "12345678910abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" + "No limit thanks to C++11's variadic templates"); +} + +TEST(StrCat, VectorBoolReferenceTypes) { + std::vector<bool> v; + v.push_back(true); + v.push_back(false); + std::vector<bool> const& cv = v; + // Test that vector<bool>::reference and vector<bool>::const_reference + // are handled as if the were really bool types and not the proxy types + // they really are. + std::string result = absl::StrCat(v[0], v[1], cv[0], cv[1]); // NOLINT + EXPECT_EQ(result, "1010"); +} + +// Passing nullptr to memcpy is undefined behavior and this test +// provides coverage of codepaths that handle empty strings with nullptrs. +TEST(StrCat, AvoidsMemcpyWithNullptr) { + EXPECT_EQ(absl::StrCat(42, absl::string_view{}), "42"); + + // Cover CatPieces code. + EXPECT_EQ(absl::StrCat(1, 2, 3, 4, 5, absl::string_view{}), "12345"); + + // Cover AppendPieces. + std::string result; + absl::StrAppend(&result, 1, 2, 3, 4, 5, absl::string_view{}); + EXPECT_EQ(result, "12345"); +} + +#ifdef GTEST_HAS_DEATH_TEST +TEST(StrAppend, Death) { + std::string s = "self"; + // on linux it's "assertion", on mac it's "Assertion", + // on chromiumos it's "Assertion ... failed". + ABSL_EXPECT_DEBUG_DEATH(absl::StrAppend(&s, s.c_str() + 1), + "ssertion.*failed"); + ABSL_EXPECT_DEBUG_DEATH(absl::StrAppend(&s, s), "ssertion.*failed"); +} +#endif // GTEST_HAS_DEATH_TEST + +TEST(StrAppend, CornerCases) { + std::string result; + absl::StrAppend(&result, ""); + EXPECT_EQ(result, ""); + absl::StrAppend(&result, "", ""); + EXPECT_EQ(result, ""); + absl::StrAppend(&result, "", "", ""); + EXPECT_EQ(result, ""); + absl::StrAppend(&result, "", "", "", ""); + EXPECT_EQ(result, ""); + absl::StrAppend(&result, "", "", "", "", ""); + EXPECT_EQ(result, ""); +} + +TEST(StrAppend, CornerCasesNonEmptyAppend) { + for (std::string result : {"hello", "a string too long to fit in the SSO"}) { + const std::string expected = result; + absl::StrAppend(&result, ""); + EXPECT_EQ(result, expected); + absl::StrAppend(&result, "", ""); + EXPECT_EQ(result, expected); + absl::StrAppend(&result, "", "", ""); + EXPECT_EQ(result, expected); + absl::StrAppend(&result, "", "", "", ""); + EXPECT_EQ(result, expected); + absl::StrAppend(&result, "", "", "", "", ""); + EXPECT_EQ(result, expected); + } +} + +template <typename IntType> +void CheckHex(IntType v, const char* nopad_format, const char* zeropad_format, + const char* spacepad_format) { + char expected[256]; + + std::string actual = absl::StrCat(absl::Hex(v, absl::kNoPad)); + snprintf(expected, sizeof(expected), nopad_format, v); + EXPECT_EQ(expected, actual) << " decimal value " << v; + + for (int spec = absl::kZeroPad2; spec <= absl::kZeroPad20; ++spec) { + std::string actual = + absl::StrCat(absl::Hex(v, static_cast<absl::PadSpec>(spec))); + snprintf(expected, sizeof(expected), zeropad_format, + spec - absl::kZeroPad2 + 2, v); + EXPECT_EQ(expected, actual) << " decimal value " << v; + } + + for (int spec = absl::kSpacePad2; spec <= absl::kSpacePad20; ++spec) { + std::string actual = + absl::StrCat(absl::Hex(v, static_cast<absl::PadSpec>(spec))); + snprintf(expected, sizeof(expected), spacepad_format, + spec - absl::kSpacePad2 + 2, v); + EXPECT_EQ(expected, actual) << " decimal value " << v; + } +} + +template <typename IntType> +void CheckDec(IntType v, const char* nopad_format, const char* zeropad_format, + const char* spacepad_format) { + char expected[256]; + + std::string actual = absl::StrCat(absl::Dec(v, absl::kNoPad)); + snprintf(expected, sizeof(expected), nopad_format, v); + EXPECT_EQ(expected, actual) << " decimal value " << v; + + for (int spec = absl::kZeroPad2; spec <= absl::kZeroPad20; ++spec) { + std::string actual = + absl::StrCat(absl::Dec(v, static_cast<absl::PadSpec>(spec))); + snprintf(expected, sizeof(expected), zeropad_format, + spec - absl::kZeroPad2 + 2, v); + EXPECT_EQ(expected, actual) + << " decimal value " << v << " format '" << zeropad_format + << "' digits " << (spec - absl::kZeroPad2 + 2); + } + + for (int spec = absl::kSpacePad2; spec <= absl::kSpacePad20; ++spec) { + std::string actual = + absl::StrCat(absl::Dec(v, static_cast<absl::PadSpec>(spec))); + snprintf(expected, sizeof(expected), spacepad_format, + spec - absl::kSpacePad2 + 2, v); + EXPECT_EQ(expected, actual) + << " decimal value " << v << " format '" << spacepad_format + << "' digits " << (spec - absl::kSpacePad2 + 2); + } +} + +void CheckHexDec64(uint64_t v) { + unsigned long long ullv = v; // NOLINT(runtime/int) + + CheckHex(ullv, "%llx", "%0*llx", "%*llx"); + CheckDec(ullv, "%llu", "%0*llu", "%*llu"); + + long long llv = static_cast<long long>(ullv); // NOLINT(runtime/int) + CheckDec(llv, "%lld", "%0*lld", "%*lld"); + + if (sizeof(v) == sizeof(&v)) { + auto uintptr = static_cast<uintptr_t>(v); + void* ptr = reinterpret_cast<void*>(uintptr); + CheckHex(ptr, "%llx", "%0*llx", "%*llx"); + } +} + +void CheckHexDec32(uint32_t uv) { + CheckHex(uv, "%x", "%0*x", "%*x"); + CheckDec(uv, "%u", "%0*u", "%*u"); + int32_t v = static_cast<int32_t>(uv); + CheckDec(v, "%d", "%0*d", "%*d"); + + if (sizeof(v) == sizeof(&v)) { + auto uintptr = static_cast<uintptr_t>(v); + void* ptr = reinterpret_cast<void*>(uintptr); + CheckHex(ptr, "%x", "%0*x", "%*x"); + } +} + +void CheckAll(uint64_t v) { + CheckHexDec64(v); + CheckHexDec32(static_cast<uint32_t>(v)); +} + +void TestFastPrints() { + // Test all small ints; there aren't many and they're common. + for (int i = 0; i < 10000; i++) { + CheckAll(i); + } + + CheckAll(std::numeric_limits<uint64_t>::max()); + CheckAll(std::numeric_limits<uint64_t>::max() - 1); + CheckAll(std::numeric_limits<int64_t>::min()); + CheckAll(std::numeric_limits<int64_t>::min() + 1); + CheckAll(std::numeric_limits<uint32_t>::max()); + CheckAll(std::numeric_limits<uint32_t>::max() - 1); + CheckAll(std::numeric_limits<int32_t>::min()); + CheckAll(std::numeric_limits<int32_t>::min() + 1); + CheckAll(999999999); // fits in 32 bits + CheckAll(1000000000); // fits in 32 bits + CheckAll(9999999999); // doesn't fit in 32 bits + CheckAll(10000000000); // doesn't fit in 32 bits + CheckAll(999999999999999999); // fits in signed 64-bit + CheckAll(9999999999999999999u); // fits in unsigned 64-bit, but not signed. + CheckAll(1000000000000000000); // fits in signed 64-bit + CheckAll(10000000000000000000u); // fits in unsigned 64-bit, but not signed. + + CheckAll(999999999876543210); // check all decimal digits, signed + CheckAll(9999999999876543210u); // check all decimal digits, unsigned. + CheckAll(0x123456789abcdef0); // check all hex digits + CheckAll(0x12345678); + + int8_t minus_one_8bit = -1; + EXPECT_EQ("ff", absl::StrCat(absl::Hex(minus_one_8bit))); + + int16_t minus_one_16bit = -1; + EXPECT_EQ("ffff", absl::StrCat(absl::Hex(minus_one_16bit))); +} + +TEST(Numbers, TestFunctionsMovedOverFromNumbersMain) { + TestFastPrints(); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_format.h b/third_party/abseil_cpp/absl/strings/str_format.h new file mode 100644 index 0000000000..f833a80aba --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_format.h @@ -0,0 +1,543 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: str_format.h +// ----------------------------------------------------------------------------- +// +// The `str_format` library is a typesafe replacement for the family of +// `printf()` string formatting routines within the `<cstdio>` standard library +// header. Like the `printf` family, the `str_format` uses a "format string" to +// perform argument substitutions based on types. See the `FormatSpec` section +// below for format string documentation. +// +// Example: +// +// std::string s = absl::StrFormat( +// "%s %s You have $%d!", "Hello", name, dollars); +// +// The library consists of the following basic utilities: +// +// * `absl::StrFormat()`, a type-safe replacement for `std::sprintf()`, to +// write a format string to a `string` value. +// * `absl::StrAppendFormat()` to append a format string to a `string` +// * `absl::StreamFormat()` to more efficiently write a format string to a +// stream, such as`std::cout`. +// * `absl::PrintF()`, `absl::FPrintF()` and `absl::SNPrintF()` as +// replacements for `std::printf()`, `std::fprintf()` and `std::snprintf()`. +// +// Note: a version of `std::sprintf()` is not supported as it is +// generally unsafe due to buffer overflows. +// +// Additionally, you can provide a format string (and its associated arguments) +// using one of the following abstractions: +// +// * A `FormatSpec` class template fully encapsulates a format string and its +// type arguments and is usually provided to `str_format` functions as a +// variadic argument of type `FormatSpec<Arg...>`. The `FormatSpec<Args...>` +// template is evaluated at compile-time, providing type safety. +// * A `ParsedFormat` instance, which encapsulates a specific, pre-compiled +// format string for a specific set of type(s), and which can be passed +// between API boundaries. (The `FormatSpec` type should not be used +// directly except as an argument type for wrapper functions.) +// +// The `str_format` library provides the ability to output its format strings to +// arbitrary sink types: +// +// * A generic `Format()` function to write outputs to arbitrary sink types, +// which must implement a `FormatRawSink` interface. +// +// * A `FormatUntyped()` function that is similar to `Format()` except it is +// loosely typed. `FormatUntyped()` is not a template and does not perform +// any compile-time checking of the format string; instead, it returns a +// boolean from a runtime check. + +#ifndef ABSL_STRINGS_STR_FORMAT_H_ +#define ABSL_STRINGS_STR_FORMAT_H_ + +#include <cstdio> +#include <string> + +#include "absl/strings/internal/str_format/arg.h" // IWYU pragma: export +#include "absl/strings/internal/str_format/bind.h" // IWYU pragma: export +#include "absl/strings/internal/str_format/checker.h" // IWYU pragma: export +#include "absl/strings/internal/str_format/extension.h" // IWYU pragma: export +#include "absl/strings/internal/str_format/parser.h" // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// UntypedFormatSpec +// +// A type-erased class that can be used directly within untyped API entry +// points. An `UntypedFormatSpec` is specifically used as an argument to +// `FormatUntyped()`. +// +// Example: +// +// absl::UntypedFormatSpec format("%d"); +// std::string out; +// CHECK(absl::FormatUntyped(&out, format, {absl::FormatArg(1)})); +class UntypedFormatSpec { + public: + UntypedFormatSpec() = delete; + UntypedFormatSpec(const UntypedFormatSpec&) = delete; + UntypedFormatSpec& operator=(const UntypedFormatSpec&) = delete; + + explicit UntypedFormatSpec(string_view s) : spec_(s) {} + + protected: + explicit UntypedFormatSpec(const str_format_internal::ParsedFormatBase* pc) + : spec_(pc) {} + + private: + friend str_format_internal::UntypedFormatSpecImpl; + str_format_internal::UntypedFormatSpecImpl spec_; +}; + +// FormatStreamed() +// +// Takes a streamable argument and returns an object that can print it +// with '%s'. Allows printing of types that have an `operator<<` but no +// intrinsic type support within `StrFormat()` itself. +// +// Example: +// +// absl::StrFormat("%s", absl::FormatStreamed(obj)); +template <typename T> +str_format_internal::StreamedWrapper<T> FormatStreamed(const T& v) { + return str_format_internal::StreamedWrapper<T>(v); +} + +// FormatCountCapture +// +// This class provides a way to safely wrap `StrFormat()` captures of `%n` +// conversions, which denote the number of characters written by a formatting +// operation to this point, into an integer value. +// +// This wrapper is designed to allow safe usage of `%n` within `StrFormat(); in +// the `printf()` family of functions, `%n` is not safe to use, as the `int *` +// buffer can be used to capture arbitrary data. +// +// Example: +// +// int n = 0; +// std::string s = absl::StrFormat("%s%d%n", "hello", 123, +// absl::FormatCountCapture(&n)); +// EXPECT_EQ(8, n); +class FormatCountCapture { + public: + explicit FormatCountCapture(int* p) : p_(p) {} + + private: + // FormatCountCaptureHelper is used to define FormatConvertImpl() for this + // class. + friend struct str_format_internal::FormatCountCaptureHelper; + // Unused() is here because of the false positive from -Wunused-private-field + // p_ is used in the templated function of the friend FormatCountCaptureHelper + // class. + int* Unused() { return p_; } + int* p_; +}; + +// FormatSpec +// +// The `FormatSpec` type defines the makeup of a format string within the +// `str_format` library. It is a variadic class template that is evaluated at +// compile-time, according to the format string and arguments that are passed to +// it. +// +// You should not need to manipulate this type directly. You should only name it +// if you are writing wrapper functions which accept format arguments that will +// be provided unmodified to functions in this library. Such a wrapper function +// might be a class method that provides format arguments and/or internally uses +// the result of formatting. +// +// For a `FormatSpec` to be valid at compile-time, it must be provided as +// either: +// +// * A `constexpr` literal or `absl::string_view`, which is how it most often +// used. +// * A `ParsedFormat` instantiation, which ensures the format string is +// valid before use. (See below.) +// +// Example: +// +// // Provided as a string literal. +// absl::StrFormat("Welcome to %s, Number %d!", "The Village", 6); +// +// // Provided as a constexpr absl::string_view. +// constexpr absl::string_view formatString = "Welcome to %s, Number %d!"; +// absl::StrFormat(formatString, "The Village", 6); +// +// // Provided as a pre-compiled ParsedFormat object. +// // Note that this example is useful only for illustration purposes. +// absl::ParsedFormat<'s', 'd'> formatString("Welcome to %s, Number %d!"); +// absl::StrFormat(formatString, "TheVillage", 6); +// +// A format string generally follows the POSIX syntax as used within the POSIX +// `printf` specification. +// +// (See http://pubs.opengroup.org/onlinepubs/9699919799/functions/fprintf.html.) +// +// In specific, the `FormatSpec` supports the following type specifiers: +// * `c` for characters +// * `s` for strings +// * `d` or `i` for integers +// * `o` for unsigned integer conversions into octal +// * `x` or `X` for unsigned integer conversions into hex +// * `u` for unsigned integers +// * `f` or `F` for floating point values into decimal notation +// * `e` or `E` for floating point values into exponential notation +// * `a` or `A` for floating point values into hex exponential notation +// * `g` or `G` for floating point values into decimal or exponential +// notation based on their precision +// * `p` for pointer address values +// * `n` for the special case of writing out the number of characters +// written to this point. The resulting value must be captured within an +// `absl::FormatCountCapture` type. +// +// Implementation-defined behavior: +// * A null pointer provided to "%s" or "%p" is output as "(nil)". +// * A non-null pointer provided to "%p" is output in hex as if by %#x or +// %#lx. +// +// NOTE: `o`, `x\X` and `u` will convert signed values to their unsigned +// counterpart before formatting. +// +// Examples: +// "%c", 'a' -> "a" +// "%c", 32 -> " " +// "%s", "C" -> "C" +// "%s", std::string("C++") -> "C++" +// "%d", -10 -> "-10" +// "%o", 10 -> "12" +// "%x", 16 -> "10" +// "%f", 123456789 -> "123456789.000000" +// "%e", .01 -> "1.00000e-2" +// "%a", -3.0 -> "-0x1.8p+1" +// "%g", .01 -> "1e-2" +// "%p", (void*)&value -> "0x7ffdeb6ad2a4" +// +// int n = 0; +// std::string s = absl::StrFormat( +// "%s%d%n", "hello", 123, absl::FormatCountCapture(&n)); +// EXPECT_EQ(8, n); +// +// The `FormatSpec` intrinsically supports all of these fundamental C++ types: +// +// * Characters: `char`, `signed char`, `unsigned char` +// * Integers: `int`, `short`, `unsigned short`, `unsigned`, `long`, +// `unsigned long`, `long long`, `unsigned long long` +// * Floating-point: `float`, `double`, `long double` +// +// However, in the `str_format` library, a format conversion specifies a broader +// C++ conceptual category instead of an exact type. For example, `%s` binds to +// any string-like argument, so `std::string`, `absl::string_view`, and +// `const char*` are all accepted. Likewise, `%d` accepts any integer-like +// argument, etc. + +template <typename... Args> +using FormatSpec = str_format_internal::FormatSpecTemplate< + str_format_internal::ArgumentToConv<Args>()...>; + +// ParsedFormat +// +// A `ParsedFormat` is a class template representing a preparsed `FormatSpec`, +// with template arguments specifying the conversion characters used within the +// format string. Such characters must be valid format type specifiers, and +// these type specifiers are checked at compile-time. +// +// Instances of `ParsedFormat` can be created, copied, and reused to speed up +// formatting loops. A `ParsedFormat` may either be constructed statically, or +// dynamically through its `New()` factory function, which only constructs a +// runtime object if the format is valid at that time. +// +// Example: +// +// // Verified at compile time. +// absl::ParsedFormat<'s', 'd'> formatString("Welcome to %s, Number %d!"); +// absl::StrFormat(formatString, "TheVillage", 6); +// +// // Verified at runtime. +// auto format_runtime = absl::ParsedFormat<'d'>::New(format_string); +// if (format_runtime) { +// value = absl::StrFormat(*format_runtime, i); +// } else { +// ... error case ... +// } +template <char... Conv> +using ParsedFormat = str_format_internal::ExtendedParsedFormat< + absl::str_format_internal::ToFormatConversionCharSet(Conv)...>; + +// StrFormat() +// +// Returns a `string` given a `printf()`-style format string and zero or more +// additional arguments. Use it as you would `sprintf()`. `StrFormat()` is the +// primary formatting function within the `str_format` library, and should be +// used in most cases where you need type-safe conversion of types into +// formatted strings. +// +// The format string generally consists of ordinary character data along with +// one or more format conversion specifiers (denoted by the `%` character). +// Ordinary character data is returned unchanged into the result string, while +// each conversion specification performs a type substitution from +// `StrFormat()`'s other arguments. See the comments for `FormatSpec` for full +// information on the makeup of this format string. +// +// Example: +// +// std::string s = absl::StrFormat( +// "Welcome to %s, Number %d!", "The Village", 6); +// EXPECT_EQ("Welcome to The Village, Number 6!", s); +// +// Returns an empty string in case of error. +template <typename... Args> +ABSL_MUST_USE_RESULT std::string StrFormat(const FormatSpec<Args...>& format, + const Args&... args) { + return str_format_internal::FormatPack( + str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// StrAppendFormat() +// +// Appends to a `dst` string given a format string, and zero or more additional +// arguments, returning `*dst` as a convenience for chaining purposes. Appends +// nothing in case of error (but possibly alters its capacity). +// +// Example: +// +// std::string orig("For example PI is approximately "); +// std::cout << StrAppendFormat(&orig, "%12.6f", 3.14); +template <typename... Args> +std::string& StrAppendFormat(std::string* dst, + const FormatSpec<Args...>& format, + const Args&... args) { + return str_format_internal::AppendPack( + dst, str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// StreamFormat() +// +// Writes to an output stream given a format string and zero or more arguments, +// generally in a manner that is more efficient than streaming the result of +// `absl:: StrFormat()`. The returned object must be streamed before the full +// expression ends. +// +// Example: +// +// std::cout << StreamFormat("%12.6f", 3.14); +template <typename... Args> +ABSL_MUST_USE_RESULT str_format_internal::Streamable StreamFormat( + const FormatSpec<Args...>& format, const Args&... args) { + return str_format_internal::Streamable( + str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// PrintF() +// +// Writes to stdout given a format string and zero or more arguments. This +// function is functionally equivalent to `std::printf()` (and type-safe); +// prefer `absl::PrintF()` over `std::printf()`. +// +// Example: +// +// std::string_view s = "Ulaanbaatar"; +// absl::PrintF("The capital of Mongolia is %s", s); +// +// Outputs: "The capital of Mongolia is Ulaanbaatar" +// +template <typename... Args> +int PrintF(const FormatSpec<Args...>& format, const Args&... args) { + return str_format_internal::FprintF( + stdout, str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// FPrintF() +// +// Writes to a file given a format string and zero or more arguments. This +// function is functionally equivalent to `std::fprintf()` (and type-safe); +// prefer `absl::FPrintF()` over `std::fprintf()`. +// +// Example: +// +// std::string_view s = "Ulaanbaatar"; +// absl::FPrintF(stdout, "The capital of Mongolia is %s", s); +// +// Outputs: "The capital of Mongolia is Ulaanbaatar" +// +template <typename... Args> +int FPrintF(std::FILE* output, const FormatSpec<Args...>& format, + const Args&... args) { + return str_format_internal::FprintF( + output, str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// SNPrintF() +// +// Writes to a sized buffer given a format string and zero or more arguments. +// This function is functionally equivalent to `std::snprintf()` (and +// type-safe); prefer `absl::SNPrintF()` over `std::snprintf()`. +// +// In particular, a successful call to `absl::SNPrintF()` writes at most `size` +// bytes of the formatted output to `output`, including a NUL-terminator, and +// returns the number of bytes that would have been written if truncation did +// not occur. In the event of an error, a negative value is returned and `errno` +// is set. +// +// Example: +// +// std::string_view s = "Ulaanbaatar"; +// char output[128]; +// absl::SNPrintF(output, sizeof(output), +// "The capital of Mongolia is %s", s); +// +// Post-condition: output == "The capital of Mongolia is Ulaanbaatar" +// +template <typename... Args> +int SNPrintF(char* output, std::size_t size, const FormatSpec<Args...>& format, + const Args&... args) { + return str_format_internal::SnprintF( + output, size, str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// ----------------------------------------------------------------------------- +// Custom Output Formatting Functions +// ----------------------------------------------------------------------------- + +// FormatRawSink +// +// FormatRawSink is a type erased wrapper around arbitrary sink objects +// specifically used as an argument to `Format()`. +// +// All the object has to do define an overload of `AbslFormatFlush()` for the +// sink, usually by adding a ADL-based free function in the same namespace as +// the sink: +// +// void AbslFormatFlush(MySink* dest, absl::string_view part); +// +// where `dest` is the pointer passed to `absl::Format()`. The function should +// append `part` to `dest`. +// +// FormatRawSink does not own the passed sink object. The passed object must +// outlive the FormatRawSink. +class FormatRawSink { + public: + // Implicitly convert from any type that provides the hook function as + // described above. + template <typename T, + typename = typename std::enable_if<std::is_constructible< + str_format_internal::FormatRawSinkImpl, T*>::value>::type> + FormatRawSink(T* raw) // NOLINT + : sink_(raw) {} + + private: + friend str_format_internal::FormatRawSinkImpl; + str_format_internal::FormatRawSinkImpl sink_; +}; + +// Format() +// +// Writes a formatted string to an arbitrary sink object (implementing the +// `absl::FormatRawSink` interface), using a format string and zero or more +// additional arguments. +// +// By default, `std::string`, `std::ostream`, and `absl::Cord` are supported as +// destination objects. If a `std::string` is used the formatted string is +// appended to it. +// +// `absl::Format()` is a generic version of `absl::StrAppendFormat()`, for +// custom sinks. The format string, like format strings for `StrFormat()`, is +// checked at compile-time. +// +// On failure, this function returns `false` and the state of the sink is +// unspecified. +template <typename... Args> +bool Format(FormatRawSink raw_sink, const FormatSpec<Args...>& format, + const Args&... args) { + return str_format_internal::FormatUntyped( + str_format_internal::FormatRawSinkImpl::Extract(raw_sink), + str_format_internal::UntypedFormatSpecImpl::Extract(format), + {str_format_internal::FormatArgImpl(args)...}); +} + +// FormatArg +// +// A type-erased handle to a format argument specifically used as an argument to +// `FormatUntyped()`. You may construct `FormatArg` by passing +// reference-to-const of any printable type. `FormatArg` is both copyable and +// assignable. The source data must outlive the `FormatArg` instance. See +// example below. +// +using FormatArg = str_format_internal::FormatArgImpl; + +// FormatUntyped() +// +// Writes a formatted string to an arbitrary sink object (implementing the +// `absl::FormatRawSink` interface), using an `UntypedFormatSpec` and zero or +// more additional arguments. +// +// This function acts as the most generic formatting function in the +// `str_format` library. The caller provides a raw sink, an unchecked format +// string, and (usually) a runtime specified list of arguments; no compile-time +// checking of formatting is performed within this function. As a result, a +// caller should check the return value to verify that no error occurred. +// On failure, this function returns `false` and the state of the sink is +// unspecified. +// +// The arguments are provided in an `absl::Span<const absl::FormatArg>`. +// Each `absl::FormatArg` object binds to a single argument and keeps a +// reference to it. The values used to create the `FormatArg` objects must +// outlive this function call. (See `str_format_arg.h` for information on +// the `FormatArg` class.)_ +// +// Example: +// +// std::optional<std::string> FormatDynamic( +// const std::string& in_format, +// const vector<std::string>& in_args) { +// std::string out; +// std::vector<absl::FormatArg> args; +// for (const auto& v : in_args) { +// // It is important that 'v' is a reference to the objects in in_args. +// // The values we pass to FormatArg must outlive the call to +// // FormatUntyped. +// args.emplace_back(v); +// } +// absl::UntypedFormatSpec format(in_format); +// if (!absl::FormatUntyped(&out, format, args)) { +// return std::nullopt; +// } +// return std::move(out); +// } +// +ABSL_MUST_USE_RESULT inline bool FormatUntyped( + FormatRawSink raw_sink, const UntypedFormatSpec& format, + absl::Span<const FormatArg> args) { + return str_format_internal::FormatUntyped( + str_format_internal::FormatRawSinkImpl::Extract(raw_sink), + str_format_internal::UntypedFormatSpecImpl::Extract(format), args); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STR_FORMAT_H_ diff --git a/third_party/abseil_cpp/absl/strings/str_format_test.cc b/third_party/abseil_cpp/absl/strings/str_format_test.cc new file mode 100644 index 0000000000..49a68849f0 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_format_test.cc @@ -0,0 +1,685 @@ + +#include "absl/strings/str_format.h" + +#include <cstdarg> +#include <cstdint> +#include <cstdio> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { +using str_format_internal::FormatArgImpl; +using str_format_internal::FormatConversionCharSetInternal; + +using FormatEntryPointTest = ::testing::Test; + +TEST_F(FormatEntryPointTest, Format) { + std::string sink; + EXPECT_TRUE(Format(&sink, "A format %d", 123)); + EXPECT_EQ("A format 123", sink); + sink.clear(); + + ParsedFormat<'d'> pc("A format %d"); + EXPECT_TRUE(Format(&sink, pc, 123)); + EXPECT_EQ("A format 123", sink); +} +TEST_F(FormatEntryPointTest, UntypedFormat) { + constexpr const char* formats[] = { + "", + "a", + "%80d", +#if !defined(_MSC_VER) && !defined(__ANDROID__) && !defined(__native_client__) + // MSVC, NaCL and Android don't support positional syntax. + "complicated multipart %% %1$d format %1$0999d", +#endif // _MSC_VER + }; + for (const char* fmt : formats) { + std::string actual; + int i = 123; + FormatArgImpl arg_123(i); + absl::Span<const FormatArgImpl> args(&arg_123, 1); + UntypedFormatSpec format(fmt); + + EXPECT_TRUE(FormatUntyped(&actual, format, args)); + char buf[4096]{}; + snprintf(buf, sizeof(buf), fmt, 123); + EXPECT_EQ( + str_format_internal::FormatPack( + str_format_internal::UntypedFormatSpecImpl::Extract(format), args), + buf); + EXPECT_EQ(actual, buf); + } + // The internal version works with a preparsed format. + ParsedFormat<'d'> pc("A format %d"); + int i = 345; + FormatArg arg(i); + std::string out; + EXPECT_TRUE(str_format_internal::FormatUntyped( + &out, str_format_internal::UntypedFormatSpecImpl(&pc), {&arg, 1})); + EXPECT_EQ("A format 345", out); +} + +TEST_F(FormatEntryPointTest, StringFormat) { + EXPECT_EQ("123", StrFormat("%d", 123)); + constexpr absl::string_view view("=%d=", 4); + EXPECT_EQ("=123=", StrFormat(view, 123)); +} + +TEST_F(FormatEntryPointTest, AppendFormat) { + std::string s; + std::string& r = StrAppendFormat(&s, "%d", 123); + EXPECT_EQ(&s, &r); // should be same object + EXPECT_EQ("123", r); +} + +TEST_F(FormatEntryPointTest, AppendFormatFail) { + std::string s = "orig"; + + UntypedFormatSpec format(" more %d"); + FormatArgImpl arg("not an int"); + + EXPECT_EQ("orig", + str_format_internal::AppendPack( + &s, str_format_internal::UntypedFormatSpecImpl::Extract(format), + {&arg, 1})); +} + + +TEST_F(FormatEntryPointTest, ManyArgs) { + EXPECT_EQ("24", StrFormat("%24$d", 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, + 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24)); + EXPECT_EQ("60", StrFormat("%60$d", 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, + 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, + 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, + 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, + 53, 54, 55, 56, 57, 58, 59, 60)); +} + +TEST_F(FormatEntryPointTest, Preparsed) { + ParsedFormat<'d'> pc("%d"); + EXPECT_EQ("123", StrFormat(pc, 123)); + // rvalue ok? + EXPECT_EQ("123", StrFormat(ParsedFormat<'d'>("%d"), 123)); + constexpr absl::string_view view("=%d=", 4); + EXPECT_EQ("=123=", StrFormat(ParsedFormat<'d'>(view), 123)); +} + +TEST_F(FormatEntryPointTest, FormatCountCapture) { + int n = 0; + EXPECT_EQ("", StrFormat("%n", FormatCountCapture(&n))); + EXPECT_EQ(0, n); + EXPECT_EQ("123", StrFormat("%d%n", 123, FormatCountCapture(&n))); + EXPECT_EQ(3, n); +} + +TEST_F(FormatEntryPointTest, FormatCountCaptureWrongType) { + // Should reject int*. + int n = 0; + UntypedFormatSpec format("%d%n"); + int i = 123, *ip = &n; + FormatArgImpl args[2] = {FormatArgImpl(i), FormatArgImpl(ip)}; + + EXPECT_EQ("", str_format_internal::FormatPack( + str_format_internal::UntypedFormatSpecImpl::Extract(format), + absl::MakeSpan(args))); +} + +TEST_F(FormatEntryPointTest, FormatCountCaptureMultiple) { + int n1 = 0; + int n2 = 0; + EXPECT_EQ(" 1 2", + StrFormat("%5d%n%10d%n", 1, FormatCountCapture(&n1), 2, + FormatCountCapture(&n2))); + EXPECT_EQ(5, n1); + EXPECT_EQ(15, n2); +} + +TEST_F(FormatEntryPointTest, FormatCountCaptureExample) { + int n; + std::string s; + StrAppendFormat(&s, "%s: %n%s\n", "(1,1)", FormatCountCapture(&n), "(1,2)"); + StrAppendFormat(&s, "%*s%s\n", n, "", "(2,2)"); + EXPECT_EQ(7, n); + EXPECT_EQ( + "(1,1): (1,2)\n" + " (2,2)\n", + s); +} + +TEST_F(FormatEntryPointTest, Stream) { + const std::string formats[] = { + "", + "a", + "%80d", + "%d %u %c %s %f %g", +#if !defined(_MSC_VER) && !defined(__ANDROID__) && !defined(__native_client__) + // MSVC, NaCL and Android don't support positional syntax. + "complicated multipart %% %1$d format %1$080d", +#endif // _MSC_VER + }; + std::string buf(4096, '\0'); + for (const auto& fmt : formats) { + const auto parsed = + ParsedFormat<'d', 'u', 'c', 's', 'f', 'g'>::NewAllowIgnored(fmt); + std::ostringstream oss; + oss << StreamFormat(*parsed, 123, 3, 49, "multistreaming!!!", 1.01, 1.01); + int fmt_result = snprintf(&*buf.begin(), buf.size(), fmt.c_str(), // + 123, 3, 49, "multistreaming!!!", 1.01, 1.01); + ASSERT_TRUE(oss) << fmt; + ASSERT_TRUE(fmt_result >= 0 && static_cast<size_t>(fmt_result) < buf.size()) + << fmt_result; + EXPECT_EQ(buf.c_str(), oss.str()); + } +} + +TEST_F(FormatEntryPointTest, StreamOk) { + std::ostringstream oss; + oss << StreamFormat("hello %d", 123); + EXPECT_EQ("hello 123", oss.str()); + EXPECT_TRUE(oss.good()); +} + +TEST_F(FormatEntryPointTest, StreamFail) { + std::ostringstream oss; + UntypedFormatSpec format("hello %d"); + FormatArgImpl arg("non-numeric"); + oss << str_format_internal::Streamable( + str_format_internal::UntypedFormatSpecImpl::Extract(format), {&arg, 1}); + EXPECT_EQ("hello ", oss.str()); // partial write + EXPECT_TRUE(oss.fail()); +} + +std::string WithSnprintf(const char* fmt, ...) { + std::string buf; + buf.resize(128); + va_list va; + va_start(va, fmt); + int r = vsnprintf(&*buf.begin(), buf.size(), fmt, va); + va_end(va); + EXPECT_GE(r, 0); + EXPECT_LT(r, buf.size()); + buf.resize(r); + return buf; +} + +TEST_F(FormatEntryPointTest, FloatPrecisionArg) { + // Test that positional parameters for width and precision + // are indexed to precede the value. + // Also sanity check the same formats against snprintf. + EXPECT_EQ("0.1", StrFormat("%.1f", 0.1)); + EXPECT_EQ("0.1", WithSnprintf("%.1f", 0.1)); + EXPECT_EQ(" 0.1", StrFormat("%*.1f", 5, 0.1)); + EXPECT_EQ(" 0.1", WithSnprintf("%*.1f", 5, 0.1)); + EXPECT_EQ("0.1", StrFormat("%.*f", 1, 0.1)); + EXPECT_EQ("0.1", WithSnprintf("%.*f", 1, 0.1)); + EXPECT_EQ(" 0.1", StrFormat("%*.*f", 5, 1, 0.1)); + EXPECT_EQ(" 0.1", WithSnprintf("%*.*f", 5, 1, 0.1)); +} +namespace streamed_test { +struct X {}; +std::ostream& operator<<(std::ostream& os, const X&) { + return os << "X"; +} +} // streamed_test + +TEST_F(FormatEntryPointTest, FormatStreamed) { + EXPECT_EQ("123", StrFormat("%s", FormatStreamed(123))); + EXPECT_EQ(" 123", StrFormat("%5s", FormatStreamed(123))); + EXPECT_EQ("123 ", StrFormat("%-5s", FormatStreamed(123))); + EXPECT_EQ("X", StrFormat("%s", FormatStreamed(streamed_test::X()))); + EXPECT_EQ("123", StrFormat("%s", FormatStreamed(StreamFormat("%d", 123)))); +} + +// Helper class that creates a temporary file and exposes a FILE* to it. +// It will close the file on destruction. +class TempFile { + public: + TempFile() : file_(std::tmpfile()) {} + ~TempFile() { std::fclose(file_); } + + std::FILE* file() const { return file_; } + + // Read the file into a string. + std::string ReadFile() { + std::fseek(file_, 0, SEEK_END); + int size = std::ftell(file_); + EXPECT_GT(size, 0); + std::rewind(file_); + std::string str(2 * size, ' '); + int read_bytes = std::fread(&str[0], 1, str.size(), file_); + EXPECT_EQ(read_bytes, size); + str.resize(read_bytes); + EXPECT_TRUE(std::feof(file_)); + return str; + } + + private: + std::FILE* file_; +}; + +TEST_F(FormatEntryPointTest, FPrintF) { + TempFile tmp; + int result = + FPrintF(tmp.file(), "STRING: %s NUMBER: %010d", std::string("ABC"), -19); + EXPECT_EQ(result, 30); + EXPECT_EQ(tmp.ReadFile(), "STRING: ABC NUMBER: -000000019"); +} + +TEST_F(FormatEntryPointTest, FPrintFError) { + errno = 0; + int result = FPrintF(stdin, "ABC"); + EXPECT_LT(result, 0); + EXPECT_EQ(errno, EBADF); +} + +#ifdef __GLIBC__ +TEST_F(FormatEntryPointTest, FprintfTooLarge) { + std::FILE* f = std::fopen("/dev/null", "w"); + int width = 2000000000; + errno = 0; + int result = FPrintF(f, "%*d %*d", width, 0, width, 0); + EXPECT_LT(result, 0); + EXPECT_EQ(errno, EFBIG); + std::fclose(f); +} + +TEST_F(FormatEntryPointTest, PrintF) { + int stdout_tmp = dup(STDOUT_FILENO); + + TempFile tmp; + std::fflush(stdout); + dup2(fileno(tmp.file()), STDOUT_FILENO); + + int result = PrintF("STRING: %s NUMBER: %010d", std::string("ABC"), -19); + + std::fflush(stdout); + dup2(stdout_tmp, STDOUT_FILENO); + close(stdout_tmp); + + EXPECT_EQ(result, 30); + EXPECT_EQ(tmp.ReadFile(), "STRING: ABC NUMBER: -000000019"); +} +#endif // __GLIBC__ + +TEST_F(FormatEntryPointTest, SNPrintF) { + char buffer[16]; + int result = + SNPrintF(buffer, sizeof(buffer), "STRING: %s", std::string("ABC")); + EXPECT_EQ(result, 11); + EXPECT_EQ(std::string(buffer), "STRING: ABC"); + + result = SNPrintF(buffer, sizeof(buffer), "NUMBER: %d", 123456); + EXPECT_EQ(result, 14); + EXPECT_EQ(std::string(buffer), "NUMBER: 123456"); + + result = SNPrintF(buffer, sizeof(buffer), "NUMBER: %d", 1234567); + EXPECT_EQ(result, 15); + EXPECT_EQ(std::string(buffer), "NUMBER: 1234567"); + + result = SNPrintF(buffer, sizeof(buffer), "NUMBER: %d", 12345678); + EXPECT_EQ(result, 16); + EXPECT_EQ(std::string(buffer), "NUMBER: 1234567"); + + result = SNPrintF(buffer, sizeof(buffer), "NUMBER: %d", 123456789); + EXPECT_EQ(result, 17); + EXPECT_EQ(std::string(buffer), "NUMBER: 1234567"); + + result = SNPrintF(nullptr, 0, "Just checking the %s of the output.", "size"); + EXPECT_EQ(result, 37); +} + +TEST(StrFormat, BehavesAsDocumented) { + std::string s = absl::StrFormat("%s, %d!", "Hello", 123); + EXPECT_EQ("Hello, 123!", s); + // The format of a replacement is + // '%'[position][flags][width['.'precision]][length_modifier][format] + EXPECT_EQ(absl::StrFormat("%1$+3.2Lf", 1.1), "+1.10"); + // Text conversion: + // "c" - Character. Eg: 'a' -> "A", 20 -> " " + EXPECT_EQ(StrFormat("%c", 'a'), "a"); + EXPECT_EQ(StrFormat("%c", 0x20), " "); + // Formats char and integral types: int, long, uint64_t, etc. + EXPECT_EQ(StrFormat("%c", int{'a'}), "a"); + EXPECT_EQ(StrFormat("%c", long{'a'}), "a"); // NOLINT + EXPECT_EQ(StrFormat("%c", uint64_t{'a'}), "a"); + // "s" - string Eg: "C" -> "C", std::string("C++") -> "C++" + // Formats std::string, char*, string_view, and Cord. + EXPECT_EQ(StrFormat("%s", "C"), "C"); + EXPECT_EQ(StrFormat("%s", std::string("C++")), "C++"); + EXPECT_EQ(StrFormat("%s", string_view("view")), "view"); + // Integral Conversion + // These format integral types: char, int, long, uint64_t, etc. + EXPECT_EQ(StrFormat("%d", char{10}), "10"); + EXPECT_EQ(StrFormat("%d", int{10}), "10"); + EXPECT_EQ(StrFormat("%d", long{10}), "10"); // NOLINT + EXPECT_EQ(StrFormat("%d", uint64_t{10}), "10"); + // d,i - signed decimal Eg: -10 -> "-10" + EXPECT_EQ(StrFormat("%d", -10), "-10"); + EXPECT_EQ(StrFormat("%i", -10), "-10"); + // o - octal Eg: 10 -> "12" + EXPECT_EQ(StrFormat("%o", 10), "12"); + // u - unsigned decimal Eg: 10 -> "10" + EXPECT_EQ(StrFormat("%u", 10), "10"); + // x/X - lower,upper case hex Eg: 10 -> "a"/"A" + EXPECT_EQ(StrFormat("%x", 10), "a"); + EXPECT_EQ(StrFormat("%X", 10), "A"); + // Floating-point, with upper/lower-case output. + // These format floating points types: float, double, long double, etc. + EXPECT_EQ(StrFormat("%.1f", float{1}), "1.0"); + EXPECT_EQ(StrFormat("%.1f", double{1}), "1.0"); + const long double long_double = 1.0; + EXPECT_EQ(StrFormat("%.1f", long_double), "1.0"); + // These also format integral types: char, int, long, uint64_t, etc.: + EXPECT_EQ(StrFormat("%.1f", char{1}), "1.0"); + EXPECT_EQ(StrFormat("%.1f", int{1}), "1.0"); + EXPECT_EQ(StrFormat("%.1f", long{1}), "1.0"); // NOLINT + EXPECT_EQ(StrFormat("%.1f", uint64_t{1}), "1.0"); + // f/F - decimal. Eg: 123456789 -> "123456789.000000" + EXPECT_EQ(StrFormat("%f", 123456789), "123456789.000000"); + EXPECT_EQ(StrFormat("%F", 123456789), "123456789.000000"); + // e/E - exponentiated Eg: .01 -> "1.00000e-2"/"1.00000E-2" + EXPECT_EQ(StrFormat("%e", .01), "1.000000e-02"); + EXPECT_EQ(StrFormat("%E", .01), "1.000000E-02"); + // g/G - exponentiate to fit Eg: .01 -> "0.01", 1e10 ->"1e+10"/"1E+10" + EXPECT_EQ(StrFormat("%g", .01), "0.01"); + EXPECT_EQ(StrFormat("%g", 1e10), "1e+10"); + EXPECT_EQ(StrFormat("%G", 1e10), "1E+10"); + // a/A - lower,upper case hex Eg: -3.0 -> "-0x1.8p+1"/"-0X1.8P+1" + +// On Android platform <=21, there is a regression in hexfloat formatting. +#if !defined(__ANDROID_API__) || __ANDROID_API__ > 21 + EXPECT_EQ(StrFormat("%.1a", -3.0), "-0x1.8p+1"); // .1 to fix MSVC output + EXPECT_EQ(StrFormat("%.1A", -3.0), "-0X1.8P+1"); // .1 to fix MSVC output +#endif + + // Other conversion + int64_t value = 0x7ffdeb4; + auto ptr_value = static_cast<uintptr_t>(value); + const int& something = *reinterpret_cast<const int*>(ptr_value); + EXPECT_EQ(StrFormat("%p", &something), StrFormat("0x%x", ptr_value)); + + // Output widths are supported, with optional flags. + EXPECT_EQ(StrFormat("%3d", 1), " 1"); + EXPECT_EQ(StrFormat("%3d", 123456), "123456"); + EXPECT_EQ(StrFormat("%06.2f", 1.234), "001.23"); + EXPECT_EQ(StrFormat("%+d", 1), "+1"); + EXPECT_EQ(StrFormat("% d", 1), " 1"); + EXPECT_EQ(StrFormat("%-4d", -1), "-1 "); + EXPECT_EQ(StrFormat("%#o", 10), "012"); + EXPECT_EQ(StrFormat("%#x", 15), "0xf"); + EXPECT_EQ(StrFormat("%04d", 8), "0008"); + // Posix positional substitution. + EXPECT_EQ(absl::StrFormat("%2$s, %3$s, %1$s!", "vici", "veni", "vidi"), + "veni, vidi, vici!"); + // Length modifiers are ignored. + EXPECT_EQ(StrFormat("%hhd", int{1}), "1"); + EXPECT_EQ(StrFormat("%hd", int{1}), "1"); + EXPECT_EQ(StrFormat("%ld", int{1}), "1"); + EXPECT_EQ(StrFormat("%lld", int{1}), "1"); + EXPECT_EQ(StrFormat("%Ld", int{1}), "1"); + EXPECT_EQ(StrFormat("%jd", int{1}), "1"); + EXPECT_EQ(StrFormat("%zd", int{1}), "1"); + EXPECT_EQ(StrFormat("%td", int{1}), "1"); + EXPECT_EQ(StrFormat("%qd", int{1}), "1"); +} + +using str_format_internal::ExtendedParsedFormat; +using str_format_internal::ParsedFormatBase; + +struct SummarizeConsumer { + std::string* out; + explicit SummarizeConsumer(std::string* out) : out(out) {} + + bool Append(string_view s) { + *out += "[" + std::string(s) + "]"; + return true; + } + + bool ConvertOne(const str_format_internal::UnboundConversion& conv, + string_view s) { + *out += "{"; + *out += std::string(s); + *out += ":"; + *out += std::to_string(conv.arg_position) + "$"; + if (conv.width.is_from_arg()) { + *out += std::to_string(conv.width.get_from_arg()) + "$*"; + } + if (conv.precision.is_from_arg()) { + *out += "." + std::to_string(conv.precision.get_from_arg()) + "$*"; + } + *out += str_format_internal::FormatConversionCharToChar(conv.conv); + *out += "}"; + return true; + } +}; + +std::string SummarizeParsedFormat(const ParsedFormatBase& pc) { + std::string out; + if (!pc.ProcessFormat(SummarizeConsumer(&out))) out += "!"; + return out; +} + +using ParsedFormatTest = ::testing::Test; + +TEST_F(ParsedFormatTest, SimpleChecked) { + EXPECT_EQ("[ABC]{d:1$d}[DEF]", + SummarizeParsedFormat(ParsedFormat<'d'>("ABC%dDEF"))); + EXPECT_EQ("{s:1$s}[FFF]{d:2$d}[ZZZ]{f:3$f}", + SummarizeParsedFormat(ParsedFormat<'s', 'd', 'f'>("%sFFF%dZZZ%f"))); + EXPECT_EQ("{s:1$s}[ ]{.*d:3$.2$*d}", + SummarizeParsedFormat(ParsedFormat<'s', '*', 'd'>("%s %.*d"))); +} + +TEST_F(ParsedFormatTest, SimpleUncheckedCorrect) { + auto f = ParsedFormat<'d'>::New("ABC%dDEF"); + ASSERT_TRUE(f); + EXPECT_EQ("[ABC]{d:1$d}[DEF]", SummarizeParsedFormat(*f)); + + std::string format = "%sFFF%dZZZ%f"; + auto f2 = ParsedFormat<'s', 'd', 'f'>::New(format); + + ASSERT_TRUE(f2); + EXPECT_EQ("{s:1$s}[FFF]{d:2$d}[ZZZ]{f:3$f}", SummarizeParsedFormat(*f2)); + + f2 = ParsedFormat<'s', 'd', 'f'>::New("%s %d %f"); + + ASSERT_TRUE(f2); + EXPECT_EQ("{s:1$s}[ ]{d:2$d}[ ]{f:3$f}", SummarizeParsedFormat(*f2)); + + auto star = ParsedFormat<'*', 'd'>::New("%*d"); + ASSERT_TRUE(star); + EXPECT_EQ("{*d:2$1$*d}", SummarizeParsedFormat(*star)); + + auto dollar = ParsedFormat<'d', 's'>::New("%2$s %1$d"); + ASSERT_TRUE(dollar); + EXPECT_EQ("{2$s:2$s}[ ]{1$d:1$d}", SummarizeParsedFormat(*dollar)); + // with reuse + dollar = ParsedFormat<'d', 's'>::New("%2$s %1$d %1$d"); + ASSERT_TRUE(dollar); + EXPECT_EQ("{2$s:2$s}[ ]{1$d:1$d}[ ]{1$d:1$d}", + SummarizeParsedFormat(*dollar)); +} + +TEST_F(ParsedFormatTest, SimpleUncheckedIgnoredArgs) { + EXPECT_FALSE((ParsedFormat<'d', 's'>::New("ABC"))); + EXPECT_FALSE((ParsedFormat<'d', 's'>::New("%dABC"))); + EXPECT_FALSE((ParsedFormat<'d', 's'>::New("ABC%2$s"))); + auto f = ParsedFormat<'d', 's'>::NewAllowIgnored("ABC"); + ASSERT_TRUE(f); + EXPECT_EQ("[ABC]", SummarizeParsedFormat(*f)); + f = ParsedFormat<'d', 's'>::NewAllowIgnored("%dABC"); + ASSERT_TRUE(f); + EXPECT_EQ("{d:1$d}[ABC]", SummarizeParsedFormat(*f)); + f = ParsedFormat<'d', 's'>::NewAllowIgnored("ABC%2$s"); + ASSERT_TRUE(f); + EXPECT_EQ("[ABC]{2$s:2$s}", SummarizeParsedFormat(*f)); +} + +TEST_F(ParsedFormatTest, SimpleUncheckedUnsupported) { + EXPECT_FALSE(ParsedFormat<'d'>::New("%1$d %1$x")); + EXPECT_FALSE(ParsedFormat<'x'>::New("%1$d %1$x")); +} + +TEST_F(ParsedFormatTest, SimpleUncheckedIncorrect) { + EXPECT_FALSE(ParsedFormat<'d'>::New("")); + + EXPECT_FALSE(ParsedFormat<'d'>::New("ABC%dDEF%d")); + + std::string format = "%sFFF%dZZZ%f"; + EXPECT_FALSE((ParsedFormat<'s', 'd', 'g'>::New(format))); +} + +using absl::str_format_internal::FormatConversionCharSet; + +TEST_F(ParsedFormatTest, UncheckedCorrect) { + auto f = + ExtendedParsedFormat<FormatConversionCharSetInternal::d>::New("ABC%dDEF"); + ASSERT_TRUE(f); + EXPECT_EQ("[ABC]{d:1$d}[DEF]", SummarizeParsedFormat(*f)); + + std::string format = "%sFFF%dZZZ%f"; + auto f2 = ExtendedParsedFormat< + FormatConversionCharSetInternal::kString, + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::kFloating>::New(format); + + ASSERT_TRUE(f2); + EXPECT_EQ("{s:1$s}[FFF]{d:2$d}[ZZZ]{f:3$f}", SummarizeParsedFormat(*f2)); + + f2 = ExtendedParsedFormat< + FormatConversionCharSetInternal::kString, + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::kFloating>::New("%s %d %f"); + + ASSERT_TRUE(f2); + EXPECT_EQ("{s:1$s}[ ]{d:2$d}[ ]{f:3$f}", SummarizeParsedFormat(*f2)); + + auto star = + ExtendedParsedFormat<FormatConversionCharSetInternal::kStar, + FormatConversionCharSetInternal::d>::New("%*d"); + ASSERT_TRUE(star); + EXPECT_EQ("{*d:2$1$*d}", SummarizeParsedFormat(*star)); + + auto dollar = ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::New("%2$s %1$d"); + ASSERT_TRUE(dollar); + EXPECT_EQ("{2$s:2$s}[ ]{1$d:1$d}", SummarizeParsedFormat(*dollar)); + // with reuse + dollar = ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::New("%2$s %1$d %1$d"); + ASSERT_TRUE(dollar); + EXPECT_EQ("{2$s:2$s}[ ]{1$d:1$d}[ ]{1$d:1$d}", + SummarizeParsedFormat(*dollar)); +} + +TEST_F(ParsedFormatTest, UncheckedIgnoredArgs) { + EXPECT_FALSE( + (ExtendedParsedFormat<FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::New("ABC"))); + EXPECT_FALSE( + (ExtendedParsedFormat<FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::New("%dABC"))); + EXPECT_FALSE((ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::New("ABC%2$s"))); + auto f = ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::NewAllowIgnored("ABC"); + ASSERT_TRUE(f); + EXPECT_EQ("[ABC]", SummarizeParsedFormat(*f)); + f = ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::NewAllowIgnored("%dABC"); + ASSERT_TRUE(f); + EXPECT_EQ("{d:1$d}[ABC]", SummarizeParsedFormat(*f)); + f = ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::s>::NewAllowIgnored("ABC%2$s"); + ASSERT_TRUE(f); + EXPECT_EQ("[ABC]{2$s:2$s}", SummarizeParsedFormat(*f)); +} + +TEST_F(ParsedFormatTest, UncheckedMultipleTypes) { + auto dx = ExtendedParsedFormat< + FormatConversionCharSetInternal::d | + FormatConversionCharSetInternal::x>::New("%1$d %1$x"); + EXPECT_TRUE(dx); + EXPECT_EQ("{1$d:1$d}[ ]{1$x:1$x}", SummarizeParsedFormat(*dx)); + + dx = ExtendedParsedFormat<FormatConversionCharSetInternal::d | + FormatConversionCharSetInternal::x>::New("%1$d"); + EXPECT_TRUE(dx); + EXPECT_EQ("{1$d:1$d}", SummarizeParsedFormat(*dx)); +} + +TEST_F(ParsedFormatTest, UncheckedIncorrect) { + EXPECT_FALSE( + ExtendedParsedFormat<FormatConversionCharSetInternal::d>::New("")); + + EXPECT_FALSE(ExtendedParsedFormat<FormatConversionCharSetInternal::d>::New( + "ABC%dDEF%d")); + + std::string format = "%sFFF%dZZZ%f"; + EXPECT_FALSE( + (ExtendedParsedFormat<FormatConversionCharSetInternal::s, + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::g>::New(format))); +} + +TEST_F(ParsedFormatTest, RegressionMixPositional) { + EXPECT_FALSE((ExtendedParsedFormat< + FormatConversionCharSetInternal::d, + FormatConversionCharSetInternal::o>::New("%1$d %o"))); +} + +using FormatWrapperTest = ::testing::Test; + +// Plain wrapper for StrFormat. +template <typename... Args> +std::string WrappedFormat(const absl::FormatSpec<Args...>& format, + const Args&... args) { + return StrFormat(format, args...); +} + +TEST_F(FormatWrapperTest, ConstexprStringFormat) { + EXPECT_EQ(WrappedFormat("%s there", "hello"), "hello there"); +} + +TEST_F(FormatWrapperTest, ParsedFormat) { + ParsedFormat<'s'> format("%s there"); + EXPECT_EQ(WrappedFormat(format, "hello"), "hello there"); +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl + +// Some codegen thunks that we can use to easily dump the generated assembly for +// different StrFormat calls. + +std::string CodegenAbslStrFormatInt(int i) { // NOLINT + return absl::StrFormat("%d", i); +} + +std::string CodegenAbslStrFormatIntStringInt64(int i, const std::string& s, + int64_t i64) { // NOLINT + return absl::StrFormat("%d %s %d", i, s, i64); +} + +void CodegenAbslStrAppendFormatInt(std::string* out, int i) { // NOLINT + absl::StrAppendFormat(out, "%d", i); +} + +void CodegenAbslStrAppendFormatIntStringInt64(std::string* out, int i, + const std::string& s, + int64_t i64) { // NOLINT + absl::StrAppendFormat(out, "%d %s %d", i, s, i64); +} diff --git a/third_party/abseil_cpp/absl/strings/str_join.h b/third_party/abseil_cpp/absl/strings/str_join.h new file mode 100644 index 0000000000..ae5731a42b --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_join.h @@ -0,0 +1,293 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: str_join.h +// ----------------------------------------------------------------------------- +// +// This header file contains functions for joining a range of elements and +// returning the result as a std::string. StrJoin operations are specified by +// passing a range, a separator string to use between the elements joined, and +// an optional Formatter responsible for converting each argument in the range +// to a string. If omitted, a default `AlphaNumFormatter()` is called on the +// elements to be joined, using the same formatting that `absl::StrCat()` uses. +// This package defines a number of default formatters, and you can define your +// own implementations. +// +// Ranges are specified by passing a container with `std::begin()` and +// `std::end()` iterators, container-specific `begin()` and `end()` iterators, a +// brace-initialized `std::initializer_list`, or a `std::tuple` of heterogeneous +// objects. The separator string is specified as an `absl::string_view`. +// +// Because the default formatter uses the `absl::AlphaNum` class, +// `absl::StrJoin()`, like `absl::StrCat()`, will work out-of-the-box on +// collections of strings, ints, floats, doubles, etc. +// +// Example: +// +// std::vector<std::string> v = {"foo", "bar", "baz"}; +// std::string s = absl::StrJoin(v, "-"); +// EXPECT_EQ("foo-bar-baz", s); +// +// See comments on the `absl::StrJoin()` function for more examples. + +#ifndef ABSL_STRINGS_STR_JOIN_H_ +#define ABSL_STRINGS_STR_JOIN_H_ + +#include <cstdio> +#include <cstring> +#include <initializer_list> +#include <iterator> +#include <string> +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/base/macros.h" +#include "absl/strings/internal/str_join_internal.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// Concept: Formatter +// ----------------------------------------------------------------------------- +// +// A Formatter is a function object that is responsible for formatting its +// argument as a string and appending it to a given output std::string. +// Formatters may be implemented as function objects, lambdas, or normal +// functions. You may provide your own Formatter to enable `absl::StrJoin()` to +// work with arbitrary types. +// +// The following is an example of a custom Formatter that simply uses +// `std::to_string()` to format an integer as a std::string. +// +// struct MyFormatter { +// void operator()(std::string* out, int i) const { +// out->append(std::to_string(i)); +// } +// }; +// +// You would use the above formatter by passing an instance of it as the final +// argument to `absl::StrJoin()`: +// +// std::vector<int> v = {1, 2, 3, 4}; +// std::string s = absl::StrJoin(v, "-", MyFormatter()); +// EXPECT_EQ("1-2-3-4", s); +// +// The following standard formatters are provided within this file: +// +// - `AlphaNumFormatter()` (the default) +// - `StreamFormatter()` +// - `PairFormatter()` +// - `DereferenceFormatter()` + +// AlphaNumFormatter() +// +// Default formatter used if none is specified. Uses `absl::AlphaNum` to convert +// numeric arguments to strings. +inline strings_internal::AlphaNumFormatterImpl AlphaNumFormatter() { + return strings_internal::AlphaNumFormatterImpl(); +} + +// StreamFormatter() +// +// Formats its argument using the << operator. +inline strings_internal::StreamFormatterImpl StreamFormatter() { + return strings_internal::StreamFormatterImpl(); +} + +// Function Template: PairFormatter(Formatter, absl::string_view, Formatter) +// +// Formats a `std::pair` by putting a given separator between the pair's +// `.first` and `.second` members. This formatter allows you to specify +// custom Formatters for both the first and second member of each pair. +template <typename FirstFormatter, typename SecondFormatter> +inline strings_internal::PairFormatterImpl<FirstFormatter, SecondFormatter> +PairFormatter(FirstFormatter f1, absl::string_view sep, SecondFormatter f2) { + return strings_internal::PairFormatterImpl<FirstFormatter, SecondFormatter>( + std::move(f1), sep, std::move(f2)); +} + +// Function overload of PairFormatter() for using a default +// `AlphaNumFormatter()` for each Formatter in the pair. +inline strings_internal::PairFormatterImpl< + strings_internal::AlphaNumFormatterImpl, + strings_internal::AlphaNumFormatterImpl> +PairFormatter(absl::string_view sep) { + return PairFormatter(AlphaNumFormatter(), sep, AlphaNumFormatter()); +} + +// Function Template: DereferenceFormatter(Formatter) +// +// Formats its argument by dereferencing it and then applying the given +// formatter. This formatter is useful for formatting a container of +// pointer-to-T. This pattern often shows up when joining repeated fields in +// protocol buffers. +template <typename Formatter> +strings_internal::DereferenceFormatterImpl<Formatter> DereferenceFormatter( + Formatter&& f) { + return strings_internal::DereferenceFormatterImpl<Formatter>( + std::forward<Formatter>(f)); +} + +// Function overload of `DererefenceFormatter()` for using a default +// `AlphaNumFormatter()`. +inline strings_internal::DereferenceFormatterImpl< + strings_internal::AlphaNumFormatterImpl> +DereferenceFormatter() { + return strings_internal::DereferenceFormatterImpl< + strings_internal::AlphaNumFormatterImpl>(AlphaNumFormatter()); +} + +// ----------------------------------------------------------------------------- +// StrJoin() +// ----------------------------------------------------------------------------- +// +// Joins a range of elements and returns the result as a std::string. +// `absl::StrJoin()` takes a range, a separator string to use between the +// elements joined, and an optional Formatter responsible for converting each +// argument in the range to a string. +// +// If omitted, the default `AlphaNumFormatter()` is called on the elements to be +// joined. +// +// Example 1: +// // Joins a collection of strings. This pattern also works with a collection +// // of `absl::string_view` or even `const char*`. +// std::vector<std::string> v = {"foo", "bar", "baz"}; +// std::string s = absl::StrJoin(v, "-"); +// EXPECT_EQ("foo-bar-baz", s); +// +// Example 2: +// // Joins the values in the given `std::initializer_list<>` specified using +// // brace initialization. This pattern also works with an initializer_list +// // of ints or `absl::string_view` -- any `AlphaNum`-compatible type. +// std::string s = absl::StrJoin({"foo", "bar", "baz"}, "-"); +// EXPECT_EQ("foo-bar-baz", s); +// +// Example 3: +// // Joins a collection of ints. This pattern also works with floats, +// // doubles, int64s -- any `StrCat()`-compatible type. +// std::vector<int> v = {1, 2, 3, -4}; +// std::string s = absl::StrJoin(v, "-"); +// EXPECT_EQ("1-2-3--4", s); +// +// Example 4: +// // Joins a collection of pointer-to-int. By default, pointers are +// // dereferenced and the pointee is formatted using the default format for +// // that type; such dereferencing occurs for all levels of indirection, so +// // this pattern works just as well for `std::vector<int**>` as for +// // `std::vector<int*>`. +// int x = 1, y = 2, z = 3; +// std::vector<int*> v = {&x, &y, &z}; +// std::string s = absl::StrJoin(v, "-"); +// EXPECT_EQ("1-2-3", s); +// +// Example 5: +// // Dereferencing of `std::unique_ptr<>` is also supported: +// std::vector<std::unique_ptr<int>> v +// v.emplace_back(new int(1)); +// v.emplace_back(new int(2)); +// v.emplace_back(new int(3)); +// std::string s = absl::StrJoin(v, "-"); +// EXPECT_EQ("1-2-3", s); +// +// Example 6: +// // Joins a `std::map`, with each key-value pair separated by an equals +// // sign. This pattern would also work with, say, a +// // `std::vector<std::pair<>>`. +// std::map<std::string, int> m = { +// std::make_pair("a", 1), +// std::make_pair("b", 2), +// std::make_pair("c", 3)}; +// std::string s = absl::StrJoin(m, ",", absl::PairFormatter("=")); +// EXPECT_EQ("a=1,b=2,c=3", s); +// +// Example 7: +// // These examples show how `absl::StrJoin()` handles a few common edge +// // cases: +// std::vector<std::string> v_empty; +// EXPECT_EQ("", absl::StrJoin(v_empty, "-")); +// +// std::vector<std::string> v_one_item = {"foo"}; +// EXPECT_EQ("foo", absl::StrJoin(v_one_item, "-")); +// +// std::vector<std::string> v_empty_string = {""}; +// EXPECT_EQ("", absl::StrJoin(v_empty_string, "-")); +// +// std::vector<std::string> v_one_item_empty_string = {"a", ""}; +// EXPECT_EQ("a-", absl::StrJoin(v_one_item_empty_string, "-")); +// +// std::vector<std::string> v_two_empty_string = {"", ""}; +// EXPECT_EQ("-", absl::StrJoin(v_two_empty_string, "-")); +// +// Example 8: +// // Joins a `std::tuple<T...>` of heterogeneous types, converting each to +// // a std::string using the `absl::AlphaNum` class. +// std::string s = absl::StrJoin(std::make_tuple(123, "abc", 0.456), "-"); +// EXPECT_EQ("123-abc-0.456", s); + +template <typename Iterator, typename Formatter> +std::string StrJoin(Iterator start, Iterator end, absl::string_view sep, + Formatter&& fmt) { + return strings_internal::JoinAlgorithm(start, end, sep, fmt); +} + +template <typename Range, typename Formatter> +std::string StrJoin(const Range& range, absl::string_view separator, + Formatter&& fmt) { + return strings_internal::JoinRange(range, separator, fmt); +} + +template <typename T, typename Formatter> +std::string StrJoin(std::initializer_list<T> il, absl::string_view separator, + Formatter&& fmt) { + return strings_internal::JoinRange(il, separator, fmt); +} + +template <typename... T, typename Formatter> +std::string StrJoin(const std::tuple<T...>& value, absl::string_view separator, + Formatter&& fmt) { + return strings_internal::JoinAlgorithm(value, separator, fmt); +} + +template <typename Iterator> +std::string StrJoin(Iterator start, Iterator end, absl::string_view separator) { + return strings_internal::JoinRange(start, end, separator); +} + +template <typename Range> +std::string StrJoin(const Range& range, absl::string_view separator) { + return strings_internal::JoinRange(range, separator); +} + +template <typename T> +std::string StrJoin(std::initializer_list<T> il, + absl::string_view separator) { + return strings_internal::JoinRange(il, separator); +} + +template <typename... T> +std::string StrJoin(const std::tuple<T...>& value, + absl::string_view separator) { + return strings_internal::JoinAlgorithm(value, separator, AlphaNumFormatter()); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STR_JOIN_H_ diff --git a/third_party/abseil_cpp/absl/strings/str_join_benchmark.cc b/third_party/abseil_cpp/absl/strings/str_join_benchmark.cc new file mode 100644 index 0000000000..d6f689ff30 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_join_benchmark.cc @@ -0,0 +1,97 @@ +// +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_join.h" + +#include <string> +#include <vector> +#include <utility> + +#include "benchmark/benchmark.h" + +namespace { + +void BM_Join2_Strings(benchmark::State& state) { + const int string_len = state.range(0); + const int num_strings = state.range(1); + const std::string s(string_len, 'x'); + const std::vector<std::string> v(num_strings, s); + for (auto _ : state) { + std::string s = absl::StrJoin(v, "-"); + benchmark::DoNotOptimize(s); + } +} +BENCHMARK(BM_Join2_Strings) + ->ArgPair(1 << 0, 1 << 3) + ->ArgPair(1 << 10, 1 << 3) + ->ArgPair(1 << 13, 1 << 3) + ->ArgPair(1 << 0, 1 << 10) + ->ArgPair(1 << 10, 1 << 10) + ->ArgPair(1 << 13, 1 << 10) + ->ArgPair(1 << 0, 1 << 13) + ->ArgPair(1 << 10, 1 << 13) + ->ArgPair(1 << 13, 1 << 13); + +void BM_Join2_Ints(benchmark::State& state) { + const int num_ints = state.range(0); + const std::vector<int> v(num_ints, 42); + for (auto _ : state) { + std::string s = absl::StrJoin(v, "-"); + benchmark::DoNotOptimize(s); + } +} +BENCHMARK(BM_Join2_Ints)->Range(0, 1 << 13); + +void BM_Join2_KeysAndValues(benchmark::State& state) { + const int string_len = state.range(0); + const int num_pairs = state.range(1); + const std::string s(string_len, 'x'); + const std::vector<std::pair<std::string, int>> v(num_pairs, + std::make_pair(s, 42)); + for (auto _ : state) { + std::string s = absl::StrJoin(v, ",", absl::PairFormatter("=")); + benchmark::DoNotOptimize(s); + } +} +BENCHMARK(BM_Join2_KeysAndValues) + ->ArgPair(1 << 0, 1 << 3) + ->ArgPair(1 << 10, 1 << 3) + ->ArgPair(1 << 13, 1 << 3) + ->ArgPair(1 << 0, 1 << 10) + ->ArgPair(1 << 10, 1 << 10) + ->ArgPair(1 << 13, 1 << 10) + ->ArgPair(1 << 0, 1 << 13) + ->ArgPair(1 << 10, 1 << 13) + ->ArgPair(1 << 13, 1 << 13); + +void BM_JoinStreamable(benchmark::State& state) { + const int string_len = state.range(0); + const int num_strings = state.range(1); + const std::vector<std::string> v(num_strings, std::string(string_len, 'x')); + for (auto _ : state) { + std::string s = absl::StrJoin(v, "", absl::StreamFormatter()); + benchmark::DoNotOptimize(s); + } +} +BENCHMARK(BM_JoinStreamable) + ->ArgPair(0, 0) + ->ArgPair(16, 1) + ->ArgPair(256, 1) + ->ArgPair(16, 16) + ->ArgPair(256, 16) + ->ArgPair(16, 256) + ->ArgPair(256, 256); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_join_test.cc b/third_party/abseil_cpp/absl/strings/str_join_test.cc new file mode 100644 index 0000000000..2be6256e43 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_join_test.cc @@ -0,0 +1,474 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Unit tests for all join.h functions + +#include "absl/strings/str_join.h" + +#include <cstddef> +#include <cstdint> +#include <cstdio> +#include <functional> +#include <initializer_list> +#include <map> +#include <memory> +#include <ostream> +#include <tuple> +#include <type_traits> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/macros.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" + +namespace { + +TEST(StrJoin, APIExamples) { + { + // Collection of strings + std::vector<std::string> v = {"foo", "bar", "baz"}; + EXPECT_EQ("foo-bar-baz", absl::StrJoin(v, "-")); + } + + { + // Collection of absl::string_view + std::vector<absl::string_view> v = {"foo", "bar", "baz"}; + EXPECT_EQ("foo-bar-baz", absl::StrJoin(v, "-")); + } + + { + // Collection of const char* + std::vector<const char*> v = {"foo", "bar", "baz"}; + EXPECT_EQ("foo-bar-baz", absl::StrJoin(v, "-")); + } + + { + // Collection of non-const char* + std::string a = "foo", b = "bar", c = "baz"; + std::vector<char*> v = {&a[0], &b[0], &c[0]}; + EXPECT_EQ("foo-bar-baz", absl::StrJoin(v, "-")); + } + + { + // Collection of ints + std::vector<int> v = {1, 2, 3, -4}; + EXPECT_EQ("1-2-3--4", absl::StrJoin(v, "-")); + } + + { + // Literals passed as a std::initializer_list + std::string s = absl::StrJoin({"a", "b", "c"}, "-"); + EXPECT_EQ("a-b-c", s); + } + { + // Join a std::tuple<T...>. + std::string s = absl::StrJoin(std::make_tuple(123, "abc", 0.456), "-"); + EXPECT_EQ("123-abc-0.456", s); + } + + { + // Collection of unique_ptrs + std::vector<std::unique_ptr<int>> v; + v.emplace_back(new int(1)); + v.emplace_back(new int(2)); + v.emplace_back(new int(3)); + EXPECT_EQ("1-2-3", absl::StrJoin(v, "-")); + } + + { + // Array of ints + const int a[] = {1, 2, 3, -4}; + EXPECT_EQ("1-2-3--4", absl::StrJoin(a, a + ABSL_ARRAYSIZE(a), "-")); + } + + { + // Collection of pointers + int x = 1, y = 2, z = 3; + std::vector<int*> v = {&x, &y, &z}; + EXPECT_EQ("1-2-3", absl::StrJoin(v, "-")); + } + + { + // Collection of pointers to pointers + int x = 1, y = 2, z = 3; + int *px = &x, *py = &y, *pz = &z; + std::vector<int**> v = {&px, &py, &pz}; + EXPECT_EQ("1-2-3", absl::StrJoin(v, "-")); + } + + { + // Collection of pointers to std::string + std::string a("a"), b("b"); + std::vector<std::string*> v = {&a, &b}; + EXPECT_EQ("a-b", absl::StrJoin(v, "-")); + } + + { + // A std::map, which is a collection of std::pair<>s. + std::map<std::string, int> m = {{"a", 1}, {"b", 2}, {"c", 3}}; + EXPECT_EQ("a=1,b=2,c=3", absl::StrJoin(m, ",", absl::PairFormatter("="))); + } + + { + // Shows absl::StrSplit and absl::StrJoin working together. This example is + // equivalent to s/=/-/g. + const std::string s = "a=b=c=d"; + EXPECT_EQ("a-b-c-d", absl::StrJoin(absl::StrSplit(s, "="), "-")); + } + + // + // A few examples of edge cases + // + + { + // Empty range yields an empty string. + std::vector<std::string> v; + EXPECT_EQ("", absl::StrJoin(v, "-")); + } + + { + // A range of 1 element gives a string with that element but no + // separator. + std::vector<std::string> v = {"foo"}; + EXPECT_EQ("foo", absl::StrJoin(v, "-")); + } + + { + // A range with a single empty string element + std::vector<std::string> v = {""}; + EXPECT_EQ("", absl::StrJoin(v, "-")); + } + + { + // A range with 2 elements, one of which is an empty string + std::vector<std::string> v = {"a", ""}; + EXPECT_EQ("a-", absl::StrJoin(v, "-")); + } + + { + // A range with 2 empty elements. + std::vector<std::string> v = {"", ""}; + EXPECT_EQ("-", absl::StrJoin(v, "-")); + } + + { + // A std::vector of bool. + std::vector<bool> v = {true, false, true}; + EXPECT_EQ("1-0-1", absl::StrJoin(v, "-")); + } +} + +TEST(StrJoin, CustomFormatter) { + std::vector<std::string> v{"One", "Two", "Three"}; + { + std::string joined = + absl::StrJoin(v, "", [](std::string* out, const std::string& in) { + absl::StrAppend(out, "(", in, ")"); + }); + EXPECT_EQ("(One)(Two)(Three)", joined); + } + { + class ImmovableFormatter { + public: + void operator()(std::string* out, const std::string& in) { + absl::StrAppend(out, "(", in, ")"); + } + ImmovableFormatter() {} + ImmovableFormatter(const ImmovableFormatter&) = delete; + }; + EXPECT_EQ("(One)(Two)(Three)", absl::StrJoin(v, "", ImmovableFormatter())); + } + { + class OverloadedFormatter { + public: + void operator()(std::string* out, const std::string& in) { + absl::StrAppend(out, "(", in, ")"); + } + void operator()(std::string* out, const std::string& in) const { + absl::StrAppend(out, "[", in, "]"); + } + }; + EXPECT_EQ("(One)(Two)(Three)", absl::StrJoin(v, "", OverloadedFormatter())); + const OverloadedFormatter fmt = {}; + EXPECT_EQ("[One][Two][Three]", absl::StrJoin(v, "", fmt)); + } +} + +// +// Tests the Formatters +// + +TEST(AlphaNumFormatter, FormatterAPI) { + // Not an exhaustive test. See strings/strcat_test.h for the exhaustive test + // of what AlphaNum can convert. + auto f = absl::AlphaNumFormatter(); + std::string s; + f(&s, "Testing: "); + f(&s, static_cast<int>(1)); + f(&s, static_cast<int16_t>(2)); + f(&s, static_cast<int64_t>(3)); + f(&s, static_cast<float>(4)); + f(&s, static_cast<double>(5)); + f(&s, static_cast<unsigned>(6)); + f(&s, static_cast<size_t>(7)); + f(&s, absl::string_view(" OK")); + EXPECT_EQ("Testing: 1234567 OK", s); +} + +// Make sure people who are mistakenly using std::vector<bool> even though +// they're not memory-constrained can use absl::AlphaNumFormatter(). +TEST(AlphaNumFormatter, VectorOfBool) { + auto f = absl::AlphaNumFormatter(); + std::string s; + std::vector<bool> v = {true, false, true}; + f(&s, *v.cbegin()); + f(&s, *v.begin()); + f(&s, v[1]); + EXPECT_EQ("110", s); +} + +TEST(AlphaNumFormatter, AlphaNum) { + auto f = absl::AlphaNumFormatter(); + std::string s; + f(&s, absl::AlphaNum("hello")); + EXPECT_EQ("hello", s); +} + +struct StreamableType { + std::string contents; +}; +inline std::ostream& operator<<(std::ostream& os, const StreamableType& t) { + os << "Streamable:" << t.contents; + return os; +} + +TEST(StreamFormatter, FormatterAPI) { + auto f = absl::StreamFormatter(); + std::string s; + f(&s, "Testing: "); + f(&s, static_cast<int>(1)); + f(&s, static_cast<int16_t>(2)); + f(&s, static_cast<int64_t>(3)); + f(&s, static_cast<float>(4)); + f(&s, static_cast<double>(5)); + f(&s, static_cast<unsigned>(6)); + f(&s, static_cast<size_t>(7)); + f(&s, absl::string_view(" OK ")); + StreamableType streamable = {"object"}; + f(&s, streamable); + EXPECT_EQ("Testing: 1234567 OK Streamable:object", s); +} + +// A dummy formatter that wraps each element in parens. Used in some tests +// below. +struct TestingParenFormatter { + template <typename T> + void operator()(std::string* s, const T& t) { + absl::StrAppend(s, "(", t, ")"); + } +}; + +TEST(PairFormatter, FormatterAPI) { + { + // Tests default PairFormatter(sep) that uses AlphaNumFormatter for the + // 'first' and 'second' members. + const auto f = absl::PairFormatter("="); + std::string s; + f(&s, std::make_pair("a", "b")); + f(&s, std::make_pair(1, 2)); + EXPECT_EQ("a=b1=2", s); + } + + { + // Tests using a custom formatter for the 'first' and 'second' members. + auto f = absl::PairFormatter(TestingParenFormatter(), "=", + TestingParenFormatter()); + std::string s; + f(&s, std::make_pair("a", "b")); + f(&s, std::make_pair(1, 2)); + EXPECT_EQ("(a)=(b)(1)=(2)", s); + } +} + +TEST(DereferenceFormatter, FormatterAPI) { + { + // Tests wrapping the default AlphaNumFormatter. + const absl::strings_internal::DereferenceFormatterImpl< + absl::strings_internal::AlphaNumFormatterImpl> + f; + int x = 1, y = 2, z = 3; + std::string s; + f(&s, &x); + f(&s, &y); + f(&s, &z); + EXPECT_EQ("123", s); + } + + { + // Tests wrapping std::string's default formatter. + absl::strings_internal::DereferenceFormatterImpl< + absl::strings_internal::DefaultFormatter<std::string>::Type> + f; + + std::string x = "x"; + std::string y = "y"; + std::string z = "z"; + std::string s; + f(&s, &x); + f(&s, &y); + f(&s, &z); + EXPECT_EQ(s, "xyz"); + } + + { + // Tests wrapping a custom formatter. + auto f = absl::DereferenceFormatter(TestingParenFormatter()); + int x = 1, y = 2, z = 3; + std::string s; + f(&s, &x); + f(&s, &y); + f(&s, &z); + EXPECT_EQ("(1)(2)(3)", s); + } + + { + absl::strings_internal::DereferenceFormatterImpl< + absl::strings_internal::AlphaNumFormatterImpl> + f; + auto x = std::unique_ptr<int>(new int(1)); + auto y = std::unique_ptr<int>(new int(2)); + auto z = std::unique_ptr<int>(new int(3)); + std::string s; + f(&s, x); + f(&s, y); + f(&s, z); + EXPECT_EQ("123", s); + } +} + +// +// Tests the interfaces for the 4 public Join function overloads. The semantics +// of the algorithm is covered in the above APIExamples test. +// +TEST(StrJoin, PublicAPIOverloads) { + std::vector<std::string> v = {"a", "b", "c"}; + + // Iterators + formatter + EXPECT_EQ("a-b-c", + absl::StrJoin(v.begin(), v.end(), "-", absl::AlphaNumFormatter())); + // Range + formatter + EXPECT_EQ("a-b-c", absl::StrJoin(v, "-", absl::AlphaNumFormatter())); + // Iterators, no formatter + EXPECT_EQ("a-b-c", absl::StrJoin(v.begin(), v.end(), "-")); + // Range, no formatter + EXPECT_EQ("a-b-c", absl::StrJoin(v, "-")); +} + +TEST(StrJoin, Array) { + const absl::string_view a[] = {"a", "b", "c"}; + EXPECT_EQ("a-b-c", absl::StrJoin(a, "-")); +} + +TEST(StrJoin, InitializerList) { + { EXPECT_EQ("a-b-c", absl::StrJoin({"a", "b", "c"}, "-")); } + + { + auto a = {"a", "b", "c"}; + EXPECT_EQ("a-b-c", absl::StrJoin(a, "-")); + } + + { + std::initializer_list<const char*> a = {"a", "b", "c"}; + EXPECT_EQ("a-b-c", absl::StrJoin(a, "-")); + } + + { + std::initializer_list<std::string> a = {"a", "b", "c"}; + EXPECT_EQ("a-b-c", absl::StrJoin(a, "-")); + } + + { + std::initializer_list<absl::string_view> a = {"a", "b", "c"}; + EXPECT_EQ("a-b-c", absl::StrJoin(a, "-")); + } + + { + // Tests initializer_list with a non-default formatter + auto a = {"a", "b", "c"}; + TestingParenFormatter f; + EXPECT_EQ("(a)-(b)-(c)", absl::StrJoin(a, "-", f)); + } + + { + // initializer_list of ints + EXPECT_EQ("1-2-3", absl::StrJoin({1, 2, 3}, "-")); + } + + { + // Tests initializer_list of ints with a non-default formatter + auto a = {1, 2, 3}; + TestingParenFormatter f; + EXPECT_EQ("(1)-(2)-(3)", absl::StrJoin(a, "-", f)); + } +} + +TEST(StrJoin, Tuple) { + EXPECT_EQ("", absl::StrJoin(std::make_tuple(), "-")); + EXPECT_EQ("hello", absl::StrJoin(std::make_tuple("hello"), "-")); + + int x(10); + std::string y("hello"); + double z(3.14); + EXPECT_EQ("10-hello-3.14", absl::StrJoin(std::make_tuple(x, y, z), "-")); + + // Faster! Faster!! + EXPECT_EQ("10-hello-3.14", + absl::StrJoin(std::make_tuple(x, std::cref(y), z), "-")); + + struct TestFormatter { + char buffer[128]; + void operator()(std::string* out, int v) { + snprintf(buffer, sizeof(buffer), "%#.8x", v); + out->append(buffer); + } + void operator()(std::string* out, double v) { + snprintf(buffer, sizeof(buffer), "%#.0f", v); + out->append(buffer); + } + void operator()(std::string* out, const std::string& v) { + snprintf(buffer, sizeof(buffer), "%.4s", v.c_str()); + out->append(buffer); + } + }; + EXPECT_EQ("0x0000000a-hell-3.", + absl::StrJoin(std::make_tuple(x, y, z), "-", TestFormatter())); + EXPECT_EQ( + "0x0000000a-hell-3.", + absl::StrJoin(std::make_tuple(x, std::cref(y), z), "-", TestFormatter())); + EXPECT_EQ("0x0000000a-hell-3.", + absl::StrJoin(std::make_tuple(&x, &y, &z), "-", + absl::DereferenceFormatter(TestFormatter()))); + EXPECT_EQ("0x0000000a-hell-3.", + absl::StrJoin(std::make_tuple(absl::make_unique<int>(x), + absl::make_unique<std::string>(y), + absl::make_unique<double>(z)), + "-", absl::DereferenceFormatter(TestFormatter()))); + EXPECT_EQ("0x0000000a-hell-3.", + absl::StrJoin(std::make_tuple(absl::make_unique<int>(x), &y, &z), + "-", absl::DereferenceFormatter(TestFormatter()))); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_replace.cc b/third_party/abseil_cpp/absl/strings/str_replace.cc new file mode 100644 index 0000000000..2bd5fa9821 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_replace.cc @@ -0,0 +1,82 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_replace.h" + +#include "absl/strings/str_cat.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace strings_internal { + +using FixedMapping = + std::initializer_list<std::pair<absl::string_view, absl::string_view>>; + +// Applies the ViableSubstitutions in subs_ptr to the absl::string_view s, and +// stores the result in *result_ptr. Returns the number of substitutions that +// occurred. +int ApplySubstitutions( + absl::string_view s, + std::vector<strings_internal::ViableSubstitution>* subs_ptr, + std::string* result_ptr) { + auto& subs = *subs_ptr; + int substitutions = 0; + size_t pos = 0; + while (!subs.empty()) { + auto& sub = subs.back(); + if (sub.offset >= pos) { + if (pos <= s.size()) { + StrAppend(result_ptr, s.substr(pos, sub.offset - pos), sub.replacement); + } + pos = sub.offset + sub.old.size(); + substitutions += 1; + } + sub.offset = s.find(sub.old, pos); + if (sub.offset == s.npos) { + subs.pop_back(); + } else { + // Insertion sort to ensure the last ViableSubstitution continues to be + // before all the others. + size_t index = subs.size(); + while (--index && subs[index - 1].OccursBefore(subs[index])) { + std::swap(subs[index], subs[index - 1]); + } + } + } + result_ptr->append(s.data() + pos, s.size() - pos); + return substitutions; +} + +} // namespace strings_internal + +// We can implement this in terms of the generic StrReplaceAll, but +// we must specify the template overload because C++ cannot deduce the type +// of an initializer_list parameter to a function, and also if we don't specify +// the type, we just call ourselves. +// +// Note that we implement them here, rather than in the header, so that they +// aren't inlined. + +std::string StrReplaceAll(absl::string_view s, + strings_internal::FixedMapping replacements) { + return StrReplaceAll<strings_internal::FixedMapping>(s, replacements); +} + +int StrReplaceAll(strings_internal::FixedMapping replacements, + std::string* target) { + return StrReplaceAll<strings_internal::FixedMapping>(replacements, target); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/str_replace.h b/third_party/abseil_cpp/absl/strings/str_replace.h new file mode 100644 index 0000000000..273c707735 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_replace.h @@ -0,0 +1,219 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: str_replace.h +// ----------------------------------------------------------------------------- +// +// This file defines `absl::StrReplaceAll()`, a general-purpose string +// replacement function designed for large, arbitrary text substitutions, +// especially on strings which you are receiving from some other system for +// further processing (e.g. processing regular expressions, escaping HTML +// entities, etc.). `StrReplaceAll` is designed to be efficient even when only +// one substitution is being performed, or when substitution is rare. +// +// If the string being modified is known at compile-time, and the substitutions +// vary, `absl::Substitute()` may be a better choice. +// +// Example: +// +// std::string html_escaped = absl::StrReplaceAll(user_input, { +// {"&", "&"}, +// {"<", "<"}, +// {">", ">"}, +// {"\"", """}, +// {"'", "'"}}); +#ifndef ABSL_STRINGS_STR_REPLACE_H_ +#define ABSL_STRINGS_STR_REPLACE_H_ + +#include <string> +#include <utility> +#include <vector> + +#include "absl/base/attributes.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// StrReplaceAll() +// +// Replaces character sequences within a given string with replacements provided +// within an initializer list of key/value pairs. Candidate replacements are +// considered in order as they occur within the string, with earlier matches +// taking precedence, and longer matches taking precedence for candidates +// starting at the same position in the string. Once a substitution is made, the +// replaced text is not considered for any further substitutions. +// +// Example: +// +// std::string s = absl::StrReplaceAll( +// "$who bought $count #Noun. Thanks $who!", +// {{"$count", absl::StrCat(5)}, +// {"$who", "Bob"}, +// {"#Noun", "Apples"}}); +// EXPECT_EQ("Bob bought 5 Apples. Thanks Bob!", s); +ABSL_MUST_USE_RESULT std::string StrReplaceAll( + absl::string_view s, + std::initializer_list<std::pair<absl::string_view, absl::string_view>> + replacements); + +// Overload of `StrReplaceAll()` to accept a container of key/value replacement +// pairs (typically either an associative map or a `std::vector` of `std::pair` +// elements). A vector of pairs is generally more efficient. +// +// Examples: +// +// std::map<const absl::string_view, const absl::string_view> replacements; +// replacements["$who"] = "Bob"; +// replacements["$count"] = "5"; +// replacements["#Noun"] = "Apples"; +// std::string s = absl::StrReplaceAll( +// "$who bought $count #Noun. Thanks $who!", +// replacements); +// EXPECT_EQ("Bob bought 5 Apples. Thanks Bob!", s); +// +// // A std::vector of std::pair elements can be more efficient. +// std::vector<std::pair<const absl::string_view, std::string>> replacements; +// replacements.push_back({"&", "&"}); +// replacements.push_back({"<", "<"}); +// replacements.push_back({">", ">"}); +// std::string s = absl::StrReplaceAll("if (ptr < &foo)", +// replacements); +// EXPECT_EQ("if (ptr < &foo)", s); +template <typename StrToStrMapping> +std::string StrReplaceAll(absl::string_view s, + const StrToStrMapping& replacements); + +// Overload of `StrReplaceAll()` to replace character sequences within a given +// output string *in place* with replacements provided within an initializer +// list of key/value pairs, returning the number of substitutions that occurred. +// +// Example: +// +// std::string s = std::string("$who bought $count #Noun. Thanks $who!"); +// int count; +// count = absl::StrReplaceAll({{"$count", absl::StrCat(5)}, +// {"$who", "Bob"}, +// {"#Noun", "Apples"}}, &s); +// EXPECT_EQ(count, 4); +// EXPECT_EQ("Bob bought 5 Apples. Thanks Bob!", s); +int StrReplaceAll( + std::initializer_list<std::pair<absl::string_view, absl::string_view>> + replacements, + std::string* target); + +// Overload of `StrReplaceAll()` to replace patterns within a given output +// string *in place* with replacements provided within a container of key/value +// pairs. +// +// Example: +// +// std::string s = std::string("if (ptr < &foo)"); +// int count = absl::StrReplaceAll({{"&", "&"}, +// {"<", "<"}, +// {">", ">"}}, &s); +// EXPECT_EQ(count, 2); +// EXPECT_EQ("if (ptr < &foo)", s); +template <typename StrToStrMapping> +int StrReplaceAll(const StrToStrMapping& replacements, std::string* target); + +// Implementation details only, past this point. +namespace strings_internal { + +struct ViableSubstitution { + absl::string_view old; + absl::string_view replacement; + size_t offset; + + ViableSubstitution(absl::string_view old_str, + absl::string_view replacement_str, size_t offset_val) + : old(old_str), replacement(replacement_str), offset(offset_val) {} + + // One substitution occurs "before" another (takes priority) if either + // it has the lowest offset, or it has the same offset but a larger size. + bool OccursBefore(const ViableSubstitution& y) const { + if (offset != y.offset) return offset < y.offset; + return old.size() > y.old.size(); + } +}; + +// Build a vector of ViableSubstitutions based on the given list of +// replacements. subs can be implemented as a priority_queue. However, it turns +// out that most callers have small enough a list of substitutions that the +// overhead of such a queue isn't worth it. +template <typename StrToStrMapping> +std::vector<ViableSubstitution> FindSubstitutions( + absl::string_view s, const StrToStrMapping& replacements) { + std::vector<ViableSubstitution> subs; + subs.reserve(replacements.size()); + + for (const auto& rep : replacements) { + using std::get; + absl::string_view old(get<0>(rep)); + + size_t pos = s.find(old); + if (pos == s.npos) continue; + + // Ignore attempts to replace "". This condition is almost never true, + // but above condition is frequently true. That's why we test for this + // now and not before. + if (old.empty()) continue; + + subs.emplace_back(old, get<1>(rep), pos); + + // Insertion sort to ensure the last ViableSubstitution comes before + // all the others. + size_t index = subs.size(); + while (--index && subs[index - 1].OccursBefore(subs[index])) { + std::swap(subs[index], subs[index - 1]); + } + } + return subs; +} + +int ApplySubstitutions(absl::string_view s, + std::vector<ViableSubstitution>* subs_ptr, + std::string* result_ptr); + +} // namespace strings_internal + +template <typename StrToStrMapping> +std::string StrReplaceAll(absl::string_view s, + const StrToStrMapping& replacements) { + auto subs = strings_internal::FindSubstitutions(s, replacements); + std::string result; + result.reserve(s.size()); + strings_internal::ApplySubstitutions(s, &subs, &result); + return result; +} + +template <typename StrToStrMapping> +int StrReplaceAll(const StrToStrMapping& replacements, std::string* target) { + auto subs = strings_internal::FindSubstitutions(*target, replacements); + if (subs.empty()) return 0; + + std::string result; + result.reserve(target->size()); + int substitutions = + strings_internal::ApplySubstitutions(*target, &subs, &result); + target->swap(result); + return substitutions; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STR_REPLACE_H_ diff --git a/third_party/abseil_cpp/absl/strings/str_replace_benchmark.cc b/third_party/abseil_cpp/absl/strings/str_replace_benchmark.cc new file mode 100644 index 0000000000..01331da29f --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_replace_benchmark.cc @@ -0,0 +1,122 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_replace.h" + +#include <cstring> +#include <string> + +#include "benchmark/benchmark.h" +#include "absl/base/internal/raw_logging.h" + +namespace { + +std::string* big_string; +std::string* after_replacing_the; +std::string* after_replacing_many; + +struct Replacement { + const char* needle; + const char* replacement; +} replacements[] = { + {"the", "box"}, // + {"brown", "quick"}, // + {"jumped", "liquored"}, // + {"dozen", "brown"}, // + {"lazy", "pack"}, // + {"liquor", "shakes"}, // +}; + +// Here, we set up a string for use in global-replace benchmarks. +// We started with a million blanks, and then deterministically insert +// 10,000 copies each of two pangrams. The result is a string that is +// 40% blank space and 60% these words. 'the' occurs 18,247 times and +// all the substitutions together occur 49,004 times. +// +// We then create "after_replacing_the" to be a string that is a result of +// replacing "the" with "box" in big_string. +// +// And then we create "after_replacing_many" to be a string that is result +// of preferring several substitutions. +void SetUpStrings() { + if (big_string == nullptr) { + size_t r = 0; + big_string = new std::string(1000 * 1000, ' '); + for (std::string phrase : {"the quick brown fox jumped over the lazy dogs", + "pack my box with the five dozen liquor jugs"}) { + for (int i = 0; i < 10 * 1000; ++i) { + r = r * 237 + 41; // not very random. + memcpy(&(*big_string)[r % (big_string->size() - phrase.size())], + phrase.data(), phrase.size()); + } + } + // big_string->resize(50); + // OK, we've set up the string, now let's set up expectations - first by + // just replacing "the" with "box" + after_replacing_the = new std::string(*big_string); + for (size_t pos = 0; + (pos = after_replacing_the->find("the", pos)) != std::string::npos;) { + memcpy(&(*after_replacing_the)[pos], "box", 3); + } + // And then with all the replacements. + after_replacing_many = new std::string(*big_string); + for (size_t pos = 0;;) { + size_t next_pos = static_cast<size_t>(-1); + const char* needle_string = nullptr; + const char* replacement_string = nullptr; + for (const auto& r : replacements) { + auto needlepos = after_replacing_many->find(r.needle, pos); + if (needlepos != std::string::npos && needlepos < next_pos) { + next_pos = needlepos; + needle_string = r.needle; + replacement_string = r.replacement; + } + } + if (next_pos > after_replacing_many->size()) break; + after_replacing_many->replace(next_pos, strlen(needle_string), + replacement_string); + next_pos += strlen(replacement_string); + pos = next_pos; + } + } +} + +void BM_StrReplaceAllOneReplacement(benchmark::State& state) { + SetUpStrings(); + std::string src = *big_string; + for (auto _ : state) { + std::string dest = absl::StrReplaceAll(src, {{"the", "box"}}); + ABSL_RAW_CHECK(dest == *after_replacing_the, + "not benchmarking intended behavior"); + } +} +BENCHMARK(BM_StrReplaceAllOneReplacement); + +void BM_StrReplaceAll(benchmark::State& state) { + SetUpStrings(); + std::string src = *big_string; + for (auto _ : state) { + std::string dest = absl::StrReplaceAll(src, {{"the", "box"}, + {"brown", "quick"}, + {"jumped", "liquored"}, + {"dozen", "brown"}, + {"lazy", "pack"}, + {"liquor", "shakes"}}); + ABSL_RAW_CHECK(dest == *after_replacing_many, + "not benchmarking intended behavior"); + } +} +BENCHMARK(BM_StrReplaceAll); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_replace_test.cc b/third_party/abseil_cpp/absl/strings/str_replace_test.cc new file mode 100644 index 0000000000..9d8c7f75b5 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_replace_test.cc @@ -0,0 +1,341 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_replace.h" + +#include <list> +#include <map> +#include <tuple> + +#include "gtest/gtest.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" + +TEST(StrReplaceAll, OneReplacement) { + std::string s; + + // Empty string. + s = absl::StrReplaceAll(s, {{"", ""}}); + EXPECT_EQ(s, ""); + s = absl::StrReplaceAll(s, {{"x", ""}}); + EXPECT_EQ(s, ""); + s = absl::StrReplaceAll(s, {{"", "y"}}); + EXPECT_EQ(s, ""); + s = absl::StrReplaceAll(s, {{"x", "y"}}); + EXPECT_EQ(s, ""); + + // Empty substring. + s = absl::StrReplaceAll("abc", {{"", ""}}); + EXPECT_EQ(s, "abc"); + s = absl::StrReplaceAll("abc", {{"", "y"}}); + EXPECT_EQ(s, "abc"); + s = absl::StrReplaceAll("abc", {{"x", ""}}); + EXPECT_EQ(s, "abc"); + + // Substring not found. + s = absl::StrReplaceAll("abc", {{"xyz", "123"}}); + EXPECT_EQ(s, "abc"); + + // Replace entire string. + s = absl::StrReplaceAll("abc", {{"abc", "xyz"}}); + EXPECT_EQ(s, "xyz"); + + // Replace once at the start. + s = absl::StrReplaceAll("abc", {{"a", "x"}}); + EXPECT_EQ(s, "xbc"); + + // Replace once in the middle. + s = absl::StrReplaceAll("abc", {{"b", "x"}}); + EXPECT_EQ(s, "axc"); + + // Replace once at the end. + s = absl::StrReplaceAll("abc", {{"c", "x"}}); + EXPECT_EQ(s, "abx"); + + // Replace multiple times with varying lengths of original/replacement. + s = absl::StrReplaceAll("ababa", {{"a", "xxx"}}); + EXPECT_EQ(s, "xxxbxxxbxxx"); + + s = absl::StrReplaceAll("ababa", {{"b", "xxx"}}); + EXPECT_EQ(s, "axxxaxxxa"); + + s = absl::StrReplaceAll("aaabaaabaaa", {{"aaa", "x"}}); + EXPECT_EQ(s, "xbxbx"); + + s = absl::StrReplaceAll("abbbabbba", {{"bbb", "x"}}); + EXPECT_EQ(s, "axaxa"); + + // Overlapping matches are replaced greedily. + s = absl::StrReplaceAll("aaa", {{"aa", "x"}}); + EXPECT_EQ(s, "xa"); + + // The replacements are not recursive. + s = absl::StrReplaceAll("aaa", {{"aa", "a"}}); + EXPECT_EQ(s, "aa"); +} + +TEST(StrReplaceAll, ManyReplacements) { + std::string s; + + // Empty string. + s = absl::StrReplaceAll("", {{"", ""}, {"x", ""}, {"", "y"}, {"x", "y"}}); + EXPECT_EQ(s, ""); + + // Empty substring. + s = absl::StrReplaceAll("abc", {{"", ""}, {"", "y"}, {"x", ""}}); + EXPECT_EQ(s, "abc"); + + // Replace entire string, one char at a time + s = absl::StrReplaceAll("abc", {{"a", "x"}, {"b", "y"}, {"c", "z"}}); + EXPECT_EQ(s, "xyz"); + s = absl::StrReplaceAll("zxy", {{"z", "x"}, {"x", "y"}, {"y", "z"}}); + EXPECT_EQ(s, "xyz"); + + // Replace once at the start (longer matches take precedence) + s = absl::StrReplaceAll("abc", {{"a", "x"}, {"ab", "xy"}, {"abc", "xyz"}}); + EXPECT_EQ(s, "xyz"); + + // Replace once in the middle. + s = absl::StrReplaceAll( + "Abc!", {{"a", "x"}, {"ab", "xy"}, {"b", "y"}, {"bc", "yz"}, {"c", "z"}}); + EXPECT_EQ(s, "Ayz!"); + + // Replace once at the end. + s = absl::StrReplaceAll( + "Abc!", + {{"a", "x"}, {"ab", "xy"}, {"b", "y"}, {"bc!", "yz?"}, {"c!", "z;"}}); + EXPECT_EQ(s, "Ayz?"); + + // Replace multiple times with varying lengths of original/replacement. + s = absl::StrReplaceAll("ababa", {{"a", "xxx"}, {"b", "XXXX"}}); + EXPECT_EQ(s, "xxxXXXXxxxXXXXxxx"); + + // Overlapping matches are replaced greedily. + s = absl::StrReplaceAll("aaa", {{"aa", "x"}, {"a", "X"}}); + EXPECT_EQ(s, "xX"); + s = absl::StrReplaceAll("aaa", {{"a", "X"}, {"aa", "x"}}); + EXPECT_EQ(s, "xX"); + + // Two well-known sentences + s = absl::StrReplaceAll("the quick brown fox jumped over the lazy dogs", + { + {"brown", "box"}, + {"dogs", "jugs"}, + {"fox", "with"}, + {"jumped", "five"}, + {"over", "dozen"}, + {"quick", "my"}, + {"the", "pack"}, + {"the lazy", "liquor"}, + }); + EXPECT_EQ(s, "pack my box with five dozen liquor jugs"); +} + +TEST(StrReplaceAll, ManyReplacementsInMap) { + std::map<const char *, const char *> replacements; + replacements["$who"] = "Bob"; + replacements["$count"] = "5"; + replacements["#Noun"] = "Apples"; + std::string s = absl::StrReplaceAll("$who bought $count #Noun. Thanks $who!", + replacements); + EXPECT_EQ("Bob bought 5 Apples. Thanks Bob!", s); +} + +TEST(StrReplaceAll, ReplacementsInPlace) { + std::string s = std::string("$who bought $count #Noun. Thanks $who!"); + int count; + count = absl::StrReplaceAll({{"$count", absl::StrCat(5)}, + {"$who", "Bob"}, + {"#Noun", "Apples"}}, &s); + EXPECT_EQ(count, 4); + EXPECT_EQ("Bob bought 5 Apples. Thanks Bob!", s); +} + +TEST(StrReplaceAll, ReplacementsInPlaceInMap) { + std::string s = std::string("$who bought $count #Noun. Thanks $who!"); + std::map<absl::string_view, absl::string_view> replacements; + replacements["$who"] = "Bob"; + replacements["$count"] = "5"; + replacements["#Noun"] = "Apples"; + int count; + count = absl::StrReplaceAll(replacements, &s); + EXPECT_EQ(count, 4); + EXPECT_EQ("Bob bought 5 Apples. Thanks Bob!", s); +} + +struct Cont { + Cont() {} + explicit Cont(absl::string_view src) : data(src) {} + + absl::string_view data; +}; + +template <int index> +absl::string_view get(const Cont& c) { + auto splitter = absl::StrSplit(c.data, ':'); + auto it = splitter.begin(); + for (int i = 0; i < index; ++i) ++it; + + return *it; +} + +TEST(StrReplaceAll, VariableNumber) { + std::string s; + { + std::vector<std::pair<std::string, std::string>> replacements; + + s = "abc"; + EXPECT_EQ(0, absl::StrReplaceAll(replacements, &s)); + EXPECT_EQ("abc", s); + + s = "abc"; + replacements.push_back({"a", "A"}); + EXPECT_EQ(1, absl::StrReplaceAll(replacements, &s)); + EXPECT_EQ("Abc", s); + + s = "abc"; + replacements.push_back({"b", "B"}); + EXPECT_EQ(2, absl::StrReplaceAll(replacements, &s)); + EXPECT_EQ("ABc", s); + + s = "abc"; + replacements.push_back({"d", "D"}); + EXPECT_EQ(2, absl::StrReplaceAll(replacements, &s)); + EXPECT_EQ("ABc", s); + + EXPECT_EQ("ABcABc", absl::StrReplaceAll("abcabc", replacements)); + } + + { + std::map<const char*, const char*> replacements; + replacements["aa"] = "x"; + replacements["a"] = "X"; + s = "aaa"; + EXPECT_EQ(2, absl::StrReplaceAll(replacements, &s)); + EXPECT_EQ("xX", s); + + EXPECT_EQ("xxX", absl::StrReplaceAll("aaaaa", replacements)); + } + + { + std::list<std::pair<absl::string_view, absl::string_view>> replacements = { + {"a", "x"}, {"b", "y"}, {"c", "z"}}; + + std::string s = absl::StrReplaceAll("abc", replacements); + EXPECT_EQ(s, "xyz"); + } + + { + using X = std::tuple<absl::string_view, std::string, int>; + std::vector<X> replacements(3); + replacements[0] = X{"a", "x", 1}; + replacements[1] = X{"b", "y", 0}; + replacements[2] = X{"c", "z", -1}; + + std::string s = absl::StrReplaceAll("abc", replacements); + EXPECT_EQ(s, "xyz"); + } + + { + std::vector<Cont> replacements(3); + replacements[0] = Cont{"a:x"}; + replacements[1] = Cont{"b:y"}; + replacements[2] = Cont{"c:z"}; + + std::string s = absl::StrReplaceAll("abc", replacements); + EXPECT_EQ(s, "xyz"); + } +} + +// Same as above, but using the in-place variant of absl::StrReplaceAll, +// that returns the # of replacements performed. +TEST(StrReplaceAll, Inplace) { + std::string s; + int reps; + + // Empty string. + s = ""; + reps = absl::StrReplaceAll({{"", ""}, {"x", ""}, {"", "y"}, {"x", "y"}}, &s); + EXPECT_EQ(reps, 0); + EXPECT_EQ(s, ""); + + // Empty substring. + s = "abc"; + reps = absl::StrReplaceAll({{"", ""}, {"", "y"}, {"x", ""}}, &s); + EXPECT_EQ(reps, 0); + EXPECT_EQ(s, "abc"); + + // Replace entire string, one char at a time + s = "abc"; + reps = absl::StrReplaceAll({{"a", "x"}, {"b", "y"}, {"c", "z"}}, &s); + EXPECT_EQ(reps, 3); + EXPECT_EQ(s, "xyz"); + s = "zxy"; + reps = absl::StrReplaceAll({{"z", "x"}, {"x", "y"}, {"y", "z"}}, &s); + EXPECT_EQ(reps, 3); + EXPECT_EQ(s, "xyz"); + + // Replace once at the start (longer matches take precedence) + s = "abc"; + reps = absl::StrReplaceAll({{"a", "x"}, {"ab", "xy"}, {"abc", "xyz"}}, &s); + EXPECT_EQ(reps, 1); + EXPECT_EQ(s, "xyz"); + + // Replace once in the middle. + s = "Abc!"; + reps = absl::StrReplaceAll( + {{"a", "x"}, {"ab", "xy"}, {"b", "y"}, {"bc", "yz"}, {"c", "z"}}, &s); + EXPECT_EQ(reps, 1); + EXPECT_EQ(s, "Ayz!"); + + // Replace once at the end. + s = "Abc!"; + reps = absl::StrReplaceAll( + {{"a", "x"}, {"ab", "xy"}, {"b", "y"}, {"bc!", "yz?"}, {"c!", "z;"}}, &s); + EXPECT_EQ(reps, 1); + EXPECT_EQ(s, "Ayz?"); + + // Replace multiple times with varying lengths of original/replacement. + s = "ababa"; + reps = absl::StrReplaceAll({{"a", "xxx"}, {"b", "XXXX"}}, &s); + EXPECT_EQ(reps, 5); + EXPECT_EQ(s, "xxxXXXXxxxXXXXxxx"); + + // Overlapping matches are replaced greedily. + s = "aaa"; + reps = absl::StrReplaceAll({{"aa", "x"}, {"a", "X"}}, &s); + EXPECT_EQ(reps, 2); + EXPECT_EQ(s, "xX"); + s = "aaa"; + reps = absl::StrReplaceAll({{"a", "X"}, {"aa", "x"}}, &s); + EXPECT_EQ(reps, 2); + EXPECT_EQ(s, "xX"); + + // Two well-known sentences + s = "the quick brown fox jumped over the lazy dogs"; + reps = absl::StrReplaceAll( + { + {"brown", "box"}, + {"dogs", "jugs"}, + {"fox", "with"}, + {"jumped", "five"}, + {"over", "dozen"}, + {"quick", "my"}, + {"the", "pack"}, + {"the lazy", "liquor"}, + }, + &s); + EXPECT_EQ(reps, 8); + EXPECT_EQ(s, "pack my box with five dozen liquor jugs"); +} diff --git a/third_party/abseil_cpp/absl/strings/str_split.cc b/third_party/abseil_cpp/absl/strings/str_split.cc new file mode 100644 index 0000000000..e08c26b6bb --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_split.cc @@ -0,0 +1,139 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_split.h" + +#include <algorithm> +#include <cassert> +#include <cstdint> +#include <cstdlib> +#include <cstring> +#include <iterator> +#include <limits> +#include <memory> + +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/ascii.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +// This GenericFind() template function encapsulates the finding algorithm +// shared between the ByString and ByAnyChar delimiters. The FindPolicy +// template parameter allows each delimiter to customize the actual find +// function to use and the length of the found delimiter. For example, the +// Literal delimiter will ultimately use absl::string_view::find(), and the +// AnyOf delimiter will use absl::string_view::find_first_of(). +template <typename FindPolicy> +absl::string_view GenericFind(absl::string_view text, + absl::string_view delimiter, size_t pos, + FindPolicy find_policy) { + if (delimiter.empty() && text.length() > 0) { + // Special case for empty string delimiters: always return a zero-length + // absl::string_view referring to the item at position 1 past pos. + return absl::string_view(text.data() + pos + 1, 0); + } + size_t found_pos = absl::string_view::npos; + absl::string_view found(text.data() + text.size(), + 0); // By default, not found + found_pos = find_policy.Find(text, delimiter, pos); + if (found_pos != absl::string_view::npos) { + found = absl::string_view(text.data() + found_pos, + find_policy.Length(delimiter)); + } + return found; +} + +// Finds using absl::string_view::find(), therefore the length of the found +// delimiter is delimiter.length(). +struct LiteralPolicy { + size_t Find(absl::string_view text, absl::string_view delimiter, size_t pos) { + return text.find(delimiter, pos); + } + size_t Length(absl::string_view delimiter) { return delimiter.length(); } +}; + +// Finds using absl::string_view::find_first_of(), therefore the length of the +// found delimiter is 1. +struct AnyOfPolicy { + size_t Find(absl::string_view text, absl::string_view delimiter, size_t pos) { + return text.find_first_of(delimiter, pos); + } + size_t Length(absl::string_view /* delimiter */) { return 1; } +}; + +} // namespace + +// +// ByString +// + +ByString::ByString(absl::string_view sp) : delimiter_(sp) {} + +absl::string_view ByString::Find(absl::string_view text, size_t pos) const { + if (delimiter_.length() == 1) { + // Much faster to call find on a single character than on an + // absl::string_view. + size_t found_pos = text.find(delimiter_[0], pos); + if (found_pos == absl::string_view::npos) + return absl::string_view(text.data() + text.size(), 0); + return text.substr(found_pos, 1); + } + return GenericFind(text, delimiter_, pos, LiteralPolicy()); +} + +// +// ByChar +// + +absl::string_view ByChar::Find(absl::string_view text, size_t pos) const { + size_t found_pos = text.find(c_, pos); + if (found_pos == absl::string_view::npos) + return absl::string_view(text.data() + text.size(), 0); + return text.substr(found_pos, 1); +} + +// +// ByAnyChar +// + +ByAnyChar::ByAnyChar(absl::string_view sp) : delimiters_(sp) {} + +absl::string_view ByAnyChar::Find(absl::string_view text, size_t pos) const { + return GenericFind(text, delimiters_, pos, AnyOfPolicy()); +} + +// +// ByLength +// +ByLength::ByLength(ptrdiff_t length) : length_(length) { + ABSL_RAW_CHECK(length > 0, ""); +} + +absl::string_view ByLength::Find(absl::string_view text, + size_t pos) const { + pos = std::min(pos, text.size()); // truncate `pos` + absl::string_view substr = text.substr(pos); + // If the string is shorter than the chunk size we say we + // "can't find the delimiter" so this will be the last chunk. + if (substr.length() <= static_cast<size_t>(length_)) + return absl::string_view(text.data() + text.size(), 0); + + return absl::string_view(substr.data() + length_, 0); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/str_split.h b/third_party/abseil_cpp/absl/strings/str_split.h new file mode 100644 index 0000000000..a79cd4a0ce --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_split.h @@ -0,0 +1,513 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: str_split.h +// ----------------------------------------------------------------------------- +// +// This file contains functions for splitting strings. It defines the main +// `StrSplit()` function, several delimiters for determining the boundaries on +// which to split the string, and predicates for filtering delimited results. +// `StrSplit()` adapts the returned collection to the type specified by the +// caller. +// +// Example: +// +// // Splits the given string on commas. Returns the results in a +// // vector of strings. +// std::vector<std::string> v = absl::StrSplit("a,b,c", ','); +// // Can also use "," +// // v[0] == "a", v[1] == "b", v[2] == "c" +// +// See StrSplit() below for more information. +#ifndef ABSL_STRINGS_STR_SPLIT_H_ +#define ABSL_STRINGS_STR_SPLIT_H_ + +#include <algorithm> +#include <cstddef> +#include <map> +#include <set> +#include <string> +#include <utility> +#include <vector> + +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/internal/str_split_internal.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +//------------------------------------------------------------------------------ +// Delimiters +//------------------------------------------------------------------------------ +// +// `StrSplit()` uses delimiters to define the boundaries between elements in the +// provided input. Several `Delimiter` types are defined below. If a string +// (`const char*`, `std::string`, or `absl::string_view`) is passed in place of +// an explicit `Delimiter` object, `StrSplit()` treats it the same way as if it +// were passed a `ByString` delimiter. +// +// A `Delimiter` is an object with a `Find()` function that knows how to find +// the first occurrence of itself in a given `absl::string_view`. +// +// The following `Delimiter` types are available for use within `StrSplit()`: +// +// - `ByString` (default for string arguments) +// - `ByChar` (default for a char argument) +// - `ByAnyChar` +// - `ByLength` +// - `MaxSplits` +// +// A Delimiter's `Find()` member function will be passed an input `text` that is +// to be split and a position (`pos`) to begin searching for the next delimiter +// in `text`. The returned absl::string_view should refer to the next occurrence +// (after `pos`) of the represented delimiter; this returned absl::string_view +// represents the next location where the input `text` should be broken. +// +// The returned absl::string_view may be zero-length if the Delimiter does not +// represent a part of the string (e.g., a fixed-length delimiter). If no +// delimiter is found in the input `text`, a zero-length absl::string_view +// referring to `text.end()` should be returned (e.g., +// `text.substr(text.size())`). It is important that the returned +// absl::string_view always be within the bounds of the input `text` given as an +// argument--it must not refer to a string that is physically located outside of +// the given string. +// +// The following example is a simple Delimiter object that is created with a +// single char and will look for that char in the text passed to the `Find()` +// function: +// +// struct SimpleDelimiter { +// const char c_; +// explicit SimpleDelimiter(char c) : c_(c) {} +// absl::string_view Find(absl::string_view text, size_t pos) { +// auto found = text.find(c_, pos); +// if (found == absl::string_view::npos) +// return text.substr(text.size()); +// +// return text.substr(found, 1); +// } +// }; + +// ByString +// +// A sub-string delimiter. If `StrSplit()` is passed a string in place of a +// `Delimiter` object, the string will be implicitly converted into a +// `ByString` delimiter. +// +// Example: +// +// // Because a string literal is converted to an `absl::ByString`, +// // the following two splits are equivalent. +// +// std::vector<std::string> v1 = absl::StrSplit("a, b, c", ", "); +// +// using absl::ByString; +// std::vector<std::string> v2 = absl::StrSplit("a, b, c", +// ByString(", ")); +// // v[0] == "a", v[1] == "b", v[2] == "c" +class ByString { + public: + explicit ByString(absl::string_view sp); + absl::string_view Find(absl::string_view text, size_t pos) const; + + private: + const std::string delimiter_; +}; + +// ByChar +// +// A single character delimiter. `ByChar` is functionally equivalent to a +// 1-char string within a `ByString` delimiter, but slightly more efficient. +// +// Example: +// +// // Because a char literal is converted to a absl::ByChar, +// // the following two splits are equivalent. +// std::vector<std::string> v1 = absl::StrSplit("a,b,c", ','); +// using absl::ByChar; +// std::vector<std::string> v2 = absl::StrSplit("a,b,c", ByChar(',')); +// // v[0] == "a", v[1] == "b", v[2] == "c" +// +// `ByChar` is also the default delimiter if a single character is given +// as the delimiter to `StrSplit()`. For example, the following calls are +// equivalent: +// +// std::vector<std::string> v = absl::StrSplit("a-b", '-'); +// +// using absl::ByChar; +// std::vector<std::string> v = absl::StrSplit("a-b", ByChar('-')); +// +class ByChar { + public: + explicit ByChar(char c) : c_(c) {} + absl::string_view Find(absl::string_view text, size_t pos) const; + + private: + char c_; +}; + +// ByAnyChar +// +// A delimiter that will match any of the given byte-sized characters within +// its provided string. +// +// Note: this delimiter works with single-byte string data, but does not work +// with variable-width encodings, such as UTF-8. +// +// Example: +// +// using absl::ByAnyChar; +// std::vector<std::string> v = absl::StrSplit("a,b=c", ByAnyChar(",=")); +// // v[0] == "a", v[1] == "b", v[2] == "c" +// +// If `ByAnyChar` is given the empty string, it behaves exactly like +// `ByString` and matches each individual character in the input string. +// +class ByAnyChar { + public: + explicit ByAnyChar(absl::string_view sp); + absl::string_view Find(absl::string_view text, size_t pos) const; + + private: + const std::string delimiters_; +}; + +// ByLength +// +// A delimiter for splitting into equal-length strings. The length argument to +// the constructor must be greater than 0. +// +// Note: this delimiter works with single-byte string data, but does not work +// with variable-width encodings, such as UTF-8. +// +// Example: +// +// using absl::ByLength; +// std::vector<std::string> v = absl::StrSplit("123456789", ByLength(3)); + +// // v[0] == "123", v[1] == "456", v[2] == "789" +// +// Note that the string does not have to be a multiple of the fixed split +// length. In such a case, the last substring will be shorter. +// +// using absl::ByLength; +// std::vector<std::string> v = absl::StrSplit("12345", ByLength(2)); +// +// // v[0] == "12", v[1] == "34", v[2] == "5" +class ByLength { + public: + explicit ByLength(ptrdiff_t length); + absl::string_view Find(absl::string_view text, size_t pos) const; + + private: + const ptrdiff_t length_; +}; + +namespace strings_internal { + +// A traits-like metafunction for selecting the default Delimiter object type +// for a particular Delimiter type. The base case simply exposes type Delimiter +// itself as the delimiter's Type. However, there are specializations for +// string-like objects that map them to the ByString delimiter object. +// This allows functions like absl::StrSplit() and absl::MaxSplits() to accept +// string-like objects (e.g., ',') as delimiter arguments but they will be +// treated as if a ByString delimiter was given. +template <typename Delimiter> +struct SelectDelimiter { + using type = Delimiter; +}; + +template <> +struct SelectDelimiter<char> { + using type = ByChar; +}; +template <> +struct SelectDelimiter<char*> { + using type = ByString; +}; +template <> +struct SelectDelimiter<const char*> { + using type = ByString; +}; +template <> +struct SelectDelimiter<absl::string_view> { + using type = ByString; +}; +template <> +struct SelectDelimiter<std::string> { + using type = ByString; +}; + +// Wraps another delimiter and sets a max number of matches for that delimiter. +template <typename Delimiter> +class MaxSplitsImpl { + public: + MaxSplitsImpl(Delimiter delimiter, int limit) + : delimiter_(delimiter), limit_(limit), count_(0) {} + absl::string_view Find(absl::string_view text, size_t pos) { + if (count_++ == limit_) { + return absl::string_view(text.data() + text.size(), + 0); // No more matches. + } + return delimiter_.Find(text, pos); + } + + private: + Delimiter delimiter_; + const int limit_; + int count_; +}; + +} // namespace strings_internal + +// MaxSplits() +// +// A delimiter that limits the number of matches which can occur to the passed +// `limit`. The last element in the returned collection will contain all +// remaining unsplit pieces, which may contain instances of the delimiter. +// The collection will contain at most `limit` + 1 elements. +// Example: +// +// using absl::MaxSplits; +// std::vector<std::string> v = absl::StrSplit("a,b,c", MaxSplits(',', 1)); +// +// // v[0] == "a", v[1] == "b,c" +template <typename Delimiter> +inline strings_internal::MaxSplitsImpl< + typename strings_internal::SelectDelimiter<Delimiter>::type> +MaxSplits(Delimiter delimiter, int limit) { + typedef + typename strings_internal::SelectDelimiter<Delimiter>::type DelimiterType; + return strings_internal::MaxSplitsImpl<DelimiterType>( + DelimiterType(delimiter), limit); +} + +//------------------------------------------------------------------------------ +// Predicates +//------------------------------------------------------------------------------ +// +// Predicates filter the results of a `StrSplit()` by determining whether or not +// a resultant element is included in the result set. A predicate may be passed +// as an optional third argument to the `StrSplit()` function. +// +// Predicates are unary functions (or functors) that take a single +// `absl::string_view` argument and return a bool indicating whether the +// argument should be included (`true`) or excluded (`false`). +// +// Predicates are useful when filtering out empty substrings. By default, empty +// substrings may be returned by `StrSplit()`, which is similar to the way split +// functions work in other programming languages. + +// AllowEmpty() +// +// Always returns `true`, indicating that all strings--including empty +// strings--should be included in the split output. This predicate is not +// strictly needed because this is the default behavior of `StrSplit()`; +// however, it might be useful at some call sites to make the intent explicit. +// +// Example: +// +// std::vector<std::string> v = absl::StrSplit(" a , ,,b,", ',', AllowEmpty()); +// +// // v[0] == " a ", v[1] == " ", v[2] == "", v[3] = "b", v[4] == "" +struct AllowEmpty { + bool operator()(absl::string_view) const { return true; } +}; + +// SkipEmpty() +// +// Returns `false` if the given `absl::string_view` is empty, indicating that +// `StrSplit()` should omit the empty string. +// +// Example: +// +// std::vector<std::string> v = absl::StrSplit(",a,,b,", ',', SkipEmpty()); +// +// // v[0] == "a", v[1] == "b" +// +// Note: `SkipEmpty()` does not consider a string containing only whitespace +// to be empty. To skip such whitespace as well, use the `SkipWhitespace()` +// predicate. +struct SkipEmpty { + bool operator()(absl::string_view sp) const { return !sp.empty(); } +}; + +// SkipWhitespace() +// +// Returns `false` if the given `absl::string_view` is empty *or* contains only +// whitespace, indicating that `StrSplit()` should omit the string. +// +// Example: +// +// std::vector<std::string> v = absl::StrSplit(" a , ,,b,", +// ',', SkipWhitespace()); +// // v[0] == " a ", v[1] == "b" +// +// // SkipEmpty() would return whitespace elements +// std::vector<std::string> v = absl::StrSplit(" a , ,,b,", ',', SkipEmpty()); +// // v[0] == " a ", v[1] == " ", v[2] == "b" +struct SkipWhitespace { + bool operator()(absl::string_view sp) const { + sp = absl::StripAsciiWhitespace(sp); + return !sp.empty(); + } +}; + +//------------------------------------------------------------------------------ +// StrSplit() +//------------------------------------------------------------------------------ + +// StrSplit() +// +// Splits a given string based on the provided `Delimiter` object, returning the +// elements within the type specified by the caller. Optionally, you may pass a +// `Predicate` to `StrSplit()` indicating whether to include or exclude the +// resulting element within the final result set. (See the overviews for +// Delimiters and Predicates above.) +// +// Example: +// +// std::vector<std::string> v = absl::StrSplit("a,b,c,d", ','); +// // v[0] == "a", v[1] == "b", v[2] == "c", v[3] == "d" +// +// You can also provide an explicit `Delimiter` object: +// +// Example: +// +// using absl::ByAnyChar; +// std::vector<std::string> v = absl::StrSplit("a,b=c", ByAnyChar(",=")); +// // v[0] == "a", v[1] == "b", v[2] == "c" +// +// See above for more information on delimiters. +// +// By default, empty strings are included in the result set. You can optionally +// include a third `Predicate` argument to apply a test for whether the +// resultant element should be included in the result set: +// +// Example: +// +// std::vector<std::string> v = absl::StrSplit(" a , ,,b,", +// ',', SkipWhitespace()); +// // v[0] == " a ", v[1] == "b" +// +// See above for more information on predicates. +// +//------------------------------------------------------------------------------ +// StrSplit() Return Types +//------------------------------------------------------------------------------ +// +// The `StrSplit()` function adapts the returned collection to the collection +// specified by the caller (e.g. `std::vector` above). The returned collections +// may contain `std::string`, `absl::string_view` (in which case the original +// string being split must ensure that it outlives the collection), or any +// object that can be explicitly created from an `absl::string_view`. This +// behavior works for: +// +// 1) All standard STL containers including `std::vector`, `std::list`, +// `std::deque`, `std::set`,`std::multiset`, 'std::map`, and `std::multimap` +// 2) `std::pair` (which is not actually a container). See below. +// +// Example: +// +// // The results are returned as `absl::string_view` objects. Note that we +// // have to ensure that the input string outlives any results. +// std::vector<absl::string_view> v = absl::StrSplit("a,b,c", ','); +// +// // Stores results in a std::set<std::string>, which also performs +// // de-duplication and orders the elements in ascending order. +// std::set<std::string> a = absl::StrSplit("b,a,c,a,b", ','); +// // v[0] == "a", v[1] == "b", v[2] = "c" +// +// // `StrSplit()` can be used within a range-based for loop, in which case +// // each element will be of type `absl::string_view`. +// std::vector<std::string> v; +// for (const auto sv : absl::StrSplit("a,b,c", ',')) { +// if (sv != "b") v.emplace_back(sv); +// } +// // v[0] == "a", v[1] == "c" +// +// // Stores results in a map. The map implementation assumes that the input +// // is provided as a series of key/value pairs. For example, the 0th element +// // resulting from the split will be stored as a key to the 1st element. If +// // an odd number of elements are resolved, the last element is paired with +// // a default-constructed value (e.g., empty string). +// std::map<std::string, std::string> m = absl::StrSplit("a,b,c", ','); +// // m["a"] == "b", m["c"] == "" // last component value equals "" +// +// Splitting to `std::pair` is an interesting case because it can hold only two +// elements and is not a collection type. When splitting to a `std::pair` the +// first two split strings become the `std::pair` `.first` and `.second` +// members, respectively. The remaining split substrings are discarded. If there +// are less than two split substrings, the empty string is used for the +// corresponding +// `std::pair` member. +// +// Example: +// +// // Stores first two split strings as the members in a std::pair. +// std::pair<std::string, std::string> p = absl::StrSplit("a,b,c", ','); +// // p.first == "a", p.second == "b" // "c" is omitted. +// +// The `StrSplit()` function can be used multiple times to perform more +// complicated splitting logic, such as intelligently parsing key-value pairs. +// +// Example: +// +// // The input string "a=b=c,d=e,f=,g" becomes +// // { "a" => "b=c", "d" => "e", "f" => "", "g" => "" } +// std::map<std::string, std::string> m; +// for (absl::string_view sp : absl::StrSplit("a=b=c,d=e,f=,g", ',')) { +// m.insert(absl::StrSplit(sp, absl::MaxSplits('=', 1))); +// } +// EXPECT_EQ("b=c", m.find("a")->second); +// EXPECT_EQ("e", m.find("d")->second); +// EXPECT_EQ("", m.find("f")->second); +// EXPECT_EQ("", m.find("g")->second); +// +// WARNING: Due to a legacy bug that is maintained for backward compatibility, +// splitting the following empty string_views produces different results: +// +// absl::StrSplit(absl::string_view(""), '-'); // {""} +// absl::StrSplit(absl::string_view(), '-'); // {}, but should be {""} +// +// Try not to depend on this distinction because the bug may one day be fixed. +template <typename Delimiter> +strings_internal::Splitter< + typename strings_internal::SelectDelimiter<Delimiter>::type, AllowEmpty> +StrSplit(strings_internal::ConvertibleToStringView text, Delimiter d) { + using DelimiterType = + typename strings_internal::SelectDelimiter<Delimiter>::type; + return strings_internal::Splitter<DelimiterType, AllowEmpty>( + std::move(text), DelimiterType(d), AllowEmpty()); +} + +template <typename Delimiter, typename Predicate> +strings_internal::Splitter< + typename strings_internal::SelectDelimiter<Delimiter>::type, Predicate> +StrSplit(strings_internal::ConvertibleToStringView text, Delimiter d, + Predicate p) { + using DelimiterType = + typename strings_internal::SelectDelimiter<Delimiter>::type; + return strings_internal::Splitter<DelimiterType, Predicate>( + std::move(text), DelimiterType(d), std::move(p)); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STR_SPLIT_H_ diff --git a/third_party/abseil_cpp/absl/strings/str_split_benchmark.cc b/third_party/abseil_cpp/absl/strings/str_split_benchmark.cc new file mode 100644 index 0000000000..f38dfcfe5a --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_split_benchmark.cc @@ -0,0 +1,180 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_split.h" + +#include <iterator> +#include <string> +#include <unordered_map> +#include <unordered_set> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/string_view.h" + +namespace { + +std::string MakeTestString(int desired_length) { + static const int kAverageValueLen = 25; + std::string test(desired_length * kAverageValueLen, 'x'); + for (int i = 1; i < test.size(); i += kAverageValueLen) { + test[i] = ';'; + } + return test; +} + +void BM_Split2StringView(benchmark::State& state) { + std::string test = MakeTestString(state.range(0)); + for (auto _ : state) { + std::vector<absl::string_view> result = absl::StrSplit(test, ';'); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_Split2StringView, 0, 1 << 20); + +static const absl::string_view kDelimiters = ";:,."; + +std::string MakeMultiDelimiterTestString(int desired_length) { + static const int kAverageValueLen = 25; + std::string test(desired_length * kAverageValueLen, 'x'); + for (int i = 0; i * kAverageValueLen < test.size(); ++i) { + // Cycle through a variety of delimiters. + test[i * kAverageValueLen] = kDelimiters[i % kDelimiters.size()]; + } + return test; +} + +// Measure StrSplit with ByAnyChar with four delimiters to choose from. +void BM_Split2StringViewByAnyChar(benchmark::State& state) { + std::string test = MakeMultiDelimiterTestString(state.range(0)); + for (auto _ : state) { + std::vector<absl::string_view> result = + absl::StrSplit(test, absl::ByAnyChar(kDelimiters)); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_Split2StringViewByAnyChar, 0, 1 << 20); + +void BM_Split2StringViewLifted(benchmark::State& state) { + std::string test = MakeTestString(state.range(0)); + std::vector<absl::string_view> result; + for (auto _ : state) { + result = absl::StrSplit(test, ';'); + } + benchmark::DoNotOptimize(result); +} +BENCHMARK_RANGE(BM_Split2StringViewLifted, 0, 1 << 20); + +void BM_Split2String(benchmark::State& state) { + std::string test = MakeTestString(state.range(0)); + for (auto _ : state) { + std::vector<std::string> result = absl::StrSplit(test, ';'); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_Split2String, 0, 1 << 20); + +// This benchmark is for comparing Split2 to Split1 (SplitStringUsing). In +// particular, this benchmark uses SkipEmpty() to match SplitStringUsing's +// behavior. +void BM_Split2SplitStringUsing(benchmark::State& state) { + std::string test = MakeTestString(state.range(0)); + for (auto _ : state) { + std::vector<std::string> result = + absl::StrSplit(test, ';', absl::SkipEmpty()); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_Split2SplitStringUsing, 0, 1 << 20); + +void BM_SplitStringToUnorderedSet(benchmark::State& state) { + const int len = state.range(0); + std::string test(len, 'x'); + for (int i = 1; i < len; i += 2) { + test[i] = ';'; + } + for (auto _ : state) { + std::unordered_set<std::string> result = + absl::StrSplit(test, ':', absl::SkipEmpty()); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_SplitStringToUnorderedSet, 0, 1 << 20); + +void BM_SplitStringToUnorderedMap(benchmark::State& state) { + const int len = state.range(0); + std::string test(len, 'x'); + for (int i = 1; i < len; i += 2) { + test[i] = ';'; + } + for (auto _ : state) { + std::unordered_map<std::string, std::string> result = + absl::StrSplit(test, ':', absl::SkipEmpty()); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_SplitStringToUnorderedMap, 0, 1 << 20); + +void BM_SplitStringAllowEmpty(benchmark::State& state) { + const int len = state.range(0); + std::string test(len, 'x'); + for (int i = 1; i < len; i += 2) { + test[i] = ';'; + } + for (auto _ : state) { + std::vector<std::string> result = absl::StrSplit(test, ';'); + benchmark::DoNotOptimize(result); + } +} +BENCHMARK_RANGE(BM_SplitStringAllowEmpty, 0, 1 << 20); + +struct OneCharLiteral { + char operator()() const { return 'X'; } +}; + +struct OneCharStringLiteral { + const char* operator()() const { return "X"; } +}; + +template <typename DelimiterFactory> +void BM_SplitStringWithOneChar(benchmark::State& state) { + const auto delimiter = DelimiterFactory()(); + std::vector<absl::string_view> pieces; + size_t v = 0; + for (auto _ : state) { + pieces = absl::StrSplit("The quick brown fox jumps over the lazy dog", + delimiter); + v += pieces.size(); + } + ABSL_RAW_CHECK(v == state.iterations(), ""); +} +BENCHMARK_TEMPLATE(BM_SplitStringWithOneChar, OneCharLiteral); +BENCHMARK_TEMPLATE(BM_SplitStringWithOneChar, OneCharStringLiteral); + +template <typename DelimiterFactory> +void BM_SplitStringWithOneCharNoVector(benchmark::State& state) { + const auto delimiter = DelimiterFactory()(); + size_t v = 0; + for (auto _ : state) { + auto splitter = absl::StrSplit( + "The quick brown fox jumps over the lazy dog", delimiter); + v += std::distance(splitter.begin(), splitter.end()); + } + ABSL_RAW_CHECK(v == state.iterations(), ""); +} +BENCHMARK_TEMPLATE(BM_SplitStringWithOneCharNoVector, OneCharLiteral); +BENCHMARK_TEMPLATE(BM_SplitStringWithOneCharNoVector, OneCharStringLiteral); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/str_split_test.cc b/third_party/abseil_cpp/absl/strings/str_split_test.cc new file mode 100644 index 0000000000..fcd58d2ee8 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/str_split_test.cc @@ -0,0 +1,953 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/str_split.h" + +#include <deque> +#include <initializer_list> +#include <list> +#include <map> +#include <memory> +#include <string> +#include <type_traits> +#include <unordered_map> +#include <unordered_set> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/dynamic_annotations.h" // for RunningOnValgrind +#include "absl/base/macros.h" +#include "absl/container/flat_hash_map.h" +#include "absl/container/node_hash_map.h" +#include "absl/strings/numbers.h" + +namespace { + +using ::testing::ElementsAre; +using ::testing::Pair; +using ::testing::UnorderedElementsAre; + +TEST(Split, TraitsTest) { + static_assert(!absl::strings_internal::SplitterIsConvertibleTo<int>::value, + ""); + static_assert( + !absl::strings_internal::SplitterIsConvertibleTo<std::string>::value, ""); + static_assert(absl::strings_internal::SplitterIsConvertibleTo< + std::vector<std::string>>::value, + ""); + static_assert( + !absl::strings_internal::SplitterIsConvertibleTo<std::vector<int>>::value, + ""); + static_assert(absl::strings_internal::SplitterIsConvertibleTo< + std::vector<absl::string_view>>::value, + ""); + static_assert(absl::strings_internal::SplitterIsConvertibleTo< + std::map<std::string, std::string>>::value, + ""); + static_assert(absl::strings_internal::SplitterIsConvertibleTo< + std::map<absl::string_view, absl::string_view>>::value, + ""); + static_assert(!absl::strings_internal::SplitterIsConvertibleTo< + std::map<int, std::string>>::value, + ""); + static_assert(!absl::strings_internal::SplitterIsConvertibleTo< + std::map<std::string, int>>::value, + ""); +} + +// This tests the overall split API, which is made up of the absl::StrSplit() +// function and the Delimiter objects in the absl:: namespace. +// This TEST macro is outside of any namespace to require full specification of +// namespaces just like callers will need to use. +TEST(Split, APIExamples) { + { + // Passes string delimiter. Assumes the default of ByString. + std::vector<std::string> v = absl::StrSplit("a,b,c", ","); // NOLINT + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + + // Equivalent to... + using absl::ByString; + v = absl::StrSplit("a,b,c", ByString(",")); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + + // Equivalent to... + EXPECT_THAT(absl::StrSplit("a,b,c", ByString(",")), + ElementsAre("a", "b", "c")); + } + + { + // Same as above, but using a single character as the delimiter. + std::vector<std::string> v = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + + // Equivalent to... + using absl::ByChar; + v = absl::StrSplit("a,b,c", ByChar(',')); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Uses the Literal string "=>" as the delimiter. + const std::vector<std::string> v = absl::StrSplit("a=>b=>c", "=>"); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // The substrings are returned as string_views, eliminating copying. + std::vector<absl::string_view> v = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Leading and trailing empty substrings. + std::vector<std::string> v = absl::StrSplit(",a,b,c,", ','); + EXPECT_THAT(v, ElementsAre("", "a", "b", "c", "")); + } + + { + // Splits on a delimiter that is not found. + std::vector<std::string> v = absl::StrSplit("abc", ','); + EXPECT_THAT(v, ElementsAre("abc")); + } + + { + // Splits the input string into individual characters by using an empty + // string as the delimiter. + std::vector<std::string> v = absl::StrSplit("abc", ""); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Splits string data with embedded NUL characters, using NUL as the + // delimiter. A simple delimiter of "\0" doesn't work because strlen() will + // say that's the empty string when constructing the absl::string_view + // delimiter. Instead, a non-empty string containing NUL can be used as the + // delimiter. + std::string embedded_nulls("a\0b\0c", 5); + std::string null_delim("\0", 1); + std::vector<std::string> v = absl::StrSplit(embedded_nulls, null_delim); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Stores first two split strings as the members in a std::pair. + std::pair<std::string, std::string> p = absl::StrSplit("a,b,c", ','); + EXPECT_EQ("a", p.first); + EXPECT_EQ("b", p.second); + // "c" is omitted because std::pair can hold only two elements. + } + + { + // Results stored in std::set<std::string> + std::set<std::string> v = absl::StrSplit("a,b,c,a,b,c,a,b,c", ','); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Uses a non-const char* delimiter. + char a[] = ","; + char* d = a + 0; + std::vector<std::string> v = absl::StrSplit("a,b,c", d); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Results split using either of , or ; + using absl::ByAnyChar; + std::vector<std::string> v = absl::StrSplit("a,b;c", ByAnyChar(",;")); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Uses the SkipWhitespace predicate. + using absl::SkipWhitespace; + std::vector<std::string> v = + absl::StrSplit(" a , ,,b,", ',', SkipWhitespace()); + EXPECT_THAT(v, ElementsAre(" a ", "b")); + } + + { + // Uses the ByLength delimiter. + using absl::ByLength; + std::vector<std::string> v = absl::StrSplit("abcdefg", ByLength(3)); + EXPECT_THAT(v, ElementsAre("abc", "def", "g")); + } + + { + // Different forms of initialization / conversion. + std::vector<std::string> v1 = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(v1, ElementsAre("a", "b", "c")); + std::vector<std::string> v2(absl::StrSplit("a,b,c", ',')); + EXPECT_THAT(v2, ElementsAre("a", "b", "c")); + auto v3 = std::vector<std::string>(absl::StrSplit("a,b,c", ',')); + EXPECT_THAT(v3, ElementsAre("a", "b", "c")); + v3 = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(v3, ElementsAre("a", "b", "c")); + } + + { + // Results stored in a std::map. + std::map<std::string, std::string> m = absl::StrSplit("a,1,b,2,a,3", ','); + EXPECT_EQ(2, m.size()); + EXPECT_EQ("3", m["a"]); + EXPECT_EQ("2", m["b"]); + } + + { + // Results stored in a std::multimap. + std::multimap<std::string, std::string> m = + absl::StrSplit("a,1,b,2,a,3", ','); + EXPECT_EQ(3, m.size()); + auto it = m.find("a"); + EXPECT_EQ("1", it->second); + ++it; + EXPECT_EQ("3", it->second); + it = m.find("b"); + EXPECT_EQ("2", it->second); + } + + { + // Demonstrates use in a range-based for loop in C++11. + std::string s = "x,x,x,x,x,x,x"; + for (absl::string_view sp : absl::StrSplit(s, ',')) { + EXPECT_EQ("x", sp); + } + } + + { + // Demonstrates use with a Predicate in a range-based for loop. + using absl::SkipWhitespace; + std::string s = " ,x,,x,,x,x,x,,"; + for (absl::string_view sp : absl::StrSplit(s, ',', SkipWhitespace())) { + EXPECT_EQ("x", sp); + } + } + + { + // Demonstrates a "smart" split to std::map using two separate calls to + // absl::StrSplit. One call to split the records, and another call to split + // the keys and values. This also uses the Limit delimiter so that the + // std::string "a=b=c" will split to "a" -> "b=c". + std::map<std::string, std::string> m; + for (absl::string_view sp : absl::StrSplit("a=b=c,d=e,f=,g", ',')) { + m.insert(absl::StrSplit(sp, absl::MaxSplits('=', 1))); + } + EXPECT_EQ("b=c", m.find("a")->second); + EXPECT_EQ("e", m.find("d")->second); + EXPECT_EQ("", m.find("f")->second); + EXPECT_EQ("", m.find("g")->second); + } +} + +// +// Tests for SplitIterator +// + +TEST(SplitIterator, Basics) { + auto splitter = absl::StrSplit("a,b", ','); + auto it = splitter.begin(); + auto end = splitter.end(); + + EXPECT_NE(it, end); + EXPECT_EQ("a", *it); // tests dereference + ++it; // tests preincrement + EXPECT_NE(it, end); + EXPECT_EQ("b", + std::string(it->data(), it->size())); // tests dereference as ptr + it++; // tests postincrement + EXPECT_EQ(it, end); +} + +// Simple Predicate to skip a particular string. +class Skip { + public: + explicit Skip(const std::string& s) : s_(s) {} + bool operator()(absl::string_view sp) { return sp != s_; } + + private: + std::string s_; +}; + +TEST(SplitIterator, Predicate) { + auto splitter = absl::StrSplit("a,b,c", ',', Skip("b")); + auto it = splitter.begin(); + auto end = splitter.end(); + + EXPECT_NE(it, end); + EXPECT_EQ("a", *it); // tests dereference + ++it; // tests preincrement -- "b" should be skipped here. + EXPECT_NE(it, end); + EXPECT_EQ("c", + std::string(it->data(), it->size())); // tests dereference as ptr + it++; // tests postincrement + EXPECT_EQ(it, end); +} + +TEST(SplitIterator, EdgeCases) { + // Expected input and output, assuming a delimiter of ',' + struct { + std::string in; + std::vector<std::string> expect; + } specs[] = { + {"", {""}}, + {"foo", {"foo"}}, + {",", {"", ""}}, + {",foo", {"", "foo"}}, + {"foo,", {"foo", ""}}, + {",foo,", {"", "foo", ""}}, + {"foo,bar", {"foo", "bar"}}, + }; + + for (const auto& spec : specs) { + SCOPED_TRACE(spec.in); + auto splitter = absl::StrSplit(spec.in, ','); + auto it = splitter.begin(); + auto end = splitter.end(); + for (const auto& expected : spec.expect) { + EXPECT_NE(it, end); + EXPECT_EQ(expected, *it++); + } + EXPECT_EQ(it, end); + } +} + +TEST(Splitter, Const) { + const auto splitter = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(splitter, ElementsAre("a", "b", "c")); +} + +TEST(Split, EmptyAndNull) { + // Attention: Splitting a null absl::string_view is different than splitting + // an empty absl::string_view even though both string_views are considered + // equal. This behavior is likely surprising and undesirable. However, to + // maintain backward compatibility, there is a small "hack" in + // str_split_internal.h that preserves this behavior. If that behavior is ever + // changed/fixed, this test will need to be updated. + EXPECT_THAT(absl::StrSplit(absl::string_view(""), '-'), ElementsAre("")); + EXPECT_THAT(absl::StrSplit(absl::string_view(), '-'), ElementsAre()); +} + +TEST(SplitIterator, EqualityAsEndCondition) { + auto splitter = absl::StrSplit("a,b,c", ','); + auto it = splitter.begin(); + auto it2 = it; + + // Increments it2 twice to point to "c" in the input text. + ++it2; + ++it2; + EXPECT_EQ("c", *it2); + + // This test uses a non-end SplitIterator as the terminating condition in a + // for loop. This relies on SplitIterator equality for non-end SplitIterators + // working correctly. At this point it2 points to "c", and we use that as the + // "end" condition in this test. + std::vector<absl::string_view> v; + for (; it != it2; ++it) { + v.push_back(*it); + } + EXPECT_THAT(v, ElementsAre("a", "b")); +} + +// +// Tests for Splitter +// + +TEST(Splitter, RangeIterators) { + auto splitter = absl::StrSplit("a,b,c", ','); + std::vector<absl::string_view> output; + for (const absl::string_view p : splitter) { + output.push_back(p); + } + EXPECT_THAT(output, ElementsAre("a", "b", "c")); +} + +// Some template functions for use in testing conversion operators +template <typename ContainerType, typename Splitter> +void TestConversionOperator(const Splitter& splitter) { + ContainerType output = splitter; + EXPECT_THAT(output, UnorderedElementsAre("a", "b", "c", "d")); +} + +template <typename MapType, typename Splitter> +void TestMapConversionOperator(const Splitter& splitter) { + MapType m = splitter; + EXPECT_THAT(m, UnorderedElementsAre(Pair("a", "b"), Pair("c", "d"))); +} + +template <typename FirstType, typename SecondType, typename Splitter> +void TestPairConversionOperator(const Splitter& splitter) { + std::pair<FirstType, SecondType> p = splitter; + EXPECT_EQ(p, (std::pair<FirstType, SecondType>("a", "b"))); +} + +TEST(Splitter, ConversionOperator) { + auto splitter = absl::StrSplit("a,b,c,d", ','); + + TestConversionOperator<std::vector<absl::string_view>>(splitter); + TestConversionOperator<std::vector<std::string>>(splitter); + TestConversionOperator<std::list<absl::string_view>>(splitter); + TestConversionOperator<std::list<std::string>>(splitter); + TestConversionOperator<std::deque<absl::string_view>>(splitter); + TestConversionOperator<std::deque<std::string>>(splitter); + TestConversionOperator<std::set<absl::string_view>>(splitter); + TestConversionOperator<std::set<std::string>>(splitter); + TestConversionOperator<std::multiset<absl::string_view>>(splitter); + TestConversionOperator<std::multiset<std::string>>(splitter); + TestConversionOperator<std::unordered_set<std::string>>(splitter); + + // Tests conversion to map-like objects. + + TestMapConversionOperator<std::map<absl::string_view, absl::string_view>>( + splitter); + TestMapConversionOperator<std::map<absl::string_view, std::string>>(splitter); + TestMapConversionOperator<std::map<std::string, absl::string_view>>(splitter); + TestMapConversionOperator<std::map<std::string, std::string>>(splitter); + TestMapConversionOperator< + std::multimap<absl::string_view, absl::string_view>>(splitter); + TestMapConversionOperator<std::multimap<absl::string_view, std::string>>( + splitter); + TestMapConversionOperator<std::multimap<std::string, absl::string_view>>( + splitter); + TestMapConversionOperator<std::multimap<std::string, std::string>>(splitter); + TestMapConversionOperator<std::unordered_map<std::string, std::string>>( + splitter); + TestMapConversionOperator< + absl::node_hash_map<absl::string_view, absl::string_view>>(splitter); + TestMapConversionOperator< + absl::node_hash_map<absl::string_view, std::string>>(splitter); + TestMapConversionOperator< + absl::node_hash_map<std::string, absl::string_view>>(splitter); + TestMapConversionOperator< + absl::flat_hash_map<absl::string_view, absl::string_view>>(splitter); + TestMapConversionOperator< + absl::flat_hash_map<absl::string_view, std::string>>(splitter); + TestMapConversionOperator< + absl::flat_hash_map<std::string, absl::string_view>>(splitter); + + // Tests conversion to std::pair + + TestPairConversionOperator<absl::string_view, absl::string_view>(splitter); + TestPairConversionOperator<absl::string_view, std::string>(splitter); + TestPairConversionOperator<std::string, absl::string_view>(splitter); + TestPairConversionOperator<std::string, std::string>(splitter); +} + +// A few additional tests for conversion to std::pair. This conversion is +// different from others because a std::pair always has exactly two elements: +// .first and .second. The split has to work even when the split has +// less-than, equal-to, and more-than 2 strings. +TEST(Splitter, ToPair) { + { + // Empty string + std::pair<std::string, std::string> p = absl::StrSplit("", ','); + EXPECT_EQ("", p.first); + EXPECT_EQ("", p.second); + } + + { + // Only first + std::pair<std::string, std::string> p = absl::StrSplit("a", ','); + EXPECT_EQ("a", p.first); + EXPECT_EQ("", p.second); + } + + { + // Only second + std::pair<std::string, std::string> p = absl::StrSplit(",b", ','); + EXPECT_EQ("", p.first); + EXPECT_EQ("b", p.second); + } + + { + // First and second. + std::pair<std::string, std::string> p = absl::StrSplit("a,b", ','); + EXPECT_EQ("a", p.first); + EXPECT_EQ("b", p.second); + } + + { + // First and second and then more stuff that will be ignored. + std::pair<std::string, std::string> p = absl::StrSplit("a,b,c", ','); + EXPECT_EQ("a", p.first); + EXPECT_EQ("b", p.second); + // "c" is omitted. + } +} + +TEST(Splitter, Predicates) { + static const char kTestChars[] = ",a, ,b,"; + using absl::AllowEmpty; + using absl::SkipEmpty; + using absl::SkipWhitespace; + + { + // No predicate. Does not skip empties. + auto splitter = absl::StrSplit(kTestChars, ','); + std::vector<std::string> v = splitter; + EXPECT_THAT(v, ElementsAre("", "a", " ", "b", "")); + } + + { + // Allows empty strings. Same behavior as no predicate at all. + auto splitter = absl::StrSplit(kTestChars, ',', AllowEmpty()); + std::vector<std::string> v_allowempty = splitter; + EXPECT_THAT(v_allowempty, ElementsAre("", "a", " ", "b", "")); + + // Ensures AllowEmpty equals the behavior with no predicate. + auto splitter_nopredicate = absl::StrSplit(kTestChars, ','); + std::vector<std::string> v_nopredicate = splitter_nopredicate; + EXPECT_EQ(v_allowempty, v_nopredicate); + } + + { + // Skips empty strings. + auto splitter = absl::StrSplit(kTestChars, ',', SkipEmpty()); + std::vector<std::string> v = splitter; + EXPECT_THAT(v, ElementsAre("a", " ", "b")); + } + + { + // Skips empty and all-whitespace strings. + auto splitter = absl::StrSplit(kTestChars, ',', SkipWhitespace()); + std::vector<std::string> v = splitter; + EXPECT_THAT(v, ElementsAre("a", "b")); + } +} + +// +// Tests for StrSplit() +// + +TEST(Split, Basics) { + { + // Doesn't really do anything useful because the return value is ignored, + // but it should work. + absl::StrSplit("a,b,c", ','); + } + + { + std::vector<absl::string_view> v = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + std::vector<std::string> v = absl::StrSplit("a,b,c", ','); + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + } + + { + // Ensures that assignment works. This requires a little extra work with + // C++11 because of overloads with initializer_list. + std::vector<std::string> v; + v = absl::StrSplit("a,b,c", ','); + + EXPECT_THAT(v, ElementsAre("a", "b", "c")); + std::map<std::string, std::string> m; + m = absl::StrSplit("a,b,c", ','); + EXPECT_EQ(2, m.size()); + std::unordered_map<std::string, std::string> hm; + hm = absl::StrSplit("a,b,c", ','); + EXPECT_EQ(2, hm.size()); + } +} + +absl::string_view ReturnStringView() { return "Hello World"; } +const char* ReturnConstCharP() { return "Hello World"; } +char* ReturnCharP() { return const_cast<char*>("Hello World"); } + +TEST(Split, AcceptsCertainTemporaries) { + std::vector<std::string> v; + v = absl::StrSplit(ReturnStringView(), ' '); + EXPECT_THAT(v, ElementsAre("Hello", "World")); + v = absl::StrSplit(ReturnConstCharP(), ' '); + EXPECT_THAT(v, ElementsAre("Hello", "World")); + v = absl::StrSplit(ReturnCharP(), ' '); + EXPECT_THAT(v, ElementsAre("Hello", "World")); +} + +TEST(Split, Temporary) { + // Use a std::string longer than the SSO length, so that when the temporary is + // destroyed, if the splitter keeps a reference to the string's contents, + // it'll reference freed memory instead of just dead on-stack memory. + const char input[] = "a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u"; + EXPECT_LT(sizeof(std::string), ABSL_ARRAYSIZE(input)) + << "Input should be larger than fits on the stack."; + + // This happens more often in C++11 as part of a range-based for loop. + auto splitter = absl::StrSplit(std::string(input), ','); + std::string expected = "a"; + for (absl::string_view letter : splitter) { + EXPECT_EQ(expected, letter); + ++expected[0]; + } + EXPECT_EQ("v", expected); + + // This happens more often in C++11 as part of a range-based for loop. + auto std_splitter = absl::StrSplit(std::string(input), ','); + expected = "a"; + for (absl::string_view letter : std_splitter) { + EXPECT_EQ(expected, letter); + ++expected[0]; + } + EXPECT_EQ("v", expected); +} + +template <typename T> +static std::unique_ptr<T> CopyToHeap(const T& value) { + return std::unique_ptr<T>(new T(value)); +} + +TEST(Split, LvalueCaptureIsCopyable) { + std::string input = "a,b"; + auto heap_splitter = CopyToHeap(absl::StrSplit(input, ',')); + auto stack_splitter = *heap_splitter; + heap_splitter.reset(); + std::vector<std::string> result = stack_splitter; + EXPECT_THAT(result, testing::ElementsAre("a", "b")); +} + +TEST(Split, TemporaryCaptureIsCopyable) { + auto heap_splitter = CopyToHeap(absl::StrSplit(std::string("a,b"), ',')); + auto stack_splitter = *heap_splitter; + heap_splitter.reset(); + std::vector<std::string> result = stack_splitter; + EXPECT_THAT(result, testing::ElementsAre("a", "b")); +} + +TEST(Split, SplitterIsCopyableAndMoveable) { + auto a = absl::StrSplit("foo", '-'); + + // Ensures that the following expressions compile. + auto b = a; // Copy construct + auto c = std::move(a); // Move construct + b = c; // Copy assign + c = std::move(b); // Move assign + + EXPECT_THAT(c, ElementsAre("foo")); +} + +TEST(Split, StringDelimiter) { + { + std::vector<absl::string_view> v = absl::StrSplit("a,b", ','); + EXPECT_THAT(v, ElementsAre("a", "b")); + } + + { + std::vector<absl::string_view> v = absl::StrSplit("a,b", std::string(",")); + EXPECT_THAT(v, ElementsAre("a", "b")); + } + + { + std::vector<absl::string_view> v = + absl::StrSplit("a,b", absl::string_view(",")); + EXPECT_THAT(v, ElementsAre("a", "b")); + } +} + +#if !defined(__cpp_char8_t) +#if defined(__clang__) +#pragma clang diagnostic push +#pragma clang diagnostic ignored "-Wc++2a-compat" +#endif +TEST(Split, UTF8) { + // Tests splitting utf8 strings and utf8 delimiters. + std::string utf8_string = u8"\u03BA\u1F79\u03C3\u03BC\u03B5"; + { + // A utf8 input string with an ascii delimiter. + std::string to_split = "a," + utf8_string; + std::vector<absl::string_view> v = absl::StrSplit(to_split, ','); + EXPECT_THAT(v, ElementsAre("a", utf8_string)); + } + + { + // A utf8 input string and a utf8 delimiter. + std::string to_split = "a," + utf8_string + ",b"; + std::string unicode_delimiter = "," + utf8_string + ","; + std::vector<absl::string_view> v = + absl::StrSplit(to_split, unicode_delimiter); + EXPECT_THAT(v, ElementsAre("a", "b")); + } + + { + // A utf8 input string and ByAnyChar with ascii chars. + std::vector<absl::string_view> v = + absl::StrSplit(u8"Foo h\u00E4llo th\u4E1Ere", absl::ByAnyChar(" \t")); + EXPECT_THAT(v, ElementsAre("Foo", u8"h\u00E4llo", u8"th\u4E1Ere")); + } +} +#if defined(__clang__) +#pragma clang diagnostic pop +#endif +#endif // !defined(__cpp_char8_t) + +TEST(Split, EmptyStringDelimiter) { + { + std::vector<std::string> v = absl::StrSplit("", ""); + EXPECT_THAT(v, ElementsAre("")); + } + + { + std::vector<std::string> v = absl::StrSplit("a", ""); + EXPECT_THAT(v, ElementsAre("a")); + } + + { + std::vector<std::string> v = absl::StrSplit("ab", ""); + EXPECT_THAT(v, ElementsAre("a", "b")); + } + + { + std::vector<std::string> v = absl::StrSplit("a b", ""); + EXPECT_THAT(v, ElementsAre("a", " ", "b")); + } +} + +TEST(Split, SubstrDelimiter) { + std::vector<absl::string_view> results; + absl::string_view delim("//"); + + results = absl::StrSplit("", delim); + EXPECT_THAT(results, ElementsAre("")); + + results = absl::StrSplit("//", delim); + EXPECT_THAT(results, ElementsAre("", "")); + + results = absl::StrSplit("ab", delim); + EXPECT_THAT(results, ElementsAre("ab")); + + results = absl::StrSplit("ab//", delim); + EXPECT_THAT(results, ElementsAre("ab", "")); + + results = absl::StrSplit("ab/", delim); + EXPECT_THAT(results, ElementsAre("ab/")); + + results = absl::StrSplit("a/b", delim); + EXPECT_THAT(results, ElementsAre("a/b")); + + results = absl::StrSplit("a//b", delim); + EXPECT_THAT(results, ElementsAre("a", "b")); + + results = absl::StrSplit("a///b", delim); + EXPECT_THAT(results, ElementsAre("a", "/b")); + + results = absl::StrSplit("a////b", delim); + EXPECT_THAT(results, ElementsAre("a", "", "b")); +} + +TEST(Split, EmptyResults) { + std::vector<absl::string_view> results; + + results = absl::StrSplit("", '#'); + EXPECT_THAT(results, ElementsAre("")); + + results = absl::StrSplit("#", '#'); + EXPECT_THAT(results, ElementsAre("", "")); + + results = absl::StrSplit("#cd", '#'); + EXPECT_THAT(results, ElementsAre("", "cd")); + + results = absl::StrSplit("ab#cd#", '#'); + EXPECT_THAT(results, ElementsAre("ab", "cd", "")); + + results = absl::StrSplit("ab##cd", '#'); + EXPECT_THAT(results, ElementsAre("ab", "", "cd")); + + results = absl::StrSplit("ab##", '#'); + EXPECT_THAT(results, ElementsAre("ab", "", "")); + + results = absl::StrSplit("ab#ab#", '#'); + EXPECT_THAT(results, ElementsAre("ab", "ab", "")); + + results = absl::StrSplit("aaaa", 'a'); + EXPECT_THAT(results, ElementsAre("", "", "", "", "")); + + results = absl::StrSplit("", '#', absl::SkipEmpty()); + EXPECT_THAT(results, ElementsAre()); +} + +template <typename Delimiter> +static bool IsFoundAtStartingPos(absl::string_view text, Delimiter d, + size_t starting_pos, int expected_pos) { + absl::string_view found = d.Find(text, starting_pos); + return found.data() != text.data() + text.size() && + expected_pos == found.data() - text.data(); +} + +// Helper function for testing Delimiter objects. Returns true if the given +// Delimiter is found in the given string at the given position. This function +// tests two cases: +// 1. The actual text given, staring at position 0 +// 2. The text given with leading padding that should be ignored +template <typename Delimiter> +static bool IsFoundAt(absl::string_view text, Delimiter d, int expected_pos) { + const std::string leading_text = ",x,y,z,"; + return IsFoundAtStartingPos(text, d, 0, expected_pos) && + IsFoundAtStartingPos(leading_text + std::string(text), d, + leading_text.length(), + expected_pos + leading_text.length()); +} + +// +// Tests for ByString +// + +// Tests using any delimiter that represents a single comma. +template <typename Delimiter> +void TestComma(Delimiter d) { + EXPECT_TRUE(IsFoundAt(",", d, 0)); + EXPECT_TRUE(IsFoundAt("a,", d, 1)); + EXPECT_TRUE(IsFoundAt(",b", d, 0)); + EXPECT_TRUE(IsFoundAt("a,b", d, 1)); + EXPECT_TRUE(IsFoundAt("a,b,", d, 1)); + EXPECT_TRUE(IsFoundAt("a,b,c", d, 1)); + EXPECT_FALSE(IsFoundAt("", d, -1)); + EXPECT_FALSE(IsFoundAt(" ", d, -1)); + EXPECT_FALSE(IsFoundAt("a", d, -1)); + EXPECT_FALSE(IsFoundAt("a b c", d, -1)); + EXPECT_FALSE(IsFoundAt("a;b;c", d, -1)); + EXPECT_FALSE(IsFoundAt(";", d, -1)); +} + +TEST(Delimiter, ByString) { + using absl::ByString; + TestComma(ByString(",")); + + // Works as named variable. + ByString comma_string(","); + TestComma(comma_string); + + // The first occurrence of empty string ("") in a string is at position 0. + // There is a test below that demonstrates this for absl::string_view::find(). + // If the ByString delimiter returned position 0 for this, there would + // be an infinite loop in the SplitIterator code. To avoid this, empty string + // is a special case in that it always returns the item at position 1. + absl::string_view abc("abc"); + EXPECT_EQ(0, abc.find("")); // "" is found at position 0 + ByString empty(""); + EXPECT_FALSE(IsFoundAt("", empty, 0)); + EXPECT_FALSE(IsFoundAt("a", empty, 0)); + EXPECT_TRUE(IsFoundAt("ab", empty, 1)); + EXPECT_TRUE(IsFoundAt("abc", empty, 1)); +} + +TEST(Split, ByChar) { + using absl::ByChar; + TestComma(ByChar(',')); + + // Works as named variable. + ByChar comma_char(','); + TestComma(comma_char); +} + +// +// Tests for ByAnyChar +// + +TEST(Delimiter, ByAnyChar) { + using absl::ByAnyChar; + ByAnyChar one_delim(","); + // Found + EXPECT_TRUE(IsFoundAt(",", one_delim, 0)); + EXPECT_TRUE(IsFoundAt("a,", one_delim, 1)); + EXPECT_TRUE(IsFoundAt("a,b", one_delim, 1)); + EXPECT_TRUE(IsFoundAt(",b", one_delim, 0)); + // Not found + EXPECT_FALSE(IsFoundAt("", one_delim, -1)); + EXPECT_FALSE(IsFoundAt(" ", one_delim, -1)); + EXPECT_FALSE(IsFoundAt("a", one_delim, -1)); + EXPECT_FALSE(IsFoundAt("a;b;c", one_delim, -1)); + EXPECT_FALSE(IsFoundAt(";", one_delim, -1)); + + ByAnyChar two_delims(",;"); + // Found + EXPECT_TRUE(IsFoundAt(",", two_delims, 0)); + EXPECT_TRUE(IsFoundAt(";", two_delims, 0)); + EXPECT_TRUE(IsFoundAt(",;", two_delims, 0)); + EXPECT_TRUE(IsFoundAt(";,", two_delims, 0)); + EXPECT_TRUE(IsFoundAt(",;b", two_delims, 0)); + EXPECT_TRUE(IsFoundAt(";,b", two_delims, 0)); + EXPECT_TRUE(IsFoundAt("a;,", two_delims, 1)); + EXPECT_TRUE(IsFoundAt("a,;", two_delims, 1)); + EXPECT_TRUE(IsFoundAt("a;,b", two_delims, 1)); + EXPECT_TRUE(IsFoundAt("a,;b", two_delims, 1)); + // Not found + EXPECT_FALSE(IsFoundAt("", two_delims, -1)); + EXPECT_FALSE(IsFoundAt(" ", two_delims, -1)); + EXPECT_FALSE(IsFoundAt("a", two_delims, -1)); + EXPECT_FALSE(IsFoundAt("a=b=c", two_delims, -1)); + EXPECT_FALSE(IsFoundAt("=", two_delims, -1)); + + // ByAnyChar behaves just like ByString when given a delimiter of empty + // string. That is, it always returns a zero-length absl::string_view + // referring to the item at position 1, not position 0. + ByAnyChar empty(""); + EXPECT_FALSE(IsFoundAt("", empty, 0)); + EXPECT_FALSE(IsFoundAt("a", empty, 0)); + EXPECT_TRUE(IsFoundAt("ab", empty, 1)); + EXPECT_TRUE(IsFoundAt("abc", empty, 1)); +} + +// +// Tests for ByLength +// + +TEST(Delimiter, ByLength) { + using absl::ByLength; + + ByLength four_char_delim(4); + + // Found + EXPECT_TRUE(IsFoundAt("abcde", four_char_delim, 4)); + EXPECT_TRUE(IsFoundAt("abcdefghijklmnopqrstuvwxyz", four_char_delim, 4)); + EXPECT_TRUE(IsFoundAt("a b,c\nd", four_char_delim, 4)); + // Not found + EXPECT_FALSE(IsFoundAt("", four_char_delim, 0)); + EXPECT_FALSE(IsFoundAt("a", four_char_delim, 0)); + EXPECT_FALSE(IsFoundAt("ab", four_char_delim, 0)); + EXPECT_FALSE(IsFoundAt("abc", four_char_delim, 0)); + EXPECT_FALSE(IsFoundAt("abcd", four_char_delim, 0)); +} + +TEST(Split, WorksWithLargeStrings) { + if (sizeof(size_t) > 4) { + std::string s((uint32_t{1} << 31) + 1, 'x'); // 2G + 1 byte + s.back() = '-'; + std::vector<absl::string_view> v = absl::StrSplit(s, '-'); + EXPECT_EQ(2, v.size()); + // The first element will contain 2G of 'x's. + // testing::StartsWith is too slow with a 2G string. + EXPECT_EQ('x', v[0][0]); + EXPECT_EQ('x', v[0][1]); + EXPECT_EQ('x', v[0][3]); + EXPECT_EQ("", v[1]); + } +} + +TEST(SplitInternalTest, TypeTraits) { + EXPECT_FALSE(absl::strings_internal::HasMappedType<int>::value); + EXPECT_TRUE( + (absl::strings_internal::HasMappedType<std::map<int, int>>::value)); + EXPECT_FALSE(absl::strings_internal::HasValueType<int>::value); + EXPECT_TRUE( + (absl::strings_internal::HasValueType<std::map<int, int>>::value)); + EXPECT_FALSE(absl::strings_internal::HasConstIterator<int>::value); + EXPECT_TRUE( + (absl::strings_internal::HasConstIterator<std::map<int, int>>::value)); + EXPECT_FALSE(absl::strings_internal::IsInitializerList<int>::value); + EXPECT_TRUE((absl::strings_internal::IsInitializerList< + std::initializer_list<int>>::value)); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/string_view.cc b/third_party/abseil_cpp/absl/strings/string_view.cc new file mode 100644 index 0000000000..c5f5de936d --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/string_view.cc @@ -0,0 +1,235 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/string_view.h" + +#ifndef ABSL_USES_STD_STRING_VIEW + +#include <algorithm> +#include <climits> +#include <cstring> +#include <ostream> + +#include "absl/strings/internal/memutil.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { +void WritePadding(std::ostream& o, size_t pad) { + char fill_buf[32]; + memset(fill_buf, o.fill(), sizeof(fill_buf)); + while (pad) { + size_t n = std::min(pad, sizeof(fill_buf)); + o.write(fill_buf, n); + pad -= n; + } +} + +class LookupTable { + public: + // For each character in wanted, sets the index corresponding + // to the ASCII code of that character. This is used by + // the find_.*_of methods below to tell whether or not a character is in + // the lookup table in constant time. + explicit LookupTable(string_view wanted) { + for (char c : wanted) { + table_[Index(c)] = true; + } + } + bool operator[](char c) const { return table_[Index(c)]; } + + private: + static unsigned char Index(char c) { return static_cast<unsigned char>(c); } + bool table_[UCHAR_MAX + 1] = {}; +}; + +} // namespace + +std::ostream& operator<<(std::ostream& o, string_view piece) { + std::ostream::sentry sentry(o); + if (sentry) { + size_t lpad = 0; + size_t rpad = 0; + if (static_cast<size_t>(o.width()) > piece.size()) { + size_t pad = o.width() - piece.size(); + if ((o.flags() & o.adjustfield) == o.left) { + rpad = pad; + } else { + lpad = pad; + } + } + if (lpad) WritePadding(o, lpad); + o.write(piece.data(), piece.size()); + if (rpad) WritePadding(o, rpad); + o.width(0); + } + return o; +} + +string_view::size_type string_view::find(string_view s, size_type pos) const + noexcept { + if (empty() || pos > length_) { + if (empty() && pos == 0 && s.empty()) return 0; + return npos; + } + const char* result = + strings_internal::memmatch(ptr_ + pos, length_ - pos, s.ptr_, s.length_); + return result ? result - ptr_ : npos; +} + +string_view::size_type string_view::find(char c, size_type pos) const noexcept { + if (empty() || pos >= length_) { + return npos; + } + const char* result = + static_cast<const char*>(memchr(ptr_ + pos, c, length_ - pos)); + return result != nullptr ? result - ptr_ : npos; +} + +string_view::size_type string_view::rfind(string_view s, size_type pos) const + noexcept { + if (length_ < s.length_) return npos; + if (s.empty()) return std::min(length_, pos); + const char* last = ptr_ + std::min(length_ - s.length_, pos) + s.length_; + const char* result = std::find_end(ptr_, last, s.ptr_, s.ptr_ + s.length_); + return result != last ? result - ptr_ : npos; +} + +// Search range is [0..pos] inclusive. If pos == npos, search everything. +string_view::size_type string_view::rfind(char c, size_type pos) const + noexcept { + // Note: memrchr() is not available on Windows. + if (empty()) return npos; + for (size_type i = std::min(pos, length_ - 1);; --i) { + if (ptr_[i] == c) { + return i; + } + if (i == 0) break; + } + return npos; +} + +string_view::size_type string_view::find_first_of(string_view s, + size_type pos) const + noexcept { + if (empty() || s.empty()) { + return npos; + } + // Avoid the cost of LookupTable() for a single-character search. + if (s.length_ == 1) return find_first_of(s.ptr_[0], pos); + LookupTable tbl(s); + for (size_type i = pos; i < length_; ++i) { + if (tbl[ptr_[i]]) { + return i; + } + } + return npos; +} + +string_view::size_type string_view::find_first_not_of(string_view s, + size_type pos) const + noexcept { + if (empty()) return npos; + // Avoid the cost of LookupTable() for a single-character search. + if (s.length_ == 1) return find_first_not_of(s.ptr_[0], pos); + LookupTable tbl(s); + for (size_type i = pos; i < length_; ++i) { + if (!tbl[ptr_[i]]) { + return i; + } + } + return npos; +} + +string_view::size_type string_view::find_first_not_of(char c, + size_type pos) const + noexcept { + if (empty()) return npos; + for (; pos < length_; ++pos) { + if (ptr_[pos] != c) { + return pos; + } + } + return npos; +} + +string_view::size_type string_view::find_last_of(string_view s, + size_type pos) const noexcept { + if (empty() || s.empty()) return npos; + // Avoid the cost of LookupTable() for a single-character search. + if (s.length_ == 1) return find_last_of(s.ptr_[0], pos); + LookupTable tbl(s); + for (size_type i = std::min(pos, length_ - 1);; --i) { + if (tbl[ptr_[i]]) { + return i; + } + if (i == 0) break; + } + return npos; +} + +string_view::size_type string_view::find_last_not_of(string_view s, + size_type pos) const + noexcept { + if (empty()) return npos; + size_type i = std::min(pos, length_ - 1); + if (s.empty()) return i; + // Avoid the cost of LookupTable() for a single-character search. + if (s.length_ == 1) return find_last_not_of(s.ptr_[0], pos); + LookupTable tbl(s); + for (;; --i) { + if (!tbl[ptr_[i]]) { + return i; + } + if (i == 0) break; + } + return npos; +} + +string_view::size_type string_view::find_last_not_of(char c, + size_type pos) const + noexcept { + if (empty()) return npos; + size_type i = std::min(pos, length_ - 1); + for (;; --i) { + if (ptr_[i] != c) { + return i; + } + if (i == 0) break; + } + return npos; +} + +// MSVC has non-standard behavior that implicitly creates definitions for static +// const members. These implicit definitions conflict with explicit out-of-class +// member definitions that are required by the C++ standard, resulting in +// LNK1169 "multiply defined" errors at link time. __declspec(selectany) asks +// MSVC to choose only one definition for the symbol it decorates. See details +// at https://msdn.microsoft.com/en-us/library/34h23df8(v=vs.100).aspx +#ifdef _MSC_VER +#define ABSL_STRING_VIEW_SELECTANY __declspec(selectany) +#else +#define ABSL_STRING_VIEW_SELECTANY +#endif + +ABSL_STRING_VIEW_SELECTANY +constexpr string_view::size_type string_view::npos; +ABSL_STRING_VIEW_SELECTANY +constexpr string_view::size_type string_view::kMaxSize; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_STRING_VIEW diff --git a/third_party/abseil_cpp/absl/strings/string_view.h b/third_party/abseil_cpp/absl/strings/string_view.h new file mode 100644 index 0000000000..8a9db8c3d7 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/string_view.h @@ -0,0 +1,623 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: string_view.h +// ----------------------------------------------------------------------------- +// +// This file contains the definition of the `absl::string_view` class. A +// `string_view` points to a contiguous span of characters, often part or all of +// another `std::string`, double-quoted string literal, character array, or even +// another `string_view`. +// +// This `absl::string_view` abstraction is designed to be a drop-in +// replacement for the C++17 `std::string_view` abstraction. +#ifndef ABSL_STRINGS_STRING_VIEW_H_ +#define ABSL_STRINGS_STRING_VIEW_H_ + +#include <algorithm> +#include <cassert> +#include <cstddef> +#include <cstring> +#include <iosfwd> +#include <iterator> +#include <limits> +#include <string> + +#include "absl/base/config.h" +#include "absl/base/internal/throw_delegate.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" + +#ifdef ABSL_USES_STD_STRING_VIEW + +#include <string_view> // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN +using string_view = std::string_view; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_STRING_VIEW + +#if ABSL_HAVE_BUILTIN(__builtin_memcmp) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_INTERNAL_STRING_VIEW_MEMCMP __builtin_memcmp +#else // ABSL_HAVE_BUILTIN(__builtin_memcmp) +#define ABSL_INTERNAL_STRING_VIEW_MEMCMP memcmp +#endif // ABSL_HAVE_BUILTIN(__builtin_memcmp) + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// absl::string_view +// +// A `string_view` provides a lightweight view into the string data provided by +// a `std::string`, double-quoted string literal, character array, or even +// another `string_view`. A `string_view` does *not* own the string to which it +// points, and that data cannot be modified through the view. +// +// You can use `string_view` as a function or method parameter anywhere a +// parameter can receive a double-quoted string literal, `const char*`, +// `std::string`, or another `absl::string_view` argument with no need to copy +// the string data. Systematic use of `string_view` within function arguments +// reduces data copies and `strlen()` calls. +// +// Because of its small size, prefer passing `string_view` by value: +// +// void MyFunction(absl::string_view arg); +// +// If circumstances require, you may also pass one by const reference: +// +// void MyFunction(const absl::string_view& arg); // not preferred +// +// Passing by value generates slightly smaller code for many architectures. +// +// In either case, the source data of the `string_view` must outlive the +// `string_view` itself. +// +// A `string_view` is also suitable for local variables if you know that the +// lifetime of the underlying object is longer than the lifetime of your +// `string_view` variable. However, beware of binding a `string_view` to a +// temporary value: +// +// // BAD use of string_view: lifetime problem +// absl::string_view sv = obj.ReturnAString(); +// +// // GOOD use of string_view: str outlives sv +// std::string str = obj.ReturnAString(); +// absl::string_view sv = str; +// +// Due to lifetime issues, a `string_view` is sometimes a poor choice for a +// return value and usually a poor choice for a data member. If you do use a +// `string_view` this way, it is your responsibility to ensure that the object +// pointed to by the `string_view` outlives the `string_view`. +// +// A `string_view` may represent a whole string or just part of a string. For +// example, when splitting a string, `std::vector<absl::string_view>` is a +// natural data type for the output. +// +// When constructed from a source which is NUL-terminated, the `string_view` +// itself will not include the NUL-terminator unless a specific size (including +// the NUL) is passed to the constructor. As a result, common idioms that work +// on NUL-terminated strings do not work on `string_view` objects. If you write +// code that scans a `string_view`, you must check its length rather than test +// for nul, for example. Note, however, that nuls may still be embedded within +// a `string_view` explicitly. +// +// You may create a null `string_view` in two ways: +// +// absl::string_view sv; +// absl::string_view sv(nullptr, 0); +// +// For the above, `sv.data() == nullptr`, `sv.length() == 0`, and +// `sv.empty() == true`. Also, if you create a `string_view` with a non-null +// pointer then `sv.data() != nullptr`. Thus, you can use `string_view()` to +// signal an undefined value that is different from other `string_view` values +// in a similar fashion to how `const char* p1 = nullptr;` is different from +// `const char* p2 = "";`. However, in practice, it is not recommended to rely +// on this behavior. +// +// Be careful not to confuse a null `string_view` with an empty one. A null +// `string_view` is an empty `string_view`, but some empty `string_view`s are +// not null. Prefer checking for emptiness over checking for null. +// +// There are many ways to create an empty string_view: +// +// const char* nullcp = nullptr; +// // string_view.size() will return 0 in all cases. +// absl::string_view(); +// absl::string_view(nullcp, 0); +// absl::string_view(""); +// absl::string_view("", 0); +// absl::string_view("abcdef", 0); +// absl::string_view("abcdef" + 6, 0); +// +// All empty `string_view` objects whether null or not, are equal: +// +// absl::string_view() == absl::string_view("", 0) +// absl::string_view(nullptr, 0) == absl::string_view("abcdef"+6, 0) +class string_view { + public: + using traits_type = std::char_traits<char>; + using value_type = char; + using pointer = char*; + using const_pointer = const char*; + using reference = char&; + using const_reference = const char&; + using const_iterator = const char*; + using iterator = const_iterator; + using const_reverse_iterator = std::reverse_iterator<const_iterator>; + using reverse_iterator = const_reverse_iterator; + using size_type = size_t; + using difference_type = std::ptrdiff_t; + + static constexpr size_type npos = static_cast<size_type>(-1); + + // Null `string_view` constructor + constexpr string_view() noexcept : ptr_(nullptr), length_(0) {} + + // Implicit constructors + + template <typename Allocator> + string_view( // NOLINT(runtime/explicit) + const std::basic_string<char, std::char_traits<char>, Allocator>& + str) noexcept + // This is implemented in terms of `string_view(p, n)` so `str.size()` + // doesn't need to be reevaluated after `ptr_` is set. + : string_view(str.data(), str.size()) {} + + // Implicit constructor of a `string_view` from NUL-terminated `str`. When + // accepting possibly null strings, use `absl::NullSafeStringView(str)` + // instead (see below). + constexpr string_view(const char* str) // NOLINT(runtime/explicit) + : ptr_(str), + length_(str ? CheckLengthInternal(StrlenInternal(str)) : 0) {} + + // Implicit constructor of a `string_view` from a `const char*` and length. + constexpr string_view(const char* data, size_type len) + : ptr_(data), length_(CheckLengthInternal(len)) {} + + // NOTE: Harmlessly omitted to work around gdb bug. + // constexpr string_view(const string_view&) noexcept = default; + // string_view& operator=(const string_view&) noexcept = default; + + // Iterators + + // string_view::begin() + // + // Returns an iterator pointing to the first character at the beginning of the + // `string_view`, or `end()` if the `string_view` is empty. + constexpr const_iterator begin() const noexcept { return ptr_; } + + // string_view::end() + // + // Returns an iterator pointing just beyond the last character at the end of + // the `string_view`. This iterator acts as a placeholder; attempting to + // access it results in undefined behavior. + constexpr const_iterator end() const noexcept { return ptr_ + length_; } + + // string_view::cbegin() + // + // Returns a const iterator pointing to the first character at the beginning + // of the `string_view`, or `end()` if the `string_view` is empty. + constexpr const_iterator cbegin() const noexcept { return begin(); } + + // string_view::cend() + // + // Returns a const iterator pointing just beyond the last character at the end + // of the `string_view`. This pointer acts as a placeholder; attempting to + // access its element results in undefined behavior. + constexpr const_iterator cend() const noexcept { return end(); } + + // string_view::rbegin() + // + // Returns a reverse iterator pointing to the last character at the end of the + // `string_view`, or `rend()` if the `string_view` is empty. + const_reverse_iterator rbegin() const noexcept { + return const_reverse_iterator(end()); + } + + // string_view::rend() + // + // Returns a reverse iterator pointing just before the first character at the + // beginning of the `string_view`. This pointer acts as a placeholder; + // attempting to access its element results in undefined behavior. + const_reverse_iterator rend() const noexcept { + return const_reverse_iterator(begin()); + } + + // string_view::crbegin() + // + // Returns a const reverse iterator pointing to the last character at the end + // of the `string_view`, or `crend()` if the `string_view` is empty. + const_reverse_iterator crbegin() const noexcept { return rbegin(); } + + // string_view::crend() + // + // Returns a const reverse iterator pointing just before the first character + // at the beginning of the `string_view`. This pointer acts as a placeholder; + // attempting to access its element results in undefined behavior. + const_reverse_iterator crend() const noexcept { return rend(); } + + // Capacity Utilities + + // string_view::size() + // + // Returns the number of characters in the `string_view`. + constexpr size_type size() const noexcept { + return length_; + } + + // string_view::length() + // + // Returns the number of characters in the `string_view`. Alias for `size()`. + constexpr size_type length() const noexcept { return size(); } + + // string_view::max_size() + // + // Returns the maximum number of characters the `string_view` can hold. + constexpr size_type max_size() const noexcept { return kMaxSize; } + + // string_view::empty() + // + // Checks if the `string_view` is empty (refers to no characters). + constexpr bool empty() const noexcept { return length_ == 0; } + + // string_view::operator[] + // + // Returns the ith element of the `string_view` using the array operator. + // Note that this operator does not perform any bounds checking. + constexpr const_reference operator[](size_type i) const { + return ABSL_HARDENING_ASSERT(i < size()), ptr_[i]; + } + + // string_view::at() + // + // Returns the ith element of the `string_view`. Bounds checking is performed, + // and an exception of type `std::out_of_range` will be thrown on invalid + // access. + constexpr const_reference at(size_type i) const { + return ABSL_PREDICT_TRUE(i < size()) + ? ptr_[i] + : ((void)base_internal::ThrowStdOutOfRange( + "absl::string_view::at"), + ptr_[i]); + } + + // string_view::front() + // + // Returns the first element of a `string_view`. + constexpr const_reference front() const { + return ABSL_HARDENING_ASSERT(!empty()), ptr_[0]; + } + + // string_view::back() + // + // Returns the last element of a `string_view`. + constexpr const_reference back() const { + return ABSL_HARDENING_ASSERT(!empty()), ptr_[size() - 1]; + } + + // string_view::data() + // + // Returns a pointer to the underlying character array (which is of course + // stored elsewhere). Note that `string_view::data()` may contain embedded nul + // characters, but the returned buffer may or may not be NUL-terminated; + // therefore, do not pass `data()` to a routine that expects a NUL-terminated + // string. + constexpr const_pointer data() const noexcept { return ptr_; } + + // Modifiers + + // string_view::remove_prefix() + // + // Removes the first `n` characters from the `string_view`. Note that the + // underlying string is not changed, only the view. + void remove_prefix(size_type n) { + ABSL_HARDENING_ASSERT(n <= length_); + ptr_ += n; + length_ -= n; + } + + // string_view::remove_suffix() + // + // Removes the last `n` characters from the `string_view`. Note that the + // underlying string is not changed, only the view. + void remove_suffix(size_type n) { + ABSL_HARDENING_ASSERT(n <= length_); + length_ -= n; + } + + // string_view::swap() + // + // Swaps this `string_view` with another `string_view`. + void swap(string_view& s) noexcept { + auto t = *this; + *this = s; + s = t; + } + + // Explicit conversion operators + + // Converts to `std::basic_string`. + template <typename A> + explicit operator std::basic_string<char, traits_type, A>() const { + if (!data()) return {}; + return std::basic_string<char, traits_type, A>(data(), size()); + } + + // string_view::copy() + // + // Copies the contents of the `string_view` at offset `pos` and length `n` + // into `buf`. + size_type copy(char* buf, size_type n, size_type pos = 0) const { + if (ABSL_PREDICT_FALSE(pos > length_)) { + base_internal::ThrowStdOutOfRange("absl::string_view::copy"); + } + size_type rlen = (std::min)(length_ - pos, n); + if (rlen > 0) { + const char* start = ptr_ + pos; + traits_type::copy(buf, start, rlen); + } + return rlen; + } + + // string_view::substr() + // + // Returns a "substring" of the `string_view` (at offset `pos` and length + // `n`) as another string_view. This function throws `std::out_of_bounds` if + // `pos > size`. + constexpr string_view substr(size_type pos, size_type n = npos) const { + return ABSL_PREDICT_FALSE(pos > length_) + ? (base_internal::ThrowStdOutOfRange( + "absl::string_view::substr"), + string_view()) + : string_view(ptr_ + pos, Min(n, length_ - pos)); + } + + // string_view::compare() + // + // Performs a lexicographical comparison between the `string_view` and + // another `absl::string_view`, returning -1 if `this` is less than, 0 if + // `this` is equal to, and 1 if `this` is greater than the passed string + // view. Note that in the case of data equality, a further comparison is made + // on the respective sizes of the two `string_view`s to determine which is + // smaller, equal, or greater. + constexpr int compare(string_view x) const noexcept { + return CompareImpl(length_, x.length_, + Min(length_, x.length_) == 0 + ? 0 + : ABSL_INTERNAL_STRING_VIEW_MEMCMP( + ptr_, x.ptr_, Min(length_, x.length_))); + } + + // Overload of `string_view::compare()` for comparing a substring of the + // 'string_view` and another `absl::string_view`. + int compare(size_type pos1, size_type count1, string_view v) const { + return substr(pos1, count1).compare(v); + } + + // Overload of `string_view::compare()` for comparing a substring of the + // `string_view` and a substring of another `absl::string_view`. + int compare(size_type pos1, size_type count1, string_view v, size_type pos2, + size_type count2) const { + return substr(pos1, count1).compare(v.substr(pos2, count2)); + } + + // Overload of `string_view::compare()` for comparing a `string_view` and a + // a different C-style string `s`. + int compare(const char* s) const { return compare(string_view(s)); } + + // Overload of `string_view::compare()` for comparing a substring of the + // `string_view` and a different string C-style string `s`. + int compare(size_type pos1, size_type count1, const char* s) const { + return substr(pos1, count1).compare(string_view(s)); + } + + // Overload of `string_view::compare()` for comparing a substring of the + // `string_view` and a substring of a different C-style string `s`. + int compare(size_type pos1, size_type count1, const char* s, + size_type count2) const { + return substr(pos1, count1).compare(string_view(s, count2)); + } + + // Find Utilities + + // string_view::find() + // + // Finds the first occurrence of the substring `s` within the `string_view`, + // returning the position of the first character's match, or `npos` if no + // match was found. + size_type find(string_view s, size_type pos = 0) const noexcept; + + // Overload of `string_view::find()` for finding the given character `c` + // within the `string_view`. + size_type find(char c, size_type pos = 0) const noexcept; + + // string_view::rfind() + // + // Finds the last occurrence of a substring `s` within the `string_view`, + // returning the position of the first character's match, or `npos` if no + // match was found. + size_type rfind(string_view s, size_type pos = npos) const + noexcept; + + // Overload of `string_view::rfind()` for finding the last given character `c` + // within the `string_view`. + size_type rfind(char c, size_type pos = npos) const noexcept; + + // string_view::find_first_of() + // + // Finds the first occurrence of any of the characters in `s` within the + // `string_view`, returning the start position of the match, or `npos` if no + // match was found. + size_type find_first_of(string_view s, size_type pos = 0) const + noexcept; + + // Overload of `string_view::find_first_of()` for finding a character `c` + // within the `string_view`. + size_type find_first_of(char c, size_type pos = 0) const + noexcept { + return find(c, pos); + } + + // string_view::find_last_of() + // + // Finds the last occurrence of any of the characters in `s` within the + // `string_view`, returning the start position of the match, or `npos` if no + // match was found. + size_type find_last_of(string_view s, size_type pos = npos) const + noexcept; + + // Overload of `string_view::find_last_of()` for finding a character `c` + // within the `string_view`. + size_type find_last_of(char c, size_type pos = npos) const + noexcept { + return rfind(c, pos); + } + + // string_view::find_first_not_of() + // + // Finds the first occurrence of any of the characters not in `s` within the + // `string_view`, returning the start position of the first non-match, or + // `npos` if no non-match was found. + size_type find_first_not_of(string_view s, size_type pos = 0) const noexcept; + + // Overload of `string_view::find_first_not_of()` for finding a character + // that is not `c` within the `string_view`. + size_type find_first_not_of(char c, size_type pos = 0) const noexcept; + + // string_view::find_last_not_of() + // + // Finds the last occurrence of any of the characters not in `s` within the + // `string_view`, returning the start position of the last non-match, or + // `npos` if no non-match was found. + size_type find_last_not_of(string_view s, + size_type pos = npos) const noexcept; + + // Overload of `string_view::find_last_not_of()` for finding a character + // that is not `c` within the `string_view`. + size_type find_last_not_of(char c, size_type pos = npos) const + noexcept; + + private: + static constexpr size_type kMaxSize = + (std::numeric_limits<difference_type>::max)(); + + static constexpr size_type CheckLengthInternal(size_type len) { + return ABSL_HARDENING_ASSERT(len <= kMaxSize), len; + } + + static constexpr size_type StrlenInternal(const char* str) { +#if defined(_MSC_VER) && _MSC_VER >= 1910 && !defined(__clang__) + // MSVC 2017+ can evaluate this at compile-time. + const char* begin = str; + while (*str != '\0') ++str; + return str - begin; +#elif ABSL_HAVE_BUILTIN(__builtin_strlen) || \ + (defined(__GNUC__) && !defined(__clang__)) + // GCC has __builtin_strlen according to + // https://gcc.gnu.org/onlinedocs/gcc-4.7.0/gcc/Other-Builtins.html, but + // ABSL_HAVE_BUILTIN doesn't detect that, so we use the extra checks above. + // __builtin_strlen is constexpr. + return __builtin_strlen(str); +#else + return str ? strlen(str) : 0; +#endif + } + + static constexpr size_t Min(size_type length_a, size_type length_b) { + return length_a < length_b ? length_a : length_b; + } + + static constexpr int CompareImpl(size_type length_a, size_type length_b, + int compare_result) { + return compare_result == 0 ? static_cast<int>(length_a > length_b) - + static_cast<int>(length_a < length_b) + : (compare_result < 0 ? -1 : 1); + } + + const char* ptr_; + size_type length_; +}; + +// This large function is defined inline so that in a fairly common case where +// one of the arguments is a literal, the compiler can elide a lot of the +// following comparisons. +constexpr bool operator==(string_view x, string_view y) noexcept { + return x.size() == y.size() && + (x.empty() || + ABSL_INTERNAL_STRING_VIEW_MEMCMP(x.data(), y.data(), x.size()) == 0); +} + +constexpr bool operator!=(string_view x, string_view y) noexcept { + return !(x == y); +} + +constexpr bool operator<(string_view x, string_view y) noexcept { + return x.compare(y) < 0; +} + +constexpr bool operator>(string_view x, string_view y) noexcept { + return y < x; +} + +constexpr bool operator<=(string_view x, string_view y) noexcept { + return !(y < x); +} + +constexpr bool operator>=(string_view x, string_view y) noexcept { + return !(x < y); +} + +// IO Insertion Operator +std::ostream& operator<<(std::ostream& o, string_view piece); + +ABSL_NAMESPACE_END +} // namespace absl + +#undef ABSL_INTERNAL_STRING_VIEW_MEMCMP + +#endif // ABSL_USES_STD_STRING_VIEW + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ClippedSubstr() +// +// Like `s.substr(pos, n)`, but clips `pos` to an upper bound of `s.size()`. +// Provided because std::string_view::substr throws if `pos > size()` +inline string_view ClippedSubstr(string_view s, size_t pos, + size_t n = string_view::npos) { + pos = (std::min)(pos, static_cast<size_t>(s.size())); + return s.substr(pos, n); +} + +// NullSafeStringView() +// +// Creates an `absl::string_view` from a pointer `p` even if it's null-valued. +// This function should be used where an `absl::string_view` can be created from +// a possibly-null pointer. +constexpr string_view NullSafeStringView(const char* p) { + return p ? string_view(p) : string_view(); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STRING_VIEW_H_ diff --git a/third_party/abseil_cpp/absl/strings/string_view_benchmark.cc b/third_party/abseil_cpp/absl/strings/string_view_benchmark.cc new file mode 100644 index 0000000000..0d74e23e2f --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/string_view_benchmark.cc @@ -0,0 +1,381 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/string_view.h" + +#include <algorithm> +#include <cstdint> +#include <map> +#include <random> +#include <string> +#include <unordered_set> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" +#include "absl/strings/str_cat.h" + +namespace { + +void BM_StringViewFromString(benchmark::State& state) { + std::string s(state.range(0), 'x'); + std::string* ps = &s; + struct SV { + SV() = default; + explicit SV(const std::string& s) : sv(s) {} + absl::string_view sv; + } sv; + SV* psv = &sv; + benchmark::DoNotOptimize(ps); + benchmark::DoNotOptimize(psv); + for (auto _ : state) { + new (psv) SV(*ps); + benchmark::DoNotOptimize(sv); + } +} +BENCHMARK(BM_StringViewFromString)->Arg(12)->Arg(128); + +// Provide a forcibly out-of-line wrapper for operator== that can be used in +// benchmarks to measure the impact of inlining. +ABSL_ATTRIBUTE_NOINLINE +bool NonInlinedEq(absl::string_view a, absl::string_view b) { return a == b; } + +// We use functions that cannot be inlined to perform the comparison loops so +// that inlining of the operator== can't optimize away *everything*. +ABSL_ATTRIBUTE_NOINLINE +void DoEqualityComparisons(benchmark::State& state, absl::string_view a, + absl::string_view b) { + for (auto _ : state) { + benchmark::DoNotOptimize(a == b); + } +} + +void BM_EqualIdentical(benchmark::State& state) { + std::string x(state.range(0), 'a'); + DoEqualityComparisons(state, x, x); +} +BENCHMARK(BM_EqualIdentical)->DenseRange(0, 3)->Range(4, 1 << 10); + +void BM_EqualSame(benchmark::State& state) { + std::string x(state.range(0), 'a'); + std::string y = x; + DoEqualityComparisons(state, x, y); +} +BENCHMARK(BM_EqualSame) + ->DenseRange(0, 10) + ->Arg(20) + ->Arg(40) + ->Arg(70) + ->Arg(110) + ->Range(160, 4096); + +void BM_EqualDifferent(benchmark::State& state) { + const int len = state.range(0); + std::string x(len, 'a'); + std::string y = x; + if (len > 0) { + y[len - 1] = 'b'; + } + DoEqualityComparisons(state, x, y); +} +BENCHMARK(BM_EqualDifferent)->DenseRange(0, 3)->Range(4, 1 << 10); + +// This benchmark is intended to check that important simplifications can be +// made with absl::string_view comparisons against constant strings. The idea is +// that if constant strings cause redundant components of the comparison, the +// compiler should detect and eliminate them. Here we use 8 different strings, +// each with the same size. Provided our comparison makes the implementation +// inline-able by the compiler, it should fold all of these away into a single +// size check once per loop iteration. +ABSL_ATTRIBUTE_NOINLINE +void DoConstantSizeInlinedEqualityComparisons(benchmark::State& state, + absl::string_view a) { + for (auto _ : state) { + benchmark::DoNotOptimize(a == "aaa"); + benchmark::DoNotOptimize(a == "bbb"); + benchmark::DoNotOptimize(a == "ccc"); + benchmark::DoNotOptimize(a == "ddd"); + benchmark::DoNotOptimize(a == "eee"); + benchmark::DoNotOptimize(a == "fff"); + benchmark::DoNotOptimize(a == "ggg"); + benchmark::DoNotOptimize(a == "hhh"); + } +} +void BM_EqualConstantSizeInlined(benchmark::State& state) { + std::string x(state.range(0), 'a'); + DoConstantSizeInlinedEqualityComparisons(state, x); +} +// We only need to check for size of 3, and <> 3 as this benchmark only has to +// do with size differences. +BENCHMARK(BM_EqualConstantSizeInlined)->DenseRange(2, 4); + +// This benchmark exists purely to give context to the above timings: this is +// what they would look like if the compiler is completely unable to simplify +// between two comparisons when they are comparing against constant strings. +ABSL_ATTRIBUTE_NOINLINE +void DoConstantSizeNonInlinedEqualityComparisons(benchmark::State& state, + absl::string_view a) { + for (auto _ : state) { + // Force these out-of-line to compare with the above function. + benchmark::DoNotOptimize(NonInlinedEq(a, "aaa")); + benchmark::DoNotOptimize(NonInlinedEq(a, "bbb")); + benchmark::DoNotOptimize(NonInlinedEq(a, "ccc")); + benchmark::DoNotOptimize(NonInlinedEq(a, "ddd")); + benchmark::DoNotOptimize(NonInlinedEq(a, "eee")); + benchmark::DoNotOptimize(NonInlinedEq(a, "fff")); + benchmark::DoNotOptimize(NonInlinedEq(a, "ggg")); + benchmark::DoNotOptimize(NonInlinedEq(a, "hhh")); + } +} + +void BM_EqualConstantSizeNonInlined(benchmark::State& state) { + std::string x(state.range(0), 'a'); + DoConstantSizeNonInlinedEqualityComparisons(state, x); +} +// We only need to check for size of 3, and <> 3 as this benchmark only has to +// do with size differences. +BENCHMARK(BM_EqualConstantSizeNonInlined)->DenseRange(2, 4); + +void BM_CompareSame(benchmark::State& state) { + const int len = state.range(0); + std::string x; + for (int i = 0; i < len; i++) { + x += 'a'; + } + std::string y = x; + absl::string_view a = x; + absl::string_view b = y; + + for (auto _ : state) { + benchmark::DoNotOptimize(a); + benchmark::DoNotOptimize(b); + benchmark::DoNotOptimize(a.compare(b)); + } +} +BENCHMARK(BM_CompareSame)->DenseRange(0, 3)->Range(4, 1 << 10); + +void BM_CompareFirstOneLess(benchmark::State& state) { + const int len = state.range(0); + std::string x(len, 'a'); + std::string y = x; + y.back() = 'b'; + absl::string_view a = x; + absl::string_view b = y; + + for (auto _ : state) { + benchmark::DoNotOptimize(a); + benchmark::DoNotOptimize(b); + benchmark::DoNotOptimize(a.compare(b)); + } +} +BENCHMARK(BM_CompareFirstOneLess)->DenseRange(1, 3)->Range(4, 1 << 10); + +void BM_CompareSecondOneLess(benchmark::State& state) { + const int len = state.range(0); + std::string x(len, 'a'); + std::string y = x; + x.back() = 'b'; + absl::string_view a = x; + absl::string_view b = y; + + for (auto _ : state) { + benchmark::DoNotOptimize(a); + benchmark::DoNotOptimize(b); + benchmark::DoNotOptimize(a.compare(b)); + } +} +BENCHMARK(BM_CompareSecondOneLess)->DenseRange(1, 3)->Range(4, 1 << 10); + +void BM_find_string_view_len_one(benchmark::State& state) { + std::string haystack(state.range(0), '0'); + absl::string_view s(haystack); + for (auto _ : state) { + benchmark::DoNotOptimize(s.find("x")); // not present; length 1 + } +} +BENCHMARK(BM_find_string_view_len_one)->Range(1, 1 << 20); + +void BM_find_string_view_len_two(benchmark::State& state) { + std::string haystack(state.range(0), '0'); + absl::string_view s(haystack); + for (auto _ : state) { + benchmark::DoNotOptimize(s.find("xx")); // not present; length 2 + } +} +BENCHMARK(BM_find_string_view_len_two)->Range(1, 1 << 20); + +void BM_find_one_char(benchmark::State& state) { + std::string haystack(state.range(0), '0'); + absl::string_view s(haystack); + for (auto _ : state) { + benchmark::DoNotOptimize(s.find('x')); // not present + } +} +BENCHMARK(BM_find_one_char)->Range(1, 1 << 20); + +void BM_rfind_one_char(benchmark::State& state) { + std::string haystack(state.range(0), '0'); + absl::string_view s(haystack); + for (auto _ : state) { + benchmark::DoNotOptimize(s.rfind('x')); // not present + } +} +BENCHMARK(BM_rfind_one_char)->Range(1, 1 << 20); + +void BM_worst_case_find_first_of(benchmark::State& state, int haystack_len) { + const int needle_len = state.range(0); + std::string needle; + for (int i = 0; i < needle_len; ++i) { + needle += 'a' + i; + } + std::string haystack(haystack_len, '0'); // 1000 zeros. + + absl::string_view s(haystack); + for (auto _ : state) { + benchmark::DoNotOptimize(s.find_first_of(needle)); + } +} + +void BM_find_first_of_short(benchmark::State& state) { + BM_worst_case_find_first_of(state, 10); +} + +void BM_find_first_of_medium(benchmark::State& state) { + BM_worst_case_find_first_of(state, 100); +} + +void BM_find_first_of_long(benchmark::State& state) { + BM_worst_case_find_first_of(state, 1000); +} + +BENCHMARK(BM_find_first_of_short)->DenseRange(0, 4)->Arg(8)->Arg(16)->Arg(32); +BENCHMARK(BM_find_first_of_medium)->DenseRange(0, 4)->Arg(8)->Arg(16)->Arg(32); +BENCHMARK(BM_find_first_of_long)->DenseRange(0, 4)->Arg(8)->Arg(16)->Arg(32); + +struct EasyMap : public std::map<absl::string_view, uint64_t> { + explicit EasyMap(size_t) {} +}; + +// This templated benchmark helper function is intended to stress operator== or +// operator< in a realistic test. It surely isn't entirely realistic, but it's +// a start. The test creates a map of type Map, a template arg, and populates +// it with table_size key/value pairs. Each key has WordsPerKey words. After +// creating the map, a number of lookups are done in random order. Some keys +// are used much more frequently than others in this phase of the test. +template <typename Map, int WordsPerKey> +void StringViewMapBenchmark(benchmark::State& state) { + const int table_size = state.range(0); + const double kFractionOfKeysThatAreHot = 0.2; + const int kNumLookupsOfHotKeys = 20; + const int kNumLookupsOfColdKeys = 1; + const char* words[] = {"the", "quick", "brown", "fox", "jumped", + "over", "the", "lazy", "dog", "and", + "found", "a", "large", "mushroom", "and", + "a", "couple", "crickets", "eating", "pie"}; + // Create some keys that consist of words in random order. + std::random_device r; + std::seed_seq seed({r(), r(), r(), r(), r(), r(), r(), r()}); + std::mt19937 rng(seed); + std::vector<std::string> keys(table_size); + std::vector<int> all_indices; + const int kBlockSize = 1 << 12; + std::unordered_set<std::string> t(kBlockSize); + std::uniform_int_distribution<int> uniform(0, ABSL_ARRAYSIZE(words) - 1); + for (int i = 0; i < table_size; i++) { + all_indices.push_back(i); + do { + keys[i].clear(); + for (int j = 0; j < WordsPerKey; j++) { + absl::StrAppend(&keys[i], j > 0 ? " " : "", words[uniform(rng)]); + } + } while (!t.insert(keys[i]).second); + } + + // Create a list of strings to lookup: a permutation of the array of + // keys we just created, with repeats. "Hot" keys get repeated more. + std::shuffle(all_indices.begin(), all_indices.end(), rng); + const int num_hot = table_size * kFractionOfKeysThatAreHot; + const int num_cold = table_size - num_hot; + std::vector<int> hot_indices(all_indices.begin(), + all_indices.begin() + num_hot); + std::vector<int> indices; + for (int i = 0; i < kNumLookupsOfColdKeys; i++) { + indices.insert(indices.end(), all_indices.begin(), all_indices.end()); + } + for (int i = 0; i < kNumLookupsOfHotKeys - kNumLookupsOfColdKeys; i++) { + indices.insert(indices.end(), hot_indices.begin(), hot_indices.end()); + } + std::shuffle(indices.begin(), indices.end(), rng); + ABSL_RAW_CHECK( + num_cold * kNumLookupsOfColdKeys + num_hot * kNumLookupsOfHotKeys == + indices.size(), + ""); + // After constructing the array we probe it with absl::string_views built from + // test_strings. This means operator== won't see equal pointers, so + // it'll have to check for equal lengths and equal characters. + std::vector<std::string> test_strings(indices.size()); + for (int i = 0; i < indices.size(); i++) { + test_strings[i] = keys[indices[i]]; + } + + // Run the benchmark. It includes map construction but is mostly + // map lookups. + for (auto _ : state) { + Map h(table_size); + for (int i = 0; i < table_size; i++) { + h[keys[i]] = i * 2; + } + ABSL_RAW_CHECK(h.size() == table_size, ""); + uint64_t sum = 0; + for (int i = 0; i < indices.size(); i++) { + sum += h[test_strings[i]]; + } + benchmark::DoNotOptimize(sum); + } +} + +void BM_StdMap_4(benchmark::State& state) { + StringViewMapBenchmark<EasyMap, 4>(state); +} +BENCHMARK(BM_StdMap_4)->Range(1 << 10, 1 << 16); + +void BM_StdMap_8(benchmark::State& state) { + StringViewMapBenchmark<EasyMap, 8>(state); +} +BENCHMARK(BM_StdMap_8)->Range(1 << 10, 1 << 16); + +void BM_CopyToStringNative(benchmark::State& state) { + std::string src(state.range(0), 'x'); + absl::string_view sv(src); + std::string dst; + for (auto _ : state) { + dst.assign(sv.begin(), sv.end()); + } +} +BENCHMARK(BM_CopyToStringNative)->Range(1 << 3, 1 << 12); + +void BM_AppendToStringNative(benchmark::State& state) { + std::string src(state.range(0), 'x'); + absl::string_view sv(src); + std::string dst; + for (auto _ : state) { + dst.clear(); + dst.insert(dst.end(), sv.begin(), sv.end()); + } +} +BENCHMARK(BM_AppendToStringNative)->Range(1 << 3, 1 << 12); + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/string_view_test.cc b/third_party/abseil_cpp/absl/strings/string_view_test.cc new file mode 100644 index 0000000000..ff31b51e87 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/string_view_test.cc @@ -0,0 +1,1264 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/string_view.h" + +#include <stdlib.h> +#include <iomanip> +#include <iterator> +#include <limits> +#include <map> +#include <sstream> +#include <stdexcept> +#include <string> +#include <type_traits> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/base/config.h" +#include "absl/base/dynamic_annotations.h" +#include "absl/base/options.h" + +#if defined(ABSL_HAVE_STD_STRING_VIEW) || defined(__ANDROID__) +// We don't control the death messaging when using std::string_view. +// Android assert messages only go to system log, so death tests cannot inspect +// the message for matching. +#define ABSL_EXPECT_DEATH_IF_SUPPORTED(statement, regex) \ + EXPECT_DEATH_IF_SUPPORTED(statement, ".*") +#else +#define ABSL_EXPECT_DEATH_IF_SUPPORTED(statement, regex) \ + EXPECT_DEATH_IF_SUPPORTED(statement, regex) +#endif + +namespace { + +// A minimal allocator that uses malloc(). +template <typename T> +struct Mallocator { + typedef T value_type; + typedef size_t size_type; + typedef ptrdiff_t difference_type; + typedef T* pointer; + typedef const T* const_pointer; + typedef T& reference; + typedef const T& const_reference; + + size_type max_size() const { + return size_t(std::numeric_limits<size_type>::max()) / sizeof(value_type); + } + template <typename U> + struct rebind { + typedef Mallocator<U> other; + }; + Mallocator() = default; + template <class U> + Mallocator(const Mallocator<U>&) {} // NOLINT(runtime/explicit) + + T* allocate(size_t n) { return static_cast<T*>(std::malloc(n * sizeof(T))); } + void deallocate(T* p, size_t) { std::free(p); } +}; +template <typename T, typename U> +bool operator==(const Mallocator<T>&, const Mallocator<U>&) { + return true; +} +template <typename T, typename U> +bool operator!=(const Mallocator<T>&, const Mallocator<U>&) { + return false; +} + +TEST(StringViewTest, Ctor) { + { + // Null. + absl::string_view s10; + EXPECT_TRUE(s10.data() == nullptr); + EXPECT_EQ(0, s10.length()); + } + + { + // const char* without length. + const char* hello = "hello"; + absl::string_view s20(hello); + EXPECT_TRUE(s20.data() == hello); + EXPECT_EQ(5, s20.length()); + + // const char* with length. + absl::string_view s21(hello, 4); + EXPECT_TRUE(s21.data() == hello); + EXPECT_EQ(4, s21.length()); + + // Not recommended, but valid C++ + absl::string_view s22(hello, 6); + EXPECT_TRUE(s22.data() == hello); + EXPECT_EQ(6, s22.length()); + } + + { + // std::string. + std::string hola = "hola"; + absl::string_view s30(hola); + EXPECT_TRUE(s30.data() == hola.data()); + EXPECT_EQ(4, s30.length()); + + // std::string with embedded '\0'. + hola.push_back('\0'); + hola.append("h2"); + hola.push_back('\0'); + absl::string_view s31(hola); + EXPECT_TRUE(s31.data() == hola.data()); + EXPECT_EQ(8, s31.length()); + } + + { + using mstring = + std::basic_string<char, std::char_traits<char>, Mallocator<char>>; + mstring str1("BUNGIE-JUMPING!"); + const mstring str2("SLEEPING!"); + + absl::string_view s1(str1); + s1.remove_prefix(strlen("BUNGIE-JUM")); + + absl::string_view s2(str2); + s2.remove_prefix(strlen("SLEE")); + + EXPECT_EQ(s1, s2); + EXPECT_EQ(s1, "PING!"); + } + + // TODO(mec): absl::string_view(const absl::string_view&); +} + +TEST(StringViewTest, Swap) { + absl::string_view a("a"); + absl::string_view b("bbb"); + EXPECT_TRUE(noexcept(a.swap(b))); + a.swap(b); + EXPECT_EQ(a, "bbb"); + EXPECT_EQ(b, "a"); + a.swap(b); + EXPECT_EQ(a, "a"); + EXPECT_EQ(b, "bbb"); +} + +TEST(StringViewTest, STLComparator) { + std::string s1("foo"); + std::string s2("bar"); + std::string s3("baz"); + + absl::string_view p1(s1); + absl::string_view p2(s2); + absl::string_view p3(s3); + + typedef std::map<absl::string_view, int> TestMap; + TestMap map; + + map.insert(std::make_pair(p1, 0)); + map.insert(std::make_pair(p2, 1)); + map.insert(std::make_pair(p3, 2)); + EXPECT_EQ(map.size(), 3); + + TestMap::const_iterator iter = map.begin(); + EXPECT_EQ(iter->second, 1); + ++iter; + EXPECT_EQ(iter->second, 2); + ++iter; + EXPECT_EQ(iter->second, 0); + ++iter; + EXPECT_TRUE(iter == map.end()); + + TestMap::iterator new_iter = map.find("zot"); + EXPECT_TRUE(new_iter == map.end()); + + new_iter = map.find("bar"); + EXPECT_TRUE(new_iter != map.end()); + + map.erase(new_iter); + EXPECT_EQ(map.size(), 2); + + iter = map.begin(); + EXPECT_EQ(iter->second, 2); + ++iter; + EXPECT_EQ(iter->second, 0); + ++iter; + EXPECT_TRUE(iter == map.end()); +} + +#define COMPARE(result, op, x, y) \ + EXPECT_EQ(result, absl::string_view((x)) op absl::string_view((y))); \ + EXPECT_EQ(result, absl::string_view((x)).compare(absl::string_view((y))) op 0) + +TEST(StringViewTest, ComparisonOperators) { + COMPARE(true, ==, "", ""); + COMPARE(true, ==, "", absl::string_view()); + COMPARE(true, ==, absl::string_view(), ""); + COMPARE(true, ==, "a", "a"); + COMPARE(true, ==, "aa", "aa"); + COMPARE(false, ==, "a", ""); + COMPARE(false, ==, "", "a"); + COMPARE(false, ==, "a", "b"); + COMPARE(false, ==, "a", "aa"); + COMPARE(false, ==, "aa", "a"); + + COMPARE(false, !=, "", ""); + COMPARE(false, !=, "a", "a"); + COMPARE(false, !=, "aa", "aa"); + COMPARE(true, !=, "a", ""); + COMPARE(true, !=, "", "a"); + COMPARE(true, !=, "a", "b"); + COMPARE(true, !=, "a", "aa"); + COMPARE(true, !=, "aa", "a"); + + COMPARE(true, <, "a", "b"); + COMPARE(true, <, "a", "aa"); + COMPARE(true, <, "aa", "b"); + COMPARE(true, <, "aa", "bb"); + COMPARE(false, <, "a", "a"); + COMPARE(false, <, "b", "a"); + COMPARE(false, <, "aa", "a"); + COMPARE(false, <, "b", "aa"); + COMPARE(false, <, "bb", "aa"); + + COMPARE(true, <=, "a", "a"); + COMPARE(true, <=, "a", "b"); + COMPARE(true, <=, "a", "aa"); + COMPARE(true, <=, "aa", "b"); + COMPARE(true, <=, "aa", "bb"); + COMPARE(false, <=, "b", "a"); + COMPARE(false, <=, "aa", "a"); + COMPARE(false, <=, "b", "aa"); + COMPARE(false, <=, "bb", "aa"); + + COMPARE(false, >=, "a", "b"); + COMPARE(false, >=, "a", "aa"); + COMPARE(false, >=, "aa", "b"); + COMPARE(false, >=, "aa", "bb"); + COMPARE(true, >=, "a", "a"); + COMPARE(true, >=, "b", "a"); + COMPARE(true, >=, "aa", "a"); + COMPARE(true, >=, "b", "aa"); + COMPARE(true, >=, "bb", "aa"); + + COMPARE(false, >, "a", "a"); + COMPARE(false, >, "a", "b"); + COMPARE(false, >, "a", "aa"); + COMPARE(false, >, "aa", "b"); + COMPARE(false, >, "aa", "bb"); + COMPARE(true, >, "b", "a"); + COMPARE(true, >, "aa", "a"); + COMPARE(true, >, "b", "aa"); + COMPARE(true, >, "bb", "aa"); +} + +TEST(StringViewTest, ComparisonOperatorsByCharacterPosition) { + std::string x; + for (int i = 0; i < 256; i++) { + x += 'a'; + std::string y = x; + COMPARE(true, ==, x, y); + for (int j = 0; j < i; j++) { + std::string z = x; + z[j] = 'b'; // Differs in position 'j' + COMPARE(false, ==, x, z); + COMPARE(true, <, x, z); + COMPARE(true, >, z, x); + if (j + 1 < i) { + z[j + 1] = 'A'; // Differs in position 'j+1' as well + COMPARE(false, ==, x, z); + COMPARE(true, <, x, z); + COMPARE(true, >, z, x); + z[j + 1] = 'z'; // Differs in position 'j+1' as well + COMPARE(false, ==, x, z); + COMPARE(true, <, x, z); + COMPARE(true, >, z, x); + } + } + } +} +#undef COMPARE + +// Sadly, our users often confuse std::string::npos with +// absl::string_view::npos; So much so that we test here that they are the same. +// They need to both be unsigned, and both be the maximum-valued integer of +// their type. + +template <typename T> +struct is_type { + template <typename U> + static bool same(U) { + return false; + } + static bool same(T) { return true; } +}; + +TEST(StringViewTest, NposMatchesStdStringView) { + EXPECT_EQ(absl::string_view::npos, std::string::npos); + + EXPECT_TRUE(is_type<size_t>::same(absl::string_view::npos)); + EXPECT_FALSE(is_type<size_t>::same("")); + + // Make sure absl::string_view::npos continues to be a header constant. + char test[absl::string_view::npos & 1] = {0}; + EXPECT_EQ(0, test[0]); +} + +TEST(StringViewTest, STL1) { + const absl::string_view a("abcdefghijklmnopqrstuvwxyz"); + const absl::string_view b("abc"); + const absl::string_view c("xyz"); + const absl::string_view d("foobar"); + const absl::string_view e; + std::string temp("123"); + temp += '\0'; + temp += "456"; + const absl::string_view f(temp); + + EXPECT_EQ(a[6], 'g'); + EXPECT_EQ(b[0], 'a'); + EXPECT_EQ(c[2], 'z'); + EXPECT_EQ(f[3], '\0'); + EXPECT_EQ(f[5], '5'); + + EXPECT_EQ(*d.data(), 'f'); + EXPECT_EQ(d.data()[5], 'r'); + EXPECT_TRUE(e.data() == nullptr); + + EXPECT_EQ(*a.begin(), 'a'); + EXPECT_EQ(*(b.begin() + 2), 'c'); + EXPECT_EQ(*(c.end() - 1), 'z'); + + EXPECT_EQ(*a.rbegin(), 'z'); + EXPECT_EQ(*(b.rbegin() + 2), 'a'); + EXPECT_EQ(*(c.rend() - 1), 'x'); + EXPECT_TRUE(a.rbegin() + 26 == a.rend()); + + EXPECT_EQ(a.size(), 26); + EXPECT_EQ(b.size(), 3); + EXPECT_EQ(c.size(), 3); + EXPECT_EQ(d.size(), 6); + EXPECT_EQ(e.size(), 0); + EXPECT_EQ(f.size(), 7); + + EXPECT_TRUE(!d.empty()); + EXPECT_TRUE(d.begin() != d.end()); + EXPECT_TRUE(d.begin() + 6 == d.end()); + + EXPECT_TRUE(e.empty()); + EXPECT_TRUE(e.begin() == e.end()); + + char buf[4] = { '%', '%', '%', '%' }; + EXPECT_EQ(a.copy(buf, 4), 4); + EXPECT_EQ(buf[0], a[0]); + EXPECT_EQ(buf[1], a[1]); + EXPECT_EQ(buf[2], a[2]); + EXPECT_EQ(buf[3], a[3]); + EXPECT_EQ(a.copy(buf, 3, 7), 3); + EXPECT_EQ(buf[0], a[7]); + EXPECT_EQ(buf[1], a[8]); + EXPECT_EQ(buf[2], a[9]); + EXPECT_EQ(buf[3], a[3]); + EXPECT_EQ(c.copy(buf, 99), 3); + EXPECT_EQ(buf[0], c[0]); + EXPECT_EQ(buf[1], c[1]); + EXPECT_EQ(buf[2], c[2]); + EXPECT_EQ(buf[3], a[3]); +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW(a.copy(buf, 1, 27), std::out_of_range); +#else + ABSL_EXPECT_DEATH_IF_SUPPORTED(a.copy(buf, 1, 27), "absl::string_view::copy"); +#endif +} + +// Separated from STL1() because some compilers produce an overly +// large stack frame for the combined function. +TEST(StringViewTest, STL2) { + const absl::string_view a("abcdefghijklmnopqrstuvwxyz"); + const absl::string_view b("abc"); + const absl::string_view c("xyz"); + absl::string_view d("foobar"); + const absl::string_view e; + const absl::string_view f( + "123" + "\0" + "456", + 7); + + d = absl::string_view(); + EXPECT_EQ(d.size(), 0); + EXPECT_TRUE(d.empty()); + EXPECT_TRUE(d.data() == nullptr); + EXPECT_TRUE(d.begin() == d.end()); + + EXPECT_EQ(a.find(b), 0); + EXPECT_EQ(a.find(b, 1), absl::string_view::npos); + EXPECT_EQ(a.find(c), 23); + EXPECT_EQ(a.find(c, 9), 23); + EXPECT_EQ(a.find(c, absl::string_view::npos), absl::string_view::npos); + EXPECT_EQ(b.find(c), absl::string_view::npos); + EXPECT_EQ(b.find(c, absl::string_view::npos), absl::string_view::npos); + EXPECT_EQ(a.find(d), 0); + EXPECT_EQ(a.find(e), 0); + EXPECT_EQ(a.find(d, 12), 12); + EXPECT_EQ(a.find(e, 17), 17); + absl::string_view g("xx not found bb"); + EXPECT_EQ(a.find(g), absl::string_view::npos); + // empty string nonsense + EXPECT_EQ(d.find(b), absl::string_view::npos); + EXPECT_EQ(e.find(b), absl::string_view::npos); + EXPECT_EQ(d.find(b, 4), absl::string_view::npos); + EXPECT_EQ(e.find(b, 7), absl::string_view::npos); + + size_t empty_search_pos = std::string().find(std::string()); + EXPECT_EQ(d.find(d), empty_search_pos); + EXPECT_EQ(d.find(e), empty_search_pos); + EXPECT_EQ(e.find(d), empty_search_pos); + EXPECT_EQ(e.find(e), empty_search_pos); + EXPECT_EQ(d.find(d, 4), std::string().find(std::string(), 4)); + EXPECT_EQ(d.find(e, 4), std::string().find(std::string(), 4)); + EXPECT_EQ(e.find(d, 4), std::string().find(std::string(), 4)); + EXPECT_EQ(e.find(e, 4), std::string().find(std::string(), 4)); + + EXPECT_EQ(a.find('a'), 0); + EXPECT_EQ(a.find('c'), 2); + EXPECT_EQ(a.find('z'), 25); + EXPECT_EQ(a.find('$'), absl::string_view::npos); + EXPECT_EQ(a.find('\0'), absl::string_view::npos); + EXPECT_EQ(f.find('\0'), 3); + EXPECT_EQ(f.find('3'), 2); + EXPECT_EQ(f.find('5'), 5); + EXPECT_EQ(g.find('o'), 4); + EXPECT_EQ(g.find('o', 4), 4); + EXPECT_EQ(g.find('o', 5), 8); + EXPECT_EQ(a.find('b', 5), absl::string_view::npos); + // empty string nonsense + EXPECT_EQ(d.find('\0'), absl::string_view::npos); + EXPECT_EQ(e.find('\0'), absl::string_view::npos); + EXPECT_EQ(d.find('\0', 4), absl::string_view::npos); + EXPECT_EQ(e.find('\0', 7), absl::string_view::npos); + EXPECT_EQ(d.find('x'), absl::string_view::npos); + EXPECT_EQ(e.find('x'), absl::string_view::npos); + EXPECT_EQ(d.find('x', 4), absl::string_view::npos); + EXPECT_EQ(e.find('x', 7), absl::string_view::npos); + + EXPECT_EQ(a.rfind(b), 0); + EXPECT_EQ(a.rfind(b, 1), 0); + EXPECT_EQ(a.rfind(c), 23); + EXPECT_EQ(a.rfind(c, 22), absl::string_view::npos); + EXPECT_EQ(a.rfind(c, 1), absl::string_view::npos); + EXPECT_EQ(a.rfind(c, 0), absl::string_view::npos); + EXPECT_EQ(b.rfind(c), absl::string_view::npos); + EXPECT_EQ(b.rfind(c, 0), absl::string_view::npos); + EXPECT_EQ(a.rfind(d), std::string(a).rfind(std::string())); + EXPECT_EQ(a.rfind(e), std::string(a).rfind(std::string())); + EXPECT_EQ(a.rfind(d, 12), 12); + EXPECT_EQ(a.rfind(e, 17), 17); + EXPECT_EQ(a.rfind(g), absl::string_view::npos); + EXPECT_EQ(d.rfind(b), absl::string_view::npos); + EXPECT_EQ(e.rfind(b), absl::string_view::npos); + EXPECT_EQ(d.rfind(b, 4), absl::string_view::npos); + EXPECT_EQ(e.rfind(b, 7), absl::string_view::npos); + // empty string nonsense + EXPECT_EQ(d.rfind(d, 4), std::string().rfind(std::string())); + EXPECT_EQ(e.rfind(d, 7), std::string().rfind(std::string())); + EXPECT_EQ(d.rfind(e, 4), std::string().rfind(std::string())); + EXPECT_EQ(e.rfind(e, 7), std::string().rfind(std::string())); + EXPECT_EQ(d.rfind(d), std::string().rfind(std::string())); + EXPECT_EQ(e.rfind(d), std::string().rfind(std::string())); + EXPECT_EQ(d.rfind(e), std::string().rfind(std::string())); + EXPECT_EQ(e.rfind(e), std::string().rfind(std::string())); + + EXPECT_EQ(g.rfind('o'), 8); + EXPECT_EQ(g.rfind('q'), absl::string_view::npos); + EXPECT_EQ(g.rfind('o', 8), 8); + EXPECT_EQ(g.rfind('o', 7), 4); + EXPECT_EQ(g.rfind('o', 3), absl::string_view::npos); + EXPECT_EQ(f.rfind('\0'), 3); + EXPECT_EQ(f.rfind('\0', 12), 3); + EXPECT_EQ(f.rfind('3'), 2); + EXPECT_EQ(f.rfind('5'), 5); + // empty string nonsense + EXPECT_EQ(d.rfind('o'), absl::string_view::npos); + EXPECT_EQ(e.rfind('o'), absl::string_view::npos); + EXPECT_EQ(d.rfind('o', 4), absl::string_view::npos); + EXPECT_EQ(e.rfind('o', 7), absl::string_view::npos); +} + +// Continued from STL2 +TEST(StringViewTest, STL2FindFirst) { + const absl::string_view a("abcdefghijklmnopqrstuvwxyz"); + const absl::string_view b("abc"); + const absl::string_view c("xyz"); + absl::string_view d("foobar"); + const absl::string_view e; + const absl::string_view f( + "123" + "\0" + "456", + 7); + absl::string_view g("xx not found bb"); + + d = absl::string_view(); + EXPECT_EQ(a.find_first_of(b), 0); + EXPECT_EQ(a.find_first_of(b, 0), 0); + EXPECT_EQ(a.find_first_of(b, 1), 1); + EXPECT_EQ(a.find_first_of(b, 2), 2); + EXPECT_EQ(a.find_first_of(b, 3), absl::string_view::npos); + EXPECT_EQ(a.find_first_of(c), 23); + EXPECT_EQ(a.find_first_of(c, 23), 23); + EXPECT_EQ(a.find_first_of(c, 24), 24); + EXPECT_EQ(a.find_first_of(c, 25), 25); + EXPECT_EQ(a.find_first_of(c, 26), absl::string_view::npos); + EXPECT_EQ(g.find_first_of(b), 13); + EXPECT_EQ(g.find_first_of(c), 0); + EXPECT_EQ(a.find_first_of(f), absl::string_view::npos); + EXPECT_EQ(f.find_first_of(a), absl::string_view::npos); + // empty string nonsense + EXPECT_EQ(a.find_first_of(d), absl::string_view::npos); + EXPECT_EQ(a.find_first_of(e), absl::string_view::npos); + EXPECT_EQ(d.find_first_of(b), absl::string_view::npos); + EXPECT_EQ(e.find_first_of(b), absl::string_view::npos); + EXPECT_EQ(d.find_first_of(d), absl::string_view::npos); + EXPECT_EQ(e.find_first_of(d), absl::string_view::npos); + EXPECT_EQ(d.find_first_of(e), absl::string_view::npos); + EXPECT_EQ(e.find_first_of(e), absl::string_view::npos); + + EXPECT_EQ(a.find_first_not_of(b), 3); + EXPECT_EQ(a.find_first_not_of(c), 0); + EXPECT_EQ(b.find_first_not_of(a), absl::string_view::npos); + EXPECT_EQ(c.find_first_not_of(a), absl::string_view::npos); + EXPECT_EQ(f.find_first_not_of(a), 0); + EXPECT_EQ(a.find_first_not_of(f), 0); + EXPECT_EQ(a.find_first_not_of(d), 0); + EXPECT_EQ(a.find_first_not_of(e), 0); + // empty string nonsense + EXPECT_EQ(a.find_first_not_of(d), 0); + EXPECT_EQ(a.find_first_not_of(e), 0); + EXPECT_EQ(a.find_first_not_of(d, 1), 1); + EXPECT_EQ(a.find_first_not_of(e, 1), 1); + EXPECT_EQ(a.find_first_not_of(d, a.size() - 1), a.size() - 1); + EXPECT_EQ(a.find_first_not_of(e, a.size() - 1), a.size() - 1); + EXPECT_EQ(a.find_first_not_of(d, a.size()), absl::string_view::npos); + EXPECT_EQ(a.find_first_not_of(e, a.size()), absl::string_view::npos); + EXPECT_EQ(a.find_first_not_of(d, absl::string_view::npos), + absl::string_view::npos); + EXPECT_EQ(a.find_first_not_of(e, absl::string_view::npos), + absl::string_view::npos); + EXPECT_EQ(d.find_first_not_of(a), absl::string_view::npos); + EXPECT_EQ(e.find_first_not_of(a), absl::string_view::npos); + EXPECT_EQ(d.find_first_not_of(d), absl::string_view::npos); + EXPECT_EQ(e.find_first_not_of(d), absl::string_view::npos); + EXPECT_EQ(d.find_first_not_of(e), absl::string_view::npos); + EXPECT_EQ(e.find_first_not_of(e), absl::string_view::npos); + + absl::string_view h("===="); + EXPECT_EQ(h.find_first_not_of('='), absl::string_view::npos); + EXPECT_EQ(h.find_first_not_of('=', 3), absl::string_view::npos); + EXPECT_EQ(h.find_first_not_of('\0'), 0); + EXPECT_EQ(g.find_first_not_of('x'), 2); + EXPECT_EQ(f.find_first_not_of('\0'), 0); + EXPECT_EQ(f.find_first_not_of('\0', 3), 4); + EXPECT_EQ(f.find_first_not_of('\0', 2), 2); + // empty string nonsense + EXPECT_EQ(d.find_first_not_of('x'), absl::string_view::npos); + EXPECT_EQ(e.find_first_not_of('x'), absl::string_view::npos); + EXPECT_EQ(d.find_first_not_of('\0'), absl::string_view::npos); + EXPECT_EQ(e.find_first_not_of('\0'), absl::string_view::npos); +} + +// Continued from STL2 +TEST(StringViewTest, STL2FindLast) { + const absl::string_view a("abcdefghijklmnopqrstuvwxyz"); + const absl::string_view b("abc"); + const absl::string_view c("xyz"); + absl::string_view d("foobar"); + const absl::string_view e; + const absl::string_view f( + "123" + "\0" + "456", + 7); + absl::string_view g("xx not found bb"); + absl::string_view h("===="); + absl::string_view i("56"); + + d = absl::string_view(); + EXPECT_EQ(h.find_last_of(a), absl::string_view::npos); + EXPECT_EQ(g.find_last_of(a), g.size()-1); + EXPECT_EQ(a.find_last_of(b), 2); + EXPECT_EQ(a.find_last_of(c), a.size()-1); + EXPECT_EQ(f.find_last_of(i), 6); + EXPECT_EQ(a.find_last_of('a'), 0); + EXPECT_EQ(a.find_last_of('b'), 1); + EXPECT_EQ(a.find_last_of('z'), 25); + EXPECT_EQ(a.find_last_of('a', 5), 0); + EXPECT_EQ(a.find_last_of('b', 5), 1); + EXPECT_EQ(a.find_last_of('b', 0), absl::string_view::npos); + EXPECT_EQ(a.find_last_of('z', 25), 25); + EXPECT_EQ(a.find_last_of('z', 24), absl::string_view::npos); + EXPECT_EQ(f.find_last_of(i, 5), 5); + EXPECT_EQ(f.find_last_of(i, 6), 6); + EXPECT_EQ(f.find_last_of(a, 4), absl::string_view::npos); + // empty string nonsense + EXPECT_EQ(f.find_last_of(d), absl::string_view::npos); + EXPECT_EQ(f.find_last_of(e), absl::string_view::npos); + EXPECT_EQ(f.find_last_of(d, 4), absl::string_view::npos); + EXPECT_EQ(f.find_last_of(e, 4), absl::string_view::npos); + EXPECT_EQ(d.find_last_of(d), absl::string_view::npos); + EXPECT_EQ(d.find_last_of(e), absl::string_view::npos); + EXPECT_EQ(e.find_last_of(d), absl::string_view::npos); + EXPECT_EQ(e.find_last_of(e), absl::string_view::npos); + EXPECT_EQ(d.find_last_of(f), absl::string_view::npos); + EXPECT_EQ(e.find_last_of(f), absl::string_view::npos); + EXPECT_EQ(d.find_last_of(d, 4), absl::string_view::npos); + EXPECT_EQ(d.find_last_of(e, 4), absl::string_view::npos); + EXPECT_EQ(e.find_last_of(d, 4), absl::string_view::npos); + EXPECT_EQ(e.find_last_of(e, 4), absl::string_view::npos); + EXPECT_EQ(d.find_last_of(f, 4), absl::string_view::npos); + EXPECT_EQ(e.find_last_of(f, 4), absl::string_view::npos); + + EXPECT_EQ(a.find_last_not_of(b), a.size()-1); + EXPECT_EQ(a.find_last_not_of(c), 22); + EXPECT_EQ(b.find_last_not_of(a), absl::string_view::npos); + EXPECT_EQ(b.find_last_not_of(b), absl::string_view::npos); + EXPECT_EQ(f.find_last_not_of(i), 4); + EXPECT_EQ(a.find_last_not_of(c, 24), 22); + EXPECT_EQ(a.find_last_not_of(b, 3), 3); + EXPECT_EQ(a.find_last_not_of(b, 2), absl::string_view::npos); + // empty string nonsense + EXPECT_EQ(f.find_last_not_of(d), f.size()-1); + EXPECT_EQ(f.find_last_not_of(e), f.size()-1); + EXPECT_EQ(f.find_last_not_of(d, 4), 4); + EXPECT_EQ(f.find_last_not_of(e, 4), 4); + EXPECT_EQ(d.find_last_not_of(d), absl::string_view::npos); + EXPECT_EQ(d.find_last_not_of(e), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of(d), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of(e), absl::string_view::npos); + EXPECT_EQ(d.find_last_not_of(f), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of(f), absl::string_view::npos); + EXPECT_EQ(d.find_last_not_of(d, 4), absl::string_view::npos); + EXPECT_EQ(d.find_last_not_of(e, 4), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of(d, 4), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of(e, 4), absl::string_view::npos); + EXPECT_EQ(d.find_last_not_of(f, 4), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of(f, 4), absl::string_view::npos); + + EXPECT_EQ(h.find_last_not_of('x'), h.size() - 1); + EXPECT_EQ(h.find_last_not_of('='), absl::string_view::npos); + EXPECT_EQ(b.find_last_not_of('c'), 1); + EXPECT_EQ(h.find_last_not_of('x', 2), 2); + EXPECT_EQ(h.find_last_not_of('=', 2), absl::string_view::npos); + EXPECT_EQ(b.find_last_not_of('b', 1), 0); + // empty string nonsense + EXPECT_EQ(d.find_last_not_of('x'), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of('x'), absl::string_view::npos); + EXPECT_EQ(d.find_last_not_of('\0'), absl::string_view::npos); + EXPECT_EQ(e.find_last_not_of('\0'), absl::string_view::npos); +} + +// Continued from STL2 +TEST(StringViewTest, STL2Substr) { + const absl::string_view a("abcdefghijklmnopqrstuvwxyz"); + const absl::string_view b("abc"); + const absl::string_view c("xyz"); + absl::string_view d("foobar"); + const absl::string_view e; + + d = absl::string_view(); + EXPECT_EQ(a.substr(0, 3), b); + EXPECT_EQ(a.substr(23), c); + EXPECT_EQ(a.substr(23, 3), c); + EXPECT_EQ(a.substr(23, 99), c); + EXPECT_EQ(a.substr(0), a); + EXPECT_EQ(a.substr(3, 2), "de"); + // empty string nonsense + EXPECT_EQ(d.substr(0, 99), e); + // use of npos + EXPECT_EQ(a.substr(0, absl::string_view::npos), a); + EXPECT_EQ(a.substr(23, absl::string_view::npos), c); + // throw exception +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW((void)a.substr(99, 2), std::out_of_range); +#else + ABSL_EXPECT_DEATH_IF_SUPPORTED((void)a.substr(99, 2), + "absl::string_view::substr"); +#endif +} + +TEST(StringViewTest, TruncSubstr) { + const absl::string_view hi("hi"); + EXPECT_EQ("", absl::ClippedSubstr(hi, 0, 0)); + EXPECT_EQ("h", absl::ClippedSubstr(hi, 0, 1)); + EXPECT_EQ("hi", absl::ClippedSubstr(hi, 0)); + EXPECT_EQ("i", absl::ClippedSubstr(hi, 1)); + EXPECT_EQ("", absl::ClippedSubstr(hi, 2)); + EXPECT_EQ("", absl::ClippedSubstr(hi, 3)); // truncation + EXPECT_EQ("", absl::ClippedSubstr(hi, 3, 2)); // truncation +} + +TEST(StringViewTest, UTF8) { + std::string utf8 = "\u00E1"; + std::string utf8_twice = utf8 + " " + utf8; + int utf8_len = strlen(utf8.data()); + EXPECT_EQ(utf8_len, absl::string_view(utf8_twice).find_first_of(" ")); + EXPECT_EQ(utf8_len, absl::string_view(utf8_twice).find_first_of(" \t")); +} + +TEST(StringViewTest, FindConformance) { + struct { + std::string haystack; + std::string needle; + } specs[] = { + {"", ""}, + {"", "a"}, + {"a", ""}, + {"a", "a"}, + {"a", "b"}, + {"aa", ""}, + {"aa", "a"}, + {"aa", "b"}, + {"ab", "a"}, + {"ab", "b"}, + {"abcd", ""}, + {"abcd", "a"}, + {"abcd", "d"}, + {"abcd", "ab"}, + {"abcd", "bc"}, + {"abcd", "cd"}, + {"abcd", "abcd"}, + }; + for (const auto& s : specs) { + SCOPED_TRACE(s.haystack); + SCOPED_TRACE(s.needle); + std::string st = s.haystack; + absl::string_view sp = s.haystack; + for (size_t i = 0; i <= sp.size(); ++i) { + size_t pos = (i == sp.size()) ? absl::string_view::npos : i; + SCOPED_TRACE(pos); + EXPECT_EQ(sp.find(s.needle, pos), + st.find(s.needle, pos)); + EXPECT_EQ(sp.rfind(s.needle, pos), + st.rfind(s.needle, pos)); + EXPECT_EQ(sp.find_first_of(s.needle, pos), + st.find_first_of(s.needle, pos)); + EXPECT_EQ(sp.find_first_not_of(s.needle, pos), + st.find_first_not_of(s.needle, pos)); + EXPECT_EQ(sp.find_last_of(s.needle, pos), + st.find_last_of(s.needle, pos)); + EXPECT_EQ(sp.find_last_not_of(s.needle, pos), + st.find_last_not_of(s.needle, pos)); + } + } +} + +TEST(StringViewTest, Remove) { + absl::string_view a("foobar"); + std::string s1("123"); + s1 += '\0'; + s1 += "456"; + absl::string_view e; + std::string s2; + + // remove_prefix + absl::string_view c(a); + c.remove_prefix(3); + EXPECT_EQ(c, "bar"); + c = a; + c.remove_prefix(0); + EXPECT_EQ(c, a); + c.remove_prefix(c.size()); + EXPECT_EQ(c, e); + + // remove_suffix + c = a; + c.remove_suffix(3); + EXPECT_EQ(c, "foo"); + c = a; + c.remove_suffix(0); + EXPECT_EQ(c, a); + c.remove_suffix(c.size()); + EXPECT_EQ(c, e); +} + +TEST(StringViewTest, Set) { + absl::string_view a("foobar"); + absl::string_view empty; + absl::string_view b; + + // set + b = absl::string_view("foobar", 6); + EXPECT_EQ(b, a); + b = absl::string_view("foobar", 0); + EXPECT_EQ(b, empty); + b = absl::string_view("foobar", 7); + EXPECT_NE(b, a); + + b = absl::string_view("foobar"); + EXPECT_EQ(b, a); +} + +TEST(StringViewTest, FrontBack) { + static const char arr[] = "abcd"; + const absl::string_view csp(arr, 4); + EXPECT_EQ(&arr[0], &csp.front()); + EXPECT_EQ(&arr[3], &csp.back()); +} + +TEST(StringViewTest, FrontBackSingleChar) { + static const char c = 'a'; + const absl::string_view csp(&c, 1); + EXPECT_EQ(&c, &csp.front()); + EXPECT_EQ(&c, &csp.back()); +} + +TEST(StringViewTest, FrontBackEmpty) { +#ifndef ABSL_USES_STD_STRING_VIEW +#if !defined(NDEBUG) || ABSL_OPTION_HARDENED + // Abseil's string_view implementation has debug assertions that check that + // front() and back() are not called on an empty string_view. + absl::string_view sv; + ABSL_EXPECT_DEATH_IF_SUPPORTED(sv.front(), ""); + ABSL_EXPECT_DEATH_IF_SUPPORTED(sv.back(), ""); +#endif +#endif +} + +// `std::string_view::string_view(const char*)` calls +// `std::char_traits<char>::length(const char*)` to get the string length. In +// libc++, it doesn't allow `nullptr` in the constexpr context, with the error +// "read of dereferenced null pointer is not allowed in a constant expression". +// At run time, the behavior of `std::char_traits::length()` on `nullptr` is +// undefined by the standard and usually results in crash with libc++. +// GCC also started rejected this in libstdc++ starting in GCC9. +// In MSVC, creating a constexpr string_view from nullptr also triggers an +// "unevaluable pointer value" error. This compiler implementation conforms +// to the standard, but `absl::string_view` implements a different +// behavior for historical reasons. We work around tests that construct +// `string_view` from `nullptr` when using libc++. +#if !defined(ABSL_USES_STD_STRING_VIEW) || \ + (!(defined(_GLIBCXX_RELEASE) && _GLIBCXX_RELEASE >= 9) && \ + !defined(_LIBCPP_VERSION) && !defined(_MSC_VER)) +#define ABSL_HAVE_STRING_VIEW_FROM_NULLPTR 1 +#endif + +TEST(StringViewTest, NULLInput) { + absl::string_view s; + EXPECT_EQ(s.data(), nullptr); + EXPECT_EQ(s.size(), 0); + +#ifdef ABSL_HAVE_STRING_VIEW_FROM_NULLPTR + s = absl::string_view(nullptr); + EXPECT_EQ(s.data(), nullptr); + EXPECT_EQ(s.size(), 0); + + // .ToString() on a absl::string_view with nullptr should produce the empty + // string. + EXPECT_EQ("", std::string(s)); +#endif // ABSL_HAVE_STRING_VIEW_FROM_NULLPTR +} + +TEST(StringViewTest, Comparisons2) { + // The `compare` member has 6 overloads (v: string_view, s: const char*): + // (1) compare(v) + // (2) compare(pos1, count1, v) + // (3) compare(pos1, count1, v, pos2, count2) + // (4) compare(s) + // (5) compare(pos1, count1, s) + // (6) compare(pos1, count1, s, count2) + + absl::string_view abc("abcdefghijklmnopqrstuvwxyz"); + + // check comparison operations on strings longer than 4 bytes. + EXPECT_EQ(abc, absl::string_view("abcdefghijklmnopqrstuvwxyz")); + EXPECT_EQ(abc.compare(absl::string_view("abcdefghijklmnopqrstuvwxyz")), 0); + + EXPECT_LT(abc, absl::string_view("abcdefghijklmnopqrstuvwxzz")); + EXPECT_LT(abc.compare(absl::string_view("abcdefghijklmnopqrstuvwxzz")), 0); + + EXPECT_GT(abc, absl::string_view("abcdefghijklmnopqrstuvwxyy")); + EXPECT_GT(abc.compare(absl::string_view("abcdefghijklmnopqrstuvwxyy")), 0); + + // The "substr" variants of `compare`. + absl::string_view digits("0123456789"); + auto npos = absl::string_view::npos; + + // Taking string_view + EXPECT_EQ(digits.compare(3, npos, absl::string_view("3456789")), 0); // 2 + EXPECT_EQ(digits.compare(3, 4, absl::string_view("3456")), 0); // 2 + EXPECT_EQ(digits.compare(10, 0, absl::string_view()), 0); // 2 + EXPECT_EQ(digits.compare(3, 4, absl::string_view("0123456789"), 3, 4), + 0); // 3 + EXPECT_LT(digits.compare(3, 4, absl::string_view("0123456789"), 3, 5), + 0); // 3 + EXPECT_LT(digits.compare(0, npos, absl::string_view("0123456789"), 3, 5), + 0); // 3 + // Taking const char* + EXPECT_EQ(digits.compare(3, 4, "3456"), 0); // 5 + EXPECT_EQ(digits.compare(3, npos, "3456789"), 0); // 5 + EXPECT_EQ(digits.compare(10, 0, ""), 0); // 5 + EXPECT_EQ(digits.compare(3, 4, "0123456789", 3, 4), 0); // 6 + EXPECT_LT(digits.compare(3, 4, "0123456789", 3, 5), 0); // 6 + EXPECT_LT(digits.compare(0, npos, "0123456789", 3, 5), 0); // 6 +} + +TEST(StringViewTest, At) { + absl::string_view abc = "abc"; + EXPECT_EQ(abc.at(0), 'a'); + EXPECT_EQ(abc.at(1), 'b'); + EXPECT_EQ(abc.at(2), 'c'); +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW(abc.at(3), std::out_of_range); +#else + ABSL_EXPECT_DEATH_IF_SUPPORTED(abc.at(3), "absl::string_view::at"); +#endif +} + +struct MyCharAlloc : std::allocator<char> {}; + +TEST(StringViewTest, ExplicitConversionOperator) { + absl::string_view sp = "hi"; + EXPECT_EQ(sp, std::string(sp)); +} + +TEST(StringViewTest, NullSafeStringView) { + { + absl::string_view s = absl::NullSafeStringView(nullptr); + EXPECT_EQ(nullptr, s.data()); + EXPECT_EQ(0, s.size()); + EXPECT_EQ(absl::string_view(), s); + } + { + static const char kHi[] = "hi"; + absl::string_view s = absl::NullSafeStringView(kHi); + EXPECT_EQ(kHi, s.data()); + EXPECT_EQ(strlen(kHi), s.size()); + EXPECT_EQ(absl::string_view("hi"), s); + } +} + +TEST(StringViewTest, ConstexprNullSafeStringView) { + { + constexpr absl::string_view s = absl::NullSafeStringView(nullptr); + EXPECT_EQ(nullptr, s.data()); + EXPECT_EQ(0, s.size()); + EXPECT_EQ(absl::string_view(), s); + } +#if !defined(_MSC_VER) || _MSC_VER >= 1910 + // MSVC 2017+ is required for good constexpr string_view support. + // See the implementation of `absl::string_view::StrlenInternal()`. + { + static constexpr char kHi[] = "hi"; + absl::string_view s = absl::NullSafeStringView(kHi); + EXPECT_EQ(kHi, s.data()); + EXPECT_EQ(strlen(kHi), s.size()); + EXPECT_EQ(absl::string_view("hi"), s); + } + { + constexpr absl::string_view s = absl::NullSafeStringView("hello"); + EXPECT_EQ(s.size(), 5); + EXPECT_EQ("hello", s); + } +#endif +} + +TEST(StringViewTest, ConstexprCompiles) { + constexpr absl::string_view sp; +#ifdef ABSL_HAVE_STRING_VIEW_FROM_NULLPTR + constexpr absl::string_view cstr(nullptr); +#endif + constexpr absl::string_view cstr_len("cstr", 4); + +#if defined(ABSL_USES_STD_STRING_VIEW) + // In libstdc++ (as of 7.2), `std::string_view::string_view(const char*)` + // calls `std::char_traits<char>::length(const char*)` to get the string + // length, but it is not marked constexpr yet. See GCC bug: + // https://gcc.gnu.org/bugzilla/show_bug.cgi?id=78156 + // Also, there is a LWG issue that adds constexpr to length() which was just + // resolved 2017-06-02. See + // http://www.open-std.org/jtc1/sc22/wg21/docs/lwg-defects.html#2232 + // TODO(zhangxy): Update the condition when libstdc++ adopts the constexpr + // length(). +#if !defined(__GLIBCXX__) +#define ABSL_HAVE_CONSTEXPR_STRING_VIEW_FROM_CSTR 1 +#endif // !__GLIBCXX__ + +#else // ABSL_USES_STD_STRING_VIEW + +// This duplicates the check for __builtin_strlen in the header. +#if ABSL_HAVE_BUILTIN(__builtin_strlen) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_HAVE_CONSTEXPR_STRING_VIEW_FROM_CSTR 1 +#elif defined(__GNUC__) // GCC or clang +#error GCC/clang should have constexpr string_view. +#endif + +// MSVC 2017+ should be able to construct a constexpr string_view from a cstr. +#if defined(_MSC_VER) && _MSC_VER >= 1910 +#define ABSL_HAVE_CONSTEXPR_STRING_VIEW_FROM_CSTR 1 +#endif + +#endif // ABSL_USES_STD_STRING_VIEW + +#ifdef ABSL_HAVE_CONSTEXPR_STRING_VIEW_FROM_CSTR + constexpr absl::string_view cstr_strlen("foo"); + EXPECT_EQ(cstr_strlen.length(), 3); + constexpr absl::string_view cstr_strlen2 = "bar"; + EXPECT_EQ(cstr_strlen2, "bar"); + +#if ABSL_HAVE_BUILTIN(__builtin_memcmp) || \ + (defined(__GNUC__) && !defined(__clang__)) +#define ABSL_HAVE_CONSTEXPR_STRING_VIEW_COMPARISON 1 +#endif +#ifdef ABSL_HAVE_CONSTEXPR_STRING_VIEW_COMPARISON + constexpr absl::string_view foo = "foo"; + constexpr absl::string_view bar = "bar"; + constexpr bool foo_eq_bar = foo == bar; + constexpr bool foo_ne_bar = foo != bar; + constexpr bool foo_lt_bar = foo < bar; + constexpr bool foo_le_bar = foo <= bar; + constexpr bool foo_gt_bar = foo > bar; + constexpr bool foo_ge_bar = foo >= bar; + constexpr int foo_compare_bar = foo.compare(bar); + EXPECT_FALSE(foo_eq_bar); + EXPECT_TRUE(foo_ne_bar); + EXPECT_FALSE(foo_lt_bar); + EXPECT_FALSE(foo_le_bar); + EXPECT_TRUE(foo_gt_bar); + EXPECT_TRUE(foo_ge_bar); + EXPECT_GT(foo_compare_bar, 0); +#endif +#endif + +#if !defined(__clang__) || 3 < __clang_major__ || \ + (3 == __clang_major__ && 4 < __clang_minor__) + // older clang versions (< 3.5) complain that: + // "cannot perform pointer arithmetic on null pointer" + constexpr absl::string_view::iterator const_begin_empty = sp.begin(); + constexpr absl::string_view::iterator const_end_empty = sp.end(); + EXPECT_EQ(const_begin_empty, const_end_empty); + +#ifdef ABSL_HAVE_STRING_VIEW_FROM_NULLPTR + constexpr absl::string_view::iterator const_begin_nullptr = cstr.begin(); + constexpr absl::string_view::iterator const_end_nullptr = cstr.end(); + EXPECT_EQ(const_begin_nullptr, const_end_nullptr); +#endif // ABSL_HAVE_STRING_VIEW_FROM_NULLPTR +#endif // !defined(__clang__) || ... + + constexpr absl::string_view::iterator const_begin = cstr_len.begin(); + constexpr absl::string_view::iterator const_end = cstr_len.end(); + constexpr absl::string_view::size_type const_size = cstr_len.size(); + constexpr absl::string_view::size_type const_length = cstr_len.length(); + static_assert(const_begin + const_size == const_end, + "pointer arithmetic check"); + static_assert(const_begin + const_length == const_end, + "pointer arithmetic check"); +#ifndef _MSC_VER + // MSVC has bugs doing constexpr pointer arithmetic. + // https://developercommunity.visualstudio.com/content/problem/482192/bad-pointer-arithmetic-in-constepxr-2019-rc1-svc1.html + EXPECT_EQ(const_begin + const_size, const_end); + EXPECT_EQ(const_begin + const_length, const_end); +#endif + + constexpr bool isempty = sp.empty(); + EXPECT_TRUE(isempty); + + constexpr const char c = cstr_len[2]; + EXPECT_EQ(c, 't'); + + constexpr const char cfront = cstr_len.front(); + constexpr const char cback = cstr_len.back(); + EXPECT_EQ(cfront, 'c'); + EXPECT_EQ(cback, 'r'); + + constexpr const char* np = sp.data(); + constexpr const char* cstr_ptr = cstr_len.data(); + EXPECT_EQ(np, nullptr); + EXPECT_NE(cstr_ptr, nullptr); + + constexpr size_t sp_npos = sp.npos; + EXPECT_EQ(sp_npos, -1); +} + +TEST(StringViewTest, ConstexprSubstr) { + constexpr absl::string_view foobar("foobar", 6); + constexpr absl::string_view foo = foobar.substr(0, 3); + constexpr absl::string_view bar = foobar.substr(3); + EXPECT_EQ(foo, "foo"); + EXPECT_EQ(bar, "bar"); +} + +TEST(StringViewTest, Noexcept) { + EXPECT_TRUE((std::is_nothrow_constructible<absl::string_view, + const std::string&>::value)); + EXPECT_TRUE((std::is_nothrow_constructible<absl::string_view, + const std::string&>::value)); + EXPECT_TRUE(std::is_nothrow_constructible<absl::string_view>::value); + constexpr absl::string_view sp; + EXPECT_TRUE(noexcept(sp.begin())); + EXPECT_TRUE(noexcept(sp.end())); + EXPECT_TRUE(noexcept(sp.cbegin())); + EXPECT_TRUE(noexcept(sp.cend())); + EXPECT_TRUE(noexcept(sp.rbegin())); + EXPECT_TRUE(noexcept(sp.rend())); + EXPECT_TRUE(noexcept(sp.crbegin())); + EXPECT_TRUE(noexcept(sp.crend())); + EXPECT_TRUE(noexcept(sp.size())); + EXPECT_TRUE(noexcept(sp.length())); + EXPECT_TRUE(noexcept(sp.empty())); + EXPECT_TRUE(noexcept(sp.data())); + EXPECT_TRUE(noexcept(sp.compare(sp))); + EXPECT_TRUE(noexcept(sp.find(sp))); + EXPECT_TRUE(noexcept(sp.find('f'))); + EXPECT_TRUE(noexcept(sp.rfind(sp))); + EXPECT_TRUE(noexcept(sp.rfind('f'))); + EXPECT_TRUE(noexcept(sp.find_first_of(sp))); + EXPECT_TRUE(noexcept(sp.find_first_of('f'))); + EXPECT_TRUE(noexcept(sp.find_last_of(sp))); + EXPECT_TRUE(noexcept(sp.find_last_of('f'))); + EXPECT_TRUE(noexcept(sp.find_first_not_of(sp))); + EXPECT_TRUE(noexcept(sp.find_first_not_of('f'))); + EXPECT_TRUE(noexcept(sp.find_last_not_of(sp))); + EXPECT_TRUE(noexcept(sp.find_last_not_of('f'))); +} + +TEST(StringViewTest, BoundsCheck) { +#ifndef ABSL_USES_STD_STRING_VIEW +#if !defined(NDEBUG) || ABSL_OPTION_HARDENED + // Abseil's string_view implementation has bounds-checking in debug mode. + absl::string_view h = "hello"; + ABSL_EXPECT_DEATH_IF_SUPPORTED(h[5], ""); + ABSL_EXPECT_DEATH_IF_SUPPORTED(h[-1], ""); +#endif +#endif +} + +TEST(ComparisonOpsTest, StringCompareNotAmbiguous) { + EXPECT_EQ("hello", std::string("hello")); + EXPECT_LT("hello", std::string("world")); +} + +TEST(ComparisonOpsTest, HeterogenousStringViewEquals) { + EXPECT_EQ(absl::string_view("hello"), std::string("hello")); + EXPECT_EQ("hello", absl::string_view("hello")); +} + +TEST(FindOneCharTest, EdgeCases) { + absl::string_view a("xxyyyxx"); + + // Set a = "xyyyx". + a.remove_prefix(1); + a.remove_suffix(1); + + EXPECT_EQ(0, a.find('x')); + EXPECT_EQ(0, a.find('x', 0)); + EXPECT_EQ(4, a.find('x', 1)); + EXPECT_EQ(4, a.find('x', 4)); + EXPECT_EQ(absl::string_view::npos, a.find('x', 5)); + + EXPECT_EQ(4, a.rfind('x')); + EXPECT_EQ(4, a.rfind('x', 5)); + EXPECT_EQ(4, a.rfind('x', 4)); + EXPECT_EQ(0, a.rfind('x', 3)); + EXPECT_EQ(0, a.rfind('x', 0)); + + // Set a = "yyy". + a.remove_prefix(1); + a.remove_suffix(1); + + EXPECT_EQ(absl::string_view::npos, a.find('x')); + EXPECT_EQ(absl::string_view::npos, a.rfind('x')); +} + +#ifndef THREAD_SANITIZER // Allocates too much memory for tsan. +TEST(HugeStringView, TwoPointTwoGB) { + if (sizeof(size_t) <= 4 || RunningOnValgrind()) + return; + // Try a huge string piece. + const size_t size = size_t{2200} * 1000 * 1000; + std::string s(size, 'a'); + absl::string_view sp(s); + EXPECT_EQ(size, sp.length()); + sp.remove_prefix(1); + EXPECT_EQ(size - 1, sp.length()); + sp.remove_suffix(2); + EXPECT_EQ(size - 1 - 2, sp.length()); +} +#endif // THREAD_SANITIZER + +#if !defined(NDEBUG) && !defined(ABSL_USES_STD_STRING_VIEW) +TEST(NonNegativeLenTest, NonNegativeLen) { + ABSL_EXPECT_DEATH_IF_SUPPORTED(absl::string_view("xyz", -1), + "len <= kMaxSize"); +} + +TEST(LenExceedsMaxSizeTest, LenExceedsMaxSize) { + auto max_size = absl::string_view().max_size(); + + // This should construct ok (although the view itself is obviously invalid). + absl::string_view ok_view("", max_size); + + // Adding one to the max should trigger an assertion. + ABSL_EXPECT_DEATH_IF_SUPPORTED(absl::string_view("", max_size + 1), + "len <= kMaxSize"); +} +#endif // !defined(NDEBUG) && !defined(ABSL_USES_STD_STRING_VIEW) + +class StringViewStreamTest : public ::testing::Test { + public: + // Set negative 'width' for right justification. + template <typename T> + std::string Pad(const T& s, int width, char fill = 0) { + std::ostringstream oss; + if (fill != 0) { + oss << std::setfill(fill); + } + if (width < 0) { + width = -width; + oss << std::right; + } + oss << std::setw(width) << s; + return oss.str(); + } +}; + +TEST_F(StringViewStreamTest, Padding) { + std::string s("hello"); + absl::string_view sp(s); + for (int w = -64; w < 64; ++w) { + SCOPED_TRACE(w); + EXPECT_EQ(Pad(s, w), Pad(sp, w)); + } + for (int w = -64; w < 64; ++w) { + SCOPED_TRACE(w); + EXPECT_EQ(Pad(s, w, '#'), Pad(sp, w, '#')); + } +} + +TEST_F(StringViewStreamTest, ResetsWidth) { + // Width should reset after one formatted write. + // If we weren't resetting width after formatting the string_view, + // we'd have width=5 carrying over to the printing of the "]", + // creating "[###hi####]". + std::string s = "hi"; + absl::string_view sp = s; + { + std::ostringstream oss; + oss << "[" << std::setfill('#') << std::setw(5) << s << "]"; + ASSERT_EQ("[###hi]", oss.str()); + } + { + std::ostringstream oss; + oss << "[" << std::setfill('#') << std::setw(5) << sp << "]"; + EXPECT_EQ("[###hi]", oss.str()); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/strip.h b/third_party/abseil_cpp/absl/strings/strip.h new file mode 100644 index 0000000000..111872ca54 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/strip.h @@ -0,0 +1,91 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: strip.h +// ----------------------------------------------------------------------------- +// +// This file contains various functions for stripping substrings from a string. +#ifndef ABSL_STRINGS_STRIP_H_ +#define ABSL_STRINGS_STRIP_H_ + +#include <cstddef> +#include <string> + +#include "absl/base/macros.h" +#include "absl/strings/ascii.h" +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ConsumePrefix() +// +// Strips the `expected` prefix from the start of the given string, returning +// `true` if the strip operation succeeded or false otherwise. +// +// Example: +// +// absl::string_view input("abc"); +// EXPECT_TRUE(absl::ConsumePrefix(&input, "a")); +// EXPECT_EQ(input, "bc"); +inline bool ConsumePrefix(absl::string_view* str, absl::string_view expected) { + if (!absl::StartsWith(*str, expected)) return false; + str->remove_prefix(expected.size()); + return true; +} +// ConsumeSuffix() +// +// Strips the `expected` suffix from the end of the given string, returning +// `true` if the strip operation succeeded or false otherwise. +// +// Example: +// +// absl::string_view input("abcdef"); +// EXPECT_TRUE(absl::ConsumeSuffix(&input, "def")); +// EXPECT_EQ(input, "abc"); +inline bool ConsumeSuffix(absl::string_view* str, absl::string_view expected) { + if (!absl::EndsWith(*str, expected)) return false; + str->remove_suffix(expected.size()); + return true; +} + +// StripPrefix() +// +// Returns a view into the input string 'str' with the given 'prefix' removed, +// but leaving the original string intact. If the prefix does not match at the +// start of the string, returns the original string instead. +ABSL_MUST_USE_RESULT inline absl::string_view StripPrefix( + absl::string_view str, absl::string_view prefix) { + if (absl::StartsWith(str, prefix)) str.remove_prefix(prefix.size()); + return str; +} + +// StripSuffix() +// +// Returns a view into the input string 'str' with the given 'suffix' removed, +// but leaving the original string intact. If the suffix does not match at the +// end of the string, returns the original string instead. +ABSL_MUST_USE_RESULT inline absl::string_view StripSuffix( + absl::string_view str, absl::string_view suffix) { + if (absl::EndsWith(str, suffix)) str.remove_suffix(suffix.size()); + return str; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_STRIP_H_ diff --git a/third_party/abseil_cpp/absl/strings/strip_test.cc b/third_party/abseil_cpp/absl/strings/strip_test.cc new file mode 100644 index 0000000000..e4e00cb66e --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/strip_test.cc @@ -0,0 +1,198 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file contains functions that remove a defined part from the string, +// i.e., strip the string. + +#include "absl/strings/strip.h" + +#include <cassert> +#include <cstdio> +#include <cstring> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/strings/string_view.h" + +namespace { + +TEST(Strip, ConsumePrefixOneChar) { + absl::string_view input("abc"); + EXPECT_TRUE(absl::ConsumePrefix(&input, "a")); + EXPECT_EQ(input, "bc"); + + EXPECT_FALSE(absl::ConsumePrefix(&input, "x")); + EXPECT_EQ(input, "bc"); + + EXPECT_TRUE(absl::ConsumePrefix(&input, "b")); + EXPECT_EQ(input, "c"); + + EXPECT_TRUE(absl::ConsumePrefix(&input, "c")); + EXPECT_EQ(input, ""); + + EXPECT_FALSE(absl::ConsumePrefix(&input, "a")); + EXPECT_EQ(input, ""); +} + +TEST(Strip, ConsumePrefix) { + absl::string_view input("abcdef"); + EXPECT_FALSE(absl::ConsumePrefix(&input, "abcdefg")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_FALSE(absl::ConsumePrefix(&input, "abce")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_TRUE(absl::ConsumePrefix(&input, "")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_FALSE(absl::ConsumePrefix(&input, "abcdeg")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_TRUE(absl::ConsumePrefix(&input, "abcdef")); + EXPECT_EQ(input, ""); + + input = "abcdef"; + EXPECT_TRUE(absl::ConsumePrefix(&input, "abcde")); + EXPECT_EQ(input, "f"); +} + +TEST(Strip, ConsumeSuffix) { + absl::string_view input("abcdef"); + EXPECT_FALSE(absl::ConsumeSuffix(&input, "abcdefg")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_TRUE(absl::ConsumeSuffix(&input, "")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_TRUE(absl::ConsumeSuffix(&input, "def")); + EXPECT_EQ(input, "abc"); + + input = "abcdef"; + EXPECT_FALSE(absl::ConsumeSuffix(&input, "abcdeg")); + EXPECT_EQ(input, "abcdef"); + + EXPECT_TRUE(absl::ConsumeSuffix(&input, "f")); + EXPECT_EQ(input, "abcde"); + + EXPECT_TRUE(absl::ConsumeSuffix(&input, "abcde")); + EXPECT_EQ(input, ""); +} + +TEST(Strip, StripPrefix) { + const absl::string_view null_str; + + EXPECT_EQ(absl::StripPrefix("foobar", "foo"), "bar"); + EXPECT_EQ(absl::StripPrefix("foobar", ""), "foobar"); + EXPECT_EQ(absl::StripPrefix("foobar", null_str), "foobar"); + EXPECT_EQ(absl::StripPrefix("foobar", "foobar"), ""); + EXPECT_EQ(absl::StripPrefix("foobar", "bar"), "foobar"); + EXPECT_EQ(absl::StripPrefix("foobar", "foobarr"), "foobar"); + EXPECT_EQ(absl::StripPrefix("", ""), ""); +} + +TEST(Strip, StripSuffix) { + const absl::string_view null_str; + + EXPECT_EQ(absl::StripSuffix("foobar", "bar"), "foo"); + EXPECT_EQ(absl::StripSuffix("foobar", ""), "foobar"); + EXPECT_EQ(absl::StripSuffix("foobar", null_str), "foobar"); + EXPECT_EQ(absl::StripSuffix("foobar", "foobar"), ""); + EXPECT_EQ(absl::StripSuffix("foobar", "foo"), "foobar"); + EXPECT_EQ(absl::StripSuffix("foobar", "ffoobar"), "foobar"); + EXPECT_EQ(absl::StripSuffix("", ""), ""); +} + +TEST(Strip, RemoveExtraAsciiWhitespace) { + const char* inputs[] = { + "No extra space", + " Leading whitespace", + "Trailing whitespace ", + " Leading and trailing ", + " Whitespace \t in\v middle ", + "'Eeeeep! \n Newlines!\n", + "nospaces", + }; + const char* outputs[] = { + "No extra space", + "Leading whitespace", + "Trailing whitespace", + "Leading and trailing", + "Whitespace in middle", + "'Eeeeep! Newlines!", + "nospaces", + }; + int NUM_TESTS = 7; + + for (int i = 0; i < NUM_TESTS; i++) { + std::string s(inputs[i]); + absl::RemoveExtraAsciiWhitespace(&s); + EXPECT_STREQ(outputs[i], s.c_str()); + } + + // Test that absl::RemoveExtraAsciiWhitespace returns immediately for empty + // strings (It was adding the \0 character to the C++ std::string, which broke + // tests involving empty()) + std::string zero_string = ""; + assert(zero_string.empty()); + absl::RemoveExtraAsciiWhitespace(&zero_string); + EXPECT_EQ(zero_string.size(), 0); + EXPECT_TRUE(zero_string.empty()); +} + +TEST(Strip, StripTrailingAsciiWhitespace) { + std::string test = "foo "; + absl::StripTrailingAsciiWhitespace(&test); + EXPECT_EQ(test, "foo"); + + test = " "; + absl::StripTrailingAsciiWhitespace(&test); + EXPECT_EQ(test, ""); + + test = ""; + absl::StripTrailingAsciiWhitespace(&test); + EXPECT_EQ(test, ""); + + test = " abc\t"; + absl::StripTrailingAsciiWhitespace(&test); + EXPECT_EQ(test, " abc"); +} + +TEST(String, StripLeadingAsciiWhitespace) { + absl::string_view orig = "\t \n\f\r\n\vfoo"; + EXPECT_EQ("foo", absl::StripLeadingAsciiWhitespace(orig)); + orig = "\t \n\f\r\v\n\t \n\f\r\v\n"; + EXPECT_EQ(absl::string_view(), absl::StripLeadingAsciiWhitespace(orig)); +} + +TEST(Strip, StripAsciiWhitespace) { + std::string test2 = "\t \f\r\n\vfoo \t\f\r\v\n"; + absl::StripAsciiWhitespace(&test2); + EXPECT_EQ(test2, "foo"); + std::string test3 = "bar"; + absl::StripAsciiWhitespace(&test3); + EXPECT_EQ(test3, "bar"); + std::string test4 = "\t \f\r\n\vfoo"; + absl::StripAsciiWhitespace(&test4); + EXPECT_EQ(test4, "foo"); + std::string test5 = "foo \t\f\r\v\n"; + absl::StripAsciiWhitespace(&test5); + EXPECT_EQ(test5, "foo"); + absl::string_view test6("\t \f\r\n\vfoo \t\f\r\v\n"); + test6 = absl::StripAsciiWhitespace(test6); + EXPECT_EQ(test6, "foo"); + test6 = absl::StripAsciiWhitespace(test6); + EXPECT_EQ(test6, "foo"); // already stripped +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/strings/substitute.cc b/third_party/abseil_cpp/absl/strings/substitute.cc new file mode 100644 index 0000000000..1f3c7409ab --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/substitute.cc @@ -0,0 +1,171 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/substitute.h" + +#include <algorithm> + +#include "absl/base/internal/raw_logging.h" +#include "absl/strings/ascii.h" +#include "absl/strings/escaping.h" +#include "absl/strings/internal/resize_uninitialized.h" +#include "absl/strings/string_view.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace substitute_internal { + +void SubstituteAndAppendArray(std::string* output, absl::string_view format, + const absl::string_view* args_array, + size_t num_args) { + // Determine total size needed. + size_t size = 0; + for (size_t i = 0; i < format.size(); i++) { + if (format[i] == '$') { + if (i + 1 >= format.size()) { +#ifndef NDEBUG + ABSL_RAW_LOG(FATAL, + "Invalid absl::Substitute() format string: \"%s\".", + absl::CEscape(format).c_str()); +#endif + return; + } else if (absl::ascii_isdigit(format[i + 1])) { + int index = format[i + 1] - '0'; + if (static_cast<size_t>(index) >= num_args) { +#ifndef NDEBUG + ABSL_RAW_LOG( + FATAL, + "Invalid absl::Substitute() format string: asked for \"$" + "%d\", but only %d args were given. Full format string was: " + "\"%s\".", + index, static_cast<int>(num_args), absl::CEscape(format).c_str()); +#endif + return; + } + size += args_array[index].size(); + ++i; // Skip next char. + } else if (format[i + 1] == '$') { + ++size; + ++i; // Skip next char. + } else { +#ifndef NDEBUG + ABSL_RAW_LOG(FATAL, + "Invalid absl::Substitute() format string: \"%s\".", + absl::CEscape(format).c_str()); +#endif + return; + } + } else { + ++size; + } + } + + if (size == 0) return; + + // Build the string. + size_t original_size = output->size(); + strings_internal::STLStringResizeUninitialized(output, original_size + size); + char* target = &(*output)[original_size]; + for (size_t i = 0; i < format.size(); i++) { + if (format[i] == '$') { + if (absl::ascii_isdigit(format[i + 1])) { + const absl::string_view src = args_array[format[i + 1] - '0']; + target = std::copy(src.begin(), src.end(), target); + ++i; // Skip next char. + } else if (format[i + 1] == '$') { + *target++ = '$'; + ++i; // Skip next char. + } + } else { + *target++ = format[i]; + } + } + + assert(target == output->data() + output->size()); +} + +Arg::Arg(const void* value) { + static_assert(sizeof(scratch_) >= sizeof(value) * 2 + 2, + "fix sizeof(scratch_)"); + if (value == nullptr) { + piece_ = "NULL"; + } else { + char* ptr = scratch_ + sizeof(scratch_); + uintptr_t num = reinterpret_cast<uintptr_t>(value); + do { + *--ptr = absl::numbers_internal::kHexChar[num & 0xf]; + num >>= 4; + } while (num != 0); + *--ptr = 'x'; + *--ptr = '0'; + piece_ = absl::string_view(ptr, scratch_ + sizeof(scratch_) - ptr); + } +} + +// TODO(jorg): Don't duplicate so much code between here and str_cat.cc +Arg::Arg(Hex hex) { + char* const end = &scratch_[numbers_internal::kFastToBufferSize]; + char* writer = end; + uint64_t value = hex.value; + do { + *--writer = absl::numbers_internal::kHexChar[value & 0xF]; + value >>= 4; + } while (value != 0); + + char* beg; + if (end - writer < hex.width) { + beg = end - hex.width; + std::fill_n(beg, writer - beg, hex.fill); + } else { + beg = writer; + } + + piece_ = absl::string_view(beg, end - beg); +} + +// TODO(jorg): Don't duplicate so much code between here and str_cat.cc +Arg::Arg(Dec dec) { + assert(dec.width <= numbers_internal::kFastToBufferSize); + char* const end = &scratch_[numbers_internal::kFastToBufferSize]; + char* const minfill = end - dec.width; + char* writer = end; + uint64_t value = dec.value; + bool neg = dec.neg; + while (value > 9) { + *--writer = '0' + (value % 10); + value /= 10; + } + *--writer = '0' + value; + if (neg) *--writer = '-'; + + ptrdiff_t fillers = writer - minfill; + if (fillers > 0) { + // Tricky: if the fill character is ' ', then it's <fill><+/-><digits> + // But...: if the fill character is '0', then it's <+/-><fill><digits> + bool add_sign_again = false; + if (neg && dec.fill == '0') { // If filling with '0', + ++writer; // ignore the sign we just added + add_sign_again = true; // and re-add the sign later. + } + writer -= fillers; + std::fill_n(writer, fillers, dec.fill); + if (add_sign_again) *--writer = '-'; + } + + piece_ = absl::string_view(writer, end - writer); +} + +} // namespace substitute_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/strings/substitute.h b/third_party/abseil_cpp/absl/strings/substitute.h new file mode 100644 index 0000000000..c6da4dc6e7 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/substitute.h @@ -0,0 +1,696 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: substitute.h +// ----------------------------------------------------------------------------- +// +// This package contains functions for efficiently performing string +// substitutions using a format string with positional notation: +// `Substitute()` and `SubstituteAndAppend()`. +// +// Unlike printf-style format specifiers, `Substitute()` functions do not need +// to specify the type of the substitution arguments. Supported arguments +// following the format string, such as strings, string_views, ints, +// floats, and bools, are automatically converted to strings during the +// substitution process. (See below for a full list of supported types.) +// +// `Substitute()` does not allow you to specify *how* to format a value, beyond +// the default conversion to string. For example, you cannot format an integer +// in hex. +// +// The format string uses positional identifiers indicated by a dollar sign ($) +// and single digit positional ids to indicate which substitution arguments to +// use at that location within the format string. +// +// A '$$' sequence in the format string causes a literal '$' character to be +// output. +// +// Example 1: +// std::string s = Substitute("$1 purchased $0 $2 for $$10. Thanks $1!", +// 5, "Bob", "Apples"); +// EXPECT_EQ("Bob purchased 5 Apples for $10. Thanks Bob!", s); +// +// Example 2: +// std::string s = "Hi. "; +// SubstituteAndAppend(&s, "My name is $0 and I am $1 years old.", "Bob", 5); +// EXPECT_EQ("Hi. My name is Bob and I am 5 years old.", s); +// +// Supported types: +// * absl::string_view, std::string, const char* (null is equivalent to "") +// * int32_t, int64_t, uint32_t, uint64_t +// * float, double +// * bool (Printed as "true" or "false") +// * pointer types other than char* (Printed as "0x<lower case hex string>", +// except that null is printed as "NULL") +// +// If an invalid format string is provided, Substitute returns an empty string +// and SubstituteAndAppend does not change the provided output string. +// A format string is invalid if it: +// * ends in an unescaped $ character, +// e.g. "Hello $", or +// * calls for a position argument which is not provided, +// e.g. Substitute("Hello $2", "world"), or +// * specifies a non-digit, non-$ character after an unescaped $ character, +// e.g. "Hello $f". +// In debug mode, i.e. #ifndef NDEBUG, such errors terminate the program. + +#ifndef ABSL_STRINGS_SUBSTITUTE_H_ +#define ABSL_STRINGS_SUBSTITUTE_H_ + +#include <cstring> +#include <string> +#include <type_traits> +#include <vector> + +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/strings/ascii.h" +#include "absl/strings/escaping.h" +#include "absl/strings/numbers.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/str_split.h" +#include "absl/strings/string_view.h" +#include "absl/strings/strip.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace substitute_internal { + +// Arg +// +// This class provides an argument type for `absl::Substitute()` and +// `absl::SubstituteAndAppend()`. `Arg` handles implicit conversion of various +// types to a string. (`Arg` is very similar to the `AlphaNum` class in +// `StrCat()`.) +// +// This class has implicit constructors. +class Arg { + public: + // Overloads for string-y things + // + // Explicitly overload `const char*` so the compiler doesn't cast to `bool`. + Arg(const char* value) // NOLINT(runtime/explicit) + : piece_(absl::NullSafeStringView(value)) {} + template <typename Allocator> + Arg( // NOLINT + const std::basic_string<char, std::char_traits<char>, Allocator>& + value) noexcept + : piece_(value) {} + Arg(absl::string_view value) // NOLINT(runtime/explicit) + : piece_(value) {} + + // Overloads for primitives + // + // No overloads are available for signed and unsigned char because if people + // are explicitly declaring their chars as signed or unsigned then they are + // probably using them as 8-bit integers and would probably prefer an integer + // representation. However, we can't really know, so we make the caller decide + // what to do. + Arg(char value) // NOLINT(runtime/explicit) + : piece_(scratch_, 1) { + scratch_[0] = value; + } + Arg(short value) // NOLINT(*) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(unsigned short value) // NOLINT(*) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(int value) // NOLINT(runtime/explicit) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(unsigned int value) // NOLINT(runtime/explicit) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(long value) // NOLINT(*) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(unsigned long value) // NOLINT(*) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(long long value) // NOLINT(*) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(unsigned long long value) // NOLINT(*) + : piece_(scratch_, + numbers_internal::FastIntToBuffer(value, scratch_) - scratch_) {} + Arg(float value) // NOLINT(runtime/explicit) + : piece_(scratch_, numbers_internal::SixDigitsToBuffer(value, scratch_)) { + } + Arg(double value) // NOLINT(runtime/explicit) + : piece_(scratch_, numbers_internal::SixDigitsToBuffer(value, scratch_)) { + } + Arg(bool value) // NOLINT(runtime/explicit) + : piece_(value ? "true" : "false") {} + + Arg(Hex hex); // NOLINT(runtime/explicit) + Arg(Dec dec); // NOLINT(runtime/explicit) + + // vector<bool>::reference and const_reference require special help to + // convert to `AlphaNum` because it requires two user defined conversions. + template <typename T, + absl::enable_if_t< + std::is_class<T>::value && + (std::is_same<T, std::vector<bool>::reference>::value || + std::is_same<T, std::vector<bool>::const_reference>::value)>* = + nullptr> + Arg(T value) // NOLINT(google-explicit-constructor) + : Arg(static_cast<bool>(value)) {} + + // `void*` values, with the exception of `char*`, are printed as + // "0x<hex value>". However, in the case of `nullptr`, "NULL" is printed. + Arg(const void* value); // NOLINT(runtime/explicit) + + Arg(const Arg&) = delete; + Arg& operator=(const Arg&) = delete; + + absl::string_view piece() const { return piece_; } + + private: + absl::string_view piece_; + char scratch_[numbers_internal::kFastToBufferSize]; +}; + +// Internal helper function. Don't call this from outside this implementation. +// This interface may change without notice. +void SubstituteAndAppendArray(std::string* output, absl::string_view format, + const absl::string_view* args_array, + size_t num_args); + +#if defined(ABSL_BAD_CALL_IF) +constexpr int CalculateOneBit(const char* format) { + // Returns: + // * 2^N for '$N' when N is in [0-9] + // * 0 for correct '$' escaping: '$$'. + // * -1 otherwise. + return (*format < '0' || *format > '9') ? (*format == '$' ? 0 : -1) + : (1 << (*format - '0')); +} + +constexpr const char* SkipNumber(const char* format) { + return !*format ? format : (format + 1); +} + +constexpr int PlaceholderBitmask(const char* format) { + return !*format + ? 0 + : *format != '$' ? PlaceholderBitmask(format + 1) + : (CalculateOneBit(format + 1) | + PlaceholderBitmask(SkipNumber(format + 1))); +} +#endif // ABSL_BAD_CALL_IF + +} // namespace substitute_internal + +// +// PUBLIC API +// + +// SubstituteAndAppend() +// +// Substitutes variables into a given format string and appends to a given +// output string. See file comments above for usage. +// +// The declarations of `SubstituteAndAppend()` below consist of overloads +// for passing 0 to 10 arguments, respectively. +// +// NOTE: A zero-argument `SubstituteAndAppend()` may be used within variadic +// templates to allow a variable number of arguments. +// +// Example: +// template <typename... Args> +// void VarMsg(std::string* boilerplate, absl::string_view format, +// const Args&... args) { +// absl::SubstituteAndAppend(boilerplate, format, args...); +// } +// +inline void SubstituteAndAppend(std::string* output, absl::string_view format) { + substitute_internal::SubstituteAndAppendArray(output, format, nullptr, 0); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0) { + const absl::string_view args[] = {a0.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1) { + const absl::string_view args[] = {a0.piece(), a1.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece(), + a3.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece(), + a3.piece(), a4.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece(), + a3.piece(), a4.piece(), a5.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend(std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, + const substitute_internal::Arg& a6) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece(), + a3.piece(), a4.piece(), a5.piece(), + a6.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend( + std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, const substitute_internal::Arg& a5, + const substitute_internal::Arg& a6, const substitute_internal::Arg& a7) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece(), + a3.piece(), a4.piece(), a5.piece(), + a6.piece(), a7.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend( + std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, const substitute_internal::Arg& a5, + const substitute_internal::Arg& a6, const substitute_internal::Arg& a7, + const substitute_internal::Arg& a8) { + const absl::string_view args[] = {a0.piece(), a1.piece(), a2.piece(), + a3.piece(), a4.piece(), a5.piece(), + a6.piece(), a7.piece(), a8.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +inline void SubstituteAndAppend( + std::string* output, absl::string_view format, + const substitute_internal::Arg& a0, const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, const substitute_internal::Arg& a5, + const substitute_internal::Arg& a6, const substitute_internal::Arg& a7, + const substitute_internal::Arg& a8, const substitute_internal::Arg& a9) { + const absl::string_view args[] = { + a0.piece(), a1.piece(), a2.piece(), a3.piece(), a4.piece(), + a5.piece(), a6.piece(), a7.piece(), a8.piece(), a9.piece()}; + substitute_internal::SubstituteAndAppendArray(output, format, args, + ABSL_ARRAYSIZE(args)); +} + +#if defined(ABSL_BAD_CALL_IF) +// This body of functions catches cases where the number of placeholders +// doesn't match the number of data arguments. +void SubstituteAndAppend(std::string* output, const char* format) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 0, + "There were no substitution arguments " + "but this format string has a $[0-9] in it"); + +void SubstituteAndAppend(std::string* output, const char* format, + const substitute_internal::Arg& a0) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 1, + "There was 1 substitution argument given, but " + "this format string is either missing its $0, or " + "contains one of $1-$9"); + +void SubstituteAndAppend(std::string* output, const char* format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 3, + "There were 2 substitution arguments given, but " + "this format string is either missing its $0/$1, or " + "contains one of $2-$9"); + +void SubstituteAndAppend(std::string* output, const char* format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 7, + "There were 3 substitution arguments given, but " + "this format string is either missing its $0/$1/$2, or " + "contains one of $3-$9"); + +void SubstituteAndAppend(std::string* output, const char* format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 15, + "There were 4 substitution arguments given, but " + "this format string is either missing its $0-$3, or " + "contains one of $4-$9"); + +void SubstituteAndAppend(std::string* output, const char* format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 31, + "There were 5 substitution arguments given, but " + "this format string is either missing its $0-$4, or " + "contains one of $5-$9"); + +void SubstituteAndAppend(std::string* output, const char* format, + const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 63, + "There were 6 substitution arguments given, but " + "this format string is either missing its $0-$5, or " + "contains one of $6-$9"); + +void SubstituteAndAppend( + std::string* output, const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 127, + "There were 7 substitution arguments given, but " + "this format string is either missing its $0-$6, or " + "contains one of $7-$9"); + +void SubstituteAndAppend( + std::string* output, const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 255, + "There were 8 substitution arguments given, but " + "this format string is either missing its $0-$7, or " + "contains one of $8-$9"); + +void SubstituteAndAppend( + std::string* output, const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7, const substitute_internal::Arg& a8) + ABSL_BAD_CALL_IF( + substitute_internal::PlaceholderBitmask(format) != 511, + "There were 9 substitution arguments given, but " + "this format string is either missing its $0-$8, or contains a $9"); + +void SubstituteAndAppend( + std::string* output, const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7, const substitute_internal::Arg& a8, + const substitute_internal::Arg& a9) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 1023, + "There were 10 substitution arguments given, but this " + "format string doesn't contain all of $0 through $9"); +#endif // ABSL_BAD_CALL_IF + +// Substitute() +// +// Substitutes variables into a given format string. See file comments above +// for usage. +// +// The declarations of `Substitute()` below consist of overloads for passing 0 +// to 10 arguments, respectively. +// +// NOTE: A zero-argument `Substitute()` may be used within variadic templates to +// allow a variable number of arguments. +// +// Example: +// template <typename... Args> +// void VarMsg(absl::string_view format, const Args&... args) { +// std::string s = absl::Substitute(format, args...); + +ABSL_MUST_USE_RESULT inline std::string Substitute(absl::string_view format) { + std::string result; + SubstituteAndAppend(&result, format); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0) { + std::string result; + SubstituteAndAppend(&result, format, a0); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3, a4); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3, a4, a5); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3, a4, a5, a6); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3, a4, a5, a6, a7); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7, const substitute_internal::Arg& a8) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3, a4, a5, a6, a7, a8); + return result; +} + +ABSL_MUST_USE_RESULT inline std::string Substitute( + absl::string_view format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7, const substitute_internal::Arg& a8, + const substitute_internal::Arg& a9) { + std::string result; + SubstituteAndAppend(&result, format, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9); + return result; +} + +#if defined(ABSL_BAD_CALL_IF) +// This body of functions catches cases where the number of placeholders +// doesn't match the number of data arguments. +std::string Substitute(const char* format) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 0, + "There were no substitution arguments " + "but this format string has a $[0-9] in it"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 1, + "There was 1 substitution argument given, but " + "this format string is either missing its $0, or " + "contains one of $1-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 3, + "There were 2 substitution arguments given, but " + "this format string is either missing its $0/$1, or " + "contains one of $2-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 7, + "There were 3 substitution arguments given, but " + "this format string is either missing its $0/$1/$2, or " + "contains one of $3-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 15, + "There were 4 substitution arguments given, but " + "this format string is either missing its $0-$3, or " + "contains one of $4-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 31, + "There were 5 substitution arguments given, but " + "this format string is either missing its $0-$4, or " + "contains one of $5-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 63, + "There were 6 substitution arguments given, but " + "this format string is either missing its $0-$5, or " + "contains one of $6-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, + const substitute_internal::Arg& a6) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 127, + "There were 7 substitution arguments given, but " + "this format string is either missing its $0-$6, or " + "contains one of $7-$9"); + +std::string Substitute(const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, + const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, + const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, + const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 255, + "There were 8 substitution arguments given, but " + "this format string is either missing its $0-$7, or " + "contains one of $8-$9"); + +std::string Substitute( + const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7, const substitute_internal::Arg& a8) + ABSL_BAD_CALL_IF( + substitute_internal::PlaceholderBitmask(format) != 511, + "There were 9 substitution arguments given, but " + "this format string is either missing its $0-$8, or contains a $9"); + +std::string Substitute( + const char* format, const substitute_internal::Arg& a0, + const substitute_internal::Arg& a1, const substitute_internal::Arg& a2, + const substitute_internal::Arg& a3, const substitute_internal::Arg& a4, + const substitute_internal::Arg& a5, const substitute_internal::Arg& a6, + const substitute_internal::Arg& a7, const substitute_internal::Arg& a8, + const substitute_internal::Arg& a9) + ABSL_BAD_CALL_IF(substitute_internal::PlaceholderBitmask(format) != 1023, + "There were 10 substitution arguments given, but this " + "format string doesn't contain all of $0 through $9"); +#endif // ABSL_BAD_CALL_IF + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_STRINGS_SUBSTITUTE_H_ diff --git a/third_party/abseil_cpp/absl/strings/substitute_test.cc b/third_party/abseil_cpp/absl/strings/substitute_test.cc new file mode 100644 index 0000000000..442c921528 --- /dev/null +++ b/third_party/abseil_cpp/absl/strings/substitute_test.cc @@ -0,0 +1,204 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/strings/substitute.h" + +#include <cstdint> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/strings/str_cat.h" + +namespace { + +TEST(SubstituteTest, Substitute) { + // Basic. + EXPECT_EQ("Hello, world!", absl::Substitute("$0, $1!", "Hello", "world")); + + // Non-char* types. + EXPECT_EQ("123 0.2 0.1 foo true false x", + absl::Substitute("$0 $1 $2 $3 $4 $5 $6", 123, 0.2, 0.1f, + std::string("foo"), true, false, 'x')); + + // All int types. + EXPECT_EQ( + "-32767 65535 " + "-1234567890 3234567890 " + "-1234567890 3234567890 " + "-1234567890123456789 9234567890123456789", + absl::Substitute( + "$0 $1 $2 $3 $4 $5 $6 $7", + static_cast<short>(-32767), // NOLINT(runtime/int) + static_cast<unsigned short>(65535), // NOLINT(runtime/int) + -1234567890, 3234567890U, -1234567890L, 3234567890UL, + -int64_t{1234567890123456789}, uint64_t{9234567890123456789u})); + + // Hex format + EXPECT_EQ("0 1 f ffff0ffff 0123456789abcdef", + absl::Substitute("$0$1$2$3$4 $5", // + absl::Hex(0), absl::Hex(1, absl::kSpacePad2), + absl::Hex(0xf, absl::kSpacePad2), + absl::Hex(int16_t{-1}, absl::kSpacePad5), + absl::Hex(int16_t{-1}, absl::kZeroPad5), + absl::Hex(0x123456789abcdef, absl::kZeroPad16))); + + // Dec format + EXPECT_EQ("0 115 -1-0001 81985529216486895", + absl::Substitute("$0$1$2$3$4 $5", // + absl::Dec(0), absl::Dec(1, absl::kSpacePad2), + absl::Dec(0xf, absl::kSpacePad2), + absl::Dec(int16_t{-1}, absl::kSpacePad5), + absl::Dec(int16_t{-1}, absl::kZeroPad5), + absl::Dec(0x123456789abcdef, absl::kZeroPad16))); + + // Pointer. + const int* int_p = reinterpret_cast<const int*>(0x12345); + std::string str = absl::Substitute("$0", int_p); + EXPECT_EQ(absl::StrCat("0x", absl::Hex(int_p)), str); + + // Volatile Pointer. + // Like C++ streamed I/O, such pointers implicitly become bool + volatile int vol = 237; + volatile int *volatile volptr = &vol; + str = absl::Substitute("$0", volptr); + EXPECT_EQ("true", str); + + // null is special. StrCat prints 0x0. Substitute prints NULL. + const uint64_t* null_p = nullptr; + str = absl::Substitute("$0", null_p); + EXPECT_EQ("NULL", str); + + // char* is also special. + const char* char_p = "print me"; + str = absl::Substitute("$0", char_p); + EXPECT_EQ("print me", str); + + char char_buf[16]; + strncpy(char_buf, "print me too", sizeof(char_buf)); + str = absl::Substitute("$0", char_buf); + EXPECT_EQ("print me too", str); + + // null char* is "doubly" special. Represented as the empty string. + char_p = nullptr; + str = absl::Substitute("$0", char_p); + EXPECT_EQ("", str); + + // Out-of-order. + EXPECT_EQ("b, a, c, b", absl::Substitute("$1, $0, $2, $1", "a", "b", "c")); + + // Literal $ + EXPECT_EQ("$", absl::Substitute("$$")); + + EXPECT_EQ("$1", absl::Substitute("$$1")); + + // Test all overloads. + EXPECT_EQ("a", absl::Substitute("$0", "a")); + EXPECT_EQ("a b", absl::Substitute("$0 $1", "a", "b")); + EXPECT_EQ("a b c", absl::Substitute("$0 $1 $2", "a", "b", "c")); + EXPECT_EQ("a b c d", absl::Substitute("$0 $1 $2 $3", "a", "b", "c", "d")); + EXPECT_EQ("a b c d e", + absl::Substitute("$0 $1 $2 $3 $4", "a", "b", "c", "d", "e")); + EXPECT_EQ("a b c d e f", absl::Substitute("$0 $1 $2 $3 $4 $5", "a", "b", "c", + "d", "e", "f")); + EXPECT_EQ("a b c d e f g", absl::Substitute("$0 $1 $2 $3 $4 $5 $6", "a", "b", + "c", "d", "e", "f", "g")); + EXPECT_EQ("a b c d e f g h", + absl::Substitute("$0 $1 $2 $3 $4 $5 $6 $7", "a", "b", "c", "d", "e", + "f", "g", "h")); + EXPECT_EQ("a b c d e f g h i", + absl::Substitute("$0 $1 $2 $3 $4 $5 $6 $7 $8", "a", "b", "c", "d", + "e", "f", "g", "h", "i")); + EXPECT_EQ("a b c d e f g h i j", + absl::Substitute("$0 $1 $2 $3 $4 $5 $6 $7 $8 $9", "a", "b", "c", + "d", "e", "f", "g", "h", "i", "j")); + EXPECT_EQ("a b c d e f g h i j b0", + absl::Substitute("$0 $1 $2 $3 $4 $5 $6 $7 $8 $9 $10", "a", "b", "c", + "d", "e", "f", "g", "h", "i", "j")); + + const char* null_cstring = nullptr; + EXPECT_EQ("Text: ''", absl::Substitute("Text: '$0'", null_cstring)); +} + +TEST(SubstituteTest, SubstituteAndAppend) { + std::string str = "Hello"; + absl::SubstituteAndAppend(&str, ", $0!", "world"); + EXPECT_EQ("Hello, world!", str); + + // Test all overloads. + str.clear(); + absl::SubstituteAndAppend(&str, "$0", "a"); + EXPECT_EQ("a", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1", "a", "b"); + EXPECT_EQ("a b", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2", "a", "b", "c"); + EXPECT_EQ("a b c", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3", "a", "b", "c", "d"); + EXPECT_EQ("a b c d", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3 $4", "a", "b", "c", "d", "e"); + EXPECT_EQ("a b c d e", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3 $4 $5", "a", "b", "c", "d", "e", + "f"); + EXPECT_EQ("a b c d e f", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3 $4 $5 $6", "a", "b", "c", "d", + "e", "f", "g"); + EXPECT_EQ("a b c d e f g", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3 $4 $5 $6 $7", "a", "b", "c", "d", + "e", "f", "g", "h"); + EXPECT_EQ("a b c d e f g h", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3 $4 $5 $6 $7 $8", "a", "b", "c", + "d", "e", "f", "g", "h", "i"); + EXPECT_EQ("a b c d e f g h i", str); + str.clear(); + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3 $4 $5 $6 $7 $8 $9", "a", "b", + "c", "d", "e", "f", "g", "h", "i", "j"); + EXPECT_EQ("a b c d e f g h i j", str); +} + +TEST(SubstituteTest, VectorBoolRef) { + std::vector<bool> v = {true, false}; + const auto& cv = v; + EXPECT_EQ("true false true false", + absl::Substitute("$0 $1 $2 $3", v[0], v[1], cv[0], cv[1])); + + std::string str = "Logic be like: "; + absl::SubstituteAndAppend(&str, "$0 $1 $2 $3", v[0], v[1], cv[0], cv[1]); + EXPECT_EQ("Logic be like: true false true false", str); +} + +#ifdef GTEST_HAS_DEATH_TEST + +TEST(SubstituteDeathTest, SubstituteDeath) { + EXPECT_DEBUG_DEATH( + static_cast<void>(absl::Substitute(absl::string_view("-$2"), "a", "b")), + "Invalid absl::Substitute\\(\\) format string: asked for \"\\$2\", " + "but only 2 args were given."); + EXPECT_DEBUG_DEATH( + static_cast<void>(absl::Substitute(absl::string_view("-$z-"))), + "Invalid absl::Substitute\\(\\) format string: \"-\\$z-\""); + EXPECT_DEBUG_DEATH( + static_cast<void>(absl::Substitute(absl::string_view("-$"))), + "Invalid absl::Substitute\\(\\) format string: \"-\\$\""); +} + +#endif // GTEST_HAS_DEATH_TEST + +} // namespace diff --git a/third_party/abseil_cpp/absl/synchronization/BUILD.bazel b/third_party/abseil_cpp/absl/synchronization/BUILD.bazel new file mode 100644 index 0000000000..3f876b9fdc --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/BUILD.bazel @@ -0,0 +1,285 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +# Internal data structure for efficiently detecting mutex dependency cycles +cc_library( + name = "graphcycles_internal", + srcs = [ + "internal/graphcycles.cc", + ], + hdrs = [ + "internal/graphcycles.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + "//absl/base", + "//absl/base:base_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:malloc_internal", + "//absl/base:raw_logging_internal", + ], +) + +cc_library( + name = "kernel_timeout_internal", + hdrs = ["internal/kernel_timeout.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/synchronization:__pkg__", + ], + deps = [ + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/time", + ], +) + +cc_library( + name = "synchronization", + srcs = [ + "barrier.cc", + "blocking_counter.cc", + "internal/create_thread_identity.cc", + "internal/per_thread_sem.cc", + "internal/waiter.cc", + "notification.cc", + ] + select({ + "//conditions:default": ["mutex.cc"], + }), + hdrs = [ + "barrier.h", + "blocking_counter.h", + "internal/create_thread_identity.h", + "internal/mutex_nonprod.inc", + "internal/per_thread_sem.h", + "internal/waiter.h", + "mutex.h", + "notification.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = select({ + "//absl:windows": [], + "//conditions:default": ["-pthread"], + }) + ABSL_DEFAULT_LINKOPTS, + deps = [ + ":graphcycles_internal", + ":kernel_timeout_internal", + "//absl/base", + "//absl/base:atomic_hook", + "//absl/base:base_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:dynamic_annotations", + "//absl/base:malloc_internal", + "//absl/base:raw_logging_internal", + "//absl/debugging:stacktrace", + "//absl/debugging:symbolize", + "//absl/time", + ], +) + +cc_test( + name = "barrier_test", + size = "small", + srcs = ["barrier_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":synchronization", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "blocking_counter_test", + size = "small", + srcs = ["blocking_counter_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":synchronization", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "graphcycles_test", + size = "medium", + srcs = ["internal/graphcycles_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":graphcycles_internal", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "graphcycles_benchmark", + srcs = ["internal/graphcycles_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = [ + "benchmark", + ], + deps = [ + ":graphcycles_internal", + "//absl/base:raw_logging_internal", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_library( + name = "thread_pool", + testonly = 1, + hdrs = ["internal/thread_pool.h"], + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl:__subpackages__", + ], + deps = [ + ":synchronization", + "//absl/base:core_headers", + ], +) + +cc_test( + name = "mutex_test", + size = "large", + srcs = ["mutex_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + shard_count = 25, + deps = [ + ":synchronization", + ":thread_pool", + "//absl/base", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/memory", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "mutex_benchmark_common", + testonly = 1, + srcs = ["mutex_benchmark.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/synchronization:__pkg__", + ], + deps = [ + ":synchronization", + ":thread_pool", + "//absl/base", + "@com_github_google_benchmark//:benchmark_main", + ], + alwayslink = 1, +) + +cc_binary( + name = "mutex_benchmark", + testonly = 1, + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + ":mutex_benchmark_common", + ], +) + +cc_test( + name = "notification_test", + size = "small", + srcs = ["notification_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":synchronization", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "per_thread_sem_test_common", + testonly = 1, + srcs = ["internal/per_thread_sem_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":synchronization", + "//absl/base", + "//absl/strings", + "//absl/time", + "@com_google_googletest//:gtest", + ], + alwayslink = 1, +) + +cc_test( + name = "per_thread_sem_test", + size = "medium", + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":per_thread_sem_test_common", + ":synchronization", + "//absl/strings", + "//absl/time", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "lifetime_test", + srcs = [ + "lifetime_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["no_test_ios_x86_64"], + deps = [ + ":synchronization", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + ], +) diff --git a/third_party/abseil_cpp/absl/synchronization/CMakeLists.txt b/third_party/abseil_cpp/absl/synchronization/CMakeLists.txt new file mode 100644 index 0000000000..dfe5d05df2 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/CMakeLists.txt @@ -0,0 +1,214 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + graphcycles_internal + HDRS + "internal/graphcycles.h" + SRCS + "internal/graphcycles.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base + absl::base_internal + absl::config + absl::core_headers + absl::malloc_internal + absl::raw_logging_internal +) + +absl_cc_library( + NAME + kernel_timeout_internal + HDRS + "internal/kernel_timeout.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::raw_logging_internal + absl::time +) + +absl_cc_library( + NAME + synchronization + HDRS + "barrier.h" + "blocking_counter.h" + "internal/create_thread_identity.h" + "internal/mutex_nonprod.inc" + "internal/per_thread_sem.h" + "internal/waiter.h" + "mutex.h" + "notification.h" + SRCS + "barrier.cc" + "blocking_counter.cc" + "internal/create_thread_identity.cc" + "internal/per_thread_sem.cc" + "internal/waiter.cc" + "notification.cc" + "mutex.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::graphcycles_internal + absl::kernel_timeout_internal + absl::atomic_hook + absl::base + absl::base_internal + absl::config + absl::core_headers + absl::dynamic_annotations + absl::malloc_internal + absl::raw_logging_internal + absl::stacktrace + absl::symbolize + absl::time + Threads::Threads + PUBLIC +) + +absl_cc_test( + NAME + barrier_test + SRCS + "barrier_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::synchronization + absl::time + gmock_main +) + +absl_cc_test( + NAME + blocking_counter_test + SRCS + "blocking_counter_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::synchronization + absl::time + gmock_main +) + +absl_cc_test( + NAME + graphcycles_test + SRCS + "internal/graphcycles_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::graphcycles_internal + absl::core_headers + absl::raw_logging_internal + gmock_main +) + +absl_cc_library( + NAME + thread_pool + HDRS + "internal/thread_pool.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::synchronization + absl::core_headers + TESTONLY +) + +absl_cc_test( + NAME + mutex_test + SRCS + "mutex_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::synchronization + absl::thread_pool + absl::base + absl::core_headers + absl::memory + absl::raw_logging_internal + absl::time + gmock_main +) + +absl_cc_test( + NAME + notification_test + SRCS + "notification_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::synchronization + absl::time + gmock_main +) + +absl_cc_library( + NAME + per_thread_sem_test_common + SRCS + "internal/per_thread_sem_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::synchronization + absl::base + absl::strings + absl::time + gmock + TESTONLY +) + +absl_cc_test( + NAME + per_thread_sem_test + SRCS + "internal/per_thread_sem_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::per_thread_sem_test_common + absl::synchronization + absl::strings + absl::time + gmock_main +) + +absl_cc_test( + NAME + lifetime_test + SRCS + "lifetime_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::synchronization + absl::core_headers + absl::raw_logging_internal +) diff --git a/third_party/abseil_cpp/absl/synchronization/barrier.cc b/third_party/abseil_cpp/absl/synchronization/barrier.cc new file mode 100644 index 0000000000..0dfd795e7b --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/barrier.cc @@ -0,0 +1,52 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/barrier.h" + +#include "absl/base/internal/raw_logging.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Return whether int *arg is zero. +static bool IsZero(void *arg) { + return 0 == *reinterpret_cast<int *>(arg); +} + +bool Barrier::Block() { + MutexLock l(&this->lock_); + + this->num_to_block_--; + if (this->num_to_block_ < 0) { + ABSL_RAW_LOG( + FATAL, + "Block() called too many times. num_to_block_=%d out of total=%d", + this->num_to_block_, this->num_to_exit_); + } + + this->lock_.Await(Condition(IsZero, &this->num_to_block_)); + + // Determine which thread can safely delete this Barrier object + this->num_to_exit_--; + ABSL_RAW_CHECK(this->num_to_exit_ >= 0, "barrier underflow"); + + // If num_to_exit_ == 0 then all other threads in the barrier have + // exited the Wait() and have released the Mutex so this thread is + // free to delete the barrier. + return this->num_to_exit_ == 0; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/barrier.h b/third_party/abseil_cpp/absl/synchronization/barrier.h new file mode 100644 index 0000000000..d8e754406f --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/barrier.h @@ -0,0 +1,79 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// barrier.h +// ----------------------------------------------------------------------------- + +#ifndef ABSL_SYNCHRONIZATION_BARRIER_H_ +#define ABSL_SYNCHRONIZATION_BARRIER_H_ + +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Barrier +// +// This class creates a barrier which blocks threads until a prespecified +// threshold of threads (`num_threads`) utilizes the barrier. A thread utilizes +// the `Barrier` by calling `Block()` on the barrier, which will block that +// thread; no call to `Block()` will return until `num_threads` threads have +// called it. +// +// Exactly one call to `Block()` will return `true`, which is then responsible +// for destroying the barrier; because stack allocation will cause the barrier +// to be deleted when it is out of scope, barriers should not be stack +// allocated. +// +// Example: +// +// // Main thread creates a `Barrier`: +// barrier = new Barrier(num_threads); +// +// // Each participating thread could then call: +// if (barrier->Block()) delete barrier; // Exactly one call to `Block()` +// // returns `true`; that call +// // deletes the barrier. +class Barrier { + public: + // `num_threads` is the number of threads that will participate in the barrier + explicit Barrier(int num_threads) + : num_to_block_(num_threads), num_to_exit_(num_threads) {} + + Barrier(const Barrier&) = delete; + Barrier& operator=(const Barrier&) = delete; + + // Barrier::Block() + // + // Blocks the current thread, and returns only when the `num_threads` + // threshold of threads utilizing this barrier has been reached. `Block()` + // returns `true` for precisely one caller, which may then destroy the + // barrier. + // + // Memory ordering: For any threads X and Y, any action taken by X + // before X calls `Block()` will be visible to Y after Y returns from + // `Block()`. + bool Block(); + + private: + Mutex lock_; + int num_to_block_ ABSL_GUARDED_BY(lock_); + int num_to_exit_ ABSL_GUARDED_BY(lock_); +}; + +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_SYNCHRONIZATION_BARRIER_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/barrier_test.cc b/third_party/abseil_cpp/absl/synchronization/barrier_test.cc new file mode 100644 index 0000000000..bfc6cb1883 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/barrier_test.cc @@ -0,0 +1,75 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/barrier.h" + +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gtest/gtest.h" +#include "absl/synchronization/mutex.h" +#include "absl/time/clock.h" + + +TEST(Barrier, SanityTest) { + constexpr int kNumThreads = 10; + absl::Barrier* barrier = new absl::Barrier(kNumThreads); + + absl::Mutex mutex; + int counter = 0; // Guarded by mutex. + + auto thread_func = [&] { + if (barrier->Block()) { + // This thread is the last thread to reach the barrier so it is + // responsible for deleting it. + delete barrier; + } + + // Increment the counter. + absl::MutexLock lock(&mutex); + ++counter; + }; + + // Start (kNumThreads - 1) threads running thread_func. + std::vector<std::thread> threads; + for (int i = 0; i < kNumThreads - 1; ++i) { + threads.push_back(std::thread(thread_func)); + } + + // Give (kNumThreads - 1) threads a chance to reach the barrier. + // This test assumes at least one thread will have run after the + // sleep has elapsed. Sleeping in a test is usually bad form, but we + // need to make sure that we are testing the barrier instead of some + // other synchronization method. + absl::SleepFor(absl::Seconds(1)); + + // The counter should still be zero since no thread should have + // been able to pass the barrier yet. + { + absl::MutexLock lock(&mutex); + EXPECT_EQ(counter, 0); + } + + // Start 1 more thread. This should make all threads pass the barrier. + threads.push_back(std::thread(thread_func)); + + // All threads should now be able to proceed and finish. + for (auto& thread : threads) { + thread.join(); + } + + // All threads should now have incremented the counter. + absl::MutexLock lock(&mutex); + EXPECT_EQ(counter, kNumThreads); +} diff --git a/third_party/abseil_cpp/absl/synchronization/blocking_counter.cc b/third_party/abseil_cpp/absl/synchronization/blocking_counter.cc new file mode 100644 index 0000000000..3cea7aed24 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/blocking_counter.cc @@ -0,0 +1,57 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/blocking_counter.h" + +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Return whether int *arg is zero. +static bool IsZero(void *arg) { + return 0 == *reinterpret_cast<int *>(arg); +} + +bool BlockingCounter::DecrementCount() { + MutexLock l(&lock_); + count_--; + if (count_ < 0) { + ABSL_RAW_LOG( + FATAL, + "BlockingCounter::DecrementCount() called too many times. count=%d", + count_); + } + return count_ == 0; +} + +void BlockingCounter::Wait() { + MutexLock l(&this->lock_); + ABSL_RAW_CHECK(count_ >= 0, "BlockingCounter underflow"); + + // only one thread may call Wait(). To support more than one thread, + // implement a counter num_to_exit, like in the Barrier class. + ABSL_RAW_CHECK(num_waiting_ == 0, "multiple threads called Wait()"); + num_waiting_++; + + this->lock_.Await(Condition(IsZero, &this->count_)); + + // At this point, We know that all threads executing DecrementCount have + // released the lock, and so will not touch this object again. + // Therefore, the thread calling this method is free to delete the object + // after we return from this method. +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/blocking_counter.h b/third_party/abseil_cpp/absl/synchronization/blocking_counter.h new file mode 100644 index 0000000000..1f53f9f240 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/blocking_counter.h @@ -0,0 +1,99 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// blocking_counter.h +// ----------------------------------------------------------------------------- + +#ifndef ABSL_SYNCHRONIZATION_BLOCKING_COUNTER_H_ +#define ABSL_SYNCHRONIZATION_BLOCKING_COUNTER_H_ + +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// BlockingCounter +// +// This class allows a thread to block for a pre-specified number of actions. +// `BlockingCounter` maintains a single non-negative abstract integer "count" +// with an initial value `initial_count`. A thread can then call `Wait()` on +// this blocking counter to block until the specified number of events occur; +// worker threads then call 'DecrementCount()` on the counter upon completion of +// their work. Once the counter's internal "count" reaches zero, the blocked +// thread unblocks. +// +// A `BlockingCounter` requires the following: +// - its `initial_count` is non-negative. +// - the number of calls to `DecrementCount()` on it is at most +// `initial_count`. +// - `Wait()` is called at most once on it. +// +// Given the above requirements, a `BlockingCounter` provides the following +// guarantees: +// - Once its internal "count" reaches zero, no legal action on the object +// can further change the value of "count". +// - When `Wait()` returns, it is legal to destroy the `BlockingCounter`. +// - When `Wait()` returns, the number of calls to `DecrementCount()` on +// this blocking counter exactly equals `initial_count`. +// +// Example: +// BlockingCounter bcount(N); // there are N items of work +// ... Allow worker threads to start. +// ... On completing each work item, workers do: +// ... bcount.DecrementCount(); // an item of work has been completed +// +// bcount.Wait(); // wait for all work to be complete +// +class BlockingCounter { + public: + explicit BlockingCounter(int initial_count) + : count_(initial_count), num_waiting_(0) {} + + BlockingCounter(const BlockingCounter&) = delete; + BlockingCounter& operator=(const BlockingCounter&) = delete; + + // BlockingCounter::DecrementCount() + // + // Decrements the counter's "count" by one, and return "count == 0". This + // function requires that "count != 0" when it is called. + // + // Memory ordering: For any threads X and Y, any action taken by X + // before it calls `DecrementCount()` is visible to thread Y after + // Y's call to `DecrementCount()`, provided Y's call returns `true`. + bool DecrementCount(); + + // BlockingCounter::Wait() + // + // Blocks until the counter reaches zero. This function may be called at most + // once. On return, `DecrementCount()` will have been called "initial_count" + // times and the blocking counter may be destroyed. + // + // Memory ordering: For any threads X and Y, any action taken by X + // before X calls `DecrementCount()` is visible to Y after Y returns + // from `Wait()`. + void Wait(); + + private: + Mutex lock_; + int count_ ABSL_GUARDED_BY(lock_); + int num_waiting_ ABSL_GUARDED_BY(lock_); +}; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_SYNCHRONIZATION_BLOCKING_COUNTER_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/blocking_counter_test.cc b/third_party/abseil_cpp/absl/synchronization/blocking_counter_test.cc new file mode 100644 index 0000000000..2926224af7 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/blocking_counter_test.cc @@ -0,0 +1,68 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/blocking_counter.h" + +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gtest/gtest.h" +#include "absl/time/clock.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +void PauseAndDecreaseCounter(BlockingCounter* counter, int* done) { + absl::SleepFor(absl::Seconds(1)); + *done = 1; + counter->DecrementCount(); +} + +TEST(BlockingCounterTest, BasicFunctionality) { + // This test verifies that BlockingCounter functions correctly. Starts a + // number of threads that just sleep for a second and decrement a counter. + + // Initialize the counter. + const int num_workers = 10; + BlockingCounter counter(num_workers); + + std::vector<std::thread> workers; + std::vector<int> done(num_workers, 0); + + // Start a number of parallel tasks that will just wait for a seconds and + // then decrement the count. + workers.reserve(num_workers); + for (int k = 0; k < num_workers; k++) { + workers.emplace_back( + [&counter, &done, k] { PauseAndDecreaseCounter(&counter, &done[k]); }); + } + + // Wait for the threads to have all finished. + counter.Wait(); + + // Check that all the workers have completed. + for (int k = 0; k < num_workers; k++) { + EXPECT_EQ(1, done[k]); + } + + for (std::thread& w : workers) { + w.join(); + } +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/internal/create_thread_identity.cc b/third_party/abseil_cpp/absl/synchronization/internal/create_thread_identity.cc new file mode 100644 index 0000000000..53a71b342b --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/create_thread_identity.cc @@ -0,0 +1,140 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <stdint.h> +#include <new> + +// This file is a no-op if the required LowLevelAlloc support is missing. +#include "absl/base/internal/low_level_alloc.h" +#ifndef ABSL_LOW_LEVEL_ALLOC_MISSING + +#include <string.h> + +#include "absl/base/attributes.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/synchronization/internal/per_thread_sem.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +// ThreadIdentity storage is persistent, we maintain a free-list of previously +// released ThreadIdentity objects. +ABSL_CONST_INIT static base_internal::SpinLock freelist_lock( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); +ABSL_CONST_INIT static base_internal::ThreadIdentity* thread_identity_freelist; + +// A per-thread destructor for reclaiming associated ThreadIdentity objects. +// Since we must preserve their storage we cache them for re-use. +void ReclaimThreadIdentity(void* v) { + base_internal::ThreadIdentity* identity = + static_cast<base_internal::ThreadIdentity*>(v); + + // all_locks might have been allocated by the Mutex implementation. + // We free it here when we are notified that our thread is dying. + if (identity->per_thread_synch.all_locks != nullptr) { + base_internal::LowLevelAlloc::Free(identity->per_thread_synch.all_locks); + } + + PerThreadSem::Destroy(identity); + + // We must explicitly clear the current thread's identity: + // (a) Subsequent (unrelated) per-thread destructors may require an identity. + // We must guarantee a new identity is used in this case (this instructor + // will be reinvoked up to PTHREAD_DESTRUCTOR_ITERATIONS in this case). + // (b) ThreadIdentity implementations may depend on memory that is not + // reinitialized before reuse. We must allow explicit clearing of the + // association state in this case. + base_internal::ClearCurrentThreadIdentity(); + { + base_internal::SpinLockHolder l(&freelist_lock); + identity->next = thread_identity_freelist; + thread_identity_freelist = identity; + } +} + +// Return value rounded up to next multiple of align. +// Align must be a power of two. +static intptr_t RoundUp(intptr_t addr, intptr_t align) { + return (addr + align - 1) & ~(align - 1); +} + +static void ResetThreadIdentity(base_internal::ThreadIdentity* identity) { + base_internal::PerThreadSynch* pts = &identity->per_thread_synch; + pts->next = nullptr; + pts->skip = nullptr; + pts->may_skip = false; + pts->waitp = nullptr; + pts->suppress_fatal_errors = false; + pts->readers = 0; + pts->priority = 0; + pts->next_priority_read_cycles = 0; + pts->state.store(base_internal::PerThreadSynch::State::kAvailable, + std::memory_order_relaxed); + pts->maybe_unlocking = false; + pts->wake = false; + pts->cond_waiter = false; + pts->all_locks = nullptr; + identity->blocked_count_ptr = nullptr; + identity->ticker.store(0, std::memory_order_relaxed); + identity->wait_start.store(0, std::memory_order_relaxed); + identity->is_idle.store(false, std::memory_order_relaxed); + identity->next = nullptr; +} + +static base_internal::ThreadIdentity* NewThreadIdentity() { + base_internal::ThreadIdentity* identity = nullptr; + + { + // Re-use a previously released object if possible. + base_internal::SpinLockHolder l(&freelist_lock); + if (thread_identity_freelist) { + identity = thread_identity_freelist; // Take list-head. + thread_identity_freelist = thread_identity_freelist->next; + } + } + + if (identity == nullptr) { + // Allocate enough space to align ThreadIdentity to a multiple of + // PerThreadSynch::kAlignment. This space is never released (it is + // added to a freelist by ReclaimThreadIdentity instead). + void* allocation = base_internal::LowLevelAlloc::Alloc( + sizeof(*identity) + base_internal::PerThreadSynch::kAlignment - 1); + // Round up the address to the required alignment. + identity = reinterpret_cast<base_internal::ThreadIdentity*>( + RoundUp(reinterpret_cast<intptr_t>(allocation), + base_internal::PerThreadSynch::kAlignment)); + } + ResetThreadIdentity(identity); + + return identity; +} + +// Allocates and attaches ThreadIdentity object for the calling thread. Returns +// the new identity. +// REQUIRES: CurrentThreadIdentity(false) == nullptr +base_internal::ThreadIdentity* CreateThreadIdentity() { + base_internal::ThreadIdentity* identity = NewThreadIdentity(); + PerThreadSem::Init(identity); + // Associate the value with the current thread, and attach our destructor. + base_internal::SetCurrentThreadIdentity(identity, ReclaimThreadIdentity); + return identity; +} + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_LOW_LEVEL_ALLOC_MISSING diff --git a/third_party/abseil_cpp/absl/synchronization/internal/create_thread_identity.h b/third_party/abseil_cpp/absl/synchronization/internal/create_thread_identity.h new file mode 100644 index 0000000000..e121f68377 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/create_thread_identity.h @@ -0,0 +1,60 @@ +/* + * Copyright 2017 The Abseil Authors. + * + * Licensed under the Apache License, Version 2.0 (the "License"); + * you may not use this file except in compliance with the License. + * You may obtain a copy of the License at + * + * https://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +// Interface for getting the current ThreadIdentity, creating one if necessary. +// See thread_identity.h. +// +// This file is separate from thread_identity.h because creating a new +// ThreadIdentity requires slightly higher level libraries (per_thread_sem +// and low_level_alloc) than accessing an existing one. This separation allows +// us to have a smaller //absl/base:base. + +#ifndef ABSL_SYNCHRONIZATION_INTERNAL_CREATE_THREAD_IDENTITY_H_ +#define ABSL_SYNCHRONIZATION_INTERNAL_CREATE_THREAD_IDENTITY_H_ + +#include "absl/base/internal/thread_identity.h" +#include "absl/base/port.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +// Allocates and attaches a ThreadIdentity object for the calling thread. +// For private use only. +base_internal::ThreadIdentity* CreateThreadIdentity(); + +// A per-thread destructor for reclaiming associated ThreadIdentity objects. +// For private use only. +void ReclaimThreadIdentity(void* v); + +// Returns the ThreadIdentity object representing the calling thread; guaranteed +// to be unique for its lifetime. The returned object will remain valid for the +// program's lifetime; although it may be re-assigned to a subsequent thread. +// If one does not exist for the calling thread, allocate it now. +inline base_internal::ThreadIdentity* GetOrCreateCurrentThreadIdentity() { + base_internal::ThreadIdentity* identity = + base_internal::CurrentThreadIdentityIfPresent(); + if (ABSL_PREDICT_FALSE(identity == nullptr)) { + return CreateThreadIdentity(); + } + return identity; +} + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_SYNCHRONIZATION_INTERNAL_CREATE_THREAD_IDENTITY_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/internal/graphcycles.cc b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles.cc new file mode 100644 index 0000000000..19f9aab5b1 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles.cc @@ -0,0 +1,697 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// GraphCycles provides incremental cycle detection on a dynamic +// graph using the following algorithm: +// +// A dynamic topological sort algorithm for directed acyclic graphs +// David J. Pearce, Paul H. J. Kelly +// Journal of Experimental Algorithmics (JEA) JEA Homepage archive +// Volume 11, 2006, Article No. 1.7 +// +// Brief summary of the algorithm: +// +// (1) Maintain a rank for each node that is consistent +// with the topological sort of the graph. I.e., path from x to y +// implies rank[x] < rank[y]. +// (2) When a new edge (x->y) is inserted, do nothing if rank[x] < rank[y]. +// (3) Otherwise: adjust ranks in the neighborhood of x and y. + +#include "absl/base/attributes.h" +// This file is a no-op if the required LowLevelAlloc support is missing. +#include "absl/base/internal/low_level_alloc.h" +#ifndef ABSL_LOW_LEVEL_ALLOC_MISSING + +#include "absl/synchronization/internal/graphcycles.h" + +#include <algorithm> +#include <array> +#include "absl/base/internal/hide_ptr.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" + +// Do not use STL. This module does not use standard memory allocation. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +namespace { + +// Avoid LowLevelAlloc's default arena since it calls malloc hooks in +// which people are doing things like acquiring Mutexes. +ABSL_CONST_INIT static absl::base_internal::SpinLock arena_mu( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); +ABSL_CONST_INIT static base_internal::LowLevelAlloc::Arena* arena; + +static void InitArenaIfNecessary() { + arena_mu.Lock(); + if (arena == nullptr) { + arena = base_internal::LowLevelAlloc::NewArena(0); + } + arena_mu.Unlock(); +} + +// Number of inlined elements in Vec. Hash table implementation +// relies on this being a power of two. +static const uint32_t kInline = 8; + +// A simple LowLevelAlloc based resizable vector with inlined storage +// for a few elements. T must be a plain type since constructor +// and destructor are not run on elements of type T managed by Vec. +template <typename T> +class Vec { + public: + Vec() { Init(); } + ~Vec() { Discard(); } + + void clear() { + Discard(); + Init(); + } + + bool empty() const { return size_ == 0; } + uint32_t size() const { return size_; } + T* begin() { return ptr_; } + T* end() { return ptr_ + size_; } + const T& operator[](uint32_t i) const { return ptr_[i]; } + T& operator[](uint32_t i) { return ptr_[i]; } + const T& back() const { return ptr_[size_-1]; } + void pop_back() { size_--; } + + void push_back(const T& v) { + if (size_ == capacity_) Grow(size_ + 1); + ptr_[size_] = v; + size_++; + } + + void resize(uint32_t n) { + if (n > capacity_) Grow(n); + size_ = n; + } + + void fill(const T& val) { + for (uint32_t i = 0; i < size(); i++) { + ptr_[i] = val; + } + } + + // Guarantees src is empty at end. + // Provided for the hash table resizing code below. + void MoveFrom(Vec<T>* src) { + if (src->ptr_ == src->space_) { + // Need to actually copy + resize(src->size_); + std::copy(src->ptr_, src->ptr_ + src->size_, ptr_); + src->size_ = 0; + } else { + Discard(); + ptr_ = src->ptr_; + size_ = src->size_; + capacity_ = src->capacity_; + src->Init(); + } + } + + private: + T* ptr_; + T space_[kInline]; + uint32_t size_; + uint32_t capacity_; + + void Init() { + ptr_ = space_; + size_ = 0; + capacity_ = kInline; + } + + void Discard() { + if (ptr_ != space_) base_internal::LowLevelAlloc::Free(ptr_); + } + + void Grow(uint32_t n) { + while (capacity_ < n) { + capacity_ *= 2; + } + size_t request = static_cast<size_t>(capacity_) * sizeof(T); + T* copy = static_cast<T*>( + base_internal::LowLevelAlloc::AllocWithArena(request, arena)); + std::copy(ptr_, ptr_ + size_, copy); + Discard(); + ptr_ = copy; + } + + Vec(const Vec&) = delete; + Vec& operator=(const Vec&) = delete; +}; + +// A hash set of non-negative int32_t that uses Vec for its underlying storage. +class NodeSet { + public: + NodeSet() { Init(); } + + void clear() { Init(); } + bool contains(int32_t v) const { return table_[FindIndex(v)] == v; } + + bool insert(int32_t v) { + uint32_t i = FindIndex(v); + if (table_[i] == v) { + return false; + } + if (table_[i] == kEmpty) { + // Only inserting over an empty cell increases the number of occupied + // slots. + occupied_++; + } + table_[i] = v; + // Double when 75% full. + if (occupied_ >= table_.size() - table_.size()/4) Grow(); + return true; + } + + void erase(uint32_t v) { + uint32_t i = FindIndex(v); + if (static_cast<uint32_t>(table_[i]) == v) { + table_[i] = kDel; + } + } + + // Iteration: is done via HASH_FOR_EACH + // Example: + // HASH_FOR_EACH(elem, node->out) { ... } +#define HASH_FOR_EACH(elem, eset) \ + for (int32_t elem, _cursor = 0; (eset).Next(&_cursor, &elem); ) + bool Next(int32_t* cursor, int32_t* elem) { + while (static_cast<uint32_t>(*cursor) < table_.size()) { + int32_t v = table_[*cursor]; + (*cursor)++; + if (v >= 0) { + *elem = v; + return true; + } + } + return false; + } + + private: + enum : int32_t { kEmpty = -1, kDel = -2 }; + Vec<int32_t> table_; + uint32_t occupied_; // Count of non-empty slots (includes deleted slots) + + static uint32_t Hash(uint32_t a) { return a * 41; } + + // Return index for storing v. May return an empty index or deleted index + int FindIndex(int32_t v) const { + // Search starting at hash index. + const uint32_t mask = table_.size() - 1; + uint32_t i = Hash(v) & mask; + int deleted_index = -1; // If >= 0, index of first deleted element we see + while (true) { + int32_t e = table_[i]; + if (v == e) { + return i; + } else if (e == kEmpty) { + // Return any previously encountered deleted slot. + return (deleted_index >= 0) ? deleted_index : i; + } else if (e == kDel && deleted_index < 0) { + // Keep searching since v might be present later. + deleted_index = i; + } + i = (i + 1) & mask; // Linear probing; quadratic is slightly slower. + } + } + + void Init() { + table_.clear(); + table_.resize(kInline); + table_.fill(kEmpty); + occupied_ = 0; + } + + void Grow() { + Vec<int32_t> copy; + copy.MoveFrom(&table_); + occupied_ = 0; + table_.resize(copy.size() * 2); + table_.fill(kEmpty); + + for (const auto& e : copy) { + if (e >= 0) insert(e); + } + } + + NodeSet(const NodeSet&) = delete; + NodeSet& operator=(const NodeSet&) = delete; +}; + +// We encode a node index and a node version in GraphId. The version +// number is incremented when the GraphId is freed which automatically +// invalidates all copies of the GraphId. + +inline GraphId MakeId(int32_t index, uint32_t version) { + GraphId g; + g.handle = + (static_cast<uint64_t>(version) << 32) | static_cast<uint32_t>(index); + return g; +} + +inline int32_t NodeIndex(GraphId id) { + return static_cast<uint32_t>(id.handle & 0xfffffffful); +} + +inline uint32_t NodeVersion(GraphId id) { + return static_cast<uint32_t>(id.handle >> 32); +} + +struct Node { + int32_t rank; // rank number assigned by Pearce-Kelly algorithm + uint32_t version; // Current version number + int32_t next_hash; // Next entry in hash table + bool visited; // Temporary marker used by depth-first-search + uintptr_t masked_ptr; // User-supplied pointer + NodeSet in; // List of immediate predecessor nodes in graph + NodeSet out; // List of immediate successor nodes in graph + int priority; // Priority of recorded stack trace. + int nstack; // Depth of recorded stack trace. + void* stack[40]; // stack[0,nstack-1] holds stack trace for node. +}; + +// Hash table for pointer to node index lookups. +class PointerMap { + public: + explicit PointerMap(const Vec<Node*>* nodes) : nodes_(nodes) { + table_.fill(-1); + } + + int32_t Find(void* ptr) { + auto masked = base_internal::HidePtr(ptr); + for (int32_t i = table_[Hash(ptr)]; i != -1;) { + Node* n = (*nodes_)[i]; + if (n->masked_ptr == masked) return i; + i = n->next_hash; + } + return -1; + } + + void Add(void* ptr, int32_t i) { + int32_t* head = &table_[Hash(ptr)]; + (*nodes_)[i]->next_hash = *head; + *head = i; + } + + int32_t Remove(void* ptr) { + // Advance through linked list while keeping track of the + // predecessor slot that points to the current entry. + auto masked = base_internal::HidePtr(ptr); + for (int32_t* slot = &table_[Hash(ptr)]; *slot != -1; ) { + int32_t index = *slot; + Node* n = (*nodes_)[index]; + if (n->masked_ptr == masked) { + *slot = n->next_hash; // Remove n from linked list + n->next_hash = -1; + return index; + } + slot = &n->next_hash; + } + return -1; + } + + private: + // Number of buckets in hash table for pointer lookups. + static constexpr uint32_t kHashTableSize = 8171; // should be prime + + const Vec<Node*>* nodes_; + std::array<int32_t, kHashTableSize> table_; + + static uint32_t Hash(void* ptr) { + return reinterpret_cast<uintptr_t>(ptr) % kHashTableSize; + } +}; + +} // namespace + +struct GraphCycles::Rep { + Vec<Node*> nodes_; + Vec<int32_t> free_nodes_; // Indices for unused entries in nodes_ + PointerMap ptrmap_; + + // Temporary state. + Vec<int32_t> deltaf_; // Results of forward DFS + Vec<int32_t> deltab_; // Results of backward DFS + Vec<int32_t> list_; // All nodes to reprocess + Vec<int32_t> merged_; // Rank values to assign to list_ entries + Vec<int32_t> stack_; // Emulates recursion stack for depth-first searches + + Rep() : ptrmap_(&nodes_) {} +}; + +static Node* FindNode(GraphCycles::Rep* rep, GraphId id) { + Node* n = rep->nodes_[NodeIndex(id)]; + return (n->version == NodeVersion(id)) ? n : nullptr; +} + +GraphCycles::GraphCycles() { + InitArenaIfNecessary(); + rep_ = new (base_internal::LowLevelAlloc::AllocWithArena(sizeof(Rep), arena)) + Rep; +} + +GraphCycles::~GraphCycles() { + for (auto* node : rep_->nodes_) { + node->Node::~Node(); + base_internal::LowLevelAlloc::Free(node); + } + rep_->Rep::~Rep(); + base_internal::LowLevelAlloc::Free(rep_); +} + +bool GraphCycles::CheckInvariants() const { + Rep* r = rep_; + NodeSet ranks; // Set of ranks seen so far. + for (uint32_t x = 0; x < r->nodes_.size(); x++) { + Node* nx = r->nodes_[x]; + void* ptr = base_internal::UnhidePtr<void>(nx->masked_ptr); + if (ptr != nullptr && static_cast<uint32_t>(r->ptrmap_.Find(ptr)) != x) { + ABSL_RAW_LOG(FATAL, "Did not find live node in hash table %u %p", x, ptr); + } + if (nx->visited) { + ABSL_RAW_LOG(FATAL, "Did not clear visited marker on node %u", x); + } + if (!ranks.insert(nx->rank)) { + ABSL_RAW_LOG(FATAL, "Duplicate occurrence of rank %d", nx->rank); + } + HASH_FOR_EACH(y, nx->out) { + Node* ny = r->nodes_[y]; + if (nx->rank >= ny->rank) { + ABSL_RAW_LOG(FATAL, "Edge %u->%d has bad rank assignment %d->%d", x, y, + nx->rank, ny->rank); + } + } + } + return true; +} + +GraphId GraphCycles::GetId(void* ptr) { + int32_t i = rep_->ptrmap_.Find(ptr); + if (i != -1) { + return MakeId(i, rep_->nodes_[i]->version); + } else if (rep_->free_nodes_.empty()) { + Node* n = + new (base_internal::LowLevelAlloc::AllocWithArena(sizeof(Node), arena)) + Node; + n->version = 1; // Avoid 0 since it is used by InvalidGraphId() + n->visited = false; + n->rank = rep_->nodes_.size(); + n->masked_ptr = base_internal::HidePtr(ptr); + n->nstack = 0; + n->priority = 0; + rep_->nodes_.push_back(n); + rep_->ptrmap_.Add(ptr, n->rank); + return MakeId(n->rank, n->version); + } else { + // Preserve preceding rank since the set of ranks in use must be + // a permutation of [0,rep_->nodes_.size()-1]. + int32_t r = rep_->free_nodes_.back(); + rep_->free_nodes_.pop_back(); + Node* n = rep_->nodes_[r]; + n->masked_ptr = base_internal::HidePtr(ptr); + n->nstack = 0; + n->priority = 0; + rep_->ptrmap_.Add(ptr, r); + return MakeId(r, n->version); + } +} + +void GraphCycles::RemoveNode(void* ptr) { + int32_t i = rep_->ptrmap_.Remove(ptr); + if (i == -1) { + return; + } + Node* x = rep_->nodes_[i]; + HASH_FOR_EACH(y, x->out) { + rep_->nodes_[y]->in.erase(i); + } + HASH_FOR_EACH(y, x->in) { + rep_->nodes_[y]->out.erase(i); + } + x->in.clear(); + x->out.clear(); + x->masked_ptr = base_internal::HidePtr<void>(nullptr); + if (x->version == std::numeric_limits<uint32_t>::max()) { + // Cannot use x any more + } else { + x->version++; // Invalidates all copies of node. + rep_->free_nodes_.push_back(i); + } +} + +void* GraphCycles::Ptr(GraphId id) { + Node* n = FindNode(rep_, id); + return n == nullptr ? nullptr + : base_internal::UnhidePtr<void>(n->masked_ptr); +} + +bool GraphCycles::HasNode(GraphId node) { + return FindNode(rep_, node) != nullptr; +} + +bool GraphCycles::HasEdge(GraphId x, GraphId y) const { + Node* xn = FindNode(rep_, x); + return xn && FindNode(rep_, y) && xn->out.contains(NodeIndex(y)); +} + +void GraphCycles::RemoveEdge(GraphId x, GraphId y) { + Node* xn = FindNode(rep_, x); + Node* yn = FindNode(rep_, y); + if (xn && yn) { + xn->out.erase(NodeIndex(y)); + yn->in.erase(NodeIndex(x)); + // No need to update the rank assignment since a previous valid + // rank assignment remains valid after an edge deletion. + } +} + +static bool ForwardDFS(GraphCycles::Rep* r, int32_t n, int32_t upper_bound); +static void BackwardDFS(GraphCycles::Rep* r, int32_t n, int32_t lower_bound); +static void Reorder(GraphCycles::Rep* r); +static void Sort(const Vec<Node*>&, Vec<int32_t>* delta); +static void MoveToList( + GraphCycles::Rep* r, Vec<int32_t>* src, Vec<int32_t>* dst); + +bool GraphCycles::InsertEdge(GraphId idx, GraphId idy) { + Rep* r = rep_; + const int32_t x = NodeIndex(idx); + const int32_t y = NodeIndex(idy); + Node* nx = FindNode(r, idx); + Node* ny = FindNode(r, idy); + if (nx == nullptr || ny == nullptr) return true; // Expired ids + + if (nx == ny) return false; // Self edge + if (!nx->out.insert(y)) { + // Edge already exists. + return true; + } + + ny->in.insert(x); + + if (nx->rank <= ny->rank) { + // New edge is consistent with existing rank assignment. + return true; + } + + // Current rank assignments are incompatible with the new edge. Recompute. + // We only need to consider nodes that fall in the range [ny->rank,nx->rank]. + if (!ForwardDFS(r, y, nx->rank)) { + // Found a cycle. Undo the insertion and tell caller. + nx->out.erase(y); + ny->in.erase(x); + // Since we do not call Reorder() on this path, clear any visited + // markers left by ForwardDFS. + for (const auto& d : r->deltaf_) { + r->nodes_[d]->visited = false; + } + return false; + } + BackwardDFS(r, x, ny->rank); + Reorder(r); + return true; +} + +static bool ForwardDFS(GraphCycles::Rep* r, int32_t n, int32_t upper_bound) { + // Avoid recursion since stack space might be limited. + // We instead keep a stack of nodes to visit. + r->deltaf_.clear(); + r->stack_.clear(); + r->stack_.push_back(n); + while (!r->stack_.empty()) { + n = r->stack_.back(); + r->stack_.pop_back(); + Node* nn = r->nodes_[n]; + if (nn->visited) continue; + + nn->visited = true; + r->deltaf_.push_back(n); + + HASH_FOR_EACH(w, nn->out) { + Node* nw = r->nodes_[w]; + if (nw->rank == upper_bound) { + return false; // Cycle + } + if (!nw->visited && nw->rank < upper_bound) { + r->stack_.push_back(w); + } + } + } + return true; +} + +static void BackwardDFS(GraphCycles::Rep* r, int32_t n, int32_t lower_bound) { + r->deltab_.clear(); + r->stack_.clear(); + r->stack_.push_back(n); + while (!r->stack_.empty()) { + n = r->stack_.back(); + r->stack_.pop_back(); + Node* nn = r->nodes_[n]; + if (nn->visited) continue; + + nn->visited = true; + r->deltab_.push_back(n); + + HASH_FOR_EACH(w, nn->in) { + Node* nw = r->nodes_[w]; + if (!nw->visited && lower_bound < nw->rank) { + r->stack_.push_back(w); + } + } + } +} + +static void Reorder(GraphCycles::Rep* r) { + Sort(r->nodes_, &r->deltab_); + Sort(r->nodes_, &r->deltaf_); + + // Adds contents of delta lists to list_ (backwards deltas first). + r->list_.clear(); + MoveToList(r, &r->deltab_, &r->list_); + MoveToList(r, &r->deltaf_, &r->list_); + + // Produce sorted list of all ranks that will be reassigned. + r->merged_.resize(r->deltab_.size() + r->deltaf_.size()); + std::merge(r->deltab_.begin(), r->deltab_.end(), + r->deltaf_.begin(), r->deltaf_.end(), + r->merged_.begin()); + + // Assign the ranks in order to the collected list. + for (uint32_t i = 0; i < r->list_.size(); i++) { + r->nodes_[r->list_[i]]->rank = r->merged_[i]; + } +} + +static void Sort(const Vec<Node*>& nodes, Vec<int32_t>* delta) { + struct ByRank { + const Vec<Node*>* nodes; + bool operator()(int32_t a, int32_t b) const { + return (*nodes)[a]->rank < (*nodes)[b]->rank; + } + }; + ByRank cmp; + cmp.nodes = &nodes; + std::sort(delta->begin(), delta->end(), cmp); +} + +static void MoveToList( + GraphCycles::Rep* r, Vec<int32_t>* src, Vec<int32_t>* dst) { + for (auto& v : *src) { + int32_t w = v; + v = r->nodes_[w]->rank; // Replace v entry with its rank + r->nodes_[w]->visited = false; // Prepare for future DFS calls + dst->push_back(w); + } +} + +int GraphCycles::FindPath(GraphId idx, GraphId idy, int max_path_len, + GraphId path[]) const { + Rep* r = rep_; + if (FindNode(r, idx) == nullptr || FindNode(r, idy) == nullptr) return 0; + const int32_t x = NodeIndex(idx); + const int32_t y = NodeIndex(idy); + + // Forward depth first search starting at x until we hit y. + // As we descend into a node, we push it onto the path. + // As we leave a node, we remove it from the path. + int path_len = 0; + + NodeSet seen; + r->stack_.clear(); + r->stack_.push_back(x); + while (!r->stack_.empty()) { + int32_t n = r->stack_.back(); + r->stack_.pop_back(); + if (n < 0) { + // Marker to indicate that we are leaving a node + path_len--; + continue; + } + + if (path_len < max_path_len) { + path[path_len] = MakeId(n, rep_->nodes_[n]->version); + } + path_len++; + r->stack_.push_back(-1); // Will remove tentative path entry + + if (n == y) { + return path_len; + } + + HASH_FOR_EACH(w, r->nodes_[n]->out) { + if (seen.insert(w)) { + r->stack_.push_back(w); + } + } + } + + return 0; +} + +bool GraphCycles::IsReachable(GraphId x, GraphId y) const { + return FindPath(x, y, 0, nullptr) > 0; +} + +void GraphCycles::UpdateStackTrace(GraphId id, int priority, + int (*get_stack_trace)(void** stack, int)) { + Node* n = FindNode(rep_, id); + if (n == nullptr || n->priority >= priority) { + return; + } + n->nstack = (*get_stack_trace)(n->stack, ABSL_ARRAYSIZE(n->stack)); + n->priority = priority; +} + +int GraphCycles::GetStackTrace(GraphId id, void*** ptr) { + Node* n = FindNode(rep_, id); + if (n == nullptr) { + *ptr = nullptr; + return 0; + } else { + *ptr = n->stack; + return n->nstack; + } +} + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_LOW_LEVEL_ALLOC_MISSING diff --git a/third_party/abseil_cpp/absl/synchronization/internal/graphcycles.h b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles.h new file mode 100644 index 0000000000..ceba33e4de --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles.h @@ -0,0 +1,141 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_SYNCHRONIZATION_INTERNAL_GRAPHCYCLES_H_ +#define ABSL_SYNCHRONIZATION_INTERNAL_GRAPHCYCLES_H_ + +// GraphCycles detects the introduction of a cycle into a directed +// graph that is being built up incrementally. +// +// Nodes are identified by small integers. It is not possible to +// record multiple edges with the same (source, destination) pair; +// requests to add an edge where one already exists are silently +// ignored. +// +// It is also not possible to introduce a cycle; an attempt to insert +// an edge that would introduce a cycle fails and returns false. +// +// GraphCycles uses no internal locking; calls into it should be +// serialized externally. + +// Performance considerations: +// Works well on sparse graphs, poorly on dense graphs. +// Extra information is maintained incrementally to detect cycles quickly. +// InsertEdge() is very fast when the edge already exists, and reasonably fast +// otherwise. +// FindPath() is linear in the size of the graph. +// The current implementation uses O(|V|+|E|) space. + +#include <cstdint> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +// Opaque identifier for a graph node. +struct GraphId { + uint64_t handle; + + bool operator==(const GraphId& x) const { return handle == x.handle; } + bool operator!=(const GraphId& x) const { return handle != x.handle; } +}; + +// Return an invalid graph id that will never be assigned by GraphCycles. +inline GraphId InvalidGraphId() { + return GraphId{0}; +} + +class GraphCycles { + public: + GraphCycles(); + ~GraphCycles(); + + // Return the id to use for ptr, assigning one if necessary. + // Subsequent calls with the same ptr value will return the same id + // until Remove(). + GraphId GetId(void* ptr); + + // Remove "ptr" from the graph. Its corresponding node and all + // edges to and from it are removed. + void RemoveNode(void* ptr); + + // Return the pointer associated with id, or nullptr if id is not + // currently in the graph. + void* Ptr(GraphId id); + + // Attempt to insert an edge from source_node to dest_node. If the + // edge would introduce a cycle, return false without making any + // changes. Otherwise add the edge and return true. + bool InsertEdge(GraphId source_node, GraphId dest_node); + + // Remove any edge that exists from source_node to dest_node. + void RemoveEdge(GraphId source_node, GraphId dest_node); + + // Return whether node exists in the graph. + bool HasNode(GraphId node); + + // Return whether there is an edge directly from source_node to dest_node. + bool HasEdge(GraphId source_node, GraphId dest_node) const; + + // Return whether dest_node is reachable from source_node + // by following edges. + bool IsReachable(GraphId source_node, GraphId dest_node) const; + + // Find a path from "source" to "dest". If such a path exists, + // place the nodes on the path in the array path[], and return + // the number of nodes on the path. If the path is longer than + // max_path_len nodes, only the first max_path_len nodes are placed + // in path[]. The client should compare the return value with + // max_path_len" to see when this occurs. If no path exists, return + // 0. Any valid path stored in path[] will start with "source" and + // end with "dest". There is no guarantee that the path is the + // shortest, but no node will appear twice in the path, except the + // source and destination node if they are identical; therefore, the + // return value is at most one greater than the number of nodes in + // the graph. + int FindPath(GraphId source, GraphId dest, int max_path_len, + GraphId path[]) const; + + // Update the stack trace recorded for id with the current stack + // trace if the last time it was updated had a smaller priority + // than the priority passed on this call. + // + // *get_stack_trace is called to get the stack trace. + void UpdateStackTrace(GraphId id, int priority, + int (*get_stack_trace)(void**, int)); + + // Set *ptr to the beginning of the array that holds the recorded + // stack trace for id and return the depth of the stack trace. + int GetStackTrace(GraphId id, void*** ptr); + + // Check internal invariants. Crashes on failure, returns true on success. + // Expensive: should only be called from graphcycles_test.cc. + bool CheckInvariants() const; + + // ---------------------------------------------------- + struct Rep; + private: + Rep *rep_; // opaque representation + GraphCycles(const GraphCycles&) = delete; + GraphCycles& operator=(const GraphCycles&) = delete; +}; + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif diff --git a/third_party/abseil_cpp/absl/synchronization/internal/graphcycles_benchmark.cc b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles_benchmark.cc new file mode 100644 index 0000000000..54823e0ba5 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles_benchmark.cc @@ -0,0 +1,44 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/internal/graphcycles.h" + +#include <algorithm> +#include <cstdint> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/base/internal/raw_logging.h" + +namespace { + +void BM_StressTest(benchmark::State& state) { + const int num_nodes = state.range(0); + while (state.KeepRunningBatch(num_nodes)) { + absl::synchronization_internal::GraphCycles g; + std::vector<absl::synchronization_internal::GraphId> nodes(num_nodes); + for (int i = 0; i < num_nodes; i++) { + nodes[i] = g.GetId(reinterpret_cast<void*>(static_cast<uintptr_t>(i))); + } + for (int i = 0; i < num_nodes; i++) { + int end = std::min(num_nodes, i + 5); + for (int j = i + 1; j < end; j++) { + ABSL_RAW_CHECK(g.InsertEdge(nodes[i], nodes[j]), ""); + } + } + } +} +BENCHMARK(BM_StressTest)->Range(2048, 1048576); + +} // namespace diff --git a/third_party/abseil_cpp/absl/synchronization/internal/graphcycles_test.cc b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles_test.cc new file mode 100644 index 0000000000..74eaffe7a8 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/graphcycles_test.cc @@ -0,0 +1,464 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/internal/graphcycles.h" + +#include <map> +#include <random> +#include <unordered_set> +#include <utility> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/macros.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +// We emulate a GraphCycles object with a node vector and an edge vector. +// We then compare the two implementations. + +using Nodes = std::vector<int>; +struct Edge { + int from; + int to; +}; +using Edges = std::vector<Edge>; +using RandomEngine = std::mt19937_64; + +// Mapping from integer index to GraphId. +typedef std::map<int, GraphId> IdMap; +static GraphId Get(const IdMap& id, int num) { + auto iter = id.find(num); + return (iter == id.end()) ? InvalidGraphId() : iter->second; +} + +// Return whether "to" is reachable from "from". +static bool IsReachable(Edges *edges, int from, int to, + std::unordered_set<int> *seen) { + seen->insert(from); // we are investigating "from"; don't do it again + if (from == to) return true; + for (const auto &edge : *edges) { + if (edge.from == from) { + if (edge.to == to) { // success via edge directly + return true; + } else if (seen->find(edge.to) == seen->end() && // success via edge + IsReachable(edges, edge.to, to, seen)) { + return true; + } + } + } + return false; +} + +static void PrintEdges(Edges *edges) { + ABSL_RAW_LOG(INFO, "EDGES (%zu)", edges->size()); + for (const auto &edge : *edges) { + int a = edge.from; + int b = edge.to; + ABSL_RAW_LOG(INFO, "%d %d", a, b); + } + ABSL_RAW_LOG(INFO, "---"); +} + +static void PrintGCEdges(Nodes *nodes, const IdMap &id, GraphCycles *gc) { + ABSL_RAW_LOG(INFO, "GC EDGES"); + for (int a : *nodes) { + for (int b : *nodes) { + if (gc->HasEdge(Get(id, a), Get(id, b))) { + ABSL_RAW_LOG(INFO, "%d %d", a, b); + } + } + } + ABSL_RAW_LOG(INFO, "---"); +} + +static void PrintTransitiveClosure(Nodes *nodes, Edges *edges) { + ABSL_RAW_LOG(INFO, "Transitive closure"); + for (int a : *nodes) { + for (int b : *nodes) { + std::unordered_set<int> seen; + if (IsReachable(edges, a, b, &seen)) { + ABSL_RAW_LOG(INFO, "%d %d", a, b); + } + } + } + ABSL_RAW_LOG(INFO, "---"); +} + +static void PrintGCTransitiveClosure(Nodes *nodes, const IdMap &id, + GraphCycles *gc) { + ABSL_RAW_LOG(INFO, "GC Transitive closure"); + for (int a : *nodes) { + for (int b : *nodes) { + if (gc->IsReachable(Get(id, a), Get(id, b))) { + ABSL_RAW_LOG(INFO, "%d %d", a, b); + } + } + } + ABSL_RAW_LOG(INFO, "---"); +} + +static void CheckTransitiveClosure(Nodes *nodes, Edges *edges, const IdMap &id, + GraphCycles *gc) { + std::unordered_set<int> seen; + for (const auto &a : *nodes) { + for (const auto &b : *nodes) { + seen.clear(); + bool gc_reachable = gc->IsReachable(Get(id, a), Get(id, b)); + bool reachable = IsReachable(edges, a, b, &seen); + if (gc_reachable != reachable) { + PrintEdges(edges); + PrintGCEdges(nodes, id, gc); + PrintTransitiveClosure(nodes, edges); + PrintGCTransitiveClosure(nodes, id, gc); + ABSL_RAW_LOG(FATAL, "gc_reachable %s reachable %s a %d b %d", + gc_reachable ? "true" : "false", + reachable ? "true" : "false", a, b); + } + } + } +} + +static void CheckEdges(Nodes *nodes, Edges *edges, const IdMap &id, + GraphCycles *gc) { + int count = 0; + for (const auto &edge : *edges) { + int a = edge.from; + int b = edge.to; + if (!gc->HasEdge(Get(id, a), Get(id, b))) { + PrintEdges(edges); + PrintGCEdges(nodes, id, gc); + ABSL_RAW_LOG(FATAL, "!gc->HasEdge(%d, %d)", a, b); + } + } + for (const auto &a : *nodes) { + for (const auto &b : *nodes) { + if (gc->HasEdge(Get(id, a), Get(id, b))) { + count++; + } + } + } + if (count != edges->size()) { + PrintEdges(edges); + PrintGCEdges(nodes, id, gc); + ABSL_RAW_LOG(FATAL, "edges->size() %zu count %d", edges->size(), count); + } +} + +static void CheckInvariants(const GraphCycles &gc) { + if (ABSL_PREDICT_FALSE(!gc.CheckInvariants())) + ABSL_RAW_LOG(FATAL, "CheckInvariants"); +} + +// Returns the index of a randomly chosen node in *nodes. +// Requires *nodes be non-empty. +static int RandomNode(RandomEngine* rng, Nodes *nodes) { + std::uniform_int_distribution<int> uniform(0, nodes->size()-1); + return uniform(*rng); +} + +// Returns the index of a randomly chosen edge in *edges. +// Requires *edges be non-empty. +static int RandomEdge(RandomEngine* rng, Edges *edges) { + std::uniform_int_distribution<int> uniform(0, edges->size()-1); + return uniform(*rng); +} + +// Returns the index of edge (from, to) in *edges or -1 if it is not in *edges. +static int EdgeIndex(Edges *edges, int from, int to) { + int i = 0; + while (i != edges->size() && + ((*edges)[i].from != from || (*edges)[i].to != to)) { + i++; + } + return i == edges->size()? -1 : i; +} + +TEST(GraphCycles, RandomizedTest) { + int next_node = 0; + Nodes nodes; + Edges edges; // from, to + IdMap id; + GraphCycles graph_cycles; + static const int kMaxNodes = 7; // use <= 7 nodes to keep test short + static const int kDataOffset = 17; // an offset to the node-specific data + int n = 100000; + int op = 0; + RandomEngine rng(testing::UnitTest::GetInstance()->random_seed()); + std::uniform_int_distribution<int> uniform(0, 5); + + auto ptr = [](intptr_t i) { + return reinterpret_cast<void*>(i + kDataOffset); + }; + + for (int iter = 0; iter != n; iter++) { + for (const auto &node : nodes) { + ASSERT_EQ(graph_cycles.Ptr(Get(id, node)), ptr(node)) << " node " << node; + } + CheckEdges(&nodes, &edges, id, &graph_cycles); + CheckTransitiveClosure(&nodes, &edges, id, &graph_cycles); + op = uniform(rng); + switch (op) { + case 0: // Add a node + if (nodes.size() < kMaxNodes) { + int new_node = next_node++; + GraphId new_gnode = graph_cycles.GetId(ptr(new_node)); + ASSERT_NE(new_gnode, InvalidGraphId()); + id[new_node] = new_gnode; + ASSERT_EQ(ptr(new_node), graph_cycles.Ptr(new_gnode)); + nodes.push_back(new_node); + } + break; + + case 1: // Remove a node + if (nodes.size() > 0) { + int node_index = RandomNode(&rng, &nodes); + int node = nodes[node_index]; + nodes[node_index] = nodes.back(); + nodes.pop_back(); + graph_cycles.RemoveNode(ptr(node)); + ASSERT_EQ(graph_cycles.Ptr(Get(id, node)), nullptr); + id.erase(node); + int i = 0; + while (i != edges.size()) { + if (edges[i].from == node || edges[i].to == node) { + edges[i] = edges.back(); + edges.pop_back(); + } else { + i++; + } + } + } + break; + + case 2: // Add an edge + if (nodes.size() > 0) { + int from = RandomNode(&rng, &nodes); + int to = RandomNode(&rng, &nodes); + if (EdgeIndex(&edges, nodes[from], nodes[to]) == -1) { + if (graph_cycles.InsertEdge(id[nodes[from]], id[nodes[to]])) { + Edge new_edge; + new_edge.from = nodes[from]; + new_edge.to = nodes[to]; + edges.push_back(new_edge); + } else { + std::unordered_set<int> seen; + ASSERT_TRUE(IsReachable(&edges, nodes[to], nodes[from], &seen)) + << "Edge " << nodes[to] << "->" << nodes[from]; + } + } + } + break; + + case 3: // Remove an edge + if (edges.size() > 0) { + int i = RandomEdge(&rng, &edges); + int from = edges[i].from; + int to = edges[i].to; + ASSERT_EQ(i, EdgeIndex(&edges, from, to)); + edges[i] = edges.back(); + edges.pop_back(); + ASSERT_EQ(-1, EdgeIndex(&edges, from, to)); + graph_cycles.RemoveEdge(id[from], id[to]); + } + break; + + case 4: // Check a path + if (nodes.size() > 0) { + int from = RandomNode(&rng, &nodes); + int to = RandomNode(&rng, &nodes); + GraphId path[2*kMaxNodes]; + int path_len = graph_cycles.FindPath(id[nodes[from]], id[nodes[to]], + ABSL_ARRAYSIZE(path), path); + std::unordered_set<int> seen; + bool reachable = IsReachable(&edges, nodes[from], nodes[to], &seen); + bool gc_reachable = + graph_cycles.IsReachable(Get(id, nodes[from]), Get(id, nodes[to])); + ASSERT_EQ(path_len != 0, reachable); + ASSERT_EQ(path_len != 0, gc_reachable); + // In the following line, we add one because a node can appear + // twice, if the path is from that node to itself, perhaps via + // every other node. + ASSERT_LE(path_len, kMaxNodes + 1); + if (path_len != 0) { + ASSERT_EQ(id[nodes[from]], path[0]); + ASSERT_EQ(id[nodes[to]], path[path_len-1]); + for (int i = 1; i < path_len; i++) { + ASSERT_TRUE(graph_cycles.HasEdge(path[i-1], path[i])); + } + } + } + break; + + case 5: // Check invariants + CheckInvariants(graph_cycles); + break; + + default: + ABSL_RAW_LOG(FATAL, "op %d", op); + } + + // Very rarely, test graph expansion by adding then removing many nodes. + std::bernoulli_distribution one_in_1024(1.0 / 1024); + if (one_in_1024(rng)) { + CheckEdges(&nodes, &edges, id, &graph_cycles); + CheckTransitiveClosure(&nodes, &edges, id, &graph_cycles); + for (int i = 0; i != 256; i++) { + int new_node = next_node++; + GraphId new_gnode = graph_cycles.GetId(ptr(new_node)); + ASSERT_NE(InvalidGraphId(), new_gnode); + id[new_node] = new_gnode; + ASSERT_EQ(ptr(new_node), graph_cycles.Ptr(new_gnode)); + for (const auto &node : nodes) { + ASSERT_NE(node, new_node); + } + nodes.push_back(new_node); + } + for (int i = 0; i != 256; i++) { + ASSERT_GT(nodes.size(), 0); + int node_index = RandomNode(&rng, &nodes); + int node = nodes[node_index]; + nodes[node_index] = nodes.back(); + nodes.pop_back(); + graph_cycles.RemoveNode(ptr(node)); + id.erase(node); + int j = 0; + while (j != edges.size()) { + if (edges[j].from == node || edges[j].to == node) { + edges[j] = edges.back(); + edges.pop_back(); + } else { + j++; + } + } + } + CheckInvariants(graph_cycles); + } + } +} + +class GraphCyclesTest : public ::testing::Test { + public: + IdMap id_; + GraphCycles g_; + + static void* Ptr(int i) { + return reinterpret_cast<void*>(static_cast<uintptr_t>(i)); + } + + static int Num(void* ptr) { + return static_cast<int>(reinterpret_cast<uintptr_t>(ptr)); + } + + // Test relies on ith NewNode() call returning Node numbered i + GraphCyclesTest() { + for (int i = 0; i < 100; i++) { + id_[i] = g_.GetId(Ptr(i)); + } + CheckInvariants(g_); + } + + bool AddEdge(int x, int y) { + return g_.InsertEdge(Get(id_, x), Get(id_, y)); + } + + void AddMultiples() { + // For every node x > 0: add edge to 2*x, 3*x + for (int x = 1; x < 25; x++) { + EXPECT_TRUE(AddEdge(x, 2*x)) << x; + EXPECT_TRUE(AddEdge(x, 3*x)) << x; + } + CheckInvariants(g_); + } + + std::string Path(int x, int y) { + GraphId path[5]; + int np = g_.FindPath(Get(id_, x), Get(id_, y), ABSL_ARRAYSIZE(path), path); + std::string result; + for (int i = 0; i < np; i++) { + if (i >= ABSL_ARRAYSIZE(path)) { + result += " ..."; + break; + } + if (!result.empty()) result.push_back(' '); + char buf[20]; + snprintf(buf, sizeof(buf), "%d", Num(g_.Ptr(path[i]))); + result += buf; + } + return result; + } +}; + +TEST_F(GraphCyclesTest, NoCycle) { + AddMultiples(); + CheckInvariants(g_); +} + +TEST_F(GraphCyclesTest, SimpleCycle) { + AddMultiples(); + EXPECT_FALSE(AddEdge(8, 4)); + EXPECT_EQ("4 8", Path(4, 8)); + CheckInvariants(g_); +} + +TEST_F(GraphCyclesTest, IndirectCycle) { + AddMultiples(); + EXPECT_TRUE(AddEdge(16, 9)); + CheckInvariants(g_); + EXPECT_FALSE(AddEdge(9, 2)); + EXPECT_EQ("2 4 8 16 9", Path(2, 9)); + CheckInvariants(g_); +} + +TEST_F(GraphCyclesTest, LongPath) { + ASSERT_TRUE(AddEdge(2, 4)); + ASSERT_TRUE(AddEdge(4, 6)); + ASSERT_TRUE(AddEdge(6, 8)); + ASSERT_TRUE(AddEdge(8, 10)); + ASSERT_TRUE(AddEdge(10, 12)); + ASSERT_FALSE(AddEdge(12, 2)); + EXPECT_EQ("2 4 6 8 10 ...", Path(2, 12)); + CheckInvariants(g_); +} + +TEST_F(GraphCyclesTest, RemoveNode) { + ASSERT_TRUE(AddEdge(1, 2)); + ASSERT_TRUE(AddEdge(2, 3)); + ASSERT_TRUE(AddEdge(3, 4)); + ASSERT_TRUE(AddEdge(4, 5)); + g_.RemoveNode(g_.Ptr(id_[3])); + id_.erase(3); + ASSERT_TRUE(AddEdge(5, 1)); +} + +TEST_F(GraphCyclesTest, ManyEdges) { + const int N = 50; + for (int i = 0; i < N; i++) { + for (int j = 1; j < N; j++) { + ASSERT_TRUE(AddEdge(i, i+j)); + } + } + CheckInvariants(g_); + ASSERT_TRUE(AddEdge(2*N-1, 0)); + CheckInvariants(g_); + ASSERT_FALSE(AddEdge(10, 9)); + CheckInvariants(g_); +} + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/internal/kernel_timeout.h b/third_party/abseil_cpp/absl/synchronization/internal/kernel_timeout.h new file mode 100644 index 0000000000..d6ac5db0af --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/kernel_timeout.h @@ -0,0 +1,155 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// An optional absolute timeout, with nanosecond granularity, +// compatible with absl::Time. Suitable for in-register +// parameter-passing (e.g. syscalls.) +// Constructible from a absl::Time (for a timeout to be respected) or {} +// (for "no timeout".) +// This is a private low-level API for use by a handful of low-level +// components that are friends of this class. Higher-level components +// should build APIs based on absl::Time and absl::Duration. + +#ifndef ABSL_SYNCHRONIZATION_INTERNAL_KERNEL_TIMEOUT_H_ +#define ABSL_SYNCHRONIZATION_INTERNAL_KERNEL_TIMEOUT_H_ + +#include <time.h> +#include <algorithm> +#include <limits> + +#include "absl/base/internal/raw_logging.h" +#include "absl/time/clock.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +class Futex; +class Waiter; + +class KernelTimeout { + public: + // A timeout that should expire at <t>. Any value, in the full + // InfinitePast() to InfiniteFuture() range, is valid here and will be + // respected. + explicit KernelTimeout(absl::Time t) : ns_(MakeNs(t)) {} + // No timeout. + KernelTimeout() : ns_(0) {} + + // A more explicit factory for those who prefer it. Equivalent to {}. + static KernelTimeout Never() { return {}; } + + // We explicitly do not support other custom formats: timespec, int64_t nanos. + // Unify on this and absl::Time, please. + + bool has_timeout() const { return ns_ != 0; } + + private: + // internal rep, not user visible: ns after unix epoch. + // zero = no timeout. + // Negative we treat as an unlikely (and certainly expired!) but valid + // timeout. + int64_t ns_; + + static int64_t MakeNs(absl::Time t) { + // optimization--InfiniteFuture is common "no timeout" value + // and cheaper to compare than convert. + if (t == absl::InfiniteFuture()) return 0; + int64_t x = ToUnixNanos(t); + + // A timeout that lands exactly on the epoch (x=0) needs to be respected, + // so we alter it unnoticably to 1. Negative timeouts are in + // theory supported, but handled poorly by the kernel (long + // delays) so push them forward too; since all such times have + // already passed, it's indistinguishable. + if (x <= 0) x = 1; + // A time larger than what can be represented to the kernel is treated + // as no timeout. + if (x == (std::numeric_limits<int64_t>::max)()) x = 0; + return x; + } + + // Convert to parameter for sem_timedwait/futex/similar. Only for approved + // users. Do not call if !has_timeout. + struct timespec MakeAbsTimespec() { + int64_t n = ns_; + static const int64_t kNanosPerSecond = 1000 * 1000 * 1000; + if (n == 0) { + ABSL_RAW_LOG( + ERROR, + "Tried to create a timespec from a non-timeout; never do this."); + // But we'll try to continue sanely. no-timeout ~= saturated timeout. + n = (std::numeric_limits<int64_t>::max)(); + } + + // Kernel APIs validate timespecs as being at or after the epoch, + // despite the kernel time type being signed. However, no one can + // tell the difference between a timeout at or before the epoch (since + // all such timeouts have expired!) + if (n < 0) n = 0; + + struct timespec abstime; + int64_t seconds = (std::min)(n / kNanosPerSecond, + int64_t{(std::numeric_limits<time_t>::max)()}); + abstime.tv_sec = static_cast<time_t>(seconds); + abstime.tv_nsec = + static_cast<decltype(abstime.tv_nsec)>(n % kNanosPerSecond); + return abstime; + } + +#ifdef _WIN32 + // Converts to milliseconds from now, or INFINITE when + // !has_timeout(). For use by SleepConditionVariableSRW on + // Windows. Callers should recognize that the return value is a + // relative duration (it should be recomputed by calling this method + // in the case of a spurious wakeup). + // This header file may be included transitively by public header files, + // so we define our own DWORD and INFINITE instead of getting them from + // <intsafe.h> and <WinBase.h>. + typedef unsigned long DWord; // NOLINT + DWord InMillisecondsFromNow() const { + constexpr DWord kInfinite = (std::numeric_limits<DWord>::max)(); + if (!has_timeout()) { + return kInfinite; + } + // The use of absl::Now() to convert from absolute time to + // relative time means that absl::Now() cannot use anything that + // depends on KernelTimeout (for example, Mutex) on Windows. + int64_t now = ToUnixNanos(absl::Now()); + if (ns_ >= now) { + // Round up so that Now() + ms_from_now >= ns_. + constexpr uint64_t max_nanos = + (std::numeric_limits<int64_t>::max)() - 999999u; + uint64_t ms_from_now = + (std::min<uint64_t>(max_nanos, ns_ - now) + 999999u) / 1000000u; + if (ms_from_now > kInfinite) { + return kInfinite; + } + return static_cast<DWord>(ms_from_now); + } + return 0; + } +#endif + + friend class Futex; + friend class Waiter; +}; + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_SYNCHRONIZATION_INTERNAL_KERNEL_TIMEOUT_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/internal/mutex_nonprod.cc b/third_party/abseil_cpp/absl/synchronization/internal/mutex_nonprod.cc new file mode 100644 index 0000000000..1732f83650 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/mutex_nonprod.cc @@ -0,0 +1,324 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Implementation of a small subset of Mutex and CondVar functionality +// for platforms where the production implementation hasn't been fully +// ported yet. + +#include "absl/synchronization/mutex.h" + +#if defined(_WIN32) +#include <chrono> // NOLINT(build/c++11) +#else +#include <sys/time.h> +#include <time.h> +#endif + +#include <algorithm> + +#include "absl/base/internal/raw_logging.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +void SetMutexDeadlockDetectionMode(OnDeadlockCycle) {} +void EnableMutexInvariantDebugging(bool) {} + +namespace synchronization_internal { + +namespace { + +// Return the current time plus the timeout. +absl::Time DeadlineFromTimeout(absl::Duration timeout) { + return absl::Now() + timeout; +} + +// Limit the deadline to a positive, 32-bit time_t value to accommodate +// implementation restrictions. This also deals with InfinitePast and +// InfiniteFuture. +absl::Time LimitedDeadline(absl::Time deadline) { + deadline = std::max(absl::FromTimeT(0), deadline); + deadline = std::min(deadline, absl::FromTimeT(0x7fffffff)); + return deadline; +} + +} // namespace + +#if defined(_WIN32) + +MutexImpl::MutexImpl() {} + +MutexImpl::~MutexImpl() { + if (locked_) { + std_mutex_.unlock(); + } +} + +void MutexImpl::Lock() { + std_mutex_.lock(); + locked_ = true; +} + +bool MutexImpl::TryLock() { + bool locked = std_mutex_.try_lock(); + if (locked) locked_ = true; + return locked; +} + +void MutexImpl::Unlock() { + locked_ = false; + released_.SignalAll(); + std_mutex_.unlock(); +} + +CondVarImpl::CondVarImpl() {} + +CondVarImpl::~CondVarImpl() {} + +void CondVarImpl::Signal() { std_cv_.notify_one(); } + +void CondVarImpl::SignalAll() { std_cv_.notify_all(); } + +void CondVarImpl::Wait(MutexImpl* mu) { + mu->released_.SignalAll(); + std_cv_.wait(mu->std_mutex_); +} + +bool CondVarImpl::WaitWithDeadline(MutexImpl* mu, absl::Time deadline) { + mu->released_.SignalAll(); + time_t when = ToTimeT(deadline); + int64_t nanos = ToInt64Nanoseconds(deadline - absl::FromTimeT(when)); + std::chrono::system_clock::time_point deadline_tp = + std::chrono::system_clock::from_time_t(when) + + std::chrono::duration_cast<std::chrono::system_clock::duration>( + std::chrono::nanoseconds(nanos)); + auto deadline_since_epoch = + std::chrono::duration_cast<std::chrono::duration<double>>( + deadline_tp - std::chrono::system_clock::from_time_t(0)); + return std_cv_.wait_until(mu->std_mutex_, deadline_tp) == + std::cv_status::timeout; +} + +#else // ! _WIN32 + +MutexImpl::MutexImpl() { + ABSL_RAW_CHECK(pthread_mutex_init(&pthread_mutex_, nullptr) == 0, + "pthread error"); +} + +MutexImpl::~MutexImpl() { + if (locked_) { + ABSL_RAW_CHECK(pthread_mutex_unlock(&pthread_mutex_) == 0, "pthread error"); + } + ABSL_RAW_CHECK(pthread_mutex_destroy(&pthread_mutex_) == 0, "pthread error"); +} + +void MutexImpl::Lock() { + ABSL_RAW_CHECK(pthread_mutex_lock(&pthread_mutex_) == 0, "pthread error"); + locked_ = true; +} + +bool MutexImpl::TryLock() { + bool locked = (0 == pthread_mutex_trylock(&pthread_mutex_)); + if (locked) locked_ = true; + return locked; +} + +void MutexImpl::Unlock() { + locked_ = false; + released_.SignalAll(); + ABSL_RAW_CHECK(pthread_mutex_unlock(&pthread_mutex_) == 0, "pthread error"); +} + +CondVarImpl::CondVarImpl() { + ABSL_RAW_CHECK(pthread_cond_init(&pthread_cv_, nullptr) == 0, + "pthread error"); +} + +CondVarImpl::~CondVarImpl() { + ABSL_RAW_CHECK(pthread_cond_destroy(&pthread_cv_) == 0, "pthread error"); +} + +void CondVarImpl::Signal() { + ABSL_RAW_CHECK(pthread_cond_signal(&pthread_cv_) == 0, "pthread error"); +} + +void CondVarImpl::SignalAll() { + ABSL_RAW_CHECK(pthread_cond_broadcast(&pthread_cv_) == 0, "pthread error"); +} + +void CondVarImpl::Wait(MutexImpl* mu) { + mu->released_.SignalAll(); + ABSL_RAW_CHECK(pthread_cond_wait(&pthread_cv_, &mu->pthread_mutex_) == 0, + "pthread error"); +} + +bool CondVarImpl::WaitWithDeadline(MutexImpl* mu, absl::Time deadline) { + mu->released_.SignalAll(); + struct timespec ts = ToTimespec(deadline); + int rc = pthread_cond_timedwait(&pthread_cv_, &mu->pthread_mutex_, &ts); + if (rc == ETIMEDOUT) return true; + ABSL_RAW_CHECK(rc == 0, "pthread error"); + return false; +} + +#endif // ! _WIN32 + +void MutexImpl::Await(const Condition& cond) { + if (cond.Eval()) return; + released_.SignalAll(); + do { + released_.Wait(this); + } while (!cond.Eval()); +} + +bool MutexImpl::AwaitWithDeadline(const Condition& cond, absl::Time deadline) { + if (cond.Eval()) return true; + released_.SignalAll(); + while (true) { + if (released_.WaitWithDeadline(this, deadline)) return false; + if (cond.Eval()) return true; + } +} + +} // namespace synchronization_internal + +Mutex::Mutex() {} + +Mutex::~Mutex() {} + +void Mutex::Lock() { impl()->Lock(); } + +void Mutex::Unlock() { impl()->Unlock(); } + +bool Mutex::TryLock() { return impl()->TryLock(); } + +void Mutex::ReaderLock() { Lock(); } + +void Mutex::ReaderUnlock() { Unlock(); } + +void Mutex::Await(const Condition& cond) { impl()->Await(cond); } + +void Mutex::LockWhen(const Condition& cond) { + Lock(); + Await(cond); +} + +bool Mutex::AwaitWithDeadline(const Condition& cond, absl::Time deadline) { + return impl()->AwaitWithDeadline( + cond, synchronization_internal::LimitedDeadline(deadline)); +} + +bool Mutex::AwaitWithTimeout(const Condition& cond, absl::Duration timeout) { + return AwaitWithDeadline( + cond, synchronization_internal::DeadlineFromTimeout(timeout)); +} + +bool Mutex::LockWhenWithDeadline(const Condition& cond, absl::Time deadline) { + Lock(); + return AwaitWithDeadline(cond, deadline); +} + +bool Mutex::LockWhenWithTimeout(const Condition& cond, absl::Duration timeout) { + return LockWhenWithDeadline( + cond, synchronization_internal::DeadlineFromTimeout(timeout)); +} + +void Mutex::ReaderLockWhen(const Condition& cond) { + ReaderLock(); + Await(cond); +} + +bool Mutex::ReaderLockWhenWithTimeout(const Condition& cond, + absl::Duration timeout) { + return LockWhenWithTimeout(cond, timeout); +} +bool Mutex::ReaderLockWhenWithDeadline(const Condition& cond, + absl::Time deadline) { + return LockWhenWithDeadline(cond, deadline); +} + +void Mutex::EnableDebugLog(const char*) {} +void Mutex::EnableInvariantDebugging(void (*)(void*), void*) {} +void Mutex::ForgetDeadlockInfo() {} +void Mutex::AssertHeld() const {} +void Mutex::AssertReaderHeld() const {} +void Mutex::AssertNotHeld() const {} + +CondVar::CondVar() {} + +CondVar::~CondVar() {} + +void CondVar::Signal() { impl()->Signal(); } + +void CondVar::SignalAll() { impl()->SignalAll(); } + +void CondVar::Wait(Mutex* mu) { return impl()->Wait(mu->impl()); } + +bool CondVar::WaitWithDeadline(Mutex* mu, absl::Time deadline) { + return impl()->WaitWithDeadline( + mu->impl(), synchronization_internal::LimitedDeadline(deadline)); +} + +bool CondVar::WaitWithTimeout(Mutex* mu, absl::Duration timeout) { + return WaitWithDeadline(mu, absl::Now() + timeout); +} + +void CondVar::EnableDebugLog(const char*) {} + +#ifdef THREAD_SANITIZER +extern "C" void __tsan_read1(void *addr); +#else +#define __tsan_read1(addr) // do nothing if TSan not enabled +#endif + +// A function that just returns its argument, dereferenced +static bool Dereference(void *arg) { + // ThreadSanitizer does not instrument this file for memory accesses. + // This function dereferences a user variable that can participate + // in a data race, so we need to manually tell TSan about this memory access. + __tsan_read1(arg); + return *(static_cast<bool *>(arg)); +} + +Condition::Condition() {} // null constructor, used for kTrue only +const Condition Condition::kTrue; + +Condition::Condition(bool (*func)(void *), void *arg) + : eval_(&CallVoidPtrFunction), + function_(func), + method_(nullptr), + arg_(arg) {} + +bool Condition::CallVoidPtrFunction(const Condition *c) { + return (*c->function_)(c->arg_); +} + +Condition::Condition(const bool *cond) + : eval_(CallVoidPtrFunction), + function_(Dereference), + method_(nullptr), + // const_cast is safe since Dereference does not modify arg + arg_(const_cast<bool *>(cond)) {} + +bool Condition::Eval() const { + // eval_ == null for kTrue + return (this->eval_ == nullptr) || (*this->eval_)(this); +} + +void RegisterSymbolizer(bool (*)(const void*, char*, int)) {} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/internal/mutex_nonprod.inc b/third_party/abseil_cpp/absl/synchronization/internal/mutex_nonprod.inc new file mode 100644 index 0000000000..d83bc8a94c --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/mutex_nonprod.inc @@ -0,0 +1,249 @@ +// Do not include. This is an implementation detail of base/mutex.h. +// +// Declares three classes: +// +// base::internal::MutexImpl - implementation helper for Mutex +// base::internal::CondVarImpl - implementation helper for CondVar +// base::internal::SynchronizationStorage<T> - implementation helper for +// Mutex, CondVar + +#include <type_traits> + +#if defined(_WIN32) +#include <condition_variable> +#include <mutex> +#else +#include <pthread.h> +#endif + +#include "absl/base/call_once.h" +#include "absl/time/time.h" + +// Declare that Mutex::ReaderLock is actually Lock(). Intended primarily +// for tests, and even then as a last resort. +#ifdef ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE +#error ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE cannot be directly set +#else +#define ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE 1 +#endif + +// Declare that Mutex::EnableInvariantDebugging is not implemented. +// Intended primarily for tests, and even then as a last resort. +#ifdef ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED +#error ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED cannot be directly set +#else +#define ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED 1 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +class Condition; + +namespace synchronization_internal { + +class MutexImpl; + +// Do not use this implementation detail of CondVar. Provides most of the +// implementation, but should not be placed directly in static storage +// because it will not linker initialize properly. See +// SynchronizationStorage<T> below for what we mean by linker +// initialization. +class CondVarImpl { + public: + CondVarImpl(); + CondVarImpl(const CondVarImpl&) = delete; + CondVarImpl& operator=(const CondVarImpl&) = delete; + ~CondVarImpl(); + + void Signal(); + void SignalAll(); + void Wait(MutexImpl* mutex); + bool WaitWithDeadline(MutexImpl* mutex, absl::Time deadline); + + private: +#if defined(_WIN32) + std::condition_variable_any std_cv_; +#else + pthread_cond_t pthread_cv_; +#endif +}; + +// Do not use this implementation detail of Mutex. Provides most of the +// implementation, but should not be placed directly in static storage +// because it will not linker initialize properly. See +// SynchronizationStorage<T> below for what we mean by linker +// initialization. +class MutexImpl { + public: + MutexImpl(); + MutexImpl(const MutexImpl&) = delete; + MutexImpl& operator=(const MutexImpl&) = delete; + ~MutexImpl(); + + void Lock(); + bool TryLock(); + void Unlock(); + void Await(const Condition& cond); + bool AwaitWithDeadline(const Condition& cond, absl::Time deadline); + + private: + friend class CondVarImpl; + +#if defined(_WIN32) + std::mutex std_mutex_; +#else + pthread_mutex_t pthread_mutex_; +#endif + + // True if the underlying mutex is locked. If the destructor is entered + // while locked_, the underlying mutex is unlocked. Mutex supports + // destruction while locked, but the same is undefined behavior for both + // pthread_mutex_t and std::mutex. + bool locked_ = false; + + // Signaled before releasing the lock, in support of Await. + CondVarImpl released_; +}; + +// Do not use this implementation detail of CondVar and Mutex. A storage +// space for T that supports a LinkerInitialized constructor. T must +// have a default constructor, which is called by the first call to +// get(). T's destructor is never called if the LinkerInitialized +// constructor is called. +// +// Objects constructed with the default constructor are constructed and +// destructed like any other object, and should never be allocated in +// static storage. +// +// Objects constructed with the LinkerInitialized constructor should +// always be in static storage. For such objects, calls to get() are always +// valid, except from signal handlers. +// +// Note that this implementation relies on undefined language behavior that +// are known to hold for the set of supported compilers. An analysis +// follows. +// +// From the C++11 standard: +// +// [basic.life] says an object has non-trivial initialization if it is of +// class type and it is initialized by a constructor other than a trivial +// default constructor. (the LinkerInitialized constructor is +// non-trivial) +// +// [basic.life] says the lifetime of an object with a non-trivial +// constructor begins when the call to the constructor is complete. +// +// [basic.life] says the lifetime of an object with non-trivial destructor +// ends when the call to the destructor begins. +// +// [basic.life] p5 specifies undefined behavior when accessing non-static +// members of an instance outside its +// lifetime. (SynchronizationStorage::get() access non-static members) +// +// So, LinkerInitialized object of SynchronizationStorage uses a +// non-trivial constructor, which is called at some point during dynamic +// initialization, and is therefore subject to order of dynamic +// initialization bugs, where get() is called before the object's +// constructor is, resulting in undefined behavior. +// +// Similarly, a LinkerInitialized SynchronizationStorage object has a +// non-trivial destructor, and so its lifetime ends at some point during +// destruction of objects with static storage duration [basic.start.term] +// p4. There is a window where other exit code could call get() after this +// occurs, resulting in undefined behavior. +// +// Combined, these statements imply that LinkerInitialized instances +// of SynchronizationStorage<T> rely on undefined behavior. +// +// However, in practice, the implementation works on all supported +// compilers. Specifically, we rely on: +// +// a) zero-initialization being sufficient to initialize +// LinkerInitialized instances for the purposes of calling +// get(), regardless of when the constructor is called. This is +// because the is_dynamic_ boolean is correctly zero-initialized to +// false. +// +// b) the LinkerInitialized constructor is a NOP, and immaterial to +// even to concurrent calls to get(). +// +// c) the destructor being a NOP for LinkerInitialized objects +// (guaranteed by a check for !is_dynamic_), and so any concurrent and +// subsequent calls to get() functioning as if the destructor were not +// called, by virtue of the instances' storage remaining valid after the +// destructor runs. +// +// d) That a-c apply transitively when SynchronizationStorage<T> is the +// only member of a class allocated in static storage. +// +// Nothing in the language standard guarantees that a-d hold. In practice, +// these hold in all supported compilers. +// +// Future direction: +// +// Ideally, we would simply use std::mutex or a similar class, which when +// allocated statically would support use immediately after static +// initialization up until static storage is reclaimed (i.e. the properties +// we require of all "linker initialized" instances). +// +// Regarding construction in static storage, std::mutex is required to +// provide a constexpr default constructor [thread.mutex.class], which +// ensures the instance's lifetime begins with static initialization +// [basic.start.init], and so is immune to any problems caused by the order +// of dynamic initialization. However, as of this writing Microsoft's +// Visual Studio does not provide a constexpr constructor for std::mutex. +// See +// https://blogs.msdn.microsoft.com/vcblog/2015/06/02/constexpr-complete-for-vs-2015-rtm-c11-compiler-c17-stl/ +// +// Regarding destruction of instances in static storage, [basic.life] does +// say an object ends when storage in which the occupies is released, in +// the case of non-trivial destructor. However, std::mutex is not specified +// to have a trivial destructor. +// +// So, we would need a class with a constexpr default constructor and a +// trivial destructor. Today, we can achieve neither desired property using +// std::mutex directly. +template <typename T> +class SynchronizationStorage { + public: + // Instances allocated on the heap or on the stack should use the default + // constructor. + SynchronizationStorage() + : destruct_(true), once_() {} + + constexpr explicit SynchronizationStorage(absl::ConstInitType) + : destruct_(false), once_(), space_{{0}} {} + + SynchronizationStorage(SynchronizationStorage&) = delete; + SynchronizationStorage& operator=(SynchronizationStorage&) = delete; + + ~SynchronizationStorage() { + if (destruct_) { + get()->~T(); + } + } + + // Retrieve the object in storage. This is fast and thread safe, but does + // incur the cost of absl::call_once(). + T* get() { + absl::call_once(once_, SynchronizationStorage::Construct, this); + return reinterpret_cast<T*>(&space_); + } + + private: + static void Construct(SynchronizationStorage<T>* self) { + new (&self->space_) T(); + } + + // When true, T's destructor is run when this is destructed. + const bool destruct_; + + absl::once_flag once_; + + // An aligned space for the T. + alignas(T) unsigned char space_[sizeof(T)]; +}; + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem.cc b/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem.cc new file mode 100644 index 0000000000..821ca9b4e9 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem.cc @@ -0,0 +1,106 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file is a no-op if the required LowLevelAlloc support is missing. +#include "absl/base/internal/low_level_alloc.h" +#ifndef ABSL_LOW_LEVEL_ALLOC_MISSING + +#include "absl/synchronization/internal/per_thread_sem.h" + +#include <atomic> + +#include "absl/base/attributes.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/synchronization/internal/waiter.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +void PerThreadSem::SetThreadBlockedCounter(std::atomic<int> *counter) { + base_internal::ThreadIdentity *identity; + identity = GetOrCreateCurrentThreadIdentity(); + identity->blocked_count_ptr = counter; +} + +std::atomic<int> *PerThreadSem::GetThreadBlockedCounter() { + base_internal::ThreadIdentity *identity; + identity = GetOrCreateCurrentThreadIdentity(); + return identity->blocked_count_ptr; +} + +void PerThreadSem::Init(base_internal::ThreadIdentity *identity) { + new (Waiter::GetWaiter(identity)) Waiter(); + identity->ticker.store(0, std::memory_order_relaxed); + identity->wait_start.store(0, std::memory_order_relaxed); + identity->is_idle.store(false, std::memory_order_relaxed); +} + +void PerThreadSem::Destroy(base_internal::ThreadIdentity *identity) { + Waiter::GetWaiter(identity)->~Waiter(); +} + +void PerThreadSem::Tick(base_internal::ThreadIdentity *identity) { + const int ticker = + identity->ticker.fetch_add(1, std::memory_order_relaxed) + 1; + const int wait_start = identity->wait_start.load(std::memory_order_relaxed); + const bool is_idle = identity->is_idle.load(std::memory_order_relaxed); + if (wait_start && (ticker - wait_start > Waiter::kIdlePeriods) && !is_idle) { + // Wakeup the waiting thread since it is time for it to become idle. + Waiter::GetWaiter(identity)->Poke(); + } +} + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +extern "C" { + +ABSL_ATTRIBUTE_WEAK void AbslInternalPerThreadSemPost( + absl::base_internal::ThreadIdentity *identity) { + absl::synchronization_internal::Waiter::GetWaiter(identity)->Post(); +} + +ABSL_ATTRIBUTE_WEAK bool AbslInternalPerThreadSemWait( + absl::synchronization_internal::KernelTimeout t) { + bool timeout = false; + absl::base_internal::ThreadIdentity *identity; + identity = absl::synchronization_internal::GetOrCreateCurrentThreadIdentity(); + + // Ensure wait_start != 0. + int ticker = identity->ticker.load(std::memory_order_relaxed); + identity->wait_start.store(ticker ? ticker : 1, std::memory_order_relaxed); + identity->is_idle.store(false, std::memory_order_relaxed); + + if (identity->blocked_count_ptr != nullptr) { + // Increment count of threads blocked in a given thread pool. + identity->blocked_count_ptr->fetch_add(1, std::memory_order_relaxed); + } + + timeout = + !absl::synchronization_internal::Waiter::GetWaiter(identity)->Wait(t); + + if (identity->blocked_count_ptr != nullptr) { + identity->blocked_count_ptr->fetch_sub(1, std::memory_order_relaxed); + } + + identity->is_idle.store(false, std::memory_order_relaxed); + identity->wait_start.store(0, std::memory_order_relaxed); + return !timeout; +} + +} // extern "C" + +#endif // ABSL_LOW_LEVEL_ALLOC_MISSING diff --git a/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem.h b/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem.h new file mode 100644 index 0000000000..8ab439153a --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem.h @@ -0,0 +1,115 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +// PerThreadSem is a low-level synchronization primitive controlling the +// runnability of a single thread, used internally by Mutex and CondVar. +// +// This is NOT a general-purpose synchronization mechanism, and should not be +// used directly by applications. Applications should use Mutex and CondVar. +// +// The semantics of PerThreadSem are the same as that of a counting semaphore. +// Each thread maintains an abstract "count" value associated with its identity. + +#ifndef ABSL_SYNCHRONIZATION_INTERNAL_PER_THREAD_SEM_H_ +#define ABSL_SYNCHRONIZATION_INTERNAL_PER_THREAD_SEM_H_ + +#include <atomic> + +#include "absl/base/internal/thread_identity.h" +#include "absl/synchronization/internal/create_thread_identity.h" +#include "absl/synchronization/internal/kernel_timeout.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class Mutex; + +namespace synchronization_internal { + +class PerThreadSem { + public: + PerThreadSem() = delete; + PerThreadSem(const PerThreadSem&) = delete; + PerThreadSem& operator=(const PerThreadSem&) = delete; + + // Routine invoked periodically (once a second) by a background thread. + // Has no effect on user-visible state. + static void Tick(base_internal::ThreadIdentity* identity); + + // --------------------------------------------------------------------------- + // Routines used by autosizing threadpools to detect when threads are + // blocked. Each thread has a counter pointer, initially zero. If non-zero, + // the implementation atomically increments the counter when it blocks on a + // semaphore, a decrements it again when it wakes. This allows a threadpool + // to keep track of how many of its threads are blocked. + // SetThreadBlockedCounter() should be used only by threadpool + // implementations. GetThreadBlockedCounter() should be used by modules that + // block threads; if the pointer returned is non-zero, the location should be + // incremented before the thread blocks, and decremented after it wakes. + static void SetThreadBlockedCounter(std::atomic<int> *counter); + static std::atomic<int> *GetThreadBlockedCounter(); + + private: + // Create the PerThreadSem associated with "identity". Initializes count=0. + // REQUIRES: May only be called by ThreadIdentity. + static void Init(base_internal::ThreadIdentity* identity); + + // Destroy the PerThreadSem associated with "identity". + // REQUIRES: May only be called by ThreadIdentity. + static void Destroy(base_internal::ThreadIdentity* identity); + + // Increments "identity"'s count. + static inline void Post(base_internal::ThreadIdentity* identity); + + // Waits until either our count > 0 or t has expired. + // If count > 0, decrements count and returns true. Otherwise returns false. + // !t.has_timeout() => Wait(t) will return true. + static inline bool Wait(KernelTimeout t); + + // White-listed callers. + friend class PerThreadSemTest; + friend class absl::Mutex; + friend absl::base_internal::ThreadIdentity* CreateThreadIdentity(); + friend void ReclaimThreadIdentity(void* v); +}; + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +// In some build configurations we pass --detect-odr-violations to the +// gold linker. This causes it to flag weak symbol overrides as ODR +// violations. Because ODR only applies to C++ and not C, +// --detect-odr-violations ignores symbols not mangled with C++ names. +// By changing our extension points to be extern "C", we dodge this +// check. +extern "C" { +void AbslInternalPerThreadSemPost( + absl::base_internal::ThreadIdentity* identity); +bool AbslInternalPerThreadSemWait( + absl::synchronization_internal::KernelTimeout t); +} // extern "C" + +void absl::synchronization_internal::PerThreadSem::Post( + absl::base_internal::ThreadIdentity* identity) { + AbslInternalPerThreadSemPost(identity); +} + +bool absl::synchronization_internal::PerThreadSem::Wait( + absl::synchronization_internal::KernelTimeout t) { + return AbslInternalPerThreadSemWait(t); +} + +#endif // ABSL_SYNCHRONIZATION_INTERNAL_PER_THREAD_SEM_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem_test.cc b/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem_test.cc new file mode 100644 index 0000000000..b5a2f6d4b5 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/per_thread_sem_test.cc @@ -0,0 +1,180 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/internal/per_thread_sem.h" + +#include <atomic> +#include <condition_variable> // NOLINT(build/c++11) +#include <functional> +#include <limits> +#include <mutex> // NOLINT(build/c++11) +#include <string> +#include <thread> // NOLINT(build/c++11) + +#include "gtest/gtest.h" +#include "absl/base/internal/cycleclock.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/strings/str_cat.h" +#include "absl/time/clock.h" +#include "absl/time/time.h" + +// In this test we explicitly avoid the use of synchronization +// primitives which might use PerThreadSem, most notably absl::Mutex. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +class SimpleSemaphore { + public: + SimpleSemaphore() : count_(0) {} + + // Decrements (locks) the semaphore. If the semaphore's value is + // greater than zero, then the decrement proceeds, and the function + // returns, immediately. If the semaphore currently has the value + // zero, then the call blocks until it becomes possible to perform + // the decrement. + void Wait() { + std::unique_lock<std::mutex> lock(mu_); + cv_.wait(lock, [this]() { return count_ > 0; }); + --count_; + cv_.notify_one(); + } + + // Increments (unlocks) the semaphore. If the semaphore's value + // consequently becomes greater than zero, then another thread + // blocked Wait() call will be woken up and proceed to lock the + // semaphore. + void Post() { + std::lock_guard<std::mutex> lock(mu_); + ++count_; + cv_.notify_one(); + } + + private: + std::mutex mu_; + std::condition_variable cv_; + int count_; +}; + +struct ThreadData { + int num_iterations; // Number of replies to send. + SimpleSemaphore identity2_written; // Posted by thread writing identity2. + base_internal::ThreadIdentity *identity1; // First Post()-er. + base_internal::ThreadIdentity *identity2; // First Wait()-er. + KernelTimeout timeout; +}; + +// Need friendship with PerThreadSem. +class PerThreadSemTest : public testing::Test { + public: + static void TimingThread(ThreadData* t) { + t->identity2 = GetOrCreateCurrentThreadIdentity(); + t->identity2_written.Post(); + while (t->num_iterations--) { + Wait(t->timeout); + Post(t->identity1); + } + } + + void TestTiming(const char *msg, bool timeout) { + static const int kNumIterations = 100; + ThreadData t; + t.num_iterations = kNumIterations; + t.timeout = timeout ? + KernelTimeout(absl::Now() + absl::Seconds(10000)) // far in the future + : KernelTimeout::Never(); + t.identity1 = GetOrCreateCurrentThreadIdentity(); + + // We can't use the Thread class here because it uses the Mutex + // class which will invoke PerThreadSem, so we use std::thread instead. + std::thread partner_thread(std::bind(TimingThread, &t)); + + // Wait for our partner thread to register their identity. + t.identity2_written.Wait(); + + int64_t min_cycles = std::numeric_limits<int64_t>::max(); + int64_t total_cycles = 0; + for (int i = 0; i < kNumIterations; ++i) { + absl::SleepFor(absl::Milliseconds(20)); + int64_t cycles = base_internal::CycleClock::Now(); + Post(t.identity2); + Wait(t.timeout); + cycles = base_internal::CycleClock::Now() - cycles; + min_cycles = std::min(min_cycles, cycles); + total_cycles += cycles; + } + std::string out = StrCat( + msg, "min cycle count=", min_cycles, " avg cycle count=", + absl::SixDigits(static_cast<double>(total_cycles) / kNumIterations)); + printf("%s\n", out.c_str()); + + partner_thread.join(); + } + + protected: + static void Post(base_internal::ThreadIdentity *id) { + PerThreadSem::Post(id); + } + static bool Wait(KernelTimeout t) { + return PerThreadSem::Wait(t); + } + + // convenience overload + static bool Wait(absl::Time t) { + return Wait(KernelTimeout(t)); + } + + static void Tick(base_internal::ThreadIdentity *identity) { + PerThreadSem::Tick(identity); + } +}; + +namespace { + +TEST_F(PerThreadSemTest, WithoutTimeout) { + PerThreadSemTest::TestTiming("Without timeout: ", false); +} + +TEST_F(PerThreadSemTest, WithTimeout) { + PerThreadSemTest::TestTiming("With timeout: ", true); +} + +TEST_F(PerThreadSemTest, Timeouts) { + const absl::Duration delay = absl::Milliseconds(50); + const absl::Time start = absl::Now(); + EXPECT_FALSE(Wait(start + delay)); + const absl::Duration elapsed = absl::Now() - start; + // Allow for a slight early return, to account for quality of implementation + // issues on various platforms. + const absl::Duration slop = absl::Microseconds(200); + EXPECT_LE(delay - slop, elapsed) + << "Wait returned " << delay - elapsed + << " early (with " << slop << " slop), start time was " << start; + + absl::Time negative_timeout = absl::UnixEpoch() - absl::Milliseconds(100); + EXPECT_FALSE(Wait(negative_timeout)); + EXPECT_LE(negative_timeout, absl::Now() + slop); // trivially true :) + + Post(GetOrCreateCurrentThreadIdentity()); + // The wait here has an expired timeout, but we have a wake to consume, + // so this should succeed + EXPECT_TRUE(Wait(negative_timeout)); +} + +} // namespace + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/internal/thread_pool.h b/third_party/abseil_cpp/absl/synchronization/internal/thread_pool.h new file mode 100644 index 0000000000..0cb96dacde --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/thread_pool.h @@ -0,0 +1,93 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_SYNCHRONIZATION_INTERNAL_THREAD_POOL_H_ +#define ABSL_SYNCHRONIZATION_INTERNAL_THREAD_POOL_H_ + +#include <cassert> +#include <cstddef> +#include <functional> +#include <queue> +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +// A simple ThreadPool implementation for tests. +class ThreadPool { + public: + explicit ThreadPool(int num_threads) { + for (int i = 0; i < num_threads; ++i) { + threads_.push_back(std::thread(&ThreadPool::WorkLoop, this)); + } + } + + ThreadPool(const ThreadPool &) = delete; + ThreadPool &operator=(const ThreadPool &) = delete; + + ~ThreadPool() { + { + absl::MutexLock l(&mu_); + for (size_t i = 0; i < threads_.size(); i++) { + queue_.push(nullptr); // Shutdown signal. + } + } + for (auto &t : threads_) { + t.join(); + } + } + + // Schedule a function to be run on a ThreadPool thread immediately. + void Schedule(std::function<void()> func) { + assert(func != nullptr); + absl::MutexLock l(&mu_); + queue_.push(std::move(func)); + } + + private: + bool WorkAvailable() const ABSL_EXCLUSIVE_LOCKS_REQUIRED(mu_) { + return !queue_.empty(); + } + + void WorkLoop() { + while (true) { + std::function<void()> func; + { + absl::MutexLock l(&mu_); + mu_.Await(absl::Condition(this, &ThreadPool::WorkAvailable)); + func = std::move(queue_.front()); + queue_.pop(); + } + if (func == nullptr) { // Shutdown signal. + break; + } + func(); + } + } + + absl::Mutex mu_; + std::queue<std::function<void()>> queue_ ABSL_GUARDED_BY(mu_); + std::vector<std::thread> threads_; +}; + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_SYNCHRONIZATION_INTERNAL_THREAD_POOL_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/internal/waiter.cc b/third_party/abseil_cpp/absl/synchronization/internal/waiter.cc new file mode 100644 index 0000000000..b6150b9b2b --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/waiter.cc @@ -0,0 +1,492 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/internal/waiter.h" + +#include "absl/base/config.h" + +#ifdef _WIN32 +#include <windows.h> +#else +#include <pthread.h> +#include <sys/time.h> +#include <unistd.h> +#endif + +#ifdef __linux__ +#include <linux/futex.h> +#include <sys/syscall.h> +#endif + +#ifdef ABSL_HAVE_SEMAPHORE_H +#include <semaphore.h> +#endif + +#include <errno.h> +#include <stdio.h> +#include <time.h> + +#include <atomic> +#include <cassert> +#include <cstdint> +#include <new> +#include <type_traits> + +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/base/optimization.h" +#include "absl/synchronization/internal/kernel_timeout.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +static void MaybeBecomeIdle() { + base_internal::ThreadIdentity *identity = + base_internal::CurrentThreadIdentityIfPresent(); + assert(identity != nullptr); + const bool is_idle = identity->is_idle.load(std::memory_order_relaxed); + const int ticker = identity->ticker.load(std::memory_order_relaxed); + const int wait_start = identity->wait_start.load(std::memory_order_relaxed); + if (!is_idle && ticker - wait_start > Waiter::kIdlePeriods) { + identity->is_idle.store(true, std::memory_order_relaxed); + } +} + +#if ABSL_WAITER_MODE == ABSL_WAITER_MODE_FUTEX + +// Some Android headers are missing these definitions even though they +// support these futex operations. +#ifdef __BIONIC__ +#ifndef SYS_futex +#define SYS_futex __NR_futex +#endif +#ifndef FUTEX_WAIT_BITSET +#define FUTEX_WAIT_BITSET 9 +#endif +#ifndef FUTEX_PRIVATE_FLAG +#define FUTEX_PRIVATE_FLAG 128 +#endif +#ifndef FUTEX_CLOCK_REALTIME +#define FUTEX_CLOCK_REALTIME 256 +#endif +#ifndef FUTEX_BITSET_MATCH_ANY +#define FUTEX_BITSET_MATCH_ANY 0xFFFFFFFF +#endif +#endif + +#if defined(__NR_futex_time64) && !defined(SYS_futex_time64) +#define SYS_futex_time64 __NR_futex_time64 +#endif + +#if defined(SYS_futex_time64) && !defined(SYS_futex) +#define SYS_futex SYS_futex_time64 +#endif + +class Futex { + public: + static int WaitUntil(std::atomic<int32_t> *v, int32_t val, + KernelTimeout t) { + int err = 0; + if (t.has_timeout()) { + // https://locklessinc.com/articles/futex_cheat_sheet/ + // Unlike FUTEX_WAIT, FUTEX_WAIT_BITSET uses absolute time. + struct timespec abs_timeout = t.MakeAbsTimespec(); + // Atomically check that the futex value is still 0, and if it + // is, sleep until abs_timeout or until woken by FUTEX_WAKE. + err = syscall( + SYS_futex, reinterpret_cast<int32_t *>(v), + FUTEX_WAIT_BITSET | FUTEX_PRIVATE_FLAG | FUTEX_CLOCK_REALTIME, val, + &abs_timeout, nullptr, FUTEX_BITSET_MATCH_ANY); + } else { + // Atomically check that the futex value is still 0, and if it + // is, sleep until woken by FUTEX_WAKE. + err = syscall(SYS_futex, reinterpret_cast<int32_t *>(v), + FUTEX_WAIT | FUTEX_PRIVATE_FLAG, val, nullptr); + } + if (err != 0) { + err = -errno; + } + return err; + } + + static int Wake(std::atomic<int32_t> *v, int32_t count) { + int err = syscall(SYS_futex, reinterpret_cast<int32_t *>(v), + FUTEX_WAKE | FUTEX_PRIVATE_FLAG, count); + if (ABSL_PREDICT_FALSE(err < 0)) { + err = -errno; + } + return err; + } +}; + +Waiter::Waiter() { + futex_.store(0, std::memory_order_relaxed); +} + +Waiter::~Waiter() = default; + +bool Waiter::Wait(KernelTimeout t) { + // Loop until we can atomically decrement futex from a positive + // value, waiting on a futex while we believe it is zero. + // Note that, since the thread ticker is just reset, we don't need to check + // whether the thread is idle on the very first pass of the loop. + bool first_pass = true; + while (true) { + int32_t x = futex_.load(std::memory_order_relaxed); + while (x != 0) { + if (!futex_.compare_exchange_weak(x, x - 1, + std::memory_order_acquire, + std::memory_order_relaxed)) { + continue; // Raced with someone, retry. + } + return true; // Consumed a wakeup, we are done. + } + + + if (!first_pass) MaybeBecomeIdle(); + const int err = Futex::WaitUntil(&futex_, 0, t); + if (err != 0) { + if (err == -EINTR || err == -EWOULDBLOCK) { + // Do nothing, the loop will retry. + } else if (err == -ETIMEDOUT) { + return false; + } else { + ABSL_RAW_LOG(FATAL, "Futex operation failed with error %d\n", err); + } + } + first_pass = false; + } +} + +void Waiter::Post() { + if (futex_.fetch_add(1, std::memory_order_release) == 0) { + // We incremented from 0, need to wake a potential waiter. + Poke(); + } +} + +void Waiter::Poke() { + // Wake one thread waiting on the futex. + const int err = Futex::Wake(&futex_, 1); + if (ABSL_PREDICT_FALSE(err < 0)) { + ABSL_RAW_LOG(FATAL, "Futex operation failed with error %d\n", err); + } +} + +#elif ABSL_WAITER_MODE == ABSL_WAITER_MODE_CONDVAR + +class PthreadMutexHolder { + public: + explicit PthreadMutexHolder(pthread_mutex_t *mu) : mu_(mu) { + const int err = pthread_mutex_lock(mu_); + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_mutex_lock failed: %d", err); + } + } + + PthreadMutexHolder(const PthreadMutexHolder &rhs) = delete; + PthreadMutexHolder &operator=(const PthreadMutexHolder &rhs) = delete; + + ~PthreadMutexHolder() { + const int err = pthread_mutex_unlock(mu_); + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_mutex_unlock failed: %d", err); + } + } + + private: + pthread_mutex_t *mu_; +}; + +Waiter::Waiter() { + const int err = pthread_mutex_init(&mu_, 0); + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_mutex_init failed: %d", err); + } + + const int err2 = pthread_cond_init(&cv_, 0); + if (err2 != 0) { + ABSL_RAW_LOG(FATAL, "pthread_cond_init failed: %d", err2); + } + + waiter_count_ = 0; + wakeup_count_ = 0; +} + +Waiter::~Waiter() { + const int err = pthread_mutex_destroy(&mu_); + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_mutex_destroy failed: %d", err); + } + + const int err2 = pthread_cond_destroy(&cv_); + if (err2 != 0) { + ABSL_RAW_LOG(FATAL, "pthread_cond_destroy failed: %d", err2); + } +} + +bool Waiter::Wait(KernelTimeout t) { + struct timespec abs_timeout; + if (t.has_timeout()) { + abs_timeout = t.MakeAbsTimespec(); + } + + PthreadMutexHolder h(&mu_); + ++waiter_count_; + // Loop until we find a wakeup to consume or timeout. + // Note that, since the thread ticker is just reset, we don't need to check + // whether the thread is idle on the very first pass of the loop. + bool first_pass = true; + while (wakeup_count_ == 0) { + if (!first_pass) MaybeBecomeIdle(); + // No wakeups available, time to wait. + if (!t.has_timeout()) { + const int err = pthread_cond_wait(&cv_, &mu_); + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_cond_wait failed: %d", err); + } + } else { + const int err = pthread_cond_timedwait(&cv_, &mu_, &abs_timeout); + if (err == ETIMEDOUT) { + --waiter_count_; + return false; + } + if (err != 0) { + ABSL_RAW_LOG(FATAL, "pthread_cond_timedwait failed: %d", err); + } + } + first_pass = false; + } + // Consume a wakeup and we're done. + --wakeup_count_; + --waiter_count_; + return true; +} + +void Waiter::Post() { + PthreadMutexHolder h(&mu_); + ++wakeup_count_; + InternalCondVarPoke(); +} + +void Waiter::Poke() { + PthreadMutexHolder h(&mu_); + InternalCondVarPoke(); +} + +void Waiter::InternalCondVarPoke() { + if (waiter_count_ != 0) { + const int err = pthread_cond_signal(&cv_); + if (ABSL_PREDICT_FALSE(err != 0)) { + ABSL_RAW_LOG(FATAL, "pthread_cond_signal failed: %d", err); + } + } +} + +#elif ABSL_WAITER_MODE == ABSL_WAITER_MODE_SEM + +Waiter::Waiter() { + if (sem_init(&sem_, 0, 0) != 0) { + ABSL_RAW_LOG(FATAL, "sem_init failed with errno %d\n", errno); + } + wakeups_.store(0, std::memory_order_relaxed); +} + +Waiter::~Waiter() { + if (sem_destroy(&sem_) != 0) { + ABSL_RAW_LOG(FATAL, "sem_destroy failed with errno %d\n", errno); + } +} + +bool Waiter::Wait(KernelTimeout t) { + struct timespec abs_timeout; + if (t.has_timeout()) { + abs_timeout = t.MakeAbsTimespec(); + } + + // Loop until we timeout or consume a wakeup. + // Note that, since the thread ticker is just reset, we don't need to check + // whether the thread is idle on the very first pass of the loop. + bool first_pass = true; + while (true) { + int x = wakeups_.load(std::memory_order_relaxed); + while (x != 0) { + if (!wakeups_.compare_exchange_weak(x, x - 1, + std::memory_order_acquire, + std::memory_order_relaxed)) { + continue; // Raced with someone, retry. + } + // Successfully consumed a wakeup, we're done. + return true; + } + + if (!first_pass) MaybeBecomeIdle(); + // Nothing to consume, wait (looping on EINTR). + while (true) { + if (!t.has_timeout()) { + if (sem_wait(&sem_) == 0) break; + if (errno == EINTR) continue; + ABSL_RAW_LOG(FATAL, "sem_wait failed: %d", errno); + } else { + if (sem_timedwait(&sem_, &abs_timeout) == 0) break; + if (errno == EINTR) continue; + if (errno == ETIMEDOUT) return false; + ABSL_RAW_LOG(FATAL, "sem_timedwait failed: %d", errno); + } + } + first_pass = false; + } +} + +void Waiter::Post() { + // Post a wakeup. + if (wakeups_.fetch_add(1, std::memory_order_release) == 0) { + // We incremented from 0, need to wake a potential waiter. + Poke(); + } +} + +void Waiter::Poke() { + if (sem_post(&sem_) != 0) { // Wake any semaphore waiter. + ABSL_RAW_LOG(FATAL, "sem_post failed with errno %d\n", errno); + } +} + +#elif ABSL_WAITER_MODE == ABSL_WAITER_MODE_WIN32 + +class Waiter::WinHelper { + public: + static SRWLOCK *GetLock(Waiter *w) { + return reinterpret_cast<SRWLOCK *>(&w->mu_storage_); + } + + static CONDITION_VARIABLE *GetCond(Waiter *w) { + return reinterpret_cast<CONDITION_VARIABLE *>(&w->cv_storage_); + } + + static_assert(sizeof(SRWLOCK) == sizeof(void *), + "`mu_storage_` does not have the same size as SRWLOCK"); + static_assert(alignof(SRWLOCK) == alignof(void *), + "`mu_storage_` does not have the same alignment as SRWLOCK"); + + static_assert(sizeof(CONDITION_VARIABLE) == sizeof(void *), + "`ABSL_CONDITION_VARIABLE_STORAGE` does not have the same size " + "as `CONDITION_VARIABLE`"); + static_assert( + alignof(CONDITION_VARIABLE) == alignof(void *), + "`cv_storage_` does not have the same alignment as `CONDITION_VARIABLE`"); + + // The SRWLOCK and CONDITION_VARIABLE types must be trivially constructible + // and destructible because we never call their constructors or destructors. + static_assert(std::is_trivially_constructible<SRWLOCK>::value, + "The `SRWLOCK` type must be trivially constructible"); + static_assert( + std::is_trivially_constructible<CONDITION_VARIABLE>::value, + "The `CONDITION_VARIABLE` type must be trivially constructible"); + static_assert(std::is_trivially_destructible<SRWLOCK>::value, + "The `SRWLOCK` type must be trivially destructible"); + static_assert(std::is_trivially_destructible<CONDITION_VARIABLE>::value, + "The `CONDITION_VARIABLE` type must be trivially destructible"); +}; + +class LockHolder { + public: + explicit LockHolder(SRWLOCK* mu) : mu_(mu) { + AcquireSRWLockExclusive(mu_); + } + + LockHolder(const LockHolder&) = delete; + LockHolder& operator=(const LockHolder&) = delete; + + ~LockHolder() { + ReleaseSRWLockExclusive(mu_); + } + + private: + SRWLOCK* mu_; +}; + +Waiter::Waiter() { + auto *mu = ::new (static_cast<void *>(&mu_storage_)) SRWLOCK; + auto *cv = ::new (static_cast<void *>(&cv_storage_)) CONDITION_VARIABLE; + InitializeSRWLock(mu); + InitializeConditionVariable(cv); + waiter_count_ = 0; + wakeup_count_ = 0; +} + +// SRW locks and condition variables do not need to be explicitly destroyed. +// https://docs.microsoft.com/en-us/windows/win32/api/synchapi/nf-synchapi-initializesrwlock +// https://stackoverflow.com/questions/28975958/why-does-windows-have-no-deleteconditionvariable-function-to-go-together-with +Waiter::~Waiter() = default; + +bool Waiter::Wait(KernelTimeout t) { + SRWLOCK *mu = WinHelper::GetLock(this); + CONDITION_VARIABLE *cv = WinHelper::GetCond(this); + + LockHolder h(mu); + ++waiter_count_; + + // Loop until we find a wakeup to consume or timeout. + // Note that, since the thread ticker is just reset, we don't need to check + // whether the thread is idle on the very first pass of the loop. + bool first_pass = true; + while (wakeup_count_ == 0) { + if (!first_pass) MaybeBecomeIdle(); + // No wakeups available, time to wait. + if (!SleepConditionVariableSRW(cv, mu, t.InMillisecondsFromNow(), 0)) { + // GetLastError() returns a Win32 DWORD, but we assign to + // unsigned long to simplify the ABSL_RAW_LOG case below. The uniform + // initialization guarantees this is not a narrowing conversion. + const unsigned long err{GetLastError()}; // NOLINT(runtime/int) + if (err == ERROR_TIMEOUT) { + --waiter_count_; + return false; + } else { + ABSL_RAW_LOG(FATAL, "SleepConditionVariableSRW failed: %lu", err); + } + } + first_pass = false; + } + // Consume a wakeup and we're done. + --wakeup_count_; + --waiter_count_; + return true; +} + +void Waiter::Post() { + LockHolder h(WinHelper::GetLock(this)); + ++wakeup_count_; + InternalCondVarPoke(); +} + +void Waiter::Poke() { + LockHolder h(WinHelper::GetLock(this)); + InternalCondVarPoke(); +} + +void Waiter::InternalCondVarPoke() { + if (waiter_count_ != 0) { + WakeConditionVariable(WinHelper::GetCond(this)); + } +} + +#else +#error Unknown ABSL_WAITER_MODE +#endif + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/internal/waiter.h b/third_party/abseil_cpp/absl/synchronization/internal/waiter.h new file mode 100644 index 0000000000..ae83907b1c --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/internal/waiter.h @@ -0,0 +1,159 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// + +#ifndef ABSL_SYNCHRONIZATION_INTERNAL_WAITER_H_ +#define ABSL_SYNCHRONIZATION_INTERNAL_WAITER_H_ + +#include "absl/base/config.h" + +#ifdef _WIN32 +#include <sdkddkver.h> +#else +#include <pthread.h> +#endif + +#ifdef __linux__ +#include <linux/futex.h> +#endif + +#ifdef ABSL_HAVE_SEMAPHORE_H +#include <semaphore.h> +#endif + +#include <atomic> +#include <cstdint> + +#include "absl/base/internal/thread_identity.h" +#include "absl/synchronization/internal/kernel_timeout.h" + +// May be chosen at compile time via -DABSL_FORCE_WAITER_MODE=<index> +#define ABSL_WAITER_MODE_FUTEX 0 +#define ABSL_WAITER_MODE_SEM 1 +#define ABSL_WAITER_MODE_CONDVAR 2 +#define ABSL_WAITER_MODE_WIN32 3 + +#if defined(ABSL_FORCE_WAITER_MODE) +#define ABSL_WAITER_MODE ABSL_FORCE_WAITER_MODE +#elif defined(_WIN32) && _WIN32_WINNT >= _WIN32_WINNT_VISTA +#define ABSL_WAITER_MODE ABSL_WAITER_MODE_WIN32 +#elif defined(__BIONIC__) +// Bionic supports all the futex operations we need even when some of the futex +// definitions are missing. +#define ABSL_WAITER_MODE ABSL_WAITER_MODE_FUTEX +#elif defined(__linux__) && defined(FUTEX_CLOCK_REALTIME) +// FUTEX_CLOCK_REALTIME requires Linux >= 2.6.28. +#define ABSL_WAITER_MODE ABSL_WAITER_MODE_FUTEX +#elif defined(ABSL_HAVE_SEMAPHORE_H) +#define ABSL_WAITER_MODE ABSL_WAITER_MODE_SEM +#else +#define ABSL_WAITER_MODE ABSL_WAITER_MODE_CONDVAR +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace synchronization_internal { + +// Waiter is an OS-specific semaphore. +class Waiter { + public: + // Prepare any data to track waits. + Waiter(); + + // Not copyable or movable + Waiter(const Waiter&) = delete; + Waiter& operator=(const Waiter&) = delete; + + // Destroy any data to track waits. + ~Waiter(); + + // Blocks the calling thread until a matching call to `Post()` or + // `t` has passed. Returns `true` if woken (`Post()` called), + // `false` on timeout. + bool Wait(KernelTimeout t); + + // Restart the caller of `Wait()` as with a normal semaphore. + void Post(); + + // If anyone is waiting, wake them up temporarily and cause them to + // call `MaybeBecomeIdle()`. They will then return to waiting for a + // `Post()` or timeout. + void Poke(); + + // Returns the Waiter associated with the identity. + static Waiter* GetWaiter(base_internal::ThreadIdentity* identity) { + static_assert( + sizeof(Waiter) <= sizeof(base_internal::ThreadIdentity::WaiterState), + "Insufficient space for Waiter"); + return reinterpret_cast<Waiter*>(identity->waiter_state.data); + } + + // How many periods to remain idle before releasing resources +#ifndef THREAD_SANITIZER + static constexpr int kIdlePeriods = 60; +#else + // Memory consumption under ThreadSanitizer is a serious concern, + // so we release resources sooner. The value of 1 leads to 1 to 2 second + // delay before marking a thread as idle. + static const int kIdlePeriods = 1; +#endif + + private: +#if ABSL_WAITER_MODE == ABSL_WAITER_MODE_FUTEX + // Futexes are defined by specification to be 32-bits. + // Thus std::atomic<int32_t> must be just an int32_t with lockfree methods. + std::atomic<int32_t> futex_; + static_assert(sizeof(int32_t) == sizeof(futex_), "Wrong size for futex"); + +#elif ABSL_WAITER_MODE == ABSL_WAITER_MODE_CONDVAR + // REQUIRES: mu_ must be held. + void InternalCondVarPoke(); + + pthread_mutex_t mu_; + pthread_cond_t cv_; + int waiter_count_; + int wakeup_count_; // Unclaimed wakeups. + +#elif ABSL_WAITER_MODE == ABSL_WAITER_MODE_SEM + sem_t sem_; + // This seems superfluous, but for Poke() we need to cause spurious + // wakeups on the semaphore. Hence we can't actually use the + // semaphore's count. + std::atomic<int> wakeups_; + +#elif ABSL_WAITER_MODE == ABSL_WAITER_MODE_WIN32 + // WinHelper - Used to define utilities for accessing the lock and + // condition variable storage once the types are complete. + class WinHelper; + + // REQUIRES: WinHelper::GetLock(this) must be held. + void InternalCondVarPoke(); + + // We can't include Windows.h in our headers, so we use aligned charachter + // buffers to define the storage of SRWLOCK and CONDITION_VARIABLE. + alignas(void*) unsigned char mu_storage_[sizeof(void*)]; + alignas(void*) unsigned char cv_storage_[sizeof(void*)]; + int waiter_count_; + int wakeup_count_; + +#else + #error Unknown ABSL_WAITER_MODE +#endif +}; + +} // namespace synchronization_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_SYNCHRONIZATION_INTERNAL_WAITER_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/lifetime_test.cc b/third_party/abseil_cpp/absl/synchronization/lifetime_test.cc new file mode 100644 index 0000000000..cc973a3290 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/lifetime_test.cc @@ -0,0 +1,181 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdlib> +#include <thread> // NOLINT(build/c++11), Abseil test +#include <type_traits> + +#include "absl/base/attributes.h" +#include "absl/base/const_init.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/mutex.h" +#include "absl/synchronization/notification.h" + +namespace { + +// A two-threaded test which checks that Mutex, CondVar, and Notification have +// correct basic functionality. The intent is to establish that they +// function correctly in various phases of construction and destruction. +// +// Thread one acquires a lock on 'mutex', wakes thread two via 'notification', +// then waits for 'state' to be set, as signalled by 'condvar'. +// +// Thread two waits on 'notification', then sets 'state' inside the 'mutex', +// signalling the change via 'condvar'. +// +// These tests use ABSL_RAW_CHECK to validate invariants, rather than EXPECT or +// ASSERT from gUnit, because we need to invoke them during global destructors, +// when gUnit teardown would have already begun. +void ThreadOne(absl::Mutex* mutex, absl::CondVar* condvar, + absl::Notification* notification, bool* state) { + // Test that the notification is in a valid initial state. + ABSL_RAW_CHECK(!notification->HasBeenNotified(), "invalid Notification"); + ABSL_RAW_CHECK(*state == false, "*state not initialized"); + + { + absl::MutexLock lock(mutex); + + notification->Notify(); + ABSL_RAW_CHECK(notification->HasBeenNotified(), "invalid Notification"); + + while (*state == false) { + condvar->Wait(mutex); + } + } +} + +void ThreadTwo(absl::Mutex* mutex, absl::CondVar* condvar, + absl::Notification* notification, bool* state) { + ABSL_RAW_CHECK(*state == false, "*state not initialized"); + + // Wake thread one + notification->WaitForNotification(); + ABSL_RAW_CHECK(notification->HasBeenNotified(), "invalid Notification"); + { + absl::MutexLock lock(mutex); + *state = true; + condvar->Signal(); + } +} + +// Launch thread 1 and thread 2, and block on their completion. +// If any of 'mutex', 'condvar', or 'notification' is nullptr, use a locally +// constructed instance instead. +void RunTests(absl::Mutex* mutex, absl::CondVar* condvar) { + absl::Mutex default_mutex; + absl::CondVar default_condvar; + absl::Notification notification; + if (!mutex) { + mutex = &default_mutex; + } + if (!condvar) { + condvar = &default_condvar; + } + bool state = false; + std::thread thread_one(ThreadOne, mutex, condvar, ¬ification, &state); + std::thread thread_two(ThreadTwo, mutex, condvar, ¬ification, &state); + thread_one.join(); + thread_two.join(); +} + +void TestLocals() { + absl::Mutex mutex; + absl::CondVar condvar; + RunTests(&mutex, &condvar); +} + +// Normal kConstInit usage +ABSL_CONST_INIT absl::Mutex const_init_mutex(absl::kConstInit); +void TestConstInitGlobal() { RunTests(&const_init_mutex, nullptr); } + +// Global variables during start and termination +// +// In a translation unit, static storage duration variables are initialized in +// the order of their definitions, and destroyed in the reverse order of their +// definitions. We can use this to arrange for tests to be run on these objects +// before they are created, and after they are destroyed. + +using Function = void (*)(); + +class OnConstruction { + public: + explicit OnConstruction(Function fn) { fn(); } +}; + +class OnDestruction { + public: + explicit OnDestruction(Function fn) : fn_(fn) {} + ~OnDestruction() { fn_(); } + private: + Function fn_; +}; + +// These tests require that the compiler correctly supports C++11 constant +// initialization... but MSVC has a known regression since v19.10: +// https://developercommunity.visualstudio.com/content/problem/336946/class-with-constexpr-constructor-not-using-static.html +// TODO(epastor): Limit the affected range once MSVC fixes this bug. +#if defined(__clang__) || !(defined(_MSC_VER) && _MSC_VER > 1900) +// kConstInit +// Test early usage. (Declaration comes first; definitions must appear after +// the test runner.) +extern absl::Mutex early_const_init_mutex; +// (Normally I'd write this +[], to make the cast-to-function-pointer explicit, +// but in some MSVC setups we support, lambdas provide conversion operators to +// different flavors of function pointers, making this trick ambiguous.) +OnConstruction test_early_const_init([] { + RunTests(&early_const_init_mutex, nullptr); +}); +// This definition appears before test_early_const_init, but it should be +// initialized first (due to constant initialization). Test that the object +// actually works when constructed this way. +ABSL_CONST_INIT absl::Mutex early_const_init_mutex(absl::kConstInit); + +// Furthermore, test that the const-init c'tor doesn't stomp over the state of +// a Mutex. Really, this is a test that the platform under test correctly +// supports C++11 constant initialization. (The constant-initialization +// constructors of globals "happen at link time"; memory is pre-initialized, +// before the constructors of either grab_lock or check_still_locked are run.) +extern absl::Mutex const_init_sanity_mutex; +OnConstruction grab_lock([]() ABSL_NO_THREAD_SAFETY_ANALYSIS { + const_init_sanity_mutex.Lock(); +}); +ABSL_CONST_INIT absl::Mutex const_init_sanity_mutex(absl::kConstInit); +OnConstruction check_still_locked([]() ABSL_NO_THREAD_SAFETY_ANALYSIS { + const_init_sanity_mutex.AssertHeld(); + const_init_sanity_mutex.Unlock(); +}); +#endif // defined(__clang__) || !(defined(_MSC_VER) && _MSC_VER > 1900) + +// Test shutdown usage. (Declarations come first; definitions must appear after +// the test runner.) +extern absl::Mutex late_const_init_mutex; +// OnDestruction is being used here as a global variable, even though it has a +// non-trivial destructor. This is against the style guide. We're violating +// that rule here to check that the exception we allow for kConstInit is safe. +// NOLINTNEXTLINE +OnDestruction test_late_const_init([] { + RunTests(&late_const_init_mutex, nullptr); +}); +ABSL_CONST_INIT absl::Mutex late_const_init_mutex(absl::kConstInit); + +} // namespace + +int main() { + TestLocals(); + TestConstInitGlobal(); + // Explicitly call exit(0) here, to make it clear that we intend for the + // above global object destructors to run. + std::exit(0); +} diff --git a/third_party/abseil_cpp/absl/synchronization/mutex.cc b/third_party/abseil_cpp/absl/synchronization/mutex.cc new file mode 100644 index 0000000000..1f8a696e08 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/mutex.cc @@ -0,0 +1,2726 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/mutex.h" + +#ifdef _WIN32 +#include <windows.h> +#ifdef ERROR +#undef ERROR +#endif +#else +#include <fcntl.h> +#include <pthread.h> +#include <sched.h> +#include <sys/time.h> +#endif + +#include <assert.h> +#include <errno.h> +#include <stdio.h> +#include <stdlib.h> +#include <string.h> +#include <time.h> + +#include <algorithm> +#include <atomic> +#include <cinttypes> +#include <thread> // NOLINT(build/c++11) + +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/dynamic_annotations.h" +#include "absl/base/internal/atomic_hook.h" +#include "absl/base/internal/cycleclock.h" +#include "absl/base/internal/hide_ptr.h" +#include "absl/base/internal/low_level_alloc.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/spinlock.h" +#include "absl/base/internal/sysinfo.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/base/port.h" +#include "absl/debugging/stacktrace.h" +#include "absl/debugging/symbolize.h" +#include "absl/synchronization/internal/graphcycles.h" +#include "absl/synchronization/internal/per_thread_sem.h" +#include "absl/time/time.h" + +using absl::base_internal::CurrentThreadIdentityIfPresent; +using absl::base_internal::PerThreadSynch; +using absl::base_internal::ThreadIdentity; +using absl::synchronization_internal::GetOrCreateCurrentThreadIdentity; +using absl::synchronization_internal::GraphCycles; +using absl::synchronization_internal::GraphId; +using absl::synchronization_internal::InvalidGraphId; +using absl::synchronization_internal::KernelTimeout; +using absl::synchronization_internal::PerThreadSem; + +extern "C" { +ABSL_ATTRIBUTE_WEAK void AbslInternalMutexYield() { std::this_thread::yield(); } +} // extern "C" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +#if defined(THREAD_SANITIZER) +constexpr OnDeadlockCycle kDeadlockDetectionDefault = OnDeadlockCycle::kIgnore; +#else +constexpr OnDeadlockCycle kDeadlockDetectionDefault = OnDeadlockCycle::kAbort; +#endif + +ABSL_CONST_INIT std::atomic<OnDeadlockCycle> synch_deadlock_detection( + kDeadlockDetectionDefault); +ABSL_CONST_INIT std::atomic<bool> synch_check_invariants(false); + +// ------------------------------------------ spinlock support + +// Make sure read-only globals used in the Mutex code are contained on the +// same cacheline and cacheline aligned to eliminate any false sharing with +// other globals from this and other modules. +static struct MutexGlobals { + MutexGlobals() { + // Find machine-specific data needed for Delay() and + // TryAcquireWithSpinning(). This runs in the global constructor + // sequence, and before that zeros are safe values. + num_cpus = absl::base_internal::NumCPUs(); + spinloop_iterations = num_cpus > 1 ? 1500 : 0; + } + int num_cpus; + int spinloop_iterations; + // Pad this struct to a full cacheline to prevent false sharing. + char padding[ABSL_CACHELINE_SIZE - 2 * sizeof(int)]; +} ABSL_CACHELINE_ALIGNED mutex_globals; +static_assert( + sizeof(MutexGlobals) == ABSL_CACHELINE_SIZE, + "MutexGlobals must occupy an entire cacheline to prevent false sharing"); + +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES + absl::base_internal::AtomicHook<void (*)(int64_t wait_cycles)> + submit_profile_data; +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES absl::base_internal::AtomicHook<void (*)( + const char *msg, const void *obj, int64_t wait_cycles)> + mutex_tracer; +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES + absl::base_internal::AtomicHook<void (*)(const char *msg, const void *cv)> + cond_var_tracer; +ABSL_INTERNAL_ATOMIC_HOOK_ATTRIBUTES absl::base_internal::AtomicHook< + bool (*)(const void *pc, char *out, int out_size)> + symbolizer(absl::Symbolize); + +} // namespace + +static inline bool EvalConditionAnnotated(const Condition *cond, Mutex *mu, + bool locking, bool trylock, + bool read_lock); + +void RegisterMutexProfiler(void (*fn)(int64_t wait_timestamp)) { + submit_profile_data.Store(fn); +} + +void RegisterMutexTracer(void (*fn)(const char *msg, const void *obj, + int64_t wait_cycles)) { + mutex_tracer.Store(fn); +} + +void RegisterCondVarTracer(void (*fn)(const char *msg, const void *cv)) { + cond_var_tracer.Store(fn); +} + +void RegisterSymbolizer(bool (*fn)(const void *pc, char *out, int out_size)) { + symbolizer.Store(fn); +} + +// spinlock delay on iteration c. Returns new c. +namespace { + enum DelayMode { AGGRESSIVE, GENTLE }; +}; +static int Delay(int32_t c, DelayMode mode) { + // If this a uniprocessor, only yield/sleep. Otherwise, if the mode is + // aggressive then spin many times before yielding. If the mode is + // gentle then spin only a few times before yielding. Aggressive spinning is + // used to ensure that an Unlock() call, which must get the spin lock for + // any thread to make progress gets it without undue delay. + int32_t limit = (mutex_globals.num_cpus > 1) ? + ((mode == AGGRESSIVE) ? 5000 : 250) : 0; + if (c < limit) { + c++; // spin + } else { + ABSL_TSAN_MUTEX_PRE_DIVERT(nullptr, 0); + if (c == limit) { // yield once + AbslInternalMutexYield(); + c++; + } else { // then wait + absl::SleepFor(absl::Microseconds(10)); + c = 0; + } + ABSL_TSAN_MUTEX_POST_DIVERT(nullptr, 0); + } + return (c); +} + +// --------------------------Generic atomic ops +// Ensure that "(*pv & bits) == bits" by doing an atomic update of "*pv" to +// "*pv | bits" if necessary. Wait until (*pv & wait_until_clear)==0 +// before making any change. +// This is used to set flags in mutex and condition variable words. +static void AtomicSetBits(std::atomic<intptr_t>* pv, intptr_t bits, + intptr_t wait_until_clear) { + intptr_t v; + do { + v = pv->load(std::memory_order_relaxed); + } while ((v & bits) != bits && + ((v & wait_until_clear) != 0 || + !pv->compare_exchange_weak(v, v | bits, + std::memory_order_release, + std::memory_order_relaxed))); +} + +// Ensure that "(*pv & bits) == 0" by doing an atomic update of "*pv" to +// "*pv & ~bits" if necessary. Wait until (*pv & wait_until_clear)==0 +// before making any change. +// This is used to unset flags in mutex and condition variable words. +static void AtomicClearBits(std::atomic<intptr_t>* pv, intptr_t bits, + intptr_t wait_until_clear) { + intptr_t v; + do { + v = pv->load(std::memory_order_relaxed); + } while ((v & bits) != 0 && + ((v & wait_until_clear) != 0 || + !pv->compare_exchange_weak(v, v & ~bits, + std::memory_order_release, + std::memory_order_relaxed))); +} + +//------------------------------------------------------------------ + +// Data for doing deadlock detection. +ABSL_CONST_INIT static absl::base_internal::SpinLock deadlock_graph_mu( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); + +// Graph used to detect deadlocks. +ABSL_CONST_INIT static GraphCycles *deadlock_graph + ABSL_GUARDED_BY(deadlock_graph_mu) ABSL_PT_GUARDED_BY(deadlock_graph_mu); + +//------------------------------------------------------------------ +// An event mechanism for debugging mutex use. +// It also allows mutexes to be given names for those who can't handle +// addresses, and instead like to give their data structures names like +// "Henry", "Fido", or "Rupert IV, King of Yondavia". + +namespace { // to prevent name pollution +enum { // Mutex and CondVar events passed as "ev" to PostSynchEvent + // Mutex events + SYNCH_EV_TRYLOCK_SUCCESS, + SYNCH_EV_TRYLOCK_FAILED, + SYNCH_EV_READERTRYLOCK_SUCCESS, + SYNCH_EV_READERTRYLOCK_FAILED, + SYNCH_EV_LOCK, + SYNCH_EV_LOCK_RETURNING, + SYNCH_EV_READERLOCK, + SYNCH_EV_READERLOCK_RETURNING, + SYNCH_EV_UNLOCK, + SYNCH_EV_READERUNLOCK, + + // CondVar events + SYNCH_EV_WAIT, + SYNCH_EV_WAIT_RETURNING, + SYNCH_EV_SIGNAL, + SYNCH_EV_SIGNALALL, +}; + +enum { // Event flags + SYNCH_F_R = 0x01, // reader event + SYNCH_F_LCK = 0x02, // PostSynchEvent called with mutex held + SYNCH_F_TRY = 0x04, // TryLock or ReaderTryLock + SYNCH_F_UNLOCK = 0x08, // Unlock or ReaderUnlock + + SYNCH_F_LCK_W = SYNCH_F_LCK, + SYNCH_F_LCK_R = SYNCH_F_LCK | SYNCH_F_R, +}; +} // anonymous namespace + +// Properties of the events. +static const struct { + int flags; + const char *msg; +} event_properties[] = { + {SYNCH_F_LCK_W | SYNCH_F_TRY, "TryLock succeeded "}, + {0, "TryLock failed "}, + {SYNCH_F_LCK_R | SYNCH_F_TRY, "ReaderTryLock succeeded "}, + {0, "ReaderTryLock failed "}, + {0, "Lock blocking "}, + {SYNCH_F_LCK_W, "Lock returning "}, + {0, "ReaderLock blocking "}, + {SYNCH_F_LCK_R, "ReaderLock returning "}, + {SYNCH_F_LCK_W | SYNCH_F_UNLOCK, "Unlock "}, + {SYNCH_F_LCK_R | SYNCH_F_UNLOCK, "ReaderUnlock "}, + {0, "Wait on "}, + {0, "Wait unblocked "}, + {0, "Signal on "}, + {0, "SignalAll on "}, +}; + +ABSL_CONST_INIT static absl::base_internal::SpinLock synch_event_mu( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); + +// Hash table size; should be prime > 2. +// Can't be too small, as it's used for deadlock detection information. +static constexpr uint32_t kNSynchEvent = 1031; + +static struct SynchEvent { // this is a trivial hash table for the events + // struct is freed when refcount reaches 0 + int refcount ABSL_GUARDED_BY(synch_event_mu); + + // buckets have linear, 0-terminated chains + SynchEvent *next ABSL_GUARDED_BY(synch_event_mu); + + // Constant after initialization + uintptr_t masked_addr; // object at this address is called "name" + + // No explicit synchronization used. Instead we assume that the + // client who enables/disables invariants/logging on a Mutex does so + // while the Mutex is not being concurrently accessed by others. + void (*invariant)(void *arg); // called on each event + void *arg; // first arg to (*invariant)() + bool log; // logging turned on + + // Constant after initialization + char name[1]; // actually longer---NUL-terminated string +} * synch_event[kNSynchEvent] ABSL_GUARDED_BY(synch_event_mu); + +// Ensure that the object at "addr" has a SynchEvent struct associated with it, +// set "bits" in the word there (waiting until lockbit is clear before doing +// so), and return a refcounted reference that will remain valid until +// UnrefSynchEvent() is called. If a new SynchEvent is allocated, +// the string name is copied into it. +// When used with a mutex, the caller should also ensure that kMuEvent +// is set in the mutex word, and similarly for condition variables and kCVEvent. +static SynchEvent *EnsureSynchEvent(std::atomic<intptr_t> *addr, + const char *name, intptr_t bits, + intptr_t lockbit) { + uint32_t h = reinterpret_cast<intptr_t>(addr) % kNSynchEvent; + SynchEvent *e; + // first look for existing SynchEvent struct.. + synch_event_mu.Lock(); + for (e = synch_event[h]; + e != nullptr && e->masked_addr != base_internal::HidePtr(addr); + e = e->next) { + } + if (e == nullptr) { // no SynchEvent struct found; make one. + if (name == nullptr) { + name = ""; + } + size_t l = strlen(name); + e = reinterpret_cast<SynchEvent *>( + base_internal::LowLevelAlloc::Alloc(sizeof(*e) + l)); + e->refcount = 2; // one for return value, one for linked list + e->masked_addr = base_internal::HidePtr(addr); + e->invariant = nullptr; + e->arg = nullptr; + e->log = false; + strcpy(e->name, name); // NOLINT(runtime/printf) + e->next = synch_event[h]; + AtomicSetBits(addr, bits, lockbit); + synch_event[h] = e; + } else { + e->refcount++; // for return value + } + synch_event_mu.Unlock(); + return e; +} + +// Deallocate the SynchEvent *e, whose refcount has fallen to zero. +static void DeleteSynchEvent(SynchEvent *e) { + base_internal::LowLevelAlloc::Free(e); +} + +// Decrement the reference count of *e, or do nothing if e==null. +static void UnrefSynchEvent(SynchEvent *e) { + if (e != nullptr) { + synch_event_mu.Lock(); + bool del = (--(e->refcount) == 0); + synch_event_mu.Unlock(); + if (del) { + DeleteSynchEvent(e); + } + } +} + +// Forget the mapping from the object (Mutex or CondVar) at address addr +// to SynchEvent object, and clear "bits" in its word (waiting until lockbit +// is clear before doing so). +static void ForgetSynchEvent(std::atomic<intptr_t> *addr, intptr_t bits, + intptr_t lockbit) { + uint32_t h = reinterpret_cast<intptr_t>(addr) % kNSynchEvent; + SynchEvent **pe; + SynchEvent *e; + synch_event_mu.Lock(); + for (pe = &synch_event[h]; + (e = *pe) != nullptr && e->masked_addr != base_internal::HidePtr(addr); + pe = &e->next) { + } + bool del = false; + if (e != nullptr) { + *pe = e->next; + del = (--(e->refcount) == 0); + } + AtomicClearBits(addr, bits, lockbit); + synch_event_mu.Unlock(); + if (del) { + DeleteSynchEvent(e); + } +} + +// Return a refcounted reference to the SynchEvent of the object at address +// "addr", if any. The pointer returned is valid until the UnrefSynchEvent() is +// called. +static SynchEvent *GetSynchEvent(const void *addr) { + uint32_t h = reinterpret_cast<intptr_t>(addr) % kNSynchEvent; + SynchEvent *e; + synch_event_mu.Lock(); + for (e = synch_event[h]; + e != nullptr && e->masked_addr != base_internal::HidePtr(addr); + e = e->next) { + } + if (e != nullptr) { + e->refcount++; + } + synch_event_mu.Unlock(); + return e; +} + +// Called when an event "ev" occurs on a Mutex of CondVar "obj" +// if event recording is on +static void PostSynchEvent(void *obj, int ev) { + SynchEvent *e = GetSynchEvent(obj); + // logging is on if event recording is on and either there's no event struct, + // or it explicitly says to log + if (e == nullptr || e->log) { + void *pcs[40]; + int n = absl::GetStackTrace(pcs, ABSL_ARRAYSIZE(pcs), 1); + // A buffer with enough space for the ASCII for all the PCs, even on a + // 64-bit machine. + char buffer[ABSL_ARRAYSIZE(pcs) * 24]; + int pos = snprintf(buffer, sizeof (buffer), " @"); + for (int i = 0; i != n; i++) { + pos += snprintf(&buffer[pos], sizeof (buffer) - pos, " %p", pcs[i]); + } + ABSL_RAW_LOG(INFO, "%s%p %s %s", event_properties[ev].msg, obj, + (e == nullptr ? "" : e->name), buffer); + } + const int flags = event_properties[ev].flags; + if ((flags & SYNCH_F_LCK) != 0 && e != nullptr && e->invariant != nullptr) { + // Calling the invariant as is causes problems under ThreadSanitizer. + // We are currently inside of Mutex Lock/Unlock and are ignoring all + // memory accesses and synchronization. If the invariant transitively + // synchronizes something else and we ignore the synchronization, we will + // get false positive race reports later. + // Reuse EvalConditionAnnotated to properly call into user code. + struct local { + static bool pred(SynchEvent *ev) { + (*ev->invariant)(ev->arg); + return false; + } + }; + Condition cond(&local::pred, e); + Mutex *mu = static_cast<Mutex *>(obj); + const bool locking = (flags & SYNCH_F_UNLOCK) == 0; + const bool trylock = (flags & SYNCH_F_TRY) != 0; + const bool read_lock = (flags & SYNCH_F_R) != 0; + EvalConditionAnnotated(&cond, mu, locking, trylock, read_lock); + } + UnrefSynchEvent(e); +} + +//------------------------------------------------------------------ + +// The SynchWaitParams struct encapsulates the way in which a thread is waiting: +// whether it has a timeout, the condition, exclusive/shared, and whether a +// condition variable wait has an associated Mutex (as opposed to another +// type of lock). It also points to the PerThreadSynch struct of its thread. +// cv_word tells Enqueue() to enqueue on a CondVar using CondVarEnqueue(). +// +// This structure is held on the stack rather than directly in +// PerThreadSynch because a thread can be waiting on multiple Mutexes if, +// while waiting on one Mutex, the implementation calls a client callback +// (such as a Condition function) that acquires another Mutex. We don't +// strictly need to allow this, but programmers become confused if we do not +// allow them to use functions such a LOG() within Condition functions. The +// PerThreadSynch struct points at the most recent SynchWaitParams struct when +// the thread is on a Mutex's waiter queue. +struct SynchWaitParams { + SynchWaitParams(Mutex::MuHow how_arg, const Condition *cond_arg, + KernelTimeout timeout_arg, Mutex *cvmu_arg, + PerThreadSynch *thread_arg, + std::atomic<intptr_t> *cv_word_arg) + : how(how_arg), + cond(cond_arg), + timeout(timeout_arg), + cvmu(cvmu_arg), + thread(thread_arg), + cv_word(cv_word_arg), + contention_start_cycles(base_internal::CycleClock::Now()) {} + + const Mutex::MuHow how; // How this thread needs to wait. + const Condition *cond; // The condition that this thread is waiting for. + // In Mutex, this field is set to zero if a timeout + // expires. + KernelTimeout timeout; // timeout expiry---absolute time + // In Mutex, this field is set to zero if a timeout + // expires. + Mutex *const cvmu; // used for transfer from cond var to mutex + PerThreadSynch *const thread; // thread that is waiting + + // If not null, thread should be enqueued on the CondVar whose state + // word is cv_word instead of queueing normally on the Mutex. + std::atomic<intptr_t> *cv_word; + + int64_t contention_start_cycles; // Time (in cycles) when this thread started + // to contend for the mutex. +}; + +struct SynchLocksHeld { + int n; // number of valid entries in locks[] + bool overflow; // true iff we overflowed the array at some point + struct { + Mutex *mu; // lock acquired + int32_t count; // times acquired + GraphId id; // deadlock_graph id of acquired lock + } locks[40]; + // If a thread overfills the array during deadlock detection, we + // continue, discarding information as needed. If no overflow has + // taken place, we can provide more error checking, such as + // detecting when a thread releases a lock it does not hold. +}; + +// A sentinel value in lists that is not 0. +// A 0 value is used to mean "not on a list". +static PerThreadSynch *const kPerThreadSynchNull = + reinterpret_cast<PerThreadSynch *>(1); + +static SynchLocksHeld *LocksHeldAlloc() { + SynchLocksHeld *ret = reinterpret_cast<SynchLocksHeld *>( + base_internal::LowLevelAlloc::Alloc(sizeof(SynchLocksHeld))); + ret->n = 0; + ret->overflow = false; + return ret; +} + +// Return the PerThreadSynch-struct for this thread. +static PerThreadSynch *Synch_GetPerThread() { + ThreadIdentity *identity = GetOrCreateCurrentThreadIdentity(); + return &identity->per_thread_synch; +} + +static PerThreadSynch *Synch_GetPerThreadAnnotated(Mutex *mu) { + if (mu) { + ABSL_TSAN_MUTEX_PRE_DIVERT(mu, 0); + } + PerThreadSynch *w = Synch_GetPerThread(); + if (mu) { + ABSL_TSAN_MUTEX_POST_DIVERT(mu, 0); + } + return w; +} + +static SynchLocksHeld *Synch_GetAllLocks() { + PerThreadSynch *s = Synch_GetPerThread(); + if (s->all_locks == nullptr) { + s->all_locks = LocksHeldAlloc(); // Freed by ReclaimThreadIdentity. + } + return s->all_locks; +} + +// Post on "w"'s associated PerThreadSem. +inline void Mutex::IncrementSynchSem(Mutex *mu, PerThreadSynch *w) { + if (mu) { + ABSL_TSAN_MUTEX_PRE_DIVERT(mu, 0); + } + PerThreadSem::Post(w->thread_identity()); + if (mu) { + ABSL_TSAN_MUTEX_POST_DIVERT(mu, 0); + } +} + +// Wait on "w"'s associated PerThreadSem; returns false if timeout expired. +bool Mutex::DecrementSynchSem(Mutex *mu, PerThreadSynch *w, KernelTimeout t) { + if (mu) { + ABSL_TSAN_MUTEX_PRE_DIVERT(mu, 0); + } + assert(w == Synch_GetPerThread()); + static_cast<void>(w); + bool res = PerThreadSem::Wait(t); + if (mu) { + ABSL_TSAN_MUTEX_POST_DIVERT(mu, 0); + } + return res; +} + +// We're in a fatal signal handler that hopes to use Mutex and to get +// lucky by not deadlocking. We try to improve its chances of success +// by effectively disabling some of the consistency checks. This will +// prevent certain ABSL_RAW_CHECK() statements from being triggered when +// re-rentry is detected. The ABSL_RAW_CHECK() statements are those in the +// Mutex code checking that the "waitp" field has not been reused. +void Mutex::InternalAttemptToUseMutexInFatalSignalHandler() { + // Fix the per-thread state only if it exists. + ThreadIdentity *identity = CurrentThreadIdentityIfPresent(); + if (identity != nullptr) { + identity->per_thread_synch.suppress_fatal_errors = true; + } + // Don't do deadlock detection when we are already failing. + synch_deadlock_detection.store(OnDeadlockCycle::kIgnore, + std::memory_order_release); +} + +// --------------------------time support + +// Return the current time plus the timeout. Use the same clock as +// PerThreadSem::Wait() for consistency. Unfortunately, we don't have +// such a choice when a deadline is given directly. +static absl::Time DeadlineFromTimeout(absl::Duration timeout) { +#ifndef _WIN32 + struct timeval tv; + gettimeofday(&tv, nullptr); + return absl::TimeFromTimeval(tv) + timeout; +#else + return absl::Now() + timeout; +#endif +} + +// --------------------------Mutexes + +// In the layout below, the msb of the bottom byte is currently unused. Also, +// the following constraints were considered in choosing the layout: +// o Both the debug allocator's "uninitialized" and "freed" patterns (0xab and +// 0xcd) are illegal: reader and writer lock both held. +// o kMuWriter and kMuEvent should exceed kMuDesig and kMuWait, to enable the +// bit-twiddling trick in Mutex::Unlock(). +// o kMuWriter / kMuReader == kMuWrWait / kMuWait, +// to enable the bit-twiddling trick in CheckForMutexCorruption(). +static const intptr_t kMuReader = 0x0001L; // a reader holds the lock +static const intptr_t kMuDesig = 0x0002L; // there's a designated waker +static const intptr_t kMuWait = 0x0004L; // threads are waiting +static const intptr_t kMuWriter = 0x0008L; // a writer holds the lock +static const intptr_t kMuEvent = 0x0010L; // record this mutex's events +// INVARIANT1: there's a thread that was blocked on the mutex, is +// no longer, yet has not yet acquired the mutex. If there's a +// designated waker, all threads can avoid taking the slow path in +// unlock because the designated waker will subsequently acquire +// the lock and wake someone. To maintain INVARIANT1 the bit is +// set when a thread is unblocked(INV1a), and threads that were +// unblocked reset the bit when they either acquire or re-block +// (INV1b). +static const intptr_t kMuWrWait = 0x0020L; // runnable writer is waiting + // for a reader +static const intptr_t kMuSpin = 0x0040L; // spinlock protects wait list +static const intptr_t kMuLow = 0x00ffL; // mask all mutex bits +static const intptr_t kMuHigh = ~kMuLow; // mask pointer/reader count + +// Hack to make constant values available to gdb pretty printer +enum { + kGdbMuSpin = kMuSpin, + kGdbMuEvent = kMuEvent, + kGdbMuWait = kMuWait, + kGdbMuWriter = kMuWriter, + kGdbMuDesig = kMuDesig, + kGdbMuWrWait = kMuWrWait, + kGdbMuReader = kMuReader, + kGdbMuLow = kMuLow, +}; + +// kMuWrWait implies kMuWait. +// kMuReader and kMuWriter are mutually exclusive. +// If kMuReader is zero, there are no readers. +// Otherwise, if kMuWait is zero, the high order bits contain a count of the +// number of readers. Otherwise, the reader count is held in +// PerThreadSynch::readers of the most recently queued waiter, again in the +// bits above kMuLow. +static const intptr_t kMuOne = 0x0100; // a count of one reader + +// flags passed to Enqueue and LockSlow{,WithTimeout,Loop} +static const int kMuHasBlocked = 0x01; // already blocked (MUST == 1) +static const int kMuIsCond = 0x02; // conditional waiter (CV or Condition) + +static_assert(PerThreadSynch::kAlignment > kMuLow, + "PerThreadSynch::kAlignment must be greater than kMuLow"); + +// This struct contains various bitmasks to be used in +// acquiring and releasing a mutex in a particular mode. +struct MuHowS { + // if all the bits in fast_need_zero are zero, the lock can be acquired by + // adding fast_add and oring fast_or. The bit kMuDesig should be reset iff + // this is the designated waker. + intptr_t fast_need_zero; + intptr_t fast_or; + intptr_t fast_add; + + intptr_t slow_need_zero; // fast_need_zero with events (e.g. logging) + + intptr_t slow_inc_need_zero; // if all the bits in slow_inc_need_zero are + // zero a reader can acquire a read share by + // setting the reader bit and incrementing + // the reader count (in last waiter since + // we're now slow-path). kMuWrWait be may + // be ignored if we already waited once. +}; + +static const MuHowS kSharedS = { + // shared or read lock + kMuWriter | kMuWait | kMuEvent, // fast_need_zero + kMuReader, // fast_or + kMuOne, // fast_add + kMuWriter | kMuWait, // slow_need_zero + kMuSpin | kMuWriter | kMuWrWait, // slow_inc_need_zero +}; +static const MuHowS kExclusiveS = { + // exclusive or write lock + kMuWriter | kMuReader | kMuEvent, // fast_need_zero + kMuWriter, // fast_or + 0, // fast_add + kMuWriter | kMuReader, // slow_need_zero + ~static_cast<intptr_t>(0), // slow_inc_need_zero +}; +static const Mutex::MuHow kShared = &kSharedS; // shared lock +static const Mutex::MuHow kExclusive = &kExclusiveS; // exclusive lock + +#ifdef NDEBUG +static constexpr bool kDebugMode = false; +#else +static constexpr bool kDebugMode = true; +#endif + +#ifdef THREAD_SANITIZER +static unsigned TsanFlags(Mutex::MuHow how) { + return how == kShared ? __tsan_mutex_read_lock : 0; +} +#endif + +static bool DebugOnlyIsExiting() { + return false; +} + +Mutex::~Mutex() { + intptr_t v = mu_.load(std::memory_order_relaxed); + if ((v & kMuEvent) != 0 && !DebugOnlyIsExiting()) { + ForgetSynchEvent(&this->mu_, kMuEvent, kMuSpin); + } + if (kDebugMode) { + this->ForgetDeadlockInfo(); + } + ABSL_TSAN_MUTEX_DESTROY(this, __tsan_mutex_not_static); +} + +void Mutex::EnableDebugLog(const char *name) { + SynchEvent *e = EnsureSynchEvent(&this->mu_, name, kMuEvent, kMuSpin); + e->log = true; + UnrefSynchEvent(e); +} + +void EnableMutexInvariantDebugging(bool enabled) { + synch_check_invariants.store(enabled, std::memory_order_release); +} + +void Mutex::EnableInvariantDebugging(void (*invariant)(void *), + void *arg) { + if (synch_check_invariants.load(std::memory_order_acquire) && + invariant != nullptr) { + SynchEvent *e = EnsureSynchEvent(&this->mu_, nullptr, kMuEvent, kMuSpin); + e->invariant = invariant; + e->arg = arg; + UnrefSynchEvent(e); + } +} + +void SetMutexDeadlockDetectionMode(OnDeadlockCycle mode) { + synch_deadlock_detection.store(mode, std::memory_order_release); +} + +// Return true iff threads x and y are waiting on the same condition for the +// same type of lock. Requires that x and y be waiting on the same Mutex +// queue. +static bool MuSameCondition(PerThreadSynch *x, PerThreadSynch *y) { + return x->waitp->how == y->waitp->how && + Condition::GuaranteedEqual(x->waitp->cond, y->waitp->cond); +} + +// Given the contents of a mutex word containing a PerThreadSynch pointer, +// return the pointer. +static inline PerThreadSynch *GetPerThreadSynch(intptr_t v) { + return reinterpret_cast<PerThreadSynch *>(v & kMuHigh); +} + +// The next several routines maintain the per-thread next and skip fields +// used in the Mutex waiter queue. +// The queue is a circular singly-linked list, of which the "head" is the +// last element, and head->next if the first element. +// The skip field has the invariant: +// For thread x, x->skip is one of: +// - invalid (iff x is not in a Mutex wait queue), +// - null, or +// - a pointer to a distinct thread waiting later in the same Mutex queue +// such that all threads in [x, x->skip] have the same condition and +// lock type (MuSameCondition() is true for all pairs in [x, x->skip]). +// In addition, if x->skip is valid, (x->may_skip || x->skip == null) +// +// By the spec of MuSameCondition(), it is not necessary when removing the +// first runnable thread y from the front a Mutex queue to adjust the skip +// field of another thread x because if x->skip==y, x->skip must (have) become +// invalid before y is removed. The function TryRemove can remove a specified +// thread from an arbitrary position in the queue whether runnable or not, so +// it fixes up skip fields that would otherwise be left dangling. +// The statement +// if (x->may_skip && MuSameCondition(x, x->next)) { x->skip = x->next; } +// maintains the invariant provided x is not the last waiter in a Mutex queue +// The statement +// if (x->skip != null) { x->skip = x->skip->skip; } +// maintains the invariant. + +// Returns the last thread y in a mutex waiter queue such that all threads in +// [x, y] inclusive share the same condition. Sets skip fields of some threads +// in that range to optimize future evaluation of Skip() on x values in +// the range. Requires thread x is in a mutex waiter queue. +// The locking is unusual. Skip() is called under these conditions: +// - spinlock is held in call from Enqueue(), with maybe_unlocking == false +// - Mutex is held in call from UnlockSlow() by last unlocker, with +// maybe_unlocking == true +// - both Mutex and spinlock are held in call from DequeueAllWakeable() (from +// UnlockSlow()) and TryRemove() +// These cases are mutually exclusive, so Skip() never runs concurrently +// with itself on the same Mutex. The skip chain is used in these other places +// that cannot occur concurrently: +// - FixSkip() (from TryRemove()) - spinlock and Mutex are held) +// - Dequeue() (with spinlock and Mutex held) +// - UnlockSlow() (with spinlock and Mutex held) +// A more complex case is Enqueue() +// - Enqueue() (with spinlock held and maybe_unlocking == false) +// This is the first case in which Skip is called, above. +// - Enqueue() (without spinlock held; but queue is empty and being freshly +// formed) +// - Enqueue() (with spinlock held and maybe_unlocking == true) +// The first case has mutual exclusion, and the second isolation through +// working on an otherwise unreachable data structure. +// In the last case, Enqueue() is required to change no skip/next pointers +// except those in the added node and the former "head" node. This implies +// that the new node is added after head, and so must be the new head or the +// new front of the queue. +static PerThreadSynch *Skip(PerThreadSynch *x) { + PerThreadSynch *x0 = nullptr; + PerThreadSynch *x1 = x; + PerThreadSynch *x2 = x->skip; + if (x2 != nullptr) { + // Each iteration attempts to advance sequence (x0,x1,x2) to next sequence + // such that x1 == x0->skip && x2 == x1->skip + while ((x0 = x1, x1 = x2, x2 = x2->skip) != nullptr) { + x0->skip = x2; // short-circuit skip from x0 to x2 + } + x->skip = x1; // short-circuit skip from x to result + } + return x1; +} + +// "ancestor" appears before "to_be_removed" in the same Mutex waiter queue. +// The latter is going to be removed out of order, because of a timeout. +// Check whether "ancestor" has a skip field pointing to "to_be_removed", +// and fix it if it does. +static void FixSkip(PerThreadSynch *ancestor, PerThreadSynch *to_be_removed) { + if (ancestor->skip == to_be_removed) { // ancestor->skip left dangling + if (to_be_removed->skip != nullptr) { + ancestor->skip = to_be_removed->skip; // can skip past to_be_removed + } else if (ancestor->next != to_be_removed) { // they are not adjacent + ancestor->skip = ancestor->next; // can skip one past ancestor + } else { + ancestor->skip = nullptr; // can't skip at all + } + } +} + +static void CondVarEnqueue(SynchWaitParams *waitp); + +// Enqueue thread "waitp->thread" on a waiter queue. +// Called with mutex spinlock held if head != nullptr +// If head==nullptr and waitp->cv_word==nullptr, then Enqueue() is +// idempotent; it alters no state associated with the existing (empty) +// queue. +// +// If waitp->cv_word == nullptr, queue the thread at either the front or +// the end (according to its priority) of the circular mutex waiter queue whose +// head is "head", and return the new head. mu is the previous mutex state, +// which contains the reader count (perhaps adjusted for the operation in +// progress) if the list was empty and a read lock held, and the holder hint if +// the list was empty and a write lock held. (flags & kMuIsCond) indicates +// whether this thread was transferred from a CondVar or is waiting for a +// non-trivial condition. In this case, Enqueue() never returns nullptr +// +// If waitp->cv_word != nullptr, CondVarEnqueue() is called, and "head" is +// returned. This mechanism is used by CondVar to queue a thread on the +// condition variable queue instead of the mutex queue in implementing Wait(). +// In this case, Enqueue() can return nullptr (if head==nullptr). +static PerThreadSynch *Enqueue(PerThreadSynch *head, + SynchWaitParams *waitp, intptr_t mu, int flags) { + // If we have been given a cv_word, call CondVarEnqueue() and return + // the previous head of the Mutex waiter queue. + if (waitp->cv_word != nullptr) { + CondVarEnqueue(waitp); + return head; + } + + PerThreadSynch *s = waitp->thread; + ABSL_RAW_CHECK( + s->waitp == nullptr || // normal case + s->waitp == waitp || // Fer()---transfer from condition variable + s->suppress_fatal_errors, + "detected illegal recursion into Mutex code"); + s->waitp = waitp; + s->skip = nullptr; // maintain skip invariant (see above) + s->may_skip = true; // always true on entering queue + s->wake = false; // not being woken + s->cond_waiter = ((flags & kMuIsCond) != 0); + if (head == nullptr) { // s is the only waiter + s->next = s; // it's the only entry in the cycle + s->readers = mu; // reader count is from mu word + s->maybe_unlocking = false; // no one is searching an empty list + head = s; // s is new head + } else { + PerThreadSynch *enqueue_after = nullptr; // we'll put s after this element +#ifdef ABSL_HAVE_PTHREAD_GETSCHEDPARAM + int64_t now_cycles = base_internal::CycleClock::Now(); + if (s->next_priority_read_cycles < now_cycles) { + // Every so often, update our idea of the thread's priority. + // pthread_getschedparam() is 5% of the block/wakeup time; + // base_internal::CycleClock::Now() is 0.5%. + int policy; + struct sched_param param; + const int err = pthread_getschedparam(pthread_self(), &policy, ¶m); + if (err != 0) { + ABSL_RAW_LOG(ERROR, "pthread_getschedparam failed: %d", err); + } else { + s->priority = param.sched_priority; + s->next_priority_read_cycles = + now_cycles + + static_cast<int64_t>(base_internal::CycleClock::Frequency()); + } + } + if (s->priority > head->priority) { // s's priority is above head's + // try to put s in priority-fifo order, or failing that at the front. + if (!head->maybe_unlocking) { + // No unlocker can be scanning the queue, so we can insert between + // skip-chains, and within a skip-chain if it has the same condition as + // s. We insert in priority-fifo order, examining the end of every + // skip-chain, plus every element with the same condition as s. + PerThreadSynch *advance_to = head; // next value of enqueue_after + PerThreadSynch *cur; // successor of enqueue_after + do { + enqueue_after = advance_to; + cur = enqueue_after->next; // this advance ensures progress + advance_to = Skip(cur); // normally, advance to end of skip chain + // (side-effect: optimizes skip chain) + if (advance_to != cur && s->priority > advance_to->priority && + MuSameCondition(s, cur)) { + // but this skip chain is not a singleton, s has higher priority + // than its tail and has the same condition as the chain, + // so we can insert within the skip-chain + advance_to = cur; // advance by just one + } + } while (s->priority <= advance_to->priority); + // termination guaranteed because s->priority > head->priority + // and head is the end of a skip chain + } else if (waitp->how == kExclusive && + Condition::GuaranteedEqual(waitp->cond, nullptr)) { + // An unlocker could be scanning the queue, but we know it will recheck + // the queue front for writers that have no condition, which is what s + // is, so an insert at front is safe. + enqueue_after = head; // add after head, at front + } + } +#endif + if (enqueue_after != nullptr) { + s->next = enqueue_after->next; + enqueue_after->next = s; + + // enqueue_after can be: head, Skip(...), or cur. + // The first two imply enqueue_after->skip == nullptr, and + // the last is used only if MuSameCondition(s, cur). + // We require this because clearing enqueue_after->skip + // is impossible; enqueue_after's predecessors might also + // incorrectly skip over s if we were to allow other + // insertion points. + ABSL_RAW_CHECK( + enqueue_after->skip == nullptr || MuSameCondition(enqueue_after, s), + "Mutex Enqueue failure"); + + if (enqueue_after != head && enqueue_after->may_skip && + MuSameCondition(enqueue_after, enqueue_after->next)) { + // enqueue_after can skip to its new successor, s + enqueue_after->skip = enqueue_after->next; + } + if (MuSameCondition(s, s->next)) { // s->may_skip is known to be true + s->skip = s->next; // s may skip to its successor + } + } else { // enqueue not done any other way, so + // we're inserting s at the back + // s will become new head; copy data from head into it + s->next = head->next; // add s after head + head->next = s; + s->readers = head->readers; // reader count is from previous head + s->maybe_unlocking = head->maybe_unlocking; // same for unlock hint + if (head->may_skip && MuSameCondition(head, s)) { + // head now has successor; may skip + head->skip = s; + } + head = s; // s is new head + } + } + s->state.store(PerThreadSynch::kQueued, std::memory_order_relaxed); + return head; +} + +// Dequeue the successor pw->next of thread pw from the Mutex waiter queue +// whose last element is head. The new head element is returned, or null +// if the list is made empty. +// Dequeue is called with both spinlock and Mutex held. +static PerThreadSynch *Dequeue(PerThreadSynch *head, PerThreadSynch *pw) { + PerThreadSynch *w = pw->next; + pw->next = w->next; // snip w out of list + if (head == w) { // we removed the head + head = (pw == w) ? nullptr : pw; // either emptied list, or pw is new head + } else if (pw != head && MuSameCondition(pw, pw->next)) { + // pw can skip to its new successor + if (pw->next->skip != + nullptr) { // either skip to its successors skip target + pw->skip = pw->next->skip; + } else { // or to pw's successor + pw->skip = pw->next; + } + } + return head; +} + +// Traverse the elements [ pw->next, h] of the circular list whose last element +// is head. +// Remove all elements with wake==true and place them in the +// singly-linked list wake_list in the order found. Assumes that +// there is only one such element if the element has how == kExclusive. +// Return the new head. +static PerThreadSynch *DequeueAllWakeable(PerThreadSynch *head, + PerThreadSynch *pw, + PerThreadSynch **wake_tail) { + PerThreadSynch *orig_h = head; + PerThreadSynch *w = pw->next; + bool skipped = false; + do { + if (w->wake) { // remove this element + ABSL_RAW_CHECK(pw->skip == nullptr, "bad skip in DequeueAllWakeable"); + // we're removing pw's successor so either pw->skip is zero or we should + // already have removed pw since if pw->skip!=null, pw has the same + // condition as w. + head = Dequeue(head, pw); + w->next = *wake_tail; // keep list terminated + *wake_tail = w; // add w to wake_list; + wake_tail = &w->next; // next addition to end + if (w->waitp->how == kExclusive) { // wake at most 1 writer + break; + } + } else { // not waking this one; skip + pw = Skip(w); // skip as much as possible + skipped = true; + } + w = pw->next; + // We want to stop processing after we've considered the original head, + // orig_h. We can't test for w==orig_h in the loop because w may skip over + // it; we are guaranteed only that w's predecessor will not skip over + // orig_h. When we've considered orig_h, either we've processed it and + // removed it (so orig_h != head), or we considered it and skipped it (so + // skipped==true && pw == head because skipping from head always skips by + // just one, leaving pw pointing at head). So we want to + // continue the loop with the negation of that expression. + } while (orig_h == head && (pw != head || !skipped)); + return head; +} + +// Try to remove thread s from the list of waiters on this mutex. +// Does nothing if s is not on the waiter list. +void Mutex::TryRemove(PerThreadSynch *s) { + intptr_t v = mu_.load(std::memory_order_relaxed); + // acquire spinlock & lock + if ((v & (kMuWait | kMuSpin | kMuWriter | kMuReader)) == kMuWait && + mu_.compare_exchange_strong(v, v | kMuSpin | kMuWriter, + std::memory_order_acquire, + std::memory_order_relaxed)) { + PerThreadSynch *h = GetPerThreadSynch(v); + if (h != nullptr) { + PerThreadSynch *pw = h; // pw is w's predecessor + PerThreadSynch *w; + if ((w = pw->next) != s) { // search for thread, + do { // processing at least one element + if (!MuSameCondition(s, w)) { // seeking different condition + pw = Skip(w); // so skip all that won't match + // we don't have to worry about dangling skip fields + // in the threads we skipped; none can point to s + // because their condition differs from s + } else { // seeking same condition + FixSkip(w, s); // fix up any skip pointer from w to s + pw = w; + } + // don't search further if we found the thread, or we're about to + // process the first thread again. + } while ((w = pw->next) != s && pw != h); + } + if (w == s) { // found thread; remove it + // pw->skip may be non-zero here; the loop above ensured that + // no ancestor of s can skip to s, so removal is safe anyway. + h = Dequeue(h, pw); + s->next = nullptr; + s->state.store(PerThreadSynch::kAvailable, std::memory_order_release); + } + } + intptr_t nv; + do { // release spinlock and lock + v = mu_.load(std::memory_order_relaxed); + nv = v & (kMuDesig | kMuEvent); + if (h != nullptr) { + nv |= kMuWait | reinterpret_cast<intptr_t>(h); + h->readers = 0; // we hold writer lock + h->maybe_unlocking = false; // finished unlocking + } + } while (!mu_.compare_exchange_weak(v, nv, + std::memory_order_release, + std::memory_order_relaxed)); + } +} + +// Wait until thread "s", which must be the current thread, is removed from the +// this mutex's waiter queue. If "s->waitp->timeout" has a timeout, wake up +// if the wait extends past the absolute time specified, even if "s" is still +// on the mutex queue. In this case, remove "s" from the queue and return +// true, otherwise return false. +ABSL_XRAY_LOG_ARGS(1) void Mutex::Block(PerThreadSynch *s) { + while (s->state.load(std::memory_order_acquire) == PerThreadSynch::kQueued) { + if (!DecrementSynchSem(this, s, s->waitp->timeout)) { + // After a timeout, we go into a spin loop until we remove ourselves + // from the queue, or someone else removes us. We can't be sure to be + // able to remove ourselves in a single lock acquisition because this + // mutex may be held, and the holder has the right to read the centre + // of the waiter queue without holding the spinlock. + this->TryRemove(s); + int c = 0; + while (s->next != nullptr) { + c = Delay(c, GENTLE); + this->TryRemove(s); + } + if (kDebugMode) { + // This ensures that we test the case that TryRemove() is called when s + // is not on the queue. + this->TryRemove(s); + } + s->waitp->timeout = KernelTimeout::Never(); // timeout is satisfied + s->waitp->cond = nullptr; // condition no longer relevant for wakeups + } + } + ABSL_RAW_CHECK(s->waitp != nullptr || s->suppress_fatal_errors, + "detected illegal recursion in Mutex code"); + s->waitp = nullptr; +} + +// Wake thread w, and return the next thread in the list. +PerThreadSynch *Mutex::Wakeup(PerThreadSynch *w) { + PerThreadSynch *next = w->next; + w->next = nullptr; + w->state.store(PerThreadSynch::kAvailable, std::memory_order_release); + IncrementSynchSem(this, w); + + return next; +} + +static GraphId GetGraphIdLocked(Mutex *mu) + ABSL_EXCLUSIVE_LOCKS_REQUIRED(deadlock_graph_mu) { + if (!deadlock_graph) { // (re)create the deadlock graph. + deadlock_graph = + new (base_internal::LowLevelAlloc::Alloc(sizeof(*deadlock_graph))) + GraphCycles; + } + return deadlock_graph->GetId(mu); +} + +static GraphId GetGraphId(Mutex *mu) ABSL_LOCKS_EXCLUDED(deadlock_graph_mu) { + deadlock_graph_mu.Lock(); + GraphId id = GetGraphIdLocked(mu); + deadlock_graph_mu.Unlock(); + return id; +} + +// Record a lock acquisition. This is used in debug mode for deadlock +// detection. The held_locks pointer points to the relevant data +// structure for each case. +static void LockEnter(Mutex* mu, GraphId id, SynchLocksHeld *held_locks) { + int n = held_locks->n; + int i = 0; + while (i != n && held_locks->locks[i].id != id) { + i++; + } + if (i == n) { + if (n == ABSL_ARRAYSIZE(held_locks->locks)) { + held_locks->overflow = true; // lost some data + } else { // we have room for lock + held_locks->locks[i].mu = mu; + held_locks->locks[i].count = 1; + held_locks->locks[i].id = id; + held_locks->n = n + 1; + } + } else { + held_locks->locks[i].count++; + } +} + +// Record a lock release. Each call to LockEnter(mu, id, x) should be +// eventually followed by a call to LockLeave(mu, id, x) by the same thread. +// It does not process the event if is not needed when deadlock detection is +// disabled. +static void LockLeave(Mutex* mu, GraphId id, SynchLocksHeld *held_locks) { + int n = held_locks->n; + int i = 0; + while (i != n && held_locks->locks[i].id != id) { + i++; + } + if (i == n) { + if (!held_locks->overflow) { + // The deadlock id may have been reassigned after ForgetDeadlockInfo, + // but in that case mu should still be present. + i = 0; + while (i != n && held_locks->locks[i].mu != mu) { + i++; + } + if (i == n) { // mu missing means releasing unheld lock + SynchEvent *mu_events = GetSynchEvent(mu); + ABSL_RAW_LOG(FATAL, + "thread releasing lock it does not hold: %p %s; " + , + static_cast<void *>(mu), + mu_events == nullptr ? "" : mu_events->name); + } + } + } else if (held_locks->locks[i].count == 1) { + held_locks->n = n - 1; + held_locks->locks[i] = held_locks->locks[n - 1]; + held_locks->locks[n - 1].id = InvalidGraphId(); + held_locks->locks[n - 1].mu = + nullptr; // clear mu to please the leak detector. + } else { + assert(held_locks->locks[i].count > 0); + held_locks->locks[i].count--; + } +} + +// Call LockEnter() if in debug mode and deadlock detection is enabled. +static inline void DebugOnlyLockEnter(Mutex *mu) { + if (kDebugMode) { + if (synch_deadlock_detection.load(std::memory_order_acquire) != + OnDeadlockCycle::kIgnore) { + LockEnter(mu, GetGraphId(mu), Synch_GetAllLocks()); + } + } +} + +// Call LockEnter() if in debug mode and deadlock detection is enabled. +static inline void DebugOnlyLockEnter(Mutex *mu, GraphId id) { + if (kDebugMode) { + if (synch_deadlock_detection.load(std::memory_order_acquire) != + OnDeadlockCycle::kIgnore) { + LockEnter(mu, id, Synch_GetAllLocks()); + } + } +} + +// Call LockLeave() if in debug mode and deadlock detection is enabled. +static inline void DebugOnlyLockLeave(Mutex *mu) { + if (kDebugMode) { + if (synch_deadlock_detection.load(std::memory_order_acquire) != + OnDeadlockCycle::kIgnore) { + LockLeave(mu, GetGraphId(mu), Synch_GetAllLocks()); + } + } +} + +static char *StackString(void **pcs, int n, char *buf, int maxlen, + bool symbolize) { + static const int kSymLen = 200; + char sym[kSymLen]; + int len = 0; + for (int i = 0; i != n; i++) { + if (symbolize) { + if (!symbolizer(pcs[i], sym, kSymLen)) { + sym[0] = '\0'; + } + snprintf(buf + len, maxlen - len, "%s\t@ %p %s\n", + (i == 0 ? "\n" : ""), + pcs[i], sym); + } else { + snprintf(buf + len, maxlen - len, " %p", pcs[i]); + } + len += strlen(&buf[len]); + } + return buf; +} + +static char *CurrentStackString(char *buf, int maxlen, bool symbolize) { + void *pcs[40]; + return StackString(pcs, absl::GetStackTrace(pcs, ABSL_ARRAYSIZE(pcs), 2), buf, + maxlen, symbolize); +} + +namespace { +enum { kMaxDeadlockPathLen = 10 }; // maximum length of a deadlock cycle; + // a path this long would be remarkable +// Buffers required to report a deadlock. +// We do not allocate them on stack to avoid large stack frame. +struct DeadlockReportBuffers { + char buf[6100]; + GraphId path[kMaxDeadlockPathLen]; +}; + +struct ScopedDeadlockReportBuffers { + ScopedDeadlockReportBuffers() { + b = reinterpret_cast<DeadlockReportBuffers *>( + base_internal::LowLevelAlloc::Alloc(sizeof(*b))); + } + ~ScopedDeadlockReportBuffers() { base_internal::LowLevelAlloc::Free(b); } + DeadlockReportBuffers *b; +}; + +// Helper to pass to GraphCycles::UpdateStackTrace. +int GetStack(void** stack, int max_depth) { + return absl::GetStackTrace(stack, max_depth, 3); +} +} // anonymous namespace + +// Called in debug mode when a thread is about to acquire a lock in a way that +// may block. +static GraphId DeadlockCheck(Mutex *mu) { + if (synch_deadlock_detection.load(std::memory_order_acquire) == + OnDeadlockCycle::kIgnore) { + return InvalidGraphId(); + } + + SynchLocksHeld *all_locks = Synch_GetAllLocks(); + + absl::base_internal::SpinLockHolder lock(&deadlock_graph_mu); + const GraphId mu_id = GetGraphIdLocked(mu); + + if (all_locks->n == 0) { + // There are no other locks held. Return now so that we don't need to + // call GetSynchEvent(). This way we do not record the stack trace + // for this Mutex. It's ok, since if this Mutex is involved in a deadlock, + // it can't always be the first lock acquired by a thread. + return mu_id; + } + + // We prefer to keep stack traces that show a thread holding and acquiring + // as many locks as possible. This increases the chances that a given edge + // in the acquires-before graph will be represented in the stack traces + // recorded for the locks. + deadlock_graph->UpdateStackTrace(mu_id, all_locks->n + 1, GetStack); + + // For each other mutex already held by this thread: + for (int i = 0; i != all_locks->n; i++) { + const GraphId other_node_id = all_locks->locks[i].id; + const Mutex *other = + static_cast<const Mutex *>(deadlock_graph->Ptr(other_node_id)); + if (other == nullptr) { + // Ignore stale lock + continue; + } + + // Add the acquired-before edge to the graph. + if (!deadlock_graph->InsertEdge(other_node_id, mu_id)) { + ScopedDeadlockReportBuffers scoped_buffers; + DeadlockReportBuffers *b = scoped_buffers.b; + static int number_of_reported_deadlocks = 0; + number_of_reported_deadlocks++; + // Symbolize only 2 first deadlock report to avoid huge slowdowns. + bool symbolize = number_of_reported_deadlocks <= 2; + ABSL_RAW_LOG(ERROR, "Potential Mutex deadlock: %s", + CurrentStackString(b->buf, sizeof (b->buf), symbolize)); + int len = 0; + for (int j = 0; j != all_locks->n; j++) { + void* pr = deadlock_graph->Ptr(all_locks->locks[j].id); + if (pr != nullptr) { + snprintf(b->buf + len, sizeof (b->buf) - len, " %p", pr); + len += static_cast<int>(strlen(&b->buf[len])); + } + } + ABSL_RAW_LOG(ERROR, "Acquiring %p Mutexes held: %s", + static_cast<void *>(mu), b->buf); + ABSL_RAW_LOG(ERROR, "Cycle: "); + int path_len = deadlock_graph->FindPath( + mu_id, other_node_id, ABSL_ARRAYSIZE(b->path), b->path); + for (int j = 0; j != path_len; j++) { + GraphId id = b->path[j]; + Mutex *path_mu = static_cast<Mutex *>(deadlock_graph->Ptr(id)); + if (path_mu == nullptr) continue; + void** stack; + int depth = deadlock_graph->GetStackTrace(id, &stack); + snprintf(b->buf, sizeof(b->buf), + "mutex@%p stack: ", static_cast<void *>(path_mu)); + StackString(stack, depth, b->buf + strlen(b->buf), + static_cast<int>(sizeof(b->buf) - strlen(b->buf)), + symbolize); + ABSL_RAW_LOG(ERROR, "%s", b->buf); + } + if (synch_deadlock_detection.load(std::memory_order_acquire) == + OnDeadlockCycle::kAbort) { + deadlock_graph_mu.Unlock(); // avoid deadlock in fatal sighandler + ABSL_RAW_LOG(FATAL, "dying due to potential deadlock"); + return mu_id; + } + break; // report at most one potential deadlock per acquisition + } + } + + return mu_id; +} + +// Invoke DeadlockCheck() iff we're in debug mode and +// deadlock checking has been enabled. +static inline GraphId DebugOnlyDeadlockCheck(Mutex *mu) { + if (kDebugMode && synch_deadlock_detection.load(std::memory_order_acquire) != + OnDeadlockCycle::kIgnore) { + return DeadlockCheck(mu); + } else { + return InvalidGraphId(); + } +} + +void Mutex::ForgetDeadlockInfo() { + if (kDebugMode && synch_deadlock_detection.load(std::memory_order_acquire) != + OnDeadlockCycle::kIgnore) { + deadlock_graph_mu.Lock(); + if (deadlock_graph != nullptr) { + deadlock_graph->RemoveNode(this); + } + deadlock_graph_mu.Unlock(); + } +} + +void Mutex::AssertNotHeld() const { + // We have the data to allow this check only if in debug mode and deadlock + // detection is enabled. + if (kDebugMode && + (mu_.load(std::memory_order_relaxed) & (kMuWriter | kMuReader)) != 0 && + synch_deadlock_detection.load(std::memory_order_acquire) != + OnDeadlockCycle::kIgnore) { + GraphId id = GetGraphId(const_cast<Mutex *>(this)); + SynchLocksHeld *locks = Synch_GetAllLocks(); + for (int i = 0; i != locks->n; i++) { + if (locks->locks[i].id == id) { + SynchEvent *mu_events = GetSynchEvent(this); + ABSL_RAW_LOG(FATAL, "thread should not hold mutex %p %s", + static_cast<const void *>(this), + (mu_events == nullptr ? "" : mu_events->name)); + } + } + } +} + +// Attempt to acquire *mu, and return whether successful. The implementation +// may spin for a short while if the lock cannot be acquired immediately. +static bool TryAcquireWithSpinning(std::atomic<intptr_t>* mu) { + int c = mutex_globals.spinloop_iterations; + do { // do/while somewhat faster on AMD + intptr_t v = mu->load(std::memory_order_relaxed); + if ((v & (kMuReader|kMuEvent)) != 0) { + return false; // a reader or tracing -> give up + } else if (((v & kMuWriter) == 0) && // no holder -> try to acquire + mu->compare_exchange_strong(v, kMuWriter | v, + std::memory_order_acquire, + std::memory_order_relaxed)) { + return true; + } + } while (--c > 0); + return false; +} + +ABSL_XRAY_LOG_ARGS(1) void Mutex::Lock() { + ABSL_TSAN_MUTEX_PRE_LOCK(this, 0); + GraphId id = DebugOnlyDeadlockCheck(this); + intptr_t v = mu_.load(std::memory_order_relaxed); + // try fast acquire, then spin loop + if ((v & (kMuWriter | kMuReader | kMuEvent)) != 0 || + !mu_.compare_exchange_strong(v, kMuWriter | v, + std::memory_order_acquire, + std::memory_order_relaxed)) { + // try spin acquire, then slow loop + if (!TryAcquireWithSpinning(&this->mu_)) { + this->LockSlow(kExclusive, nullptr, 0); + } + } + DebugOnlyLockEnter(this, id); + ABSL_TSAN_MUTEX_POST_LOCK(this, 0, 0); +} + +ABSL_XRAY_LOG_ARGS(1) void Mutex::ReaderLock() { + ABSL_TSAN_MUTEX_PRE_LOCK(this, __tsan_mutex_read_lock); + GraphId id = DebugOnlyDeadlockCheck(this); + intptr_t v = mu_.load(std::memory_order_relaxed); + // try fast acquire, then slow loop + if ((v & (kMuWriter | kMuWait | kMuEvent)) != 0 || + !mu_.compare_exchange_strong(v, (kMuReader | v) + kMuOne, + std::memory_order_acquire, + std::memory_order_relaxed)) { + this->LockSlow(kShared, nullptr, 0); + } + DebugOnlyLockEnter(this, id); + ABSL_TSAN_MUTEX_POST_LOCK(this, __tsan_mutex_read_lock, 0); +} + +void Mutex::LockWhen(const Condition &cond) { + ABSL_TSAN_MUTEX_PRE_LOCK(this, 0); + GraphId id = DebugOnlyDeadlockCheck(this); + this->LockSlow(kExclusive, &cond, 0); + DebugOnlyLockEnter(this, id); + ABSL_TSAN_MUTEX_POST_LOCK(this, 0, 0); +} + +bool Mutex::LockWhenWithTimeout(const Condition &cond, absl::Duration timeout) { + return LockWhenWithDeadline(cond, DeadlineFromTimeout(timeout)); +} + +bool Mutex::LockWhenWithDeadline(const Condition &cond, absl::Time deadline) { + ABSL_TSAN_MUTEX_PRE_LOCK(this, 0); + GraphId id = DebugOnlyDeadlockCheck(this); + bool res = LockSlowWithDeadline(kExclusive, &cond, + KernelTimeout(deadline), 0); + DebugOnlyLockEnter(this, id); + ABSL_TSAN_MUTEX_POST_LOCK(this, 0, 0); + return res; +} + +void Mutex::ReaderLockWhen(const Condition &cond) { + ABSL_TSAN_MUTEX_PRE_LOCK(this, __tsan_mutex_read_lock); + GraphId id = DebugOnlyDeadlockCheck(this); + this->LockSlow(kShared, &cond, 0); + DebugOnlyLockEnter(this, id); + ABSL_TSAN_MUTEX_POST_LOCK(this, __tsan_mutex_read_lock, 0); +} + +bool Mutex::ReaderLockWhenWithTimeout(const Condition &cond, + absl::Duration timeout) { + return ReaderLockWhenWithDeadline(cond, DeadlineFromTimeout(timeout)); +} + +bool Mutex::ReaderLockWhenWithDeadline(const Condition &cond, + absl::Time deadline) { + ABSL_TSAN_MUTEX_PRE_LOCK(this, __tsan_mutex_read_lock); + GraphId id = DebugOnlyDeadlockCheck(this); + bool res = LockSlowWithDeadline(kShared, &cond, KernelTimeout(deadline), 0); + DebugOnlyLockEnter(this, id); + ABSL_TSAN_MUTEX_POST_LOCK(this, __tsan_mutex_read_lock, 0); + return res; +} + +void Mutex::Await(const Condition &cond) { + if (cond.Eval()) { // condition already true; nothing to do + if (kDebugMode) { + this->AssertReaderHeld(); + } + } else { // normal case + ABSL_RAW_CHECK(this->AwaitCommon(cond, KernelTimeout::Never()), + "condition untrue on return from Await"); + } +} + +bool Mutex::AwaitWithTimeout(const Condition &cond, absl::Duration timeout) { + return AwaitWithDeadline(cond, DeadlineFromTimeout(timeout)); +} + +bool Mutex::AwaitWithDeadline(const Condition &cond, absl::Time deadline) { + if (cond.Eval()) { // condition already true; nothing to do + if (kDebugMode) { + this->AssertReaderHeld(); + } + return true; + } + + KernelTimeout t{deadline}; + bool res = this->AwaitCommon(cond, t); + ABSL_RAW_CHECK(res || t.has_timeout(), + "condition untrue on return from Await"); + return res; +} + +bool Mutex::AwaitCommon(const Condition &cond, KernelTimeout t) { + this->AssertReaderHeld(); + MuHow how = + (mu_.load(std::memory_order_relaxed) & kMuWriter) ? kExclusive : kShared; + ABSL_TSAN_MUTEX_PRE_UNLOCK(this, TsanFlags(how)); + SynchWaitParams waitp( + how, &cond, t, nullptr /*no cvmu*/, Synch_GetPerThreadAnnotated(this), + nullptr /*no cv_word*/); + int flags = kMuHasBlocked; + if (!Condition::GuaranteedEqual(&cond, nullptr)) { + flags |= kMuIsCond; + } + this->UnlockSlow(&waitp); + this->Block(waitp.thread); + ABSL_TSAN_MUTEX_POST_UNLOCK(this, TsanFlags(how)); + ABSL_TSAN_MUTEX_PRE_LOCK(this, TsanFlags(how)); + this->LockSlowLoop(&waitp, flags); + bool res = waitp.cond != nullptr || // => cond known true from LockSlowLoop + EvalConditionAnnotated(&cond, this, true, false, how == kShared); + ABSL_TSAN_MUTEX_POST_LOCK(this, TsanFlags(how), 0); + return res; +} + +ABSL_XRAY_LOG_ARGS(1) bool Mutex::TryLock() { + ABSL_TSAN_MUTEX_PRE_LOCK(this, __tsan_mutex_try_lock); + intptr_t v = mu_.load(std::memory_order_relaxed); + if ((v & (kMuWriter | kMuReader | kMuEvent)) == 0 && // try fast acquire + mu_.compare_exchange_strong(v, kMuWriter | v, + std::memory_order_acquire, + std::memory_order_relaxed)) { + DebugOnlyLockEnter(this); + ABSL_TSAN_MUTEX_POST_LOCK(this, __tsan_mutex_try_lock, 0); + return true; + } + if ((v & kMuEvent) != 0) { // we're recording events + if ((v & kExclusive->slow_need_zero) == 0 && // try fast acquire + mu_.compare_exchange_strong( + v, (kExclusive->fast_or | v) + kExclusive->fast_add, + std::memory_order_acquire, std::memory_order_relaxed)) { + DebugOnlyLockEnter(this); + PostSynchEvent(this, SYNCH_EV_TRYLOCK_SUCCESS); + ABSL_TSAN_MUTEX_POST_LOCK(this, __tsan_mutex_try_lock, 0); + return true; + } else { + PostSynchEvent(this, SYNCH_EV_TRYLOCK_FAILED); + } + } + ABSL_TSAN_MUTEX_POST_LOCK( + this, __tsan_mutex_try_lock | __tsan_mutex_try_lock_failed, 0); + return false; +} + +ABSL_XRAY_LOG_ARGS(1) bool Mutex::ReaderTryLock() { + ABSL_TSAN_MUTEX_PRE_LOCK(this, + __tsan_mutex_read_lock | __tsan_mutex_try_lock); + intptr_t v = mu_.load(std::memory_order_relaxed); + // The while-loops (here and below) iterate only if the mutex word keeps + // changing (typically because the reader count changes) under the CAS. We + // limit the number of attempts to avoid having to think about livelock. + int loop_limit = 5; + while ((v & (kMuWriter|kMuWait|kMuEvent)) == 0 && loop_limit != 0) { + if (mu_.compare_exchange_strong(v, (kMuReader | v) + kMuOne, + std::memory_order_acquire, + std::memory_order_relaxed)) { + DebugOnlyLockEnter(this); + ABSL_TSAN_MUTEX_POST_LOCK( + this, __tsan_mutex_read_lock | __tsan_mutex_try_lock, 0); + return true; + } + loop_limit--; + v = mu_.load(std::memory_order_relaxed); + } + if ((v & kMuEvent) != 0) { // we're recording events + loop_limit = 5; + while ((v & kShared->slow_need_zero) == 0 && loop_limit != 0) { + if (mu_.compare_exchange_strong(v, (kMuReader | v) + kMuOne, + std::memory_order_acquire, + std::memory_order_relaxed)) { + DebugOnlyLockEnter(this); + PostSynchEvent(this, SYNCH_EV_READERTRYLOCK_SUCCESS); + ABSL_TSAN_MUTEX_POST_LOCK( + this, __tsan_mutex_read_lock | __tsan_mutex_try_lock, 0); + return true; + } + loop_limit--; + v = mu_.load(std::memory_order_relaxed); + } + if ((v & kMuEvent) != 0) { + PostSynchEvent(this, SYNCH_EV_READERTRYLOCK_FAILED); + } + } + ABSL_TSAN_MUTEX_POST_LOCK(this, + __tsan_mutex_read_lock | __tsan_mutex_try_lock | + __tsan_mutex_try_lock_failed, + 0); + return false; +} + +ABSL_XRAY_LOG_ARGS(1) void Mutex::Unlock() { + ABSL_TSAN_MUTEX_PRE_UNLOCK(this, 0); + DebugOnlyLockLeave(this); + intptr_t v = mu_.load(std::memory_order_relaxed); + + if (kDebugMode && ((v & (kMuWriter | kMuReader)) != kMuWriter)) { + ABSL_RAW_LOG(FATAL, "Mutex unlocked when destroyed or not locked: v=0x%x", + static_cast<unsigned>(v)); + } + + // should_try_cas is whether we'll try a compare-and-swap immediately. + // NOTE: optimized out when kDebugMode is false. + bool should_try_cas = ((v & (kMuEvent | kMuWriter)) == kMuWriter && + (v & (kMuWait | kMuDesig)) != kMuWait); + // But, we can use an alternate computation of it, that compilers + // currently don't find on their own. When that changes, this function + // can be simplified. + intptr_t x = (v ^ (kMuWriter | kMuWait)) & (kMuWriter | kMuEvent); + intptr_t y = (v ^ (kMuWriter | kMuWait)) & (kMuWait | kMuDesig); + // Claim: "x == 0 && y > 0" is equal to should_try_cas. + // Also, because kMuWriter and kMuEvent exceed kMuDesig and kMuWait, + // all possible non-zero values for x exceed all possible values for y. + // Therefore, (x == 0 && y > 0) == (x < y). + if (kDebugMode && should_try_cas != (x < y)) { + // We would usually use PRIdPTR here, but is not correctly implemented + // within the android toolchain. + ABSL_RAW_LOG(FATAL, "internal logic error %llx %llx %llx\n", + static_cast<long long>(v), static_cast<long long>(x), + static_cast<long long>(y)); + } + if (x < y && + mu_.compare_exchange_strong(v, v & ~(kMuWrWait | kMuWriter), + std::memory_order_release, + std::memory_order_relaxed)) { + // fast writer release (writer with no waiters or with designated waker) + } else { + this->UnlockSlow(nullptr /*no waitp*/); // take slow path + } + ABSL_TSAN_MUTEX_POST_UNLOCK(this, 0); +} + +// Requires v to represent a reader-locked state. +static bool ExactlyOneReader(intptr_t v) { + assert((v & (kMuWriter|kMuReader)) == kMuReader); + assert((v & kMuHigh) != 0); + // The more straightforward "(v & kMuHigh) == kMuOne" also works, but + // on some architectures the following generates slightly smaller code. + // It may be faster too. + constexpr intptr_t kMuMultipleWaitersMask = kMuHigh ^ kMuOne; + return (v & kMuMultipleWaitersMask) == 0; +} + +ABSL_XRAY_LOG_ARGS(1) void Mutex::ReaderUnlock() { + ABSL_TSAN_MUTEX_PRE_UNLOCK(this, __tsan_mutex_read_lock); + DebugOnlyLockLeave(this); + intptr_t v = mu_.load(std::memory_order_relaxed); + assert((v & (kMuWriter|kMuReader)) == kMuReader); + if ((v & (kMuReader|kMuWait|kMuEvent)) == kMuReader) { + // fast reader release (reader with no waiters) + intptr_t clear = ExactlyOneReader(v) ? kMuReader|kMuOne : kMuOne; + if (mu_.compare_exchange_strong(v, v - clear, + std::memory_order_release, + std::memory_order_relaxed)) { + ABSL_TSAN_MUTEX_POST_UNLOCK(this, __tsan_mutex_read_lock); + return; + } + } + this->UnlockSlow(nullptr /*no waitp*/); // take slow path + ABSL_TSAN_MUTEX_POST_UNLOCK(this, __tsan_mutex_read_lock); +} + +// The zap_desig_waker bitmask is used to clear the designated waker flag in +// the mutex if this thread has blocked, and therefore may be the designated +// waker. +static const intptr_t zap_desig_waker[] = { + ~static_cast<intptr_t>(0), // not blocked + ~static_cast<intptr_t>( + kMuDesig) // blocked; turn off the designated waker bit +}; + +// The ignore_waiting_writers bitmask is used to ignore the existence +// of waiting writers if a reader that has already blocked once +// wakes up. +static const intptr_t ignore_waiting_writers[] = { + ~static_cast<intptr_t>(0), // not blocked + ~static_cast<intptr_t>( + kMuWrWait) // blocked; pretend there are no waiting writers +}; + +// Internal version of LockWhen(). See LockSlowWithDeadline() +ABSL_ATTRIBUTE_NOINLINE void Mutex::LockSlow(MuHow how, const Condition *cond, + int flags) { + ABSL_RAW_CHECK( + this->LockSlowWithDeadline(how, cond, KernelTimeout::Never(), flags), + "condition untrue on return from LockSlow"); +} + +// Compute cond->Eval() and tell race detectors that we do it under mutex mu. +static inline bool EvalConditionAnnotated(const Condition *cond, Mutex *mu, + bool locking, bool trylock, + bool read_lock) { + // Delicate annotation dance. + // We are currently inside of read/write lock/unlock operation. + // All memory accesses are ignored inside of mutex operations + for unlock + // operation tsan considers that we've already released the mutex. + bool res = false; +#ifdef THREAD_SANITIZER + const int flags = read_lock ? __tsan_mutex_read_lock : 0; + const int tryflags = flags | (trylock ? __tsan_mutex_try_lock : 0); +#endif + if (locking) { + // For lock we pretend that we have finished the operation, + // evaluate the predicate, then unlock the mutex and start locking it again + // to match the annotation at the end of outer lock operation. + // Note: we can't simply do POST_LOCK, Eval, PRE_LOCK, because then tsan + // will think the lock acquisition is recursive which will trigger + // deadlock detector. + ABSL_TSAN_MUTEX_POST_LOCK(mu, tryflags, 0); + res = cond->Eval(); + // There is no "try" version of Unlock, so use flags instead of tryflags. + ABSL_TSAN_MUTEX_PRE_UNLOCK(mu, flags); + ABSL_TSAN_MUTEX_POST_UNLOCK(mu, flags); + ABSL_TSAN_MUTEX_PRE_LOCK(mu, tryflags); + } else { + // Similarly, for unlock we pretend that we have unlocked the mutex, + // lock the mutex, evaluate the predicate, and start unlocking it again + // to match the annotation at the end of outer unlock operation. + ABSL_TSAN_MUTEX_POST_UNLOCK(mu, flags); + ABSL_TSAN_MUTEX_PRE_LOCK(mu, flags); + ABSL_TSAN_MUTEX_POST_LOCK(mu, flags, 0); + res = cond->Eval(); + ABSL_TSAN_MUTEX_PRE_UNLOCK(mu, flags); + } + // Prevent unused param warnings in non-TSAN builds. + static_cast<void>(mu); + static_cast<void>(trylock); + static_cast<void>(read_lock); + return res; +} + +// Compute cond->Eval() hiding it from race detectors. +// We are hiding it because inside of UnlockSlow we can evaluate a predicate +// that was just added by a concurrent Lock operation; Lock adds the predicate +// to the internal Mutex list without actually acquiring the Mutex +// (it only acquires the internal spinlock, which is rightfully invisible for +// tsan). As the result there is no tsan-visible synchronization between the +// addition and this thread. So if we would enable race detection here, +// it would race with the predicate initialization. +static inline bool EvalConditionIgnored(Mutex *mu, const Condition *cond) { + // Memory accesses are already ignored inside of lock/unlock operations, + // but synchronization operations are also ignored. When we evaluate the + // predicate we must ignore only memory accesses but not synchronization, + // because missed synchronization can lead to false reports later. + // So we "divert" (which un-ignores both memory accesses and synchronization) + // and then separately turn on ignores of memory accesses. + ABSL_TSAN_MUTEX_PRE_DIVERT(mu, 0); + ANNOTATE_IGNORE_READS_AND_WRITES_BEGIN(); + bool res = cond->Eval(); + ANNOTATE_IGNORE_READS_AND_WRITES_END(); + ABSL_TSAN_MUTEX_POST_DIVERT(mu, 0); + static_cast<void>(mu); // Prevent unused param warning in non-TSAN builds. + return res; +} + +// Internal equivalent of *LockWhenWithDeadline(), where +// "t" represents the absolute timeout; !t.has_timeout() means "forever". +// "how" is "kShared" (for ReaderLockWhen) or "kExclusive" (for LockWhen) +// In flags, bits are ored together: +// - kMuHasBlocked indicates that the client has already blocked on the call so +// the designated waker bit must be cleared and waiting writers should not +// obstruct this call +// - kMuIsCond indicates that this is a conditional acquire (condition variable, +// Await, LockWhen) so contention profiling should be suppressed. +bool Mutex::LockSlowWithDeadline(MuHow how, const Condition *cond, + KernelTimeout t, int flags) { + intptr_t v = mu_.load(std::memory_order_relaxed); + bool unlock = false; + if ((v & how->fast_need_zero) == 0 && // try fast acquire + mu_.compare_exchange_strong( + v, (how->fast_or | (v & zap_desig_waker[flags & kMuHasBlocked])) + + how->fast_add, + std::memory_order_acquire, std::memory_order_relaxed)) { + if (cond == nullptr || + EvalConditionAnnotated(cond, this, true, false, how == kShared)) { + return true; + } + unlock = true; + } + SynchWaitParams waitp( + how, cond, t, nullptr /*no cvmu*/, Synch_GetPerThreadAnnotated(this), + nullptr /*no cv_word*/); + if (!Condition::GuaranteedEqual(cond, nullptr)) { + flags |= kMuIsCond; + } + if (unlock) { + this->UnlockSlow(&waitp); + this->Block(waitp.thread); + flags |= kMuHasBlocked; + } + this->LockSlowLoop(&waitp, flags); + return waitp.cond != nullptr || // => cond known true from LockSlowLoop + cond == nullptr || + EvalConditionAnnotated(cond, this, true, false, how == kShared); +} + +// RAW_CHECK_FMT() takes a condition, a printf-style format string, and +// the printf-style argument list. The format string must be a literal. +// Arguments after the first are not evaluated unless the condition is true. +#define RAW_CHECK_FMT(cond, ...) \ + do { \ + if (ABSL_PREDICT_FALSE(!(cond))) { \ + ABSL_RAW_LOG(FATAL, "Check " #cond " failed: " __VA_ARGS__); \ + } \ + } while (0) + +static void CheckForMutexCorruption(intptr_t v, const char* label) { + // Test for either of two situations that should not occur in v: + // kMuWriter and kMuReader + // kMuWrWait and !kMuWait + const uintptr_t w = v ^ kMuWait; + // By flipping that bit, we can now test for: + // kMuWriter and kMuReader in w + // kMuWrWait and kMuWait in w + // We've chosen these two pairs of values to be so that they will overlap, + // respectively, when the word is left shifted by three. This allows us to + // save a branch in the common (correct) case of them not being coincident. + static_assert(kMuReader << 3 == kMuWriter, "must match"); + static_assert(kMuWait << 3 == kMuWrWait, "must match"); + if (ABSL_PREDICT_TRUE((w & (w << 3) & (kMuWriter | kMuWrWait)) == 0)) return; + RAW_CHECK_FMT((v & (kMuWriter | kMuReader)) != (kMuWriter | kMuReader), + "%s: Mutex corrupt: both reader and writer lock held: %p", + label, reinterpret_cast<void *>(v)); + RAW_CHECK_FMT((v & (kMuWait | kMuWrWait)) != kMuWrWait, + "%s: Mutex corrupt: waiting writer with no waiters: %p", + label, reinterpret_cast<void *>(v)); + assert(false); +} + +void Mutex::LockSlowLoop(SynchWaitParams *waitp, int flags) { + int c = 0; + intptr_t v = mu_.load(std::memory_order_relaxed); + if ((v & kMuEvent) != 0) { + PostSynchEvent(this, + waitp->how == kExclusive? SYNCH_EV_LOCK: SYNCH_EV_READERLOCK); + } + ABSL_RAW_CHECK( + waitp->thread->waitp == nullptr || waitp->thread->suppress_fatal_errors, + "detected illegal recursion into Mutex code"); + for (;;) { + v = mu_.load(std::memory_order_relaxed); + CheckForMutexCorruption(v, "Lock"); + if ((v & waitp->how->slow_need_zero) == 0) { + if (mu_.compare_exchange_strong( + v, (waitp->how->fast_or | + (v & zap_desig_waker[flags & kMuHasBlocked])) + + waitp->how->fast_add, + std::memory_order_acquire, std::memory_order_relaxed)) { + if (waitp->cond == nullptr || + EvalConditionAnnotated(waitp->cond, this, true, false, + waitp->how == kShared)) { + break; // we timed out, or condition true, so return + } + this->UnlockSlow(waitp); // got lock but condition false + this->Block(waitp->thread); + flags |= kMuHasBlocked; + c = 0; + } + } else { // need to access waiter list + bool dowait = false; + if ((v & (kMuSpin|kMuWait)) == 0) { // no waiters + // This thread tries to become the one and only waiter. + PerThreadSynch *new_h = Enqueue(nullptr, waitp, v, flags); + intptr_t nv = (v & zap_desig_waker[flags & kMuHasBlocked] & kMuLow) | + kMuWait; + ABSL_RAW_CHECK(new_h != nullptr, "Enqueue to empty list failed"); + if (waitp->how == kExclusive && (v & kMuReader) != 0) { + nv |= kMuWrWait; + } + if (mu_.compare_exchange_strong( + v, reinterpret_cast<intptr_t>(new_h) | nv, + std::memory_order_release, std::memory_order_relaxed)) { + dowait = true; + } else { // attempted Enqueue() failed + // zero out the waitp field set by Enqueue() + waitp->thread->waitp = nullptr; + } + } else if ((v & waitp->how->slow_inc_need_zero & + ignore_waiting_writers[flags & kMuHasBlocked]) == 0) { + // This is a reader that needs to increment the reader count, + // but the count is currently held in the last waiter. + if (mu_.compare_exchange_strong( + v, (v & zap_desig_waker[flags & kMuHasBlocked]) | kMuSpin | + kMuReader, + std::memory_order_acquire, std::memory_order_relaxed)) { + PerThreadSynch *h = GetPerThreadSynch(v); + h->readers += kMuOne; // inc reader count in waiter + do { // release spinlock + v = mu_.load(std::memory_order_relaxed); + } while (!mu_.compare_exchange_weak(v, (v & ~kMuSpin) | kMuReader, + std::memory_order_release, + std::memory_order_relaxed)); + if (waitp->cond == nullptr || + EvalConditionAnnotated(waitp->cond, this, true, false, + waitp->how == kShared)) { + break; // we timed out, or condition true, so return + } + this->UnlockSlow(waitp); // got lock but condition false + this->Block(waitp->thread); + flags |= kMuHasBlocked; + c = 0; + } + } else if ((v & kMuSpin) == 0 && // attempt to queue ourselves + mu_.compare_exchange_strong( + v, (v & zap_desig_waker[flags & kMuHasBlocked]) | kMuSpin | + kMuWait, + std::memory_order_acquire, std::memory_order_relaxed)) { + PerThreadSynch *h = GetPerThreadSynch(v); + PerThreadSynch *new_h = Enqueue(h, waitp, v, flags); + intptr_t wr_wait = 0; + ABSL_RAW_CHECK(new_h != nullptr, "Enqueue to list failed"); + if (waitp->how == kExclusive && (v & kMuReader) != 0) { + wr_wait = kMuWrWait; // give priority to a waiting writer + } + do { // release spinlock + v = mu_.load(std::memory_order_relaxed); + } while (!mu_.compare_exchange_weak( + v, (v & (kMuLow & ~kMuSpin)) | kMuWait | wr_wait | + reinterpret_cast<intptr_t>(new_h), + std::memory_order_release, std::memory_order_relaxed)); + dowait = true; + } + if (dowait) { + this->Block(waitp->thread); // wait until removed from list or timeout + flags |= kMuHasBlocked; + c = 0; + } + } + ABSL_RAW_CHECK( + waitp->thread->waitp == nullptr || waitp->thread->suppress_fatal_errors, + "detected illegal recursion into Mutex code"); + c = Delay(c, GENTLE); // delay, then try again + } + ABSL_RAW_CHECK( + waitp->thread->waitp == nullptr || waitp->thread->suppress_fatal_errors, + "detected illegal recursion into Mutex code"); + if ((v & kMuEvent) != 0) { + PostSynchEvent(this, + waitp->how == kExclusive? SYNCH_EV_LOCK_RETURNING : + SYNCH_EV_READERLOCK_RETURNING); + } +} + +// Unlock this mutex, which is held by the current thread. +// If waitp is non-zero, it must be the wait parameters for the current thread +// which holds the lock but is not runnable because its condition is false +// or it is in the process of blocking on a condition variable; it must requeue +// itself on the mutex/condvar to wait for its condition to become true. +ABSL_ATTRIBUTE_NOINLINE void Mutex::UnlockSlow(SynchWaitParams *waitp) { + intptr_t v = mu_.load(std::memory_order_relaxed); + this->AssertReaderHeld(); + CheckForMutexCorruption(v, "Unlock"); + if ((v & kMuEvent) != 0) { + PostSynchEvent(this, + (v & kMuWriter) != 0? SYNCH_EV_UNLOCK: SYNCH_EV_READERUNLOCK); + } + int c = 0; + // the waiter under consideration to wake, or zero + PerThreadSynch *w = nullptr; + // the predecessor to w or zero + PerThreadSynch *pw = nullptr; + // head of the list searched previously, or zero + PerThreadSynch *old_h = nullptr; + // a condition that's known to be false. + const Condition *known_false = nullptr; + PerThreadSynch *wake_list = kPerThreadSynchNull; // list of threads to wake + intptr_t wr_wait = 0; // set to kMuWrWait if we wake a reader and a + // later writer could have acquired the lock + // (starvation avoidance) + ABSL_RAW_CHECK(waitp == nullptr || waitp->thread->waitp == nullptr || + waitp->thread->suppress_fatal_errors, + "detected illegal recursion into Mutex code"); + // This loop finds threads wake_list to wakeup if any, and removes them from + // the list of waiters. In addition, it places waitp.thread on the queue of + // waiters if waitp is non-zero. + for (;;) { + v = mu_.load(std::memory_order_relaxed); + if ((v & kMuWriter) != 0 && (v & (kMuWait | kMuDesig)) != kMuWait && + waitp == nullptr) { + // fast writer release (writer with no waiters or with designated waker) + if (mu_.compare_exchange_strong(v, v & ~(kMuWrWait | kMuWriter), + std::memory_order_release, + std::memory_order_relaxed)) { + return; + } + } else if ((v & (kMuReader | kMuWait)) == kMuReader && waitp == nullptr) { + // fast reader release (reader with no waiters) + intptr_t clear = ExactlyOneReader(v) ? kMuReader | kMuOne : kMuOne; + if (mu_.compare_exchange_strong(v, v - clear, + std::memory_order_release, + std::memory_order_relaxed)) { + return; + } + } else if ((v & kMuSpin) == 0 && // attempt to get spinlock + mu_.compare_exchange_strong(v, v | kMuSpin, + std::memory_order_acquire, + std::memory_order_relaxed)) { + if ((v & kMuWait) == 0) { // no one to wake + intptr_t nv; + bool do_enqueue = true; // always Enqueue() the first time + ABSL_RAW_CHECK(waitp != nullptr, + "UnlockSlow is confused"); // about to sleep + do { // must loop to release spinlock as reader count may change + v = mu_.load(std::memory_order_relaxed); + // decrement reader count if there are readers + intptr_t new_readers = (v >= kMuOne)? v - kMuOne : v; + PerThreadSynch *new_h = nullptr; + if (do_enqueue) { + // If we are enqueuing on a CondVar (waitp->cv_word != nullptr) then + // we must not retry here. The initial attempt will always have + // succeeded, further attempts would enqueue us against *this due to + // Fer() handling. + do_enqueue = (waitp->cv_word == nullptr); + new_h = Enqueue(nullptr, waitp, new_readers, kMuIsCond); + } + intptr_t clear = kMuWrWait | kMuWriter; // by default clear write bit + if ((v & kMuWriter) == 0 && ExactlyOneReader(v)) { // last reader + clear = kMuWrWait | kMuReader; // clear read bit + } + nv = (v & kMuLow & ~clear & ~kMuSpin); + if (new_h != nullptr) { + nv |= kMuWait | reinterpret_cast<intptr_t>(new_h); + } else { // new_h could be nullptr if we queued ourselves on a + // CondVar + // In that case, we must place the reader count back in the mutex + // word, as Enqueue() did not store it in the new waiter. + nv |= new_readers & kMuHigh; + } + // release spinlock & our lock; retry if reader-count changed + // (writer count cannot change since we hold lock) + } while (!mu_.compare_exchange_weak(v, nv, + std::memory_order_release, + std::memory_order_relaxed)); + break; + } + + // There are waiters. + // Set h to the head of the circular waiter list. + PerThreadSynch *h = GetPerThreadSynch(v); + if ((v & kMuReader) != 0 && (h->readers & kMuHigh) > kMuOne) { + // a reader but not the last + h->readers -= kMuOne; // release our lock + intptr_t nv = v; // normally just release spinlock + if (waitp != nullptr) { // but waitp!=nullptr => must queue ourselves + PerThreadSynch *new_h = Enqueue(h, waitp, v, kMuIsCond); + ABSL_RAW_CHECK(new_h != nullptr, + "waiters disappeared during Enqueue()!"); + nv &= kMuLow; + nv |= kMuWait | reinterpret_cast<intptr_t>(new_h); + } + mu_.store(nv, std::memory_order_release); // release spinlock + // can release with a store because there were waiters + break; + } + + // Either we didn't search before, or we marked the queue + // as "maybe_unlocking" and no one else should have changed it. + ABSL_RAW_CHECK(old_h == nullptr || h->maybe_unlocking, + "Mutex queue changed beneath us"); + + // The lock is becoming free, and there's a waiter + if (old_h != nullptr && + !old_h->may_skip) { // we used old_h as a terminator + old_h->may_skip = true; // allow old_h to skip once more + ABSL_RAW_CHECK(old_h->skip == nullptr, "illegal skip from head"); + if (h != old_h && MuSameCondition(old_h, old_h->next)) { + old_h->skip = old_h->next; // old_h not head & can skip to successor + } + } + if (h->next->waitp->how == kExclusive && + Condition::GuaranteedEqual(h->next->waitp->cond, nullptr)) { + // easy case: writer with no condition; no need to search + pw = h; // wake w, the successor of h (=pw) + w = h->next; + w->wake = true; + // We are waking up a writer. This writer may be racing against + // an already awake reader for the lock. We want the + // writer to usually win this race, + // because if it doesn't, we can potentially keep taking a reader + // perpetually and writers will starve. Worse than + // that, this can also starve other readers if kMuWrWait gets set + // later. + wr_wait = kMuWrWait; + } else if (w != nullptr && (w->waitp->how == kExclusive || h == old_h)) { + // we found a waiter w to wake on a previous iteration and either it's + // a writer, or we've searched the entire list so we have all the + // readers. + if (pw == nullptr) { // if w's predecessor is unknown, it must be h + pw = h; + } + } else { + // At this point we don't know all the waiters to wake, and the first + // waiter has a condition or is a reader. We avoid searching over + // waiters we've searched on previous iterations by starting at + // old_h if it's set. If old_h==h, there's no one to wakeup at all. + if (old_h == h) { // we've searched before, and nothing's new + // so there's no one to wake. + intptr_t nv = (v & ~(kMuReader|kMuWriter|kMuWrWait)); + h->readers = 0; + h->maybe_unlocking = false; // finished unlocking + if (waitp != nullptr) { // we must queue ourselves and sleep + PerThreadSynch *new_h = Enqueue(h, waitp, v, kMuIsCond); + nv &= kMuLow; + if (new_h != nullptr) { + nv |= kMuWait | reinterpret_cast<intptr_t>(new_h); + } // else new_h could be nullptr if we queued ourselves on a + // CondVar + } + // release spinlock & lock + // can release with a store because there were waiters + mu_.store(nv, std::memory_order_release); + break; + } + + // set up to walk the list + PerThreadSynch *w_walk; // current waiter during list walk + PerThreadSynch *pw_walk; // previous waiter during list walk + if (old_h != nullptr) { // we've searched up to old_h before + pw_walk = old_h; + w_walk = old_h->next; + } else { // no prior search, start at beginning + pw_walk = + nullptr; // h->next's predecessor may change; don't record it + w_walk = h->next; + } + + h->may_skip = false; // ensure we never skip past h in future searches + // even if other waiters are queued after it. + ABSL_RAW_CHECK(h->skip == nullptr, "illegal skip from head"); + + h->maybe_unlocking = true; // we're about to scan the waiter list + // without the spinlock held. + // Enqueue must be conservative about + // priority queuing. + + // We must release the spinlock to evaluate the conditions. + mu_.store(v, std::memory_order_release); // release just spinlock + // can release with a store because there were waiters + + // h is the last waiter queued, and w_walk the first unsearched waiter. + // Without the spinlock, the locations mu_ and h->next may now change + // underneath us, but since we hold the lock itself, the only legal + // change is to add waiters between h and w_walk. Therefore, it's safe + // to walk the path from w_walk to h inclusive. (TryRemove() can remove + // a waiter anywhere, but it acquires both the spinlock and the Mutex) + + old_h = h; // remember we searched to here + + // Walk the path upto and including h looking for waiters we can wake. + while (pw_walk != h) { + w_walk->wake = false; + if (w_walk->waitp->cond == + nullptr || // no condition => vacuously true OR + (w_walk->waitp->cond != known_false && + // this thread's condition is not known false, AND + // is in fact true + EvalConditionIgnored(this, w_walk->waitp->cond))) { + if (w == nullptr) { + w_walk->wake = true; // can wake this waiter + w = w_walk; + pw = pw_walk; + if (w_walk->waitp->how == kExclusive) { + wr_wait = kMuWrWait; + break; // bail if waking this writer + } + } else if (w_walk->waitp->how == kShared) { // wake if a reader + w_walk->wake = true; + } else { // writer with true condition + wr_wait = kMuWrWait; + } + } else { // can't wake; condition false + known_false = w_walk->waitp->cond; // remember last false condition + } + if (w_walk->wake) { // we're waking reader w_walk + pw_walk = w_walk; // don't skip similar waiters + } else { // not waking; skip as much as possible + pw_walk = Skip(w_walk); + } + // If pw_walk == h, then load of pw_walk->next can race with + // concurrent write in Enqueue(). However, at the same time + // we do not need to do the load, because we will bail out + // from the loop anyway. + if (pw_walk != h) { + w_walk = pw_walk->next; + } + } + + continue; // restart for(;;)-loop to wakeup w or to find more waiters + } + ABSL_RAW_CHECK(pw->next == w, "pw not w's predecessor"); + // The first (and perhaps only) waiter we've chosen to wake is w, whose + // predecessor is pw. If w is a reader, we must wake all the other + // waiters with wake==true as well. We may also need to queue + // ourselves if waitp != null. The spinlock and the lock are still + // held. + + // This traverses the list in [ pw->next, h ], where h is the head, + // removing all elements with wake==true and placing them in the + // singly-linked list wake_list. Returns the new head. + h = DequeueAllWakeable(h, pw, &wake_list); + + intptr_t nv = (v & kMuEvent) | kMuDesig; + // assume no waiters left, + // set kMuDesig for INV1a + + if (waitp != nullptr) { // we must queue ourselves and sleep + h = Enqueue(h, waitp, v, kMuIsCond); + // h is new last waiter; could be null if we queued ourselves on a + // CondVar + } + + ABSL_RAW_CHECK(wake_list != kPerThreadSynchNull, + "unexpected empty wake list"); + + if (h != nullptr) { // there are waiters left + h->readers = 0; + h->maybe_unlocking = false; // finished unlocking + nv |= wr_wait | kMuWait | reinterpret_cast<intptr_t>(h); + } + + // release both spinlock & lock + // can release with a store because there were waiters + mu_.store(nv, std::memory_order_release); + break; // out of for(;;)-loop + } + c = Delay(c, AGGRESSIVE); // aggressive here; no one can proceed till we do + } // end of for(;;)-loop + + if (wake_list != kPerThreadSynchNull) { + int64_t enqueue_timestamp = wake_list->waitp->contention_start_cycles; + bool cond_waiter = wake_list->cond_waiter; + do { + wake_list = Wakeup(wake_list); // wake waiters + } while (wake_list != kPerThreadSynchNull); + if (!cond_waiter) { + // Sample lock contention events only if the (first) waiter was trying to + // acquire the lock, not waiting on a condition variable or Condition. + int64_t wait_cycles = base_internal::CycleClock::Now() - enqueue_timestamp; + mutex_tracer("slow release", this, wait_cycles); + ABSL_TSAN_MUTEX_PRE_DIVERT(this, 0); + submit_profile_data(enqueue_timestamp); + ABSL_TSAN_MUTEX_POST_DIVERT(this, 0); + } + } +} + +// Used by CondVar implementation to reacquire mutex after waking from +// condition variable. This routine is used instead of Lock() because the +// waiting thread may have been moved from the condition variable queue to the +// mutex queue without a wakeup, by Trans(). In that case, when the thread is +// finally woken, the woken thread will believe it has been woken from the +// condition variable (i.e. its PC will be in when in the CondVar code), when +// in fact it has just been woken from the mutex. Thus, it must enter the slow +// path of the mutex in the same state as if it had just woken from the mutex. +// That is, it must ensure to clear kMuDesig (INV1b). +void Mutex::Trans(MuHow how) { + this->LockSlow(how, nullptr, kMuHasBlocked | kMuIsCond); +} + +// Used by CondVar implementation to effectively wake thread w from the +// condition variable. If this mutex is free, we simply wake the thread. +// It will later acquire the mutex with high probability. Otherwise, we +// enqueue thread w on this mutex. +void Mutex::Fer(PerThreadSynch *w) { + int c = 0; + ABSL_RAW_CHECK(w->waitp->cond == nullptr, + "Mutex::Fer while waiting on Condition"); + ABSL_RAW_CHECK(!w->waitp->timeout.has_timeout(), + "Mutex::Fer while in timed wait"); + ABSL_RAW_CHECK(w->waitp->cv_word == nullptr, + "Mutex::Fer with pending CondVar queueing"); + for (;;) { + intptr_t v = mu_.load(std::memory_order_relaxed); + // Note: must not queue if the mutex is unlocked (nobody will wake it). + // For example, we can have only kMuWait (conditional) or maybe + // kMuWait|kMuWrWait. + // conflicting != 0 implies that the waking thread cannot currently take + // the mutex, which in turn implies that someone else has it and can wake + // us if we queue. + const intptr_t conflicting = + kMuWriter | (w->waitp->how == kShared ? 0 : kMuReader); + if ((v & conflicting) == 0) { + w->next = nullptr; + w->state.store(PerThreadSynch::kAvailable, std::memory_order_release); + IncrementSynchSem(this, w); + return; + } else { + if ((v & (kMuSpin|kMuWait)) == 0) { // no waiters + // This thread tries to become the one and only waiter. + PerThreadSynch *new_h = Enqueue(nullptr, w->waitp, v, kMuIsCond); + ABSL_RAW_CHECK(new_h != nullptr, + "Enqueue failed"); // we must queue ourselves + if (mu_.compare_exchange_strong( + v, reinterpret_cast<intptr_t>(new_h) | (v & kMuLow) | kMuWait, + std::memory_order_release, std::memory_order_relaxed)) { + return; + } + } else if ((v & kMuSpin) == 0 && + mu_.compare_exchange_strong(v, v | kMuSpin | kMuWait)) { + PerThreadSynch *h = GetPerThreadSynch(v); + PerThreadSynch *new_h = Enqueue(h, w->waitp, v, kMuIsCond); + ABSL_RAW_CHECK(new_h != nullptr, + "Enqueue failed"); // we must queue ourselves + do { + v = mu_.load(std::memory_order_relaxed); + } while (!mu_.compare_exchange_weak( + v, + (v & kMuLow & ~kMuSpin) | kMuWait | + reinterpret_cast<intptr_t>(new_h), + std::memory_order_release, std::memory_order_relaxed)); + return; + } + } + c = Delay(c, GENTLE); + } +} + +void Mutex::AssertHeld() const { + if ((mu_.load(std::memory_order_relaxed) & kMuWriter) == 0) { + SynchEvent *e = GetSynchEvent(this); + ABSL_RAW_LOG(FATAL, "thread should hold write lock on Mutex %p %s", + static_cast<const void *>(this), + (e == nullptr ? "" : e->name)); + } +} + +void Mutex::AssertReaderHeld() const { + if ((mu_.load(std::memory_order_relaxed) & (kMuReader | kMuWriter)) == 0) { + SynchEvent *e = GetSynchEvent(this); + ABSL_RAW_LOG( + FATAL, "thread should hold at least a read lock on Mutex %p %s", + static_cast<const void *>(this), (e == nullptr ? "" : e->name)); + } +} + +// -------------------------------- condition variables +static const intptr_t kCvSpin = 0x0001L; // spinlock protects waiter list +static const intptr_t kCvEvent = 0x0002L; // record events + +static const intptr_t kCvLow = 0x0003L; // low order bits of CV + +// Hack to make constant values available to gdb pretty printer +enum { kGdbCvSpin = kCvSpin, kGdbCvEvent = kCvEvent, kGdbCvLow = kCvLow, }; + +static_assert(PerThreadSynch::kAlignment > kCvLow, + "PerThreadSynch::kAlignment must be greater than kCvLow"); + +void CondVar::EnableDebugLog(const char *name) { + SynchEvent *e = EnsureSynchEvent(&this->cv_, name, kCvEvent, kCvSpin); + e->log = true; + UnrefSynchEvent(e); +} + +CondVar::~CondVar() { + if ((cv_.load(std::memory_order_relaxed) & kCvEvent) != 0) { + ForgetSynchEvent(&this->cv_, kCvEvent, kCvSpin); + } +} + + +// Remove thread s from the list of waiters on this condition variable. +void CondVar::Remove(PerThreadSynch *s) { + intptr_t v; + int c = 0; + for (v = cv_.load(std::memory_order_relaxed);; + v = cv_.load(std::memory_order_relaxed)) { + if ((v & kCvSpin) == 0 && // attempt to acquire spinlock + cv_.compare_exchange_strong(v, v | kCvSpin, + std::memory_order_acquire, + std::memory_order_relaxed)) { + PerThreadSynch *h = reinterpret_cast<PerThreadSynch *>(v & ~kCvLow); + if (h != nullptr) { + PerThreadSynch *w = h; + while (w->next != s && w->next != h) { // search for thread + w = w->next; + } + if (w->next == s) { // found thread; remove it + w->next = s->next; + if (h == s) { + h = (w == s) ? nullptr : w; + } + s->next = nullptr; + s->state.store(PerThreadSynch::kAvailable, std::memory_order_release); + } + } + // release spinlock + cv_.store((v & kCvEvent) | reinterpret_cast<intptr_t>(h), + std::memory_order_release); + return; + } else { + c = Delay(c, GENTLE); // try again after a delay + } + } +} + +// Queue thread waitp->thread on condition variable word cv_word using +// wait parameters waitp. +// We split this into a separate routine, rather than simply doing it as part +// of WaitCommon(). If we were to queue ourselves on the condition variable +// before calling Mutex::UnlockSlow(), the Mutex code might be re-entered (via +// the logging code, or via a Condition function) and might potentially attempt +// to block this thread. That would be a problem if the thread were already on +// a the condition variable waiter queue. Thus, we use the waitp->cv_word +// to tell the unlock code to call CondVarEnqueue() to queue the thread on the +// condition variable queue just before the mutex is to be unlocked, and (most +// importantly) after any call to an external routine that might re-enter the +// mutex code. +static void CondVarEnqueue(SynchWaitParams *waitp) { + // This thread might be transferred to the Mutex queue by Fer() when + // we are woken. To make sure that is what happens, Enqueue() doesn't + // call CondVarEnqueue() again but instead uses its normal code. We + // must do this before we queue ourselves so that cv_word will be null + // when seen by the dequeuer, who may wish immediately to requeue + // this thread on another queue. + std::atomic<intptr_t> *cv_word = waitp->cv_word; + waitp->cv_word = nullptr; + + intptr_t v = cv_word->load(std::memory_order_relaxed); + int c = 0; + while ((v & kCvSpin) != 0 || // acquire spinlock + !cv_word->compare_exchange_weak(v, v | kCvSpin, + std::memory_order_acquire, + std::memory_order_relaxed)) { + c = Delay(c, GENTLE); + v = cv_word->load(std::memory_order_relaxed); + } + ABSL_RAW_CHECK(waitp->thread->waitp == nullptr, "waiting when shouldn't be"); + waitp->thread->waitp = waitp; // prepare ourselves for waiting + PerThreadSynch *h = reinterpret_cast<PerThreadSynch *>(v & ~kCvLow); + if (h == nullptr) { // add this thread to waiter list + waitp->thread->next = waitp->thread; + } else { + waitp->thread->next = h->next; + h->next = waitp->thread; + } + waitp->thread->state.store(PerThreadSynch::kQueued, + std::memory_order_relaxed); + cv_word->store((v & kCvEvent) | reinterpret_cast<intptr_t>(waitp->thread), + std::memory_order_release); +} + +bool CondVar::WaitCommon(Mutex *mutex, KernelTimeout t) { + bool rc = false; // return value; true iff we timed-out + + intptr_t mutex_v = mutex->mu_.load(std::memory_order_relaxed); + Mutex::MuHow mutex_how = ((mutex_v & kMuWriter) != 0) ? kExclusive : kShared; + ABSL_TSAN_MUTEX_PRE_UNLOCK(mutex, TsanFlags(mutex_how)); + + // maybe trace this call + intptr_t v = cv_.load(std::memory_order_relaxed); + cond_var_tracer("Wait", this); + if ((v & kCvEvent) != 0) { + PostSynchEvent(this, SYNCH_EV_WAIT); + } + + // Release mu and wait on condition variable. + SynchWaitParams waitp(mutex_how, nullptr, t, mutex, + Synch_GetPerThreadAnnotated(mutex), &cv_); + // UnlockSlow() will call CondVarEnqueue() just before releasing the + // Mutex, thus queuing this thread on the condition variable. See + // CondVarEnqueue() for the reasons. + mutex->UnlockSlow(&waitp); + + // wait for signal + while (waitp.thread->state.load(std::memory_order_acquire) == + PerThreadSynch::kQueued) { + if (!Mutex::DecrementSynchSem(mutex, waitp.thread, t)) { + this->Remove(waitp.thread); + rc = true; + } + } + + ABSL_RAW_CHECK(waitp.thread->waitp != nullptr, "not waiting when should be"); + waitp.thread->waitp = nullptr; // cleanup + + // maybe trace this call + cond_var_tracer("Unwait", this); + if ((v & kCvEvent) != 0) { + PostSynchEvent(this, SYNCH_EV_WAIT_RETURNING); + } + + // From synchronization point of view Wait is unlock of the mutex followed + // by lock of the mutex. We've annotated start of unlock in the beginning + // of the function. Now, finish unlock and annotate lock of the mutex. + // (Trans is effectively lock). + ABSL_TSAN_MUTEX_POST_UNLOCK(mutex, TsanFlags(mutex_how)); + ABSL_TSAN_MUTEX_PRE_LOCK(mutex, TsanFlags(mutex_how)); + mutex->Trans(mutex_how); // Reacquire mutex + ABSL_TSAN_MUTEX_POST_LOCK(mutex, TsanFlags(mutex_how), 0); + return rc; +} + +bool CondVar::WaitWithTimeout(Mutex *mu, absl::Duration timeout) { + return WaitWithDeadline(mu, DeadlineFromTimeout(timeout)); +} + +bool CondVar::WaitWithDeadline(Mutex *mu, absl::Time deadline) { + return WaitCommon(mu, KernelTimeout(deadline)); +} + +void CondVar::Wait(Mutex *mu) { + WaitCommon(mu, KernelTimeout::Never()); +} + +// Wake thread w +// If it was a timed wait, w will be waiting on w->cv +// Otherwise, if it was not a Mutex mutex, w will be waiting on w->sem +// Otherwise, w is transferred to the Mutex mutex via Mutex::Fer(). +void CondVar::Wakeup(PerThreadSynch *w) { + if (w->waitp->timeout.has_timeout() || w->waitp->cvmu == nullptr) { + // The waiting thread only needs to observe "w->state == kAvailable" to be + // released, we must cache "cvmu" before clearing "next". + Mutex *mu = w->waitp->cvmu; + w->next = nullptr; + w->state.store(PerThreadSynch::kAvailable, std::memory_order_release); + Mutex::IncrementSynchSem(mu, w); + } else { + w->waitp->cvmu->Fer(w); + } +} + +void CondVar::Signal() { + ABSL_TSAN_MUTEX_PRE_SIGNAL(nullptr, 0); + intptr_t v; + int c = 0; + for (v = cv_.load(std::memory_order_relaxed); v != 0; + v = cv_.load(std::memory_order_relaxed)) { + if ((v & kCvSpin) == 0 && // attempt to acquire spinlock + cv_.compare_exchange_strong(v, v | kCvSpin, + std::memory_order_acquire, + std::memory_order_relaxed)) { + PerThreadSynch *h = reinterpret_cast<PerThreadSynch *>(v & ~kCvLow); + PerThreadSynch *w = nullptr; + if (h != nullptr) { // remove first waiter + w = h->next; + if (w == h) { + h = nullptr; + } else { + h->next = w->next; + } + } + // release spinlock + cv_.store((v & kCvEvent) | reinterpret_cast<intptr_t>(h), + std::memory_order_release); + if (w != nullptr) { + CondVar::Wakeup(w); // wake waiter, if there was one + cond_var_tracer("Signal wakeup", this); + } + if ((v & kCvEvent) != 0) { + PostSynchEvent(this, SYNCH_EV_SIGNAL); + } + ABSL_TSAN_MUTEX_POST_SIGNAL(nullptr, 0); + return; + } else { + c = Delay(c, GENTLE); + } + } + ABSL_TSAN_MUTEX_POST_SIGNAL(nullptr, 0); +} + +void CondVar::SignalAll () { + ABSL_TSAN_MUTEX_PRE_SIGNAL(nullptr, 0); + intptr_t v; + int c = 0; + for (v = cv_.load(std::memory_order_relaxed); v != 0; + v = cv_.load(std::memory_order_relaxed)) { + // empty the list if spinlock free + // We do this by simply setting the list to empty using + // compare and swap. We then have the entire list in our hands, + // which cannot be changing since we grabbed it while no one + // held the lock. + if ((v & kCvSpin) == 0 && + cv_.compare_exchange_strong(v, v & kCvEvent, std::memory_order_acquire, + std::memory_order_relaxed)) { + PerThreadSynch *h = reinterpret_cast<PerThreadSynch *>(v & ~kCvLow); + if (h != nullptr) { + PerThreadSynch *w; + PerThreadSynch *n = h->next; + do { // for every thread, wake it up + w = n; + n = n->next; + CondVar::Wakeup(w); + } while (w != h); + cond_var_tracer("SignalAll wakeup", this); + } + if ((v & kCvEvent) != 0) { + PostSynchEvent(this, SYNCH_EV_SIGNALALL); + } + ABSL_TSAN_MUTEX_POST_SIGNAL(nullptr, 0); + return; + } else { + c = Delay(c, GENTLE); // try again after a delay + } + } + ABSL_TSAN_MUTEX_POST_SIGNAL(nullptr, 0); +} + +void ReleasableMutexLock::Release() { + ABSL_RAW_CHECK(this->mu_ != nullptr, + "ReleasableMutexLock::Release may only be called once"); + this->mu_->Unlock(); + this->mu_ = nullptr; +} + +#ifdef THREAD_SANITIZER +extern "C" void __tsan_read1(void *addr); +#else +#define __tsan_read1(addr) // do nothing if TSan not enabled +#endif + +// A function that just returns its argument, dereferenced +static bool Dereference(void *arg) { + // ThreadSanitizer does not instrument this file for memory accesses. + // This function dereferences a user variable that can participate + // in a data race, so we need to manually tell TSan about this memory access. + __tsan_read1(arg); + return *(static_cast<bool *>(arg)); +} + +Condition::Condition() {} // null constructor, used for kTrue only +const Condition Condition::kTrue; + +Condition::Condition(bool (*func)(void *), void *arg) + : eval_(&CallVoidPtrFunction), + function_(func), + method_(nullptr), + arg_(arg) {} + +bool Condition::CallVoidPtrFunction(const Condition *c) { + return (*c->function_)(c->arg_); +} + +Condition::Condition(const bool *cond) + : eval_(CallVoidPtrFunction), + function_(Dereference), + method_(nullptr), + // const_cast is safe since Dereference does not modify arg + arg_(const_cast<bool *>(cond)) {} + +bool Condition::Eval() const { + // eval_ == null for kTrue + return (this->eval_ == nullptr) || (*this->eval_)(this); +} + +bool Condition::GuaranteedEqual(const Condition *a, const Condition *b) { + if (a == nullptr) { + return b == nullptr || b->eval_ == nullptr; + } + if (b == nullptr || b->eval_ == nullptr) { + return a->eval_ == nullptr; + } + return a->eval_ == b->eval_ && a->function_ == b->function_ && + a->arg_ == b->arg_ && a->method_ == b->method_; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/mutex.h b/third_party/abseil_cpp/absl/synchronization/mutex.h new file mode 100644 index 0000000000..876698ca5f --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/mutex.h @@ -0,0 +1,1060 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// mutex.h +// ----------------------------------------------------------------------------- +// +// This header file defines a `Mutex` -- a mutually exclusive lock -- and the +// most common type of synchronization primitive for facilitating locks on +// shared resources. A mutex is used to prevent multiple threads from accessing +// and/or writing to a shared resource concurrently. +// +// Unlike a `std::mutex`, the Abseil `Mutex` provides the following additional +// features: +// * Conditional predicates intrinsic to the `Mutex` object +// * Shared/reader locks, in addition to standard exclusive/writer locks +// * Deadlock detection and debug support. +// +// The following helper classes are also defined within this file: +// +// MutexLock - An RAII wrapper to acquire and release a `Mutex` for exclusive/ +// write access within the current scope. +// ReaderMutexLock +// - An RAII wrapper to acquire and release a `Mutex` for shared/read +// access within the current scope. +// +// WriterMutexLock +// - Alias for `MutexLock` above, designed for use in distinguishing +// reader and writer locks within code. +// +// In addition to simple mutex locks, this file also defines ways to perform +// locking under certain conditions. +// +// Condition - (Preferred) Used to wait for a particular predicate that +// depends on state protected by the `Mutex` to become true. +// CondVar - A lower-level variant of `Condition` that relies on +// application code to explicitly signal the `CondVar` when +// a condition has been met. +// +// See below for more information on using `Condition` or `CondVar`. +// +// Mutexes and mutex behavior can be quite complicated. The information within +// this header file is limited, as a result. Please consult the Mutex guide for +// more complete information and examples. + +#ifndef ABSL_SYNCHRONIZATION_MUTEX_H_ +#define ABSL_SYNCHRONIZATION_MUTEX_H_ + +#include <atomic> +#include <cstdint> +#include <string> + +#include "absl/base/const_init.h" +#include "absl/base/internal/identity.h" +#include "absl/base/internal/low_level_alloc.h" +#include "absl/base/internal/thread_identity.h" +#include "absl/base/internal/tsan_mutex_interface.h" +#include "absl/base/port.h" +#include "absl/base/thread_annotations.h" +#include "absl/synchronization/internal/kernel_timeout.h" +#include "absl/synchronization/internal/per_thread_sem.h" +#include "absl/time/time.h" + +// Decide if we should use the non-production implementation because +// the production implementation hasn't been fully ported yet. +#ifdef ABSL_INTERNAL_USE_NONPROD_MUTEX +#error ABSL_INTERNAL_USE_NONPROD_MUTEX cannot be directly set +#elif defined(ABSL_LOW_LEVEL_ALLOC_MISSING) +#define ABSL_INTERNAL_USE_NONPROD_MUTEX 1 +#include "absl/synchronization/internal/mutex_nonprod.inc" +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class Condition; +struct SynchWaitParams; + +// ----------------------------------------------------------------------------- +// Mutex +// ----------------------------------------------------------------------------- +// +// A `Mutex` is a non-reentrant (aka non-recursive) Mutually Exclusive lock +// on some resource, typically a variable or data structure with associated +// invariants. Proper usage of mutexes prevents concurrent access by different +// threads to the same resource. +// +// A `Mutex` has two basic operations: `Mutex::Lock()` and `Mutex::Unlock()`. +// The `Lock()` operation *acquires* a `Mutex` (in a state known as an +// *exclusive* -- or write -- lock), while the `Unlock()` operation *releases* a +// Mutex. During the span of time between the Lock() and Unlock() operations, +// a mutex is said to be *held*. By design all mutexes support exclusive/write +// locks, as this is the most common way to use a mutex. +// +// The `Mutex` state machine for basic lock/unlock operations is quite simple: +// +// | | Lock() | Unlock() | +// |----------------+------------+----------| +// | Free | Exclusive | invalid | +// | Exclusive | blocks | Free | +// +// Attempts to `Unlock()` must originate from the thread that performed the +// corresponding `Lock()` operation. +// +// An "invalid" operation is disallowed by the API. The `Mutex` implementation +// is allowed to do anything on an invalid call, including but not limited to +// crashing with a useful error message, silently succeeding, or corrupting +// data structures. In debug mode, the implementation attempts to crash with a +// useful error message. +// +// `Mutex` is not guaranteed to be "fair" in prioritizing waiting threads; it +// is, however, approximately fair over long periods, and starvation-free for +// threads at the same priority. +// +// The lock/unlock primitives are now annotated with lock annotations +// defined in (base/thread_annotations.h). When writing multi-threaded code, +// you should use lock annotations whenever possible to document your lock +// synchronization policy. Besides acting as documentation, these annotations +// also help compilers or static analysis tools to identify and warn about +// issues that could potentially result in race conditions and deadlocks. +// +// For more information about the lock annotations, please see +// [Thread Safety Analysis](http://clang.llvm.org/docs/ThreadSafetyAnalysis.html) +// in the Clang documentation. +// +// See also `MutexLock`, below, for scoped `Mutex` acquisition. + +class ABSL_LOCKABLE Mutex { + public: + // Creates a `Mutex` that is not held by anyone. This constructor is + // typically used for Mutexes allocated on the heap or the stack. + // + // To create `Mutex` instances with static storage duration + // (e.g. a namespace-scoped or global variable), see + // `Mutex::Mutex(absl::kConstInit)` below instead. + Mutex(); + + // Creates a mutex with static storage duration. A global variable + // constructed this way avoids the lifetime issues that can occur on program + // startup and shutdown. (See absl/base/const_init.h.) + // + // For Mutexes allocated on the heap and stack, instead use the default + // constructor, which can interact more fully with the thread sanitizer. + // + // Example usage: + // namespace foo { + // ABSL_CONST_INIT Mutex mu(absl::kConstInit); + // } + explicit constexpr Mutex(absl::ConstInitType); + + ~Mutex(); + + // Mutex::Lock() + // + // Blocks the calling thread, if necessary, until this `Mutex` is free, and + // then acquires it exclusively. (This lock is also known as a "write lock.") + void Lock() ABSL_EXCLUSIVE_LOCK_FUNCTION(); + + // Mutex::Unlock() + // + // Releases this `Mutex` and returns it from the exclusive/write state to the + // free state. Caller must hold the `Mutex` exclusively. + void Unlock() ABSL_UNLOCK_FUNCTION(); + + // Mutex::TryLock() + // + // If the mutex can be acquired without blocking, does so exclusively and + // returns `true`. Otherwise, returns `false`. Returns `true` with high + // probability if the `Mutex` was free. + bool TryLock() ABSL_EXCLUSIVE_TRYLOCK_FUNCTION(true); + + // Mutex::AssertHeld() + // + // Return immediately if this thread holds the `Mutex` exclusively (in write + // mode). Otherwise, may report an error (typically by crashing with a + // diagnostic), or may return immediately. + void AssertHeld() const ABSL_ASSERT_EXCLUSIVE_LOCK(); + + // --------------------------------------------------------------------------- + // Reader-Writer Locking + // --------------------------------------------------------------------------- + + // A Mutex can also be used as a starvation-free reader-writer lock. + // Neither read-locks nor write-locks are reentrant/recursive to avoid + // potential client programming errors. + // + // The Mutex API provides `Writer*()` aliases for the existing `Lock()`, + // `Unlock()` and `TryLock()` methods for use within applications mixing + // reader/writer locks. Using `Reader*()` and `Writer*()` operations in this + // manner can make locking behavior clearer when mixing read and write modes. + // + // Introducing reader locks necessarily complicates the `Mutex` state + // machine somewhat. The table below illustrates the allowed state transitions + // of a mutex in such cases. Note that ReaderLock() may block even if the lock + // is held in shared mode; this occurs when another thread is blocked on a + // call to WriterLock(). + // + // --------------------------------------------------------------------------- + // Operation: WriterLock() Unlock() ReaderLock() ReaderUnlock() + // --------------------------------------------------------------------------- + // State + // --------------------------------------------------------------------------- + // Free Exclusive invalid Shared(1) invalid + // Shared(1) blocks invalid Shared(2) or blocks Free + // Shared(n) n>1 blocks invalid Shared(n+1) or blocks Shared(n-1) + // Exclusive blocks Free blocks invalid + // --------------------------------------------------------------------------- + // + // In comments below, "shared" refers to a state of Shared(n) for any n > 0. + + // Mutex::ReaderLock() + // + // Blocks the calling thread, if necessary, until this `Mutex` is either free, + // or in shared mode, and then acquires a share of it. Note that + // `ReaderLock()` will block if some other thread has an exclusive/writer lock + // on the mutex. + + void ReaderLock() ABSL_SHARED_LOCK_FUNCTION(); + + // Mutex::ReaderUnlock() + // + // Releases a read share of this `Mutex`. `ReaderUnlock` may return a mutex to + // the free state if this thread holds the last reader lock on the mutex. Note + // that you cannot call `ReaderUnlock()` on a mutex held in write mode. + void ReaderUnlock() ABSL_UNLOCK_FUNCTION(); + + // Mutex::ReaderTryLock() + // + // If the mutex can be acquired without blocking, acquires this mutex for + // shared access and returns `true`. Otherwise, returns `false`. Returns + // `true` with high probability if the `Mutex` was free or shared. + bool ReaderTryLock() ABSL_SHARED_TRYLOCK_FUNCTION(true); + + // Mutex::AssertReaderHeld() + // + // Returns immediately if this thread holds the `Mutex` in at least shared + // mode (read mode). Otherwise, may report an error (typically by + // crashing with a diagnostic), or may return immediately. + void AssertReaderHeld() const ABSL_ASSERT_SHARED_LOCK(); + + // Mutex::WriterLock() + // Mutex::WriterUnlock() + // Mutex::WriterTryLock() + // + // Aliases for `Mutex::Lock()`, `Mutex::Unlock()`, and `Mutex::TryLock()`. + // + // These methods may be used (along with the complementary `Reader*()` + // methods) to distingish simple exclusive `Mutex` usage (`Lock()`, + // etc.) from reader/writer lock usage. + void WriterLock() ABSL_EXCLUSIVE_LOCK_FUNCTION() { this->Lock(); } + + void WriterUnlock() ABSL_UNLOCK_FUNCTION() { this->Unlock(); } + + bool WriterTryLock() ABSL_EXCLUSIVE_TRYLOCK_FUNCTION(true) { + return this->TryLock(); + } + + // --------------------------------------------------------------------------- + // Conditional Critical Regions + // --------------------------------------------------------------------------- + + // Conditional usage of a `Mutex` can occur using two distinct paradigms: + // + // * Use of `Mutex` member functions with `Condition` objects. + // * Use of the separate `CondVar` abstraction. + // + // In general, prefer use of `Condition` and the `Mutex` member functions + // listed below over `CondVar`. When there are multiple threads waiting on + // distinctly different conditions, however, a battery of `CondVar`s may be + // more efficient. This section discusses use of `Condition` objects. + // + // `Mutex` contains member functions for performing lock operations only under + // certain conditions, of class `Condition`. For correctness, the `Condition` + // must return a boolean that is a pure function, only of state protected by + // the `Mutex`. The condition must be invariant w.r.t. environmental state + // such as thread, cpu id, or time, and must be `noexcept`. The condition will + // always be invoked with the mutex held in at least read mode, so you should + // not block it for long periods or sleep it on a timer. + // + // Since a condition must not depend directly on the current time, use + // `*WithTimeout()` member function variants to make your condition + // effectively true after a given duration, or `*WithDeadline()` variants to + // make your condition effectively true after a given time. + // + // The condition function should have no side-effects aside from debug + // logging; as a special exception, the function may acquire other mutexes + // provided it releases all those that it acquires. (This exception was + // required to allow logging.) + + // Mutex::Await() + // + // Unlocks this `Mutex` and blocks until simultaneously both `cond` is `true` + // and this `Mutex` can be reacquired, then reacquires this `Mutex` in the + // same mode in which it was previously held. If the condition is initially + // `true`, `Await()` *may* skip the release/re-acquire step. + // + // `Await()` requires that this thread holds this `Mutex` in some mode. + void Await(const Condition &cond); + + // Mutex::LockWhen() + // Mutex::ReaderLockWhen() + // Mutex::WriterLockWhen() + // + // Blocks until simultaneously both `cond` is `true` and this `Mutex` can + // be acquired, then atomically acquires this `Mutex`. `LockWhen()` is + // logically equivalent to `*Lock(); Await();` though they may have different + // performance characteristics. + void LockWhen(const Condition &cond) ABSL_EXCLUSIVE_LOCK_FUNCTION(); + + void ReaderLockWhen(const Condition &cond) ABSL_SHARED_LOCK_FUNCTION(); + + void WriterLockWhen(const Condition &cond) ABSL_EXCLUSIVE_LOCK_FUNCTION() { + this->LockWhen(cond); + } + + // --------------------------------------------------------------------------- + // Mutex Variants with Timeouts/Deadlines + // --------------------------------------------------------------------------- + + // Mutex::AwaitWithTimeout() + // Mutex::AwaitWithDeadline() + // + // Unlocks this `Mutex` and blocks until simultaneously: + // - either `cond` is true or the {timeout has expired, deadline has passed} + // and + // - this `Mutex` can be reacquired, + // then reacquire this `Mutex` in the same mode in which it was previously + // held, returning `true` iff `cond` is `true` on return. + // + // If the condition is initially `true`, the implementation *may* skip the + // release/re-acquire step and return immediately. + // + // Deadlines in the past are equivalent to an immediate deadline. + // Negative timeouts are equivalent to a zero timeout. + // + // This method requires that this thread holds this `Mutex` in some mode. + bool AwaitWithTimeout(const Condition &cond, absl::Duration timeout); + + bool AwaitWithDeadline(const Condition &cond, absl::Time deadline); + + // Mutex::LockWhenWithTimeout() + // Mutex::ReaderLockWhenWithTimeout() + // Mutex::WriterLockWhenWithTimeout() + // + // Blocks until simultaneously both: + // - either `cond` is `true` or the timeout has expired, and + // - this `Mutex` can be acquired, + // then atomically acquires this `Mutex`, returning `true` iff `cond` is + // `true` on return. + // + // Negative timeouts are equivalent to a zero timeout. + bool LockWhenWithTimeout(const Condition &cond, absl::Duration timeout) + ABSL_EXCLUSIVE_LOCK_FUNCTION(); + bool ReaderLockWhenWithTimeout(const Condition &cond, absl::Duration timeout) + ABSL_SHARED_LOCK_FUNCTION(); + bool WriterLockWhenWithTimeout(const Condition &cond, absl::Duration timeout) + ABSL_EXCLUSIVE_LOCK_FUNCTION() { + return this->LockWhenWithTimeout(cond, timeout); + } + + // Mutex::LockWhenWithDeadline() + // Mutex::ReaderLockWhenWithDeadline() + // Mutex::WriterLockWhenWithDeadline() + // + // Blocks until simultaneously both: + // - either `cond` is `true` or the deadline has been passed, and + // - this `Mutex` can be acquired, + // then atomically acquires this Mutex, returning `true` iff `cond` is `true` + // on return. + // + // Deadlines in the past are equivalent to an immediate deadline. + bool LockWhenWithDeadline(const Condition &cond, absl::Time deadline) + ABSL_EXCLUSIVE_LOCK_FUNCTION(); + bool ReaderLockWhenWithDeadline(const Condition &cond, absl::Time deadline) + ABSL_SHARED_LOCK_FUNCTION(); + bool WriterLockWhenWithDeadline(const Condition &cond, absl::Time deadline) + ABSL_EXCLUSIVE_LOCK_FUNCTION() { + return this->LockWhenWithDeadline(cond, deadline); + } + + // --------------------------------------------------------------------------- + // Debug Support: Invariant Checking, Deadlock Detection, Logging. + // --------------------------------------------------------------------------- + + // Mutex::EnableInvariantDebugging() + // + // If `invariant`!=null and if invariant debugging has been enabled globally, + // cause `(*invariant)(arg)` to be called at moments when the invariant for + // this `Mutex` should hold (for example: just after acquire, just before + // release). + // + // The routine `invariant` should have no side-effects since it is not + // guaranteed how many times it will be called; it should check the invariant + // and crash if it does not hold. Enabling global invariant debugging may + // substantially reduce `Mutex` performance; it should be set only for + // non-production runs. Optimization options may also disable invariant + // checks. + void EnableInvariantDebugging(void (*invariant)(void *), void *arg); + + // Mutex::EnableDebugLog() + // + // Cause all subsequent uses of this `Mutex` to be logged via + // `ABSL_RAW_LOG(INFO)`. Log entries are tagged with `name` if no previous + // call to `EnableInvariantDebugging()` or `EnableDebugLog()` has been made. + // + // Note: This method substantially reduces `Mutex` performance. + void EnableDebugLog(const char *name); + + // Deadlock detection + + // Mutex::ForgetDeadlockInfo() + // + // Forget any deadlock-detection information previously gathered + // about this `Mutex`. Call this method in debug mode when the lock ordering + // of a `Mutex` changes. + void ForgetDeadlockInfo(); + + // Mutex::AssertNotHeld() + // + // Return immediately if this thread does not hold this `Mutex` in any + // mode; otherwise, may report an error (typically by crashing with a + // diagnostic), or may return immediately. + // + // Currently this check is performed only if all of: + // - in debug mode + // - SetMutexDeadlockDetectionMode() has been set to kReport or kAbort + // - number of locks concurrently held by this thread is not large. + // are true. + void AssertNotHeld() const; + + // Special cases. + + // A `MuHow` is a constant that indicates how a lock should be acquired. + // Internal implementation detail. Clients should ignore. + typedef const struct MuHowS *MuHow; + + // Mutex::InternalAttemptToUseMutexInFatalSignalHandler() + // + // Causes the `Mutex` implementation to prepare itself for re-entry caused by + // future use of `Mutex` within a fatal signal handler. This method is + // intended for use only for last-ditch attempts to log crash information. + // It does not guarantee that attempts to use Mutexes within the handler will + // not deadlock; it merely makes other faults less likely. + // + // WARNING: This routine must be invoked from a signal handler, and the + // signal handler must either loop forever or terminate the process. + // Attempts to return from (or `longjmp` out of) the signal handler once this + // call has been made may cause arbitrary program behaviour including + // crashes and deadlocks. + static void InternalAttemptToUseMutexInFatalSignalHandler(); + + private: +#ifdef ABSL_INTERNAL_USE_NONPROD_MUTEX + friend class CondVar; + + synchronization_internal::MutexImpl *impl() { return impl_.get(); } + + synchronization_internal::SynchronizationStorage< + synchronization_internal::MutexImpl> + impl_; +#else + std::atomic<intptr_t> mu_; // The Mutex state. + + // Post()/Wait() versus associated PerThreadSem; in class for required + // friendship with PerThreadSem. + static inline void IncrementSynchSem(Mutex *mu, + base_internal::PerThreadSynch *w); + static inline bool DecrementSynchSem( + Mutex *mu, base_internal::PerThreadSynch *w, + synchronization_internal::KernelTimeout t); + + // slow path acquire + void LockSlowLoop(SynchWaitParams *waitp, int flags); + // wrappers around LockSlowLoop() + bool LockSlowWithDeadline(MuHow how, const Condition *cond, + synchronization_internal::KernelTimeout t, + int flags); + void LockSlow(MuHow how, const Condition *cond, + int flags) ABSL_ATTRIBUTE_COLD; + // slow path release + void UnlockSlow(SynchWaitParams *waitp) ABSL_ATTRIBUTE_COLD; + // Common code between Await() and AwaitWithTimeout/Deadline() + bool AwaitCommon(const Condition &cond, + synchronization_internal::KernelTimeout t); + // Attempt to remove thread s from queue. + void TryRemove(base_internal::PerThreadSynch *s); + // Block a thread on mutex. + void Block(base_internal::PerThreadSynch *s); + // Wake a thread; return successor. + base_internal::PerThreadSynch *Wakeup(base_internal::PerThreadSynch *w); + + friend class CondVar; // for access to Trans()/Fer(). + void Trans(MuHow how); // used for CondVar->Mutex transfer + void Fer( + base_internal::PerThreadSynch *w); // used for CondVar->Mutex transfer +#endif + + // Catch the error of writing Mutex when intending MutexLock. + Mutex(const volatile Mutex * /*ignored*/) {} // NOLINT(runtime/explicit) + + Mutex(const Mutex&) = delete; + Mutex& operator=(const Mutex&) = delete; +}; + +// ----------------------------------------------------------------------------- +// Mutex RAII Wrappers +// ----------------------------------------------------------------------------- + +// MutexLock +// +// `MutexLock` is a helper class, which acquires and releases a `Mutex` via +// RAII. +// +// Example: +// +// Class Foo { +// +// Foo::Bar* Baz() { +// MutexLock l(&lock_); +// ... +// return bar; +// } +// +// private: +// Mutex lock_; +// }; +class ABSL_SCOPED_LOCKABLE MutexLock { + public: + explicit MutexLock(Mutex *mu) ABSL_EXCLUSIVE_LOCK_FUNCTION(mu) : mu_(mu) { + this->mu_->Lock(); + } + + MutexLock(const MutexLock &) = delete; // NOLINT(runtime/mutex) + MutexLock(MutexLock&&) = delete; // NOLINT(runtime/mutex) + MutexLock& operator=(const MutexLock&) = delete; + MutexLock& operator=(MutexLock&&) = delete; + + ~MutexLock() ABSL_UNLOCK_FUNCTION() { this->mu_->Unlock(); } + + private: + Mutex *const mu_; +}; + +// ReaderMutexLock +// +// The `ReaderMutexLock` is a helper class, like `MutexLock`, which acquires and +// releases a shared lock on a `Mutex` via RAII. +class ABSL_SCOPED_LOCKABLE ReaderMutexLock { + public: + explicit ReaderMutexLock(Mutex *mu) ABSL_SHARED_LOCK_FUNCTION(mu) : mu_(mu) { + mu->ReaderLock(); + } + + ReaderMutexLock(const ReaderMutexLock&) = delete; + ReaderMutexLock(ReaderMutexLock&&) = delete; + ReaderMutexLock& operator=(const ReaderMutexLock&) = delete; + ReaderMutexLock& operator=(ReaderMutexLock&&) = delete; + + ~ReaderMutexLock() ABSL_UNLOCK_FUNCTION() { this->mu_->ReaderUnlock(); } + + private: + Mutex *const mu_; +}; + +// WriterMutexLock +// +// The `WriterMutexLock` is a helper class, like `MutexLock`, which acquires and +// releases a write (exclusive) lock on a `Mutex` via RAII. +class ABSL_SCOPED_LOCKABLE WriterMutexLock { + public: + explicit WriterMutexLock(Mutex *mu) ABSL_EXCLUSIVE_LOCK_FUNCTION(mu) + : mu_(mu) { + mu->WriterLock(); + } + + WriterMutexLock(const WriterMutexLock&) = delete; + WriterMutexLock(WriterMutexLock&&) = delete; + WriterMutexLock& operator=(const WriterMutexLock&) = delete; + WriterMutexLock& operator=(WriterMutexLock&&) = delete; + + ~WriterMutexLock() ABSL_UNLOCK_FUNCTION() { this->mu_->WriterUnlock(); } + + private: + Mutex *const mu_; +}; + +// ----------------------------------------------------------------------------- +// Condition +// ----------------------------------------------------------------------------- +// +// As noted above, `Mutex` contains a number of member functions which take a +// `Condition` as an argument; clients can wait for conditions to become `true` +// before attempting to acquire the mutex. These sections are known as +// "condition critical" sections. To use a `Condition`, you simply need to +// construct it, and use within an appropriate `Mutex` member function; +// everything else in the `Condition` class is an implementation detail. +// +// A `Condition` is specified as a function pointer which returns a boolean. +// `Condition` functions should be pure functions -- their results should depend +// only on passed arguments, should not consult any external state (such as +// clocks), and should have no side-effects, aside from debug logging. Any +// objects that the function may access should be limited to those which are +// constant while the mutex is blocked on the condition (e.g. a stack variable), +// or objects of state protected explicitly by the mutex. +// +// No matter which construction is used for `Condition`, the underlying +// function pointer / functor / callable must not throw any +// exceptions. Correctness of `Mutex` / `Condition` is not guaranteed in +// the face of a throwing `Condition`. (When Abseil is allowed to depend +// on C++17, these function pointers will be explicitly marked +// `noexcept`; until then this requirement cannot be enforced in the +// type system.) +// +// Note: to use a `Condition`, you need only construct it and pass it within the +// appropriate `Mutex' member function, such as `Mutex::Await()`. +// +// Example: +// +// // assume count_ is not internal reference count +// int count_ ABSL_GUARDED_BY(mu_); +// +// mu_.LockWhen(Condition(+[](int* count) { return *count == 0; }, +// &count_)); +// +// When multiple threads are waiting on exactly the same condition, make sure +// that they are constructed with the same parameters (same pointer to function +// + arg, or same pointer to object + method), so that the mutex implementation +// can avoid redundantly evaluating the same condition for each thread. +class Condition { + public: + // A Condition that returns the result of "(*func)(arg)" + Condition(bool (*func)(void *), void *arg); + + // Templated version for people who are averse to casts. + // + // To use a lambda, prepend it with unary plus, which converts the lambda + // into a function pointer: + // Condition(+[](T* t) { return ...; }, arg). + // + // Note: lambdas in this case must contain no bound variables. + // + // See class comment for performance advice. + template<typename T> + Condition(bool (*func)(T *), T *arg); + + // Templated version for invoking a method that returns a `bool`. + // + // `Condition(object, &Class::Method)` constructs a `Condition` that evaluates + // `object->Method()`. + // + // Implementation Note: `absl::internal::identity` is used to allow methods to + // come from base classes. A simpler signature like + // `Condition(T*, bool (T::*)())` does not suffice. + template<typename T> + Condition(T *object, bool (absl::internal::identity<T>::type::* method)()); + + // Same as above, for const members + template<typename T> + Condition(const T *object, + bool (absl::internal::identity<T>::type::* method)() const); + + // A Condition that returns the value of `*cond` + explicit Condition(const bool *cond); + + // Templated version for invoking a functor that returns a `bool`. + // This approach accepts pointers to non-mutable lambdas, `std::function`, + // the result of` std::bind` and user-defined functors that define + // `bool F::operator()() const`. + // + // Example: + // + // auto reached = [this, current]() { + // mu_.AssertReaderHeld(); // For annotalysis. + // return processed_ >= current; + // }; + // mu_.Await(Condition(&reached)); + + // See class comment for performance advice. In particular, if there + // might be more than one waiter for the same condition, make sure + // that all waiters construct the condition with the same pointers. + + // Implementation note: The second template parameter ensures that this + // constructor doesn't participate in overload resolution if T doesn't have + // `bool operator() const`. + template <typename T, typename E = decltype( + static_cast<bool (T::*)() const>(&T::operator()))> + explicit Condition(const T *obj) + : Condition(obj, static_cast<bool (T::*)() const>(&T::operator())) {} + + // A Condition that always returns `true`. + static const Condition kTrue; + + // Evaluates the condition. + bool Eval() const; + + // Returns `true` if the two conditions are guaranteed to return the same + // value if evaluated at the same time, `false` if the evaluation *may* return + // different results. + // + // Two `Condition` values are guaranteed equal if both their `func` and `arg` + // components are the same. A null pointer is equivalent to a `true` + // condition. + static bool GuaranteedEqual(const Condition *a, const Condition *b); + + private: + typedef bool (*InternalFunctionType)(void * arg); + typedef bool (Condition::*InternalMethodType)(); + typedef bool (*InternalMethodCallerType)(void * arg, + InternalMethodType internal_method); + + bool (*eval_)(const Condition*); // Actual evaluator + InternalFunctionType function_; // function taking pointer returning bool + InternalMethodType method_; // method returning bool + void *arg_; // arg of function_ or object of method_ + + Condition(); // null constructor used only to create kTrue + + // Various functions eval_ can point to: + static bool CallVoidPtrFunction(const Condition*); + template <typename T> static bool CastAndCallFunction(const Condition* c); + template <typename T> static bool CastAndCallMethod(const Condition* c); +}; + +// ----------------------------------------------------------------------------- +// CondVar +// ----------------------------------------------------------------------------- +// +// A condition variable, reflecting state evaluated separately outside of the +// `Mutex` object, which can be signaled to wake callers. +// This class is not normally needed; use `Mutex` member functions such as +// `Mutex::Await()` and intrinsic `Condition` abstractions. In rare cases +// with many threads and many conditions, `CondVar` may be faster. +// +// The implementation may deliver signals to any condition variable at +// any time, even when no call to `Signal()` or `SignalAll()` is made; as a +// result, upon being awoken, you must check the logical condition you have +// been waiting upon. +// +// Examples: +// +// Usage for a thread waiting for some condition C protected by mutex mu: +// mu.Lock(); +// while (!C) { cv->Wait(&mu); } // releases and reacquires mu +// // C holds; process data +// mu.Unlock(); +// +// Usage to wake T is: +// mu.Lock(); +// // process data, possibly establishing C +// if (C) { cv->Signal(); } +// mu.Unlock(); +// +// If C may be useful to more than one waiter, use `SignalAll()` instead of +// `Signal()`. +// +// With this implementation it is efficient to use `Signal()/SignalAll()` inside +// the locked region; this usage can make reasoning about your program easier. +// +class CondVar { + public: + // A `CondVar` allocated on the heap or on the stack can use the this + // constructor. + CondVar(); + ~CondVar(); + + // CondVar::Wait() + // + // Atomically releases a `Mutex` and blocks on this condition variable. + // Waits until awakened by a call to `Signal()` or `SignalAll()` (or a + // spurious wakeup), then reacquires the `Mutex` and returns. + // + // Requires and ensures that the current thread holds the `Mutex`. + void Wait(Mutex *mu); + + // CondVar::WaitWithTimeout() + // + // Atomically releases a `Mutex` and blocks on this condition variable. + // Waits until awakened by a call to `Signal()` or `SignalAll()` (or a + // spurious wakeup), or until the timeout has expired, then reacquires + // the `Mutex` and returns. + // + // Returns true if the timeout has expired without this `CondVar` + // being signalled in any manner. If both the timeout has expired + // and this `CondVar` has been signalled, the implementation is free + // to return `true` or `false`. + // + // Requires and ensures that the current thread holds the `Mutex`. + bool WaitWithTimeout(Mutex *mu, absl::Duration timeout); + + // CondVar::WaitWithDeadline() + // + // Atomically releases a `Mutex` and blocks on this condition variable. + // Waits until awakened by a call to `Signal()` or `SignalAll()` (or a + // spurious wakeup), or until the deadline has passed, then reacquires + // the `Mutex` and returns. + // + // Deadlines in the past are equivalent to an immediate deadline. + // + // Returns true if the deadline has passed without this `CondVar` + // being signalled in any manner. If both the deadline has passed + // and this `CondVar` has been signalled, the implementation is free + // to return `true` or `false`. + // + // Requires and ensures that the current thread holds the `Mutex`. + bool WaitWithDeadline(Mutex *mu, absl::Time deadline); + + // CondVar::Signal() + // + // Signal this `CondVar`; wake at least one waiter if one exists. + void Signal(); + + // CondVar::SignalAll() + // + // Signal this `CondVar`; wake all waiters. + void SignalAll(); + + // CondVar::EnableDebugLog() + // + // Causes all subsequent uses of this `CondVar` to be logged via + // `ABSL_RAW_LOG(INFO)`. Log entries are tagged with `name` if `name != 0`. + // Note: this method substantially reduces `CondVar` performance. + void EnableDebugLog(const char *name); + + private: +#ifdef ABSL_INTERNAL_USE_NONPROD_MUTEX + synchronization_internal::CondVarImpl *impl() { return impl_.get(); } + synchronization_internal::SynchronizationStorage< + synchronization_internal::CondVarImpl> + impl_; +#else + bool WaitCommon(Mutex *mutex, synchronization_internal::KernelTimeout t); + void Remove(base_internal::PerThreadSynch *s); + void Wakeup(base_internal::PerThreadSynch *w); + std::atomic<intptr_t> cv_; // Condition variable state. +#endif + CondVar(const CondVar&) = delete; + CondVar& operator=(const CondVar&) = delete; +}; + + +// Variants of MutexLock. +// +// If you find yourself using one of these, consider instead using +// Mutex::Unlock() and/or if-statements for clarity. + +// MutexLockMaybe +// +// MutexLockMaybe is like MutexLock, but is a no-op when mu is null. +class ABSL_SCOPED_LOCKABLE MutexLockMaybe { + public: + explicit MutexLockMaybe(Mutex *mu) ABSL_EXCLUSIVE_LOCK_FUNCTION(mu) + : mu_(mu) { + if (this->mu_ != nullptr) { + this->mu_->Lock(); + } + } + ~MutexLockMaybe() ABSL_UNLOCK_FUNCTION() { + if (this->mu_ != nullptr) { this->mu_->Unlock(); } + } + + private: + Mutex *const mu_; + MutexLockMaybe(const MutexLockMaybe&) = delete; + MutexLockMaybe(MutexLockMaybe&&) = delete; + MutexLockMaybe& operator=(const MutexLockMaybe&) = delete; + MutexLockMaybe& operator=(MutexLockMaybe&&) = delete; +}; + +// ReleasableMutexLock +// +// ReleasableMutexLock is like MutexLock, but permits `Release()` of its +// mutex before destruction. `Release()` may be called at most once. +class ABSL_SCOPED_LOCKABLE ReleasableMutexLock { + public: + explicit ReleasableMutexLock(Mutex *mu) ABSL_EXCLUSIVE_LOCK_FUNCTION(mu) + : mu_(mu) { + this->mu_->Lock(); + } + ~ReleasableMutexLock() ABSL_UNLOCK_FUNCTION() { + if (this->mu_ != nullptr) { this->mu_->Unlock(); } + } + + void Release() ABSL_UNLOCK_FUNCTION(); + + private: + Mutex *mu_; + ReleasableMutexLock(const ReleasableMutexLock&) = delete; + ReleasableMutexLock(ReleasableMutexLock&&) = delete; + ReleasableMutexLock& operator=(const ReleasableMutexLock&) = delete; + ReleasableMutexLock& operator=(ReleasableMutexLock&&) = delete; +}; + +#ifdef ABSL_INTERNAL_USE_NONPROD_MUTEX + +inline constexpr Mutex::Mutex(absl::ConstInitType) : impl_(absl::kConstInit) {} + +#else + +inline Mutex::Mutex() : mu_(0) { + ABSL_TSAN_MUTEX_CREATE(this, __tsan_mutex_not_static); +} + +inline constexpr Mutex::Mutex(absl::ConstInitType) : mu_(0) {} + +inline CondVar::CondVar() : cv_(0) {} + +#endif // ABSL_INTERNAL_USE_NONPROD_MUTEX + +// static +template <typename T> +bool Condition::CastAndCallMethod(const Condition *c) { + typedef bool (T::*MemberType)(); + MemberType rm = reinterpret_cast<MemberType>(c->method_); + T *x = static_cast<T *>(c->arg_); + return (x->*rm)(); +} + +// static +template <typename T> +bool Condition::CastAndCallFunction(const Condition *c) { + typedef bool (*FuncType)(T *); + FuncType fn = reinterpret_cast<FuncType>(c->function_); + T *x = static_cast<T *>(c->arg_); + return (*fn)(x); +} + +template <typename T> +inline Condition::Condition(bool (*func)(T *), T *arg) + : eval_(&CastAndCallFunction<T>), + function_(reinterpret_cast<InternalFunctionType>(func)), + method_(nullptr), + arg_(const_cast<void *>(static_cast<const void *>(arg))) {} + +template <typename T> +inline Condition::Condition(T *object, + bool (absl::internal::identity<T>::type::*method)()) + : eval_(&CastAndCallMethod<T>), + function_(nullptr), + method_(reinterpret_cast<InternalMethodType>(method)), + arg_(object) {} + +template <typename T> +inline Condition::Condition(const T *object, + bool (absl::internal::identity<T>::type::*method)() + const) + : eval_(&CastAndCallMethod<T>), + function_(nullptr), + method_(reinterpret_cast<InternalMethodType>(method)), + arg_(reinterpret_cast<void *>(const_cast<T *>(object))) {} + +// Register a hook for profiling support. +// +// The function pointer registered here will be called whenever a mutex is +// contended. The callback is given the absl/base/cycleclock.h timestamp when +// waiting began. +// +// Calls to this function do not race or block, but there is no ordering +// guaranteed between calls to this function and call to the provided hook. +// In particular, the previously registered hook may still be called for some +// time after this function returns. +void RegisterMutexProfiler(void (*fn)(int64_t wait_timestamp)); + +// Register a hook for Mutex tracing. +// +// The function pointer registered here will be called whenever a mutex is +// contended. The callback is given an opaque handle to the contended mutex, +// an event name, and the number of wait cycles (as measured by +// //absl/base/internal/cycleclock.h, and which may not be real +// "cycle" counts.) +// +// The only event name currently sent is "slow release". +// +// This has the same memory ordering concerns as RegisterMutexProfiler() above. +void RegisterMutexTracer(void (*fn)(const char *msg, const void *obj, + int64_t wait_cycles)); + +// TODO(gfalcon): Combine RegisterMutexProfiler() and RegisterMutexTracer() +// into a single interface, since they are only ever called in pairs. + +// Register a hook for CondVar tracing. +// +// The function pointer registered here will be called here on various CondVar +// events. The callback is given an opaque handle to the CondVar object and +// a string identifying the event. This is thread-safe, but only a single +// tracer can be registered. +// +// Events that can be sent are "Wait", "Unwait", "Signal wakeup", and +// "SignalAll wakeup". +// +// This has the same memory ordering concerns as RegisterMutexProfiler() above. +void RegisterCondVarTracer(void (*fn)(const char *msg, const void *cv)); + +// Register a hook for symbolizing stack traces in deadlock detector reports. +// +// 'pc' is the program counter being symbolized, 'out' is the buffer to write +// into, and 'out_size' is the size of the buffer. This function can return +// false if symbolizing failed, or true if a NUL-terminated symbol was written +// to 'out.' +// +// This has the same memory ordering concerns as RegisterMutexProfiler() above. +// +// DEPRECATED: The default symbolizer function is absl::Symbolize() and the +// ability to register a different hook for symbolizing stack traces will be +// removed on or after 2023-05-01. +ABSL_DEPRECATED("absl::RegisterSymbolizer() is deprecated and will be removed " + "on or after 2023-05-01") +void RegisterSymbolizer(bool (*fn)(const void *pc, char *out, int out_size)); + +// EnableMutexInvariantDebugging() +// +// Enable or disable global support for Mutex invariant debugging. If enabled, +// then invariant predicates can be registered per-Mutex for debug checking. +// See Mutex::EnableInvariantDebugging(). +void EnableMutexInvariantDebugging(bool enabled); + +// When in debug mode, and when the feature has been enabled globally, the +// implementation will keep track of lock ordering and complain (or optionally +// crash) if a cycle is detected in the acquired-before graph. + +// Possible modes of operation for the deadlock detector in debug mode. +enum class OnDeadlockCycle { + kIgnore, // Neither report on nor attempt to track cycles in lock ordering + kReport, // Report lock cycles to stderr when detected + kAbort, // Report lock cycles to stderr when detected, then abort +}; + +// SetMutexDeadlockDetectionMode() +// +// Enable or disable global support for detection of potential deadlocks +// due to Mutex lock ordering inversions. When set to 'kIgnore', tracking of +// lock ordering is disabled. Otherwise, in debug builds, a lock ordering graph +// will be maintained internally, and detected cycles will be reported in +// the manner chosen here. +void SetMutexDeadlockDetectionMode(OnDeadlockCycle mode); + +ABSL_NAMESPACE_END +} // namespace absl + +// In some build configurations we pass --detect-odr-violations to the +// gold linker. This causes it to flag weak symbol overrides as ODR +// violations. Because ODR only applies to C++ and not C, +// --detect-odr-violations ignores symbols not mangled with C++ names. +// By changing our extension points to be extern "C", we dodge this +// check. +extern "C" { +void AbslInternalMutexYield(); +} // extern "C" + +#endif // ABSL_SYNCHRONIZATION_MUTEX_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/mutex_benchmark.cc b/third_party/abseil_cpp/absl/synchronization/mutex_benchmark.cc new file mode 100644 index 0000000000..ab1880012a --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/mutex_benchmark.cc @@ -0,0 +1,223 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdint> +#include <mutex> // NOLINT(build/c++11) +#include <vector> + +#include "absl/base/internal/cycleclock.h" +#include "absl/base/internal/spinlock.h" +#include "absl/synchronization/blocking_counter.h" +#include "absl/synchronization/internal/thread_pool.h" +#include "absl/synchronization/mutex.h" +#include "benchmark/benchmark.h" + +namespace { + +void BM_Mutex(benchmark::State& state) { + static absl::Mutex* mu = new absl::Mutex; + for (auto _ : state) { + absl::MutexLock lock(mu); + } +} +BENCHMARK(BM_Mutex)->UseRealTime()->Threads(1)->ThreadPerCpu(); + +static void DelayNs(int64_t ns, int* data) { + int64_t end = absl::base_internal::CycleClock::Now() + + ns * absl::base_internal::CycleClock::Frequency() / 1e9; + while (absl::base_internal::CycleClock::Now() < end) { + ++(*data); + benchmark::DoNotOptimize(*data); + } +} + +template <typename MutexType> +class RaiiLocker { + public: + explicit RaiiLocker(MutexType* mu) : mu_(mu) { mu_->Lock(); } + ~RaiiLocker() { mu_->Unlock(); } + private: + MutexType* mu_; +}; + +template <> +class RaiiLocker<std::mutex> { + public: + explicit RaiiLocker(std::mutex* mu) : mu_(mu) { mu_->lock(); } + ~RaiiLocker() { mu_->unlock(); } + private: + std::mutex* mu_; +}; + +template <typename MutexType> +void BM_Contended(benchmark::State& state) { + struct Shared { + MutexType mu; + int data = 0; + }; + static auto* shared = new Shared; + int local = 0; + for (auto _ : state) { + // Here we model both local work outside of the critical section as well as + // some work inside of the critical section. The idea is to capture some + // more or less realisitic contention levels. + // If contention is too low, the benchmark won't measure anything useful. + // If contention is unrealistically high, the benchmark will favor + // bad mutex implementations that block and otherwise distract threads + // from the mutex and shared state for as much as possible. + // To achieve this amount of local work is multiplied by number of threads + // to keep ratio between local work and critical section approximately + // equal regardless of number of threads. + DelayNs(100 * state.threads, &local); + RaiiLocker<MutexType> locker(&shared->mu); + DelayNs(state.range(0), &shared->data); + } +} + +BENCHMARK_TEMPLATE(BM_Contended, absl::Mutex) + ->UseRealTime() + // ThreadPerCpu poorly handles non-power-of-two CPU counts. + ->Threads(1) + ->Threads(2) + ->Threads(4) + ->Threads(6) + ->Threads(8) + ->Threads(12) + ->Threads(16) + ->Threads(24) + ->Threads(32) + ->Threads(48) + ->Threads(64) + ->Threads(96) + ->Threads(128) + ->Threads(192) + ->Threads(256) + // Some empirically chosen amounts of work in critical section. + // 1 is low contention, 200 is high contention and few values in between. + ->Arg(1) + ->Arg(20) + ->Arg(50) + ->Arg(200); + +BENCHMARK_TEMPLATE(BM_Contended, absl::base_internal::SpinLock) + ->UseRealTime() + // ThreadPerCpu poorly handles non-power-of-two CPU counts. + ->Threads(1) + ->Threads(2) + ->Threads(4) + ->Threads(6) + ->Threads(8) + ->Threads(12) + ->Threads(16) + ->Threads(24) + ->Threads(32) + ->Threads(48) + ->Threads(64) + ->Threads(96) + ->Threads(128) + ->Threads(192) + ->Threads(256) + // Some empirically chosen amounts of work in critical section. + // 1 is low contention, 200 is high contention and few values in between. + ->Arg(1) + ->Arg(20) + ->Arg(50) + ->Arg(200); + +BENCHMARK_TEMPLATE(BM_Contended, std::mutex) + ->UseRealTime() + // ThreadPerCpu poorly handles non-power-of-two CPU counts. + ->Threads(1) + ->Threads(2) + ->Threads(4) + ->Threads(6) + ->Threads(8) + ->Threads(12) + ->Threads(16) + ->Threads(24) + ->Threads(32) + ->Threads(48) + ->Threads(64) + ->Threads(96) + ->Threads(128) + ->Threads(192) + ->Threads(256) + // Some empirically chosen amounts of work in critical section. + // 1 is low contention, 200 is high contention and few values in between. + ->Arg(1) + ->Arg(20) + ->Arg(50) + ->Arg(200); + +// Measure the overhead of conditions on mutex release (when they must be +// evaluated). Mutex has (some) support for equivalence classes allowing +// Conditions with the same function/argument to potentially not be multiply +// evaluated. +// +// num_classes==0 is used for the special case of every waiter being distinct. +void BM_ConditionWaiters(benchmark::State& state) { + int num_classes = state.range(0); + int num_waiters = state.range(1); + + struct Helper { + static void Waiter(absl::BlockingCounter* init, absl::Mutex* m, int* p) { + init->DecrementCount(); + m->LockWhen(absl::Condition( + static_cast<bool (*)(int*)>([](int* v) { return *v == 0; }), p)); + m->Unlock(); + } + }; + + if (num_classes == 0) { + // No equivalence classes. + num_classes = num_waiters; + } + + absl::BlockingCounter init(num_waiters); + absl::Mutex mu; + std::vector<int> equivalence_classes(num_classes, 1); + + // Must be declared last to be destroyed first. + absl::synchronization_internal::ThreadPool pool(num_waiters); + + for (int i = 0; i < num_waiters; i++) { + // Mutex considers Conditions with the same function and argument + // to be equivalent. + pool.Schedule([&, i] { + Helper::Waiter(&init, &mu, &equivalence_classes[i % num_classes]); + }); + } + init.Wait(); + + for (auto _ : state) { + mu.Lock(); + mu.Unlock(); // Each unlock requires Condition evaluation for our waiters. + } + + mu.Lock(); + for (int i = 0; i < num_classes; i++) { + equivalence_classes[i] = 0; + } + mu.Unlock(); +} + +// Some configurations have higher thread limits than others. +#if defined(__linux__) && !defined(THREAD_SANITIZER) +constexpr int kMaxConditionWaiters = 8192; +#else +constexpr int kMaxConditionWaiters = 1024; +#endif +BENCHMARK(BM_ConditionWaiters)->RangePair(0, 2, 1, kMaxConditionWaiters); + +} // namespace diff --git a/third_party/abseil_cpp/absl/synchronization/mutex_test.cc b/third_party/abseil_cpp/absl/synchronization/mutex_test.cc new file mode 100644 index 0000000000..afb363af61 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/mutex_test.cc @@ -0,0 +1,1675 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/mutex.h" + +#ifdef _WIN32 +#include <windows.h> +#endif + +#include <algorithm> +#include <atomic> +#include <cstdlib> +#include <functional> +#include <memory> +#include <random> +#include <string> +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/base/internal/sysinfo.h" +#include "absl/memory/memory.h" +#include "absl/synchronization/internal/thread_pool.h" +#include "absl/time/clock.h" +#include "absl/time/time.h" + +namespace { + +// TODO(dmauro): Replace with a commandline flag. +static constexpr bool kExtendedTest = false; + +std::unique_ptr<absl::synchronization_internal::ThreadPool> CreatePool( + int threads) { + return absl::make_unique<absl::synchronization_internal::ThreadPool>(threads); +} + +std::unique_ptr<absl::synchronization_internal::ThreadPool> +CreateDefaultPool() { + return CreatePool(kExtendedTest ? 32 : 10); +} + +// Hack to schedule a function to run on a thread pool thread after a +// duration has elapsed. +static void ScheduleAfter(absl::synchronization_internal::ThreadPool *tp, + absl::Duration after, + const std::function<void()> &func) { + tp->Schedule([func, after] { + absl::SleepFor(after); + func(); + }); +} + +struct TestContext { + int iterations; + int threads; + int g0; // global 0 + int g1; // global 1 + absl::Mutex mu; + absl::CondVar cv; +}; + +// To test whether the invariant check call occurs +static std::atomic<bool> invariant_checked; + +static bool GetInvariantChecked() { + return invariant_checked.load(std::memory_order_relaxed); +} + +static void SetInvariantChecked(bool new_value) { + invariant_checked.store(new_value, std::memory_order_relaxed); +} + +static void CheckSumG0G1(void *v) { + TestContext *cxt = static_cast<TestContext *>(v); + ABSL_RAW_CHECK(cxt->g0 == -cxt->g1, "Error in CheckSumG0G1"); + SetInvariantChecked(true); +} + +static void TestMu(TestContext *cxt, int c) { + for (int i = 0; i != cxt->iterations; i++) { + absl::MutexLock l(&cxt->mu); + int a = cxt->g0 + 1; + cxt->g0 = a; + cxt->g1--; + } +} + +static void TestTry(TestContext *cxt, int c) { + for (int i = 0; i != cxt->iterations; i++) { + do { + std::this_thread::yield(); + } while (!cxt->mu.TryLock()); + int a = cxt->g0 + 1; + cxt->g0 = a; + cxt->g1--; + cxt->mu.Unlock(); + } +} + +static void TestR20ms(TestContext *cxt, int c) { + for (int i = 0; i != cxt->iterations; i++) { + absl::ReaderMutexLock l(&cxt->mu); + absl::SleepFor(absl::Milliseconds(20)); + cxt->mu.AssertReaderHeld(); + } +} + +static void TestRW(TestContext *cxt, int c) { + if ((c & 1) == 0) { + for (int i = 0; i != cxt->iterations; i++) { + absl::WriterMutexLock l(&cxt->mu); + cxt->g0++; + cxt->g1--; + cxt->mu.AssertHeld(); + cxt->mu.AssertReaderHeld(); + } + } else { + for (int i = 0; i != cxt->iterations; i++) { + absl::ReaderMutexLock l(&cxt->mu); + ABSL_RAW_CHECK(cxt->g0 == -cxt->g1, "Error in TestRW"); + cxt->mu.AssertReaderHeld(); + } + } +} + +struct MyContext { + int target; + TestContext *cxt; + bool MyTurn(); +}; + +bool MyContext::MyTurn() { + TestContext *cxt = this->cxt; + return cxt->g0 == this->target || cxt->g0 == cxt->iterations; +} + +static void TestAwait(TestContext *cxt, int c) { + MyContext mc; + mc.target = c; + mc.cxt = cxt; + absl::MutexLock l(&cxt->mu); + cxt->mu.AssertHeld(); + while (cxt->g0 < cxt->iterations) { + cxt->mu.Await(absl::Condition(&mc, &MyContext::MyTurn)); + ABSL_RAW_CHECK(mc.MyTurn(), "Error in TestAwait"); + cxt->mu.AssertHeld(); + if (cxt->g0 < cxt->iterations) { + int a = cxt->g0 + 1; + cxt->g0 = a; + mc.target += cxt->threads; + } + } +} + +static void TestSignalAll(TestContext *cxt, int c) { + int target = c; + absl::MutexLock l(&cxt->mu); + cxt->mu.AssertHeld(); + while (cxt->g0 < cxt->iterations) { + while (cxt->g0 != target && cxt->g0 != cxt->iterations) { + cxt->cv.Wait(&cxt->mu); + } + if (cxt->g0 < cxt->iterations) { + int a = cxt->g0 + 1; + cxt->g0 = a; + cxt->cv.SignalAll(); + target += cxt->threads; + } + } +} + +static void TestSignal(TestContext *cxt, int c) { + ABSL_RAW_CHECK(cxt->threads == 2, "TestSignal should use 2 threads"); + int target = c; + absl::MutexLock l(&cxt->mu); + cxt->mu.AssertHeld(); + while (cxt->g0 < cxt->iterations) { + while (cxt->g0 != target && cxt->g0 != cxt->iterations) { + cxt->cv.Wait(&cxt->mu); + } + if (cxt->g0 < cxt->iterations) { + int a = cxt->g0 + 1; + cxt->g0 = a; + cxt->cv.Signal(); + target += cxt->threads; + } + } +} + +static void TestCVTimeout(TestContext *cxt, int c) { + int target = c; + absl::MutexLock l(&cxt->mu); + cxt->mu.AssertHeld(); + while (cxt->g0 < cxt->iterations) { + while (cxt->g0 != target && cxt->g0 != cxt->iterations) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(100)); + } + if (cxt->g0 < cxt->iterations) { + int a = cxt->g0 + 1; + cxt->g0 = a; + cxt->cv.SignalAll(); + target += cxt->threads; + } + } +} + +static bool G0GE2(TestContext *cxt) { return cxt->g0 >= 2; } + +static void TestTime(TestContext *cxt, int c, bool use_cv) { + ABSL_RAW_CHECK(cxt->iterations == 1, "TestTime should only use 1 iteration"); + ABSL_RAW_CHECK(cxt->threads > 2, "TestTime should use more than 2 threads"); + const bool kFalse = false; + absl::Condition false_cond(&kFalse); + absl::Condition g0ge2(G0GE2, cxt); + if (c == 0) { + absl::MutexLock l(&cxt->mu); + + absl::Time start = absl::Now(); + if (use_cv) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(1)); + } else { + ABSL_RAW_CHECK(!cxt->mu.AwaitWithTimeout(false_cond, absl::Seconds(1)), + "TestTime failed"); + } + absl::Duration elapsed = absl::Now() - start; + ABSL_RAW_CHECK( + absl::Seconds(0.9) <= elapsed && elapsed <= absl::Seconds(2.0), + "TestTime failed"); + ABSL_RAW_CHECK(cxt->g0 == 1, "TestTime failed"); + + start = absl::Now(); + if (use_cv) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(1)); + } else { + ABSL_RAW_CHECK(!cxt->mu.AwaitWithTimeout(false_cond, absl::Seconds(1)), + "TestTime failed"); + } + elapsed = absl::Now() - start; + ABSL_RAW_CHECK( + absl::Seconds(0.9) <= elapsed && elapsed <= absl::Seconds(2.0), + "TestTime failed"); + cxt->g0++; + if (use_cv) { + cxt->cv.Signal(); + } + + start = absl::Now(); + if (use_cv) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(4)); + } else { + ABSL_RAW_CHECK(!cxt->mu.AwaitWithTimeout(false_cond, absl::Seconds(4)), + "TestTime failed"); + } + elapsed = absl::Now() - start; + ABSL_RAW_CHECK( + absl::Seconds(3.9) <= elapsed && elapsed <= absl::Seconds(6.0), + "TestTime failed"); + ABSL_RAW_CHECK(cxt->g0 >= 3, "TestTime failed"); + + start = absl::Now(); + if (use_cv) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(1)); + } else { + ABSL_RAW_CHECK(!cxt->mu.AwaitWithTimeout(false_cond, absl::Seconds(1)), + "TestTime failed"); + } + elapsed = absl::Now() - start; + ABSL_RAW_CHECK( + absl::Seconds(0.9) <= elapsed && elapsed <= absl::Seconds(2.0), + "TestTime failed"); + if (use_cv) { + cxt->cv.SignalAll(); + } + + start = absl::Now(); + if (use_cv) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(1)); + } else { + ABSL_RAW_CHECK(!cxt->mu.AwaitWithTimeout(false_cond, absl::Seconds(1)), + "TestTime failed"); + } + elapsed = absl::Now() - start; + ABSL_RAW_CHECK(absl::Seconds(0.9) <= elapsed && + elapsed <= absl::Seconds(2.0), "TestTime failed"); + ABSL_RAW_CHECK(cxt->g0 == cxt->threads, "TestTime failed"); + + } else if (c == 1) { + absl::MutexLock l(&cxt->mu); + const absl::Time start = absl::Now(); + if (use_cv) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Milliseconds(500)); + } else { + ABSL_RAW_CHECK( + !cxt->mu.AwaitWithTimeout(false_cond, absl::Milliseconds(500)), + "TestTime failed"); + } + const absl::Duration elapsed = absl::Now() - start; + ABSL_RAW_CHECK( + absl::Seconds(0.4) <= elapsed && elapsed <= absl::Seconds(0.9), + "TestTime failed"); + cxt->g0++; + } else if (c == 2) { + absl::MutexLock l(&cxt->mu); + if (use_cv) { + while (cxt->g0 < 2) { + cxt->cv.WaitWithTimeout(&cxt->mu, absl::Seconds(100)); + } + } else { + ABSL_RAW_CHECK(cxt->mu.AwaitWithTimeout(g0ge2, absl::Seconds(100)), + "TestTime failed"); + } + cxt->g0++; + } else { + absl::MutexLock l(&cxt->mu); + if (use_cv) { + while (cxt->g0 < 2) { + cxt->cv.Wait(&cxt->mu); + } + } else { + cxt->mu.Await(g0ge2); + } + cxt->g0++; + } +} + +static void TestMuTime(TestContext *cxt, int c) { TestTime(cxt, c, false); } + +static void TestCVTime(TestContext *cxt, int c) { TestTime(cxt, c, true); } + +static void EndTest(int *c0, int *c1, absl::Mutex *mu, absl::CondVar *cv, + const std::function<void(int)>& cb) { + mu->Lock(); + int c = (*c0)++; + mu->Unlock(); + cb(c); + absl::MutexLock l(mu); + (*c1)++; + cv->Signal(); +} + +// Code common to RunTest() and RunTestWithInvariantDebugging(). +static int RunTestCommon(TestContext *cxt, void (*test)(TestContext *cxt, int), + int threads, int iterations, int operations) { + absl::Mutex mu2; + absl::CondVar cv2; + int c0 = 0; + int c1 = 0; + cxt->g0 = 0; + cxt->g1 = 0; + cxt->iterations = iterations; + cxt->threads = threads; + absl::synchronization_internal::ThreadPool tp(threads); + for (int i = 0; i != threads; i++) { + tp.Schedule(std::bind(&EndTest, &c0, &c1, &mu2, &cv2, + std::function<void(int)>( + std::bind(test, cxt, std::placeholders::_1)))); + } + mu2.Lock(); + while (c1 != threads) { + cv2.Wait(&mu2); + } + mu2.Unlock(); + return cxt->g0; +} + +// Basis for the parameterized tests configured below. +static int RunTest(void (*test)(TestContext *cxt, int), int threads, + int iterations, int operations) { + TestContext cxt; + return RunTestCommon(&cxt, test, threads, iterations, operations); +} + +// Like RunTest(), but sets an invariant on the tested Mutex and +// verifies that the invariant check happened. The invariant function +// will be passed the TestContext* as its arg and must call +// SetInvariantChecked(true); +#if !defined(ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED) +static int RunTestWithInvariantDebugging(void (*test)(TestContext *cxt, int), + int threads, int iterations, + int operations, + void (*invariant)(void *)) { + absl::EnableMutexInvariantDebugging(true); + SetInvariantChecked(false); + TestContext cxt; + cxt.mu.EnableInvariantDebugging(invariant, &cxt); + int ret = RunTestCommon(&cxt, test, threads, iterations, operations); + ABSL_RAW_CHECK(GetInvariantChecked(), "Invariant not checked"); + absl::EnableMutexInvariantDebugging(false); // Restore. + return ret; +} +#endif + +// -------------------------------------------------------- +// Test for fix of bug in TryRemove() +struct TimeoutBugStruct { + absl::Mutex mu; + bool a; + int a_waiter_count; +}; + +static void WaitForA(TimeoutBugStruct *x) { + x->mu.LockWhen(absl::Condition(&x->a)); + x->a_waiter_count--; + x->mu.Unlock(); +} + +static bool NoAWaiters(TimeoutBugStruct *x) { return x->a_waiter_count == 0; } + +// Test that a CondVar.Wait(&mutex) can un-block a call to mutex.Await() in +// another thread. +TEST(Mutex, CondVarWaitSignalsAwait) { + // Use a struct so the lock annotations apply. + struct { + absl::Mutex barrier_mu; + bool barrier ABSL_GUARDED_BY(barrier_mu) = false; + + absl::Mutex release_mu; + bool release ABSL_GUARDED_BY(release_mu) = false; + absl::CondVar released_cv; + } state; + + auto pool = CreateDefaultPool(); + + // Thread A. Sets barrier, waits for release using Mutex::Await, then + // signals released_cv. + pool->Schedule([&state] { + state.release_mu.Lock(); + + state.barrier_mu.Lock(); + state.barrier = true; + state.barrier_mu.Unlock(); + + state.release_mu.Await(absl::Condition(&state.release)); + state.released_cv.Signal(); + state.release_mu.Unlock(); + }); + + state.barrier_mu.LockWhen(absl::Condition(&state.barrier)); + state.barrier_mu.Unlock(); + state.release_mu.Lock(); + // Thread A is now blocked on release by way of Mutex::Await(). + + // Set release. Calling released_cv.Wait() should un-block thread A, + // which will signal released_cv. If not, the test will hang. + state.release = true; + state.released_cv.Wait(&state.release_mu); + state.release_mu.Unlock(); +} + +// Test that a CondVar.WaitWithTimeout(&mutex) can un-block a call to +// mutex.Await() in another thread. +TEST(Mutex, CondVarWaitWithTimeoutSignalsAwait) { + // Use a struct so the lock annotations apply. + struct { + absl::Mutex barrier_mu; + bool barrier ABSL_GUARDED_BY(barrier_mu) = false; + + absl::Mutex release_mu; + bool release ABSL_GUARDED_BY(release_mu) = false; + absl::CondVar released_cv; + } state; + + auto pool = CreateDefaultPool(); + + // Thread A. Sets barrier, waits for release using Mutex::Await, then + // signals released_cv. + pool->Schedule([&state] { + state.release_mu.Lock(); + + state.barrier_mu.Lock(); + state.barrier = true; + state.barrier_mu.Unlock(); + + state.release_mu.Await(absl::Condition(&state.release)); + state.released_cv.Signal(); + state.release_mu.Unlock(); + }); + + state.barrier_mu.LockWhen(absl::Condition(&state.barrier)); + state.barrier_mu.Unlock(); + state.release_mu.Lock(); + // Thread A is now blocked on release by way of Mutex::Await(). + + // Set release. Calling released_cv.Wait() should un-block thread A, + // which will signal released_cv. If not, the test will hang. + state.release = true; + EXPECT_TRUE( + !state.released_cv.WaitWithTimeout(&state.release_mu, absl::Seconds(10))) + << "; Unrecoverable test failure: CondVar::WaitWithTimeout did not " + "unblock the absl::Mutex::Await call in another thread."; + + state.release_mu.Unlock(); +} + +// Test for regression of a bug in loop of TryRemove() +TEST(Mutex, MutexTimeoutBug) { + auto tp = CreateDefaultPool(); + + TimeoutBugStruct x; + x.a = false; + x.a_waiter_count = 2; + tp->Schedule(std::bind(&WaitForA, &x)); + tp->Schedule(std::bind(&WaitForA, &x)); + absl::SleepFor(absl::Seconds(1)); // Allow first two threads to hang. + // The skip field of the second will point to the first because there are + // only two. + + // Now cause a thread waiting on an always-false to time out + // This would deadlock when the bug was present. + bool always_false = false; + x.mu.LockWhenWithTimeout(absl::Condition(&always_false), + absl::Milliseconds(500)); + + // if we get here, the bug is not present. Cleanup the state. + + x.a = true; // wakeup the two waiters on A + x.mu.Await(absl::Condition(&NoAWaiters, &x)); // wait for them to exit + x.mu.Unlock(); +} + +struct CondVarWaitDeadlock : testing::TestWithParam<int> { + absl::Mutex mu; + absl::CondVar cv; + bool cond1 = false; + bool cond2 = false; + bool read_lock1; + bool read_lock2; + bool signal_unlocked; + + CondVarWaitDeadlock() { + read_lock1 = GetParam() & (1 << 0); + read_lock2 = GetParam() & (1 << 1); + signal_unlocked = GetParam() & (1 << 2); + } + + void Waiter1() { + if (read_lock1) { + mu.ReaderLock(); + while (!cond1) { + cv.Wait(&mu); + } + mu.ReaderUnlock(); + } else { + mu.Lock(); + while (!cond1) { + cv.Wait(&mu); + } + mu.Unlock(); + } + } + + void Waiter2() { + if (read_lock2) { + mu.ReaderLockWhen(absl::Condition(&cond2)); + mu.ReaderUnlock(); + } else { + mu.LockWhen(absl::Condition(&cond2)); + mu.Unlock(); + } + } +}; + +// Test for a deadlock bug in Mutex::Fer(). +// The sequence of events that lead to the deadlock is: +// 1. waiter1 blocks on cv in read mode (mu bits = 0). +// 2. waiter2 blocks on mu in either mode (mu bits = kMuWait). +// 3. main thread locks mu, sets cond1, unlocks mu (mu bits = kMuWait). +// 4. main thread signals on cv and this eventually calls Mutex::Fer(). +// Currently Fer wakes waiter1 since mu bits = kMuWait (mutex is unlocked). +// Before the bug fix Fer neither woke waiter1 nor queued it on mutex, +// which resulted in deadlock. +TEST_P(CondVarWaitDeadlock, Test) { + auto waiter1 = CreatePool(1); + auto waiter2 = CreatePool(1); + waiter1->Schedule([this] { this->Waiter1(); }); + waiter2->Schedule([this] { this->Waiter2(); }); + + // Wait while threads block (best-effort is fine). + absl::SleepFor(absl::Milliseconds(100)); + + // Wake condwaiter. + mu.Lock(); + cond1 = true; + if (signal_unlocked) { + mu.Unlock(); + cv.Signal(); + } else { + cv.Signal(); + mu.Unlock(); + } + waiter1.reset(); // "join" waiter1 + + // Wake waiter. + mu.Lock(); + cond2 = true; + mu.Unlock(); + waiter2.reset(); // "join" waiter2 +} + +INSTANTIATE_TEST_SUITE_P(CondVarWaitDeadlockTest, CondVarWaitDeadlock, + ::testing::Range(0, 8), + ::testing::PrintToStringParamName()); + +// -------------------------------------------------------- +// Test for fix of bug in DequeueAllWakeable() +// Bug was that if there was more than one waiting reader +// and all should be woken, the most recently blocked one +// would not be. + +struct DequeueAllWakeableBugStruct { + absl::Mutex mu; + absl::Mutex mu2; // protects all fields below + int unfinished_count; // count of unfinished readers; under mu2 + bool done1; // unfinished_count == 0; under mu2 + int finished_count; // count of finished readers, under mu2 + bool done2; // finished_count == 0; under mu2 +}; + +// Test for regression of a bug in loop of DequeueAllWakeable() +static void AcquireAsReader(DequeueAllWakeableBugStruct *x) { + x->mu.ReaderLock(); + x->mu2.Lock(); + x->unfinished_count--; + x->done1 = (x->unfinished_count == 0); + x->mu2.Unlock(); + // make sure that both readers acquired mu before we release it. + absl::SleepFor(absl::Seconds(2)); + x->mu.ReaderUnlock(); + + x->mu2.Lock(); + x->finished_count--; + x->done2 = (x->finished_count == 0); + x->mu2.Unlock(); +} + +// Test for regression of a bug in loop of DequeueAllWakeable() +TEST(Mutex, MutexReaderWakeupBug) { + auto tp = CreateDefaultPool(); + + DequeueAllWakeableBugStruct x; + x.unfinished_count = 2; + x.done1 = false; + x.finished_count = 2; + x.done2 = false; + x.mu.Lock(); // acquire mu exclusively + // queue two thread that will block on reader locks on x.mu + tp->Schedule(std::bind(&AcquireAsReader, &x)); + tp->Schedule(std::bind(&AcquireAsReader, &x)); + absl::SleepFor(absl::Seconds(1)); // give time for reader threads to block + x.mu.Unlock(); // wake them up + + // both readers should finish promptly + EXPECT_TRUE( + x.mu2.LockWhenWithTimeout(absl::Condition(&x.done1), absl::Seconds(10))); + x.mu2.Unlock(); + + EXPECT_TRUE( + x.mu2.LockWhenWithTimeout(absl::Condition(&x.done2), absl::Seconds(10))); + x.mu2.Unlock(); +} + +struct LockWhenTestStruct { + absl::Mutex mu1; + bool cond = false; + + absl::Mutex mu2; + bool waiting = false; +}; + +static bool LockWhenTestIsCond(LockWhenTestStruct* s) { + s->mu2.Lock(); + s->waiting = true; + s->mu2.Unlock(); + return s->cond; +} + +static void LockWhenTestWaitForIsCond(LockWhenTestStruct* s) { + s->mu1.LockWhen(absl::Condition(&LockWhenTestIsCond, s)); + s->mu1.Unlock(); +} + +TEST(Mutex, LockWhen) { + LockWhenTestStruct s; + + std::thread t(LockWhenTestWaitForIsCond, &s); + s.mu2.LockWhen(absl::Condition(&s.waiting)); + s.mu2.Unlock(); + + s.mu1.Lock(); + s.cond = true; + s.mu1.Unlock(); + + t.join(); +} + +// -------------------------------------------------------- +// The following test requires Mutex::ReaderLock to be a real shared +// lock, which is not the case in all builds. +#if !defined(ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE) + +// Test for fix of bug in UnlockSlow() that incorrectly decremented the reader +// count when putting a thread to sleep waiting for a false condition when the +// lock was not held. + +// For this bug to strike, we make a thread wait on a free mutex with no +// waiters by causing its wakeup condition to be false. Then the +// next two acquirers must be readers. The bug causes the lock +// to be released when one reader unlocks, rather than both. + +struct ReaderDecrementBugStruct { + bool cond; // to delay first thread (under mu) + int done; // reference count (under mu) + absl::Mutex mu; + + bool waiting_on_cond; // under mu2 + bool have_reader_lock; // under mu2 + bool complete; // under mu2 + absl::Mutex mu2; // > mu +}; + +// L >= mu, L < mu_waiting_on_cond +static bool IsCond(void *v) { + ReaderDecrementBugStruct *x = reinterpret_cast<ReaderDecrementBugStruct *>(v); + x->mu2.Lock(); + x->waiting_on_cond = true; + x->mu2.Unlock(); + return x->cond; +} + +// L >= mu +static bool AllDone(void *v) { + ReaderDecrementBugStruct *x = reinterpret_cast<ReaderDecrementBugStruct *>(v); + return x->done == 0; +} + +// L={} +static void WaitForCond(ReaderDecrementBugStruct *x) { + absl::Mutex dummy; + absl::MutexLock l(&dummy); + x->mu.LockWhen(absl::Condition(&IsCond, x)); + x->done--; + x->mu.Unlock(); +} + +// L={} +static void GetReadLock(ReaderDecrementBugStruct *x) { + x->mu.ReaderLock(); + x->mu2.Lock(); + x->have_reader_lock = true; + x->mu2.Await(absl::Condition(&x->complete)); + x->mu2.Unlock(); + x->mu.ReaderUnlock(); + x->mu.Lock(); + x->done--; + x->mu.Unlock(); +} + +// Test for reader counter being decremented incorrectly by waiter +// with false condition. +TEST(Mutex, MutexReaderDecrementBug) ABSL_NO_THREAD_SAFETY_ANALYSIS { + ReaderDecrementBugStruct x; + x.cond = false; + x.waiting_on_cond = false; + x.have_reader_lock = false; + x.complete = false; + x.done = 2; // initial ref count + + // Run WaitForCond() and wait for it to sleep + std::thread thread1(WaitForCond, &x); + x.mu2.LockWhen(absl::Condition(&x.waiting_on_cond)); + x.mu2.Unlock(); + + // Run GetReadLock(), and wait for it to get the read lock + std::thread thread2(GetReadLock, &x); + x.mu2.LockWhen(absl::Condition(&x.have_reader_lock)); + x.mu2.Unlock(); + + // Get the reader lock ourselves, and release it. + x.mu.ReaderLock(); + x.mu.ReaderUnlock(); + + // The lock should be held in read mode by GetReadLock(). + // If we have the bug, the lock will be free. + x.mu.AssertReaderHeld(); + + // Wake up all the threads. + x.mu2.Lock(); + x.complete = true; + x.mu2.Unlock(); + + // TODO(delesley): turn on analysis once lock upgrading is supported. + // (This call upgrades the lock from shared to exclusive.) + x.mu.Lock(); + x.cond = true; + x.mu.Await(absl::Condition(&AllDone, &x)); + x.mu.Unlock(); + + thread1.join(); + thread2.join(); +} +#endif // !ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE + +// Test that we correctly handle the situation when a lock is +// held and then destroyed (w/o unlocking). +#ifdef THREAD_SANITIZER +// TSAN reports errors when locked Mutexes are destroyed. +TEST(Mutex, DISABLED_LockedMutexDestructionBug) NO_THREAD_SAFETY_ANALYSIS { +#else +TEST(Mutex, LockedMutexDestructionBug) ABSL_NO_THREAD_SAFETY_ANALYSIS { +#endif + for (int i = 0; i != 10; i++) { + // Create, lock and destroy 10 locks. + const int kNumLocks = 10; + auto mu = absl::make_unique<absl::Mutex[]>(kNumLocks); + for (int j = 0; j != kNumLocks; j++) { + if ((j % 2) == 0) { + mu[j].WriterLock(); + } else { + mu[j].ReaderLock(); + } + } + } +} + +// -------------------------------------------------------- +// Test for bug with pattern of readers using a condvar. The bug was that if a +// reader went to sleep on a condition variable while one or more other readers +// held the lock, but there were no waiters, the reader count (held in the +// mutex word) would be lost. (This is because Enqueue() had at one time +// always placed the thread on the Mutex queue. Later (CL 4075610), to +// tolerate re-entry into Mutex from a Condition predicate, Enqueue() was +// changed so that it could also place a thread on a condition-variable. This +// introduced the case where Enqueue() returned with an empty queue, and this +// case was handled incorrectly in one place.) + +static void ReaderForReaderOnCondVar(absl::Mutex *mu, absl::CondVar *cv, + int *running) { + std::random_device dev; + std::mt19937 gen(dev()); + std::uniform_int_distribution<int> random_millis(0, 15); + mu->ReaderLock(); + while (*running == 3) { + absl::SleepFor(absl::Milliseconds(random_millis(gen))); + cv->WaitWithTimeout(mu, absl::Milliseconds(random_millis(gen))); + } + mu->ReaderUnlock(); + mu->Lock(); + (*running)--; + mu->Unlock(); +} + +struct True { + template <class... Args> + bool operator()(Args...) const { + return true; + } +}; + +struct DerivedTrue : True {}; + +TEST(Mutex, FunctorCondition) { + { // Variadic + True f; + EXPECT_TRUE(absl::Condition(&f).Eval()); + } + + { // Inherited + DerivedTrue g; + EXPECT_TRUE(absl::Condition(&g).Eval()); + } + + { // lambda + int value = 3; + auto is_zero = [&value] { return value == 0; }; + absl::Condition c(&is_zero); + EXPECT_FALSE(c.Eval()); + value = 0; + EXPECT_TRUE(c.Eval()); + } + + { // bind + int value = 0; + auto is_positive = std::bind(std::less<int>(), 0, std::cref(value)); + absl::Condition c(&is_positive); + EXPECT_FALSE(c.Eval()); + value = 1; + EXPECT_TRUE(c.Eval()); + } + + { // std::function + int value = 3; + std::function<bool()> is_zero = [&value] { return value == 0; }; + absl::Condition c(&is_zero); + EXPECT_FALSE(c.Eval()); + value = 0; + EXPECT_TRUE(c.Eval()); + } +} + +static bool IntIsZero(int *x) { return *x == 0; } + +// Test for reader waiting condition variable when there are other readers +// but no waiters. +TEST(Mutex, TestReaderOnCondVar) { + auto tp = CreateDefaultPool(); + absl::Mutex mu; + absl::CondVar cv; + int running = 3; + tp->Schedule(std::bind(&ReaderForReaderOnCondVar, &mu, &cv, &running)); + tp->Schedule(std::bind(&ReaderForReaderOnCondVar, &mu, &cv, &running)); + absl::SleepFor(absl::Seconds(2)); + mu.Lock(); + running--; + mu.Await(absl::Condition(&IntIsZero, &running)); + mu.Unlock(); +} + +// -------------------------------------------------------- +struct AcquireFromConditionStruct { + absl::Mutex mu0; // protects value, done + int value; // times condition function is called; under mu0, + bool done; // done with test? under mu0 + absl::Mutex mu1; // used to attempt to mess up state of mu0 + absl::CondVar cv; // so the condition function can be invoked from + // CondVar::Wait(). +}; + +static bool ConditionWithAcquire(AcquireFromConditionStruct *x) { + x->value++; // count times this function is called + + if (x->value == 2 || x->value == 3) { + // On the second and third invocation of this function, sleep for 100ms, + // but with the side-effect of altering the state of a Mutex other than + // than one for which this is a condition. The spec now explicitly allows + // this side effect; previously it did not. it was illegal. + bool always_false = false; + x->mu1.LockWhenWithTimeout(absl::Condition(&always_false), + absl::Milliseconds(100)); + x->mu1.Unlock(); + } + ABSL_RAW_CHECK(x->value < 4, "should not be invoked a fourth time"); + + // We arrange for the condition to return true on only the 2nd and 3rd calls. + return x->value == 2 || x->value == 3; +} + +static void WaitForCond2(AcquireFromConditionStruct *x) { + // wait for cond0 to become true + x->mu0.LockWhen(absl::Condition(&ConditionWithAcquire, x)); + x->done = true; + x->mu0.Unlock(); +} + +// Test for Condition whose function acquires other Mutexes +TEST(Mutex, AcquireFromCondition) { + auto tp = CreateDefaultPool(); + + AcquireFromConditionStruct x; + x.value = 0; + x.done = false; + tp->Schedule( + std::bind(&WaitForCond2, &x)); // run WaitForCond2() in a thread T + // T will hang because the first invocation of ConditionWithAcquire() will + // return false. + absl::SleepFor(absl::Milliseconds(500)); // allow T time to hang + + x.mu0.Lock(); + x.cv.WaitWithTimeout(&x.mu0, absl::Milliseconds(500)); // wake T + // T will be woken because the Wait() will call ConditionWithAcquire() + // for the second time, and it will return true. + + x.mu0.Unlock(); + + // T will then acquire the lock and recheck its own condition. + // It will find the condition true, as this is the third invocation, + // but the use of another Mutex by the calling function will + // cause the old mutex implementation to think that the outer + // LockWhen() has timed out because the inner LockWhenWithTimeout() did. + // T will then check the condition a fourth time because it finds a + // timeout occurred. This should not happen in the new + // implementation that allows the Condition function to use Mutexes. + + // It should also succeed, even though the Condition function + // is being invoked from CondVar::Wait, and thus this thread + // is conceptually waiting both on the condition variable, and on mu2. + + x.mu0.LockWhen(absl::Condition(&x.done)); + x.mu0.Unlock(); +} + +// The deadlock detector is not part of non-prod builds, so do not test it. +#if !defined(ABSL_INTERNAL_USE_NONPROD_MUTEX) + +TEST(Mutex, DeadlockDetector) { + absl::SetMutexDeadlockDetectionMode(absl::OnDeadlockCycle::kAbort); + + // check that we can call ForgetDeadlockInfo() on a lock with the lock held + absl::Mutex m1; + absl::Mutex m2; + absl::Mutex m3; + absl::Mutex m4; + + m1.Lock(); // m1 gets ID1 + m2.Lock(); // m2 gets ID2 + m3.Lock(); // m3 gets ID3 + m3.Unlock(); + m2.Unlock(); + // m1 still held + m1.ForgetDeadlockInfo(); // m1 loses ID + m2.Lock(); // m2 gets ID2 + m3.Lock(); // m3 gets ID3 + m4.Lock(); // m4 gets ID4 + m3.Unlock(); + m2.Unlock(); + m4.Unlock(); + m1.Unlock(); +} + +// Bazel has a test "warning" file that programs can write to if the +// test should pass with a warning. This class disables the warning +// file until it goes out of scope. +class ScopedDisableBazelTestWarnings { + public: + ScopedDisableBazelTestWarnings() { +#ifdef _WIN32 + char file[MAX_PATH]; + if (GetEnvironmentVariableA(kVarName, file, sizeof(file)) < sizeof(file)) { + warnings_output_file_ = file; + SetEnvironmentVariableA(kVarName, nullptr); + } +#else + const char *file = getenv(kVarName); + if (file != nullptr) { + warnings_output_file_ = file; + unsetenv(kVarName); + } +#endif + } + + ~ScopedDisableBazelTestWarnings() { + if (!warnings_output_file_.empty()) { +#ifdef _WIN32 + SetEnvironmentVariableA(kVarName, warnings_output_file_.c_str()); +#else + setenv(kVarName, warnings_output_file_.c_str(), 0); +#endif + } + } + + private: + static const char kVarName[]; + std::string warnings_output_file_; +}; +const char ScopedDisableBazelTestWarnings::kVarName[] = + "TEST_WARNINGS_OUTPUT_FILE"; + +#ifdef THREAD_SANITIZER +// This test intentionally creates deadlocks to test the deadlock detector. +TEST(Mutex, DISABLED_DeadlockDetectorBazelWarning) { +#else +TEST(Mutex, DeadlockDetectorBazelWarning) { +#endif + absl::SetMutexDeadlockDetectionMode(absl::OnDeadlockCycle::kReport); + + // Cause deadlock detection to detect something, if it's + // compiled in and enabled. But turn off the bazel warning. + ScopedDisableBazelTestWarnings disable_bazel_test_warnings; + + absl::Mutex mu0; + absl::Mutex mu1; + bool got_mu0 = mu0.TryLock(); + mu1.Lock(); // acquire mu1 while holding mu0 + if (got_mu0) { + mu0.Unlock(); + } + if (mu0.TryLock()) { // try lock shouldn't cause deadlock detector to fire + mu0.Unlock(); + } + mu0.Lock(); // acquire mu0 while holding mu1; should get one deadlock + // report here + mu0.Unlock(); + mu1.Unlock(); + + absl::SetMutexDeadlockDetectionMode(absl::OnDeadlockCycle::kAbort); +} + +// This test is tagged with NO_THREAD_SAFETY_ANALYSIS because the +// annotation-based static thread-safety analysis is not currently +// predicate-aware and cannot tell if the two for-loops that acquire and +// release the locks have the same predicates. +TEST(Mutex, DeadlockDetectorStessTest) ABSL_NO_THREAD_SAFETY_ANALYSIS { + // Stress test: Here we create a large number of locks and use all of them. + // If a deadlock detector keeps a full graph of lock acquisition order, + // it will likely be too slow for this test to pass. + const int n_locks = 1 << 17; + auto array_of_locks = absl::make_unique<absl::Mutex[]>(n_locks); + for (int i = 0; i < n_locks; i++) { + int end = std::min(n_locks, i + 5); + // acquire and then release locks i, i+1, ..., i+4 + for (int j = i; j < end; j++) { + array_of_locks[j].Lock(); + } + for (int j = i; j < end; j++) { + array_of_locks[j].Unlock(); + } + } +} + +#ifdef THREAD_SANITIZER +// TSAN reports errors when locked Mutexes are destroyed. +TEST(Mutex, DISABLED_DeadlockIdBug) NO_THREAD_SAFETY_ANALYSIS { +#else +TEST(Mutex, DeadlockIdBug) ABSL_NO_THREAD_SAFETY_ANALYSIS { +#endif + // Test a scenario where a cached deadlock graph node id in the + // list of held locks is not invalidated when the corresponding + // mutex is deleted. + absl::SetMutexDeadlockDetectionMode(absl::OnDeadlockCycle::kAbort); + // Mutex that will be destroyed while being held + absl::Mutex *a = new absl::Mutex; + // Other mutexes needed by test + absl::Mutex b, c; + + // Hold mutex. + a->Lock(); + + // Force deadlock id assignment by acquiring another lock. + b.Lock(); + b.Unlock(); + + // Delete the mutex. The Mutex destructor tries to remove held locks, + // but the attempt isn't foolproof. It can fail if: + // (a) Deadlock detection is currently disabled. + // (b) The destruction is from another thread. + // We exploit (a) by temporarily disabling deadlock detection. + absl::SetMutexDeadlockDetectionMode(absl::OnDeadlockCycle::kIgnore); + delete a; + absl::SetMutexDeadlockDetectionMode(absl::OnDeadlockCycle::kAbort); + + // Now acquire another lock which will force a deadlock id assignment. + // We should end up getting assigned the same deadlock id that was + // freed up when "a" was deleted, which will cause a spurious deadlock + // report if the held lock entry for "a" was not invalidated. + c.Lock(); + c.Unlock(); +} +#endif // !defined(ABSL_INTERNAL_USE_NONPROD_MUTEX) + +// -------------------------------------------------------- +// Test for timeouts/deadlines on condition waits that are specified using +// absl::Duration and absl::Time. For each waiting function we test with +// a timeout/deadline that has already expired/passed, one that is infinite +// and so never expires/passes, and one that will expire/pass in the near +// future. + +static absl::Duration TimeoutTestAllowedSchedulingDelay() { + // Note: we use a function here because Microsoft Visual Studio fails to + // properly initialize constexpr static absl::Duration variables. + return absl::Milliseconds(150); +} + +// Returns true if `actual_delay` is close enough to `expected_delay` to pass +// the timeouts/deadlines test. Otherwise, logs warnings and returns false. +ABSL_MUST_USE_RESULT +static bool DelayIsWithinBounds(absl::Duration expected_delay, + absl::Duration actual_delay) { + bool pass = true; + // Do not allow the observed delay to be less than expected. This may occur + // in practice due to clock skew or when the synchronization primitives use a + // different clock than absl::Now(), but these cases should be handled by the + // the retry mechanism in each TimeoutTest. + if (actual_delay < expected_delay) { + ABSL_RAW_LOG(WARNING, + "Actual delay %s was too short, expected %s (difference %s)", + absl::FormatDuration(actual_delay).c_str(), + absl::FormatDuration(expected_delay).c_str(), + absl::FormatDuration(actual_delay - expected_delay).c_str()); + pass = false; + } + // If the expected delay is <= zero then allow a small error tolerance, since + // we do not expect context switches to occur during test execution. + // Otherwise, thread scheduling delays may be substantial in rare cases, so + // tolerate up to kTimeoutTestAllowedSchedulingDelay of error. + absl::Duration tolerance = expected_delay <= absl::ZeroDuration() + ? absl::Milliseconds(10) + : TimeoutTestAllowedSchedulingDelay(); + if (actual_delay > expected_delay + tolerance) { + ABSL_RAW_LOG(WARNING, + "Actual delay %s was too long, expected %s (difference %s)", + absl::FormatDuration(actual_delay).c_str(), + absl::FormatDuration(expected_delay).c_str(), + absl::FormatDuration(actual_delay - expected_delay).c_str()); + pass = false; + } + return pass; +} + +// Parameters for TimeoutTest, below. +struct TimeoutTestParam { + // The file and line number (used for logging purposes only). + const char *from_file; + int from_line; + + // Should the absolute deadline API based on absl::Time be tested? If false, + // the relative deadline API based on absl::Duration is tested. + bool use_absolute_deadline; + + // The deadline/timeout used when calling the API being tested + // (e.g. Mutex::LockWhenWithDeadline). + absl::Duration wait_timeout; + + // The delay before the condition will be set true by the test code. If zero + // or negative, the condition is set true immediately (before calling the API + // being tested). Otherwise, if infinite, the condition is never set true. + // Otherwise a closure is scheduled for the future that sets the condition + // true. + absl::Duration satisfy_condition_delay; + + // The expected result of the condition after the call to the API being + // tested. Generally `true` means the condition was true when the API returns, + // `false` indicates an expected timeout. + bool expected_result; + + // The expected delay before the API under test returns. This is inherently + // flaky, so some slop is allowed (see `DelayIsWithinBounds` above), and the + // test keeps trying indefinitely until this constraint passes. + absl::Duration expected_delay; +}; + +// Print a `TimeoutTestParam` to a debug log. +std::ostream &operator<<(std::ostream &os, const TimeoutTestParam ¶m) { + return os << "from: " << param.from_file << ":" << param.from_line + << " use_absolute_deadline: " + << (param.use_absolute_deadline ? "true" : "false") + << " wait_timeout: " << param.wait_timeout + << " satisfy_condition_delay: " << param.satisfy_condition_delay + << " expected_result: " + << (param.expected_result ? "true" : "false") + << " expected_delay: " << param.expected_delay; +} + +std::string FormatString(const TimeoutTestParam ¶m) { + std::ostringstream os; + os << param; + return os.str(); +} + +// Like `thread::Executor::ScheduleAt` except: +// a) Delays zero or negative are executed immediately in the current thread. +// b) Infinite delays are never scheduled. +// c) Calls this test's `ScheduleAt` helper instead of using `pool` directly. +static void RunAfterDelay(absl::Duration delay, + absl::synchronization_internal::ThreadPool *pool, + const std::function<void()> &callback) { + if (delay <= absl::ZeroDuration()) { + callback(); // immediate + } else if (delay != absl::InfiniteDuration()) { + ScheduleAfter(pool, delay, callback); + } +} + +class TimeoutTest : public ::testing::Test, + public ::testing::WithParamInterface<TimeoutTestParam> {}; + +std::vector<TimeoutTestParam> MakeTimeoutTestParamValues() { + // The `finite` delay is a finite, relatively short, delay. We make it larger + // than our allowed scheduling delay (slop factor) to avoid confusion when + // diagnosing test failures. The other constants here have clear meanings. + const absl::Duration finite = 3 * TimeoutTestAllowedSchedulingDelay(); + const absl::Duration never = absl::InfiniteDuration(); + const absl::Duration negative = -absl::InfiniteDuration(); + const absl::Duration immediate = absl::ZeroDuration(); + + // Every test case is run twice; once using the absolute deadline API and once + // using the relative timeout API. + std::vector<TimeoutTestParam> values; + for (bool use_absolute_deadline : {false, true}) { + // Tests with a negative timeout (deadline in the past), which should + // immediately return current state of the condition. + + // The condition is already true: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + negative, // wait_timeout + immediate, // satisfy_condition_delay + true, // expected_result + immediate, // expected_delay + }); + + // The condition becomes true, but the timeout has already expired: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + negative, // wait_timeout + finite, // satisfy_condition_delay + false, // expected_result + immediate // expected_delay + }); + + // The condition never becomes true: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + negative, // wait_timeout + never, // satisfy_condition_delay + false, // expected_result + immediate // expected_delay + }); + + // Tests with an infinite timeout (deadline in the infinite future), which + // should only return when the condition becomes true. + + // The condition is already true: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + never, // wait_timeout + immediate, // satisfy_condition_delay + true, // expected_result + immediate // expected_delay + }); + + // The condition becomes true before the (infinite) expiry: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + never, // wait_timeout + finite, // satisfy_condition_delay + true, // expected_result + finite, // expected_delay + }); + + // Tests with a (small) finite timeout (deadline soon), with the condition + // becoming true both before and after its expiry. + + // The condition is already true: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + never, // wait_timeout + immediate, // satisfy_condition_delay + true, // expected_result + immediate // expected_delay + }); + + // The condition becomes true before the expiry: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + finite * 2, // wait_timeout + finite, // satisfy_condition_delay + true, // expected_result + finite // expected_delay + }); + + // The condition becomes true, but the timeout has already expired: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + finite, // wait_timeout + finite * 2, // satisfy_condition_delay + false, // expected_result + finite // expected_delay + }); + + // The condition never becomes true: + values.push_back(TimeoutTestParam{ + __FILE__, __LINE__, use_absolute_deadline, + finite, // wait_timeout + never, // satisfy_condition_delay + false, // expected_result + finite // expected_delay + }); + } + return values; +} + +// Instantiate `TimeoutTest` with `MakeTimeoutTestParamValues()`. +INSTANTIATE_TEST_SUITE_P(All, TimeoutTest, + testing::ValuesIn(MakeTimeoutTestParamValues())); + +TEST_P(TimeoutTest, Await) { + const TimeoutTestParam params = GetParam(); + ABSL_RAW_LOG(INFO, "Params: %s", FormatString(params).c_str()); + + // Because this test asserts bounds on scheduling delays it is flaky. To + // compensate it loops forever until it passes. Failures express as test + // timeouts, in which case the test log can be used to diagnose the issue. + for (int attempt = 1;; ++attempt) { + ABSL_RAW_LOG(INFO, "Attempt %d", attempt); + + absl::Mutex mu; + bool value = false; // condition value (under mu) + + std::unique_ptr<absl::synchronization_internal::ThreadPool> pool = + CreateDefaultPool(); + RunAfterDelay(params.satisfy_condition_delay, pool.get(), [&] { + absl::MutexLock l(&mu); + value = true; + }); + + absl::MutexLock lock(&mu); + absl::Time start_time = absl::Now(); + absl::Condition cond(&value); + bool result = + params.use_absolute_deadline + ? mu.AwaitWithDeadline(cond, start_time + params.wait_timeout) + : mu.AwaitWithTimeout(cond, params.wait_timeout); + if (DelayIsWithinBounds(params.expected_delay, absl::Now() - start_time)) { + EXPECT_EQ(params.expected_result, result); + break; + } + } +} + +TEST_P(TimeoutTest, LockWhen) { + const TimeoutTestParam params = GetParam(); + ABSL_RAW_LOG(INFO, "Params: %s", FormatString(params).c_str()); + + // Because this test asserts bounds on scheduling delays it is flaky. To + // compensate it loops forever until it passes. Failures express as test + // timeouts, in which case the test log can be used to diagnose the issue. + for (int attempt = 1;; ++attempt) { + ABSL_RAW_LOG(INFO, "Attempt %d", attempt); + + absl::Mutex mu; + bool value = false; // condition value (under mu) + + std::unique_ptr<absl::synchronization_internal::ThreadPool> pool = + CreateDefaultPool(); + RunAfterDelay(params.satisfy_condition_delay, pool.get(), [&] { + absl::MutexLock l(&mu); + value = true; + }); + + absl::Time start_time = absl::Now(); + absl::Condition cond(&value); + bool result = + params.use_absolute_deadline + ? mu.LockWhenWithDeadline(cond, start_time + params.wait_timeout) + : mu.LockWhenWithTimeout(cond, params.wait_timeout); + mu.Unlock(); + + if (DelayIsWithinBounds(params.expected_delay, absl::Now() - start_time)) { + EXPECT_EQ(params.expected_result, result); + break; + } + } +} + +TEST_P(TimeoutTest, ReaderLockWhen) { + const TimeoutTestParam params = GetParam(); + ABSL_RAW_LOG(INFO, "Params: %s", FormatString(params).c_str()); + + // Because this test asserts bounds on scheduling delays it is flaky. To + // compensate it loops forever until it passes. Failures express as test + // timeouts, in which case the test log can be used to diagnose the issue. + for (int attempt = 0;; ++attempt) { + ABSL_RAW_LOG(INFO, "Attempt %d", attempt); + + absl::Mutex mu; + bool value = false; // condition value (under mu) + + std::unique_ptr<absl::synchronization_internal::ThreadPool> pool = + CreateDefaultPool(); + RunAfterDelay(params.satisfy_condition_delay, pool.get(), [&] { + absl::MutexLock l(&mu); + value = true; + }); + + absl::Time start_time = absl::Now(); + bool result = + params.use_absolute_deadline + ? mu.ReaderLockWhenWithDeadline(absl::Condition(&value), + start_time + params.wait_timeout) + : mu.ReaderLockWhenWithTimeout(absl::Condition(&value), + params.wait_timeout); + mu.ReaderUnlock(); + + if (DelayIsWithinBounds(params.expected_delay, absl::Now() - start_time)) { + EXPECT_EQ(params.expected_result, result); + break; + } + } +} + +TEST_P(TimeoutTest, Wait) { + const TimeoutTestParam params = GetParam(); + ABSL_RAW_LOG(INFO, "Params: %s", FormatString(params).c_str()); + + // Because this test asserts bounds on scheduling delays it is flaky. To + // compensate it loops forever until it passes. Failures express as test + // timeouts, in which case the test log can be used to diagnose the issue. + for (int attempt = 0;; ++attempt) { + ABSL_RAW_LOG(INFO, "Attempt %d", attempt); + + absl::Mutex mu; + bool value = false; // condition value (under mu) + absl::CondVar cv; // signals a change of `value` + + std::unique_ptr<absl::synchronization_internal::ThreadPool> pool = + CreateDefaultPool(); + RunAfterDelay(params.satisfy_condition_delay, pool.get(), [&] { + absl::MutexLock l(&mu); + value = true; + cv.Signal(); + }); + + absl::MutexLock lock(&mu); + absl::Time start_time = absl::Now(); + absl::Duration timeout = params.wait_timeout; + absl::Time deadline = start_time + timeout; + while (!value) { + if (params.use_absolute_deadline ? cv.WaitWithDeadline(&mu, deadline) + : cv.WaitWithTimeout(&mu, timeout)) { + break; // deadline/timeout exceeded + } + timeout = deadline - absl::Now(); // recompute + } + bool result = value; // note: `mu` is still held + + if (DelayIsWithinBounds(params.expected_delay, absl::Now() - start_time)) { + EXPECT_EQ(params.expected_result, result); + break; + } + } +} + +TEST(Mutex, Logging) { + // Allow user to look at logging output + absl::Mutex logged_mutex; + logged_mutex.EnableDebugLog("fido_mutex"); + absl::CondVar logged_cv; + logged_cv.EnableDebugLog("rover_cv"); + logged_mutex.Lock(); + logged_cv.WaitWithTimeout(&logged_mutex, absl::Milliseconds(20)); + logged_mutex.Unlock(); + logged_mutex.ReaderLock(); + logged_mutex.ReaderUnlock(); + logged_mutex.Lock(); + logged_mutex.Unlock(); + logged_cv.Signal(); + logged_cv.SignalAll(); +} + +// -------------------------------------------------------- + +// Generate the vector of thread counts for tests parameterized on thread count. +static std::vector<int> AllThreadCountValues() { + if (kExtendedTest) { + return {2, 4, 8, 10, 16, 20, 24, 30, 32}; + } + return {2, 4, 10}; +} + +// A test fixture parameterized by thread count. +class MutexVariableThreadCountTest : public ::testing::TestWithParam<int> {}; + +// Instantiate the above with AllThreadCountOptions(). +INSTANTIATE_TEST_SUITE_P(ThreadCounts, MutexVariableThreadCountTest, + ::testing::ValuesIn(AllThreadCountValues()), + ::testing::PrintToStringParamName()); + +// Reduces iterations by some factor for slow platforms +// (determined empirically). +static int ScaleIterations(int x) { + // ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE is set in the implementation + // of Mutex that uses either std::mutex or pthread_mutex_t. Use + // these as keys to determine the slow implementation. +#if defined(ABSL_MUTEX_READER_LOCK_IS_EXCLUSIVE) + return x / 10; +#else + return x; +#endif +} + +TEST_P(MutexVariableThreadCountTest, Mutex) { + int threads = GetParam(); + int iterations = ScaleIterations(10000000) / threads; + int operations = threads * iterations; + EXPECT_EQ(RunTest(&TestMu, threads, iterations, operations), operations); +#if !defined(ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED) + iterations = std::min(iterations, 10); + operations = threads * iterations; + EXPECT_EQ(RunTestWithInvariantDebugging(&TestMu, threads, iterations, + operations, CheckSumG0G1), + operations); +#endif +} + +TEST_P(MutexVariableThreadCountTest, Try) { + int threads = GetParam(); + int iterations = 1000000 / threads; + int operations = iterations * threads; + EXPECT_EQ(RunTest(&TestTry, threads, iterations, operations), operations); +#if !defined(ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED) + iterations = std::min(iterations, 10); + operations = threads * iterations; + EXPECT_EQ(RunTestWithInvariantDebugging(&TestTry, threads, iterations, + operations, CheckSumG0G1), + operations); +#endif +} + +TEST_P(MutexVariableThreadCountTest, R20ms) { + int threads = GetParam(); + int iterations = 100; + int operations = iterations * threads; + EXPECT_EQ(RunTest(&TestR20ms, threads, iterations, operations), 0); +} + +TEST_P(MutexVariableThreadCountTest, RW) { + int threads = GetParam(); + int iterations = ScaleIterations(20000000) / threads; + int operations = iterations * threads; + EXPECT_EQ(RunTest(&TestRW, threads, iterations, operations), operations / 2); +#if !defined(ABSL_MUTEX_ENABLE_INVARIANT_DEBUGGING_NOT_IMPLEMENTED) + iterations = std::min(iterations, 10); + operations = threads * iterations; + EXPECT_EQ(RunTestWithInvariantDebugging(&TestRW, threads, iterations, + operations, CheckSumG0G1), + operations / 2); +#endif +} + +TEST_P(MutexVariableThreadCountTest, Await) { + int threads = GetParam(); + int iterations = ScaleIterations(500000); + int operations = iterations; + EXPECT_EQ(RunTest(&TestAwait, threads, iterations, operations), operations); +} + +TEST_P(MutexVariableThreadCountTest, SignalAll) { + int threads = GetParam(); + int iterations = 200000 / threads; + int operations = iterations; + EXPECT_EQ(RunTest(&TestSignalAll, threads, iterations, operations), + operations); +} + +TEST(Mutex, Signal) { + int threads = 2; // TestSignal must use two threads + int iterations = 200000; + int operations = iterations; + EXPECT_EQ(RunTest(&TestSignal, threads, iterations, operations), operations); +} + +TEST(Mutex, Timed) { + int threads = 10; // Use a fixed thread count of 10 + int iterations = 1000; + int operations = iterations; + EXPECT_EQ(RunTest(&TestCVTimeout, threads, iterations, operations), + operations); +} + +TEST(Mutex, CVTime) { + int threads = 10; // Use a fixed thread count of 10 + int iterations = 1; + EXPECT_EQ(RunTest(&TestCVTime, threads, iterations, 1), + threads * iterations); +} + +TEST(Mutex, MuTime) { + int threads = 10; // Use a fixed thread count of 10 + int iterations = 1; + EXPECT_EQ(RunTest(&TestMuTime, threads, iterations, 1), threads * iterations); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/synchronization/notification.cc b/third_party/abseil_cpp/absl/synchronization/notification.cc new file mode 100644 index 0000000000..e91b903822 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/notification.cc @@ -0,0 +1,78 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/notification.h" + +#include <atomic> + +#include "absl/base/attributes.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/synchronization/mutex.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +void Notification::Notify() { + MutexLock l(&this->mutex_); + +#ifndef NDEBUG + if (ABSL_PREDICT_FALSE(notified_yet_.load(std::memory_order_relaxed))) { + ABSL_RAW_LOG( + FATAL, + "Notify() method called more than once for Notification object %p", + static_cast<void *>(this)); + } +#endif + + notified_yet_.store(true, std::memory_order_release); +} + +Notification::~Notification() { + // Make sure that the thread running Notify() exits before the object is + // destructed. + MutexLock l(&this->mutex_); +} + +void Notification::WaitForNotification() const { + if (!HasBeenNotifiedInternal(&this->notified_yet_)) { + this->mutex_.LockWhen(Condition(&HasBeenNotifiedInternal, + &this->notified_yet_)); + this->mutex_.Unlock(); + } +} + +bool Notification::WaitForNotificationWithTimeout( + absl::Duration timeout) const { + bool notified = HasBeenNotifiedInternal(&this->notified_yet_); + if (!notified) { + notified = this->mutex_.LockWhenWithTimeout( + Condition(&HasBeenNotifiedInternal, &this->notified_yet_), timeout); + this->mutex_.Unlock(); + } + return notified; +} + +bool Notification::WaitForNotificationWithDeadline(absl::Time deadline) const { + bool notified = HasBeenNotifiedInternal(&this->notified_yet_); + if (!notified) { + notified = this->mutex_.LockWhenWithDeadline( + Condition(&HasBeenNotifiedInternal, &this->notified_yet_), deadline); + this->mutex_.Unlock(); + } + return notified; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/synchronization/notification.h b/third_party/abseil_cpp/absl/synchronization/notification.h new file mode 100644 index 0000000000..9a354ca2c0 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/notification.h @@ -0,0 +1,123 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// notification.h +// ----------------------------------------------------------------------------- +// +// This header file defines a `Notification` abstraction, which allows threads +// to receive notification of a single occurrence of a single event. +// +// The `Notification` object maintains a private boolean "notified" state that +// transitions to `true` at most once. The `Notification` class provides the +// following primary member functions: +// * `HasBeenNotified() `to query its state +// * `WaitForNotification*()` to have threads wait until the "notified" state +// is `true`. +// * `Notify()` to set the notification's "notified" state to `true` and +// notify all waiting threads that the event has occurred. +// This method may only be called once. +// +// Note that while `Notify()` may only be called once, it is perfectly valid to +// call any of the `WaitForNotification*()` methods multiple times, from +// multiple threads -- even after the notification's "notified" state has been +// set -- in which case those methods will immediately return. +// +// Note that the lifetime of a `Notification` requires careful consideration; +// it might not be safe to destroy a notification after calling `Notify()` since +// it is still legal for other threads to call `WaitForNotification*()` methods +// on the notification. However, observers responding to a "notified" state of +// `true` can safely delete the notification without interfering with the call +// to `Notify()` in the other thread. +// +// Memory ordering: For any threads X and Y, if X calls `Notify()`, then any +// action taken by X before it calls `Notify()` is visible to thread Y after: +// * Y returns from `WaitForNotification()`, or +// * Y receives a `true` return value from either `HasBeenNotified()` or +// `WaitForNotificationWithTimeout()`. + +#ifndef ABSL_SYNCHRONIZATION_NOTIFICATION_H_ +#define ABSL_SYNCHRONIZATION_NOTIFICATION_H_ + +#include <atomic> + +#include "absl/base/macros.h" +#include "absl/synchronization/mutex.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// Notification +// ----------------------------------------------------------------------------- +class Notification { + public: + // Initializes the "notified" state to unnotified. + Notification() : notified_yet_(false) {} + explicit Notification(bool prenotify) : notified_yet_(prenotify) {} + Notification(const Notification&) = delete; + Notification& operator=(const Notification&) = delete; + ~Notification(); + + // Notification::HasBeenNotified() + // + // Returns the value of the notification's internal "notified" state. + bool HasBeenNotified() const { + return HasBeenNotifiedInternal(&this->notified_yet_); + } + + // Notification::WaitForNotification() + // + // Blocks the calling thread until the notification's "notified" state is + // `true`. Note that if `Notify()` has been previously called on this + // notification, this function will immediately return. + void WaitForNotification() const; + + // Notification::WaitForNotificationWithTimeout() + // + // Blocks until either the notification's "notified" state is `true` (which + // may occur immediately) or the timeout has elapsed, returning the value of + // its "notified" state in either case. + bool WaitForNotificationWithTimeout(absl::Duration timeout) const; + + // Notification::WaitForNotificationWithDeadline() + // + // Blocks until either the notification's "notified" state is `true` (which + // may occur immediately) or the deadline has expired, returning the value of + // its "notified" state in either case. + bool WaitForNotificationWithDeadline(absl::Time deadline) const; + + // Notification::Notify() + // + // Sets the "notified" state of this notification to `true` and wakes waiting + // threads. Note: do not call `Notify()` multiple times on the same + // `Notification`; calling `Notify()` more than once on the same notification + // results in undefined behavior. + void Notify(); + + private: + static inline bool HasBeenNotifiedInternal( + const std::atomic<bool>* notified_yet) { + return notified_yet->load(std::memory_order_acquire); + } + + mutable Mutex mutex_; + std::atomic<bool> notified_yet_; // written under mutex_ +}; + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_SYNCHRONIZATION_NOTIFICATION_H_ diff --git a/third_party/abseil_cpp/absl/synchronization/notification_test.cc b/third_party/abseil_cpp/absl/synchronization/notification_test.cc new file mode 100644 index 0000000000..100ea76f33 --- /dev/null +++ b/third_party/abseil_cpp/absl/synchronization/notification_test.cc @@ -0,0 +1,133 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/synchronization/notification.h" + +#include <thread> // NOLINT(build/c++11) +#include <vector> + +#include "gtest/gtest.h" +#include "absl/synchronization/mutex.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// A thread-safe class that holds a counter. +class ThreadSafeCounter { + public: + ThreadSafeCounter() : count_(0) {} + + void Increment() { + MutexLock lock(&mutex_); + ++count_; + } + + int Get() const { + MutexLock lock(&mutex_); + return count_; + } + + void WaitUntilGreaterOrEqual(int n) { + MutexLock lock(&mutex_); + auto cond = [this, n]() { return count_ >= n; }; + mutex_.Await(Condition(&cond)); + } + + private: + mutable Mutex mutex_; + int count_; +}; + +// Runs the |i|'th worker thread for the tests in BasicTests(). Increments the +// |ready_counter|, waits on the |notification|, and then increments the +// |done_counter|. +static void RunWorker(int i, ThreadSafeCounter* ready_counter, + Notification* notification, + ThreadSafeCounter* done_counter) { + ready_counter->Increment(); + notification->WaitForNotification(); + done_counter->Increment(); +} + +// Tests that the |notification| properly blocks and awakens threads. Assumes +// that the |notification| is not yet triggered. If |notify_before_waiting| is +// true, the |notification| is triggered before any threads are created, so the +// threads never block in WaitForNotification(). Otherwise, the |notification| +// is triggered at a later point when most threads are likely to be blocking in +// WaitForNotification(). +static void BasicTests(bool notify_before_waiting, Notification* notification) { + EXPECT_FALSE(notification->HasBeenNotified()); + EXPECT_FALSE( + notification->WaitForNotificationWithTimeout(absl::Milliseconds(0))); + EXPECT_FALSE(notification->WaitForNotificationWithDeadline(absl::Now())); + + const absl::Duration delay = absl::Milliseconds(50); + const absl::Time start = absl::Now(); + EXPECT_FALSE(notification->WaitForNotificationWithTimeout(delay)); + const absl::Duration elapsed = absl::Now() - start; + + // Allow for a slight early return, to account for quality of implementation + // issues on various platforms. + const absl::Duration slop = absl::Microseconds(200); + EXPECT_LE(delay - slop, elapsed) + << "WaitForNotificationWithTimeout returned " << delay - elapsed + << " early (with " << slop << " slop), start time was " << start; + + ThreadSafeCounter ready_counter; + ThreadSafeCounter done_counter; + + if (notify_before_waiting) { + notification->Notify(); + } + + // Create a bunch of threads that increment the |done_counter| after being + // notified. + const int kNumThreads = 10; + std::vector<std::thread> workers; + for (int i = 0; i < kNumThreads; ++i) { + workers.push_back(std::thread(&RunWorker, i, &ready_counter, notification, + &done_counter)); + } + + if (!notify_before_waiting) { + ready_counter.WaitUntilGreaterOrEqual(kNumThreads); + + // Workers have not been notified yet, so the |done_counter| should be + // unmodified. + EXPECT_EQ(0, done_counter.Get()); + + notification->Notify(); + } + + // After notifying and then joining the workers, both counters should be + // fully incremented. + notification->WaitForNotification(); // should exit immediately + EXPECT_TRUE(notification->HasBeenNotified()); + EXPECT_TRUE(notification->WaitForNotificationWithTimeout(absl::Seconds(0))); + EXPECT_TRUE(notification->WaitForNotificationWithDeadline(absl::Now())); + for (std::thread& worker : workers) { + worker.join(); + } + EXPECT_EQ(kNumThreads, ready_counter.Get()); + EXPECT_EQ(kNumThreads, done_counter.Get()); +} + +TEST(NotificationTest, SanityTest) { + Notification local_notification1, local_notification2; + BasicTests(false, &local_notification1); + BasicTests(true, &local_notification2); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/BUILD.bazel b/third_party/abseil_cpp/absl/time/BUILD.bazel new file mode 100644 index 0000000000..9ab2adb886 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/BUILD.bazel @@ -0,0 +1,124 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "time", + srcs = [ + "civil_time.cc", + "clock.cc", + "duration.cc", + "format.cc", + "internal/get_current_time_chrono.inc", + "internal/get_current_time_posix.inc", + "time.cc", + ], + hdrs = [ + "civil_time.h", + "clock.h", + "time.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base", + "//absl/base:core_headers", + "//absl/base:raw_logging_internal", + "//absl/numeric:int128", + "//absl/strings", + "//absl/time/internal/cctz:civil_time", + "//absl/time/internal/cctz:time_zone", + ], +) + +cc_library( + name = "test_util", + testonly = 1, + srcs = [ + "internal/test_util.cc", + "internal/zoneinfo.inc", + ], + hdrs = ["internal/test_util.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = [ + "//absl/time:__pkg__", + ], + deps = [ + ":time", + "//absl/base:raw_logging_internal", + "//absl/time/internal/cctz:time_zone", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "time_test", + srcs = [ + "civil_time_test.cc", + "clock_test.cc", + "duration_test.cc", + "format_test.cc", + "time_test.cc", + "time_zone_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":test_util", + ":time", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/numeric:int128", + "//absl/time/internal/cctz:time_zone", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "time_benchmark", + srcs = [ + "civil_time_benchmark.cc", + "clock_benchmark.cc", + "duration_benchmark.cc", + "format_benchmark.cc", + "time_benchmark.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = [ + "benchmark", + ], + deps = [ + ":test_util", + ":time", + "//absl/base", + "//absl/base:core_headers", + "//absl/hash", + "@com_github_google_benchmark//:benchmark_main", + ], +) diff --git a/third_party/abseil_cpp/absl/time/CMakeLists.txt b/third_party/abseil_cpp/absl/time/CMakeLists.txt new file mode 100644 index 0000000000..853563e875 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/CMakeLists.txt @@ -0,0 +1,127 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + time + HDRS + "civil_time.h" + "clock.h" + "time.h" + SRCS + "civil_time.cc" + "clock.cc" + "duration.cc" + "format.cc" + "internal/get_current_time_chrono.inc" + "internal/get_current_time_posix.inc" + "time.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base + absl::civil_time + absl::core_headers + absl::int128 + absl::raw_logging_internal + absl::strings + absl::time_zone + PUBLIC +) + +absl_cc_library( + NAME + civil_time + HDRS + "internal/cctz/include/cctz/civil_time.h" + "internal/cctz/include/cctz/civil_time_detail.h" + SRCS + "internal/cctz/src/civil_time_detail.cc" + COPTS + ${ABSL_DEFAULT_COPTS} +) + +if(APPLE) + find_library(CoreFoundation CoreFoundation) +endif() + +absl_cc_library( + NAME + time_zone + HDRS + "internal/cctz/include/cctz/time_zone.h" + "internal/cctz/include/cctz/zone_info_source.h" + SRCS + "internal/cctz/src/time_zone_fixed.cc" + "internal/cctz/src/time_zone_fixed.h" + "internal/cctz/src/time_zone_format.cc" + "internal/cctz/src/time_zone_if.cc" + "internal/cctz/src/time_zone_if.h" + "internal/cctz/src/time_zone_impl.cc" + "internal/cctz/src/time_zone_impl.h" + "internal/cctz/src/time_zone_info.cc" + "internal/cctz/src/time_zone_info.h" + "internal/cctz/src/time_zone_libc.cc" + "internal/cctz/src/time_zone_libc.h" + "internal/cctz/src/time_zone_lookup.cc" + "internal/cctz/src/time_zone_posix.cc" + "internal/cctz/src/time_zone_posix.h" + "internal/cctz/src/tzfile.h" + "internal/cctz/src/zone_info_source.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + $<$<PLATFORM_ID:Darwin>:${CoreFoundation}> +) + +absl_cc_library( + NAME + time_internal_test_util + HDRS + "internal/test_util.h" + SRCS + "internal/test_util.cc" + "internal/zoneinfo.inc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::time + absl::raw_logging_internal + absl::time_zone + gmock + TESTONLY +) + +absl_cc_test( + NAME + time_test + SRCS + "civil_time_test.cc" + "clock_test.cc" + "duration_test.cc" + "format_test.cc" + "time_test.cc" + "time_zone_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::time_internal_test_util + absl::time + absl::config + absl::core_headers + absl::time_zone + gmock_main +) diff --git a/third_party/abseil_cpp/absl/time/civil_time.cc b/third_party/abseil_cpp/absl/time/civil_time.cc new file mode 100644 index 0000000000..c4202c7399 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/civil_time.cc @@ -0,0 +1,175 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/civil_time.h" + +#include <cstdlib> +#include <string> + +#include "absl/strings/str_cat.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +// Since a civil time has a larger year range than absl::Time (64-bit years vs +// 64-bit seconds, respectively) we normalize years to roughly +/- 400 years +// around the year 2400, which will produce an equivalent year in a range that +// absl::Time can handle. +inline civil_year_t NormalizeYear(civil_year_t year) { + return 2400 + year % 400; +} + +// Formats the given CivilSecond according to the given format. +std::string FormatYearAnd(string_view fmt, CivilSecond cs) { + const CivilSecond ncs(NormalizeYear(cs.year()), cs.month(), cs.day(), + cs.hour(), cs.minute(), cs.second()); + const TimeZone utc = UTCTimeZone(); + // TODO(absl-team): Avoid conversion of fmt string. + return StrCat(cs.year(), + FormatTime(std::string(fmt), FromCivil(ncs, utc), utc)); +} + +template <typename CivilT> +bool ParseYearAnd(string_view fmt, string_view s, CivilT* c) { + // Civil times support a larger year range than absl::Time, so we need to + // parse the year separately, normalize it, then use absl::ParseTime on the + // normalized string. + const std::string ss = std::string(s); // TODO(absl-team): Avoid conversion. + const char* const np = ss.c_str(); + char* endp; + errno = 0; + const civil_year_t y = + std::strtoll(np, &endp, 10); // NOLINT(runtime/deprecated_fn) + if (endp == np || errno == ERANGE) return false; + const std::string norm = StrCat(NormalizeYear(y), endp); + + const TimeZone utc = UTCTimeZone(); + Time t; + if (ParseTime(StrCat("%Y", fmt), norm, utc, &t, nullptr)) { + const auto cs = ToCivilSecond(t, utc); + *c = CivilT(y, cs.month(), cs.day(), cs.hour(), cs.minute(), cs.second()); + return true; + } + + return false; +} + +// Tries to parse the type as a CivilT1, but then assigns the result to the +// argument of type CivilT2. +template <typename CivilT1, typename CivilT2> +bool ParseAs(string_view s, CivilT2* c) { + CivilT1 t1; + if (ParseCivilTime(s, &t1)) { + *c = CivilT2(t1); + return true; + } + return false; +} + +template <typename CivilT> +bool ParseLenient(string_view s, CivilT* c) { + // A fastpath for when the given string data parses exactly into the given + // type T (e.g., s="YYYY-MM-DD" and CivilT=CivilDay). + if (ParseCivilTime(s, c)) return true; + // Try parsing as each of the 6 types, trying the most common types first + // (based on csearch results). + if (ParseAs<CivilDay>(s, c)) return true; + if (ParseAs<CivilSecond>(s, c)) return true; + if (ParseAs<CivilHour>(s, c)) return true; + if (ParseAs<CivilMonth>(s, c)) return true; + if (ParseAs<CivilMinute>(s, c)) return true; + if (ParseAs<CivilYear>(s, c)) return true; + return false; +} +} // namespace + +std::string FormatCivilTime(CivilSecond c) { + return FormatYearAnd("-%m-%dT%H:%M:%S", c); +} +std::string FormatCivilTime(CivilMinute c) { + return FormatYearAnd("-%m-%dT%H:%M", c); +} +std::string FormatCivilTime(CivilHour c) { + return FormatYearAnd("-%m-%dT%H", c); +} +std::string FormatCivilTime(CivilDay c) { return FormatYearAnd("-%m-%d", c); } +std::string FormatCivilTime(CivilMonth c) { return FormatYearAnd("-%m", c); } +std::string FormatCivilTime(CivilYear c) { return FormatYearAnd("", c); } + +bool ParseCivilTime(string_view s, CivilSecond* c) { + return ParseYearAnd("-%m-%dT%H:%M:%S", s, c); +} +bool ParseCivilTime(string_view s, CivilMinute* c) { + return ParseYearAnd("-%m-%dT%H:%M", s, c); +} +bool ParseCivilTime(string_view s, CivilHour* c) { + return ParseYearAnd("-%m-%dT%H", s, c); +} +bool ParseCivilTime(string_view s, CivilDay* c) { + return ParseYearAnd("-%m-%d", s, c); +} +bool ParseCivilTime(string_view s, CivilMonth* c) { + return ParseYearAnd("-%m", s, c); +} +bool ParseCivilTime(string_view s, CivilYear* c) { + return ParseYearAnd("", s, c); +} + +bool ParseLenientCivilTime(string_view s, CivilSecond* c) { + return ParseLenient(s, c); +} +bool ParseLenientCivilTime(string_view s, CivilMinute* c) { + return ParseLenient(s, c); +} +bool ParseLenientCivilTime(string_view s, CivilHour* c) { + return ParseLenient(s, c); +} +bool ParseLenientCivilTime(string_view s, CivilDay* c) { + return ParseLenient(s, c); +} +bool ParseLenientCivilTime(string_view s, CivilMonth* c) { + return ParseLenient(s, c); +} +bool ParseLenientCivilTime(string_view s, CivilYear* c) { + return ParseLenient(s, c); +} + +namespace time_internal { + +std::ostream& operator<<(std::ostream& os, CivilYear y) { + return os << FormatCivilTime(y); +} +std::ostream& operator<<(std::ostream& os, CivilMonth m) { + return os << FormatCivilTime(m); +} +std::ostream& operator<<(std::ostream& os, CivilDay d) { + return os << FormatCivilTime(d); +} +std::ostream& operator<<(std::ostream& os, CivilHour h) { + return os << FormatCivilTime(h); +} +std::ostream& operator<<(std::ostream& os, CivilMinute m) { + return os << FormatCivilTime(m); +} +std::ostream& operator<<(std::ostream& os, CivilSecond s) { + return os << FormatCivilTime(s); +} + +} // namespace time_internal + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/civil_time.h b/third_party/abseil_cpp/absl/time/civil_time.h new file mode 100644 index 0000000000..bb46004434 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/civil_time.h @@ -0,0 +1,538 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: civil_time.h +// ----------------------------------------------------------------------------- +// +// This header file defines abstractions for computing with "civil time". +// The term "civil time" refers to the legally recognized human-scale time +// that is represented by the six fields `YYYY-MM-DD hh:mm:ss`. A "date" +// is perhaps the most common example of a civil time (represented here as +// an `absl::CivilDay`). +// +// Modern-day civil time follows the Gregorian Calendar and is a +// time-zone-independent concept: a civil time of "2015-06-01 12:00:00", for +// example, is not tied to a time zone. Put another way, a civil time does not +// map to a unique point in time; a civil time must be mapped to an absolute +// time *through* a time zone. +// +// Because a civil time is what most people think of as "time," it is common to +// map absolute times to civil times to present to users. +// +// Time zones define the relationship between absolute and civil times. Given an +// absolute or civil time and a time zone, you can compute the other time: +// +// Civil Time = F(Absolute Time, Time Zone) +// Absolute Time = G(Civil Time, Time Zone) +// +// The Abseil time library allows you to construct such civil times from +// absolute times; consult time.h for such functionality. +// +// This library provides six classes for constructing civil-time objects, and +// provides several helper functions for rounding, iterating, and performing +// arithmetic on civil-time objects, while avoiding complications like +// daylight-saving time (DST): +// +// * `absl::CivilSecond` +// * `absl::CivilMinute` +// * `absl::CivilHour` +// * `absl::CivilDay` +// * `absl::CivilMonth` +// * `absl::CivilYear` +// +// Example: +// +// // Construct a civil-time object for a specific day +// const absl::CivilDay cd(1969, 07, 20); +// +// // Construct a civil-time object for a specific second +// const absl::CivilSecond cd(2018, 8, 1, 12, 0, 1); +// +// Note: In C++14 and later, this library is usable in a constexpr context. +// +// Example: +// +// // Valid in C++14 +// constexpr absl::CivilDay cd(1969, 07, 20); + +#ifndef ABSL_TIME_CIVIL_TIME_H_ +#define ABSL_TIME_CIVIL_TIME_H_ + +#include <string> + +#include "absl/strings/string_view.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace time_internal { +struct second_tag : cctz::detail::second_tag {}; +struct minute_tag : second_tag, cctz::detail::minute_tag {}; +struct hour_tag : minute_tag, cctz::detail::hour_tag {}; +struct day_tag : hour_tag, cctz::detail::day_tag {}; +struct month_tag : day_tag, cctz::detail::month_tag {}; +struct year_tag : month_tag, cctz::detail::year_tag {}; +} // namespace time_internal + +// ----------------------------------------------------------------------------- +// CivilSecond, CivilMinute, CivilHour, CivilDay, CivilMonth, CivilYear +// ----------------------------------------------------------------------------- +// +// Each of these civil-time types is a simple value type with the same +// interface for construction and the same six accessors for each of the civil +// time fields (year, month, day, hour, minute, and second, aka YMDHMS). These +// classes differ only in their alignment, which is indicated by the type name +// and specifies the field on which arithmetic operates. +// +// CONSTRUCTION +// +// Each of the civil-time types can be constructed in two ways: by directly +// passing to the constructor up to six integers representing the YMDHMS fields, +// or by copying the YMDHMS fields from a differently aligned civil-time type. +// Omitted fields are assigned their minimum valid value. Hours, minutes, and +// seconds will be set to 0, month and day will be set to 1. Since there is no +// minimum year, the default is 1970. +// +// Examples: +// +// absl::CivilDay default_value; // 1970-01-01 00:00:00 +// +// absl::CivilDay a(2015, 2, 3); // 2015-02-03 00:00:00 +// absl::CivilDay b(2015, 2, 3, 4, 5, 6); // 2015-02-03 00:00:00 +// absl::CivilDay c(2015); // 2015-01-01 00:00:00 +// +// absl::CivilSecond ss(2015, 2, 3, 4, 5, 6); // 2015-02-03 04:05:06 +// absl::CivilMinute mm(ss); // 2015-02-03 04:05:00 +// absl::CivilHour hh(mm); // 2015-02-03 04:00:00 +// absl::CivilDay d(hh); // 2015-02-03 00:00:00 +// absl::CivilMonth m(d); // 2015-02-01 00:00:00 +// absl::CivilYear y(m); // 2015-01-01 00:00:00 +// +// m = absl::CivilMonth(y); // 2015-01-01 00:00:00 +// d = absl::CivilDay(m); // 2015-01-01 00:00:00 +// hh = absl::CivilHour(d); // 2015-01-01 00:00:00 +// mm = absl::CivilMinute(hh); // 2015-01-01 00:00:00 +// ss = absl::CivilSecond(mm); // 2015-01-01 00:00:00 +// +// Each civil-time class is aligned to the civil-time field indicated in the +// class's name after normalization. Alignment is performed by setting all the +// inferior fields to their minimum valid value (as described above). The +// following are examples of how each of the six types would align the fields +// representing November 22, 2015 at 12:34:56 in the afternoon. (Note: the +// string format used here is not important; it's just a shorthand way of +// showing the six YMDHMS fields.) +// +// absl::CivilSecond : 2015-11-22 12:34:56 +// absl::CivilMinute : 2015-11-22 12:34:00 +// absl::CivilHour : 2015-11-22 12:00:00 +// absl::CivilDay : 2015-11-22 00:00:00 +// absl::CivilMonth : 2015-11-01 00:00:00 +// absl::CivilYear : 2015-01-01 00:00:00 +// +// Each civil-time type performs arithmetic on the field to which it is +// aligned. This means that adding 1 to an absl::CivilDay increments the day +// field (normalizing as necessary), and subtracting 7 from an absl::CivilMonth +// operates on the month field (normalizing as necessary). All arithmetic +// produces a valid civil time. Difference requires two similarly aligned +// civil-time objects and returns the scalar answer in units of the objects' +// alignment. For example, the difference between two absl::CivilHour objects +// will give an answer in units of civil hours. +// +// ALIGNMENT CONVERSION +// +// The alignment of a civil-time object cannot change, but the object may be +// used to construct a new object with a different alignment. This is referred +// to as "realigning". When realigning to a type with the same or more +// precision (e.g., absl::CivilDay -> absl::CivilSecond), the conversion may be +// performed implicitly since no information is lost. However, if information +// could be discarded (e.g., CivilSecond -> CivilDay), the conversion must +// be explicit at the call site. +// +// Examples: +// +// void UseDay(absl::CivilDay day); +// +// absl::CivilSecond cs; +// UseDay(cs); // Won't compile because data may be discarded +// UseDay(absl::CivilDay(cs)); // OK: explicit conversion +// +// absl::CivilDay cd; +// UseDay(cd); // OK: no conversion needed +// +// absl::CivilMonth cm; +// UseDay(cm); // OK: implicit conversion to absl::CivilDay +// +// NORMALIZATION +// +// Normalization takes invalid values and adjusts them to produce valid values. +// Within the civil-time library, integer arguments passed to the Civil* +// constructors may be out-of-range, in which case they are normalized by +// carrying overflow into a field of courser granularity to produce valid +// civil-time objects. This normalization enables natural arithmetic on +// constructor arguments without worrying about the field's range. +// +// Examples: +// +// // Out-of-range; normalized to 2016-11-01 +// absl::CivilDay d(2016, 10, 32); +// // Out-of-range, negative: normalized to 2016-10-30T23 +// absl::CivilHour h1(2016, 10, 31, -1); +// // Normalization is cumulative: normalized to 2016-10-30T23 +// absl::CivilHour h2(2016, 10, 32, -25); +// +// Note: If normalization is undesired, you can signal an error by comparing +// the constructor arguments to the normalized values returned by the YMDHMS +// properties. +// +// COMPARISON +// +// Comparison between civil-time objects considers all six YMDHMS fields, +// regardless of the type's alignment. Comparison between differently aligned +// civil-time types is allowed. +// +// Examples: +// +// absl::CivilDay feb_3(2015, 2, 3); // 2015-02-03 00:00:00 +// absl::CivilDay mar_4(2015, 3, 4); // 2015-03-04 00:00:00 +// // feb_3 < mar_4 +// // absl::CivilYear(feb_3) == absl::CivilYear(mar_4) +// +// absl::CivilSecond feb_3_noon(2015, 2, 3, 12, 0, 0); // 2015-02-03 12:00:00 +// // feb_3 < feb_3_noon +// // feb_3 == absl::CivilDay(feb_3_noon) +// +// // Iterates all the days of February 2015. +// for (absl::CivilDay d(2015, 2, 1); d < absl::CivilMonth(2015, 3); ++d) { +// // ... +// } +// +// ARITHMETIC +// +// Civil-time types support natural arithmetic operators such as addition, +// subtraction, and difference. Arithmetic operates on the civil-time field +// indicated in the type's name. Difference operators require arguments with +// the same alignment and return the answer in units of the alignment. +// +// Example: +// +// absl::CivilDay a(2015, 2, 3); +// ++a; // 2015-02-04 00:00:00 +// --a; // 2015-02-03 00:00:00 +// absl::CivilDay b = a + 1; // 2015-02-04 00:00:00 +// absl::CivilDay c = 1 + b; // 2015-02-05 00:00:00 +// int n = c - a; // n = 2 (civil days) +// int m = c - absl::CivilMonth(c); // Won't compile: different types. +// +// ACCESSORS +// +// Each civil-time type has accessors for all six of the civil-time fields: +// year, month, day, hour, minute, and second. +// +// civil_year_t year() +// int month() +// int day() +// int hour() +// int minute() +// int second() +// +// Recall that fields inferior to the type's alignment will be set to their +// minimum valid value. +// +// Example: +// +// absl::CivilDay d(2015, 6, 28); +// // d.year() == 2015 +// // d.month() == 6 +// // d.day() == 28 +// // d.hour() == 0 +// // d.minute() == 0 +// // d.second() == 0 +// +// CASE STUDY: Adding a month to January 31. +// +// One of the classic questions that arises when considering a civil time +// library (or a date library or a date/time library) is this: +// "What is the result of adding a month to January 31?" +// This is an interesting question because it is unclear what is meant by a +// "month", and several different answers are possible, depending on context: +// +// 1. March 3 (or 2 if a leap year), if "add a month" means to add a month to +// the current month, and adjust the date to overflow the extra days into +// March. In this case the result of "February 31" would be normalized as +// within the civil-time library. +// 2. February 28 (or 29 if a leap year), if "add a month" means to add a +// month, and adjust the date while holding the resulting month constant. +// In this case, the result of "February 31" would be truncated to the last +// day in February. +// 3. An error. The caller may get some error, an exception, an invalid date +// object, or perhaps return `false`. This may make sense because there is +// no single unambiguously correct answer to the question. +// +// Practically speaking, any answer that is not what the programmer intended +// is the wrong answer. +// +// The Abseil time library avoids this problem by making it impossible to +// ask ambiguous questions. All civil-time objects are aligned to a particular +// civil-field boundary (such as aligned to a year, month, day, hour, minute, +// or second), and arithmetic operates on the field to which the object is +// aligned. This means that in order to "add a month" the object must first be +// aligned to a month boundary, which is equivalent to the first day of that +// month. +// +// Of course, there are ways to compute an answer the question at hand using +// this Abseil time library, but they require the programmer to be explicit +// about the answer they expect. To illustrate, let's see how to compute all +// three of the above possible answers to the question of "Jan 31 plus 1 +// month": +// +// Example: +// +// const absl::CivilDay d(2015, 1, 31); +// +// // Answer 1: +// // Add 1 to the month field in the constructor, and rely on normalization. +// const auto normalized = absl::CivilDay(d.year(), d.month() + 1, d.day()); +// // normalized == 2015-03-03 (aka Feb 31) +// +// // Answer 2: +// // Add 1 to month field, capping to the end of next month. +// const auto next_month = absl::CivilMonth(d) + 1; +// const auto last_day_of_next_month = absl::CivilDay(next_month + 1) - 1; +// const auto capped = std::min(normalized, last_day_of_next_month); +// // capped == 2015-02-28 +// +// // Answer 3: +// // Signal an error if the normalized answer is not in next month. +// if (absl::CivilMonth(normalized) != next_month) { +// // error, month overflow +// } +// +using CivilSecond = + time_internal::cctz::detail::civil_time<time_internal::second_tag>; +using CivilMinute = + time_internal::cctz::detail::civil_time<time_internal::minute_tag>; +using CivilHour = + time_internal::cctz::detail::civil_time<time_internal::hour_tag>; +using CivilDay = + time_internal::cctz::detail::civil_time<time_internal::day_tag>; +using CivilMonth = + time_internal::cctz::detail::civil_time<time_internal::month_tag>; +using CivilYear = + time_internal::cctz::detail::civil_time<time_internal::year_tag>; + +// civil_year_t +// +// Type alias of a civil-time year value. This type is guaranteed to (at least) +// support any year value supported by `time_t`. +// +// Example: +// +// absl::CivilSecond cs = ...; +// absl::civil_year_t y = cs.year(); +// cs = absl::CivilSecond(y, 1, 1, 0, 0, 0); // CivilSecond(CivilYear(cs)) +// +using civil_year_t = time_internal::cctz::year_t; + +// civil_diff_t +// +// Type alias of the difference between two civil-time values. +// This type is used to indicate arguments that are not +// normalized (such as parameters to the civil-time constructors), the results +// of civil-time subtraction, or the operand to civil-time addition. +// +// Example: +// +// absl::civil_diff_t n_sec = cs1 - cs2; // cs1 == cs2 + n_sec; +// +using civil_diff_t = time_internal::cctz::diff_t; + +// Weekday::monday, Weekday::tuesday, Weekday::wednesday, Weekday::thursday, +// Weekday::friday, Weekday::saturday, Weekday::sunday +// +// The Weekday enum class represents the civil-time concept of a "weekday" with +// members for all days of the week. +// +// absl::Weekday wd = absl::Weekday::thursday; +// +using Weekday = time_internal::cctz::weekday; + +// GetWeekday() +// +// Returns the absl::Weekday for the given (realigned) civil-time value. +// +// Example: +// +// absl::CivilDay a(2015, 8, 13); +// absl::Weekday wd = absl::GetWeekday(a); // wd == absl::Weekday::thursday +// +inline Weekday GetWeekday(CivilSecond cs) { + return time_internal::cctz::get_weekday(cs); +} + +// NextWeekday() +// PrevWeekday() +// +// Returns the absl::CivilDay that strictly follows or precedes a given +// absl::CivilDay, and that falls on the given absl::Weekday. +// +// Example, given the following month: +// +// August 2015 +// Su Mo Tu We Th Fr Sa +// 1 +// 2 3 4 5 6 7 8 +// 9 10 11 12 13 14 15 +// 16 17 18 19 20 21 22 +// 23 24 25 26 27 28 29 +// 30 31 +// +// absl::CivilDay a(2015, 8, 13); +// // absl::GetWeekday(a) == absl::Weekday::thursday +// absl::CivilDay b = absl::NextWeekday(a, absl::Weekday::thursday); +// // b = 2015-08-20 +// absl::CivilDay c = absl::PrevWeekday(a, absl::Weekday::thursday); +// // c = 2015-08-06 +// +// absl::CivilDay d = ... +// // Gets the following Thursday if d is not already Thursday +// absl::CivilDay thurs1 = absl::NextWeekday(d - 1, absl::Weekday::thursday); +// // Gets the previous Thursday if d is not already Thursday +// absl::CivilDay thurs2 = absl::PrevWeekday(d + 1, absl::Weekday::thursday); +// +inline CivilDay NextWeekday(CivilDay cd, Weekday wd) { + return CivilDay(time_internal::cctz::next_weekday(cd, wd)); +} +inline CivilDay PrevWeekday(CivilDay cd, Weekday wd) { + return CivilDay(time_internal::cctz::prev_weekday(cd, wd)); +} + +// GetYearDay() +// +// Returns the day-of-year for the given (realigned) civil-time value. +// +// Example: +// +// absl::CivilDay a(2015, 1, 1); +// int yd_jan_1 = absl::GetYearDay(a); // yd_jan_1 = 1 +// absl::CivilDay b(2015, 12, 31); +// int yd_dec_31 = absl::GetYearDay(b); // yd_dec_31 = 365 +// +inline int GetYearDay(CivilSecond cs) { + return time_internal::cctz::get_yearday(cs); +} + +// FormatCivilTime() +// +// Formats the given civil-time value into a string value of the following +// format: +// +// Type | Format +// --------------------------------- +// CivilSecond | YYYY-MM-DDTHH:MM:SS +// CivilMinute | YYYY-MM-DDTHH:MM +// CivilHour | YYYY-MM-DDTHH +// CivilDay | YYYY-MM-DD +// CivilMonth | YYYY-MM +// CivilYear | YYYY +// +// Example: +// +// absl::CivilDay d = absl::CivilDay(1969, 7, 20); +// std::string day_string = absl::FormatCivilTime(d); // "1969-07-20" +// +std::string FormatCivilTime(CivilSecond c); +std::string FormatCivilTime(CivilMinute c); +std::string FormatCivilTime(CivilHour c); +std::string FormatCivilTime(CivilDay c); +std::string FormatCivilTime(CivilMonth c); +std::string FormatCivilTime(CivilYear c); + +// absl::ParseCivilTime() +// +// Parses a civil-time value from the specified `absl::string_view` into the +// passed output parameter. Returns `true` upon successful parsing. +// +// The expected form of the input string is as follows: +// +// Type | Format +// --------------------------------- +// CivilSecond | YYYY-MM-DDTHH:MM:SS +// CivilMinute | YYYY-MM-DDTHH:MM +// CivilHour | YYYY-MM-DDTHH +// CivilDay | YYYY-MM-DD +// CivilMonth | YYYY-MM +// CivilYear | YYYY +// +// Example: +// +// absl::CivilDay d; +// bool ok = absl::ParseCivilTime("2018-01-02", &d); // OK +// +// Note that parsing will fail if the string's format does not match the +// expected type exactly. `ParseLenientCivilTime()` below is more lenient. +// +bool ParseCivilTime(absl::string_view s, CivilSecond* c); +bool ParseCivilTime(absl::string_view s, CivilMinute* c); +bool ParseCivilTime(absl::string_view s, CivilHour* c); +bool ParseCivilTime(absl::string_view s, CivilDay* c); +bool ParseCivilTime(absl::string_view s, CivilMonth* c); +bool ParseCivilTime(absl::string_view s, CivilYear* c); + +// ParseLenientCivilTime() +// +// Parses any of the formats accepted by `absl::ParseCivilTime()`, but is more +// lenient if the format of the string does not exactly match the associated +// type. +// +// Example: +// +// absl::CivilDay d; +// bool ok = absl::ParseLenientCivilTime("1969-07-20", &d); // OK +// ok = absl::ParseLenientCivilTime("1969-07-20T10", &d); // OK: T10 floored +// ok = absl::ParseLenientCivilTime("1969-07", &d); // OK: day defaults to 1 +// +bool ParseLenientCivilTime(absl::string_view s, CivilSecond* c); +bool ParseLenientCivilTime(absl::string_view s, CivilMinute* c); +bool ParseLenientCivilTime(absl::string_view s, CivilHour* c); +bool ParseLenientCivilTime(absl::string_view s, CivilDay* c); +bool ParseLenientCivilTime(absl::string_view s, CivilMonth* c); +bool ParseLenientCivilTime(absl::string_view s, CivilYear* c); + +namespace time_internal { // For functions found via ADL on civil-time tags. + +// Streaming Operators +// +// Each civil-time type may be sent to an output stream using operator<<(). +// The result matches the string produced by `FormatCivilTime()`. +// +// Example: +// +// absl::CivilDay d = absl::CivilDay(1969, 7, 20); +// std::cout << "Date is: " << d << "\n"; +// +std::ostream& operator<<(std::ostream& os, CivilYear y); +std::ostream& operator<<(std::ostream& os, CivilMonth m); +std::ostream& operator<<(std::ostream& os, CivilDay d); +std::ostream& operator<<(std::ostream& os, CivilHour h); +std::ostream& operator<<(std::ostream& os, CivilMinute m); +std::ostream& operator<<(std::ostream& os, CivilSecond s); + +} // namespace time_internal + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_CIVIL_TIME_H_ diff --git a/third_party/abseil_cpp/absl/time/civil_time_benchmark.cc b/third_party/abseil_cpp/absl/time/civil_time_benchmark.cc new file mode 100644 index 0000000000..f04dbe200e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/civil_time_benchmark.cc @@ -0,0 +1,127 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/civil_time.h" + +#include <numeric> +#include <vector> + +#include "absl/hash/hash.h" +#include "benchmark/benchmark.h" + +namespace { + +// Run on (12 X 3492 MHz CPUs); 2018-11-05T13:44:29.814239103-08:00 +// CPU: Intel Haswell with HyperThreading (6 cores) dL1:32KB dL2:256KB dL3:15MB +// Benchmark Time(ns) CPU(ns) Iterations +// ---------------------------------------------------------------- +// BM_Difference_Days 14.5 14.5 48531105 +// BM_Step_Days 12.6 12.6 54876006 +// BM_Format 587 587 1000000 +// BM_Parse 692 692 1000000 +// BM_RoundTripFormatParse 1309 1309 532075 +// BM_CivilYearAbslHash 0.710 0.710 976400000 +// BM_CivilMonthAbslHash 1.13 1.13 619500000 +// BM_CivilDayAbslHash 1.70 1.70 426000000 +// BM_CivilHourAbslHash 2.45 2.45 287600000 +// BM_CivilMinuteAbslHash 3.21 3.21 226200000 +// BM_CivilSecondAbslHash 4.10 4.10 171800000 + +void BM_Difference_Days(benchmark::State& state) { + const absl::CivilDay c(2014, 8, 22); + const absl::CivilDay epoch(1970, 1, 1); + while (state.KeepRunning()) { + const absl::civil_diff_t n = c - epoch; + benchmark::DoNotOptimize(n); + } +} +BENCHMARK(BM_Difference_Days); + +void BM_Step_Days(benchmark::State& state) { + const absl::CivilDay kStart(2014, 8, 22); + absl::CivilDay c = kStart; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(++c); + } +} +BENCHMARK(BM_Step_Days); + +void BM_Format(benchmark::State& state) { + const absl::CivilSecond c(2014, 1, 2, 3, 4, 5); + while (state.KeepRunning()) { + const std::string s = absl::FormatCivilTime(c); + benchmark::DoNotOptimize(s); + } +} +BENCHMARK(BM_Format); + +void BM_Parse(benchmark::State& state) { + const std::string f = "2014-01-02T03:04:05"; + absl::CivilSecond c; + while (state.KeepRunning()) { + const bool b = absl::ParseCivilTime(f, &c); + benchmark::DoNotOptimize(b); + } +} +BENCHMARK(BM_Parse); + +void BM_RoundTripFormatParse(benchmark::State& state) { + const absl::CivilSecond c(2014, 1, 2, 3, 4, 5); + absl::CivilSecond out; + while (state.KeepRunning()) { + const bool b = absl::ParseCivilTime(absl::FormatCivilTime(c), &out); + benchmark::DoNotOptimize(b); + } +} +BENCHMARK(BM_RoundTripFormatParse); + +template <typename T> +void BM_CivilTimeAbslHash(benchmark::State& state) { + const int kSize = 100000; + std::vector<T> civil_times(kSize); + std::iota(civil_times.begin(), civil_times.end(), T(2018)); + + absl::Hash<T> absl_hasher; + while (state.KeepRunningBatch(kSize)) { + for (const T civil_time : civil_times) { + benchmark::DoNotOptimize(absl_hasher(civil_time)); + } + } +} +void BM_CivilYearAbslHash(benchmark::State& state) { + BM_CivilTimeAbslHash<absl::CivilYear>(state); +} +void BM_CivilMonthAbslHash(benchmark::State& state) { + BM_CivilTimeAbslHash<absl::CivilMonth>(state); +} +void BM_CivilDayAbslHash(benchmark::State& state) { + BM_CivilTimeAbslHash<absl::CivilDay>(state); +} +void BM_CivilHourAbslHash(benchmark::State& state) { + BM_CivilTimeAbslHash<absl::CivilHour>(state); +} +void BM_CivilMinuteAbslHash(benchmark::State& state) { + BM_CivilTimeAbslHash<absl::CivilMinute>(state); +} +void BM_CivilSecondAbslHash(benchmark::State& state) { + BM_CivilTimeAbslHash<absl::CivilSecond>(state); +} +BENCHMARK(BM_CivilYearAbslHash); +BENCHMARK(BM_CivilMonthAbslHash); +BENCHMARK(BM_CivilDayAbslHash); +BENCHMARK(BM_CivilHourAbslHash); +BENCHMARK(BM_CivilMinuteAbslHash); +BENCHMARK(BM_CivilSecondAbslHash); + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/civil_time_test.cc b/third_party/abseil_cpp/absl/time/civil_time_test.cc new file mode 100644 index 0000000000..0ebd97adbc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/civil_time_test.cc @@ -0,0 +1,1243 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/civil_time.h" + +#include <limits> +#include <sstream> +#include <type_traits> + +#include "absl/base/macros.h" +#include "gtest/gtest.h" + +namespace { + +TEST(CivilTime, DefaultConstruction) { + absl::CivilSecond ss; + EXPECT_EQ("1970-01-01T00:00:00", absl::FormatCivilTime(ss)); + + absl::CivilMinute mm; + EXPECT_EQ("1970-01-01T00:00", absl::FormatCivilTime(mm)); + + absl::CivilHour hh; + EXPECT_EQ("1970-01-01T00", absl::FormatCivilTime(hh)); + + absl::CivilDay d; + EXPECT_EQ("1970-01-01", absl::FormatCivilTime(d)); + + absl::CivilMonth m; + EXPECT_EQ("1970-01", absl::FormatCivilTime(m)); + + absl::CivilYear y; + EXPECT_EQ("1970", absl::FormatCivilTime(y)); +} + +TEST(CivilTime, StructMember) { + struct S { + absl::CivilDay day; + }; + S s = {}; + EXPECT_EQ(absl::CivilDay{}, s.day); +} + +TEST(CivilTime, FieldsConstruction) { + EXPECT_EQ("2015-01-02T03:04:05", + absl::FormatCivilTime(absl::CivilSecond(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02T03:04:00", + absl::FormatCivilTime(absl::CivilSecond(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02T03:00:00", + absl::FormatCivilTime(absl::CivilSecond(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02T00:00:00", + absl::FormatCivilTime(absl::CivilSecond(2015, 1, 2))); + EXPECT_EQ("2015-01-01T00:00:00", + absl::FormatCivilTime(absl::CivilSecond(2015, 1))); + EXPECT_EQ("2015-01-01T00:00:00", + absl::FormatCivilTime(absl::CivilSecond(2015))); + + EXPECT_EQ("2015-01-02T03:04", + absl::FormatCivilTime(absl::CivilMinute(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02T03:04", + absl::FormatCivilTime(absl::CivilMinute(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02T03:00", + absl::FormatCivilTime(absl::CivilMinute(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02T00:00", + absl::FormatCivilTime(absl::CivilMinute(2015, 1, 2))); + EXPECT_EQ("2015-01-01T00:00", + absl::FormatCivilTime(absl::CivilMinute(2015, 1))); + EXPECT_EQ("2015-01-01T00:00", + absl::FormatCivilTime(absl::CivilMinute(2015))); + + EXPECT_EQ("2015-01-02T03", + absl::FormatCivilTime(absl::CivilHour(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02T03", + absl::FormatCivilTime(absl::CivilHour(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02T03", + absl::FormatCivilTime(absl::CivilHour(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02T00", + absl::FormatCivilTime(absl::CivilHour(2015, 1, 2))); + EXPECT_EQ("2015-01-01T00", + absl::FormatCivilTime(absl::CivilHour(2015, 1))); + EXPECT_EQ("2015-01-01T00", + absl::FormatCivilTime(absl::CivilHour(2015))); + + EXPECT_EQ("2015-01-02", + absl::FormatCivilTime(absl::CivilDay(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02", + absl::FormatCivilTime(absl::CivilDay(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02", + absl::FormatCivilTime(absl::CivilDay(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02", + absl::FormatCivilTime(absl::CivilDay(2015, 1, 2))); + EXPECT_EQ("2015-01-01", + absl::FormatCivilTime(absl::CivilDay(2015, 1))); + EXPECT_EQ("2015-01-01", + absl::FormatCivilTime(absl::CivilDay(2015))); + + EXPECT_EQ("2015-01", + absl::FormatCivilTime(absl::CivilMonth(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01", + absl::FormatCivilTime(absl::CivilMonth(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01", + absl::FormatCivilTime(absl::CivilMonth(2015, 1, 2, 3))); + EXPECT_EQ("2015-01", + absl::FormatCivilTime(absl::CivilMonth(2015, 1, 2))); + EXPECT_EQ("2015-01", + absl::FormatCivilTime(absl::CivilMonth(2015, 1))); + EXPECT_EQ("2015-01", + absl::FormatCivilTime(absl::CivilMonth(2015))); + + EXPECT_EQ("2015", + absl::FormatCivilTime(absl::CivilYear(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015", + absl::FormatCivilTime(absl::CivilYear(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015", + absl::FormatCivilTime(absl::CivilYear(2015, 1, 2, 3))); + EXPECT_EQ("2015", + absl::FormatCivilTime(absl::CivilYear(2015, 1, 2))); + EXPECT_EQ("2015", + absl::FormatCivilTime(absl::CivilYear(2015, 1))); + EXPECT_EQ("2015", + absl::FormatCivilTime(absl::CivilYear(2015))); +} + +TEST(CivilTime, FieldsConstructionLimits) { + const int kIntMax = std::numeric_limits<int>::max(); + EXPECT_EQ("2038-01-19T03:14:07", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, 1, 0, 0, kIntMax))); + EXPECT_EQ("6121-02-11T05:21:07", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, 1, 0, kIntMax, kIntMax))); + EXPECT_EQ("251104-11-20T12:21:07", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, 1, kIntMax, kIntMax, kIntMax))); + EXPECT_EQ("6130715-05-30T12:21:07", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, kIntMax, kIntMax, kIntMax, kIntMax))); + EXPECT_EQ("185087685-11-26T12:21:07", + absl::FormatCivilTime(absl::CivilSecond( + 1970, kIntMax, kIntMax, kIntMax, kIntMax, kIntMax))); + + const int kIntMin = std::numeric_limits<int>::min(); + EXPECT_EQ("1901-12-13T20:45:52", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, 1, 0, 0, kIntMin))); + EXPECT_EQ("-2182-11-20T18:37:52", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, 1, 0, kIntMin, kIntMin))); + EXPECT_EQ("-247165-02-11T10:37:52", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, 1, kIntMin, kIntMin, kIntMin))); + EXPECT_EQ("-6126776-08-01T10:37:52", + absl::FormatCivilTime(absl::CivilSecond( + 1970, 1, kIntMin, kIntMin, kIntMin, kIntMin))); + EXPECT_EQ("-185083747-10-31T10:37:52", + absl::FormatCivilTime(absl::CivilSecond( + 1970, kIntMin, kIntMin, kIntMin, kIntMin, kIntMin))); +} + +TEST(CivilTime, RangeLimits) { + const absl::civil_year_t kYearMax = + std::numeric_limits<absl::civil_year_t>::max(); + EXPECT_EQ(absl::CivilYear(kYearMax), + absl::CivilYear::max()); + EXPECT_EQ(absl::CivilMonth(kYearMax, 12), + absl::CivilMonth::max()); + EXPECT_EQ(absl::CivilDay(kYearMax, 12, 31), + absl::CivilDay::max()); + EXPECT_EQ(absl::CivilHour(kYearMax, 12, 31, 23), + absl::CivilHour::max()); + EXPECT_EQ(absl::CivilMinute(kYearMax, 12, 31, 23, 59), + absl::CivilMinute::max()); + EXPECT_EQ(absl::CivilSecond(kYearMax, 12, 31, 23, 59, 59), + absl::CivilSecond::max()); + + const absl::civil_year_t kYearMin = + std::numeric_limits<absl::civil_year_t>::min(); + EXPECT_EQ(absl::CivilYear(kYearMin), + absl::CivilYear::min()); + EXPECT_EQ(absl::CivilMonth(kYearMin, 1), + absl::CivilMonth::min()); + EXPECT_EQ(absl::CivilDay(kYearMin, 1, 1), + absl::CivilDay::min()); + EXPECT_EQ(absl::CivilHour(kYearMin, 1, 1, 0), + absl::CivilHour::min()); + EXPECT_EQ(absl::CivilMinute(kYearMin, 1, 1, 0, 0), + absl::CivilMinute::min()); + EXPECT_EQ(absl::CivilSecond(kYearMin, 1, 1, 0, 0, 0), + absl::CivilSecond::min()); +} + +TEST(CivilTime, ImplicitCrossAlignment) { + absl::CivilYear year(2015); + absl::CivilMonth month = year; + absl::CivilDay day = month; + absl::CivilHour hour = day; + absl::CivilMinute minute = hour; + absl::CivilSecond second = minute; + + second = year; + EXPECT_EQ(second, year); + second = month; + EXPECT_EQ(second, month); + second = day; + EXPECT_EQ(second, day); + second = hour; + EXPECT_EQ(second, hour); + second = minute; + EXPECT_EQ(second, minute); + + minute = year; + EXPECT_EQ(minute, year); + minute = month; + EXPECT_EQ(minute, month); + minute = day; + EXPECT_EQ(minute, day); + minute = hour; + EXPECT_EQ(minute, hour); + + hour = year; + EXPECT_EQ(hour, year); + hour = month; + EXPECT_EQ(hour, month); + hour = day; + EXPECT_EQ(hour, day); + + day = year; + EXPECT_EQ(day, year); + day = month; + EXPECT_EQ(day, month); + + month = year; + EXPECT_EQ(month, year); + + // Ensures unsafe conversions are not allowed. + EXPECT_FALSE( + (std::is_convertible<absl::CivilSecond, absl::CivilMinute>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilSecond, absl::CivilHour>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilSecond, absl::CivilDay>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilSecond, absl::CivilMonth>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilSecond, absl::CivilYear>::value)); + + EXPECT_FALSE( + (std::is_convertible<absl::CivilMinute, absl::CivilHour>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilMinute, absl::CivilDay>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilMinute, absl::CivilMonth>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilMinute, absl::CivilYear>::value)); + + EXPECT_FALSE( + (std::is_convertible<absl::CivilHour, absl::CivilDay>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilHour, absl::CivilMonth>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilHour, absl::CivilYear>::value)); + + EXPECT_FALSE( + (std::is_convertible<absl::CivilDay, absl::CivilMonth>::value)); + EXPECT_FALSE( + (std::is_convertible<absl::CivilDay, absl::CivilYear>::value)); + + EXPECT_FALSE( + (std::is_convertible<absl::CivilMonth, absl::CivilYear>::value)); +} + +TEST(CivilTime, ExplicitCrossAlignment) { + // + // Assign from smaller units -> larger units + // + + absl::CivilSecond second(2015, 1, 2, 3, 4, 5); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(second)); + + absl::CivilMinute minute(second); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(minute)); + + absl::CivilHour hour(minute); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(hour)); + + absl::CivilDay day(hour); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(day)); + + absl::CivilMonth month(day); + EXPECT_EQ("2015-01", absl::FormatCivilTime(month)); + + absl::CivilYear year(month); + EXPECT_EQ("2015", absl::FormatCivilTime(year)); + + // + // Now assign from larger units -> smaller units + // + + month = absl::CivilMonth(year); + EXPECT_EQ("2015-01", absl::FormatCivilTime(month)); + + day = absl::CivilDay(month); + EXPECT_EQ("2015-01-01", absl::FormatCivilTime(day)); + + hour = absl::CivilHour(day); + EXPECT_EQ("2015-01-01T00", absl::FormatCivilTime(hour)); + + minute = absl::CivilMinute(hour); + EXPECT_EQ("2015-01-01T00:00", absl::FormatCivilTime(minute)); + + second = absl::CivilSecond(minute); + EXPECT_EQ("2015-01-01T00:00:00", absl::FormatCivilTime(second)); +} + +// Metafunction to test whether difference is allowed between two types. +template <typename T1, typename T2> +struct HasDiff { + template <typename U1, typename U2> + static std::false_type test(...); + template <typename U1, typename U2> + static std::true_type test(decltype(std::declval<U1>() - std::declval<U2>())); + static constexpr bool value = decltype(test<T1, T2>(0))::value; +}; + +TEST(CivilTime, DisallowCrossAlignedDifference) { + // Difference is allowed between types with the same alignment. + static_assert(HasDiff<absl::CivilSecond, absl::CivilSecond>::value, ""); + static_assert(HasDiff<absl::CivilMinute, absl::CivilMinute>::value, ""); + static_assert(HasDiff<absl::CivilHour, absl::CivilHour>::value, ""); + static_assert(HasDiff<absl::CivilDay, absl::CivilDay>::value, ""); + static_assert(HasDiff<absl::CivilMonth, absl::CivilMonth>::value, ""); + static_assert(HasDiff<absl::CivilYear, absl::CivilYear>::value, ""); + + // Difference is disallowed between types with different alignments. + static_assert(!HasDiff<absl::CivilSecond, absl::CivilMinute>::value, ""); + static_assert(!HasDiff<absl::CivilSecond, absl::CivilHour>::value, ""); + static_assert(!HasDiff<absl::CivilSecond, absl::CivilDay>::value, ""); + static_assert(!HasDiff<absl::CivilSecond, absl::CivilMonth>::value, ""); + static_assert(!HasDiff<absl::CivilSecond, absl::CivilYear>::value, ""); + + static_assert(!HasDiff<absl::CivilMinute, absl::CivilHour>::value, ""); + static_assert(!HasDiff<absl::CivilMinute, absl::CivilDay>::value, ""); + static_assert(!HasDiff<absl::CivilMinute, absl::CivilMonth>::value, ""); + static_assert(!HasDiff<absl::CivilMinute, absl::CivilYear>::value, ""); + + static_assert(!HasDiff<absl::CivilHour, absl::CivilDay>::value, ""); + static_assert(!HasDiff<absl::CivilHour, absl::CivilMonth>::value, ""); + static_assert(!HasDiff<absl::CivilHour, absl::CivilYear>::value, ""); + + static_assert(!HasDiff<absl::CivilDay, absl::CivilMonth>::value, ""); + static_assert(!HasDiff<absl::CivilDay, absl::CivilYear>::value, ""); + + static_assert(!HasDiff<absl::CivilMonth, absl::CivilYear>::value, ""); +} + +TEST(CivilTime, ValueSemantics) { + const absl::CivilHour a(2015, 1, 2, 3); + const absl::CivilHour b = a; + const absl::CivilHour c(b); + absl::CivilHour d; + d = c; + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(d)); +} + +TEST(CivilTime, Relational) { + // Tests that the alignment unit is ignored in comparison. + const absl::CivilYear year(2014); + const absl::CivilMonth month(year); + EXPECT_EQ(year, month); + +#define TEST_RELATIONAL(OLDER, YOUNGER) \ + do { \ + EXPECT_FALSE(OLDER < OLDER); \ + EXPECT_FALSE(OLDER > OLDER); \ + EXPECT_TRUE(OLDER >= OLDER); \ + EXPECT_TRUE(OLDER <= OLDER); \ + EXPECT_FALSE(YOUNGER < YOUNGER); \ + EXPECT_FALSE(YOUNGER > YOUNGER); \ + EXPECT_TRUE(YOUNGER >= YOUNGER); \ + EXPECT_TRUE(YOUNGER <= YOUNGER); \ + EXPECT_EQ(OLDER, OLDER); \ + EXPECT_NE(OLDER, YOUNGER); \ + EXPECT_LT(OLDER, YOUNGER); \ + EXPECT_LE(OLDER, YOUNGER); \ + EXPECT_GT(YOUNGER, OLDER); \ + EXPECT_GE(YOUNGER, OLDER); \ + } while (0) + + // Alignment is ignored in comparison (verified above), so CivilSecond is + // used to test comparison in all field positions. + TEST_RELATIONAL(absl::CivilSecond(2014, 1, 1, 0, 0, 0), + absl::CivilSecond(2015, 1, 1, 0, 0, 0)); + TEST_RELATIONAL(absl::CivilSecond(2014, 1, 1, 0, 0, 0), + absl::CivilSecond(2014, 2, 1, 0, 0, 0)); + TEST_RELATIONAL(absl::CivilSecond(2014, 1, 1, 0, 0, 0), + absl::CivilSecond(2014, 1, 2, 0, 0, 0)); + TEST_RELATIONAL(absl::CivilSecond(2014, 1, 1, 0, 0, 0), + absl::CivilSecond(2014, 1, 1, 1, 0, 0)); + TEST_RELATIONAL(absl::CivilSecond(2014, 1, 1, 1, 0, 0), + absl::CivilSecond(2014, 1, 1, 1, 1, 0)); + TEST_RELATIONAL(absl::CivilSecond(2014, 1, 1, 1, 1, 0), + absl::CivilSecond(2014, 1, 1, 1, 1, 1)); + + // Tests the relational operators of two different civil-time types. + TEST_RELATIONAL(absl::CivilDay(2014, 1, 1), + absl::CivilMinute(2014, 1, 1, 1, 1)); + TEST_RELATIONAL(absl::CivilDay(2014, 1, 1), + absl::CivilMonth(2014, 2)); + +#undef TEST_RELATIONAL +} + +TEST(CivilTime, Arithmetic) { + absl::CivilSecond second(2015, 1, 2, 3, 4, 5); + EXPECT_EQ("2015-01-02T03:04:06", absl::FormatCivilTime(second += 1)); + EXPECT_EQ("2015-01-02T03:04:07", absl::FormatCivilTime(second + 1)); + EXPECT_EQ("2015-01-02T03:04:08", absl::FormatCivilTime(2 + second)); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(second - 1)); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(second -= 1)); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(second++)); + EXPECT_EQ("2015-01-02T03:04:07", absl::FormatCivilTime(++second)); + EXPECT_EQ("2015-01-02T03:04:07", absl::FormatCivilTime(second--)); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(--second)); + + absl::CivilMinute minute(2015, 1, 2, 3, 4); + EXPECT_EQ("2015-01-02T03:05", absl::FormatCivilTime(minute += 1)); + EXPECT_EQ("2015-01-02T03:06", absl::FormatCivilTime(minute + 1)); + EXPECT_EQ("2015-01-02T03:07", absl::FormatCivilTime(2 + minute)); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(minute - 1)); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(minute -= 1)); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(minute++)); + EXPECT_EQ("2015-01-02T03:06", absl::FormatCivilTime(++minute)); + EXPECT_EQ("2015-01-02T03:06", absl::FormatCivilTime(minute--)); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(--minute)); + + absl::CivilHour hour(2015, 1, 2, 3); + EXPECT_EQ("2015-01-02T04", absl::FormatCivilTime(hour += 1)); + EXPECT_EQ("2015-01-02T05", absl::FormatCivilTime(hour + 1)); + EXPECT_EQ("2015-01-02T06", absl::FormatCivilTime(2 + hour)); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(hour - 1)); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(hour -= 1)); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(hour++)); + EXPECT_EQ("2015-01-02T05", absl::FormatCivilTime(++hour)); + EXPECT_EQ("2015-01-02T05", absl::FormatCivilTime(hour--)); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(--hour)); + + absl::CivilDay day(2015, 1, 2); + EXPECT_EQ("2015-01-03", absl::FormatCivilTime(day += 1)); + EXPECT_EQ("2015-01-04", absl::FormatCivilTime(day + 1)); + EXPECT_EQ("2015-01-05", absl::FormatCivilTime(2 + day)); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(day - 1)); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(day -= 1)); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(day++)); + EXPECT_EQ("2015-01-04", absl::FormatCivilTime(++day)); + EXPECT_EQ("2015-01-04", absl::FormatCivilTime(day--)); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(--day)); + + absl::CivilMonth month(2015, 1); + EXPECT_EQ("2015-02", absl::FormatCivilTime(month += 1)); + EXPECT_EQ("2015-03", absl::FormatCivilTime(month + 1)); + EXPECT_EQ("2015-04", absl::FormatCivilTime(2 + month)); + EXPECT_EQ("2015-01", absl::FormatCivilTime(month - 1)); + EXPECT_EQ("2015-01", absl::FormatCivilTime(month -= 1)); + EXPECT_EQ("2015-01", absl::FormatCivilTime(month++)); + EXPECT_EQ("2015-03", absl::FormatCivilTime(++month)); + EXPECT_EQ("2015-03", absl::FormatCivilTime(month--)); + EXPECT_EQ("2015-01", absl::FormatCivilTime(--month)); + + absl::CivilYear year(2015); + EXPECT_EQ("2016", absl::FormatCivilTime(year += 1)); + EXPECT_EQ("2017", absl::FormatCivilTime(year + 1)); + EXPECT_EQ("2018", absl::FormatCivilTime(2 + year)); + EXPECT_EQ("2015", absl::FormatCivilTime(year - 1)); + EXPECT_EQ("2015", absl::FormatCivilTime(year -= 1)); + EXPECT_EQ("2015", absl::FormatCivilTime(year++)); + EXPECT_EQ("2017", absl::FormatCivilTime(++year)); + EXPECT_EQ("2017", absl::FormatCivilTime(year--)); + EXPECT_EQ("2015", absl::FormatCivilTime(--year)); +} + +TEST(CivilTime, ArithmeticLimits) { + const int kIntMax = std::numeric_limits<int>::max(); + const int kIntMin = std::numeric_limits<int>::min(); + + absl::CivilSecond second(1970, 1, 1, 0, 0, 0); + second += kIntMax; + EXPECT_EQ("2038-01-19T03:14:07", absl::FormatCivilTime(second)); + second -= kIntMax; + EXPECT_EQ("1970-01-01T00:00:00", absl::FormatCivilTime(second)); + second += kIntMin; + EXPECT_EQ("1901-12-13T20:45:52", absl::FormatCivilTime(second)); + second -= kIntMin; + EXPECT_EQ("1970-01-01T00:00:00", absl::FormatCivilTime(second)); + + absl::CivilMinute minute(1970, 1, 1, 0, 0); + minute += kIntMax; + EXPECT_EQ("6053-01-23T02:07", absl::FormatCivilTime(minute)); + minute -= kIntMax; + EXPECT_EQ("1970-01-01T00:00", absl::FormatCivilTime(minute)); + minute += kIntMin; + EXPECT_EQ("-2114-12-08T21:52", absl::FormatCivilTime(minute)); + minute -= kIntMin; + EXPECT_EQ("1970-01-01T00:00", absl::FormatCivilTime(minute)); + + absl::CivilHour hour(1970, 1, 1, 0); + hour += kIntMax; + EXPECT_EQ("246953-10-09T07", absl::FormatCivilTime(hour)); + hour -= kIntMax; + EXPECT_EQ("1970-01-01T00", absl::FormatCivilTime(hour)); + hour += kIntMin; + EXPECT_EQ("-243014-03-24T16", absl::FormatCivilTime(hour)); + hour -= kIntMin; + EXPECT_EQ("1970-01-01T00", absl::FormatCivilTime(hour)); + + absl::CivilDay day(1970, 1, 1); + day += kIntMax; + EXPECT_EQ("5881580-07-11", absl::FormatCivilTime(day)); + day -= kIntMax; + EXPECT_EQ("1970-01-01", absl::FormatCivilTime(day)); + day += kIntMin; + EXPECT_EQ("-5877641-06-23", absl::FormatCivilTime(day)); + day -= kIntMin; + EXPECT_EQ("1970-01-01", absl::FormatCivilTime(day)); + + absl::CivilMonth month(1970, 1); + month += kIntMax; + EXPECT_EQ("178958940-08", absl::FormatCivilTime(month)); + month -= kIntMax; + EXPECT_EQ("1970-01", absl::FormatCivilTime(month)); + month += kIntMin; + EXPECT_EQ("-178955001-05", absl::FormatCivilTime(month)); + month -= kIntMin; + EXPECT_EQ("1970-01", absl::FormatCivilTime(month)); + + absl::CivilYear year(0); + year += kIntMax; + EXPECT_EQ("2147483647", absl::FormatCivilTime(year)); + year -= kIntMax; + EXPECT_EQ("0", absl::FormatCivilTime(year)); + year += kIntMin; + EXPECT_EQ("-2147483648", absl::FormatCivilTime(year)); + year -= kIntMin; + EXPECT_EQ("0", absl::FormatCivilTime(year)); +} + +TEST(CivilTime, Difference) { + absl::CivilSecond second(2015, 1, 2, 3, 4, 5); + EXPECT_EQ(0, second - second); + EXPECT_EQ(10, (second + 10) - second); + EXPECT_EQ(-10, (second - 10) - second); + + absl::CivilMinute minute(2015, 1, 2, 3, 4); + EXPECT_EQ(0, minute - minute); + EXPECT_EQ(10, (minute + 10) - minute); + EXPECT_EQ(-10, (minute - 10) - minute); + + absl::CivilHour hour(2015, 1, 2, 3); + EXPECT_EQ(0, hour - hour); + EXPECT_EQ(10, (hour + 10) - hour); + EXPECT_EQ(-10, (hour - 10) - hour); + + absl::CivilDay day(2015, 1, 2); + EXPECT_EQ(0, day - day); + EXPECT_EQ(10, (day + 10) - day); + EXPECT_EQ(-10, (day - 10) - day); + + absl::CivilMonth month(2015, 1); + EXPECT_EQ(0, month - month); + EXPECT_EQ(10, (month + 10) - month); + EXPECT_EQ(-10, (month - 10) - month); + + absl::CivilYear year(2015); + EXPECT_EQ(0, year - year); + EXPECT_EQ(10, (year + 10) - year); + EXPECT_EQ(-10, (year - 10) - year); +} + +TEST(CivilTime, DifferenceLimits) { + const absl::civil_diff_t kDiffMax = + std::numeric_limits<absl::civil_diff_t>::max(); + const absl::civil_diff_t kDiffMin = + std::numeric_limits<absl::civil_diff_t>::min(); + + // Check day arithmetic at the end of the year range. + const absl::CivilDay max_day(kDiffMax, 12, 31); + EXPECT_EQ(1, max_day - (max_day - 1)); + EXPECT_EQ(-1, (max_day - 1) - max_day); + + // Check day arithmetic at the start of the year range. + const absl::CivilDay min_day(kDiffMin, 1, 1); + EXPECT_EQ(1, (min_day + 1) - min_day); + EXPECT_EQ(-1, min_day - (min_day + 1)); + + // Check the limits of the return value. + const absl::CivilDay d1(1970, 1, 1); + const absl::CivilDay d2(25252734927768524, 7, 27); + EXPECT_EQ(kDiffMax, d2 - d1); + EXPECT_EQ(kDiffMin, d1 - (d2 + 1)); +} + +TEST(CivilTime, Properties) { + absl::CivilSecond ss(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, ss.year()); + EXPECT_EQ(2, ss.month()); + EXPECT_EQ(3, ss.day()); + EXPECT_EQ(4, ss.hour()); + EXPECT_EQ(5, ss.minute()); + EXPECT_EQ(6, ss.second()); + EXPECT_EQ(absl::Weekday::tuesday, absl::GetWeekday(ss)); + EXPECT_EQ(34, absl::GetYearDay(ss)); + + absl::CivilMinute mm(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, mm.year()); + EXPECT_EQ(2, mm.month()); + EXPECT_EQ(3, mm.day()); + EXPECT_EQ(4, mm.hour()); + EXPECT_EQ(5, mm.minute()); + EXPECT_EQ(0, mm.second()); + EXPECT_EQ(absl::Weekday::tuesday, absl::GetWeekday(mm)); + EXPECT_EQ(34, absl::GetYearDay(mm)); + + absl::CivilHour hh(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, hh.year()); + EXPECT_EQ(2, hh.month()); + EXPECT_EQ(3, hh.day()); + EXPECT_EQ(4, hh.hour()); + EXPECT_EQ(0, hh.minute()); + EXPECT_EQ(0, hh.second()); + EXPECT_EQ(absl::Weekday::tuesday, absl::GetWeekday(hh)); + EXPECT_EQ(34, absl::GetYearDay(hh)); + + absl::CivilDay d(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, d.year()); + EXPECT_EQ(2, d.month()); + EXPECT_EQ(3, d.day()); + EXPECT_EQ(0, d.hour()); + EXPECT_EQ(0, d.minute()); + EXPECT_EQ(0, d.second()); + EXPECT_EQ(absl::Weekday::tuesday, absl::GetWeekday(d)); + EXPECT_EQ(34, absl::GetYearDay(d)); + + absl::CivilMonth m(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, m.year()); + EXPECT_EQ(2, m.month()); + EXPECT_EQ(1, m.day()); + EXPECT_EQ(0, m.hour()); + EXPECT_EQ(0, m.minute()); + EXPECT_EQ(0, m.second()); + EXPECT_EQ(absl::Weekday::sunday, absl::GetWeekday(m)); + EXPECT_EQ(32, absl::GetYearDay(m)); + + absl::CivilYear y(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, y.year()); + EXPECT_EQ(1, y.month()); + EXPECT_EQ(1, y.day()); + EXPECT_EQ(0, y.hour()); + EXPECT_EQ(0, y.minute()); + EXPECT_EQ(0, y.second()); + EXPECT_EQ(absl::Weekday::thursday, absl::GetWeekday(y)); + EXPECT_EQ(1, absl::GetYearDay(y)); +} + +TEST(CivilTime, Format) { + absl::CivilSecond ss; + EXPECT_EQ("1970-01-01T00:00:00", absl::FormatCivilTime(ss)); + + absl::CivilMinute mm; + EXPECT_EQ("1970-01-01T00:00", absl::FormatCivilTime(mm)); + + absl::CivilHour hh; + EXPECT_EQ("1970-01-01T00", absl::FormatCivilTime(hh)); + + absl::CivilDay d; + EXPECT_EQ("1970-01-01", absl::FormatCivilTime(d)); + + absl::CivilMonth m; + EXPECT_EQ("1970-01", absl::FormatCivilTime(m)); + + absl::CivilYear y; + EXPECT_EQ("1970", absl::FormatCivilTime(y)); +} + +TEST(CivilTime, Parse) { + absl::CivilSecond ss; + absl::CivilMinute mm; + absl::CivilHour hh; + absl::CivilDay d; + absl::CivilMonth m; + absl::CivilYear y; + + // CivilSecond OK; others fail + EXPECT_TRUE(absl::ParseCivilTime("2015-01-02T03:04:05", &ss)); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(ss)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04:05", &mm)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04:05", &hh)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04:05", &d)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04:05", &m)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04:05", &y)); + + // CivilMinute OK; others fail + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04", &ss)); + EXPECT_TRUE(absl::ParseCivilTime("2015-01-02T03:04", &mm)); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(mm)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04", &hh)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04", &d)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04", &m)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03:04", &y)); + + // CivilHour OK; others fail + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03", &ss)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03", &mm)); + EXPECT_TRUE(absl::ParseCivilTime("2015-01-02T03", &hh)); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(hh)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03", &d)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03", &m)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02T03", &y)); + + // CivilDay OK; others fail + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02", &ss)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02", &mm)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02", &hh)); + EXPECT_TRUE(absl::ParseCivilTime("2015-01-02", &d)); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(d)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02", &m)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01-02", &y)); + + // CivilMonth OK; others fail + EXPECT_FALSE(absl::ParseCivilTime("2015-01", &ss)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01", &mm)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01", &hh)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01", &d)); + EXPECT_TRUE(absl::ParseCivilTime("2015-01", &m)); + EXPECT_EQ("2015-01", absl::FormatCivilTime(m)); + EXPECT_FALSE(absl::ParseCivilTime("2015-01", &y)); + + // CivilYear OK; others fail + EXPECT_FALSE(absl::ParseCivilTime("2015", &ss)); + EXPECT_FALSE(absl::ParseCivilTime("2015", &mm)); + EXPECT_FALSE(absl::ParseCivilTime("2015", &hh)); + EXPECT_FALSE(absl::ParseCivilTime("2015", &d)); + EXPECT_FALSE(absl::ParseCivilTime("2015", &m)); + EXPECT_TRUE(absl::ParseCivilTime("2015", &y)); + EXPECT_EQ("2015", absl::FormatCivilTime(y)); +} + +TEST(CivilTime, FormatAndParseLenient) { + absl::CivilSecond ss; + EXPECT_EQ("1970-01-01T00:00:00", absl::FormatCivilTime(ss)); + + absl::CivilMinute mm; + EXPECT_EQ("1970-01-01T00:00", absl::FormatCivilTime(mm)); + + absl::CivilHour hh; + EXPECT_EQ("1970-01-01T00", absl::FormatCivilTime(hh)); + + absl::CivilDay d; + EXPECT_EQ("1970-01-01", absl::FormatCivilTime(d)); + + absl::CivilMonth m; + EXPECT_EQ("1970-01", absl::FormatCivilTime(m)); + + absl::CivilYear y; + EXPECT_EQ("1970", absl::FormatCivilTime(y)); + + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-01-02T03:04:05", &ss)); + EXPECT_EQ("2015-01-02T03:04:05", absl::FormatCivilTime(ss)); + + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-01-02T03:04:05", &mm)); + EXPECT_EQ("2015-01-02T03:04", absl::FormatCivilTime(mm)); + + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-01-02T03:04:05", &hh)); + EXPECT_EQ("2015-01-02T03", absl::FormatCivilTime(hh)); + + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-01-02T03:04:05", &d)); + EXPECT_EQ("2015-01-02", absl::FormatCivilTime(d)); + + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-01-02T03:04:05", &m)); + EXPECT_EQ("2015-01", absl::FormatCivilTime(m)); + + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-01-02T03:04:05", &y)); + EXPECT_EQ("2015", absl::FormatCivilTime(y)); +} + +TEST(CivilTime, ParseEdgeCases) { + absl::CivilSecond ss; + EXPECT_TRUE( + absl::ParseLenientCivilTime("9223372036854775807-12-31T23:59:59", &ss)); + EXPECT_EQ("9223372036854775807-12-31T23:59:59", absl::FormatCivilTime(ss)); + EXPECT_TRUE( + absl::ParseLenientCivilTime("-9223372036854775808-01-01T00:00:00", &ss)); + EXPECT_EQ("-9223372036854775808-01-01T00:00:00", absl::FormatCivilTime(ss)); + + absl::CivilMinute mm; + EXPECT_TRUE( + absl::ParseLenientCivilTime("9223372036854775807-12-31T23:59", &mm)); + EXPECT_EQ("9223372036854775807-12-31T23:59", absl::FormatCivilTime(mm)); + EXPECT_TRUE( + absl::ParseLenientCivilTime("-9223372036854775808-01-01T00:00", &mm)); + EXPECT_EQ("-9223372036854775808-01-01T00:00", absl::FormatCivilTime(mm)); + + absl::CivilHour hh; + EXPECT_TRUE( + absl::ParseLenientCivilTime("9223372036854775807-12-31T23", &hh)); + EXPECT_EQ("9223372036854775807-12-31T23", absl::FormatCivilTime(hh)); + EXPECT_TRUE( + absl::ParseLenientCivilTime("-9223372036854775808-01-01T00", &hh)); + EXPECT_EQ("-9223372036854775808-01-01T00", absl::FormatCivilTime(hh)); + + absl::CivilDay d; + EXPECT_TRUE(absl::ParseLenientCivilTime("9223372036854775807-12-31", &d)); + EXPECT_EQ("9223372036854775807-12-31", absl::FormatCivilTime(d)); + EXPECT_TRUE(absl::ParseLenientCivilTime("-9223372036854775808-01-01", &d)); + EXPECT_EQ("-9223372036854775808-01-01", absl::FormatCivilTime(d)); + + absl::CivilMonth m; + EXPECT_TRUE(absl::ParseLenientCivilTime("9223372036854775807-12", &m)); + EXPECT_EQ("9223372036854775807-12", absl::FormatCivilTime(m)); + EXPECT_TRUE(absl::ParseLenientCivilTime("-9223372036854775808-01", &m)); + EXPECT_EQ("-9223372036854775808-01", absl::FormatCivilTime(m)); + + absl::CivilYear y; + EXPECT_TRUE(absl::ParseLenientCivilTime("9223372036854775807", &y)); + EXPECT_EQ("9223372036854775807", absl::FormatCivilTime(y)); + EXPECT_TRUE(absl::ParseLenientCivilTime("-9223372036854775808", &y)); + EXPECT_EQ("-9223372036854775808", absl::FormatCivilTime(y)); + + // Tests some valid, but interesting, cases + EXPECT_TRUE(absl::ParseLenientCivilTime("0", &ss)) << ss; + EXPECT_EQ(absl::CivilYear(0), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime("0-1", &ss)) << ss; + EXPECT_EQ(absl::CivilMonth(0, 1), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime(" 2015 ", &ss)) << ss; + EXPECT_EQ(absl::CivilYear(2015), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime(" 2015-6 ", &ss)) << ss; + EXPECT_EQ(absl::CivilMonth(2015, 6), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-6-7", &ss)) << ss; + EXPECT_EQ(absl::CivilDay(2015, 6, 7), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime(" 2015-6-7 ", &ss)) << ss; + EXPECT_EQ(absl::CivilDay(2015, 6, 7), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime("2015-06-07T10:11:12 ", &ss)) << ss; + EXPECT_EQ(absl::CivilSecond(2015, 6, 7, 10, 11, 12), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime(" 2015-06-07T10:11:12 ", &ss)) << ss; + EXPECT_EQ(absl::CivilSecond(2015, 6, 7, 10, 11, 12), ss); + EXPECT_TRUE(absl::ParseLenientCivilTime("-01-01", &ss)) << ss; + EXPECT_EQ(absl::CivilMonth(-1, 1), ss); + + // Tests some invalid cases + EXPECT_FALSE(absl::ParseLenientCivilTime("01-01-2015", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015-", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("0xff-01", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015-02-30T04:05:06", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015-02-03T04:05:96", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("X2015-02-03T04:05:06", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015-02-03T04:05:003", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015 -02-03T04:05:06", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015-02-03-04:05:06", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("2015:02:03T04-05-06", &ss)) << ss; + EXPECT_FALSE(absl::ParseLenientCivilTime("9223372036854775808", &y)) << y; +} + +TEST(CivilTime, OutputStream) { + absl::CivilSecond cs(2016, 2, 3, 4, 5, 6); + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::CivilYear(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016.................X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::CivilMonth(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02..............X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::CivilDay(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03...........X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::CivilHour(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03T04........X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::CivilMinute(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03T04:05.....X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::CivilSecond(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03T04:05:06..X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << absl::Weekday::wednesday; + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..Wednesday............X..", ss.str()); + } +} + +TEST(CivilTime, Weekday) { + absl::CivilDay d(1970, 1, 1); + EXPECT_EQ(absl::Weekday::thursday, absl::GetWeekday(d)) << d; + + // We used to get this wrong for years < -30. + d = absl::CivilDay(-31, 12, 24); + EXPECT_EQ(absl::Weekday::wednesday, absl::GetWeekday(d)) << d; +} + +TEST(CivilTime, NextPrevWeekday) { + // Jan 1, 1970 was a Thursday. + const absl::CivilDay thursday(1970, 1, 1); + + // Thursday -> Thursday + absl::CivilDay d = absl::NextWeekday(thursday, absl::Weekday::thursday); + EXPECT_EQ(7, d - thursday) << d; + EXPECT_EQ(d - 14, absl::PrevWeekday(thursday, absl::Weekday::thursday)); + + // Thursday -> Friday + d = absl::NextWeekday(thursday, absl::Weekday::friday); + EXPECT_EQ(1, d - thursday) << d; + EXPECT_EQ(d - 7, absl::PrevWeekday(thursday, absl::Weekday::friday)); + + // Thursday -> Saturday + d = absl::NextWeekday(thursday, absl::Weekday::saturday); + EXPECT_EQ(2, d - thursday) << d; + EXPECT_EQ(d - 7, absl::PrevWeekday(thursday, absl::Weekday::saturday)); + + // Thursday -> Sunday + d = absl::NextWeekday(thursday, absl::Weekday::sunday); + EXPECT_EQ(3, d - thursday) << d; + EXPECT_EQ(d - 7, absl::PrevWeekday(thursday, absl::Weekday::sunday)); + + // Thursday -> Monday + d = absl::NextWeekday(thursday, absl::Weekday::monday); + EXPECT_EQ(4, d - thursday) << d; + EXPECT_EQ(d - 7, absl::PrevWeekday(thursday, absl::Weekday::monday)); + + // Thursday -> Tuesday + d = absl::NextWeekday(thursday, absl::Weekday::tuesday); + EXPECT_EQ(5, d - thursday) << d; + EXPECT_EQ(d - 7, absl::PrevWeekday(thursday, absl::Weekday::tuesday)); + + // Thursday -> Wednesday + d = absl::NextWeekday(thursday, absl::Weekday::wednesday); + EXPECT_EQ(6, d - thursday) << d; + EXPECT_EQ(d - 7, absl::PrevWeekday(thursday, absl::Weekday::wednesday)); +} + +// NOTE: Run this with --copt=-ftrapv to detect overflow problems. +TEST(CivilTime, DifferenceWithHugeYear) { + absl::CivilDay d1(9223372036854775807, 1, 1); + absl::CivilDay d2(9223372036854775807, 12, 31); + EXPECT_EQ(364, d2 - d1); + + d1 = absl::CivilDay(-9223372036854775807 - 1, 1, 1); + d2 = absl::CivilDay(-9223372036854775807 - 1, 12, 31); + EXPECT_EQ(365, d2 - d1); + + // Check the limits of the return value at the end of the year range. + d1 = absl::CivilDay(9223372036854775807, 1, 1); + d2 = absl::CivilDay(9198119301927009252, 6, 6); + EXPECT_EQ(9223372036854775807, d1 - d2); + d2 = d2 - 1; + EXPECT_EQ(-9223372036854775807 - 1, d2 - d1); + + // Check the limits of the return value at the start of the year range. + d1 = absl::CivilDay(-9223372036854775807 - 1, 1, 1); + d2 = absl::CivilDay(-9198119301927009254, 7, 28); + EXPECT_EQ(9223372036854775807, d2 - d1); + d2 = d2 + 1; + EXPECT_EQ(-9223372036854775807 - 1, d1 - d2); + + // Check the limits of the return value from either side of year 0. + d1 = absl::CivilDay(-12626367463883278, 9, 3); + d2 = absl::CivilDay(12626367463883277, 3, 28); + EXPECT_EQ(9223372036854775807, d2 - d1); + d2 = d2 + 1; + EXPECT_EQ(-9223372036854775807 - 1, d1 - d2); +} + +// NOTE: Run this with --copt=-ftrapv to detect overflow problems. +TEST(CivilTime, DifferenceNoIntermediateOverflow) { + // The difference up to the minute field would be below the minimum + // int64_t, but the 52 extra seconds brings us back to the minimum. + absl::CivilSecond s1(-292277022657, 1, 27, 8, 29 - 1, 52); + absl::CivilSecond s2(1970, 1, 1, 0, 0 - 1, 0); + EXPECT_EQ(-9223372036854775807 - 1, s1 - s2); + + // The difference up to the minute field would be above the maximum + // int64_t, but the -53 extra seconds brings us back to the maximum. + s1 = absl::CivilSecond(292277026596, 12, 4, 15, 30, 7 - 7); + s2 = absl::CivilSecond(1970, 1, 1, 0, 0, 0 - 7); + EXPECT_EQ(9223372036854775807, s1 - s2); +} + +TEST(CivilTime, NormalizeSimpleOverflow) { + absl::CivilSecond cs; + cs = absl::CivilSecond(2013, 11, 15, 16, 32, 59 + 1); + EXPECT_EQ("2013-11-15T16:33:00", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16, 59 + 1, 14); + EXPECT_EQ("2013-11-15T17:00:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 23 + 1, 32, 14); + EXPECT_EQ("2013-11-16T00:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 30 + 1, 16, 32, 14); + EXPECT_EQ("2013-12-01T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 12 + 1, 15, 16, 32, 14); + EXPECT_EQ("2014-01-15T16:32:14", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeSimpleUnderflow) { + absl::CivilSecond cs; + cs = absl::CivilSecond(2013, 11, 15, 16, 32, 0 - 1); + EXPECT_EQ("2013-11-15T16:31:59", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16, 0 - 1, 14); + EXPECT_EQ("2013-11-15T15:59:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 0 - 1, 32, 14); + EXPECT_EQ("2013-11-14T23:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 1 - 1, 16, 32, 14); + EXPECT_EQ("2013-10-31T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 1 - 1, 15, 16, 32, 14); + EXPECT_EQ("2012-12-15T16:32:14", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeMultipleOverflow) { + absl::CivilSecond cs(2013, 12, 31, 23, 59, 59 + 1); + EXPECT_EQ("2014-01-01T00:00:00", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeMultipleUnderflow) { + absl::CivilSecond cs(2014, 1, 1, 0, 0, 0 - 1); + EXPECT_EQ("2013-12-31T23:59:59", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeOverflowLimits) { + absl::CivilSecond cs; + + const int kintmax = std::numeric_limits<int>::max(); + cs = absl::CivilSecond(0, kintmax, kintmax, kintmax, kintmax, kintmax); + EXPECT_EQ("185085715-11-27T12:21:07", absl::FormatCivilTime(cs)); + + const int kintmin = std::numeric_limits<int>::min(); + cs = absl::CivilSecond(0, kintmin, kintmin, kintmin, kintmin, kintmin); + EXPECT_EQ("-185085717-10-31T10:37:52", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeComplexOverflow) { + absl::CivilSecond cs; + cs = absl::CivilSecond(2013, 11, 15, 16, 32, 14 + 123456789); + EXPECT_EQ("2017-10-14T14:05:23", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16, 32 + 1234567, 14); + EXPECT_EQ("2016-03-22T00:39:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16 + 123456, 32, 14); + EXPECT_EQ("2027-12-16T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15 + 1234, 16, 32, 14); + EXPECT_EQ("2017-04-02T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11 + 123, 15, 16, 32, 14); + EXPECT_EQ("2024-02-15T16:32:14", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeComplexUnderflow) { + absl::CivilSecond cs; + cs = absl::CivilSecond(1999, 3, 0, 0, 0, 0); // year 400 + EXPECT_EQ("1999-02-28T00:00:00", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16, 32, 14 - 123456789); + EXPECT_EQ("2009-12-17T18:59:05", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16, 32 - 1234567, 14); + EXPECT_EQ("2011-07-12T08:25:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15, 16 - 123456, 32, 14); + EXPECT_EQ("1999-10-16T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11, 15 - 1234, 16, 32, 14); + EXPECT_EQ("2010-06-30T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11 - 123, 15, 16, 32, 14); + EXPECT_EQ("2003-08-15T16:32:14", absl::FormatCivilTime(cs)); +} + +TEST(CivilTime, NormalizeMishmash) { + absl::CivilSecond cs; + cs = absl::CivilSecond(2013, 11 - 123, 15 + 1234, 16 - 123456, 32 + 1234567, + 14 - 123456789); + EXPECT_EQ("1991-05-09T03:06:05", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11 + 123, 15 - 1234, 16 + 123456, 32 - 1234567, + 14 + 123456789); + EXPECT_EQ("2036-05-24T05:58:23", absl::FormatCivilTime(cs)); + + cs = absl::CivilSecond(2013, 11, -146097 + 1, 16, 32, 14); + EXPECT_EQ("1613-11-01T16:32:14", absl::FormatCivilTime(cs)); + cs = absl::CivilSecond(2013, 11 + 400 * 12, -146097 + 1, 16, 32, 14); + EXPECT_EQ("2013-11-01T16:32:14", absl::FormatCivilTime(cs)); +} + +// Convert all the days from 1970-1-1 to 1970-1-146097 (aka 2369-12-31) +// and check that they normalize to the expected time. 146097 days span +// the 400-year Gregorian cycle used during normalization. +TEST(CivilTime, NormalizeAllTheDays) { + absl::CivilDay expected(1970, 1, 1); + for (int day = 1; day <= 146097; ++day) { + absl::CivilSecond cs(1970, 1, day, 0, 0, 0); + EXPECT_EQ(expected, cs); + ++expected; + } +} + +TEST(CivilTime, NormalizeWithHugeYear) { + absl::CivilMonth c(9223372036854775807, 1); + EXPECT_EQ("9223372036854775807-01", absl::FormatCivilTime(c)); + c = c - 1; // Causes normalization + EXPECT_EQ("9223372036854775806-12", absl::FormatCivilTime(c)); + + c = absl::CivilMonth(-9223372036854775807 - 1, 1); + EXPECT_EQ("-9223372036854775808-01", absl::FormatCivilTime(c)); + c = c + 12; // Causes normalization + EXPECT_EQ("-9223372036854775807-01", absl::FormatCivilTime(c)); +} + +TEST(CivilTime, LeapYears) { + const absl::CivilSecond s1(2013, 2, 28 + 1, 0, 0, 0); + EXPECT_EQ("2013-03-01T00:00:00", absl::FormatCivilTime(s1)); + + const absl::CivilSecond s2(2012, 2, 28 + 1, 0, 0, 0); + EXPECT_EQ("2012-02-29T00:00:00", absl::FormatCivilTime(s2)); + + const absl::CivilSecond s3(1900, 2, 28 + 1, 0, 0, 0); + EXPECT_EQ("1900-03-01T00:00:00", absl::FormatCivilTime(s3)); + + const struct { + int year; + int days; + struct { + int month; + int day; + } leap_day; // The date of the day after Feb 28. + } kLeapYearTable[]{ + {1900, 365, {3, 1}}, + {1999, 365, {3, 1}}, + {2000, 366, {2, 29}}, // leap year + {2001, 365, {3, 1}}, + {2002, 365, {3, 1}}, + {2003, 365, {3, 1}}, + {2004, 366, {2, 29}}, // leap year + {2005, 365, {3, 1}}, + {2006, 365, {3, 1}}, + {2007, 365, {3, 1}}, + {2008, 366, {2, 29}}, // leap year + {2009, 365, {3, 1}}, + {2100, 365, {3, 1}}, + }; + + for (int i = 0; i < ABSL_ARRAYSIZE(kLeapYearTable); ++i) { + const int y = kLeapYearTable[i].year; + const int m = kLeapYearTable[i].leap_day.month; + const int d = kLeapYearTable[i].leap_day.day; + const int n = kLeapYearTable[i].days; + + // Tests incrementing through the leap day. + const absl::CivilDay feb28(y, 2, 28); + const absl::CivilDay next_day = feb28 + 1; + EXPECT_EQ(m, next_day.month()); + EXPECT_EQ(d, next_day.day()); + + // Tests difference in days of leap years. + const absl::CivilYear year(feb28); + const absl::CivilYear next_year = year + 1; + EXPECT_EQ(n, absl::CivilDay(next_year) - absl::CivilDay(year)); + } +} + +TEST(CivilTime, FirstThursdayInMonth) { + const absl::CivilDay nov1(2014, 11, 1); + const absl::CivilDay thursday = + absl::NextWeekday(nov1 - 1, absl::Weekday::thursday); + EXPECT_EQ("2014-11-06", absl::FormatCivilTime(thursday)); + + // Bonus: Date of Thanksgiving in the United States + // Rule: Fourth Thursday of November + const absl::CivilDay thanksgiving = thursday + 7 * 3; + EXPECT_EQ("2014-11-27", absl::FormatCivilTime(thanksgiving)); +} + +TEST(CivilTime, DocumentationExample) { + absl::CivilSecond second(2015, 6, 28, 1, 2, 3); // 2015-06-28 01:02:03 + absl::CivilMinute minute(second); // 2015-06-28 01:02:00 + absl::CivilDay day(minute); // 2015-06-28 00:00:00 + + second -= 1; // 2015-06-28 01:02:02 + --second; // 2015-06-28 01:02:01 + EXPECT_EQ(minute, second - 1); // Comparison between types + EXPECT_LT(minute, second); + + // int diff = second - minute; // ERROR: Mixed types, won't compile + + absl::CivilDay june_1(2015, 6, 1); // Pass fields to c'tor. + int diff = day - june_1; // Num days between 'day' and June 1 + EXPECT_EQ(27, diff); + + // Fields smaller than alignment are floored to their minimum value. + absl::CivilDay day_floor(2015, 1, 2, 9, 9, 9); + EXPECT_EQ(0, day_floor.hour()); // 09:09:09 is floored + EXPECT_EQ(absl::CivilDay(2015, 1, 2), day_floor); + + // Unspecified fields default to their minium value + absl::CivilDay day_default(2015); // Defaults to Jan 1 + EXPECT_EQ(absl::CivilDay(2015, 1, 1), day_default); + + // Iterates all the days of June. + absl::CivilMonth june(day); // CivilDay -> CivilMonth + absl::CivilMonth july = june + 1; + for (absl::CivilDay day = june_1; day < july; ++day) { + // ... + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/clock.cc b/third_party/abseil_cpp/absl/time/clock.cc new file mode 100644 index 0000000000..e5c423c7e4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/clock.cc @@ -0,0 +1,569 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/clock.h" + +#include "absl/base/attributes.h" + +#ifdef _WIN32 +#include <windows.h> +#endif + +#include <algorithm> +#include <atomic> +#include <cerrno> +#include <cstdint> +#include <ctime> +#include <limits> + +#include "absl/base/internal/spinlock.h" +#include "absl/base/internal/unscaledcycleclock.h" +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/base/thread_annotations.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +Time Now() { + // TODO(bww): Get a timespec instead so we don't have to divide. + int64_t n = absl::GetCurrentTimeNanos(); + if (n >= 0) { + return time_internal::FromUnixDuration( + time_internal::MakeDuration(n / 1000000000, n % 1000000000 * 4)); + } + return time_internal::FromUnixDuration(absl::Nanoseconds(n)); +} +ABSL_NAMESPACE_END +} // namespace absl + +// Decide if we should use the fast GetCurrentTimeNanos() algorithm +// based on the cyclecounter, otherwise just get the time directly +// from the OS on every call. This can be chosen at compile-time via +// -DABSL_USE_CYCLECLOCK_FOR_GET_CURRENT_TIME_NANOS=[0|1] +#ifndef ABSL_USE_CYCLECLOCK_FOR_GET_CURRENT_TIME_NANOS +#if ABSL_USE_UNSCALED_CYCLECLOCK +#define ABSL_USE_CYCLECLOCK_FOR_GET_CURRENT_TIME_NANOS 1 +#else +#define ABSL_USE_CYCLECLOCK_FOR_GET_CURRENT_TIME_NANOS 0 +#endif +#endif + +#if defined(__APPLE__) || defined(_WIN32) +#include "absl/time/internal/get_current_time_chrono.inc" +#else +#include "absl/time/internal/get_current_time_posix.inc" +#endif + +// Allows override by test. +#ifndef GET_CURRENT_TIME_NANOS_FROM_SYSTEM +#define GET_CURRENT_TIME_NANOS_FROM_SYSTEM() \ + ::absl::time_internal::GetCurrentTimeNanosFromSystem() +#endif + +#if !ABSL_USE_CYCLECLOCK_FOR_GET_CURRENT_TIME_NANOS +namespace absl { +ABSL_NAMESPACE_BEGIN +int64_t GetCurrentTimeNanos() { + return GET_CURRENT_TIME_NANOS_FROM_SYSTEM(); +} +ABSL_NAMESPACE_END +} // namespace absl +#else // Use the cyclecounter-based implementation below. + +// Allows override by test. +#ifndef GET_CURRENT_TIME_NANOS_CYCLECLOCK_NOW +#define GET_CURRENT_TIME_NANOS_CYCLECLOCK_NOW() \ + ::absl::time_internal::UnscaledCycleClockWrapperForGetCurrentTime::Now() +#endif + +// The following counters are used only by the test code. +static int64_t stats_initializations; +static int64_t stats_reinitializations; +static int64_t stats_calibrations; +static int64_t stats_slow_paths; +static int64_t stats_fast_slow_paths; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +// This is a friend wrapper around UnscaledCycleClock::Now() +// (needed to access UnscaledCycleClock). +class UnscaledCycleClockWrapperForGetCurrentTime { + public: + static int64_t Now() { return base_internal::UnscaledCycleClock::Now(); } +}; +} // namespace time_internal + +// uint64_t is used in this module to provide an extra bit in multiplications + +// Return the time in ns as told by the kernel interface. Place in *cycleclock +// the value of the cycleclock at about the time of the syscall. +// This call represents the time base that this module synchronizes to. +// Ensures that *cycleclock does not step back by up to (1 << 16) from +// last_cycleclock, to discard small backward counter steps. (Larger steps are +// assumed to be complete resyncs, which shouldn't happen. If they do, a full +// reinitialization of the outer algorithm should occur.) +static int64_t GetCurrentTimeNanosFromKernel(uint64_t last_cycleclock, + uint64_t *cycleclock) { + // We try to read clock values at about the same time as the kernel clock. + // This value gets adjusted up or down as estimate of how long that should + // take, so we can reject attempts that take unusually long. + static std::atomic<uint64_t> approx_syscall_time_in_cycles{10 * 1000}; + + uint64_t local_approx_syscall_time_in_cycles = // local copy + approx_syscall_time_in_cycles.load(std::memory_order_relaxed); + + int64_t current_time_nanos_from_system; + uint64_t before_cycles; + uint64_t after_cycles; + uint64_t elapsed_cycles; + int loops = 0; + do { + before_cycles = GET_CURRENT_TIME_NANOS_CYCLECLOCK_NOW(); + current_time_nanos_from_system = GET_CURRENT_TIME_NANOS_FROM_SYSTEM(); + after_cycles = GET_CURRENT_TIME_NANOS_CYCLECLOCK_NOW(); + // elapsed_cycles is unsigned, so is large on overflow + elapsed_cycles = after_cycles - before_cycles; + if (elapsed_cycles >= local_approx_syscall_time_in_cycles && + ++loops == 20) { // clock changed frequencies? Back off. + loops = 0; + if (local_approx_syscall_time_in_cycles < 1000 * 1000) { + local_approx_syscall_time_in_cycles = + (local_approx_syscall_time_in_cycles + 1) << 1; + } + approx_syscall_time_in_cycles.store( + local_approx_syscall_time_in_cycles, + std::memory_order_relaxed); + } + } while (elapsed_cycles >= local_approx_syscall_time_in_cycles || + last_cycleclock - after_cycles < (static_cast<uint64_t>(1) << 16)); + + // Number of times in a row we've seen a kernel time call take substantially + // less than approx_syscall_time_in_cycles. + static std::atomic<uint32_t> seen_smaller{ 0 }; + + // Adjust approx_syscall_time_in_cycles to be within a factor of 2 + // of the typical time to execute one iteration of the loop above. + if ((local_approx_syscall_time_in_cycles >> 1) < elapsed_cycles) { + // measured time is no smaller than half current approximation + seen_smaller.store(0, std::memory_order_relaxed); + } else if (seen_smaller.fetch_add(1, std::memory_order_relaxed) >= 3) { + // smaller delays several times in a row; reduce approximation by 12.5% + const uint64_t new_approximation = + local_approx_syscall_time_in_cycles - + (local_approx_syscall_time_in_cycles >> 3); + approx_syscall_time_in_cycles.store(new_approximation, + std::memory_order_relaxed); + seen_smaller.store(0, std::memory_order_relaxed); + } + + *cycleclock = after_cycles; + return current_time_nanos_from_system; +} + + +// --------------------------------------------------------------------- +// An implementation of reader-write locks that use no atomic ops in the read +// case. This is a generalization of Lamport's method for reading a multiword +// clock. Increment a word on each write acquisition, using the low-order bit +// as a spinlock; the word is the high word of the "clock". Readers read the +// high word, then all other data, then the high word again, and repeat the +// read if the reads of the high words yields different answers, or an odd +// value (either case suggests possible interference from a writer). +// Here we use a spinlock to ensure only one writer at a time, rather than +// spinning on the bottom bit of the word to benefit from SpinLock +// spin-delay tuning. + +// Acquire seqlock (*seq) and return the value to be written to unlock. +static inline uint64_t SeqAcquire(std::atomic<uint64_t> *seq) { + uint64_t x = seq->fetch_add(1, std::memory_order_relaxed); + + // We put a release fence between update to *seq and writes to shared data. + // Thus all stores to shared data are effectively release operations and + // update to *seq above cannot be re-ordered past any of them. Note that + // this barrier is not for the fetch_add above. A release barrier for the + // fetch_add would be before it, not after. + std::atomic_thread_fence(std::memory_order_release); + + return x + 2; // original word plus 2 +} + +// Release seqlock (*seq) by writing x to it---a value previously returned by +// SeqAcquire. +static inline void SeqRelease(std::atomic<uint64_t> *seq, uint64_t x) { + // The unlock store to *seq must have release ordering so that all + // updates to shared data must finish before this store. + seq->store(x, std::memory_order_release); // release lock for readers +} + +// --------------------------------------------------------------------- + +// "nsscaled" is unit of time equal to a (2**kScale)th of a nanosecond. +enum { kScale = 30 }; + +// The minimum interval between samples of the time base. +// We pick enough time to amortize the cost of the sample, +// to get a reasonably accurate cycle counter rate reading, +// and not so much that calculations will overflow 64-bits. +static const uint64_t kMinNSBetweenSamples = 2000 << 20; + +// We require that kMinNSBetweenSamples shifted by kScale +// have at least a bit left over for 64-bit calculations. +static_assert(((kMinNSBetweenSamples << (kScale + 1)) >> (kScale + 1)) == + kMinNSBetweenSamples, + "cannot represent kMaxBetweenSamplesNSScaled"); + +// A reader-writer lock protecting the static locations below. +// See SeqAcquire() and SeqRelease() above. +ABSL_CONST_INIT static absl::base_internal::SpinLock lock( + absl::kConstInit, base_internal::SCHEDULE_KERNEL_ONLY); +ABSL_CONST_INIT static std::atomic<uint64_t> seq(0); + +// data from a sample of the kernel's time value +struct TimeSampleAtomic { + std::atomic<uint64_t> raw_ns; // raw kernel time + std::atomic<uint64_t> base_ns; // our estimate of time + std::atomic<uint64_t> base_cycles; // cycle counter reading + std::atomic<uint64_t> nsscaled_per_cycle; // cycle period + // cycles before we'll sample again (a scaled reciprocal of the period, + // to avoid a division on the fast path). + std::atomic<uint64_t> min_cycles_per_sample; +}; +// Same again, but with non-atomic types +struct TimeSample { + uint64_t raw_ns; // raw kernel time + uint64_t base_ns; // our estimate of time + uint64_t base_cycles; // cycle counter reading + uint64_t nsscaled_per_cycle; // cycle period + uint64_t min_cycles_per_sample; // approx cycles before next sample +}; + +static struct TimeSampleAtomic last_sample; // the last sample; under seq + +static int64_t GetCurrentTimeNanosSlowPath() ABSL_ATTRIBUTE_COLD; + +// Read the contents of *atomic into *sample. +// Each field is read atomically, but to maintain atomicity between fields, +// the access must be done under a lock. +static void ReadTimeSampleAtomic(const struct TimeSampleAtomic *atomic, + struct TimeSample *sample) { + sample->base_ns = atomic->base_ns.load(std::memory_order_relaxed); + sample->base_cycles = atomic->base_cycles.load(std::memory_order_relaxed); + sample->nsscaled_per_cycle = + atomic->nsscaled_per_cycle.load(std::memory_order_relaxed); + sample->min_cycles_per_sample = + atomic->min_cycles_per_sample.load(std::memory_order_relaxed); + sample->raw_ns = atomic->raw_ns.load(std::memory_order_relaxed); +} + +// Public routine. +// Algorithm: We wish to compute real time from a cycle counter. In normal +// operation, we construct a piecewise linear approximation to the kernel time +// source, using the cycle counter value. The start of each line segment is at +// the same point as the end of the last, but may have a different slope (that +// is, a different idea of the cycle counter frequency). Every couple of +// seconds, the kernel time source is sampled and compared with the current +// approximation. A new slope is chosen that, if followed for another couple +// of seconds, will correct the error at the current position. The information +// for a sample is in the "last_sample" struct. The linear approximation is +// estimated_time = last_sample.base_ns + +// last_sample.ns_per_cycle * (counter_reading - last_sample.base_cycles) +// (ns_per_cycle is actually stored in different units and scaled, to avoid +// overflow). The base_ns of the next linear approximation is the +// estimated_time using the last approximation; the base_cycles is the cycle +// counter value at that time; the ns_per_cycle is the number of ns per cycle +// measured since the last sample, but adjusted so that most of the difference +// between the estimated_time and the kernel time will be corrected by the +// estimated time to the next sample. In normal operation, this algorithm +// relies on: +// - the cycle counter and kernel time rates not changing a lot in a few +// seconds. +// - the client calling into the code often compared to a couple of seconds, so +// the time to the next correction can be estimated. +// Any time ns_per_cycle is not known, a major error is detected, or the +// assumption about frequent calls is violated, the implementation returns the +// kernel time. It records sufficient data that a linear approximation can +// resume a little later. + +int64_t GetCurrentTimeNanos() { + // read the data from the "last_sample" struct (but don't need raw_ns yet) + // The reads of "seq" and test of the values emulate a reader lock. + uint64_t base_ns; + uint64_t base_cycles; + uint64_t nsscaled_per_cycle; + uint64_t min_cycles_per_sample; + uint64_t seq_read0; + uint64_t seq_read1; + + // If we have enough information to interpolate, the value returned will be + // derived from this cycleclock-derived time estimate. On some platforms + // (POWER) the function to retrieve this value has enough complexity to + // contribute to register pressure - reading it early before initializing + // the other pieces of the calculation minimizes spill/restore instructions, + // minimizing icache cost. + uint64_t now_cycles = GET_CURRENT_TIME_NANOS_CYCLECLOCK_NOW(); + + // Acquire pairs with the barrier in SeqRelease - if this load sees that + // store, the shared-data reads necessarily see that SeqRelease's updates + // to the same shared data. + seq_read0 = seq.load(std::memory_order_acquire); + + base_ns = last_sample.base_ns.load(std::memory_order_relaxed); + base_cycles = last_sample.base_cycles.load(std::memory_order_relaxed); + nsscaled_per_cycle = + last_sample.nsscaled_per_cycle.load(std::memory_order_relaxed); + min_cycles_per_sample = + last_sample.min_cycles_per_sample.load(std::memory_order_relaxed); + + // This acquire fence pairs with the release fence in SeqAcquire. Since it + // is sequenced between reads of shared data and seq_read1, the reads of + // shared data are effectively acquiring. + std::atomic_thread_fence(std::memory_order_acquire); + + // The shared-data reads are effectively acquire ordered, and the + // shared-data writes are effectively release ordered. Therefore if our + // shared-data reads see any of a particular update's shared-data writes, + // seq_read1 is guaranteed to see that update's SeqAcquire. + seq_read1 = seq.load(std::memory_order_relaxed); + + // Fast path. Return if min_cycles_per_sample has not yet elapsed since the + // last sample, and we read a consistent sample. The fast path activates + // only when min_cycles_per_sample is non-zero, which happens when we get an + // estimate for the cycle time. The predicate will fail if now_cycles < + // base_cycles, or if some other thread is in the slow path. + // + // Since we now read now_cycles before base_ns, it is possible for now_cycles + // to be less than base_cycles (if we were interrupted between those loads and + // last_sample was updated). This is harmless, because delta_cycles will wrap + // and report a time much much bigger than min_cycles_per_sample. In that case + // we will take the slow path. + uint64_t delta_cycles = now_cycles - base_cycles; + if (seq_read0 == seq_read1 && (seq_read0 & 1) == 0 && + delta_cycles < min_cycles_per_sample) { + return base_ns + ((delta_cycles * nsscaled_per_cycle) >> kScale); + } + return GetCurrentTimeNanosSlowPath(); +} + +// Return (a << kScale)/b. +// Zero is returned if b==0. Scaling is performed internally to +// preserve precision without overflow. +static uint64_t SafeDivideAndScale(uint64_t a, uint64_t b) { + // Find maximum safe_shift so that + // 0 <= safe_shift <= kScale and (a << safe_shift) does not overflow. + int safe_shift = kScale; + while (((a << safe_shift) >> safe_shift) != a) { + safe_shift--; + } + uint64_t scaled_b = b >> (kScale - safe_shift); + uint64_t quotient = 0; + if (scaled_b != 0) { + quotient = (a << safe_shift) / scaled_b; + } + return quotient; +} + +static uint64_t UpdateLastSample( + uint64_t now_cycles, uint64_t now_ns, uint64_t delta_cycles, + const struct TimeSample *sample) ABSL_ATTRIBUTE_COLD; + +// The slow path of GetCurrentTimeNanos(). This is taken while gathering +// initial samples, when enough time has elapsed since the last sample, and if +// any other thread is writing to last_sample. +// +// Manually mark this 'noinline' to minimize stack frame size of the fast +// path. Without this, sometimes a compiler may inline this big block of code +// into the fast path. That causes lots of register spills and reloads that +// are unnecessary unless the slow path is taken. +// +// TODO(absl-team): Remove this attribute when our compiler is smart enough +// to do the right thing. +ABSL_ATTRIBUTE_NOINLINE +static int64_t GetCurrentTimeNanosSlowPath() ABSL_LOCKS_EXCLUDED(lock) { + // Serialize access to slow-path. Fast-path readers are not blocked yet, and + // code below must not modify last_sample until the seqlock is acquired. + lock.Lock(); + + // Sample the kernel time base. This is the definition of + // "now" if we take the slow path. + static uint64_t last_now_cycles; // protected by lock + uint64_t now_cycles; + uint64_t now_ns = GetCurrentTimeNanosFromKernel(last_now_cycles, &now_cycles); + last_now_cycles = now_cycles; + + uint64_t estimated_base_ns; + + // ---------- + // Read the "last_sample" values again; this time holding the write lock. + struct TimeSample sample; + ReadTimeSampleAtomic(&last_sample, &sample); + + // ---------- + // Try running the fast path again; another thread may have updated the + // sample between our run of the fast path and the sample we just read. + uint64_t delta_cycles = now_cycles - sample.base_cycles; + if (delta_cycles < sample.min_cycles_per_sample) { + // Another thread updated the sample. This path does not take the seqlock + // so that blocked readers can make progress without blocking new readers. + estimated_base_ns = sample.base_ns + + ((delta_cycles * sample.nsscaled_per_cycle) >> kScale); + stats_fast_slow_paths++; + } else { + estimated_base_ns = + UpdateLastSample(now_cycles, now_ns, delta_cycles, &sample); + } + + lock.Unlock(); + + return estimated_base_ns; +} + +// Main part of the algorithm. Locks out readers, updates the approximation +// using the new sample from the kernel, and stores the result in last_sample +// for readers. Returns the new estimated time. +static uint64_t UpdateLastSample(uint64_t now_cycles, uint64_t now_ns, + uint64_t delta_cycles, + const struct TimeSample *sample) + ABSL_EXCLUSIVE_LOCKS_REQUIRED(lock) { + uint64_t estimated_base_ns = now_ns; + uint64_t lock_value = SeqAcquire(&seq); // acquire seqlock to block readers + + // The 5s in the next if-statement limits the time for which we will trust + // the cycle counter and our last sample to give a reasonable result. + // Errors in the rate of the source clock can be multiplied by the ratio + // between this limit and kMinNSBetweenSamples. + if (sample->raw_ns == 0 || // no recent sample, or clock went backwards + sample->raw_ns + static_cast<uint64_t>(5) * 1000 * 1000 * 1000 < now_ns || + now_ns < sample->raw_ns || now_cycles < sample->base_cycles) { + // record this sample, and forget any previously known slope. + last_sample.raw_ns.store(now_ns, std::memory_order_relaxed); + last_sample.base_ns.store(estimated_base_ns, std::memory_order_relaxed); + last_sample.base_cycles.store(now_cycles, std::memory_order_relaxed); + last_sample.nsscaled_per_cycle.store(0, std::memory_order_relaxed); + last_sample.min_cycles_per_sample.store(0, std::memory_order_relaxed); + stats_initializations++; + } else if (sample->raw_ns + 500 * 1000 * 1000 < now_ns && + sample->base_cycles + 50 < now_cycles) { + // Enough time has passed to compute the cycle time. + if (sample->nsscaled_per_cycle != 0) { // Have a cycle time estimate. + // Compute time from counter reading, but avoiding overflow + // delta_cycles may be larger than on the fast path. + uint64_t estimated_scaled_ns; + int s = -1; + do { + s++; + estimated_scaled_ns = (delta_cycles >> s) * sample->nsscaled_per_cycle; + } while (estimated_scaled_ns / sample->nsscaled_per_cycle != + (delta_cycles >> s)); + estimated_base_ns = sample->base_ns + + (estimated_scaled_ns >> (kScale - s)); + } + + // Compute the assumed cycle time kMinNSBetweenSamples ns into the future + // assuming the cycle counter rate stays the same as the last interval. + uint64_t ns = now_ns - sample->raw_ns; + uint64_t measured_nsscaled_per_cycle = SafeDivideAndScale(ns, delta_cycles); + + uint64_t assumed_next_sample_delta_cycles = + SafeDivideAndScale(kMinNSBetweenSamples, measured_nsscaled_per_cycle); + + int64_t diff_ns = now_ns - estimated_base_ns; // estimate low by this much + + // We want to set nsscaled_per_cycle so that our estimate of the ns time + // at the assumed cycle time is the assumed ns time. + // That is, we want to set nsscaled_per_cycle so: + // kMinNSBetweenSamples + diff_ns == + // (assumed_next_sample_delta_cycles * nsscaled_per_cycle) >> kScale + // But we wish to damp oscillations, so instead correct only most + // of our current error, by solving: + // kMinNSBetweenSamples + diff_ns - (diff_ns / 16) == + // (assumed_next_sample_delta_cycles * nsscaled_per_cycle) >> kScale + ns = kMinNSBetweenSamples + diff_ns - (diff_ns / 16); + uint64_t new_nsscaled_per_cycle = + SafeDivideAndScale(ns, assumed_next_sample_delta_cycles); + if (new_nsscaled_per_cycle != 0 && + diff_ns < 100 * 1000 * 1000 && -diff_ns < 100 * 1000 * 1000) { + // record the cycle time measurement + last_sample.nsscaled_per_cycle.store( + new_nsscaled_per_cycle, std::memory_order_relaxed); + uint64_t new_min_cycles_per_sample = + SafeDivideAndScale(kMinNSBetweenSamples, new_nsscaled_per_cycle); + last_sample.min_cycles_per_sample.store( + new_min_cycles_per_sample, std::memory_order_relaxed); + stats_calibrations++; + } else { // something went wrong; forget the slope + last_sample.nsscaled_per_cycle.store(0, std::memory_order_relaxed); + last_sample.min_cycles_per_sample.store(0, std::memory_order_relaxed); + estimated_base_ns = now_ns; + stats_reinitializations++; + } + last_sample.raw_ns.store(now_ns, std::memory_order_relaxed); + last_sample.base_ns.store(estimated_base_ns, std::memory_order_relaxed); + last_sample.base_cycles.store(now_cycles, std::memory_order_relaxed); + } else { + // have a sample, but no slope; waiting for enough time for a calibration + stats_slow_paths++; + } + + SeqRelease(&seq, lock_value); // release the readers + + return estimated_base_ns; +} +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_USE_CYCLECLOCK_FOR_GET_CURRENT_TIME_NANOS + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +// Returns the maximum duration that SleepOnce() can sleep for. +constexpr absl::Duration MaxSleep() { +#ifdef _WIN32 + // Windows Sleep() takes unsigned long argument in milliseconds. + return absl::Milliseconds( + std::numeric_limits<unsigned long>::max()); // NOLINT(runtime/int) +#else + return absl::Seconds(std::numeric_limits<time_t>::max()); +#endif +} + +// Sleeps for the given duration. +// REQUIRES: to_sleep <= MaxSleep(). +void SleepOnce(absl::Duration to_sleep) { +#ifdef _WIN32 + Sleep(to_sleep / absl::Milliseconds(1)); +#else + struct timespec sleep_time = absl::ToTimespec(to_sleep); + while (nanosleep(&sleep_time, &sleep_time) != 0 && errno == EINTR) { + // Ignore signals and wait for the full interval to elapse. + } +#endif +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl + +extern "C" { + +ABSL_ATTRIBUTE_WEAK void AbslInternalSleepFor(absl::Duration duration) { + while (duration > absl::ZeroDuration()) { + absl::Duration to_sleep = std::min(duration, absl::MaxSleep()); + absl::SleepOnce(to_sleep); + duration -= to_sleep; + } +} + +} // extern "C" diff --git a/third_party/abseil_cpp/absl/time/clock.h b/third_party/abseil_cpp/absl/time/clock.h new file mode 100644 index 0000000000..27764a922d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/clock.h @@ -0,0 +1,74 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: clock.h +// ----------------------------------------------------------------------------- +// +// This header file contains utility functions for working with the system-wide +// realtime clock. For descriptions of the main time abstractions used within +// this header file, consult the time.h header file. +#ifndef ABSL_TIME_CLOCK_H_ +#define ABSL_TIME_CLOCK_H_ + +#include "absl/base/macros.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Now() +// +// Returns the current time, expressed as an `absl::Time` absolute time value. +absl::Time Now(); + +// GetCurrentTimeNanos() +// +// Returns the current time, expressed as a count of nanoseconds since the Unix +// Epoch (https://en.wikipedia.org/wiki/Unix_time). Prefer `absl::Now()` instead +// for all but the most performance-sensitive cases (i.e. when you are calling +// this function hundreds of thousands of times per second). +int64_t GetCurrentTimeNanos(); + +// SleepFor() +// +// Sleeps for the specified duration, expressed as an `absl::Duration`. +// +// Notes: +// * Signal interruptions will not reduce the sleep duration. +// * Returns immediately when passed a nonpositive duration. +void SleepFor(absl::Duration duration); + +ABSL_NAMESPACE_END +} // namespace absl + +// ----------------------------------------------------------------------------- +// Implementation Details +// ----------------------------------------------------------------------------- + +// In some build configurations we pass --detect-odr-violations to the +// gold linker. This causes it to flag weak symbol overrides as ODR +// violations. Because ODR only applies to C++ and not C, +// --detect-odr-violations ignores symbols not mangled with C++ names. +// By changing our extension points to be extern "C", we dodge this +// check. +extern "C" { +void AbslInternalSleepFor(absl::Duration duration); +} // extern "C" + +inline void absl::SleepFor(absl::Duration duration) { + AbslInternalSleepFor(duration); +} + +#endif // ABSL_TIME_CLOCK_H_ diff --git a/third_party/abseil_cpp/absl/time/clock_benchmark.cc b/third_party/abseil_cpp/absl/time/clock_benchmark.cc new file mode 100644 index 0000000000..c5c795ecbd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/clock_benchmark.cc @@ -0,0 +1,74 @@ +// Copyright 2018 The Abseil Authors. +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/clock.h" + +#if !defined(_WIN32) +#include <sys/time.h> +#else +#include <winsock2.h> +#endif // _WIN32 +#include <cstdio> + +#include "absl/base/internal/cycleclock.h" +#include "benchmark/benchmark.h" + +namespace { + +void BM_Clock_Now_AbslTime(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Now()); + } +} +BENCHMARK(BM_Clock_Now_AbslTime); + +void BM_Clock_Now_GetCurrentTimeNanos(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::GetCurrentTimeNanos()); + } +} +BENCHMARK(BM_Clock_Now_GetCurrentTimeNanos); + +void BM_Clock_Now_AbslTime_ToUnixNanos(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToUnixNanos(absl::Now())); + } +} +BENCHMARK(BM_Clock_Now_AbslTime_ToUnixNanos); + +void BM_Clock_Now_CycleClock(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::base_internal::CycleClock::Now()); + } +} +BENCHMARK(BM_Clock_Now_CycleClock); + +#if !defined(_WIN32) +static void BM_Clock_Now_gettimeofday(benchmark::State& state) { + struct timeval tv; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(gettimeofday(&tv, nullptr)); + } +} +BENCHMARK(BM_Clock_Now_gettimeofday); + +static void BM_Clock_Now_clock_gettime(benchmark::State& state) { + struct timespec ts; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(clock_gettime(CLOCK_REALTIME, &ts)); + } +} +BENCHMARK(BM_Clock_Now_clock_gettime); +#endif // _WIN32 + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/clock_test.cc b/third_party/abseil_cpp/absl/time/clock_test.cc new file mode 100644 index 0000000000..4bcfc6bc72 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/clock_test.cc @@ -0,0 +1,118 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/clock.h" + +#include "absl/base/config.h" +#if defined(ABSL_HAVE_ALARM) +#include <signal.h> +#include <unistd.h> +#elif defined(__linux__) || defined(__APPLE__) +#error all known Linux and Apple targets have alarm +#endif + +#include "gtest/gtest.h" +#include "absl/time/time.h" + +namespace { + +TEST(Time, Now) { + const absl::Time before = absl::FromUnixNanos(absl::GetCurrentTimeNanos()); + const absl::Time now = absl::Now(); + const absl::Time after = absl::FromUnixNanos(absl::GetCurrentTimeNanos()); + EXPECT_GE(now, before); + EXPECT_GE(after, now); +} + +enum class AlarmPolicy { kWithoutAlarm, kWithAlarm }; + +#if defined(ABSL_HAVE_ALARM) +bool alarm_handler_invoked = false; + +void AlarmHandler(int signo) { + ASSERT_EQ(signo, SIGALRM); + alarm_handler_invoked = true; +} +#endif + +// Does SleepFor(d) take between lower_bound and upper_bound at least +// once between now and (now + timeout)? If requested (and supported), +// add an alarm for the middle of the sleep period and expect it to fire. +bool SleepForBounded(absl::Duration d, absl::Duration lower_bound, + absl::Duration upper_bound, absl::Duration timeout, + AlarmPolicy alarm_policy, int* attempts) { + const absl::Time deadline = absl::Now() + timeout; + while (absl::Now() < deadline) { +#if defined(ABSL_HAVE_ALARM) + sig_t old_alarm = SIG_DFL; + if (alarm_policy == AlarmPolicy::kWithAlarm) { + alarm_handler_invoked = false; + old_alarm = signal(SIGALRM, AlarmHandler); + alarm(absl::ToInt64Seconds(d / 2)); + } +#else + EXPECT_EQ(alarm_policy, AlarmPolicy::kWithoutAlarm); +#endif + ++*attempts; + absl::Time start = absl::Now(); + absl::SleepFor(d); + absl::Duration actual = absl::Now() - start; +#if defined(ABSL_HAVE_ALARM) + if (alarm_policy == AlarmPolicy::kWithAlarm) { + signal(SIGALRM, old_alarm); + if (!alarm_handler_invoked) continue; + } +#endif + if (lower_bound <= actual && actual <= upper_bound) { + return true; // yes, the SleepFor() was correctly bounded + } + } + return false; +} + +testing::AssertionResult AssertSleepForBounded(absl::Duration d, + absl::Duration early, + absl::Duration late, + absl::Duration timeout, + AlarmPolicy alarm_policy) { + const absl::Duration lower_bound = d - early; + const absl::Duration upper_bound = d + late; + int attempts = 0; + if (SleepForBounded(d, lower_bound, upper_bound, timeout, alarm_policy, + &attempts)) { + return testing::AssertionSuccess(); + } + return testing::AssertionFailure() + << "SleepFor(" << d << ") did not return within [" << lower_bound + << ":" << upper_bound << "] in " << attempts << " attempt" + << (attempts == 1 ? "" : "s") << " over " << timeout + << (alarm_policy == AlarmPolicy::kWithAlarm ? " with" : " without") + << " an alarm"; +} + +// Tests that SleepFor() returns neither too early nor too late. +TEST(SleepFor, Bounded) { + const absl::Duration d = absl::Milliseconds(2500); + const absl::Duration early = absl::Milliseconds(100); + const absl::Duration late = absl::Milliseconds(300); + const absl::Duration timeout = 48 * d; + EXPECT_TRUE(AssertSleepForBounded(d, early, late, timeout, + AlarmPolicy::kWithoutAlarm)); +#if defined(ABSL_HAVE_ALARM) + EXPECT_TRUE(AssertSleepForBounded(d, early, late, timeout, + AlarmPolicy::kWithAlarm)); +#endif +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/duration.cc b/third_party/abseil_cpp/absl/time/duration.cc new file mode 100644 index 0000000000..d0f1aadbf2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/duration.cc @@ -0,0 +1,951 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// The implementation of the absl::Duration class, which is declared in +// //absl/time.h. This class behaves like a numeric type; it has no public +// methods and is used only through the operators defined here. +// +// Implementation notes: +// +// An absl::Duration is represented as +// +// rep_hi_ : (int64_t) Whole seconds +// rep_lo_ : (uint32_t) Fractions of a second +// +// The seconds value (rep_hi_) may be positive or negative as appropriate. +// The fractional seconds (rep_lo_) is always a positive offset from rep_hi_. +// The API for Duration guarantees at least nanosecond resolution, which +// means rep_lo_ could have a max value of 1B - 1 if it stored nanoseconds. +// However, to utilize more of the available 32 bits of space in rep_lo_, +// we instead store quarters of a nanosecond in rep_lo_ resulting in a max +// value of 4B - 1. This allows us to correctly handle calculations like +// 0.5 nanos + 0.5 nanos = 1 nano. The following example shows the actual +// Duration rep using quarters of a nanosecond. +// +// 2.5 sec = {rep_hi_=2, rep_lo_=2000000000} // lo = 4 * 500000000 +// -2.5 sec = {rep_hi_=-3, rep_lo_=2000000000} +// +// Infinite durations are represented as Durations with the rep_lo_ field set +// to all 1s. +// +// +InfiniteDuration: +// rep_hi_ : kint64max +// rep_lo_ : ~0U +// +// -InfiniteDuration: +// rep_hi_ : kint64min +// rep_lo_ : ~0U +// +// Arithmetic overflows/underflows to +/- infinity and saturates. + +#if defined(_MSC_VER) +#include <winsock2.h> // for timeval +#endif + +#include <algorithm> +#include <cassert> +#include <cctype> +#include <cerrno> +#include <cmath> +#include <cstdint> +#include <cstdlib> +#include <cstring> +#include <ctime> +#include <functional> +#include <limits> +#include <string> + +#include "absl/base/casts.h" +#include "absl/base/macros.h" +#include "absl/numeric/int128.h" +#include "absl/strings/strip.h" +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +using time_internal::kTicksPerNanosecond; +using time_internal::kTicksPerSecond; + +constexpr int64_t kint64max = std::numeric_limits<int64_t>::max(); +constexpr int64_t kint64min = std::numeric_limits<int64_t>::min(); + +// Can't use std::isinfinite() because it doesn't exist on windows. +inline bool IsFinite(double d) { + if (std::isnan(d)) return false; + return d != std::numeric_limits<double>::infinity() && + d != -std::numeric_limits<double>::infinity(); +} + +inline bool IsValidDivisor(double d) { + if (std::isnan(d)) return false; + return d != 0.0; +} + +// Can't use std::round() because it is only available in C++11. +// Note that we ignore the possibility of floating-point over/underflow. +template <typename Double> +inline double Round(Double d) { + return d < 0 ? std::ceil(d - 0.5) : std::floor(d + 0.5); +} + +// *sec may be positive or negative. *ticks must be in the range +// -kTicksPerSecond < *ticks < kTicksPerSecond. If *ticks is negative it +// will be normalized to a positive value by adjusting *sec accordingly. +inline void NormalizeTicks(int64_t* sec, int64_t* ticks) { + if (*ticks < 0) { + --*sec; + *ticks += kTicksPerSecond; + } +} + +// Makes a uint128 from the absolute value of the given scalar. +inline uint128 MakeU128(int64_t a) { + uint128 u128 = 0; + if (a < 0) { + ++u128; + ++a; // Makes it safe to negate 'a' + a = -a; + } + u128 += static_cast<uint64_t>(a); + return u128; +} + +// Makes a uint128 count of ticks out of the absolute value of the Duration. +inline uint128 MakeU128Ticks(Duration d) { + int64_t rep_hi = time_internal::GetRepHi(d); + uint32_t rep_lo = time_internal::GetRepLo(d); + if (rep_hi < 0) { + ++rep_hi; + rep_hi = -rep_hi; + rep_lo = kTicksPerSecond - rep_lo; + } + uint128 u128 = static_cast<uint64_t>(rep_hi); + u128 *= static_cast<uint64_t>(kTicksPerSecond); + u128 += rep_lo; + return u128; +} + +// Breaks a uint128 of ticks into a Duration. +inline Duration MakeDurationFromU128(uint128 u128, bool is_neg) { + int64_t rep_hi; + uint32_t rep_lo; + const uint64_t h64 = Uint128High64(u128); + const uint64_t l64 = Uint128Low64(u128); + if (h64 == 0) { // fastpath + const uint64_t hi = l64 / kTicksPerSecond; + rep_hi = static_cast<int64_t>(hi); + rep_lo = static_cast<uint32_t>(l64 - hi * kTicksPerSecond); + } else { + // kMaxRepHi64 is the high 64 bits of (2^63 * kTicksPerSecond). + // Any positive tick count whose high 64 bits are >= kMaxRepHi64 + // is not representable as a Duration. A negative tick count can + // have its high 64 bits == kMaxRepHi64 but only when the low 64 + // bits are all zero, otherwise it is not representable either. + const uint64_t kMaxRepHi64 = 0x77359400UL; + if (h64 >= kMaxRepHi64) { + if (is_neg && h64 == kMaxRepHi64 && l64 == 0) { + // Avoid trying to represent -kint64min below. + return time_internal::MakeDuration(kint64min); + } + return is_neg ? -InfiniteDuration() : InfiniteDuration(); + } + const uint128 kTicksPerSecond128 = static_cast<uint64_t>(kTicksPerSecond); + const uint128 hi = u128 / kTicksPerSecond128; + rep_hi = static_cast<int64_t>(Uint128Low64(hi)); + rep_lo = + static_cast<uint32_t>(Uint128Low64(u128 - hi * kTicksPerSecond128)); + } + if (is_neg) { + rep_hi = -rep_hi; + if (rep_lo != 0) { + --rep_hi; + rep_lo = kTicksPerSecond - rep_lo; + } + } + return time_internal::MakeDuration(rep_hi, rep_lo); +} + +// Convert between int64_t and uint64_t, preserving representation. This +// allows us to do arithmetic in the unsigned domain, where overflow has +// well-defined behavior. See operator+=() and operator-=(). +// +// C99 7.20.1.1.1, as referenced by C++11 18.4.1.2, says, "The typedef +// name intN_t designates a signed integer type with width N, no padding +// bits, and a two's complement representation." So, we can convert to +// and from the corresponding uint64_t value using a bit cast. +inline uint64_t EncodeTwosComp(int64_t v) { + return absl::bit_cast<uint64_t>(v); +} +inline int64_t DecodeTwosComp(uint64_t v) { return absl::bit_cast<int64_t>(v); } + +// Note: The overflow detection in this function is done using greater/less *or +// equal* because kint64max/min is too large to be represented exactly in a +// double (which only has 53 bits of precision). In order to avoid assigning to +// rep->hi a double value that is too large for an int64_t (and therefore is +// undefined), we must consider computations that equal kint64max/min as a +// double as overflow cases. +inline bool SafeAddRepHi(double a_hi, double b_hi, Duration* d) { + double c = a_hi + b_hi; + if (c >= static_cast<double>(kint64max)) { + *d = InfiniteDuration(); + return false; + } + if (c <= static_cast<double>(kint64min)) { + *d = -InfiniteDuration(); + return false; + } + *d = time_internal::MakeDuration(c, time_internal::GetRepLo(*d)); + return true; +} + +// A functor that's similar to std::multiplies<T>, except this returns the max +// T value instead of overflowing. This is only defined for uint128. +template <typename Ignored> +struct SafeMultiply { + uint128 operator()(uint128 a, uint128 b) const { + // b hi is always zero because it originated as an int64_t. + assert(Uint128High64(b) == 0); + // Fastpath to avoid the expensive overflow check with division. + if (Uint128High64(a) == 0) { + return (((Uint128Low64(a) | Uint128Low64(b)) >> 32) == 0) + ? static_cast<uint128>(Uint128Low64(a) * Uint128Low64(b)) + : a * b; + } + return b == 0 ? b : (a > kuint128max / b) ? kuint128max : a * b; + } +}; + +// Scales (i.e., multiplies or divides, depending on the Operation template) +// the Duration d by the int64_t r. +template <template <typename> class Operation> +inline Duration ScaleFixed(Duration d, int64_t r) { + const uint128 a = MakeU128Ticks(d); + const uint128 b = MakeU128(r); + const uint128 q = Operation<uint128>()(a, b); + const bool is_neg = (time_internal::GetRepHi(d) < 0) != (r < 0); + return MakeDurationFromU128(q, is_neg); +} + +// Scales (i.e., multiplies or divides, depending on the Operation template) +// the Duration d by the double r. +template <template <typename> class Operation> +inline Duration ScaleDouble(Duration d, double r) { + Operation<double> op; + double hi_doub = op(time_internal::GetRepHi(d), r); + double lo_doub = op(time_internal::GetRepLo(d), r); + + double hi_int = 0; + double hi_frac = std::modf(hi_doub, &hi_int); + + // Moves hi's fractional bits to lo. + lo_doub /= kTicksPerSecond; + lo_doub += hi_frac; + + double lo_int = 0; + double lo_frac = std::modf(lo_doub, &lo_int); + + // Rolls lo into hi if necessary. + int64_t lo64 = Round(lo_frac * kTicksPerSecond); + + Duration ans; + if (!SafeAddRepHi(hi_int, lo_int, &ans)) return ans; + int64_t hi64 = time_internal::GetRepHi(ans); + if (!SafeAddRepHi(hi64, lo64 / kTicksPerSecond, &ans)) return ans; + hi64 = time_internal::GetRepHi(ans); + lo64 %= kTicksPerSecond; + NormalizeTicks(&hi64, &lo64); + return time_internal::MakeDuration(hi64, lo64); +} + +// Tries to divide num by den as fast as possible by looking for common, easy +// cases. If the division was done, the quotient is in *q and the remainder is +// in *rem and true will be returned. +inline bool IDivFastPath(const Duration num, const Duration den, int64_t* q, + Duration* rem) { + // Bail if num or den is an infinity. + if (time_internal::IsInfiniteDuration(num) || + time_internal::IsInfiniteDuration(den)) + return false; + + int64_t num_hi = time_internal::GetRepHi(num); + uint32_t num_lo = time_internal::GetRepLo(num); + int64_t den_hi = time_internal::GetRepHi(den); + uint32_t den_lo = time_internal::GetRepLo(den); + + if (den_hi == 0 && den_lo == kTicksPerNanosecond) { + // Dividing by 1ns + if (num_hi >= 0 && num_hi < (kint64max - kTicksPerSecond) / 1000000000) { + *q = num_hi * 1000000000 + num_lo / kTicksPerNanosecond; + *rem = time_internal::MakeDuration(0, num_lo % den_lo); + return true; + } + } else if (den_hi == 0 && den_lo == 100 * kTicksPerNanosecond) { + // Dividing by 100ns (common when converting to Universal time) + if (num_hi >= 0 && num_hi < (kint64max - kTicksPerSecond) / 10000000) { + *q = num_hi * 10000000 + num_lo / (100 * kTicksPerNanosecond); + *rem = time_internal::MakeDuration(0, num_lo % den_lo); + return true; + } + } else if (den_hi == 0 && den_lo == 1000 * kTicksPerNanosecond) { + // Dividing by 1us + if (num_hi >= 0 && num_hi < (kint64max - kTicksPerSecond) / 1000000) { + *q = num_hi * 1000000 + num_lo / (1000 * kTicksPerNanosecond); + *rem = time_internal::MakeDuration(0, num_lo % den_lo); + return true; + } + } else if (den_hi == 0 && den_lo == 1000000 * kTicksPerNanosecond) { + // Dividing by 1ms + if (num_hi >= 0 && num_hi < (kint64max - kTicksPerSecond) / 1000) { + *q = num_hi * 1000 + num_lo / (1000000 * kTicksPerNanosecond); + *rem = time_internal::MakeDuration(0, num_lo % den_lo); + return true; + } + } else if (den_hi > 0 && den_lo == 0) { + // Dividing by positive multiple of 1s + if (num_hi >= 0) { + if (den_hi == 1) { + *q = num_hi; + *rem = time_internal::MakeDuration(0, num_lo); + return true; + } + *q = num_hi / den_hi; + *rem = time_internal::MakeDuration(num_hi % den_hi, num_lo); + return true; + } + if (num_lo != 0) { + num_hi += 1; + } + int64_t quotient = num_hi / den_hi; + int64_t rem_sec = num_hi % den_hi; + if (rem_sec > 0) { + rem_sec -= den_hi; + quotient += 1; + } + if (num_lo != 0) { + rem_sec -= 1; + } + *q = quotient; + *rem = time_internal::MakeDuration(rem_sec, num_lo); + return true; + } + + return false; +} + +} // namespace + +namespace time_internal { + +// The 'satq' argument indicates whether the quotient should saturate at the +// bounds of int64_t. If it does saturate, the difference will spill over to +// the remainder. If it does not saturate, the remainder remain accurate, +// but the returned quotient will over/underflow int64_t and should not be used. +int64_t IDivDuration(bool satq, const Duration num, const Duration den, + Duration* rem) { + int64_t q = 0; + if (IDivFastPath(num, den, &q, rem)) { + return q; + } + + const bool num_neg = num < ZeroDuration(); + const bool den_neg = den < ZeroDuration(); + const bool quotient_neg = num_neg != den_neg; + + if (time_internal::IsInfiniteDuration(num) || den == ZeroDuration()) { + *rem = num_neg ? -InfiniteDuration() : InfiniteDuration(); + return quotient_neg ? kint64min : kint64max; + } + if (time_internal::IsInfiniteDuration(den)) { + *rem = num; + return 0; + } + + const uint128 a = MakeU128Ticks(num); + const uint128 b = MakeU128Ticks(den); + uint128 quotient128 = a / b; + + if (satq) { + // Limits the quotient to the range of int64_t. + if (quotient128 > uint128(static_cast<uint64_t>(kint64max))) { + quotient128 = quotient_neg ? uint128(static_cast<uint64_t>(kint64min)) + : uint128(static_cast<uint64_t>(kint64max)); + } + } + + const uint128 remainder128 = a - quotient128 * b; + *rem = MakeDurationFromU128(remainder128, num_neg); + + if (!quotient_neg || quotient128 == 0) { + return Uint128Low64(quotient128) & kint64max; + } + // The quotient needs to be negated, but we need to carefully handle + // quotient128s with the top bit on. + return -static_cast<int64_t>(Uint128Low64(quotient128 - 1) & kint64max) - 1; +} + +} // namespace time_internal + +// +// Additive operators. +// + +Duration& Duration::operator+=(Duration rhs) { + if (time_internal::IsInfiniteDuration(*this)) return *this; + if (time_internal::IsInfiniteDuration(rhs)) return *this = rhs; + const int64_t orig_rep_hi = rep_hi_; + rep_hi_ = + DecodeTwosComp(EncodeTwosComp(rep_hi_) + EncodeTwosComp(rhs.rep_hi_)); + if (rep_lo_ >= kTicksPerSecond - rhs.rep_lo_) { + rep_hi_ = DecodeTwosComp(EncodeTwosComp(rep_hi_) + 1); + rep_lo_ -= kTicksPerSecond; + } + rep_lo_ += rhs.rep_lo_; + if (rhs.rep_hi_ < 0 ? rep_hi_ > orig_rep_hi : rep_hi_ < orig_rep_hi) { + return *this = rhs.rep_hi_ < 0 ? -InfiniteDuration() : InfiniteDuration(); + } + return *this; +} + +Duration& Duration::operator-=(Duration rhs) { + if (time_internal::IsInfiniteDuration(*this)) return *this; + if (time_internal::IsInfiniteDuration(rhs)) { + return *this = rhs.rep_hi_ >= 0 ? -InfiniteDuration() : InfiniteDuration(); + } + const int64_t orig_rep_hi = rep_hi_; + rep_hi_ = + DecodeTwosComp(EncodeTwosComp(rep_hi_) - EncodeTwosComp(rhs.rep_hi_)); + if (rep_lo_ < rhs.rep_lo_) { + rep_hi_ = DecodeTwosComp(EncodeTwosComp(rep_hi_) - 1); + rep_lo_ += kTicksPerSecond; + } + rep_lo_ -= rhs.rep_lo_; + if (rhs.rep_hi_ < 0 ? rep_hi_ < orig_rep_hi : rep_hi_ > orig_rep_hi) { + return *this = rhs.rep_hi_ >= 0 ? -InfiniteDuration() : InfiniteDuration(); + } + return *this; +} + +// +// Multiplicative operators. +// + +Duration& Duration::operator*=(int64_t r) { + if (time_internal::IsInfiniteDuration(*this)) { + const bool is_neg = (r < 0) != (rep_hi_ < 0); + return *this = is_neg ? -InfiniteDuration() : InfiniteDuration(); + } + return *this = ScaleFixed<SafeMultiply>(*this, r); +} + +Duration& Duration::operator*=(double r) { + if (time_internal::IsInfiniteDuration(*this) || !IsFinite(r)) { + const bool is_neg = (std::signbit(r) != 0) != (rep_hi_ < 0); + return *this = is_neg ? -InfiniteDuration() : InfiniteDuration(); + } + return *this = ScaleDouble<std::multiplies>(*this, r); +} + +Duration& Duration::operator/=(int64_t r) { + if (time_internal::IsInfiniteDuration(*this) || r == 0) { + const bool is_neg = (r < 0) != (rep_hi_ < 0); + return *this = is_neg ? -InfiniteDuration() : InfiniteDuration(); + } + return *this = ScaleFixed<std::divides>(*this, r); +} + +Duration& Duration::operator/=(double r) { + if (time_internal::IsInfiniteDuration(*this) || !IsValidDivisor(r)) { + const bool is_neg = (std::signbit(r) != 0) != (rep_hi_ < 0); + return *this = is_neg ? -InfiniteDuration() : InfiniteDuration(); + } + return *this = ScaleDouble<std::divides>(*this, r); +} + +Duration& Duration::operator%=(Duration rhs) { + time_internal::IDivDuration(false, *this, rhs, this); + return *this; +} + +double FDivDuration(Duration num, Duration den) { + // Arithmetic with infinity is sticky. + if (time_internal::IsInfiniteDuration(num) || den == ZeroDuration()) { + return (num < ZeroDuration()) == (den < ZeroDuration()) + ? std::numeric_limits<double>::infinity() + : -std::numeric_limits<double>::infinity(); + } + if (time_internal::IsInfiniteDuration(den)) return 0.0; + + double a = + static_cast<double>(time_internal::GetRepHi(num)) * kTicksPerSecond + + time_internal::GetRepLo(num); + double b = + static_cast<double>(time_internal::GetRepHi(den)) * kTicksPerSecond + + time_internal::GetRepLo(den); + return a / b; +} + +// +// Trunc/Floor/Ceil. +// + +Duration Trunc(Duration d, Duration unit) { + return d - (d % unit); +} + +Duration Floor(const Duration d, const Duration unit) { + const absl::Duration td = Trunc(d, unit); + return td <= d ? td : td - AbsDuration(unit); +} + +Duration Ceil(const Duration d, const Duration unit) { + const absl::Duration td = Trunc(d, unit); + return td >= d ? td : td + AbsDuration(unit); +} + +// +// Factory functions. +// + +Duration DurationFromTimespec(timespec ts) { + if (static_cast<uint64_t>(ts.tv_nsec) < 1000 * 1000 * 1000) { + int64_t ticks = ts.tv_nsec * kTicksPerNanosecond; + return time_internal::MakeDuration(ts.tv_sec, ticks); + } + return Seconds(ts.tv_sec) + Nanoseconds(ts.tv_nsec); +} + +Duration DurationFromTimeval(timeval tv) { + if (static_cast<uint64_t>(tv.tv_usec) < 1000 * 1000) { + int64_t ticks = tv.tv_usec * 1000 * kTicksPerNanosecond; + return time_internal::MakeDuration(tv.tv_sec, ticks); + } + return Seconds(tv.tv_sec) + Microseconds(tv.tv_usec); +} + +// +// Conversion to other duration types. +// + +int64_t ToInt64Nanoseconds(Duration d) { + if (time_internal::GetRepHi(d) >= 0 && + time_internal::GetRepHi(d) >> 33 == 0) { + return (time_internal::GetRepHi(d) * 1000 * 1000 * 1000) + + (time_internal::GetRepLo(d) / kTicksPerNanosecond); + } + return d / Nanoseconds(1); +} +int64_t ToInt64Microseconds(Duration d) { + if (time_internal::GetRepHi(d) >= 0 && + time_internal::GetRepHi(d) >> 43 == 0) { + return (time_internal::GetRepHi(d) * 1000 * 1000) + + (time_internal::GetRepLo(d) / (kTicksPerNanosecond * 1000)); + } + return d / Microseconds(1); +} +int64_t ToInt64Milliseconds(Duration d) { + if (time_internal::GetRepHi(d) >= 0 && + time_internal::GetRepHi(d) >> 53 == 0) { + return (time_internal::GetRepHi(d) * 1000) + + (time_internal::GetRepLo(d) / (kTicksPerNanosecond * 1000 * 1000)); + } + return d / Milliseconds(1); +} +int64_t ToInt64Seconds(Duration d) { + int64_t hi = time_internal::GetRepHi(d); + if (time_internal::IsInfiniteDuration(d)) return hi; + if (hi < 0 && time_internal::GetRepLo(d) != 0) ++hi; + return hi; +} +int64_t ToInt64Minutes(Duration d) { + int64_t hi = time_internal::GetRepHi(d); + if (time_internal::IsInfiniteDuration(d)) return hi; + if (hi < 0 && time_internal::GetRepLo(d) != 0) ++hi; + return hi / 60; +} +int64_t ToInt64Hours(Duration d) { + int64_t hi = time_internal::GetRepHi(d); + if (time_internal::IsInfiniteDuration(d)) return hi; + if (hi < 0 && time_internal::GetRepLo(d) != 0) ++hi; + return hi / (60 * 60); +} + +double ToDoubleNanoseconds(Duration d) { + return FDivDuration(d, Nanoseconds(1)); +} +double ToDoubleMicroseconds(Duration d) { + return FDivDuration(d, Microseconds(1)); +} +double ToDoubleMilliseconds(Duration d) { + return FDivDuration(d, Milliseconds(1)); +} +double ToDoubleSeconds(Duration d) { + return FDivDuration(d, Seconds(1)); +} +double ToDoubleMinutes(Duration d) { + return FDivDuration(d, Minutes(1)); +} +double ToDoubleHours(Duration d) { + return FDivDuration(d, Hours(1)); +} + +timespec ToTimespec(Duration d) { + timespec ts; + if (!time_internal::IsInfiniteDuration(d)) { + int64_t rep_hi = time_internal::GetRepHi(d); + uint32_t rep_lo = time_internal::GetRepLo(d); + if (rep_hi < 0) { + // Tweak the fields so that unsigned division of rep_lo + // maps to truncation (towards zero) for the timespec. + rep_lo += kTicksPerNanosecond - 1; + if (rep_lo >= kTicksPerSecond) { + rep_hi += 1; + rep_lo -= kTicksPerSecond; + } + } + ts.tv_sec = rep_hi; + if (ts.tv_sec == rep_hi) { // no time_t narrowing + ts.tv_nsec = rep_lo / kTicksPerNanosecond; + return ts; + } + } + if (d >= ZeroDuration()) { + ts.tv_sec = std::numeric_limits<time_t>::max(); + ts.tv_nsec = 1000 * 1000 * 1000 - 1; + } else { + ts.tv_sec = std::numeric_limits<time_t>::min(); + ts.tv_nsec = 0; + } + return ts; +} + +timeval ToTimeval(Duration d) { + timeval tv; + timespec ts = ToTimespec(d); + if (ts.tv_sec < 0) { + // Tweak the fields so that positive division of tv_nsec + // maps to truncation (towards zero) for the timeval. + ts.tv_nsec += 1000 - 1; + if (ts.tv_nsec >= 1000 * 1000 * 1000) { + ts.tv_sec += 1; + ts.tv_nsec -= 1000 * 1000 * 1000; + } + } + tv.tv_sec = ts.tv_sec; + if (tv.tv_sec != ts.tv_sec) { // narrowing + if (ts.tv_sec < 0) { + tv.tv_sec = std::numeric_limits<decltype(tv.tv_sec)>::min(); + tv.tv_usec = 0; + } else { + tv.tv_sec = std::numeric_limits<decltype(tv.tv_sec)>::max(); + tv.tv_usec = 1000 * 1000 - 1; + } + return tv; + } + tv.tv_usec = static_cast<int>(ts.tv_nsec / 1000); // suseconds_t + return tv; +} + +std::chrono::nanoseconds ToChronoNanoseconds(Duration d) { + return time_internal::ToChronoDuration<std::chrono::nanoseconds>(d); +} +std::chrono::microseconds ToChronoMicroseconds(Duration d) { + return time_internal::ToChronoDuration<std::chrono::microseconds>(d); +} +std::chrono::milliseconds ToChronoMilliseconds(Duration d) { + return time_internal::ToChronoDuration<std::chrono::milliseconds>(d); +} +std::chrono::seconds ToChronoSeconds(Duration d) { + return time_internal::ToChronoDuration<std::chrono::seconds>(d); +} +std::chrono::minutes ToChronoMinutes(Duration d) { + return time_internal::ToChronoDuration<std::chrono::minutes>(d); +} +std::chrono::hours ToChronoHours(Duration d) { + return time_internal::ToChronoDuration<std::chrono::hours>(d); +} + +// +// To/From string formatting. +// + +namespace { + +// Formats a positive 64-bit integer in the given field width. Note that +// it is up to the caller of Format64() to ensure that there is sufficient +// space before ep to hold the conversion. +char* Format64(char* ep, int width, int64_t v) { + do { + --width; + *--ep = '0' + (v % 10); // contiguous digits + } while (v /= 10); + while (--width >= 0) *--ep = '0'; // zero pad + return ep; +} + +// Helpers for FormatDuration() that format 'n' and append it to 'out' +// followed by the given 'unit'. If 'n' formats to "0", nothing is +// appended (not even the unit). + +// A type that encapsulates how to display a value of a particular unit. For +// values that are displayed with fractional parts, the precision indicates +// where to round the value. The precision varies with the display unit because +// a Duration can hold only quarters of a nanosecond, so displaying information +// beyond that is just noise. +// +// For example, a microsecond value of 42.00025xxxxx should not display beyond 5 +// fractional digits, because it is in the noise of what a Duration can +// represent. +struct DisplayUnit { + const char* abbr; + int prec; + double pow10; +}; +const DisplayUnit kDisplayNano = {"ns", 2, 1e2}; +const DisplayUnit kDisplayMicro = {"us", 5, 1e5}; +const DisplayUnit kDisplayMilli = {"ms", 8, 1e8}; +const DisplayUnit kDisplaySec = {"s", 11, 1e11}; +const DisplayUnit kDisplayMin = {"m", -1, 0.0}; // prec ignored +const DisplayUnit kDisplayHour = {"h", -1, 0.0}; // prec ignored + +void AppendNumberUnit(std::string* out, int64_t n, DisplayUnit unit) { + char buf[sizeof("2562047788015216")]; // hours in max duration + char* const ep = buf + sizeof(buf); + char* bp = Format64(ep, 0, n); + if (*bp != '0' || bp + 1 != ep) { + out->append(bp, ep - bp); + out->append(unit.abbr); + } +} + +// Note: unit.prec is limited to double's digits10 value (typically 15) so it +// always fits in buf[]. +void AppendNumberUnit(std::string* out, double n, DisplayUnit unit) { + constexpr int kBufferSize = std::numeric_limits<double>::digits10; + const int prec = std::min(kBufferSize, unit.prec); + char buf[kBufferSize]; // also large enough to hold integer part + char* ep = buf + sizeof(buf); + double d = 0; + int64_t frac_part = Round(std::modf(n, &d) * unit.pow10); + int64_t int_part = d; + if (int_part != 0 || frac_part != 0) { + char* bp = Format64(ep, 0, int_part); // always < 1000 + out->append(bp, ep - bp); + if (frac_part != 0) { + out->push_back('.'); + bp = Format64(ep, prec, frac_part); + while (ep[-1] == '0') --ep; + out->append(bp, ep - bp); + } + out->append(unit.abbr); + } +} + +} // namespace + +// From Go's doc at https://golang.org/pkg/time/#Duration.String +// [FormatDuration] returns a string representing the duration in the +// form "72h3m0.5s". Leading zero units are omitted. As a special +// case, durations less than one second format use a smaller unit +// (milli-, micro-, or nanoseconds) to ensure that the leading digit +// is non-zero. The zero duration formats as 0, with no unit. +std::string FormatDuration(Duration d) { + const Duration min_duration = Seconds(kint64min); + if (d == min_duration) { + // Avoid needing to negate kint64min by directly returning what the + // following code should produce in that case. + return "-2562047788015215h30m8s"; + } + std::string s; + if (d < ZeroDuration()) { + s.append("-"); + d = -d; + } + if (d == InfiniteDuration()) { + s.append("inf"); + } else if (d < Seconds(1)) { + // Special case for durations with a magnitude < 1 second. The duration + // is printed as a fraction of a single unit, e.g., "1.2ms". + if (d < Microseconds(1)) { + AppendNumberUnit(&s, FDivDuration(d, Nanoseconds(1)), kDisplayNano); + } else if (d < Milliseconds(1)) { + AppendNumberUnit(&s, FDivDuration(d, Microseconds(1)), kDisplayMicro); + } else { + AppendNumberUnit(&s, FDivDuration(d, Milliseconds(1)), kDisplayMilli); + } + } else { + AppendNumberUnit(&s, IDivDuration(d, Hours(1), &d), kDisplayHour); + AppendNumberUnit(&s, IDivDuration(d, Minutes(1), &d), kDisplayMin); + AppendNumberUnit(&s, FDivDuration(d, Seconds(1)), kDisplaySec); + } + if (s.empty() || s == "-") { + s = "0"; + } + return s; +} + +namespace { + +// A helper for ParseDuration() that parses a leading number from the given +// string and stores the result in *int_part/*frac_part/*frac_scale. The +// given string pointer is modified to point to the first unconsumed char. +bool ConsumeDurationNumber(const char** dpp, const char* ep, int64_t* int_part, + int64_t* frac_part, int64_t* frac_scale) { + *int_part = 0; + *frac_part = 0; + *frac_scale = 1; // invariant: *frac_part < *frac_scale + const char* start = *dpp; + for (; *dpp != ep; *dpp += 1) { + const int d = **dpp - '0'; // contiguous digits + if (d < 0 || 10 <= d) break; + + if (*int_part > kint64max / 10) return false; + *int_part *= 10; + if (*int_part > kint64max - d) return false; + *int_part += d; + } + const bool int_part_empty = (*dpp == start); + if (*dpp == ep || **dpp != '.') return !int_part_empty; + + for (*dpp += 1; *dpp != ep; *dpp += 1) { + const int d = **dpp - '0'; // contiguous digits + if (d < 0 || 10 <= d) break; + if (*frac_scale <= kint64max / 10) { + *frac_part *= 10; + *frac_part += d; + *frac_scale *= 10; + } + } + return !int_part_empty || *frac_scale != 1; +} + +// A helper for ParseDuration() that parses a leading unit designator (e.g., +// ns, us, ms, s, m, h) from the given string and stores the resulting unit +// in "*unit". The given string pointer is modified to point to the first +// unconsumed char. +bool ConsumeDurationUnit(const char** start, const char* end, Duration* unit) { + size_t size = end - *start; + switch (size) { + case 0: + return false; + default: + switch (**start) { + case 'n': + if (*(*start + 1) == 's') { + *start += 2; + *unit = Nanoseconds(1); + return true; + } + break; + case 'u': + if (*(*start + 1) == 's') { + *start += 2; + *unit = Microseconds(1); + return true; + } + break; + case 'm': + if (*(*start + 1) == 's') { + *start += 2; + *unit = Milliseconds(1); + return true; + } + break; + default: + break; + } + ABSL_FALLTHROUGH_INTENDED; + case 1: + switch (**start) { + case 's': + *unit = Seconds(1); + *start += 1; + return true; + case 'm': + *unit = Minutes(1); + *start += 1; + return true; + case 'h': + *unit = Hours(1); + *start += 1; + return true; + default: + return false; + } + } +} + +} // namespace + +// From Go's doc at https://golang.org/pkg/time/#ParseDuration +// [ParseDuration] parses a duration string. A duration string is +// a possibly signed sequence of decimal numbers, each with optional +// fraction and a unit suffix, such as "300ms", "-1.5h" or "2h45m". +// Valid time units are "ns", "us" "ms", "s", "m", "h". +bool ParseDuration(absl::string_view dur_sv, Duration* d) { + int sign = 1; + if (absl::ConsumePrefix(&dur_sv, "-")) { + sign = -1; + } else { + absl::ConsumePrefix(&dur_sv, "+"); + } + if (dur_sv.empty()) return false; + + // Special case for a string of "0". + if (dur_sv == "0") { + *d = ZeroDuration(); + return true; + } + + if (dur_sv == "inf") { + *d = sign * InfiniteDuration(); + return true; + } + + const char* start = dur_sv.data(); + const char* end = start + dur_sv.size(); + + Duration dur; + while (start != end) { + int64_t int_part; + int64_t frac_part; + int64_t frac_scale; + Duration unit; + if (!ConsumeDurationNumber(&start, end, &int_part, &frac_part, + &frac_scale) || + !ConsumeDurationUnit(&start, end, &unit)) { + return false; + } + if (int_part != 0) dur += sign * int_part * unit; + if (frac_part != 0) dur += sign * frac_part * unit / frac_scale; + } + *d = dur; + return true; +} + +bool AbslParseFlag(absl::string_view text, Duration* dst, std::string*) { + return ParseDuration(text, dst); +} + +std::string AbslUnparseFlag(Duration d) { return FormatDuration(d); } +bool ParseFlag(const std::string& text, Duration* dst, std::string* ) { + return ParseDuration(text, dst); +} + +std::string UnparseFlag(Duration d) { return FormatDuration(d); } + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/duration_benchmark.cc b/third_party/abseil_cpp/absl/time/duration_benchmark.cc new file mode 100644 index 0000000000..83a836c8c8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/duration_benchmark.cc @@ -0,0 +1,428 @@ +// Copyright 2018 The Abseil Authors. +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cmath> +#include <cstddef> +#include <cstdint> +#include <ctime> +#include <string> + +#include "absl/base/attributes.h" +#include "absl/time/time.h" +#include "benchmark/benchmark.h" + +namespace { + +// +// Factory functions +// + +void BM_Duration_Factory_Nanoseconds(benchmark::State& state) { + int64_t i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Nanoseconds(i)); + i += 314159; + } +} +BENCHMARK(BM_Duration_Factory_Nanoseconds); + +void BM_Duration_Factory_Microseconds(benchmark::State& state) { + int64_t i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Microseconds(i)); + i += 314; + } +} +BENCHMARK(BM_Duration_Factory_Microseconds); + +void BM_Duration_Factory_Milliseconds(benchmark::State& state) { + int64_t i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Milliseconds(i)); + i += 1; + } +} +BENCHMARK(BM_Duration_Factory_Milliseconds); + +void BM_Duration_Factory_Seconds(benchmark::State& state) { + int64_t i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Seconds(i)); + i += 1; + } +} +BENCHMARK(BM_Duration_Factory_Seconds); + +void BM_Duration_Factory_Minutes(benchmark::State& state) { + int64_t i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Minutes(i)); + i += 1; + } +} +BENCHMARK(BM_Duration_Factory_Minutes); + +void BM_Duration_Factory_Hours(benchmark::State& state) { + int64_t i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Hours(i)); + i += 1; + } +} +BENCHMARK(BM_Duration_Factory_Hours); + +void BM_Duration_Factory_DoubleNanoseconds(benchmark::State& state) { + double d = 1; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Nanoseconds(d)); + d = d * 1.00000001 + 1; + } +} +BENCHMARK(BM_Duration_Factory_DoubleNanoseconds); + +void BM_Duration_Factory_DoubleMicroseconds(benchmark::State& state) { + double d = 1e-3; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Microseconds(d)); + d = d * 1.00000001 + 1e-3; + } +} +BENCHMARK(BM_Duration_Factory_DoubleMicroseconds); + +void BM_Duration_Factory_DoubleMilliseconds(benchmark::State& state) { + double d = 1e-6; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Milliseconds(d)); + d = d * 1.00000001 + 1e-6; + } +} +BENCHMARK(BM_Duration_Factory_DoubleMilliseconds); + +void BM_Duration_Factory_DoubleSeconds(benchmark::State& state) { + double d = 1e-9; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Seconds(d)); + d = d * 1.00000001 + 1e-9; + } +} +BENCHMARK(BM_Duration_Factory_DoubleSeconds); + +void BM_Duration_Factory_DoubleMinutes(benchmark::State& state) { + double d = 1e-9; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Minutes(d)); + d = d * 1.00000001 + 1e-9; + } +} +BENCHMARK(BM_Duration_Factory_DoubleMinutes); + +void BM_Duration_Factory_DoubleHours(benchmark::State& state) { + double d = 1e-9; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::Hours(d)); + d = d * 1.00000001 + 1e-9; + } +} +BENCHMARK(BM_Duration_Factory_DoubleHours); + +// +// Arithmetic +// + +void BM_Duration_Addition(benchmark::State& state) { + absl::Duration d = absl::Nanoseconds(1); + absl::Duration step = absl::Milliseconds(1); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(d += step); + } +} +BENCHMARK(BM_Duration_Addition); + +void BM_Duration_Subtraction(benchmark::State& state) { + absl::Duration d = absl::Seconds(std::numeric_limits<int64_t>::max()); + absl::Duration step = absl::Milliseconds(1); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(d -= step); + } +} +BENCHMARK(BM_Duration_Subtraction); + +void BM_Duration_Multiplication_Fixed(benchmark::State& state) { + absl::Duration d = absl::Milliseconds(1); + absl::Duration s; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(s += d * (i + 1)); + ++i; + } +} +BENCHMARK(BM_Duration_Multiplication_Fixed); + +void BM_Duration_Multiplication_Double(benchmark::State& state) { + absl::Duration d = absl::Milliseconds(1); + absl::Duration s; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(s += d * (i + 1.0)); + ++i; + } +} +BENCHMARK(BM_Duration_Multiplication_Double); + +void BM_Duration_Division_Fixed(benchmark::State& state) { + absl::Duration d = absl::Seconds(1); + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(d /= i + 1); + ++i; + } +} +BENCHMARK(BM_Duration_Division_Fixed); + +void BM_Duration_Division_Double(benchmark::State& state) { + absl::Duration d = absl::Seconds(1); + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(d /= i + 1.0); + ++i; + } +} +BENCHMARK(BM_Duration_Division_Double); + +void BM_Duration_FDivDuration_Nanoseconds(benchmark::State& state) { + double d = 1; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize( + d += absl::FDivDuration(absl::Milliseconds(i), absl::Nanoseconds(1))); + ++i; + } +} +BENCHMARK(BM_Duration_FDivDuration_Nanoseconds); + +void BM_Duration_IDivDuration_Nanoseconds(benchmark::State& state) { + int64_t a = 1; + absl::Duration ignore; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(a += + absl::IDivDuration(absl::Nanoseconds(i), + absl::Nanoseconds(1), &ignore)); + ++i; + } +} +BENCHMARK(BM_Duration_IDivDuration_Nanoseconds); + +void BM_Duration_IDivDuration_Microseconds(benchmark::State& state) { + int64_t a = 1; + absl::Duration ignore; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(a += absl::IDivDuration(absl::Microseconds(i), + absl::Microseconds(1), + &ignore)); + ++i; + } +} +BENCHMARK(BM_Duration_IDivDuration_Microseconds); + +void BM_Duration_IDivDuration_Milliseconds(benchmark::State& state) { + int64_t a = 1; + absl::Duration ignore; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(a += absl::IDivDuration(absl::Milliseconds(i), + absl::Milliseconds(1), + &ignore)); + ++i; + } +} +BENCHMARK(BM_Duration_IDivDuration_Milliseconds); + +void BM_Duration_IDivDuration_Seconds(benchmark::State& state) { + int64_t a = 1; + absl::Duration ignore; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize( + a += absl::IDivDuration(absl::Seconds(i), absl::Seconds(1), &ignore)); + ++i; + } +} +BENCHMARK(BM_Duration_IDivDuration_Seconds); + +void BM_Duration_IDivDuration_Minutes(benchmark::State& state) { + int64_t a = 1; + absl::Duration ignore; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize( + a += absl::IDivDuration(absl::Minutes(i), absl::Minutes(1), &ignore)); + ++i; + } +} +BENCHMARK(BM_Duration_IDivDuration_Minutes); + +void BM_Duration_IDivDuration_Hours(benchmark::State& state) { + int64_t a = 1; + absl::Duration ignore; + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize( + a += absl::IDivDuration(absl::Hours(i), absl::Hours(1), &ignore)); + ++i; + } +} +BENCHMARK(BM_Duration_IDivDuration_Hours); + +void BM_Duration_ToInt64Nanoseconds(benchmark::State& state) { + absl::Duration d = absl::Seconds(100000); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToInt64Nanoseconds(d)); + } +} +BENCHMARK(BM_Duration_ToInt64Nanoseconds); + +void BM_Duration_ToInt64Microseconds(benchmark::State& state) { + absl::Duration d = absl::Seconds(100000); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToInt64Microseconds(d)); + } +} +BENCHMARK(BM_Duration_ToInt64Microseconds); + +void BM_Duration_ToInt64Milliseconds(benchmark::State& state) { + absl::Duration d = absl::Seconds(100000); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToInt64Milliseconds(d)); + } +} +BENCHMARK(BM_Duration_ToInt64Milliseconds); + +void BM_Duration_ToInt64Seconds(benchmark::State& state) { + absl::Duration d = absl::Seconds(100000); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToInt64Seconds(d)); + } +} +BENCHMARK(BM_Duration_ToInt64Seconds); + +void BM_Duration_ToInt64Minutes(benchmark::State& state) { + absl::Duration d = absl::Seconds(100000); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToInt64Minutes(d)); + } +} +BENCHMARK(BM_Duration_ToInt64Minutes); + +void BM_Duration_ToInt64Hours(benchmark::State& state) { + absl::Duration d = absl::Seconds(100000); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToInt64Hours(d)); + } +} +BENCHMARK(BM_Duration_ToInt64Hours); + +// +// To/FromTimespec +// + +void BM_Duration_ToTimespec_AbslTime(benchmark::State& state) { + absl::Duration d = absl::Seconds(1); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToTimespec(d)); + } +} +BENCHMARK(BM_Duration_ToTimespec_AbslTime); + +ABSL_ATTRIBUTE_NOINLINE timespec DoubleToTimespec(double seconds) { + timespec ts; + ts.tv_sec = seconds; + ts.tv_nsec = (seconds - ts.tv_sec) * (1000 * 1000 * 1000); + return ts; +} + +void BM_Duration_ToTimespec_Double(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(DoubleToTimespec(1.0)); + } +} +BENCHMARK(BM_Duration_ToTimespec_Double); + +void BM_Duration_FromTimespec_AbslTime(benchmark::State& state) { + timespec ts; + ts.tv_sec = 0; + ts.tv_nsec = 0; + while (state.KeepRunning()) { + if (++ts.tv_nsec == 1000 * 1000 * 1000) { + ++ts.tv_sec; + ts.tv_nsec = 0; + } + benchmark::DoNotOptimize(absl::DurationFromTimespec(ts)); + } +} +BENCHMARK(BM_Duration_FromTimespec_AbslTime); + +ABSL_ATTRIBUTE_NOINLINE double TimespecToDouble(timespec ts) { + return ts.tv_sec + (ts.tv_nsec / (1000 * 1000 * 1000)); +} + +void BM_Duration_FromTimespec_Double(benchmark::State& state) { + timespec ts; + ts.tv_sec = 0; + ts.tv_nsec = 0; + while (state.KeepRunning()) { + if (++ts.tv_nsec == 1000 * 1000 * 1000) { + ++ts.tv_sec; + ts.tv_nsec = 0; + } + benchmark::DoNotOptimize(TimespecToDouble(ts)); + } +} +BENCHMARK(BM_Duration_FromTimespec_Double); + +// +// String conversions +// + +const char* const kDurations[] = { + "0", // 0 + "123ns", // 1 + "1h2m3s", // 2 + "-2h3m4.005006007s", // 3 + "2562047788015215h30m7.99999999975s", // 4 +}; +const int kNumDurations = sizeof(kDurations) / sizeof(kDurations[0]); + +void BM_Duration_FormatDuration(benchmark::State& state) { + const std::string s = kDurations[state.range(0)]; + state.SetLabel(s); + absl::Duration d; + absl::ParseDuration(kDurations[state.range(0)], &d); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::FormatDuration(d)); + } +} +BENCHMARK(BM_Duration_FormatDuration)->DenseRange(0, kNumDurations - 1); + +void BM_Duration_ParseDuration(benchmark::State& state) { + const std::string s = kDurations[state.range(0)]; + state.SetLabel(s); + absl::Duration d; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ParseDuration(s, &d)); + } +} +BENCHMARK(BM_Duration_ParseDuration)->DenseRange(0, kNumDurations - 1); + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/duration_test.cc b/third_party/abseil_cpp/absl/time/duration_test.cc new file mode 100644 index 0000000000..4d85a2c4f4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/duration_test.cc @@ -0,0 +1,1808 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#if defined(_MSC_VER) +#include <winsock2.h> // for timeval +#endif + +#include <chrono> // NOLINT(build/c++11) +#include <cmath> +#include <cstdint> +#include <ctime> +#include <iomanip> +#include <limits> +#include <random> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/time/time.h" + +namespace { + +constexpr int64_t kint64max = std::numeric_limits<int64_t>::max(); +constexpr int64_t kint64min = std::numeric_limits<int64_t>::min(); + +// Approximates the given number of years. This is only used to make some test +// code more readable. +absl::Duration ApproxYears(int64_t n) { return absl::Hours(n) * 365 * 24; } + +// A gMock matcher to match timespec values. Use this matcher like: +// timespec ts1, ts2; +// EXPECT_THAT(ts1, TimespecMatcher(ts2)); +MATCHER_P(TimespecMatcher, ts, "") { + if (ts.tv_sec == arg.tv_sec && ts.tv_nsec == arg.tv_nsec) + return true; + *result_listener << "expected: {" << ts.tv_sec << ", " << ts.tv_nsec << "} "; + *result_listener << "actual: {" << arg.tv_sec << ", " << arg.tv_nsec << "}"; + return false; +} + +// A gMock matcher to match timeval values. Use this matcher like: +// timeval tv1, tv2; +// EXPECT_THAT(tv1, TimevalMatcher(tv2)); +MATCHER_P(TimevalMatcher, tv, "") { + if (tv.tv_sec == arg.tv_sec && tv.tv_usec == arg.tv_usec) + return true; + *result_listener << "expected: {" << tv.tv_sec << ", " << tv.tv_usec << "} "; + *result_listener << "actual: {" << arg.tv_sec << ", " << arg.tv_usec << "}"; + return false; +} + +TEST(Duration, ConstExpr) { + constexpr absl::Duration d0 = absl::ZeroDuration(); + static_assert(d0 == absl::ZeroDuration(), "ZeroDuration()"); + constexpr absl::Duration d1 = absl::Seconds(1); + static_assert(d1 == absl::Seconds(1), "Seconds(1)"); + static_assert(d1 != absl::ZeroDuration(), "Seconds(1)"); + constexpr absl::Duration d2 = absl::InfiniteDuration(); + static_assert(d2 == absl::InfiniteDuration(), "InfiniteDuration()"); + static_assert(d2 != absl::ZeroDuration(), "InfiniteDuration()"); +} + +TEST(Duration, ValueSemantics) { + // If this compiles, the test passes. + constexpr absl::Duration a; // Default construction + constexpr absl::Duration b = a; // Copy construction + constexpr absl::Duration c(b); // Copy construction (again) + + absl::Duration d; + d = c; // Assignment +} + +TEST(Duration, Factories) { + constexpr absl::Duration zero = absl::ZeroDuration(); + constexpr absl::Duration nano = absl::Nanoseconds(1); + constexpr absl::Duration micro = absl::Microseconds(1); + constexpr absl::Duration milli = absl::Milliseconds(1); + constexpr absl::Duration sec = absl::Seconds(1); + constexpr absl::Duration min = absl::Minutes(1); + constexpr absl::Duration hour = absl::Hours(1); + + EXPECT_EQ(zero, absl::Duration()); + EXPECT_EQ(zero, absl::Seconds(0)); + EXPECT_EQ(nano, absl::Nanoseconds(1)); + EXPECT_EQ(micro, absl::Nanoseconds(1000)); + EXPECT_EQ(milli, absl::Microseconds(1000)); + EXPECT_EQ(sec, absl::Milliseconds(1000)); + EXPECT_EQ(min, absl::Seconds(60)); + EXPECT_EQ(hour, absl::Minutes(60)); + + // Tests factory limits + const absl::Duration inf = absl::InfiniteDuration(); + + EXPECT_GT(inf, absl::Seconds(kint64max)); + EXPECT_LT(-inf, absl::Seconds(kint64min)); + EXPECT_LT(-inf, absl::Seconds(-kint64max)); + + EXPECT_EQ(inf, absl::Minutes(kint64max)); + EXPECT_EQ(-inf, absl::Minutes(kint64min)); + EXPECT_EQ(-inf, absl::Minutes(-kint64max)); + EXPECT_GT(inf, absl::Minutes(kint64max / 60)); + EXPECT_LT(-inf, absl::Minutes(kint64min / 60)); + EXPECT_LT(-inf, absl::Minutes(-kint64max / 60)); + + EXPECT_EQ(inf, absl::Hours(kint64max)); + EXPECT_EQ(-inf, absl::Hours(kint64min)); + EXPECT_EQ(-inf, absl::Hours(-kint64max)); + EXPECT_GT(inf, absl::Hours(kint64max / 3600)); + EXPECT_LT(-inf, absl::Hours(kint64min / 3600)); + EXPECT_LT(-inf, absl::Hours(-kint64max / 3600)); +} + +TEST(Duration, ToConversion) { +#define TEST_DURATION_CONVERSION(UNIT) \ + do { \ + const absl::Duration d = absl::UNIT(1.5); \ + constexpr absl::Duration z = absl::ZeroDuration(); \ + constexpr absl::Duration inf = absl::InfiniteDuration(); \ + constexpr double dbl_inf = std::numeric_limits<double>::infinity(); \ + EXPECT_EQ(kint64min, absl::ToInt64##UNIT(-inf)); \ + EXPECT_EQ(-1, absl::ToInt64##UNIT(-d)); \ + EXPECT_EQ(0, absl::ToInt64##UNIT(z)); \ + EXPECT_EQ(1, absl::ToInt64##UNIT(d)); \ + EXPECT_EQ(kint64max, absl::ToInt64##UNIT(inf)); \ + EXPECT_EQ(-dbl_inf, absl::ToDouble##UNIT(-inf)); \ + EXPECT_EQ(-1.5, absl::ToDouble##UNIT(-d)); \ + EXPECT_EQ(0, absl::ToDouble##UNIT(z)); \ + EXPECT_EQ(1.5, absl::ToDouble##UNIT(d)); \ + EXPECT_EQ(dbl_inf, absl::ToDouble##UNIT(inf)); \ + } while (0) + + TEST_DURATION_CONVERSION(Nanoseconds); + TEST_DURATION_CONVERSION(Microseconds); + TEST_DURATION_CONVERSION(Milliseconds); + TEST_DURATION_CONVERSION(Seconds); + TEST_DURATION_CONVERSION(Minutes); + TEST_DURATION_CONVERSION(Hours); + +#undef TEST_DURATION_CONVERSION +} + +template <int64_t N> +void TestToConversion() { + constexpr absl::Duration nano = absl::Nanoseconds(N); + EXPECT_EQ(N, absl::ToInt64Nanoseconds(nano)); + EXPECT_EQ(0, absl::ToInt64Microseconds(nano)); + EXPECT_EQ(0, absl::ToInt64Milliseconds(nano)); + EXPECT_EQ(0, absl::ToInt64Seconds(nano)); + EXPECT_EQ(0, absl::ToInt64Minutes(nano)); + EXPECT_EQ(0, absl::ToInt64Hours(nano)); + const absl::Duration micro = absl::Microseconds(N); + EXPECT_EQ(N * 1000, absl::ToInt64Nanoseconds(micro)); + EXPECT_EQ(N, absl::ToInt64Microseconds(micro)); + EXPECT_EQ(0, absl::ToInt64Milliseconds(micro)); + EXPECT_EQ(0, absl::ToInt64Seconds(micro)); + EXPECT_EQ(0, absl::ToInt64Minutes(micro)); + EXPECT_EQ(0, absl::ToInt64Hours(micro)); + const absl::Duration milli = absl::Milliseconds(N); + EXPECT_EQ(N * 1000 * 1000, absl::ToInt64Nanoseconds(milli)); + EXPECT_EQ(N * 1000, absl::ToInt64Microseconds(milli)); + EXPECT_EQ(N, absl::ToInt64Milliseconds(milli)); + EXPECT_EQ(0, absl::ToInt64Seconds(milli)); + EXPECT_EQ(0, absl::ToInt64Minutes(milli)); + EXPECT_EQ(0, absl::ToInt64Hours(milli)); + const absl::Duration sec = absl::Seconds(N); + EXPECT_EQ(N * 1000 * 1000 * 1000, absl::ToInt64Nanoseconds(sec)); + EXPECT_EQ(N * 1000 * 1000, absl::ToInt64Microseconds(sec)); + EXPECT_EQ(N * 1000, absl::ToInt64Milliseconds(sec)); + EXPECT_EQ(N, absl::ToInt64Seconds(sec)); + EXPECT_EQ(0, absl::ToInt64Minutes(sec)); + EXPECT_EQ(0, absl::ToInt64Hours(sec)); + const absl::Duration min = absl::Minutes(N); + EXPECT_EQ(N * 60 * 1000 * 1000 * 1000, absl::ToInt64Nanoseconds(min)); + EXPECT_EQ(N * 60 * 1000 * 1000, absl::ToInt64Microseconds(min)); + EXPECT_EQ(N * 60 * 1000, absl::ToInt64Milliseconds(min)); + EXPECT_EQ(N * 60, absl::ToInt64Seconds(min)); + EXPECT_EQ(N, absl::ToInt64Minutes(min)); + EXPECT_EQ(0, absl::ToInt64Hours(min)); + const absl::Duration hour = absl::Hours(N); + EXPECT_EQ(N * 60 * 60 * 1000 * 1000 * 1000, absl::ToInt64Nanoseconds(hour)); + EXPECT_EQ(N * 60 * 60 * 1000 * 1000, absl::ToInt64Microseconds(hour)); + EXPECT_EQ(N * 60 * 60 * 1000, absl::ToInt64Milliseconds(hour)); + EXPECT_EQ(N * 60 * 60, absl::ToInt64Seconds(hour)); + EXPECT_EQ(N * 60, absl::ToInt64Minutes(hour)); + EXPECT_EQ(N, absl::ToInt64Hours(hour)); +} + +TEST(Duration, ToConversionDeprecated) { + TestToConversion<43>(); + TestToConversion<1>(); + TestToConversion<0>(); + TestToConversion<-1>(); + TestToConversion<-43>(); +} + +template <int64_t N> +void TestFromChronoBasicEquality() { + using std::chrono::nanoseconds; + using std::chrono::microseconds; + using std::chrono::milliseconds; + using std::chrono::seconds; + using std::chrono::minutes; + using std::chrono::hours; + + static_assert(absl::Nanoseconds(N) == absl::FromChrono(nanoseconds(N)), ""); + static_assert(absl::Microseconds(N) == absl::FromChrono(microseconds(N)), ""); + static_assert(absl::Milliseconds(N) == absl::FromChrono(milliseconds(N)), ""); + static_assert(absl::Seconds(N) == absl::FromChrono(seconds(N)), ""); + static_assert(absl::Minutes(N) == absl::FromChrono(minutes(N)), ""); + static_assert(absl::Hours(N) == absl::FromChrono(hours(N)), ""); +} + +TEST(Duration, FromChrono) { + TestFromChronoBasicEquality<-123>(); + TestFromChronoBasicEquality<-1>(); + TestFromChronoBasicEquality<0>(); + TestFromChronoBasicEquality<1>(); + TestFromChronoBasicEquality<123>(); + + // Minutes (might, depending on the platform) saturate at +inf. + const auto chrono_minutes_max = std::chrono::minutes::max(); + const auto minutes_max = absl::FromChrono(chrono_minutes_max); + const int64_t minutes_max_count = chrono_minutes_max.count(); + if (minutes_max_count > kint64max / 60) { + EXPECT_EQ(absl::InfiniteDuration(), minutes_max); + } else { + EXPECT_EQ(absl::Minutes(minutes_max_count), minutes_max); + } + + // Minutes (might, depending on the platform) saturate at -inf. + const auto chrono_minutes_min = std::chrono::minutes::min(); + const auto minutes_min = absl::FromChrono(chrono_minutes_min); + const int64_t minutes_min_count = chrono_minutes_min.count(); + if (minutes_min_count < kint64min / 60) { + EXPECT_EQ(-absl::InfiniteDuration(), minutes_min); + } else { + EXPECT_EQ(absl::Minutes(minutes_min_count), minutes_min); + } + + // Hours (might, depending on the platform) saturate at +inf. + const auto chrono_hours_max = std::chrono::hours::max(); + const auto hours_max = absl::FromChrono(chrono_hours_max); + const int64_t hours_max_count = chrono_hours_max.count(); + if (hours_max_count > kint64max / 3600) { + EXPECT_EQ(absl::InfiniteDuration(), hours_max); + } else { + EXPECT_EQ(absl::Hours(hours_max_count), hours_max); + } + + // Hours (might, depending on the platform) saturate at -inf. + const auto chrono_hours_min = std::chrono::hours::min(); + const auto hours_min = absl::FromChrono(chrono_hours_min); + const int64_t hours_min_count = chrono_hours_min.count(); + if (hours_min_count < kint64min / 3600) { + EXPECT_EQ(-absl::InfiniteDuration(), hours_min); + } else { + EXPECT_EQ(absl::Hours(hours_min_count), hours_min); + } +} + +template <int64_t N> +void TestToChrono() { + using std::chrono::nanoseconds; + using std::chrono::microseconds; + using std::chrono::milliseconds; + using std::chrono::seconds; + using std::chrono::minutes; + using std::chrono::hours; + + EXPECT_EQ(nanoseconds(N), absl::ToChronoNanoseconds(absl::Nanoseconds(N))); + EXPECT_EQ(microseconds(N), absl::ToChronoMicroseconds(absl::Microseconds(N))); + EXPECT_EQ(milliseconds(N), absl::ToChronoMilliseconds(absl::Milliseconds(N))); + EXPECT_EQ(seconds(N), absl::ToChronoSeconds(absl::Seconds(N))); + + constexpr auto absl_minutes = absl::Minutes(N); + auto chrono_minutes = minutes(N); + if (absl_minutes == -absl::InfiniteDuration()) { + chrono_minutes = minutes::min(); + } else if (absl_minutes == absl::InfiniteDuration()) { + chrono_minutes = minutes::max(); + } + EXPECT_EQ(chrono_minutes, absl::ToChronoMinutes(absl_minutes)); + + constexpr auto absl_hours = absl::Hours(N); + auto chrono_hours = hours(N); + if (absl_hours == -absl::InfiniteDuration()) { + chrono_hours = hours::min(); + } else if (absl_hours == absl::InfiniteDuration()) { + chrono_hours = hours::max(); + } + EXPECT_EQ(chrono_hours, absl::ToChronoHours(absl_hours)); +} + +TEST(Duration, ToChrono) { + using std::chrono::nanoseconds; + using std::chrono::microseconds; + using std::chrono::milliseconds; + using std::chrono::seconds; + using std::chrono::minutes; + using std::chrono::hours; + + TestToChrono<kint64min>(); + TestToChrono<-1>(); + TestToChrono<0>(); + TestToChrono<1>(); + TestToChrono<kint64max>(); + + // Verify truncation toward zero. + const auto tick = absl::Nanoseconds(1) / 4; + EXPECT_EQ(nanoseconds(0), absl::ToChronoNanoseconds(tick)); + EXPECT_EQ(nanoseconds(0), absl::ToChronoNanoseconds(-tick)); + EXPECT_EQ(microseconds(0), absl::ToChronoMicroseconds(tick)); + EXPECT_EQ(microseconds(0), absl::ToChronoMicroseconds(-tick)); + EXPECT_EQ(milliseconds(0), absl::ToChronoMilliseconds(tick)); + EXPECT_EQ(milliseconds(0), absl::ToChronoMilliseconds(-tick)); + EXPECT_EQ(seconds(0), absl::ToChronoSeconds(tick)); + EXPECT_EQ(seconds(0), absl::ToChronoSeconds(-tick)); + EXPECT_EQ(minutes(0), absl::ToChronoMinutes(tick)); + EXPECT_EQ(minutes(0), absl::ToChronoMinutes(-tick)); + EXPECT_EQ(hours(0), absl::ToChronoHours(tick)); + EXPECT_EQ(hours(0), absl::ToChronoHours(-tick)); + + // Verifies +/- infinity saturation at max/min. + constexpr auto inf = absl::InfiniteDuration(); + EXPECT_EQ(nanoseconds::min(), absl::ToChronoNanoseconds(-inf)); + EXPECT_EQ(nanoseconds::max(), absl::ToChronoNanoseconds(inf)); + EXPECT_EQ(microseconds::min(), absl::ToChronoMicroseconds(-inf)); + EXPECT_EQ(microseconds::max(), absl::ToChronoMicroseconds(inf)); + EXPECT_EQ(milliseconds::min(), absl::ToChronoMilliseconds(-inf)); + EXPECT_EQ(milliseconds::max(), absl::ToChronoMilliseconds(inf)); + EXPECT_EQ(seconds::min(), absl::ToChronoSeconds(-inf)); + EXPECT_EQ(seconds::max(), absl::ToChronoSeconds(inf)); + EXPECT_EQ(minutes::min(), absl::ToChronoMinutes(-inf)); + EXPECT_EQ(minutes::max(), absl::ToChronoMinutes(inf)); + EXPECT_EQ(hours::min(), absl::ToChronoHours(-inf)); + EXPECT_EQ(hours::max(), absl::ToChronoHours(inf)); +} + +TEST(Duration, FactoryOverloads) { + enum E { kOne = 1 }; +#define TEST_FACTORY_OVERLOADS(NAME) \ + EXPECT_EQ(1, NAME(kOne) / NAME(kOne)); \ + EXPECT_EQ(1, NAME(static_cast<int8_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<int16_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<int32_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<int64_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<uint8_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<uint16_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<uint32_t>(1)) / NAME(1)); \ + EXPECT_EQ(1, NAME(static_cast<uint64_t>(1)) / NAME(1)); \ + EXPECT_EQ(NAME(1) / 2, NAME(static_cast<float>(0.5))); \ + EXPECT_EQ(NAME(1) / 2, NAME(static_cast<double>(0.5))); \ + EXPECT_EQ(1.5, absl::FDivDuration(NAME(static_cast<float>(1.5)), NAME(1))); \ + EXPECT_EQ(1.5, absl::FDivDuration(NAME(static_cast<double>(1.5)), NAME(1))); + + TEST_FACTORY_OVERLOADS(absl::Nanoseconds); + TEST_FACTORY_OVERLOADS(absl::Microseconds); + TEST_FACTORY_OVERLOADS(absl::Milliseconds); + TEST_FACTORY_OVERLOADS(absl::Seconds); + TEST_FACTORY_OVERLOADS(absl::Minutes); + TEST_FACTORY_OVERLOADS(absl::Hours); + +#undef TEST_FACTORY_OVERLOADS + + EXPECT_EQ(absl::Milliseconds(1500), absl::Seconds(1.5)); + EXPECT_LT(absl::Nanoseconds(1), absl::Nanoseconds(1.5)); + EXPECT_GT(absl::Nanoseconds(2), absl::Nanoseconds(1.5)); + + const double dbl_inf = std::numeric_limits<double>::infinity(); + EXPECT_EQ(absl::InfiniteDuration(), absl::Nanoseconds(dbl_inf)); + EXPECT_EQ(absl::InfiniteDuration(), absl::Microseconds(dbl_inf)); + EXPECT_EQ(absl::InfiniteDuration(), absl::Milliseconds(dbl_inf)); + EXPECT_EQ(absl::InfiniteDuration(), absl::Seconds(dbl_inf)); + EXPECT_EQ(absl::InfiniteDuration(), absl::Minutes(dbl_inf)); + EXPECT_EQ(absl::InfiniteDuration(), absl::Hours(dbl_inf)); + EXPECT_EQ(-absl::InfiniteDuration(), absl::Nanoseconds(-dbl_inf)); + EXPECT_EQ(-absl::InfiniteDuration(), absl::Microseconds(-dbl_inf)); + EXPECT_EQ(-absl::InfiniteDuration(), absl::Milliseconds(-dbl_inf)); + EXPECT_EQ(-absl::InfiniteDuration(), absl::Seconds(-dbl_inf)); + EXPECT_EQ(-absl::InfiniteDuration(), absl::Minutes(-dbl_inf)); + EXPECT_EQ(-absl::InfiniteDuration(), absl::Hours(-dbl_inf)); +} + +TEST(Duration, InfinityExamples) { + // These examples are used in the documentation in time.h. They are + // written so that they can be copy-n-pasted easily. + + constexpr absl::Duration inf = absl::InfiniteDuration(); + constexpr absl::Duration d = absl::Seconds(1); // Any finite duration + + EXPECT_TRUE(inf == inf + inf); + EXPECT_TRUE(inf == inf + d); + EXPECT_TRUE(inf == inf - inf); + EXPECT_TRUE(-inf == d - inf); + + EXPECT_TRUE(inf == d * 1e100); + EXPECT_TRUE(0 == d / inf); // NOLINT(readability/check) + + // Division by zero returns infinity, or kint64min/MAX where necessary. + EXPECT_TRUE(inf == d / 0); + EXPECT_TRUE(kint64max == d / absl::ZeroDuration()); +} + +TEST(Duration, InfinityComparison) { + const absl::Duration inf = absl::InfiniteDuration(); + const absl::Duration any_dur = absl::Seconds(1); + + // Equality + EXPECT_EQ(inf, inf); + EXPECT_EQ(-inf, -inf); + EXPECT_NE(inf, -inf); + EXPECT_NE(any_dur, inf); + EXPECT_NE(any_dur, -inf); + + // Relational + EXPECT_GT(inf, any_dur); + EXPECT_LT(-inf, any_dur); + EXPECT_LT(-inf, inf); + EXPECT_GT(inf, -inf); +} + +TEST(Duration, InfinityAddition) { + const absl::Duration sec_max = absl::Seconds(kint64max); + const absl::Duration sec_min = absl::Seconds(kint64min); + const absl::Duration any_dur = absl::Seconds(1); + const absl::Duration inf = absl::InfiniteDuration(); + + // Addition + EXPECT_EQ(inf, inf + inf); + EXPECT_EQ(inf, inf + -inf); + EXPECT_EQ(-inf, -inf + inf); + EXPECT_EQ(-inf, -inf + -inf); + + EXPECT_EQ(inf, inf + any_dur); + EXPECT_EQ(inf, any_dur + inf); + EXPECT_EQ(-inf, -inf + any_dur); + EXPECT_EQ(-inf, any_dur + -inf); + + // Interesting case + absl::Duration almost_inf = sec_max + absl::Nanoseconds(999999999); + EXPECT_GT(inf, almost_inf); + almost_inf += -absl::Nanoseconds(999999999); + EXPECT_GT(inf, almost_inf); + + // Addition overflow/underflow + EXPECT_EQ(inf, sec_max + absl::Seconds(1)); + EXPECT_EQ(inf, sec_max + sec_max); + EXPECT_EQ(-inf, sec_min + -absl::Seconds(1)); + EXPECT_EQ(-inf, sec_min + -sec_max); + + // For reference: IEEE 754 behavior + const double dbl_inf = std::numeric_limits<double>::infinity(); + EXPECT_TRUE(std::isinf(dbl_inf + dbl_inf)); + EXPECT_TRUE(std::isnan(dbl_inf + -dbl_inf)); // We return inf + EXPECT_TRUE(std::isnan(-dbl_inf + dbl_inf)); // We return inf + EXPECT_TRUE(std::isinf(-dbl_inf + -dbl_inf)); +} + +TEST(Duration, InfinitySubtraction) { + const absl::Duration sec_max = absl::Seconds(kint64max); + const absl::Duration sec_min = absl::Seconds(kint64min); + const absl::Duration any_dur = absl::Seconds(1); + const absl::Duration inf = absl::InfiniteDuration(); + + // Subtraction + EXPECT_EQ(inf, inf - inf); + EXPECT_EQ(inf, inf - -inf); + EXPECT_EQ(-inf, -inf - inf); + EXPECT_EQ(-inf, -inf - -inf); + + EXPECT_EQ(inf, inf - any_dur); + EXPECT_EQ(-inf, any_dur - inf); + EXPECT_EQ(-inf, -inf - any_dur); + EXPECT_EQ(inf, any_dur - -inf); + + // Subtraction overflow/underflow + EXPECT_EQ(inf, sec_max - -absl::Seconds(1)); + EXPECT_EQ(inf, sec_max - -sec_max); + EXPECT_EQ(-inf, sec_min - absl::Seconds(1)); + EXPECT_EQ(-inf, sec_min - sec_max); + + // Interesting case + absl::Duration almost_neg_inf = sec_min; + EXPECT_LT(-inf, almost_neg_inf); + almost_neg_inf -= -absl::Nanoseconds(1); + EXPECT_LT(-inf, almost_neg_inf); + + // For reference: IEEE 754 behavior + const double dbl_inf = std::numeric_limits<double>::infinity(); + EXPECT_TRUE(std::isnan(dbl_inf - dbl_inf)); // We return inf + EXPECT_TRUE(std::isinf(dbl_inf - -dbl_inf)); + EXPECT_TRUE(std::isinf(-dbl_inf - dbl_inf)); + EXPECT_TRUE(std::isnan(-dbl_inf - -dbl_inf)); // We return inf +} + +TEST(Duration, InfinityMultiplication) { + const absl::Duration sec_max = absl::Seconds(kint64max); + const absl::Duration sec_min = absl::Seconds(kint64min); + const absl::Duration inf = absl::InfiniteDuration(); + +#define TEST_INF_MUL_WITH_TYPE(T) \ + EXPECT_EQ(inf, inf * static_cast<T>(2)); \ + EXPECT_EQ(-inf, inf * static_cast<T>(-2)); \ + EXPECT_EQ(-inf, -inf * static_cast<T>(2)); \ + EXPECT_EQ(inf, -inf * static_cast<T>(-2)); \ + EXPECT_EQ(inf, inf * static_cast<T>(0)); \ + EXPECT_EQ(-inf, -inf * static_cast<T>(0)); \ + EXPECT_EQ(inf, sec_max * static_cast<T>(2)); \ + EXPECT_EQ(inf, sec_min * static_cast<T>(-2)); \ + EXPECT_EQ(inf, (sec_max / static_cast<T>(2)) * static_cast<T>(3)); \ + EXPECT_EQ(-inf, sec_max * static_cast<T>(-2)); \ + EXPECT_EQ(-inf, sec_min * static_cast<T>(2)); \ + EXPECT_EQ(-inf, (sec_min / static_cast<T>(2)) * static_cast<T>(3)); + + TEST_INF_MUL_WITH_TYPE(int64_t); // NOLINT(readability/function) + TEST_INF_MUL_WITH_TYPE(double); // NOLINT(readability/function) + +#undef TEST_INF_MUL_WITH_TYPE + + const double dbl_inf = std::numeric_limits<double>::infinity(); + EXPECT_EQ(inf, inf * dbl_inf); + EXPECT_EQ(-inf, -inf * dbl_inf); + EXPECT_EQ(-inf, inf * -dbl_inf); + EXPECT_EQ(inf, -inf * -dbl_inf); + + const absl::Duration any_dur = absl::Seconds(1); + EXPECT_EQ(inf, any_dur * dbl_inf); + EXPECT_EQ(-inf, -any_dur * dbl_inf); + EXPECT_EQ(-inf, any_dur * -dbl_inf); + EXPECT_EQ(inf, -any_dur * -dbl_inf); + + // Fixed-point multiplication will produce a finite value, whereas floating + // point fuzziness will overflow to inf. + EXPECT_NE(absl::InfiniteDuration(), absl::Seconds(1) * kint64max); + EXPECT_EQ(inf, absl::Seconds(1) * static_cast<double>(kint64max)); + EXPECT_NE(-absl::InfiniteDuration(), absl::Seconds(1) * kint64min); + EXPECT_EQ(-inf, absl::Seconds(1) * static_cast<double>(kint64min)); + + // Note that sec_max * or / by 1.0 overflows to inf due to the 53-bit + // limitations of double. + EXPECT_NE(inf, sec_max); + EXPECT_NE(inf, sec_max / 1); + EXPECT_EQ(inf, sec_max / 1.0); + EXPECT_NE(inf, sec_max * 1); + EXPECT_EQ(inf, sec_max * 1.0); +} + +TEST(Duration, InfinityDivision) { + const absl::Duration sec_max = absl::Seconds(kint64max); + const absl::Duration sec_min = absl::Seconds(kint64min); + const absl::Duration inf = absl::InfiniteDuration(); + + // Division of Duration by a double +#define TEST_INF_DIV_WITH_TYPE(T) \ + EXPECT_EQ(inf, inf / static_cast<T>(2)); \ + EXPECT_EQ(-inf, inf / static_cast<T>(-2)); \ + EXPECT_EQ(-inf, -inf / static_cast<T>(2)); \ + EXPECT_EQ(inf, -inf / static_cast<T>(-2)); + + TEST_INF_DIV_WITH_TYPE(int64_t); // NOLINT(readability/function) + TEST_INF_DIV_WITH_TYPE(double); // NOLINT(readability/function) + +#undef TEST_INF_DIV_WITH_TYPE + + // Division of Duration by a double overflow/underflow + EXPECT_EQ(inf, sec_max / 0.5); + EXPECT_EQ(inf, sec_min / -0.5); + EXPECT_EQ(inf, ((sec_max / 0.5) + absl::Seconds(1)) / 0.5); + EXPECT_EQ(-inf, sec_max / -0.5); + EXPECT_EQ(-inf, sec_min / 0.5); + EXPECT_EQ(-inf, ((sec_min / 0.5) - absl::Seconds(1)) / 0.5); + + const double dbl_inf = std::numeric_limits<double>::infinity(); + EXPECT_EQ(inf, inf / dbl_inf); + EXPECT_EQ(-inf, inf / -dbl_inf); + EXPECT_EQ(-inf, -inf / dbl_inf); + EXPECT_EQ(inf, -inf / -dbl_inf); + + const absl::Duration any_dur = absl::Seconds(1); + EXPECT_EQ(absl::ZeroDuration(), any_dur / dbl_inf); + EXPECT_EQ(absl::ZeroDuration(), any_dur / -dbl_inf); + EXPECT_EQ(absl::ZeroDuration(), -any_dur / dbl_inf); + EXPECT_EQ(absl::ZeroDuration(), -any_dur / -dbl_inf); +} + +TEST(Duration, InfinityModulus) { + const absl::Duration sec_max = absl::Seconds(kint64max); + const absl::Duration any_dur = absl::Seconds(1); + const absl::Duration inf = absl::InfiniteDuration(); + + EXPECT_EQ(inf, inf % inf); + EXPECT_EQ(inf, inf % -inf); + EXPECT_EQ(-inf, -inf % -inf); + EXPECT_EQ(-inf, -inf % inf); + + EXPECT_EQ(any_dur, any_dur % inf); + EXPECT_EQ(any_dur, any_dur % -inf); + EXPECT_EQ(-any_dur, -any_dur % inf); + EXPECT_EQ(-any_dur, -any_dur % -inf); + + EXPECT_EQ(inf, inf % -any_dur); + EXPECT_EQ(inf, inf % any_dur); + EXPECT_EQ(-inf, -inf % -any_dur); + EXPECT_EQ(-inf, -inf % any_dur); + + // Remainder isn't affected by overflow. + EXPECT_EQ(absl::ZeroDuration(), sec_max % absl::Seconds(1)); + EXPECT_EQ(absl::ZeroDuration(), sec_max % absl::Milliseconds(1)); + EXPECT_EQ(absl::ZeroDuration(), sec_max % absl::Microseconds(1)); + EXPECT_EQ(absl::ZeroDuration(), sec_max % absl::Nanoseconds(1)); + EXPECT_EQ(absl::ZeroDuration(), sec_max % absl::Nanoseconds(1) / 4); +} + +TEST(Duration, InfinityIDiv) { + const absl::Duration sec_max = absl::Seconds(kint64max); + const absl::Duration any_dur = absl::Seconds(1); + const absl::Duration inf = absl::InfiniteDuration(); + const double dbl_inf = std::numeric_limits<double>::infinity(); + + // IDivDuration (int64_t return value + a remainer) + absl::Duration rem = absl::ZeroDuration(); + EXPECT_EQ(kint64max, absl::IDivDuration(inf, inf, &rem)); + EXPECT_EQ(inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64max, absl::IDivDuration(-inf, -inf, &rem)); + EXPECT_EQ(-inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64max, absl::IDivDuration(inf, any_dur, &rem)); + EXPECT_EQ(inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(0, absl::IDivDuration(any_dur, inf, &rem)); + EXPECT_EQ(any_dur, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64max, absl::IDivDuration(-inf, -any_dur, &rem)); + EXPECT_EQ(-inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(0, absl::IDivDuration(-any_dur, -inf, &rem)); + EXPECT_EQ(-any_dur, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64min, absl::IDivDuration(-inf, inf, &rem)); + EXPECT_EQ(-inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64min, absl::IDivDuration(inf, -inf, &rem)); + EXPECT_EQ(inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64min, absl::IDivDuration(-inf, any_dur, &rem)); + EXPECT_EQ(-inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(0, absl::IDivDuration(-any_dur, inf, &rem)); + EXPECT_EQ(-any_dur, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(kint64min, absl::IDivDuration(inf, -any_dur, &rem)); + EXPECT_EQ(inf, rem); + + rem = absl::ZeroDuration(); + EXPECT_EQ(0, absl::IDivDuration(any_dur, -inf, &rem)); + EXPECT_EQ(any_dur, rem); + + // IDivDuration overflow/underflow + rem = any_dur; + EXPECT_EQ(kint64max, + absl::IDivDuration(sec_max, absl::Nanoseconds(1) / 4, &rem)); + EXPECT_EQ(sec_max - absl::Nanoseconds(kint64max) / 4, rem); + + rem = any_dur; + EXPECT_EQ(kint64max, + absl::IDivDuration(sec_max, absl::Milliseconds(1), &rem)); + EXPECT_EQ(sec_max - absl::Milliseconds(kint64max), rem); + + rem = any_dur; + EXPECT_EQ(kint64max, + absl::IDivDuration(-sec_max, -absl::Milliseconds(1), &rem)); + EXPECT_EQ(-sec_max + absl::Milliseconds(kint64max), rem); + + rem = any_dur; + EXPECT_EQ(kint64min, + absl::IDivDuration(-sec_max, absl::Milliseconds(1), &rem)); + EXPECT_EQ(-sec_max - absl::Milliseconds(kint64min), rem); + + rem = any_dur; + EXPECT_EQ(kint64min, + absl::IDivDuration(sec_max, -absl::Milliseconds(1), &rem)); + EXPECT_EQ(sec_max + absl::Milliseconds(kint64min), rem); + + // + // operator/(Duration, Duration) is a wrapper for IDivDuration(). + // + + // IEEE 754 says inf / inf should be nan, but int64_t doesn't have + // nan so we'll return kint64max/kint64min instead. + EXPECT_TRUE(std::isnan(dbl_inf / dbl_inf)); + EXPECT_EQ(kint64max, inf / inf); + EXPECT_EQ(kint64max, -inf / -inf); + EXPECT_EQ(kint64min, -inf / inf); + EXPECT_EQ(kint64min, inf / -inf); + + EXPECT_TRUE(std::isinf(dbl_inf / 2.0)); + EXPECT_EQ(kint64max, inf / any_dur); + EXPECT_EQ(kint64max, -inf / -any_dur); + EXPECT_EQ(kint64min, -inf / any_dur); + EXPECT_EQ(kint64min, inf / -any_dur); + + EXPECT_EQ(0.0, 2.0 / dbl_inf); + EXPECT_EQ(0, any_dur / inf); + EXPECT_EQ(0, any_dur / -inf); + EXPECT_EQ(0, -any_dur / inf); + EXPECT_EQ(0, -any_dur / -inf); + EXPECT_EQ(0, absl::ZeroDuration() / inf); + + // Division of Duration by a Duration overflow/underflow + EXPECT_EQ(kint64max, sec_max / absl::Milliseconds(1)); + EXPECT_EQ(kint64max, -sec_max / -absl::Milliseconds(1)); + EXPECT_EQ(kint64min, -sec_max / absl::Milliseconds(1)); + EXPECT_EQ(kint64min, sec_max / -absl::Milliseconds(1)); +} + +TEST(Duration, InfinityFDiv) { + const absl::Duration any_dur = absl::Seconds(1); + const absl::Duration inf = absl::InfiniteDuration(); + const double dbl_inf = std::numeric_limits<double>::infinity(); + + EXPECT_EQ(dbl_inf, absl::FDivDuration(inf, inf)); + EXPECT_EQ(dbl_inf, absl::FDivDuration(-inf, -inf)); + EXPECT_EQ(dbl_inf, absl::FDivDuration(inf, any_dur)); + EXPECT_EQ(0.0, absl::FDivDuration(any_dur, inf)); + EXPECT_EQ(dbl_inf, absl::FDivDuration(-inf, -any_dur)); + EXPECT_EQ(0.0, absl::FDivDuration(-any_dur, -inf)); + + EXPECT_EQ(-dbl_inf, absl::FDivDuration(-inf, inf)); + EXPECT_EQ(-dbl_inf, absl::FDivDuration(inf, -inf)); + EXPECT_EQ(-dbl_inf, absl::FDivDuration(-inf, any_dur)); + EXPECT_EQ(0.0, absl::FDivDuration(-any_dur, inf)); + EXPECT_EQ(-dbl_inf, absl::FDivDuration(inf, -any_dur)); + EXPECT_EQ(0.0, absl::FDivDuration(any_dur, -inf)); +} + +TEST(Duration, DivisionByZero) { + const absl::Duration zero = absl::ZeroDuration(); + const absl::Duration inf = absl::InfiniteDuration(); + const absl::Duration any_dur = absl::Seconds(1); + const double dbl_inf = std::numeric_limits<double>::infinity(); + const double dbl_denorm = std::numeric_limits<double>::denorm_min(); + + // Operator/(Duration, double) + EXPECT_EQ(inf, zero / 0.0); + EXPECT_EQ(-inf, zero / -0.0); + EXPECT_EQ(inf, any_dur / 0.0); + EXPECT_EQ(-inf, any_dur / -0.0); + EXPECT_EQ(-inf, -any_dur / 0.0); + EXPECT_EQ(inf, -any_dur / -0.0); + + // Tests dividing by a number very close to, but not quite zero. + EXPECT_EQ(zero, zero / dbl_denorm); + EXPECT_EQ(zero, zero / -dbl_denorm); + EXPECT_EQ(inf, any_dur / dbl_denorm); + EXPECT_EQ(-inf, any_dur / -dbl_denorm); + EXPECT_EQ(-inf, -any_dur / dbl_denorm); + EXPECT_EQ(inf, -any_dur / -dbl_denorm); + + // IDiv + absl::Duration rem = zero; + EXPECT_EQ(kint64max, absl::IDivDuration(zero, zero, &rem)); + EXPECT_EQ(inf, rem); + + rem = zero; + EXPECT_EQ(kint64max, absl::IDivDuration(any_dur, zero, &rem)); + EXPECT_EQ(inf, rem); + + rem = zero; + EXPECT_EQ(kint64min, absl::IDivDuration(-any_dur, zero, &rem)); + EXPECT_EQ(-inf, rem); + + // Operator/(Duration, Duration) + EXPECT_EQ(kint64max, zero / zero); + EXPECT_EQ(kint64max, any_dur / zero); + EXPECT_EQ(kint64min, -any_dur / zero); + + // FDiv + EXPECT_EQ(dbl_inf, absl::FDivDuration(zero, zero)); + EXPECT_EQ(dbl_inf, absl::FDivDuration(any_dur, zero)); + EXPECT_EQ(-dbl_inf, absl::FDivDuration(-any_dur, zero)); +} + +TEST(Duration, NaN) { + // Note that IEEE 754 does not define the behavior of a nan's sign when it is + // copied, so the code below allows for either + or - InfiniteDuration. +#define TEST_NAN_HANDLING(NAME, NAN) \ + do { \ + const auto inf = absl::InfiniteDuration(); \ + auto x = NAME(NAN); \ + EXPECT_TRUE(x == inf || x == -inf); \ + auto y = NAME(42); \ + y *= NAN; \ + EXPECT_TRUE(y == inf || y == -inf); \ + auto z = NAME(42); \ + z /= NAN; \ + EXPECT_TRUE(z == inf || z == -inf); \ + } while (0) + + const double nan = std::numeric_limits<double>::quiet_NaN(); + TEST_NAN_HANDLING(absl::Nanoseconds, nan); + TEST_NAN_HANDLING(absl::Microseconds, nan); + TEST_NAN_HANDLING(absl::Milliseconds, nan); + TEST_NAN_HANDLING(absl::Seconds, nan); + TEST_NAN_HANDLING(absl::Minutes, nan); + TEST_NAN_HANDLING(absl::Hours, nan); + + TEST_NAN_HANDLING(absl::Nanoseconds, -nan); + TEST_NAN_HANDLING(absl::Microseconds, -nan); + TEST_NAN_HANDLING(absl::Milliseconds, -nan); + TEST_NAN_HANDLING(absl::Seconds, -nan); + TEST_NAN_HANDLING(absl::Minutes, -nan); + TEST_NAN_HANDLING(absl::Hours, -nan); + +#undef TEST_NAN_HANDLING +} + +TEST(Duration, Range) { + const absl::Duration range = ApproxYears(100 * 1e9); + const absl::Duration range_future = range; + const absl::Duration range_past = -range; + + EXPECT_LT(range_future, absl::InfiniteDuration()); + EXPECT_GT(range_past, -absl::InfiniteDuration()); + + const absl::Duration full_range = range_future - range_past; + EXPECT_GT(full_range, absl::ZeroDuration()); + EXPECT_LT(full_range, absl::InfiniteDuration()); + + const absl::Duration neg_full_range = range_past - range_future; + EXPECT_LT(neg_full_range, absl::ZeroDuration()); + EXPECT_GT(neg_full_range, -absl::InfiniteDuration()); + + EXPECT_LT(neg_full_range, full_range); + EXPECT_EQ(neg_full_range, -full_range); +} + +TEST(Duration, RelationalOperators) { +#define TEST_REL_OPS(UNIT) \ + static_assert(UNIT(2) == UNIT(2), ""); \ + static_assert(UNIT(1) != UNIT(2), ""); \ + static_assert(UNIT(1) < UNIT(2), ""); \ + static_assert(UNIT(3) > UNIT(2), ""); \ + static_assert(UNIT(1) <= UNIT(2), ""); \ + static_assert(UNIT(2) <= UNIT(2), ""); \ + static_assert(UNIT(3) >= UNIT(2), ""); \ + static_assert(UNIT(2) >= UNIT(2), ""); + + TEST_REL_OPS(absl::Nanoseconds); + TEST_REL_OPS(absl::Microseconds); + TEST_REL_OPS(absl::Milliseconds); + TEST_REL_OPS(absl::Seconds); + TEST_REL_OPS(absl::Minutes); + TEST_REL_OPS(absl::Hours); + +#undef TEST_REL_OPS +} + +TEST(Duration, Addition) { +#define TEST_ADD_OPS(UNIT) \ + do { \ + EXPECT_EQ(UNIT(2), UNIT(1) + UNIT(1)); \ + EXPECT_EQ(UNIT(1), UNIT(2) - UNIT(1)); \ + EXPECT_EQ(UNIT(0), UNIT(2) - UNIT(2)); \ + EXPECT_EQ(UNIT(-1), UNIT(1) - UNIT(2)); \ + EXPECT_EQ(UNIT(-2), UNIT(0) - UNIT(2)); \ + EXPECT_EQ(UNIT(-2), UNIT(1) - UNIT(3)); \ + absl::Duration a = UNIT(1); \ + a += UNIT(1); \ + EXPECT_EQ(UNIT(2), a); \ + a -= UNIT(1); \ + EXPECT_EQ(UNIT(1), a); \ + } while (0) + + TEST_ADD_OPS(absl::Nanoseconds); + TEST_ADD_OPS(absl::Microseconds); + TEST_ADD_OPS(absl::Milliseconds); + TEST_ADD_OPS(absl::Seconds); + TEST_ADD_OPS(absl::Minutes); + TEST_ADD_OPS(absl::Hours); + +#undef TEST_ADD_OPS + + EXPECT_EQ(absl::Seconds(2), absl::Seconds(3) - 2 * absl::Milliseconds(500)); + EXPECT_EQ(absl::Seconds(2) + absl::Milliseconds(500), + absl::Seconds(3) - absl::Milliseconds(500)); + + EXPECT_EQ(absl::Seconds(1) + absl::Milliseconds(998), + absl::Milliseconds(999) + absl::Milliseconds(999)); + + EXPECT_EQ(absl::Milliseconds(-1), + absl::Milliseconds(998) - absl::Milliseconds(999)); + + // Tests fractions of a nanoseconds. These are implementation details only. + EXPECT_GT(absl::Nanoseconds(1), absl::Nanoseconds(1) / 2); + EXPECT_EQ(absl::Nanoseconds(1), + absl::Nanoseconds(1) / 2 + absl::Nanoseconds(1) / 2); + EXPECT_GT(absl::Nanoseconds(1) / 4, absl::Nanoseconds(0)); + EXPECT_EQ(absl::Nanoseconds(1) / 8, absl::Nanoseconds(0)); + + // Tests subtraction that will cause wrap around of the rep_lo_ bits. + absl::Duration d_7_5 = absl::Seconds(7) + absl::Milliseconds(500); + absl::Duration d_3_7 = absl::Seconds(3) + absl::Milliseconds(700); + absl::Duration ans_3_8 = absl::Seconds(3) + absl::Milliseconds(800); + EXPECT_EQ(ans_3_8, d_7_5 - d_3_7); + + // Subtracting min_duration + absl::Duration min_dur = absl::Seconds(kint64min); + EXPECT_EQ(absl::Seconds(0), min_dur - min_dur); + EXPECT_EQ(absl::Seconds(kint64max), absl::Seconds(-1) - min_dur); +} + +TEST(Duration, Negation) { + // By storing negations of various values in constexpr variables we + // verify that the initializers are constant expressions. + constexpr absl::Duration negated_zero_duration = -absl::ZeroDuration(); + EXPECT_EQ(negated_zero_duration, absl::ZeroDuration()); + + constexpr absl::Duration negated_infinite_duration = + -absl::InfiniteDuration(); + EXPECT_NE(negated_infinite_duration, absl::InfiniteDuration()); + EXPECT_EQ(-negated_infinite_duration, absl::InfiniteDuration()); + + // The public APIs to check if a duration is infinite depend on using + // -InfiniteDuration(), but we're trying to test operator- here, so we + // need to use the lower-level internal query IsInfiniteDuration. + EXPECT_TRUE( + absl::time_internal::IsInfiniteDuration(negated_infinite_duration)); + + // The largest Duration is kint64max seconds and kTicksPerSecond - 1 ticks. + // Using the absl::time_internal::MakeDuration API is the cleanest way to + // construct that Duration. + constexpr absl::Duration max_duration = absl::time_internal::MakeDuration( + kint64max, absl::time_internal::kTicksPerSecond - 1); + constexpr absl::Duration negated_max_duration = -max_duration; + // The largest negatable value is one tick above the minimum representable; + // it's the negation of max_duration. + constexpr absl::Duration nearly_min_duration = + absl::time_internal::MakeDuration(kint64min, int64_t{1}); + constexpr absl::Duration negated_nearly_min_duration = -nearly_min_duration; + + EXPECT_EQ(negated_max_duration, nearly_min_duration); + EXPECT_EQ(negated_nearly_min_duration, max_duration); + EXPECT_EQ(-(-max_duration), max_duration); + + constexpr absl::Duration min_duration = + absl::time_internal::MakeDuration(kint64min); + constexpr absl::Duration negated_min_duration = -min_duration; + EXPECT_EQ(negated_min_duration, absl::InfiniteDuration()); +} + +TEST(Duration, AbsoluteValue) { + EXPECT_EQ(absl::ZeroDuration(), AbsDuration(absl::ZeroDuration())); + EXPECT_EQ(absl::Seconds(1), AbsDuration(absl::Seconds(1))); + EXPECT_EQ(absl::Seconds(1), AbsDuration(absl::Seconds(-1))); + + EXPECT_EQ(absl::InfiniteDuration(), AbsDuration(absl::InfiniteDuration())); + EXPECT_EQ(absl::InfiniteDuration(), AbsDuration(-absl::InfiniteDuration())); + + absl::Duration max_dur = + absl::Seconds(kint64max) + (absl::Seconds(1) - absl::Nanoseconds(1) / 4); + EXPECT_EQ(max_dur, AbsDuration(max_dur)); + + absl::Duration min_dur = absl::Seconds(kint64min); + EXPECT_EQ(absl::InfiniteDuration(), AbsDuration(min_dur)); + EXPECT_EQ(max_dur, AbsDuration(min_dur + absl::Nanoseconds(1) / 4)); +} + +TEST(Duration, Multiplication) { +#define TEST_MUL_OPS(UNIT) \ + do { \ + EXPECT_EQ(UNIT(5), UNIT(2) * 2.5); \ + EXPECT_EQ(UNIT(2), UNIT(5) / 2.5); \ + EXPECT_EQ(UNIT(-5), UNIT(-2) * 2.5); \ + EXPECT_EQ(UNIT(-5), -UNIT(2) * 2.5); \ + EXPECT_EQ(UNIT(-5), UNIT(2) * -2.5); \ + EXPECT_EQ(UNIT(-2), UNIT(-5) / 2.5); \ + EXPECT_EQ(UNIT(-2), -UNIT(5) / 2.5); \ + EXPECT_EQ(UNIT(-2), UNIT(5) / -2.5); \ + EXPECT_EQ(UNIT(2), UNIT(11) % UNIT(3)); \ + absl::Duration a = UNIT(2); \ + a *= 2.5; \ + EXPECT_EQ(UNIT(5), a); \ + a /= 2.5; \ + EXPECT_EQ(UNIT(2), a); \ + a %= UNIT(1); \ + EXPECT_EQ(UNIT(0), a); \ + absl::Duration big = UNIT(1000000000); \ + big *= 3; \ + big /= 3; \ + EXPECT_EQ(UNIT(1000000000), big); \ + EXPECT_EQ(-UNIT(2), -UNIT(2)); \ + EXPECT_EQ(-UNIT(2), UNIT(2) * -1); \ + EXPECT_EQ(-UNIT(2), -1 * UNIT(2)); \ + EXPECT_EQ(-UNIT(-2), UNIT(2)); \ + EXPECT_EQ(2, UNIT(2) / UNIT(1)); \ + absl::Duration rem; \ + EXPECT_EQ(2, absl::IDivDuration(UNIT(2), UNIT(1), &rem)); \ + EXPECT_EQ(2.0, absl::FDivDuration(UNIT(2), UNIT(1))); \ + } while (0) + + TEST_MUL_OPS(absl::Nanoseconds); + TEST_MUL_OPS(absl::Microseconds); + TEST_MUL_OPS(absl::Milliseconds); + TEST_MUL_OPS(absl::Seconds); + TEST_MUL_OPS(absl::Minutes); + TEST_MUL_OPS(absl::Hours); + +#undef TEST_MUL_OPS + + // Ensures that multiplication and division by 1 with a maxed-out durations + // doesn't lose precision. + absl::Duration max_dur = + absl::Seconds(kint64max) + (absl::Seconds(1) - absl::Nanoseconds(1) / 4); + absl::Duration min_dur = absl::Seconds(kint64min); + EXPECT_EQ(max_dur, max_dur * 1); + EXPECT_EQ(max_dur, max_dur / 1); + EXPECT_EQ(min_dur, min_dur * 1); + EXPECT_EQ(min_dur, min_dur / 1); + + // Tests division on a Duration with a large number of significant digits. + // Tests when the digits span hi and lo as well as only in hi. + absl::Duration sigfigs = absl::Seconds(2000000000) + absl::Nanoseconds(3); + EXPECT_EQ(absl::Seconds(666666666) + absl::Nanoseconds(666666667) + + absl::Nanoseconds(1) / 2, + sigfigs / 3); + sigfigs = absl::Seconds(int64_t{7000000000}); + EXPECT_EQ(absl::Seconds(2333333333) + absl::Nanoseconds(333333333) + + absl::Nanoseconds(1) / 4, + sigfigs / 3); + + EXPECT_EQ(absl::Seconds(7) + absl::Milliseconds(500), absl::Seconds(3) * 2.5); + EXPECT_EQ(absl::Seconds(8) * -1 + absl::Milliseconds(300), + (absl::Seconds(2) + absl::Milliseconds(200)) * -3.5); + EXPECT_EQ(-absl::Seconds(8) + absl::Milliseconds(300), + (absl::Seconds(2) + absl::Milliseconds(200)) * -3.5); + EXPECT_EQ(absl::Seconds(1) + absl::Milliseconds(875), + (absl::Seconds(7) + absl::Milliseconds(500)) / 4); + EXPECT_EQ(absl::Seconds(30), + (absl::Seconds(7) + absl::Milliseconds(500)) / 0.25); + EXPECT_EQ(absl::Seconds(3), + (absl::Seconds(7) + absl::Milliseconds(500)) / 2.5); + + // Tests division remainder. + EXPECT_EQ(absl::Nanoseconds(0), absl::Nanoseconds(7) % absl::Nanoseconds(1)); + EXPECT_EQ(absl::Nanoseconds(0), absl::Nanoseconds(0) % absl::Nanoseconds(10)); + EXPECT_EQ(absl::Nanoseconds(2), absl::Nanoseconds(7) % absl::Nanoseconds(5)); + EXPECT_EQ(absl::Nanoseconds(2), absl::Nanoseconds(2) % absl::Nanoseconds(5)); + + EXPECT_EQ(absl::Nanoseconds(1), absl::Nanoseconds(10) % absl::Nanoseconds(3)); + EXPECT_EQ(absl::Nanoseconds(1), + absl::Nanoseconds(10) % absl::Nanoseconds(-3)); + EXPECT_EQ(absl::Nanoseconds(-1), + absl::Nanoseconds(-10) % absl::Nanoseconds(3)); + EXPECT_EQ(absl::Nanoseconds(-1), + absl::Nanoseconds(-10) % absl::Nanoseconds(-3)); + + EXPECT_EQ(absl::Milliseconds(100), + absl::Seconds(1) % absl::Milliseconds(300)); + EXPECT_EQ( + absl::Milliseconds(300), + (absl::Seconds(3) + absl::Milliseconds(800)) % absl::Milliseconds(500)); + + EXPECT_EQ(absl::Nanoseconds(1), absl::Nanoseconds(1) % absl::Seconds(1)); + EXPECT_EQ(absl::Nanoseconds(-1), absl::Nanoseconds(-1) % absl::Seconds(1)); + EXPECT_EQ(0, absl::Nanoseconds(-1) / absl::Seconds(1)); // Actual -1e-9 + + // Tests identity a = (a/b)*b + a%b +#define TEST_MOD_IDENTITY(a, b) \ + EXPECT_EQ((a), ((a) / (b))*(b) + ((a)%(b))) + + TEST_MOD_IDENTITY(absl::Seconds(0), absl::Seconds(2)); + TEST_MOD_IDENTITY(absl::Seconds(1), absl::Seconds(1)); + TEST_MOD_IDENTITY(absl::Seconds(1), absl::Seconds(2)); + TEST_MOD_IDENTITY(absl::Seconds(2), absl::Seconds(1)); + + TEST_MOD_IDENTITY(absl::Seconds(-2), absl::Seconds(1)); + TEST_MOD_IDENTITY(absl::Seconds(2), absl::Seconds(-1)); + TEST_MOD_IDENTITY(absl::Seconds(-2), absl::Seconds(-1)); + + TEST_MOD_IDENTITY(absl::Nanoseconds(0), absl::Nanoseconds(2)); + TEST_MOD_IDENTITY(absl::Nanoseconds(1), absl::Nanoseconds(1)); + TEST_MOD_IDENTITY(absl::Nanoseconds(1), absl::Nanoseconds(2)); + TEST_MOD_IDENTITY(absl::Nanoseconds(2), absl::Nanoseconds(1)); + + TEST_MOD_IDENTITY(absl::Nanoseconds(-2), absl::Nanoseconds(1)); + TEST_MOD_IDENTITY(absl::Nanoseconds(2), absl::Nanoseconds(-1)); + TEST_MOD_IDENTITY(absl::Nanoseconds(-2), absl::Nanoseconds(-1)); + + // Mixed seconds + subseconds + absl::Duration mixed_a = absl::Seconds(1) + absl::Nanoseconds(2); + absl::Duration mixed_b = absl::Seconds(1) + absl::Nanoseconds(3); + + TEST_MOD_IDENTITY(absl::Seconds(0), mixed_a); + TEST_MOD_IDENTITY(mixed_a, mixed_a); + TEST_MOD_IDENTITY(mixed_a, mixed_b); + TEST_MOD_IDENTITY(mixed_b, mixed_a); + + TEST_MOD_IDENTITY(-mixed_a, mixed_b); + TEST_MOD_IDENTITY(mixed_a, -mixed_b); + TEST_MOD_IDENTITY(-mixed_a, -mixed_b); + +#undef TEST_MOD_IDENTITY +} + +TEST(Duration, Truncation) { + const absl::Duration d = absl::Nanoseconds(1234567890); + const absl::Duration inf = absl::InfiniteDuration(); + for (int unit_sign : {1, -1}) { // sign shouldn't matter + EXPECT_EQ(absl::Nanoseconds(1234567890), + Trunc(d, unit_sign * absl::Nanoseconds(1))); + EXPECT_EQ(absl::Microseconds(1234567), + Trunc(d, unit_sign * absl::Microseconds(1))); + EXPECT_EQ(absl::Milliseconds(1234), + Trunc(d, unit_sign * absl::Milliseconds(1))); + EXPECT_EQ(absl::Seconds(1), Trunc(d, unit_sign * absl::Seconds(1))); + EXPECT_EQ(inf, Trunc(inf, unit_sign * absl::Seconds(1))); + + EXPECT_EQ(absl::Nanoseconds(-1234567890), + Trunc(-d, unit_sign * absl::Nanoseconds(1))); + EXPECT_EQ(absl::Microseconds(-1234567), + Trunc(-d, unit_sign * absl::Microseconds(1))); + EXPECT_EQ(absl::Milliseconds(-1234), + Trunc(-d, unit_sign * absl::Milliseconds(1))); + EXPECT_EQ(absl::Seconds(-1), Trunc(-d, unit_sign * absl::Seconds(1))); + EXPECT_EQ(-inf, Trunc(-inf, unit_sign * absl::Seconds(1))); + } +} + +TEST(Duration, Flooring) { + const absl::Duration d = absl::Nanoseconds(1234567890); + const absl::Duration inf = absl::InfiniteDuration(); + for (int unit_sign : {1, -1}) { // sign shouldn't matter + EXPECT_EQ(absl::Nanoseconds(1234567890), + absl::Floor(d, unit_sign * absl::Nanoseconds(1))); + EXPECT_EQ(absl::Microseconds(1234567), + absl::Floor(d, unit_sign * absl::Microseconds(1))); + EXPECT_EQ(absl::Milliseconds(1234), + absl::Floor(d, unit_sign * absl::Milliseconds(1))); + EXPECT_EQ(absl::Seconds(1), absl::Floor(d, unit_sign * absl::Seconds(1))); + EXPECT_EQ(inf, absl::Floor(inf, unit_sign * absl::Seconds(1))); + + EXPECT_EQ(absl::Nanoseconds(-1234567890), + absl::Floor(-d, unit_sign * absl::Nanoseconds(1))); + EXPECT_EQ(absl::Microseconds(-1234568), + absl::Floor(-d, unit_sign * absl::Microseconds(1))); + EXPECT_EQ(absl::Milliseconds(-1235), + absl::Floor(-d, unit_sign * absl::Milliseconds(1))); + EXPECT_EQ(absl::Seconds(-2), absl::Floor(-d, unit_sign * absl::Seconds(1))); + EXPECT_EQ(-inf, absl::Floor(-inf, unit_sign * absl::Seconds(1))); + } +} + +TEST(Duration, Ceiling) { + const absl::Duration d = absl::Nanoseconds(1234567890); + const absl::Duration inf = absl::InfiniteDuration(); + for (int unit_sign : {1, -1}) { // // sign shouldn't matter + EXPECT_EQ(absl::Nanoseconds(1234567890), + absl::Ceil(d, unit_sign * absl::Nanoseconds(1))); + EXPECT_EQ(absl::Microseconds(1234568), + absl::Ceil(d, unit_sign * absl::Microseconds(1))); + EXPECT_EQ(absl::Milliseconds(1235), + absl::Ceil(d, unit_sign * absl::Milliseconds(1))); + EXPECT_EQ(absl::Seconds(2), absl::Ceil(d, unit_sign * absl::Seconds(1))); + EXPECT_EQ(inf, absl::Ceil(inf, unit_sign * absl::Seconds(1))); + + EXPECT_EQ(absl::Nanoseconds(-1234567890), + absl::Ceil(-d, unit_sign * absl::Nanoseconds(1))); + EXPECT_EQ(absl::Microseconds(-1234567), + absl::Ceil(-d, unit_sign * absl::Microseconds(1))); + EXPECT_EQ(absl::Milliseconds(-1234), + absl::Ceil(-d, unit_sign * absl::Milliseconds(1))); + EXPECT_EQ(absl::Seconds(-1), absl::Ceil(-d, unit_sign * absl::Seconds(1))); + EXPECT_EQ(-inf, absl::Ceil(-inf, unit_sign * absl::Seconds(1))); + } +} + +TEST(Duration, RoundTripUnits) { + const int kRange = 100000; + +#define ROUND_TRIP_UNIT(U, LOW, HIGH) \ + do { \ + for (int64_t i = LOW; i < HIGH; ++i) { \ + absl::Duration d = absl::U(i); \ + if (d == absl::InfiniteDuration()) \ + EXPECT_EQ(kint64max, d / absl::U(1)); \ + else if (d == -absl::InfiniteDuration()) \ + EXPECT_EQ(kint64min, d / absl::U(1)); \ + else \ + EXPECT_EQ(i, absl::U(i) / absl::U(1)); \ + } \ + } while (0) + + ROUND_TRIP_UNIT(Nanoseconds, kint64min, kint64min + kRange); + ROUND_TRIP_UNIT(Nanoseconds, -kRange, kRange); + ROUND_TRIP_UNIT(Nanoseconds, kint64max - kRange, kint64max); + + ROUND_TRIP_UNIT(Microseconds, kint64min, kint64min + kRange); + ROUND_TRIP_UNIT(Microseconds, -kRange, kRange); + ROUND_TRIP_UNIT(Microseconds, kint64max - kRange, kint64max); + + ROUND_TRIP_UNIT(Milliseconds, kint64min, kint64min + kRange); + ROUND_TRIP_UNIT(Milliseconds, -kRange, kRange); + ROUND_TRIP_UNIT(Milliseconds, kint64max - kRange, kint64max); + + ROUND_TRIP_UNIT(Seconds, kint64min, kint64min + kRange); + ROUND_TRIP_UNIT(Seconds, -kRange, kRange); + ROUND_TRIP_UNIT(Seconds, kint64max - kRange, kint64max); + + ROUND_TRIP_UNIT(Minutes, kint64min / 60, kint64min / 60 + kRange); + ROUND_TRIP_UNIT(Minutes, -kRange, kRange); + ROUND_TRIP_UNIT(Minutes, kint64max / 60 - kRange, kint64max / 60); + + ROUND_TRIP_UNIT(Hours, kint64min / 3600, kint64min / 3600 + kRange); + ROUND_TRIP_UNIT(Hours, -kRange, kRange); + ROUND_TRIP_UNIT(Hours, kint64max / 3600 - kRange, kint64max / 3600); + +#undef ROUND_TRIP_UNIT +} + +TEST(Duration, TruncConversions) { + // Tests ToTimespec()/DurationFromTimespec() + const struct { + absl::Duration d; + timespec ts; + } to_ts[] = { + {absl::Seconds(1) + absl::Nanoseconds(1), {1, 1}}, + {absl::Seconds(1) + absl::Nanoseconds(1) / 2, {1, 0}}, + {absl::Seconds(1) + absl::Nanoseconds(0), {1, 0}}, + {absl::Seconds(0) + absl::Nanoseconds(0), {0, 0}}, + {absl::Seconds(0) - absl::Nanoseconds(1) / 2, {0, 0}}, + {absl::Seconds(0) - absl::Nanoseconds(1), {-1, 999999999}}, + {absl::Seconds(-1) + absl::Nanoseconds(1), {-1, 1}}, + {absl::Seconds(-1) + absl::Nanoseconds(1) / 2, {-1, 1}}, + {absl::Seconds(-1) + absl::Nanoseconds(0), {-1, 0}}, + {absl::Seconds(-1) - absl::Nanoseconds(1) / 2, {-1, 0}}, + }; + for (const auto& test : to_ts) { + EXPECT_THAT(absl::ToTimespec(test.d), TimespecMatcher(test.ts)); + } + const struct { + timespec ts; + absl::Duration d; + } from_ts[] = { + {{1, 1}, absl::Seconds(1) + absl::Nanoseconds(1)}, + {{1, 0}, absl::Seconds(1) + absl::Nanoseconds(0)}, + {{0, 0}, absl::Seconds(0) + absl::Nanoseconds(0)}, + {{0, -1}, absl::Seconds(0) - absl::Nanoseconds(1)}, + {{-1, 999999999}, absl::Seconds(0) - absl::Nanoseconds(1)}, + {{-1, 1}, absl::Seconds(-1) + absl::Nanoseconds(1)}, + {{-1, 0}, absl::Seconds(-1) + absl::Nanoseconds(0)}, + {{-1, -1}, absl::Seconds(-1) - absl::Nanoseconds(1)}, + {{-2, 999999999}, absl::Seconds(-1) - absl::Nanoseconds(1)}, + }; + for (const auto& test : from_ts) { + EXPECT_EQ(test.d, absl::DurationFromTimespec(test.ts)); + } + + // Tests ToTimeval()/DurationFromTimeval() (same as timespec above) + const struct { + absl::Duration d; + timeval tv; + } to_tv[] = { + {absl::Seconds(1) + absl::Microseconds(1), {1, 1}}, + {absl::Seconds(1) + absl::Microseconds(1) / 2, {1, 0}}, + {absl::Seconds(1) + absl::Microseconds(0), {1, 0}}, + {absl::Seconds(0) + absl::Microseconds(0), {0, 0}}, + {absl::Seconds(0) - absl::Microseconds(1) / 2, {0, 0}}, + {absl::Seconds(0) - absl::Microseconds(1), {-1, 999999}}, + {absl::Seconds(-1) + absl::Microseconds(1), {-1, 1}}, + {absl::Seconds(-1) + absl::Microseconds(1) / 2, {-1, 1}}, + {absl::Seconds(-1) + absl::Microseconds(0), {-1, 0}}, + {absl::Seconds(-1) - absl::Microseconds(1) / 2, {-1, 0}}, + }; + for (const auto& test : to_tv) { + EXPECT_THAT(absl::ToTimeval(test.d), TimevalMatcher(test.tv)); + } + const struct { + timeval tv; + absl::Duration d; + } from_tv[] = { + {{1, 1}, absl::Seconds(1) + absl::Microseconds(1)}, + {{1, 0}, absl::Seconds(1) + absl::Microseconds(0)}, + {{0, 0}, absl::Seconds(0) + absl::Microseconds(0)}, + {{0, -1}, absl::Seconds(0) - absl::Microseconds(1)}, + {{-1, 999999}, absl::Seconds(0) - absl::Microseconds(1)}, + {{-1, 1}, absl::Seconds(-1) + absl::Microseconds(1)}, + {{-1, 0}, absl::Seconds(-1) + absl::Microseconds(0)}, + {{-1, -1}, absl::Seconds(-1) - absl::Microseconds(1)}, + {{-2, 999999}, absl::Seconds(-1) - absl::Microseconds(1)}, + }; + for (const auto& test : from_tv) { + EXPECT_EQ(test.d, absl::DurationFromTimeval(test.tv)); + } +} + +TEST(Duration, SmallConversions) { + // Special tests for conversions of small durations. + + EXPECT_EQ(absl::ZeroDuration(), absl::Seconds(0)); + // TODO(bww): Is the next one OK? + EXPECT_EQ(absl::ZeroDuration(), absl::Seconds(0.124999999e-9)); + EXPECT_EQ(absl::Nanoseconds(1) / 4, absl::Seconds(0.125e-9)); + EXPECT_EQ(absl::Nanoseconds(1) / 4, absl::Seconds(0.250e-9)); + EXPECT_EQ(absl::Nanoseconds(1) / 2, absl::Seconds(0.375e-9)); + EXPECT_EQ(absl::Nanoseconds(1) / 2, absl::Seconds(0.500e-9)); + EXPECT_EQ(absl::Nanoseconds(3) / 4, absl::Seconds(0.625e-9)); + EXPECT_EQ(absl::Nanoseconds(3) / 4, absl::Seconds(0.750e-9)); + EXPECT_EQ(absl::Nanoseconds(1), absl::Seconds(0.875e-9)); + EXPECT_EQ(absl::Nanoseconds(1), absl::Seconds(1.000e-9)); + + EXPECT_EQ(absl::ZeroDuration(), absl::Seconds(-0.124999999e-9)); + EXPECT_EQ(-absl::Nanoseconds(1) / 4, absl::Seconds(-0.125e-9)); + EXPECT_EQ(-absl::Nanoseconds(1) / 4, absl::Seconds(-0.250e-9)); + EXPECT_EQ(-absl::Nanoseconds(1) / 2, absl::Seconds(-0.375e-9)); + EXPECT_EQ(-absl::Nanoseconds(1) / 2, absl::Seconds(-0.500e-9)); + EXPECT_EQ(-absl::Nanoseconds(3) / 4, absl::Seconds(-0.625e-9)); + EXPECT_EQ(-absl::Nanoseconds(3) / 4, absl::Seconds(-0.750e-9)); + EXPECT_EQ(-absl::Nanoseconds(1), absl::Seconds(-0.875e-9)); + EXPECT_EQ(-absl::Nanoseconds(1), absl::Seconds(-1.000e-9)); + + timespec ts; + ts.tv_sec = 0; + ts.tv_nsec = 0; + EXPECT_THAT(ToTimespec(absl::Nanoseconds(0)), TimespecMatcher(ts)); + // TODO(bww): Are the next three OK? + EXPECT_THAT(ToTimespec(absl::Nanoseconds(1) / 4), TimespecMatcher(ts)); + EXPECT_THAT(ToTimespec(absl::Nanoseconds(2) / 4), TimespecMatcher(ts)); + EXPECT_THAT(ToTimespec(absl::Nanoseconds(3) / 4), TimespecMatcher(ts)); + ts.tv_nsec = 1; + EXPECT_THAT(ToTimespec(absl::Nanoseconds(4) / 4), TimespecMatcher(ts)); + EXPECT_THAT(ToTimespec(absl::Nanoseconds(5) / 4), TimespecMatcher(ts)); + EXPECT_THAT(ToTimespec(absl::Nanoseconds(6) / 4), TimespecMatcher(ts)); + EXPECT_THAT(ToTimespec(absl::Nanoseconds(7) / 4), TimespecMatcher(ts)); + ts.tv_nsec = 2; + EXPECT_THAT(ToTimespec(absl::Nanoseconds(8) / 4), TimespecMatcher(ts)); + + timeval tv; + tv.tv_sec = 0; + tv.tv_usec = 0; + EXPECT_THAT(ToTimeval(absl::Nanoseconds(0)), TimevalMatcher(tv)); + // TODO(bww): Is the next one OK? + EXPECT_THAT(ToTimeval(absl::Nanoseconds(999)), TimevalMatcher(tv)); + tv.tv_usec = 1; + EXPECT_THAT(ToTimeval(absl::Nanoseconds(1000)), TimevalMatcher(tv)); + EXPECT_THAT(ToTimeval(absl::Nanoseconds(1999)), TimevalMatcher(tv)); + tv.tv_usec = 2; + EXPECT_THAT(ToTimeval(absl::Nanoseconds(2000)), TimevalMatcher(tv)); +} + +void VerifySameAsMul(double time_as_seconds, int* const misses) { + auto direct_seconds = absl::Seconds(time_as_seconds); + auto mul_by_one_second = time_as_seconds * absl::Seconds(1); + if (direct_seconds != mul_by_one_second) { + if (*misses > 10) return; + ASSERT_LE(++(*misses), 10) << "Too many errors, not reporting more."; + EXPECT_EQ(direct_seconds, mul_by_one_second) + << "given double time_as_seconds = " << std::setprecision(17) + << time_as_seconds; + } +} + +// For a variety of interesting durations, we find the exact point +// where one double converts to that duration, and the very next double +// converts to the next duration. For both of those points, verify that +// Seconds(point) returns the same duration as point * Seconds(1.0) +TEST(Duration, ToDoubleSecondsCheckEdgeCases) { + constexpr uint32_t kTicksPerSecond = absl::time_internal::kTicksPerSecond; + constexpr auto duration_tick = absl::time_internal::MakeDuration(0, 1u); + int misses = 0; + for (int64_t seconds = 0; seconds < 99; ++seconds) { + uint32_t tick_vals[] = {0, +999, +999999, +999999999, kTicksPerSecond - 1, + 0, 1000, 1000000, 1000000000, kTicksPerSecond, + 1, 1001, 1000001, 1000000001, kTicksPerSecond + 1, + 2, 1002, 1000002, 1000000002, kTicksPerSecond + 2, + 3, 1003, 1000003, 1000000003, kTicksPerSecond + 3, + 4, 1004, 1000004, 1000000004, kTicksPerSecond + 4, + 5, 6, 7, 8, 9}; + for (uint32_t ticks : tick_vals) { + absl::Duration s_plus_t = absl::Seconds(seconds) + ticks * duration_tick; + for (absl::Duration d : {s_plus_t, -s_plus_t}) { + absl::Duration after_d = d + duration_tick; + EXPECT_NE(d, after_d); + EXPECT_EQ(after_d - d, duration_tick); + + double low_edge = ToDoubleSeconds(d); + EXPECT_EQ(d, absl::Seconds(low_edge)); + + double high_edge = ToDoubleSeconds(after_d); + EXPECT_EQ(after_d, absl::Seconds(high_edge)); + + for (;;) { + double midpoint = low_edge + (high_edge - low_edge) / 2; + if (midpoint == low_edge || midpoint == high_edge) break; + absl::Duration mid_duration = absl::Seconds(midpoint); + if (mid_duration == d) { + low_edge = midpoint; + } else { + EXPECT_EQ(mid_duration, after_d); + high_edge = midpoint; + } + } + // Now low_edge is the highest double that converts to Duration d, + // and high_edge is the lowest double that converts to Duration after_d. + VerifySameAsMul(low_edge, &misses); + VerifySameAsMul(high_edge, &misses); + } + } + } +} + +TEST(Duration, ToDoubleSecondsCheckRandom) { + std::random_device rd; + std::seed_seq seed({rd(), rd(), rd(), rd(), rd(), rd(), rd(), rd()}); + std::mt19937_64 gen(seed); + // We want doubles distributed from 1/8ns up to 2^63, where + // as many values are tested from 1ns to 2ns as from 1sec to 2sec, + // so even distribute along a log-scale of those values, and + // exponentiate before using them. (9.223377e+18 is just slightly + // out of bounds for absl::Duration.) + std::uniform_real_distribution<double> uniform(std::log(0.125e-9), + std::log(9.223377e+18)); + int misses = 0; + for (int i = 0; i < 1000000; ++i) { + double d = std::exp(uniform(gen)); + VerifySameAsMul(d, &misses); + VerifySameAsMul(-d, &misses); + } +} + +TEST(Duration, ConversionSaturation) { + absl::Duration d; + + const auto max_timeval_sec = + std::numeric_limits<decltype(timeval::tv_sec)>::max(); + const auto min_timeval_sec = + std::numeric_limits<decltype(timeval::tv_sec)>::min(); + timeval tv; + tv.tv_sec = max_timeval_sec; + tv.tv_usec = 999998; + d = absl::DurationFromTimeval(tv); + tv = ToTimeval(d); + EXPECT_EQ(max_timeval_sec, tv.tv_sec); + EXPECT_EQ(999998, tv.tv_usec); + d += absl::Microseconds(1); + tv = ToTimeval(d); + EXPECT_EQ(max_timeval_sec, tv.tv_sec); + EXPECT_EQ(999999, tv.tv_usec); + d += absl::Microseconds(1); // no effect + tv = ToTimeval(d); + EXPECT_EQ(max_timeval_sec, tv.tv_sec); + EXPECT_EQ(999999, tv.tv_usec); + + tv.tv_sec = min_timeval_sec; + tv.tv_usec = 1; + d = absl::DurationFromTimeval(tv); + tv = ToTimeval(d); + EXPECT_EQ(min_timeval_sec, tv.tv_sec); + EXPECT_EQ(1, tv.tv_usec); + d -= absl::Microseconds(1); + tv = ToTimeval(d); + EXPECT_EQ(min_timeval_sec, tv.tv_sec); + EXPECT_EQ(0, tv.tv_usec); + d -= absl::Microseconds(1); // no effect + tv = ToTimeval(d); + EXPECT_EQ(min_timeval_sec, tv.tv_sec); + EXPECT_EQ(0, tv.tv_usec); + + const auto max_timespec_sec = + std::numeric_limits<decltype(timespec::tv_sec)>::max(); + const auto min_timespec_sec = + std::numeric_limits<decltype(timespec::tv_sec)>::min(); + timespec ts; + ts.tv_sec = max_timespec_sec; + ts.tv_nsec = 999999998; + d = absl::DurationFromTimespec(ts); + ts = absl::ToTimespec(d); + EXPECT_EQ(max_timespec_sec, ts.tv_sec); + EXPECT_EQ(999999998, ts.tv_nsec); + d += absl::Nanoseconds(1); + ts = absl::ToTimespec(d); + EXPECT_EQ(max_timespec_sec, ts.tv_sec); + EXPECT_EQ(999999999, ts.tv_nsec); + d += absl::Nanoseconds(1); // no effect + ts = absl::ToTimespec(d); + EXPECT_EQ(max_timespec_sec, ts.tv_sec); + EXPECT_EQ(999999999, ts.tv_nsec); + + ts.tv_sec = min_timespec_sec; + ts.tv_nsec = 1; + d = absl::DurationFromTimespec(ts); + ts = absl::ToTimespec(d); + EXPECT_EQ(min_timespec_sec, ts.tv_sec); + EXPECT_EQ(1, ts.tv_nsec); + d -= absl::Nanoseconds(1); + ts = absl::ToTimespec(d); + EXPECT_EQ(min_timespec_sec, ts.tv_sec); + EXPECT_EQ(0, ts.tv_nsec); + d -= absl::Nanoseconds(1); // no effect + ts = absl::ToTimespec(d); + EXPECT_EQ(min_timespec_sec, ts.tv_sec); + EXPECT_EQ(0, ts.tv_nsec); +} + +TEST(Duration, FormatDuration) { + // Example from Go's docs. + EXPECT_EQ("72h3m0.5s", + absl::FormatDuration(absl::Hours(72) + absl::Minutes(3) + + absl::Milliseconds(500))); + // Go's largest time: 2540400h10m10.000000000s + EXPECT_EQ("2540400h10m10s", + absl::FormatDuration(absl::Hours(2540400) + absl::Minutes(10) + + absl::Seconds(10))); + + EXPECT_EQ("0", absl::FormatDuration(absl::ZeroDuration())); + EXPECT_EQ("0", absl::FormatDuration(absl::Seconds(0))); + EXPECT_EQ("0", absl::FormatDuration(absl::Nanoseconds(0))); + + EXPECT_EQ("1ns", absl::FormatDuration(absl::Nanoseconds(1))); + EXPECT_EQ("1us", absl::FormatDuration(absl::Microseconds(1))); + EXPECT_EQ("1ms", absl::FormatDuration(absl::Milliseconds(1))); + EXPECT_EQ("1s", absl::FormatDuration(absl::Seconds(1))); + EXPECT_EQ("1m", absl::FormatDuration(absl::Minutes(1))); + EXPECT_EQ("1h", absl::FormatDuration(absl::Hours(1))); + + EXPECT_EQ("1h1m", absl::FormatDuration(absl::Hours(1) + absl::Minutes(1))); + EXPECT_EQ("1h1s", absl::FormatDuration(absl::Hours(1) + absl::Seconds(1))); + EXPECT_EQ("1m1s", absl::FormatDuration(absl::Minutes(1) + absl::Seconds(1))); + + EXPECT_EQ("1h0.25s", + absl::FormatDuration(absl::Hours(1) + absl::Milliseconds(250))); + EXPECT_EQ("1m0.25s", + absl::FormatDuration(absl::Minutes(1) + absl::Milliseconds(250))); + EXPECT_EQ("1h1m0.25s", + absl::FormatDuration(absl::Hours(1) + absl::Minutes(1) + + absl::Milliseconds(250))); + EXPECT_EQ("1h0.0005s", + absl::FormatDuration(absl::Hours(1) + absl::Microseconds(500))); + EXPECT_EQ("1h0.0000005s", + absl::FormatDuration(absl::Hours(1) + absl::Nanoseconds(500))); + + // Subsecond special case. + EXPECT_EQ("1.5ns", absl::FormatDuration(absl::Nanoseconds(1) + + absl::Nanoseconds(1) / 2)); + EXPECT_EQ("1.25ns", absl::FormatDuration(absl::Nanoseconds(1) + + absl::Nanoseconds(1) / 4)); + EXPECT_EQ("1ns", absl::FormatDuration(absl::Nanoseconds(1) + + absl::Nanoseconds(1) / 9)); + EXPECT_EQ("1.2us", absl::FormatDuration(absl::Microseconds(1) + + absl::Nanoseconds(200))); + EXPECT_EQ("1.2ms", absl::FormatDuration(absl::Milliseconds(1) + + absl::Microseconds(200))); + EXPECT_EQ("1.0002ms", absl::FormatDuration(absl::Milliseconds(1) + + absl::Nanoseconds(200))); + EXPECT_EQ("1.00001ms", absl::FormatDuration(absl::Milliseconds(1) + + absl::Nanoseconds(10))); + EXPECT_EQ("1.000001ms", + absl::FormatDuration(absl::Milliseconds(1) + absl::Nanoseconds(1))); + + // Negative durations. + EXPECT_EQ("-1ns", absl::FormatDuration(absl::Nanoseconds(-1))); + EXPECT_EQ("-1us", absl::FormatDuration(absl::Microseconds(-1))); + EXPECT_EQ("-1ms", absl::FormatDuration(absl::Milliseconds(-1))); + EXPECT_EQ("-1s", absl::FormatDuration(absl::Seconds(-1))); + EXPECT_EQ("-1m", absl::FormatDuration(absl::Minutes(-1))); + EXPECT_EQ("-1h", absl::FormatDuration(absl::Hours(-1))); + + EXPECT_EQ("-1h1m", + absl::FormatDuration(-(absl::Hours(1) + absl::Minutes(1)))); + EXPECT_EQ("-1h1s", + absl::FormatDuration(-(absl::Hours(1) + absl::Seconds(1)))); + EXPECT_EQ("-1m1s", + absl::FormatDuration(-(absl::Minutes(1) + absl::Seconds(1)))); + + EXPECT_EQ("-1ns", absl::FormatDuration(absl::Nanoseconds(-1))); + EXPECT_EQ("-1.2us", absl::FormatDuration( + -(absl::Microseconds(1) + absl::Nanoseconds(200)))); + EXPECT_EQ("-1.2ms", absl::FormatDuration( + -(absl::Milliseconds(1) + absl::Microseconds(200)))); + EXPECT_EQ("-1.0002ms", absl::FormatDuration(-(absl::Milliseconds(1) + + absl::Nanoseconds(200)))); + EXPECT_EQ("-1.00001ms", absl::FormatDuration(-(absl::Milliseconds(1) + + absl::Nanoseconds(10)))); + EXPECT_EQ("-1.000001ms", absl::FormatDuration(-(absl::Milliseconds(1) + + absl::Nanoseconds(1)))); + + // + // Interesting corner cases. + // + + const absl::Duration qns = absl::Nanoseconds(1) / 4; + const absl::Duration max_dur = + absl::Seconds(kint64max) + (absl::Seconds(1) - qns); + const absl::Duration min_dur = absl::Seconds(kint64min); + + EXPECT_EQ("0.25ns", absl::FormatDuration(qns)); + EXPECT_EQ("-0.25ns", absl::FormatDuration(-qns)); + EXPECT_EQ("2562047788015215h30m7.99999999975s", + absl::FormatDuration(max_dur)); + EXPECT_EQ("-2562047788015215h30m8s", absl::FormatDuration(min_dur)); + + // Tests printing full precision from units that print using FDivDuration + EXPECT_EQ("55.00000000025s", absl::FormatDuration(absl::Seconds(55) + qns)); + EXPECT_EQ("55.00000025ms", + absl::FormatDuration(absl::Milliseconds(55) + qns)); + EXPECT_EQ("55.00025us", absl::FormatDuration(absl::Microseconds(55) + qns)); + EXPECT_EQ("55.25ns", absl::FormatDuration(absl::Nanoseconds(55) + qns)); + + // Formatting infinity + EXPECT_EQ("inf", absl::FormatDuration(absl::InfiniteDuration())); + EXPECT_EQ("-inf", absl::FormatDuration(-absl::InfiniteDuration())); + + // Formatting approximately +/- 100 billion years + const absl::Duration huge_range = ApproxYears(100000000000); + EXPECT_EQ("876000000000000h", absl::FormatDuration(huge_range)); + EXPECT_EQ("-876000000000000h", absl::FormatDuration(-huge_range)); + + EXPECT_EQ("876000000000000h0.999999999s", + absl::FormatDuration(huge_range + + (absl::Seconds(1) - absl::Nanoseconds(1)))); + EXPECT_EQ("876000000000000h0.9999999995s", + absl::FormatDuration( + huge_range + (absl::Seconds(1) - absl::Nanoseconds(1) / 2))); + EXPECT_EQ("876000000000000h0.99999999975s", + absl::FormatDuration( + huge_range + (absl::Seconds(1) - absl::Nanoseconds(1) / 4))); + + EXPECT_EQ("-876000000000000h0.999999999s", + absl::FormatDuration(-huge_range - + (absl::Seconds(1) - absl::Nanoseconds(1)))); + EXPECT_EQ("-876000000000000h0.9999999995s", + absl::FormatDuration( + -huge_range - (absl::Seconds(1) - absl::Nanoseconds(1) / 2))); + EXPECT_EQ("-876000000000000h0.99999999975s", + absl::FormatDuration( + -huge_range - (absl::Seconds(1) - absl::Nanoseconds(1) / 4))); +} + +TEST(Duration, ParseDuration) { + absl::Duration d; + + // No specified unit. Should only work for zero and infinity. + EXPECT_TRUE(absl::ParseDuration("0", &d)); + EXPECT_EQ(absl::ZeroDuration(), d); + EXPECT_TRUE(absl::ParseDuration("+0", &d)); + EXPECT_EQ(absl::ZeroDuration(), d); + EXPECT_TRUE(absl::ParseDuration("-0", &d)); + EXPECT_EQ(absl::ZeroDuration(), d); + + EXPECT_TRUE(absl::ParseDuration("inf", &d)); + EXPECT_EQ(absl::InfiniteDuration(), d); + EXPECT_TRUE(absl::ParseDuration("+inf", &d)); + EXPECT_EQ(absl::InfiniteDuration(), d); + EXPECT_TRUE(absl::ParseDuration("-inf", &d)); + EXPECT_EQ(-absl::InfiniteDuration(), d); + EXPECT_FALSE(absl::ParseDuration("infBlah", &d)); + + // Illegal input forms. + EXPECT_FALSE(absl::ParseDuration("", &d)); + EXPECT_FALSE(absl::ParseDuration("0.0", &d)); + EXPECT_FALSE(absl::ParseDuration(".0", &d)); + EXPECT_FALSE(absl::ParseDuration(".", &d)); + EXPECT_FALSE(absl::ParseDuration("01", &d)); + EXPECT_FALSE(absl::ParseDuration("1", &d)); + EXPECT_FALSE(absl::ParseDuration("-1", &d)); + EXPECT_FALSE(absl::ParseDuration("2", &d)); + EXPECT_FALSE(absl::ParseDuration("2 s", &d)); + EXPECT_FALSE(absl::ParseDuration(".s", &d)); + EXPECT_FALSE(absl::ParseDuration("-.s", &d)); + EXPECT_FALSE(absl::ParseDuration("s", &d)); + EXPECT_FALSE(absl::ParseDuration(" 2s", &d)); + EXPECT_FALSE(absl::ParseDuration("2s ", &d)); + EXPECT_FALSE(absl::ParseDuration(" 2s ", &d)); + EXPECT_FALSE(absl::ParseDuration("2mt", &d)); + EXPECT_FALSE(absl::ParseDuration("1e3s", &d)); + + // One unit type. + EXPECT_TRUE(absl::ParseDuration("1ns", &d)); + EXPECT_EQ(absl::Nanoseconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1us", &d)); + EXPECT_EQ(absl::Microseconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1ms", &d)); + EXPECT_EQ(absl::Milliseconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1s", &d)); + EXPECT_EQ(absl::Seconds(1), d); + EXPECT_TRUE(absl::ParseDuration("2m", &d)); + EXPECT_EQ(absl::Minutes(2), d); + EXPECT_TRUE(absl::ParseDuration("2h", &d)); + EXPECT_EQ(absl::Hours(2), d); + + // Huge counts of a unit. + EXPECT_TRUE(absl::ParseDuration("9223372036854775807us", &d)); + EXPECT_EQ(absl::Microseconds(9223372036854775807), d); + EXPECT_TRUE(absl::ParseDuration("-9223372036854775807us", &d)); + EXPECT_EQ(absl::Microseconds(-9223372036854775807), d); + + // Multiple units. + EXPECT_TRUE(absl::ParseDuration("2h3m4s", &d)); + EXPECT_EQ(absl::Hours(2) + absl::Minutes(3) + absl::Seconds(4), d); + EXPECT_TRUE(absl::ParseDuration("3m4s5us", &d)); + EXPECT_EQ(absl::Minutes(3) + absl::Seconds(4) + absl::Microseconds(5), d); + EXPECT_TRUE(absl::ParseDuration("2h3m4s5ms6us7ns", &d)); + EXPECT_EQ(absl::Hours(2) + absl::Minutes(3) + absl::Seconds(4) + + absl::Milliseconds(5) + absl::Microseconds(6) + + absl::Nanoseconds(7), + d); + + // Multiple units out of order. + EXPECT_TRUE(absl::ParseDuration("2us3m4s5h", &d)); + EXPECT_EQ(absl::Hours(5) + absl::Minutes(3) + absl::Seconds(4) + + absl::Microseconds(2), + d); + + // Fractional values of units. + EXPECT_TRUE(absl::ParseDuration("1.5ns", &d)); + EXPECT_EQ(1.5 * absl::Nanoseconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1.5us", &d)); + EXPECT_EQ(1.5 * absl::Microseconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1.5ms", &d)); + EXPECT_EQ(1.5 * absl::Milliseconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1.5s", &d)); + EXPECT_EQ(1.5 * absl::Seconds(1), d); + EXPECT_TRUE(absl::ParseDuration("1.5m", &d)); + EXPECT_EQ(1.5 * absl::Minutes(1), d); + EXPECT_TRUE(absl::ParseDuration("1.5h", &d)); + EXPECT_EQ(1.5 * absl::Hours(1), d); + + // Huge fractional counts of a unit. + EXPECT_TRUE(absl::ParseDuration("0.4294967295s", &d)); + EXPECT_EQ(absl::Nanoseconds(429496729) + absl::Nanoseconds(1) / 2, d); + EXPECT_TRUE(absl::ParseDuration("0.429496729501234567890123456789s", &d)); + EXPECT_EQ(absl::Nanoseconds(429496729) + absl::Nanoseconds(1) / 2, d); + + // Negative durations. + EXPECT_TRUE(absl::ParseDuration("-1s", &d)); + EXPECT_EQ(absl::Seconds(-1), d); + EXPECT_TRUE(absl::ParseDuration("-1m", &d)); + EXPECT_EQ(absl::Minutes(-1), d); + EXPECT_TRUE(absl::ParseDuration("-1h", &d)); + EXPECT_EQ(absl::Hours(-1), d); + + EXPECT_TRUE(absl::ParseDuration("-1h2s", &d)); + EXPECT_EQ(-(absl::Hours(1) + absl::Seconds(2)), d); + EXPECT_FALSE(absl::ParseDuration("1h-2s", &d)); + EXPECT_FALSE(absl::ParseDuration("-1h-2s", &d)); + EXPECT_FALSE(absl::ParseDuration("-1h -2s", &d)); +} + +TEST(Duration, FormatParseRoundTrip) { +#define TEST_PARSE_ROUNDTRIP(d) \ + do { \ + std::string s = absl::FormatDuration(d); \ + absl::Duration dur; \ + EXPECT_TRUE(absl::ParseDuration(s, &dur)); \ + EXPECT_EQ(d, dur); \ + } while (0) + + TEST_PARSE_ROUNDTRIP(absl::Nanoseconds(1)); + TEST_PARSE_ROUNDTRIP(absl::Microseconds(1)); + TEST_PARSE_ROUNDTRIP(absl::Milliseconds(1)); + TEST_PARSE_ROUNDTRIP(absl::Seconds(1)); + TEST_PARSE_ROUNDTRIP(absl::Minutes(1)); + TEST_PARSE_ROUNDTRIP(absl::Hours(1)); + TEST_PARSE_ROUNDTRIP(absl::Hours(1) + absl::Nanoseconds(2)); + + TEST_PARSE_ROUNDTRIP(absl::Nanoseconds(-1)); + TEST_PARSE_ROUNDTRIP(absl::Microseconds(-1)); + TEST_PARSE_ROUNDTRIP(absl::Milliseconds(-1)); + TEST_PARSE_ROUNDTRIP(absl::Seconds(-1)); + TEST_PARSE_ROUNDTRIP(absl::Minutes(-1)); + TEST_PARSE_ROUNDTRIP(absl::Hours(-1)); + + TEST_PARSE_ROUNDTRIP(absl::Hours(-1) + absl::Nanoseconds(2)); + TEST_PARSE_ROUNDTRIP(absl::Hours(1) + absl::Nanoseconds(-2)); + TEST_PARSE_ROUNDTRIP(absl::Hours(-1) + absl::Nanoseconds(-2)); + + TEST_PARSE_ROUNDTRIP(absl::Nanoseconds(1) + + absl::Nanoseconds(1) / 4); // 1.25ns + + const absl::Duration huge_range = ApproxYears(100000000000); + TEST_PARSE_ROUNDTRIP(huge_range); + TEST_PARSE_ROUNDTRIP(huge_range + (absl::Seconds(1) - absl::Nanoseconds(1))); + +#undef TEST_PARSE_ROUNDTRIP +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/format.cc b/third_party/abseil_cpp/absl/time/format.cc new file mode 100644 index 0000000000..228940ed1b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/format.cc @@ -0,0 +1,163 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <string.h> + +#include <cctype> +#include <cstdint> + +#include "absl/strings/match.h" +#include "absl/strings/string_view.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" +#include "absl/time/time.h" + +namespace cctz = absl::time_internal::cctz; + +namespace absl { +ABSL_NAMESPACE_BEGIN + +ABSL_DLL extern const char RFC3339_full[] = + "%Y-%m-%dT%H:%M:%E*S%Ez"; +ABSL_DLL extern const char RFC3339_sec[] = "%Y-%m-%dT%H:%M:%S%Ez"; + +ABSL_DLL extern const char RFC1123_full[] = + "%a, %d %b %E4Y %H:%M:%S %z"; +ABSL_DLL extern const char RFC1123_no_wday[] = + "%d %b %E4Y %H:%M:%S %z"; + +namespace { + +const char kInfiniteFutureStr[] = "infinite-future"; +const char kInfinitePastStr[] = "infinite-past"; + +struct cctz_parts { + cctz::time_point<cctz::seconds> sec; + cctz::detail::femtoseconds fem; +}; + +inline cctz::time_point<cctz::seconds> unix_epoch() { + return std::chrono::time_point_cast<cctz::seconds>( + std::chrono::system_clock::from_time_t(0)); +} + +// Splits a Time into seconds and femtoseconds, which can be used with CCTZ. +// Requires that 't' is finite. See duration.cc for details about rep_hi and +// rep_lo. +cctz_parts Split(absl::Time t) { + const auto d = time_internal::ToUnixDuration(t); + const int64_t rep_hi = time_internal::GetRepHi(d); + const int64_t rep_lo = time_internal::GetRepLo(d); + const auto sec = unix_epoch() + cctz::seconds(rep_hi); + const auto fem = cctz::detail::femtoseconds(rep_lo * (1000 * 1000 / 4)); + return {sec, fem}; +} + +// Joins the given seconds and femtoseconds into a Time. See duration.cc for +// details about rep_hi and rep_lo. +absl::Time Join(const cctz_parts& parts) { + const int64_t rep_hi = (parts.sec - unix_epoch()).count(); + const uint32_t rep_lo = parts.fem.count() / (1000 * 1000 / 4); + const auto d = time_internal::MakeDuration(rep_hi, rep_lo); + return time_internal::FromUnixDuration(d); +} + +} // namespace + +std::string FormatTime(absl::string_view format, absl::Time t, + absl::TimeZone tz) { + if (t == absl::InfiniteFuture()) return std::string(kInfiniteFutureStr); + if (t == absl::InfinitePast()) return std::string(kInfinitePastStr); + const auto parts = Split(t); + return cctz::detail::format(std::string(format), parts.sec, parts.fem, + cctz::time_zone(tz)); +} + +std::string FormatTime(absl::Time t, absl::TimeZone tz) { + return FormatTime(RFC3339_full, t, tz); +} + +std::string FormatTime(absl::Time t) { + return absl::FormatTime(RFC3339_full, t, absl::LocalTimeZone()); +} + +bool ParseTime(absl::string_view format, absl::string_view input, + absl::Time* time, std::string* err) { + return absl::ParseTime(format, input, absl::UTCTimeZone(), time, err); +} + +// If the input string does not contain an explicit UTC offset, interpret +// the fields with respect to the given TimeZone. +bool ParseTime(absl::string_view format, absl::string_view input, + absl::TimeZone tz, absl::Time* time, std::string* err) { + auto strip_leading_space = [](absl::string_view* sv) { + while (!sv->empty()) { + if (!std::isspace(sv->front())) return; + sv->remove_prefix(1); + } + }; + + // Portable toolchains means we don't get nice constexpr here. + struct Literal { + const char* name; + size_t size; + absl::Time value; + }; + static Literal literals[] = { + {kInfiniteFutureStr, strlen(kInfiniteFutureStr), InfiniteFuture()}, + {kInfinitePastStr, strlen(kInfinitePastStr), InfinitePast()}, + }; + strip_leading_space(&input); + for (const auto& lit : literals) { + if (absl::StartsWith(input, absl::string_view(lit.name, lit.size))) { + absl::string_view tail = input; + tail.remove_prefix(lit.size); + strip_leading_space(&tail); + if (tail.empty()) { + *time = lit.value; + return true; + } + } + } + + std::string error; + cctz_parts parts; + const bool b = + cctz::detail::parse(std::string(format), std::string(input), + cctz::time_zone(tz), &parts.sec, &parts.fem, &error); + if (b) { + *time = Join(parts); + } else if (err != nullptr) { + *err = error; + } + return b; +} + +// Functions required to support absl::Time flags. +bool AbslParseFlag(absl::string_view text, absl::Time* t, std::string* error) { + return absl::ParseTime(RFC3339_full, text, absl::UTCTimeZone(), t, error); +} + +std::string AbslUnparseFlag(absl::Time t) { + return absl::FormatTime(RFC3339_full, t, absl::UTCTimeZone()); +} +bool ParseFlag(const std::string& text, absl::Time* t, std::string* error) { + return absl::ParseTime(RFC3339_full, text, absl::UTCTimeZone(), t, error); +} + +std::string UnparseFlag(absl::Time t) { + return absl::FormatTime(RFC3339_full, t, absl::UTCTimeZone()); +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/format_benchmark.cc b/third_party/abseil_cpp/absl/time/format_benchmark.cc new file mode 100644 index 0000000000..249c51d875 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/format_benchmark.cc @@ -0,0 +1,64 @@ +// Copyright 2018 The Abseil Authors. +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstddef> +#include <string> + +#include "absl/time/internal/test_util.h" +#include "absl/time/time.h" +#include "benchmark/benchmark.h" + +namespace { + +namespace { +const char* const kFormats[] = { + absl::RFC1123_full, // 0 + absl::RFC1123_no_wday, // 1 + absl::RFC3339_full, // 2 + absl::RFC3339_sec, // 3 + "%Y-%m-%dT%H:%M:%S", // 4 + "%Y-%m-%d", // 5 +}; +const int kNumFormats = sizeof(kFormats) / sizeof(kFormats[0]); +} // namespace + +void BM_Format_FormatTime(benchmark::State& state) { + const std::string fmt = kFormats[state.range(0)]; + state.SetLabel(fmt); + const absl::TimeZone lax = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + const absl::Time t = + absl::FromCivil(absl::CivilSecond(1977, 6, 28, 9, 8, 7), lax) + + absl::Nanoseconds(1); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::FormatTime(fmt, t, lax).length()); + } +} +BENCHMARK(BM_Format_FormatTime)->DenseRange(0, kNumFormats - 1); + +void BM_Format_ParseTime(benchmark::State& state) { + const std::string fmt = kFormats[state.range(0)]; + state.SetLabel(fmt); + const absl::TimeZone lax = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + absl::Time t = absl::FromCivil(absl::CivilSecond(1977, 6, 28, 9, 8, 7), lax) + + absl::Nanoseconds(1); + const std::string when = absl::FormatTime(fmt, t, lax); + std::string err; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ParseTime(fmt, when, lax, &t, &err)); + } +} +BENCHMARK(BM_Format_ParseTime)->DenseRange(0, kNumFormats - 1); + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/format_test.cc b/third_party/abseil_cpp/absl/time/format_test.cc new file mode 100644 index 0000000000..a9a1eb8ee1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/format_test.cc @@ -0,0 +1,441 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <cstdint> +#include <limits> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/time/internal/test_util.h" +#include "absl/time/time.h" + +using testing::HasSubstr; + +namespace { + +// A helper that tests the given format specifier by itself, and with leading +// and trailing characters. For example: TestFormatSpecifier(t, "%a", "Thu"). +void TestFormatSpecifier(absl::Time t, absl::TimeZone tz, + const std::string& fmt, const std::string& ans) { + EXPECT_EQ(ans, absl::FormatTime(fmt, t, tz)); + EXPECT_EQ("xxx " + ans, absl::FormatTime("xxx " + fmt, t, tz)); + EXPECT_EQ(ans + " yyy", absl::FormatTime(fmt + " yyy", t, tz)); + EXPECT_EQ("xxx " + ans + " yyy", + absl::FormatTime("xxx " + fmt + " yyy", t, tz)); +} + +// +// Testing FormatTime() +// + +TEST(FormatTime, Basics) { + absl::TimeZone tz = absl::UTCTimeZone(); + absl::Time t = absl::FromTimeT(0); + + // Starts with a couple basic edge cases. + EXPECT_EQ("", absl::FormatTime("", t, tz)); + EXPECT_EQ(" ", absl::FormatTime(" ", t, tz)); + EXPECT_EQ(" ", absl::FormatTime(" ", t, tz)); + EXPECT_EQ("xxx", absl::FormatTime("xxx", t, tz)); + std::string big(128, 'x'); + EXPECT_EQ(big, absl::FormatTime(big, t, tz)); + // Cause the 1024-byte buffer to grow. + std::string bigger(100000, 'x'); + EXPECT_EQ(bigger, absl::FormatTime(bigger, t, tz)); + + t += absl::Hours(13) + absl::Minutes(4) + absl::Seconds(5); + t += absl::Milliseconds(6) + absl::Microseconds(7) + absl::Nanoseconds(8); + EXPECT_EQ("1970-01-01", absl::FormatTime("%Y-%m-%d", t, tz)); + EXPECT_EQ("13:04:05", absl::FormatTime("%H:%M:%S", t, tz)); + EXPECT_EQ("13:04:05.006", absl::FormatTime("%H:%M:%E3S", t, tz)); + EXPECT_EQ("13:04:05.006007", absl::FormatTime("%H:%M:%E6S", t, tz)); + EXPECT_EQ("13:04:05.006007008", absl::FormatTime("%H:%M:%E9S", t, tz)); +} + +TEST(FormatTime, LocaleSpecific) { + const absl::TimeZone tz = absl::UTCTimeZone(); + absl::Time t = absl::FromTimeT(0); + + TestFormatSpecifier(t, tz, "%a", "Thu"); + TestFormatSpecifier(t, tz, "%A", "Thursday"); + TestFormatSpecifier(t, tz, "%b", "Jan"); + TestFormatSpecifier(t, tz, "%B", "January"); + + // %c should at least produce the numeric year and time-of-day. + const std::string s = + absl::FormatTime("%c", absl::FromTimeT(0), absl::UTCTimeZone()); + EXPECT_THAT(s, HasSubstr("1970")); + EXPECT_THAT(s, HasSubstr("00:00:00")); + + TestFormatSpecifier(t, tz, "%p", "AM"); + TestFormatSpecifier(t, tz, "%x", "01/01/70"); + TestFormatSpecifier(t, tz, "%X", "00:00:00"); +} + +TEST(FormatTime, ExtendedSeconds) { + const absl::TimeZone tz = absl::UTCTimeZone(); + + // No subseconds. + absl::Time t = absl::FromTimeT(0) + absl::Seconds(5); + EXPECT_EQ("05", absl::FormatTime("%E*S", t, tz)); + EXPECT_EQ("05.000000000000000", absl::FormatTime("%E15S", t, tz)); + + // With subseconds. + t += absl::Milliseconds(6) + absl::Microseconds(7) + absl::Nanoseconds(8); + EXPECT_EQ("05.006007008", absl::FormatTime("%E*S", t, tz)); + EXPECT_EQ("05", absl::FormatTime("%E0S", t, tz)); + EXPECT_EQ("05.006007008000000", absl::FormatTime("%E15S", t, tz)); + + // Times before the Unix epoch. + t = absl::FromUnixMicros(-1); + EXPECT_EQ("1969-12-31 23:59:59.999999", + absl::FormatTime("%Y-%m-%d %H:%M:%E*S", t, tz)); + + // Here is a "%E*S" case we got wrong for a while. While the first + // instant below is correctly rendered as "...:07.333304", the second + // one used to appear as "...:07.33330499999999999". + t = absl::FromUnixMicros(1395024427333304); + EXPECT_EQ("2014-03-17 02:47:07.333304", + absl::FormatTime("%Y-%m-%d %H:%M:%E*S", t, tz)); + t += absl::Microseconds(1); + EXPECT_EQ("2014-03-17 02:47:07.333305", + absl::FormatTime("%Y-%m-%d %H:%M:%E*S", t, tz)); +} + +TEST(FormatTime, RFC1123FormatPadsYear) { // locale specific + absl::TimeZone tz = absl::UTCTimeZone(); + + // A year of 77 should be padded to 0077. + absl::Time t = absl::FromCivil(absl::CivilSecond(77, 6, 28, 9, 8, 7), tz); + EXPECT_EQ("Mon, 28 Jun 0077 09:08:07 +0000", + absl::FormatTime(absl::RFC1123_full, t, tz)); + EXPECT_EQ("28 Jun 0077 09:08:07 +0000", + absl::FormatTime(absl::RFC1123_no_wday, t, tz)); +} + +TEST(FormatTime, InfiniteTime) { + absl::TimeZone tz = absl::time_internal::LoadTimeZone("America/Los_Angeles"); + + // The format and timezone are ignored. + EXPECT_EQ("infinite-future", + absl::FormatTime("%H:%M blah", absl::InfiniteFuture(), tz)); + EXPECT_EQ("infinite-past", + absl::FormatTime("%H:%M blah", absl::InfinitePast(), tz)); +} + +// +// Testing ParseTime() +// + +TEST(ParseTime, Basics) { + absl::Time t = absl::FromTimeT(1234567890); + std::string err; + + // Simple edge cases. + EXPECT_TRUE(absl::ParseTime("", "", &t, &err)) << err; + EXPECT_EQ(absl::UnixEpoch(), t); // everything defaulted + EXPECT_TRUE(absl::ParseTime(" ", " ", &t, &err)) << err; + EXPECT_TRUE(absl::ParseTime(" ", " ", &t, &err)) << err; + EXPECT_TRUE(absl::ParseTime("x", "x", &t, &err)) << err; + EXPECT_TRUE(absl::ParseTime("xxx", "xxx", &t, &err)) << err; + + EXPECT_TRUE(absl::ParseTime("%Y-%m-%d %H:%M:%S %z", + "2013-06-28 19:08:09 -0800", &t, &err)) + << err; + const auto ci = absl::FixedTimeZone(-8 * 60 * 60).At(t); + EXPECT_EQ(absl::CivilSecond(2013, 6, 28, 19, 8, 9), ci.cs); + EXPECT_EQ(absl::ZeroDuration(), ci.subsecond); +} + +TEST(ParseTime, NullErrorString) { + absl::Time t; + EXPECT_FALSE(absl::ParseTime("%Q", "invalid format", &t, nullptr)); + EXPECT_FALSE(absl::ParseTime("%H", "12 trailing data", &t, nullptr)); + EXPECT_FALSE( + absl::ParseTime("%H out of range", "42 out of range", &t, nullptr)); +} + +TEST(ParseTime, WithTimeZone) { + const absl::TimeZone tz = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + absl::Time t; + std::string e; + + // We can parse a string without a UTC offset if we supply a timezone. + EXPECT_TRUE( + absl::ParseTime("%Y-%m-%d %H:%M:%S", "2013-06-28 19:08:09", tz, &t, &e)) + << e; + auto ci = tz.At(t); + EXPECT_EQ(absl::CivilSecond(2013, 6, 28, 19, 8, 9), ci.cs); + EXPECT_EQ(absl::ZeroDuration(), ci.subsecond); + + // But the timezone is ignored when a UTC offset is present. + EXPECT_TRUE(absl::ParseTime("%Y-%m-%d %H:%M:%S %z", + "2013-06-28 19:08:09 +0800", tz, &t, &e)) + << e; + ci = absl::FixedTimeZone(8 * 60 * 60).At(t); + EXPECT_EQ(absl::CivilSecond(2013, 6, 28, 19, 8, 9), ci.cs); + EXPECT_EQ(absl::ZeroDuration(), ci.subsecond); +} + +TEST(ParseTime, ErrorCases) { + absl::Time t = absl::FromTimeT(0); + std::string err; + + EXPECT_FALSE(absl::ParseTime("%S", "123", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); + + // Can't parse an illegal format specifier. + err.clear(); + EXPECT_FALSE(absl::ParseTime("%Q", "x", &t, &err)) << err; + // Exact contents of "err" are platform-dependent because of + // differences in the strptime implementation between macOS and Linux. + EXPECT_FALSE(err.empty()); + + // Fails because of trailing, unparsed data "blah". + EXPECT_FALSE(absl::ParseTime("%m-%d", "2-3 blah", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); + + // Feb 31 requires normalization. + EXPECT_FALSE(absl::ParseTime("%m-%d", "2-31", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Out-of-range")); + + // Check that we cannot have spaces in UTC offsets. + EXPECT_TRUE(absl::ParseTime("%z", "-0203", &t, &err)) << err; + EXPECT_FALSE(absl::ParseTime("%z", "- 2 3", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_TRUE(absl::ParseTime("%Ez", "-02:03", &t, &err)) << err; + EXPECT_FALSE(absl::ParseTime("%Ez", "- 2: 3", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + + // Check that we reject other malformed UTC offsets. + EXPECT_FALSE(absl::ParseTime("%Ez", "+-08:00", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%Ez", "-+08:00", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + + // Check that we do not accept "-0" in fields that allow zero. + EXPECT_FALSE(absl::ParseTime("%Y", "-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%E4Y", "-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%H", "-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%M", "-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%S", "-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%z", "+-000", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%Ez", "+-0:00", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + EXPECT_FALSE(absl::ParseTime("%z", "-00-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); + EXPECT_FALSE(absl::ParseTime("%Ez", "-00:-0", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); +} + +TEST(ParseTime, ExtendedSeconds) { + std::string err; + absl::Time t; + + // Here is a "%E*S" case we got wrong for a while. The fractional + // part of the first instant is less than 2^31 and was correctly + // parsed, while the second (and any subsecond field >=2^31) failed. + t = absl::UnixEpoch(); + EXPECT_TRUE(absl::ParseTime("%E*S", "0.2147483647", &t, &err)) << err; + EXPECT_EQ(absl::UnixEpoch() + absl::Nanoseconds(214748364) + + absl::Nanoseconds(1) / 2, + t); + t = absl::UnixEpoch(); + EXPECT_TRUE(absl::ParseTime("%E*S", "0.2147483648", &t, &err)) << err; + EXPECT_EQ(absl::UnixEpoch() + absl::Nanoseconds(214748364) + + absl::Nanoseconds(3) / 4, + t); + + // We should also be able to specify long strings of digits far + // beyond the current resolution and have them convert the same way. + t = absl::UnixEpoch(); + EXPECT_TRUE(absl::ParseTime( + "%E*S", "0.214748364801234567890123456789012345678901234567890123456789", + &t, &err)) + << err; + EXPECT_EQ(absl::UnixEpoch() + absl::Nanoseconds(214748364) + + absl::Nanoseconds(3) / 4, + t); +} + +TEST(ParseTime, ExtendedOffsetErrors) { + std::string err; + absl::Time t; + + // %z against +-HHMM. + EXPECT_FALSE(absl::ParseTime("%z", "-123", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); + + // %z against +-HH. + EXPECT_FALSE(absl::ParseTime("%z", "-1", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); + + // %Ez against +-HH:MM. + EXPECT_FALSE(absl::ParseTime("%Ez", "-12:3", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); + + // %Ez against +-HHMM. + EXPECT_FALSE(absl::ParseTime("%Ez", "-123", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Illegal trailing data")); + + // %Ez against +-HH. + EXPECT_FALSE(absl::ParseTime("%Ez", "-1", &t, &err)) << err; + EXPECT_THAT(err, HasSubstr("Failed to parse")); +} + +TEST(ParseTime, InfiniteTime) { + absl::Time t; + std::string err; + EXPECT_TRUE(absl::ParseTime("%H:%M blah", "infinite-future", &t, &err)); + EXPECT_EQ(absl::InfiniteFuture(), t); + + // Surrounding whitespace. + EXPECT_TRUE(absl::ParseTime("%H:%M blah", " infinite-future", &t, &err)); + EXPECT_EQ(absl::InfiniteFuture(), t); + EXPECT_TRUE(absl::ParseTime("%H:%M blah", "infinite-future ", &t, &err)); + EXPECT_EQ(absl::InfiniteFuture(), t); + EXPECT_TRUE(absl::ParseTime("%H:%M blah", " infinite-future ", &t, &err)); + EXPECT_EQ(absl::InfiniteFuture(), t); + + EXPECT_TRUE(absl::ParseTime("%H:%M blah", "infinite-past", &t, &err)); + EXPECT_EQ(absl::InfinitePast(), t); + + // Surrounding whitespace. + EXPECT_TRUE(absl::ParseTime("%H:%M blah", " infinite-past", &t, &err)); + EXPECT_EQ(absl::InfinitePast(), t); + EXPECT_TRUE(absl::ParseTime("%H:%M blah", "infinite-past ", &t, &err)); + EXPECT_EQ(absl::InfinitePast(), t); + EXPECT_TRUE(absl::ParseTime("%H:%M blah", " infinite-past ", &t, &err)); + EXPECT_EQ(absl::InfinitePast(), t); + + // "infinite-future" as literal string + absl::TimeZone tz = absl::UTCTimeZone(); + EXPECT_TRUE(absl::ParseTime("infinite-future %H:%M", "infinite-future 03:04", + &t, &err)); + EXPECT_NE(absl::InfiniteFuture(), t); + EXPECT_EQ(3, tz.At(t).cs.hour()); + EXPECT_EQ(4, tz.At(t).cs.minute()); + + // "infinite-past" as literal string + EXPECT_TRUE( + absl::ParseTime("infinite-past %H:%M", "infinite-past 03:04", &t, &err)); + EXPECT_NE(absl::InfinitePast(), t); + EXPECT_EQ(3, tz.At(t).cs.hour()); + EXPECT_EQ(4, tz.At(t).cs.minute()); + + // The input doesn't match the format. + EXPECT_FALSE(absl::ParseTime("infinite-future %H:%M", "03:04", &t, &err)); + EXPECT_FALSE(absl::ParseTime("infinite-past %H:%M", "03:04", &t, &err)); +} + +TEST(ParseTime, FailsOnUnrepresentableTime) { + const absl::TimeZone utc = absl::UTCTimeZone(); + absl::Time t; + EXPECT_FALSE( + absl::ParseTime("%Y-%m-%d", "-292277022657-01-27", utc, &t, nullptr)); + EXPECT_TRUE( + absl::ParseTime("%Y-%m-%d", "-292277022657-01-28", utc, &t, nullptr)); + EXPECT_TRUE( + absl::ParseTime("%Y-%m-%d", "292277026596-12-04", utc, &t, nullptr)); + EXPECT_FALSE( + absl::ParseTime("%Y-%m-%d", "292277026596-12-05", utc, &t, nullptr)); +} + +// +// Roundtrip test for FormatTime()/ParseTime(). +// + +TEST(FormatParse, RoundTrip) { + const absl::TimeZone lax = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + const absl::Time in = + absl::FromCivil(absl::CivilSecond(1977, 6, 28, 9, 8, 7), lax); + const absl::Duration subseconds = absl::Nanoseconds(654321); + std::string err; + + // RFC3339, which renders subseconds. + { + absl::Time out; + const std::string s = + absl::FormatTime(absl::RFC3339_full, in + subseconds, lax); + EXPECT_TRUE(absl::ParseTime(absl::RFC3339_full, s, &out, &err)) + << s << ": " << err; + EXPECT_EQ(in + subseconds, out); // RFC3339_full includes %Ez + } + + // RFC1123, which only does whole seconds. + { + absl::Time out; + const std::string s = absl::FormatTime(absl::RFC1123_full, in, lax); + EXPECT_TRUE(absl::ParseTime(absl::RFC1123_full, s, &out, &err)) + << s << ": " << err; + EXPECT_EQ(in, out); // RFC1123_full includes %z + } + + // `absl::FormatTime()` falls back to strftime() for "%c", which appears to + // work. On Windows, `absl::ParseTime()` falls back to std::get_time() which + // appears to fail on "%c" (or at least on the "%c" text produced by + // `strftime()`). This makes it fail the round-trip test. + // + // Under the emscripten compiler `absl::ParseTime() falls back to + // `strptime()`, but that ends up using a different definition for "%c" + // compared to `strftime()`, also causing the round-trip test to fail + // (see https://github.com/kripken/emscripten/pull/7491). +#if !defined(_MSC_VER) && !defined(__EMSCRIPTEN__) + // Even though we don't know what %c will produce, it should roundtrip, + // but only in the 0-offset timezone. + { + absl::Time out; + const std::string s = absl::FormatTime("%c", in, absl::UTCTimeZone()); + EXPECT_TRUE(absl::ParseTime("%c", s, &out, &err)) << s << ": " << err; + EXPECT_EQ(in, out); + } +#endif // !_MSC_VER && !__EMSCRIPTEN__ +} + +TEST(FormatParse, RoundTripDistantFuture) { + const absl::TimeZone tz = absl::UTCTimeZone(); + const absl::Time in = + absl::FromUnixSeconds(std::numeric_limits<int64_t>::max()); + std::string err; + + absl::Time out; + const std::string s = absl::FormatTime(absl::RFC3339_full, in, tz); + EXPECT_TRUE(absl::ParseTime(absl::RFC3339_full, s, &out, &err)) + << s << ": " << err; + EXPECT_EQ(in, out); +} + +TEST(FormatParse, RoundTripDistantPast) { + const absl::TimeZone tz = absl::UTCTimeZone(); + const absl::Time in = + absl::FromUnixSeconds(std::numeric_limits<int64_t>::min()); + std::string err; + + absl::Time out; + const std::string s = absl::FormatTime(absl::RFC3339_full, in, tz); + EXPECT_TRUE(absl::ParseTime(absl::RFC3339_full, s, &out, &err)) + << s << ": " << err; + EXPECT_EQ(in, out); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/BUILD.bazel b/third_party/abseil_cpp/absl/time/internal/cctz/BUILD.bazel new file mode 100644 index 0000000000..7a53c815b9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/BUILD.bazel @@ -0,0 +1,166 @@ +# Copyright 2016 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") + +package(features = ["-parse_headers"]) + +licenses(["notice"]) # Apache License + +filegroup( + name = "zoneinfo", + srcs = glob(["testdata/zoneinfo/**"]), +) + +config_setting( + name = "osx", + constraint_values = [ + "@bazel_tools//platforms:osx", + ], +) + +config_setting( + name = "ios", + constraint_values = [ + "@bazel_tools//platforms:ios", + ], +) + +### libraries + +cc_library( + name = "civil_time", + srcs = ["src/civil_time_detail.cc"], + hdrs = [ + "include/cctz/civil_time.h", + ], + textual_hdrs = ["include/cctz/civil_time_detail.h"], + visibility = ["//visibility:public"], + deps = ["//absl/base:config"], +) + +cc_library( + name = "time_zone", + srcs = [ + "src/time_zone_fixed.cc", + "src/time_zone_fixed.h", + "src/time_zone_format.cc", + "src/time_zone_if.cc", + "src/time_zone_if.h", + "src/time_zone_impl.cc", + "src/time_zone_impl.h", + "src/time_zone_info.cc", + "src/time_zone_info.h", + "src/time_zone_libc.cc", + "src/time_zone_libc.h", + "src/time_zone_lookup.cc", + "src/time_zone_posix.cc", + "src/time_zone_posix.h", + "src/tzfile.h", + "src/zone_info_source.cc", + ], + hdrs = [ + "include/cctz/time_zone.h", + "include/cctz/zone_info_source.h", + ], + linkopts = select({ + ":osx": [ + "-framework Foundation", + ], + ":ios": [ + "-framework Foundation", + ], + "//conditions:default": [], + }), + visibility = ["//visibility:public"], + deps = [ + ":civil_time", + "//absl/base:config", + ], +) + +### tests + +cc_test( + name = "civil_time_test", + size = "small", + srcs = ["src/civil_time_test.cc"], + deps = [ + ":civil_time", + "//absl/base:config", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "time_zone_format_test", + size = "small", + srcs = ["src/time_zone_format_test.cc"], + data = [":zoneinfo"], + tags = [ + "no_test_android_arm", + "no_test_android_arm64", + "no_test_android_x86", + ], + deps = [ + ":civil_time", + ":time_zone", + "//absl/base:config", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "time_zone_lookup_test", + size = "small", + timeout = "moderate", + srcs = ["src/time_zone_lookup_test.cc"], + data = [":zoneinfo"], + tags = [ + "no_test_android_arm", + "no_test_android_arm64", + "no_test_android_x86", + ], + deps = [ + ":civil_time", + ":time_zone", + "//absl/base:config", + "@com_google_googletest//:gtest_main", + ], +) + +### benchmarks + +cc_test( + name = "cctz_benchmark", + srcs = [ + "src/cctz_benchmark.cc", + "src/time_zone_if.h", + "src/time_zone_impl.h", + "src/time_zone_info.h", + "src/tzfile.h", + ], + linkstatic = 1, + tags = ["benchmark"], + deps = [ + ":civil_time", + ":time_zone", + "//absl/base:config", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +### examples + +### binaries diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/civil_time.h b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/civil_time.h new file mode 100644 index 0000000000..d47ff86fe4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/civil_time.h @@ -0,0 +1,332 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_CIVIL_TIME_H_ +#define ABSL_TIME_INTERNAL_CCTZ_CIVIL_TIME_H_ + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time_detail.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// The term "civil time" refers to the legally recognized human-scale time +// that is represented by the six fields YYYY-MM-DD hh:mm:ss. Modern-day civil +// time follows the Gregorian Calendar and is a time-zone-independent concept. +// A "date" is perhaps the most common example of a civil time (represented in +// this library as cctz::civil_day). This library provides six classes and a +// handful of functions that help with rounding, iterating, and arithmetic on +// civil times while avoiding complications like daylight-saving time (DST). +// +// The following six classes form the core of this civil-time library: +// +// * civil_second +// * civil_minute +// * civil_hour +// * civil_day +// * civil_month +// * civil_year +// +// Each class is a simple value type with the same interface for construction +// and the same six accessors for each of the civil fields (year, month, day, +// hour, minute, and second, aka YMDHMS). These classes differ only in their +// alignment, which is indicated by the type name and specifies the field on +// which arithmetic operates. +// +// Each class can be constructed by passing up to six optional integer +// arguments representing the YMDHMS fields (in that order) to the +// constructor. Omitted fields are assigned their minimum valid value. Hours, +// minutes, and seconds will be set to 0, month and day will be set to 1, and +// since there is no minimum valid year, it will be set to 1970. So, a +// default-constructed civil-time object will have YMDHMS fields representing +// "1970-01-01 00:00:00". Fields that are out-of-range are normalized (e.g., +// October 32 -> November 1) so that all civil-time objects represent valid +// values. +// +// Each civil-time class is aligned to the civil-time field indicated in the +// class's name after normalization. Alignment is performed by setting all the +// inferior fields to their minimum valid value (as described above). The +// following are examples of how each of the six types would align the fields +// representing November 22, 2015 at 12:34:56 in the afternoon. (Note: the +// string format used here is not important; it's just a shorthand way of +// showing the six YMDHMS fields.) +// +// civil_second 2015-11-22 12:34:56 +// civil_minute 2015-11-22 12:34:00 +// civil_hour 2015-11-22 12:00:00 +// civil_day 2015-11-22 00:00:00 +// civil_month 2015-11-01 00:00:00 +// civil_year 2015-01-01 00:00:00 +// +// Each civil-time type performs arithmetic on the field to which it is +// aligned. This means that adding 1 to a civil_day increments the day field +// (normalizing as necessary), and subtracting 7 from a civil_month operates +// on the month field (normalizing as necessary). All arithmetic produces a +// valid civil time. Difference requires two similarly aligned civil-time +// objects and returns the scalar answer in units of the objects' alignment. +// For example, the difference between two civil_hour objects will give an +// answer in units of civil hours. +// +// In addition to the six civil-time types just described, there are +// a handful of helper functions and algorithms for performing common +// calculations. These are described below. +// +// Note: In C++14 and later, this library is usable in a constexpr context. +// +// CONSTRUCTION: +// +// Each of the civil-time types can be constructed in two ways: by directly +// passing to the constructor up to six (optional) integers representing the +// YMDHMS fields, or by copying the YMDHMS fields from a differently aligned +// civil-time type. +// +// civil_day default_value; // 1970-01-01 00:00:00 +// +// civil_day a(2015, 2, 3); // 2015-02-03 00:00:00 +// civil_day b(2015, 2, 3, 4, 5, 6); // 2015-02-03 00:00:00 +// civil_day c(2015); // 2015-01-01 00:00:00 +// +// civil_second ss(2015, 2, 3, 4, 5, 6); // 2015-02-03 04:05:06 +// civil_minute mm(ss); // 2015-02-03 04:05:00 +// civil_hour hh(mm); // 2015-02-03 04:00:00 +// civil_day d(hh); // 2015-02-03 00:00:00 +// civil_month m(d); // 2015-02-01 00:00:00 +// civil_year y(m); // 2015-01-01 00:00:00 +// +// m = civil_month(y); // 2015-01-01 00:00:00 +// d = civil_day(m); // 2015-01-01 00:00:00 +// hh = civil_hour(d); // 2015-01-01 00:00:00 +// mm = civil_minute(hh); // 2015-01-01 00:00:00 +// ss = civil_second(mm); // 2015-01-01 00:00:00 +// +// ALIGNMENT CONVERSION: +// +// The alignment of a civil-time object cannot change, but the object may be +// used to construct a new object with a different alignment. This is referred +// to as "realigning". When realigning to a type with the same or more +// precision (e.g., civil_day -> civil_second), the conversion may be +// performed implicitly since no information is lost. However, if information +// could be discarded (e.g., civil_second -> civil_day), the conversion must +// be explicit at the call site. +// +// void fun(const civil_day& day); +// +// civil_second cs; +// fun(cs); // Won't compile because data may be discarded +// fun(civil_day(cs)); // OK: explicit conversion +// +// civil_day cd; +// fun(cd); // OK: no conversion needed +// +// civil_month cm; +// fun(cm); // OK: implicit conversion to civil_day +// +// NORMALIZATION: +// +// Integer arguments passed to the constructor may be out-of-range, in which +// case they are normalized to produce a valid civil-time object. This enables +// natural arithmetic on constructor arguments without worrying about the +// field's range. Normalization guarantees that there are no invalid +// civil-time objects. +// +// civil_day d(2016, 10, 32); // Out-of-range day; normalized to 2016-11-01 +// +// Note: If normalization is undesired, you can signal an error by comparing +// the constructor arguments to the normalized values returned by the YMDHMS +// properties. +// +// PROPERTIES: +// +// All civil-time types have accessors for all six of the civil-time fields: +// year, month, day, hour, minute, and second. Recall that fields inferior to +// the type's alignment will be set to their minimum valid value. +// +// civil_day d(2015, 6, 28); +// // d.year() == 2015 +// // d.month() == 6 +// // d.day() == 28 +// // d.hour() == 0 +// // d.minute() == 0 +// // d.second() == 0 +// +// COMPARISON: +// +// Comparison always considers all six YMDHMS fields, regardless of the type's +// alignment. Comparison between differently aligned civil-time types is +// allowed. +// +// civil_day feb_3(2015, 2, 3); // 2015-02-03 00:00:00 +// civil_day mar_4(2015, 3, 4); // 2015-03-04 00:00:00 +// // feb_3 < mar_4 +// // civil_year(feb_3) == civil_year(mar_4) +// +// civil_second feb_3_noon(2015, 2, 3, 12, 0, 0); // 2015-02-03 12:00:00 +// // feb_3 < feb_3_noon +// // feb_3 == civil_day(feb_3_noon) +// +// // Iterates all the days of February 2015. +// for (civil_day d(2015, 2, 1); d < civil_month(2015, 3); ++d) { +// // ... +// } +// +// STREAMING: +// +// Each civil-time type may be sent to an output stream using operator<<(). +// The output format follows the pattern "YYYY-MM-DDThh:mm:ss" where fields +// inferior to the type's alignment are omitted. +// +// civil_second cs(2015, 2, 3, 4, 5, 6); +// std::cout << cs << "\n"; // Outputs: 2015-02-03T04:05:06 +// +// civil_day cd(cs); +// std::cout << cd << "\n"; // Outputs: 2015-02-03 +// +// civil_year cy(cs); +// std::cout << cy << "\n"; // Outputs: 2015 +// +// ARITHMETIC: +// +// Civil-time types support natural arithmetic operators such as addition, +// subtraction, and difference. Arithmetic operates on the civil-time field +// indicated in the type's name. Difference requires arguments with the same +// alignment and returns the answer in units of the alignment. +// +// civil_day a(2015, 2, 3); +// ++a; // 2015-02-04 00:00:00 +// --a; // 2015-02-03 00:00:00 +// civil_day b = a + 1; // 2015-02-04 00:00:00 +// civil_day c = 1 + b; // 2015-02-05 00:00:00 +// int n = c - a; // n = 2 (civil days) +// int m = c - civil_month(c); // Won't compile: different types. +// +// EXAMPLE: Adding a month to January 31. +// +// One of the classic questions that arises when considering a civil-time +// library (or a date library or a date/time library) is this: "What happens +// when you add a month to January 31?" This is an interesting question +// because there could be a number of possible answers: +// +// 1. March 3 (or 2 if a leap year). This may make sense if the operation +// wants the equivalent of February 31. +// 2. February 28 (or 29 if a leap year). This may make sense if the operation +// wants the last day of January to go to the last day of February. +// 3. Error. The caller may get some error, an exception, an invalid date +// object, or maybe false is returned. This may make sense because there is +// no single unambiguously correct answer to the question. +// +// Practically speaking, any answer that is not what the programmer intended +// is the wrong answer. +// +// This civil-time library avoids the problem by making it impossible to ask +// ambiguous questions. All civil-time objects are aligned to a particular +// civil-field boundary (such as aligned to a year, month, day, hour, minute, +// or second), and arithmetic operates on the field to which the object is +// aligned. This means that in order to "add a month" the object must first be +// aligned to a month boundary, which is equivalent to the first day of that +// month. +// +// Of course, there are ways to compute an answer the question at hand using +// this civil-time library, but they require the programmer to be explicit +// about the answer they expect. To illustrate, let's see how to compute all +// three of the above possible answers to the question of "Jan 31 plus 1 +// month": +// +// const civil_day d(2015, 1, 31); +// +// // Answer 1: +// // Add 1 to the month field in the constructor, and rely on normalization. +// const auto ans_normalized = civil_day(d.year(), d.month() + 1, d.day()); +// // ans_normalized == 2015-03-03 (aka Feb 31) +// +// // Answer 2: +// // Add 1 to month field, capping to the end of next month. +// const auto next_month = civil_month(d) + 1; +// const auto last_day_of_next_month = civil_day(next_month + 1) - 1; +// const auto ans_capped = std::min(ans_normalized, last_day_of_next_month); +// // ans_capped == 2015-02-28 +// +// // Answer 3: +// // Signal an error if the normalized answer is not in next month. +// if (civil_month(ans_normalized) != next_month) { +// // error, month overflow +// } +// +using civil_year = detail::civil_year; +using civil_month = detail::civil_month; +using civil_day = detail::civil_day; +using civil_hour = detail::civil_hour; +using civil_minute = detail::civil_minute; +using civil_second = detail::civil_second; + +// An enum class with members monday, tuesday, wednesday, thursday, friday, +// saturday, and sunday. These enum values may be sent to an output stream +// using operator<<(). The result is the full weekday name in English with a +// leading capital letter. +// +// weekday wd = weekday::thursday; +// std::cout << wd << "\n"; // Outputs: Thursday +// +using detail::weekday; + +// Returns the weekday for the given civil-time value. +// +// civil_day a(2015, 8, 13); +// weekday wd = get_weekday(a); // wd == weekday::thursday +// +using detail::get_weekday; + +// Returns the civil_day that strictly follows or precedes the given +// civil_day, and that falls on the given weekday. +// +// For example, given: +// +// August 2015 +// Su Mo Tu We Th Fr Sa +// 1 +// 2 3 4 5 6 7 8 +// 9 10 11 12 13 14 15 +// 16 17 18 19 20 21 22 +// 23 24 25 26 27 28 29 +// 30 31 +// +// civil_day a(2015, 8, 13); // get_weekday(a) == weekday::thursday +// civil_day b = next_weekday(a, weekday::thursday); // b = 2015-08-20 +// civil_day c = prev_weekday(a, weekday::thursday); // c = 2015-08-06 +// +// civil_day d = ... +// // Gets the following Thursday if d is not already Thursday +// civil_day thurs1 = next_weekday(d - 1, weekday::thursday); +// // Gets the previous Thursday if d is not already Thursday +// civil_day thurs2 = prev_weekday(d + 1, weekday::thursday); +// +using detail::next_weekday; +using detail::prev_weekday; + +// Returns the day-of-year for the given civil-time value. +// +// civil_day a(2015, 1, 1); +// int yd_jan_1 = get_yearday(a); // yd_jan_1 = 1 +// civil_day b(2015, 12, 31); +// int yd_dec_31 = get_yearday(b); // yd_dec_31 = 365 +// +using detail::get_yearday; + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_CIVIL_TIME_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/civil_time_detail.h b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/civil_time_detail.h new file mode 100644 index 0000000000..4cde96f1aa --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/civil_time_detail.h @@ -0,0 +1,622 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_CIVIL_TIME_DETAIL_H_ +#define ABSL_TIME_INTERNAL_CCTZ_CIVIL_TIME_DETAIL_H_ + +#include <cstdint> +#include <limits> +#include <ostream> +#include <type_traits> + +#include "absl/base/config.h" + +// Disable constexpr support unless we are in C++14 mode. +#if __cpp_constexpr >= 201304 || (defined(_MSC_VER) && _MSC_VER >= 1910) +#define CONSTEXPR_D constexpr // data +#define CONSTEXPR_F constexpr // function +#define CONSTEXPR_M constexpr // member +#else +#define CONSTEXPR_D const +#define CONSTEXPR_F inline +#define CONSTEXPR_M +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// Support years that at least span the range of 64-bit time_t values. +using year_t = std::int_fast64_t; + +// Type alias that indicates an argument is not normalized (e.g., the +// constructor parameters and operands/results of addition/subtraction). +using diff_t = std::int_fast64_t; + +namespace detail { + +// Type aliases that indicate normalized argument values. +using month_t = std::int_fast8_t; // [1:12] +using day_t = std::int_fast8_t; // [1:31] +using hour_t = std::int_fast8_t; // [0:23] +using minute_t = std::int_fast8_t; // [0:59] +using second_t = std::int_fast8_t; // [0:59] + +// Normalized civil-time fields: Y-M-D HH:MM:SS. +struct fields { + CONSTEXPR_M fields(year_t year, month_t month, day_t day, hour_t hour, + minute_t minute, second_t second) + : y(year), m(month), d(day), hh(hour), mm(minute), ss(second) {} + std::int_least64_t y; + std::int_least8_t m; + std::int_least8_t d; + std::int_least8_t hh; + std::int_least8_t mm; + std::int_least8_t ss; +}; + +struct second_tag {}; +struct minute_tag : second_tag {}; +struct hour_tag : minute_tag {}; +struct day_tag : hour_tag {}; +struct month_tag : day_tag {}; +struct year_tag : month_tag {}; + +//////////////////////////////////////////////////////////////////////// + +// Field normalization (without avoidable overflow). + +namespace impl { + +CONSTEXPR_F bool is_leap_year(year_t y) noexcept { + return y % 4 == 0 && (y % 100 != 0 || y % 400 == 0); +} +CONSTEXPR_F int year_index(year_t y, month_t m) noexcept { + return (static_cast<int>((y + (m > 2)) % 400) + 400) % 400; +} +CONSTEXPR_F int days_per_century(year_t y, month_t m) noexcept { + const int yi = year_index(y, m); + return 36524 + (yi == 0 || yi > 300); +} +CONSTEXPR_F int days_per_4years(year_t y, month_t m) noexcept { + const int yi = year_index(y, m); + return 1460 + (yi == 0 || yi > 300 || (yi - 1) % 100 < 96); +} +CONSTEXPR_F int days_per_year(year_t y, month_t m) noexcept { + return is_leap_year(y + (m > 2)) ? 366 : 365; +} +CONSTEXPR_F int days_per_month(year_t y, month_t m) noexcept { + CONSTEXPR_D int k_days_per_month[1 + 12] = { + -1, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 // non leap year + }; + return k_days_per_month[m] + (m == 2 && is_leap_year(y)); +} + +CONSTEXPR_F fields n_day(year_t y, month_t m, diff_t d, diff_t cd, hour_t hh, + minute_t mm, second_t ss) noexcept { + y += (cd / 146097) * 400; + cd %= 146097; + if (cd < 0) { + y -= 400; + cd += 146097; + } + y += (d / 146097) * 400; + d = d % 146097 + cd; + if (d > 0) { + if (d > 146097) { + y += 400; + d -= 146097; + } + } else { + if (d > -365) { + // We often hit the previous year when stepping a civil time backwards, + // so special case it to avoid counting up by 100/4/1-year chunks. + y -= 1; + d += days_per_year(y, m); + } else { + y -= 400; + d += 146097; + } + } + if (d > 365) { + for (int n = days_per_century(y, m); d > n; n = days_per_century(y, m)) { + d -= n; + y += 100; + } + for (int n = days_per_4years(y, m); d > n; n = days_per_4years(y, m)) { + d -= n; + y += 4; + } + for (int n = days_per_year(y, m); d > n; n = days_per_year(y, m)) { + d -= n; + ++y; + } + } + if (d > 28) { + for (int n = days_per_month(y, m); d > n; n = days_per_month(y, m)) { + d -= n; + if (++m > 12) { + ++y; + m = 1; + } + } + } + return fields(y, m, static_cast<day_t>(d), hh, mm, ss); +} +CONSTEXPR_F fields n_mon(year_t y, diff_t m, diff_t d, diff_t cd, hour_t hh, + minute_t mm, second_t ss) noexcept { + if (m != 12) { + y += m / 12; + m %= 12; + if (m <= 0) { + y -= 1; + m += 12; + } + } + return n_day(y, static_cast<month_t>(m), d, cd, hh, mm, ss); +} +CONSTEXPR_F fields n_hour(year_t y, diff_t m, diff_t d, diff_t cd, diff_t hh, + minute_t mm, second_t ss) noexcept { + cd += hh / 24; + hh %= 24; + if (hh < 0) { + cd -= 1; + hh += 24; + } + return n_mon(y, m, d, cd, static_cast<hour_t>(hh), mm, ss); +} +CONSTEXPR_F fields n_min(year_t y, diff_t m, diff_t d, diff_t hh, diff_t ch, + diff_t mm, second_t ss) noexcept { + ch += mm / 60; + mm %= 60; + if (mm < 0) { + ch -= 1; + mm += 60; + } + return n_hour(y, m, d, hh / 24 + ch / 24, hh % 24 + ch % 24, + static_cast<minute_t>(mm), ss); +} +CONSTEXPR_F fields n_sec(year_t y, diff_t m, diff_t d, diff_t hh, diff_t mm, + diff_t ss) noexcept { + // Optimization for when (non-constexpr) fields are already normalized. + if (0 <= ss && ss < 60) { + const second_t nss = static_cast<second_t>(ss); + if (0 <= mm && mm < 60) { + const minute_t nmm = static_cast<minute_t>(mm); + if (0 <= hh && hh < 24) { + const hour_t nhh = static_cast<hour_t>(hh); + if (1 <= d && d <= 28 && 1 <= m && m <= 12) { + const day_t nd = static_cast<day_t>(d); + const month_t nm = static_cast<month_t>(m); + return fields(y, nm, nd, nhh, nmm, nss); + } + return n_mon(y, m, d, 0, nhh, nmm, nss); + } + return n_hour(y, m, d, hh / 24, hh % 24, nmm, nss); + } + return n_min(y, m, d, hh, mm / 60, mm % 60, nss); + } + diff_t cm = ss / 60; + ss %= 60; + if (ss < 0) { + cm -= 1; + ss += 60; + } + return n_min(y, m, d, hh, mm / 60 + cm / 60, mm % 60 + cm % 60, + static_cast<second_t>(ss)); +} + +} // namespace impl + +//////////////////////////////////////////////////////////////////////// + +// Increments the indicated (normalized) field by "n". +CONSTEXPR_F fields step(second_tag, fields f, diff_t n) noexcept { + return impl::n_sec(f.y, f.m, f.d, f.hh, f.mm + n / 60, f.ss + n % 60); +} +CONSTEXPR_F fields step(minute_tag, fields f, diff_t n) noexcept { + return impl::n_min(f.y, f.m, f.d, f.hh + n / 60, 0, f.mm + n % 60, f.ss); +} +CONSTEXPR_F fields step(hour_tag, fields f, diff_t n) noexcept { + return impl::n_hour(f.y, f.m, f.d + n / 24, 0, f.hh + n % 24, f.mm, f.ss); +} +CONSTEXPR_F fields step(day_tag, fields f, diff_t n) noexcept { + return impl::n_day(f.y, f.m, f.d, n, f.hh, f.mm, f.ss); +} +CONSTEXPR_F fields step(month_tag, fields f, diff_t n) noexcept { + return impl::n_mon(f.y + n / 12, f.m + n % 12, f.d, 0, f.hh, f.mm, f.ss); +} +CONSTEXPR_F fields step(year_tag, fields f, diff_t n) noexcept { + return fields(f.y + n, f.m, f.d, f.hh, f.mm, f.ss); +} + +//////////////////////////////////////////////////////////////////////// + +namespace impl { + +// Returns (v * f + a) but avoiding intermediate overflow when possible. +CONSTEXPR_F diff_t scale_add(diff_t v, diff_t f, diff_t a) noexcept { + return (v < 0) ? ((v + 1) * f + a) - f : ((v - 1) * f + a) + f; +} + +// Map a (normalized) Y/M/D to the number of days before/after 1970-01-01. +// Probably overflows for years outside [-292277022656:292277026595]. +CONSTEXPR_F diff_t ymd_ord(year_t y, month_t m, day_t d) noexcept { + const diff_t eyear = (m <= 2) ? y - 1 : y; + const diff_t era = (eyear >= 0 ? eyear : eyear - 399) / 400; + const diff_t yoe = eyear - era * 400; + const diff_t doy = (153 * (m + (m > 2 ? -3 : 9)) + 2) / 5 + d - 1; + const diff_t doe = yoe * 365 + yoe / 4 - yoe / 100 + doy; + return era * 146097 + doe - 719468; +} + +// Returns the difference in days between two normalized Y-M-D tuples. +// ymd_ord() will encounter integer overflow given extreme year values, +// yet the difference between two such extreme values may actually be +// small, so we take a little care to avoid overflow when possible by +// exploiting the 146097-day cycle. +CONSTEXPR_F diff_t day_difference(year_t y1, month_t m1, day_t d1, year_t y2, + month_t m2, day_t d2) noexcept { + const diff_t a_c4_off = y1 % 400; + const diff_t b_c4_off = y2 % 400; + diff_t c4_diff = (y1 - a_c4_off) - (y2 - b_c4_off); + diff_t delta = ymd_ord(a_c4_off, m1, d1) - ymd_ord(b_c4_off, m2, d2); + if (c4_diff > 0 && delta < 0) { + delta += 2 * 146097; + c4_diff -= 2 * 400; + } else if (c4_diff < 0 && delta > 0) { + delta -= 2 * 146097; + c4_diff += 2 * 400; + } + return (c4_diff / 400 * 146097) + delta; +} + +} // namespace impl + +// Returns the difference between fields structs using the indicated unit. +CONSTEXPR_F diff_t difference(year_tag, fields f1, fields f2) noexcept { + return f1.y - f2.y; +} +CONSTEXPR_F diff_t difference(month_tag, fields f1, fields f2) noexcept { + return impl::scale_add(difference(year_tag{}, f1, f2), 12, (f1.m - f2.m)); +} +CONSTEXPR_F diff_t difference(day_tag, fields f1, fields f2) noexcept { + return impl::day_difference(f1.y, f1.m, f1.d, f2.y, f2.m, f2.d); +} +CONSTEXPR_F diff_t difference(hour_tag, fields f1, fields f2) noexcept { + return impl::scale_add(difference(day_tag{}, f1, f2), 24, (f1.hh - f2.hh)); +} +CONSTEXPR_F diff_t difference(minute_tag, fields f1, fields f2) noexcept { + return impl::scale_add(difference(hour_tag{}, f1, f2), 60, (f1.mm - f2.mm)); +} +CONSTEXPR_F diff_t difference(second_tag, fields f1, fields f2) noexcept { + return impl::scale_add(difference(minute_tag{}, f1, f2), 60, f1.ss - f2.ss); +} + +//////////////////////////////////////////////////////////////////////// + +// Aligns the (normalized) fields struct to the indicated field. +CONSTEXPR_F fields align(second_tag, fields f) noexcept { return f; } +CONSTEXPR_F fields align(minute_tag, fields f) noexcept { + return fields{f.y, f.m, f.d, f.hh, f.mm, 0}; +} +CONSTEXPR_F fields align(hour_tag, fields f) noexcept { + return fields{f.y, f.m, f.d, f.hh, 0, 0}; +} +CONSTEXPR_F fields align(day_tag, fields f) noexcept { + return fields{f.y, f.m, f.d, 0, 0, 0}; +} +CONSTEXPR_F fields align(month_tag, fields f) noexcept { + return fields{f.y, f.m, 1, 0, 0, 0}; +} +CONSTEXPR_F fields align(year_tag, fields f) noexcept { + return fields{f.y, 1, 1, 0, 0, 0}; +} + +//////////////////////////////////////////////////////////////////////// + +namespace impl { + +template <typename H> +H AbslHashValueImpl(second_tag, H h, fields f) { + return H::combine(std::move(h), f.y, f.m, f.d, f.hh, f.mm, f.ss); +} +template <typename H> +H AbslHashValueImpl(minute_tag, H h, fields f) { + return H::combine(std::move(h), f.y, f.m, f.d, f.hh, f.mm); +} +template <typename H> +H AbslHashValueImpl(hour_tag, H h, fields f) { + return H::combine(std::move(h), f.y, f.m, f.d, f.hh); +} +template <typename H> +H AbslHashValueImpl(day_tag, H h, fields f) { + return H::combine(std::move(h), f.y, f.m, f.d); +} +template <typename H> +H AbslHashValueImpl(month_tag, H h, fields f) { + return H::combine(std::move(h), f.y, f.m); +} +template <typename H> +H AbslHashValueImpl(year_tag, H h, fields f) { + return H::combine(std::move(h), f.y); +} + +} // namespace impl + +//////////////////////////////////////////////////////////////////////// + +template <typename T> +class civil_time { + public: + explicit CONSTEXPR_M civil_time(year_t y, diff_t m = 1, diff_t d = 1, + diff_t hh = 0, diff_t mm = 0, + diff_t ss = 0) noexcept + : civil_time(impl::n_sec(y, m, d, hh, mm, ss)) {} + + CONSTEXPR_M civil_time() noexcept : f_{1970, 1, 1, 0, 0, 0} {} + civil_time(const civil_time&) = default; + civil_time& operator=(const civil_time&) = default; + + // Conversion between civil times of different alignment. Conversion to + // a more precise alignment is allowed implicitly (e.g., day -> hour), + // but conversion where information is discarded must be explicit + // (e.g., second -> minute). + template <typename U, typename S> + using preserves_data = + typename std::enable_if<std::is_base_of<U, S>::value>::type; + template <typename U> + CONSTEXPR_M civil_time(const civil_time<U>& ct, + preserves_data<T, U>* = nullptr) noexcept + : civil_time(ct.f_) {} + template <typename U> + explicit CONSTEXPR_M civil_time(const civil_time<U>& ct, + preserves_data<U, T>* = nullptr) noexcept + : civil_time(ct.f_) {} + + // Factories for the maximum/minimum representable civil_time. + static CONSTEXPR_F civil_time(max)() { + const auto max_year = (std::numeric_limits<std::int_least64_t>::max)(); + return civil_time(max_year, 12, 31, 23, 59, 59); + } + static CONSTEXPR_F civil_time(min)() { + const auto min_year = (std::numeric_limits<std::int_least64_t>::min)(); + return civil_time(min_year, 1, 1, 0, 0, 0); + } + + // Field accessors. Note: All but year() return an int. + CONSTEXPR_M year_t year() const noexcept { return f_.y; } + CONSTEXPR_M int month() const noexcept { return f_.m; } + CONSTEXPR_M int day() const noexcept { return f_.d; } + CONSTEXPR_M int hour() const noexcept { return f_.hh; } + CONSTEXPR_M int minute() const noexcept { return f_.mm; } + CONSTEXPR_M int second() const noexcept { return f_.ss; } + + // Assigning arithmetic. + CONSTEXPR_M civil_time& operator+=(diff_t n) noexcept { + f_ = step(T{}, f_, n); + return *this; + } + CONSTEXPR_M civil_time& operator-=(diff_t n) noexcept { + if (n != (std::numeric_limits<diff_t>::min)()) { + f_ = step(T{}, f_, -n); + } else { + f_ = step(T{}, step(T{}, f_, -(n + 1)), 1); + } + return *this; + } + CONSTEXPR_M civil_time& operator++() noexcept { return *this += 1; } + CONSTEXPR_M civil_time operator++(int) noexcept { + const civil_time a = *this; + ++*this; + return a; + } + CONSTEXPR_M civil_time& operator--() noexcept { return *this -= 1; } + CONSTEXPR_M civil_time operator--(int) noexcept { + const civil_time a = *this; + --*this; + return a; + } + + // Binary arithmetic operators. + friend CONSTEXPR_F civil_time operator+(civil_time a, diff_t n) noexcept { + return a += n; + } + friend CONSTEXPR_F civil_time operator+(diff_t n, civil_time a) noexcept { + return a += n; + } + friend CONSTEXPR_F civil_time operator-(civil_time a, diff_t n) noexcept { + return a -= n; + } + friend CONSTEXPR_F diff_t operator-(civil_time lhs, civil_time rhs) noexcept { + return difference(T{}, lhs.f_, rhs.f_); + } + + template <typename H> + friend H AbslHashValue(H h, civil_time a) { + return impl::AbslHashValueImpl(T{}, std::move(h), a.f_); + } + + private: + // All instantiations of this template are allowed to call the following + // private constructor and access the private fields member. + template <typename U> + friend class civil_time; + + // The designated constructor that all others eventually call. + explicit CONSTEXPR_M civil_time(fields f) noexcept : f_(align(T{}, f)) {} + + fields f_; +}; + +// Disallows difference between differently aligned types. +// auto n = civil_day(...) - civil_hour(...); // would be confusing. +template <typename T, typename U> +CONSTEXPR_F diff_t operator-(civil_time<T>, civil_time<U>) = delete; + +using civil_year = civil_time<year_tag>; +using civil_month = civil_time<month_tag>; +using civil_day = civil_time<day_tag>; +using civil_hour = civil_time<hour_tag>; +using civil_minute = civil_time<minute_tag>; +using civil_second = civil_time<second_tag>; + +//////////////////////////////////////////////////////////////////////// + +// Relational operators that work with differently aligned objects. +// Always compares all six fields. +template <typename T1, typename T2> +CONSTEXPR_F bool operator<(const civil_time<T1>& lhs, + const civil_time<T2>& rhs) noexcept { + return ( + lhs.year() < rhs.year() || + (lhs.year() == rhs.year() && + (lhs.month() < rhs.month() || + (lhs.month() == rhs.month() && + (lhs.day() < rhs.day() || (lhs.day() == rhs.day() && + (lhs.hour() < rhs.hour() || + (lhs.hour() == rhs.hour() && + (lhs.minute() < rhs.minute() || + (lhs.minute() == rhs.minute() && + (lhs.second() < rhs.second()))))))))))); +} +template <typename T1, typename T2> +CONSTEXPR_F bool operator<=(const civil_time<T1>& lhs, + const civil_time<T2>& rhs) noexcept { + return !(rhs < lhs); +} +template <typename T1, typename T2> +CONSTEXPR_F bool operator>=(const civil_time<T1>& lhs, + const civil_time<T2>& rhs) noexcept { + return !(lhs < rhs); +} +template <typename T1, typename T2> +CONSTEXPR_F bool operator>(const civil_time<T1>& lhs, + const civil_time<T2>& rhs) noexcept { + return rhs < lhs; +} +template <typename T1, typename T2> +CONSTEXPR_F bool operator==(const civil_time<T1>& lhs, + const civil_time<T2>& rhs) noexcept { + return lhs.year() == rhs.year() && lhs.month() == rhs.month() && + lhs.day() == rhs.day() && lhs.hour() == rhs.hour() && + lhs.minute() == rhs.minute() && lhs.second() == rhs.second(); +} +template <typename T1, typename T2> +CONSTEXPR_F bool operator!=(const civil_time<T1>& lhs, + const civil_time<T2>& rhs) noexcept { + return !(lhs == rhs); +} + +//////////////////////////////////////////////////////////////////////// + +enum class weekday { + monday, + tuesday, + wednesday, + thursday, + friday, + saturday, + sunday, +}; + +CONSTEXPR_F weekday get_weekday(const civil_second& cs) noexcept { + CONSTEXPR_D weekday k_weekday_by_mon_off[13] = { + weekday::monday, weekday::tuesday, weekday::wednesday, + weekday::thursday, weekday::friday, weekday::saturday, + weekday::sunday, weekday::monday, weekday::tuesday, + weekday::wednesday, weekday::thursday, weekday::friday, + weekday::saturday, + }; + CONSTEXPR_D int k_weekday_offsets[1 + 12] = { + -1, 0, 3, 2, 5, 0, 3, 5, 1, 4, 6, 2, 4, + }; + year_t wd = 2400 + (cs.year() % 400) - (cs.month() < 3); + wd += wd / 4 - wd / 100 + wd / 400; + wd += k_weekday_offsets[cs.month()] + cs.day(); + return k_weekday_by_mon_off[wd % 7 + 6]; +} + +//////////////////////////////////////////////////////////////////////// + +CONSTEXPR_F civil_day next_weekday(civil_day cd, weekday wd) noexcept { + CONSTEXPR_D weekday k_weekdays_forw[14] = { + weekday::monday, weekday::tuesday, weekday::wednesday, + weekday::thursday, weekday::friday, weekday::saturday, + weekday::sunday, weekday::monday, weekday::tuesday, + weekday::wednesday, weekday::thursday, weekday::friday, + weekday::saturday, weekday::sunday, + }; + weekday base = get_weekday(cd); + for (int i = 0;; ++i) { + if (base == k_weekdays_forw[i]) { + for (int j = i + 1;; ++j) { + if (wd == k_weekdays_forw[j]) { + return cd + (j - i); + } + } + } + } +} + +CONSTEXPR_F civil_day prev_weekday(civil_day cd, weekday wd) noexcept { + CONSTEXPR_D weekday k_weekdays_back[14] = { + weekday::sunday, weekday::saturday, weekday::friday, + weekday::thursday, weekday::wednesday, weekday::tuesday, + weekday::monday, weekday::sunday, weekday::saturday, + weekday::friday, weekday::thursday, weekday::wednesday, + weekday::tuesday, weekday::monday, + }; + weekday base = get_weekday(cd); + for (int i = 0;; ++i) { + if (base == k_weekdays_back[i]) { + for (int j = i + 1;; ++j) { + if (wd == k_weekdays_back[j]) { + return cd - (j - i); + } + } + } + } +} + +CONSTEXPR_F int get_yearday(const civil_second& cs) noexcept { + CONSTEXPR_D int k_month_offsets[1 + 12] = { + -1, 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334, + }; + const int feb29 = (cs.month() > 2 && impl::is_leap_year(cs.year())); + return k_month_offsets[cs.month()] + feb29 + cs.day(); +} + +//////////////////////////////////////////////////////////////////////// + +std::ostream& operator<<(std::ostream& os, const civil_year& y); +std::ostream& operator<<(std::ostream& os, const civil_month& m); +std::ostream& operator<<(std::ostream& os, const civil_day& d); +std::ostream& operator<<(std::ostream& os, const civil_hour& h); +std::ostream& operator<<(std::ostream& os, const civil_minute& m); +std::ostream& operator<<(std::ostream& os, const civil_second& s); +std::ostream& operator<<(std::ostream& os, weekday wd); + +} // namespace detail +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#undef CONSTEXPR_M +#undef CONSTEXPR_F +#undef CONSTEXPR_D + +#endif // ABSL_TIME_INTERNAL_CCTZ_CIVIL_TIME_DETAIL_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/time_zone.h b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/time_zone.h new file mode 100644 index 0000000000..d4ea90ef7e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/time_zone.h @@ -0,0 +1,384 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// A library for translating between absolute times (represented by +// std::chrono::time_points of the std::chrono::system_clock) and civil +// times (represented by cctz::civil_second) using the rules defined by +// a time zone (cctz::time_zone). + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_H_ + +#include <chrono> +#include <cstdint> +#include <string> +#include <utility> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// Convenience aliases. Not intended as public API points. +template <typename D> +using time_point = std::chrono::time_point<std::chrono::system_clock, D>; +using seconds = std::chrono::duration<std::int_fast64_t>; +using sys_seconds = seconds; // Deprecated. Use cctz::seconds instead. + +namespace detail { +template <typename D> +inline std::pair<time_point<seconds>, D> split_seconds( + const time_point<D>& tp) { + auto sec = std::chrono::time_point_cast<seconds>(tp); + auto sub = tp - sec; + if (sub.count() < 0) { + sec -= seconds(1); + sub += seconds(1); + } + return {sec, std::chrono::duration_cast<D>(sub)}; +} +inline std::pair<time_point<seconds>, seconds> split_seconds( + const time_point<seconds>& tp) { + return {tp, seconds::zero()}; +} +} // namespace detail + +// cctz::time_zone is an opaque, small, value-type class representing a +// geo-political region within which particular rules are used for mapping +// between absolute and civil times. Time zones are named using the TZ +// identifiers from the IANA Time Zone Database, such as "America/Los_Angeles" +// or "Australia/Sydney". Time zones are created from factory functions such +// as load_time_zone(). Note: strings like "PST" and "EDT" are not valid TZ +// identifiers. +// +// Example: +// cctz::time_zone utc = cctz::utc_time_zone(); +// cctz::time_zone pst = cctz::fixed_time_zone(std::chrono::hours(-8)); +// cctz::time_zone loc = cctz::local_time_zone(); +// cctz::time_zone lax; +// if (!cctz::load_time_zone("America/Los_Angeles", &lax)) { ... } +// +// See also: +// - http://www.iana.org/time-zones +// - https://en.wikipedia.org/wiki/Zoneinfo +class time_zone { + public: + time_zone() : time_zone(nullptr) {} // Equivalent to UTC + time_zone(const time_zone&) = default; + time_zone& operator=(const time_zone&) = default; + + std::string name() const; + + // An absolute_lookup represents the civil time (cctz::civil_second) within + // this time_zone at the given absolute time (time_point). There are + // additionally a few other fields that may be useful when working with + // older APIs, such as std::tm. + // + // Example: + // const cctz::time_zone tz = ... + // const auto tp = std::chrono::system_clock::now(); + // const cctz::time_zone::absolute_lookup al = tz.lookup(tp); + struct absolute_lookup { + civil_second cs; + // Note: The following fields exist for backward compatibility with older + // APIs. Accessing these fields directly is a sign of imprudent logic in + // the calling code. Modern time-related code should only access this data + // indirectly by way of cctz::format(). + int offset; // civil seconds east of UTC + bool is_dst; // is offset non-standard? + const char* abbr; // time-zone abbreviation (e.g., "PST") + }; + absolute_lookup lookup(const time_point<seconds>& tp) const; + template <typename D> + absolute_lookup lookup(const time_point<D>& tp) const { + return lookup(detail::split_seconds(tp).first); + } + + // A civil_lookup represents the absolute time(s) (time_point) that + // correspond to the given civil time (cctz::civil_second) within this + // time_zone. Usually the given civil time represents a unique instant + // in time, in which case the conversion is unambiguous. However, + // within this time zone, the given civil time may be skipped (e.g., + // during a positive UTC offset shift), or repeated (e.g., during a + // negative UTC offset shift). To account for these possibilities, + // civil_lookup is richer than just a single time_point. + // + // In all cases the civil_lookup::kind enum will indicate the nature + // of the given civil-time argument, and the pre, trans, and post + // members will give the absolute time answers using the pre-transition + // offset, the transition point itself, and the post-transition offset, + // respectively (all three times are equal if kind == UNIQUE). If any + // of these three absolute times is outside the representable range of a + // time_point<seconds> the field is set to its maximum/minimum value. + // + // Example: + // cctz::time_zone lax; + // if (!cctz::load_time_zone("America/Los_Angeles", &lax)) { ... } + // + // // A unique civil time. + // auto jan01 = lax.lookup(cctz::civil_second(2011, 1, 1, 0, 0, 0)); + // // jan01.kind == cctz::time_zone::civil_lookup::UNIQUE + // // jan01.pre is 2011/01/01 00:00:00 -0800 + // // jan01.trans is 2011/01/01 00:00:00 -0800 + // // jan01.post is 2011/01/01 00:00:00 -0800 + // + // // A Spring DST transition, when there is a gap in civil time. + // auto mar13 = lax.lookup(cctz::civil_second(2011, 3, 13, 2, 15, 0)); + // // mar13.kind == cctz::time_zone::civil_lookup::SKIPPED + // // mar13.pre is 2011/03/13 03:15:00 -0700 + // // mar13.trans is 2011/03/13 03:00:00 -0700 + // // mar13.post is 2011/03/13 01:15:00 -0800 + // + // // A Fall DST transition, when civil times are repeated. + // auto nov06 = lax.lookup(cctz::civil_second(2011, 11, 6, 1, 15, 0)); + // // nov06.kind == cctz::time_zone::civil_lookup::REPEATED + // // nov06.pre is 2011/11/06 01:15:00 -0700 + // // nov06.trans is 2011/11/06 01:00:00 -0800 + // // nov06.post is 2011/11/06 01:15:00 -0800 + struct civil_lookup { + enum civil_kind { + UNIQUE, // the civil time was singular (pre == trans == post) + SKIPPED, // the civil time did not exist (pre >= trans > post) + REPEATED, // the civil time was ambiguous (pre < trans <= post) + } kind; + time_point<seconds> pre; // uses the pre-transition offset + time_point<seconds> trans; // instant of civil-offset change + time_point<seconds> post; // uses the post-transition offset + }; + civil_lookup lookup(const civil_second& cs) const; + + // Finds the time of the next/previous offset change in this time zone. + // + // By definition, next_transition(tp, &trans) returns false when tp has + // its maximum value, and prev_transition(tp, &trans) returns false + // when tp has its minimum value. If the zone has no transitions, the + // result will also be false no matter what the argument. + // + // Otherwise, when tp has its minimum value, next_transition(tp, &trans) + // returns true and sets trans to the first recorded transition. Chains + // of calls to next_transition()/prev_transition() will eventually return + // false, but it is unspecified exactly when next_transition(tp, &trans) + // jumps to false, or what time is set by prev_transition(tp, &trans) for + // a very distant tp. + // + // Note: Enumeration of time-zone transitions is for informational purposes + // only. Modern time-related code should not care about when offset changes + // occur. + // + // Example: + // cctz::time_zone nyc; + // if (!cctz::load_time_zone("America/New_York", &nyc)) { ... } + // const auto now = std::chrono::system_clock::now(); + // auto tp = cctz::time_point<cctz::seconds>::min(); + // cctz::time_zone::civil_transition trans; + // while (tp <= now && nyc.next_transition(tp, &trans)) { + // // transition: trans.from -> trans.to + // tp = nyc.lookup(trans.to).trans; + // } + struct civil_transition { + civil_second from; // the civil time we jump from + civil_second to; // the civil time we jump to + }; + bool next_transition(const time_point<seconds>& tp, + civil_transition* trans) const; + template <typename D> + bool next_transition(const time_point<D>& tp, civil_transition* trans) const { + return next_transition(detail::split_seconds(tp).first, trans); + } + bool prev_transition(const time_point<seconds>& tp, + civil_transition* trans) const; + template <typename D> + bool prev_transition(const time_point<D>& tp, civil_transition* trans) const { + return prev_transition(detail::split_seconds(tp).first, trans); + } + + // version() and description() provide additional information about the + // time zone. The content of each of the returned strings is unspecified, + // however, when the IANA Time Zone Database is the underlying data source + // the version() string will be in the familar form (e.g, "2018e") or + // empty when unavailable. + // + // Note: These functions are for informational or testing purposes only. + std::string version() const; // empty when unknown + std::string description() const; + + // Relational operators. + friend bool operator==(time_zone lhs, time_zone rhs) { + return &lhs.effective_impl() == &rhs.effective_impl(); + } + friend bool operator!=(time_zone lhs, time_zone rhs) { return !(lhs == rhs); } + + template <typename H> + friend H AbslHashValue(H h, time_zone tz) { + return H::combine(std::move(h), &tz.effective_impl()); + } + + class Impl; + + private: + explicit time_zone(const Impl* impl) : impl_(impl) {} + const Impl& effective_impl() const; // handles implicit UTC + const Impl* impl_; +}; + +// Loads the named time zone. May perform I/O on the initial load. +// If the name is invalid, or some other kind of error occurs, returns +// false and "*tz" is set to the UTC time zone. +bool load_time_zone(const std::string& name, time_zone* tz); + +// Returns a time_zone representing UTC. Cannot fail. +time_zone utc_time_zone(); + +// Returns a time zone that is a fixed offset (seconds east) from UTC. +// Note: If the absolute value of the offset is greater than 24 hours +// you'll get UTC (i.e., zero offset) instead. +time_zone fixed_time_zone(const seconds& offset); + +// Returns a time zone representing the local time zone. Falls back to UTC. +// Note: local_time_zone.name() may only be something like "localtime". +time_zone local_time_zone(); + +// Returns the civil time (cctz::civil_second) within the given time zone at +// the given absolute time (time_point). Since the additional fields provided +// by the time_zone::absolute_lookup struct should rarely be needed in modern +// code, this convert() function is simpler and should be preferred. +template <typename D> +inline civil_second convert(const time_point<D>& tp, const time_zone& tz) { + return tz.lookup(tp).cs; +} + +// Returns the absolute time (time_point) that corresponds to the given civil +// time within the given time zone. If the civil time is not unique (i.e., if +// it was either repeated or non-existent), then the returned time_point is +// the best estimate that preserves relative order. That is, this function +// guarantees that if cs1 < cs2, then convert(cs1, tz) <= convert(cs2, tz). +inline time_point<seconds> convert(const civil_second& cs, + const time_zone& tz) { + const time_zone::civil_lookup cl = tz.lookup(cs); + if (cl.kind == time_zone::civil_lookup::SKIPPED) return cl.trans; + return cl.pre; +} + +namespace detail { +using femtoseconds = std::chrono::duration<std::int_fast64_t, std::femto>; +std::string format(const std::string&, const time_point<seconds>&, + const femtoseconds&, const time_zone&); +bool parse(const std::string&, const std::string&, const time_zone&, + time_point<seconds>*, femtoseconds*, std::string* err = nullptr); +} // namespace detail + +// Formats the given time_point in the given cctz::time_zone according to +// the provided format string. Uses strftime()-like formatting options, +// with the following extensions: +// +// - %Ez - RFC3339-compatible numeric UTC offset (+hh:mm or -hh:mm) +// - %E*z - Full-resolution numeric UTC offset (+hh:mm:ss or -hh:mm:ss) +// - %E#S - Seconds with # digits of fractional precision +// - %E*S - Seconds with full fractional precision (a literal '*') +// - %E#f - Fractional seconds with # digits of precision +// - %E*f - Fractional seconds with full precision (a literal '*') +// - %E4Y - Four-character years (-999 ... -001, 0000, 0001 ... 9999) +// +// Note that %E0S behaves like %S, and %E0f produces no characters. In +// contrast %E*f always produces at least one digit, which may be '0'. +// +// Note that %Y produces as many characters as it takes to fully render the +// year. A year outside of [-999:9999] when formatted with %E4Y will produce +// more than four characters, just like %Y. +// +// Tip: Format strings should include the UTC offset (e.g., %z, %Ez, or %E*z) +// so that the resulting string uniquely identifies an absolute time. +// +// Example: +// cctz::time_zone lax; +// if (!cctz::load_time_zone("America/Los_Angeles", &lax)) { ... } +// auto tp = cctz::convert(cctz::civil_second(2013, 1, 2, 3, 4, 5), lax); +// std::string f = cctz::format("%H:%M:%S", tp, lax); // "03:04:05" +// f = cctz::format("%H:%M:%E3S", tp, lax); // "03:04:05.000" +template <typename D> +inline std::string format(const std::string& fmt, const time_point<D>& tp, + const time_zone& tz) { + const auto p = detail::split_seconds(tp); + const auto n = std::chrono::duration_cast<detail::femtoseconds>(p.second); + return detail::format(fmt, p.first, n, tz); +} + +// Parses an input string according to the provided format string and +// returns the corresponding time_point. Uses strftime()-like formatting +// options, with the same extensions as cctz::format(), but with the +// exceptions that %E#S is interpreted as %E*S, and %E#f as %E*f. %Ez +// and %E*z also accept the same inputs. +// +// %Y consumes as many numeric characters as it can, so the matching data +// should always be terminated with a non-numeric. %E4Y always consumes +// exactly four characters, including any sign. +// +// Unspecified fields are taken from the default date and time of ... +// +// "1970-01-01 00:00:00.0 +0000" +// +// For example, parsing a string of "15:45" (%H:%M) will return a time_point +// that represents "1970-01-01 15:45:00.0 +0000". +// +// Note that parse() returns time instants, so it makes most sense to parse +// fully-specified date/time strings that include a UTC offset (%z, %Ez, or +// %E*z). +// +// Note also that parse() only heeds the fields year, month, day, hour, +// minute, (fractional) second, and UTC offset. Other fields, like weekday (%a +// or %A), while parsed for syntactic validity, are ignored in the conversion. +// +// Date and time fields that are out-of-range will be treated as errors rather +// than normalizing them like cctz::civil_second() would do. For example, it +// is an error to parse the date "Oct 32, 2013" because 32 is out of range. +// +// A second of ":60" is normalized to ":00" of the following minute with +// fractional seconds discarded. The following table shows how the given +// seconds and subseconds will be parsed: +// +// "59.x" -> 59.x // exact +// "60.x" -> 00.0 // normalized +// "00.x" -> 00.x // exact +// +// Errors are indicated by returning false. +// +// Example: +// const cctz::time_zone tz = ... +// std::chrono::system_clock::time_point tp; +// if (cctz::parse("%Y-%m-%d", "2015-10-09", tz, &tp)) { +// ... +// } +template <typename D> +inline bool parse(const std::string& fmt, const std::string& input, + const time_zone& tz, time_point<D>* tpp) { + time_point<seconds> sec; + detail::femtoseconds fs; + const bool b = detail::parse(fmt, input, tz, &sec, &fs); + if (b) { + // TODO: Return false if unrepresentable as a time_point<D>. + *tpp = std::chrono::time_point_cast<D>(sec); + *tpp += std::chrono::duration_cast<D>(fs); + } + return b; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/zone_info_source.h b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/zone_info_source.h new file mode 100644 index 0000000000..012eb4ec30 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/include/cctz/zone_info_source.h @@ -0,0 +1,102 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_ZONE_INFO_SOURCE_H_ +#define ABSL_TIME_INTERNAL_CCTZ_ZONE_INFO_SOURCE_H_ + +#include <cstddef> +#include <functional> +#include <memory> +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// A stdio-like interface for providing zoneinfo data for a particular zone. +class ZoneInfoSource { + public: + virtual ~ZoneInfoSource(); + + virtual std::size_t Read(void* ptr, std::size_t size) = 0; // like fread() + virtual int Skip(std::size_t offset) = 0; // like fseek() + + // Until the zoneinfo data supports versioning information, we provide + // a way for a ZoneInfoSource to indicate it out-of-band. The default + // implementation returns an empty string. + virtual std::string Version() const; +}; + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz_extension { + +// A function-pointer type for a factory that returns a ZoneInfoSource +// given the name of a time zone and a fallback factory. Returns null +// when the data for the named zone cannot be found. +using ZoneInfoSourceFactory = + std::unique_ptr<absl::time_internal::cctz::ZoneInfoSource> (*)( + const std::string&, + const std::function<std::unique_ptr< + absl::time_internal::cctz::ZoneInfoSource>(const std::string&)>&); + +// The user can control the mapping of zone names to zoneinfo data by +// providing a definition for cctz_extension::zone_info_source_factory. +// For example, given functions my_factory() and my_other_factory() that +// can return a ZoneInfoSource for a named zone, we could inject them into +// cctz::load_time_zone() with: +// +// namespace cctz_extension { +// namespace { +// std::unique_ptr<cctz::ZoneInfoSource> CustomFactory( +// const std::string& name, +// const std::function<std::unique_ptr<cctz::ZoneInfoSource>( +// const std::string& name)>& fallback_factory) { +// if (auto zip = my_factory(name)) return zip; +// if (auto zip = fallback_factory(name)) return zip; +// if (auto zip = my_other_factory(name)) return zip; +// return nullptr; +// } +// } // namespace +// ZoneInfoSourceFactory zone_info_source_factory = CustomFactory; +// } // namespace cctz_extension +// +// This might be used, say, to use zoneinfo data embedded in the program, +// or read from a (possibly compressed) file archive, or both. +// +// cctz_extension::zone_info_source_factory() will be called: +// (1) from the same thread as the cctz::load_time_zone() call, +// (2) only once for any zone name, and +// (3) serially (i.e., no concurrent execution). +// +// The fallback factory obtains zoneinfo data by reading files in ${TZDIR}, +// and it is used automatically when no zone_info_source_factory definition +// is linked into the program. +extern ZoneInfoSourceFactory zone_info_source_factory; + +} // namespace cctz_extension +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_ZONE_INFO_SOURCE_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/cctz_benchmark.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/cctz_benchmark.cc new file mode 100644 index 0000000000..a402760d19 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/cctz_benchmark.cc @@ -0,0 +1,1030 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <algorithm> +#include <cassert> +#include <chrono> +#include <ctime> +#include <random> +#include <string> +#include <vector> + +#include "benchmark/benchmark.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" +#include "time_zone_impl.h" + +namespace { + +namespace cctz = absl::time_internal::cctz; + +void BM_Difference_Days(benchmark::State& state) { + const cctz::civil_day c(2014, 8, 22); + const cctz::civil_day epoch(1970, 1, 1); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(c - epoch); + } +} +BENCHMARK(BM_Difference_Days); + +void BM_Step_Days(benchmark::State& state) { + const cctz::civil_day kStart(2014, 8, 22); + cctz::civil_day c = kStart; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(++c); + } +} +BENCHMARK(BM_Step_Days); + +void BM_GetWeekday(benchmark::State& state) { + const cctz::civil_day c(2014, 8, 22); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::get_weekday(c)); + } +} +BENCHMARK(BM_GetWeekday); + +void BM_NextWeekday(benchmark::State& state) { + const cctz::civil_day kStart(2014, 8, 22); + const cctz::civil_day kDays[7] = { + kStart + 0, kStart + 1, kStart + 2, kStart + 3, + kStart + 4, kStart + 5, kStart + 6, + }; + const cctz::weekday kWeekdays[7] = { + cctz::weekday::monday, cctz::weekday::tuesday, cctz::weekday::wednesday, + cctz::weekday::thursday, cctz::weekday::friday, cctz::weekday::saturday, + cctz::weekday::sunday, + }; + while (state.KeepRunningBatch(7 * 7)) { + for (const auto from : kDays) { + for (const auto to : kWeekdays) { + benchmark::DoNotOptimize(cctz::next_weekday(from, to)); + } + } + } +} +BENCHMARK(BM_NextWeekday); + +void BM_PrevWeekday(benchmark::State& state) { + const cctz::civil_day kStart(2014, 8, 22); + const cctz::civil_day kDays[7] = { + kStart + 0, kStart + 1, kStart + 2, kStart + 3, + kStart + 4, kStart + 5, kStart + 6, + }; + const cctz::weekday kWeekdays[7] = { + cctz::weekday::monday, cctz::weekday::tuesday, cctz::weekday::wednesday, + cctz::weekday::thursday, cctz::weekday::friday, cctz::weekday::saturday, + cctz::weekday::sunday, + }; + while (state.KeepRunningBatch(7 * 7)) { + for (const auto from : kDays) { + for (const auto to : kWeekdays) { + benchmark::DoNotOptimize(cctz::prev_weekday(from, to)); + } + } + } +} +BENCHMARK(BM_PrevWeekday); + +const char RFC3339_full[] = "%Y-%m-%dT%H:%M:%E*S%Ez"; +const char RFC3339_sec[] = "%Y-%m-%dT%H:%M:%S%Ez"; + +const char RFC1123_full[] = "%a, %d %b %Y %H:%M:%S %z"; +const char RFC1123_no_wday[] = "%d %b %Y %H:%M:%S %z"; + +// A list of known time-zone names. +// TODO: Refactor with src/time_zone_lookup_test.cc. +const char* const kTimeZoneNames[] = {"Africa/Abidjan", + "Africa/Accra", + "Africa/Addis_Ababa", + "Africa/Algiers", + "Africa/Asmara", + "Africa/Asmera", + "Africa/Bamako", + "Africa/Bangui", + "Africa/Banjul", + "Africa/Bissau", + "Africa/Blantyre", + "Africa/Brazzaville", + "Africa/Bujumbura", + "Africa/Cairo", + "Africa/Casablanca", + "Africa/Ceuta", + "Africa/Conakry", + "Africa/Dakar", + "Africa/Dar_es_Salaam", + "Africa/Djibouti", + "Africa/Douala", + "Africa/El_Aaiun", + "Africa/Freetown", + "Africa/Gaborone", + "Africa/Harare", + "Africa/Johannesburg", + "Africa/Juba", + "Africa/Kampala", + "Africa/Khartoum", + "Africa/Kigali", + "Africa/Kinshasa", + "Africa/Lagos", + "Africa/Libreville", + "Africa/Lome", + "Africa/Luanda", + "Africa/Lubumbashi", + "Africa/Lusaka", + "Africa/Malabo", + "Africa/Maputo", + "Africa/Maseru", + "Africa/Mbabane", + "Africa/Mogadishu", + "Africa/Monrovia", + "Africa/Nairobi", + "Africa/Ndjamena", + "Africa/Niamey", + "Africa/Nouakchott", + "Africa/Ouagadougou", + "Africa/Porto-Novo", + "Africa/Sao_Tome", + "Africa/Timbuktu", + "Africa/Tripoli", + "Africa/Tunis", + "Africa/Windhoek", + "America/Adak", + "America/Anchorage", + "America/Anguilla", + "America/Antigua", + "America/Araguaina", + "America/Argentina/Buenos_Aires", + "America/Argentina/Catamarca", + "America/Argentina/ComodRivadavia", + "America/Argentina/Cordoba", + "America/Argentina/Jujuy", + "America/Argentina/La_Rioja", + "America/Argentina/Mendoza", + "America/Argentina/Rio_Gallegos", + "America/Argentina/Salta", + "America/Argentina/San_Juan", + "America/Argentina/San_Luis", + "America/Argentina/Tucuman", + "America/Argentina/Ushuaia", + "America/Aruba", + "America/Asuncion", + "America/Atikokan", + "America/Atka", + "America/Bahia", + "America/Bahia_Banderas", + "America/Barbados", + "America/Belem", + "America/Belize", + "America/Blanc-Sablon", + "America/Boa_Vista", + "America/Bogota", + "America/Boise", + "America/Buenos_Aires", + "America/Cambridge_Bay", + "America/Campo_Grande", + "America/Cancun", + "America/Caracas", + "America/Catamarca", + "America/Cayenne", + "America/Cayman", + "America/Chicago", + "America/Chihuahua", + "America/Coral_Harbour", + "America/Cordoba", + "America/Costa_Rica", + "America/Creston", + "America/Cuiaba", + "America/Curacao", + "America/Danmarkshavn", + "America/Dawson", + "America/Dawson_Creek", + "America/Denver", + "America/Detroit", + "America/Dominica", + "America/Edmonton", + "America/Eirunepe", + "America/El_Salvador", + "America/Ensenada", + "America/Fort_Nelson", + "America/Fort_Wayne", + "America/Fortaleza", + "America/Glace_Bay", + "America/Godthab", + "America/Goose_Bay", + "America/Grand_Turk", + "America/Grenada", + "America/Guadeloupe", + "America/Guatemala", + "America/Guayaquil", + "America/Guyana", + "America/Halifax", + "America/Havana", + "America/Hermosillo", + "America/Indiana/Indianapolis", + "America/Indiana/Knox", + "America/Indiana/Marengo", + "America/Indiana/Petersburg", + "America/Indiana/Tell_City", + "America/Indiana/Vevay", + "America/Indiana/Vincennes", + "America/Indiana/Winamac", + "America/Indianapolis", + "America/Inuvik", + "America/Iqaluit", + "America/Jamaica", + "America/Jujuy", + "America/Juneau", + "America/Kentucky/Louisville", + "America/Kentucky/Monticello", + "America/Knox_IN", + "America/Kralendijk", + "America/La_Paz", + "America/Lima", + "America/Los_Angeles", + "America/Louisville", + "America/Lower_Princes", + "America/Maceio", + "America/Managua", + "America/Manaus", + "America/Marigot", + "America/Martinique", + "America/Matamoros", + "America/Mazatlan", + "America/Mendoza", + "America/Menominee", + "America/Merida", + "America/Metlakatla", + "America/Mexico_City", + "America/Miquelon", + "America/Moncton", + "America/Monterrey", + "America/Montevideo", + "America/Montreal", + "America/Montserrat", + "America/Nassau", + "America/New_York", + "America/Nipigon", + "America/Nome", + "America/Noronha", + "America/North_Dakota/Beulah", + "America/North_Dakota/Center", + "America/North_Dakota/New_Salem", + "America/Nuuk", + "America/Ojinaga", + "America/Panama", + "America/Pangnirtung", + "America/Paramaribo", + "America/Phoenix", + "America/Port-au-Prince", + "America/Port_of_Spain", + "America/Porto_Acre", + "America/Porto_Velho", + "America/Puerto_Rico", + "America/Punta_Arenas", + "America/Rainy_River", + "America/Rankin_Inlet", + "America/Recife", + "America/Regina", + "America/Resolute", + "America/Rio_Branco", + "America/Rosario", + "America/Santa_Isabel", + "America/Santarem", + "America/Santiago", + "America/Santo_Domingo", + "America/Sao_Paulo", + "America/Scoresbysund", + "America/Shiprock", + "America/Sitka", + "America/St_Barthelemy", + "America/St_Johns", + "America/St_Kitts", + "America/St_Lucia", + "America/St_Thomas", + "America/St_Vincent", + "America/Swift_Current", + "America/Tegucigalpa", + "America/Thule", + "America/Thunder_Bay", + "America/Tijuana", + "America/Toronto", + "America/Tortola", + "America/Vancouver", + "America/Virgin", + "America/Whitehorse", + "America/Winnipeg", + "America/Yakutat", + "America/Yellowknife", + "Antarctica/Casey", + "Antarctica/Davis", + "Antarctica/DumontDUrville", + "Antarctica/Macquarie", + "Antarctica/Mawson", + "Antarctica/McMurdo", + "Antarctica/Palmer", + "Antarctica/Rothera", + "Antarctica/South_Pole", + "Antarctica/Syowa", + "Antarctica/Troll", + "Antarctica/Vostok", + "Arctic/Longyearbyen", + "Asia/Aden", + "Asia/Almaty", + "Asia/Amman", + "Asia/Anadyr", + "Asia/Aqtau", + "Asia/Aqtobe", + "Asia/Ashgabat", + "Asia/Ashkhabad", + "Asia/Atyrau", + "Asia/Baghdad", + "Asia/Bahrain", + "Asia/Baku", + "Asia/Bangkok", + "Asia/Barnaul", + "Asia/Beirut", + "Asia/Bishkek", + "Asia/Brunei", + "Asia/Calcutta", + "Asia/Chita", + "Asia/Choibalsan", + "Asia/Chongqing", + "Asia/Chungking", + "Asia/Colombo", + "Asia/Dacca", + "Asia/Damascus", + "Asia/Dhaka", + "Asia/Dili", + "Asia/Dubai", + "Asia/Dushanbe", + "Asia/Famagusta", + "Asia/Gaza", + "Asia/Harbin", + "Asia/Hebron", + "Asia/Ho_Chi_Minh", + "Asia/Hong_Kong", + "Asia/Hovd", + "Asia/Irkutsk", + "Asia/Istanbul", + "Asia/Jakarta", + "Asia/Jayapura", + "Asia/Jerusalem", + "Asia/Kabul", + "Asia/Kamchatka", + "Asia/Karachi", + "Asia/Kashgar", + "Asia/Kathmandu", + "Asia/Katmandu", + "Asia/Khandyga", + "Asia/Kolkata", + "Asia/Krasnoyarsk", + "Asia/Kuala_Lumpur", + "Asia/Kuching", + "Asia/Kuwait", + "Asia/Macao", + "Asia/Macau", + "Asia/Magadan", + "Asia/Makassar", + "Asia/Manila", + "Asia/Muscat", + "Asia/Nicosia", + "Asia/Novokuznetsk", + "Asia/Novosibirsk", + "Asia/Omsk", + "Asia/Oral", + "Asia/Phnom_Penh", + "Asia/Pontianak", + "Asia/Pyongyang", + "Asia/Qatar", + "Asia/Qostanay", + "Asia/Qyzylorda", + "Asia/Rangoon", + "Asia/Riyadh", + "Asia/Saigon", + "Asia/Sakhalin", + "Asia/Samarkand", + "Asia/Seoul", + "Asia/Shanghai", + "Asia/Singapore", + "Asia/Srednekolymsk", + "Asia/Taipei", + "Asia/Tashkent", + "Asia/Tbilisi", + "Asia/Tehran", + "Asia/Tel_Aviv", + "Asia/Thimbu", + "Asia/Thimphu", + "Asia/Tokyo", + "Asia/Tomsk", + "Asia/Ujung_Pandang", + "Asia/Ulaanbaatar", + "Asia/Ulan_Bator", + "Asia/Urumqi", + "Asia/Ust-Nera", + "Asia/Vientiane", + "Asia/Vladivostok", + "Asia/Yakutsk", + "Asia/Yangon", + "Asia/Yekaterinburg", + "Asia/Yerevan", + "Atlantic/Azores", + "Atlantic/Bermuda", + "Atlantic/Canary", + "Atlantic/Cape_Verde", + "Atlantic/Faeroe", + "Atlantic/Faroe", + "Atlantic/Jan_Mayen", + "Atlantic/Madeira", + "Atlantic/Reykjavik", + "Atlantic/South_Georgia", + "Atlantic/St_Helena", + "Atlantic/Stanley", + "Australia/ACT", + "Australia/Adelaide", + "Australia/Brisbane", + "Australia/Broken_Hill", + "Australia/Canberra", + "Australia/Currie", + "Australia/Darwin", + "Australia/Eucla", + "Australia/Hobart", + "Australia/LHI", + "Australia/Lindeman", + "Australia/Lord_Howe", + "Australia/Melbourne", + "Australia/NSW", + "Australia/North", + "Australia/Perth", + "Australia/Queensland", + "Australia/South", + "Australia/Sydney", + "Australia/Tasmania", + "Australia/Victoria", + "Australia/West", + "Australia/Yancowinna", + "Brazil/Acre", + "Brazil/DeNoronha", + "Brazil/East", + "Brazil/West", + "CET", + "CST6CDT", + "Canada/Atlantic", + "Canada/Central", + "Canada/Eastern", + "Canada/Mountain", + "Canada/Newfoundland", + "Canada/Pacific", + "Canada/Saskatchewan", + "Canada/Yukon", + "Chile/Continental", + "Chile/EasterIsland", + "Cuba", + "EET", + "EST", + "EST5EDT", + "Egypt", + "Eire", + "Etc/GMT", + "Etc/GMT+0", + "Etc/GMT+1", + "Etc/GMT+10", + "Etc/GMT+11", + "Etc/GMT+12", + "Etc/GMT+2", + "Etc/GMT+3", + "Etc/GMT+4", + "Etc/GMT+5", + "Etc/GMT+6", + "Etc/GMT+7", + "Etc/GMT+8", + "Etc/GMT+9", + "Etc/GMT-0", + "Etc/GMT-1", + "Etc/GMT-10", + "Etc/GMT-11", + "Etc/GMT-12", + "Etc/GMT-13", + "Etc/GMT-14", + "Etc/GMT-2", + "Etc/GMT-3", + "Etc/GMT-4", + "Etc/GMT-5", + "Etc/GMT-6", + "Etc/GMT-7", + "Etc/GMT-8", + "Etc/GMT-9", + "Etc/GMT0", + "Etc/Greenwich", + "Etc/UCT", + "Etc/UTC", + "Etc/Universal", + "Etc/Zulu", + "Europe/Amsterdam", + "Europe/Andorra", + "Europe/Astrakhan", + "Europe/Athens", + "Europe/Belfast", + "Europe/Belgrade", + "Europe/Berlin", + "Europe/Bratislava", + "Europe/Brussels", + "Europe/Bucharest", + "Europe/Budapest", + "Europe/Busingen", + "Europe/Chisinau", + "Europe/Copenhagen", + "Europe/Dublin", + "Europe/Gibraltar", + "Europe/Guernsey", + "Europe/Helsinki", + "Europe/Isle_of_Man", + "Europe/Istanbul", + "Europe/Jersey", + "Europe/Kaliningrad", + "Europe/Kiev", + "Europe/Kirov", + "Europe/Lisbon", + "Europe/Ljubljana", + "Europe/London", + "Europe/Luxembourg", + "Europe/Madrid", + "Europe/Malta", + "Europe/Mariehamn", + "Europe/Minsk", + "Europe/Monaco", + "Europe/Moscow", + "Europe/Nicosia", + "Europe/Oslo", + "Europe/Paris", + "Europe/Podgorica", + "Europe/Prague", + "Europe/Riga", + "Europe/Rome", + "Europe/Samara", + "Europe/San_Marino", + "Europe/Sarajevo", + "Europe/Saratov", + "Europe/Simferopol", + "Europe/Skopje", + "Europe/Sofia", + "Europe/Stockholm", + "Europe/Tallinn", + "Europe/Tirane", + "Europe/Tiraspol", + "Europe/Ulyanovsk", + "Europe/Uzhgorod", + "Europe/Vaduz", + "Europe/Vatican", + "Europe/Vienna", + "Europe/Vilnius", + "Europe/Volgograd", + "Europe/Warsaw", + "Europe/Zagreb", + "Europe/Zaporozhye", + "Europe/Zurich", + "GB", + "GB-Eire", + "GMT", + "GMT+0", + "GMT-0", + "GMT0", + "Greenwich", + "HST", + "Hongkong", + "Iceland", + "Indian/Antananarivo", + "Indian/Chagos", + "Indian/Christmas", + "Indian/Cocos", + "Indian/Comoro", + "Indian/Kerguelen", + "Indian/Mahe", + "Indian/Maldives", + "Indian/Mauritius", + "Indian/Mayotte", + "Indian/Reunion", + "Iran", + "Israel", + "Jamaica", + "Japan", + "Kwajalein", + "Libya", + "MET", + "MST", + "MST7MDT", + "Mexico/BajaNorte", + "Mexico/BajaSur", + "Mexico/General", + "NZ", + "NZ-CHAT", + "Navajo", + "PRC", + "PST8PDT", + "Pacific/Apia", + "Pacific/Auckland", + "Pacific/Bougainville", + "Pacific/Chatham", + "Pacific/Chuuk", + "Pacific/Easter", + "Pacific/Efate", + "Pacific/Enderbury", + "Pacific/Fakaofo", + "Pacific/Fiji", + "Pacific/Funafuti", + "Pacific/Galapagos", + "Pacific/Gambier", + "Pacific/Guadalcanal", + "Pacific/Guam", + "Pacific/Honolulu", + "Pacific/Johnston", + "Pacific/Kiritimati", + "Pacific/Kosrae", + "Pacific/Kwajalein", + "Pacific/Majuro", + "Pacific/Marquesas", + "Pacific/Midway", + "Pacific/Nauru", + "Pacific/Niue", + "Pacific/Norfolk", + "Pacific/Noumea", + "Pacific/Pago_Pago", + "Pacific/Palau", + "Pacific/Pitcairn", + "Pacific/Pohnpei", + "Pacific/Ponape", + "Pacific/Port_Moresby", + "Pacific/Rarotonga", + "Pacific/Saipan", + "Pacific/Samoa", + "Pacific/Tahiti", + "Pacific/Tarawa", + "Pacific/Tongatapu", + "Pacific/Truk", + "Pacific/Wake", + "Pacific/Wallis", + "Pacific/Yap", + "Poland", + "Portugal", + "ROC", + "ROK", + "Singapore", + "Turkey", + "UCT", + "US/Alaska", + "US/Aleutian", + "US/Arizona", + "US/Central", + "US/East-Indiana", + "US/Eastern", + "US/Hawaii", + "US/Indiana-Starke", + "US/Michigan", + "US/Mountain", + "US/Pacific", + "US/Samoa", + "UTC", + "Universal", + "W-SU", + "WET", + "Zulu", + nullptr}; + +std::vector<std::string> AllTimeZoneNames() { + std::vector<std::string> names; + for (const char* const* namep = kTimeZoneNames; *namep != nullptr; ++namep) { + names.push_back(std::string("file:") + *namep); + } + assert(!names.empty()); + + std::mt19937 urbg(42); // a UniformRandomBitGenerator with fixed seed + std::shuffle(names.begin(), names.end(), urbg); + return names; +} + +cctz::time_zone TestTimeZone() { + cctz::time_zone tz; + cctz::load_time_zone("America/Los_Angeles", &tz); + return tz; +} + +void BM_Zone_LoadUTCTimeZoneFirst(benchmark::State& state) { + cctz::time_zone tz; + cctz::load_time_zone("UTC", &tz); // in case we're first + cctz::time_zone::Impl::ClearTimeZoneMapTestOnly(); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::load_time_zone("UTC", &tz)); + } +} +BENCHMARK(BM_Zone_LoadUTCTimeZoneFirst); + +void BM_Zone_LoadUTCTimeZoneLast(benchmark::State& state) { + cctz::time_zone tz; + for (const auto& name : AllTimeZoneNames()) { + cctz::load_time_zone(name, &tz); // prime cache + } + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::load_time_zone("UTC", &tz)); + } +} +BENCHMARK(BM_Zone_LoadUTCTimeZoneLast); + +void BM_Zone_LoadTimeZoneFirst(benchmark::State& state) { + cctz::time_zone tz = cctz::utc_time_zone(); // in case we're first + const std::string name = "file:America/Los_Angeles"; + while (state.KeepRunning()) { + state.PauseTiming(); + cctz::time_zone::Impl::ClearTimeZoneMapTestOnly(); + state.ResumeTiming(); + benchmark::DoNotOptimize(cctz::load_time_zone(name, &tz)); + } +} +BENCHMARK(BM_Zone_LoadTimeZoneFirst); + +void BM_Zone_LoadTimeZoneCached(benchmark::State& state) { + cctz::time_zone tz = cctz::utc_time_zone(); // in case we're first + cctz::time_zone::Impl::ClearTimeZoneMapTestOnly(); + const std::string name = "file:America/Los_Angeles"; + cctz::load_time_zone(name, &tz); // prime cache + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::load_time_zone(name, &tz)); + } +} +BENCHMARK(BM_Zone_LoadTimeZoneCached); + +void BM_Zone_LoadLocalTimeZoneCached(benchmark::State& state) { + cctz::utc_time_zone(); // in case we're first + cctz::time_zone::Impl::ClearTimeZoneMapTestOnly(); + cctz::local_time_zone(); // prime cache + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::local_time_zone()); + } +} +BENCHMARK(BM_Zone_LoadLocalTimeZoneCached); + +void BM_Zone_LoadAllTimeZonesFirst(benchmark::State& state) { + cctz::time_zone tz; + const std::vector<std::string> names = AllTimeZoneNames(); + for (auto index = names.size(); state.KeepRunning(); ++index) { + if (index == names.size()) { + index = 0; + } + if (index == 0) { + state.PauseTiming(); + cctz::time_zone::Impl::ClearTimeZoneMapTestOnly(); + state.ResumeTiming(); + } + benchmark::DoNotOptimize(cctz::load_time_zone(names[index], &tz)); + } +} +BENCHMARK(BM_Zone_LoadAllTimeZonesFirst); + +void BM_Zone_LoadAllTimeZonesCached(benchmark::State& state) { + cctz::time_zone tz; + const std::vector<std::string> names = AllTimeZoneNames(); + for (const auto& name : names) { + cctz::load_time_zone(name, &tz); // prime cache + } + for (auto index = names.size(); state.KeepRunning(); ++index) { + if (index == names.size()) { + index = 0; + } + benchmark::DoNotOptimize(cctz::load_time_zone(names[index], &tz)); + } +} +BENCHMARK(BM_Zone_LoadAllTimeZonesCached); + +void BM_Zone_TimeZoneEqualityImplicit(benchmark::State& state) { + cctz::time_zone tz; // implicit UTC + while (state.KeepRunning()) { + benchmark::DoNotOptimize(tz == tz); + } +} +BENCHMARK(BM_Zone_TimeZoneEqualityImplicit); + +void BM_Zone_TimeZoneEqualityExplicit(benchmark::State& state) { + cctz::time_zone tz = cctz::utc_time_zone(); // explicit UTC + while (state.KeepRunning()) { + benchmark::DoNotOptimize(tz == tz); + } +} +BENCHMARK(BM_Zone_TimeZoneEqualityExplicit); + +void BM_Zone_UTCTimeZone(benchmark::State& state) { + cctz::time_zone tz; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::utc_time_zone()); + } +} +BENCHMARK(BM_Zone_UTCTimeZone); + +// In each "ToCivil" benchmark we switch between two instants separated +// by at least one transition in order to defeat any internal caching of +// previous results (e.g., see local_time_hint_). +// +// The "UTC" variants use UTC instead of the Google/local time zone. + +void BM_Time_ToCivil_CCTZ(benchmark::State& state) { + const cctz::time_zone tz = TestTimeZone(); + std::chrono::system_clock::time_point tp = + std::chrono::system_clock::from_time_t(1384569027); + std::chrono::system_clock::time_point tp2 = + std::chrono::system_clock::from_time_t(1418962578); + while (state.KeepRunning()) { + std::swap(tp, tp2); + tp += std::chrono::seconds(1); + benchmark::DoNotOptimize(cctz::convert(tp, tz)); + } +} +BENCHMARK(BM_Time_ToCivil_CCTZ); + +void BM_Time_ToCivil_Libc(benchmark::State& state) { + // No timezone support, so just use localtime. + time_t t = 1384569027; + time_t t2 = 1418962578; + struct tm tm; + while (state.KeepRunning()) { + std::swap(t, t2); + t += 1; +#if defined(_WIN32) || defined(_WIN64) + benchmark::DoNotOptimize(localtime_s(&tm, &t)); +#else + benchmark::DoNotOptimize(localtime_r(&t, &tm)); +#endif + } +} +BENCHMARK(BM_Time_ToCivil_Libc); + +void BM_Time_ToCivilUTC_CCTZ(benchmark::State& state) { + const cctz::time_zone tz = cctz::utc_time_zone(); + std::chrono::system_clock::time_point tp = + std::chrono::system_clock::from_time_t(1384569027); + while (state.KeepRunning()) { + tp += std::chrono::seconds(1); + benchmark::DoNotOptimize(cctz::convert(tp, tz)); + } +} +BENCHMARK(BM_Time_ToCivilUTC_CCTZ); + +void BM_Time_ToCivilUTC_Libc(benchmark::State& state) { + time_t t = 1384569027; + struct tm tm; + while (state.KeepRunning()) { + t += 1; +#if defined(_WIN32) || defined(_WIN64) + benchmark::DoNotOptimize(gmtime_s(&tm, &t)); +#else + benchmark::DoNotOptimize(gmtime_r(&t, &tm)); +#endif + } +} +BENCHMARK(BM_Time_ToCivilUTC_Libc); + +// In each "FromCivil" benchmark we switch between two YMDhms values +// separated by at least one transition in order to defeat any internal +// caching of previous results (e.g., see time_local_hint_). +// +// The "UTC" variants use UTC instead of the Google/local time zone. +// The "Day0" variants require normalization of the day of month. + +void BM_Time_FromCivil_CCTZ(benchmark::State& state) { + const cctz::time_zone tz = TestTimeZone(); + int i = 0; + while (state.KeepRunning()) { + if ((i++ & 1) == 0) { + benchmark::DoNotOptimize( + cctz::convert(cctz::civil_second(2014, 12, 18, 20, 16, 18), tz)); + } else { + benchmark::DoNotOptimize( + cctz::convert(cctz::civil_second(2013, 11, 15, 18, 30, 27), tz)); + } + } +} +BENCHMARK(BM_Time_FromCivil_CCTZ); + +void BM_Time_FromCivil_Libc(benchmark::State& state) { + // No timezone support, so just use localtime. + int i = 0; + while (state.KeepRunning()) { + struct tm tm; + if ((i++ & 1) == 0) { + tm.tm_year = 2014 - 1900; + tm.tm_mon = 12 - 1; + tm.tm_mday = 18; + tm.tm_hour = 20; + tm.tm_min = 16; + tm.tm_sec = 18; + } else { + tm.tm_year = 2013 - 1900; + tm.tm_mon = 11 - 1; + tm.tm_mday = 15; + tm.tm_hour = 18; + tm.tm_min = 30; + tm.tm_sec = 27; + } + tm.tm_isdst = -1; + benchmark::DoNotOptimize(mktime(&tm)); + } +} +BENCHMARK(BM_Time_FromCivil_Libc); + +void BM_Time_FromCivilUTC_CCTZ(benchmark::State& state) { + const cctz::time_zone tz = cctz::utc_time_zone(); + while (state.KeepRunning()) { + benchmark::DoNotOptimize( + cctz::convert(cctz::civil_second(2014, 12, 18, 20, 16, 18), tz)); + } +} +BENCHMARK(BM_Time_FromCivilUTC_CCTZ); + +// There is no BM_Time_FromCivilUTC_Libc. + +void BM_Time_FromCivilDay0_CCTZ(benchmark::State& state) { + const cctz::time_zone tz = TestTimeZone(); + int i = 0; + while (state.KeepRunning()) { + if ((i++ & 1) == 0) { + benchmark::DoNotOptimize( + cctz::convert(cctz::civil_second(2014, 12, 0, 20, 16, 18), tz)); + } else { + benchmark::DoNotOptimize( + cctz::convert(cctz::civil_second(2013, 11, 0, 18, 30, 27), tz)); + } + } +} +BENCHMARK(BM_Time_FromCivilDay0_CCTZ); + +void BM_Time_FromCivilDay0_Libc(benchmark::State& state) { + // No timezone support, so just use localtime. + int i = 0; + while (state.KeepRunning()) { + struct tm tm; + if ((i++ & 1) == 0) { + tm.tm_year = 2014 - 1900; + tm.tm_mon = 12 - 1; + tm.tm_mday = 0; + tm.tm_hour = 20; + tm.tm_min = 16; + tm.tm_sec = 18; + } else { + tm.tm_year = 2013 - 1900; + tm.tm_mon = 11 - 1; + tm.tm_mday = 0; + tm.tm_hour = 18; + tm.tm_min = 30; + tm.tm_sec = 27; + } + tm.tm_isdst = -1; + benchmark::DoNotOptimize(mktime(&tm)); + } +} +BENCHMARK(BM_Time_FromCivilDay0_Libc); + +const char* const kFormats[] = { + RFC1123_full, // 0 + RFC1123_no_wday, // 1 + RFC3339_full, // 2 + RFC3339_sec, // 3 + "%Y-%m-%dT%H:%M:%S", // 4 + "%Y-%m-%d", // 5 +}; +const int kNumFormats = sizeof(kFormats) / sizeof(kFormats[0]); + +void BM_Format_FormatTime(benchmark::State& state) { + const std::string fmt = kFormats[state.range(0)]; + state.SetLabel(fmt); + const cctz::time_zone tz = TestTimeZone(); + const std::chrono::system_clock::time_point tp = + cctz::convert(cctz::civil_second(1977, 6, 28, 9, 8, 7), tz) + + std::chrono::microseconds(1); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::format(fmt, tp, tz)); + } +} +BENCHMARK(BM_Format_FormatTime)->DenseRange(0, kNumFormats - 1); + +void BM_Format_ParseTime(benchmark::State& state) { + const std::string fmt = kFormats[state.range(0)]; + state.SetLabel(fmt); + const cctz::time_zone tz = TestTimeZone(); + std::chrono::system_clock::time_point tp = + cctz::convert(cctz::civil_second(1977, 6, 28, 9, 8, 7), tz) + + std::chrono::microseconds(1); + const std::string when = cctz::format(fmt, tp, tz); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(cctz::parse(fmt, when, tz, &tp)); + } +} +BENCHMARK(BM_Format_ParseTime)->DenseRange(0, kNumFormats - 1); + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/civil_time_detail.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/civil_time_detail.cc new file mode 100644 index 0000000000..0b07e397e5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/civil_time_detail.cc @@ -0,0 +1,94 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/internal/cctz/include/cctz/civil_time_detail.h" + +#include <iomanip> +#include <ostream> +#include <sstream> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { +namespace detail { + +// Output stream operators output a format matching YYYY-MM-DDThh:mm:ss, +// while omitting fields inferior to the type's alignment. For example, +// civil_day is formatted only as YYYY-MM-DD. +std::ostream& operator<<(std::ostream& os, const civil_year& y) { + std::stringstream ss; + ss << y.year(); // No padding. + return os << ss.str(); +} +std::ostream& operator<<(std::ostream& os, const civil_month& m) { + std::stringstream ss; + ss << civil_year(m) << '-'; + ss << std::setfill('0') << std::setw(2) << m.month(); + return os << ss.str(); +} +std::ostream& operator<<(std::ostream& os, const civil_day& d) { + std::stringstream ss; + ss << civil_month(d) << '-'; + ss << std::setfill('0') << std::setw(2) << d.day(); + return os << ss.str(); +} +std::ostream& operator<<(std::ostream& os, const civil_hour& h) { + std::stringstream ss; + ss << civil_day(h) << 'T'; + ss << std::setfill('0') << std::setw(2) << h.hour(); + return os << ss.str(); +} +std::ostream& operator<<(std::ostream& os, const civil_minute& m) { + std::stringstream ss; + ss << civil_hour(m) << ':'; + ss << std::setfill('0') << std::setw(2) << m.minute(); + return os << ss.str(); +} +std::ostream& operator<<(std::ostream& os, const civil_second& s) { + std::stringstream ss; + ss << civil_minute(s) << ':'; + ss << std::setfill('0') << std::setw(2) << s.second(); + return os << ss.str(); +} + +//////////////////////////////////////////////////////////////////////// + +std::ostream& operator<<(std::ostream& os, weekday wd) { + switch (wd) { + case weekday::monday: + return os << "Monday"; + case weekday::tuesday: + return os << "Tuesday"; + case weekday::wednesday: + return os << "Wednesday"; + case weekday::thursday: + return os << "Thursday"; + case weekday::friday: + return os << "Friday"; + case weekday::saturday: + return os << "Saturday"; + case weekday::sunday: + return os << "Sunday"; + } + return os; // Should never get here, but -Wreturn-type may warn without this. +} + +} // namespace detail +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/civil_time_test.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/civil_time_test.cc new file mode 100644 index 0000000000..be894d7072 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/civil_time_test.cc @@ -0,0 +1,1056 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/internal/cctz/include/cctz/civil_time.h" + +#include <iomanip> +#include <limits> +#include <sstream> +#include <string> +#include <type_traits> + +#include "gtest/gtest.h" +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +template <typename T> +std::string Format(const T& t) { + std::stringstream ss; + ss << t; + return ss.str(); +} + +} // namespace + +#if __cpp_constexpr >= 201304 || (defined(_MSC_VER) && _MSC_VER >= 1910) +// Construction constexpr tests + +TEST(CivilTime, Normal) { + constexpr civil_second css(2016, 1, 28, 17, 14, 12); + static_assert(css.second() == 12, "Normal.second"); + constexpr civil_minute cmm(2016, 1, 28, 17, 14); + static_assert(cmm.minute() == 14, "Normal.minute"); + constexpr civil_hour chh(2016, 1, 28, 17); + static_assert(chh.hour() == 17, "Normal.hour"); + constexpr civil_day cd(2016, 1, 28); + static_assert(cd.day() == 28, "Normal.day"); + constexpr civil_month cm(2016, 1); + static_assert(cm.month() == 1, "Normal.month"); + constexpr civil_year cy(2016); + static_assert(cy.year() == 2016, "Normal.year"); +} + +TEST(CivilTime, Conversion) { + constexpr civil_year cy(2016); + static_assert(cy.year() == 2016, "Conversion.year"); + constexpr civil_month cm(cy); + static_assert(cm.month() == 1, "Conversion.month"); + constexpr civil_day cd(cm); + static_assert(cd.day() == 1, "Conversion.day"); + constexpr civil_hour chh(cd); + static_assert(chh.hour() == 0, "Conversion.hour"); + constexpr civil_minute cmm(chh); + static_assert(cmm.minute() == 0, "Conversion.minute"); + constexpr civil_second css(cmm); + static_assert(css.second() == 0, "Conversion.second"); +} + +// Normalization constexpr tests + +TEST(CivilTime, Normalized) { + constexpr civil_second cs(2016, 1, 28, 17, 14, 12); + static_assert(cs.year() == 2016, "Normalized.year"); + static_assert(cs.month() == 1, "Normalized.month"); + static_assert(cs.day() == 28, "Normalized.day"); + static_assert(cs.hour() == 17, "Normalized.hour"); + static_assert(cs.minute() == 14, "Normalized.minute"); + static_assert(cs.second() == 12, "Normalized.second"); +} + +TEST(CivilTime, SecondOverflow) { + constexpr civil_second cs(2016, 1, 28, 17, 14, 121); + static_assert(cs.year() == 2016, "SecondOverflow.year"); + static_assert(cs.month() == 1, "SecondOverflow.month"); + static_assert(cs.day() == 28, "SecondOverflow.day"); + static_assert(cs.hour() == 17, "SecondOverflow.hour"); + static_assert(cs.minute() == 16, "SecondOverflow.minute"); + static_assert(cs.second() == 1, "SecondOverflow.second"); +} + +TEST(CivilTime, SecondUnderflow) { + constexpr civil_second cs(2016, 1, 28, 17, 14, -121); + static_assert(cs.year() == 2016, "SecondUnderflow.year"); + static_assert(cs.month() == 1, "SecondUnderflow.month"); + static_assert(cs.day() == 28, "SecondUnderflow.day"); + static_assert(cs.hour() == 17, "SecondUnderflow.hour"); + static_assert(cs.minute() == 11, "SecondUnderflow.minute"); + static_assert(cs.second() == 59, "SecondUnderflow.second"); +} + +TEST(CivilTime, MinuteOverflow) { + constexpr civil_second cs(2016, 1, 28, 17, 121, 12); + static_assert(cs.year() == 2016, "MinuteOverflow.year"); + static_assert(cs.month() == 1, "MinuteOverflow.month"); + static_assert(cs.day() == 28, "MinuteOverflow.day"); + static_assert(cs.hour() == 19, "MinuteOverflow.hour"); + static_assert(cs.minute() == 1, "MinuteOverflow.minute"); + static_assert(cs.second() == 12, "MinuteOverflow.second"); +} + +TEST(CivilTime, MinuteUnderflow) { + constexpr civil_second cs(2016, 1, 28, 17, -121, 12); + static_assert(cs.year() == 2016, "MinuteUnderflow.year"); + static_assert(cs.month() == 1, "MinuteUnderflow.month"); + static_assert(cs.day() == 28, "MinuteUnderflow.day"); + static_assert(cs.hour() == 14, "MinuteUnderflow.hour"); + static_assert(cs.minute() == 59, "MinuteUnderflow.minute"); + static_assert(cs.second() == 12, "MinuteUnderflow.second"); +} + +TEST(CivilTime, HourOverflow) { + constexpr civil_second cs(2016, 1, 28, 49, 14, 12); + static_assert(cs.year() == 2016, "HourOverflow.year"); + static_assert(cs.month() == 1, "HourOverflow.month"); + static_assert(cs.day() == 30, "HourOverflow.day"); + static_assert(cs.hour() == 1, "HourOverflow.hour"); + static_assert(cs.minute() == 14, "HourOverflow.minute"); + static_assert(cs.second() == 12, "HourOverflow.second"); +} + +TEST(CivilTime, HourUnderflow) { + constexpr civil_second cs(2016, 1, 28, -49, 14, 12); + static_assert(cs.year() == 2016, "HourUnderflow.year"); + static_assert(cs.month() == 1, "HourUnderflow.month"); + static_assert(cs.day() == 25, "HourUnderflow.day"); + static_assert(cs.hour() == 23, "HourUnderflow.hour"); + static_assert(cs.minute() == 14, "HourUnderflow.minute"); + static_assert(cs.second() == 12, "HourUnderflow.second"); +} + +TEST(CivilTime, MonthOverflow) { + constexpr civil_second cs(2016, 25, 28, 17, 14, 12); + static_assert(cs.year() == 2018, "MonthOverflow.year"); + static_assert(cs.month() == 1, "MonthOverflow.month"); + static_assert(cs.day() == 28, "MonthOverflow.day"); + static_assert(cs.hour() == 17, "MonthOverflow.hour"); + static_assert(cs.minute() == 14, "MonthOverflow.minute"); + static_assert(cs.second() == 12, "MonthOverflow.second"); +} + +TEST(CivilTime, MonthUnderflow) { + constexpr civil_second cs(2016, -25, 28, 17, 14, 12); + static_assert(cs.year() == 2013, "MonthUnderflow.year"); + static_assert(cs.month() == 11, "MonthUnderflow.month"); + static_assert(cs.day() == 28, "MonthUnderflow.day"); + static_assert(cs.hour() == 17, "MonthUnderflow.hour"); + static_assert(cs.minute() == 14, "MonthUnderflow.minute"); + static_assert(cs.second() == 12, "MonthUnderflow.second"); +} + +TEST(CivilTime, C4Overflow) { + constexpr civil_second cs(2016, 1, 292195, 17, 14, 12); + static_assert(cs.year() == 2816, "C4Overflow.year"); + static_assert(cs.month() == 1, "C4Overflow.month"); + static_assert(cs.day() == 1, "C4Overflow.day"); + static_assert(cs.hour() == 17, "C4Overflow.hour"); + static_assert(cs.minute() == 14, "C4Overflow.minute"); + static_assert(cs.second() == 12, "C4Overflow.second"); +} + +TEST(CivilTime, C4Underflow) { + constexpr civil_second cs(2016, 1, -292195, 17, 14, 12); + static_assert(cs.year() == 1215, "C4Underflow.year"); + static_assert(cs.month() == 12, "C4Underflow.month"); + static_assert(cs.day() == 30, "C4Underflow.day"); + static_assert(cs.hour() == 17, "C4Underflow.hour"); + static_assert(cs.minute() == 14, "C4Underflow.minute"); + static_assert(cs.second() == 12, "C4Underflow.second"); +} + +TEST(CivilTime, MixedNormalization) { + constexpr civil_second cs(2016, -42, 122, 99, -147, 4949); + static_assert(cs.year() == 2012, "MixedNormalization.year"); + static_assert(cs.month() == 10, "MixedNormalization.month"); + static_assert(cs.day() == 4, "MixedNormalization.day"); + static_assert(cs.hour() == 1, "MixedNormalization.hour"); + static_assert(cs.minute() == 55, "MixedNormalization.minute"); + static_assert(cs.second() == 29, "MixedNormalization.second"); +} + +// Relational constexpr tests + +TEST(CivilTime, Less) { + constexpr civil_second cs1(2016, 1, 28, 17, 14, 12); + constexpr civil_second cs2(2016, 1, 28, 17, 14, 13); + constexpr bool less = cs1 < cs2; + static_assert(less, "Less"); +} + +// Arithmetic constexpr tests + +TEST(CivilTime, Addition) { + constexpr civil_second cs1(2016, 1, 28, 17, 14, 12); + constexpr civil_second cs2 = cs1 + 50; + static_assert(cs2.year() == 2016, "Addition.year"); + static_assert(cs2.month() == 1, "Addition.month"); + static_assert(cs2.day() == 28, "Addition.day"); + static_assert(cs2.hour() == 17, "Addition.hour"); + static_assert(cs2.minute() == 15, "Addition.minute"); + static_assert(cs2.second() == 2, "Addition.second"); +} + +TEST(CivilTime, Subtraction) { + constexpr civil_second cs1(2016, 1, 28, 17, 14, 12); + constexpr civil_second cs2 = cs1 - 50; + static_assert(cs2.year() == 2016, "Subtraction.year"); + static_assert(cs2.month() == 1, "Subtraction.month"); + static_assert(cs2.day() == 28, "Subtraction.day"); + static_assert(cs2.hour() == 17, "Subtraction.hour"); + static_assert(cs2.minute() == 13, "Subtraction.minute"); + static_assert(cs2.second() == 22, "Subtraction.second"); +} + +TEST(CivilTime, Difference) { + constexpr civil_day cd1(2016, 1, 28); + constexpr civil_day cd2(2015, 1, 28); + constexpr int diff = cd1 - cd2; + static_assert(diff == 365, "Difference"); +} + +// NOTE: Run this with --copt=-ftrapv to detect overflow problems. +TEST(CivilTime, DifferenceWithHugeYear) { + { + constexpr civil_day d1(9223372036854775807, 1, 1); + constexpr civil_day d2(9223372036854775807, 12, 31); + static_assert(d2 - d1 == 364, "DifferenceWithHugeYear"); + } + { + constexpr civil_day d1(-9223372036854775807 - 1, 1, 1); + constexpr civil_day d2(-9223372036854775807 - 1, 12, 31); + static_assert(d2 - d1 == 365, "DifferenceWithHugeYear"); + } + { + // Check the limits of the return value at the end of the year range. + constexpr civil_day d1(9223372036854775807, 1, 1); + constexpr civil_day d2(9198119301927009252, 6, 6); + static_assert(d1 - d2 == 9223372036854775807, "DifferenceWithHugeYear"); + static_assert((d2 - 1) - d1 == -9223372036854775807 - 1, + "DifferenceWithHugeYear"); + } + { + // Check the limits of the return value at the start of the year range. + constexpr civil_day d1(-9223372036854775807 - 1, 1, 1); + constexpr civil_day d2(-9198119301927009254, 7, 28); + static_assert(d2 - d1 == 9223372036854775807, "DifferenceWithHugeYear"); + static_assert(d1 - (d2 + 1) == -9223372036854775807 - 1, + "DifferenceWithHugeYear"); + } + { + // Check the limits of the return value from either side of year 0. + constexpr civil_day d1(-12626367463883278, 9, 3); + constexpr civil_day d2(12626367463883277, 3, 28); + static_assert(d2 - d1 == 9223372036854775807, "DifferenceWithHugeYear"); + static_assert(d1 - (d2 + 1) == -9223372036854775807 - 1, + "DifferenceWithHugeYear"); + } +} + +// NOTE: Run this with --copt=-ftrapv to detect overflow problems. +TEST(CivilTime, DifferenceNoIntermediateOverflow) { + { + // The difference up to the minute field would be below the minimum + // diff_t, but the 52 extra seconds brings us back to the minimum. + constexpr civil_second s1(-292277022657, 1, 27, 8, 29 - 1, 52); + constexpr civil_second s2(1970, 1, 1, 0, 0 - 1, 0); + static_assert(s1 - s2 == -9223372036854775807 - 1, + "DifferenceNoIntermediateOverflow"); + } + { + // The difference up to the minute field would be above the maximum + // diff_t, but the -53 extra seconds brings us back to the maximum. + constexpr civil_second s1(292277026596, 12, 4, 15, 30, 7 - 7); + constexpr civil_second s2(1970, 1, 1, 0, 0, 0 - 7); + static_assert(s1 - s2 == 9223372036854775807, + "DifferenceNoIntermediateOverflow"); + } +} + +// Helper constexpr tests + +TEST(CivilTime, WeekDay) { + constexpr civil_day cd(2016, 1, 28); + constexpr weekday wd = get_weekday(cd); + static_assert(wd == weekday::thursday, "Weekday"); +} + +TEST(CivilTime, NextWeekDay) { + constexpr civil_day cd(2016, 1, 28); + constexpr civil_day next = next_weekday(cd, weekday::thursday); + static_assert(next.year() == 2016, "NextWeekDay.year"); + static_assert(next.month() == 2, "NextWeekDay.month"); + static_assert(next.day() == 4, "NextWeekDay.day"); +} + +TEST(CivilTime, PrevWeekDay) { + constexpr civil_day cd(2016, 1, 28); + constexpr civil_day prev = prev_weekday(cd, weekday::thursday); + static_assert(prev.year() == 2016, "PrevWeekDay.year"); + static_assert(prev.month() == 1, "PrevWeekDay.month"); + static_assert(prev.day() == 21, "PrevWeekDay.day"); +} + +TEST(CivilTime, YearDay) { + constexpr civil_day cd(2016, 1, 28); + constexpr int yd = get_yearday(cd); + static_assert(yd == 28, "YearDay"); +} +#endif // __cpp_constexpr >= 201304 || (defined(_MSC_VER) && _MSC_VER >= 1910) + +// The remaining tests do not use constexpr. + +TEST(CivilTime, DefaultConstruction) { + civil_second ss; + EXPECT_EQ("1970-01-01T00:00:00", Format(ss)); + + civil_minute mm; + EXPECT_EQ("1970-01-01T00:00", Format(mm)); + + civil_hour hh; + EXPECT_EQ("1970-01-01T00", Format(hh)); + + civil_day d; + EXPECT_EQ("1970-01-01", Format(d)); + + civil_month m; + EXPECT_EQ("1970-01", Format(m)); + + civil_year y; + EXPECT_EQ("1970", Format(y)); +} + +TEST(CivilTime, StructMember) { + struct S { + civil_day day; + }; + S s = {}; + EXPECT_EQ(civil_day{}, s.day); +} + +TEST(CivilTime, FieldsConstruction) { + EXPECT_EQ("2015-01-02T03:04:05", Format(civil_second(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02T03:04:00", Format(civil_second(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02T03:00:00", Format(civil_second(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02T00:00:00", Format(civil_second(2015, 1, 2))); + EXPECT_EQ("2015-01-01T00:00:00", Format(civil_second(2015, 1))); + EXPECT_EQ("2015-01-01T00:00:00", Format(civil_second(2015))); + + EXPECT_EQ("2015-01-02T03:04", Format(civil_minute(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02T03:04", Format(civil_minute(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02T03:00", Format(civil_minute(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02T00:00", Format(civil_minute(2015, 1, 2))); + EXPECT_EQ("2015-01-01T00:00", Format(civil_minute(2015, 1))); + EXPECT_EQ("2015-01-01T00:00", Format(civil_minute(2015))); + + EXPECT_EQ("2015-01-02T03", Format(civil_hour(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02T03", Format(civil_hour(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02T03", Format(civil_hour(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02T00", Format(civil_hour(2015, 1, 2))); + EXPECT_EQ("2015-01-01T00", Format(civil_hour(2015, 1))); + EXPECT_EQ("2015-01-01T00", Format(civil_hour(2015))); + + EXPECT_EQ("2015-01-02", Format(civil_day(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01-02", Format(civil_day(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01-02", Format(civil_day(2015, 1, 2, 3))); + EXPECT_EQ("2015-01-02", Format(civil_day(2015, 1, 2))); + EXPECT_EQ("2015-01-01", Format(civil_day(2015, 1))); + EXPECT_EQ("2015-01-01", Format(civil_day(2015))); + + EXPECT_EQ("2015-01", Format(civil_month(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015-01", Format(civil_month(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015-01", Format(civil_month(2015, 1, 2, 3))); + EXPECT_EQ("2015-01", Format(civil_month(2015, 1, 2))); + EXPECT_EQ("2015-01", Format(civil_month(2015, 1))); + EXPECT_EQ("2015-01", Format(civil_month(2015))); + + EXPECT_EQ("2015", Format(civil_year(2015, 1, 2, 3, 4, 5))); + EXPECT_EQ("2015", Format(civil_year(2015, 1, 2, 3, 4))); + EXPECT_EQ("2015", Format(civil_year(2015, 1, 2, 3))); + EXPECT_EQ("2015", Format(civil_year(2015, 1, 2))); + EXPECT_EQ("2015", Format(civil_year(2015, 1))); + EXPECT_EQ("2015", Format(civil_year(2015))); +} + +TEST(CivilTime, FieldsConstructionLimits) { + const int kIntMax = std::numeric_limits<int>::max(); + EXPECT_EQ("2038-01-19T03:14:07", + Format(civil_second(1970, 1, 1, 0, 0, kIntMax))); + EXPECT_EQ("6121-02-11T05:21:07", + Format(civil_second(1970, 1, 1, 0, kIntMax, kIntMax))); + EXPECT_EQ("251104-11-20T12:21:07", + Format(civil_second(1970, 1, 1, kIntMax, kIntMax, kIntMax))); + EXPECT_EQ("6130715-05-30T12:21:07", + Format(civil_second(1970, 1, kIntMax, kIntMax, kIntMax, kIntMax))); + EXPECT_EQ( + "185087685-11-26T12:21:07", + Format(civil_second(1970, kIntMax, kIntMax, kIntMax, kIntMax, kIntMax))); + + const int kIntMin = std::numeric_limits<int>::min(); + EXPECT_EQ("1901-12-13T20:45:52", + Format(civil_second(1970, 1, 1, 0, 0, kIntMin))); + EXPECT_EQ("-2182-11-20T18:37:52", + Format(civil_second(1970, 1, 1, 0, kIntMin, kIntMin))); + EXPECT_EQ("-247165-02-11T10:37:52", + Format(civil_second(1970, 1, 1, kIntMin, kIntMin, kIntMin))); + EXPECT_EQ("-6126776-08-01T10:37:52", + Format(civil_second(1970, 1, kIntMin, kIntMin, kIntMin, kIntMin))); + EXPECT_EQ( + "-185083747-10-31T10:37:52", + Format(civil_second(1970, kIntMin, kIntMin, kIntMin, kIntMin, kIntMin))); +} + +TEST(CivilTime, ImplicitCrossAlignment) { + civil_year year(2015); + civil_month month = year; + civil_day day = month; + civil_hour hour = day; + civil_minute minute = hour; + civil_second second = minute; + + second = year; + EXPECT_EQ(second, year); + second = month; + EXPECT_EQ(second, month); + second = day; + EXPECT_EQ(second, day); + second = hour; + EXPECT_EQ(second, hour); + second = minute; + EXPECT_EQ(second, minute); + + minute = year; + EXPECT_EQ(minute, year); + minute = month; + EXPECT_EQ(minute, month); + minute = day; + EXPECT_EQ(minute, day); + minute = hour; + EXPECT_EQ(minute, hour); + + hour = year; + EXPECT_EQ(hour, year); + hour = month; + EXPECT_EQ(hour, month); + hour = day; + EXPECT_EQ(hour, day); + + day = year; + EXPECT_EQ(day, year); + day = month; + EXPECT_EQ(day, month); + + month = year; + EXPECT_EQ(month, year); + + // Ensures unsafe conversions are not allowed. + EXPECT_FALSE((std::is_convertible<civil_second, civil_minute>::value)); + EXPECT_FALSE((std::is_convertible<civil_second, civil_hour>::value)); + EXPECT_FALSE((std::is_convertible<civil_second, civil_day>::value)); + EXPECT_FALSE((std::is_convertible<civil_second, civil_month>::value)); + EXPECT_FALSE((std::is_convertible<civil_second, civil_year>::value)); + + EXPECT_FALSE((std::is_convertible<civil_minute, civil_hour>::value)); + EXPECT_FALSE((std::is_convertible<civil_minute, civil_day>::value)); + EXPECT_FALSE((std::is_convertible<civil_minute, civil_month>::value)); + EXPECT_FALSE((std::is_convertible<civil_minute, civil_year>::value)); + + EXPECT_FALSE((std::is_convertible<civil_hour, civil_day>::value)); + EXPECT_FALSE((std::is_convertible<civil_hour, civil_month>::value)); + EXPECT_FALSE((std::is_convertible<civil_hour, civil_year>::value)); + + EXPECT_FALSE((std::is_convertible<civil_day, civil_month>::value)); + EXPECT_FALSE((std::is_convertible<civil_day, civil_year>::value)); + + EXPECT_FALSE((std::is_convertible<civil_month, civil_year>::value)); +} + +TEST(CivilTime, ExplicitCrossAlignment) { + // + // Assign from smaller units -> larger units + // + + civil_second second(2015, 1, 2, 3, 4, 5); + EXPECT_EQ("2015-01-02T03:04:05", Format(second)); + + civil_minute minute(second); + EXPECT_EQ("2015-01-02T03:04", Format(minute)); + + civil_hour hour(minute); + EXPECT_EQ("2015-01-02T03", Format(hour)); + + civil_day day(hour); + EXPECT_EQ("2015-01-02", Format(day)); + + civil_month month(day); + EXPECT_EQ("2015-01", Format(month)); + + civil_year year(month); + EXPECT_EQ("2015", Format(year)); + + // + // Now assign from larger units -> smaller units + // + + month = civil_month(year); + EXPECT_EQ("2015-01", Format(month)); + + day = civil_day(month); + EXPECT_EQ("2015-01-01", Format(day)); + + hour = civil_hour(day); + EXPECT_EQ("2015-01-01T00", Format(hour)); + + minute = civil_minute(hour); + EXPECT_EQ("2015-01-01T00:00", Format(minute)); + + second = civil_second(minute); + EXPECT_EQ("2015-01-01T00:00:00", Format(second)); +} + +// Metafunction to test whether difference is allowed between two types. +template <typename T1, typename T2> +struct HasDifference { + template <typename U1, typename U2> + static std::false_type test(...); + template <typename U1, typename U2> + static std::true_type test(decltype(std::declval<U1>() - std::declval<U2>())); + static constexpr bool value = decltype(test<T1, T2>(0))::value; +}; + +TEST(CivilTime, DisallowCrossAlignedDifference) { + // Difference is allowed between types with the same alignment. + static_assert(HasDifference<civil_second, civil_second>::value, ""); + static_assert(HasDifference<civil_minute, civil_minute>::value, ""); + static_assert(HasDifference<civil_hour, civil_hour>::value, ""); + static_assert(HasDifference<civil_day, civil_day>::value, ""); + static_assert(HasDifference<civil_month, civil_month>::value, ""); + static_assert(HasDifference<civil_year, civil_year>::value, ""); + + // Difference is disallowed between types with different alignments. + static_assert(!HasDifference<civil_second, civil_minute>::value, ""); + static_assert(!HasDifference<civil_second, civil_hour>::value, ""); + static_assert(!HasDifference<civil_second, civil_day>::value, ""); + static_assert(!HasDifference<civil_second, civil_month>::value, ""); + static_assert(!HasDifference<civil_second, civil_year>::value, ""); + + static_assert(!HasDifference<civil_minute, civil_hour>::value, ""); + static_assert(!HasDifference<civil_minute, civil_day>::value, ""); + static_assert(!HasDifference<civil_minute, civil_month>::value, ""); + static_assert(!HasDifference<civil_minute, civil_year>::value, ""); + + static_assert(!HasDifference<civil_hour, civil_day>::value, ""); + static_assert(!HasDifference<civil_hour, civil_month>::value, ""); + static_assert(!HasDifference<civil_hour, civil_year>::value, ""); + + static_assert(!HasDifference<civil_day, civil_month>::value, ""); + static_assert(!HasDifference<civil_day, civil_year>::value, ""); + + static_assert(!HasDifference<civil_month, civil_year>::value, ""); +} + +TEST(CivilTime, ValueSemantics) { + const civil_hour a(2015, 1, 2, 3); + const civil_hour b = a; + const civil_hour c(b); + civil_hour d; + d = c; + EXPECT_EQ("2015-01-02T03", Format(d)); +} + +TEST(CivilTime, Relational) { + // Tests that the alignment unit is ignored in comparison. + const civil_year year(2014); + const civil_month month(year); + EXPECT_EQ(year, month); + +#define TEST_RELATIONAL(OLDER, YOUNGER) \ + do { \ + EXPECT_FALSE(OLDER < OLDER); \ + EXPECT_FALSE(OLDER > OLDER); \ + EXPECT_TRUE(OLDER >= OLDER); \ + EXPECT_TRUE(OLDER <= OLDER); \ + EXPECT_FALSE(YOUNGER < YOUNGER); \ + EXPECT_FALSE(YOUNGER > YOUNGER); \ + EXPECT_TRUE(YOUNGER >= YOUNGER); \ + EXPECT_TRUE(YOUNGER <= YOUNGER); \ + EXPECT_EQ(OLDER, OLDER); \ + EXPECT_NE(OLDER, YOUNGER); \ + EXPECT_LT(OLDER, YOUNGER); \ + EXPECT_LE(OLDER, YOUNGER); \ + EXPECT_GT(YOUNGER, OLDER); \ + EXPECT_GE(YOUNGER, OLDER); \ + } while (0) + + // Alignment is ignored in comparison (verified above), so kSecond is used + // to test comparison in all field positions. + TEST_RELATIONAL(civil_second(2014, 1, 1, 0, 0, 0), + civil_second(2015, 1, 1, 0, 0, 0)); + TEST_RELATIONAL(civil_second(2014, 1, 1, 0, 0, 0), + civil_second(2014, 2, 1, 0, 0, 0)); + TEST_RELATIONAL(civil_second(2014, 1, 1, 0, 0, 0), + civil_second(2014, 1, 2, 0, 0, 0)); + TEST_RELATIONAL(civil_second(2014, 1, 1, 0, 0, 0), + civil_second(2014, 1, 1, 1, 0, 0)); + TEST_RELATIONAL(civil_second(2014, 1, 1, 1, 0, 0), + civil_second(2014, 1, 1, 1, 1, 0)); + TEST_RELATIONAL(civil_second(2014, 1, 1, 1, 1, 0), + civil_second(2014, 1, 1, 1, 1, 1)); + + // Tests the relational operators of two different civil-time types. + TEST_RELATIONAL(civil_day(2014, 1, 1), civil_minute(2014, 1, 1, 1, 1)); + TEST_RELATIONAL(civil_day(2014, 1, 1), civil_month(2014, 2)); + +#undef TEST_RELATIONAL +} + +TEST(CivilTime, Arithmetic) { + civil_second second(2015, 1, 2, 3, 4, 5); + EXPECT_EQ("2015-01-02T03:04:06", Format(second += 1)); + EXPECT_EQ("2015-01-02T03:04:07", Format(second + 1)); + EXPECT_EQ("2015-01-02T03:04:08", Format(2 + second)); + EXPECT_EQ("2015-01-02T03:04:05", Format(second - 1)); + EXPECT_EQ("2015-01-02T03:04:05", Format(second -= 1)); + EXPECT_EQ("2015-01-02T03:04:05", Format(second++)); + EXPECT_EQ("2015-01-02T03:04:07", Format(++second)); + EXPECT_EQ("2015-01-02T03:04:07", Format(second--)); + EXPECT_EQ("2015-01-02T03:04:05", Format(--second)); + + civil_minute minute(2015, 1, 2, 3, 4); + EXPECT_EQ("2015-01-02T03:05", Format(minute += 1)); + EXPECT_EQ("2015-01-02T03:06", Format(minute + 1)); + EXPECT_EQ("2015-01-02T03:07", Format(2 + minute)); + EXPECT_EQ("2015-01-02T03:04", Format(minute - 1)); + EXPECT_EQ("2015-01-02T03:04", Format(minute -= 1)); + EXPECT_EQ("2015-01-02T03:04", Format(minute++)); + EXPECT_EQ("2015-01-02T03:06", Format(++minute)); + EXPECT_EQ("2015-01-02T03:06", Format(minute--)); + EXPECT_EQ("2015-01-02T03:04", Format(--minute)); + + civil_hour hour(2015, 1, 2, 3); + EXPECT_EQ("2015-01-02T04", Format(hour += 1)); + EXPECT_EQ("2015-01-02T05", Format(hour + 1)); + EXPECT_EQ("2015-01-02T06", Format(2 + hour)); + EXPECT_EQ("2015-01-02T03", Format(hour - 1)); + EXPECT_EQ("2015-01-02T03", Format(hour -= 1)); + EXPECT_EQ("2015-01-02T03", Format(hour++)); + EXPECT_EQ("2015-01-02T05", Format(++hour)); + EXPECT_EQ("2015-01-02T05", Format(hour--)); + EXPECT_EQ("2015-01-02T03", Format(--hour)); + + civil_day day(2015, 1, 2); + EXPECT_EQ("2015-01-03", Format(day += 1)); + EXPECT_EQ("2015-01-04", Format(day + 1)); + EXPECT_EQ("2015-01-05", Format(2 + day)); + EXPECT_EQ("2015-01-02", Format(day - 1)); + EXPECT_EQ("2015-01-02", Format(day -= 1)); + EXPECT_EQ("2015-01-02", Format(day++)); + EXPECT_EQ("2015-01-04", Format(++day)); + EXPECT_EQ("2015-01-04", Format(day--)); + EXPECT_EQ("2015-01-02", Format(--day)); + + civil_month month(2015, 1); + EXPECT_EQ("2015-02", Format(month += 1)); + EXPECT_EQ("2015-03", Format(month + 1)); + EXPECT_EQ("2015-04", Format(2 + month)); + EXPECT_EQ("2015-01", Format(month - 1)); + EXPECT_EQ("2015-01", Format(month -= 1)); + EXPECT_EQ("2015-01", Format(month++)); + EXPECT_EQ("2015-03", Format(++month)); + EXPECT_EQ("2015-03", Format(month--)); + EXPECT_EQ("2015-01", Format(--month)); + + civil_year year(2015); + EXPECT_EQ("2016", Format(year += 1)); + EXPECT_EQ("2017", Format(year + 1)); + EXPECT_EQ("2018", Format(2 + year)); + EXPECT_EQ("2015", Format(year - 1)); + EXPECT_EQ("2015", Format(year -= 1)); + EXPECT_EQ("2015", Format(year++)); + EXPECT_EQ("2017", Format(++year)); + EXPECT_EQ("2017", Format(year--)); + EXPECT_EQ("2015", Format(--year)); +} + +TEST(CivilTime, ArithmeticLimits) { + const int kIntMax = std::numeric_limits<int>::max(); + const int kIntMin = std::numeric_limits<int>::min(); + + civil_second second(1970, 1, 1, 0, 0, 0); + second += kIntMax; + EXPECT_EQ("2038-01-19T03:14:07", Format(second)); + second -= kIntMax; + EXPECT_EQ("1970-01-01T00:00:00", Format(second)); + second += kIntMin; + EXPECT_EQ("1901-12-13T20:45:52", Format(second)); + second -= kIntMin; + EXPECT_EQ("1970-01-01T00:00:00", Format(second)); + + civil_minute minute(1970, 1, 1, 0, 0); + minute += kIntMax; + EXPECT_EQ("6053-01-23T02:07", Format(minute)); + minute -= kIntMax; + EXPECT_EQ("1970-01-01T00:00", Format(minute)); + minute += kIntMin; + EXPECT_EQ("-2114-12-08T21:52", Format(minute)); + minute -= kIntMin; + EXPECT_EQ("1970-01-01T00:00", Format(minute)); + + civil_hour hour(1970, 1, 1, 0); + hour += kIntMax; + EXPECT_EQ("246953-10-09T07", Format(hour)); + hour -= kIntMax; + EXPECT_EQ("1970-01-01T00", Format(hour)); + hour += kIntMin; + EXPECT_EQ("-243014-03-24T16", Format(hour)); + hour -= kIntMin; + EXPECT_EQ("1970-01-01T00", Format(hour)); + + civil_day day(1970, 1, 1); + day += kIntMax; + EXPECT_EQ("5881580-07-11", Format(day)); + day -= kIntMax; + EXPECT_EQ("1970-01-01", Format(day)); + day += kIntMin; + EXPECT_EQ("-5877641-06-23", Format(day)); + day -= kIntMin; + EXPECT_EQ("1970-01-01", Format(day)); + + civil_month month(1970, 1); + month += kIntMax; + EXPECT_EQ("178958940-08", Format(month)); + month -= kIntMax; + EXPECT_EQ("1970-01", Format(month)); + month += kIntMin; + EXPECT_EQ("-178955001-05", Format(month)); + month -= kIntMin; + EXPECT_EQ("1970-01", Format(month)); + + civil_year year(0); + year += kIntMax; + EXPECT_EQ("2147483647", Format(year)); + year -= kIntMax; + EXPECT_EQ("0", Format(year)); + year += kIntMin; + EXPECT_EQ("-2147483648", Format(year)); + year -= kIntMin; + EXPECT_EQ("0", Format(year)); +} + +TEST(CivilTime, ArithmeticDifference) { + civil_second second(2015, 1, 2, 3, 4, 5); + EXPECT_EQ(0, second - second); + EXPECT_EQ(10, (second + 10) - second); + EXPECT_EQ(-10, (second - 10) - second); + + civil_minute minute(2015, 1, 2, 3, 4); + EXPECT_EQ(0, minute - minute); + EXPECT_EQ(10, (minute + 10) - minute); + EXPECT_EQ(-10, (minute - 10) - minute); + + civil_hour hour(2015, 1, 2, 3); + EXPECT_EQ(0, hour - hour); + EXPECT_EQ(10, (hour + 10) - hour); + EXPECT_EQ(-10, (hour - 10) - hour); + + civil_day day(2015, 1, 2); + EXPECT_EQ(0, day - day); + EXPECT_EQ(10, (day + 10) - day); + EXPECT_EQ(-10, (day - 10) - day); + + civil_month month(2015, 1); + EXPECT_EQ(0, month - month); + EXPECT_EQ(10, (month + 10) - month); + EXPECT_EQ(-10, (month - 10) - month); + + civil_year year(2015); + EXPECT_EQ(0, year - year); + EXPECT_EQ(10, (year + 10) - year); + EXPECT_EQ(-10, (year - 10) - year); +} + +TEST(CivilTime, DifferenceLimits) { + const int kIntMax = std::numeric_limits<int>::max(); + const int kIntMin = std::numeric_limits<int>::min(); + + // Check day arithmetic at the end of the year range. + const civil_day max_day(kIntMax, 12, 31); + EXPECT_EQ(1, max_day - (max_day - 1)); + EXPECT_EQ(-1, (max_day - 1) - max_day); + + // Check day arithmetic at the end of the year range. + const civil_day min_day(kIntMin, 1, 1); + EXPECT_EQ(1, (min_day + 1) - min_day); + EXPECT_EQ(-1, min_day - (min_day + 1)); + + // Check the limits of the return value. + const civil_day d1(1970, 1, 1); + const civil_day d2(5881580, 7, 11); + EXPECT_EQ(kIntMax, d2 - d1); + EXPECT_EQ(kIntMin, d1 - (d2 + 1)); +} + +TEST(CivilTime, Properties) { + civil_second ss(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, ss.year()); + EXPECT_EQ(2, ss.month()); + EXPECT_EQ(3, ss.day()); + EXPECT_EQ(4, ss.hour()); + EXPECT_EQ(5, ss.minute()); + EXPECT_EQ(6, ss.second()); + EXPECT_EQ(weekday::tuesday, get_weekday(ss)); + EXPECT_EQ(34, get_yearday(ss)); + + civil_minute mm(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, mm.year()); + EXPECT_EQ(2, mm.month()); + EXPECT_EQ(3, mm.day()); + EXPECT_EQ(4, mm.hour()); + EXPECT_EQ(5, mm.minute()); + EXPECT_EQ(0, mm.second()); + EXPECT_EQ(weekday::tuesday, get_weekday(mm)); + EXPECT_EQ(34, get_yearday(mm)); + + civil_hour hh(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, hh.year()); + EXPECT_EQ(2, hh.month()); + EXPECT_EQ(3, hh.day()); + EXPECT_EQ(4, hh.hour()); + EXPECT_EQ(0, hh.minute()); + EXPECT_EQ(0, hh.second()); + EXPECT_EQ(weekday::tuesday, get_weekday(hh)); + EXPECT_EQ(34, get_yearday(hh)); + + civil_day d(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, d.year()); + EXPECT_EQ(2, d.month()); + EXPECT_EQ(3, d.day()); + EXPECT_EQ(0, d.hour()); + EXPECT_EQ(0, d.minute()); + EXPECT_EQ(0, d.second()); + EXPECT_EQ(weekday::tuesday, get_weekday(d)); + EXPECT_EQ(34, get_yearday(d)); + + civil_month m(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, m.year()); + EXPECT_EQ(2, m.month()); + EXPECT_EQ(1, m.day()); + EXPECT_EQ(0, m.hour()); + EXPECT_EQ(0, m.minute()); + EXPECT_EQ(0, m.second()); + EXPECT_EQ(weekday::sunday, get_weekday(m)); + EXPECT_EQ(32, get_yearday(m)); + + civil_year y(2015, 2, 3, 4, 5, 6); + EXPECT_EQ(2015, y.year()); + EXPECT_EQ(1, y.month()); + EXPECT_EQ(1, y.day()); + EXPECT_EQ(0, y.hour()); + EXPECT_EQ(0, y.minute()); + EXPECT_EQ(0, y.second()); + EXPECT_EQ(weekday::thursday, get_weekday(y)); + EXPECT_EQ(1, get_yearday(y)); +} + +TEST(CivilTime, OutputStream) { + // Tests formatting of civil_year, which does not pad. + EXPECT_EQ("2016", Format(civil_year(2016))); + EXPECT_EQ("123", Format(civil_year(123))); + EXPECT_EQ("0", Format(civil_year(0))); + EXPECT_EQ("-1", Format(civil_year(-1))); + + // Tests formatting of sub-year types, which pad to 2 digits + EXPECT_EQ("2016-02", Format(civil_month(2016, 2))); + EXPECT_EQ("2016-02-03", Format(civil_day(2016, 2, 3))); + EXPECT_EQ("2016-02-03T04", Format(civil_hour(2016, 2, 3, 4))); + EXPECT_EQ("2016-02-03T04:05", Format(civil_minute(2016, 2, 3, 4, 5))); + EXPECT_EQ("2016-02-03T04:05:06", Format(civil_second(2016, 2, 3, 4, 5, 6))); + + // Tests formatting of weekday. + EXPECT_EQ("Monday", Format(weekday::monday)); + EXPECT_EQ("Tuesday", Format(weekday::tuesday)); + EXPECT_EQ("Wednesday", Format(weekday::wednesday)); + EXPECT_EQ("Thursday", Format(weekday::thursday)); + EXPECT_EQ("Friday", Format(weekday::friday)); + EXPECT_EQ("Saturday", Format(weekday::saturday)); + EXPECT_EQ("Sunday", Format(weekday::sunday)); +} + +TEST(CivilTime, OutputStreamLeftFillWidth) { + civil_second cs(2016, 2, 3, 4, 5, 6); + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << civil_year(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016.................X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << civil_month(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02..............X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << civil_day(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03...........X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << civil_hour(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03T04........X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << civil_minute(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03T04:05.....X..", ss.str()); + } + { + std::stringstream ss; + ss << std::left << std::setfill('.'); + ss << std::setw(3) << 'X'; + ss << std::setw(21) << civil_second(cs); + ss << std::setw(3) << 'X'; + EXPECT_EQ("X..2016-02-03T04:05:06..X..", ss.str()); + } +} + +TEST(CivilTime, NextPrevWeekday) { + // Jan 1, 1970 was a Thursday. + const civil_day thursday(1970, 1, 1); + EXPECT_EQ(weekday::thursday, get_weekday(thursday)); + + // Thursday -> Thursday + civil_day d = next_weekday(thursday, weekday::thursday); + EXPECT_EQ(7, d - thursday) << Format(d); + EXPECT_EQ(d - 14, prev_weekday(thursday, weekday::thursday)); + + // Thursday -> Friday + d = next_weekday(thursday, weekday::friday); + EXPECT_EQ(1, d - thursday) << Format(d); + EXPECT_EQ(d - 7, prev_weekday(thursday, weekday::friday)); + + // Thursday -> Saturday + d = next_weekday(thursday, weekday::saturday); + EXPECT_EQ(2, d - thursday) << Format(d); + EXPECT_EQ(d - 7, prev_weekday(thursday, weekday::saturday)); + + // Thursday -> Sunday + d = next_weekday(thursday, weekday::sunday); + EXPECT_EQ(3, d - thursday) << Format(d); + EXPECT_EQ(d - 7, prev_weekday(thursday, weekday::sunday)); + + // Thursday -> Monday + d = next_weekday(thursday, weekday::monday); + EXPECT_EQ(4, d - thursday) << Format(d); + EXPECT_EQ(d - 7, prev_weekday(thursday, weekday::monday)); + + // Thursday -> Tuesday + d = next_weekday(thursday, weekday::tuesday); + EXPECT_EQ(5, d - thursday) << Format(d); + EXPECT_EQ(d - 7, prev_weekday(thursday, weekday::tuesday)); + + // Thursday -> Wednesday + d = next_weekday(thursday, weekday::wednesday); + EXPECT_EQ(6, d - thursday) << Format(d); + EXPECT_EQ(d - 7, prev_weekday(thursday, weekday::wednesday)); +} + +TEST(CivilTime, NormalizeWithHugeYear) { + civil_month c(9223372036854775807, 1); + EXPECT_EQ("9223372036854775807-01", Format(c)); + c = c - 1; // Causes normalization + EXPECT_EQ("9223372036854775806-12", Format(c)); + + c = civil_month(-9223372036854775807 - 1, 1); + EXPECT_EQ("-9223372036854775808-01", Format(c)); + c = c + 12; // Causes normalization + EXPECT_EQ("-9223372036854775807-01", Format(c)); +} + +TEST(CivilTime, LeapYears) { + // Test data for leap years. + const struct { + int year; + int days; + struct { + int month; + int day; + } leap_day; // The date of the day after Feb 28. + } kLeapYearTable[]{ + {1900, 365, {3, 1}}, {1999, 365, {3, 1}}, + {2000, 366, {2, 29}}, // leap year + {2001, 365, {3, 1}}, {2002, 365, {3, 1}}, + {2003, 365, {3, 1}}, {2004, 366, {2, 29}}, // leap year + {2005, 365, {3, 1}}, {2006, 365, {3, 1}}, + {2007, 365, {3, 1}}, {2008, 366, {2, 29}}, // leap year + {2009, 365, {3, 1}}, {2100, 365, {3, 1}}, + }; + + for (const auto& e : kLeapYearTable) { + // Tests incrementing through the leap day. + const civil_day feb28(e.year, 2, 28); + const civil_day next_day = feb28 + 1; + EXPECT_EQ(e.leap_day.month, next_day.month()); + EXPECT_EQ(e.leap_day.day, next_day.day()); + + // Tests difference in days of leap years. + const civil_year year(feb28); + const civil_year next_year = year + 1; + EXPECT_EQ(e.days, civil_day(next_year) - civil_day(year)); + } +} + +TEST(CivilTime, FirstThursdayInMonth) { + const civil_day nov1(2014, 11, 1); + const civil_day thursday = next_weekday(nov1 - 1, weekday::thursday); + EXPECT_EQ("2014-11-06", Format(thursday)); + + // Bonus: Date of Thanksgiving in the United States + // Rule: Fourth Thursday of November + const civil_day thanksgiving = thursday + 7 * 3; + EXPECT_EQ("2014-11-27", Format(thanksgiving)); +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_fixed.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_fixed.cc new file mode 100644 index 0000000000..303c0244a8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_fixed.cc @@ -0,0 +1,140 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "time_zone_fixed.h" + +#include <algorithm> +#include <cassert> +#include <chrono> +#include <cstring> +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +// The prefix used for the internal names of fixed-offset zones. +const char kFixedZonePrefix[] = "Fixed/UTC"; + +const char kDigits[] = "0123456789"; + +char* Format02d(char* p, int v) { + *p++ = kDigits[(v / 10) % 10]; + *p++ = kDigits[v % 10]; + return p; +} + +int Parse02d(const char* p) { + if (const char* ap = std::strchr(kDigits, *p)) { + int v = static_cast<int>(ap - kDigits); + if (const char* bp = std::strchr(kDigits, *++p)) { + return (v * 10) + static_cast<int>(bp - kDigits); + } + } + return -1; +} + +} // namespace + +bool FixedOffsetFromName(const std::string& name, seconds* offset) { + if (name.compare(0, std::string::npos, "UTC", 3) == 0) { + *offset = seconds::zero(); + return true; + } + + const std::size_t prefix_len = sizeof(kFixedZonePrefix) - 1; + const char* const ep = kFixedZonePrefix + prefix_len; + if (name.size() != prefix_len + 9) // <prefix>+99:99:99 + return false; + if (!std::equal(kFixedZonePrefix, ep, name.begin())) return false; + const char* np = name.data() + prefix_len; + if (np[0] != '+' && np[0] != '-') return false; + if (np[3] != ':' || np[6] != ':') // see note below about large offsets + return false; + + int hours = Parse02d(np + 1); + if (hours == -1) return false; + int mins = Parse02d(np + 4); + if (mins == -1) return false; + int secs = Parse02d(np + 7); + if (secs == -1) return false; + + secs += ((hours * 60) + mins) * 60; + if (secs > 24 * 60 * 60) return false; // outside supported offset range + *offset = seconds(secs * (np[0] == '-' ? -1 : 1)); // "-" means west + return true; +} + +std::string FixedOffsetToName(const seconds& offset) { + if (offset == seconds::zero()) return "UTC"; + if (offset < std::chrono::hours(-24) || offset > std::chrono::hours(24)) { + // We don't support fixed-offset zones more than 24 hours + // away from UTC to avoid complications in rendering such + // offsets and to (somewhat) limit the total number of zones. + return "UTC"; + } + int offset_seconds = static_cast<int>(offset.count()); + const char sign = (offset_seconds < 0 ? '-' : '+'); + int offset_minutes = offset_seconds / 60; + offset_seconds %= 60; + if (sign == '-') { + if (offset_seconds > 0) { + offset_seconds -= 60; + offset_minutes += 1; + } + offset_seconds = -offset_seconds; + offset_minutes = -offset_minutes; + } + int offset_hours = offset_minutes / 60; + offset_minutes %= 60; + const std::size_t prefix_len = sizeof(kFixedZonePrefix) - 1; + char buf[prefix_len + sizeof("-24:00:00")]; + char* ep = std::copy(kFixedZonePrefix, kFixedZonePrefix + prefix_len, buf); + *ep++ = sign; + ep = Format02d(ep, offset_hours); + *ep++ = ':'; + ep = Format02d(ep, offset_minutes); + *ep++ = ':'; + ep = Format02d(ep, offset_seconds); + *ep++ = '\0'; + assert(ep == buf + sizeof(buf)); + return buf; +} + +std::string FixedOffsetToAbbr(const seconds& offset) { + std::string abbr = FixedOffsetToName(offset); + const std::size_t prefix_len = sizeof(kFixedZonePrefix) - 1; + if (abbr.size() == prefix_len + 9) { // <prefix>+99:99:99 + abbr.erase(0, prefix_len); // +99:99:99 + abbr.erase(6, 1); // +99:9999 + abbr.erase(3, 1); // +999999 + if (abbr[5] == '0' && abbr[6] == '0') { // +999900 + abbr.erase(5, 2); // +9999 + if (abbr[3] == '0' && abbr[4] == '0') { // +9900 + abbr.erase(3, 2); // +99 + } + } + } + return abbr; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_fixed.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_fixed.h new file mode 100644 index 0000000000..e74a0bbd9d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_fixed.h @@ -0,0 +1,52 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_FIXED_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_FIXED_H_ + +#include <string> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// Helper functions for dealing with the names and abbreviations +// of time zones that are a fixed offset (seconds east) from UTC. +// FixedOffsetFromName() extracts the offset from a valid fixed-offset +// name, while FixedOffsetToName() and FixedOffsetToAbbr() generate +// the canonical zone name and abbreviation respectively for the given +// offset. +// +// A fixed-offset name looks like "Fixed/UTC<+-><hours>:<mins>:<secs>". +// Its abbreviation is of the form "UTC(<+->H?H(MM(SS)?)?)?" where the +// optional pieces are omitted when their values are zero. (Note that +// the sign is the opposite of that used in a POSIX TZ specification.) +// +// Note: FixedOffsetFromName() fails on syntax errors or when the parsed +// offset exceeds 24 hours. FixedOffsetToName() and FixedOffsetToAbbr() +// both produce "UTC" when the argument offset exceeds 24 hours. +bool FixedOffsetFromName(const std::string& name, seconds* offset); +std::string FixedOffsetToName(const seconds& offset); +std::string FixedOffsetToAbbr(const seconds& offset); + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_FIXED_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_format.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_format.cc new file mode 100644 index 0000000000..179975e062 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_format.cc @@ -0,0 +1,922 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#if !defined(HAS_STRPTIME) +#if !defined(_MSC_VER) && !defined(__MINGW32__) +#define HAS_STRPTIME 1 // assume everyone has strptime() except windows +#endif +#endif + +#if defined(HAS_STRPTIME) && HAS_STRPTIME +#if !defined(_XOPEN_SOURCE) +#define _XOPEN_SOURCE // Definedness suffices for strptime. +#endif +#endif + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +// Include time.h directly since, by C++ standards, ctime doesn't have to +// declare strptime. +#include <time.h> + +#include <cctype> +#include <chrono> +#include <cstddef> +#include <cstdint> +#include <cstring> +#include <ctime> +#include <limits> +#include <string> +#include <vector> +#if !HAS_STRPTIME +#include <iomanip> +#include <sstream> +#endif + +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "time_zone_if.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { +namespace detail { + +namespace { + +#if !HAS_STRPTIME +// Build a strptime() using C++11's std::get_time(). +char* strptime(const char* s, const char* fmt, std::tm* tm) { + std::istringstream input(s); + input >> std::get_time(tm, fmt); + if (input.fail()) return nullptr; + return const_cast<char*>(s) + + (input.eof() ? strlen(s) : static_cast<std::size_t>(input.tellg())); +} +#endif + +std::tm ToTM(const time_zone::absolute_lookup& al) { + std::tm tm{}; + tm.tm_sec = al.cs.second(); + tm.tm_min = al.cs.minute(); + tm.tm_hour = al.cs.hour(); + tm.tm_mday = al.cs.day(); + tm.tm_mon = al.cs.month() - 1; + + // Saturate tm.tm_year is cases of over/underflow. + if (al.cs.year() < std::numeric_limits<int>::min() + 1900) { + tm.tm_year = std::numeric_limits<int>::min(); + } else if (al.cs.year() - 1900 > std::numeric_limits<int>::max()) { + tm.tm_year = std::numeric_limits<int>::max(); + } else { + tm.tm_year = static_cast<int>(al.cs.year() - 1900); + } + + switch (get_weekday(al.cs)) { + case weekday::sunday: + tm.tm_wday = 0; + break; + case weekday::monday: + tm.tm_wday = 1; + break; + case weekday::tuesday: + tm.tm_wday = 2; + break; + case weekday::wednesday: + tm.tm_wday = 3; + break; + case weekday::thursday: + tm.tm_wday = 4; + break; + case weekday::friday: + tm.tm_wday = 5; + break; + case weekday::saturday: + tm.tm_wday = 6; + break; + } + tm.tm_yday = get_yearday(al.cs) - 1; + tm.tm_isdst = al.is_dst ? 1 : 0; + return tm; +} + +const char kDigits[] = "0123456789"; + +// Formats a 64-bit integer in the given field width. Note that it is up +// to the caller of Format64() [and Format02d()/FormatOffset()] to ensure +// that there is sufficient space before ep to hold the conversion. +char* Format64(char* ep, int width, std::int_fast64_t v) { + bool neg = false; + if (v < 0) { + --width; + neg = true; + if (v == std::numeric_limits<std::int_fast64_t>::min()) { + // Avoid negating minimum value. + std::int_fast64_t last_digit = -(v % 10); + v /= 10; + if (last_digit < 0) { + ++v; + last_digit += 10; + } + --width; + *--ep = kDigits[last_digit]; + } + v = -v; + } + do { + --width; + *--ep = kDigits[v % 10]; + } while (v /= 10); + while (--width >= 0) *--ep = '0'; // zero pad + if (neg) *--ep = '-'; + return ep; +} + +// Formats [0 .. 99] as %02d. +char* Format02d(char* ep, int v) { + *--ep = kDigits[v % 10]; + *--ep = kDigits[(v / 10) % 10]; + return ep; +} + +// Formats a UTC offset, like +00:00. +char* FormatOffset(char* ep, int offset, const char* mode) { + // TODO: Follow the RFC3339 "Unknown Local Offset Convention" and + // generate a "negative zero" when we're formatting a zero offset + // as the result of a failed load_time_zone(). + char sign = '+'; + if (offset < 0) { + offset = -offset; // bounded by 24h so no overflow + sign = '-'; + } + const int seconds = offset % 60; + const int minutes = (offset /= 60) % 60; + const int hours = offset /= 60; + const char sep = mode[0]; + const bool ext = (sep != '\0' && mode[1] == '*'); + const bool ccc = (ext && mode[2] == ':'); + if (ext && (!ccc || seconds != 0)) { + ep = Format02d(ep, seconds); + *--ep = sep; + } else { + // If we're not rendering seconds, sub-minute negative offsets + // should get a positive sign (e.g., offset=-10s => "+00:00"). + if (hours == 0 && minutes == 0) sign = '+'; + } + if (!ccc || minutes != 0 || seconds != 0) { + ep = Format02d(ep, minutes); + if (sep != '\0') *--ep = sep; + } + ep = Format02d(ep, hours); + *--ep = sign; + return ep; +} + +// Formats a std::tm using strftime(3). +void FormatTM(std::string* out, const std::string& fmt, const std::tm& tm) { + // strftime(3) returns the number of characters placed in the output + // array (which may be 0 characters). It also returns 0 to indicate + // an error, like the array wasn't large enough. To accommodate this, + // the following code grows the buffer size from 2x the format string + // length up to 32x. + for (std::size_t i = 2; i != 32; i *= 2) { + std::size_t buf_size = fmt.size() * i; + std::vector<char> buf(buf_size); + if (std::size_t len = strftime(&buf[0], buf_size, fmt.c_str(), &tm)) { + out->append(&buf[0], len); + return; + } + } +} + +// Used for %E#S/%E#f specifiers and for data values in parse(). +template <typename T> +const char* ParseInt(const char* dp, int width, T min, T max, T* vp) { + if (dp != nullptr) { + const T kmin = std::numeric_limits<T>::min(); + bool erange = false; + bool neg = false; + T value = 0; + if (*dp == '-') { + neg = true; + if (width <= 0 || --width != 0) { + ++dp; + } else { + dp = nullptr; // width was 1 + } + } + if (const char* const bp = dp) { + while (const char* cp = strchr(kDigits, *dp)) { + int d = static_cast<int>(cp - kDigits); + if (d >= 10) break; + if (value < kmin / 10) { + erange = true; + break; + } + value *= 10; + if (value < kmin + d) { + erange = true; + break; + } + value -= d; + dp += 1; + if (width > 0 && --width == 0) break; + } + if (dp != bp && !erange && (neg || value != kmin)) { + if (!neg || value != 0) { + if (!neg) value = -value; // make positive + if (min <= value && value <= max) { + *vp = value; + } else { + dp = nullptr; + } + } else { + dp = nullptr; + } + } else { + dp = nullptr; + } + } + } + return dp; +} + +// The number of base-10 digits that can be represented by a signed 64-bit +// integer. That is, 10^kDigits10_64 <= 2^63 - 1 < 10^(kDigits10_64 + 1). +const int kDigits10_64 = 18; + +// 10^n for everything that can be represented by a signed 64-bit integer. +const std::int_fast64_t kExp10[kDigits10_64 + 1] = { + 1, + 10, + 100, + 1000, + 10000, + 100000, + 1000000, + 10000000, + 100000000, + 1000000000, + 10000000000, + 100000000000, + 1000000000000, + 10000000000000, + 100000000000000, + 1000000000000000, + 10000000000000000, + 100000000000000000, + 1000000000000000000, +}; + +} // namespace + +// Uses strftime(3) to format the given Time. The following extended format +// specifiers are also supported: +// +// - %Ez - RFC3339-compatible numeric UTC offset (+hh:mm or -hh:mm) +// - %E*z - Full-resolution numeric UTC offset (+hh:mm:ss or -hh:mm:ss) +// - %E#S - Seconds with # digits of fractional precision +// - %E*S - Seconds with full fractional precision (a literal '*') +// - %E4Y - Four-character years (-999 ... -001, 0000, 0001 ... 9999) +// +// The standard specifiers from RFC3339_* (%Y, %m, %d, %H, %M, and %S) are +// handled internally for performance reasons. strftime(3) is slow due to +// a POSIX requirement to respect changes to ${TZ}. +// +// The TZ/GNU %s extension is handled internally because strftime() has +// to use mktime() to generate it, and that assumes the local time zone. +// +// We also handle the %z and %Z specifiers to accommodate platforms that do +// not support the tm_gmtoff and tm_zone extensions to std::tm. +// +// Requires that zero() <= fs < seconds(1). +std::string format(const std::string& format, const time_point<seconds>& tp, + const detail::femtoseconds& fs, const time_zone& tz) { + std::string result; + result.reserve(format.size()); // A reasonable guess for the result size. + const time_zone::absolute_lookup al = tz.lookup(tp); + const std::tm tm = ToTM(al); + + // Scratch buffer for internal conversions. + char buf[3 + kDigits10_64]; // enough for longest conversion + char* const ep = buf + sizeof(buf); + char* bp; // works back from ep + + // Maintain three, disjoint subsequences that span format. + // [format.begin() ... pending) : already formatted into result + // [pending ... cur) : formatting pending, but no special cases + // [cur ... format.end()) : unexamined + // Initially, everything is in the unexamined part. + const char* pending = format.c_str(); // NUL terminated + const char* cur = pending; + const char* end = pending + format.length(); + + while (cur != end) { // while something is unexamined + // Moves cur to the next percent sign. + const char* start = cur; + while (cur != end && *cur != '%') ++cur; + + // If the new pending text is all ordinary, copy it out. + if (cur != start && pending == start) { + result.append(pending, static_cast<std::size_t>(cur - pending)); + pending = start = cur; + } + + // Span the sequential percent signs. + const char* percent = cur; + while (cur != end && *cur == '%') ++cur; + + // If the new pending text is all percents, copy out one + // percent for every matched pair, then skip those pairs. + if (cur != start && pending == start) { + std::size_t escaped = static_cast<std::size_t>(cur - pending) / 2; + result.append(pending, escaped); + pending += escaped * 2; + // Also copy out a single trailing percent. + if (pending != cur && cur == end) { + result.push_back(*pending++); + } + } + + // Loop unless we have an unescaped percent. + if (cur == end || (cur - percent) % 2 == 0) continue; + + // Simple specifiers that we handle ourselves. + if (strchr("YmdeHMSzZs%", *cur)) { + if (cur - 1 != pending) { + FormatTM(&result, std::string(pending, cur - 1), tm); + } + switch (*cur) { + case 'Y': + // This avoids the tm.tm_year overflow problem for %Y, however + // tm.tm_year will still be used by other specifiers like %D. + bp = Format64(ep, 0, al.cs.year()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'm': + bp = Format02d(ep, al.cs.month()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'd': + case 'e': + bp = Format02d(ep, al.cs.day()); + if (*cur == 'e' && *bp == '0') *bp = ' '; // for Windows + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'H': + bp = Format02d(ep, al.cs.hour()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'M': + bp = Format02d(ep, al.cs.minute()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'S': + bp = Format02d(ep, al.cs.second()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'z': + bp = FormatOffset(ep, al.offset, ""); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case 'Z': + result.append(al.abbr); + break; + case 's': + bp = Format64(ep, 0, ToUnixSeconds(tp)); + result.append(bp, static_cast<std::size_t>(ep - bp)); + break; + case '%': + result.push_back('%'); + break; + } + pending = ++cur; + continue; + } + + // More complex specifiers that we handle ourselves. + if (*cur == ':' && cur + 1 != end) { + if (*(cur + 1) == 'z') { + // Formats %:z. + if (cur - 1 != pending) { + FormatTM(&result, std::string(pending, cur - 1), tm); + } + bp = FormatOffset(ep, al.offset, ":"); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = cur += 2; + continue; + } + if (*(cur + 1) == ':' && cur + 2 != end) { + if (*(cur + 2) == 'z') { + // Formats %::z. + if (cur - 1 != pending) { + FormatTM(&result, std::string(pending, cur - 1), tm); + } + bp = FormatOffset(ep, al.offset, ":*"); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = cur += 3; + continue; + } + if (*(cur + 2) == ':' && cur + 3 != end) { + if (*(cur + 3) == 'z') { + // Formats %:::z. + if (cur - 1 != pending) { + FormatTM(&result, std::string(pending, cur - 1), tm); + } + bp = FormatOffset(ep, al.offset, ":*:"); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = cur += 4; + continue; + } + } + } + } + + // Loop if there is no E modifier. + if (*cur != 'E' || ++cur == end) continue; + + // Format our extensions. + if (*cur == 'z') { + // Formats %Ez. + if (cur - 2 != pending) { + FormatTM(&result, std::string(pending, cur - 2), tm); + } + bp = FormatOffset(ep, al.offset, ":"); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = ++cur; + } else if (*cur == '*' && cur + 1 != end && *(cur + 1) == 'z') { + // Formats %E*z. + if (cur - 2 != pending) { + FormatTM(&result, std::string(pending, cur - 2), tm); + } + bp = FormatOffset(ep, al.offset, ":*"); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = cur += 2; + } else if (*cur == '*' && cur + 1 != end && + (*(cur + 1) == 'S' || *(cur + 1) == 'f')) { + // Formats %E*S or %E*F. + if (cur - 2 != pending) { + FormatTM(&result, std::string(pending, cur - 2), tm); + } + char* cp = ep; + bp = Format64(cp, 15, fs.count()); + while (cp != bp && cp[-1] == '0') --cp; + switch (*(cur + 1)) { + case 'S': + if (cp != bp) *--bp = '.'; + bp = Format02d(bp, al.cs.second()); + break; + case 'f': + if (cp == bp) *--bp = '0'; + break; + } + result.append(bp, static_cast<std::size_t>(cp - bp)); + pending = cur += 2; + } else if (*cur == '4' && cur + 1 != end && *(cur + 1) == 'Y') { + // Formats %E4Y. + if (cur - 2 != pending) { + FormatTM(&result, std::string(pending, cur - 2), tm); + } + bp = Format64(ep, 4, al.cs.year()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = cur += 2; + } else if (std::isdigit(*cur)) { + // Possibly found %E#S or %E#f. + int n = 0; + if (const char* np = ParseInt(cur, 0, 0, 1024, &n)) { + if (*np == 'S' || *np == 'f') { + // Formats %E#S or %E#f. + if (cur - 2 != pending) { + FormatTM(&result, std::string(pending, cur - 2), tm); + } + bp = ep; + if (n > 0) { + if (n > kDigits10_64) n = kDigits10_64; + bp = Format64(bp, n, + (n > 15) ? fs.count() * kExp10[n - 15] + : fs.count() / kExp10[15 - n]); + if (*np == 'S') *--bp = '.'; + } + if (*np == 'S') bp = Format02d(bp, al.cs.second()); + result.append(bp, static_cast<std::size_t>(ep - bp)); + pending = cur = ++np; + } + } + } + } + + // Formats any remaining data. + if (end != pending) { + FormatTM(&result, std::string(pending, end), tm); + } + + return result; +} + +namespace { + +const char* ParseOffset(const char* dp, const char* mode, int* offset) { + if (dp != nullptr) { + const char first = *dp++; + if (first == '+' || first == '-') { + char sep = mode[0]; + int hours = 0; + int minutes = 0; + int seconds = 0; + const char* ap = ParseInt(dp, 2, 0, 23, &hours); + if (ap != nullptr && ap - dp == 2) { + dp = ap; + if (sep != '\0' && *ap == sep) ++ap; + const char* bp = ParseInt(ap, 2, 0, 59, &minutes); + if (bp != nullptr && bp - ap == 2) { + dp = bp; + if (sep != '\0' && *bp == sep) ++bp; + const char* cp = ParseInt(bp, 2, 0, 59, &seconds); + if (cp != nullptr && cp - bp == 2) dp = cp; + } + *offset = ((hours * 60 + minutes) * 60) + seconds; + if (first == '-') *offset = -*offset; + } else { + dp = nullptr; + } + } else if (first == 'Z') { // Zulu + *offset = 0; + } else { + dp = nullptr; + } + } + return dp; +} + +const char* ParseZone(const char* dp, std::string* zone) { + zone->clear(); + if (dp != nullptr) { + while (*dp != '\0' && !std::isspace(*dp)) zone->push_back(*dp++); + if (zone->empty()) dp = nullptr; + } + return dp; +} + +const char* ParseSubSeconds(const char* dp, detail::femtoseconds* subseconds) { + if (dp != nullptr) { + std::int_fast64_t v = 0; + std::int_fast64_t exp = 0; + const char* const bp = dp; + while (const char* cp = strchr(kDigits, *dp)) { + int d = static_cast<int>(cp - kDigits); + if (d >= 10) break; + if (exp < 15) { + exp += 1; + v *= 10; + v += d; + } + ++dp; + } + if (dp != bp) { + v *= kExp10[15 - exp]; + *subseconds = detail::femtoseconds(v); + } else { + dp = nullptr; + } + } + return dp; +} + +// Parses a string into a std::tm using strptime(3). +const char* ParseTM(const char* dp, const char* fmt, std::tm* tm) { + if (dp != nullptr) { + dp = strptime(dp, fmt, tm); + } + return dp; +} + +} // namespace + +// Uses strptime(3) to parse the given input. Supports the same extended +// format specifiers as format(), although %E#S and %E*S are treated +// identically (and similarly for %E#f and %E*f). %Ez and %E*z also accept +// the same inputs. +// +// The standard specifiers from RFC3339_* (%Y, %m, %d, %H, %M, and %S) are +// handled internally so that we can normally avoid strptime() altogether +// (which is particularly helpful when the native implementation is broken). +// +// The TZ/GNU %s extension is handled internally because strptime() has to +// use localtime_r() to generate it, and that assumes the local time zone. +// +// We also handle the %z specifier to accommodate platforms that do not +// support the tm_gmtoff extension to std::tm. %Z is parsed but ignored. +bool parse(const std::string& format, const std::string& input, + const time_zone& tz, time_point<seconds>* sec, + detail::femtoseconds* fs, std::string* err) { + // The unparsed input. + const char* data = input.c_str(); // NUL terminated + + // Skips leading whitespace. + while (std::isspace(*data)) ++data; + + const year_t kyearmax = std::numeric_limits<year_t>::max(); + const year_t kyearmin = std::numeric_limits<year_t>::min(); + + // Sets default values for unspecified fields. + bool saw_year = false; + year_t year = 1970; + std::tm tm{}; + tm.tm_year = 1970 - 1900; + tm.tm_mon = 1 - 1; // Jan + tm.tm_mday = 1; + tm.tm_hour = 0; + tm.tm_min = 0; + tm.tm_sec = 0; + tm.tm_wday = 4; // Thu + tm.tm_yday = 0; + tm.tm_isdst = 0; + auto subseconds = detail::femtoseconds::zero(); + bool saw_offset = false; + int offset = 0; // No offset from passed tz. + std::string zone = "UTC"; + + const char* fmt = format.c_str(); // NUL terminated + bool twelve_hour = false; + bool afternoon = false; + + bool saw_percent_s = false; + std::int_fast64_t percent_s = 0; + + // Steps through format, one specifier at a time. + while (data != nullptr && *fmt != '\0') { + if (std::isspace(*fmt)) { + while (std::isspace(*data)) ++data; + while (std::isspace(*++fmt)) continue; + continue; + } + + if (*fmt != '%') { + if (*data == *fmt) { + ++data; + ++fmt; + } else { + data = nullptr; + } + continue; + } + + const char* percent = fmt; + if (*++fmt == '\0') { + data = nullptr; + continue; + } + switch (*fmt++) { + case 'Y': + // Symmetrically with FormatTime(), directly handing %Y avoids the + // tm.tm_year overflow problem. However, tm.tm_year will still be + // used by other specifiers like %D. + data = ParseInt(data, 0, kyearmin, kyearmax, &year); + if (data != nullptr) saw_year = true; + continue; + case 'm': + data = ParseInt(data, 2, 1, 12, &tm.tm_mon); + if (data != nullptr) tm.tm_mon -= 1; + continue; + case 'd': + case 'e': + data = ParseInt(data, 2, 1, 31, &tm.tm_mday); + continue; + case 'H': + data = ParseInt(data, 2, 0, 23, &tm.tm_hour); + twelve_hour = false; + continue; + case 'M': + data = ParseInt(data, 2, 0, 59, &tm.tm_min); + continue; + case 'S': + data = ParseInt(data, 2, 0, 60, &tm.tm_sec); + continue; + case 'I': + case 'l': + case 'r': // probably uses %I + twelve_hour = true; + break; + case 'R': // uses %H + case 'T': // uses %H + case 'c': // probably uses %H + case 'X': // probably uses %H + twelve_hour = false; + break; + case 'z': + data = ParseOffset(data, "", &offset); + if (data != nullptr) saw_offset = true; + continue; + case 'Z': // ignored; zone abbreviations are ambiguous + data = ParseZone(data, &zone); + continue; + case 's': + data = + ParseInt(data, 0, std::numeric_limits<std::int_fast64_t>::min(), + std::numeric_limits<std::int_fast64_t>::max(), &percent_s); + if (data != nullptr) saw_percent_s = true; + continue; + case ':': + if (fmt[0] == 'z' || + (fmt[0] == ':' && + (fmt[1] == 'z' || (fmt[1] == ':' && fmt[2] == 'z')))) { + data = ParseOffset(data, ":", &offset); + if (data != nullptr) saw_offset = true; + fmt += (fmt[0] == 'z') ? 1 : (fmt[1] == 'z') ? 2 : 3; + continue; + } + break; + case '%': + data = (*data == '%' ? data + 1 : nullptr); + continue; + case 'E': + if (fmt[0] == 'z' || (fmt[0] == '*' && fmt[1] == 'z')) { + data = ParseOffset(data, ":", &offset); + if (data != nullptr) saw_offset = true; + fmt += (fmt[0] == 'z') ? 1 : 2; + continue; + } + if (fmt[0] == '*' && fmt[1] == 'S') { + data = ParseInt(data, 2, 0, 60, &tm.tm_sec); + if (data != nullptr && *data == '.') { + data = ParseSubSeconds(data + 1, &subseconds); + } + fmt += 2; + continue; + } + if (fmt[0] == '*' && fmt[1] == 'f') { + if (data != nullptr && std::isdigit(*data)) { + data = ParseSubSeconds(data, &subseconds); + } + fmt += 2; + continue; + } + if (fmt[0] == '4' && fmt[1] == 'Y') { + const char* bp = data; + data = ParseInt(data, 4, year_t{-999}, year_t{9999}, &year); + if (data != nullptr) { + if (data - bp == 4) { + saw_year = true; + } else { + data = nullptr; // stopped too soon + } + } + fmt += 2; + continue; + } + if (std::isdigit(*fmt)) { + int n = 0; // value ignored + if (const char* np = ParseInt(fmt, 0, 0, 1024, &n)) { + if (*np == 'S') { + data = ParseInt(data, 2, 0, 60, &tm.tm_sec); + if (data != nullptr && *data == '.') { + data = ParseSubSeconds(data + 1, &subseconds); + } + fmt = ++np; + continue; + } + if (*np == 'f') { + if (data != nullptr && std::isdigit(*data)) { + data = ParseSubSeconds(data, &subseconds); + } + fmt = ++np; + continue; + } + } + } + if (*fmt == 'c') twelve_hour = false; // probably uses %H + if (*fmt == 'X') twelve_hour = false; // probably uses %H + if (*fmt != '\0') ++fmt; + break; + case 'O': + if (*fmt == 'H') twelve_hour = false; + if (*fmt == 'I') twelve_hour = true; + if (*fmt != '\0') ++fmt; + break; + } + + // Parses the current specifier. + const char* orig_data = data; + std::string spec(percent, static_cast<std::size_t>(fmt - percent)); + data = ParseTM(data, spec.c_str(), &tm); + + // If we successfully parsed %p we need to remember whether the result + // was AM or PM so that we can adjust tm_hour before time_zone::lookup(). + // So reparse the input with a known AM hour, and check if it is shifted + // to a PM hour. + if (spec == "%p" && data != nullptr) { + std::string test_input = "1"; + test_input.append(orig_data, static_cast<std::size_t>(data - orig_data)); + const char* test_data = test_input.c_str(); + std::tm tmp{}; + ParseTM(test_data, "%I%p", &tmp); + afternoon = (tmp.tm_hour == 13); + } + } + + // Adjust a 12-hour tm_hour value if it should be in the afternoon. + if (twelve_hour && afternoon && tm.tm_hour < 12) { + tm.tm_hour += 12; + } + + if (data == nullptr) { + if (err != nullptr) *err = "Failed to parse input"; + return false; + } + + // Skip any remaining whitespace. + while (std::isspace(*data)) ++data; + + // parse() must consume the entire input string. + if (*data != '\0') { + if (err != nullptr) *err = "Illegal trailing data in input string"; + return false; + } + + // If we saw %s then we ignore anything else and return that time. + if (saw_percent_s) { + *sec = FromUnixSeconds(percent_s); + *fs = detail::femtoseconds::zero(); + return true; + } + + // If we saw %z, %Ez, or %E*z then we want to interpret the parsed fields + // in UTC and then shift by that offset. Otherwise we want to interpret + // the fields directly in the passed time_zone. + time_zone ptz = saw_offset ? utc_time_zone() : tz; + + // Allows a leap second of 60 to normalize forward to the following ":00". + if (tm.tm_sec == 60) { + tm.tm_sec -= 1; + offset -= 1; + subseconds = detail::femtoseconds::zero(); + } + + if (!saw_year) { + year = year_t{tm.tm_year}; + if (year > kyearmax - 1900) { + // Platform-dependent, maybe unreachable. + if (err != nullptr) *err = "Out-of-range year"; + return false; + } + year += 1900; + } + + const int month = tm.tm_mon + 1; + civil_second cs(year, month, tm.tm_mday, tm.tm_hour, tm.tm_min, tm.tm_sec); + + // parse() should not allow normalization. Due to the restricted field + // ranges above (see ParseInt()), the only possibility is for days to roll + // into months. That is, parsing "Sep 31" should not produce "Oct 1". + if (cs.month() != month || cs.day() != tm.tm_mday) { + if (err != nullptr) *err = "Out-of-range field"; + return false; + } + + // Accounts for the offset adjustment before converting to absolute time. + if ((offset < 0 && cs > civil_second::max() + offset) || + (offset > 0 && cs < civil_second::min() + offset)) { + if (err != nullptr) *err = "Out-of-range field"; + return false; + } + cs -= offset; + + const auto tp = ptz.lookup(cs).pre; + // Checks for overflow/underflow and returns an error as necessary. + if (tp == time_point<seconds>::max()) { + const auto al = ptz.lookup(time_point<seconds>::max()); + if (cs > al.cs) { + if (err != nullptr) *err = "Out-of-range field"; + return false; + } + } + if (tp == time_point<seconds>::min()) { + const auto al = ptz.lookup(time_point<seconds>::min()); + if (cs < al.cs) { + if (err != nullptr) *err = "Out-of-range field"; + return false; + } + } + + *sec = tp; + *fs = subseconds; + return true; +} + +} // namespace detail +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_format_test.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_format_test.cc new file mode 100644 index 0000000000..87382e156d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_format_test.cc @@ -0,0 +1,1500 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <chrono> +#include <iomanip> +#include <sstream> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace chrono = std::chrono; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +// This helper is a macro so that failed expectations show up with the +// correct line numbers. +#define ExpectTime(tp, tz, y, m, d, hh, mm, ss, off, isdst, zone) \ + do { \ + time_zone::absolute_lookup al = tz.lookup(tp); \ + EXPECT_EQ(y, al.cs.year()); \ + EXPECT_EQ(m, al.cs.month()); \ + EXPECT_EQ(d, al.cs.day()); \ + EXPECT_EQ(hh, al.cs.hour()); \ + EXPECT_EQ(mm, al.cs.minute()); \ + EXPECT_EQ(ss, al.cs.second()); \ + EXPECT_EQ(off, al.offset); \ + EXPECT_TRUE(isdst == al.is_dst); \ + EXPECT_STREQ(zone, al.abbr); \ + } while (0) + +const char RFC3339_full[] = "%Y-%m-%dT%H:%M:%E*S%Ez"; +const char RFC3339_sec[] = "%Y-%m-%dT%H:%M:%S%Ez"; + +const char RFC1123_full[] = "%a, %d %b %Y %H:%M:%S %z"; +const char RFC1123_no_wday[] = "%d %b %Y %H:%M:%S %z"; + +// A helper that tests the given format specifier by itself, and with leading +// and trailing characters. For example: TestFormatSpecifier(tp, "%a", "Thu"). +template <typename D> +void TestFormatSpecifier(time_point<D> tp, time_zone tz, const std::string& fmt, + const std::string& ans) { + EXPECT_EQ(ans, format(fmt, tp, tz)) << fmt; + EXPECT_EQ("xxx " + ans, format("xxx " + fmt, tp, tz)); + EXPECT_EQ(ans + " yyy", format(fmt + " yyy", tp, tz)); + EXPECT_EQ("xxx " + ans + " yyy", format("xxx " + fmt + " yyy", tp, tz)); +} + +} // namespace + +// +// Testing format() +// + +TEST(Format, TimePointResolution) { + const char kFmt[] = "%H:%M:%E*S"; + const time_zone utc = utc_time_zone(); + const time_point<chrono::nanoseconds> t0 = + chrono::system_clock::from_time_t(1420167845) + + chrono::milliseconds(123) + chrono::microseconds(456) + + chrono::nanoseconds(789); + EXPECT_EQ( + "03:04:05.123456789", + format(kFmt, chrono::time_point_cast<chrono::nanoseconds>(t0), utc)); + EXPECT_EQ( + "03:04:05.123456", + format(kFmt, chrono::time_point_cast<chrono::microseconds>(t0), utc)); + EXPECT_EQ( + "03:04:05.123", + format(kFmt, chrono::time_point_cast<chrono::milliseconds>(t0), utc)); + EXPECT_EQ("03:04:05", + format(kFmt, chrono::time_point_cast<chrono::seconds>(t0), utc)); + EXPECT_EQ( + "03:04:05", + format(kFmt, + chrono::time_point_cast<absl::time_internal::cctz::seconds>(t0), + utc)); + EXPECT_EQ("03:04:00", + format(kFmt, chrono::time_point_cast<chrono::minutes>(t0), utc)); + EXPECT_EQ("03:00:00", + format(kFmt, chrono::time_point_cast<chrono::hours>(t0), utc)); +} + +TEST(Format, TimePointExtendedResolution) { + const char kFmt[] = "%H:%M:%E*S"; + const time_zone utc = utc_time_zone(); + const time_point<absl::time_internal::cctz::seconds> tp = + chrono::time_point_cast<absl::time_internal::cctz::seconds>( + chrono::system_clock::from_time_t(0)) + + chrono::hours(12) + chrono::minutes(34) + chrono::seconds(56); + + EXPECT_EQ( + "12:34:56.123456789012345", + detail::format(kFmt, tp, detail::femtoseconds(123456789012345), utc)); + EXPECT_EQ( + "12:34:56.012345678901234", + detail::format(kFmt, tp, detail::femtoseconds(12345678901234), utc)); + EXPECT_EQ("12:34:56.001234567890123", + detail::format(kFmt, tp, detail::femtoseconds(1234567890123), utc)); + EXPECT_EQ("12:34:56.000123456789012", + detail::format(kFmt, tp, detail::femtoseconds(123456789012), utc)); + + EXPECT_EQ("12:34:56.000000000000123", + detail::format(kFmt, tp, detail::femtoseconds(123), utc)); + EXPECT_EQ("12:34:56.000000000000012", + detail::format(kFmt, tp, detail::femtoseconds(12), utc)); + EXPECT_EQ("12:34:56.000000000000001", + detail::format(kFmt, tp, detail::femtoseconds(1), utc)); +} + +TEST(Format, Basics) { + time_zone tz = utc_time_zone(); + time_point<chrono::nanoseconds> tp = chrono::system_clock::from_time_t(0); + + // Starts with a couple basic edge cases. + EXPECT_EQ("", format("", tp, tz)); + EXPECT_EQ(" ", format(" ", tp, tz)); + EXPECT_EQ(" ", format(" ", tp, tz)); + EXPECT_EQ("xxx", format("xxx", tp, tz)); + std::string big(128, 'x'); + EXPECT_EQ(big, format(big, tp, tz)); + // Cause the 1024-byte buffer to grow. + std::string bigger(100000, 'x'); + EXPECT_EQ(bigger, format(bigger, tp, tz)); + + tp += chrono::hours(13) + chrono::minutes(4) + chrono::seconds(5); + tp += chrono::milliseconds(6) + chrono::microseconds(7) + + chrono::nanoseconds(8); + EXPECT_EQ("1970-01-01", format("%Y-%m-%d", tp, tz)); + EXPECT_EQ("13:04:05", format("%H:%M:%S", tp, tz)); + EXPECT_EQ("13:04:05.006", format("%H:%M:%E3S", tp, tz)); + EXPECT_EQ("13:04:05.006007", format("%H:%M:%E6S", tp, tz)); + EXPECT_EQ("13:04:05.006007008", format("%H:%M:%E9S", tp, tz)); +} + +TEST(Format, PosixConversions) { + const time_zone tz = utc_time_zone(); + auto tp = chrono::system_clock::from_time_t(0); + + TestFormatSpecifier(tp, tz, "%d", "01"); + TestFormatSpecifier(tp, tz, "%e", " 1"); // extension but internal support + TestFormatSpecifier(tp, tz, "%H", "00"); + TestFormatSpecifier(tp, tz, "%I", "12"); + TestFormatSpecifier(tp, tz, "%j", "001"); + TestFormatSpecifier(tp, tz, "%m", "01"); + TestFormatSpecifier(tp, tz, "%M", "00"); + TestFormatSpecifier(tp, tz, "%S", "00"); + TestFormatSpecifier(tp, tz, "%U", "00"); +#if !defined(__EMSCRIPTEN__) + TestFormatSpecifier(tp, tz, "%w", "4"); // 4=Thursday +#endif + TestFormatSpecifier(tp, tz, "%W", "00"); + TestFormatSpecifier(tp, tz, "%y", "70"); + TestFormatSpecifier(tp, tz, "%Y", "1970"); + TestFormatSpecifier(tp, tz, "%z", "+0000"); + TestFormatSpecifier(tp, tz, "%Z", "UTC"); + TestFormatSpecifier(tp, tz, "%%", "%"); + +#if defined(__linux__) + // SU/C99/TZ extensions + TestFormatSpecifier(tp, tz, "%C", "19"); + TestFormatSpecifier(tp, tz, "%D", "01/01/70"); + TestFormatSpecifier(tp, tz, "%F", "1970-01-01"); + TestFormatSpecifier(tp, tz, "%g", "70"); + TestFormatSpecifier(tp, tz, "%G", "1970"); + TestFormatSpecifier(tp, tz, "%k", " 0"); + TestFormatSpecifier(tp, tz, "%l", "12"); + TestFormatSpecifier(tp, tz, "%n", "\n"); + TestFormatSpecifier(tp, tz, "%R", "00:00"); + TestFormatSpecifier(tp, tz, "%t", "\t"); + TestFormatSpecifier(tp, tz, "%T", "00:00:00"); + TestFormatSpecifier(tp, tz, "%u", "4"); // 4=Thursday + TestFormatSpecifier(tp, tz, "%V", "01"); + TestFormatSpecifier(tp, tz, "%s", "0"); +#endif +} + +TEST(Format, LocaleSpecific) { + const time_zone tz = utc_time_zone(); + auto tp = chrono::system_clock::from_time_t(0); + + TestFormatSpecifier(tp, tz, "%a", "Thu"); + TestFormatSpecifier(tp, tz, "%A", "Thursday"); + TestFormatSpecifier(tp, tz, "%b", "Jan"); + TestFormatSpecifier(tp, tz, "%B", "January"); + + // %c should at least produce the numeric year and time-of-day. + const std::string s = format("%c", tp, utc_time_zone()); + EXPECT_THAT(s, testing::HasSubstr("1970")); + EXPECT_THAT(s, testing::HasSubstr("00:00:00")); + + TestFormatSpecifier(tp, tz, "%p", "AM"); + TestFormatSpecifier(tp, tz, "%x", "01/01/70"); + TestFormatSpecifier(tp, tz, "%X", "00:00:00"); + +#if defined(__linux__) + // SU/C99/TZ extensions + TestFormatSpecifier(tp, tz, "%h", "Jan"); // Same as %b + TestFormatSpecifier(tp, tz, "%P", "am"); + TestFormatSpecifier(tp, tz, "%r", "12:00:00 AM"); + + // Modified conversion specifiers %E_ + TestFormatSpecifier(tp, tz, "%Ec", "Thu Jan 1 00:00:00 1970"); + TestFormatSpecifier(tp, tz, "%EC", "19"); + TestFormatSpecifier(tp, tz, "%Ex", "01/01/70"); + TestFormatSpecifier(tp, tz, "%EX", "00:00:00"); + TestFormatSpecifier(tp, tz, "%Ey", "70"); + TestFormatSpecifier(tp, tz, "%EY", "1970"); + + // Modified conversion specifiers %O_ + TestFormatSpecifier(tp, tz, "%Od", "01"); + TestFormatSpecifier(tp, tz, "%Oe", " 1"); + TestFormatSpecifier(tp, tz, "%OH", "00"); + TestFormatSpecifier(tp, tz, "%OI", "12"); + TestFormatSpecifier(tp, tz, "%Om", "01"); + TestFormatSpecifier(tp, tz, "%OM", "00"); + TestFormatSpecifier(tp, tz, "%OS", "00"); + TestFormatSpecifier(tp, tz, "%Ou", "4"); // 4=Thursday + TestFormatSpecifier(tp, tz, "%OU", "00"); + TestFormatSpecifier(tp, tz, "%OV", "01"); + TestFormatSpecifier(tp, tz, "%Ow", "4"); // 4=Thursday + TestFormatSpecifier(tp, tz, "%OW", "00"); + TestFormatSpecifier(tp, tz, "%Oy", "70"); +#endif +} + +TEST(Format, Escaping) { + const time_zone tz = utc_time_zone(); + auto tp = chrono::system_clock::from_time_t(0); + + TestFormatSpecifier(tp, tz, "%%", "%"); + TestFormatSpecifier(tp, tz, "%%a", "%a"); + TestFormatSpecifier(tp, tz, "%%b", "%b"); + TestFormatSpecifier(tp, tz, "%%Ea", "%Ea"); + TestFormatSpecifier(tp, tz, "%%Es", "%Es"); + TestFormatSpecifier(tp, tz, "%%E3S", "%E3S"); + TestFormatSpecifier(tp, tz, "%%OS", "%OS"); + TestFormatSpecifier(tp, tz, "%%O3S", "%O3S"); + + // Multiple levels of escaping. + TestFormatSpecifier(tp, tz, "%%%Y", "%1970"); + TestFormatSpecifier(tp, tz, "%%%E3S", "%00.000"); + TestFormatSpecifier(tp, tz, "%%%%E3S", "%%E3S"); +} + +TEST(Format, ExtendedSeconds) { + const time_zone tz = utc_time_zone(); + + // No subseconds. + time_point<chrono::nanoseconds> tp = chrono::system_clock::from_time_t(0); + tp += chrono::seconds(5); + EXPECT_EQ("05", format("%E*S", tp, tz)); + EXPECT_EQ("05", format("%E0S", tp, tz)); + EXPECT_EQ("05.0", format("%E1S", tp, tz)); + EXPECT_EQ("05.00", format("%E2S", tp, tz)); + EXPECT_EQ("05.000", format("%E3S", tp, tz)); + EXPECT_EQ("05.0000", format("%E4S", tp, tz)); + EXPECT_EQ("05.00000", format("%E5S", tp, tz)); + EXPECT_EQ("05.000000", format("%E6S", tp, tz)); + EXPECT_EQ("05.0000000", format("%E7S", tp, tz)); + EXPECT_EQ("05.00000000", format("%E8S", tp, tz)); + EXPECT_EQ("05.000000000", format("%E9S", tp, tz)); + EXPECT_EQ("05.0000000000", format("%E10S", tp, tz)); + EXPECT_EQ("05.00000000000", format("%E11S", tp, tz)); + EXPECT_EQ("05.000000000000", format("%E12S", tp, tz)); + EXPECT_EQ("05.0000000000000", format("%E13S", tp, tz)); + EXPECT_EQ("05.00000000000000", format("%E14S", tp, tz)); + EXPECT_EQ("05.000000000000000", format("%E15S", tp, tz)); + + // With subseconds. + tp += chrono::milliseconds(6) + chrono::microseconds(7) + + chrono::nanoseconds(8); + EXPECT_EQ("05.006007008", format("%E*S", tp, tz)); + EXPECT_EQ("05", format("%E0S", tp, tz)); + EXPECT_EQ("05.0", format("%E1S", tp, tz)); + EXPECT_EQ("05.00", format("%E2S", tp, tz)); + EXPECT_EQ("05.006", format("%E3S", tp, tz)); + EXPECT_EQ("05.0060", format("%E4S", tp, tz)); + EXPECT_EQ("05.00600", format("%E5S", tp, tz)); + EXPECT_EQ("05.006007", format("%E6S", tp, tz)); + EXPECT_EQ("05.0060070", format("%E7S", tp, tz)); + EXPECT_EQ("05.00600700", format("%E8S", tp, tz)); + EXPECT_EQ("05.006007008", format("%E9S", tp, tz)); + EXPECT_EQ("05.0060070080", format("%E10S", tp, tz)); + EXPECT_EQ("05.00600700800", format("%E11S", tp, tz)); + EXPECT_EQ("05.006007008000", format("%E12S", tp, tz)); + EXPECT_EQ("05.0060070080000", format("%E13S", tp, tz)); + EXPECT_EQ("05.00600700800000", format("%E14S", tp, tz)); + EXPECT_EQ("05.006007008000000", format("%E15S", tp, tz)); + + // Times before the Unix epoch. + tp = chrono::system_clock::from_time_t(0) + chrono::microseconds(-1); + EXPECT_EQ("1969-12-31 23:59:59.999999", + format("%Y-%m-%d %H:%M:%E*S", tp, tz)); + + // Here is a "%E*S" case we got wrong for a while. While the first + // instant below is correctly rendered as "...:07.333304", the second + // one used to appear as "...:07.33330499999999999". + tp = chrono::system_clock::from_time_t(0) + + chrono::microseconds(1395024427333304); + EXPECT_EQ("2014-03-17 02:47:07.333304", + format("%Y-%m-%d %H:%M:%E*S", tp, tz)); + tp += chrono::microseconds(1); + EXPECT_EQ("2014-03-17 02:47:07.333305", + format("%Y-%m-%d %H:%M:%E*S", tp, tz)); +} + +TEST(Format, ExtendedSubeconds) { + const time_zone tz = utc_time_zone(); + + // No subseconds. + time_point<chrono::nanoseconds> tp = chrono::system_clock::from_time_t(0); + tp += chrono::seconds(5); + EXPECT_EQ("0", format("%E*f", tp, tz)); + EXPECT_EQ("", format("%E0f", tp, tz)); + EXPECT_EQ("0", format("%E1f", tp, tz)); + EXPECT_EQ("00", format("%E2f", tp, tz)); + EXPECT_EQ("000", format("%E3f", tp, tz)); + EXPECT_EQ("0000", format("%E4f", tp, tz)); + EXPECT_EQ("00000", format("%E5f", tp, tz)); + EXPECT_EQ("000000", format("%E6f", tp, tz)); + EXPECT_EQ("0000000", format("%E7f", tp, tz)); + EXPECT_EQ("00000000", format("%E8f", tp, tz)); + EXPECT_EQ("000000000", format("%E9f", tp, tz)); + EXPECT_EQ("0000000000", format("%E10f", tp, tz)); + EXPECT_EQ("00000000000", format("%E11f", tp, tz)); + EXPECT_EQ("000000000000", format("%E12f", tp, tz)); + EXPECT_EQ("0000000000000", format("%E13f", tp, tz)); + EXPECT_EQ("00000000000000", format("%E14f", tp, tz)); + EXPECT_EQ("000000000000000", format("%E15f", tp, tz)); + + // With subseconds. + tp += chrono::milliseconds(6) + chrono::microseconds(7) + + chrono::nanoseconds(8); + EXPECT_EQ("006007008", format("%E*f", tp, tz)); + EXPECT_EQ("", format("%E0f", tp, tz)); + EXPECT_EQ("0", format("%E1f", tp, tz)); + EXPECT_EQ("00", format("%E2f", tp, tz)); + EXPECT_EQ("006", format("%E3f", tp, tz)); + EXPECT_EQ("0060", format("%E4f", tp, tz)); + EXPECT_EQ("00600", format("%E5f", tp, tz)); + EXPECT_EQ("006007", format("%E6f", tp, tz)); + EXPECT_EQ("0060070", format("%E7f", tp, tz)); + EXPECT_EQ("00600700", format("%E8f", tp, tz)); + EXPECT_EQ("006007008", format("%E9f", tp, tz)); + EXPECT_EQ("0060070080", format("%E10f", tp, tz)); + EXPECT_EQ("00600700800", format("%E11f", tp, tz)); + EXPECT_EQ("006007008000", format("%E12f", tp, tz)); + EXPECT_EQ("0060070080000", format("%E13f", tp, tz)); + EXPECT_EQ("00600700800000", format("%E14f", tp, tz)); + EXPECT_EQ("006007008000000", format("%E15f", tp, tz)); + + // Times before the Unix epoch. + tp = chrono::system_clock::from_time_t(0) + chrono::microseconds(-1); + EXPECT_EQ("1969-12-31 23:59:59.999999", + format("%Y-%m-%d %H:%M:%S.%E*f", tp, tz)); + + // Here is a "%E*S" case we got wrong for a while. While the first + // instant below is correctly rendered as "...:07.333304", the second + // one used to appear as "...:07.33330499999999999". + tp = chrono::system_clock::from_time_t(0) + + chrono::microseconds(1395024427333304); + EXPECT_EQ("2014-03-17 02:47:07.333304", + format("%Y-%m-%d %H:%M:%S.%E*f", tp, tz)); + tp += chrono::microseconds(1); + EXPECT_EQ("2014-03-17 02:47:07.333305", + format("%Y-%m-%d %H:%M:%S.%E*f", tp, tz)); +} + +TEST(Format, CompareExtendSecondsVsSubseconds) { + const time_zone tz = utc_time_zone(); + + // This test case illustrates the differences/similarities between: + // fmt_A: %E<prec>S + // fmt_B: %S.%E<prec>f + auto fmt_A = [](const std::string& prec) { return "%E" + prec + "S"; }; + auto fmt_B = [](const std::string& prec) { return "%S.%E" + prec + "f"; }; + + // No subseconds: + time_point<chrono::nanoseconds> tp = chrono::system_clock::from_time_t(0); + tp += chrono::seconds(5); + // ... %E*S and %S.%E*f are different. + EXPECT_EQ("05", format(fmt_A("*"), tp, tz)); + EXPECT_EQ("05.0", format(fmt_B("*"), tp, tz)); + // ... %E0S and %S.%E0f are different. + EXPECT_EQ("05", format(fmt_A("0"), tp, tz)); + EXPECT_EQ("05.", format(fmt_B("0"), tp, tz)); + // ... %E<prec>S and %S.%E<prec>f are the same for prec in [1:15]. + for (int prec = 1; prec <= 15; ++prec) { + const std::string a = format(fmt_A(std::to_string(prec)), tp, tz); + const std::string b = format(fmt_B(std::to_string(prec)), tp, tz); + EXPECT_EQ(a, b) << "prec=" << prec; + } + + // With subseconds: + // ... %E*S and %S.%E*f are the same. + tp += chrono::milliseconds(6) + chrono::microseconds(7) + + chrono::nanoseconds(8); + EXPECT_EQ("05.006007008", format(fmt_A("*"), tp, tz)); + EXPECT_EQ("05.006007008", format(fmt_B("*"), tp, tz)); + // ... %E0S and %S.%E0f are different. + EXPECT_EQ("05", format(fmt_A("0"), tp, tz)); + EXPECT_EQ("05.", format(fmt_B("0"), tp, tz)); + // ... %E<prec>S and %S.%E<prec>f are the same for prec in [1:15]. + for (int prec = 1; prec <= 15; ++prec) { + const std::string a = format(fmt_A(std::to_string(prec)), tp, tz); + const std::string b = format(fmt_B(std::to_string(prec)), tp, tz); + EXPECT_EQ(a, b) << "prec=" << prec; + } +} + +TEST(Format, ExtendedOffset) { + const auto tp = chrono::system_clock::from_time_t(0); + + auto tz = fixed_time_zone(absl::time_internal::cctz::seconds::zero()); + TestFormatSpecifier(tp, tz, "%z", "+0000"); + TestFormatSpecifier(tp, tz, "%:z", "+00:00"); + TestFormatSpecifier(tp, tz, "%Ez", "+00:00"); + + tz = fixed_time_zone(chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "+0000"); + TestFormatSpecifier(tp, tz, "%:z", "+00:00"); + TestFormatSpecifier(tp, tz, "%Ez", "+00:00"); + + tz = fixed_time_zone(-chrono::seconds(56)); // NOTE: +00:00 + TestFormatSpecifier(tp, tz, "%z", "+0000"); + TestFormatSpecifier(tp, tz, "%:z", "+00:00"); + TestFormatSpecifier(tp, tz, "%Ez", "+00:00"); + + tz = fixed_time_zone(chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%z", "+0034"); + TestFormatSpecifier(tp, tz, "%:z", "+00:34"); + TestFormatSpecifier(tp, tz, "%Ez", "+00:34"); + + tz = fixed_time_zone(-chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%z", "-0034"); + TestFormatSpecifier(tp, tz, "%:z", "-00:34"); + TestFormatSpecifier(tp, tz, "%Ez", "-00:34"); + + tz = fixed_time_zone(chrono::minutes(34) + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "+0034"); + TestFormatSpecifier(tp, tz, "%:z", "+00:34"); + TestFormatSpecifier(tp, tz, "%Ez", "+00:34"); + + tz = fixed_time_zone(-chrono::minutes(34) - chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "-0034"); + TestFormatSpecifier(tp, tz, "%:z", "-00:34"); + TestFormatSpecifier(tp, tz, "%Ez", "-00:34"); + + tz = fixed_time_zone(chrono::hours(12)); + TestFormatSpecifier(tp, tz, "%z", "+1200"); + TestFormatSpecifier(tp, tz, "%:z", "+12:00"); + TestFormatSpecifier(tp, tz, "%Ez", "+12:00"); + + tz = fixed_time_zone(-chrono::hours(12)); + TestFormatSpecifier(tp, tz, "%z", "-1200"); + TestFormatSpecifier(tp, tz, "%:z", "-12:00"); + TestFormatSpecifier(tp, tz, "%Ez", "-12:00"); + + tz = fixed_time_zone(chrono::hours(12) + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "+1200"); + TestFormatSpecifier(tp, tz, "%:z", "+12:00"); + TestFormatSpecifier(tp, tz, "%Ez", "+12:00"); + + tz = fixed_time_zone(-chrono::hours(12) - chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "-1200"); + TestFormatSpecifier(tp, tz, "%:z", "-12:00"); + TestFormatSpecifier(tp, tz, "%Ez", "-12:00"); + + tz = fixed_time_zone(chrono::hours(12) + chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%z", "+1234"); + TestFormatSpecifier(tp, tz, "%:z", "+12:34"); + TestFormatSpecifier(tp, tz, "%Ez", "+12:34"); + + tz = fixed_time_zone(-chrono::hours(12) - chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%z", "-1234"); + TestFormatSpecifier(tp, tz, "%:z", "-12:34"); + TestFormatSpecifier(tp, tz, "%Ez", "-12:34"); + + tz = fixed_time_zone(chrono::hours(12) + chrono::minutes(34) + + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "+1234"); + TestFormatSpecifier(tp, tz, "%:z", "+12:34"); + TestFormatSpecifier(tp, tz, "%Ez", "+12:34"); + + tz = fixed_time_zone(-chrono::hours(12) - chrono::minutes(34) - + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%z", "-1234"); + TestFormatSpecifier(tp, tz, "%:z", "-12:34"); + TestFormatSpecifier(tp, tz, "%Ez", "-12:34"); +} + +TEST(Format, ExtendedSecondOffset) { + const auto tp = chrono::system_clock::from_time_t(0); + + auto tz = fixed_time_zone(absl::time_internal::cctz::seconds::zero()); + TestFormatSpecifier(tp, tz, "%E*z", "+00:00:00"); + TestFormatSpecifier(tp, tz, "%::z", "+00:00:00"); + TestFormatSpecifier(tp, tz, "%:::z", "+00"); + + tz = fixed_time_zone(chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "+00:00:56"); + TestFormatSpecifier(tp, tz, "%::z", "+00:00:56"); + TestFormatSpecifier(tp, tz, "%:::z", "+00:00:56"); + + tz = fixed_time_zone(-chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "-00:00:56"); + TestFormatSpecifier(tp, tz, "%::z", "-00:00:56"); + TestFormatSpecifier(tp, tz, "%:::z", "-00:00:56"); + + tz = fixed_time_zone(chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%E*z", "+00:34:00"); + TestFormatSpecifier(tp, tz, "%::z", "+00:34:00"); + TestFormatSpecifier(tp, tz, "%:::z", "+00:34"); + + tz = fixed_time_zone(-chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%E*z", "-00:34:00"); + TestFormatSpecifier(tp, tz, "%::z", "-00:34:00"); + TestFormatSpecifier(tp, tz, "%:::z", "-00:34"); + + tz = fixed_time_zone(chrono::minutes(34) + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "+00:34:56"); + TestFormatSpecifier(tp, tz, "%::z", "+00:34:56"); + TestFormatSpecifier(tp, tz, "%:::z", "+00:34:56"); + + tz = fixed_time_zone(-chrono::minutes(34) - chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "-00:34:56"); + TestFormatSpecifier(tp, tz, "%::z", "-00:34:56"); + TestFormatSpecifier(tp, tz, "%:::z", "-00:34:56"); + + tz = fixed_time_zone(chrono::hours(12)); + TestFormatSpecifier(tp, tz, "%E*z", "+12:00:00"); + TestFormatSpecifier(tp, tz, "%::z", "+12:00:00"); + TestFormatSpecifier(tp, tz, "%:::z", "+12"); + + tz = fixed_time_zone(-chrono::hours(12)); + TestFormatSpecifier(tp, tz, "%E*z", "-12:00:00"); + TestFormatSpecifier(tp, tz, "%::z", "-12:00:00"); + TestFormatSpecifier(tp, tz, "%:::z", "-12"); + + tz = fixed_time_zone(chrono::hours(12) + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "+12:00:56"); + TestFormatSpecifier(tp, tz, "%::z", "+12:00:56"); + TestFormatSpecifier(tp, tz, "%:::z", "+12:00:56"); + + tz = fixed_time_zone(-chrono::hours(12) - chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "-12:00:56"); + TestFormatSpecifier(tp, tz, "%::z", "-12:00:56"); + TestFormatSpecifier(tp, tz, "%:::z", "-12:00:56"); + + tz = fixed_time_zone(chrono::hours(12) + chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%E*z", "+12:34:00"); + TestFormatSpecifier(tp, tz, "%::z", "+12:34:00"); + TestFormatSpecifier(tp, tz, "%:::z", "+12:34"); + + tz = fixed_time_zone(-chrono::hours(12) - chrono::minutes(34)); + TestFormatSpecifier(tp, tz, "%E*z", "-12:34:00"); + TestFormatSpecifier(tp, tz, "%::z", "-12:34:00"); + TestFormatSpecifier(tp, tz, "%:::z", "-12:34"); + + tz = fixed_time_zone(chrono::hours(12) + chrono::minutes(34) + + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "+12:34:56"); + TestFormatSpecifier(tp, tz, "%::z", "+12:34:56"); + TestFormatSpecifier(tp, tz, "%:::z", "+12:34:56"); + + tz = fixed_time_zone(-chrono::hours(12) - chrono::minutes(34) - + chrono::seconds(56)); + TestFormatSpecifier(tp, tz, "%E*z", "-12:34:56"); + TestFormatSpecifier(tp, tz, "%::z", "-12:34:56"); + TestFormatSpecifier(tp, tz, "%:::z", "-12:34:56"); +} + +TEST(Format, ExtendedYears) { + const time_zone utc = utc_time_zone(); + const char e4y_fmt[] = "%E4Y%m%d"; // no separators + + // %E4Y zero-pads the year to produce at least 4 chars, including the sign. + auto tp = convert(civil_second(-999, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("-9991127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(-99, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("-0991127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(-9, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("-0091127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(-1, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("-0011127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(0, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("00001127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(1, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("00011127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(9, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("00091127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(99, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("00991127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(999, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("09991127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(9999, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("99991127", format(e4y_fmt, tp, utc)); + + // When the year is outside [-999:9999], more than 4 chars are produced. + tp = convert(civil_second(-1000, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("-10001127", format(e4y_fmt, tp, utc)); + tp = convert(civil_second(10000, 11, 27, 0, 0, 0), utc); + EXPECT_EQ("100001127", format(e4y_fmt, tp, utc)); +} + +TEST(Format, RFC3339Format) { + time_zone tz; + EXPECT_TRUE(load_time_zone("America/Los_Angeles", &tz)); + + time_point<chrono::nanoseconds> tp = + convert(civil_second(1977, 6, 28, 9, 8, 7), tz); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::milliseconds(100); + EXPECT_EQ("1977-06-28T09:08:07.1-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::milliseconds(20); + EXPECT_EQ("1977-06-28T09:08:07.12-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::milliseconds(3); + EXPECT_EQ("1977-06-28T09:08:07.123-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::microseconds(400); + EXPECT_EQ("1977-06-28T09:08:07.1234-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::microseconds(50); + EXPECT_EQ("1977-06-28T09:08:07.12345-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::microseconds(6); + EXPECT_EQ("1977-06-28T09:08:07.123456-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::nanoseconds(700); + EXPECT_EQ("1977-06-28T09:08:07.1234567-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::nanoseconds(80); + EXPECT_EQ("1977-06-28T09:08:07.12345678-07:00", format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); + + tp += chrono::nanoseconds(9); + EXPECT_EQ("1977-06-28T09:08:07.123456789-07:00", + format(RFC3339_full, tp, tz)); + EXPECT_EQ("1977-06-28T09:08:07-07:00", format(RFC3339_sec, tp, tz)); +} + +TEST(Format, RFC1123Format) { // locale specific + time_zone tz; + EXPECT_TRUE(load_time_zone("America/Los_Angeles", &tz)); + + auto tp = convert(civil_second(1977, 6, 28, 9, 8, 7), tz); + EXPECT_EQ("Tue, 28 Jun 1977 09:08:07 -0700", format(RFC1123_full, tp, tz)); + EXPECT_EQ("28 Jun 1977 09:08:07 -0700", format(RFC1123_no_wday, tp, tz)); +} + +// +// Testing parse() +// + +TEST(Parse, TimePointResolution) { + const char kFmt[] = "%H:%M:%E*S"; + const time_zone utc = utc_time_zone(); + + time_point<chrono::nanoseconds> tp_ns; + EXPECT_TRUE(parse(kFmt, "03:04:05.123456789", utc, &tp_ns)); + EXPECT_EQ("03:04:05.123456789", format(kFmt, tp_ns, utc)); + EXPECT_TRUE(parse(kFmt, "03:04:05.123456", utc, &tp_ns)); + EXPECT_EQ("03:04:05.123456", format(kFmt, tp_ns, utc)); + + time_point<chrono::microseconds> tp_us; + EXPECT_TRUE(parse(kFmt, "03:04:05.123456789", utc, &tp_us)); + EXPECT_EQ("03:04:05.123456", format(kFmt, tp_us, utc)); + EXPECT_TRUE(parse(kFmt, "03:04:05.123456", utc, &tp_us)); + EXPECT_EQ("03:04:05.123456", format(kFmt, tp_us, utc)); + EXPECT_TRUE(parse(kFmt, "03:04:05.123", utc, &tp_us)); + EXPECT_EQ("03:04:05.123", format(kFmt, tp_us, utc)); + + time_point<chrono::milliseconds> tp_ms; + EXPECT_TRUE(parse(kFmt, "03:04:05.123456", utc, &tp_ms)); + EXPECT_EQ("03:04:05.123", format(kFmt, tp_ms, utc)); + EXPECT_TRUE(parse(kFmt, "03:04:05.123", utc, &tp_ms)); + EXPECT_EQ("03:04:05.123", format(kFmt, tp_ms, utc)); + EXPECT_TRUE(parse(kFmt, "03:04:05", utc, &tp_ms)); + EXPECT_EQ("03:04:05", format(kFmt, tp_ms, utc)); + + time_point<chrono::seconds> tp_s; + EXPECT_TRUE(parse(kFmt, "03:04:05.123", utc, &tp_s)); + EXPECT_EQ("03:04:05", format(kFmt, tp_s, utc)); + EXPECT_TRUE(parse(kFmt, "03:04:05", utc, &tp_s)); + EXPECT_EQ("03:04:05", format(kFmt, tp_s, utc)); + + time_point<chrono::minutes> tp_m; + EXPECT_TRUE(parse(kFmt, "03:04:05", utc, &tp_m)); + EXPECT_EQ("03:04:00", format(kFmt, tp_m, utc)); + + time_point<chrono::hours> tp_h; + EXPECT_TRUE(parse(kFmt, "03:04:05", utc, &tp_h)); + EXPECT_EQ("03:00:00", format(kFmt, tp_h, utc)); +} + +TEST(Parse, TimePointExtendedResolution) { + const char kFmt[] = "%H:%M:%E*S"; + const time_zone utc = utc_time_zone(); + + time_point<absl::time_internal::cctz::seconds> tp; + detail::femtoseconds fs; + EXPECT_TRUE(detail::parse(kFmt, "12:34:56.123456789012345", utc, &tp, &fs)); + EXPECT_EQ("12:34:56.123456789012345", detail::format(kFmt, tp, fs, utc)); + EXPECT_TRUE(detail::parse(kFmt, "12:34:56.012345678901234", utc, &tp, &fs)); + EXPECT_EQ("12:34:56.012345678901234", detail::format(kFmt, tp, fs, utc)); + EXPECT_TRUE(detail::parse(kFmt, "12:34:56.001234567890123", utc, &tp, &fs)); + EXPECT_EQ("12:34:56.001234567890123", detail::format(kFmt, tp, fs, utc)); + EXPECT_TRUE(detail::parse(kFmt, "12:34:56.000000000000123", utc, &tp, &fs)); + EXPECT_EQ("12:34:56.000000000000123", detail::format(kFmt, tp, fs, utc)); + EXPECT_TRUE(detail::parse(kFmt, "12:34:56.000000000000012", utc, &tp, &fs)); + EXPECT_EQ("12:34:56.000000000000012", detail::format(kFmt, tp, fs, utc)); + EXPECT_TRUE(detail::parse(kFmt, "12:34:56.000000000000001", utc, &tp, &fs)); + EXPECT_EQ("12:34:56.000000000000001", detail::format(kFmt, tp, fs, utc)); +} + +TEST(Parse, Basics) { + time_zone tz = utc_time_zone(); + time_point<chrono::nanoseconds> tp = + chrono::system_clock::from_time_t(1234567890); + + // Simple edge cases. + EXPECT_TRUE(parse("", "", tz, &tp)); + EXPECT_EQ(chrono::system_clock::from_time_t(0), tp); // everything defaulted + EXPECT_TRUE(parse(" ", " ", tz, &tp)); + EXPECT_TRUE(parse(" ", " ", tz, &tp)); + EXPECT_TRUE(parse("x", "x", tz, &tp)); + EXPECT_TRUE(parse("xxx", "xxx", tz, &tp)); + + EXPECT_TRUE( + parse("%Y-%m-%d %H:%M:%S %z", "2013-06-28 19:08:09 -0800", tz, &tp)); + ExpectTime(tp, tz, 2013, 6, 29, 3, 8, 9, 0, false, "UTC"); +} + +TEST(Parse, WithTimeZone) { + time_zone tz; + EXPECT_TRUE(load_time_zone("America/Los_Angeles", &tz)); + time_point<chrono::nanoseconds> tp; + + // We can parse a string without a UTC offset if we supply a timezone. + EXPECT_TRUE(parse("%Y-%m-%d %H:%M:%S", "2013-06-28 19:08:09", tz, &tp)); + ExpectTime(tp, tz, 2013, 6, 28, 19, 8, 9, -7 * 60 * 60, true, "PDT"); + + // But the timezone is ignored when a UTC offset is present. + EXPECT_TRUE(parse("%Y-%m-%d %H:%M:%S %z", "2013-06-28 19:08:09 +0800", + utc_time_zone(), &tp)); + ExpectTime(tp, tz, 2013, 6, 28, 19 - 8 - 7, 8, 9, -7 * 60 * 60, true, "PDT"); + + // Check a skipped time (a Spring DST transition). parse() uses the + // pre-transition offset. + EXPECT_TRUE(parse("%Y-%m-%d %H:%M:%S", "2011-03-13 02:15:00", tz, &tp)); + ExpectTime(tp, tz, 2011, 3, 13, 3, 15, 0, -7 * 60 * 60, true, "PDT"); + + // Check a repeated time (a Fall DST transition). parse() uses the + // pre-transition offset. + EXPECT_TRUE(parse("%Y-%m-%d %H:%M:%S", "2011-11-06 01:15:00", tz, &tp)); + ExpectTime(tp, tz, 2011, 11, 6, 1, 15, 0, -7 * 60 * 60, true, "PDT"); +} + +TEST(Parse, LeapSecond) { + time_zone tz; + EXPECT_TRUE(load_time_zone("America/Los_Angeles", &tz)); + time_point<chrono::nanoseconds> tp; + + // ":59" -> ":59" + EXPECT_TRUE(parse(RFC3339_full, "2013-06-28T07:08:59-08:00", tz, &tp)); + ExpectTime(tp, tz, 2013, 6, 28, 8, 8, 59, -7 * 60 * 60, true, "PDT"); + + // ":59.5" -> ":59.5" + EXPECT_TRUE(parse(RFC3339_full, "2013-06-28T07:08:59.5-08:00", tz, &tp)); + ExpectTime(tp, tz, 2013, 6, 28, 8, 8, 59, -7 * 60 * 60, true, "PDT"); + + // ":60" -> ":00" + EXPECT_TRUE(parse(RFC3339_full, "2013-06-28T07:08:60-08:00", tz, &tp)); + ExpectTime(tp, tz, 2013, 6, 28, 8, 9, 0, -7 * 60 * 60, true, "PDT"); + + // ":60.5" -> ":00.0" + EXPECT_TRUE(parse(RFC3339_full, "2013-06-28T07:08:60.5-08:00", tz, &tp)); + ExpectTime(tp, tz, 2013, 6, 28, 8, 9, 0, -7 * 60 * 60, true, "PDT"); + + // ":61" -> error + EXPECT_FALSE(parse(RFC3339_full, "2013-06-28T07:08:61-08:00", tz, &tp)); +} + +TEST(Parse, ErrorCases) { + const time_zone tz = utc_time_zone(); + auto tp = chrono::system_clock::from_time_t(0); + + // Illegal trailing data. + EXPECT_FALSE(parse("%S", "123", tz, &tp)); + + // Can't parse an illegal format specifier. + EXPECT_FALSE(parse("%Q", "x", tz, &tp)); + + // Fails because of trailing, unparsed data "blah". + EXPECT_FALSE(parse("%m-%d", "2-3 blah", tz, &tp)); + + // Trailing whitespace is allowed. + EXPECT_TRUE(parse("%m-%d", "2-3 ", tz, &tp)); + EXPECT_EQ(2, convert(tp, utc_time_zone()).month()); + EXPECT_EQ(3, convert(tp, utc_time_zone()).day()); + + // Feb 31 requires normalization. + EXPECT_FALSE(parse("%m-%d", "2-31", tz, &tp)); + + // Check that we cannot have spaces in UTC offsets. + EXPECT_TRUE(parse("%z", "-0203", tz, &tp)); + EXPECT_FALSE(parse("%z", "- 2 3", tz, &tp)); + EXPECT_TRUE(parse("%Ez", "-02:03", tz, &tp)); + EXPECT_FALSE(parse("%Ez", "- 2: 3", tz, &tp)); + + // Check that we reject other malformed UTC offsets. + EXPECT_FALSE(parse("%Ez", "+-08:00", tz, &tp)); + EXPECT_FALSE(parse("%Ez", "-+08:00", tz, &tp)); + + // Check that we do not accept "-0" in fields that allow zero. + EXPECT_FALSE(parse("%Y", "-0", tz, &tp)); + EXPECT_FALSE(parse("%E4Y", "-0", tz, &tp)); + EXPECT_FALSE(parse("%H", "-0", tz, &tp)); + EXPECT_FALSE(parse("%M", "-0", tz, &tp)); + EXPECT_FALSE(parse("%S", "-0", tz, &tp)); + EXPECT_FALSE(parse("%z", "+-000", tz, &tp)); + EXPECT_FALSE(parse("%Ez", "+-0:00", tz, &tp)); + EXPECT_FALSE(parse("%z", "-00-0", tz, &tp)); + EXPECT_FALSE(parse("%Ez", "-00:-0", tz, &tp)); +} + +TEST(Parse, PosixConversions) { + time_zone tz = utc_time_zone(); + auto tp = chrono::system_clock::from_time_t(0); + const auto reset = convert(civil_second(1977, 6, 28, 9, 8, 7), tz); + + tp = reset; + EXPECT_TRUE(parse("%d", "15", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).day()); + + // %e is an extension, but is supported internally. + tp = reset; + EXPECT_TRUE(parse("%e", "15", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).day()); // Equivalent to %d + + tp = reset; + EXPECT_TRUE(parse("%H", "17", tz, &tp)); + EXPECT_EQ(17, convert(tp, tz).hour()); + + tp = reset; + EXPECT_TRUE(parse("%I", "5", tz, &tp)); + EXPECT_EQ(5, convert(tp, tz).hour()); + + // %j is parsed but ignored. + EXPECT_TRUE(parse("%j", "32", tz, &tp)); + + tp = reset; + EXPECT_TRUE(parse("%m", "11", tz, &tp)); + EXPECT_EQ(11, convert(tp, tz).month()); + + tp = reset; + EXPECT_TRUE(parse("%M", "33", tz, &tp)); + EXPECT_EQ(33, convert(tp, tz).minute()); + + tp = reset; + EXPECT_TRUE(parse("%S", "55", tz, &tp)); + EXPECT_EQ(55, convert(tp, tz).second()); + + // %U is parsed but ignored. + EXPECT_TRUE(parse("%U", "15", tz, &tp)); + + // %w is parsed but ignored. + EXPECT_TRUE(parse("%w", "2", tz, &tp)); + + // %W is parsed but ignored. + EXPECT_TRUE(parse("%W", "22", tz, &tp)); + + tp = reset; + EXPECT_TRUE(parse("%y", "04", tz, &tp)); + EXPECT_EQ(2004, convert(tp, tz).year()); + + tp = reset; + EXPECT_TRUE(parse("%Y", "2004", tz, &tp)); + EXPECT_EQ(2004, convert(tp, tz).year()); + + EXPECT_TRUE(parse("%%", "%", tz, &tp)); + +#if defined(__linux__) + // SU/C99/TZ extensions + + // Because we handle each (non-internal) specifier in a separate call + // to strptime(), there is no way to group %C and %y together. So we + // just skip the %C/%y case. +#if 0 + tp = reset; + EXPECT_TRUE(parse("%C %y", "20 04", tz, &tp)); + EXPECT_EQ(2004, convert(tp, tz).year()); +#endif + + tp = reset; + EXPECT_TRUE(parse("%D", "02/03/04", tz, &tp)); + EXPECT_EQ(2, convert(tp, tz).month()); + EXPECT_EQ(3, convert(tp, tz).day()); + EXPECT_EQ(2004, convert(tp, tz).year()); + + EXPECT_TRUE(parse("%n", "\n", tz, &tp)); + + tp = reset; + EXPECT_TRUE(parse("%R", "03:44", tz, &tp)); + EXPECT_EQ(3, convert(tp, tz).hour()); + EXPECT_EQ(44, convert(tp, tz).minute()); + + EXPECT_TRUE(parse("%t", "\t\v\f\n\r ", tz, &tp)); + + tp = reset; + EXPECT_TRUE(parse("%T", "03:44:55", tz, &tp)); + EXPECT_EQ(3, convert(tp, tz).hour()); + EXPECT_EQ(44, convert(tp, tz).minute()); + EXPECT_EQ(55, convert(tp, tz).second()); + + tp = reset; + EXPECT_TRUE(parse("%s", "1234567890", tz, &tp)); + EXPECT_EQ(chrono::system_clock::from_time_t(1234567890), tp); + + // %s conversion, like %z/%Ez, pays no heed to the optional zone. + time_zone lax; + EXPECT_TRUE(load_time_zone("America/Los_Angeles", &lax)); + tp = reset; + EXPECT_TRUE(parse("%s", "1234567890", lax, &tp)); + EXPECT_EQ(chrono::system_clock::from_time_t(1234567890), tp); + + // This is most important when the time has the same YMDhms + // breakdown in the zone as some other time. For example, ... + // 1414917000 in US/Pacific -> Sun Nov 2 01:30:00 2014 (PDT) + // 1414920600 in US/Pacific -> Sun Nov 2 01:30:00 2014 (PST) + tp = reset; + EXPECT_TRUE(parse("%s", "1414917000", lax, &tp)); + EXPECT_EQ(chrono::system_clock::from_time_t(1414917000), tp); + tp = reset; + EXPECT_TRUE(parse("%s", "1414920600", lax, &tp)); + EXPECT_EQ(chrono::system_clock::from_time_t(1414920600), tp); +#endif +} + +TEST(Parse, LocaleSpecific) { + time_zone tz = utc_time_zone(); + auto tp = chrono::system_clock::from_time_t(0); + const auto reset = convert(civil_second(1977, 6, 28, 9, 8, 7), tz); + + // %a is parsed but ignored. + EXPECT_TRUE(parse("%a", "Mon", tz, &tp)); + + // %A is parsed but ignored. + EXPECT_TRUE(parse("%A", "Monday", tz, &tp)); + + tp = reset; + EXPECT_TRUE(parse("%b", "Feb", tz, &tp)); + EXPECT_EQ(2, convert(tp, tz).month()); + + tp = reset; + EXPECT_TRUE(parse("%B", "February", tz, &tp)); + EXPECT_EQ(2, convert(tp, tz).month()); + + // %p is parsed but ignored if it's alone. But it's used with %I. + EXPECT_TRUE(parse("%p", "AM", tz, &tp)); + tp = reset; + EXPECT_TRUE(parse("%I %p", "5 PM", tz, &tp)); + EXPECT_EQ(17, convert(tp, tz).hour()); + + tp = reset; + EXPECT_TRUE(parse("%x", "02/03/04", tz, &tp)); + if (convert(tp, tz).month() == 2) { + EXPECT_EQ(3, convert(tp, tz).day()); + } else { + EXPECT_EQ(2, convert(tp, tz).day()); + EXPECT_EQ(3, convert(tp, tz).month()); + } + EXPECT_EQ(2004, convert(tp, tz).year()); + + tp = reset; + EXPECT_TRUE(parse("%X", "15:44:55", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).hour()); + EXPECT_EQ(44, convert(tp, tz).minute()); + EXPECT_EQ(55, convert(tp, tz).second()); + +#if defined(__linux__) + // SU/C99/TZ extensions + + tp = reset; + EXPECT_TRUE(parse("%h", "Feb", tz, &tp)); + EXPECT_EQ(2, convert(tp, tz).month()); // Equivalent to %b + + tp = reset; + EXPECT_TRUE(parse("%l %p", "5 PM", tz, &tp)); + EXPECT_EQ(17, convert(tp, tz).hour()); + + tp = reset; + EXPECT_TRUE(parse("%r", "03:44:55 PM", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).hour()); + EXPECT_EQ(44, convert(tp, tz).minute()); + EXPECT_EQ(55, convert(tp, tz).second()); + + tp = reset; + EXPECT_TRUE(parse("%Ec", "Tue Nov 19 05:06:07 2013", tz, &tp)); + EXPECT_EQ(convert(civil_second(2013, 11, 19, 5, 6, 7), tz), tp); + + // Modified conversion specifiers %E_ + + tp = reset; + EXPECT_TRUE(parse("%Ex", "02/03/04", tz, &tp)); + EXPECT_EQ(2, convert(tp, tz).month()); + EXPECT_EQ(3, convert(tp, tz).day()); + EXPECT_EQ(2004, convert(tp, tz).year()); + + tp = reset; + EXPECT_TRUE(parse("%EX", "15:44:55", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).hour()); + EXPECT_EQ(44, convert(tp, tz).minute()); + EXPECT_EQ(55, convert(tp, tz).second()); + + // %Ey, the year offset from %EC, doesn't really make sense alone as there + // is no way to represent it in tm_year (%EC is not simply the century). + // Yet, because we handle each (non-internal) specifier in a separate call + // to strptime(), there is no way to group %EC and %Ey either. So we just + // skip the %EC and %Ey cases. + + tp = reset; + EXPECT_TRUE(parse("%EY", "2004", tz, &tp)); + EXPECT_EQ(2004, convert(tp, tz).year()); + + // Modified conversion specifiers %O_ + + tp = reset; + EXPECT_TRUE(parse("%Od", "15", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).day()); + + tp = reset; + EXPECT_TRUE(parse("%Oe", "15", tz, &tp)); + EXPECT_EQ(15, convert(tp, tz).day()); // Equivalent to %d + + tp = reset; + EXPECT_TRUE(parse("%OH", "17", tz, &tp)); + EXPECT_EQ(17, convert(tp, tz).hour()); + + tp = reset; + EXPECT_TRUE(parse("%OI", "5", tz, &tp)); + EXPECT_EQ(5, convert(tp, tz).hour()); + + tp = reset; + EXPECT_TRUE(parse("%Om", "11", tz, &tp)); + EXPECT_EQ(11, convert(tp, tz).month()); + + tp = reset; + EXPECT_TRUE(parse("%OM", "33", tz, &tp)); + EXPECT_EQ(33, convert(tp, tz).minute()); + + tp = reset; + EXPECT_TRUE(parse("%OS", "55", tz, &tp)); + EXPECT_EQ(55, convert(tp, tz).second()); + + // %OU is parsed but ignored. + EXPECT_TRUE(parse("%OU", "15", tz, &tp)); + + // %Ow is parsed but ignored. + EXPECT_TRUE(parse("%Ow", "2", tz, &tp)); + + // %OW is parsed but ignored. + EXPECT_TRUE(parse("%OW", "22", tz, &tp)); + + tp = reset; + EXPECT_TRUE(parse("%Oy", "04", tz, &tp)); + EXPECT_EQ(2004, convert(tp, tz).year()); +#endif +} + +TEST(Parse, ExtendedSeconds) { + const time_zone tz = utc_time_zone(); + const time_point<chrono::nanoseconds> unix_epoch = + chrono::system_clock::from_time_t(0); + + // All %E<prec>S cases are treated the same as %E*S on input. + auto precisions = {"*", "0", "1", "2", "3", "4", "5", "6", "7", + "8", "9", "10", "11", "12", "13", "14", "15"}; + for (const std::string& prec : precisions) { + const std::string fmt = "%E" + prec + "S"; + SCOPED_TRACE(fmt); + time_point<chrono::nanoseconds> tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "5", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.0", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.00", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.6", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5) + chrono::milliseconds(600), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.60", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5) + chrono::milliseconds(600), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.600", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5) + chrono::milliseconds(600), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.67", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5) + chrono::milliseconds(670), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.670", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5) + chrono::milliseconds(670), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "05.678", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::seconds(5) + chrono::milliseconds(678), tp); + } + + // Here is a "%E*S" case we got wrong for a while. The fractional + // part of the first instant is less than 2^31 and was correctly + // parsed, while the second (and any subsecond field >=2^31) failed. + time_point<chrono::nanoseconds> tp = unix_epoch; + EXPECT_TRUE(parse("%E*S", "0.2147483647", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::nanoseconds(214748364), tp); + tp = unix_epoch; + EXPECT_TRUE(parse("%E*S", "0.2147483648", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::nanoseconds(214748364), tp); + + // We should also be able to specify long strings of digits far + // beyond the current resolution and have them convert the same way. + tp = unix_epoch; + EXPECT_TRUE(parse( + "%E*S", "0.214748364801234567890123456789012345678901234567890123456789", + tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::nanoseconds(214748364), tp); +} + +TEST(Parse, ExtendedSecondsScan) { + const time_zone tz = utc_time_zone(); + time_point<chrono::nanoseconds> tp; + for (int ms = 0; ms < 1000; ms += 111) { + for (int us = 0; us < 1000; us += 27) { + const int micros = ms * 1000 + us; + for (int ns = 0; ns < 1000; ns += 9) { + const auto expected = chrono::system_clock::from_time_t(0) + + chrono::nanoseconds(micros * 1000 + ns); + std::ostringstream oss; + oss << "0." << std::setfill('0') << std::setw(3); + oss << ms << std::setw(3) << us << std::setw(3) << ns; + const std::string input = oss.str(); + EXPECT_TRUE(parse("%E*S", input, tz, &tp)); + EXPECT_EQ(expected, tp) << input; + } + } + } +} + +TEST(Parse, ExtendedSubeconds) { + const time_zone tz = utc_time_zone(); + const time_point<chrono::nanoseconds> unix_epoch = + chrono::system_clock::from_time_t(0); + + // All %E<prec>f cases are treated the same as %E*f on input. + auto precisions = {"*", "0", "1", "2", "3", "4", "5", "6", "7", + "8", "9", "10", "11", "12", "13", "14", "15"}; + for (const std::string& prec : precisions) { + const std::string fmt = "%E" + prec + "f"; + SCOPED_TRACE(fmt); + time_point<chrono::nanoseconds> tp = unix_epoch - chrono::seconds(1); + EXPECT_TRUE(parse(fmt, "", tz, &tp)); + EXPECT_EQ(unix_epoch, tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "6", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::milliseconds(600), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "60", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::milliseconds(600), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "600", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::milliseconds(600), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "67", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::milliseconds(670), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "670", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::milliseconds(670), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "678", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::milliseconds(678), tp); + tp = unix_epoch; + EXPECT_TRUE(parse(fmt, "6789", tz, &tp)); + EXPECT_EQ( + unix_epoch + chrono::milliseconds(678) + chrono::microseconds(900), tp); + } + + // Here is a "%E*f" case we got wrong for a while. The fractional + // part of the first instant is less than 2^31 and was correctly + // parsed, while the second (and any subsecond field >=2^31) failed. + time_point<chrono::nanoseconds> tp = unix_epoch; + EXPECT_TRUE(parse("%E*f", "2147483647", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::nanoseconds(214748364), tp); + tp = unix_epoch; + EXPECT_TRUE(parse("%E*f", "2147483648", tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::nanoseconds(214748364), tp); + + // We should also be able to specify long strings of digits far + // beyond the current resolution and have them convert the same way. + tp = unix_epoch; + EXPECT_TRUE(parse( + "%E*f", "214748364801234567890123456789012345678901234567890123456789", + tz, &tp)); + EXPECT_EQ(unix_epoch + chrono::nanoseconds(214748364), tp); +} + +TEST(Parse, ExtendedSubecondsScan) { + time_point<chrono::nanoseconds> tp; + const time_zone tz = utc_time_zone(); + for (int ms = 0; ms < 1000; ms += 111) { + for (int us = 0; us < 1000; us += 27) { + const int micros = ms * 1000 + us; + for (int ns = 0; ns < 1000; ns += 9) { + std::ostringstream oss; + oss << std::setfill('0') << std::setw(3) << ms; + oss << std::setw(3) << us << std::setw(3) << ns; + const std::string nanos = oss.str(); + const auto expected = chrono::system_clock::from_time_t(0) + + chrono::nanoseconds(micros * 1000 + ns); + for (int ps = 0; ps < 1000; ps += 250) { + std::ostringstream ps_oss; + oss << std::setfill('0') << std::setw(3) << ps; + const std::string input = nanos + ps_oss.str() + "999"; + EXPECT_TRUE(parse("%E*f", input, tz, &tp)); + EXPECT_EQ(expected + chrono::nanoseconds(ps) / 1000, tp) << input; + } + } + } + } +} + +TEST(Parse, ExtendedOffset) { + const time_zone utc = utc_time_zone(); + time_point<absl::time_internal::cctz::seconds> tp; + + EXPECT_TRUE(parse("%Ez", "+00:00", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse("%Ez", "-12:34", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 34, 0), utc), tp); + EXPECT_TRUE(parse("%Ez", "+12:34", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 11, 26, 0), utc), tp); + EXPECT_FALSE(parse("%Ez", "-12:3", utc, &tp)); + + for (auto fmt : {"%Ez", "%z"}) { + EXPECT_TRUE(parse(fmt, "+0000", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-1234", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 34, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "+1234", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 11, 26, 0), utc), tp); + EXPECT_FALSE(parse(fmt, "-123", utc, &tp)); + + EXPECT_TRUE(parse(fmt, "+00", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-12", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "+12", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 12, 0, 0), utc), tp); + EXPECT_FALSE(parse(fmt, "-1", utc, &tp)); + } +} + +TEST(Parse, ExtendedSecondOffset) { + const time_zone utc = utc_time_zone(); + time_point<absl::time_internal::cctz::seconds> tp; + + for (auto fmt : {"%Ez", "%E*z", "%:z", "%::z", "%:::z"}) { + EXPECT_TRUE(parse(fmt, "+00:00:00", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-12:34:56", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 34, 56), utc), tp); + EXPECT_TRUE(parse(fmt, "+12:34:56", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 11, 25, 4), utc), tp); + EXPECT_FALSE(parse(fmt, "-12:34:5", utc, &tp)); + + EXPECT_TRUE(parse(fmt, "+000000", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-123456", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 34, 56), utc), tp); + EXPECT_TRUE(parse(fmt, "+123456", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 11, 25, 4), utc), tp); + EXPECT_FALSE(parse(fmt, "-12345", utc, &tp)); + + EXPECT_TRUE(parse(fmt, "+00:00", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-12:34", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 34, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "+12:34", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 11, 26, 0), utc), tp); + EXPECT_FALSE(parse(fmt, "-12:3", utc, &tp)); + + EXPECT_TRUE(parse(fmt, "+0000", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-1234", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 34, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "+1234", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 11, 26, 0), utc), tp); + EXPECT_FALSE(parse(fmt, "-123", utc, &tp)); + + EXPECT_TRUE(parse(fmt, "+00", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "-12", utc, &tp)); + EXPECT_EQ(convert(civil_second(1970, 1, 1, 12, 0, 0), utc), tp); + EXPECT_TRUE(parse(fmt, "+12", utc, &tp)); + EXPECT_EQ(convert(civil_second(1969, 12, 31, 12, 0, 0), utc), tp); + EXPECT_FALSE(parse(fmt, "-1", utc, &tp)); + } +} + +TEST(Parse, ExtendedYears) { + const time_zone utc = utc_time_zone(); + const char e4y_fmt[] = "%E4Y%m%d"; // no separators + time_point<absl::time_internal::cctz::seconds> tp; + + // %E4Y consumes exactly four chars, including any sign. + EXPECT_TRUE(parse(e4y_fmt, "-9991127", utc, &tp)); + EXPECT_EQ(convert(civil_second(-999, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "-0991127", utc, &tp)); + EXPECT_EQ(convert(civil_second(-99, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "-0091127", utc, &tp)); + EXPECT_EQ(convert(civil_second(-9, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "-0011127", utc, &tp)); + EXPECT_EQ(convert(civil_second(-1, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "00001127", utc, &tp)); + EXPECT_EQ(convert(civil_second(0, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "00011127", utc, &tp)); + EXPECT_EQ(convert(civil_second(1, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "00091127", utc, &tp)); + EXPECT_EQ(convert(civil_second(9, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "00991127", utc, &tp)); + EXPECT_EQ(convert(civil_second(99, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "09991127", utc, &tp)); + EXPECT_EQ(convert(civil_second(999, 11, 27, 0, 0, 0), utc), tp); + EXPECT_TRUE(parse(e4y_fmt, "99991127", utc, &tp)); + EXPECT_EQ(convert(civil_second(9999, 11, 27, 0, 0, 0), utc), tp); + + // When the year is outside [-999:9999], the parse fails. + EXPECT_FALSE(parse(e4y_fmt, "-10001127", utc, &tp)); + EXPECT_FALSE(parse(e4y_fmt, "100001127", utc, &tp)); +} + +TEST(Parse, RFC3339Format) { + const time_zone tz = utc_time_zone(); + time_point<chrono::nanoseconds> tp; + EXPECT_TRUE(parse(RFC3339_sec, "2014-02-12T20:21:00+00:00", tz, &tp)); + ExpectTime(tp, tz, 2014, 2, 12, 20, 21, 0, 0, false, "UTC"); + + // Check that %Ez also accepts "Z" as a synonym for "+00:00". + time_point<chrono::nanoseconds> tp2; + EXPECT_TRUE(parse(RFC3339_sec, "2014-02-12T20:21:00Z", tz, &tp2)); + EXPECT_EQ(tp, tp2); +} + +TEST(Parse, MaxRange) { + const time_zone utc = utc_time_zone(); + time_point<absl::time_internal::cctz::seconds> tp; + + // tests the upper limit using +00:00 offset + EXPECT_TRUE( + parse(RFC3339_sec, "292277026596-12-04T15:30:07+00:00", utc, &tp)); + EXPECT_EQ(tp, time_point<absl::time_internal::cctz::seconds>::max()); + EXPECT_FALSE( + parse(RFC3339_sec, "292277026596-12-04T15:30:08+00:00", utc, &tp)); + + // tests the upper limit using -01:00 offset + EXPECT_TRUE( + parse(RFC3339_sec, "292277026596-12-04T14:30:07-01:00", utc, &tp)); + EXPECT_EQ(tp, time_point<absl::time_internal::cctz::seconds>::max()); + EXPECT_FALSE( + parse(RFC3339_sec, "292277026596-12-04T15:30:07-01:00", utc, &tp)); + + // tests the lower limit using +00:00 offset + EXPECT_TRUE( + parse(RFC3339_sec, "-292277022657-01-27T08:29:52+00:00", utc, &tp)); + EXPECT_EQ(tp, time_point<absl::time_internal::cctz::seconds>::min()); + EXPECT_FALSE( + parse(RFC3339_sec, "-292277022657-01-27T08:29:51+00:00", utc, &tp)); + + // tests the lower limit using +01:00 offset + EXPECT_TRUE( + parse(RFC3339_sec, "-292277022657-01-27T09:29:52+01:00", utc, &tp)); + EXPECT_EQ(tp, time_point<absl::time_internal::cctz::seconds>::min()); + EXPECT_FALSE( + parse(RFC3339_sec, "-292277022657-01-27T08:29:51+01:00", utc, &tp)); + + // tests max/min civil-second overflow + EXPECT_FALSE( + parse(RFC3339_sec, "9223372036854775807-12-31T23:59:59-00:01", utc, &tp)); + EXPECT_FALSE(parse(RFC3339_sec, "-9223372036854775808-01-01T00:00:00+00:01", + utc, &tp)); + + // TODO: Add tests that parsing times with fractional seconds overflow + // appropriately. This can't be done until cctz::parse() properly detects + // overflow when combining the chrono seconds and femto. +} + +// +// Roundtrip test for format()/parse(). +// + +TEST(FormatParse, RoundTrip) { + time_zone lax; + EXPECT_TRUE(load_time_zone("America/Los_Angeles", &lax)); + const auto in = convert(civil_second(1977, 6, 28, 9, 8, 7), lax); + const auto subseconds = chrono::nanoseconds(654321); + + // RFC3339, which renders subseconds. + { + time_point<chrono::nanoseconds> out; + const std::string s = format(RFC3339_full, in + subseconds, lax); + EXPECT_TRUE(parse(RFC3339_full, s, lax, &out)) << s; + EXPECT_EQ(in + subseconds, out); // RFC3339_full includes %Ez + } + + // RFC1123, which only does whole seconds. + { + time_point<chrono::nanoseconds> out; + const std::string s = format(RFC1123_full, in, lax); + EXPECT_TRUE(parse(RFC1123_full, s, lax, &out)) << s; + EXPECT_EQ(in, out); // RFC1123_full includes %z + } + +#if defined(_WIN32) || defined(_WIN64) + // Initial investigations indicate the %c does not roundtrip on Windows. + // TODO: Figure out what is going on here (perhaps a locale problem). +#elif defined(__EMSCRIPTEN__) + // strftime() and strptime() use different defintions for "%c" under + // emscripten (see https://github.com/kripken/emscripten/pull/7491), + // causing its round-trip test to fail. +#else + // Even though we don't know what %c will produce, it should roundtrip, + // but only in the 0-offset timezone. + { + time_point<chrono::nanoseconds> out; + time_zone utc = utc_time_zone(); + const std::string s = format("%c", in, utc); + EXPECT_TRUE(parse("%c", s, utc, &out)) << s; + EXPECT_EQ(in, out); + } +#endif +} + +TEST(FormatParse, RoundTripDistantFuture) { + const time_zone utc = utc_time_zone(); + const time_point<absl::time_internal::cctz::seconds> in = + time_point<absl::time_internal::cctz::seconds>::max(); + const std::string s = format(RFC3339_full, in, utc); + time_point<absl::time_internal::cctz::seconds> out; + EXPECT_TRUE(parse(RFC3339_full, s, utc, &out)) << s; + EXPECT_EQ(in, out); +} + +TEST(FormatParse, RoundTripDistantPast) { + const time_zone utc = utc_time_zone(); + const time_point<absl::time_internal::cctz::seconds> in = + time_point<absl::time_internal::cctz::seconds>::min(); + const std::string s = format(RFC3339_full, in, utc); + time_point<absl::time_internal::cctz::seconds> out; + EXPECT_TRUE(parse(RFC3339_full, s, utc, &out)) << s; + EXPECT_EQ(in, out); +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_if.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_if.cc new file mode 100644 index 0000000000..0319b2f98e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_if.cc @@ -0,0 +1,45 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "time_zone_if.h" + +#include "absl/base/config.h" +#include "time_zone_info.h" +#include "time_zone_libc.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +std::unique_ptr<TimeZoneIf> TimeZoneIf::Load(const std::string& name) { + // Support "libc:localtime" and "libc:*" to access the legacy + // localtime and UTC support respectively from the C library. + if (name.compare(0, 5, "libc:") == 0) { + return std::unique_ptr<TimeZoneIf>(new TimeZoneLibC(name.substr(5))); + } + + // Otherwise use the "zoneinfo" implementation by default. + std::unique_ptr<TimeZoneInfo> tz(new TimeZoneInfo); + if (!tz->Load(name)) tz.reset(); + return std::unique_ptr<TimeZoneIf>(tz.release()); +} + +// Defined out-of-line to avoid emitting a weak vtable in all TUs. +TimeZoneIf::~TimeZoneIf() {} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_if.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_if.h new file mode 100644 index 0000000000..32c0891c1e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_if.h @@ -0,0 +1,76 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_IF_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_IF_H_ + +#include <chrono> +#include <cstdint> +#include <memory> +#include <string> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// A simple interface used to hide time-zone complexities from time_zone::Impl. +// Subclasses implement the functions for civil-time conversions in the zone. +class TimeZoneIf { + public: + // A factory function for TimeZoneIf implementations. + static std::unique_ptr<TimeZoneIf> Load(const std::string& name); + + virtual ~TimeZoneIf(); + + virtual time_zone::absolute_lookup BreakTime( + const time_point<seconds>& tp) const = 0; + virtual time_zone::civil_lookup MakeTime(const civil_second& cs) const = 0; + + virtual bool NextTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const = 0; + virtual bool PrevTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const = 0; + + virtual std::string Version() const = 0; + virtual std::string Description() const = 0; + + protected: + TimeZoneIf() {} +}; + +// Convert between time_point<seconds> and a count of seconds since the +// Unix epoch. We assume that the std::chrono::system_clock and the +// Unix clock are second aligned, but not that they share an epoch. +inline std::int_fast64_t ToUnixSeconds(const time_point<seconds>& tp) { + return (tp - std::chrono::time_point_cast<seconds>( + std::chrono::system_clock::from_time_t(0))) + .count(); +} +inline time_point<seconds> FromUnixSeconds(std::int_fast64_t t) { + return std::chrono::time_point_cast<seconds>( + std::chrono::system_clock::from_time_t(0)) + + seconds(t); +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_IF_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_impl.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_impl.cc new file mode 100644 index 0000000000..030ae0e19e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_impl.cc @@ -0,0 +1,121 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "time_zone_impl.h" + +#include <deque> +#include <mutex> +#include <string> +#include <unordered_map> +#include <utility> + +#include "absl/base/config.h" +#include "time_zone_fixed.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +// time_zone::Impls are linked into a map to support fast lookup by name. +using TimeZoneImplByName = + std::unordered_map<std::string, const time_zone::Impl*>; +TimeZoneImplByName* time_zone_map = nullptr; + +// Mutual exclusion for time_zone_map. +std::mutex& TimeZoneMutex() { + // This mutex is intentionally "leaked" to avoid the static deinitialization + // order fiasco (std::mutex's destructor is not trivial on many platforms). + static std::mutex* time_zone_mutex = new std::mutex; + return *time_zone_mutex; +} + +} // namespace + +time_zone time_zone::Impl::UTC() { return time_zone(UTCImpl()); } + +bool time_zone::Impl::LoadTimeZone(const std::string& name, time_zone* tz) { + const time_zone::Impl* const utc_impl = UTCImpl(); + + // First check for UTC (which is never a key in time_zone_map). + auto offset = seconds::zero(); + if (FixedOffsetFromName(name, &offset) && offset == seconds::zero()) { + *tz = time_zone(utc_impl); + return true; + } + + // Then check, under a shared lock, whether the time zone has already + // been loaded. This is the common path. TODO: Move to shared_mutex. + { + std::lock_guard<std::mutex> lock(TimeZoneMutex()); + if (time_zone_map != nullptr) { + TimeZoneImplByName::const_iterator itr = time_zone_map->find(name); + if (itr != time_zone_map->end()) { + *tz = time_zone(itr->second); + return itr->second != utc_impl; + } + } + } + + // Now check again, under an exclusive lock. + std::lock_guard<std::mutex> lock(TimeZoneMutex()); + if (time_zone_map == nullptr) time_zone_map = new TimeZoneImplByName; + const Impl*& impl = (*time_zone_map)[name]; + if (impl == nullptr) { + // The first thread in loads the new time zone. + Impl* new_impl = new Impl(name); + new_impl->zone_ = TimeZoneIf::Load(new_impl->name_); + if (new_impl->zone_ == nullptr) { + delete new_impl; // free the nascent Impl + impl = utc_impl; // and fallback to UTC + } else { + impl = new_impl; // install new time zone + } + } + *tz = time_zone(impl); + return impl != utc_impl; +} + +void time_zone::Impl::ClearTimeZoneMapTestOnly() { + std::lock_guard<std::mutex> lock(TimeZoneMutex()); + if (time_zone_map != nullptr) { + // Existing time_zone::Impl* entries are in the wild, so we can't delete + // them. Instead, we move them to a private container, where they are + // logically unreachable but not "leaked". Future requests will result + // in reloading the data. + static auto* cleared = new std::deque<const time_zone::Impl*>; + for (const auto& element : *time_zone_map) { + cleared->push_back(element.second); + } + time_zone_map->clear(); + } +} + +time_zone::Impl::Impl(const std::string& name) : name_(name) {} + +const time_zone::Impl* time_zone::Impl::UTCImpl() { + static Impl* utc_impl = [] { + Impl* impl = new Impl("UTC"); + impl->zone_ = TimeZoneIf::Load(impl->name_); // never fails + return impl; + }(); + return utc_impl; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_impl.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_impl.h new file mode 100644 index 0000000000..7d747ba966 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_impl.h @@ -0,0 +1,93 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_IMPL_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_IMPL_H_ + +#include <memory> +#include <string> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" +#include "time_zone_if.h" +#include "time_zone_info.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// time_zone::Impl is the internal object referenced by a cctz::time_zone. +class time_zone::Impl { + public: + // The UTC time zone. Also used for other time zones that fail to load. + static time_zone UTC(); + + // Load a named time zone. Returns false if the name is invalid, or if + // some other kind of error occurs. Note that loading "UTC" never fails. + static bool LoadTimeZone(const std::string& name, time_zone* tz); + + // Clears the map of cached time zones. Primarily for use in benchmarks + // that gauge the performance of loading/parsing the time-zone data. + static void ClearTimeZoneMapTestOnly(); + + // The primary key is the time-zone ID (e.g., "America/New_York"). + const std::string& Name() const { + // TODO: It would nice if the zoneinfo data included the zone name. + return name_; + } + + // Breaks a time_point down to civil-time components in this time zone. + time_zone::absolute_lookup BreakTime(const time_point<seconds>& tp) const { + return zone_->BreakTime(tp); + } + + // Converts the civil-time components in this time zone into a time_point. + // That is, the opposite of BreakTime(). The requested civil time may be + // ambiguous or illegal due to a change of UTC offset. + time_zone::civil_lookup MakeTime(const civil_second& cs) const { + return zone_->MakeTime(cs); + } + + // Finds the time of the next/previous offset change in this time zone. + bool NextTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const { + return zone_->NextTransition(tp, trans); + } + bool PrevTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const { + return zone_->PrevTransition(tp, trans); + } + + // Returns an implementation-defined version string for this time zone. + std::string Version() const { return zone_->Version(); } + + // Returns an implementation-defined description of this time zone. + std::string Description() const { return zone_->Description(); } + + private: + explicit Impl(const std::string& name); + static const Impl* UTCImpl(); + + const std::string name_; + std::unique_ptr<TimeZoneIf> zone_; +}; + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_IMPL_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_info.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_info.cc new file mode 100644 index 0000000000..665fb424fe --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_info.cc @@ -0,0 +1,958 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// This file implements the TimeZoneIf interface using the "zoneinfo" +// data provided by the IANA Time Zone Database (i.e., the only real game +// in town). +// +// TimeZoneInfo represents the history of UTC-offset changes within a time +// zone. Most changes are due to daylight-saving rules, but occasionally +// shifts are made to the time-zone's base offset. The database only attempts +// to be definitive for times since 1970, so be wary of local-time conversions +// before that. Also, rule and zone-boundary changes are made at the whim +// of governments, so the conversion of future times needs to be taken with +// a grain of salt. +// +// For more information see tzfile(5), http://www.iana.org/time-zones, or +// https://en.wikipedia.org/wiki/Zoneinfo. +// +// Note that we assume the proleptic Gregorian calendar and 60-second +// minutes throughout. + +#include "time_zone_info.h" + +#include <algorithm> +#include <cassert> +#include <chrono> +#include <cstdint> +#include <cstdio> +#include <cstdlib> +#include <cstring> +#include <functional> +#include <iostream> +#include <memory> +#include <sstream> +#include <string> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "time_zone_fixed.h" +#include "time_zone_posix.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +inline bool IsLeap(year_t year) { + return (year % 4) == 0 && ((year % 100) != 0 || (year % 400) == 0); +} + +// The number of days in non-leap and leap years respectively. +const std::int_least32_t kDaysPerYear[2] = {365, 366}; + +// The day offsets of the beginning of each (1-based) month in non-leap and +// leap years respectively (e.g., 335 days before December in a leap year). +const std::int_least16_t kMonthOffsets[2][1 + 12 + 1] = { + {-1, 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334, 365}, + {-1, 0, 31, 60, 91, 121, 152, 182, 213, 244, 274, 305, 335, 366}, +}; + +// We reject leap-second encoded zoneinfo and so assume 60-second minutes. +const std::int_least32_t kSecsPerDay = 24 * 60 * 60; + +// 400-year chunks always have 146097 days (20871 weeks). +const std::int_least64_t kSecsPer400Years = 146097LL * kSecsPerDay; + +// Like kDaysPerYear[] but scaled up by a factor of kSecsPerDay. +const std::int_least32_t kSecsPerYear[2] = { + 365 * kSecsPerDay, + 366 * kSecsPerDay, +}; + +// Single-byte, unsigned numeric values are encoded directly. +inline std::uint_fast8_t Decode8(const char* cp) { + return static_cast<std::uint_fast8_t>(*cp) & 0xff; +} + +// Multi-byte, numeric values are encoded using a MSB first, +// twos-complement representation. These helpers decode, from +// the given address, 4-byte and 8-byte values respectively. +// Note: If int_fastXX_t == intXX_t and this machine is not +// twos complement, then there will be at least one input value +// we cannot represent. +std::int_fast32_t Decode32(const char* cp) { + std::uint_fast32_t v = 0; + for (int i = 0; i != (32 / 8); ++i) v = (v << 8) | Decode8(cp++); + const std::int_fast32_t s32max = 0x7fffffff; + const auto s32maxU = static_cast<std::uint_fast32_t>(s32max); + if (v <= s32maxU) return static_cast<std::int_fast32_t>(v); + return static_cast<std::int_fast32_t>(v - s32maxU - 1) - s32max - 1; +} + +std::int_fast64_t Decode64(const char* cp) { + std::uint_fast64_t v = 0; + for (int i = 0; i != (64 / 8); ++i) v = (v << 8) | Decode8(cp++); + const std::int_fast64_t s64max = 0x7fffffffffffffff; + const auto s64maxU = static_cast<std::uint_fast64_t>(s64max); + if (v <= s64maxU) return static_cast<std::int_fast64_t>(v); + return static_cast<std::int_fast64_t>(v - s64maxU - 1) - s64max - 1; +} + +// Generate a year-relative offset for a PosixTransition. +std::int_fast64_t TransOffset(bool leap_year, int jan1_weekday, + const PosixTransition& pt) { + std::int_fast64_t days = 0; + switch (pt.date.fmt) { + case PosixTransition::J: { + days = pt.date.j.day; + if (!leap_year || days < kMonthOffsets[1][3]) days -= 1; + break; + } + case PosixTransition::N: { + days = pt.date.n.day; + break; + } + case PosixTransition::M: { + const bool last_week = (pt.date.m.week == 5); + days = kMonthOffsets[leap_year][pt.date.m.month + last_week]; + const std::int_fast64_t weekday = (jan1_weekday + days) % 7; + if (last_week) { + days -= (weekday + 7 - 1 - pt.date.m.weekday) % 7 + 1; + } else { + days += (pt.date.m.weekday + 7 - weekday) % 7; + days += (pt.date.m.week - 1) * 7; + } + break; + } + } + return (days * kSecsPerDay) + pt.time.offset; +} + +inline time_zone::civil_lookup MakeUnique(const time_point<seconds>& tp) { + time_zone::civil_lookup cl; + cl.kind = time_zone::civil_lookup::UNIQUE; + cl.pre = cl.trans = cl.post = tp; + return cl; +} + +inline time_zone::civil_lookup MakeUnique(std::int_fast64_t unix_time) { + return MakeUnique(FromUnixSeconds(unix_time)); +} + +inline time_zone::civil_lookup MakeSkipped(const Transition& tr, + const civil_second& cs) { + time_zone::civil_lookup cl; + cl.kind = time_zone::civil_lookup::SKIPPED; + cl.pre = FromUnixSeconds(tr.unix_time - 1 + (cs - tr.prev_civil_sec)); + cl.trans = FromUnixSeconds(tr.unix_time); + cl.post = FromUnixSeconds(tr.unix_time - (tr.civil_sec - cs)); + return cl; +} + +inline time_zone::civil_lookup MakeRepeated(const Transition& tr, + const civil_second& cs) { + time_zone::civil_lookup cl; + cl.kind = time_zone::civil_lookup::REPEATED; + cl.pre = FromUnixSeconds(tr.unix_time - 1 - (tr.prev_civil_sec - cs)); + cl.trans = FromUnixSeconds(tr.unix_time); + cl.post = FromUnixSeconds(tr.unix_time + (cs - tr.civil_sec)); + return cl; +} + +inline civil_second YearShift(const civil_second& cs, year_t shift) { + return civil_second(cs.year() + shift, cs.month(), cs.day(), cs.hour(), + cs.minute(), cs.second()); +} + +} // namespace + +// What (no leap-seconds) UTC+seconds zoneinfo would look like. +bool TimeZoneInfo::ResetToBuiltinUTC(const seconds& offset) { + transition_types_.resize(1); + TransitionType& tt(transition_types_.back()); + tt.utc_offset = static_cast<std::int_least32_t>(offset.count()); + tt.is_dst = false; + tt.abbr_index = 0; + + // We temporarily add some redundant, contemporary (2013 through 2023) + // transitions for performance reasons. See TimeZoneInfo::LocalTime(). + // TODO: Fix the performance issue and remove the extra transitions. + transitions_.clear(); + transitions_.reserve(12); + for (const std::int_fast64_t unix_time : { + -(1LL << 59), // BIG_BANG + 1356998400LL, // 2013-01-01T00:00:00+00:00 + 1388534400LL, // 2014-01-01T00:00:00+00:00 + 1420070400LL, // 2015-01-01T00:00:00+00:00 + 1451606400LL, // 2016-01-01T00:00:00+00:00 + 1483228800LL, // 2017-01-01T00:00:00+00:00 + 1514764800LL, // 2018-01-01T00:00:00+00:00 + 1546300800LL, // 2019-01-01T00:00:00+00:00 + 1577836800LL, // 2020-01-01T00:00:00+00:00 + 1609459200LL, // 2021-01-01T00:00:00+00:00 + 1640995200LL, // 2022-01-01T00:00:00+00:00 + 1672531200LL, // 2023-01-01T00:00:00+00:00 + 2147483647LL, // 2^31 - 1 + }) { + Transition& tr(*transitions_.emplace(transitions_.end())); + tr.unix_time = unix_time; + tr.type_index = 0; + tr.civil_sec = LocalTime(tr.unix_time, tt).cs; + tr.prev_civil_sec = tr.civil_sec - 1; + } + + default_transition_type_ = 0; + abbreviations_ = FixedOffsetToAbbr(offset); + abbreviations_.append(1, '\0'); // add NUL + future_spec_.clear(); // never needed for a fixed-offset zone + extended_ = false; + + tt.civil_max = LocalTime(seconds::max().count(), tt).cs; + tt.civil_min = LocalTime(seconds::min().count(), tt).cs; + + transitions_.shrink_to_fit(); + return true; +} + +// Builds the in-memory header using the raw bytes from the file. +bool TimeZoneInfo::Header::Build(const tzhead& tzh) { + std::int_fast32_t v; + if ((v = Decode32(tzh.tzh_timecnt)) < 0) return false; + timecnt = static_cast<std::size_t>(v); + if ((v = Decode32(tzh.tzh_typecnt)) < 0) return false; + typecnt = static_cast<std::size_t>(v); + if ((v = Decode32(tzh.tzh_charcnt)) < 0) return false; + charcnt = static_cast<std::size_t>(v); + if ((v = Decode32(tzh.tzh_leapcnt)) < 0) return false; + leapcnt = static_cast<std::size_t>(v); + if ((v = Decode32(tzh.tzh_ttisstdcnt)) < 0) return false; + ttisstdcnt = static_cast<std::size_t>(v); + if ((v = Decode32(tzh.tzh_ttisutcnt)) < 0) return false; + ttisutcnt = static_cast<std::size_t>(v); + return true; +} + +// How many bytes of data are associated with this header. The result +// depends upon whether this is a section with 4-byte or 8-byte times. +std::size_t TimeZoneInfo::Header::DataLength(std::size_t time_len) const { + std::size_t len = 0; + len += (time_len + 1) * timecnt; // unix_time + type_index + len += (4 + 1 + 1) * typecnt; // utc_offset + is_dst + abbr_index + len += 1 * charcnt; // abbreviations + len += (time_len + 4) * leapcnt; // leap-time + TAI-UTC + len += 1 * ttisstdcnt; // UTC/local indicators + len += 1 * ttisutcnt; // standard/wall indicators + return len; +} + +// Check that the TransitionType has the expected offset/is_dst/abbreviation. +void TimeZoneInfo::CheckTransition(const std::string& name, + const TransitionType& tt, + std::int_fast32_t offset, bool is_dst, + const std::string& abbr) const { + if (tt.utc_offset != offset || tt.is_dst != is_dst || + &abbreviations_[tt.abbr_index] != abbr) { + std::clog << name << ": Transition" + << " offset=" << tt.utc_offset << "/" + << (tt.is_dst ? "DST" : "STD") + << "/abbr=" << &abbreviations_[tt.abbr_index] + << " does not match POSIX spec '" << future_spec_ << "'\n"; + } +} + +// zic(8) can generate no-op transitions when a zone changes rules at an +// instant when there is actually no discontinuity. So we check whether +// two transitions have equivalent types (same offset/is_dst/abbr). +bool TimeZoneInfo::EquivTransitions(std::uint_fast8_t tt1_index, + std::uint_fast8_t tt2_index) const { + if (tt1_index == tt2_index) return true; + const TransitionType& tt1(transition_types_[tt1_index]); + const TransitionType& tt2(transition_types_[tt2_index]); + if (tt1.is_dst != tt2.is_dst) return false; + if (tt1.utc_offset != tt2.utc_offset) return false; + if (tt1.abbr_index != tt2.abbr_index) return false; + return true; +} + +// Use the POSIX-TZ-environment-variable-style string to handle times +// in years after the last transition stored in the zoneinfo data. +void TimeZoneInfo::ExtendTransitions(const std::string& name, + const Header& hdr) { + extended_ = false; + bool extending = !future_spec_.empty(); + + PosixTimeZone posix; + if (extending && !ParsePosixSpec(future_spec_, &posix)) { + std::clog << name << ": Failed to parse '" << future_spec_ << "'\n"; + extending = false; + } + + if (extending && posix.dst_abbr.empty()) { // std only + // The future specification should match the last/default transition, + // and that means that handling the future will fall out naturally. + std::uint_fast8_t index = default_transition_type_; + if (hdr.timecnt != 0) index = transitions_[hdr.timecnt - 1].type_index; + const TransitionType& tt(transition_types_[index]); + CheckTransition(name, tt, posix.std_offset, false, posix.std_abbr); + extending = false; + } + + if (extending && hdr.timecnt < 2) { + std::clog << name << ": Too few transitions for POSIX spec\n"; + extending = false; + } + + if (!extending) { + // Ensure that there is always a transition in the second half of the + // time line (the BIG_BANG transition is in the first half) so that the + // signed difference between a civil_second and the civil_second of its + // previous transition is always representable, without overflow. + const Transition& last(transitions_.back()); + if (last.unix_time < 0) { + const std::uint_fast8_t type_index = last.type_index; + Transition& tr(*transitions_.emplace(transitions_.end())); + tr.unix_time = 2147483647; // 2038-01-19T03:14:07+00:00 + tr.type_index = type_index; + } + return; // last transition wins + } + + // Extend the transitions for an additional 400 years using the + // future specification. Years beyond those can be handled by + // mapping back to a cycle-equivalent year within that range. + // zic(8) should probably do this so that we don't have to. + // TODO: Reduce the extension by the number of compatible + // transitions already in place. + transitions_.reserve(hdr.timecnt + 400 * 2 + 1); + transitions_.resize(hdr.timecnt + 400 * 2); + extended_ = true; + + // The future specification should match the last two transitions, + // and those transitions should have different is_dst flags. Note + // that nothing says the UTC offset used by the is_dst transition + // must be greater than that used by the !is_dst transition. (See + // Europe/Dublin, for example.) + const Transition* tr0 = &transitions_[hdr.timecnt - 1]; + const Transition* tr1 = &transitions_[hdr.timecnt - 2]; + const TransitionType* tt0 = &transition_types_[tr0->type_index]; + const TransitionType* tt1 = &transition_types_[tr1->type_index]; + const TransitionType& dst(tt0->is_dst ? *tt0 : *tt1); + const TransitionType& std(tt0->is_dst ? *tt1 : *tt0); + CheckTransition(name, dst, posix.dst_offset, true, posix.dst_abbr); + CheckTransition(name, std, posix.std_offset, false, posix.std_abbr); + + // Add the transitions to tr1 and back to tr0 for each extra year. + last_year_ = LocalTime(tr0->unix_time, *tt0).cs.year(); + bool leap_year = IsLeap(last_year_); + const civil_day jan1(last_year_, 1, 1); + std::int_fast64_t jan1_time = civil_second(jan1) - civil_second(); + int jan1_weekday = (static_cast<int>(get_weekday(jan1)) + 1) % 7; + Transition* tr = &transitions_[hdr.timecnt]; // next trans to fill + if (LocalTime(tr1->unix_time, *tt1).cs.year() != last_year_) { + // Add a single extra transition to align to a calendar year. + transitions_.resize(transitions_.size() + 1); + assert(tr == &transitions_[hdr.timecnt]); // no reallocation + const PosixTransition& pt1(tt0->is_dst ? posix.dst_end : posix.dst_start); + std::int_fast64_t tr1_offset = TransOffset(leap_year, jan1_weekday, pt1); + tr->unix_time = jan1_time + tr1_offset - tt0->utc_offset; + tr++->type_index = tr1->type_index; + tr0 = &transitions_[hdr.timecnt]; + tr1 = &transitions_[hdr.timecnt - 1]; + tt0 = &transition_types_[tr0->type_index]; + tt1 = &transition_types_[tr1->type_index]; + } + const PosixTransition& pt1(tt0->is_dst ? posix.dst_end : posix.dst_start); + const PosixTransition& pt0(tt0->is_dst ? posix.dst_start : posix.dst_end); + for (const year_t limit = last_year_ + 400; last_year_ < limit;) { + last_year_ += 1; // an additional year of generated transitions + jan1_time += kSecsPerYear[leap_year]; + jan1_weekday = (jan1_weekday + kDaysPerYear[leap_year]) % 7; + leap_year = !leap_year && IsLeap(last_year_); + std::int_fast64_t tr1_offset = TransOffset(leap_year, jan1_weekday, pt1); + tr->unix_time = jan1_time + tr1_offset - tt0->utc_offset; + tr++->type_index = tr1->type_index; + std::int_fast64_t tr0_offset = TransOffset(leap_year, jan1_weekday, pt0); + tr->unix_time = jan1_time + tr0_offset - tt1->utc_offset; + tr++->type_index = tr0->type_index; + } + assert(tr == &transitions_[0] + transitions_.size()); +} + +bool TimeZoneInfo::Load(const std::string& name, ZoneInfoSource* zip) { + // Read and validate the header. + tzhead tzh; + if (zip->Read(&tzh, sizeof(tzh)) != sizeof(tzh)) return false; + if (strncmp(tzh.tzh_magic, TZ_MAGIC, sizeof(tzh.tzh_magic)) != 0) + return false; + Header hdr; + if (!hdr.Build(tzh)) return false; + std::size_t time_len = 4; + if (tzh.tzh_version[0] != '\0') { + // Skip the 4-byte data. + if (zip->Skip(hdr.DataLength(time_len)) != 0) return false; + // Read and validate the header for the 8-byte data. + if (zip->Read(&tzh, sizeof(tzh)) != sizeof(tzh)) return false; + if (strncmp(tzh.tzh_magic, TZ_MAGIC, sizeof(tzh.tzh_magic)) != 0) + return false; + if (tzh.tzh_version[0] == '\0') return false; + if (!hdr.Build(tzh)) return false; + time_len = 8; + } + if (hdr.typecnt == 0) return false; + if (hdr.leapcnt != 0) { + // This code assumes 60-second minutes so we do not want + // the leap-second encoded zoneinfo. We could reverse the + // compensation, but the "right" encoding is rarely used + // so currently we simply reject such data. + return false; + } + if (hdr.ttisstdcnt != 0 && hdr.ttisstdcnt != hdr.typecnt) return false; + if (hdr.ttisutcnt != 0 && hdr.ttisutcnt != hdr.typecnt) return false; + + // Read the data into a local buffer. + std::size_t len = hdr.DataLength(time_len); + std::vector<char> tbuf(len); + if (zip->Read(tbuf.data(), len) != len) return false; + const char* bp = tbuf.data(); + + // Decode and validate the transitions. + transitions_.reserve(hdr.timecnt + 2); // We might add a couple. + transitions_.resize(hdr.timecnt); + for (std::size_t i = 0; i != hdr.timecnt; ++i) { + transitions_[i].unix_time = (time_len == 4) ? Decode32(bp) : Decode64(bp); + bp += time_len; + if (i != 0) { + // Check that the transitions are ordered by time (as zic guarantees). + if (!Transition::ByUnixTime()(transitions_[i - 1], transitions_[i])) + return false; // out of order + } + } + bool seen_type_0 = false; + for (std::size_t i = 0; i != hdr.timecnt; ++i) { + transitions_[i].type_index = Decode8(bp++); + if (transitions_[i].type_index >= hdr.typecnt) return false; + if (transitions_[i].type_index == 0) seen_type_0 = true; + } + + // Decode and validate the transition types. + transition_types_.resize(hdr.typecnt); + for (std::size_t i = 0; i != hdr.typecnt; ++i) { + transition_types_[i].utc_offset = + static_cast<std::int_least32_t>(Decode32(bp)); + if (transition_types_[i].utc_offset >= kSecsPerDay || + transition_types_[i].utc_offset <= -kSecsPerDay) + return false; + bp += 4; + transition_types_[i].is_dst = (Decode8(bp++) != 0); + transition_types_[i].abbr_index = Decode8(bp++); + if (transition_types_[i].abbr_index >= hdr.charcnt) return false; + } + + // Determine the before-first-transition type. + default_transition_type_ = 0; + if (seen_type_0 && hdr.timecnt != 0) { + std::uint_fast8_t index = 0; + if (transition_types_[0].is_dst) { + index = transitions_[0].type_index; + while (index != 0 && transition_types_[index].is_dst) --index; + } + while (index != hdr.typecnt && transition_types_[index].is_dst) ++index; + if (index != hdr.typecnt) default_transition_type_ = index; + } + + // Copy all the abbreviations. + abbreviations_.assign(bp, hdr.charcnt); + bp += hdr.charcnt; + + // Skip the unused portions. We've already dispensed with leap-second + // encoded zoneinfo. The ttisstd/ttisgmt indicators only apply when + // interpreting a POSIX spec that does not include start/end rules, and + // that isn't the case here (see "zic -p"). + bp += (8 + 4) * hdr.leapcnt; // leap-time + TAI-UTC + bp += 1 * hdr.ttisstdcnt; // UTC/local indicators + bp += 1 * hdr.ttisutcnt; // standard/wall indicators + assert(bp == tbuf.data() + tbuf.size()); + + future_spec_.clear(); + if (tzh.tzh_version[0] != '\0') { + // Snarf up the NL-enclosed future POSIX spec. Note + // that version '3' files utilize an extended format. + auto get_char = [](ZoneInfoSource* azip) -> int { + unsigned char ch; // all non-EOF results are positive + return (azip->Read(&ch, 1) == 1) ? ch : EOF; + }; + if (get_char(zip) != '\n') return false; + for (int c = get_char(zip); c != '\n'; c = get_char(zip)) { + if (c == EOF) return false; + future_spec_.push_back(static_cast<char>(c)); + } + } + + // We don't check for EOF so that we're forwards compatible. + + // If we did not find version information during the standard loading + // process (as of tzh_version '3' that is unsupported), then ask the + // ZoneInfoSource for any out-of-bound version string it may be privy to. + if (version_.empty()) { + version_ = zip->Version(); + } + + // Trim redundant transitions. zic may have added these to work around + // differences between the glibc and reference implementations (see + // zic.c:dontmerge) and the Qt library (see zic.c:WORK_AROUND_QTBUG_53071). + // For us, they just get in the way when we do future_spec_ extension. + while (hdr.timecnt > 1) { + if (!EquivTransitions(transitions_[hdr.timecnt - 1].type_index, + transitions_[hdr.timecnt - 2].type_index)) { + break; + } + hdr.timecnt -= 1; + } + transitions_.resize(hdr.timecnt); + + // Ensure that there is always a transition in the first half of the + // time line (the second half is handled in ExtendTransitions()) so that + // the signed difference between a civil_second and the civil_second of + // its previous transition is always representable, without overflow. + // A contemporary zic will usually have already done this for us. + if (transitions_.empty() || transitions_.front().unix_time >= 0) { + Transition& tr(*transitions_.emplace(transitions_.begin())); + tr.unix_time = -(1LL << 59); // see tz/zic.c "BIG_BANG" + tr.type_index = default_transition_type_; + hdr.timecnt += 1; + } + + // Extend the transitions using the future specification. + ExtendTransitions(name, hdr); + + // Compute the local civil time for each transition and the preceding + // second. These will be used for reverse conversions in MakeTime(). + const TransitionType* ttp = &transition_types_[default_transition_type_]; + for (std::size_t i = 0; i != transitions_.size(); ++i) { + Transition& tr(transitions_[i]); + tr.prev_civil_sec = LocalTime(tr.unix_time, *ttp).cs - 1; + ttp = &transition_types_[tr.type_index]; + tr.civil_sec = LocalTime(tr.unix_time, *ttp).cs; + if (i != 0) { + // Check that the transitions are ordered by civil time. Essentially + // this means that an offset change cannot cross another such change. + // No one does this in practice, and we depend on it in MakeTime(). + if (!Transition::ByCivilTime()(transitions_[i - 1], tr)) + return false; // out of order + } + } + + // Compute the maximum/minimum civil times that can be converted to a + // time_point<seconds> for each of the zone's transition types. + for (auto& tt : transition_types_) { + tt.civil_max = LocalTime(seconds::max().count(), tt).cs; + tt.civil_min = LocalTime(seconds::min().count(), tt).cs; + } + + transitions_.shrink_to_fit(); + return true; +} + +namespace { + +// fopen(3) adaptor. +inline FILE* FOpen(const char* path, const char* mode) { +#if defined(_MSC_VER) + FILE* fp; + if (fopen_s(&fp, path, mode) != 0) fp = nullptr; + return fp; +#else + return fopen(path, mode); // TODO: Enable the close-on-exec flag. +#endif +} + +// A stdio(3)-backed implementation of ZoneInfoSource. +class FileZoneInfoSource : public ZoneInfoSource { + public: + static std::unique_ptr<ZoneInfoSource> Open(const std::string& name); + + std::size_t Read(void* ptr, std::size_t size) override { + size = std::min(size, len_); + std::size_t nread = fread(ptr, 1, size, fp_.get()); + len_ -= nread; + return nread; + } + int Skip(std::size_t offset) override { + offset = std::min(offset, len_); + int rc = fseek(fp_.get(), static_cast<long>(offset), SEEK_CUR); + if (rc == 0) len_ -= offset; + return rc; + } + std::string Version() const override { + // TODO: It would nice if the zoneinfo data included the tzdb version. + return std::string(); + } + + protected: + explicit FileZoneInfoSource( + FILE* fp, std::size_t len = std::numeric_limits<std::size_t>::max()) + : fp_(fp, fclose), len_(len) {} + + private: + std::unique_ptr<FILE, int (*)(FILE*)> fp_; + std::size_t len_; +}; + +std::unique_ptr<ZoneInfoSource> FileZoneInfoSource::Open( + const std::string& name) { + // Use of the "file:" prefix is intended for testing purposes only. + const std::size_t pos = (name.compare(0, 5, "file:") == 0) ? 5 : 0; + + // Map the time-zone name to a path name. + std::string path; + if (pos == name.size() || name[pos] != '/') { + const char* tzdir = "/usr/share/zoneinfo"; + char* tzdir_env = nullptr; +#if defined(_MSC_VER) + _dupenv_s(&tzdir_env, nullptr, "TZDIR"); +#else + tzdir_env = std::getenv("TZDIR"); +#endif + if (tzdir_env && *tzdir_env) tzdir = tzdir_env; + path += tzdir; + path += '/'; +#if defined(_MSC_VER) + free(tzdir_env); +#endif + } + path.append(name, pos, std::string::npos); + + // Open the zoneinfo file. + FILE* fp = FOpen(path.c_str(), "rb"); + if (fp == nullptr) return nullptr; + std::size_t length = 0; + if (fseek(fp, 0, SEEK_END) == 0) { + long offset = ftell(fp); + if (offset >= 0) { + length = static_cast<std::size_t>(offset); + } + rewind(fp); + } + return std::unique_ptr<ZoneInfoSource>(new FileZoneInfoSource(fp, length)); +} + +class AndroidZoneInfoSource : public FileZoneInfoSource { + public: + static std::unique_ptr<ZoneInfoSource> Open(const std::string& name); + std::string Version() const override { return version_; } + + private: + explicit AndroidZoneInfoSource(FILE* fp, std::size_t len, const char* vers) + : FileZoneInfoSource(fp, len), version_(vers) {} + std::string version_; +}; + +std::unique_ptr<ZoneInfoSource> AndroidZoneInfoSource::Open( + const std::string& name) { + // Use of the "file:" prefix is intended for testing purposes only. + const std::size_t pos = (name.compare(0, 5, "file:") == 0) ? 5 : 0; + + // See Android's libc/tzcode/bionic.cpp for additional information. + for (const char* tzdata : {"/data/misc/zoneinfo/current/tzdata", + "/system/usr/share/zoneinfo/tzdata"}) { + std::unique_ptr<FILE, int (*)(FILE*)> fp(FOpen(tzdata, "rb"), fclose); + if (fp.get() == nullptr) continue; + + char hbuf[24]; // covers header.zonetab_offset too + if (fread(hbuf, 1, sizeof(hbuf), fp.get()) != sizeof(hbuf)) continue; + if (strncmp(hbuf, "tzdata", 6) != 0) continue; + const char* vers = (hbuf[11] == '\0') ? hbuf + 6 : ""; + const std::int_fast32_t index_offset = Decode32(hbuf + 12); + const std::int_fast32_t data_offset = Decode32(hbuf + 16); + if (index_offset < 0 || data_offset < index_offset) continue; + if (fseek(fp.get(), static_cast<long>(index_offset), SEEK_SET) != 0) + continue; + + char ebuf[52]; // covers entry.unused too + const std::size_t index_size = + static_cast<std::size_t>(data_offset - index_offset); + const std::size_t zonecnt = index_size / sizeof(ebuf); + if (zonecnt * sizeof(ebuf) != index_size) continue; + for (std::size_t i = 0; i != zonecnt; ++i) { + if (fread(ebuf, 1, sizeof(ebuf), fp.get()) != sizeof(ebuf)) break; + const std::int_fast32_t start = data_offset + Decode32(ebuf + 40); + const std::int_fast32_t length = Decode32(ebuf + 44); + if (start < 0 || length < 0) break; + ebuf[40] = '\0'; // ensure zone name is NUL terminated + if (strcmp(name.c_str() + pos, ebuf) == 0) { + if (fseek(fp.get(), static_cast<long>(start), SEEK_SET) != 0) break; + return std::unique_ptr<ZoneInfoSource>(new AndroidZoneInfoSource( + fp.release(), static_cast<std::size_t>(length), vers)); + } + } + } + + return nullptr; +} + +} // namespace + +bool TimeZoneInfo::Load(const std::string& name) { + // We can ensure that the loading of UTC or any other fixed-offset + // zone never fails because the simple, fixed-offset state can be + // internally generated. Note that this depends on our choice to not + // accept leap-second encoded ("right") zoneinfo. + auto offset = seconds::zero(); + if (FixedOffsetFromName(name, &offset)) { + return ResetToBuiltinUTC(offset); + } + + // Find and use a ZoneInfoSource to load the named zone. + auto zip = cctz_extension::zone_info_source_factory( + name, [](const std::string& name) -> std::unique_ptr<ZoneInfoSource> { + if (auto zip = FileZoneInfoSource::Open(name)) return zip; + if (auto zip = AndroidZoneInfoSource::Open(name)) return zip; + return nullptr; + }); + return zip != nullptr && Load(name, zip.get()); +} + +// BreakTime() translation for a particular transition type. +time_zone::absolute_lookup TimeZoneInfo::LocalTime( + std::int_fast64_t unix_time, const TransitionType& tt) const { + // A civil time in "+offset" looks like (time+offset) in UTC. + // Note: We perform two additions in the civil_second domain to + // sidestep the chance of overflow in (unix_time + tt.utc_offset). + return {(civil_second() + unix_time) + tt.utc_offset, tt.utc_offset, + tt.is_dst, &abbreviations_[tt.abbr_index]}; +} + +// BreakTime() translation for a particular transition. +time_zone::absolute_lookup TimeZoneInfo::LocalTime(std::int_fast64_t unix_time, + const Transition& tr) const { + const TransitionType& tt = transition_types_[tr.type_index]; + // Note: (unix_time - tr.unix_time) will never overflow as we + // have ensured that there is always a "nearby" transition. + return {tr.civil_sec + (unix_time - tr.unix_time), // TODO: Optimize. + tt.utc_offset, tt.is_dst, &abbreviations_[tt.abbr_index]}; +} + +// MakeTime() translation with a conversion-preserving +N * 400-year shift. +time_zone::civil_lookup TimeZoneInfo::TimeLocal(const civil_second& cs, + year_t c4_shift) const { + assert(last_year_ - 400 < cs.year() && cs.year() <= last_year_); + time_zone::civil_lookup cl = MakeTime(cs); + if (c4_shift > seconds::max().count() / kSecsPer400Years) { + cl.pre = cl.trans = cl.post = time_point<seconds>::max(); + } else { + const auto offset = seconds(c4_shift * kSecsPer400Years); + const auto limit = time_point<seconds>::max() - offset; + for (auto* tp : {&cl.pre, &cl.trans, &cl.post}) { + if (*tp > limit) { + *tp = time_point<seconds>::max(); + } else { + *tp += offset; + } + } + } + return cl; +} + +time_zone::absolute_lookup TimeZoneInfo::BreakTime( + const time_point<seconds>& tp) const { + std::int_fast64_t unix_time = ToUnixSeconds(tp); + const std::size_t timecnt = transitions_.size(); + assert(timecnt != 0); // We always add a transition. + + if (unix_time < transitions_[0].unix_time) { + return LocalTime(unix_time, transition_types_[default_transition_type_]); + } + if (unix_time >= transitions_[timecnt - 1].unix_time) { + // After the last transition. If we extended the transitions using + // future_spec_, shift back to a supported year using the 400-year + // cycle of calendaric equivalence and then compensate accordingly. + if (extended_) { + const std::int_fast64_t diff = + unix_time - transitions_[timecnt - 1].unix_time; + const year_t shift = diff / kSecsPer400Years + 1; + const auto d = seconds(shift * kSecsPer400Years); + time_zone::absolute_lookup al = BreakTime(tp - d); + al.cs = YearShift(al.cs, shift * 400); + return al; + } + return LocalTime(unix_time, transitions_[timecnt - 1]); + } + + const std::size_t hint = local_time_hint_.load(std::memory_order_relaxed); + if (0 < hint && hint < timecnt) { + if (transitions_[hint - 1].unix_time <= unix_time) { + if (unix_time < transitions_[hint].unix_time) { + return LocalTime(unix_time, transitions_[hint - 1]); + } + } + } + + const Transition target = {unix_time, 0, civil_second(), civil_second()}; + const Transition* begin = &transitions_[0]; + const Transition* tr = std::upper_bound(begin, begin + timecnt, target, + Transition::ByUnixTime()); + local_time_hint_.store(static_cast<std::size_t>(tr - begin), + std::memory_order_relaxed); + return LocalTime(unix_time, *--tr); +} + +time_zone::civil_lookup TimeZoneInfo::MakeTime(const civil_second& cs) const { + const std::size_t timecnt = transitions_.size(); + assert(timecnt != 0); // We always add a transition. + + // Find the first transition after our target civil time. + const Transition* tr = nullptr; + const Transition* begin = &transitions_[0]; + const Transition* end = begin + timecnt; + if (cs < begin->civil_sec) { + tr = begin; + } else if (cs >= transitions_[timecnt - 1].civil_sec) { + tr = end; + } else { + const std::size_t hint = time_local_hint_.load(std::memory_order_relaxed); + if (0 < hint && hint < timecnt) { + if (transitions_[hint - 1].civil_sec <= cs) { + if (cs < transitions_[hint].civil_sec) { + tr = begin + hint; + } + } + } + if (tr == nullptr) { + const Transition target = {0, 0, cs, civil_second()}; + tr = std::upper_bound(begin, end, target, Transition::ByCivilTime()); + time_local_hint_.store(static_cast<std::size_t>(tr - begin), + std::memory_order_relaxed); + } + } + + if (tr == begin) { + if (tr->prev_civil_sec >= cs) { + // Before first transition, so use the default offset. + const TransitionType& tt(transition_types_[default_transition_type_]); + if (cs < tt.civil_min) return MakeUnique(time_point<seconds>::min()); + return MakeUnique(cs - (civil_second() + tt.utc_offset)); + } + // tr->prev_civil_sec < cs < tr->civil_sec + return MakeSkipped(*tr, cs); + } + + if (tr == end) { + if (cs > (--tr)->prev_civil_sec) { + // After the last transition. If we extended the transitions using + // future_spec_, shift back to a supported year using the 400-year + // cycle of calendaric equivalence and then compensate accordingly. + if (extended_ && cs.year() > last_year_) { + const year_t shift = (cs.year() - last_year_ - 1) / 400 + 1; + return TimeLocal(YearShift(cs, shift * -400), shift); + } + const TransitionType& tt(transition_types_[tr->type_index]); + if (cs > tt.civil_max) return MakeUnique(time_point<seconds>::max()); + return MakeUnique(tr->unix_time + (cs - tr->civil_sec)); + } + // tr->civil_sec <= cs <= tr->prev_civil_sec + return MakeRepeated(*tr, cs); + } + + if (tr->prev_civil_sec < cs) { + // tr->prev_civil_sec < cs < tr->civil_sec + return MakeSkipped(*tr, cs); + } + + if (cs <= (--tr)->prev_civil_sec) { + // tr->civil_sec <= cs <= tr->prev_civil_sec + return MakeRepeated(*tr, cs); + } + + // In between transitions. + return MakeUnique(tr->unix_time + (cs - tr->civil_sec)); +} + +std::string TimeZoneInfo::Version() const { return version_; } + +std::string TimeZoneInfo::Description() const { + std::ostringstream oss; + oss << "#trans=" << transitions_.size(); + oss << " #types=" << transition_types_.size(); + oss << " spec='" << future_spec_ << "'"; + return oss.str(); +} + +bool TimeZoneInfo::NextTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const { + if (transitions_.empty()) return false; + const Transition* begin = &transitions_[0]; + const Transition* end = begin + transitions_.size(); + if (begin->unix_time <= -(1LL << 59)) { + // Do not report the BIG_BANG found in recent zoneinfo data as it is + // really a sentinel, not a transition. See tz/zic.c. + ++begin; + } + std::int_fast64_t unix_time = ToUnixSeconds(tp); + const Transition target = {unix_time, 0, civil_second(), civil_second()}; + const Transition* tr = + std::upper_bound(begin, end, target, Transition::ByUnixTime()); + for (; tr != end; ++tr) { // skip no-op transitions + std::uint_fast8_t prev_type_index = + (tr == begin) ? default_transition_type_ : tr[-1].type_index; + if (!EquivTransitions(prev_type_index, tr[0].type_index)) break; + } + // When tr == end we return false, ignoring future_spec_. + if (tr == end) return false; + trans->from = tr->prev_civil_sec + 1; + trans->to = tr->civil_sec; + return true; +} + +bool TimeZoneInfo::PrevTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const { + if (transitions_.empty()) return false; + const Transition* begin = &transitions_[0]; + const Transition* end = begin + transitions_.size(); + if (begin->unix_time <= -(1LL << 59)) { + // Do not report the BIG_BANG found in recent zoneinfo data as it is + // really a sentinel, not a transition. See tz/zic.c. + ++begin; + } + std::int_fast64_t unix_time = ToUnixSeconds(tp); + if (FromUnixSeconds(unix_time) != tp) { + if (unix_time == std::numeric_limits<std::int_fast64_t>::max()) { + if (end == begin) return false; // Ignore future_spec_. + trans->from = (--end)->prev_civil_sec + 1; + trans->to = end->civil_sec; + return true; + } + unix_time += 1; // ceils + } + const Transition target = {unix_time, 0, civil_second(), civil_second()}; + const Transition* tr = + std::lower_bound(begin, end, target, Transition::ByUnixTime()); + for (; tr != begin; --tr) { // skip no-op transitions + std::uint_fast8_t prev_type_index = + (tr - 1 == begin) ? default_transition_type_ : tr[-2].type_index; + if (!EquivTransitions(prev_type_index, tr[-1].type_index)) break; + } + // When tr == end we return the "last" transition, ignoring future_spec_. + if (tr == begin) return false; + trans->from = (--tr)->prev_civil_sec + 1; + trans->to = tr->civil_sec; + return true; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_info.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_info.h new file mode 100644 index 0000000000..2a10c06c77 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_info.h @@ -0,0 +1,138 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_INFO_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_INFO_H_ + +#include <atomic> +#include <cstddef> +#include <cstdint> +#include <string> +#include <vector> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" +#include "absl/time/internal/cctz/include/cctz/zone_info_source.h" +#include "time_zone_if.h" +#include "tzfile.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// A transition to a new UTC offset. +struct Transition { + std::int_least64_t unix_time; // the instant of this transition + std::uint_least8_t type_index; // index of the transition type + civil_second civil_sec; // local civil time of transition + civil_second prev_civil_sec; // local civil time one second earlier + + struct ByUnixTime { + inline bool operator()(const Transition& lhs, const Transition& rhs) const { + return lhs.unix_time < rhs.unix_time; + } + }; + struct ByCivilTime { + inline bool operator()(const Transition& lhs, const Transition& rhs) const { + return lhs.civil_sec < rhs.civil_sec; + } + }; +}; + +// The characteristics of a particular transition. +struct TransitionType { + std::int_least32_t utc_offset; // the new prevailing UTC offset + civil_second civil_max; // max convertible civil time for offset + civil_second civil_min; // min convertible civil time for offset + bool is_dst; // did we move into daylight-saving time + std::uint_least8_t abbr_index; // index of the new abbreviation +}; + +// A time zone backed by the IANA Time Zone Database (zoneinfo). +class TimeZoneInfo : public TimeZoneIf { + public: + TimeZoneInfo() = default; + TimeZoneInfo(const TimeZoneInfo&) = delete; + TimeZoneInfo& operator=(const TimeZoneInfo&) = delete; + + // Loads the zoneinfo for the given name, returning true if successful. + bool Load(const std::string& name); + + // TimeZoneIf implementations. + time_zone::absolute_lookup BreakTime( + const time_point<seconds>& tp) const override; + time_zone::civil_lookup MakeTime(const civil_second& cs) const override; + bool NextTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const override; + bool PrevTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const override; + std::string Version() const override; + std::string Description() const override; + + private: + struct Header { // counts of: + std::size_t timecnt; // transition times + std::size_t typecnt; // transition types + std::size_t charcnt; // zone abbreviation characters + std::size_t leapcnt; // leap seconds (we expect none) + std::size_t ttisstdcnt; // UTC/local indicators (unused) + std::size_t ttisutcnt; // standard/wall indicators (unused) + + bool Build(const tzhead& tzh); + std::size_t DataLength(std::size_t time_len) const; + }; + + void CheckTransition(const std::string& name, const TransitionType& tt, + std::int_fast32_t offset, bool is_dst, + const std::string& abbr) const; + bool EquivTransitions(std::uint_fast8_t tt1_index, + std::uint_fast8_t tt2_index) const; + void ExtendTransitions(const std::string& name, const Header& hdr); + + bool ResetToBuiltinUTC(const seconds& offset); + bool Load(const std::string& name, ZoneInfoSource* zip); + + // Helpers for BreakTime() and MakeTime(). + time_zone::absolute_lookup LocalTime(std::int_fast64_t unix_time, + const TransitionType& tt) const; + time_zone::absolute_lookup LocalTime(std::int_fast64_t unix_time, + const Transition& tr) const; + time_zone::civil_lookup TimeLocal(const civil_second& cs, + year_t c4_shift) const; + + std::vector<Transition> transitions_; // ordered by unix_time and civil_sec + std::vector<TransitionType> transition_types_; // distinct transition types + std::uint_fast8_t default_transition_type_; // for before first transition + std::string abbreviations_; // all the NUL-terminated abbreviations + + std::string version_; // the tzdata version if available + std::string future_spec_; // for after the last zic transition + bool extended_; // future_spec_ was used to generate transitions + year_t last_year_; // the final year of the generated transitions + + // We remember the transitions found during the last BreakTime() and + // MakeTime() calls. If the next request is for the same transition we + // will avoid re-searching. + mutable std::atomic<std::size_t> local_time_hint_ = {}; // BreakTime() hint + mutable std::atomic<std::size_t> time_local_hint_ = {}; // MakeTime() hint +}; + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_INFO_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_libc.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_libc.cc new file mode 100644 index 0000000000..47cf84c663 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_libc.cc @@ -0,0 +1,308 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#if defined(_WIN32) || defined(_WIN64) +#define _CRT_SECURE_NO_WARNINGS 1 +#endif + +#include "time_zone_libc.h" + +#include <chrono> +#include <ctime> +#include <limits> +#include <utility> + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +#if defined(_WIN32) || defined(_WIN64) +// Uses the globals: '_timezone', '_dstbias' and '_tzname'. +auto tm_gmtoff(const std::tm& tm) -> decltype(_timezone + _dstbias) { + const bool is_dst = tm.tm_isdst > 0; + return _timezone + (is_dst ? _dstbias : 0); +} +auto tm_zone(const std::tm& tm) -> decltype(_tzname[0]) { + const bool is_dst = tm.tm_isdst > 0; + return _tzname[is_dst]; +} +#elif defined(__sun) +// Uses the globals: 'timezone', 'altzone' and 'tzname'. +auto tm_gmtoff(const std::tm& tm) -> decltype(timezone) { + const bool is_dst = tm.tm_isdst > 0; + return is_dst ? altzone : timezone; +} +auto tm_zone(const std::tm& tm) -> decltype(tzname[0]) { + const bool is_dst = tm.tm_isdst > 0; + return tzname[is_dst]; +} +#elif defined(__native_client__) || defined(__myriad2__) || \ + defined(__EMSCRIPTEN__) +// Uses the globals: 'timezone' and 'tzname'. +auto tm_gmtoff(const std::tm& tm) -> decltype(_timezone + 0) { + const bool is_dst = tm.tm_isdst > 0; + return _timezone + (is_dst ? 60 * 60 : 0); +} +auto tm_zone(const std::tm& tm) -> decltype(tzname[0]) { + const bool is_dst = tm.tm_isdst > 0; + return tzname[is_dst]; +} +#else +// Adapt to different spellings of the struct std::tm extension fields. +#if defined(tm_gmtoff) +auto tm_gmtoff(const std::tm& tm) -> decltype(tm.tm_gmtoff) { + return tm.tm_gmtoff; +} +#elif defined(__tm_gmtoff) +auto tm_gmtoff(const std::tm& tm) -> decltype(tm.__tm_gmtoff) { + return tm.__tm_gmtoff; +} +#else +template <typename T> +auto tm_gmtoff(const T& tm) -> decltype(tm.tm_gmtoff) { + return tm.tm_gmtoff; +} +template <typename T> +auto tm_gmtoff(const T& tm) -> decltype(tm.__tm_gmtoff) { + return tm.__tm_gmtoff; +} +#endif // tm_gmtoff +#if defined(tm_zone) +auto tm_zone(const std::tm& tm) -> decltype(tm.tm_zone) { return tm.tm_zone; } +#elif defined(__tm_zone) +auto tm_zone(const std::tm& tm) -> decltype(tm.__tm_zone) { + return tm.__tm_zone; +} +#else +template <typename T> +auto tm_zone(const T& tm) -> decltype(tm.tm_zone) { + return tm.tm_zone; +} +template <typename T> +auto tm_zone(const T& tm) -> decltype(tm.__tm_zone) { + return tm.__tm_zone; +} +#endif // tm_zone +#endif + +inline std::tm* gm_time(const std::time_t* timep, std::tm* result) { +#if defined(_WIN32) || defined(_WIN64) + return gmtime_s(result, timep) ? nullptr : result; +#else + return gmtime_r(timep, result); +#endif +} + +inline std::tm* local_time(const std::time_t* timep, std::tm* result) { +#if defined(_WIN32) || defined(_WIN64) + return localtime_s(result, timep) ? nullptr : result; +#else + return localtime_r(timep, result); +#endif +} + +// Converts a civil second and "dst" flag into a time_t and UTC offset. +// Returns false if time_t cannot represent the requested civil second. +// Caller must have already checked that cs.year() will fit into a tm_year. +bool make_time(const civil_second& cs, int is_dst, std::time_t* t, int* off) { + std::tm tm; + tm.tm_year = static_cast<int>(cs.year() - year_t{1900}); + tm.tm_mon = cs.month() - 1; + tm.tm_mday = cs.day(); + tm.tm_hour = cs.hour(); + tm.tm_min = cs.minute(); + tm.tm_sec = cs.second(); + tm.tm_isdst = is_dst; + *t = std::mktime(&tm); + if (*t == std::time_t{-1}) { + std::tm tm2; + const std::tm* tmp = local_time(t, &tm2); + if (tmp == nullptr || tmp->tm_year != tm.tm_year || + tmp->tm_mon != tm.tm_mon || tmp->tm_mday != tm.tm_mday || + tmp->tm_hour != tm.tm_hour || tmp->tm_min != tm.tm_min || + tmp->tm_sec != tm.tm_sec) { + // A true error (not just one second before the epoch). + return false; + } + } + *off = static_cast<int>(tm_gmtoff(tm)); + return true; +} + +// Find the least time_t in [lo:hi] where local time matches offset, given: +// (1) lo doesn't match, (2) hi does, and (3) there is only one transition. +std::time_t find_trans(std::time_t lo, std::time_t hi, int offset) { + std::tm tm; + while (lo + 1 != hi) { + const std::time_t mid = lo + (hi - lo) / 2; + if (std::tm* tmp = local_time(&mid, &tm)) { + if (tm_gmtoff(*tmp) == offset) { + hi = mid; + } else { + lo = mid; + } + } else { + // If std::tm cannot hold some result we resort to a linear search, + // ignoring all failed conversions. Slow, but never really happens. + while (++lo != hi) { + if (std::tm* tmp = local_time(&lo, &tm)) { + if (tm_gmtoff(*tmp) == offset) break; + } + } + return lo; + } + } + return hi; +} + +} // namespace + +TimeZoneLibC::TimeZoneLibC(const std::string& name) + : local_(name == "localtime") {} + +time_zone::absolute_lookup TimeZoneLibC::BreakTime( + const time_point<seconds>& tp) const { + time_zone::absolute_lookup al; + al.offset = 0; + al.is_dst = false; + al.abbr = "-00"; + + const std::int_fast64_t s = ToUnixSeconds(tp); + + // If std::time_t cannot hold the input we saturate the output. + if (s < std::numeric_limits<std::time_t>::min()) { + al.cs = civil_second::min(); + return al; + } + if (s > std::numeric_limits<std::time_t>::max()) { + al.cs = civil_second::max(); + return al; + } + + const std::time_t t = static_cast<std::time_t>(s); + std::tm tm; + std::tm* tmp = local_ ? local_time(&t, &tm) : gm_time(&t, &tm); + + // If std::tm cannot hold the result we saturate the output. + if (tmp == nullptr) { + al.cs = (s < 0) ? civil_second::min() : civil_second::max(); + return al; + } + + const year_t year = tmp->tm_year + year_t{1900}; + al.cs = civil_second(year, tmp->tm_mon + 1, tmp->tm_mday, tmp->tm_hour, + tmp->tm_min, tmp->tm_sec); + al.offset = static_cast<int>(tm_gmtoff(*tmp)); + al.abbr = local_ ? tm_zone(*tmp) : "UTC"; // as expected by cctz + al.is_dst = tmp->tm_isdst > 0; + return al; +} + +time_zone::civil_lookup TimeZoneLibC::MakeTime(const civil_second& cs) const { + if (!local_) { + // If time_point<seconds> cannot hold the result we saturate. + static const civil_second min_tp_cs = + civil_second() + ToUnixSeconds(time_point<seconds>::min()); + static const civil_second max_tp_cs = + civil_second() + ToUnixSeconds(time_point<seconds>::max()); + const time_point<seconds> tp = + (cs < min_tp_cs) + ? time_point<seconds>::min() + : (cs > max_tp_cs) ? time_point<seconds>::max() + : FromUnixSeconds(cs - civil_second()); + return {time_zone::civil_lookup::UNIQUE, tp, tp, tp}; + } + + // If tm_year cannot hold the requested year we saturate the result. + if (cs.year() < 0) { + if (cs.year() < std::numeric_limits<int>::min() + year_t{1900}) { + const time_point<seconds> tp = time_point<seconds>::min(); + return {time_zone::civil_lookup::UNIQUE, tp, tp, tp}; + } + } else { + if (cs.year() - year_t{1900} > std::numeric_limits<int>::max()) { + const time_point<seconds> tp = time_point<seconds>::max(); + return {time_zone::civil_lookup::UNIQUE, tp, tp, tp}; + } + } + + // We probe with "is_dst" values of 0 and 1 to try to distinguish unique + // civil seconds from skipped or repeated ones. This is not always possible + // however, as the "dst" flag does not change over some offset transitions. + // We are also subject to the vagaries of mktime() implementations. + std::time_t t0, t1; + int offset0, offset1; + if (make_time(cs, 0, &t0, &offset0) && make_time(cs, 1, &t1, &offset1)) { + if (t0 == t1) { + // The civil time was singular (pre == trans == post). + const time_point<seconds> tp = FromUnixSeconds(t0); + return {time_zone::civil_lookup::UNIQUE, tp, tp, tp}; + } + + if (t0 > t1) { + std::swap(t0, t1); + std::swap(offset0, offset1); + } + const std::time_t tt = find_trans(t0, t1, offset1); + const time_point<seconds> trans = FromUnixSeconds(tt); + + if (offset0 < offset1) { + // The civil time did not exist (pre >= trans > post). + const time_point<seconds> pre = FromUnixSeconds(t1); + const time_point<seconds> post = FromUnixSeconds(t0); + return {time_zone::civil_lookup::SKIPPED, pre, trans, post}; + } + + // The civil time was ambiguous (pre < trans <= post). + const time_point<seconds> pre = FromUnixSeconds(t0); + const time_point<seconds> post = FromUnixSeconds(t1); + return {time_zone::civil_lookup::REPEATED, pre, trans, post}; + } + + // make_time() failed somehow so we saturate the result. + const time_point<seconds> tp = (cs < civil_second()) + ? time_point<seconds>::min() + : time_point<seconds>::max(); + return {time_zone::civil_lookup::UNIQUE, tp, tp, tp}; +} + +bool TimeZoneLibC::NextTransition(const time_point<seconds>&, + time_zone::civil_transition*) const { + return false; +} + +bool TimeZoneLibC::PrevTransition(const time_point<seconds>&, + time_zone::civil_transition*) const { + return false; +} + +std::string TimeZoneLibC::Version() const { + return std::string(); // unknown +} + +std::string TimeZoneLibC::Description() const { + return local_ ? "localtime" : "UTC"; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_libc.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_libc.h new file mode 100644 index 0000000000..1da9039a15 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_libc.h @@ -0,0 +1,55 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_LIBC_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_LIBC_H_ + +#include <string> + +#include "absl/base/config.h" +#include "time_zone_if.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// A time zone backed by gmtime_r(3), localtime_r(3), and mktime(3), +// and which therefore only supports UTC and the local time zone. +// TODO: Add support for fixed offsets from UTC. +class TimeZoneLibC : public TimeZoneIf { + public: + explicit TimeZoneLibC(const std::string& name); + + // TimeZoneIf implementations. + time_zone::absolute_lookup BreakTime( + const time_point<seconds>& tp) const override; + time_zone::civil_lookup MakeTime(const civil_second& cs) const override; + bool NextTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const override; + bool PrevTransition(const time_point<seconds>& tp, + time_zone::civil_transition* trans) const override; + std::string Version() const override; + std::string Description() const override; + + private: + const bool local_; // localtime or UTC +}; + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_LIBC_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_lookup.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_lookup.cc new file mode 100644 index 0000000000..efdea64b4e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_lookup.cc @@ -0,0 +1,187 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +#if defined(__ANDROID__) +#include <sys/system_properties.h> +#if defined(__ANDROID_API__) && __ANDROID_API__ >= 21 +#include <dlfcn.h> +#endif +#endif + +#if defined(__APPLE__) +#include <CoreFoundation/CFTimeZone.h> + +#include <vector> +#endif + +#include <cstdlib> +#include <cstring> +#include <string> + +#include "time_zone_fixed.h" +#include "time_zone_impl.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +#if defined(__ANDROID__) && defined(__ANDROID_API__) && __ANDROID_API__ >= 21 +namespace { +// Android 'L' removes __system_property_get() from the NDK, however +// it is still a hidden symbol in libc so we use dlsym() to access it. +// See Chromium's base/sys_info_android.cc for a similar example. + +using property_get_func = int (*)(const char*, char*); + +property_get_func LoadSystemPropertyGet() { + int flag = RTLD_LAZY | RTLD_GLOBAL; +#if defined(RTLD_NOLOAD) + flag |= RTLD_NOLOAD; // libc.so should already be resident +#endif + if (void* handle = dlopen("libc.so", flag)) { + void* sym = dlsym(handle, "__system_property_get"); + dlclose(handle); + return reinterpret_cast<property_get_func>(sym); + } + return nullptr; +} + +int __system_property_get(const char* name, char* value) { + static property_get_func system_property_get = LoadSystemPropertyGet(); + return system_property_get ? system_property_get(name, value) : -1; +} + +} // namespace +#endif + +std::string time_zone::name() const { return effective_impl().Name(); } + +time_zone::absolute_lookup time_zone::lookup( + const time_point<seconds>& tp) const { + return effective_impl().BreakTime(tp); +} + +time_zone::civil_lookup time_zone::lookup(const civil_second& cs) const { + return effective_impl().MakeTime(cs); +} + +bool time_zone::next_transition(const time_point<seconds>& tp, + civil_transition* trans) const { + return effective_impl().NextTransition(tp, trans); +} + +bool time_zone::prev_transition(const time_point<seconds>& tp, + civil_transition* trans) const { + return effective_impl().PrevTransition(tp, trans); +} + +std::string time_zone::version() const { return effective_impl().Version(); } + +std::string time_zone::description() const { + return effective_impl().Description(); +} + +const time_zone::Impl& time_zone::effective_impl() const { + if (impl_ == nullptr) { + // Dereferencing an implicit-UTC time_zone is expected to be + // rare, so we don't mind paying a small synchronization cost. + return *time_zone::Impl::UTC().impl_; + } + return *impl_; +} + +bool load_time_zone(const std::string& name, time_zone* tz) { + return time_zone::Impl::LoadTimeZone(name, tz); +} + +time_zone utc_time_zone() { + return time_zone::Impl::UTC(); // avoid name lookup +} + +time_zone fixed_time_zone(const seconds& offset) { + time_zone tz; + load_time_zone(FixedOffsetToName(offset), &tz); + return tz; +} + +time_zone local_time_zone() { + const char* zone = ":localtime"; +#if defined(__ANDROID__) + char sysprop[PROP_VALUE_MAX]; + if (__system_property_get("persist.sys.timezone", sysprop) > 0) { + zone = sysprop; + } +#endif +#if defined(__APPLE__) + std::vector<char> buffer; + CFTimeZoneRef tz_default = CFTimeZoneCopyDefault(); + if (CFStringRef tz_name = CFTimeZoneGetName(tz_default)) { + CFStringEncoding encoding = kCFStringEncodingUTF8; + CFIndex length = CFStringGetLength(tz_name); + buffer.resize(CFStringGetMaximumSizeForEncoding(length, encoding) + 1); + if (CFStringGetCString(tz_name, &buffer[0], buffer.size(), encoding)) { + zone = &buffer[0]; + } + } + CFRelease(tz_default); +#endif + + // Allow ${TZ} to override to default zone. + char* tz_env = nullptr; +#if defined(_MSC_VER) + _dupenv_s(&tz_env, nullptr, "TZ"); +#else + tz_env = std::getenv("TZ"); +#endif + if (tz_env) zone = tz_env; + + // We only support the "[:]<zone-name>" form. + if (*zone == ':') ++zone; + + // Map "localtime" to a system-specific name, but + // allow ${LOCALTIME} to override the default name. + char* localtime_env = nullptr; + if (strcmp(zone, "localtime") == 0) { +#if defined(_MSC_VER) + // System-specific default is just "localtime". + _dupenv_s(&localtime_env, nullptr, "LOCALTIME"); +#else + zone = "/etc/localtime"; // System-specific default. + localtime_env = std::getenv("LOCALTIME"); +#endif + if (localtime_env) zone = localtime_env; + } + + const std::string name = zone; +#if defined(_MSC_VER) + free(localtime_env); + free(tz_env); +#endif + + time_zone tz; + load_time_zone(name, &tz); // Falls back to UTC. + // TODO: Follow the RFC3339 "Unknown Local Offset Convention" and + // arrange for %z to generate "-0000" when we don't know the local + // offset because the load_time_zone() failed and we're using UTC. + return tz; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_lookup_test.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_lookup_test.cc new file mode 100644 index 0000000000..0b0c1a3b72 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_lookup_test.cc @@ -0,0 +1,1438 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <chrono> +#include <cstddef> +#include <cstdlib> +#include <future> +#include <limits> +#include <string> +#include <thread> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/config.h" +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace chrono = std::chrono; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +// A list of known time-zone names. +const char* const kTimeZoneNames[] = {"Africa/Abidjan", + "Africa/Accra", + "Africa/Addis_Ababa", + "Africa/Algiers", + "Africa/Asmara", + "Africa/Asmera", + "Africa/Bamako", + "Africa/Bangui", + "Africa/Banjul", + "Africa/Bissau", + "Africa/Blantyre", + "Africa/Brazzaville", + "Africa/Bujumbura", + "Africa/Cairo", + "Africa/Casablanca", + "Africa/Ceuta", + "Africa/Conakry", + "Africa/Dakar", + "Africa/Dar_es_Salaam", + "Africa/Djibouti", + "Africa/Douala", + "Africa/El_Aaiun", + "Africa/Freetown", + "Africa/Gaborone", + "Africa/Harare", + "Africa/Johannesburg", + "Africa/Juba", + "Africa/Kampala", + "Africa/Khartoum", + "Africa/Kigali", + "Africa/Kinshasa", + "Africa/Lagos", + "Africa/Libreville", + "Africa/Lome", + "Africa/Luanda", + "Africa/Lubumbashi", + "Africa/Lusaka", + "Africa/Malabo", + "Africa/Maputo", + "Africa/Maseru", + "Africa/Mbabane", + "Africa/Mogadishu", + "Africa/Monrovia", + "Africa/Nairobi", + "Africa/Ndjamena", + "Africa/Niamey", + "Africa/Nouakchott", + "Africa/Ouagadougou", + "Africa/Porto-Novo", + "Africa/Sao_Tome", + "Africa/Timbuktu", + "Africa/Tripoli", + "Africa/Tunis", + "Africa/Windhoek", + "America/Adak", + "America/Anchorage", + "America/Anguilla", + "America/Antigua", + "America/Araguaina", + "America/Argentina/Buenos_Aires", + "America/Argentina/Catamarca", + "America/Argentina/ComodRivadavia", + "America/Argentina/Cordoba", + "America/Argentina/Jujuy", + "America/Argentina/La_Rioja", + "America/Argentina/Mendoza", + "America/Argentina/Rio_Gallegos", + "America/Argentina/Salta", + "America/Argentina/San_Juan", + "America/Argentina/San_Luis", + "America/Argentina/Tucuman", + "America/Argentina/Ushuaia", + "America/Aruba", + "America/Asuncion", + "America/Atikokan", + "America/Atka", + "America/Bahia", + "America/Bahia_Banderas", + "America/Barbados", + "America/Belem", + "America/Belize", + "America/Blanc-Sablon", + "America/Boa_Vista", + "America/Bogota", + "America/Boise", + "America/Buenos_Aires", + "America/Cambridge_Bay", + "America/Campo_Grande", + "America/Cancun", + "America/Caracas", + "America/Catamarca", + "America/Cayenne", + "America/Cayman", + "America/Chicago", + "America/Chihuahua", + "America/Coral_Harbour", + "America/Cordoba", + "America/Costa_Rica", + "America/Creston", + "America/Cuiaba", + "America/Curacao", + "America/Danmarkshavn", + "America/Dawson", + "America/Dawson_Creek", + "America/Denver", + "America/Detroit", + "America/Dominica", + "America/Edmonton", + "America/Eirunepe", + "America/El_Salvador", + "America/Ensenada", + "America/Fort_Nelson", + "America/Fort_Wayne", + "America/Fortaleza", + "America/Glace_Bay", + "America/Godthab", + "America/Goose_Bay", + "America/Grand_Turk", + "America/Grenada", + "America/Guadeloupe", + "America/Guatemala", + "America/Guayaquil", + "America/Guyana", + "America/Halifax", + "America/Havana", + "America/Hermosillo", + "America/Indiana/Indianapolis", + "America/Indiana/Knox", + "America/Indiana/Marengo", + "America/Indiana/Petersburg", + "America/Indiana/Tell_City", + "America/Indiana/Vevay", + "America/Indiana/Vincennes", + "America/Indiana/Winamac", + "America/Indianapolis", + "America/Inuvik", + "America/Iqaluit", + "America/Jamaica", + "America/Jujuy", + "America/Juneau", + "America/Kentucky/Louisville", + "America/Kentucky/Monticello", + "America/Knox_IN", + "America/Kralendijk", + "America/La_Paz", + "America/Lima", + "America/Los_Angeles", + "America/Louisville", + "America/Lower_Princes", + "America/Maceio", + "America/Managua", + "America/Manaus", + "America/Marigot", + "America/Martinique", + "America/Matamoros", + "America/Mazatlan", + "America/Mendoza", + "America/Menominee", + "America/Merida", + "America/Metlakatla", + "America/Mexico_City", + "America/Miquelon", + "America/Moncton", + "America/Monterrey", + "America/Montevideo", + "America/Montreal", + "America/Montserrat", + "America/Nassau", + "America/New_York", + "America/Nipigon", + "America/Nome", + "America/Noronha", + "America/North_Dakota/Beulah", + "America/North_Dakota/Center", + "America/North_Dakota/New_Salem", + "America/Nuuk", + "America/Ojinaga", + "America/Panama", + "America/Pangnirtung", + "America/Paramaribo", + "America/Phoenix", + "America/Port-au-Prince", + "America/Port_of_Spain", + "America/Porto_Acre", + "America/Porto_Velho", + "America/Puerto_Rico", + "America/Punta_Arenas", + "America/Rainy_River", + "America/Rankin_Inlet", + "America/Recife", + "America/Regina", + "America/Resolute", + "America/Rio_Branco", + "America/Rosario", + "America/Santa_Isabel", + "America/Santarem", + "America/Santiago", + "America/Santo_Domingo", + "America/Sao_Paulo", + "America/Scoresbysund", + "America/Shiprock", + "America/Sitka", + "America/St_Barthelemy", + "America/St_Johns", + "America/St_Kitts", + "America/St_Lucia", + "America/St_Thomas", + "America/St_Vincent", + "America/Swift_Current", + "America/Tegucigalpa", + "America/Thule", + "America/Thunder_Bay", + "America/Tijuana", + "America/Toronto", + "America/Tortola", + "America/Vancouver", + "America/Virgin", + "America/Whitehorse", + "America/Winnipeg", + "America/Yakutat", + "America/Yellowknife", + "Antarctica/Casey", + "Antarctica/Davis", + "Antarctica/DumontDUrville", + "Antarctica/Macquarie", + "Antarctica/Mawson", + "Antarctica/McMurdo", + "Antarctica/Palmer", + "Antarctica/Rothera", + "Antarctica/South_Pole", + "Antarctica/Syowa", + "Antarctica/Troll", + "Antarctica/Vostok", + "Arctic/Longyearbyen", + "Asia/Aden", + "Asia/Almaty", + "Asia/Amman", + "Asia/Anadyr", + "Asia/Aqtau", + "Asia/Aqtobe", + "Asia/Ashgabat", + "Asia/Ashkhabad", + "Asia/Atyrau", + "Asia/Baghdad", + "Asia/Bahrain", + "Asia/Baku", + "Asia/Bangkok", + "Asia/Barnaul", + "Asia/Beirut", + "Asia/Bishkek", + "Asia/Brunei", + "Asia/Calcutta", + "Asia/Chita", + "Asia/Choibalsan", + "Asia/Chongqing", + "Asia/Chungking", + "Asia/Colombo", + "Asia/Dacca", + "Asia/Damascus", + "Asia/Dhaka", + "Asia/Dili", + "Asia/Dubai", + "Asia/Dushanbe", + "Asia/Famagusta", + "Asia/Gaza", + "Asia/Harbin", + "Asia/Hebron", + "Asia/Ho_Chi_Minh", + "Asia/Hong_Kong", + "Asia/Hovd", + "Asia/Irkutsk", + "Asia/Istanbul", + "Asia/Jakarta", + "Asia/Jayapura", + "Asia/Jerusalem", + "Asia/Kabul", + "Asia/Kamchatka", + "Asia/Karachi", + "Asia/Kashgar", + "Asia/Kathmandu", + "Asia/Katmandu", + "Asia/Khandyga", + "Asia/Kolkata", + "Asia/Krasnoyarsk", + "Asia/Kuala_Lumpur", + "Asia/Kuching", + "Asia/Kuwait", + "Asia/Macao", + "Asia/Macau", + "Asia/Magadan", + "Asia/Makassar", + "Asia/Manila", + "Asia/Muscat", + "Asia/Nicosia", + "Asia/Novokuznetsk", + "Asia/Novosibirsk", + "Asia/Omsk", + "Asia/Oral", + "Asia/Phnom_Penh", + "Asia/Pontianak", + "Asia/Pyongyang", + "Asia/Qatar", + "Asia/Qostanay", + "Asia/Qyzylorda", + "Asia/Rangoon", + "Asia/Riyadh", + "Asia/Saigon", + "Asia/Sakhalin", + "Asia/Samarkand", + "Asia/Seoul", + "Asia/Shanghai", + "Asia/Singapore", + "Asia/Srednekolymsk", + "Asia/Taipei", + "Asia/Tashkent", + "Asia/Tbilisi", + "Asia/Tehran", + "Asia/Tel_Aviv", + "Asia/Thimbu", + "Asia/Thimphu", + "Asia/Tokyo", + "Asia/Tomsk", + "Asia/Ujung_Pandang", + "Asia/Ulaanbaatar", + "Asia/Ulan_Bator", + "Asia/Urumqi", + "Asia/Ust-Nera", + "Asia/Vientiane", + "Asia/Vladivostok", + "Asia/Yakutsk", + "Asia/Yangon", + "Asia/Yekaterinburg", + "Asia/Yerevan", + "Atlantic/Azores", + "Atlantic/Bermuda", + "Atlantic/Canary", + "Atlantic/Cape_Verde", + "Atlantic/Faeroe", + "Atlantic/Faroe", + "Atlantic/Jan_Mayen", + "Atlantic/Madeira", + "Atlantic/Reykjavik", + "Atlantic/South_Georgia", + "Atlantic/St_Helena", + "Atlantic/Stanley", + "Australia/ACT", + "Australia/Adelaide", + "Australia/Brisbane", + "Australia/Broken_Hill", + "Australia/Canberra", + "Australia/Currie", + "Australia/Darwin", + "Australia/Eucla", + "Australia/Hobart", + "Australia/LHI", + "Australia/Lindeman", + "Australia/Lord_Howe", + "Australia/Melbourne", + "Australia/NSW", + "Australia/North", + "Australia/Perth", + "Australia/Queensland", + "Australia/South", + "Australia/Sydney", + "Australia/Tasmania", + "Australia/Victoria", + "Australia/West", + "Australia/Yancowinna", + "Brazil/Acre", + "Brazil/DeNoronha", + "Brazil/East", + "Brazil/West", + "CET", + "CST6CDT", + "Canada/Atlantic", + "Canada/Central", + "Canada/Eastern", + "Canada/Mountain", + "Canada/Newfoundland", + "Canada/Pacific", + "Canada/Saskatchewan", + "Canada/Yukon", + "Chile/Continental", + "Chile/EasterIsland", + "Cuba", + "EET", + "EST", + "EST5EDT", + "Egypt", + "Eire", + "Etc/GMT", + "Etc/GMT+0", + "Etc/GMT+1", + "Etc/GMT+10", + "Etc/GMT+11", + "Etc/GMT+12", + "Etc/GMT+2", + "Etc/GMT+3", + "Etc/GMT+4", + "Etc/GMT+5", + "Etc/GMT+6", + "Etc/GMT+7", + "Etc/GMT+8", + "Etc/GMT+9", + "Etc/GMT-0", + "Etc/GMT-1", + "Etc/GMT-10", + "Etc/GMT-11", + "Etc/GMT-12", + "Etc/GMT-13", + "Etc/GMT-14", + "Etc/GMT-2", + "Etc/GMT-3", + "Etc/GMT-4", + "Etc/GMT-5", + "Etc/GMT-6", + "Etc/GMT-7", + "Etc/GMT-8", + "Etc/GMT-9", + "Etc/GMT0", + "Etc/Greenwich", + "Etc/UCT", + "Etc/UTC", + "Etc/Universal", + "Etc/Zulu", + "Europe/Amsterdam", + "Europe/Andorra", + "Europe/Astrakhan", + "Europe/Athens", + "Europe/Belfast", + "Europe/Belgrade", + "Europe/Berlin", + "Europe/Bratislava", + "Europe/Brussels", + "Europe/Bucharest", + "Europe/Budapest", + "Europe/Busingen", + "Europe/Chisinau", + "Europe/Copenhagen", + "Europe/Dublin", + "Europe/Gibraltar", + "Europe/Guernsey", + "Europe/Helsinki", + "Europe/Isle_of_Man", + "Europe/Istanbul", + "Europe/Jersey", + "Europe/Kaliningrad", + "Europe/Kiev", + "Europe/Kirov", + "Europe/Lisbon", + "Europe/Ljubljana", + "Europe/London", + "Europe/Luxembourg", + "Europe/Madrid", + "Europe/Malta", + "Europe/Mariehamn", + "Europe/Minsk", + "Europe/Monaco", + "Europe/Moscow", + "Europe/Nicosia", + "Europe/Oslo", + "Europe/Paris", + "Europe/Podgorica", + "Europe/Prague", + "Europe/Riga", + "Europe/Rome", + "Europe/Samara", + "Europe/San_Marino", + "Europe/Sarajevo", + "Europe/Saratov", + "Europe/Simferopol", + "Europe/Skopje", + "Europe/Sofia", + "Europe/Stockholm", + "Europe/Tallinn", + "Europe/Tirane", + "Europe/Tiraspol", + "Europe/Ulyanovsk", + "Europe/Uzhgorod", + "Europe/Vaduz", + "Europe/Vatican", + "Europe/Vienna", + "Europe/Vilnius", + "Europe/Volgograd", + "Europe/Warsaw", + "Europe/Zagreb", + "Europe/Zaporozhye", + "Europe/Zurich", + "GB", + "GB-Eire", + "GMT", + "GMT+0", + "GMT-0", + "GMT0", + "Greenwich", + "HST", + "Hongkong", + "Iceland", + "Indian/Antananarivo", + "Indian/Chagos", + "Indian/Christmas", + "Indian/Cocos", + "Indian/Comoro", + "Indian/Kerguelen", + "Indian/Mahe", + "Indian/Maldives", + "Indian/Mauritius", + "Indian/Mayotte", + "Indian/Reunion", + "Iran", + "Israel", + "Jamaica", + "Japan", + "Kwajalein", + "Libya", + "MET", + "MST", + "MST7MDT", + "Mexico/BajaNorte", + "Mexico/BajaSur", + "Mexico/General", + "NZ", + "NZ-CHAT", + "Navajo", + "PRC", + "PST8PDT", + "Pacific/Apia", + "Pacific/Auckland", + "Pacific/Bougainville", + "Pacific/Chatham", + "Pacific/Chuuk", + "Pacific/Easter", + "Pacific/Efate", + "Pacific/Enderbury", + "Pacific/Fakaofo", + "Pacific/Fiji", + "Pacific/Funafuti", + "Pacific/Galapagos", + "Pacific/Gambier", + "Pacific/Guadalcanal", + "Pacific/Guam", + "Pacific/Honolulu", + "Pacific/Johnston", + "Pacific/Kiritimati", + "Pacific/Kosrae", + "Pacific/Kwajalein", + "Pacific/Majuro", + "Pacific/Marquesas", + "Pacific/Midway", + "Pacific/Nauru", + "Pacific/Niue", + "Pacific/Norfolk", + "Pacific/Noumea", + "Pacific/Pago_Pago", + "Pacific/Palau", + "Pacific/Pitcairn", + "Pacific/Pohnpei", + "Pacific/Ponape", + "Pacific/Port_Moresby", + "Pacific/Rarotonga", + "Pacific/Saipan", + "Pacific/Samoa", + "Pacific/Tahiti", + "Pacific/Tarawa", + "Pacific/Tongatapu", + "Pacific/Truk", + "Pacific/Wake", + "Pacific/Wallis", + "Pacific/Yap", + "Poland", + "Portugal", + "ROC", + "ROK", + "Singapore", + "Turkey", + "UCT", + "US/Alaska", + "US/Aleutian", + "US/Arizona", + "US/Central", + "US/East-Indiana", + "US/Eastern", + "US/Hawaii", + "US/Indiana-Starke", + "US/Michigan", + "US/Mountain", + "US/Pacific", + "US/Samoa", + "UTC", + "Universal", + "W-SU", + "WET", + "Zulu", + nullptr}; + +// Helper to return a loaded time zone by value (UTC on error). +time_zone LoadZone(const std::string& name) { + time_zone tz; + load_time_zone(name, &tz); + return tz; +} + +// This helper is a macro so that failed expectations show up with the +// correct line numbers. +#define ExpectTime(tp, tz, y, m, d, hh, mm, ss, off, isdst, zone) \ + do { \ + time_zone::absolute_lookup al = tz.lookup(tp); \ + EXPECT_EQ(y, al.cs.year()); \ + EXPECT_EQ(m, al.cs.month()); \ + EXPECT_EQ(d, al.cs.day()); \ + EXPECT_EQ(hh, al.cs.hour()); \ + EXPECT_EQ(mm, al.cs.minute()); \ + EXPECT_EQ(ss, al.cs.second()); \ + EXPECT_EQ(off, al.offset); \ + EXPECT_TRUE(isdst == al.is_dst); \ + /* EXPECT_STREQ(zone, al.abbr); */ \ + } while (0) + +// These tests sometimes run on platforms that have zoneinfo data so old +// that the transition we are attempting to check does not exist, most +// notably Android emulators. Fortunately, AndroidZoneInfoSource supports +// time_zone::version() so, in cases where we've learned that it matters, +// we can make the check conditionally. +int VersionCmp(time_zone tz, const std::string& target) { + std::string version = tz.version(); + if (version.empty() && !target.empty()) return 1; // unknown > known + return version.compare(target); +} + +} // namespace + +#if !defined(__EMSCRIPTEN__) +TEST(TimeZones, LoadZonesConcurrently) { + std::promise<void> ready_promise; + std::shared_future<void> ready_future(ready_promise.get_future()); + auto load_zones = [ready_future](std::promise<void>* started, + std::set<std::string>* failures) { + started->set_value(); + ready_future.wait(); + for (const char* const* np = kTimeZoneNames; *np != nullptr; ++np) { + std::string zone = *np; + time_zone tz; + if (load_time_zone(zone, &tz)) { + EXPECT_EQ(zone, tz.name()); + } else { + failures->insert(zone); + } + } + }; + + const std::size_t n_threads = 128; + std::vector<std::thread> threads; + std::vector<std::set<std::string>> thread_failures(n_threads); + for (std::size_t i = 0; i != n_threads; ++i) { + std::promise<void> started; + threads.emplace_back(load_zones, &started, &thread_failures[i]); + started.get_future().wait(); + } + ready_promise.set_value(); + for (auto& thread : threads) { + thread.join(); + } + + // Allow a small number of failures to account for skew between + // the contents of kTimeZoneNames and the zoneinfo data source. +#if defined(__ANDROID__) + // Cater to the possibility of using an even older zoneinfo data + // source when running on Android, where it is difficult to override + // the bionic tzdata provided by the test environment. + const std::size_t max_failures = 20; +#else + const std::size_t max_failures = 3; +#endif + std::set<std::string> failures; + for (const auto& thread_failure : thread_failures) { + failures.insert(thread_failure.begin(), thread_failure.end()); + } + EXPECT_LE(failures.size(), max_failures) << testing::PrintToString(failures); +} +#endif + +TEST(TimeZone, NamedTimeZones) { + const time_zone utc = utc_time_zone(); + EXPECT_EQ("UTC", utc.name()); + const time_zone nyc = LoadZone("America/New_York"); + EXPECT_EQ("America/New_York", nyc.name()); + const time_zone syd = LoadZone("Australia/Sydney"); + EXPECT_EQ("Australia/Sydney", syd.name()); + const time_zone fixed0 = + fixed_time_zone(absl::time_internal::cctz::seconds::zero()); + EXPECT_EQ("UTC", fixed0.name()); + const time_zone fixed_pos = fixed_time_zone( + chrono::hours(3) + chrono::minutes(25) + chrono::seconds(45)); + EXPECT_EQ("Fixed/UTC+03:25:45", fixed_pos.name()); + const time_zone fixed_neg = fixed_time_zone( + -(chrono::hours(12) + chrono::minutes(34) + chrono::seconds(56))); + EXPECT_EQ("Fixed/UTC-12:34:56", fixed_neg.name()); +} + +TEST(TimeZone, Failures) { + time_zone tz; + EXPECT_FALSE(load_time_zone(":America/Los_Angeles", &tz)); + + tz = LoadZone("America/Los_Angeles"); + EXPECT_FALSE(load_time_zone("Invalid/TimeZone", &tz)); + EXPECT_EQ(chrono::system_clock::from_time_t(0), + convert(civil_second(1970, 1, 1, 0, 0, 0), tz)); // UTC + + // Ensures that the load still fails on a subsequent attempt. + tz = LoadZone("America/Los_Angeles"); + EXPECT_FALSE(load_time_zone("Invalid/TimeZone", &tz)); + EXPECT_EQ(chrono::system_clock::from_time_t(0), + convert(civil_second(1970, 1, 1, 0, 0, 0), tz)); // UTC + + // Loading an empty string timezone should fail. + tz = LoadZone("America/Los_Angeles"); + EXPECT_FALSE(load_time_zone("", &tz)); + EXPECT_EQ(chrono::system_clock::from_time_t(0), + convert(civil_second(1970, 1, 1, 0, 0, 0), tz)); // UTC +} + +TEST(TimeZone, Equality) { + const time_zone a; + const time_zone b; + EXPECT_EQ(a, b); + EXPECT_EQ(a.name(), b.name()); + + const time_zone implicit_utc; + const time_zone explicit_utc = utc_time_zone(); + EXPECT_EQ(implicit_utc, explicit_utc); + EXPECT_EQ(implicit_utc.name(), explicit_utc.name()); + + const time_zone fixed_zero = + fixed_time_zone(absl::time_internal::cctz::seconds::zero()); + EXPECT_EQ(fixed_zero, LoadZone(fixed_zero.name())); + EXPECT_EQ(fixed_zero, explicit_utc); + + const time_zone fixed_utc = LoadZone("Fixed/UTC+00:00:00"); + EXPECT_EQ(fixed_utc, LoadZone(fixed_utc.name())); + EXPECT_EQ(fixed_utc, explicit_utc); + + const time_zone fixed_pos = fixed_time_zone( + chrono::hours(3) + chrono::minutes(25) + chrono::seconds(45)); + EXPECT_EQ(fixed_pos, LoadZone(fixed_pos.name())); + EXPECT_NE(fixed_pos, explicit_utc); + const time_zone fixed_neg = fixed_time_zone( + -(chrono::hours(12) + chrono::minutes(34) + chrono::seconds(56))); + EXPECT_EQ(fixed_neg, LoadZone(fixed_neg.name())); + EXPECT_NE(fixed_neg, explicit_utc); + + const time_zone fixed_lim = fixed_time_zone(chrono::hours(24)); + EXPECT_EQ(fixed_lim, LoadZone(fixed_lim.name())); + EXPECT_NE(fixed_lim, explicit_utc); + const time_zone fixed_ovfl = + fixed_time_zone(chrono::hours(24) + chrono::seconds(1)); + EXPECT_EQ(fixed_ovfl, LoadZone(fixed_ovfl.name())); + EXPECT_EQ(fixed_ovfl, explicit_utc); + + EXPECT_EQ(fixed_time_zone(chrono::seconds(1)), + fixed_time_zone(chrono::seconds(1))); + + const time_zone local = local_time_zone(); + EXPECT_EQ(local, LoadZone(local.name())); + + time_zone la = LoadZone("America/Los_Angeles"); + time_zone nyc = LoadZone("America/New_York"); + EXPECT_NE(la, nyc); +} + +TEST(StdChronoTimePoint, TimeTAlignment) { + // Ensures that the Unix epoch and the system clock epoch are an integral + // number of seconds apart. This simplifies conversions to/from time_t. + auto diff = + chrono::system_clock::time_point() - chrono::system_clock::from_time_t(0); + EXPECT_EQ(chrono::system_clock::time_point::duration::zero(), + diff % chrono::seconds(1)); +} + +TEST(BreakTime, TimePointResolution) { + const time_zone utc = utc_time_zone(); + const auto t0 = chrono::system_clock::from_time_t(0); + + ExpectTime(chrono::time_point_cast<chrono::nanoseconds>(t0), utc, 1970, 1, 1, + 0, 0, 0, 0, false, "UTC"); + ExpectTime(chrono::time_point_cast<chrono::microseconds>(t0), utc, 1970, 1, 1, + 0, 0, 0, 0, false, "UTC"); + ExpectTime(chrono::time_point_cast<chrono::milliseconds>(t0), utc, 1970, 1, 1, + 0, 0, 0, 0, false, "UTC"); + ExpectTime(chrono::time_point_cast<chrono::seconds>(t0), utc, 1970, 1, 1, 0, + 0, 0, 0, false, "UTC"); + ExpectTime(chrono::time_point_cast<absl::time_internal::cctz::seconds>(t0), + utc, 1970, 1, 1, 0, 0, 0, 0, false, "UTC"); + ExpectTime(chrono::time_point_cast<chrono::minutes>(t0), utc, 1970, 1, 1, 0, + 0, 0, 0, false, "UTC"); + ExpectTime(chrono::time_point_cast<chrono::hours>(t0), utc, 1970, 1, 1, 0, 0, + 0, 0, false, "UTC"); +} + +TEST(BreakTime, LocalTimeInUTC) { + const time_zone tz = utc_time_zone(); + const auto tp = chrono::system_clock::from_time_t(0); + ExpectTime(tp, tz, 1970, 1, 1, 0, 0, 0, 0, false, "UTC"); + EXPECT_EQ(weekday::thursday, get_weekday(convert(tp, tz))); +} + +TEST(BreakTime, LocalTimeInUTCUnaligned) { + const time_zone tz = utc_time_zone(); + const auto tp = + chrono::system_clock::from_time_t(0) - chrono::milliseconds(500); + ExpectTime(tp, tz, 1969, 12, 31, 23, 59, 59, 0, false, "UTC"); + EXPECT_EQ(weekday::wednesday, get_weekday(convert(tp, tz))); +} + +TEST(BreakTime, LocalTimePosix) { + // See IEEE Std 1003.1-1988 B.2.3 General Terms, Epoch. + const time_zone tz = utc_time_zone(); + const auto tp = chrono::system_clock::from_time_t(536457599); + ExpectTime(tp, tz, 1986, 12, 31, 23, 59, 59, 0, false, "UTC"); + EXPECT_EQ(weekday::wednesday, get_weekday(convert(tp, tz))); +} + +TEST(TimeZoneImpl, LocalTimeInFixed) { + const absl::time_internal::cctz::seconds offset = + -(chrono::hours(8) + chrono::minutes(33) + chrono::seconds(47)); + const time_zone tz = fixed_time_zone(offset); + const auto tp = chrono::system_clock::from_time_t(0); + ExpectTime(tp, tz, 1969, 12, 31, 15, 26, 13, offset.count(), false, + "-083347"); + EXPECT_EQ(weekday::wednesday, get_weekday(convert(tp, tz))); +} + +TEST(BreakTime, LocalTimeInNewYork) { + const time_zone tz = LoadZone("America/New_York"); + const auto tp = chrono::system_clock::from_time_t(45); + ExpectTime(tp, tz, 1969, 12, 31, 19, 0, 45, -5 * 60 * 60, false, "EST"); + EXPECT_EQ(weekday::wednesday, get_weekday(convert(tp, tz))); +} + +TEST(BreakTime, LocalTimeInMTV) { + const time_zone tz = LoadZone("America/Los_Angeles"); + const auto tp = chrono::system_clock::from_time_t(1380855729); + ExpectTime(tp, tz, 2013, 10, 3, 20, 2, 9, -7 * 60 * 60, true, "PDT"); + EXPECT_EQ(weekday::thursday, get_weekday(convert(tp, tz))); +} + +TEST(BreakTime, LocalTimeInSydney) { + const time_zone tz = LoadZone("Australia/Sydney"); + const auto tp = chrono::system_clock::from_time_t(90); + ExpectTime(tp, tz, 1970, 1, 1, 10, 1, 30, 10 * 60 * 60, false, "AEST"); + EXPECT_EQ(weekday::thursday, get_weekday(convert(tp, tz))); +} + +TEST(MakeTime, TimePointResolution) { + const time_zone utc = utc_time_zone(); + const time_point<chrono::nanoseconds> tp_ns = + convert(civil_second(2015, 1, 2, 3, 4, 5), utc); + EXPECT_EQ("04:05", format("%M:%E*S", tp_ns, utc)); + const time_point<chrono::microseconds> tp_us = + convert(civil_second(2015, 1, 2, 3, 4, 5), utc); + EXPECT_EQ("04:05", format("%M:%E*S", tp_us, utc)); + const time_point<chrono::milliseconds> tp_ms = + convert(civil_second(2015, 1, 2, 3, 4, 5), utc); + EXPECT_EQ("04:05", format("%M:%E*S", tp_ms, utc)); + const time_point<chrono::seconds> tp_s = + convert(civil_second(2015, 1, 2, 3, 4, 5), utc); + EXPECT_EQ("04:05", format("%M:%E*S", tp_s, utc)); + const time_point<absl::time_internal::cctz::seconds> tp_s64 = + convert(civil_second(2015, 1, 2, 3, 4, 5), utc); + EXPECT_EQ("04:05", format("%M:%E*S", tp_s64, utc)); + + // These next two require chrono::time_point_cast because the conversion + // from a resolution of seconds (the return value of convert()) to a + // coarser resolution requires an explicit cast. + const time_point<chrono::minutes> tp_m = + chrono::time_point_cast<chrono::minutes>( + convert(civil_second(2015, 1, 2, 3, 4, 5), utc)); + EXPECT_EQ("04:00", format("%M:%E*S", tp_m, utc)); + const time_point<chrono::hours> tp_h = chrono::time_point_cast<chrono::hours>( + convert(civil_second(2015, 1, 2, 3, 4, 5), utc)); + EXPECT_EQ("00:00", format("%M:%E*S", tp_h, utc)); +} + +TEST(MakeTime, Normalization) { + const time_zone tz = LoadZone("America/New_York"); + const auto tp = convert(civil_second(2009, 2, 13, 18, 31, 30), tz); + EXPECT_EQ(chrono::system_clock::from_time_t(1234567890), tp); + + // Now requests for the same time_point but with out-of-range fields. + EXPECT_EQ(tp, convert(civil_second(2008, 14, 13, 18, 31, 30), tz)); // month + EXPECT_EQ(tp, convert(civil_second(2009, 1, 44, 18, 31, 30), tz)); // day + EXPECT_EQ(tp, convert(civil_second(2009, 2, 12, 42, 31, 30), tz)); // hour + EXPECT_EQ(tp, convert(civil_second(2009, 2, 13, 17, 91, 30), tz)); // minute + EXPECT_EQ(tp, convert(civil_second(2009, 2, 13, 18, 30, 90), tz)); // second +} + +// NOTE: Run this with -ftrapv to detect overflow problems. +TEST(MakeTime, SysSecondsLimits) { + const char RFC3339[] = "%Y-%m-%dT%H:%M:%S%Ez"; + const time_zone utc = utc_time_zone(); + const time_zone east = fixed_time_zone(chrono::hours(14)); + const time_zone west = fixed_time_zone(-chrono::hours(14)); + time_point<absl::time_internal::cctz::seconds> tp; + + // Approach the maximal time_point<cctz::seconds> value from below. + tp = convert(civil_second(292277026596, 12, 4, 15, 30, 6), utc); + EXPECT_EQ("292277026596-12-04T15:30:06+00:00", format(RFC3339, tp, utc)); + tp = convert(civil_second(292277026596, 12, 4, 15, 30, 7), utc); + EXPECT_EQ("292277026596-12-04T15:30:07+00:00", format(RFC3339, tp, utc)); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + tp = convert(civil_second(292277026596, 12, 4, 15, 30, 8), utc); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + tp = convert(civil_second::max(), utc); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + + // Checks that we can also get the maximal value for a far-east zone. + tp = convert(civil_second(292277026596, 12, 5, 5, 30, 7), east); + EXPECT_EQ("292277026596-12-05T05:30:07+14:00", format(RFC3339, tp, east)); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + tp = convert(civil_second(292277026596, 12, 5, 5, 30, 8), east); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + tp = convert(civil_second::max(), east); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + + // Checks that we can also get the maximal value for a far-west zone. + tp = convert(civil_second(292277026596, 12, 4, 1, 30, 7), west); + EXPECT_EQ("292277026596-12-04T01:30:07-14:00", format(RFC3339, tp, west)); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + tp = convert(civil_second(292277026596, 12, 4, 7, 30, 8), west); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + tp = convert(civil_second::max(), west); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::max(), tp); + + // Approach the minimal time_point<cctz::seconds> value from above. + tp = convert(civil_second(-292277022657, 1, 27, 8, 29, 53), utc); + EXPECT_EQ("-292277022657-01-27T08:29:53+00:00", format(RFC3339, tp, utc)); + tp = convert(civil_second(-292277022657, 1, 27, 8, 29, 52), utc); + EXPECT_EQ("-292277022657-01-27T08:29:52+00:00", format(RFC3339, tp, utc)); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + tp = convert(civil_second(-292277022657, 1, 27, 8, 29, 51), utc); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + tp = convert(civil_second::min(), utc); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + + // Checks that we can also get the minimal value for a far-east zone. + tp = convert(civil_second(-292277022657, 1, 27, 22, 29, 52), east); + EXPECT_EQ("-292277022657-01-27T22:29:52+14:00", format(RFC3339, tp, east)); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + tp = convert(civil_second(-292277022657, 1, 27, 22, 29, 51), east); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + tp = convert(civil_second::min(), east); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + + // Checks that we can also get the minimal value for a far-west zone. + tp = convert(civil_second(-292277022657, 1, 26, 18, 29, 52), west); + EXPECT_EQ("-292277022657-01-26T18:29:52-14:00", format(RFC3339, tp, west)); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + tp = convert(civil_second(-292277022657, 1, 26, 18, 29, 51), west); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + tp = convert(civil_second::min(), west); + EXPECT_EQ(time_point<absl::time_internal::cctz::seconds>::min(), tp); + + // Some similar checks for the "libc" time-zone implementation. + if (sizeof(std::time_t) >= 8) { + // Checks that "tm_year + 1900", as used by the "libc" implementation, + // can produce year values beyond the range on an int without overflow. +#if defined(_WIN32) || defined(_WIN64) + // localtime_s() and gmtime_s() don't believe in years outside [1970:3000]. +#else + const time_zone utc = LoadZone("libc:UTC"); + const year_t max_tm_year = year_t{std::numeric_limits<int>::max()} + 1900; + tp = convert(civil_second(max_tm_year, 12, 31, 23, 59, 59), utc); + EXPECT_EQ("2147485547-12-31T23:59:59+00:00", format(RFC3339, tp, utc)); + const year_t min_tm_year = year_t{std::numeric_limits<int>::min()} + 1900; + tp = convert(civil_second(min_tm_year, 1, 1, 0, 0, 0), utc); + EXPECT_EQ("-2147481748-01-01T00:00:00+00:00", format(RFC3339, tp, utc)); +#endif + } +} + +TEST(MakeTime, LocalTimeLibC) { + // Checks that cctz and libc agree on transition points in [1970:2037]. + // + // We limit this test case to environments where: + // 1) we know how to change the time zone used by localtime()/mktime(), + // 2) cctz and localtime()/mktime() will use similar-enough tzdata, and + // 3) we have some idea about how mktime() behaves during transitions. +#if defined(__linux__) && !defined(__ANDROID__) + const char* const ep = getenv("TZ"); + std::string tz_name = (ep != nullptr) ? ep : ""; + for (const char* const* np = kTimeZoneNames; *np != nullptr; ++np) { + ASSERT_EQ(0, setenv("TZ", *np, 1)); // change what "localtime" means + const auto zi = local_time_zone(); + const auto lc = LoadZone("libc:localtime"); + time_zone::civil_transition transition; + for (auto tp = zi.lookup(civil_second()).trans; + zi.next_transition(tp, &transition); + tp = zi.lookup(transition.to).trans) { + const auto fcl = zi.lookup(transition.from); + const auto tcl = zi.lookup(transition.to); + civil_second cs; // compare cs in zi and lc + if (fcl.kind == time_zone::civil_lookup::UNIQUE) { + if (tcl.kind == time_zone::civil_lookup::UNIQUE) { + // Both unique; must be an is_dst or abbr change. + ASSERT_EQ(transition.from, transition.to); + const auto trans = fcl.trans; + const auto tal = zi.lookup(trans); + const auto tprev = trans - absl::time_internal::cctz::seconds(1); + const auto pal = zi.lookup(tprev); + if (pal.is_dst == tal.is_dst) { + ASSERT_STRNE(pal.abbr, tal.abbr); + } + continue; + } + ASSERT_EQ(time_zone::civil_lookup::REPEATED, tcl.kind); + cs = transition.to; + } else { + ASSERT_EQ(time_zone::civil_lookup::UNIQUE, tcl.kind); + ASSERT_EQ(time_zone::civil_lookup::SKIPPED, fcl.kind); + cs = transition.from; + } + if (cs.year() > 2037) break; // limit test time (and to 32-bit time_t) + const auto cl_zi = zi.lookup(cs); + if (zi.lookup(cl_zi.pre).is_dst == zi.lookup(cl_zi.post).is_dst) { + // The "libc" implementation cannot correctly classify transitions + // that don't change the "tm_isdst" flag. In Europe/Volgograd, for + // example, there is a SKIPPED transition from +03 to +04 with dst=F + // on both sides ... + // 1540681199 = 2018-10-28 01:59:59 +03:00:00 [dst=F off=10800] + // 1540681200 = 2018-10-28 03:00:00 +04:00:00 [dst=F off=14400] + // but std::mktime(2018-10-28 02:00:00, tm_isdst=0) fails, unlike, + // say, the similar Europe/Chisinau transition from +02 to +03 ... + // 1521935999 = 2018-03-25 01:59:59 +02:00:00 [dst=F off=7200] + // 1521936000 = 2018-03-25 03:00:00 +03:00:00 [dst=T off=10800] + // where std::mktime(2018-03-25 02:00:00, tm_isdst=0) succeeds and + // returns 1521936000. + continue; + } + if (cs == civil_second(2037, 10, 4, 2, 0, 0)) { + const std::string tzname = *np; + if (tzname == "Africa/Casablanca" || tzname == "Africa/El_Aaiun") { + // The "libc" implementation gets this transition wrong (at least + // until 2018g when it was removed), returning an offset of 3600 + // instead of 0. TODO: Revert this when 2018g is ubiquitous. + continue; + } + } + const auto cl_lc = lc.lookup(cs); + SCOPED_TRACE(testing::Message() << "For " << cs << " in " << *np); + EXPECT_EQ(cl_zi.kind, cl_lc.kind); + EXPECT_EQ(cl_zi.pre, cl_lc.pre); + EXPECT_EQ(cl_zi.trans, cl_lc.trans); + EXPECT_EQ(cl_zi.post, cl_lc.post); + } + } + if (ep == nullptr) { + ASSERT_EQ(0, unsetenv("TZ")); + } else { + ASSERT_EQ(0, setenv("TZ", tz_name.c_str(), 1)); + } +#endif +} + +TEST(NextTransition, UTC) { + const auto tz = utc_time_zone(); + time_zone::civil_transition trans; + + auto tp = time_point<absl::time_internal::cctz::seconds>::min(); + EXPECT_FALSE(tz.next_transition(tp, &trans)); + + tp = time_point<absl::time_internal::cctz::seconds>::max(); + EXPECT_FALSE(tz.next_transition(tp, &trans)); +} + +TEST(PrevTransition, UTC) { + const auto tz = utc_time_zone(); + time_zone::civil_transition trans; + + auto tp = time_point<absl::time_internal::cctz::seconds>::max(); + EXPECT_FALSE(tz.prev_transition(tp, &trans)); + + tp = time_point<absl::time_internal::cctz::seconds>::min(); + EXPECT_FALSE(tz.prev_transition(tp, &trans)); +} + +TEST(NextTransition, AmericaNewYork) { + const auto tz = LoadZone("America/New_York"); + time_zone::civil_transition trans; + + auto tp = convert(civil_second(2018, 6, 30, 0, 0, 0), tz); + EXPECT_TRUE(tz.next_transition(tp, &trans)); + EXPECT_EQ(civil_second(2018, 11, 4, 2, 0, 0), trans.from); + EXPECT_EQ(civil_second(2018, 11, 4, 1, 0, 0), trans.to); + + tp = time_point<absl::time_internal::cctz::seconds>::max(); + EXPECT_FALSE(tz.next_transition(tp, &trans)); + + tp = time_point<absl::time_internal::cctz::seconds>::min(); + EXPECT_TRUE(tz.next_transition(tp, &trans)); + if (trans.from == civil_second(1918, 3, 31, 2, 0, 0)) { + // It looks like the tzdata is only 32 bit (probably macOS), + // which bottoms out at 1901-12-13T20:45:52+00:00. + EXPECT_EQ(civil_second(1918, 3, 31, 3, 0, 0), trans.to); + } else { + EXPECT_EQ(civil_second(1883, 11, 18, 12, 3, 58), trans.from); + EXPECT_EQ(civil_second(1883, 11, 18, 12, 0, 0), trans.to); + } +} + +TEST(PrevTransition, AmericaNewYork) { + const auto tz = LoadZone("America/New_York"); + time_zone::civil_transition trans; + + auto tp = convert(civil_second(2018, 6, 30, 0, 0, 0), tz); + EXPECT_TRUE(tz.prev_transition(tp, &trans)); + EXPECT_EQ(civil_second(2018, 3, 11, 2, 0, 0), trans.from); + EXPECT_EQ(civil_second(2018, 3, 11, 3, 0, 0), trans.to); + + tp = time_point<absl::time_internal::cctz::seconds>::min(); + EXPECT_FALSE(tz.prev_transition(tp, &trans)); + + tp = time_point<absl::time_internal::cctz::seconds>::max(); + EXPECT_TRUE(tz.prev_transition(tp, &trans)); + // We have a transition but we don't know which one. +} + +TEST(TimeZoneEdgeCase, AmericaNewYork) { + const time_zone tz = LoadZone("America/New_York"); + + // Spring 1:59:59 -> 3:00:00 + auto tp = convert(civil_second(2013, 3, 10, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 3, 10, 1, 59, 59, -5 * 3600, false, "EST"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 3, 10, 3, 0, 0, -4 * 3600, true, "EDT"); + + // Fall 1:59:59 -> 1:00:00 + tp = convert(civil_second(2013, 11, 3, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 11, 3, 1, 59, 59, -4 * 3600, true, "EDT"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 11, 3, 1, 0, 0, -5 * 3600, false, "EST"); +} + +TEST(TimeZoneEdgeCase, AmericaLosAngeles) { + const time_zone tz = LoadZone("America/Los_Angeles"); + + // Spring 1:59:59 -> 3:00:00 + auto tp = convert(civil_second(2013, 3, 10, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 3, 10, 1, 59, 59, -8 * 3600, false, "PST"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 3, 10, 3, 0, 0, -7 * 3600, true, "PDT"); + + // Fall 1:59:59 -> 1:00:00 + tp = convert(civil_second(2013, 11, 3, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 11, 3, 1, 59, 59, -7 * 3600, true, "PDT"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 11, 3, 1, 0, 0, -8 * 3600, false, "PST"); +} + +TEST(TimeZoneEdgeCase, ArizonaNoTransition) { + const time_zone tz = LoadZone("America/Phoenix"); + + // No transition in Spring. + auto tp = convert(civil_second(2013, 3, 10, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 3, 10, 1, 59, 59, -7 * 3600, false, "MST"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 3, 10, 2, 0, 0, -7 * 3600, false, "MST"); + + // No transition in Fall. + tp = convert(civil_second(2013, 11, 3, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 11, 3, 1, 59, 59, -7 * 3600, false, "MST"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 11, 3, 2, 0, 0, -7 * 3600, false, "MST"); +} + +TEST(TimeZoneEdgeCase, AsiaKathmandu) { + const time_zone tz = LoadZone("Asia/Kathmandu"); + + // A non-DST offset change from +0530 to +0545 + // + // 504901799 == Tue, 31 Dec 1985 23:59:59 +0530 (+0530) + // 504901800 == Wed, 1 Jan 1986 00:15:00 +0545 (+0545) + auto tp = convert(civil_second(1985, 12, 31, 23, 59, 59), tz); + ExpectTime(tp, tz, 1985, 12, 31, 23, 59, 59, 5.5 * 3600, false, "+0530"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 1986, 1, 1, 0, 15, 0, 5.75 * 3600, false, "+0545"); +} + +TEST(TimeZoneEdgeCase, PacificChatham) { + const time_zone tz = LoadZone("Pacific/Chatham"); + + // One-hour DST offset changes, but at atypical values + // + // 1365256799 == Sun, 7 Apr 2013 03:44:59 +1345 (+1345) + // 1365256800 == Sun, 7 Apr 2013 02:45:00 +1245 (+1245) + auto tp = convert(civil_second(2013, 4, 7, 3, 44, 59), tz); + ExpectTime(tp, tz, 2013, 4, 7, 3, 44, 59, 13.75 * 3600, true, "+1345"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 4, 7, 2, 45, 0, 12.75 * 3600, false, "+1245"); + + // 1380376799 == Sun, 29 Sep 2013 02:44:59 +1245 (+1245) + // 1380376800 == Sun, 29 Sep 2013 03:45:00 +1345 (+1345) + tp = convert(civil_second(2013, 9, 29, 2, 44, 59), tz); + ExpectTime(tp, tz, 2013, 9, 29, 2, 44, 59, 12.75 * 3600, false, "+1245"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 9, 29, 3, 45, 0, 13.75 * 3600, true, "+1345"); +} + +TEST(TimeZoneEdgeCase, AustraliaLordHowe) { + const time_zone tz = LoadZone("Australia/Lord_Howe"); + + // Half-hour DST offset changes + // + // 1365260399 == Sun, 7 Apr 2013 01:59:59 +1100 (+11) + // 1365260400 == Sun, 7 Apr 2013 01:30:00 +1030 (+1030) + auto tp = convert(civil_second(2013, 4, 7, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 4, 7, 1, 59, 59, 11 * 3600, true, "+11"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 4, 7, 1, 30, 0, 10.5 * 3600, false, "+1030"); + + // 1380986999 == Sun, 6 Oct 2013 01:59:59 +1030 (+1030) + // 1380987000 == Sun, 6 Oct 2013 02:30:00 +1100 (+11) + tp = convert(civil_second(2013, 10, 6, 1, 59, 59), tz); + ExpectTime(tp, tz, 2013, 10, 6, 1, 59, 59, 10.5 * 3600, false, "+1030"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2013, 10, 6, 2, 30, 0, 11 * 3600, true, "+11"); +} + +TEST(TimeZoneEdgeCase, PacificApia) { + const time_zone tz = LoadZone("Pacific/Apia"); + + // At the end of December 2011, Samoa jumped forward by one day, + // skipping 30 December from the local calendar, when the nation + // moved to the west of the International Date Line. + // + // A one-day, non-DST offset change + // + // 1325239199 == Thu, 29 Dec 2011 23:59:59 -1000 (-10) + // 1325239200 == Sat, 31 Dec 2011 00:00:00 +1400 (+14) + auto tp = convert(civil_second(2011, 12, 29, 23, 59, 59), tz); + ExpectTime(tp, tz, 2011, 12, 29, 23, 59, 59, -10 * 3600, true, "-10"); + EXPECT_EQ(363, get_yearday(convert(tp, tz))); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2011, 12, 31, 0, 0, 0, 14 * 3600, true, "+14"); + EXPECT_EQ(365, get_yearday(convert(tp, tz))); +} + +TEST(TimeZoneEdgeCase, AfricaCairo) { + const time_zone tz = LoadZone("Africa/Cairo"); + + if (VersionCmp(tz, "2014c") >= 0) { + // An interesting case of midnight not existing. + // + // 1400191199 == Thu, 15 May 2014 23:59:59 +0200 (EET) + // 1400191200 == Fri, 16 May 2014 01:00:00 +0300 (EEST) + auto tp = convert(civil_second(2014, 5, 15, 23, 59, 59), tz); + ExpectTime(tp, tz, 2014, 5, 15, 23, 59, 59, 2 * 3600, false, "EET"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2014, 5, 16, 1, 0, 0, 3 * 3600, true, "EEST"); + } +} + +TEST(TimeZoneEdgeCase, AfricaMonrovia) { + const time_zone tz = LoadZone("Africa/Monrovia"); + + if (VersionCmp(tz, "2017b") >= 0) { + // Strange offset change -00:44:30 -> +00:00:00 (non-DST) + // + // 63593069 == Thu, 6 Jan 1972 23:59:59 -0044 (MMT) + // 63593070 == Fri, 7 Jan 1972 00:44:30 +0000 (GMT) + auto tp = convert(civil_second(1972, 1, 6, 23, 59, 59), tz); + ExpectTime(tp, tz, 1972, 1, 6, 23, 59, 59, -44.5 * 60, false, "MMT"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 1972, 1, 7, 0, 44, 30, 0 * 60, false, "GMT"); + } +} + +TEST(TimeZoneEdgeCase, AmericaJamaica) { + // Jamaica discontinued DST transitions in 1983, and is now at a + // constant -0500. This makes it an interesting edge-case target. + // Note that the 32-bit times used in a (tzh_version == 0) zoneinfo + // file cannot represent the abbreviation-only transition of 1890, + // so we ignore the abbreviation by expecting what we received. + const time_zone tz = LoadZone("America/Jamaica"); + + // Before the first transition. + if (!tz.version().empty() && VersionCmp(tz, "2018d") >= 0) { + // We avoid the expectations on the -18430 offset below unless we are + // certain we have commit 907241e (Fix off-by-1 error for Jamaica and + // T&C before 1913) from 2018d. TODO: Remove the "version() not empty" + // part when 2018d is generally available from /usr/share/zoneinfo. + auto tp = convert(civil_second(1889, 12, 31, 0, 0, 0), tz); + ExpectTime(tp, tz, 1889, 12, 31, 0, 0, 0, -18430, false, + tz.lookup(tp).abbr); + + // Over the first (abbreviation-change only) transition. + // -2524503170 == Tue, 31 Dec 1889 23:59:59 -0507 (LMT) + // -2524503169 == Wed, 1 Jan 1890 00:00:00 -0507 (KMT) + tp = convert(civil_second(1889, 12, 31, 23, 59, 59), tz); + ExpectTime(tp, tz, 1889, 12, 31, 23, 59, 59, -18430, false, + tz.lookup(tp).abbr); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 1890, 1, 1, 0, 0, 0, -18430, false, "KMT"); + } + + // Over the last (DST) transition. + // 436341599 == Sun, 30 Oct 1983 01:59:59 -0400 (EDT) + // 436341600 == Sun, 30 Oct 1983 01:00:00 -0500 (EST) + auto tp = convert(civil_second(1983, 10, 30, 1, 59, 59), tz); + ExpectTime(tp, tz, 1983, 10, 30, 1, 59, 59, -4 * 3600, true, "EDT"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 1983, 10, 30, 1, 0, 0, -5 * 3600, false, "EST"); + + // After the last transition. + tp = convert(civil_second(1983, 12, 31, 23, 59, 59), tz); + ExpectTime(tp, tz, 1983, 12, 31, 23, 59, 59, -5 * 3600, false, "EST"); +} + +TEST(TimeZoneEdgeCase, WET) { + // Cover some non-existent times within forward transitions. + const time_zone tz = LoadZone("WET"); + + // Before the first transition. + auto tp = convert(civil_second(1977, 1, 1, 0, 0, 0), tz); + ExpectTime(tp, tz, 1977, 1, 1, 0, 0, 0, 0, false, "WET"); + + // Over the first transition. + // 228877199 == Sun, 3 Apr 1977 00:59:59 +0000 (WET) + // 228877200 == Sun, 3 Apr 1977 02:00:00 +0100 (WEST) + tp = convert(civil_second(1977, 4, 3, 0, 59, 59), tz); + ExpectTime(tp, tz, 1977, 4, 3, 0, 59, 59, 0, false, "WET"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 1977, 4, 3, 2, 0, 0, 1 * 3600, true, "WEST"); + + // A non-existent time within the first transition. + time_zone::civil_lookup cl1 = tz.lookup(civil_second(1977, 4, 3, 1, 15, 0)); + EXPECT_EQ(time_zone::civil_lookup::SKIPPED, cl1.kind); + ExpectTime(cl1.pre, tz, 1977, 4, 3, 2, 15, 0, 1 * 3600, true, "WEST"); + ExpectTime(cl1.trans, tz, 1977, 4, 3, 2, 0, 0, 1 * 3600, true, "WEST"); + ExpectTime(cl1.post, tz, 1977, 4, 3, 0, 15, 0, 0 * 3600, false, "WET"); + + // A non-existent time within the second forward transition. + time_zone::civil_lookup cl2 = tz.lookup(civil_second(1978, 4, 2, 1, 15, 0)); + EXPECT_EQ(time_zone::civil_lookup::SKIPPED, cl2.kind); + ExpectTime(cl2.pre, tz, 1978, 4, 2, 2, 15, 0, 1 * 3600, true, "WEST"); + ExpectTime(cl2.trans, tz, 1978, 4, 2, 2, 0, 0, 1 * 3600, true, "WEST"); + ExpectTime(cl2.post, tz, 1978, 4, 2, 0, 15, 0, 0 * 3600, false, "WET"); +} + +TEST(TimeZoneEdgeCase, FixedOffsets) { + const time_zone gmtm5 = LoadZone("Etc/GMT+5"); // -0500 + auto tp = convert(civil_second(1970, 1, 1, 0, 0, 0), gmtm5); + ExpectTime(tp, gmtm5, 1970, 1, 1, 0, 0, 0, -5 * 3600, false, "-05"); + EXPECT_EQ(chrono::system_clock::from_time_t(5 * 3600), tp); + + const time_zone gmtp5 = LoadZone("Etc/GMT-5"); // +0500 + tp = convert(civil_second(1970, 1, 1, 0, 0, 0), gmtp5); + ExpectTime(tp, gmtp5, 1970, 1, 1, 0, 0, 0, 5 * 3600, false, "+05"); + EXPECT_EQ(chrono::system_clock::from_time_t(-5 * 3600), tp); +} + +TEST(TimeZoneEdgeCase, NegativeYear) { + // Tests transition from year 0 (aka 1BCE) to year -1. + const time_zone tz = utc_time_zone(); + auto tp = convert(civil_second(0, 1, 1, 0, 0, 0), tz); + ExpectTime(tp, tz, 0, 1, 1, 0, 0, 0, 0 * 3600, false, "UTC"); + EXPECT_EQ(weekday::saturday, get_weekday(convert(tp, tz))); + tp -= absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, -1, 12, 31, 23, 59, 59, 0 * 3600, false, "UTC"); + EXPECT_EQ(weekday::friday, get_weekday(convert(tp, tz))); +} + +TEST(TimeZoneEdgeCase, UTC32bitLimit) { + const time_zone tz = utc_time_zone(); + + // Limits of signed 32-bit time_t + // + // 2147483647 == Tue, 19 Jan 2038 03:14:07 +0000 (UTC) + // 2147483648 == Tue, 19 Jan 2038 03:14:08 +0000 (UTC) + auto tp = convert(civil_second(2038, 1, 19, 3, 14, 7), tz); + ExpectTime(tp, tz, 2038, 1, 19, 3, 14, 7, 0 * 3600, false, "UTC"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 2038, 1, 19, 3, 14, 8, 0 * 3600, false, "UTC"); +} + +TEST(TimeZoneEdgeCase, UTC5DigitYear) { + const time_zone tz = utc_time_zone(); + + // Rollover to 5-digit year + // + // 253402300799 == Fri, 31 Dec 9999 23:59:59 +0000 (UTC) + // 253402300800 == Sat, 1 Jan 1000 00:00:00 +0000 (UTC) + auto tp = convert(civil_second(9999, 12, 31, 23, 59, 59), tz); + ExpectTime(tp, tz, 9999, 12, 31, 23, 59, 59, 0 * 3600, false, "UTC"); + tp += absl::time_internal::cctz::seconds(1); + ExpectTime(tp, tz, 10000, 1, 1, 0, 0, 0, 0 * 3600, false, "UTC"); +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_posix.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_posix.cc new file mode 100644 index 0000000000..5cdd09e89d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_posix.cc @@ -0,0 +1,159 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "time_zone_posix.h" + +#include <cstddef> +#include <cstring> +#include <limits> +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +namespace { + +const char kDigits[] = "0123456789"; + +const char* ParseInt(const char* p, int min, int max, int* vp) { + int value = 0; + const char* op = p; + const int kMaxInt = std::numeric_limits<int>::max(); + for (; const char* dp = strchr(kDigits, *p); ++p) { + int d = static_cast<int>(dp - kDigits); + if (d >= 10) break; // '\0' + if (value > kMaxInt / 10) return nullptr; + value *= 10; + if (value > kMaxInt - d) return nullptr; + value += d; + } + if (p == op || value < min || value > max) return nullptr; + *vp = value; + return p; +} + +// abbr = <.*?> | [^-+,\d]{3,} +const char* ParseAbbr(const char* p, std::string* abbr) { + const char* op = p; + if (*p == '<') { // special zoneinfo <...> form + while (*++p != '>') { + if (*p == '\0') return nullptr; + } + abbr->assign(op + 1, static_cast<std::size_t>(p - op) - 1); + return ++p; + } + while (*p != '\0') { + if (strchr("-+,", *p)) break; + if (strchr(kDigits, *p)) break; + ++p; + } + if (p - op < 3) return nullptr; + abbr->assign(op, static_cast<std::size_t>(p - op)); + return p; +} + +// offset = [+|-]hh[:mm[:ss]] (aggregated into single seconds value) +const char* ParseOffset(const char* p, int min_hour, int max_hour, int sign, + std::int_fast32_t* offset) { + if (p == nullptr) return nullptr; + if (*p == '+' || *p == '-') { + if (*p++ == '-') sign = -sign; + } + int hours = 0; + int minutes = 0; + int seconds = 0; + + p = ParseInt(p, min_hour, max_hour, &hours); + if (p == nullptr) return nullptr; + if (*p == ':') { + p = ParseInt(p + 1, 0, 59, &minutes); + if (p == nullptr) return nullptr; + if (*p == ':') { + p = ParseInt(p + 1, 0, 59, &seconds); + if (p == nullptr) return nullptr; + } + } + *offset = sign * ((((hours * 60) + minutes) * 60) + seconds); + return p; +} + +// datetime = ( Jn | n | Mm.w.d ) [ / offset ] +const char* ParseDateTime(const char* p, PosixTransition* res) { + if (p != nullptr && *p == ',') { + if (*++p == 'M') { + int month = 0; + if ((p = ParseInt(p + 1, 1, 12, &month)) != nullptr && *p == '.') { + int week = 0; + if ((p = ParseInt(p + 1, 1, 5, &week)) != nullptr && *p == '.') { + int weekday = 0; + if ((p = ParseInt(p + 1, 0, 6, &weekday)) != nullptr) { + res->date.fmt = PosixTransition::M; + res->date.m.month = static_cast<std::int_fast8_t>(month); + res->date.m.week = static_cast<std::int_fast8_t>(week); + res->date.m.weekday = static_cast<std::int_fast8_t>(weekday); + } + } + } + } else if (*p == 'J') { + int day = 0; + if ((p = ParseInt(p + 1, 1, 365, &day)) != nullptr) { + res->date.fmt = PosixTransition::J; + res->date.j.day = static_cast<std::int_fast16_t>(day); + } + } else { + int day = 0; + if ((p = ParseInt(p, 0, 365, &day)) != nullptr) { + res->date.fmt = PosixTransition::N; + res->date.n.day = static_cast<std::int_fast16_t>(day); + } + } + } + if (p != nullptr) { + res->time.offset = 2 * 60 * 60; // default offset is 02:00:00 + if (*p == '/') p = ParseOffset(p + 1, -167, 167, 1, &res->time.offset); + } + return p; +} + +} // namespace + +// spec = std offset [ dst [ offset ] , datetime , datetime ] +bool ParsePosixSpec(const std::string& spec, PosixTimeZone* res) { + const char* p = spec.c_str(); + if (*p == ':') return false; + + p = ParseAbbr(p, &res->std_abbr); + p = ParseOffset(p, 0, 24, -1, &res->std_offset); + if (p == nullptr) return false; + if (*p == '\0') return true; + + p = ParseAbbr(p, &res->dst_abbr); + if (p == nullptr) return false; + res->dst_offset = res->std_offset + (60 * 60); // default + if (*p != ',') p = ParseOffset(p, 0, 24, -1, &res->dst_offset); + + p = ParseDateTime(p, &res->dst_start); + p = ParseDateTime(p, &res->dst_end); + + return p != nullptr && *p == '\0'; +} + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_posix.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_posix.h new file mode 100644 index 0000000000..0cf29055f5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/time_zone_posix.h @@ -0,0 +1,132 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Parsing of a POSIX zone spec as described in the TZ part of section 8.3 in +// http://pubs.opengroup.org/onlinepubs/009695399/basedefs/xbd_chap08.html. +// +// The current POSIX spec for America/Los_Angeles is "PST8PDT,M3.2.0,M11.1.0", +// which would be broken down as ... +// +// PosixTimeZone { +// std_abbr = "PST" +// std_offset = -28800 +// dst_abbr = "PDT" +// dst_offset = -25200 +// dst_start = PosixTransition { +// date { +// m { +// month = 3 +// week = 2 +// weekday = 0 +// } +// } +// time { +// offset = 7200 +// } +// } +// dst_end = PosixTransition { +// date { +// m { +// month = 11 +// week = 1 +// weekday = 0 +// } +// } +// time { +// offset = 7200 +// } +// } +// } + +#ifndef ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_POSIX_H_ +#define ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_POSIX_H_ + +#include <cstdint> +#include <string> + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// The date/time of the transition. The date is specified as either: +// (J) the Nth day of the year (1 <= N <= 365), excluding leap days, or +// (N) the Nth day of the year (0 <= N <= 365), including leap days, or +// (M) the Nth weekday of a month (e.g., the 2nd Sunday in March). +// The time, specified as a day offset, identifies the particular moment +// of the transition, and may be negative or >= 24h, and in which case +// it would take us to another day, and perhaps week, or even month. +struct PosixTransition { + enum DateFormat { J, N, M }; + + struct Date { + struct NonLeapDay { + std::int_fast16_t day; // day of non-leap year [1:365] + }; + struct Day { + std::int_fast16_t day; // day of year [0:365] + }; + struct MonthWeekWeekday { + std::int_fast8_t month; // month of year [1:12] + std::int_fast8_t week; // week of month [1:5] (5==last) + std::int_fast8_t weekday; // 0==Sun, ..., 6=Sat + }; + + DateFormat fmt; + + union { + NonLeapDay j; + Day n; + MonthWeekWeekday m; + }; + }; + + struct Time { + std::int_fast32_t offset; // seconds before/after 00:00:00 + }; + + Date date; + Time time; +}; + +// The entirety of a POSIX-string specified time-zone rule. The standard +// abbreviation and offset are always given. If the time zone includes +// daylight saving, then the daylight abbrevation is non-empty and the +// remaining fields are also valid. Note that the start/end transitions +// are not ordered---in the southern hemisphere the transition to end +// daylight time occurs first in any particular year. +struct PosixTimeZone { + std::string std_abbr; + std::int_fast32_t std_offset; + + std::string dst_abbr; + std::int_fast32_t dst_offset; + PosixTransition dst_start; + PosixTransition dst_end; +}; + +// Breaks down a POSIX time-zone specification into its constituent pieces, +// filling in any missing values (DST offset, or start/end transition times) +// with the standard-defined defaults. Returns false if the specification +// could not be parsed (although some fields of *res may have been altered). +bool ParsePosixSpec(const std::string& spec, PosixTimeZone* res); + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_CCTZ_TIME_ZONE_POSIX_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/tzfile.h b/third_party/abseil_cpp/absl/time/internal/cctz/src/tzfile.h new file mode 100644 index 0000000000..269fa36c53 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/tzfile.h @@ -0,0 +1,122 @@ +/* Layout and location of TZif files. */ + +#ifndef TZFILE_H + +#define TZFILE_H + +/* +** This file is in the public domain, so clarified as of +** 1996-06-05 by Arthur David Olson. +*/ + +/* +** This header is for use ONLY with the time conversion code. +** There is no guarantee that it will remain unchanged, +** or that it will remain at all. +** Do NOT copy it to any system include directory. +** Thank you! +*/ + +/* +** Information about time zone files. +*/ + +#ifndef TZDIR +#define TZDIR "/usr/share/zoneinfo" /* Time zone object file directory */ +#endif /* !defined TZDIR */ + +#ifndef TZDEFAULT +#define TZDEFAULT "/etc/localtime" +#endif /* !defined TZDEFAULT */ + +#ifndef TZDEFRULES +#define TZDEFRULES "posixrules" +#endif /* !defined TZDEFRULES */ + +/* See Internet RFC 8536 for more details about the following format. */ + +/* +** Each file begins with. . . +*/ + +#define TZ_MAGIC "TZif" + +struct tzhead { + char tzh_magic[4]; /* TZ_MAGIC */ + char tzh_version[1]; /* '\0' or '2' or '3' as of 2013 */ + char tzh_reserved[15]; /* reserved; must be zero */ + char tzh_ttisutcnt[4]; /* coded number of trans. time flags */ + char tzh_ttisstdcnt[4]; /* coded number of trans. time flags */ + char tzh_leapcnt[4]; /* coded number of leap seconds */ + char tzh_timecnt[4]; /* coded number of transition times */ + char tzh_typecnt[4]; /* coded number of local time types */ + char tzh_charcnt[4]; /* coded number of abbr. chars */ +}; + +/* +** . . .followed by. . . +** +** tzh_timecnt (char [4])s coded transition times a la time(2) +** tzh_timecnt (unsigned char)s types of local time starting at above +** tzh_typecnt repetitions of +** one (char [4]) coded UT offset in seconds +** one (unsigned char) used to set tm_isdst +** one (unsigned char) that's an abbreviation list index +** tzh_charcnt (char)s '\0'-terminated zone abbreviations +** tzh_leapcnt repetitions of +** one (char [4]) coded leap second transition times +** one (char [4]) total correction after above +** tzh_ttisstdcnt (char)s indexed by type; if 1, transition +** time is standard time, if 0, +** transition time is local (wall clock) +** time; if absent, transition times are +** assumed to be local time +** tzh_ttisutcnt (char)s indexed by type; if 1, transition +** time is UT, if 0, transition time is +** local time; if absent, transition +** times are assumed to be local time. +** When this is 1, the corresponding +** std/wall indicator must also be 1. +*/ + +/* +** If tzh_version is '2' or greater, the above is followed by a second instance +** of tzhead and a second instance of the data in which each coded transition +** time uses 8 rather than 4 chars, +** then a POSIX-TZ-environment-variable-style string for use in handling +** instants after the last transition time stored in the file +** (with nothing between the newlines if there is no POSIX representation for +** such instants). +** +** If tz_version is '3' or greater, the above is extended as follows. +** First, the POSIX TZ string's hour offset may range from -167 +** through 167 as compared to the POSIX-required 0 through 24. +** Second, its DST start time may be January 1 at 00:00 and its stop +** time December 31 at 24:00 plus the difference between DST and +** standard time, indicating DST all year. +*/ + +/* +** In the current implementation, "tzset()" refuses to deal with files that +** exceed any of the limits below. +*/ + +#ifndef TZ_MAX_TIMES +#define TZ_MAX_TIMES 2000 +#endif /* !defined TZ_MAX_TIMES */ + +#ifndef TZ_MAX_TYPES +/* This must be at least 17 for Europe/Samara and Europe/Vilnius. */ +#define TZ_MAX_TYPES 256 /* Limited by what (unsigned char)'s can hold */ +#endif /* !defined TZ_MAX_TYPES */ + +#ifndef TZ_MAX_CHARS +#define TZ_MAX_CHARS 50 /* Maximum number of abbreviation characters */ + /* (limited by what unsigned chars can hold) */ +#endif /* !defined TZ_MAX_CHARS */ + +#ifndef TZ_MAX_LEAPS +#define TZ_MAX_LEAPS 50 /* Maximum number of leap second corrections */ +#endif /* !defined TZ_MAX_LEAPS */ + +#endif /* !defined TZFILE_H */ diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/src/zone_info_source.cc b/third_party/abseil_cpp/absl/time/internal/cctz/src/zone_info_source.cc new file mode 100644 index 0000000000..98ea161267 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/src/zone_info_source.cc @@ -0,0 +1,115 @@ +// Copyright 2016 Google Inc. All Rights Reserved. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/internal/cctz/include/cctz/zone_info_source.h" + +#include "absl/base/config.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz { + +// Defined out-of-line to avoid emitting a weak vtable in all TUs. +ZoneInfoSource::~ZoneInfoSource() {} +std::string ZoneInfoSource::Version() const { return std::string(); } + +} // namespace cctz +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz_extension { + +namespace { + +// A default for cctz_extension::zone_info_source_factory, which simply +// defers to the fallback factory. +std::unique_ptr<absl::time_internal::cctz::ZoneInfoSource> DefaultFactory( + const std::string& name, + const std::function< + std::unique_ptr<absl::time_internal::cctz::ZoneInfoSource>( + const std::string& name)>& fallback_factory) { + return fallback_factory(name); +} + +} // namespace + +// A "weak" definition for cctz_extension::zone_info_source_factory. +// The user may override this with their own "strong" definition (see +// zone_info_source.h). +#if !defined(__has_attribute) +#define __has_attribute(x) 0 +#endif +// MinGW is GCC on Windows, so while it asserts __has_attribute(weak), the +// Windows linker cannot handle that. Nor does the MinGW compiler know how to +// pass "#pragma comment(linker, ...)" to the Windows linker. +#if (__has_attribute(weak) || defined(__GNUC__)) && !defined(__MINGW32__) +ZoneInfoSourceFactory zone_info_source_factory __attribute__((weak)) = + DefaultFactory; +#elif defined(_MSC_VER) && !defined(__MINGW32__) && !defined(_LIBCPP_VERSION) +extern ZoneInfoSourceFactory zone_info_source_factory; +extern ZoneInfoSourceFactory default_factory; +ZoneInfoSourceFactory default_factory = DefaultFactory; +#if defined(_M_IX86) +#pragma comment( \ + linker, \ + "/alternatename:?zone_info_source_factory@cctz_extension@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@3P6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@ABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@ABV?$function@$$A6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@ABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@2@@Z@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@@ZA=?default_factory@cctz_extension@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@3P6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@ABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@ABV?$function@$$A6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@ABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@2@@Z@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@@ZA") +#elif defined(_M_IA_64) || defined(_M_AMD64) || defined(_M_ARM64) +#pragma comment( \ + linker, \ + "/alternatename:?zone_info_source_factory@cctz_extension@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@3P6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@AEBV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@AEBV?$function@$$A6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@AEBV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@2@@Z@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@@ZEA=?default_factory@cctz_extension@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@3P6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@AEBV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@AEBV?$function@$$A6A?AV?$unique_ptr@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@U?$default_delete@VZoneInfoSource@cctz@time_internal@" ABSL_INTERNAL_MANGLED_NS \ + "@@@std@@@std@@AEBV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@2@@Z@" ABSL_INTERNAL_MANGLED_BACKREFERENCE \ + "@@ZEA") +#else +#error Unsupported MSVC platform +#endif // _M_<PLATFORM> +#else +// Make it a "strong" definition if we have no other choice. +ZoneInfoSourceFactory zone_info_source_factory = DefaultFactory; +#endif + +} // namespace cctz_extension +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/README.zoneinfo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/README.zoneinfo new file mode 100644 index 0000000000..95fb4a91d1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/README.zoneinfo @@ -0,0 +1,37 @@ +testdata/zoneinfo contains time-zone data files that may be used with CCTZ. +Install them in a location referenced by the ${TZDIR} environment variable. +Symbolic and hard links have been eliminated for portability. + +On Linux systems the distribution's versions of these files can probably +already be found in the default ${TZDIR} location, /usr/share/zoneinfo. + +New versions can be generated using the following shell script. + + #!/bin/sh - + set -e + DESTDIR=$(mktemp -d) + trap "rm -fr ${DESTDIR}" 0 2 15 + ( + cd ${DESTDIR} + git clone https://github.com/eggert/tz.git + make --directory=tz \ + install DESTDIR=${DESTDIR} \ + DATAFORM=vanguard \ + TZDIR=/zoneinfo \ + REDO=posix_only \ + LOCALTIME=Factory \ + TZDATA_TEXT= \ + ZONETABLES=zone1970.tab + tar --create --dereference --hard-dereference --file tzfile.tar \ + --directory=tz tzfile.h + tar --create --dereference --hard-dereference --file zoneinfo.tar \ + --exclude=zoneinfo/posixrules zoneinfo \ + --directory=tz version + ) + tar --extract --directory src --file ${DESTDIR}/tzfile.tar + tar --extract --directory testdata --file ${DESTDIR}/zoneinfo.tar + exit 0 + +To run the CCTZ tests using the testdata/zoneinfo files, execute: + + bazel test --test_env=TZDIR=${PWD}/testdata/zoneinfo ... diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/version b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/version new file mode 100644 index 0000000000..7f680eec36 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/version @@ -0,0 +1 @@ +2020a diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Abidjan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Abidjan new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Abidjan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Accra b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Accra new file mode 100644 index 0000000000..697b9933eb --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Accra Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Addis_Ababa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Addis_Ababa new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Addis_Ababa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Algiers b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Algiers new file mode 100644 index 0000000000..ae04342313 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Algiers Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Asmara b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Asmara new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Asmara Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Asmera b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Asmera new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Asmera Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bamako b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bamako new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bamako Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bangui b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bangui new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bangui Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Banjul b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Banjul new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Banjul Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bissau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bissau new file mode 100644 index 0000000000..82ea5aaf0c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bissau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Blantyre b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Blantyre new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Blantyre Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Brazzaville b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Brazzaville new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Brazzaville Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bujumbura b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bujumbura new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Bujumbura Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Cairo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Cairo new file mode 100644 index 0000000000..d3f819623f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Cairo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Casablanca b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Casablanca new file mode 100644 index 0000000000..d39016b89d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Casablanca Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ceuta b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ceuta new file mode 100644 index 0000000000..850c8f06fa --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ceuta Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Conakry b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Conakry new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Conakry Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Dakar b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Dakar new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Dakar Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Dar_es_Salaam b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Dar_es_Salaam new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Dar_es_Salaam Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Djibouti b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Djibouti new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Djibouti Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Douala b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Douala new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Douala Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/El_Aaiun b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/El_Aaiun new file mode 100644 index 0000000000..066fbed008 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/El_Aaiun Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Freetown b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Freetown new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Freetown Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Gaborone b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Gaborone new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Gaborone Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Harare b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Harare new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Harare Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Johannesburg b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Johannesburg new file mode 100644 index 0000000000..b1c425dace --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Johannesburg Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Juba b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Juba new file mode 100644 index 0000000000..625b1acccf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Juba Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kampala b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kampala new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kampala Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Khartoum b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Khartoum new file mode 100644 index 0000000000..8ee8cb92e7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Khartoum Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kigali b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kigali new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kigali Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kinshasa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kinshasa new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Kinshasa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lagos b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lagos new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lagos Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Libreville b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Libreville new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Libreville Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lome b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lome new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lome Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Luanda b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Luanda new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Luanda Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lubumbashi b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lubumbashi new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lubumbashi Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lusaka b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lusaka new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Lusaka Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Malabo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Malabo new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Malabo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Maputo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Maputo new file mode 100644 index 0000000000..52753c0f87 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Maputo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Maseru b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Maseru new file mode 100644 index 0000000000..b1c425dace --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Maseru Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Mbabane b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Mbabane new file mode 100644 index 0000000000..b1c425dace --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Mbabane Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Mogadishu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Mogadishu new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Mogadishu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Monrovia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Monrovia new file mode 100644 index 0000000000..6d688502a1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Monrovia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Nairobi b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Nairobi new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Nairobi Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ndjamena b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ndjamena new file mode 100644 index 0000000000..a968845e29 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ndjamena Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Niamey b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Niamey new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Niamey Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Nouakchott b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Nouakchott new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Nouakchott Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ouagadougou b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ouagadougou new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Ouagadougou Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Porto-Novo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Porto-Novo new file mode 100644 index 0000000000..0c80137c74 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Porto-Novo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Sao_Tome b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Sao_Tome new file mode 100644 index 0000000000..59f3759c40 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Sao_Tome Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Timbuktu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Timbuktu new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Timbuktu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Tripoli b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Tripoli new file mode 100644 index 0000000000..07b393bb7d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Tripoli Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Tunis b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Tunis new file mode 100644 index 0000000000..427fa56303 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Tunis Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Windhoek b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Windhoek new file mode 100644 index 0000000000..abecd137b1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Africa/Windhoek Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Adak b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Adak new file mode 100644 index 0000000000..43236498f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Adak Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Anchorage b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Anchorage new file mode 100644 index 0000000000..9bbb2fd3b3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Anchorage Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Anguilla b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Anguilla new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Anguilla Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Antigua b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Antigua new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Antigua Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Araguaina b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Araguaina new file mode 100644 index 0000000000..49381b4108 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Araguaina Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Buenos_Aires b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Buenos_Aires new file mode 100644 index 0000000000..260f86a918 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Buenos_Aires Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Catamarca b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Catamarca new file mode 100644 index 0000000000..0ae222a2f8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Catamarca Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/ComodRivadavia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/ComodRivadavia new file mode 100644 index 0000000000..0ae222a2f8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/ComodRivadavia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Cordoba b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Cordoba new file mode 100644 index 0000000000..da4c23a545 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Cordoba Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Jujuy b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Jujuy new file mode 100644 index 0000000000..604b856636 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Jujuy Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/La_Rioja b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/La_Rioja new file mode 100644 index 0000000000..2218e36bfd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/La_Rioja Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Mendoza b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Mendoza new file mode 100644 index 0000000000..f9e677f171 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Mendoza Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Rio_Gallegos b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Rio_Gallegos new file mode 100644 index 0000000000..c36587e1c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Rio_Gallegos Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Salta b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Salta new file mode 100644 index 0000000000..0e797f2215 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Salta Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/San_Juan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/San_Juan new file mode 100644 index 0000000000..2698495bb3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/San_Juan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/San_Luis b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/San_Luis new file mode 100644 index 0000000000..fe50f6211c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/San_Luis Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Tucuman b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Tucuman new file mode 100644 index 0000000000..c954000ba9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Tucuman Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Ushuaia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Ushuaia new file mode 100644 index 0000000000..3643628a24 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Argentina/Ushuaia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Aruba b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Aruba new file mode 100644 index 0000000000..f7ab6efcc0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Aruba Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Asuncion b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Asuncion new file mode 100644 index 0000000000..2f3bbda6d3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Asuncion Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Atikokan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Atikokan new file mode 100644 index 0000000000..629ed42319 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Atikokan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Atka b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Atka new file mode 100644 index 0000000000..43236498f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Atka Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bahia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bahia new file mode 100644 index 0000000000..15808d30fb --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bahia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bahia_Banderas b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bahia_Banderas new file mode 100644 index 0000000000..896af3f56a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bahia_Banderas Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Barbados b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Barbados new file mode 100644 index 0000000000..9b90e306a6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Barbados Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Belem b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Belem new file mode 100644 index 0000000000..60b5924dc1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Belem Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Belize b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Belize new file mode 100644 index 0000000000..851051ae94 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Belize Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Blanc-Sablon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Blanc-Sablon new file mode 100644 index 0000000000..f9f13a1679 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Blanc-Sablon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Boa_Vista b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Boa_Vista new file mode 100644 index 0000000000..978c33100f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Boa_Vista Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bogota b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bogota new file mode 100644 index 0000000000..b2647d7a83 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Bogota Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Boise b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Boise new file mode 100644 index 0000000000..f8d54e2747 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Boise Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Buenos_Aires b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Buenos_Aires new file mode 100644 index 0000000000..260f86a918 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Buenos_Aires Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cambridge_Bay b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cambridge_Bay new file mode 100644 index 0000000000..f8db4b6ebf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cambridge_Bay Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Campo_Grande b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Campo_Grande new file mode 100644 index 0000000000..81206247d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Campo_Grande Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cancun b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cancun new file mode 100644 index 0000000000..f907f0a5ba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cancun Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Caracas b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Caracas new file mode 100644 index 0000000000..eedf725e8d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Caracas Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Catamarca b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Catamarca new file mode 100644 index 0000000000..0ae222a2f8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Catamarca Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cayenne b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cayenne new file mode 100644 index 0000000000..e5bc06fdbe --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cayenne Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cayman b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cayman new file mode 100644 index 0000000000..9964b9a334 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cayman Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Chicago b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Chicago new file mode 100644 index 0000000000..a5b1617c7f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Chicago Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Chihuahua b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Chihuahua new file mode 100644 index 0000000000..8ed5f93b02 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Chihuahua Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Coral_Harbour b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Coral_Harbour new file mode 100644 index 0000000000..629ed42319 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Coral_Harbour Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cordoba b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cordoba new file mode 100644 index 0000000000..da4c23a545 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cordoba Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Costa_Rica b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Costa_Rica new file mode 100644 index 0000000000..37cb85e4db --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Costa_Rica Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Creston b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Creston new file mode 100644 index 0000000000..ca648573e4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Creston Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cuiaba b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cuiaba new file mode 100644 index 0000000000..9bea3d4079 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Cuiaba Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Curacao b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Curacao new file mode 100644 index 0000000000..f7ab6efcc0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Curacao Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Danmarkshavn b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Danmarkshavn new file mode 100644 index 0000000000..9549adcb65 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Danmarkshavn Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dawson b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dawson new file mode 100644 index 0000000000..2b6c3eeaba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dawson Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dawson_Creek b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dawson_Creek new file mode 100644 index 0000000000..db9e339655 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dawson_Creek Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Denver b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Denver new file mode 100644 index 0000000000..5fbe26b1d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Denver Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Detroit b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Detroit new file mode 100644 index 0000000000..e104faa465 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Detroit Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dominica b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dominica new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Dominica Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Edmonton b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Edmonton new file mode 100644 index 0000000000..cd78a6f8be --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Edmonton Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Eirunepe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Eirunepe new file mode 100644 index 0000000000..39d6daeb9b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Eirunepe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/El_Salvador b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/El_Salvador new file mode 100644 index 0000000000..e2f22304aa --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/El_Salvador Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Ensenada b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Ensenada new file mode 100644 index 0000000000..ada6bf78b2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Ensenada Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fort_Nelson b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fort_Nelson new file mode 100644 index 0000000000..5a0b7f1ca0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fort_Nelson Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fort_Wayne b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fort_Wayne new file mode 100644 index 0000000000..09511ccdcf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fort_Wayne Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fortaleza b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fortaleza new file mode 100644 index 0000000000..be57dc20b4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Fortaleza Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Glace_Bay b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Glace_Bay new file mode 100644 index 0000000000..48412a4cbf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Glace_Bay Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Godthab b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Godthab new file mode 100644 index 0000000000..0160308bf6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Godthab Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Goose_Bay b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Goose_Bay new file mode 100644 index 0000000000..a3f299079a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Goose_Bay Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Grand_Turk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Grand_Turk new file mode 100644 index 0000000000..b9bb063b62 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Grand_Turk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Grenada b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Grenada new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Grenada Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guadeloupe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guadeloupe new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guadeloupe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guatemala b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guatemala new file mode 100644 index 0000000000..407138caf9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guatemala Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guayaquil b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guayaquil new file mode 100644 index 0000000000..0559a7a4a4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guayaquil Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guyana b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guyana new file mode 100644 index 0000000000..d5dab14969 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Guyana Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Halifax b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Halifax new file mode 100644 index 0000000000..756099abe6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Halifax Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Havana b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Havana new file mode 100644 index 0000000000..b69ac45107 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Havana Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Hermosillo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Hermosillo new file mode 100644 index 0000000000..791a9fa2b3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Hermosillo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Indianapolis b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Indianapolis new file mode 100644 index 0000000000..09511ccdcf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Indianapolis Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Knox b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Knox new file mode 100644 index 0000000000..fcd408d74d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Knox Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Marengo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Marengo new file mode 100644 index 0000000000..1abf75e7e8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Marengo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Petersburg b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Petersburg new file mode 100644 index 0000000000..0133548eca --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Petersburg Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Tell_City b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Tell_City new file mode 100644 index 0000000000..7bbb653cd7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Tell_City Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Vevay b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Vevay new file mode 100644 index 0000000000..d236b7c077 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Vevay Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Vincennes b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Vincennes new file mode 100644 index 0000000000..c818929d19 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Vincennes Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Winamac b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Winamac new file mode 100644 index 0000000000..630935c1e1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indiana/Winamac Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indianapolis b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indianapolis new file mode 100644 index 0000000000..09511ccdcf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Indianapolis Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Inuvik b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Inuvik new file mode 100644 index 0000000000..87bb355295 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Inuvik Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Iqaluit b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Iqaluit new file mode 100644 index 0000000000..c8138bdbb3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Iqaluit Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Jamaica b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Jamaica new file mode 100644 index 0000000000..2a9b7fd52d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Jamaica Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Jujuy b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Jujuy new file mode 100644 index 0000000000..604b856636 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Jujuy Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Juneau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Juneau new file mode 100644 index 0000000000..451f349009 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Juneau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kentucky/Louisville b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kentucky/Louisville new file mode 100644 index 0000000000..177836e4fd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kentucky/Louisville Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kentucky/Monticello b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kentucky/Monticello new file mode 100644 index 0000000000..438e3eab4a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kentucky/Monticello Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Knox_IN b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Knox_IN new file mode 100644 index 0000000000..fcd408d74d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Knox_IN Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kralendijk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kralendijk new file mode 100644 index 0000000000..f7ab6efcc0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Kralendijk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/La_Paz b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/La_Paz new file mode 100644 index 0000000000..a101372435 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/La_Paz Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Lima b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Lima new file mode 100644 index 0000000000..3c6529b756 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Lima Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Los_Angeles b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Los_Angeles new file mode 100644 index 0000000000..9dad4f4c75 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Los_Angeles Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Louisville b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Louisville new file mode 100644 index 0000000000..177836e4fd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Louisville Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Lower_Princes b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Lower_Princes new file mode 100644 index 0000000000..f7ab6efcc0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Lower_Princes Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Maceio b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Maceio new file mode 100644 index 0000000000..bc8b951d2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Maceio Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Managua b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Managua new file mode 100644 index 0000000000..e0242bff6e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Managua Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Manaus b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Manaus new file mode 100644 index 0000000000..63d58f80f5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Manaus Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Marigot b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Marigot new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Marigot Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Martinique b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Martinique new file mode 100644 index 0000000000..8df43dcf1c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Martinique Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Matamoros b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Matamoros new file mode 100644 index 0000000000..047968dfff --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Matamoros Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mazatlan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mazatlan new file mode 100644 index 0000000000..e4a785743d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mazatlan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mendoza b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mendoza new file mode 100644 index 0000000000..f9e677f171 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mendoza Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Menominee b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Menominee new file mode 100644 index 0000000000..314613866d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Menominee Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Merida b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Merida new file mode 100644 index 0000000000..ea852da33a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Merida Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Metlakatla b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Metlakatla new file mode 100644 index 0000000000..1e94be3d55 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Metlakatla Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mexico_City b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mexico_City new file mode 100644 index 0000000000..e7fb6f2953 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Mexico_City Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Miquelon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Miquelon new file mode 100644 index 0000000000..b924b71004 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Miquelon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Moncton b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Moncton new file mode 100644 index 0000000000..9df8d0f2ec --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Moncton Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Monterrey b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Monterrey new file mode 100644 index 0000000000..a8928c8dc9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Monterrey Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montevideo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montevideo new file mode 100644 index 0000000000..2f357bcf50 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montevideo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montreal b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montreal new file mode 100644 index 0000000000..6752c5b052 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montreal Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montserrat b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montserrat new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Montserrat Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nassau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nassau new file mode 100644 index 0000000000..33cc6c6265 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nassau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/New_York b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/New_York new file mode 100644 index 0000000000..2f75480e06 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/New_York Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nipigon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nipigon new file mode 100644 index 0000000000..f6a856e693 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nipigon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nome b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nome new file mode 100644 index 0000000000..10998df3bb --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nome Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Noronha b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Noronha new file mode 100644 index 0000000000..f140726f2a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Noronha Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/Beulah b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/Beulah new file mode 100644 index 0000000000..246345dde7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/Beulah Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/Center b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/Center new file mode 100644 index 0000000000..1fa0703778 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/Center Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/New_Salem b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/New_Salem new file mode 100644 index 0000000000..123f2aeecf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/North_Dakota/New_Salem Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nuuk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nuuk new file mode 100644 index 0000000000..0160308bf6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Nuuk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Ojinaga b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Ojinaga new file mode 100644 index 0000000000..fc4a03e369 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Ojinaga Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Panama b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Panama new file mode 100644 index 0000000000..9964b9a334 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Panama Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Pangnirtung b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Pangnirtung new file mode 100644 index 0000000000..3e4e0db6ae --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Pangnirtung Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Paramaribo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Paramaribo new file mode 100644 index 0000000000..bc8a6edf13 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Paramaribo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Phoenix b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Phoenix new file mode 100644 index 0000000000..ac6bb0c782 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Phoenix Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Port-au-Prince b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Port-au-Prince new file mode 100644 index 0000000000..287f143926 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Port-au-Prince Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Port_of_Spain b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Port_of_Spain new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Port_of_Spain Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Porto_Acre b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Porto_Acre new file mode 100644 index 0000000000..a374cb43d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Porto_Acre Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Porto_Velho b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Porto_Velho new file mode 100644 index 0000000000..2e873a5aa8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Porto_Velho Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Puerto_Rico b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Puerto_Rico new file mode 100644 index 0000000000..a662a57137 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Puerto_Rico Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Punta_Arenas b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Punta_Arenas new file mode 100644 index 0000000000..a5a8af52c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Punta_Arenas Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rainy_River b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rainy_River new file mode 100644 index 0000000000..ea66099155 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rainy_River Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rankin_Inlet b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rankin_Inlet new file mode 100644 index 0000000000..3a70587472 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rankin_Inlet Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Recife b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Recife new file mode 100644 index 0000000000..d7abb168a7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Recife Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Regina b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Regina new file mode 100644 index 0000000000..20c9c84df4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Regina Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Resolute b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Resolute new file mode 100644 index 0000000000..0a73b753ba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Resolute Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rio_Branco b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rio_Branco new file mode 100644 index 0000000000..a374cb43d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rio_Branco Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rosario b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rosario new file mode 100644 index 0000000000..da4c23a545 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Rosario Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santa_Isabel b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santa_Isabel new file mode 100644 index 0000000000..ada6bf78b2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santa_Isabel Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santarem b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santarem new file mode 100644 index 0000000000..c28f36063b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santarem Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santiago b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santiago new file mode 100644 index 0000000000..816a042818 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santiago Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santo_Domingo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santo_Domingo new file mode 100644 index 0000000000..4fe36fd4c1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Santo_Domingo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Sao_Paulo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Sao_Paulo new file mode 100644 index 0000000000..13ff083869 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Sao_Paulo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Scoresbysund b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Scoresbysund new file mode 100644 index 0000000000..e20e9e1c42 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Scoresbysund Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Shiprock b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Shiprock new file mode 100644 index 0000000000..5fbe26b1d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Shiprock Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Sitka b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Sitka new file mode 100644 index 0000000000..31f7061371 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Sitka Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Barthelemy b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Barthelemy new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Barthelemy Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Johns b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Johns new file mode 100644 index 0000000000..65a5b0c720 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Johns Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Kitts b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Kitts new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Kitts Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Lucia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Lucia new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Lucia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Thomas b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Thomas new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Thomas Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Vincent b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Vincent new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/St_Vincent Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Swift_Current b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Swift_Current new file mode 100644 index 0000000000..8e9ef255ee --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Swift_Current Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tegucigalpa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tegucigalpa new file mode 100644 index 0000000000..2adacb2e50 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tegucigalpa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Thule b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Thule new file mode 100644 index 0000000000..6f802f1c2a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Thule Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Thunder_Bay b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Thunder_Bay new file mode 100644 index 0000000000..e504c9acf1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Thunder_Bay Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tijuana b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tijuana new file mode 100644 index 0000000000..ada6bf78b2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tijuana Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Toronto b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Toronto new file mode 100644 index 0000000000..6752c5b052 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Toronto Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tortola b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tortola new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Tortola Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Vancouver b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Vancouver new file mode 100644 index 0000000000..bb60cbced3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Vancouver Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Virgin b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Virgin new file mode 100644 index 0000000000..697cf5bcf7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Virgin Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Whitehorse b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Whitehorse new file mode 100644 index 0000000000..062b58cedc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Whitehorse Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Winnipeg b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Winnipeg new file mode 100644 index 0000000000..ac40299f6b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Winnipeg Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Yakutat b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Yakutat new file mode 100644 index 0000000000..da209f9f0a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Yakutat Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Yellowknife b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Yellowknife new file mode 100644 index 0000000000..e6afa390e8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/America/Yellowknife Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Casey b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Casey new file mode 100644 index 0000000000..f100f47461 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Casey Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Davis b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Davis new file mode 100644 index 0000000000..916f2c2592 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Davis Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/DumontDUrville b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/DumontDUrville new file mode 100644 index 0000000000..a71b39c004 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/DumontDUrville Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Macquarie b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Macquarie new file mode 100644 index 0000000000..616afd9c83 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Macquarie Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Mawson b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Mawson new file mode 100644 index 0000000000..b32e7fd6c6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Mawson Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/McMurdo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/McMurdo new file mode 100644 index 0000000000..6575fdce31 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/McMurdo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Palmer b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Palmer new file mode 100644 index 0000000000..3dd85f84ff --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Palmer Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Rothera b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Rothera new file mode 100644 index 0000000000..8b2430a20e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Rothera Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/South_Pole b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/South_Pole new file mode 100644 index 0000000000..6575fdce31 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/South_Pole Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Syowa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Syowa new file mode 100644 index 0000000000..254af7d12f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Syowa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Troll b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Troll new file mode 100644 index 0000000000..5e565da2f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Troll Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Vostok b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Vostok new file mode 100644 index 0000000000..728305305d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Antarctica/Vostok Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Arctic/Longyearbyen b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Arctic/Longyearbyen new file mode 100644 index 0000000000..15a34c3ced --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Arctic/Longyearbyen Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aden b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aden new file mode 100644 index 0000000000..2aea25f8c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aden Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Almaty b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Almaty new file mode 100644 index 0000000000..a4b0077900 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Almaty Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Amman b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Amman new file mode 100644 index 0000000000..c9e8707912 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Amman Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Anadyr b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Anadyr new file mode 100644 index 0000000000..6ed8b7cb07 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Anadyr Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aqtau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aqtau new file mode 100644 index 0000000000..e2d0f91954 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aqtau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aqtobe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aqtobe new file mode 100644 index 0000000000..06f0a13a66 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Aqtobe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ashgabat b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ashgabat new file mode 100644 index 0000000000..73891af1ee --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ashgabat Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ashkhabad b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ashkhabad new file mode 100644 index 0000000000..73891af1ee --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ashkhabad Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Atyrau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Atyrau new file mode 100644 index 0000000000..8b5153e054 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Atyrau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Baghdad b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Baghdad new file mode 100644 index 0000000000..f7162edf93 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Baghdad Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bahrain b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bahrain new file mode 100644 index 0000000000..63188b269d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bahrain Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Baku b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Baku new file mode 100644 index 0000000000..a0de74b958 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Baku Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bangkok b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bangkok new file mode 100644 index 0000000000..c292ac5b5f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bangkok Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Barnaul b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Barnaul new file mode 100644 index 0000000000..759592a255 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Barnaul Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Beirut b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Beirut new file mode 100644 index 0000000000..fb266ede22 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Beirut Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bishkek b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bishkek new file mode 100644 index 0000000000..f6e20dd3a8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Bishkek Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Brunei b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Brunei new file mode 100644 index 0000000000..3dab0abf4e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Brunei Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Calcutta b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Calcutta new file mode 100644 index 0000000000..0014046d29 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Calcutta Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chita b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chita new file mode 100644 index 0000000000..c4149c05ce --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chita Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Choibalsan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Choibalsan new file mode 100644 index 0000000000..e48daa8243 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Choibalsan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chongqing b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chongqing new file mode 100644 index 0000000000..91f6f8bc2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chongqing Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chungking b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chungking new file mode 100644 index 0000000000..91f6f8bc2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Chungking Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Colombo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Colombo new file mode 100644 index 0000000000..62c64d85df --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Colombo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dacca b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dacca new file mode 100644 index 0000000000..b11c928410 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dacca Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Damascus b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Damascus new file mode 100644 index 0000000000..d9104a7ab8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Damascus Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dhaka b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dhaka new file mode 100644 index 0000000000..b11c928410 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dhaka Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dili b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dili new file mode 100644 index 0000000000..30943bbd0a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dili Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dubai b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dubai new file mode 100644 index 0000000000..fc0a589e2b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dubai Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dushanbe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dushanbe new file mode 100644 index 0000000000..82d85b8c1b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Dushanbe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Famagusta b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Famagusta new file mode 100644 index 0000000000..653b146a60 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Famagusta Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Gaza b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Gaza new file mode 100644 index 0000000000..592b632606 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Gaza Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Harbin b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Harbin new file mode 100644 index 0000000000..91f6f8bc2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Harbin Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hebron b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hebron new file mode 100644 index 0000000000..ae82f9b546 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hebron Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ho_Chi_Minh b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ho_Chi_Minh new file mode 100644 index 0000000000..e2934e371b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ho_Chi_Minh Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hong_Kong b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hong_Kong new file mode 100644 index 0000000000..23d0375fba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hong_Kong Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hovd b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hovd new file mode 100644 index 0000000000..4cb800a918 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Hovd Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Irkutsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Irkutsk new file mode 100644 index 0000000000..4dcbbb7ea2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Irkutsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Istanbul b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Istanbul new file mode 100644 index 0000000000..508446bb6a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Istanbul Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jakarta b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jakarta new file mode 100644 index 0000000000..5baa3a8f2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jakarta Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jayapura b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jayapura new file mode 100644 index 0000000000..3002c82022 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jayapura Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jerusalem b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jerusalem new file mode 100644 index 0000000000..440ef06b5d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Jerusalem Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kabul b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kabul new file mode 100644 index 0000000000..d19b9bd51d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kabul Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kamchatka b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kamchatka new file mode 100644 index 0000000000..3e80b4e09f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kamchatka Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Karachi b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Karachi new file mode 100644 index 0000000000..ba65c0e8d3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Karachi Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kashgar b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kashgar new file mode 100644 index 0000000000..faa14d92d5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kashgar Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kathmandu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kathmandu new file mode 100644 index 0000000000..a5d510753f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kathmandu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Katmandu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Katmandu new file mode 100644 index 0000000000..a5d510753f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Katmandu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Khandyga b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Khandyga new file mode 100644 index 0000000000..72bea64ba8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Khandyga Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kolkata b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kolkata new file mode 100644 index 0000000000..0014046d29 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kolkata Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Krasnoyarsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Krasnoyarsk new file mode 100644 index 0000000000..30c6f16505 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Krasnoyarsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuala_Lumpur b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuala_Lumpur new file mode 100644 index 0000000000..612b01e71c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuala_Lumpur Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuching b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuching new file mode 100644 index 0000000000..c86750cb7d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuching Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuwait b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuwait new file mode 100644 index 0000000000..2aea25f8c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Kuwait Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Macao b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Macao new file mode 100644 index 0000000000..cac65063d0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Macao Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Macau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Macau new file mode 100644 index 0000000000..cac65063d0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Macau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Magadan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Magadan new file mode 100644 index 0000000000..b4fcac18e3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Magadan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Makassar b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Makassar new file mode 100644 index 0000000000..556ba86693 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Makassar Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Manila b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Manila new file mode 100644 index 0000000000..f4f4b04efa --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Manila Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Muscat b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Muscat new file mode 100644 index 0000000000..fc0a589e2b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Muscat Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Nicosia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Nicosia new file mode 100644 index 0000000000..f7f10ab766 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Nicosia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Novokuznetsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Novokuznetsk new file mode 100644 index 0000000000..d983276119 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Novokuznetsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Novosibirsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Novosibirsk new file mode 100644 index 0000000000..e0ee5fcea9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Novosibirsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Omsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Omsk new file mode 100644 index 0000000000..b29b769311 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Omsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Oral b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Oral new file mode 100644 index 0000000000..ad1f9ca1ca --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Oral Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Phnom_Penh b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Phnom_Penh new file mode 100644 index 0000000000..c292ac5b5f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Phnom_Penh Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Pontianak b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Pontianak new file mode 100644 index 0000000000..12ce24cbea --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Pontianak Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Pyongyang b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Pyongyang new file mode 100644 index 0000000000..7ad7e0b2cf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Pyongyang Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qatar b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qatar new file mode 100644 index 0000000000..63188b269d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qatar Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qostanay b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qostanay new file mode 100644 index 0000000000..73b9d963ef --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qostanay Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qyzylorda b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qyzylorda new file mode 100644 index 0000000000..c2fe4c144c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Qyzylorda Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Rangoon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Rangoon new file mode 100644 index 0000000000..dd77395b05 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Rangoon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Riyadh b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Riyadh new file mode 100644 index 0000000000..2aea25f8c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Riyadh Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Saigon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Saigon new file mode 100644 index 0000000000..e2934e371b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Saigon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Sakhalin b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Sakhalin new file mode 100644 index 0000000000..485459ce03 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Sakhalin Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Samarkand b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Samarkand new file mode 100644 index 0000000000..030d47ce07 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Samarkand Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Seoul b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Seoul new file mode 100644 index 0000000000..96199e73e7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Seoul Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Shanghai b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Shanghai new file mode 100644 index 0000000000..91f6f8bc2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Shanghai Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Singapore b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Singapore new file mode 100644 index 0000000000..2364b2178b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Singapore Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Srednekolymsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Srednekolymsk new file mode 100644 index 0000000000..261a9832b3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Srednekolymsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Taipei b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Taipei new file mode 100644 index 0000000000..24c43444b6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Taipei Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tashkent b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tashkent new file mode 100644 index 0000000000..32a9d7d0c9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tashkent Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tbilisi b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tbilisi new file mode 100644 index 0000000000..b608d79748 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tbilisi Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tehran b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tehran new file mode 100644 index 0000000000..8cec5ad7de --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tehran Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tel_Aviv b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tel_Aviv new file mode 100644 index 0000000000..440ef06b5d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tel_Aviv Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Thimbu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Thimbu new file mode 100644 index 0000000000..fe409c7a2a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Thimbu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Thimphu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Thimphu new file mode 100644 index 0000000000..fe409c7a2a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Thimphu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tokyo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tokyo new file mode 100644 index 0000000000..26f4d34d67 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tokyo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tomsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tomsk new file mode 100644 index 0000000000..670e2ad2ce --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Tomsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ujung_Pandang b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ujung_Pandang new file mode 100644 index 0000000000..556ba86693 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ujung_Pandang Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ulaanbaatar b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ulaanbaatar new file mode 100644 index 0000000000..2e20cc3a43 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ulaanbaatar Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ulan_Bator b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ulan_Bator new file mode 100644 index 0000000000..2e20cc3a43 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ulan_Bator Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Urumqi b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Urumqi new file mode 100644 index 0000000000..faa14d92d5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Urumqi Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ust-Nera b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ust-Nera new file mode 100644 index 0000000000..9e4a78f6a5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Ust-Nera Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Vientiane b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Vientiane new file mode 100644 index 0000000000..c292ac5b5f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Vientiane Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Vladivostok b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Vladivostok new file mode 100644 index 0000000000..8ab253ce73 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Vladivostok Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yakutsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yakutsk new file mode 100644 index 0000000000..c815e99b1a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yakutsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yangon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yangon new file mode 100644 index 0000000000..dd77395b05 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yangon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yekaterinburg b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yekaterinburg new file mode 100644 index 0000000000..6958d7eddd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yekaterinburg Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yerevan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yerevan new file mode 100644 index 0000000000..250bfe020a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Asia/Yerevan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Azores b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Azores new file mode 100644 index 0000000000..56593dbfff --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Azores Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Bermuda b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Bermuda new file mode 100644 index 0000000000..419c660ba7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Bermuda Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Canary b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Canary new file mode 100644 index 0000000000..f3192156ff --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Canary Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Cape_Verde b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Cape_Verde new file mode 100644 index 0000000000..e2a49d248d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Cape_Verde Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Faeroe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Faeroe new file mode 100644 index 0000000000..4dab7ef085 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Faeroe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Faroe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Faroe new file mode 100644 index 0000000000..4dab7ef085 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Faroe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Jan_Mayen b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Jan_Mayen new file mode 100644 index 0000000000..15a34c3ced --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Jan_Mayen Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Madeira b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Madeira new file mode 100644 index 0000000000..5213761f89 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Madeira Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Reykjavik b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Reykjavik new file mode 100644 index 0000000000..10e0fc8190 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Reykjavik Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/South_Georgia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/South_Georgia new file mode 100644 index 0000000000..4466608612 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/South_Georgia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/St_Helena b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/St_Helena new file mode 100644 index 0000000000..28b32ab2e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/St_Helena Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Stanley b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Stanley new file mode 100644 index 0000000000..88077f1107 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Atlantic/Stanley Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/ACT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/ACT new file mode 100644 index 0000000000..7636592aa7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/ACT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Adelaide b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Adelaide new file mode 100644 index 0000000000..0b1252abb7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Adelaide Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Brisbane b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Brisbane new file mode 100644 index 0000000000..3021bdb614 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Brisbane Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Broken_Hill b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Broken_Hill new file mode 100644 index 0000000000..1ac3fc8f52 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Broken_Hill Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Canberra b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Canberra new file mode 100644 index 0000000000..7636592aa7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Canberra Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Currie b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Currie new file mode 100644 index 0000000000..f65a990efe --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Currie Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Darwin b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Darwin new file mode 100644 index 0000000000..1cf502984a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Darwin Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Eucla b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Eucla new file mode 100644 index 0000000000..98ae557064 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Eucla Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Hobart b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Hobart new file mode 100644 index 0000000000..02b07ca232 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Hobart Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/LHI b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/LHI new file mode 100644 index 0000000000..9e04a80ece --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/LHI Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Lindeman b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Lindeman new file mode 100644 index 0000000000..eab0fb998a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Lindeman Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Lord_Howe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Lord_Howe new file mode 100644 index 0000000000..9e04a80ece --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Lord_Howe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Melbourne b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Melbourne new file mode 100644 index 0000000000..ba457338ba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Melbourne Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/NSW b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/NSW new file mode 100644 index 0000000000..7636592aa7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/NSW Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/North b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/North new file mode 100644 index 0000000000..1cf502984a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/North Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Perth b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Perth new file mode 100644 index 0000000000..a876b9e785 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Perth Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Queensland b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Queensland new file mode 100644 index 0000000000..3021bdb614 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Queensland Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/South b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/South new file mode 100644 index 0000000000..0b1252abb7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/South Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Sydney b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Sydney new file mode 100644 index 0000000000..7636592aa7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Sydney Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Tasmania b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Tasmania new file mode 100644 index 0000000000..02b07ca232 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Tasmania Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Victoria b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Victoria new file mode 100644 index 0000000000..ba457338ba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Victoria Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/West b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/West new file mode 100644 index 0000000000..a876b9e785 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/West Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Yancowinna b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Yancowinna new file mode 100644 index 0000000000..1ac3fc8f52 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Australia/Yancowinna Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/Acre b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/Acre new file mode 100644 index 0000000000..a374cb43d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/Acre Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/DeNoronha b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/DeNoronha new file mode 100644 index 0000000000..f140726f2a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/DeNoronha Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/East b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/East new file mode 100644 index 0000000000..13ff083869 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/East Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/West b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/West new file mode 100644 index 0000000000..63d58f80f5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Brazil/West Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/CET b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/CET new file mode 100644 index 0000000000..122e934210 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/CET Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/CST6CDT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/CST6CDT new file mode 100644 index 0000000000..ca67929fbe --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/CST6CDT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Atlantic b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Atlantic new file mode 100644 index 0000000000..756099abe6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Atlantic Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Central b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Central new file mode 100644 index 0000000000..ac40299f6b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Central Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Eastern b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Eastern new file mode 100644 index 0000000000..6752c5b052 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Eastern Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Mountain b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Mountain new file mode 100644 index 0000000000..cd78a6f8be --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Mountain Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Newfoundland b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Newfoundland new file mode 100644 index 0000000000..65a5b0c720 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Newfoundland Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Pacific b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Pacific new file mode 100644 index 0000000000..bb60cbced3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Pacific Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Saskatchewan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Saskatchewan new file mode 100644 index 0000000000..20c9c84df4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Saskatchewan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Yukon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Yukon new file mode 100644 index 0000000000..062b58cedc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Canada/Yukon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Chile/Continental b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Chile/Continental new file mode 100644 index 0000000000..816a042818 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Chile/Continental Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Chile/EasterIsland b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Chile/EasterIsland new file mode 100644 index 0000000000..cae3744096 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Chile/EasterIsland Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Cuba b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Cuba new file mode 100644 index 0000000000..b69ac45107 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Cuba Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EET b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EET new file mode 100644 index 0000000000..cbdb71ddd3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EET Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EST b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EST new file mode 100644 index 0000000000..21ebc00b3f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EST Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EST5EDT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EST5EDT new file mode 100644 index 0000000000..9bce5007d4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/EST5EDT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Egypt b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Egypt new file mode 100644 index 0000000000..d3f819623f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Egypt Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Eire b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Eire new file mode 100644 index 0000000000..1d994902db --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Eire Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+0 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+0 new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+0 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+1 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+1 new file mode 100644 index 0000000000..4dab6f9005 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+1 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+10 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+10 new file mode 100644 index 0000000000..c749290af2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+10 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+11 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+11 new file mode 100644 index 0000000000..d969982309 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+11 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+12 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+12 new file mode 100644 index 0000000000..cdeec90973 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+12 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+2 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+2 new file mode 100644 index 0000000000..fbd2a941fd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+2 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+3 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+3 new file mode 100644 index 0000000000..ee246ef56f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+3 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+4 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+4 new file mode 100644 index 0000000000..5a25ff2a6a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+4 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+5 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+5 new file mode 100644 index 0000000000..c0b745f1cc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+5 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+6 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+6 new file mode 100644 index 0000000000..06e777d57e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+6 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+7 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+7 new file mode 100644 index 0000000000..4e0b53a082 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+7 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+8 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+8 new file mode 100644 index 0000000000..714b0c5628 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+8 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+9 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+9 new file mode 100644 index 0000000000..78b9daa373 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT+9 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-0 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-0 new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-0 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-1 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-1 new file mode 100644 index 0000000000..a838bebf5e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-1 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-10 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-10 new file mode 100644 index 0000000000..68ff77db0d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-10 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-11 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-11 new file mode 100644 index 0000000000..66af5a42be --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-11 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-12 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-12 new file mode 100644 index 0000000000..17ba505772 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-12 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-13 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-13 new file mode 100644 index 0000000000..5f3706ce64 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-13 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-14 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-14 new file mode 100644 index 0000000000..7e9f9c465c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-14 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-2 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-2 new file mode 100644 index 0000000000..fcef6d9acb --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-2 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-3 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-3 new file mode 100644 index 0000000000..27973bc857 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-3 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-4 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-4 new file mode 100644 index 0000000000..1efd841261 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-4 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-5 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-5 new file mode 100644 index 0000000000..1f761844fc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-5 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-6 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-6 new file mode 100644 index 0000000000..952681ed46 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-6 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-7 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-7 new file mode 100644 index 0000000000..cefc9126c6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-7 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-8 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-8 new file mode 100644 index 0000000000..afb093da00 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-8 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-9 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-9 new file mode 100644 index 0000000000..9265fb7c20 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT-9 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT0 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT0 new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/GMT0 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Greenwich b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Greenwich new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Greenwich Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/UCT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/UCT new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/UCT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/UTC b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/UTC new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/UTC Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Universal b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Universal new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Universal Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Zulu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Zulu new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Etc/Zulu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Amsterdam b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Amsterdam new file mode 100644 index 0000000000..c3ff07b436 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Amsterdam Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Andorra b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Andorra new file mode 100644 index 0000000000..5962550392 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Andorra Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Astrakhan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Astrakhan new file mode 100644 index 0000000000..73a4d013fc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Astrakhan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Athens b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Athens new file mode 100644 index 0000000000..9f3a0678d7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Athens Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Belfast b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Belfast new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Belfast Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Belgrade b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Belgrade new file mode 100644 index 0000000000..27de456f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Belgrade Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Berlin b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Berlin new file mode 100644 index 0000000000..7f6d958f86 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Berlin Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Bratislava b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Bratislava new file mode 100644 index 0000000000..ce8f433ece --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Bratislava Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Brussels b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Brussels new file mode 100644 index 0000000000..40d7124e53 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Brussels Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Bucharest b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Bucharest new file mode 100644 index 0000000000..4303b903e5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Bucharest Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Budapest b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Budapest new file mode 100644 index 0000000000..6b94a4f312 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Budapest Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Busingen b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Busingen new file mode 100644 index 0000000000..ad6cf59281 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Busingen Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Chisinau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Chisinau new file mode 100644 index 0000000000..5ee23fe0e5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Chisinau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Copenhagen b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Copenhagen new file mode 100644 index 0000000000..776be6e4a6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Copenhagen Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Dublin b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Dublin new file mode 100644 index 0000000000..1d994902db --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Dublin Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Gibraltar b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Gibraltar new file mode 100644 index 0000000000..117aadb836 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Gibraltar Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Guernsey b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Guernsey new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Guernsey Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Helsinki b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Helsinki new file mode 100644 index 0000000000..b4f8f9cbb5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Helsinki Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Isle_of_Man b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Isle_of_Man new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Isle_of_Man Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Istanbul b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Istanbul new file mode 100644 index 0000000000..508446bb6a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Istanbul Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Jersey b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Jersey new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Jersey Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kaliningrad b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kaliningrad new file mode 100644 index 0000000000..cc99beabe4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kaliningrad Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kiev b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kiev new file mode 100644 index 0000000000..9337c9ea27 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kiev Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kirov b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kirov new file mode 100644 index 0000000000..a3b5320a0b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Kirov Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Lisbon b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Lisbon new file mode 100644 index 0000000000..355817b52b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Lisbon Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Ljubljana b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Ljubljana new file mode 100644 index 0000000000..27de456f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Ljubljana Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/London b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/London new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/London Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Luxembourg b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Luxembourg new file mode 100644 index 0000000000..c4ca733f53 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Luxembourg Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Madrid b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Madrid new file mode 100644 index 0000000000..16f6420ab7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Madrid Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Malta b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Malta new file mode 100644 index 0000000000..bf2452da40 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Malta Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Mariehamn b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Mariehamn new file mode 100644 index 0000000000..b4f8f9cbb5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Mariehamn Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Minsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Minsk new file mode 100644 index 0000000000..453306c075 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Minsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Monaco b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Monaco new file mode 100644 index 0000000000..686ae88315 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Monaco Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Moscow b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Moscow new file mode 100644 index 0000000000..ddb3f4e99a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Moscow Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Nicosia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Nicosia new file mode 100644 index 0000000000..f7f10ab766 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Nicosia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Oslo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Oslo new file mode 100644 index 0000000000..15a34c3ced --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Oslo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Paris b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Paris new file mode 100644 index 0000000000..ca85435168 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Paris Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Podgorica b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Podgorica new file mode 100644 index 0000000000..27de456f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Podgorica Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Prague b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Prague new file mode 100644 index 0000000000..ce8f433ece --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Prague Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Riga b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Riga new file mode 100644 index 0000000000..8db477d017 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Riga Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Rome b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Rome new file mode 100644 index 0000000000..ac4c16342b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Rome Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Samara b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Samara new file mode 100644 index 0000000000..97d5dd9e6e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Samara Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/San_Marino b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/San_Marino new file mode 100644 index 0000000000..ac4c16342b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/San_Marino Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Sarajevo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Sarajevo new file mode 100644 index 0000000000..27de456f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Sarajevo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Saratov b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Saratov new file mode 100644 index 0000000000..8fd5f6d4b8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Saratov Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Simferopol b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Simferopol new file mode 100644 index 0000000000..432e8315bc --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Simferopol Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Skopje b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Skopje new file mode 100644 index 0000000000..27de456f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Skopje Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Sofia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Sofia new file mode 100644 index 0000000000..0e4d879332 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Sofia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Stockholm b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Stockholm new file mode 100644 index 0000000000..f3e0c7f0f2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Stockholm Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tallinn b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tallinn new file mode 100644 index 0000000000..b5acca3cf5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tallinn Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tirane b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tirane new file mode 100644 index 0000000000..0b86017d24 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tirane Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tiraspol b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tiraspol new file mode 100644 index 0000000000..5ee23fe0e5 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Tiraspol Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Ulyanovsk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Ulyanovsk new file mode 100644 index 0000000000..7b61bdc522 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Ulyanovsk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Uzhgorod b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Uzhgorod new file mode 100644 index 0000000000..66ae8d69e3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Uzhgorod Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vaduz b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vaduz new file mode 100644 index 0000000000..ad6cf59281 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vaduz Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vatican b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vatican new file mode 100644 index 0000000000..ac4c16342b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vatican Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vienna b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vienna new file mode 100644 index 0000000000..3582bb15cd --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vienna Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vilnius b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vilnius new file mode 100644 index 0000000000..7abd63fa60 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Vilnius Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Volgograd b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Volgograd new file mode 100644 index 0000000000..d1cfac0e38 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Volgograd Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Warsaw b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Warsaw new file mode 100644 index 0000000000..e33cf67171 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Warsaw Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zagreb b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zagreb new file mode 100644 index 0000000000..27de456f16 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zagreb Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zaporozhye b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zaporozhye new file mode 100644 index 0000000000..e42edfc850 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zaporozhye Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zurich b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zurich new file mode 100644 index 0000000000..ad6cf59281 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Europe/Zurich Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Factory b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Factory new file mode 100644 index 0000000000..60aa2a0d69 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Factory Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GB b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GB new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GB Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GB-Eire b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GB-Eire new file mode 100644 index 0000000000..ac02a81440 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GB-Eire Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT+0 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT+0 new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT+0 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT-0 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT-0 new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT-0 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT0 b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT0 new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/GMT0 Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Greenwich b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Greenwich new file mode 100644 index 0000000000..c63474664a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Greenwich Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/HST b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/HST new file mode 100644 index 0000000000..cccd45eb8c --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/HST Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Hongkong b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Hongkong new file mode 100644 index 0000000000..23d0375fba --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Hongkong Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Iceland b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Iceland new file mode 100644 index 0000000000..10e0fc8190 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Iceland Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Antananarivo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Antananarivo new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Antananarivo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Chagos b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Chagos new file mode 100644 index 0000000000..93d6dda50f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Chagos Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Christmas b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Christmas new file mode 100644 index 0000000000..d18c3810d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Christmas Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Cocos b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Cocos new file mode 100644 index 0000000000..f8116e7025 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Cocos Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Comoro b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Comoro new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Comoro Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Kerguelen b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Kerguelen new file mode 100644 index 0000000000..cde4cf7ea7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Kerguelen Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mahe b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mahe new file mode 100644 index 0000000000..cba7dfe735 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mahe Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Maldives b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Maldives new file mode 100644 index 0000000000..7c839cfa9b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Maldives Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mauritius b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mauritius new file mode 100644 index 0000000000..17f2616990 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mauritius Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mayotte b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mayotte new file mode 100644 index 0000000000..9a2918f404 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Mayotte Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Reunion b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Reunion new file mode 100644 index 0000000000..dfe08313df --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Indian/Reunion Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Iran b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Iran new file mode 100644 index 0000000000..8cec5ad7de --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Iran Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Israel b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Israel new file mode 100644 index 0000000000..440ef06b5d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Israel Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Jamaica b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Jamaica new file mode 100644 index 0000000000..2a9b7fd52d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Jamaica Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Japan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Japan new file mode 100644 index 0000000000..26f4d34d67 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Japan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Kwajalein b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Kwajalein new file mode 100644 index 0000000000..1a7975fad7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Kwajalein Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Libya b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Libya new file mode 100644 index 0000000000..07b393bb7d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Libya Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MET b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MET new file mode 100644 index 0000000000..4a826bb185 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MET Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MST b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MST new file mode 100644 index 0000000000..c93a58eee8 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MST Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MST7MDT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MST7MDT new file mode 100644 index 0000000000..4506a6e150 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/MST7MDT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/BajaNorte b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/BajaNorte new file mode 100644 index 0000000000..ada6bf78b2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/BajaNorte Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/BajaSur b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/BajaSur new file mode 100644 index 0000000000..e4a785743d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/BajaSur Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/General b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/General new file mode 100644 index 0000000000..e7fb6f2953 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Mexico/General Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/NZ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/NZ new file mode 100644 index 0000000000..6575fdce31 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/NZ Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/NZ-CHAT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/NZ-CHAT new file mode 100644 index 0000000000..c004109882 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/NZ-CHAT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Navajo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Navajo new file mode 100644 index 0000000000..5fbe26b1d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Navajo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/PRC b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/PRC new file mode 100644 index 0000000000..91f6f8bc2e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/PRC Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/PST8PDT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/PST8PDT new file mode 100644 index 0000000000..99d246baa3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/PST8PDT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Apia b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Apia new file mode 100644 index 0000000000..dab1f3f602 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Apia Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Auckland b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Auckland new file mode 100644 index 0000000000..6575fdce31 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Auckland Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Bougainville b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Bougainville new file mode 100644 index 0000000000..2892d26809 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Bougainville Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Chatham b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Chatham new file mode 100644 index 0000000000..c004109882 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Chatham Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Chuuk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Chuuk new file mode 100644 index 0000000000..07c84b7110 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Chuuk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Easter b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Easter new file mode 100644 index 0000000000..cae3744096 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Easter Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Efate b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Efate new file mode 100644 index 0000000000..60150175c0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Efate Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Enderbury b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Enderbury new file mode 100644 index 0000000000..f0b8252362 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Enderbury Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Fakaofo b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Fakaofo new file mode 100644 index 0000000000..e40307f6aa --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Fakaofo Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Fiji b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Fiji new file mode 100644 index 0000000000..d39bf53645 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Fiji Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Funafuti b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Funafuti new file mode 100644 index 0000000000..ea728637ac --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Funafuti Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Galapagos b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Galapagos new file mode 100644 index 0000000000..31f0921ea0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Galapagos Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Gambier b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Gambier new file mode 100644 index 0000000000..e1fc3daa55 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Gambier Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Guadalcanal b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Guadalcanal new file mode 100644 index 0000000000..7e9d10a100 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Guadalcanal Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Guam b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Guam new file mode 100644 index 0000000000..66490d25df --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Guam Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Honolulu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Honolulu new file mode 100644 index 0000000000..c7cd060159 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Honolulu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Johnston b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Johnston new file mode 100644 index 0000000000..c7cd060159 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Johnston Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kiritimati b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kiritimati new file mode 100644 index 0000000000..7cae0cb756 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kiritimati Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kosrae b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kosrae new file mode 100644 index 0000000000..a584aae5eb --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kosrae Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kwajalein b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kwajalein new file mode 100644 index 0000000000..1a7975fad7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Kwajalein Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Majuro b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Majuro new file mode 100644 index 0000000000..9ef8374de4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Majuro Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Marquesas b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Marquesas new file mode 100644 index 0000000000..74d6792bf6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Marquesas Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Midway b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Midway new file mode 100644 index 0000000000..cb56709a77 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Midway Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Nauru b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Nauru new file mode 100644 index 0000000000..acec0429f1 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Nauru Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Niue b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Niue new file mode 100644 index 0000000000..684b010e8b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Niue Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Norfolk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Norfolk new file mode 100644 index 0000000000..53c1aad4e0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Norfolk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Noumea b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Noumea new file mode 100644 index 0000000000..931a1a306f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Noumea Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pago_Pago b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pago_Pago new file mode 100644 index 0000000000..cb56709a77 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pago_Pago Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Palau b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Palau new file mode 100644 index 0000000000..146b35152a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Palau Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pitcairn b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pitcairn new file mode 100644 index 0000000000..ef91b061bb --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pitcairn Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pohnpei b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pohnpei new file mode 100644 index 0000000000..c298ddd4de --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Pohnpei Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Ponape b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Ponape new file mode 100644 index 0000000000..c298ddd4de --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Ponape Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Port_Moresby b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Port_Moresby new file mode 100644 index 0000000000..920ad27e62 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Port_Moresby Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Rarotonga b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Rarotonga new file mode 100644 index 0000000000..da6b0fadea --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Rarotonga Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Saipan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Saipan new file mode 100644 index 0000000000..66490d25df --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Saipan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Samoa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Samoa new file mode 100644 index 0000000000..cb56709a77 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Samoa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tahiti b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tahiti new file mode 100644 index 0000000000..442b8eb5a4 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tahiti Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tarawa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tarawa new file mode 100644 index 0000000000..3db6c75033 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tarawa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tongatapu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tongatapu new file mode 100644 index 0000000000..5553c6009a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Tongatapu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Truk b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Truk new file mode 100644 index 0000000000..07c84b7110 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Truk Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Wake b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Wake new file mode 100644 index 0000000000..c9e310670f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Wake Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Wallis b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Wallis new file mode 100644 index 0000000000..b35344b312 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Wallis Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Yap b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Yap new file mode 100644 index 0000000000..07c84b7110 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Pacific/Yap Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Poland b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Poland new file mode 100644 index 0000000000..e33cf67171 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Poland Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Portugal b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Portugal new file mode 100644 index 0000000000..355817b52b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Portugal Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/ROC b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/ROC new file mode 100644 index 0000000000..24c43444b6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/ROC Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/ROK b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/ROK new file mode 100644 index 0000000000..96199e73e7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/ROK Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Singapore b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Singapore new file mode 100644 index 0000000000..2364b2178b --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Singapore Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Turkey b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Turkey new file mode 100644 index 0000000000..508446bb6a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Turkey Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/UCT b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/UCT new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/UCT Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Alaska b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Alaska new file mode 100644 index 0000000000..9bbb2fd3b3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Alaska Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Aleutian b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Aleutian new file mode 100644 index 0000000000..43236498f6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Aleutian Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Arizona b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Arizona new file mode 100644 index 0000000000..ac6bb0c782 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Arizona Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Central b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Central new file mode 100644 index 0000000000..a5b1617c7f --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Central Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/East-Indiana b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/East-Indiana new file mode 100644 index 0000000000..09511ccdcf --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/East-Indiana Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Eastern b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Eastern new file mode 100644 index 0000000000..2f75480e06 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Eastern Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Hawaii b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Hawaii new file mode 100644 index 0000000000..c7cd060159 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Hawaii Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Indiana-Starke b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Indiana-Starke new file mode 100644 index 0000000000..fcd408d74d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Indiana-Starke Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Michigan b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Michigan new file mode 100644 index 0000000000..e104faa465 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Michigan Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Mountain b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Mountain new file mode 100644 index 0000000000..5fbe26b1d9 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Mountain Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Pacific b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Pacific new file mode 100644 index 0000000000..9dad4f4c75 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Pacific Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Samoa b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Samoa new file mode 100644 index 0000000000..cb56709a77 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/US/Samoa Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/UTC b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/UTC new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/UTC Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Universal b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Universal new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Universal Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/W-SU b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/W-SU new file mode 100644 index 0000000000..ddb3f4e99a --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/W-SU Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/WET b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/WET new file mode 100644 index 0000000000..c27390b5b6 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/WET Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Zulu b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Zulu new file mode 100644 index 0000000000..91558be0c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/Zulu Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/iso3166.tab b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/iso3166.tab new file mode 100644 index 0000000000..a4ff61a4d3 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/iso3166.tab @@ -0,0 +1,274 @@ +# ISO 3166 alpha-2 country codes +# +# This file is in the public domain, so clarified as of +# 2009-05-17 by Arthur David Olson. +# +# From Paul Eggert (2015-05-02): +# This file contains a table of two-letter country codes. Columns are +# separated by a single tab. Lines beginning with '#' are comments. +# All text uses UTF-8 encoding. The columns of the table are as follows: +# +# 1. ISO 3166-1 alpha-2 country code, current as of +# ISO 3166-1 N976 (2018-11-06). See: Updates on ISO 3166-1 +# https://isotc.iso.org/livelink/livelink/Open/16944257 +# 2. The usual English name for the coded region, +# chosen so that alphabetic sorting of subsets produces helpful lists. +# This is not the same as the English name in the ISO 3166 tables. +# +# The table is sorted by country code. +# +# This table is intended as an aid for users, to help them select time +# zone data appropriate for their practical needs. It is not intended +# to take or endorse any position on legal or territorial claims. +# +#country- +#code name of country, territory, area, or subdivision +AD Andorra +AE United Arab Emirates +AF Afghanistan +AG Antigua & Barbuda +AI Anguilla +AL Albania +AM Armenia +AO Angola +AQ Antarctica +AR Argentina +AS Samoa (American) +AT Austria +AU Australia +AW Aruba +AX Åland Islands +AZ Azerbaijan +BA Bosnia & Herzegovina +BB Barbados +BD Bangladesh +BE Belgium +BF Burkina Faso +BG Bulgaria +BH Bahrain +BI Burundi +BJ Benin +BL St Barthelemy +BM Bermuda +BN Brunei +BO Bolivia +BQ Caribbean NL +BR Brazil +BS Bahamas +BT Bhutan +BV Bouvet Island +BW Botswana +BY Belarus +BZ Belize +CA Canada +CC Cocos (Keeling) Islands +CD Congo (Dem. Rep.) +CF Central African Rep. +CG Congo (Rep.) +CH Switzerland +CI Côte d'Ivoire +CK Cook Islands +CL Chile +CM Cameroon +CN China +CO Colombia +CR Costa Rica +CU Cuba +CV Cape Verde +CW Curaçao +CX Christmas Island +CY Cyprus +CZ Czech Republic +DE Germany +DJ Djibouti +DK Denmark +DM Dominica +DO Dominican Republic +DZ Algeria +EC Ecuador +EE Estonia +EG Egypt +EH Western Sahara +ER Eritrea +ES Spain +ET Ethiopia +FI Finland +FJ Fiji +FK Falkland Islands +FM Micronesia +FO Faroe Islands +FR France +GA Gabon +GB Britain (UK) +GD Grenada +GE Georgia +GF French Guiana +GG Guernsey +GH Ghana +GI Gibraltar +GL Greenland +GM Gambia +GN Guinea +GP Guadeloupe +GQ Equatorial Guinea +GR Greece +GS South Georgia & the South Sandwich Islands +GT Guatemala +GU Guam +GW Guinea-Bissau +GY Guyana +HK Hong Kong +HM Heard Island & McDonald Islands +HN Honduras +HR Croatia +HT Haiti +HU Hungary +ID Indonesia +IE Ireland +IL Israel +IM Isle of Man +IN India +IO British Indian Ocean Territory +IQ Iraq +IR Iran +IS Iceland +IT Italy +JE Jersey +JM Jamaica +JO Jordan +JP Japan +KE Kenya +KG Kyrgyzstan +KH Cambodia +KI Kiribati +KM Comoros +KN St Kitts & Nevis +KP Korea (North) +KR Korea (South) +KW Kuwait +KY Cayman Islands +KZ Kazakhstan +LA Laos +LB Lebanon +LC St Lucia +LI Liechtenstein +LK Sri Lanka +LR Liberia +LS Lesotho +LT Lithuania +LU Luxembourg +LV Latvia +LY Libya +MA Morocco +MC Monaco +MD Moldova +ME Montenegro +MF St Martin (French) +MG Madagascar +MH Marshall Islands +MK North Macedonia +ML Mali +MM Myanmar (Burma) +MN Mongolia +MO Macau +MP Northern Mariana Islands +MQ Martinique +MR Mauritania +MS Montserrat +MT Malta +MU Mauritius +MV Maldives +MW Malawi +MX Mexico +MY Malaysia +MZ Mozambique +NA Namibia +NC New Caledonia +NE Niger +NF Norfolk Island +NG Nigeria +NI Nicaragua +NL Netherlands +NO Norway +NP Nepal +NR Nauru +NU Niue +NZ New Zealand +OM Oman +PA Panama +PE Peru +PF French Polynesia +PG Papua New Guinea +PH Philippines +PK Pakistan +PL Poland +PM St Pierre & Miquelon +PN Pitcairn +PR Puerto Rico +PS Palestine +PT Portugal +PW Palau +PY Paraguay +QA Qatar +RE Réunion +RO Romania +RS Serbia +RU Russia +RW Rwanda +SA Saudi Arabia +SB Solomon Islands +SC Seychelles +SD Sudan +SE Sweden +SG Singapore +SH St Helena +SI Slovenia +SJ Svalbard & Jan Mayen +SK Slovakia +SL Sierra Leone +SM San Marino +SN Senegal +SO Somalia +SR Suriname +SS South Sudan +ST Sao Tome & Principe +SV El Salvador +SX St Maarten (Dutch) +SY Syria +SZ Eswatini (Swaziland) +TC Turks & Caicos Is +TD Chad +TF French Southern & Antarctic Lands +TG Togo +TH Thailand +TJ Tajikistan +TK Tokelau +TL East Timor +TM Turkmenistan +TN Tunisia +TO Tonga +TR Turkey +TT Trinidad & Tobago +TV Tuvalu +TW Taiwan +TZ Tanzania +UA Ukraine +UG Uganda +UM US minor outlying islands +US United States +UY Uruguay +UZ Uzbekistan +VA Vatican City +VC St Vincent +VE Venezuela +VG Virgin Islands (UK) +VI Virgin Islands (US) +VN Vietnam +VU Vanuatu +WF Wallis & Futuna +WS Samoa (western) +YE Yemen +YT Mayotte +ZA South Africa +ZM Zambia +ZW Zimbabwe diff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/localtime b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/localtime new file mode 100644 index 0000000000..afeeb88d06 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/localtime Binary files differdiff --git a/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/zone1970.tab b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/zone1970.tab new file mode 100644 index 0000000000..53ee77e88e --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/cctz/testdata/zoneinfo/zone1970.tab @@ -0,0 +1,384 @@ +# tzdb timezone descriptions +# +# This file is in the public domain. +# +# From Paul Eggert (2018-06-27): +# This file contains a table where each row stands for a timezone where +# civil timestamps have agreed since 1970. Columns are separated by +# a single tab. Lines beginning with '#' are comments. All text uses +# UTF-8 encoding. The columns of the table are as follows: +# +# 1. The countries that overlap the timezone, as a comma-separated list +# of ISO 3166 2-character country codes. See the file 'iso3166.tab'. +# 2. Latitude and longitude of the timezone's principal location +# in ISO 6709 sign-degrees-minutes-seconds format, +# either ±DDMM±DDDMM or ±DDMMSS±DDDMMSS, +# first latitude (+ is north), then longitude (+ is east). +# 3. Timezone name used in value of TZ environment variable. +# Please see the theory.html file for how these names are chosen. +# If multiple timezones overlap a country, each has a row in the +# table, with each column 1 containing the country code. +# 4. Comments; present if and only if a country has multiple timezones. +# +# If a timezone covers multiple countries, the most-populous city is used, +# and that country is listed first in column 1; any other countries +# are listed alphabetically by country code. The table is sorted +# first by country code, then (if possible) by an order within the +# country that (1) makes some geographical sense, and (2) puts the +# most populous timezones first, where that does not contradict (1). +# +# This table is intended as an aid for users, to help them select timezones +# appropriate for their practical needs. It is not intended to take or +# endorse any position on legal or territorial claims. +# +#country- +#codes coordinates TZ comments +AD +4230+00131 Europe/Andorra +AE,OM +2518+05518 Asia/Dubai +AF +3431+06912 Asia/Kabul +AL +4120+01950 Europe/Tirane +AM +4011+04430 Asia/Yerevan +AQ -6617+11031 Antarctica/Casey Casey +AQ -6835+07758 Antarctica/Davis Davis +AQ -6640+14001 Antarctica/DumontDUrville Dumont-d'Urville +AQ -6736+06253 Antarctica/Mawson Mawson +AQ -6448-06406 Antarctica/Palmer Palmer +AQ -6734-06808 Antarctica/Rothera Rothera +AQ -690022+0393524 Antarctica/Syowa Syowa +AQ -720041+0023206 Antarctica/Troll Troll +AQ -7824+10654 Antarctica/Vostok Vostok +AR -3436-05827 America/Argentina/Buenos_Aires Buenos Aires (BA, CF) +AR -3124-06411 America/Argentina/Cordoba Argentina (most areas: CB, CC, CN, ER, FM, MN, SE, SF) +AR -2447-06525 America/Argentina/Salta Salta (SA, LP, NQ, RN) +AR -2411-06518 America/Argentina/Jujuy Jujuy (JY) +AR -2649-06513 America/Argentina/Tucuman Tucumán (TM) +AR -2828-06547 America/Argentina/Catamarca Catamarca (CT); Chubut (CH) +AR -2926-06651 America/Argentina/La_Rioja La Rioja (LR) +AR -3132-06831 America/Argentina/San_Juan San Juan (SJ) +AR -3253-06849 America/Argentina/Mendoza Mendoza (MZ) +AR -3319-06621 America/Argentina/San_Luis San Luis (SL) +AR -5138-06913 America/Argentina/Rio_Gallegos Santa Cruz (SC) +AR -5448-06818 America/Argentina/Ushuaia Tierra del Fuego (TF) +AS,UM -1416-17042 Pacific/Pago_Pago Samoa, Midway +AT +4813+01620 Europe/Vienna +AU -3133+15905 Australia/Lord_Howe Lord Howe Island +AU -5430+15857 Antarctica/Macquarie Macquarie Island +AU -4253+14719 Australia/Hobart Tasmania (most areas) +AU -3956+14352 Australia/Currie Tasmania (King Island) +AU -3749+14458 Australia/Melbourne Victoria +AU -3352+15113 Australia/Sydney New South Wales (most areas) +AU -3157+14127 Australia/Broken_Hill New South Wales (Yancowinna) +AU -2728+15302 Australia/Brisbane Queensland (most areas) +AU -2016+14900 Australia/Lindeman Queensland (Whitsunday Islands) +AU -3455+13835 Australia/Adelaide South Australia +AU -1228+13050 Australia/Darwin Northern Territory +AU -3157+11551 Australia/Perth Western Australia (most areas) +AU -3143+12852 Australia/Eucla Western Australia (Eucla) +AZ +4023+04951 Asia/Baku +BB +1306-05937 America/Barbados +BD +2343+09025 Asia/Dhaka +BE +5050+00420 Europe/Brussels +BG +4241+02319 Europe/Sofia +BM +3217-06446 Atlantic/Bermuda +BN +0456+11455 Asia/Brunei +BO -1630-06809 America/La_Paz +BR -0351-03225 America/Noronha Atlantic islands +BR -0127-04829 America/Belem Pará (east); Amapá +BR -0343-03830 America/Fortaleza Brazil (northeast: MA, PI, CE, RN, PB) +BR -0803-03454 America/Recife Pernambuco +BR -0712-04812 America/Araguaina Tocantins +BR -0940-03543 America/Maceio Alagoas, Sergipe +BR -1259-03831 America/Bahia Bahia +BR -2332-04637 America/Sao_Paulo Brazil (southeast: GO, DF, MG, ES, RJ, SP, PR, SC, RS) +BR -2027-05437 America/Campo_Grande Mato Grosso do Sul +BR -1535-05605 America/Cuiaba Mato Grosso +BR -0226-05452 America/Santarem Pará (west) +BR -0846-06354 America/Porto_Velho Rondônia +BR +0249-06040 America/Boa_Vista Roraima +BR -0308-06001 America/Manaus Amazonas (east) +BR -0640-06952 America/Eirunepe Amazonas (west) +BR -0958-06748 America/Rio_Branco Acre +BS +2505-07721 America/Nassau +BT +2728+08939 Asia/Thimphu +BY +5354+02734 Europe/Minsk +BZ +1730-08812 America/Belize +CA +4734-05243 America/St_Johns Newfoundland; Labrador (southeast) +CA +4439-06336 America/Halifax Atlantic - NS (most areas); PE +CA +4612-05957 America/Glace_Bay Atlantic - NS (Cape Breton) +CA +4606-06447 America/Moncton Atlantic - New Brunswick +CA +5320-06025 America/Goose_Bay Atlantic - Labrador (most areas) +CA +5125-05707 America/Blanc-Sablon AST - QC (Lower North Shore) +CA +4339-07923 America/Toronto Eastern - ON, QC (most areas) +CA +4901-08816 America/Nipigon Eastern - ON, QC (no DST 1967-73) +CA +4823-08915 America/Thunder_Bay Eastern - ON (Thunder Bay) +CA +6344-06828 America/Iqaluit Eastern - NU (most east areas) +CA +6608-06544 America/Pangnirtung Eastern - NU (Pangnirtung) +CA +484531-0913718 America/Atikokan EST - ON (Atikokan); NU (Coral H) +CA +4953-09709 America/Winnipeg Central - ON (west); Manitoba +CA +4843-09434 America/Rainy_River Central - ON (Rainy R, Ft Frances) +CA +744144-0944945 America/Resolute Central - NU (Resolute) +CA +624900-0920459 America/Rankin_Inlet Central - NU (central) +CA +5024-10439 America/Regina CST - SK (most areas) +CA +5017-10750 America/Swift_Current CST - SK (midwest) +CA +5333-11328 America/Edmonton Mountain - AB; BC (E); SK (W) +CA +690650-1050310 America/Cambridge_Bay Mountain - NU (west) +CA +6227-11421 America/Yellowknife Mountain - NT (central) +CA +682059-1334300 America/Inuvik Mountain - NT (west) +CA +4906-11631 America/Creston MST - BC (Creston) +CA +5946-12014 America/Dawson_Creek MST - BC (Dawson Cr, Ft St John) +CA +5848-12242 America/Fort_Nelson MST - BC (Ft Nelson) +CA +4916-12307 America/Vancouver Pacific - BC (most areas) +CA +6043-13503 America/Whitehorse Pacific - Yukon (east) +CA +6404-13925 America/Dawson Pacific - Yukon (west) +CC -1210+09655 Indian/Cocos +CH,DE,LI +4723+00832 Europe/Zurich Swiss time +CI,BF,GM,GN,ML,MR,SH,SL,SN,TG +0519-00402 Africa/Abidjan +CK -2114-15946 Pacific/Rarotonga +CL -3327-07040 America/Santiago Chile (most areas) +CL -5309-07055 America/Punta_Arenas Region of Magallanes +CL -2709-10926 Pacific/Easter Easter Island +CN +3114+12128 Asia/Shanghai Beijing Time +CN +4348+08735 Asia/Urumqi Xinjiang Time +CO +0436-07405 America/Bogota +CR +0956-08405 America/Costa_Rica +CU +2308-08222 America/Havana +CV +1455-02331 Atlantic/Cape_Verde +CW,AW,BQ,SX +1211-06900 America/Curacao +CX -1025+10543 Indian/Christmas +CY +3510+03322 Asia/Nicosia Cyprus (most areas) +CY +3507+03357 Asia/Famagusta Northern Cyprus +CZ,SK +5005+01426 Europe/Prague +DE +5230+01322 Europe/Berlin Germany (most areas) +DK +5540+01235 Europe/Copenhagen +DO +1828-06954 America/Santo_Domingo +DZ +3647+00303 Africa/Algiers +EC -0210-07950 America/Guayaquil Ecuador (mainland) +EC -0054-08936 Pacific/Galapagos Galápagos Islands +EE +5925+02445 Europe/Tallinn +EG +3003+03115 Africa/Cairo +EH +2709-01312 Africa/El_Aaiun +ES +4024-00341 Europe/Madrid Spain (mainland) +ES +3553-00519 Africa/Ceuta Ceuta, Melilla +ES +2806-01524 Atlantic/Canary Canary Islands +FI,AX +6010+02458 Europe/Helsinki +FJ -1808+17825 Pacific/Fiji +FK -5142-05751 Atlantic/Stanley +FM +0725+15147 Pacific/Chuuk Chuuk/Truk, Yap +FM +0658+15813 Pacific/Pohnpei Pohnpei/Ponape +FM +0519+16259 Pacific/Kosrae Kosrae +FO +6201-00646 Atlantic/Faroe +FR +4852+00220 Europe/Paris +GB,GG,IM,JE +513030-0000731 Europe/London +GE +4143+04449 Asia/Tbilisi +GF +0456-05220 America/Cayenne +GH +0533-00013 Africa/Accra +GI +3608-00521 Europe/Gibraltar +GL +6411-05144 America/Nuuk Greenland (most areas) +GL +7646-01840 America/Danmarkshavn National Park (east coast) +GL +7029-02158 America/Scoresbysund Scoresbysund/Ittoqqortoormiit +GL +7634-06847 America/Thule Thule/Pituffik +GR +3758+02343 Europe/Athens +GS -5416-03632 Atlantic/South_Georgia +GT +1438-09031 America/Guatemala +GU,MP +1328+14445 Pacific/Guam +GW +1151-01535 Africa/Bissau +GY +0648-05810 America/Guyana +HK +2217+11409 Asia/Hong_Kong +HN +1406-08713 America/Tegucigalpa +HT +1832-07220 America/Port-au-Prince +HU +4730+01905 Europe/Budapest +ID -0610+10648 Asia/Jakarta Java, Sumatra +ID -0002+10920 Asia/Pontianak Borneo (west, central) +ID -0507+11924 Asia/Makassar Borneo (east, south); Sulawesi/Celebes, Bali, Nusa Tengarra; Timor (west) +ID -0232+14042 Asia/Jayapura New Guinea (West Papua / Irian Jaya); Malukus/Moluccas +IE +5320-00615 Europe/Dublin +IL +314650+0351326 Asia/Jerusalem +IN +2232+08822 Asia/Kolkata +IO -0720+07225 Indian/Chagos +IQ +3321+04425 Asia/Baghdad +IR +3540+05126 Asia/Tehran +IS +6409-02151 Atlantic/Reykjavik +IT,SM,VA +4154+01229 Europe/Rome +JM +175805-0764736 America/Jamaica +JO +3157+03556 Asia/Amman +JP +353916+1394441 Asia/Tokyo +KE,DJ,ER,ET,KM,MG,SO,TZ,UG,YT -0117+03649 Africa/Nairobi +KG +4254+07436 Asia/Bishkek +KI +0125+17300 Pacific/Tarawa Gilbert Islands +KI -0308-17105 Pacific/Enderbury Phoenix Islands +KI +0152-15720 Pacific/Kiritimati Line Islands +KP +3901+12545 Asia/Pyongyang +KR +3733+12658 Asia/Seoul +KZ +4315+07657 Asia/Almaty Kazakhstan (most areas) +KZ +4448+06528 Asia/Qyzylorda Qyzylorda/Kyzylorda/Kzyl-Orda +KZ +5312+06337 Asia/Qostanay Qostanay/Kostanay/Kustanay +KZ +5017+05710 Asia/Aqtobe Aqtöbe/Aktobe +KZ +4431+05016 Asia/Aqtau Mangghystaū/Mankistau +KZ +4707+05156 Asia/Atyrau Atyraū/Atirau/Gur'yev +KZ +5113+05121 Asia/Oral West Kazakhstan +LB +3353+03530 Asia/Beirut +LK +0656+07951 Asia/Colombo +LR +0618-01047 Africa/Monrovia +LT +5441+02519 Europe/Vilnius +LU +4936+00609 Europe/Luxembourg +LV +5657+02406 Europe/Riga +LY +3254+01311 Africa/Tripoli +MA +3339-00735 Africa/Casablanca +MC +4342+00723 Europe/Monaco +MD +4700+02850 Europe/Chisinau +MH +0709+17112 Pacific/Majuro Marshall Islands (most areas) +MH +0905+16720 Pacific/Kwajalein Kwajalein +MM +1647+09610 Asia/Yangon +MN +4755+10653 Asia/Ulaanbaatar Mongolia (most areas) +MN +4801+09139 Asia/Hovd Bayan-Ölgii, Govi-Altai, Hovd, Uvs, Zavkhan +MN +4804+11430 Asia/Choibalsan Dornod, Sükhbaatar +MO +221150+1133230 Asia/Macau +MQ +1436-06105 America/Martinique +MT +3554+01431 Europe/Malta +MU -2010+05730 Indian/Mauritius +MV +0410+07330 Indian/Maldives +MX +1924-09909 America/Mexico_City Central Time +MX +2105-08646 America/Cancun Eastern Standard Time - Quintana Roo +MX +2058-08937 America/Merida Central Time - Campeche, Yucatán +MX +2540-10019 America/Monterrey Central Time - Durango; Coahuila, Nuevo León, Tamaulipas (most areas) +MX +2550-09730 America/Matamoros Central Time US - Coahuila, Nuevo León, Tamaulipas (US border) +MX +2313-10625 America/Mazatlan Mountain Time - Baja California Sur, Nayarit, Sinaloa +MX +2838-10605 America/Chihuahua Mountain Time - Chihuahua (most areas) +MX +2934-10425 America/Ojinaga Mountain Time US - Chihuahua (US border) +MX +2904-11058 America/Hermosillo Mountain Standard Time - Sonora +MX +3232-11701 America/Tijuana Pacific Time US - Baja California +MX +2048-10515 America/Bahia_Banderas Central Time - Bahía de Banderas +MY +0310+10142 Asia/Kuala_Lumpur Malaysia (peninsula) +MY +0133+11020 Asia/Kuching Sabah, Sarawak +MZ,BI,BW,CD,MW,RW,ZM,ZW -2558+03235 Africa/Maputo Central Africa Time +NA -2234+01706 Africa/Windhoek +NC -2216+16627 Pacific/Noumea +NF -2903+16758 Pacific/Norfolk +NG,AO,BJ,CD,CF,CG,CM,GA,GQ,NE +0627+00324 Africa/Lagos West Africa Time +NI +1209-08617 America/Managua +NL +5222+00454 Europe/Amsterdam +NO,SJ +5955+01045 Europe/Oslo +NP +2743+08519 Asia/Kathmandu +NR -0031+16655 Pacific/Nauru +NU -1901-16955 Pacific/Niue +NZ,AQ -3652+17446 Pacific/Auckland New Zealand time +NZ -4357-17633 Pacific/Chatham Chatham Islands +PA,KY +0858-07932 America/Panama +PE -1203-07703 America/Lima +PF -1732-14934 Pacific/Tahiti Society Islands +PF -0900-13930 Pacific/Marquesas Marquesas Islands +PF -2308-13457 Pacific/Gambier Gambier Islands +PG -0930+14710 Pacific/Port_Moresby Papua New Guinea (most areas) +PG -0613+15534 Pacific/Bougainville Bougainville +PH +1435+12100 Asia/Manila +PK +2452+06703 Asia/Karachi +PL +5215+02100 Europe/Warsaw +PM +4703-05620 America/Miquelon +PN -2504-13005 Pacific/Pitcairn +PR +182806-0660622 America/Puerto_Rico +PS +3130+03428 Asia/Gaza Gaza Strip +PS +313200+0350542 Asia/Hebron West Bank +PT +3843-00908 Europe/Lisbon Portugal (mainland) +PT +3238-01654 Atlantic/Madeira Madeira Islands +PT +3744-02540 Atlantic/Azores Azores +PW +0720+13429 Pacific/Palau +PY -2516-05740 America/Asuncion +QA,BH +2517+05132 Asia/Qatar +RE,TF -2052+05528 Indian/Reunion Réunion, Crozet, Scattered Islands +RO +4426+02606 Europe/Bucharest +RS,BA,HR,ME,MK,SI +4450+02030 Europe/Belgrade +RU +5443+02030 Europe/Kaliningrad MSK-01 - Kaliningrad +RU +554521+0373704 Europe/Moscow MSK+00 - Moscow area +# Mention RU and UA alphabetically. See "territorial claims" above. +RU,UA +4457+03406 Europe/Simferopol Crimea +RU +5836+04939 Europe/Kirov MSK+00 - Kirov +RU +4621+04803 Europe/Astrakhan MSK+01 - Astrakhan +RU +4844+04425 Europe/Volgograd MSK+01 - Volgograd +RU +5134+04602 Europe/Saratov MSK+01 - Saratov +RU +5420+04824 Europe/Ulyanovsk MSK+01 - Ulyanovsk +RU +5312+05009 Europe/Samara MSK+01 - Samara, Udmurtia +RU +5651+06036 Asia/Yekaterinburg MSK+02 - Urals +RU +5500+07324 Asia/Omsk MSK+03 - Omsk +RU +5502+08255 Asia/Novosibirsk MSK+04 - Novosibirsk +RU +5322+08345 Asia/Barnaul MSK+04 - Altai +RU +5630+08458 Asia/Tomsk MSK+04 - Tomsk +RU +5345+08707 Asia/Novokuznetsk MSK+04 - Kemerovo +RU +5601+09250 Asia/Krasnoyarsk MSK+04 - Krasnoyarsk area +RU +5216+10420 Asia/Irkutsk MSK+05 - Irkutsk, Buryatia +RU +5203+11328 Asia/Chita MSK+06 - Zabaykalsky +RU +6200+12940 Asia/Yakutsk MSK+06 - Lena River +RU +623923+1353314 Asia/Khandyga MSK+06 - Tomponsky, Ust-Maysky +RU +4310+13156 Asia/Vladivostok MSK+07 - Amur River +RU +643337+1431336 Asia/Ust-Nera MSK+07 - Oymyakonsky +RU +5934+15048 Asia/Magadan MSK+08 - Magadan +RU +4658+14242 Asia/Sakhalin MSK+08 - Sakhalin Island +RU +6728+15343 Asia/Srednekolymsk MSK+08 - Sakha (E); North Kuril Is +RU +5301+15839 Asia/Kamchatka MSK+09 - Kamchatka +RU +6445+17729 Asia/Anadyr MSK+09 - Bering Sea +SA,KW,YE +2438+04643 Asia/Riyadh +SB -0932+16012 Pacific/Guadalcanal +SC -0440+05528 Indian/Mahe +SD +1536+03232 Africa/Khartoum +SE +5920+01803 Europe/Stockholm +SG +0117+10351 Asia/Singapore +SR +0550-05510 America/Paramaribo +SS +0451+03137 Africa/Juba +ST +0020+00644 Africa/Sao_Tome +SV +1342-08912 America/El_Salvador +SY +3330+03618 Asia/Damascus +TC +2128-07108 America/Grand_Turk +TD +1207+01503 Africa/Ndjamena +TF -492110+0701303 Indian/Kerguelen Kerguelen, St Paul Island, Amsterdam Island +TH,KH,LA,VN +1345+10031 Asia/Bangkok Indochina (most areas) +TJ +3835+06848 Asia/Dushanbe +TK -0922-17114 Pacific/Fakaofo +TL -0833+12535 Asia/Dili +TM +3757+05823 Asia/Ashgabat +TN +3648+01011 Africa/Tunis +TO -2110-17510 Pacific/Tongatapu +TR +4101+02858 Europe/Istanbul +TT,AG,AI,BL,DM,GD,GP,KN,LC,MF,MS,VC,VG,VI +1039-06131 America/Port_of_Spain +TV -0831+17913 Pacific/Funafuti +TW +2503+12130 Asia/Taipei +UA +5026+03031 Europe/Kiev Ukraine (most areas) +UA +4837+02218 Europe/Uzhgorod Transcarpathia +UA +4750+03510 Europe/Zaporozhye Zaporozhye and east Lugansk +UM +1917+16637 Pacific/Wake Wake Island +US +404251-0740023 America/New_York Eastern (most areas) +US +421953-0830245 America/Detroit Eastern - MI (most areas) +US +381515-0854534 America/Kentucky/Louisville Eastern - KY (Louisville area) +US +364947-0845057 America/Kentucky/Monticello Eastern - KY (Wayne) +US +394606-0860929 America/Indiana/Indianapolis Eastern - IN (most areas) +US +384038-0873143 America/Indiana/Vincennes Eastern - IN (Da, Du, K, Mn) +US +410305-0863611 America/Indiana/Winamac Eastern - IN (Pulaski) +US +382232-0862041 America/Indiana/Marengo Eastern - IN (Crawford) +US +382931-0871643 America/Indiana/Petersburg Eastern - IN (Pike) +US +384452-0850402 America/Indiana/Vevay Eastern - IN (Switzerland) +US +415100-0873900 America/Chicago Central (most areas) +US +375711-0864541 America/Indiana/Tell_City Central - IN (Perry) +US +411745-0863730 America/Indiana/Knox Central - IN (Starke) +US +450628-0873651 America/Menominee Central - MI (Wisconsin border) +US +470659-1011757 America/North_Dakota/Center Central - ND (Oliver) +US +465042-1012439 America/North_Dakota/New_Salem Central - ND (Morton rural) +US +471551-1014640 America/North_Dakota/Beulah Central - ND (Mercer) +US +394421-1045903 America/Denver Mountain (most areas) +US +433649-1161209 America/Boise Mountain - ID (south); OR (east) +US +332654-1120424 America/Phoenix MST - Arizona (except Navajo) +US +340308-1181434 America/Los_Angeles Pacific +US +611305-1495401 America/Anchorage Alaska (most areas) +US +581807-1342511 America/Juneau Alaska - Juneau area +US +571035-1351807 America/Sitka Alaska - Sitka area +US +550737-1313435 America/Metlakatla Alaska - Annette Island +US +593249-1394338 America/Yakutat Alaska - Yakutat +US +643004-1652423 America/Nome Alaska (west) +US +515248-1763929 America/Adak Aleutian Islands +US,UM +211825-1575130 Pacific/Honolulu Hawaii +UY -345433-0561245 America/Montevideo +UZ +3940+06648 Asia/Samarkand Uzbekistan (west) +UZ +4120+06918 Asia/Tashkent Uzbekistan (east) +VE +1030-06656 America/Caracas +VN +1045+10640 Asia/Ho_Chi_Minh Vietnam (south) +VU -1740+16825 Pacific/Efate +WF -1318-17610 Pacific/Wallis +WS -1350-17144 Pacific/Apia +ZA,LS,SZ -2615+02800 Africa/Johannesburg diff --git a/third_party/abseil_cpp/absl/time/internal/get_current_time_chrono.inc b/third_party/abseil_cpp/absl/time/internal/get_current_time_chrono.inc new file mode 100644 index 0000000000..5eeb6406aa --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/get_current_time_chrono.inc @@ -0,0 +1,31 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <chrono> +#include <cstdint> + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { + +static int64_t GetCurrentTimeNanosFromSystem() { + return std::chrono::duration_cast<std::chrono::nanoseconds>( + std::chrono::system_clock::now() - + std::chrono::system_clock::from_time_t(0)) + .count(); +} + +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/get_current_time_posix.inc b/third_party/abseil_cpp/absl/time/internal/get_current_time_posix.inc new file mode 100644 index 0000000000..42072000ae --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/get_current_time_posix.inc @@ -0,0 +1,24 @@ +#include "absl/time/clock.h" + +#include <sys/time.h> +#include <ctime> +#include <cstdint> + +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { + +static int64_t GetCurrentTimeNanosFromSystem() { + const int64_t kNanosPerSecond = 1000 * 1000 * 1000; + struct timespec ts; + ABSL_RAW_CHECK(clock_gettime(CLOCK_REALTIME, &ts) == 0, + "Failed to read real-time clock."); + return (int64_t{ts.tv_sec} * kNanosPerSecond + + int64_t{ts.tv_nsec}); +} + +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/test_util.cc b/third_party/abseil_cpp/absl/time/internal/test_util.cc new file mode 100644 index 0000000000..9bffe121da --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/test_util.cc @@ -0,0 +1,130 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/internal/test_util.h" + +#include <algorithm> +#include <cstddef> +#include <cstring> + +#include "absl/base/internal/raw_logging.h" +#include "absl/time/internal/cctz/include/cctz/zone_info_source.h" + +namespace cctz = absl::time_internal::cctz; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { + +TimeZone LoadTimeZone(const std::string& name) { + TimeZone tz; + ABSL_RAW_CHECK(LoadTimeZone(name, &tz), name.c_str()); + return tz; +} + +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { +namespace cctz_extension { +namespace { + +// Embed the zoneinfo data for time zones used during tests and benchmarks. +// The data was generated using "xxd -i zoneinfo-file". There is no need +// to update the data as long as the tests do not depend on recent changes +// (and the past rules remain the same). +#include "absl/time/internal/zoneinfo.inc" + +const struct ZoneInfo { + const char* name; + const char* data; + std::size_t length; +} kZoneInfo[] = { + // The three real time zones used by :time_test and :time_benchmark. + {"America/Los_Angeles", // + reinterpret_cast<char*>(America_Los_Angeles), America_Los_Angeles_len}, + {"America/New_York", // + reinterpret_cast<char*>(America_New_York), America_New_York_len}, + {"Australia/Sydney", // + reinterpret_cast<char*>(Australia_Sydney), Australia_Sydney_len}, + + // Other zones named in tests but which should fail to load. + {"Invalid/TimeZone", nullptr, 0}, + {"", nullptr, 0}, + + // Also allow for loading the local time zone under TZ=US/Pacific. + {"US/Pacific", // + reinterpret_cast<char*>(America_Los_Angeles), America_Los_Angeles_len}, + + // Allows use of the local time zone from a system-specific location. +#ifdef _MSC_VER + {"localtime", // + reinterpret_cast<char*>(America_Los_Angeles), America_Los_Angeles_len}, +#else + {"/etc/localtime", // + reinterpret_cast<char*>(America_Los_Angeles), America_Los_Angeles_len}, +#endif +}; + +class TestZoneInfoSource : public cctz::ZoneInfoSource { + public: + TestZoneInfoSource(const char* data, std::size_t size) + : data_(data), end_(data + size) {} + + std::size_t Read(void* ptr, std::size_t size) override { + const std::size_t len = std::min<std::size_t>(size, end_ - data_); + memcpy(ptr, data_, len); + data_ += len; + return len; + } + + int Skip(std::size_t offset) override { + data_ += std::min<std::size_t>(offset, end_ - data_); + return 0; + } + + private: + const char* data_; + const char* const end_; +}; + +std::unique_ptr<cctz::ZoneInfoSource> TestFactory( + const std::string& name, + const std::function<std::unique_ptr<cctz::ZoneInfoSource>( + const std::string& name)>& /*fallback_factory*/) { + for (const ZoneInfo& zoneinfo : kZoneInfo) { + if (name == zoneinfo.name) { + if (zoneinfo.data == nullptr) return nullptr; + return std::unique_ptr<cctz::ZoneInfoSource>( + new TestZoneInfoSource(zoneinfo.data, zoneinfo.length)); + } + } + ABSL_RAW_LOG(FATAL, "Unexpected time zone \"%s\" in test", name.c_str()); + return nullptr; +} + +} // namespace + +#if !defined(__MINGW32__) +// MinGW does not support the weak symbol extension mechanism. +ZoneInfoSourceFactory zone_info_source_factory = TestFactory; +#endif + +} // namespace cctz_extension +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/internal/test_util.h b/third_party/abseil_cpp/absl/time/internal/test_util.h new file mode 100644 index 0000000000..5c4bf1f680 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/test_util.h @@ -0,0 +1,33 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TIME_INTERNAL_TEST_UTIL_H_ +#define ABSL_TIME_INTERNAL_TEST_UTIL_H_ + +#include <string> + +#include "absl/time/time.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace time_internal { + +// Loads the named timezone, but dies on any failure. +absl::TimeZone LoadTimeZone(const std::string& name); + +} // namespace time_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_INTERNAL_TEST_UTIL_H_ diff --git a/third_party/abseil_cpp/absl/time/internal/zoneinfo.inc b/third_party/abseil_cpp/absl/time/internal/zoneinfo.inc new file mode 100644 index 0000000000..bfed82990d --- /dev/null +++ b/third_party/abseil_cpp/absl/time/internal/zoneinfo.inc @@ -0,0 +1,729 @@ +unsigned char America_Los_Angeles[] = { + 0x54, 0x5a, 0x69, 0x66, 0x32, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xba, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x14, 0x80, 0x00, 0x00, 0x00, + 0x9e, 0xa6, 0x48, 0xa0, 0x9f, 0xbb, 0x15, 0x90, 0xa0, 0x86, 0x2a, 0xa0, + 0xa1, 0x9a, 0xf7, 0x90, 0xcb, 0x89, 0x1a, 0xa0, 0xd2, 0x23, 0xf4, 0x70, + 0xd2, 0x61, 0x26, 0x10, 0xd6, 0xfe, 0x74, 0x5c, 0xd8, 0x80, 0xad, 0x90, + 0xda, 0xfe, 0xc3, 0x90, 0xdb, 0xc0, 0x90, 0x10, 0xdc, 0xde, 0xa5, 0x90, + 0xdd, 0xa9, 0xac, 0x90, 0xde, 0xbe, 0x87, 0x90, 0xdf, 0x89, 0x8e, 0x90, + 0xe0, 0x9e, 0x69, 0x90, 0xe1, 0x69, 0x70, 0x90, 0xe2, 0x7e, 0x4b, 0x90, + 0xe3, 0x49, 0x52, 0x90, 0xe4, 0x5e, 0x2d, 0x90, 0xe5, 0x29, 0x34, 0x90, + 0xe6, 0x47, 0x4a, 0x10, 0xe7, 0x12, 0x51, 0x10, 0xe8, 0x27, 0x2c, 0x10, + 0xe8, 0xf2, 0x33, 0x10, 0xea, 0x07, 0x0e, 0x10, 0xea, 0xd2, 0x15, 0x10, + 0xeb, 0xe6, 0xf0, 0x10, 0xec, 0xb1, 0xf7, 0x10, 0xed, 0xc6, 0xd2, 0x10, + 0xee, 0x91, 0xd9, 0x10, 0xef, 0xaf, 0xee, 0x90, 0xf0, 0x71, 0xbb, 0x10, + 0xf1, 0x8f, 0xd0, 0x90, 0xf2, 0x7f, 0xc1, 0x90, 0xf3, 0x6f, 0xb2, 0x90, + 0xf4, 0x5f, 0xa3, 0x90, 0xf5, 0x4f, 0x94, 0x90, 0xf6, 0x3f, 0x85, 0x90, + 0xf7, 0x2f, 0x76, 0x90, 0xf8, 0x28, 0xa2, 0x10, 0xf9, 0x0f, 0x58, 0x90, + 0xfa, 0x08, 0x84, 0x10, 0xfa, 0xf8, 0x83, 0x20, 0xfb, 0xe8, 0x66, 0x10, + 0xfc, 0xd8, 0x65, 0x20, 0xfd, 0xc8, 0x48, 0x10, 0xfe, 0xb8, 0x47, 0x20, + 0xff, 0xa8, 0x2a, 0x10, 0x00, 0x98, 0x29, 0x20, 0x01, 0x88, 0x0c, 0x10, + 0x02, 0x78, 0x0b, 0x20, 0x03, 0x71, 0x28, 0x90, 0x04, 0x61, 0x27, 0xa0, + 0x05, 0x51, 0x0a, 0x90, 0x06, 0x41, 0x09, 0xa0, 0x07, 0x30, 0xec, 0x90, + 0x07, 0x8d, 0x43, 0xa0, 0x09, 0x10, 0xce, 0x90, 0x09, 0xad, 0xbf, 0x20, + 0x0a, 0xf0, 0xb0, 0x90, 0x0b, 0xe0, 0xaf, 0xa0, 0x0c, 0xd9, 0xcd, 0x10, + 0x0d, 0xc0, 0x91, 0xa0, 0x0e, 0xb9, 0xaf, 0x10, 0x0f, 0xa9, 0xae, 0x20, + 0x10, 0x99, 0x91, 0x10, 0x11, 0x89, 0x90, 0x20, 0x12, 0x79, 0x73, 0x10, + 0x13, 0x69, 0x72, 0x20, 0x14, 0x59, 0x55, 0x10, 0x15, 0x49, 0x54, 0x20, + 0x16, 0x39, 0x37, 0x10, 0x17, 0x29, 0x36, 0x20, 0x18, 0x22, 0x53, 0x90, + 0x19, 0x09, 0x18, 0x20, 0x1a, 0x02, 0x35, 0x90, 0x1a, 0xf2, 0x34, 0xa0, + 0x1b, 0xe2, 0x17, 0x90, 0x1c, 0xd2, 0x16, 0xa0, 0x1d, 0xc1, 0xf9, 0x90, + 0x1e, 0xb1, 0xf8, 0xa0, 0x1f, 0xa1, 0xdb, 0x90, 0x20, 0x76, 0x2b, 0x20, + 0x21, 0x81, 0xbd, 0x90, 0x22, 0x56, 0x0d, 0x20, 0x23, 0x6a, 0xda, 0x10, + 0x24, 0x35, 0xef, 0x20, 0x25, 0x4a, 0xbc, 0x10, 0x26, 0x15, 0xd1, 0x20, + 0x27, 0x2a, 0x9e, 0x10, 0x27, 0xfe, 0xed, 0xa0, 0x29, 0x0a, 0x80, 0x10, + 0x29, 0xde, 0xcf, 0xa0, 0x2a, 0xea, 0x62, 0x10, 0x2b, 0xbe, 0xb1, 0xa0, + 0x2c, 0xd3, 0x7e, 0x90, 0x2d, 0x9e, 0x93, 0xa0, 0x2e, 0xb3, 0x60, 0x90, + 0x2f, 0x7e, 0x75, 0xa0, 0x30, 0x93, 0x42, 0x90, 0x31, 0x67, 0x92, 0x20, + 0x32, 0x73, 0x24, 0x90, 0x33, 0x47, 0x74, 0x20, 0x34, 0x53, 0x06, 0x90, + 0x35, 0x27, 0x56, 0x20, 0x36, 0x32, 0xe8, 0x90, 0x37, 0x07, 0x38, 0x20, + 0x38, 0x1c, 0x05, 0x10, 0x38, 0xe7, 0x1a, 0x20, 0x39, 0xfb, 0xe7, 0x10, + 0x3a, 0xc6, 0xfc, 0x20, 0x3b, 0xdb, 0xc9, 0x10, 0x3c, 0xb0, 0x18, 0xa0, + 0x3d, 0xbb, 0xab, 0x10, 0x3e, 0x8f, 0xfa, 0xa0, 0x3f, 0x9b, 0x8d, 0x10, + 0x40, 0x6f, 0xdc, 0xa0, 0x41, 0x84, 0xa9, 0x90, 0x42, 0x4f, 0xbe, 0xa0, + 0x43, 0x64, 0x8b, 0x90, 0x44, 0x2f, 0xa0, 0xa0, 0x45, 0x44, 0x6d, 0x90, + 0x45, 0xf3, 0xd3, 0x20, 0x47, 0x2d, 0x8a, 0x10, 0x47, 0xd3, 0xb5, 0x20, + 0x49, 0x0d, 0x6c, 0x10, 0x49, 0xb3, 0x97, 0x20, 0x4a, 0xed, 0x4e, 0x10, + 0x4b, 0x9c, 0xb3, 0xa0, 0x4c, 0xd6, 0x6a, 0x90, 0x4d, 0x7c, 0x95, 0xa0, + 0x4e, 0xb6, 0x4c, 0x90, 0x4f, 0x5c, 0x77, 0xa0, 0x50, 0x96, 0x2e, 0x90, + 0x51, 0x3c, 0x59, 0xa0, 0x52, 0x76, 0x10, 0x90, 0x53, 0x1c, 0x3b, 0xa0, + 0x54, 0x55, 0xf2, 0x90, 0x54, 0xfc, 0x1d, 0xa0, 0x56, 0x35, 0xd4, 0x90, + 0x56, 0xe5, 0x3a, 0x20, 0x58, 0x1e, 0xf1, 0x10, 0x58, 0xc5, 0x1c, 0x20, + 0x59, 0xfe, 0xd3, 0x10, 0x5a, 0xa4, 0xfe, 0x20, 0x5b, 0xde, 0xb5, 0x10, + 0x5c, 0x84, 0xe0, 0x20, 0x5d, 0xbe, 0x97, 0x10, 0x5e, 0x64, 0xc2, 0x20, + 0x5f, 0x9e, 0x79, 0x10, 0x60, 0x4d, 0xde, 0xa0, 0x61, 0x87, 0x95, 0x90, + 0x62, 0x2d, 0xc0, 0xa0, 0x63, 0x67, 0x77, 0x90, 0x64, 0x0d, 0xa2, 0xa0, + 0x65, 0x47, 0x59, 0x90, 0x65, 0xed, 0x84, 0xa0, 0x67, 0x27, 0x3b, 0x90, + 0x67, 0xcd, 0x66, 0xa0, 0x69, 0x07, 0x1d, 0x90, 0x69, 0xad, 0x48, 0xa0, + 0x6a, 0xe6, 0xff, 0x90, 0x6b, 0x96, 0x65, 0x20, 0x6c, 0xd0, 0x1c, 0x10, + 0x6d, 0x76, 0x47, 0x20, 0x6e, 0xaf, 0xfe, 0x10, 0x6f, 0x56, 0x29, 0x20, + 0x70, 0x8f, 0xe0, 0x10, 0x71, 0x36, 0x0b, 0x20, 0x72, 0x6f, 0xc2, 0x10, + 0x73, 0x15, 0xed, 0x20, 0x74, 0x4f, 0xa4, 0x10, 0x74, 0xff, 0x09, 0xa0, + 0x76, 0x38, 0xc0, 0x90, 0x76, 0xde, 0xeb, 0xa0, 0x78, 0x18, 0xa2, 0x90, + 0x78, 0xbe, 0xcd, 0xa0, 0x79, 0xf8, 0x84, 0x90, 0x7a, 0x9e, 0xaf, 0xa0, + 0x7b, 0xd8, 0x66, 0x90, 0x7c, 0x7e, 0x91, 0xa0, 0x7d, 0xb8, 0x48, 0x90, + 0x7e, 0x5e, 0x73, 0xa0, 0x7f, 0x98, 0x2a, 0x90, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x03, 0x04, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0xff, 0xff, 0x91, 0x26, 0x00, 0x00, 0xff, 0xff, 0x9d, 0x90, + 0x01, 0x04, 0xff, 0xff, 0x8f, 0x80, 0x00, 0x08, 0xff, 0xff, 0x9d, 0x90, + 0x01, 0x0c, 0xff, 0xff, 0x9d, 0x90, 0x01, 0x10, 0x4c, 0x4d, 0x54, 0x00, + 0x50, 0x44, 0x54, 0x00, 0x50, 0x53, 0x54, 0x00, 0x50, 0x57, 0x54, 0x00, + 0x50, 0x50, 0x54, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, + 0x00, 0x01, 0x54, 0x5a, 0x69, 0x66, 0x32, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x05, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0xbb, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x14, 0xf8, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff, 0x5e, 0x04, + 0x1a, 0xc0, 0xff, 0xff, 0xff, 0xff, 0x9e, 0xa6, 0x48, 0xa0, 0xff, 0xff, + 0xff, 0xff, 0x9f, 0xbb, 0x15, 0x90, 0xff, 0xff, 0xff, 0xff, 0xa0, 0x86, + 0x2a, 0xa0, 0xff, 0xff, 0xff, 0xff, 0xa1, 0x9a, 0xf7, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xcb, 0x89, 0x1a, 0xa0, 0xff, 0xff, 0xff, 0xff, 0xd2, 0x23, + 0xf4, 0x70, 0xff, 0xff, 0xff, 0xff, 0xd2, 0x61, 0x26, 0x10, 0xff, 0xff, + 0xff, 0xff, 0xd6, 0xfe, 0x74, 0x5c, 0xff, 0xff, 0xff, 0xff, 0xd8, 0x80, + 0xad, 0x90, 0xff, 0xff, 0xff, 0xff, 0xda, 0xfe, 0xc3, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xdb, 0xc0, 0x90, 0x10, 0xff, 0xff, 0xff, 0xff, 0xdc, 0xde, + 0xa5, 0x90, 0xff, 0xff, 0xff, 0xff, 0xdd, 0xa9, 0xac, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xde, 0xbe, 0x87, 0x90, 0xff, 0xff, 0xff, 0xff, 0xdf, 0x89, + 0x8e, 0x90, 0xff, 0xff, 0xff, 0xff, 0xe0, 0x9e, 0x69, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xe1, 0x69, 0x70, 0x90, 0xff, 0xff, 0xff, 0xff, 0xe2, 0x7e, + 0x4b, 0x90, 0xff, 0xff, 0xff, 0xff, 0xe3, 0x49, 0x52, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xe4, 0x5e, 0x2d, 0x90, 0xff, 0xff, 0xff, 0xff, 0xe5, 0x29, + 0x34, 0x90, 0xff, 0xff, 0xff, 0xff, 0xe6, 0x47, 0x4a, 0x10, 0xff, 0xff, + 0xff, 0xff, 0xe7, 0x12, 0x51, 0x10, 0xff, 0xff, 0xff, 0xff, 0xe8, 0x27, + 0x2c, 0x10, 0xff, 0xff, 0xff, 0xff, 0xe8, 0xf2, 0x33, 0x10, 0xff, 0xff, + 0xff, 0xff, 0xea, 0x07, 0x0e, 0x10, 0xff, 0xff, 0xff, 0xff, 0xea, 0xd2, + 0x15, 0x10, 0xff, 0xff, 0xff, 0xff, 0xeb, 0xe6, 0xf0, 0x10, 0xff, 0xff, + 0xff, 0xff, 0xec, 0xb1, 0xf7, 0x10, 0xff, 0xff, 0xff, 0xff, 0xed, 0xc6, + 0xd2, 0x10, 0xff, 0xff, 0xff, 0xff, 0xee, 0x91, 0xd9, 0x10, 0xff, 0xff, + 0xff, 0xff, 0xef, 0xaf, 0xee, 0x90, 0xff, 0xff, 0xff, 0xff, 0xf0, 0x71, + 0xbb, 0x10, 0xff, 0xff, 0xff, 0xff, 0xf1, 0x8f, 0xd0, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xf2, 0x7f, 0xc1, 0x90, 0xff, 0xff, 0xff, 0xff, 0xf3, 0x6f, + 0xb2, 0x90, 0xff, 0xff, 0xff, 0xff, 0xf4, 0x5f, 0xa3, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xf5, 0x4f, 0x94, 0x90, 0xff, 0xff, 0xff, 0xff, 0xf6, 0x3f, + 0x85, 0x90, 0xff, 0xff, 0xff, 0xff, 0xf7, 0x2f, 0x76, 0x90, 0xff, 0xff, + 0xff, 0xff, 0xf8, 0x28, 0xa2, 0x10, 0xff, 0xff, 0xff, 0xff, 0xf9, 0x0f, + 0x58, 0x90, 0xff, 0xff, 0xff, 0xff, 0xfa, 0x08, 0x84, 0x10, 0xff, 0xff, + 0xff, 0xff, 0xfa, 0xf8, 0x83, 0x20, 0xff, 0xff, 0xff, 0xff, 0xfb, 0xe8, + 0x66, 0x10, 0xff, 0xff, 0xff, 0xff, 0xfc, 0xd8, 0x65, 0x20, 0xff, 0xff, + 0xff, 0xff, 0xfd, 0xc8, 0x48, 0x10, 0xff, 0xff, 0xff, 0xff, 0xfe, 0xb8, + 0x47, 0x20, 0xff, 0xff, 0xff, 0xff, 0xff, 0xa8, 0x2a, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x98, 0x29, 0x20, 0x00, 0x00, 0x00, 0x00, 0x01, 0x88, + 0x0c, 0x10, 0x00, 0x00, 0x00, 0x00, 0x02, 0x78, 0x0b, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x03, 0x71, 0x28, 0x90, 0x00, 0x00, 0x00, 0x00, 0x04, 0x61, + 0x27, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x05, 0x51, 0x0a, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x06, 0x41, 0x09, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x07, 0x30, + 0xec, 0x90, 0x00, 0x00, 0x00, 0x00, 0x07, 0x8d, 0x43, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x09, 0x10, 0xce, 0x90, 0x00, 0x00, 0x00, 0x00, 0x09, 0xad, + 0xbf, 0x20, 0x00, 0x00, 0x00, 0x00, 0x0a, 0xf0, 0xb0, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x0b, 0xe0, 0xaf, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x0c, 0xd9, + 0xcd, 0x10, 0x00, 0x00, 0x00, 0x00, 0x0d, 0xc0, 0x91, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x0e, 0xb9, 0xaf, 0x10, 0x00, 0x00, 0x00, 0x00, 0x0f, 0xa9, + 0xae, 0x20, 0x00, 0x00, 0x00, 0x00, 0x10, 0x99, 0x91, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x11, 0x89, 0x90, 0x20, 0x00, 0x00, 0x00, 0x00, 0x12, 0x79, + 0x73, 0x10, 0x00, 0x00, 0x00, 0x00, 0x13, 0x69, 0x72, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x14, 0x59, 0x55, 0x10, 0x00, 0x00, 0x00, 0x00, 0x15, 0x49, + 0x54, 0x20, 0x00, 0x00, 0x00, 0x00, 0x16, 0x39, 0x37, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x17, 0x29, 0x36, 0x20, 0x00, 0x00, 0x00, 0x00, 0x18, 0x22, + 0x53, 0x90, 0x00, 0x00, 0x00, 0x00, 0x19, 0x09, 0x18, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x1a, 0x02, 0x35, 0x90, 0x00, 0x00, 0x00, 0x00, 0x1a, 0xf2, + 0x34, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x1b, 0xe2, 0x17, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x1c, 0xd2, 0x16, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x1d, 0xc1, + 0xf9, 0x90, 0x00, 0x00, 0x00, 0x00, 0x1e, 0xb1, 0xf8, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x1f, 0xa1, 0xdb, 0x90, 0x00, 0x00, 0x00, 0x00, 0x20, 0x76, + 0x2b, 0x20, 0x00, 0x00, 0x00, 0x00, 0x21, 0x81, 0xbd, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x22, 0x56, 0x0d, 0x20, 0x00, 0x00, 0x00, 0x00, 0x23, 0x6a, + 0xda, 0x10, 0x00, 0x00, 0x00, 0x00, 0x24, 0x35, 0xef, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x25, 0x4a, 0xbc, 0x10, 0x00, 0x00, 0x00, 0x00, 0x26, 0x15, + 0xd1, 0x20, 0x00, 0x00, 0x00, 0x00, 0x27, 0x2a, 0x9e, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x27, 0xfe, 0xed, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x29, 0x0a, + 0x80, 0x10, 0x00, 0x00, 0x00, 0x00, 0x29, 0xde, 0xcf, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x2a, 0xea, 0x62, 0x10, 0x00, 0x00, 0x00, 0x00, 0x2b, 0xbe, + 0xb1, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x2c, 0xd3, 0x7e, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x2d, 0x9e, 0x93, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x2e, 0xb3, + 0x60, 0x90, 0x00, 0x00, 0x00, 0x00, 0x2f, 0x7e, 0x75, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x30, 0x93, 0x42, 0x90, 0x00, 0x00, 0x00, 0x00, 0x31, 0x67, + 0x92, 0x20, 0x00, 0x00, 0x00, 0x00, 0x32, 0x73, 0x24, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x33, 0x47, 0x74, 0x20, 0x00, 0x00, 0x00, 0x00, 0x34, 0x53, + 0x06, 0x90, 0x00, 0x00, 0x00, 0x00, 0x35, 0x27, 0x56, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x36, 0x32, 0xe8, 0x90, 0x00, 0x00, 0x00, 0x00, 0x37, 0x07, + 0x38, 0x20, 0x00, 0x00, 0x00, 0x00, 0x38, 0x1c, 0x05, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x38, 0xe7, 0x1a, 0x20, 0x00, 0x00, 0x00, 0x00, 0x39, 0xfb, + 0xe7, 0x10, 0x00, 0x00, 0x00, 0x00, 0x3a, 0xc6, 0xfc, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x3b, 0xdb, 0xc9, 0x10, 0x00, 0x00, 0x00, 0x00, 0x3c, 0xb0, + 0x18, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x3d, 0xbb, 0xab, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x3e, 0x8f, 0xfa, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x3f, 0x9b, + 0x8d, 0x10, 0x00, 0x00, 0x00, 0x00, 0x40, 0x6f, 0xdc, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x41, 0x84, 0xa9, 0x90, 0x00, 0x00, 0x00, 0x00, 0x42, 0x4f, + 0xbe, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x43, 0x64, 0x8b, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x44, 0x2f, 0xa0, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x45, 0x44, + 0x6d, 0x90, 0x00, 0x00, 0x00, 0x00, 0x45, 0xf3, 0xd3, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x47, 0x2d, 0x8a, 0x10, 0x00, 0x00, 0x00, 0x00, 0x47, 0xd3, + 0xb5, 0x20, 0x00, 0x00, 0x00, 0x00, 0x49, 0x0d, 0x6c, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x49, 0xb3, 0x97, 0x20, 0x00, 0x00, 0x00, 0x00, 0x4a, 0xed, + 0x4e, 0x10, 0x00, 0x00, 0x00, 0x00, 0x4b, 0x9c, 0xb3, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x4c, 0xd6, 0x6a, 0x90, 0x00, 0x00, 0x00, 0x00, 0x4d, 0x7c, + 0x95, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x4e, 0xb6, 0x4c, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x4f, 0x5c, 0x77, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x50, 0x96, + 0x2e, 0x90, 0x00, 0x00, 0x00, 0x00, 0x51, 0x3c, 0x59, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x52, 0x76, 0x10, 0x90, 0x00, 0x00, 0x00, 0x00, 0x53, 0x1c, + 0x3b, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x54, 0x55, 0xf2, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x54, 0xfc, 0x1d, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x56, 0x35, + 0xd4, 0x90, 0x00, 0x00, 0x00, 0x00, 0x56, 0xe5, 0x3a, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x58, 0x1e, 0xf1, 0x10, 0x00, 0x00, 0x00, 0x00, 0x58, 0xc5, + 0x1c, 0x20, 0x00, 0x00, 0x00, 0x00, 0x59, 0xfe, 0xd3, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x5a, 0xa4, 0xfe, 0x20, 0x00, 0x00, 0x00, 0x00, 0x5b, 0xde, + 0xb5, 0x10, 0x00, 0x00, 0x00, 0x00, 0x5c, 0x84, 0xe0, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x5d, 0xbe, 0x97, 0x10, 0x00, 0x00, 0x00, 0x00, 0x5e, 0x64, + 0xc2, 0x20, 0x00, 0x00, 0x00, 0x00, 0x5f, 0x9e, 0x79, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x60, 0x4d, 0xde, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x61, 0x87, + 0x95, 0x90, 0x00, 0x00, 0x00, 0x00, 0x62, 0x2d, 0xc0, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x63, 0x67, 0x77, 0x90, 0x00, 0x00, 0x00, 0x00, 0x64, 0x0d, + 0xa2, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x65, 0x47, 0x59, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x65, 0xed, 0x84, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x67, 0x27, + 0x3b, 0x90, 0x00, 0x00, 0x00, 0x00, 0x67, 0xcd, 0x66, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x69, 0x07, 0x1d, 0x90, 0x00, 0x00, 0x00, 0x00, 0x69, 0xad, + 0x48, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x6a, 0xe6, 0xff, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x6b, 0x96, 0x65, 0x20, 0x00, 0x00, 0x00, 0x00, 0x6c, 0xd0, + 0x1c, 0x10, 0x00, 0x00, 0x00, 0x00, 0x6d, 0x76, 0x47, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x6e, 0xaf, 0xfe, 0x10, 0x00, 0x00, 0x00, 0x00, 0x6f, 0x56, + 0x29, 0x20, 0x00, 0x00, 0x00, 0x00, 0x70, 0x8f, 0xe0, 0x10, 0x00, 0x00, + 0x00, 0x00, 0x71, 0x36, 0x0b, 0x20, 0x00, 0x00, 0x00, 0x00, 0x72, 0x6f, + 0xc2, 0x10, 0x00, 0x00, 0x00, 0x00, 0x73, 0x15, 0xed, 0x20, 0x00, 0x00, + 0x00, 0x00, 0x74, 0x4f, 0xa4, 0x10, 0x00, 0x00, 0x00, 0x00, 0x74, 0xff, + 0x09, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x76, 0x38, 0xc0, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x76, 0xde, 0xeb, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x78, 0x18, + 0xa2, 0x90, 0x00, 0x00, 0x00, 0x00, 0x78, 0xbe, 0xcd, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x79, 0xf8, 0x84, 0x90, 0x00, 0x00, 0x00, 0x00, 0x7a, 0x9e, + 0xaf, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x7b, 0xd8, 0x66, 0x90, 0x00, 0x00, + 0x00, 0x00, 0x7c, 0x7e, 0x91, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x7d, 0xb8, + 0x48, 0x90, 0x00, 0x00, 0x00, 0x00, 0x7e, 0x5e, 0x73, 0xa0, 0x00, 0x00, + 0x00, 0x00, 0x7f, 0x98, 0x2a, 0x90, 0x00, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x03, 0x04, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0xff, 0xff, 0x91, 0x26, 0x00, 0x00, 0xff, 0xff, 0x9d, 0x90, 0x01, + 0x04, 0xff, 0xff, 0x8f, 0x80, 0x00, 0x08, 0xff, 0xff, 0x9d, 0x90, 0x01, + 0x0c, 0xff, 0xff, 0x9d, 0x90, 0x01, 0x10, 0x4c, 0x4d, 0x54, 0x00, 0x50, + 0x44, 0x54, 0x00, 0x50, 0x53, 0x54, 0x00, 0x50, 0x57, 0x54, 0x00, 0x50, + 0x50, 0x54, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, + 0x01, 0x0a, 0x50, 0x53, 0x54, 0x38, 0x50, 0x44, 0x54, 0x2c, 0x4d, 0x33, + 0x2e, 0x32, 0x2e, 0x30, 0x2c, 0x4d, 0x31, 0x31, 0x2e, 0x31, 0x2e, 0x30, + 0x0a +}; +unsigned int America_Los_Angeles_len = 2845; +unsigned char America_New_York[] = { + 0x54, 0x5a, 0x69, 0x66, 0x32, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xec, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x14, 0x80, 0x00, 0x00, 0x00, + 0x9e, 0xa6, 0x1e, 0x70, 0x9f, 0xba, 0xeb, 0x60, 0xa0, 0x86, 0x00, 0x70, + 0xa1, 0x9a, 0xcd, 0x60, 0xa2, 0x65, 0xe2, 0x70, 0xa3, 0x83, 0xe9, 0xe0, + 0xa4, 0x6a, 0xae, 0x70, 0xa5, 0x35, 0xa7, 0x60, 0xa6, 0x53, 0xca, 0xf0, + 0xa7, 0x15, 0x89, 0x60, 0xa8, 0x33, 0xac, 0xf0, 0xa8, 0xfe, 0xa5, 0xe0, + 0xaa, 0x13, 0x8e, 0xf0, 0xaa, 0xde, 0x87, 0xe0, 0xab, 0xf3, 0x70, 0xf0, + 0xac, 0xbe, 0x69, 0xe0, 0xad, 0xd3, 0x52, 0xf0, 0xae, 0x9e, 0x4b, 0xe0, + 0xaf, 0xb3, 0x34, 0xf0, 0xb0, 0x7e, 0x2d, 0xe0, 0xb1, 0x9c, 0x51, 0x70, + 0xb2, 0x67, 0x4a, 0x60, 0xb3, 0x7c, 0x33, 0x70, 0xb4, 0x47, 0x2c, 0x60, + 0xb5, 0x5c, 0x15, 0x70, 0xb6, 0x27, 0x0e, 0x60, 0xb7, 0x3b, 0xf7, 0x70, + 0xb8, 0x06, 0xf0, 0x60, 0xb9, 0x1b, 0xd9, 0x70, 0xb9, 0xe6, 0xd2, 0x60, + 0xbb, 0x04, 0xf5, 0xf0, 0xbb, 0xc6, 0xb4, 0x60, 0xbc, 0xe4, 0xd7, 0xf0, + 0xbd, 0xaf, 0xd0, 0xe0, 0xbe, 0xc4, 0xb9, 0xf0, 0xbf, 0x8f, 0xb2, 0xe0, + 0xc0, 0xa4, 0x9b, 0xf0, 0xc1, 0x6f, 0x94, 0xe0, 0xc2, 0x84, 0x7d, 0xf0, + 0xc3, 0x4f, 0x76, 0xe0, 0xc4, 0x64, 0x5f, 0xf0, 0xc5, 0x2f, 0x58, 0xe0, + 0xc6, 0x4d, 0x7c, 0x70, 0xc7, 0x0f, 0x3a, 0xe0, 0xc8, 0x2d, 0x5e, 0x70, + 0xc8, 0xf8, 0x57, 0x60, 0xca, 0x0d, 0x40, 0x70, 0xca, 0xd8, 0x39, 0x60, + 0xcb, 0x88, 0xf0, 0x70, 0xd2, 0x23, 0xf4, 0x70, 0xd2, 0x60, 0xfb, 0xe0, + 0xd3, 0x75, 0xe4, 0xf0, 0xd4, 0x40, 0xdd, 0xe0, 0xd5, 0x55, 0xc6, 0xf0, + 0xd6, 0x20, 0xbf, 0xe0, 0xd7, 0x35, 0xa8, 0xf0, 0xd8, 0x00, 0xa1, 0xe0, + 0xd9, 0x15, 0x8a, 0xf0, 0xd9, 0xe0, 0x83, 0xe0, 0xda, 0xfe, 0xa7, 0x70, + 0xdb, 0xc0, 0x65, 0xe0, 0xdc, 0xde, 0x89, 0x70, 0xdd, 0xa9, 0x82, 0x60, + 0xde, 0xbe, 0x6b, 0x70, 0xdf, 0x89, 0x64, 0x60, 0xe0, 0x9e, 0x4d, 0x70, + 0xe1, 0x69, 0x46, 0x60, 0xe2, 0x7e, 0x2f, 0x70, 0xe3, 0x49, 0x28, 0x60, + 0xe4, 0x5e, 0x11, 0x70, 0xe5, 0x57, 0x2e, 0xe0, 0xe6, 0x47, 0x2d, 0xf0, + 0xe7, 0x37, 0x10, 0xe0, 0xe8, 0x27, 0x0f, 0xf0, 0xe9, 0x16, 0xf2, 0xe0, + 0xea, 0x06, 0xf1, 0xf0, 0xea, 0xf6, 0xd4, 0xe0, 0xeb, 0xe6, 0xd3, 0xf0, + 0xec, 0xd6, 0xb6, 0xe0, 0xed, 0xc6, 0xb5, 0xf0, 0xee, 0xbf, 0xd3, 0x60, + 0xef, 0xaf, 0xd2, 0x70, 0xf0, 0x9f, 0xb5, 0x60, 0xf1, 0x8f, 0xb4, 0x70, + 0xf2, 0x7f, 0x97, 0x60, 0xf3, 0x6f, 0x96, 0x70, 0xf4, 0x5f, 0x79, 0x60, + 0xf5, 0x4f, 0x78, 0x70, 0xf6, 0x3f, 0x5b, 0x60, 0xf7, 0x2f, 0x5a, 0x70, + 0xf8, 0x28, 0x77, 0xe0, 0xf9, 0x0f, 0x3c, 0x70, 0xfa, 0x08, 0x59, 0xe0, + 0xfa, 0xf8, 0x58, 0xf0, 0xfb, 0xe8, 0x3b, 0xe0, 0xfc, 0xd8, 0x3a, 0xf0, + 0xfd, 0xc8, 0x1d, 0xe0, 0xfe, 0xb8, 0x1c, 0xf0, 0xff, 0xa7, 0xff, 0xe0, + 0x00, 0x97, 0xfe, 0xf0, 0x01, 0x87, 0xe1, 0xe0, 0x02, 0x77, 0xe0, 0xf0, + 0x03, 0x70, 0xfe, 0x60, 0x04, 0x60, 0xfd, 0x70, 0x05, 0x50, 0xe0, 0x60, + 0x06, 0x40, 0xdf, 0x70, 0x07, 0x30, 0xc2, 0x60, 0x07, 0x8d, 0x19, 0x70, + 0x09, 0x10, 0xa4, 0x60, 0x09, 0xad, 0x94, 0xf0, 0x0a, 0xf0, 0x86, 0x60, + 0x0b, 0xe0, 0x85, 0x70, 0x0c, 0xd9, 0xa2, 0xe0, 0x0d, 0xc0, 0x67, 0x70, + 0x0e, 0xb9, 0x84, 0xe0, 0x0f, 0xa9, 0x83, 0xf0, 0x10, 0x99, 0x66, 0xe0, + 0x11, 0x89, 0x65, 0xf0, 0x12, 0x79, 0x48, 0xe0, 0x13, 0x69, 0x47, 0xf0, + 0x14, 0x59, 0x2a, 0xe0, 0x15, 0x49, 0x29, 0xf0, 0x16, 0x39, 0x0c, 0xe0, + 0x17, 0x29, 0x0b, 0xf0, 0x18, 0x22, 0x29, 0x60, 0x19, 0x08, 0xed, 0xf0, + 0x1a, 0x02, 0x0b, 0x60, 0x1a, 0xf2, 0x0a, 0x70, 0x1b, 0xe1, 0xed, 0x60, + 0x1c, 0xd1, 0xec, 0x70, 0x1d, 0xc1, 0xcf, 0x60, 0x1e, 0xb1, 0xce, 0x70, + 0x1f, 0xa1, 0xb1, 0x60, 0x20, 0x76, 0x00, 0xf0, 0x21, 0x81, 0x93, 0x60, + 0x22, 0x55, 0xe2, 0xf0, 0x23, 0x6a, 0xaf, 0xe0, 0x24, 0x35, 0xc4, 0xf0, + 0x25, 0x4a, 0x91, 0xe0, 0x26, 0x15, 0xa6, 0xf0, 0x27, 0x2a, 0x73, 0xe0, + 0x27, 0xfe, 0xc3, 0x70, 0x29, 0x0a, 0x55, 0xe0, 0x29, 0xde, 0xa5, 0x70, + 0x2a, 0xea, 0x37, 0xe0, 0x2b, 0xbe, 0x87, 0x70, 0x2c, 0xd3, 0x54, 0x60, + 0x2d, 0x9e, 0x69, 0x70, 0x2e, 0xb3, 0x36, 0x60, 0x2f, 0x7e, 0x4b, 0x70, + 0x30, 0x93, 0x18, 0x60, 0x31, 0x67, 0x67, 0xf0, 0x32, 0x72, 0xfa, 0x60, + 0x33, 0x47, 0x49, 0xf0, 0x34, 0x52, 0xdc, 0x60, 0x35, 0x27, 0x2b, 0xf0, + 0x36, 0x32, 0xbe, 0x60, 0x37, 0x07, 0x0d, 0xf0, 0x38, 0x1b, 0xda, 0xe0, + 0x38, 0xe6, 0xef, 0xf0, 0x39, 0xfb, 0xbc, 0xe0, 0x3a, 0xc6, 0xd1, 0xf0, + 0x3b, 0xdb, 0x9e, 0xe0, 0x3c, 0xaf, 0xee, 0x70, 0x3d, 0xbb, 0x80, 0xe0, + 0x3e, 0x8f, 0xd0, 0x70, 0x3f, 0x9b, 0x62, 0xe0, 0x40, 0x6f, 0xb2, 0x70, + 0x41, 0x84, 0x7f, 0x60, 0x42, 0x4f, 0x94, 0x70, 0x43, 0x64, 0x61, 0x60, + 0x44, 0x2f, 0x76, 0x70, 0x45, 0x44, 0x43, 0x60, 0x45, 0xf3, 0xa8, 0xf0, + 0x47, 0x2d, 0x5f, 0xe0, 0x47, 0xd3, 0x8a, 0xf0, 0x49, 0x0d, 0x41, 0xe0, + 0x49, 0xb3, 0x6c, 0xf0, 0x4a, 0xed, 0x23, 0xe0, 0x4b, 0x9c, 0x89, 0x70, + 0x4c, 0xd6, 0x40, 0x60, 0x4d, 0x7c, 0x6b, 0x70, 0x4e, 0xb6, 0x22, 0x60, + 0x4f, 0x5c, 0x4d, 0x70, 0x50, 0x96, 0x04, 0x60, 0x51, 0x3c, 0x2f, 0x70, + 0x52, 0x75, 0xe6, 0x60, 0x53, 0x1c, 0x11, 0x70, 0x54, 0x55, 0xc8, 0x60, + 0x54, 0xfb, 0xf3, 0x70, 0x56, 0x35, 0xaa, 0x60, 0x56, 0xe5, 0x0f, 0xf0, + 0x58, 0x1e, 0xc6, 0xe0, 0x58, 0xc4, 0xf1, 0xf0, 0x59, 0xfe, 0xa8, 0xe0, + 0x5a, 0xa4, 0xd3, 0xf0, 0x5b, 0xde, 0x8a, 0xe0, 0x5c, 0x84, 0xb5, 0xf0, + 0x5d, 0xbe, 0x6c, 0xe0, 0x5e, 0x64, 0x97, 0xf0, 0x5f, 0x9e, 0x4e, 0xe0, + 0x60, 0x4d, 0xb4, 0x70, 0x61, 0x87, 0x6b, 0x60, 0x62, 0x2d, 0x96, 0x70, + 0x63, 0x67, 0x4d, 0x60, 0x64, 0x0d, 0x78, 0x70, 0x65, 0x47, 0x2f, 0x60, + 0x65, 0xed, 0x5a, 0x70, 0x67, 0x27, 0x11, 0x60, 0x67, 0xcd, 0x3c, 0x70, + 0x69, 0x06, 0xf3, 0x60, 0x69, 0xad, 0x1e, 0x70, 0x6a, 0xe6, 0xd5, 0x60, + 0x6b, 0x96, 0x3a, 0xf0, 0x6c, 0xcf, 0xf1, 0xe0, 0x6d, 0x76, 0x1c, 0xf0, + 0x6e, 0xaf, 0xd3, 0xe0, 0x6f, 0x55, 0xfe, 0xf0, 0x70, 0x8f, 0xb5, 0xe0, + 0x71, 0x35, 0xe0, 0xf0, 0x72, 0x6f, 0x97, 0xe0, 0x73, 0x15, 0xc2, 0xf0, + 0x74, 0x4f, 0x79, 0xe0, 0x74, 0xfe, 0xdf, 0x70, 0x76, 0x38, 0x96, 0x60, + 0x76, 0xde, 0xc1, 0x70, 0x78, 0x18, 0x78, 0x60, 0x78, 0xbe, 0xa3, 0x70, + 0x79, 0xf8, 0x5a, 0x60, 0x7a, 0x9e, 0x85, 0x70, 0x7b, 0xd8, 0x3c, 0x60, + 0x7c, 0x7e, 0x67, 0x70, 0x7d, 0xb8, 0x1e, 0x60, 0x7e, 0x5e, 0x49, 0x70, + 0x7f, 0x98, 0x00, 0x60, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x03, 0x04, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0xff, 0xff, 0xba, 0x9e, 0x00, 0x00, 0xff, 0xff, 0xc7, 0xc0, 0x01, 0x04, + 0xff, 0xff, 0xb9, 0xb0, 0x00, 0x08, 0xff, 0xff, 0xc7, 0xc0, 0x01, 0x0c, + 0xff, 0xff, 0xc7, 0xc0, 0x01, 0x10, 0x4c, 0x4d, 0x54, 0x00, 0x45, 0x44, + 0x54, 0x00, 0x45, 0x53, 0x54, 0x00, 0x45, 0x57, 0x54, 0x00, 0x45, 0x50, + 0x54, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x01, + 0x54, 0x5a, 0x69, 0x66, 0x32, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xed, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x14, 0xf8, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff, 0x5e, 0x03, 0xf0, 0x90, + 0xff, 0xff, 0xff, 0xff, 0x9e, 0xa6, 0x1e, 0x70, 0xff, 0xff, 0xff, 0xff, + 0x9f, 0xba, 0xeb, 0x60, 0xff, 0xff, 0xff, 0xff, 0xa0, 0x86, 0x00, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xa1, 0x9a, 0xcd, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xa2, 0x65, 0xe2, 0x70, 0xff, 0xff, 0xff, 0xff, 0xa3, 0x83, 0xe9, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xa4, 0x6a, 0xae, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xa5, 0x35, 0xa7, 0x60, 0xff, 0xff, 0xff, 0xff, 0xa6, 0x53, 0xca, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xa7, 0x15, 0x89, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xa8, 0x33, 0xac, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xa8, 0xfe, 0xa5, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xaa, 0x13, 0x8e, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xaa, 0xde, 0x87, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xab, 0xf3, 0x70, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xac, 0xbe, 0x69, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xad, 0xd3, 0x52, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xae, 0x9e, 0x4b, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xaf, 0xb3, 0x34, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xb0, 0x7e, 0x2d, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xb1, 0x9c, 0x51, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xb2, 0x67, 0x4a, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xb3, 0x7c, 0x33, 0x70, 0xff, 0xff, 0xff, 0xff, 0xb4, 0x47, 0x2c, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xb5, 0x5c, 0x15, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xb6, 0x27, 0x0e, 0x60, 0xff, 0xff, 0xff, 0xff, 0xb7, 0x3b, 0xf7, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xb8, 0x06, 0xf0, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xb9, 0x1b, 0xd9, 0x70, 0xff, 0xff, 0xff, 0xff, 0xb9, 0xe6, 0xd2, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xbb, 0x04, 0xf5, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xbb, 0xc6, 0xb4, 0x60, 0xff, 0xff, 0xff, 0xff, 0xbc, 0xe4, 0xd7, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xbd, 0xaf, 0xd0, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xbe, 0xc4, 0xb9, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xbf, 0x8f, 0xb2, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xc0, 0xa4, 0x9b, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xc1, 0x6f, 0x94, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xc2, 0x84, 0x7d, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xc3, 0x4f, 0x76, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xc4, 0x64, 0x5f, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xc5, 0x2f, 0x58, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xc6, 0x4d, 0x7c, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xc7, 0x0f, 0x3a, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xc8, 0x2d, 0x5e, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xc8, 0xf8, 0x57, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xca, 0x0d, 0x40, 0x70, 0xff, 0xff, 0xff, 0xff, 0xca, 0xd8, 0x39, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xcb, 0x88, 0xf0, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xd2, 0x23, 0xf4, 0x70, 0xff, 0xff, 0xff, 0xff, 0xd2, 0x60, 0xfb, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xd3, 0x75, 0xe4, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xd4, 0x40, 0xdd, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xd5, 0x55, 0xc6, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xd6, 0x20, 0xbf, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xd7, 0x35, 0xa8, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xd8, 0x00, 0xa1, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xd9, 0x15, 0x8a, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xd9, 0xe0, 0x83, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xda, 0xfe, 0xa7, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xdb, 0xc0, 0x65, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xdc, 0xde, 0x89, 0x70, 0xff, 0xff, 0xff, 0xff, 0xdd, 0xa9, 0x82, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xde, 0xbe, 0x6b, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xdf, 0x89, 0x64, 0x60, 0xff, 0xff, 0xff, 0xff, 0xe0, 0x9e, 0x4d, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xe1, 0x69, 0x46, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xe2, 0x7e, 0x2f, 0x70, 0xff, 0xff, 0xff, 0xff, 0xe3, 0x49, 0x28, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xe4, 0x5e, 0x11, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xe5, 0x57, 0x2e, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xe6, 0x47, 0x2d, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xe7, 0x37, 0x10, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xe8, 0x27, 0x0f, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xe9, 0x16, 0xf2, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xea, 0x06, 0xf1, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xea, 0xf6, 0xd4, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xeb, 0xe6, 0xd3, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xec, 0xd6, 0xb6, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xed, 0xc6, 0xb5, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xee, 0xbf, 0xd3, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xef, 0xaf, 0xd2, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xf0, 0x9f, 0xb5, 0x60, 0xff, 0xff, 0xff, 0xff, 0xf1, 0x8f, 0xb4, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xf2, 0x7f, 0x97, 0x60, 0xff, 0xff, 0xff, 0xff, + 0xf3, 0x6f, 0x96, 0x70, 0xff, 0xff, 0xff, 0xff, 0xf4, 0x5f, 0x79, 0x60, + 0xff, 0xff, 0xff, 0xff, 0xf5, 0x4f, 0x78, 0x70, 0xff, 0xff, 0xff, 0xff, + 0xf6, 0x3f, 0x5b, 0x60, 0xff, 0xff, 0xff, 0xff, 0xf7, 0x2f, 0x5a, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xf8, 0x28, 0x77, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xf9, 0x0f, 0x3c, 0x70, 0xff, 0xff, 0xff, 0xff, 0xfa, 0x08, 0x59, 0xe0, + 0xff, 0xff, 0xff, 0xff, 0xfa, 0xf8, 0x58, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xfb, 0xe8, 0x3b, 0xe0, 0xff, 0xff, 0xff, 0xff, 0xfc, 0xd8, 0x3a, 0xf0, + 0xff, 0xff, 0xff, 0xff, 0xfd, 0xc8, 0x1d, 0xe0, 0xff, 0xff, 0xff, 0xff, + 0xfe, 0xb8, 0x1c, 0xf0, 0xff, 0xff, 0xff, 0xff, 0xff, 0xa7, 0xff, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x97, 0xfe, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x01, 0x87, 0xe1, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x02, 0x77, 0xe0, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x03, 0x70, 0xfe, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x04, 0x60, 0xfd, 0x70, 0x00, 0x00, 0x00, 0x00, 0x05, 0x50, 0xe0, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x06, 0x40, 0xdf, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x07, 0x30, 0xc2, 0x60, 0x00, 0x00, 0x00, 0x00, 0x07, 0x8d, 0x19, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x09, 0x10, 0xa4, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x09, 0xad, 0x94, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x0a, 0xf0, 0x86, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x0b, 0xe0, 0x85, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x0c, 0xd9, 0xa2, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x0d, 0xc0, 0x67, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x0e, 0xb9, 0x84, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x0f, 0xa9, 0x83, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x10, 0x99, 0x66, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x11, 0x89, 0x65, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x12, 0x79, 0x48, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x13, 0x69, 0x47, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x14, 0x59, 0x2a, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x15, 0x49, 0x29, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x16, 0x39, 0x0c, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x17, 0x29, 0x0b, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x18, 0x22, 0x29, 0x60, 0x00, 0x00, 0x00, 0x00, 0x19, 0x08, 0xed, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x1a, 0x02, 0x0b, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x1a, 0xf2, 0x0a, 0x70, 0x00, 0x00, 0x00, 0x00, 0x1b, 0xe1, 0xed, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x1c, 0xd1, 0xec, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x1d, 0xc1, 0xcf, 0x60, 0x00, 0x00, 0x00, 0x00, 0x1e, 0xb1, 0xce, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x1f, 0xa1, 0xb1, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x20, 0x76, 0x00, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x21, 0x81, 0x93, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x22, 0x55, 0xe2, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x23, 0x6a, 0xaf, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x24, 0x35, 0xc4, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x25, 0x4a, 0x91, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x26, 0x15, 0xa6, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x27, 0x2a, 0x73, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x27, 0xfe, 0xc3, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x29, 0x0a, 0x55, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x29, 0xde, 0xa5, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x2a, 0xea, 0x37, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x2b, 0xbe, 0x87, 0x70, 0x00, 0x00, 0x00, 0x00, 0x2c, 0xd3, 0x54, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x2d, 0x9e, 0x69, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x2e, 0xb3, 0x36, 0x60, 0x00, 0x00, 0x00, 0x00, 0x2f, 0x7e, 0x4b, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x30, 0x93, 0x18, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x31, 0x67, 0x67, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x32, 0x72, 0xfa, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x33, 0x47, 0x49, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x34, 0x52, 0xdc, 0x60, 0x00, 0x00, 0x00, 0x00, 0x35, 0x27, 0x2b, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x36, 0x32, 0xbe, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x37, 0x07, 0x0d, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x38, 0x1b, 0xda, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x38, 0xe6, 0xef, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x39, 0xfb, 0xbc, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x3a, 0xc6, 0xd1, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x3b, 0xdb, 0x9e, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x3c, 0xaf, 0xee, 0x70, 0x00, 0x00, 0x00, 0x00, 0x3d, 0xbb, 0x80, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x3e, 0x8f, 0xd0, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x3f, 0x9b, 0x62, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x40, 0x6f, 0xb2, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x41, 0x84, 0x7f, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x42, 0x4f, 0x94, 0x70, 0x00, 0x00, 0x00, 0x00, 0x43, 0x64, 0x61, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x44, 0x2f, 0x76, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x45, 0x44, 0x43, 0x60, 0x00, 0x00, 0x00, 0x00, 0x45, 0xf3, 0xa8, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x47, 0x2d, 0x5f, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x47, 0xd3, 0x8a, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x49, 0x0d, 0x41, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x49, 0xb3, 0x6c, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x4a, 0xed, 0x23, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x4b, 0x9c, 0x89, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x4c, 0xd6, 0x40, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x4d, 0x7c, 0x6b, 0x70, 0x00, 0x00, 0x00, 0x00, 0x4e, 0xb6, 0x22, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x4f, 0x5c, 0x4d, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x50, 0x96, 0x04, 0x60, 0x00, 0x00, 0x00, 0x00, 0x51, 0x3c, 0x2f, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x52, 0x75, 0xe6, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x53, 0x1c, 0x11, 0x70, 0x00, 0x00, 0x00, 0x00, 0x54, 0x55, 0xc8, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x54, 0xfb, 0xf3, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x56, 0x35, 0xaa, 0x60, 0x00, 0x00, 0x00, 0x00, 0x56, 0xe5, 0x0f, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x58, 0x1e, 0xc6, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x58, 0xc4, 0xf1, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x59, 0xfe, 0xa8, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x5a, 0xa4, 0xd3, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x5b, 0xde, 0x8a, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x5c, 0x84, 0xb5, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x5d, 0xbe, 0x6c, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x5e, 0x64, 0x97, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x5f, 0x9e, 0x4e, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x60, 0x4d, 0xb4, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x61, 0x87, 0x6b, 0x60, 0x00, 0x00, 0x00, 0x00, 0x62, 0x2d, 0x96, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x63, 0x67, 0x4d, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x64, 0x0d, 0x78, 0x70, 0x00, 0x00, 0x00, 0x00, 0x65, 0x47, 0x2f, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x65, 0xed, 0x5a, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x67, 0x27, 0x11, 0x60, 0x00, 0x00, 0x00, 0x00, 0x67, 0xcd, 0x3c, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x69, 0x06, 0xf3, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x69, 0xad, 0x1e, 0x70, 0x00, 0x00, 0x00, 0x00, 0x6a, 0xe6, 0xd5, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x6b, 0x96, 0x3a, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x6c, 0xcf, 0xf1, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x6d, 0x76, 0x1c, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x6e, 0xaf, 0xd3, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x6f, 0x55, 0xfe, 0xf0, 0x00, 0x00, 0x00, 0x00, 0x70, 0x8f, 0xb5, 0xe0, + 0x00, 0x00, 0x00, 0x00, 0x71, 0x35, 0xe0, 0xf0, 0x00, 0x00, 0x00, 0x00, + 0x72, 0x6f, 0x97, 0xe0, 0x00, 0x00, 0x00, 0x00, 0x73, 0x15, 0xc2, 0xf0, + 0x00, 0x00, 0x00, 0x00, 0x74, 0x4f, 0x79, 0xe0, 0x00, 0x00, 0x00, 0x00, + 0x74, 0xfe, 0xdf, 0x70, 0x00, 0x00, 0x00, 0x00, 0x76, 0x38, 0x96, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x76, 0xde, 0xc1, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x78, 0x18, 0x78, 0x60, 0x00, 0x00, 0x00, 0x00, 0x78, 0xbe, 0xa3, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x79, 0xf8, 0x5a, 0x60, 0x00, 0x00, 0x00, 0x00, + 0x7a, 0x9e, 0x85, 0x70, 0x00, 0x00, 0x00, 0x00, 0x7b, 0xd8, 0x3c, 0x60, + 0x00, 0x00, 0x00, 0x00, 0x7c, 0x7e, 0x67, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x7d, 0xb8, 0x1e, 0x60, 0x00, 0x00, 0x00, 0x00, 0x7e, 0x5e, 0x49, 0x70, + 0x00, 0x00, 0x00, 0x00, 0x7f, 0x98, 0x00, 0x60, 0x00, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x03, 0x04, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, + 0x02, 0x01, 0x02, 0x01, 0x02, 0xff, 0xff, 0xba, 0x9e, 0x00, 0x00, 0xff, + 0xff, 0xc7, 0xc0, 0x01, 0x04, 0xff, 0xff, 0xb9, 0xb0, 0x00, 0x08, 0xff, + 0xff, 0xc7, 0xc0, 0x01, 0x0c, 0xff, 0xff, 0xc7, 0xc0, 0x01, 0x10, 0x4c, + 0x4d, 0x54, 0x00, 0x45, 0x44, 0x54, 0x00, 0x45, 0x53, 0x54, 0x00, 0x45, + 0x57, 0x54, 0x00, 0x45, 0x50, 0x54, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, + 0x00, 0x00, 0x00, 0x00, 0x01, 0x0a, 0x45, 0x53, 0x54, 0x35, 0x45, 0x44, + 0x54, 0x2c, 0x4d, 0x33, 0x2e, 0x32, 0x2e, 0x30, 0x2c, 0x4d, 0x31, 0x31, + 0x2e, 0x31, 0x2e, 0x30, 0x0a +}; +unsigned int America_New_York_len = 3545; +unsigned char Australia_Sydney[] = { + 0x54, 0x5a, 0x69, 0x66, 0x32, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x8e, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x0e, 0x80, 0x00, 0x00, 0x00, + 0x9c, 0x4e, 0xa6, 0x9c, 0x9c, 0xbc, 0x20, 0xf0, 0xcb, 0x54, 0xb3, 0x00, + 0xcb, 0xc7, 0x57, 0x70, 0xcc, 0xb7, 0x56, 0x80, 0xcd, 0xa7, 0x39, 0x70, + 0xce, 0xa0, 0x73, 0x00, 0xcf, 0x87, 0x1b, 0x70, 0x03, 0x70, 0x39, 0x80, + 0x04, 0x0d, 0x1c, 0x00, 0x05, 0x50, 0x1b, 0x80, 0x05, 0xf6, 0x38, 0x80, + 0x07, 0x2f, 0xfd, 0x80, 0x07, 0xd6, 0x1a, 0x80, 0x09, 0x0f, 0xdf, 0x80, + 0x09, 0xb5, 0xfc, 0x80, 0x0a, 0xef, 0xc1, 0x80, 0x0b, 0x9f, 0x19, 0x00, + 0x0c, 0xd8, 0xde, 0x00, 0x0d, 0x7e, 0xfb, 0x00, 0x0e, 0xb8, 0xc0, 0x00, + 0x0f, 0x5e, 0xdd, 0x00, 0x10, 0x98, 0xa2, 0x00, 0x11, 0x3e, 0xbf, 0x00, + 0x12, 0x78, 0x84, 0x00, 0x13, 0x1e, 0xa1, 0x00, 0x14, 0x58, 0x66, 0x00, + 0x14, 0xfe, 0x83, 0x00, 0x16, 0x38, 0x48, 0x00, 0x17, 0x0c, 0x89, 0x80, + 0x18, 0x21, 0x64, 0x80, 0x18, 0xc7, 0x81, 0x80, 0x1a, 0x01, 0x46, 0x80, + 0x1a, 0xa7, 0x63, 0x80, 0x1b, 0xe1, 0x28, 0x80, 0x1c, 0x87, 0x45, 0x80, + 0x1d, 0xc1, 0x0a, 0x80, 0x1e, 0x79, 0x9c, 0x80, 0x1f, 0x97, 0xb2, 0x00, + 0x20, 0x59, 0x7e, 0x80, 0x21, 0x80, 0xce, 0x80, 0x22, 0x42, 0x9b, 0x00, + 0x23, 0x69, 0xeb, 0x00, 0x24, 0x22, 0x7d, 0x00, 0x25, 0x49, 0xcd, 0x00, + 0x25, 0xef, 0xea, 0x00, 0x27, 0x29, 0xaf, 0x00, 0x27, 0xcf, 0xcc, 0x00, + 0x29, 0x09, 0x91, 0x00, 0x29, 0xaf, 0xae, 0x00, 0x2a, 0xe9, 0x73, 0x00, + 0x2b, 0x98, 0xca, 0x80, 0x2c, 0xd2, 0x8f, 0x80, 0x2d, 0x78, 0xac, 0x80, + 0x2e, 0xb2, 0x71, 0x80, 0x2f, 0x58, 0x8e, 0x80, 0x30, 0x92, 0x53, 0x80, + 0x31, 0x5d, 0x5a, 0x80, 0x32, 0x72, 0x35, 0x80, 0x33, 0x3d, 0x3c, 0x80, + 0x34, 0x52, 0x17, 0x80, 0x35, 0x1d, 0x1e, 0x80, 0x36, 0x31, 0xf9, 0x80, + 0x36, 0xfd, 0x00, 0x80, 0x38, 0x1b, 0x16, 0x00, 0x38, 0xdc, 0xe2, 0x80, + 0x39, 0xa7, 0xe9, 0x80, 0x3a, 0xbc, 0xc4, 0x80, 0x3b, 0xda, 0xda, 0x00, + 0x3c, 0xa5, 0xe1, 0x00, 0x3d, 0xba, 0xbc, 0x00, 0x3e, 0x85, 0xc3, 0x00, + 0x3f, 0x9a, 0x9e, 0x00, 0x40, 0x65, 0xa5, 0x00, 0x41, 0x83, 0xba, 0x80, + 0x42, 0x45, 0x87, 0x00, 0x43, 0x63, 0x9c, 0x80, 0x44, 0x2e, 0xa3, 0x80, + 0x45, 0x43, 0x7e, 0x80, 0x46, 0x05, 0x4b, 0x00, 0x47, 0x23, 0x60, 0x80, + 0x47, 0xf7, 0xa2, 0x00, 0x48, 0xe7, 0x93, 0x00, 0x49, 0xd7, 0x84, 0x00, + 0x4a, 0xc7, 0x75, 0x00, 0x4b, 0xb7, 0x66, 0x00, 0x4c, 0xa7, 0x57, 0x00, + 0x4d, 0x97, 0x48, 0x00, 0x4e, 0x87, 0x39, 0x00, 0x4f, 0x77, 0x2a, 0x00, + 0x50, 0x70, 0x55, 0x80, 0x51, 0x60, 0x46, 0x80, 0x52, 0x50, 0x37, 0x80, + 0x53, 0x40, 0x28, 0x80, 0x54, 0x30, 0x19, 0x80, 0x55, 0x20, 0x0a, 0x80, + 0x56, 0x0f, 0xfb, 0x80, 0x56, 0xff, 0xec, 0x80, 0x57, 0xef, 0xdd, 0x80, + 0x58, 0xdf, 0xce, 0x80, 0x59, 0xcf, 0xbf, 0x80, 0x5a, 0xbf, 0xb0, 0x80, + 0x5b, 0xb8, 0xdc, 0x00, 0x5c, 0xa8, 0xcd, 0x00, 0x5d, 0x98, 0xbe, 0x00, + 0x5e, 0x88, 0xaf, 0x00, 0x5f, 0x78, 0xa0, 0x00, 0x60, 0x68, 0x91, 0x00, + 0x61, 0x58, 0x82, 0x00, 0x62, 0x48, 0x73, 0x00, 0x63, 0x38, 0x64, 0x00, + 0x64, 0x28, 0x55, 0x00, 0x65, 0x18, 0x46, 0x00, 0x66, 0x11, 0x71, 0x80, + 0x67, 0x01, 0x62, 0x80, 0x67, 0xf1, 0x53, 0x80, 0x68, 0xe1, 0x44, 0x80, + 0x69, 0xd1, 0x35, 0x80, 0x6a, 0xc1, 0x26, 0x80, 0x6b, 0xb1, 0x17, 0x80, + 0x6c, 0xa1, 0x08, 0x80, 0x6d, 0x90, 0xf9, 0x80, 0x6e, 0x80, 0xea, 0x80, + 0x6f, 0x70, 0xdb, 0x80, 0x70, 0x6a, 0x07, 0x00, 0x71, 0x59, 0xf8, 0x00, + 0x72, 0x49, 0xe9, 0x00, 0x73, 0x39, 0xda, 0x00, 0x74, 0x29, 0xcb, 0x00, + 0x75, 0x19, 0xbc, 0x00, 0x76, 0x09, 0xad, 0x00, 0x76, 0xf9, 0x9e, 0x00, + 0x77, 0xe9, 0x8f, 0x00, 0x78, 0xd9, 0x80, 0x00, 0x79, 0xc9, 0x71, 0x00, + 0x7a, 0xb9, 0x62, 0x00, 0x7b, 0xb2, 0x8d, 0x80, 0x7c, 0xa2, 0x7e, 0x80, + 0x7d, 0x92, 0x6f, 0x80, 0x7e, 0x82, 0x60, 0x80, 0x7f, 0x72, 0x51, 0x80, + 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, + 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x00, 0x00, + 0x8d, 0xc4, 0x00, 0x00, 0x00, 0x00, 0x9a, 0xb0, 0x01, 0x04, 0x00, 0x00, + 0x8c, 0xa0, 0x00, 0x09, 0x00, 0x00, 0x9a, 0xb0, 0x01, 0x04, 0x00, 0x00, + 0x8c, 0xa0, 0x00, 0x09, 0x4c, 0x4d, 0x54, 0x00, 0x41, 0x45, 0x44, 0x54, + 0x00, 0x41, 0x45, 0x53, 0x54, 0x00, 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x54, 0x5a, 0x69, 0x66, 0x32, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, + 0x00, 0x00, 0x00, 0x8f, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x0e, + 0xf8, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff, + 0x73, 0x16, 0x7f, 0x3c, 0xff, 0xff, 0xff, 0xff, 0x9c, 0x4e, 0xa6, 0x9c, + 0xff, 0xff, 0xff, 0xff, 0x9c, 0xbc, 0x20, 0xf0, 0xff, 0xff, 0xff, 0xff, + 0xcb, 0x54, 0xb3, 0x00, 0xff, 0xff, 0xff, 0xff, 0xcb, 0xc7, 0x57, 0x70, + 0xff, 0xff, 0xff, 0xff, 0xcc, 0xb7, 0x56, 0x80, 0xff, 0xff, 0xff, 0xff, + 0xcd, 0xa7, 0x39, 0x70, 0xff, 0xff, 0xff, 0xff, 0xce, 0xa0, 0x73, 0x00, + 0xff, 0xff, 0xff, 0xff, 0xcf, 0x87, 0x1b, 0x70, 0x00, 0x00, 0x00, 0x00, + 0x03, 0x70, 0x39, 0x80, 0x00, 0x00, 0x00, 0x00, 0x04, 0x0d, 0x1c, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x05, 0x50, 0x1b, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x05, 0xf6, 0x38, 0x80, 0x00, 0x00, 0x00, 0x00, 0x07, 0x2f, 0xfd, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x07, 0xd6, 0x1a, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x09, 0x0f, 0xdf, 0x80, 0x00, 0x00, 0x00, 0x00, 0x09, 0xb5, 0xfc, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x0a, 0xef, 0xc1, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x0b, 0x9f, 0x19, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0c, 0xd8, 0xde, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x0d, 0x7e, 0xfb, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x0e, 0xb8, 0xc0, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0f, 0x5e, 0xdd, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x10, 0x98, 0xa2, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x11, 0x3e, 0xbf, 0x00, 0x00, 0x00, 0x00, 0x00, 0x12, 0x78, 0x84, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x13, 0x1e, 0xa1, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x14, 0x58, 0x66, 0x00, 0x00, 0x00, 0x00, 0x00, 0x14, 0xfe, 0x83, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x16, 0x38, 0x48, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x17, 0x0c, 0x89, 0x80, 0x00, 0x00, 0x00, 0x00, 0x18, 0x21, 0x64, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x18, 0xc7, 0x81, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x1a, 0x01, 0x46, 0x80, 0x00, 0x00, 0x00, 0x00, 0x1a, 0xa7, 0x63, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x1b, 0xe1, 0x28, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x1c, 0x87, 0x45, 0x80, 0x00, 0x00, 0x00, 0x00, 0x1d, 0xc1, 0x0a, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x1e, 0x79, 0x9c, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x1f, 0x97, 0xb2, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x59, 0x7e, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x21, 0x80, 0xce, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x22, 0x42, 0x9b, 0x00, 0x00, 0x00, 0x00, 0x00, 0x23, 0x69, 0xeb, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x24, 0x22, 0x7d, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x25, 0x49, 0xcd, 0x00, 0x00, 0x00, 0x00, 0x00, 0x25, 0xef, 0xea, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x27, 0x29, 0xaf, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x27, 0xcf, 0xcc, 0x00, 0x00, 0x00, 0x00, 0x00, 0x29, 0x09, 0x91, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x29, 0xaf, 0xae, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x2a, 0xe9, 0x73, 0x00, 0x00, 0x00, 0x00, 0x00, 0x2b, 0x98, 0xca, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x2c, 0xd2, 0x8f, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x2d, 0x78, 0xac, 0x80, 0x00, 0x00, 0x00, 0x00, 0x2e, 0xb2, 0x71, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x2f, 0x58, 0x8e, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x30, 0x92, 0x53, 0x80, 0x00, 0x00, 0x00, 0x00, 0x31, 0x5d, 0x5a, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x32, 0x72, 0x35, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x33, 0x3d, 0x3c, 0x80, 0x00, 0x00, 0x00, 0x00, 0x34, 0x52, 0x17, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x35, 0x1d, 0x1e, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x36, 0x31, 0xf9, 0x80, 0x00, 0x00, 0x00, 0x00, 0x36, 0xfd, 0x00, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x38, 0x1b, 0x16, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x38, 0xdc, 0xe2, 0x80, 0x00, 0x00, 0x00, 0x00, 0x39, 0xa7, 0xe9, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x3a, 0xbc, 0xc4, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x3b, 0xda, 0xda, 0x00, 0x00, 0x00, 0x00, 0x00, 0x3c, 0xa5, 0xe1, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x3d, 0xba, 0xbc, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x3e, 0x85, 0xc3, 0x00, 0x00, 0x00, 0x00, 0x00, 0x3f, 0x9a, 0x9e, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x40, 0x65, 0xa5, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x41, 0x83, 0xba, 0x80, 0x00, 0x00, 0x00, 0x00, 0x42, 0x45, 0x87, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x43, 0x63, 0x9c, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x44, 0x2e, 0xa3, 0x80, 0x00, 0x00, 0x00, 0x00, 0x45, 0x43, 0x7e, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x46, 0x05, 0x4b, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x47, 0x23, 0x60, 0x80, 0x00, 0x00, 0x00, 0x00, 0x47, 0xf7, 0xa2, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x48, 0xe7, 0x93, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x49, 0xd7, 0x84, 0x00, 0x00, 0x00, 0x00, 0x00, 0x4a, 0xc7, 0x75, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x4b, 0xb7, 0x66, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x4c, 0xa7, 0x57, 0x00, 0x00, 0x00, 0x00, 0x00, 0x4d, 0x97, 0x48, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x4e, 0x87, 0x39, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x4f, 0x77, 0x2a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x50, 0x70, 0x55, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x51, 0x60, 0x46, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x52, 0x50, 0x37, 0x80, 0x00, 0x00, 0x00, 0x00, 0x53, 0x40, 0x28, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x54, 0x30, 0x19, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x55, 0x20, 0x0a, 0x80, 0x00, 0x00, 0x00, 0x00, 0x56, 0x0f, 0xfb, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x56, 0xff, 0xec, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x57, 0xef, 0xdd, 0x80, 0x00, 0x00, 0x00, 0x00, 0x58, 0xdf, 0xce, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x59, 0xcf, 0xbf, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x5a, 0xbf, 0xb0, 0x80, 0x00, 0x00, 0x00, 0x00, 0x5b, 0xb8, 0xdc, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x5c, 0xa8, 0xcd, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x5d, 0x98, 0xbe, 0x00, 0x00, 0x00, 0x00, 0x00, 0x5e, 0x88, 0xaf, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x5f, 0x78, 0xa0, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x60, 0x68, 0x91, 0x00, 0x00, 0x00, 0x00, 0x00, 0x61, 0x58, 0x82, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x62, 0x48, 0x73, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x63, 0x38, 0x64, 0x00, 0x00, 0x00, 0x00, 0x00, 0x64, 0x28, 0x55, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x65, 0x18, 0x46, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x66, 0x11, 0x71, 0x80, 0x00, 0x00, 0x00, 0x00, 0x67, 0x01, 0x62, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x67, 0xf1, 0x53, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x68, 0xe1, 0x44, 0x80, 0x00, 0x00, 0x00, 0x00, 0x69, 0xd1, 0x35, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x6a, 0xc1, 0x26, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x6b, 0xb1, 0x17, 0x80, 0x00, 0x00, 0x00, 0x00, 0x6c, 0xa1, 0x08, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x6d, 0x90, 0xf9, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x6e, 0x80, 0xea, 0x80, 0x00, 0x00, 0x00, 0x00, 0x6f, 0x70, 0xdb, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x70, 0x6a, 0x07, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x71, 0x59, 0xf8, 0x00, 0x00, 0x00, 0x00, 0x00, 0x72, 0x49, 0xe9, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x73, 0x39, 0xda, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x74, 0x29, 0xcb, 0x00, 0x00, 0x00, 0x00, 0x00, 0x75, 0x19, 0xbc, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x76, 0x09, 0xad, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x76, 0xf9, 0x9e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x77, 0xe9, 0x8f, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x78, 0xd9, 0x80, 0x00, 0x00, 0x00, 0x00, 0x00, + 0x79, 0xc9, 0x71, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7a, 0xb9, 0x62, 0x00, + 0x00, 0x00, 0x00, 0x00, 0x7b, 0xb2, 0x8d, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x7c, 0xa2, 0x7e, 0x80, 0x00, 0x00, 0x00, 0x00, 0x7d, 0x92, 0x6f, 0x80, + 0x00, 0x00, 0x00, 0x00, 0x7e, 0x82, 0x60, 0x80, 0x00, 0x00, 0x00, 0x00, + 0x7f, 0x72, 0x51, 0x80, 0x00, 0x02, 0x01, 0x02, 0x01, 0x02, 0x01, 0x02, + 0x01, 0x02, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, 0x03, 0x04, + 0x03, 0x04, 0x03, 0x00, 0x00, 0x8d, 0xc4, 0x00, 0x00, 0x00, 0x00, 0x9a, + 0xb0, 0x01, 0x04, 0x00, 0x00, 0x8c, 0xa0, 0x00, 0x09, 0x00, 0x00, 0x9a, + 0xb0, 0x01, 0x04, 0x00, 0x00, 0x8c, 0xa0, 0x00, 0x09, 0x4c, 0x4d, 0x54, + 0x00, 0x41, 0x45, 0x44, 0x54, 0x00, 0x41, 0x45, 0x53, 0x54, 0x00, 0x00, + 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x41, 0x45, + 0x53, 0x54, 0x2d, 0x31, 0x30, 0x41, 0x45, 0x44, 0x54, 0x2c, 0x4d, 0x31, + 0x30, 0x2e, 0x31, 0x2e, 0x30, 0x2c, 0x4d, 0x34, 0x2e, 0x31, 0x2e, 0x30, + 0x2f, 0x33, 0x0a +}; +unsigned int Australia_Sydney_len = 2223; diff --git a/third_party/abseil_cpp/absl/time/time.cc b/third_party/abseil_cpp/absl/time/time.cc new file mode 100644 index 0000000000..6bb36cb3e7 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/time.cc @@ -0,0 +1,499 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// The implementation of the absl::Time class, which is declared in +// //absl/time.h. +// +// The representation for an absl::Time is an absl::Duration offset from the +// epoch. We use the traditional Unix epoch (1970-01-01 00:00:00 +0000) +// for convenience, but this is not exposed in the API and could be changed. +// +// NOTE: To keep type verbosity to a minimum, the following variable naming +// conventions are used throughout this file. +// +// tz: An absl::TimeZone +// ci: An absl::TimeZone::CivilInfo +// ti: An absl::TimeZone::TimeInfo +// cd: An absl::CivilDay or a cctz::civil_day +// cs: An absl::CivilSecond or a cctz::civil_second +// bd: An absl::Time::Breakdown +// cl: A cctz::time_zone::civil_lookup +// al: A cctz::time_zone::absolute_lookup + +#include "absl/time/time.h" + +#if defined(_MSC_VER) +#include <winsock2.h> // for timeval +#endif + +#include <cstring> +#include <ctime> +#include <limits> + +#include "absl/time/internal/cctz/include/cctz/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace cctz = absl::time_internal::cctz; + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +inline cctz::time_point<cctz::seconds> unix_epoch() { + return std::chrono::time_point_cast<cctz::seconds>( + std::chrono::system_clock::from_time_t(0)); +} + +// Floors d to the next unit boundary closer to negative infinity. +inline int64_t FloorToUnit(absl::Duration d, absl::Duration unit) { + absl::Duration rem; + int64_t q = absl::IDivDuration(d, unit, &rem); + return (q > 0 || + rem >= ZeroDuration() || + q == std::numeric_limits<int64_t>::min()) ? q : q - 1; +} + +inline absl::Time::Breakdown InfiniteFutureBreakdown() { + absl::Time::Breakdown bd; + bd.year = std::numeric_limits<int64_t>::max(); + bd.month = 12; + bd.day = 31; + bd.hour = 23; + bd.minute = 59; + bd.second = 59; + bd.subsecond = absl::InfiniteDuration(); + bd.weekday = 4; + bd.yearday = 365; + bd.offset = 0; + bd.is_dst = false; + bd.zone_abbr = "-00"; + return bd; +} + +inline absl::Time::Breakdown InfinitePastBreakdown() { + Time::Breakdown bd; + bd.year = std::numeric_limits<int64_t>::min(); + bd.month = 1; + bd.day = 1; + bd.hour = 0; + bd.minute = 0; + bd.second = 0; + bd.subsecond = -absl::InfiniteDuration(); + bd.weekday = 7; + bd.yearday = 1; + bd.offset = 0; + bd.is_dst = false; + bd.zone_abbr = "-00"; + return bd; +} + +inline absl::TimeZone::CivilInfo InfiniteFutureCivilInfo() { + TimeZone::CivilInfo ci; + ci.cs = CivilSecond::max(); + ci.subsecond = InfiniteDuration(); + ci.offset = 0; + ci.is_dst = false; + ci.zone_abbr = "-00"; + return ci; +} + +inline absl::TimeZone::CivilInfo InfinitePastCivilInfo() { + TimeZone::CivilInfo ci; + ci.cs = CivilSecond::min(); + ci.subsecond = -InfiniteDuration(); + ci.offset = 0; + ci.is_dst = false; + ci.zone_abbr = "-00"; + return ci; +} + +inline absl::TimeConversion InfiniteFutureTimeConversion() { + absl::TimeConversion tc; + tc.pre = tc.trans = tc.post = absl::InfiniteFuture(); + tc.kind = absl::TimeConversion::UNIQUE; + tc.normalized = true; + return tc; +} + +inline TimeConversion InfinitePastTimeConversion() { + absl::TimeConversion tc; + tc.pre = tc.trans = tc.post = absl::InfinitePast(); + tc.kind = absl::TimeConversion::UNIQUE; + tc.normalized = true; + return tc; +} + +// Makes a Time from sec, overflowing to InfiniteFuture/InfinitePast as +// necessary. If sec is min/max, then consult cs+tz to check for overlow. +Time MakeTimeWithOverflow(const cctz::time_point<cctz::seconds>& sec, + const cctz::civil_second& cs, + const cctz::time_zone& tz, + bool* normalized = nullptr) { + const auto max = cctz::time_point<cctz::seconds>::max(); + const auto min = cctz::time_point<cctz::seconds>::min(); + if (sec == max) { + const auto al = tz.lookup(max); + if (cs > al.cs) { + if (normalized) *normalized = true; + return absl::InfiniteFuture(); + } + } + if (sec == min) { + const auto al = tz.lookup(min); + if (cs < al.cs) { + if (normalized) *normalized = true; + return absl::InfinitePast(); + } + } + const auto hi = (sec - unix_epoch()).count(); + return time_internal::FromUnixDuration(time_internal::MakeDuration(hi)); +} + +// Returns Mon=1..Sun=7. +inline int MapWeekday(const cctz::weekday& wd) { + switch (wd) { + case cctz::weekday::monday: + return 1; + case cctz::weekday::tuesday: + return 2; + case cctz::weekday::wednesday: + return 3; + case cctz::weekday::thursday: + return 4; + case cctz::weekday::friday: + return 5; + case cctz::weekday::saturday: + return 6; + case cctz::weekday::sunday: + return 7; + } + return 1; +} + +bool FindTransition(const cctz::time_zone& tz, + bool (cctz::time_zone::*find_transition)( + const cctz::time_point<cctz::seconds>& tp, + cctz::time_zone::civil_transition* trans) const, + Time t, TimeZone::CivilTransition* trans) { + // Transitions are second-aligned, so we can discard any fractional part. + const auto tp = unix_epoch() + cctz::seconds(ToUnixSeconds(t)); + cctz::time_zone::civil_transition tr; + if (!(tz.*find_transition)(tp, &tr)) return false; + trans->from = CivilSecond(tr.from); + trans->to = CivilSecond(tr.to); + return true; +} + +} // namespace + +// +// Time +// + +absl::Time::Breakdown Time::In(absl::TimeZone tz) const { + if (*this == absl::InfiniteFuture()) return InfiniteFutureBreakdown(); + if (*this == absl::InfinitePast()) return InfinitePastBreakdown(); + + const auto tp = unix_epoch() + cctz::seconds(time_internal::GetRepHi(rep_)); + const auto al = cctz::time_zone(tz).lookup(tp); + const auto cs = al.cs; + const auto cd = cctz::civil_day(cs); + + absl::Time::Breakdown bd; + bd.year = cs.year(); + bd.month = cs.month(); + bd.day = cs.day(); + bd.hour = cs.hour(); + bd.minute = cs.minute(); + bd.second = cs.second(); + bd.subsecond = time_internal::MakeDuration(0, time_internal::GetRepLo(rep_)); + bd.weekday = MapWeekday(cctz::get_weekday(cd)); + bd.yearday = cctz::get_yearday(cd); + bd.offset = al.offset; + bd.is_dst = al.is_dst; + bd.zone_abbr = al.abbr; + return bd; +} + +// +// Conversions from/to other time types. +// + +absl::Time FromUDate(double udate) { + return time_internal::FromUnixDuration(absl::Milliseconds(udate)); +} + +absl::Time FromUniversal(int64_t universal) { + return absl::UniversalEpoch() + 100 * absl::Nanoseconds(universal); +} + +int64_t ToUnixNanos(Time t) { + if (time_internal::GetRepHi(time_internal::ToUnixDuration(t)) >= 0 && + time_internal::GetRepHi(time_internal::ToUnixDuration(t)) >> 33 == 0) { + return (time_internal::GetRepHi(time_internal::ToUnixDuration(t)) * + 1000 * 1000 * 1000) + + (time_internal::GetRepLo(time_internal::ToUnixDuration(t)) / 4); + } + return FloorToUnit(time_internal::ToUnixDuration(t), absl::Nanoseconds(1)); +} + +int64_t ToUnixMicros(Time t) { + if (time_internal::GetRepHi(time_internal::ToUnixDuration(t)) >= 0 && + time_internal::GetRepHi(time_internal::ToUnixDuration(t)) >> 43 == 0) { + return (time_internal::GetRepHi(time_internal::ToUnixDuration(t)) * + 1000 * 1000) + + (time_internal::GetRepLo(time_internal::ToUnixDuration(t)) / 4000); + } + return FloorToUnit(time_internal::ToUnixDuration(t), absl::Microseconds(1)); +} + +int64_t ToUnixMillis(Time t) { + if (time_internal::GetRepHi(time_internal::ToUnixDuration(t)) >= 0 && + time_internal::GetRepHi(time_internal::ToUnixDuration(t)) >> 53 == 0) { + return (time_internal::GetRepHi(time_internal::ToUnixDuration(t)) * 1000) + + (time_internal::GetRepLo(time_internal::ToUnixDuration(t)) / + (4000 * 1000)); + } + return FloorToUnit(time_internal::ToUnixDuration(t), absl::Milliseconds(1)); +} + +int64_t ToUnixSeconds(Time t) { + return time_internal::GetRepHi(time_internal::ToUnixDuration(t)); +} + +time_t ToTimeT(Time t) { return absl::ToTimespec(t).tv_sec; } + +double ToUDate(Time t) { + return absl::FDivDuration(time_internal::ToUnixDuration(t), + absl::Milliseconds(1)); +} + +int64_t ToUniversal(absl::Time t) { + return absl::FloorToUnit(t - absl::UniversalEpoch(), absl::Nanoseconds(100)); +} + +absl::Time TimeFromTimespec(timespec ts) { + return time_internal::FromUnixDuration(absl::DurationFromTimespec(ts)); +} + +absl::Time TimeFromTimeval(timeval tv) { + return time_internal::FromUnixDuration(absl::DurationFromTimeval(tv)); +} + +timespec ToTimespec(Time t) { + timespec ts; + absl::Duration d = time_internal::ToUnixDuration(t); + if (!time_internal::IsInfiniteDuration(d)) { + ts.tv_sec = time_internal::GetRepHi(d); + if (ts.tv_sec == time_internal::GetRepHi(d)) { // no time_t narrowing + ts.tv_nsec = time_internal::GetRepLo(d) / 4; // floor + return ts; + } + } + if (d >= absl::ZeroDuration()) { + ts.tv_sec = std::numeric_limits<time_t>::max(); + ts.tv_nsec = 1000 * 1000 * 1000 - 1; + } else { + ts.tv_sec = std::numeric_limits<time_t>::min(); + ts.tv_nsec = 0; + } + return ts; +} + +timeval ToTimeval(Time t) { + timeval tv; + timespec ts = absl::ToTimespec(t); + tv.tv_sec = ts.tv_sec; + if (tv.tv_sec != ts.tv_sec) { // narrowing + if (ts.tv_sec < 0) { + tv.tv_sec = std::numeric_limits<decltype(tv.tv_sec)>::min(); + tv.tv_usec = 0; + } else { + tv.tv_sec = std::numeric_limits<decltype(tv.tv_sec)>::max(); + tv.tv_usec = 1000 * 1000 - 1; + } + return tv; + } + tv.tv_usec = static_cast<int>(ts.tv_nsec / 1000); // suseconds_t + return tv; +} + +Time FromChrono(const std::chrono::system_clock::time_point& tp) { + return time_internal::FromUnixDuration(time_internal::FromChrono( + tp - std::chrono::system_clock::from_time_t(0))); +} + +std::chrono::system_clock::time_point ToChronoTime(absl::Time t) { + using D = std::chrono::system_clock::duration; + auto d = time_internal::ToUnixDuration(t); + if (d < ZeroDuration()) d = Floor(d, FromChrono(D{1})); + return std::chrono::system_clock::from_time_t(0) + + time_internal::ToChronoDuration<D>(d); +} + +// +// TimeZone +// + +absl::TimeZone::CivilInfo TimeZone::At(Time t) const { + if (t == absl::InfiniteFuture()) return InfiniteFutureCivilInfo(); + if (t == absl::InfinitePast()) return InfinitePastCivilInfo(); + + const auto ud = time_internal::ToUnixDuration(t); + const auto tp = unix_epoch() + cctz::seconds(time_internal::GetRepHi(ud)); + const auto al = cz_.lookup(tp); + + TimeZone::CivilInfo ci; + ci.cs = CivilSecond(al.cs); + ci.subsecond = time_internal::MakeDuration(0, time_internal::GetRepLo(ud)); + ci.offset = al.offset; + ci.is_dst = al.is_dst; + ci.zone_abbr = al.abbr; + return ci; +} + +absl::TimeZone::TimeInfo TimeZone::At(CivilSecond ct) const { + const cctz::civil_second cs(ct); + const auto cl = cz_.lookup(cs); + + TimeZone::TimeInfo ti; + switch (cl.kind) { + case cctz::time_zone::civil_lookup::UNIQUE: + ti.kind = TimeZone::TimeInfo::UNIQUE; + break; + case cctz::time_zone::civil_lookup::SKIPPED: + ti.kind = TimeZone::TimeInfo::SKIPPED; + break; + case cctz::time_zone::civil_lookup::REPEATED: + ti.kind = TimeZone::TimeInfo::REPEATED; + break; + } + ti.pre = MakeTimeWithOverflow(cl.pre, cs, cz_); + ti.trans = MakeTimeWithOverflow(cl.trans, cs, cz_); + ti.post = MakeTimeWithOverflow(cl.post, cs, cz_); + return ti; +} + +bool TimeZone::NextTransition(Time t, CivilTransition* trans) const { + return FindTransition(cz_, &cctz::time_zone::next_transition, t, trans); +} + +bool TimeZone::PrevTransition(Time t, CivilTransition* trans) const { + return FindTransition(cz_, &cctz::time_zone::prev_transition, t, trans); +} + +// +// Conversions involving time zones. +// + +absl::TimeConversion ConvertDateTime(int64_t year, int mon, int day, int hour, + int min, int sec, TimeZone tz) { + // Avoids years that are too extreme for CivilSecond to normalize. + if (year > 300000000000) return InfiniteFutureTimeConversion(); + if (year < -300000000000) return InfinitePastTimeConversion(); + + const CivilSecond cs(year, mon, day, hour, min, sec); + const auto ti = tz.At(cs); + + TimeConversion tc; + tc.pre = ti.pre; + tc.trans = ti.trans; + tc.post = ti.post; + switch (ti.kind) { + case TimeZone::TimeInfo::UNIQUE: + tc.kind = TimeConversion::UNIQUE; + break; + case TimeZone::TimeInfo::SKIPPED: + tc.kind = TimeConversion::SKIPPED; + break; + case TimeZone::TimeInfo::REPEATED: + tc.kind = TimeConversion::REPEATED; + break; + } + tc.normalized = false; + if (year != cs.year() || mon != cs.month() || day != cs.day() || + hour != cs.hour() || min != cs.minute() || sec != cs.second()) { + tc.normalized = true; + } + return tc; +} + +absl::Time FromTM(const struct tm& tm, absl::TimeZone tz) { + civil_year_t tm_year = tm.tm_year; + // Avoids years that are too extreme for CivilSecond to normalize. + if (tm_year > 300000000000ll) return InfiniteFuture(); + if (tm_year < -300000000000ll) return InfinitePast(); + int tm_mon = tm.tm_mon; + if (tm_mon == std::numeric_limits<int>::max()) { + tm_mon -= 12; + tm_year += 1; + } + const auto ti = tz.At(CivilSecond(tm_year + 1900, tm_mon + 1, tm.tm_mday, + tm.tm_hour, tm.tm_min, tm.tm_sec)); + return tm.tm_isdst == 0 ? ti.post : ti.pre; +} + +struct tm ToTM(absl::Time t, absl::TimeZone tz) { + struct tm tm = {}; + + const auto ci = tz.At(t); + const auto& cs = ci.cs; + tm.tm_sec = cs.second(); + tm.tm_min = cs.minute(); + tm.tm_hour = cs.hour(); + tm.tm_mday = cs.day(); + tm.tm_mon = cs.month() - 1; + + // Saturates tm.tm_year in cases of over/underflow, accounting for the fact + // that tm.tm_year is years since 1900. + if (cs.year() < std::numeric_limits<int>::min() + 1900) { + tm.tm_year = std::numeric_limits<int>::min(); + } else if (cs.year() > std::numeric_limits<int>::max()) { + tm.tm_year = std::numeric_limits<int>::max() - 1900; + } else { + tm.tm_year = static_cast<int>(cs.year() - 1900); + } + + switch (GetWeekday(cs)) { + case Weekday::sunday: + tm.tm_wday = 0; + break; + case Weekday::monday: + tm.tm_wday = 1; + break; + case Weekday::tuesday: + tm.tm_wday = 2; + break; + case Weekday::wednesday: + tm.tm_wday = 3; + break; + case Weekday::thursday: + tm.tm_wday = 4; + break; + case Weekday::friday: + tm.tm_wday = 5; + break; + case Weekday::saturday: + tm.tm_wday = 6; + break; + } + tm.tm_yday = GetYearDay(cs) - 1; + tm.tm_isdst = ci.is_dst ? 1 : 0; + + return tm; +} + +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/time/time.h b/third_party/abseil_cpp/absl/time/time.h new file mode 100644 index 0000000000..b456a13e85 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/time.h @@ -0,0 +1,1584 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// File: time.h +// ----------------------------------------------------------------------------- +// +// This header file defines abstractions for computing with absolute points +// in time, durations of time, and formatting and parsing time within a given +// time zone. The following abstractions are defined: +// +// * `absl::Time` defines an absolute, specific instance in time +// * `absl::Duration` defines a signed, fixed-length span of time +// * `absl::TimeZone` defines geopolitical time zone regions (as collected +// within the IANA Time Zone database (https://www.iana.org/time-zones)). +// +// Note: Absolute times are distinct from civil times, which refer to the +// human-scale time commonly represented by `YYYY-MM-DD hh:mm:ss`. The mapping +// between absolute and civil times can be specified by use of time zones +// (`absl::TimeZone` within this API). That is: +// +// Civil Time = F(Absolute Time, Time Zone) +// Absolute Time = G(Civil Time, Time Zone) +// +// See civil_time.h for abstractions related to constructing and manipulating +// civil time. +// +// Example: +// +// absl::TimeZone nyc; +// // LoadTimeZone() may fail so it's always better to check for success. +// if (!absl::LoadTimeZone("America/New_York", &nyc)) { +// // handle error case +// } +// +// // My flight leaves NYC on Jan 2, 2017 at 03:04:05 +// absl::CivilSecond cs(2017, 1, 2, 3, 4, 5); +// absl::Time takeoff = absl::FromCivil(cs, nyc); +// +// absl::Duration flight_duration = absl::Hours(21) + absl::Minutes(35); +// absl::Time landing = takeoff + flight_duration; +// +// absl::TimeZone syd; +// if (!absl::LoadTimeZone("Australia/Sydney", &syd)) { +// // handle error case +// } +// std::string s = absl::FormatTime( +// "My flight will land in Sydney on %Y-%m-%d at %H:%M:%S", +// landing, syd); + +#ifndef ABSL_TIME_TIME_H_ +#define ABSL_TIME_TIME_H_ + +#if !defined(_MSC_VER) +#include <sys/time.h> +#else +// We don't include `winsock2.h` because it drags in `windows.h` and friends, +// and they define conflicting macros like OPAQUE, ERROR, and more. This has the +// potential to break Abseil users. +// +// Instead we only forward declare `timeval` and require Windows users include +// `winsock2.h` themselves. This is both inconsistent and troublesome, but so is +// including 'windows.h' so we are picking the lesser of two evils here. +struct timeval; +#endif +#include <chrono> // NOLINT(build/c++11) +#include <cmath> +#include <cstdint> +#include <ctime> +#include <ostream> +#include <string> +#include <type_traits> +#include <utility> + +#include "absl/base/macros.h" +#include "absl/strings/string_view.h" +#include "absl/time/civil_time.h" +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class Duration; // Defined below +class Time; // Defined below +class TimeZone; // Defined below + +namespace time_internal { +int64_t IDivDuration(bool satq, Duration num, Duration den, Duration* rem); +constexpr Time FromUnixDuration(Duration d); +constexpr Duration ToUnixDuration(Time t); +constexpr int64_t GetRepHi(Duration d); +constexpr uint32_t GetRepLo(Duration d); +constexpr Duration MakeDuration(int64_t hi, uint32_t lo); +constexpr Duration MakeDuration(int64_t hi, int64_t lo); +inline Duration MakePosDoubleDuration(double n); +constexpr int64_t kTicksPerNanosecond = 4; +constexpr int64_t kTicksPerSecond = 1000 * 1000 * 1000 * kTicksPerNanosecond; +template <std::intmax_t N> +constexpr Duration FromInt64(int64_t v, std::ratio<1, N>); +constexpr Duration FromInt64(int64_t v, std::ratio<60>); +constexpr Duration FromInt64(int64_t v, std::ratio<3600>); +template <typename T> +using EnableIfIntegral = typename std::enable_if< + std::is_integral<T>::value || std::is_enum<T>::value, int>::type; +template <typename T> +using EnableIfFloat = + typename std::enable_if<std::is_floating_point<T>::value, int>::type; +} // namespace time_internal + +// Duration +// +// The `absl::Duration` class represents a signed, fixed-length span of time. +// A `Duration` is generated using a unit-specific factory function, or is +// the result of subtracting one `absl::Time` from another. Durations behave +// like unit-safe integers and they support all the natural integer-like +// arithmetic operations. Arithmetic overflows and saturates at +/- infinity. +// `Duration` should be passed by value rather than const reference. +// +// Factory functions `Nanoseconds()`, `Microseconds()`, `Milliseconds()`, +// `Seconds()`, `Minutes()`, `Hours()` and `InfiniteDuration()` allow for +// creation of constexpr `Duration` values +// +// Examples: +// +// constexpr absl::Duration ten_ns = absl::Nanoseconds(10); +// constexpr absl::Duration min = absl::Minutes(1); +// constexpr absl::Duration hour = absl::Hours(1); +// absl::Duration dur = 60 * min; // dur == hour +// absl::Duration half_sec = absl::Milliseconds(500); +// absl::Duration quarter_sec = 0.25 * absl::Seconds(1); +// +// `Duration` values can be easily converted to an integral number of units +// using the division operator. +// +// Example: +// +// constexpr absl::Duration dur = absl::Milliseconds(1500); +// int64_t ns = dur / absl::Nanoseconds(1); // ns == 1500000000 +// int64_t ms = dur / absl::Milliseconds(1); // ms == 1500 +// int64_t sec = dur / absl::Seconds(1); // sec == 1 (subseconds truncated) +// int64_t min = dur / absl::Minutes(1); // min == 0 +// +// See the `IDivDuration()` and `FDivDuration()` functions below for details on +// how to access the fractional parts of the quotient. +// +// Alternatively, conversions can be performed using helpers such as +// `ToInt64Microseconds()` and `ToDoubleSeconds()`. +class Duration { + public: + // Value semantics. + constexpr Duration() : rep_hi_(0), rep_lo_(0) {} // zero-length duration + + // Copyable. +#if !defined(__clang__) && defined(_MSC_VER) && _MSC_VER < 1910 + // Explicitly defining the constexpr copy constructor avoids an MSVC bug. + constexpr Duration(const Duration& d) + : rep_hi_(d.rep_hi_), rep_lo_(d.rep_lo_) {} +#else + constexpr Duration(const Duration& d) = default; +#endif + Duration& operator=(const Duration& d) = default; + + // Compound assignment operators. + Duration& operator+=(Duration d); + Duration& operator-=(Duration d); + Duration& operator*=(int64_t r); + Duration& operator*=(double r); + Duration& operator/=(int64_t r); + Duration& operator/=(double r); + Duration& operator%=(Duration rhs); + + // Overloads that forward to either the int64_t or double overloads above. + // Integer operands must be representable as int64_t. + template <typename T> + Duration& operator*=(T r) { + int64_t x = r; + return *this *= x; + } + template <typename T> + Duration& operator/=(T r) { + int64_t x = r; + return *this /= x; + } + Duration& operator*=(float r) { return *this *= static_cast<double>(r); } + Duration& operator/=(float r) { return *this /= static_cast<double>(r); } + + template <typename H> + friend H AbslHashValue(H h, Duration d) { + return H::combine(std::move(h), d.rep_hi_, d.rep_lo_); + } + + private: + friend constexpr int64_t time_internal::GetRepHi(Duration d); + friend constexpr uint32_t time_internal::GetRepLo(Duration d); + friend constexpr Duration time_internal::MakeDuration(int64_t hi, + uint32_t lo); + constexpr Duration(int64_t hi, uint32_t lo) : rep_hi_(hi), rep_lo_(lo) {} + int64_t rep_hi_; + uint32_t rep_lo_; +}; + +// Relational Operators +constexpr bool operator<(Duration lhs, Duration rhs); +constexpr bool operator>(Duration lhs, Duration rhs) { return rhs < lhs; } +constexpr bool operator>=(Duration lhs, Duration rhs) { return !(lhs < rhs); } +constexpr bool operator<=(Duration lhs, Duration rhs) { return !(rhs < lhs); } +constexpr bool operator==(Duration lhs, Duration rhs); +constexpr bool operator!=(Duration lhs, Duration rhs) { return !(lhs == rhs); } + +// Additive Operators +constexpr Duration operator-(Duration d); +inline Duration operator+(Duration lhs, Duration rhs) { return lhs += rhs; } +inline Duration operator-(Duration lhs, Duration rhs) { return lhs -= rhs; } + +// Multiplicative Operators +// Integer operands must be representable as int64_t. +template <typename T> +Duration operator*(Duration lhs, T rhs) { + return lhs *= rhs; +} +template <typename T> +Duration operator*(T lhs, Duration rhs) { + return rhs *= lhs; +} +template <typename T> +Duration operator/(Duration lhs, T rhs) { + return lhs /= rhs; +} +inline int64_t operator/(Duration lhs, Duration rhs) { + return time_internal::IDivDuration(true, lhs, rhs, + &lhs); // trunc towards zero +} +inline Duration operator%(Duration lhs, Duration rhs) { return lhs %= rhs; } + +// IDivDuration() +// +// Divides a numerator `Duration` by a denominator `Duration`, returning the +// quotient and remainder. The remainder always has the same sign as the +// numerator. The returned quotient and remainder respect the identity: +// +// numerator = denominator * quotient + remainder +// +// Returned quotients are capped to the range of `int64_t`, with the difference +// spilling into the remainder to uphold the above identity. This means that the +// remainder returned could differ from the remainder returned by +// `Duration::operator%` for huge quotients. +// +// See also the notes on `InfiniteDuration()` below regarding the behavior of +// division involving zero and infinite durations. +// +// Example: +// +// constexpr absl::Duration a = +// absl::Seconds(std::numeric_limits<int64_t>::max()); // big +// constexpr absl::Duration b = absl::Nanoseconds(1); // small +// +// absl::Duration rem = a % b; +// // rem == absl::ZeroDuration() +// +// // Here, q would overflow int64_t, so rem accounts for the difference. +// int64_t q = absl::IDivDuration(a, b, &rem); +// // q == std::numeric_limits<int64_t>::max(), rem == a - b * q +inline int64_t IDivDuration(Duration num, Duration den, Duration* rem) { + return time_internal::IDivDuration(true, num, den, + rem); // trunc towards zero +} + +// FDivDuration() +// +// Divides a `Duration` numerator into a fractional number of units of a +// `Duration` denominator. +// +// See also the notes on `InfiniteDuration()` below regarding the behavior of +// division involving zero and infinite durations. +// +// Example: +// +// double d = absl::FDivDuration(absl::Milliseconds(1500), absl::Seconds(1)); +// // d == 1.5 +double FDivDuration(Duration num, Duration den); + +// ZeroDuration() +// +// Returns a zero-length duration. This function behaves just like the default +// constructor, but the name helps make the semantics clear at call sites. +constexpr Duration ZeroDuration() { return Duration(); } + +// AbsDuration() +// +// Returns the absolute value of a duration. +inline Duration AbsDuration(Duration d) { + return (d < ZeroDuration()) ? -d : d; +} + +// Trunc() +// +// Truncates a duration (toward zero) to a multiple of a non-zero unit. +// +// Example: +// +// absl::Duration d = absl::Nanoseconds(123456789); +// absl::Duration a = absl::Trunc(d, absl::Microseconds(1)); // 123456us +Duration Trunc(Duration d, Duration unit); + +// Floor() +// +// Floors a duration using the passed duration unit to its largest value not +// greater than the duration. +// +// Example: +// +// absl::Duration d = absl::Nanoseconds(123456789); +// absl::Duration b = absl::Floor(d, absl::Microseconds(1)); // 123456us +Duration Floor(Duration d, Duration unit); + +// Ceil() +// +// Returns the ceiling of a duration using the passed duration unit to its +// smallest value not less than the duration. +// +// Example: +// +// absl::Duration d = absl::Nanoseconds(123456789); +// absl::Duration c = absl::Ceil(d, absl::Microseconds(1)); // 123457us +Duration Ceil(Duration d, Duration unit); + +// InfiniteDuration() +// +// Returns an infinite `Duration`. To get a `Duration` representing negative +// infinity, use `-InfiniteDuration()`. +// +// Duration arithmetic overflows to +/- infinity and saturates. In general, +// arithmetic with `Duration` infinities is similar to IEEE 754 infinities +// except where IEEE 754 NaN would be involved, in which case +/- +// `InfiniteDuration()` is used in place of a "nan" Duration. +// +// Examples: +// +// constexpr absl::Duration inf = absl::InfiniteDuration(); +// const absl::Duration d = ... any finite duration ... +// +// inf == inf + inf +// inf == inf + d +// inf == inf - inf +// -inf == d - inf +// +// inf == d * 1e100 +// inf == inf / 2 +// 0 == d / inf +// INT64_MAX == inf / d +// +// d < inf +// -inf < d +// +// // Division by zero returns infinity, or INT64_MIN/MAX where appropriate. +// inf == d / 0 +// INT64_MAX == d / absl::ZeroDuration() +// +// The examples involving the `/` operator above also apply to `IDivDuration()` +// and `FDivDuration()`. +constexpr Duration InfiniteDuration(); + +// Nanoseconds() +// Microseconds() +// Milliseconds() +// Seconds() +// Minutes() +// Hours() +// +// Factory functions for constructing `Duration` values from an integral number +// of the unit indicated by the factory function's name. The number must be +// representable as int64_t. +// +// NOTE: no "Days()" factory function exists because "a day" is ambiguous. +// Civil days are not always 24 hours long, and a 24-hour duration often does +// not correspond with a civil day. If a 24-hour duration is needed, use +// `absl::Hours(24)`. If you actually want a civil day, use absl::CivilDay +// from civil_time.h. +// +// Example: +// +// absl::Duration a = absl::Seconds(60); +// absl::Duration b = absl::Minutes(1); // b == a +constexpr Duration Nanoseconds(int64_t n); +constexpr Duration Microseconds(int64_t n); +constexpr Duration Milliseconds(int64_t n); +constexpr Duration Seconds(int64_t n); +constexpr Duration Minutes(int64_t n); +constexpr Duration Hours(int64_t n); + +// Factory overloads for constructing `Duration` values from a floating-point +// number of the unit indicated by the factory function's name. These functions +// exist for convenience, but they are not as efficient as the integral +// factories, which should be preferred. +// +// Example: +// +// auto a = absl::Seconds(1.5); // OK +// auto b = absl::Milliseconds(1500); // BETTER +template <typename T, time_internal::EnableIfFloat<T> = 0> +Duration Nanoseconds(T n) { + return n * Nanoseconds(1); +} +template <typename T, time_internal::EnableIfFloat<T> = 0> +Duration Microseconds(T n) { + return n * Microseconds(1); +} +template <typename T, time_internal::EnableIfFloat<T> = 0> +Duration Milliseconds(T n) { + return n * Milliseconds(1); +} +template <typename T, time_internal::EnableIfFloat<T> = 0> +Duration Seconds(T n) { + if (n >= 0) { // Note: `NaN >= 0` is false. + if (n >= static_cast<T>((std::numeric_limits<int64_t>::max)())) { + return InfiniteDuration(); + } + return time_internal::MakePosDoubleDuration(n); + } else { + if (std::isnan(n)) + return std::signbit(n) ? -InfiniteDuration() : InfiniteDuration(); + if (n <= (std::numeric_limits<int64_t>::min)()) return -InfiniteDuration(); + return -time_internal::MakePosDoubleDuration(-n); + } +} +template <typename T, time_internal::EnableIfFloat<T> = 0> +Duration Minutes(T n) { + return n * Minutes(1); +} +template <typename T, time_internal::EnableIfFloat<T> = 0> +Duration Hours(T n) { + return n * Hours(1); +} + +// ToInt64Nanoseconds() +// ToInt64Microseconds() +// ToInt64Milliseconds() +// ToInt64Seconds() +// ToInt64Minutes() +// ToInt64Hours() +// +// Helper functions that convert a Duration to an integral count of the +// indicated unit. These functions are shorthand for the `IDivDuration()` +// function above; see its documentation for details about overflow, etc. +// +// Example: +// +// absl::Duration d = absl::Milliseconds(1500); +// int64_t isec = absl::ToInt64Seconds(d); // isec == 1 +int64_t ToInt64Nanoseconds(Duration d); +int64_t ToInt64Microseconds(Duration d); +int64_t ToInt64Milliseconds(Duration d); +int64_t ToInt64Seconds(Duration d); +int64_t ToInt64Minutes(Duration d); +int64_t ToInt64Hours(Duration d); + +// ToDoubleNanoSeconds() +// ToDoubleMicroseconds() +// ToDoubleMilliseconds() +// ToDoubleSeconds() +// ToDoubleMinutes() +// ToDoubleHours() +// +// Helper functions that convert a Duration to a floating point count of the +// indicated unit. These functions are shorthand for the `FDivDuration()` +// function above; see its documentation for details about overflow, etc. +// +// Example: +// +// absl::Duration d = absl::Milliseconds(1500); +// double dsec = absl::ToDoubleSeconds(d); // dsec == 1.5 +double ToDoubleNanoseconds(Duration d); +double ToDoubleMicroseconds(Duration d); +double ToDoubleMilliseconds(Duration d); +double ToDoubleSeconds(Duration d); +double ToDoubleMinutes(Duration d); +double ToDoubleHours(Duration d); + +// FromChrono() +// +// Converts any of the pre-defined std::chrono durations to an absl::Duration. +// +// Example: +// +// std::chrono::milliseconds ms(123); +// absl::Duration d = absl::FromChrono(ms); +constexpr Duration FromChrono(const std::chrono::nanoseconds& d); +constexpr Duration FromChrono(const std::chrono::microseconds& d); +constexpr Duration FromChrono(const std::chrono::milliseconds& d); +constexpr Duration FromChrono(const std::chrono::seconds& d); +constexpr Duration FromChrono(const std::chrono::minutes& d); +constexpr Duration FromChrono(const std::chrono::hours& d); + +// ToChronoNanoseconds() +// ToChronoMicroseconds() +// ToChronoMilliseconds() +// ToChronoSeconds() +// ToChronoMinutes() +// ToChronoHours() +// +// Converts an absl::Duration to any of the pre-defined std::chrono durations. +// If overflow would occur, the returned value will saturate at the min/max +// chrono duration value instead. +// +// Example: +// +// absl::Duration d = absl::Microseconds(123); +// auto x = absl::ToChronoMicroseconds(d); +// auto y = absl::ToChronoNanoseconds(d); // x == y +// auto z = absl::ToChronoSeconds(absl::InfiniteDuration()); +// // z == std::chrono::seconds::max() +std::chrono::nanoseconds ToChronoNanoseconds(Duration d); +std::chrono::microseconds ToChronoMicroseconds(Duration d); +std::chrono::milliseconds ToChronoMilliseconds(Duration d); +std::chrono::seconds ToChronoSeconds(Duration d); +std::chrono::minutes ToChronoMinutes(Duration d); +std::chrono::hours ToChronoHours(Duration d); + +// FormatDuration() +// +// Returns a string representing the duration in the form "72h3m0.5s". +// Returns "inf" or "-inf" for +/- `InfiniteDuration()`. +std::string FormatDuration(Duration d); + +// Output stream operator. +inline std::ostream& operator<<(std::ostream& os, Duration d) { + return os << FormatDuration(d); +} + +// ParseDuration() +// +// Parses a duration string consisting of a possibly signed sequence of +// decimal numbers, each with an optional fractional part and a unit +// suffix. The valid suffixes are "ns", "us" "ms", "s", "m", and "h". +// Simple examples include "300ms", "-1.5h", and "2h45m". Parses "0" as +// `ZeroDuration()`. Parses "inf" and "-inf" as +/- `InfiniteDuration()`. +bool ParseDuration(absl::string_view dur_string, Duration* d); + +// Support for flag values of type Duration. Duration flags must be specified +// in a format that is valid input for absl::ParseDuration(). +bool AbslParseFlag(absl::string_view text, Duration* dst, std::string* error); +std::string AbslUnparseFlag(Duration d); +ABSL_DEPRECATED("Use AbslParseFlag() instead.") +bool ParseFlag(const std::string& text, Duration* dst, std::string* error); +ABSL_DEPRECATED("Use AbslUnparseFlag() instead.") +std::string UnparseFlag(Duration d); + +// Time +// +// An `absl::Time` represents a specific instant in time. Arithmetic operators +// are provided for naturally expressing time calculations. Instances are +// created using `absl::Now()` and the `absl::From*()` factory functions that +// accept the gamut of other time representations. Formatting and parsing +// functions are provided for conversion to and from strings. `absl::Time` +// should be passed by value rather than const reference. +// +// `absl::Time` assumes there are 60 seconds in a minute, which means the +// underlying time scales must be "smeared" to eliminate leap seconds. +// See https://developers.google.com/time/smear. +// +// Even though `absl::Time` supports a wide range of timestamps, exercise +// caution when using values in the distant past. `absl::Time` uses the +// Proleptic Gregorian calendar, which extends the Gregorian calendar backward +// to dates before its introduction in 1582. +// See https://en.wikipedia.org/wiki/Proleptic_Gregorian_calendar +// for more information. Use the ICU calendar classes to convert a date in +// some other calendar (http://userguide.icu-project.org/datetime/calendar). +// +// Similarly, standardized time zones are a reasonably recent innovation, with +// the Greenwich prime meridian being established in 1884. The TZ database +// itself does not profess accurate offsets for timestamps prior to 1970. The +// breakdown of future timestamps is subject to the whim of regional +// governments. +// +// The `absl::Time` class represents an instant in time as a count of clock +// ticks of some granularity (resolution) from some starting point (epoch). +// +// `absl::Time` uses a resolution that is high enough to avoid loss in +// precision, and a range that is wide enough to avoid overflow, when +// converting between tick counts in most Google time scales (i.e., resolution +// of at least one nanosecond, and range +/-100 billion years). Conversions +// between the time scales are performed by truncating (towards negative +// infinity) to the nearest representable point. +// +// Examples: +// +// absl::Time t1 = ...; +// absl::Time t2 = t1 + absl::Minutes(2); +// absl::Duration d = t2 - t1; // == absl::Minutes(2) +// +class Time { + public: + // Value semantics. + + // Returns the Unix epoch. However, those reading your code may not know + // or expect the Unix epoch as the default value, so make your code more + // readable by explicitly initializing all instances before use. + // + // Example: + // absl::Time t = absl::UnixEpoch(); + // absl::Time t = absl::Now(); + // absl::Time t = absl::TimeFromTimeval(tv); + // absl::Time t = absl::InfinitePast(); + constexpr Time() = default; + + // Copyable. + constexpr Time(const Time& t) = default; + Time& operator=(const Time& t) = default; + + // Assignment operators. + Time& operator+=(Duration d) { + rep_ += d; + return *this; + } + Time& operator-=(Duration d) { + rep_ -= d; + return *this; + } + + // Time::Breakdown + // + // The calendar and wall-clock (aka "civil time") components of an + // `absl::Time` in a certain `absl::TimeZone`. This struct is not + // intended to represent an instant in time. So, rather than passing + // a `Time::Breakdown` to a function, pass an `absl::Time` and an + // `absl::TimeZone`. + // + // Deprecated. Use `absl::TimeZone::CivilInfo`. + struct + Breakdown { + int64_t year; // year (e.g., 2013) + int month; // month of year [1:12] + int day; // day of month [1:31] + int hour; // hour of day [0:23] + int minute; // minute of hour [0:59] + int second; // second of minute [0:59] + Duration subsecond; // [Seconds(0):Seconds(1)) if finite + int weekday; // 1==Mon, ..., 7=Sun + int yearday; // day of year [1:366] + + // Note: The following fields exist for backward compatibility + // with older APIs. Accessing these fields directly is a sign of + // imprudent logic in the calling code. Modern time-related code + // should only access this data indirectly by way of FormatTime(). + // These fields are undefined for InfiniteFuture() and InfinitePast(). + int offset; // seconds east of UTC + bool is_dst; // is offset non-standard? + const char* zone_abbr; // time-zone abbreviation (e.g., "PST") + }; + + // Time::In() + // + // Returns the breakdown of this instant in the given TimeZone. + // + // Deprecated. Use `absl::TimeZone::At(Time)`. + Breakdown In(TimeZone tz) const; + + template <typename H> + friend H AbslHashValue(H h, Time t) { + return H::combine(std::move(h), t.rep_); + } + + private: + friend constexpr Time time_internal::FromUnixDuration(Duration d); + friend constexpr Duration time_internal::ToUnixDuration(Time t); + friend constexpr bool operator<(Time lhs, Time rhs); + friend constexpr bool operator==(Time lhs, Time rhs); + friend Duration operator-(Time lhs, Time rhs); + friend constexpr Time UniversalEpoch(); + friend constexpr Time InfiniteFuture(); + friend constexpr Time InfinitePast(); + constexpr explicit Time(Duration rep) : rep_(rep) {} + Duration rep_; +}; + +// Relational Operators +constexpr bool operator<(Time lhs, Time rhs) { return lhs.rep_ < rhs.rep_; } +constexpr bool operator>(Time lhs, Time rhs) { return rhs < lhs; } +constexpr bool operator>=(Time lhs, Time rhs) { return !(lhs < rhs); } +constexpr bool operator<=(Time lhs, Time rhs) { return !(rhs < lhs); } +constexpr bool operator==(Time lhs, Time rhs) { return lhs.rep_ == rhs.rep_; } +constexpr bool operator!=(Time lhs, Time rhs) { return !(lhs == rhs); } + +// Additive Operators +inline Time operator+(Time lhs, Duration rhs) { return lhs += rhs; } +inline Time operator+(Duration lhs, Time rhs) { return rhs += lhs; } +inline Time operator-(Time lhs, Duration rhs) { return lhs -= rhs; } +inline Duration operator-(Time lhs, Time rhs) { return lhs.rep_ - rhs.rep_; } + +// UnixEpoch() +// +// Returns the `absl::Time` representing "1970-01-01 00:00:00.0 +0000". +constexpr Time UnixEpoch() { return Time(); } + +// UniversalEpoch() +// +// Returns the `absl::Time` representing "0001-01-01 00:00:00.0 +0000", the +// epoch of the ICU Universal Time Scale. +constexpr Time UniversalEpoch() { + // 719162 is the number of days from 0001-01-01 to 1970-01-01, + // assuming the Gregorian calendar. + return Time(time_internal::MakeDuration(-24 * 719162 * int64_t{3600}, 0U)); +} + +// InfiniteFuture() +// +// Returns an `absl::Time` that is infinitely far in the future. +constexpr Time InfiniteFuture() { + return Time( + time_internal::MakeDuration((std::numeric_limits<int64_t>::max)(), ~0U)); +} + +// InfinitePast() +// +// Returns an `absl::Time` that is infinitely far in the past. +constexpr Time InfinitePast() { + return Time( + time_internal::MakeDuration((std::numeric_limits<int64_t>::min)(), ~0U)); +} + +// FromUnixNanos() +// FromUnixMicros() +// FromUnixMillis() +// FromUnixSeconds() +// FromTimeT() +// FromUDate() +// FromUniversal() +// +// Creates an `absl::Time` from a variety of other representations. +constexpr Time FromUnixNanos(int64_t ns); +constexpr Time FromUnixMicros(int64_t us); +constexpr Time FromUnixMillis(int64_t ms); +constexpr Time FromUnixSeconds(int64_t s); +constexpr Time FromTimeT(time_t t); +Time FromUDate(double udate); +Time FromUniversal(int64_t universal); + +// ToUnixNanos() +// ToUnixMicros() +// ToUnixMillis() +// ToUnixSeconds() +// ToTimeT() +// ToUDate() +// ToUniversal() +// +// Converts an `absl::Time` to a variety of other representations. Note that +// these operations round down toward negative infinity where necessary to +// adjust to the resolution of the result type. Beware of possible time_t +// over/underflow in ToTime{T,val,spec}() on 32-bit platforms. +int64_t ToUnixNanos(Time t); +int64_t ToUnixMicros(Time t); +int64_t ToUnixMillis(Time t); +int64_t ToUnixSeconds(Time t); +time_t ToTimeT(Time t); +double ToUDate(Time t); +int64_t ToUniversal(Time t); + +// DurationFromTimespec() +// DurationFromTimeval() +// ToTimespec() +// ToTimeval() +// TimeFromTimespec() +// TimeFromTimeval() +// ToTimespec() +// ToTimeval() +// +// Some APIs use a timespec or a timeval as a Duration (e.g., nanosleep(2) +// and select(2)), while others use them as a Time (e.g. clock_gettime(2) +// and gettimeofday(2)), so conversion functions are provided for both cases. +// The "to timespec/val" direction is easily handled via overloading, but +// for "from timespec/val" the desired type is part of the function name. +Duration DurationFromTimespec(timespec ts); +Duration DurationFromTimeval(timeval tv); +timespec ToTimespec(Duration d); +timeval ToTimeval(Duration d); +Time TimeFromTimespec(timespec ts); +Time TimeFromTimeval(timeval tv); +timespec ToTimespec(Time t); +timeval ToTimeval(Time t); + +// FromChrono() +// +// Converts a std::chrono::system_clock::time_point to an absl::Time. +// +// Example: +// +// auto tp = std::chrono::system_clock::from_time_t(123); +// absl::Time t = absl::FromChrono(tp); +// // t == absl::FromTimeT(123) +Time FromChrono(const std::chrono::system_clock::time_point& tp); + +// ToChronoTime() +// +// Converts an absl::Time to a std::chrono::system_clock::time_point. If +// overflow would occur, the returned value will saturate at the min/max time +// point value instead. +// +// Example: +// +// absl::Time t = absl::FromTimeT(123); +// auto tp = absl::ToChronoTime(t); +// // tp == std::chrono::system_clock::from_time_t(123); +std::chrono::system_clock::time_point ToChronoTime(Time); + +// Support for flag values of type Time. Time flags must be specified in a +// format that matches absl::RFC3339_full. For example: +// +// --start_time=2016-01-02T03:04:05.678+08:00 +// +// Note: A UTC offset (or 'Z' indicating a zero-offset from UTC) is required. +// +// Additionally, if you'd like to specify a time as a count of +// seconds/milliseconds/etc from the Unix epoch, use an absl::Duration flag +// and add that duration to absl::UnixEpoch() to get an absl::Time. +bool AbslParseFlag(absl::string_view text, Time* t, std::string* error); +std::string AbslUnparseFlag(Time t); +ABSL_DEPRECATED("Use AbslParseFlag() instead.") +bool ParseFlag(const std::string& text, Time* t, std::string* error); +ABSL_DEPRECATED("Use AbslUnparseFlag() instead.") +std::string UnparseFlag(Time t); + +// TimeZone +// +// The `absl::TimeZone` is an opaque, small, value-type class representing a +// geo-political region within which particular rules are used for converting +// between absolute and civil times (see https://git.io/v59Ly). `absl::TimeZone` +// values are named using the TZ identifiers from the IANA Time Zone Database, +// such as "America/Los_Angeles" or "Australia/Sydney". `absl::TimeZone` values +// are created from factory functions such as `absl::LoadTimeZone()`. Note: +// strings like "PST" and "EDT" are not valid TZ identifiers. Prefer to pass by +// value rather than const reference. +// +// For more on the fundamental concepts of time zones, absolute times, and civil +// times, see https://github.com/google/cctz#fundamental-concepts +// +// Examples: +// +// absl::TimeZone utc = absl::UTCTimeZone(); +// absl::TimeZone pst = absl::FixedTimeZone(-8 * 60 * 60); +// absl::TimeZone loc = absl::LocalTimeZone(); +// absl::TimeZone lax; +// if (!absl::LoadTimeZone("America/Los_Angeles", &lax)) { +// // handle error case +// } +// +// See also: +// - https://github.com/google/cctz +// - https://www.iana.org/time-zones +// - https://en.wikipedia.org/wiki/Zoneinfo +class TimeZone { + public: + explicit TimeZone(time_internal::cctz::time_zone tz) : cz_(tz) {} + TimeZone() = default; // UTC, but prefer UTCTimeZone() to be explicit. + + // Copyable. + TimeZone(const TimeZone&) = default; + TimeZone& operator=(const TimeZone&) = default; + + explicit operator time_internal::cctz::time_zone() const { return cz_; } + + std::string name() const { return cz_.name(); } + + // TimeZone::CivilInfo + // + // Information about the civil time corresponding to an absolute time. + // This struct is not intended to represent an instant in time. So, rather + // than passing a `TimeZone::CivilInfo` to a function, pass an `absl::Time` + // and an `absl::TimeZone`. + struct CivilInfo { + CivilSecond cs; + Duration subsecond; + + // Note: The following fields exist for backward compatibility + // with older APIs. Accessing these fields directly is a sign of + // imprudent logic in the calling code. Modern time-related code + // should only access this data indirectly by way of FormatTime(). + // These fields are undefined for InfiniteFuture() and InfinitePast(). + int offset; // seconds east of UTC + bool is_dst; // is offset non-standard? + const char* zone_abbr; // time-zone abbreviation (e.g., "PST") + }; + + // TimeZone::At(Time) + // + // Returns the civil time for this TimeZone at a certain `absl::Time`. + // If the input time is infinite, the output civil second will be set to + // CivilSecond::max() or min(), and the subsecond will be infinite. + // + // Example: + // + // const auto epoch = lax.At(absl::UnixEpoch()); + // // epoch.cs == 1969-12-31 16:00:00 + // // epoch.subsecond == absl::ZeroDuration() + // // epoch.offset == -28800 + // // epoch.is_dst == false + // // epoch.abbr == "PST" + CivilInfo At(Time t) const; + + // TimeZone::TimeInfo + // + // Information about the absolute times corresponding to a civil time. + // (Subseconds must be handled separately.) + // + // It is possible for a caller to pass a civil-time value that does + // not represent an actual or unique instant in time (due to a shift + // in UTC offset in the TimeZone, which results in a discontinuity in + // the civil-time components). For example, a daylight-saving-time + // transition skips or repeats civil times---in the United States, + // March 13, 2011 02:15 never occurred, while November 6, 2011 01:15 + // occurred twice---so requests for such times are not well-defined. + // To account for these possibilities, `absl::TimeZone::TimeInfo` is + // richer than just a single `absl::Time`. + struct TimeInfo { + enum CivilKind { + UNIQUE, // the civil time was singular (pre == trans == post) + SKIPPED, // the civil time did not exist (pre >= trans > post) + REPEATED, // the civil time was ambiguous (pre < trans <= post) + } kind; + Time pre; // time calculated using the pre-transition offset + Time trans; // when the civil-time discontinuity occurred + Time post; // time calculated using the post-transition offset + }; + + // TimeZone::At(CivilSecond) + // + // Returns an `absl::TimeInfo` containing the absolute time(s) for this + // TimeZone at an `absl::CivilSecond`. When the civil time is skipped or + // repeated, returns times calculated using the pre-transition and post- + // transition UTC offsets, plus the transition time itself. + // + // Examples: + // + // // A unique civil time + // const auto jan01 = lax.At(absl::CivilSecond(2011, 1, 1, 0, 0, 0)); + // // jan01.kind == TimeZone::TimeInfo::UNIQUE + // // jan01.pre is 2011-01-01 00:00:00 -0800 + // // jan01.trans is 2011-01-01 00:00:00 -0800 + // // jan01.post is 2011-01-01 00:00:00 -0800 + // + // // A Spring DST transition, when there is a gap in civil time + // const auto mar13 = lax.At(absl::CivilSecond(2011, 3, 13, 2, 15, 0)); + // // mar13.kind == TimeZone::TimeInfo::SKIPPED + // // mar13.pre is 2011-03-13 03:15:00 -0700 + // // mar13.trans is 2011-03-13 03:00:00 -0700 + // // mar13.post is 2011-03-13 01:15:00 -0800 + // + // // A Fall DST transition, when civil times are repeated + // const auto nov06 = lax.At(absl::CivilSecond(2011, 11, 6, 1, 15, 0)); + // // nov06.kind == TimeZone::TimeInfo::REPEATED + // // nov06.pre is 2011-11-06 01:15:00 -0700 + // // nov06.trans is 2011-11-06 01:00:00 -0800 + // // nov06.post is 2011-11-06 01:15:00 -0800 + TimeInfo At(CivilSecond ct) const; + + // TimeZone::NextTransition() + // TimeZone::PrevTransition() + // + // Finds the time of the next/previous offset change in this time zone. + // + // By definition, `NextTransition(t, &trans)` returns false when `t` is + // `InfiniteFuture()`, and `PrevTransition(t, &trans)` returns false + // when `t` is `InfinitePast()`. If the zone has no transitions, the + // result will also be false no matter what the argument. + // + // Otherwise, when `t` is `InfinitePast()`, `NextTransition(t, &trans)` + // returns true and sets `trans` to the first recorded transition. Chains + // of calls to `NextTransition()/PrevTransition()` will eventually return + // false, but it is unspecified exactly when `NextTransition(t, &trans)` + // jumps to false, or what time is set by `PrevTransition(t, &trans)` for + // a very distant `t`. + // + // Note: Enumeration of time-zone transitions is for informational purposes + // only. Modern time-related code should not care about when offset changes + // occur. + // + // Example: + // absl::TimeZone nyc; + // if (!absl::LoadTimeZone("America/New_York", &nyc)) { ... } + // const auto now = absl::Now(); + // auto t = absl::InfinitePast(); + // absl::TimeZone::CivilTransition trans; + // while (t <= now && nyc.NextTransition(t, &trans)) { + // // transition: trans.from -> trans.to + // t = nyc.At(trans.to).trans; + // } + struct CivilTransition { + CivilSecond from; // the civil time we jump from + CivilSecond to; // the civil time we jump to + }; + bool NextTransition(Time t, CivilTransition* trans) const; + bool PrevTransition(Time t, CivilTransition* trans) const; + + template <typename H> + friend H AbslHashValue(H h, TimeZone tz) { + return H::combine(std::move(h), tz.cz_); + } + + private: + friend bool operator==(TimeZone a, TimeZone b) { return a.cz_ == b.cz_; } + friend bool operator!=(TimeZone a, TimeZone b) { return a.cz_ != b.cz_; } + friend std::ostream& operator<<(std::ostream& os, TimeZone tz) { + return os << tz.name(); + } + + time_internal::cctz::time_zone cz_; +}; + +// LoadTimeZone() +// +// Loads the named zone. May perform I/O on the initial load of the named +// zone. If the name is invalid, or some other kind of error occurs, returns +// `false` and `*tz` is set to the UTC time zone. +inline bool LoadTimeZone(absl::string_view name, TimeZone* tz) { + if (name == "localtime") { + *tz = TimeZone(time_internal::cctz::local_time_zone()); + return true; + } + time_internal::cctz::time_zone cz; + const bool b = time_internal::cctz::load_time_zone(std::string(name), &cz); + *tz = TimeZone(cz); + return b; +} + +// FixedTimeZone() +// +// Returns a TimeZone that is a fixed offset (seconds east) from UTC. +// Note: If the absolute value of the offset is greater than 24 hours +// you'll get UTC (i.e., no offset) instead. +inline TimeZone FixedTimeZone(int seconds) { + return TimeZone( + time_internal::cctz::fixed_time_zone(std::chrono::seconds(seconds))); +} + +// UTCTimeZone() +// +// Convenience method returning the UTC time zone. +inline TimeZone UTCTimeZone() { + return TimeZone(time_internal::cctz::utc_time_zone()); +} + +// LocalTimeZone() +// +// Convenience method returning the local time zone, or UTC if there is +// no configured local zone. Warning: Be wary of using LocalTimeZone(), +// and particularly so in a server process, as the zone configured for the +// local machine should be irrelevant. Prefer an explicit zone name. +inline TimeZone LocalTimeZone() { + return TimeZone(time_internal::cctz::local_time_zone()); +} + +// ToCivilSecond() +// ToCivilMinute() +// ToCivilHour() +// ToCivilDay() +// ToCivilMonth() +// ToCivilYear() +// +// Helpers for TimeZone::At(Time) to return particularly aligned civil times. +// +// Example: +// +// absl::Time t = ...; +// absl::TimeZone tz = ...; +// const auto cd = absl::ToCivilDay(t, tz); +inline CivilSecond ToCivilSecond(Time t, TimeZone tz) { + return tz.At(t).cs; // already a CivilSecond +} +inline CivilMinute ToCivilMinute(Time t, TimeZone tz) { + return CivilMinute(tz.At(t).cs); +} +inline CivilHour ToCivilHour(Time t, TimeZone tz) { + return CivilHour(tz.At(t).cs); +} +inline CivilDay ToCivilDay(Time t, TimeZone tz) { + return CivilDay(tz.At(t).cs); +} +inline CivilMonth ToCivilMonth(Time t, TimeZone tz) { + return CivilMonth(tz.At(t).cs); +} +inline CivilYear ToCivilYear(Time t, TimeZone tz) { + return CivilYear(tz.At(t).cs); +} + +// FromCivil() +// +// Helper for TimeZone::At(CivilSecond) that provides "order-preserving +// semantics." If the civil time maps to a unique time, that time is +// returned. If the civil time is repeated in the given time zone, the +// time using the pre-transition offset is returned. Otherwise, the +// civil time is skipped in the given time zone, and the transition time +// is returned. This means that for any two civil times, ct1 and ct2, +// (ct1 < ct2) => (FromCivil(ct1) <= FromCivil(ct2)), the equal case +// being when two non-existent civil times map to the same transition time. +// +// Note: Accepts civil times of any alignment. +inline Time FromCivil(CivilSecond ct, TimeZone tz) { + const auto ti = tz.At(ct); + if (ti.kind == TimeZone::TimeInfo::SKIPPED) return ti.trans; + return ti.pre; +} + +// TimeConversion +// +// An `absl::TimeConversion` represents the conversion of year, month, day, +// hour, minute, and second values (i.e., a civil time), in a particular +// `absl::TimeZone`, to a time instant (an absolute time), as returned by +// `absl::ConvertDateTime()`. Legacy version of `absl::TimeZone::TimeInfo`. +// +// Deprecated. Use `absl::TimeZone::TimeInfo`. +struct + TimeConversion { + Time pre; // time calculated using the pre-transition offset + Time trans; // when the civil-time discontinuity occurred + Time post; // time calculated using the post-transition offset + + enum Kind { + UNIQUE, // the civil time was singular (pre == trans == post) + SKIPPED, // the civil time did not exist + REPEATED, // the civil time was ambiguous + }; + Kind kind; + + bool normalized; // input values were outside their valid ranges +}; + +// ConvertDateTime() +// +// Legacy version of `absl::TimeZone::At(absl::CivilSecond)` that takes +// the civil time as six, separate values (YMDHMS). +// +// The input month, day, hour, minute, and second values can be outside +// of their valid ranges, in which case they will be "normalized" during +// the conversion. +// +// Example: +// +// // "October 32" normalizes to "November 1". +// absl::TimeConversion tc = +// absl::ConvertDateTime(2013, 10, 32, 8, 30, 0, lax); +// // tc.kind == TimeConversion::UNIQUE && tc.normalized == true +// // absl::ToCivilDay(tc.pre, tz).month() == 11 +// // absl::ToCivilDay(tc.pre, tz).day() == 1 +// +// Deprecated. Use `absl::TimeZone::At(CivilSecond)`. +TimeConversion ConvertDateTime(int64_t year, int mon, int day, int hour, + int min, int sec, TimeZone tz); + +// FromDateTime() +// +// A convenience wrapper for `absl::ConvertDateTime()` that simply returns +// the "pre" `absl::Time`. That is, the unique result, or the instant that +// is correct using the pre-transition offset (as if the transition never +// happened). +// +// Example: +// +// absl::Time t = absl::FromDateTime(2017, 9, 26, 9, 30, 0, lax); +// // t = 2017-09-26 09:30:00 -0700 +// +// Deprecated. Use `absl::FromCivil(CivilSecond, TimeZone)`. Note that the +// behavior of `FromCivil()` differs from `FromDateTime()` for skipped civil +// times. If you care about that see `absl::TimeZone::At(absl::CivilSecond)`. +inline Time FromDateTime(int64_t year, int mon, int day, int hour, + int min, int sec, TimeZone tz) { + return ConvertDateTime(year, mon, day, hour, min, sec, tz).pre; +} + +// FromTM() +// +// Converts the `tm_year`, `tm_mon`, `tm_mday`, `tm_hour`, `tm_min`, and +// `tm_sec` fields to an `absl::Time` using the given time zone. See ctime(3) +// for a description of the expected values of the tm fields. If the indicated +// time instant is not unique (see `absl::TimeZone::At(absl::CivilSecond)` +// above), the `tm_isdst` field is consulted to select the desired instant +// (`tm_isdst` > 0 means DST, `tm_isdst` == 0 means no DST, `tm_isdst` < 0 +// means use the post-transition offset). +Time FromTM(const struct tm& tm, TimeZone tz); + +// ToTM() +// +// Converts the given `absl::Time` to a struct tm using the given time zone. +// See ctime(3) for a description of the values of the tm fields. +struct tm ToTM(Time t, TimeZone tz); + +// RFC3339_full +// RFC3339_sec +// +// FormatTime()/ParseTime() format specifiers for RFC3339 date/time strings, +// with trailing zeros trimmed or with fractional seconds omitted altogether. +// +// Note that RFC3339_sec[] matches an ISO 8601 extended format for date and +// time with UTC offset. Also note the use of "%Y": RFC3339 mandates that +// years have exactly four digits, but we allow them to take their natural +// width. +ABSL_DLL extern const char + RFC3339_full[]; // %Y-%m-%dT%H:%M:%E*S%Ez +ABSL_DLL extern const char RFC3339_sec[]; // %Y-%m-%dT%H:%M:%S%Ez + +// RFC1123_full +// RFC1123_no_wday +// +// FormatTime()/ParseTime() format specifiers for RFC1123 date/time strings. +ABSL_DLL extern const char + RFC1123_full[]; // %a, %d %b %E4Y %H:%M:%S %z +ABSL_DLL extern const char + RFC1123_no_wday[]; // %d %b %E4Y %H:%M:%S %z + +// FormatTime() +// +// Formats the given `absl::Time` in the `absl::TimeZone` according to the +// provided format string. Uses strftime()-like formatting options, with +// the following extensions: +// +// - %Ez - RFC3339-compatible numeric UTC offset (+hh:mm or -hh:mm) +// - %E*z - Full-resolution numeric UTC offset (+hh:mm:ss or -hh:mm:ss) +// - %E#S - Seconds with # digits of fractional precision +// - %E*S - Seconds with full fractional precision (a literal '*') +// - %E#f - Fractional seconds with # digits of precision +// - %E*f - Fractional seconds with full precision (a literal '*') +// - %E4Y - Four-character years (-999 ... -001, 0000, 0001 ... 9999) +// +// Note that %E0S behaves like %S, and %E0f produces no characters. In +// contrast %E*f always produces at least one digit, which may be '0'. +// +// Note that %Y produces as many characters as it takes to fully render the +// year. A year outside of [-999:9999] when formatted with %E4Y will produce +// more than four characters, just like %Y. +// +// We recommend that format strings include the UTC offset (%z, %Ez, or %E*z) +// so that the result uniquely identifies a time instant. +// +// Example: +// +// absl::CivilSecond cs(2013, 1, 2, 3, 4, 5); +// absl::Time t = absl::FromCivil(cs, lax); +// std::string f = absl::FormatTime("%H:%M:%S", t, lax); // "03:04:05" +// f = absl::FormatTime("%H:%M:%E3S", t, lax); // "03:04:05.000" +// +// Note: If the given `absl::Time` is `absl::InfiniteFuture()`, the returned +// string will be exactly "infinite-future". If the given `absl::Time` is +// `absl::InfinitePast()`, the returned string will be exactly "infinite-past". +// In both cases the given format string and `absl::TimeZone` are ignored. +// +std::string FormatTime(absl::string_view format, Time t, TimeZone tz); + +// Convenience functions that format the given time using the RFC3339_full +// format. The first overload uses the provided TimeZone, while the second +// uses LocalTimeZone(). +std::string FormatTime(Time t, TimeZone tz); +std::string FormatTime(Time t); + +// Output stream operator. +inline std::ostream& operator<<(std::ostream& os, Time t) { + return os << FormatTime(t); +} + +// ParseTime() +// +// Parses an input string according to the provided format string and +// returns the corresponding `absl::Time`. Uses strftime()-like formatting +// options, with the same extensions as FormatTime(), but with the +// exceptions that %E#S is interpreted as %E*S, and %E#f as %E*f. %Ez +// and %E*z also accept the same inputs. +// +// %Y consumes as many numeric characters as it can, so the matching data +// should always be terminated with a non-numeric. %E4Y always consumes +// exactly four characters, including any sign. +// +// Unspecified fields are taken from the default date and time of ... +// +// "1970-01-01 00:00:00.0 +0000" +// +// For example, parsing a string of "15:45" (%H:%M) will return an absl::Time +// that represents "1970-01-01 15:45:00.0 +0000". +// +// Note that since ParseTime() returns time instants, it makes the most sense +// to parse fully-specified date/time strings that include a UTC offset (%z, +// %Ez, or %E*z). +// +// Note also that `absl::ParseTime()` only heeds the fields year, month, day, +// hour, minute, (fractional) second, and UTC offset. Other fields, like +// weekday (%a or %A), while parsed for syntactic validity, are ignored +// in the conversion. +// +// Date and time fields that are out-of-range will be treated as errors +// rather than normalizing them like `absl::CivilSecond` does. For example, +// it is an error to parse the date "Oct 32, 2013" because 32 is out of range. +// +// A leap second of ":60" is normalized to ":00" of the following minute +// with fractional seconds discarded. The following table shows how the +// given seconds and subseconds will be parsed: +// +// "59.x" -> 59.x // exact +// "60.x" -> 00.0 // normalized +// "00.x" -> 00.x // exact +// +// Errors are indicated by returning false and assigning an error message +// to the "err" out param if it is non-null. +// +// Note: If the input string is exactly "infinite-future", the returned +// `absl::Time` will be `absl::InfiniteFuture()` and `true` will be returned. +// If the input string is "infinite-past", the returned `absl::Time` will be +// `absl::InfinitePast()` and `true` will be returned. +// +bool ParseTime(absl::string_view format, absl::string_view input, Time* time, + std::string* err); + +// Like ParseTime() above, but if the format string does not contain a UTC +// offset specification (%z/%Ez/%E*z) then the input is interpreted in the +// given TimeZone. This means that the input, by itself, does not identify a +// unique instant. Being time-zone dependent, it also admits the possibility +// of ambiguity or non-existence, in which case the "pre" time (as defined +// by TimeZone::TimeInfo) is returned. For these reasons we recommend that +// all date/time strings include a UTC offset so they're context independent. +bool ParseTime(absl::string_view format, absl::string_view input, TimeZone tz, + Time* time, std::string* err); + +// ============================================================================ +// Implementation Details Follow +// ============================================================================ + +namespace time_internal { + +// Creates a Duration with a given representation. +// REQUIRES: hi,lo is a valid representation of a Duration as specified +// in time/duration.cc. +constexpr Duration MakeDuration(int64_t hi, uint32_t lo = 0) { + return Duration(hi, lo); +} + +constexpr Duration MakeDuration(int64_t hi, int64_t lo) { + return MakeDuration(hi, static_cast<uint32_t>(lo)); +} + +// Make a Duration value from a floating-point number, as long as that number +// is in the range [ 0 .. numeric_limits<int64_t>::max ), that is, as long as +// it's positive and can be converted to int64_t without risk of UB. +inline Duration MakePosDoubleDuration(double n) { + const int64_t int_secs = static_cast<int64_t>(n); + const uint32_t ticks = static_cast<uint32_t>( + (n - static_cast<double>(int_secs)) * kTicksPerSecond + 0.5); + return ticks < kTicksPerSecond + ? MakeDuration(int_secs, ticks) + : MakeDuration(int_secs + 1, ticks - kTicksPerSecond); +} + +// Creates a normalized Duration from an almost-normalized (sec,ticks) +// pair. sec may be positive or negative. ticks must be in the range +// -kTicksPerSecond < *ticks < kTicksPerSecond. If ticks is negative it +// will be normalized to a positive value in the resulting Duration. +constexpr Duration MakeNormalizedDuration(int64_t sec, int64_t ticks) { + return (ticks < 0) ? MakeDuration(sec - 1, ticks + kTicksPerSecond) + : MakeDuration(sec, ticks); +} + +// Provide access to the Duration representation. +constexpr int64_t GetRepHi(Duration d) { return d.rep_hi_; } +constexpr uint32_t GetRepLo(Duration d) { return d.rep_lo_; } + +// Returns true iff d is positive or negative infinity. +constexpr bool IsInfiniteDuration(Duration d) { return GetRepLo(d) == ~0U; } + +// Returns an infinite Duration with the opposite sign. +// REQUIRES: IsInfiniteDuration(d) +constexpr Duration OppositeInfinity(Duration d) { + return GetRepHi(d) < 0 + ? MakeDuration((std::numeric_limits<int64_t>::max)(), ~0U) + : MakeDuration((std::numeric_limits<int64_t>::min)(), ~0U); +} + +// Returns (-n)-1 (equivalently -(n+1)) without avoidable overflow. +constexpr int64_t NegateAndSubtractOne(int64_t n) { + // Note: Good compilers will optimize this expression to ~n when using + // a two's-complement representation (which is required for int64_t). + return (n < 0) ? -(n + 1) : (-n) - 1; +} + +// Map between a Time and a Duration since the Unix epoch. Note that these +// functions depend on the above mentioned choice of the Unix epoch for the +// Time representation (and both need to be Time friends). Without this +// knowledge, we would need to add-in/subtract-out UnixEpoch() respectively. +constexpr Time FromUnixDuration(Duration d) { return Time(d); } +constexpr Duration ToUnixDuration(Time t) { return t.rep_; } + +template <std::intmax_t N> +constexpr Duration FromInt64(int64_t v, std::ratio<1, N>) { + static_assert(0 < N && N <= 1000 * 1000 * 1000, "Unsupported ratio"); + // Subsecond ratios cannot overflow. + return MakeNormalizedDuration( + v / N, v % N * kTicksPerNanosecond * 1000 * 1000 * 1000 / N); +} +constexpr Duration FromInt64(int64_t v, std::ratio<60>) { + return (v <= (std::numeric_limits<int64_t>::max)() / 60 && + v >= (std::numeric_limits<int64_t>::min)() / 60) + ? MakeDuration(v * 60) + : v > 0 ? InfiniteDuration() : -InfiniteDuration(); +} +constexpr Duration FromInt64(int64_t v, std::ratio<3600>) { + return (v <= (std::numeric_limits<int64_t>::max)() / 3600 && + v >= (std::numeric_limits<int64_t>::min)() / 3600) + ? MakeDuration(v * 3600) + : v > 0 ? InfiniteDuration() : -InfiniteDuration(); +} + +// IsValidRep64<T>(0) is true if the expression `int64_t{std::declval<T>()}` is +// valid. That is, if a T can be assigned to an int64_t without narrowing. +template <typename T> +constexpr auto IsValidRep64(int) -> decltype(int64_t{std::declval<T>()} == 0) { + return true; +} +template <typename T> +constexpr auto IsValidRep64(char) -> bool { + return false; +} + +// Converts a std::chrono::duration to an absl::Duration. +template <typename Rep, typename Period> +constexpr Duration FromChrono(const std::chrono::duration<Rep, Period>& d) { + static_assert(IsValidRep64<Rep>(0), "duration::rep is invalid"); + return FromInt64(int64_t{d.count()}, Period{}); +} + +template <typename Ratio> +int64_t ToInt64(Duration d, Ratio) { + // Note: This may be used on MSVC, which may have a system_clock period of + // std::ratio<1, 10 * 1000 * 1000> + return ToInt64Seconds(d * Ratio::den / Ratio::num); +} +// Fastpath implementations for the 6 common duration units. +inline int64_t ToInt64(Duration d, std::nano) { + return ToInt64Nanoseconds(d); +} +inline int64_t ToInt64(Duration d, std::micro) { + return ToInt64Microseconds(d); +} +inline int64_t ToInt64(Duration d, std::milli) { + return ToInt64Milliseconds(d); +} +inline int64_t ToInt64(Duration d, std::ratio<1>) { + return ToInt64Seconds(d); +} +inline int64_t ToInt64(Duration d, std::ratio<60>) { + return ToInt64Minutes(d); +} +inline int64_t ToInt64(Duration d, std::ratio<3600>) { + return ToInt64Hours(d); +} + +// Converts an absl::Duration to a chrono duration of type T. +template <typename T> +T ToChronoDuration(Duration d) { + using Rep = typename T::rep; + using Period = typename T::period; + static_assert(IsValidRep64<Rep>(0), "duration::rep is invalid"); + if (time_internal::IsInfiniteDuration(d)) + return d < ZeroDuration() ? (T::min)() : (T::max)(); + const auto v = ToInt64(d, Period{}); + if (v > (std::numeric_limits<Rep>::max)()) return (T::max)(); + if (v < (std::numeric_limits<Rep>::min)()) return (T::min)(); + return T{v}; +} + +} // namespace time_internal + +constexpr Duration Nanoseconds(int64_t n) { + return time_internal::FromInt64(n, std::nano{}); +} +constexpr Duration Microseconds(int64_t n) { + return time_internal::FromInt64(n, std::micro{}); +} +constexpr Duration Milliseconds(int64_t n) { + return time_internal::FromInt64(n, std::milli{}); +} +constexpr Duration Seconds(int64_t n) { + return time_internal::FromInt64(n, std::ratio<1>{}); +} +constexpr Duration Minutes(int64_t n) { + return time_internal::FromInt64(n, std::ratio<60>{}); +} +constexpr Duration Hours(int64_t n) { + return time_internal::FromInt64(n, std::ratio<3600>{}); +} + +constexpr bool operator<(Duration lhs, Duration rhs) { + return time_internal::GetRepHi(lhs) != time_internal::GetRepHi(rhs) + ? time_internal::GetRepHi(lhs) < time_internal::GetRepHi(rhs) + : time_internal::GetRepHi(lhs) == + (std::numeric_limits<int64_t>::min)() + ? time_internal::GetRepLo(lhs) + 1 < + time_internal::GetRepLo(rhs) + 1 + : time_internal::GetRepLo(lhs) < + time_internal::GetRepLo(rhs); +} + +constexpr bool operator==(Duration lhs, Duration rhs) { + return time_internal::GetRepHi(lhs) == time_internal::GetRepHi(rhs) && + time_internal::GetRepLo(lhs) == time_internal::GetRepLo(rhs); +} + +constexpr Duration operator-(Duration d) { + // This is a little interesting because of the special cases. + // + // If rep_lo_ is zero, we have it easy; it's safe to negate rep_hi_, we're + // dealing with an integral number of seconds, and the only special case is + // the maximum negative finite duration, which can't be negated. + // + // Infinities stay infinite, and just change direction. + // + // Finally we're in the case where rep_lo_ is non-zero, and we can borrow + // a second's worth of ticks and avoid overflow (as negating int64_t-min + 1 + // is safe). + return time_internal::GetRepLo(d) == 0 + ? time_internal::GetRepHi(d) == + (std::numeric_limits<int64_t>::min)() + ? InfiniteDuration() + : time_internal::MakeDuration(-time_internal::GetRepHi(d)) + : time_internal::IsInfiniteDuration(d) + ? time_internal::OppositeInfinity(d) + : time_internal::MakeDuration( + time_internal::NegateAndSubtractOne( + time_internal::GetRepHi(d)), + time_internal::kTicksPerSecond - + time_internal::GetRepLo(d)); +} + +constexpr Duration InfiniteDuration() { + return time_internal::MakeDuration((std::numeric_limits<int64_t>::max)(), + ~0U); +} + +constexpr Duration FromChrono(const std::chrono::nanoseconds& d) { + return time_internal::FromChrono(d); +} +constexpr Duration FromChrono(const std::chrono::microseconds& d) { + return time_internal::FromChrono(d); +} +constexpr Duration FromChrono(const std::chrono::milliseconds& d) { + return time_internal::FromChrono(d); +} +constexpr Duration FromChrono(const std::chrono::seconds& d) { + return time_internal::FromChrono(d); +} +constexpr Duration FromChrono(const std::chrono::minutes& d) { + return time_internal::FromChrono(d); +} +constexpr Duration FromChrono(const std::chrono::hours& d) { + return time_internal::FromChrono(d); +} + +constexpr Time FromUnixNanos(int64_t ns) { + return time_internal::FromUnixDuration(Nanoseconds(ns)); +} + +constexpr Time FromUnixMicros(int64_t us) { + return time_internal::FromUnixDuration(Microseconds(us)); +} + +constexpr Time FromUnixMillis(int64_t ms) { + return time_internal::FromUnixDuration(Milliseconds(ms)); +} + +constexpr Time FromUnixSeconds(int64_t s) { + return time_internal::FromUnixDuration(Seconds(s)); +} + +constexpr Time FromTimeT(time_t t) { + return time_internal::FromUnixDuration(Seconds(t)); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TIME_TIME_H_ diff --git a/third_party/abseil_cpp/absl/time/time_benchmark.cc b/third_party/abseil_cpp/absl/time/time_benchmark.cc new file mode 100644 index 0000000000..99e6279984 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/time_benchmark.cc @@ -0,0 +1,316 @@ +// Copyright 2018 The Abseil Authors. +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/time.h" + +#if !defined(_WIN32) +#include <sys/time.h> +#endif // _WIN32 +#include <algorithm> +#include <cmath> +#include <cstddef> +#include <cstring> +#include <ctime> +#include <memory> +#include <string> + +#include "absl/time/clock.h" +#include "absl/time/internal/test_util.h" +#include "benchmark/benchmark.h" + +namespace { + +// +// Addition/Subtraction of a duration +// + +void BM_Time_Arithmetic(benchmark::State& state) { + const absl::Duration nano = absl::Nanoseconds(1); + const absl::Duration sec = absl::Seconds(1); + absl::Time t = absl::UnixEpoch(); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(t += nano); + benchmark::DoNotOptimize(t -= sec); + } +} +BENCHMARK(BM_Time_Arithmetic); + +// +// Time difference +// + +void BM_Time_Difference(benchmark::State& state) { + absl::Time start = absl::Now(); + absl::Time end = start + absl::Nanoseconds(1); + absl::Duration diff; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(diff += end - start); + } +} +BENCHMARK(BM_Time_Difference); + +// +// ToDateTime +// +// In each "ToDateTime" benchmark we switch between two instants +// separated by at least one transition in order to defeat any +// internal caching of previous results (e.g., see local_time_hint_). +// +// The "UTC" variants use UTC instead of the Google/local time zone. +// + +void BM_Time_ToDateTime_Absl(benchmark::State& state) { + const absl::TimeZone tz = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + absl::Time t = absl::FromUnixSeconds(1384569027); + absl::Time t2 = absl::FromUnixSeconds(1418962578); + while (state.KeepRunning()) { + std::swap(t, t2); + t += absl::Seconds(1); + benchmark::DoNotOptimize(t.In(tz)); + } +} +BENCHMARK(BM_Time_ToDateTime_Absl); + +void BM_Time_ToDateTime_Libc(benchmark::State& state) { + // No timezone support, so just use localtime. + time_t t = 1384569027; + time_t t2 = 1418962578; + while (state.KeepRunning()) { + std::swap(t, t2); + t += 1; + struct tm tm; +#if !defined(_WIN32) + benchmark::DoNotOptimize(localtime_r(&t, &tm)); +#else // _WIN32 + benchmark::DoNotOptimize(localtime_s(&tm, &t)); +#endif // _WIN32 + } +} +BENCHMARK(BM_Time_ToDateTime_Libc); + +void BM_Time_ToDateTimeUTC_Absl(benchmark::State& state) { + const absl::TimeZone tz = absl::UTCTimeZone(); + absl::Time t = absl::FromUnixSeconds(1384569027); + while (state.KeepRunning()) { + t += absl::Seconds(1); + benchmark::DoNotOptimize(t.In(tz)); + } +} +BENCHMARK(BM_Time_ToDateTimeUTC_Absl); + +void BM_Time_ToDateTimeUTC_Libc(benchmark::State& state) { + time_t t = 1384569027; + while (state.KeepRunning()) { + t += 1; + struct tm tm; +#if !defined(_WIN32) + benchmark::DoNotOptimize(gmtime_r(&t, &tm)); +#else // _WIN32 + benchmark::DoNotOptimize(gmtime_s(&tm, &t)); +#endif // _WIN32 + } +} +BENCHMARK(BM_Time_ToDateTimeUTC_Libc); + +// +// FromUnixMicros +// + +void BM_Time_FromUnixMicros(benchmark::State& state) { + int i = 0; + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::FromUnixMicros(i)); + ++i; + } +} +BENCHMARK(BM_Time_FromUnixMicros); + +void BM_Time_ToUnixNanos(benchmark::State& state) { + const absl::Time t = absl::UnixEpoch() + absl::Seconds(123); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(ToUnixNanos(t)); + } +} +BENCHMARK(BM_Time_ToUnixNanos); + +void BM_Time_ToUnixMicros(benchmark::State& state) { + const absl::Time t = absl::UnixEpoch() + absl::Seconds(123); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(ToUnixMicros(t)); + } +} +BENCHMARK(BM_Time_ToUnixMicros); + +void BM_Time_ToUnixMillis(benchmark::State& state) { + const absl::Time t = absl::UnixEpoch() + absl::Seconds(123); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(ToUnixMillis(t)); + } +} +BENCHMARK(BM_Time_ToUnixMillis); + +void BM_Time_ToUnixSeconds(benchmark::State& state) { + const absl::Time t = absl::UnixEpoch() + absl::Seconds(123); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToUnixSeconds(t)); + } +} +BENCHMARK(BM_Time_ToUnixSeconds); + +// +// FromCivil +// +// In each "FromCivil" benchmark we switch between two YMDhms values +// separated by at least one transition in order to defeat any internal +// caching of previous results (e.g., see time_local_hint_). +// +// The "UTC" variants use UTC instead of the Google/local time zone. +// The "Day0" variants require normalization of the day of month. +// + +void BM_Time_FromCivil_Absl(benchmark::State& state) { + const absl::TimeZone tz = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + int i = 0; + while (state.KeepRunning()) { + if ((i & 1) == 0) { + absl::FromCivil(absl::CivilSecond(2014, 12, 18, 20, 16, 18), tz); + } else { + absl::FromCivil(absl::CivilSecond(2013, 11, 15, 18, 30, 27), tz); + } + ++i; + } +} +BENCHMARK(BM_Time_FromCivil_Absl); + +void BM_Time_FromCivil_Libc(benchmark::State& state) { + // No timezone support, so just use localtime. + int i = 0; + while (state.KeepRunning()) { + struct tm tm; + if ((i & 1) == 0) { + tm.tm_year = 2014 - 1900; + tm.tm_mon = 12 - 1; + tm.tm_mday = 18; + tm.tm_hour = 20; + tm.tm_min = 16; + tm.tm_sec = 18; + } else { + tm.tm_year = 2013 - 1900; + tm.tm_mon = 11 - 1; + tm.tm_mday = 15; + tm.tm_hour = 18; + tm.tm_min = 30; + tm.tm_sec = 27; + } + tm.tm_isdst = -1; + mktime(&tm); + ++i; + } +} +BENCHMARK(BM_Time_FromCivil_Libc); + +void BM_Time_FromCivilUTC_Absl(benchmark::State& state) { + const absl::TimeZone tz = absl::UTCTimeZone(); + while (state.KeepRunning()) { + absl::FromCivil(absl::CivilSecond(2014, 12, 18, 20, 16, 18), tz); + } +} +BENCHMARK(BM_Time_FromCivilUTC_Absl); + +void BM_Time_FromCivilDay0_Absl(benchmark::State& state) { + const absl::TimeZone tz = + absl::time_internal::LoadTimeZone("America/Los_Angeles"); + int i = 0; + while (state.KeepRunning()) { + if ((i & 1) == 0) { + absl::FromCivil(absl::CivilSecond(2014, 12, 0, 20, 16, 18), tz); + } else { + absl::FromCivil(absl::CivilSecond(2013, 11, 0, 18, 30, 27), tz); + } + ++i; + } +} +BENCHMARK(BM_Time_FromCivilDay0_Absl); + +void BM_Time_FromCivilDay0_Libc(benchmark::State& state) { + // No timezone support, so just use localtime. + int i = 0; + while (state.KeepRunning()) { + struct tm tm; + if ((i & 1) == 0) { + tm.tm_year = 2014 - 1900; + tm.tm_mon = 12 - 1; + tm.tm_mday = 0; + tm.tm_hour = 20; + tm.tm_min = 16; + tm.tm_sec = 18; + } else { + tm.tm_year = 2013 - 1900; + tm.tm_mon = 11 - 1; + tm.tm_mday = 0; + tm.tm_hour = 18; + tm.tm_min = 30; + tm.tm_sec = 27; + } + tm.tm_isdst = -1; + mktime(&tm); + ++i; + } +} +BENCHMARK(BM_Time_FromCivilDay0_Libc); + +// +// To/FromTimespec +// + +void BM_Time_ToTimespec(benchmark::State& state) { + absl::Time now = absl::Now(); + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::ToTimespec(now)); + } +} +BENCHMARK(BM_Time_ToTimespec); + +void BM_Time_FromTimespec(benchmark::State& state) { + timespec ts = absl::ToTimespec(absl::Now()); + while (state.KeepRunning()) { + if (++ts.tv_nsec == 1000 * 1000 * 1000) { + ++ts.tv_sec; + ts.tv_nsec = 0; + } + benchmark::DoNotOptimize(absl::TimeFromTimespec(ts)); + } +} +BENCHMARK(BM_Time_FromTimespec); + +// +// Comparison with InfiniteFuture/Past +// + +void BM_Time_InfiniteFuture(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::InfiniteFuture()); + } +} +BENCHMARK(BM_Time_InfiniteFuture); + +void BM_Time_InfinitePast(benchmark::State& state) { + while (state.KeepRunning()) { + benchmark::DoNotOptimize(absl::InfinitePast()); + } +} +BENCHMARK(BM_Time_InfinitePast); + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/time_test.cc b/third_party/abseil_cpp/absl/time/time_test.cc new file mode 100644 index 0000000000..6f89672c66 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/time_test.cc @@ -0,0 +1,1274 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/time.h" + +#if defined(_MSC_VER) +#include <winsock2.h> // for timeval +#endif + +#include <chrono> // NOLINT(build/c++11) +#include <cstring> +#include <ctime> +#include <iomanip> +#include <limits> +#include <string> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/numeric/int128.h" +#include "absl/time/clock.h" +#include "absl/time/internal/test_util.h" + +namespace { + +#if defined(GTEST_USES_SIMPLE_RE) && GTEST_USES_SIMPLE_RE +const char kZoneAbbrRE[] = ".*"; // just punt +#else +const char kZoneAbbrRE[] = "[A-Za-z]{3,4}|[-+][0-9]{2}([0-9]{2})?"; +#endif + +// This helper is a macro so that failed expectations show up with the +// correct line numbers. +#define EXPECT_CIVIL_INFO(ci, y, m, d, h, min, s, off, isdst) \ + do { \ + EXPECT_EQ(y, ci.cs.year()); \ + EXPECT_EQ(m, ci.cs.month()); \ + EXPECT_EQ(d, ci.cs.day()); \ + EXPECT_EQ(h, ci.cs.hour()); \ + EXPECT_EQ(min, ci.cs.minute()); \ + EXPECT_EQ(s, ci.cs.second()); \ + EXPECT_EQ(off, ci.offset); \ + EXPECT_EQ(isdst, ci.is_dst); \ + EXPECT_THAT(ci.zone_abbr, testing::MatchesRegex(kZoneAbbrRE)); \ + } while (0) + +// A gMock matcher to match timespec values. Use this matcher like: +// timespec ts1, ts2; +// EXPECT_THAT(ts1, TimespecMatcher(ts2)); +MATCHER_P(TimespecMatcher, ts, "") { + if (ts.tv_sec == arg.tv_sec && ts.tv_nsec == arg.tv_nsec) + return true; + *result_listener << "expected: {" << ts.tv_sec << ", " << ts.tv_nsec << "} "; + *result_listener << "actual: {" << arg.tv_sec << ", " << arg.tv_nsec << "}"; + return false; +} + +// A gMock matcher to match timeval values. Use this matcher like: +// timeval tv1, tv2; +// EXPECT_THAT(tv1, TimevalMatcher(tv2)); +MATCHER_P(TimevalMatcher, tv, "") { + if (tv.tv_sec == arg.tv_sec && tv.tv_usec == arg.tv_usec) + return true; + *result_listener << "expected: {" << tv.tv_sec << ", " << tv.tv_usec << "} "; + *result_listener << "actual: {" << arg.tv_sec << ", " << arg.tv_usec << "}"; + return false; +} + +TEST(Time, ConstExpr) { + constexpr absl::Time t0 = absl::UnixEpoch(); + static_assert(t0 == absl::Time(), "UnixEpoch"); + constexpr absl::Time t1 = absl::InfiniteFuture(); + static_assert(t1 != absl::Time(), "InfiniteFuture"); + constexpr absl::Time t2 = absl::InfinitePast(); + static_assert(t2 != absl::Time(), "InfinitePast"); + constexpr absl::Time t3 = absl::FromUnixNanos(0); + static_assert(t3 == absl::Time(), "FromUnixNanos"); + constexpr absl::Time t4 = absl::FromUnixMicros(0); + static_assert(t4 == absl::Time(), "FromUnixMicros"); + constexpr absl::Time t5 = absl::FromUnixMillis(0); + static_assert(t5 == absl::Time(), "FromUnixMillis"); + constexpr absl::Time t6 = absl::FromUnixSeconds(0); + static_assert(t6 == absl::Time(), "FromUnixSeconds"); + constexpr absl::Time t7 = absl::FromTimeT(0); + static_assert(t7 == absl::Time(), "FromTimeT"); +} + +TEST(Time, ValueSemantics) { + absl::Time a; // Default construction + absl::Time b = a; // Copy construction + EXPECT_EQ(a, b); + absl::Time c(a); // Copy construction (again) + EXPECT_EQ(a, b); + EXPECT_EQ(a, c); + EXPECT_EQ(b, c); + b = c; // Assignment + EXPECT_EQ(a, b); + EXPECT_EQ(a, c); + EXPECT_EQ(b, c); +} + +TEST(Time, UnixEpoch) { + const auto ci = absl::UTCTimeZone().At(absl::UnixEpoch()); + EXPECT_EQ(absl::CivilSecond(1970, 1, 1, 0, 0, 0), ci.cs); + EXPECT_EQ(absl::ZeroDuration(), ci.subsecond); + EXPECT_EQ(absl::Weekday::thursday, absl::GetWeekday(ci.cs)); +} + +TEST(Time, Breakdown) { + absl::TimeZone tz = absl::time_internal::LoadTimeZone("America/New_York"); + absl::Time t = absl::UnixEpoch(); + + // The Unix epoch as seen in NYC. + auto ci = tz.At(t); + EXPECT_CIVIL_INFO(ci, 1969, 12, 31, 19, 0, 0, -18000, false); + EXPECT_EQ(absl::ZeroDuration(), ci.subsecond); + EXPECT_EQ(absl::Weekday::wednesday, absl::GetWeekday(ci.cs)); + + // Just before the epoch. + t -= absl::Nanoseconds(1); + ci = tz.At(t); + EXPECT_CIVIL_INFO(ci, 1969, 12, 31, 18, 59, 59, -18000, false); + EXPECT_EQ(absl::Nanoseconds(999999999), ci.subsecond); + EXPECT_EQ(absl::Weekday::wednesday, absl::GetWeekday(ci.cs)); + + // Some time later. + t += absl::Hours(24) * 2735; + t += absl::Hours(18) + absl::Minutes(30) + absl::Seconds(15) + + absl::Nanoseconds(9); + ci = tz.At(t); + EXPECT_CIVIL_INFO(ci, 1977, 6, 28, 14, 30, 15, -14400, true); + EXPECT_EQ(8, ci.subsecond / absl::Nanoseconds(1)); + EXPECT_EQ(absl::Weekday::tuesday, absl::GetWeekday(ci.cs)); +} + +TEST(Time, AdditiveOperators) { + const absl::Duration d = absl::Nanoseconds(1); + const absl::Time t0; + const absl::Time t1 = t0 + d; + + EXPECT_EQ(d, t1 - t0); + EXPECT_EQ(-d, t0 - t1); + EXPECT_EQ(t0, t1 - d); + + absl::Time t(t0); + EXPECT_EQ(t0, t); + t += d; + EXPECT_EQ(t0 + d, t); + EXPECT_EQ(d, t - t0); + t -= d; + EXPECT_EQ(t0, t); + + // Tests overflow between subseconds and seconds. + t = absl::UnixEpoch(); + t += absl::Milliseconds(500); + EXPECT_EQ(absl::UnixEpoch() + absl::Milliseconds(500), t); + t += absl::Milliseconds(600); + EXPECT_EQ(absl::UnixEpoch() + absl::Milliseconds(1100), t); + t -= absl::Milliseconds(600); + EXPECT_EQ(absl::UnixEpoch() + absl::Milliseconds(500), t); + t -= absl::Milliseconds(500); + EXPECT_EQ(absl::UnixEpoch(), t); +} + +TEST(Time, RelationalOperators) { + constexpr absl::Time t1 = absl::FromUnixNanos(0); + constexpr absl::Time t2 = absl::FromUnixNanos(1); + constexpr absl::Time t3 = absl::FromUnixNanos(2); + + static_assert(absl::Time() == t1, ""); + static_assert(t1 == t1, ""); + static_assert(t2 == t2, ""); + static_assert(t3 == t3, ""); + + static_assert(t1 < t2, ""); + static_assert(t2 < t3, ""); + static_assert(t1 < t3, ""); + + static_assert(t1 <= t1, ""); + static_assert(t1 <= t2, ""); + static_assert(t2 <= t2, ""); + static_assert(t2 <= t3, ""); + static_assert(t3 <= t3, ""); + static_assert(t1 <= t3, ""); + + static_assert(t2 > t1, ""); + static_assert(t3 > t2, ""); + static_assert(t3 > t1, ""); + + static_assert(t2 >= t2, ""); + static_assert(t2 >= t1, ""); + static_assert(t3 >= t3, ""); + static_assert(t3 >= t2, ""); + static_assert(t1 >= t1, ""); + static_assert(t3 >= t1, ""); +} + +TEST(Time, Infinity) { + constexpr absl::Time ifuture = absl::InfiniteFuture(); + constexpr absl::Time ipast = absl::InfinitePast(); + + static_assert(ifuture == ifuture, ""); + static_assert(ipast == ipast, ""); + static_assert(ipast < ifuture, ""); + static_assert(ifuture > ipast, ""); + + // Arithmetic saturates + EXPECT_EQ(ifuture, ifuture + absl::Seconds(1)); + EXPECT_EQ(ifuture, ifuture - absl::Seconds(1)); + EXPECT_EQ(ipast, ipast + absl::Seconds(1)); + EXPECT_EQ(ipast, ipast - absl::Seconds(1)); + + EXPECT_EQ(absl::InfiniteDuration(), ifuture - ifuture); + EXPECT_EQ(absl::InfiniteDuration(), ifuture - ipast); + EXPECT_EQ(-absl::InfiniteDuration(), ipast - ifuture); + EXPECT_EQ(-absl::InfiniteDuration(), ipast - ipast); + + constexpr absl::Time t = absl::UnixEpoch(); // Any finite time. + static_assert(t < ifuture, ""); + static_assert(t > ipast, ""); +} + +TEST(Time, FloorConversion) { +#define TEST_FLOOR_CONVERSION(TO, FROM) \ + EXPECT_EQ(1, TO(FROM(1001))); \ + EXPECT_EQ(1, TO(FROM(1000))); \ + EXPECT_EQ(0, TO(FROM(999))); \ + EXPECT_EQ(0, TO(FROM(1))); \ + EXPECT_EQ(0, TO(FROM(0))); \ + EXPECT_EQ(-1, TO(FROM(-1))); \ + EXPECT_EQ(-1, TO(FROM(-999))); \ + EXPECT_EQ(-1, TO(FROM(-1000))); \ + EXPECT_EQ(-2, TO(FROM(-1001))); + + TEST_FLOOR_CONVERSION(absl::ToUnixMicros, absl::FromUnixNanos); + TEST_FLOOR_CONVERSION(absl::ToUnixMillis, absl::FromUnixMicros); + TEST_FLOOR_CONVERSION(absl::ToUnixSeconds, absl::FromUnixMillis); + TEST_FLOOR_CONVERSION(absl::ToTimeT, absl::FromUnixMillis); + +#undef TEST_FLOOR_CONVERSION + + // Tests ToUnixNanos. + EXPECT_EQ(1, absl::ToUnixNanos(absl::UnixEpoch() + absl::Nanoseconds(3) / 2)); + EXPECT_EQ(1, absl::ToUnixNanos(absl::UnixEpoch() + absl::Nanoseconds(1))); + EXPECT_EQ(0, absl::ToUnixNanos(absl::UnixEpoch() + absl::Nanoseconds(1) / 2)); + EXPECT_EQ(0, absl::ToUnixNanos(absl::UnixEpoch() + absl::Nanoseconds(0))); + EXPECT_EQ(-1, + absl::ToUnixNanos(absl::UnixEpoch() - absl::Nanoseconds(1) / 2)); + EXPECT_EQ(-1, absl::ToUnixNanos(absl::UnixEpoch() - absl::Nanoseconds(1))); + EXPECT_EQ(-2, + absl::ToUnixNanos(absl::UnixEpoch() - absl::Nanoseconds(3) / 2)); + + // Tests ToUniversal, which uses a different epoch than the tests above. + EXPECT_EQ(1, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(101))); + EXPECT_EQ(1, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(100))); + EXPECT_EQ(0, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(99))); + EXPECT_EQ(0, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(1))); + EXPECT_EQ(0, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(0))); + EXPECT_EQ(-1, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(-1))); + EXPECT_EQ(-1, + absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(-99))); + EXPECT_EQ( + -1, absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(-100))); + EXPECT_EQ( + -2, absl::ToUniversal(absl::UniversalEpoch() + absl::Nanoseconds(-101))); + + // Tests ToTimespec()/TimeFromTimespec() + const struct { + absl::Time t; + timespec ts; + } to_ts[] = { + {absl::FromUnixSeconds(1) + absl::Nanoseconds(1), {1, 1}}, + {absl::FromUnixSeconds(1) + absl::Nanoseconds(1) / 2, {1, 0}}, + {absl::FromUnixSeconds(1) + absl::Nanoseconds(0), {1, 0}}, + {absl::FromUnixSeconds(0) + absl::Nanoseconds(0), {0, 0}}, + {absl::FromUnixSeconds(0) - absl::Nanoseconds(1) / 2, {-1, 999999999}}, + {absl::FromUnixSeconds(0) - absl::Nanoseconds(1), {-1, 999999999}}, + {absl::FromUnixSeconds(-1) + absl::Nanoseconds(1), {-1, 1}}, + {absl::FromUnixSeconds(-1) + absl::Nanoseconds(1) / 2, {-1, 0}}, + {absl::FromUnixSeconds(-1) + absl::Nanoseconds(0), {-1, 0}}, + {absl::FromUnixSeconds(-1) - absl::Nanoseconds(1) / 2, {-2, 999999999}}, + }; + for (const auto& test : to_ts) { + EXPECT_THAT(absl::ToTimespec(test.t), TimespecMatcher(test.ts)); + } + const struct { + timespec ts; + absl::Time t; + } from_ts[] = { + {{1, 1}, absl::FromUnixSeconds(1) + absl::Nanoseconds(1)}, + {{1, 0}, absl::FromUnixSeconds(1) + absl::Nanoseconds(0)}, + {{0, 0}, absl::FromUnixSeconds(0) + absl::Nanoseconds(0)}, + {{0, -1}, absl::FromUnixSeconds(0) - absl::Nanoseconds(1)}, + {{-1, 999999999}, absl::FromUnixSeconds(0) - absl::Nanoseconds(1)}, + {{-1, 1}, absl::FromUnixSeconds(-1) + absl::Nanoseconds(1)}, + {{-1, 0}, absl::FromUnixSeconds(-1) + absl::Nanoseconds(0)}, + {{-1, -1}, absl::FromUnixSeconds(-1) - absl::Nanoseconds(1)}, + {{-2, 999999999}, absl::FromUnixSeconds(-1) - absl::Nanoseconds(1)}, + }; + for (const auto& test : from_ts) { + EXPECT_EQ(test.t, absl::TimeFromTimespec(test.ts)); + } + + // Tests ToTimeval()/TimeFromTimeval() (same as timespec above) + const struct { + absl::Time t; + timeval tv; + } to_tv[] = { + {absl::FromUnixSeconds(1) + absl::Microseconds(1), {1, 1}}, + {absl::FromUnixSeconds(1) + absl::Microseconds(1) / 2, {1, 0}}, + {absl::FromUnixSeconds(1) + absl::Microseconds(0), {1, 0}}, + {absl::FromUnixSeconds(0) + absl::Microseconds(0), {0, 0}}, + {absl::FromUnixSeconds(0) - absl::Microseconds(1) / 2, {-1, 999999}}, + {absl::FromUnixSeconds(0) - absl::Microseconds(1), {-1, 999999}}, + {absl::FromUnixSeconds(-1) + absl::Microseconds(1), {-1, 1}}, + {absl::FromUnixSeconds(-1) + absl::Microseconds(1) / 2, {-1, 0}}, + {absl::FromUnixSeconds(-1) + absl::Microseconds(0), {-1, 0}}, + {absl::FromUnixSeconds(-1) - absl::Microseconds(1) / 2, {-2, 999999}}, + }; + for (const auto& test : to_tv) { + EXPECT_THAT(ToTimeval(test.t), TimevalMatcher(test.tv)); + } + const struct { + timeval tv; + absl::Time t; + } from_tv[] = { + {{1, 1}, absl::FromUnixSeconds(1) + absl::Microseconds(1)}, + {{1, 0}, absl::FromUnixSeconds(1) + absl::Microseconds(0)}, + {{0, 0}, absl::FromUnixSeconds(0) + absl::Microseconds(0)}, + {{0, -1}, absl::FromUnixSeconds(0) - absl::Microseconds(1)}, + {{-1, 999999}, absl::FromUnixSeconds(0) - absl::Microseconds(1)}, + {{-1, 1}, absl::FromUnixSeconds(-1) + absl::Microseconds(1)}, + {{-1, 0}, absl::FromUnixSeconds(-1) + absl::Microseconds(0)}, + {{-1, -1}, absl::FromUnixSeconds(-1) - absl::Microseconds(1)}, + {{-2, 999999}, absl::FromUnixSeconds(-1) - absl::Microseconds(1)}, + }; + for (const auto& test : from_tv) { + EXPECT_EQ(test.t, absl::TimeFromTimeval(test.tv)); + } + + // Tests flooring near negative infinity. + const int64_t min_plus_1 = std::numeric_limits<int64_t>::min() + 1; + EXPECT_EQ(min_plus_1, absl::ToUnixSeconds(absl::FromUnixSeconds(min_plus_1))); + EXPECT_EQ(std::numeric_limits<int64_t>::min(), + absl::ToUnixSeconds( + absl::FromUnixSeconds(min_plus_1) - absl::Nanoseconds(1) / 2)); + + // Tests flooring near positive infinity. + EXPECT_EQ(std::numeric_limits<int64_t>::max(), + absl::ToUnixSeconds(absl::FromUnixSeconds( + std::numeric_limits<int64_t>::max()) + absl::Nanoseconds(1) / 2)); + EXPECT_EQ(std::numeric_limits<int64_t>::max(), + absl::ToUnixSeconds( + absl::FromUnixSeconds(std::numeric_limits<int64_t>::max()))); + EXPECT_EQ(std::numeric_limits<int64_t>::max() - 1, + absl::ToUnixSeconds(absl::FromUnixSeconds( + std::numeric_limits<int64_t>::max()) - absl::Nanoseconds(1) / 2)); +} + +TEST(Time, RoundtripConversion) { +#define TEST_CONVERSION_ROUND_TRIP(SOURCE, FROM, TO, MATCHER) \ + EXPECT_THAT(TO(FROM(SOURCE)), MATCHER(SOURCE)) + + // FromUnixNanos() and ToUnixNanos() + int64_t now_ns = absl::GetCurrentTimeNanos(); + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromUnixNanos, absl::ToUnixNanos, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromUnixNanos, absl::ToUnixNanos, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromUnixNanos, absl::ToUnixNanos, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(now_ns, absl::FromUnixNanos, absl::ToUnixNanos, + testing::Eq) + << now_ns; + + // FromUnixMicros() and ToUnixMicros() + int64_t now_us = absl::GetCurrentTimeNanos() / 1000; + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromUnixMicros, absl::ToUnixMicros, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromUnixMicros, absl::ToUnixMicros, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromUnixMicros, absl::ToUnixMicros, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(now_us, absl::FromUnixMicros, absl::ToUnixMicros, + testing::Eq) + << now_us; + + // FromUnixMillis() and ToUnixMillis() + int64_t now_ms = absl::GetCurrentTimeNanos() / 1000000; + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromUnixMillis, absl::ToUnixMillis, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromUnixMillis, absl::ToUnixMillis, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromUnixMillis, absl::ToUnixMillis, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(now_ms, absl::FromUnixMillis, absl::ToUnixMillis, + testing::Eq) + << now_ms; + + // FromUnixSeconds() and ToUnixSeconds() + int64_t now_s = std::time(nullptr); + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromUnixSeconds, absl::ToUnixSeconds, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromUnixSeconds, absl::ToUnixSeconds, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromUnixSeconds, absl::ToUnixSeconds, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(now_s, absl::FromUnixSeconds, absl::ToUnixSeconds, + testing::Eq) + << now_s; + + // FromTimeT() and ToTimeT() + time_t now_time_t = std::time(nullptr); + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromTimeT, absl::ToTimeT, testing::Eq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromTimeT, absl::ToTimeT, testing::Eq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromTimeT, absl::ToTimeT, testing::Eq); + TEST_CONVERSION_ROUND_TRIP(now_time_t, absl::FromTimeT, absl::ToTimeT, + testing::Eq) + << now_time_t; + + // TimeFromTimeval() and ToTimeval() + timeval tv; + tv.tv_sec = -1; + tv.tv_usec = 0; + TEST_CONVERSION_ROUND_TRIP(tv, absl::TimeFromTimeval, absl::ToTimeval, + TimevalMatcher); + tv.tv_sec = -1; + tv.tv_usec = 999999; + TEST_CONVERSION_ROUND_TRIP(tv, absl::TimeFromTimeval, absl::ToTimeval, + TimevalMatcher); + tv.tv_sec = 0; + tv.tv_usec = 0; + TEST_CONVERSION_ROUND_TRIP(tv, absl::TimeFromTimeval, absl::ToTimeval, + TimevalMatcher); + tv.tv_sec = 0; + tv.tv_usec = 1; + TEST_CONVERSION_ROUND_TRIP(tv, absl::TimeFromTimeval, absl::ToTimeval, + TimevalMatcher); + tv.tv_sec = 1; + tv.tv_usec = 0; + TEST_CONVERSION_ROUND_TRIP(tv, absl::TimeFromTimeval, absl::ToTimeval, + TimevalMatcher); + + // TimeFromTimespec() and ToTimespec() + timespec ts; + ts.tv_sec = -1; + ts.tv_nsec = 0; + TEST_CONVERSION_ROUND_TRIP(ts, absl::TimeFromTimespec, absl::ToTimespec, + TimespecMatcher); + ts.tv_sec = -1; + ts.tv_nsec = 999999999; + TEST_CONVERSION_ROUND_TRIP(ts, absl::TimeFromTimespec, absl::ToTimespec, + TimespecMatcher); + ts.tv_sec = 0; + ts.tv_nsec = 0; + TEST_CONVERSION_ROUND_TRIP(ts, absl::TimeFromTimespec, absl::ToTimespec, + TimespecMatcher); + ts.tv_sec = 0; + ts.tv_nsec = 1; + TEST_CONVERSION_ROUND_TRIP(ts, absl::TimeFromTimespec, absl::ToTimespec, + TimespecMatcher); + ts.tv_sec = 1; + ts.tv_nsec = 0; + TEST_CONVERSION_ROUND_TRIP(ts, absl::TimeFromTimespec, absl::ToTimespec, + TimespecMatcher); + + // FromUDate() and ToUDate() + double now_ud = absl::GetCurrentTimeNanos() / 1000000; + TEST_CONVERSION_ROUND_TRIP(-1.5, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(-0.5, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(0.5, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(1.5, absl::FromUDate, absl::ToUDate, + testing::DoubleEq); + TEST_CONVERSION_ROUND_TRIP(now_ud, absl::FromUDate, absl::ToUDate, + testing::DoubleEq) + << std::fixed << std::setprecision(17) << now_ud; + + // FromUniversal() and ToUniversal() + int64_t now_uni = ((719162LL * (24 * 60 * 60)) * (1000 * 1000 * 10)) + + (absl::GetCurrentTimeNanos() / 100); + TEST_CONVERSION_ROUND_TRIP(-1, absl::FromUniversal, absl::ToUniversal, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(0, absl::FromUniversal, absl::ToUniversal, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(1, absl::FromUniversal, absl::ToUniversal, + testing::Eq); + TEST_CONVERSION_ROUND_TRIP(now_uni, absl::FromUniversal, absl::ToUniversal, + testing::Eq) + << now_uni; + +#undef TEST_CONVERSION_ROUND_TRIP +} + +template <typename Duration> +std::chrono::system_clock::time_point MakeChronoUnixTime(const Duration& d) { + return std::chrono::system_clock::from_time_t(0) + d; +} + +TEST(Time, FromChrono) { + EXPECT_EQ(absl::FromTimeT(-1), + absl::FromChrono(std::chrono::system_clock::from_time_t(-1))); + EXPECT_EQ(absl::FromTimeT(0), + absl::FromChrono(std::chrono::system_clock::from_time_t(0))); + EXPECT_EQ(absl::FromTimeT(1), + absl::FromChrono(std::chrono::system_clock::from_time_t(1))); + + EXPECT_EQ( + absl::FromUnixMillis(-1), + absl::FromChrono(MakeChronoUnixTime(std::chrono::milliseconds(-1)))); + EXPECT_EQ(absl::FromUnixMillis(0), + absl::FromChrono(MakeChronoUnixTime(std::chrono::milliseconds(0)))); + EXPECT_EQ(absl::FromUnixMillis(1), + absl::FromChrono(MakeChronoUnixTime(std::chrono::milliseconds(1)))); + + // Chrono doesn't define exactly its range and precision (neither does + // absl::Time), so let's simply test +/- ~100 years to make sure things work. + const auto century_sec = 60 * 60 * 24 * 365 * int64_t{100}; + const auto century = std::chrono::seconds(century_sec); + const auto chrono_future = MakeChronoUnixTime(century); + const auto chrono_past = MakeChronoUnixTime(-century); + EXPECT_EQ(absl::FromUnixSeconds(century_sec), + absl::FromChrono(chrono_future)); + EXPECT_EQ(absl::FromUnixSeconds(-century_sec), absl::FromChrono(chrono_past)); + + // Roundtrip them both back to chrono. + EXPECT_EQ(chrono_future, + absl::ToChronoTime(absl::FromUnixSeconds(century_sec))); + EXPECT_EQ(chrono_past, + absl::ToChronoTime(absl::FromUnixSeconds(-century_sec))); +} + +TEST(Time, ToChronoTime) { + EXPECT_EQ(std::chrono::system_clock::from_time_t(-1), + absl::ToChronoTime(absl::FromTimeT(-1))); + EXPECT_EQ(std::chrono::system_clock::from_time_t(0), + absl::ToChronoTime(absl::FromTimeT(0))); + EXPECT_EQ(std::chrono::system_clock::from_time_t(1), + absl::ToChronoTime(absl::FromTimeT(1))); + + EXPECT_EQ(MakeChronoUnixTime(std::chrono::milliseconds(-1)), + absl::ToChronoTime(absl::FromUnixMillis(-1))); + EXPECT_EQ(MakeChronoUnixTime(std::chrono::milliseconds(0)), + absl::ToChronoTime(absl::FromUnixMillis(0))); + EXPECT_EQ(MakeChronoUnixTime(std::chrono::milliseconds(1)), + absl::ToChronoTime(absl::FromUnixMillis(1))); + + // Time before the Unix epoch should floor, not trunc. + const auto tick = absl::Nanoseconds(1) / 4; + EXPECT_EQ(std::chrono::system_clock::from_time_t(0) - + std::chrono::system_clock::duration(1), + absl::ToChronoTime(absl::UnixEpoch() - tick)); +} + +// Check that absl::int128 works as a std::chrono::duration representation. +TEST(Time, Chrono128) { + // Define a std::chrono::time_point type whose time[sic]_since_epoch() is + // a signed 128-bit count of attoseconds. This has a range and resolution + // (currently) beyond those of absl::Time, and undoubtedly also beyond those + // of std::chrono::system_clock::time_point. + // + // Note: The to/from-chrono support should probably be updated to handle + // such wide representations. + using Timestamp = + std::chrono::time_point<std::chrono::system_clock, + std::chrono::duration<absl::int128, std::atto>>; + + // Expect that we can round-trip the std::chrono::system_clock::time_point + // extremes through both absl::Time and Timestamp, and that Timestamp can + // handle the (current) absl::Time extremes. + // + // Note: We should use std::chrono::floor() instead of time_point_cast(), + // but floor() is only available since c++17. + for (const auto tp : {std::chrono::system_clock::time_point::min(), + std::chrono::system_clock::time_point::max()}) { + EXPECT_EQ(tp, absl::ToChronoTime(absl::FromChrono(tp))); + EXPECT_EQ(tp, std::chrono::time_point_cast< + std::chrono::system_clock::time_point::duration>( + std::chrono::time_point_cast<Timestamp::duration>(tp))); + } + Timestamp::duration::rep v = std::numeric_limits<int64_t>::min(); + v *= Timestamp::duration::period::den; + auto ts = Timestamp(Timestamp::duration(v)); + ts += std::chrono::duration<int64_t, std::atto>(0); + EXPECT_EQ(std::numeric_limits<int64_t>::min(), + ts.time_since_epoch().count() / Timestamp::duration::period::den); + EXPECT_EQ(0, + ts.time_since_epoch().count() % Timestamp::duration::period::den); + v = std::numeric_limits<int64_t>::max(); + v *= Timestamp::duration::period::den; + ts = Timestamp(Timestamp::duration(v)); + ts += std::chrono::duration<int64_t, std::atto>(999999999750000000); + EXPECT_EQ(std::numeric_limits<int64_t>::max(), + ts.time_since_epoch().count() / Timestamp::duration::period::den); + EXPECT_EQ(999999999750000000, + ts.time_since_epoch().count() % Timestamp::duration::period::den); +} + +TEST(Time, TimeZoneAt) { + const absl::TimeZone nyc = + absl::time_internal::LoadTimeZone("America/New_York"); + const std::string fmt = "%a, %e %b %Y %H:%M:%S %z (%Z)"; + + // A non-transition where the civil time is unique. + absl::CivilSecond nov01(2013, 11, 1, 8, 30, 0); + const auto nov01_ci = nyc.At(nov01); + EXPECT_EQ(absl::TimeZone::TimeInfo::UNIQUE, nov01_ci.kind); + EXPECT_EQ("Fri, 1 Nov 2013 08:30:00 -0400 (EDT)", + absl::FormatTime(fmt, nov01_ci.pre, nyc)); + EXPECT_EQ(nov01_ci.pre, nov01_ci.trans); + EXPECT_EQ(nov01_ci.pre, nov01_ci.post); + EXPECT_EQ(nov01_ci.pre, absl::FromCivil(nov01, nyc)); + + // A Spring DST transition, when there is a gap in civil time + // and we prefer the later of the possible interpretations of a + // non-existent time. + absl::CivilSecond mar13(2011, 3, 13, 2, 15, 0); + const auto mar_ci = nyc.At(mar13); + EXPECT_EQ(absl::TimeZone::TimeInfo::SKIPPED, mar_ci.kind); + EXPECT_EQ("Sun, 13 Mar 2011 03:15:00 -0400 (EDT)", + absl::FormatTime(fmt, mar_ci.pre, nyc)); + EXPECT_EQ("Sun, 13 Mar 2011 03:00:00 -0400 (EDT)", + absl::FormatTime(fmt, mar_ci.trans, nyc)); + EXPECT_EQ("Sun, 13 Mar 2011 01:15:00 -0500 (EST)", + absl::FormatTime(fmt, mar_ci.post, nyc)); + EXPECT_EQ(mar_ci.trans, absl::FromCivil(mar13, nyc)); + + // A Fall DST transition, when civil times are repeated and + // we prefer the earlier of the possible interpretations of an + // ambiguous time. + absl::CivilSecond nov06(2011, 11, 6, 1, 15, 0); + const auto nov06_ci = nyc.At(nov06); + EXPECT_EQ(absl::TimeZone::TimeInfo::REPEATED, nov06_ci.kind); + EXPECT_EQ("Sun, 6 Nov 2011 01:15:00 -0400 (EDT)", + absl::FormatTime(fmt, nov06_ci.pre, nyc)); + EXPECT_EQ("Sun, 6 Nov 2011 01:00:00 -0500 (EST)", + absl::FormatTime(fmt, nov06_ci.trans, nyc)); + EXPECT_EQ("Sun, 6 Nov 2011 01:15:00 -0500 (EST)", + absl::FormatTime(fmt, nov06_ci.post, nyc)); + EXPECT_EQ(nov06_ci.pre, absl::FromCivil(nov06, nyc)); + + // Check that (time_t) -1 is handled correctly. + absl::CivilSecond minus1(1969, 12, 31, 18, 59, 59); + const auto minus1_cl = nyc.At(minus1); + EXPECT_EQ(absl::TimeZone::TimeInfo::UNIQUE, minus1_cl.kind); + EXPECT_EQ(-1, absl::ToTimeT(minus1_cl.pre)); + EXPECT_EQ("Wed, 31 Dec 1969 18:59:59 -0500 (EST)", + absl::FormatTime(fmt, minus1_cl.pre, nyc)); + EXPECT_EQ("Wed, 31 Dec 1969 23:59:59 +0000 (UTC)", + absl::FormatTime(fmt, minus1_cl.pre, absl::UTCTimeZone())); +} + +// FromCivil(CivilSecond(year, mon, day, hour, min, sec), UTCTimeZone()) +// has a specialized fastpath implementation, which we exercise here. +TEST(Time, FromCivilUTC) { + const absl::TimeZone utc = absl::UTCTimeZone(); + const std::string fmt = "%a, %e %b %Y %H:%M:%S %z (%Z)"; + const int kMax = std::numeric_limits<int>::max(); + const int kMin = std::numeric_limits<int>::min(); + absl::Time t; + + // 292091940881 is the last positive year to use the fastpath. + t = absl::FromCivil( + absl::CivilSecond(292091940881, kMax, kMax, kMax, kMax, kMax), utc); + EXPECT_EQ("Fri, 25 Nov 292277026596 12:21:07 +0000 (UTC)", + absl::FormatTime(fmt, t, utc)); + t = absl::FromCivil( + absl::CivilSecond(292091940882, kMax, kMax, kMax, kMax, kMax), utc); + EXPECT_EQ("infinite-future", absl::FormatTime(fmt, t, utc)); // no overflow + + // -292091936940 is the last negative year to use the fastpath. + t = absl::FromCivil( + absl::CivilSecond(-292091936940, kMin, kMin, kMin, kMin, kMin), utc); + EXPECT_EQ("Fri, 1 Nov -292277022657 10:37:52 +0000 (UTC)", + absl::FormatTime(fmt, t, utc)); + t = absl::FromCivil( + absl::CivilSecond(-292091936941, kMin, kMin, kMin, kMin, kMin), utc); + EXPECT_EQ("infinite-past", absl::FormatTime(fmt, t, utc)); // no underflow + + // Check that we're counting leap years correctly. + t = absl::FromCivil(absl::CivilSecond(1900, 2, 28, 23, 59, 59), utc); + EXPECT_EQ("Wed, 28 Feb 1900 23:59:59 +0000 (UTC)", + absl::FormatTime(fmt, t, utc)); + t = absl::FromCivil(absl::CivilSecond(1900, 3, 1, 0, 0, 0), utc); + EXPECT_EQ("Thu, 1 Mar 1900 00:00:00 +0000 (UTC)", + absl::FormatTime(fmt, t, utc)); + t = absl::FromCivil(absl::CivilSecond(2000, 2, 29, 23, 59, 59), utc); + EXPECT_EQ("Tue, 29 Feb 2000 23:59:59 +0000 (UTC)", + absl::FormatTime(fmt, t, utc)); + t = absl::FromCivil(absl::CivilSecond(2000, 3, 1, 0, 0, 0), utc); + EXPECT_EQ("Wed, 1 Mar 2000 00:00:00 +0000 (UTC)", + absl::FormatTime(fmt, t, utc)); +} + +TEST(Time, ToTM) { + const absl::TimeZone utc = absl::UTCTimeZone(); + + // Compares the results of ToTM() to gmtime_r() for lots of times over the + // course of a few days. + const absl::Time start = + absl::FromCivil(absl::CivilSecond(2014, 1, 2, 3, 4, 5), utc); + const absl::Time end = + absl::FromCivil(absl::CivilSecond(2014, 1, 5, 3, 4, 5), utc); + for (absl::Time t = start; t < end; t += absl::Seconds(30)) { + const struct tm tm_bt = ToTM(t, utc); + const time_t tt = absl::ToTimeT(t); + struct tm tm_lc; +#ifdef _WIN32 + gmtime_s(&tm_lc, &tt); +#else + gmtime_r(&tt, &tm_lc); +#endif + EXPECT_EQ(tm_lc.tm_year, tm_bt.tm_year); + EXPECT_EQ(tm_lc.tm_mon, tm_bt.tm_mon); + EXPECT_EQ(tm_lc.tm_mday, tm_bt.tm_mday); + EXPECT_EQ(tm_lc.tm_hour, tm_bt.tm_hour); + EXPECT_EQ(tm_lc.tm_min, tm_bt.tm_min); + EXPECT_EQ(tm_lc.tm_sec, tm_bt.tm_sec); + EXPECT_EQ(tm_lc.tm_wday, tm_bt.tm_wday); + EXPECT_EQ(tm_lc.tm_yday, tm_bt.tm_yday); + EXPECT_EQ(tm_lc.tm_isdst, tm_bt.tm_isdst); + + ASSERT_FALSE(HasFailure()); + } + + // Checks that the tm_isdst field is correct when in standard time. + const absl::TimeZone nyc = + absl::time_internal::LoadTimeZone("America/New_York"); + absl::Time t = absl::FromCivil(absl::CivilSecond(2014, 3, 1, 0, 0, 0), nyc); + struct tm tm = ToTM(t, nyc); + EXPECT_FALSE(tm.tm_isdst); + + // Checks that the tm_isdst field is correct when in daylight time. + t = absl::FromCivil(absl::CivilSecond(2014, 4, 1, 0, 0, 0), nyc); + tm = ToTM(t, nyc); + EXPECT_TRUE(tm.tm_isdst); + + // Checks overflow. + tm = ToTM(absl::InfiniteFuture(), nyc); + EXPECT_EQ(std::numeric_limits<int>::max() - 1900, tm.tm_year); + EXPECT_EQ(11, tm.tm_mon); + EXPECT_EQ(31, tm.tm_mday); + EXPECT_EQ(23, tm.tm_hour); + EXPECT_EQ(59, tm.tm_min); + EXPECT_EQ(59, tm.tm_sec); + EXPECT_EQ(4, tm.tm_wday); + EXPECT_EQ(364, tm.tm_yday); + EXPECT_FALSE(tm.tm_isdst); + + // Checks underflow. + tm = ToTM(absl::InfinitePast(), nyc); + EXPECT_EQ(std::numeric_limits<int>::min(), tm.tm_year); + EXPECT_EQ(0, tm.tm_mon); + EXPECT_EQ(1, tm.tm_mday); + EXPECT_EQ(0, tm.tm_hour); + EXPECT_EQ(0, tm.tm_min); + EXPECT_EQ(0, tm.tm_sec); + EXPECT_EQ(0, tm.tm_wday); + EXPECT_EQ(0, tm.tm_yday); + EXPECT_FALSE(tm.tm_isdst); +} + +TEST(Time, FromTM) { + const absl::TimeZone nyc = + absl::time_internal::LoadTimeZone("America/New_York"); + + // Verifies that tm_isdst doesn't affect anything when the time is unique. + struct tm tm; + std::memset(&tm, 0, sizeof(tm)); + tm.tm_year = 2014 - 1900; + tm.tm_mon = 6 - 1; + tm.tm_mday = 28; + tm.tm_hour = 1; + tm.tm_min = 2; + tm.tm_sec = 3; + tm.tm_isdst = -1; + absl::Time t = FromTM(tm, nyc); + EXPECT_EQ("2014-06-28T01:02:03-04:00", absl::FormatTime(t, nyc)); // DST + tm.tm_isdst = 0; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-06-28T01:02:03-04:00", absl::FormatTime(t, nyc)); // DST + tm.tm_isdst = 1; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-06-28T01:02:03-04:00", absl::FormatTime(t, nyc)); // DST + + // Adjusts tm to refer to an ambiguous time. + tm.tm_year = 2014 - 1900; + tm.tm_mon = 11 - 1; + tm.tm_mday = 2; + tm.tm_hour = 1; + tm.tm_min = 30; + tm.tm_sec = 42; + tm.tm_isdst = -1; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-11-02T01:30:42-04:00", absl::FormatTime(t, nyc)); // DST + tm.tm_isdst = 0; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-11-02T01:30:42-05:00", absl::FormatTime(t, nyc)); // STD + tm.tm_isdst = 1; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-11-02T01:30:42-04:00", absl::FormatTime(t, nyc)); // DST + + // Adjusts tm to refer to a skipped time. + tm.tm_year = 2014 - 1900; + tm.tm_mon = 3 - 1; + tm.tm_mday = 9; + tm.tm_hour = 2; + tm.tm_min = 30; + tm.tm_sec = 42; + tm.tm_isdst = -1; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-03-09T03:30:42-04:00", absl::FormatTime(t, nyc)); // DST + tm.tm_isdst = 0; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-03-09T01:30:42-05:00", absl::FormatTime(t, nyc)); // STD + tm.tm_isdst = 1; + t = FromTM(tm, nyc); + EXPECT_EQ("2014-03-09T03:30:42-04:00", absl::FormatTime(t, nyc)); // DST + + // Adjusts tm to refer to a time with a year larger than 2147483647. + tm.tm_year = 2147483647 - 1900 + 1; + tm.tm_mon = 6 - 1; + tm.tm_mday = 28; + tm.tm_hour = 1; + tm.tm_min = 2; + tm.tm_sec = 3; + tm.tm_isdst = -1; + t = FromTM(tm, absl::UTCTimeZone()); + EXPECT_EQ("2147483648-06-28T01:02:03+00:00", + absl::FormatTime(t, absl::UTCTimeZone())); + + // Adjusts tm to refer to a time with a very large month. + tm.tm_year = 2019 - 1900; + tm.tm_mon = 2147483647; + tm.tm_mday = 28; + tm.tm_hour = 1; + tm.tm_min = 2; + tm.tm_sec = 3; + tm.tm_isdst = -1; + t = FromTM(tm, absl::UTCTimeZone()); + EXPECT_EQ("178958989-08-28T01:02:03+00:00", + absl::FormatTime(t, absl::UTCTimeZone())); +} + +TEST(Time, TMRoundTrip) { + const absl::TimeZone nyc = + absl::time_internal::LoadTimeZone("America/New_York"); + + // Test round-tripping across a skipped transition + absl::Time start = absl::FromCivil(absl::CivilHour(2014, 3, 9, 0), nyc); + absl::Time end = absl::FromCivil(absl::CivilHour(2014, 3, 9, 4), nyc); + for (absl::Time t = start; t < end; t += absl::Minutes(1)) { + struct tm tm = ToTM(t, nyc); + absl::Time rt = FromTM(tm, nyc); + EXPECT_EQ(rt, t); + } + + // Test round-tripping across an ambiguous transition + start = absl::FromCivil(absl::CivilHour(2014, 11, 2, 0), nyc); + end = absl::FromCivil(absl::CivilHour(2014, 11, 2, 4), nyc); + for (absl::Time t = start; t < end; t += absl::Minutes(1)) { + struct tm tm = ToTM(t, nyc); + absl::Time rt = FromTM(tm, nyc); + EXPECT_EQ(rt, t); + } + + // Test round-tripping of unique instants crossing a day boundary + start = absl::FromCivil(absl::CivilHour(2014, 6, 27, 22), nyc); + end = absl::FromCivil(absl::CivilHour(2014, 6, 28, 4), nyc); + for (absl::Time t = start; t < end; t += absl::Minutes(1)) { + struct tm tm = ToTM(t, nyc); + absl::Time rt = FromTM(tm, nyc); + EXPECT_EQ(rt, t); + } +} + +TEST(Time, Range) { + // The API's documented range is +/- 100 billion years. + const absl::Duration range = absl::Hours(24) * 365.2425 * 100000000000; + + // Arithmetic and comparison still works at +/-range around base values. + absl::Time bases[2] = {absl::UnixEpoch(), absl::Now()}; + for (const auto base : bases) { + absl::Time bottom = base - range; + EXPECT_GT(bottom, bottom - absl::Nanoseconds(1)); + EXPECT_LT(bottom, bottom + absl::Nanoseconds(1)); + absl::Time top = base + range; + EXPECT_GT(top, top - absl::Nanoseconds(1)); + EXPECT_LT(top, top + absl::Nanoseconds(1)); + absl::Duration full_range = 2 * range; + EXPECT_EQ(full_range, top - bottom); + EXPECT_EQ(-full_range, bottom - top); + } +} + +TEST(Time, Limits) { + // It is an implementation detail that Time().rep_ == ZeroDuration(), + // and that the resolution of a Duration is 1/4 of a nanosecond. + const absl::Time zero; + const absl::Time max = + zero + absl::Seconds(std::numeric_limits<int64_t>::max()) + + absl::Nanoseconds(999999999) + absl::Nanoseconds(3) / 4; + const absl::Time min = + zero + absl::Seconds(std::numeric_limits<int64_t>::min()); + + // Some simple max/min bounds checks. + EXPECT_LT(max, absl::InfiniteFuture()); + EXPECT_GT(min, absl::InfinitePast()); + EXPECT_LT(zero, max); + EXPECT_GT(zero, min); + EXPECT_GE(absl::UnixEpoch(), min); + EXPECT_LT(absl::UnixEpoch(), max); + + // Check sign of Time differences. + EXPECT_LT(absl::ZeroDuration(), max - zero); + EXPECT_LT(absl::ZeroDuration(), + zero - absl::Nanoseconds(1) / 4 - min); // avoid zero - min + + // Arithmetic works at max - 0.25ns and min + 0.25ns. + EXPECT_GT(max, max - absl::Nanoseconds(1) / 4); + EXPECT_LT(min, min + absl::Nanoseconds(1) / 4); +} + +TEST(Time, ConversionSaturation) { + const absl::TimeZone utc = absl::UTCTimeZone(); + absl::Time t; + + const auto max_time_t = std::numeric_limits<time_t>::max(); + const auto min_time_t = std::numeric_limits<time_t>::min(); + time_t tt = max_time_t - 1; + t = absl::FromTimeT(tt); + tt = absl::ToTimeT(t); + EXPECT_EQ(max_time_t - 1, tt); + t += absl::Seconds(1); + tt = absl::ToTimeT(t); + EXPECT_EQ(max_time_t, tt); + t += absl::Seconds(1); // no effect + tt = absl::ToTimeT(t); + EXPECT_EQ(max_time_t, tt); + + tt = min_time_t + 1; + t = absl::FromTimeT(tt); + tt = absl::ToTimeT(t); + EXPECT_EQ(min_time_t + 1, tt); + t -= absl::Seconds(1); + tt = absl::ToTimeT(t); + EXPECT_EQ(min_time_t, tt); + t -= absl::Seconds(1); // no effect + tt = absl::ToTimeT(t); + EXPECT_EQ(min_time_t, tt); + + const auto max_timeval_sec = + std::numeric_limits<decltype(timeval::tv_sec)>::max(); + const auto min_timeval_sec = + std::numeric_limits<decltype(timeval::tv_sec)>::min(); + timeval tv; + tv.tv_sec = max_timeval_sec; + tv.tv_usec = 999998; + t = absl::TimeFromTimeval(tv); + tv = ToTimeval(t); + EXPECT_EQ(max_timeval_sec, tv.tv_sec); + EXPECT_EQ(999998, tv.tv_usec); + t += absl::Microseconds(1); + tv = ToTimeval(t); + EXPECT_EQ(max_timeval_sec, tv.tv_sec); + EXPECT_EQ(999999, tv.tv_usec); + t += absl::Microseconds(1); // no effect + tv = ToTimeval(t); + EXPECT_EQ(max_timeval_sec, tv.tv_sec); + EXPECT_EQ(999999, tv.tv_usec); + + tv.tv_sec = min_timeval_sec; + tv.tv_usec = 1; + t = absl::TimeFromTimeval(tv); + tv = ToTimeval(t); + EXPECT_EQ(min_timeval_sec, tv.tv_sec); + EXPECT_EQ(1, tv.tv_usec); + t -= absl::Microseconds(1); + tv = ToTimeval(t); + EXPECT_EQ(min_timeval_sec, tv.tv_sec); + EXPECT_EQ(0, tv.tv_usec); + t -= absl::Microseconds(1); // no effect + tv = ToTimeval(t); + EXPECT_EQ(min_timeval_sec, tv.tv_sec); + EXPECT_EQ(0, tv.tv_usec); + + const auto max_timespec_sec = + std::numeric_limits<decltype(timespec::tv_sec)>::max(); + const auto min_timespec_sec = + std::numeric_limits<decltype(timespec::tv_sec)>::min(); + timespec ts; + ts.tv_sec = max_timespec_sec; + ts.tv_nsec = 999999998; + t = absl::TimeFromTimespec(ts); + ts = absl::ToTimespec(t); + EXPECT_EQ(max_timespec_sec, ts.tv_sec); + EXPECT_EQ(999999998, ts.tv_nsec); + t += absl::Nanoseconds(1); + ts = absl::ToTimespec(t); + EXPECT_EQ(max_timespec_sec, ts.tv_sec); + EXPECT_EQ(999999999, ts.tv_nsec); + t += absl::Nanoseconds(1); // no effect + ts = absl::ToTimespec(t); + EXPECT_EQ(max_timespec_sec, ts.tv_sec); + EXPECT_EQ(999999999, ts.tv_nsec); + + ts.tv_sec = min_timespec_sec; + ts.tv_nsec = 1; + t = absl::TimeFromTimespec(ts); + ts = absl::ToTimespec(t); + EXPECT_EQ(min_timespec_sec, ts.tv_sec); + EXPECT_EQ(1, ts.tv_nsec); + t -= absl::Nanoseconds(1); + ts = absl::ToTimespec(t); + EXPECT_EQ(min_timespec_sec, ts.tv_sec); + EXPECT_EQ(0, ts.tv_nsec); + t -= absl::Nanoseconds(1); // no effect + ts = absl::ToTimespec(t); + EXPECT_EQ(min_timespec_sec, ts.tv_sec); + EXPECT_EQ(0, ts.tv_nsec); + + // Checks how TimeZone::At() saturates on infinities. + auto ci = utc.At(absl::InfiniteFuture()); + EXPECT_CIVIL_INFO(ci, std::numeric_limits<int64_t>::max(), 12, 31, 23, + 59, 59, 0, false); + EXPECT_EQ(absl::InfiniteDuration(), ci.subsecond); + EXPECT_EQ(absl::Weekday::thursday, absl::GetWeekday(ci.cs)); + EXPECT_EQ(365, absl::GetYearDay(ci.cs)); + EXPECT_STREQ("-00", ci.zone_abbr); // artifact of TimeZone::At() + ci = utc.At(absl::InfinitePast()); + EXPECT_CIVIL_INFO(ci, std::numeric_limits<int64_t>::min(), 1, 1, 0, 0, + 0, 0, false); + EXPECT_EQ(-absl::InfiniteDuration(), ci.subsecond); + EXPECT_EQ(absl::Weekday::sunday, absl::GetWeekday(ci.cs)); + EXPECT_EQ(1, absl::GetYearDay(ci.cs)); + EXPECT_STREQ("-00", ci.zone_abbr); // artifact of TimeZone::At() + + // Approach the maximal Time value from below. + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 4, 15, 30, 6), utc); + EXPECT_EQ("292277026596-12-04T15:30:06+00:00", + absl::FormatTime(absl::RFC3339_full, t, utc)); + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 4, 15, 30, 7), utc); + EXPECT_EQ("292277026596-12-04T15:30:07+00:00", + absl::FormatTime(absl::RFC3339_full, t, utc)); + EXPECT_EQ( + absl::UnixEpoch() + absl::Seconds(std::numeric_limits<int64_t>::max()), t); + + // Checks that we can also get the maximal Time value for a far-east zone. + const absl::TimeZone plus14 = absl::FixedTimeZone(14 * 60 * 60); + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 5, 5, 30, 7), plus14); + EXPECT_EQ("292277026596-12-05T05:30:07+14:00", + absl::FormatTime(absl::RFC3339_full, t, plus14)); + EXPECT_EQ( + absl::UnixEpoch() + absl::Seconds(std::numeric_limits<int64_t>::max()), t); + + // One second later should push us to infinity. + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 4, 15, 30, 8), utc); + EXPECT_EQ("infinite-future", absl::FormatTime(absl::RFC3339_full, t, utc)); + + // Approach the minimal Time value from above. + t = absl::FromCivil(absl::CivilSecond(-292277022657, 1, 27, 8, 29, 53), utc); + EXPECT_EQ("-292277022657-01-27T08:29:53+00:00", + absl::FormatTime(absl::RFC3339_full, t, utc)); + t = absl::FromCivil(absl::CivilSecond(-292277022657, 1, 27, 8, 29, 52), utc); + EXPECT_EQ("-292277022657-01-27T08:29:52+00:00", + absl::FormatTime(absl::RFC3339_full, t, utc)); + EXPECT_EQ( + absl::UnixEpoch() + absl::Seconds(std::numeric_limits<int64_t>::min()), t); + + // Checks that we can also get the minimal Time value for a far-west zone. + const absl::TimeZone minus12 = absl::FixedTimeZone(-12 * 60 * 60); + t = absl::FromCivil(absl::CivilSecond(-292277022657, 1, 26, 20, 29, 52), + minus12); + EXPECT_EQ("-292277022657-01-26T20:29:52-12:00", + absl::FormatTime(absl::RFC3339_full, t, minus12)); + EXPECT_EQ( + absl::UnixEpoch() + absl::Seconds(std::numeric_limits<int64_t>::min()), t); + + // One second before should push us to -infinity. + t = absl::FromCivil(absl::CivilSecond(-292277022657, 1, 27, 8, 29, 51), utc); + EXPECT_EQ("infinite-past", absl::FormatTime(absl::RFC3339_full, t, utc)); +} + +// In zones with POSIX-style recurring rules we use special logic to +// handle conversions in the distant future. Here we check the limits +// of those conversions, particularly with respect to integer overflow. +TEST(Time, ExtendedConversionSaturation) { + const absl::TimeZone syd = + absl::time_internal::LoadTimeZone("Australia/Sydney"); + const absl::TimeZone nyc = + absl::time_internal::LoadTimeZone("America/New_York"); + const absl::Time max = + absl::FromUnixSeconds(std::numeric_limits<int64_t>::max()); + absl::TimeZone::CivilInfo ci; + absl::Time t; + + // The maximal time converted in each zone. + ci = syd.At(max); + EXPECT_CIVIL_INFO(ci, 292277026596, 12, 5, 2, 30, 7, 39600, true); + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 5, 2, 30, 7), syd); + EXPECT_EQ(max, t); + ci = nyc.At(max); + EXPECT_CIVIL_INFO(ci, 292277026596, 12, 4, 10, 30, 7, -18000, false); + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 4, 10, 30, 7), nyc); + EXPECT_EQ(max, t); + + // One second later should push us to infinity. + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 5, 2, 30, 8), syd); + EXPECT_EQ(absl::InfiniteFuture(), t); + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 4, 10, 30, 8), nyc); + EXPECT_EQ(absl::InfiniteFuture(), t); + + // And we should stick there. + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 5, 2, 30, 9), syd); + EXPECT_EQ(absl::InfiniteFuture(), t); + t = absl::FromCivil(absl::CivilSecond(292277026596, 12, 4, 10, 30, 9), nyc); + EXPECT_EQ(absl::InfiniteFuture(), t); + + // All the way up to a saturated date/time, without overflow. + t = absl::FromCivil(absl::CivilSecond::max(), syd); + EXPECT_EQ(absl::InfiniteFuture(), t); + t = absl::FromCivil(absl::CivilSecond::max(), nyc); + EXPECT_EQ(absl::InfiniteFuture(), t); +} + +TEST(Time, FromCivilAlignment) { + const absl::TimeZone utc = absl::UTCTimeZone(); + const absl::CivilSecond cs(2015, 2, 3, 4, 5, 6); + absl::Time t = absl::FromCivil(cs, utc); + EXPECT_EQ("2015-02-03T04:05:06+00:00", absl::FormatTime(t, utc)); + t = absl::FromCivil(absl::CivilMinute(cs), utc); + EXPECT_EQ("2015-02-03T04:05:00+00:00", absl::FormatTime(t, utc)); + t = absl::FromCivil(absl::CivilHour(cs), utc); + EXPECT_EQ("2015-02-03T04:00:00+00:00", absl::FormatTime(t, utc)); + t = absl::FromCivil(absl::CivilDay(cs), utc); + EXPECT_EQ("2015-02-03T00:00:00+00:00", absl::FormatTime(t, utc)); + t = absl::FromCivil(absl::CivilMonth(cs), utc); + EXPECT_EQ("2015-02-01T00:00:00+00:00", absl::FormatTime(t, utc)); + t = absl::FromCivil(absl::CivilYear(cs), utc); + EXPECT_EQ("2015-01-01T00:00:00+00:00", absl::FormatTime(t, utc)); +} + +TEST(Time, LegacyDateTime) { + const absl::TimeZone utc = absl::UTCTimeZone(); + const std::string ymdhms = "%Y-%m-%d %H:%M:%S"; + const int kMax = std::numeric_limits<int>::max(); + const int kMin = std::numeric_limits<int>::min(); + absl::Time t; + + t = absl::FromDateTime(std::numeric_limits<absl::civil_year_t>::max(), + kMax, kMax, kMax, kMax, kMax, utc); + EXPECT_EQ("infinite-future", + absl::FormatTime(ymdhms, t, utc)); // no overflow + t = absl::FromDateTime(std::numeric_limits<absl::civil_year_t>::min(), + kMin, kMin, kMin, kMin, kMin, utc); + EXPECT_EQ("infinite-past", + absl::FormatTime(ymdhms, t, utc)); // no overflow + + // Check normalization. + EXPECT_TRUE(absl::ConvertDateTime(2013, 10, 32, 8, 30, 0, utc).normalized); + t = absl::FromDateTime(2015, 1, 1, 0, 0, 60, utc); + EXPECT_EQ("2015-01-01 00:01:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, 1, 0, 60, 0, utc); + EXPECT_EQ("2015-01-01 01:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, 1, 24, 0, 0, utc); + EXPECT_EQ("2015-01-02 00:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, 32, 0, 0, 0, utc); + EXPECT_EQ("2015-02-01 00:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 13, 1, 0, 0, 0, utc); + EXPECT_EQ("2016-01-01 00:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 13, 32, 60, 60, 60, utc); + EXPECT_EQ("2016-02-03 13:01:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, 1, 0, 0, -1, utc); + EXPECT_EQ("2014-12-31 23:59:59", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, 1, 0, -1, 0, utc); + EXPECT_EQ("2014-12-31 23:59:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, 1, -1, 0, 0, utc); + EXPECT_EQ("2014-12-31 23:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, 1, -1, 0, 0, 0, utc); + EXPECT_EQ("2014-12-30 00:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, -1, 1, 0, 0, 0, utc); + EXPECT_EQ("2014-11-01 00:00:00", absl::FormatTime(ymdhms, t, utc)); + t = absl::FromDateTime(2015, -1, -1, -1, -1, -1, utc); + EXPECT_EQ("2014-10-29 22:58:59", absl::FormatTime(ymdhms, t, utc)); +} + +TEST(Time, NextTransitionUTC) { + const auto tz = absl::UTCTimeZone(); + absl::TimeZone::CivilTransition trans; + + auto t = absl::InfinitePast(); + EXPECT_FALSE(tz.NextTransition(t, &trans)); + + t = absl::InfiniteFuture(); + EXPECT_FALSE(tz.NextTransition(t, &trans)); +} + +TEST(Time, PrevTransitionUTC) { + const auto tz = absl::UTCTimeZone(); + absl::TimeZone::CivilTransition trans; + + auto t = absl::InfiniteFuture(); + EXPECT_FALSE(tz.PrevTransition(t, &trans)); + + t = absl::InfinitePast(); + EXPECT_FALSE(tz.PrevTransition(t, &trans)); +} + +TEST(Time, NextTransitionNYC) { + const auto tz = absl::time_internal::LoadTimeZone("America/New_York"); + absl::TimeZone::CivilTransition trans; + + auto t = absl::FromCivil(absl::CivilSecond(2018, 6, 30, 0, 0, 0), tz); + EXPECT_TRUE(tz.NextTransition(t, &trans)); + EXPECT_EQ(absl::CivilSecond(2018, 11, 4, 2, 0, 0), trans.from); + EXPECT_EQ(absl::CivilSecond(2018, 11, 4, 1, 0, 0), trans.to); + + t = absl::InfiniteFuture(); + EXPECT_FALSE(tz.NextTransition(t, &trans)); + + t = absl::InfinitePast(); + EXPECT_TRUE(tz.NextTransition(t, &trans)); + if (trans.from == absl::CivilSecond(1918, 03, 31, 2, 0, 0)) { + // It looks like the tzdata is only 32 bit (probably macOS), + // which bottoms out at 1901-12-13T20:45:52+00:00. + EXPECT_EQ(absl::CivilSecond(1918, 3, 31, 3, 0, 0), trans.to); + } else { + EXPECT_EQ(absl::CivilSecond(1883, 11, 18, 12, 3, 58), trans.from); + EXPECT_EQ(absl::CivilSecond(1883, 11, 18, 12, 0, 0), trans.to); + } +} + +TEST(Time, PrevTransitionNYC) { + const auto tz = absl::time_internal::LoadTimeZone("America/New_York"); + absl::TimeZone::CivilTransition trans; + + auto t = absl::FromCivil(absl::CivilSecond(2018, 6, 30, 0, 0, 0), tz); + EXPECT_TRUE(tz.PrevTransition(t, &trans)); + EXPECT_EQ(absl::CivilSecond(2018, 3, 11, 2, 0, 0), trans.from); + EXPECT_EQ(absl::CivilSecond(2018, 3, 11, 3, 0, 0), trans.to); + + t = absl::InfinitePast(); + EXPECT_FALSE(tz.PrevTransition(t, &trans)); + + t = absl::InfiniteFuture(); + EXPECT_TRUE(tz.PrevTransition(t, &trans)); + // We have a transition but we don't know which one. +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/time/time_zone_test.cc b/third_party/abseil_cpp/absl/time/time_zone_test.cc new file mode 100644 index 0000000000..229fcfccb0 --- /dev/null +++ b/third_party/abseil_cpp/absl/time/time_zone_test.cc @@ -0,0 +1,97 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/time/internal/cctz/include/cctz/time_zone.h" + +#include "gtest/gtest.h" +#include "absl/time/internal/test_util.h" +#include "absl/time/time.h" + +namespace cctz = absl::time_internal::cctz; + +namespace { + +TEST(TimeZone, ValueSemantics) { + absl::TimeZone tz; + absl::TimeZone tz2 = tz; // Copy-construct + EXPECT_EQ(tz, tz2); + tz2 = tz; // Copy-assign + EXPECT_EQ(tz, tz2); +} + +TEST(TimeZone, Equality) { + absl::TimeZone a, b; + EXPECT_EQ(a, b); + EXPECT_EQ(a.name(), b.name()); + + absl::TimeZone implicit_utc; + absl::TimeZone explicit_utc = absl::UTCTimeZone(); + EXPECT_EQ(implicit_utc, explicit_utc); + EXPECT_EQ(implicit_utc.name(), explicit_utc.name()); + + absl::TimeZone la = absl::time_internal::LoadTimeZone("America/Los_Angeles"); + absl::TimeZone nyc = absl::time_internal::LoadTimeZone("America/New_York"); + EXPECT_NE(la, nyc); +} + +TEST(TimeZone, CCTZConversion) { + const cctz::time_zone cz = cctz::utc_time_zone(); + const absl::TimeZone tz(cz); + EXPECT_EQ(cz, cctz::time_zone(tz)); +} + +TEST(TimeZone, DefaultTimeZones) { + absl::TimeZone tz; + EXPECT_EQ("UTC", absl::TimeZone().name()); + EXPECT_EQ("UTC", absl::UTCTimeZone().name()); +} + +TEST(TimeZone, FixedTimeZone) { + const absl::TimeZone tz = absl::FixedTimeZone(123); + const cctz::time_zone cz = cctz::fixed_time_zone(cctz::seconds(123)); + EXPECT_EQ(tz, absl::TimeZone(cz)); +} + +TEST(TimeZone, LocalTimeZone) { + const absl::TimeZone local_tz = absl::LocalTimeZone(); + absl::TimeZone tz = absl::time_internal::LoadTimeZone("localtime"); + EXPECT_EQ(tz, local_tz); +} + +TEST(TimeZone, NamedTimeZones) { + absl::TimeZone nyc = absl::time_internal::LoadTimeZone("America/New_York"); + EXPECT_EQ("America/New_York", nyc.name()); + absl::TimeZone syd = absl::time_internal::LoadTimeZone("Australia/Sydney"); + EXPECT_EQ("Australia/Sydney", syd.name()); + absl::TimeZone fixed = absl::FixedTimeZone((((3 * 60) + 25) * 60) + 45); + EXPECT_EQ("Fixed/UTC+03:25:45", fixed.name()); +} + +TEST(TimeZone, Failures) { + absl::TimeZone tz = absl::time_internal::LoadTimeZone("America/Los_Angeles"); + EXPECT_FALSE(LoadTimeZone("Invalid/TimeZone", &tz)); + EXPECT_EQ(absl::UTCTimeZone(), tz); // guaranteed fallback to UTC + + // Ensures that the load still fails on a subsequent attempt. + tz = absl::time_internal::LoadTimeZone("America/Los_Angeles"); + EXPECT_FALSE(LoadTimeZone("Invalid/TimeZone", &tz)); + EXPECT_EQ(absl::UTCTimeZone(), tz); // guaranteed fallback to UTC + + // Loading an empty string timezone should fail. + tz = absl::time_internal::LoadTimeZone("America/Los_Angeles"); + EXPECT_FALSE(LoadTimeZone("", &tz)); + EXPECT_EQ(absl::UTCTimeZone(), tz); // guaranteed fallback to UTC +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/types/BUILD.bazel b/third_party/abseil_cpp/absl/types/BUILD.bazel new file mode 100644 index 0000000000..de71c7347f --- /dev/null +++ b/third_party/abseil_cpp/absl/types/BUILD.bazel @@ -0,0 +1,337 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "any", + hdrs = ["any.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bad_any_cast", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:fast_type_id", + "//absl/meta:type_traits", + "//absl/utility", + ], +) + +cc_library( + name = "bad_any_cast", + hdrs = ["bad_any_cast.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bad_any_cast_impl", + "//absl/base:config", + ], +) + +cc_library( + name = "bad_any_cast_impl", + srcs = [ + "bad_any_cast.cc", + "bad_any_cast.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + visibility = ["//visibility:private"], + deps = [ + "//absl/base:config", + "//absl/base:raw_logging_internal", + ], +) + +cc_test( + name = "any_test", + size = "small", + srcs = [ + "any_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":any", + "//absl/base:config", + "//absl/base:exception_testing", + "//absl/base:raw_logging_internal", + "//absl/container:test_instance_tracker", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "any_exception_safety_test", + srcs = ["any_exception_safety_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":any", + "//absl/base:config", + "//absl/base:exception_safety_testing", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "span", + srcs = [ + "internal/span.h", + ], + hdrs = [ + "span.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/algorithm", + "//absl/base:core_headers", + "//absl/base:throw_delegate", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "span_test", + size = "small", + srcs = ["span_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":span", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/base:exception_testing", + "//absl/container:fixed_array", + "//absl/container:inlined_vector", + "//absl/hash:hash_testing", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "optional", + srcs = ["internal/optional.h"], + hdrs = ["optional.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bad_optional_access", + "//absl/base:base_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/utility", + ], +) + +cc_library( + name = "bad_optional_access", + srcs = ["bad_optional_access.cc"], + hdrs = ["bad_optional_access.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:raw_logging_internal", + ], +) + +cc_library( + name = "bad_variant_access", + srcs = ["bad_variant_access.cc"], + hdrs = ["bad_variant_access.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:config", + "//absl/base:raw_logging_internal", + ], +) + +cc_test( + name = "optional_test", + size = "small", + srcs = [ + "optional_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":optional", + "//absl/base:config", + "//absl/base:raw_logging_internal", + "//absl/meta:type_traits", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "optional_exception_safety_test", + srcs = [ + "optional_exception_safety_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":optional", + "//absl/base:config", + "//absl/base:exception_safety_testing", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "conformance_testing", + testonly = 1, + hdrs = [ + "internal/conformance_aliases.h", + "internal/conformance_archetype.h", + "internal/conformance_profile.h", + "internal/conformance_testing.h", + "internal/conformance_testing_helpers.h", + "internal/parentheses.h", + "internal/transform_args.h", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/algorithm:container", + "//absl/meta:type_traits", + "//absl/strings", + "//absl/utility", + "@com_google_googletest//:gtest", + ], +) + +cc_test( + name = "conformance_testing_test", + size = "small", + srcs = [ + "internal/conformance_testing_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":conformance_testing", + "//absl/meta:type_traits", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "variant", + srcs = ["internal/variant.h"], + hdrs = ["variant.h"], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":bad_variant_access", + "//absl/base:base_internal", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/meta:type_traits", + "//absl/utility", + ], +) + +cc_test( + name = "variant_test", + size = "small", + srcs = ["variant_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":variant", + "//absl/base:config", + "//absl/base:core_headers", + "//absl/memory", + "//absl/meta:type_traits", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) + +cc_test( + name = "variant_benchmark", + srcs = [ + "variant_benchmark.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + tags = ["benchmark"], + deps = [ + ":variant", + "//absl/utility", + "@com_github_google_benchmark//:benchmark_main", + ], +) + +cc_test( + name = "variant_exception_safety_test", + size = "small", + srcs = [ + "variant_exception_safety_test.cc", + ], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":variant", + "//absl/base:config", + "//absl/base:exception_safety_testing", + "//absl/memory", + "@com_google_googletest//:gtest_main", + ], +) + +cc_library( + name = "compare", + hdrs = ["compare.h"], + copts = ABSL_DEFAULT_COPTS, + deps = [ + "//absl/base:core_headers", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "compare_test", + size = "small", + srcs = [ + "compare_test.cc", + ], + copts = ABSL_TEST_COPTS, + deps = [ + ":compare", + "//absl/base", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/types/CMakeLists.txt b/third_party/abseil_cpp/absl/types/CMakeLists.txt new file mode 100644 index 0000000000..0dc0d2c7c9 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/CMakeLists.txt @@ -0,0 +1,373 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +absl_cc_library( + NAME + any + HDRS + "any.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bad_any_cast + absl::config + absl::core_headers + absl::fast_type_id + absl::type_traits + absl::utility + PUBLIC +) + +absl_cc_library( + NAME + bad_any_cast + HDRS + "bad_any_cast.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bad_any_cast_impl + absl::config + PUBLIC +) + +absl_cc_library( + NAME + bad_any_cast_impl + SRCS + "bad_any_cast.h" + "bad_any_cast.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::raw_logging_internal +) + +absl_cc_test( + NAME + any_test + SRCS + "any_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::any + absl::config + absl::exception_testing + absl::raw_logging_internal + absl::test_instance_tracker + gmock_main +) + +absl_cc_test( + NAME + any_test_noexceptions + SRCS + "any_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::any + absl::config + absl::exception_testing + absl::raw_logging_internal + absl::test_instance_tracker + gmock_main +) + +absl_cc_test( + NAME + any_exception_safety_test + SRCS + "any_exception_safety_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::any + absl::config + absl::exception_safety_testing + gmock_main +) + +absl_cc_library( + NAME + span + HDRS + "span.h" + SRCS + "internal/span.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::algorithm + absl::core_headers + absl::throw_delegate + absl::type_traits + PUBLIC +) + +absl_cc_test( + NAME + span_test + SRCS + "span_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::span + absl::base + absl::config + absl::core_headers + absl::exception_testing + absl::fixed_array + absl::inlined_vector + absl::hash_testing + absl::strings + gmock_main +) + +absl_cc_test( + NAME + span_test_noexceptions + SRCS + "span_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::span + absl::base + absl::config + absl::core_headers + absl::exception_testing + absl::fixed_array + absl::inlined_vector + absl::hash_testing + absl::strings + gmock_main +) + +absl_cc_library( + NAME + optional + HDRS + "optional.h" + SRCS + "internal/optional.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bad_optional_access + absl::base_internal + absl::config + absl::core_headers + absl::memory + absl::type_traits + absl::utility + PUBLIC +) + +absl_cc_library( + NAME + bad_optional_access + HDRS + "bad_optional_access.h" + SRCS + "bad_optional_access.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::raw_logging_internal + PUBLIC +) + +absl_cc_library( + NAME + bad_variant_access + HDRS + "bad_variant_access.h" + SRCS + "bad_variant_access.cc" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::config + absl::raw_logging_internal + PUBLIC +) + +absl_cc_test( + NAME + optional_test + SRCS + "optional_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::optional + absl::config + absl::raw_logging_internal + absl::strings + absl::type_traits + gmock_main +) + +absl_cc_test( + NAME + optional_exception_safety_test + SRCS + "optional_exception_safety_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::optional + absl::config + absl::exception_safety_testing + gmock_main +) + +absl_cc_library( + NAME + conformance_testing + HDRS + "internal/conformance_aliases.h" + "internal/conformance_archetype.h" + "internal/conformance_profile.h" + "internal/conformance_testing.h" + "internal/conformance_testing_helpers.h" + "internal/parentheses.h" + "internal/transform_args.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::algorithm + absl::debugging + absl::type_traits + absl::strings + absl::utility + gmock_main + PUBLIC +) + +absl_cc_test( + NAME + conformance_testing_test + SRCS + "internal/conformance_testing_test.cc" + COPTS + ${ABSL_TEST_COPTS} + ${ABSL_EXCEPTIONS_FLAG} + LINKOPTS + ${ABSL_EXCEPTIONS_FLAG_LINKOPTS} + DEPS + absl::conformance_testing + absl::type_traits + gmock_main +) + +absl_cc_test( + NAME + conformance_testing_test_no_exceptions + SRCS + "internal/conformance_testing_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::conformance_testing + absl::type_traits + gmock_main +) + +absl_cc_library( + NAME + variant + HDRS + "variant.h" + SRCS + "internal/variant.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::bad_variant_access + absl::base_internal + absl::config + absl::core_headers + absl::type_traits + absl::utility + PUBLIC +) + +absl_cc_test( + NAME + variant_test + SRCS + "variant_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::variant + absl::config + absl::core_headers + absl::memory + absl::type_traits + absl::strings + gmock_main +) + +absl_cc_library( + NAME + compare + HDRS + "compare.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::core_headers + absl::type_traits + PUBLIC +) + +absl_cc_test( + NAME + compare_test + SRCS + "compare_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::base + absl::compare + gmock_main +) + +# TODO(cohenjon,zhangxy) Figure out why this test is failing on gcc 4.8 +if(CMAKE_CXX_COMPILER_ID STREQUAL "GNU" AND CMAKE_CXX_COMPILER_VERSION VERSION_LESS 4.9) +else() +absl_cc_test( + NAME + variant_exception_safety_test + SRCS + "variant_exception_safety_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::variant + absl::config + absl::exception_safety_testing + absl::memory + gmock_main +) +endif() diff --git a/third_party/abseil_cpp/absl/types/any.h b/third_party/abseil_cpp/absl/types/any.h new file mode 100644 index 0000000000..7eed519791 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/any.h @@ -0,0 +1,528 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// any.h +// ----------------------------------------------------------------------------- +// +// This header file define the `absl::any` type for holding a type-safe value +// of any type. The 'absl::any` type is useful for providing a way to hold +// something that is, as yet, unspecified. Such unspecified types +// traditionally are passed between API boundaries until they are later cast to +// their "destination" types. To cast to such a destination type, use +// `absl::any_cast()`. Note that when casting an `absl::any`, you must cast it +// to an explicit type; implicit conversions will throw. +// +// Example: +// +// auto a = absl::any(65); +// absl::any_cast<int>(a); // 65 +// absl::any_cast<char>(a); // throws absl::bad_any_cast +// absl::any_cast<std::string>(a); // throws absl::bad_any_cast +// +// `absl::any` is a C++11 compatible version of the C++17 `std::any` abstraction +// and is designed to be a drop-in replacement for code compliant with C++17. +// +// Traditionally, the behavior of casting to a temporary unspecified type has +// been accomplished with the `void *` paradigm, where the pointer was to some +// other unspecified type. `absl::any` provides an "owning" version of `void *` +// that avoids issues of pointer management. +// +// Note: just as in the case of `void *`, use of `absl::any` (and its C++17 +// version `std::any`) is a code smell indicating that your API might not be +// constructed correctly. We have seen that most uses of `any` are unwarranted, +// and `absl::any`, like `std::any`, is difficult to use properly. Before using +// this abstraction, make sure that you should not instead be rewriting your +// code to be more specific. +// +// Abseil expects to release an `absl::variant` type shortly (a C++11 compatible +// version of the C++17 `std::variant), which is generally preferred for use +// over `absl::any`. +#ifndef ABSL_TYPES_ANY_H_ +#define ABSL_TYPES_ANY_H_ + +#include "absl/base/config.h" +#include "absl/utility/utility.h" + +#ifdef ABSL_USES_STD_ANY + +#include <any> // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN +using std::any; +using std::any_cast; +using std::bad_any_cast; +using std::make_any; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_ANY + +#include <algorithm> +#include <cstddef> +#include <initializer_list> +#include <memory> +#include <stdexcept> +#include <type_traits> +#include <typeinfo> +#include <utility> + +#include "absl/base/internal/fast_type_id.h" +#include "absl/base/macros.h" +#include "absl/meta/type_traits.h" +#include "absl/types/bad_any_cast.h" + +// NOTE: This macro is an implementation detail that is undefined at the bottom +// of the file. It is not intended for expansion directly from user code. +#ifdef ABSL_ANY_DETAIL_HAS_RTTI +#error ABSL_ANY_DETAIL_HAS_RTTI cannot be directly set +#elif !defined(__GNUC__) || defined(__GXX_RTTI) +#define ABSL_ANY_DETAIL_HAS_RTTI 1 +#endif // !defined(__GNUC__) || defined(__GXX_RTTI) + +namespace absl { +ABSL_NAMESPACE_BEGIN + +class any; + +// swap() +// +// Swaps two `absl::any` values. Equivalent to `x.swap(y) where `x` and `y` are +// `absl::any` types. +void swap(any& x, any& y) noexcept; + +// make_any() +// +// Constructs an `absl::any` of type `T` with the given arguments. +template <typename T, typename... Args> +any make_any(Args&&... args); + +// Overload of `absl::make_any()` for constructing an `absl::any` type from an +// initializer list. +template <typename T, typename U, typename... Args> +any make_any(std::initializer_list<U> il, Args&&... args); + +// any_cast() +// +// Statically casts the value of a `const absl::any` type to the given type. +// This function will throw `absl::bad_any_cast` if the stored value type of the +// `absl::any` does not match the cast. +// +// `any_cast()` can also be used to get a reference to the internal storage iff +// a reference type is passed as its `ValueType`: +// +// Example: +// +// absl::any my_any = std::vector<int>(); +// absl::any_cast<std::vector<int>&>(my_any).push_back(42); +template <typename ValueType> +ValueType any_cast(const any& operand); + +// Overload of `any_cast()` to statically cast the value of a non-const +// `absl::any` type to the given type. This function will throw +// `absl::bad_any_cast` if the stored value type of the `absl::any` does not +// match the cast. +template <typename ValueType> +ValueType any_cast(any& operand); // NOLINT(runtime/references) + +// Overload of `any_cast()` to statically cast the rvalue of an `absl::any` +// type. This function will throw `absl::bad_any_cast` if the stored value type +// of the `absl::any` does not match the cast. +template <typename ValueType> +ValueType any_cast(any&& operand); + +// Overload of `any_cast()` to statically cast the value of a const pointer +// `absl::any` type to the given pointer type, or `nullptr` if the stored value +// type of the `absl::any` does not match the cast. +template <typename ValueType> +const ValueType* any_cast(const any* operand) noexcept; + +// Overload of `any_cast()` to statically cast the value of a pointer +// `absl::any` type to the given pointer type, or `nullptr` if the stored value +// type of the `absl::any` does not match the cast. +template <typename ValueType> +ValueType* any_cast(any* operand) noexcept; + +// ----------------------------------------------------------------------------- +// absl::any +// ----------------------------------------------------------------------------- +// +// An `absl::any` object provides the facility to either store an instance of a +// type, known as the "contained object", or no value. An `absl::any` is used to +// store values of types that are unknown at compile time. The `absl::any` +// object, when containing a value, must contain a value type; storing a +// reference type is neither desired nor supported. +// +// An `absl::any` can only store a type that is copy-constructible; move-only +// types are not allowed within an `any` object. +// +// Example: +// +// auto a = absl::any(65); // Literal, copyable +// auto b = absl::any(std::vector<int>()); // Default-initialized, copyable +// std::unique_ptr<Foo> my_foo; +// auto c = absl::any(std::move(my_foo)); // Error, not copy-constructible +// +// Note that `absl::any` makes use of decayed types (`absl::decay_t` in this +// context) to remove const-volatile qualifiers (known as "cv qualifiers"), +// decay functions to function pointers, etc. We essentially "decay" a given +// type into its essential type. +// +// `absl::any` makes use of decayed types when determining the basic type `T` of +// the value to store in the any's contained object. In the documentation below, +// we explicitly denote this by using the phrase "a decayed type of `T`". +// +// Example: +// +// const int a = 4; +// absl::any foo(a); // Decay ensures we store an "int", not a "const int&". +// +// void my_function() {} +// absl::any bar(my_function); // Decay ensures we store a function pointer. +// +// `absl::any` is a C++11 compatible version of the C++17 `std::any` abstraction +// and is designed to be a drop-in replacement for code compliant with C++17. +class any { + private: + template <typename T> + struct IsInPlaceType; + + public: + // Constructors + + // Constructs an empty `absl::any` object (`any::has_value()` will return + // `false`). + constexpr any() noexcept; + + // Copy constructs an `absl::any` object with a "contained object" of the + // passed type of `other` (or an empty `absl::any` if `other.has_value()` is + // `false`. + any(const any& other) + : obj_(other.has_value() ? other.obj_->Clone() + : std::unique_ptr<ObjInterface>()) {} + + // Move constructs an `absl::any` object with a "contained object" of the + // passed type of `other` (or an empty `absl::any` if `other.has_value()` is + // `false`). + any(any&& other) noexcept = default; + + // Constructs an `absl::any` object with a "contained object" of the decayed + // type of `T`, which is initialized via `std::forward<T>(value)`. + // + // This constructor will not participate in overload resolution if the + // decayed type of `T` is not copy-constructible. + template < + typename T, typename VT = absl::decay_t<T>, + absl::enable_if_t<!absl::disjunction< + std::is_same<any, VT>, IsInPlaceType<VT>, + absl::negation<std::is_copy_constructible<VT> > >::value>* = nullptr> + any(T&& value) : obj_(new Obj<VT>(in_place, std::forward<T>(value))) {} + + // Constructs an `absl::any` object with a "contained object" of the decayed + // type of `T`, which is initialized via `std::forward<T>(value)`. + template <typename T, typename... Args, typename VT = absl::decay_t<T>, + absl::enable_if_t<absl::conjunction< + std::is_copy_constructible<VT>, + std::is_constructible<VT, Args...>>::value>* = nullptr> + explicit any(in_place_type_t<T> /*tag*/, Args&&... args) + : obj_(new Obj<VT>(in_place, std::forward<Args>(args)...)) {} + + // Constructs an `absl::any` object with a "contained object" of the passed + // type `VT` as a decayed type of `T`. `VT` is initialized as if + // direct-non-list-initializing an object of type `VT` with the arguments + // `initializer_list, std::forward<Args>(args)...`. + template < + typename T, typename U, typename... Args, typename VT = absl::decay_t<T>, + absl::enable_if_t< + absl::conjunction<std::is_copy_constructible<VT>, + std::is_constructible<VT, std::initializer_list<U>&, + Args...>>::value>* = nullptr> + explicit any(in_place_type_t<T> /*tag*/, std::initializer_list<U> ilist, + Args&&... args) + : obj_(new Obj<VT>(in_place, ilist, std::forward<Args>(args)...)) {} + + // Assignment operators + + // Copy assigns an `absl::any` object with a "contained object" of the + // passed type. + any& operator=(const any& rhs) { + any(rhs).swap(*this); + return *this; + } + + // Move assigns an `absl::any` object with a "contained object" of the + // passed type. `rhs` is left in a valid but otherwise unspecified state. + any& operator=(any&& rhs) noexcept { + any(std::move(rhs)).swap(*this); + return *this; + } + + // Assigns an `absl::any` object with a "contained object" of the passed type. + template <typename T, typename VT = absl::decay_t<T>, + absl::enable_if_t<absl::conjunction< + absl::negation<std::is_same<VT, any>>, + std::is_copy_constructible<VT>>::value>* = nullptr> + any& operator=(T&& rhs) { + any tmp(in_place_type_t<VT>(), std::forward<T>(rhs)); + tmp.swap(*this); + return *this; + } + + // Modifiers + + // any::emplace() + // + // Emplaces a value within an `absl::any` object by calling `any::reset()`, + // initializing the contained value as if direct-non-list-initializing an + // object of type `VT` with the arguments `std::forward<Args>(args)...`, and + // returning a reference to the new contained value. + // + // Note: If an exception is thrown during the call to `VT`'s constructor, + // `*this` does not contain a value, and any previously contained value has + // been destroyed. + template < + typename T, typename... Args, typename VT = absl::decay_t<T>, + absl::enable_if_t<std::is_copy_constructible<VT>::value && + std::is_constructible<VT, Args...>::value>* = nullptr> + VT& emplace(Args&&... args) { + reset(); // NOTE: reset() is required here even in the world of exceptions. + Obj<VT>* const object_ptr = + new Obj<VT>(in_place, std::forward<Args>(args)...); + obj_ = std::unique_ptr<ObjInterface>(object_ptr); + return object_ptr->value; + } + + // Overload of `any::emplace()` to emplace a value within an `absl::any` + // object by calling `any::reset()`, initializing the contained value as if + // direct-non-list-initializing an object of type `VT` with the arguments + // `initializer_list, std::forward<Args>(args)...`, and returning a reference + // to the new contained value. + // + // Note: If an exception is thrown during the call to `VT`'s constructor, + // `*this` does not contain a value, and any previously contained value has + // been destroyed. The function shall not participate in overload resolution + // unless `is_copy_constructible_v<VT>` is `true` and + // `is_constructible_v<VT, initializer_list<U>&, Args...>` is `true`. + template < + typename T, typename U, typename... Args, typename VT = absl::decay_t<T>, + absl::enable_if_t<std::is_copy_constructible<VT>::value && + std::is_constructible<VT, std::initializer_list<U>&, + Args...>::value>* = nullptr> + VT& emplace(std::initializer_list<U> ilist, Args&&... args) { + reset(); // NOTE: reset() is required here even in the world of exceptions. + Obj<VT>* const object_ptr = + new Obj<VT>(in_place, ilist, std::forward<Args>(args)...); + obj_ = std::unique_ptr<ObjInterface>(object_ptr); + return object_ptr->value; + } + + // any::reset() + // + // Resets the state of the `absl::any` object, destroying the contained object + // if present. + void reset() noexcept { obj_ = nullptr; } + + // any::swap() + // + // Swaps the passed value and the value of this `absl::any` object. + void swap(any& other) noexcept { obj_.swap(other.obj_); } + + // Observers + + // any::has_value() + // + // Returns `true` if the `any` object has a contained value, otherwise + // returns `false`. + bool has_value() const noexcept { return obj_ != nullptr; } + +#if ABSL_ANY_DETAIL_HAS_RTTI + // Returns: typeid(T) if *this has a contained object of type T, otherwise + // typeid(void). + const std::type_info& type() const noexcept { + if (has_value()) { + return obj_->Type(); + } + + return typeid(void); + } +#endif // ABSL_ANY_DETAIL_HAS_RTTI + + private: + // Tagged type-erased abstraction for holding a cloneable object. + class ObjInterface { + public: + virtual ~ObjInterface() = default; + virtual std::unique_ptr<ObjInterface> Clone() const = 0; + virtual const void* ObjTypeId() const noexcept = 0; +#if ABSL_ANY_DETAIL_HAS_RTTI + virtual const std::type_info& Type() const noexcept = 0; +#endif // ABSL_ANY_DETAIL_HAS_RTTI + }; + + // Hold a value of some queryable type, with an ability to Clone it. + template <typename T> + class Obj : public ObjInterface { + public: + template <typename... Args> + explicit Obj(in_place_t /*tag*/, Args&&... args) + : value(std::forward<Args>(args)...) {} + + std::unique_ptr<ObjInterface> Clone() const final { + return std::unique_ptr<ObjInterface>(new Obj(in_place, value)); + } + + const void* ObjTypeId() const noexcept final { return IdForType<T>(); } + +#if ABSL_ANY_DETAIL_HAS_RTTI + const std::type_info& Type() const noexcept final { return typeid(T); } +#endif // ABSL_ANY_DETAIL_HAS_RTTI + + T value; + }; + + std::unique_ptr<ObjInterface> CloneObj() const { + if (!obj_) return nullptr; + return obj_->Clone(); + } + + template <typename T> + constexpr static const void* IdForType() { + // Note: This type dance is to make the behavior consistent with typeid. + using NormalizedType = + typename std::remove_cv<typename std::remove_reference<T>::type>::type; + + return base_internal::FastTypeId<NormalizedType>(); + } + + const void* GetObjTypeId() const { + return obj_ ? obj_->ObjTypeId() : base_internal::FastTypeId<void>(); + } + + // `absl::any` nonmember functions // + + // Description at the declaration site (top of file). + template <typename ValueType> + friend ValueType any_cast(const any& operand); + + // Description at the declaration site (top of file). + template <typename ValueType> + friend ValueType any_cast(any& operand); // NOLINT(runtime/references) + + // Description at the declaration site (top of file). + template <typename T> + friend const T* any_cast(const any* operand) noexcept; + + // Description at the declaration site (top of file). + template <typename T> + friend T* any_cast(any* operand) noexcept; + + std::unique_ptr<ObjInterface> obj_; +}; + +// ----------------------------------------------------------------------------- +// Implementation Details +// ----------------------------------------------------------------------------- + +constexpr any::any() noexcept = default; + +template <typename T> +struct any::IsInPlaceType : std::false_type {}; + +template <typename T> +struct any::IsInPlaceType<in_place_type_t<T>> : std::true_type {}; + +inline void swap(any& x, any& y) noexcept { x.swap(y); } + +// Description at the declaration site (top of file). +template <typename T, typename... Args> +any make_any(Args&&... args) { + return any(in_place_type_t<T>(), std::forward<Args>(args)...); +} + +// Description at the declaration site (top of file). +template <typename T, typename U, typename... Args> +any make_any(std::initializer_list<U> il, Args&&... args) { + return any(in_place_type_t<T>(), il, std::forward<Args>(args)...); +} + +// Description at the declaration site (top of file). +template <typename ValueType> +ValueType any_cast(const any& operand) { + using U = typename std::remove_cv< + typename std::remove_reference<ValueType>::type>::type; + static_assert(std::is_constructible<ValueType, const U&>::value, + "Invalid ValueType"); + auto* const result = (any_cast<U>)(&operand); + if (result == nullptr) { + any_internal::ThrowBadAnyCast(); + } + return static_cast<ValueType>(*result); +} + +// Description at the declaration site (top of file). +template <typename ValueType> +ValueType any_cast(any& operand) { // NOLINT(runtime/references) + using U = typename std::remove_cv< + typename std::remove_reference<ValueType>::type>::type; + static_assert(std::is_constructible<ValueType, U&>::value, + "Invalid ValueType"); + auto* result = (any_cast<U>)(&operand); + if (result == nullptr) { + any_internal::ThrowBadAnyCast(); + } + return static_cast<ValueType>(*result); +} + +// Description at the declaration site (top of file). +template <typename ValueType> +ValueType any_cast(any&& operand) { + using U = typename std::remove_cv< + typename std::remove_reference<ValueType>::type>::type; + static_assert(std::is_constructible<ValueType, U>::value, + "Invalid ValueType"); + return static_cast<ValueType>(std::move((any_cast<U&>)(operand))); +} + +// Description at the declaration site (top of file). +template <typename T> +const T* any_cast(const any* operand) noexcept { + using U = + typename std::remove_cv<typename std::remove_reference<T>::type>::type; + return operand && operand->GetObjTypeId() == any::IdForType<U>() + ? std::addressof( + static_cast<const any::Obj<U>*>(operand->obj_.get())->value) + : nullptr; +} + +// Description at the declaration site (top of file). +template <typename T> +T* any_cast(any* operand) noexcept { + using U = + typename std::remove_cv<typename std::remove_reference<T>::type>::type; + return operand && operand->GetObjTypeId() == any::IdForType<U>() + ? std::addressof( + static_cast<any::Obj<U>*>(operand->obj_.get())->value) + : nullptr; +} + +ABSL_NAMESPACE_END +} // namespace absl + +#undef ABSL_ANY_DETAIL_HAS_RTTI + +#endif // ABSL_USES_STD_ANY + +#endif // ABSL_TYPES_ANY_H_ diff --git a/third_party/abseil_cpp/absl/types/any_exception_safety_test.cc b/third_party/abseil_cpp/absl/types/any_exception_safety_test.cc new file mode 100644 index 0000000000..31c1140135 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/any_exception_safety_test.cc @@ -0,0 +1,173 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/any.h" + +#include "absl/base/config.h" + +// This test is a no-op when absl::any is an alias for std::any and when +// exceptions are not enabled. +#if !defined(ABSL_USES_STD_ANY) && defined(ABSL_HAVE_EXCEPTIONS) + +#include <typeinfo> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/internal/exception_safety_testing.h" + +using Thrower = testing::ThrowingValue<>; +using NoThrowMoveThrower = + testing::ThrowingValue<testing::TypeSpec::kNoThrowMove>; +using ThrowerList = std::initializer_list<Thrower>; +using ThrowerVec = std::vector<Thrower>; +using ThrowingAlloc = testing::ThrowingAllocator<Thrower>; +using ThrowingThrowerVec = std::vector<Thrower, ThrowingAlloc>; + +namespace { + +testing::AssertionResult AnyInvariants(absl::any* a) { + using testing::AssertionFailure; + using testing::AssertionSuccess; + + if (a->has_value()) { + if (a->type() == typeid(void)) { + return AssertionFailure() + << "A non-empty any should not have type `void`"; + } + } else { + if (a->type() != typeid(void)) { + return AssertionFailure() + << "An empty any should have type void, but has type " + << a->type().name(); + } + } + + // Make sure that reset() changes any to a valid state. + a->reset(); + if (a->has_value()) { + return AssertionFailure() << "A reset `any` should be valueless"; + } + if (a->type() != typeid(void)) { + return AssertionFailure() << "A reset `any` should have type() of `void`, " + "but instead has type " + << a->type().name(); + } + try { + auto unused = absl::any_cast<Thrower>(*a); + static_cast<void>(unused); + return AssertionFailure() + << "A reset `any` should not be able to be any_cast"; + } catch (const absl::bad_any_cast&) { + } catch (...) { + return AssertionFailure() + << "Unexpected exception thrown from absl::any_cast"; + } + return AssertionSuccess(); +} + +testing::AssertionResult AnyIsEmpty(absl::any* a) { + if (!a->has_value()) { + return testing::AssertionSuccess(); + } + return testing::AssertionFailure() + << "a should be empty, but instead has value " + << absl::any_cast<Thrower>(*a).Get(); +} + +TEST(AnyExceptionSafety, Ctors) { + Thrower val(1); + testing::TestThrowingCtor<absl::any>(val); + + Thrower copy(val); + testing::TestThrowingCtor<absl::any>(copy); + + testing::TestThrowingCtor<absl::any>(absl::in_place_type_t<Thrower>(), 1); + + testing::TestThrowingCtor<absl::any>(absl::in_place_type_t<ThrowerVec>(), + ThrowerList{val}); + + testing::TestThrowingCtor<absl::any, + absl::in_place_type_t<ThrowingThrowerVec>, + ThrowerList, ThrowingAlloc>( + absl::in_place_type_t<ThrowingThrowerVec>(), {val}, ThrowingAlloc()); +} + +TEST(AnyExceptionSafety, Assignment) { + auto original = + absl::any(absl::in_place_type_t<Thrower>(), 1, testing::nothrow_ctor); + auto any_is_strong = [original](absl::any* ap) { + return testing::AssertionResult(ap->has_value() && + absl::any_cast<Thrower>(original) == + absl::any_cast<Thrower>(*ap)); + }; + auto any_strong_tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(original) + .WithContracts(AnyInvariants, any_is_strong); + + Thrower val(2); + absl::any any_val(val); + NoThrowMoveThrower mv_val(2); + + auto assign_any = [&any_val](absl::any* ap) { *ap = any_val; }; + auto assign_val = [&val](absl::any* ap) { *ap = val; }; + auto move = [&val](absl::any* ap) { *ap = std::move(val); }; + auto move_movable = [&mv_val](absl::any* ap) { *ap = std::move(mv_val); }; + + EXPECT_TRUE(any_strong_tester.Test(assign_any)); + EXPECT_TRUE(any_strong_tester.Test(assign_val)); + EXPECT_TRUE(any_strong_tester.Test(move)); + EXPECT_TRUE(any_strong_tester.Test(move_movable)); + + auto empty_any_is_strong = [](absl::any* ap) { + return testing::AssertionResult{!ap->has_value()}; + }; + auto strong_empty_any_tester = + testing::MakeExceptionSafetyTester() + .WithInitialValue(absl::any{}) + .WithContracts(AnyInvariants, empty_any_is_strong); + + EXPECT_TRUE(strong_empty_any_tester.Test(assign_any)); + EXPECT_TRUE(strong_empty_any_tester.Test(assign_val)); + EXPECT_TRUE(strong_empty_any_tester.Test(move)); +} + +TEST(AnyExceptionSafety, Emplace) { + auto initial_val = + absl::any{absl::in_place_type_t<Thrower>(), 1, testing::nothrow_ctor}; + auto one_tester = testing::MakeExceptionSafetyTester() + .WithInitialValue(initial_val) + .WithContracts(AnyInvariants, AnyIsEmpty); + + auto emp_thrower = [](absl::any* ap) { ap->emplace<Thrower>(2); }; + auto emp_throwervec = [](absl::any* ap) { + std::initializer_list<Thrower> il{Thrower(2, testing::nothrow_ctor)}; + ap->emplace<ThrowerVec>(il); + }; + auto emp_movethrower = [](absl::any* ap) { + ap->emplace<NoThrowMoveThrower>(2); + }; + + EXPECT_TRUE(one_tester.Test(emp_thrower)); + EXPECT_TRUE(one_tester.Test(emp_throwervec)); + EXPECT_TRUE(one_tester.Test(emp_movethrower)); + + auto empty_tester = one_tester.WithInitialValue(absl::any{}); + + EXPECT_TRUE(empty_tester.Test(emp_thrower)); + EXPECT_TRUE(empty_tester.Test(emp_throwervec)); +} + +} // namespace + +#endif // #if !defined(ABSL_USES_STD_ANY) && defined(ABSL_HAVE_EXCEPTIONS) diff --git a/third_party/abseil_cpp/absl/types/any_test.cc b/third_party/abseil_cpp/absl/types/any_test.cc new file mode 100644 index 0000000000..70e4ba22b1 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/any_test.cc @@ -0,0 +1,781 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/any.h" + +// This test is a no-op when absl::any is an alias for std::any. +#if !defined(ABSL_USES_STD_ANY) + +#include <initializer_list> +#include <type_traits> +#include <utility> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/base/config.h" +#include "absl/base/internal/exception_testing.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/container/internal/test_instance_tracker.h" + +namespace { +using absl::test_internal::CopyableOnlyInstance; +using absl::test_internal::InstanceTracker; + +template <typename T> +const T& AsConst(const T& t) { + return t; +} + +struct MoveOnly { + MoveOnly() = default; + explicit MoveOnly(int value) : value(value) {} + MoveOnly(MoveOnly&&) = default; + MoveOnly& operator=(MoveOnly&&) = default; + + int value = 0; +}; + +struct CopyOnly { + CopyOnly() = default; + explicit CopyOnly(int value) : value(value) {} + CopyOnly(CopyOnly&&) = delete; + CopyOnly& operator=(CopyOnly&&) = delete; + CopyOnly(const CopyOnly&) = default; + CopyOnly& operator=(const CopyOnly&) = default; + + int value = 0; +}; + +struct MoveOnlyWithListConstructor { + MoveOnlyWithListConstructor() = default; + explicit MoveOnlyWithListConstructor(std::initializer_list<int> /*ilist*/, + int value) + : value(value) {} + MoveOnlyWithListConstructor(MoveOnlyWithListConstructor&&) = default; + MoveOnlyWithListConstructor& operator=(MoveOnlyWithListConstructor&&) = + default; + + int value = 0; +}; + +struct IntMoveOnlyCopyOnly { + IntMoveOnlyCopyOnly(int value, MoveOnly /*move_only*/, CopyOnly /*copy_only*/) + : value(value) {} + + int value; +}; + +struct ListMoveOnlyCopyOnly { + ListMoveOnlyCopyOnly(std::initializer_list<int> ilist, MoveOnly /*move_only*/, + CopyOnly /*copy_only*/) + : values(ilist) {} + + std::vector<int> values; +}; + +using FunctionType = void(); +void FunctionToEmplace() {} + +using ArrayType = int[2]; +using DecayedArray = absl::decay_t<ArrayType>; + +TEST(AnyTest, Noexcept) { + static_assert(std::is_nothrow_default_constructible<absl::any>(), ""); + static_assert(std::is_nothrow_move_constructible<absl::any>(), ""); + static_assert(std::is_nothrow_move_assignable<absl::any>(), ""); + static_assert(noexcept(std::declval<absl::any&>().has_value()), ""); + static_assert(noexcept(std::declval<absl::any&>().type()), ""); + static_assert(noexcept(absl::any_cast<int>(std::declval<absl::any*>())), ""); + static_assert( + noexcept(std::declval<absl::any&>().swap(std::declval<absl::any&>())), + ""); + + using std::swap; + static_assert( + noexcept(swap(std::declval<absl::any&>(), std::declval<absl::any&>())), + ""); +} + +TEST(AnyTest, HasValue) { + absl::any o; + EXPECT_FALSE(o.has_value()); + o.emplace<int>(); + EXPECT_TRUE(o.has_value()); + o.reset(); + EXPECT_FALSE(o.has_value()); +} + +TEST(AnyTest, Type) { + absl::any o; + EXPECT_EQ(typeid(void), o.type()); + o.emplace<int>(5); + EXPECT_EQ(typeid(int), o.type()); + o.emplace<float>(5.f); + EXPECT_EQ(typeid(float), o.type()); + o.reset(); + EXPECT_EQ(typeid(void), o.type()); +} + +TEST(AnyTest, EmptyPointerCast) { + // pointer-to-unqualified overload + { + absl::any o; + EXPECT_EQ(nullptr, absl::any_cast<int>(&o)); + o.emplace<int>(); + EXPECT_NE(nullptr, absl::any_cast<int>(&o)); + o.reset(); + EXPECT_EQ(nullptr, absl::any_cast<int>(&o)); + } + + // pointer-to-const overload + { + absl::any o; + EXPECT_EQ(nullptr, absl::any_cast<int>(&AsConst(o))); + o.emplace<int>(); + EXPECT_NE(nullptr, absl::any_cast<int>(&AsConst(o))); + o.reset(); + EXPECT_EQ(nullptr, absl::any_cast<int>(&AsConst(o))); + } +} + +TEST(AnyTest, InPlaceConstruction) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type_t<IntMoveOnlyCopyOnly>(), 5, MoveOnly(), + copy_only); + IntMoveOnlyCopyOnly& v = absl::any_cast<IntMoveOnlyCopyOnly&>(o); + EXPECT_EQ(5, v.value); +} + +TEST(AnyTest, InPlaceConstructionVariableTemplate) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type<IntMoveOnlyCopyOnly>, 5, MoveOnly(), + copy_only); + auto& v = absl::any_cast<IntMoveOnlyCopyOnly&>(o); + EXPECT_EQ(5, v.value); +} + +TEST(AnyTest, InPlaceConstructionWithCV) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type_t<const volatile IntMoveOnlyCopyOnly>(), 5, + MoveOnly(), copy_only); + IntMoveOnlyCopyOnly& v = absl::any_cast<IntMoveOnlyCopyOnly&>(o); + EXPECT_EQ(5, v.value); +} + +TEST(AnyTest, InPlaceConstructionWithCVVariableTemplate) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type<const volatile IntMoveOnlyCopyOnly>, 5, + MoveOnly(), copy_only); + auto& v = absl::any_cast<IntMoveOnlyCopyOnly&>(o); + EXPECT_EQ(5, v.value); +} + +TEST(AnyTest, InPlaceConstructionWithFunction) { + absl::any o(absl::in_place_type_t<FunctionType>(), FunctionToEmplace); + FunctionType*& construction_result = absl::any_cast<FunctionType*&>(o); + EXPECT_EQ(&FunctionToEmplace, construction_result); +} + +TEST(AnyTest, InPlaceConstructionWithFunctionVariableTemplate) { + absl::any o(absl::in_place_type<FunctionType>, FunctionToEmplace); + auto& construction_result = absl::any_cast<FunctionType*&>(o); + EXPECT_EQ(&FunctionToEmplace, construction_result); +} + +TEST(AnyTest, InPlaceConstructionWithArray) { + ArrayType ar = {5, 42}; + absl::any o(absl::in_place_type_t<ArrayType>(), ar); + DecayedArray& construction_result = absl::any_cast<DecayedArray&>(o); + EXPECT_EQ(&ar[0], construction_result); +} + +TEST(AnyTest, InPlaceConstructionWithArrayVariableTemplate) { + ArrayType ar = {5, 42}; + absl::any o(absl::in_place_type<ArrayType>, ar); + auto& construction_result = absl::any_cast<DecayedArray&>(o); + EXPECT_EQ(&ar[0], construction_result); +} + +TEST(AnyTest, InPlaceConstructionIlist) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type_t<ListMoveOnlyCopyOnly>(), {1, 2, 3, 4}, + MoveOnly(), copy_only); + ListMoveOnlyCopyOnly& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + std::vector<int> expected_values = {1, 2, 3, 4}; + EXPECT_EQ(expected_values, v.values); +} + +TEST(AnyTest, InPlaceConstructionIlistVariableTemplate) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type<ListMoveOnlyCopyOnly>, {1, 2, 3, 4}, + MoveOnly(), copy_only); + auto& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + std::vector<int> expected_values = {1, 2, 3, 4}; + EXPECT_EQ(expected_values, v.values); +} + +TEST(AnyTest, InPlaceConstructionIlistWithCV) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type_t<const volatile ListMoveOnlyCopyOnly>(), + {1, 2, 3, 4}, MoveOnly(), copy_only); + ListMoveOnlyCopyOnly& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + std::vector<int> expected_values = {1, 2, 3, 4}; + EXPECT_EQ(expected_values, v.values); +} + +TEST(AnyTest, InPlaceConstructionIlistWithCVVariableTemplate) { + const CopyOnly copy_only{}; + absl::any o(absl::in_place_type<const volatile ListMoveOnlyCopyOnly>, + {1, 2, 3, 4}, MoveOnly(), copy_only); + auto& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + std::vector<int> expected_values = {1, 2, 3, 4}; + EXPECT_EQ(expected_values, v.values); +} + +TEST(AnyTest, InPlaceNoArgs) { + absl::any o(absl::in_place_type_t<int>{}); + EXPECT_EQ(0, absl::any_cast<int&>(o)); +} + +TEST(AnyTest, InPlaceNoArgsVariableTemplate) { + absl::any o(absl::in_place_type<int>); + EXPECT_EQ(0, absl::any_cast<int&>(o)); +} + +template <typename Enabler, typename T, typename... Args> +struct CanEmplaceAnyImpl : std::false_type {}; + +template <typename T, typename... Args> +struct CanEmplaceAnyImpl< + absl::void_t<decltype( + std::declval<absl::any&>().emplace<T>(std::declval<Args>()...))>, + T, Args...> : std::true_type {}; + +template <typename T, typename... Args> +using CanEmplaceAny = CanEmplaceAnyImpl<void, T, Args...>; + +TEST(AnyTest, Emplace) { + const CopyOnly copy_only{}; + absl::any o; + EXPECT_TRUE((std::is_same<decltype(o.emplace<IntMoveOnlyCopyOnly>( + 5, MoveOnly(), copy_only)), + IntMoveOnlyCopyOnly&>::value)); + IntMoveOnlyCopyOnly& emplace_result = + o.emplace<IntMoveOnlyCopyOnly>(5, MoveOnly(), copy_only); + EXPECT_EQ(5, emplace_result.value); + IntMoveOnlyCopyOnly& v = absl::any_cast<IntMoveOnlyCopyOnly&>(o); + EXPECT_EQ(5, v.value); + EXPECT_EQ(&emplace_result, &v); + + static_assert(!CanEmplaceAny<int, int, int>::value, ""); + static_assert(!CanEmplaceAny<MoveOnly, MoveOnly>::value, ""); +} + +TEST(AnyTest, EmplaceWithCV) { + const CopyOnly copy_only{}; + absl::any o; + EXPECT_TRUE( + (std::is_same<decltype(o.emplace<const volatile IntMoveOnlyCopyOnly>( + 5, MoveOnly(), copy_only)), + IntMoveOnlyCopyOnly&>::value)); + IntMoveOnlyCopyOnly& emplace_result = + o.emplace<const volatile IntMoveOnlyCopyOnly>(5, MoveOnly(), copy_only); + EXPECT_EQ(5, emplace_result.value); + IntMoveOnlyCopyOnly& v = absl::any_cast<IntMoveOnlyCopyOnly&>(o); + EXPECT_EQ(5, v.value); + EXPECT_EQ(&emplace_result, &v); +} + +TEST(AnyTest, EmplaceWithFunction) { + absl::any o; + EXPECT_TRUE( + (std::is_same<decltype(o.emplace<FunctionType>(FunctionToEmplace)), + FunctionType*&>::value)); + FunctionType*& emplace_result = o.emplace<FunctionType>(FunctionToEmplace); + EXPECT_EQ(&FunctionToEmplace, emplace_result); +} + +TEST(AnyTest, EmplaceWithArray) { + absl::any o; + ArrayType ar = {5, 42}; + EXPECT_TRUE( + (std::is_same<decltype(o.emplace<ArrayType>(ar)), DecayedArray&>::value)); + DecayedArray& emplace_result = o.emplace<ArrayType>(ar); + EXPECT_EQ(&ar[0], emplace_result); +} + +TEST(AnyTest, EmplaceIlist) { + const CopyOnly copy_only{}; + absl::any o; + EXPECT_TRUE((std::is_same<decltype(o.emplace<ListMoveOnlyCopyOnly>( + {1, 2, 3, 4}, MoveOnly(), copy_only)), + ListMoveOnlyCopyOnly&>::value)); + ListMoveOnlyCopyOnly& emplace_result = + o.emplace<ListMoveOnlyCopyOnly>({1, 2, 3, 4}, MoveOnly(), copy_only); + ListMoveOnlyCopyOnly& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + EXPECT_EQ(&v, &emplace_result); + std::vector<int> expected_values = {1, 2, 3, 4}; + EXPECT_EQ(expected_values, v.values); + + static_assert(!CanEmplaceAny<int, std::initializer_list<int>>::value, ""); + static_assert(!CanEmplaceAny<MoveOnlyWithListConstructor, + std::initializer_list<int>, int>::value, + ""); +} + +TEST(AnyTest, EmplaceIlistWithCV) { + const CopyOnly copy_only{}; + absl::any o; + EXPECT_TRUE( + (std::is_same<decltype(o.emplace<const volatile ListMoveOnlyCopyOnly>( + {1, 2, 3, 4}, MoveOnly(), copy_only)), + ListMoveOnlyCopyOnly&>::value)); + ListMoveOnlyCopyOnly& emplace_result = + o.emplace<const volatile ListMoveOnlyCopyOnly>({1, 2, 3, 4}, MoveOnly(), + copy_only); + ListMoveOnlyCopyOnly& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + EXPECT_EQ(&v, &emplace_result); + std::vector<int> expected_values = {1, 2, 3, 4}; + EXPECT_EQ(expected_values, v.values); +} + +TEST(AnyTest, EmplaceNoArgs) { + absl::any o; + o.emplace<int>(); + EXPECT_EQ(0, absl::any_cast<int>(o)); +} + +TEST(AnyTest, ConversionConstruction) { + { + absl::any o = 5; + EXPECT_EQ(5, absl::any_cast<int>(o)); + } + + { + const CopyOnly copy_only(5); + absl::any o = copy_only; + EXPECT_EQ(5, absl::any_cast<CopyOnly&>(o).value); + } + + static_assert(!std::is_convertible<MoveOnly, absl::any>::value, ""); +} + +TEST(AnyTest, ConversionAssignment) { + { + absl::any o; + o = 5; + EXPECT_EQ(5, absl::any_cast<int>(o)); + } + + { + const CopyOnly copy_only(5); + absl::any o; + o = copy_only; + EXPECT_EQ(5, absl::any_cast<CopyOnly&>(o).value); + } + + static_assert(!std::is_assignable<MoveOnly, absl::any>::value, ""); +} + +// Suppress MSVC warnings. +// 4521: multiple copy constructors specified +// We wrote multiple of them to test that the correct overloads are selected. +#ifdef _MSC_VER +#pragma warning( push ) +#pragma warning( disable : 4521) +#endif + +// Weird type for testing, only used to make sure we "properly" perfect-forward +// when being placed into an absl::any (use the l-value constructor if given an +// l-value rather than use the copy constructor). +struct WeirdConstructor42 { + explicit WeirdConstructor42(int value) : value(value) {} + + // Copy-constructor + WeirdConstructor42(const WeirdConstructor42& other) : value(other.value) {} + + // L-value "weird" constructor (used when given an l-value) + WeirdConstructor42( + WeirdConstructor42& /*other*/) // NOLINT(runtime/references) + : value(42) {} + + int value; +}; +#ifdef _MSC_VER +#pragma warning( pop ) +#endif + +TEST(AnyTest, WeirdConversionConstruction) { + { + const WeirdConstructor42 source(5); + absl::any o = source; // Actual copy + EXPECT_EQ(5, absl::any_cast<WeirdConstructor42&>(o).value); + } + + { + WeirdConstructor42 source(5); + absl::any o = source; // Weird "conversion" + EXPECT_EQ(42, absl::any_cast<WeirdConstructor42&>(o).value); + } +} + +TEST(AnyTest, WeirdConversionAssignment) { + { + const WeirdConstructor42 source(5); + absl::any o; + o = source; // Actual copy + EXPECT_EQ(5, absl::any_cast<WeirdConstructor42&>(o).value); + } + + { + WeirdConstructor42 source(5); + absl::any o; + o = source; // Weird "conversion" + EXPECT_EQ(42, absl::any_cast<WeirdConstructor42&>(o).value); + } +} + +struct Value {}; + +TEST(AnyTest, AnyCastValue) { + { + absl::any o; + o.emplace<int>(5); + EXPECT_EQ(5, absl::any_cast<int>(o)); + EXPECT_EQ(5, absl::any_cast<int>(AsConst(o))); + static_assert( + std::is_same<decltype(absl::any_cast<Value>(o)), Value>::value, ""); + } + + { + absl::any o; + o.emplace<int>(5); + EXPECT_EQ(5, absl::any_cast<const int>(o)); + EXPECT_EQ(5, absl::any_cast<const int>(AsConst(o))); + static_assert(std::is_same<decltype(absl::any_cast<const Value>(o)), + const Value>::value, + ""); + } +} + +TEST(AnyTest, AnyCastReference) { + { + absl::any o; + o.emplace<int>(5); + EXPECT_EQ(5, absl::any_cast<int&>(o)); + EXPECT_EQ(5, absl::any_cast<const int&>(AsConst(o))); + static_assert( + std::is_same<decltype(absl::any_cast<Value&>(o)), Value&>::value, ""); + } + + { + absl::any o; + o.emplace<int>(5); + EXPECT_EQ(5, absl::any_cast<const int>(o)); + EXPECT_EQ(5, absl::any_cast<const int>(AsConst(o))); + static_assert(std::is_same<decltype(absl::any_cast<const Value&>(o)), + const Value&>::value, + ""); + } + + { + absl::any o; + o.emplace<int>(5); + EXPECT_EQ(5, absl::any_cast<int&&>(std::move(o))); + static_assert(std::is_same<decltype(absl::any_cast<Value&&>(std::move(o))), + Value&&>::value, + ""); + } + + { + absl::any o; + o.emplace<int>(5); + EXPECT_EQ(5, absl::any_cast<const int>(std::move(o))); + static_assert( + std::is_same<decltype(absl::any_cast<const Value&&>(std::move(o))), + const Value&&>::value, + ""); + } +} + +TEST(AnyTest, AnyCastPointer) { + { + absl::any o; + EXPECT_EQ(nullptr, absl::any_cast<char>(&o)); + o.emplace<int>(5); + EXPECT_EQ(nullptr, absl::any_cast<char>(&o)); + o.emplace<char>('a'); + EXPECT_EQ('a', *absl::any_cast<char>(&o)); + static_assert( + std::is_same<decltype(absl::any_cast<Value>(&o)), Value*>::value, ""); + } + + { + absl::any o; + EXPECT_EQ(nullptr, absl::any_cast<const char>(&o)); + o.emplace<int>(5); + EXPECT_EQ(nullptr, absl::any_cast<const char>(&o)); + o.emplace<char>('a'); + EXPECT_EQ('a', *absl::any_cast<const char>(&o)); + static_assert(std::is_same<decltype(absl::any_cast<const Value>(&o)), + const Value*>::value, + ""); + } +} + +TEST(AnyTest, MakeAny) { + const CopyOnly copy_only{}; + auto o = absl::make_any<IntMoveOnlyCopyOnly>(5, MoveOnly(), copy_only); + static_assert(std::is_same<decltype(o), absl::any>::value, ""); + EXPECT_EQ(5, absl::any_cast<IntMoveOnlyCopyOnly&>(o).value); +} + +TEST(AnyTest, MakeAnyIList) { + const CopyOnly copy_only{}; + auto o = + absl::make_any<ListMoveOnlyCopyOnly>({1, 2, 3}, MoveOnly(), copy_only); + static_assert(std::is_same<decltype(o), absl::any>::value, ""); + ListMoveOnlyCopyOnly& v = absl::any_cast<ListMoveOnlyCopyOnly&>(o); + std::vector<int> expected_values = {1, 2, 3}; + EXPECT_EQ(expected_values, v.values); +} + +// Test the use of copy constructor and operator= +TEST(AnyTest, Copy) { + InstanceTracker tracker_raii; + + { + absl::any o(absl::in_place_type<CopyableOnlyInstance>, 123); + CopyableOnlyInstance* f1 = absl::any_cast<CopyableOnlyInstance>(&o); + + absl::any o2(o); + const CopyableOnlyInstance* f2 = absl::any_cast<CopyableOnlyInstance>(&o2); + EXPECT_EQ(123, f2->value()); + EXPECT_NE(f1, f2); + + absl::any o3; + o3 = o2; + const CopyableOnlyInstance* f3 = absl::any_cast<CopyableOnlyInstance>(&o3); + EXPECT_EQ(123, f3->value()); + EXPECT_NE(f2, f3); + + const absl::any o4(4); + // copy construct from const lvalue ref. + absl::any o5 = o4; + EXPECT_EQ(4, absl::any_cast<int>(o4)); + EXPECT_EQ(4, absl::any_cast<int>(o5)); + + // Copy construct from const rvalue ref. + absl::any o6 = std::move(o4); // NOLINT + EXPECT_EQ(4, absl::any_cast<int>(o4)); + EXPECT_EQ(4, absl::any_cast<int>(o6)); + } +} + +TEST(AnyTest, Move) { + InstanceTracker tracker_raii; + + absl::any any1; + any1.emplace<CopyableOnlyInstance>(5); + + // This is a copy, so copy count increases to 1. + absl::any any2 = any1; + EXPECT_EQ(5, absl::any_cast<CopyableOnlyInstance&>(any1).value()); + EXPECT_EQ(5, absl::any_cast<CopyableOnlyInstance&>(any2).value()); + EXPECT_EQ(1, tracker_raii.copies()); + + // This isn't a copy, so copy count doesn't increase. + absl::any any3 = std::move(any2); + EXPECT_EQ(5, absl::any_cast<CopyableOnlyInstance&>(any3).value()); + EXPECT_EQ(1, tracker_raii.copies()); + + absl::any any4; + any4 = std::move(any3); + EXPECT_EQ(5, absl::any_cast<CopyableOnlyInstance&>(any4).value()); + EXPECT_EQ(1, tracker_raii.copies()); + + absl::any tmp4(4); + absl::any o4(std::move(tmp4)); // move construct + EXPECT_EQ(4, absl::any_cast<int>(o4)); + o4 = *&o4; // self assign + EXPECT_EQ(4, absl::any_cast<int>(o4)); + EXPECT_TRUE(o4.has_value()); + + absl::any o5; + absl::any tmp5(5); + o5 = std::move(tmp5); // move assign + EXPECT_EQ(5, absl::any_cast<int>(o5)); +} + +// Reset the ObjectOwner with an object of a different type +TEST(AnyTest, Reset) { + absl::any o; + o.emplace<int>(); + + o.reset(); + EXPECT_FALSE(o.has_value()); + + o.emplace<char>(); + EXPECT_TRUE(o.has_value()); +} + +TEST(AnyTest, ConversionConstructionCausesOneCopy) { + InstanceTracker tracker_raii; + CopyableOnlyInstance counter(5); + absl::any o(counter); + EXPECT_EQ(5, absl::any_cast<CopyableOnlyInstance&>(o).value()); + EXPECT_EQ(1, tracker_raii.copies()); +} + +////////////////////////////////// +// Tests for Exception Behavior // +////////////////////////////////// + +#if defined(ABSL_USES_STD_ANY) + +// If using a std `any` implementation, we can't check for a specific message. +#define ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(...) \ + ABSL_BASE_INTERNAL_EXPECT_FAIL((__VA_ARGS__), absl::bad_any_cast, \ + "") + +#else + +// If using the absl `any` implementation, we can rely on a specific message. +#define ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(...) \ + ABSL_BASE_INTERNAL_EXPECT_FAIL((__VA_ARGS__), absl::bad_any_cast, \ + "Bad any cast") + +#endif // defined(ABSL_USES_STD_ANY) + +TEST(AnyTest, ThrowBadAlloc) { + { + absl::any a; + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<int&>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const int&>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<int&&>(absl::any{})); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const int&&>(absl::any{})); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<int>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const int>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<int>(absl::any{})); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const int>(absl::any{})); + + // const absl::any operand + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const int&>(AsConst(a))); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<int>(AsConst(a))); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const int>(AsConst(a))); + } + + { + absl::any a(absl::in_place_type<int>); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<float&>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const float&>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<float&&>(absl::any{})); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST( + absl::any_cast<const float&&>(absl::any{})); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<float>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const float>(a)); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<float>(absl::any{})); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const float>(absl::any{})); + + // const absl::any operand + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const float&>(AsConst(a))); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<float>(AsConst(a))); + ABSL_ANY_TEST_EXPECT_BAD_ANY_CAST(absl::any_cast<const float>(AsConst(a))); + } +} + +class BadCopy {}; + +struct BadCopyable { + BadCopyable() = default; + BadCopyable(BadCopyable&&) = default; + BadCopyable(const BadCopyable&) { +#ifdef ABSL_HAVE_EXCEPTIONS + throw BadCopy(); +#else + ABSL_RAW_LOG(FATAL, "Bad copy"); +#endif + } +}; + +#define ABSL_ANY_TEST_EXPECT_BAD_COPY(...) \ + ABSL_BASE_INTERNAL_EXPECT_FAIL((__VA_ARGS__), BadCopy, "Bad copy") + +// Test the guarantees regarding exceptions in copy/assign. +TEST(AnyTest, FailedCopy) { + { + const BadCopyable bad{}; + ABSL_ANY_TEST_EXPECT_BAD_COPY(absl::any{bad}); + } + + { + absl::any src(absl::in_place_type<BadCopyable>); + ABSL_ANY_TEST_EXPECT_BAD_COPY(absl::any{src}); + } + + { + BadCopyable bad; + absl::any target; + ABSL_ANY_TEST_EXPECT_BAD_COPY(target = bad); + } + + { + BadCopyable bad; + absl::any target(absl::in_place_type<BadCopyable>); + ABSL_ANY_TEST_EXPECT_BAD_COPY(target = bad); + EXPECT_TRUE(target.has_value()); + } + + { + absl::any src(absl::in_place_type<BadCopyable>); + absl::any target; + ABSL_ANY_TEST_EXPECT_BAD_COPY(target = src); + EXPECT_FALSE(target.has_value()); + } + + { + absl::any src(absl::in_place_type<BadCopyable>); + absl::any target(absl::in_place_type<BadCopyable>); + ABSL_ANY_TEST_EXPECT_BAD_COPY(target = src); + EXPECT_TRUE(target.has_value()); + } +} + +// Test the guarantees regarding exceptions in emplace. +TEST(AnyTest, FailedEmplace) { + { + BadCopyable bad; + absl::any target; + ABSL_ANY_TEST_EXPECT_BAD_COPY(target.emplace<BadCopyable>(bad)); + } + + { + BadCopyable bad; + absl::any target(absl::in_place_type<int>); + ABSL_ANY_TEST_EXPECT_BAD_COPY(target.emplace<BadCopyable>(bad)); +#if defined(ABSL_USES_STD_ANY) && defined(__GLIBCXX__) + // libstdc++ std::any::emplace() implementation (as of 7.2) has a bug: if an + // exception is thrown, *this contains a value. +#define ABSL_GLIBCXX_ANY_EMPLACE_EXCEPTION_BUG 1 +#endif +#if defined(ABSL_HAVE_EXCEPTIONS) && \ + !defined(ABSL_GLIBCXX_ANY_EMPLACE_EXCEPTION_BUG) + EXPECT_FALSE(target.has_value()); +#endif + } +} + +} // namespace + +#endif // #if !defined(ABSL_USES_STD_ANY) diff --git a/third_party/abseil_cpp/absl/types/bad_any_cast.cc b/third_party/abseil_cpp/absl/types/bad_any_cast.cc new file mode 100644 index 0000000000..b0592cc9bc --- /dev/null +++ b/third_party/abseil_cpp/absl/types/bad_any_cast.cc @@ -0,0 +1,46 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/bad_any_cast.h" + +#ifndef ABSL_USES_STD_ANY + +#include <cstdlib> + +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +bad_any_cast::~bad_any_cast() = default; + +const char* bad_any_cast::what() const noexcept { return "Bad any cast"; } + +namespace any_internal { + +void ThrowBadAnyCast() { +#ifdef ABSL_HAVE_EXCEPTIONS + throw bad_any_cast(); +#else + ABSL_RAW_LOG(FATAL, "Bad any cast"); + std::abort(); +#endif +} + +} // namespace any_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_ANY diff --git a/third_party/abseil_cpp/absl/types/bad_any_cast.h b/third_party/abseil_cpp/absl/types/bad_any_cast.h new file mode 100644 index 0000000000..114cef80cd --- /dev/null +++ b/third_party/abseil_cpp/absl/types/bad_any_cast.h @@ -0,0 +1,75 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// bad_any_cast.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::bad_any_cast` type. + +#ifndef ABSL_TYPES_BAD_ANY_CAST_H_ +#define ABSL_TYPES_BAD_ANY_CAST_H_ + +#include <typeinfo> + +#include "absl/base/config.h" + +#ifdef ABSL_USES_STD_ANY + +#include <any> + +namespace absl { +ABSL_NAMESPACE_BEGIN +using std::bad_any_cast; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_ANY + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// bad_any_cast +// ----------------------------------------------------------------------------- +// +// An `absl::bad_any_cast` type is an exception type that is thrown when +// failing to successfully cast the return value of an `absl::any` object. +// +// Example: +// +// auto a = absl::any(65); +// absl::any_cast<int>(a); // 65 +// try { +// absl::any_cast<char>(a); +// } catch(const absl::bad_any_cast& e) { +// std::cout << "Bad any cast: " << e.what() << '\n'; +// } +class bad_any_cast : public std::bad_cast { + public: + ~bad_any_cast() override; + const char* what() const noexcept override; +}; + +namespace any_internal { + +[[noreturn]] void ThrowBadAnyCast(); + +} // namespace any_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_ANY + +#endif // ABSL_TYPES_BAD_ANY_CAST_H_ diff --git a/third_party/abseil_cpp/absl/types/bad_optional_access.cc b/third_party/abseil_cpp/absl/types/bad_optional_access.cc new file mode 100644 index 0000000000..26aca70d9c --- /dev/null +++ b/third_party/abseil_cpp/absl/types/bad_optional_access.cc @@ -0,0 +1,48 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/bad_optional_access.h" + +#ifndef ABSL_USES_STD_OPTIONAL + +#include <cstdlib> + +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +bad_optional_access::~bad_optional_access() = default; + +const char* bad_optional_access::what() const noexcept { + return "optional has no value"; +} + +namespace optional_internal { + +void throw_bad_optional_access() { +#ifdef ABSL_HAVE_EXCEPTIONS + throw bad_optional_access(); +#else + ABSL_RAW_LOG(FATAL, "Bad optional access"); + abort(); +#endif +} + +} // namespace optional_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_OPTIONAL diff --git a/third_party/abseil_cpp/absl/types/bad_optional_access.h b/third_party/abseil_cpp/absl/types/bad_optional_access.h new file mode 100644 index 0000000000..a500286adc --- /dev/null +++ b/third_party/abseil_cpp/absl/types/bad_optional_access.h @@ -0,0 +1,78 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// bad_optional_access.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::bad_optional_access` type. + +#ifndef ABSL_TYPES_BAD_OPTIONAL_ACCESS_H_ +#define ABSL_TYPES_BAD_OPTIONAL_ACCESS_H_ + +#include <stdexcept> + +#include "absl/base/config.h" + +#ifdef ABSL_USES_STD_OPTIONAL + +#include <optional> + +namespace absl { +ABSL_NAMESPACE_BEGIN +using std::bad_optional_access; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_OPTIONAL + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// bad_optional_access +// ----------------------------------------------------------------------------- +// +// An `absl::bad_optional_access` type is an exception type that is thrown when +// attempting to access an `absl::optional` object that does not contain a +// value. +// +// Example: +// +// absl::optional<int> o; +// +// try { +// int n = o.value(); +// } catch(const absl::bad_optional_access& e) { +// std::cout << "Bad optional access: " << e.what() << '\n'; +// } +class bad_optional_access : public std::exception { + public: + bad_optional_access() = default; + ~bad_optional_access() override; + const char* what() const noexcept override; +}; + +namespace optional_internal { + +// throw delegator +[[noreturn]] void throw_bad_optional_access(); + +} // namespace optional_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_OPTIONAL + +#endif // ABSL_TYPES_BAD_OPTIONAL_ACCESS_H_ diff --git a/third_party/abseil_cpp/absl/types/bad_variant_access.cc b/third_party/abseil_cpp/absl/types/bad_variant_access.cc new file mode 100644 index 0000000000..3dc88cc09f --- /dev/null +++ b/third_party/abseil_cpp/absl/types/bad_variant_access.cc @@ -0,0 +1,64 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/bad_variant_access.h" + +#ifndef ABSL_USES_STD_VARIANT + +#include <cstdlib> +#include <stdexcept> + +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +////////////////////////// +// [variant.bad.access] // +////////////////////////// + +bad_variant_access::~bad_variant_access() = default; + +const char* bad_variant_access::what() const noexcept { + return "Bad variant access"; +} + +namespace variant_internal { + +void ThrowBadVariantAccess() { +#ifdef ABSL_HAVE_EXCEPTIONS + throw bad_variant_access(); +#else + ABSL_RAW_LOG(FATAL, "Bad variant access"); + abort(); // TODO(calabrese) Remove once RAW_LOG FATAL is noreturn. +#endif +} + +void Rethrow() { +#ifdef ABSL_HAVE_EXCEPTIONS + throw; +#else + ABSL_RAW_LOG(FATAL, + "Internal error in absl::variant implementation. Attempted to " + "rethrow an exception when building with exceptions disabled."); + abort(); // TODO(calabrese) Remove once RAW_LOG FATAL is noreturn. +#endif +} + +} // namespace variant_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_VARIANT diff --git a/third_party/abseil_cpp/absl/types/bad_variant_access.h b/third_party/abseil_cpp/absl/types/bad_variant_access.h new file mode 100644 index 0000000000..095969f91e --- /dev/null +++ b/third_party/abseil_cpp/absl/types/bad_variant_access.h @@ -0,0 +1,82 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// bad_variant_access.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::bad_variant_access` type. + +#ifndef ABSL_TYPES_BAD_VARIANT_ACCESS_H_ +#define ABSL_TYPES_BAD_VARIANT_ACCESS_H_ + +#include <stdexcept> + +#include "absl/base/config.h" + +#ifdef ABSL_USES_STD_VARIANT + +#include <variant> + +namespace absl { +ABSL_NAMESPACE_BEGIN +using std::bad_variant_access; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_VARIANT + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// bad_variant_access +// ----------------------------------------------------------------------------- +// +// An `absl::bad_variant_access` type is an exception type that is thrown in +// the following cases: +// +// * Calling `absl::get(absl::variant) with an index or type that does not +// match the currently selected alternative type +// * Calling `absl::visit on an `absl::variant` that is in the +// `variant::valueless_by_exception` state. +// +// Example: +// +// absl::variant<int, std::string> v; +// v = 1; +// try { +// absl::get<std::string>(v); +// } catch(const absl::bad_variant_access& e) { +// std::cout << "Bad variant access: " << e.what() << '\n'; +// } +class bad_variant_access : public std::exception { + public: + bad_variant_access() noexcept = default; + ~bad_variant_access() override; + const char* what() const noexcept override; +}; + +namespace variant_internal { + +[[noreturn]] void ThrowBadVariantAccess(); +[[noreturn]] void Rethrow(); + +} // namespace variant_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_USES_STD_VARIANT + +#endif // ABSL_TYPES_BAD_VARIANT_ACCESS_H_ diff --git a/third_party/abseil_cpp/absl/types/compare.h b/third_party/abseil_cpp/absl/types/compare.h new file mode 100644 index 0000000000..62ca70f9a7 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/compare.h @@ -0,0 +1,598 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// compare.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::weak_equality`, `absl::strong_equality`, +// `absl::partial_ordering`, `absl::weak_ordering`, and `absl::strong_ordering` +// types for storing the results of three way comparisons. +// +// Example: +// absl::weak_ordering compare(const std::string& a, const std::string& b); +// +// These are C++11 compatible versions of the C++20 corresponding types +// (`std::weak_equality`, etc.) and are designed to be drop-in replacements +// for code compliant with C++20. + +#ifndef ABSL_TYPES_COMPARE_H_ +#define ABSL_TYPES_COMPARE_H_ + +#include <cstddef> +#include <cstdint> +#include <cstdlib> +#include <type_traits> + +#include "absl/base/attributes.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace compare_internal { + +using value_type = int8_t; + +template <typename T> +struct Fail { + static_assert(sizeof(T) < 0, "Only literal `0` is allowed."); +}; + +// We need the NullPtrT template to avoid triggering the modernize-use-nullptr +// ClangTidy warning in user code. +template <typename NullPtrT = std::nullptr_t> +struct OnlyLiteralZero { + constexpr OnlyLiteralZero(NullPtrT) noexcept {} // NOLINT + + // Fails compilation when `nullptr` or integral type arguments other than + // `int` are passed. This constructor doesn't accept `int` because literal `0` + // has type `int`. Literal `0` arguments will be implicitly converted to + // `std::nullptr_t` and accepted by the above constructor, while other `int` + // arguments will fail to be converted and cause compilation failure. + template < + typename T, + typename = typename std::enable_if< + std::is_same<T, std::nullptr_t>::value || + (std::is_integral<T>::value && !std::is_same<T, int>::value)>::type, + typename = typename Fail<T>::type> + OnlyLiteralZero(T); // NOLINT +}; + +enum class eq : value_type { + equal = 0, + equivalent = equal, + nonequal = 1, + nonequivalent = nonequal, +}; + +enum class ord : value_type { less = -1, greater = 1 }; + +enum class ncmp : value_type { unordered = -127 }; + +// Define macros to allow for creation or emulation of C++17 inline variables +// based on whether the feature is supported. Note: we can't use +// ABSL_INTERNAL_INLINE_CONSTEXPR here because the variables here are of +// incomplete types so they need to be defined after the types are complete. +#ifdef __cpp_inline_variables + +#define ABSL_COMPARE_INLINE_BASECLASS_DECL(name) + +#define ABSL_COMPARE_INLINE_SUBCLASS_DECL(type, name) \ + static const type name + +#define ABSL_COMPARE_INLINE_INIT(type, name, init) \ + inline constexpr type type::name(init) + +#else // __cpp_inline_variables + +#define ABSL_COMPARE_INLINE_BASECLASS_DECL(name) \ + ABSL_CONST_INIT static const T name + +#define ABSL_COMPARE_INLINE_SUBCLASS_DECL(type, name) + +#define ABSL_COMPARE_INLINE_INIT(type, name, init) \ + template <typename T> \ + const T compare_internal::type##_base<T>::name(init) + +#endif // __cpp_inline_variables + +// These template base classes allow for defining the values of the constants +// in the header file (for performance) without using inline variables (which +// aren't available in C++11). +template <typename T> +struct weak_equality_base { + ABSL_COMPARE_INLINE_BASECLASS_DECL(equivalent); + ABSL_COMPARE_INLINE_BASECLASS_DECL(nonequivalent); +}; + +template <typename T> +struct strong_equality_base { + ABSL_COMPARE_INLINE_BASECLASS_DECL(equal); + ABSL_COMPARE_INLINE_BASECLASS_DECL(nonequal); + ABSL_COMPARE_INLINE_BASECLASS_DECL(equivalent); + ABSL_COMPARE_INLINE_BASECLASS_DECL(nonequivalent); +}; + +template <typename T> +struct partial_ordering_base { + ABSL_COMPARE_INLINE_BASECLASS_DECL(less); + ABSL_COMPARE_INLINE_BASECLASS_DECL(equivalent); + ABSL_COMPARE_INLINE_BASECLASS_DECL(greater); + ABSL_COMPARE_INLINE_BASECLASS_DECL(unordered); +}; + +template <typename T> +struct weak_ordering_base { + ABSL_COMPARE_INLINE_BASECLASS_DECL(less); + ABSL_COMPARE_INLINE_BASECLASS_DECL(equivalent); + ABSL_COMPARE_INLINE_BASECLASS_DECL(greater); +}; + +template <typename T> +struct strong_ordering_base { + ABSL_COMPARE_INLINE_BASECLASS_DECL(less); + ABSL_COMPARE_INLINE_BASECLASS_DECL(equal); + ABSL_COMPARE_INLINE_BASECLASS_DECL(equivalent); + ABSL_COMPARE_INLINE_BASECLASS_DECL(greater); +}; + +} // namespace compare_internal + +class weak_equality + : public compare_internal::weak_equality_base<weak_equality> { + explicit constexpr weak_equality(compare_internal::eq v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + friend struct compare_internal::weak_equality_base<weak_equality>; + + public: + ABSL_COMPARE_INLINE_SUBCLASS_DECL(weak_equality, equivalent); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(weak_equality, nonequivalent); + + // Comparisons + friend constexpr bool operator==( + weak_equality v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ == 0; + } + friend constexpr bool operator!=( + weak_equality v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ != 0; + } + friend constexpr bool operator==(compare_internal::OnlyLiteralZero<>, + weak_equality v) noexcept { + return 0 == v.value_; + } + friend constexpr bool operator!=(compare_internal::OnlyLiteralZero<>, + weak_equality v) noexcept { + return 0 != v.value_; + } + friend constexpr bool operator==(weak_equality v1, + weak_equality v2) noexcept { + return v1.value_ == v2.value_; + } + friend constexpr bool operator!=(weak_equality v1, + weak_equality v2) noexcept { + return v1.value_ != v2.value_; + } + + private: + compare_internal::value_type value_; +}; +ABSL_COMPARE_INLINE_INIT(weak_equality, equivalent, + compare_internal::eq::equivalent); +ABSL_COMPARE_INLINE_INIT(weak_equality, nonequivalent, + compare_internal::eq::nonequivalent); + +class strong_equality + : public compare_internal::strong_equality_base<strong_equality> { + explicit constexpr strong_equality(compare_internal::eq v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + friend struct compare_internal::strong_equality_base<strong_equality>; + + public: + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_equality, equal); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_equality, nonequal); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_equality, equivalent); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_equality, nonequivalent); + + // Conversion + constexpr operator weak_equality() const noexcept { // NOLINT + return value_ == 0 ? weak_equality::equivalent + : weak_equality::nonequivalent; + } + // Comparisons + friend constexpr bool operator==( + strong_equality v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ == 0; + } + friend constexpr bool operator!=( + strong_equality v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ != 0; + } + friend constexpr bool operator==(compare_internal::OnlyLiteralZero<>, + strong_equality v) noexcept { + return 0 == v.value_; + } + friend constexpr bool operator!=(compare_internal::OnlyLiteralZero<>, + strong_equality v) noexcept { + return 0 != v.value_; + } + friend constexpr bool operator==(strong_equality v1, + strong_equality v2) noexcept { + return v1.value_ == v2.value_; + } + friend constexpr bool operator!=(strong_equality v1, + strong_equality v2) noexcept { + return v1.value_ != v2.value_; + } + + private: + compare_internal::value_type value_; +}; +ABSL_COMPARE_INLINE_INIT(strong_equality, equal, compare_internal::eq::equal); +ABSL_COMPARE_INLINE_INIT(strong_equality, nonequal, + compare_internal::eq::nonequal); +ABSL_COMPARE_INLINE_INIT(strong_equality, equivalent, + compare_internal::eq::equivalent); +ABSL_COMPARE_INLINE_INIT(strong_equality, nonequivalent, + compare_internal::eq::nonequivalent); + +class partial_ordering + : public compare_internal::partial_ordering_base<partial_ordering> { + explicit constexpr partial_ordering(compare_internal::eq v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + explicit constexpr partial_ordering(compare_internal::ord v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + explicit constexpr partial_ordering(compare_internal::ncmp v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + friend struct compare_internal::partial_ordering_base<partial_ordering>; + + constexpr bool is_ordered() const noexcept { + return value_ != + compare_internal::value_type(compare_internal::ncmp::unordered); + } + + public: + ABSL_COMPARE_INLINE_SUBCLASS_DECL(partial_ordering, less); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(partial_ordering, equivalent); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(partial_ordering, greater); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(partial_ordering, unordered); + + // Conversion + constexpr operator weak_equality() const noexcept { // NOLINT + return value_ == 0 ? weak_equality::equivalent + : weak_equality::nonequivalent; + } + // Comparisons + friend constexpr bool operator==( + partial_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.is_ordered() && v.value_ == 0; + } + friend constexpr bool operator!=( + partial_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return !v.is_ordered() || v.value_ != 0; + } + friend constexpr bool operator<( + partial_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.is_ordered() && v.value_ < 0; + } + friend constexpr bool operator<=( + partial_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.is_ordered() && v.value_ <= 0; + } + friend constexpr bool operator>( + partial_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.is_ordered() && v.value_ > 0; + } + friend constexpr bool operator>=( + partial_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.is_ordered() && v.value_ >= 0; + } + friend constexpr bool operator==(compare_internal::OnlyLiteralZero<>, + partial_ordering v) noexcept { + return v.is_ordered() && 0 == v.value_; + } + friend constexpr bool operator!=(compare_internal::OnlyLiteralZero<>, + partial_ordering v) noexcept { + return !v.is_ordered() || 0 != v.value_; + } + friend constexpr bool operator<(compare_internal::OnlyLiteralZero<>, + partial_ordering v) noexcept { + return v.is_ordered() && 0 < v.value_; + } + friend constexpr bool operator<=(compare_internal::OnlyLiteralZero<>, + partial_ordering v) noexcept { + return v.is_ordered() && 0 <= v.value_; + } + friend constexpr bool operator>(compare_internal::OnlyLiteralZero<>, + partial_ordering v) noexcept { + return v.is_ordered() && 0 > v.value_; + } + friend constexpr bool operator>=(compare_internal::OnlyLiteralZero<>, + partial_ordering v) noexcept { + return v.is_ordered() && 0 >= v.value_; + } + friend constexpr bool operator==(partial_ordering v1, + partial_ordering v2) noexcept { + return v1.value_ == v2.value_; + } + friend constexpr bool operator!=(partial_ordering v1, + partial_ordering v2) noexcept { + return v1.value_ != v2.value_; + } + + private: + compare_internal::value_type value_; +}; +ABSL_COMPARE_INLINE_INIT(partial_ordering, less, compare_internal::ord::less); +ABSL_COMPARE_INLINE_INIT(partial_ordering, equivalent, + compare_internal::eq::equivalent); +ABSL_COMPARE_INLINE_INIT(partial_ordering, greater, + compare_internal::ord::greater); +ABSL_COMPARE_INLINE_INIT(partial_ordering, unordered, + compare_internal::ncmp::unordered); + +class weak_ordering + : public compare_internal::weak_ordering_base<weak_ordering> { + explicit constexpr weak_ordering(compare_internal::eq v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + explicit constexpr weak_ordering(compare_internal::ord v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + friend struct compare_internal::weak_ordering_base<weak_ordering>; + + public: + ABSL_COMPARE_INLINE_SUBCLASS_DECL(weak_ordering, less); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(weak_ordering, equivalent); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(weak_ordering, greater); + + // Conversions + constexpr operator weak_equality() const noexcept { // NOLINT + return value_ == 0 ? weak_equality::equivalent + : weak_equality::nonequivalent; + } + constexpr operator partial_ordering() const noexcept { // NOLINT + return value_ == 0 ? partial_ordering::equivalent + : (value_ < 0 ? partial_ordering::less + : partial_ordering::greater); + } + // Comparisons + friend constexpr bool operator==( + weak_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ == 0; + } + friend constexpr bool operator!=( + weak_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ != 0; + } + friend constexpr bool operator<( + weak_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ < 0; + } + friend constexpr bool operator<=( + weak_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ <= 0; + } + friend constexpr bool operator>( + weak_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ > 0; + } + friend constexpr bool operator>=( + weak_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ >= 0; + } + friend constexpr bool operator==(compare_internal::OnlyLiteralZero<>, + weak_ordering v) noexcept { + return 0 == v.value_; + } + friend constexpr bool operator!=(compare_internal::OnlyLiteralZero<>, + weak_ordering v) noexcept { + return 0 != v.value_; + } + friend constexpr bool operator<(compare_internal::OnlyLiteralZero<>, + weak_ordering v) noexcept { + return 0 < v.value_; + } + friend constexpr bool operator<=(compare_internal::OnlyLiteralZero<>, + weak_ordering v) noexcept { + return 0 <= v.value_; + } + friend constexpr bool operator>(compare_internal::OnlyLiteralZero<>, + weak_ordering v) noexcept { + return 0 > v.value_; + } + friend constexpr bool operator>=(compare_internal::OnlyLiteralZero<>, + weak_ordering v) noexcept { + return 0 >= v.value_; + } + friend constexpr bool operator==(weak_ordering v1, + weak_ordering v2) noexcept { + return v1.value_ == v2.value_; + } + friend constexpr bool operator!=(weak_ordering v1, + weak_ordering v2) noexcept { + return v1.value_ != v2.value_; + } + + private: + compare_internal::value_type value_; +}; +ABSL_COMPARE_INLINE_INIT(weak_ordering, less, compare_internal::ord::less); +ABSL_COMPARE_INLINE_INIT(weak_ordering, equivalent, + compare_internal::eq::equivalent); +ABSL_COMPARE_INLINE_INIT(weak_ordering, greater, + compare_internal::ord::greater); + +class strong_ordering + : public compare_internal::strong_ordering_base<strong_ordering> { + explicit constexpr strong_ordering(compare_internal::eq v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + explicit constexpr strong_ordering(compare_internal::ord v) noexcept + : value_(static_cast<compare_internal::value_type>(v)) {} + friend struct compare_internal::strong_ordering_base<strong_ordering>; + + public: + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_ordering, less); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_ordering, equal); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_ordering, equivalent); + ABSL_COMPARE_INLINE_SUBCLASS_DECL(strong_ordering, greater); + + // Conversions + constexpr operator weak_equality() const noexcept { // NOLINT + return value_ == 0 ? weak_equality::equivalent + : weak_equality::nonequivalent; + } + constexpr operator strong_equality() const noexcept { // NOLINT + return value_ == 0 ? strong_equality::equal : strong_equality::nonequal; + } + constexpr operator partial_ordering() const noexcept { // NOLINT + return value_ == 0 ? partial_ordering::equivalent + : (value_ < 0 ? partial_ordering::less + : partial_ordering::greater); + } + constexpr operator weak_ordering() const noexcept { // NOLINT + return value_ == 0 + ? weak_ordering::equivalent + : (value_ < 0 ? weak_ordering::less : weak_ordering::greater); + } + // Comparisons + friend constexpr bool operator==( + strong_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ == 0; + } + friend constexpr bool operator!=( + strong_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ != 0; + } + friend constexpr bool operator<( + strong_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ < 0; + } + friend constexpr bool operator<=( + strong_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ <= 0; + } + friend constexpr bool operator>( + strong_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ > 0; + } + friend constexpr bool operator>=( + strong_ordering v, compare_internal::OnlyLiteralZero<>) noexcept { + return v.value_ >= 0; + } + friend constexpr bool operator==(compare_internal::OnlyLiteralZero<>, + strong_ordering v) noexcept { + return 0 == v.value_; + } + friend constexpr bool operator!=(compare_internal::OnlyLiteralZero<>, + strong_ordering v) noexcept { + return 0 != v.value_; + } + friend constexpr bool operator<(compare_internal::OnlyLiteralZero<>, + strong_ordering v) noexcept { + return 0 < v.value_; + } + friend constexpr bool operator<=(compare_internal::OnlyLiteralZero<>, + strong_ordering v) noexcept { + return 0 <= v.value_; + } + friend constexpr bool operator>(compare_internal::OnlyLiteralZero<>, + strong_ordering v) noexcept { + return 0 > v.value_; + } + friend constexpr bool operator>=(compare_internal::OnlyLiteralZero<>, + strong_ordering v) noexcept { + return 0 >= v.value_; + } + friend constexpr bool operator==(strong_ordering v1, + strong_ordering v2) noexcept { + return v1.value_ == v2.value_; + } + friend constexpr bool operator!=(strong_ordering v1, + strong_ordering v2) noexcept { + return v1.value_ != v2.value_; + } + + private: + compare_internal::value_type value_; +}; +ABSL_COMPARE_INLINE_INIT(strong_ordering, less, compare_internal::ord::less); +ABSL_COMPARE_INLINE_INIT(strong_ordering, equal, compare_internal::eq::equal); +ABSL_COMPARE_INLINE_INIT(strong_ordering, equivalent, + compare_internal::eq::equivalent); +ABSL_COMPARE_INLINE_INIT(strong_ordering, greater, + compare_internal::ord::greater); + +#undef ABSL_COMPARE_INLINE_BASECLASS_DECL +#undef ABSL_COMPARE_INLINE_SUBCLASS_DECL +#undef ABSL_COMPARE_INLINE_INIT + +namespace compare_internal { +// We also provide these comparator adapter functions for internal absl use. + +// Helper functions to do a boolean comparison of two keys given a boolean +// or three-way comparator. +// SFINAE prevents implicit conversions to bool (such as from int). +template <typename Bool, + absl::enable_if_t<std::is_same<bool, Bool>::value, int> = 0> +constexpr bool compare_result_as_less_than(const Bool r) { return r; } +constexpr bool compare_result_as_less_than(const absl::weak_ordering r) { + return r < 0; +} + +template <typename Compare, typename K, typename LK> +constexpr bool do_less_than_comparison(const Compare &compare, const K &x, + const LK &y) { + return compare_result_as_less_than(compare(x, y)); +} + +// Helper functions to do a three-way comparison of two keys given a boolean or +// three-way comparator. +// SFINAE prevents implicit conversions to int (such as from bool). +template <typename Int, + absl::enable_if_t<std::is_same<int, Int>::value, int> = 0> +constexpr absl::weak_ordering compare_result_as_ordering(const Int c) { + return c < 0 ? absl::weak_ordering::less + : c == 0 ? absl::weak_ordering::equivalent + : absl::weak_ordering::greater; +} +constexpr absl::weak_ordering compare_result_as_ordering( + const absl::weak_ordering c) { + return c; +} + +template < + typename Compare, typename K, typename LK, + absl::enable_if_t<!std::is_same<bool, absl::result_of_t<Compare( + const K &, const LK &)>>::value, + int> = 0> +constexpr absl::weak_ordering do_three_way_comparison(const Compare &compare, + const K &x, const LK &y) { + return compare_result_as_ordering(compare(x, y)); +} +template < + typename Compare, typename K, typename LK, + absl::enable_if_t<std::is_same<bool, absl::result_of_t<Compare( + const K &, const LK &)>>::value, + int> = 0> +constexpr absl::weak_ordering do_three_way_comparison(const Compare &compare, + const K &x, const LK &y) { + return compare(x, y) ? absl::weak_ordering::less + : compare(y, x) ? absl::weak_ordering::greater + : absl::weak_ordering::equivalent; +} + +} // namespace compare_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TYPES_COMPARE_H_ diff --git a/third_party/abseil_cpp/absl/types/compare_test.cc b/third_party/abseil_cpp/absl/types/compare_test.cc new file mode 100644 index 0000000000..8095baf956 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/compare_test.cc @@ -0,0 +1,389 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/compare.h" + +#include "gtest/gtest.h" +#include "absl/base/casts.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +// This is necessary to avoid a bunch of lint warnings suggesting that we use +// EXPECT_EQ/etc., which doesn't work in this case because they convert the `0` +// to an int, which can't be converted to the unspecified zero type. +bool Identity(bool b) { return b; } + +TEST(Compare, WeakEquality) { + EXPECT_TRUE(Identity(weak_equality::equivalent == 0)); + EXPECT_TRUE(Identity(0 == weak_equality::equivalent)); + EXPECT_TRUE(Identity(weak_equality::nonequivalent != 0)); + EXPECT_TRUE(Identity(0 != weak_equality::nonequivalent)); + const weak_equality values[] = {weak_equality::equivalent, + weak_equality::nonequivalent}; + for (const auto& lhs : values) { + for (const auto& rhs : values) { + const bool are_equal = &lhs == &rhs; + EXPECT_EQ(lhs == rhs, are_equal); + EXPECT_EQ(lhs != rhs, !are_equal); + } + } +} + +TEST(Compare, StrongEquality) { + EXPECT_TRUE(Identity(strong_equality::equal == 0)); + EXPECT_TRUE(Identity(0 == strong_equality::equal)); + EXPECT_TRUE(Identity(strong_equality::nonequal != 0)); + EXPECT_TRUE(Identity(0 != strong_equality::nonequal)); + EXPECT_TRUE(Identity(strong_equality::equivalent == 0)); + EXPECT_TRUE(Identity(0 == strong_equality::equivalent)); + EXPECT_TRUE(Identity(strong_equality::nonequivalent != 0)); + EXPECT_TRUE(Identity(0 != strong_equality::nonequivalent)); + const strong_equality values[] = {strong_equality::equal, + strong_equality::nonequal}; + for (const auto& lhs : values) { + for (const auto& rhs : values) { + const bool are_equal = &lhs == &rhs; + EXPECT_EQ(lhs == rhs, are_equal); + EXPECT_EQ(lhs != rhs, !are_equal); + } + } + EXPECT_TRUE(Identity(strong_equality::equivalent == strong_equality::equal)); + EXPECT_TRUE( + Identity(strong_equality::nonequivalent == strong_equality::nonequal)); +} + +TEST(Compare, PartialOrdering) { + EXPECT_TRUE(Identity(partial_ordering::less < 0)); + EXPECT_TRUE(Identity(0 > partial_ordering::less)); + EXPECT_TRUE(Identity(partial_ordering::less <= 0)); + EXPECT_TRUE(Identity(0 >= partial_ordering::less)); + EXPECT_TRUE(Identity(partial_ordering::equivalent == 0)); + EXPECT_TRUE(Identity(0 == partial_ordering::equivalent)); + EXPECT_TRUE(Identity(partial_ordering::greater > 0)); + EXPECT_TRUE(Identity(0 < partial_ordering::greater)); + EXPECT_TRUE(Identity(partial_ordering::greater >= 0)); + EXPECT_TRUE(Identity(0 <= partial_ordering::greater)); + EXPECT_TRUE(Identity(partial_ordering::unordered != 0)); + EXPECT_TRUE(Identity(0 != partial_ordering::unordered)); + EXPECT_FALSE(Identity(partial_ordering::unordered < 0)); + EXPECT_FALSE(Identity(0 < partial_ordering::unordered)); + EXPECT_FALSE(Identity(partial_ordering::unordered <= 0)); + EXPECT_FALSE(Identity(0 <= partial_ordering::unordered)); + EXPECT_FALSE(Identity(partial_ordering::unordered > 0)); + EXPECT_FALSE(Identity(0 > partial_ordering::unordered)); + EXPECT_FALSE(Identity(partial_ordering::unordered >= 0)); + EXPECT_FALSE(Identity(0 >= partial_ordering::unordered)); + const partial_ordering values[] = { + partial_ordering::less, partial_ordering::equivalent, + partial_ordering::greater, partial_ordering::unordered}; + for (const auto& lhs : values) { + for (const auto& rhs : values) { + const bool are_equal = &lhs == &rhs; + EXPECT_EQ(lhs == rhs, are_equal); + EXPECT_EQ(lhs != rhs, !are_equal); + } + } +} + +TEST(Compare, WeakOrdering) { + EXPECT_TRUE(Identity(weak_ordering::less < 0)); + EXPECT_TRUE(Identity(0 > weak_ordering::less)); + EXPECT_TRUE(Identity(weak_ordering::less <= 0)); + EXPECT_TRUE(Identity(0 >= weak_ordering::less)); + EXPECT_TRUE(Identity(weak_ordering::equivalent == 0)); + EXPECT_TRUE(Identity(0 == weak_ordering::equivalent)); + EXPECT_TRUE(Identity(weak_ordering::greater > 0)); + EXPECT_TRUE(Identity(0 < weak_ordering::greater)); + EXPECT_TRUE(Identity(weak_ordering::greater >= 0)); + EXPECT_TRUE(Identity(0 <= weak_ordering::greater)); + const weak_ordering values[] = { + weak_ordering::less, weak_ordering::equivalent, weak_ordering::greater}; + for (const auto& lhs : values) { + for (const auto& rhs : values) { + const bool are_equal = &lhs == &rhs; + EXPECT_EQ(lhs == rhs, are_equal); + EXPECT_EQ(lhs != rhs, !are_equal); + } + } +} + +TEST(Compare, StrongOrdering) { + EXPECT_TRUE(Identity(strong_ordering::less < 0)); + EXPECT_TRUE(Identity(0 > strong_ordering::less)); + EXPECT_TRUE(Identity(strong_ordering::less <= 0)); + EXPECT_TRUE(Identity(0 >= strong_ordering::less)); + EXPECT_TRUE(Identity(strong_ordering::equal == 0)); + EXPECT_TRUE(Identity(0 == strong_ordering::equal)); + EXPECT_TRUE(Identity(strong_ordering::equivalent == 0)); + EXPECT_TRUE(Identity(0 == strong_ordering::equivalent)); + EXPECT_TRUE(Identity(strong_ordering::greater > 0)); + EXPECT_TRUE(Identity(0 < strong_ordering::greater)); + EXPECT_TRUE(Identity(strong_ordering::greater >= 0)); + EXPECT_TRUE(Identity(0 <= strong_ordering::greater)); + const strong_ordering values[] = { + strong_ordering::less, strong_ordering::equal, strong_ordering::greater}; + for (const auto& lhs : values) { + for (const auto& rhs : values) { + const bool are_equal = &lhs == &rhs; + EXPECT_EQ(lhs == rhs, are_equal); + EXPECT_EQ(lhs != rhs, !are_equal); + } + } + EXPECT_TRUE(Identity(strong_ordering::equivalent == strong_ordering::equal)); +} + +TEST(Compare, Conversions) { + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_equality::equal) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_equality::nonequal) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_equality::equivalent) == 0)); + EXPECT_TRUE(Identity( + implicit_cast<weak_equality>(strong_equality::nonequivalent) != 0)); + + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(partial_ordering::less) != 0)); + EXPECT_TRUE(Identity( + implicit_cast<weak_equality>(partial_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(partial_ordering::greater) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(partial_ordering::unordered) != 0)); + + EXPECT_TRUE(implicit_cast<weak_equality>(weak_ordering::less) != 0); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(weak_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(weak_ordering::greater) != 0)); + + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(weak_ordering::less) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(weak_ordering::less) < 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(weak_ordering::less) <= 0)); + EXPECT_TRUE(Identity( + implicit_cast<partial_ordering>(weak_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(weak_ordering::greater) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(weak_ordering::greater) > 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(weak_ordering::greater) >= 0)); + + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_ordering::less) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_ordering::equal) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_equality>(strong_ordering::greater) != 0)); + + EXPECT_TRUE( + Identity(implicit_cast<strong_equality>(strong_ordering::less) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<strong_equality>(strong_ordering::equal) == 0)); + EXPECT_TRUE(Identity( + implicit_cast<strong_equality>(strong_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<strong_equality>(strong_ordering::greater) != 0)); + + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::less) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::less) < 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::less) <= 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::equal) == 0)); + EXPECT_TRUE(Identity( + implicit_cast<partial_ordering>(strong_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::greater) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::greater) > 0)); + EXPECT_TRUE( + Identity(implicit_cast<partial_ordering>(strong_ordering::greater) >= 0)); + + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::less) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::less) < 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::less) <= 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::equal) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::equivalent) == 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::greater) != 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::greater) > 0)); + EXPECT_TRUE( + Identity(implicit_cast<weak_ordering>(strong_ordering::greater) >= 0)); +} + +struct WeakOrderingLess { + template <typename T> + absl::weak_ordering operator()(const T& a, const T& b) const { + return a < b ? absl::weak_ordering::less + : a == b ? absl::weak_ordering::equivalent + : absl::weak_ordering::greater; + } +}; + +TEST(CompareResultAsLessThan, SanityTest) { + EXPECT_FALSE(absl::compare_internal::compare_result_as_less_than(false)); + EXPECT_TRUE(absl::compare_internal::compare_result_as_less_than(true)); + + EXPECT_TRUE( + absl::compare_internal::compare_result_as_less_than(weak_ordering::less)); + EXPECT_FALSE(absl::compare_internal::compare_result_as_less_than( + weak_ordering::equivalent)); + EXPECT_FALSE(absl::compare_internal::compare_result_as_less_than( + weak_ordering::greater)); +} + +TEST(DoLessThanComparison, SanityTest) { + std::less<int> less; + WeakOrderingLess weak; + + EXPECT_TRUE(absl::compare_internal::do_less_than_comparison(less, -1, 0)); + EXPECT_TRUE(absl::compare_internal::do_less_than_comparison(weak, -1, 0)); + + EXPECT_FALSE(absl::compare_internal::do_less_than_comparison(less, 10, 10)); + EXPECT_FALSE(absl::compare_internal::do_less_than_comparison(weak, 10, 10)); + + EXPECT_FALSE(absl::compare_internal::do_less_than_comparison(less, 10, 5)); + EXPECT_FALSE(absl::compare_internal::do_less_than_comparison(weak, 10, 5)); +} + +TEST(CompareResultAsOrdering, SanityTest) { + EXPECT_TRUE( + Identity(absl::compare_internal::compare_result_as_ordering(-1) < 0)); + EXPECT_FALSE( + Identity(absl::compare_internal::compare_result_as_ordering(-1) == 0)); + EXPECT_FALSE( + Identity(absl::compare_internal::compare_result_as_ordering(-1) > 0)); + EXPECT_TRUE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::less) < 0)); + EXPECT_FALSE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::less) == 0)); + EXPECT_FALSE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::less) > 0)); + + EXPECT_FALSE( + Identity(absl::compare_internal::compare_result_as_ordering(0) < 0)); + EXPECT_TRUE( + Identity(absl::compare_internal::compare_result_as_ordering(0) == 0)); + EXPECT_FALSE( + Identity(absl::compare_internal::compare_result_as_ordering(0) > 0)); + EXPECT_FALSE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::equivalent) < 0)); + EXPECT_TRUE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::equivalent) == 0)); + EXPECT_FALSE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::equivalent) > 0)); + + EXPECT_FALSE( + Identity(absl::compare_internal::compare_result_as_ordering(1) < 0)); + EXPECT_FALSE( + Identity(absl::compare_internal::compare_result_as_ordering(1) == 0)); + EXPECT_TRUE( + Identity(absl::compare_internal::compare_result_as_ordering(1) > 0)); + EXPECT_FALSE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::greater) < 0)); + EXPECT_FALSE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::greater) == 0)); + EXPECT_TRUE(Identity(absl::compare_internal::compare_result_as_ordering( + weak_ordering::greater) > 0)); +} + +TEST(DoThreeWayComparison, SanityTest) { + std::less<int> less; + WeakOrderingLess weak; + + EXPECT_TRUE(Identity( + absl::compare_internal::do_three_way_comparison(less, -1, 0) < 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(less, -1, 0) == 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(less, -1, 0) > 0)); + EXPECT_TRUE(Identity( + absl::compare_internal::do_three_way_comparison(weak, -1, 0) < 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(weak, -1, 0) == 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(weak, -1, 0) > 0)); + + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(less, 10, 10) < 0)); + EXPECT_TRUE(Identity( + absl::compare_internal::do_three_way_comparison(less, 10, 10) == 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(less, 10, 10) > 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(weak, 10, 10) < 0)); + EXPECT_TRUE(Identity( + absl::compare_internal::do_three_way_comparison(weak, 10, 10) == 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(weak, 10, 10) > 0)); + + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(less, 10, 5) < 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(less, 10, 5) == 0)); + EXPECT_TRUE(Identity( + absl::compare_internal::do_three_way_comparison(less, 10, 5) > 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(weak, 10, 5) < 0)); + EXPECT_FALSE(Identity( + absl::compare_internal::do_three_way_comparison(weak, 10, 5) == 0)); + EXPECT_TRUE(Identity( + absl::compare_internal::do_three_way_comparison(weak, 10, 5) > 0)); +} + +#ifdef __cpp_inline_variables +TEST(Compare, StaticAsserts) { + static_assert(weak_equality::equivalent == 0, ""); + static_assert(weak_equality::nonequivalent != 0, ""); + + static_assert(strong_equality::equal == 0, ""); + static_assert(strong_equality::nonequal != 0, ""); + static_assert(strong_equality::equivalent == 0, ""); + static_assert(strong_equality::nonequivalent != 0, ""); + + static_assert(partial_ordering::less < 0, ""); + static_assert(partial_ordering::equivalent == 0, ""); + static_assert(partial_ordering::greater > 0, ""); + static_assert(partial_ordering::unordered != 0, ""); + + static_assert(weak_ordering::less < 0, ""); + static_assert(weak_ordering::equivalent == 0, ""); + static_assert(weak_ordering::greater > 0, ""); + + static_assert(strong_ordering::less < 0, ""); + static_assert(strong_ordering::equal == 0, ""); + static_assert(strong_ordering::equivalent == 0, ""); + static_assert(strong_ordering::greater > 0, ""); +} +#endif // __cpp_inline_variables + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/types/internal/conformance_aliases.h b/third_party/abseil_cpp/absl/types/internal/conformance_aliases.h new file mode 100644 index 0000000000..0cc6884e30 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/conformance_aliases.h @@ -0,0 +1,447 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// regularity_aliases.h +// ----------------------------------------------------------------------------- +// +// This file contains type aliases of common ConformanceProfiles and Archetypes +// so that they can be directly used by name without creating them from scratch. + +#ifndef ABSL_TYPES_INTERNAL_CONFORMANCE_ALIASES_H_ +#define ABSL_TYPES_INTERNAL_CONFORMANCE_ALIASES_H_ + +#include "absl/types/internal/conformance_archetype.h" +#include "absl/types/internal/conformance_profile.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace types_internal { + +// Creates both a Profile and a corresponding Archetype with root name "name". +#define ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS(name, ...) \ + struct name##Profile : __VA_ARGS__ {}; \ + \ + using name##Archetype = ::absl::types_internal::Archetype<name##Profile>; \ + \ + template <class AbslInternalProfileTag> \ + using name##Archetype##_ = ::absl::types_internal::Archetype< \ + ::absl::types_internal::StrongProfileTypedef<name##Profile, \ + AbslInternalProfileTag>> + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasTrivialDefaultConstructor, + ConformanceProfile<default_constructible::trivial>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowDefaultConstructor, + ConformanceProfile<default_constructible::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasDefaultConstructor, ConformanceProfile<default_constructible::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasTrivialMoveConstructor, ConformanceProfile<default_constructible::maybe, + move_constructible::trivial>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowMoveConstructor, ConformanceProfile<default_constructible::maybe, + move_constructible::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasMoveConstructor, + ConformanceProfile<default_constructible::maybe, move_constructible::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasTrivialCopyConstructor, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::trivial>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowCopyConstructor, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasCopyConstructor, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasTrivialMoveAssign, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::trivial>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowMoveAssign, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasMoveAssign, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasTrivialCopyAssign, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::trivial>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowCopyAssign, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasCopyAssign, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasTrivialDestructor, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::trivial>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowDestructor, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasDestructor, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowEquality, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasEquality, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowInequality, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::maybe, + inequality_comparable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasInequality, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::maybe, inequality_comparable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowLessThan, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::maybe, inequality_comparable::maybe, + less_than_comparable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasLessThan, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::maybe, inequality_comparable::maybe, + less_than_comparable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowLessEqual, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::maybe, inequality_comparable::maybe, + less_than_comparable::maybe, + less_equal_comparable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasLessEqual, + ConformanceProfile<default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, + equality_comparable::maybe, inequality_comparable::maybe, + less_than_comparable::maybe, + less_equal_comparable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowGreaterEqual, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasGreaterEqual, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowGreaterThan, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::maybe, + greater_than_comparable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasGreaterThan, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::maybe, + greater_than_comparable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasNothrowSwap, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::maybe, + greater_than_comparable::maybe, swappable::nothrow>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasSwap, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::maybe, + greater_than_comparable::maybe, swappable::yes>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HasStdHashSpecialization, + ConformanceProfile< + default_constructible::maybe, move_constructible::maybe, + copy_constructible::maybe, move_assignable::maybe, + copy_assignable::maybe, destructible::maybe, equality_comparable::maybe, + inequality_comparable::maybe, less_than_comparable::maybe, + less_equal_comparable::maybe, greater_equal_comparable::maybe, + greater_than_comparable::maybe, swappable::maybe, hashable::yes>); + +//////////////////////////////////////////////////////////////////////////////// +//// The remaining aliases are combinations of the previous aliases. //// +//////////////////////////////////////////////////////////////////////////////// + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + Equatable, CombineProfiles<HasEqualityProfile, HasInequalityProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + Comparable, + CombineProfiles<EquatableProfile, HasLessThanProfile, HasLessEqualProfile, + HasGreaterEqualProfile, HasGreaterThanProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + NothrowEquatable, + CombineProfiles<HasNothrowEqualityProfile, HasNothrowInequalityProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + NothrowComparable, + CombineProfiles<NothrowEquatableProfile, HasNothrowLessThanProfile, + HasNothrowLessEqualProfile, HasNothrowGreaterEqualProfile, + HasNothrowGreaterThanProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + Value, + CombineProfiles<HasNothrowMoveConstructorProfile, HasCopyConstructorProfile, + HasNothrowMoveAssignProfile, HasCopyAssignProfile, + HasNothrowDestructorProfile, HasNothrowSwapProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + EquatableValue, CombineProfiles<EquatableProfile, ValueProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + ComparableValue, CombineProfiles<ComparableProfile, ValueProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + DefaultConstructibleValue, + CombineProfiles<HasDefaultConstructorProfile, ValueProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + NothrowMoveConstructible, CombineProfiles<HasNothrowMoveConstructorProfile, + HasNothrowDestructorProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + EquatableNothrowMoveConstructible, + CombineProfiles<EquatableProfile, NothrowMoveConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + ComparableNothrowMoveConstructible, + CombineProfiles<ComparableProfile, NothrowMoveConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + DefaultConstructibleNothrowMoveConstructible, + CombineProfiles<HasDefaultConstructorProfile, + NothrowMoveConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + CopyConstructible, + CombineProfiles<HasNothrowMoveConstructorProfile, HasCopyConstructorProfile, + HasNothrowDestructorProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + EquatableCopyConstructible, + CombineProfiles<EquatableProfile, CopyConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + ComparableCopyConstructible, + CombineProfiles<ComparableProfile, CopyConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + DefaultConstructibleCopyConstructible, + CombineProfiles<HasDefaultConstructorProfile, CopyConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + NothrowMovable, + CombineProfiles<HasNothrowMoveConstructorProfile, + HasNothrowMoveAssignProfile, HasNothrowDestructorProfile, + HasNothrowSwapProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + EquatableNothrowMovable, + CombineProfiles<EquatableProfile, NothrowMovableProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + ComparableNothrowMovable, + CombineProfiles<ComparableProfile, NothrowMovableProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + DefaultConstructibleNothrowMovable, + CombineProfiles<HasDefaultConstructorProfile, NothrowMovableProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + TrivialSpecialMemberFunctions, + CombineProfiles<HasTrivialDefaultConstructorProfile, + HasTrivialMoveConstructorProfile, + HasTrivialCopyConstructorProfile, + HasTrivialMoveAssignProfile, HasTrivialCopyAssignProfile, + HasTrivialDestructorProfile, HasNothrowSwapProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + TriviallyComplete, + CombineProfiles<TrivialSpecialMemberFunctionsProfile, ComparableProfile, + HasStdHashSpecializationProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HashableNothrowMoveConstructible, + CombineProfiles<HasStdHashSpecializationProfile, + NothrowMoveConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HashableCopyConstructible, + CombineProfiles<HasStdHashSpecializationProfile, CopyConstructibleProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HashableNothrowMovable, + CombineProfiles<HasStdHashSpecializationProfile, NothrowMovableProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + HashableValue, + CombineProfiles<HasStdHashSpecializationProfile, ValueProfile>); + +ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS( + ComparableHashableValue, + CombineProfiles<HashableValueProfile, ComparableProfile>); + +// The "preferred" profiles that we support in Abseil. +template <template <class...> class Receiver> +using ExpandBasicProfiles = + Receiver<NothrowMoveConstructibleProfile, CopyConstructibleProfile, + NothrowMovableProfile, ValueProfile>; + +// The basic profiles except that they are also all Equatable. +template <template <class...> class Receiver> +using ExpandBasicEquatableProfiles = + Receiver<EquatableNothrowMoveConstructibleProfile, + EquatableCopyConstructibleProfile, EquatableNothrowMovableProfile, + EquatableValueProfile>; + +// The basic profiles except that they are also all Comparable. +template <template <class...> class Receiver> +using ExpandBasicComparableProfiles = + Receiver<ComparableNothrowMoveConstructibleProfile, + ComparableCopyConstructibleProfile, + ComparableNothrowMovableProfile, ComparableValueProfile>; + +// The basic profiles except that they are also all Hashable. +template <template <class...> class Receiver> +using ExpandBasicHashableProfiles = + Receiver<HashableNothrowMoveConstructibleProfile, + HashableCopyConstructibleProfile, HashableNothrowMovableProfile, + HashableValueProfile>; + +// The basic profiles except that they are also all DefaultConstructible. +template <template <class...> class Receiver> +using ExpandBasicDefaultConstructibleProfiles = + Receiver<DefaultConstructibleNothrowMoveConstructibleProfile, + DefaultConstructibleCopyConstructibleProfile, + DefaultConstructibleNothrowMovableProfile, + DefaultConstructibleValueProfile>; + +// The type profiles that we support in Abseil (all of the previous lists). +template <template <class...> class Receiver> +using ExpandSupportedProfiles = Receiver< + NothrowMoveConstructibleProfile, CopyConstructibleProfile, + NothrowMovableProfile, ValueProfile, + EquatableNothrowMoveConstructibleProfile, EquatableCopyConstructibleProfile, + EquatableNothrowMovableProfile, EquatableValueProfile, + ComparableNothrowMoveConstructibleProfile, + ComparableCopyConstructibleProfile, ComparableNothrowMovableProfile, + ComparableValueProfile, DefaultConstructibleNothrowMoveConstructibleProfile, + DefaultConstructibleCopyConstructibleProfile, + DefaultConstructibleNothrowMovableProfile, DefaultConstructibleValueProfile, + HashableNothrowMoveConstructibleProfile, HashableCopyConstructibleProfile, + HashableNothrowMovableProfile, HashableValueProfile>; + +// TODO(calabrese) Include types that have throwing move constructors, since in +// practice we still need to support them because of standard library types with +// (potentially) non-noexcept moves. + +} // namespace types_internal +ABSL_NAMESPACE_END +} // namespace absl + +#undef ABSL_INTERNAL_PROFILE_AND_ARCHETYPE_ALIAS + +#endif // ABSL_TYPES_INTERNAL_CONFORMANCE_ALIASES_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/conformance_archetype.h b/third_party/abseil_cpp/absl/types/internal/conformance_archetype.h new file mode 100644 index 0000000000..2349e0f726 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/conformance_archetype.h @@ -0,0 +1,978 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// conformance_archetype.h +// ----------------------------------------------------------------------------- +// +// This file contains a facility for generating "archetypes" of out of +// "Conformance Profiles" (see "conformance_profiles.h" for more information +// about Conformance Profiles). An archetype is a type that aims to support the +// bare minimum requirements of a given Conformance Profile. For instance, an +// archetype that corresponds to an ImmutableProfile has exactly a nothrow +// move-constructor, a potentially-throwing copy constructor, a nothrow +// destructor, with all other special-member-functions deleted. These archetypes +// are useful for testing to make sure that templates are able to work with the +// kinds of types that they claim to support (i.e. that they do not accidentally +// under-constrain), +// +// The main type template in this file is the Archetype template, which takes +// a Conformance Profile as a template argument and its instantiations are a +// minimum-conforming model of that profile. + +#ifndef ABSL_TYPES_INTERNAL_CONFORMANCE_ARCHETYPE_H_ +#define ABSL_TYPES_INTERNAL_CONFORMANCE_ARCHETYPE_H_ + +#include <cstddef> +#include <functional> +#include <type_traits> +#include <utility> + +#include "absl/meta/type_traits.h" +#include "absl/types/internal/conformance_profile.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace types_internal { + +// A minimum-conforming implementation of a type with properties specified in +// `Prof`, where `Prof` is a valid Conformance Profile. +template <class Prof, class /*Enabler*/ = void> +class Archetype; + +// Given an Archetype, obtain the properties of the profile associated with that +// archetype. +template <class Archetype> +struct PropertiesOfArchetype; + +template <class Prof> +struct PropertiesOfArchetype<Archetype<Prof>> { + using type = PropertiesOfT<Prof>; +}; + +template <class Archetype> +using PropertiesOfArchetypeT = typename PropertiesOfArchetype<Archetype>::type; + +// A metafunction to determine if a type is an `Archetype`. +template <class T> +struct IsArchetype : std::false_type {}; + +template <class Prof> +struct IsArchetype<Archetype<Prof>> : std::true_type {}; + +// A constructor tag type used when creating an Archetype with internal state. +struct MakeArchetypeState {}; + +// Data stored within an archetype that is copied/compared/hashed when the +// corresponding operations are used. +using ArchetypeState = std::size_t; + +//////////////////////////////////////////////////////////////////////////////// +// This section of the file defines a chain of base classes for Archetype, // +// where each base defines a specific special member function with the // +// appropriate properties (deleted, noexcept(false), noexcept, or trivial). // +//////////////////////////////////////////////////////////////////////////////// + +// The bottom-most base, which contains the state and the default constructor. +template <default_constructible DefaultConstructibleValue> +struct ArchetypeStateBase { + static_assert(DefaultConstructibleValue == default_constructible::yes || + DefaultConstructibleValue == default_constructible::nothrow, + ""); + + ArchetypeStateBase() noexcept( + DefaultConstructibleValue == + default_constructible:: + nothrow) /*Vacuous archetype_state initialization*/ {} + explicit ArchetypeStateBase(MakeArchetypeState, ArchetypeState state) noexcept + : archetype_state(state) {} + + ArchetypeState archetype_state; +}; + +template <> +struct ArchetypeStateBase<default_constructible::maybe> { + explicit ArchetypeStateBase() = delete; + explicit ArchetypeStateBase(MakeArchetypeState, ArchetypeState state) noexcept + : archetype_state(state) {} + + ArchetypeState archetype_state; +}; + +template <> +struct ArchetypeStateBase<default_constructible::trivial> { + ArchetypeStateBase() = default; + explicit ArchetypeStateBase(MakeArchetypeState, ArchetypeState state) noexcept + : archetype_state(state) {} + + ArchetypeState archetype_state; +}; + +// The move-constructor base +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue> +struct ArchetypeMoveConstructor + : ArchetypeStateBase<DefaultConstructibleValue> { + static_assert(MoveConstructibleValue == move_constructible::yes || + MoveConstructibleValue == move_constructible::nothrow, + ""); + + explicit ArchetypeMoveConstructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeStateBase<DefaultConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeMoveConstructor() = default; + ArchetypeMoveConstructor(ArchetypeMoveConstructor&& other) noexcept( + MoveConstructibleValue == move_constructible::nothrow) + : ArchetypeStateBase<DefaultConstructibleValue>(MakeArchetypeState(), + other.archetype_state) {} + ArchetypeMoveConstructor(const ArchetypeMoveConstructor&) = default; + ArchetypeMoveConstructor& operator=(ArchetypeMoveConstructor&&) = default; + ArchetypeMoveConstructor& operator=(const ArchetypeMoveConstructor&) = + default; +}; + +template <default_constructible DefaultConstructibleValue> +struct ArchetypeMoveConstructor<DefaultConstructibleValue, + move_constructible::trivial> + : ArchetypeStateBase<DefaultConstructibleValue> { + explicit ArchetypeMoveConstructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeStateBase<DefaultConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeMoveConstructor() = default; +}; + +// The copy-constructor base +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue> +struct ArchetypeCopyConstructor + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue> { + static_assert(CopyConstructibleValue == copy_constructible::yes || + CopyConstructibleValue == copy_constructible::nothrow, + ""); + explicit ArchetypeCopyConstructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeCopyConstructor() = default; + ArchetypeCopyConstructor(ArchetypeCopyConstructor&&) = default; + ArchetypeCopyConstructor(const ArchetypeCopyConstructor& other) noexcept( + CopyConstructibleValue == copy_constructible::nothrow) + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue>( + MakeArchetypeState(), other.archetype_state) {} + ArchetypeCopyConstructor& operator=(ArchetypeCopyConstructor&&) = default; + ArchetypeCopyConstructor& operator=(const ArchetypeCopyConstructor&) = + default; +}; + +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue> +struct ArchetypeCopyConstructor<DefaultConstructibleValue, + MoveConstructibleValue, + copy_constructible::maybe> + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue> { + explicit ArchetypeCopyConstructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeCopyConstructor() = default; + ArchetypeCopyConstructor(ArchetypeCopyConstructor&&) = default; + ArchetypeCopyConstructor(const ArchetypeCopyConstructor&) = delete; + ArchetypeCopyConstructor& operator=(ArchetypeCopyConstructor&&) = default; + ArchetypeCopyConstructor& operator=(const ArchetypeCopyConstructor&) = + default; +}; + +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue> +struct ArchetypeCopyConstructor<DefaultConstructibleValue, + MoveConstructibleValue, + copy_constructible::trivial> + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue> { + explicit ArchetypeCopyConstructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeMoveConstructor<DefaultConstructibleValue, + MoveConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeCopyConstructor() = default; +}; + +// The move-assign base +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue> +struct ArchetypeMoveAssign + : ArchetypeCopyConstructor<DefaultConstructibleValue, + MoveConstructibleValue, CopyConstructibleValue> { + static_assert(MoveAssignableValue == move_assignable::yes || + MoveAssignableValue == move_assignable::nothrow, + ""); + explicit ArchetypeMoveAssign(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeCopyConstructor<DefaultConstructibleValue, + MoveConstructibleValue, + CopyConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeMoveAssign() = default; + ArchetypeMoveAssign(ArchetypeMoveAssign&&) = default; + ArchetypeMoveAssign(const ArchetypeMoveAssign&) = default; + ArchetypeMoveAssign& operator=(ArchetypeMoveAssign&& other) noexcept( + MoveAssignableValue == move_assignable::nothrow) { + this->archetype_state = other.archetype_state; + return *this; + } + + ArchetypeMoveAssign& operator=(const ArchetypeMoveAssign&) = default; +}; + +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue> +struct ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, move_assignable::trivial> + : ArchetypeCopyConstructor<DefaultConstructibleValue, + MoveConstructibleValue, CopyConstructibleValue> { + explicit ArchetypeMoveAssign(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeCopyConstructor<DefaultConstructibleValue, + MoveConstructibleValue, + CopyConstructibleValue>(MakeArchetypeState(), + state) {} + + ArchetypeMoveAssign() = default; +}; + +// The copy-assign base +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue, + copy_assignable CopyAssignableValue> +struct ArchetypeCopyAssign + : ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue> { + static_assert(CopyAssignableValue == copy_assignable::yes || + CopyAssignableValue == copy_assignable::nothrow, + ""); + explicit ArchetypeCopyAssign(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue>( + MakeArchetypeState(), state) {} + + ArchetypeCopyAssign() = default; + ArchetypeCopyAssign(ArchetypeCopyAssign&&) = default; + ArchetypeCopyAssign(const ArchetypeCopyAssign&) = default; + ArchetypeCopyAssign& operator=(ArchetypeCopyAssign&&) = default; + + ArchetypeCopyAssign& operator=(const ArchetypeCopyAssign& other) noexcept( + CopyAssignableValue == copy_assignable::nothrow) { + this->archetype_state = other.archetype_state; + return *this; + } +}; + +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue> +struct ArchetypeCopyAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + copy_assignable::maybe> + : ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue> { + explicit ArchetypeCopyAssign(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue>( + MakeArchetypeState(), state) {} + + ArchetypeCopyAssign() = default; + ArchetypeCopyAssign(ArchetypeCopyAssign&&) = default; + ArchetypeCopyAssign(const ArchetypeCopyAssign&) = default; + ArchetypeCopyAssign& operator=(ArchetypeCopyAssign&&) = default; + ArchetypeCopyAssign& operator=(const ArchetypeCopyAssign&) = delete; +}; + +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue> +struct ArchetypeCopyAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + copy_assignable::trivial> + : ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue> { + explicit ArchetypeCopyAssign(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeMoveAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue>( + MakeArchetypeState(), state) {} + + ArchetypeCopyAssign() = default; +}; + +// The destructor base +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue, + copy_assignable CopyAssignableValue, destructible DestructibleValue> +struct ArchetypeDestructor + : ArchetypeCopyAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + CopyAssignableValue> { + static_assert(DestructibleValue == destructible::yes || + DestructibleValue == destructible::nothrow, + ""); + + explicit ArchetypeDestructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeCopyAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + CopyAssignableValue>(MakeArchetypeState(), state) {} + + ArchetypeDestructor() = default; + ArchetypeDestructor(ArchetypeDestructor&&) = default; + ArchetypeDestructor(const ArchetypeDestructor&) = default; + ArchetypeDestructor& operator=(ArchetypeDestructor&&) = default; + ArchetypeDestructor& operator=(const ArchetypeDestructor&) = default; + ~ArchetypeDestructor() noexcept(DestructibleValue == destructible::nothrow) {} +}; + +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue, + copy_assignable CopyAssignableValue> +struct ArchetypeDestructor<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + CopyAssignableValue, destructible::trivial> + : ArchetypeCopyAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + CopyAssignableValue> { + explicit ArchetypeDestructor(MakeArchetypeState, + ArchetypeState state) noexcept + : ArchetypeCopyAssign<DefaultConstructibleValue, MoveConstructibleValue, + CopyConstructibleValue, MoveAssignableValue, + CopyAssignableValue>(MakeArchetypeState(), state) {} + + ArchetypeDestructor() = default; +}; + +// An alias to the top of the chain of bases for special-member functions. +// NOTE: move_constructible::maybe, move_assignable::maybe, and +// destructible::maybe are handled in the top-level type by way of SFINAE. +// Because of this, we never instantiate the base classes with +// move_constructible::maybe, move_assignable::maybe, or destructible::maybe so +// that we minimize the number of different possible type-template +// instantiations. +template <default_constructible DefaultConstructibleValue, + move_constructible MoveConstructibleValue, + copy_constructible CopyConstructibleValue, + move_assignable MoveAssignableValue, + copy_assignable CopyAssignableValue, destructible DestructibleValue> +using ArchetypeSpecialMembersBase = ArchetypeDestructor< + DefaultConstructibleValue, + MoveConstructibleValue != move_constructible::maybe + ? MoveConstructibleValue + : move_constructible::nothrow, + CopyConstructibleValue, + MoveAssignableValue != move_assignable::maybe ? MoveAssignableValue + : move_assignable::nothrow, + CopyAssignableValue, + DestructibleValue != destructible::maybe ? DestructibleValue + : destructible::nothrow>; + +// A function that is used to create an archetype with some associated state. +template <class Arch> +Arch MakeArchetype(ArchetypeState state) noexcept { + static_assert(IsArchetype<Arch>::value, + "The explicit template argument to MakeArchetype is required " + "to be an Archetype."); + return Arch(MakeArchetypeState(), state); +} + +// This is used to conditionally delete "copy" and "move" constructors in a way +// that is consistent with what the ConformanceProfile requires and that also +// strictly enforces the arguments to the copy/move to not come from implicit +// conversions when dealing with the Archetype. +template <class Prof, class T> +constexpr bool ShouldDeleteConstructor() { + return !((PropertiesOfT<Prof>::move_constructible_support != + move_constructible::maybe && + std::is_same<T, Archetype<Prof>>::value) || + (PropertiesOfT<Prof>::copy_constructible_support != + copy_constructible::maybe && + (std::is_same<T, const Archetype<Prof>&>::value || + std::is_same<T, Archetype<Prof>&>::value || + std::is_same<T, const Archetype<Prof>>::value))); +} + +// This is used to conditionally delete "copy" and "move" assigns in a way +// that is consistent with what the ConformanceProfile requires and that also +// strictly enforces the arguments to the copy/move to not come from implicit +// conversions when dealing with the Archetype. +template <class Prof, class T> +constexpr bool ShouldDeleteAssign() { + return !( + (PropertiesOfT<Prof>::move_assignable_support != move_assignable::maybe && + std::is_same<T, Archetype<Prof>>::value) || + (PropertiesOfT<Prof>::copy_assignable_support != copy_assignable::maybe && + (std::is_same<T, const Archetype<Prof>&>::value || + std::is_same<T, Archetype<Prof>&>::value || + std::is_same<T, const Archetype<Prof>>::value))); +} + +// TODO(calabrese) Inherit from a chain of secondary bases to pull in the +// associated functions of other concepts. +template <class Prof, class Enabler> +class Archetype : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + static_assert(std::is_same<Enabler, void>::value, + "An explicit type must not be passed as the second template " + "argument to 'Archetype`."); + + // The cases mentioned in these static_asserts are expected to be handled in + // the partial template specializations of Archetype that follow this + // definition. + static_assert(PropertiesOfT<Prof>::destructible_support != + destructible::maybe, + ""); + static_assert(PropertiesOfT<Prof>::move_constructible_support != + move_constructible::maybe || + PropertiesOfT<Prof>::copy_constructible_support == + copy_constructible::maybe, + ""); + static_assert(PropertiesOfT<Prof>::move_assignable_support != + move_assignable::maybe || + PropertiesOfT<Prof>::copy_assignable_support == + copy_assignable::maybe, + ""); + + public: + Archetype() = default; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +template <class Prof> +class Archetype<Prof, typename std::enable_if< + PropertiesOfT<Prof>::move_constructible_support != + move_constructible::maybe && + PropertiesOfT<Prof>::move_assignable_support == + move_assignable::maybe && + PropertiesOfT<Prof>::destructible_support != + destructible::maybe>::type> + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + public: + Archetype() = default; + Archetype(Archetype&&) = default; + Archetype(const Archetype&) = default; + Archetype& operator=(Archetype&&) = delete; + Archetype& operator=(const Archetype&) = default; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +template <class Prof> +class Archetype<Prof, typename std::enable_if< + PropertiesOfT<Prof>::move_constructible_support == + move_constructible::maybe && + PropertiesOfT<Prof>::move_assignable_support == + move_assignable::maybe && + PropertiesOfT<Prof>::destructible_support != + destructible::maybe>::type> + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + public: + Archetype() = default; + Archetype(Archetype&&) = delete; + Archetype(const Archetype&) = default; + Archetype& operator=(Archetype&&) = delete; + Archetype& operator=(const Archetype&) = default; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +template <class Prof> +class Archetype<Prof, typename std::enable_if< + PropertiesOfT<Prof>::move_constructible_support == + move_constructible::maybe && + PropertiesOfT<Prof>::move_assignable_support != + move_assignable::maybe && + PropertiesOfT<Prof>::destructible_support != + destructible::maybe>::type> + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + public: + Archetype() = default; + Archetype(Archetype&&) = delete; + Archetype(const Archetype&) = default; + Archetype& operator=(Archetype&&) = default; + Archetype& operator=(const Archetype&) = default; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +template <class Prof> +class Archetype<Prof, typename std::enable_if< + PropertiesOfT<Prof>::move_constructible_support != + move_constructible::maybe && + PropertiesOfT<Prof>::move_assignable_support == + move_assignable::maybe && + PropertiesOfT<Prof>::destructible_support == + destructible::maybe>::type> + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + public: + Archetype() = default; + Archetype(Archetype&&) = default; + Archetype(const Archetype&) = default; + Archetype& operator=(Archetype&&) = delete; + Archetype& operator=(const Archetype&) = default; + ~Archetype() = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +template <class Prof> +class Archetype<Prof, typename std::enable_if< + PropertiesOfT<Prof>::move_constructible_support == + move_constructible::maybe && + PropertiesOfT<Prof>::move_assignable_support == + move_assignable::maybe && + PropertiesOfT<Prof>::destructible_support == + destructible::maybe>::type> + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + public: + Archetype() = default; + Archetype(Archetype&&) = delete; + Archetype(const Archetype&) = default; + Archetype& operator=(Archetype&&) = delete; + Archetype& operator=(const Archetype&) = default; + ~Archetype() = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +template <class Prof> +class Archetype<Prof, typename std::enable_if< + PropertiesOfT<Prof>::move_constructible_support == + move_constructible::maybe && + PropertiesOfT<Prof>::move_assignable_support != + move_assignable::maybe && + PropertiesOfT<Prof>::destructible_support == + destructible::maybe>::type> + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support> { + public: + Archetype() = default; + Archetype(Archetype&&) = delete; + Archetype(const Archetype&) = default; + Archetype& operator=(Archetype&&) = default; + Archetype& operator=(const Archetype&) = default; + ~Archetype() = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteConstructor<Prof, T>()>::type* = nullptr> + Archetype(T&&) = delete; + + // Disallow moves when requested, and disallow implicit conversions. + template <class T, typename std::enable_if< + ShouldDeleteAssign<Prof, T>()>::type* = nullptr> + Archetype& operator=(T&&) = delete; + + using ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>::archetype_state; + + private: + explicit Archetype(MakeArchetypeState, ArchetypeState state) noexcept + : ArchetypeSpecialMembersBase< + PropertiesOfT<Prof>::default_constructible_support, + PropertiesOfT<Prof>::move_constructible_support, + PropertiesOfT<Prof>::copy_constructible_support, + PropertiesOfT<Prof>::move_assignable_support, + PropertiesOfT<Prof>::copy_assignable_support, + PropertiesOfT<Prof>::destructible_support>(MakeArchetypeState(), + state) {} + + friend Archetype MakeArchetype<Archetype>(ArchetypeState) noexcept; +}; + +// Explicitly deleted swap for Archetype if the profile does not require swap. +// It is important to delete it rather than simply leave it out so that the +// "using std::swap;" idiom will result in this deleted overload being picked. +template <class Prof, + absl::enable_if_t<!PropertiesOfT<Prof>::is_swappable, int> = 0> +void swap(Archetype<Prof>&, Archetype<Prof>&) = delete; // NOLINT + +// A conditionally-noexcept swap implementation for Archetype when the profile +// supports swap. +template <class Prof, + absl::enable_if_t<PropertiesOfT<Prof>::is_swappable, int> = 0> +void swap(Archetype<Prof>& lhs, Archetype<Prof>& rhs) // NOLINT + noexcept(PropertiesOfT<Prof>::swappable_support != swappable::yes) { + std::swap(lhs.archetype_state, rhs.archetype_state); +} + +// A convertible-to-bool type that is used as the return type of comparison +// operators since the standard doesn't always require exactly bool. +struct NothrowBool { + explicit NothrowBool() = delete; + ~NothrowBool() = default; + + // TODO(calabrese) Delete the copy constructor in C++17 mode since guaranteed + // elision makes it not required when returning from a function. + // NothrowBool(NothrowBool const&) = delete; + + NothrowBool& operator=(NothrowBool const&) = delete; + + explicit operator bool() const noexcept { return value; } + + static NothrowBool make(bool const value) noexcept { + return NothrowBool(value); + } + + private: + explicit NothrowBool(bool const value) noexcept : value(value) {} + + bool value; +}; + +// A convertible-to-bool type that is used as the return type of comparison +// operators since the standard doesn't always require exactly bool. +// Note: ExceptionalBool has a conversion operator that is not noexcept, so +// that even when a comparison operator is noexcept, that operation may still +// potentially throw when converted to bool. +struct ExceptionalBool { + explicit ExceptionalBool() = delete; + ~ExceptionalBool() = default; + + // TODO(calabrese) Delete the copy constructor in C++17 mode since guaranteed + // elision makes it not required when returning from a function. + // ExceptionalBool(ExceptionalBool const&) = delete; + + ExceptionalBool& operator=(ExceptionalBool const&) = delete; + + explicit operator bool() const { return value; } // NOLINT + + static ExceptionalBool make(bool const value) noexcept { + return ExceptionalBool(value); + } + + private: + explicit ExceptionalBool(bool const value) noexcept : value(value) {} + + bool value; +}; + +// The following macro is only used as a helper in this file to stamp out +// comparison operator definitions. It is undefined after usage. +// +// NOTE: Non-nothrow operators throw via their result's conversion to bool even +// though the operation itself is noexcept. +#define ABSL_TYPES_INTERNAL_OP(enum_name, op) \ + template <class Prof> \ + absl::enable_if_t<!PropertiesOfT<Prof>::is_##enum_name, bool> operator op( \ + const Archetype<Prof>&, const Archetype<Prof>&) = delete; \ + \ + template <class Prof> \ + typename absl::enable_if_t< \ + PropertiesOfT<Prof>::is_##enum_name, \ + std::conditional<PropertiesOfT<Prof>::enum_name##_support == \ + enum_name::nothrow, \ + NothrowBool, ExceptionalBool>>::type \ + operator op(const Archetype<Prof>& lhs, \ + const Archetype<Prof>& rhs) noexcept { \ + return absl::conditional_t< \ + PropertiesOfT<Prof>::enum_name##_support == enum_name::nothrow, \ + NothrowBool, ExceptionalBool>::make(lhs.archetype_state op \ + rhs.archetype_state); \ + } + +ABSL_TYPES_INTERNAL_OP(equality_comparable, ==); +ABSL_TYPES_INTERNAL_OP(inequality_comparable, !=); +ABSL_TYPES_INTERNAL_OP(less_than_comparable, <); +ABSL_TYPES_INTERNAL_OP(less_equal_comparable, <=); +ABSL_TYPES_INTERNAL_OP(greater_equal_comparable, >=); +ABSL_TYPES_INTERNAL_OP(greater_than_comparable, >); + +#undef ABSL_TYPES_INTERNAL_OP + +// Base class for std::hash specializations when an Archetype doesn't support +// hashing. +struct PoisonedHash { + PoisonedHash() = delete; + PoisonedHash(const PoisonedHash&) = delete; + PoisonedHash& operator=(const PoisonedHash&) = delete; +}; + +// Base class for std::hash specializations when an Archetype supports hashing. +template <class Prof> +struct EnabledHash { + using argument_type = Archetype<Prof>; + using result_type = std::size_t; + result_type operator()(const argument_type& arg) const { + return std::hash<ArchetypeState>()(arg.archetype_state); + } +}; + +} // namespace types_internal +ABSL_NAMESPACE_END +} // namespace absl + +namespace std { + +template <class Prof> // NOLINT +struct hash<::absl::types_internal::Archetype<Prof>> + : conditional<::absl::types_internal::PropertiesOfT<Prof>::is_hashable, + ::absl::types_internal::EnabledHash<Prof>, + ::absl::types_internal::PoisonedHash>::type {}; + +} // namespace std + +#endif // ABSL_TYPES_INTERNAL_CONFORMANCE_ARCHETYPE_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/conformance_profile.h b/third_party/abseil_cpp/absl/types/internal/conformance_profile.h new file mode 100644 index 0000000000..cf64ff4fcd --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/conformance_profile.h @@ -0,0 +1,931 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// conformance_profiles.h +// ----------------------------------------------------------------------------- +// +// This file contains templates for representing "Regularity Profiles" and +// concisely-named versions of commonly used Regularity Profiles. +// +// A Regularity Profile is a compile-time description of the types of operations +// that a given type supports, along with properties of those operations when +// they do exist. For instance, a Regularity Profile may describe a type that +// has a move-constructor that is noexcept and a copy constructor that is not +// noexcept. This description can then be examined and passed around to other +// templates for the purposes of asserting expectations on user-defined types +// via a series trait checks, or for determining what kinds of run-time tests +// are able to be performed. +// +// Regularity Profiles are also used when creating "archetypes," which are +// minimum-conforming types that meet all of the requirements of a given +// Regularity Profile. For more information regarding archetypes, see +// "conformance_archetypes.h". + +#ifndef ABSL_TYPES_INTERNAL_CONFORMANCE_PROFILE_H_ +#define ABSL_TYPES_INTERNAL_CONFORMANCE_PROFILE_H_ + +#include <set> +#include <type_traits> +#include <utility> +#include <vector> + +#include "gtest/gtest.h" +#include "absl/algorithm/container.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/ascii.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/types/internal/conformance_testing_helpers.h" +#include "absl/utility/utility.h" + +// TODO(calabrese) Add support for extending profiles. + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace types_internal { + +// Converts an enum to its underlying integral value. +template <typename Enum> +constexpr absl::underlying_type_t<Enum> UnderlyingValue(Enum value) { + return static_cast<absl::underlying_type_t<Enum>>(value); +} + +// A tag type used in place of a matcher when checking that an assertion result +// does not actually contain any errors. +struct NoError {}; + +// ----------------------------------------------------------------------------- +// ConformanceErrors +// ----------------------------------------------------------------------------- +class ConformanceErrors { + public: + // Setup the error reporting mechanism by seeding it with the name of the type + // that is being tested. + explicit ConformanceErrors(std::string type_name) + : assertion_result_(false), type_name_(std::move(type_name)) { + assertion_result_ << "\n\n" + "Assuming the following type alias:\n" + "\n" + " using _T = " + << type_name_ << ";\n\n"; + outputDivider(); + } + + // Adds the test name to the list of successfully run tests iff it was not + // previously reported as failing. This behavior is useful for tests that + // have multiple parts, where failures and successes are reported individually + // with the same test name. + void addTestSuccess(absl::string_view test_name) { + auto normalized_test_name = absl::AsciiStrToLower(test_name); + + // If the test is already reported as failing, do not add it to the list of + // successes. + if (test_failures_.find(normalized_test_name) == test_failures_.end()) { + test_successes_.insert(std::move(normalized_test_name)); + } + } + + // Streams a single error description into the internal buffer (a visual + // divider is automatically inserted after the error so that multiple errors + // are visibly distinct). + // + // This function increases the error count by 1. + // + // TODO(calabrese) Determine desired behavior when if this function throws. + template <class... P> + void addTestFailure(absl::string_view test_name, const P&... args) { + // Output a message related to the test failure. + assertion_result_ << "\n\n" + "Failed test: " + << test_name << "\n\n"; + addTestFailureImpl(args...); + assertion_result_ << "\n\n"; + outputDivider(); + + auto normalized_test_name = absl::AsciiStrToLower(test_name); + + // If previous parts of this test succeeded, remove it from that set. + test_successes_.erase(normalized_test_name); + + // Add the test name to the list of failed tests. + test_failures_.insert(std::move(normalized_test_name)); + + has_error_ = true; + } + + // Convert this object into a testing::AssertionResult instance such that it + // can be used with gtest. + ::testing::AssertionResult assertionResult() const { + return has_error_ ? assertion_result_ : ::testing::AssertionSuccess(); + } + + // Convert this object into a testing::AssertionResult instance such that it + // can be used with gtest. This overload expects errors, using the specified + // matcher. + ::testing::AssertionResult expectFailedTests( + const std::set<std::string>& test_names) const { + // Since we are expecting nonconformance, output an error message when the + // type actually conformed to the specified profile. + if (!has_error_) { + return ::testing::AssertionFailure() + << "Unexpected conformance of type:\n" + " " + << type_name_ << "\n\n"; + } + + // Get a list of all expected failures that did not actually fail + // (or that were not run). + std::vector<std::string> nonfailing_tests; + absl::c_set_difference(test_names, test_failures_, + std::back_inserter(nonfailing_tests)); + + // Get a list of all "expected failures" that were never actually run. + std::vector<std::string> unrun_tests; + absl::c_set_difference(nonfailing_tests, test_successes_, + std::back_inserter(unrun_tests)); + + // Report when the user specified tests that were not run. + if (!unrun_tests.empty()) { + const bool tests_were_run = + !(test_failures_.empty() && test_successes_.empty()); + + // Prepare an assertion result used in the case that tests pass that were + // expected to fail. + ::testing::AssertionResult result = ::testing::AssertionFailure(); + result << "When testing type:\n " << type_name_ + << "\n\nThe following tests were expected to fail but were not " + "run"; + + if (tests_were_run) result << " (was the test name spelled correctly?)"; + + result << ":\n\n"; + + // List all of the tests that unexpectedly passed. + for (const auto& test_name : unrun_tests) { + result << " " << test_name << "\n"; + } + + if (!tests_were_run) result << "\nNo tests were run."; + + if (!test_failures_.empty()) { + // List test failures + result << "\nThe tests that were run and failed are:\n\n"; + for (const auto& test_name : test_failures_) { + result << " " << test_name << "\n"; + } + } + + if (!test_successes_.empty()) { + // List test successes + result << "\nThe tests that were run and succeeded are:\n\n"; + for (const auto& test_name : test_successes_) { + result << " " << test_name << "\n"; + } + } + + return result; + } + + // If some tests passed when they were expected to fail, alert the caller. + if (nonfailing_tests.empty()) return ::testing::AssertionSuccess(); + + // Prepare an assertion result used in the case that tests pass that were + // expected to fail. + ::testing::AssertionResult unexpected_successes = + ::testing::AssertionFailure(); + unexpected_successes << "When testing type:\n " << type_name_ + << "\n\nThe following tests passed when they were " + "expected to fail:\n\n"; + + // List all of the tests that unexpectedly passed. + for (const auto& test_name : nonfailing_tests) { + unexpected_successes << " " << test_name << "\n"; + } + + return unexpected_successes; + } + + private: + void outputDivider() { + assertion_result_ << "========================================"; + } + + void addTestFailureImpl() {} + + template <class H, class... T> + void addTestFailureImpl(const H& head, const T&... tail) { + assertion_result_ << head; + addTestFailureImpl(tail...); + } + + ::testing::AssertionResult assertion_result_; + std::set<std::string> test_failures_; + std::set<std::string> test_successes_; + std::string type_name_; + bool has_error_ = false; +}; + +template <class T, class /*Enabler*/ = void> +struct PropertiesOfImpl {}; + +template <class T> +struct PropertiesOfImpl<T, absl::void_t<typename T::properties>> { + using type = typename T::properties; +}; + +template <class T> +struct PropertiesOfImpl<T, absl::void_t<typename T::profile_alias_of>> { + using type = typename PropertiesOfImpl<typename T::profile_alias_of>::type; +}; + +template <class T> +struct PropertiesOf : PropertiesOfImpl<T> {}; + +template <class T> +using PropertiesOfT = typename PropertiesOf<T>::type; + +// NOTE: These enums use this naming convention to be consistent with the +// standard trait names, which is useful since it allows us to match up each +// enum name with a corresponding trait name in macro definitions. + +// An enum that describes the various expectations on an operations existence. +enum class function_support { maybe, yes, nothrow, trivial }; + +constexpr const char* PessimisticPropertyDescription(function_support v) { + return v == function_support::maybe + ? "no" + : v == function_support::yes + ? "yes, potentially throwing" + : v == function_support::nothrow ? "yes, nothrow" + : "yes, trivial"; +} + +// Return a string that describes the kind of property support that was +// expected. +inline std::string ExpectedFunctionKindList(function_support min, + function_support max) { + if (min == max) { + std::string result = + absl::StrCat("Expected:\n ", + PessimisticPropertyDescription( + static_cast<function_support>(UnderlyingValue(min))), + "\n"); + return result; + } + + std::string result = "Expected one of:\n"; + for (auto curr_support = UnderlyingValue(min); + curr_support <= UnderlyingValue(max); ++curr_support) { + absl::StrAppend(&result, " ", + PessimisticPropertyDescription( + static_cast<function_support>(curr_support)), + "\n"); + } + + return result; +} + +template <class Enum> +void ExpectModelOfImpl(ConformanceErrors* errors, Enum min_support, + Enum max_support, Enum kind) { + const auto kind_value = UnderlyingValue(kind); + const auto min_support_value = UnderlyingValue(min_support); + const auto max_support_value = UnderlyingValue(max_support); + + if (!(kind_value >= min_support_value && kind_value <= max_support_value)) { + errors->addTestFailure( + PropertyName(kind), "**Failed property expectation**\n\n", + ExpectedFunctionKindList( + static_cast<function_support>(min_support_value), + static_cast<function_support>(max_support_value)), + '\n', "Actual:\n ", + PessimisticPropertyDescription( + static_cast<function_support>(kind_value))); + } else { + errors->addTestSuccess(PropertyName(kind)); + } +} + +#define ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM(description, name) \ + enum class name { maybe, yes, nothrow, trivial }; \ + \ + constexpr const char* PropertyName(name v) { return description; } \ + static_assert(true, "") // Force a semicolon when using this macro. + +ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM("support for default construction", + default_constructible); +ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM("support for move construction", + move_constructible); +ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM("support for copy construction", + copy_constructible); +ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM("support for move assignment", + move_assignable); +ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM("support for copy assignment", + copy_assignable); +ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM("support for destruction", + destructible); + +#undef ABSL_INTERNAL_SPECIAL_MEMBER_FUNCTION_ENUM + +#define ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM(description, name) \ + enum class name { maybe, yes, nothrow }; \ + \ + constexpr const char* PropertyName(name v) { return description; } \ + static_assert(true, "") // Force a semicolon when using this macro. + +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for ==", equality_comparable); +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for !=", inequality_comparable); +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for <", less_than_comparable); +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for <=", less_equal_comparable); +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for >=", + greater_equal_comparable); +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for >", greater_than_comparable); + +ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM("support for swap", swappable); + +#undef ABSL_INTERNAL_INTRINSIC_FUNCTION_ENUM + +enum class hashable { maybe, yes }; + +constexpr const char* PropertyName(hashable v) { + return "support for std::hash"; +} + +template <class T> +using AlwaysFalse = std::false_type; + +#define ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(name, property) \ + template <class T> \ + constexpr property property##_support_of() { \ + return std::is_##property<T>::value \ + ? std::is_nothrow_##property<T>::value \ + ? absl::is_trivially_##property<T>::value \ + ? property::trivial \ + : property::nothrow \ + : property::yes \ + : property::maybe; \ + } \ + \ + template <class T, class MinProf, class MaxProf> \ + void ExpectModelOf##name(ConformanceErrors* errors) { \ + (ExpectModelOfImpl)(errors, PropertiesOfT<MinProf>::property##_support, \ + PropertiesOfT<MaxProf>::property##_support, \ + property##_support_of<T>()); \ + } + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(DefaultConstructible, + default_constructible); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(MoveConstructible, + move_constructible); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(CopyConstructible, + copy_constructible); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(MoveAssignable, + move_assignable); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(CopyAssignable, + copy_assignable); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER(Destructible, destructible); + +#undef ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_SPECIAL_MEMBER + +void BoolFunction(bool) noexcept; + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction for checking if an operation exists through SFINAE. +// +// `T` is the type to test and Op is an alias containing the expression to test. +template <class T, template <class...> class Op, class = void> +struct IsOpableImpl : std::false_type {}; + +template <class T, template <class...> class Op> +struct IsOpableImpl<T, Op, absl::void_t<Op<T>>> : std::true_type {}; + +template <template <class...> class Op> +struct IsOpable { + template <class T> + using apply = typename IsOpableImpl<T, Op>::type; +}; +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction for checking if an operation exists and is also noexcept +// through SFINAE and the noexcept operator. +/// +// `T` is the type to test and Op is an alias containing the expression to test. +template <class T, template <class...> class Op, class = void> +struct IsNothrowOpableImpl : std::false_type {}; + +template <class T, template <class...> class Op> +struct IsNothrowOpableImpl<T, Op, absl::enable_if_t<Op<T>::value>> + : std::true_type {}; + +template <template <class...> class Op> +struct IsNothrowOpable { + template <class T> + using apply = typename IsNothrowOpableImpl<T, Op>::type; +}; +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// A macro that produces the necessary function for reporting what kind of +// support a specific comparison operation has and a function for reporting an +// error if a given type's support for that operation does not meet the expected +// requirements. +#define ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(name, property, op) \ + template <class T, \ + class Result = std::integral_constant< \ + bool, noexcept((BoolFunction)(std::declval<const T&>() op \ + std::declval<const T&>()))>> \ + using name = Result; \ + \ + template <class T> \ + constexpr property property##_support_of() { \ + return IsOpable<name>::apply<T>::value \ + ? IsNothrowOpable<name>::apply<T>::value ? property::nothrow \ + : property::yes \ + : property::maybe; \ + } \ + \ + template <class T, class MinProf, class MaxProf> \ + void ExpectModelOf##name(ConformanceErrors* errors) { \ + (ExpectModelOfImpl)(errors, PropertiesOfT<MinProf>::property##_support, \ + PropertiesOfT<MaxProf>::property##_support, \ + property##_support_of<T>()); \ + } +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// Generate the necessary support-checking and error reporting functions for +// each of the comparison operators. +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(EqualityComparable, + equality_comparable, ==); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(InequalityComparable, + inequality_comparable, !=); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(LessThanComparable, + less_than_comparable, <); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(LessEqualComparable, + less_equal_comparable, <=); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(GreaterEqualComparable, + greater_equal_comparable, >=); + +ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON(GreaterThanComparable, + greater_than_comparable, >); + +#undef ABSL_INTERNAL_PESSIMISTIC_MODEL_OF_COMPARISON +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// The necessary support-checking and error-reporting functions for swap. +template <class T> +constexpr swappable swappable_support_of() { + return type_traits_internal::IsSwappable<T>::value + ? type_traits_internal::IsNothrowSwappable<T>::value + ? swappable::nothrow + : swappable::yes + : swappable::maybe; +} + +template <class T, class MinProf, class MaxProf> +void ExpectModelOfSwappable(ConformanceErrors* errors) { + (ExpectModelOfImpl)(errors, PropertiesOfT<MinProf>::swappable_support, + PropertiesOfT<MaxProf>::swappable_support, + swappable_support_of<T>()); +} +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// The necessary support-checking and error-reporting functions for std::hash. +template <class T> +constexpr hashable hashable_support_of() { + return type_traits_internal::IsHashable<T>::value ? hashable::yes + : hashable::maybe; +} + +template <class T, class MinProf, class MaxProf> +void ExpectModelOfHashable(ConformanceErrors* errors) { + (ExpectModelOfImpl)(errors, PropertiesOfT<MinProf>::hashable_support, + PropertiesOfT<MaxProf>::hashable_support, + hashable_support_of<T>()); +} +// +//////////////////////////////////////////////////////////////////////////////// + +template < + default_constructible DefaultConstructibleValue = + default_constructible::maybe, + move_constructible MoveConstructibleValue = move_constructible::maybe, + copy_constructible CopyConstructibleValue = copy_constructible::maybe, + move_assignable MoveAssignableValue = move_assignable::maybe, + copy_assignable CopyAssignableValue = copy_assignable::maybe, + destructible DestructibleValue = destructible::maybe, + equality_comparable EqualityComparableValue = equality_comparable::maybe, + inequality_comparable InequalityComparableValue = + inequality_comparable::maybe, + less_than_comparable LessThanComparableValue = less_than_comparable::maybe, + less_equal_comparable LessEqualComparableValue = + less_equal_comparable::maybe, + greater_equal_comparable GreaterEqualComparableValue = + greater_equal_comparable::maybe, + greater_than_comparable GreaterThanComparableValue = + greater_than_comparable::maybe, + swappable SwappableValue = swappable::maybe, + hashable HashableValue = hashable::maybe> +struct ConformanceProfile { + using properties = ConformanceProfile; + + static constexpr default_constructible + default_constructible_support = // NOLINT + DefaultConstructibleValue; + + static constexpr move_constructible move_constructible_support = // NOLINT + MoveConstructibleValue; + + static constexpr copy_constructible copy_constructible_support = // NOLINT + CopyConstructibleValue; + + static constexpr move_assignable move_assignable_support = // NOLINT + MoveAssignableValue; + + static constexpr copy_assignable copy_assignable_support = // NOLINT + CopyAssignableValue; + + static constexpr destructible destructible_support = // NOLINT + DestructibleValue; + + static constexpr equality_comparable equality_comparable_support = // NOLINT + EqualityComparableValue; + + static constexpr inequality_comparable + inequality_comparable_support = // NOLINT + InequalityComparableValue; + + static constexpr less_than_comparable + less_than_comparable_support = // NOLINT + LessThanComparableValue; + + static constexpr less_equal_comparable + less_equal_comparable_support = // NOLINT + LessEqualComparableValue; + + static constexpr greater_equal_comparable + greater_equal_comparable_support = // NOLINT + GreaterEqualComparableValue; + + static constexpr greater_than_comparable + greater_than_comparable_support = // NOLINT + GreaterThanComparableValue; + + static constexpr swappable swappable_support = SwappableValue; // NOLINT + + static constexpr hashable hashable_support = HashableValue; // NOLINT + + static constexpr bool is_default_constructible = // NOLINT + DefaultConstructibleValue != default_constructible::maybe; + + static constexpr bool is_move_constructible = // NOLINT + MoveConstructibleValue != move_constructible::maybe; + + static constexpr bool is_copy_constructible = // NOLINT + CopyConstructibleValue != copy_constructible::maybe; + + static constexpr bool is_move_assignable = // NOLINT + MoveAssignableValue != move_assignable::maybe; + + static constexpr bool is_copy_assignable = // NOLINT + CopyAssignableValue != copy_assignable::maybe; + + static constexpr bool is_destructible = // NOLINT + DestructibleValue != destructible::maybe; + + static constexpr bool is_equality_comparable = // NOLINT + EqualityComparableValue != equality_comparable::maybe; + + static constexpr bool is_inequality_comparable = // NOLINT + InequalityComparableValue != inequality_comparable::maybe; + + static constexpr bool is_less_than_comparable = // NOLINT + LessThanComparableValue != less_than_comparable::maybe; + + static constexpr bool is_less_equal_comparable = // NOLINT + LessEqualComparableValue != less_equal_comparable::maybe; + + static constexpr bool is_greater_equal_comparable = // NOLINT + GreaterEqualComparableValue != greater_equal_comparable::maybe; + + static constexpr bool is_greater_than_comparable = // NOLINT + GreaterThanComparableValue != greater_than_comparable::maybe; + + static constexpr bool is_swappable = // NOLINT + SwappableValue != swappable::maybe; + + static constexpr bool is_hashable = // NOLINT + HashableValue != hashable::maybe; +}; + +//////////////////////////////////////////////////////////////////////////////// +// +// Compliant SFINAE-friendliness is not always present on the standard library +// implementations that we support. This helper-struct (and associated enum) is +// used as a means to conditionally check the hashability support of a type. +enum class CheckHashability { no, yes }; + +template <class T, CheckHashability ShouldCheckHashability> +struct conservative_hashable_support_of; + +template <class T> +struct conservative_hashable_support_of<T, CheckHashability::no> { + static constexpr hashable Invoke() { return hashable::maybe; } +}; + +template <class T> +struct conservative_hashable_support_of<T, CheckHashability::yes> { + static constexpr hashable Invoke() { return hashable_support_of<T>(); } +}; +// +//////////////////////////////////////////////////////////////////////////////// + +// The ConformanceProfile that is expected based on introspection into the type +// by way of trait checks. +template <class T, CheckHashability ShouldCheckHashability> +struct SyntacticConformanceProfileOf { + using properties = ConformanceProfile< + default_constructible_support_of<T>(), move_constructible_support_of<T>(), + copy_constructible_support_of<T>(), move_assignable_support_of<T>(), + copy_assignable_support_of<T>(), destructible_support_of<T>(), + equality_comparable_support_of<T>(), + inequality_comparable_support_of<T>(), + less_than_comparable_support_of<T>(), + less_equal_comparable_support_of<T>(), + greater_equal_comparable_support_of<T>(), + greater_than_comparable_support_of<T>(), swappable_support_of<T>(), + conservative_hashable_support_of<T, ShouldCheckHashability>::Invoke()>; +}; + +#define ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF_IMPL(type, name) \ + template <default_constructible DefaultConstructibleValue, \ + move_constructible MoveConstructibleValue, \ + copy_constructible CopyConstructibleValue, \ + move_assignable MoveAssignableValue, \ + copy_assignable CopyAssignableValue, \ + destructible DestructibleValue, \ + equality_comparable EqualityComparableValue, \ + inequality_comparable InequalityComparableValue, \ + less_than_comparable LessThanComparableValue, \ + less_equal_comparable LessEqualComparableValue, \ + greater_equal_comparable GreaterEqualComparableValue, \ + greater_than_comparable GreaterThanComparableValue, \ + swappable SwappableValue, hashable HashableValue> \ + constexpr type ConformanceProfile< \ + DefaultConstructibleValue, MoveConstructibleValue, \ + CopyConstructibleValue, MoveAssignableValue, CopyAssignableValue, \ + DestructibleValue, EqualityComparableValue, InequalityComparableValue, \ + LessThanComparableValue, LessEqualComparableValue, \ + GreaterEqualComparableValue, GreaterThanComparableValue, SwappableValue, \ + HashableValue>::name + +#define ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(type) \ + ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF_IMPL(type, \ + type##_support); \ + ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF_IMPL(bool, is_##type) + +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(default_constructible); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(move_constructible); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(copy_constructible); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(move_assignable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(copy_assignable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(destructible); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(equality_comparable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(inequality_comparable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(less_than_comparable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(less_equal_comparable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(greater_equal_comparable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(greater_than_comparable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(swappable); +ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF(hashable); + +#undef ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF +#undef ABSL_INTERNAL_CONFORMANCE_TESTING_DATA_MEMBER_DEF_IMPL + +// Retrieve the enum with the minimum underlying value. +// Note: std::min is not constexpr in C++11, which is why this is necessary. +template <class H> +constexpr H MinEnum(H head) { + return head; +} + +template <class H, class N, class... T> +constexpr H MinEnum(H head, N next, T... tail) { + return (UnderlyingValue)(head) < (UnderlyingValue)(next) + ? (MinEnum)(head, tail...) + : (MinEnum)(next, tail...); +} + +template <class... Profs> +struct MinimalProfiles { + static constexpr default_constructible + default_constructible_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::default_constructible_support...); + + static constexpr move_constructible move_constructible_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::move_constructible_support...); + + static constexpr copy_constructible copy_constructible_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::copy_constructible_support...); + + static constexpr move_assignable move_assignable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::move_assignable_support...); + + static constexpr copy_assignable copy_assignable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::copy_assignable_support...); + + static constexpr destructible destructible_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::destructible_support...); + + static constexpr equality_comparable equality_comparable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::equality_comparable_support...); + + static constexpr inequality_comparable + inequality_comparable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::inequality_comparable_support...); + + static constexpr less_than_comparable + less_than_comparable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::less_than_comparable_support...); + + static constexpr less_equal_comparable + less_equal_comparable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::less_equal_comparable_support...); + + static constexpr greater_equal_comparable + greater_equal_comparable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::greater_equal_comparable_support...); + + static constexpr greater_than_comparable + greater_than_comparable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::greater_than_comparable_support...); + + static constexpr swappable swappable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::swappable_support...); + + static constexpr hashable hashable_support = // NOLINT + (MinEnum)(PropertiesOfT<Profs>::hashable_support...); + + using properties = ConformanceProfile< + default_constructible_support, move_constructible_support, + copy_constructible_support, move_assignable_support, + copy_assignable_support, destructible_support, + equality_comparable_support, inequality_comparable_support, + less_than_comparable_support, less_equal_comparable_support, + greater_equal_comparable_support, greater_than_comparable_support, + swappable_support, hashable_support>; +}; + +// Retrieve the enum with the greatest underlying value. +// Note: std::max is not constexpr in C++11, which is why this is necessary. +template <class H> +constexpr H MaxEnum(H head) { + return head; +} + +template <class H, class N, class... T> +constexpr H MaxEnum(H head, N next, T... tail) { + return (UnderlyingValue)(next) < (UnderlyingValue)(head) + ? (MaxEnum)(head, tail...) + : (MaxEnum)(next, tail...); +} + +template <class... Profs> +struct CombineProfilesImpl { + static constexpr default_constructible + default_constructible_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::default_constructible_support...); + + static constexpr move_constructible move_constructible_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::move_constructible_support...); + + static constexpr copy_constructible copy_constructible_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::copy_constructible_support...); + + static constexpr move_assignable move_assignable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::move_assignable_support...); + + static constexpr copy_assignable copy_assignable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::copy_assignable_support...); + + static constexpr destructible destructible_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::destructible_support...); + + static constexpr equality_comparable equality_comparable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::equality_comparable_support...); + + static constexpr inequality_comparable + inequality_comparable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::inequality_comparable_support...); + + static constexpr less_than_comparable + less_than_comparable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::less_than_comparable_support...); + + static constexpr less_equal_comparable + less_equal_comparable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::less_equal_comparable_support...); + + static constexpr greater_equal_comparable + greater_equal_comparable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::greater_equal_comparable_support...); + + static constexpr greater_than_comparable + greater_than_comparable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::greater_than_comparable_support...); + + static constexpr swappable swappable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::swappable_support...); + + static constexpr hashable hashable_support = // NOLINT + (MaxEnum)(PropertiesOfT<Profs>::hashable_support...); + + using properties = ConformanceProfile< + default_constructible_support, move_constructible_support, + copy_constructible_support, move_assignable_support, + copy_assignable_support, destructible_support, + equality_comparable_support, inequality_comparable_support, + less_than_comparable_support, less_equal_comparable_support, + greater_equal_comparable_support, greater_than_comparable_support, + swappable_support, hashable_support>; +}; + +// NOTE: We use this as opposed to a direct alias of CombineProfilesImpl so that +// when named aliases of CombineProfiles are created (such as in +// conformance_aliases.h), we only pay for the combination algorithm on the +// profiles that are actually used. +template <class... Profs> +struct CombineProfiles { + using profile_alias_of = CombineProfilesImpl<Profs...>; +}; + +template <> +struct CombineProfiles<> { + using properties = ConformanceProfile<>; +}; + +template <class Profile, class Tag> +struct StrongProfileTypedef { + using properties = PropertiesOfT<Profile>; +}; + +template <class T, class /*Enabler*/ = void> +struct IsProfileImpl : std::false_type {}; + +template <class T> +struct IsProfileImpl<T, absl::void_t<PropertiesOfT<T>>> : std::true_type {}; + +template <class T> +struct IsProfile : IsProfileImpl<T>::type {}; + +// A tag that describes which set of properties we will check when the user +// requires a strict match in conformance (as opposed to a loose match which +// allows more-refined support of any given operation). +// +// Currently only the RegularityDomain exists and it includes all operations +// that the conformance testing suite knows about. The intent is that if the +// suite is expanded to support extension, such as for checking conformance of +// concepts like Iterators or Containers, additional corresponding domains can +// be created. +struct RegularityDomain {}; + +} // namespace types_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TYPES_INTERNAL_CONFORMANCE_PROFILE_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/conformance_testing.h b/third_party/abseil_cpp/absl/types/internal/conformance_testing.h new file mode 100644 index 0000000000..487b0f786b --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/conformance_testing.h @@ -0,0 +1,1386 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// conformance_testing.h +// ----------------------------------------------------------------------------- +// + +#ifndef ABSL_TYPES_INTERNAL_CONFORMANCE_TESTING_H_ +#define ABSL_TYPES_INTERNAL_CONFORMANCE_TESTING_H_ + +//////////////////////////////////////////////////////////////////////////////// +// // +// Many templates in this file take a `T` and a `Prof` type as explicit // +// template arguments. These are a type to be checked and a // +// "Regularity Profile" that describes what operations that type `T` is // +// expected to support. See "regularity_profiles.h" for more details // +// regarding Regularity Profiles. // +// // +//////////////////////////////////////////////////////////////////////////////// + +#include <cstddef> +#include <set> +#include <tuple> +#include <type_traits> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/ascii.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" +#include "absl/types/internal/conformance_aliases.h" +#include "absl/types/internal/conformance_archetype.h" +#include "absl/types/internal/conformance_profile.h" +#include "absl/types/internal/conformance_testing_helpers.h" +#include "absl/types/internal/parentheses.h" +#include "absl/types/internal/transform_args.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace types_internal { + +// Returns true if the compiler incorrectly greedily instantiates constexpr +// templates in any unevaluated context. +constexpr bool constexpr_instantiation_when_unevaluated() { +#if defined(__apple_build_version__) // TODO(calabrese) Make more specific + return true; +#elif defined(__clang__) + return __clang_major__ < 4; +#elif defined(__GNUC__) + // TODO(calabrese) Figure out why gcc 7 fails (seems like a different bug) + return __GNUC__ < 5 || (__GNUC__ == 5 && __GNUC_MINOR__ < 2) || __GNUC__ >= 7; +#else + return false; +#endif +} + +// Returns true if the standard library being used incorrectly produces an error +// when instantiating the definition of a poisoned std::hash specialization. +constexpr bool poisoned_hash_fails_instantiation() { +#if defined(_MSC_VER) && !defined(_LIBCPP_VERSION) + return _MSC_VER < 1914; +#else + return false; +#endif +} + +template <class Fun> +struct GeneratorType { + decltype(std::declval<const Fun&>()()) operator()() const + noexcept(noexcept(std::declval<const Fun&>()())) { + return fun(); + } + + Fun fun; + const char* description; +}; + +// A "make" function for the GeneratorType template that deduces the function +// object type. +template <class Fun, + absl::enable_if_t<IsNullaryCallable<Fun>::value>** = nullptr> +GeneratorType<Fun> Generator(Fun fun, const char* description) { + return GeneratorType<Fun>{absl::move(fun), description}; +} + +// A type that contains a set of nullary function objects that each return an +// instance of the same type and value (though possibly different +// representations, such as +0 and -0 or two vectors with the same elements but +// with different capacities). +template <class... Funs> +struct EquivalenceClassType { + std::tuple<GeneratorType<Funs>...> generators; +}; + +// A "make" function for the EquivalenceClassType template that deduces the +// function object types and is constrained such that a user can only pass in +// function objects that all have the same return type. +template <class... Funs, absl::enable_if_t<AreGeneratorsWithTheSameReturnType< + Funs...>::value>** = nullptr> +EquivalenceClassType<Funs...> EquivalenceClass(GeneratorType<Funs>... funs) { + return {std::make_tuple(absl::move(funs)...)}; +} + +// A type that contains an ordered series of EquivalenceClassTypes, from +// smallest value to largest value. +template <class... EqClasses> +struct OrderedEquivalenceClasses { + std::tuple<EqClasses...> eq_classes; +}; + +// An object containing the parts of a given (name, initialization expression), +// and is capable of generating a string that describes the given. +struct GivenDeclaration { + std::string outputDeclaration(std::size_t width) const { + const std::size_t indent_size = 2; + std::string result = absl::StrCat(" ", name); + + if (!expression.empty()) { + // Indent + result.resize(indent_size + width, ' '); + absl::StrAppend(&result, " = ", expression, ";\n"); + } else { + absl::StrAppend(&result, ";\n"); + } + + return result; + } + + std::string name; + std::string expression; +}; + +// Produce a string that contains all of the givens of an error report. +template <class... Decls> +std::string PrepareGivenContext(const Decls&... decls) { + const std::size_t width = (std::max)({decls.name.size()...}); + return absl::StrCat("Given:\n", decls.outputDeclaration(width)..., "\n"); +} + +//////////////////////////////////////////////////////////////////////////////// +// Function objects that perform a check for each comparison operator // +//////////////////////////////////////////////////////////////////////////////// + +#define ABSL_INTERNAL_EXPECT_OP(name, op) \ + struct Expect##name { \ + template <class T> \ + void operator()(absl::string_view test_name, absl::string_view context, \ + const T& lhs, const T& rhs, absl::string_view lhs_name, \ + absl::string_view rhs_name) const { \ + if (!static_cast<bool>(lhs op rhs)) { \ + errors->addTestFailure( \ + test_name, absl::StrCat(context, \ + "**Unexpected comparison result**\n" \ + "\n" \ + "Expression:\n" \ + " ", \ + lhs_name, " " #op " ", rhs_name, \ + "\n" \ + "\n" \ + "Expected: true\n" \ + " Actual: false")); \ + } else { \ + errors->addTestSuccess(test_name); \ + } \ + } \ + \ + ConformanceErrors* errors; \ + }; \ + \ + struct ExpectNot##name { \ + template <class T> \ + void operator()(absl::string_view test_name, absl::string_view context, \ + const T& lhs, const T& rhs, absl::string_view lhs_name, \ + absl::string_view rhs_name) const { \ + if (lhs op rhs) { \ + errors->addTestFailure( \ + test_name, absl::StrCat(context, \ + "**Unexpected comparison result**\n" \ + "\n" \ + "Expression:\n" \ + " ", \ + lhs_name, " " #op " ", rhs_name, \ + "\n" \ + "\n" \ + "Expected: false\n" \ + " Actual: true")); \ + } else { \ + errors->addTestSuccess(test_name); \ + } \ + } \ + \ + ConformanceErrors* errors; \ + } + +ABSL_INTERNAL_EXPECT_OP(Eq, ==); +ABSL_INTERNAL_EXPECT_OP(Ne, !=); +ABSL_INTERNAL_EXPECT_OP(Lt, <); +ABSL_INTERNAL_EXPECT_OP(Le, <=); +ABSL_INTERNAL_EXPECT_OP(Ge, >=); +ABSL_INTERNAL_EXPECT_OP(Gt, >); + +#undef ABSL_INTERNAL_EXPECT_OP + +// A function object that verifies that two objects hash to the same value by +// way of the std::hash specialization. +struct ExpectSameHash { + template <class T> + void operator()(absl::string_view test_name, absl::string_view context, + const T& lhs, const T& rhs, absl::string_view lhs_name, + absl::string_view rhs_name) const { + if (std::hash<T>()(lhs) != std::hash<T>()(rhs)) { + errors->addTestFailure( + test_name, absl::StrCat(context, + "**Unexpected hash result**\n" + "\n" + "Expression:\n" + " std::hash<T>()(", + lhs_name, ") == std::hash<T>()(", rhs_name, + ")\n" + "\n" + "Expected: true\n" + " Actual: false")); + } else { + errors->addTestSuccess(test_name); + } + } + + ConformanceErrors* errors; +}; + +// A function template that takes two objects and verifies that each comparison +// operator behaves in a way that is consistent with equality. It has "OneWay" +// in the name because the first argument will always be the left-hand operand +// of the corresponding comparison operator and the second argument will +// always be the right-hand operand. It will never switch that order. +// At a higher level in the test suite, the one-way form is called once for each +// of the two possible orders whenever lhs and rhs are not the same initializer. +template <class T, class Prof> +void ExpectOneWayEquality(ConformanceErrors* errors, + absl::string_view test_name, + absl::string_view context, const T& lhs, const T& rhs, + absl::string_view lhs_name, + absl::string_view rhs_name) { + If<PropertiesOfT<Prof>::is_equality_comparable>::Invoke( + ExpectEq{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); + + If<PropertiesOfT<Prof>::is_inequality_comparable>::Invoke( + ExpectNotNe{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); + + If<PropertiesOfT<Prof>::is_less_than_comparable>::Invoke( + ExpectNotLt{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); + + If<PropertiesOfT<Prof>::is_less_equal_comparable>::Invoke( + ExpectLe{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); + + If<PropertiesOfT<Prof>::is_greater_equal_comparable>::Invoke( + ExpectGe{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); + + If<PropertiesOfT<Prof>::is_greater_than_comparable>::Invoke( + ExpectNotGt{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); + + If<PropertiesOfT<Prof>::is_hashable>::Invoke( + ExpectSameHash{errors}, test_name, context, lhs, rhs, lhs_name, rhs_name); +} + +// A function template that takes two objects and verifies that each comparison +// operator behaves in a way that is consistent with equality. This function +// differs from ExpectOneWayEquality in that this will do checks with argument +// order reversed in addition to in-order. +template <class T, class Prof> +void ExpectEquality(ConformanceErrors* errors, absl::string_view test_name, + absl::string_view context, const T& lhs, const T& rhs, + absl::string_view lhs_name, absl::string_view rhs_name) { + (ExpectOneWayEquality<T, Prof>)(errors, test_name, context, lhs, rhs, + lhs_name, rhs_name); + (ExpectOneWayEquality<T, Prof>)(errors, test_name, context, rhs, lhs, + rhs_name, lhs_name); +} + +// Given a generator, makes sure that a generated value and a moved-from +// generated value are equal. +template <class T, class Prof> +struct ExpectMoveConstructOneGenerator { + template <class Fun> + void operator()(const Fun& generator) const { + const T object = generator(); + const T moved_object = absl::move(generator()); // Force no elision. + + (ExpectEquality<T, Prof>)(errors, "Move construction", + PrepareGivenContext( + GivenDeclaration{"const _T object", + generator.description}, + GivenDeclaration{"const _T moved_object", + std::string("std::move(") + + generator.description + + ")"}), + object, moved_object, "object", "moved_object"); + } + + ConformanceErrors* errors; +}; + +// Given a generator, makes sure that a generated value and a copied-from +// generated value are equal. +template <class T, class Prof> +struct ExpectCopyConstructOneGenerator { + template <class Fun> + void operator()(const Fun& generator) const { + const T object = generator(); + const T copied_object = static_cast<const T&>(generator()); + + (ExpectEquality<T, Prof>)(errors, "Copy construction", + PrepareGivenContext( + GivenDeclaration{"const _T object", + generator.description}, + GivenDeclaration{ + "const _T copied_object", + std::string("static_cast<const _T&>(") + + generator.description + ")"}), + object, copied_object, "object", "copied_object"); + } + + ConformanceErrors* errors; +}; + +// Default-construct and do nothing before destruction. +// +// This is useful in exercising the codepath of default construction followed by +// destruction, but does not explicitly test anything. An example of where this +// might fail is a default destructor that default-initializes a scalar and a +// destructor reads the value of that member. Sanitizers can catch this as long +// as our test attempts to execute such a case. +template <class T> +struct ExpectDefaultConstructWithDestruct { + void operator()() const { + // Scoped so that destructor gets called before reporting success. + { + T object; + static_cast<void>(object); + } + + errors->addTestSuccess("Default construction"); + } + + ConformanceErrors* errors; +}; + +// Check move-assign into a default-constructed object. +template <class T, class Prof> +struct ExpectDefaultConstructWithMoveAssign { + template <class Fun> + void operator()(const Fun& generator) const { + const T source_of_truth = generator(); + T object; + object = generator(); + + (ExpectEquality<T, Prof>)(errors, "Move assignment", + PrepareGivenContext( + GivenDeclaration{"const _T object", + generator.description}, + GivenDeclaration{"_T object", ""}, + GivenDeclaration{"object", + generator.description}), + object, source_of_truth, "std::as_const(object)", + "source_of_truth"); + } + + ConformanceErrors* errors; +}; + +// Check copy-assign into a default-constructed object. +template <class T, class Prof> +struct ExpectDefaultConstructWithCopyAssign { + template <class Fun> + void operator()(const Fun& generator) const { + const T source_of_truth = generator(); + T object; + object = static_cast<const T&>(generator()); + + (ExpectEquality<T, Prof>)(errors, "Copy assignment", + PrepareGivenContext( + GivenDeclaration{"const _T source_of_truth", + generator.description}, + GivenDeclaration{"_T object", ""}, + GivenDeclaration{ + "object", + std::string("static_cast<const _T&>(") + + generator.description + ")"}), + object, source_of_truth, "std::as_const(object)", + "source_of_truth"); + } + + ConformanceErrors* errors; +}; + +// Perform a self move-assign. +template <class T, class Prof> +struct ExpectSelfMoveAssign { + template <class Fun> + void operator()(const Fun& generator) const { + T object = generator(); + object = absl::move(object); + + // NOTE: Self move-assign results in a valid-but-unspecified state. + + (ExpectEquality<T, Prof>)(errors, "Move assignment", + PrepareGivenContext( + GivenDeclaration{"_T object", + generator.description}, + GivenDeclaration{"object", + "std::move(object)"}), + object, object, "object", "object"); + } + + ConformanceErrors* errors; +}; + +// Perform a self copy-assign. +template <class T, class Prof> +struct ExpectSelfCopyAssign { + template <class Fun> + void operator()(const Fun& generator) const { + const T source_of_truth = generator(); + T object = generator(); + const T& const_object = object; + object = const_object; + + (ExpectEquality<T, Prof>)(errors, "Copy assignment", + PrepareGivenContext( + GivenDeclaration{"const _T source_of_truth", + generator.description}, + GivenDeclaration{"_T object", + generator.description}, + GivenDeclaration{"object", + "std::as_const(object)"}), + const_object, source_of_truth, + "std::as_const(object)", "source_of_truth"); + } + + ConformanceErrors* errors; +}; + +// Perform a self-swap. +template <class T, class Prof> +struct ExpectSelfSwap { + template <class Fun> + void operator()(const Fun& generator) const { + const T source_of_truth = generator(); + T object = generator(); + + type_traits_internal::Swap(object, object); + + std::string preliminary_info = absl::StrCat( + PrepareGivenContext( + GivenDeclaration{"const _T source_of_truth", generator.description}, + GivenDeclaration{"_T object", generator.description}), + "After performing a self-swap:\n" + " using std::swap;\n" + " swap(object, object);\n" + "\n"); + + (ExpectEquality<T, Prof>)(errors, "Swap", std::move(preliminary_info), + object, source_of_truth, "std::as_const(object)", + "source_of_truth"); + } + + ConformanceErrors* errors; +}; + +// Perform each of the single-generator checks when necessary operations are +// supported. +template <class T, class Prof> +struct ExpectSelfComparison { + template <class Fun> + void operator()(const Fun& generator) const { + const T object = generator(); + (ExpectOneWayEquality<T, Prof>)(errors, "Comparison", + PrepareGivenContext(GivenDeclaration{ + "const _T object", + generator.description}), + object, object, "object", "object"); + } + + ConformanceErrors* errors; +}; + +// Perform each of the single-generator checks when necessary operations are +// supported. +template <class T, class Prof> +struct ExpectConsistency { + template <class Fun> + void operator()(const Fun& generator) const { + If<PropertiesOfT<Prof>::is_move_constructible>::Invoke( + ExpectMoveConstructOneGenerator<T, Prof>{errors}, generator); + + If<PropertiesOfT<Prof>::is_copy_constructible>::Invoke( + ExpectCopyConstructOneGenerator<T, Prof>{errors}, generator); + + If<PropertiesOfT<Prof>::is_default_constructible && + PropertiesOfT<Prof>::is_move_assignable>:: + Invoke(ExpectDefaultConstructWithMoveAssign<T, Prof>{errors}, + generator); + + If<PropertiesOfT<Prof>::is_default_constructible && + PropertiesOfT<Prof>::is_copy_assignable>:: + Invoke(ExpectDefaultConstructWithCopyAssign<T, Prof>{errors}, + generator); + + If<PropertiesOfT<Prof>::is_move_assignable>::Invoke( + ExpectSelfMoveAssign<T, Prof>{errors}, generator); + + If<PropertiesOfT<Prof>::is_copy_assignable>::Invoke( + ExpectSelfCopyAssign<T, Prof>{errors}, generator); + + If<PropertiesOfT<Prof>::is_swappable>::Invoke( + ExpectSelfSwap<T, Prof>{errors}, generator); + } + + ConformanceErrors* errors; +}; + +// Check move-assign with two different values. +template <class T, class Prof> +struct ExpectMoveAssign { + template <class Fun0, class Fun1> + void operator()(const Fun0& generator0, const Fun1& generator1) const { + const T source_of_truth1 = generator1(); + T object = generator0(); + object = generator1(); + + (ExpectEquality<T, Prof>)(errors, "Move assignment", + PrepareGivenContext( + GivenDeclaration{"const _T source_of_truth1", + generator1.description}, + GivenDeclaration{"_T object", + generator0.description}, + GivenDeclaration{"object", + generator1.description}), + object, source_of_truth1, "std::as_const(object)", + "source_of_truth1"); + } + + ConformanceErrors* errors; +}; + +// Check copy-assign with two different values. +template <class T, class Prof> +struct ExpectCopyAssign { + template <class Fun0, class Fun1> + void operator()(const Fun0& generator0, const Fun1& generator1) const { + const T source_of_truth1 = generator1(); + T object = generator0(); + object = static_cast<const T&>(generator1()); + + (ExpectEquality<T, Prof>)(errors, "Copy assignment", + PrepareGivenContext( + GivenDeclaration{"const _T source_of_truth1", + generator1.description}, + GivenDeclaration{"_T object", + generator0.description}, + GivenDeclaration{ + "object", + std::string("static_cast<const _T&>(") + + generator1.description + ")"}), + object, source_of_truth1, "std::as_const(object)", + "source_of_truth1"); + } + + ConformanceErrors* errors; +}; + +// Check swap with two different values. +template <class T, class Prof> +struct ExpectSwap { + template <class Fun0, class Fun1> + void operator()(const Fun0& generator0, const Fun1& generator1) const { + const T source_of_truth0 = generator0(); + const T source_of_truth1 = generator1(); + T object0 = generator0(); + T object1 = generator1(); + + type_traits_internal::Swap(object0, object1); + + const std::string context = + PrepareGivenContext( + GivenDeclaration{"const _T source_of_truth0", + generator0.description}, + GivenDeclaration{"const _T source_of_truth1", + generator1.description}, + GivenDeclaration{"_T object0", generator0.description}, + GivenDeclaration{"_T object1", generator1.description}) + + "After performing a swap:\n" + " using std::swap;\n" + " swap(object0, object1);\n" + "\n"; + + (ExpectEquality<T, Prof>)(errors, "Swap", context, object0, + source_of_truth1, "std::as_const(object0)", + "source_of_truth1"); + (ExpectEquality<T, Prof>)(errors, "Swap", context, object1, + source_of_truth0, "std::as_const(object1)", + "source_of_truth0"); + } + + ConformanceErrors* errors; +}; + +// Validate that `generator0` and `generator1` produce values that are equal. +template <class T, class Prof> +struct ExpectEquivalenceClassComparison { + template <class Fun0, class Fun1> + void operator()(const Fun0& generator0, const Fun1& generator1) const { + const T object0 = generator0(); + const T object1 = generator1(); + + (ExpectEquality<T, Prof>)(errors, "Comparison", + PrepareGivenContext( + GivenDeclaration{"const _T object0", + generator0.description}, + GivenDeclaration{"const _T object1", + generator1.description}), + object0, object1, "object0", "object1"); + } + + ConformanceErrors* errors; +}; + +// Validate that all objects in the same equivalence-class have the same value. +template <class T, class Prof> +struct ExpectEquivalenceClassConsistency { + template <class Fun0, class Fun1> + void operator()(const Fun0& generator0, const Fun1& generator1) const { + If<PropertiesOfT<Prof>::is_move_assignable>::Invoke( + ExpectMoveAssign<T, Prof>{errors}, generator0, generator1); + + If<PropertiesOfT<Prof>::is_copy_assignable>::Invoke( + ExpectCopyAssign<T, Prof>{errors}, generator0, generator1); + + If<PropertiesOfT<Prof>::is_swappable>::Invoke(ExpectSwap<T, Prof>{errors}, + generator0, generator1); + } + + ConformanceErrors* errors; +}; + +// Given a "lesser" object and a "greater" object, perform every combination of +// comparison operators supported for the type, expecting consistent results. +template <class T, class Prof> +void ExpectOrdered(ConformanceErrors* errors, absl::string_view context, + const T& small, const T& big, absl::string_view small_name, + absl::string_view big_name) { + const absl::string_view test_name = "Comparison"; + + If<PropertiesOfT<Prof>::is_equality_comparable>::Invoke( + ExpectNotEq{errors}, test_name, context, small, big, small_name, + big_name); + If<PropertiesOfT<Prof>::is_equality_comparable>::Invoke( + ExpectNotEq{errors}, test_name, context, big, small, big_name, + small_name); + + If<PropertiesOfT<Prof>::is_inequality_comparable>::Invoke( + ExpectNe{errors}, test_name, context, small, big, small_name, big_name); + If<PropertiesOfT<Prof>::is_inequality_comparable>::Invoke( + ExpectNe{errors}, test_name, context, big, small, big_name, small_name); + + If<PropertiesOfT<Prof>::is_less_than_comparable>::Invoke( + ExpectLt{errors}, test_name, context, small, big, small_name, big_name); + If<PropertiesOfT<Prof>::is_less_than_comparable>::Invoke( + ExpectNotLt{errors}, test_name, context, big, small, big_name, + small_name); + + If<PropertiesOfT<Prof>::is_less_equal_comparable>::Invoke( + ExpectLe{errors}, test_name, context, small, big, small_name, big_name); + If<PropertiesOfT<Prof>::is_less_equal_comparable>::Invoke( + ExpectNotLe{errors}, test_name, context, big, small, big_name, + small_name); + + If<PropertiesOfT<Prof>::is_greater_equal_comparable>::Invoke( + ExpectNotGe{errors}, test_name, context, small, big, small_name, + big_name); + If<PropertiesOfT<Prof>::is_greater_equal_comparable>::Invoke( + ExpectGe{errors}, test_name, context, big, small, big_name, small_name); + + If<PropertiesOfT<Prof>::is_greater_than_comparable>::Invoke( + ExpectNotGt{errors}, test_name, context, small, big, small_name, + big_name); + If<PropertiesOfT<Prof>::is_greater_than_comparable>::Invoke( + ExpectGt{errors}, test_name, context, big, small, big_name, small_name); +} + +// For every two elements of an equivalence class, makes sure that those two +// elements compare equal, including checks with the same argument passed as +// both operands. +template <class T, class Prof> +struct ExpectEquivalenceClassComparisons { + template <class... Funs> + void operator()(EquivalenceClassType<Funs...> eq_class) const { + (ForEachTupleElement)(ExpectSelfComparison<T, Prof>{errors}, + eq_class.generators); + + (ForEveryTwo)(ExpectEquivalenceClassComparison<T, Prof>{errors}, + eq_class.generators); + } + + ConformanceErrors* errors; +}; + +// For every element of an equivalence class, makes sure that the element is +// self-consistent (in other words, if any of move/copy/swap are defined, +// perform those operations and make such that results and operands still +// compare equal to known values whenever it is required for that operation. +template <class T, class Prof> +struct ExpectEquivalenceClass { + template <class... Funs> + void operator()(EquivalenceClassType<Funs...> eq_class) const { + (ForEachTupleElement)(ExpectConsistency<T, Prof>{errors}, + eq_class.generators); + + (ForEveryTwo)(ExpectEquivalenceClassConsistency<T, Prof>{errors}, + eq_class.generators); + } + + ConformanceErrors* errors; +}; + +// Validate that the passed-in argument is a generator of a greater value than +// the one produced by the "small_gen" datamember with respect to all of the +// comparison operators that Prof requires, with both argument orders to test. +template <class T, class Prof, class SmallGenerator> +struct ExpectBiggerGeneratorThanComparisons { + template <class BigGenerator> + void operator()(BigGenerator big_gen) const { + const T small = small_gen(); + const T big = big_gen(); + + (ExpectOrdered<T, Prof>)(errors, + PrepareGivenContext( + GivenDeclaration{"const _T small", + small_gen.description}, + GivenDeclaration{"const _T big", + big_gen.description}), + small, big, "small", "big"); + } + + SmallGenerator small_gen; + ConformanceErrors* errors; +}; + +// Perform all of the move, copy, and swap checks on the value generated by +// `small_gen` and the value generated by `big_gen`. +template <class T, class Prof, class SmallGenerator> +struct ExpectBiggerGeneratorThan { + template <class BigGenerator> + void operator()(BigGenerator big_gen) const { + If<PropertiesOfT<Prof>::is_move_assignable>::Invoke( + ExpectMoveAssign<T, Prof>{errors}, small_gen, big_gen); + If<PropertiesOfT<Prof>::is_move_assignable>::Invoke( + ExpectMoveAssign<T, Prof>{errors}, big_gen, small_gen); + + If<PropertiesOfT<Prof>::is_copy_assignable>::Invoke( + ExpectCopyAssign<T, Prof>{errors}, small_gen, big_gen); + If<PropertiesOfT<Prof>::is_copy_assignable>::Invoke( + ExpectCopyAssign<T, Prof>{errors}, big_gen, small_gen); + + If<PropertiesOfT<Prof>::is_swappable>::Invoke(ExpectSwap<T, Prof>{errors}, + small_gen, big_gen); + } + + SmallGenerator small_gen; + ConformanceErrors* errors; +}; + +// Validate that the result of a generator is greater than the results of all +// generators in an equivalence class with respect to comparisons. +template <class T, class Prof, class SmallGenerator> +struct ExpectBiggerGeneratorThanEqClassesComparisons { + template <class BigEqClass> + void operator()(BigEqClass big_eq_class) const { + (ForEachTupleElement)( + ExpectBiggerGeneratorThanComparisons<T, Prof, SmallGenerator>{small_gen, + errors}, + big_eq_class.generators); + } + + SmallGenerator small_gen; + ConformanceErrors* errors; +}; + +// Validate that the non-comparison binary operations required by Prof are +// correct for the result of each generator of big_eq_class and a generator of +// the logically smaller value returned by small_gen. +template <class T, class Prof, class SmallGenerator> +struct ExpectBiggerGeneratorThanEqClasses { + template <class BigEqClass> + void operator()(BigEqClass big_eq_class) const { + (ForEachTupleElement)( + ExpectBiggerGeneratorThan<T, Prof, SmallGenerator>{small_gen, errors}, + big_eq_class.generators); + } + + SmallGenerator small_gen; + ConformanceErrors* errors; +}; + +// Validate that each equivalence class that is passed is logically less than +// the equivalence classes that comes later on in the argument list. +template <class T, class Prof> +struct ExpectOrderedEquivalenceClassesComparisons { + template <class... BigEqClasses> + struct Impl { + // Validate that the value produced by `small_gen` is less than all of the + // values generated by those of the logically larger equivalence classes. + template <class SmallGenerator> + void operator()(SmallGenerator small_gen) const { + (ForEachTupleElement)(ExpectBiggerGeneratorThanEqClassesComparisons< + T, Prof, SmallGenerator>{small_gen, errors}, + big_eq_classes); + } + + std::tuple<BigEqClasses...> big_eq_classes; + ConformanceErrors* errors; + }; + + // When given no equivalence classes, no validation is necessary. + void operator()() const {} + + template <class SmallEqClass, class... BigEqClasses> + void operator()(SmallEqClass small_eq_class, + BigEqClasses... big_eq_classes) const { + // For each generator in the first equivalence class, make sure that it is + // less than each of those in the logically greater equivalence classes. + (ForEachTupleElement)( + Impl<BigEqClasses...>{std::make_tuple(absl::move(big_eq_classes)...), + errors}, + small_eq_class.generators); + + // Recurse so that all equivalence class combinations are checked. + (*this)(absl::move(big_eq_classes)...); + } + + ConformanceErrors* errors; +}; + +// Validate that the non-comparison binary operations required by Prof are +// correct for the result of each generator of big_eq_classes and a generator of +// the logically smaller value returned by small_gen. +template <class T, class Prof> +struct ExpectOrderedEquivalenceClasses { + template <class... BigEqClasses> + struct Impl { + template <class SmallGenerator> + void operator()(SmallGenerator small_gen) const { + (ForEachTupleElement)( + ExpectBiggerGeneratorThanEqClasses<T, Prof, SmallGenerator>{small_gen, + errors}, + big_eq_classes); + } + + std::tuple<BigEqClasses...> big_eq_classes; + ConformanceErrors* errors; + }; + + // Check that small_eq_class is logically consistent and also is logically + // less than all values in big_eq_classes. + template <class SmallEqClass, class... BigEqClasses> + void operator()(SmallEqClass small_eq_class, + BigEqClasses... big_eq_classes) const { + (ForEachTupleElement)( + Impl<BigEqClasses...>{std::make_tuple(absl::move(big_eq_classes)...), + errors}, + small_eq_class.generators); + + (*this)(absl::move(big_eq_classes)...); + } + + // Terminating case of operator(). + void operator()() const {} + + ConformanceErrors* errors; +}; + +// Validate that a type meets the syntactic requirements of std::hash if the +// range of profiles requires it. +template <class T, class MinProf, class MaxProf> +struct ExpectHashable { + void operator()() const { + ExpectModelOfHashable<T, MinProf, MaxProf>(errors); + } + + ConformanceErrors* errors; +}; + +// Validate that the type `T` meets all of the requirements associated with +// `MinProf` and without going beyond the syntactic properties of `MaxProf`. +template <class T, class MinProf, class MaxProf> +struct ExpectModels { + void operator()(ConformanceErrors* errors) const { + ExpectModelOfDefaultConstructible<T, MinProf, MaxProf>(errors); + ExpectModelOfMoveConstructible<T, MinProf, MaxProf>(errors); + ExpectModelOfCopyConstructible<T, MinProf, MaxProf>(errors); + ExpectModelOfMoveAssignable<T, MinProf, MaxProf>(errors); + ExpectModelOfCopyAssignable<T, MinProf, MaxProf>(errors); + ExpectModelOfDestructible<T, MinProf, MaxProf>(errors); + ExpectModelOfEqualityComparable<T, MinProf, MaxProf>(errors); + ExpectModelOfInequalityComparable<T, MinProf, MaxProf>(errors); + ExpectModelOfLessThanComparable<T, MinProf, MaxProf>(errors); + ExpectModelOfLessEqualComparable<T, MinProf, MaxProf>(errors); + ExpectModelOfGreaterEqualComparable<T, MinProf, MaxProf>(errors); + ExpectModelOfGreaterThanComparable<T, MinProf, MaxProf>(errors); + ExpectModelOfSwappable<T, MinProf, MaxProf>(errors); + + // Only check hashability on compilers that have a compliant default-hash. + If<!poisoned_hash_fails_instantiation()>::Invoke( + ExpectHashable<T, MinProf, MaxProf>{errors}); + } +}; + +// A metafunction that yields a Profile matching the set of properties that are +// safe to be checked (lack-of-hashability is only checked on standard library +// implementations that are standards compliant in that they provide a std::hash +// primary template that is SFINAE-friendly) +template <class LogicalProf, class T> +struct MinimalCheckableProfile { + using type = + MinimalProfiles<PropertiesOfT<LogicalProf>, + PropertiesOfT<SyntacticConformanceProfileOf< + T, !PropertiesOfT<LogicalProf>::is_hashable && + poisoned_hash_fails_instantiation() + ? CheckHashability::no + : CheckHashability::yes>>>; +}; + +// An identity metafunction +template <class T> +struct Always { + using type = T; +}; + +// Validate the T meets all of the necessary requirements of LogicalProf, with +// syntactic requirements defined by the profile range [MinProf, MaxProf]. +template <class T, class LogicalProf, class MinProf, class MaxProf, + class... EqClasses> +ConformanceErrors ExpectRegularityImpl( + OrderedEquivalenceClasses<EqClasses...> vals) { + ConformanceErrors errors((NameOf<T>())); + + If<!constexpr_instantiation_when_unevaluated()>::Invoke( + ExpectModels<T, MinProf, MaxProf>(), &errors); + + using minimal_profile = typename absl::conditional_t< + constexpr_instantiation_when_unevaluated(), Always<LogicalProf>, + MinimalCheckableProfile<LogicalProf, T>>::type; + + If<PropertiesOfT<minimal_profile>::is_default_constructible>::Invoke( + ExpectDefaultConstructWithDestruct<T>{&errors}); + + ////////////////////////////////////////////////////////////////////////////// + // Perform all comparison checks first, since later checks depend on their + // correctness. + // + // Check all of the comparisons for all values in the same equivalence + // class (equal with respect to comparison operators and hash the same). + (ForEachTupleElement)( + ExpectEquivalenceClassComparisons<T, minimal_profile>{&errors}, + vals.eq_classes); + + // Check all of the comparisons for each combination of values that are in + // different equivalence classes (not equal with respect to comparison + // operators). + absl::apply( + ExpectOrderedEquivalenceClassesComparisons<T, minimal_profile>{&errors}, + vals.eq_classes); + // + ////////////////////////////////////////////////////////////////////////////// + + // Perform remaining checks, relying on comparisons. + // TODO(calabrese) short circuit if any comparisons above failed. + (ForEachTupleElement)(ExpectEquivalenceClass<T, minimal_profile>{&errors}, + vals.eq_classes); + + absl::apply(ExpectOrderedEquivalenceClasses<T, minimal_profile>{&errors}, + vals.eq_classes); + + return errors; +} + +// A type that represents a range of profiles that are acceptable to be matched. +// +// `MinProf` is the minimum set of syntactic requirements that must be met. +// +// `MaxProf` is the maximum set of syntactic requirements that must be met. +// This maximum is particularly useful for certain "strictness" checking. Some +// examples for when this is useful: +// +// * Making sure that a type is move-only (rather than simply movable) +// +// * Making sure that a member function is *not* noexcept in cases where it +// cannot be noexcept, such as if a dependent datamember has certain +// operations that are not noexcept. +// +// * Making sure that a type tightly matches a spec, such as the standard. +// +// `LogicalProf` is the Profile for which run-time testing is to take place. +// +// Note: The reason for `LogicalProf` is because it is often the case, when +// dealing with templates, that a declaration of a given operation is specified, +// but whose body would fail to instantiate. Examples include the +// copy-constructor of a standard container when the element-type is move-only, +// or the comparison operators of a standard container when the element-type +// does not have the necessary comparison operations defined. The `LogicalProf` +// parameter allows us to capture the intent of what should be tested at +// run-time, even in the cases where syntactically it might otherwise appear as +// though the type undergoing testing supports more than it actually does. +template <class LogicalProf, class MinProf = LogicalProf, + class MaxProf = MinProf> +struct ProfileRange { + using logical_profile = LogicalProf; + using min_profile = MinProf; + using max_profile = MaxProf; +}; + +// Similar to ProfileRange except that it creates a profile range that is +// coupled with a Domain and is used when testing that a type matches exactly +// the "minimum" requirements of LogicalProf. +template <class StrictnessDomain, class LogicalProf, + class MinProf = LogicalProf, class MaxProf = MinProf> +struct StrictProfileRange { + // We do not yet support extension. + static_assert( + std::is_same<StrictnessDomain, RegularityDomain>::value, + "Currently, the only valid StrictnessDomain is RegularityDomain."); + using strictness_domain = StrictnessDomain; + using logical_profile = LogicalProf; + using min_profile = MinProf; + using max_profile = MaxProf; +}; + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction that creates a StrictProfileRange from a Domain and either a +// Profile or ProfileRange. +template <class StrictnessDomain, class ProfOrRange> +struct MakeStrictProfileRange; + +template <class StrictnessDomain, class LogicalProf> +struct MakeStrictProfileRange { + using type = StrictProfileRange<StrictnessDomain, LogicalProf>; +}; + +template <class StrictnessDomain, class LogicalProf, class MinProf, + class MaxProf> +struct MakeStrictProfileRange<StrictnessDomain, + ProfileRange<LogicalProf, MinProf, MaxProf>> { + using type = + StrictProfileRange<StrictnessDomain, LogicalProf, MinProf, MaxProf>; +}; + +template <class StrictnessDomain, class ProfOrRange> +using MakeStrictProfileRangeT = + typename MakeStrictProfileRange<StrictnessDomain, ProfOrRange>::type; +// +//////////////////////////////////////////////////////////////////////////////// + +// A profile in the RegularityDomain with the strongest possible requirements. +using MostStrictProfile = + CombineProfiles<TriviallyCompleteProfile, NothrowComparableProfile>; + +// Forms a ProfileRange that treats the Profile as the bare minimum requirements +// of a type. +template <class LogicalProf, class MinProf = LogicalProf> +using LooseProfileRange = StrictProfileRange<RegularityDomain, LogicalProf, + MinProf, MostStrictProfile>; + +template <class Prof> +using MakeLooseProfileRangeT = Prof; + +//////////////////////////////////////////////////////////////////////////////// +// +// The following classes implement the metafunction ProfileRangeOfT<T> that +// takes either a Profile or ProfileRange and yields the ProfileRange to be +// used during testing. +// +template <class T, class /*Enabler*/ = void> +struct ProfileRangeOfImpl; + +template <class T> +struct ProfileRangeOfImpl<T, absl::void_t<PropertiesOfT<T>>> { + using type = LooseProfileRange<T>; +}; + +template <class T> +struct ProfileRangeOf : ProfileRangeOfImpl<T> {}; + +template <class StrictnessDomain, class LogicalProf, class MinProf, + class MaxProf> +struct ProfileRangeOf< + StrictProfileRange<StrictnessDomain, LogicalProf, MinProf, MaxProf>> { + using type = + StrictProfileRange<StrictnessDomain, LogicalProf, MinProf, MaxProf>; +}; + +template <class T> +using ProfileRangeOfT = typename ProfileRangeOf<T>::type; +// +//////////////////////////////////////////////////////////////////////////////// + +// Extract the logical profile of a range (what will be runtime tested). +template <class T> +using LogicalProfileOfT = typename ProfileRangeOfT<T>::logical_profile; + +// Extract the minimal syntactic profile of a range (error if not at least). +template <class T> +using MinProfileOfT = typename ProfileRangeOfT<T>::min_profile; + +// Extract the maximum syntactic profile of a range (error if more than). +template <class T> +using MaxProfileOfT = typename ProfileRangeOfT<T>::max_profile; + +//////////////////////////////////////////////////////////////////////////////// +// +template <class T> +struct IsProfileOrProfileRange : IsProfile<T>::type {}; + +template <class StrictnessDomain, class LogicalProf, class MinProf, + class MaxProf> +struct IsProfileOrProfileRange< + StrictProfileRange<StrictnessDomain, LogicalProf, MinProf, MaxProf>> + : std::true_type {}; +// +//////////////////////////////////////////////////////////////////////////////// + +// TODO(calabrese): Consider naming the functions in this class the same as +// the macros (defined later on) so that auto-complete leads to the correct name +// and so that a user cannot accidentally call a function rather than the macro +// form. +template <bool ExpectSuccess, class T, class... EqClasses> +struct ExpectConformanceOf { + // Add a value to be tested. Subsequent calls to this function on the same + // object must specify logically "larger" values with respect to the + // comparison operators of the type, if any. + // + // NOTE: This function should not be called directly. A stateless lambda is + // implicitly formed and passed when using the INITIALIZER macro at the bottom + // of this file. + template <class Fun, + absl::enable_if_t<std::is_same< + ResultOfGeneratorT<GeneratorType<Fun>>, T>::value>** = nullptr> + ABSL_MUST_USE_RESULT ExpectConformanceOf<ExpectSuccess, T, EqClasses..., + EquivalenceClassType<Fun>> + initializer(GeneratorType<Fun> fun) && { + return { + {std::tuple_cat(absl::move(ordered_vals.eq_classes), + std::make_tuple((EquivalenceClass)(absl::move(fun))))}, + std::move(expected_failed_tests)}; + } + + template <class... TestNames, + absl::enable_if_t<!ExpectSuccess && sizeof...(EqClasses) == 0 && + absl::conjunction<std::is_convertible< + TestNames, absl::string_view>...>::value>** = + nullptr> + ABSL_MUST_USE_RESULT ExpectConformanceOf<ExpectSuccess, T, EqClasses...> + due_to(TestNames&&... test_names) && { + (InsertEach)(&expected_failed_tests, + absl::AsciiStrToLower(absl::string_view(test_names))...); + + return {absl::move(ordered_vals), std::move(expected_failed_tests)}; + } + + template <class... TestNames, int = 0, // MSVC disambiguator + absl::enable_if_t<ExpectSuccess && sizeof...(EqClasses) == 0 && + absl::conjunction<std::is_convertible< + TestNames, absl::string_view>...>::value>** = + nullptr> + ABSL_MUST_USE_RESULT ExpectConformanceOf<ExpectSuccess, T, EqClasses...> + due_to(TestNames&&... test_names) && { + // TODO(calabrese) Instead have DUE_TO only exist via a CRTP base. + // This would produce better errors messages than the static_assert. + static_assert(!ExpectSuccess, + "DUE_TO cannot be called when conformance is expected -- did " + "you mean to use ASSERT_NONCONFORMANCE_OF?"); + } + + // Add a value to be tested. Subsequent calls to this function on the same + // object must specify logically "larger" values with respect to the + // comparison operators of the type, if any. + // + // NOTE: This function should not be called directly. A stateful lambda is + // implicitly formed and passed when using the INITIALIZER macro at the bottom + // of this file. + template <class Fun, + absl::enable_if_t<std::is_same< + ResultOfGeneratorT<GeneratorType<Fun>>, T>::value>** = nullptr> + ABSL_MUST_USE_RESULT ExpectConformanceOf<ExpectSuccess, T, EqClasses..., + EquivalenceClassType<Fun>> + dont_class_directly_stateful_initializer(GeneratorType<Fun> fun) && { + return { + {std::tuple_cat(absl::move(ordered_vals.eq_classes), + std::make_tuple((EquivalenceClass)(absl::move(fun))))}, + std::move(expected_failed_tests)}; + } + + // Add a set of value to be tested, where each value is equal with respect to + // the comparison operators and std::hash specialization, if defined. + template < + class... Funs, + absl::void_t<absl::enable_if_t<std::is_same< + ResultOfGeneratorT<GeneratorType<Funs>>, T>::value>...>** = nullptr> + ABSL_MUST_USE_RESULT ExpectConformanceOf<ExpectSuccess, T, EqClasses..., + EquivalenceClassType<Funs...>> + equivalence_class(GeneratorType<Funs>... funs) && { + return {{std::tuple_cat( + absl::move(ordered_vals.eq_classes), + std::make_tuple((EquivalenceClass)(absl::move(funs)...)))}, + std::move(expected_failed_tests)}; + } + + // Execute the tests for the captured set of values, strictly matching a range + // of expected profiles in a given domain. + template < + class ProfRange, + absl::enable_if_t<IsProfileOrProfileRange<ProfRange>::value>** = nullptr> + ABSL_MUST_USE_RESULT ::testing::AssertionResult with_strict_profile( + ProfRange /*profile*/) { + ConformanceErrors test_result = + (ExpectRegularityImpl< + T, LogicalProfileOfT<ProfRange>, MinProfileOfT<ProfRange>, + MaxProfileOfT<ProfRange>>)(absl::move(ordered_vals)); + + return ExpectSuccess ? test_result.assertionResult() + : test_result.expectFailedTests(expected_failed_tests); + } + + // Execute the tests for the captured set of values, loosely matching a range + // of expected profiles (loose in that an interface is allowed to be more + // refined that a profile suggests, such as a type having a noexcept copy + // constructor when all that is required is that the copy constructor exists). + template <class Prof, absl::enable_if_t<IsProfile<Prof>::value>** = nullptr> + ABSL_MUST_USE_RESULT ::testing::AssertionResult with_loose_profile( + Prof /*profile*/) { + ConformanceErrors test_result = + (ExpectRegularityImpl< + T, Prof, Prof, + CombineProfiles<TriviallyCompleteProfile, + NothrowComparableProfile>>)(absl:: + move(ordered_vals)); + + return ExpectSuccess ? test_result.assertionResult() + : test_result.expectFailedTests(expected_failed_tests); + } + + OrderedEquivalenceClasses<EqClasses...> ordered_vals; + std::set<std::string> expected_failed_tests; +}; + +template <class T> +using ExpectConformanceOfType = ExpectConformanceOf</*ExpectSuccess=*/true, T>; + +template <class T> +using ExpectNonconformanceOfType = + ExpectConformanceOf</*ExpectSuccess=*/false, T>; + +struct EquivalenceClassMaker { + // TODO(calabrese) Constrain to callable + template <class Fun> + static GeneratorType<Fun> initializer(GeneratorType<Fun> fun) { + return fun; + } +}; + +// A top-level macro that begins the builder pattern. +// +// The argument here takes the datatype to be tested. +#define ABSL_INTERNAL_ASSERT_CONFORMANCE_OF(...) \ + GTEST_AMBIGUOUS_ELSE_BLOCKER_ \ + if ABSL_INTERNAL_LPAREN \ + const ::testing::AssertionResult gtest_ar = \ + ABSL_INTERNAL_LPAREN ::absl::types_internal::ExpectConformanceOfType< \ + __VA_ARGS__>() + +// Akin to ASSERT_CONFORMANCE_OF except that it expects failure and tries to +// match text. +#define ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(...) \ + GTEST_AMBIGUOUS_ELSE_BLOCKER_ \ + if ABSL_INTERNAL_LPAREN \ + const ::testing::AssertionResult gtest_ar = \ + ABSL_INTERNAL_LPAREN ::absl::types_internal::ExpectNonconformanceOfType< \ + __VA_ARGS__>() + +//////////////////////////////////////////////////////////////////////////////// +// NOTE: The following macros look like they are recursive, but are not (macros +// cannot recurse). These actually refer to member functions of the same name. +// This is done intentionally so that a user cannot accidentally invoke a +// member function of the conformance-testing suite without going through the +// macro. +//////////////////////////////////////////////////////////////////////////////// + +// Specify expected test failures as comma-separated strings. +#define DUE_TO(...) due_to(__VA_ARGS__) + +// Specify a value to be tested. +// +// Note: Internally, this takes an expression and turns it into the return value +// of lambda that captures no data. The expression is stringized during +// preprocessing so that it can be used in error reports. +#define INITIALIZER(...) \ + initializer(::absl::types_internal::Generator( \ + [] { return __VA_ARGS__; }, ABSL_INTERNAL_STRINGIZE(__VA_ARGS__))) + +// Specify a value to be tested. +// +// Note: Internally, this takes an expression and turns it into the return value +// of lambda that captures data by reference. The expression is stringized +// during preprocessing so that it can be used in error reports. +#define STATEFUL_INITIALIZER(...) \ + stateful_initializer(::absl::types_internal::Generator( \ + [&] { return __VA_ARGS__; }, ABSL_INTERNAL_STRINGIZE(__VA_ARGS__))) + +// Used in the builder-pattern. +// +// Takes a series of INITIALIZER and/or STATEFUL_INITIALIZER invocations and +// forwards them along to be tested, grouping them such that the testing suite +// knows that they are supposed to represent the same logical value (the values +// compare the same, hash the same, etc.). +#define EQUIVALENCE_CLASS(...) \ + equivalence_class(ABSL_INTERNAL_TRANSFORM_ARGS( \ + ABSL_INTERNAL_PREPEND_EQ_MAKER, __VA_ARGS__)) + +// An invocation of this or WITH_STRICT_PROFILE must end the builder-pattern. +// It takes a Profile as its argument. +// +// This executes the tests and allows types that are "more referined" than the +// profile specifies, but not less. For instance, if the Profile specifies +// noexcept copy-constructiblity, the test will fail if the copy-constructor is +// not noexcept, however, it will succeed if the copy constructor is trivial. +// +// This is useful for testing that a type meets some minimum set of +// requirements. +#define WITH_LOOSE_PROFILE(...) \ + with_loose_profile( \ + ::absl::types_internal::MakeLooseProfileRangeT<__VA_ARGS__>()) \ + ABSL_INTERNAL_RPAREN ABSL_INTERNAL_RPAREN; \ + else GTEST_FATAL_FAILURE_(gtest_ar.failure_message()) // NOLINT + +// An invocation of this or WITH_STRICT_PROFILE must end the builder-pattern. +// It takes a Domain and a Profile as its arguments. +// +// This executes the tests and disallows types that differ at all from the +// properties of the Profile. For instance, if the Profile specifies noexcept +// copy-constructiblity, the test will fail if the copy constructor is trivial. +// +// This is useful for testing that a type does not do anything more than a +// specification requires, such as to minimize things like Hyrum's Law, or more +// commonly, to prevent a type from being "accidentally" copy-constructible in +// a way that may produce incorrect results, simply because the user forget to +// delete that operation. +#define WITH_STRICT_PROFILE(...) \ + with_strict_profile( \ + ::absl::types_internal::MakeStrictProfileRangeT<__VA_ARGS__>()) \ + ABSL_INTERNAL_RPAREN ABSL_INTERNAL_RPAREN; \ + else GTEST_FATAL_FAILURE_(gtest_ar.failure_message()) // NOLINT + +// Internal macro that is used in the internals of the EDSL when forming +// equivalence classes. +#define ABSL_INTERNAL_PREPEND_EQ_MAKER(arg) \ + ::absl::types_internal::EquivalenceClassMaker().arg + +} // namespace types_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TYPES_INTERNAL_CONFORMANCE_TESTING_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/conformance_testing_helpers.h b/third_party/abseil_cpp/absl/types/internal/conformance_testing_helpers.h new file mode 100644 index 0000000000..00775f960c --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/conformance_testing_helpers.h @@ -0,0 +1,391 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#ifndef ABSL_TYPES_INTERNAL_CONFORMANCE_TESTING_HELPERS_H_ +#define ABSL_TYPES_INTERNAL_CONFORMANCE_TESTING_HELPERS_H_ + +// Checks to determine whether or not we can use abi::__cxa_demangle +#if (defined(__ANDROID__) || defined(ANDROID)) && !defined(OS_ANDROID) +#define ABSL_INTERNAL_OS_ANDROID +#endif + +// We support certain compilers only. See demangle.h for details. +#if defined(OS_ANDROID) && (defined(__i386__) || defined(__x86_64__)) +#define ABSL_TYPES_INTERNAL_HAS_CXA_DEMANGLE 0 +#elif (__GNUC__ >= 4 || (__GNUC__ >= 3 && __GNUC_MINOR__ >= 4)) && \ + !defined(__mips__) +#define ABSL_TYPES_INTERNAL_HAS_CXA_DEMANGLE 1 +#elif defined(__clang__) && !defined(_MSC_VER) +#define ABSL_TYPES_INTERNAL_HAS_CXA_DEMANGLE 1 +#else +#define ABSL_TYPES_INTERNAL_HAS_CXA_DEMANGLE 0 +#endif + +#include <tuple> +#include <type_traits> +#include <utility> + +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" +#include "absl/utility/utility.h" + +#if ABSL_TYPES_INTERNAL_HAS_CXA_DEMANGLE +#include <cxxabi.h> + +#include <cstdlib> +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace types_internal { + +// Return a readable name for type T. +template <class T> +absl::string_view NameOfImpl() { +// TODO(calabrese) Investigate using debugging:internal_demangle as a fallback. +#if ABSL_TYPES_INTERNAL_HAS_CXA_DEMANGLE + int status = 0; + char* demangled_name = nullptr; + + demangled_name = + abi::__cxa_demangle(typeid(T).name(), nullptr, nullptr, &status); + + if (status == 0 && demangled_name != nullptr) { + return demangled_name; + } else { + return typeid(T).name(); + } +#else + return typeid(T).name(); +#endif + // NOTE: We intentionally leak demangled_name so that it remains valid + // throughout the remainder of the program. +} + +// Given a type, returns as nice of a type name as we can produce (demangled). +// +// Note: This currently strips cv-qualifiers and references, but that is okay +// because we only use this internally with unqualified object types. +template <class T> +std::string NameOf() { + static const absl::string_view result = NameOfImpl<T>(); + return std::string(result); +} + +//////////////////////////////////////////////////////////////////////////////// +// +// Metafunction to check if a type is callable with no explicit arguments +template <class Fun, class /*Enabler*/ = void> +struct IsNullaryCallableImpl : std::false_type {}; + +template <class Fun> +struct IsNullaryCallableImpl< + Fun, absl::void_t<decltype(std::declval<const Fun&>()())>> + : std::true_type { + using result_type = decltype(std::declval<const Fun&>()()); + + template <class ValueType> + using for_type = std::is_same<ValueType, result_type>; + + using void_if_true = void; +}; + +template <class Fun> +struct IsNullaryCallable : IsNullaryCallableImpl<Fun> {}; +// +//////////////////////////////////////////////////////////////////////////////// + +// A type that contains a function object that returns an instance of a type +// that is undergoing conformance testing. This function is required to always +// return the same value upon invocation. +template <class Fun> +struct GeneratorType; + +// A type that contains a tuple of GeneratorType<Fun> where each Fun has the +// same return type. The result of each of the different generators should all +// be equal values, though the underlying object representation may differ (such +// as if one returns 0.0 and another return -0.0, or if one returns an empty +// vector and another returns an empty vector with a different capacity. +template <class... Funs> +struct EquivalenceClassType; + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction to check if a type is a specialization of EquivalenceClassType +template <class T> +struct IsEquivalenceClass : std::false_type {}; + +template <> +struct IsEquivalenceClass<EquivalenceClassType<>> : std::true_type { + using self = IsEquivalenceClass; + + // A metafunction to check if this EquivalenceClassType is a valid + // EquivalenceClassType for a type `ValueType` that is undergoing testing + template <class ValueType> + using for_type = std::true_type; +}; + +template <class Head, class... Tail> +struct IsEquivalenceClass<EquivalenceClassType<Head, Tail...>> + : std::true_type { + using self = IsEquivalenceClass; + + // The type undergoing conformance testing that this EquivalenceClass + // corresponds to + using result_type = typename IsNullaryCallable<Head>::result_type; + + // A metafunction to check if this EquivalenceClassType is a valid + // EquivalenceClassType for a type `ValueType` that is undergoing testing + template <class ValueType> + using for_type = std::is_same<ValueType, result_type>; +}; +// +//////////////////////////////////////////////////////////////////////////////// + +// A type that contains an ordered series of EquivalenceClassTypes, where the +// the function object of each underlying GeneratorType has the same return type +// +// These equivalence classes are required to be in a logical ascending order +// that is consistent with comparison operators that are defined for the return +// type of each GeneratorType, if any. +template <class... EqClasses> +struct OrderedEquivalenceClasses; + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction to determine the return type of the function object contained +// in a GeneratorType specialization. +template <class T> +struct ResultOfGenerator {}; + +template <class Fun> +struct ResultOfGenerator<GeneratorType<Fun>> { + using type = decltype(std::declval<const Fun&>()()); +}; + +template <class Fun> +using ResultOfGeneratorT = typename ResultOfGenerator<GeneratorType<Fun>>::type; +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction that yields true iff each of Funs is a GeneratorType +// specialization and they all contain functions with the same return type +template <class /*Enabler*/, class... Funs> +struct AreGeneratorsWithTheSameReturnTypeImpl : std::false_type {}; + +template <> +struct AreGeneratorsWithTheSameReturnTypeImpl<void> : std::true_type {}; + +template <class Head, class... Tail> +struct AreGeneratorsWithTheSameReturnTypeImpl< + typename std::enable_if<absl::conjunction<std::is_same< + ResultOfGeneratorT<Head>, ResultOfGeneratorT<Tail>>...>::value>::type, + Head, Tail...> : std::true_type {}; + +template <class... Funs> +struct AreGeneratorsWithTheSameReturnType + : AreGeneratorsWithTheSameReturnTypeImpl<void, Funs...>::type {}; +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// A metafunction that yields true iff each of Funs is an EquivalenceClassType +// specialization and they all contain GeneratorType specializations that have +// the same return type +template <class... EqClasses> +struct AreEquivalenceClassesOfTheSameType { + static_assert(sizeof...(EqClasses) != sizeof...(EqClasses), ""); +}; + +template <> +struct AreEquivalenceClassesOfTheSameType<> : std::true_type { + using self = AreEquivalenceClassesOfTheSameType; + + // Metafunction to check that a type is the same as all of the equivalence + // classes, if any. + // Note: In this specialization there are no equivalence classes, so the + // value type is always compatible. + template <class /*ValueType*/> + using for_type = std::true_type; +}; + +template <class... Funs> +struct AreEquivalenceClassesOfTheSameType<EquivalenceClassType<Funs...>> + : std::true_type { + using self = AreEquivalenceClassesOfTheSameType; + + // Metafunction to check that a type is the same as all of the equivalence + // classes, if any. + template <class ValueType> + using for_type = typename IsEquivalenceClass< + EquivalenceClassType<Funs...>>::template for_type<ValueType>; +}; + +template <class... TailEqClasses> +struct AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<>, EquivalenceClassType<>, TailEqClasses...> + : AreEquivalenceClassesOfTheSameType<TailEqClasses...>::self {}; + +template <class HeadNextFun, class... TailNextFuns, class... TailEqClasses> +struct AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<>, EquivalenceClassType<HeadNextFun, TailNextFuns...>, + TailEqClasses...> + : AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<HeadNextFun, TailNextFuns...>, + TailEqClasses...>::self {}; + +template <class HeadHeadFun, class... TailHeadFuns, class... TailEqClasses> +struct AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<HeadHeadFun, TailHeadFuns...>, EquivalenceClassType<>, + TailEqClasses...> + : AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<HeadHeadFun, TailHeadFuns...>, + TailEqClasses...>::self {}; + +template <class HeadHeadFun, class... TailHeadFuns, class HeadNextFun, + class... TailNextFuns, class... TailEqClasses> +struct AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<HeadHeadFun, TailHeadFuns...>, + EquivalenceClassType<HeadNextFun, TailNextFuns...>, TailEqClasses...> + : absl::conditional_t< + IsNullaryCallable<HeadNextFun>::template for_type< + typename IsNullaryCallable<HeadHeadFun>::result_type>::value, + AreEquivalenceClassesOfTheSameType< + EquivalenceClassType<HeadHeadFun, TailHeadFuns...>, + TailEqClasses...>, + std::false_type> {}; +// +//////////////////////////////////////////////////////////////////////////////// + +// Execute a function for each passed-in parameter. +template <class Fun, class... Cases> +void ForEachParameter(const Fun& fun, const Cases&... cases) { + const std::initializer_list<bool> results = { + (static_cast<void>(fun(cases)), true)...}; + + (void)results; +} + +// Execute a function on each passed-in parameter (using a bound function). +template <class Fun> +struct ForEachParameterFun { + template <class... T> + void operator()(const T&... cases) const { + (ForEachParameter)(fun, cases...); + } + + Fun fun; +}; + +// Execute a function on each element of a tuple. +template <class Fun, class Tup> +void ForEachTupleElement(const Fun& fun, const Tup& tup) { + absl::apply(ForEachParameterFun<Fun>{fun}, tup); +} + +//////////////////////////////////////////////////////////////////////////////// +// +// Execute a function for each combination of two elements of a tuple, including +// combinations of an element with itself. +template <class Fun, class... T> +struct ForEveryTwoImpl { + template <class Lhs> + struct WithBoundLhs { + template <class Rhs> + void operator()(const Rhs& rhs) const { + fun(lhs, rhs); + } + + Fun fun; + Lhs lhs; + }; + + template <class Lhs> + void operator()(const Lhs& lhs) const { + (ForEachTupleElement)(WithBoundLhs<Lhs>{fun, lhs}, args); + } + + Fun fun; + std::tuple<T...> args; +}; + +template <class Fun, class... T> +void ForEveryTwo(const Fun& fun, std::tuple<T...> args) { + (ForEachTupleElement)(ForEveryTwoImpl<Fun, T...>{fun, args}, args); +} +// +//////////////////////////////////////////////////////////////////////////////// + +//////////////////////////////////////////////////////////////////////////////// +// +// Insert all values into an associative container +template<class Container> +void InsertEach(Container* cont) { +} + +template<class Container, class H, class... T> +void InsertEach(Container* cont, H&& head, T&&... tail) { + cont->insert(head); + (InsertEach)(cont, tail...); +} +// +//////////////////////////////////////////////////////////////////////////////// +// A template with a nested "Invoke" static-member-function that executes a +// passed-in Callable when `Condition` is true, otherwise it ignores the +// Callable. This is useful for executing a function object with a condition +// that corresponds to whether or not the Callable can be safely instantiated. +// It has some overlapping uses with C++17 `if constexpr`. +template <bool Condition> +struct If; + +template <> +struct If</*Condition =*/false> { + template <class Fun, class... P> + static void Invoke(const Fun& /*fun*/, P&&... /*args*/) {} +}; + +template <> +struct If</*Condition =*/true> { + template <class Fun, class... P> + static void Invoke(const Fun& fun, P&&... args) { + // TODO(calabrese) Use std::invoke equivalent instead of function-call. + fun(absl::forward<P>(args)...); + } +}; + +// +// ABSL_INTERNAL_STRINGIZE(...) +// +// This variadic macro transforms its arguments into a c-string literal after +// expansion. +// +// Example: +// +// ABSL_INTERNAL_STRINGIZE(std::array<int, 10>) +// +// Results in: +// +// "std::array<int, 10>" +#define ABSL_INTERNAL_STRINGIZE(...) ABSL_INTERNAL_STRINGIZE_IMPL((__VA_ARGS__)) +#define ABSL_INTERNAL_STRINGIZE_IMPL(arg) ABSL_INTERNAL_STRINGIZE_IMPL2 arg +#define ABSL_INTERNAL_STRINGIZE_IMPL2(...) #__VA_ARGS__ + +} // namespace types_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TYPES_INTERNAL_CONFORMANCE_TESTING_HELPERS_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/conformance_testing_test.cc b/third_party/abseil_cpp/absl/types/internal/conformance_testing_test.cc new file mode 100644 index 0000000000..cf262fa6c2 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/conformance_testing_test.cc @@ -0,0 +1,1556 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/internal/conformance_testing.h" + +#include <new> +#include <type_traits> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/meta/type_traits.h" +#include "absl/types/internal/conformance_aliases.h" +#include "absl/types/internal/conformance_profile.h" + +namespace { + +namespace ti = absl::types_internal; + +template <class T> +using DefaultConstructibleWithNewImpl = decltype(::new (std::nothrow) T); + +template <class T> +using DefaultConstructibleWithNew = + absl::type_traits_internal::is_detected<DefaultConstructibleWithNewImpl, T>; + +template <class T> +using MoveConstructibleWithNewImpl = + decltype(::new (std::nothrow) T(std::declval<T>())); + +template <class T> +using MoveConstructibleWithNew = + absl::type_traits_internal::is_detected<MoveConstructibleWithNewImpl, T>; + +template <class T> +using CopyConstructibleWithNewImpl = + decltype(::new (std::nothrow) T(std::declval<const T&>())); + +template <class T> +using CopyConstructibleWithNew = + absl::type_traits_internal::is_detected<CopyConstructibleWithNewImpl, T>; + +template <class T, + class Result = + std::integral_constant<bool, noexcept(::new (std::nothrow) T)>> +using NothrowDefaultConstructibleWithNewImpl = + typename std::enable_if<Result::value>::type; + +template <class T> +using NothrowDefaultConstructibleWithNew = + absl::type_traits_internal::is_detected< + NothrowDefaultConstructibleWithNewImpl, T>; + +template <class T, + class Result = std::integral_constant< + bool, noexcept(::new (std::nothrow) T(std::declval<T>()))>> +using NothrowMoveConstructibleWithNewImpl = + typename std::enable_if<Result::value>::type; + +template <class T> +using NothrowMoveConstructibleWithNew = + absl::type_traits_internal::is_detected<NothrowMoveConstructibleWithNewImpl, + T>; + +template <class T, + class Result = std::integral_constant< + bool, noexcept(::new (std::nothrow) T(std::declval<const T&>()))>> +using NothrowCopyConstructibleWithNewImpl = + typename std::enable_if<Result::value>::type; + +template <class T> +using NothrowCopyConstructibleWithNew = + absl::type_traits_internal::is_detected<NothrowCopyConstructibleWithNewImpl, + T>; + +// NOTE: ?: is used to verify contextually-convertible to bool and not simply +// implicit or explicit convertibility. +#define ABSL_INTERNAL_COMPARISON_OP_EXPR(op) \ + ((std::declval<const T&>() op std::declval<const T&>()) ? true : true) + +#define ABSL_INTERNAL_COMPARISON_OP_TRAIT(name, op) \ + template <class T> \ + using name##Impl = decltype(ABSL_INTERNAL_COMPARISON_OP_EXPR(op)); \ + \ + template <class T> \ + using name = absl::type_traits_internal::is_detected<name##Impl, T>; \ + \ + template <class T, \ + class Result = std::integral_constant< \ + bool, noexcept(ABSL_INTERNAL_COMPARISON_OP_EXPR(op))>> \ + using Nothrow##name##Impl = typename std::enable_if<Result::value>::type; \ + \ + template <class T> \ + using Nothrow##name = \ + absl::type_traits_internal::is_detected<Nothrow##name##Impl, T> + +ABSL_INTERNAL_COMPARISON_OP_TRAIT(EqualityComparable, ==); +ABSL_INTERNAL_COMPARISON_OP_TRAIT(InequalityComparable, !=); +ABSL_INTERNAL_COMPARISON_OP_TRAIT(LessThanComparable, <); +ABSL_INTERNAL_COMPARISON_OP_TRAIT(LessEqualComparable, <=); +ABSL_INTERNAL_COMPARISON_OP_TRAIT(GreaterEqualComparable, >=); +ABSL_INTERNAL_COMPARISON_OP_TRAIT(GreaterThanComparable, >); + +#undef ABSL_INTERNAL_COMPARISON_OP_TRAIT + +template <class T> +class ProfileTest : public ::testing::Test {}; + +TYPED_TEST_SUITE_P(ProfileTest); + +TYPED_TEST_P(ProfileTest, HasAppropriateConstructionProperties) { + using profile = typename TypeParam::profile; + using arch = typename TypeParam::arch; + using expected_profile = typename TypeParam::expected_profile; + + using props = ti::PropertiesOfT<profile>; + using arch_props = ti::PropertiesOfArchetypeT<arch>; + using expected_props = ti::PropertiesOfT<expected_profile>; + + // Make sure all of the properties are as expected. + // There are seemingly redundant tests here to make it easier to diagnose + // the specifics of the failure if something were to go wrong. + EXPECT_TRUE((std::is_same<props, arch_props>::value)); + EXPECT_TRUE((std::is_same<props, expected_props>::value)); + EXPECT_TRUE((std::is_same<arch_props, expected_props>::value)); + + EXPECT_EQ(props::default_constructible_support, + expected_props::default_constructible_support); + + EXPECT_EQ(props::move_constructible_support, + expected_props::move_constructible_support); + + EXPECT_EQ(props::copy_constructible_support, + expected_props::copy_constructible_support); + + EXPECT_EQ(props::destructible_support, expected_props::destructible_support); + + // Avoid additional error message noise when profile and archetype match with + // each other but were not what was expected. + if (!std::is_same<props, arch_props>::value) { + EXPECT_EQ(arch_props::default_constructible_support, + expected_props::default_constructible_support); + + EXPECT_EQ(arch_props::move_constructible_support, + expected_props::move_constructible_support); + + EXPECT_EQ(arch_props::copy_constructible_support, + expected_props::copy_constructible_support); + + EXPECT_EQ(arch_props::destructible_support, + expected_props::destructible_support); + } + + ////////////////////////////////////////////////////////////////////////////// + // Default constructor checks // + ////////////////////////////////////////////////////////////////////////////// + EXPECT_EQ(props::default_constructible_support, + expected_props::default_constructible_support); + + switch (expected_props::default_constructible_support) { + case ti::default_constructible::maybe: + EXPECT_FALSE(DefaultConstructibleWithNew<arch>::value); + EXPECT_FALSE(NothrowDefaultConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_FALSE(std::is_default_constructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_default_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_default_constructible<arch>::value); + } + break; + case ti::default_constructible::yes: + EXPECT_TRUE(DefaultConstructibleWithNew<arch>::value); + EXPECT_FALSE(NothrowDefaultConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_default_constructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_default_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_default_constructible<arch>::value); + } + break; + case ti::default_constructible::nothrow: + EXPECT_TRUE(DefaultConstructibleWithNew<arch>::value); + EXPECT_TRUE(NothrowDefaultConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_default_constructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_default_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_default_constructible<arch>::value); + + // Constructor traits also check the destructor. + if (std::is_nothrow_destructible<arch>::value) { + EXPECT_TRUE(std::is_nothrow_default_constructible<arch>::value); + } + } + break; + case ti::default_constructible::trivial: + EXPECT_TRUE(DefaultConstructibleWithNew<arch>::value); + EXPECT_TRUE(NothrowDefaultConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_default_constructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_default_constructible<arch>::value); + + // Constructor triviality traits require trivially destructible types. + if (absl::is_trivially_destructible<arch>::value) { + EXPECT_TRUE(absl::is_trivially_default_constructible<arch>::value); + } + } + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Move constructor checks // + ////////////////////////////////////////////////////////////////////////////// + EXPECT_EQ(props::move_constructible_support, + expected_props::move_constructible_support); + + switch (expected_props::move_constructible_support) { + case ti::move_constructible::maybe: + EXPECT_FALSE(MoveConstructibleWithNew<arch>::value); + EXPECT_FALSE(NothrowMoveConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_FALSE(std::is_move_constructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_move_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_move_constructible<arch>::value); + } + break; + case ti::move_constructible::yes: + EXPECT_TRUE(MoveConstructibleWithNew<arch>::value); + EXPECT_FALSE(NothrowMoveConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_move_constructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_move_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_move_constructible<arch>::value); + } + break; + case ti::move_constructible::nothrow: + EXPECT_TRUE(MoveConstructibleWithNew<arch>::value); + EXPECT_TRUE(NothrowMoveConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_move_constructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_move_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_move_constructible<arch>::value); + + // Constructor traits also check the destructor. + if (std::is_nothrow_destructible<arch>::value) { + EXPECT_TRUE(std::is_nothrow_move_constructible<arch>::value); + } + } + break; + case ti::move_constructible::trivial: + EXPECT_TRUE(MoveConstructibleWithNew<arch>::value); + EXPECT_TRUE(NothrowMoveConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_move_constructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_move_constructible<arch>::value); + + // Constructor triviality traits require trivially destructible types. + if (absl::is_trivially_destructible<arch>::value) { + EXPECT_TRUE(absl::is_trivially_move_constructible<arch>::value); + } + } + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Copy constructor checks // + ////////////////////////////////////////////////////////////////////////////// + EXPECT_EQ(props::copy_constructible_support, + expected_props::copy_constructible_support); + + switch (expected_props::copy_constructible_support) { + case ti::copy_constructible::maybe: + EXPECT_FALSE(CopyConstructibleWithNew<arch>::value); + EXPECT_FALSE(NothrowCopyConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_FALSE(std::is_copy_constructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_copy_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<arch>::value); + } + break; + case ti::copy_constructible::yes: + EXPECT_TRUE(CopyConstructibleWithNew<arch>::value); + EXPECT_FALSE(NothrowCopyConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_copy_constructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_copy_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<arch>::value); + } + break; + case ti::copy_constructible::nothrow: + EXPECT_TRUE(CopyConstructibleWithNew<arch>::value); + EXPECT_TRUE(NothrowCopyConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_copy_constructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_copy_constructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<arch>::value); + + // Constructor traits also check the destructor. + if (std::is_nothrow_destructible<arch>::value) { + EXPECT_TRUE(std::is_nothrow_copy_constructible<arch>::value); + } + } + break; + case ti::copy_constructible::trivial: + EXPECT_TRUE(CopyConstructibleWithNew<arch>::value); + EXPECT_TRUE(NothrowCopyConstructibleWithNew<arch>::value); + + // Standard constructible traits depend on the destructor. + if (std::is_destructible<arch>::value) { + EXPECT_TRUE(std::is_copy_constructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_copy_constructible<arch>::value); + + // Constructor triviality traits require trivially destructible types. + if (absl::is_trivially_destructible<arch>::value) { + EXPECT_TRUE(absl::is_trivially_copy_constructible<arch>::value); + } + } + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Destructible checks // + ////////////////////////////////////////////////////////////////////////////// + EXPECT_EQ(props::destructible_support, expected_props::destructible_support); + + switch (expected_props::destructible_support) { + case ti::destructible::maybe: + EXPECT_FALSE(std::is_destructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_destructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_destructible<arch>::value); + break; + case ti::destructible::yes: + EXPECT_TRUE(std::is_destructible<arch>::value); + EXPECT_FALSE(std::is_nothrow_destructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_destructible<arch>::value); + break; + case ti::destructible::nothrow: + EXPECT_TRUE(std::is_destructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_destructible<arch>::value); + EXPECT_FALSE(absl::is_trivially_destructible<arch>::value); + break; + case ti::destructible::trivial: + EXPECT_TRUE(std::is_destructible<arch>::value); + EXPECT_TRUE(std::is_nothrow_destructible<arch>::value); + EXPECT_TRUE(absl::is_trivially_destructible<arch>::value); + break; + } +} + +TYPED_TEST_P(ProfileTest, HasAppropriateAssignmentProperties) { + using profile = typename TypeParam::profile; + using arch = typename TypeParam::arch; + using expected_profile = typename TypeParam::expected_profile; + + using props = ti::PropertiesOfT<profile>; + using arch_props = ti::PropertiesOfArchetypeT<arch>; + using expected_props = ti::PropertiesOfT<expected_profile>; + + // Make sure all of the properties are as expected. + // There are seemingly redundant tests here to make it easier to diagnose + // the specifics of the failure if something were to go wrong. + EXPECT_TRUE((std::is_same<props, arch_props>::value)); + EXPECT_TRUE((std::is_same<props, expected_props>::value)); + EXPECT_TRUE((std::is_same<arch_props, expected_props>::value)); + + EXPECT_EQ(props::move_assignable_support, + expected_props::move_assignable_support); + + EXPECT_EQ(props::copy_assignable_support, + expected_props::copy_assignable_support); + + // Avoid additional error message noise when profile and archetype match with + // each other but were not what was expected. + if (!std::is_same<props, arch_props>::value) { + EXPECT_EQ(arch_props::move_assignable_support, + expected_props::move_assignable_support); + + EXPECT_EQ(arch_props::copy_assignable_support, + expected_props::copy_assignable_support); + } + + ////////////////////////////////////////////////////////////////////////////// + // Move assignment checks // + ////////////////////////////////////////////////////////////////////////////// + EXPECT_EQ(props::move_assignable_support, + expected_props::move_assignable_support); + + switch (expected_props::move_assignable_support) { + case ti::move_assignable::maybe: + EXPECT_FALSE(std::is_move_assignable<arch>::value); + EXPECT_FALSE(std::is_nothrow_move_assignable<arch>::value); + EXPECT_FALSE(absl::is_trivially_move_assignable<arch>::value); + break; + case ti::move_assignable::yes: + EXPECT_TRUE(std::is_move_assignable<arch>::value); + EXPECT_FALSE(std::is_nothrow_move_assignable<arch>::value); + EXPECT_FALSE(absl::is_trivially_move_assignable<arch>::value); + break; + case ti::move_assignable::nothrow: + EXPECT_TRUE(std::is_move_assignable<arch>::value); + EXPECT_TRUE(std::is_nothrow_move_assignable<arch>::value); + EXPECT_FALSE(absl::is_trivially_move_assignable<arch>::value); + break; + case ti::move_assignable::trivial: + EXPECT_TRUE(std::is_move_assignable<arch>::value); + EXPECT_TRUE(std::is_nothrow_move_assignable<arch>::value); + EXPECT_TRUE(absl::is_trivially_move_assignable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Copy assignment checks // + ////////////////////////////////////////////////////////////////////////////// + EXPECT_EQ(props::copy_assignable_support, + expected_props::copy_assignable_support); + + switch (expected_props::copy_assignable_support) { + case ti::copy_assignable::maybe: + EXPECT_FALSE(std::is_copy_assignable<arch>::value); + EXPECT_FALSE(std::is_nothrow_copy_assignable<arch>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<arch>::value); + break; + case ti::copy_assignable::yes: + EXPECT_TRUE(std::is_copy_assignable<arch>::value); + EXPECT_FALSE(std::is_nothrow_copy_assignable<arch>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<arch>::value); + break; + case ti::copy_assignable::nothrow: + EXPECT_TRUE(std::is_copy_assignable<arch>::value); + EXPECT_TRUE(std::is_nothrow_copy_assignable<arch>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<arch>::value); + break; + case ti::copy_assignable::trivial: + EXPECT_TRUE(std::is_copy_assignable<arch>::value); + EXPECT_TRUE(std::is_nothrow_copy_assignable<arch>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<arch>::value); + break; + } +} + +TYPED_TEST_P(ProfileTest, HasAppropriateComparisonProperties) { + using profile = typename TypeParam::profile; + using arch = typename TypeParam::arch; + using expected_profile = typename TypeParam::expected_profile; + + using props = ti::PropertiesOfT<profile>; + using arch_props = ti::PropertiesOfArchetypeT<arch>; + using expected_props = ti::PropertiesOfT<expected_profile>; + + // Make sure all of the properties are as expected. + // There are seemingly redundant tests here to make it easier to diagnose + // the specifics of the failure if something were to go wrong. + EXPECT_TRUE((std::is_same<props, arch_props>::value)); + EXPECT_TRUE((std::is_same<props, expected_props>::value)); + EXPECT_TRUE((std::is_same<arch_props, expected_props>::value)); + + EXPECT_EQ(props::equality_comparable_support, + expected_props::equality_comparable_support); + + EXPECT_EQ(props::inequality_comparable_support, + expected_props::inequality_comparable_support); + + EXPECT_EQ(props::less_than_comparable_support, + expected_props::less_than_comparable_support); + + EXPECT_EQ(props::less_equal_comparable_support, + expected_props::less_equal_comparable_support); + + EXPECT_EQ(props::greater_equal_comparable_support, + expected_props::greater_equal_comparable_support); + + EXPECT_EQ(props::greater_than_comparable_support, + expected_props::greater_than_comparable_support); + + // Avoid additional error message noise when profile and archetype match with + // each other but were not what was expected. + if (!std::is_same<props, arch_props>::value) { + EXPECT_EQ(arch_props::equality_comparable_support, + expected_props::equality_comparable_support); + + EXPECT_EQ(arch_props::inequality_comparable_support, + expected_props::inequality_comparable_support); + + EXPECT_EQ(arch_props::less_than_comparable_support, + expected_props::less_than_comparable_support); + + EXPECT_EQ(arch_props::less_equal_comparable_support, + expected_props::less_equal_comparable_support); + + EXPECT_EQ(arch_props::greater_equal_comparable_support, + expected_props::greater_equal_comparable_support); + + EXPECT_EQ(arch_props::greater_than_comparable_support, + expected_props::greater_than_comparable_support); + } + + ////////////////////////////////////////////////////////////////////////////// + // Equality comparable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::equality_comparable_support) { + case ti::equality_comparable::maybe: + EXPECT_FALSE(EqualityComparable<arch>::value); + EXPECT_FALSE(NothrowEqualityComparable<arch>::value); + break; + case ti::equality_comparable::yes: + EXPECT_TRUE(EqualityComparable<arch>::value); + EXPECT_FALSE(NothrowEqualityComparable<arch>::value); + break; + case ti::equality_comparable::nothrow: + EXPECT_TRUE(EqualityComparable<arch>::value); + EXPECT_TRUE(NothrowEqualityComparable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Inequality comparable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::inequality_comparable_support) { + case ti::inequality_comparable::maybe: + EXPECT_FALSE(InequalityComparable<arch>::value); + EXPECT_FALSE(NothrowInequalityComparable<arch>::value); + break; + case ti::inequality_comparable::yes: + EXPECT_TRUE(InequalityComparable<arch>::value); + EXPECT_FALSE(NothrowInequalityComparable<arch>::value); + break; + case ti::inequality_comparable::nothrow: + EXPECT_TRUE(InequalityComparable<arch>::value); + EXPECT_TRUE(NothrowInequalityComparable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Less than comparable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::less_than_comparable_support) { + case ti::less_than_comparable::maybe: + EXPECT_FALSE(LessThanComparable<arch>::value); + EXPECT_FALSE(NothrowLessThanComparable<arch>::value); + break; + case ti::less_than_comparable::yes: + EXPECT_TRUE(LessThanComparable<arch>::value); + EXPECT_FALSE(NothrowLessThanComparable<arch>::value); + break; + case ti::less_than_comparable::nothrow: + EXPECT_TRUE(LessThanComparable<arch>::value); + EXPECT_TRUE(NothrowLessThanComparable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Less equal comparable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::less_equal_comparable_support) { + case ti::less_equal_comparable::maybe: + EXPECT_FALSE(LessEqualComparable<arch>::value); + EXPECT_FALSE(NothrowLessEqualComparable<arch>::value); + break; + case ti::less_equal_comparable::yes: + EXPECT_TRUE(LessEqualComparable<arch>::value); + EXPECT_FALSE(NothrowLessEqualComparable<arch>::value); + break; + case ti::less_equal_comparable::nothrow: + EXPECT_TRUE(LessEqualComparable<arch>::value); + EXPECT_TRUE(NothrowLessEqualComparable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Greater equal comparable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::greater_equal_comparable_support) { + case ti::greater_equal_comparable::maybe: + EXPECT_FALSE(GreaterEqualComparable<arch>::value); + EXPECT_FALSE(NothrowGreaterEqualComparable<arch>::value); + break; + case ti::greater_equal_comparable::yes: + EXPECT_TRUE(GreaterEqualComparable<arch>::value); + EXPECT_FALSE(NothrowGreaterEqualComparable<arch>::value); + break; + case ti::greater_equal_comparable::nothrow: + EXPECT_TRUE(GreaterEqualComparable<arch>::value); + EXPECT_TRUE(NothrowGreaterEqualComparable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Greater than comparable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::greater_than_comparable_support) { + case ti::greater_than_comparable::maybe: + EXPECT_FALSE(GreaterThanComparable<arch>::value); + EXPECT_FALSE(NothrowGreaterThanComparable<arch>::value); + break; + case ti::greater_than_comparable::yes: + EXPECT_TRUE(GreaterThanComparable<arch>::value); + EXPECT_FALSE(NothrowGreaterThanComparable<arch>::value); + break; + case ti::greater_than_comparable::nothrow: + EXPECT_TRUE(GreaterThanComparable<arch>::value); + EXPECT_TRUE(NothrowGreaterThanComparable<arch>::value); + break; + } +} + +TYPED_TEST_P(ProfileTest, HasAppropriateAuxilliaryProperties) { + using profile = typename TypeParam::profile; + using arch = typename TypeParam::arch; + using expected_profile = typename TypeParam::expected_profile; + + using props = ti::PropertiesOfT<profile>; + using arch_props = ti::PropertiesOfArchetypeT<arch>; + using expected_props = ti::PropertiesOfT<expected_profile>; + + // Make sure all of the properties are as expected. + // There are seemingly redundant tests here to make it easier to diagnose + // the specifics of the failure if something were to go wrong. + EXPECT_TRUE((std::is_same<props, arch_props>::value)); + EXPECT_TRUE((std::is_same<props, expected_props>::value)); + EXPECT_TRUE((std::is_same<arch_props, expected_props>::value)); + + EXPECT_EQ(props::swappable_support, expected_props::swappable_support); + + EXPECT_EQ(props::hashable_support, expected_props::hashable_support); + + // Avoid additional error message noise when profile and archetype match with + // each other but were not what was expected. + if (!std::is_same<props, arch_props>::value) { + EXPECT_EQ(arch_props::swappable_support, expected_props::swappable_support); + + EXPECT_EQ(arch_props::hashable_support, expected_props::hashable_support); + } + + ////////////////////////////////////////////////////////////////////////////// + // Swappable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::swappable_support) { + case ti::swappable::maybe: + EXPECT_FALSE(absl::type_traits_internal::IsSwappable<arch>::value); + EXPECT_FALSE(absl::type_traits_internal::IsNothrowSwappable<arch>::value); + break; + case ti::swappable::yes: + EXPECT_TRUE(absl::type_traits_internal::IsSwappable<arch>::value); + EXPECT_FALSE(absl::type_traits_internal::IsNothrowSwappable<arch>::value); + break; + case ti::swappable::nothrow: + EXPECT_TRUE(absl::type_traits_internal::IsSwappable<arch>::value); + EXPECT_TRUE(absl::type_traits_internal::IsNothrowSwappable<arch>::value); + break; + } + + ////////////////////////////////////////////////////////////////////////////// + // Hashable checks // + ////////////////////////////////////////////////////////////////////////////// + switch (expected_props::hashable_support) { + case ti::hashable::maybe: +#if ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + EXPECT_FALSE(absl::type_traits_internal::IsHashable<arch>::value); +#endif // ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + break; + case ti::hashable::yes: + EXPECT_TRUE(absl::type_traits_internal::IsHashable<arch>::value); + break; + } +} + +REGISTER_TYPED_TEST_SUITE_P(ProfileTest, HasAppropriateConstructionProperties, + HasAppropriateAssignmentProperties, + HasAppropriateComparisonProperties, + HasAppropriateAuxilliaryProperties); + +template <class Profile, class Arch, class ExpectedProfile> +struct ProfileAndExpectation { + using profile = Profile; + using arch = Arch; + using expected_profile = ExpectedProfile; +}; + +using CoreProfilesToTest = ::testing::Types< + // The terminating case of combine (all properties are "maybe"). + ProfileAndExpectation<ti::CombineProfiles<>, + ti::Archetype<ti::CombineProfiles<>>, + ti::ConformanceProfile<>>, + + // Core default constructor profiles + ProfileAndExpectation< + ti::HasDefaultConstructorProfile, ti::HasDefaultConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::yes>>, + ProfileAndExpectation< + ti::HasNothrowDefaultConstructorProfile, + ti::HasNothrowDefaultConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::nothrow>>, + ProfileAndExpectation< + ti::HasTrivialDefaultConstructorProfile, + ti::HasTrivialDefaultConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::trivial>>, + + // Core move constructor profiles + ProfileAndExpectation< + ti::HasMoveConstructorProfile, ti::HasMoveConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::maybe, + ti::move_constructible::yes>>, + ProfileAndExpectation< + ti::HasNothrowMoveConstructorProfile, + ti::HasNothrowMoveConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::maybe, + ti::move_constructible::nothrow>>, + ProfileAndExpectation< + ti::HasTrivialMoveConstructorProfile, + ti::HasTrivialMoveConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::maybe, + ti::move_constructible::trivial>>, + + // Core copy constructor profiles + ProfileAndExpectation< + ti::HasCopyConstructorProfile, ti::HasCopyConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::maybe, + ti::move_constructible::maybe, + ti::copy_constructible::yes>>, + ProfileAndExpectation< + ti::HasNothrowCopyConstructorProfile, + ti::HasNothrowCopyConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::maybe, + ti::move_constructible::maybe, + ti::copy_constructible::nothrow>>, + ProfileAndExpectation< + ti::HasTrivialCopyConstructorProfile, + ti::HasTrivialCopyConstructorArchetype, + ti::ConformanceProfile<ti::default_constructible::maybe, + ti::move_constructible::maybe, + ti::copy_constructible::trivial>>, + + // Core move assignment profiles + ProfileAndExpectation< + ti::HasMoveAssignProfile, ti::HasMoveAssignArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::yes>>, + ProfileAndExpectation< + ti::HasNothrowMoveAssignProfile, ti::HasNothrowMoveAssignArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::nothrow>>, + ProfileAndExpectation< + ti::HasTrivialMoveAssignProfile, ti::HasTrivialMoveAssignArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::trivial>>, + + // Core copy assignment profiles + ProfileAndExpectation< + ti::HasCopyAssignProfile, ti::HasCopyAssignArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::yes>>, + ProfileAndExpectation< + ti::HasNothrowCopyAssignProfile, ti::HasNothrowCopyAssignArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::nothrow>>, + ProfileAndExpectation< + ti::HasTrivialCopyAssignProfile, ti::HasTrivialCopyAssignArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::trivial>>, + + // Core destructor profiles + ProfileAndExpectation< + ti::HasDestructorProfile, ti::HasDestructorArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::yes>>, + ProfileAndExpectation< + ti::HasNothrowDestructorProfile, ti::HasNothrowDestructorArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow>>, + ProfileAndExpectation< + ti::HasTrivialDestructorProfile, ti::HasTrivialDestructorArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::trivial>>, + + // Core equality comparable profiles + ProfileAndExpectation< + ti::HasEqualityProfile, ti::HasEqualityArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::yes>>, + ProfileAndExpectation< + ti::HasNothrowEqualityProfile, ti::HasNothrowEqualityArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::nothrow>>, + + // Core inequality comparable profiles + ProfileAndExpectation< + ti::HasInequalityProfile, ti::HasInequalityArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::yes>>, + ProfileAndExpectation< + ti::HasNothrowInequalityProfile, ti::HasNothrowInequalityArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, + ti::inequality_comparable::nothrow>>, + + // Core less than comparable profiles + ProfileAndExpectation< + ti::HasLessThanProfile, ti::HasLessThanArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::yes>>, + ProfileAndExpectation< + ti::HasNothrowLessThanProfile, ti::HasNothrowLessThanArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::nothrow>>, + + // Core less equal comparable profiles + ProfileAndExpectation< + ti::HasLessEqualProfile, ti::HasLessEqualArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::yes>>, + ProfileAndExpectation< + ti::HasNothrowLessEqualProfile, ti::HasNothrowLessEqualArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, + ti::less_equal_comparable::nothrow>>, + + // Core greater equal comparable profiles + ProfileAndExpectation< + ti::HasGreaterEqualProfile, ti::HasGreaterEqualArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::yes>>, + ProfileAndExpectation< + ti::HasNothrowGreaterEqualProfile, ti::HasNothrowGreaterEqualArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::nothrow>>, + + // Core greater than comparable profiles + ProfileAndExpectation< + ti::HasGreaterThanProfile, ti::HasGreaterThanArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::yes>>, + ProfileAndExpectation< + ti::HasNothrowGreaterThanProfile, ti::HasNothrowGreaterThanArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::nothrow>>, + + // Core swappable profiles + ProfileAndExpectation< + ti::HasSwapProfile, ti::HasSwapArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::yes>>, + ProfileAndExpectation< + ti::HasNothrowSwapProfile, ti::HasNothrowSwapArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::nothrow>>, + + // Core hashable profiles + ProfileAndExpectation< + ti::HasStdHashSpecializationProfile, + ti::HasStdHashSpecializationArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::maybe, + ti::hashable::yes>>>; + +using CommonProfilesToTest = ::testing::Types< + // NothrowMoveConstructible + ProfileAndExpectation< + ti::NothrowMoveConstructibleProfile, + ti::NothrowMoveConstructibleArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow>>, + + // CopyConstructible + ProfileAndExpectation< + ti::CopyConstructibleProfile, ti::CopyConstructibleArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::yes, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow>>, + + // NothrowMovable + ProfileAndExpectation< + ti::NothrowMovableProfile, ti::NothrowMovableArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::maybe, ti::move_assignable::nothrow, + ti::copy_assignable::maybe, ti::destructible::nothrow, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::nothrow>>, + + // Value + ProfileAndExpectation< + ti::ValueProfile, ti::ValueArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::yes, ti::move_assignable::nothrow, + ti::copy_assignable::yes, ti::destructible::nothrow, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::nothrow>>, + + //////////////////////////////////////////////////////////////////////////// + // Common but also DefaultConstructible // + //////////////////////////////////////////////////////////////////////////// + + // DefaultConstructibleNothrowMoveConstructible + ProfileAndExpectation< + ti::DefaultConstructibleNothrowMoveConstructibleProfile, + ti::DefaultConstructibleNothrowMoveConstructibleArchetype, + ti::ConformanceProfile< + ti::default_constructible::yes, ti::move_constructible::nothrow, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow>>, + + // DefaultConstructibleCopyConstructible + ProfileAndExpectation< + ti::DefaultConstructibleCopyConstructibleProfile, + ti::DefaultConstructibleCopyConstructibleArchetype, + ti::ConformanceProfile< + ti::default_constructible::yes, ti::move_constructible::nothrow, + ti::copy_constructible::yes, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow>>, + + // DefaultConstructibleNothrowMovable + ProfileAndExpectation< + ti::DefaultConstructibleNothrowMovableProfile, + ti::DefaultConstructibleNothrowMovableArchetype, + ti::ConformanceProfile< + ti::default_constructible::yes, ti::move_constructible::nothrow, + ti::copy_constructible::maybe, ti::move_assignable::nothrow, + ti::copy_assignable::maybe, ti::destructible::nothrow, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::nothrow>>, + + // DefaultConstructibleValue + ProfileAndExpectation< + ti::DefaultConstructibleValueProfile, + ti::DefaultConstructibleValueArchetype, + ti::ConformanceProfile< + ti::default_constructible::yes, ti::move_constructible::nothrow, + ti::copy_constructible::yes, ti::move_assignable::nothrow, + ti::copy_assignable::yes, ti::destructible::nothrow, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::nothrow>>>; + +using ComparableHelpersProfilesToTest = ::testing::Types< + // Equatable + ProfileAndExpectation< + ti::EquatableProfile, ti::EquatableArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::yes, ti::inequality_comparable::yes>>, + + // Comparable + ProfileAndExpectation< + ti::ComparableProfile, ti::ComparableArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::yes, ti::inequality_comparable::yes, + ti::less_than_comparable::yes, ti::less_equal_comparable::yes, + ti::greater_equal_comparable::yes, + ti::greater_than_comparable::yes>>, + + // NothrowEquatable + ProfileAndExpectation< + ti::NothrowEquatableProfile, ti::NothrowEquatableArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::nothrow, + ti::inequality_comparable::nothrow>>, + + // NothrowComparable + ProfileAndExpectation< + ti::NothrowComparableProfile, ti::NothrowComparableArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::maybe, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::maybe, + ti::equality_comparable::nothrow, + ti::inequality_comparable::nothrow, + ti::less_than_comparable::nothrow, + ti::less_equal_comparable::nothrow, + ti::greater_equal_comparable::nothrow, + ti::greater_than_comparable::nothrow>>>; + +using CommonComparableProfilesToTest = ::testing::Types< + // ComparableNothrowMoveConstructible + ProfileAndExpectation< + ti::ComparableNothrowMoveConstructibleProfile, + ti::ComparableNothrowMoveConstructibleArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::maybe, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow, + ti::equality_comparable::yes, ti::inequality_comparable::yes, + ti::less_than_comparable::yes, ti::less_equal_comparable::yes, + ti::greater_equal_comparable::yes, + ti::greater_than_comparable::yes>>, + + // ComparableCopyConstructible + ProfileAndExpectation< + ti::ComparableCopyConstructibleProfile, + ti::ComparableCopyConstructibleArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::yes, ti::move_assignable::maybe, + ti::copy_assignable::maybe, ti::destructible::nothrow, + ti::equality_comparable::yes, ti::inequality_comparable::yes, + ti::less_than_comparable::yes, ti::less_equal_comparable::yes, + ti::greater_equal_comparable::yes, + ti::greater_than_comparable::yes>>, + + // ComparableNothrowMovable + ProfileAndExpectation< + ti::ComparableNothrowMovableProfile, + ti::ComparableNothrowMovableArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::maybe, ti::move_assignable::nothrow, + ti::copy_assignable::maybe, ti::destructible::nothrow, + ti::equality_comparable::yes, ti::inequality_comparable::yes, + ti::less_than_comparable::yes, ti::less_equal_comparable::yes, + ti::greater_equal_comparable::yes, ti::greater_than_comparable::yes, + ti::swappable::nothrow>>, + + // ComparableValue + ProfileAndExpectation< + ti::ComparableValueProfile, ti::ComparableValueArchetype, + ti::ConformanceProfile< + ti::default_constructible::maybe, ti::move_constructible::nothrow, + ti::copy_constructible::yes, ti::move_assignable::nothrow, + ti::copy_assignable::yes, ti::destructible::nothrow, + ti::equality_comparable::yes, ti::inequality_comparable::yes, + ti::less_than_comparable::yes, ti::less_equal_comparable::yes, + ti::greater_equal_comparable::yes, ti::greater_than_comparable::yes, + ti::swappable::nothrow>>>; + +using TrivialProfilesToTest = ::testing::Types< + ProfileAndExpectation< + ti::TrivialSpecialMemberFunctionsProfile, + ti::TrivialSpecialMemberFunctionsArchetype, + ti::ConformanceProfile< + ti::default_constructible::trivial, ti::move_constructible::trivial, + ti::copy_constructible::trivial, ti::move_assignable::trivial, + ti::copy_assignable::trivial, ti::destructible::trivial, + ti::equality_comparable::maybe, ti::inequality_comparable::maybe, + ti::less_than_comparable::maybe, ti::less_equal_comparable::maybe, + ti::greater_equal_comparable::maybe, + ti::greater_than_comparable::maybe, ti::swappable::nothrow>>, + + ProfileAndExpectation< + ti::TriviallyCompleteProfile, ti::TriviallyCompleteArchetype, + ti::ConformanceProfile< + ti::default_constructible::trivial, ti::move_constructible::trivial, + ti::copy_constructible::trivial, ti::move_assignable::trivial, + ti::copy_assignable::trivial, ti::destructible::trivial, + ti::equality_comparable::yes, ti::inequality_comparable::yes, + ti::less_than_comparable::yes, ti::less_equal_comparable::yes, + ti::greater_equal_comparable::yes, ti::greater_than_comparable::yes, + ti::swappable::nothrow, ti::hashable::yes>>>; + +INSTANTIATE_TYPED_TEST_SUITE_P(Core, ProfileTest, CoreProfilesToTest); +INSTANTIATE_TYPED_TEST_SUITE_P(Common, ProfileTest, CommonProfilesToTest); +INSTANTIATE_TYPED_TEST_SUITE_P(ComparableHelpers, ProfileTest, + ComparableHelpersProfilesToTest); +INSTANTIATE_TYPED_TEST_SUITE_P(CommonComparable, ProfileTest, + CommonComparableProfilesToTest); +INSTANTIATE_TYPED_TEST_SUITE_P(Trivial, ProfileTest, TrivialProfilesToTest); + +TEST(ConformanceTestingTest, Basic) { + using profile = ti::CombineProfiles<ti::TriviallyCompleteProfile, + ti::NothrowComparableProfile>; + + using lim = std::numeric_limits<float>; + + ABSL_INTERNAL_ASSERT_CONFORMANCE_OF(float) + .INITIALIZER(-lim::infinity()) + .INITIALIZER(lim::lowest()) + .INITIALIZER(-1.f) + .INITIALIZER(-lim::min()) + .EQUIVALENCE_CLASS(INITIALIZER(-0.f), INITIALIZER(0.f)) + .INITIALIZER(lim::min()) + .INITIALIZER(1.f) + .INITIALIZER(lim::max()) + .INITIALIZER(lim::infinity()) + .WITH_STRICT_PROFILE(absl::types_internal::RegularityDomain, profile); +} + +struct BadMoveConstruct { + BadMoveConstruct() = default; + BadMoveConstruct(BadMoveConstruct&& other) noexcept + : value(other.value + 1) {} + BadMoveConstruct& operator=(BadMoveConstruct&& other) noexcept = default; + int value = 0; + + friend bool operator==(BadMoveConstruct const& lhs, + BadMoveConstruct const& rhs) { + return lhs.value == rhs.value; + } + friend bool operator!=(BadMoveConstruct const& lhs, + BadMoveConstruct const& rhs) { + return lhs.value != rhs.value; + } +}; + +struct BadMoveAssign { + BadMoveAssign() = default; + BadMoveAssign(BadMoveAssign&& other) noexcept = default; + BadMoveAssign& operator=(BadMoveAssign&& other) noexcept { + int new_value = other.value + 1; + value = new_value; + return *this; + } + int value = 0; + + friend bool operator==(BadMoveAssign const& lhs, BadMoveAssign const& rhs) { + return lhs.value == rhs.value; + } + friend bool operator!=(BadMoveAssign const& lhs, BadMoveAssign const& rhs) { + return lhs.value != rhs.value; + } +}; + +enum class WhichCompIsBad { eq, ne, lt, le, ge, gt }; + +template <WhichCompIsBad Which> +struct BadCompare { + int value; + + friend bool operator==(BadCompare const& lhs, BadCompare const& rhs) { + return Which == WhichCompIsBad::eq ? lhs.value != rhs.value + : lhs.value == rhs.value; + } + + friend bool operator!=(BadCompare const& lhs, BadCompare const& rhs) { + return Which == WhichCompIsBad::ne ? lhs.value == rhs.value + : lhs.value != rhs.value; + } + + friend bool operator<(BadCompare const& lhs, BadCompare const& rhs) { + return Which == WhichCompIsBad::lt ? lhs.value >= rhs.value + : lhs.value < rhs.value; + } + + friend bool operator<=(BadCompare const& lhs, BadCompare const& rhs) { + return Which == WhichCompIsBad::le ? lhs.value > rhs.value + : lhs.value <= rhs.value; + } + + friend bool operator>=(BadCompare const& lhs, BadCompare const& rhs) { + return Which == WhichCompIsBad::ge ? lhs.value < rhs.value + : lhs.value >= rhs.value; + } + + friend bool operator>(BadCompare const& lhs, BadCompare const& rhs) { + return Which == WhichCompIsBad::gt ? lhs.value <= rhs.value + : lhs.value > rhs.value; + } +}; + +TEST(ConformanceTestingDeathTest, Failures) { + { + using profile = ti::CombineProfiles<ti::TriviallyCompleteProfile, + ti::NothrowComparableProfile>; + + // Note: The initializers are intentionally in the wrong order. + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(float) + .INITIALIZER(1.f) + .INITIALIZER(0.f) + .WITH_LOOSE_PROFILE(profile); + } + + { + using profile = + ti::CombineProfiles<ti::NothrowMovableProfile, ti::EquatableProfile>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadMoveConstruct) + .DUE_TO("Move construction") + .INITIALIZER(BadMoveConstruct()) + .WITH_LOOSE_PROFILE(profile); + } + + { + using profile = + ti::CombineProfiles<ti::NothrowMovableProfile, ti::EquatableProfile>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadMoveAssign) + .DUE_TO("Move assignment") + .INITIALIZER(BadMoveAssign()) + .WITH_LOOSE_PROFILE(profile); + } +} + +TEST(ConformanceTestingDeathTest, CompFailures) { + using profile = ti::ComparableProfile; + + { + using BadComp = BadCompare<WhichCompIsBad::eq>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadComp) + .DUE_TO("Comparison") + .INITIALIZER(BadComp{0}) + .INITIALIZER(BadComp{1}) + .WITH_LOOSE_PROFILE(profile); + } + + { + using BadComp = BadCompare<WhichCompIsBad::ne>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadComp) + .DUE_TO("Comparison") + .INITIALIZER(BadComp{0}) + .INITIALIZER(BadComp{1}) + .WITH_LOOSE_PROFILE(profile); + } + + { + using BadComp = BadCompare<WhichCompIsBad::lt>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadComp) + .DUE_TO("Comparison") + .INITIALIZER(BadComp{0}) + .INITIALIZER(BadComp{1}) + .WITH_LOOSE_PROFILE(profile); + } + + { + using BadComp = BadCompare<WhichCompIsBad::le>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadComp) + .DUE_TO("Comparison") + .INITIALIZER(BadComp{0}) + .INITIALIZER(BadComp{1}) + .WITH_LOOSE_PROFILE(profile); + } + + { + using BadComp = BadCompare<WhichCompIsBad::ge>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadComp) + .DUE_TO("Comparison") + .INITIALIZER(BadComp{0}) + .INITIALIZER(BadComp{1}) + .WITH_LOOSE_PROFILE(profile); + } + + { + using BadComp = BadCompare<WhichCompIsBad::gt>; + + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadComp) + .DUE_TO("Comparison") + .INITIALIZER(BadComp{0}) + .INITIALIZER(BadComp{1}) + .WITH_LOOSE_PROFILE(profile); + } +} + +struct BadSelfMove { + BadSelfMove() = default; + BadSelfMove(BadSelfMove&&) = default; + BadSelfMove& operator=(BadSelfMove&& other) noexcept { + if (this == &other) { + broken_state = true; + } + return *this; + } + + friend bool operator==(const BadSelfMove& lhs, const BadSelfMove& rhs) { + return !(lhs.broken_state || rhs.broken_state); + } + + friend bool operator!=(const BadSelfMove& lhs, const BadSelfMove& rhs) { + return lhs.broken_state || rhs.broken_state; + } + + bool broken_state = false; +}; + +TEST(ConformanceTestingDeathTest, SelfMoveFailure) { + using profile = ti::EquatableNothrowMovableProfile; + + { + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadSelfMove) + .DUE_TO("Move assignment") + .INITIALIZER(BadSelfMove()) + .WITH_LOOSE_PROFILE(profile); + } +} + +struct BadSelfCopy { + BadSelfCopy() = default; + BadSelfCopy(BadSelfCopy&&) = default; + BadSelfCopy(const BadSelfCopy&) = default; + BadSelfCopy& operator=(BadSelfCopy&&) = default; + BadSelfCopy& operator=(BadSelfCopy const& other) { + if (this == &other) { + broken_state = true; + } + return *this; + } + + friend bool operator==(const BadSelfCopy& lhs, const BadSelfCopy& rhs) { + return !(lhs.broken_state || rhs.broken_state); + } + + friend bool operator!=(const BadSelfCopy& lhs, const BadSelfCopy& rhs) { + return lhs.broken_state || rhs.broken_state; + } + + bool broken_state = false; +}; + +TEST(ConformanceTestingDeathTest, SelfCopyFailure) { + using profile = ti::EquatableValueProfile; + + { + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadSelfCopy) + .DUE_TO("Copy assignment") + .INITIALIZER(BadSelfCopy()) + .WITH_LOOSE_PROFILE(profile); + } +} + +struct BadSelfSwap { + friend void swap(BadSelfSwap& lhs, BadSelfSwap& rhs) noexcept { + if (&lhs == &rhs) lhs.broken_state = true; + } + + friend bool operator==(const BadSelfSwap& lhs, const BadSelfSwap& rhs) { + return !(lhs.broken_state || rhs.broken_state); + } + + friend bool operator!=(const BadSelfSwap& lhs, const BadSelfSwap& rhs) { + return lhs.broken_state || rhs.broken_state; + } + + bool broken_state = false; +}; + +TEST(ConformanceTestingDeathTest, SelfSwapFailure) { + using profile = ti::EquatableNothrowMovableProfile; + + { + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadSelfSwap) + .DUE_TO("Swap") + .INITIALIZER(BadSelfSwap()) + .WITH_LOOSE_PROFILE(profile); + } +} + +struct BadDefaultInitializedMoveAssign { + BadDefaultInitializedMoveAssign() : default_initialized(true) {} + explicit BadDefaultInitializedMoveAssign(int v) : value(v) {} + BadDefaultInitializedMoveAssign( + BadDefaultInitializedMoveAssign&& other) noexcept + : value(other.value) {} + BadDefaultInitializedMoveAssign& operator=( + BadDefaultInitializedMoveAssign&& other) noexcept { + value = other.value; + if (default_initialized) ++value; // Bad move if lhs is default initialized + return *this; + } + + friend bool operator==(const BadDefaultInitializedMoveAssign& lhs, + const BadDefaultInitializedMoveAssign& rhs) { + return lhs.value == rhs.value; + } + + friend bool operator!=(const BadDefaultInitializedMoveAssign& lhs, + const BadDefaultInitializedMoveAssign& rhs) { + return lhs.value != rhs.value; + } + + bool default_initialized = false; + int value = 0; +}; + +TEST(ConformanceTestingDeathTest, DefaultInitializedMoveAssignFailure) { + using profile = + ti::CombineProfiles<ti::DefaultConstructibleNothrowMovableProfile, + ti::EquatableProfile>; + + { + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadDefaultInitializedMoveAssign) + .DUE_TO("move assignment") + .INITIALIZER(BadDefaultInitializedMoveAssign(0)) + .WITH_LOOSE_PROFILE(profile); + } +} + +struct BadDefaultInitializedCopyAssign { + BadDefaultInitializedCopyAssign() : default_initialized(true) {} + explicit BadDefaultInitializedCopyAssign(int v) : value(v) {} + BadDefaultInitializedCopyAssign( + BadDefaultInitializedCopyAssign&& other) noexcept + : value(other.value) {} + BadDefaultInitializedCopyAssign(const BadDefaultInitializedCopyAssign& other) + : value(other.value) {} + + BadDefaultInitializedCopyAssign& operator=( + BadDefaultInitializedCopyAssign&& other) noexcept { + value = other.value; + return *this; + } + + BadDefaultInitializedCopyAssign& operator=( + const BadDefaultInitializedCopyAssign& other) { + value = other.value; + if (default_initialized) ++value; // Bad move if lhs is default initialized + return *this; + } + + friend bool operator==(const BadDefaultInitializedCopyAssign& lhs, + const BadDefaultInitializedCopyAssign& rhs) { + return lhs.value == rhs.value; + } + + friend bool operator!=(const BadDefaultInitializedCopyAssign& lhs, + const BadDefaultInitializedCopyAssign& rhs) { + return lhs.value != rhs.value; + } + + bool default_initialized = false; + int value = 0; +}; + +TEST(ConformanceTestingDeathTest, DefaultInitializedAssignFailure) { + using profile = ti::CombineProfiles<ti::DefaultConstructibleValueProfile, + ti::EquatableProfile>; + + { + ABSL_INTERNAL_ASSERT_NONCONFORMANCE_OF(BadDefaultInitializedCopyAssign) + .DUE_TO("copy assignment") + .INITIALIZER(BadDefaultInitializedCopyAssign(0)) + .WITH_LOOSE_PROFILE(profile); + } +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/types/internal/optional.h b/third_party/abseil_cpp/absl/types/internal/optional.h new file mode 100644 index 0000000000..92932b6001 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/optional.h @@ -0,0 +1,396 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#ifndef ABSL_TYPES_INTERNAL_OPTIONAL_H_ +#define ABSL_TYPES_INTERNAL_OPTIONAL_H_ + +#include <functional> +#include <new> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/inline_variable.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/utility/utility.h" + +// ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS +// +// Inheriting constructors is supported in GCC 4.8+, Clang 3.3+ and MSVC 2015. +// __cpp_inheriting_constructors is a predefined macro and a recommended way to +// check for this language feature, but GCC doesn't support it until 5.0 and +// Clang doesn't support it until 3.6. +// Also, MSVC 2015 has a bug: it doesn't inherit the constexpr template +// constructor. For example, the following code won't work on MSVC 2015 Update3: +// struct Base { +// int t; +// template <typename T> +// constexpr Base(T t_) : t(t_) {} +// }; +// struct Foo : Base { +// using Base::Base; +// } +// constexpr Foo foo(0); // doesn't work on MSVC 2015 +#if defined(__clang__) +#if __has_feature(cxx_inheriting_constructors) +#define ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS 1 +#endif +#elif (defined(__GNUC__) && \ + (__GNUC__ > 4 || __GNUC__ == 4 && __GNUC_MINOR__ >= 8)) || \ + (__cpp_inheriting_constructors >= 200802) || \ + (defined(_MSC_VER) && _MSC_VER >= 1910) +#define ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS 1 +#endif + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// Forward declaration +template <typename T> +class optional; + +namespace optional_internal { + +// This tag type is used as a constructor parameter type for `nullopt_t`. +struct init_t { + explicit init_t() = default; +}; + +struct empty_struct {}; + +// This class stores the data in optional<T>. +// It is specialized based on whether T is trivially destructible. +// This is the specialization for non trivially destructible type. +template <typename T, bool unused = std::is_trivially_destructible<T>::value> +class optional_data_dtor_base { + struct dummy_type { + static_assert(sizeof(T) % sizeof(empty_struct) == 0, ""); + // Use an array to avoid GCC 6 placement-new warning. + empty_struct data[sizeof(T) / sizeof(empty_struct)]; + }; + + protected: + // Whether there is data or not. + bool engaged_; + // Data storage + union { + T data_; + dummy_type dummy_; + }; + + void destruct() noexcept { + if (engaged_) { + data_.~T(); + engaged_ = false; + } + } + + // dummy_ must be initialized for constexpr constructor. + constexpr optional_data_dtor_base() noexcept : engaged_(false), dummy_{{}} {} + + template <typename... Args> + constexpr explicit optional_data_dtor_base(in_place_t, Args&&... args) + : engaged_(true), data_(absl::forward<Args>(args)...) {} + + ~optional_data_dtor_base() { destruct(); } +}; + +// Specialization for trivially destructible type. +template <typename T> +class optional_data_dtor_base<T, true> { + struct dummy_type { + static_assert(sizeof(T) % sizeof(empty_struct) == 0, ""); + // Use array to avoid GCC 6 placement-new warning. + empty_struct data[sizeof(T) / sizeof(empty_struct)]; + }; + + protected: + // Whether there is data or not. + bool engaged_; + // Data storage + union { + T data_; + dummy_type dummy_; + }; + void destruct() noexcept { engaged_ = false; } + + // dummy_ must be initialized for constexpr constructor. + constexpr optional_data_dtor_base() noexcept : engaged_(false), dummy_{{}} {} + + template <typename... Args> + constexpr explicit optional_data_dtor_base(in_place_t, Args&&... args) + : engaged_(true), data_(absl::forward<Args>(args)...) {} +}; + +template <typename T> +class optional_data_base : public optional_data_dtor_base<T> { + protected: + using base = optional_data_dtor_base<T>; +#ifdef ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS + using base::base; +#else + optional_data_base() = default; + + template <typename... Args> + constexpr explicit optional_data_base(in_place_t t, Args&&... args) + : base(t, absl::forward<Args>(args)...) {} +#endif + + template <typename... Args> + void construct(Args&&... args) { + // Use dummy_'s address to work around casting cv-qualified T* to void*. + ::new (static_cast<void*>(&this->dummy_)) T(std::forward<Args>(args)...); + this->engaged_ = true; + } + + template <typename U> + void assign(U&& u) { + if (this->engaged_) { + this->data_ = std::forward<U>(u); + } else { + construct(std::forward<U>(u)); + } + } +}; + +// TODO(absl-team): Add another class using +// std::is_trivially_move_constructible trait when available to match +// http://cplusplus.github.io/LWG/lwg-defects.html#2900, for types that +// have trivial move but nontrivial copy. +// Also, we should be checking is_trivially_copyable here, which is not +// supported now, so we use is_trivially_* traits instead. +template <typename T, + bool unused = absl::is_trivially_copy_constructible<T>::value&& + absl::is_trivially_copy_assignable<typename std::remove_cv< + T>::type>::value&& std::is_trivially_destructible<T>::value> +class optional_data; + +// Trivially copyable types +template <typename T> +class optional_data<T, true> : public optional_data_base<T> { + protected: +#ifdef ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS + using optional_data_base<T>::optional_data_base; +#else + optional_data() = default; + + template <typename... Args> + constexpr explicit optional_data(in_place_t t, Args&&... args) + : optional_data_base<T>(t, absl::forward<Args>(args)...) {} +#endif +}; + +template <typename T> +class optional_data<T, false> : public optional_data_base<T> { + protected: +#ifdef ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS + using optional_data_base<T>::optional_data_base; +#else + template <typename... Args> + constexpr explicit optional_data(in_place_t t, Args&&... args) + : optional_data_base<T>(t, absl::forward<Args>(args)...) {} +#endif + + optional_data() = default; + + optional_data(const optional_data& rhs) : optional_data_base<T>() { + if (rhs.engaged_) { + this->construct(rhs.data_); + } + } + + optional_data(optional_data&& rhs) noexcept( + absl::default_allocator_is_nothrow::value || + std::is_nothrow_move_constructible<T>::value) + : optional_data_base<T>() { + if (rhs.engaged_) { + this->construct(std::move(rhs.data_)); + } + } + + optional_data& operator=(const optional_data& rhs) { + if (rhs.engaged_) { + this->assign(rhs.data_); + } else { + this->destruct(); + } + return *this; + } + + optional_data& operator=(optional_data&& rhs) noexcept( + std::is_nothrow_move_assignable<T>::value&& + std::is_nothrow_move_constructible<T>::value) { + if (rhs.engaged_) { + this->assign(std::move(rhs.data_)); + } else { + this->destruct(); + } + return *this; + } +}; + +// Ordered by level of restriction, from low to high. +// Copyable implies movable. +enum class copy_traits { copyable = 0, movable = 1, non_movable = 2 }; + +// Base class for enabling/disabling copy/move constructor. +template <copy_traits> +class optional_ctor_base; + +template <> +class optional_ctor_base<copy_traits::copyable> { + public: + constexpr optional_ctor_base() = default; + optional_ctor_base(const optional_ctor_base&) = default; + optional_ctor_base(optional_ctor_base&&) = default; + optional_ctor_base& operator=(const optional_ctor_base&) = default; + optional_ctor_base& operator=(optional_ctor_base&&) = default; +}; + +template <> +class optional_ctor_base<copy_traits::movable> { + public: + constexpr optional_ctor_base() = default; + optional_ctor_base(const optional_ctor_base&) = delete; + optional_ctor_base(optional_ctor_base&&) = default; + optional_ctor_base& operator=(const optional_ctor_base&) = default; + optional_ctor_base& operator=(optional_ctor_base&&) = default; +}; + +template <> +class optional_ctor_base<copy_traits::non_movable> { + public: + constexpr optional_ctor_base() = default; + optional_ctor_base(const optional_ctor_base&) = delete; + optional_ctor_base(optional_ctor_base&&) = delete; + optional_ctor_base& operator=(const optional_ctor_base&) = default; + optional_ctor_base& operator=(optional_ctor_base&&) = default; +}; + +// Base class for enabling/disabling copy/move assignment. +template <copy_traits> +class optional_assign_base; + +template <> +class optional_assign_base<copy_traits::copyable> { + public: + constexpr optional_assign_base() = default; + optional_assign_base(const optional_assign_base&) = default; + optional_assign_base(optional_assign_base&&) = default; + optional_assign_base& operator=(const optional_assign_base&) = default; + optional_assign_base& operator=(optional_assign_base&&) = default; +}; + +template <> +class optional_assign_base<copy_traits::movable> { + public: + constexpr optional_assign_base() = default; + optional_assign_base(const optional_assign_base&) = default; + optional_assign_base(optional_assign_base&&) = default; + optional_assign_base& operator=(const optional_assign_base&) = delete; + optional_assign_base& operator=(optional_assign_base&&) = default; +}; + +template <> +class optional_assign_base<copy_traits::non_movable> { + public: + constexpr optional_assign_base() = default; + optional_assign_base(const optional_assign_base&) = default; + optional_assign_base(optional_assign_base&&) = default; + optional_assign_base& operator=(const optional_assign_base&) = delete; + optional_assign_base& operator=(optional_assign_base&&) = delete; +}; + +template <typename T> +struct ctor_copy_traits { + static constexpr copy_traits traits = + std::is_copy_constructible<T>::value + ? copy_traits::copyable + : std::is_move_constructible<T>::value ? copy_traits::movable + : copy_traits::non_movable; +}; + +template <typename T> +struct assign_copy_traits { + static constexpr copy_traits traits = + absl::is_copy_assignable<T>::value && std::is_copy_constructible<T>::value + ? copy_traits::copyable + : absl::is_move_assignable<T>::value && + std::is_move_constructible<T>::value + ? copy_traits::movable + : copy_traits::non_movable; +}; + +// Whether T is constructible or convertible from optional<U>. +template <typename T, typename U> +struct is_constructible_convertible_from_optional + : std::integral_constant< + bool, std::is_constructible<T, optional<U>&>::value || + std::is_constructible<T, optional<U>&&>::value || + std::is_constructible<T, const optional<U>&>::value || + std::is_constructible<T, const optional<U>&&>::value || + std::is_convertible<optional<U>&, T>::value || + std::is_convertible<optional<U>&&, T>::value || + std::is_convertible<const optional<U>&, T>::value || + std::is_convertible<const optional<U>&&, T>::value> {}; + +// Whether T is constructible or convertible or assignable from optional<U>. +template <typename T, typename U> +struct is_constructible_convertible_assignable_from_optional + : std::integral_constant< + bool, is_constructible_convertible_from_optional<T, U>::value || + std::is_assignable<T&, optional<U>&>::value || + std::is_assignable<T&, optional<U>&&>::value || + std::is_assignable<T&, const optional<U>&>::value || + std::is_assignable<T&, const optional<U>&&>::value> {}; + +// Helper function used by [optional.relops], [optional.comp_with_t], +// for checking whether an expression is convertible to bool. +bool convertible_to_bool(bool); + +// Base class for std::hash<absl::optional<T>>: +// If std::hash<std::remove_const_t<T>> is enabled, it provides operator() to +// compute the hash; Otherwise, it is disabled. +// Reference N4659 23.14.15 [unord.hash]. +template <typename T, typename = size_t> +struct optional_hash_base { + optional_hash_base() = delete; + optional_hash_base(const optional_hash_base&) = delete; + optional_hash_base(optional_hash_base&&) = delete; + optional_hash_base& operator=(const optional_hash_base&) = delete; + optional_hash_base& operator=(optional_hash_base&&) = delete; +}; + +template <typename T> +struct optional_hash_base<T, decltype(std::hash<absl::remove_const_t<T> >()( + std::declval<absl::remove_const_t<T> >()))> { + using argument_type = absl::optional<T>; + using result_type = size_t; + size_t operator()(const absl::optional<T>& opt) const { + absl::type_traits_internal::AssertHashEnabled<absl::remove_const_t<T>>(); + if (opt) { + return std::hash<absl::remove_const_t<T> >()(*opt); + } else { + return static_cast<size_t>(0x297814aaad196e6dULL); + } + } +}; + +} // namespace optional_internal +ABSL_NAMESPACE_END +} // namespace absl + +#undef ABSL_OPTIONAL_USE_INHERITING_CONSTRUCTORS + +#endif // ABSL_TYPES_INTERNAL_OPTIONAL_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/parentheses.h b/third_party/abseil_cpp/absl/types/internal/parentheses.h new file mode 100644 index 0000000000..5aebee8fde --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/parentheses.h @@ -0,0 +1,34 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// parentheses.h +// ----------------------------------------------------------------------------- +// +// This file contains macros that expand to a left parenthesis and a right +// parenthesis. These are in their own file and are generated from macros +// because otherwise clang-format gets confused and clang-format off directives +// do not help. +// +// The parentheses macros are used when wanting to require a rescan before +// expansion of parenthesized text appearing after a function-style macro name. + +#ifndef ABSL_TYPES_INTERNAL_PARENTHESES_H_ +#define ABSL_TYPES_INTERNAL_PARENTHESES_H_ + +#define ABSL_INTERNAL_LPAREN ( + +#define ABSL_INTERNAL_RPAREN ) + +#endif // ABSL_TYPES_INTERNAL_PARENTHESES_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/span.h b/third_party/abseil_cpp/absl/types/internal/span.h new file mode 100644 index 0000000000..112612f4bd --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/span.h @@ -0,0 +1,128 @@ +// +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +#ifndef ABSL_TYPES_INTERNAL_SPAN_H_ +#define ABSL_TYPES_INTERNAL_SPAN_H_ + +#include <algorithm> +#include <cstddef> +#include <string> +#include <type_traits> + +#include "absl/algorithm/algorithm.h" +#include "absl/base/internal/throw_delegate.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace span_internal { +// A constexpr min function +constexpr size_t Min(size_t a, size_t b) noexcept { return a < b ? a : b; } + +// Wrappers for access to container data pointers. +template <typename C> +constexpr auto GetDataImpl(C& c, char) noexcept // NOLINT(runtime/references) + -> decltype(c.data()) { + return c.data(); +} + +// Before C++17, std::string::data returns a const char* in all cases. +inline char* GetDataImpl(std::string& s, // NOLINT(runtime/references) + int) noexcept { + return &s[0]; +} + +template <typename C> +constexpr auto GetData(C& c) noexcept // NOLINT(runtime/references) + -> decltype(GetDataImpl(c, 0)) { + return GetDataImpl(c, 0); +} + +// Detection idioms for size() and data(). +template <typename C> +using HasSize = + std::is_integral<absl::decay_t<decltype(std::declval<C&>().size())>>; + +// We want to enable conversion from vector<T*> to Span<const T* const> but +// disable conversion from vector<Derived> to Span<Base>. Here we use +// the fact that U** is convertible to Q* const* if and only if Q is the same +// type or a more cv-qualified version of U. We also decay the result type of +// data() to avoid problems with classes which have a member function data() +// which returns a reference. +template <typename T, typename C> +using HasData = + std::is_convertible<absl::decay_t<decltype(GetData(std::declval<C&>()))>*, + T* const*>; + +// Extracts value type from a Container +template <typename C> +struct ElementType { + using type = typename absl::remove_reference_t<C>::value_type; +}; + +template <typename T, size_t N> +struct ElementType<T (&)[N]> { + using type = T; +}; + +template <typename C> +using ElementT = typename ElementType<C>::type; + +template <typename T> +using EnableIfMutable = + typename std::enable_if<!std::is_const<T>::value, int>::type; + +template <template <typename> class SpanT, typename T> +bool EqualImpl(SpanT<T> a, SpanT<T> b) { + static_assert(std::is_const<T>::value, ""); + return absl::equal(a.begin(), a.end(), b.begin(), b.end()); +} + +template <template <typename> class SpanT, typename T> +bool LessThanImpl(SpanT<T> a, SpanT<T> b) { + // We can't use value_type since that is remove_cv_t<T>, so we go the long way + // around. + static_assert(std::is_const<T>::value, ""); + return std::lexicographical_compare(a.begin(), a.end(), b.begin(), b.end()); +} + +// The `IsConvertible` classes here are needed because of the +// `std::is_convertible` bug in libcxx when compiled with GCC. This build +// configuration is used by Android NDK toolchain. Reference link: +// https://bugs.llvm.org/show_bug.cgi?id=27538. +template <typename From, typename To> +struct IsConvertibleHelper { + private: + static std::true_type testval(To); + static std::false_type testval(...); + + public: + using type = decltype(testval(std::declval<From>())); +}; + +template <typename From, typename To> +struct IsConvertible : IsConvertibleHelper<From, To>::type {}; + +// TODO(zhangxy): replace `IsConvertible` with `std::is_convertible` once the +// older version of libcxx is not supported. +template <typename From, typename To> +using EnableIfConvertibleTo = + typename std::enable_if<IsConvertible<From, To>::value>::type; +} // namespace span_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TYPES_INTERNAL_SPAN_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/transform_args.h b/third_party/abseil_cpp/absl/types/internal/transform_args.h new file mode 100644 index 0000000000..4a0ab42ac4 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/transform_args.h @@ -0,0 +1,246 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// transform_args.h +// ----------------------------------------------------------------------------- +// +// This file contains a higher-order macro that "transforms" each element of a +// a variadic argument by a provided secondary macro. + +#ifndef ABSL_TYPES_INTERNAL_TRANSFORM_ARGS_H_ +#define ABSL_TYPES_INTERNAL_TRANSFORM_ARGS_H_ + +// +// ABSL_INTERNAL_CAT(a, b) +// +// This macro takes two arguments and concatenates them together via ## after +// expansion. +// +// Example: +// +// ABSL_INTERNAL_CAT(foo_, bar) +// +// Results in: +// +// foo_bar +#define ABSL_INTERNAL_CAT(a, b) ABSL_INTERNAL_CAT_IMPL(a, b) +#define ABSL_INTERNAL_CAT_IMPL(a, b) a##b + +// +// ABSL_INTERNAL_TRANSFORM_ARGS(m, ...) +// +// This macro takes another macro as an argument followed by a trailing series +// of additional parameters (up to 32 additional arguments). It invokes the +// passed-in macro once for each of the additional arguments, with the +// expansions separated by commas. +// +// Example: +// +// ABSL_INTERNAL_TRANSFORM_ARGS(MY_MACRO, a, b, c) +// +// Results in: +// +// MY_MACRO(a), MY_MACRO(b), MY_MACRO(c) +// +// TODO(calabrese) Handle no arguments as a special case. +#define ABSL_INTERNAL_TRANSFORM_ARGS(m, ...) \ + ABSL_INTERNAL_CAT(ABSL_INTERNAL_TRANSFORM_ARGS, \ + ABSL_INTERNAL_NUM_ARGS(__VA_ARGS__)) \ + (m, __VA_ARGS__) + +#define ABSL_INTERNAL_TRANSFORM_ARGS1(m, a0) m(a0) + +#define ABSL_INTERNAL_TRANSFORM_ARGS2(m, a0, a1) m(a0), m(a1) + +#define ABSL_INTERNAL_TRANSFORM_ARGS3(m, a0, a1, a2) m(a0), m(a1), m(a2) + +#define ABSL_INTERNAL_TRANSFORM_ARGS4(m, a0, a1, a2, a3) \ + m(a0), m(a1), m(a2), m(a3) + +#define ABSL_INTERNAL_TRANSFORM_ARGS5(m, a0, a1, a2, a3, a4) \ + m(a0), m(a1), m(a2), m(a3), m(a4) + +#define ABSL_INTERNAL_TRANSFORM_ARGS6(m, a0, a1, a2, a3, a4, a5) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5) + +#define ABSL_INTERNAL_TRANSFORM_ARGS7(m, a0, a1, a2, a3, a4, a5, a6) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6) + +#define ABSL_INTERNAL_TRANSFORM_ARGS8(m, a0, a1, a2, a3, a4, a5, a6, a7) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7) + +#define ABSL_INTERNAL_TRANSFORM_ARGS9(m, a0, a1, a2, a3, a4, a5, a6, a7, a8) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8) + +#define ABSL_INTERNAL_TRANSFORM_ARGS10(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9) + +#define ABSL_INTERNAL_TRANSFORM_ARGS11(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), m(a10) + +#define ABSL_INTERNAL_TRANSFORM_ARGS12(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11) + +#define ABSL_INTERNAL_TRANSFORM_ARGS13(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12) + +#define ABSL_INTERNAL_TRANSFORM_ARGS14(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13) + +#define ABSL_INTERNAL_TRANSFORM_ARGS15(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14) + +#define ABSL_INTERNAL_TRANSFORM_ARGS16(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15) + +#define ABSL_INTERNAL_TRANSFORM_ARGS17(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16) + +#define ABSL_INTERNAL_TRANSFORM_ARGS18(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17) + +#define ABSL_INTERNAL_TRANSFORM_ARGS19(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18) + +#define ABSL_INTERNAL_TRANSFORM_ARGS20(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19) + +#define ABSL_INTERNAL_TRANSFORM_ARGS21(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19, a20) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20) + +#define ABSL_INTERNAL_TRANSFORM_ARGS22(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19, a20, a21) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21) + +#define ABSL_INTERNAL_TRANSFORM_ARGS23(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19, a20, a21, a22) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22) + +#define ABSL_INTERNAL_TRANSFORM_ARGS24(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19, a20, a21, a22, a23) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23) + +#define ABSL_INTERNAL_TRANSFORM_ARGS25(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19, a20, a21, a22, a23, a24) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24) + +#define ABSL_INTERNAL_TRANSFORM_ARGS26( \ + m, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, \ + a16, a17, a18, a19, a20, a21, a22, a23, a24, a25) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25) + +#define ABSL_INTERNAL_TRANSFORM_ARGS27( \ + m, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, \ + a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25), m(a26) + +#define ABSL_INTERNAL_TRANSFORM_ARGS28( \ + m, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, \ + a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25), m(a26), m(a27) + +#define ABSL_INTERNAL_TRANSFORM_ARGS29( \ + m, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, \ + a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27, a28) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25), m(a26), m(a27), \ + m(a28) + +#define ABSL_INTERNAL_TRANSFORM_ARGS30( \ + m, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, \ + a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27, a28, a29) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25), m(a26), m(a27), \ + m(a28), m(a29) + +#define ABSL_INTERNAL_TRANSFORM_ARGS31( \ + m, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, \ + a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27, a28, a29, a30) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25), m(a26), m(a27), \ + m(a28), m(a29), m(a30) + +#define ABSL_INTERNAL_TRANSFORM_ARGS32(m, a0, a1, a2, a3, a4, a5, a6, a7, a8, \ + a9, a10, a11, a12, a13, a14, a15, a16, \ + a17, a18, a19, a20, a21, a22, a23, a24, \ + a25, a26, a27, a28, a29, a30, a31) \ + m(a0), m(a1), m(a2), m(a3), m(a4), m(a5), m(a6), m(a7), m(a8), m(a9), \ + m(a10), m(a11), m(a12), m(a13), m(a14), m(a15), m(a16), m(a17), m(a18), \ + m(a19), m(a20), m(a21), m(a22), m(a23), m(a24), m(a25), m(a26), m(a27), \ + m(a28), m(a29), m(a30), m(a31) + +#define ABSL_INTERNAL_NUM_ARGS_IMPL(a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, \ + a10, a11, a12, a13, a14, a15, a16, a17, \ + a18, a19, a20, a21, a22, a23, a24, a25, \ + a26, a27, a28, a29, a30, a31, result, ...) \ + result + +#define ABSL_INTERNAL_FORCE_EXPANSION(...) __VA_ARGS__ + +#define ABSL_INTERNAL_NUM_ARGS(...) \ + ABSL_INTERNAL_FORCE_EXPANSION(ABSL_INTERNAL_NUM_ARGS_IMPL( \ + __VA_ARGS__, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, \ + 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, )) + +#endif // ABSL_TYPES_INTERNAL_TRANSFORM_ARGS_H_ diff --git a/third_party/abseil_cpp/absl/types/internal/variant.h b/third_party/abseil_cpp/absl/types/internal/variant.h new file mode 100644 index 0000000000..71bd3adfc6 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/internal/variant.h @@ -0,0 +1,1646 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// Implementation details of absl/types/variant.h, pulled into a +// separate file to avoid cluttering the top of the API header with +// implementation details. + +#ifndef ABSL_TYPES_variant_internal_H_ +#define ABSL_TYPES_variant_internal_H_ + +#include <cassert> +#include <cstddef> +#include <cstdlib> +#include <memory> +#include <stdexcept> +#include <tuple> +#include <type_traits> + +#include "absl/base/config.h" +#include "absl/base/internal/identity.h" +#include "absl/base/internal/inline_variable.h" +#include "absl/base/internal/invoke.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/meta/type_traits.h" +#include "absl/types/bad_variant_access.h" +#include "absl/utility/utility.h" + +#if !defined(ABSL_USES_STD_VARIANT) + +namespace absl { +ABSL_NAMESPACE_BEGIN + +template <class... Types> +class variant; + +ABSL_INTERNAL_INLINE_CONSTEXPR(size_t, variant_npos, -1); + +template <class T> +struct variant_size; + +template <std::size_t I, class T> +struct variant_alternative; + +namespace variant_internal { + +// NOTE: See specializations below for details. +template <std::size_t I, class T> +struct VariantAlternativeSfinae {}; + +// Requires: I < variant_size_v<T>. +// +// Value: The Ith type of Types... +template <std::size_t I, class T0, class... Tn> +struct VariantAlternativeSfinae<I, variant<T0, Tn...>> + : VariantAlternativeSfinae<I - 1, variant<Tn...>> {}; + +// Value: T0 +template <class T0, class... Ts> +struct VariantAlternativeSfinae<0, variant<T0, Ts...>> { + using type = T0; +}; + +template <std::size_t I, class T> +using VariantAlternativeSfinaeT = typename VariantAlternativeSfinae<I, T>::type; + +// NOTE: Requires T to be a reference type. +template <class T, class U> +struct GiveQualsTo; + +template <class T, class U> +struct GiveQualsTo<T&, U> { + using type = U&; +}; + +template <class T, class U> +struct GiveQualsTo<T&&, U> { + using type = U&&; +}; + +template <class T, class U> +struct GiveQualsTo<const T&, U> { + using type = const U&; +}; + +template <class T, class U> +struct GiveQualsTo<const T&&, U> { + using type = const U&&; +}; + +template <class T, class U> +struct GiveQualsTo<volatile T&, U> { + using type = volatile U&; +}; + +template <class T, class U> +struct GiveQualsTo<volatile T&&, U> { + using type = volatile U&&; +}; + +template <class T, class U> +struct GiveQualsTo<volatile const T&, U> { + using type = volatile const U&; +}; + +template <class T, class U> +struct GiveQualsTo<volatile const T&&, U> { + using type = volatile const U&&; +}; + +template <class T, class U> +using GiveQualsToT = typename GiveQualsTo<T, U>::type; + +// Convenience alias, since size_t integral_constant is used a lot in this file. +template <std::size_t I> +using SizeT = std::integral_constant<std::size_t, I>; + +using NPos = SizeT<variant_npos>; + +template <class Variant, class T, class = void> +struct IndexOfConstructedType {}; + +template <std::size_t I, class Variant> +struct VariantAccessResultImpl; + +template <std::size_t I, template <class...> class Variantemplate, class... T> +struct VariantAccessResultImpl<I, Variantemplate<T...>&> { + using type = typename absl::variant_alternative<I, variant<T...>>::type&; +}; + +template <std::size_t I, template <class...> class Variantemplate, class... T> +struct VariantAccessResultImpl<I, const Variantemplate<T...>&> { + using type = + const typename absl::variant_alternative<I, variant<T...>>::type&; +}; + +template <std::size_t I, template <class...> class Variantemplate, class... T> +struct VariantAccessResultImpl<I, Variantemplate<T...>&&> { + using type = typename absl::variant_alternative<I, variant<T...>>::type&&; +}; + +template <std::size_t I, template <class...> class Variantemplate, class... T> +struct VariantAccessResultImpl<I, const Variantemplate<T...>&&> { + using type = + const typename absl::variant_alternative<I, variant<T...>>::type&&; +}; + +template <std::size_t I, class Variant> +using VariantAccessResult = + typename VariantAccessResultImpl<I, Variant&&>::type; + +// NOTE: This is used instead of std::array to reduce instantiation overhead. +template <class T, std::size_t Size> +struct SimpleArray { + static_assert(Size != 0, ""); + T value[Size]; +}; + +template <class T> +struct AccessedType { + using type = T; +}; + +template <class T> +using AccessedTypeT = typename AccessedType<T>::type; + +template <class T, std::size_t Size> +struct AccessedType<SimpleArray<T, Size>> { + using type = AccessedTypeT<T>; +}; + +template <class T> +constexpr T AccessSimpleArray(const T& value) { + return value; +} + +template <class T, std::size_t Size, class... SizeT> +constexpr AccessedTypeT<T> AccessSimpleArray(const SimpleArray<T, Size>& table, + std::size_t head_index, + SizeT... tail_indices) { + return AccessSimpleArray(table.value[head_index], tail_indices...); +} + +// Note: Intentionally is an alias. +template <class T> +using AlwaysZero = SizeT<0>; + +template <class Op, class... Vs> +struct VisitIndicesResultImpl { + using type = absl::result_of_t<Op(AlwaysZero<Vs>...)>; +}; + +template <class Op, class... Vs> +using VisitIndicesResultT = typename VisitIndicesResultImpl<Op, Vs...>::type; + +template <class ReturnType, class FunctionObject, class EndIndices, + class BoundIndices> +struct MakeVisitationMatrix; + +template <class ReturnType, class FunctionObject, std::size_t... Indices> +constexpr ReturnType call_with_indices(FunctionObject&& function) { + static_assert( + std::is_same<ReturnType, decltype(std::declval<FunctionObject>()( + SizeT<Indices>()...))>::value, + "Not all visitation overloads have the same return type."); + return absl::forward<FunctionObject>(function)(SizeT<Indices>()...); +} + +template <class ReturnType, class FunctionObject, std::size_t... BoundIndices> +struct MakeVisitationMatrix<ReturnType, FunctionObject, index_sequence<>, + index_sequence<BoundIndices...>> { + using ResultType = ReturnType (*)(FunctionObject&&); + static constexpr ResultType Run() { + return &call_with_indices<ReturnType, FunctionObject, + (BoundIndices - 1)...>; + } +}; + +template <typename Is, std::size_t J> +struct AppendToIndexSequence; + +template <typename Is, std::size_t J> +using AppendToIndexSequenceT = typename AppendToIndexSequence<Is, J>::type; + +template <std::size_t... Is, std::size_t J> +struct AppendToIndexSequence<index_sequence<Is...>, J> { + using type = index_sequence<Is..., J>; +}; + +template <class ReturnType, class FunctionObject, class EndIndices, + class CurrIndices, class BoundIndices> +struct MakeVisitationMatrixImpl; + +template <class ReturnType, class FunctionObject, class EndIndices, + std::size_t... CurrIndices, class BoundIndices> +struct MakeVisitationMatrixImpl<ReturnType, FunctionObject, EndIndices, + index_sequence<CurrIndices...>, BoundIndices> { + using ResultType = SimpleArray< + typename MakeVisitationMatrix<ReturnType, FunctionObject, EndIndices, + index_sequence<>>::ResultType, + sizeof...(CurrIndices)>; + + static constexpr ResultType Run() { + return {{MakeVisitationMatrix< + ReturnType, FunctionObject, EndIndices, + AppendToIndexSequenceT<BoundIndices, CurrIndices>>::Run()...}}; + } +}; + +template <class ReturnType, class FunctionObject, std::size_t HeadEndIndex, + std::size_t... TailEndIndices, std::size_t... BoundIndices> +struct MakeVisitationMatrix<ReturnType, FunctionObject, + index_sequence<HeadEndIndex, TailEndIndices...>, + index_sequence<BoundIndices...>> + : MakeVisitationMatrixImpl<ReturnType, FunctionObject, + index_sequence<TailEndIndices...>, + absl::make_index_sequence<HeadEndIndex>, + index_sequence<BoundIndices...>> {}; + +struct UnreachableSwitchCase { + template <class Op> + [[noreturn]] static VisitIndicesResultT<Op, std::size_t> Run( + Op&& /*ignored*/) { +#if ABSL_HAVE_BUILTIN(__builtin_unreachable) || \ + (defined(__GNUC__) && !defined(__clang__)) + __builtin_unreachable(); +#elif defined(_MSC_VER) + __assume(false); +#else + // Try to use assert of false being identified as an unreachable intrinsic. + // NOTE: We use assert directly to increase chances of exploiting an assume + // intrinsic. + assert(false); // NOLINT + + // Hack to silence potential no return warning -- cause an infinite loop. + return Run(absl::forward<Op>(op)); +#endif // Checks for __builtin_unreachable + } +}; + +template <class Op, std::size_t I> +struct ReachableSwitchCase { + static VisitIndicesResultT<Op, std::size_t> Run(Op&& op) { + return absl::base_internal::Invoke(absl::forward<Op>(op), SizeT<I>()); + } +}; + +// The number 33 is just a guess at a reasonable maximum to our switch. It is +// not based on any analysis. The reason it is a power of 2 plus 1 instead of a +// power of 2 is because the number was picked to correspond to a power of 2 +// amount of "normal" alternatives, plus one for the possibility of the user +// providing "monostate" in addition to the more natural alternatives. +ABSL_INTERNAL_INLINE_CONSTEXPR(std::size_t, MaxUnrolledVisitCases, 33); + +// Note: The default-definition is for unreachable cases. +template <bool IsReachable> +struct PickCaseImpl { + template <class Op, std::size_t I> + using Apply = UnreachableSwitchCase; +}; + +template <> +struct PickCaseImpl</*IsReachable =*/true> { + template <class Op, std::size_t I> + using Apply = ReachableSwitchCase<Op, I>; +}; + +// Note: This form of dance with template aliases is to make sure that we +// instantiate a number of templates proportional to the number of variant +// alternatives rather than a number of templates proportional to our +// maximum unrolled amount of visitation cases (aliases are effectively +// "free" whereas other template instantiations are costly). +template <class Op, std::size_t I, std::size_t EndIndex> +using PickCase = typename PickCaseImpl<(I < EndIndex)>::template Apply<Op, I>; + +template <class ReturnType> +[[noreturn]] ReturnType TypedThrowBadVariantAccess() { + absl::variant_internal::ThrowBadVariantAccess(); +} + +// Given N variant sizes, determine the number of cases there would need to be +// in a single switch-statement that would cover every possibility in the +// corresponding N-ary visit operation. +template <std::size_t... NumAlternatives> +struct NumCasesOfSwitch; + +template <std::size_t HeadNumAlternatives, std::size_t... TailNumAlternatives> +struct NumCasesOfSwitch<HeadNumAlternatives, TailNumAlternatives...> { + static constexpr std::size_t value = + (HeadNumAlternatives + 1) * + NumCasesOfSwitch<TailNumAlternatives...>::value; +}; + +template <> +struct NumCasesOfSwitch<> { + static constexpr std::size_t value = 1; +}; + +// A switch statement optimizes better than the table of function pointers. +template <std::size_t EndIndex> +struct VisitIndicesSwitch { + static_assert(EndIndex <= MaxUnrolledVisitCases, + "Maximum unrolled switch size exceeded."); + + template <class Op> + static VisitIndicesResultT<Op, std::size_t> Run(Op&& op, std::size_t i) { + switch (i) { + case 0: + return PickCase<Op, 0, EndIndex>::Run(absl::forward<Op>(op)); + case 1: + return PickCase<Op, 1, EndIndex>::Run(absl::forward<Op>(op)); + case 2: + return PickCase<Op, 2, EndIndex>::Run(absl::forward<Op>(op)); + case 3: + return PickCase<Op, 3, EndIndex>::Run(absl::forward<Op>(op)); + case 4: + return PickCase<Op, 4, EndIndex>::Run(absl::forward<Op>(op)); + case 5: + return PickCase<Op, 5, EndIndex>::Run(absl::forward<Op>(op)); + case 6: + return PickCase<Op, 6, EndIndex>::Run(absl::forward<Op>(op)); + case 7: + return PickCase<Op, 7, EndIndex>::Run(absl::forward<Op>(op)); + case 8: + return PickCase<Op, 8, EndIndex>::Run(absl::forward<Op>(op)); + case 9: + return PickCase<Op, 9, EndIndex>::Run(absl::forward<Op>(op)); + case 10: + return PickCase<Op, 10, EndIndex>::Run(absl::forward<Op>(op)); + case 11: + return PickCase<Op, 11, EndIndex>::Run(absl::forward<Op>(op)); + case 12: + return PickCase<Op, 12, EndIndex>::Run(absl::forward<Op>(op)); + case 13: + return PickCase<Op, 13, EndIndex>::Run(absl::forward<Op>(op)); + case 14: + return PickCase<Op, 14, EndIndex>::Run(absl::forward<Op>(op)); + case 15: + return PickCase<Op, 15, EndIndex>::Run(absl::forward<Op>(op)); + case 16: + return PickCase<Op, 16, EndIndex>::Run(absl::forward<Op>(op)); + case 17: + return PickCase<Op, 17, EndIndex>::Run(absl::forward<Op>(op)); + case 18: + return PickCase<Op, 18, EndIndex>::Run(absl::forward<Op>(op)); + case 19: + return PickCase<Op, 19, EndIndex>::Run(absl::forward<Op>(op)); + case 20: + return PickCase<Op, 20, EndIndex>::Run(absl::forward<Op>(op)); + case 21: + return PickCase<Op, 21, EndIndex>::Run(absl::forward<Op>(op)); + case 22: + return PickCase<Op, 22, EndIndex>::Run(absl::forward<Op>(op)); + case 23: + return PickCase<Op, 23, EndIndex>::Run(absl::forward<Op>(op)); + case 24: + return PickCase<Op, 24, EndIndex>::Run(absl::forward<Op>(op)); + case 25: + return PickCase<Op, 25, EndIndex>::Run(absl::forward<Op>(op)); + case 26: + return PickCase<Op, 26, EndIndex>::Run(absl::forward<Op>(op)); + case 27: + return PickCase<Op, 27, EndIndex>::Run(absl::forward<Op>(op)); + case 28: + return PickCase<Op, 28, EndIndex>::Run(absl::forward<Op>(op)); + case 29: + return PickCase<Op, 29, EndIndex>::Run(absl::forward<Op>(op)); + case 30: + return PickCase<Op, 30, EndIndex>::Run(absl::forward<Op>(op)); + case 31: + return PickCase<Op, 31, EndIndex>::Run(absl::forward<Op>(op)); + case 32: + return PickCase<Op, 32, EndIndex>::Run(absl::forward<Op>(op)); + default: + ABSL_ASSERT(i == variant_npos); + return absl::base_internal::Invoke(absl::forward<Op>(op), NPos()); + } + } +}; + +template <std::size_t... EndIndices> +struct VisitIndicesFallback { + template <class Op, class... SizeT> + static VisitIndicesResultT<Op, SizeT...> Run(Op&& op, SizeT... indices) { + return AccessSimpleArray( + MakeVisitationMatrix<VisitIndicesResultT<Op, SizeT...>, Op, + index_sequence<(EndIndices + 1)...>, + index_sequence<>>::Run(), + (indices + 1)...)(absl::forward<Op>(op)); + } +}; + +// Take an N-dimensional series of indices and convert them into a single index +// without loss of information. The purpose of this is to be able to convert an +// N-ary visit operation into a single switch statement. +template <std::size_t...> +struct FlattenIndices; + +template <std::size_t HeadSize, std::size_t... TailSize> +struct FlattenIndices<HeadSize, TailSize...> { + template<class... SizeType> + static constexpr std::size_t Run(std::size_t head, SizeType... tail) { + return head + HeadSize * FlattenIndices<TailSize...>::Run(tail...); + } +}; + +template <> +struct FlattenIndices<> { + static constexpr std::size_t Run() { return 0; } +}; + +// Take a single "flattened" index (flattened by FlattenIndices) and determine +// the value of the index of one of the logically represented dimensions. +template <std::size_t I, std::size_t IndexToGet, std::size_t HeadSize, + std::size_t... TailSize> +struct UnflattenIndex { + static constexpr std::size_t value = + UnflattenIndex<I / HeadSize, IndexToGet - 1, TailSize...>::value; +}; + +template <std::size_t I, std::size_t HeadSize, std::size_t... TailSize> +struct UnflattenIndex<I, 0, HeadSize, TailSize...> { + static constexpr std::size_t value = (I % HeadSize); +}; + +// The backend for converting an N-ary visit operation into a unary visit. +template <class IndexSequence, std::size_t... EndIndices> +struct VisitIndicesVariadicImpl; + +template <std::size_t... N, std::size_t... EndIndices> +struct VisitIndicesVariadicImpl<absl::index_sequence<N...>, EndIndices...> { + // A type that can take an N-ary function object and converts it to a unary + // function object that takes a single, flattened index, and "unflattens" it + // into its individual dimensions when forwarding to the wrapped object. + template <class Op> + struct FlattenedOp { + template <std::size_t I> + VisitIndicesResultT<Op, decltype(EndIndices)...> operator()( + SizeT<I> /*index*/) && { + return base_internal::Invoke( + absl::forward<Op>(op), + SizeT<UnflattenIndex<I, N, (EndIndices + 1)...>::value - + std::size_t{1}>()...); + } + + Op&& op; + }; + + template <class Op, class... SizeType> + static VisitIndicesResultT<Op, decltype(EndIndices)...> Run( + Op&& op, SizeType... i) { + return VisitIndicesSwitch<NumCasesOfSwitch<EndIndices...>::value>::Run( + FlattenedOp<Op>{absl::forward<Op>(op)}, + FlattenIndices<(EndIndices + std::size_t{1})...>::Run( + (i + std::size_t{1})...)); + } +}; + +template <std::size_t... EndIndices> +struct VisitIndicesVariadic + : VisitIndicesVariadicImpl<absl::make_index_sequence<sizeof...(EndIndices)>, + EndIndices...> {}; + +// This implementation will flatten N-ary visit operations into a single switch +// statement when the number of cases would be less than our maximum specified +// switch-statement size. +// TODO(calabrese) +// Based on benchmarks, determine whether the function table approach actually +// does optimize better than a chain of switch statements and possibly update +// the implementation accordingly. Also consider increasing the maximum switch +// size. +template <std::size_t... EndIndices> +struct VisitIndices + : absl::conditional_t<(NumCasesOfSwitch<EndIndices...>::value <= + MaxUnrolledVisitCases), + VisitIndicesVariadic<EndIndices...>, + VisitIndicesFallback<EndIndices...>> {}; + +template <std::size_t EndIndex> +struct VisitIndices<EndIndex> + : absl::conditional_t<(EndIndex <= MaxUnrolledVisitCases), + VisitIndicesSwitch<EndIndex>, + VisitIndicesFallback<EndIndex>> {}; + +// Suppress bogus warning on MSVC: MSVC complains that the `reinterpret_cast` +// below is returning the address of a temporary or local object. +#ifdef _MSC_VER +#pragma warning(push) +#pragma warning(disable : 4172) +#endif // _MSC_VER + +// TODO(calabrese) std::launder +// TODO(calabrese) constexpr +// NOTE: DO NOT REMOVE the `inline` keyword as it is necessary to work around a +// MSVC bug. See https://github.com/abseil/abseil-cpp/issues/129 for details. +template <class Self, std::size_t I> +inline VariantAccessResult<I, Self> AccessUnion(Self&& self, SizeT<I> /*i*/) { + return reinterpret_cast<VariantAccessResult<I, Self>>(self); +} + +#ifdef _MSC_VER +#pragma warning(pop) +#endif // _MSC_VER + +template <class T> +void DeducedDestroy(T& self) { // NOLINT + self.~T(); +} + +// NOTE: This type exists as a single entity for variant and its bases to +// befriend. It contains helper functionality that manipulates the state of the +// variant, such as the implementation of things like assignment and emplace +// operations. +struct VariantCoreAccess { + template <class VariantType> + static typename VariantType::Variant& Derived(VariantType& self) { // NOLINT + return static_cast<typename VariantType::Variant&>(self); + } + + template <class VariantType> + static const typename VariantType::Variant& Derived( + const VariantType& self) { // NOLINT + return static_cast<const typename VariantType::Variant&>(self); + } + + template <class VariantType> + static void Destroy(VariantType& self) { // NOLINT + Derived(self).destroy(); + self.index_ = absl::variant_npos; + } + + template <class Variant> + static void SetIndex(Variant& self, std::size_t i) { // NOLINT + self.index_ = i; + } + + template <class Variant> + static void InitFrom(Variant& self, Variant&& other) { // NOLINT + VisitIndices<absl::variant_size<Variant>::value>::Run( + InitFromVisitor<Variant, Variant&&>{&self, + std::forward<Variant>(other)}, + other.index()); + self.index_ = other.index(); + } + + // Access a variant alternative, assuming the index is correct. + template <std::size_t I, class Variant> + static VariantAccessResult<I, Variant> Access(Variant&& self) { + // This cast instead of invocation of AccessUnion with an rvalue is a + // workaround for msvc. Without this there is a runtime failure when dealing + // with rvalues. + // TODO(calabrese) Reduce test case and find a simpler workaround. + return static_cast<VariantAccessResult<I, Variant>>( + variant_internal::AccessUnion(self.state_, SizeT<I>())); + } + + // Access a variant alternative, throwing if the index is incorrect. + template <std::size_t I, class Variant> + static VariantAccessResult<I, Variant> CheckedAccess(Variant&& self) { + if (ABSL_PREDICT_FALSE(self.index_ != I)) { + TypedThrowBadVariantAccess<VariantAccessResult<I, Variant>>(); + } + + return Access<I>(absl::forward<Variant>(self)); + } + + // The implementation of the move-assignment operation for a variant. + template <class VType> + struct MoveAssignVisitor { + using DerivedType = typename VType::Variant; + template <std::size_t NewIndex> + void operator()(SizeT<NewIndex> /*new_i*/) const { + if (left->index_ == NewIndex) { + Access<NewIndex>(*left) = std::move(Access<NewIndex>(*right)); + } else { + Derived(*left).template emplace<NewIndex>( + std::move(Access<NewIndex>(*right))); + } + } + + void operator()(SizeT<absl::variant_npos> /*new_i*/) const { + Destroy(*left); + } + + VType* left; + VType* right; + }; + + template <class VType> + static MoveAssignVisitor<VType> MakeMoveAssignVisitor(VType* left, + VType* other) { + return {left, other}; + } + + // The implementation of the assignment operation for a variant. + template <class VType> + struct CopyAssignVisitor { + using DerivedType = typename VType::Variant; + template <std::size_t NewIndex> + void operator()(SizeT<NewIndex> /*new_i*/) const { + using New = + typename absl::variant_alternative<NewIndex, DerivedType>::type; + + if (left->index_ == NewIndex) { + Access<NewIndex>(*left) = Access<NewIndex>(*right); + } else if (std::is_nothrow_copy_constructible<New>::value || + !std::is_nothrow_move_constructible<New>::value) { + Derived(*left).template emplace<NewIndex>(Access<NewIndex>(*right)); + } else { + Derived(*left) = DerivedType(Derived(*right)); + } + } + + void operator()(SizeT<absl::variant_npos> /*new_i*/) const { + Destroy(*left); + } + + VType* left; + const VType* right; + }; + + template <class VType> + static CopyAssignVisitor<VType> MakeCopyAssignVisitor(VType* left, + const VType& other) { + return {left, &other}; + } + + // The implementation of conversion-assignment operations for variant. + template <class Left, class QualifiedNew> + struct ConversionAssignVisitor { + using NewIndex = + variant_internal::IndexOfConstructedType<Left, QualifiedNew>; + + void operator()(SizeT<NewIndex::value> /*old_i*/ + ) const { + Access<NewIndex::value>(*left) = absl::forward<QualifiedNew>(other); + } + + template <std::size_t OldIndex> + void operator()(SizeT<OldIndex> /*old_i*/ + ) const { + using New = + typename absl::variant_alternative<NewIndex::value, Left>::type; + if (std::is_nothrow_constructible<New, QualifiedNew>::value || + !std::is_nothrow_move_constructible<New>::value) { + left->template emplace<NewIndex::value>( + absl::forward<QualifiedNew>(other)); + } else { + // the standard says "equivalent to + // operator=(variant(std::forward<T>(t)))", but we use `emplace` here + // because the variant's move assignment operator could be deleted. + left->template emplace<NewIndex::value>( + New(absl::forward<QualifiedNew>(other))); + } + } + + Left* left; + QualifiedNew&& other; + }; + + template <class Left, class QualifiedNew> + static ConversionAssignVisitor<Left, QualifiedNew> + MakeConversionAssignVisitor(Left* left, QualifiedNew&& qual) { + return {left, absl::forward<QualifiedNew>(qual)}; + } + + // Backend for operations for `emplace()` which destructs `*self` then + // construct a new alternative with `Args...`. + template <std::size_t NewIndex, class Self, class... Args> + static typename absl::variant_alternative<NewIndex, Self>::type& Replace( + Self* self, Args&&... args) { + Destroy(*self); + using New = typename absl::variant_alternative<NewIndex, Self>::type; + New* const result = ::new (static_cast<void*>(&self->state_)) + New(absl::forward<Args>(args)...); + self->index_ = NewIndex; + return *result; + } + + template <class LeftVariant, class QualifiedRightVariant> + struct InitFromVisitor { + template <std::size_t NewIndex> + void operator()(SizeT<NewIndex> /*new_i*/) const { + using Alternative = + typename variant_alternative<NewIndex, LeftVariant>::type; + ::new (static_cast<void*>(&left->state_)) Alternative( + Access<NewIndex>(std::forward<QualifiedRightVariant>(right))); + } + + void operator()(SizeT<absl::variant_npos> /*new_i*/) const { + // This space intentionally left blank. + } + LeftVariant* left; + QualifiedRightVariant&& right; + }; +}; + +template <class Expected, class... T> +struct IndexOfImpl; + +template <class Expected> +struct IndexOfImpl<Expected> { + using IndexFromEnd = SizeT<0>; + using MatchedIndexFromEnd = IndexFromEnd; + using MultipleMatches = std::false_type; +}; + +template <class Expected, class Head, class... Tail> +struct IndexOfImpl<Expected, Head, Tail...> : IndexOfImpl<Expected, Tail...> { + using IndexFromEnd = + SizeT<IndexOfImpl<Expected, Tail...>::IndexFromEnd::value + 1>; +}; + +template <class Expected, class... Tail> +struct IndexOfImpl<Expected, Expected, Tail...> + : IndexOfImpl<Expected, Tail...> { + using IndexFromEnd = + SizeT<IndexOfImpl<Expected, Tail...>::IndexFromEnd::value + 1>; + using MatchedIndexFromEnd = IndexFromEnd; + using MultipleMatches = std::integral_constant< + bool, IndexOfImpl<Expected, Tail...>::MatchedIndexFromEnd::value != 0>; +}; + +template <class Expected, class... Types> +struct IndexOfMeta { + using Results = IndexOfImpl<Expected, Types...>; + static_assert(!Results::MultipleMatches::value, + "Attempted to access a variant by specifying a type that " + "matches more than one alternative."); + static_assert(Results::MatchedIndexFromEnd::value != 0, + "Attempted to access a variant by specifying a type that does " + "not match any alternative."); + using type = SizeT<sizeof...(Types) - Results::MatchedIndexFromEnd::value>; +}; + +template <class Expected, class... Types> +using IndexOf = typename IndexOfMeta<Expected, Types...>::type; + +template <class Variant, class T, std::size_t CurrIndex> +struct UnambiguousIndexOfImpl; + +// Terminating case encountered once we've checked all of the alternatives +template <class T, std::size_t CurrIndex> +struct UnambiguousIndexOfImpl<variant<>, T, CurrIndex> : SizeT<CurrIndex> {}; + +// Case where T is not Head +template <class Head, class... Tail, class T, std::size_t CurrIndex> +struct UnambiguousIndexOfImpl<variant<Head, Tail...>, T, CurrIndex> + : UnambiguousIndexOfImpl<variant<Tail...>, T, CurrIndex + 1>::type {}; + +// Case where T is Head +template <class Head, class... Tail, std::size_t CurrIndex> +struct UnambiguousIndexOfImpl<variant<Head, Tail...>, Head, CurrIndex> + : SizeT<UnambiguousIndexOfImpl<variant<Tail...>, Head, 0>::value == + sizeof...(Tail) + ? CurrIndex + : CurrIndex + sizeof...(Tail) + 1> {}; + +template <class Variant, class T> +struct UnambiguousIndexOf; + +struct NoMatch { + struct type {}; +}; + +template <class... Alts, class T> +struct UnambiguousIndexOf<variant<Alts...>, T> + : std::conditional<UnambiguousIndexOfImpl<variant<Alts...>, T, 0>::value != + sizeof...(Alts), + UnambiguousIndexOfImpl<variant<Alts...>, T, 0>, + NoMatch>::type::type {}; + +template <class T, std::size_t /*Dummy*/> +using UnambiguousTypeOfImpl = T; + +template <class Variant, class T> +using UnambiguousTypeOfT = + UnambiguousTypeOfImpl<T, UnambiguousIndexOf<Variant, T>::value>; + +template <class H, class... T> +class VariantStateBase; + +// This is an implementation of the "imaginary function" that is described in +// [variant.ctor] +// It is used in order to determine which alternative to construct during +// initialization from some type T. +template <class Variant, std::size_t I = 0> +struct ImaginaryFun; + +template <std::size_t I> +struct ImaginaryFun<variant<>, I> { + static void Run() = delete; +}; + +template <class H, class... T, std::size_t I> +struct ImaginaryFun<variant<H, T...>, I> : ImaginaryFun<variant<T...>, I + 1> { + using ImaginaryFun<variant<T...>, I + 1>::Run; + + // NOTE: const& and && are used instead of by-value due to lack of guaranteed + // move elision of C++17. This may have other minor differences, but tests + // pass. + static SizeT<I> Run(const H&, SizeT<I>); + static SizeT<I> Run(H&&, SizeT<I>); +}; + +// The following metafunctions are used in constructor and assignment +// constraints. +template <class Self, class T> +struct IsNeitherSelfNorInPlace : std::true_type {}; + +template <class Self> +struct IsNeitherSelfNorInPlace<Self, Self> : std::false_type {}; + +template <class Self, class T> +struct IsNeitherSelfNorInPlace<Self, in_place_type_t<T>> : std::false_type {}; + +template <class Self, std::size_t I> +struct IsNeitherSelfNorInPlace<Self, in_place_index_t<I>> : std::false_type {}; + +template <class Variant, class T, class = void> +struct ConversionIsPossibleImpl : std::false_type {}; + +template <class Variant, class T> +struct ConversionIsPossibleImpl< + Variant, T, + void_t<decltype(ImaginaryFun<Variant>::Run(std::declval<T>(), {}))>> + : std::true_type {}; + +template <class Variant, class T> +struct ConversionIsPossible : ConversionIsPossibleImpl<Variant, T>::type {}; + +template <class Variant, class T> +struct IndexOfConstructedType< + Variant, T, + void_t<decltype(ImaginaryFun<Variant>::Run(std::declval<T>(), {}))>> + : decltype(ImaginaryFun<Variant>::Run(std::declval<T>(), {})) {}; + +template <std::size_t... Is> +struct ContainsVariantNPos + : absl::negation<std::is_same< // NOLINT + absl::integer_sequence<bool, 0 <= Is...>, + absl::integer_sequence<bool, Is != absl::variant_npos...>>> {}; + +template <class Op, class... QualifiedVariants> +using RawVisitResult = + absl::result_of_t<Op(VariantAccessResult<0, QualifiedVariants>...)>; + +// NOTE: The spec requires that all return-paths yield the same type and is not +// SFINAE-friendly, so we can deduce the return type by examining the first +// result. If it's not callable, then we get an error, but are compliant and +// fast to compile. +// TODO(calabrese) Possibly rewrite in a way that yields better compile errors +// at the cost of longer compile-times. +template <class Op, class... QualifiedVariants> +struct VisitResultImpl { + using type = + absl::result_of_t<Op(VariantAccessResult<0, QualifiedVariants>...)>; +}; + +// Done in two steps intentionally so that we don't cause substitution to fail. +template <class Op, class... QualifiedVariants> +using VisitResult = typename VisitResultImpl<Op, QualifiedVariants...>::type; + +template <class Op, class... QualifiedVariants> +struct PerformVisitation { + using ReturnType = VisitResult<Op, QualifiedVariants...>; + + template <std::size_t... Is> + constexpr ReturnType operator()(SizeT<Is>... indices) const { + return Run(typename ContainsVariantNPos<Is...>::type{}, + absl::index_sequence_for<QualifiedVariants...>(), indices...); + } + + template <std::size_t... TupIs, std::size_t... Is> + constexpr ReturnType Run(std::false_type /*has_valueless*/, + index_sequence<TupIs...>, SizeT<Is>...) const { + static_assert( + std::is_same<ReturnType, + absl::result_of_t<Op(VariantAccessResult< + Is, QualifiedVariants>...)>>::value, + "All visitation overloads must have the same return type."); + return absl::base_internal::Invoke( + absl::forward<Op>(op), + VariantCoreAccess::Access<Is>( + absl::forward<QualifiedVariants>(std::get<TupIs>(variant_tup)))...); + } + + template <std::size_t... TupIs, std::size_t... Is> + [[noreturn]] ReturnType Run(std::true_type /*has_valueless*/, + index_sequence<TupIs...>, SizeT<Is>...) const { + absl::variant_internal::ThrowBadVariantAccess(); + } + + // TODO(calabrese) Avoid using a tuple, which causes lots of instantiations + // Attempts using lambda variadic captures fail on current GCC. + std::tuple<QualifiedVariants&&...> variant_tup; + Op&& op; +}; + +template <class... T> +union Union; + +// We want to allow for variant<> to be trivial. For that, we need the default +// constructor to be trivial, which means we can't define it ourselves. +// Instead, we use a non-default constructor that takes NoopConstructorTag +// that doesn't affect the triviality of the types. +struct NoopConstructorTag {}; + +template <std::size_t I> +struct EmplaceTag {}; + +template <> +union Union<> { + constexpr explicit Union(NoopConstructorTag) noexcept {} +}; + +// Suppress bogus warning on MSVC: MSVC complains that Union<T...> has a defined +// deleted destructor from the `std::is_destructible` check below. +#ifdef _MSC_VER +#pragma warning(push) +#pragma warning(disable : 4624) +#endif // _MSC_VER + +template <class Head, class... Tail> +union Union<Head, Tail...> { + using TailUnion = Union<Tail...>; + + explicit constexpr Union(NoopConstructorTag /*tag*/) noexcept + : tail(NoopConstructorTag()) {} + + template <class... P> + explicit constexpr Union(EmplaceTag<0>, P&&... args) + : head(absl::forward<P>(args)...) {} + + template <std::size_t I, class... P> + explicit constexpr Union(EmplaceTag<I>, P&&... args) + : tail(EmplaceTag<I - 1>{}, absl::forward<P>(args)...) {} + + Head head; + TailUnion tail; +}; + +#ifdef _MSC_VER +#pragma warning(pop) +#endif // _MSC_VER + +// TODO(calabrese) Just contain a Union in this union (certain configs fail). +template <class... T> +union DestructibleUnionImpl; + +template <> +union DestructibleUnionImpl<> { + constexpr explicit DestructibleUnionImpl(NoopConstructorTag) noexcept {} +}; + +template <class Head, class... Tail> +union DestructibleUnionImpl<Head, Tail...> { + using TailUnion = DestructibleUnionImpl<Tail...>; + + explicit constexpr DestructibleUnionImpl(NoopConstructorTag /*tag*/) noexcept + : tail(NoopConstructorTag()) {} + + template <class... P> + explicit constexpr DestructibleUnionImpl(EmplaceTag<0>, P&&... args) + : head(absl::forward<P>(args)...) {} + + template <std::size_t I, class... P> + explicit constexpr DestructibleUnionImpl(EmplaceTag<I>, P&&... args) + : tail(EmplaceTag<I - 1>{}, absl::forward<P>(args)...) {} + + ~DestructibleUnionImpl() {} + + Head head; + TailUnion tail; +}; + +// This union type is destructible even if one or more T are not trivially +// destructible. In the case that all T are trivially destructible, then so is +// this resultant type. +template <class... T> +using DestructibleUnion = + absl::conditional_t<std::is_destructible<Union<T...>>::value, Union<T...>, + DestructibleUnionImpl<T...>>; + +// Deepest base, containing the actual union and the discriminator +template <class H, class... T> +class VariantStateBase { + protected: + using Variant = variant<H, T...>; + + template <class LazyH = H, + class ConstructibleH = absl::enable_if_t< + std::is_default_constructible<LazyH>::value, LazyH>> + constexpr VariantStateBase() noexcept( + std::is_nothrow_default_constructible<ConstructibleH>::value) + : state_(EmplaceTag<0>()), index_(0) {} + + template <std::size_t I, class... P> + explicit constexpr VariantStateBase(EmplaceTag<I> tag, P&&... args) + : state_(tag, absl::forward<P>(args)...), index_(I) {} + + explicit constexpr VariantStateBase(NoopConstructorTag) + : state_(NoopConstructorTag()), index_(variant_npos) {} + + void destroy() {} // Does nothing (shadowed in child if non-trivial) + + DestructibleUnion<H, T...> state_; + std::size_t index_; +}; + +using absl::internal::identity; + +// OverloadSet::Overload() is a unary function which is overloaded to +// take any of the element types of the variant, by reference-to-const. +// The return type of the overload on T is identity<T>, so that you +// can statically determine which overload was called. +// +// Overload() is not defined, so it can only be called in unevaluated +// contexts. +template <typename... Ts> +struct OverloadSet; + +template <typename T, typename... Ts> +struct OverloadSet<T, Ts...> : OverloadSet<Ts...> { + using Base = OverloadSet<Ts...>; + static identity<T> Overload(const T&); + using Base::Overload; +}; + +template <> +struct OverloadSet<> { + // For any case not handled above. + static void Overload(...); +}; + +template <class T> +using LessThanResult = decltype(std::declval<T>() < std::declval<T>()); + +template <class T> +using GreaterThanResult = decltype(std::declval<T>() > std::declval<T>()); + +template <class T> +using LessThanOrEqualResult = decltype(std::declval<T>() <= std::declval<T>()); + +template <class T> +using GreaterThanOrEqualResult = + decltype(std::declval<T>() >= std::declval<T>()); + +template <class T> +using EqualResult = decltype(std::declval<T>() == std::declval<T>()); + +template <class T> +using NotEqualResult = decltype(std::declval<T>() != std::declval<T>()); + +using type_traits_internal::is_detected_convertible; + +template <class... T> +using RequireAllHaveEqualT = absl::enable_if_t< + absl::conjunction<is_detected_convertible<bool, EqualResult, T>...>::value, + bool>; + +template <class... T> +using RequireAllHaveNotEqualT = + absl::enable_if_t<absl::conjunction<is_detected_convertible< + bool, NotEqualResult, T>...>::value, + bool>; + +template <class... T> +using RequireAllHaveLessThanT = + absl::enable_if_t<absl::conjunction<is_detected_convertible< + bool, LessThanResult, T>...>::value, + bool>; + +template <class... T> +using RequireAllHaveLessThanOrEqualT = + absl::enable_if_t<absl::conjunction<is_detected_convertible< + bool, LessThanOrEqualResult, T>...>::value, + bool>; + +template <class... T> +using RequireAllHaveGreaterThanOrEqualT = + absl::enable_if_t<absl::conjunction<is_detected_convertible< + bool, GreaterThanOrEqualResult, T>...>::value, + bool>; + +template <class... T> +using RequireAllHaveGreaterThanT = + absl::enable_if_t<absl::conjunction<is_detected_convertible< + bool, GreaterThanResult, T>...>::value, + bool>; + +// Helper template containing implementations details of variant that can't go +// in the private section. For convenience, this takes the variant type as a +// single template parameter. +template <typename T> +struct VariantHelper; + +template <typename... Ts> +struct VariantHelper<variant<Ts...>> { + // Type metafunction which returns the element type selected if + // OverloadSet::Overload() is well-formed when called with argument type U. + template <typename U> + using BestMatch = decltype( + variant_internal::OverloadSet<Ts...>::Overload(std::declval<U>())); + + // Type metafunction which returns true if OverloadSet::Overload() is + // well-formed when called with argument type U. + // CanAccept can't be just an alias because there is a MSVC bug on parameter + // pack expansion involving decltype. + template <typename U> + struct CanAccept : + std::integral_constant<bool, !std::is_void<BestMatch<U>>::value> {}; + + // Type metafunction which returns true if Other is an instantiation of + // variant, and variants's converting constructor from Other will be + // well-formed. We will use this to remove constructors that would be + // ill-formed from the overload set. + template <typename Other> + struct CanConvertFrom; + + template <typename... Us> + struct CanConvertFrom<variant<Us...>> + : public absl::conjunction<CanAccept<Us>...> {}; +}; + +// A type with nontrivial copy ctor and trivial move ctor. +struct TrivialMoveOnly { + TrivialMoveOnly(TrivialMoveOnly&&) = default; +}; + +// Trait class to detect whether a type is trivially move constructible. +// A union's defaulted copy/move constructor is deleted if any variant member's +// copy/move constructor is nontrivial. +template <typename T> +struct IsTriviallyMoveConstructible: + std::is_move_constructible<Union<T, TrivialMoveOnly>> {}; + +// To guarantee triviality of all special-member functions that can be trivial, +// we use a chain of conditional bases for each one. +// The order of inheritance of bases from child to base are logically: +// +// variant +// VariantCopyAssignBase +// VariantMoveAssignBase +// VariantCopyBase +// VariantMoveBase +// VariantStateBaseDestructor +// VariantStateBase +// +// Note that there is a separate branch at each base that is dependent on +// whether or not that corresponding special-member-function can be trivial in +// the resultant variant type. + +template <class... T> +class VariantStateBaseDestructorNontrivial; + +template <class... T> +class VariantMoveBaseNontrivial; + +template <class... T> +class VariantCopyBaseNontrivial; + +template <class... T> +class VariantMoveAssignBaseNontrivial; + +template <class... T> +class VariantCopyAssignBaseNontrivial; + +// Base that is dependent on whether or not the destructor can be trivial. +template <class... T> +using VariantStateBaseDestructor = + absl::conditional_t<std::is_destructible<Union<T...>>::value, + VariantStateBase<T...>, + VariantStateBaseDestructorNontrivial<T...>>; + +// Base that is dependent on whether or not the move-constructor can be +// implicitly generated by the compiler (trivial or deleted). +// Previously we were using `std::is_move_constructible<Union<T...>>` to check +// whether all Ts have trivial move constructor, but it ran into a GCC bug: +// https://gcc.gnu.org/bugzilla/show_bug.cgi?id=84866 +// So we have to use a different approach (i.e. `HasTrivialMoveConstructor`) to +// work around the bug. +template <class... T> +using VariantMoveBase = absl::conditional_t< + absl::disjunction< + absl::negation<absl::conjunction<std::is_move_constructible<T>...>>, + absl::conjunction<IsTriviallyMoveConstructible<T>...>>::value, + VariantStateBaseDestructor<T...>, VariantMoveBaseNontrivial<T...>>; + +// Base that is dependent on whether or not the copy-constructor can be trivial. +template <class... T> +using VariantCopyBase = absl::conditional_t< + absl::disjunction< + absl::negation<absl::conjunction<std::is_copy_constructible<T>...>>, + std::is_copy_constructible<Union<T...>>>::value, + VariantMoveBase<T...>, VariantCopyBaseNontrivial<T...>>; + +// Base that is dependent on whether or not the move-assign can be trivial. +template <class... T> +using VariantMoveAssignBase = absl::conditional_t< + absl::disjunction< + absl::conjunction<absl::is_move_assignable<Union<T...>>, + std::is_move_constructible<Union<T...>>, + std::is_destructible<Union<T...>>>, + absl::negation<absl::conjunction<std::is_move_constructible<T>..., + // Note: We're not qualifying this with + // absl:: because it doesn't compile + // under MSVC. + is_move_assignable<T>...>>>::value, + VariantCopyBase<T...>, VariantMoveAssignBaseNontrivial<T...>>; + +// Base that is dependent on whether or not the copy-assign can be trivial. +template <class... T> +using VariantCopyAssignBase = absl::conditional_t< + absl::disjunction< + absl::conjunction<absl::is_copy_assignable<Union<T...>>, + std::is_copy_constructible<Union<T...>>, + std::is_destructible<Union<T...>>>, + absl::negation<absl::conjunction<std::is_copy_constructible<T>..., + // Note: We're not qualifying this with + // absl:: because it doesn't compile + // under MSVC. + is_copy_assignable<T>...>>>::value, + VariantMoveAssignBase<T...>, VariantCopyAssignBaseNontrivial<T...>>; + +template <class... T> +using VariantBase = VariantCopyAssignBase<T...>; + +template <class... T> +class VariantStateBaseDestructorNontrivial : protected VariantStateBase<T...> { + private: + using Base = VariantStateBase<T...>; + + protected: + using Base::Base; + + VariantStateBaseDestructorNontrivial() = default; + VariantStateBaseDestructorNontrivial(VariantStateBaseDestructorNontrivial&&) = + default; + VariantStateBaseDestructorNontrivial( + const VariantStateBaseDestructorNontrivial&) = default; + VariantStateBaseDestructorNontrivial& operator=( + VariantStateBaseDestructorNontrivial&&) = default; + VariantStateBaseDestructorNontrivial& operator=( + const VariantStateBaseDestructorNontrivial&) = default; + + struct Destroyer { + template <std::size_t I> + void operator()(SizeT<I> i) const { + using Alternative = + typename absl::variant_alternative<I, variant<T...>>::type; + variant_internal::AccessUnion(self->state_, i).~Alternative(); + } + + void operator()(SizeT<absl::variant_npos> /*i*/) const { + // This space intentionally left blank + } + + VariantStateBaseDestructorNontrivial* self; + }; + + void destroy() { VisitIndices<sizeof...(T)>::Run(Destroyer{this}, index_); } + + ~VariantStateBaseDestructorNontrivial() { destroy(); } + + protected: + using Base::index_; + using Base::state_; +}; + +template <class... T> +class VariantMoveBaseNontrivial : protected VariantStateBaseDestructor<T...> { + private: + using Base = VariantStateBaseDestructor<T...>; + + protected: + using Base::Base; + + struct Construct { + template <std::size_t I> + void operator()(SizeT<I> i) const { + using Alternative = + typename absl::variant_alternative<I, variant<T...>>::type; + ::new (static_cast<void*>(&self->state_)) Alternative( + variant_internal::AccessUnion(absl::move(other->state_), i)); + } + + void operator()(SizeT<absl::variant_npos> /*i*/) const {} + + VariantMoveBaseNontrivial* self; + VariantMoveBaseNontrivial* other; + }; + + VariantMoveBaseNontrivial() = default; + VariantMoveBaseNontrivial(VariantMoveBaseNontrivial&& other) noexcept( + absl::conjunction<std::is_nothrow_move_constructible<T>...>::value) + : Base(NoopConstructorTag()) { + VisitIndices<sizeof...(T)>::Run(Construct{this, &other}, other.index_); + index_ = other.index_; + } + + VariantMoveBaseNontrivial(VariantMoveBaseNontrivial const&) = default; + + VariantMoveBaseNontrivial& operator=(VariantMoveBaseNontrivial&&) = default; + VariantMoveBaseNontrivial& operator=(VariantMoveBaseNontrivial const&) = + default; + + protected: + using Base::index_; + using Base::state_; +}; + +template <class... T> +class VariantCopyBaseNontrivial : protected VariantMoveBase<T...> { + private: + using Base = VariantMoveBase<T...>; + + protected: + using Base::Base; + + VariantCopyBaseNontrivial() = default; + VariantCopyBaseNontrivial(VariantCopyBaseNontrivial&&) = default; + + struct Construct { + template <std::size_t I> + void operator()(SizeT<I> i) const { + using Alternative = + typename absl::variant_alternative<I, variant<T...>>::type; + ::new (static_cast<void*>(&self->state_)) + Alternative(variant_internal::AccessUnion(other->state_, i)); + } + + void operator()(SizeT<absl::variant_npos> /*i*/) const {} + + VariantCopyBaseNontrivial* self; + const VariantCopyBaseNontrivial* other; + }; + + VariantCopyBaseNontrivial(VariantCopyBaseNontrivial const& other) + : Base(NoopConstructorTag()) { + VisitIndices<sizeof...(T)>::Run(Construct{this, &other}, other.index_); + index_ = other.index_; + } + + VariantCopyBaseNontrivial& operator=(VariantCopyBaseNontrivial&&) = default; + VariantCopyBaseNontrivial& operator=(VariantCopyBaseNontrivial const&) = + default; + + protected: + using Base::index_; + using Base::state_; +}; + +template <class... T> +class VariantMoveAssignBaseNontrivial : protected VariantCopyBase<T...> { + friend struct VariantCoreAccess; + + private: + using Base = VariantCopyBase<T...>; + + protected: + using Base::Base; + + VariantMoveAssignBaseNontrivial() = default; + VariantMoveAssignBaseNontrivial(VariantMoveAssignBaseNontrivial&&) = default; + VariantMoveAssignBaseNontrivial(const VariantMoveAssignBaseNontrivial&) = + default; + VariantMoveAssignBaseNontrivial& operator=( + VariantMoveAssignBaseNontrivial const&) = default; + + VariantMoveAssignBaseNontrivial& + operator=(VariantMoveAssignBaseNontrivial&& other) noexcept( + absl::conjunction<std::is_nothrow_move_constructible<T>..., + std::is_nothrow_move_assignable<T>...>::value) { + VisitIndices<sizeof...(T)>::Run( + VariantCoreAccess::MakeMoveAssignVisitor(this, &other), other.index_); + return *this; + } + + protected: + using Base::index_; + using Base::state_; +}; + +template <class... T> +class VariantCopyAssignBaseNontrivial : protected VariantMoveAssignBase<T...> { + friend struct VariantCoreAccess; + + private: + using Base = VariantMoveAssignBase<T...>; + + protected: + using Base::Base; + + VariantCopyAssignBaseNontrivial() = default; + VariantCopyAssignBaseNontrivial(VariantCopyAssignBaseNontrivial&&) = default; + VariantCopyAssignBaseNontrivial(const VariantCopyAssignBaseNontrivial&) = + default; + VariantCopyAssignBaseNontrivial& operator=( + VariantCopyAssignBaseNontrivial&&) = default; + + VariantCopyAssignBaseNontrivial& operator=( + const VariantCopyAssignBaseNontrivial& other) { + VisitIndices<sizeof...(T)>::Run( + VariantCoreAccess::MakeCopyAssignVisitor(this, other), other.index_); + return *this; + } + + protected: + using Base::index_; + using Base::state_; +}; + +//////////////////////////////////////// +// Visitors for Comparison Operations // +//////////////////////////////////////// + +template <class... Types> +struct EqualsOp { + const variant<Types...>* v; + const variant<Types...>* w; + + constexpr bool operator()(SizeT<absl::variant_npos> /*v_i*/) const { + return true; + } + + template <std::size_t I> + constexpr bool operator()(SizeT<I> /*v_i*/) const { + return VariantCoreAccess::Access<I>(*v) == VariantCoreAccess::Access<I>(*w); + } +}; + +template <class... Types> +struct NotEqualsOp { + const variant<Types...>* v; + const variant<Types...>* w; + + constexpr bool operator()(SizeT<absl::variant_npos> /*v_i*/) const { + return false; + } + + template <std::size_t I> + constexpr bool operator()(SizeT<I> /*v_i*/) const { + return VariantCoreAccess::Access<I>(*v) != VariantCoreAccess::Access<I>(*w); + } +}; + +template <class... Types> +struct LessThanOp { + const variant<Types...>* v; + const variant<Types...>* w; + + constexpr bool operator()(SizeT<absl::variant_npos> /*v_i*/) const { + return false; + } + + template <std::size_t I> + constexpr bool operator()(SizeT<I> /*v_i*/) const { + return VariantCoreAccess::Access<I>(*v) < VariantCoreAccess::Access<I>(*w); + } +}; + +template <class... Types> +struct GreaterThanOp { + const variant<Types...>* v; + const variant<Types...>* w; + + constexpr bool operator()(SizeT<absl::variant_npos> /*v_i*/) const { + return false; + } + + template <std::size_t I> + constexpr bool operator()(SizeT<I> /*v_i*/) const { + return VariantCoreAccess::Access<I>(*v) > VariantCoreAccess::Access<I>(*w); + } +}; + +template <class... Types> +struct LessThanOrEqualsOp { + const variant<Types...>* v; + const variant<Types...>* w; + + constexpr bool operator()(SizeT<absl::variant_npos> /*v_i*/) const { + return true; + } + + template <std::size_t I> + constexpr bool operator()(SizeT<I> /*v_i*/) const { + return VariantCoreAccess::Access<I>(*v) <= VariantCoreAccess::Access<I>(*w); + } +}; + +template <class... Types> +struct GreaterThanOrEqualsOp { + const variant<Types...>* v; + const variant<Types...>* w; + + constexpr bool operator()(SizeT<absl::variant_npos> /*v_i*/) const { + return true; + } + + template <std::size_t I> + constexpr bool operator()(SizeT<I> /*v_i*/) const { + return VariantCoreAccess::Access<I>(*v) >= VariantCoreAccess::Access<I>(*w); + } +}; + +// Precondition: v.index() == w.index(); +template <class... Types> +struct SwapSameIndex { + variant<Types...>* v; + variant<Types...>* w; + template <std::size_t I> + void operator()(SizeT<I>) const { + type_traits_internal::Swap(VariantCoreAccess::Access<I>(*v), + VariantCoreAccess::Access<I>(*w)); + } + + void operator()(SizeT<variant_npos>) const {} +}; + +// TODO(calabrese) do this from a different namespace for proper adl usage +template <class... Types> +struct Swap { + variant<Types...>* v; + variant<Types...>* w; + + void generic_swap() const { + variant<Types...> tmp(std::move(*w)); + VariantCoreAccess::Destroy(*w); + VariantCoreAccess::InitFrom(*w, std::move(*v)); + VariantCoreAccess::Destroy(*v); + VariantCoreAccess::InitFrom(*v, std::move(tmp)); + } + + void operator()(SizeT<absl::variant_npos> /*w_i*/) const { + if (!v->valueless_by_exception()) { + generic_swap(); + } + } + + template <std::size_t Wi> + void operator()(SizeT<Wi> /*w_i*/) { + if (v->index() == Wi) { + VisitIndices<sizeof...(Types)>::Run(SwapSameIndex<Types...>{v, w}, Wi); + } else { + generic_swap(); + } + } +}; + +template <typename Variant, typename = void, typename... Ts> +struct VariantHashBase { + VariantHashBase() = delete; + VariantHashBase(const VariantHashBase&) = delete; + VariantHashBase(VariantHashBase&&) = delete; + VariantHashBase& operator=(const VariantHashBase&) = delete; + VariantHashBase& operator=(VariantHashBase&&) = delete; +}; + +struct VariantHashVisitor { + template <typename T> + size_t operator()(const T& t) { + return std::hash<T>{}(t); + } +}; + +template <typename Variant, typename... Ts> +struct VariantHashBase<Variant, + absl::enable_if_t<absl::conjunction< + type_traits_internal::IsHashable<Ts>...>::value>, + Ts...> { + using argument_type = Variant; + using result_type = size_t; + size_t operator()(const Variant& var) const { + type_traits_internal::AssertHashEnabled<Ts...>(); + if (var.valueless_by_exception()) { + return 239799884; + } + size_t result = VisitIndices<variant_size<Variant>::value>::Run( + PerformVisitation<VariantHashVisitor, const Variant&>{ + std::forward_as_tuple(var), VariantHashVisitor{}}, + var.index()); + // Combine the index and the hash result in order to distinguish + // std::variant<int, int> holding the same value as different alternative. + return result ^ var.index(); + } +}; + +} // namespace variant_internal +ABSL_NAMESPACE_END +} // namespace absl + +#endif // !defined(ABSL_USES_STD_VARIANT) +#endif // ABSL_TYPES_variant_internal_H_ diff --git a/third_party/abseil_cpp/absl/types/optional.h b/third_party/abseil_cpp/absl/types/optional.h new file mode 100644 index 0000000000..61540cfdb2 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/optional.h @@ -0,0 +1,776 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// optional.h +// ----------------------------------------------------------------------------- +// +// This header file defines the `absl::optional` type for holding a value which +// may or may not be present. This type is useful for providing value semantics +// for operations that may either wish to return or hold "something-or-nothing". +// +// Example: +// +// // A common way to signal operation failure is to provide an output +// // parameter and a bool return type: +// bool AcquireResource(const Input&, Resource * out); +// +// // Providing an absl::optional return type provides a cleaner API: +// absl::optional<Resource> AcquireResource(const Input&); +// +// `absl::optional` is a C++11 compatible version of the C++17 `std::optional` +// abstraction and is designed to be a drop-in replacement for code compliant +// with C++17. +#ifndef ABSL_TYPES_OPTIONAL_H_ +#define ABSL_TYPES_OPTIONAL_H_ + +#include "absl/base/config.h" // TODO(calabrese) IWYU removal? +#include "absl/utility/utility.h" + +#ifdef ABSL_USES_STD_OPTIONAL + +#include <optional> // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN +using std::bad_optional_access; +using std::optional; +using std::make_optional; +using std::nullopt_t; +using std::nullopt; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_OPTIONAL + +#include <cassert> +#include <functional> +#include <initializer_list> +#include <type_traits> +#include <utility> + +#include "absl/base/attributes.h" +#include "absl/base/internal/inline_variable.h" +#include "absl/meta/type_traits.h" +#include "absl/types/bad_optional_access.h" +#include "absl/types/internal/optional.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// nullopt_t +// +// Class type for `absl::nullopt` used to indicate an `absl::optional<T>` type +// that does not contain a value. +struct nullopt_t { + // It must not be default-constructible to avoid ambiguity for opt = {}. + explicit constexpr nullopt_t(optional_internal::init_t) noexcept {} +}; + +// nullopt +// +// A tag constant of type `absl::nullopt_t` used to indicate an empty +// `absl::optional` in certain functions, such as construction or assignment. +ABSL_INTERNAL_INLINE_CONSTEXPR(nullopt_t, nullopt, + nullopt_t(optional_internal::init_t())); + +// ----------------------------------------------------------------------------- +// absl::optional +// ----------------------------------------------------------------------------- +// +// A value of type `absl::optional<T>` holds either a value of `T` or an +// "empty" value. When it holds a value of `T`, it stores it as a direct +// sub-object, so `sizeof(optional<T>)` is approximately +// `sizeof(T) + sizeof(bool)`. +// +// This implementation is based on the specification in the latest draft of the +// C++17 `std::optional` specification as of May 2017, section 20.6. +// +// Differences between `absl::optional<T>` and `std::optional<T>` include: +// +// * `constexpr` is not used for non-const member functions. +// (dependency on some differences between C++11 and C++14.) +// * `absl::nullopt` and `absl::in_place` are not declared `constexpr`. We +// need the inline variable support in C++17 for external linkage. +// * Throws `absl::bad_optional_access` instead of +// `std::bad_optional_access`. +// * `make_optional()` cannot be declared `constexpr` due to the absence of +// guaranteed copy elision. +// * The move constructor's `noexcept` specification is stronger, i.e. if the +// default allocator is non-throwing (via setting +// `ABSL_ALLOCATOR_NOTHROW`), it evaluates to `noexcept(true)`, because +// we assume +// a) move constructors should only throw due to allocation failure and +// b) if T's move constructor allocates, it uses the same allocation +// function as the default allocator. +// +template <typename T> +class optional : private optional_internal::optional_data<T>, + private optional_internal::optional_ctor_base< + optional_internal::ctor_copy_traits<T>::traits>, + private optional_internal::optional_assign_base< + optional_internal::assign_copy_traits<T>::traits> { + using data_base = optional_internal::optional_data<T>; + + public: + typedef T value_type; + + // Constructors + + // Constructs an `optional` holding an empty value, NOT a default constructed + // `T`. + constexpr optional() noexcept {} + + // Constructs an `optional` initialized with `nullopt` to hold an empty value. + constexpr optional(nullopt_t) noexcept {} // NOLINT(runtime/explicit) + + // Copy constructor, standard semantics + optional(const optional&) = default; + + // Move constructor, standard semantics + optional(optional&&) = default; + + // Constructs a non-empty `optional` direct-initialized value of type `T` from + // the arguments `std::forward<Args>(args)...` within the `optional`. + // (The `in_place_t` is a tag used to indicate that the contained object + // should be constructed in-place.) + template <typename InPlaceT, typename... Args, + absl::enable_if_t<absl::conjunction< + std::is_same<InPlaceT, in_place_t>, + std::is_constructible<T, Args&&...> >::value>* = nullptr> + constexpr explicit optional(InPlaceT, Args&&... args) + : data_base(in_place_t(), absl::forward<Args>(args)...) {} + + // Constructs a non-empty `optional` direct-initialized value of type `T` from + // the arguments of an initializer_list and `std::forward<Args>(args)...`. + // (The `in_place_t` is a tag used to indicate that the contained object + // should be constructed in-place.) + template <typename U, typename... Args, + typename = typename std::enable_if<std::is_constructible< + T, std::initializer_list<U>&, Args&&...>::value>::type> + constexpr explicit optional(in_place_t, std::initializer_list<U> il, + Args&&... args) + : data_base(in_place_t(), il, absl::forward<Args>(args)...) { + } + + // Value constructor (implicit) + template < + typename U = T, + typename std::enable_if< + absl::conjunction<absl::negation<std::is_same< + in_place_t, typename std::decay<U>::type> >, + absl::negation<std::is_same< + optional<T>, typename std::decay<U>::type> >, + std::is_convertible<U&&, T>, + std::is_constructible<T, U&&> >::value, + bool>::type = false> + constexpr optional(U&& v) : data_base(in_place_t(), absl::forward<U>(v)) {} + + // Value constructor (explicit) + template < + typename U = T, + typename std::enable_if< + absl::conjunction<absl::negation<std::is_same< + in_place_t, typename std::decay<U>::type>>, + absl::negation<std::is_same< + optional<T>, typename std::decay<U>::type>>, + absl::negation<std::is_convertible<U&&, T>>, + std::is_constructible<T, U&&>>::value, + bool>::type = false> + explicit constexpr optional(U&& v) + : data_base(in_place_t(), absl::forward<U>(v)) {} + + // Converting copy constructor (implicit) + template <typename U, + typename std::enable_if< + absl::conjunction< + absl::negation<std::is_same<T, U> >, + std::is_constructible<T, const U&>, + absl::negation< + optional_internal:: + is_constructible_convertible_from_optional<T, U> >, + std::is_convertible<const U&, T> >::value, + bool>::type = false> + optional(const optional<U>& rhs) { + if (rhs) { + this->construct(*rhs); + } + } + + // Converting copy constructor (explicit) + template <typename U, + typename std::enable_if< + absl::conjunction< + absl::negation<std::is_same<T, U>>, + std::is_constructible<T, const U&>, + absl::negation< + optional_internal:: + is_constructible_convertible_from_optional<T, U>>, + absl::negation<std::is_convertible<const U&, T>>>::value, + bool>::type = false> + explicit optional(const optional<U>& rhs) { + if (rhs) { + this->construct(*rhs); + } + } + + // Converting move constructor (implicit) + template <typename U, + typename std::enable_if< + absl::conjunction< + absl::negation<std::is_same<T, U> >, + std::is_constructible<T, U&&>, + absl::negation< + optional_internal:: + is_constructible_convertible_from_optional<T, U> >, + std::is_convertible<U&&, T> >::value, + bool>::type = false> + optional(optional<U>&& rhs) { + if (rhs) { + this->construct(std::move(*rhs)); + } + } + + // Converting move constructor (explicit) + template < + typename U, + typename std::enable_if< + absl::conjunction< + absl::negation<std::is_same<T, U>>, std::is_constructible<T, U&&>, + absl::negation< + optional_internal::is_constructible_convertible_from_optional< + T, U>>, + absl::negation<std::is_convertible<U&&, T>>>::value, + bool>::type = false> + explicit optional(optional<U>&& rhs) { + if (rhs) { + this->construct(std::move(*rhs)); + } + } + + // Destructor. Trivial if `T` is trivially destructible. + ~optional() = default; + + // Assignment Operators + + // Assignment from `nullopt` + // + // Example: + // + // struct S { int value; }; + // optional<S> opt = absl::nullopt; // Could also use opt = { }; + optional& operator=(nullopt_t) noexcept { + this->destruct(); + return *this; + } + + // Copy assignment operator, standard semantics + optional& operator=(const optional& src) = default; + + // Move assignment operator, standard semantics + optional& operator=(optional&& src) = default; + + // Value assignment operators + template < + typename U = T, + typename = typename std::enable_if<absl::conjunction< + absl::negation< + std::is_same<optional<T>, typename std::decay<U>::type>>, + absl::negation< + absl::conjunction<std::is_scalar<T>, + std::is_same<T, typename std::decay<U>::type>>>, + std::is_constructible<T, U>, std::is_assignable<T&, U>>::value>::type> + optional& operator=(U&& v) { + this->assign(std::forward<U>(v)); + return *this; + } + + template < + typename U, + typename = typename std::enable_if<absl::conjunction< + absl::negation<std::is_same<T, U>>, + std::is_constructible<T, const U&>, std::is_assignable<T&, const U&>, + absl::negation< + optional_internal:: + is_constructible_convertible_assignable_from_optional< + T, U>>>::value>::type> + optional& operator=(const optional<U>& rhs) { + if (rhs) { + this->assign(*rhs); + } else { + this->destruct(); + } + return *this; + } + + template <typename U, + typename = typename std::enable_if<absl::conjunction< + absl::negation<std::is_same<T, U>>, std::is_constructible<T, U>, + std::is_assignable<T&, U>, + absl::negation< + optional_internal:: + is_constructible_convertible_assignable_from_optional< + T, U>>>::value>::type> + optional& operator=(optional<U>&& rhs) { + if (rhs) { + this->assign(std::move(*rhs)); + } else { + this->destruct(); + } + return *this; + } + + // Modifiers + + // optional::reset() + // + // Destroys the inner `T` value of an `absl::optional` if one is present. + ABSL_ATTRIBUTE_REINITIALIZES void reset() noexcept { this->destruct(); } + + // optional::emplace() + // + // (Re)constructs the underlying `T` in-place with the given forwarded + // arguments. + // + // Example: + // + // optional<Foo> opt; + // opt.emplace(arg1,arg2,arg3); // Constructs Foo(arg1,arg2,arg3) + // + // If the optional is non-empty, and the `args` refer to subobjects of the + // current object, then behaviour is undefined, because the current object + // will be destructed before the new object is constructed with `args`. + template <typename... Args, + typename = typename std::enable_if< + std::is_constructible<T, Args&&...>::value>::type> + T& emplace(Args&&... args) { + this->destruct(); + this->construct(std::forward<Args>(args)...); + return reference(); + } + + // Emplace reconstruction overload for an initializer list and the given + // forwarded arguments. + // + // Example: + // + // struct Foo { + // Foo(std::initializer_list<int>); + // }; + // + // optional<Foo> opt; + // opt.emplace({1,2,3}); // Constructs Foo({1,2,3}) + template <typename U, typename... Args, + typename = typename std::enable_if<std::is_constructible< + T, std::initializer_list<U>&, Args&&...>::value>::type> + T& emplace(std::initializer_list<U> il, Args&&... args) { + this->destruct(); + this->construct(il, std::forward<Args>(args)...); + return reference(); + } + + // Swaps + + // Swap, standard semantics + void swap(optional& rhs) noexcept( + std::is_nothrow_move_constructible<T>::value&& + type_traits_internal::IsNothrowSwappable<T>::value) { + if (*this) { + if (rhs) { + type_traits_internal::Swap(**this, *rhs); + } else { + rhs.construct(std::move(**this)); + this->destruct(); + } + } else { + if (rhs) { + this->construct(std::move(*rhs)); + rhs.destruct(); + } else { + // No effect (swap(disengaged, disengaged)). + } + } + } + + // Observers + + // optional::operator->() + // + // Accesses the underlying `T` value's member `m` of an `optional`. If the + // `optional` is empty, behavior is undefined. + // + // If you need myOpt->foo in constexpr, use (*myOpt).foo instead. + const T* operator->() const { + ABSL_HARDENING_ASSERT(this->engaged_); + return std::addressof(this->data_); + } + T* operator->() { + ABSL_HARDENING_ASSERT(this->engaged_); + return std::addressof(this->data_); + } + + // optional::operator*() + // + // Accesses the underlying `T` value of an `optional`. If the `optional` is + // empty, behavior is undefined. + constexpr const T& operator*() const& { + return ABSL_HARDENING_ASSERT(this->engaged_), reference(); + } + T& operator*() & { + ABSL_HARDENING_ASSERT(this->engaged_); + return reference(); + } + constexpr const T&& operator*() const && { + return ABSL_HARDENING_ASSERT(this->engaged_), absl::move(reference()); + } + T&& operator*() && { + ABSL_HARDENING_ASSERT(this->engaged_); + return std::move(reference()); + } + + // optional::operator bool() + // + // Returns false if and only if the `optional` is empty. + // + // if (opt) { + // // do something with *opt or opt->; + // } else { + // // opt is empty. + // } + // + constexpr explicit operator bool() const noexcept { return this->engaged_; } + + // optional::has_value() + // + // Determines whether the `optional` contains a value. Returns `false` if and + // only if `*this` is empty. + constexpr bool has_value() const noexcept { return this->engaged_; } + +// Suppress bogus warning on MSVC: MSVC complains call to reference() after +// throw_bad_optional_access() is unreachable. +#ifdef _MSC_VER +#pragma warning(push) +#pragma warning(disable : 4702) +#endif // _MSC_VER + // optional::value() + // + // Returns a reference to an `optional`s underlying value. The constness + // and lvalue/rvalue-ness of the `optional` is preserved to the view of + // the `T` sub-object. Throws `absl::bad_optional_access` when the `optional` + // is empty. + constexpr const T& value() const & { + return static_cast<bool>(*this) + ? reference() + : (optional_internal::throw_bad_optional_access(), reference()); + } + T& value() & { + return static_cast<bool>(*this) + ? reference() + : (optional_internal::throw_bad_optional_access(), reference()); + } + T&& value() && { // NOLINT(build/c++11) + return std::move( + static_cast<bool>(*this) + ? reference() + : (optional_internal::throw_bad_optional_access(), reference())); + } + constexpr const T&& value() const && { // NOLINT(build/c++11) + return absl::move( + static_cast<bool>(*this) + ? reference() + : (optional_internal::throw_bad_optional_access(), reference())); + } +#ifdef _MSC_VER +#pragma warning(pop) +#endif // _MSC_VER + + // optional::value_or() + // + // Returns either the value of `T` or a passed default `v` if the `optional` + // is empty. + template <typename U> + constexpr T value_or(U&& v) const& { + static_assert(std::is_copy_constructible<value_type>::value, + "optional<T>::value_or: T must be copy constructible"); + static_assert(std::is_convertible<U&&, value_type>::value, + "optional<T>::value_or: U must be convertible to T"); + return static_cast<bool>(*this) + ? **this + : static_cast<T>(absl::forward<U>(v)); + } + template <typename U> + T value_or(U&& v) && { // NOLINT(build/c++11) + static_assert(std::is_move_constructible<value_type>::value, + "optional<T>::value_or: T must be move constructible"); + static_assert(std::is_convertible<U&&, value_type>::value, + "optional<T>::value_or: U must be convertible to T"); + return static_cast<bool>(*this) ? std::move(**this) + : static_cast<T>(std::forward<U>(v)); + } + + private: + // Private accessors for internal storage viewed as reference to T. + constexpr const T& reference() const { return this->data_; } + T& reference() { return this->data_; } + + // T constraint checks. You can't have an optional of nullopt_t, in_place_t + // or a reference. + static_assert( + !std::is_same<nullopt_t, typename std::remove_cv<T>::type>::value, + "optional<nullopt_t> is not allowed."); + static_assert( + !std::is_same<in_place_t, typename std::remove_cv<T>::type>::value, + "optional<in_place_t> is not allowed."); + static_assert(!std::is_reference<T>::value, + "optional<reference> is not allowed."); +}; + +// Non-member functions + +// swap() +// +// Performs a swap between two `absl::optional` objects, using standard +// semantics. +template <typename T, typename std::enable_if< + std::is_move_constructible<T>::value && + type_traits_internal::IsSwappable<T>::value, + bool>::type = false> +void swap(optional<T>& a, optional<T>& b) noexcept(noexcept(a.swap(b))) { + a.swap(b); +} + +// make_optional() +// +// Creates a non-empty `optional<T>` where the type of `T` is deduced. An +// `absl::optional` can also be explicitly instantiated with +// `make_optional<T>(v)`. +// +// Note: `make_optional()` constructions may be declared `constexpr` for +// trivially copyable types `T`. Non-trivial types require copy elision +// support in C++17 for `make_optional` to support `constexpr` on such +// non-trivial types. +// +// Example: +// +// constexpr absl::optional<int> opt = absl::make_optional(1); +// static_assert(opt.value() == 1, ""); +template <typename T> +constexpr optional<typename std::decay<T>::type> make_optional(T&& v) { + return optional<typename std::decay<T>::type>(absl::forward<T>(v)); +} + +template <typename T, typename... Args> +constexpr optional<T> make_optional(Args&&... args) { + return optional<T>(in_place_t(), absl::forward<Args>(args)...); +} + +template <typename T, typename U, typename... Args> +constexpr optional<T> make_optional(std::initializer_list<U> il, + Args&&... args) { + return optional<T>(in_place_t(), il, + absl::forward<Args>(args)...); +} + +// Relational operators [optional.relops] + +// Empty optionals are considered equal to each other and less than non-empty +// optionals. Supports relations between optional<T> and optional<U>, between +// optional<T> and U, and between optional<T> and nullopt. +// +// Note: We're careful to support T having non-bool relationals. + +// Requires: The expression, e.g. "*x == *y" shall be well-formed and its result +// shall be convertible to bool. +// The C++17 (N4606) "Returns:" statements are translated into +// code in an obvious way here, and the original text retained as function docs. +// Returns: If bool(x) != bool(y), false; otherwise if bool(x) == false, true; +// otherwise *x == *y. +template <typename T, typename U> +constexpr auto operator==(const optional<T>& x, const optional<U>& y) + -> decltype(optional_internal::convertible_to_bool(*x == *y)) { + return static_cast<bool>(x) != static_cast<bool>(y) + ? false + : static_cast<bool>(x) == false ? true + : static_cast<bool>(*x == *y); +} + +// Returns: If bool(x) != bool(y), true; otherwise, if bool(x) == false, false; +// otherwise *x != *y. +template <typename T, typename U> +constexpr auto operator!=(const optional<T>& x, const optional<U>& y) + -> decltype(optional_internal::convertible_to_bool(*x != *y)) { + return static_cast<bool>(x) != static_cast<bool>(y) + ? true + : static_cast<bool>(x) == false ? false + : static_cast<bool>(*x != *y); +} +// Returns: If !y, false; otherwise, if !x, true; otherwise *x < *y. +template <typename T, typename U> +constexpr auto operator<(const optional<T>& x, const optional<U>& y) + -> decltype(optional_internal::convertible_to_bool(*x < *y)) { + return !y ? false : !x ? true : static_cast<bool>(*x < *y); +} +// Returns: If !x, false; otherwise, if !y, true; otherwise *x > *y. +template <typename T, typename U> +constexpr auto operator>(const optional<T>& x, const optional<U>& y) + -> decltype(optional_internal::convertible_to_bool(*x > *y)) { + return !x ? false : !y ? true : static_cast<bool>(*x > *y); +} +// Returns: If !x, true; otherwise, if !y, false; otherwise *x <= *y. +template <typename T, typename U> +constexpr auto operator<=(const optional<T>& x, const optional<U>& y) + -> decltype(optional_internal::convertible_to_bool(*x <= *y)) { + return !x ? true : !y ? false : static_cast<bool>(*x <= *y); +} +// Returns: If !y, true; otherwise, if !x, false; otherwise *x >= *y. +template <typename T, typename U> +constexpr auto operator>=(const optional<T>& x, const optional<U>& y) + -> decltype(optional_internal::convertible_to_bool(*x >= *y)) { + return !y ? true : !x ? false : static_cast<bool>(*x >= *y); +} + +// Comparison with nullopt [optional.nullops] +// The C++17 (N4606) "Returns:" statements are used directly here. +template <typename T> +constexpr bool operator==(const optional<T>& x, nullopt_t) noexcept { + return !x; +} +template <typename T> +constexpr bool operator==(nullopt_t, const optional<T>& x) noexcept { + return !x; +} +template <typename T> +constexpr bool operator!=(const optional<T>& x, nullopt_t) noexcept { + return static_cast<bool>(x); +} +template <typename T> +constexpr bool operator!=(nullopt_t, const optional<T>& x) noexcept { + return static_cast<bool>(x); +} +template <typename T> +constexpr bool operator<(const optional<T>&, nullopt_t) noexcept { + return false; +} +template <typename T> +constexpr bool operator<(nullopt_t, const optional<T>& x) noexcept { + return static_cast<bool>(x); +} +template <typename T> +constexpr bool operator<=(const optional<T>& x, nullopt_t) noexcept { + return !x; +} +template <typename T> +constexpr bool operator<=(nullopt_t, const optional<T>&) noexcept { + return true; +} +template <typename T> +constexpr bool operator>(const optional<T>& x, nullopt_t) noexcept { + return static_cast<bool>(x); +} +template <typename T> +constexpr bool operator>(nullopt_t, const optional<T>&) noexcept { + return false; +} +template <typename T> +constexpr bool operator>=(const optional<T>&, nullopt_t) noexcept { + return true; +} +template <typename T> +constexpr bool operator>=(nullopt_t, const optional<T>& x) noexcept { + return !x; +} + +// Comparison with T [optional.comp_with_t] + +// Requires: The expression, e.g. "*x == v" shall be well-formed and its result +// shall be convertible to bool. +// The C++17 (N4606) "Equivalent to:" statements are used directly here. +template <typename T, typename U> +constexpr auto operator==(const optional<T>& x, const U& v) + -> decltype(optional_internal::convertible_to_bool(*x == v)) { + return static_cast<bool>(x) ? static_cast<bool>(*x == v) : false; +} +template <typename T, typename U> +constexpr auto operator==(const U& v, const optional<T>& x) + -> decltype(optional_internal::convertible_to_bool(v == *x)) { + return static_cast<bool>(x) ? static_cast<bool>(v == *x) : false; +} +template <typename T, typename U> +constexpr auto operator!=(const optional<T>& x, const U& v) + -> decltype(optional_internal::convertible_to_bool(*x != v)) { + return static_cast<bool>(x) ? static_cast<bool>(*x != v) : true; +} +template <typename T, typename U> +constexpr auto operator!=(const U& v, const optional<T>& x) + -> decltype(optional_internal::convertible_to_bool(v != *x)) { + return static_cast<bool>(x) ? static_cast<bool>(v != *x) : true; +} +template <typename T, typename U> +constexpr auto operator<(const optional<T>& x, const U& v) + -> decltype(optional_internal::convertible_to_bool(*x < v)) { + return static_cast<bool>(x) ? static_cast<bool>(*x < v) : true; +} +template <typename T, typename U> +constexpr auto operator<(const U& v, const optional<T>& x) + -> decltype(optional_internal::convertible_to_bool(v < *x)) { + return static_cast<bool>(x) ? static_cast<bool>(v < *x) : false; +} +template <typename T, typename U> +constexpr auto operator<=(const optional<T>& x, const U& v) + -> decltype(optional_internal::convertible_to_bool(*x <= v)) { + return static_cast<bool>(x) ? static_cast<bool>(*x <= v) : true; +} +template <typename T, typename U> +constexpr auto operator<=(const U& v, const optional<T>& x) + -> decltype(optional_internal::convertible_to_bool(v <= *x)) { + return static_cast<bool>(x) ? static_cast<bool>(v <= *x) : false; +} +template <typename T, typename U> +constexpr auto operator>(const optional<T>& x, const U& v) + -> decltype(optional_internal::convertible_to_bool(*x > v)) { + return static_cast<bool>(x) ? static_cast<bool>(*x > v) : false; +} +template <typename T, typename U> +constexpr auto operator>(const U& v, const optional<T>& x) + -> decltype(optional_internal::convertible_to_bool(v > *x)) { + return static_cast<bool>(x) ? static_cast<bool>(v > *x) : true; +} +template <typename T, typename U> +constexpr auto operator>=(const optional<T>& x, const U& v) + -> decltype(optional_internal::convertible_to_bool(*x >= v)) { + return static_cast<bool>(x) ? static_cast<bool>(*x >= v) : false; +} +template <typename T, typename U> +constexpr auto operator>=(const U& v, const optional<T>& x) + -> decltype(optional_internal::convertible_to_bool(v >= *x)) { + return static_cast<bool>(x) ? static_cast<bool>(v >= *x) : true; +} + +ABSL_NAMESPACE_END +} // namespace absl + +namespace std { + +// std::hash specialization for absl::optional. +template <typename T> +struct hash<absl::optional<T> > + : absl::optional_internal::optional_hash_base<T> {}; + +} // namespace std + +#undef ABSL_MSVC_CONSTEXPR_BUG_IN_UNION_LIKE_CLASS + +#endif // ABSL_USES_STD_OPTIONAL + +#endif // ABSL_TYPES_OPTIONAL_H_ diff --git a/third_party/abseil_cpp/absl/types/optional_exception_safety_test.cc b/third_party/abseil_cpp/absl/types/optional_exception_safety_test.cc new file mode 100644 index 0000000000..8e5fe851db --- /dev/null +++ b/third_party/abseil_cpp/absl/types/optional_exception_safety_test.cc @@ -0,0 +1,292 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/optional.h" + +#include "absl/base/config.h" + +// This test is a no-op when absl::optional is an alias for std::optional and +// when exceptions are not enabled. +#if !defined(ABSL_USES_STD_OPTIONAL) && defined(ABSL_HAVE_EXCEPTIONS) + +#include "gtest/gtest.h" +#include "absl/base/internal/exception_safety_testing.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +namespace { + +using ::testing::AssertionFailure; +using ::testing::AssertionResult; +using ::testing::AssertionSuccess; +using ::testing::MakeExceptionSafetyTester; + +using Thrower = testing::ThrowingValue<testing::TypeSpec::kEverythingThrows>; +using Optional = absl::optional<Thrower>; + +using MoveThrower = testing::ThrowingValue<testing::TypeSpec::kNoThrowMove>; +using MoveOptional = absl::optional<MoveThrower>; + +constexpr int kInitialInteger = 5; +constexpr int kUpdatedInteger = 10; + +template <typename OptionalT> +bool ValueThrowsBadOptionalAccess(const OptionalT& optional) try { + return (static_cast<void>(optional.value()), false); +} catch (const absl::bad_optional_access&) { + return true; +} + +template <typename OptionalT> +AssertionResult OptionalInvariants(OptionalT* optional_ptr) { + // Check the current state post-throw for validity + auto& optional = *optional_ptr; + + if (optional.has_value() && ValueThrowsBadOptionalAccess(optional)) { + return AssertionFailure() + << "Optional with value should not throw bad_optional_access when " + "accessing the value."; + } + if (!optional.has_value() && !ValueThrowsBadOptionalAccess(optional)) { + return AssertionFailure() + << "Optional without a value should throw bad_optional_access when " + "accessing the value."; + } + + // Reset to a known state + optional.reset(); + + // Confirm that the known post-reset state is valid + if (optional.has_value()) { + return AssertionFailure() + << "Optional should not contain a value after being reset."; + } + if (!ValueThrowsBadOptionalAccess(optional)) { + return AssertionFailure() << "Optional should throw bad_optional_access " + "when accessing the value after being reset."; + } + + return AssertionSuccess(); +} + +template <typename OptionalT> +AssertionResult CheckDisengaged(OptionalT* optional_ptr) { + auto& optional = *optional_ptr; + + if (optional.has_value()) { + return AssertionFailure() + << "Expected optional to not contain a value but a value was found."; + } + + return AssertionSuccess(); +} + +template <typename OptionalT> +AssertionResult CheckEngaged(OptionalT* optional_ptr) { + auto& optional = *optional_ptr; + + if (!optional.has_value()) { + return AssertionFailure() + << "Expected optional to contain a value but no value was found."; + } + + return AssertionSuccess(); +} + +TEST(OptionalExceptionSafety, ThrowingConstructors) { + auto thrower_nonempty = Optional(Thrower(kInitialInteger)); + testing::TestThrowingCtor<Optional>(thrower_nonempty); + + auto integer_nonempty = absl::optional<int>(kInitialInteger); + testing::TestThrowingCtor<Optional>(integer_nonempty); + testing::TestThrowingCtor<Optional>(std::move(integer_nonempty)); // NOLINT + + testing::TestThrowingCtor<Optional>(kInitialInteger); + using ThrowerVec = std::vector<Thrower, testing::ThrowingAllocator<Thrower>>; + testing::TestThrowingCtor<absl::optional<ThrowerVec>>( + absl::in_place, + std::initializer_list<Thrower>{Thrower(), Thrower(), Thrower()}, + testing::ThrowingAllocator<Thrower>()); +} + +TEST(OptionalExceptionSafety, NothrowConstructors) { + // This constructor is marked noexcept. If it throws, the program will + // terminate. + testing::TestThrowingCtor<MoveOptional>(MoveOptional(kUpdatedInteger)); +} + +TEST(OptionalExceptionSafety, Emplace) { + // Test the basic guarantee plus test the result of optional::has_value() + // is false in all cases + auto disengaged_test = MakeExceptionSafetyTester().WithContracts( + OptionalInvariants<Optional>, CheckDisengaged<Optional>); + auto disengaged_test_empty = disengaged_test.WithInitialValue(Optional()); + auto disengaged_test_nonempty = + disengaged_test.WithInitialValue(Optional(kInitialInteger)); + + auto emplace_thrower_directly = [](Optional* optional_ptr) { + optional_ptr->emplace(kUpdatedInteger); + }; + EXPECT_TRUE(disengaged_test_empty.Test(emplace_thrower_directly)); + EXPECT_TRUE(disengaged_test_nonempty.Test(emplace_thrower_directly)); + + auto emplace_thrower_copy = [](Optional* optional_ptr) { + auto thrower = Thrower(kUpdatedInteger, testing::nothrow_ctor); + optional_ptr->emplace(thrower); + }; + EXPECT_TRUE(disengaged_test_empty.Test(emplace_thrower_copy)); + EXPECT_TRUE(disengaged_test_nonempty.Test(emplace_thrower_copy)); +} + +TEST(OptionalExceptionSafety, EverythingThrowsSwap) { + // Test the basic guarantee plus test the result of optional::has_value() + // remains the same + auto test = + MakeExceptionSafetyTester().WithContracts(OptionalInvariants<Optional>); + auto disengaged_test_empty = test.WithInitialValue(Optional()) + .WithContracts(CheckDisengaged<Optional>); + auto engaged_test_nonempty = test.WithInitialValue(Optional(kInitialInteger)) + .WithContracts(CheckEngaged<Optional>); + + auto swap_empty = [](Optional* optional_ptr) { + auto empty = Optional(); + optional_ptr->swap(empty); + }; + EXPECT_TRUE(engaged_test_nonempty.Test(swap_empty)); + + auto swap_nonempty = [](Optional* optional_ptr) { + auto nonempty = + Optional(absl::in_place, kUpdatedInteger, testing::nothrow_ctor); + optional_ptr->swap(nonempty); + }; + EXPECT_TRUE(disengaged_test_empty.Test(swap_nonempty)); + EXPECT_TRUE(engaged_test_nonempty.Test(swap_nonempty)); +} + +TEST(OptionalExceptionSafety, NoThrowMoveSwap) { + // Tests the nothrow guarantee for optional of T with non-throwing move + { + auto empty = MoveOptional(); + auto nonempty = MoveOptional(kInitialInteger); + EXPECT_TRUE(testing::TestNothrowOp([&]() { nonempty.swap(empty); })); + } + { + auto nonempty = MoveOptional(kUpdatedInteger); + auto empty = MoveOptional(); + EXPECT_TRUE(testing::TestNothrowOp([&]() { empty.swap(nonempty); })); + } + { + auto nonempty_from = MoveOptional(kUpdatedInteger); + auto nonempty_to = MoveOptional(kInitialInteger); + EXPECT_TRUE( + testing::TestNothrowOp([&]() { nonempty_to.swap(nonempty_from); })); + } +} + +TEST(OptionalExceptionSafety, CopyAssign) { + // Test the basic guarantee plus test the result of optional::has_value() + // remains the same + auto test = + MakeExceptionSafetyTester().WithContracts(OptionalInvariants<Optional>); + auto disengaged_test_empty = test.WithInitialValue(Optional()) + .WithContracts(CheckDisengaged<Optional>); + auto engaged_test_nonempty = test.WithInitialValue(Optional(kInitialInteger)) + .WithContracts(CheckEngaged<Optional>); + + auto copyassign_nonempty = [](Optional* optional_ptr) { + auto nonempty = + Optional(absl::in_place, kUpdatedInteger, testing::nothrow_ctor); + *optional_ptr = nonempty; + }; + EXPECT_TRUE(disengaged_test_empty.Test(copyassign_nonempty)); + EXPECT_TRUE(engaged_test_nonempty.Test(copyassign_nonempty)); + + auto copyassign_thrower = [](Optional* optional_ptr) { + auto thrower = Thrower(kUpdatedInteger, testing::nothrow_ctor); + *optional_ptr = thrower; + }; + EXPECT_TRUE(disengaged_test_empty.Test(copyassign_thrower)); + EXPECT_TRUE(engaged_test_nonempty.Test(copyassign_thrower)); +} + +TEST(OptionalExceptionSafety, MoveAssign) { + // Test the basic guarantee plus test the result of optional::has_value() + // remains the same + auto test = + MakeExceptionSafetyTester().WithContracts(OptionalInvariants<Optional>); + auto disengaged_test_empty = test.WithInitialValue(Optional()) + .WithContracts(CheckDisengaged<Optional>); + auto engaged_test_nonempty = test.WithInitialValue(Optional(kInitialInteger)) + .WithContracts(CheckEngaged<Optional>); + + auto moveassign_empty = [](Optional* optional_ptr) { + auto empty = Optional(); + *optional_ptr = std::move(empty); + }; + EXPECT_TRUE(engaged_test_nonempty.Test(moveassign_empty)); + + auto moveassign_nonempty = [](Optional* optional_ptr) { + auto nonempty = + Optional(absl::in_place, kUpdatedInteger, testing::nothrow_ctor); + *optional_ptr = std::move(nonempty); + }; + EXPECT_TRUE(disengaged_test_empty.Test(moveassign_nonempty)); + EXPECT_TRUE(engaged_test_nonempty.Test(moveassign_nonempty)); + + auto moveassign_thrower = [](Optional* optional_ptr) { + auto thrower = Thrower(kUpdatedInteger, testing::nothrow_ctor); + *optional_ptr = std::move(thrower); + }; + EXPECT_TRUE(disengaged_test_empty.Test(moveassign_thrower)); + EXPECT_TRUE(engaged_test_nonempty.Test(moveassign_thrower)); +} + +TEST(OptionalExceptionSafety, NothrowMoveAssign) { + // Tests the nothrow guarantee for optional of T with non-throwing move + { + auto empty = MoveOptional(); + auto nonempty = MoveOptional(kInitialInteger); + EXPECT_TRUE(testing::TestNothrowOp([&]() { nonempty = std::move(empty); })); + } + { + auto nonempty = MoveOptional(kInitialInteger); + auto empty = MoveOptional(); + EXPECT_TRUE(testing::TestNothrowOp([&]() { empty = std::move(nonempty); })); + } + { + auto nonempty_from = MoveOptional(kUpdatedInteger); + auto nonempty_to = MoveOptional(kInitialInteger); + EXPECT_TRUE(testing::TestNothrowOp( + [&]() { nonempty_to = std::move(nonempty_from); })); + } + { + auto thrower = MoveThrower(kUpdatedInteger); + auto empty = MoveOptional(); + EXPECT_TRUE(testing::TestNothrowOp([&]() { empty = std::move(thrower); })); + } + { + auto thrower = MoveThrower(kUpdatedInteger); + auto nonempty = MoveOptional(kInitialInteger); + EXPECT_TRUE( + testing::TestNothrowOp([&]() { nonempty = std::move(thrower); })); + } +} + +} // namespace + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // #if !defined(ABSL_USES_STD_OPTIONAL) && defined(ABSL_HAVE_EXCEPTIONS) diff --git a/third_party/abseil_cpp/absl/types/optional_test.cc b/third_party/abseil_cpp/absl/types/optional_test.cc new file mode 100644 index 0000000000..7ef142cb99 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/optional_test.cc @@ -0,0 +1,1659 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/optional.h" + +// This test is a no-op when absl::optional is an alias for std::optional. +#if !defined(ABSL_USES_STD_OPTIONAL) + +#include <string> +#include <type_traits> +#include <utility> + +#include "gtest/gtest.h" +#include "absl/base/config.h" +#include "absl/base/internal/raw_logging.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" + +struct Hashable {}; + +namespace std { +template <> +struct hash<Hashable> { + size_t operator()(const Hashable&) { return 0; } +}; +} // namespace std + +struct NonHashable {}; + +namespace { + +std::string TypeQuals(std::string&) { return "&"; } +std::string TypeQuals(std::string&&) { return "&&"; } +std::string TypeQuals(const std::string&) { return "c&"; } +std::string TypeQuals(const std::string&&) { return "c&&"; } + +struct StructorListener { + int construct0 = 0; + int construct1 = 0; + int construct2 = 0; + int listinit = 0; + int copy = 0; + int move = 0; + int copy_assign = 0; + int move_assign = 0; + int destruct = 0; + int volatile_copy = 0; + int volatile_move = 0; + int volatile_copy_assign = 0; + int volatile_move_assign = 0; +}; + +// Suppress MSVC warnings. +// 4521: multiple copy constructors specified +// 4522: multiple assignment operators specified +// We wrote multiple of them to test that the correct overloads are selected. +#ifdef _MSC_VER +#pragma warning( push ) +#pragma warning( disable : 4521) +#pragma warning( disable : 4522) +#endif +struct Listenable { + static StructorListener* listener; + + Listenable() { ++listener->construct0; } + explicit Listenable(int /*unused*/) { ++listener->construct1; } + Listenable(int /*unused*/, int /*unused*/) { ++listener->construct2; } + Listenable(std::initializer_list<int> /*unused*/) { ++listener->listinit; } + Listenable(const Listenable& /*unused*/) { ++listener->copy; } + Listenable(const volatile Listenable& /*unused*/) { + ++listener->volatile_copy; + } + Listenable(volatile Listenable&& /*unused*/) { ++listener->volatile_move; } + Listenable(Listenable&& /*unused*/) { ++listener->move; } + Listenable& operator=(const Listenable& /*unused*/) { + ++listener->copy_assign; + return *this; + } + Listenable& operator=(Listenable&& /*unused*/) { + ++listener->move_assign; + return *this; + } + // use void return type instead of volatile T& to work around GCC warning + // when the assignment's returned reference is ignored. + void operator=(const volatile Listenable& /*unused*/) volatile { + ++listener->volatile_copy_assign; + } + void operator=(volatile Listenable&& /*unused*/) volatile { + ++listener->volatile_move_assign; + } + ~Listenable() { ++listener->destruct; } +}; +#ifdef _MSC_VER +#pragma warning( pop ) +#endif + +StructorListener* Listenable::listener = nullptr; + +// ABSL_HAVE_NO_CONSTEXPR_INITIALIZER_LIST is defined to 1 when the standard +// library implementation doesn't marked initializer_list's default constructor +// constexpr. The C++11 standard doesn't specify constexpr on it, but C++14 +// added it. However, libstdc++ 4.7 marked it constexpr. +#if defined(_LIBCPP_VERSION) && \ + (_LIBCPP_STD_VER <= 11 || defined(_LIBCPP_HAS_NO_CXX14_CONSTEXPR)) +#define ABSL_HAVE_NO_CONSTEXPR_INITIALIZER_LIST 1 +#endif + +struct ConstexprType { + enum CtorTypes { + kCtorDefault, + kCtorInt, + kCtorInitializerList, + kCtorConstChar + }; + constexpr ConstexprType() : x(kCtorDefault) {} + constexpr explicit ConstexprType(int i) : x(kCtorInt) {} +#ifndef ABSL_HAVE_NO_CONSTEXPR_INITIALIZER_LIST + constexpr ConstexprType(std::initializer_list<int> il) + : x(kCtorInitializerList) {} +#endif + constexpr ConstexprType(const char*) // NOLINT(runtime/explicit) + : x(kCtorConstChar) {} + int x; +}; + +struct Copyable { + Copyable() {} + Copyable(const Copyable&) {} + Copyable& operator=(const Copyable&) { return *this; } +}; + +struct MoveableThrow { + MoveableThrow() {} + MoveableThrow(MoveableThrow&&) {} + MoveableThrow& operator=(MoveableThrow&&) { return *this; } +}; + +struct MoveableNoThrow { + MoveableNoThrow() {} + MoveableNoThrow(MoveableNoThrow&&) noexcept {} + MoveableNoThrow& operator=(MoveableNoThrow&&) noexcept { return *this; } +}; + +struct NonMovable { + NonMovable() {} + NonMovable(const NonMovable&) = delete; + NonMovable& operator=(const NonMovable&) = delete; + NonMovable(NonMovable&&) = delete; + NonMovable& operator=(NonMovable&&) = delete; +}; + +struct NoDefault { + NoDefault() = delete; + NoDefault(const NoDefault&) {} + NoDefault& operator=(const NoDefault&) { return *this; } +}; + +struct ConvertsFromInPlaceT { + ConvertsFromInPlaceT(absl::in_place_t) {} // NOLINT +}; + +TEST(optionalTest, DefaultConstructor) { + absl::optional<int> empty; + EXPECT_FALSE(empty); + constexpr absl::optional<int> cempty; + static_assert(!cempty.has_value(), ""); + EXPECT_TRUE( + std::is_nothrow_default_constructible<absl::optional<int>>::value); +} + +TEST(optionalTest, nulloptConstructor) { + absl::optional<int> empty(absl::nullopt); + EXPECT_FALSE(empty); + constexpr absl::optional<int> cempty{absl::nullopt}; + static_assert(!cempty.has_value(), ""); + EXPECT_TRUE((std::is_nothrow_constructible<absl::optional<int>, + absl::nullopt_t>::value)); +} + +TEST(optionalTest, CopyConstructor) { + { + absl::optional<int> empty, opt42 = 42; + absl::optional<int> empty_copy(empty); + EXPECT_FALSE(empty_copy); + absl::optional<int> opt42_copy(opt42); + EXPECT_TRUE(opt42_copy); + EXPECT_EQ(42, *opt42_copy); + } + { + absl::optional<const int> empty, opt42 = 42; + absl::optional<const int> empty_copy(empty); + EXPECT_FALSE(empty_copy); + absl::optional<const int> opt42_copy(opt42); + EXPECT_TRUE(opt42_copy); + EXPECT_EQ(42, *opt42_copy); + } + { + absl::optional<volatile int> empty, opt42 = 42; + absl::optional<volatile int> empty_copy(empty); + EXPECT_FALSE(empty_copy); + absl::optional<volatile int> opt42_copy(opt42); + EXPECT_TRUE(opt42_copy); + EXPECT_EQ(42, *opt42_copy); + } + // test copyablility + EXPECT_TRUE(std::is_copy_constructible<absl::optional<int>>::value); + EXPECT_TRUE(std::is_copy_constructible<absl::optional<Copyable>>::value); + EXPECT_FALSE( + std::is_copy_constructible<absl::optional<MoveableThrow>>::value); + EXPECT_FALSE( + std::is_copy_constructible<absl::optional<MoveableNoThrow>>::value); + EXPECT_FALSE(std::is_copy_constructible<absl::optional<NonMovable>>::value); + + EXPECT_FALSE( + absl::is_trivially_copy_constructible<absl::optional<Copyable>>::value); +#if defined(ABSL_USES_STD_OPTIONAL) && defined(__GLIBCXX__) + // libstdc++ std::optional implementation (as of 7.2) has a bug: when T is + // trivially copyable, optional<T> is not trivially copyable (due to one of + // its base class is unconditionally nontrivial). +#define ABSL_GLIBCXX_OPTIONAL_TRIVIALITY_BUG 1 +#endif +#ifndef ABSL_GLIBCXX_OPTIONAL_TRIVIALITY_BUG + EXPECT_TRUE( + absl::is_trivially_copy_constructible<absl::optional<int>>::value); + EXPECT_TRUE( + absl::is_trivially_copy_constructible<absl::optional<const int>>::value); +#ifndef _MSC_VER + // See defect report "Trivial copy/move constructor for class with volatile + // member" at + // http://www.open-std.org/jtc1/sc22/wg21/docs/cwg_defects.html#2094 + // A class with non-static data member of volatile-qualified type should still + // have a trivial copy constructor if the data member is trivial. + // Also a cv-qualified scalar type should be trivially copyable. + EXPECT_TRUE(absl::is_trivially_copy_constructible< + absl::optional<volatile int>>::value); +#endif // _MSC_VER +#endif // ABSL_GLIBCXX_OPTIONAL_TRIVIALITY_BUG + + // constexpr copy constructor for trivially copyable types + { + constexpr absl::optional<int> o1; + constexpr absl::optional<int> o2 = o1; + static_assert(!o2, ""); + } + { + constexpr absl::optional<int> o1 = 42; + constexpr absl::optional<int> o2 = o1; + static_assert(o2, ""); + static_assert(*o2 == 42, ""); + } + { + struct TrivialCopyable { + constexpr TrivialCopyable() : x(0) {} + constexpr explicit TrivialCopyable(int i) : x(i) {} + int x; + }; + constexpr absl::optional<TrivialCopyable> o1(42); + constexpr absl::optional<TrivialCopyable> o2 = o1; + static_assert(o2, ""); + static_assert((*o2).x == 42, ""); +#ifndef ABSL_GLIBCXX_OPTIONAL_TRIVIALITY_BUG + EXPECT_TRUE(absl::is_trivially_copy_constructible< + absl::optional<TrivialCopyable>>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible< + absl::optional<const TrivialCopyable>>::value); +#endif + // When testing with VS 2017 15.3, there seems to be a bug in MSVC + // std::optional when T is volatile-qualified. So skipping this test. + // Bug report: + // https://connect.microsoft.com/VisualStudio/feedback/details/3142534 +#if defined(ABSL_USES_STD_OPTIONAL) && defined(_MSC_VER) && _MSC_VER >= 1911 +#define ABSL_MSVC_OPTIONAL_VOLATILE_COPY_BUG 1 +#endif +#ifndef ABSL_MSVC_OPTIONAL_VOLATILE_COPY_BUG + EXPECT_FALSE(std::is_copy_constructible< + absl::optional<volatile TrivialCopyable>>::value); +#endif + } +} + +TEST(optionalTest, MoveConstructor) { + absl::optional<int> empty, opt42 = 42; + absl::optional<int> empty_move(std::move(empty)); + EXPECT_FALSE(empty_move); + absl::optional<int> opt42_move(std::move(opt42)); + EXPECT_TRUE(opt42_move); + EXPECT_EQ(42, opt42_move); + // test movability + EXPECT_TRUE(std::is_move_constructible<absl::optional<int>>::value); + EXPECT_TRUE(std::is_move_constructible<absl::optional<Copyable>>::value); + EXPECT_TRUE(std::is_move_constructible<absl::optional<MoveableThrow>>::value); + EXPECT_TRUE( + std::is_move_constructible<absl::optional<MoveableNoThrow>>::value); + EXPECT_FALSE(std::is_move_constructible<absl::optional<NonMovable>>::value); + // test noexcept + EXPECT_TRUE(std::is_nothrow_move_constructible<absl::optional<int>>::value); +#ifndef ABSL_USES_STD_OPTIONAL + EXPECT_EQ( + absl::default_allocator_is_nothrow::value, + std::is_nothrow_move_constructible<absl::optional<MoveableThrow>>::value); +#endif + EXPECT_TRUE(std::is_nothrow_move_constructible< + absl::optional<MoveableNoThrow>>::value); +} + +TEST(optionalTest, Destructor) { + struct Trivial {}; + + struct NonTrivial { + NonTrivial(const NonTrivial&) {} + NonTrivial& operator=(const NonTrivial&) { return *this; } + ~NonTrivial() {} + }; + + EXPECT_TRUE(std::is_trivially_destructible<absl::optional<int>>::value); + EXPECT_TRUE(std::is_trivially_destructible<absl::optional<Trivial>>::value); + EXPECT_FALSE( + std::is_trivially_destructible<absl::optional<NonTrivial>>::value); +} + +TEST(optionalTest, InPlaceConstructor) { + constexpr absl::optional<ConstexprType> opt0{absl::in_place_t()}; + static_assert(opt0, ""); + static_assert((*opt0).x == ConstexprType::kCtorDefault, ""); + constexpr absl::optional<ConstexprType> opt1{absl::in_place_t(), 1}; + static_assert(opt1, ""); + static_assert((*opt1).x == ConstexprType::kCtorInt, ""); +#ifndef ABSL_HAVE_NO_CONSTEXPR_INITIALIZER_LIST + constexpr absl::optional<ConstexprType> opt2{absl::in_place_t(), {1, 2}}; + static_assert(opt2, ""); + static_assert((*opt2).x == ConstexprType::kCtorInitializerList, ""); +#endif + + EXPECT_FALSE((std::is_constructible<absl::optional<ConvertsFromInPlaceT>, + absl::in_place_t>::value)); + EXPECT_FALSE((std::is_constructible<absl::optional<ConvertsFromInPlaceT>, + const absl::in_place_t&>::value)); + EXPECT_TRUE( + (std::is_constructible<absl::optional<ConvertsFromInPlaceT>, + absl::in_place_t, absl::in_place_t>::value)); + + EXPECT_FALSE((std::is_constructible<absl::optional<NoDefault>, + absl::in_place_t>::value)); + EXPECT_FALSE((std::is_constructible<absl::optional<NoDefault>, + absl::in_place_t&&>::value)); +} + +// template<U=T> optional(U&&); +TEST(optionalTest, ValueConstructor) { + constexpr absl::optional<int> opt0(0); + static_assert(opt0, ""); + static_assert(*opt0 == 0, ""); + EXPECT_TRUE((std::is_convertible<int, absl::optional<int>>::value)); + // Copy initialization ( = "abc") won't work due to optional(optional&&) + // is not constexpr. Use list initialization instead. This invokes + // absl::optional<ConstexprType>::absl::optional<U>(U&&), with U = const char + // (&) [4], which direct-initializes the ConstexprType value held by the + // optional via ConstexprType::ConstexprType(const char*). + constexpr absl::optional<ConstexprType> opt1 = {"abc"}; + static_assert(opt1, ""); + static_assert(ConstexprType::kCtorConstChar == (*opt1).x, ""); + EXPECT_TRUE( + (std::is_convertible<const char*, absl::optional<ConstexprType>>::value)); + // direct initialization + constexpr absl::optional<ConstexprType> opt2{2}; + static_assert(opt2, ""); + static_assert(ConstexprType::kCtorInt == (*opt2).x, ""); + EXPECT_FALSE( + (std::is_convertible<int, absl::optional<ConstexprType>>::value)); + + // this invokes absl::optional<int>::optional(int&&) + // NOTE: this has different behavior than assignment, e.g. + // "opt3 = {};" clears the optional rather than setting the value to 0 + // According to C++17 standard N4659 [over.ics.list] 16.3.3.1.5, (9.2)- "if + // the initializer list has no elements, the implicit conversion is the + // identity conversion", so `optional(int&&)` should be a better match than + // `optional(optional&&)` which is a user-defined conversion. + // Note: GCC 7 has a bug with this overload selection when compiled with + // `-std=c++17`. +#if defined(__GNUC__) && !defined(__clang__) && __GNUC__ == 7 && \ + __cplusplus == 201703L +#define ABSL_GCC7_OVER_ICS_LIST_BUG 1 +#endif +#ifndef ABSL_GCC7_OVER_ICS_LIST_BUG + constexpr absl::optional<int> opt3({}); + static_assert(opt3, ""); + static_assert(*opt3 == 0, ""); +#endif + + // this invokes the move constructor with a default constructed optional + // because non-template function is a better match than template function. + absl::optional<ConstexprType> opt4({}); + EXPECT_FALSE(opt4); +} + +struct Implicit {}; + +struct Explicit {}; + +struct Convert { + Convert(const Implicit&) // NOLINT(runtime/explicit) + : implicit(true), move(false) {} + Convert(Implicit&&) // NOLINT(runtime/explicit) + : implicit(true), move(true) {} + explicit Convert(const Explicit&) : implicit(false), move(false) {} + explicit Convert(Explicit&&) : implicit(false), move(true) {} + + bool implicit; + bool move; +}; + +struct ConvertFromOptional { + ConvertFromOptional(const Implicit&) // NOLINT(runtime/explicit) + : implicit(true), move(false), from_optional(false) {} + ConvertFromOptional(Implicit&&) // NOLINT(runtime/explicit) + : implicit(true), move(true), from_optional(false) {} + ConvertFromOptional( + const absl::optional<Implicit>&) // NOLINT(runtime/explicit) + : implicit(true), move(false), from_optional(true) {} + ConvertFromOptional(absl::optional<Implicit>&&) // NOLINT(runtime/explicit) + : implicit(true), move(true), from_optional(true) {} + explicit ConvertFromOptional(const Explicit&) + : implicit(false), move(false), from_optional(false) {} + explicit ConvertFromOptional(Explicit&&) + : implicit(false), move(true), from_optional(false) {} + explicit ConvertFromOptional(const absl::optional<Explicit>&) + : implicit(false), move(false), from_optional(true) {} + explicit ConvertFromOptional(absl::optional<Explicit>&&) + : implicit(false), move(true), from_optional(true) {} + + bool implicit; + bool move; + bool from_optional; +}; + +TEST(optionalTest, ConvertingConstructor) { + absl::optional<Implicit> i_empty; + absl::optional<Implicit> i(absl::in_place); + absl::optional<Explicit> e_empty; + absl::optional<Explicit> e(absl::in_place); + { + // implicitly constructing absl::optional<Convert> from + // absl::optional<Implicit> + absl::optional<Convert> empty = i_empty; + EXPECT_FALSE(empty); + absl::optional<Convert> opt_copy = i; + EXPECT_TRUE(opt_copy); + EXPECT_TRUE(opt_copy->implicit); + EXPECT_FALSE(opt_copy->move); + absl::optional<Convert> opt_move = absl::optional<Implicit>(absl::in_place); + EXPECT_TRUE(opt_move); + EXPECT_TRUE(opt_move->implicit); + EXPECT_TRUE(opt_move->move); + } + { + // explicitly constructing absl::optional<Convert> from + // absl::optional<Explicit> + absl::optional<Convert> empty(e_empty); + EXPECT_FALSE(empty); + absl::optional<Convert> opt_copy(e); + EXPECT_TRUE(opt_copy); + EXPECT_FALSE(opt_copy->implicit); + EXPECT_FALSE(opt_copy->move); + EXPECT_FALSE((std::is_convertible<const absl::optional<Explicit>&, + absl::optional<Convert>>::value)); + absl::optional<Convert> opt_move{absl::optional<Explicit>(absl::in_place)}; + EXPECT_TRUE(opt_move); + EXPECT_FALSE(opt_move->implicit); + EXPECT_TRUE(opt_move->move); + EXPECT_FALSE((std::is_convertible<absl::optional<Explicit>&&, + absl::optional<Convert>>::value)); + } + { + // implicitly constructing absl::optional<ConvertFromOptional> from + // absl::optional<Implicit> via + // ConvertFromOptional(absl::optional<Implicit>&&) check that + // ConvertFromOptional(Implicit&&) is NOT called + static_assert( + std::is_convertible<absl::optional<Implicit>, + absl::optional<ConvertFromOptional>>::value, + ""); + absl::optional<ConvertFromOptional> opt0 = i_empty; + EXPECT_TRUE(opt0); + EXPECT_TRUE(opt0->implicit); + EXPECT_FALSE(opt0->move); + EXPECT_TRUE(opt0->from_optional); + absl::optional<ConvertFromOptional> opt1 = absl::optional<Implicit>(); + EXPECT_TRUE(opt1); + EXPECT_TRUE(opt1->implicit); + EXPECT_TRUE(opt1->move); + EXPECT_TRUE(opt1->from_optional); + } + { + // implicitly constructing absl::optional<ConvertFromOptional> from + // absl::optional<Explicit> via + // ConvertFromOptional(absl::optional<Explicit>&&) check that + // ConvertFromOptional(Explicit&&) is NOT called + absl::optional<ConvertFromOptional> opt0(e_empty); + EXPECT_TRUE(opt0); + EXPECT_FALSE(opt0->implicit); + EXPECT_FALSE(opt0->move); + EXPECT_TRUE(opt0->from_optional); + EXPECT_FALSE( + (std::is_convertible<const absl::optional<Explicit>&, + absl::optional<ConvertFromOptional>>::value)); + absl::optional<ConvertFromOptional> opt1{absl::optional<Explicit>()}; + EXPECT_TRUE(opt1); + EXPECT_FALSE(opt1->implicit); + EXPECT_TRUE(opt1->move); + EXPECT_TRUE(opt1->from_optional); + EXPECT_FALSE( + (std::is_convertible<absl::optional<Explicit>&&, + absl::optional<ConvertFromOptional>>::value)); + } +} + +TEST(optionalTest, StructorBasic) { + StructorListener listener; + Listenable::listener = &listener; + { + absl::optional<Listenable> empty; + EXPECT_FALSE(empty); + absl::optional<Listenable> opt0(absl::in_place); + EXPECT_TRUE(opt0); + absl::optional<Listenable> opt1(absl::in_place, 1); + EXPECT_TRUE(opt1); + absl::optional<Listenable> opt2(absl::in_place, 1, 2); + EXPECT_TRUE(opt2); + } + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(1, listener.construct1); + EXPECT_EQ(1, listener.construct2); + EXPECT_EQ(3, listener.destruct); +} + +TEST(optionalTest, CopyMoveStructor) { + StructorListener listener; + Listenable::listener = &listener; + absl::optional<Listenable> original(absl::in_place); + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(0, listener.copy); + EXPECT_EQ(0, listener.move); + absl::optional<Listenable> copy(original); + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(1, listener.copy); + EXPECT_EQ(0, listener.move); + absl::optional<Listenable> move(std::move(original)); + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(1, listener.copy); + EXPECT_EQ(1, listener.move); +} + +TEST(optionalTest, ListInit) { + StructorListener listener; + Listenable::listener = &listener; + absl::optional<Listenable> listinit1(absl::in_place, {1}); + absl::optional<Listenable> listinit2(absl::in_place, {1, 2}); + EXPECT_EQ(2, listener.listinit); +} + +TEST(optionalTest, AssignFromNullopt) { + absl::optional<int> opt(1); + opt = absl::nullopt; + EXPECT_FALSE(opt); + + StructorListener listener; + Listenable::listener = &listener; + absl::optional<Listenable> opt1(absl::in_place); + opt1 = absl::nullopt; + EXPECT_FALSE(opt1); + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(1, listener.destruct); + + EXPECT_TRUE(( + std::is_nothrow_assignable<absl::optional<int>, absl::nullopt_t>::value)); + EXPECT_TRUE((std::is_nothrow_assignable<absl::optional<Listenable>, + absl::nullopt_t>::value)); +} + +TEST(optionalTest, CopyAssignment) { + const absl::optional<int> empty, opt1 = 1, opt2 = 2; + absl::optional<int> empty_to_opt1, opt1_to_opt2, opt2_to_empty; + + EXPECT_FALSE(empty_to_opt1); + empty_to_opt1 = empty; + EXPECT_FALSE(empty_to_opt1); + empty_to_opt1 = opt1; + EXPECT_TRUE(empty_to_opt1); + EXPECT_EQ(1, empty_to_opt1.value()); + + EXPECT_FALSE(opt1_to_opt2); + opt1_to_opt2 = opt1; + EXPECT_TRUE(opt1_to_opt2); + EXPECT_EQ(1, opt1_to_opt2.value()); + opt1_to_opt2 = opt2; + EXPECT_TRUE(opt1_to_opt2); + EXPECT_EQ(2, opt1_to_opt2.value()); + + EXPECT_FALSE(opt2_to_empty); + opt2_to_empty = opt2; + EXPECT_TRUE(opt2_to_empty); + EXPECT_EQ(2, opt2_to_empty.value()); + opt2_to_empty = empty; + EXPECT_FALSE(opt2_to_empty); + + EXPECT_FALSE(absl::is_copy_assignable<absl::optional<const int>>::value); + EXPECT_TRUE(absl::is_copy_assignable<absl::optional<Copyable>>::value); + EXPECT_FALSE(absl::is_copy_assignable<absl::optional<MoveableThrow>>::value); + EXPECT_FALSE( + absl::is_copy_assignable<absl::optional<MoveableNoThrow>>::value); + EXPECT_FALSE(absl::is_copy_assignable<absl::optional<NonMovable>>::value); + + EXPECT_TRUE(absl::is_trivially_copy_assignable<int>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<volatile int>::value); + + struct Trivial { + int i; + }; + struct NonTrivial { + NonTrivial& operator=(const NonTrivial&) { return *this; } + int i; + }; + + EXPECT_TRUE(absl::is_trivially_copy_assignable<Trivial>::value); + EXPECT_FALSE(absl::is_copy_assignable<const Trivial>::value); + EXPECT_FALSE(absl::is_copy_assignable<volatile Trivial>::value); + EXPECT_TRUE(absl::is_copy_assignable<NonTrivial>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<NonTrivial>::value); + + // std::optional doesn't support volatile nontrivial types. +#ifndef ABSL_USES_STD_OPTIONAL + { + StructorListener listener; + Listenable::listener = &listener; + + absl::optional<volatile Listenable> empty, set(absl::in_place); + EXPECT_EQ(1, listener.construct0); + absl::optional<volatile Listenable> empty_to_empty, empty_to_set, + set_to_empty(absl::in_place), set_to_set(absl::in_place); + EXPECT_EQ(3, listener.construct0); + empty_to_empty = empty; // no effect + empty_to_set = set; // copy construct + set_to_empty = empty; // destruct + set_to_set = set; // copy assign + EXPECT_EQ(1, listener.volatile_copy); + EXPECT_EQ(0, listener.volatile_move); + EXPECT_EQ(1, listener.destruct); + EXPECT_EQ(1, listener.volatile_copy_assign); + } +#endif // ABSL_USES_STD_OPTIONAL +} + +TEST(optionalTest, MoveAssignment) { + { + StructorListener listener; + Listenable::listener = &listener; + + absl::optional<Listenable> empty1, empty2, set1(absl::in_place), + set2(absl::in_place); + EXPECT_EQ(2, listener.construct0); + absl::optional<Listenable> empty_to_empty, empty_to_set, + set_to_empty(absl::in_place), set_to_set(absl::in_place); + EXPECT_EQ(4, listener.construct0); + empty_to_empty = std::move(empty1); + empty_to_set = std::move(set1); + set_to_empty = std::move(empty2); + set_to_set = std::move(set2); + EXPECT_EQ(0, listener.copy); + EXPECT_EQ(1, listener.move); + EXPECT_EQ(1, listener.destruct); + EXPECT_EQ(1, listener.move_assign); + } + // std::optional doesn't support volatile nontrivial types. +#ifndef ABSL_USES_STD_OPTIONAL + { + StructorListener listener; + Listenable::listener = &listener; + + absl::optional<volatile Listenable> empty1, empty2, set1(absl::in_place), + set2(absl::in_place); + EXPECT_EQ(2, listener.construct0); + absl::optional<volatile Listenable> empty_to_empty, empty_to_set, + set_to_empty(absl::in_place), set_to_set(absl::in_place); + EXPECT_EQ(4, listener.construct0); + empty_to_empty = std::move(empty1); // no effect + empty_to_set = std::move(set1); // move construct + set_to_empty = std::move(empty2); // destruct + set_to_set = std::move(set2); // move assign + EXPECT_EQ(0, listener.volatile_copy); + EXPECT_EQ(1, listener.volatile_move); + EXPECT_EQ(1, listener.destruct); + EXPECT_EQ(1, listener.volatile_move_assign); + } +#endif // ABSL_USES_STD_OPTIONAL + EXPECT_FALSE(absl::is_move_assignable<absl::optional<const int>>::value); + EXPECT_TRUE(absl::is_move_assignable<absl::optional<Copyable>>::value); + EXPECT_TRUE(absl::is_move_assignable<absl::optional<MoveableThrow>>::value); + EXPECT_TRUE(absl::is_move_assignable<absl::optional<MoveableNoThrow>>::value); + EXPECT_FALSE(absl::is_move_assignable<absl::optional<NonMovable>>::value); + + EXPECT_FALSE( + std::is_nothrow_move_assignable<absl::optional<MoveableThrow>>::value); + EXPECT_TRUE( + std::is_nothrow_move_assignable<absl::optional<MoveableNoThrow>>::value); +} + +struct NoConvertToOptional { + // disable implicit conversion from const NoConvertToOptional& + // to absl::optional<NoConvertToOptional>. + NoConvertToOptional(const NoConvertToOptional&) = delete; +}; + +struct CopyConvert { + CopyConvert(const NoConvertToOptional&); + CopyConvert& operator=(const CopyConvert&) = delete; + CopyConvert& operator=(const NoConvertToOptional&); +}; + +struct CopyConvertFromOptional { + CopyConvertFromOptional(const NoConvertToOptional&); + CopyConvertFromOptional(const absl::optional<NoConvertToOptional>&); + CopyConvertFromOptional& operator=(const CopyConvertFromOptional&) = delete; + CopyConvertFromOptional& operator=(const NoConvertToOptional&); + CopyConvertFromOptional& operator=( + const absl::optional<NoConvertToOptional>&); +}; + +struct MoveConvert { + MoveConvert(NoConvertToOptional&&); + MoveConvert& operator=(const MoveConvert&) = delete; + MoveConvert& operator=(NoConvertToOptional&&); +}; + +struct MoveConvertFromOptional { + MoveConvertFromOptional(NoConvertToOptional&&); + MoveConvertFromOptional(absl::optional<NoConvertToOptional>&&); + MoveConvertFromOptional& operator=(const MoveConvertFromOptional&) = delete; + MoveConvertFromOptional& operator=(NoConvertToOptional&&); + MoveConvertFromOptional& operator=(absl::optional<NoConvertToOptional>&&); +}; + +// template <typename U = T> absl::optional<T>& operator=(U&& v); +TEST(optionalTest, ValueAssignment) { + absl::optional<int> opt; + EXPECT_FALSE(opt); + opt = 42; + EXPECT_TRUE(opt); + EXPECT_EQ(42, opt.value()); + opt = absl::nullopt; + EXPECT_FALSE(opt); + opt = 42; + EXPECT_TRUE(opt); + EXPECT_EQ(42, opt.value()); + opt = 43; + EXPECT_TRUE(opt); + EXPECT_EQ(43, opt.value()); + opt = {}; // this should clear optional + EXPECT_FALSE(opt); + + opt = {44}; + EXPECT_TRUE(opt); + EXPECT_EQ(44, opt.value()); + + // U = const NoConvertToOptional& + EXPECT_TRUE((std::is_assignable<absl::optional<CopyConvert>&, + const NoConvertToOptional&>::value)); + // U = const absl::optional<NoConvertToOptional>& + EXPECT_TRUE((std::is_assignable<absl::optional<CopyConvertFromOptional>&, + const NoConvertToOptional&>::value)); + // U = const NoConvertToOptional& triggers SFINAE because + // std::is_constructible_v<MoveConvert, const NoConvertToOptional&> is false + EXPECT_FALSE((std::is_assignable<absl::optional<MoveConvert>&, + const NoConvertToOptional&>::value)); + // U = NoConvertToOptional + EXPECT_TRUE((std::is_assignable<absl::optional<MoveConvert>&, + NoConvertToOptional&&>::value)); + // U = const NoConvertToOptional& triggers SFINAE because + // std::is_constructible_v<MoveConvertFromOptional, const + // NoConvertToOptional&> is false + EXPECT_FALSE((std::is_assignable<absl::optional<MoveConvertFromOptional>&, + const NoConvertToOptional&>::value)); + // U = NoConvertToOptional + EXPECT_TRUE((std::is_assignable<absl::optional<MoveConvertFromOptional>&, + NoConvertToOptional&&>::value)); + // U = const absl::optional<NoConvertToOptional>& + EXPECT_TRUE( + (std::is_assignable<absl::optional<CopyConvertFromOptional>&, + const absl::optional<NoConvertToOptional>&>::value)); + // U = absl::optional<NoConvertToOptional> + EXPECT_TRUE( + (std::is_assignable<absl::optional<MoveConvertFromOptional>&, + absl::optional<NoConvertToOptional>&&>::value)); +} + +// template <typename U> absl::optional<T>& operator=(const absl::optional<U>& +// rhs); template <typename U> absl::optional<T>& operator=(absl::optional<U>&& +// rhs); +TEST(optionalTest, ConvertingAssignment) { + absl::optional<int> opt_i; + absl::optional<char> opt_c('c'); + opt_i = opt_c; + EXPECT_TRUE(opt_i); + EXPECT_EQ(*opt_c, *opt_i); + opt_i = absl::optional<char>(); + EXPECT_FALSE(opt_i); + opt_i = absl::optional<char>('d'); + EXPECT_TRUE(opt_i); + EXPECT_EQ('d', *opt_i); + + absl::optional<std::string> opt_str; + absl::optional<const char*> opt_cstr("abc"); + opt_str = opt_cstr; + EXPECT_TRUE(opt_str); + EXPECT_EQ(std::string("abc"), *opt_str); + opt_str = absl::optional<const char*>(); + EXPECT_FALSE(opt_str); + opt_str = absl::optional<const char*>("def"); + EXPECT_TRUE(opt_str); + EXPECT_EQ(std::string("def"), *opt_str); + + // operator=(const absl::optional<U>&) with U = NoConvertToOptional + EXPECT_TRUE( + (std::is_assignable<absl::optional<CopyConvert>, + const absl::optional<NoConvertToOptional>&>::value)); + // operator=(const absl::optional<U>&) with U = NoConvertToOptional + // triggers SFINAE because + // std::is_constructible_v<MoveConvert, const NoConvertToOptional&> is false + EXPECT_FALSE( + (std::is_assignable<absl::optional<MoveConvert>&, + const absl::optional<NoConvertToOptional>&>::value)); + // operator=(absl::optional<U>&&) with U = NoConvertToOptional + EXPECT_TRUE( + (std::is_assignable<absl::optional<MoveConvert>&, + absl::optional<NoConvertToOptional>&&>::value)); + // operator=(const absl::optional<U>&) with U = NoConvertToOptional triggers + // SFINAE because std::is_constructible_v<MoveConvertFromOptional, const + // NoConvertToOptional&> is false. operator=(U&&) with U = const + // absl::optional<NoConverToOptional>& triggers SFINAE because + // std::is_constructible<MoveConvertFromOptional, + // absl::optional<NoConvertToOptional>&&> is true. + EXPECT_FALSE( + (std::is_assignable<absl::optional<MoveConvertFromOptional>&, + const absl::optional<NoConvertToOptional>&>::value)); +} + +TEST(optionalTest, ResetAndHasValue) { + StructorListener listener; + Listenable::listener = &listener; + absl::optional<Listenable> opt; + EXPECT_FALSE(opt); + EXPECT_FALSE(opt.has_value()); + opt.emplace(); + EXPECT_TRUE(opt); + EXPECT_TRUE(opt.has_value()); + opt.reset(); + EXPECT_FALSE(opt); + EXPECT_FALSE(opt.has_value()); + EXPECT_EQ(1, listener.destruct); + opt.reset(); + EXPECT_FALSE(opt); + EXPECT_FALSE(opt.has_value()); + + constexpr absl::optional<int> empty; + static_assert(!empty.has_value(), ""); + constexpr absl::optional<int> nonempty(1); + static_assert(nonempty.has_value(), ""); +} + +TEST(optionalTest, Emplace) { + StructorListener listener; + Listenable::listener = &listener; + absl::optional<Listenable> opt; + EXPECT_FALSE(opt); + opt.emplace(1); + EXPECT_TRUE(opt); + opt.emplace(1, 2); + EXPECT_EQ(1, listener.construct1); + EXPECT_EQ(1, listener.construct2); + EXPECT_EQ(1, listener.destruct); + + absl::optional<std::string> o; + EXPECT_TRUE((std::is_same<std::string&, decltype(o.emplace("abc"))>::value)); + std::string& ref = o.emplace("abc"); + EXPECT_EQ(&ref, &o.value()); +} + +TEST(optionalTest, ListEmplace) { + StructorListener listener; + Listenable::listener = &listener; + absl::optional<Listenable> opt; + EXPECT_FALSE(opt); + opt.emplace({1}); + EXPECT_TRUE(opt); + opt.emplace({1, 2}); + EXPECT_EQ(2, listener.listinit); + EXPECT_EQ(1, listener.destruct); + + absl::optional<Listenable> o; + EXPECT_TRUE((std::is_same<Listenable&, decltype(o.emplace({1}))>::value)); + Listenable& ref = o.emplace({1}); + EXPECT_EQ(&ref, &o.value()); +} + +TEST(optionalTest, Swap) { + absl::optional<int> opt_empty, opt1 = 1, opt2 = 2; + EXPECT_FALSE(opt_empty); + EXPECT_TRUE(opt1); + EXPECT_EQ(1, opt1.value()); + EXPECT_TRUE(opt2); + EXPECT_EQ(2, opt2.value()); + swap(opt_empty, opt1); + EXPECT_FALSE(opt1); + EXPECT_TRUE(opt_empty); + EXPECT_EQ(1, opt_empty.value()); + EXPECT_TRUE(opt2); + EXPECT_EQ(2, opt2.value()); + swap(opt_empty, opt1); + EXPECT_FALSE(opt_empty); + EXPECT_TRUE(opt1); + EXPECT_EQ(1, opt1.value()); + EXPECT_TRUE(opt2); + EXPECT_EQ(2, opt2.value()); + swap(opt1, opt2); + EXPECT_FALSE(opt_empty); + EXPECT_TRUE(opt1); + EXPECT_EQ(2, opt1.value()); + EXPECT_TRUE(opt2); + EXPECT_EQ(1, opt2.value()); + + EXPECT_TRUE(noexcept(opt1.swap(opt2))); + EXPECT_TRUE(noexcept(swap(opt1, opt2))); +} + +template <int v> +struct DeletedOpAddr { + int value = v; + constexpr DeletedOpAddr() = default; + constexpr const DeletedOpAddr<v>* operator&() const = delete; // NOLINT + DeletedOpAddr<v>* operator&() = delete; // NOLINT +}; + +// The static_assert featuring a constexpr call to operator->() is commented out +// to document the fact that the current implementation of absl::optional<T> +// expects such usecases to be malformed and not compile. +TEST(optionalTest, OperatorAddr) { + constexpr int v = -1; + { // constexpr + constexpr absl::optional<DeletedOpAddr<v>> opt(absl::in_place_t{}); + static_assert(opt.has_value(), ""); + // static_assert(opt->value == v, ""); + static_assert((*opt).value == v, ""); + } + { // non-constexpr + const absl::optional<DeletedOpAddr<v>> opt(absl::in_place_t{}); + EXPECT_TRUE(opt.has_value()); + EXPECT_TRUE(opt->value == v); + EXPECT_TRUE((*opt).value == v); + } +} + +TEST(optionalTest, PointerStuff) { + absl::optional<std::string> opt(absl::in_place, "foo"); + EXPECT_EQ("foo", *opt); + const auto& opt_const = opt; + EXPECT_EQ("foo", *opt_const); + EXPECT_EQ(opt->size(), 3); + EXPECT_EQ(opt_const->size(), 3); + + constexpr absl::optional<ConstexprType> opt1(1); + static_assert((*opt1).x == ConstexprType::kCtorInt, ""); +} + +// gcc has a bug pre 4.9.1 where it doesn't do correct overload resolution +// when overloads are const-qualified and *this is an raluve. +// Skip that test to make the build green again when using the old compiler. +// https://gcc.gnu.org/bugzilla/show_bug.cgi?id=59296 is fixed in 4.9.1. +#if defined(__GNUC__) && !defined(__clang__) +#define GCC_VERSION (__GNUC__ * 10000 \ + + __GNUC_MINOR__ * 100 \ + + __GNUC_PATCHLEVEL__) +#if GCC_VERSION < 40901 +#define ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG +#endif +#endif + +// MSVC has a bug with "cv-qualifiers in class construction", fixed in 2017. See +// https://docs.microsoft.com/en-us/cpp/cpp-conformance-improvements-2017#bug-fixes +// The compiler some incorrectly ingores the cv-qualifier when generating a +// class object via a constructor call. For example: +// +// class optional { +// constexpr T&& value() &&; +// constexpr const T&& value() const &&; +// } +// +// using COI = const absl::optional<int>; +// static_assert(2 == COI(2).value(), ""); // const && +// +// This should invoke the "const &&" overload but since it ignores the const +// qualifier it finds the "&&" overload the best candidate. +#if defined(_MSC_VER) && _MSC_VER < 1910 +#define ABSL_SKIP_OVERLOAD_TEST_DUE_TO_MSVC_BUG +#endif + +TEST(optionalTest, Value) { + using O = absl::optional<std::string>; + using CO = const absl::optional<std::string>; + using OC = absl::optional<const std::string>; + O lvalue(absl::in_place, "lvalue"); + CO clvalue(absl::in_place, "clvalue"); + OC lvalue_c(absl::in_place, "lvalue_c"); + EXPECT_EQ("lvalue", lvalue.value()); + EXPECT_EQ("clvalue", clvalue.value()); + EXPECT_EQ("lvalue_c", lvalue_c.value()); + EXPECT_EQ("xvalue", O(absl::in_place, "xvalue").value()); + EXPECT_EQ("xvalue_c", OC(absl::in_place, "xvalue_c").value()); +#ifndef ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG + EXPECT_EQ("cxvalue", CO(absl::in_place, "cxvalue").value()); +#endif + EXPECT_EQ("&", TypeQuals(lvalue.value())); + EXPECT_EQ("c&", TypeQuals(clvalue.value())); + EXPECT_EQ("c&", TypeQuals(lvalue_c.value())); + EXPECT_EQ("&&", TypeQuals(O(absl::in_place, "xvalue").value())); +#if !defined(ABSL_SKIP_OVERLOAD_TEST_DUE_TO_MSVC_BUG) && \ + !defined(ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG) + EXPECT_EQ("c&&", TypeQuals(CO(absl::in_place, "cxvalue").value())); +#endif + EXPECT_EQ("c&&", TypeQuals(OC(absl::in_place, "xvalue_c").value())); + + // test on volatile type + using OV = absl::optional<volatile int>; + OV lvalue_v(absl::in_place, 42); + EXPECT_EQ(42, lvalue_v.value()); + EXPECT_EQ(42, OV(42).value()); + EXPECT_TRUE((std::is_same<volatile int&, decltype(lvalue_v.value())>::value)); + EXPECT_TRUE((std::is_same<volatile int&&, decltype(OV(42).value())>::value)); + + // test exception throw on value() + absl::optional<int> empty; +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW((void)empty.value(), absl::bad_optional_access); +#else + EXPECT_DEATH_IF_SUPPORTED((void)empty.value(), "Bad optional access"); +#endif + + // test constexpr value() + constexpr absl::optional<int> o1(1); + static_assert(1 == o1.value(), ""); // const & +#if !defined(_MSC_VER) && !defined(ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG) + using COI = const absl::optional<int>; + static_assert(2 == COI(2).value(), ""); // const && +#endif +} + +TEST(optionalTest, DerefOperator) { + using O = absl::optional<std::string>; + using CO = const absl::optional<std::string>; + using OC = absl::optional<const std::string>; + O lvalue(absl::in_place, "lvalue"); + CO clvalue(absl::in_place, "clvalue"); + OC lvalue_c(absl::in_place, "lvalue_c"); + EXPECT_EQ("lvalue", *lvalue); + EXPECT_EQ("clvalue", *clvalue); + EXPECT_EQ("lvalue_c", *lvalue_c); + EXPECT_EQ("xvalue", *O(absl::in_place, "xvalue")); + EXPECT_EQ("xvalue_c", *OC(absl::in_place, "xvalue_c")); +#ifndef ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG + EXPECT_EQ("cxvalue", *CO(absl::in_place, "cxvalue")); +#endif + EXPECT_EQ("&", TypeQuals(*lvalue)); + EXPECT_EQ("c&", TypeQuals(*clvalue)); + EXPECT_EQ("&&", TypeQuals(*O(absl::in_place, "xvalue"))); +#if !defined(ABSL_SKIP_OVERLOAD_TEST_DUE_TO_MSVC_BUG) && \ + !defined(ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG) + EXPECT_EQ("c&&", TypeQuals(*CO(absl::in_place, "cxvalue"))); +#endif + EXPECT_EQ("c&&", TypeQuals(*OC(absl::in_place, "xvalue_c"))); + + // test on volatile type + using OV = absl::optional<volatile int>; + OV lvalue_v(absl::in_place, 42); + EXPECT_EQ(42, *lvalue_v); + EXPECT_EQ(42, *OV(42)); + EXPECT_TRUE((std::is_same<volatile int&, decltype(*lvalue_v)>::value)); + EXPECT_TRUE((std::is_same<volatile int&&, decltype(*OV(42))>::value)); + + constexpr absl::optional<int> opt1(1); + static_assert(*opt1 == 1, ""); +#if !defined(_MSC_VER) && !defined(ABSL_SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG) + using COI = const absl::optional<int>; + static_assert(*COI(2) == 2, ""); +#endif +} + +TEST(optionalTest, ValueOr) { + absl::optional<double> opt_empty, opt_set = 1.2; + EXPECT_EQ(42.0, opt_empty.value_or(42)); + EXPECT_EQ(1.2, opt_set.value_or(42)); + EXPECT_EQ(42.0, absl::optional<double>().value_or(42)); + EXPECT_EQ(1.2, absl::optional<double>(1.2).value_or(42)); + + constexpr absl::optional<double> copt_empty, copt_set = {1.2}; + static_assert(42.0 == copt_empty.value_or(42), ""); + static_assert(1.2 == copt_set.value_or(42), ""); +#ifndef ABSL_SKIP_OVERLOAD_TEST_DUE_TO_MSVC_BUG + using COD = const absl::optional<double>; + static_assert(42.0 == COD().value_or(42), ""); + static_assert(1.2 == COD(1.2).value_or(42), ""); +#endif +} + +// make_optional cannot be constexpr until C++17 +TEST(optionalTest, make_optional) { + auto opt_int = absl::make_optional(42); + EXPECT_TRUE((std::is_same<decltype(opt_int), absl::optional<int>>::value)); + EXPECT_EQ(42, opt_int); + + StructorListener listener; + Listenable::listener = &listener; + + absl::optional<Listenable> opt0 = absl::make_optional<Listenable>(); + EXPECT_EQ(1, listener.construct0); + absl::optional<Listenable> opt1 = absl::make_optional<Listenable>(1); + EXPECT_EQ(1, listener.construct1); + absl::optional<Listenable> opt2 = absl::make_optional<Listenable>(1, 2); + EXPECT_EQ(1, listener.construct2); + absl::optional<Listenable> opt3 = absl::make_optional<Listenable>({1}); + absl::optional<Listenable> opt4 = absl::make_optional<Listenable>({1, 2}); + EXPECT_EQ(2, listener.listinit); + + // Constexpr tests on trivially copyable types + // optional<T> has trivial copy/move ctors when T is trivially copyable. + // For nontrivial types with constexpr constructors, we need copy elision in + // C++17 for make_optional to be constexpr. + { + constexpr absl::optional<int> c_opt = absl::make_optional(42); + static_assert(c_opt.value() == 42, ""); + } + { + struct TrivialCopyable { + constexpr TrivialCopyable() : x(0) {} + constexpr explicit TrivialCopyable(int i) : x(i) {} + int x; + }; + + constexpr TrivialCopyable v; + constexpr absl::optional<TrivialCopyable> c_opt0 = absl::make_optional(v); + static_assert((*c_opt0).x == 0, ""); + constexpr absl::optional<TrivialCopyable> c_opt1 = + absl::make_optional<TrivialCopyable>(); + static_assert((*c_opt1).x == 0, ""); + constexpr absl::optional<TrivialCopyable> c_opt2 = + absl::make_optional<TrivialCopyable>(42); + static_assert((*c_opt2).x == 42, ""); + } +} + +template <typename T, typename U> +void optionalTest_Comparisons_EXPECT_LESS(T x, U y) { + EXPECT_FALSE(x == y); + EXPECT_TRUE(x != y); + EXPECT_TRUE(x < y); + EXPECT_FALSE(x > y); + EXPECT_TRUE(x <= y); + EXPECT_FALSE(x >= y); +} + +template <typename T, typename U> +void optionalTest_Comparisons_EXPECT_SAME(T x, U y) { + EXPECT_TRUE(x == y); + EXPECT_FALSE(x != y); + EXPECT_FALSE(x < y); + EXPECT_FALSE(x > y); + EXPECT_TRUE(x <= y); + EXPECT_TRUE(x >= y); +} + +template <typename T, typename U> +void optionalTest_Comparisons_EXPECT_GREATER(T x, U y) { + EXPECT_FALSE(x == y); + EXPECT_TRUE(x != y); + EXPECT_FALSE(x < y); + EXPECT_TRUE(x > y); + EXPECT_FALSE(x <= y); + EXPECT_TRUE(x >= y); +} + + +template <typename T, typename U, typename V> +void TestComparisons() { + absl::optional<T> ae, a2{2}, a4{4}; + absl::optional<U> be, b2{2}, b4{4}; + V v3 = 3; + + // LHS: absl::nullopt, ae, a2, v3, a4 + // RHS: absl::nullopt, be, b2, v3, b4 + + // optionalTest_Comparisons_EXPECT_NOT_TO_WORK(absl::nullopt,absl::nullopt); + optionalTest_Comparisons_EXPECT_SAME(absl::nullopt, be); + optionalTest_Comparisons_EXPECT_LESS(absl::nullopt, b2); + // optionalTest_Comparisons_EXPECT_NOT_TO_WORK(absl::nullopt,v3); + optionalTest_Comparisons_EXPECT_LESS(absl::nullopt, b4); + + optionalTest_Comparisons_EXPECT_SAME(ae, absl::nullopt); + optionalTest_Comparisons_EXPECT_SAME(ae, be); + optionalTest_Comparisons_EXPECT_LESS(ae, b2); + optionalTest_Comparisons_EXPECT_LESS(ae, v3); + optionalTest_Comparisons_EXPECT_LESS(ae, b4); + + optionalTest_Comparisons_EXPECT_GREATER(a2, absl::nullopt); + optionalTest_Comparisons_EXPECT_GREATER(a2, be); + optionalTest_Comparisons_EXPECT_SAME(a2, b2); + optionalTest_Comparisons_EXPECT_LESS(a2, v3); + optionalTest_Comparisons_EXPECT_LESS(a2, b4); + + // optionalTest_Comparisons_EXPECT_NOT_TO_WORK(v3,absl::nullopt); + optionalTest_Comparisons_EXPECT_GREATER(v3, be); + optionalTest_Comparisons_EXPECT_GREATER(v3, b2); + optionalTest_Comparisons_EXPECT_SAME(v3, v3); + optionalTest_Comparisons_EXPECT_LESS(v3, b4); + + optionalTest_Comparisons_EXPECT_GREATER(a4, absl::nullopt); + optionalTest_Comparisons_EXPECT_GREATER(a4, be); + optionalTest_Comparisons_EXPECT_GREATER(a4, b2); + optionalTest_Comparisons_EXPECT_GREATER(a4, v3); + optionalTest_Comparisons_EXPECT_SAME(a4, b4); +} + +struct Int1 { + Int1() = default; + Int1(int i) : i(i) {} // NOLINT(runtime/explicit) + int i; +}; + +struct Int2 { + Int2() = default; + Int2(int i) : i(i) {} // NOLINT(runtime/explicit) + int i; +}; + +// comparison between Int1 and Int2 +constexpr bool operator==(const Int1& lhs, const Int2& rhs) { + return lhs.i == rhs.i; +} +constexpr bool operator!=(const Int1& lhs, const Int2& rhs) { + return !(lhs == rhs); +} +constexpr bool operator<(const Int1& lhs, const Int2& rhs) { + return lhs.i < rhs.i; +} +constexpr bool operator<=(const Int1& lhs, const Int2& rhs) { + return lhs < rhs || lhs == rhs; +} +constexpr bool operator>(const Int1& lhs, const Int2& rhs) { + return !(lhs <= rhs); +} +constexpr bool operator>=(const Int1& lhs, const Int2& rhs) { + return !(lhs < rhs); +} + +TEST(optionalTest, Comparisons) { + TestComparisons<int, int, int>(); + TestComparisons<const int, int, int>(); + TestComparisons<Int1, int, int>(); + TestComparisons<int, Int2, int>(); + TestComparisons<Int1, Int2, int>(); + + // compare absl::optional<std::string> with const char* + absl::optional<std::string> opt_str = "abc"; + const char* cstr = "abc"; + EXPECT_TRUE(opt_str == cstr); + // compare absl::optional<std::string> with absl::optional<const char*> + absl::optional<const char*> opt_cstr = cstr; + EXPECT_TRUE(opt_str == opt_cstr); + // compare absl::optional<std::string> with absl::optional<absl::string_view> + absl::optional<absl::string_view> e1; + absl::optional<std::string> e2; + EXPECT_TRUE(e1 == e2); +} + + +TEST(optionalTest, SwapRegression) { + StructorListener listener; + Listenable::listener = &listener; + + { + absl::optional<Listenable> a; + absl::optional<Listenable> b(absl::in_place); + a.swap(b); + } + + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(1, listener.move); + EXPECT_EQ(2, listener.destruct); + + { + absl::optional<Listenable> a(absl::in_place); + absl::optional<Listenable> b; + a.swap(b); + } + + EXPECT_EQ(2, listener.construct0); + EXPECT_EQ(2, listener.move); + EXPECT_EQ(4, listener.destruct); +} + +TEST(optionalTest, BigStringLeakCheck) { + constexpr size_t n = 1 << 16; + + using OS = absl::optional<std::string>; + + OS a; + OS b = absl::nullopt; + OS c = std::string(n, 'c'); + std::string sd(n, 'd'); + OS d = sd; + OS e(absl::in_place, n, 'e'); + OS f; + f.emplace(n, 'f'); + + OS ca(a); + OS cb(b); + OS cc(c); + OS cd(d); + OS ce(e); + + OS oa; + OS ob = absl::nullopt; + OS oc = std::string(n, 'c'); + std::string sod(n, 'd'); + OS od = sod; + OS oe(absl::in_place, n, 'e'); + OS of; + of.emplace(n, 'f'); + + OS ma(std::move(oa)); + OS mb(std::move(ob)); + OS mc(std::move(oc)); + OS md(std::move(od)); + OS me(std::move(oe)); + OS mf(std::move(of)); + + OS aa1; + OS ab1 = absl::nullopt; + OS ac1 = std::string(n, 'c'); + std::string sad1(n, 'd'); + OS ad1 = sad1; + OS ae1(absl::in_place, n, 'e'); + OS af1; + af1.emplace(n, 'f'); + + OS aa2; + OS ab2 = absl::nullopt; + OS ac2 = std::string(n, 'c'); + std::string sad2(n, 'd'); + OS ad2 = sad2; + OS ae2(absl::in_place, n, 'e'); + OS af2; + af2.emplace(n, 'f'); + + aa1 = af2; + ab1 = ae2; + ac1 = ad2; + ad1 = ac2; + ae1 = ab2; + af1 = aa2; + + OS aa3; + OS ab3 = absl::nullopt; + OS ac3 = std::string(n, 'c'); + std::string sad3(n, 'd'); + OS ad3 = sad3; + OS ae3(absl::in_place, n, 'e'); + OS af3; + af3.emplace(n, 'f'); + + aa3 = absl::nullopt; + ab3 = absl::nullopt; + ac3 = absl::nullopt; + ad3 = absl::nullopt; + ae3 = absl::nullopt; + af3 = absl::nullopt; + + OS aa4; + OS ab4 = absl::nullopt; + OS ac4 = std::string(n, 'c'); + std::string sad4(n, 'd'); + OS ad4 = sad4; + OS ae4(absl::in_place, n, 'e'); + OS af4; + af4.emplace(n, 'f'); + + aa4 = OS(absl::in_place, n, 'a'); + ab4 = OS(absl::in_place, n, 'b'); + ac4 = OS(absl::in_place, n, 'c'); + ad4 = OS(absl::in_place, n, 'd'); + ae4 = OS(absl::in_place, n, 'e'); + af4 = OS(absl::in_place, n, 'f'); + + OS aa5; + OS ab5 = absl::nullopt; + OS ac5 = std::string(n, 'c'); + std::string sad5(n, 'd'); + OS ad5 = sad5; + OS ae5(absl::in_place, n, 'e'); + OS af5; + af5.emplace(n, 'f'); + + std::string saa5(n, 'a'); + std::string sab5(n, 'a'); + std::string sac5(n, 'a'); + std::string sad52(n, 'a'); + std::string sae5(n, 'a'); + std::string saf5(n, 'a'); + + aa5 = saa5; + ab5 = sab5; + ac5 = sac5; + ad5 = sad52; + ae5 = sae5; + af5 = saf5; + + OS aa6; + OS ab6 = absl::nullopt; + OS ac6 = std::string(n, 'c'); + std::string sad6(n, 'd'); + OS ad6 = sad6; + OS ae6(absl::in_place, n, 'e'); + OS af6; + af6.emplace(n, 'f'); + + aa6 = std::string(n, 'a'); + ab6 = std::string(n, 'b'); + ac6 = std::string(n, 'c'); + ad6 = std::string(n, 'd'); + ae6 = std::string(n, 'e'); + af6 = std::string(n, 'f'); + + OS aa7; + OS ab7 = absl::nullopt; + OS ac7 = std::string(n, 'c'); + std::string sad7(n, 'd'); + OS ad7 = sad7; + OS ae7(absl::in_place, n, 'e'); + OS af7; + af7.emplace(n, 'f'); + + aa7.emplace(n, 'A'); + ab7.emplace(n, 'B'); + ac7.emplace(n, 'C'); + ad7.emplace(n, 'D'); + ae7.emplace(n, 'E'); + af7.emplace(n, 'F'); +} + +TEST(optionalTest, MoveAssignRegression) { + StructorListener listener; + Listenable::listener = &listener; + + { + absl::optional<Listenable> a; + Listenable b; + a = std::move(b); + } + + EXPECT_EQ(1, listener.construct0); + EXPECT_EQ(1, listener.move); + EXPECT_EQ(2, listener.destruct); +} + +TEST(optionalTest, ValueType) { + EXPECT_TRUE((std::is_same<absl::optional<int>::value_type, int>::value)); + EXPECT_TRUE((std::is_same<absl::optional<std::string>::value_type, + std::string>::value)); + EXPECT_FALSE( + (std::is_same<absl::optional<int>::value_type, absl::nullopt_t>::value)); +} + +template <typename T> +struct is_hash_enabled_for { + template <typename U, typename = decltype(std::hash<U>()(std::declval<U>()))> + static std::true_type test(int); + + template <typename U> + static std::false_type test(...); + + static constexpr bool value = decltype(test<T>(0))::value; +}; + +TEST(optionalTest, Hash) { + std::hash<absl::optional<int>> hash; + std::set<size_t> hashcodes; + hashcodes.insert(hash(absl::nullopt)); + for (int i = 0; i < 100; ++i) { + hashcodes.insert(hash(i)); + } + EXPECT_GT(hashcodes.size(), 90); + + static_assert(is_hash_enabled_for<absl::optional<int>>::value, ""); + static_assert(is_hash_enabled_for<absl::optional<Hashable>>::value, ""); + static_assert( + absl::type_traits_internal::IsHashable<absl::optional<int>>::value, ""); + static_assert( + absl::type_traits_internal::IsHashable<absl::optional<Hashable>>::value, + ""); + absl::type_traits_internal::AssertHashEnabled<absl::optional<int>>(); + absl::type_traits_internal::AssertHashEnabled<absl::optional<Hashable>>(); + +#if ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + static_assert(!is_hash_enabled_for<absl::optional<NonHashable>>::value, ""); + static_assert(!absl::type_traits_internal::IsHashable< + absl::optional<NonHashable>>::value, + ""); +#endif + + // libstdc++ std::optional is missing remove_const_t, i.e. it's using + // std::hash<T> rather than std::hash<std::remove_const_t<T>>. + // Reference: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=82262 +#ifndef __GLIBCXX__ + static_assert(is_hash_enabled_for<absl::optional<const int>>::value, ""); + static_assert(is_hash_enabled_for<absl::optional<const Hashable>>::value, ""); + std::hash<absl::optional<const int>> c_hash; + for (int i = 0; i < 100; ++i) { + EXPECT_EQ(hash(i), c_hash(i)); + } +#endif +} + +struct MoveMeNoThrow { + MoveMeNoThrow() : x(0) {} + [[noreturn]] MoveMeNoThrow(const MoveMeNoThrow& other) : x(other.x) { + ABSL_RAW_LOG(FATAL, "Should not be called."); + abort(); + } + MoveMeNoThrow(MoveMeNoThrow&& other) noexcept : x(other.x) {} + int x; +}; + +struct MoveMeThrow { + MoveMeThrow() : x(0) {} + MoveMeThrow(const MoveMeThrow& other) : x(other.x) {} + MoveMeThrow(MoveMeThrow&& other) : x(other.x) {} + int x; +}; + +TEST(optionalTest, NoExcept) { + static_assert( + std::is_nothrow_move_constructible<absl::optional<MoveMeNoThrow>>::value, + ""); +#ifndef ABSL_USES_STD_OPTIONAL + static_assert(absl::default_allocator_is_nothrow::value == + std::is_nothrow_move_constructible< + absl::optional<MoveMeThrow>>::value, + ""); +#endif + std::vector<absl::optional<MoveMeNoThrow>> v; + for (int i = 0; i < 10; ++i) v.emplace_back(); +} + +struct AnyLike { + AnyLike(AnyLike&&) = default; + AnyLike(const AnyLike&) = default; + + template <typename ValueType, + typename T = typename std::decay<ValueType>::type, + typename std::enable_if< + !absl::disjunction< + std::is_same<AnyLike, T>, + absl::negation<std::is_copy_constructible<T>>>::value, + int>::type = 0> + AnyLike(ValueType&&) {} // NOLINT(runtime/explicit) + + AnyLike& operator=(AnyLike&&) = default; + AnyLike& operator=(const AnyLike&) = default; + + template <typename ValueType, + typename T = typename std::decay<ValueType>::type> + typename std::enable_if< + absl::conjunction<absl::negation<std::is_same<AnyLike, T>>, + std::is_copy_constructible<T>>::value, + AnyLike&>::type + operator=(ValueType&& /* rhs */) { + return *this; + } +}; + +TEST(optionalTest, ConstructionConstraints) { + EXPECT_TRUE((std::is_constructible<AnyLike, absl::optional<AnyLike>>::value)); + + EXPECT_TRUE( + (std::is_constructible<AnyLike, const absl::optional<AnyLike>&>::value)); + + EXPECT_TRUE((std::is_constructible<absl::optional<AnyLike>, AnyLike>::value)); + EXPECT_TRUE( + (std::is_constructible<absl::optional<AnyLike>, const AnyLike&>::value)); + + EXPECT_TRUE((std::is_convertible<absl::optional<AnyLike>, AnyLike>::value)); + + EXPECT_TRUE( + (std::is_convertible<const absl::optional<AnyLike>&, AnyLike>::value)); + + EXPECT_TRUE((std::is_convertible<AnyLike, absl::optional<AnyLike>>::value)); + EXPECT_TRUE( + (std::is_convertible<const AnyLike&, absl::optional<AnyLike>>::value)); + + EXPECT_TRUE(std::is_move_constructible<absl::optional<AnyLike>>::value); + EXPECT_TRUE(std::is_copy_constructible<absl::optional<AnyLike>>::value); +} + +TEST(optionalTest, AssignmentConstraints) { + EXPECT_TRUE((std::is_assignable<AnyLike&, absl::optional<AnyLike>>::value)); + EXPECT_TRUE( + (std::is_assignable<AnyLike&, const absl::optional<AnyLike>&>::value)); + EXPECT_TRUE((std::is_assignable<absl::optional<AnyLike>&, AnyLike>::value)); + EXPECT_TRUE( + (std::is_assignable<absl::optional<AnyLike>&, const AnyLike&>::value)); + EXPECT_TRUE(std::is_move_assignable<absl::optional<AnyLike>>::value); + EXPECT_TRUE(absl::is_copy_assignable<absl::optional<AnyLike>>::value); +} + +#if !defined(__EMSCRIPTEN__) +struct NestedClassBug { + struct Inner { + bool dummy = false; + }; + absl::optional<Inner> value; +}; + +TEST(optionalTest, InPlaceTSFINAEBug) { + NestedClassBug b; + ((void)b); + using Inner = NestedClassBug::Inner; + + EXPECT_TRUE((std::is_default_constructible<Inner>::value)); + EXPECT_TRUE((std::is_constructible<Inner>::value)); + EXPECT_TRUE( + (std::is_constructible<absl::optional<Inner>, absl::in_place_t>::value)); + + absl::optional<Inner> o(absl::in_place); + EXPECT_TRUE(o.has_value()); + o.emplace(); + EXPECT_TRUE(o.has_value()); +} +#endif // !defined(__EMSCRIPTEN__) + +} // namespace + +#endif // #if !defined(ABSL_USES_STD_OPTIONAL) diff --git a/third_party/abseil_cpp/absl/types/span.h b/third_party/abseil_cpp/absl/types/span.h new file mode 100644 index 0000000000..734db695e3 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/span.h @@ -0,0 +1,727 @@ +// +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// span.h +// ----------------------------------------------------------------------------- +// +// This header file defines a `Span<T>` type for holding a view of an existing +// array of data. The `Span` object, much like the `absl::string_view` object, +// does not own such data itself. A span provides a lightweight way to pass +// around view of such data. +// +// Additionally, this header file defines `MakeSpan()` and `MakeConstSpan()` +// factory functions, for clearly creating spans of type `Span<T>` or read-only +// `Span<const T>` when such types may be difficult to identify due to issues +// with implicit conversion. +// +// The C++ standards committee currently has a proposal for a `std::span` type, +// (http://wg21.link/p0122), which is not yet part of the standard (though may +// become part of C++20). As of August 2017, the differences between +// `absl::Span` and this proposal are: +// * `absl::Span` uses `size_t` for `size_type` +// * `absl::Span` has no `operator()` +// * `absl::Span` has no constructors for `std::unique_ptr` or +// `std::shared_ptr` +// * `absl::Span` has the factory functions `MakeSpan()` and +// `MakeConstSpan()` +// * `absl::Span` has `front()` and `back()` methods +// * bounds-checked access to `absl::Span` is accomplished with `at()` +// * `absl::Span` has compiler-provided move and copy constructors and +// assignment. This is due to them being specified as `constexpr`, but that +// implies const in C++11. +// * `absl::Span` has no `element_type` or `index_type` typedefs +// * A read-only `absl::Span<const T>` can be implicitly constructed from an +// initializer list. +// * `absl::Span` has no `bytes()`, `size_bytes()`, `as_bytes()`, or +// `as_mutable_bytes()` methods +// * `absl::Span` has no static extent template parameter, nor constructors +// which exist only because of the static extent parameter. +// * `absl::Span` has an explicit mutable-reference constructor +// +// For more information, see the class comments below. +#ifndef ABSL_TYPES_SPAN_H_ +#define ABSL_TYPES_SPAN_H_ + +#include <algorithm> +#include <cassert> +#include <cstddef> +#include <initializer_list> +#include <iterator> +#include <type_traits> +#include <utility> + +#include "absl/base/internal/throw_delegate.h" +#include "absl/base/macros.h" +#include "absl/base/optimization.h" +#include "absl/base/port.h" // TODO(strel): remove this include +#include "absl/meta/type_traits.h" +#include "absl/types/internal/span.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +//------------------------------------------------------------------------------ +// Span +//------------------------------------------------------------------------------ +// +// A `Span` is an "array view" type for holding a view of a contiguous data +// array; the `Span` object does not and cannot own such data itself. A span +// provides an easy way to provide overloads for anything operating on +// contiguous sequences without needing to manage pointers and array lengths +// manually. + +// A span is conceptually a pointer (ptr) and a length (size) into an already +// existing array of contiguous memory; the array it represents references the +// elements "ptr[0] .. ptr[size-1]". Passing a properly-constructed `Span` +// instead of raw pointers avoids many issues related to index out of bounds +// errors. +// +// Spans may also be constructed from containers holding contiguous sequences. +// Such containers must supply `data()` and `size() const` methods (e.g +// `std::vector<T>`, `absl::InlinedVector<T, N>`). All implicit conversions to +// `absl::Span` from such containers will create spans of type `const T`; +// spans which can mutate their values (of type `T`) must use explicit +// constructors. +// +// A `Span<T>` is somewhat analogous to an `absl::string_view`, but for an array +// of elements of type `T`. A user of `Span` must ensure that the data being +// pointed to outlives the `Span` itself. +// +// You can construct a `Span<T>` in several ways: +// +// * Explicitly from a reference to a container type +// * Explicitly from a pointer and size +// * Implicitly from a container type (but only for spans of type `const T`) +// * Using the `MakeSpan()` or `MakeConstSpan()` factory functions. +// +// Examples: +// +// // Construct a Span explicitly from a container: +// std::vector<int> v = {1, 2, 3, 4, 5}; +// auto span = absl::Span<const int>(v); +// +// // Construct a Span explicitly from a C-style array: +// int a[5] = {1, 2, 3, 4, 5}; +// auto span = absl::Span<const int>(a); +// +// // Construct a Span implicitly from a container +// void MyRoutine(absl::Span<const int> a) { +// ... +// } +// std::vector v = {1,2,3,4,5}; +// MyRoutine(v) // convert to Span<const T> +// +// Note that `Span` objects, in addition to requiring that the memory they +// point to remains alive, must also ensure that such memory does not get +// reallocated. Therefore, to avoid undefined behavior, containers with +// associated span views should not invoke operations that may reallocate memory +// (such as resizing) or invalidate iterators into the container. +// +// One common use for a `Span` is when passing arguments to a routine that can +// accept a variety of array types (e.g. a `std::vector`, `absl::InlinedVector`, +// a C-style array, etc.). Instead of creating overloads for each case, you +// can simply specify a `Span` as the argument to such a routine. +// +// Example: +// +// void MyRoutine(absl::Span<const int> a) { +// ... +// } +// +// std::vector v = {1,2,3,4,5}; +// MyRoutine(v); +// +// absl::InlinedVector<int, 4> my_inline_vector; +// MyRoutine(my_inline_vector); +// +// // Explicit constructor from pointer,size +// int* my_array = new int[10]; +// MyRoutine(absl::Span<const int>(my_array, 10)); +template <typename T> +class Span { + private: + // Used to determine whether a Span can be constructed from a container of + // type C. + template <typename C> + using EnableIfConvertibleFrom = + typename std::enable_if<span_internal::HasData<T, C>::value && + span_internal::HasSize<C>::value>::type; + + // Used to SFINAE-enable a function when the slice elements are const. + template <typename U> + using EnableIfConstView = + typename std::enable_if<std::is_const<T>::value, U>::type; + + // Used to SFINAE-enable a function when the slice elements are mutable. + template <typename U> + using EnableIfMutableView = + typename std::enable_if<!std::is_const<T>::value, U>::type; + + public: + using value_type = absl::remove_cv_t<T>; + using pointer = T*; + using const_pointer = const T*; + using reference = T&; + using const_reference = const T&; + using iterator = pointer; + using const_iterator = const_pointer; + using reverse_iterator = std::reverse_iterator<iterator>; + using const_reverse_iterator = std::reverse_iterator<const_iterator>; + using size_type = size_t; + using difference_type = ptrdiff_t; + + static const size_type npos = ~(size_type(0)); + + constexpr Span() noexcept : Span(nullptr, 0) {} + constexpr Span(pointer array, size_type length) noexcept + : ptr_(array), len_(length) {} + + // Implicit conversion constructors + template <size_t N> + constexpr Span(T (&a)[N]) noexcept // NOLINT(runtime/explicit) + : Span(a, N) {} + + // Explicit reference constructor for a mutable `Span<T>` type. Can be + // replaced with MakeSpan() to infer the type parameter. + template <typename V, typename = EnableIfConvertibleFrom<V>, + typename = EnableIfMutableView<V>> + explicit Span(V& v) noexcept // NOLINT(runtime/references) + : Span(span_internal::GetData(v), v.size()) {} + + // Implicit reference constructor for a read-only `Span<const T>` type + template <typename V, typename = EnableIfConvertibleFrom<V>, + typename = EnableIfConstView<V>> + constexpr Span(const V& v) noexcept // NOLINT(runtime/explicit) + : Span(span_internal::GetData(v), v.size()) {} + + // Implicit constructor from an initializer list, making it possible to pass a + // brace-enclosed initializer list to a function expecting a `Span`. Such + // spans constructed from an initializer list must be of type `Span<const T>`. + // + // void Process(absl::Span<const int> x); + // Process({1, 2, 3}); + // + // Note that as always the array referenced by the span must outlive the span. + // Since an initializer list constructor acts as if it is fed a temporary + // array (cf. C++ standard [dcl.init.list]/5), it's safe to use this + // constructor only when the `std::initializer_list` itself outlives the span. + // In order to meet this requirement it's sufficient to ensure that neither + // the span nor a copy of it is used outside of the expression in which it's + // created: + // + // // Assume that this function uses the array directly, not retaining any + // // copy of the span or pointer to any of its elements. + // void Process(absl::Span<const int> ints); + // + // // Okay: the std::initializer_list<int> will reference a temporary array + // // that isn't destroyed until after the call to Process returns. + // Process({ 17, 19 }); + // + // // Not okay: the storage used by the std::initializer_list<int> is not + // // allowed to be referenced after the first line. + // absl::Span<const int> ints = { 17, 19 }; + // Process(ints); + // + // // Not okay for the same reason as above: even when the elements of the + // // initializer list expression are not temporaries the underlying array + // // is, so the initializer list must still outlive the span. + // const int foo = 17; + // absl::Span<const int> ints = { foo }; + // Process(ints); + // + template <typename LazyT = T, + typename = EnableIfConstView<LazyT>> + Span( + std::initializer_list<value_type> v) noexcept // NOLINT(runtime/explicit) + : Span(v.begin(), v.size()) {} + + // Accessors + + // Span::data() + // + // Returns a pointer to the span's underlying array of data (which is held + // outside the span). + constexpr pointer data() const noexcept { return ptr_; } + + // Span::size() + // + // Returns the size of this span. + constexpr size_type size() const noexcept { return len_; } + + // Span::length() + // + // Returns the length (size) of this span. + constexpr size_type length() const noexcept { return size(); } + + // Span::empty() + // + // Returns a boolean indicating whether or not this span is considered empty. + constexpr bool empty() const noexcept { return size() == 0; } + + // Span::operator[] + // + // Returns a reference to the i'th element of this span. + constexpr reference operator[](size_type i) const noexcept { + // MSVC 2015 accepts this as constexpr, but not ptr_[i] + return ABSL_HARDENING_ASSERT(i < size()), *(data() + i); + } + + // Span::at() + // + // Returns a reference to the i'th element of this span. + constexpr reference at(size_type i) const { + return ABSL_PREDICT_TRUE(i < size()) // + ? *(data() + i) + : (base_internal::ThrowStdOutOfRange( + "Span::at failed bounds check"), + *(data() + i)); + } + + // Span::front() + // + // Returns a reference to the first element of this span. The span must not + // be empty. + constexpr reference front() const noexcept { + return ABSL_HARDENING_ASSERT(size() > 0), *data(); + } + + // Span::back() + // + // Returns a reference to the last element of this span. The span must not + // be empty. + constexpr reference back() const noexcept { + return ABSL_HARDENING_ASSERT(size() > 0), *(data() + size() - 1); + } + + // Span::begin() + // + // Returns an iterator pointing to the first element of this span, or `end()` + // if the span is empty. + constexpr iterator begin() const noexcept { return data(); } + + // Span::cbegin() + // + // Returns a const iterator pointing to the first element of this span, or + // `end()` if the span is empty. + constexpr const_iterator cbegin() const noexcept { return begin(); } + + // Span::end() + // + // Returns an iterator pointing just beyond the last element at the + // end of this span. This iterator acts as a placeholder; attempting to + // access it results in undefined behavior. + constexpr iterator end() const noexcept { return data() + size(); } + + // Span::cend() + // + // Returns a const iterator pointing just beyond the last element at the + // end of this span. This iterator acts as a placeholder; attempting to + // access it results in undefined behavior. + constexpr const_iterator cend() const noexcept { return end(); } + + // Span::rbegin() + // + // Returns a reverse iterator pointing to the last element at the end of this + // span, or `rend()` if the span is empty. + constexpr reverse_iterator rbegin() const noexcept { + return reverse_iterator(end()); + } + + // Span::crbegin() + // + // Returns a const reverse iterator pointing to the last element at the end of + // this span, or `crend()` if the span is empty. + constexpr const_reverse_iterator crbegin() const noexcept { return rbegin(); } + + // Span::rend() + // + // Returns a reverse iterator pointing just before the first element + // at the beginning of this span. This pointer acts as a placeholder; + // attempting to access its element results in undefined behavior. + constexpr reverse_iterator rend() const noexcept { + return reverse_iterator(begin()); + } + + // Span::crend() + // + // Returns a reverse const iterator pointing just before the first element + // at the beginning of this span. This pointer acts as a placeholder; + // attempting to access its element results in undefined behavior. + constexpr const_reverse_iterator crend() const noexcept { return rend(); } + + // Span mutations + + // Span::remove_prefix() + // + // Removes the first `n` elements from the span. + void remove_prefix(size_type n) noexcept { + ABSL_HARDENING_ASSERT(size() >= n); + ptr_ += n; + len_ -= n; + } + + // Span::remove_suffix() + // + // Removes the last `n` elements from the span. + void remove_suffix(size_type n) noexcept { + ABSL_HARDENING_ASSERT(size() >= n); + len_ -= n; + } + + // Span::subspan() + // + // Returns a `Span` starting at element `pos` and of length `len`. Both `pos` + // and `len` are of type `size_type` and thus non-negative. Parameter `pos` + // must be <= size(). Any `len` value that points past the end of the span + // will be trimmed to at most size() - `pos`. A default `len` value of `npos` + // ensures the returned subspan continues until the end of the span. + // + // Examples: + // + // std::vector<int> vec = {10, 11, 12, 13}; + // absl::MakeSpan(vec).subspan(1, 2); // {11, 12} + // absl::MakeSpan(vec).subspan(2, 8); // {12, 13} + // absl::MakeSpan(vec).subspan(1); // {11, 12, 13} + // absl::MakeSpan(vec).subspan(4); // {} + // absl::MakeSpan(vec).subspan(5); // throws std::out_of_range + constexpr Span subspan(size_type pos = 0, size_type len = npos) const { + return (pos <= size()) + ? Span(data() + pos, span_internal::Min(size() - pos, len)) + : (base_internal::ThrowStdOutOfRange("pos > size()"), Span()); + } + + // Span::first() + // + // Returns a `Span` containing first `len` elements. Parameter `len` is of + // type `size_type` and thus non-negative. `len` value must be <= size(). + // + // Examples: + // + // std::vector<int> vec = {10, 11, 12, 13}; + // absl::MakeSpan(vec).first(1); // {10} + // absl::MakeSpan(vec).first(3); // {10, 11, 12} + // absl::MakeSpan(vec).first(5); // throws std::out_of_range + constexpr Span first(size_type len) const { + return (len <= size()) + ? Span(data(), len) + : (base_internal::ThrowStdOutOfRange("len > size()"), Span()); + } + + // Span::last() + // + // Returns a `Span` containing last `len` elements. Parameter `len` is of + // type `size_type` and thus non-negative. `len` value must be <= size(). + // + // Examples: + // + // std::vector<int> vec = {10, 11, 12, 13}; + // absl::MakeSpan(vec).last(1); // {13} + // absl::MakeSpan(vec).last(3); // {11, 12, 13} + // absl::MakeSpan(vec).last(5); // throws std::out_of_range + constexpr Span last(size_type len) const { + return (len <= size()) + ? Span(size() - len + data(), len) + : (base_internal::ThrowStdOutOfRange("len > size()"), Span()); + } + + // Support for absl::Hash. + template <typename H> + friend H AbslHashValue(H h, Span v) { + return H::combine(H::combine_contiguous(std::move(h), v.data(), v.size()), + v.size()); + } + + private: + pointer ptr_; + size_type len_; +}; + +template <typename T> +const typename Span<T>::size_type Span<T>::npos; + +// Span relationals + +// Equality is compared element-by-element, while ordering is lexicographical. +// We provide three overloads for each operator to cover any combination on the +// left or right hand side of mutable Span<T>, read-only Span<const T>, and +// convertible-to-read-only Span<T>. +// TODO(zhangxy): Due to MSVC overload resolution bug with partial ordering +// template functions, 5 overloads per operator is needed as a workaround. We +// should update them to 3 overloads per operator using non-deduced context like +// string_view, i.e. +// - (Span<T>, Span<T>) +// - (Span<T>, non_deduced<Span<const T>>) +// - (non_deduced<Span<const T>>, Span<T>) + +// operator== +template <typename T> +bool operator==(Span<T> a, Span<T> b) { + return span_internal::EqualImpl<Span, const T>(a, b); +} +template <typename T> +bool operator==(Span<const T> a, Span<T> b) { + return span_internal::EqualImpl<Span, const T>(a, b); +} +template <typename T> +bool operator==(Span<T> a, Span<const T> b) { + return span_internal::EqualImpl<Span, const T>(a, b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator==(const U& a, Span<T> b) { + return span_internal::EqualImpl<Span, const T>(a, b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator==(Span<T> a, const U& b) { + return span_internal::EqualImpl<Span, const T>(a, b); +} + +// operator!= +template <typename T> +bool operator!=(Span<T> a, Span<T> b) { + return !(a == b); +} +template <typename T> +bool operator!=(Span<const T> a, Span<T> b) { + return !(a == b); +} +template <typename T> +bool operator!=(Span<T> a, Span<const T> b) { + return !(a == b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator!=(const U& a, Span<T> b) { + return !(a == b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator!=(Span<T> a, const U& b) { + return !(a == b); +} + +// operator< +template <typename T> +bool operator<(Span<T> a, Span<T> b) { + return span_internal::LessThanImpl<Span, const T>(a, b); +} +template <typename T> +bool operator<(Span<const T> a, Span<T> b) { + return span_internal::LessThanImpl<Span, const T>(a, b); +} +template <typename T> +bool operator<(Span<T> a, Span<const T> b) { + return span_internal::LessThanImpl<Span, const T>(a, b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator<(const U& a, Span<T> b) { + return span_internal::LessThanImpl<Span, const T>(a, b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator<(Span<T> a, const U& b) { + return span_internal::LessThanImpl<Span, const T>(a, b); +} + +// operator> +template <typename T> +bool operator>(Span<T> a, Span<T> b) { + return b < a; +} +template <typename T> +bool operator>(Span<const T> a, Span<T> b) { + return b < a; +} +template <typename T> +bool operator>(Span<T> a, Span<const T> b) { + return b < a; +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator>(const U& a, Span<T> b) { + return b < a; +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator>(Span<T> a, const U& b) { + return b < a; +} + +// operator<= +template <typename T> +bool operator<=(Span<T> a, Span<T> b) { + return !(b < a); +} +template <typename T> +bool operator<=(Span<const T> a, Span<T> b) { + return !(b < a); +} +template <typename T> +bool operator<=(Span<T> a, Span<const T> b) { + return !(b < a); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator<=(const U& a, Span<T> b) { + return !(b < a); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator<=(Span<T> a, const U& b) { + return !(b < a); +} + +// operator>= +template <typename T> +bool operator>=(Span<T> a, Span<T> b) { + return !(a < b); +} +template <typename T> +bool operator>=(Span<const T> a, Span<T> b) { + return !(a < b); +} +template <typename T> +bool operator>=(Span<T> a, Span<const T> b) { + return !(a < b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator>=(const U& a, Span<T> b) { + return !(a < b); +} +template < + typename T, typename U, + typename = span_internal::EnableIfConvertibleTo<U, absl::Span<const T>>> +bool operator>=(Span<T> a, const U& b) { + return !(a < b); +} + +// MakeSpan() +// +// Constructs a mutable `Span<T>`, deducing `T` automatically from either a +// container or pointer+size. +// +// Because a read-only `Span<const T>` is implicitly constructed from container +// types regardless of whether the container itself is a const container, +// constructing mutable spans of type `Span<T>` from containers requires +// explicit constructors. The container-accepting version of `MakeSpan()` +// deduces the type of `T` by the constness of the pointer received from the +// container's `data()` member. Similarly, the pointer-accepting version returns +// a `Span<const T>` if `T` is `const`, and a `Span<T>` otherwise. +// +// Examples: +// +// void MyRoutine(absl::Span<MyComplicatedType> a) { +// ... +// }; +// // my_vector is a container of non-const types +// std::vector<MyComplicatedType> my_vector; +// +// // Constructing a Span implicitly attempts to create a Span of type +// // `Span<const T>` +// MyRoutine(my_vector); // error, type mismatch +// +// // Explicitly constructing the Span is verbose +// MyRoutine(absl::Span<MyComplicatedType>(my_vector)); +// +// // Use MakeSpan() to make an absl::Span<T> +// MyRoutine(absl::MakeSpan(my_vector)); +// +// // Construct a span from an array ptr+size +// absl::Span<T> my_span() { +// return absl::MakeSpan(&array[0], num_elements_); +// } +// +template <int&... ExplicitArgumentBarrier, typename T> +constexpr Span<T> MakeSpan(T* ptr, size_t size) noexcept { + return Span<T>(ptr, size); +} + +template <int&... ExplicitArgumentBarrier, typename T> +Span<T> MakeSpan(T* begin, T* end) noexcept { + return ABSL_HARDENING_ASSERT(begin <= end), Span<T>(begin, end - begin); +} + +template <int&... ExplicitArgumentBarrier, typename C> +constexpr auto MakeSpan(C& c) noexcept // NOLINT(runtime/references) + -> decltype(absl::MakeSpan(span_internal::GetData(c), c.size())) { + return MakeSpan(span_internal::GetData(c), c.size()); +} + +template <int&... ExplicitArgumentBarrier, typename T, size_t N> +constexpr Span<T> MakeSpan(T (&array)[N]) noexcept { + return Span<T>(array, N); +} + +// MakeConstSpan() +// +// Constructs a `Span<const T>` as with `MakeSpan`, deducing `T` automatically, +// but always returning a `Span<const T>`. +// +// Examples: +// +// void ProcessInts(absl::Span<const int> some_ints); +// +// // Call with a pointer and size. +// int array[3] = { 0, 0, 0 }; +// ProcessInts(absl::MakeConstSpan(&array[0], 3)); +// +// // Call with a [begin, end) pair. +// ProcessInts(absl::MakeConstSpan(&array[0], &array[3])); +// +// // Call directly with an array. +// ProcessInts(absl::MakeConstSpan(array)); +// +// // Call with a contiguous container. +// std::vector<int> some_ints = ...; +// ProcessInts(absl::MakeConstSpan(some_ints)); +// ProcessInts(absl::MakeConstSpan(std::vector<int>{ 0, 0, 0 })); +// +template <int&... ExplicitArgumentBarrier, typename T> +constexpr Span<const T> MakeConstSpan(T* ptr, size_t size) noexcept { + return Span<const T>(ptr, size); +} + +template <int&... ExplicitArgumentBarrier, typename T> +Span<const T> MakeConstSpan(T* begin, T* end) noexcept { + return ABSL_HARDENING_ASSERT(begin <= end), Span<const T>(begin, end - begin); +} + +template <int&... ExplicitArgumentBarrier, typename C> +constexpr auto MakeConstSpan(const C& c) noexcept -> decltype(MakeSpan(c)) { + return MakeSpan(c); +} + +template <int&... ExplicitArgumentBarrier, typename T, size_t N> +constexpr Span<const T> MakeConstSpan(const T (&array)[N]) noexcept { + return Span<const T>(array, N); +} +ABSL_NAMESPACE_END +} // namespace absl +#endif // ABSL_TYPES_SPAN_H_ diff --git a/third_party/abseil_cpp/absl/types/span_test.cc b/third_party/abseil_cpp/absl/types/span_test.cc new file mode 100644 index 0000000000..2584339bd3 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/span_test.cc @@ -0,0 +1,846 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/span.h" + +#include <array> +#include <initializer_list> +#include <numeric> +#include <stdexcept> +#include <string> +#include <type_traits> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/base/config.h" +#include "absl/base/internal/exception_testing.h" +#include "absl/base/options.h" +#include "absl/container/fixed_array.h" +#include "absl/container/inlined_vector.h" +#include "absl/hash/hash_testing.h" +#include "absl/strings/str_cat.h" + +namespace { + +MATCHER_P(DataIs, data, + absl::StrCat("data() ", negation ? "isn't " : "is ", + testing::PrintToString(data))) { + return arg.data() == data; +} + +template <typename T> +auto SpanIs(T data, size_t size) + -> decltype(testing::AllOf(DataIs(data), testing::SizeIs(size))) { + return testing::AllOf(DataIs(data), testing::SizeIs(size)); +} + +template <typename Container> +auto SpanIs(const Container& c) -> decltype(SpanIs(c.data(), c.size())) { + return SpanIs(c.data(), c.size()); +} + +std::vector<int> MakeRamp(int len, int offset = 0) { + std::vector<int> v(len); + std::iota(v.begin(), v.end(), offset); + return v; +} + +TEST(IntSpan, EmptyCtors) { + absl::Span<int> s; + EXPECT_THAT(s, SpanIs(nullptr, 0)); +} + +TEST(IntSpan, PtrLenCtor) { + int a[] = {1, 2, 3}; + absl::Span<int> s(&a[0], 2); + EXPECT_THAT(s, SpanIs(a, 2)); +} + +TEST(IntSpan, ArrayCtor) { + int a[] = {1, 2, 3}; + absl::Span<int> s(a); + EXPECT_THAT(s, SpanIs(a, 3)); + + EXPECT_TRUE((std::is_constructible<absl::Span<const int>, int[3]>::value)); + EXPECT_TRUE( + (std::is_constructible<absl::Span<const int>, const int[3]>::value)); + EXPECT_FALSE((std::is_constructible<absl::Span<int>, const int[3]>::value)); + EXPECT_TRUE((std::is_convertible<int[3], absl::Span<const int>>::value)); + EXPECT_TRUE( + (std::is_convertible<const int[3], absl::Span<const int>>::value)); +} + +template <typename T> +void TakesGenericSpan(absl::Span<T>) {} + +TEST(IntSpan, ContainerCtor) { + std::vector<int> empty; + absl::Span<int> s_empty(empty); + EXPECT_THAT(s_empty, SpanIs(empty)); + + std::vector<int> filled{1, 2, 3}; + absl::Span<int> s_filled(filled); + EXPECT_THAT(s_filled, SpanIs(filled)); + + absl::Span<int> s_from_span(filled); + EXPECT_THAT(s_from_span, SpanIs(s_filled)); + + absl::Span<const int> const_filled = filled; + EXPECT_THAT(const_filled, SpanIs(filled)); + + absl::Span<const int> const_from_span = s_filled; + EXPECT_THAT(const_from_span, SpanIs(s_filled)); + + EXPECT_TRUE( + (std::is_convertible<std::vector<int>&, absl::Span<const int>>::value)); + EXPECT_TRUE( + (std::is_convertible<absl::Span<int>&, absl::Span<const int>>::value)); + + TakesGenericSpan(absl::Span<int>(filled)); +} + +// A struct supplying shallow data() const. +struct ContainerWithShallowConstData { + std::vector<int> storage; + int* data() const { return const_cast<int*>(storage.data()); } + int size() const { return storage.size(); } +}; + +TEST(IntSpan, ShallowConstness) { + const ContainerWithShallowConstData c{MakeRamp(20)}; + absl::Span<int> s( + c); // We should be able to do this even though data() is const. + s[0] = -1; + EXPECT_EQ(c.storage[0], -1); +} + +TEST(CharSpan, StringCtor) { + std::string empty = ""; + absl::Span<char> s_empty(empty); + EXPECT_THAT(s_empty, SpanIs(empty)); + + std::string abc = "abc"; + absl::Span<char> s_abc(abc); + EXPECT_THAT(s_abc, SpanIs(abc)); + + absl::Span<const char> s_const_abc = abc; + EXPECT_THAT(s_const_abc, SpanIs(abc)); + + EXPECT_FALSE((std::is_constructible<absl::Span<int>, std::string>::value)); + EXPECT_FALSE( + (std::is_constructible<absl::Span<const int>, std::string>::value)); + EXPECT_TRUE( + (std::is_convertible<std::string, absl::Span<const char>>::value)); +} + +TEST(IntSpan, FromConstPointer) { + EXPECT_TRUE((std::is_constructible<absl::Span<const int* const>, + std::vector<int*>>::value)); + EXPECT_TRUE((std::is_constructible<absl::Span<const int* const>, + std::vector<const int*>>::value)); + EXPECT_FALSE(( + std::is_constructible<absl::Span<const int*>, std::vector<int*>>::value)); + EXPECT_FALSE(( + std::is_constructible<absl::Span<int*>, std::vector<const int*>>::value)); +} + +struct TypeWithMisleadingData { + int& data() { return i; } + int size() { return 1; } + int i; +}; + +struct TypeWithMisleadingSize { + int* data() { return &i; } + const char* size() { return "1"; } + int i; +}; + +TEST(IntSpan, EvilTypes) { + EXPECT_FALSE( + (std::is_constructible<absl::Span<int>, TypeWithMisleadingData&>::value)); + EXPECT_FALSE( + (std::is_constructible<absl::Span<int>, TypeWithMisleadingSize&>::value)); +} + +struct Base { + int* data() { return &i; } + int size() { return 1; } + int i; +}; +struct Derived : Base {}; + +TEST(IntSpan, SpanOfDerived) { + EXPECT_TRUE((std::is_constructible<absl::Span<int>, Base&>::value)); + EXPECT_TRUE((std::is_constructible<absl::Span<int>, Derived&>::value)); + EXPECT_FALSE( + (std::is_constructible<absl::Span<Base>, std::vector<Derived>>::value)); +} + +void TestInitializerList(absl::Span<const int> s, const std::vector<int>& v) { + EXPECT_TRUE(absl::equal(s.begin(), s.end(), v.begin(), v.end())); +} + +TEST(ConstIntSpan, InitializerListConversion) { + TestInitializerList({}, {}); + TestInitializerList({1}, {1}); + TestInitializerList({1, 2, 3}, {1, 2, 3}); + + EXPECT_FALSE((std::is_constructible<absl::Span<int>, + std::initializer_list<int>>::value)); + EXPECT_FALSE(( + std::is_convertible<absl::Span<int>, std::initializer_list<int>>::value)); +} + +TEST(IntSpan, Data) { + int i; + absl::Span<int> s(&i, 1); + EXPECT_EQ(&i, s.data()); +} + +TEST(IntSpan, SizeLengthEmpty) { + absl::Span<int> empty; + EXPECT_EQ(empty.size(), 0); + EXPECT_TRUE(empty.empty()); + EXPECT_EQ(empty.size(), empty.length()); + + auto v = MakeRamp(10); + absl::Span<int> s(v); + EXPECT_EQ(s.size(), 10); + EXPECT_FALSE(s.empty()); + EXPECT_EQ(s.size(), s.length()); +} + +TEST(IntSpan, ElementAccess) { + auto v = MakeRamp(10); + absl::Span<int> s(v); + for (int i = 0; i < s.size(); ++i) { + EXPECT_EQ(s[i], s.at(i)); + } + + EXPECT_EQ(s.front(), s[0]); + EXPECT_EQ(s.back(), s[9]); + +#if !defined(NDEBUG) || ABSL_OPTION_HARDENED + EXPECT_DEATH_IF_SUPPORTED(s[-1], ""); + EXPECT_DEATH_IF_SUPPORTED(s[10], ""); +#endif +} + +TEST(IntSpan, AtThrows) { + auto v = MakeRamp(10); + absl::Span<int> s(v); + + EXPECT_EQ(s.at(9), 9); + ABSL_BASE_INTERNAL_EXPECT_FAIL(s.at(10), std::out_of_range, + "failed bounds check"); +} + +TEST(IntSpan, RemovePrefixAndSuffix) { + auto v = MakeRamp(20, 1); + absl::Span<int> s(v); + EXPECT_EQ(s.size(), 20); + + s.remove_suffix(0); + s.remove_prefix(0); + EXPECT_EQ(s.size(), 20); + + s.remove_prefix(1); + EXPECT_EQ(s.size(), 19); + EXPECT_EQ(s[0], 2); + + s.remove_suffix(1); + EXPECT_EQ(s.size(), 18); + EXPECT_EQ(s.back(), 19); + + s.remove_prefix(7); + EXPECT_EQ(s.size(), 11); + EXPECT_EQ(s[0], 9); + + s.remove_suffix(11); + EXPECT_EQ(s.size(), 0); + + EXPECT_EQ(v, MakeRamp(20, 1)); + +#if !defined(NDEBUG) || ABSL_OPTION_HARDENED + absl::Span<int> prefix_death(v); + EXPECT_DEATH_IF_SUPPORTED(prefix_death.remove_prefix(21), ""); + absl::Span<int> suffix_death(v); + EXPECT_DEATH_IF_SUPPORTED(suffix_death.remove_suffix(21), ""); +#endif +} + +TEST(IntSpan, Subspan) { + std::vector<int> empty; + EXPECT_EQ(absl::MakeSpan(empty).subspan(), empty); + EXPECT_THAT(absl::MakeSpan(empty).subspan(0, 0), SpanIs(empty)); + EXPECT_THAT(absl::MakeSpan(empty).subspan(0, absl::Span<const int>::npos), + SpanIs(empty)); + + auto ramp = MakeRamp(10); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(), SpanIs(ramp)); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(0, 10), SpanIs(ramp)); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(0, absl::Span<const int>::npos), + SpanIs(ramp)); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(0, 3), SpanIs(ramp.data(), 3)); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(5, absl::Span<const int>::npos), + SpanIs(ramp.data() + 5, 5)); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(3, 3), SpanIs(ramp.data() + 3, 3)); + EXPECT_THAT(absl::MakeSpan(ramp).subspan(10, 5), SpanIs(ramp.data() + 10, 0)); + +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW(absl::MakeSpan(ramp).subspan(11, 5), std::out_of_range); +#else + EXPECT_DEATH_IF_SUPPORTED(absl::MakeSpan(ramp).subspan(11, 5), ""); +#endif +} + +TEST(IntSpan, First) { + std::vector<int> empty; + EXPECT_THAT(absl::MakeSpan(empty).first(0), SpanIs(empty)); + + auto ramp = MakeRamp(10); + EXPECT_THAT(absl::MakeSpan(ramp).first(0), SpanIs(ramp.data(), 0)); + EXPECT_THAT(absl::MakeSpan(ramp).first(10), SpanIs(ramp)); + EXPECT_THAT(absl::MakeSpan(ramp).first(3), SpanIs(ramp.data(), 3)); + +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW(absl::MakeSpan(ramp).first(11), std::out_of_range); +#else + EXPECT_DEATH_IF_SUPPORTED(absl::MakeSpan(ramp).first(11), ""); +#endif +} + +TEST(IntSpan, Last) { + std::vector<int> empty; + EXPECT_THAT(absl::MakeSpan(empty).last(0), SpanIs(empty)); + + auto ramp = MakeRamp(10); + EXPECT_THAT(absl::MakeSpan(ramp).last(0), SpanIs(ramp.data() + 10, 0)); + EXPECT_THAT(absl::MakeSpan(ramp).last(10), SpanIs(ramp)); + EXPECT_THAT(absl::MakeSpan(ramp).last(3), SpanIs(ramp.data() + 7, 3)); + +#ifdef ABSL_HAVE_EXCEPTIONS + EXPECT_THROW(absl::MakeSpan(ramp).last(11), std::out_of_range); +#else + EXPECT_DEATH_IF_SUPPORTED(absl::MakeSpan(ramp).last(11), ""); +#endif +} + +TEST(IntSpan, MakeSpanPtrLength) { + std::vector<int> empty; + auto s_empty = absl::MakeSpan(empty.data(), empty.size()); + EXPECT_THAT(s_empty, SpanIs(empty)); + + std::array<int, 3> a{{1, 2, 3}}; + auto s = absl::MakeSpan(a.data(), a.size()); + EXPECT_THAT(s, SpanIs(a)); + + EXPECT_THAT(absl::MakeConstSpan(empty.data(), empty.size()), SpanIs(s_empty)); + EXPECT_THAT(absl::MakeConstSpan(a.data(), a.size()), SpanIs(s)); +} + +TEST(IntSpan, MakeSpanTwoPtrs) { + std::vector<int> empty; + auto s_empty = absl::MakeSpan(empty.data(), empty.data()); + EXPECT_THAT(s_empty, SpanIs(empty)); + + std::vector<int> v{1, 2, 3}; + auto s = absl::MakeSpan(v.data(), v.data() + 1); + EXPECT_THAT(s, SpanIs(v.data(), 1)); + + EXPECT_THAT(absl::MakeConstSpan(empty.data(), empty.data()), SpanIs(s_empty)); + EXPECT_THAT(absl::MakeConstSpan(v.data(), v.data() + 1), SpanIs(s)); +} + +TEST(IntSpan, MakeSpanContainer) { + std::vector<int> empty; + auto s_empty = absl::MakeSpan(empty); + EXPECT_THAT(s_empty, SpanIs(empty)); + + std::vector<int> v{1, 2, 3}; + auto s = absl::MakeSpan(v); + EXPECT_THAT(s, SpanIs(v)); + + EXPECT_THAT(absl::MakeConstSpan(empty), SpanIs(s_empty)); + EXPECT_THAT(absl::MakeConstSpan(v), SpanIs(s)); + + EXPECT_THAT(absl::MakeSpan(s), SpanIs(s)); + EXPECT_THAT(absl::MakeConstSpan(s), SpanIs(s)); +} + +TEST(CharSpan, MakeSpanString) { + std::string empty = ""; + auto s_empty = absl::MakeSpan(empty); + EXPECT_THAT(s_empty, SpanIs(empty)); + + std::string str = "abc"; + auto s_str = absl::MakeSpan(str); + EXPECT_THAT(s_str, SpanIs(str)); + + EXPECT_THAT(absl::MakeConstSpan(empty), SpanIs(s_empty)); + EXPECT_THAT(absl::MakeConstSpan(str), SpanIs(s_str)); +} + +TEST(IntSpan, MakeSpanArray) { + int a[] = {1, 2, 3}; + auto s = absl::MakeSpan(a); + EXPECT_THAT(s, SpanIs(a, 3)); + + const int ca[] = {1, 2, 3}; + auto s_ca = absl::MakeSpan(ca); + EXPECT_THAT(s_ca, SpanIs(ca, 3)); + + EXPECT_THAT(absl::MakeConstSpan(a), SpanIs(s)); + EXPECT_THAT(absl::MakeConstSpan(ca), SpanIs(s_ca)); +} + +// Compile-asserts that the argument has the expected decayed type. +template <typename Expected, typename T> +void CheckType(const T& /* value */) { + testing::StaticAssertTypeEq<Expected, T>(); +} + +TEST(IntSpan, MakeSpanTypes) { + std::vector<int> vec; + const std::vector<int> cvec; + int a[1]; + const int ca[] = {1}; + int* ip = a; + const int* cip = ca; + std::string s = ""; + const std::string cs = ""; + CheckType<absl::Span<int>>(absl::MakeSpan(vec)); + CheckType<absl::Span<const int>>(absl::MakeSpan(cvec)); + CheckType<absl::Span<int>>(absl::MakeSpan(ip, ip + 1)); + CheckType<absl::Span<int>>(absl::MakeSpan(ip, 1)); + CheckType<absl::Span<const int>>(absl::MakeSpan(cip, cip + 1)); + CheckType<absl::Span<const int>>(absl::MakeSpan(cip, 1)); + CheckType<absl::Span<int>>(absl::MakeSpan(a)); + CheckType<absl::Span<int>>(absl::MakeSpan(a, a + 1)); + CheckType<absl::Span<int>>(absl::MakeSpan(a, 1)); + CheckType<absl::Span<const int>>(absl::MakeSpan(ca)); + CheckType<absl::Span<const int>>(absl::MakeSpan(ca, ca + 1)); + CheckType<absl::Span<const int>>(absl::MakeSpan(ca, 1)); + CheckType<absl::Span<char>>(absl::MakeSpan(s)); + CheckType<absl::Span<const char>>(absl::MakeSpan(cs)); +} + +TEST(ConstIntSpan, MakeConstSpanTypes) { + std::vector<int> vec; + const std::vector<int> cvec; + int array[1]; + const int carray[] = {0}; + int* ptr = array; + const int* cptr = carray; + std::string s = ""; + std::string cs = ""; + CheckType<absl::Span<const int>>(absl::MakeConstSpan(vec)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(cvec)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(ptr, ptr + 1)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(ptr, 1)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(cptr, cptr + 1)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(cptr, 1)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(array)); + CheckType<absl::Span<const int>>(absl::MakeConstSpan(carray)); + CheckType<absl::Span<const char>>(absl::MakeConstSpan(s)); + CheckType<absl::Span<const char>>(absl::MakeConstSpan(cs)); +} + +TEST(IntSpan, Equality) { + const int arr1[] = {1, 2, 3, 4, 5}; + int arr2[] = {1, 2, 3, 4, 5}; + std::vector<int> vec1(std::begin(arr1), std::end(arr1)); + std::vector<int> vec2 = vec1; + std::vector<int> other_vec = {2, 4, 6, 8, 10}; + // These two slices are from different vectors, but have the same size and + // have the same elements (right now). They should compare equal. Test both + // == and !=. + const absl::Span<const int> from1 = vec1; + const absl::Span<const int> from2 = vec2; + EXPECT_EQ(from1, from1); + EXPECT_FALSE(from1 != from1); + EXPECT_EQ(from1, from2); + EXPECT_FALSE(from1 != from2); + + // These two slices have different underlying vector values. They should be + // considered not equal. Test both == and !=. + const absl::Span<const int> from_other = other_vec; + EXPECT_NE(from1, from_other); + EXPECT_FALSE(from1 == from_other); + + // Comparison between a vector and its slice should be equal. And vice-versa. + // This ensures implicit conversion to Span works on both sides of ==. + EXPECT_EQ(vec1, from1); + EXPECT_FALSE(vec1 != from1); + EXPECT_EQ(from1, vec1); + EXPECT_FALSE(from1 != vec1); + + // This verifies that absl::Span<T> can be compared freely with + // absl::Span<const T>. + const absl::Span<int> mutable_from1(vec1); + const absl::Span<int> mutable_from2(vec2); + EXPECT_EQ(from1, mutable_from1); + EXPECT_EQ(mutable_from1, from1); + EXPECT_EQ(mutable_from1, mutable_from2); + EXPECT_EQ(mutable_from2, mutable_from1); + + // Comparison between a vector and its slice should be equal for mutable + // Spans as well. + EXPECT_EQ(vec1, mutable_from1); + EXPECT_FALSE(vec1 != mutable_from1); + EXPECT_EQ(mutable_from1, vec1); + EXPECT_FALSE(mutable_from1 != vec1); + + // Comparison between convertible-to-Span-of-const and Span-of-mutable. Arrays + // are used because they're the only value type which converts to a + // Span-of-mutable. EXPECT_TRUE is used instead of EXPECT_EQ to avoid + // array-to-pointer decay. + EXPECT_TRUE(arr1 == mutable_from1); + EXPECT_FALSE(arr1 != mutable_from1); + EXPECT_TRUE(mutable_from1 == arr1); + EXPECT_FALSE(mutable_from1 != arr1); + + // Comparison between convertible-to-Span-of-mutable and Span-of-const + EXPECT_TRUE(arr2 == from1); + EXPECT_FALSE(arr2 != from1); + EXPECT_TRUE(from1 == arr2); + EXPECT_FALSE(from1 != arr2); + + // With a different size, the array slices should not be equal. + EXPECT_NE(from1, absl::Span<const int>(from1).subspan(0, from1.size() - 1)); + + // With different contents, the array slices should not be equal. + ++vec2.back(); + EXPECT_NE(from1, from2); +} + +class IntSpanOrderComparisonTest : public testing::Test { + public: + IntSpanOrderComparisonTest() + : arr_before_{1, 2, 3}, + arr_after_{1, 2, 4}, + carr_after_{1, 2, 4}, + vec_before_(std::begin(arr_before_), std::end(arr_before_)), + vec_after_(std::begin(arr_after_), std::end(arr_after_)), + before_(vec_before_), + after_(vec_after_), + cbefore_(vec_before_), + cafter_(vec_after_) {} + + protected: + int arr_before_[3], arr_after_[3]; + const int carr_after_[3]; + std::vector<int> vec_before_, vec_after_; + absl::Span<int> before_, after_; + absl::Span<const int> cbefore_, cafter_; +}; + +TEST_F(IntSpanOrderComparisonTest, CompareSpans) { + EXPECT_TRUE(cbefore_ < cafter_); + EXPECT_TRUE(cbefore_ <= cafter_); + EXPECT_TRUE(cafter_ > cbefore_); + EXPECT_TRUE(cafter_ >= cbefore_); + + EXPECT_FALSE(cbefore_ > cafter_); + EXPECT_FALSE(cafter_ < cbefore_); + + EXPECT_TRUE(before_ < after_); + EXPECT_TRUE(before_ <= after_); + EXPECT_TRUE(after_ > before_); + EXPECT_TRUE(after_ >= before_); + + EXPECT_FALSE(before_ > after_); + EXPECT_FALSE(after_ < before_); + + EXPECT_TRUE(cbefore_ < after_); + EXPECT_TRUE(cbefore_ <= after_); + EXPECT_TRUE(after_ > cbefore_); + EXPECT_TRUE(after_ >= cbefore_); + + EXPECT_FALSE(cbefore_ > after_); + EXPECT_FALSE(after_ < cbefore_); +} + +TEST_F(IntSpanOrderComparisonTest, SpanOfConstAndContainer) { + EXPECT_TRUE(cbefore_ < vec_after_); + EXPECT_TRUE(cbefore_ <= vec_after_); + EXPECT_TRUE(vec_after_ > cbefore_); + EXPECT_TRUE(vec_after_ >= cbefore_); + + EXPECT_FALSE(cbefore_ > vec_after_); + EXPECT_FALSE(vec_after_ < cbefore_); + + EXPECT_TRUE(arr_before_ < cafter_); + EXPECT_TRUE(arr_before_ <= cafter_); + EXPECT_TRUE(cafter_ > arr_before_); + EXPECT_TRUE(cafter_ >= arr_before_); + + EXPECT_FALSE(arr_before_ > cafter_); + EXPECT_FALSE(cafter_ < arr_before_); +} + +TEST_F(IntSpanOrderComparisonTest, SpanOfMutableAndContainer) { + EXPECT_TRUE(vec_before_ < after_); + EXPECT_TRUE(vec_before_ <= after_); + EXPECT_TRUE(after_ > vec_before_); + EXPECT_TRUE(after_ >= vec_before_); + + EXPECT_FALSE(vec_before_ > after_); + EXPECT_FALSE(after_ < vec_before_); + + EXPECT_TRUE(before_ < carr_after_); + EXPECT_TRUE(before_ <= carr_after_); + EXPECT_TRUE(carr_after_ > before_); + EXPECT_TRUE(carr_after_ >= before_); + + EXPECT_FALSE(before_ > carr_after_); + EXPECT_FALSE(carr_after_ < before_); +} + +TEST_F(IntSpanOrderComparisonTest, EqualSpans) { + EXPECT_FALSE(before_ < before_); + EXPECT_TRUE(before_ <= before_); + EXPECT_FALSE(before_ > before_); + EXPECT_TRUE(before_ >= before_); +} + +TEST_F(IntSpanOrderComparisonTest, Subspans) { + auto subspan = before_.subspan(0, 1); + EXPECT_TRUE(subspan < before_); + EXPECT_TRUE(subspan <= before_); + EXPECT_TRUE(before_ > subspan); + EXPECT_TRUE(before_ >= subspan); + + EXPECT_FALSE(subspan > before_); + EXPECT_FALSE(before_ < subspan); +} + +TEST_F(IntSpanOrderComparisonTest, EmptySpans) { + absl::Span<int> empty; + EXPECT_FALSE(empty < empty); + EXPECT_TRUE(empty <= empty); + EXPECT_FALSE(empty > empty); + EXPECT_TRUE(empty >= empty); + + EXPECT_TRUE(empty < before_); + EXPECT_TRUE(empty <= before_); + EXPECT_TRUE(before_ > empty); + EXPECT_TRUE(before_ >= empty); + + EXPECT_FALSE(empty > before_); + EXPECT_FALSE(before_ < empty); +} + +TEST(IntSpan, ExposesContainerTypesAndConsts) { + absl::Span<int> slice; + CheckType<absl::Span<int>::iterator>(slice.begin()); + EXPECT_TRUE((std::is_convertible<decltype(slice.begin()), + absl::Span<int>::const_iterator>::value)); + CheckType<absl::Span<int>::const_iterator>(slice.cbegin()); + EXPECT_TRUE((std::is_convertible<decltype(slice.end()), + absl::Span<int>::const_iterator>::value)); + CheckType<absl::Span<int>::const_iterator>(slice.cend()); + CheckType<absl::Span<int>::reverse_iterator>(slice.rend()); + EXPECT_TRUE( + (std::is_convertible<decltype(slice.rend()), + absl::Span<int>::const_reverse_iterator>::value)); + CheckType<absl::Span<int>::const_reverse_iterator>(slice.crend()); + testing::StaticAssertTypeEq<int, absl::Span<int>::value_type>(); + testing::StaticAssertTypeEq<int, absl::Span<const int>::value_type>(); + testing::StaticAssertTypeEq<int*, absl::Span<int>::pointer>(); + testing::StaticAssertTypeEq<const int*, absl::Span<const int>::pointer>(); + testing::StaticAssertTypeEq<int&, absl::Span<int>::reference>(); + testing::StaticAssertTypeEq<const int&, absl::Span<const int>::reference>(); + testing::StaticAssertTypeEq<const int&, absl::Span<int>::const_reference>(); + testing::StaticAssertTypeEq<const int&, + absl::Span<const int>::const_reference>(); + EXPECT_EQ(static_cast<absl::Span<int>::size_type>(-1), absl::Span<int>::npos); +} + +TEST(IntSpan, IteratorsAndReferences) { + auto accept_pointer = [](int*) {}; + auto accept_reference = [](int&) {}; + auto accept_iterator = [](absl::Span<int>::iterator) {}; + auto accept_const_iterator = [](absl::Span<int>::const_iterator) {}; + auto accept_reverse_iterator = [](absl::Span<int>::reverse_iterator) {}; + auto accept_const_reverse_iterator = + [](absl::Span<int>::const_reverse_iterator) {}; + + int a[1]; + absl::Span<int> s = a; + + accept_pointer(s.data()); + accept_iterator(s.begin()); + accept_const_iterator(s.begin()); + accept_const_iterator(s.cbegin()); + accept_iterator(s.end()); + accept_const_iterator(s.end()); + accept_const_iterator(s.cend()); + accept_reverse_iterator(s.rbegin()); + accept_const_reverse_iterator(s.rbegin()); + accept_const_reverse_iterator(s.crbegin()); + accept_reverse_iterator(s.rend()); + accept_const_reverse_iterator(s.rend()); + accept_const_reverse_iterator(s.crend()); + + accept_reference(s[0]); + accept_reference(s.at(0)); + accept_reference(s.front()); + accept_reference(s.back()); +} + +TEST(IntSpan, IteratorsAndReferences_Const) { + auto accept_pointer = [](int*) {}; + auto accept_reference = [](int&) {}; + auto accept_iterator = [](absl::Span<int>::iterator) {}; + auto accept_const_iterator = [](absl::Span<int>::const_iterator) {}; + auto accept_reverse_iterator = [](absl::Span<int>::reverse_iterator) {}; + auto accept_const_reverse_iterator = + [](absl::Span<int>::const_reverse_iterator) {}; + + int a[1]; + const absl::Span<int> s = a; + + accept_pointer(s.data()); + accept_iterator(s.begin()); + accept_const_iterator(s.begin()); + accept_const_iterator(s.cbegin()); + accept_iterator(s.end()); + accept_const_iterator(s.end()); + accept_const_iterator(s.cend()); + accept_reverse_iterator(s.rbegin()); + accept_const_reverse_iterator(s.rbegin()); + accept_const_reverse_iterator(s.crbegin()); + accept_reverse_iterator(s.rend()); + accept_const_reverse_iterator(s.rend()); + accept_const_reverse_iterator(s.crend()); + + accept_reference(s[0]); + accept_reference(s.at(0)); + accept_reference(s.front()); + accept_reference(s.back()); +} + +TEST(IntSpan, NoexceptTest) { + int a[] = {1, 2, 3}; + std::vector<int> v; + EXPECT_TRUE(noexcept(absl::Span<const int>())); + EXPECT_TRUE(noexcept(absl::Span<const int>(a, 2))); + EXPECT_TRUE(noexcept(absl::Span<const int>(a))); + EXPECT_TRUE(noexcept(absl::Span<const int>(v))); + EXPECT_TRUE(noexcept(absl::Span<int>(v))); + EXPECT_TRUE(noexcept(absl::Span<const int>({1, 2, 3}))); + EXPECT_TRUE(noexcept(absl::MakeSpan(v))); + EXPECT_TRUE(noexcept(absl::MakeSpan(a))); + EXPECT_TRUE(noexcept(absl::MakeSpan(a, 2))); + EXPECT_TRUE(noexcept(absl::MakeSpan(a, a + 1))); + EXPECT_TRUE(noexcept(absl::MakeConstSpan(v))); + EXPECT_TRUE(noexcept(absl::MakeConstSpan(a))); + EXPECT_TRUE(noexcept(absl::MakeConstSpan(a, 2))); + EXPECT_TRUE(noexcept(absl::MakeConstSpan(a, a + 1))); + + absl::Span<int> s(v); + EXPECT_TRUE(noexcept(s.data())); + EXPECT_TRUE(noexcept(s.size())); + EXPECT_TRUE(noexcept(s.length())); + EXPECT_TRUE(noexcept(s.empty())); + EXPECT_TRUE(noexcept(s[0])); + EXPECT_TRUE(noexcept(s.front())); + EXPECT_TRUE(noexcept(s.back())); + EXPECT_TRUE(noexcept(s.begin())); + EXPECT_TRUE(noexcept(s.cbegin())); + EXPECT_TRUE(noexcept(s.end())); + EXPECT_TRUE(noexcept(s.cend())); + EXPECT_TRUE(noexcept(s.rbegin())); + EXPECT_TRUE(noexcept(s.crbegin())); + EXPECT_TRUE(noexcept(s.rend())); + EXPECT_TRUE(noexcept(s.crend())); + EXPECT_TRUE(noexcept(s.remove_prefix(0))); + EXPECT_TRUE(noexcept(s.remove_suffix(0))); +} + +// ConstexprTester exercises expressions in a constexpr context. Simply placing +// the expression in a constexpr function is not enough, as some compilers will +// simply compile the constexpr function as runtime code. Using template +// parameters forces compile-time execution. +template <int i> +struct ConstexprTester {}; + +#define ABSL_TEST_CONSTEXPR(expr) \ + do { \ + ABSL_ATTRIBUTE_UNUSED ConstexprTester<(expr, 1)> t; \ + } while (0) + +struct ContainerWithConstexprMethods { + constexpr int size() const { return 1; } + constexpr const int* data() const { return &i; } + const int i; +}; + +TEST(ConstIntSpan, ConstexprTest) { + static constexpr int a[] = {1, 2, 3}; + static constexpr int sized_arr[2] = {1, 2}; + static constexpr ContainerWithConstexprMethods c{1}; + ABSL_TEST_CONSTEXPR(absl::Span<const int>()); + ABSL_TEST_CONSTEXPR(absl::Span<const int>(a, 2)); + ABSL_TEST_CONSTEXPR(absl::Span<const int>(sized_arr)); + ABSL_TEST_CONSTEXPR(absl::Span<const int>(c)); + ABSL_TEST_CONSTEXPR(absl::MakeSpan(&a[0], 1)); + ABSL_TEST_CONSTEXPR(absl::MakeSpan(c)); + ABSL_TEST_CONSTEXPR(absl::MakeSpan(a)); + ABSL_TEST_CONSTEXPR(absl::MakeConstSpan(&a[0], 1)); + ABSL_TEST_CONSTEXPR(absl::MakeConstSpan(c)); + ABSL_TEST_CONSTEXPR(absl::MakeConstSpan(a)); + + constexpr absl::Span<const int> span = c; + ABSL_TEST_CONSTEXPR(span.data()); + ABSL_TEST_CONSTEXPR(span.size()); + ABSL_TEST_CONSTEXPR(span.length()); + ABSL_TEST_CONSTEXPR(span.empty()); + ABSL_TEST_CONSTEXPR(span.begin()); + ABSL_TEST_CONSTEXPR(span.cbegin()); + ABSL_TEST_CONSTEXPR(span.subspan(0, 0)); + ABSL_TEST_CONSTEXPR(span.first(1)); + ABSL_TEST_CONSTEXPR(span.last(1)); + ABSL_TEST_CONSTEXPR(span[0]); +} + +struct BigStruct { + char bytes[10000]; +}; + +TEST(Span, SpanSize) { + EXPECT_LE(sizeof(absl::Span<int>), 2 * sizeof(void*)); + EXPECT_LE(sizeof(absl::Span<BigStruct>), 2 * sizeof(void*)); +} + +TEST(Span, Hash) { + int array[] = {1, 2, 3, 4}; + int array2[] = {1, 2, 3}; + using T = absl::Span<const int>; + EXPECT_TRUE(absl::VerifyTypeImplementsAbslHashCorrectly( + {// Empties + T(), T(nullptr, 0), T(array, 0), T(array2, 0), + // Different array with same value + T(array, 3), T(array2), T({1, 2, 3}), + // Same array, but different length + T(array, 1), T(array, 2), + // Same length, but different array + T(array + 1, 2), T(array + 2, 2)})); +} + +} // namespace diff --git a/third_party/abseil_cpp/absl/types/variant.h b/third_party/abseil_cpp/absl/types/variant.h new file mode 100644 index 0000000000..776d19a1c5 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/variant.h @@ -0,0 +1,861 @@ +// Copyright 2018 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// ----------------------------------------------------------------------------- +// variant.h +// ----------------------------------------------------------------------------- +// +// This header file defines an `absl::variant` type for holding a type-safe +// value of some prescribed set of types (noted as alternative types), and +// associated functions for managing variants. +// +// The `absl::variant` type is a form of type-safe union. An `absl::variant` +// should always hold a value of one of its alternative types (except in the +// "valueless by exception state" -- see below). A default-constructed +// `absl::variant` will hold the value of its first alternative type, provided +// it is default-constructible. +// +// In exceptional cases due to error, an `absl::variant` can hold no +// value (known as a "valueless by exception" state), though this is not the +// norm. +// +// As with `absl::optional`, an `absl::variant` -- when it holds a value -- +// allocates a value of that type directly within the `variant` itself; it +// cannot hold a reference, array, or the type `void`; it can, however, hold a +// pointer to externally managed memory. +// +// `absl::variant` is a C++11 compatible version of the C++17 `std::variant` +// abstraction and is designed to be a drop-in replacement for code compliant +// with C++17. + +#ifndef ABSL_TYPES_VARIANT_H_ +#define ABSL_TYPES_VARIANT_H_ + +#include "absl/base/config.h" +#include "absl/utility/utility.h" + +#ifdef ABSL_USES_STD_VARIANT + +#include <variant> // IWYU pragma: export + +namespace absl { +ABSL_NAMESPACE_BEGIN +using std::bad_variant_access; +using std::get; +using std::get_if; +using std::holds_alternative; +using std::monostate; +using std::variant; +using std::variant_alternative; +using std::variant_alternative_t; +using std::variant_npos; +using std::variant_size; +using std::variant_size_v; +using std::visit; +ABSL_NAMESPACE_END +} // namespace absl + +#else // ABSL_USES_STD_VARIANT + +#include <functional> +#include <new> +#include <type_traits> +#include <utility> + +#include "absl/base/macros.h" +#include "absl/base/port.h" +#include "absl/meta/type_traits.h" +#include "absl/types/internal/variant.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// ----------------------------------------------------------------------------- +// absl::variant +// ----------------------------------------------------------------------------- +// +// An `absl::variant` type is a form of type-safe union. An `absl::variant` -- +// except in exceptional cases -- always holds a value of one of its alternative +// types. +// +// Example: +// +// // Construct a variant that holds either an integer or a std::string and +// // assign it to a std::string. +// absl::variant<int, std::string> v = std::string("abc"); +// +// // A default-constructed variant will hold a value-initialized value of +// // the first alternative type. +// auto a = absl::variant<int, std::string>(); // Holds an int of value '0'. +// +// // variants are assignable. +// +// // copy assignment +// auto v1 = absl::variant<int, std::string>("abc"); +// auto v2 = absl::variant<int, std::string>(10); +// v2 = v1; // copy assign +// +// // move assignment +// auto v1 = absl::variant<int, std::string>("abc"); +// v1 = absl::variant<int, std::string>(10); +// +// // assignment through type conversion +// a = 128; // variant contains int +// a = "128"; // variant contains std::string +// +// An `absl::variant` holding a value of one of its alternative types `T` holds +// an allocation of `T` directly within the variant itself. An `absl::variant` +// is not allowed to allocate additional storage, such as dynamic memory, to +// allocate the contained value. The contained value shall be allocated in a +// region of the variant storage suitably aligned for all alternative types. +template <typename... Ts> +class variant; + +// swap() +// +// Swaps two `absl::variant` values. This function is equivalent to `v.swap(w)` +// where `v` and `w` are `absl::variant` types. +// +// Note that this function requires all alternative types to be both swappable +// and move-constructible, because any two variants may refer to either the same +// type (in which case, they will be swapped) or to two different types (in +// which case the values will need to be moved). +// +template < + typename... Ts, + absl::enable_if_t< + absl::conjunction<std::is_move_constructible<Ts>..., + type_traits_internal::IsSwappable<Ts>...>::value, + int> = 0> +void swap(variant<Ts...>& v, variant<Ts...>& w) noexcept(noexcept(v.swap(w))) { + v.swap(w); +} + +// variant_size +// +// Returns the number of alternative types available for a given `absl::variant` +// type as a compile-time constant expression. As this is a class template, it +// is not generally useful for accessing the number of alternative types of +// any given `absl::variant` instance. +// +// Example: +// +// auto a = absl::variant<int, std::string>; +// constexpr int num_types = +// absl::variant_size<absl::variant<int, std::string>>(); +// +// // You can also use the member constant `value`. +// constexpr int num_types = +// absl::variant_size<absl::variant<int, std::string>>::value; +// +// // `absl::variant_size` is more valuable for use in generic code: +// template <typename Variant> +// constexpr bool IsVariantMultivalue() { +// return absl::variant_size<Variant>() > 1; +// } +// +// Note that the set of cv-qualified specializations of `variant_size` are +// provided to ensure that those specializations compile (especially when passed +// within template logic). +template <class T> +struct variant_size; + +template <class... Ts> +struct variant_size<variant<Ts...>> + : std::integral_constant<std::size_t, sizeof...(Ts)> {}; + +// Specialization of `variant_size` for const qualified variants. +template <class T> +struct variant_size<const T> : variant_size<T>::type {}; + +// Specialization of `variant_size` for volatile qualified variants. +template <class T> +struct variant_size<volatile T> : variant_size<T>::type {}; + +// Specialization of `variant_size` for const volatile qualified variants. +template <class T> +struct variant_size<const volatile T> : variant_size<T>::type {}; + +// variant_alternative +// +// Returns the alternative type for a given `absl::variant` at the passed +// index value as a compile-time constant expression. As this is a class +// template resulting in a type, it is not useful for access of the run-time +// value of any given `absl::variant` variable. +// +// Example: +// +// // The type of the 0th alternative is "int". +// using alternative_type_0 +// = absl::variant_alternative<0, absl::variant<int, std::string>>::type; +// +// static_assert(std::is_same<alternative_type_0, int>::value, ""); +// +// // `absl::variant_alternative` is more valuable for use in generic code: +// template <typename Variant> +// constexpr bool IsFirstElementTrivial() { +// return std::is_trivial_v<variant_alternative<0, Variant>::type>; +// } +// +// Note that the set of cv-qualified specializations of `variant_alternative` +// are provided to ensure that those specializations compile (especially when +// passed within template logic). +template <std::size_t I, class T> +struct variant_alternative; + +template <std::size_t I, class... Types> +struct variant_alternative<I, variant<Types...>> { + using type = + variant_internal::VariantAlternativeSfinaeT<I, variant<Types...>>; +}; + +// Specialization of `variant_alternative` for const qualified variants. +template <std::size_t I, class T> +struct variant_alternative<I, const T> { + using type = const typename variant_alternative<I, T>::type; +}; + +// Specialization of `variant_alternative` for volatile qualified variants. +template <std::size_t I, class T> +struct variant_alternative<I, volatile T> { + using type = volatile typename variant_alternative<I, T>::type; +}; + +// Specialization of `variant_alternative` for const volatile qualified +// variants. +template <std::size_t I, class T> +struct variant_alternative<I, const volatile T> { + using type = const volatile typename variant_alternative<I, T>::type; +}; + +// Template type alias for variant_alternative<I, T>::type. +// +// Example: +// +// using alternative_type_0 +// = absl::variant_alternative_t<0, absl::variant<int, std::string>>; +// static_assert(std::is_same<alternative_type_0, int>::value, ""); +template <std::size_t I, class T> +using variant_alternative_t = typename variant_alternative<I, T>::type; + +// holds_alternative() +// +// Checks whether the given variant currently holds a given alternative type, +// returning `true` if so. +// +// Example: +// +// absl::variant<int, std::string> foo = 42; +// if (absl::holds_alternative<int>(foo)) { +// std::cout << "The variant holds an integer"; +// } +template <class T, class... Types> +constexpr bool holds_alternative(const variant<Types...>& v) noexcept { + static_assert( + variant_internal::UnambiguousIndexOfImpl<variant<Types...>, T, + 0>::value != sizeof...(Types), + "The type T must occur exactly once in Types..."); + return v.index() == + variant_internal::UnambiguousIndexOf<variant<Types...>, T>::value; +} + +// get() +// +// Returns a reference to the value currently within a given variant, using +// either a unique alternative type amongst the variant's set of alternative +// types, or the variant's index value. Attempting to get a variant's value +// using a type that is not unique within the variant's set of alternative types +// is a compile-time error. If the index of the alternative being specified is +// different from the index of the alternative that is currently stored, throws +// `absl::bad_variant_access`. +// +// Example: +// +// auto a = absl::variant<int, std::string>; +// +// // Get the value by type (if unique). +// int i = absl::get<int>(a); +// +// auto b = absl::variant<int, int>; +// +// // Getting the value by a type that is not unique is ill-formed. +// int j = absl::get<int>(b); // Compile Error! +// +// // Getting value by index not ambiguous and allowed. +// int k = absl::get<1>(b); + +// Overload for getting a variant's lvalue by type. +template <class T, class... Types> +constexpr T& get(variant<Types...>& v) { // NOLINT + return variant_internal::VariantCoreAccess::CheckedAccess< + variant_internal::IndexOf<T, Types...>::value>(v); +} + +// Overload for getting a variant's rvalue by type. +// Note: `absl::move()` is required to allow use of constexpr in C++11. +template <class T, class... Types> +constexpr T&& get(variant<Types...>&& v) { + return variant_internal::VariantCoreAccess::CheckedAccess< + variant_internal::IndexOf<T, Types...>::value>(absl::move(v)); +} + +// Overload for getting a variant's const lvalue by type. +template <class T, class... Types> +constexpr const T& get(const variant<Types...>& v) { + return variant_internal::VariantCoreAccess::CheckedAccess< + variant_internal::IndexOf<T, Types...>::value>(v); +} + +// Overload for getting a variant's const rvalue by type. +// Note: `absl::move()` is required to allow use of constexpr in C++11. +template <class T, class... Types> +constexpr const T&& get(const variant<Types...>&& v) { + return variant_internal::VariantCoreAccess::CheckedAccess< + variant_internal::IndexOf<T, Types...>::value>(absl::move(v)); +} + +// Overload for getting a variant's lvalue by index. +template <std::size_t I, class... Types> +constexpr variant_alternative_t<I, variant<Types...>>& get( + variant<Types...>& v) { // NOLINT + return variant_internal::VariantCoreAccess::CheckedAccess<I>(v); +} + +// Overload for getting a variant's rvalue by index. +// Note: `absl::move()` is required to allow use of constexpr in C++11. +template <std::size_t I, class... Types> +constexpr variant_alternative_t<I, variant<Types...>>&& get( + variant<Types...>&& v) { + return variant_internal::VariantCoreAccess::CheckedAccess<I>(absl::move(v)); +} + +// Overload for getting a variant's const lvalue by index. +template <std::size_t I, class... Types> +constexpr const variant_alternative_t<I, variant<Types...>>& get( + const variant<Types...>& v) { + return variant_internal::VariantCoreAccess::CheckedAccess<I>(v); +} + +// Overload for getting a variant's const rvalue by index. +// Note: `absl::move()` is required to allow use of constexpr in C++11. +template <std::size_t I, class... Types> +constexpr const variant_alternative_t<I, variant<Types...>>&& get( + const variant<Types...>&& v) { + return variant_internal::VariantCoreAccess::CheckedAccess<I>(absl::move(v)); +} + +// get_if() +// +// Returns a pointer to the value currently stored within a given variant, if +// present, using either a unique alternative type amongst the variant's set of +// alternative types, or the variant's index value. If such a value does not +// exist, returns `nullptr`. +// +// As with `get`, attempting to get a variant's value using a type that is not +// unique within the variant's set of alternative types is a compile-time error. + +// Overload for getting a pointer to the value stored in the given variant by +// index. +template <std::size_t I, class... Types> +constexpr absl::add_pointer_t<variant_alternative_t<I, variant<Types...>>> +get_if(variant<Types...>* v) noexcept { + return (v != nullptr && v->index() == I) + ? std::addressof( + variant_internal::VariantCoreAccess::Access<I>(*v)) + : nullptr; +} + +// Overload for getting a pointer to the const value stored in the given +// variant by index. +template <std::size_t I, class... Types> +constexpr absl::add_pointer_t<const variant_alternative_t<I, variant<Types...>>> +get_if(const variant<Types...>* v) noexcept { + return (v != nullptr && v->index() == I) + ? std::addressof( + variant_internal::VariantCoreAccess::Access<I>(*v)) + : nullptr; +} + +// Overload for getting a pointer to the value stored in the given variant by +// type. +template <class T, class... Types> +constexpr absl::add_pointer_t<T> get_if(variant<Types...>* v) noexcept { + return absl::get_if<variant_internal::IndexOf<T, Types...>::value>(v); +} + +// Overload for getting a pointer to the const value stored in the given variant +// by type. +template <class T, class... Types> +constexpr absl::add_pointer_t<const T> get_if( + const variant<Types...>* v) noexcept { + return absl::get_if<variant_internal::IndexOf<T, Types...>::value>(v); +} + +// visit() +// +// Calls a provided functor on a given set of variants. `absl::visit()` is +// commonly used to conditionally inspect the state of a given variant (or set +// of variants). +// +// The functor must return the same type when called with any of the variants' +// alternatives. +// +// Example: +// +// // Define a visitor functor +// struct GetVariant { +// template<typename T> +// void operator()(const T& i) const { +// std::cout << "The variant's value is: " << i; +// } +// }; +// +// // Declare our variant, and call `absl::visit()` on it. +// // Note that `GetVariant()` returns void in either case. +// absl::variant<int, std::string> foo = std::string("foo"); +// GetVariant visitor; +// absl::visit(visitor, foo); // Prints `The variant's value is: foo' +template <typename Visitor, typename... Variants> +variant_internal::VisitResult<Visitor, Variants...> visit(Visitor&& vis, + Variants&&... vars) { + return variant_internal:: + VisitIndices<variant_size<absl::decay_t<Variants> >::value...>::Run( + variant_internal::PerformVisitation<Visitor, Variants...>{ + std::forward_as_tuple(absl::forward<Variants>(vars)...), + absl::forward<Visitor>(vis)}, + vars.index()...); +} + +// monostate +// +// The monostate class serves as a first alternative type for a variant for +// which the first variant type is otherwise not default-constructible. +struct monostate {}; + +// `absl::monostate` Relational Operators + +constexpr bool operator<(monostate, monostate) noexcept { return false; } +constexpr bool operator>(monostate, monostate) noexcept { return false; } +constexpr bool operator<=(monostate, monostate) noexcept { return true; } +constexpr bool operator>=(monostate, monostate) noexcept { return true; } +constexpr bool operator==(monostate, monostate) noexcept { return true; } +constexpr bool operator!=(monostate, monostate) noexcept { return false; } + + +//------------------------------------------------------------------------------ +// `absl::variant` Template Definition +//------------------------------------------------------------------------------ +template <typename T0, typename... Tn> +class variant<T0, Tn...> : private variant_internal::VariantBase<T0, Tn...> { + static_assert(absl::conjunction<std::is_object<T0>, + std::is_object<Tn>...>::value, + "Attempted to instantiate a variant containing a non-object " + "type."); + // Intentionally not qualifying `negation` with `absl::` to work around a bug + // in MSVC 2015 with inline namespace and variadic template. + static_assert(absl::conjunction<negation<std::is_array<T0> >, + negation<std::is_array<Tn> >...>::value, + "Attempted to instantiate a variant containing an array type."); + static_assert(absl::conjunction<std::is_nothrow_destructible<T0>, + std::is_nothrow_destructible<Tn>...>::value, + "Attempted to instantiate a variant containing a non-nothrow " + "destructible type."); + + friend struct variant_internal::VariantCoreAccess; + + private: + using Base = variant_internal::VariantBase<T0, Tn...>; + + public: + // Constructors + + // Constructs a variant holding a default-initialized value of the first + // alternative type. + constexpr variant() /*noexcept(see 111above)*/ = default; + + // Copy constructor, standard semantics + variant(const variant& other) = default; + + // Move constructor, standard semantics + variant(variant&& other) /*noexcept(see above)*/ = default; + + // Constructs a variant of an alternative type specified by overload + // resolution of the provided forwarding arguments through + // direct-initialization. + // + // Note: If the selected constructor is a constexpr constructor, this + // constructor shall be a constexpr constructor. + // + // NOTE: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0608r1.html + // has been voted passed the design phase in the C++ standard meeting in Mar + // 2018. It will be implemented and integrated into `absl::variant`. + template < + class T, + std::size_t I = std::enable_if< + variant_internal::IsNeitherSelfNorInPlace<variant, + absl::decay_t<T>>::value, + variant_internal::IndexOfConstructedType<variant, T>>::type::value, + class Tj = absl::variant_alternative_t<I, variant>, + absl::enable_if_t<std::is_constructible<Tj, T>::value>* = + nullptr> + constexpr variant(T&& t) noexcept(std::is_nothrow_constructible<Tj, T>::value) + : Base(variant_internal::EmplaceTag<I>(), absl::forward<T>(t)) {} + + // Constructs a variant of an alternative type from the arguments through + // direct-initialization. + // + // Note: If the selected constructor is a constexpr constructor, this + // constructor shall be a constexpr constructor. + template <class T, class... Args, + typename std::enable_if<std::is_constructible< + variant_internal::UnambiguousTypeOfT<variant, T>, + Args...>::value>::type* = nullptr> + constexpr explicit variant(in_place_type_t<T>, Args&&... args) + : Base(variant_internal::EmplaceTag< + variant_internal::UnambiguousIndexOf<variant, T>::value>(), + absl::forward<Args>(args)...) {} + + // Constructs a variant of an alternative type from an initializer list + // and other arguments through direct-initialization. + // + // Note: If the selected constructor is a constexpr constructor, this + // constructor shall be a constexpr constructor. + template <class T, class U, class... Args, + typename std::enable_if<std::is_constructible< + variant_internal::UnambiguousTypeOfT<variant, T>, + std::initializer_list<U>&, Args...>::value>::type* = nullptr> + constexpr explicit variant(in_place_type_t<T>, std::initializer_list<U> il, + Args&&... args) + : Base(variant_internal::EmplaceTag< + variant_internal::UnambiguousIndexOf<variant, T>::value>(), + il, absl::forward<Args>(args)...) {} + + // Constructs a variant of an alternative type from a provided index, + // through value-initialization using the provided forwarded arguments. + template <std::size_t I, class... Args, + typename std::enable_if<std::is_constructible< + variant_internal::VariantAlternativeSfinaeT<I, variant>, + Args...>::value>::type* = nullptr> + constexpr explicit variant(in_place_index_t<I>, Args&&... args) + : Base(variant_internal::EmplaceTag<I>(), absl::forward<Args>(args)...) {} + + // Constructs a variant of an alternative type from a provided index, + // through value-initialization of an initializer list and the provided + // forwarded arguments. + template <std::size_t I, class U, class... Args, + typename std::enable_if<std::is_constructible< + variant_internal::VariantAlternativeSfinaeT<I, variant>, + std::initializer_list<U>&, Args...>::value>::type* = nullptr> + constexpr explicit variant(in_place_index_t<I>, std::initializer_list<U> il, + Args&&... args) + : Base(variant_internal::EmplaceTag<I>(), il, + absl::forward<Args>(args)...) {} + + // Destructors + + // Destroys the variant's currently contained value, provided that + // `absl::valueless_by_exception()` is false. + ~variant() = default; + + // Assignment Operators + + // Copy assignment operator + variant& operator=(const variant& other) = default; + + // Move assignment operator + variant& operator=(variant&& other) /*noexcept(see above)*/ = default; + + // Converting assignment operator + // + // NOTE: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0608r1.html + // has been voted passed the design phase in the C++ standard meeting in Mar + // 2018. It will be implemented and integrated into `absl::variant`. + template < + class T, + std::size_t I = std::enable_if< + !std::is_same<absl::decay_t<T>, variant>::value, + variant_internal::IndexOfConstructedType<variant, T>>::type::value, + class Tj = absl::variant_alternative_t<I, variant>, + typename std::enable_if<std::is_assignable<Tj&, T>::value && + std::is_constructible<Tj, T>::value>::type* = + nullptr> + variant& operator=(T&& t) noexcept( + std::is_nothrow_assignable<Tj&, T>::value&& + std::is_nothrow_constructible<Tj, T>::value) { + variant_internal::VisitIndices<sizeof...(Tn) + 1>::Run( + variant_internal::VariantCoreAccess::MakeConversionAssignVisitor( + this, absl::forward<T>(t)), + index()); + + return *this; + } + + + // emplace() Functions + + // Constructs a value of the given alternative type T within the variant. + // + // Example: + // + // absl::variant<std::vector<int>, int, std::string> v; + // v.emplace<int>(99); + // v.emplace<std::string>("abc"); + template < + class T, class... Args, + typename std::enable_if<std::is_constructible< + absl::variant_alternative_t< + variant_internal::UnambiguousIndexOf<variant, T>::value, variant>, + Args...>::value>::type* = nullptr> + T& emplace(Args&&... args) { + return variant_internal::VariantCoreAccess::Replace< + variant_internal::UnambiguousIndexOf<variant, T>::value>( + this, absl::forward<Args>(args)...); + } + + // Constructs a value of the given alternative type T within the variant using + // an initializer list. + // + // Example: + // + // absl::variant<std::vector<int>, int, std::string> v; + // v.emplace<std::vector<int>>({0, 1, 2}); + template < + class T, class U, class... Args, + typename std::enable_if<std::is_constructible< + absl::variant_alternative_t< + variant_internal::UnambiguousIndexOf<variant, T>::value, variant>, + std::initializer_list<U>&, Args...>::value>::type* = nullptr> + T& emplace(std::initializer_list<U> il, Args&&... args) { + return variant_internal::VariantCoreAccess::Replace< + variant_internal::UnambiguousIndexOf<variant, T>::value>( + this, il, absl::forward<Args>(args)...); + } + + // Destroys the current value of the variant (provided that + // `absl::valueless_by_exception()` is false, and constructs a new value at + // the given index. + // + // Example: + // + // absl::variant<std::vector<int>, int, int> v; + // v.emplace<1>(99); + // v.emplace<2>(98); + // v.emplace<int>(99); // Won't compile. 'int' isn't a unique type. + template <std::size_t I, class... Args, + typename std::enable_if< + std::is_constructible<absl::variant_alternative_t<I, variant>, + Args...>::value>::type* = nullptr> + absl::variant_alternative_t<I, variant>& emplace(Args&&... args) { + return variant_internal::VariantCoreAccess::Replace<I>( + this, absl::forward<Args>(args)...); + } + + // Destroys the current value of the variant (provided that + // `absl::valueless_by_exception()` is false, and constructs a new value at + // the given index using an initializer list and the provided arguments. + // + // Example: + // + // absl::variant<std::vector<int>, int, int> v; + // v.emplace<0>({0, 1, 2}); + template <std::size_t I, class U, class... Args, + typename std::enable_if<std::is_constructible< + absl::variant_alternative_t<I, variant>, + std::initializer_list<U>&, Args...>::value>::type* = nullptr> + absl::variant_alternative_t<I, variant>& emplace(std::initializer_list<U> il, + Args&&... args) { + return variant_internal::VariantCoreAccess::Replace<I>( + this, il, absl::forward<Args>(args)...); + } + + // variant::valueless_by_exception() + // + // Returns false if and only if the variant currently holds a valid value. + constexpr bool valueless_by_exception() const noexcept { + return this->index_ == absl::variant_npos; + } + + // variant::index() + // + // Returns the index value of the variant's currently selected alternative + // type. + constexpr std::size_t index() const noexcept { return this->index_; } + + // variant::swap() + // + // Swaps the values of two variant objects. + // + void swap(variant& rhs) noexcept( + absl::conjunction< + std::is_nothrow_move_constructible<T0>, + std::is_nothrow_move_constructible<Tn>..., + type_traits_internal::IsNothrowSwappable<T0>, + type_traits_internal::IsNothrowSwappable<Tn>...>::value) { + return variant_internal::VisitIndices<sizeof...(Tn) + 1>::Run( + variant_internal::Swap<T0, Tn...>{this, &rhs}, rhs.index()); + } +}; + +// We need a valid declaration of variant<> for SFINAE and overload resolution +// to work properly above, but we don't need a full declaration since this type +// will never be constructed. This declaration, though incomplete, suffices. +template <> +class variant<>; + +//------------------------------------------------------------------------------ +// Relational Operators +//------------------------------------------------------------------------------ +// +// If neither operand is in the `variant::valueless_by_exception` state: +// +// * If the index of both variants is the same, the relational operator +// returns the result of the corresponding relational operator for the +// corresponding alternative type. +// * If the index of both variants is not the same, the relational operator +// returns the result of that operation applied to the value of the left +// operand's index and the value of the right operand's index. +// * If at least one operand is in the valueless_by_exception state: +// - A variant in the valueless_by_exception state is only considered equal +// to another variant in the valueless_by_exception state. +// - If exactly one operand is in the valueless_by_exception state, the +// variant in the valueless_by_exception state is less than the variant +// that is not in the valueless_by_exception state. +// +// Note: The value 1 is added to each index in the relational comparisons such +// that the index corresponding to the valueless_by_exception state wraps around +// to 0 (the lowest value for the index type), and the remaining indices stay in +// the same relative order. + +// Equal-to operator +template <typename... Types> +constexpr variant_internal::RequireAllHaveEqualT<Types...> operator==( + const variant<Types...>& a, const variant<Types...>& b) { + return (a.index() == b.index()) && + variant_internal::VisitIndices<sizeof...(Types)>::Run( + variant_internal::EqualsOp<Types...>{&a, &b}, a.index()); +} + +// Not equal operator +template <typename... Types> +constexpr variant_internal::RequireAllHaveNotEqualT<Types...> operator!=( + const variant<Types...>& a, const variant<Types...>& b) { + return (a.index() != b.index()) || + variant_internal::VisitIndices<sizeof...(Types)>::Run( + variant_internal::NotEqualsOp<Types...>{&a, &b}, a.index()); +} + +// Less-than operator +template <typename... Types> +constexpr variant_internal::RequireAllHaveLessThanT<Types...> operator<( + const variant<Types...>& a, const variant<Types...>& b) { + return (a.index() != b.index()) + ? (a.index() + 1) < (b.index() + 1) + : variant_internal::VisitIndices<sizeof...(Types)>::Run( + variant_internal::LessThanOp<Types...>{&a, &b}, a.index()); +} + +// Greater-than operator +template <typename... Types> +constexpr variant_internal::RequireAllHaveGreaterThanT<Types...> operator>( + const variant<Types...>& a, const variant<Types...>& b) { + return (a.index() != b.index()) + ? (a.index() + 1) > (b.index() + 1) + : variant_internal::VisitIndices<sizeof...(Types)>::Run( + variant_internal::GreaterThanOp<Types...>{&a, &b}, + a.index()); +} + +// Less-than or equal-to operator +template <typename... Types> +constexpr variant_internal::RequireAllHaveLessThanOrEqualT<Types...> operator<=( + const variant<Types...>& a, const variant<Types...>& b) { + return (a.index() != b.index()) + ? (a.index() + 1) < (b.index() + 1) + : variant_internal::VisitIndices<sizeof...(Types)>::Run( + variant_internal::LessThanOrEqualsOp<Types...>{&a, &b}, + a.index()); +} + +// Greater-than or equal-to operator +template <typename... Types> +constexpr variant_internal::RequireAllHaveGreaterThanOrEqualT<Types...> +operator>=(const variant<Types...>& a, const variant<Types...>& b) { + return (a.index() != b.index()) + ? (a.index() + 1) > (b.index() + 1) + : variant_internal::VisitIndices<sizeof...(Types)>::Run( + variant_internal::GreaterThanOrEqualsOp<Types...>{&a, &b}, + a.index()); +} + +ABSL_NAMESPACE_END +} // namespace absl + +namespace std { + +// hash() +template <> // NOLINT +struct hash<absl::monostate> { + std::size_t operator()(absl::monostate) const { return 0; } +}; + +template <class... T> // NOLINT +struct hash<absl::variant<T...>> + : absl::variant_internal::VariantHashBase<absl::variant<T...>, void, + absl::remove_const_t<T>...> {}; + +} // namespace std + +#endif // ABSL_USES_STD_VARIANT + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace variant_internal { + +// Helper visitor for converting a variant<Ts...>` into another type (mostly +// variant) that can be constructed from any type. +template <typename To> +struct ConversionVisitor { + template <typename T> + To operator()(T&& v) const { + return To(std::forward<T>(v)); + } +}; + +} // namespace variant_internal + +// ConvertVariantTo() +// +// Helper functions to convert an `absl::variant` to a variant of another set of +// types, provided that the alternative type of the new variant type can be +// converted from any type in the source variant. +// +// Example: +// +// absl::variant<name1, name2, float> InternalReq(const Req&); +// +// // name1 and name2 are convertible to name +// absl::variant<name, float> ExternalReq(const Req& req) { +// return absl::ConvertVariantTo<absl::variant<name, float>>( +// InternalReq(req)); +// } +template <typename To, typename Variant> +To ConvertVariantTo(Variant&& variant) { + return absl::visit(variant_internal::ConversionVisitor<To>{}, + std::forward<Variant>(variant)); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_TYPES_VARIANT_H_ diff --git a/third_party/abseil_cpp/absl/types/variant_benchmark.cc b/third_party/abseil_cpp/absl/types/variant_benchmark.cc new file mode 100644 index 0000000000..350b175364 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/variant_benchmark.cc @@ -0,0 +1,222 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Unit tests for the variant template. The 'is' and 'IsEmpty' methods +// of variant are not explicitly tested because they are used repeatedly +// in building other tests. All other public variant methods should have +// explicit tests. + +#include "absl/types/variant.h" + +#include <cstddef> +#include <cstdlib> +#include <string> +#include <tuple> + +#include "benchmark/benchmark.h" +#include "absl/utility/utility.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +template <std::size_t I> +struct VariantAlternative { + char member; +}; + +template <class Indices> +struct VariantOfAlternativesImpl; + +template <std::size_t... Indices> +struct VariantOfAlternativesImpl<absl::index_sequence<Indices...>> { + using type = absl::variant<VariantAlternative<Indices>...>; +}; + +template <std::size_t NumAlternatives> +using VariantOfAlternatives = typename VariantOfAlternativesImpl< + absl::make_index_sequence<NumAlternatives>>::type; + +struct Empty {}; + +template <class... T> +void Ignore(T...) noexcept {} + +template <class T> +Empty DoNotOptimizeAndReturnEmpty(T&& arg) noexcept { + benchmark::DoNotOptimize(arg); + return {}; +} + +struct VisitorApplier { + struct Visitor { + template <class... T> + void operator()(T&&... args) const noexcept { + Ignore(DoNotOptimizeAndReturnEmpty(args)...); + } + }; + + template <class... Vars> + void operator()(const Vars&... vars) const noexcept { + absl::visit(Visitor(), vars...); + } +}; + +template <std::size_t NumIndices, std::size_t CurrIndex = NumIndices - 1> +struct MakeWithIndex { + using Variant = VariantOfAlternatives<NumIndices>; + + static Variant Run(std::size_t index) { + return index == CurrIndex + ? Variant(absl::in_place_index_t<CurrIndex>()) + : MakeWithIndex<NumIndices, CurrIndex - 1>::Run(index); + } +}; + +template <std::size_t NumIndices> +struct MakeWithIndex<NumIndices, 0> { + using Variant = VariantOfAlternatives<NumIndices>; + + static Variant Run(std::size_t /*index*/) { return Variant(); } +}; + +template <std::size_t NumIndices, class Dimensions> +struct MakeVariantTuple; + +template <class T, std::size_t /*I*/> +using always_t = T; + +template <std::size_t NumIndices> +VariantOfAlternatives<NumIndices> MakeVariant(std::size_t dimension, + std::size_t index) { + return dimension == 0 + ? MakeWithIndex<NumIndices>::Run(index % NumIndices) + : MakeVariant<NumIndices>(dimension - 1, index / NumIndices); +} + +template <std::size_t NumIndices, std::size_t... Dimensions> +struct MakeVariantTuple<NumIndices, absl::index_sequence<Dimensions...>> { + using VariantTuple = + std::tuple<always_t<VariantOfAlternatives<NumIndices>, Dimensions>...>; + + static VariantTuple Run(int index) { + return std::make_tuple(MakeVariant<NumIndices>(Dimensions, index)...); + } +}; + +constexpr std::size_t integral_pow(std::size_t base, std::size_t power) { + return power == 0 ? 1 : base * integral_pow(base, power - 1); +} + +template <std::size_t End, std::size_t I = 0> +struct VisitTestBody { + template <class Vars, class State> + static bool Run(Vars& vars, State& state) { + if (state.KeepRunning()) { + absl::apply(VisitorApplier(), vars[I]); + return VisitTestBody<End, I + 1>::Run(vars, state); + } + return false; + } +}; + +template <std::size_t End> +struct VisitTestBody<End, End> { + template <class Vars, class State> + static bool Run(Vars& /*vars*/, State& /*state*/) { + return true; + } +}; + +// Visit operations where branch prediction is likely to give a boost. +template <std::size_t NumIndices, std::size_t NumDimensions = 1> +void BM_RedundantVisit(benchmark::State& state) { + auto vars = + MakeVariantTuple<NumIndices, absl::make_index_sequence<NumDimensions>>:: + Run(static_cast<std::size_t>(state.range(0))); + + for (auto _ : state) { // NOLINT + benchmark::DoNotOptimize(vars); + absl::apply(VisitorApplier(), vars); + } +} + +// Visit operations where branch prediction is unlikely to give a boost. +template <std::size_t NumIndices, std::size_t NumDimensions = 1> +void BM_Visit(benchmark::State& state) { + constexpr std::size_t num_possibilities = + integral_pow(NumIndices, NumDimensions); + + using VariantTupleMaker = + MakeVariantTuple<NumIndices, absl::make_index_sequence<NumDimensions>>; + using Tuple = typename VariantTupleMaker::VariantTuple; + + Tuple vars[num_possibilities]; + for (std::size_t i = 0; i < num_possibilities; ++i) + vars[i] = VariantTupleMaker::Run(i); + + while (VisitTestBody<num_possibilities>::Run(vars, state)) { + } +} + +// Visitation +// Each visit is on a different variant with a different active alternative) + +// Unary visit +BENCHMARK_TEMPLATE(BM_Visit, 1); +BENCHMARK_TEMPLATE(BM_Visit, 2); +BENCHMARK_TEMPLATE(BM_Visit, 3); +BENCHMARK_TEMPLATE(BM_Visit, 4); +BENCHMARK_TEMPLATE(BM_Visit, 5); +BENCHMARK_TEMPLATE(BM_Visit, 6); +BENCHMARK_TEMPLATE(BM_Visit, 7); +BENCHMARK_TEMPLATE(BM_Visit, 8); +BENCHMARK_TEMPLATE(BM_Visit, 16); +BENCHMARK_TEMPLATE(BM_Visit, 32); +BENCHMARK_TEMPLATE(BM_Visit, 64); + +// Binary visit +BENCHMARK_TEMPLATE(BM_Visit, 1, 2); +BENCHMARK_TEMPLATE(BM_Visit, 2, 2); +BENCHMARK_TEMPLATE(BM_Visit, 3, 2); +BENCHMARK_TEMPLATE(BM_Visit, 4, 2); +BENCHMARK_TEMPLATE(BM_Visit, 5, 2); + +// Ternary visit +BENCHMARK_TEMPLATE(BM_Visit, 1, 3); +BENCHMARK_TEMPLATE(BM_Visit, 2, 3); +BENCHMARK_TEMPLATE(BM_Visit, 3, 3); + +// Quaternary visit +BENCHMARK_TEMPLATE(BM_Visit, 1, 4); +BENCHMARK_TEMPLATE(BM_Visit, 2, 4); + +// Redundant Visitation +// Each visit consistently has the same alternative active + +// Unary visit +BENCHMARK_TEMPLATE(BM_RedundantVisit, 1)->Arg(0); +BENCHMARK_TEMPLATE(BM_RedundantVisit, 2)->DenseRange(0, 1); +BENCHMARK_TEMPLATE(BM_RedundantVisit, 8)->DenseRange(0, 7); + +// Binary visit +BENCHMARK_TEMPLATE(BM_RedundantVisit, 1, 2)->Arg(0); +BENCHMARK_TEMPLATE(BM_RedundantVisit, 2, 2) + ->DenseRange(0, integral_pow(2, 2) - 1); +BENCHMARK_TEMPLATE(BM_RedundantVisit, 4, 2) + ->DenseRange(0, integral_pow(4, 2) - 1); + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl diff --git a/third_party/abseil_cpp/absl/types/variant_exception_safety_test.cc b/third_party/abseil_cpp/absl/types/variant_exception_safety_test.cc new file mode 100644 index 0000000000..439c6e1df3 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/variant_exception_safety_test.cc @@ -0,0 +1,532 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/types/variant.h" + +#include "absl/base/config.h" + +// This test is a no-op when absl::variant is an alias for std::variant and when +// exceptions are not enabled. +#if !defined(ABSL_USES_STD_VARIANT) && defined(ABSL_HAVE_EXCEPTIONS) + +#include <iostream> +#include <memory> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/internal/exception_safety_testing.h" +#include "absl/memory/memory.h" + +// See comment in absl/base/config.h +#if !defined(ABSL_INTERNAL_MSVC_2017_DBG_MODE) + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +using ::testing::MakeExceptionSafetyTester; +using ::testing::strong_guarantee; +using ::testing::TestNothrowOp; +using ::testing::TestThrowingCtor; + +using Thrower = testing::ThrowingValue<>; +using CopyNothrow = testing::ThrowingValue<testing::TypeSpec::kNoThrowCopy>; +using MoveNothrow = testing::ThrowingValue<testing::TypeSpec::kNoThrowMove>; +using ThrowingAlloc = testing::ThrowingAllocator<Thrower>; +using ThrowerVec = std::vector<Thrower, ThrowingAlloc>; +using ThrowingVariant = + absl::variant<Thrower, CopyNothrow, MoveNothrow, ThrowerVec>; + +struct ConversionException {}; + +template <class T> +struct ExceptionOnConversion { + operator T() const { // NOLINT + throw ConversionException(); + } +}; + +// Forces a variant into the valueless by exception state. +void ToValuelessByException(ThrowingVariant& v) { // NOLINT + try { + v.emplace<Thrower>(); + v.emplace<Thrower>(ExceptionOnConversion<Thrower>()); + } catch (const ConversionException&) { + // This space intentionally left blank. + } +} + +// Check that variant is still in a usable state after an exception is thrown. +testing::AssertionResult VariantInvariants(ThrowingVariant* v) { + using testing::AssertionFailure; + using testing::AssertionSuccess; + + // Try using the active alternative + if (absl::holds_alternative<Thrower>(*v)) { + auto& t = absl::get<Thrower>(*v); + t = Thrower{-100}; + if (t.Get() != -100) { + return AssertionFailure() << "Thrower should be assigned -100"; + } + } else if (absl::holds_alternative<ThrowerVec>(*v)) { + auto& tv = absl::get<ThrowerVec>(*v); + tv.clear(); + tv.emplace_back(-100); + if (tv.size() != 1 || tv[0].Get() != -100) { + return AssertionFailure() << "ThrowerVec should be {Thrower{-100}}"; + } + } else if (absl::holds_alternative<CopyNothrow>(*v)) { + auto& t = absl::get<CopyNothrow>(*v); + t = CopyNothrow{-100}; + if (t.Get() != -100) { + return AssertionFailure() << "CopyNothrow should be assigned -100"; + } + } else if (absl::holds_alternative<MoveNothrow>(*v)) { + auto& t = absl::get<MoveNothrow>(*v); + t = MoveNothrow{-100}; + if (t.Get() != -100) { + return AssertionFailure() << "MoveNothrow should be assigned -100"; + } + } + + // Try making variant valueless_by_exception + if (!v->valueless_by_exception()) ToValuelessByException(*v); + if (!v->valueless_by_exception()) { + return AssertionFailure() << "Variant should be valueless_by_exception"; + } + try { + auto unused = absl::get<Thrower>(*v); + static_cast<void>(unused); + return AssertionFailure() << "Variant should not contain Thrower"; + } catch (const absl::bad_variant_access&) { + } catch (...) { + return AssertionFailure() << "Unexpected exception throw from absl::get"; + } + + // Try using the variant + v->emplace<Thrower>(100); + if (!absl::holds_alternative<Thrower>(*v) || + absl::get<Thrower>(*v) != Thrower(100)) { + return AssertionFailure() << "Variant should contain Thrower(100)"; + } + v->emplace<ThrowerVec>({Thrower(100)}); + if (!absl::holds_alternative<ThrowerVec>(*v) || + absl::get<ThrowerVec>(*v)[0] != Thrower(100)) { + return AssertionFailure() + << "Variant should contain ThrowerVec{Thrower(100)}"; + } + return AssertionSuccess(); +} + +template <typename... Args> +Thrower ExpectedThrower(Args&&... args) { + return Thrower(42, args...); +} + +ThrowerVec ExpectedThrowerVec() { return {Thrower(100), Thrower(200)}; } +ThrowingVariant ValuelessByException() { + ThrowingVariant v; + ToValuelessByException(v); + return v; +} +ThrowingVariant WithThrower() { return Thrower(39); } +ThrowingVariant WithThrowerVec() { + return ThrowerVec{Thrower(1), Thrower(2), Thrower(3)}; +} +ThrowingVariant WithCopyNoThrow() { return CopyNothrow(39); } +ThrowingVariant WithMoveNoThrow() { return MoveNothrow(39); } + +TEST(VariantExceptionSafetyTest, DefaultConstructor) { + TestThrowingCtor<ThrowingVariant>(); +} + +TEST(VariantExceptionSafetyTest, CopyConstructor) { + { + ThrowingVariant v(ExpectedThrower()); + TestThrowingCtor<ThrowingVariant>(v); + } + { + ThrowingVariant v(ExpectedThrowerVec()); + TestThrowingCtor<ThrowingVariant>(v); + } + { + ThrowingVariant v(ValuelessByException()); + TestThrowingCtor<ThrowingVariant>(v); + } +} + +TEST(VariantExceptionSafetyTest, MoveConstructor) { + { + ThrowingVariant v(ExpectedThrower()); + TestThrowingCtor<ThrowingVariant>(std::move(v)); + } + { + ThrowingVariant v(ExpectedThrowerVec()); + TestThrowingCtor<ThrowingVariant>(std::move(v)); + } + { + ThrowingVariant v(ValuelessByException()); + TestThrowingCtor<ThrowingVariant>(std::move(v)); + } +} + +TEST(VariantExceptionSafetyTest, ValueConstructor) { + TestThrowingCtor<ThrowingVariant>(ExpectedThrower()); + TestThrowingCtor<ThrowingVariant>(ExpectedThrowerVec()); +} + +TEST(VariantExceptionSafetyTest, InPlaceTypeConstructor) { + TestThrowingCtor<ThrowingVariant>(absl::in_place_type_t<Thrower>{}, + ExpectedThrower()); + TestThrowingCtor<ThrowingVariant>(absl::in_place_type_t<ThrowerVec>{}, + ExpectedThrowerVec()); +} + +TEST(VariantExceptionSafetyTest, InPlaceIndexConstructor) { + TestThrowingCtor<ThrowingVariant>(absl::in_place_index_t<0>{}, + ExpectedThrower()); + TestThrowingCtor<ThrowingVariant>(absl::in_place_index_t<3>{}, + ExpectedThrowerVec()); +} + +TEST(VariantExceptionSafetyTest, CopyAssign) { + // variant& operator=(const variant& rhs); + // Let j be rhs.index() + { + // - neither *this nor rhs holds a value + const ThrowingVariant rhs = ValuelessByException(); + ThrowingVariant lhs = ValuelessByException(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = rhs; })); + } + { + // - *this holds a value but rhs does not + const ThrowingVariant rhs = ValuelessByException(); + ThrowingVariant lhs = WithThrower(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = rhs; })); + } + // - index() == j + { + const ThrowingVariant rhs(ExpectedThrower()); + auto tester = + MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithOperation([&rhs](ThrowingVariant* lhs) { *lhs = rhs; }); + EXPECT_TRUE(tester.WithContracts(VariantInvariants).Test()); + EXPECT_FALSE(tester.WithContracts(strong_guarantee).Test()); + } + { + const ThrowingVariant rhs(ExpectedThrowerVec()); + auto tester = + MakeExceptionSafetyTester() + .WithInitialValue(WithThrowerVec()) + .WithOperation([&rhs](ThrowingVariant* lhs) { *lhs = rhs; }); + EXPECT_TRUE(tester.WithContracts(VariantInvariants).Test()); + EXPECT_FALSE(tester.WithContracts(strong_guarantee).Test()); + } + // libstdc++ std::variant has bugs on copy assignment regarding exception + // safety. +#if !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) + // index() != j + // if is_nothrow_copy_constructible_v<Tj> or + // !is_nothrow_move_constructible<Tj> is true, equivalent to + // emplace<j>(get<j>(rhs)) + { + // is_nothrow_copy_constructible_v<Tj> == true + // should not throw because emplace() invokes Tj's copy ctor + // which should not throw. + const ThrowingVariant rhs(CopyNothrow{}); + ThrowingVariant lhs = WithThrower(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = rhs; })); + } + { + // is_nothrow_copy_constructible<Tj> == false && + // is_nothrow_move_constructible<Tj> == false + // should provide basic guarantee because emplace() invokes Tj's copy ctor + // which may throw. + const ThrowingVariant rhs(ExpectedThrower()); + auto tester = + MakeExceptionSafetyTester() + .WithInitialValue(WithCopyNoThrow()) + .WithOperation([&rhs](ThrowingVariant* lhs) { *lhs = rhs; }); + EXPECT_TRUE(tester + .WithContracts(VariantInvariants, + [](ThrowingVariant* lhs) { + return lhs->valueless_by_exception(); + }) + .Test()); + EXPECT_FALSE(tester.WithContracts(strong_guarantee).Test()); + } +#endif // !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) + { + // is_nothrow_copy_constructible_v<Tj> == false && + // is_nothrow_move_constructible_v<Tj> == true + // should provide strong guarantee because it is equivalent to + // operator=(variant(rhs)) which creates a temporary then invoke the move + // ctor which shouldn't throw. + const ThrowingVariant rhs(MoveNothrow{}); + EXPECT_TRUE(MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithContracts(VariantInvariants, strong_guarantee) + .Test([&rhs](ThrowingVariant* lhs) { *lhs = rhs; })); + } +} + +TEST(VariantExceptionSafetyTest, MoveAssign) { + // variant& operator=(variant&& rhs); + // Let j be rhs.index() + { + // - neither *this nor rhs holds a value + ThrowingVariant rhs = ValuelessByException(); + ThrowingVariant lhs = ValuelessByException(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = std::move(rhs); })); + } + { + // - *this holds a value but rhs does not + ThrowingVariant rhs = ValuelessByException(); + ThrowingVariant lhs = WithThrower(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = std::move(rhs); })); + } + { + // - index() == j + // assign get<j>(std::move(rhs)) to the value contained in *this. + // If an exception is thrown during call to Tj's move assignment, the state + // of the contained value is as defined by the exception safety guarantee of + // Tj's move assignment; index() will be j. + ThrowingVariant rhs(ExpectedThrower()); + size_t j = rhs.index(); + // Since Thrower's move assignment has basic guarantee, so should variant's. + auto tester = MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithOperation([&](ThrowingVariant* lhs) { + auto copy = rhs; + *lhs = std::move(copy); + }); + EXPECT_TRUE(tester + .WithContracts( + VariantInvariants, + [&](ThrowingVariant* lhs) { return lhs->index() == j; }) + .Test()); + EXPECT_FALSE(tester.WithContracts(strong_guarantee).Test()); + } + { + // libstdc++ introduced a regression between 2018-09-25 and 2019-01-06. + // The fix is targeted for gcc-9. + // https://gcc.gnu.org/bugzilla/show_bug.cgi?id=87431#c7 + // https://gcc.gnu.org/viewcvs/gcc?view=revision&revision=267614 +#if !(defined(ABSL_USES_STD_VARIANT) && \ + defined(_GLIBCXX_RELEASE) && _GLIBCXX_RELEASE == 8) + // - otherwise (index() != j), equivalent to + // emplace<j>(get<j>(std::move(rhs))) + // - If an exception is thrown during the call to Tj's move construction + // (with j being rhs.index()), the variant will hold no value. + ThrowingVariant rhs(CopyNothrow{}); + EXPECT_TRUE(MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithContracts(VariantInvariants, + [](ThrowingVariant* lhs) { + return lhs->valueless_by_exception(); + }) + .Test([&](ThrowingVariant* lhs) { + auto copy = rhs; + *lhs = std::move(copy); + })); +#endif // !(defined(ABSL_USES_STD_VARIANT) && + // defined(_GLIBCXX_RELEASE) && _GLIBCXX_RELEASE == 8) + } +} + +TEST(VariantExceptionSafetyTest, ValueAssign) { + // template<class T> variant& operator=(T&& t); + // Let Tj be the type that is selected by overload resolution to be assigned. + { + // If *this holds a Tj, assigns std::forward<T>(t) to the value contained in + // *this. If an exception is thrown during the assignment of + // std::forward<T>(t) to the value contained in *this, the state of the + // contained value and t are as defined by the exception safety guarantee of + // the assignment expression; valueless_by_exception() will be false. + // Since Thrower's copy/move assignment has basic guarantee, so should + // variant's. + Thrower rhs = ExpectedThrower(); + // copy assign + auto copy_tester = + MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithOperation([rhs](ThrowingVariant* lhs) { *lhs = rhs; }); + EXPECT_TRUE(copy_tester + .WithContracts(VariantInvariants, + [](ThrowingVariant* lhs) { + return !lhs->valueless_by_exception(); + }) + .Test()); + EXPECT_FALSE(copy_tester.WithContracts(strong_guarantee).Test()); + // move assign + auto move_tester = MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithOperation([&](ThrowingVariant* lhs) { + auto copy = rhs; + *lhs = std::move(copy); + }); + EXPECT_TRUE(move_tester + .WithContracts(VariantInvariants, + [](ThrowingVariant* lhs) { + return !lhs->valueless_by_exception(); + }) + .Test()); + + EXPECT_FALSE(move_tester.WithContracts(strong_guarantee).Test()); + } + // Otherwise (*this holds something else), if is_nothrow_constructible_v<Tj, + // T> || !is_nothrow_move_constructible_v<Tj> is true, equivalent to + // emplace<j>(std::forward<T>(t)). + // We simplify the test by letting T = `const Tj&` or `Tj&&`, so we can reuse + // the CopyNothrow and MoveNothrow types. + + // if is_nothrow_constructible_v<Tj, T> + // (i.e. is_nothrow_copy/move_constructible_v<Tj>) is true, emplace() just + // invokes the copy/move constructor and it should not throw. + { + const CopyNothrow rhs; + ThrowingVariant lhs = WithThrower(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = rhs; })); + } + { + MoveNothrow rhs; + ThrowingVariant lhs = WithThrower(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs = std::move(rhs); })); + } + // if is_nothrow_constructible_v<Tj, T> == false && + // is_nothrow_move_constructible<Tj> == false + // emplace() invokes the copy/move constructor which may throw so it should + // provide basic guarantee and variant object might not hold a value. + { + Thrower rhs = ExpectedThrower(); + // copy + auto copy_tester = + MakeExceptionSafetyTester() + .WithInitialValue(WithCopyNoThrow()) + .WithOperation([&rhs](ThrowingVariant* lhs) { *lhs = rhs; }); + EXPECT_TRUE(copy_tester + .WithContracts(VariantInvariants, + [](ThrowingVariant* lhs) { + return lhs->valueless_by_exception(); + }) + .Test()); + EXPECT_FALSE(copy_tester.WithContracts(strong_guarantee).Test()); + // move + auto move_tester = MakeExceptionSafetyTester() + .WithInitialValue(WithCopyNoThrow()) + .WithOperation([](ThrowingVariant* lhs) { + *lhs = ExpectedThrower(testing::nothrow_ctor); + }); + EXPECT_TRUE(move_tester + .WithContracts(VariantInvariants, + [](ThrowingVariant* lhs) { + return lhs->valueless_by_exception(); + }) + .Test()); + EXPECT_FALSE(move_tester.WithContracts(strong_guarantee).Test()); + } + // Otherwise (if is_nothrow_constructible_v<Tj, T> == false && + // is_nothrow_move_constructible<Tj> == true), + // equivalent to operator=(variant(std::forward<T>(t))) + // This should have strong guarantee because it creates a temporary variant + // and operator=(variant&&) invokes Tj's move ctor which doesn't throw. + // libstdc++ std::variant has bugs on conversion assignment regarding + // exception safety. +#if !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) + { + MoveNothrow rhs; + EXPECT_TRUE(MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithContracts(VariantInvariants, strong_guarantee) + .Test([&rhs](ThrowingVariant* lhs) { *lhs = rhs; })); + } +#endif // !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) +} + +TEST(VariantExceptionSafetyTest, Emplace) { + // If an exception during the initialization of the contained value, the + // variant might not hold a value. The standard requires emplace() to provide + // only basic guarantee. + { + Thrower args = ExpectedThrower(); + auto tester = MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithOperation([&args](ThrowingVariant* v) { + v->emplace<Thrower>(args); + }); + EXPECT_TRUE(tester + .WithContracts(VariantInvariants, + [](ThrowingVariant* v) { + return v->valueless_by_exception(); + }) + .Test()); + EXPECT_FALSE(tester.WithContracts(strong_guarantee).Test()); + } +} + +TEST(VariantExceptionSafetyTest, Swap) { + // if both are valueless_by_exception(), no effect + { + ThrowingVariant rhs = ValuelessByException(); + ThrowingVariant lhs = ValuelessByException(); + EXPECT_TRUE(TestNothrowOp([&]() { lhs.swap(rhs); })); + } + // if index() == rhs.index(), calls swap(get<i>(*this), get<i>(rhs)) + // where i is index(). + { + ThrowingVariant rhs = ExpectedThrower(); + EXPECT_TRUE(MakeExceptionSafetyTester() + .WithInitialValue(WithThrower()) + .WithContracts(VariantInvariants) + .Test([&](ThrowingVariant* lhs) { + auto copy = rhs; + lhs->swap(copy); + })); + } + // Otherwise, exchanges the value of rhs and *this. The exception safety + // involves variant in moved-from state which is not specified in the + // standard, and since swap is 3-step it's impossible for it to provide a + // overall strong guarantee. So, we are only checking basic guarantee here. + { + ThrowingVariant rhs = ExpectedThrower(); + EXPECT_TRUE(MakeExceptionSafetyTester() + .WithInitialValue(WithCopyNoThrow()) + .WithContracts(VariantInvariants) + .Test([&](ThrowingVariant* lhs) { + auto copy = rhs; + lhs->swap(copy); + })); + } + { + ThrowingVariant rhs = ExpectedThrower(); + EXPECT_TRUE(MakeExceptionSafetyTester() + .WithInitialValue(WithCopyNoThrow()) + .WithContracts(VariantInvariants) + .Test([&](ThrowingVariant* lhs) { + auto copy = rhs; + copy.swap(*lhs); + })); + } +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl + +#endif // !defined(ABSL_INTERNAL_MSVC_2017_DBG_MODE) + +#endif // #if !defined(ABSL_USES_STD_VARIANT) && defined(ABSL_HAVE_EXCEPTIONS) diff --git a/third_party/abseil_cpp/absl/types/variant_test.cc b/third_party/abseil_cpp/absl/types/variant_test.cc new file mode 100644 index 0000000000..cf8f7f3374 --- /dev/null +++ b/third_party/abseil_cpp/absl/types/variant_test.cc @@ -0,0 +1,2716 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Unit tests for the variant template. The 'is' and 'IsEmpty' methods +// of variant are not explicitly tested because they are used repeatedly +// in building other tests. All other public variant methods should have +// explicit tests. + +#include "absl/types/variant.h" + +// This test is a no-op when absl::variant is an alias for std::variant. +#if !defined(ABSL_USES_STD_VARIANT) + +#include <algorithm> +#include <cstddef> +#include <functional> +#include <initializer_list> +#include <memory> +#include <ostream> +#include <queue> +#include <type_traits> +#include <unordered_set> +#include <utility> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/config.h" +#include "absl/base/port.h" +#include "absl/memory/memory.h" +#include "absl/meta/type_traits.h" +#include "absl/strings/string_view.h" + +#ifdef ABSL_HAVE_EXCEPTIONS + +#define ABSL_VARIANT_TEST_EXPECT_FAIL(expr, exception_t, text) \ + EXPECT_THROW(expr, exception_t) + +#else + +#define ABSL_VARIANT_TEST_EXPECT_FAIL(expr, exception_t, text) \ + EXPECT_DEATH_IF_SUPPORTED(expr, text) + +#endif // ABSL_HAVE_EXCEPTIONS + +#define ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(...) \ + ABSL_VARIANT_TEST_EXPECT_FAIL((void)(__VA_ARGS__), absl::bad_variant_access, \ + "Bad variant access") + +struct Hashable {}; + +namespace std { +template <> +struct hash<Hashable> { + size_t operator()(const Hashable&); +}; +} // namespace std + +struct NonHashable {}; + +namespace absl { +ABSL_NAMESPACE_BEGIN +namespace { + +using ::testing::DoubleEq; +using ::testing::Pointee; +using ::testing::VariantWith; + +struct MoveCanThrow { + MoveCanThrow() : v(0) {} + MoveCanThrow(int v) : v(v) {} // NOLINT(runtime/explicit) + MoveCanThrow(const MoveCanThrow& other) : v(other.v) {} + MoveCanThrow& operator=(const MoveCanThrow& /*other*/) { return *this; } + int v; +}; + +bool operator==(MoveCanThrow lhs, MoveCanThrow rhs) { return lhs.v == rhs.v; } +bool operator!=(MoveCanThrow lhs, MoveCanThrow rhs) { return lhs.v != rhs.v; } +bool operator<(MoveCanThrow lhs, MoveCanThrow rhs) { return lhs.v < rhs.v; } +bool operator<=(MoveCanThrow lhs, MoveCanThrow rhs) { return lhs.v <= rhs.v; } +bool operator>=(MoveCanThrow lhs, MoveCanThrow rhs) { return lhs.v >= rhs.v; } +bool operator>(MoveCanThrow lhs, MoveCanThrow rhs) { return lhs.v > rhs.v; } + +// This helper class allows us to determine if it was swapped with std::swap() +// or with its friend swap() function. +struct SpecialSwap { + explicit SpecialSwap(int i) : i(i) {} + friend void swap(SpecialSwap& a, SpecialSwap& b) { + a.special_swap = b.special_swap = true; + std::swap(a.i, b.i); + } + bool operator==(SpecialSwap other) const { return i == other.i; } + int i; + bool special_swap = false; +}; + +struct MoveOnlyWithListConstructor { + MoveOnlyWithListConstructor() = default; + explicit MoveOnlyWithListConstructor(std::initializer_list<int> /*ilist*/, + int value) + : value(value) {} + MoveOnlyWithListConstructor(MoveOnlyWithListConstructor&&) = default; + MoveOnlyWithListConstructor& operator=(MoveOnlyWithListConstructor&&) = + default; + + int value = 0; +}; + +#ifdef ABSL_HAVE_EXCEPTIONS + +struct ConversionException {}; + +template <class T> +struct ExceptionOnConversion { + operator T() const { // NOLINT(runtime/explicit) + throw ConversionException(); + } +}; + +// Forces a variant into the valueless by exception state. +template <class H, class... T> +void ToValuelessByException(absl::variant<H, T...>& v) { // NOLINT + try { + v.template emplace<0>(ExceptionOnConversion<H>()); + } catch (ConversionException& /*e*/) { + // This space intentionally left blank. + } +} + +#endif // ABSL_HAVE_EXCEPTIONS + +// An indexed sequence of distinct structures holding a single +// value of type T +template<typename T, size_t N> +struct ValueHolder { + explicit ValueHolder(const T& x) : value(x) {} + typedef T value_type; + value_type value; + static const size_t kIndex = N; +}; +template<typename T, size_t N> +const size_t ValueHolder<T, N>::kIndex; + +// The following three functions make ValueHolder compatible with +// EXPECT_EQ and EXPECT_NE +template<typename T, size_t N> +inline bool operator==(const ValueHolder<T, N>& left, + const ValueHolder<T, N>& right) { + return left.value == right.value; +} + +template<typename T, size_t N> +inline bool operator!=(const ValueHolder<T, N>& left, + const ValueHolder<T, N>& right) { + return left.value != right.value; +} + +template<typename T, size_t N> +inline std::ostream& operator<<( + std::ostream& stream, const ValueHolder<T, N>& object) { + return stream << object.value; +} + +// Makes a variant holding twelve uniquely typed T wrappers. +template<typename T> +struct VariantFactory { + typedef variant<ValueHolder<T, 1>, ValueHolder<T, 2>, ValueHolder<T, 3>, + ValueHolder<T, 4>> + Type; +}; + +// A typelist in 1:1 with VariantFactory, to use type driven unit tests. +typedef ::testing::Types<ValueHolder<size_t, 1>, ValueHolder<size_t, 2>, + ValueHolder<size_t, 3>, + ValueHolder<size_t, 4>> VariantTypes; + +// Increments the provided counter pointer in the destructor +struct IncrementInDtor { + explicit IncrementInDtor(int* counter) : counter(counter) {} + ~IncrementInDtor() { *counter += 1; } + int* counter; +}; + +struct IncrementInDtorCopyCanThrow { + explicit IncrementInDtorCopyCanThrow(int* counter) : counter(counter) {} + IncrementInDtorCopyCanThrow(IncrementInDtorCopyCanThrow&& other) noexcept = + default; + IncrementInDtorCopyCanThrow(const IncrementInDtorCopyCanThrow& other) + : counter(other.counter) {} + IncrementInDtorCopyCanThrow& operator=( + IncrementInDtorCopyCanThrow&&) noexcept = default; + IncrementInDtorCopyCanThrow& operator=( + IncrementInDtorCopyCanThrow const& other) { + counter = other.counter; + return *this; + } + ~IncrementInDtorCopyCanThrow() { *counter += 1; } + int* counter; +}; + +// This is defined so operator== for ValueHolder<IncrementInDtor> will +// return true if two IncrementInDtor objects increment the same +// counter +inline bool operator==(const IncrementInDtor& left, + const IncrementInDtor& right) { + return left.counter == right.counter; +} + +// This is defined so EXPECT_EQ can work with IncrementInDtor +inline std::ostream& operator<<( + std::ostream& stream, const IncrementInDtor& object) { + return stream << object.counter; +} + +// A class that can be copied, but not assigned. +class CopyNoAssign { + public: + explicit CopyNoAssign(int value) : foo(value) {} + CopyNoAssign(const CopyNoAssign& other) : foo(other.foo) {} + int foo; + private: + const CopyNoAssign& operator=(const CopyNoAssign&); +}; + +// A class that can neither be copied nor assigned. We provide +// overloads for the constructor with up to four parameters so we can +// test the overloads of variant::emplace. +class NonCopyable { + public: + NonCopyable() + : value(0) {} + explicit NonCopyable(int value1) + : value(value1) {} + + NonCopyable(int value1, int value2) + : value(value1 + value2) {} + + NonCopyable(int value1, int value2, int value3) + : value(value1 + value2 + value3) {} + + NonCopyable(int value1, int value2, int value3, int value4) + : value(value1 + value2 + value3 + value4) {} + NonCopyable(const NonCopyable&) = delete; + NonCopyable& operator=(const NonCopyable&) = delete; + int value; +}; + +// A typed test and typed test case over the VariantTypes typelist, +// from which we derive a number of tests that will execute for one of +// each type. +template <typename T> +class VariantTypesTest : public ::testing::Test {}; +TYPED_TEST_SUITE(VariantTypesTest, VariantTypes); + +//////////////////// +// [variant.ctor] // +//////////////////// + +struct NonNoexceptDefaultConstructible { + NonNoexceptDefaultConstructible() {} + int value = 5; +}; + +struct NonDefaultConstructible { + NonDefaultConstructible() = delete; +}; + +TEST(VariantTest, TestDefaultConstructor) { + { + using X = variant<int>; + constexpr variant<int> x{}; + ASSERT_FALSE(x.valueless_by_exception()); + ASSERT_EQ(0, x.index()); + EXPECT_EQ(0, absl::get<0>(x)); + EXPECT_TRUE(std::is_nothrow_default_constructible<X>::value); + } + + { + using X = variant<NonNoexceptDefaultConstructible>; + X x{}; + ASSERT_FALSE(x.valueless_by_exception()); + ASSERT_EQ(0, x.index()); + EXPECT_EQ(5, absl::get<0>(x).value); + EXPECT_FALSE(std::is_nothrow_default_constructible<X>::value); + } + + { + using X = variant<int, NonNoexceptDefaultConstructible>; + X x{}; + ASSERT_FALSE(x.valueless_by_exception()); + ASSERT_EQ(0, x.index()); + EXPECT_EQ(0, absl::get<0>(x)); + EXPECT_TRUE(std::is_nothrow_default_constructible<X>::value); + } + + { + using X = variant<NonNoexceptDefaultConstructible, int>; + X x{}; + ASSERT_FALSE(x.valueless_by_exception()); + ASSERT_EQ(0, x.index()); + EXPECT_EQ(5, absl::get<0>(x).value); + EXPECT_FALSE(std::is_nothrow_default_constructible<X>::value); + } + EXPECT_FALSE( + std::is_default_constructible<variant<NonDefaultConstructible>>::value); + EXPECT_FALSE((std::is_default_constructible< + variant<NonDefaultConstructible, int>>::value)); + EXPECT_TRUE((std::is_default_constructible< + variant<int, NonDefaultConstructible>>::value)); +} + +// Test that for each slot, copy constructing a variant with that type +// produces a sensible object that correctly reports its type, and +// that copies the provided value. +TYPED_TEST(VariantTypesTest, TestCopyCtor) { + typedef typename VariantFactory<typename TypeParam::value_type>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + using value_type2 = absl::variant_alternative_t<1, Variant>; + using value_type3 = absl::variant_alternative_t<2, Variant>; + using value_type4 = absl::variant_alternative_t<3, Variant>; + const TypeParam value(TypeParam::kIndex); + Variant original(value); + Variant copied(original); + EXPECT_TRUE(absl::holds_alternative<value_type1>(copied) || + TypeParam::kIndex != 1); + EXPECT_TRUE(absl::holds_alternative<value_type2>(copied) || + TypeParam::kIndex != 2); + EXPECT_TRUE(absl::holds_alternative<value_type3>(copied) || + TypeParam::kIndex != 3); + EXPECT_TRUE(absl::holds_alternative<value_type4>(copied) || + TypeParam::kIndex != 4); + EXPECT_TRUE((absl::get_if<value_type1>(&original) == + absl::get_if<value_type1>(&copied)) || + TypeParam::kIndex == 1); + EXPECT_TRUE((absl::get_if<value_type2>(&original) == + absl::get_if<value_type2>(&copied)) || + TypeParam::kIndex == 2); + EXPECT_TRUE((absl::get_if<value_type3>(&original) == + absl::get_if<value_type3>(&copied)) || + TypeParam::kIndex == 3); + EXPECT_TRUE((absl::get_if<value_type4>(&original) == + absl::get_if<value_type4>(&copied)) || + TypeParam::kIndex == 4); + EXPECT_TRUE((absl::get_if<value_type1>(&original) == + absl::get_if<value_type1>(&copied)) || + TypeParam::kIndex == 1); + EXPECT_TRUE((absl::get_if<value_type2>(&original) == + absl::get_if<value_type2>(&copied)) || + TypeParam::kIndex == 2); + EXPECT_TRUE((absl::get_if<value_type3>(&original) == + absl::get_if<value_type3>(&copied)) || + TypeParam::kIndex == 3); + EXPECT_TRUE((absl::get_if<value_type4>(&original) == + absl::get_if<value_type4>(&copied)) || + TypeParam::kIndex == 4); + const TypeParam* ovalptr = absl::get_if<TypeParam>(&original); + const TypeParam* cvalptr = absl::get_if<TypeParam>(&copied); + ASSERT_TRUE(ovalptr != nullptr); + ASSERT_TRUE(cvalptr != nullptr); + EXPECT_EQ(*ovalptr, *cvalptr); + TypeParam* mutable_ovalptr = absl::get_if<TypeParam>(&original); + TypeParam* mutable_cvalptr = absl::get_if<TypeParam>(&copied); + ASSERT_TRUE(mutable_ovalptr != nullptr); + ASSERT_TRUE(mutable_cvalptr != nullptr); + EXPECT_EQ(*mutable_ovalptr, *mutable_cvalptr); +} + +template <class> +struct MoveOnly { + MoveOnly() = default; + explicit MoveOnly(int value) : value(value) {} + MoveOnly(MoveOnly&&) = default; + MoveOnly& operator=(MoveOnly&&) = default; + int value = 5; +}; + +TEST(VariantTest, TestMoveConstruct) { + using V = variant<MoveOnly<class A>, MoveOnly<class B>, MoveOnly<class C>>; + + V v(in_place_index<1>, 10); + V v2 = absl::move(v); + EXPECT_EQ(10, absl::get<1>(v2).value); +} + +// Used internally to emulate missing triviality traits for tests. +template <class T> +union SingleUnion { + T member; +}; + +// NOTE: These don't work with types that can't be union members. +// They are just for testing. +template <class T> +struct is_trivially_move_constructible + : std::is_move_constructible<SingleUnion<T>>::type {}; + +template <class T> +struct is_trivially_move_assignable + : absl::is_move_assignable<SingleUnion<T>>::type {}; + +TEST(VariantTest, NothrowMoveConstructible) { + // Verify that variant is nothrow move constructible iff its template + // arguments are. + using U = std::unique_ptr<int>; + struct E { + E(E&&) {} + }; + static_assert(std::is_nothrow_move_constructible<variant<U>>::value, ""); + static_assert(std::is_nothrow_move_constructible<variant<U, int>>::value, ""); + static_assert(!std::is_nothrow_move_constructible<variant<U, E>>::value, ""); +} + +// Test that for each slot, constructing a variant with that type +// produces a sensible object that correctly reports its type, and +// that copies the provided value. +TYPED_TEST(VariantTypesTest, TestValueCtor) { + typedef typename VariantFactory<typename TypeParam::value_type>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + using value_type2 = absl::variant_alternative_t<1, Variant>; + using value_type3 = absl::variant_alternative_t<2, Variant>; + using value_type4 = absl::variant_alternative_t<3, Variant>; + const TypeParam value(TypeParam::kIndex); + Variant v(value); + EXPECT_TRUE(absl::holds_alternative<value_type1>(v) || + TypeParam::kIndex != 1); + EXPECT_TRUE(absl::holds_alternative<value_type2>(v) || + TypeParam::kIndex != 2); + EXPECT_TRUE(absl::holds_alternative<value_type3>(v) || + TypeParam::kIndex != 3); + EXPECT_TRUE(absl::holds_alternative<value_type4>(v) || + TypeParam::kIndex != 4); + EXPECT_TRUE(nullptr != absl::get_if<value_type1>(&v) || + TypeParam::kIndex != 1); + EXPECT_TRUE(nullptr != absl::get_if<value_type2>(&v) || + TypeParam::kIndex != 2); + EXPECT_TRUE(nullptr != absl::get_if<value_type3>(&v) || + TypeParam::kIndex != 3); + EXPECT_TRUE(nullptr != absl::get_if<value_type4>(&v) || + TypeParam::kIndex != 4); + EXPECT_TRUE(nullptr != absl::get_if<value_type1>(&v) || + TypeParam::kIndex != 1); + EXPECT_TRUE(nullptr != absl::get_if<value_type2>(&v) || + TypeParam::kIndex != 2); + EXPECT_TRUE(nullptr != absl::get_if<value_type3>(&v) || + TypeParam::kIndex != 3); + EXPECT_TRUE(nullptr != absl::get_if<value_type4>(&v) || + TypeParam::kIndex != 4); + const TypeParam* valptr = absl::get_if<TypeParam>(&v); + ASSERT_TRUE(nullptr != valptr); + EXPECT_EQ(value.value, valptr->value); + const TypeParam* mutable_valptr = absl::get_if<TypeParam>(&v); + ASSERT_TRUE(nullptr != mutable_valptr); + EXPECT_EQ(value.value, mutable_valptr->value); +} + +TEST(VariantTest, AmbiguousValueConstructor) { + EXPECT_FALSE((std::is_convertible<int, absl::variant<int, int>>::value)); + EXPECT_FALSE((std::is_constructible<absl::variant<int, int>, int>::value)); +} + +TEST(VariantTest, InPlaceType) { + using Var = variant<int, std::string, NonCopyable, std::vector<int>>; + + Var v1(in_place_type_t<int>(), 7); + ASSERT_TRUE(absl::holds_alternative<int>(v1)); + EXPECT_EQ(7, absl::get<int>(v1)); + + Var v2(in_place_type_t<std::string>(), "ABC"); + ASSERT_TRUE(absl::holds_alternative<std::string>(v2)); + EXPECT_EQ("ABC", absl::get<std::string>(v2)); + + Var v3(in_place_type_t<std::string>(), "ABC", 2); + ASSERT_TRUE(absl::holds_alternative<std::string>(v3)); + EXPECT_EQ("AB", absl::get<std::string>(v3)); + + Var v4(in_place_type_t<NonCopyable>{}); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v4)); + + Var v5(in_place_type_t<std::vector<int>>(), {1, 2, 3}); + ASSERT_TRUE(absl::holds_alternative<std::vector<int>>(v5)); + EXPECT_THAT(absl::get<std::vector<int>>(v5), ::testing::ElementsAre(1, 2, 3)); +} + +TEST(VariantTest, InPlaceTypeVariableTemplate) { + using Var = variant<int, std::string, NonCopyable, std::vector<int>>; + + Var v1(in_place_type<int>, 7); + ASSERT_TRUE(absl::holds_alternative<int>(v1)); + EXPECT_EQ(7, absl::get<int>(v1)); + + Var v2(in_place_type<std::string>, "ABC"); + ASSERT_TRUE(absl::holds_alternative<std::string>(v2)); + EXPECT_EQ("ABC", absl::get<std::string>(v2)); + + Var v3(in_place_type<std::string>, "ABC", 2); + ASSERT_TRUE(absl::holds_alternative<std::string>(v3)); + EXPECT_EQ("AB", absl::get<std::string>(v3)); + + Var v4(in_place_type<NonCopyable>); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v4)); + + Var v5(in_place_type<std::vector<int>>, {1, 2, 3}); + ASSERT_TRUE(absl::holds_alternative<std::vector<int>>(v5)); + EXPECT_THAT(absl::get<std::vector<int>>(v5), ::testing::ElementsAre(1, 2, 3)); +} + +TEST(VariantTest, InPlaceTypeInitializerList) { + using Var = + variant<int, std::string, NonCopyable, MoveOnlyWithListConstructor>; + + Var v1(in_place_type_t<MoveOnlyWithListConstructor>(), {1, 2, 3, 4, 5}, 6); + ASSERT_TRUE(absl::holds_alternative<MoveOnlyWithListConstructor>(v1)); + EXPECT_EQ(6, absl::get<MoveOnlyWithListConstructor>(v1).value); +} + +TEST(VariantTest, InPlaceTypeInitializerListVariabletemplate) { + using Var = + variant<int, std::string, NonCopyable, MoveOnlyWithListConstructor>; + + Var v1(in_place_type<MoveOnlyWithListConstructor>, {1, 2, 3, 4, 5}, 6); + ASSERT_TRUE(absl::holds_alternative<MoveOnlyWithListConstructor>(v1)); + EXPECT_EQ(6, absl::get<MoveOnlyWithListConstructor>(v1).value); +} + +TEST(VariantTest, InPlaceIndex) { + using Var = variant<int, std::string, NonCopyable, std::vector<int>>; + + Var v1(in_place_index_t<0>(), 7); + ASSERT_TRUE(absl::holds_alternative<int>(v1)); + EXPECT_EQ(7, absl::get<int>(v1)); + + Var v2(in_place_index_t<1>(), "ABC"); + ASSERT_TRUE(absl::holds_alternative<std::string>(v2)); + EXPECT_EQ("ABC", absl::get<std::string>(v2)); + + Var v3(in_place_index_t<1>(), "ABC", 2); + ASSERT_TRUE(absl::holds_alternative<std::string>(v3)); + EXPECT_EQ("AB", absl::get<std::string>(v3)); + + Var v4(in_place_index_t<2>{}); + EXPECT_TRUE(absl::holds_alternative<NonCopyable>(v4)); + + // Verify that a variant with only non-copyables can still be constructed. + EXPECT_TRUE(absl::holds_alternative<NonCopyable>( + variant<NonCopyable>(in_place_index_t<0>{}))); + + Var v5(in_place_index_t<3>(), {1, 2, 3}); + ASSERT_TRUE(absl::holds_alternative<std::vector<int>>(v5)); + EXPECT_THAT(absl::get<std::vector<int>>(v5), ::testing::ElementsAre(1, 2, 3)); +} + +TEST(VariantTest, InPlaceIndexVariableTemplate) { + using Var = variant<int, std::string, NonCopyable, std::vector<int>>; + + Var v1(in_place_index<0>, 7); + ASSERT_TRUE(absl::holds_alternative<int>(v1)); + EXPECT_EQ(7, absl::get<int>(v1)); + + Var v2(in_place_index<1>, "ABC"); + ASSERT_TRUE(absl::holds_alternative<std::string>(v2)); + EXPECT_EQ("ABC", absl::get<std::string>(v2)); + + Var v3(in_place_index<1>, "ABC", 2); + ASSERT_TRUE(absl::holds_alternative<std::string>(v3)); + EXPECT_EQ("AB", absl::get<std::string>(v3)); + + Var v4(in_place_index<2>); + EXPECT_TRUE(absl::holds_alternative<NonCopyable>(v4)); + + // Verify that a variant with only non-copyables can still be constructed. + EXPECT_TRUE(absl::holds_alternative<NonCopyable>( + variant<NonCopyable>(in_place_index<0>))); + + Var v5(in_place_index<3>, {1, 2, 3}); + ASSERT_TRUE(absl::holds_alternative<std::vector<int>>(v5)); + EXPECT_THAT(absl::get<std::vector<int>>(v5), ::testing::ElementsAre(1, 2, 3)); +} + +TEST(VariantTest, InPlaceIndexInitializerList) { + using Var = + variant<int, std::string, NonCopyable, MoveOnlyWithListConstructor>; + + Var v1(in_place_index_t<3>(), {1, 2, 3, 4, 5}, 6); + ASSERT_TRUE(absl::holds_alternative<MoveOnlyWithListConstructor>(v1)); + EXPECT_EQ(6, absl::get<MoveOnlyWithListConstructor>(v1).value); +} + +TEST(VariantTest, InPlaceIndexInitializerListVariableTemplate) { + using Var = + variant<int, std::string, NonCopyable, MoveOnlyWithListConstructor>; + + Var v1(in_place_index<3>, {1, 2, 3, 4, 5}, 6); + ASSERT_TRUE(absl::holds_alternative<MoveOnlyWithListConstructor>(v1)); + EXPECT_EQ(6, absl::get<MoveOnlyWithListConstructor>(v1).value); +} + +//////////////////// +// [variant.dtor] // +//////////////////// + +// Make sure that the destructor destroys the contained value +TEST(VariantTest, TestDtor) { + typedef VariantFactory<IncrementInDtor>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + using value_type2 = absl::variant_alternative_t<1, Variant>; + using value_type3 = absl::variant_alternative_t<2, Variant>; + using value_type4 = absl::variant_alternative_t<3, Variant>; + int counter = 0; + IncrementInDtor counter_adjuster(&counter); + EXPECT_EQ(0, counter); + + value_type1 value1(counter_adjuster); + { Variant object(value1); } + EXPECT_EQ(1, counter); + + value_type2 value2(counter_adjuster); + { Variant object(value2); } + EXPECT_EQ(2, counter); + + value_type3 value3(counter_adjuster); + { Variant object(value3); } + EXPECT_EQ(3, counter); + + value_type4 value4(counter_adjuster); + { Variant object(value4); } + EXPECT_EQ(4, counter); +} + +#ifdef ABSL_HAVE_EXCEPTIONS + +// See comment in absl/base/config.h +#if defined(ABSL_INTERNAL_MSVC_2017_DBG_MODE) +TEST(VariantTest, DISABLED_TestDtorValuelessByException) +#else +// Test destruction when in the valueless_by_exception state. +TEST(VariantTest, TestDtorValuelessByException) +#endif +{ + int counter = 0; + IncrementInDtor counter_adjuster(&counter); + + { + using Variant = VariantFactory<IncrementInDtor>::Type; + + Variant v(in_place_index<0>, counter_adjuster); + EXPECT_EQ(0, counter); + + ToValuelessByException(v); + ASSERT_TRUE(v.valueless_by_exception()); + EXPECT_EQ(1, counter); + } + EXPECT_EQ(1, counter); +} + +#endif // ABSL_HAVE_EXCEPTIONS + +////////////////////// +// [variant.assign] // +////////////////////// + +// Test that self-assignment doesn't destroy the current value +TEST(VariantTest, TestSelfAssignment) { + typedef VariantFactory<IncrementInDtor>::Type Variant; + int counter = 0; + IncrementInDtor counter_adjuster(&counter); + absl::variant_alternative_t<0, Variant> value(counter_adjuster); + Variant object(value); + object.operator=(object); + EXPECT_EQ(0, counter); + + // A string long enough that it's likely to defeat any inline representation + // optimization. + const std::string long_str(128, 'a'); + + std::string foo = long_str; + foo = *&foo; + EXPECT_EQ(long_str, foo); + + variant<int, std::string> so = long_str; + ASSERT_EQ(1, so.index()); + EXPECT_EQ(long_str, absl::get<1>(so)); + so = *&so; + + ASSERT_EQ(1, so.index()); + EXPECT_EQ(long_str, absl::get<1>(so)); +} + +// Test that assigning a variant<..., T, ...> to a variant<..., T, ...> produces +// a variant<..., T, ...> with the correct value. +TYPED_TEST(VariantTypesTest, TestAssignmentCopiesValueSameTypes) { + typedef typename VariantFactory<typename TypeParam::value_type>::Type Variant; + const TypeParam value(TypeParam::kIndex); + const Variant source(value); + Variant target(TypeParam(value.value + 1)); + ASSERT_TRUE(absl::holds_alternative<TypeParam>(source)); + ASSERT_TRUE(absl::holds_alternative<TypeParam>(target)); + ASSERT_NE(absl::get<TypeParam>(source), absl::get<TypeParam>(target)); + target = source; + ASSERT_TRUE(absl::holds_alternative<TypeParam>(source)); + ASSERT_TRUE(absl::holds_alternative<TypeParam>(target)); + EXPECT_EQ(absl::get<TypeParam>(source), absl::get<TypeParam>(target)); +} + +// Test that assisnging a variant<..., T, ...> to a variant<1, ...> +// produces a variant<..., T, ...> with the correct value. +TYPED_TEST(VariantTypesTest, TestAssignmentCopiesValuesVaryingSourceType) { + typedef typename VariantFactory<typename TypeParam::value_type>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + const TypeParam value(TypeParam::kIndex); + const Variant source(value); + ASSERT_TRUE(absl::holds_alternative<TypeParam>(source)); + Variant target(value_type1(1)); + ASSERT_TRUE(absl::holds_alternative<value_type1>(target)); + target = source; + EXPECT_TRUE(absl::holds_alternative<TypeParam>(source)); + EXPECT_TRUE(absl::holds_alternative<TypeParam>(target)); + EXPECT_EQ(absl::get<TypeParam>(source), absl::get<TypeParam>(target)); +} + +// Test that assigning a variant<1, ...> to a variant<..., T, ...> +// produces a variant<1, ...> with the correct value. +TYPED_TEST(VariantTypesTest, TestAssignmentCopiesValuesVaryingTargetType) { + typedef typename VariantFactory<typename TypeParam::value_type>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + const Variant source(value_type1(1)); + ASSERT_TRUE(absl::holds_alternative<value_type1>(source)); + const TypeParam value(TypeParam::kIndex); + Variant target(value); + ASSERT_TRUE(absl::holds_alternative<TypeParam>(target)); + target = source; + EXPECT_TRUE(absl::holds_alternative<value_type1>(target)); + EXPECT_TRUE(absl::holds_alternative<value_type1>(source)); + EXPECT_EQ(absl::get<value_type1>(source), absl::get<value_type1>(target)); +} + +// Test that operator=<T> works, that assigning a new value destroys +// the old and that assigning the new value again does not redestroy +// the old +TEST(VariantTest, TestAssign) { + typedef VariantFactory<IncrementInDtor>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + using value_type2 = absl::variant_alternative_t<1, Variant>; + using value_type3 = absl::variant_alternative_t<2, Variant>; + using value_type4 = absl::variant_alternative_t<3, Variant>; + + const int kSize = 4; + int counter[kSize]; + std::unique_ptr<IncrementInDtor> counter_adjustor[kSize]; + for (int i = 0; i != kSize; i++) { + counter[i] = 0; + counter_adjustor[i] = absl::make_unique<IncrementInDtor>(&counter[i]); + } + + value_type1 v1(*counter_adjustor[0]); + value_type2 v2(*counter_adjustor[1]); + value_type3 v3(*counter_adjustor[2]); + value_type4 v4(*counter_adjustor[3]); + + // Test that reassignment causes destruction of old value + { + Variant object(v1); + object = v2; + object = v3; + object = v4; + object = v1; + } + + EXPECT_EQ(2, counter[0]); + EXPECT_EQ(1, counter[1]); + EXPECT_EQ(1, counter[2]); + EXPECT_EQ(1, counter[3]); + + std::fill(std::begin(counter), std::end(counter), 0); + + // Test that self-assignment does not cause destruction of old value + { + Variant object(v1); + object.operator=(object); + EXPECT_EQ(0, counter[0]); + } + { + Variant object(v2); + object.operator=(object); + EXPECT_EQ(0, counter[1]); + } + { + Variant object(v3); + object.operator=(object); + EXPECT_EQ(0, counter[2]); + } + { + Variant object(v4); + object.operator=(object); + EXPECT_EQ(0, counter[3]); + } + + EXPECT_EQ(1, counter[0]); + EXPECT_EQ(1, counter[1]); + EXPECT_EQ(1, counter[2]); + EXPECT_EQ(1, counter[3]); +} + +// This tests that we perform a backup if the copy-assign can throw but the move +// cannot throw. +TEST(VariantTest, TestBackupAssign) { + typedef VariantFactory<IncrementInDtorCopyCanThrow>::Type Variant; + using value_type1 = absl::variant_alternative_t<0, Variant>; + using value_type2 = absl::variant_alternative_t<1, Variant>; + using value_type3 = absl::variant_alternative_t<2, Variant>; + using value_type4 = absl::variant_alternative_t<3, Variant>; + + const int kSize = 4; + int counter[kSize]; + std::unique_ptr<IncrementInDtorCopyCanThrow> counter_adjustor[kSize]; + for (int i = 0; i != kSize; i++) { + counter[i] = 0; + counter_adjustor[i].reset(new IncrementInDtorCopyCanThrow(&counter[i])); + } + + value_type1 v1(*counter_adjustor[0]); + value_type2 v2(*counter_adjustor[1]); + value_type3 v3(*counter_adjustor[2]); + value_type4 v4(*counter_adjustor[3]); + + // Test that reassignment causes destruction of old value + { + Variant object(v1); + object = v2; + object = v3; + object = v4; + object = v1; + } + + // libstdc++ doesn't pass this test +#if !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) + EXPECT_EQ(3, counter[0]); + EXPECT_EQ(2, counter[1]); + EXPECT_EQ(2, counter[2]); + EXPECT_EQ(2, counter[3]); +#endif + + std::fill(std::begin(counter), std::end(counter), 0); + + // Test that self-assignment does not cause destruction of old value + { + Variant object(v1); + object.operator=(object); + EXPECT_EQ(0, counter[0]); + } + { + Variant object(v2); + object.operator=(object); + EXPECT_EQ(0, counter[1]); + } + { + Variant object(v3); + object.operator=(object); + EXPECT_EQ(0, counter[2]); + } + { + Variant object(v4); + object.operator=(object); + EXPECT_EQ(0, counter[3]); + } + + EXPECT_EQ(1, counter[0]); + EXPECT_EQ(1, counter[1]); + EXPECT_EQ(1, counter[2]); + EXPECT_EQ(1, counter[3]); +} + +/////////////////// +// [variant.mod] // +/////////////////// + +TEST(VariantTest, TestEmplaceBasic) { + using Variant = variant<int, char>; + + Variant v(absl::in_place_index<0>, 0); + + { + char& emplace_result = v.emplace<char>(); + ASSERT_TRUE(absl::holds_alternative<char>(v)); + EXPECT_EQ(absl::get<char>(v), 0); + EXPECT_EQ(&emplace_result, &absl::get<char>(v)); + } + + // Make sure that another emplace does zero-initialization + absl::get<char>(v) = 'a'; + v.emplace<char>('b'); + ASSERT_TRUE(absl::holds_alternative<char>(v)); + EXPECT_EQ(absl::get<char>(v), 'b'); + + { + int& emplace_result = v.emplace<int>(); + EXPECT_TRUE(absl::holds_alternative<int>(v)); + EXPECT_EQ(absl::get<int>(v), 0); + EXPECT_EQ(&emplace_result, &absl::get<int>(v)); + } +} + +TEST(VariantTest, TestEmplaceInitializerList) { + using Var = + variant<int, std::string, NonCopyable, MoveOnlyWithListConstructor>; + + Var v1(absl::in_place_index<0>, 555); + MoveOnlyWithListConstructor& emplace_result = + v1.emplace<MoveOnlyWithListConstructor>({1, 2, 3, 4, 5}, 6); + ASSERT_TRUE(absl::holds_alternative<MoveOnlyWithListConstructor>(v1)); + EXPECT_EQ(6, absl::get<MoveOnlyWithListConstructor>(v1).value); + EXPECT_EQ(&emplace_result, &absl::get<MoveOnlyWithListConstructor>(v1)); +} + +TEST(VariantTest, TestEmplaceIndex) { + using Variant = variant<int, char>; + + Variant v(absl::in_place_index<0>, 555); + + { + char& emplace_result = v.emplace<1>(); + ASSERT_TRUE(absl::holds_alternative<char>(v)); + EXPECT_EQ(absl::get<char>(v), 0); + EXPECT_EQ(&emplace_result, &absl::get<char>(v)); + } + + // Make sure that another emplace does zero-initialization + absl::get<char>(v) = 'a'; + v.emplace<1>('b'); + ASSERT_TRUE(absl::holds_alternative<char>(v)); + EXPECT_EQ(absl::get<char>(v), 'b'); + + { + int& emplace_result = v.emplace<0>(); + EXPECT_TRUE(absl::holds_alternative<int>(v)); + EXPECT_EQ(absl::get<int>(v), 0); + EXPECT_EQ(&emplace_result, &absl::get<int>(v)); + } +} + +TEST(VariantTest, TestEmplaceIndexInitializerList) { + using Var = + variant<int, std::string, NonCopyable, MoveOnlyWithListConstructor>; + + Var v1(absl::in_place_index<0>, 555); + MoveOnlyWithListConstructor& emplace_result = + v1.emplace<3>({1, 2, 3, 4, 5}, 6); + ASSERT_TRUE(absl::holds_alternative<MoveOnlyWithListConstructor>(v1)); + EXPECT_EQ(6, absl::get<MoveOnlyWithListConstructor>(v1).value); + EXPECT_EQ(&emplace_result, &absl::get<MoveOnlyWithListConstructor>(v1)); +} + +////////////////////// +// [variant.status] // +////////////////////// + +TEST(VariantTest, Index) { + using Var = variant<int, std::string, double>; + + Var v = 1; + EXPECT_EQ(0, v.index()); + v = "str"; + EXPECT_EQ(1, v.index()); + v = 0.; + EXPECT_EQ(2, v.index()); + + Var v2 = v; + EXPECT_EQ(2, v2.index()); + v2.emplace<int>(3); + EXPECT_EQ(0, v2.index()); +} + +TEST(VariantTest, NotValuelessByException) { + using Var = variant<int, std::string, double>; + + Var v = 1; + EXPECT_FALSE(v.valueless_by_exception()); + v = "str"; + EXPECT_FALSE(v.valueless_by_exception()); + v = 0.; + EXPECT_FALSE(v.valueless_by_exception()); + + Var v2 = v; + EXPECT_FALSE(v.valueless_by_exception()); + v2.emplace<int>(3); + EXPECT_FALSE(v.valueless_by_exception()); +} + +#ifdef ABSL_HAVE_EXCEPTIONS + +TEST(VariantTest, IndexValuelessByException) { + using Var = variant<MoveCanThrow, std::string, double>; + + Var v(absl::in_place_index<0>); + EXPECT_EQ(0, v.index()); + ToValuelessByException(v); + EXPECT_EQ(absl::variant_npos, v.index()); + v = "str"; + EXPECT_EQ(1, v.index()); +} + +TEST(VariantTest, ValuelessByException) { + using Var = variant<MoveCanThrow, std::string, double>; + + Var v(absl::in_place_index<0>); + EXPECT_FALSE(v.valueless_by_exception()); + ToValuelessByException(v); + EXPECT_TRUE(v.valueless_by_exception()); + v = "str"; + EXPECT_FALSE(v.valueless_by_exception()); +} + +#endif // ABSL_HAVE_EXCEPTIONS + +//////////////////// +// [variant.swap] // +//////////////////// + +TEST(VariantTest, MemberSwap) { + SpecialSwap v1(3); + SpecialSwap v2(7); + + variant<SpecialSwap> a = v1, b = v2; + + EXPECT_THAT(a, VariantWith<SpecialSwap>(v1)); + EXPECT_THAT(b, VariantWith<SpecialSwap>(v2)); + + a.swap(b); + EXPECT_THAT(a, VariantWith<SpecialSwap>(v2)); + EXPECT_THAT(b, VariantWith<SpecialSwap>(v1)); + EXPECT_TRUE(absl::get<SpecialSwap>(a).special_swap); + + using V = variant<MoveCanThrow, std::string, int>; + int i = 33; + std::string s = "abc"; + { + // lhs and rhs holds different alternative + V lhs(i), rhs(s); + lhs.swap(rhs); + EXPECT_THAT(lhs, VariantWith<std::string>(s)); + EXPECT_THAT(rhs, VariantWith<int>(i)); + } +#ifdef ABSL_HAVE_EXCEPTIONS + V valueless(in_place_index<0>); + ToValuelessByException(valueless); + { + // lhs is valueless + V lhs(valueless), rhs(i); + lhs.swap(rhs); + EXPECT_THAT(lhs, VariantWith<int>(i)); + EXPECT_TRUE(rhs.valueless_by_exception()); + } + { + // rhs is valueless + V lhs(s), rhs(valueless); + lhs.swap(rhs); + EXPECT_THAT(rhs, VariantWith<std::string>(s)); + EXPECT_TRUE(lhs.valueless_by_exception()); + } + { + // both are valueless + V lhs(valueless), rhs(valueless); + lhs.swap(rhs); + EXPECT_TRUE(lhs.valueless_by_exception()); + EXPECT_TRUE(rhs.valueless_by_exception()); + } +#endif // ABSL_HAVE_EXCEPTIONS +} + +////////////////////// +// [variant.helper] // +////////////////////// + +TEST(VariantTest, VariantSize) { + { + using Size1Variant = absl::variant<int>; + EXPECT_EQ(1, absl::variant_size<Size1Variant>::value); + EXPECT_EQ(1, absl::variant_size<const Size1Variant>::value); + EXPECT_EQ(1, absl::variant_size<volatile Size1Variant>::value); + EXPECT_EQ(1, absl::variant_size<const volatile Size1Variant>::value); + } + + { + using Size3Variant = absl::variant<int, float, int>; + EXPECT_EQ(3, absl::variant_size<Size3Variant>::value); + EXPECT_EQ(3, absl::variant_size<const Size3Variant>::value); + EXPECT_EQ(3, absl::variant_size<volatile Size3Variant>::value); + EXPECT_EQ(3, absl::variant_size<const volatile Size3Variant>::value); + } +} + +TEST(VariantTest, VariantAlternative) { + { + using V = absl::variant<float, int, const char*>; + EXPECT_TRUE( + (std::is_same<float, absl::variant_alternative_t<0, V>>::value)); + EXPECT_TRUE((std::is_same<const float, + absl::variant_alternative_t<0, const V>>::value)); + EXPECT_TRUE( + (std::is_same<volatile float, + absl::variant_alternative_t<0, volatile V>>::value)); + EXPECT_TRUE(( + std::is_same<const volatile float, + absl::variant_alternative_t<0, const volatile V>>::value)); + + EXPECT_TRUE((std::is_same<int, absl::variant_alternative_t<1, V>>::value)); + EXPECT_TRUE((std::is_same<const int, + absl::variant_alternative_t<1, const V>>::value)); + EXPECT_TRUE( + (std::is_same<volatile int, + absl::variant_alternative_t<1, volatile V>>::value)); + EXPECT_TRUE(( + std::is_same<const volatile int, + absl::variant_alternative_t<1, const volatile V>>::value)); + + EXPECT_TRUE( + (std::is_same<const char*, absl::variant_alternative_t<2, V>>::value)); + EXPECT_TRUE((std::is_same<const char* const, + absl::variant_alternative_t<2, const V>>::value)); + EXPECT_TRUE( + (std::is_same<const char* volatile, + absl::variant_alternative_t<2, volatile V>>::value)); + EXPECT_TRUE(( + std::is_same<const char* const volatile, + absl::variant_alternative_t<2, const volatile V>>::value)); + } + + { + using V = absl::variant<float, volatile int, const char*>; + EXPECT_TRUE( + (std::is_same<float, absl::variant_alternative_t<0, V>>::value)); + EXPECT_TRUE((std::is_same<const float, + absl::variant_alternative_t<0, const V>>::value)); + EXPECT_TRUE( + (std::is_same<volatile float, + absl::variant_alternative_t<0, volatile V>>::value)); + EXPECT_TRUE(( + std::is_same<const volatile float, + absl::variant_alternative_t<0, const volatile V>>::value)); + + EXPECT_TRUE( + (std::is_same<volatile int, absl::variant_alternative_t<1, V>>::value)); + EXPECT_TRUE((std::is_same<const volatile int, + absl::variant_alternative_t<1, const V>>::value)); + EXPECT_TRUE( + (std::is_same<volatile int, + absl::variant_alternative_t<1, volatile V>>::value)); + EXPECT_TRUE(( + std::is_same<const volatile int, + absl::variant_alternative_t<1, const volatile V>>::value)); + + EXPECT_TRUE( + (std::is_same<const char*, absl::variant_alternative_t<2, V>>::value)); + EXPECT_TRUE((std::is_same<const char* const, + absl::variant_alternative_t<2, const V>>::value)); + EXPECT_TRUE( + (std::is_same<const char* volatile, + absl::variant_alternative_t<2, volatile V>>::value)); + EXPECT_TRUE(( + std::is_same<const char* const volatile, + absl::variant_alternative_t<2, const volatile V>>::value)); + } +} + +/////////////////// +// [variant.get] // +/////////////////// + +TEST(VariantTest, HoldsAlternative) { + using Var = variant<int, std::string, double>; + + Var v = 1; + EXPECT_TRUE(absl::holds_alternative<int>(v)); + EXPECT_FALSE(absl::holds_alternative<std::string>(v)); + EXPECT_FALSE(absl::holds_alternative<double>(v)); + v = "str"; + EXPECT_FALSE(absl::holds_alternative<int>(v)); + EXPECT_TRUE(absl::holds_alternative<std::string>(v)); + EXPECT_FALSE(absl::holds_alternative<double>(v)); + v = 0.; + EXPECT_FALSE(absl::holds_alternative<int>(v)); + EXPECT_FALSE(absl::holds_alternative<std::string>(v)); + EXPECT_TRUE(absl::holds_alternative<double>(v)); + + Var v2 = v; + EXPECT_FALSE(absl::holds_alternative<int>(v2)); + EXPECT_FALSE(absl::holds_alternative<std::string>(v2)); + EXPECT_TRUE(absl::holds_alternative<double>(v2)); + v2.emplace<int>(3); + EXPECT_TRUE(absl::holds_alternative<int>(v2)); + EXPECT_FALSE(absl::holds_alternative<std::string>(v2)); + EXPECT_FALSE(absl::holds_alternative<double>(v2)); +} + +TEST(VariantTest, GetIndex) { + using Var = variant<int, std::string, double, int>; + + { + Var v(absl::in_place_index<0>, 0); + + using LValueGetType = decltype(absl::get<0>(v)); + using RValueGetType = decltype(absl::get<0>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, int&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, int&&>::value)); + EXPECT_EQ(absl::get<0>(v), 0); + EXPECT_EQ(absl::get<0>(absl::move(v)), 0); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<0>(const_v)); + using ConstRValueGetType = decltype(absl::get<0>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const int&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const int&&>::value)); + EXPECT_EQ(absl::get<0>(const_v), 0); + EXPECT_EQ(absl::get<0>(absl::move(const_v)), 0); + } + + { + Var v = std::string("Hello"); + + using LValueGetType = decltype(absl::get<1>(v)); + using RValueGetType = decltype(absl::get<1>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, std::string&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, std::string&&>::value)); + EXPECT_EQ(absl::get<1>(v), "Hello"); + EXPECT_EQ(absl::get<1>(absl::move(v)), "Hello"); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<1>(const_v)); + using ConstRValueGetType = decltype(absl::get<1>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const std::string&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const std::string&&>::value)); + EXPECT_EQ(absl::get<1>(const_v), "Hello"); + EXPECT_EQ(absl::get<1>(absl::move(const_v)), "Hello"); + } + + { + Var v = 2.0; + + using LValueGetType = decltype(absl::get<2>(v)); + using RValueGetType = decltype(absl::get<2>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, double&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, double&&>::value)); + EXPECT_EQ(absl::get<2>(v), 2.); + EXPECT_EQ(absl::get<2>(absl::move(v)), 2.); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<2>(const_v)); + using ConstRValueGetType = decltype(absl::get<2>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const double&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const double&&>::value)); + EXPECT_EQ(absl::get<2>(const_v), 2.); + EXPECT_EQ(absl::get<2>(absl::move(const_v)), 2.); + } + + { + Var v(absl::in_place_index<0>, 0); + v.emplace<3>(1); + + using LValueGetType = decltype(absl::get<3>(v)); + using RValueGetType = decltype(absl::get<3>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, int&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, int&&>::value)); + EXPECT_EQ(absl::get<3>(v), 1); + EXPECT_EQ(absl::get<3>(absl::move(v)), 1); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<3>(const_v)); + using ConstRValueGetType = decltype(absl::get<3>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const int&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const int&&>::value)); + EXPECT_EQ(absl::get<3>(const_v), 1); + EXPECT_EQ(absl::get<3>(absl::move(const_v)), 1); // NOLINT + } +} + +TEST(VariantTest, BadGetIndex) { + using Var = variant<int, std::string, double>; + + { + Var v = 1; + + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<1>(v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<1>(std::move(v))); + + const Var& const_v = v; + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<1>(const_v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS( + absl::get<1>(std::move(const_v))); // NOLINT + } + + { + Var v = std::string("Hello"); + + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<0>(v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<0>(std::move(v))); + + const Var& const_v = v; + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<0>(const_v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS( + absl::get<0>(std::move(const_v))); // NOLINT + } +} + +TEST(VariantTest, GetType) { + using Var = variant<int, std::string, double>; + + { + Var v = 1; + + using LValueGetType = decltype(absl::get<int>(v)); + using RValueGetType = decltype(absl::get<int>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, int&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, int&&>::value)); + EXPECT_EQ(absl::get<int>(v), 1); + EXPECT_EQ(absl::get<int>(absl::move(v)), 1); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<int>(const_v)); + using ConstRValueGetType = decltype(absl::get<int>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const int&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const int&&>::value)); + EXPECT_EQ(absl::get<int>(const_v), 1); + EXPECT_EQ(absl::get<int>(absl::move(const_v)), 1); + } + + { + Var v = std::string("Hello"); + + using LValueGetType = decltype(absl::get<1>(v)); + using RValueGetType = decltype(absl::get<1>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, std::string&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, std::string&&>::value)); + EXPECT_EQ(absl::get<std::string>(v), "Hello"); + EXPECT_EQ(absl::get<std::string>(absl::move(v)), "Hello"); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<1>(const_v)); + using ConstRValueGetType = decltype(absl::get<1>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const std::string&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const std::string&&>::value)); + EXPECT_EQ(absl::get<std::string>(const_v), "Hello"); + EXPECT_EQ(absl::get<std::string>(absl::move(const_v)), "Hello"); + } + + { + Var v = 2.0; + + using LValueGetType = decltype(absl::get<2>(v)); + using RValueGetType = decltype(absl::get<2>(absl::move(v))); + + EXPECT_TRUE((std::is_same<LValueGetType, double&>::value)); + EXPECT_TRUE((std::is_same<RValueGetType, double&&>::value)); + EXPECT_EQ(absl::get<double>(v), 2.); + EXPECT_EQ(absl::get<double>(absl::move(v)), 2.); + + const Var& const_v = v; + using ConstLValueGetType = decltype(absl::get<2>(const_v)); + using ConstRValueGetType = decltype(absl::get<2>(absl::move(const_v))); + EXPECT_TRUE((std::is_same<ConstLValueGetType, const double&>::value)); + EXPECT_TRUE((std::is_same<ConstRValueGetType, const double&&>::value)); + EXPECT_EQ(absl::get<double>(const_v), 2.); + EXPECT_EQ(absl::get<double>(absl::move(const_v)), 2.); + } +} + +TEST(VariantTest, BadGetType) { + using Var = variant<int, std::string, double>; + + { + Var v = 1; + + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<std::string>(v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS( + absl::get<std::string>(std::move(v))); + + const Var& const_v = v; + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS( + absl::get<std::string>(const_v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS( + absl::get<std::string>(std::move(const_v))); // NOLINT + } + + { + Var v = std::string("Hello"); + + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<int>(v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<int>(std::move(v))); + + const Var& const_v = v; + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS(absl::get<int>(const_v)); + ABSL_VARIANT_TEST_EXPECT_BAD_VARIANT_ACCESS( + absl::get<int>(std::move(const_v))); // NOLINT + } +} + +TEST(VariantTest, GetIfIndex) { + using Var = variant<int, std::string, double, int>; + + { + Var v(absl::in_place_index<0>, 0); + EXPECT_TRUE(noexcept(absl::get_if<0>(&v))); + + { + auto* elem = absl::get_if<0>(&v); + EXPECT_TRUE((std::is_same<decltype(elem), int*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, 0); + { + auto* bad_elem = absl::get_if<1>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), std::string*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<2>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), double*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<3>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + } + + const Var& const_v = v; + EXPECT_TRUE(noexcept(absl::get_if<0>(&const_v))); + + { + auto* elem = absl::get_if<0>(&const_v); + EXPECT_TRUE((std::is_same<decltype(elem), const int*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, 0); + { + auto* bad_elem = absl::get_if<1>(&const_v); + EXPECT_TRUE( + (std::is_same<decltype(bad_elem), const std::string*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<2>(&const_v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const double*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<3>(&const_v); + EXPECT_EQ(bad_elem, nullptr); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const int*>::value)); + } + } + } + + { + Var v = std::string("Hello"); + EXPECT_TRUE(noexcept(absl::get_if<1>(&v))); + + { + auto* elem = absl::get_if<1>(&v); + EXPECT_TRUE((std::is_same<decltype(elem), std::string*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, "Hello"); + { + auto* bad_elem = absl::get_if<0>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<2>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), double*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<3>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + } + + const Var& const_v = v; + EXPECT_TRUE(noexcept(absl::get_if<1>(&const_v))); + + { + auto* elem = absl::get_if<1>(&const_v); + EXPECT_TRUE((std::is_same<decltype(elem), const std::string*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, "Hello"); + { + auto* bad_elem = absl::get_if<0>(&const_v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<2>(&const_v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const double*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<3>(&const_v); + EXPECT_EQ(bad_elem, nullptr); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const int*>::value)); + } + } + } + + { + Var v = 2.0; + EXPECT_TRUE(noexcept(absl::get_if<2>(&v))); + + { + auto* elem = absl::get_if<2>(&v); + EXPECT_TRUE((std::is_same<decltype(elem), double*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, 2.0); + { + auto* bad_elem = absl::get_if<0>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<1>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), std::string*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<3>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + } + + const Var& const_v = v; + EXPECT_TRUE(noexcept(absl::get_if<2>(&const_v))); + + { + auto* elem = absl::get_if<2>(&const_v); + EXPECT_TRUE((std::is_same<decltype(elem), const double*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, 2.0); + { + auto* bad_elem = absl::get_if<0>(&const_v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<1>(&const_v); + EXPECT_TRUE( + (std::is_same<decltype(bad_elem), const std::string*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<3>(&const_v); + EXPECT_EQ(bad_elem, nullptr); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const int*>::value)); + } + } + } + + { + Var v(absl::in_place_index<0>, 0); + v.emplace<3>(1); + EXPECT_TRUE(noexcept(absl::get_if<3>(&v))); + + { + auto* elem = absl::get_if<3>(&v); + EXPECT_TRUE((std::is_same<decltype(elem), int*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, 1); + { + auto* bad_elem = absl::get_if<0>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<1>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), std::string*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<2>(&v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), double*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + } + + const Var& const_v = v; + EXPECT_TRUE(noexcept(absl::get_if<3>(&const_v))); + + { + auto* elem = absl::get_if<3>(&const_v); + EXPECT_TRUE((std::is_same<decltype(elem), const int*>::value)); + ASSERT_NE(elem, nullptr); + EXPECT_EQ(*elem, 1); + { + auto* bad_elem = absl::get_if<0>(&const_v); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const int*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<1>(&const_v); + EXPECT_TRUE( + (std::is_same<decltype(bad_elem), const std::string*>::value)); + EXPECT_EQ(bad_elem, nullptr); + } + { + auto* bad_elem = absl::get_if<2>(&const_v); + EXPECT_EQ(bad_elem, nullptr); + EXPECT_TRUE((std::is_same<decltype(bad_elem), const double*>::value)); + } + } + } +} + +////////////////////// +// [variant.relops] // +////////////////////// + +TEST(VariantTest, OperatorEquals) { + variant<int, std::string> a(1), b(1); + EXPECT_TRUE(a == b); + EXPECT_TRUE(b == a); + EXPECT_FALSE(a != b); + EXPECT_FALSE(b != a); + + b = "str"; + EXPECT_FALSE(a == b); + EXPECT_FALSE(b == a); + EXPECT_TRUE(a != b); + EXPECT_TRUE(b != a); + + b = 0; + EXPECT_FALSE(a == b); + EXPECT_FALSE(b == a); + EXPECT_TRUE(a != b); + EXPECT_TRUE(b != a); + + a = b = "foo"; + EXPECT_TRUE(a == b); + EXPECT_TRUE(b == a); + EXPECT_FALSE(a != b); + EXPECT_FALSE(b != a); + + a = "bar"; + EXPECT_FALSE(a == b); + EXPECT_FALSE(b == a); + EXPECT_TRUE(a != b); + EXPECT_TRUE(b != a); +} + +TEST(VariantTest, OperatorRelational) { + variant<int, std::string> a(1), b(1); + EXPECT_FALSE(a < b); + EXPECT_FALSE(b < a); + EXPECT_FALSE(a > b); + EXPECT_FALSE(b > a); + EXPECT_TRUE(a <= b); + EXPECT_TRUE(b <= a); + EXPECT_TRUE(a >= b); + EXPECT_TRUE(b >= a); + + b = "str"; + EXPECT_TRUE(a < b); + EXPECT_FALSE(b < a); + EXPECT_FALSE(a > b); + EXPECT_TRUE(b > a); + EXPECT_TRUE(a <= b); + EXPECT_FALSE(b <= a); + EXPECT_FALSE(a >= b); + EXPECT_TRUE(b >= a); + + b = 0; + EXPECT_FALSE(a < b); + EXPECT_TRUE(b < a); + EXPECT_TRUE(a > b); + EXPECT_FALSE(b > a); + EXPECT_FALSE(a <= b); + EXPECT_TRUE(b <= a); + EXPECT_TRUE(a >= b); + EXPECT_FALSE(b >= a); + + a = b = "foo"; + EXPECT_FALSE(a < b); + EXPECT_FALSE(b < a); + EXPECT_FALSE(a > b); + EXPECT_FALSE(b > a); + EXPECT_TRUE(a <= b); + EXPECT_TRUE(b <= a); + EXPECT_TRUE(a >= b); + EXPECT_TRUE(b >= a); + + a = "bar"; + EXPECT_TRUE(a < b); + EXPECT_FALSE(b < a); + EXPECT_FALSE(a > b); + EXPECT_TRUE(b > a); + EXPECT_TRUE(a <= b); + EXPECT_FALSE(b <= a); + EXPECT_FALSE(a >= b); + EXPECT_TRUE(b >= a); +} + +#ifdef ABSL_HAVE_EXCEPTIONS + +TEST(VariantTest, ValuelessOperatorEquals) { + variant<MoveCanThrow, std::string> int_v(1), string_v("Hello"), + valueless(absl::in_place_index<0>), + other_valueless(absl::in_place_index<0>); + ToValuelessByException(valueless); + ToValuelessByException(other_valueless); + + EXPECT_TRUE(valueless == other_valueless); + EXPECT_TRUE(other_valueless == valueless); + EXPECT_FALSE(valueless == int_v); + EXPECT_FALSE(valueless == string_v); + EXPECT_FALSE(int_v == valueless); + EXPECT_FALSE(string_v == valueless); + + EXPECT_FALSE(valueless != other_valueless); + EXPECT_FALSE(other_valueless != valueless); + EXPECT_TRUE(valueless != int_v); + EXPECT_TRUE(valueless != string_v); + EXPECT_TRUE(int_v != valueless); + EXPECT_TRUE(string_v != valueless); +} + +TEST(VariantTest, ValuelessOperatorRelational) { + variant<MoveCanThrow, std::string> int_v(1), string_v("Hello"), + valueless(absl::in_place_index<0>), + other_valueless(absl::in_place_index<0>); + ToValuelessByException(valueless); + ToValuelessByException(other_valueless); + + EXPECT_FALSE(valueless < other_valueless); + EXPECT_FALSE(other_valueless < valueless); + EXPECT_TRUE(valueless < int_v); + EXPECT_TRUE(valueless < string_v); + EXPECT_FALSE(int_v < valueless); + EXPECT_FALSE(string_v < valueless); + + EXPECT_TRUE(valueless <= other_valueless); + EXPECT_TRUE(other_valueless <= valueless); + EXPECT_TRUE(valueless <= int_v); + EXPECT_TRUE(valueless <= string_v); + EXPECT_FALSE(int_v <= valueless); + EXPECT_FALSE(string_v <= valueless); + + EXPECT_TRUE(valueless >= other_valueless); + EXPECT_TRUE(other_valueless >= valueless); + EXPECT_FALSE(valueless >= int_v); + EXPECT_FALSE(valueless >= string_v); + EXPECT_TRUE(int_v >= valueless); + EXPECT_TRUE(string_v >= valueless); + + EXPECT_FALSE(valueless > other_valueless); + EXPECT_FALSE(other_valueless > valueless); + EXPECT_FALSE(valueless > int_v); + EXPECT_FALSE(valueless > string_v); + EXPECT_TRUE(int_v > valueless); + EXPECT_TRUE(string_v > valueless); +} + +#endif + +///////////////////// +// [variant.visit] // +///////////////////// + +template <typename T> +struct ConvertTo { + template <typename U> + T operator()(const U& u) const { + return u; + } +}; + +TEST(VariantTest, VisitSimple) { + variant<std::string, const char*> v = "A"; + + std::string str = absl::visit(ConvertTo<std::string>{}, v); + EXPECT_EQ("A", str); + + v = std::string("B"); + + absl::string_view piece = absl::visit(ConvertTo<absl::string_view>{}, v); + EXPECT_EQ("B", piece); + + struct StrLen { + int operator()(const char* s) const { return strlen(s); } + int operator()(const std::string& s) const { return s.size(); } + }; + + v = "SomeStr"; + EXPECT_EQ(7, absl::visit(StrLen{}, v)); + v = std::string("VeryLargeThisTime"); + EXPECT_EQ(17, absl::visit(StrLen{}, v)); +} + +TEST(VariantTest, VisitRValue) { + variant<std::string> v = std::string("X"); + struct Visitor { + bool operator()(const std::string&) const { return false; } + bool operator()(std::string&&) const { return true; } // NOLINT + + int operator()(const std::string&, const std::string&) const { return 0; } + int operator()(const std::string&, std::string&&) const { + return 1; + } // NOLINT + int operator()(std::string&&, const std::string&) const { + return 2; + } // NOLINT + int operator()(std::string&&, std::string&&) const { return 3; } // NOLINT + }; + EXPECT_FALSE(absl::visit(Visitor{}, v)); + EXPECT_TRUE(absl::visit(Visitor{}, absl::move(v))); + + // Also test the variadic overload. + EXPECT_EQ(0, absl::visit(Visitor{}, v, v)); + EXPECT_EQ(1, absl::visit(Visitor{}, v, absl::move(v))); + EXPECT_EQ(2, absl::visit(Visitor{}, absl::move(v), v)); + EXPECT_EQ(3, absl::visit(Visitor{}, absl::move(v), absl::move(v))); +} + +TEST(VariantTest, VisitRValueVisitor) { + variant<std::string> v = std::string("X"); + struct Visitor { + bool operator()(const std::string&) const& { return false; } + bool operator()(const std::string&) && { return true; } + }; + Visitor visitor; + EXPECT_FALSE(absl::visit(visitor, v)); + EXPECT_TRUE(absl::visit(Visitor{}, v)); +} + +TEST(VariantTest, VisitResultTypeDifferent) { + variant<std::string> v = std::string("X"); + struct LValue_LValue {}; + struct RValue_LValue {}; + struct LValue_RValue {}; + struct RValue_RValue {}; + struct Visitor { + LValue_LValue operator()(const std::string&) const& { return {}; } + RValue_LValue operator()(std::string&&) const& { return {}; } // NOLINT + LValue_RValue operator()(const std::string&) && { return {}; } + RValue_RValue operator()(std::string&&) && { return {}; } // NOLINT + } visitor; + + EXPECT_TRUE( + (std::is_same<LValue_LValue, decltype(absl::visit(visitor, v))>::value)); + EXPECT_TRUE( + (std::is_same<RValue_LValue, + decltype(absl::visit(visitor, absl::move(v)))>::value)); + EXPECT_TRUE(( + std::is_same<LValue_RValue, decltype(absl::visit(Visitor{}, v))>::value)); + EXPECT_TRUE( + (std::is_same<RValue_RValue, + decltype(absl::visit(Visitor{}, absl::move(v)))>::value)); +} + +TEST(VariantTest, VisitVariadic) { + using A = variant<int, std::string>; + using B = variant<std::unique_ptr<int>, absl::string_view>; + + struct Visitor { + std::pair<int, int> operator()(int a, std::unique_ptr<int> b) const { + return {a, *b}; + } + std::pair<int, int> operator()(absl::string_view a, + std::unique_ptr<int> b) const { + return {static_cast<int>(a.size()), static_cast<int>(*b)}; + } + std::pair<int, int> operator()(int a, absl::string_view b) const { + return {a, static_cast<int>(b.size())}; + } + std::pair<int, int> operator()(absl::string_view a, + absl::string_view b) const { + return {static_cast<int>(a.size()), static_cast<int>(b.size())}; + } + }; + + EXPECT_THAT(absl::visit(Visitor(), A(1), B(std::unique_ptr<int>(new int(7)))), + ::testing::Pair(1, 7)); + EXPECT_THAT(absl::visit(Visitor(), A(1), B(absl::string_view("ABC"))), + ::testing::Pair(1, 3)); + EXPECT_THAT(absl::visit(Visitor(), A(std::string("BBBBB")), + B(std::unique_ptr<int>(new int(7)))), + ::testing::Pair(5, 7)); + EXPECT_THAT(absl::visit(Visitor(), A(std::string("BBBBB")), + B(absl::string_view("ABC"))), + ::testing::Pair(5, 3)); +} + +TEST(VariantTest, VisitNoArgs) { + EXPECT_EQ(5, absl::visit([] { return 5; })); +} + +struct ConstFunctor { + int operator()(int a, int b) const { return a - b; } +}; + +struct MutableFunctor { + int operator()(int a, int b) { return a - b; } +}; + +struct Class { + int Method(int a, int b) { return a - b; } + int ConstMethod(int a, int b) const { return a - b; } + + int member; +}; + +TEST(VariantTest, VisitReferenceWrapper) { + ConstFunctor cf; + MutableFunctor mf; + absl::variant<int> three = 3; + absl::variant<int> two = 2; + + EXPECT_EQ(1, absl::visit(std::cref(cf), three, two)); + EXPECT_EQ(1, absl::visit(std::ref(cf), three, two)); + EXPECT_EQ(1, absl::visit(std::ref(mf), three, two)); +} + +// libstdc++ std::variant doesn't support the INVOKE semantics. +#if !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) +TEST(VariantTest, VisitMemberFunction) { + absl::variant<std::unique_ptr<Class>> p(absl::make_unique<Class>()); + absl::variant<std::unique_ptr<const Class>> cp( + absl::make_unique<const Class>()); + absl::variant<int> three = 3; + absl::variant<int> two = 2; + + EXPECT_EQ(1, absl::visit(&Class::Method, p, three, two)); + EXPECT_EQ(1, absl::visit(&Class::ConstMethod, p, three, two)); + EXPECT_EQ(1, absl::visit(&Class::ConstMethod, cp, three, two)); +} + +TEST(VariantTest, VisitDataMember) { + absl::variant<std::unique_ptr<Class>> p(absl::make_unique<Class>(Class{42})); + absl::variant<std::unique_ptr<const Class>> cp( + absl::make_unique<const Class>(Class{42})); + EXPECT_EQ(42, absl::visit(&Class::member, p)); + + absl::visit(&Class::member, p) = 5; + EXPECT_EQ(5, absl::visit(&Class::member, p)); + + EXPECT_EQ(42, absl::visit(&Class::member, cp)); +} +#endif // !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) + +///////////////////////// +// [variant.monostate] // +///////////////////////// + +TEST(VariantTest, MonostateBasic) { + absl::monostate mono; + (void)mono; + + // TODO(mattcalabrese) Expose move triviality metafunctions in absl. + EXPECT_TRUE(absl::is_trivially_default_constructible<absl::monostate>::value); + EXPECT_TRUE(is_trivially_move_constructible<absl::monostate>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<absl::monostate>::value); + EXPECT_TRUE(is_trivially_move_assignable<absl::monostate>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<absl::monostate>::value); + EXPECT_TRUE(absl::is_trivially_destructible<absl::monostate>::value); +} + +TEST(VariantTest, VariantMonostateDefaultConstruction) { + absl::variant<absl::monostate, NonDefaultConstructible> var; + EXPECT_EQ(var.index(), 0); +} + +//////////////////////////////// +// [variant.monostate.relops] // +//////////////////////////////// + +TEST(VariantTest, MonostateComparisons) { + absl::monostate lhs, rhs; + + EXPECT_EQ(lhs, lhs); + EXPECT_EQ(lhs, rhs); + + EXPECT_FALSE(lhs != lhs); + EXPECT_FALSE(lhs != rhs); + EXPECT_FALSE(lhs < lhs); + EXPECT_FALSE(lhs < rhs); + EXPECT_FALSE(lhs > lhs); + EXPECT_FALSE(lhs > rhs); + + EXPECT_LE(lhs, lhs); + EXPECT_LE(lhs, rhs); + EXPECT_GE(lhs, lhs); + EXPECT_GE(lhs, rhs); + + EXPECT_TRUE(noexcept(std::declval<absl::monostate>() == + std::declval<absl::monostate>())); + EXPECT_TRUE(noexcept(std::declval<absl::monostate>() != + std::declval<absl::monostate>())); + EXPECT_TRUE(noexcept(std::declval<absl::monostate>() < + std::declval<absl::monostate>())); + EXPECT_TRUE(noexcept(std::declval<absl::monostate>() > + std::declval<absl::monostate>())); + EXPECT_TRUE(noexcept(std::declval<absl::monostate>() <= + std::declval<absl::monostate>())); + EXPECT_TRUE(noexcept(std::declval<absl::monostate>() >= + std::declval<absl::monostate>())); +} + +/////////////////////// +// [variant.specalg] // +/////////////////////// + +TEST(VariantTest, NonmemberSwap) { + using std::swap; + + SpecialSwap v1(3); + SpecialSwap v2(7); + + variant<SpecialSwap> a = v1, b = v2; + + EXPECT_THAT(a, VariantWith<SpecialSwap>(v1)); + EXPECT_THAT(b, VariantWith<SpecialSwap>(v2)); + + std::swap(a, b); + EXPECT_THAT(a, VariantWith<SpecialSwap>(v2)); + EXPECT_THAT(b, VariantWith<SpecialSwap>(v1)); +#ifndef ABSL_USES_STD_VARIANT + EXPECT_FALSE(absl::get<SpecialSwap>(a).special_swap); +#endif + + swap(a, b); + EXPECT_THAT(a, VariantWith<SpecialSwap>(v1)); + EXPECT_THAT(b, VariantWith<SpecialSwap>(v2)); + EXPECT_TRUE(absl::get<SpecialSwap>(b).special_swap); +} + +////////////////////////// +// [variant.bad.access] // +////////////////////////// + +TEST(VariantTest, BadAccess) { + EXPECT_TRUE(noexcept(absl::bad_variant_access())); + absl::bad_variant_access exception_obj; + std::exception* base = &exception_obj; + (void)base; +} + +//////////////////// +// [variant.hash] // +//////////////////// + +TEST(VariantTest, MonostateHash) { + absl::monostate mono, other_mono; + std::hash<absl::monostate> const hasher{}; + static_assert(std::is_same<decltype(hasher(mono)), std::size_t>::value, ""); + EXPECT_EQ(hasher(mono), hasher(other_mono)); +} + +TEST(VariantTest, Hash) { + static_assert(type_traits_internal::IsHashable<variant<int>>::value, ""); + static_assert(type_traits_internal::IsHashable<variant<Hashable>>::value, ""); + static_assert(type_traits_internal::IsHashable<variant<int, Hashable>>::value, + ""); + +#if ABSL_META_INTERNAL_STD_HASH_SFINAE_FRIENDLY_ + static_assert(!type_traits_internal::IsHashable<variant<NonHashable>>::value, + ""); + static_assert( + !type_traits_internal::IsHashable<variant<Hashable, NonHashable>>::value, + ""); +#endif + +// MSVC std::hash<std::variant> does not use the index, thus produce the same +// result on the same value as different alternative. +#if !(defined(_MSC_VER) && defined(ABSL_USES_STD_VARIANT)) + { + // same value as different alternative + variant<int, int> v0(in_place_index<0>, 42); + variant<int, int> v1(in_place_index<1>, 42); + std::hash<variant<int, int>> hash; + EXPECT_NE(hash(v0), hash(v1)); + } +#endif // !(defined(_MSC_VER) && defined(ABSL_USES_STD_VARIANT)) + + { + std::hash<variant<int>> hash; + std::set<size_t> hashcodes; + for (int i = 0; i < 100; ++i) { + hashcodes.insert(hash(i)); + } + EXPECT_GT(hashcodes.size(), 90); + + // test const-qualified + static_assert(type_traits_internal::IsHashable<variant<const int>>::value, + ""); + static_assert( + type_traits_internal::IsHashable<variant<const Hashable>>::value, ""); + std::hash<absl::variant<const int>> c_hash; + for (int i = 0; i < 100; ++i) { + EXPECT_EQ(hash(i), c_hash(i)); + } + } +} + +//////////////////////////////////////// +// Miscellaneous and deprecated tests // +//////////////////////////////////////// + +// Test that a set requiring a basic type conversion works correctly +#if !defined(ABSL_USES_STD_VARIANT) +TEST(VariantTest, TestConvertingSet) { + typedef variant<double> Variant; + Variant v(1.0); + const int two = 2; + v = two; + EXPECT_TRUE(absl::holds_alternative<double>(v)); + ASSERT_TRUE(nullptr != absl::get_if<double>(&v)); + EXPECT_DOUBLE_EQ(2, absl::get<double>(v)); +} +#endif // ABSL_USES_STD_VARIANT + +// Test that a vector of variants behaves reasonably. +TEST(VariantTest, Container) { + typedef variant<int, float> Variant; + + // Creation of vector should work + std::vector<Variant> vec; + vec.push_back(Variant(10)); + vec.push_back(Variant(20.0f)); + + // Vector resizing should work if we supply a value for new slots + vec.resize(10, Variant(0)); +} + +// Test that a variant with a non-copyable type can be constructed and +// manipulated to some degree. +TEST(VariantTest, TestVariantWithNonCopyableType) { + typedef variant<int, NonCopyable> Variant; + const int kValue = 1; + Variant v(kValue); + ASSERT_TRUE(absl::holds_alternative<int>(v)); + EXPECT_EQ(kValue, absl::get<int>(v)); +} + +// Test that a variant with a non-copyable type can be transformed to +// the non-copyable type with a call to `emplace` for different numbers +// of arguments. We do not need to test this for each of T1 ... T8 +// because `emplace` does not overload on T1 ... to T8, so if this +// works for any one of T1 ... T8, then it works for all of them. We +// do need to test that it works with varying numbers of parameters +// though. +TEST(VariantTest, TestEmplace) { + typedef variant<int, NonCopyable> Variant; + const int kValue = 1; + Variant v(kValue); + ASSERT_TRUE(absl::holds_alternative<int>(v)); + EXPECT_EQ(kValue, absl::get<int>(v)); + + // emplace with zero arguments, then back to 'int' + v.emplace<NonCopyable>(); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v)); + EXPECT_EQ(0, absl::get<NonCopyable>(v).value); + v = kValue; + ASSERT_TRUE(absl::holds_alternative<int>(v)); + + // emplace with one argument: + v.emplace<NonCopyable>(1); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v)); + EXPECT_EQ(1, absl::get<NonCopyable>(v).value); + v = kValue; + ASSERT_TRUE(absl::holds_alternative<int>(v)); + + // emplace with two arguments: + v.emplace<NonCopyable>(1, 2); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v)); + EXPECT_EQ(3, absl::get<NonCopyable>(v).value); + v = kValue; + ASSERT_TRUE(absl::holds_alternative<int>(v)); + + // emplace with three arguments + v.emplace<NonCopyable>(1, 2, 3); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v)); + EXPECT_EQ(6, absl::get<NonCopyable>(v).value); + v = kValue; + ASSERT_TRUE(absl::holds_alternative<int>(v)); + + // emplace with four arguments + v.emplace<NonCopyable>(1, 2, 3, 4); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v)); + EXPECT_EQ(10, absl::get<NonCopyable>(v).value); + v = kValue; + ASSERT_TRUE(absl::holds_alternative<int>(v)); +} + +TEST(VariantTest, TestEmplaceDestroysCurrentValue) { + typedef variant<int, IncrementInDtor, NonCopyable> Variant; + int counter = 0; + Variant v(0); + ASSERT_TRUE(absl::holds_alternative<int>(v)); + v.emplace<IncrementInDtor>(&counter); + ASSERT_TRUE(absl::holds_alternative<IncrementInDtor>(v)); + ASSERT_EQ(0, counter); + v.emplace<NonCopyable>(); + ASSERT_TRUE(absl::holds_alternative<NonCopyable>(v)); + EXPECT_EQ(1, counter); +} + +TEST(VariantTest, TestMoveSemantics) { + typedef variant<std::unique_ptr<int>, std::unique_ptr<std::string>> Variant; + + // Construct a variant by moving from an element value. + Variant v(absl::WrapUnique(new int(10))); + EXPECT_TRUE(absl::holds_alternative<std::unique_ptr<int>>(v)); + + // Construct a variant by moving from another variant. + Variant v2(absl::move(v)); + ASSERT_TRUE(absl::holds_alternative<std::unique_ptr<int>>(v2)); + ASSERT_NE(nullptr, absl::get<std::unique_ptr<int>>(v2)); + EXPECT_EQ(10, *absl::get<std::unique_ptr<int>>(v2)); + + // Moving from a variant object leaves it holding moved-from value of the + // same element type. + EXPECT_TRUE(absl::holds_alternative<std::unique_ptr<int>>(v)); + ASSERT_NE(nullptr, absl::get_if<std::unique_ptr<int>>(&v)); + EXPECT_EQ(nullptr, absl::get<std::unique_ptr<int>>(v)); + + // Assign a variant from an element value by move. + v = absl::make_unique<std::string>("foo"); + ASSERT_TRUE(absl::holds_alternative<std::unique_ptr<std::string>>(v)); + EXPECT_EQ("foo", *absl::get<std::unique_ptr<std::string>>(v)); + + // Move-assign a variant. + v2 = absl::move(v); + ASSERT_TRUE(absl::holds_alternative<std::unique_ptr<std::string>>(v2)); + EXPECT_EQ("foo", *absl::get<std::unique_ptr<std::string>>(v2)); + EXPECT_TRUE(absl::holds_alternative<std::unique_ptr<std::string>>(v)); +} + +variant<int, std::string> PassThrough(const variant<int, std::string>& arg) { + return arg; +} + +TEST(VariantTest, TestImplicitConversion) { + EXPECT_TRUE(absl::holds_alternative<int>(PassThrough(0))); + + // We still need the explicit cast for std::string, because C++ won't apply + // two user-defined implicit conversions in a row. + EXPECT_TRUE( + absl::holds_alternative<std::string>(PassThrough(std::string("foo")))); +} + +struct Convertible2; +struct Convertible1 { + Convertible1() {} + Convertible1(const Convertible1&) {} + Convertible1& operator=(const Convertible1&) { return *this; } + + // implicit conversion from Convertible2 + Convertible1(const Convertible2&) {} // NOLINT(runtime/explicit) +}; + +struct Convertible2 { + Convertible2() {} + Convertible2(const Convertible2&) {} + Convertible2& operator=(const Convertible2&) { return *this; } + + // implicit conversion from Convertible1 + Convertible2(const Convertible1&) {} // NOLINT(runtime/explicit) +}; + +TEST(VariantTest, TestRvalueConversion) { +#if !defined(ABSL_USES_STD_VARIANT) + variant<double, std::string> var( + ConvertVariantTo<variant<double, std::string>>( + variant<std::string, int>(0))); + ASSERT_TRUE(absl::holds_alternative<double>(var)); + EXPECT_EQ(0.0, absl::get<double>(var)); + + var = ConvertVariantTo<variant<double, std::string>>( + variant<const char*, float>("foo")); + ASSERT_TRUE(absl::holds_alternative<std::string>(var)); + EXPECT_EQ("foo", absl::get<std::string>(var)); + + variant<double> singleton( + ConvertVariantTo<variant<double>>(variant<int, float>(42))); + ASSERT_TRUE(absl::holds_alternative<double>(singleton)); + EXPECT_EQ(42.0, absl::get<double>(singleton)); + + singleton = ConvertVariantTo<variant<double>>(variant<int, float>(3.14f)); + ASSERT_TRUE(absl::holds_alternative<double>(singleton)); + EXPECT_FLOAT_EQ(3.14f, static_cast<float>(absl::get<double>(singleton))); + + singleton = ConvertVariantTo<variant<double>>(variant<int>(0)); + ASSERT_TRUE(absl::holds_alternative<double>(singleton)); + EXPECT_EQ(0.0, absl::get<double>(singleton)); + + variant<int32_t, uint32_t> variant2( + ConvertVariantTo<variant<int32_t, uint32_t>>(variant<int32_t>(42))); + ASSERT_TRUE(absl::holds_alternative<int32_t>(variant2)); + EXPECT_EQ(42, absl::get<int32_t>(variant2)); + + variant2 = ConvertVariantTo<variant<int32_t, uint32_t>>(variant<uint32_t>(42)); + ASSERT_TRUE(absl::holds_alternative<uint32_t>(variant2)); + EXPECT_EQ(42, absl::get<uint32_t>(variant2)); +#endif // !ABSL_USES_STD_VARIANT + + variant<Convertible1, Convertible2> variant3( + ConvertVariantTo<variant<Convertible1, Convertible2>>( + (variant<Convertible2, Convertible1>(Convertible1())))); + ASSERT_TRUE(absl::holds_alternative<Convertible1>(variant3)); + + variant3 = ConvertVariantTo<variant<Convertible1, Convertible2>>( + variant<Convertible2, Convertible1>(Convertible2())); + ASSERT_TRUE(absl::holds_alternative<Convertible2>(variant3)); +} + +TEST(VariantTest, TestLvalueConversion) { +#if !defined(ABSL_USES_STD_VARIANT) + variant<std::string, int> source1 = 0; + variant<double, std::string> destination( + ConvertVariantTo<variant<double, std::string>>(source1)); + ASSERT_TRUE(absl::holds_alternative<double>(destination)); + EXPECT_EQ(0.0, absl::get<double>(destination)); + + variant<const char*, float> source2 = "foo"; + destination = ConvertVariantTo<variant<double, std::string>>(source2); + ASSERT_TRUE(absl::holds_alternative<std::string>(destination)); + EXPECT_EQ("foo", absl::get<std::string>(destination)); + + variant<int, float> source3(42); + variant<double> singleton(ConvertVariantTo<variant<double>>(source3)); + ASSERT_TRUE(absl::holds_alternative<double>(singleton)); + EXPECT_EQ(42.0, absl::get<double>(singleton)); + + source3 = 3.14f; + singleton = ConvertVariantTo<variant<double>>(source3); + ASSERT_TRUE(absl::holds_alternative<double>(singleton)); + EXPECT_FLOAT_EQ(3.14f, static_cast<float>(absl::get<double>(singleton))); + + variant<int> source4(0); + singleton = ConvertVariantTo<variant<double>>(source4); + ASSERT_TRUE(absl::holds_alternative<double>(singleton)); + EXPECT_EQ(0.0, absl::get<double>(singleton)); + + variant<int32_t> source5(42); + variant<int32_t, uint32_t> variant2( + ConvertVariantTo<variant<int32_t, uint32_t>>(source5)); + ASSERT_TRUE(absl::holds_alternative<int32_t>(variant2)); + EXPECT_EQ(42, absl::get<int32_t>(variant2)); + + variant<uint32_t> source6(42); + variant2 = ConvertVariantTo<variant<int32_t, uint32_t>>(source6); + ASSERT_TRUE(absl::holds_alternative<uint32_t>(variant2)); + EXPECT_EQ(42, absl::get<uint32_t>(variant2)); +#endif + + variant<Convertible2, Convertible1> source7((Convertible1())); + variant<Convertible1, Convertible2> variant3( + ConvertVariantTo<variant<Convertible1, Convertible2>>(source7)); + ASSERT_TRUE(absl::holds_alternative<Convertible1>(variant3)); + + source7 = Convertible2(); + variant3 = ConvertVariantTo<variant<Convertible1, Convertible2>>(source7); + ASSERT_TRUE(absl::holds_alternative<Convertible2>(variant3)); +} + +TEST(VariantTest, TestMoveConversion) { + using Variant = + variant<std::unique_ptr<const int>, std::unique_ptr<const std::string>>; + using OtherVariant = + variant<std::unique_ptr<int>, std::unique_ptr<std::string>>; + + Variant var( + ConvertVariantTo<Variant>(OtherVariant{absl::make_unique<int>(0)})); + ASSERT_TRUE(absl::holds_alternative<std::unique_ptr<const int>>(var)); + ASSERT_NE(absl::get<std::unique_ptr<const int>>(var), nullptr); + EXPECT_EQ(0, *absl::get<std::unique_ptr<const int>>(var)); + + var = ConvertVariantTo<Variant>( + OtherVariant(absl::make_unique<std::string>("foo"))); + ASSERT_TRUE(absl::holds_alternative<std::unique_ptr<const std::string>>(var)); + EXPECT_EQ("foo", *absl::get<std::unique_ptr<const std::string>>(var)); +} + +TEST(VariantTest, DoesNotMoveFromLvalues) { + // We use shared_ptr here because it's both copyable and movable, and + // a moved-from shared_ptr is guaranteed to be null, so we can detect + // whether moving or copying has occurred. + using Variant = + variant<std::shared_ptr<const int>, std::shared_ptr<const std::string>>; + using OtherVariant = + variant<std::shared_ptr<int>, std::shared_ptr<std::string>>; + + Variant v1(std::make_shared<const int>(0)); + + // Test copy constructor + Variant v2(v1); + EXPECT_EQ(absl::get<std::shared_ptr<const int>>(v1), + absl::get<std::shared_ptr<const int>>(v2)); + + // Test copy-assignment operator + v1 = std::make_shared<const std::string>("foo"); + v2 = v1; + EXPECT_EQ(absl::get<std::shared_ptr<const std::string>>(v1), + absl::get<std::shared_ptr<const std::string>>(v2)); + + // Test converting copy constructor + OtherVariant other(std::make_shared<int>(0)); + Variant v3(ConvertVariantTo<Variant>(other)); + EXPECT_EQ(absl::get<std::shared_ptr<int>>(other), + absl::get<std::shared_ptr<const int>>(v3)); + + other = std::make_shared<std::string>("foo"); + v3 = ConvertVariantTo<Variant>(other); + EXPECT_EQ(absl::get<std::shared_ptr<std::string>>(other), + absl::get<std::shared_ptr<const std::string>>(v3)); +} + +TEST(VariantTest, TestRvalueConversionViaConvertVariantTo) { +#if !defined(ABSL_USES_STD_VARIANT) + variant<double, std::string> var( + ConvertVariantTo<variant<double, std::string>>( + variant<std::string, int>(3))); + EXPECT_THAT(absl::get_if<double>(&var), Pointee(3.0)); + + var = ConvertVariantTo<variant<double, std::string>>( + variant<const char*, float>("foo")); + EXPECT_THAT(absl::get_if<std::string>(&var), Pointee(std::string("foo"))); + + variant<double> singleton( + ConvertVariantTo<variant<double>>(variant<int, float>(42))); + EXPECT_THAT(absl::get_if<double>(&singleton), Pointee(42.0)); + + singleton = ConvertVariantTo<variant<double>>(variant<int, float>(3.14f)); + EXPECT_THAT(absl::get_if<double>(&singleton), Pointee(DoubleEq(3.14f))); + + singleton = ConvertVariantTo<variant<double>>(variant<int>(3)); + EXPECT_THAT(absl::get_if<double>(&singleton), Pointee(3.0)); + + variant<int32_t, uint32_t> variant2( + ConvertVariantTo<variant<int32_t, uint32_t>>(variant<int32_t>(42))); + EXPECT_THAT(absl::get_if<int32_t>(&variant2), Pointee(42)); + + variant2 = ConvertVariantTo<variant<int32_t, uint32_t>>(variant<uint32_t>(42)); + EXPECT_THAT(absl::get_if<uint32_t>(&variant2), Pointee(42)); +#endif + + variant<Convertible1, Convertible2> variant3( + ConvertVariantTo<variant<Convertible1, Convertible2>>( + (variant<Convertible2, Convertible1>(Convertible1())))); + ASSERT_TRUE(absl::holds_alternative<Convertible1>(variant3)); + + variant3 = ConvertVariantTo<variant<Convertible1, Convertible2>>( + variant<Convertible2, Convertible1>(Convertible2())); + ASSERT_TRUE(absl::holds_alternative<Convertible2>(variant3)); +} + +TEST(VariantTest, TestLvalueConversionViaConvertVariantTo) { +#if !defined(ABSL_USES_STD_VARIANT) + variant<std::string, int> source1 = 3; + variant<double, std::string> destination( + ConvertVariantTo<variant<double, std::string>>(source1)); + EXPECT_THAT(absl::get_if<double>(&destination), Pointee(3.0)); + + variant<const char*, float> source2 = "foo"; + destination = ConvertVariantTo<variant<double, std::string>>(source2); + EXPECT_THAT(absl::get_if<std::string>(&destination), + Pointee(std::string("foo"))); + + variant<int, float> source3(42); + variant<double> singleton(ConvertVariantTo<variant<double>>(source3)); + EXPECT_THAT(absl::get_if<double>(&singleton), Pointee(42.0)); + + source3 = 3.14f; + singleton = ConvertVariantTo<variant<double>>(source3); + EXPECT_FLOAT_EQ(3.14f, static_cast<float>(absl::get<double>(singleton))); + EXPECT_THAT(absl::get_if<double>(&singleton), Pointee(DoubleEq(3.14f))); + + variant<int> source4(3); + singleton = ConvertVariantTo<variant<double>>(source4); + EXPECT_THAT(absl::get_if<double>(&singleton), Pointee(3.0)); + + variant<int32_t> source5(42); + variant<int32_t, uint32_t> variant2( + ConvertVariantTo<variant<int32_t, uint32_t>>(source5)); + EXPECT_THAT(absl::get_if<int32_t>(&variant2), Pointee(42)); + + variant<uint32_t> source6(42); + variant2 = ConvertVariantTo<variant<int32_t, uint32_t>>(source6); + EXPECT_THAT(absl::get_if<uint32_t>(&variant2), Pointee(42)); +#endif // !ABSL_USES_STD_VARIANT + + variant<Convertible2, Convertible1> source7((Convertible1())); + variant<Convertible1, Convertible2> variant3( + ConvertVariantTo<variant<Convertible1, Convertible2>>(source7)); + ASSERT_TRUE(absl::holds_alternative<Convertible1>(variant3)); + + source7 = Convertible2(); + variant3 = ConvertVariantTo<variant<Convertible1, Convertible2>>(source7); + ASSERT_TRUE(absl::holds_alternative<Convertible2>(variant3)); +} + +TEST(VariantTest, TestMoveConversionViaConvertVariantTo) { + using Variant = + variant<std::unique_ptr<const int>, std::unique_ptr<const std::string>>; + using OtherVariant = + variant<std::unique_ptr<int>, std::unique_ptr<std::string>>; + + Variant var( + ConvertVariantTo<Variant>(OtherVariant{absl::make_unique<int>(3)})); + EXPECT_THAT(absl::get_if<std::unique_ptr<const int>>(&var), + Pointee(Pointee(3))); + + var = ConvertVariantTo<Variant>( + OtherVariant(absl::make_unique<std::string>("foo"))); + EXPECT_THAT(absl::get_if<std::unique_ptr<const std::string>>(&var), + Pointee(Pointee(std::string("foo")))); +} + +// If all alternatives are trivially copy/move constructible, variant should +// also be trivially copy/move constructible. This is not required by the +// standard and we know that libstdc++ variant doesn't have this feature. +// For more details see the paper: +// http://open-std.org/JTC1/SC22/WG21/docs/papers/2017/p0602r0.html +#if !(defined(ABSL_USES_STD_VARIANT) && defined(__GLIBCXX__)) +#define ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY 1 +#endif + +TEST(VariantTest, TestCopyAndMoveTypeTraits) { + EXPECT_TRUE(std::is_copy_constructible<variant<std::string>>::value); + EXPECT_TRUE(absl::is_copy_assignable<variant<std::string>>::value); + EXPECT_TRUE(std::is_move_constructible<variant<std::string>>::value); + EXPECT_TRUE(absl::is_move_assignable<variant<std::string>>::value); + EXPECT_TRUE(std::is_move_constructible<variant<std::unique_ptr<int>>>::value); + EXPECT_TRUE(absl::is_move_assignable<variant<std::unique_ptr<int>>>::value); + EXPECT_FALSE( + std::is_copy_constructible<variant<std::unique_ptr<int>>>::value); + EXPECT_FALSE(absl::is_copy_assignable<variant<std::unique_ptr<int>>>::value); + + EXPECT_FALSE( + absl::is_trivially_copy_constructible<variant<std::string>>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<variant<std::string>>::value); +#if ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY + EXPECT_TRUE(absl::is_trivially_copy_constructible<variant<int>>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<variant<int>>::value); + EXPECT_TRUE(is_trivially_move_constructible<variant<int>>::value); + EXPECT_TRUE(is_trivially_move_assignable<variant<int>>::value); +#endif // ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY +} + +TEST(VariantTest, TestVectorOfMoveonlyVariant) { + // Verify that variant<MoveonlyType> works correctly as a std::vector element. + std::vector<variant<std::unique_ptr<int>, std::string>> vec; + vec.push_back(absl::make_unique<int>(42)); + vec.emplace_back("Hello"); + vec.reserve(3); + auto another_vec = absl::move(vec); + // As a sanity check, verify vector contents. + ASSERT_EQ(2, another_vec.size()); + EXPECT_EQ(42, *absl::get<std::unique_ptr<int>>(another_vec[0])); + EXPECT_EQ("Hello", absl::get<std::string>(another_vec[1])); +} + +TEST(VariantTest, NestedVariant) { +#if ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY + static_assert(absl::is_trivially_copy_constructible<variant<int>>(), ""); + static_assert(absl::is_trivially_copy_assignable<variant<int>>(), ""); + static_assert(is_trivially_move_constructible<variant<int>>(), ""); + static_assert(is_trivially_move_assignable<variant<int>>(), ""); + + static_assert(absl::is_trivially_copy_constructible<variant<variant<int>>>(), + ""); + static_assert(absl::is_trivially_copy_assignable<variant<variant<int>>>(), + ""); + static_assert(is_trivially_move_constructible<variant<variant<int>>>(), ""); + static_assert(is_trivially_move_assignable<variant<variant<int>>>(), ""); +#endif // ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY + + variant<int> x(42); + variant<variant<int>> y(x); + variant<variant<int>> z(y); + EXPECT_TRUE(absl::holds_alternative<variant<int>>(z)); + EXPECT_EQ(x, absl::get<variant<int>>(z)); +} + +struct TriviallyDestructible { + TriviallyDestructible(TriviallyDestructible&&) {} + TriviallyDestructible(const TriviallyDestructible&) {} + TriviallyDestructible& operator=(TriviallyDestructible&&) { return *this; } + TriviallyDestructible& operator=(const TriviallyDestructible&) { + return *this; + } +}; + +struct TriviallyMovable { + TriviallyMovable(TriviallyMovable&&) = default; + TriviallyMovable(TriviallyMovable const&) {} + TriviallyMovable& operator=(const TriviallyMovable&) { return *this; } +}; + +struct TriviallyCopyable { + TriviallyCopyable(const TriviallyCopyable&) = default; + TriviallyCopyable& operator=(const TriviallyCopyable&) { return *this; } +}; + +struct TriviallyMoveAssignable { + TriviallyMoveAssignable(TriviallyMoveAssignable&&) = default; + TriviallyMoveAssignable(const TriviallyMoveAssignable&) {} + TriviallyMoveAssignable& operator=(TriviallyMoveAssignable&&) = default; + TriviallyMoveAssignable& operator=(const TriviallyMoveAssignable&) { + return *this; + } +}; + +struct TriviallyCopyAssignable {}; + +#if ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY +TEST(VariantTest, TestTriviality) { + { + using TrivDestVar = absl::variant<TriviallyDestructible>; + + EXPECT_FALSE(is_trivially_move_constructible<TrivDestVar>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<TrivDestVar>::value); + EXPECT_FALSE(is_trivially_move_assignable<TrivDestVar>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<TrivDestVar>::value); + EXPECT_TRUE(absl::is_trivially_destructible<TrivDestVar>::value); + } + + { + using TrivMoveVar = absl::variant<TriviallyMovable>; + + EXPECT_TRUE(is_trivially_move_constructible<TrivMoveVar>::value); + EXPECT_FALSE(absl::is_trivially_copy_constructible<TrivMoveVar>::value); + EXPECT_FALSE(is_trivially_move_assignable<TrivMoveVar>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<TrivMoveVar>::value); + EXPECT_TRUE(absl::is_trivially_destructible<TrivMoveVar>::value); + } + + { + using TrivCopyVar = absl::variant<TriviallyCopyable>; + + EXPECT_TRUE(is_trivially_move_constructible<TrivCopyVar>::value); + EXPECT_TRUE(absl::is_trivially_copy_constructible<TrivCopyVar>::value); + EXPECT_FALSE(is_trivially_move_assignable<TrivCopyVar>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<TrivCopyVar>::value); + EXPECT_TRUE(absl::is_trivially_destructible<TrivCopyVar>::value); + } + + { + using TrivMoveAssignVar = absl::variant<TriviallyMoveAssignable>; + + EXPECT_TRUE(is_trivially_move_constructible<TrivMoveAssignVar>::value); + EXPECT_FALSE( + absl::is_trivially_copy_constructible<TrivMoveAssignVar>::value); + EXPECT_TRUE(is_trivially_move_assignable<TrivMoveAssignVar>::value); + EXPECT_FALSE(absl::is_trivially_copy_assignable<TrivMoveAssignVar>::value); + EXPECT_TRUE(absl::is_trivially_destructible<TrivMoveAssignVar>::value); + } + + { + using TrivCopyAssignVar = absl::variant<TriviallyCopyAssignable>; + + EXPECT_TRUE(is_trivially_move_constructible<TrivCopyAssignVar>::value); + EXPECT_TRUE( + absl::is_trivially_copy_constructible<TrivCopyAssignVar>::value); + EXPECT_TRUE(is_trivially_move_assignable<TrivCopyAssignVar>::value); + EXPECT_TRUE(absl::is_trivially_copy_assignable<TrivCopyAssignVar>::value); + EXPECT_TRUE(absl::is_trivially_destructible<TrivCopyAssignVar>::value); + } +} +#endif // ABSL_VARIANT_PROPAGATE_COPY_MOVE_TRIVIALITY + +// To verify that absl::variant correctly use the nontrivial move ctor of its +// member rather than use the trivial copy constructor. +TEST(VariantTest, MoveCtorBug) { + // To simulate std::tuple in libstdc++. + struct TrivialCopyNontrivialMove { + TrivialCopyNontrivialMove() = default; + TrivialCopyNontrivialMove(const TrivialCopyNontrivialMove&) = default; + TrivialCopyNontrivialMove(TrivialCopyNontrivialMove&&) { called = true; } + bool called = false; + }; + { + using V = absl::variant<TrivialCopyNontrivialMove, int>; + V v1(absl::in_place_index<0>); + // this should invoke the move ctor, rather than the trivial copy ctor. + V v2(std::move(v1)); + EXPECT_TRUE(absl::get<0>(v2).called); + } + { + // this case failed to compile before our fix due to a GCC bug. + using V = absl::variant<int, TrivialCopyNontrivialMove>; + V v1(absl::in_place_index<1>); + // this should invoke the move ctor, rather than the trivial copy ctor. + V v2(std::move(v1)); + EXPECT_TRUE(absl::get<1>(v2).called); + } +} + +} // namespace +ABSL_NAMESPACE_END +} // namespace absl + +#endif // #if !defined(ABSL_USES_STD_VARIANT) diff --git a/third_party/abseil_cpp/absl/utility/BUILD.bazel b/third_party/abseil_cpp/absl/utility/BUILD.bazel new file mode 100644 index 0000000000..6881f939c5 --- /dev/null +++ b/third_party/abseil_cpp/absl/utility/BUILD.bazel @@ -0,0 +1,55 @@ +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +load("@rules_cc//cc:defs.bzl", "cc_library", "cc_test") +load( + "//absl:copts/configure_copts.bzl", + "ABSL_DEFAULT_COPTS", + "ABSL_DEFAULT_LINKOPTS", + "ABSL_TEST_COPTS", +) + +package(default_visibility = ["//visibility:public"]) + +licenses(["notice"]) # Apache 2.0 + +cc_library( + name = "utility", + hdrs = [ + "utility.h", + ], + copts = ABSL_DEFAULT_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + "//absl/base:base_internal", + "//absl/base:config", + "//absl/meta:type_traits", + ], +) + +cc_test( + name = "utility_test", + srcs = ["utility_test.cc"], + copts = ABSL_TEST_COPTS, + linkopts = ABSL_DEFAULT_LINKOPTS, + deps = [ + ":utility", + "//absl/base:core_headers", + "//absl/memory", + "//absl/strings", + "@com_google_googletest//:gtest_main", + ], +) diff --git a/third_party/abseil_cpp/absl/utility/CMakeLists.txt b/third_party/abseil_cpp/absl/utility/CMakeLists.txt new file mode 100644 index 0000000000..e1edd19aa0 --- /dev/null +++ b/third_party/abseil_cpp/absl/utility/CMakeLists.txt @@ -0,0 +1,44 @@ +# +# Copyright 2017 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +absl_cc_library( + NAME + utility + HDRS + "utility.h" + COPTS + ${ABSL_DEFAULT_COPTS} + DEPS + absl::base_internal + absl::config + absl::type_traits + PUBLIC +) + +absl_cc_test( + NAME + utility_test + SRCS + "utility_test.cc" + COPTS + ${ABSL_TEST_COPTS} + DEPS + absl::utility + absl::core_headers + absl::memory + absl::strings + gmock_main +) diff --git a/third_party/abseil_cpp/absl/utility/utility.h b/third_party/abseil_cpp/absl/utility/utility.h new file mode 100644 index 0000000000..e6647c7b2e --- /dev/null +++ b/third_party/abseil_cpp/absl/utility/utility.h @@ -0,0 +1,350 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. +// +// This header file contains C++11 versions of standard <utility> header +// abstractions available within C++14 and C++17, and are designed to be drop-in +// replacement for code compliant with C++14 and C++17. +// +// The following abstractions are defined: +// +// * integer_sequence<T, Ints...> == std::integer_sequence<T, Ints...> +// * index_sequence<Ints...> == std::index_sequence<Ints...> +// * make_integer_sequence<T, N> == std::make_integer_sequence<T, N> +// * make_index_sequence<N> == std::make_index_sequence<N> +// * index_sequence_for<Ts...> == std::index_sequence_for<Ts...> +// * apply<Functor, Tuple> == std::apply<Functor, Tuple> +// * exchange<T> == std::exchange<T> +// * make_from_tuple<T> == std::make_from_tuple<T> +// +// This header file also provides the tag types `in_place_t`, `in_place_type_t`, +// and `in_place_index_t`, as well as the constant `in_place`, and +// `constexpr` `std::move()` and `std::forward()` implementations in C++11. +// +// References: +// +// https://en.cppreference.com/w/cpp/utility/integer_sequence +// https://en.cppreference.com/w/cpp/utility/apply +// http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2013/n3658.html + +#ifndef ABSL_UTILITY_UTILITY_H_ +#define ABSL_UTILITY_UTILITY_H_ + +#include <cstddef> +#include <cstdlib> +#include <tuple> +#include <utility> + +#include "absl/base/config.h" +#include "absl/base/internal/inline_variable.h" +#include "absl/base/internal/invoke.h" +#include "absl/meta/type_traits.h" + +namespace absl { +ABSL_NAMESPACE_BEGIN + +// integer_sequence +// +// Class template representing a compile-time integer sequence. An instantiation +// of `integer_sequence<T, Ints...>` has a sequence of integers encoded in its +// type through its template arguments (which is a common need when +// working with C++11 variadic templates). `absl::integer_sequence` is designed +// to be a drop-in replacement for C++14's `std::integer_sequence`. +// +// Example: +// +// template< class T, T... Ints > +// void user_function(integer_sequence<T, Ints...>); +// +// int main() +// { +// // user_function's `T` will be deduced to `int` and `Ints...` +// // will be deduced to `0, 1, 2, 3, 4`. +// user_function(make_integer_sequence<int, 5>()); +// } +template <typename T, T... Ints> +struct integer_sequence { + using value_type = T; + static constexpr size_t size() noexcept { return sizeof...(Ints); } +}; + +// index_sequence +// +// A helper template for an `integer_sequence` of `size_t`, +// `absl::index_sequence` is designed to be a drop-in replacement for C++14's +// `std::index_sequence`. +template <size_t... Ints> +using index_sequence = integer_sequence<size_t, Ints...>; + +namespace utility_internal { + +template <typename Seq, size_t SeqSize, size_t Rem> +struct Extend; + +// Note that SeqSize == sizeof...(Ints). It's passed explicitly for efficiency. +template <typename T, T... Ints, size_t SeqSize> +struct Extend<integer_sequence<T, Ints...>, SeqSize, 0> { + using type = integer_sequence<T, Ints..., (Ints + SeqSize)...>; +}; + +template <typename T, T... Ints, size_t SeqSize> +struct Extend<integer_sequence<T, Ints...>, SeqSize, 1> { + using type = integer_sequence<T, Ints..., (Ints + SeqSize)..., 2 * SeqSize>; +}; + +// Recursion helper for 'make_integer_sequence<T, N>'. +// 'Gen<T, N>::type' is an alias for 'integer_sequence<T, 0, 1, ... N-1>'. +template <typename T, size_t N> +struct Gen { + using type = + typename Extend<typename Gen<T, N / 2>::type, N / 2, N % 2>::type; +}; + +template <typename T> +struct Gen<T, 0> { + using type = integer_sequence<T>; +}; + +template <typename T> +struct InPlaceTypeTag { + explicit InPlaceTypeTag() = delete; + InPlaceTypeTag(const InPlaceTypeTag&) = delete; + InPlaceTypeTag& operator=(const InPlaceTypeTag&) = delete; +}; + +template <size_t I> +struct InPlaceIndexTag { + explicit InPlaceIndexTag() = delete; + InPlaceIndexTag(const InPlaceIndexTag&) = delete; + InPlaceIndexTag& operator=(const InPlaceIndexTag&) = delete; +}; + +} // namespace utility_internal + +// Compile-time sequences of integers + +// make_integer_sequence +// +// This template alias is equivalent to +// `integer_sequence<int, 0, 1, ..., N-1>`, and is designed to be a drop-in +// replacement for C++14's `std::make_integer_sequence`. +template <typename T, T N> +using make_integer_sequence = typename utility_internal::Gen<T, N>::type; + +// make_index_sequence +// +// This template alias is equivalent to `index_sequence<0, 1, ..., N-1>`, +// and is designed to be a drop-in replacement for C++14's +// `std::make_index_sequence`. +template <size_t N> +using make_index_sequence = make_integer_sequence<size_t, N>; + +// index_sequence_for +// +// Converts a typename pack into an index sequence of the same length, and +// is designed to be a drop-in replacement for C++14's +// `std::index_sequence_for()` +template <typename... Ts> +using index_sequence_for = make_index_sequence<sizeof...(Ts)>; + +// Tag types + +#ifdef ABSL_USES_STD_OPTIONAL + +using std::in_place_t; +using std::in_place; + +#else // ABSL_USES_STD_OPTIONAL + +// in_place_t +// +// Tag type used to specify in-place construction, such as with +// `absl::optional`, designed to be a drop-in replacement for C++17's +// `std::in_place_t`. +struct in_place_t {}; + +ABSL_INTERNAL_INLINE_CONSTEXPR(in_place_t, in_place, {}); + +#endif // ABSL_USES_STD_OPTIONAL + +#if defined(ABSL_USES_STD_ANY) || defined(ABSL_USES_STD_VARIANT) +using std::in_place_type; +using std::in_place_type_t; +#else + +// in_place_type_t +// +// Tag type used for in-place construction when the type to construct needs to +// be specified, such as with `absl::any`, designed to be a drop-in replacement +// for C++17's `std::in_place_type_t`. +template <typename T> +using in_place_type_t = void (*)(utility_internal::InPlaceTypeTag<T>); + +template <typename T> +void in_place_type(utility_internal::InPlaceTypeTag<T>) {} +#endif // ABSL_USES_STD_ANY || ABSL_USES_STD_VARIANT + +#ifdef ABSL_USES_STD_VARIANT +using std::in_place_index; +using std::in_place_index_t; +#else + +// in_place_index_t +// +// Tag type used for in-place construction when the type to construct needs to +// be specified, such as with `absl::any`, designed to be a drop-in replacement +// for C++17's `std::in_place_index_t`. +template <size_t I> +using in_place_index_t = void (*)(utility_internal::InPlaceIndexTag<I>); + +template <size_t I> +void in_place_index(utility_internal::InPlaceIndexTag<I>) {} +#endif // ABSL_USES_STD_VARIANT + +// Constexpr move and forward + +// move() +// +// A constexpr version of `std::move()`, designed to be a drop-in replacement +// for C++14's `std::move()`. +template <typename T> +constexpr absl::remove_reference_t<T>&& move(T&& t) noexcept { + return static_cast<absl::remove_reference_t<T>&&>(t); +} + +// forward() +// +// A constexpr version of `std::forward()`, designed to be a drop-in replacement +// for C++14's `std::forward()`. +template <typename T> +constexpr T&& forward( + absl::remove_reference_t<T>& t) noexcept { // NOLINT(runtime/references) + return static_cast<T&&>(t); +} + +namespace utility_internal { +// Helper method for expanding tuple into a called method. +template <typename Functor, typename Tuple, std::size_t... Indexes> +auto apply_helper(Functor&& functor, Tuple&& t, index_sequence<Indexes...>) + -> decltype(absl::base_internal::Invoke( + absl::forward<Functor>(functor), + std::get<Indexes>(absl::forward<Tuple>(t))...)) { + return absl::base_internal::Invoke( + absl::forward<Functor>(functor), + std::get<Indexes>(absl::forward<Tuple>(t))...); +} + +} // namespace utility_internal + +// apply +// +// Invokes a Callable using elements of a tuple as its arguments. +// Each element of the tuple corresponds to an argument of the call (in order). +// Both the Callable argument and the tuple argument are perfect-forwarded. +// For member-function Callables, the first tuple element acts as the `this` +// pointer. `absl::apply` is designed to be a drop-in replacement for C++17's +// `std::apply`. Unlike C++17's `std::apply`, this is not currently `constexpr`. +// +// Example: +// +// class Foo { +// public: +// void Bar(int); +// }; +// void user_function1(int, std::string); +// void user_function2(std::unique_ptr<Foo>); +// auto user_lambda = [](int, int) {}; +// +// int main() +// { +// std::tuple<int, std::string> tuple1(42, "bar"); +// // Invokes the first user function on int, std::string. +// absl::apply(&user_function1, tuple1); +// +// std::tuple<std::unique_ptr<Foo>> tuple2(absl::make_unique<Foo>()); +// // Invokes the user function that takes ownership of the unique +// // pointer. +// absl::apply(&user_function2, std::move(tuple2)); +// +// auto foo = absl::make_unique<Foo>(); +// std::tuple<Foo*, int> tuple3(foo.get(), 42); +// // Invokes the method Bar on foo with one argument, 42. +// absl::apply(&Foo::Bar, tuple3); +// +// std::tuple<int, int> tuple4(8, 9); +// // Invokes a lambda. +// absl::apply(user_lambda, tuple4); +// } +template <typename Functor, typename Tuple> +auto apply(Functor&& functor, Tuple&& t) + -> decltype(utility_internal::apply_helper( + absl::forward<Functor>(functor), absl::forward<Tuple>(t), + absl::make_index_sequence<std::tuple_size< + typename std::remove_reference<Tuple>::type>::value>{})) { + return utility_internal::apply_helper( + absl::forward<Functor>(functor), absl::forward<Tuple>(t), + absl::make_index_sequence<std::tuple_size< + typename std::remove_reference<Tuple>::type>::value>{}); +} + +// exchange +// +// Replaces the value of `obj` with `new_value` and returns the old value of +// `obj`. `absl::exchange` is designed to be a drop-in replacement for C++14's +// `std::exchange`. +// +// Example: +// +// Foo& operator=(Foo&& other) { +// ptr1_ = absl::exchange(other.ptr1_, nullptr); +// int1_ = absl::exchange(other.int1_, -1); +// return *this; +// } +template <typename T, typename U = T> +T exchange(T& obj, U&& new_value) { + T old_value = absl::move(obj); + obj = absl::forward<U>(new_value); + return old_value; +} + +namespace utility_internal { +template <typename T, typename Tuple, size_t... I> +T make_from_tuple_impl(Tuple&& tup, absl::index_sequence<I...>) { + return T(std::get<I>(std::forward<Tuple>(tup))...); +} +} // namespace utility_internal + +// make_from_tuple +// +// Given the template parameter type `T` and a tuple of arguments +// `std::tuple(arg0, arg1, ..., argN)` constructs an object of type `T` as if by +// calling `T(arg0, arg1, ..., argN)`. +// +// Example: +// +// std::tuple<const char*, size_t> args("hello world", 5); +// auto s = absl::make_from_tuple<std::string>(args); +// assert(s == "hello"); +// +template <typename T, typename Tuple> +constexpr T make_from_tuple(Tuple&& tup) { + return utility_internal::make_from_tuple_impl<T>( + std::forward<Tuple>(tup), + absl::make_index_sequence< + std::tuple_size<absl::decay_t<Tuple>>::value>{}); +} + +ABSL_NAMESPACE_END +} // namespace absl + +#endif // ABSL_UTILITY_UTILITY_H_ diff --git a/third_party/abseil_cpp/absl/utility/utility_test.cc b/third_party/abseil_cpp/absl/utility/utility_test.cc new file mode 100644 index 0000000000..f044ad644a --- /dev/null +++ b/third_party/abseil_cpp/absl/utility/utility_test.cc @@ -0,0 +1,376 @@ +// Copyright 2017 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include "absl/utility/utility.h" + +#include <sstream> +#include <string> +#include <tuple> +#include <type_traits> +#include <vector> + +#include "gmock/gmock.h" +#include "gtest/gtest.h" +#include "absl/base/attributes.h" +#include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" + +namespace { + +#ifdef _MSC_VER +// Warnings for unused variables in this test are false positives. On other +// platforms, they are suppressed by ABSL_ATTRIBUTE_UNUSED, but that doesn't +// work on MSVC. +// Both the unused variables and the name length warnings are due to calls +// to absl::make_index_sequence with very large values, creating very long type +// names. The resulting warnings are so long they make build output unreadable. +#pragma warning( push ) +#pragma warning( disable : 4503 ) // decorated name length exceeded +#pragma warning( disable : 4101 ) // unreferenced local variable +#endif // _MSC_VER + +using ::testing::ElementsAre; +using ::testing::Pointee; +using ::testing::StaticAssertTypeEq; + +TEST(IntegerSequenceTest, ValueType) { + StaticAssertTypeEq<int, absl::integer_sequence<int>::value_type>(); + StaticAssertTypeEq<char, absl::integer_sequence<char>::value_type>(); +} + +TEST(IntegerSequenceTest, Size) { + EXPECT_EQ(0, (absl::integer_sequence<int>::size())); + EXPECT_EQ(1, (absl::integer_sequence<int, 0>::size())); + EXPECT_EQ(1, (absl::integer_sequence<int, 1>::size())); + EXPECT_EQ(2, (absl::integer_sequence<int, 1, 2>::size())); + EXPECT_EQ(3, (absl::integer_sequence<int, 0, 1, 2>::size())); + EXPECT_EQ(3, (absl::integer_sequence<int, -123, 123, 456>::size())); + constexpr size_t sz = absl::integer_sequence<int, 0, 1>::size(); + EXPECT_EQ(2, sz); +} + +TEST(IntegerSequenceTest, MakeIndexSequence) { + StaticAssertTypeEq<absl::index_sequence<>, absl::make_index_sequence<0>>(); + StaticAssertTypeEq<absl::index_sequence<0>, absl::make_index_sequence<1>>(); + StaticAssertTypeEq<absl::index_sequence<0, 1>, + absl::make_index_sequence<2>>(); + StaticAssertTypeEq<absl::index_sequence<0, 1, 2>, + absl::make_index_sequence<3>>(); +} + +TEST(IntegerSequenceTest, MakeIntegerSequence) { + StaticAssertTypeEq<absl::integer_sequence<int>, + absl::make_integer_sequence<int, 0>>(); + StaticAssertTypeEq<absl::integer_sequence<int, 0>, + absl::make_integer_sequence<int, 1>>(); + StaticAssertTypeEq<absl::integer_sequence<int, 0, 1>, + absl::make_integer_sequence<int, 2>>(); + StaticAssertTypeEq<absl::integer_sequence<int, 0, 1, 2>, + absl::make_integer_sequence<int, 3>>(); +} + +template <typename... Ts> +class Counter {}; + +template <size_t... Is> +void CountAll(absl::index_sequence<Is...>) { + // We only need an alias here, but instantiate a variable to silence warnings + // for unused typedefs in some compilers. + ABSL_ATTRIBUTE_UNUSED Counter<absl::make_index_sequence<Is>...> seq; +} + +// This test verifies that absl::make_index_sequence can handle large arguments +// without blowing up template instantiation stack, going OOM or taking forever +// to compile (there is hard 15 minutes limit imposed by forge). +TEST(IntegerSequenceTest, MakeIndexSequencePerformance) { + // O(log N) template instantiations. + // We only need an alias here, but instantiate a variable to silence warnings + // for unused typedefs in some compilers. + ABSL_ATTRIBUTE_UNUSED absl::make_index_sequence<(1 << 16) - 1> seq; + // O(N) template instantiations. + CountAll(absl::make_index_sequence<(1 << 8) - 1>()); +} + +template <typename F, typename Tup, size_t... Is> +auto ApplyFromTupleImpl(F f, const Tup& tup, absl::index_sequence<Is...>) + -> decltype(f(std::get<Is>(tup)...)) { + return f(std::get<Is>(tup)...); +} + +template <typename Tup> +using TupIdxSeq = absl::make_index_sequence<std::tuple_size<Tup>::value>; + +template <typename F, typename Tup> +auto ApplyFromTuple(F f, const Tup& tup) + -> decltype(ApplyFromTupleImpl(f, tup, TupIdxSeq<Tup>{})) { + return ApplyFromTupleImpl(f, tup, TupIdxSeq<Tup>{}); +} + +template <typename T> +std::string Fmt(const T& x) { + std::ostringstream os; + os << x; + return os.str(); +} + +struct PoorStrCat { + template <typename... Args> + std::string operator()(const Args&... args) const { + std::string r; + for (const auto& e : {Fmt(args)...}) r += e; + return r; + } +}; + +template <typename Tup, size_t... Is> +std::vector<std::string> TupStringVecImpl(const Tup& tup, + absl::index_sequence<Is...>) { + return {Fmt(std::get<Is>(tup))...}; +} + +template <typename... Ts> +std::vector<std::string> TupStringVec(const std::tuple<Ts...>& tup) { + return TupStringVecImpl(tup, absl::index_sequence_for<Ts...>()); +} + +TEST(MakeIndexSequenceTest, ApplyFromTupleExample) { + PoorStrCat f{}; + EXPECT_EQ("12abc3.14", f(12, "abc", 3.14)); + EXPECT_EQ("12abc3.14", ApplyFromTuple(f, std::make_tuple(12, "abc", 3.14))); +} + +TEST(IndexSequenceForTest, Basic) { + StaticAssertTypeEq<absl::index_sequence<>, absl::index_sequence_for<>>(); + StaticAssertTypeEq<absl::index_sequence<0>, absl::index_sequence_for<int>>(); + StaticAssertTypeEq<absl::index_sequence<0, 1, 2, 3>, + absl::index_sequence_for<int, void, char, int>>(); +} + +TEST(IndexSequenceForTest, Example) { + EXPECT_THAT(TupStringVec(std::make_tuple(12, "abc", 3.14)), + ElementsAre("12", "abc", "3.14")); +} + +int Function(int a, int b) { return a - b; } + +int Sink(std::unique_ptr<int> p) { return *p; } + +std::unique_ptr<int> Factory(int n) { return absl::make_unique<int>(n); } + +void NoOp() {} + +struct ConstFunctor { + int operator()(int a, int b) const { return a - b; } +}; + +struct MutableFunctor { + int operator()(int a, int b) { return a - b; } +}; + +struct EphemeralFunctor { + EphemeralFunctor() {} + EphemeralFunctor(const EphemeralFunctor&) {} + EphemeralFunctor(EphemeralFunctor&&) {} + int operator()(int a, int b) && { return a - b; } +}; + +struct OverloadedFunctor { + OverloadedFunctor() {} + OverloadedFunctor(const OverloadedFunctor&) {} + OverloadedFunctor(OverloadedFunctor&&) {} + template <typename... Args> + std::string operator()(const Args&... args) & { + return absl::StrCat("&", args...); + } + template <typename... Args> + std::string operator()(const Args&... args) const& { + return absl::StrCat("const&", args...); + } + template <typename... Args> + std::string operator()(const Args&... args) && { + return absl::StrCat("&&", args...); + } +}; + +struct Class { + int Method(int a, int b) { return a - b; } + int ConstMethod(int a, int b) const { return a - b; } + + int member; +}; + +struct FlipFlop { + int ConstMethod() const { return member; } + FlipFlop operator*() const { return {-member}; } + + int member; +}; + +TEST(ApplyTest, Function) { + EXPECT_EQ(1, absl::apply(Function, std::make_tuple(3, 2))); + EXPECT_EQ(1, absl::apply(&Function, std::make_tuple(3, 2))); +} + +TEST(ApplyTest, NonCopyableArgument) { + EXPECT_EQ(42, absl::apply(Sink, std::make_tuple(absl::make_unique<int>(42)))); +} + +TEST(ApplyTest, NonCopyableResult) { + EXPECT_THAT(absl::apply(Factory, std::make_tuple(42)), + ::testing::Pointee(42)); +} + +TEST(ApplyTest, VoidResult) { absl::apply(NoOp, std::tuple<>()); } + +TEST(ApplyTest, ConstFunctor) { + EXPECT_EQ(1, absl::apply(ConstFunctor(), std::make_tuple(3, 2))); +} + +TEST(ApplyTest, MutableFunctor) { + MutableFunctor f; + EXPECT_EQ(1, absl::apply(f, std::make_tuple(3, 2))); + EXPECT_EQ(1, absl::apply(MutableFunctor(), std::make_tuple(3, 2))); +} +TEST(ApplyTest, EphemeralFunctor) { + EphemeralFunctor f; + EXPECT_EQ(1, absl::apply(std::move(f), std::make_tuple(3, 2))); + EXPECT_EQ(1, absl::apply(EphemeralFunctor(), std::make_tuple(3, 2))); +} +TEST(ApplyTest, OverloadedFunctor) { + OverloadedFunctor f; + const OverloadedFunctor& cf = f; + + EXPECT_EQ("&", absl::apply(f, std::tuple<>{})); + EXPECT_EQ("& 42", absl::apply(f, std::make_tuple(" 42"))); + + EXPECT_EQ("const&", absl::apply(cf, std::tuple<>{})); + EXPECT_EQ("const& 42", absl::apply(cf, std::make_tuple(" 42"))); + + EXPECT_EQ("&&", absl::apply(std::move(f), std::tuple<>{})); + OverloadedFunctor f2; + EXPECT_EQ("&& 42", absl::apply(std::move(f2), std::make_tuple(" 42"))); +} + +TEST(ApplyTest, ReferenceWrapper) { + ConstFunctor cf; + MutableFunctor mf; + EXPECT_EQ(1, absl::apply(std::cref(cf), std::make_tuple(3, 2))); + EXPECT_EQ(1, absl::apply(std::ref(cf), std::make_tuple(3, 2))); + EXPECT_EQ(1, absl::apply(std::ref(mf), std::make_tuple(3, 2))); +} + +TEST(ApplyTest, MemberFunction) { + std::unique_ptr<Class> p(new Class); + std::unique_ptr<const Class> cp(new Class); + EXPECT_EQ( + 1, absl::apply(&Class::Method, + std::tuple<std::unique_ptr<Class>&, int, int>(p, 3, 2))); + EXPECT_EQ(1, absl::apply(&Class::Method, + std::tuple<Class*, int, int>(p.get(), 3, 2))); + EXPECT_EQ( + 1, absl::apply(&Class::Method, std::tuple<Class&, int, int>(*p, 3, 2))); + + EXPECT_EQ( + 1, absl::apply(&Class::ConstMethod, + std::tuple<std::unique_ptr<Class>&, int, int>(p, 3, 2))); + EXPECT_EQ(1, absl::apply(&Class::ConstMethod, + std::tuple<Class*, int, int>(p.get(), 3, 2))); + EXPECT_EQ(1, absl::apply(&Class::ConstMethod, + std::tuple<Class&, int, int>(*p, 3, 2))); + + EXPECT_EQ(1, absl::apply(&Class::ConstMethod, + std::tuple<std::unique_ptr<const Class>&, int, int>( + cp, 3, 2))); + EXPECT_EQ(1, absl::apply(&Class::ConstMethod, + std::tuple<const Class*, int, int>(cp.get(), 3, 2))); + EXPECT_EQ(1, absl::apply(&Class::ConstMethod, + std::tuple<const Class&, int, int>(*cp, 3, 2))); + + EXPECT_EQ(1, absl::apply(&Class::Method, + std::make_tuple(absl::make_unique<Class>(), 3, 2))); + EXPECT_EQ(1, absl::apply(&Class::ConstMethod, + std::make_tuple(absl::make_unique<Class>(), 3, 2))); + EXPECT_EQ( + 1, absl::apply(&Class::ConstMethod, + std::make_tuple(absl::make_unique<const Class>(), 3, 2))); +} + +TEST(ApplyTest, DataMember) { + std::unique_ptr<Class> p(new Class{42}); + std::unique_ptr<const Class> cp(new Class{42}); + EXPECT_EQ( + 42, absl::apply(&Class::member, std::tuple<std::unique_ptr<Class>&>(p))); + EXPECT_EQ(42, absl::apply(&Class::member, std::tuple<Class&>(*p))); + EXPECT_EQ(42, absl::apply(&Class::member, std::tuple<Class*>(p.get()))); + + absl::apply(&Class::member, std::tuple<std::unique_ptr<Class>&>(p)) = 42; + absl::apply(&Class::member, std::tuple<Class*>(p.get())) = 42; + absl::apply(&Class::member, std::tuple<Class&>(*p)) = 42; + + EXPECT_EQ(42, absl::apply(&Class::member, + std::tuple<std::unique_ptr<const Class>&>(cp))); + EXPECT_EQ(42, absl::apply(&Class::member, std::tuple<const Class&>(*cp))); + EXPECT_EQ(42, + absl::apply(&Class::member, std::tuple<const Class*>(cp.get()))); +} + +TEST(ApplyTest, FlipFlop) { + FlipFlop obj = {42}; + // This call could resolve to (obj.*&FlipFlop::ConstMethod)() or + // ((*obj).*&FlipFlop::ConstMethod)(). We verify that it's the former. + EXPECT_EQ(42, absl::apply(&FlipFlop::ConstMethod, std::make_tuple(obj))); + EXPECT_EQ(42, absl::apply(&FlipFlop::member, std::make_tuple(obj))); +} + +TEST(ExchangeTest, MoveOnly) { + auto a = Factory(1); + EXPECT_EQ(1, *a); + auto b = absl::exchange(a, Factory(2)); + EXPECT_EQ(2, *a); + EXPECT_EQ(1, *b); +} + +TEST(MakeFromTupleTest, String) { + EXPECT_EQ( + absl::make_from_tuple<std::string>(std::make_tuple("hello world", 5)), + "hello"); +} + +TEST(MakeFromTupleTest, MoveOnlyParameter) { + struct S { + S(std::unique_ptr<int> n, std::unique_ptr<int> m) : value(*n + *m) {} + int value = 0; + }; + auto tup = + std::make_tuple(absl::make_unique<int>(3), absl::make_unique<int>(4)); + auto s = absl::make_from_tuple<S>(std::move(tup)); + EXPECT_EQ(s.value, 7); +} + +TEST(MakeFromTupleTest, NoParameters) { + struct S { + S() : value(1) {} + int value = 2; + }; + EXPECT_EQ(absl::make_from_tuple<S>(std::make_tuple()).value, 1); +} + +TEST(MakeFromTupleTest, Pair) { + EXPECT_EQ( + (absl::make_from_tuple<std::pair<bool, int>>(std::make_tuple(true, 17))), + std::make_pair(true, 17)); +} + +} // namespace + diff --git a/third_party/abseil_cpp/ci/absl_alternate_options.h b/third_party/abseil_cpp/ci/absl_alternate_options.h new file mode 100644 index 0000000000..29b020d9fa --- /dev/null +++ b/third_party/abseil_cpp/ci/absl_alternate_options.h @@ -0,0 +1,29 @@ +// Copyright 2019 The Abseil Authors. +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// https://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +// Alternate options.h file, used in continuous integration testing to exercise +// option settings not used by default. + +#ifndef ABSL_BASE_OPTIONS_H_ +#define ABSL_BASE_OPTIONS_H_ + +#define ABSL_OPTION_USE_STD_ANY 0 +#define ABSL_OPTION_USE_STD_OPTIONAL 0 +#define ABSL_OPTION_USE_STD_STRING_VIEW 0 +#define ABSL_OPTION_USE_STD_VARIANT 0 +#define ABSL_OPTION_USE_INLINE_NAMESPACE 1 +#define ABSL_OPTION_INLINE_NAMESPACE_NAME ns +#define ABSL_OPTION_HARDENED 1 + +#endif // ABSL_BASE_OPTIONS_H_ diff --git a/third_party/abseil_cpp/ci/cmake_install_test.sh b/third_party/abseil_cpp/ci/cmake_install_test.sh new file mode 100755 index 0000000000..b31e4b8cdb --- /dev/null +++ b/third_party/abseil_cpp/ci/cmake_install_test.sh @@ -0,0 +1,35 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_GCC_LATEST_CONTAINER} + +time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --tmpfs=/buildfs:exec \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CFLAGS="-Werror" \ + -e CXXFLAGS="-Werror" \ + ${DOCKER_CONTAINER} \ + /bin/bash CMake/install_test_project/test.sh $@ diff --git a/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_asan_bazel.sh b/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_asan_bazel.sh new file mode 100755 index 0000000000..44794eb5db --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_asan_bazel.sh @@ -0,0 +1,103 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script that can be invoked to test abseil-cpp in a hermetic environment +# using a Docker image on Linux. You must have Docker installed to use this +# script. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${STD:-} ]]; then + STD="c++11 c++14 c++17 c++20" +fi + +if [[ -z ${COMPILATION_MODE:-} ]]; then + COMPILATION_MODE="fastbuild opt" +fi + +if [[ -z ${EXCEPTIONS_MODE:-} ]]; then + EXCEPTIONS_MODE="-fno-exceptions -fexceptions" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_CLANG_LATEST_CONTAINER} + +# USE_BAZEL_CACHE=1 only works on Kokoro. +# Without access to the credentials this won't work. +if [[ ${USE_BAZEL_CACHE:-0} -ne 0 ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_KEYSTORE_DIR}:/keystore:ro ${DOCKER_EXTRA_ARGS:-}" + # Bazel doesn't track changes to tools outside of the workspace + # (e.g. /usr/bin/gcc), so by appending the docker container to the + # remote_http_cache url, we make changes to the container part of + # the cache key. Hashing the key is to make it shorter and url-safe. + container_key=$(echo ${DOCKER_CONTAINER} | sha256sum | head -c 16) + BAZEL_EXTRA_ARGS="--remote_http_cache=https://storage.googleapis.com/absl-bazel-remote-cache/${container_key} --google_credentials=/keystore/73103_absl-bazel-remote-cache ${BAZEL_EXTRA_ARGS:-}" +fi + +# Avoid depending on external sites like GitHub by checking --distdir for +# external dependencies first. +# https://docs.bazel.build/versions/master/guide.html#distdir +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -d "${KOKORO_GFILE_DIR}/distdir" ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_GFILE_DIR}/distdir:/distdir:ro ${DOCKER_EXTRA_ARGS:-}" + BAZEL_EXTRA_ARGS="--distdir=/distdir ${BAZEL_EXTRA_ARGS:-}" +fi + +for std in ${STD}; do + for compilation_mode in ${COMPILATION_MODE}; do + for exceptions_mode in ${EXCEPTIONS_MODE}; do + echo "--------------------------------------------------------------------" + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CC="/opt/llvm/clang/bin/clang" \ + -e BAZEL_COMPILER="llvm" \ + -e BAZEL_CXXOPTS="-std=${std}:-nostdinc++" \ + -e BAZEL_LINKOPTS="-L/opt/llvm/libcxx/lib:-lc++:-lc++abi:-lm:-Wl,-rpath=/opt/llvm/libcxx/lib" \ + -e CPLUS_INCLUDE_PATH="/opt/llvm/libcxx/include/c++/v1" \ + ${DOCKER_EXTRA_ARGS:-} \ + ${DOCKER_CONTAINER} \ + /usr/local/bin/bazel test ... \ + --compilation_mode="${compilation_mode}" \ + --copt="${exceptions_mode}" \ + --copt="-DDYNAMIC_ANNOTATIONS_ENABLED=1" \ + --copt="-DADDRESS_SANITIZER" \ + --copt="-DUNDEFINED_BEHAVIOR_SANITIZER" \ + --copt="-fsanitize=address" \ + --copt="-fsanitize=float-divide-by-zero" \ + --copt="-fsanitize=nullability" \ + --copt="-fsanitize=undefined" \ + --copt="-fno-sanitize-blacklist" \ + --copt=-Werror \ + --keep_going \ + --linkopt="-fsanitize=address" \ + --linkopt="-fsanitize-link-c++-runtime" \ + --show_timestamps \ + --test_env="ASAN_SYMBOLIZER_PATH=/opt/llvm/clang/bin/llvm-symbolizer" \ + --test_env="TZDIR=/abseil-cpp/absl/time/internal/cctz/testdata/zoneinfo" \ + --test_env="UBSAN_OPTIONS=print_stacktrace=1" \ + --test_env="UBSAN_SYMBOLIZER_PATH=/opt/llvm/clang/bin/llvm-symbolizer" \ + --test_output=errors \ + --test_tag_filters="-benchmark,-noasan" \ + ${BAZEL_EXTRA_ARGS:-} + done + done +done diff --git a/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_bazel.sh b/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_bazel.sh new file mode 100755 index 0000000000..eb04e69e36 --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_bazel.sh @@ -0,0 +1,98 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script that can be invoked to test abseil-cpp in a hermetic environment +# using a Docker image on Linux. You must have Docker installed to use this +# script. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${STD:-} ]]; then + STD="c++11 c++14 c++17 c++20" +fi + +if [[ -z ${COMPILATION_MODE:-} ]]; then + COMPILATION_MODE="fastbuild opt" +fi + +if [[ -z ${EXCEPTIONS_MODE:-} ]]; then + EXCEPTIONS_MODE="-fno-exceptions -fexceptions" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_CLANG_LATEST_CONTAINER} + +# USE_BAZEL_CACHE=1 only works on Kokoro. +# Without access to the credentials this won't work. +if [[ ${USE_BAZEL_CACHE:-0} -ne 0 ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_KEYSTORE_DIR}:/keystore:ro ${DOCKER_EXTRA_ARGS:-}" + # Bazel doesn't track changes to tools outside of the workspace + # (e.g. /usr/bin/gcc), so by appending the docker container to the + # remote_http_cache url, we make changes to the container part of + # the cache key. Hashing the key is to make it shorter and url-safe. + container_key=$(echo ${DOCKER_CONTAINER} | sha256sum | head -c 16) + BAZEL_EXTRA_ARGS="--remote_http_cache=https://storage.googleapis.com/absl-bazel-remote-cache/${container_key} --google_credentials=/keystore/73103_absl-bazel-remote-cache ${BAZEL_EXTRA_ARGS:-}" +fi + +# Avoid depending on external sites like GitHub by checking --distdir for +# external dependencies first. +# https://docs.bazel.build/versions/master/guide.html#distdir +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -d "${KOKORO_GFILE_DIR}/distdir" ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_GFILE_DIR}/distdir:/distdir:ro ${DOCKER_EXTRA_ARGS:-}" + BAZEL_EXTRA_ARGS="--distdir=/distdir ${BAZEL_EXTRA_ARGS:-}" +fi + +for std in ${STD}; do + for compilation_mode in ${COMPILATION_MODE}; do + for exceptions_mode in ${EXCEPTIONS_MODE}; do + echo "--------------------------------------------------------------------" + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp-ro:ro" \ + --tmpfs=/abseil-cpp \ + --workdir=/abseil-cpp \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CC="/opt/llvm/clang/bin/clang" \ + -e BAZEL_COMPILER="llvm" \ + -e BAZEL_CXXOPTS="-std=${std}:-nostdinc++" \ + -e BAZEL_LINKOPTS="-L/opt/llvm/libcxx/lib:-lc++:-lc++abi:-lm:-Wl,-rpath=/opt/llvm/libcxx/lib" \ + -e CPLUS_INCLUDE_PATH="/opt/llvm/libcxx/include/c++/v1" \ + ${DOCKER_EXTRA_ARGS:-} \ + ${DOCKER_CONTAINER} \ + /bin/sh -c " + cp -r /abseil-cpp-ro/* /abseil-cpp/ + if [ -n \"${ALTERNATE_OPTIONS:-}\" ]; then + cp ${ALTERNATE_OPTIONS:-} absl/base/options.h || exit 1 + fi + /usr/local/bin/bazel test ... \ + --compilation_mode=\"${compilation_mode}\" \ + --copt=\"${exceptions_mode}\" \ + --copt=-Werror \ + --define=\"absl=1\" \ + --keep_going \ + --show_timestamps \ + --test_env=\"GTEST_INSTALL_FAILURE_SIGNAL_HANDLER=1\" \ + --test_env=\"TZDIR=/abseil-cpp/absl/time/internal/cctz/testdata/zoneinfo\" \ + --test_output=errors \ + --test_tag_filters=-benchmark \ + ${BAZEL_EXTRA_ARGS:-}" + done + done +done diff --git a/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_tsan_bazel.sh b/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_tsan_bazel.sh new file mode 100755 index 0000000000..c2eb5baee2 --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_clang-latest_libcxx_tsan_bazel.sh @@ -0,0 +1,98 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script that can be invoked to test abseil-cpp in a hermetic environment +# using a Docker image on Linux. You must have Docker installed to use this +# script. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${STD:-} ]]; then + STD="c++11 c++14 c++17 c++20" +fi + +if [[ -z ${COMPILATION_MODE:-} ]]; then + COMPILATION_MODE="fastbuild opt" +fi + +if [[ -z ${EXCEPTIONS_MODE:-} ]]; then + EXCEPTIONS_MODE="-fno-exceptions -fexceptions" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_CLANG_LATEST_CONTAINER} + +# USE_BAZEL_CACHE=1 only works on Kokoro. +# Without access to the credentials this won't work. +if [[ ${USE_BAZEL_CACHE:-0} -ne 0 ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_KEYSTORE_DIR}:/keystore:ro ${DOCKER_EXTRA_ARGS:-}" + # Bazel doesn't track changes to tools outside of the workspace + # (e.g. /usr/bin/gcc), so by appending the docker container to the + # remote_http_cache url, we make changes to the container part of + # the cache key. Hashing the key is to make it shorter and url-safe. + container_key=$(echo ${DOCKER_CONTAINER} | sha256sum | head -c 16) + BAZEL_EXTRA_ARGS="--remote_http_cache=https://storage.googleapis.com/absl-bazel-remote-cache/${container_key} --google_credentials=/keystore/73103_absl-bazel-remote-cache ${BAZEL_EXTRA_ARGS:-}" +fi + +# Avoid depending on external sites like GitHub by checking --distdir for +# external dependencies first. +# https://docs.bazel.build/versions/master/guide.html#distdir +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -d "${KOKORO_GFILE_DIR}/distdir" ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_GFILE_DIR}/distdir:/distdir:ro ${DOCKER_EXTRA_ARGS:-}" + BAZEL_EXTRA_ARGS="--distdir=/distdir ${BAZEL_EXTRA_ARGS:-}" +fi + +for std in ${STD}; do + for compilation_mode in ${COMPILATION_MODE}; do + for exceptions_mode in ${EXCEPTIONS_MODE}; do + echo "--------------------------------------------------------------------" + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CC="/opt/llvm/clang/bin/clang" \ + -e BAZEL_COMPILER="llvm" \ + -e BAZEL_CXXOPTS="-std=${std}:-nostdinc++" \ + -e BAZEL_LINKOPTS="-L/opt/llvm/libcxx-tsan/lib:-lc++:-lc++abi:-lm:-Wl,-rpath=/opt/llvm/libcxx-tsan/lib" \ + -e CPLUS_INCLUDE_PATH="/opt/llvm/libcxx-tsan/include/c++/v1" \ + ${DOCKER_EXTRA_ARGS:-} \ + ${DOCKER_CONTAINER} \ + /usr/local/bin/bazel test ... \ + --build_tag_filters="-notsan" \ + --compilation_mode="${compilation_mode}" \ + --copt="${exceptions_mode}" \ + --copt="-DDYNAMIC_ANNOTATIONS_ENABLED=1" \ + --copt="-DTHREAD_SANITIZER" \ + --copt="-fsanitize=thread" \ + --copt="-fno-sanitize-blacklist" \ + --copt=-Werror \ + --keep_going \ + --linkopt="-fsanitize=thread" \ + --show_timestamps \ + --test_env="TSAN_OPTIONS=report_atomic_races=0" \ + --test_env="TSAN_SYMBOLIZER_PATH=/opt/llvm/clang/bin/llvm-symbolizer" \ + --test_env="TZDIR=/abseil-cpp/absl/time/internal/cctz/testdata/zoneinfo" \ + --test_output=errors \ + --test_tag_filters="-benchmark,-notsan" \ + ${BAZEL_EXTRA_ARGS:-} + done + done +done diff --git a/third_party/abseil_cpp/ci/linux_clang-latest_libstdcxx_bazel.sh b/third_party/abseil_cpp/ci/linux_clang-latest_libstdcxx_bazel.sh new file mode 100755 index 0000000000..0192ee49a5 --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_clang-latest_libstdcxx_bazel.sh @@ -0,0 +1,91 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script that can be invoked to test abseil-cpp in a hermetic environment +# using a Docker image on Linux. You must have Docker installed to use this +# script. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${STD:-} ]]; then + STD="c++11 c++14 c++17 c++20" +fi + +if [[ -z ${COMPILATION_MODE:-} ]]; then + COMPILATION_MODE="fastbuild opt" +fi + +if [[ -z ${EXCEPTIONS_MODE:-} ]]; then + EXCEPTIONS_MODE="-fno-exceptions -fexceptions" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_CLANG_LATEST_CONTAINER} + +# USE_BAZEL_CACHE=1 only works on Kokoro. +# Without access to the credentials this won't work. +if [[ ${USE_BAZEL_CACHE:-0} -ne 0 ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_KEYSTORE_DIR}:/keystore:ro ${DOCKER_EXTRA_ARGS:-}" + # Bazel doesn't track changes to tools outside of the workspace + # (e.g. /usr/bin/gcc), so by appending the docker container to the + # remote_http_cache url, we make changes to the container part of + # the cache key. Hashing the key is to make it shorter and url-safe. + container_key=$(echo ${DOCKER_CONTAINER} | sha256sum | head -c 16) + BAZEL_EXTRA_ARGS="--remote_http_cache=https://storage.googleapis.com/absl-bazel-remote-cache/${container_key} --google_credentials=/keystore/73103_absl-bazel-remote-cache ${BAZEL_EXTRA_ARGS:-}" +fi + +# Avoid depending on external sites like GitHub by checking --distdir for +# external dependencies first. +# https://docs.bazel.build/versions/master/guide.html#distdir +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -d "${KOKORO_GFILE_DIR}/distdir" ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_GFILE_DIR}/distdir:/distdir:ro ${DOCKER_EXTRA_ARGS:-}" + BAZEL_EXTRA_ARGS="--distdir=/distdir ${BAZEL_EXTRA_ARGS:-}" +fi + +for std in ${STD}; do + for compilation_mode in ${COMPILATION_MODE}; do + for exceptions_mode in ${EXCEPTIONS_MODE}; do + echo "--------------------------------------------------------------------" + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CC="/opt/llvm/clang/bin/clang" \ + -e BAZEL_COMPILER="llvm" \ + -e BAZEL_CXXOPTS="-std=${std}" \ + -e CPLUS_INCLUDE_PATH="/usr/include/c++/8" \ + ${DOCKER_EXTRA_ARGS:-} \ + ${DOCKER_CONTAINER} \ + /usr/local/bin/bazel test ... \ + --compilation_mode="${compilation_mode}" \ + --copt="${exceptions_mode}" \ + --copt=-Werror \ + --define="absl=1" \ + --keep_going \ + --show_timestamps \ + --test_env="GTEST_INSTALL_FAILURE_SIGNAL_HANDLER=1" \ + --test_env="TZDIR=/abseil-cpp/absl/time/internal/cctz/testdata/zoneinfo" \ + --test_output=errors \ + --test_tag_filters=-benchmark \ + ${BAZEL_EXTRA_ARGS:-} + done + done +done diff --git a/third_party/abseil_cpp/ci/linux_docker_containers.sh b/third_party/abseil_cpp/ci/linux_docker_containers.sh new file mode 100644 index 0000000000..82a10ac623 --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_docker_containers.sh @@ -0,0 +1,21 @@ +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# The file contains Docker container identifiers currently used by test scripts. +# Test scripts should source this file to get the identifiers. + +readonly LINUX_ALPINE_CONTAINER="gcr.io/google.com/absl-177019/alpine:20191016" +readonly LINUX_CLANG_LATEST_CONTAINER="gcr.io/google.com/absl-177019/linux_clang-latest:20200401" +readonly LINUX_GCC_LATEST_CONTAINER="gcr.io/google.com/absl-177019/linux_gcc-latest:20200319" +readonly LINUX_GCC_49_CONTAINER="gcr.io/google.com/absl-177019/linux_gcc-4.9:20191018" diff --git a/third_party/abseil_cpp/ci/linux_gcc-4.9_libstdcxx_bazel.sh b/third_party/abseil_cpp/ci/linux_gcc-4.9_libstdcxx_bazel.sh new file mode 100755 index 0000000000..8e6540cf02 --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_gcc-4.9_libstdcxx_bazel.sh @@ -0,0 +1,89 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script that can be invoked to test abseil-cpp in a hermetic environment +# using a Docker image on Linux. You must have Docker installed to use this +# script. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${STD:-} ]]; then + STD="c++11 c++14" +fi + +if [[ -z ${COMPILATION_MODE:-} ]]; then + COMPILATION_MODE="fastbuild opt" +fi + +if [[ -z ${EXCEPTIONS_MODE:-} ]]; then + EXCEPTIONS_MODE="-fno-exceptions -fexceptions" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_GCC_49_CONTAINER} + +# USE_BAZEL_CACHE=1 only works on Kokoro. +# Without access to the credentials this won't work. +if [[ ${USE_BAZEL_CACHE:-0} -ne 0 ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_KEYSTORE_DIR}:/keystore:ro ${DOCKER_EXTRA_ARGS:-}" + # Bazel doesn't track changes to tools outside of the workspace + # (e.g. /usr/bin/gcc), so by appending the docker container to the + # remote_http_cache url, we make changes to the container part of + # the cache key. Hashing the key is to make it shorter and url-safe. + container_key=$(echo ${DOCKER_CONTAINER} | sha256sum | head -c 16) + BAZEL_EXTRA_ARGS="--remote_http_cache=https://storage.googleapis.com/absl-bazel-remote-cache/${container_key} --google_credentials=/keystore/73103_absl-bazel-remote-cache ${BAZEL_EXTRA_ARGS:-}" +fi + +# Avoid depending on external sites like GitHub by checking --distdir for +# external dependencies first. +# https://docs.bazel.build/versions/master/guide.html#distdir +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -d "${KOKORO_GFILE_DIR}/distdir" ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_GFILE_DIR}/distdir:/distdir:ro ${DOCKER_EXTRA_ARGS:-}" + BAZEL_EXTRA_ARGS="--distdir=/distdir ${BAZEL_EXTRA_ARGS:-}" +fi + +for std in ${STD}; do + for compilation_mode in ${COMPILATION_MODE}; do + for exceptions_mode in ${EXCEPTIONS_MODE}; do + echo "--------------------------------------------------------------------" + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CC="/usr/bin/gcc-4.9" \ + -e BAZEL_CXXOPTS="-std=${std}" \ + ${DOCKER_EXTRA_ARGS:-} \ + ${DOCKER_CONTAINER} \ + /usr/local/bin/bazel test ... \ + --compilation_mode="${compilation_mode}" \ + --copt="${exceptions_mode}" \ + --copt=-Werror \ + --define="absl=1" \ + --keep_going \ + --show_timestamps \ + --test_env="GTEST_INSTALL_FAILURE_SIGNAL_HANDLER=1" \ + --test_env="TZDIR=/abseil-cpp/absl/time/internal/cctz/testdata/zoneinfo" \ + --test_output=errors \ + --test_tag_filters=-benchmark \ + ${BAZEL_EXTRA_ARGS:-} + done + done +done diff --git a/third_party/abseil_cpp/ci/linux_gcc-latest_libstdcxx_bazel.sh b/third_party/abseil_cpp/ci/linux_gcc-latest_libstdcxx_bazel.sh new file mode 100755 index 0000000000..3ec0226201 --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_gcc-latest_libstdcxx_bazel.sh @@ -0,0 +1,95 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script that can be invoked to test abseil-cpp in a hermetic environment +# using a Docker image on Linux. You must have Docker installed to use this +# script. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${STD:-} ]]; then + STD="c++11 c++14 c++17 c++2a" +fi + +if [[ -z ${COMPILATION_MODE:-} ]]; then + COMPILATION_MODE="fastbuild opt" +fi + +if [[ -z ${EXCEPTIONS_MODE:-} ]]; then + EXCEPTIONS_MODE="-fno-exceptions -fexceptions" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_GCC_LATEST_CONTAINER} + +# USE_BAZEL_CACHE=1 only works on Kokoro. +# Without access to the credentials this won't work. +if [[ ${USE_BAZEL_CACHE:-0} -ne 0 ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_KEYSTORE_DIR}:/keystore:ro ${DOCKER_EXTRA_ARGS:-}" + # Bazel doesn't track changes to tools outside of the workspace + # (e.g. /usr/bin/gcc), so by appending the docker container to the + # remote_http_cache url, we make changes to the container part of + # the cache key. Hashing the key is to make it shorter and url-safe. + container_key=$(echo ${DOCKER_CONTAINER} | sha256sum | head -c 16) + BAZEL_EXTRA_ARGS="--remote_http_cache=https://storage.googleapis.com/absl-bazel-remote-cache/${container_key} --google_credentials=/keystore/73103_absl-bazel-remote-cache ${BAZEL_EXTRA_ARGS:-}" +fi + +# Avoid depending on external sites like GitHub by checking --distdir for +# external dependencies first. +# https://docs.bazel.build/versions/master/guide.html#distdir +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -d "${KOKORO_GFILE_DIR}/distdir" ]]; then + DOCKER_EXTRA_ARGS="--volume=${KOKORO_GFILE_DIR}/distdir:/distdir:ro ${DOCKER_EXTRA_ARGS:-}" + BAZEL_EXTRA_ARGS="--distdir=/distdir ${BAZEL_EXTRA_ARGS:-}" +fi + +for std in ${STD}; do + for compilation_mode in ${COMPILATION_MODE}; do + for exceptions_mode in ${EXCEPTIONS_MODE}; do + echo "--------------------------------------------------------------------" + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp-ro:ro" \ + --tmpfs=/abseil-cpp \ + --workdir=/abseil-cpp \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CC="/usr/local/bin/gcc" \ + -e BAZEL_CXXOPTS="-std=${std}" \ + ${DOCKER_EXTRA_ARGS:-} \ + ${DOCKER_CONTAINER} \ + /bin/sh -c " + cp -r /abseil-cpp-ro/* /abseil-cpp/ + if [[ -n \"${ALTERNATE_OPTIONS:-}\" ]]; then + cp ${ALTERNATE_OPTIONS:-} absl/base/options.h || exit 1 + fi + /usr/local/bin/bazel test ... \ + --compilation_mode=\"${compilation_mode}\" \ + --copt=\"${exceptions_mode}\" \ + --copt=-Werror \ + --define=\"absl=1\" \ + --keep_going \ + --show_timestamps \ + --test_env=\"GTEST_INSTALL_FAILURE_SIGNAL_HANDLER=1\" \ + --test_env=\"TZDIR=/abseil-cpp/absl/time/internal/cctz/testdata/zoneinfo\" \ + --test_output=errors \ + --test_tag_filters=-benchmark \ + ${BAZEL_EXTRA_ARGS:-}" + done + done +done diff --git a/third_party/abseil_cpp/ci/linux_gcc-latest_libstdcxx_cmake.sh b/third_party/abseil_cpp/ci/linux_gcc-latest_libstdcxx_cmake.sh new file mode 100755 index 0000000000..db5f69181e --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_gcc-latest_libstdcxx_cmake.sh @@ -0,0 +1,64 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# TODO(absl-team): This script isn't fully hermetic because +# -DABSL_USE_GOOGLETEST_HEAD=ON means that this script isn't pinned to a fixed +# version of GoogleTest. This means that an upstream change to GoogleTest could +# break this test. Fix this by allowing this script to pin to a known-good +# version of GoogleTest. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${ABSL_CMAKE_CXX_STANDARDS:-} ]]; then + ABSL_CMAKE_CXX_STANDARDS="11 14 17" +fi + +if [[ -z ${ABSL_CMAKE_BUILD_TYPES:-} ]]; then + ABSL_CMAKE_BUILD_TYPES="Debug Release" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_GCC_LATEST_CONTAINER} + +for std in ${ABSL_CMAKE_CXX_STANDARDS}; do + for compilation_mode in ${ABSL_CMAKE_BUILD_TYPES}; do + echo "--------------------------------------------------------------------" + echo "Testing with CMAKE_BUILD_TYPE=${compilation_mode} and -std=c++${std}" + + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --tmpfs=/buildfs:exec \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CFLAGS="-Werror" \ + -e CXXFLAGS="-Werror" \ + ${DOCKER_CONTAINER} \ + /bin/bash -c " + cd /buildfs && \ + cmake /abseil-cpp \ + -DABSL_USE_GOOGLETEST_HEAD=ON \ + -DABSL_RUN_TESTS=ON \ + -DCMAKE_BUILD_TYPE=${compilation_mode} \ + -DCMAKE_CXX_STANDARD=${std} && \ + make -j$(nproc) && \ + ctest -j$(nproc) --output-on-failure" + done +done diff --git a/third_party/abseil_cpp/ci/linux_gcc_alpine_cmake.sh b/third_party/abseil_cpp/ci/linux_gcc_alpine_cmake.sh new file mode 100755 index 0000000000..f57ab12b1f --- /dev/null +++ b/third_party/abseil_cpp/ci/linux_gcc_alpine_cmake.sh @@ -0,0 +1,64 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# TODO(absl-team): This script isn't fully hermetic because +# -DABSL_USE_GOOGLETEST_HEAD=ON means that this script isn't pinned to a fixed +# version of GoogleTest. This means that an upstream change to GoogleTest could +# break this test. Fix this by allowing this script to pin to a known-good +# version of GoogleTest. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +if [[ -z ${ABSL_CMAKE_CXX_STANDARDS:-} ]]; then + ABSL_CMAKE_CXX_STANDARDS="11 14 17" +fi + +if [[ -z ${ABSL_CMAKE_BUILD_TYPES:-} ]]; then + ABSL_CMAKE_BUILD_TYPES="Debug Release" +fi + +source "${ABSEIL_ROOT}/ci/linux_docker_containers.sh" +readonly DOCKER_CONTAINER=${LINUX_ALPINE_CONTAINER} + +for std in ${ABSL_CMAKE_CXX_STANDARDS}; do + for compilation_mode in ${ABSL_CMAKE_BUILD_TYPES}; do + echo "--------------------------------------------------------------------" + echo "Testing with CMAKE_BUILD_TYPE=${compilation_mode} and -std=c++${std}" + + time docker run \ + --volume="${ABSEIL_ROOT}:/abseil-cpp:ro" \ + --workdir=/abseil-cpp \ + --tmpfs=/buildfs:exec \ + --cap-add=SYS_PTRACE \ + --rm \ + -e CFLAGS="-Werror" \ + -e CXXFLAGS="-Werror" \ + "${DOCKER_CONTAINER}" \ + /bin/sh -c " + cd /buildfs && \ + cmake /abseil-cpp \ + -DABSL_USE_GOOGLETEST_HEAD=ON \ + -DABSL_RUN_TESTS=ON \ + -DCMAKE_BUILD_TYPE=${compilation_mode} \ + -DCMAKE_CXX_STANDARD=${std} && \ + make -j$(nproc) && \ + ctest -j$(nproc) --output-on-failure" + done +done diff --git a/third_party/abseil_cpp/ci/macos_xcode_bazel.sh b/third_party/abseil_cpp/ci/macos_xcode_bazel.sh new file mode 100755 index 0000000000..738adf9476 --- /dev/null +++ b/third_party/abseil_cpp/ci/macos_xcode_bazel.sh @@ -0,0 +1,54 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script is invoked on Kokoro to test Abseil on macOS. +# It is not hermetic and may break when Kokoro is updated. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(realpath $(dirname ${0})/..)" +fi + +# If we are running on Kokoro, check for a versioned Bazel binary. +KOKORO_GFILE_BAZEL_BIN="bazel-2.0.0-darwin-x86_64" +if [[ ${KOKORO_GFILE_DIR:-} ]] && [[ -f ${KOKORO_GFILE_DIR}/${KOKORO_GFILE_BAZEL_BIN} ]]; then + BAZEL_BIN="${KOKORO_GFILE_DIR}/${KOKORO_GFILE_BAZEL_BIN}" + chmod +x ${BAZEL_BIN} +else + BAZEL_BIN="bazel" +fi + +# Print the compiler and Bazel versions. +echo "---------------" +gcc -v +echo "---------------" +${BAZEL_BIN} version +echo "---------------" + +cd ${ABSEIL_ROOT} + +if [[ -n "${ALTERNATE_OPTIONS:-}" ]]; then + cp ${ALTERNATE_OPTIONS:-} absl/base/options.h || exit 1 +fi + +${BAZEL_BIN} test ... \ + --copt=-Werror \ + --keep_going \ + --show_timestamps \ + --test_env="TZDIR=${ABSEIL_ROOT}/absl/time/internal/cctz/testdata/zoneinfo" \ + --test_output=errors \ + --test_tag_filters=-benchmark diff --git a/third_party/abseil_cpp/ci/macos_xcode_cmake.sh b/third_party/abseil_cpp/ci/macos_xcode_cmake.sh new file mode 100755 index 0000000000..cf78e207e3 --- /dev/null +++ b/third_party/abseil_cpp/ci/macos_xcode_cmake.sh @@ -0,0 +1,44 @@ +#!/bin/bash +# +# Copyright 2019 The Abseil Authors. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# https://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# This script is invoked on Kokoro to test Abseil on macOS. +# It is not hermetic and may break when Kokoro is updated. + +set -euox pipefail + +if [[ -z ${ABSEIL_ROOT:-} ]]; then + ABSEIL_ROOT="$(dirname ${0})/.." +fi +ABSEIL_ROOT=$(realpath ${ABSEIL_ROOT}) + +if [[ -z ${ABSL_CMAKE_BUILD_TYPES:-} ]]; then + ABSL_CMAKE_BUILD_TYPES="Debug" +fi + +for compilation_mode in ${ABSL_CMAKE_BUILD_TYPES}; do + BUILD_DIR=$(mktemp -d ${compilation_mode}.XXXXXXXX) + cd ${BUILD_DIR} + + # TODO(absl-team): Enable -Werror once all warnings are fixed. + time cmake ${ABSEIL_ROOT} \ + -GXcode \ + -DCMAKE_BUILD_TYPE=${compilation_mode} \ + -DCMAKE_CXX_STANDARD=11 \ + -DABSL_USE_GOOGLETEST_HEAD=ON \ + -DABSL_RUN_TESTS=ON + time cmake --build . + time ctest -C ${compilation_mode} --output-on-failure +done diff --git a/third_party/abseil_cpp/conanfile.py b/third_party/abseil_cpp/conanfile.py new file mode 100644 index 0000000000..926ec5ccd6 --- /dev/null +++ b/third_party/abseil_cpp/conanfile.py @@ -0,0 +1,51 @@ +#!/usr/bin/env python +# -*- coding: utf-8 -*- + +# Note: Conan is supported on a best-effort basis. Abseil doesn't use Conan +# internally, so we won't know if it stops working. We may ask community +# members to help us debug any problems that arise. + +from conans import ConanFile, CMake, tools +from conans.errors import ConanInvalidConfiguration +from conans.model.version import Version + + +class AbseilConan(ConanFile): + name = "abseil" + url = "https://github.com/abseil/abseil-cpp" + homepage = url + author = "Abseil <abseil-io@googlegroups.com>" + description = "Abseil Common Libraries (C++) from Google" + license = "Apache-2.0" + topics = ("conan", "abseil", "abseil-cpp", "google", "common-libraries") + exports = ["LICENSE"] + exports_sources = ["CMakeLists.txt", "CMake/*", "absl/*"] + generators = "cmake" + settings = "os", "arch", "compiler", "build_type" + + def configure(self): + if self.settings.os == "Windows" and \ + self.settings.compiler == "Visual Studio" and \ + Version(self.settings.compiler.version.value) < "14": + raise ConanInvalidConfiguration("Abseil does not support MSVC < 14") + + def build(self): + tools.replace_in_file("CMakeLists.txt", "project(absl CXX)", "project(absl CXX)\ninclude(conanbuildinfo.cmake)\nconan_basic_setup()") + cmake = CMake(self) + cmake.definitions["BUILD_TESTING"] = False + cmake.configure() + cmake.build() + + def package(self): + self.copy("LICENSE", dst="licenses") + self.copy("*.h", dst="include", src=".") + self.copy("*.inc", dst="include", src=".") + self.copy("*.a", dst="lib", src=".", keep_path=False) + self.copy("*.lib", dst="lib", src=".", keep_path=False) + + def package_info(self): + if self.settings.os == "Linux": + self.cpp_info.libs = ["-Wl,--start-group"] + self.cpp_info.libs.extend(tools.collect_libs(self)) + if self.settings.os == "Linux": + self.cpp_info.libs.extend(["-Wl,--end-group", "pthread"]) diff --git a/third_party/abseil_cpp/default.nix b/third_party/abseil_cpp/default.nix new file mode 100644 index 0000000000..ddc5c1c7b7 --- /dev/null +++ b/third_party/abseil_cpp/default.nix @@ -0,0 +1,6 @@ +{ pkgs, ... }: + +pkgs.originals.abseil-cpp.overrideAttrs(_: { + version = "20200519-768eb2ca"; + src = ./.; +}) diff --git a/third_party/cgit/.gitignore b/third_party/cgit/.gitignore new file mode 100644 index 0000000000..661df346c2 --- /dev/null +++ b/third_party/cgit/.gitignore @@ -0,0 +1,12 @@ +# Files I don't care to see in git-status/commit +/cgit +cgit.conf +CGIT-CFLAGS +VERSION +cgitrc.5 +cgitrc.5.fo +cgitrc.5.html +cgitrc.5.pdf +cgitrc.5.xml +*.o +*.d diff --git a/third_party/cgit/.mailmap b/third_party/cgit/.mailmap new file mode 100644 index 0000000000..03b54796cf --- /dev/null +++ b/third_party/cgit/.mailmap @@ -0,0 +1,10 @@ +Florian Pritz <bluewind@xinu.at> <bluewind@xssn.at> +Harley Laue <losinggeneration@gmail.com> <losinggeneration@aim.com> +John Keeping <john@keeping.me.uk> <john@metanate.com> +Lars Hjemli <hjemli@gmail.com> <larsh@hal-2004.(none)> +Lars Hjemli <hjemli@gmail.com> <larsh@hatman.(none)> +Lars Hjemli <hjemli@gmail.com> <larsh@slackbox.hjemli.net> +Lars Hjemli <hjemli@gmail.com> <larsh@slaptop.hjemli.net> +Lukas Fleischer <lfleischer@lfos.de> <cgit@cryptocrack.de> +Lukas Fleischer <lfleischer@lfos.de> <info@cryptocrack.de> +Stefan Bühler <source@stbuehler.de> <lighttpd@stbuehler.de> diff --git a/third_party/cgit/.skip-subtree b/third_party/cgit/.skip-subtree new file mode 100644 index 0000000000..c108a7d34f --- /dev/null +++ b/third_party/cgit/.skip-subtree @@ -0,0 +1 @@ +Subtrees of this directory belong to cgit (third-party). diff --git a/third_party/cgit/AUTHORS b/third_party/cgit/AUTHORS new file mode 100644 index 0000000000..031de338f9 --- /dev/null +++ b/third_party/cgit/AUTHORS @@ -0,0 +1,13 @@ +Maintainer: + Jason A. Donenfeld <Jason@zx2c4.com> + +Contributors: + Jason A. Donenfeld <Jason@zx2c4.com> + Lukas Fleischer <cgit@cryptocrack.de> + Johan Herland <johan@herland.net> + Lars Hjemli <hjemli@gmail.com> + Ferry Huberts <ferry.huberts@pelagic.nl> + John Keeping <john@keeping.me.uk> + +Previous Maintainer: + Lars Hjemli <hjemli@gmail.com> diff --git a/third_party/cgit/COPYING b/third_party/cgit/COPYING new file mode 100644 index 0000000000..d159169d10 --- /dev/null +++ b/third_party/cgit/COPYING @@ -0,0 +1,339 @@ + GNU GENERAL PUBLIC LICENSE + Version 2, June 1991 + + Copyright (C) 1989, 1991 Free Software Foundation, Inc., + 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + + Preamble + + The licenses for most software are designed to take away your +freedom to share and change it. By contrast, the GNU General Public +License is intended to guarantee your freedom to share and change free +software--to make sure the software is free for all its users. This +General Public License applies to most of the Free Software +Foundation's software and to any other program whose authors commit to +using it. (Some other Free Software Foundation software is covered by +the GNU Lesser General Public License instead.) You can apply it to +your programs, too. + + When we speak of free software, we are referring to freedom, not +price. Our General Public Licenses are designed to make sure that you +have the freedom to distribute copies of free software (and charge for +this service if you wish), that you receive source code or can get it +if you want it, that you can change the software or use pieces of it +in new free programs; and that you know you can do these things. + + To protect your rights, we need to make restrictions that forbid +anyone to deny you these rights or to ask you to surrender the rights. +These restrictions translate to certain responsibilities for you if you +distribute copies of the software, or if you modify it. + + For example, if you distribute copies of such a program, whether +gratis or for a fee, you must give the recipients all the rights that +you have. You must make sure that they, too, receive or can get the +source code. And you must show them these terms so they know their +rights. + + We protect your rights with two steps: (1) copyright the software, and +(2) offer you this license which gives you legal permission to copy, +distribute and/or modify the software. + + Also, for each author's protection and ours, we want to make certain +that everyone understands that there is no warranty for this free +software. If the software is modified by someone else and passed on, we +want its recipients to know that what they have is not the original, so +that any problems introduced by others will not reflect on the original +authors' reputations. + + Finally, any free program is threatened constantly by software +patents. We wish to avoid the danger that redistributors of a free +program will individually obtain patent licenses, in effect making the +program proprietary. To prevent this, we have made it clear that any +patent must be licensed for everyone's free use or not licensed at all. + + The precise terms and conditions for copying, distribution and +modification follow. + + GNU GENERAL PUBLIC LICENSE + TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION + + 0. This License applies to any program or other work which contains +a notice placed by the copyright holder saying it may be distributed +under the terms of this General Public License. The "Program", below, +refers to any such program or work, and a "work based on the Program" +means either the Program or any derivative work under copyright law: +that is to say, a work containing the Program or a portion of it, +either verbatim or with modifications and/or translated into another +language. (Hereinafter, translation is included without limitation in +the term "modification".) Each licensee is addressed as "you". + +Activities other than copying, distribution and modification are not +covered by this License; they are outside its scope. The act of +running the Program is not restricted, and the output from the Program +is covered only if its contents constitute a work based on the +Program (independent of having been made by running the Program). +Whether that is true depends on what the Program does. + + 1. You may copy and distribute verbatim copies of the Program's +source code as you receive it, in any medium, provided that you +conspicuously and appropriately publish on each copy an appropriate +copyright notice and disclaimer of warranty; keep intact all the +notices that refer to this License and to the absence of any warranty; +and give any other recipients of the Program a copy of this License +along with the Program. + +You may charge a fee for the physical act of transferring a copy, and +you may at your option offer warranty protection in exchange for a fee. + + 2. You may modify your copy or copies of the Program or any portion +of it, thus forming a work based on the Program, and copy and +distribute such modifications or work under the terms of Section 1 +above, provided that you also meet all of these conditions: + + a) You must cause the modified files to carry prominent notices + stating that you changed the files and the date of any change. + + b) You must cause any work that you distribute or publish, that in + whole or in part contains or is derived from the Program or any + part thereof, to be licensed as a whole at no charge to all third + parties under the terms of this License. + + c) If the modified program normally reads commands interactively + when run, you must cause it, when started running for such + interactive use in the most ordinary way, to print or display an + announcement including an appropriate copyright notice and a + notice that there is no warranty (or else, saying that you provide + a warranty) and that users may redistribute the program under + these conditions, and telling the user how to view a copy of this + License. (Exception: if the Program itself is interactive but + does not normally print such an announcement, your work based on + the Program is not required to print an announcement.) + +These requirements apply to the modified work as a whole. If +identifiable sections of that work are not derived from the Program, +and can be reasonably considered independent and separate works in +themselves, then this License, and its terms, do not apply to those +sections when you distribute them as separate works. But when you +distribute the same sections as part of a whole which is a work based +on the Program, the distribution of the whole must be on the terms of +this License, whose permissions for other licensees extend to the +entire whole, and thus to each and every part regardless of who wrote it. + +Thus, it is not the intent of this section to claim rights or contest +your rights to work written entirely by you; rather, the intent is to +exercise the right to control the distribution of derivative or +collective works based on the Program. + +In addition, mere aggregation of another work not based on the Program +with the Program (or with a work based on the Program) on a volume of +a storage or distribution medium does not bring the other work under +the scope of this License. + + 3. You may copy and distribute the Program (or a work based on it, +under Section 2) in object code or executable form under the terms of +Sections 1 and 2 above provided that you also do one of the following: + + a) Accompany it with the complete corresponding machine-readable + source code, which must be distributed under the terms of Sections + 1 and 2 above on a medium customarily used for software interchange; or, + + b) Accompany it with a written offer, valid for at least three + years, to give any third party, for a charge no more than your + cost of physically performing source distribution, a complete + machine-readable copy of the corresponding source code, to be + distributed under the terms of Sections 1 and 2 above on a medium + customarily used for software interchange; or, + + c) Accompany it with the information you received as to the offer + to distribute corresponding source code. (This alternative is + allowed only for noncommercial distribution and only if you + received the program in object code or executable form with such + an offer, in accord with Subsection b above.) + +The source code for a work means the preferred form of the work for +making modifications to it. For an executable work, complete source +code means all the source code for all modules it contains, plus any +associated interface definition files, plus the scripts used to +control compilation and installation of the executable. However, as a +special exception, the source code distributed need not include +anything that is normally distributed (in either source or binary +form) with the major components (compiler, kernel, and so on) of the +operating system on which the executable runs, unless that component +itself accompanies the executable. + +If distribution of executable or object code is made by offering +access to copy from a designated place, then offering equivalent +access to copy the source code from the same place counts as +distribution of the source code, even though third parties are not +compelled to copy the source along with the object code. + + 4. You may not copy, modify, sublicense, or distribute the Program +except as expressly provided under this License. Any attempt +otherwise to copy, modify, sublicense or distribute the Program is +void, and will automatically terminate your rights under this License. +However, parties who have received copies, or rights, from you under +this License will not have their licenses terminated so long as such +parties remain in full compliance. + + 5. You are not required to accept this License, since you have not +signed it. However, nothing else grants you permission to modify or +distribute the Program or its derivative works. These actions are +prohibited by law if you do not accept this License. Therefore, by +modifying or distributing the Program (or any work based on the +Program), you indicate your acceptance of this License to do so, and +all its terms and conditions for copying, distributing or modifying +the Program or works based on it. + + 6. Each time you redistribute the Program (or any work based on the +Program), the recipient automatically receives a license from the +original licensor to copy, distribute or modify the Program subject to +these terms and conditions. You may not impose any further +restrictions on the recipients' exercise of the rights granted herein. +You are not responsible for enforcing compliance by third parties to +this License. + + 7. If, as a consequence of a court judgment or allegation of patent +infringement or for any other reason (not limited to patent issues), +conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot +distribute so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you +may not distribute the Program at all. For example, if a patent +license would not permit royalty-free redistribution of the Program by +all those who receive copies directly or indirectly through you, then +the only way you could satisfy both it and this License would be to +refrain entirely from distribution of the Program. + +If any portion of this section is held invalid or unenforceable under +any particular circumstance, the balance of the section is intended to +apply and the section as a whole is intended to apply in other +circumstances. + +It is not the purpose of this section to induce you to infringe any +patents or other property right claims or to contest validity of any +such claims; this section has the sole purpose of protecting the +integrity of the free software distribution system, which is +implemented by public license practices. Many people have made +generous contributions to the wide range of software distributed +through that system in reliance on consistent application of that +system; it is up to the author/donor to decide if he or she is willing +to distribute software through any other system and a licensee cannot +impose that choice. + +This section is intended to make thoroughly clear what is believed to +be a consequence of the rest of this License. + + 8. If the distribution and/or use of the Program is restricted in +certain countries either by patents or by copyrighted interfaces, the +original copyright holder who places the Program under this License +may add an explicit geographical distribution limitation excluding +those countries, so that distribution is permitted only in or among +countries not thus excluded. In such case, this License incorporates +the limitation as if written in the body of this License. + + 9. The Free Software Foundation may publish revised and/or new versions +of the General Public License from time to time. Such new versions will +be similar in spirit to the present version, but may differ in detail to +address new problems or concerns. + +Each version is given a distinguishing version number. If the Program +specifies a version number of this License which applies to it and "any +later version", you have the option of following the terms and conditions +either of that version or of any later version published by the Free +Software Foundation. If the Program does not specify a version number of +this License, you may choose any version ever published by the Free Software +Foundation. + + 10. If you wish to incorporate parts of the Program into other free +programs whose distribution conditions are different, write to the author +to ask for permission. For software which is copyrighted by the Free +Software Foundation, write to the Free Software Foundation; we sometimes +make exceptions for this. Our decision will be guided by the two goals +of preserving the free status of all derivatives of our free software and +of promoting the sharing and reuse of software generally. + + NO WARRANTY + + 11. BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY +FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN +OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES +PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED +OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF +MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS +TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE +PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, +REPAIR OR CORRECTION. + + 12. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING +WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR +REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, +INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING +OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED +TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY +YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER +PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE +POSSIBILITY OF SUCH DAMAGES. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Programs + + If you develop a new program, and you want it to be of the greatest +possible use to the public, the best way to achieve this is to make it +free software which everyone can redistribute and change under these terms. + + To do so, attach the following notices to the program. It is safest +to attach them to the start of each source file to most effectively +convey the exclusion of warranty; and each file should have at least +the "copyright" line and a pointer to where the full notice is found. + + <one line to give the program's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This program is free software; you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation; either version 2 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License along + with this program; if not, write to the Free Software Foundation, Inc., + 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA. + +Also add information on how to contact you by electronic and paper mail. + +If the program is interactive, make it output a short notice like this +when it starts in an interactive mode: + + Gnomovision version 69, Copyright (C) year name of author + Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'. + This is free software, and you are welcome to redistribute it + under certain conditions; type `show c' for details. + +The hypothetical commands `show w' and `show c' should show the appropriate +parts of the General Public License. Of course, the commands you use may +be called something other than `show w' and `show c'; they could even be +mouse-clicks or menu items--whatever suits your program. + +You should also get your employer (if you work as a programmer) or your +school, if any, to sign a "copyright disclaimer" for the program, if +necessary. Here is a sample; alter the names: + + Yoyodyne, Inc., hereby disclaims all copyright interest in the program + `Gnomovision' (which makes passes at compilers) written by James Hacker. + + <signature of Ty Coon>, 1 April 1989 + Ty Coon, President of Vice + +This General Public License does not permit incorporating your program into +proprietary programs. If your program is a subroutine library, you may +consider it more useful to permit linking proprietary applications with the +library. If this is what you want to do, use the GNU Lesser General +Public License instead of this License. diff --git a/third_party/cgit/Makefile b/third_party/cgit/Makefile new file mode 100644 index 0000000000..96ad7cd878 --- /dev/null +++ b/third_party/cgit/Makefile @@ -0,0 +1,170 @@ +all:: + +CGIT_VERSION = v1.2.1 +CGIT_SCRIPT_NAME = cgit.cgi +CGIT_SCRIPT_PATH = /var/www/htdocs/cgit +CGIT_DATA_PATH = $(CGIT_SCRIPT_PATH) +CGIT_CONFIG = /etc/cgitrc +CACHE_ROOT = /var/cache/cgit +prefix = /usr/local +libdir = $(prefix)/lib +filterdir = $(libdir)/cgit/filters +docdir = $(prefix)/share/doc/cgit +htmldir = $(docdir) +pdfdir = $(docdir) +mandir = $(prefix)/share/man +SHA1_HEADER = <openssl/sha.h> +GIT_VER = 2.23.0 +GIT_URL = https://www.kernel.org/pub/software/scm/git/git-$(GIT_VER).tar.xz +INSTALL = install +COPYTREE = cp -r +MAN5_TXT = $(wildcard *.5.txt) +MAN_TXT = $(MAN5_TXT) +DOC_MAN5 = $(patsubst %.txt,%,$(MAN5_TXT)) +DOC_HTML = $(patsubst %.txt,%.html,$(MAN_TXT)) +DOC_PDF = $(patsubst %.txt,%.pdf,$(MAN_TXT)) + +ASCIIDOC = asciidoc +ASCIIDOC_EXTRA = +ASCIIDOC_HTML = xhtml11 +ASCIIDOC_COMMON = $(ASCIIDOC) $(ASCIIDOC_EXTRA) +TXT_TO_HTML = $(ASCIIDOC_COMMON) -b $(ASCIIDOC_HTML) + +# Define NO_C99_FORMAT if your formatted IO functions (printf/scanf et.al.) +# do not support the 'size specifiers' introduced by C99, namely ll, hh, +# j, z, t. (representing long long int, char, intmax_t, size_t, ptrdiff_t). +# some C compilers supported these specifiers prior to C99 as an extension. +# +# Define HAVE_LINUX_SENDFILE to use sendfile() + +#-include config.mak + +-include git/config.mak.uname +# +# Let the user override the above settings. +# +-include cgit.conf + +export CGIT_VERSION CGIT_SCRIPT_NAME CGIT_SCRIPT_PATH CGIT_DATA_PATH CGIT_CONFIG CACHE_ROOT + +# +# Define a way to invoke make in subdirs quietly, shamelessly ripped +# from git.git +# +QUIET_SUBDIR0 = +$(MAKE) -C # space to separate -C and subdir +QUIET_SUBDIR1 = + +ifneq ($(findstring w,$(MAKEFLAGS)),w) +PRINT_DIR = --no-print-directory +else # "make -w" +NO_SUBDIR = : +endif + +ifndef V + QUIET_SUBDIR0 = +@subdir= + QUIET_SUBDIR1 = ;$(NO_SUBDIR) echo ' ' SUBDIR $$subdir; \ + $(MAKE) $(PRINT_DIR) -C $$subdir + QUIET_TAGS = @echo ' ' TAGS $@; + export V +endif + +.SUFFIXES: + +all:: cgit + +cgit: + $(QUIET_SUBDIR0)git $(QUIET_SUBDIR1) -f ../cgit.mk ../cgit $(EXTRA_GIT_TARGETS) NO_CURL=1 + +sparse: + $(QUIET_SUBDIR0)git $(QUIET_SUBDIR1) -f ../cgit.mk NO_CURL=1 cgit-sparse + +test: + @$(MAKE) --no-print-directory cgit EXTRA_GIT_TARGETS=all + $(QUIET_SUBDIR0)tests $(QUIET_SUBDIR1) all + +install: all + $(INSTALL) -m 0755 -d $(DESTDIR)$(CGIT_SCRIPT_PATH) + $(INSTALL) -m 0755 cgit $(DESTDIR)$(CGIT_SCRIPT_PATH)/$(CGIT_SCRIPT_NAME) + $(INSTALL) -m 0755 -d $(DESTDIR)$(CGIT_DATA_PATH) + $(INSTALL) -m 0644 cgit.css $(DESTDIR)$(CGIT_DATA_PATH)/cgit.css + $(INSTALL) -m 0644 cgit.png $(DESTDIR)$(CGIT_DATA_PATH)/cgit.png + $(INSTALL) -m 0644 favicon.ico $(DESTDIR)$(CGIT_DATA_PATH)/favicon.ico + $(INSTALL) -m 0644 robots.txt $(DESTDIR)$(CGIT_DATA_PATH)/robots.txt + $(INSTALL) -m 0755 -d $(DESTDIR)$(filterdir) + $(COPYTREE) filters/* $(DESTDIR)$(filterdir) + +install-doc: install-man install-html install-pdf + +install-man: doc-man + $(INSTALL) -m 0755 -d $(DESTDIR)$(mandir)/man5 + $(INSTALL) -m 0644 $(DOC_MAN5) $(DESTDIR)$(mandir)/man5 + +install-html: doc-html + $(INSTALL) -m 0755 -d $(DESTDIR)$(htmldir) + $(INSTALL) -m 0644 $(DOC_HTML) $(DESTDIR)$(htmldir) + +install-pdf: doc-pdf + $(INSTALL) -m 0755 -d $(DESTDIR)$(pdfdir) + $(INSTALL) -m 0644 $(DOC_PDF) $(DESTDIR)$(pdfdir) + +uninstall: + rm -f $(DESTDIR)$(CGIT_SCRIPT_PATH)/$(CGIT_SCRIPT_NAME) + rm -f $(DESTDIR)$(CGIT_DATA_PATH)/cgit.css + rm -f $(DESTDIR)$(CGIT_DATA_PATH)/cgit.png + rm -f $(DESTDIR)$(CGIT_DATA_PATH)/favicon.ico + +uninstall-doc: uninstall-man uninstall-html uninstall-pdf + +uninstall-man: + @for i in $(DOC_MAN5); do \ + rm -fv $(DESTDIR)$(mandir)/man5/$$i; \ + done + +uninstall-html: + @for i in $(DOC_HTML); do \ + rm -fv $(DESTDIR)$(htmldir)/$$i; \ + done + +uninstall-pdf: + @for i in $(DOC_PDF); do \ + rm -fv $(DESTDIR)$(pdfdir)/$$i; \ + done + +doc: doc-man doc-html doc-pdf +doc-man: doc-man5 +doc-man5: $(DOC_MAN5) +doc-html: $(DOC_HTML) +doc-pdf: $(DOC_PDF) + +%.5 : %.5.txt + a2x -f manpage $< + +$(DOC_HTML): %.html : %.txt + $(TXT_TO_HTML) -o $@+ $< && \ + mv $@+ $@ + +$(DOC_PDF): %.pdf : %.txt + a2x -f pdf cgitrc.5.txt + +clean: clean-doc + $(RM) cgit VERSION CGIT-CFLAGS *.o tags + $(RM) -r .deps + +cleanall: clean + $(MAKE) -C git clean + +clean-doc: + $(RM) cgitrc.5 cgitrc.5.html cgitrc.5.pdf cgitrc.5.xml cgitrc.5.fo + +get-git: + curl -L $(GIT_URL) | tar -xJf - && rm -rf git && mv git-$(GIT_VER) git + +tags: + $(QUIET_TAGS)find . -name '*.[ch]' | xargs ctags + +.PHONY: all cgit git get-git +.PHONY: clean clean-doc cleanall +.PHONY: doc doc-html doc-man doc-pdf +.PHONY: install install-doc install-html install-man install-pdf +.PHONY: tags test +.PHONY: uninstall uninstall-doc uninstall-html uninstall-man uninstall-pdf diff --git a/third_party/cgit/README b/third_party/cgit/README new file mode 100644 index 0000000000..7a6b4a40ca --- /dev/null +++ b/third_party/cgit/README @@ -0,0 +1,99 @@ +cgit - CGI for Git +================== + +This is an attempt to create a fast web interface for the Git SCM, using a +built-in cache to decrease server I/O pressure. + +Installation +------------ + +Building cgit involves building a proper version of Git. How to do this +depends on how you obtained the cgit sources: + +a) If you're working in a cloned cgit repository, you first need to +initialize and update the Git submodule: + + $ git submodule init # register the Git submodule in .git/config + $ $EDITOR .git/config # if you want to specify a different url for git + $ git submodule update # clone/fetch and checkout correct git version + +b) If you're building from a cgit tarball, you can download a proper git +version like this: + + $ make get-git + +When either a) or b) has been performed, you can build and install cgit like +this: + + $ make + $ sudo make install + +This will install `cgit.cgi` and `cgit.css` into `/var/www/htdocs/cgit`. You +can configure this location (and a few other things) by providing a `cgit.conf` +file (see the Makefile for details). + +If you'd like to compile without Lua support, you may use: + + $ make NO_LUA=1 + +And if you'd like to specify a Lua implementation, you may use: + + $ make LUA_PKGCONFIG=lua5.1 + +If this is not specified, the Lua implementation will be auto-detected, +preferring LuaJIT if many are present. Acceptable values are generally "lua", +"luajit", "lua5.1", and "lua5.2". + + +Dependencies +------------ + +* libzip +* libcrypto (OpenSSL) +* libssl (OpenSSL) +* optional: luajit or lua, most reliably used when pkg-config is available + +Apache configuration +-------------------- + +A new `Directory` section must probably be added for cgit, possibly something +like this: + + <Directory "/var/www/htdocs/cgit/"> + AllowOverride None + Options +ExecCGI + Order allow,deny + Allow from all + </Directory> + + +Runtime configuration +--------------------- + +The file `/etc/cgitrc` is read by cgit before handling a request. In addition +to runtime parameters, this file may also contain a list of repositories +displayed by cgit (see `cgitrc.5.txt` for further details). + +The cache +--------- + +When cgit is invoked it looks for a cache file matching the request and +returns it to the client. If no such cache file exists (or if it has expired), +the content for the request is written into the proper cache file before the +file is returned. + +If the cache file has expired but cgit is unable to obtain a lock for it, the +stale cache file is returned to the client. This is done to favour page +throughput over page freshness. + +The generated content contains the complete response to the client, including +the HTTP headers `Modified` and `Expires`. + +Online presence +--------------- + +* The cgit homepage is hosted by cgit at <https://git.zx2c4.com/cgit/about/> + +* Patches, bug reports, discussions and support should go to the cgit + mailing list: <cgit@lists.zx2c4.com>. To sign up, visit + <https://lists.zx2c4.com/mailman/listinfo/cgit> diff --git a/third_party/cgit/cache.c b/third_party/cgit/cache.c new file mode 100644 index 0000000000..2c70be784d --- /dev/null +++ b/third_party/cgit/cache.c @@ -0,0 +1,468 @@ +/* cache.c: cache management + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + * + * + * The cache is just a directory structure where each file is a cache slot, + * and each filename is based on the hash of some key (e.g. the cgit url). + * Each file contains the full key followed by the cached content for that + * key. + * + */ + +#include "cgit.h" +#include "cache.h" +#include "html.h" +#ifdef HAVE_LINUX_SENDFILE +#include <sys/sendfile.h> +#endif + +#define CACHE_BUFSIZE (1024 * 4) + +struct cache_slot { + const char *key; + size_t keylen; + int ttl; + cache_fill_fn fn; + int cache_fd; + int lock_fd; + int stdout_fd; + const char *cache_name; + const char *lock_name; + int match; + struct stat cache_st; + int bufsize; + char buf[CACHE_BUFSIZE]; +}; + +/* Open an existing cache slot and fill the cache buffer with + * (part of) the content of the cache file. Return 0 on success + * and errno otherwise. + */ +static int open_slot(struct cache_slot *slot) +{ + char *bufz; + ssize_t bufkeylen = -1; + + slot->cache_fd = open(slot->cache_name, O_RDONLY); + if (slot->cache_fd == -1) + return errno; + + if (fstat(slot->cache_fd, &slot->cache_st)) + return errno; + + slot->bufsize = xread(slot->cache_fd, slot->buf, sizeof(slot->buf)); + if (slot->bufsize < 0) + return errno; + + bufz = memchr(slot->buf, 0, slot->bufsize); + if (bufz) + bufkeylen = bufz - slot->buf; + + if (slot->key) + slot->match = bufkeylen == slot->keylen && + !memcmp(slot->key, slot->buf, bufkeylen + 1); + + return 0; +} + +/* Close the active cache slot */ +static int close_slot(struct cache_slot *slot) +{ + int err = 0; + if (slot->cache_fd > 0) { + if (close(slot->cache_fd)) + err = errno; + else + slot->cache_fd = -1; + } + return err; +} + +/* Print the content of the active cache slot (but skip the key). */ +static int print_slot(struct cache_slot *slot) +{ +#ifdef HAVE_LINUX_SENDFILE + off_t start_off; + int ret; + + start_off = slot->keylen + 1; + + do { + ret = sendfile(STDOUT_FILENO, slot->cache_fd, &start_off, + slot->cache_st.st_size - start_off); + if (ret < 0) { + if (errno == EAGAIN || errno == EINTR) + continue; + return errno; + } + return 0; + } while (1); +#else + ssize_t i, j; + + i = lseek(slot->cache_fd, slot->keylen + 1, SEEK_SET); + if (i != slot->keylen + 1) + return errno; + + do { + i = j = xread(slot->cache_fd, slot->buf, sizeof(slot->buf)); + if (i > 0) + j = xwrite(STDOUT_FILENO, slot->buf, i); + } while (i > 0 && j == i); + + if (i < 0 || j != i) + return errno; + else + return 0; +#endif +} + +/* Check if the slot has expired */ +static int is_expired(struct cache_slot *slot) +{ + if (slot->ttl < 0) + return 0; + else + return slot->cache_st.st_mtime + slot->ttl * 60 < time(NULL); +} + +/* Check if the slot has been modified since we opened it. + * NB: If stat() fails, we pretend the file is modified. + */ +static int is_modified(struct cache_slot *slot) +{ + struct stat st; + + if (stat(slot->cache_name, &st)) + return 1; + return (st.st_ino != slot->cache_st.st_ino || + st.st_mtime != slot->cache_st.st_mtime || + st.st_size != slot->cache_st.st_size); +} + +/* Close an open lockfile */ +static int close_lock(struct cache_slot *slot) +{ + int err = 0; + if (slot->lock_fd > 0) { + if (close(slot->lock_fd)) + err = errno; + else + slot->lock_fd = -1; + } + return err; +} + +/* Create a lockfile used to store the generated content for a cache + * slot, and write the slot key + \0 into it. + * Returns 0 on success and errno otherwise. + */ +static int lock_slot(struct cache_slot *slot) +{ + struct flock lock = { + .l_type = F_WRLCK, + .l_whence = SEEK_SET, + .l_start = 0, + .l_len = 0, + }; + + slot->lock_fd = open(slot->lock_name, O_RDWR | O_CREAT, + S_IRUSR | S_IWUSR); + if (slot->lock_fd == -1) + return errno; + if (fcntl(slot->lock_fd, F_SETLK, &lock) < 0) { + int saved_errno = errno; + close(slot->lock_fd); + slot->lock_fd = -1; + return saved_errno; + } + if (xwrite(slot->lock_fd, slot->key, slot->keylen + 1) < 0) + return errno; + return 0; +} + +/* Release the current lockfile. If `replace_old_slot` is set the + * lockfile replaces the old cache slot, otherwise the lockfile is + * just deleted. + */ +static int unlock_slot(struct cache_slot *slot, int replace_old_slot) +{ + int err; + + if (replace_old_slot) + err = rename(slot->lock_name, slot->cache_name); + else + err = unlink(slot->lock_name); + + /* Restore stdout and close the temporary FD. */ + if (slot->stdout_fd >= 0) { + dup2(slot->stdout_fd, STDOUT_FILENO); + close(slot->stdout_fd); + slot->stdout_fd = -1; + } + + if (err) + return errno; + + return 0; +} + +/* Generate the content for the current cache slot by redirecting + * stdout to the lock-fd and invoking the callback function + */ +static int fill_slot(struct cache_slot *slot) +{ + /* Preserve stdout */ + slot->stdout_fd = dup(STDOUT_FILENO); + if (slot->stdout_fd == -1) + return errno; + + /* Redirect stdout to lockfile */ + if (dup2(slot->lock_fd, STDOUT_FILENO) == -1) + return errno; + + /* Generate cache content */ + slot->fn(); + + /* Make sure any buffered data is flushed to the file */ + if (fflush(stdout)) + return errno; + + /* update stat info */ + if (fstat(slot->lock_fd, &slot->cache_st)) + return errno; + + return 0; +} + +/* Crude implementation of 32-bit FNV-1 hash algorithm, + * see http://www.isthe.com/chongo/tech/comp/fnv/ for details + * about the magic numbers. + */ +#define FNV_OFFSET 0x811c9dc5 +#define FNV_PRIME 0x01000193 + +unsigned long hash_str(const char *str) +{ + unsigned long h = FNV_OFFSET; + unsigned char *s = (unsigned char *)str; + + if (!s) + return h; + + while (*s) { + h *= FNV_PRIME; + h ^= *s++; + } + return h; +} + +static int process_slot(struct cache_slot *slot) +{ + int err; + + err = open_slot(slot); + if (!err && slot->match) { + if (is_expired(slot)) { + if (!lock_slot(slot)) { + /* If the cachefile has been replaced between + * `open_slot` and `lock_slot`, we'll just + * serve the stale content from the original + * cachefile. This way we avoid pruning the + * newly generated slot. The same code-path + * is chosen if fill_slot() fails for some + * reason. + * + * TODO? check if the new slot contains the + * same key as the old one, since we would + * prefer to serve the newest content. + * This will require us to open yet another + * file-descriptor and read and compare the + * key from the new file, so for now we're + * lazy and just ignore the new file. + */ + if (is_modified(slot) || fill_slot(slot)) { + unlock_slot(slot, 0); + close_lock(slot); + } else { + close_slot(slot); + unlock_slot(slot, 1); + slot->cache_fd = slot->lock_fd; + } + } + } + if ((err = print_slot(slot)) != 0) { + cache_log("[cgit] error printing cache %s: %s (%d)\n", + slot->cache_name, + strerror(err), + err); + } + close_slot(slot); + return err; + } + + /* If the cache slot does not exist (or its key doesn't match the + * current key), lets try to create a new cache slot for this + * request. If this fails (for whatever reason), lets just generate + * the content without caching it and fool the caller to believe + * everything worked out (but print a warning on stdout). + */ + + close_slot(slot); + if ((err = lock_slot(slot)) != 0) { + cache_log("[cgit] Unable to lock slot %s: %s (%d)\n", + slot->lock_name, strerror(err), err); + slot->fn(); + return 0; + } + + if ((err = fill_slot(slot)) != 0) { + cache_log("[cgit] Unable to fill slot %s: %s (%d)\n", + slot->lock_name, strerror(err), err); + unlock_slot(slot, 0); + close_lock(slot); + slot->fn(); + return 0; + } + // We've got a valid cache slot in the lock file, which + // is about to replace the old cache slot. But if we + // release the lockfile and then try to open the new cache + // slot, we might get a race condition with a concurrent + // writer for the same cache slot (with a different key). + // Lets avoid such a race by just printing the content of + // the lock file. + slot->cache_fd = slot->lock_fd; + unlock_slot(slot, 1); + if ((err = print_slot(slot)) != 0) { + cache_log("[cgit] error printing cache %s: %s (%d)\n", + slot->cache_name, + strerror(err), + err); + } + close_slot(slot); + return err; +} + +/* Print cached content to stdout, generate the content if necessary. */ +int cache_process(int size, const char *path, const char *key, int ttl, + cache_fill_fn fn) +{ + unsigned long hash; + int i; + struct strbuf filename = STRBUF_INIT; + struct strbuf lockname = STRBUF_INIT; + struct cache_slot slot; + int result; + + /* If the cache is disabled, just generate the content */ + if (size <= 0 || ttl == 0) { + fn(); + return 0; + } + + /* Verify input, calculate filenames */ + if (!path) { + cache_log("[cgit] Cache path not specified, caching is disabled\n"); + fn(); + return 0; + } + if (!key) + key = ""; + hash = hash_str(key) % size; + strbuf_addstr(&filename, path); + strbuf_ensure_end(&filename, '/'); + for (i = 0; i < 8; i++) { + strbuf_addf(&filename, "%x", (unsigned char)(hash & 0xf)); + hash >>= 4; + } + strbuf_addbuf(&lockname, &filename); + strbuf_addstr(&lockname, ".lock"); + slot.fn = fn; + slot.ttl = ttl; + slot.stdout_fd = -1; + slot.cache_name = filename.buf; + slot.lock_name = lockname.buf; + slot.key = key; + slot.keylen = strlen(key); + result = process_slot(&slot); + + strbuf_release(&filename); + strbuf_release(&lockname); + return result; +} + +/* Return a strftime formatted date/time + * NB: the result from this function is to shared memory + */ +static char *sprintftime(const char *format, time_t time) +{ + static char buf[64]; + struct tm *tm; + + if (!time) + return NULL; + tm = gmtime(&time); + strftime(buf, sizeof(buf)-1, format, tm); + return buf; +} + +int cache_ls(const char *path) +{ + DIR *dir; + struct dirent *ent; + int err = 0; + struct cache_slot slot = { NULL }; + struct strbuf fullname = STRBUF_INIT; + size_t prefixlen; + + if (!path) { + cache_log("[cgit] cache path not specified\n"); + return -1; + } + dir = opendir(path); + if (!dir) { + err = errno; + cache_log("[cgit] unable to open path %s: %s (%d)\n", + path, strerror(err), err); + return err; + } + strbuf_addstr(&fullname, path); + strbuf_ensure_end(&fullname, '/'); + prefixlen = fullname.len; + while ((ent = readdir(dir)) != NULL) { + if (strlen(ent->d_name) != 8) + continue; + strbuf_setlen(&fullname, prefixlen); + strbuf_addstr(&fullname, ent->d_name); + slot.cache_name = fullname.buf; + if ((err = open_slot(&slot)) != 0) { + cache_log("[cgit] unable to open path %s: %s (%d)\n", + fullname.buf, strerror(err), err); + continue; + } + htmlf("%s %s %10"PRIuMAX" %s\n", + fullname.buf, + sprintftime("%Y-%m-%d %H:%M:%S", + slot.cache_st.st_mtime), + (uintmax_t)slot.cache_st.st_size, + slot.buf); + close_slot(&slot); + } + closedir(dir); + strbuf_release(&fullname); + return 0; +} + +/* Print a message to stdout */ +void cache_log(const char *format, ...) +{ + va_list args; + va_start(args, format); + vfprintf(stderr, format, args); + va_end(args); +} + diff --git a/third_party/cgit/cache.h b/third_party/cgit/cache.h new file mode 100644 index 0000000000..470da4fc15 --- /dev/null +++ b/third_party/cgit/cache.h @@ -0,0 +1,37 @@ +/* + * Since git has it's own cache.h which we include, + * lets test on CGIT_CACHE_H to avoid confusion + */ + +#ifndef CGIT_CACHE_H +#define CGIT_CACHE_H + +typedef void (*cache_fill_fn)(void); + + +/* Print cached content to stdout, generate the content if necessary. + * + * Parameters + * size max number of cache files + * path directory used to store cache files + * key the key used to lookup cache files + * ttl max cache time in seconds for this key + * fn content generator function for this key + * + * Return value + * 0 indicates success, everything else is an error + */ +extern int cache_process(int size, const char *path, const char *key, int ttl, + cache_fill_fn fn); + + +/* List info about all cache entries on stdout */ +extern int cache_ls(const char *path); + +/* Print a message to stdout */ +__attribute__((format (printf,1,2))) +extern void cache_log(const char *format, ...); + +extern unsigned long hash_str(const char *str); + +#endif /* CGIT_CACHE_H */ diff --git a/third_party/cgit/cgit.c b/third_party/cgit/cgit.c new file mode 100644 index 0000000000..ac8c6418ba --- /dev/null +++ b/third_party/cgit/cgit.c @@ -0,0 +1,1112 @@ +/* cgit.c: cgi for the git scm + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "cache.h" +#include "cmd.h" +#include "configfile.h" +#include "html.h" +#include "ui-shared.h" +#include "ui-stats.h" +#include "ui-blob.h" +#include "ui-summary.h" +#include "scan-tree.h" + +const char *cgit_version = CGIT_VERSION; + +__attribute__((constructor)) +static void constructor_environment() +{ + /* Do not look in /etc/ for gitconfig and gitattributes. */ + setenv("GIT_CONFIG_NOSYSTEM", "1", 1); + setenv("GIT_ATTR_NOSYSTEM", "1", 1); + unsetenv("HOME"); + unsetenv("XDG_CONFIG_HOME"); +} + +static void add_mimetype(const char *name, const char *value) +{ + struct string_list_item *item; + + item = string_list_insert(&ctx.cfg.mimetypes, name); + item->util = xstrdup(value); +} + +static void process_cached_repolist(const char *path); + +static void repo_config(struct cgit_repo *repo, const char *name, const char *value) +{ + const char *path; + struct string_list_item *item; + + if (!strcmp(name, "name")) + repo->name = xstrdup(value); + else if (!strcmp(name, "clone-url")) + repo->clone_url = xstrdup(value); + else if (!strcmp(name, "desc")) + repo->desc = xstrdup(value); + else if (!strcmp(name, "owner")) + repo->owner = xstrdup(value); + else if (!strcmp(name, "homepage")) + repo->homepage = xstrdup(value); + else if (!strcmp(name, "defbranch")) + repo->defbranch = xstrdup(value); + else if (!strcmp(name, "extra-head-content")) + repo->extra_head_content = xstrdup(value); + else if (!strcmp(name, "snapshots")) + repo->snapshots = ctx.cfg.snapshots & cgit_parse_snapshots_mask(value); + else if (!strcmp(name, "enable-blame")) + repo->enable_blame = atoi(value); + else if (!strcmp(name, "enable-commit-graph")) + repo->enable_commit_graph = atoi(value); + else if (!strcmp(name, "enable-log-filecount")) + repo->enable_log_filecount = atoi(value); + else if (!strcmp(name, "enable-log-linecount")) + repo->enable_log_linecount = atoi(value); + else if (!strcmp(name, "enable-remote-branches")) + repo->enable_remote_branches = atoi(value); + else if (!strcmp(name, "enable-subject-links")) + repo->enable_subject_links = atoi(value); + else if (!strcmp(name, "enable-html-serving")) + repo->enable_html_serving = atoi(value); + else if (!strcmp(name, "branch-sort")) { + if (!strcmp(value, "age")) + repo->branch_sort = 1; + if (!strcmp(value, "name")) + repo->branch_sort = 0; + } else if (!strcmp(name, "commit-sort")) { + if (!strcmp(value, "date")) + repo->commit_sort = 1; + if (!strcmp(value, "topo")) + repo->commit_sort = 2; + } else if (!strcmp(name, "max-stats")) + repo->max_stats = cgit_find_stats_period(value, NULL); + else if (!strcmp(name, "module-link")) + repo->module_link= xstrdup(value); + else if (skip_prefix(name, "module-link.", &path)) { + item = string_list_append(&repo->submodules, xstrdup(path)); + item->util = xstrdup(value); + } else if (!strcmp(name, "section")) + repo->section = xstrdup(value); + else if (!strcmp(name, "snapshot-prefix")) + repo->snapshot_prefix = xstrdup(value); + else if (!strcmp(name, "readme") && value != NULL) { + if (repo->readme.items == ctx.cfg.readme.items) + memset(&repo->readme, 0, sizeof(repo->readme)); + string_list_append(&repo->readme, xstrdup(value)); + } else if (!strcmp(name, "logo") && value != NULL) + repo->logo = xstrdup(value); + else if (!strcmp(name, "logo-link") && value != NULL) + repo->logo_link = xstrdup(value); + else if (!strcmp(name, "hide")) + repo->hide = atoi(value); + else if (!strcmp(name, "ignore")) + repo->ignore = atoi(value); + else if (ctx.cfg.enable_filter_overrides) { + if (!strcmp(name, "about-filter")) + repo->about_filter = cgit_new_filter(value, ABOUT); + else if (!strcmp(name, "commit-filter")) + repo->commit_filter = cgit_new_filter(value, COMMIT); + else if (!strcmp(name, "source-filter")) + repo->source_filter = cgit_new_filter(value, SOURCE); + else if (!strcmp(name, "email-filter")) + repo->email_filter = cgit_new_filter(value, EMAIL); + else if (!strcmp(name, "owner-filter")) + repo->owner_filter = cgit_new_filter(value, OWNER); + } +} + +static void config_cb(const char *name, const char *value) +{ + const char *arg; + + if (!strcmp(name, "section")) + ctx.cfg.section = xstrdup(value); + else if (!strcmp(name, "repo.url")) + ctx.repo = cgit_add_repo(value); + else if (ctx.repo && !strcmp(name, "repo.path")) + ctx.repo->path = trim_end(value, '/'); + else if (ctx.repo && skip_prefix(name, "repo.", &arg)) + repo_config(ctx.repo, arg, value); + else if (!strcmp(name, "readme")) + string_list_append(&ctx.cfg.readme, xstrdup(value)); + else if (!strcmp(name, "root-title")) + ctx.cfg.root_title = xstrdup(value); + else if (!strcmp(name, "root-desc")) + ctx.cfg.root_desc = xstrdup(value); + else if (!strcmp(name, "root-readme")) + ctx.cfg.root_readme = xstrdup(value); + else if (!strcmp(name, "css")) + ctx.cfg.css = xstrdup(value); + else if (!strcmp(name, "favicon")) + ctx.cfg.favicon = xstrdup(value); + else if (!strcmp(name, "footer")) + ctx.cfg.footer = xstrdup(value); + else if (!strcmp(name, "head-include")) + ctx.cfg.head_include = xstrdup(value); + else if (!strcmp(name, "header")) + ctx.cfg.header = xstrdup(value); + else if (!strcmp(name, "logo")) + ctx.cfg.logo = xstrdup(value); + else if (!strcmp(name, "logo-link")) + ctx.cfg.logo_link = xstrdup(value); + else if (!strcmp(name, "module-link")) + ctx.cfg.module_link = xstrdup(value); + else if (!strcmp(name, "strict-export")) + ctx.cfg.strict_export = xstrdup(value); + else if (!strcmp(name, "virtual-root")) + ctx.cfg.virtual_root = ensure_end(value, '/'); + else if (!strcmp(name, "noplainemail")) + ctx.cfg.noplainemail = atoi(value); + else if (!strcmp(name, "noheader")) + ctx.cfg.noheader = atoi(value); + else if (!strcmp(name, "snapshots")) + ctx.cfg.snapshots = cgit_parse_snapshots_mask(value); + else if (!strcmp(name, "enable-filter-overrides")) + ctx.cfg.enable_filter_overrides = atoi(value); + else if (!strcmp(name, "enable-follow-links")) + ctx.cfg.enable_follow_links = atoi(value); + else if (!strcmp(name, "enable-http-clone")) + ctx.cfg.enable_http_clone = atoi(value); + else if (!strcmp(name, "enable-index-links")) + ctx.cfg.enable_index_links = atoi(value); + else if (!strcmp(name, "enable-index-owner")) + ctx.cfg.enable_index_owner = atoi(value); + else if (!strcmp(name, "enable-blame")) + ctx.cfg.enable_blame = atoi(value); + else if (!strcmp(name, "enable-commit-graph")) + ctx.cfg.enable_commit_graph = atoi(value); + else if (!strcmp(name, "enable-log-filecount")) + ctx.cfg.enable_log_filecount = atoi(value); + else if (!strcmp(name, "enable-log-linecount")) + ctx.cfg.enable_log_linecount = atoi(value); + else if (!strcmp(name, "enable-remote-branches")) + ctx.cfg.enable_remote_branches = atoi(value); + else if (!strcmp(name, "enable-subject-links")) + ctx.cfg.enable_subject_links = atoi(value); + else if (!strcmp(name, "enable-html-serving")) + ctx.cfg.enable_html_serving = atoi(value); + else if (!strcmp(name, "enable-tree-linenumbers")) + ctx.cfg.enable_tree_linenumbers = atoi(value); + else if (!strcmp(name, "enable-git-config")) + ctx.cfg.enable_git_config = atoi(value); + else if (!strcmp(name, "max-stats")) + ctx.cfg.max_stats = cgit_find_stats_period(value, NULL); + else if (!strcmp(name, "cache-size")) + ctx.cfg.cache_size = atoi(value); + else if (!strcmp(name, "cache-root")) + ctx.cfg.cache_root = xstrdup(expand_macros(value)); + else if (!strcmp(name, "cache-root-ttl")) + ctx.cfg.cache_root_ttl = atoi(value); + else if (!strcmp(name, "cache-repo-ttl")) + ctx.cfg.cache_repo_ttl = atoi(value); + else if (!strcmp(name, "cache-scanrc-ttl")) + ctx.cfg.cache_scanrc_ttl = atoi(value); + else if (!strcmp(name, "cache-static-ttl")) + ctx.cfg.cache_static_ttl = atoi(value); + else if (!strcmp(name, "cache-dynamic-ttl")) + ctx.cfg.cache_dynamic_ttl = atoi(value); + else if (!strcmp(name, "cache-about-ttl")) + ctx.cfg.cache_about_ttl = atoi(value); + else if (!strcmp(name, "cache-snapshot-ttl")) + ctx.cfg.cache_snapshot_ttl = atoi(value); + else if (!strcmp(name, "case-sensitive-sort")) + ctx.cfg.case_sensitive_sort = atoi(value); + else if (!strcmp(name, "about-filter")) + ctx.cfg.about_filter = cgit_new_filter(value, ABOUT); + else if (!strcmp(name, "commit-filter")) + ctx.cfg.commit_filter = cgit_new_filter(value, COMMIT); + else if (!strcmp(name, "email-filter")) + ctx.cfg.email_filter = cgit_new_filter(value, EMAIL); + else if (!strcmp(name, "owner-filter")) + ctx.cfg.owner_filter = cgit_new_filter(value, OWNER); + else if (!strcmp(name, "auth-filter")) + ctx.cfg.auth_filter = cgit_new_filter(value, AUTH); + else if (!strcmp(name, "embedded")) + ctx.cfg.embedded = atoi(value); + else if (!strcmp(name, "max-atom-items")) + ctx.cfg.max_atom_items = atoi(value); + else if (!strcmp(name, "max-message-length")) + ctx.cfg.max_msg_len = atoi(value); + else if (!strcmp(name, "max-repodesc-length")) + ctx.cfg.max_repodesc_len = atoi(value); + else if (!strcmp(name, "max-blob-size")) + ctx.cfg.max_blob_size = atoi(value); + else if (!strcmp(name, "max-repo-count")) + ctx.cfg.max_repo_count = atoi(value); + else if (!strcmp(name, "max-commit-count")) + ctx.cfg.max_commit_count = atoi(value); + else if (!strcmp(name, "project-list")) + ctx.cfg.project_list = xstrdup(expand_macros(value)); + else if (!strcmp(name, "scan-path")) + if (ctx.cfg.cache_size) + process_cached_repolist(expand_macros(value)); + else if (ctx.cfg.project_list) + scan_projects(expand_macros(value), + ctx.cfg.project_list, repo_config); + else + scan_tree(expand_macros(value), repo_config); + else if (!strcmp(name, "scan-hidden-path")) + ctx.cfg.scan_hidden_path = atoi(value); + else if (!strcmp(name, "section-from-path")) + ctx.cfg.section_from_path = atoi(value); + else if (!strcmp(name, "repository-sort")) + ctx.cfg.repository_sort = xstrdup(value); + else if (!strcmp(name, "section-sort")) + ctx.cfg.section_sort = atoi(value); + else if (!strcmp(name, "source-filter")) + ctx.cfg.source_filter = cgit_new_filter(value, SOURCE); + else if (!strcmp(name, "summary-log")) + ctx.cfg.summary_log = atoi(value); + else if (!strcmp(name, "summary-branches")) + ctx.cfg.summary_branches = atoi(value); + else if (!strcmp(name, "summary-tags")) + ctx.cfg.summary_tags = atoi(value); + else if (!strcmp(name, "side-by-side-diffs")) + ctx.cfg.difftype = atoi(value) ? DIFF_SSDIFF : DIFF_UNIFIED; + else if (!strcmp(name, "agefile")) + ctx.cfg.agefile = xstrdup(value); + else if (!strcmp(name, "mimetype-file")) + ctx.cfg.mimetype_file = xstrdup(value); + else if (!strcmp(name, "renamelimit")) + ctx.cfg.renamelimit = atoi(value); + else if (!strcmp(name, "remove-suffix")) + ctx.cfg.remove_suffix = atoi(value); + else if (!strcmp(name, "robots")) + ctx.cfg.robots = xstrdup(value); + else if (!strcmp(name, "clone-prefix")) + ctx.cfg.clone_prefix = xstrdup(value); + else if (!strcmp(name, "clone-url")) + ctx.cfg.clone_url = xstrdup(value); + else if (!strcmp(name, "local-time")) + ctx.cfg.local_time = atoi(value); + else if (!strcmp(name, "commit-sort")) { + if (!strcmp(value, "date")) + ctx.cfg.commit_sort = 1; + if (!strcmp(value, "topo")) + ctx.cfg.commit_sort = 2; + } else if (!strcmp(name, "branch-sort")) { + if (!strcmp(value, "age")) + ctx.cfg.branch_sort = 1; + if (!strcmp(value, "name")) + ctx.cfg.branch_sort = 0; + } else if (skip_prefix(name, "mimetype.", &arg)) + add_mimetype(arg, value); + else if (!strcmp(name, "include")) + parse_configfile(expand_macros(value), config_cb); +} + +static void querystring_cb(const char *name, const char *value) +{ + if (!value) + value = ""; + + if (!strcmp(name,"r")) { + ctx.qry.repo = xstrdup(value); + ctx.repo = cgit_get_repoinfo(value); + } else if (!strcmp(name, "p")) { + ctx.qry.page = xstrdup(value); + } else if (!strcmp(name, "url")) { + if (*value == '/') + value++; + ctx.qry.url = xstrdup(value); + cgit_parse_url(value); + } else if (!strcmp(name, "qt")) { + ctx.qry.grep = xstrdup(value); + } else if (!strcmp(name, "q")) { + ctx.qry.search = xstrdup(value); + } else if (!strcmp(name, "h")) { + ctx.qry.head = xstrdup(value); + ctx.qry.has_symref = 1; + } else if (!strcmp(name, "id")) { + ctx.qry.sha1 = xstrdup(value); + ctx.qry.has_sha1 = 1; + } else if (!strcmp(name, "id2")) { + ctx.qry.sha2 = xstrdup(value); + ctx.qry.has_sha1 = 1; + } else if (!strcmp(name, "ofs")) { + ctx.qry.ofs = atoi(value); + } else if (!strcmp(name, "path")) { + ctx.qry.path = trim_end(value, '/'); + } else if (!strcmp(name, "name")) { + ctx.qry.name = xstrdup(value); + } else if (!strcmp(name, "s")) { + ctx.qry.sort = xstrdup(value); + } else if (!strcmp(name, "showmsg")) { + ctx.qry.showmsg = atoi(value); + } else if (!strcmp(name, "period")) { + ctx.qry.period = xstrdup(value); + } else if (!strcmp(name, "dt")) { + ctx.qry.difftype = atoi(value); + ctx.qry.has_difftype = 1; + } else if (!strcmp(name, "ss")) { + /* No longer generated, but there may be links out there. */ + ctx.qry.difftype = atoi(value) ? DIFF_SSDIFF : DIFF_UNIFIED; + ctx.qry.has_difftype = 1; + } else if (!strcmp(name, "all")) { + ctx.qry.show_all = atoi(value); + } else if (!strcmp(name, "context")) { + ctx.qry.context = atoi(value); + } else if (!strcmp(name, "ignorews")) { + ctx.qry.ignorews = atoi(value); + } else if (!strcmp(name, "follow")) { + ctx.qry.follow = atoi(value); + } +} + +static void prepare_context(void) +{ + memset(&ctx, 0, sizeof(ctx)); + ctx.cfg.agefile = "info/web/last-modified"; + ctx.cfg.cache_size = 0; + ctx.cfg.cache_max_create_time = 5; + ctx.cfg.cache_root = CGIT_CACHE_ROOT; + ctx.cfg.cache_about_ttl = 15; + ctx.cfg.cache_snapshot_ttl = 5; + ctx.cfg.cache_repo_ttl = 5; + ctx.cfg.cache_root_ttl = 5; + ctx.cfg.cache_scanrc_ttl = 15; + ctx.cfg.cache_dynamic_ttl = 5; + ctx.cfg.cache_static_ttl = -1; + ctx.cfg.case_sensitive_sort = 1; + ctx.cfg.branch_sort = 0; + ctx.cfg.commit_sort = 0; + ctx.cfg.css = "/cgit.css"; + ctx.cfg.logo = "/cgit.png"; + ctx.cfg.favicon = "/favicon.ico"; + ctx.cfg.local_time = 0; + ctx.cfg.enable_http_clone = 1; + ctx.cfg.enable_index_owner = 1; + ctx.cfg.enable_tree_linenumbers = 1; + ctx.cfg.enable_git_config = 0; + ctx.cfg.max_repo_count = 50; + ctx.cfg.max_commit_count = 50; + ctx.cfg.max_lock_attempts = 5; + ctx.cfg.max_msg_len = 80; + ctx.cfg.max_repodesc_len = 80; + ctx.cfg.max_blob_size = 0; + ctx.cfg.max_stats = 0; + ctx.cfg.project_list = NULL; + ctx.cfg.renamelimit = -1; + ctx.cfg.remove_suffix = 0; + ctx.cfg.robots = "index, nofollow"; + ctx.cfg.root_title = "Git repository browser"; + ctx.cfg.root_desc = "a fast webinterface for the git dscm"; + ctx.cfg.scan_hidden_path = 0; + ctx.cfg.script_name = CGIT_SCRIPT_NAME; + ctx.cfg.section = ""; + ctx.cfg.repository_sort = "name"; + ctx.cfg.section_sort = 1; + ctx.cfg.summary_branches = 10; + ctx.cfg.summary_log = 10; + ctx.cfg.summary_tags = 10; + ctx.cfg.max_atom_items = 10; + ctx.cfg.difftype = DIFF_UNIFIED; + ctx.env.cgit_config = getenv("CGIT_CONFIG"); + ctx.env.http_host = getenv("HTTP_HOST"); + ctx.env.https = getenv("HTTPS"); + ctx.env.no_http = getenv("NO_HTTP"); + ctx.env.path_info = getenv("PATH_INFO"); + ctx.env.query_string = getenv("QUERY_STRING"); + ctx.env.request_method = getenv("REQUEST_METHOD"); + ctx.env.script_name = getenv("SCRIPT_NAME"); + ctx.env.server_name = getenv("SERVER_NAME"); + ctx.env.server_port = getenv("SERVER_PORT"); + ctx.env.http_cookie = getenv("HTTP_COOKIE"); + ctx.env.http_referer = getenv("HTTP_REFERER"); + ctx.env.content_length = getenv("CONTENT_LENGTH") ? strtoul(getenv("CONTENT_LENGTH"), NULL, 10) : 0; + ctx.env.authenticated = 0; + ctx.page.mimetype = "text/html"; + ctx.page.charset = PAGE_ENCODING; + ctx.page.filename = NULL; + ctx.page.size = 0; + ctx.page.modified = time(NULL); + ctx.page.expires = ctx.page.modified; + ctx.page.etag = NULL; + string_list_init(&ctx.cfg.mimetypes, 1); + if (ctx.env.script_name) + ctx.cfg.script_name = xstrdup(ctx.env.script_name); + if (ctx.env.query_string) + ctx.qry.raw = xstrdup(ctx.env.query_string); + if (!ctx.env.cgit_config) + ctx.env.cgit_config = CGIT_CONFIG; +} + +struct refmatch { + char *req_ref; + char *first_ref; + int match; +}; + +static int find_current_ref(const char *refname, const struct object_id *oid, + int flags, void *cb_data) +{ + struct refmatch *info; + + info = (struct refmatch *)cb_data; + if (!strcmp(refname, info->req_ref)) + info->match = 1; + if (!info->first_ref) + info->first_ref = xstrdup(refname); + return info->match; +} + +static void free_refmatch_inner(struct refmatch *info) +{ + if (info->first_ref) + free(info->first_ref); +} + +static char *find_default_branch(struct cgit_repo *repo) +{ + struct refmatch info; + char *ref; + + info.req_ref = repo->defbranch; + info.first_ref = NULL; + info.match = 0; + for_each_branch_ref(find_current_ref, &info); + if (info.match) + ref = info.req_ref; + else + ref = info.first_ref; + if (ref) + ref = xstrdup(ref); + free_refmatch_inner(&info); + + return ref; +} + +static char *guess_defbranch(void) +{ + const char *ref, *refname; + struct object_id oid; + + ref = resolve_ref_unsafe("HEAD", 0, &oid, NULL); + if (!ref || !skip_prefix(ref, "refs/heads/", &refname)) + return "master"; + return xstrdup(refname); +} + +/* The caller must free filename and ref after calling this. */ +static inline void parse_readme(const char *readme, char **filename, char **ref, struct cgit_repo *repo) +{ + const char *colon; + + *filename = NULL; + *ref = NULL; + + if (!readme || !readme[0]) + return; + + /* Check if the readme is tracked in the git repo. */ + colon = strchr(readme, ':'); + if (colon && strlen(colon) > 1) { + /* If it starts with a colon, we want to use + * the default branch */ + if (colon == readme && repo->defbranch) + *ref = xstrdup(repo->defbranch); + else + *ref = xstrndup(readme, colon - readme); + readme = colon + 1; + } + + /* Prepend repo path to relative readme path unless tracked. */ + if (!(*ref) && readme[0] != '/') + *filename = fmtalloc("%s/%s", repo->path, readme); + else + *filename = xstrdup(readme); +} +static void choose_readme(struct cgit_repo *repo) +{ + int found; + char *filename, *ref; + struct string_list_item *entry; + + if (!repo->readme.nr) + return; + + found = 0; + for_each_string_list_item(entry, &repo->readme) { + parse_readme(entry->string, &filename, &ref, repo); + if (!filename) { + free(filename); + free(ref); + continue; + } + if (ref) { + if (cgit_ref_path_exists(filename, ref, 1)) { + found = 1; + break; + } + } + else if (!access(filename, R_OK)) { + found = 1; + break; + } + free(filename); + free(ref); + } + repo->readme.strdup_strings = 1; + string_list_clear(&repo->readme, 0); + repo->readme.strdup_strings = 0; + if (found) + string_list_append(&repo->readme, filename)->util = ref; +} + +static void print_no_repo_clone_urls(const char *url) +{ + html("<tr><td><a rel='vcs-git' href='"); + html_url_path(url); + html("' title='"); + html_attr(ctx.repo->name); + html(" Git repository'>"); + html_txt(url); + html("</a></td></tr>\n"); +} + +static void prepare_repo_env(int *nongit) +{ + /* The path to the git repository. */ + setenv("GIT_DIR", ctx.repo->path, 1); + + /* Setup the git directory and initialize the notes system. Both of these + * load local configuration from the git repository, so we do them both while + * the HOME variables are unset. */ + setup_git_directory_gently(nongit); + init_display_notes(NULL); +} + +static int prepare_repo_cmd(int nongit) +{ + struct object_id oid; + int rc; + + if (nongit) { + const char *name = ctx.repo->name; + rc = errno; + ctx.page.title = fmtalloc("%s - %s", ctx.cfg.root_title, + "config error"); + ctx.repo = NULL; + cgit_print_http_headers(); + cgit_print_docstart(); + cgit_print_pageheader(); + cgit_print_error("Failed to open %s: %s", name, + rc ? strerror(rc) : "Not a valid git repository"); + cgit_print_docend(); + return 1; + } + ctx.page.title = fmtalloc("%s - %s", ctx.repo->name, ctx.repo->desc); + + if (!ctx.repo->defbranch) + ctx.repo->defbranch = guess_defbranch(); + + if (!ctx.qry.head) { + ctx.qry.nohead = 1; + ctx.qry.head = find_default_branch(ctx.repo); + } + + if (!ctx.qry.head) { + cgit_print_http_headers(); + cgit_print_docstart(); + cgit_print_pageheader(); + cgit_print_error("Repository seems to be empty"); + if (!strcmp(ctx.qry.page, "summary")) { + html("<table class='list'><tr class='nohover'><td> </td></tr><tr class='nohover'><th class='left'>Clone</th></tr>\n"); + cgit_prepare_repo_env(ctx.repo); + cgit_add_clone_urls(print_no_repo_clone_urls); + html("</table>\n"); + } + cgit_print_docend(); + return 1; + } + + if (get_oid(ctx.qry.head, &oid)) { + char *old_head = ctx.qry.head; + ctx.qry.head = xstrdup(ctx.repo->defbranch); + cgit_print_error_page(404, "Not found", + "Invalid branch: %s", old_head); + free(old_head); + return 1; + } + string_list_sort(&ctx.repo->submodules); + cgit_prepare_repo_env(ctx.repo); + choose_readme(ctx.repo); + return 0; +} + +static inline void open_auth_filter(const char *function) +{ + cgit_open_filter(ctx.cfg.auth_filter, function, + ctx.env.http_cookie ? ctx.env.http_cookie : "", + ctx.env.request_method ? ctx.env.request_method : "", + ctx.env.query_string ? ctx.env.query_string : "", + ctx.env.http_referer ? ctx.env.http_referer : "", + ctx.env.path_info ? ctx.env.path_info : "", + ctx.env.http_host ? ctx.env.http_host : "", + ctx.env.https ? ctx.env.https : "", + ctx.qry.repo ? ctx.qry.repo : "", + ctx.qry.page ? ctx.qry.page : "", + cgit_currentfullurl(), + cgit_loginurl()); +} + +/* We intentionally keep this rather small, instead of looping and + * feeding it to the filter a couple bytes at a time. This way, the + * filter itself does not need to handle any denial of service or + * buffer bloat issues. If this winds up being too small, people + * will complain on the mailing list, and we'll increase it as needed. */ +#define MAX_AUTHENTICATION_POST_BYTES 4096 +/* The filter is expected to spit out "Status: " and all headers. */ +static inline void authenticate_post(void) +{ + char buffer[MAX_AUTHENTICATION_POST_BYTES]; + ssize_t len; + + open_auth_filter("authenticate-post"); + len = ctx.env.content_length; + if (len > MAX_AUTHENTICATION_POST_BYTES) + len = MAX_AUTHENTICATION_POST_BYTES; + if ((len = read(STDIN_FILENO, buffer, len)) < 0) + die_errno("Could not read POST from stdin"); + if (write(STDOUT_FILENO, buffer, len) < 0) + die_errno("Could not write POST to stdout"); + cgit_close_filter(ctx.cfg.auth_filter); + exit(0); +} + +static inline void authenticate_cookie(void) +{ + /* If we don't have an auth_filter, consider all cookies valid, and thus return early. */ + if (!ctx.cfg.auth_filter) { + ctx.env.authenticated = 1; + return; + } + + /* If we're having something POST'd to /login, we're authenticating POST, + * instead of the cookie, so call authenticate_post and bail out early. + * This pattern here should match /?p=login with POST. */ + if (ctx.env.request_method && ctx.qry.page && !ctx.repo && \ + !strcmp(ctx.env.request_method, "POST") && !strcmp(ctx.qry.page, "login")) { + authenticate_post(); + return; + } + + /* If we've made it this far, we're authenticating the cookie for real, so do that. */ + open_auth_filter("authenticate-cookie"); + ctx.env.authenticated = cgit_close_filter(ctx.cfg.auth_filter); +} + +static void process_request(void) +{ + struct cgit_cmd *cmd; + int nongit = 0; + + /* If we're not yet authenticated, no matter what page we're on, + * display the authentication body from the auth_filter. This should + * never be cached. */ + if (!ctx.env.authenticated) { + ctx.page.title = "Authentication Required"; + cgit_print_http_headers(); + cgit_print_docstart(); + cgit_print_pageheader(); + open_auth_filter("body"); + cgit_close_filter(ctx.cfg.auth_filter); + cgit_print_docend(); + return; + } + + if (ctx.repo) + prepare_repo_env(&nongit); + + cmd = cgit_get_cmd(); + if (!cmd) { + ctx.page.title = "cgit error"; + cgit_print_error_page(404, "Not found", "Invalid request"); + return; + } + + if (!ctx.cfg.enable_http_clone && cmd->is_clone) { + ctx.page.title = "cgit error"; + cgit_print_error_page(404, "Not found", "Invalid request"); + return; + } + + if (cmd->want_repo && !ctx.repo) { + cgit_print_error_page(400, "Bad request", + "No repository selected"); + return; + } + + /* If cmd->want_vpath is set, assume ctx.qry.path contains a "virtual" + * in-project path limit to be made available at ctx.qry.vpath. + * Otherwise, no path limit is in effect (ctx.qry.vpath = NULL). + */ + ctx.qry.vpath = cmd->want_vpath ? ctx.qry.path : NULL; + + if (ctx.repo && prepare_repo_cmd(nongit)) + return; + + cmd->fn(); +} + +static int cmp_repos(const void *a, const void *b) +{ + const struct cgit_repo *ra = a, *rb = b; + return strcmp(ra->url, rb->url); +} + +static char *build_snapshot_setting(int bitmap) +{ + const struct cgit_snapshot_format *f; + struct strbuf result = STRBUF_INIT; + + for (f = cgit_snapshot_formats; f->suffix; f++) { + if (cgit_snapshot_format_bit(f) & bitmap) { + if (result.len) + strbuf_addch(&result, ' '); + strbuf_addstr(&result, f->suffix); + } + } + return strbuf_detach(&result, NULL); +} + +static char *get_first_line(char *txt) +{ + char *t = xstrdup(txt); + char *p = strchr(t, '\n'); + if (p) + *p = '\0'; + return t; +} + +static void print_repo(FILE *f, struct cgit_repo *repo) +{ + struct string_list_item *item; + fprintf(f, "repo.url=%s\n", repo->url); + fprintf(f, "repo.name=%s\n", repo->name); + fprintf(f, "repo.path=%s\n", repo->path); + if (repo->owner) + fprintf(f, "repo.owner=%s\n", repo->owner); + if (repo->desc) { + char *tmp = get_first_line(repo->desc); + fprintf(f, "repo.desc=%s\n", tmp); + free(tmp); + } + for_each_string_list_item(item, &repo->readme) { + if (item->util) + fprintf(f, "repo.readme=%s:%s\n", (char *)item->util, item->string); + else + fprintf(f, "repo.readme=%s\n", item->string); + } + if (repo->defbranch) + fprintf(f, "repo.defbranch=%s\n", repo->defbranch); + if (repo->extra_head_content) + fprintf(f, "repo.extra-head-content=%s\n", repo->extra_head_content); + if (repo->module_link) + fprintf(f, "repo.module-link=%s\n", repo->module_link); + if (repo->section) + fprintf(f, "repo.section=%s\n", repo->section); + if (repo->homepage) + fprintf(f, "repo.homepage=%s\n", repo->homepage); + if (repo->clone_url) + fprintf(f, "repo.clone-url=%s\n", repo->clone_url); + fprintf(f, "repo.enable-blame=%d\n", + repo->enable_blame); + fprintf(f, "repo.enable-commit-graph=%d\n", + repo->enable_commit_graph); + fprintf(f, "repo.enable-log-filecount=%d\n", + repo->enable_log_filecount); + fprintf(f, "repo.enable-log-linecount=%d\n", + repo->enable_log_linecount); + if (repo->about_filter && repo->about_filter != ctx.cfg.about_filter) + cgit_fprintf_filter(repo->about_filter, f, "repo.about-filter="); + if (repo->commit_filter && repo->commit_filter != ctx.cfg.commit_filter) + cgit_fprintf_filter(repo->commit_filter, f, "repo.commit-filter="); + if (repo->source_filter && repo->source_filter != ctx.cfg.source_filter) + cgit_fprintf_filter(repo->source_filter, f, "repo.source-filter="); + if (repo->email_filter && repo->email_filter != ctx.cfg.email_filter) + cgit_fprintf_filter(repo->email_filter, f, "repo.email-filter="); + if (repo->owner_filter && repo->owner_filter != ctx.cfg.owner_filter) + cgit_fprintf_filter(repo->owner_filter, f, "repo.owner-filter="); + if (repo->snapshots != ctx.cfg.snapshots) { + char *tmp = build_snapshot_setting(repo->snapshots); + fprintf(f, "repo.snapshots=%s\n", tmp ? tmp : ""); + free(tmp); + } + if (repo->snapshot_prefix) + fprintf(f, "repo.snapshot-prefix=%s\n", repo->snapshot_prefix); + if (repo->max_stats != ctx.cfg.max_stats) + fprintf(f, "repo.max-stats=%s\n", + cgit_find_stats_periodname(repo->max_stats)); + if (repo->logo) + fprintf(f, "repo.logo=%s\n", repo->logo); + if (repo->logo_link) + fprintf(f, "repo.logo-link=%s\n", repo->logo_link); + fprintf(f, "repo.enable-remote-branches=%d\n", repo->enable_remote_branches); + fprintf(f, "repo.enable-subject-links=%d\n", repo->enable_subject_links); + fprintf(f, "repo.enable-html-serving=%d\n", repo->enable_html_serving); + if (repo->branch_sort == 1) + fprintf(f, "repo.branch-sort=age\n"); + if (repo->commit_sort) { + if (repo->commit_sort == 1) + fprintf(f, "repo.commit-sort=date\n"); + else if (repo->commit_sort == 2) + fprintf(f, "repo.commit-sort=topo\n"); + } + fprintf(f, "repo.hide=%d\n", repo->hide); + fprintf(f, "repo.ignore=%d\n", repo->ignore); + fprintf(f, "\n"); +} + +static void print_repolist(FILE *f, struct cgit_repolist *list, int start) +{ + int i; + + for (i = start; i < list->count; i++) + print_repo(f, &list->repos[i]); +} + +/* Scan 'path' for git repositories, save the resulting repolist in 'cached_rc' + * and return 0 on success. + */ +static int generate_cached_repolist(const char *path, const char *cached_rc) +{ + struct strbuf locked_rc = STRBUF_INIT; + int result = 0; + int idx; + FILE *f; + + strbuf_addf(&locked_rc, "%s.lock", cached_rc); + f = fopen(locked_rc.buf, "wx"); + if (!f) { + /* Inform about the error unless the lockfile already existed, + * since that only means we've got concurrent requests. + */ + result = errno; + if (result != EEXIST) + fprintf(stderr, "[cgit] Error opening %s: %s (%d)\n", + locked_rc.buf, strerror(result), result); + goto out; + } + idx = cgit_repolist.count; + if (ctx.cfg.project_list) + scan_projects(path, ctx.cfg.project_list, repo_config); + else + scan_tree(path, repo_config); + print_repolist(f, &cgit_repolist, idx); + if (rename(locked_rc.buf, cached_rc)) + fprintf(stderr, "[cgit] Error renaming %s to %s: %s (%d)\n", + locked_rc.buf, cached_rc, strerror(errno), errno); + fclose(f); +out: + strbuf_release(&locked_rc); + return result; +} + +static void process_cached_repolist(const char *path) +{ + struct stat st; + struct strbuf cached_rc = STRBUF_INIT; + time_t age; + unsigned long hash; + + hash = hash_str(path); + if (ctx.cfg.project_list) + hash += hash_str(ctx.cfg.project_list); + strbuf_addf(&cached_rc, "%s/rc-%8lx", ctx.cfg.cache_root, hash); + + if (stat(cached_rc.buf, &st)) { + /* Nothing is cached, we need to scan without forking. And + * if we fail to generate a cached repolist, we need to + * invoke scan_tree manually. + */ + if (generate_cached_repolist(path, cached_rc.buf)) { + if (ctx.cfg.project_list) + scan_projects(path, ctx.cfg.project_list, + repo_config); + else + scan_tree(path, repo_config); + } + goto out; + } + + parse_configfile(cached_rc.buf, config_cb); + + /* If the cached configfile hasn't expired, lets exit now */ + age = time(NULL) - st.st_mtime; + if (age <= (ctx.cfg.cache_scanrc_ttl * 60)) + goto out; + + /* The cached repolist has been parsed, but it was old. So lets + * rescan the specified path and generate a new cached repolist + * in a child-process to avoid latency for the current request. + */ + if (fork()) + goto out; + + exit(generate_cached_repolist(path, cached_rc.buf)); +out: + strbuf_release(&cached_rc); +} + +static void cgit_parse_args(int argc, const char **argv) +{ + int i; + const char *arg; + int scan = 0; + + for (i = 1; i < argc; i++) { + if (!strcmp(argv[i], "--version")) { + printf("CGit %s | https://git.zx2c4.com/cgit/\n\nCompiled in features:\n", CGIT_VERSION); +#ifdef NO_LUA + printf("[-] "); +#else + printf("[+] "); +#endif + printf("Lua scripting\n"); +#ifndef HAVE_LINUX_SENDFILE + printf("[-] "); +#else + printf("[+] "); +#endif + printf("Linux sendfile() usage\n"); + + exit(0); + } + if (skip_prefix(argv[i], "--cache=", &arg)) { + ctx.cfg.cache_root = xstrdup(arg); + } else if (!strcmp(argv[i], "--nohttp")) { + ctx.env.no_http = "1"; + } else if (skip_prefix(argv[i], "--query=", &arg)) { + ctx.qry.raw = xstrdup(arg); + } else if (skip_prefix(argv[i], "--repo=", &arg)) { + ctx.qry.repo = xstrdup(arg); + } else if (skip_prefix(argv[i], "--page=", &arg)) { + ctx.qry.page = xstrdup(arg); + } else if (skip_prefix(argv[i], "--head=", &arg)) { + ctx.qry.head = xstrdup(arg); + ctx.qry.has_symref = 1; + } else if (skip_prefix(argv[i], "--sha1=", &arg)) { + ctx.qry.sha1 = xstrdup(arg); + ctx.qry.has_sha1 = 1; + } else if (skip_prefix(argv[i], "--ofs=", &arg)) { + ctx.qry.ofs = atoi(arg); + } else if (skip_prefix(argv[i], "--scan-tree=", &arg) || + skip_prefix(argv[i], "--scan-path=", &arg)) { + /* + * HACK: The global snapshot bit mask defines the set + * of allowed snapshot formats, but the config file + * hasn't been parsed yet so the mask is currently 0. + * By setting all bits high before scanning we make + * sure that any in-repo cgitrc snapshot setting is + * respected by scan_tree(). + * + * NOTE: We assume that there aren't more than 8 + * different snapshot formats supported by cgit... + */ + ctx.cfg.snapshots = 0xFF; + scan++; + scan_tree(arg, repo_config); + } + } + if (scan) { + qsort(cgit_repolist.repos, cgit_repolist.count, + sizeof(struct cgit_repo), cmp_repos); + print_repolist(stdout, &cgit_repolist, 0); + exit(0); + } +} + +static int calc_ttl(void) +{ + if (!ctx.repo) + return ctx.cfg.cache_root_ttl; + + if (!ctx.qry.page) + return ctx.cfg.cache_repo_ttl; + + if (!strcmp(ctx.qry.page, "about")) + return ctx.cfg.cache_about_ttl; + + if (!strcmp(ctx.qry.page, "snapshot")) + return ctx.cfg.cache_snapshot_ttl; + + if (ctx.qry.has_sha1) + return ctx.cfg.cache_static_ttl; + + if (ctx.qry.has_symref) + return ctx.cfg.cache_dynamic_ttl; + + return ctx.cfg.cache_repo_ttl; +} + +int cmd_main(int argc, const char **argv) +{ + const char *path; + int err, ttl; + + cgit_init_filters(); + atexit(cgit_cleanup_filters); + + prepare_context(); + cgit_repolist.length = 0; + cgit_repolist.count = 0; + cgit_repolist.repos = NULL; + + cgit_parse_args(argc, argv); + parse_configfile(expand_macros(ctx.env.cgit_config), config_cb); + ctx.repo = NULL; + http_parse_querystring(ctx.qry.raw, querystring_cb); + + /* If virtual-root isn't specified in cgitrc, lets pretend + * that virtual-root equals SCRIPT_NAME, minus any possibly + * trailing slashes. + */ + if (!ctx.cfg.virtual_root && ctx.cfg.script_name) + ctx.cfg.virtual_root = ensure_end(ctx.cfg.script_name, '/'); + + /* If no url parameter is specified on the querystring, lets + * use PATH_INFO as url. This allows cgit to work with virtual + * urls without the need for rewriterules in the webserver (as + * long as PATH_INFO is included in the cache lookup key). + */ + path = ctx.env.path_info; + if (!ctx.qry.url && path) { + if (path[0] == '/') + path++; + ctx.qry.url = xstrdup(path); + if (ctx.qry.raw) { + char *newqry = fmtalloc("%s?%s", path, ctx.qry.raw); + free(ctx.qry.raw); + ctx.qry.raw = newqry; + } else + ctx.qry.raw = xstrdup(ctx.qry.url); + cgit_parse_url(ctx.qry.url); + } + + /* Before we go any further, we set ctx.env.authenticated by checking to see + * if the supplied cookie is valid. All cookies are valid if there is no + * auth_filter. If there is an auth_filter, the filter decides. */ + authenticate_cookie(); + + ttl = calc_ttl(); + if (ttl < 0) + ctx.page.expires += 10 * 365 * 24 * 60 * 60; /* 10 years */ + else + ctx.page.expires += ttl * 60; + if (!ctx.env.authenticated || (ctx.env.request_method && !strcmp(ctx.env.request_method, "HEAD"))) + ctx.cfg.cache_size = 0; + err = cache_process(ctx.cfg.cache_size, ctx.cfg.cache_root, + ctx.qry.raw, ttl, process_request); + cgit_cleanup_filters(); + if (err) + cgit_print_error("Error processing page: %s (%d)", + strerror(err), err); + return err; +} diff --git a/third_party/cgit/cgit.css b/third_party/cgit/cgit.css new file mode 100644 index 0000000000..d4aadbfa10 --- /dev/null +++ b/third_party/cgit/cgit.css @@ -0,0 +1,895 @@ +div#cgit { + padding: 0em; + margin: 0em; + font-family: sans-serif; + font-size: 10pt; + color: #333; + background: white; + padding: 4px; +} + +div#cgit a { + color: blue; + text-decoration: none; +} + +div#cgit a:hover { + text-decoration: underline; +} + +div#cgit table { + border-collapse: collapse; +} + +div#cgit table#header { + width: 100%; + margin-bottom: 1em; +} + +div#cgit table#header td.logo { + width: 96px; + vertical-align: top; +} + +div#cgit table#header td.main { + font-size: 250%; + padding-left: 10px; + white-space: nowrap; +} + +div#cgit table#header td.main a { + color: #000; +} + +div#cgit table#header td.form { + text-align: right; + vertical-align: bottom; + padding-right: 1em; + padding-bottom: 2px; + white-space: nowrap; +} + +div#cgit table#header td.form form, +div#cgit table#header td.form input, +div#cgit table#header td.form select { + font-size: 90%; +} + +div#cgit table#header td.sub { + color: #777; + border-top: solid 1px #ccc; + padding-left: 10px; +} + +div#cgit table.tabs { + border-bottom: solid 3px #ccc; + border-collapse: collapse; + margin-top: 2em; + margin-bottom: 0px; + width: 100%; +} + +div#cgit table.tabs td { + padding: 0px 1em; + vertical-align: bottom; +} + +div#cgit table.tabs td a { + padding: 2px 0.75em; + color: #777; + font-size: 110%; +} + +div#cgit table.tabs td a.active { + color: #000; + background-color: #ccc; +} + +div#cgit table.tabs a[href^="http://"]:after, div#cgit table.tabs a[href^="https://"]:after { + content: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAKCAQAAAAnOwc2AAAAAmJLR0QA/4ePzL8AAAAJcEhZcwAACxMAAAsTAQCanBgAAAAHdElNRQfgAhcJDQY+gm2TAAAAHWlUWHRDb21tZW50AAAAAABDcmVhdGVkIHdpdGggR0lNUGQuZQcAAABbSURBVAhbY2BABs4MU4CwhYHBh2Erww4wrGFQZHjI8B8IgUIscJWyDHcggltQhI4zGDCcRwhChPggHIggP1QoAVmQkSETrGoHsiAEsACtBYN0oDAMbgU6EBcAAL2eHUt4XUU4AAAAAElFTkSuQmCC); + opacity: 0.5; + margin: 0 0 0 5px; +} + +div#cgit table.tabs td.form { + text-align: right; +} + +div#cgit table.tabs td.form form { + padding-bottom: 2px; + font-size: 90%; + white-space: nowrap; +} + +div#cgit table.tabs td.form input, +div#cgit table.tabs td.form select { + font-size: 90%; +} + +div#cgit div.path { + margin: 0px; + padding: 5px 2em 2px 2em; + color: #000; + background-color: #eee; +} + +div#cgit div.content { + margin: 0px; + padding: 2em; + border-bottom: solid 3px #ccc; +} + + +div#cgit table.list { + width: 100%; + border: none; + border-collapse: collapse; +} + +div#cgit table.list tr { + background: white; +} + +div#cgit table.list tr.logheader { + background: #eee; +} + +div#cgit table.list tr:nth-child(even) { + background: #f7f7f7; +} + +div#cgit table.list tr:nth-child(odd) { + background: white; +} + +div#cgit table.list tr:hover { + background: #eee; +} + +div#cgit table.list tr.nohover { + background: white; +} + +div#cgit table.list tr.nohover:hover { + background: white; +} + +div#cgit table.list tr.nohover-highlight:hover:nth-child(even) { + background: #f7f7f7; +} + +div#cgit table.list tr.nohover-highlight:hover:nth-child(odd) { + background: white; +} + +div#cgit table.list th { + font-weight: bold; + /* color: #888; + border-top: dashed 1px #888; + border-bottom: dashed 1px #888; + */ + padding: 0.1em 0.5em 0.05em 0.5em; + vertical-align: baseline; +} + +div#cgit table.list td { + border: none; + padding: 0.1em 0.5em 0.1em 0.5em; +} + +div#cgit table.list td.commitgraph { + font-family: monospace; + white-space: pre; +} + +div#cgit table.list td.commitgraph .column1 { + color: #a00; +} + +div#cgit table.list td.commitgraph .column2 { + color: #0a0; +} + +div#cgit table.list td.commitgraph .column3 { + color: #aa0; +} + +div#cgit table.list td.commitgraph .column4 { + color: #00a; +} + +div#cgit table.list td.commitgraph .column5 { + color: #a0a; +} + +div#cgit table.list td.commitgraph .column6 { + color: #0aa; +} + +div#cgit table.list td.logsubject { + font-family: monospace; + font-weight: bold; +} + +div#cgit table.list td.logmsg { + font-family: monospace; + white-space: pre; + padding: 0 0.5em; +} + +div#cgit table.list td a { + color: black; +} + +div#cgit table.list td a.ls-dir { + font-weight: bold; + color: #00f; +} + +div#cgit table.list td a:hover { + color: #00f; +} + +div#cgit img { + border: none; +} + +div#cgit input#switch-btn { + margin: 2px 0px 0px 0px; +} + +div#cgit td#sidebar input.txt { + width: 100%; + margin: 2px 0px 0px 0px; +} + +div#cgit table#grid { + margin: 0px; +} + +div#cgit td#content { + vertical-align: top; + padding: 1em 2em 1em 1em; + border: none; +} + +div#cgit div#summary { + vertical-align: top; + margin-bottom: 1em; +} + +div#cgit table#downloads { + float: right; + border-collapse: collapse; + border: solid 1px #777; + margin-left: 0.5em; + margin-bottom: 0.5em; +} + +div#cgit table#downloads th { + background-color: #ccc; +} + +div#cgit div#blob { + border: solid 1px black; +} + +div#cgit div.error { + color: red; + font-weight: bold; + margin: 1em 2em; +} + +div#cgit a.ls-blob, div#cgit a.ls-dir, div#cgit .ls-mod { + font-family: monospace; +} + +div#cgit td.ls-size { + text-align: right; + font-family: monospace; + width: 10em; +} + +div#cgit td.ls-mode { + font-family: monospace; + width: 10em; +} + +div#cgit table.blob { + margin-top: 0.5em; + border-top: solid 1px black; +} + +div#cgit table.blob td.hashes, +div#cgit table.blob td.lines { + margin: 0; padding: 0 0 0 0.5em; + vertical-align: top; + color: black; +} + +div#cgit table.blob td.linenumbers { + margin: 0; padding: 0 0.5em 0 0.5em; + vertical-align: top; + text-align: right; + border-right: 1px solid gray; +} + +div#cgit table.blob pre { + padding: 0; margin: 0; +} + +div#cgit table.blob td.linenumbers a, +div#cgit table.ssdiff td.lineno a { + color: gray; + text-align: right; + text-decoration: none; +} + +div#cgit table.blob td.linenumbers a:hover, +div#cgit table.ssdiff td.lineno a:hover { + color: black; +} + +div#cgit table.blame td.hashes, +div#cgit table.blame td.lines, +div#cgit table.blame td.linenumbers { + padding: 0; +} + +div#cgit table.blame td.hashes div.alt, +div#cgit table.blame td.lines div.alt { + padding: 0 0.5em 0 0.5em; +} + +div#cgit table.blame td.linenumbers div.alt { + padding: 0 0.5em 0 0; +} + +div#cgit table.blame div.alt:nth-child(even) { + background: #eee; +} + +div#cgit table.blame div.alt:nth-child(odd) { + background: white; +} + +div#cgit table.blame td.lines > div { + position: relative; +} + +div#cgit table.blame td.lines > div > pre { + padding: 0 0 0 0.5em; + position: absolute; + top: 0; +} + +div#cgit table.bin-blob { + margin-top: 0.5em; + border: solid 1px black; +} + +div#cgit table.bin-blob th { + font-family: monospace; + white-space: pre; + border: solid 1px #777; + padding: 0.5em 1em; +} + +div#cgit table.bin-blob td { + font-family: monospace; + white-space: pre; + border-left: solid 1px #777; + padding: 0em 1em; +} + +div#cgit table.nowrap td { + white-space: nowrap; +} + +div#cgit table.commit-info { + border-collapse: collapse; + margin-top: 1.5em; +} + +div#cgit div.cgit-panel { + float: right; + margin-top: 1.5em; +} + +div#cgit div.cgit-panel table { + border-collapse: collapse; + border: solid 1px #aaa; + background-color: #eee; +} + +div#cgit div.cgit-panel th { + text-align: center; +} + +div#cgit div.cgit-panel td { + padding: 0.25em 0.5em; +} + +div#cgit div.cgit-panel td.label { + padding-right: 0.5em; +} + +div#cgit div.cgit-panel td.ctrl { + padding-left: 0.5em; +} + +div#cgit table.commit-info th { + text-align: left; + font-weight: normal; + padding: 0.1em 1em 0.1em 0.1em; + vertical-align: top; +} + +div#cgit table.commit-info td { + font-weight: normal; + padding: 0.1em 1em 0.1em 0.1em; +} + +div#cgit div.commit-subject { + font-weight: bold; + font-size: 125%; + margin: 1.5em 0em 0.5em 0em; + padding: 0em; +} + +div#cgit div.commit-msg { + white-space: pre; + font-family: monospace; +} + +div#cgit div.notes-header { + font-weight: bold; + padding-top: 1.5em; +} + +div#cgit div.notes { + white-space: pre; + font-family: monospace; + border: solid 1px #ee9; + background-color: #ffd; + padding: 0.3em 2em 0.3em 1em; + float: left; +} + +div#cgit div.notes-footer { + clear: left; +} + +div#cgit div.diffstat-header { + font-weight: bold; + padding-top: 1.5em; +} + +div#cgit table.diffstat { + border-collapse: collapse; + border: solid 1px #aaa; + background-color: #eee; +} + +div#cgit table.diffstat th { + font-weight: normal; + text-align: left; + text-decoration: underline; + padding: 0.1em 1em 0.1em 0.1em; + font-size: 100%; +} + +div#cgit table.diffstat td { + padding: 0.2em 0.2em 0.1em 0.1em; + font-size: 100%; + border: none; +} + +div#cgit table.diffstat td.mode { + white-space: nowrap; +} + +div#cgit table.diffstat td span.modechange { + padding-left: 1em; + color: red; +} + +div#cgit table.diffstat td.add a { + color: green; +} + +div#cgit table.diffstat td.del a { + color: red; +} + +div#cgit table.diffstat td.upd a { + color: blue; +} + +div#cgit table.diffstat td.graph { + width: 500px; + vertical-align: middle; +} + +div#cgit table.diffstat td.graph table { + border: none; +} + +div#cgit table.diffstat td.graph td { + padding: 0px; + border: 0px; + height: 7pt; +} + +div#cgit table.diffstat td.graph td.add { + background-color: #5c5; +} + +div#cgit table.diffstat td.graph td.rem { + background-color: #c55; +} + +div#cgit div.diffstat-summary { + color: #888; + padding-top: 0.5em; +} + +div#cgit table.diff { + width: 100%; +} + +div#cgit table.diff td { + font-family: monospace; + white-space: pre; +} + +div#cgit table.diff td div.head { + font-weight: bold; + margin-top: 1em; + color: black; +} + +div#cgit table.diff td div.hunk { + color: #009; +} + +div#cgit table.diff td div.add { + color: green; +} + +div#cgit table.diff td div.del { + color: red; +} + +div#cgit .sha1 { + font-family: monospace; + font-size: 90%; +} + +div#cgit .left { + text-align: left; +} + +div#cgit .right { + text-align: right; +} + +div#cgit table.list td.reposection { + font-style: italic; + color: #888; +} + +div#cgit a.button { + font-size: 80%; + padding: 0em 0.5em; +} + +div#cgit a.primary { + font-size: 100%; +} + +div#cgit a.secondary { + font-size: 90%; +} + +div#cgit td.toplevel-repo { + +} + +div#cgit table.list td.sublevel-repo { + padding-left: 1.5em; +} + +div#cgit ul.pager { + list-style-type: none; + text-align: center; + margin: 1em 0em 0em 0em; + padding: 0; +} + +div#cgit ul.pager li { + display: inline-block; + margin: 0.25em 0.5em; +} + +div#cgit ul.pager a { + color: #777; +} + +div#cgit ul.pager .current { + font-weight: bold; +} + +div#cgit span.age-mins { + font-weight: bold; + color: #080; +} + +div#cgit span.age-hours { + color: #080; +} + +div#cgit span.age-days { + color: #040; +} + +div#cgit span.age-weeks { + color: #444; +} + +div#cgit span.age-months { + color: #888; +} + +div#cgit span.age-years { + color: #bbb; +} + +div#cgit span.insertions { + color: #080; +} + +div#cgit span.deletions { + color: #800; +} + +div#cgit div.footer { + margin-top: 0.5em; + text-align: center; + font-size: 80%; + color: #ccc; +} + +div#cgit div.footer a { + color: #ccc; + text-decoration: none; +} + +div#cgit div.footer a:hover { + text-decoration: underline; +} + +div#cgit a.branch-deco { + color: #000; + margin: 0px 0.5em; + padding: 0px 0.25em; + background-color: #88ff88; + border: solid 1px #007700; +} + +div#cgit a.tag-deco { + color: #000; + margin: 0px 0.5em; + padding: 0px 0.25em; + background-color: #ffff88; + border: solid 1px #777700; +} + +div#cgit a.tag-annotated-deco { + color: #000; + margin: 0px 0.5em; + padding: 0px 0.25em; + background-color: #ffcc88; + border: solid 1px #777700; +} + +div#cgit a.remote-deco { + color: #000; + margin: 0px 0.5em; + padding: 0px 0.25em; + background-color: #ccccff; + border: solid 1px #000077; +} + +div#cgit a.deco { + color: #000; + margin: 0px 0.5em; + padding: 0px 0.25em; + background-color: #ff8888; + border: solid 1px #770000; +} + +div#cgit div.commit-subject a.branch-deco, +div#cgit div.commit-subject a.tag-deco, +div#cgit div.commit-subject a.tag-annotated-deco, +div#cgit div.commit-subject a.remote-deco, +div#cgit div.commit-subject a.deco { + margin-left: 1em; + font-size: 75%; +} + +div#cgit table.stats { + border: solid 1px black; + border-collapse: collapse; +} + +div#cgit table.stats th { + text-align: left; + padding: 1px 0.5em; + background-color: #eee; + border: solid 1px black; +} + +div#cgit table.stats td { + text-align: right; + padding: 1px 0.5em; + border: solid 1px black; +} + +div#cgit table.stats td.total { + font-weight: bold; + text-align: left; +} + +div#cgit table.stats td.sum { + color: #c00; + font-weight: bold; +/* background-color: #eee; */ +} + +div#cgit table.stats td.left { + text-align: left; +} + +div#cgit table.vgraph { + border-collapse: separate; + border: solid 1px black; + height: 200px; +} + +div#cgit table.vgraph th { + background-color: #eee; + font-weight: bold; + border: solid 1px white; + padding: 1px 0.5em; +} + +div#cgit table.vgraph td { + vertical-align: bottom; + padding: 0px 10px; +} + +div#cgit table.vgraph div.bar { + background-color: #eee; +} + +div#cgit table.hgraph { + border: solid 1px black; + width: 800px; +} + +div#cgit table.hgraph th { + background-color: #eee; + font-weight: bold; + border: solid 1px black; + padding: 1px 0.5em; +} + +div#cgit table.hgraph td { + vertical-align: middle; + padding: 2px 2px; +} + +div#cgit table.hgraph div.bar { + background-color: #eee; + height: 1em; +} + +div#cgit table.ssdiff { + width: 100%; +} + +div#cgit table.ssdiff td { + font-size: 75%; + font-family: monospace; + white-space: pre; + padding: 1px 4px 1px 4px; + border-left: solid 1px #aaa; + border-right: solid 1px #aaa; +} + +div#cgit table.ssdiff td.add { + color: black; + background: #cfc; + min-width: 50%; +} + +div#cgit table.ssdiff td.add_dark { + color: black; + background: #aca; + min-width: 50%; +} + +div#cgit table.ssdiff span.add { + background: #cfc; + font-weight: bold; +} + +div#cgit table.ssdiff td.del { + color: black; + background: #fcc; + min-width: 50%; +} + +div#cgit table.ssdiff td.del_dark { + color: black; + background: #caa; + min-width: 50%; +} + +div#cgit table.ssdiff span.del { + background: #fcc; + font-weight: bold; +} + +div#cgit table.ssdiff td.changed { + color: black; + background: #ffc; + min-width: 50%; +} + +div#cgit table.ssdiff td.changed_dark { + color: black; + background: #cca; + min-width: 50%; +} + +div#cgit table.ssdiff td.lineno { + color: black; + background: #eee; + text-align: right; + width: 3em; + min-width: 3em; +} + +div#cgit table.ssdiff td.hunk { + color: black; + background: #ccf; + border-top: solid 1px #aaa; + border-bottom: solid 1px #aaa; +} + +div#cgit table.ssdiff td.head { + border-top: solid 1px #aaa; + border-bottom: solid 1px #aaa; +} + +div#cgit table.ssdiff td.head div.head { + font-weight: bold; + color: black; +} + +div#cgit table.ssdiff td.foot { + border-top: solid 1px #aaa; + border-left: none; + border-right: none; + border-bottom: none; +} + +div#cgit table.ssdiff td.space { + border: none; +} + +div#cgit table.ssdiff td.space div { + min-height: 3em; +} diff --git a/third_party/cgit/cgit.h b/third_party/cgit/cgit.h new file mode 100644 index 0000000000..7ec46b4846 --- /dev/null +++ b/third_party/cgit/cgit.h @@ -0,0 +1,398 @@ +#ifndef CGIT_H +#define CGIT_H + + +#include <git-compat-util.h> +#include <stdbool.h> + +#include <cache.h> +#include <grep.h> +#include <object.h> +#include <object-store.h> +#include <tree.h> +#include <commit.h> +#include <tag.h> +#include <diff.h> +#include <diffcore.h> +#include <argv-array.h> +#include <refs.h> +#include <revision.h> +#include <log-tree.h> +#include <archive.h> +#include <string-list.h> +#include <xdiff-interface.h> +#include <xdiff/xdiff.h> +#include <utf8.h> +#include <notes.h> +#include <graph.h> + +/* Add isgraph(x) to Git's sane ctype support (see git-compat-util.h) */ +#undef isgraph +#define isgraph(x) (isprint((x)) && !isspace((x))) + + +/* + * Limits used for relative dates + */ +#define TM_MIN 60 +#define TM_HOUR (TM_MIN * 60) +#define TM_DAY (TM_HOUR * 24) +#define TM_WEEK (TM_DAY * 7) +#define TM_YEAR (TM_DAY * 365) +#define TM_MONTH (TM_YEAR / 12.0) + + +/* + * Default encoding + */ +#define PAGE_ENCODING "UTF-8" + +#define BIT(x) (1U << (x)) + +typedef void (*configfn)(const char *name, const char *value); +typedef void (*filepair_fn)(struct diff_filepair *pair); +typedef void (*linediff_fn)(char *line, int len); + +typedef enum { + DIFF_UNIFIED, DIFF_SSDIFF, DIFF_STATONLY +} diff_type; + +typedef enum { + ABOUT, COMMIT, SOURCE, EMAIL, AUTH, OWNER +} filter_type; + +struct cgit_filter { + int (*open)(struct cgit_filter *, va_list ap); + int (*close)(struct cgit_filter *); + void (*fprintf)(struct cgit_filter *, FILE *, const char *prefix); + void (*cleanup)(struct cgit_filter *); + int argument_count; +}; + +struct cgit_exec_filter { + struct cgit_filter base; + char *cmd; + char **argv; + int old_stdout; + int pid; +}; + +struct cgit_repo { + char *url; + char *name; + char *path; + char *desc; + char *extra_head_content; + char *owner; + char *homepage; + char *defbranch; + char *module_link; + struct string_list readme; + char *section; + char *clone_url; + char *logo; + char *logo_link; + char *snapshot_prefix; + int snapshots; + int enable_blame; + int enable_commit_graph; + int enable_log_filecount; + int enable_log_linecount; + int enable_remote_branches; + int enable_subject_links; + int enable_html_serving; + int max_stats; + int branch_sort; + int commit_sort; + time_t mtime; + struct cgit_filter *about_filter; + struct cgit_filter *commit_filter; + struct cgit_filter *source_filter; + struct cgit_filter *email_filter; + struct cgit_filter *owner_filter; + struct string_list submodules; + int hide; + int ignore; +}; + +typedef void (*repo_config_fn)(struct cgit_repo *repo, const char *name, + const char *value); + +struct cgit_repolist { + int length; + int count; + struct cgit_repo *repos; +}; + +struct commitinfo { + struct commit *commit; + char *author; + char *author_email; + unsigned long author_date; + int author_tz; + char *committer; + char *committer_email; + unsigned long committer_date; + int committer_tz; + char *subject; + char *msg; + char *msg_encoding; +}; + +struct taginfo { + char *tagger; + char *tagger_email; + unsigned long tagger_date; + int tagger_tz; + char *msg; +}; + +struct refinfo { + const char *refname; + struct object *object; + union { + struct taginfo *tag; + struct commitinfo *commit; + }; +}; + +struct reflist { + struct refinfo **refs; + int alloc; + int count; +}; + +struct cgit_query { + int has_symref; + int has_sha1; + int has_difftype; + char *raw; + char *repo; + char *page; + char *search; + char *grep; + char *head; + char *sha1; + char *sha2; + char *path; + char *name; + char *url; + char *period; + int ofs; + int nohead; + char *sort; + int showmsg; + diff_type difftype; + int show_all; + int context; + int ignorews; + int follow; + char *vpath; +}; + +struct cgit_config { + char *agefile; + char *cache_root; + char *clone_prefix; + char *clone_url; + char *css; + char *favicon; + char *footer; + char *head_include; + char *header; + char *logo; + char *logo_link; + char *mimetype_file; + char *module_link; + char *project_list; + struct string_list readme; + char *robots; + char *root_title; + char *root_desc; + char *root_readme; + char *script_name; + char *section; + char *repository_sort; + char *virtual_root; /* Always ends with '/'. */ + char *strict_export; + int cache_size; + int cache_dynamic_ttl; + int cache_max_create_time; + int cache_repo_ttl; + int cache_root_ttl; + int cache_scanrc_ttl; + int cache_static_ttl; + int cache_about_ttl; + int cache_snapshot_ttl; + int case_sensitive_sort; + int embedded; + int enable_filter_overrides; + int enable_follow_links; + int enable_http_clone; + int enable_index_links; + int enable_index_owner; + int enable_blame; + int enable_commit_graph; + int enable_log_filecount; + int enable_log_linecount; + int enable_remote_branches; + int enable_subject_links; + int enable_html_serving; + int enable_tree_linenumbers; + int enable_git_config; + int local_time; + int max_atom_items; + int max_repo_count; + int max_commit_count; + int max_lock_attempts; + int max_msg_len; + int max_repodesc_len; + int max_blob_size; + int max_stats; + int noplainemail; + int noheader; + int renamelimit; + int remove_suffix; + int scan_hidden_path; + int section_from_path; + int snapshots; + int section_sort; + int summary_branches; + int summary_log; + int summary_tags; + diff_type difftype; + int branch_sort; + int commit_sort; + struct string_list mimetypes; + struct cgit_filter *about_filter; + struct cgit_filter *commit_filter; + struct cgit_filter *source_filter; + struct cgit_filter *email_filter; + struct cgit_filter *owner_filter; + struct cgit_filter *auth_filter; +}; + +struct cgit_page { + time_t modified; + time_t expires; + size_t size; + const char *mimetype; + const char *charset; + const char *filename; + const char *etag; + const char *title; + int status; + const char *statusmsg; +}; + +struct cgit_environment { + const char *cgit_config; + const char *http_host; + const char *https; + const char *no_http; + const char *path_info; + const char *query_string; + const char *request_method; + const char *script_name; + const char *server_name; + const char *server_port; + const char *http_cookie; + const char *http_referer; + unsigned int content_length; + int authenticated; +}; + +struct cgit_context { + struct cgit_environment env; + struct cgit_query qry; + struct cgit_config cfg; + struct cgit_repo *repo; + struct cgit_page page; +}; + +typedef int (*write_archive_fn_t)(const char *, const char *); + +struct cgit_snapshot_format { + const char *suffix; + const char *mimetype; + write_archive_fn_t write_func; +}; + +extern const char *cgit_version; + +extern struct cgit_repolist cgit_repolist; +extern struct cgit_context ctx; +extern const struct cgit_snapshot_format cgit_snapshot_formats[]; + +extern char *cgit_default_repo_desc; +extern struct cgit_repo *cgit_add_repo(const char *url); +extern struct cgit_repo *cgit_get_repoinfo(const char *url); +extern void cgit_repo_config_cb(const char *name, const char *value); + +extern int chk_zero(int result, char *msg); +extern int chk_positive(int result, char *msg); +extern int chk_non_negative(int result, char *msg); + +extern char *trim_end(const char *str, char c); +extern char *ensure_end(const char *str, char c); + +extern void strbuf_ensure_end(struct strbuf *sb, char c); + +extern void cgit_add_ref(struct reflist *list, struct refinfo *ref); +extern void cgit_free_reflist_inner(struct reflist *list); +extern int cgit_refs_cb(const char *refname, const struct object_id *oid, + int flags, void *cb_data); + +extern void cgit_free_commitinfo(struct commitinfo *info); +extern void cgit_free_taginfo(struct taginfo *info); + +void cgit_diff_tree_cb(struct diff_queue_struct *q, + struct diff_options *options, void *data); + +extern int cgit_diff_files(const struct object_id *old_oid, + const struct object_id *new_oid, + unsigned long *old_size, unsigned long *new_size, + int *binary, int context, int ignorews, + linediff_fn fn); + +extern void cgit_diff_tree(const struct object_id *old_oid, + const struct object_id *new_oid, + filepair_fn fn, const char *prefix, int ignorews); + +extern void cgit_diff_commit(struct commit *commit, filepair_fn fn, + const char *prefix); + +__attribute__((format (printf,1,2))) +extern char *fmt(const char *format,...); + +__attribute__((format (printf,1,2))) +extern char *fmtalloc(const char *format,...); + +extern struct commitinfo *cgit_parse_commit(struct commit *commit); +extern struct taginfo *cgit_parse_tag(struct tag *tag); +extern void cgit_parse_url(const char *url); + +extern const char *cgit_repobasename(const char *reponame); + +extern int cgit_parse_snapshots_mask(const char *str); +extern const struct object_id *cgit_snapshot_get_sig(const char *ref, + const struct cgit_snapshot_format *f); +extern const unsigned cgit_snapshot_format_bit(const struct cgit_snapshot_format *f); + +extern int cgit_open_filter(struct cgit_filter *filter, ...); +extern int cgit_close_filter(struct cgit_filter *filter); +extern void cgit_fprintf_filter(struct cgit_filter *filter, FILE *f, const char *prefix); +extern void cgit_exec_filter_init(struct cgit_exec_filter *filter, char *cmd, char **argv); +extern struct cgit_filter *cgit_new_filter(const char *cmd, filter_type filtertype); +extern void cgit_cleanup_filters(void); +extern void cgit_init_filters(void); + +extern void cgit_prepare_repo_env(struct cgit_repo * repo); + +extern int readfile(const char *path, char **buf, size_t *size); + +extern char *expand_macros(const char *txt); + +extern char *get_mimetype_for_filename(const char *filename); + +#endif /* CGIT_H */ diff --git a/third_party/cgit/cgit.mk b/third_party/cgit/cgit.mk new file mode 100644 index 0000000000..3fcc1ca314 --- /dev/null +++ b/third_party/cgit/cgit.mk @@ -0,0 +1,141 @@ +# This Makefile is run in the "git" directory in order to re-use Git's +# build variables and operating system detection. Hence all files in +# CGit's directory must be prefixed with "../". +include Makefile + +CGIT_PREFIX = ../ + +-include $(CGIT_PREFIX)cgit.conf + +# The CGIT_* variables are inherited when this file is called from the +# main Makefile - they are defined there. + +$(CGIT_PREFIX)VERSION: force-version + @cd $(CGIT_PREFIX) && '$(SHELL_PATH_SQ)' ./gen-version.sh "$(CGIT_VERSION)" +-include $(CGIT_PREFIX)VERSION +.PHONY: force-version + +# CGIT_CFLAGS is a separate variable so that we can track it separately +# and avoid rebuilding all of Git when these variables change. +CGIT_CFLAGS += -DCGIT_CONFIG='"$(CGIT_CONFIG)"' +CGIT_CFLAGS += -DCGIT_SCRIPT_NAME='"$(CGIT_SCRIPT_NAME)"' +CGIT_CFLAGS += -DCGIT_CACHE_ROOT='"$(CACHE_ROOT)"' + +PKG_CONFIG ?= pkg-config + +ifdef NO_C99_FORMAT + CFLAGS += -DNO_C99_FORMAT +endif + +ifdef NO_LUA + LUA_MESSAGE := linking without specified Lua support + CGIT_CFLAGS += -DNO_LUA +else +ifeq ($(LUA_PKGCONFIG),) + LUA_PKGCONFIG := $(shell for pc in luajit lua lua5.2 lua5.1; do \ + $(PKG_CONFIG) --exists $$pc 2>/dev/null && echo $$pc && break; \ + done) + LUA_MODE := autodetected +else + LUA_MODE := specified +endif +ifneq ($(LUA_PKGCONFIG),) + LUA_MESSAGE := linking with $(LUA_MODE) $(LUA_PKGCONFIG) + LUA_LIBS := $(shell $(PKG_CONFIG) --libs $(LUA_PKGCONFIG) 2>/dev/null) + LUA_CFLAGS := $(shell $(PKG_CONFIG) --cflags $(LUA_PKGCONFIG) 2>/dev/null) + CGIT_LIBS += $(LUA_LIBS) + CGIT_CFLAGS += $(LUA_CFLAGS) +else + LUA_MESSAGE := linking without autodetected Lua support + NO_LUA := YesPlease + CGIT_CFLAGS += -DNO_LUA +endif + +endif + +# Add -ldl to linker flags on systems that commonly use GNU libc. +ifneq (,$(filter $(uname_S),Linux GNU GNU/kFreeBSD)) + CGIT_LIBS += -ldl +endif + +# glibc 2.1+ offers sendfile which the most common C library on Linux +ifeq ($(uname_S),Linux) + HAVE_LINUX_SENDFILE = YesPlease +endif + +ifdef HAVE_LINUX_SENDFILE + CGIT_CFLAGS += -DHAVE_LINUX_SENDFILE +endif + +CGIT_OBJ_NAMES += cgit.o +CGIT_OBJ_NAMES += cache.o +CGIT_OBJ_NAMES += cmd.o +CGIT_OBJ_NAMES += configfile.o +CGIT_OBJ_NAMES += filter.o +CGIT_OBJ_NAMES += html.o +CGIT_OBJ_NAMES += parsing.o +CGIT_OBJ_NAMES += scan-tree.o +CGIT_OBJ_NAMES += shared.o +CGIT_OBJ_NAMES += ui-atom.o +CGIT_OBJ_NAMES += ui-blame.o +CGIT_OBJ_NAMES += ui-blob.o +CGIT_OBJ_NAMES += ui-clone.o +CGIT_OBJ_NAMES += ui-commit.o +CGIT_OBJ_NAMES += ui-diff.o +CGIT_OBJ_NAMES += ui-log.o +CGIT_OBJ_NAMES += ui-patch.o +CGIT_OBJ_NAMES += ui-plain.o +CGIT_OBJ_NAMES += ui-refs.o +CGIT_OBJ_NAMES += ui-repolist.o +CGIT_OBJ_NAMES += ui-shared.o +CGIT_OBJ_NAMES += ui-snapshot.o +CGIT_OBJ_NAMES += ui-ssdiff.o +CGIT_OBJ_NAMES += ui-stats.o +CGIT_OBJ_NAMES += ui-summary.o +CGIT_OBJ_NAMES += ui-tag.o +CGIT_OBJ_NAMES += ui-tree.o + +CGIT_OBJS := $(addprefix $(CGIT_PREFIX),$(CGIT_OBJ_NAMES)) + +# Only cgit.c reference CGIT_VERSION so we only rebuild its objects when the +# version changes. +CGIT_VERSION_OBJS := $(addprefix $(CGIT_PREFIX),cgit.o cgit.sp) +$(CGIT_VERSION_OBJS): $(CGIT_PREFIX)VERSION +$(CGIT_VERSION_OBJS): EXTRA_CPPFLAGS = \ + -DCGIT_VERSION='"$(CGIT_VERSION)"' + +# Git handles dependencies using ":=" so dependencies in CGIT_OBJ are not +# handled by that and we must handle them ourselves. +cgit_dep_files := $(foreach f,$(CGIT_OBJS),$(dir $f).depend/$(notdir $f).d) +cgit_dep_files_present := $(wildcard $(cgit_dep_files)) +ifneq ($(cgit_dep_files_present),) +include $(cgit_dep_files_present) +endif + +ifeq ($(wildcard $(CGIT_PREFIX).depend),) +missing_dep_dirs += $(CGIT_PREFIX).depend +endif + +$(CGIT_PREFIX).depend: + @mkdir -p $@ + +$(CGIT_PREFIX)CGIT-CFLAGS: FORCE + @FLAGS='$(subst ','\'',$(CGIT_CFLAGS))'; \ + if test x"$$FLAGS" != x"`cat ../CGIT-CFLAGS 2>/dev/null`" ; then \ + echo 1>&2 " * new CGit build flags"; \ + echo "$$FLAGS" >$(CGIT_PREFIX)CGIT-CFLAGS; \ + fi + +$(CGIT_OBJS): %.o: %.c GIT-CFLAGS $(CGIT_PREFIX)CGIT-CFLAGS $(missing_dep_dirs) + $(QUIET_CC)$(CC) -o $*.o -c $(dep_args) $(ALL_CFLAGS) $(EXTRA_CPPFLAGS) $(CGIT_CFLAGS) $< + +$(CGIT_PREFIX)cgit: $(CGIT_OBJS) GIT-LDFLAGS $(GITLIBS) + @echo 1>&1 " * $(LUA_MESSAGE)" + $(QUIET_LINK)$(CC) $(ALL_CFLAGS) -o $@ $(ALL_LDFLAGS) $(filter %.o,$^) $(LIBS) $(CGIT_LIBS) + +CGIT_SP_OBJS := $(patsubst %.o,%.sp,$(CGIT_OBJS)) + +$(CGIT_SP_OBJS): %.sp: %.c GIT-CFLAGS $(CGIT_PREFIX)CGIT-CFLAGS FORCE + $(QUIET_SP)cgcc -no-compile $(ALL_CFLAGS) $(EXTRA_CPPFLAGS) $(CGIT_CFLAGS) $(SPARSE_FLAGS) $< + +cgit-sparse: $(CGIT_SP_OBJS) diff --git a/third_party/cgit/cgit.png b/third_party/cgit/cgit.png new file mode 100644 index 0000000000..425528ee39 --- /dev/null +++ b/third_party/cgit/cgit.png Binary files differdiff --git a/third_party/cgit/cgitrc.5.txt b/third_party/cgit/cgitrc.5.txt new file mode 100644 index 0000000000..ba77826fd0 --- /dev/null +++ b/third_party/cgit/cgitrc.5.txt @@ -0,0 +1,1008 @@ +:man source: cgit +:man manual: cgit + +CGITRC(5) +======== + + +NAME +---- +cgitrc - runtime configuration for cgit + + +SYNOPSIS +-------- +Cgitrc contains all runtime settings for cgit, including the list of git +repositories, formatted as a line-separated list of NAME=VALUE pairs. Blank +lines, and lines starting with '#', are ignored. + + +LOCATION +-------- +The default location of cgitrc, defined at compile time, is /etc/cgitrc. At +runtime, cgit will consult the environment variable CGIT_CONFIG and, if +defined, use its value instead. + + +GLOBAL SETTINGS +--------------- +about-filter:: + Specifies a command which will be invoked to format the content of + about pages (both top-level and for each repository). The command will + get the content of the about-file on its STDIN, the name of the file + as the first argument, and the STDOUT from the command will be + included verbatim on the about page. Default value: none. See + also: "FILTER API". + +agefile:: + Specifies a path, relative to each repository path, which can be used + to specify the date and time of the youngest commit in the repository. + The first line in the file is used as input to the "parse_date" + function in libgit. Recommended timestamp-format is "yyyy-mm-dd + hh:mm:ss". You may want to generate this file from a post-receive + hook. Default value: "info/web/last-modified". + +auth-filter:: + Specifies a command that will be invoked for authenticating repository + access. Receives quite a few arguments, and data on both stdin and + stdout for authentication processing. Details follow later in this + document. If no auth-filter is specified, no authentication is + performed. Default value: none. See also: "FILTER API". + +branch-sort:: + Flag which, when set to "age", enables date ordering in the branch ref + list, and when set to "name" enables ordering by branch name. Default + value: "name". + +cache-about-ttl:: + Number which specifies the time-to-live, in minutes, for the cached + version of the repository about page. See also: "CACHE". Default + value: "15". + +cache-dynamic-ttl:: + Number which specifies the time-to-live, in minutes, for the cached + version of repository pages accessed without a fixed SHA1. See also: + "CACHE". Default value: "5". + +cache-repo-ttl:: + Number which specifies the time-to-live, in minutes, for the cached + version of the repository summary page. See also: "CACHE". Default + value: "5". + +cache-root:: + Path used to store the cgit cache entries. Default value: + "/var/cache/cgit". See also: "MACRO EXPANSION". + +cache-root-ttl:: + Number which specifies the time-to-live, in minutes, for the cached + version of the repository index page. See also: "CACHE". Default + value: "5". + +cache-scanrc-ttl:: + Number which specifies the time-to-live, in minutes, for the result + of scanning a path for git repositories. See also: "CACHE". Default + value: "15". + +case-sensitive-sort:: + Sort items in the repo list case sensitively. Default value: "1". + See also: repository-sort, section-sort. + +cache-size:: + The maximum number of entries in the cgit cache. When set to "0", + caching is disabled. See also: "CACHE". Default value: "0" + +cache-snapshot-ttl:: + Number which specifies the time-to-live, in minutes, for the cached + version of snapshots. See also: "CACHE". Default value: "5". + +cache-static-ttl:: + Number which specifies the time-to-live, in minutes, for the cached + version of repository pages accessed with a fixed SHA1. See also: + "CACHE". Default value: -1". + +clone-prefix:: + Space-separated list of common prefixes which, when combined with a + repository url, generates valid clone urls for the repository. This + setting is only used if `repo.clone-url` is unspecified. Default value: + none. + +clone-url:: + Space-separated list of clone-url templates. This setting is only + used if `repo.clone-url` is unspecified. Default value: none. See + also: "MACRO EXPANSION", "FILTER API". + +commit-filter:: + Specifies a command which will be invoked to format commit messages. + The command will get the message on its STDIN, and the STDOUT from the + command will be included verbatim as the commit message, i.e. this can + be used to implement bugtracker integration. Default value: none. + See also: "FILTER API". + +commit-sort:: + Flag which, when set to "date", enables strict date ordering in the + commit log, and when set to "topo" enables strict topological + ordering. If unset, the default ordering of "git log" is used. Default + value: unset. + +css:: + Url which specifies the css document to include in all cgit pages. + Default value: "/cgit.css". + +email-filter:: + Specifies a command which will be invoked to format names and email + address of committers, authors, and taggers, as represented in various + places throughout the cgit interface. This command will receive an + email address and an origin page string as its command line arguments, + and the text to format on STDIN. It is to write the formatted text back + out onto STDOUT. Default value: none. See also: "FILTER API". + +embedded:: + Flag which, when set to "1", will make cgit generate a html fragment + suitable for embedding in other html pages. Default value: none. See + also: "noheader". + +enable-blame:: + Flag which, when set to "1", will allow cgit to provide a "blame" page + for files, and will make it generate links to that page in appropriate + places. Default value: "0". + +enable-commit-graph:: + Flag which, when set to "1", will make cgit print an ASCII-art commit + history graph to the left of the commit messages in the repository + log page. Default value: "0". + +enable-filter-overrides:: + Flag which, when set to "1", allows all filter settings to be + overridden in repository-specific cgitrc files. Default value: none. + +enable-follow-links:: + Flag which, when set to "1", allows users to follow a file in the log + view. Default value: "0". + +enable-git-config:: + Flag which, when set to "1", will allow cgit to use git config to set + any repo specific settings. This option is used in conjunction with + "scan-path", and must be defined prior, to augment repo-specific + settings. The keys gitweb.owner, gitweb.category, gitweb.description, + and gitweb.homepage will map to the cgit keys repo.owner, repo.section, + repo.desc, and repo.homepage respectively. All git config keys that begin + with "cgit." will be mapped to the corresponding "repo." key in cgit. + Default value: "0". See also: scan-path, section-from-path. + +enable-http-clone:: + If set to "1", cgit will act as a dumb HTTP endpoint for git clones. + You can add "http://$HTTP_HOST$SCRIPT_NAME/$CGIT_REPO_URL" to clone-url + to expose this feature. If you use an alternate way of serving git + repositories, you may wish to disable this. Default value: "1". + +enable-html-serving:: + Flag which, when set to "1", will allow the /plain handler to serve + mimetype headers that result in the file being treated as HTML by the + browser. When set to "0", such file types are returned instead as + text/plain or application/octet-stream. Default value: "0". See also: + "repo.enable-html-serving". + +enable-index-links:: + Flag which, when set to "1", will make cgit generate extra links for + each repo in the repository index (specifically, to the "summary", + "commit" and "tree" pages). Default value: "0". + +enable-index-owner:: + Flag which, when set to "1", will make cgit display the owner of + each repo in the repository index. Default value: "1". + +enable-log-filecount:: + Flag which, when set to "1", will make cgit print the number of + modified files for each commit on the repository log page. Default + value: "0". + +enable-log-linecount:: + Flag which, when set to "1", will make cgit print the number of added + and removed lines for each commit on the repository log page. Default + value: "0". + +enable-remote-branches:: + Flag which, when set to "1", will make cgit display remote branches + in the summary and refs views. Default value: "0". See also: + "repo.enable-remote-branches". + +enable-subject-links:: + Flag which, when set to "1", will make cgit use the subject of the + parent commit as link text when generating links to parent commits + in commit view. Default value: "0". See also: + "repo.enable-subject-links". + +enable-tree-linenumbers:: + Flag which, when set to "1", will make cgit generate linenumber links + for plaintext blobs printed in the tree view. Default value: "1". + +favicon:: + Url used as link to a shortcut icon for cgit. It is suggested to use + the value "/favicon.ico" since certain browsers will ignore other + values. Default value: "/favicon.ico". + +footer:: + The content of the file specified with this option will be included + verbatim at the bottom of all pages (i.e. it replaces the standard + "generated by..." message. Default value: none. + +head-include:: + The content of the file specified with this option will be included + verbatim in the html HEAD section on all pages. Default value: none. + +header:: + The content of the file specified with this option will be included + verbatim at the top of all pages. Default value: none. + +include:: + Name of a configfile to include before the rest of the current config- + file is parsed. Default value: none. See also: "MACRO EXPANSION". + +local-time:: + Flag which, if set to "1", makes cgit print commit and tag times in the + servers timezone. Default value: "0". + +logo:: + Url which specifies the source of an image which will be used as a logo + on all cgit pages. Default value: "/cgit.png". + +logo-link:: + Url loaded when clicking on the cgit logo image. If unspecified the + calculated url of the repository index page will be used. Default + value: none. + +max-atom-items:: + Specifies the number of items to display in atom feeds view. Default + value: "10". + +max-blob-size:: + Specifies the maximum size of a blob to display HTML for in KBytes. + Default value: "0" (limit disabled). + +max-commit-count:: + Specifies the number of entries to list per page in "log" view. Default + value: "50". + +max-message-length:: + Specifies the maximum number of commit message characters to display in + "log" view. Default value: "80". + +max-repo-count:: + Specifies the number of entries to list per page on the repository + index page. Default value: "50". + +max-repodesc-length:: + Specifies the maximum number of repo description characters to display + on the repository index page. Default value: "80". + +max-stats:: + Set the default maximum statistics period. Valid values are "week", + "month", "quarter" and "year". If unspecified, statistics are + disabled. Default value: none. See also: "repo.max-stats". + +mimetype.<ext>:: + Set the mimetype for the specified filename extension. This is used + by the `plain` command when returning blob content. + +mimetype-file:: + Specifies the file to use for automatic mimetype lookup. If specified + then this field is used as a fallback when no "mimetype.<ext>" match is + found. If unspecified then no such lookup is performed. The typical file + to use on a Linux system is /etc/mime.types. The format of the file must + comply to: + - a comment line is an empty line or a line starting with a hash (#), + optionally preceded by whitespace + - a non-comment line starts with the mimetype (like image/png), followed + by one or more file extensions (like jpg), all separated by whitespace + Default value: none. See also: "mimetype.<ext>". + +module-link:: + Text which will be used as the formatstring for a hyperlink when a + submodule is printed in a directory listing. The arguments for the + formatstring are the path and SHA1 of the submodule commit. Default + value: none. + +noplainemail:: + If set to "1" showing full author email addresses will be disabled. + Default value: "0". + +noheader:: + Flag which, when set to "1", will make cgit omit the standard header + on all pages. Default value: none. See also: "embedded". + +owner-filter:: + Specifies a command which will be invoked to format the Owner + column of the main page. The command will get the owner on STDIN, + and the STDOUT from the command will be included verbatim in the + table. This can be used to link to additional context such as an + owners home page. When active this filter is used instead of the + default owner query url. Default value: none. + See also: "FILTER API". + +project-list:: + A list of subdirectories inside of scan-path, relative to it, that + should loaded as git repositories. This must be defined prior to + scan-path. Default value: none. See also: scan-path, "MACRO + EXPANSION". + +readme:: + Text which will be used as default value for "repo.readme". Multiple + config keys may be specified, and cgit will use the first found file + in this list. This is useful in conjunction with scan-path. Default + value: none. See also: scan-path, repo.readme. + +remove-suffix:: + If set to "1" and scan-path is enabled, if any repositories are found + with a suffix of ".git", this suffix will be removed for the url and + name. This must be defined prior to scan-path. Default value: "0". + See also: scan-path. + +renamelimit:: + Maximum number of files to consider when detecting renames. The value + "-1" uses the compiletime value in git (for further info, look at + `man git-diff`). Default value: "-1". + +repository-sort:: + The way in which repositories in each section are sorted. Valid values + are "name" for sorting by the repo name or "age" for sorting by the + most recently updated repository. Default value: "name". See also: + section, case-sensitive-sort, section-sort. + +robots:: + Text used as content for the "robots" meta-tag. Default value: + "index, nofollow". + +root-desc:: + Text printed below the heading on the repository index page. Default + value: "a fast webinterface for the git dscm". + +root-readme:: + The content of the file specified with this option will be included + verbatim below the "about" link on the repository index page. Default + value: none. + +root-title:: + Text printed as heading on the repository index page. Default value: + "Git Repository Browser". + +scan-hidden-path:: + If set to "1" and scan-path is enabled, scan-path will recurse into + directories whose name starts with a period ('.'). Otherwise, + scan-path will stay away from such directories (considered as + "hidden"). Note that this does not apply to the ".git" directory in + non-bare repos. This must be defined prior to scan-path. + Default value: 0. See also: scan-path. + +scan-path:: + A path which will be scanned for repositories. If caching is enabled, + the result will be cached as a cgitrc include-file in the cache + directory. If project-list has been defined prior to scan-path, + scan-path loads only the directories listed in the file pointed to by + project-list. Be advised that only the global settings taken + before the scan-path directive will be applied to each repository. + Default value: none. See also: cache-scanrc-ttl, project-list, + "MACRO EXPANSION". + +section:: + The name of the current repository section - all repositories defined + after this option will inherit the current section name. Default value: + none. + +section-sort:: + Flag which, when set to "1", will sort the sections on the repository + listing by name. Set this flag to "0" if the order in the cgitrc file should + be preserved. Default value: "1". See also: section, + case-sensitive-sort, repository-sort. + +section-from-path:: + A number which, if defined prior to scan-path, specifies how many + path elements from each repo path to use as a default section name. + If negative, cgit will discard the specified number of path elements + above the repo directory. Default value: "0". + +side-by-side-diffs:: + If set to "1" shows side-by-side diffs instead of unidiffs per + default. Default value: "0". + +snapshots:: + Text which specifies the default set of snapshot formats that cgit + generates links for. The value is a space-separated list of zero or + more of the values "tar", "tar.gz", "tar.bz2", "tar.xz" and "zip". + The special value "all" enables all snapshot formats. + Default value: none. + +source-filter:: + Specifies a command which will be invoked to format plaintext blobs + in the tree view. The command will get the blob content on its STDIN + and the name of the blob as its only command line argument. The STDOUT + from the command will be included verbatim as the blob contents, i.e. + this can be used to implement e.g. syntax highlighting. Default value: + none. See also: "FILTER API". + +summary-branches:: + Specifies the number of branches to display in the repository "summary" + view. Default value: "10". + +summary-log:: + Specifies the number of log entries to display in the repository + "summary" view. Default value: "10". + +summary-tags:: + Specifies the number of tags to display in the repository "summary" + view. Default value: "10". + +strict-export:: + Filename which, if specified, needs to be present within the repository + for cgit to allow access to that repository. This can be used to emulate + gitweb's EXPORT_OK and STRICT_EXPORT functionality and limit cgit's + repositories to match those exported by git-daemon. This option must + be defined prior to scan-path. + +virtual-root:: + Url which, if specified, will be used as root for all cgit links. It + will also cause cgit to generate 'virtual urls', i.e. urls like + '/cgit/tree/README' as opposed to '?r=cgit&p=tree&path=README'. Default + value: none. + NOTE: cgit has recently learned how to use PATH_INFO to achieve the + same kind of virtual urls, so this option will probably be deprecated. + + +REPOSITORY SETTINGS +------------------- +repo.about-filter:: + Override the default about-filter. Default value: none. See also: + "enable-filter-overrides". See also: "FILTER API". + +repo.branch-sort:: + Flag which, when set to "age", enables date ordering in the branch ref + list, and when set to "name" enables ordering by branch name. Default + value: "name". + +repo.clone-url:: + A list of space-separated urls which can be used to clone this repo. + Default value: none. See also: "MACRO EXPANSION". + +repo.commit-filter:: + Override the default commit-filter. Default value: none. See also: + "enable-filter-overrides". See also: "FILTER API". + +repo.commit-sort:: + Flag which, when set to "date", enables strict date ordering in the + commit log, and when set to "topo" enables strict topological + ordering. If unset, the default ordering of "git log" is used. Default + value: unset. + +repo.defbranch:: + The name of the default branch for this repository. If no such branch + exists in the repository, the first branch name (when sorted) is used + as default instead. Default value: branch pointed to by HEAD, or + "master" if there is no suitable HEAD. + +repo.desc:: + The value to show as repository description. Default value: none. + +repo.email-filter:: + Override the default email-filter. Default value: none. See also: + "enable-filter-overrides". See also: "FILTER API". + +repo.enable-blame:: + A flag which can be used to disable the global setting + `enable-blame'. Default value: none. + +repo.enable-commit-graph:: + A flag which can be used to disable the global setting + `enable-commit-graph'. Default value: none. + +repo.enable-html-serving:: + A flag which can be used to override the global setting + `enable-html-serving`. Default value: none. + +repo.enable-log-filecount:: + A flag which can be used to disable the global setting + `enable-log-filecount'. Default value: none. + +repo.enable-log-linecount:: + A flag which can be used to disable the global setting + `enable-log-linecount'. Default value: none. + +repo.enable-remote-branches:: + Flag which, when set to "1", will make cgit display remote branches + in the summary and refs views. Default value: <enable-remote-branches>. + +repo.enable-subject-links:: + A flag which can be used to override the global setting + `enable-subject-links'. Default value: none. + +repo.extra-head-content:: + This value will be added verbatim to the head section of each page + displayed for this repo. Default value: none. + +repo.hide:: + Flag which, when set to "1", hides the repository from the repository + index. The repository can still be accessed by providing a direct path. + Default value: "0". See also: "repo.ignore". + +repo.homepage:: + The value to show as repository homepage. Default value: none. + +repo.ignore:: + Flag which, when set to "1", ignores the repository. The repository + is not shown in the index and cannot be accessed by providing a direct + path. Default value: "0". See also: "repo.hide". + +repo.logo:: + Url which specifies the source of an image which will be used as a logo + on this repo's pages. Default value: global logo. + +repo.logo-link:: + Url loaded when clicking on the cgit logo image. If unspecified the + calculated url of the repository index page will be used. Default + value: global logo-link. + +repo.module-link:: + Text which will be used as the formatstring for a hyperlink when a + submodule is printed in a directory listing. The arguments for the + formatstring are the path and SHA1 of the submodule commit. Default + value: <module-link> + +repo.module-link.<path>:: + Text which will be used as the formatstring for a hyperlink when a + submodule with the specified subdirectory path is printed in a + directory listing. The only argument for the formatstring is the SHA1 + of the submodule commit. Default value: none. + +repo.max-stats:: + Override the default maximum statistics period. Valid values are equal + to the values specified for the global "max-stats" setting. Default + value: none. + +repo.name:: + The value to show as repository name. Default value: <repo.url>. + +repo.owner:: + A value used to identify the owner of the repository. Default value: + none. + +repo.owner-filter:: + Override the default owner-filter. Default value: none. See also: + "enable-filter-overrides". See also: "FILTER API". + +repo.path:: + An absolute path to the repository directory. For non-bare repositories + this is the .git-directory. Default value: none. + +repo.readme:: + A path (relative to <repo.path>) which specifies a file to include + verbatim as the "About" page for this repo. You may also specify a + git refspec by head or by hash by prepending the refspec followed by + a colon. For example, "master:docs/readme.mkd". If the value begins + with a colon, i.e. ":docs/readme.rst", the default branch of the + repository will be used. Sharing any file will expose that entire + directory tree to the "/about/PATH" endpoints, so be sure that there + are no non-public files located in the same directory as the readme + file. Default value: <readme>. + +repo.section:: + Override the current section name for this repository. Default value: + none. + +repo.snapshots:: + A mask of snapshot formats for this repo that cgit generates links for, + restricted by the global "snapshots" setting. Default value: + <snapshots>. + +repo.snapshot-prefix:: + Prefix to use for snapshot links instead of the repository basename. + For example, the "linux-stable" repository may wish to set this to + "linux" so that snapshots are in the format "linux-3.15.4" instead + of "linux-stable-3.15.4". Default value: <empty> meaning to use + the repository basename. + +repo.source-filter:: + Override the default source-filter. Default value: none. See also: + "enable-filter-overrides". See also: "FILTER API". + +repo.url:: + The relative url used to access the repository. This must be the first + setting specified for each repo. Default value: none. + + +REPOSITORY-SPECIFIC CGITRC FILE +------------------------------- +When the option "scan-path" is used to auto-discover git repositories, cgit +will try to parse the file "cgitrc" within any found repository. Such a +repo-specific config file may contain any of the repo-specific options +described above, except "repo.url" and "repo.path". Additionally, the "filter" +options are only acknowledged in repo-specific config files when +"enable-filter-overrides" is set to "1". + +Note: the "repo." prefix is dropped from the option names in repo-specific +config files, e.g. "repo.desc" becomes "desc". + + +FILTER API +---------- +By default, filters are separate processes that are executed each time they +are needed. Alternative technologies may be used by prefixing the filter +specification with the relevant string; available values are: + +'exec:':: + The default "one process per filter" mode. + +'lua:':: + Executes the script using a built-in Lua interpreter. The script is + loaded once per execution of cgit, and may be called multiple times + during cgit's lifetime, making it a good choice for repeated filters + such as the 'email filter'. It responds to three functions: + + 'filter_open(argument1, argument2, argument3, ...)':: + This is called upon activation of the filter for a particular + set of data. + 'filter_write(buffer)':: + This is called whenever cgit writes data to the webpage. + 'filter_close()':: + This is called when the current filtering operation is + completed. It must return an integer value. Usually 0 + indicates success. + + Additionally, cgit exposes to the Lua the following built-in functions: + + 'html(str)':: + Writes 'str' to the webpage. + 'html_txt(str)':: + HTML escapes and writes 'str' to the webpage. + 'html_attr(str)':: + HTML escapes for an attribute and writes "str' to the webpage. + 'html_url_path(str)':: + URL escapes for a path and writes 'str' to the webpage. + 'html_url_arg(str)':: + URL escapes for an argument and writes 'str' to the webpage. + 'html_include(file)':: + Includes 'file' in webpage. + + +Parameters are provided to filters as follows. + +about filter:: + This filter is given a single parameter: the filename of the source + file to filter. The filter can use the filename to determine (for + example) the type of syntax to follow when formatting the readme file. + The about text that is to be filtered is available on standard input + and the filtered text is expected on standard output. + +auth filter:: + The authentication filter receives 12 parameters: + - filter action, explained below, which specifies which action the + filter is called for + - http cookie + - http method + - http referer + - http path + - http https flag + - cgit repo + - cgit page + - cgit url + - cgit login url + When the filter action is "body", this filter must write to output the + HTML for displaying the login form, which POSTs to the login url. When + the filter action is "authenticate-cookie", this filter must validate + the http cookie and return a 0 if it is invalid or 1 if it is invalid, + in the exit code / close function. If the filter action is + "authenticate-post", this filter receives POST'd parameters on + standard input, and should write a complete CGI response, preferably + with a 302 redirect, and write to output one or more "Set-Cookie" + HTTP headers, each followed by a newline. + + Please see `filters/simple-authentication.lua` for a clear example + script that may be modified. + +commit filter:: + This filter is given no arguments. The commit message text that is to + be filtered is available on standard input and the filtered text is + expected on standard output. + +email filter:: + This filter is given two parameters: the email address of the relevant + author and a string indicating the originating page. The filter will + then receive the text string to format on standard input and is + expected to write to standard output the formatted text to be included + in the page. + +owner filter:: + This filter is given no arguments. The owner text is available on + standard input and the filter is expected to write to standard + output. The output is included in the Owner column. + +source filter:: + This filter is given a single parameter: the filename of the source + file to filter. The filter can use the filename to determine (for + example) the syntax highlighting mode. The contents of the source + file that is to be filtered is available on standard input and the + filtered contents is expected on standard output. + + +All filters are handed the following environment variables: + +- CGIT_REPO_URL (from repo.url) +- CGIT_REPO_NAME (from repo.name) +- CGIT_REPO_PATH (from repo.path) +- CGIT_REPO_OWNER (from repo.owner) +- CGIT_REPO_DEFBRANCH (from repo.defbranch) +- CGIT_REPO_SECTION (from repo.section) +- CGIT_REPO_CLONE_URL (from repo.clone-url) + +If a setting is not defined for a repository and the corresponding global +setting is also not defined (if applicable), then the corresponding +environment variable will be unset. + + +MACRO EXPANSION +--------------- +The following cgitrc options support a simple macro expansion feature, +where tokens prefixed with "$" are replaced with the value of a similarly +named environment variable: + +- cache-root +- include +- project-list +- scan-path + +Macro expansion will also happen on the content of $CGIT_CONFIG, if +defined. + +One usage of this feature is virtual hosting, which in its simplest form +can be accomplished by adding the following line to /etc/cgitrc: + + include=/etc/cgitrc.d/$HTTP_HOST + +The following options are expanded during request processing, and support +the environment variables defined in "FILTER API": + +- clone-url +- repo.clone-url + + +CACHE +----- + +All cache ttl values are in minutes. Negative ttl values indicate that a page +type will never expire, and thus the first time a URL is accessed, the result +will be cached indefinitely, even if the underlying git repository changes. +Conversely, when a ttl value is zero, the cache is disabled for that +particular page type, and the page type is never cached. + +SIGNATURES +---------- + +Cgit can host .asc signatures corresponding to various snapshot formats, +through use of git notes. For example, the following command may be used to +add a signature to a .tar.xz archive: + + git notes --ref=refs/notes/signatures/tar.xz add -C "$( + gpg --output - --armor --detach-sign cgit-1.1.tar.xz | + git hash-object -w --stdin + )" v1.1 + +If it is instead desirable to attach a signature of the underlying .tar, this +will be linked, as a special case, beside a .tar.* link that does not have its +own signature. For example, a signature of a tarball of the latest tag might +be added with a similar command: + + tag="$(git describe --abbrev=0)" + git notes --ref=refs/notes/signatures/tar add -C "$( + git archive --format tar --prefix "cgit-${tag#v}/" "$tag" | + gpg --output - --armor --detach-sign | + git hash-object -w --stdin + )" "$tag" + +Since git-archive(1) is expected to produce stable output between versions, +this allows one to generate a long-term signature of the contents of a given +tag. + +EXAMPLE CGITRC FILE +------------------- + +.... +# Enable caching of up to 1000 output entries +cache-size=1000 + + +# Specify some default clone urls using macro expansion +clone-url=git://foo.org/$CGIT_REPO_URL git@foo.org:$CGIT_REPO_URL + +# Specify the css url +css=/css/cgit.css + + +# Show owner on index page +enable-index-owner=1 + + +# Allow http transport git clone +enable-http-clone=1 + + +# Show extra links for each repository on the index page +enable-index-links=1 + + +# Enable blame page and create links to it from tree page +enable-blame=1 + + +# Enable ASCII art commit history graph on the log pages +enable-commit-graph=1 + + +# Show number of affected files per commit on the log pages +enable-log-filecount=1 + + +# Show number of added/removed lines per commit on the log pages +enable-log-linecount=1 + + +# Sort branches by date +branch-sort=age + + +# Add a cgit favicon +favicon=/favicon.ico + + +# Use a custom logo +logo=/img/mylogo.png + + +# Enable statistics per week, month and quarter +max-stats=quarter + + +# Set the title and heading of the repository index page +root-title=example.com git repositories + + +# Set a subheading for the repository index page +root-desc=tracking the foobar development + + +# Include some more info about example.com on the index page +root-readme=/var/www/htdocs/about.html + + +# Allow download of tar.gz, tar.bz2 and zip-files +snapshots=tar.gz tar.bz2 zip + + +## +## List of common mimetypes +## + +mimetype.gif=image/gif +mimetype.html=text/html +mimetype.jpg=image/jpeg +mimetype.jpeg=image/jpeg +mimetype.pdf=application/pdf +mimetype.png=image/png +mimetype.svg=image/svg+xml + + +# Highlight source code with python pygments-based highlighter +source-filter=/var/www/cgit/filters/syntax-highlighting.py + +# Format markdown, restructuredtext, manpages, text files, and html files +# through the right converters +about-filter=/var/www/cgit/filters/about-formatting.sh + +## +## Search for these files in the root of the default branch of repositories +## for coming up with the about page: +## +readme=:README.md +readme=:readme.md +readme=:README.mkd +readme=:readme.mkd +readme=:README.rst +readme=:readme.rst +readme=:README.html +readme=:readme.html +readme=:README.htm +readme=:readme.htm +readme=:README.txt +readme=:readme.txt +readme=:README +readme=:readme +readme=:INSTALL.md +readme=:install.md +readme=:INSTALL.mkd +readme=:install.mkd +readme=:INSTALL.rst +readme=:install.rst +readme=:INSTALL.html +readme=:install.html +readme=:INSTALL.htm +readme=:install.htm +readme=:INSTALL.txt +readme=:install.txt +readme=:INSTALL +readme=:install + + +## +## List of repositories. +## PS: Any repositories listed when section is unset will not be +## displayed under a section heading +## PPS: This list could be kept in a different file (e.g. '/etc/cgitrepos') +## and included like this: +## include=/etc/cgitrepos +## + + +repo.url=foo +repo.path=/pub/git/foo.git +repo.desc=the master foo repository +repo.owner=fooman@example.com +repo.readme=info/web/about.html + + +repo.url=bar +repo.path=/pub/git/bar.git +repo.desc=the bars for your foo +repo.owner=barman@example.com +repo.readme=info/web/about.html + + +# The next repositories will be displayed under the 'extras' heading +section=extras + + +repo.url=baz +repo.path=/pub/git/baz.git +repo.desc=a set of extensions for bar users + +repo.url=wiz +repo.path=/pub/git/wiz.git +repo.desc=the wizard of foo + + +# Add some mirrored repositories +section=mirrors + + +repo.url=git +repo.path=/pub/git/git.git +repo.desc=the dscm + + +repo.url=linux +repo.path=/pub/git/linux.git +repo.desc=the kernel + +# Disable adhoc downloads of this repo +repo.snapshots=0 + +# Disable line-counts for this repo +repo.enable-log-linecount=0 + +# Restrict the max statistics period for this repo +repo.max-stats=month +.... + + +BUGS +---- +Comments currently cannot appear on the same line as a setting; the comment +will be included as part of the value. E.g. this line: + + robots=index # allow indexing + +will generate the following html element: + + <meta name='robots' content='index # allow indexing'/> + + + +AUTHOR +------ +Lars Hjemli <hjemli@gmail.com> +Jason A. Donenfeld <Jason@zx2c4.com> diff --git a/third_party/cgit/cmd.c b/third_party/cgit/cmd.c new file mode 100644 index 0000000000..8fac7e9c09 --- /dev/null +++ b/third_party/cgit/cmd.c @@ -0,0 +1,186 @@ +/* cmd.c: the cgit command dispatcher + * + * Copyright (C) 2006-2017 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "cmd.h" +#include "cache.h" +#include "ui-shared.h" +#include "ui-atom.h" +#include "ui-blame.h" +#include "ui-blob.h" +#include "ui-clone.h" +#include "ui-commit.h" +#include "ui-diff.h" +#include "ui-log.h" +#include "ui-patch.h" +#include "ui-plain.h" +#include "ui-refs.h" +#include "ui-repolist.h" +#include "ui-snapshot.h" +#include "ui-stats.h" +#include "ui-summary.h" +#include "ui-tag.h" +#include "ui-tree.h" + +static void HEAD_fn(void) +{ + cgit_clone_head(); +} + +static void atom_fn(void) +{ + cgit_print_atom(ctx.qry.head, ctx.qry.path, ctx.cfg.max_atom_items); +} + +static void about_fn(void) +{ + cgit_print_repo_readme(ctx.qry.path); +} + +static void blame_fn(void) +{ + if (ctx.repo->enable_blame) + cgit_print_blame(); + else + cgit_print_error_page(403, "Forbidden", "Blame is disabled"); +} + +static void blob_fn(void) +{ + cgit_print_blob(ctx.qry.sha1, ctx.qry.path, ctx.qry.head, 0); +} + +static void commit_fn(void) +{ + cgit_print_commit(ctx.qry.sha1, ctx.qry.path); +} + +static void diff_fn(void) +{ + cgit_print_diff(ctx.qry.sha1, ctx.qry.sha2, ctx.qry.path, 1, 0); +} + +static void rawdiff_fn(void) +{ + cgit_print_diff(ctx.qry.sha1, ctx.qry.sha2, ctx.qry.path, 1, 1); +} + +static void info_fn(void) +{ + cgit_clone_info(); +} + +static void log_fn(void) +{ + cgit_print_log(ctx.qry.sha1, ctx.qry.ofs, ctx.cfg.max_commit_count, + ctx.qry.grep, ctx.qry.search, ctx.qry.path, 1, + ctx.repo->enable_commit_graph, + ctx.repo->commit_sort); +} + +static void ls_cache_fn(void) +{ + ctx.page.mimetype = "text/plain"; + ctx.page.filename = "ls-cache.txt"; + cgit_print_http_headers(); + cache_ls(ctx.cfg.cache_root); +} + +static void objects_fn(void) +{ + cgit_clone_objects(); +} + +static void repolist_fn(void) +{ + cgit_print_repolist(); +} + +static void patch_fn(void) +{ + cgit_print_patch(ctx.qry.sha1, ctx.qry.sha2, ctx.qry.path); +} + +static void plain_fn(void) +{ + cgit_print_plain(); +} + +static void refs_fn(void) +{ + cgit_print_refs(); +} + +static void snapshot_fn(void) +{ + cgit_print_snapshot(ctx.qry.head, ctx.qry.sha1, ctx.qry.path, + ctx.qry.nohead); +} + +static void stats_fn(void) +{ + cgit_show_stats(); +} + +static void summary_fn(void) +{ + cgit_print_summary(); +} + +static void tag_fn(void) +{ + cgit_print_tag(ctx.qry.sha1); +} + +static void tree_fn(void) +{ + cgit_print_tree(ctx.qry.sha1, ctx.qry.path); +} + +#define def_cmd(name, want_repo, want_vpath, is_clone) \ + {#name, name##_fn, want_repo, want_vpath, is_clone} + +struct cgit_cmd *cgit_get_cmd(void) +{ + static struct cgit_cmd cmds[] = { + def_cmd(HEAD, 1, 0, 1), + def_cmd(atom, 1, 0, 0), + def_cmd(about, 1, 1, 0), + def_cmd(blame, 1, 1, 0), + def_cmd(blob, 1, 0, 0), + def_cmd(commit, 1, 1, 0), + def_cmd(diff, 1, 1, 0), + def_cmd(info, 1, 0, 1), + def_cmd(log, 1, 1, 0), + def_cmd(ls_cache, 0, 0, 0), + def_cmd(objects, 1, 0, 1), + def_cmd(patch, 1, 1, 0), + def_cmd(plain, 1, 0, 0), + def_cmd(rawdiff, 1, 1, 0), + def_cmd(refs, 1, 0, 0), + def_cmd(repolist, 0, 0, 0), + def_cmd(snapshot, 1, 0, 0), + def_cmd(stats, 1, 1, 0), + def_cmd(summary, 1, 0, 0), + def_cmd(tag, 1, 0, 0), + def_cmd(tree, 1, 1, 0), + }; + int i; + + if (ctx.qry.page == NULL) { + if (ctx.repo) + ctx.qry.page = "summary"; + else + ctx.qry.page = "repolist"; + } + + for (i = 0; i < sizeof(cmds)/sizeof(*cmds); i++) + if (!strcmp(ctx.qry.page, cmds[i].name)) + return &cmds[i]; + return NULL; +} diff --git a/third_party/cgit/cmd.h b/third_party/cgit/cmd.h new file mode 100644 index 0000000000..6249b1d892 --- /dev/null +++ b/third_party/cgit/cmd.h @@ -0,0 +1,16 @@ +#ifndef CMD_H +#define CMD_H + +typedef void (*cgit_cmd_fn)(void); + +struct cgit_cmd { + const char *name; + cgit_cmd_fn fn; + unsigned int want_repo:1, + want_vpath:1, + is_clone:1; +}; + +extern struct cgit_cmd *cgit_get_cmd(void); + +#endif /* CMD_H */ diff --git a/third_party/cgit/configfile.c b/third_party/cgit/configfile.c new file mode 100644 index 0000000000..e0391091e1 --- /dev/null +++ b/third_party/cgit/configfile.c @@ -0,0 +1,90 @@ +/* configfile.c: parsing of config files + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include <git-compat-util.h> +#include "configfile.h" + +static int next_char(FILE *f) +{ + int c = fgetc(f); + if (c == '\r') { + c = fgetc(f); + if (c != '\n') { + ungetc(c, f); + c = '\r'; + } + } + return c; +} + +static void skip_line(FILE *f) +{ + int c; + + while ((c = next_char(f)) && c != '\n' && c != EOF) + ; +} + +static int read_config_line(FILE *f, struct strbuf *name, struct strbuf *value) +{ + int c = next_char(f); + + strbuf_reset(name); + strbuf_reset(value); + + /* Skip comments and preceding spaces. */ + for(;;) { + if (c == EOF) + return 0; + else if (c == '#' || c == ';') + skip_line(f); + else if (!isspace(c)) + break; + c = next_char(f); + } + + /* Read variable name. */ + while (c != '=') { + if (c == '\n' || c == EOF) + return 0; + strbuf_addch(name, c); + c = next_char(f); + } + + /* Read variable value. */ + c = next_char(f); + while (c != '\n' && c != EOF) { + strbuf_addch(value, c); + c = next_char(f); + } + + return 1; +} + +int parse_configfile(const char *filename, configfile_value_fn fn) +{ + static int nesting; + struct strbuf name = STRBUF_INIT; + struct strbuf value = STRBUF_INIT; + FILE *f; + + /* cancel deeply nested include-commands */ + if (nesting > 8) + return -1; + if (!(f = fopen(filename, "r"))) + return -1; + nesting++; + while (read_config_line(f, &name, &value)) + fn(name.buf, value.buf); + nesting--; + fclose(f); + strbuf_release(&name); + strbuf_release(&value); + return 0; +} + diff --git a/third_party/cgit/configfile.h b/third_party/cgit/configfile.h new file mode 100644 index 0000000000..af7ca19735 --- /dev/null +++ b/third_party/cgit/configfile.h @@ -0,0 +1,10 @@ +#ifndef CONFIGFILE_H +#define CONFIGFILE_H + +#include "cgit.h" + +typedef void (*configfile_value_fn)(const char *name, const char *value); + +extern int parse_configfile(const char *filename, configfile_value_fn fn); + +#endif /* CONFIGFILE_H */ diff --git a/third_party/cgit/contrib/hooks/post-receive.agefile b/third_party/cgit/contrib/hooks/post-receive.agefile new file mode 100755 index 0000000000..2f72ae9c0d --- /dev/null +++ b/third_party/cgit/contrib/hooks/post-receive.agefile @@ -0,0 +1,19 @@ +#!/bin/sh +# +# An example hook to update the "agefile" for CGit's idle time calculation. +# +# This hook assumes that you are using the default agefile location of +# "info/web/last-modified". If you change the value in your cgitrc then you +# must also change it here. +# +# To install the hook, copy (or link) it to the file "hooks/post-receive" in +# each of your repositories. +# + +agefile="$(git rev-parse --git-dir)"/info/web/last-modified + +mkdir -p "$(dirname "$agefile")" && +git for-each-ref \ + --sort=-authordate --count=1 \ + --format='%(authordate:iso8601)' \ + >"$agefile" diff --git a/third_party/cgit/default.nix b/third_party/cgit/default.nix new file mode 100644 index 0000000000..3e58816fc7 --- /dev/null +++ b/third_party/cgit/default.nix @@ -0,0 +1,37 @@ +{ depot, ... }: + +let + inherit (depot.third_party) stdenv gzip bzip2 xz luajit zlib autoconf openssl pkgconfig; +in stdenv.mkDerivation rec { + pname = "cgit"; + version = "master"; + src = ./.; + + nativeBuildInputs = [ autoconf pkgconfig ]; + buildInputs = [ openssl zlib luajit ]; + + postPatch = '' + sed -e 's|"gzip"|"${gzip}/bin/gzip"|' \ + -e 's|"bzip2"|"${bzip2.bin}/bin/bzip2"|' \ + -e 's|"xz"|"${xz.bin}/bin/xz"|' \ + -i ui-snapshot.c + ''; + + # Give cgit the git source tree from the depot. Note that the + # versions should be kept in sync (see the Makefile for the current + # git version). + preBuild = '' + rm -rf git # remove submodule dir ... + cp -r --no-preserve=ownership,mode ${depot.third_party.git.src} git + makeFlagsArray+=(prefix="$out" CGIT_SCRIPT_PATH="$out/cgit/") + ''; + + meta = { + homepage = https://git.zx2c4.com/cgit/about/; + repositories.git = git://git.zx2c4.com/cgit; + description = "Web frontend for git repositories"; + license = stdenv.lib.licenses.gpl2; + platforms = stdenv.lib.platforms.linux; + maintainers = with stdenv.lib.maintainers; [ bjornfor ]; + }; +} diff --git a/third_party/cgit/favicon.ico b/third_party/cgit/favicon.ico new file mode 100644 index 0000000000..56ff59384f --- /dev/null +++ b/third_party/cgit/favicon.ico Binary files differdiff --git a/third_party/cgit/filter.c b/third_party/cgit/filter.c new file mode 100644 index 0000000000..70f5b74998 --- /dev/null +++ b/third_party/cgit/filter.c @@ -0,0 +1,457 @@ +/* filter.c: filter framework functions + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "html.h" +#ifndef NO_LUA +#include <dlfcn.h> +#include <lua.h> +#include <lualib.h> +#include <lauxlib.h> +#endif + +static inline void reap_filter(struct cgit_filter *filter) +{ + if (filter && filter->cleanup) + filter->cleanup(filter); +} + +void cgit_cleanup_filters(void) +{ + int i; + reap_filter(ctx.cfg.about_filter); + reap_filter(ctx.cfg.commit_filter); + reap_filter(ctx.cfg.source_filter); + reap_filter(ctx.cfg.email_filter); + reap_filter(ctx.cfg.owner_filter); + reap_filter(ctx.cfg.auth_filter); + for (i = 0; i < cgit_repolist.count; ++i) { + reap_filter(cgit_repolist.repos[i].about_filter); + reap_filter(cgit_repolist.repos[i].commit_filter); + reap_filter(cgit_repolist.repos[i].source_filter); + reap_filter(cgit_repolist.repos[i].email_filter); + reap_filter(cgit_repolist.repos[i].owner_filter); + } +} + +static int open_exec_filter(struct cgit_filter *base, va_list ap) +{ + struct cgit_exec_filter *filter = (struct cgit_exec_filter *)base; + int pipe_fh[2]; + int i; + + for (i = 0; i < filter->base.argument_count; i++) + filter->argv[i + 1] = va_arg(ap, char *); + + filter->old_stdout = chk_positive(dup(STDOUT_FILENO), + "Unable to duplicate STDOUT"); + chk_zero(pipe(pipe_fh), "Unable to create pipe to subprocess"); + filter->pid = chk_non_negative(fork(), "Unable to create subprocess"); + if (filter->pid == 0) { + close(pipe_fh[1]); + chk_non_negative(dup2(pipe_fh[0], STDIN_FILENO), + "Unable to use pipe as STDIN"); + execvp(filter->cmd, filter->argv); + die_errno("Unable to exec subprocess %s", filter->cmd); + } + close(pipe_fh[0]); + chk_non_negative(dup2(pipe_fh[1], STDOUT_FILENO), + "Unable to use pipe as STDOUT"); + close(pipe_fh[1]); + return 0; +} + +static int close_exec_filter(struct cgit_filter *base) +{ + struct cgit_exec_filter *filter = (struct cgit_exec_filter *)base; + int i, exit_status = 0; + + chk_non_negative(dup2(filter->old_stdout, STDOUT_FILENO), + "Unable to restore STDOUT"); + close(filter->old_stdout); + if (filter->pid < 0) + goto done; + waitpid(filter->pid, &exit_status, 0); + if (WIFEXITED(exit_status)) + goto done; + die("Subprocess %s exited abnormally", filter->cmd); + +done: + for (i = 0; i < filter->base.argument_count; i++) + filter->argv[i + 1] = NULL; + return WEXITSTATUS(exit_status); + +} + +static void fprintf_exec_filter(struct cgit_filter *base, FILE *f, const char *prefix) +{ + struct cgit_exec_filter *filter = (struct cgit_exec_filter *)base; + fprintf(f, "%sexec:%s\n", prefix, filter->cmd); +} + +static void cleanup_exec_filter(struct cgit_filter *base) +{ + struct cgit_exec_filter *filter = (struct cgit_exec_filter *)base; + if (filter->argv) { + free(filter->argv); + filter->argv = NULL; + } + if (filter->cmd) { + free(filter->cmd); + filter->cmd = NULL; + } +} + +static struct cgit_filter *new_exec_filter(const char *cmd, int argument_count) +{ + struct cgit_exec_filter *f; + int args_size = 0; + + f = xmalloc(sizeof(*f)); + /* We leave argv for now and assign it below. */ + cgit_exec_filter_init(f, xstrdup(cmd), NULL); + f->base.argument_count = argument_count; + args_size = (2 + argument_count) * sizeof(char *); + f->argv = xmalloc(args_size); + memset(f->argv, 0, args_size); + f->argv[0] = f->cmd; + return &f->base; +} + +void cgit_exec_filter_init(struct cgit_exec_filter *filter, char *cmd, char **argv) +{ + memset(filter, 0, sizeof(*filter)); + filter->base.open = open_exec_filter; + filter->base.close = close_exec_filter; + filter->base.fprintf = fprintf_exec_filter; + filter->base.cleanup = cleanup_exec_filter; + filter->cmd = cmd; + filter->argv = argv; + /* The argument count for open_filter is zero by default, unless called from new_filter, above. */ + filter->base.argument_count = 0; +} + +#ifdef NO_LUA +void cgit_init_filters(void) +{ +} +#endif + +#ifndef NO_LUA +static ssize_t (*libc_write)(int fd, const void *buf, size_t count); +static ssize_t (*filter_write)(struct cgit_filter *base, const void *buf, size_t count) = NULL; +static struct cgit_filter *current_write_filter = NULL; + +void cgit_init_filters(void) +{ + libc_write = dlsym(RTLD_NEXT, "write"); + if (!libc_write) + die("Could not locate libc's write function"); +} + +ssize_t write(int fd, const void *buf, size_t count) +{ + if (fd != STDOUT_FILENO || !filter_write) + return libc_write(fd, buf, count); + return filter_write(current_write_filter, buf, count); +} + +static inline void hook_write(struct cgit_filter *filter, ssize_t (*new_write)(struct cgit_filter *base, const void *buf, size_t count)) +{ + /* We want to avoid buggy nested patterns. */ + assert(filter_write == NULL); + assert(current_write_filter == NULL); + current_write_filter = filter; + filter_write = new_write; +} + +static inline void unhook_write(void) +{ + assert(filter_write != NULL); + assert(current_write_filter != NULL); + filter_write = NULL; + current_write_filter = NULL; +} + +struct lua_filter { + struct cgit_filter base; + char *script_file; + lua_State *lua_state; +}; + +static void error_lua_filter(struct lua_filter *filter) +{ + die("Lua error in %s: %s", filter->script_file, lua_tostring(filter->lua_state, -1)); + lua_pop(filter->lua_state, 1); +} + +static ssize_t write_lua_filter(struct cgit_filter *base, const void *buf, size_t count) +{ + struct lua_filter *filter = (struct lua_filter *)base; + + lua_getglobal(filter->lua_state, "filter_write"); + lua_pushlstring(filter->lua_state, buf, count); + if (lua_pcall(filter->lua_state, 1, 0, 0)) { + error_lua_filter(filter); + errno = EIO; + return -1; + } + return count; +} + +static inline int hook_lua_filter(lua_State *lua_state, void (*fn)(const char *txt)) +{ + const char *str; + ssize_t (*save_filter_write)(struct cgit_filter *base, const void *buf, size_t count); + struct cgit_filter *save_filter; + + str = lua_tostring(lua_state, 1); + if (!str) + return 0; + + save_filter_write = filter_write; + save_filter = current_write_filter; + unhook_write(); + fn(str); + hook_write(save_filter, save_filter_write); + + return 0; +} + +static int html_lua_filter(lua_State *lua_state) +{ + return hook_lua_filter(lua_state, html); +} + +static int html_txt_lua_filter(lua_State *lua_state) +{ + return hook_lua_filter(lua_state, html_txt); +} + +static int html_attr_lua_filter(lua_State *lua_state) +{ + return hook_lua_filter(lua_state, html_attr); +} + +static int html_url_path_lua_filter(lua_State *lua_state) +{ + return hook_lua_filter(lua_state, html_url_path); +} + +static int html_url_arg_lua_filter(lua_State *lua_state) +{ + return hook_lua_filter(lua_state, html_url_arg); +} + +static int html_include_lua_filter(lua_State *lua_state) +{ + return hook_lua_filter(lua_state, (void (*)(const char *))html_include); +} + +static void cleanup_lua_filter(struct cgit_filter *base) +{ + struct lua_filter *filter = (struct lua_filter *)base; + + if (!filter->lua_state) + return; + + lua_close(filter->lua_state); + filter->lua_state = NULL; + if (filter->script_file) { + free(filter->script_file); + filter->script_file = NULL; + } +} + +static int init_lua_filter(struct lua_filter *filter) +{ + if (filter->lua_state) + return 0; + + if (!(filter->lua_state = luaL_newstate())) + return 1; + + luaL_openlibs(filter->lua_state); + + lua_pushcfunction(filter->lua_state, html_lua_filter); + lua_setglobal(filter->lua_state, "html"); + lua_pushcfunction(filter->lua_state, html_txt_lua_filter); + lua_setglobal(filter->lua_state, "html_txt"); + lua_pushcfunction(filter->lua_state, html_attr_lua_filter); + lua_setglobal(filter->lua_state, "html_attr"); + lua_pushcfunction(filter->lua_state, html_url_path_lua_filter); + lua_setglobal(filter->lua_state, "html_url_path"); + lua_pushcfunction(filter->lua_state, html_url_arg_lua_filter); + lua_setglobal(filter->lua_state, "html_url_arg"); + lua_pushcfunction(filter->lua_state, html_include_lua_filter); + lua_setglobal(filter->lua_state, "html_include"); + + if (luaL_dofile(filter->lua_state, filter->script_file)) { + error_lua_filter(filter); + lua_close(filter->lua_state); + filter->lua_state = NULL; + return 1; + } + return 0; +} + +static int open_lua_filter(struct cgit_filter *base, va_list ap) +{ + struct lua_filter *filter = (struct lua_filter *)base; + int i; + + if (init_lua_filter(filter)) + return 1; + + hook_write(base, write_lua_filter); + + lua_getglobal(filter->lua_state, "filter_open"); + for (i = 0; i < filter->base.argument_count; ++i) + lua_pushstring(filter->lua_state, va_arg(ap, char *)); + if (lua_pcall(filter->lua_state, filter->base.argument_count, 0, 0)) { + error_lua_filter(filter); + return 1; + } + return 0; +} + +static int close_lua_filter(struct cgit_filter *base) +{ + struct lua_filter *filter = (struct lua_filter *)base; + int ret = 0; + + lua_getglobal(filter->lua_state, "filter_close"); + if (lua_pcall(filter->lua_state, 0, 1, 0)) { + error_lua_filter(filter); + ret = -1; + } else { + ret = lua_tonumber(filter->lua_state, -1); + lua_pop(filter->lua_state, 1); + } + + unhook_write(); + return ret; +} + +static void fprintf_lua_filter(struct cgit_filter *base, FILE *f, const char *prefix) +{ + struct lua_filter *filter = (struct lua_filter *)base; + fprintf(f, "%slua:%s\n", prefix, filter->script_file); +} + + +static struct cgit_filter *new_lua_filter(const char *cmd, int argument_count) +{ + struct lua_filter *filter; + + filter = xmalloc(sizeof(*filter)); + memset(filter, 0, sizeof(*filter)); + filter->base.open = open_lua_filter; + filter->base.close = close_lua_filter; + filter->base.fprintf = fprintf_lua_filter; + filter->base.cleanup = cleanup_lua_filter; + filter->base.argument_count = argument_count; + filter->script_file = xstrdup(cmd); + + return &filter->base; +} + +#endif + + +int cgit_open_filter(struct cgit_filter *filter, ...) +{ + int result; + va_list ap; + if (!filter) + return 0; + va_start(ap, filter); + result = filter->open(filter, ap); + va_end(ap); + return result; +} + +int cgit_close_filter(struct cgit_filter *filter) +{ + if (!filter) + return 0; + return filter->close(filter); +} + +void cgit_fprintf_filter(struct cgit_filter *filter, FILE *f, const char *prefix) +{ + filter->fprintf(filter, f, prefix); +} + + + +static const struct { + const char *prefix; + struct cgit_filter *(*ctor)(const char *cmd, int argument_count); +} filter_specs[] = { + { "exec", new_exec_filter }, +#ifndef NO_LUA + { "lua", new_lua_filter }, +#endif +}; + +struct cgit_filter *cgit_new_filter(const char *cmd, filter_type filtertype) +{ + char *colon; + int i; + size_t len; + int argument_count; + + if (!cmd || !cmd[0]) + return NULL; + + colon = strchr(cmd, ':'); + len = colon - cmd; + /* + * In case we're running on Windows, don't allow a single letter before + * the colon. + */ + if (len == 1) + colon = NULL; + + switch (filtertype) { + case AUTH: + argument_count = 12; + break; + + case EMAIL: + argument_count = 2; + break; + + case OWNER: + argument_count = 0; + break; + + case SOURCE: + case ABOUT: + argument_count = 1; + break; + + case COMMIT: + default: + argument_count = 0; + break; + } + + /* If no prefix is given, exec filter is the default. */ + if (!colon) + return new_exec_filter(cmd, argument_count); + + for (i = 0; i < ARRAY_SIZE(filter_specs); i++) { + if (len == strlen(filter_specs[i].prefix) && + !strncmp(filter_specs[i].prefix, cmd, len)) + return filter_specs[i].ctor(colon + 1, argument_count); + } + + die("Invalid filter type: %.*s", (int) len, cmd); +} diff --git a/third_party/cgit/filters/about-formatting.sh b/third_party/cgit/filters/about-formatting.sh new file mode 100755 index 0000000000..85daf9c26b --- /dev/null +++ b/third_party/cgit/filters/about-formatting.sh @@ -0,0 +1,27 @@ +#!/bin/sh + +# This may be used with the about-filter or repo.about-filter setting in cgitrc. +# It passes formatting of about pages to differing programs, depending on the usage. + +# Markdown support requires python and markdown-python. +# RestructuredText support requires python and docutils. +# Man page support requires groff. + +# The following environment variables can be used to retrieve the configuration +# of the repository for which this script is called: +# CGIT_REPO_URL ( = repo.url setting ) +# CGIT_REPO_NAME ( = repo.name setting ) +# CGIT_REPO_PATH ( = repo.path setting ) +# CGIT_REPO_OWNER ( = repo.owner setting ) +# CGIT_REPO_DEFBRANCH ( = repo.defbranch setting ) +# CGIT_REPO_SECTION ( = section setting ) +# CGIT_REPO_CLONE_URL ( = repo.clone-url setting ) + +cd "$(dirname $0)/html-converters/" +case "$(printf '%s' "$1" | tr '[:upper:]' '[:lower:]')" in + *.markdown|*.mdown|*.md|*.mkd) exec ./md2html; ;; + *.rst) exec ./rst2html; ;; + *.[1-9]) exec ./man2html; ;; + *.htm|*.html) exec cat; ;; + *.txt|*) exec ./txt2html; ;; +esac diff --git a/third_party/cgit/filters/commit-links.sh b/third_party/cgit/filters/commit-links.sh new file mode 100755 index 0000000000..58819524ce --- /dev/null +++ b/third_party/cgit/filters/commit-links.sh @@ -0,0 +1,28 @@ +#!/bin/sh +# This script can be used to generate links in commit messages. +# +# To use this script, refer to this file with either the commit-filter or the +# repo.commit-filter options in cgitrc. +# +# The following environment variables can be used to retrieve the configuration +# of the repository for which this script is called: +# CGIT_REPO_URL ( = repo.url setting ) +# CGIT_REPO_NAME ( = repo.name setting ) +# CGIT_REPO_PATH ( = repo.path setting ) +# CGIT_REPO_OWNER ( = repo.owner setting ) +# CGIT_REPO_DEFBRANCH ( = repo.defbranch setting ) +# CGIT_REPO_SECTION ( = section setting ) +# CGIT_REPO_CLONE_URL ( = repo.clone-url setting ) +# + +regex='' + +# This expression generates links to commits referenced by their SHA1. +regex=$regex' +s|\b([0-9a-fA-F]{7,40})\b|<a href="./?id=\1">\1</a>|g' + +# This expression generates links to a fictional bugtracker. +regex=$regex' +s|#([0-9]+)\b|<a href="http://bugs.example.com/?bug=\1">#\1</a>|g' + +sed -re "$regex" diff --git a/third_party/cgit/filters/email-gravatar.lua b/third_party/cgit/filters/email-gravatar.lua new file mode 100644 index 0000000000..c39b490d6b --- /dev/null +++ b/third_party/cgit/filters/email-gravatar.lua @@ -0,0 +1,35 @@ +-- This script may be used with the email-filter or repo.email-filter settings in cgitrc. +-- It adds gravatar icons to author names. It is designed to be used with the lua: +-- prefix in filters. It is much faster than the corresponding python script. +-- +-- Requirements: +-- luaossl +-- <http://25thandclement.com/~william/projects/luaossl.html> +-- + +local digest = require("openssl.digest") + +function md5_hex(input) + local b = digest.new("md5"):final(input) + local x = "" + for i = 1, #b do + x = x .. string.format("%.2x", string.byte(b, i)) + end + return x +end + +function filter_open(email, page) + buffer = "" + md5 = md5_hex(email:sub(2, -2):lower()) +end + +function filter_close() + html("<img src='//www.gravatar.com/avatar/" .. md5 .. "?s=13&d=retro' width='13' height='13' alt='Gravatar' /> " .. buffer) + return 0 +end + +function filter_write(str) + buffer = buffer .. str +end + + diff --git a/third_party/cgit/filters/email-gravatar.py b/third_party/cgit/filters/email-gravatar.py new file mode 100755 index 0000000000..d70440ea54 --- /dev/null +++ b/third_party/cgit/filters/email-gravatar.py @@ -0,0 +1,39 @@ +#!/usr/bin/env python3 + +# Please prefer the email-gravatar.lua using lua: as a prefix over this script. This +# script is very slow, in comparison. +# +# This script may be used with the email-filter or repo.email-filter settings in cgitrc. +# +# The following environment variables can be used to retrieve the configuration +# of the repository for which this script is called: +# CGIT_REPO_URL ( = repo.url setting ) +# CGIT_REPO_NAME ( = repo.name setting ) +# CGIT_REPO_PATH ( = repo.path setting ) +# CGIT_REPO_OWNER ( = repo.owner setting ) +# CGIT_REPO_DEFBRANCH ( = repo.defbranch setting ) +# CGIT_REPO_SECTION ( = section setting ) +# CGIT_REPO_CLONE_URL ( = repo.clone-url setting ) +# +# It receives an email address on argv[1] and text on stdin. It prints +# to stdout that text prepended by a gravatar at 10pt. + +import sys +import hashlib +import codecs + +email = sys.argv[1].lower().strip() +if email[0] == '<': + email = email[1:] +if email[-1] == '>': + email = email[0:-1] + +page = sys.argv[2] + +sys.stdin = codecs.getreader("utf-8")(sys.stdin.detach()) +sys.stdout = codecs.getwriter("utf-8")(sys.stdout.detach()) + +md5 = hashlib.md5(email.encode()).hexdigest() +text = sys.stdin.read().strip() + +print("<img src='//www.gravatar.com/avatar/" + md5 + "?s=13&d=retro' width='13' height='13' alt='Gravatar' /> " + text) diff --git a/third_party/cgit/filters/email-libravatar.lua b/third_party/cgit/filters/email-libravatar.lua new file mode 100644 index 0000000000..7336baf830 --- /dev/null +++ b/third_party/cgit/filters/email-libravatar.lua @@ -0,0 +1,36 @@ +-- This script may be used with the email-filter or repo.email-filter settings in cgitrc. +-- It adds libravatar icons to author names. It is designed to be used with the lua: +-- prefix in filters. +-- +-- Requirements: +-- luaossl +-- <http://25thandclement.com/~william/projects/luaossl.html> +-- + +local digest = require("openssl.digest") + +function md5_hex(input) + local b = digest.new("md5"):final(input) + local x = "" + for i = 1, #b do + x = x .. string.format("%.2x", string.byte(b, i)) + end + return x +end + +function filter_open(email, page) + buffer = "" + md5 = md5_hex(email:sub(2, -2):lower()) +end + +function filter_close() + baseurl = os.getenv("HTTPS") and "https://seccdn.libravatar.org/" or "http://cdn.libravatar.org/" + html("<img src='" .. baseurl .. "avatar/" .. md5 .. "?s=13&d=retro' width='13' height='13' alt='Libravatar' /> " .. buffer) + return 0 +end + +function filter_write(str) + buffer = buffer .. str +end + + diff --git a/third_party/cgit/filters/file-authentication.lua b/third_party/cgit/filters/file-authentication.lua new file mode 100644 index 0000000000..024880463c --- /dev/null +++ b/third_party/cgit/filters/file-authentication.lua @@ -0,0 +1,359 @@ +-- This script may be used with the auth-filter. +-- +-- Requirements: +-- luaossl +-- <http://25thandclement.com/~william/projects/luaossl.html> +-- luaposix +-- <https://github.com/luaposix/luaposix> +-- +local sysstat = require("posix.sys.stat") +local unistd = require("posix.unistd") +local rand = require("openssl.rand") +local hmac = require("openssl.hmac") + +-- This file should contain a series of lines in the form of: +-- username1:hash1 +-- username2:hash2 +-- username3:hash3 +-- ... +-- Hashes can be generated using something like `mkpasswd -m sha-512 -R 300000`. +-- This file should not be world-readable. +local users_filename = "/etc/cgit-auth/users" + +-- This file should contain a series of lines in the form of: +-- groupname1:username1,username2,username3,... +-- ... +local groups_filename = "/etc/cgit-auth/groups" + +-- This file should contain a series of lines in the form of: +-- reponame1:groupname1,groupname2,groupname3,... +-- ... +local repos_filename = "/etc/cgit-auth/repos" + +-- Set this to a path this script can write to for storing a persistent +-- cookie secret, which should not be world-readable. +local secret_filename = "/var/cache/cgit/auth-secret" + +-- +-- +-- Authentication functions follow below. Swap these out if you want different authentication semantics. +-- +-- + +-- Looks up a hash for a given user. +function lookup_hash(user) + local line + for line in io.lines(users_filename) do + local u, h = string.match(line, "(.-):(.+)") + if u:lower() == user:lower() then + return h + end + end + return nil +end + +-- Looks up users for a given repo. +function lookup_users(repo) + local users = nil + local groups = nil + local line, group, user + for line in io.lines(repos_filename) do + local r, g = string.match(line, "(.-):(.+)") + if r == repo then + groups = { } + for group in string.gmatch(g, "([^,]+)") do + groups[group:lower()] = true + end + break + end + end + if groups == nil then + return nil + end + for line in io.lines(groups_filename) do + local g, u = string.match(line, "(.-):(.+)") + if groups[g:lower()] then + if users == nil then + users = { } + end + for user in string.gmatch(u, "([^,]+)") do + users[user:lower()] = true + end + end + end + return users +end + + +-- Sets HTTP cookie headers based on post and sets up redirection. +function authenticate_post() + local hash = lookup_hash(post["username"]) + local redirect = validate_value("redirect", post["redirect"]) + + if redirect == nil then + not_found() + return 0 + end + + redirect_to(redirect) + + if hash == nil or hash ~= unistd.crypt(post["password"], hash) then + set_cookie("cgitauth", "") + else + -- One week expiration time + local username = secure_value("username", post["username"], os.time() + 604800) + set_cookie("cgitauth", username) + end + + html("\n") + return 0 +end + + +-- Returns 1 if the cookie is valid and 0 if it is not. +function authenticate_cookie() + accepted_users = lookup_users(cgit["repo"]) + if accepted_users == nil then + -- We return as valid if the repo is not protected. + return 1 + end + + local username = validate_value("username", get_cookie(http["cookie"], "cgitauth")) + if username == nil or not accepted_users[username:lower()] then + return 0 + else + return 1 + end +end + +-- Prints the html for the login form. +function body() + html("<h2>Authentication Required</h2>") + html("<form method='post' action='") + html_attr(cgit["login"]) + html("'>") + html("<input type='hidden' name='redirect' value='") + html_attr(secure_value("redirect", cgit["url"], 0)) + html("' />") + html("<table>") + html("<tr><td><label for='username'>Username:</label></td><td><input id='username' name='username' autofocus /></td></tr>") + html("<tr><td><label for='password'>Password:</label></td><td><input id='password' name='password' type='password' /></td></tr>") + html("<tr><td colspan='2'><input value='Login' type='submit' /></td></tr>") + html("</table></form>") + + return 0 +end + + + +-- +-- +-- Wrapper around filter API, exposing the http table, the cgit table, and the post table to the above functions. +-- +-- + +local actions = {} +actions["authenticate-post"] = authenticate_post +actions["authenticate-cookie"] = authenticate_cookie +actions["body"] = body + +function filter_open(...) + action = actions[select(1, ...)] + + http = {} + http["cookie"] = select(2, ...) + http["method"] = select(3, ...) + http["query"] = select(4, ...) + http["referer"] = select(5, ...) + http["path"] = select(6, ...) + http["host"] = select(7, ...) + http["https"] = select(8, ...) + + cgit = {} + cgit["repo"] = select(9, ...) + cgit["page"] = select(10, ...) + cgit["url"] = select(11, ...) + cgit["login"] = select(12, ...) + +end + +function filter_close() + return action() +end + +function filter_write(str) + post = parse_qs(str) +end + + +-- +-- +-- Utility functions based on keplerproject/wsapi. +-- +-- + +function url_decode(str) + if not str then + return "" + end + str = string.gsub(str, "+", " ") + str = string.gsub(str, "%%(%x%x)", function(h) return string.char(tonumber(h, 16)) end) + str = string.gsub(str, "\r\n", "\n") + return str +end + +function url_encode(str) + if not str then + return "" + end + str = string.gsub(str, "\n", "\r\n") + str = string.gsub(str, "([^%w ])", function(c) return string.format("%%%02X", string.byte(c)) end) + str = string.gsub(str, " ", "+") + return str +end + +function parse_qs(qs) + local tab = {} + for key, val in string.gmatch(qs, "([^&=]+)=([^&=]*)&?") do + tab[url_decode(key)] = url_decode(val) + end + return tab +end + +function get_cookie(cookies, name) + cookies = string.gsub(";" .. cookies .. ";", "%s*;%s*", ";") + return url_decode(string.match(cookies, ";" .. name .. "=(.-);")) +end + +function tohex(b) + local x = "" + for i = 1, #b do + x = x .. string.format("%.2x", string.byte(b, i)) + end + return x +end + +-- +-- +-- Cookie construction and validation helpers. +-- +-- + +local secret = nil + +-- Loads a secret from a file, creates a secret, or returns one from memory. +function get_secret() + if secret ~= nil then + return secret + end + local secret_file = io.open(secret_filename, "r") + if secret_file == nil then + local old_umask = sysstat.umask(63) + local temporary_filename = secret_filename .. ".tmp." .. tohex(rand.bytes(16)) + local temporary_file = io.open(temporary_filename, "w") + if temporary_file == nil then + os.exit(177) + end + temporary_file:write(tohex(rand.bytes(32))) + temporary_file:close() + unistd.link(temporary_filename, secret_filename) -- Intentionally fails in the case that another process is doing the same. + unistd.unlink(temporary_filename) + sysstat.umask(old_umask) + secret_file = io.open(secret_filename, "r") + end + if secret_file == nil then + os.exit(177) + end + secret = secret_file:read() + secret_file:close() + if secret:len() ~= 64 then + os.exit(177) + end + return secret +end + +-- Returns value of cookie if cookie is valid. Otherwise returns nil. +function validate_value(expected_field, cookie) + local i = 0 + local value = "" + local field = "" + local expiration = 0 + local salt = "" + local chmac = "" + + if cookie == nil or cookie:len() < 3 or cookie:sub(1, 1) == "|" then + return nil + end + + for component in string.gmatch(cookie, "[^|]+") do + if i == 0 then + field = component + elseif i == 1 then + value = component + elseif i == 2 then + expiration = tonumber(component) + if expiration == nil then + expiration = -1 + end + elseif i == 3 then + salt = component + elseif i == 4 then + chmac = component + else + break + end + i = i + 1 + end + + if chmac == nil or chmac:len() == 0 then + return nil + end + + -- Lua hashes strings, so these comparisons are time invariant. + if chmac ~= tohex(hmac.new(get_secret(), "sha256"):final(field .. "|" .. value .. "|" .. tostring(expiration) .. "|" .. salt)) then + return nil + end + + if expiration == -1 or (expiration ~= 0 and expiration <= os.time()) then + return nil + end + + if url_decode(field) ~= expected_field then + return nil + end + + return url_decode(value) +end + +function secure_value(field, value, expiration) + if value == nil or value:len() <= 0 then + return "" + end + + local authstr = "" + local salt = tohex(rand.bytes(16)) + value = url_encode(value) + field = url_encode(field) + authstr = field .. "|" .. value .. "|" .. tostring(expiration) .. "|" .. salt + authstr = authstr .. "|" .. tohex(hmac.new(get_secret(), "sha256"):final(authstr)) + return authstr +end + +function set_cookie(cookie, value) + html("Set-Cookie: " .. cookie .. "=" .. value .. "; HttpOnly") + if http["https"] == "yes" or http["https"] == "on" or http["https"] == "1" then + html("; secure") + end + html("\n") +end + +function redirect_to(url) + html("Status: 302 Redirect\n") + html("Cache-Control: no-cache, no-store\n") + html("Location: " .. url .. "\n") +end + +function not_found() + html("Status: 404 Not Found\n") + html("Cache-Control: no-cache, no-store\n\n") +end diff --git a/third_party/cgit/filters/gentoo-ldap-authentication.lua b/third_party/cgit/filters/gentoo-ldap-authentication.lua new file mode 100644 index 0000000000..673c88d102 --- /dev/null +++ b/third_party/cgit/filters/gentoo-ldap-authentication.lua @@ -0,0 +1,360 @@ +-- This script may be used with the auth-filter. Be sure to configure it as you wish. +-- +-- Requirements: +-- luaossl +-- <http://25thandclement.com/~william/projects/luaossl.html> +-- lualdap >= 1.2 +-- <https://git.zx2c4.com/lualdap/about/> +-- luaposix +-- <https://github.com/luaposix/luaposix> +-- +local sysstat = require("posix.sys.stat") +local unistd = require("posix.unistd") +local lualdap = require("lualdap") +local rand = require("openssl.rand") +local hmac = require("openssl.hmac") + +-- +-- +-- Configure these variables for your settings. +-- +-- + +-- A list of password protected repositories, with which gentooAccess +-- group is allowed to access each one. +local protected_repos = { + glouglou = "infra", + portage = "dev" +} + +-- Set this to a path this script can write to for storing a persistent +-- cookie secret, which should be guarded. +local secret_filename = "/var/cache/cgit/auth-secret" + + +-- +-- +-- Authentication functions follow below. Swap these out if you want different authentication semantics. +-- +-- + +-- Sets HTTP cookie headers based on post and sets up redirection. +function authenticate_post() + local redirect = validate_value("redirect", post["redirect"]) + + if redirect == nil then + not_found() + return 0 + end + + redirect_to(redirect) + + local groups = gentoo_ldap_user_groups(post["username"], post["password"]) + if groups == nil then + set_cookie("cgitauth", "") + else + -- One week expiration time + set_cookie("cgitauth", secure_value("gentoogroups", table.concat(groups, ","), os.time() + 604800)) + end + + html("\n") + return 0 +end + + +-- Returns 1 if the cookie is valid and 0 if it is not. +function authenticate_cookie() + local required_group = protected_repos[cgit["repo"]] + if required_group == nil then + -- We return as valid if the repo is not protected. + return 1 + end + + local user_groups = validate_value("gentoogroups", get_cookie(http["cookie"], "cgitauth")) + if user_groups == nil or user_groups == "" then + return 0 + end + for group in string.gmatch(user_groups, "[^,]+") do + if group == required_group then + return 1 + end + end + return 0 +end + +-- Prints the html for the login form. +function body() + html("<h2>Gentoo LDAP Authentication Required</h2>") + html("<form method='post' action='") + html_attr(cgit["login"]) + html("'>") + html("<input type='hidden' name='redirect' value='") + html_attr(secure_value("redirect", cgit["url"], 0)) + html("' />") + html("<table>") + html("<tr><td><label for='username'>Username:</label></td><td><input id='username' name='username' autofocus /></td></tr>") + html("<tr><td><label for='password'>Password:</label></td><td><input id='password' name='password' type='password' /></td></tr>") + html("<tr><td colspan='2'><input value='Login' type='submit' /></td></tr>") + html("</table></form>") + + return 0 +end + +-- +-- +-- Gentoo LDAP support. +-- +-- + +function gentoo_ldap_user_groups(username, password) + -- Ensure the user is alphanumeric + if username == nil or username:match("%W") then + return nil + end + + local who = "uid=" .. username .. ",ou=devs,dc=gentoo,dc=org" + + local ldap, err = lualdap.open_simple { + uri = "ldap://ldap1.gentoo.org", + who = who, + password = password, + starttls = true, + certfile = "/var/www/uwsgi/cgit/gentoo-ldap/star.gentoo.org.crt", + keyfile = "/var/www/uwsgi/cgit/gentoo-ldap/star.gentoo.org.key", + cacertfile = "/var/www/uwsgi/cgit/gentoo-ldap/ca.pem" + } + if ldap == nil then + return nil + end + + local group_suffix = ".group" + local group_suffix_len = group_suffix:len() + local groups = {} + for dn, attribs in ldap:search { base = who, scope = "subtree" } do + local access = attribs["gentooAccess"] + if dn == who and access ~= nil then + for i, v in ipairs(access) do + local vlen = v:len() + if vlen > group_suffix_len and v:sub(-group_suffix_len) == group_suffix then + table.insert(groups, v:sub(1, vlen - group_suffix_len)) + end + end + end + end + + ldap:close() + + return groups +end + +-- +-- +-- Wrapper around filter API, exposing the http table, the cgit table, and the post table to the above functions. +-- +-- + +local actions = {} +actions["authenticate-post"] = authenticate_post +actions["authenticate-cookie"] = authenticate_cookie +actions["body"] = body + +function filter_open(...) + action = actions[select(1, ...)] + + http = {} + http["cookie"] = select(2, ...) + http["method"] = select(3, ...) + http["query"] = select(4, ...) + http["referer"] = select(5, ...) + http["path"] = select(6, ...) + http["host"] = select(7, ...) + http["https"] = select(8, ...) + + cgit = {} + cgit["repo"] = select(9, ...) + cgit["page"] = select(10, ...) + cgit["url"] = select(11, ...) + cgit["login"] = select(12, ...) + +end + +function filter_close() + return action() +end + +function filter_write(str) + post = parse_qs(str) +end + + +-- +-- +-- Utility functions based on keplerproject/wsapi. +-- +-- + +function url_decode(str) + if not str then + return "" + end + str = string.gsub(str, "+", " ") + str = string.gsub(str, "%%(%x%x)", function(h) return string.char(tonumber(h, 16)) end) + str = string.gsub(str, "\r\n", "\n") + return str +end + +function url_encode(str) + if not str then + return "" + end + str = string.gsub(str, "\n", "\r\n") + str = string.gsub(str, "([^%w ])", function(c) return string.format("%%%02X", string.byte(c)) end) + str = string.gsub(str, " ", "+") + return str +end + +function parse_qs(qs) + local tab = {} + for key, val in string.gmatch(qs, "([^&=]+)=([^&=]*)&?") do + tab[url_decode(key)] = url_decode(val) + end + return tab +end + +function get_cookie(cookies, name) + cookies = string.gsub(";" .. cookies .. ";", "%s*;%s*", ";") + return string.match(cookies, ";" .. name .. "=(.-);") +end + +function tohex(b) + local x = "" + for i = 1, #b do + x = x .. string.format("%.2x", string.byte(b, i)) + end + return x +end + +-- +-- +-- Cookie construction and validation helpers. +-- +-- + +local secret = nil + +-- Loads a secret from a file, creates a secret, or returns one from memory. +function get_secret() + if secret ~= nil then + return secret + end + local secret_file = io.open(secret_filename, "r") + if secret_file == nil then + local old_umask = sysstat.umask(63) + local temporary_filename = secret_filename .. ".tmp." .. tohex(rand.bytes(16)) + local temporary_file = io.open(temporary_filename, "w") + if temporary_file == nil then + os.exit(177) + end + temporary_file:write(tohex(rand.bytes(32))) + temporary_file:close() + unistd.link(temporary_filename, secret_filename) -- Intentionally fails in the case that another process is doing the same. + unistd.unlink(temporary_filename) + sysstat.umask(old_umask) + secret_file = io.open(secret_filename, "r") + end + if secret_file == nil then + os.exit(177) + end + secret = secret_file:read() + secret_file:close() + if secret:len() ~= 64 then + os.exit(177) + end + return secret +end + +-- Returns value of cookie if cookie is valid. Otherwise returns nil. +function validate_value(expected_field, cookie) + local i = 0 + local value = "" + local field = "" + local expiration = 0 + local salt = "" + local chmac = "" + + if cookie == nil or cookie:len() < 3 or cookie:sub(1, 1) == "|" then + return nil + end + + for component in string.gmatch(cookie, "[^|]+") do + if i == 0 then + field = component + elseif i == 1 then + value = component + elseif i == 2 then + expiration = tonumber(component) + if expiration == nil then + expiration = -1 + end + elseif i == 3 then + salt = component + elseif i == 4 then + chmac = component + else + break + end + i = i + 1 + end + + if chmac == nil or chmac:len() == 0 then + return nil + end + + -- Lua hashes strings, so these comparisons are time invariant. + if chmac ~= tohex(hmac.new(get_secret(), "sha256"):final(field .. "|" .. value .. "|" .. tostring(expiration) .. "|" .. salt)) then + return nil + end + + if expiration == -1 or (expiration ~= 0 and expiration <= os.time()) then + return nil + end + + if url_decode(field) ~= expected_field then + return nil + end + + return url_decode(value) +end + +function secure_value(field, value, expiration) + if value == nil or value:len() <= 0 then + return "" + end + + local authstr = "" + local salt = tohex(rand.bytes(16)) + value = url_encode(value) + field = url_encode(field) + authstr = field .. "|" .. value .. "|" .. tostring(expiration) .. "|" .. salt + authstr = authstr .. "|" .. tohex(hmac.new(get_secret(), "sha256"):final(authstr)) + return authstr +end + +function set_cookie(cookie, value) + html("Set-Cookie: " .. cookie .. "=" .. value .. "; HttpOnly") + if http["https"] == "yes" or http["https"] == "on" or http["https"] == "1" then + html("; secure") + end + html("\n") +end + +function redirect_to(url) + html("Status: 302 Redirect\n") + html("Cache-Control: no-cache, no-store\n") + html("Location: " .. url .. "\n") +end + +function not_found() + html("Status: 404 Not Found\n") + html("Cache-Control: no-cache, no-store\n\n") +end diff --git a/third_party/cgit/filters/html-converters/man2html b/third_party/cgit/filters/html-converters/man2html new file mode 100755 index 0000000000..0ef7884181 --- /dev/null +++ b/third_party/cgit/filters/html-converters/man2html @@ -0,0 +1,4 @@ +#!/bin/sh +echo "<div style=\"font-family: monospace\">" +groff -mandoc -T html -P -r -P -l | egrep -v '(<html>|<head>|<meta|<title>|</title>|</head>|<body>|</body>|</html>|<!DOCTYPE|"http://www.w3.org)' +echo "</div>" diff --git a/third_party/cgit/filters/html-converters/md2html b/third_party/cgit/filters/html-converters/md2html new file mode 100755 index 0000000000..dc20f42a05 --- /dev/null +++ b/third_party/cgit/filters/html-converters/md2html @@ -0,0 +1,307 @@ +#!/usr/bin/env python3 +import markdown +import sys +import io +from pygments.formatters import HtmlFormatter +from markdown.extensions.toc import TocExtension +sys.stdin = io.TextIOWrapper(sys.stdin.buffer, encoding='utf-8') +sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') +sys.stdout.write(''' +<style> +.markdown-body { + font-size: 14px; + line-height: 1.6; + overflow: hidden; +} +.markdown-body>*:first-child { + margin-top: 0 !important; +} +.markdown-body>*:last-child { + margin-bottom: 0 !important; +} +.markdown-body a.absent { + color: #c00; +} +.markdown-body a.anchor { + display: block; + padding-left: 30px; + margin-left: -30px; + cursor: pointer; + position: absolute; + top: 0; + left: 0; + bottom: 0; +} +.markdown-body h1, .markdown-body h2, .markdown-body h3, .markdown-body h4, .markdown-body h5, .markdown-body h6 { + margin: 20px 0 10px; + padding: 0; + font-weight: bold; + -webkit-font-smoothing: antialiased; + cursor: text; + position: relative; +} +.markdown-body h1 .mini-icon-link, .markdown-body h2 .mini-icon-link, .markdown-body h3 .mini-icon-link, .markdown-body h4 .mini-icon-link, .markdown-body h5 .mini-icon-link, .markdown-body h6 .mini-icon-link { + display: none; + color: #000; +} +.markdown-body h1:hover a.anchor, .markdown-body h2:hover a.anchor, .markdown-body h3:hover a.anchor, .markdown-body h4:hover a.anchor, .markdown-body h5:hover a.anchor, .markdown-body h6:hover a.anchor { + text-decoration: none; + line-height: 1; + padding-left: 0; + margin-left: -22px; + top: 15%; +} +.markdown-body h1:hover a.anchor .mini-icon-link, .markdown-body h2:hover a.anchor .mini-icon-link, .markdown-body h3:hover a.anchor .mini-icon-link, .markdown-body h4:hover a.anchor .mini-icon-link, .markdown-body h5:hover a.anchor .mini-icon-link, .markdown-body h6:hover a.anchor .mini-icon-link { + display: inline-block; +} +div#cgit .markdown-body h1 a.toclink, div#cgit .markdown-body h2 a.toclink, div#cgit .markdown-body h3 a.toclink, div#cgit .markdown-body h4 a.toclink, div#cgit .markdown-body h5 a.toclink, div#cgit .markdown-body h6 a.toclink { + color: black; +} +.markdown-body h1 tt, .markdown-body h1 code, .markdown-body h2 tt, .markdown-body h2 code, .markdown-body h3 tt, .markdown-body h3 code, .markdown-body h4 tt, .markdown-body h4 code, .markdown-body h5 tt, .markdown-body h5 code, .markdown-body h6 tt, .markdown-body h6 code { + font-size: inherit; +} +.markdown-body h1 { + font-size: 28px; + color: #000; +} +.markdown-body h2 { + font-size: 24px; + border-bottom: 1px solid #ccc; + color: #000; +} +.markdown-body h3 { + font-size: 18px; +} +.markdown-body h4 { + font-size: 16px; +} +.markdown-body h5 { + font-size: 14px; +} +.markdown-body h6 { + color: #777; + font-size: 14px; +} +.markdown-body p, .markdown-body blockquote, .markdown-body ul, .markdown-body ol, .markdown-body dl, .markdown-body table, .markdown-body pre { + margin: 15px 0; +} +.markdown-body hr { + background: transparent url("/dirty-shade.png") repeat-x 0 0; + border: 0 none; + color: #ccc; + height: 4px; + padding: 0; +} +.markdown-body>h2:first-child, .markdown-body>h1:first-child, .markdown-body>h1:first-child+h2, .markdown-body>h3:first-child, .markdown-body>h4:first-child, .markdown-body>h5:first-child, .markdown-body>h6:first-child { + margin-top: 0; + padding-top: 0; +} +.markdown-body a:first-child h1, .markdown-body a:first-child h2, .markdown-body a:first-child h3, .markdown-body a:first-child h4, .markdown-body a:first-child h5, .markdown-body a:first-child h6 { + margin-top: 0; + padding-top: 0; +} +.markdown-body h1+p, .markdown-body h2+p, .markdown-body h3+p, .markdown-body h4+p, .markdown-body h5+p, .markdown-body h6+p { + margin-top: 0; +} +.markdown-body li p.first { + display: inline-block; +} +.markdown-body ul, .markdown-body ol { + padding-left: 30px; +} +.markdown-body ul.no-list, .markdown-body ol.no-list { + list-style-type: none; + padding: 0; +} +.markdown-body ul li>:first-child, .markdown-body ul li ul:first-of-type, .markdown-body ul li ol:first-of-type, .markdown-body ol li>:first-child, .markdown-body ol li ul:first-of-type, .markdown-body ol li ol:first-of-type { + margin-top: 0px; +} +.markdown-body ul li p:last-of-type, .markdown-body ol li p:last-of-type { + margin-bottom: 0; +} +.markdown-body ul ul, .markdown-body ul ol, .markdown-body ol ol, .markdown-body ol ul { + margin-bottom: 0; +} +.markdown-body dl { + padding: 0; +} +.markdown-body dl dt { + font-size: 14px; + font-weight: bold; + font-style: italic; + padding: 0; + margin: 15px 0 5px; +} +.markdown-body dl dt:first-child { + padding: 0; +} +.markdown-body dl dt>:first-child { + margin-top: 0px; +} +.markdown-body dl dt>:last-child { + margin-bottom: 0px; +} +.markdown-body dl dd { + margin: 0 0 15px; + padding: 0 15px; +} +.markdown-body dl dd>:first-child { + margin-top: 0px; +} +.markdown-body dl dd>:last-child { + margin-bottom: 0px; +} +.markdown-body blockquote { + border-left: 4px solid #DDD; + padding: 0 15px; + color: #777; +} +.markdown-body blockquote>:first-child { + margin-top: 0px; +} +.markdown-body blockquote>:last-child { + margin-bottom: 0px; +} +.markdown-body table th { + font-weight: bold; +} +.markdown-body table th, .markdown-body table td { + border: 1px solid #ccc; + padding: 6px 13px; +} +.markdown-body table tr { + border-top: 1px solid #ccc; + background-color: #fff; +} +.markdown-body table tr:nth-child(2n) { + background-color: #f8f8f8; +} +.markdown-body img { + max-width: 100%; + -moz-box-sizing: border-box; + box-sizing: border-box; +} +.markdown-body span.frame { + display: block; + overflow: hidden; +} +.markdown-body span.frame>span { + border: 1px solid #ddd; + display: block; + float: left; + overflow: hidden; + margin: 13px 0 0; + padding: 7px; + width: auto; +} +.markdown-body span.frame span img { + display: block; + float: left; +} +.markdown-body span.frame span span { + clear: both; + color: #333; + display: block; + padding: 5px 0 0; +} +.markdown-body span.align-center { + display: block; + overflow: hidden; + clear: both; +} +.markdown-body span.align-center>span { + display: block; + overflow: hidden; + margin: 13px auto 0; + text-align: center; +} +.markdown-body span.align-center span img { + margin: 0 auto; + text-align: center; +} +.markdown-body span.align-right { + display: block; + overflow: hidden; + clear: both; +} +.markdown-body span.align-right>span { + display: block; + overflow: hidden; + margin: 13px 0 0; + text-align: right; +} +.markdown-body span.align-right span img { + margin: 0; + text-align: right; +} +.markdown-body span.float-left { + display: block; + margin-right: 13px; + overflow: hidden; + float: left; +} +.markdown-body span.float-left span { + margin: 13px 0 0; +} +.markdown-body span.float-right { + display: block; + margin-left: 13px; + overflow: hidden; + float: right; +} +.markdown-body span.float-right>span { + display: block; + overflow: hidden; + margin: 13px auto 0; + text-align: right; +} +.markdown-body code, .markdown-body tt { + margin: 0 2px; + padding: 0px 5px; + border: 1px solid #eaeaea; + background-color: #f8f8f8; + border-radius: 3px; +} +.markdown-body code { + white-space: nowrap; +} +.markdown-body pre>code { + margin: 0; + padding: 0; + white-space: pre; + border: none; + background: transparent; +} +.markdown-body .highlight pre, .markdown-body pre { + background-color: #f8f8f8; + border: 1px solid #ccc; + font-size: 13px; + line-height: 19px; + overflow: auto; + padding: 6px 10px; + border-radius: 3px; +} +.markdown-body pre code, .markdown-body pre tt { + margin: 0; + padding: 0; + background-color: transparent; + border: none; +} +''') +sys.stdout.write(HtmlFormatter(style='pastie').get_style_defs('.highlight')) +sys.stdout.write(''' +</style> +''') +sys.stdout.write("<div class='markdown-body'>") +sys.stdout.flush() +# Note: you may want to run this through bleach for sanitization +markdown.markdownFromFile( + output_format="html5", + extensions=[ + "markdown.extensions.fenced_code", + "markdown.extensions.codehilite", + "markdown.extensions.tables", + TocExtension(anchorlink=True)], + extension_configs={ + "markdown.extensions.codehilite":{"css_class":"highlight"}}) +sys.stdout.write("</div>") diff --git a/third_party/cgit/filters/html-converters/rst2html b/third_party/cgit/filters/html-converters/rst2html new file mode 100755 index 0000000000..02d90f81c9 --- /dev/null +++ b/third_party/cgit/filters/html-converters/rst2html @@ -0,0 +1,2 @@ +#!/bin/bash +exec rst2html.py --template <(echo -e "%(stylesheet)s\n%(body_pre_docinfo)s\n%(docinfo)s\n%(body)s") diff --git a/third_party/cgit/filters/html-converters/txt2html b/third_party/cgit/filters/html-converters/txt2html new file mode 100755 index 0000000000..495eeceb27 --- /dev/null +++ b/third_party/cgit/filters/html-converters/txt2html @@ -0,0 +1,4 @@ +#!/bin/sh +echo "<pre>" +sed "s|&|\\&|g;s|'|\\'|g;s|\"|\\"|g;s|<|\\<|g;s|>|\\>|g" +echo "</pre>" diff --git a/third_party/cgit/filters/owner-example.lua b/third_party/cgit/filters/owner-example.lua new file mode 100644 index 0000000000..50fc25a8e5 --- /dev/null +++ b/third_party/cgit/filters/owner-example.lua @@ -0,0 +1,17 @@ +-- This script is an example of an owner-filter. It replaces the +-- usual query link with one to a fictional homepage. This script may +-- be used with the owner-filter or repo.owner-filter settings in +-- cgitrc with the `lua:` prefix. + +function filter_open() + buffer = "" +end + +function filter_close() + html(string.format("<a href=\"%s\">%s</a>", "http://wiki.example.com/about/" .. buffer, buffer)) + return 0 +end + +function filter_write(str) + buffer = buffer .. str +end diff --git a/third_party/cgit/filters/simple-authentication.lua b/third_party/cgit/filters/simple-authentication.lua new file mode 100644 index 0000000000..23d345763b --- /dev/null +++ b/third_party/cgit/filters/simple-authentication.lua @@ -0,0 +1,314 @@ +-- This script may be used with the auth-filter. Be sure to configure it as you wish. +-- +-- Requirements: +-- luaossl +-- <http://25thandclement.com/~william/projects/luaossl.html> +-- luaposix +-- <https://github.com/luaposix/luaposix> +-- +local sysstat = require("posix.sys.stat") +local unistd = require("posix.unistd") +local rand = require("openssl.rand") +local hmac = require("openssl.hmac") + +-- +-- +-- Configure these variables for your settings. +-- +-- + +-- A list of password protected repositories along with the users who can access them. +local protected_repos = { + glouglou = { laurent = true, jason = true }, + qt = { jason = true, bob = true } +} + +-- A list of users and hashes, generated with `mkpasswd -m sha-512 -R 300000`. +local users = { + jason = "$6$rounds=300000$YYJct3n/o.ruYK$HhpSeuCuW1fJkpvMZOZzVizeLsBKcGA/aF2UPuV5v60JyH2MVSG6P511UMTj2F3H75.IT2HIlnvXzNb60FcZH1", + laurent = "$6$rounds=300000$dP0KNHwYb3JKigT$pN/LG7rWxQ4HniFtx5wKyJXBJUKP7R01zTNZ0qSK/aivw8ywGAOdfYiIQFqFhZFtVGvr11/7an.nesvm8iJUi.", + bob = "$6$rounds=300000$jCLCCt6LUpTz$PI1vvd1yaVYcCzqH8QAJFcJ60b6W/6sjcOsU7mAkNo7IE8FRGW1vkjF8I/T5jt/auv5ODLb1L4S2s.CAyZyUC" +} + +-- Set this to a path this script can write to for storing a persistent +-- cookie secret, which should be guarded. +local secret_filename = "/var/cache/cgit/auth-secret" + +-- +-- +-- Authentication functions follow below. Swap these out if you want different authentication semantics. +-- +-- + +-- Sets HTTP cookie headers based on post and sets up redirection. +function authenticate_post() + local hash = users[post["username"]] + local redirect = validate_value("redirect", post["redirect"]) + + if redirect == nil then + not_found() + return 0 + end + + redirect_to(redirect) + + if hash == nil or hash ~= unistd.crypt(post["password"], hash) then + set_cookie("cgitauth", "") + else + -- One week expiration time + local username = secure_value("username", post["username"], os.time() + 604800) + set_cookie("cgitauth", username) + end + + html("\n") + return 0 +end + + +-- Returns 1 if the cookie is valid and 0 if it is not. +function authenticate_cookie() + accepted_users = protected_repos[cgit["repo"]] + if accepted_users == nil then + -- We return as valid if the repo is not protected. + return 1 + end + + local username = validate_value("username", get_cookie(http["cookie"], "cgitauth")) + if username == nil or not accepted_users[username:lower()] then + return 0 + else + return 1 + end +end + +-- Prints the html for the login form. +function body() + html("<h2>Authentication Required</h2>") + html("<form method='post' action='") + html_attr(cgit["login"]) + html("'>") + html("<input type='hidden' name='redirect' value='") + html_attr(secure_value("redirect", cgit["url"], 0)) + html("' />") + html("<table>") + html("<tr><td><label for='username'>Username:</label></td><td><input id='username' name='username' autofocus /></td></tr>") + html("<tr><td><label for='password'>Password:</label></td><td><input id='password' name='password' type='password' /></td></tr>") + html("<tr><td colspan='2'><input value='Login' type='submit' /></td></tr>") + html("</table></form>") + + return 0 +end + + + +-- +-- +-- Wrapper around filter API, exposing the http table, the cgit table, and the post table to the above functions. +-- +-- + +local actions = {} +actions["authenticate-post"] = authenticate_post +actions["authenticate-cookie"] = authenticate_cookie +actions["body"] = body + +function filter_open(...) + action = actions[select(1, ...)] + + http = {} + http["cookie"] = select(2, ...) + http["method"] = select(3, ...) + http["query"] = select(4, ...) + http["referer"] = select(5, ...) + http["path"] = select(6, ...) + http["host"] = select(7, ...) + http["https"] = select(8, ...) + + cgit = {} + cgit["repo"] = select(9, ...) + cgit["page"] = select(10, ...) + cgit["url"] = select(11, ...) + cgit["login"] = select(12, ...) + +end + +function filter_close() + return action() +end + +function filter_write(str) + post = parse_qs(str) +end + + +-- +-- +-- Utility functions based on keplerproject/wsapi. +-- +-- + +function url_decode(str) + if not str then + return "" + end + str = string.gsub(str, "+", " ") + str = string.gsub(str, "%%(%x%x)", function(h) return string.char(tonumber(h, 16)) end) + str = string.gsub(str, "\r\n", "\n") + return str +end + +function url_encode(str) + if not str then + return "" + end + str = string.gsub(str, "\n", "\r\n") + str = string.gsub(str, "([^%w ])", function(c) return string.format("%%%02X", string.byte(c)) end) + str = string.gsub(str, " ", "+") + return str +end + +function parse_qs(qs) + local tab = {} + for key, val in string.gmatch(qs, "([^&=]+)=([^&=]*)&?") do + tab[url_decode(key)] = url_decode(val) + end + return tab +end + +function get_cookie(cookies, name) + cookies = string.gsub(";" .. cookies .. ";", "%s*;%s*", ";") + return url_decode(string.match(cookies, ";" .. name .. "=(.-);")) +end + +function tohex(b) + local x = "" + for i = 1, #b do + x = x .. string.format("%.2x", string.byte(b, i)) + end + return x +end + +-- +-- +-- Cookie construction and validation helpers. +-- +-- + +local secret = nil + +-- Loads a secret from a file, creates a secret, or returns one from memory. +function get_secret() + if secret ~= nil then + return secret + end + local secret_file = io.open(secret_filename, "r") + if secret_file == nil then + local old_umask = sysstat.umask(63) + local temporary_filename = secret_filename .. ".tmp." .. tohex(rand.bytes(16)) + local temporary_file = io.open(temporary_filename, "w") + if temporary_file == nil then + os.exit(177) + end + temporary_file:write(tohex(rand.bytes(32))) + temporary_file:close() + unistd.link(temporary_filename, secret_filename) -- Intentionally fails in the case that another process is doing the same. + unistd.unlink(temporary_filename) + sysstat.umask(old_umask) + secret_file = io.open(secret_filename, "r") + end + if secret_file == nil then + os.exit(177) + end + secret = secret_file:read() + secret_file:close() + if secret:len() ~= 64 then + os.exit(177) + end + return secret +end + +-- Returns value of cookie if cookie is valid. Otherwise returns nil. +function validate_value(expected_field, cookie) + local i = 0 + local value = "" + local field = "" + local expiration = 0 + local salt = "" + local chmac = "" + + if cookie == nil or cookie:len() < 3 or cookie:sub(1, 1) == "|" then + return nil + end + + for component in string.gmatch(cookie, "[^|]+") do + if i == 0 then + field = component + elseif i == 1 then + value = component + elseif i == 2 then + expiration = tonumber(component) + if expiration == nil then + expiration = -1 + end + elseif i == 3 then + salt = component + elseif i == 4 then + chmac = component + else + break + end + i = i + 1 + end + + if chmac == nil or chmac:len() == 0 then + return nil + end + + -- Lua hashes strings, so these comparisons are time invariant. + if chmac ~= tohex(hmac.new(get_secret(), "sha256"):final(field .. "|" .. value .. "|" .. tostring(expiration) .. "|" .. salt)) then + return nil + end + + if expiration == -1 or (expiration ~= 0 and expiration <= os.time()) then + return nil + end + + if url_decode(field) ~= expected_field then + return nil + end + + return url_decode(value) +end + +function secure_value(field, value, expiration) + if value == nil or value:len() <= 0 then + return "" + end + + local authstr = "" + local salt = tohex(rand.bytes(16)) + value = url_encode(value) + field = url_encode(field) + authstr = field .. "|" .. value .. "|" .. tostring(expiration) .. "|" .. salt + authstr = authstr .. "|" .. tohex(hmac.new(get_secret(), "sha256"):final(authstr)) + return authstr +end + +function set_cookie(cookie, value) + html("Set-Cookie: " .. cookie .. "=" .. value .. "; HttpOnly") + if http["https"] == "yes" or http["https"] == "on" or http["https"] == "1" then + html("; secure") + end + html("\n") +end + +function redirect_to(url) + html("Status: 302 Redirect\n") + html("Cache-Control: no-cache, no-store\n") + html("Location: " .. url .. "\n") +end + +function not_found() + html("Status: 404 Not Found\n") + html("Cache-Control: no-cache, no-store\n\n") +end diff --git a/third_party/cgit/filters/syntax-highlighting.py b/third_party/cgit/filters/syntax-highlighting.py new file mode 100755 index 0000000000..e912594c48 --- /dev/null +++ b/third_party/cgit/filters/syntax-highlighting.py @@ -0,0 +1,55 @@ +#!/usr/bin/env python3 + +# This script uses Pygments and Python3. You must have both installed +# for this to work. +# +# http://pygments.org/ +# http://python.org/ +# +# It may be used with the source-filter or repo.source-filter settings +# in cgitrc. +# +# The following environment variables can be used to retrieve the +# configuration of the repository for which this script is called: +# CGIT_REPO_URL ( = repo.url setting ) +# CGIT_REPO_NAME ( = repo.name setting ) +# CGIT_REPO_PATH ( = repo.path setting ) +# CGIT_REPO_OWNER ( = repo.owner setting ) +# CGIT_REPO_DEFBRANCH ( = repo.defbranch setting ) +# CGIT_REPO_SECTION ( = section setting ) +# CGIT_REPO_CLONE_URL ( = repo.clone-url setting ) + + +import sys +import io +from pygments import highlight +from pygments.util import ClassNotFound +from pygments.lexers import TextLexer +from pygments.lexers import guess_lexer +from pygments.lexers import guess_lexer_for_filename +from pygments.formatters import HtmlFormatter + + +sys.stdin = io.TextIOWrapper(sys.stdin.buffer, encoding='utf-8', errors='replace') +sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace') +data = sys.stdin.read() +filename = sys.argv[1] +formatter = HtmlFormatter(style='pastie', nobackground=True) + +try: + lexer = guess_lexer_for_filename(filename, data) +except ClassNotFound: + # check if there is any shebang + if data[0:2] == '#!': + lexer = guess_lexer(data) + else: + lexer = TextLexer() +except TypeError: + lexer = TextLexer() + +# highlight! :-) +# printout pygments' css definitions as well +sys.stdout.write('<style>') +sys.stdout.write(formatter.get_style_defs('.highlight')) +sys.stdout.write('</style>') +sys.stdout.write(highlight(data, lexer, formatter, outfile=None)) diff --git a/third_party/cgit/filters/syntax-highlighting.sh b/third_party/cgit/filters/syntax-highlighting.sh new file mode 100755 index 0000000000..840bc34fff --- /dev/null +++ b/third_party/cgit/filters/syntax-highlighting.sh @@ -0,0 +1,121 @@ +#!/bin/sh +# This script can be used to implement syntax highlighting in the cgit +# tree-view by referring to this file with the source-filter or repo.source- +# filter options in cgitrc. +# +# This script requires a shell supporting the ${var##pattern} syntax. +# It is supported by at least dash and bash, however busybox environments +# might have to use an external call to sed instead. +# +# Note: the highlight command (http://www.andre-simon.de/) uses css for syntax +# highlighting, so you'll probably want something like the following included +# in your css file: +# +# Style definition file generated by highlight 2.4.8, http://www.andre-simon.de/ +# +# table.blob .num { color:#2928ff; } +# table.blob .esc { color:#ff00ff; } +# table.blob .str { color:#ff0000; } +# table.blob .dstr { color:#818100; } +# table.blob .slc { color:#838183; font-style:italic; } +# table.blob .com { color:#838183; font-style:italic; } +# table.blob .dir { color:#008200; } +# table.blob .sym { color:#000000; } +# table.blob .kwa { color:#000000; font-weight:bold; } +# table.blob .kwb { color:#830000; } +# table.blob .kwc { color:#000000; font-weight:bold; } +# table.blob .kwd { color:#010181; } +# +# +# Style definition file generated by highlight 2.6.14, http://www.andre-simon.de/ +# +# body.hl { background-color:#ffffff; } +# pre.hl { color:#000000; background-color:#ffffff; font-size:10pt; font-family:'Courier New';} +# .hl.num { color:#2928ff; } +# .hl.esc { color:#ff00ff; } +# .hl.str { color:#ff0000; } +# .hl.dstr { color:#818100; } +# .hl.slc { color:#838183; font-style:italic; } +# .hl.com { color:#838183; font-style:italic; } +# .hl.dir { color:#008200; } +# .hl.sym { color:#000000; } +# .hl.line { color:#555555; } +# .hl.mark { background-color:#ffffbb;} +# .hl.kwa { color:#000000; font-weight:bold; } +# .hl.kwb { color:#830000; } +# .hl.kwc { color:#000000; font-weight:bold; } +# .hl.kwd { color:#010181; } +# +# +# Style definition file generated by highlight 3.8, http://www.andre-simon.de/ +# +# body.hl { background-color:#e0eaee; } +# pre.hl { color:#000000; background-color:#e0eaee; font-size:10pt; font-family:'Courier New';} +# .hl.num { color:#b07e00; } +# .hl.esc { color:#ff00ff; } +# .hl.str { color:#bf0303; } +# .hl.pps { color:#818100; } +# .hl.slc { color:#838183; font-style:italic; } +# .hl.com { color:#838183; font-style:italic; } +# .hl.ppc { color:#008200; } +# .hl.opt { color:#000000; } +# .hl.lin { color:#555555; } +# .hl.kwa { color:#000000; font-weight:bold; } +# .hl.kwb { color:#0057ae; } +# .hl.kwc { color:#000000; font-weight:bold; } +# .hl.kwd { color:#010181; } +# +# +# Style definition file generated by highlight 3.13, http://www.andre-simon.de/ +# +# body.hl { background-color:#e0eaee; } +# pre.hl { color:#000000; background-color:#e0eaee; font-size:10pt; font-family:'Courier New',monospace;} +# .hl.num { color:#b07e00; } +# .hl.esc { color:#ff00ff; } +# .hl.str { color:#bf0303; } +# .hl.pps { color:#818100; } +# .hl.slc { color:#838183; font-style:italic; } +# .hl.com { color:#838183; font-style:italic; } +# .hl.ppc { color:#008200; } +# .hl.opt { color:#000000; } +# .hl.ipl { color:#0057ae; } +# .hl.lin { color:#555555; } +# .hl.kwa { color:#000000; font-weight:bold; } +# .hl.kwb { color:#0057ae; } +# .hl.kwc { color:#000000; font-weight:bold; } +# .hl.kwd { color:#010181; } +# +# +# The following environment variables can be used to retrieve the configuration +# of the repository for which this script is called: +# CGIT_REPO_URL ( = repo.url setting ) +# CGIT_REPO_NAME ( = repo.name setting ) +# CGIT_REPO_PATH ( = repo.path setting ) +# CGIT_REPO_OWNER ( = repo.owner setting ) +# CGIT_REPO_DEFBRANCH ( = repo.defbranch setting ) +# CGIT_REPO_SECTION ( = section setting ) +# CGIT_REPO_CLONE_URL ( = repo.clone-url setting ) +# + +# store filename and extension in local vars +BASENAME="$1" +EXTENSION="${BASENAME##*.}" + +[ "${BASENAME}" = "${EXTENSION}" ] && EXTENSION=txt +[ -z "${EXTENSION}" ] && EXTENSION=txt + +# map Makefile and Makefile.* to .mk +[ "${BASENAME%%.*}" = "Makefile" ] && EXTENSION=mk + +# highlight versions 2 and 3 have different commandline options. Specifically, +# the -X option that is used for version 2 is replaced by the -O xhtml option +# for version 3. +# +# Version 2 can be found (for example) on EPEL 5, while version 3 can be +# found (for example) on EPEL 6. +# +# This is for version 2 +exec highlight --force -f -I -X -S "$EXTENSION" 2>/dev/null + +# This is for version 3 +#exec highlight --force -f -I -O xhtml -S "$EXTENSION" 2>/dev/null diff --git a/third_party/cgit/gen-version.sh b/third_party/cgit/gen-version.sh new file mode 100755 index 0000000000..80cf49af48 --- /dev/null +++ b/third_party/cgit/gen-version.sh @@ -0,0 +1,20 @@ +#!/bin/sh + +# Get version-info specified in Makefile +V=$1 + +# Use `git describe` to get current version if we're inside a git repo +if test "$(git rev-parse --git-dir 2>/dev/null)" = '.git' +then + V=$(git describe --abbrev=4 HEAD 2>/dev/null) +fi + +new="CGIT_VERSION = $V" +old=$(cat VERSION 2>/dev/null) + +# Exit if VERSION is uptodate +test "$old" = "$new" && exit 0 + +# Update VERSION with new version-info +echo "$new" > VERSION +cat VERSION diff --git a/third_party/cgit/html.c b/third_party/cgit/html.c new file mode 100644 index 0000000000..7f81965fdd --- /dev/null +++ b/third_party/cgit/html.c @@ -0,0 +1,344 @@ +/* html.c: helper functions for html output + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "html.h" +#include "url.h" + +/* Percent-encoding of each character, except: a-zA-Z0-9!$()*,./:;@- */ +static const char* url_escape_table[256] = { + "%00", "%01", "%02", "%03", "%04", "%05", "%06", "%07", + "%08", "%09", "%0a", "%0b", "%0c", "%0d", "%0e", "%0f", + "%10", "%11", "%12", "%13", "%14", "%15", "%16", "%17", + "%18", "%19", "%1a", "%1b", "%1c", "%1d", "%1e", "%1f", + "%20", NULL, "%22", "%23", NULL, "%25", "%26", "%27", + NULL, NULL, NULL, "%2b", NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, "%3c", "%3d", "%3e", "%3f", + NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, "%5c", NULL, "%5e", NULL, + "%60", NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, + NULL, NULL, NULL, "%7b", "%7c", "%7d", NULL, "%7f", + "%80", "%81", "%82", "%83", "%84", "%85", "%86", "%87", + "%88", "%89", "%8a", "%8b", "%8c", "%8d", "%8e", "%8f", + "%90", "%91", "%92", "%93", "%94", "%95", "%96", "%97", + "%98", "%99", "%9a", "%9b", "%9c", "%9d", "%9e", "%9f", + "%a0", "%a1", "%a2", "%a3", "%a4", "%a5", "%a6", "%a7", + "%a8", "%a9", "%aa", "%ab", "%ac", "%ad", "%ae", "%af", + "%b0", "%b1", "%b2", "%b3", "%b4", "%b5", "%b6", "%b7", + "%b8", "%b9", "%ba", "%bb", "%bc", "%bd", "%be", "%bf", + "%c0", "%c1", "%c2", "%c3", "%c4", "%c5", "%c6", "%c7", + "%c8", "%c9", "%ca", "%cb", "%cc", "%cd", "%ce", "%cf", + "%d0", "%d1", "%d2", "%d3", "%d4", "%d5", "%d6", "%d7", + "%d8", "%d9", "%da", "%db", "%dc", "%dd", "%de", "%df", + "%e0", "%e1", "%e2", "%e3", "%e4", "%e5", "%e6", "%e7", + "%e8", "%e9", "%ea", "%eb", "%ec", "%ed", "%ee", "%ef", + "%f0", "%f1", "%f2", "%f3", "%f4", "%f5", "%f6", "%f7", + "%f8", "%f9", "%fa", "%fb", "%fc", "%fd", "%fe", "%ff" +}; + +char *fmt(const char *format, ...) +{ + static char buf[8][1024]; + static int bufidx; + int len; + va_list args; + + bufidx++; + bufidx &= 7; + + va_start(args, format); + len = vsnprintf(buf[bufidx], sizeof(buf[bufidx]), format, args); + va_end(args); + if (len > sizeof(buf[bufidx])) { + fprintf(stderr, "[html.c] string truncated: %s\n", format); + exit(1); + } + return buf[bufidx]; +} + +char *fmtalloc(const char *format, ...) +{ + struct strbuf sb = STRBUF_INIT; + va_list args; + + va_start(args, format); + strbuf_vaddf(&sb, format, args); + va_end(args); + + return strbuf_detach(&sb, NULL); +} + +void html_raw(const char *data, size_t size) +{ + if (write(STDOUT_FILENO, data, size) != size) + die_errno("write error on html output"); +} + +void html(const char *txt) +{ + html_raw(txt, strlen(txt)); +} + +void htmlf(const char *format, ...) +{ + va_list args; + struct strbuf buf = STRBUF_INIT; + + va_start(args, format); + strbuf_vaddf(&buf, format, args); + va_end(args); + html(buf.buf); + strbuf_release(&buf); +} + +void html_txtf(const char *format, ...) +{ + va_list args; + + va_start(args, format); + html_vtxtf(format, args); + va_end(args); +} + +void html_vtxtf(const char *format, va_list ap) +{ + va_list cp; + struct strbuf buf = STRBUF_INIT; + + va_copy(cp, ap); + strbuf_vaddf(&buf, format, cp); + va_end(cp); + html_txt(buf.buf); + strbuf_release(&buf); +} + +void html_txt(const char *txt) +{ + if (txt) + html_ntxt(txt, strlen(txt)); +} + +ssize_t html_ntxt(const char *txt, size_t len) +{ + const char *t = txt; + ssize_t slen; + + if (len > SSIZE_MAX) + return -1; + + slen = (ssize_t) len; + while (t && *t && slen--) { + int c = *t; + if (c == '<' || c == '>' || c == '&') { + html_raw(txt, t - txt); + if (c == '>') + html(">"); + else if (c == '<') + html("<"); + else if (c == '&') + html("&"); + txt = t + 1; + } + t++; + } + if (t != txt) + html_raw(txt, t - txt); + return slen; +} + +void html_attrf(const char *fmt, ...) +{ + va_list ap; + struct strbuf sb = STRBUF_INIT; + + va_start(ap, fmt); + strbuf_vaddf(&sb, fmt, ap); + va_end(ap); + + html_attr(sb.buf); + strbuf_release(&sb); +} + +void html_attr(const char *txt) +{ + const char *t = txt; + while (t && *t) { + int c = *t; + if (c == '<' || c == '>' || c == '\'' || c == '\"' || c == '&') { + html_raw(txt, t - txt); + if (c == '>') + html(">"); + else if (c == '<') + html("<"); + else if (c == '\'') + html("'"); + else if (c == '"') + html("""); + else if (c == '&') + html("&"); + txt = t + 1; + } + t++; + } + if (t != txt) + html(txt); +} + +void html_url_path(const char *txt) +{ + const char *t = txt; + while (t && *t) { + unsigned char c = *t; + const char *e = url_escape_table[c]; + if (e && c != '+' && c != '&') { + html_raw(txt, t - txt); + html(e); + txt = t + 1; + } + t++; + } + if (t != txt) + html(txt); +} + +void html_url_arg(const char *txt) +{ + const char *t = txt; + while (t && *t) { + unsigned char c = *t; + const char *e = url_escape_table[c]; + if (c == ' ') + e = "+"; + if (e) { + html_raw(txt, t - txt); + html(e); + txt = t + 1; + } + t++; + } + if (t != txt) + html(txt); +} + +void html_header_arg_in_quotes(const char *txt) +{ + const char *t = txt; + while (t && *t) { + unsigned char c = *t; + const char *e = NULL; + if (c == '\\') + e = "\\\\"; + else if (c == '\r') + e = "\\r"; + else if (c == '\n') + e = "\\n"; + else if (c == '"') + e = "\\\""; + if (e) { + html_raw(txt, t - txt); + html(e); + txt = t + 1; + } + t++; + } + if (t != txt) + html(txt); + +} + +void html_hidden(const char *name, const char *value) +{ + html("<input type='hidden' name='"); + html_attr(name); + html("' value='"); + html_attr(value); + html("'/>"); +} + +void html_option(const char *value, const char *text, const char *selected_value) +{ + html("<option value='"); + html_attr(value); + html("'"); + if (selected_value && !strcmp(selected_value, value)) + html(" selected='selected'"); + html(">"); + html_txt(text); + html("</option>\n"); +} + +void html_intoption(int value, const char *text, int selected_value) +{ + htmlf("<option value='%d'%s>", value, + value == selected_value ? " selected='selected'" : ""); + html_txt(text); + html("</option>"); +} + +void html_link_open(const char *url, const char *title, const char *class) +{ + html("<a href='"); + html_attr(url); + if (title) { + html("' title='"); + html_attr(title); + } + if (class) { + html("' class='"); + html_attr(class); + } + html("'>"); +} + +void html_link_close(void) +{ + html("</a>"); +} + +void html_fileperm(unsigned short mode) +{ + htmlf("%c%c%c", (mode & 4 ? 'r' : '-'), + (mode & 2 ? 'w' : '-'), (mode & 1 ? 'x' : '-')); +} + +int html_include(const char *filename) +{ + FILE *f; + char buf[4096]; + size_t len; + + if (!(f = fopen(filename, "r"))) { + fprintf(stderr, "[cgit] Failed to include file %s: %s (%d).\n", + filename, strerror(errno), errno); + return -1; + } + while ((len = fread(buf, 1, 4096, f)) > 0) + html_raw(buf, len); + fclose(f); + return 0; +} + +void http_parse_querystring(const char *txt, void (*fn)(const char *name, const char *value)) +{ + const char *t = txt; + + while (t && *t) { + char *name = url_decode_parameter_name(&t); + if (*name) { + char *value = url_decode_parameter_value(&t); + fn(name, value); + free(value); + } + free(name); + } +} diff --git a/third_party/cgit/html.h b/third_party/cgit/html.h new file mode 100644 index 0000000000..fa4de77587 --- /dev/null +++ b/third_party/cgit/html.h @@ -0,0 +1,37 @@ +#ifndef HTML_H +#define HTML_H + +#include "cgit.h" + +extern void html_raw(const char *txt, size_t size); +extern void html(const char *txt); + +__attribute__((format (printf,1,2))) +extern void htmlf(const char *format,...); + +__attribute__((format (printf,1,2))) +extern void html_txtf(const char *format,...); + +__attribute__((format (printf,1,0))) +extern void html_vtxtf(const char *format, va_list ap); + +__attribute__((format (printf,1,2))) +extern void html_attrf(const char *format,...); + +extern void html_txt(const char *txt); +extern ssize_t html_ntxt(const char *txt, size_t len); +extern void html_attr(const char *txt); +extern void html_url_path(const char *txt); +extern void html_url_arg(const char *txt); +extern void html_header_arg_in_quotes(const char *txt); +extern void html_hidden(const char *name, const char *value); +extern void html_option(const char *value, const char *text, const char *selected_value); +extern void html_intoption(int value, const char *text, int selected_value); +extern void html_link_open(const char *url, const char *title, const char *class); +extern void html_link_close(void); +extern void html_fileperm(unsigned short mode); +extern int html_include(const char *filename); + +extern void http_parse_querystring(const char *txt, void (*fn)(const char *name, const char *value)); + +#endif /* HTML_H */ diff --git a/third_party/cgit/parsing.c b/third_party/cgit/parsing.c new file mode 100644 index 0000000000..7b3980e6b1 --- /dev/null +++ b/third_party/cgit/parsing.c @@ -0,0 +1,224 @@ +/* parsing.c: parsing of config files + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" + +/* + * url syntax: [repo ['/' cmd [ '/' path]]] + * repo: any valid repo url, may contain '/' + * cmd: log | commit | diff | tree | view | blob | snapshot + * path: any valid path, may contain '/' + * + */ +void cgit_parse_url(const char *url) +{ + char *c, *cmd, *p; + struct cgit_repo *repo; + + if (!url || url[0] == '\0') + return; + + ctx.qry.page = NULL; + ctx.repo = cgit_get_repoinfo(url); + if (ctx.repo) { + ctx.qry.repo = ctx.repo->url; + return; + } + + cmd = NULL; + c = strchr(url, '/'); + while (c) { + c[0] = '\0'; + repo = cgit_get_repoinfo(url); + if (repo) { + ctx.repo = repo; + cmd = c; + } + c[0] = '/'; + c = strchr(c + 1, '/'); + } + + if (ctx.repo) { + ctx.qry.repo = ctx.repo->url; + p = strchr(cmd + 1, '/'); + if (p) { + p[0] = '\0'; + if (p[1]) + ctx.qry.path = trim_end(p + 1, '/'); + } + if (cmd[1]) + ctx.qry.page = xstrdup(cmd + 1); + } +} + +static char *substr(const char *head, const char *tail) +{ + char *buf; + + if (tail < head) + return xstrdup(""); + buf = xmalloc(tail - head + 1); + strlcpy(buf, head, tail - head + 1); + return buf; +} + +static void parse_user(const char *t, char **name, char **email, unsigned long *date, int *tz) +{ + struct ident_split ident; + unsigned email_len; + + if (!split_ident_line(&ident, t, strchrnul(t, '\n') - t)) { + *name = substr(ident.name_begin, ident.name_end); + + email_len = ident.mail_end - ident.mail_begin; + *email = xmalloc(strlen("<") + email_len + strlen(">") + 1); + xsnprintf(*email, email_len + 3, "<%.*s>", email_len, ident.mail_begin); + + if (ident.date_begin) + *date = strtoul(ident.date_begin, NULL, 10); + if (ident.tz_begin) + *tz = atoi(ident.tz_begin); + } +} + +#ifdef NO_ICONV +#define reencode(a, b, c) +#else +static const char *reencode(char **txt, const char *src_enc, const char *dst_enc) +{ + char *tmp; + + if (!txt) + return NULL; + + if (!*txt || !src_enc || !dst_enc) + return *txt; + + /* no encoding needed if src_enc equals dst_enc */ + if (!strcasecmp(src_enc, dst_enc)) + return *txt; + + tmp = reencode_string(*txt, dst_enc, src_enc); + if (tmp) { + free(*txt); + *txt = tmp; + } + return *txt; +} +#endif + +static const char *next_header_line(const char *p) +{ + p = strchr(p, '\n'); + if (!p) + return NULL; + return p + 1; +} + +static int end_of_header(const char *p) +{ + return !p || (*p == '\n'); +} + +struct commitinfo *cgit_parse_commit(struct commit *commit) +{ + const int sha1hex_len = 40; + struct commitinfo *ret; + const char *p = get_cached_commit_buffer(the_repository, commit, NULL); + const char *t; + + ret = xcalloc(1, sizeof(struct commitinfo)); + ret->commit = commit; + + if (!p) + return ret; + + if (!skip_prefix(p, "tree ", &p)) + die("Bad commit: %s", oid_to_hex(&commit->object.oid)); + p += sha1hex_len + 1; + + while (skip_prefix(p, "parent ", &p)) + p += sha1hex_len + 1; + + if (p && skip_prefix(p, "author ", &p)) { + parse_user(p, &ret->author, &ret->author_email, + &ret->author_date, &ret->author_tz); + p = next_header_line(p); + } + + if (p && skip_prefix(p, "committer ", &p)) { + parse_user(p, &ret->committer, &ret->committer_email, + &ret->committer_date, &ret->committer_tz); + p = next_header_line(p); + } + + if (p && skip_prefix(p, "encoding ", &p)) { + t = strchr(p, '\n'); + if (t) { + ret->msg_encoding = substr(p, t + 1); + p = t + 1; + } + } + + if (!ret->msg_encoding) + ret->msg_encoding = xstrdup("UTF-8"); + + while (!end_of_header(p)) + p = next_header_line(p); + while (p && *p == '\n') + p++; + if (!p) + return ret; + + t = strchrnul(p, '\n'); + ret->subject = substr(p, t); + while (*t == '\n') + t++; + ret->msg = xstrdup(t); + + reencode(&ret->author, ret->msg_encoding, PAGE_ENCODING); + reencode(&ret->author_email, ret->msg_encoding, PAGE_ENCODING); + reencode(&ret->committer, ret->msg_encoding, PAGE_ENCODING); + reencode(&ret->committer_email, ret->msg_encoding, PAGE_ENCODING); + reencode(&ret->subject, ret->msg_encoding, PAGE_ENCODING); + reencode(&ret->msg, ret->msg_encoding, PAGE_ENCODING); + + return ret; +} + +struct taginfo *cgit_parse_tag(struct tag *tag) +{ + void *data; + enum object_type type; + unsigned long size; + const char *p; + struct taginfo *ret = NULL; + + data = read_object_file(&tag->object.oid, &type, &size); + if (!data || type != OBJ_TAG) + goto cleanup; + + ret = xcalloc(1, sizeof(struct taginfo)); + + for (p = data; !end_of_header(p); p = next_header_line(p)) { + if (skip_prefix(p, "tagger ", &p)) { + parse_user(p, &ret->tagger, &ret->tagger_email, + &ret->tagger_date, &ret->tagger_tz); + } + } + + while (p && *p == '\n') + p++; + + if (p && *p) + ret->msg = xstrdup(p); + +cleanup: + free(data); + return ret; +} diff --git a/third_party/cgit/robots.txt b/third_party/cgit/robots.txt new file mode 100644 index 0000000000..4ce948fec2 --- /dev/null +++ b/third_party/cgit/robots.txt @@ -0,0 +1,3 @@ +User-agent: * +Disallow: /*/snapshot/* +Allow: / diff --git a/third_party/cgit/scan-tree.c b/third_party/cgit/scan-tree.c new file mode 100644 index 0000000000..6a2f65a86b --- /dev/null +++ b/third_party/cgit/scan-tree.c @@ -0,0 +1,270 @@ +/* scan-tree.c + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "scan-tree.h" +#include "configfile.h" +#include "html.h" +#include <config.h> + +/* return 1 if path contains a objects/ directory and a HEAD file */ +static int is_git_dir(const char *path) +{ + struct stat st; + struct strbuf pathbuf = STRBUF_INIT; + int result = 0; + + strbuf_addf(&pathbuf, "%s/objects", path); + if (stat(pathbuf.buf, &st)) { + if (errno != ENOENT) + fprintf(stderr, "Error checking path %s: %s (%d)\n", + path, strerror(errno), errno); + goto out; + } + if (!S_ISDIR(st.st_mode)) + goto out; + + strbuf_reset(&pathbuf); + strbuf_addf(&pathbuf, "%s/HEAD", path); + if (stat(pathbuf.buf, &st)) { + if (errno != ENOENT) + fprintf(stderr, "Error checking path %s: %s (%d)\n", + path, strerror(errno), errno); + goto out; + } + if (!S_ISREG(st.st_mode)) + goto out; + + result = 1; +out: + strbuf_release(&pathbuf); + return result; +} + +static struct cgit_repo *repo; +static repo_config_fn config_fn; + +static void scan_tree_repo_config(const char *name, const char *value) +{ + config_fn(repo, name, value); +} + +static int gitconfig_config(const char *key, const char *value, void *cb) +{ + const char *name; + + if (!strcmp(key, "gitweb.owner")) + config_fn(repo, "owner", value); + else if (!strcmp(key, "gitweb.description")) + config_fn(repo, "desc", value); + else if (!strcmp(key, "gitweb.category")) + config_fn(repo, "section", value); + else if (!strcmp(key, "gitweb.homepage")) + config_fn(repo, "homepage", value); + else if (skip_prefix(key, "cgit.", &name)) + config_fn(repo, name, value); + + return 0; +} + +static char *xstrrchr(char *s, char *from, int c) +{ + while (from >= s && *from != c) + from--; + return from < s ? NULL : from; +} + +static void add_repo(const char *base, struct strbuf *path, repo_config_fn fn) +{ + struct stat st; + struct passwd *pwd; + size_t pathlen; + struct strbuf rel = STRBUF_INIT; + char *p, *slash; + int n; + size_t size; + + if (stat(path->buf, &st)) { + fprintf(stderr, "Error accessing %s: %s (%d)\n", + path->buf, strerror(errno), errno); + return; + } + + strbuf_addch(path, '/'); + pathlen = path->len; + + if (ctx.cfg.strict_export) { + strbuf_addstr(path, ctx.cfg.strict_export); + if(stat(path->buf, &st)) + return; + strbuf_setlen(path, pathlen); + } + + strbuf_addstr(path, "noweb"); + if (!stat(path->buf, &st)) + return; + strbuf_setlen(path, pathlen); + + if (!starts_with(path->buf, base)) + strbuf_addbuf(&rel, path); + else + strbuf_addstr(&rel, path->buf + strlen(base) + 1); + + if (!strcmp(rel.buf + rel.len - 5, "/.git")) + strbuf_setlen(&rel, rel.len - 5); + else if (rel.len && rel.buf[rel.len - 1] == '/') + strbuf_setlen(&rel, rel.len - 1); + + repo = cgit_add_repo(rel.buf); + config_fn = fn; + if (ctx.cfg.enable_git_config) { + strbuf_addstr(path, "config"); + git_config_from_file(gitconfig_config, path->buf, NULL); + strbuf_setlen(path, pathlen); + } + + if (ctx.cfg.remove_suffix) { + size_t urllen; + strip_suffix(repo->url, ".git", &urllen); + strip_suffix_mem(repo->url, &urllen, "/"); + repo->url[urllen] = '\0'; + } + repo->path = xstrdup(path->buf); + while (!repo->owner) { + if ((pwd = getpwuid(st.st_uid)) == NULL) { + fprintf(stderr, "Error reading owner-info for %s: %s (%d)\n", + path->buf, strerror(errno), errno); + break; + } + if (pwd->pw_gecos) + if ((p = strchr(pwd->pw_gecos, ','))) + *p = '\0'; + repo->owner = xstrdup(pwd->pw_gecos ? pwd->pw_gecos : pwd->pw_name); + } + + if (repo->desc == cgit_default_repo_desc || !repo->desc) { + strbuf_addstr(path, "description"); + if (!stat(path->buf, &st)) + readfile(path->buf, &repo->desc, &size); + strbuf_setlen(path, pathlen); + } + + if (ctx.cfg.section_from_path) { + n = ctx.cfg.section_from_path; + if (n > 0) { + slash = rel.buf - 1; + while (slash && n && (slash = strchr(slash + 1, '/'))) + n--; + } else { + slash = rel.buf + rel.len; + while (slash && n && (slash = xstrrchr(rel.buf, slash - 1, '/'))) + n++; + } + if (slash && !n) { + *slash = '\0'; + repo->section = xstrdup(rel.buf); + *slash = '/'; + if (starts_with(repo->name, repo->section)) { + repo->name += strlen(repo->section); + if (*repo->name == '/') + repo->name++; + } + } + } + + strbuf_addstr(path, "cgitrc"); + if (!stat(path->buf, &st)) + parse_configfile(path->buf, &scan_tree_repo_config); + + strbuf_release(&rel); +} + +static void scan_path(const char *base, const char *path, repo_config_fn fn) +{ + DIR *dir = opendir(path); + struct dirent *ent; + struct strbuf pathbuf = STRBUF_INIT; + size_t pathlen = strlen(path); + struct stat st; + + if (!dir) { + fprintf(stderr, "Error opening directory %s: %s (%d)\n", + path, strerror(errno), errno); + return; + } + + strbuf_add(&pathbuf, path, strlen(path)); + if (is_git_dir(pathbuf.buf)) { + add_repo(base, &pathbuf, fn); + goto end; + } + strbuf_addstr(&pathbuf, "/.git"); + if (is_git_dir(pathbuf.buf)) { + add_repo(base, &pathbuf, fn); + goto end; + } + /* + * Add one because we don't want to lose the trailing '/' when we + * reset the length of pathbuf in the loop below. + */ + pathlen++; + while ((ent = readdir(dir)) != NULL) { + if (ent->d_name[0] == '.') { + if (ent->d_name[1] == '\0') + continue; + if (ent->d_name[1] == '.' && ent->d_name[2] == '\0') + continue; + if (!ctx.cfg.scan_hidden_path) + continue; + } + strbuf_setlen(&pathbuf, pathlen); + strbuf_addstr(&pathbuf, ent->d_name); + if (stat(pathbuf.buf, &st)) { + fprintf(stderr, "Error checking path %s: %s (%d)\n", + pathbuf.buf, strerror(errno), errno); + continue; + } + if (S_ISDIR(st.st_mode)) + scan_path(base, pathbuf.buf, fn); + } +end: + strbuf_release(&pathbuf); + closedir(dir); +} + +void scan_projects(const char *path, const char *projectsfile, repo_config_fn fn) +{ + struct strbuf line = STRBUF_INIT; + FILE *projects; + int err; + + projects = fopen(projectsfile, "r"); + if (!projects) { + fprintf(stderr, "Error opening projectsfile %s: %s (%d)\n", + projectsfile, strerror(errno), errno); + return; + } + while (strbuf_getline(&line, projects) != EOF) { + if (!line.len) + continue; + strbuf_insert(&line, 0, "/", 1); + strbuf_insert(&line, 0, path, strlen(path)); + scan_path(path, line.buf, fn); + } + if ((err = ferror(projects))) { + fprintf(stderr, "Error reading from projectsfile %s: %s (%d)\n", + projectsfile, strerror(err), err); + } + fclose(projects); + strbuf_release(&line); +} + +void scan_tree(const char *path, repo_config_fn fn) +{ + scan_path(path, path, fn); +} diff --git a/third_party/cgit/scan-tree.h b/third_party/cgit/scan-tree.h new file mode 100644 index 0000000000..1afbd4bbcd --- /dev/null +++ b/third_party/cgit/scan-tree.h @@ -0,0 +1,2 @@ +extern void scan_projects(const char *path, const char *projectsfile, repo_config_fn fn); +extern void scan_tree(const char *path, repo_config_fn fn); diff --git a/third_party/cgit/shared.c b/third_party/cgit/shared.c new file mode 100644 index 0000000000..8115469a7c --- /dev/null +++ b/third_party/cgit/shared.c @@ -0,0 +1,579 @@ +/* shared.c: global vars + some callback functions + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" + +struct cgit_repolist cgit_repolist; +struct cgit_context ctx; + +int chk_zero(int result, char *msg) +{ + if (result != 0) + die_errno("%s", msg); + return result; +} + +int chk_positive(int result, char *msg) +{ + if (result <= 0) + die_errno("%s", msg); + return result; +} + +int chk_non_negative(int result, char *msg) +{ + if (result < 0) + die_errno("%s", msg); + return result; +} + +char *cgit_default_repo_desc = "[no description]"; +struct cgit_repo *cgit_add_repo(const char *url) +{ + struct cgit_repo *ret; + + if (++cgit_repolist.count > cgit_repolist.length) { + if (cgit_repolist.length == 0) + cgit_repolist.length = 8; + else + cgit_repolist.length *= 2; + cgit_repolist.repos = xrealloc(cgit_repolist.repos, + cgit_repolist.length * + sizeof(struct cgit_repo)); + } + + ret = &cgit_repolist.repos[cgit_repolist.count-1]; + memset(ret, 0, sizeof(struct cgit_repo)); + ret->url = trim_end(url, '/'); + ret->name = ret->url; + ret->path = NULL; + ret->desc = cgit_default_repo_desc; + ret->extra_head_content = NULL; + ret->owner = NULL; + ret->homepage = NULL; + ret->section = ctx.cfg.section; + ret->snapshots = ctx.cfg.snapshots; + ret->enable_blame = ctx.cfg.enable_blame; + ret->enable_commit_graph = ctx.cfg.enable_commit_graph; + ret->enable_log_filecount = ctx.cfg.enable_log_filecount; + ret->enable_log_linecount = ctx.cfg.enable_log_linecount; + ret->enable_remote_branches = ctx.cfg.enable_remote_branches; + ret->enable_subject_links = ctx.cfg.enable_subject_links; + ret->enable_html_serving = ctx.cfg.enable_html_serving; + ret->max_stats = ctx.cfg.max_stats; + ret->branch_sort = ctx.cfg.branch_sort; + ret->commit_sort = ctx.cfg.commit_sort; + ret->module_link = ctx.cfg.module_link; + ret->readme = ctx.cfg.readme; + ret->mtime = -1; + ret->about_filter = ctx.cfg.about_filter; + ret->commit_filter = ctx.cfg.commit_filter; + ret->source_filter = ctx.cfg.source_filter; + ret->email_filter = ctx.cfg.email_filter; + ret->owner_filter = ctx.cfg.owner_filter; + ret->clone_url = ctx.cfg.clone_url; + ret->submodules.strdup_strings = 1; + ret->hide = ret->ignore = 0; + return ret; +} + +struct cgit_repo *cgit_get_repoinfo(const char *url) +{ + int i; + struct cgit_repo *repo; + + for (i = 0; i < cgit_repolist.count; i++) { + repo = &cgit_repolist.repos[i]; + if (repo->ignore) + continue; + if (!strcmp(repo->url, url)) + return repo; + } + return NULL; +} + +void cgit_free_commitinfo(struct commitinfo *info) +{ + free(info->author); + free(info->author_email); + free(info->committer); + free(info->committer_email); + free(info->subject); + free(info->msg); + free(info->msg_encoding); + free(info); +} + +char *trim_end(const char *str, char c) +{ + int len; + + if (str == NULL) + return NULL; + len = strlen(str); + while (len > 0 && str[len - 1] == c) + len--; + if (len == 0) + return NULL; + return xstrndup(str, len); +} + +char *ensure_end(const char *str, char c) +{ + size_t len = strlen(str); + char *result; + + if (len && str[len - 1] == c) + return xstrndup(str, len); + + result = xmalloc(len + 2); + memcpy(result, str, len); + result[len] = '/'; + result[len + 1] = '\0'; + return result; +} + +void strbuf_ensure_end(struct strbuf *sb, char c) +{ + if (!sb->len || sb->buf[sb->len - 1] != c) + strbuf_addch(sb, c); +} + +void cgit_add_ref(struct reflist *list, struct refinfo *ref) +{ + size_t size; + + if (list->count >= list->alloc) { + list->alloc += (list->alloc ? list->alloc : 4); + size = list->alloc * sizeof(struct refinfo *); + list->refs = xrealloc(list->refs, size); + } + list->refs[list->count++] = ref; +} + +static struct refinfo *cgit_mk_refinfo(const char *refname, const struct object_id *oid) +{ + struct refinfo *ref; + + ref = xmalloc(sizeof (struct refinfo)); + ref->refname = xstrdup(refname); + ref->object = parse_object(the_repository, oid); + switch (ref->object->type) { + case OBJ_TAG: + ref->tag = cgit_parse_tag((struct tag *)ref->object); + break; + case OBJ_COMMIT: + ref->commit = cgit_parse_commit((struct commit *)ref->object); + break; + } + return ref; +} + +void cgit_free_taginfo(struct taginfo *tag) +{ + if (tag->tagger) + free(tag->tagger); + if (tag->tagger_email) + free(tag->tagger_email); + if (tag->msg) + free(tag->msg); + free(tag); +} + +static void cgit_free_refinfo(struct refinfo *ref) +{ + if (ref->refname) + free((char *)ref->refname); + switch (ref->object->type) { + case OBJ_TAG: + cgit_free_taginfo(ref->tag); + break; + case OBJ_COMMIT: + cgit_free_commitinfo(ref->commit); + break; + } + free(ref); +} + +void cgit_free_reflist_inner(struct reflist *list) +{ + int i; + + for (i = 0; i < list->count; i++) { + cgit_free_refinfo(list->refs[i]); + } + free(list->refs); +} + +int cgit_refs_cb(const char *refname, const struct object_id *oid, int flags, + void *cb_data) +{ + struct reflist *list = (struct reflist *)cb_data; + struct refinfo *info = cgit_mk_refinfo(refname, oid); + + if (info) + cgit_add_ref(list, info); + return 0; +} + +void cgit_diff_tree_cb(struct diff_queue_struct *q, + struct diff_options *options, void *data) +{ + int i; + + for (i = 0; i < q->nr; i++) { + if (q->queue[i]->status == 'U') + continue; + ((filepair_fn)data)(q->queue[i]); + } +} + +static int load_mmfile(mmfile_t *file, const struct object_id *oid) +{ + enum object_type type; + + if (is_null_oid(oid)) { + file->ptr = (char *)""; + file->size = 0; + } else { + file->ptr = read_object_file(oid, &type, + (unsigned long *)&file->size); + } + return 1; +} + +/* + * Receive diff-buffers from xdiff and concatenate them as + * needed across multiple callbacks. + * + * This is basically a copy of xdiff-interface.c/xdiff_outf(), + * ripped from git and modified to use globals instead of + * a special callback-struct. + */ +static char *diffbuf = NULL; +static int buflen = 0; + +static int filediff_cb(void *priv, mmbuffer_t *mb, int nbuf) +{ + int i; + + for (i = 0; i < nbuf; i++) { + if (mb[i].ptr[mb[i].size-1] != '\n') { + /* Incomplete line */ + diffbuf = xrealloc(diffbuf, buflen + mb[i].size); + memcpy(diffbuf + buflen, mb[i].ptr, mb[i].size); + buflen += mb[i].size; + continue; + } + + /* we have a complete line */ + if (!diffbuf) { + ((linediff_fn)priv)(mb[i].ptr, mb[i].size); + continue; + } + diffbuf = xrealloc(diffbuf, buflen + mb[i].size); + memcpy(diffbuf + buflen, mb[i].ptr, mb[i].size); + ((linediff_fn)priv)(diffbuf, buflen + mb[i].size); + free(diffbuf); + diffbuf = NULL; + buflen = 0; + } + if (diffbuf) { + ((linediff_fn)priv)(diffbuf, buflen); + free(diffbuf); + diffbuf = NULL; + buflen = 0; + } + return 0; +} + +int cgit_diff_files(const struct object_id *old_oid, + const struct object_id *new_oid, unsigned long *old_size, + unsigned long *new_size, int *binary, int context, + int ignorews, linediff_fn fn) +{ + mmfile_t file1, file2; + xpparam_t diff_params; + xdemitconf_t emit_params; + xdemitcb_t emit_cb; + + if (!load_mmfile(&file1, old_oid) || !load_mmfile(&file2, new_oid)) + return 1; + + *old_size = file1.size; + *new_size = file2.size; + + if ((file1.ptr && buffer_is_binary(file1.ptr, file1.size)) || + (file2.ptr && buffer_is_binary(file2.ptr, file2.size))) { + *binary = 1; + if (file1.size) + free(file1.ptr); + if (file2.size) + free(file2.ptr); + return 0; + } + + memset(&diff_params, 0, sizeof(diff_params)); + memset(&emit_params, 0, sizeof(emit_params)); + memset(&emit_cb, 0, sizeof(emit_cb)); + diff_params.flags = XDF_NEED_MINIMAL; + if (ignorews) + diff_params.flags |= XDF_IGNORE_WHITESPACE; + emit_params.ctxlen = context > 0 ? context : 3; + emit_params.flags = XDL_EMIT_FUNCNAMES; + emit_cb.out_line = filediff_cb; + emit_cb.priv = fn; + xdl_diff(&file1, &file2, &diff_params, &emit_params, &emit_cb); + if (file1.size) + free(file1.ptr); + if (file2.size) + free(file2.ptr); + return 0; +} + +void cgit_diff_tree(const struct object_id *old_oid, + const struct object_id *new_oid, + filepair_fn fn, const char *prefix, int ignorews) +{ + struct diff_options opt; + struct pathspec_item item; + + memset(&item, 0, sizeof(item)); + diff_setup(&opt); + opt.output_format = DIFF_FORMAT_CALLBACK; + opt.detect_rename = 1; + opt.rename_limit = ctx.cfg.renamelimit; + opt.flags.recursive = 1; + if (ignorews) + DIFF_XDL_SET(&opt, IGNORE_WHITESPACE); + opt.format_callback = cgit_diff_tree_cb; + opt.format_callback_data = fn; + if (prefix) { + item.match = xstrdup(prefix); + item.len = strlen(prefix); + opt.pathspec.nr = 1; + opt.pathspec.items = &item; + } + diff_setup_done(&opt); + + if (old_oid && !is_null_oid(old_oid)) + diff_tree_oid(old_oid, new_oid, "", &opt); + else + diff_root_tree_oid(new_oid, "", &opt); + diffcore_std(&opt); + diff_flush(&opt); + + free(item.match); +} + +void cgit_diff_commit(struct commit *commit, filepair_fn fn, const char *prefix) +{ + const struct object_id *old_oid = NULL; + + if (commit->parents) + old_oid = &commit->parents->item->object.oid; + cgit_diff_tree(old_oid, &commit->object.oid, fn, prefix, + ctx.qry.ignorews); +} + +int cgit_parse_snapshots_mask(const char *str) +{ + struct string_list tokens = STRING_LIST_INIT_DUP; + struct string_list_item *item; + const struct cgit_snapshot_format *f; + int rv = 0; + + /* favor legacy setting */ + if (atoi(str)) + return 1; + + if (strcmp(str, "all") == 0) + return INT_MAX; + + string_list_split(&tokens, str, ' ', -1); + string_list_remove_empty_items(&tokens, 0); + + for_each_string_list_item(item, &tokens) { + for (f = cgit_snapshot_formats; f->suffix; f++) { + if (!strcmp(item->string, f->suffix) || + !strcmp(item->string, f->suffix + 1)) { + rv |= cgit_snapshot_format_bit(f); + break; + } + } + } + + string_list_clear(&tokens, 0); + return rv; +} + +typedef struct { + char * name; + char * value; +} cgit_env_var; + +void cgit_prepare_repo_env(struct cgit_repo * repo) +{ + cgit_env_var env_vars[] = { + { .name = "CGIT_REPO_URL", .value = repo->url }, + { .name = "CGIT_REPO_NAME", .value = repo->name }, + { .name = "CGIT_REPO_PATH", .value = repo->path }, + { .name = "CGIT_REPO_OWNER", .value = repo->owner }, + { .name = "CGIT_REPO_DEFBRANCH", .value = repo->defbranch }, + { .name = "CGIT_REPO_SECTION", .value = repo->section }, + { .name = "CGIT_REPO_CLONE_URL", .value = repo->clone_url } + }; + int env_var_count = ARRAY_SIZE(env_vars); + cgit_env_var *p, *q; + static char *warn = "cgit warning: failed to set env: %s=%s\n"; + + p = env_vars; + q = p + env_var_count; + for (; p < q; p++) + if (p->value && setenv(p->name, p->value, 1)) + fprintf(stderr, warn, p->name, p->value); +} + +/* Read the content of the specified file into a newly allocated buffer, + * zeroterminate the buffer and return 0 on success, errno otherwise. + */ +int readfile(const char *path, char **buf, size_t *size) +{ + int fd, e; + struct stat st; + + fd = open(path, O_RDONLY); + if (fd == -1) + return errno; + if (fstat(fd, &st)) { + e = errno; + close(fd); + return e; + } + if (!S_ISREG(st.st_mode)) { + close(fd); + return EISDIR; + } + *buf = xmalloc(st.st_size + 1); + *size = read_in_full(fd, *buf, st.st_size); + e = errno; + (*buf)[*size] = '\0'; + close(fd); + return (*size == st.st_size ? 0 : e); +} + +static int is_token_char(char c) +{ + return isalnum(c) || c == '_'; +} + +/* Replace name with getenv(name), return pointer to zero-terminating char + */ +static char *expand_macro(char *name, int maxlength) +{ + char *value; + size_t len; + + len = 0; + value = getenv(name); + if (value) { + len = strlen(value) + 1; + if (len > maxlength) + len = maxlength; + strlcpy(name, value, len); + --len; + } + return name + len; +} + +#define EXPBUFSIZE (1024 * 8) + +/* Replace all tokens prefixed by '$' in the specified text with the + * value of the named environment variable. + * NB: the return value is a static buffer, i.e. it must be strdup'd + * by the caller. + */ +char *expand_macros(const char *txt) +{ + static char result[EXPBUFSIZE]; + char *p, *start; + int len; + + p = result; + start = NULL; + while (p < result + EXPBUFSIZE - 1 && txt && *txt) { + *p = *txt; + if (start) { + if (!is_token_char(*txt)) { + if (p - start > 0) { + *p = '\0'; + len = result + EXPBUFSIZE - start - 1; + p = expand_macro(start, len) - 1; + } + start = NULL; + txt--; + } + p++; + txt++; + continue; + } + if (*txt == '$') { + start = p; + txt++; + continue; + } + p++; + txt++; + } + *p = '\0'; + if (start && p - start > 0) { + len = result + EXPBUFSIZE - start - 1; + p = expand_macro(start, len); + *p = '\0'; + } + return result; +} + +char *get_mimetype_for_filename(const char *filename) +{ + char *ext, *mimetype, *token, line[1024], *saveptr; + FILE *file; + struct string_list_item *mime; + + if (!filename) + return NULL; + + ext = strrchr(filename, '.'); + if (!ext) + return NULL; + ++ext; + if (!ext[0]) + return NULL; + mime = string_list_lookup(&ctx.cfg.mimetypes, ext); + if (mime) + return xstrdup(mime->util); + + if (!ctx.cfg.mimetype_file) + return NULL; + file = fopen(ctx.cfg.mimetype_file, "r"); + if (!file) + return NULL; + while (fgets(line, sizeof(line), file)) { + if (!line[0] || line[0] == '#') + continue; + mimetype = strtok_r(line, " \t\r\n", &saveptr); + while ((token = strtok_r(NULL, " \t\r\n", &saveptr))) { + if (!strcasecmp(ext, token)) { + fclose(file); + return xstrdup(mimetype); + } + } + } + fclose(file); + return NULL; +} diff --git a/third_party/cgit/tests/.gitignore b/third_party/cgit/tests/.gitignore new file mode 100644 index 0000000000..3fd2e965c8 --- /dev/null +++ b/third_party/cgit/tests/.gitignore @@ -0,0 +1,2 @@ +trash\ directory.t* +test-results diff --git a/third_party/cgit/tests/Makefile b/third_party/cgit/tests/Makefile new file mode 100644 index 0000000000..65e1117338 --- /dev/null +++ b/third_party/cgit/tests/Makefile @@ -0,0 +1,17 @@ +include ../git/config.mak.uname +-include ../cgit.conf + +SHELL_PATH ?= $(SHELL) +SHELL_PATH_SQ = $(subst ','\'',$(SHELL_PATH)) + +T = $(wildcard t[0-9][0-9][0-9][0-9]-*.sh) + +all: $(T) + +$(T): + @'$(SHELL_PATH_SQ)' $@ $(CGIT_TEST_OPTS) + +clean: + $(RM) -rf trash + +.PHONY: $(T) clean diff --git a/third_party/cgit/tests/filters/dump.lua b/third_party/cgit/tests/filters/dump.lua new file mode 100644 index 0000000000..1f15c93105 --- /dev/null +++ b/third_party/cgit/tests/filters/dump.lua @@ -0,0 +1,17 @@ +function filter_open(...) + buffer = "" + for i = 1, select("#", ...) do + buffer = buffer .. select(i, ...) .. " " + end +end + +function filter_close() + html(buffer) + return 0 +end + +function filter_write(str) + buffer = buffer .. string.upper(str) +end + + diff --git a/third_party/cgit/tests/filters/dump.sh b/third_party/cgit/tests/filters/dump.sh new file mode 100755 index 0000000000..da6f7a1b18 --- /dev/null +++ b/third_party/cgit/tests/filters/dump.sh @@ -0,0 +1,4 @@ +#!/bin/sh + +[ "$#" -gt 0 ] && printf "%s " "$*" +tr '[:lower:]' '[:upper:]' diff --git a/third_party/cgit/tests/setup.sh b/third_party/cgit/tests/setup.sh new file mode 100755 index 0000000000..7590f04944 --- /dev/null +++ b/third_party/cgit/tests/setup.sh @@ -0,0 +1,176 @@ +# This file should be sourced by all test-scripts +# +# Main functions: +# prepare_tests(description) - setup for testing, i.e. create repos+config +# run_test(description, script) - run one test, i.e. eval script +# +# Helper functions +# cgit_query(querystring) - call cgit with the specified querystring +# cgit_url(url) - call cgit with the specified virtual url +# +# Example script: +# +# . setup.sh +# prepare_tests "html validation" +# run_test 'repo index' 'cgit_url "/" | tidy -e' +# run_test 'repo summary' 'cgit_url "/foo" | tidy -e' + +# We don't want to run Git commands through Valgrind, so we filter out the +# --valgrind option here and handle it ourselves. We copy the arguments +# assuming that none contain a newline, although other whitespace is +# preserved. +LF=' +' +test_argv= + +while test $# != 0 +do + case "$1" in + --va|--val|--valg|--valgr|--valgri|--valgrin|--valgrind) + cgit_valgrind=t + test_argv="$test_argv${LF}--verbose" + ;; + *) + test_argv="$test_argv$LF$1" + ;; + esac + shift +done + +OLDIFS=$IFS +IFS=$LF +set -- $test_argv +IFS=$OLDIFS + +: ${TEST_DIRECTORY=$(pwd)/../git/t} +: ${TEST_OUTPUT_DIRECTORY=$(pwd)} +TEST_NO_CREATE_REPO=YesPlease +. "$TEST_DIRECTORY"/test-lib.sh + +# Prepend the directory containing cgit to PATH. +if test -n "$cgit_valgrind" +then + GIT_VALGRIND="$TEST_DIRECTORY/valgrind" + CGIT_VALGRIND=$(cd ../valgrind && pwd) + PATH="$CGIT_VALGRIND/bin:$PATH" + export GIT_VALGRIND CGIT_VALGRIND +else + PATH="$(pwd)/../..:$PATH" +fi + +FILTER_DIRECTORY=$(cd ../filters && pwd) + +if cgit --version | grep -F -q "[+] Lua scripting"; then + export CGIT_HAS_LUA=1 +else + export CGIT_HAS_LUA=0 +fi + +mkrepo() { + name=$1 + count=$2 + test_create_repo "$name" + ( + cd "$name" + n=1 + while test $n -le $count + do + echo $n >file-$n + git add file-$n + git commit -m "commit $n" + n=$(expr $n + 1) + done + if test "$3" = "testplus" + then + echo "hello" >a+b + git add a+b + git commit -m "add a+b" + git branch "1+2" + fi + ) +} + +setup_repos() +{ + rm -rf cache + mkdir -p cache + mkrepo repos/foo 5 >/dev/null + mkrepo repos/bar 50 >/dev/null + mkrepo repos/foo+bar 10 testplus >/dev/null + mkrepo "repos/with space" 2 >/dev/null + mkrepo repos/filter 5 testplus >/dev/null + cat >cgitrc <<EOF +virtual-root=/ +cache-root=$PWD/cache + +cache-size=1021 +snapshots=tar.gz tar.bz zip +enable-log-filecount=1 +enable-log-linecount=1 +summary-log=5 +summary-branches=5 +summary-tags=5 +clone-url=git://example.org/\$CGIT_REPO_URL.git +enable-filter-overrides=1 + +repo.url=foo +repo.path=$PWD/repos/foo/.git +# Do not specify a description for this repo, as it then will be assigned +# the constant value "[no description]" (which actually used to cause a +# segfault). + +repo.url=bar +repo.path=$PWD/repos/bar/.git +repo.desc=the bar repo + +repo.url=foo+bar +repo.path=$PWD/repos/foo+bar/.git +repo.desc=the foo+bar repo + +repo.url=with space +repo.path=$PWD/repos/with space/.git +repo.desc=spaced repo + +repo.url=filter-exec +repo.path=$PWD/repos/filter/.git +repo.desc=filtered repo +repo.about-filter=exec:$FILTER_DIRECTORY/dump.sh +repo.commit-filter=exec:$FILTER_DIRECTORY/dump.sh +repo.email-filter=exec:$FILTER_DIRECTORY/dump.sh +repo.source-filter=exec:$FILTER_DIRECTORY/dump.sh +repo.readme=master:a+b +EOF + + if [ $CGIT_HAS_LUA -eq 1 ]; then + cat >>cgitrc <<EOF +repo.url=filter-lua +repo.path=$PWD/repos/filter/.git +repo.desc=filtered repo +repo.about-filter=lua:$FILTER_DIRECTORY/dump.lua +repo.commit-filter=lua:$FILTER_DIRECTORY/dump.lua +repo.email-filter=lua:$FILTER_DIRECTORY/dump.lua +repo.source-filter=lua:$FILTER_DIRECTORY/dump.lua +repo.readme=master:a+b +EOF + fi +} + +cgit_query() +{ + CGIT_CONFIG="$PWD/cgitrc" QUERY_STRING="$1" cgit +} + +cgit_url() +{ + CGIT_CONFIG="$PWD/cgitrc" QUERY_STRING="url=$1" cgit +} + +strip_headers() { + while read -r line + do + test -z "$line" && break + done + cat +} + +test -z "$CGIT_TEST_NO_CREATE_REPOS" && setup_repos diff --git a/third_party/cgit/tests/t0001-validate-git-versions.sh b/third_party/cgit/tests/t0001-validate-git-versions.sh new file mode 100755 index 0000000000..3200f31101 --- /dev/null +++ b/third_party/cgit/tests/t0001-validate-git-versions.sh @@ -0,0 +1,41 @@ +#!/bin/sh + +test_description='Check Git version is correct' +CGIT_TEST_NO_CREATE_REPOS=YesPlease +. ./setup.sh + +test_expect_success 'extract Git version from Makefile' ' + sed -n -e "/^GIT_VER[ ]*=/ { + s/^GIT_VER[ ]*=[ ]*// + p + }" ../../Makefile >makefile_version +' + +# Note that Git's GIT-VERSION-GEN script applies "s/-/./g" to the version +# string to produce the internal version in the GIT-VERSION-FILE, so we +# must apply the same transformation to the version in the Makefile before +# comparing them. +test_expect_success 'test Git version matches Makefile' ' + ( cat ../../git/GIT-VERSION-FILE || echo "No GIT-VERSION-FILE" ) | + sed -e "s/GIT_VERSION[ ]*=[ ]*//" -e "s/\\.dirty$//" >git_version && + sed -e "s/-/./g" makefile_version >makefile_git_version && + test_cmp git_version makefile_git_version +' + +test_expect_success 'test submodule version matches Makefile' ' + if ! test -e ../../git/.git + then + echo "git/ is not a Git repository" >&2 + else + ( + cd ../.. && + sm_sha1=$(git ls-files --stage -- git | + sed -e "s/^[0-9]* \\([0-9a-f]*\\) [0-9] .*$/\\1/") && + cd git && + git describe --match "v[0-9]*" $sm_sha1 + ) | sed -e "s/^v//" -e "s/-/./" >sm_version && + test_cmp sm_version makefile_version + fi +' + +test_done diff --git a/third_party/cgit/tests/t0010-validate-html.sh b/third_party/cgit/tests/t0010-validate-html.sh new file mode 100755 index 0000000000..ca08d69d14 --- /dev/null +++ b/third_party/cgit/tests/t0010-validate-html.sh @@ -0,0 +1,40 @@ +#!/bin/sh + +test_description='Validate html with tidy' +. ./setup.sh + + +test_url() +{ + tidy_opt="-eq" + test -z "$NO_TIDY_WARNINGS" || tidy_opt+=" --show-warnings no" + cgit_url "$1" >tidy-$test_count.tmp || return + sed -e "1,4d" tidy-$test_count.tmp >tidy-$test_count || return + "$tidy" $tidy_opt tidy-$test_count + rc=$? + + # tidy returns with exitcode 1 on warnings, 2 on error + if test $rc = 2 + then + false + else + : + fi +} + +tidy=`which tidy 2>/dev/null` +test -n "$tidy" || { + skip_all='Skipping html validation tests: tidy not found' + test_done + exit +} + +test_expect_success 'index page' 'test_url ""' +test_expect_success 'foo' 'test_url "foo"' +test_expect_success 'foo/log' 'test_url "foo/log"' +test_expect_success 'foo/tree' 'test_url "foo/tree"' +test_expect_success 'foo/tree/file-1' 'test_url "foo/tree/file-1"' +test_expect_success 'foo/commit' 'test_url "foo/commit"' +test_expect_success 'foo/diff' 'test_url "foo/diff"' + +test_done diff --git a/third_party/cgit/tests/t0020-validate-cache.sh b/third_party/cgit/tests/t0020-validate-cache.sh new file mode 100755 index 0000000000..657765d897 --- /dev/null +++ b/third_party/cgit/tests/t0020-validate-cache.sh @@ -0,0 +1,78 @@ +#!/bin/sh + +test_description='Validate cache' +. ./setup.sh + +test_expect_success 'verify cache-size=0' ' + + rm -f cache/* && + sed -e "s/cache-size=1021$/cache-size=0/" cgitrc >cgitrc.tmp && + mv -f cgitrc.tmp cgitrc && + cgit_url "" && + cgit_url "foo" && + cgit_url "foo/refs" && + cgit_url "foo/tree" && + cgit_url "foo/log" && + cgit_url "foo/diff" && + cgit_url "foo/patch" && + cgit_url "bar" && + cgit_url "bar/refs" && + cgit_url "bar/tree" && + cgit_url "bar/log" && + cgit_url "bar/diff" && + cgit_url "bar/patch" && + ls cache >output && + test_line_count = 0 output +' + +test_expect_success 'verify cache-size=1' ' + + rm -f cache/* && + sed -e "s/cache-size=0$/cache-size=1/" cgitrc >cgitrc.tmp && + mv -f cgitrc.tmp cgitrc && + cgit_url "" && + cgit_url "foo" && + cgit_url "foo/refs" && + cgit_url "foo/tree" && + cgit_url "foo/log" && + cgit_url "foo/diff" && + cgit_url "foo/patch" && + cgit_url "bar" && + cgit_url "bar/refs" && + cgit_url "bar/tree" && + cgit_url "bar/log" && + cgit_url "bar/diff" && + cgit_url "bar/patch" && + ls cache >output && + test_line_count = 1 output +' + +test_expect_success 'verify cache-size=1021' ' + + rm -f cache/* && + sed -e "s/cache-size=1$/cache-size=1021/" cgitrc >cgitrc.tmp && + mv -f cgitrc.tmp cgitrc && + cgit_url "" && + cgit_url "foo" && + cgit_url "foo/refs" && + cgit_url "foo/tree" && + cgit_url "foo/log" && + cgit_url "foo/diff" && + cgit_url "foo/patch" && + cgit_url "bar" && + cgit_url "bar/refs" && + cgit_url "bar/tree" && + cgit_url "bar/log" && + cgit_url "bar/diff" && + cgit_url "bar/patch" && + ls cache >output && + test_line_count = 13 output && + cgit_url "foo/ls_cache" >output.full && + strip_headers <output.full >output && + test_line_count = 13 output && + # Check that ls_cache output is cached correctly + cgit_url "foo/ls_cache" >output.second && + test_cmp output.full output.second +' + +test_done diff --git a/third_party/cgit/tests/t0101-index.sh b/third_party/cgit/tests/t0101-index.sh new file mode 100755 index 0000000000..82ef9b04e5 --- /dev/null +++ b/third_party/cgit/tests/t0101-index.sh @@ -0,0 +1,17 @@ +#!/bin/sh + +test_description='Check content on index page' +. ./setup.sh + +test_expect_success 'generate index page' 'cgit_url "" >tmp' +test_expect_success 'find foo repo' 'grep "foo" tmp' +test_expect_success 'find foo description' 'grep "\[no description\]" tmp' +test_expect_success 'find bar repo' 'grep "bar" tmp' +test_expect_success 'find bar description' 'grep "the bar repo" tmp' +test_expect_success 'find foo+bar repo' 'grep ">foo+bar<" tmp' +test_expect_success 'verify foo+bar link' 'grep "/foo+bar/" tmp' +test_expect_success 'verify "with%20space" link' 'grep "/with%20space/" tmp' +test_expect_success 'no tree-link' '! grep "foo/tree" tmp' +test_expect_success 'no log-link' '! grep "foo/log" tmp' + +test_done diff --git a/third_party/cgit/tests/t0102-summary.sh b/third_party/cgit/tests/t0102-summary.sh new file mode 100755 index 0000000000..b8864cb187 --- /dev/null +++ b/third_party/cgit/tests/t0102-summary.sh @@ -0,0 +1,25 @@ +#!/bin/sh + +test_description='Check content on summary page' +. ./setup.sh + +test_expect_success 'generate foo summary' 'cgit_url "foo" >tmp' +test_expect_success 'find commit 1' 'grep "commit 1" tmp' +test_expect_success 'find commit 5' 'grep "commit 5" tmp' +test_expect_success 'find branch master' 'grep "master" tmp' +test_expect_success 'no tags' '! grep "tags" tmp' +test_expect_success 'clone-url expanded correctly' ' + grep "git://example.org/foo.git" tmp +' + +test_expect_success 'generate bar summary' 'cgit_url "bar" >tmp' +test_expect_success 'no commit 45' '! grep "commit 45" tmp' +test_expect_success 'find commit 46' 'grep "commit 46" tmp' +test_expect_success 'find commit 50' 'grep "commit 50" tmp' +test_expect_success 'find branch master' 'grep "master" tmp' +test_expect_success 'no tags' '! grep "tags" tmp' +test_expect_success 'clone-url expanded correctly' ' + grep "git://example.org/bar.git" tmp +' + +test_done diff --git a/third_party/cgit/tests/t0103-log.sh b/third_party/cgit/tests/t0103-log.sh new file mode 100755 index 0000000000..bdf1435a16 --- /dev/null +++ b/third_party/cgit/tests/t0103-log.sh @@ -0,0 +1,24 @@ +#!/bin/sh + +test_description='Check content on log page' +. ./setup.sh + +test_expect_success 'generate foo/log' 'cgit_url "foo/log" >tmp' +test_expect_success 'find commit 1' 'grep "commit 1" tmp' +test_expect_success 'find commit 5' 'grep "commit 5" tmp' + +test_expect_success 'generate bar/log' 'cgit_url "bar/log" >tmp' +test_expect_success 'find commit 1' 'grep "commit 1" tmp' +test_expect_success 'find commit 50' 'grep "commit 50" tmp' + +test_expect_success 'generate "with%20space/log?qt=grep&q=commit+1"' ' + cgit_url "with+space/log&qt=grep&q=commit+1" >tmp +' +test_expect_success 'find commit 1' 'grep "commit 1" tmp' +test_expect_success 'find link with %20 in path' 'grep "/with%20space/log/?qt=grep" tmp' +test_expect_success 'find link with + in arg' 'grep "/log/?qt=grep&q=commit+1" tmp' +test_expect_success 'no links with space in path' '! grep "href=./with space/" tmp' +test_expect_success 'no links with space in arg' '! grep "q=commit 1" tmp' +test_expect_success 'commit 2 is not visible' '! grep "commit 2" tmp' + +test_done diff --git a/third_party/cgit/tests/t0104-tree.sh b/third_party/cgit/tests/t0104-tree.sh new file mode 100755 index 0000000000..2e140f5939 --- /dev/null +++ b/third_party/cgit/tests/t0104-tree.sh @@ -0,0 +1,32 @@ +#!/bin/sh + +test_description='Check content on tree page' +. ./setup.sh + +test_expect_success 'generate bar/tree' 'cgit_url "bar/tree" >tmp' +test_expect_success 'find file-1' 'grep "file-1" tmp' +test_expect_success 'find file-50' 'grep "file-50" tmp' + +test_expect_success 'generate bar/tree/file-50' 'cgit_url "bar/tree/file-50" >tmp' + +test_expect_success 'find line 1' ' + grep "<a id=.n1. href=.#n1.>1</a>" tmp +' + +test_expect_success 'no line 2' ' + ! grep "<a id=.n2. href=.#n2.>2</a>" tmp +' + +test_expect_success 'generate foo+bar/tree' 'cgit_url "foo%2bbar/tree" >tmp' + +test_expect_success 'verify a+b link' ' + grep "/foo+bar/tree/a+b" tmp +' + +test_expect_success 'generate foo+bar/tree?h=1+2' 'cgit_url "foo%2bbar/tree&h=1%2b2" >tmp' + +test_expect_success 'verify a+b?h=1+2 link' ' + grep "/foo+bar/tree/a+b?h=1%2b2" tmp +' + +test_done diff --git a/third_party/cgit/tests/t0105-commit.sh b/third_party/cgit/tests/t0105-commit.sh new file mode 100755 index 0000000000..9cdf55c025 --- /dev/null +++ b/third_party/cgit/tests/t0105-commit.sh @@ -0,0 +1,36 @@ +#!/bin/sh + +test_description='Check content on commit page' +. ./setup.sh + +test_expect_success 'generate foo/commit' 'cgit_url "foo/commit" >tmp' +test_expect_success 'find tree link' 'grep "<a href=./foo/tree/.>" tmp' +test_expect_success 'find parent link' 'grep -E "<a href=./foo/commit/\?id=.+>" tmp' + +test_expect_success 'find commit subject' ' + grep "<div class=.commit-subject.>commit 5<" tmp +' + +test_expect_success 'find commit msg' 'grep "<div class=.commit-msg.></div>" tmp' +test_expect_success 'find diffstat' 'grep "<table summary=.diffstat. class=.diffstat.>" tmp' + +test_expect_success 'find diff summary' ' + grep "1 files changed, 1 insertions, 0 deletions" tmp +' + +test_expect_success 'get root commit' ' + root=$(cd repos/foo && git rev-list --reverse HEAD | head -1) && + cgit_url "foo/commit&id=$root" >tmp && + grep "</html>" tmp +' + +test_expect_success 'root commit contains diffstat' ' + grep "<a href=./foo/diff/file-1.id=[0-9a-f]\{40\}.>file-1</a>" tmp +' + +test_expect_success 'root commit contains diff' ' + grep ">diff --git a/file-1 b/file-1<" tmp && + grep "<div class=.add.>+1</div>" tmp +' + +test_done diff --git a/third_party/cgit/tests/t0106-diff.sh b/third_party/cgit/tests/t0106-diff.sh new file mode 100755 index 0000000000..82b645ec72 --- /dev/null +++ b/third_party/cgit/tests/t0106-diff.sh @@ -0,0 +1,19 @@ +#!/bin/sh + +test_description='Check content on diff page' +. ./setup.sh + +test_expect_success 'generate foo/diff' 'cgit_url "foo/diff" >tmp' +test_expect_success 'find diff header' 'grep "a/file-5 b/file-5" tmp' +test_expect_success 'find blob link' 'grep "<a href=./foo/tree/file-5?id=" tmp' +test_expect_success 'find added file' 'grep "new file mode 100644" tmp' + +test_expect_success 'find hunk header' ' + grep "<div class=.hunk.>@@ -0,0 +1 @@</div>" tmp +' + +test_expect_success 'find added line' ' + grep "<div class=.add.>+5</div>" tmp +' + +test_done diff --git a/third_party/cgit/tests/t0107-snapshot.sh b/third_party/cgit/tests/t0107-snapshot.sh new file mode 100755 index 0000000000..6cf7aaa6fc --- /dev/null +++ b/third_party/cgit/tests/t0107-snapshot.sh @@ -0,0 +1,82 @@ +#!/bin/sh + +test_description='Verify snapshot' +. ./setup.sh + +test_expect_success 'get foo/snapshot/master.tar.gz' ' + cgit_url "foo/snapshot/master.tar.gz" >tmp +' + +test_expect_success 'check html headers' ' + head -n 1 tmp | + grep "Content-Type: application/x-gzip" && + + head -n 2 tmp | + grep "Content-Disposition: inline; filename=.master.tar.gz." +' + +test_expect_success 'strip off the header lines' ' + strip_headers <tmp >master.tar.gz +' + +test_expect_success 'verify gzip format' ' + gunzip --test master.tar.gz +' + +test_expect_success 'untar' ' + rm -rf master && + tar -xzf master.tar.gz +' + +test_expect_success 'count files' ' + ls master/ >output && + test_line_count = 5 output +' + +test_expect_success 'verify untarred file-5' ' + grep "^5$" master/file-5 && + test_line_count = 1 master/file-5 +' + +test_expect_success 'get foo/snapshot/master.zip' ' + cgit_url "foo/snapshot/master.zip" >tmp +' + +test_expect_success 'check HTML headers (zip)' ' + head -n 1 tmp | + grep "Content-Type: application/x-zip" && + + head -n 2 tmp | + grep "Content-Disposition: inline; filename=.master.zip." +' + +test_expect_success 'strip off the header lines (zip)' ' + strip_headers <tmp >master.zip +' + +if test -n "$(which unzip 2>/dev/null)"; then + test_set_prereq UNZIP +else + say 'Skipping ZIP validation tests: unzip not found' +fi + +test_expect_success UNZIP 'verify zip format' ' + unzip -t master.zip +' + +test_expect_success UNZIP 'unzip' ' + rm -rf master && + unzip master.zip +' + +test_expect_success UNZIP 'count files (zip)' ' + ls master/ >output && + test_line_count = 5 output +' + +test_expect_success UNZIP 'verify unzipped file-5' ' + grep "^5$" master/file-5 && + test_line_count = 1 master/file-5 +' + +test_done diff --git a/third_party/cgit/tests/t0108-patch.sh b/third_party/cgit/tests/t0108-patch.sh new file mode 100755 index 0000000000..013d68024d --- /dev/null +++ b/third_party/cgit/tests/t0108-patch.sh @@ -0,0 +1,62 @@ +#!/bin/sh + +test_description='Check content on patch page' +. ./setup.sh + +test_expect_success 'generate foo/patch' ' + cgit_query "url=foo/patch" >tmp +' + +test_expect_success 'find `From:` line' ' + grep "^From: " tmp +' + +test_expect_success 'find `Date:` line' ' + grep "^Date: " tmp +' + +test_expect_success 'find `Subject:` line' ' + grep "^Subject: commit 5" tmp +' + +test_expect_success 'find `cgit` signature' ' + tail -2 tmp | head -1 | grep "^cgit" +' + +test_expect_success 'compare with output of git-format-patch(1)' ' + CGIT_VERSION=$(sed -n "s/CGIT_VERSION = //p" ../../VERSION) && + git --git-dir="$PWD/repos/foo/.git" format-patch --subject-prefix="" --signature="cgit $CGIT_VERSION" --stdout HEAD^ >tmp2 && + strip_headers <tmp >tmp_ && + test_cmp tmp_ tmp2 +' + +test_expect_success 'find initial commit' ' + root=$(git --git-dir="$PWD/repos/foo/.git" rev-list --max-parents=0 HEAD) +' + +test_expect_success 'generate patch for initial commit' ' + cgit_query "url=foo/patch&id=$root" >tmp +' + +test_expect_success 'find `cgit` signature' ' + tail -2 tmp | head -1 | grep "^cgit" +' + +test_expect_success 'generate patches for multiple commits' ' + id=$(git --git-dir="$PWD/repos/foo/.git" rev-parse HEAD) && + id2=$(git --git-dir="$PWD/repos/foo/.git" rev-parse HEAD~3) && + cgit_query "url=foo/patch&id=$id&id2=$id2" >tmp +' + +test_expect_success 'find `cgit` signature' ' + tail -2 tmp | head -1 | grep "^cgit" +' + +test_expect_success 'compare with output of git-format-patch(1)' ' + CGIT_VERSION=$(sed -n "s/CGIT_VERSION = //p" ../../VERSION) && + git --git-dir="$PWD/repos/foo/.git" format-patch -N --subject-prefix="" --signature="cgit $CGIT_VERSION" --stdout HEAD~3..HEAD >tmp2 && + strip_headers <tmp >tmp_ && + test_cmp tmp_ tmp2 +' + +test_done diff --git a/third_party/cgit/tests/t0109-gitconfig.sh b/third_party/cgit/tests/t0109-gitconfig.sh new file mode 100755 index 0000000000..3ba668490d --- /dev/null +++ b/third_party/cgit/tests/t0109-gitconfig.sh @@ -0,0 +1,42 @@ +#!/bin/sh + +test_description='Ensure that git does not access $HOME' +. ./setup.sh + +test -n "$(which strace 2>/dev/null)" || { + skip_all='Skipping access validation tests: strace not found' + test_done + exit +} + +test_no_home_access () { + non_existent_path="/path/to/some/place/that/does/not/possibly/exist" + while test -d "$non_existent_path"; do + non_existent_path="$non_existent_path/$(date +%N)" + done && + strace \ + -E HOME="$non_existent_path" \ + -E CGIT_CONFIG="$PWD/cgitrc" \ + -E QUERY_STRING="url=$1" \ + -e access -f -o strace.out cgit && + test_must_fail grep "$non_existent_path" strace.out +} + +test_no_home_access_success() { + test_expect_success "do not access \$HOME: $1" " + test_no_home_access '$1' + " +} + +test_no_home_access_success +test_no_home_access_success foo +test_no_home_access_success foo/refs +test_no_home_access_success foo/log +test_no_home_access_success foo/tree +test_no_home_access_success foo/tree/file-1 +test_no_home_access_success foo/commit +test_no_home_access_success foo/diff +test_no_home_access_success foo/patch +test_no_home_access_success foo/snapshot/master.tar.gz + +test_done diff --git a/third_party/cgit/tests/t0110-rawdiff.sh b/third_party/cgit/tests/t0110-rawdiff.sh new file mode 100755 index 0000000000..66fa7d5d37 --- /dev/null +++ b/third_party/cgit/tests/t0110-rawdiff.sh @@ -0,0 +1,42 @@ +#!/bin/sh + +test_description='Check content on rawdiff page' +. ./setup.sh + +test_expect_success 'generate foo/rawdiff' ' + cgit_query "url=foo/rawdiff" >tmp +' + +test_expect_success 'compare with output of git-diff(1)' ' + git --git-dir="$PWD/repos/foo/.git" diff HEAD^.. >tmp2 && + sed "1,4d" tmp >tmp_ && + cmp tmp_ tmp2 +' + +test_expect_success 'find initial commit' ' + root=$(git --git-dir="$PWD/repos/foo/.git" rev-list --max-parents=0 HEAD) +' + +test_expect_success 'generate diff for initial commit' ' + cgit_query "url=foo/rawdiff&id=$root" >tmp +' + +test_expect_success 'compare with output of git-diff-tree(1)' ' + git --git-dir="$PWD/repos/foo/.git" diff-tree -p --no-commit-id --root "$root" >tmp2 && + sed "1,4d" tmp >tmp_ && + cmp tmp_ tmp2 +' + +test_expect_success 'generate diff for multiple commits' ' + id=$(git --git-dir="$PWD/repos/foo/.git" rev-parse HEAD) && + id2=$(git --git-dir="$PWD/repos/foo/.git" rev-parse HEAD~3) && + cgit_query "url=foo/rawdiff&id=$id&id2=$id2" >tmp +' + +test_expect_success 'compare with output of git-diff(1)' ' + git --git-dir="$PWD/repos/foo/.git" diff HEAD~3..HEAD >tmp2 && + sed "1,4d" tmp >tmp_ && + cmp tmp_ tmp2 +' + +test_done diff --git a/third_party/cgit/tests/t0111-filter.sh b/third_party/cgit/tests/t0111-filter.sh new file mode 100755 index 0000000000..2fdc3669f4 --- /dev/null +++ b/third_party/cgit/tests/t0111-filter.sh @@ -0,0 +1,46 @@ +#!/bin/sh + +test_description='Check filtered content' +. ./setup.sh + +prefixes="exec" +if [ $CGIT_HAS_LUA -eq 1 ]; then + prefixes="$prefixes lua" +fi + +for prefix in $prefixes +do + test_expect_success "generate filter-$prefix/tree/a%2bb" " + cgit_url 'filter-$prefix/tree/a%2bb' >tmp + " + + test_expect_success "check whether the $prefix source filter works" ' + grep "<code>a+b HELLO$" tmp + ' + + test_expect_success "generate filter-$prefix/about/" " + cgit_url 'filter-$prefix/about/' >tmp + " + + test_expect_success "check whether the $prefix about filter works" ' + grep "<div id='"'"'summary'"'"'>a+b HELLO$" tmp + ' + + test_expect_success "generate filter-$prefix/commit/" " + cgit_url 'filter-$prefix/commit/' >tmp + " + + test_expect_success "check whether the $prefix commit filter works" ' + grep "<div class='"'"'commit-subject'"'"'>ADD A+B" tmp + ' + + test_expect_success "check whether the $prefix email filter works for authors" ' + grep "<author@example.com> commit A U THOR <AUTHOR@EXAMPLE.COM>" tmp + ' + + test_expect_success "check whether the $prefix email filter works for committers" ' + grep "<committer@example.com> commit C O MITTER <COMMITTER@EXAMPLE.COM>" tmp + ' +done + +test_done diff --git a/third_party/cgit/tests/valgrind/bin/cgit b/third_party/cgit/tests/valgrind/bin/cgit new file mode 100755 index 0000000000..dcdfbe5320 --- /dev/null +++ b/third_party/cgit/tests/valgrind/bin/cgit @@ -0,0 +1,12 @@ +#!/bin/sh + +# Note that we currently use Git's suppression file and there are variables +# $GIT_VALGRIND and $CGIT_VALGRIND which point to different places. +exec valgrind -q --error-exitcode=126 \ + --suppressions="$GIT_VALGRIND/default.supp" \ + --gen-suppressions=all \ + --leak-check=no \ + --track-origins=yes \ + --log-fd=4 \ + --input-fd=4 \ + "$CGIT_VALGRIND/../../cgit" "$@" diff --git a/third_party/cgit/ui-atom.c b/third_party/cgit/ui-atom.c new file mode 100644 index 0000000000..1056f36397 --- /dev/null +++ b/third_party/cgit/ui-atom.c @@ -0,0 +1,149 @@ +/* ui-atom.c: functions for atom feeds + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-atom.h" +#include "html.h" +#include "ui-shared.h" + +static void add_entry(struct commit *commit, const char *host) +{ + char delim = '&'; + char *hex; + char *mail, *t, *t2; + struct commitinfo *info; + + info = cgit_parse_commit(commit); + hex = oid_to_hex(&commit->object.oid); + html("<entry>\n"); + html("<title>"); + html_txt(info->subject); + html("</title>\n"); + html("<updated>"); + html_txt(show_date(info->committer_date, 0, + date_mode_from_type(DATE_ISO8601_STRICT))); + html("</updated>\n"); + html("<author>\n"); + if (info->author) { + html("<name>"); + html_txt(info->author); + html("</name>\n"); + } + if (info->author_email && !ctx.cfg.noplainemail) { + mail = xstrdup(info->author_email); + t = strchr(mail, '<'); + if (t) + t++; + else + t = mail; + t2 = strchr(t, '>'); + if (t2) + *t2 = '\0'; + html("<email>"); + html_txt(t); + html("</email>\n"); + free(mail); + } + html("</author>\n"); + html("<published>"); + html_txt(show_date(info->author_date, 0, + date_mode_from_type(DATE_ISO8601_STRICT))); + html("</published>\n"); + if (host) { + char *pageurl; + html("<link rel='alternate' type='text/html' href='"); + html(cgit_httpscheme()); + html_attr(host); + pageurl = cgit_pageurl(ctx.repo->url, "commit", NULL); + html_attr(pageurl); + if (ctx.cfg.virtual_root) + delim = '?'; + html_attrf("%cid=%s", delim, hex); + html("'/>\n"); + free(pageurl); + } + htmlf("<id>%s</id>\n", hex); + html("<content type='text'>\n"); + html_txt(info->msg); + html("</content>\n"); + html("<content type='xhtml'>\n"); + html("<div xmlns='http://www.w3.org/1999/xhtml'>\n"); + html("<pre>\n"); + html_txt(info->msg); + html("</pre>\n"); + html("</div>\n"); + html("</content>\n"); + html("</entry>\n"); + cgit_free_commitinfo(info); +} + + +void cgit_print_atom(char *tip, const char *path, int max_count) +{ + char *host; + const char *argv[] = {NULL, tip, NULL, NULL, NULL}; + struct commit *commit; + struct rev_info rev; + int argc = 2; + + if (ctx.qry.show_all) + argv[1] = "--all"; + else if (!tip) + argv[1] = ctx.qry.head; + + if (path) { + argv[argc++] = "--"; + argv[argc++] = path; + } + + init_revisions(&rev, NULL); + rev.abbrev = DEFAULT_ABBREV; + rev.commit_format = CMIT_FMT_DEFAULT; + rev.verbose_header = 1; + rev.show_root_diff = 0; + rev.max_count = max_count; + setup_revisions(argc, argv, &rev, NULL); + prepare_revision_walk(&rev); + + host = cgit_hosturl(); + ctx.page.mimetype = "text/xml"; + ctx.page.charset = "utf-8"; + cgit_print_http_headers(); + html("<feed xmlns='http://www.w3.org/2005/Atom'>\n"); + html("<title>"); + html_txt(ctx.repo->name); + if (path) { + html("/"); + html_txt(path); + } + if (tip && !ctx.qry.show_all) { + html(", branch "); + html_txt(tip); + } + html("</title>\n"); + html("<subtitle>"); + html_txt(ctx.repo->desc); + html("</subtitle>\n"); + if (host) { + char *repourl = cgit_repourl(ctx.repo->url); + html("<link rel='alternate' type='text/html' href='"); + html(cgit_httpscheme()); + html_attr(host); + html_attr(repourl); + html("'/>\n"); + free(repourl); + } + while ((commit = get_revision(&rev)) != NULL) { + add_entry(commit, host); + free_commit_buffer(the_repository->parsed_objects, commit); + free_commit_list(commit->parents); + commit->parents = NULL; + } + html("</feed>\n"); + free(host); +} diff --git a/third_party/cgit/ui-atom.h b/third_party/cgit/ui-atom.h new file mode 100644 index 0000000000..dda953bbf4 --- /dev/null +++ b/third_party/cgit/ui-atom.h @@ -0,0 +1,6 @@ +#ifndef UI_ATOM_H +#define UI_ATOM_H + +extern void cgit_print_atom(char *tip, const char *path, int max_count); + +#endif diff --git a/third_party/cgit/ui-blame.c b/third_party/cgit/ui-blame.c new file mode 100644 index 0000000000..886c4c19fd --- /dev/null +++ b/third_party/cgit/ui-blame.c @@ -0,0 +1,306 @@ +/* ui-blame.c: functions for blame output + * + * Copyright (C) 2006-2017 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-blame.h" +#include "html.h" +#include "ui-shared.h" +#include "argv-array.h" +#include "blame.h" + + +static char *emit_suspect_detail(struct blame_origin *suspect) +{ + struct commitinfo *info; + struct strbuf detail = STRBUF_INIT; + + info = cgit_parse_commit(suspect->commit); + + strbuf_addf(&detail, "author %s", info->author); + if (!ctx.cfg.noplainemail) + strbuf_addf(&detail, " %s", info->author_email); + strbuf_addf(&detail, " %s\n", + show_date(info->author_date, info->author_tz, + cgit_date_mode(DATE_DOTTIME))); + + strbuf_addf(&detail, "committer %s", info->committer); + if (!ctx.cfg.noplainemail) + strbuf_addf(&detail, " %s", info->committer_email); + strbuf_addf(&detail, " %s\n\n", + show_date(info->committer_date, info->committer_tz, + cgit_date_mode(DATE_DOTTIME))); + + strbuf_addstr(&detail, info->subject); + + cgit_free_commitinfo(info); + return strbuf_detach(&detail, NULL); +} + +static void emit_blame_entry_hash(struct blame_entry *ent) +{ + struct blame_origin *suspect = ent->suspect; + struct object_id *oid = &suspect->commit->object.oid; + unsigned long line = 0; + + char *detail = emit_suspect_detail(suspect); + html("<span class='sha1'>"); + cgit_commit_link(find_unique_abbrev(oid, DEFAULT_ABBREV), detail, + NULL, ctx.qry.head, oid_to_hex(oid), suspect->path); + html("</span>"); + free(detail); + + while (line++ < ent->num_lines) + html("\n"); +} + +static void emit_blame_entry_linenumber(struct blame_entry *ent) +{ + const char *numberfmt = "<a id='n%1$d' href='#n%1$d'>%1$d</a>\n"; + + unsigned long lineno = ent->lno; + while (lineno < ent->lno + ent->num_lines) + htmlf(numberfmt, ++lineno); +} + +static void emit_blame_entry_line_background(struct blame_scoreboard *sb, + struct blame_entry *ent) +{ + unsigned long line; + size_t len, maxlen = 2; + const char* pos, *endpos; + + for (line = ent->lno; line < ent->lno + ent->num_lines; line++) { + html("\n"); + pos = blame_nth_line(sb, line); + endpos = blame_nth_line(sb, line + 1); + len = 0; + while (pos < endpos) { + len++; + if (*pos++ == '\t') + len = (len + 7) & ~7; + } + if (len > maxlen) + maxlen = len; + } + + for (len = 0; len < maxlen - 1; len++) + html(" "); +} + +struct walk_tree_context { + char *curr_rev; + int match_baselen; + int state; +}; + +static void print_object(const struct object_id *oid, const char *path, + const char *basename, const char *rev) +{ + enum object_type type; + char *buf; + unsigned long size; + struct argv_array rev_argv = ARGV_ARRAY_INIT; + struct rev_info revs; + struct blame_scoreboard sb; + struct blame_origin *o; + struct blame_entry *ent = NULL; + + type = oid_object_info(the_repository, oid, &size); + if (type == OBJ_BAD) { + cgit_print_error_page(404, "Not found", "Bad object name: %s", + oid_to_hex(oid)); + return; + } + + buf = read_object_file(oid, &type, &size); + if (!buf) { + cgit_print_error_page(500, "Internal server error", + "Error reading object %s", oid_to_hex(oid)); + return; + } + + argv_array_push(&rev_argv, "blame"); + argv_array_push(&rev_argv, rev); + init_revisions(&revs, NULL); + revs.diffopt.flags.allow_textconv = 1; + setup_revisions(rev_argv.argc, rev_argv.argv, &revs, NULL); + init_scoreboard(&sb); + sb.revs = &revs; + sb.repo = the_repository; + setup_scoreboard(&sb, path, &o); + o->suspects = blame_entry_prepend(NULL, 0, sb.num_lines, o); + prio_queue_put(&sb.commits, o->commit); + blame_origin_decref(o); + sb.ent = NULL; + sb.path = path; + assign_blame(&sb, 0); + blame_sort_final(&sb); + blame_coalesce(&sb); + + cgit_set_title_from_path(path); + + cgit_print_layout_start(); + htmlf("blob: %s (", oid_to_hex(oid)); + cgit_plain_link("plain", NULL, NULL, ctx.qry.head, rev, path); + html(") ("); + cgit_tree_link("tree", NULL, NULL, ctx.qry.head, rev, path); + html(")\n"); + + if (buffer_is_binary(buf, size)) { + html("<div class='error'>blob is binary.</div>"); + goto cleanup; + } + if (ctx.cfg.max_blob_size && size / 1024 > ctx.cfg.max_blob_size) { + htmlf("<div class='error'>blob size (%ldKB)" + " exceeds display size limit (%dKB).</div>", + size / 1024, ctx.cfg.max_blob_size); + goto cleanup; + } + + html("<table class='blame blob'>\n<tr>\n"); + + /* Commit hashes */ + html("<td class='hashes'>"); + for (ent = sb.ent; ent; ent = ent->next) { + html("<div class='alt'><pre>"); + emit_blame_entry_hash(ent); + html("</pre></div>"); + } + html("</td>\n"); + + /* Line numbers */ + if (ctx.cfg.enable_tree_linenumbers) { + html("<td class='linenumbers'>"); + for (ent = sb.ent; ent; ent = ent->next) { + html("<div class='alt'><pre>"); + emit_blame_entry_linenumber(ent); + html("</pre></div>"); + } + html("</td>\n"); + } + + html("<td class='lines'><div>"); + + /* Colored bars behind lines */ + html("<div>"); + for (ent = sb.ent; ent; ) { + struct blame_entry *e = ent->next; + html("<div class='alt'><pre>"); + emit_blame_entry_line_background(&sb, ent); + html("</pre></div>"); + free(ent); + ent = e; + } + html("</div>"); + + free((void *)sb.final_buf); + + /* Lines */ + html("<pre><code>"); + if (ctx.repo->source_filter) { + char *filter_arg = xstrdup(basename); + cgit_open_filter(ctx.repo->source_filter, filter_arg); + html_raw(buf, size); + cgit_close_filter(ctx.repo->source_filter); + free(filter_arg); + } else { + html_txt(buf); + } + html("</code></pre>"); + + html("</div></td>\n"); + + html("</tr>\n</table>\n"); + + cgit_print_layout_end(); + +cleanup: + free(buf); +} + +static int walk_tree(const struct object_id *oid, struct strbuf *base, + const char *pathname, unsigned mode, int stage, + void *cbdata) +{ + struct walk_tree_context *walk_tree_ctx = cbdata; + + if (base->len == walk_tree_ctx->match_baselen) { + if (S_ISREG(mode)) { + struct strbuf buffer = STRBUF_INIT; + strbuf_addbuf(&buffer, base); + strbuf_addstr(&buffer, pathname); + print_object(oid, buffer.buf, pathname, + walk_tree_ctx->curr_rev); + strbuf_release(&buffer); + walk_tree_ctx->state = 1; + } else if (S_ISDIR(mode)) { + walk_tree_ctx->state = 2; + } + } else if (base->len < INT_MAX + && (int)base->len > walk_tree_ctx->match_baselen) { + walk_tree_ctx->state = 2; + } else if (S_ISDIR(mode)) { + return READ_TREE_RECURSIVE; + } + return 0; +} + +static int basedir_len(const char *path) +{ + char *p = strrchr(path, '/'); + if (p) + return p - path + 1; + return 0; +} + +void cgit_print_blame(void) +{ + const char *rev = ctx.qry.sha1; + struct object_id oid; + struct commit *commit; + struct pathspec_item path_items = { + .match = ctx.qry.path, + .len = ctx.qry.path ? strlen(ctx.qry.path) : 0 + }; + struct pathspec paths = { + .nr = 1, + .items = &path_items + }; + struct walk_tree_context walk_tree_ctx = { + .state = 0 + }; + + if (!rev) + rev = ctx.qry.head; + + if (get_oid(rev, &oid)) { + cgit_print_error_page(404, "Not found", + "Invalid revision name: %s", rev); + return; + } + commit = lookup_commit_reference(the_repository, &oid); + if (!commit || parse_commit(commit)) { + cgit_print_error_page(404, "Not found", + "Invalid commit reference: %s", rev); + return; + } + + walk_tree_ctx.curr_rev = xstrdup(rev); + walk_tree_ctx.match_baselen = (path_items.match) ? + basedir_len(path_items.match) : -1; + + read_tree_recursive(the_repository, commit->maybe_tree, "", 0, 0, + &paths, walk_tree, &walk_tree_ctx); + if (!walk_tree_ctx.state) + cgit_print_error_page(404, "Not found", "Not found"); + else if (walk_tree_ctx.state == 2) + cgit_print_error_page(404, "No blame for folders", + "Blame is not available for folders."); + + free(walk_tree_ctx.curr_rev); +} diff --git a/third_party/cgit/ui-blame.h b/third_party/cgit/ui-blame.h new file mode 100644 index 0000000000..5b97e03591 --- /dev/null +++ b/third_party/cgit/ui-blame.h @@ -0,0 +1,6 @@ +#ifndef UI_BLAME_H +#define UI_BLAME_H + +extern void cgit_print_blame(void); + +#endif /* UI_BLAME_H */ diff --git a/third_party/cgit/ui-blob.c b/third_party/cgit/ui-blob.c new file mode 100644 index 0000000000..30e2d4bf5f --- /dev/null +++ b/third_party/cgit/ui-blob.c @@ -0,0 +1,181 @@ +/* ui-blob.c: show blob content + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-blob.h" +#include "html.h" +#include "ui-shared.h" + +struct walk_tree_context { + const char *match_path; + struct object_id *matched_oid; + unsigned int found_path:1; + unsigned int file_only:1; +}; + +static int walk_tree(const struct object_id *oid, struct strbuf *base, + const char *pathname, unsigned mode, int stage, void *cbdata) +{ + struct walk_tree_context *walk_tree_ctx = cbdata; + + if (walk_tree_ctx->file_only && !S_ISREG(mode)) + return READ_TREE_RECURSIVE; + if (strncmp(base->buf, walk_tree_ctx->match_path, base->len) + || strcmp(walk_tree_ctx->match_path + base->len, pathname)) + return READ_TREE_RECURSIVE; + oidcpy(walk_tree_ctx->matched_oid, oid); + walk_tree_ctx->found_path = 1; + return 0; +} + +int cgit_ref_path_exists(const char *path, const char *ref, int file_only) +{ + struct object_id oid; + unsigned long size; + struct pathspec_item path_items = { + .match = xstrdup(path), + .len = strlen(path) + }; + struct pathspec paths = { + .nr = 1, + .items = &path_items + }; + struct walk_tree_context walk_tree_ctx = { + .match_path = path, + .matched_oid = &oid, + .found_path = 0, + .file_only = file_only + }; + + if (get_oid(ref, &oid)) + goto done; + if (oid_object_info(the_repository, &oid, &size) != OBJ_COMMIT) + goto done; + read_tree_recursive(the_repository, lookup_commit_reference(the_repository, &oid)->maybe_tree, + "", 0, 0, &paths, walk_tree, &walk_tree_ctx); + +done: + free(path_items.match); + return walk_tree_ctx.found_path; +} + +int cgit_print_file(char *path, const char *head, int file_only) +{ + struct object_id oid; + enum object_type type; + char *buf; + unsigned long size; + struct commit *commit; + struct pathspec_item path_items = { + .match = path, + .len = strlen(path) + }; + struct pathspec paths = { + .nr = 1, + .items = &path_items + }; + struct walk_tree_context walk_tree_ctx = { + .match_path = path, + .matched_oid = &oid, + .found_path = 0, + .file_only = file_only + }; + + if (get_oid(head, &oid)) + return -1; + type = oid_object_info(the_repository, &oid, &size); + if (type == OBJ_COMMIT) { + commit = lookup_commit_reference(the_repository, &oid); + read_tree_recursive(the_repository, commit->maybe_tree, + "", 0, 0, &paths, walk_tree, &walk_tree_ctx); + if (!walk_tree_ctx.found_path) + return -1; + type = oid_object_info(the_repository, &oid, &size); + } + if (type == OBJ_BAD) + return -1; + buf = read_object_file(&oid, &type, &size); + if (!buf) + return -1; + buf[size] = '\0'; + html_raw(buf, size); + free(buf); + return 0; +} + +void cgit_print_blob(const char *hex, char *path, const char *head, int file_only) +{ + struct object_id oid; + enum object_type type; + char *buf; + unsigned long size; + struct commit *commit; + struct pathspec_item path_items = { + .match = path, + .len = path ? strlen(path) : 0 + }; + struct pathspec paths = { + .nr = 1, + .items = &path_items + }; + struct walk_tree_context walk_tree_ctx = { + .match_path = path, + .matched_oid = &oid, + .found_path = 0, + .file_only = file_only + }; + + if (hex) { + if (get_oid_hex(hex, &oid)) { + cgit_print_error_page(400, "Bad request", + "Bad hex value: %s", hex); + return; + } + } else { + if (get_oid(head, &oid)) { + cgit_print_error_page(404, "Not found", + "Bad ref: %s", head); + return; + } + } + + type = oid_object_info(the_repository, &oid, &size); + + if ((!hex) && type == OBJ_COMMIT && path) { + commit = lookup_commit_reference(the_repository, &oid); + read_tree_recursive(the_repository, commit->maybe_tree, + "", 0, 0, &paths, walk_tree, &walk_tree_ctx); + type = oid_object_info(the_repository, &oid, &size); + } + + if (type == OBJ_BAD) { + cgit_print_error_page(404, "Not found", + "Bad object name: %s", hex); + return; + } + + buf = read_object_file(&oid, &type, &size); + if (!buf) { + cgit_print_error_page(500, "Internal server error", + "Error reading object %s", hex); + return; + } + + buf[size] = '\0'; + if (buffer_is_binary(buf, size)) + ctx.page.mimetype = "application/octet-stream"; + else + ctx.page.mimetype = "text/plain"; + ctx.page.filename = path; + + html("X-Content-Type-Options: nosniff\n"); + html("Content-Security-Policy: default-src 'none'\n"); + cgit_print_http_headers(); + html_raw(buf, size); + free(buf); +} diff --git a/third_party/cgit/ui-blob.h b/third_party/cgit/ui-blob.h new file mode 100644 index 0000000000..16847b20b1 --- /dev/null +++ b/third_party/cgit/ui-blob.h @@ -0,0 +1,8 @@ +#ifndef UI_BLOB_H +#define UI_BLOB_H + +extern int cgit_ref_path_exists(const char *path, const char *ref, int file_only); +extern int cgit_print_file(char *path, const char *head, int file_only); +extern void cgit_print_blob(const char *hex, char *path, const char *head, int file_only); + +#endif /* UI_BLOB_H */ diff --git a/third_party/cgit/ui-clone.c b/third_party/cgit/ui-clone.c new file mode 100644 index 0000000000..5dccb63976 --- /dev/null +++ b/third_party/cgit/ui-clone.c @@ -0,0 +1,126 @@ +/* ui-clone.c: functions for http cloning, based on + * git's http-backend.c by Shawn O. Pearce + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-clone.h" +#include "html.h" +#include "ui-shared.h" +#include "packfile.h" +#include "object-store.h" + +static int print_ref_info(const char *refname, const struct object_id *oid, + int flags, void *cb_data) +{ + struct object *obj; + + if (!(obj = parse_object(the_repository, oid))) + return 0; + + htmlf("%s\t%s\n", oid_to_hex(oid), refname); + if (obj->type == OBJ_TAG) { + if (!(obj = deref_tag(the_repository, obj, refname, 0))) + return 0; + htmlf("%s\t%s^{}\n", oid_to_hex(&obj->oid), refname); + } + return 0; +} + +static void print_pack_info(void) +{ + struct packed_git *pack; + char *offset; + + ctx.page.mimetype = "text/plain"; + ctx.page.filename = "objects/info/packs"; + cgit_print_http_headers(); + reprepare_packed_git(the_repository); + for (pack = get_packed_git(the_repository); pack; pack = pack->next) { + if (pack->pack_local) { + offset = strrchr(pack->pack_name, '/'); + if (offset && offset[1] != '\0') + ++offset; + else + offset = pack->pack_name; + htmlf("P %s\n", offset); + } + } +} + +static void send_file(const char *path) +{ + struct stat st; + + if (stat(path, &st)) { + switch (errno) { + case ENOENT: + cgit_print_error_page(404, "Not found", "Not found"); + break; + case EACCES: + cgit_print_error_page(403, "Forbidden", "Forbidden"); + break; + default: + cgit_print_error_page(400, "Bad request", "Bad request"); + } + return; + } + ctx.page.mimetype = "application/octet-stream"; + ctx.page.filename = path; + skip_prefix(path, ctx.repo->path, &ctx.page.filename); + skip_prefix(ctx.page.filename, "/", &ctx.page.filename); + cgit_print_http_headers(); + html_include(path); +} + +void cgit_clone_info(void) +{ + if (!ctx.qry.path || strcmp(ctx.qry.path, "refs")) { + cgit_print_error_page(400, "Bad request", "Bad request"); + return; + } + + ctx.page.mimetype = "text/plain"; + ctx.page.filename = "info/refs"; + cgit_print_http_headers(); + for_each_ref(print_ref_info, NULL); +} + +void cgit_clone_objects(void) +{ + char *p; + + if (!ctx.qry.path) + goto err; + + if (!strcmp(ctx.qry.path, "info/packs")) { + print_pack_info(); + return; + } + + /* Avoid directory traversal by forbidding "..", but also work around + * other funny business by just specifying a fairly strict format. For + * example, now we don't have to stress out about the Cygwin port. + */ + for (p = ctx.qry.path; *p; ++p) { + if (*p == '.' && *(p + 1) == '.') + goto err; + if (!isalnum(*p) && *p != '/' && *p != '.' && *p != '-') + goto err; + } + + send_file(git_path("objects/%s", ctx.qry.path)); + return; + +err: + cgit_print_error_page(400, "Bad request", "Bad request"); +} + +void cgit_clone_head(void) +{ + send_file(git_path("%s", "HEAD")); +} diff --git a/third_party/cgit/ui-clone.h b/third_party/cgit/ui-clone.h new file mode 100644 index 0000000000..3e460a3dbc --- /dev/null +++ b/third_party/cgit/ui-clone.h @@ -0,0 +1,8 @@ +#ifndef UI_CLONE_H +#define UI_CLONE_H + +void cgit_clone_info(void); +void cgit_clone_objects(void); +void cgit_clone_head(void); + +#endif /* UI_CLONE_H */ diff --git a/third_party/cgit/ui-commit.c b/third_party/cgit/ui-commit.c new file mode 100644 index 0000000000..f7942e10fa --- /dev/null +++ b/third_party/cgit/ui-commit.c @@ -0,0 +1,148 @@ +/* ui-commit.c: generate commit view + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-commit.h" +#include "html.h" +#include "ui-shared.h" +#include "ui-diff.h" +#include "ui-log.h" + +void cgit_print_commit(char *hex, const char *prefix) +{ + struct commit *commit, *parent; + struct commitinfo *info, *parent_info; + struct commit_list *p; + struct strbuf notes = STRBUF_INIT; + struct object_id oid; + char *tmp, *tmp2; + int parents = 0; + + if (!hex) + hex = ctx.qry.head; + + if (get_oid(hex, &oid)) { + cgit_print_error_page(400, "Bad request", + "Bad object id: %s", hex); + return; + } + commit = lookup_commit_reference(the_repository, &oid); + if (!commit) { + cgit_print_error_page(404, "Not found", + "Bad commit reference: %s", hex); + return; + } + info = cgit_parse_commit(commit); + + format_display_notes(&oid, ¬es, PAGE_ENCODING, 0); + + load_ref_decorations(NULL, DECORATE_FULL_REFS); + + ctx.page.title = fmtalloc("%s - %s", info->subject, ctx.page.title); + cgit_print_layout_start(); + cgit_print_diff_ctrls(); + html("<table summary='commit info' class='commit-info'>\n"); + html("<tr><th>author</th><td>"); + cgit_open_filter(ctx.repo->email_filter, info->author_email, "commit"); + html_txt(info->author); + if (!ctx.cfg.noplainemail) { + html(" "); + html_txt(info->author_email); + } + cgit_close_filter(ctx.repo->email_filter); + html("</td><td class='right'>"); + html_txt(show_date(info->author_date, info->author_tz, + cgit_date_mode(DATE_DOTTIME))); + html("</td></tr>\n"); + html("<tr><th>committer</th><td>"); + cgit_open_filter(ctx.repo->email_filter, info->committer_email, "commit"); + html_txt(info->committer); + if (!ctx.cfg.noplainemail) { + html(" "); + html_txt(info->committer_email); + } + cgit_close_filter(ctx.repo->email_filter); + html("</td><td class='right'>"); + html_txt(show_date(info->committer_date, info->committer_tz, + cgit_date_mode(DATE_DOTTIME))); + html("</td></tr>\n"); + html("<tr><th>commit</th><td colspan='2' class='sha1'>"); + tmp = oid_to_hex(&commit->object.oid); + cgit_commit_link(tmp, NULL, NULL, ctx.qry.head, tmp, prefix); + html(" ("); + cgit_patch_link("patch", NULL, NULL, NULL, tmp, prefix); + html(")</td></tr>\n"); + html("<tr><th>tree</th><td colspan='2' class='sha1'>"); + tmp = xstrdup(hex); + cgit_tree_link(oid_to_hex(&commit->maybe_tree->object.oid), NULL, NULL, + ctx.qry.head, tmp, NULL); + if (prefix) { + html(" /"); + cgit_tree_link(prefix, NULL, NULL, ctx.qry.head, tmp, prefix); + } + free(tmp); + html("</td></tr>\n"); + for (p = commit->parents; p; p = p->next) { + parent = lookup_commit_reference(the_repository, &p->item->object.oid); + if (!parent) { + html("<tr><td colspan='3'>"); + cgit_print_error("Error reading parent commit"); + html("</td></tr>"); + continue; + } + html("<tr><th>parent</th>" + "<td colspan='2' class='sha1'>"); + tmp = tmp2 = oid_to_hex(&p->item->object.oid); + if (ctx.repo->enable_subject_links) { + parent_info = cgit_parse_commit(parent); + tmp2 = parent_info->subject; + } + cgit_commit_link(tmp2, NULL, NULL, ctx.qry.head, tmp, prefix); + html(" ("); + cgit_diff_link("diff", NULL, NULL, ctx.qry.head, hex, + oid_to_hex(&p->item->object.oid), prefix); + html(")</td></tr>"); + parents++; + } + if (ctx.repo->snapshots) { + html("<tr><th>download</th><td colspan='2' class='sha1'>"); + cgit_print_snapshot_links(ctx.repo, hex, "<br/>"); + html("</td></tr>"); + } + html("</table>\n"); + html("<div class='commit-subject'>"); + cgit_open_filter(ctx.repo->commit_filter); + html_txt(info->subject); + cgit_close_filter(ctx.repo->commit_filter); + show_commit_decorations(commit); + html("</div>"); + html("<div class='commit-msg'>"); + cgit_open_filter(ctx.repo->commit_filter); + html_txt(info->msg); + cgit_close_filter(ctx.repo->commit_filter); + html("</div>"); + if (notes.len != 0) { + html("<div class='notes-header'>Notes</div>"); + html("<div class='notes'>"); + cgit_open_filter(ctx.repo->commit_filter); + html_txt(notes.buf); + cgit_close_filter(ctx.repo->commit_filter); + html("</div>"); + html("<div class='notes-footer'></div>"); + } + if (parents < 3) { + if (parents) + tmp = oid_to_hex(&commit->parents->item->object.oid); + else + tmp = NULL; + cgit_print_diff(ctx.qry.sha1, tmp, prefix, 0, 0); + } + strbuf_release(¬es); + cgit_free_commitinfo(info); + cgit_print_layout_end(); +} diff --git a/third_party/cgit/ui-commit.h b/third_party/cgit/ui-commit.h new file mode 100644 index 0000000000..8198b4bacc --- /dev/null +++ b/third_party/cgit/ui-commit.h @@ -0,0 +1,6 @@ +#ifndef UI_COMMIT_H +#define UI_COMMIT_H + +extern void cgit_print_commit(char *hex, const char *prefix); + +#endif /* UI_COMMIT_H */ diff --git a/third_party/cgit/ui-diff.c b/third_party/cgit/ui-diff.c new file mode 100644 index 0000000000..c60aefd1d6 --- /dev/null +++ b/third_party/cgit/ui-diff.c @@ -0,0 +1,501 @@ +/* ui-diff.c: show diff between two blobs + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-diff.h" +#include "html.h" +#include "ui-shared.h" +#include "ui-ssdiff.h" + +struct object_id old_rev_oid[1]; +struct object_id new_rev_oid[1]; + +static int files, slots; +static int total_adds, total_rems, max_changes; +static int lines_added, lines_removed; + +static struct fileinfo { + char status; + struct object_id old_oid[1]; + struct object_id new_oid[1]; + unsigned short old_mode; + unsigned short new_mode; + char *old_path; + char *new_path; + unsigned int added; + unsigned int removed; + unsigned long old_size; + unsigned long new_size; + unsigned int binary:1; +} *items; + +static int use_ssdiff = 0; +static struct diff_filepair *current_filepair; +static const char *current_prefix; + +struct diff_filespec *cgit_get_current_old_file(void) +{ + return current_filepair->one; +} + +struct diff_filespec *cgit_get_current_new_file(void) +{ + return current_filepair->two; +} + +static void print_fileinfo(struct fileinfo *info) +{ + char *class; + + switch (info->status) { + case DIFF_STATUS_ADDED: + class = "add"; + break; + case DIFF_STATUS_COPIED: + class = "cpy"; + break; + case DIFF_STATUS_DELETED: + class = "del"; + break; + case DIFF_STATUS_MODIFIED: + class = "upd"; + break; + case DIFF_STATUS_RENAMED: + class = "mov"; + break; + case DIFF_STATUS_TYPE_CHANGED: + class = "typ"; + break; + case DIFF_STATUS_UNKNOWN: + class = "unk"; + break; + case DIFF_STATUS_UNMERGED: + class = "stg"; + break; + default: + die("bug: unhandled diff status %c", info->status); + } + + html("<tr>"); + html("<td class='mode'>"); + if (is_null_oid(info->new_oid)) { + cgit_print_filemode(info->old_mode); + } else { + cgit_print_filemode(info->new_mode); + } + + if (info->old_mode != info->new_mode && + !is_null_oid(info->old_oid) && + !is_null_oid(info->new_oid)) { + html("<span class='modechange'>["); + cgit_print_filemode(info->old_mode); + html("]</span>"); + } + htmlf("</td><td class='%s'>", class); + cgit_diff_link(info->new_path, NULL, NULL, ctx.qry.head, ctx.qry.sha1, + ctx.qry.sha2, info->new_path); + if (info->status == DIFF_STATUS_COPIED || info->status == DIFF_STATUS_RENAMED) { + htmlf(" (%s from ", + info->status == DIFF_STATUS_COPIED ? "copied" : "renamed"); + html_txt(info->old_path); + html(")"); + } + html("</td><td class='right'>"); + if (info->binary) { + htmlf("bin</td><td class='graph'>%ld -> %ld bytes", + info->old_size, info->new_size); + return; + } + htmlf("%d", info->added + info->removed); + html("</td><td class='graph'>"); + htmlf("<table summary='file diffstat' width='%d%%'><tr>", (max_changes > 100 ? 100 : max_changes)); + htmlf("<td class='add' style='width: %.1f%%;'/>", + info->added * 100.0 / max_changes); + htmlf("<td class='rem' style='width: %.1f%%;'/>", + info->removed * 100.0 / max_changes); + htmlf("<td class='none' style='width: %.1f%%;'/>", + (max_changes - info->removed - info->added) * 100.0 / max_changes); + html("</tr></table></td></tr>\n"); +} + +static void count_diff_lines(char *line, int len) +{ + if (line && (len > 0)) { + if (line[0] == '+') + lines_added++; + else if (line[0] == '-') + lines_removed++; + } +} + +static int show_filepair(struct diff_filepair *pair) +{ + /* Always show if we have no limiting prefix. */ + if (!current_prefix) + return 1; + + /* Show if either path in the pair begins with the prefix. */ + if (starts_with(pair->one->path, current_prefix) || + starts_with(pair->two->path, current_prefix)) + return 1; + + /* Otherwise we don't want to show this filepair. */ + return 0; +} + +static void inspect_filepair(struct diff_filepair *pair) +{ + int binary = 0; + unsigned long old_size = 0; + unsigned long new_size = 0; + + if (!show_filepair(pair)) + return; + + files++; + lines_added = 0; + lines_removed = 0; + cgit_diff_files(&pair->one->oid, &pair->two->oid, &old_size, &new_size, + &binary, 0, ctx.qry.ignorews, count_diff_lines); + if (files >= slots) { + if (slots == 0) + slots = 4; + else + slots = slots * 2; + items = xrealloc(items, slots * sizeof(struct fileinfo)); + } + items[files-1].status = pair->status; + oidcpy(items[files-1].old_oid, &pair->one->oid); + oidcpy(items[files-1].new_oid, &pair->two->oid); + items[files-1].old_mode = pair->one->mode; + items[files-1].new_mode = pair->two->mode; + items[files-1].old_path = xstrdup(pair->one->path); + items[files-1].new_path = xstrdup(pair->two->path); + items[files-1].added = lines_added; + items[files-1].removed = lines_removed; + items[files-1].old_size = old_size; + items[files-1].new_size = new_size; + items[files-1].binary = binary; + if (lines_added + lines_removed > max_changes) + max_changes = lines_added + lines_removed; + total_adds += lines_added; + total_rems += lines_removed; +} + +static void cgit_print_diffstat(const struct object_id *old_oid, + const struct object_id *new_oid, + const char *prefix) +{ + int i; + + html("<div class='diffstat-header'>"); + cgit_diff_link("Diffstat", NULL, NULL, ctx.qry.head, ctx.qry.sha1, + ctx.qry.sha2, NULL); + if (prefix) { + html(" (limited to '"); + html_txt(prefix); + html("')"); + } + html("</div>"); + html("<table summary='diffstat' class='diffstat'>"); + max_changes = 0; + cgit_diff_tree(old_oid, new_oid, inspect_filepair, prefix, + ctx.qry.ignorews); + for (i = 0; i<files; i++) + print_fileinfo(&items[i]); + html("</table>"); + html("<div class='diffstat-summary'>"); + htmlf("%d files changed, %d insertions, %d deletions", + files, total_adds, total_rems); + html("</div>"); +} + + +/* + * print a single line returned from xdiff + */ +static void print_line(char *line, int len) +{ + char *class = "ctx"; + char c = line[len-1]; + + if (line[0] == '+') + class = "add"; + else if (line[0] == '-') + class = "del"; + else if (line[0] == '@') + class = "hunk"; + + htmlf("<div class='%s'>", class); + line[len-1] = '\0'; + html_txt(line); + html("</div>"); + line[len-1] = c; +} + +static void header(const struct object_id *oid1, char *path1, int mode1, + const struct object_id *oid2, char *path2, int mode2) +{ + char *abbrev1, *abbrev2; + int subproject; + + subproject = (S_ISGITLINK(mode1) || S_ISGITLINK(mode2)); + html("<div class='head'>"); + html("diff --git a/"); + html_txt(path1); + html(" b/"); + html_txt(path2); + + if (mode1 == 0) + htmlf("<br/>new file mode %.6o", mode2); + + if (mode2 == 0) + htmlf("<br/>deleted file mode %.6o", mode1); + + if (!subproject) { + abbrev1 = xstrdup(find_unique_abbrev(oid1, DEFAULT_ABBREV)); + abbrev2 = xstrdup(find_unique_abbrev(oid2, DEFAULT_ABBREV)); + htmlf("<br/>index %s..%s", abbrev1, abbrev2); + free(abbrev1); + free(abbrev2); + if (mode1 != 0 && mode2 != 0) { + htmlf(" %.6o", mode1); + if (mode2 != mode1) + htmlf("..%.6o", mode2); + } + if (is_null_oid(oid1)) { + path1 = "dev/null"; + html("<br/>--- /"); + } else + html("<br/>--- a/"); + if (mode1 != 0) + cgit_tree_link(path1, NULL, NULL, ctx.qry.head, + oid_to_hex(old_rev_oid), path1); + else + html_txt(path1); + if (is_null_oid(oid2)) { + path2 = "dev/null"; + html("<br/>+++ /"); + } else + html("<br/>+++ b/"); + if (mode2 != 0) + cgit_tree_link(path2, NULL, NULL, ctx.qry.head, + oid_to_hex(new_rev_oid), path2); + else + html_txt(path2); + } + html("</div>"); +} + +static void filepair_cb(struct diff_filepair *pair) +{ + unsigned long old_size = 0; + unsigned long new_size = 0; + int binary = 0; + linediff_fn print_line_fn = print_line; + + if (!show_filepair(pair)) + return; + + current_filepair = pair; + if (use_ssdiff) { + cgit_ssdiff_header_begin(); + print_line_fn = cgit_ssdiff_line_cb; + } + header(&pair->one->oid, pair->one->path, pair->one->mode, + &pair->two->oid, pair->two->path, pair->two->mode); + if (use_ssdiff) + cgit_ssdiff_header_end(); + if (S_ISGITLINK(pair->one->mode) || S_ISGITLINK(pair->two->mode)) { + if (S_ISGITLINK(pair->one->mode)) + print_line_fn(fmt("-Subproject %s", oid_to_hex(&pair->one->oid)), 52); + if (S_ISGITLINK(pair->two->mode)) + print_line_fn(fmt("+Subproject %s", oid_to_hex(&pair->two->oid)), 52); + if (use_ssdiff) + cgit_ssdiff_footer(); + return; + } + if (cgit_diff_files(&pair->one->oid, &pair->two->oid, &old_size, + &new_size, &binary, ctx.qry.context, + ctx.qry.ignorews, print_line_fn)) + cgit_print_error("Error running diff"); + if (binary) { + if (use_ssdiff) + html("<tr><td colspan='4'>Binary files differ</td></tr>"); + else + html("Binary files differ"); + } + if (use_ssdiff) + cgit_ssdiff_footer(); +} + +void cgit_print_diff_ctrls(void) +{ + int i, curr; + + html("<div class='cgit-panel'>"); + html("<b>diff options</b>"); + html("<form method='get'>"); + cgit_add_hidden_formfields(1, 0, ctx.qry.page); + html("<table>"); + html("<tr><td colspan='2'/></tr>"); + html("<tr>"); + html("<td class='label'>context:</td>"); + html("<td class='ctrl'>"); + html("<select name='context' onchange='this.form.submit();'>"); + curr = ctx.qry.context; + if (!curr) + curr = 3; + for (i = 1; i <= 10; i++) + html_intoption(i, fmt("%d", i), curr); + for (i = 15; i <= 40; i += 5) + html_intoption(i, fmt("%d", i), curr); + html("</select>"); + html("</td>"); + html("</tr><tr>"); + html("<td class='label'>space:</td>"); + html("<td class='ctrl'>"); + html("<select name='ignorews' onchange='this.form.submit();'>"); + html_intoption(0, "include", ctx.qry.ignorews); + html_intoption(1, "ignore", ctx.qry.ignorews); + html("</select>"); + html("</td>"); + html("</tr><tr>"); + html("<td class='label'>mode:</td>"); + html("<td class='ctrl'>"); + html("<select name='dt' onchange='this.form.submit();'>"); + curr = ctx.qry.has_difftype ? ctx.qry.difftype : ctx.cfg.difftype; + html_intoption(0, "unified", curr); + html_intoption(1, "ssdiff", curr); + html_intoption(2, "stat only", curr); + html("</select></td></tr>"); + html("<tr><td/><td class='ctrl'>"); + html("<noscript><input type='submit' value='reload'/></noscript>"); + html("</td></tr></table>"); + html("</form>"); + html("</div>"); +} + +void cgit_print_diff(const char *new_rev, const char *old_rev, + const char *prefix, int show_ctrls, int raw) +{ + struct commit *commit, *commit2; + const struct object_id *old_tree_oid, *new_tree_oid; + diff_type difftype; + + /* + * If "follow" is set then the diff machinery needs to examine the + * entire commit to detect renames so we must limit the paths in our + * own callbacks and not pass the prefix to the diff machinery. + */ + if (ctx.qry.follow && ctx.cfg.enable_follow_links) { + current_prefix = prefix; + prefix = ""; + } else { + current_prefix = NULL; + } + + if (!new_rev) + new_rev = ctx.qry.head; + if (get_oid(new_rev, new_rev_oid)) { + cgit_print_error_page(404, "Not found", + "Bad object name: %s", new_rev); + return; + } + commit = lookup_commit_reference(the_repository, new_rev_oid); + if (!commit || parse_commit(commit)) { + cgit_print_error_page(404, "Not found", + "Bad commit: %s", oid_to_hex(new_rev_oid)); + return; + } + new_tree_oid = &commit->maybe_tree->object.oid; + + if (old_rev) { + if (get_oid(old_rev, old_rev_oid)) { + cgit_print_error_page(404, "Not found", + "Bad object name: %s", old_rev); + return; + } + } else if (commit->parents && commit->parents->item) { + oidcpy(old_rev_oid, &commit->parents->item->object.oid); + } else { + oidclr(old_rev_oid); + } + + if (!is_null_oid(old_rev_oid)) { + commit2 = lookup_commit_reference(the_repository, old_rev_oid); + if (!commit2 || parse_commit(commit2)) { + cgit_print_error_page(404, "Not found", + "Bad commit: %s", oid_to_hex(old_rev_oid)); + return; + } + old_tree_oid = &commit2->maybe_tree->object.oid; + } else { + old_tree_oid = NULL; + } + + if (raw) { + struct diff_options diffopt; + + diff_setup(&diffopt); + diffopt.output_format = DIFF_FORMAT_PATCH; + diffopt.flags.recursive = 1; + diff_setup_done(&diffopt); + + ctx.page.mimetype = "text/plain"; + cgit_print_http_headers(); + if (old_tree_oid) { + diff_tree_oid(old_tree_oid, new_tree_oid, "", + &diffopt); + } else { + diff_root_tree_oid(new_tree_oid, "", &diffopt); + } + diffcore_std(&diffopt); + diff_flush(&diffopt); + + return; + } + + difftype = ctx.qry.has_difftype ? ctx.qry.difftype : ctx.cfg.difftype; + use_ssdiff = difftype == DIFF_SSDIFF; + + if (show_ctrls) { + cgit_print_layout_start(); + cgit_print_diff_ctrls(); + } + + /* + * Clicking on a link to a file in the diff stat should show a diff + * of the file, showing the diff stat limited to a single file is + * pretty useless. All links from this point on will be to + * individual files, so we simply reset the difftype in the query + * here to avoid propagating DIFF_STATONLY to the individual files. + */ + if (difftype == DIFF_STATONLY) + ctx.qry.difftype = ctx.cfg.difftype; + + cgit_print_diffstat(old_rev_oid, new_rev_oid, prefix); + + if (difftype == DIFF_STATONLY) + return; + + if (use_ssdiff) { + html("<table summary='ssdiff' class='ssdiff'>"); + } else { + html("<table summary='diff' class='diff'>"); + html("<tr><td>"); + } + cgit_diff_tree(old_rev_oid, new_rev_oid, filepair_cb, prefix, + ctx.qry.ignorews); + if (!use_ssdiff) + html("</td></tr>"); + html("</table>"); + + if (show_ctrls) + cgit_print_layout_end(); +} diff --git a/third_party/cgit/ui-diff.h b/third_party/cgit/ui-diff.h new file mode 100644 index 0000000000..39264a164f --- /dev/null +++ b/third_party/cgit/ui-diff.h @@ -0,0 +1,15 @@ +#ifndef UI_DIFF_H +#define UI_DIFF_H + +extern void cgit_print_diff_ctrls(void); + +extern void cgit_print_diff(const char *new_hex, const char *old_hex, + const char *prefix, int show_ctrls, int raw); + +extern struct diff_filespec *cgit_get_current_old_file(void); +extern struct diff_filespec *cgit_get_current_new_file(void); + +extern struct object_id old_rev_oid[1]; +extern struct object_id new_rev_oid[1]; + +#endif /* UI_DIFF_H */ diff --git a/third_party/cgit/ui-log.c b/third_party/cgit/ui-log.c new file mode 100644 index 0000000000..dc5cb1eb6a --- /dev/null +++ b/third_party/cgit/ui-log.c @@ -0,0 +1,550 @@ +/* ui-log.c: functions for log output + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-log.h" +#include "html.h" +#include "ui-shared.h" +#include "argv-array.h" + +static int files, add_lines, rem_lines, lines_counted; + +/* + * The list of available column colors in the commit graph. + */ +static const char *column_colors_html[] = { + "<span class='column1'>", + "<span class='column2'>", + "<span class='column3'>", + "<span class='column4'>", + "<span class='column5'>", + "<span class='column6'>", + "</span>", +}; + +#define COLUMN_COLORS_HTML_MAX (ARRAY_SIZE(column_colors_html) - 1) + +static void count_lines(char *line, int size) +{ + if (size <= 0) + return; + + if (line[0] == '+') + add_lines++; + + else if (line[0] == '-') + rem_lines++; +} + +static void inspect_files(struct diff_filepair *pair) +{ + unsigned long old_size = 0; + unsigned long new_size = 0; + int binary = 0; + + files++; + if (ctx.repo->enable_log_linecount) + cgit_diff_files(&pair->one->oid, &pair->two->oid, &old_size, + &new_size, &binary, 0, ctx.qry.ignorews, + count_lines); +} + +void show_commit_decorations(struct commit *commit) +{ + const struct name_decoration *deco; + static char buf[1024]; + + buf[sizeof(buf) - 1] = 0; + deco = get_name_decoration(&commit->object); + if (!deco) + return; + html("<span class='decoration'>"); + while (deco) { + struct object_id peeled; + int is_annotated = 0; + strlcpy(buf, prettify_refname(deco->name), sizeof(buf)); + switch(deco->type) { + case DECORATION_NONE: + /* If the git-core doesn't recognize it, + * don't display anything. */ + break; + case DECORATION_REF_LOCAL: + cgit_log_link(buf, NULL, "branch-deco", buf, NULL, + ctx.qry.vpath, 0, NULL, NULL, + ctx.qry.showmsg, 0); + break; + case DECORATION_REF_TAG: + if (!peel_ref(deco->name, &peeled)) + is_annotated = !oidcmp(&commit->object.oid, &peeled); + cgit_tag_link(buf, NULL, is_annotated ? "tag-annotated-deco" : "tag-deco", buf); + break; + case DECORATION_REF_REMOTE: + if (!ctx.repo->enable_remote_branches) + break; + cgit_log_link(buf, NULL, "remote-deco", NULL, + oid_to_hex(&commit->object.oid), + ctx.qry.vpath, 0, NULL, NULL, + ctx.qry.showmsg, 0); + break; + default: + cgit_commit_link(buf, NULL, "deco", ctx.qry.head, + oid_to_hex(&commit->object.oid), + ctx.qry.vpath); + break; + } + deco = deco->next; + } + html("</span>"); +} + +static void handle_rename(struct diff_filepair *pair) +{ + /* + * After we have seen a rename, we generate links to the previous + * name of the file so that commit & diff views get fed the path + * that is correct for the commit they are showing, avoiding the + * need to walk the entire history leading back to every commit we + * show in order detect renames. + */ + if (0 != strcmp(ctx.qry.vpath, pair->two->path)) { + free(ctx.qry.vpath); + ctx.qry.vpath = xstrdup(pair->two->path); + } + inspect_files(pair); +} + +static int show_commit(struct commit *commit, struct rev_info *revs) +{ + struct commit_list *parents = commit->parents; + struct commit *parent; + int found = 0, saved_fmt; + struct diff_flags saved_flags = revs->diffopt.flags; + + /* Always show if we're not in "follow" mode with a single file. */ + if (!ctx.qry.follow) + return 1; + + /* + * In "follow" mode, we don't show merges. This is consistent with + * "git log --follow -- <file>". + */ + if (parents && parents->next) + return 0; + + /* + * If this is the root commit, do what rev_info tells us. + */ + if (!parents) + return revs->show_root_diff; + + /* When we get here we have precisely one parent. */ + parent = parents->item; + /* If we can't parse the commit, let print_commit() report an error. */ + if (parse_commit(parent)) + return 1; + + files = 0; + add_lines = 0; + rem_lines = 0; + + revs->diffopt.flags.recursive = 1; + diff_tree_oid(&parent->maybe_tree->object.oid, + &commit->maybe_tree->object.oid, + "", &revs->diffopt); + diffcore_std(&revs->diffopt); + + found = !diff_queue_is_empty(); + saved_fmt = revs->diffopt.output_format; + revs->diffopt.output_format = DIFF_FORMAT_CALLBACK; + revs->diffopt.format_callback = cgit_diff_tree_cb; + revs->diffopt.format_callback_data = handle_rename; + diff_flush(&revs->diffopt); + revs->diffopt.output_format = saved_fmt; + revs->diffopt.flags = saved_flags; + + lines_counted = 1; + return found; +} + +static void print_commit(struct commit *commit, struct rev_info *revs) +{ + struct commitinfo *info; + int columns = revs->graph ? 4 : 3; + struct strbuf graphbuf = STRBUF_INIT; + struct strbuf msgbuf = STRBUF_INIT; + + if (ctx.repo->enable_log_filecount) + columns++; + if (ctx.repo->enable_log_linecount) + columns++; + + if (revs->graph) { + /* Advance graph until current commit */ + while (!graph_next_line(revs->graph, &graphbuf)) { + /* Print graph segment in otherwise empty table row */ + html("<tr class='nohover'><td class='commitgraph'>"); + html(graphbuf.buf); + htmlf("</td><td colspan='%d' /></tr>\n", columns); + strbuf_setlen(&graphbuf, 0); + } + /* Current commit's graph segment is now ready in graphbuf */ + } + + info = cgit_parse_commit(commit); + htmlf("<tr%s>", ctx.qry.showmsg ? " class='logheader'" : ""); + + if (revs->graph) { + /* Print graph segment for current commit */ + html("<td class='commitgraph'>"); + html(graphbuf.buf); + html("</td>"); + strbuf_setlen(&graphbuf, 0); + } + else { + html("<td>"); + cgit_print_age(info->committer_date, info->committer_tz, TM_WEEK * 2); + html("</td>"); + } + + htmlf("<td%s>", ctx.qry.showmsg ? " class='logsubject'" : ""); + if (ctx.qry.showmsg) { + /* line-wrap long commit subjects instead of truncating them */ + size_t subject_len = strlen(info->subject); + + if (subject_len > ctx.cfg.max_msg_len && + ctx.cfg.max_msg_len >= 15) { + /* symbol for signaling line-wrap (in PAGE_ENCODING) */ + const char wrap_symbol[] = { ' ', 0xE2, 0x86, 0xB5, 0 }; + int i = ctx.cfg.max_msg_len - strlen(wrap_symbol); + + /* Rewind i to preceding space character */ + while (i > 0 && !isspace(info->subject[i])) + --i; + if (!i) /* Oops, zero spaces. Reset i */ + i = ctx.cfg.max_msg_len - strlen(wrap_symbol); + + /* add remainder starting at i to msgbuf */ + strbuf_add(&msgbuf, info->subject + i, subject_len - i); + strbuf_trim(&msgbuf); + strbuf_add(&msgbuf, "\n\n", 2); + + /* Place wrap_symbol at position i in info->subject */ + strlcpy(info->subject + i, wrap_symbol, subject_len - i + 1); + } + } + cgit_commit_link(info->subject, NULL, NULL, ctx.qry.head, + oid_to_hex(&commit->object.oid), ctx.qry.vpath); + show_commit_decorations(commit); + html("</td><td>"); + cgit_open_filter(ctx.repo->email_filter, info->author_email, "log"); + html_txt(info->author); + cgit_close_filter(ctx.repo->email_filter); + + if (revs->graph) { + html("</td><td>"); + cgit_print_age(info->committer_date, info->committer_tz, TM_WEEK * 2); + } + + if (!lines_counted && (ctx.repo->enable_log_filecount || + ctx.repo->enable_log_linecount)) { + files = 0; + add_lines = 0; + rem_lines = 0; + cgit_diff_commit(commit, inspect_files, ctx.qry.vpath); + } + + if (ctx.repo->enable_log_filecount) + htmlf("</td><td>%d", files); + if (ctx.repo->enable_log_linecount) + htmlf("</td><td><span class='deletions'>-%d</span>/" + "<span class='insertions'>+%d</span>", rem_lines, add_lines); + + html("</td></tr>\n"); + + if ((revs->graph && !graph_is_commit_finished(revs->graph)) + || ctx.qry.showmsg) { /* Print a second table row */ + html("<tr class='nohover-highlight'>"); + + if (ctx.qry.showmsg) { + /* Concatenate commit message + notes in msgbuf */ + if (info->msg && *(info->msg)) { + strbuf_addstr(&msgbuf, info->msg); + strbuf_addch(&msgbuf, '\n'); + } + format_display_notes(&commit->object.oid, + &msgbuf, PAGE_ENCODING, 0); + strbuf_addch(&msgbuf, '\n'); + strbuf_ltrim(&msgbuf); + } + + if (revs->graph) { + int lines = 0; + + /* Calculate graph padding */ + if (ctx.qry.showmsg) { + /* Count #lines in commit message + notes */ + const char *p = msgbuf.buf; + lines = 1; + while ((p = strchr(p, '\n'))) { + p++; + lines++; + } + } + + /* Print graph padding */ + html("<td class='commitgraph'>"); + while (lines > 0 || !graph_is_commit_finished(revs->graph)) { + if (graphbuf.len) + html("\n"); + strbuf_setlen(&graphbuf, 0); + graph_next_line(revs->graph, &graphbuf); + html(graphbuf.buf); + lines--; + } + html("</td>\n"); + } + else + html("<td/>"); /* Empty 'Age' column */ + + /* Print msgbuf into remainder of table row */ + htmlf("<td colspan='%d'%s>\n", columns - (revs->graph ? 1 : 0), + ctx.qry.showmsg ? " class='logmsg'" : ""); + html_txt(msgbuf.buf); + html("</td></tr>\n"); + } + + strbuf_release(&msgbuf); + strbuf_release(&graphbuf); + cgit_free_commitinfo(info); +} + +static const char *disambiguate_ref(const char *ref, int *must_free_result) +{ + struct object_id oid; + struct strbuf longref = STRBUF_INIT; + + strbuf_addf(&longref, "refs/heads/%s", ref); + if (get_oid(longref.buf, &oid) == 0) { + *must_free_result = 1; + return strbuf_detach(&longref, NULL); + } + + *must_free_result = 0; + strbuf_release(&longref); + return ref; +} + +static char *next_token(char **src) +{ + char *result; + + if (!src || !*src) + return NULL; + while (isspace(**src)) + (*src)++; + if (!**src) + return NULL; + result = *src; + while (**src) { + if (isspace(**src)) { + **src = '\0'; + (*src)++; + break; + } + (*src)++; + } + return result; +} + +void cgit_print_log(const char *tip, int ofs, int cnt, char *grep, char *pattern, + const char *path, int pager, int commit_graph, int commit_sort) +{ + struct rev_info rev; + struct commit *commit; + struct argv_array rev_argv = ARGV_ARRAY_INIT; + int i, columns = commit_graph ? 4 : 3; + int must_free_tip = 0; + + /* rev_argv.argv[0] will be ignored by setup_revisions */ + argv_array_push(&rev_argv, "log_rev_setup"); + + if (!tip) + tip = ctx.qry.head; + tip = disambiguate_ref(tip, &must_free_tip); + argv_array_push(&rev_argv, tip); + + if (grep && pattern && *pattern) { + pattern = xstrdup(pattern); + if (!strcmp(grep, "grep") || !strcmp(grep, "author") || + !strcmp(grep, "committer")) { + argv_array_pushf(&rev_argv, "--%s=%s", grep, pattern); + } else if (!strcmp(grep, "range")) { + char *arg; + /* Split the pattern at whitespace and add each token + * as a revision expression. Do not accept other + * rev-list options. Also, replace the previously + * pushed tip (it's no longer relevant). + */ + argv_array_pop(&rev_argv); + while ((arg = next_token(&pattern))) { + if (*arg == '-') { + fprintf(stderr, "Bad range expr: %s\n", + arg); + break; + } + argv_array_push(&rev_argv, arg); + } + } + } + + if (!path || !ctx.cfg.enable_follow_links) { + /* + * If we don't have a path, "follow" is a no-op so make sure + * the variable is set to false to avoid needing to check + * both this and whether we have a path everywhere. + */ + ctx.qry.follow = 0; + } + + if (commit_graph && !ctx.qry.follow) { + argv_array_push(&rev_argv, "--graph"); + argv_array_push(&rev_argv, "--color"); + graph_set_column_colors(column_colors_html, + COLUMN_COLORS_HTML_MAX); + } + + if (commit_sort == 1) + argv_array_push(&rev_argv, "--date-order"); + else if (commit_sort == 2) + argv_array_push(&rev_argv, "--topo-order"); + + if (path && ctx.qry.follow) + argv_array_push(&rev_argv, "--follow"); + argv_array_push(&rev_argv, "--"); + if (path) + argv_array_push(&rev_argv, path); + + init_revisions(&rev, NULL); + rev.abbrev = DEFAULT_ABBREV; + rev.commit_format = CMIT_FMT_DEFAULT; + rev.verbose_header = 1; + rev.show_root_diff = 0; + rev.ignore_missing = 1; + rev.simplify_history = 1; + setup_revisions(rev_argv.argc, rev_argv.argv, &rev, NULL); + load_ref_decorations(NULL, DECORATE_FULL_REFS); + rev.show_decorations = 1; + rev.grep_filter.ignore_case = 1; + + rev.diffopt.detect_rename = 1; + rev.diffopt.rename_limit = ctx.cfg.renamelimit; + if (ctx.qry.ignorews) + DIFF_XDL_SET(&rev.diffopt, IGNORE_WHITESPACE); + + compile_grep_patterns(&rev.grep_filter); + prepare_revision_walk(&rev); + + if (pager) { + cgit_print_layout_start(); + html("<table class='list nowrap'>"); + } + + html("<tr class='nohover'>"); + if (commit_graph) + html("<th></th>"); + else + html("<th class='left'>Age</th>"); + html("<th class='left'>Commit message"); + if (pager) { + html(" ("); + cgit_log_link(ctx.qry.showmsg ? "Collapse" : "Expand", NULL, + NULL, ctx.qry.head, ctx.qry.sha1, + ctx.qry.vpath, ctx.qry.ofs, ctx.qry.grep, + ctx.qry.search, ctx.qry.showmsg ? 0 : 1, + ctx.qry.follow); + html(")"); + } + html("</th><th class='left'>Author</th>"); + if (rev.graph) + html("<th class='left'>Age</th>"); + if (ctx.repo->enable_log_filecount) { + html("<th class='left'>Files</th>"); + columns++; + } + if (ctx.repo->enable_log_linecount) { + html("<th class='left'>Lines</th>"); + columns++; + } + html("</tr>\n"); + + if (ofs<0) + ofs = 0; + + for (i = 0; i < ofs && (commit = get_revision(&rev)) != NULL; /* nop */) { + if (show_commit(commit, &rev)) + i++; + free_commit_buffer(the_repository->parsed_objects, commit); + free_commit_list(commit->parents); + commit->parents = NULL; + } + + for (i = 0; i < cnt && (commit = get_revision(&rev)) != NULL; /* nop */) { + /* + * In "follow" mode, we must count the files and lines the + * first time we invoke diff on a given commit, and we need + * to do that to see if the commit touches the path we care + * about, so we do it in show_commit. Hence we must clear + * lines_counted here. + * + * This has the side effect of avoiding running diff twice + * when we are both following renames and showing file + * and/or line counts. + */ + lines_counted = 0; + if (show_commit(commit, &rev)) { + i++; + print_commit(commit, &rev); + } + free_commit_buffer(the_repository->parsed_objects, commit); + free_commit_list(commit->parents); + commit->parents = NULL; + } + if (pager) { + html("</table><ul class='pager'>"); + if (ofs > 0) { + html("<li>"); + cgit_log_link("[prev]", NULL, NULL, ctx.qry.head, + ctx.qry.sha1, ctx.qry.vpath, + ofs - cnt, ctx.qry.grep, + ctx.qry.search, ctx.qry.showmsg, + ctx.qry.follow); + html("</li>"); + } + if ((commit = get_revision(&rev)) != NULL) { + html("<li>"); + cgit_log_link("[next]", NULL, NULL, ctx.qry.head, + ctx.qry.sha1, ctx.qry.vpath, + ofs + cnt, ctx.qry.grep, + ctx.qry.search, ctx.qry.showmsg, + ctx.qry.follow); + html("</li>"); + } + html("</ul>"); + cgit_print_layout_end(); + } else if ((commit = get_revision(&rev)) != NULL) { + htmlf("<tr class='nohover'><td colspan='%d'>", columns); + cgit_log_link("[...]", NULL, NULL, ctx.qry.head, NULL, + ctx.qry.vpath, 0, NULL, NULL, ctx.qry.showmsg, + ctx.qry.follow); + html("</td></tr>\n"); + } + + /* If we allocated tip then it is safe to cast away const. */ + if (must_free_tip) + free((char*) tip); +} diff --git a/third_party/cgit/ui-log.h b/third_party/cgit/ui-log.h new file mode 100644 index 0000000000..325607cdab --- /dev/null +++ b/third_party/cgit/ui-log.h @@ -0,0 +1,9 @@ +#ifndef UI_LOG_H +#define UI_LOG_H + +extern void cgit_print_log(const char *tip, int ofs, int cnt, char *grep, + char *pattern, const char *path, int pager, + int commit_graph, int commit_sort); +extern void show_commit_decorations(struct commit *commit); + +#endif /* UI_LOG_H */ diff --git a/third_party/cgit/ui-patch.c b/third_party/cgit/ui-patch.c new file mode 100644 index 0000000000..5a964108e5 --- /dev/null +++ b/third_party/cgit/ui-patch.c @@ -0,0 +1,98 @@ +/* ui-patch.c: generate patch view + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-patch.h" +#include "html.h" +#include "ui-shared.h" + +/* two commit hashes with two dots in between and termination */ +#define REV_RANGE_LEN 2 * GIT_MAX_HEXSZ + 3 + +void cgit_print_patch(const char *new_rev, const char *old_rev, + const char *prefix) +{ + struct rev_info rev; + struct commit *commit; + struct object_id new_rev_oid, old_rev_oid; + char rev_range[REV_RANGE_LEN]; + const char *rev_argv[] = { NULL, "--reverse", "--format=email", rev_range, "--", prefix, NULL }; + int rev_argc = ARRAY_SIZE(rev_argv) - 1; + char *patchname; + + if (!prefix) + rev_argc--; + + if (!new_rev) + new_rev = ctx.qry.head; + + if (get_oid(new_rev, &new_rev_oid)) { + cgit_print_error_page(404, "Not found", + "Bad object id: %s", new_rev); + return; + } + commit = lookup_commit_reference(the_repository, &new_rev_oid); + if (!commit) { + cgit_print_error_page(404, "Not found", + "Bad commit reference: %s", new_rev); + return; + } + + if (old_rev) { + if (get_oid(old_rev, &old_rev_oid)) { + cgit_print_error_page(404, "Not found", + "Bad object id: %s", old_rev); + return; + } + if (!lookup_commit_reference(the_repository, &old_rev_oid)) { + cgit_print_error_page(404, "Not found", + "Bad commit reference: %s", old_rev); + return; + } + } else if (commit->parents && commit->parents->item) { + oidcpy(&old_rev_oid, &commit->parents->item->object.oid); + } else { + oidclr(&old_rev_oid); + } + + if (is_null_oid(&old_rev_oid)) { + memcpy(rev_range, oid_to_hex(&new_rev_oid), GIT_SHA1_HEXSZ + 1); + } else { + xsnprintf(rev_range, REV_RANGE_LEN, "%s..%s", oid_to_hex(&old_rev_oid), + oid_to_hex(&new_rev_oid)); + } + + patchname = fmt("%s.patch", rev_range); + ctx.page.mimetype = "text/plain"; + ctx.page.filename = patchname; + cgit_print_http_headers(); + + if (ctx.cfg.noplainemail) { + rev_argv[2] = "--format=format:From %H Mon Sep 17 00:00:00 " + "2001%nFrom: %an%nDate: %aD%n%w(78,0,1)Subject: " + "%s%n%n%w(0)%b"; + } + + init_revisions(&rev, NULL); + rev.abbrev = DEFAULT_ABBREV; + rev.verbose_header = 1; + rev.diff = 1; + rev.show_root_diff = 1; + rev.max_parents = 1; + rev.diffopt.output_format |= DIFF_FORMAT_DIFFSTAT | + DIFF_FORMAT_PATCH | DIFF_FORMAT_SUMMARY; + if (prefix) + rev.diffopt.stat_sep = fmt("(limited to '%s')\n\n", prefix); + setup_revisions(rev_argc, rev_argv, &rev, NULL); + prepare_revision_walk(&rev); + + while ((commit = get_revision(&rev)) != NULL) { + log_tree_commit(&rev, commit); + printf("-- \ncgit %s\n\n", cgit_version); + } +} diff --git a/third_party/cgit/ui-patch.h b/third_party/cgit/ui-patch.h new file mode 100644 index 0000000000..7a6cacd5ac --- /dev/null +++ b/third_party/cgit/ui-patch.h @@ -0,0 +1,7 @@ +#ifndef UI_PATCH_H +#define UI_PATCH_H + +extern void cgit_print_patch(const char *new_rev, const char *old_rev, + const char *prefix); + +#endif /* UI_PATCH_H */ diff --git a/third_party/cgit/ui-plain.c b/third_party/cgit/ui-plain.c new file mode 100644 index 0000000000..b73c1cfed1 --- /dev/null +++ b/third_party/cgit/ui-plain.c @@ -0,0 +1,207 @@ +/* ui-plain.c: functions for output of plain blobs by path + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-plain.h" +#include "html.h" +#include "ui-shared.h" + +struct walk_tree_context { + int match_baselen; + int match; +}; + +static int print_object(const struct object_id *oid, const char *path) +{ + enum object_type type; + char *buf, *mimetype; + unsigned long size; + + type = oid_object_info(the_repository, oid, &size); + if (type == OBJ_BAD) { + cgit_print_error_page(404, "Not found", "Not found"); + return 0; + } + + buf = read_object_file(oid, &type, &size); + if (!buf) { + cgit_print_error_page(404, "Not found", "Not found"); + return 0; + } + + mimetype = get_mimetype_for_filename(path); + ctx.page.mimetype = mimetype; + + if (!ctx.repo->enable_html_serving) { + html("X-Content-Type-Options: nosniff\n"); + html("Content-Security-Policy: default-src 'none'\n"); + if (mimetype) { + /* Built-in white list allows PDF and everything that isn't text/ and application/ */ + if ((!strncmp(mimetype, "text/", 5) || !strncmp(mimetype, "application/", 12)) && strcmp(mimetype, "application/pdf")) + ctx.page.mimetype = NULL; + } + } + + if (!ctx.page.mimetype) { + if (buffer_is_binary(buf, size)) { + ctx.page.mimetype = "application/octet-stream"; + ctx.page.charset = NULL; + } else { + ctx.page.mimetype = "text/plain"; + } + } + ctx.page.filename = path; + ctx.page.size = size; + ctx.page.etag = oid_to_hex(oid); + cgit_print_http_headers(); + html_raw(buf, size); + free(mimetype); + free(buf); + return 1; +} + +static char *buildpath(const char *base, int baselen, const char *path) +{ + if (path[0]) + return fmtalloc("%.*s%s/", baselen, base, path); + else + return fmtalloc("%.*s/", baselen, base); +} + +static void print_dir(const struct object_id *oid, const char *base, + int baselen, const char *path) +{ + char *fullpath, *slash; + size_t len; + + fullpath = buildpath(base, baselen, path); + slash = (fullpath[0] == '/' ? "" : "/"); + ctx.page.etag = oid_to_hex(oid); + cgit_print_http_headers(); + htmlf("<html><head><title>%s", slash); + html_txt(fullpath); + htmlf("</title></head>\n<body>\n<h2>%s", slash); + html_txt(fullpath); + html("</h2>\n<ul>\n"); + len = strlen(fullpath); + if (len > 1) { + fullpath[len - 1] = 0; + slash = strrchr(fullpath, '/'); + if (slash) + *(slash + 1) = 0; + else { + free(fullpath); + fullpath = NULL; + } + html("<li>"); + cgit_plain_link("../", NULL, NULL, ctx.qry.head, ctx.qry.sha1, + fullpath); + html("</li>\n"); + } + free(fullpath); +} + +static void print_dir_entry(const struct object_id *oid, const char *base, + int baselen, const char *path, unsigned mode) +{ + char *fullpath; + + fullpath = buildpath(base, baselen, path); + if (!S_ISDIR(mode) && !S_ISGITLINK(mode)) + fullpath[strlen(fullpath) - 1] = 0; + html(" <li>"); + if (S_ISGITLINK(mode)) { + cgit_submodule_link(NULL, fullpath, oid_to_hex(oid)); + } else + cgit_plain_link(path, NULL, NULL, ctx.qry.head, ctx.qry.sha1, + fullpath); + html("</li>\n"); + free(fullpath); +} + +static void print_dir_tail(void) +{ + html(" </ul>\n</body></html>\n"); +} + +static int walk_tree(const struct object_id *oid, struct strbuf *base, + const char *pathname, unsigned mode, int stage, void *cbdata) +{ + struct walk_tree_context *walk_tree_ctx = cbdata; + + if (base->len == walk_tree_ctx->match_baselen) { + if (S_ISREG(mode) || S_ISLNK(mode)) { + if (print_object(oid, pathname)) + walk_tree_ctx->match = 1; + } else if (S_ISDIR(mode)) { + print_dir(oid, base->buf, base->len, pathname); + walk_tree_ctx->match = 2; + return READ_TREE_RECURSIVE; + } + } else if (base->len < INT_MAX && (int)base->len > walk_tree_ctx->match_baselen) { + print_dir_entry(oid, base->buf, base->len, pathname, mode); + walk_tree_ctx->match = 2; + } else if (S_ISDIR(mode)) { + return READ_TREE_RECURSIVE; + } + + return 0; +} + +static int basedir_len(const char *path) +{ + char *p = strrchr(path, '/'); + if (p) + return p - path + 1; + return 0; +} + +void cgit_print_plain(void) +{ + const char *rev = ctx.qry.sha1; + struct object_id oid; + struct commit *commit; + struct pathspec_item path_items = { + .match = ctx.qry.path, + .len = ctx.qry.path ? strlen(ctx.qry.path) : 0 + }; + struct pathspec paths = { + .nr = 1, + .items = &path_items + }; + struct walk_tree_context walk_tree_ctx = { + .match = 0 + }; + + if (!rev) + rev = ctx.qry.head; + + if (get_oid(rev, &oid)) { + cgit_print_error_page(404, "Not found", "Not found"); + return; + } + commit = lookup_commit_reference(the_repository, &oid); + if (!commit || parse_commit(commit)) { + cgit_print_error_page(404, "Not found", "Not found"); + return; + } + if (!path_items.match) { + path_items.match = ""; + walk_tree_ctx.match_baselen = -1; + print_dir(&commit->maybe_tree->object.oid, "", 0, ""); + walk_tree_ctx.match = 2; + } + else + walk_tree_ctx.match_baselen = basedir_len(path_items.match); + read_tree_recursive(the_repository, commit->maybe_tree, + "", 0, 0, &paths, walk_tree, &walk_tree_ctx); + if (!walk_tree_ctx.match) + cgit_print_error_page(404, "Not found", "Not found"); + else if (walk_tree_ctx.match == 2) + print_dir_tail(); +} diff --git a/third_party/cgit/ui-plain.h b/third_party/cgit/ui-plain.h new file mode 100644 index 0000000000..5bff07b83b --- /dev/null +++ b/third_party/cgit/ui-plain.h @@ -0,0 +1,6 @@ +#ifndef UI_PLAIN_H +#define UI_PLAIN_H + +extern void cgit_print_plain(void); + +#endif /* UI_PLAIN_H */ diff --git a/third_party/cgit/ui-refs.c b/third_party/cgit/ui-refs.c new file mode 100644 index 0000000000..456f610df4 --- /dev/null +++ b/third_party/cgit/ui-refs.c @@ -0,0 +1,219 @@ +/* ui-refs.c: browse symbolic refs + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-refs.h" +#include "html.h" +#include "ui-shared.h" + +static inline int cmp_age(int age1, int age2) +{ + /* age1 and age2 are assumed to be non-negative */ + return age2 - age1; +} + +static int cmp_ref_name(const void *a, const void *b) +{ + struct refinfo *r1 = *(struct refinfo **)a; + struct refinfo *r2 = *(struct refinfo **)b; + + return strcmp(r1->refname, r2->refname); +} + +static int cmp_branch_age(const void *a, const void *b) +{ + struct refinfo *r1 = *(struct refinfo **)a; + struct refinfo *r2 = *(struct refinfo **)b; + + return cmp_age(r1->commit->committer_date, r2->commit->committer_date); +} + +static int get_ref_age(struct refinfo *ref) +{ + if (!ref->object) + return 0; + switch (ref->object->type) { + case OBJ_TAG: + return ref->tag ? ref->tag->tagger_date : 0; + case OBJ_COMMIT: + return ref->commit ? ref->commit->committer_date : 0; + } + return 0; +} + +static int cmp_tag_age(const void *a, const void *b) +{ + struct refinfo *r1 = *(struct refinfo **)a; + struct refinfo *r2 = *(struct refinfo **)b; + + return cmp_age(get_ref_age(r1), get_ref_age(r2)); +} + +static int print_branch(struct refinfo *ref) +{ + struct commitinfo *info = ref->commit; + char *name = (char *)ref->refname; + + if (!info) + return 1; + html("<tr><td>"); + cgit_log_link(name, NULL, NULL, name, NULL, NULL, 0, NULL, NULL, + ctx.qry.showmsg, 0); + html("</td><td>"); + + if (ref->object->type == OBJ_COMMIT) { + cgit_commit_link(info->subject, NULL, NULL, name, NULL, NULL); + html("</td><td>"); + cgit_open_filter(ctx.repo->email_filter, info->author_email, "refs"); + html_txt(info->author); + cgit_close_filter(ctx.repo->email_filter); + html("</td><td colspan='2'>"); + cgit_print_age(info->committer_date, info->committer_tz, -1); + } else { + html("</td><td></td><td>"); + cgit_object_link(ref->object); + } + html("</td></tr>\n"); + return 0; +} + +static void print_tag_header(void) +{ + html("<tr class='nohover'><th class='left'>Tag</th>" + "<th class='left'>Download</th>" + "<th class='left'>Author</th>" + "<th class='left' colspan='2'>Age</th></tr>\n"); +} + +static int print_tag(struct refinfo *ref) +{ + struct tag *tag = NULL; + struct taginfo *info = NULL; + char *name = (char *)ref->refname; + struct object *obj = ref->object; + + if (obj->type == OBJ_TAG) { + tag = (struct tag *)obj; + obj = tag->tagged; + info = ref->tag; + if (!info) + return 1; + } + + html("<tr><td>"); + cgit_tag_link(name, NULL, NULL, name); + html("</td><td>"); + if (ctx.repo->snapshots && (obj->type == OBJ_COMMIT)) + cgit_print_snapshot_links(ctx.repo, name, " "); + else + cgit_object_link(obj); + html("</td><td>"); + if (info) { + if (info->tagger) { + cgit_open_filter(ctx.repo->email_filter, info->tagger_email, "refs"); + html_txt(info->tagger); + cgit_close_filter(ctx.repo->email_filter); + } + } else if (ref->object->type == OBJ_COMMIT) { + cgit_open_filter(ctx.repo->email_filter, ref->commit->author_email, "refs"); + html_txt(ref->commit->author); + cgit_close_filter(ctx.repo->email_filter); + } + html("</td><td colspan='2'>"); + if (info) { + if (info->tagger_date > 0) + cgit_print_age(info->tagger_date, info->tagger_tz, -1); + } else if (ref->object->type == OBJ_COMMIT) { + cgit_print_age(ref->commit->commit->date, 0, -1); + } + html("</td></tr>\n"); + + return 0; +} + +static void print_refs_link(const char *path) +{ + html("<tr class='nohover'><td colspan='5'>"); + cgit_refs_link("[...]", NULL, NULL, ctx.qry.head, NULL, path); + html("</td></tr>"); +} + +void cgit_print_branches(int maxcount) +{ + struct reflist list; + int i; + + html("<tr class='nohover'><th class='left'>Branch</th>" + "<th class='left'>Commit message</th>" + "<th class='left'>Author</th>" + "<th class='left' colspan='2'>Age</th></tr>\n"); + + list.refs = NULL; + list.alloc = list.count = 0; + for_each_branch_ref(cgit_refs_cb, &list); + if (ctx.repo->enable_remote_branches) + for_each_remote_ref(cgit_refs_cb, &list); + + if (maxcount == 0 || maxcount > list.count) + maxcount = list.count; + + qsort(list.refs, list.count, sizeof(*list.refs), cmp_branch_age); + if (ctx.repo->branch_sort == 0) + qsort(list.refs, maxcount, sizeof(*list.refs), cmp_ref_name); + + for (i = 0; i < maxcount; i++) + print_branch(list.refs[i]); + + if (maxcount < list.count) + print_refs_link("heads"); + + cgit_free_reflist_inner(&list); +} + +void cgit_print_tags(int maxcount) +{ + struct reflist list; + int i; + + list.refs = NULL; + list.alloc = list.count = 0; + for_each_tag_ref(cgit_refs_cb, &list); + if (list.count == 0) + return; + qsort(list.refs, list.count, sizeof(*list.refs), cmp_tag_age); + if (!maxcount) + maxcount = list.count; + else if (maxcount > list.count) + maxcount = list.count; + print_tag_header(); + for (i = 0; i < maxcount; i++) + print_tag(list.refs[i]); + + if (maxcount < list.count) + print_refs_link("tags"); + + cgit_free_reflist_inner(&list); +} + +void cgit_print_refs(void) +{ + cgit_print_layout_start(); + html("<table class='list nowrap'>"); + + if (ctx.qry.path && starts_with(ctx.qry.path, "heads")) + cgit_print_branches(0); + else if (ctx.qry.path && starts_with(ctx.qry.path, "tags")) + cgit_print_tags(0); + else { + cgit_print_branches(0); + html("<tr class='nohover'><td colspan='5'> </td></tr>"); + cgit_print_tags(0); + } + html("</table>"); + cgit_print_layout_end(); +} diff --git a/third_party/cgit/ui-refs.h b/third_party/cgit/ui-refs.h new file mode 100644 index 0000000000..1d4a54a2c8 --- /dev/null +++ b/third_party/cgit/ui-refs.h @@ -0,0 +1,8 @@ +#ifndef UI_REFS_H +#define UI_REFS_H + +extern void cgit_print_branches(int maxcount); +extern void cgit_print_tags(int maxcount); +extern void cgit_print_refs(void); + +#endif /* UI_REFS_H */ diff --git a/third_party/cgit/ui-repolist.c b/third_party/cgit/ui-repolist.c new file mode 100644 index 0000000000..7cf763891f --- /dev/null +++ b/third_party/cgit/ui-repolist.c @@ -0,0 +1,379 @@ +/* ui-repolist.c: functions for generating the repolist page + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-repolist.h" +#include "html.h" +#include "ui-shared.h" + +static time_t read_agefile(const char *path) +{ + time_t result; + size_t size; + char *buf = NULL; + struct strbuf date_buf = STRBUF_INIT; + + if (readfile(path, &buf, &size)) { + free(buf); + return -1; + } + + if (parse_date(buf, &date_buf) == 0) + result = strtoul(date_buf.buf, NULL, 10); + else + result = 0; + free(buf); + strbuf_release(&date_buf); + return result; +} + +static int get_repo_modtime(const struct cgit_repo *repo, time_t *mtime) +{ + struct strbuf path = STRBUF_INIT; + struct stat s; + struct cgit_repo *r = (struct cgit_repo *)repo; + + if (repo->mtime != -1) { + *mtime = repo->mtime; + return 1; + } + strbuf_addf(&path, "%s/%s", repo->path, ctx.cfg.agefile); + if (stat(path.buf, &s) == 0) { + *mtime = read_agefile(path.buf); + if (*mtime) { + r->mtime = *mtime; + goto end; + } + } + + strbuf_reset(&path); + strbuf_addf(&path, "%s/refs/heads/%s", repo->path, + repo->defbranch ? repo->defbranch : "master"); + if (stat(path.buf, &s) == 0) { + *mtime = s.st_mtime; + r->mtime = *mtime; + goto end; + } + + strbuf_reset(&path); + strbuf_addf(&path, "%s/%s", repo->path, "packed-refs"); + if (stat(path.buf, &s) == 0) { + *mtime = s.st_mtime; + r->mtime = *mtime; + goto end; + } + + *mtime = 0; + r->mtime = *mtime; +end: + strbuf_release(&path); + return (r->mtime != 0); +} + +static void print_modtime(struct cgit_repo *repo) +{ + time_t t; + if (get_repo_modtime(repo, &t)) + cgit_print_age(t, 0, -1); +} + +static int is_match(struct cgit_repo *repo) +{ + if (!ctx.qry.search) + return 1; + if (repo->url && strcasestr(repo->url, ctx.qry.search)) + return 1; + if (repo->name && strcasestr(repo->name, ctx.qry.search)) + return 1; + if (repo->desc && strcasestr(repo->desc, ctx.qry.search)) + return 1; + if (repo->owner && strcasestr(repo->owner, ctx.qry.search)) + return 1; + return 0; +} + +static int is_in_url(struct cgit_repo *repo) +{ + if (!ctx.qry.url) + return 1; + if (repo->url && starts_with(repo->url, ctx.qry.url)) + return 1; + return 0; +} + +static int is_visible(struct cgit_repo *repo) +{ + if (repo->hide || repo->ignore) + return 0; + if (!(is_match(repo) && is_in_url(repo))) + return 0; + return 1; +} + +static int any_repos_visible(void) +{ + int i; + + for (i = 0; i < cgit_repolist.count; i++) { + if (is_visible(&cgit_repolist.repos[i])) + return 1; + } + return 0; +} + +static void print_sort_header(const char *title, const char *sort) +{ + char *currenturl = cgit_currenturl(); + html("<th class='left'><a href='"); + html_attr(currenturl); + htmlf("?s=%s", sort); + if (ctx.qry.search) { + html("&q="); + html_url_arg(ctx.qry.search); + } + htmlf("'>%s</a></th>", title); + free(currenturl); +} + +static void print_header(void) +{ + html("<tr class='nohover'>"); + print_sort_header("Name", "name"); + print_sort_header("Description", "desc"); + if (ctx.cfg.enable_index_owner) + print_sort_header("Owner", "owner"); + print_sort_header("Idle", "idle"); + if (ctx.cfg.enable_index_links) + html("<th class='left'>Links</th>"); + html("</tr>\n"); +} + + +static void print_pager(int items, int pagelen, char *search, char *sort) +{ + int i, ofs; + char *class = NULL; + html("<ul class='pager'>"); + for (i = 0, ofs = 0; ofs < items; i++, ofs = i * pagelen) { + class = (ctx.qry.ofs == ofs) ? "current" : NULL; + html("<li>"); + cgit_index_link(fmt("[%d]", i + 1), fmt("Page %d", i + 1), + class, search, sort, ofs, 0); + html("</li>"); + } + html("</ul>"); +} + +static int cmp(const char *s1, const char *s2) +{ + if (s1 && s2) { + if (ctx.cfg.case_sensitive_sort) + return strcmp(s1, s2); + else + return strcasecmp(s1, s2); + } + if (s1 && !s2) + return -1; + if (s2 && !s1) + return 1; + return 0; +} + +static int sort_name(const void *a, const void *b) +{ + const struct cgit_repo *r1 = a; + const struct cgit_repo *r2 = b; + + return cmp(r1->name, r2->name); +} + +static int sort_desc(const void *a, const void *b) +{ + const struct cgit_repo *r1 = a; + const struct cgit_repo *r2 = b; + + return cmp(r1->desc, r2->desc); +} + +static int sort_owner(const void *a, const void *b) +{ + const struct cgit_repo *r1 = a; + const struct cgit_repo *r2 = b; + + return cmp(r1->owner, r2->owner); +} + +static int sort_idle(const void *a, const void *b) +{ + const struct cgit_repo *r1 = a; + const struct cgit_repo *r2 = b; + time_t t1, t2; + + t1 = t2 = 0; + get_repo_modtime(r1, &t1); + get_repo_modtime(r2, &t2); + return t2 - t1; +} + +static int sort_section(const void *a, const void *b) +{ + const struct cgit_repo *r1 = a; + const struct cgit_repo *r2 = b; + int result; + + result = cmp(r1->section, r2->section); + if (!result) { + if (!strcmp(ctx.cfg.repository_sort, "age")) + result = sort_idle(r1, r2); + if (!result) + result = cmp(r1->name, r2->name); + } + return result; +} + +struct sortcolumn { + const char *name; + int (*fn)(const void *a, const void *b); +}; + +static const struct sortcolumn sortcolumn[] = { + {"section", sort_section}, + {"name", sort_name}, + {"desc", sort_desc}, + {"owner", sort_owner}, + {"idle", sort_idle}, + {NULL, NULL} +}; + +static int sort_repolist(char *field) +{ + const struct sortcolumn *column; + + for (column = &sortcolumn[0]; column->name; column++) { + if (strcmp(field, column->name)) + continue; + qsort(cgit_repolist.repos, cgit_repolist.count, + sizeof(struct cgit_repo), column->fn); + return 1; + } + return 0; +} + + +void cgit_print_repolist(void) +{ + int i, columns = 3, hits = 0, header = 0; + char *last_section = NULL; + char *section; + char *repourl; + int sorted = 0; + + if (!any_repos_visible()) { + cgit_print_error_page(404, "Not found", "No repositories found"); + return; + } + + if (ctx.cfg.enable_index_links) + ++columns; + if (ctx.cfg.enable_index_owner) + ++columns; + + ctx.page.title = ctx.cfg.root_title; + cgit_print_http_headers(); + cgit_print_docstart(); + cgit_print_pageheader(); + + if (ctx.qry.sort) + sorted = sort_repolist(ctx.qry.sort); + else if (ctx.cfg.section_sort) + sort_repolist("section"); + + html("<table summary='repository list' class='list nowrap'>"); + for (i = 0; i < cgit_repolist.count; i++) { + ctx.repo = &cgit_repolist.repos[i]; + if (!is_visible(ctx.repo)) + continue; + hits++; + if (hits <= ctx.qry.ofs) + continue; + if (hits > ctx.qry.ofs + ctx.cfg.max_repo_count) + continue; + if (!header++) + print_header(); + section = ctx.repo->section; + if (section && !strcmp(section, "")) + section = NULL; + if (!sorted && + ((last_section == NULL && section != NULL) || + (last_section != NULL && section == NULL) || + (last_section != NULL && section != NULL && + strcmp(section, last_section)))) { + htmlf("<tr class='nohover-highlight'><td colspan='%d' class='reposection'>", + columns); + html_txt(section); + html("</td></tr>"); + last_section = section; + } + htmlf("<tr><td class='%s'>", + !sorted && section ? "sublevel-repo" : "toplevel-repo"); + cgit_summary_link(ctx.repo->name, ctx.repo->name, NULL, NULL); + html("</td><td>"); + repourl = cgit_repourl(ctx.repo->url); + html_link_open(repourl, NULL, NULL); + free(repourl); + if (html_ntxt(ctx.repo->desc, ctx.cfg.max_repodesc_len) < 0) + html("..."); + html_link_close(); + html("</td><td>"); + if (ctx.cfg.enable_index_owner) { + if (ctx.repo->owner_filter) { + cgit_open_filter(ctx.repo->owner_filter); + html_txt(ctx.repo->owner); + cgit_close_filter(ctx.repo->owner_filter); + } else { + char *currenturl = cgit_currenturl(); + html("<a href='"); + html_attr(currenturl); + html("?q="); + html_url_arg(ctx.repo->owner); + html("'>"); + html_txt(ctx.repo->owner); + html("</a>"); + free(currenturl); + } + html("</td><td>"); + } + print_modtime(ctx.repo); + html("</td>"); + if (ctx.cfg.enable_index_links) { + html("<td>"); + cgit_summary_link("summary", NULL, "button", NULL); + cgit_log_link("log", NULL, "button", NULL, NULL, NULL, + 0, NULL, NULL, ctx.qry.showmsg, 0); + cgit_tree_link("tree", NULL, "button", NULL, NULL, NULL); + html("</td>"); + } + html("</tr>\n"); + } + html("</table>"); + if (hits > ctx.cfg.max_repo_count) + print_pager(hits, ctx.cfg.max_repo_count, ctx.qry.search, ctx.qry.sort); + cgit_print_docend(); +} + +void cgit_print_site_readme(void) +{ + cgit_print_layout_start(); + if (!ctx.cfg.root_readme) + goto done; + cgit_open_filter(ctx.cfg.about_filter, ctx.cfg.root_readme); + html_include(ctx.cfg.root_readme); + cgit_close_filter(ctx.cfg.about_filter); +done: + cgit_print_layout_end(); +} diff --git a/third_party/cgit/ui-repolist.h b/third_party/cgit/ui-repolist.h new file mode 100644 index 0000000000..1b6b3227db --- /dev/null +++ b/third_party/cgit/ui-repolist.h @@ -0,0 +1,7 @@ +#ifndef UI_REPOLIST_H +#define UI_REPOLIST_H + +extern void cgit_print_repolist(void); +extern void cgit_print_site_readme(void); + +#endif /* UI_REPOLIST_H */ diff --git a/third_party/cgit/ui-shared.c b/third_party/cgit/ui-shared.c new file mode 100644 index 0000000000..af21767199 --- /dev/null +++ b/third_party/cgit/ui-shared.c @@ -0,0 +1,1209 @@ +/* ui-shared.c: common web output functions + * + * Copyright (C) 2006-2017 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-shared.h" +#include "cmd.h" +#include "html.h" +#include "version.h" + +static const char cgit_doctype[] = +"<!DOCTYPE html>\n"; + +static char *http_date(time_t t) +{ + static char day[][4] = + {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"}; + static char month[][4] = + {"Jan", "Feb", "Mar", "Apr", "May", "Jun", + "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}; + struct tm *tm = gmtime(&t); + return fmt("%s, %02d %s %04d %02d:%02d:%02d GMT", day[tm->tm_wday], + tm->tm_mday, month[tm->tm_mon], 1900 + tm->tm_year, + tm->tm_hour, tm->tm_min, tm->tm_sec); +} + +void cgit_print_error(const char *fmt, ...) +{ + va_list ap; + va_start(ap, fmt); + cgit_vprint_error(fmt, ap); + va_end(ap); +} + +void cgit_vprint_error(const char *fmt, va_list ap) +{ + va_list cp; + html("<div class='error'>"); + va_copy(cp, ap); + html_vtxtf(fmt, cp); + va_end(cp); + html("</div>\n"); +} + +const char *cgit_httpscheme(void) +{ + if (ctx.env.https && !strcmp(ctx.env.https, "on")) + return "https://"; + else + return "http://"; +} + +char *cgit_hosturl(void) +{ + if (ctx.env.http_host) + return xstrdup(ctx.env.http_host); + if (!ctx.env.server_name) + return NULL; + if (!ctx.env.server_port || atoi(ctx.env.server_port) == 80) + return xstrdup(ctx.env.server_name); + return fmtalloc("%s:%s", ctx.env.server_name, ctx.env.server_port); +} + +char *cgit_currenturl(void) +{ + const char *root = cgit_rooturl(); + + if (!ctx.qry.url) + return xstrdup(root); + if (root[0] && root[strlen(root) - 1] == '/') + return fmtalloc("%s%s", root, ctx.qry.url); + return fmtalloc("%s/%s", root, ctx.qry.url); +} + +char *cgit_currentfullurl(void) +{ + const char *root = cgit_rooturl(); + const char *orig_query = ctx.env.query_string ? ctx.env.query_string : ""; + size_t len = strlen(orig_query); + char *query = xmalloc(len + 2), *start_url, *ret; + + /* Remove all url=... parts from query string */ + memcpy(query + 1, orig_query, len + 1); + query[0] = '?'; + start_url = query; + while ((start_url = strstr(start_url, "url=")) != NULL) { + if (start_url[-1] == '?' || start_url[-1] == '&') { + const char *end_url = strchr(start_url, '&'); + if (end_url) + memmove(start_url, end_url + 1, strlen(end_url)); + else + start_url[0] = '\0'; + } else + ++start_url; + } + if (!query[1]) + query[0] = '\0'; + + if (!ctx.qry.url) + ret = fmtalloc("%s%s", root, query); + else if (root[0] && root[strlen(root) - 1] == '/') + ret = fmtalloc("%s%s%s", root, ctx.qry.url, query); + else + ret = fmtalloc("%s/%s%s", root, ctx.qry.url, query); + free(query); + return ret; +} + +const char *cgit_rooturl(void) +{ + if (ctx.cfg.virtual_root) + return ctx.cfg.virtual_root; + else + return ctx.cfg.script_name; +} + +const char *cgit_loginurl(void) +{ + static const char *login_url; + if (!login_url) + login_url = fmtalloc("%s?p=login", cgit_rooturl()); + return login_url; +} + +char *cgit_repourl(const char *reponame) +{ + // my cgit instance *only* serves the depot, hence that's the only value ever + // needed. + return fmtalloc("/"); +} + +char *cgit_fileurl(const char *reponame, const char *pagename, + const char *filename, const char *query) +{ + struct strbuf sb = STRBUF_INIT; + + strbuf_addf(&sb, "%s%s/%s", ctx.cfg.virtual_root, + pagename, (filename ? filename:"")); + + if (query) { + strbuf_addf(&sb, "%s%s", "?", query); + } + + return strbuf_detach(&sb, NULL); +} + +char *cgit_pageurl(const char *reponame, const char *pagename, + const char *query) +{ + return cgit_fileurl(reponame, pagename, NULL, query); +} + +const char *cgit_repobasename(const char *reponame) +{ + /* I assume we don't need to store more than one repo basename */ + static char rvbuf[1024]; + int p; + const char *rv; + size_t len; + + len = strlcpy(rvbuf, reponame, sizeof(rvbuf)); + if (len >= sizeof(rvbuf)) + die("cgit_repobasename: truncated repository name '%s'", reponame); + p = len - 1; + /* strip trailing slashes */ + while (p && rvbuf[p] == '/') + rvbuf[p--] = '\0'; + /* strip trailing .git */ + if (p >= 3 && starts_with(&rvbuf[p-3], ".git")) { + p -= 3; + rvbuf[p--] = '\0'; + } + /* strip more trailing slashes if any */ + while (p && rvbuf[p] == '/') + rvbuf[p--] = '\0'; + /* find last slash in the remaining string */ + rv = strrchr(rvbuf, '/'); + if (rv) + return ++rv; + return rvbuf; +} + +const char *cgit_snapshot_prefix(const struct cgit_repo *repo) +{ + if (repo->snapshot_prefix) + return repo->snapshot_prefix; + + return cgit_repobasename(repo->url); +} + +static void site_url(const char *page, const char *search, const char *sort, int ofs, int always_root) +{ + char *delim = "?"; + + if (always_root || page) + html_attr(cgit_rooturl()); + else { + char *currenturl = cgit_currenturl(); + html_attr(currenturl); + free(currenturl); + } + + if (page) { + htmlf("?p=%s", page); + delim = "&"; + } + if (search) { + html(delim); + html("q="); + html_attr(search); + delim = "&"; + } + if (sort) { + html(delim); + html("s="); + html_attr(sort); + delim = "&"; + } + if (ofs) { + html(delim); + htmlf("ofs=%d", ofs); + } +} + +static void site_link(const char *page, const char *name, const char *title, + const char *class, const char *search, const char *sort, int ofs, int always_root) +{ + html("<a"); + if (title) { + html(" title='"); + html_attr(title); + html("'"); + } + if (class) { + html(" class='"); + html_attr(class); + html("'"); + } + html(" href='"); + site_url(page, search, sort, ofs, always_root); + html("'>"); + html_txt(name); + html("</a>"); +} + +void cgit_index_link(const char *name, const char *title, const char *class, + const char *pattern, const char *sort, int ofs, int always_root) +{ + site_link(NULL, name, title, class, pattern, sort, ofs, always_root); +} + +static char *repolink(const char *title, const char *class, const char *page, + const char *head, const char *path) +{ + char *delim = "?"; + + html("<a"); + if (title) { + html(" title='"); + html_attr(title); + html("'"); + } + if (class) { + html(" class='"); + html_attr(class); + html("'"); + } + html(" href='"); + if (ctx.cfg.virtual_root) { + html_url_path(ctx.cfg.virtual_root); + if (page) { + html_url_path(page); + html("/"); + if (path) + html_url_path(path); + } + } else { + html_url_path(ctx.cfg.script_name); + html("?url="); + html_url_arg(ctx.repo->url); + if (ctx.repo->url[strlen(ctx.repo->url) - 1] != '/') + html("/"); + if (page) { + html_url_arg(page); + html("/"); + if (path) + html_url_arg(path); + } + delim = "&"; + } + if (head && ctx.repo->defbranch && strcmp(head, ctx.repo->defbranch)) { + html(delim); + html("h="); + html_url_arg(head); + delim = "&"; + } + return fmt("%s", delim); +} + +static void reporevlink(const char *page, const char *name, const char *title, + const char *class, const char *head, const char *rev, + const char *path) +{ + char *delim; + + delim = repolink(title, class, page, head, path); + if (rev && ctx.qry.head != NULL && strcmp(rev, ctx.qry.head)) { + html(delim); + html("id="); + html_url_arg(rev); + } + html("'>"); + html_txt(name); + html("</a>"); +} + +void cgit_summary_link(const char *name, const char *title, const char *class, + const char *head) +{ + reporevlink(NULL, name, title, class, head, NULL, NULL); +} + +void cgit_tag_link(const char *name, const char *title, const char *class, + const char *tag) +{ + reporevlink("tag", name, title, class, tag, NULL, NULL); +} + +void cgit_about_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + reporevlink("about", name, title, class, head, rev, path); +} + +void cgit_tree_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + reporevlink("tree", name, title, class, head, rev, path); +} + +void cgit_plain_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + reporevlink("plain", name, title, class, head, rev, path); +} + +void cgit_blame_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + reporevlink("blame", name, title, class, head, rev, path); +} + +void cgit_log_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path, + int ofs, const char *grep, const char *pattern, int showmsg, + int follow) +{ + char *delim; + + delim = repolink(title, class, "log", head, path); + if (rev && ctx.qry.head && strcmp(rev, ctx.qry.head)) { + html(delim); + html("id="); + html_url_arg(rev); + delim = "&"; + } + if (grep && pattern) { + html(delim); + html("qt="); + html_url_arg(grep); + delim = "&"; + html(delim); + html("q="); + html_url_arg(pattern); + } + if (ofs > 0) { + html(delim); + html("ofs="); + htmlf("%d", ofs); + delim = "&"; + } + if (showmsg) { + html(delim); + html("showmsg=1"); + delim = "&"; + } + if (follow) { + html(delim); + html("follow=1"); + } + html("'>"); + html_txt(name); + html("</a>"); +} + +void cgit_commit_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + char *delim; + + delim = repolink(title, class, "commit", head, path); + if (rev && ctx.qry.head && strcmp(rev, ctx.qry.head)) { + html(delim); + html("id="); + html_url_arg(rev); + delim = "&"; + } + if (ctx.qry.difftype) { + html(delim); + htmlf("dt=%d", ctx.qry.difftype); + delim = "&"; + } + if (ctx.qry.context > 0 && ctx.qry.context != 3) { + html(delim); + html("context="); + htmlf("%d", ctx.qry.context); + delim = "&"; + } + if (ctx.qry.ignorews) { + html(delim); + html("ignorews=1"); + delim = "&"; + } + if (ctx.qry.follow) { + html(delim); + html("follow=1"); + } + html("'>"); + if (name[0] != '\0') { + if (strlen(name) > ctx.cfg.max_msg_len && ctx.cfg.max_msg_len >= 15) { + html_ntxt(name, ctx.cfg.max_msg_len - 3); + html("..."); + } else + html_txt(name); + } else + html_txt("(no commit message)"); + html("</a>"); +} + +void cgit_refs_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + reporevlink("refs", name, title, class, head, rev, path); +} + +void cgit_snapshot_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, + const char *archivename) +{ + reporevlink("snapshot", name, title, class, head, rev, archivename); +} + +void cgit_diff_link(const char *name, const char *title, const char *class, + const char *head, const char *new_rev, const char *old_rev, + const char *path) +{ + char *delim; + + delim = repolink(title, class, "diff", head, path); + if (new_rev && ctx.qry.head != NULL && strcmp(new_rev, ctx.qry.head)) { + html(delim); + html("id="); + html_url_arg(new_rev); + delim = "&"; + } + if (old_rev) { + html(delim); + html("id2="); + html_url_arg(old_rev); + delim = "&"; + } + if (ctx.qry.difftype) { + html(delim); + htmlf("dt=%d", ctx.qry.difftype); + delim = "&"; + } + if (ctx.qry.context > 0 && ctx.qry.context != 3) { + html(delim); + html("context="); + htmlf("%d", ctx.qry.context); + delim = "&"; + } + if (ctx.qry.ignorews) { + html(delim); + html("ignorews=1"); + delim = "&"; + } + if (ctx.qry.follow) { + html(delim); + html("follow=1"); + } + html("'>"); + html_txt(name); + html("</a>"); +} + +void cgit_patch_link(const char *name, const char *title, const char *class, + const char *head, const char *rev, const char *path) +{ + reporevlink("patch", name, title, class, head, rev, path); +} + +void cgit_stats_link(const char *name, const char *title, const char *class, + const char *head, const char *path) +{ + reporevlink("stats", name, title, class, head, NULL, path); +} + +static void cgit_self_link(char *name, const char *title, const char *class) +{ + if (!strcmp(ctx.qry.page, "repolist")) + cgit_index_link(name, title, class, ctx.qry.search, ctx.qry.sort, + ctx.qry.ofs, 1); + else if (!strcmp(ctx.qry.page, "about")) + cgit_about_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "summary")) + cgit_summary_link(name, title, class, ctx.qry.head); + else if (!strcmp(ctx.qry.page, "tag")) + cgit_tag_link(name, title, class, ctx.qry.has_sha1 ? + ctx.qry.sha1 : ctx.qry.head); + else if (!strcmp(ctx.qry.page, "tree")) + cgit_tree_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "plain")) + cgit_plain_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "blame")) + cgit_blame_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "log")) + cgit_log_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path, ctx.qry.ofs, + ctx.qry.grep, ctx.qry.search, + ctx.qry.showmsg, ctx.qry.follow); + else if (!strcmp(ctx.qry.page, "commit")) + cgit_commit_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "patch")) + cgit_patch_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "refs")) + cgit_refs_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "snapshot")) + cgit_snapshot_link(name, title, class, ctx.qry.head, + ctx.qry.has_sha1 ? ctx.qry.sha1 : NULL, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "diff")) + cgit_diff_link(name, title, class, ctx.qry.head, + ctx.qry.sha1, ctx.qry.sha2, + ctx.qry.path); + else if (!strcmp(ctx.qry.page, "stats")) + cgit_stats_link(name, title, class, ctx.qry.head, + ctx.qry.path); + else { + /* Don't known how to make link for this page */ + repolink(title, class, ctx.qry.page, ctx.qry.head, ctx.qry.path); + html("><!-- cgit_self_link() doesn't know how to make link for page '"); + html_txt(ctx.qry.page); + html("' -->"); + html_txt(name); + html("</a>"); + } +} + +void cgit_object_link(struct object *obj) +{ + char *page, *shortrev, *fullrev, *name; + + fullrev = oid_to_hex(&obj->oid); + shortrev = xstrdup(fullrev); + shortrev[10] = '\0'; + if (obj->type == OBJ_COMMIT) { + cgit_commit_link(fmt("commit %s...", shortrev), NULL, NULL, + ctx.qry.head, fullrev, NULL); + return; + } else if (obj->type == OBJ_TREE) + page = "tree"; + else if (obj->type == OBJ_TAG) + page = "tag"; + else + page = "blob"; + name = fmt("%s %s...", type_name(obj->type), shortrev); + reporevlink(page, name, NULL, NULL, ctx.qry.head, fullrev, NULL); +} + +static struct string_list_item *lookup_path(struct string_list *list, + const char *path) +{ + struct string_list_item *item; + + while (path && path[0]) { + if ((item = string_list_lookup(list, path))) + return item; + if (!(path = strchr(path, '/'))) + break; + path++; + } + return NULL; +} + +void cgit_submodule_link(const char *class, char *path, const char *rev) +{ + struct string_list *list; + struct string_list_item *item; + char tail, *dir; + size_t len; + + len = 0; + tail = 0; + list = &ctx.repo->submodules; + item = lookup_path(list, path); + if (!item) { + len = strlen(path); + tail = path[len - 1]; + if (tail == '/') { + path[len - 1] = 0; + item = lookup_path(list, path); + } + } + if (item || ctx.repo->module_link) { + html("<a "); + if (class) + htmlf("class='%s' ", class); + html("href='"); + if (item) { + html_attrf(item->util, rev); + } else { + dir = strrchr(path, '/'); + if (dir) + dir++; + else + dir = path; + html_attrf(ctx.repo->module_link, dir, rev); + } + html("'>"); + html_txt(path); + html("</a>"); + } else { + html("<span"); + if (class) + htmlf(" class='%s'", class); + html(">"); + html_txt(path); + html("</span>"); + } + html_txtf(" @ %.7s", rev); + if (item && tail) + path[len - 1] = tail; +} + +const struct date_mode *cgit_date_mode(enum date_mode_type type) +{ + static struct date_mode mode; + mode.type = type; + mode.local = ctx.cfg.local_time; + return &mode; +} + +static void print_rel_date(time_t t, int tz, double value, + const char *class, const char *suffix) +{ + htmlf("<span class='%s' title='", class); + html_attr(show_date(t, tz, cgit_date_mode(DATE_DOTTIME))); + htmlf("'>%.0f %s</span>", value, suffix); +} + +void cgit_print_age(time_t t, int tz, time_t max_relative) +{ + time_t now, secs; + + if (!t) + return; + time(&now); + secs = now - t; + if (secs < 0) + secs = 0; + + if (secs > max_relative && max_relative >= 0) { + html("<span title='"); + html_attr(show_date(t, tz, cgit_date_mode(DATE_DOTTIME))); + html("'>"); + html_txt(show_date(t, tz, cgit_date_mode(DATE_SHORT))); + html("</span>"); + return; + } + + if (secs < TM_HOUR * 2) { + print_rel_date(t, tz, secs * 1.0 / TM_MIN, "age-mins", "min."); + return; + } + if (secs < TM_DAY * 2) { + print_rel_date(t, tz, secs * 1.0 / TM_HOUR, "age-hours", "hours"); + return; + } + if (secs < TM_WEEK * 2) { + print_rel_date(t, tz, secs * 1.0 / TM_DAY, "age-days", "days"); + return; + } + if (secs < TM_MONTH * 2) { + print_rel_date(t, tz, secs * 1.0 / TM_WEEK, "age-weeks", "weeks"); + return; + } + if (secs < TM_YEAR * 2) { + print_rel_date(t, tz, secs * 1.0 / TM_MONTH, "age-months", "months"); + return; + } + print_rel_date(t, tz, secs * 1.0 / TM_YEAR, "age-years", "years"); +} + +void cgit_print_http_headers(void) +{ + if (ctx.env.no_http && !strcmp(ctx.env.no_http, "1")) + return; + + if (ctx.page.status) + htmlf("Status: %d %s\n", ctx.page.status, ctx.page.statusmsg); + if (ctx.page.mimetype && ctx.page.charset) + htmlf("Content-Type: %s; charset=%s\n", ctx.page.mimetype, + ctx.page.charset); + else if (ctx.page.mimetype) + htmlf("Content-Type: %s\n", ctx.page.mimetype); + if (ctx.page.size) + htmlf("Content-Length: %zd\n", ctx.page.size); + if (ctx.page.filename) { + html("Content-Disposition: inline; filename=\""); + html_header_arg_in_quotes(ctx.page.filename); + html("\"\n"); + } + if (!ctx.env.authenticated) + html("Cache-Control: no-cache, no-store\n"); + htmlf("Last-Modified: %s\n", http_date(ctx.page.modified)); + htmlf("Expires: %s\n", http_date(ctx.page.expires)); + if (ctx.page.etag) + htmlf("ETag: \"%s\"\n", ctx.page.etag); + html("\n"); + if (ctx.env.request_method && !strcmp(ctx.env.request_method, "HEAD")) + exit(0); +} + +void cgit_redirect(const char *url, bool permanent) +{ + htmlf("Status: %d %s\n", permanent ? 301 : 302, permanent ? "Moved" : "Found"); + html("Location: "); + html_url_path(url); + html("\n\n"); +} + +static void print_rel_vcs_link(const char *url) +{ + html("<link rel='vcs-git' href='"); + html_attr(url); + html("' title='"); + html_attr(ctx.repo->name); + html(" Git repository'/>\n"); +} + +void cgit_print_docstart(void) +{ + char *host = cgit_hosturl(); + + if (ctx.cfg.embedded) { + if (ctx.cfg.header) + html_include(ctx.cfg.header); + return; + } + + html(cgit_doctype); + html("<html lang='en'>\n"); + html("<head>\n"); + html("<title>"); + html_txt(ctx.page.title); + html("</title>\n"); + htmlf("<meta name='generator' content='cgit %s'/>\n", cgit_version); + if (ctx.cfg.robots && *ctx.cfg.robots) + htmlf("<meta name='robots' content='%s'/>\n", ctx.cfg.robots); + html("<link rel='stylesheet' type='text/css' href='"); + html_attr(ctx.cfg.css); + html("'/>\n"); + if (ctx.cfg.favicon) { + html("<link rel='shortcut icon' href='"); + html_attr(ctx.cfg.favicon); + html("'/>\n"); + } + if (host && ctx.repo && ctx.qry.head) { + char *fileurl; + struct strbuf sb = STRBUF_INIT; + strbuf_addf(&sb, "h=%s", ctx.qry.head); + + html("<link rel='alternate' title='Atom feed' href='"); + html(cgit_httpscheme()); + html_attr(host); + fileurl = cgit_fileurl(ctx.repo->url, "atom", ctx.qry.vpath, + sb.buf); + html_attr(fileurl); + html("' type='application/atom+xml'/>\n"); + strbuf_release(&sb); + free(fileurl); + } + if (ctx.repo) + cgit_add_clone_urls(print_rel_vcs_link); + if (ctx.cfg.head_include) + html_include(ctx.cfg.head_include); + if (ctx.repo && ctx.repo->extra_head_content) + html(ctx.repo->extra_head_content); + html("</head>\n"); + html("<body>\n"); + if (ctx.cfg.header) + html_include(ctx.cfg.header); + free(host); +} + +void cgit_print_docend(void) +{ + html("</div> <!-- class=content -->\n"); + if (ctx.cfg.embedded) { + html("</div> <!-- id=cgit -->\n"); + if (ctx.cfg.footer) + html_include(ctx.cfg.footer); + return; + } + if (ctx.cfg.footer) + html_include(ctx.cfg.footer); + else { + htmlf("<div class='footer'>generated by <a href='https://git.zx2c4.com/cgit/about/'>cgit %s</a> " + "(<a href='https://git-scm.com/'>git %s</a>) at ", cgit_version, git_version_string); + html_txt(show_date(time(NULL), 0, cgit_date_mode(DATE_DOTTIME))); + html("</div>\n"); + } + html("</div> <!-- id=cgit -->\n"); + html("</body>\n</html>\n"); +} + +void cgit_print_error_page(int code, const char *msg, const char *fmt, ...) +{ + va_list ap; + ctx.page.expires = ctx.cfg.cache_dynamic_ttl; + ctx.page.status = code; + ctx.page.statusmsg = msg; + cgit_print_layout_start(); + va_start(ap, fmt); + cgit_vprint_error(fmt, ap); + va_end(ap); + cgit_print_layout_end(); +} + +void cgit_print_layout_start(void) +{ + cgit_print_http_headers(); + cgit_print_docstart(); + cgit_print_pageheader(); +} + +void cgit_print_layout_end(void) +{ + cgit_print_docend(); +} + +static void add_clone_urls(void (*fn)(const char *), char *txt, char *suffix) +{ + struct strbuf **url_list = strbuf_split_str(txt, ' ', 0); + int i; + + for (i = 0; url_list[i]; i++) { + strbuf_rtrim(url_list[i]); + if (url_list[i]->len == 0) + continue; + if (suffix && *suffix) + strbuf_addf(url_list[i], "/%s", suffix); + fn(url_list[i]->buf); + } + + strbuf_list_free(url_list); +} + +void cgit_add_clone_urls(void (*fn)(const char *)) +{ + if (ctx.repo->clone_url) + add_clone_urls(fn, expand_macros(ctx.repo->clone_url), NULL); + else if (ctx.cfg.clone_prefix) + add_clone_urls(fn, ctx.cfg.clone_prefix, ctx.repo->url); +} + +static int print_branch_option(const char *refname, const struct object_id *oid, + int flags, void *cb_data) +{ + char *name = (char *)refname; + html_option(name, name, ctx.qry.head); + return 0; +} + +void cgit_add_hidden_formfields(int incl_head, int incl_search, + const char *page) +{ + if (!ctx.cfg.virtual_root) { + struct strbuf url = STRBUF_INIT; + + strbuf_addf(&url, "%s/%s", ctx.qry.repo, page); + if (ctx.qry.vpath) + strbuf_addf(&url, "/%s", ctx.qry.vpath); + html_hidden("url", url.buf); + strbuf_release(&url); + } + + if (incl_head && ctx.qry.head && ctx.repo->defbranch && + strcmp(ctx.qry.head, ctx.repo->defbranch)) + html_hidden("h", ctx.qry.head); + + if (ctx.qry.sha1) + html_hidden("id", ctx.qry.sha1); + if (ctx.qry.sha2) + html_hidden("id2", ctx.qry.sha2); + if (ctx.qry.showmsg) + html_hidden("showmsg", "1"); + + if (incl_search) { + if (ctx.qry.grep) + html_hidden("qt", ctx.qry.grep); + if (ctx.qry.search) + html_hidden("q", ctx.qry.search); + } +} + +static const char *hc(const char *page) +{ + if (!ctx.qry.page) + return NULL; + + return strcmp(ctx.qry.page, page) ? NULL : "active"; +} + +static void cgit_print_path_crumbs(char *path) +{ + char *old_path = ctx.qry.path; + char *p = path, *q, *end = path + strlen(path); + int levels = 0; + + ctx.qry.path = NULL; + cgit_self_link("root", NULL, NULL); + ctx.qry.path = p = path; + while (p < end) { + if (!(q = strchr(p, '/')) || levels > 15) + q = end; + *q = '\0'; + html_txt("/"); + cgit_self_link(p, NULL, NULL); + if (q < end) + *q = '/'; + p = q + 1; + ++levels; + } + ctx.qry.path = old_path; +} + +static void print_header(void) +{ + char *logo = NULL, *logo_link = NULL; + + html("<table id='header'>\n"); + html("<tr>\n"); + + if (ctx.repo && ctx.repo->logo && *ctx.repo->logo) + logo = ctx.repo->logo; + else + logo = ctx.cfg.logo; + if (ctx.repo && ctx.repo->logo_link && *ctx.repo->logo_link) + logo_link = ctx.repo->logo_link; + else + logo_link = ctx.cfg.logo_link; + if (logo && *logo) { + html("<td class='logo' rowspan='2'><a href='"); + if (logo_link && *logo_link) + html_attr(logo_link); + else + html_attr(cgit_rooturl()); + html("'><img src='"); + html_attr(logo); + html("' alt='cgit logo'/></a></td>\n"); + } + + html("<td class='main'>"); + if (ctx.repo) { + cgit_summary_link(ctx.repo->name, ctx.repo->name, NULL, NULL); + if (ctx.env.authenticated) { + html("</td><td class='form'>"); + html("<form method='get'>\n"); + cgit_add_hidden_formfields(0, 1, ctx.qry.page); + html("<select name='h' onchange='this.form.submit();'>\n"); + for_each_branch_ref(print_branch_option, ctx.qry.head); + if (ctx.repo->enable_remote_branches) + for_each_remote_ref(print_branch_option, ctx.qry.head); + html("</select> "); + html("<input type='submit' value='switch'/>"); + html("</form>"); + } + } else + html_txt(ctx.cfg.root_title); + html("</td></tr>\n"); + + html("<tr><td class='sub'>"); + if (ctx.repo) { + html_txt(ctx.repo->desc); + html("</td><td class='sub right'>"); + html_txt(ctx.repo->owner); + } else { + if (ctx.cfg.root_desc) + html_txt(ctx.cfg.root_desc); + } + html("</td></tr></table>\n"); +} + +void cgit_print_pageheader(void) +{ + html("<div id='cgit'>"); + if (!ctx.env.authenticated || !ctx.cfg.noheader) + print_header(); + + html("<table class='tabs'><tr><td>\n"); + if (ctx.env.authenticated && ctx.repo) { + if (ctx.repo->readme.nr) { + cgit_about_link("about", NULL, hc("about"), ctx.qry.head, + ctx.qry.sha1, ctx.qry.vpath); + } + cgit_summary_link("summary", NULL, hc("summary"), + ctx.qry.head); + cgit_refs_link("refs", NULL, hc("refs"), ctx.qry.head, + ctx.qry.sha1, NULL); + cgit_log_link("log", NULL, hc("log"), ctx.qry.head, + NULL, ctx.qry.vpath, 0, NULL, NULL, + ctx.qry.showmsg, ctx.qry.follow); + if (ctx.qry.page && !strcmp(ctx.qry.page, "blame")) + cgit_blame_link("blame", NULL, hc("blame"), ctx.qry.head, + ctx.qry.sha1, ctx.qry.vpath); + else + cgit_tree_link("tree", NULL, hc("tree"), ctx.qry.head, + ctx.qry.sha1, ctx.qry.vpath); + cgit_commit_link("commit", NULL, hc("commit"), + ctx.qry.head, ctx.qry.sha1, ctx.qry.vpath); + cgit_diff_link("diff", NULL, hc("diff"), ctx.qry.head, + ctx.qry.sha1, ctx.qry.sha2, ctx.qry.vpath); + if (ctx.repo->max_stats) + cgit_stats_link("stats", NULL, hc("stats"), + ctx.qry.head, ctx.qry.vpath); + if (ctx.repo->homepage) { + html("<a href='"); + html_attr(ctx.repo->homepage); + html("'>homepage</a>"); + } + html("</td><td class='form'>"); + html("<form class='right' method='get' action='"); + if (ctx.cfg.virtual_root) { + char *fileurl = cgit_fileurl(ctx.qry.repo, "log", + ctx.qry.vpath, NULL); + html_url_path(fileurl); + free(fileurl); + } + html("'>\n"); + cgit_add_hidden_formfields(1, 0, "log"); + html("<select name='qt'>\n"); + html_option("grep", "log msg", ctx.qry.grep); + html_option("author", "author", ctx.qry.grep); + html_option("committer", "committer", ctx.qry.grep); + html_option("range", "range", ctx.qry.grep); + html("</select>\n"); + html("<input class='txt' type='search' size='10' name='q' value='"); + html_attr(ctx.qry.search); + html("'/>\n"); + html("<input type='submit' value='search'/>\n"); + html("</form>\n"); + } else if (ctx.env.authenticated) { + char *currenturl = cgit_currenturl(); + site_link(NULL, "index", NULL, hc("repolist"), NULL, NULL, 0, 1); + if (ctx.cfg.root_readme) + site_link("about", "about", NULL, hc("about"), + NULL, NULL, 0, 1); + html("</td><td class='form'>"); + html("<form method='get' action='"); + html_attr(currenturl); + html("'>\n"); + html("<input type='search' name='q' size='10' value='"); + html_attr(ctx.qry.search); + html("'/>\n"); + html("<input type='submit' value='search'/>\n"); + html("</form>"); + free(currenturl); + } + html("</td></tr></table>\n"); + if (ctx.env.authenticated && ctx.repo && ctx.qry.vpath) { + html("<div class='path'>"); + html("path: "); + cgit_print_path_crumbs(ctx.qry.vpath); + if (ctx.cfg.enable_follow_links && !strcmp(ctx.qry.page, "log")) { + html(" ("); + ctx.qry.follow = !ctx.qry.follow; + cgit_self_link(ctx.qry.follow ? "follow" : "unfollow", + NULL, NULL); + ctx.qry.follow = !ctx.qry.follow; + html(")"); + } + html("</div>"); + } + html("<div class='content'>"); +} + +void cgit_print_filemode(unsigned short mode) +{ + if (S_ISDIR(mode)) + html("d"); + else if (S_ISLNK(mode)) + html("l"); + else if (S_ISGITLINK(mode)) + html("m"); + else + html("-"); + html_fileperm(mode >> 6); + html_fileperm(mode >> 3); + html_fileperm(mode); +} + +void cgit_compose_snapshot_prefix(struct strbuf *filename, const char *base, + const char *ref) +{ + struct object_id oid; + + /* + * Prettify snapshot names by stripping leading "v" or "V" if the tag + * name starts with {v,V}[0-9] and the prettify mapping is injective, + * i.e. each stripped tag can be inverted without ambiguities. + */ + if (get_oid(fmt("refs/tags/%s", ref), &oid) == 0 && + (ref[0] == 'v' || ref[0] == 'V') && isdigit(ref[1]) && + ((get_oid(fmt("refs/tags/%s", ref + 1), &oid) == 0) + + (get_oid(fmt("refs/tags/v%s", ref + 1), &oid) == 0) + + (get_oid(fmt("refs/tags/V%s", ref + 1), &oid) == 0) == 1)) + ref++; + + strbuf_addf(filename, "%s-%s", base, ref); +} + +void cgit_print_snapshot_links(const struct cgit_repo *repo, const char *ref, + const char *separator) +{ + const struct cgit_snapshot_format *f; + struct strbuf filename = STRBUF_INIT; + const char *basename; + size_t prefixlen; + + basename = cgit_snapshot_prefix(repo); + if (starts_with(ref, basename)) + strbuf_addstr(&filename, ref); + else + cgit_compose_snapshot_prefix(&filename, basename, ref); + + prefixlen = filename.len; + for (f = cgit_snapshot_formats; f->suffix; f++) { + if (!(repo->snapshots & cgit_snapshot_format_bit(f))) + continue; + strbuf_setlen(&filename, prefixlen); + strbuf_addstr(&filename, f->suffix); + cgit_snapshot_link(filename.buf, NULL, NULL, NULL, NULL, + filename.buf); + if (cgit_snapshot_get_sig(ref, f)) { + strbuf_addstr(&filename, ".asc"); + html(" ("); + cgit_snapshot_link("sig", NULL, NULL, NULL, NULL, + filename.buf); + html(")"); + } else if (starts_with(f->suffix, ".tar") && cgit_snapshot_get_sig(ref, &cgit_snapshot_formats[0])) { + strbuf_setlen(&filename, strlen(filename.buf) - strlen(f->suffix)); + strbuf_addstr(&filename, ".tar.asc"); + html(" ("); + cgit_snapshot_link("sig", NULL, NULL, NULL, NULL, + filename.buf); + html(")"); + } + html(separator); + } + strbuf_release(&filename); +} + +void cgit_set_title_from_path(const char *path) +{ + struct strbuf sb = STRBUF_INIT; + const char *slash, *last_slash; + + if (!path) + return; + + for (last_slash = path + strlen(path); (slash = memrchr(path, '/', last_slash - path)) != NULL; last_slash = slash) { + strbuf_add(&sb, slash + 1, last_slash - slash - 1); + strbuf_addstr(&sb, " \xc2\xab "); + } + strbuf_add(&sb, path, last_slash - path); + strbuf_addf(&sb, " - %s", ctx.page.title); + ctx.page.title = strbuf_detach(&sb, NULL); +} diff --git a/third_party/cgit/ui-shared.h b/third_party/cgit/ui-shared.h new file mode 100644 index 0000000000..6964873a63 --- /dev/null +++ b/third_party/cgit/ui-shared.h @@ -0,0 +1,87 @@ +#ifndef UI_SHARED_H +#define UI_SHARED_H + +extern const char *cgit_httpscheme(void); +extern char *cgit_hosturl(void); +extern const char *cgit_rooturl(void); +extern char *cgit_currenturl(void); +extern char *cgit_currentfullurl(void); +extern const char *cgit_loginurl(void); +extern char *cgit_repourl(const char *reponame); +extern char *cgit_fileurl(const char *reponame, const char *pagename, + const char *filename, const char *query); +extern char *cgit_pageurl(const char *reponame, const char *pagename, + const char *query); + +extern void cgit_add_clone_urls(void (*fn)(const char *)); + +extern void cgit_index_link(const char *name, const char *title, + const char *class, const char *pattern, const char *sort, int ofs, int always_root); +extern void cgit_summary_link(const char *name, const char *title, + const char *class, const char *head); +extern void cgit_tag_link(const char *name, const char *title, + const char *class, const char *tag); +extern void cgit_tree_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *path); +extern void cgit_plain_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *path); +extern void cgit_blame_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *path); +extern void cgit_log_link(const char *name, const char *title, + const char *class, const char *head, const char *rev, + const char *path, int ofs, const char *grep, + const char *pattern, int showmsg, int follow); +extern void cgit_commit_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *path); +extern void cgit_patch_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *path); +extern void cgit_refs_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *path); +extern void cgit_snapshot_link(const char *name, const char *title, + const char *class, const char *head, + const char *rev, const char *archivename); +extern void cgit_diff_link(const char *name, const char *title, + const char *class, const char *head, + const char *new_rev, const char *old_rev, + const char *path); +extern void cgit_stats_link(const char *name, const char *title, + const char *class, const char *head, + const char *path); +extern void cgit_object_link(struct object *obj); + +extern void cgit_submodule_link(const char *class, char *path, + const char *rev); + +extern void cgit_print_layout_start(void); +extern void cgit_print_layout_end(void); + +__attribute__((format (printf,1,2))) +extern void cgit_print_error(const char *fmt, ...); +__attribute__((format (printf,1,0))) +extern void cgit_vprint_error(const char *fmt, va_list ap); +extern const struct date_mode *cgit_date_mode(enum date_mode_type type); +extern void cgit_print_age(time_t t, int tz, time_t max_relative); +extern void cgit_print_http_headers(void); +extern void cgit_redirect(const char *url, bool permanent); +extern void cgit_print_docstart(void); +extern void cgit_print_docend(void); +__attribute__((format (printf,3,4))) +extern void cgit_print_error_page(int code, const char *msg, const char *fmt, ...); +extern void cgit_print_pageheader(void); +extern void cgit_print_filemode(unsigned short mode); +extern void cgit_compose_snapshot_prefix(struct strbuf *filename, + const char *base, const char *ref); +extern void cgit_print_snapshot_links(const struct cgit_repo *repo, + const char *ref, const char *separator); +extern const char *cgit_snapshot_prefix(const struct cgit_repo *repo); +extern void cgit_add_hidden_formfields(int incl_head, int incl_search, + const char *page); + +extern void cgit_set_title_from_path(const char *path); +#endif /* UI_SHARED_H */ diff --git a/third_party/cgit/ui-snapshot.c b/third_party/cgit/ui-snapshot.c new file mode 100644 index 0000000000..9461d51a59 --- /dev/null +++ b/third_party/cgit/ui-snapshot.c @@ -0,0 +1,302 @@ +/* ui-snapshot.c: generate snapshot of a commit + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-snapshot.h" +#include "html.h" +#include "ui-shared.h" + +static int write_archive_type(const char *format, const char *hex, const char *prefix) +{ + struct argv_array argv = ARGV_ARRAY_INIT; + const char **nargv; + int result; + argv_array_push(&argv, "snapshot"); + argv_array_push(&argv, format); + if (prefix) { + struct strbuf buf = STRBUF_INIT; + strbuf_addstr(&buf, prefix); + strbuf_addch(&buf, '/'); + argv_array_push(&argv, "--prefix"); + argv_array_push(&argv, buf.buf); + strbuf_release(&buf); + } + argv_array_push(&argv, hex); + /* + * Now we need to copy the pointers to arguments into a new + * structure because write_archive will rearrange its arguments + * which may result in duplicated/missing entries causing leaks + * or double-frees in argv_array_clear. + */ + nargv = xmalloc(sizeof(char *) * (argv.argc + 1)); + /* argv_array guarantees a trailing NULL entry. */ + memcpy(nargv, argv.argv, sizeof(char *) * (argv.argc + 1)); + + result = write_archive(argv.argc, nargv, NULL, the_repository, NULL, 0); + argv_array_clear(&argv); + free(nargv); + return result; +} + +static int write_tar_archive(const char *hex, const char *prefix) +{ + return write_archive_type("--format=tar", hex, prefix); +} + +static int write_zip_archive(const char *hex, const char *prefix) +{ + return write_archive_type("--format=zip", hex, prefix); +} + +static int write_compressed_tar_archive(const char *hex, + const char *prefix, + char *filter_argv[]) +{ + int rv; + struct cgit_exec_filter f; + cgit_exec_filter_init(&f, filter_argv[0], filter_argv); + + cgit_open_filter(&f.base); + rv = write_tar_archive(hex, prefix); + cgit_close_filter(&f.base); + return rv; +} + +static int write_tar_gzip_archive(const char *hex, const char *prefix) +{ + char *argv[] = { "gzip", "-n", NULL }; + return write_compressed_tar_archive(hex, prefix, argv); +} + +static int write_tar_bzip2_archive(const char *hex, const char *prefix) +{ + char *argv[] = { "bzip2", NULL }; + return write_compressed_tar_archive(hex, prefix, argv); +} + +static int write_tar_xz_archive(const char *hex, const char *prefix) +{ + char *argv[] = { "xz", NULL }; + return write_compressed_tar_archive(hex, prefix, argv); +} + +const struct cgit_snapshot_format cgit_snapshot_formats[] = { + /* .tar must remain the 0 index */ + { ".tar", "application/x-tar", write_tar_archive }, + { ".tar.gz", "application/x-gzip", write_tar_gzip_archive }, + { ".tar.bz2", "application/x-bzip2", write_tar_bzip2_archive }, + { ".tar.xz", "application/x-xz", write_tar_xz_archive }, + { ".zip", "application/x-zip", write_zip_archive }, + { NULL } +}; + +static struct notes_tree snapshot_sig_notes[ARRAY_SIZE(cgit_snapshot_formats)]; + +const struct object_id *cgit_snapshot_get_sig(const char *ref, + const struct cgit_snapshot_format *f) +{ + struct notes_tree *tree; + struct object_id oid; + + if (get_oid(ref, &oid)) + return NULL; + + tree = &snapshot_sig_notes[f - &cgit_snapshot_formats[0]]; + if (!tree->initialized) { + struct strbuf notes_ref = STRBUF_INIT; + + strbuf_addf(¬es_ref, "refs/notes/signatures/%s", + f->suffix + 1); + + init_notes(tree, notes_ref.buf, combine_notes_ignore, 0); + strbuf_release(¬es_ref); + } + + return get_note(tree, &oid); +} + +static const struct cgit_snapshot_format *get_format(const char *filename) +{ + const struct cgit_snapshot_format *fmt; + + for (fmt = cgit_snapshot_formats; fmt->suffix; fmt++) { + if (ends_with(filename, fmt->suffix)) + return fmt; + } + return NULL; +} + +const unsigned cgit_snapshot_format_bit(const struct cgit_snapshot_format *f) +{ + return BIT(f - &cgit_snapshot_formats[0]); +} + +static int make_snapshot(const struct cgit_snapshot_format *format, + const char *hex, const char *prefix, + const char *filename) +{ + struct object_id oid; + + if (get_oid(hex, &oid)) { + cgit_print_error_page(404, "Not found", + "Bad object id: %s", hex); + return 1; + } + if (!lookup_commit_reference(the_repository, &oid)) { + cgit_print_error_page(400, "Bad request", + "Not a commit reference: %s", hex); + return 1; + } + ctx.page.etag = oid_to_hex(&oid); + ctx.page.mimetype = xstrdup(format->mimetype); + ctx.page.filename = xstrdup(filename); + cgit_print_http_headers(); + init_archivers(); + format->write_func(hex, prefix); + return 0; +} + +static int write_sig(const struct cgit_snapshot_format *format, + const char *hex, const char *archive, + const char *filename) +{ + const struct object_id *note = cgit_snapshot_get_sig(hex, format); + enum object_type type; + unsigned long size; + char *buf; + + if (!note) { + cgit_print_error_page(404, "Not found", + "No signature for %s", archive); + return 0; + } + + buf = read_object_file(note, &type, &size); + if (!buf) { + cgit_print_error_page(404, "Not found", "Not found"); + return 0; + } + + html("X-Content-Type-Options: nosniff\n"); + html("Content-Security-Policy: default-src 'none'\n"); + ctx.page.etag = oid_to_hex(note); + ctx.page.mimetype = xstrdup("application/pgp-signature"); + ctx.page.filename = xstrdup(filename); + cgit_print_http_headers(); + + html_raw(buf, size); + free(buf); + return 0; +} + +/* Try to guess the requested revision from the requested snapshot name. + * First the format extension is stripped, e.g. "cgit-0.7.2.tar.gz" become + * "cgit-0.7.2". If this is a valid commit object name we've got a winner. + * Otherwise, if the snapshot name has a prefix matching the result from + * repo_basename(), we strip the basename and any following '-' and '_' + * characters ("cgit-0.7.2" -> "0.7.2") and check the resulting name once + * more. If this still isn't a valid commit object name, we check if pre- + * pending a 'v' or a 'V' to the remaining snapshot name ("0.7.2" -> + * "v0.7.2") gives us something valid. + */ +static const char *get_ref_from_filename(const struct cgit_repo *repo, + const char *filename, + const struct cgit_snapshot_format *format) +{ + const char *reponame; + struct object_id oid; + struct strbuf snapshot = STRBUF_INIT; + int result = 1; + + strbuf_addstr(&snapshot, filename); + strbuf_setlen(&snapshot, snapshot.len - strlen(format->suffix)); + + if (get_oid(snapshot.buf, &oid) == 0) + goto out; + + reponame = cgit_snapshot_prefix(repo); + if (starts_with(snapshot.buf, reponame)) { + const char *new_start = snapshot.buf; + new_start += strlen(reponame); + while (new_start && (*new_start == '-' || *new_start == '_')) + new_start++; + strbuf_splice(&snapshot, 0, new_start - snapshot.buf, "", 0); + } + + if (get_oid(snapshot.buf, &oid) == 0) + goto out; + + strbuf_insert(&snapshot, 0, "v", 1); + if (get_oid(snapshot.buf, &oid) == 0) + goto out; + + strbuf_splice(&snapshot, 0, 1, "V", 1); + if (get_oid(snapshot.buf, &oid) == 0) + goto out; + + result = 0; + strbuf_release(&snapshot); + +out: + return result ? strbuf_detach(&snapshot, NULL) : NULL; +} + +void cgit_print_snapshot(const char *head, const char *hex, + const char *filename, int dwim) +{ + const struct cgit_snapshot_format* f; + const char *sig_filename = NULL; + char *adj_filename = NULL; + char *prefix = NULL; + + if (!filename) { + cgit_print_error_page(400, "Bad request", + "No snapshot name specified"); + return; + } + + if (ends_with(filename, ".asc")) { + sig_filename = filename; + + /* Strip ".asc" from filename for common format processing */ + adj_filename = xstrdup(filename); + adj_filename[strlen(adj_filename) - 4] = '\0'; + filename = adj_filename; + } + + f = get_format(filename); + if (!f || (!sig_filename && !(ctx.repo->snapshots & cgit_snapshot_format_bit(f)))) { + cgit_print_error_page(400, "Bad request", + "Unsupported snapshot format: %s", filename); + return; + } + + if (!hex && dwim) { + hex = get_ref_from_filename(ctx.repo, filename, f); + if (hex == NULL) { + cgit_print_error_page(404, "Not found", "Not found"); + return; + } + prefix = xstrdup(filename); + prefix[strlen(filename) - strlen(f->suffix)] = '\0'; + } + + if (!hex) + hex = head; + + if (!prefix) + prefix = xstrdup(cgit_snapshot_prefix(ctx.repo)); + + if (sig_filename) + write_sig(f, hex, filename, sig_filename); + else + make_snapshot(f, hex, prefix, filename); + + free(prefix); + free(adj_filename); +} diff --git a/third_party/cgit/ui-snapshot.h b/third_party/cgit/ui-snapshot.h new file mode 100644 index 0000000000..a8deec3697 --- /dev/null +++ b/third_party/cgit/ui-snapshot.h @@ -0,0 +1,7 @@ +#ifndef UI_SNAPSHOT_H +#define UI_SNAPSHOT_H + +extern void cgit_print_snapshot(const char *head, const char *hex, + const char *filename, int dwim); + +#endif /* UI_SNAPSHOT_H */ diff --git a/third_party/cgit/ui-ssdiff.c b/third_party/cgit/ui-ssdiff.c new file mode 100644 index 0000000000..af8bc9e065 --- /dev/null +++ b/third_party/cgit/ui-ssdiff.c @@ -0,0 +1,420 @@ +#include "cgit.h" +#include "ui-ssdiff.h" +#include "html.h" +#include "ui-shared.h" +#include "ui-diff.h" + +extern int use_ssdiff; + +static int current_old_line, current_new_line; +static int **L = NULL; + +struct deferred_lines { + int line_no; + char *line; + struct deferred_lines *next; +}; + +static struct deferred_lines *deferred_old, *deferred_old_last; +static struct deferred_lines *deferred_new, *deferred_new_last; + +static void create_or_reset_lcs_table(void) +{ + int i; + + if (L != NULL) { + memset(*L, 0, sizeof(int) * MAX_SSDIFF_SIZE); + return; + } + + // xcalloc will die if we ran out of memory; + // not very helpful for debugging + L = (int**)xcalloc(MAX_SSDIFF_M, sizeof(int *)); + *L = (int*)xcalloc(MAX_SSDIFF_SIZE, sizeof(int)); + + for (i = 1; i < MAX_SSDIFF_M; i++) { + L[i] = *L + i * MAX_SSDIFF_N; + } +} + +static char *longest_common_subsequence(char *A, char *B) +{ + int i, j, ri; + int m = strlen(A); + int n = strlen(B); + int tmp1, tmp2; + int lcs_length; + char *result; + + // We bail if the lines are too long + if (m >= MAX_SSDIFF_M || n >= MAX_SSDIFF_N) + return NULL; + + create_or_reset_lcs_table(); + + for (i = m; i >= 0; i--) { + for (j = n; j >= 0; j--) { + if (A[i] == '\0' || B[j] == '\0') { + L[i][j] = 0; + } else if (A[i] == B[j]) { + L[i][j] = 1 + L[i + 1][j + 1]; + } else { + tmp1 = L[i + 1][j]; + tmp2 = L[i][j + 1]; + L[i][j] = (tmp1 > tmp2 ? tmp1 : tmp2); + } + } + } + + lcs_length = L[0][0]; + result = xmalloc(lcs_length + 2); + memset(result, 0, sizeof(*result) * (lcs_length + 2)); + + ri = 0; + i = 0; + j = 0; + while (i < m && j < n) { + if (A[i] == B[j]) { + result[ri] = A[i]; + ri += 1; + i += 1; + j += 1; + } else if (L[i + 1][j] >= L[i][j + 1]) { + i += 1; + } else { + j += 1; + } + } + + return result; +} + +static int line_from_hunk(char *line, char type) +{ + char *buf1, *buf2; + int len, res; + + buf1 = strchr(line, type); + if (buf1 == NULL) + return 0; + buf1 += 1; + buf2 = strchr(buf1, ','); + if (buf2 == NULL) + return 0; + len = buf2 - buf1; + buf2 = xmalloc(len + 1); + strlcpy(buf2, buf1, len + 1); + res = atoi(buf2); + free(buf2); + return res; +} + +static char *replace_tabs(char *line) +{ + char *prev_buf = line; + char *cur_buf; + size_t linelen = strlen(line); + int n_tabs = 0; + int i; + char *result; + size_t result_len; + + if (linelen == 0) { + result = xmalloc(1); + result[0] = '\0'; + return result; + } + + for (i = 0; i < linelen; i++) { + if (line[i] == '\t') + n_tabs += 1; + } + result_len = linelen + n_tabs * 8; + result = xmalloc(result_len + 1); + result[0] = '\0'; + + for (;;) { + cur_buf = strchr(prev_buf, '\t'); + if (!cur_buf) { + linelen = strlen(result); + strlcpy(&result[linelen], prev_buf, result_len - linelen + 1); + break; + } else { + linelen = strlen(result); + strlcpy(&result[linelen], prev_buf, cur_buf - prev_buf + 1); + linelen = strlen(result); + memset(&result[linelen], ' ', 8 - (linelen % 8)); + result[linelen + 8 - (linelen % 8)] = '\0'; + } + prev_buf = cur_buf + 1; + } + return result; +} + +static int calc_deferred_lines(struct deferred_lines *start) +{ + struct deferred_lines *item = start; + int result = 0; + while (item) { + result += 1; + item = item->next; + } + return result; +} + +static void deferred_old_add(char *line, int line_no) +{ + struct deferred_lines *item = xmalloc(sizeof(struct deferred_lines)); + item->line = xstrdup(line); + item->line_no = line_no; + item->next = NULL; + if (deferred_old) { + deferred_old_last->next = item; + deferred_old_last = item; + } else { + deferred_old = deferred_old_last = item; + } +} + +static void deferred_new_add(char *line, int line_no) +{ + struct deferred_lines *item = xmalloc(sizeof(struct deferred_lines)); + item->line = xstrdup(line); + item->line_no = line_no; + item->next = NULL; + if (deferred_new) { + deferred_new_last->next = item; + deferred_new_last = item; + } else { + deferred_new = deferred_new_last = item; + } +} + +static void print_part_with_lcs(char *class, char *line, char *lcs) +{ + int line_len = strlen(line); + int i, j; + char c[2] = " "; + int same = 1; + + j = 0; + for (i = 0; i < line_len; i++) { + c[0] = line[i]; + if (same) { + if (line[i] == lcs[j]) + j += 1; + else { + same = 0; + htmlf("<span class='%s'>", class); + } + } else if (line[i] == lcs[j]) { + same = 1; + html("</span>"); + j += 1; + } + html_txt(c); + } + if (!same) + html("</span>"); +} + +static void print_ssdiff_line(char *class, + int old_line_no, + char *old_line, + int new_line_no, + char *new_line, int individual_chars) +{ + char *lcs = NULL; + + if (old_line) + old_line = replace_tabs(old_line + 1); + if (new_line) + new_line = replace_tabs(new_line + 1); + if (individual_chars && old_line && new_line) + lcs = longest_common_subsequence(old_line, new_line); + html("<tr>\n"); + if (old_line_no > 0) { + struct diff_filespec *old_file = cgit_get_current_old_file(); + char *lineno_str = fmt("n%d", old_line_no); + char *id_str = fmt("id=%s#%s", is_null_oid(&old_file->oid)?"HEAD":oid_to_hex(old_rev_oid), lineno_str); + char *fileurl = cgit_fileurl(ctx.repo->url, "tree", old_file->path, id_str); + html("<td class='lineno'><a href='"); + html(fileurl); + htmlf("'>%s</a>", lineno_str + 1); + html("</td>"); + htmlf("<td class='%s'>", class); + free(fileurl); + } else if (old_line) + htmlf("<td class='lineno'></td><td class='%s'>", class); + else + htmlf("<td class='lineno'></td><td class='%s_dark'>", class); + if (old_line) { + if (lcs) + print_part_with_lcs("del", old_line, lcs); + else + html_txt(old_line); + } + + html("</td>\n"); + if (new_line_no > 0) { + struct diff_filespec *new_file = cgit_get_current_new_file(); + char *lineno_str = fmt("n%d", new_line_no); + char *id_str = fmt("id=%s#%s", is_null_oid(&new_file->oid)?"HEAD":oid_to_hex(new_rev_oid), lineno_str); + char *fileurl = cgit_fileurl(ctx.repo->url, "tree", new_file->path, id_str); + html("<td class='lineno'><a href='"); + html(fileurl); + htmlf("'>%s</a>", lineno_str + 1); + html("</td>"); + htmlf("<td class='%s'>", class); + free(fileurl); + } else if (new_line) + htmlf("<td class='lineno'></td><td class='%s'>", class); + else + htmlf("<td class='lineno'></td><td class='%s_dark'>", class); + if (new_line) { + if (lcs) + print_part_with_lcs("add", new_line, lcs); + else + html_txt(new_line); + } + + html("</td></tr>"); + if (lcs) + free(lcs); + if (new_line) + free(new_line); + if (old_line) + free(old_line); +} + +static void print_deferred_old_lines(void) +{ + struct deferred_lines *iter_old, *tmp; + iter_old = deferred_old; + while (iter_old) { + print_ssdiff_line("del", iter_old->line_no, + iter_old->line, -1, NULL, 0); + tmp = iter_old->next; + free(iter_old); + iter_old = tmp; + } +} + +static void print_deferred_new_lines(void) +{ + struct deferred_lines *iter_new, *tmp; + iter_new = deferred_new; + while (iter_new) { + print_ssdiff_line("add", -1, NULL, + iter_new->line_no, iter_new->line, 0); + tmp = iter_new->next; + free(iter_new); + iter_new = tmp; + } +} + +static void print_deferred_changed_lines(void) +{ + struct deferred_lines *iter_old, *iter_new, *tmp; + int n_old_lines = calc_deferred_lines(deferred_old); + int n_new_lines = calc_deferred_lines(deferred_new); + int individual_chars = (n_old_lines == n_new_lines ? 1 : 0); + + iter_old = deferred_old; + iter_new = deferred_new; + while (iter_old || iter_new) { + if (iter_old && iter_new) + print_ssdiff_line("changed", iter_old->line_no, + iter_old->line, + iter_new->line_no, iter_new->line, + individual_chars); + else if (iter_old) + print_ssdiff_line("changed", iter_old->line_no, + iter_old->line, -1, NULL, 0); + else if (iter_new) + print_ssdiff_line("changed", -1, NULL, + iter_new->line_no, iter_new->line, 0); + if (iter_old) { + tmp = iter_old->next; + free(iter_old); + iter_old = tmp; + } + + if (iter_new) { + tmp = iter_new->next; + free(iter_new); + iter_new = tmp; + } + } +} + +void cgit_ssdiff_print_deferred_lines(void) +{ + if (!deferred_old && !deferred_new) + return; + if (deferred_old && !deferred_new) + print_deferred_old_lines(); + else if (!deferred_old && deferred_new) + print_deferred_new_lines(); + else + print_deferred_changed_lines(); + deferred_old = deferred_old_last = NULL; + deferred_new = deferred_new_last = NULL; +} + +/* + * print a single line returned from xdiff + */ +void cgit_ssdiff_line_cb(char *line, int len) +{ + char c = line[len - 1]; + line[len - 1] = '\0'; + if (line[0] == '@') { + current_old_line = line_from_hunk(line, '-'); + current_new_line = line_from_hunk(line, '+'); + } + + if (line[0] == ' ') { + if (deferred_old || deferred_new) + cgit_ssdiff_print_deferred_lines(); + print_ssdiff_line("ctx", current_old_line, line, + current_new_line, line, 0); + current_old_line += 1; + current_new_line += 1; + } else if (line[0] == '+') { + deferred_new_add(line, current_new_line); + current_new_line += 1; + } else if (line[0] == '-') { + deferred_old_add(line, current_old_line); + current_old_line += 1; + } else if (line[0] == '@') { + html("<tr><td colspan='4' class='hunk'>"); + html_txt(line); + html("</td></tr>"); + } else { + html("<tr><td colspan='4' class='ctx'>"); + html_txt(line); + html("</td></tr>"); + } + line[len - 1] = c; +} + +void cgit_ssdiff_header_begin(void) +{ + current_old_line = -1; + current_new_line = -1; + html("<tr><td class='space' colspan='4'><div></div></td></tr>"); + html("<tr><td class='head' colspan='4'>"); +} + +void cgit_ssdiff_header_end(void) +{ + html("</td></tr>"); +} + +void cgit_ssdiff_footer(void) +{ + if (deferred_old || deferred_new) + cgit_ssdiff_print_deferred_lines(); + html("<tr><td class='foot' colspan='4'></td></tr>"); +} diff --git a/third_party/cgit/ui-ssdiff.h b/third_party/cgit/ui-ssdiff.h new file mode 100644 index 0000000000..11f2714407 --- /dev/null +++ b/third_party/cgit/ui-ssdiff.h @@ -0,0 +1,25 @@ +#ifndef UI_SSDIFF_H +#define UI_SSDIFF_H + +/* + * ssdiff line limits + */ +#ifndef MAX_SSDIFF_M +#define MAX_SSDIFF_M 128 +#endif + +#ifndef MAX_SSDIFF_N +#define MAX_SSDIFF_N 128 +#endif +#define MAX_SSDIFF_SIZE ((MAX_SSDIFF_M) * (MAX_SSDIFF_N)) + +extern void cgit_ssdiff_print_deferred_lines(void); + +extern void cgit_ssdiff_line_cb(char *line, int len); + +extern void cgit_ssdiff_header_begin(void); +extern void cgit_ssdiff_header_end(void); + +extern void cgit_ssdiff_footer(void); + +#endif /* UI_SSDIFF_H */ diff --git a/third_party/cgit/ui-stats.c b/third_party/cgit/ui-stats.c new file mode 100644 index 0000000000..7272a61a2f --- /dev/null +++ b/third_party/cgit/ui-stats.c @@ -0,0 +1,426 @@ +#include "cgit.h" +#include "ui-stats.h" +#include "html.h" +#include "ui-shared.h" + +struct authorstat { + long total; + struct string_list list; +}; + +#define DAY_SECS (60 * 60 * 24) +#define WEEK_SECS (DAY_SECS * 7) + +static void trunc_week(struct tm *tm) +{ + time_t t = timegm(tm); + t -= ((tm->tm_wday + 6) % 7) * DAY_SECS; + gmtime_r(&t, tm); +} + +static void dec_week(struct tm *tm) +{ + time_t t = timegm(tm); + t -= WEEK_SECS; + gmtime_r(&t, tm); +} + +static void inc_week(struct tm *tm) +{ + time_t t = timegm(tm); + t += WEEK_SECS; + gmtime_r(&t, tm); +} + +static char *pretty_week(struct tm *tm) +{ + static char buf[10]; + + strftime(buf, sizeof(buf), "W%V %G", tm); + return buf; +} + +static void trunc_month(struct tm *tm) +{ + tm->tm_mday = 1; +} + +static void dec_month(struct tm *tm) +{ + tm->tm_mon--; + if (tm->tm_mon < 0) { + tm->tm_year--; + tm->tm_mon = 11; + } +} + +static void inc_month(struct tm *tm) +{ + tm->tm_mon++; + if (tm->tm_mon > 11) { + tm->tm_year++; + tm->tm_mon = 0; + } +} + +static char *pretty_month(struct tm *tm) +{ + static const char *months[] = { + "Jan", "Feb", "Mar", "Apr", "May", "Jun", + "Jul", "Aug", "Sep", "Oct", "Nov", "Dec" + }; + return fmt("%s %d", months[tm->tm_mon], tm->tm_year + 1900); +} + +static void trunc_quarter(struct tm *tm) +{ + trunc_month(tm); + while (tm->tm_mon % 3 != 0) + dec_month(tm); +} + +static void dec_quarter(struct tm *tm) +{ + dec_month(tm); + dec_month(tm); + dec_month(tm); +} + +static void inc_quarter(struct tm *tm) +{ + inc_month(tm); + inc_month(tm); + inc_month(tm); +} + +static char *pretty_quarter(struct tm *tm) +{ + return fmt("Q%d %d", tm->tm_mon / 3 + 1, tm->tm_year + 1900); +} + +static void trunc_year(struct tm *tm) +{ + trunc_month(tm); + tm->tm_mon = 0; +} + +static void dec_year(struct tm *tm) +{ + tm->tm_year--; +} + +static void inc_year(struct tm *tm) +{ + tm->tm_year++; +} + +static char *pretty_year(struct tm *tm) +{ + return fmt("%d", tm->tm_year + 1900); +} + +static const struct cgit_period periods[] = { + {'w', "week", 12, 4, trunc_week, dec_week, inc_week, pretty_week}, + {'m', "month", 12, 4, trunc_month, dec_month, inc_month, pretty_month}, + {'q', "quarter", 12, 4, trunc_quarter, dec_quarter, inc_quarter, pretty_quarter}, + {'y', "year", 12, 4, trunc_year, dec_year, inc_year, pretty_year}, +}; + +/* Given a period code or name, return a period index (1, 2, 3 or 4) + * and update the period pointer to the correcsponding struct. + * If no matching code is found, return 0. + */ +int cgit_find_stats_period(const char *expr, const struct cgit_period **period) +{ + int i; + char code = '\0'; + + if (!expr) + return 0; + + if (strlen(expr) == 1) + code = expr[0]; + + for (i = 0; i < sizeof(periods) / sizeof(periods[0]); i++) + if (periods[i].code == code || !strcmp(periods[i].name, expr)) { + if (period) + *period = &periods[i]; + return i + 1; + } + return 0; +} + +const char *cgit_find_stats_periodname(int idx) +{ + if (idx > 0 && idx < 4) + return periods[idx - 1].name; + else + return ""; +} + +static void add_commit(struct string_list *authors, struct commit *commit, + const struct cgit_period *period) +{ + struct commitinfo *info; + struct string_list_item *author, *item; + struct authorstat *authorstat; + struct string_list *items; + char *tmp; + struct tm *date; + time_t t; + uintptr_t *counter; + + info = cgit_parse_commit(commit); + tmp = xstrdup(info->author); + author = string_list_insert(authors, tmp); + if (!author->util) + author->util = xcalloc(1, sizeof(struct authorstat)); + else + free(tmp); + authorstat = author->util; + items = &authorstat->list; + t = info->committer_date; + date = gmtime(&t); + period->trunc(date); + tmp = xstrdup(period->pretty(date)); + item = string_list_insert(items, tmp); + counter = (uintptr_t *)&item->util; + if (*counter) + free(tmp); + (*counter)++; + + authorstat->total++; + cgit_free_commitinfo(info); +} + +static int cmp_total_commits(const void *a1, const void *a2) +{ + const struct string_list_item *i1 = a1; + const struct string_list_item *i2 = a2; + const struct authorstat *auth1 = i1->util; + const struct authorstat *auth2 = i2->util; + + return auth2->total - auth1->total; +} + +/* Walk the commit DAG and collect number of commits per author per + * timeperiod into a nested string_list collection. + */ +static struct string_list collect_stats(const struct cgit_period *period) +{ + struct string_list authors; + struct rev_info rev; + struct commit *commit; + const char *argv[] = {NULL, ctx.qry.head, NULL, NULL, NULL, NULL}; + int argc = 3; + time_t now; + long i; + struct tm *tm; + char tmp[11]; + + time(&now); + tm = gmtime(&now); + period->trunc(tm); + for (i = 1; i < period->count; i++) + period->dec(tm); + strftime(tmp, sizeof(tmp), "%Y-%m-%d", tm); + argv[2] = xstrdup(fmt("--since=%s", tmp)); + if (ctx.qry.path) { + argv[3] = "--"; + argv[4] = ctx.qry.path; + argc += 2; + } + init_revisions(&rev, NULL); + rev.abbrev = DEFAULT_ABBREV; + rev.commit_format = CMIT_FMT_DEFAULT; + rev.max_parents = 1; + rev.verbose_header = 1; + rev.show_root_diff = 0; + setup_revisions(argc, argv, &rev, NULL); + prepare_revision_walk(&rev); + memset(&authors, 0, sizeof(authors)); + while ((commit = get_revision(&rev)) != NULL) { + add_commit(&authors, commit, period); + free_commit_buffer(the_repository->parsed_objects, commit); + free_commit_list(commit->parents); + commit->parents = NULL; + } + return authors; +} + +static void print_combined_authorrow(struct string_list *authors, int from, + int to, const char *name, + const char *leftclass, + const char *centerclass, + const char *rightclass, + const struct cgit_period *period) +{ + struct string_list_item *author; + struct authorstat *authorstat; + struct string_list *items; + struct string_list_item *date; + time_t now; + long i, j, total, subtotal; + struct tm *tm; + char *tmp; + + time(&now); + tm = gmtime(&now); + period->trunc(tm); + for (i = 1; i < period->count; i++) + period->dec(tm); + + total = 0; + htmlf("<tr><td class='%s'>%s</td>", leftclass, + fmt(name, to - from + 1)); + for (j = 0; j < period->count; j++) { + tmp = period->pretty(tm); + period->inc(tm); + subtotal = 0; + for (i = from; i <= to; i++) { + author = &authors->items[i]; + authorstat = author->util; + items = &authorstat->list; + date = string_list_lookup(items, tmp); + if (date) + subtotal += (uintptr_t)date->util; + } + htmlf("<td class='%s'>%ld</td>", centerclass, subtotal); + total += subtotal; + } + htmlf("<td class='%s'>%ld</td></tr>", rightclass, total); +} + +static void print_authors(struct string_list *authors, int top, + const struct cgit_period *period) +{ + struct string_list_item *author; + struct authorstat *authorstat; + struct string_list *items; + struct string_list_item *date; + time_t now; + long i, j, total; + struct tm *tm; + char *tmp; + + time(&now); + tm = gmtime(&now); + period->trunc(tm); + for (i = 1; i < period->count; i++) + period->dec(tm); + + html("<table class='stats'><tr><th>Author</th>"); + for (j = 0; j < period->count; j++) { + tmp = period->pretty(tm); + htmlf("<th>%s</th>", tmp); + period->inc(tm); + } + html("<th>Total</th></tr>\n"); + + if (top <= 0 || top > authors->nr) + top = authors->nr; + + for (i = 0; i < top; i++) { + author = &authors->items[i]; + html("<tr><td class='left'>"); + html_txt(author->string); + html("</td>"); + authorstat = author->util; + items = &authorstat->list; + total = 0; + for (j = 0; j < period->count; j++) + period->dec(tm); + for (j = 0; j < period->count; j++) { + tmp = period->pretty(tm); + period->inc(tm); + date = string_list_lookup(items, tmp); + if (!date) + html("<td>0</td>"); + else { + htmlf("<td>%lu</td>", (uintptr_t)date->util); + total += (uintptr_t)date->util; + } + } + htmlf("<td class='sum'>%ld</td></tr>", total); + } + + if (top < authors->nr) + print_combined_authorrow(authors, top, authors->nr - 1, + "Others (%ld)", "left", "", "sum", period); + + print_combined_authorrow(authors, 0, authors->nr - 1, "Total", + "total", "sum", "sum", period); + html("</table>"); +} + +/* Create a sorted string_list with one entry per author. The util-field + * for each author is another string_list which is used to calculate the + * number of commits per time-interval. + */ +void cgit_show_stats(void) +{ + struct string_list authors; + const struct cgit_period *period; + int top, i; + const char *code = "w"; + + if (ctx.qry.period) + code = ctx.qry.period; + + i = cgit_find_stats_period(code, &period); + if (!i) { + cgit_print_error_page(404, "Not found", + "Unknown statistics type: %c", code[0]); + return; + } + if (i > ctx.repo->max_stats) { + cgit_print_error_page(400, "Bad request", + "Statistics type disabled: %s", period->name); + return; + } + authors = collect_stats(period); + qsort(authors.items, authors.nr, sizeof(struct string_list_item), + cmp_total_commits); + + top = ctx.qry.ofs; + if (!top) + top = 10; + + cgit_print_layout_start(); + html("<div class='cgit-panel'>"); + html("<b>stat options</b>"); + html("<form method='get'>"); + cgit_add_hidden_formfields(1, 0, "stats"); + html("<table><tr><td colspan='2'/></tr>"); + if (ctx.repo->max_stats > 1) { + html("<tr><td class='label'>Period:</td>"); + html("<td class='ctrl'><select name='period' onchange='this.form.submit();'>"); + for (i = 0; i < ctx.repo->max_stats; i++) + html_option(fmt("%c", periods[i].code), + periods[i].name, fmt("%c", period->code)); + html("</select></td></tr>"); + } + html("<tr><td class='label'>Authors:</td>"); + html("<td class='ctrl'><select name='ofs' onchange='this.form.submit();'>"); + html_intoption(10, "10", top); + html_intoption(25, "25", top); + html_intoption(50, "50", top); + html_intoption(100, "100", top); + html_intoption(-1, "all", top); + html("</select></td></tr>"); + html("<tr><td/><td class='ctrl'>"); + html("<noscript><input type='submit' value='Reload'/></noscript>"); + html("</td></tr></table>"); + html("</form>"); + html("</div>"); + htmlf("<h2>Commits per author per %s", period->name); + if (ctx.qry.path) { + html(" (path '"); + html_txt(ctx.qry.path); + html("')"); + } + html("</h2>"); + print_authors(&authors, top, period); + cgit_print_layout_end(); +} + diff --git a/third_party/cgit/ui-stats.h b/third_party/cgit/ui-stats.h new file mode 100644 index 0000000000..0e61b03da3 --- /dev/null +++ b/third_party/cgit/ui-stats.h @@ -0,0 +1,28 @@ +#ifndef UI_STATS_H +#define UI_STATS_H + +#include "cgit.h" + +struct cgit_period { + const char code; + const char *name; + int max_periods; + int count; + + /* Convert a tm value to the first day in the period */ + void (*trunc)(struct tm *tm); + + /* Update tm value to start of next/previous period */ + void (*dec)(struct tm *tm); + void (*inc)(struct tm *tm); + + /* Pretty-print a tm value */ + char *(*pretty)(struct tm *tm); +}; + +extern int cgit_find_stats_period(const char *expr, const struct cgit_period **period); +extern const char *cgit_find_stats_periodname(int idx); + +extern void cgit_show_stats(void); + +#endif /* UI_STATS_H */ diff --git a/third_party/cgit/ui-summary.c b/third_party/cgit/ui-summary.c new file mode 100644 index 0000000000..d1bb6a59fa --- /dev/null +++ b/third_party/cgit/ui-summary.c @@ -0,0 +1,160 @@ +/* ui-summary.c: functions for generating repo summary page + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-summary.h" +#include "html.h" +#include "ui-blob.h" +#include "ui-log.h" +#include "ui-plain.h" +#include "ui-refs.h" +#include "ui-shared.h" + +static int urls; + +static void print_url(const char *url) +{ + int columns = 3; + + if (ctx.repo->enable_log_filecount) + columns++; + if (ctx.repo->enable_log_linecount) + columns++; + + if (urls++ == 0) { + htmlf("<tr class='nohover'><td colspan='%d'> </td></tr>", columns); + htmlf("<tr class='nohover'><th class='left' colspan='%d'>Clone</th></tr>\n", columns); + } + + htmlf("<tr><td colspan='%d'><a rel='vcs-git' href='", columns); + html_url_path(url); + html("' title='"); + html_attr(ctx.repo->name); + html(" Git repository'>"); + html_txt(url); + html("</a></td></tr>\n"); +} + +void cgit_print_summary(void) +{ + int columns = 3; + + if (ctx.repo->enable_log_filecount) + columns++; + if (ctx.repo->enable_log_linecount) + columns++; + + cgit_print_layout_start(); + html("<table summary='repository info' class='list nowrap'>"); + cgit_print_branches(ctx.cfg.summary_branches); + htmlf("<tr class='nohover'><td colspan='%d'> </td></tr>", columns); + cgit_print_tags(ctx.cfg.summary_tags); + if (ctx.cfg.summary_log > 0) { + htmlf("<tr class='nohover'><td colspan='%d'> </td></tr>", columns); + cgit_print_log(ctx.qry.head, 0, ctx.cfg.summary_log, NULL, + NULL, NULL, 0, 0, 0); + } + urls = 0; + cgit_add_clone_urls(print_url); + html("</table>"); + cgit_print_layout_end(); +} + +/* The caller must free the return value. */ +static char* append_readme_path(const char *filename, const char *ref, const char *path) +{ + char *file, *base_dir, *full_path, *resolved_base = NULL, *resolved_full = NULL; + /* If a subpath is specified for the about page, make it relative + * to the directory containing the configured readme. */ + + file = xstrdup(filename); + base_dir = dirname(file); + if (!strcmp(base_dir, ".") || !strcmp(base_dir, "..")) { + if (!ref) { + free(file); + return NULL; + } + full_path = xstrdup(path); + } else + full_path = fmtalloc("%s/%s", base_dir, path); + + if (!ref) { + resolved_base = realpath(base_dir, NULL); + resolved_full = realpath(full_path, NULL); + if (!resolved_base || !resolved_full || !starts_with(resolved_full, resolved_base)) { + free(full_path); + full_path = NULL; + } + } + + free(file); + free(resolved_base); + free(resolved_full); + + return full_path; +} + +void cgit_print_repo_readme(const char *path) +{ + char *filename, *ref, *mimetype; + int free_filename = 0; + + mimetype = get_mimetype_for_filename(path); + if (mimetype && (!strncmp(mimetype, "image/", 6) || !strncmp(mimetype, "video/", 6))) { + ctx.page.mimetype = mimetype; + ctx.page.charset = NULL; + cgit_print_plain(); + free(mimetype); + return; + } + free(mimetype); + + cgit_print_layout_start(); + if (ctx.repo->readme.nr == 0) + goto done; + + filename = ctx.repo->readme.items[0].string; + ref = ctx.repo->readme.items[0].util; + + if (path) { + free_filename = 1; + filename = append_readme_path(filename, ref, path); + if (!filename) + goto done; + } + + /* Determine which file to serve by checking whether the given filename is + * already a valid file and otherwise appending the expected file name of + * the readme. + * + * If neither yield a valid file, the user gets a blank page. Could probably + * do with an error message in between there, but whatever. + */ + if (path && ref && !cgit_ref_path_exists(filename, ref, 1)) { + filename = fmtalloc("%s/%s", path, ctx.repo->readme.items[0].string); + free_filename = 1; + } + + /* Print the calculated readme, either from the git repo or from the + * filesystem, while applying the about-filter. + */ + html("<div id='summary'>"); + cgit_open_filter(ctx.repo->about_filter, filename); + if (ref) + cgit_print_file(filename, ref, 1); + else + html_include(filename); + cgit_close_filter(ctx.repo->about_filter); + + html("</div>"); + if (free_filename) + free(filename); + +done: + cgit_print_layout_end(); +} diff --git a/third_party/cgit/ui-summary.h b/third_party/cgit/ui-summary.h new file mode 100644 index 0000000000..cba696af53 --- /dev/null +++ b/third_party/cgit/ui-summary.h @@ -0,0 +1,7 @@ +#ifndef UI_SUMMARY_H +#define UI_SUMMARY_H + +extern void cgit_print_summary(void); +extern void cgit_print_repo_readme(const char *path); + +#endif /* UI_SUMMARY_H */ diff --git a/third_party/cgit/ui-tag.c b/third_party/cgit/ui-tag.c new file mode 100644 index 0000000000..2f4a525e28 --- /dev/null +++ b/third_party/cgit/ui-tag.c @@ -0,0 +1,120 @@ +/* ui-tag.c: display a tag + * + * Copyright (C) 2006-2014 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-tag.h" +#include "html.h" +#include "ui-shared.h" + +static void print_tag_content(char *buf) +{ + char *p; + + if (!buf) + return; + + html("<div class='commit-subject'>"); + p = strchr(buf, '\n'); + if (p) + *p = '\0'; + html_txt(buf); + html("</div>"); + if (p) { + html("<div class='commit-msg'>"); + html_txt(++p); + html("</div>"); + } +} + +static void print_download_links(char *revname) +{ + html("<tr><th>download</th><td class='sha1'>"); + cgit_print_snapshot_links(ctx.repo, revname, "<br/>"); + html("</td></tr>"); +} + +void cgit_print_tag(char *revname) +{ + struct strbuf fullref = STRBUF_INIT; + struct object_id oid; + struct object *obj; + + if (!revname) + revname = ctx.qry.head; + + strbuf_addf(&fullref, "refs/tags/%s", revname); + if (get_oid(fullref.buf, &oid)) { + cgit_print_error_page(404, "Not found", + "Bad tag reference: %s", revname); + goto cleanup; + } + obj = parse_object(the_repository, &oid); + if (!obj) { + cgit_print_error_page(500, "Internal server error", + "Bad object id: %s", oid_to_hex(&oid)); + goto cleanup; + } + if (obj->type == OBJ_TAG) { + struct tag *tag; + struct taginfo *info; + + tag = lookup_tag(the_repository, &oid); + if (!tag || parse_tag(tag) || !(info = cgit_parse_tag(tag))) { + cgit_print_error_page(500, "Internal server error", + "Bad tag object: %s", revname); + goto cleanup; + } + cgit_print_layout_start(); + html("<table class='commit-info'>\n"); + html("<tr><td>tag name</td><td>"); + html_txt(revname); + htmlf(" (%s)</td></tr>\n", oid_to_hex(&oid)); + if (info->tagger_date > 0) { + html("<tr><td>tag date</td><td>"); + html_txt(show_date(info->tagger_date, info->tagger_tz, + cgit_date_mode(DATE_DOTTIME))); + html("</td></tr>\n"); + } + if (info->tagger) { + html("<tr><td>tagged by</td><td>"); + cgit_open_filter(ctx.repo->email_filter, info->tagger_email, "tag"); + html_txt(info->tagger); + if (info->tagger_email && !ctx.cfg.noplainemail) { + html(" "); + html_txt(info->tagger_email); + } + cgit_close_filter(ctx.repo->email_filter); + html("</td></tr>\n"); + } + html("<tr><td>tagged object</td><td class='sha1'>"); + cgit_object_link(tag->tagged); + html("</td></tr>\n"); + if (ctx.repo->snapshots) + print_download_links(revname); + html("</table>\n"); + print_tag_content(info->msg); + cgit_print_layout_end(); + cgit_free_taginfo(info); + } else { + cgit_print_layout_start(); + html("<table class='commit-info'>\n"); + html("<tr><td>tag name</td><td>"); + html_txt(revname); + html("</td></tr>\n"); + html("<tr><td>tagged object</td><td class='sha1'>"); + cgit_object_link(obj); + html("</td></tr>\n"); + if (ctx.repo->snapshots) + print_download_links(revname); + html("</table>\n"); + cgit_print_layout_end(); + } + +cleanup: + strbuf_release(&fullref); +} diff --git a/third_party/cgit/ui-tag.h b/third_party/cgit/ui-tag.h new file mode 100644 index 0000000000..d295cdcdbd --- /dev/null +++ b/third_party/cgit/ui-tag.h @@ -0,0 +1,6 @@ +#ifndef UI_TAG_H +#define UI_TAG_H + +extern void cgit_print_tag(char *revname); + +#endif /* UI_TAG_H */ diff --git a/third_party/cgit/ui-tree.c b/third_party/cgit/ui-tree.c new file mode 100644 index 0000000000..2c6d23ec51 --- /dev/null +++ b/third_party/cgit/ui-tree.c @@ -0,0 +1,408 @@ +/* ui-tree.c: functions for tree output + * + * Copyright (C) 2006-2017 cgit Development Team <cgit@lists.zx2c4.com> + * + * Licensed under GNU General Public License v2 + * (see COPYING for full license text) + */ + +#include "cgit.h" +#include "ui-tree.h" +#include "html.h" +#include "ui-shared.h" + +struct walk_tree_context { + char *curr_rev; + char *match_path; + int state; +}; + +static void print_text_buffer(const char *name, char *buf, unsigned long size) +{ + unsigned long lineno, idx; + const char *numberfmt = "<a id='n%1$d' href='#n%1$d'>%1$d</a>\n"; + + html("<table summary='blob content' class='blob'>\n"); + + if (ctx.cfg.enable_tree_linenumbers) { + html("<tr><td class='linenumbers'><pre>"); + idx = 0; + lineno = 0; + + if (size) { + htmlf(numberfmt, ++lineno); + while (idx < size - 1) { // skip absolute last newline + if (buf[idx] == '\n') + htmlf(numberfmt, ++lineno); + idx++; + } + } + html("</pre></td>\n"); + } + else { + html("<tr>\n"); + } + + if (ctx.repo->source_filter) { + char *filter_arg = xstrdup(name); + html("<td class='lines'><pre><code>"); + cgit_open_filter(ctx.repo->source_filter, filter_arg); + html_raw(buf, size); + cgit_close_filter(ctx.repo->source_filter); + free(filter_arg); + html("</code></pre></td></tr></table>\n"); + return; + } + + html("<td class='lines'><pre><code>"); + html_txt(buf); + html("</code></pre></td></tr></table>\n"); +} + +#define ROWLEN 32 + +static void print_binary_buffer(char *buf, unsigned long size) +{ + unsigned long ofs, idx; + static char ascii[ROWLEN + 1]; + + html("<table summary='blob content' class='bin-blob'>\n"); + html("<tr><th>ofs</th><th>hex dump</th><th>ascii</th></tr>"); + for (ofs = 0; ofs < size; ofs += ROWLEN, buf += ROWLEN) { + htmlf("<tr><td class='right'>%04lx</td><td class='hex'>", ofs); + for (idx = 0; idx < ROWLEN && ofs + idx < size; idx++) + htmlf("%*s%02x", + idx == 16 ? 4 : 1, "", + buf[idx] & 0xff); + html(" </td><td class='hex'>"); + for (idx = 0; idx < ROWLEN && ofs + idx < size; idx++) + ascii[idx] = isgraph(buf[idx]) ? buf[idx] : '.'; + ascii[idx] = '\0'; + html_txt(ascii); + html("</td></tr>\n"); + } + html("</table>\n"); +} + +static void print_object(const struct object_id *oid, const char *path, const char *basename, const char *rev) +{ + enum object_type type; + char *buf; + unsigned long size; + int is_binary; + + type = oid_object_info(the_repository, oid, &size); + if (type == OBJ_BAD) { + cgit_print_error_page(404, "Not found", + "Bad object name: %s", oid_to_hex(oid)); + return; + } + + buf = read_object_file(oid, &type, &size); + if (!buf) { + cgit_print_error_page(500, "Internal server error", + "Error reading object %s", oid_to_hex(oid)); + return; + } + is_binary = buffer_is_binary(buf, size); + + cgit_set_title_from_path(path); + + cgit_print_layout_start(); + htmlf("blob: %s (", oid_to_hex(oid)); + cgit_plain_link("plain", NULL, NULL, ctx.qry.head, + rev, path); + if (ctx.repo->enable_blame && !is_binary) { + html(") ("); + cgit_blame_link("blame", NULL, NULL, ctx.qry.head, + rev, path); + } + html(")\n"); + + if (ctx.cfg.max_blob_size && size / 1024 > ctx.cfg.max_blob_size) { + htmlf("<div class='error'>blob size (%ldKB) exceeds display size limit (%dKB).</div>", + size / 1024, ctx.cfg.max_blob_size); + return; + } + + if (is_binary) + print_binary_buffer(buf, size); + else + print_text_buffer(basename, buf, size); + + free(buf); +} + +struct single_tree_ctx { + struct strbuf *path; + struct object_id oid; + char *name; + size_t count; +}; + +static int single_tree_cb(const struct object_id *oid, struct strbuf *base, + const char *pathname, unsigned mode, int stage, + void *cbdata) +{ + struct single_tree_ctx *ctx = cbdata; + + if (++ctx->count > 1) + return -1; + + if (!S_ISDIR(mode)) { + ctx->count = 2; + return -1; + } + + ctx->name = xstrdup(pathname); + oidcpy(&ctx->oid, oid); + strbuf_addf(ctx->path, "/%s", pathname); + return 0; +} + +static void write_tree_link(const struct object_id *oid, char *name, + char *rev, struct strbuf *fullpath) +{ + size_t initial_length = fullpath->len; + struct tree *tree; + struct single_tree_ctx tree_ctx = { + .path = fullpath, + .count = 1, + }; + struct pathspec paths = { + .nr = 0 + }; + + oidcpy(&tree_ctx.oid, oid); + + while (tree_ctx.count == 1) { + cgit_tree_link(name, NULL, "ls-dir", ctx.qry.head, rev, + fullpath->buf); + + tree = lookup_tree(the_repository, &tree_ctx.oid); + if (!tree) + return; + + free(tree_ctx.name); + tree_ctx.name = NULL; + tree_ctx.count = 0; + + read_tree_recursive(the_repository, tree, "", 0, 1, + &paths, single_tree_cb, &tree_ctx); + + if (tree_ctx.count != 1) + break; + + html(" / "); + name = tree_ctx.name; + } + + strbuf_setlen(fullpath, initial_length); +} + +static int ls_item(const struct object_id *oid, struct strbuf *base, + const char *pathname, unsigned mode, int stage, void *cbdata) +{ + struct walk_tree_context *walk_tree_ctx = cbdata; + char *name; + struct strbuf fullpath = STRBUF_INIT; + struct strbuf linkpath = STRBUF_INIT; + struct strbuf class = STRBUF_INIT; + enum object_type type; + unsigned long size = 0; + char *buf; + + name = xstrdup(pathname); + strbuf_addf(&fullpath, "%s%s%s", ctx.qry.path ? ctx.qry.path : "", + ctx.qry.path ? "/" : "", name); + + if (!S_ISGITLINK(mode)) { + type = oid_object_info(the_repository, oid, &size); + if (type == OBJ_BAD) { + htmlf("<tr><td colspan='3'>Bad object: %s %s</td></tr>", + name, + oid_to_hex(oid)); + goto cleanup; + } + } + + html("<tr><td class='ls-mode'>"); + cgit_print_filemode(mode); + html("</td><td>"); + if (S_ISGITLINK(mode)) { + cgit_submodule_link("ls-mod", fullpath.buf, oid_to_hex(oid)); + } else if (S_ISDIR(mode)) { + write_tree_link(oid, name, walk_tree_ctx->curr_rev, + &fullpath); + } else { + char *ext = strrchr(name, '.'); + strbuf_addstr(&class, "ls-blob"); + if (ext) + strbuf_addf(&class, " %s", ext + 1); + cgit_tree_link(name, NULL, class.buf, ctx.qry.head, + walk_tree_ctx->curr_rev, fullpath.buf); + } + if (S_ISLNK(mode)) { + html(" -> "); + buf = read_object_file(oid, &type, &size); + if (!buf) { + htmlf("Error reading object: %s", oid_to_hex(oid)); + goto cleanup; + } + strbuf_addbuf(&linkpath, &fullpath); + strbuf_addf(&linkpath, "/../%s", buf); + strbuf_normalize_path(&linkpath); + cgit_tree_link(buf, NULL, class.buf, ctx.qry.head, + walk_tree_ctx->curr_rev, linkpath.buf); + free(buf); + strbuf_release(&linkpath); + } + htmlf("</td><td class='ls-size'>%li</td>", size); + + html("<td>"); + cgit_log_link("log", NULL, "button", ctx.qry.head, + walk_tree_ctx->curr_rev, fullpath.buf, 0, NULL, NULL, + ctx.qry.showmsg, 0); + if (ctx.repo->max_stats) + cgit_stats_link("stats", NULL, "button", ctx.qry.head, + fullpath.buf); + if (!S_ISGITLINK(mode)) + cgit_plain_link("plain", NULL, "button", ctx.qry.head, + walk_tree_ctx->curr_rev, fullpath.buf); + if (!S_ISDIR(mode) && ctx.repo->enable_blame) + cgit_blame_link("blame", NULL, "button", ctx.qry.head, + walk_tree_ctx->curr_rev, fullpath.buf); + html("</td></tr>\n"); + +cleanup: + free(name); + strbuf_release(&fullpath); + strbuf_release(&class); + return 0; +} + +static void ls_head(void) +{ + cgit_print_layout_start(); + html("<table summary='tree listing' class='list'>\n"); + html("<tr class='nohover'>"); + html("<th class='left'>Mode</th>"); + html("<th class='left'>Name</th>"); + html("<th class='right'>Size</th>"); + html("<th/>"); + html("</tr>\n"); +} + +static void ls_tail(void) +{ + html("</table>\n"); + cgit_print_layout_end(); +} + +static void ls_tree(const struct object_id *oid, const char *path, struct walk_tree_context *walk_tree_ctx) +{ + struct tree *tree; + struct pathspec paths = { + .nr = 0 + }; + + tree = parse_tree_indirect(oid); + if (!tree) { + cgit_print_error_page(404, "Not found", + "Not a tree object: %s", oid_to_hex(oid)); + return; + } + + ls_head(); + read_tree_recursive(the_repository, tree, "", 0, 1, + &paths, ls_item, walk_tree_ctx); + ls_tail(); +} + + +static int walk_tree(const struct object_id *oid, struct strbuf *base, + const char *pathname, unsigned mode, int stage, void *cbdata) +{ + struct walk_tree_context *walk_tree_ctx = cbdata; + + if (walk_tree_ctx->state == 0) { + struct strbuf buffer = STRBUF_INIT; + + strbuf_addbuf(&buffer, base); + strbuf_addstr(&buffer, pathname); + if (strcmp(walk_tree_ctx->match_path, buffer.buf)) + return READ_TREE_RECURSIVE; + + if (S_ISDIR(mode)) { + walk_tree_ctx->state = 1; + cgit_set_title_from_path(buffer.buf); + strbuf_release(&buffer); + ls_head(); + return READ_TREE_RECURSIVE; + } else { + walk_tree_ctx->state = 2; + print_object(oid, buffer.buf, pathname, walk_tree_ctx->curr_rev); + strbuf_release(&buffer); + return 0; + } + } + ls_item(oid, base, pathname, mode, stage, walk_tree_ctx); + return 0; +} + +/* + * Show a tree or a blob + * rev: the commit pointing at the root tree object + * path: path to tree or blob + */ +void cgit_print_tree(const char *rev, char *path) +{ + struct object_id oid; + struct commit *commit; + struct pathspec_item path_items = { + .match = path, + .len = path ? strlen(path) : 0 + }; + struct pathspec paths = { + .nr = path ? 1 : 0, + .items = &path_items + }; + struct walk_tree_context walk_tree_ctx = { + .match_path = path, + .state = 0 + }; + + if (!rev) + rev = ctx.qry.head; + + if (get_oid(rev, &oid)) { + cgit_print_error_page(404, "Not found", + "Invalid revision name: %s", rev); + return; + } + commit = lookup_commit_reference(the_repository, &oid); + if (!commit || parse_commit(commit)) { + cgit_print_error_page(404, "Not found", + "Invalid commit reference: %s", rev); + return; + } + + walk_tree_ctx.curr_rev = xstrdup(rev); + + if (path == NULL) { + ls_tree(&commit->maybe_tree->object.oid, NULL, &walk_tree_ctx); + goto cleanup; + } + + read_tree_recursive(the_repository, commit->maybe_tree, "", 0, 0, + &paths, walk_tree, &walk_tree_ctx); + if (walk_tree_ctx.state == 1) + ls_tail(); + else if (walk_tree_ctx.state == 2) + cgit_print_layout_end(); + else + cgit_print_error_page(404, "Not found", "Path not found"); + +cleanup: + free(walk_tree_ctx.curr_rev); +} diff --git a/third_party/cgit/ui-tree.h b/third_party/cgit/ui-tree.h new file mode 100644 index 0000000000..bbd34e3566 --- /dev/null +++ b/third_party/cgit/ui-tree.h @@ -0,0 +1,6 @@ +#ifndef UI_TREE_H +#define UI_TREE_H + +extern void cgit_print_tree(const char *rev, char *path); + +#endif /* UI_TREE_H */ diff --git a/third_party/cpp/googleapis/.cmake-format.py b/third_party/cpp/googleapis/.cmake-format.py new file mode 100644 index 0000000000..f6ceafc1aa --- /dev/null +++ b/third_party/cpp/googleapis/.cmake-format.py @@ -0,0 +1,42 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +tab_size = 4 +separate_ctrl_name_with_space = True + +additional_commands = { + "externalproject_add": { + "flags": [ + ], + "kwargs": { + "BUILD_COMMAND": "+", + "BUILD_BYPRODUCTS": "+", + "CMAKE_ARGS": "+", + "COMMAND": "+", + "CONFIGURE_COMMAND": "+", + "DEPENDS": "+", + "DOWNLOAD_COMMAND": "+", + "EXCLUDE_FROM_ALL": 1, + "INSTALL_COMMAND": "+", + "INSTALL_DIR": 1, + "LOG_BUILD": 1, + "LOG_CONFIGURE": 1, + "LOG_DOWNLOAD": 1, + "LOG_INSTALL": 1, + "PREFIX": 1, + "URL": 1, + "URL_HASH": 1, + } + } +} diff --git a/third_party/cpp/googleapis/.dockerignore b/third_party/cpp/googleapis/.dockerignore new file mode 100644 index 0000000000..4b7b2c0bd2 --- /dev/null +++ b/third_party/cpp/googleapis/.dockerignore @@ -0,0 +1,22 @@ +# Common build output directory names +.build/ +_build/ +build-output/ +cmake-out/ + +# Common bazel output directories +bazel-* + +# Backup files for Emacs +*~ + +# Ignore IDEA / IntelliJ files +.idea/ +cmake-build-*/ + +# This is a staging directory used to upload the documents to gihub.io +github-io-staging/ + +# Ignore Visual Studio Code files +.vsbuild/ +.vscode/ diff --git a/third_party/cpp/googleapis/.editorconfig b/third_party/cpp/googleapis/.editorconfig new file mode 100644 index 0000000000..0983572c65 --- /dev/null +++ b/third_party/cpp/googleapis/.editorconfig @@ -0,0 +1,22 @@ +# http://editorconfig.org + +root = true + +[*] +charset = utf-8 +indent_style = space + +[BUILD] +indent_size = 4 + +[CMakeLists.*] +indent_size = 4 + +[*.h,*.cc] +indent_size = 2 + +[*.md] +indent_size = 2 + +[*.sh] +indent_size = 2 diff --git a/third_party/cpp/googleapis/.gitignore b/third_party/cpp/googleapis/.gitignore new file mode 100644 index 0000000000..4b7b2c0bd2 --- /dev/null +++ b/third_party/cpp/googleapis/.gitignore @@ -0,0 +1,22 @@ +# Common build output directory names +.build/ +_build/ +build-output/ +cmake-out/ + +# Common bazel output directories +bazel-* + +# Backup files for Emacs +*~ + +# Ignore IDEA / IntelliJ files +.idea/ +cmake-build-*/ + +# This is a staging directory used to upload the documents to gihub.io +github-io-staging/ + +# Ignore Visual Studio Code files +.vsbuild/ +.vscode/ diff --git a/third_party/cpp/googleapis/CMakeLists.txt b/third_party/cpp/googleapis/CMakeLists.txt new file mode 100644 index 0000000000..90db9c71d8 --- /dev/null +++ b/third_party/cpp/googleapis/CMakeLists.txt @@ -0,0 +1,521 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +cmake_minimum_required(VERSION 3.5) + +# Define the project name and where to report bugs. +set(PACKAGE_BUGREPORT "https://github.com/googleapis/google-cloud-cpp/issues") +project(googleapis-cpp-protos CXX C) + +set(GOOGLEAPIS_CPP_PROTOS_VERSION_MAJOR 0) +set(GOOGLEAPIS_CPP_PROTOS_VERSION_MINOR 5) +set(GOOGLEAPIS_CPP_PROTOS_VERSION_PATCH 0) + +string( + CONCAT GOOGLE_APIS_CPP_PROTOS_VERSION + "${GOOGLEAPIS_CPP_PROTOS_VERSION_MAJOR}" + "." + "${GOOGLEAPIS_CPP_PROTOS_VERSION_MINOR}" + "." + "${GOOGLEAPIS_CPP_PROTOS_VERSION_PATCH}") + +# Configure the compiler options, we will be using C++11 features. +set(CMAKE_CXX_STANDARD 11) +set(CMAKE_CXX_STANDARD_REQUIRED ON) + +set(GOOGLEAPIS_CPP_SOURCE + "${CMAKE_BINARY_DIR}/external/googleapis/src/googleapis_download") + +set(GOOGLEAPIS_CPP_PROTO_FILES + "google/api/http.proto" + "google/api/annotations.proto" + "google/api/auth.proto" + "google/api/client.proto" + "google/api/field_behavior.proto" + "google/api/label.proto" + "google/api/launch_stage.proto" + "google/api/metric.proto" + "google/api/monitored_resource.proto" + "google/api/resource.proto" + "google/devtools/cloudtrace/v2/trace.proto" + "google/devtools/cloudtrace/v2/tracing.proto" + "google/type/expr.proto" + "google/rpc/error_details.proto" + "google/rpc/status.proto" + "google/iam/v1/options.proto" + "google/iam/v1/policy.proto" + "google/iam/v1/iam_policy.proto" + "google/longrunning/operations.proto" + "google/bigtable/admin/v2/bigtable_instance_admin.proto" + "google/bigtable/admin/v2/bigtable_table_admin.proto" + "google/bigtable/admin/v2/common.proto" + "google/bigtable/admin/v2/instance.proto" + "google/bigtable/admin/v2/table.proto" + "google/bigtable/v2/bigtable.proto" + "google/bigtable/v2/data.proto" + "google/cloud/bigquery/connection/v1beta1/connection.proto" + "google/cloud/bigquery/datatransfer/v1/datatransfer.proto" + "google/cloud/bigquery/datatransfer/v1/transfer.proto" + "google/cloud/bigquery/logging/v1/audit_data.proto" + "google/cloud/bigquery/storage/v1beta1/arrow.proto" + "google/cloud/bigquery/storage/v1beta1/avro.proto" + "google/cloud/bigquery/storage/v1beta1/read_options.proto" + "google/cloud/bigquery/storage/v1beta1/storage.proto" + "google/cloud/bigquery/storage/v1beta1/table_reference.proto" + "google/cloud/bigquery/v2/encryption_config.proto" + "google/cloud/bigquery/v2/model.proto" + "google/cloud/bigquery/v2/model_reference.proto" + "google/cloud/bigquery/v2/standard_sql.proto" + "google/pubsub/v1/pubsub.proto" + "google/spanner/admin/database/v1/spanner_database_admin.proto" + "google/spanner/admin/instance/v1/spanner_instance_admin.proto" + "google/spanner/v1/keys.proto" + "google/spanner/v1/mutation.proto" + "google/spanner/v1/query_plan.proto" + "google/spanner/v1/result_set.proto" + "google/spanner/v1/spanner.proto" + "google/spanner/v1/transaction.proto" + "google/spanner/v1/type.proto" + "google/storage/v1/storage.proto" + "google/storage/v1/storage_resources.proto" + "google/logging/type/http_request.proto" + "google/logging/type/log_severity.proto" + "google/logging/v2/log_entry.proto" + "google/logging/v2/logging.proto" + "google/logging/v2/logging_config.proto" + "google/logging/v2/logging_metrics.proto" +) + +set(GOOGLEAPIS_CPP_BYPRODUCTS) +foreach (proto ${GOOGLEAPIS_CPP_PROTO_FILES}) + list(APPEND GOOGLEAPIS_CPP_BYPRODUCTS "${GOOGLEAPIS_CPP_SOURCE}/${proto}") +endforeach () + +include(ExternalProject) +ExternalProject_Add( + googleapis_download + EXCLUDE_FROM_ALL ON + PREFIX "${CMAKE_BINARY_DIR}/external/googleapis" + URL $ENV{GOOGLEAPIS_DIR} + CONFIGURE_COMMAND "" + BUILD_COMMAND "" + INSTALL_COMMAND "" + BUILD_BYPRODUCTS ${GOOGLEAPIS_CPP_BYPRODUCTS} + LOG_DOWNLOAD OFF) + +list(APPEND CMAKE_MODULE_PATH "${PROJECT_SOURCE_DIR}/cmake") +find_package(ProtobufTargets REQUIRED) +find_package(gRPC REQUIRED) + +# Define the project name and where to report bugs. +set(PACKAGE_BUGREPORT "https://github.com/googleapis/google-cloud-cpp/issues") +project(googleapis-cpp-protos CXX C) + +set(GOOGLEAPIS_CPP_PROTOS_VERSION_MAJOR 0) +set(GOOGLEAPIS_CPP_PROTOS_VERSION_MINOR 5) +set(GOOGLEAPIS_CPP_PROTOS_VERSION_PATCH 0) + +string( + CONCAT GOOGLE_APIS_CPP_PROTOS_VERSION + "${GOOGLEAPIS_CPP_PROTOS_VERSION_MAJOR}" + "." + "${GOOGLEAPIS_CPP_PROTOS_VERSION_MINOR}" + "." + "${GOOGLEAPIS_CPP_PROTOS_VERSION_PATCH}") + +# Sometimes (this happens often with vcpkg) protobuf is installed in a non- +# standard directory. We need to find out where, and then add that directory to +# the search path for protos. +find_path(PROTO_INCLUDE_DIR google/protobuf/descriptor.proto) +if (PROTO_INCLUDE_DIR) + list(INSERT PROTOBUF_IMPORT_DIRS 0 "${PROTO_INCLUDE_DIR}") +endif () + +add_library(googleapis_cpp_common_flags INTERFACE) + +include(SelectMSVCRuntime) + +# Include the functions to compile proto files. +include(CompileProtos) + +google_cloud_cpp_add_protos_property() + +function (googleapis_cpp_short_name var proto) + string(REPLACE "google/" "" short_name "${proto}") + string(REPLACE "/" "_" short_name "${short_name}") + string(REPLACE ".proto" "_protos" short_name "${short_name}") + set("${var}" + "${short_name}" + PARENT_SCOPE) +endfunction () + +# Create a single source proto library. +# +# * proto: the filename for the proto source. +# * (optional) ARGN: proto libraries the new library depends on. +function (googleapis_cpp_add_library proto) + googleapis_cpp_short_name(short_name "${proto}") + google_cloud_cpp_grpcpp_library( + googleapis_cpp_${short_name} "${GOOGLEAPIS_CPP_SOURCE}/${proto}" + PROTO_PATH_DIRECTORIES "${GOOGLEAPIS_CPP_SOURCE}" + "${PROTO_INCLUDE_DIR}") + + googleapis_cpp_set_version_and_alias("${short_name}") + + set(public_deps) + foreach (dep_short_name ${ARGN}) + list(APPEND public_deps "googleapis-c++::${dep_short_name}") + endforeach () + list(LENGTH public_deps public_deps_length) + if (public_deps_length EQUAL 0) + target_link_libraries("googleapis_cpp_${short_name}" + PRIVATE googleapis_cpp_common_flags) + else () + target_link_libraries( + "googleapis_cpp_${short_name}" + PUBLIC ${public_deps} + PRIVATE googleapis_cpp_common_flags) + endif () +endfunction () + +function (googleapis_cpp_set_version_and_alias short_name) + add_dependencies("googleapis_cpp_${short_name}" googleapis_download) + set_target_properties( + "googleapis_cpp_${short_name}" + PROPERTIES VERSION "${GOOGLE_APIS_CPP_PROTOS_VERSION}" + SOVERSION ${GOOGLEAPIS_CPP_PROTOS_VERSION_MAJOR}) + add_library("googleapis-c++::${short_name}" ALIAS + "googleapis_cpp_${short_name}") +endfunction () + +googleapis_cpp_add_library("google/api/http.proto") +googleapis_cpp_add_library("google/api/metric.proto" api_launch_stage_protos + api_label_protos) +googleapis_cpp_add_library("google/api/monitored_resource.proto" + api_launch_stage_protos api_label_protos) +googleapis_cpp_add_library("google/api/annotations.proto" api_http_protos) +googleapis_cpp_add_library("google/api/auth.proto" api_annotations_protos) +googleapis_cpp_add_library("google/api/client.proto") +googleapis_cpp_add_library("google/api/distribution.proto" api_distribution_protos) +googleapis_cpp_add_library("google/api/field_behavior.proto") +googleapis_cpp_add_library("google/api/label.proto") +googleapis_cpp_add_library("google/api/launch_stage.proto") +googleapis_cpp_add_library("google/api/resource.proto") + +googleapis_cpp_add_library("google/type/expr.proto") + +googleapis_cpp_add_library("google/rpc/error_details.proto") +googleapis_cpp_add_library("google/rpc/status.proto" rpc_error_details_protos) + +googleapis_cpp_add_library("google/iam/v1/options.proto" api_annotations_protos) +googleapis_cpp_add_library("google/iam/v1/policy.proto" api_annotations_protos + type_expr_protos) + +googleapis_cpp_add_library( + "google/iam/v1/iam_policy.proto" + api_annotations_protos + api_client_protos + api_field_behavior_protos + api_resource_protos + iam_v1_options_protos + iam_v1_policy_protos) + +googleapis_cpp_add_library( + "google/longrunning/operations.proto" api_annotations_protos + api_client_protos rpc_status_protos) + +googleapis_cpp_add_library( + "google/devtools/cloudtrace/v2/trace.proto" api_annotations_protos + api_field_behavior_protos api_resource_protos rpc_status_protos) +googleapis_cpp_add_library( + "google/devtools/cloudtrace/v2/tracing.proto" + devtools_cloudtrace_v2_trace_protos api_annotations_protos + api_client_protos api_field_behavior_protos rpc_status_protos) + +google_cloud_cpp_grpcpp_library( + googleapis_cpp_cloud_bigquery_protos + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/connection/v1beta1/connection.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/datatransfer/v1/datatransfer.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/datatransfer/v1/transfer.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/logging/v1/audit_data.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/storage/v1beta1/arrow.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/storage/v1beta1/avro.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/storage/v1beta1/read_options.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/storage/v1beta1/storage.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/storage/v1beta1/table_reference.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/v2/encryption_config.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/v2/model.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/v2/model_reference.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/cloud/bigquery/v2/standard_sql.proto" + PROTO_PATH_DIRECTORIES + "${GOOGLEAPIS_CPP_SOURCE}" + "${PROTO_INCLUDE_DIR}") +googleapis_cpp_set_version_and_alias(cloud_bigquery_protos) +target_link_libraries( + googleapis_cpp_cloud_bigquery_protos + PUBLIC googleapis-c++::api_annotations_protos + googleapis-c++::api_client_protos + googleapis-c++::api_field_behavior_protos + googleapis-c++::api_resource_protos + googleapis-c++::iam_v1_iam_policy_protos + googleapis-c++::iam_v1_policy_protos + googleapis-c++::rpc_status_protos + googleapis-c++::api_http_protos + PRIVATE googleapis_cpp_common_flags) + +google_cloud_cpp_grpcpp_library( + googleapis_cpp_bigtable_protos + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/admin/v2/bigtable_instance_admin.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/admin/v2/bigtable_table_admin.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/admin/v2/common.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/admin/v2/instance.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/admin/v2/table.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/v2/bigtable.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/bigtable/v2/data.proto" + PROTO_PATH_DIRECTORIES + "${GOOGLEAPIS_CPP_SOURCE}" + "${PROTO_INCLUDE_DIR}") +googleapis_cpp_set_version_and_alias(bigtable_protos) +target_link_libraries( + googleapis_cpp_bigtable_protos + PUBLIC googleapis-c++::api_annotations_protos + googleapis-c++::api_client_protos + googleapis-c++::api_field_behavior_protos + googleapis-c++::api_resource_protos + googleapis-c++::iam_v1_iam_policy_protos + googleapis-c++::iam_v1_policy_protos + googleapis-c++::longrunning_operations_protos + googleapis-c++::rpc_status_protos + googleapis-c++::api_auth_protos + PRIVATE googleapis_cpp_common_flags) + +google_cloud_cpp_grpcpp_library( + googleapis_cpp_pubsub_protos + "${GOOGLEAPIS_CPP_SOURCE}/google/pubsub/v1/pubsub.proto" + PROTO_PATH_DIRECTORIES "${GOOGLEAPIS_CPP_SOURCE}" "${PROTO_INCLUDE_DIR}") +googleapis_cpp_set_version_and_alias(pubsub_protos) +target_link_libraries( + googleapis_cpp_pubsub_protos + PUBLIC googleapis-c++::api_annotations_protos + googleapis-c++::api_client_protos + googleapis-c++::api_field_behavior_protos + googleapis-c++::api_resource_protos + PRIVATE googleapis_cpp_common_flags) + +google_cloud_cpp_grpcpp_library( + googleapis_cpp_spanner_protos + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/admin/database/v1/spanner_database_admin.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/admin/instance/v1/spanner_instance_admin.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/keys.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/mutation.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/query_plan.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/result_set.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/spanner.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/transaction.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/spanner/v1/type.proto" + PROTO_PATH_DIRECTORIES + "${GOOGLEAPIS_CPP_SOURCE}" + "${PROTO_INCLUDE_DIR}") +googleapis_cpp_set_version_and_alias(spanner_protos) +target_link_libraries( + googleapis_cpp_spanner_protos + PUBLIC googleapis-c++::api_annotations_protos + googleapis-c++::api_client_protos + googleapis-c++::api_field_behavior_protos + googleapis-c++::api_resource_protos + googleapis-c++::iam_v1_iam_policy_protos + googleapis-c++::iam_v1_policy_protos + googleapis-c++::longrunning_operations_protos + googleapis-c++::rpc_status_protos + PRIVATE googleapis_cpp_common_flags) + +google_cloud_cpp_grpcpp_library( + googleapis_cpp_storage_protos + "${GOOGLEAPIS_CPP_SOURCE}/google/storage/v1/storage.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/storage/v1/storage_resources.proto" + PROTO_PATH_DIRECTORIES + "${GOOGLEAPIS_CPP_SOURCE}" + "${PROTO_INCLUDE_DIR}") +googleapis_cpp_set_version_and_alias(storage_protos) +target_link_libraries( + googleapis_cpp_storage_protos + PUBLIC googleapis-c++::api_annotations_protos + googleapis-c++::api_client_protos + googleapis-c++::api_field_behavior_protos + googleapis-c++::iam_v1_iam_policy_protos + googleapis-c++::iam_v1_policy_protos + PRIVATE googleapis_cpp_common_flags) + +google_cloud_cpp_grpcpp_library( + googleapis_cpp_logging_protos + "${GOOGLEAPIS_CPP_SOURCE}/google/logging/type/http_request.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/logging/type/log_severity.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/logging/v2/log_entry.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/logging/v2/logging.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/logging/v2/logging_config.proto" + "${GOOGLEAPIS_CPP_SOURCE}/google/logging/v2/logging_metrics.proto" + PROTO_PATH_DIRECTORIES + "${GOOGLEAPIS_CPP_SOURCE}" + "${PROTO_INCLUDE_DIR}") + +googleapis_cpp_set_version_and_alias(logging_protos) + +target_link_libraries( + googleapis_cpp_logging_protos + # TODO + PUBLIC googleapis-c++::api_annotations_protos + googleapis-c++::api_distribution_protos + PRIVATE googleapis_cpp_common_flags) + +# Install the libraries and headers in the locations determined by +# GNUInstallDirs +include(GNUInstallDirs) + +set(googleapis_cpp_installed_libraries_list + googleapis_cpp_bigtable_protos + googleapis_cpp_cloud_bigquery_protos + googleapis_cpp_pubsub_protos + googleapis_cpp_spanner_protos + googleapis_cpp_storage_protos + googleapis_cpp_logging_protos + googleapis_cpp_longrunning_operations_protos + googleapis_cpp_api_http_protos + googleapis_cpp_api_annotations_protos + googleapis_cpp_api_distribution_protos + googleapis_cpp_api_auth_protos + googleapis_cpp_api_client_protos + googleapis_cpp_api_field_behavior_protos + googleapis_cpp_api_resource_protos + googleapis_cpp_devtools_cloudtrace_v2_trace_protos + googleapis_cpp_devtools_cloudtrace_v2_tracing_protos + googleapis_cpp_iam_v1_options_protos + googleapis_cpp_iam_v1_policy_protos + googleapis_cpp_iam_v1_iam_policy_protos + googleapis_cpp_rpc_error_details_protos + googleapis_cpp_rpc_status_protos + googleapis_cpp_type_expr_protos) + +install( + TARGETS ${googleapis_cpp_installed_libraries_list} + googleapis_cpp_common_flags + EXPORT googleapis-targets + RUNTIME DESTINATION bin + LIBRARY DESTINATION ${CMAKE_INSTALL_LIBDIR} + ARCHIVE DESTINATION ${CMAKE_INSTALL_LIBDIR}) + +foreach (target ${googleapis_cpp_installed_libraries_list}) + google_cloud_cpp_install_proto_library_headers("${target}") + google_cloud_cpp_install_proto_library_protos("${target}" + "${GOOGLEAPIS_CPP_SOURCE}") +endforeach () + +# Export the CMake targets to make it easy to create configuration files. +install(EXPORT googleapis-targets + DESTINATION "${CMAKE_INSTALL_LIBDIR}/cmake/googleapis") + +# Setup global variables used in the following *.in files. +set(GOOGLE_CLOUD_CPP_CONFIG_VERSION_MAJOR + ${GOOGLEAPIS_CPP_PROTOS_VERSION_MAJOR}) +set(GOOGLE_CLOUD_CPP_CONFIG_VERSION_MINOR + ${GOOGLEAPIS_CPP_PROTOS_VERSION_MINOR}) +set(GOOGLE_CLOUD_CPP_CONFIG_VERSION_PATCH + ${GOOGLEAPIS_CPP_PROTOS_VERSION_PATCH}) + +# Use a function to create a scope for the variables. +function (googleapis_cpp_install_pc target) + string(REPLACE "googleapis_cpp_" "" _short_name ${target}) + string(REPLACE "_protos" "" _short_name ${_short_name}) + set(GOOGLE_CLOUD_CPP_PC_NAME + "The Google APIS C++ ${_short_name} Proto Library") + set(GOOGLE_CLOUD_CPP_PC_DESCRIPTION "Compiled proto for C++.") + # Examine the target LINK_LIBRARIES property, use that to pull the + # dependencies between the googleapis-c++::* libraries. + set(_target_pc_requires) + get_target_property(_target_deps ${target} LINK_LIBRARIES) + foreach (dep ${_target_deps}) + if ("${dep}" MATCHES "^googleapis-c\\+\\+::") + string(REPLACE "googleapis-c++::" "googleapis_cpp_" dep "${dep}") + list(APPEND _target_pc_requires " " "${dep}") + endif () + endforeach () + # These dependencies are required for all the googleapis-c++::* libraries. + list( + APPEND + _target_pc_requires + " grpc++" + " grpc" + " openssl" + " protobuf" + " zlib" + " libcares") + string(CONCAT GOOGLE_CLOUD_CPP_PC_REQUIRES ${_target_pc_requires}) + set(GOOGLE_CLOUD_CPP_PC_LIBS "-l${target}") + configure_file("cmake/config.pc.in" "${target}.pc" @ONLY) + install(FILES "${CMAKE_CURRENT_BINARY_DIR}/${target}.pc" + DESTINATION "${CMAKE_INSTALL_LIBDIR}/pkgconfig") +endfunction () + +# Create and install the pkg-config files. +foreach (target ${googleapis_cpp_installed_libraries_list}) + googleapis_cpp_install_pc("${target}") +endforeach () + +# Create and install the googleapis pkg-config file for backwards compatibility. +set(GOOGLE_CLOUD_CPP_PC_NAME "The Google APIS C++ Proto Library") +set(GOOGLE_CLOUD_CPP_PC_DESCRIPTION + "Provides C++ APIs to access Google Cloud Platforms.") +# Note the use of spaces, `string(JOIN)` is not available in cmake-3.5, so we +# need to add the separator ourselves. +string( + CONCAT GOOGLE_CLOUD_CPP_PC_REQUIRES + "googleapis_cpp_bigtable_protos" + " googleapis_cpp_cloud_bigquery_protos" + " googleapis_pubsub_protos" + " googleapis_cpp_storage_protos" + " googleapis_cpp_iam_v1_iam_policy_protos" + " googleapis_cpp_iam_v1_options_protos" + " googleapis_cpp_iam_v1_policy_protos" + " googleapis_cpp_logging_protos" + " googleapis_cpp_longrunning_operations_protos" + " googleapis_cpp_api_auth_protos" + " googleapis_cpp_api_annotations_protos" + " googleapis_cpp_api_client_protos" + " googleapis_cpp_api_field_behavior_protos" + " googleapis_cpp_api_http_protos" + " googleapis_cpp_rpc_status_protos" + " googleapis_cpp_rpc_error_details_protos" + " grpc++" + " grpc" + " openssl" + " protobuf" + " zlib" + " libcares") +set(GOOGLE_CLOUD_CPP_PC_LIBS "") +configure_file("cmake/config.pc.in" "googleapis.pc" @ONLY) +install(FILES "${CMAKE_CURRENT_BINARY_DIR}/googleapis.pc" + DESTINATION "${CMAKE_INSTALL_LIBDIR}/pkgconfig") + +# Create and install the CMake configuration files. +configure_file("cmake/config.cmake.in" "googleapis-config.cmake" @ONLY) +configure_file("cmake/config-version.cmake.in" + "googleapis-config-version.cmake" @ONLY) +install( + FILES "${CMAKE_CURRENT_BINARY_DIR}/googleapis-config.cmake" + "${CMAKE_CURRENT_BINARY_DIR}/googleapis-config-version.cmake" + "${PROJECT_SOURCE_DIR}/cmake/FindgRPC.cmake" + "${PROJECT_SOURCE_DIR}/cmake/FindProtobufTargets.cmake" + "${PROJECT_SOURCE_DIR}/cmake/CompileProtos.cmake" + DESTINATION "${CMAKE_INSTALL_LIBDIR}/cmake/googleapis") diff --git a/third_party/cpp/googleapis/CONTRIBUTING.md b/third_party/cpp/googleapis/CONTRIBUTING.md new file mode 100644 index 0000000000..33497a3798 --- /dev/null +++ b/third_party/cpp/googleapis/CONTRIBUTING.md @@ -0,0 +1,55 @@ +# How to become a contributor and submit your own code + +## Contributor License Agreements + +We'd love to accept your patches! Before we can take them, we +have to jump a couple of legal hurdles. + +Please fill out either the individual or corporate Contributor License Agreement +(CLA). + + * If you are an individual writing original source code and you're sure you + own the intellectual property, then you'll need to sign an + [individual CLA](https://developers.google.com/open-source/cla/individual). + * If you work for a company that wants to allow you to contribute your work, + then you'll need to sign a + [corporate CLA](https://developers.google.com/open-source/cla/corporate). + +Follow either of the two links above to access the appropriate CLA and +instructions for how to sign and return it. Once we receive it, we'll be able to +accept your pull requests. + +## Contributing A Patch + +1. Submit an issue describing your proposed change to the repo in question. +1. The repo owner will respond to your issue promptly. +1. If your proposed change is accepted, and you haven't already done so, sign a + Contributor License Agreement (see details above). +1. Fork the desired repo, develop and test your code changes. +1. Ensure that your code adheres to the existing style in the sample to which + you are contributing. +1. Ensure that your code has an appropriate set of unit tests which all pass. +1. Submit a pull request. + +## Style + +This repository follow the [Google C++ Style Guide]( +https://google.github.io/styleguide/cppguide.html). +Please make sure your contributions adhere to the style guide. + +### Formatting + +The code in this project is formatted with `clang-format(1)`, and our CI builds +will check that the code matches the format generated by this tool before +accepting a pull request. Please configure your editor or IDE to use the Google +style for indentation and other whitespace. If you need to reformat one or more +files, you can simply run `clang-format` manually: + +```console +$ clang-format -i <file>.... +``` + +If you need to reformat one of the files to match the Google style. Please be +advised that `clang-format` has been known to generate slightly different +formatting in different versions. We use version 7; use the same version if you +run into problems. diff --git a/third_party/cpp/googleapis/LICENSE b/third_party/cpp/googleapis/LICENSE new file mode 100644 index 0000000000..261eeb9e9f --- /dev/null +++ b/third_party/cpp/googleapis/LICENSE @@ -0,0 +1,201 @@ + Apache License + Version 2.0, January 2004 + http://www.apache.org/licenses/ + + TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION + + 1. Definitions. + + "License" shall mean the terms and conditions for use, reproduction, + and distribution as defined by Sections 1 through 9 of this document. + + "Licensor" shall mean the copyright owner or entity authorized by + the copyright owner that is granting the License. + + "Legal Entity" shall mean the union of the acting entity and all + other entities that control, are controlled by, or are under common + control with that entity. For the purposes of this definition, + "control" means (i) the power, direct or indirect, to cause the + direction or management of such entity, whether by contract or + otherwise, or (ii) ownership of fifty percent (50%) or more of the + outstanding shares, or (iii) beneficial ownership of such entity. + + "You" (or "Your") shall mean an individual or Legal Entity + exercising permissions granted by this License. + + "Source" form shall mean the preferred form for making modifications, + including but not limited to software source code, documentation + source, and configuration files. + + "Object" form shall mean any form resulting from mechanical + transformation or translation of a Source form, including but + not limited to compiled object code, generated documentation, + and conversions to other media types. + + "Work" shall mean the work of authorship, whether in Source or + Object form, made available under the License, as indicated by a + copyright notice that is included in or attached to the work + (an example is provided in the Appendix below). + + "Derivative Works" shall mean any work, whether in Source or Object + form, that is based on (or derived from) the Work and for which the + editorial revisions, annotations, elaborations, or other modifications + represent, as a whole, an original work of authorship. For the purposes + of this License, Derivative Works shall not include works that remain + separable from, or merely link (or bind by name) to the interfaces of, + the Work and Derivative Works thereof. + + "Contribution" shall mean any work of authorship, including + the original version of the Work and any modifications or additions + to that Work or Derivative Works thereof, that is intentionally + submitted to Licensor for inclusion in the Work by the copyright owner + or by an individual or Legal Entity authorized to submit on behalf of + the copyright owner. For the purposes of this definition, "submitted" + means any form of electronic, verbal, or written communication sent + to the Licensor or its representatives, including but not limited to + communication on electronic mailing lists, source code control systems, + and issue tracking systems that are managed by, or on behalf of, the + Licensor for the purpose of discussing and improving the Work, but + excluding communication that is conspicuously marked or otherwise + designated in writing by the copyright owner as "Not a Contribution." + + "Contributor" shall mean Licensor and any individual or Legal Entity + on behalf of whom a Contribution has been received by Licensor and + subsequently incorporated within the Work. + + 2. Grant of Copyright License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + copyright license to reproduce, prepare Derivative Works of, + publicly display, publicly perform, sublicense, and distribute the + Work and such Derivative Works in Source or Object form. + + 3. Grant of Patent License. Subject to the terms and conditions of + this License, each Contributor hereby grants to You a perpetual, + worldwide, non-exclusive, no-charge, royalty-free, irrevocable + (except as stated in this section) patent license to make, have made, + use, offer to sell, sell, import, and otherwise transfer the Work, + where such license applies only to those patent claims licensable + by such Contributor that are necessarily infringed by their + Contribution(s) alone or by combination of their Contribution(s) + with the Work to which such Contribution(s) was submitted. If You + institute patent litigation against any entity (including a + cross-claim or counterclaim in a lawsuit) alleging that the Work + or a Contribution incorporated within the Work constitutes direct + or contributory patent infringement, then any patent licenses + granted to You under this License for that Work shall terminate + as of the date such litigation is filed. + + 4. Redistribution. You may reproduce and distribute copies of the + Work or Derivative Works thereof in any medium, with or without + modifications, and in Source or Object form, provided that You + meet the following conditions: + + (a) You must give any other recipients of the Work or + Derivative Works a copy of this License; and + + (b) You must cause any modified files to carry prominent notices + stating that You changed the files; and + + (c) You must retain, in the Source form of any Derivative Works + that You distribute, all copyright, patent, trademark, and + attribution notices from the Source form of the Work, + excluding those notices that do not pertain to any part of + the Derivative Works; and + + (d) If the Work includes a "NOTICE" text file as part of its + distribution, then any Derivative Works that You distribute must + include a readable copy of the attribution notices contained + within such NOTICE file, excluding those notices that do not + pertain to any part of the Derivative Works, in at least one + of the following places: within a NOTICE text file distributed + as part of the Derivative Works; within the Source form or + documentation, if provided along with the Derivative Works; or, + within a display generated by the Derivative Works, if and + wherever such third-party notices normally appear. The contents + of the NOTICE file are for informational purposes only and + do not modify the License. You may add Your own attribution + notices within Derivative Works that You distribute, alongside + or as an addendum to the NOTICE text from the Work, provided + that such additional attribution notices cannot be construed + as modifying the License. + + You may add Your own copyright statement to Your modifications and + may provide additional or different license terms and conditions + for use, reproduction, or distribution of Your modifications, or + for any such Derivative Works as a whole, provided Your use, + reproduction, and distribution of the Work otherwise complies with + the conditions stated in this License. + + 5. Submission of Contributions. Unless You explicitly state otherwise, + any Contribution intentionally submitted for inclusion in the Work + by You to the Licensor shall be under the terms and conditions of + this License, without any additional terms or conditions. + Notwithstanding the above, nothing herein shall supersede or modify + the terms of any separate license agreement you may have executed + with Licensor regarding such Contributions. + + 6. Trademarks. This License does not grant permission to use the trade + names, trademarks, service marks, or product names of the Licensor, + except as required for reasonable and customary use in describing the + origin of the Work and reproducing the content of the NOTICE file. + + 7. Disclaimer of Warranty. Unless required by applicable law or + agreed to in writing, Licensor provides the Work (and each + Contributor provides its Contributions) on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or + implied, including, without limitation, any warranties or conditions + of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A + PARTICULAR PURPOSE. You are solely responsible for determining the + appropriateness of using or redistributing the Work and assume any + risks associated with Your exercise of permissions under this License. + + 8. Limitation of Liability. In no event and under no legal theory, + whether in tort (including negligence), contract, or otherwise, + unless required by applicable law (such as deliberate and grossly + negligent acts) or agreed to in writing, shall any Contributor be + liable to You for damages, including any direct, indirect, special, + incidental, or consequential damages of any character arising as a + result of this License or out of the use or inability to use the + Work (including but not limited to damages for loss of goodwill, + work stoppage, computer failure or malfunction, or any and all + other commercial damages or losses), even if such Contributor + has been advised of the possibility of such damages. + + 9. Accepting Warranty or Additional Liability. While redistributing + the Work or Derivative Works thereof, You may choose to offer, + and charge a fee for, acceptance of support, warranty, indemnity, + or other liability obligations and/or rights consistent with this + License. However, in accepting such obligations, You may act only + on Your own behalf and on Your sole responsibility, not on behalf + of any other Contributor, and only if You agree to indemnify, + defend, and hold each Contributor harmless for any liability + incurred by, or claims asserted against, such Contributor by reason + of your accepting any such warranty or additional liability. + + END OF TERMS AND CONDITIONS + + APPENDIX: How to apply the Apache License to your work. + + To apply the Apache License to your work, attach the following + boilerplate notice, with the fields enclosed by brackets "[]" + replaced with your own identifying information. (Don't include + the brackets!) The text should be enclosed in the appropriate + comment syntax for the file format. We also recommend that a + file or class name and description of purpose be included on the + same "printed page" as the copyright notice for easier + identification within third-party archives. + + Copyright [yyyy] [name of copyright owner] + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and + limitations under the License. diff --git a/third_party/cpp/googleapis/README.md b/third_party/cpp/googleapis/README.md new file mode 100644 index 0000000000..5c2a711938 --- /dev/null +++ b/third_party/cpp/googleapis/README.md @@ -0,0 +1,68 @@ +# Google Cloud Platform C++ Proto Libraries + +Compile the protocol buffer definitions into C++ libraries. + +## Requirements + +#### Compiler + +The Google Cloud C++ libraries are tested with the following compilers: + +| Compiler | Minimum Version | +| ----------- | --------------- | +| GCC | 4.8 | +| Clang | 3.8 | +| MSVC++ | 14.1 | +| Apple Clang | 8.1 | + +#### Build Tools + +The Google Cloud C++ Client Libraries can be built with +[CMake](https://cmake.org) or [Bazel](https://bazel.io). The minimal versions +of these tools we test with are: + +| Tool | Minimum Version | +| ---------- | --------------- | +| CMake | 3.5 | +| Bazel | 0.24.0 | + +#### Libraries + +The libraries also depend on gRPC, libcurl, and the dependencies of those +libraries. The Google Cloud C++ Client libraries are tested with the following +versions of these dependencies: + +| Library | Minimum version | +| ------- | --------------- | +| gRPC | v1.16.x | +| libcurl | 7.47.0 | + + +## Versioning + +Please note that the Google Cloud C++ client libraries do **not** follow +[Semantic Versioning](http://semver.org/). + +**GA**: Libraries defined at a GA quality level are expected to be stable and +any backwards-incompatible changes will be noted in the documentation. Major +changes to the API will signaled by changing major version number +(e.g. 1.x.y -> 2.0.0). + +**Beta**: Libraries defined at a Beta quality level are expected to be mostly +stable and we're working towards their release candidate. We will address issues +and requests with a higher priority. + +**Alpha**: Libraries defined at an Alpha quality level are still a +work-in-progress and are more likely to get backwards-incompatible updates. +Additionally, it's possible for Alpha libraries to get deprecated and deleted +before ever being promoted to Beta or GA. + +## Contributing changes + +See [`CONTRIBUTING.md`](CONTRIBUTING.md) for details on how to contribute to +this project, including how to build and test your changes as well as how to +properly format your code. + +## Licensing + +Apache 2.0; see [`LICENSE`](LICENSE) for details. diff --git a/third_party/cpp/googleapis/ci/check-style.sh b/third_party/cpp/googleapis/ci/check-style.sh new file mode 100755 index 0000000000..9fe61bf034 --- /dev/null +++ b/third_party/cpp/googleapis/ci/check-style.sh @@ -0,0 +1,81 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -eu + +if [[ "${CHECK_STYLE}" != "yes" ]]; then + echo "Skipping code style check as it is disabled for this build." + exit 0 +fi + +# This script assumes it is running the top-level google-cloud-cpp directory. + +readonly BINDIR="$(dirname "$0")" + +# Build paths to ignore in find(1) commands by reading .gitignore. +declare -a ignore=( -path ./.git ) +if [[ -f .gitignore ]]; then + while read -r line; do + case "${line}" in + [^#]*/*) ignore+=( -o -path "./$(expr "${line}" : '\(.*\)/')" ) ;; + [^#]*) ignore+=( -o -name "${line}" ) ;; + esac + done < .gitignore +fi + +replace_original_if_changed() { + if [[ $# != 2 ]]; then + return 1 + fi + + local original="$1" + local reformatted="$2" + + if cmp -s "${original}" "${reformatted}"; then + rm -f "${reformatted}" + else + chmod --reference="${original}" "${reformatted}" + mv -f "${reformatted}" "${original}" + fi +} + +# Apply cmake_format to all the CMake list files. +# https://github.com/cheshirekow/cmake_format +find . \( "${ignore[@]}" \) -prune -o \ + \( -name 'CMakeLists.txt' -o -name '*.cmake' \) \ + -print0 | + while IFS= read -r -d $'\0' file; do + cmake-format "${file}" >"${file}.tmp" + replace_original_if_changed "${file}" "${file}.tmp" + done + +# Apply buildifier to fix the BUILD and .bzl formatting rules. +# https://github.com/bazelbuild/buildtools/tree/master/buildifier +find . \( "${ignore[@]}" \) -prune -o \ + \( -name BUILD -o -name '*.bzl' \) \ + -print0 | + xargs -0 buildifier -mode=fix + +# Apply shellcheck(1) to emit warnings for common scripting mistakes. +find . \( "${ignore[@]}" \) -prune -o \ + -iname '*.sh' -exec shellcheck \ + --exclude=SC1090 \ + --exclude=SC2034 \ + --exclude=SC2153 \ + --exclude=SC2181 \ + '{}' \; + +# Report any differences created by running the formatting tools. +git diff --ignore-submodules=all --color --exit-code . diff --git a/third_party/cpp/googleapis/ci/colors.sh b/third_party/cpp/googleapis/ci/colors.sh new file mode 100755 index 0000000000..23acd8e03d --- /dev/null +++ b/third_party/cpp/googleapis/ci/colors.sh @@ -0,0 +1,28 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +if [ -z "${COLOR_RESET+x}" ]; then + if type tput >/dev/null 2>&1; then + readonly COLOR_RED="$(tput setaf 1)" + readonly COLOR_GREEN="$(tput setaf 2)" + readonly COLOR_YELLOW="$(tput setaf 3)" + readonly COLOR_RESET="$(tput sgr0)" + else + readonly COLOR_RED="" + readonly COLOR_GREEN="" + readonly COLOR_YELLOW="" + readonly COLOR_RESET="" + fi +fi diff --git a/third_party/cpp/googleapis/ci/install-grpc.sh b/third_party/cpp/googleapis/ci/install-grpc.sh new file mode 100755 index 0000000000..759b355bb5 --- /dev/null +++ b/third_party/cpp/googleapis/ci/install-grpc.sh @@ -0,0 +1,41 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -eu + +mkdir -p /var/tmp/Downloads +cd /var/tmp/Downloads + +# Install protobuf +wget -q https://github.com/google/protobuf/archive/v3.8.0.tar.gz +tar -xf v3.8.0.tar.gz +(cd protobuf-3.8.0/cmake; + cmake \ + -DCMAKE_BUILD_TYPE=Release \ + -DBUILD_SHARED_LIBS=yes \ + -Dprotobuf_BUILD_TESTS=OFF \ + -H. -Bcmake-out + cmake --build cmake-out --target install -- -j "$(nproc)" + ldconfig +) + +# Install grpc +wget -q https://github.com/grpc/grpc/archive/v1.22.0.tar.gz +tar -xf v1.22.0.tar.gz +(cd grpc-1.22.0; + make -j "$(nproc)" + make install + ldconfig +) diff --git a/third_party/cpp/googleapis/ci/kokoro/Dockerfile.centos b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.centos new file mode 100644 index 0000000000..2982dae0e1 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.centos @@ -0,0 +1,51 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +ARG DISTRO_VERSION=7 +FROM centos:${DISTRO_VERSION} + +# Add /usr/local/lib + +# Search paths tweak for the build +ENV PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:/usr/local/lib64/pkgconfig +ENV LD_LIBRARY_PATH=/usr/local/lib:/usr/local/lib64 +ENV PATH=/usr/local/bin:${PATH} + +# First install the development tools and OpenSSL. The development tools +# distributed with CentOS (notably CMake) are too old to build +# `google-cloud-cpp`. In these instructions, we use `cmake3` obtained from +# [Software Collections](https://www.softwarecollections.org/). + +RUN rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm +RUN yum install -y centos-release-scl +RUN yum-config-manager --enable rhel-server-rhscl-7-rpms +RUN yum makecache && \ + yum install -y automake cmake3 curl-devel gcc gcc-c++ git libtool \ + make openssl-devel pkgconfig tar wget which zlib-devel +RUN ln -sf /usr/bin/cmake3 /usr/bin/cmake && ln -sf /usr/bin/ctest3 /usr/bin/ctest + +# Install c-ares +RUN mkdir -p /var/tmp/Downloads; \ + cd /var/tmp/Downloads; \ + wget -q https://github.com/c-ares/c-ares/archive/cares-1_15_0.tar.gz; \ + tar -xf cares-1_15_0.tar.gz; \ + cd /var/tmp/Downloads/c-ares-cares-1_15_0; \ + ./buildconf && ./configure && make -j $(nproc); \ + make install; \ + ldconfig + +# Install grpc from source +WORKDIR /var/tmp/ci +COPY install-grpc.sh /var/tmp/ci +RUN /var/tmp/ci/install-grpc.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/Dockerfile.fedora b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.fedora new file mode 100644 index 0000000000..c56ace3b1a --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.fedora @@ -0,0 +1,38 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +ARG DISTRO_VERSION=30 +FROM fedora:${DISTRO_VERSION} + +# Fedora includes packages for gRPC, libcurl, and OpenSSL that are recent enough +# for `google-cloud-cpp`. Install these packages and additional development +# tools to compile the dependencies: +RUN dnf makecache && \ + dnf install -y clang clang-tools-extra cmake doxygen findutils gcc-c++ git \ + grpc-devel grpc-plugins libcxx-devel libcxxabi-devel libcurl-devel \ + make openssl-devel pkgconfig protobuf-compiler python-pip ShellCheck \ + tar wget zlib-devel + +# Install the the buildifier tool, which does not compile with the default +# golang compiler for Ubuntu 16.04 and Ubuntu 18.04. +RUN wget -q -O /usr/bin/buildifier https://github.com/bazelbuild/buildtools/releases/download/0.17.2/buildifier +RUN chmod 755 /usr/bin/buildifier + +# Install cmake_format to automatically format the CMake list files. +# https://github.com/cheshirekow/cmake_format +# Pin this to an specific version because the formatting changes when the +# "latest" version is updated, and we do not want the builds to break just +# because some third party changed something. +RUN pip install --upgrade pip +RUN pip install numpy cmake_format==0.6.9 diff --git a/third_party/cpp/googleapis/ci/kokoro/Dockerfile.ubuntu-16.04 b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.ubuntu-16.04 new file mode 100644 index 0000000000..8ef65dd9b2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.ubuntu-16.04 @@ -0,0 +1,53 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM ubuntu:16.04 + +RUN apt update && \ + apt install -y \ + automake \ + build-essential \ + clang \ + cmake \ + curl \ + doxygen \ + gawk \ + git \ + gcc \ + golang \ + g++ \ + libssl-dev \ + libtool \ + make \ + ninja-build \ + pkg-config \ + python-pip \ + shellcheck \ + tar \ + unzip \ + wget \ + zlib1g-dev + +WORKDIR /var/tmp/Downloads +RUN wget -q https://github.com/c-ares/c-ares/archive/cares-1_15_0.tar.gz && \ + tar -xf cares-1_15_0.tar.gz && \ + cd /var/tmp/Downloads/c-ares-cares-1_15_0 && \ + ./buildconf && ./configure && make -j $(nproc) && \ + make install && \ + ldconfig + +# Install grpc from source +WORKDIR /var/tmp/ci +COPY install-grpc.sh /var/tmp/ci +RUN /var/tmp/ci/install-grpc.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/Dockerfile.ubuntu-18.04 b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.ubuntu-18.04 new file mode 100644 index 0000000000..d3660dafa2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/Dockerfile.ubuntu-18.04 @@ -0,0 +1,45 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM ubuntu:18.04 + +RUN apt update && \ + apt install -y \ + build-essential \ + clang \ + cmake \ + curl \ + doxygen \ + gawk \ + git \ + gcc \ + golang \ + g++ \ + libc-ares-dev \ + libc-ares2 \ + libssl-dev \ + make \ + ninja-build \ + pkg-config \ + python-pip \ + shellcheck \ + tar \ + unzip \ + wget \ + zlib1g-dev + +# Install grpc from source +WORKDIR /var/tmp/ci +COPY install-grpc.sh /var/tmp/ci +RUN /var/tmp/ci/install-grpc.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/build-in-docker-cmake.sh b/third_party/cpp/googleapis/ci/kokoro/docker/build-in-docker-cmake.sh new file mode 100755 index 0000000000..4dd9e7eb3d --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/build-in-docker-cmake.sh @@ -0,0 +1,112 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -eu + +if [[ $# != 2 ]]; then + echo "Usage: $(basename "$0") <source-directory> <binary-directory>" + exit 1 +fi + +readonly SOURCE_DIR="$1" +readonly BINARY_DIR="$2" + +# This script is supposed to run inside a Docker container, see +# ci/kokoro/cmake/installed-dependencies/build.sh for the expected setup. The +# /v directory is a volume pointing to a (clean-ish) checkout of the project: +if [[ -z "${PROJECT_ROOT+x}" ]]; then + readonly PROJECT_ROOT="/v" +fi +source "${PROJECT_ROOT}/ci/colors.sh" + +echo +echo "${COLOR_YELLOW}Starting docker build $(date) with $(nproc) cores${COLOR_RESET}" +echo + +echo "================================================================" +echo "Verify formatting $(date)" +(cd "${PROJECT_ROOT}" ; ./ci/check-style.sh) +echo "================================================================" + +echo "================================================================" +echo "Compiling on $(date)" +echo "================================================================" +cd "${PROJECT_ROOT}" +cmake_flags=() +if [[ "${CLANG_TIDY:-}" = "yes" ]]; then + cmake_flags+=("-DGOOGLE_CLOUD_CPP_CLANG_TIDY=yes") +fi +if [[ "${GOOGLE_CLOUD_CPP_CXX_STANDARD:-}" != "" ]]; then + cmake_flags+=( + "-DGOOGLE_CLOUD_CPP_CXX_STANDARD=${GOOGLE_CLOUD_CPP_CXX_STANDARD}") +fi + +if [[ "${CODE_COVERAGE:-}" == "yes" ]]; then + cmake_flags+=( + "-DCMAKE_BUILD_TYPE=Coverage") +fi + +if [[ "${USE_NINJA:-}" == "yes" ]]; then + cmake_flags+=( "-GNinja" ) +fi + +# Avoid unbound variable error with older bash +if [[ "${#cmake_flags[@]}" == 0 ]]; then + cmake "-H${SOURCE_DIR}" "-B${BINARY_DIR}" +else + cmake "-H${SOURCE_DIR}" "-B${BINARY_DIR}" "${cmake_flags[@]}" +fi +cmake --build "${BINARY_DIR}" -- -j "$(nproc)" + +# When user a super-build the tests are hidden in a subdirectory. We can tell +# that ${BINARY_DIR} does not have the tests by checking for this file: +if [[ -r "${BINARY_DIR}/CTestTestfile.cmake" ]]; then + echo "================================================================" + # It is Okay to skip the tests in this case because the super build + # automatically runs them. + echo "Running the unit tests $(date)" + env -C "${BINARY_DIR}" ctest \ + -LE integration-tests \ + --output-on-failure -j "$(nproc)" + echo "================================================================" +fi + +if [[ "${GENERATE_DOCS:-}" = "yes" ]]; then + echo "================================================================" + echo "Validate Doxygen documentation $(date)" + cmake --build "${BINARY_DIR}" --target doxygen-docs + echo "================================================================" +fi + +if [[ ${RUN_INTEGRATION_TESTS} == "yes" ]]; then + echo "================================================================" + echo "Running the integration tests $(date)" + echo "================================================================" + # shellcheck disable=SC1091 + source /c/spanner-integration-tests-config.sh + export GOOGLE_APPLICATION_CREDENTIALS=/c/spanner-credentials.json + + # Run the integration tests too. + env -C "${BINARY_DIR}" ctest \ + -L integration-tests \ + --output-on-failure + echo "================================================================" +fi + +echo "================================================================" +echo "Build finished at $(date)" +echo "================================================================" + +exit 0 diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/build.sh b/third_party/cpp/googleapis/ci/kokoro/docker/build.sh new file mode 100755 index 0000000000..fbd886f028 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/build.sh @@ -0,0 +1,272 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -eu + +export CC=gcc +export CXX=g++ +export DISTRO=ubuntu +export DISTRO_VERSION=18.04 +export CMAKE_SOURCE_DIR="." + +in_docker_script="ci/kokoro/docker/build-in-docker-cmake.sh" + +if [[ $# -eq 1 ]]; then + export BUILD_NAME="${1}" +elif [[ -n "${KOKORO_JOB_NAME:-}" ]]; then + # Kokoro injects the KOKORO_JOB_NAME environment variable, the value of this + # variable is cloud-cpp/spanner/<config-file-name-without-cfg> (or more + # generally <path/to/config-file-without-cfg>). By convention we name these + # files `$foo.cfg` for continuous builds and `$foo-presubmit.cfg` for + # presubmit builds. Here we extract the value of "foo" and use it as the build + # name. + BUILD_NAME="$(basename "${KOKORO_JOB_NAME}" "-presubmit")" + export BUILD_NAME +else + echo "Aborting build as the build name is not defined." + echo "If you are invoking this script via the command line use:" + echo " $0 <build-name>" + echo + echo "If this script is invoked by Kokoro, the CI system is expected to set" + echo "the KOKORO_JOB_NAME environment variable." + exit 1 +fi + +if [[ "${BUILD_NAME}" = "clang-tidy" ]]; then + # Compile with clang-tidy(1) turned on. The build treats clang-tidy warnings + # as errors. + export DISTRO=fedora + export DISTRO_VERSION=30 + export CC=clang + export CXX=clang++ + export CHECK_STYLE=yes + export CLANG_TIDY=yes +elif [[ "${BUILD_NAME}" = "ubuntu-18.04" ]]; then + export CC=gcc + export CXX=g++ +elif [[ "${BUILD_NAME}" = "ubuntu-16.04" ]]; then + export DISTRO_VERSION=16.04 + export CC=gcc + export CXX=g++ +elif [[ "${BUILD_NAME}" = "gcc-4.8" ]]; then + # The oldest version of GCC we support is 4.8, this build checks the code + # against that version. The use of CentOS 7 for that build is not a + # coincidence: the reason we support GCC 4.8 is to support this distribution + # (and its commercial cousin: RHEL 7). + export CC=gcc + export CXX=g++ + export DISTRO=centos + export DISTRO_VERSION=7 +elif [[ "${BUILD_NAME}" = "clang-3.8" ]]; then + # The oldest version of Clang we actively test is 3.8. There is nothing + # particularly interesting about that version. It is simply the version + # included with Ubuntu:16.04, and the oldest version tested by + # google-cloud-cpp. + export DISTRO=ubuntu + export DISTRO_VERSION=16.04 + export CC=clang + export CXX=clang++ +elif [[ "${BUILD_NAME}" = "ninja" ]]; then + # Compiling with Ninja can catch bugs that may not be caught using Make. + export USE_NINJA=yes +else + echo "Unknown BUILD_NAME (${BUILD_NAME}). Fix the Kokoro .cfg file." + exit 1 +fi + +if [[ -z "${PROJECT_ROOT+x}" ]]; then + readonly PROJECT_ROOT="$(cd "$(dirname "$0")/../../.."; pwd)" +fi + +if [[ -z "${PROJECT_ID+x}" ]]; then + readonly PROJECT_ID="cloud-devrel-kokoro-resources" +fi + +# Determine the image name. +readonly IMAGE="gcr.io/${PROJECT_ID}/cpp-cmakefiles/${DISTRO}-${DISTRO_VERSION}" +readonly BUILD_OUTPUT="cmake-out/${BUILD_NAME}" +readonly BUILD_HOME="cmake-out/home/${BUILD_NAME}" + +echo "================================================================" +cd "${PROJECT_ROOT}" +echo "Building with $(nproc) cores $(date) on ${PWD}." + +echo "================================================================" +echo "Capture Docker version to troubleshoot $(date)." +docker version +echo "================================================================" + +has_cache="false" + +if [[ -n "${KOKORO_JOB_NAME:-}" ]]; then + # Download the docker image from the previous build on kokoro for speed. + echo "================================================================" + echo "Downloading Docker image $(date)." + gcloud auth configure-docker + if docker pull "${IMAGE}:latest"; then + echo "Existing image successfully downloaded." + has_cache="true" + fi + echo "================================================================" +fi + +docker_build_flags=( + "-t" "${IMAGE}:latest" +) + +if [[ -f "ci/kokoro/Dockerfile.${DISTRO}-${DISTRO_VERSION}" ]]; then + docker_build_flags+=("-f" "ci/kokoro/Dockerfile.${DISTRO}-${DISTRO_VERSION}") +else + docker_build_flags+=( + "-f" "ci/kokoro/Dockerfile.${DISTRO}" + "--build-arg" "DISTRO_VERSION=${DISTRO_VERSION}" + ) +fi + +if "${has_cache}"; then + docker_build_flags+=("--cache-from=${IMAGE}:latest") +fi + +update_cache="false" +echo "================================================================" +echo "Creating Docker image with all the development tools $(date)." +if ci/retry-command.sh docker build "${docker_build_flags[@]}" ci; then + update_cache="true" + echo "Docker image created $(date)." + docker image ls | grep "${IMAGE}" +else + echo "Failed creating Docker image $(date)." + if "${has_cache}"; then + echo "Continue the build with the cache." + else + exit 1 + fi +fi +echo "================================================================" + +if [[ -n "${KOKORO_JOB_NAME:-}" ]]; then + # Upload the docker image for speeding up the future builds. + echo "================================================================" + echo "Uploading Docker image $(date)." + docker push "${IMAGE}:latest" || true + echo "================================================================" +fi + + +echo "================================================================" +echo "Running the full build $(date)." +# The default user for a Docker container has uid 0 (root). To avoid creating +# root-owned files in the build directory we tell docker to use the current +# user ID, if known. +docker_uid="${UID:-0}" +docker_user="${USER:-root}" +docker_home_prefix="${PWD}/cmake-out/home" +if [[ "${docker_uid}" == "0" ]]; then + docker_home_prefix="${PWD}/cmake-out/root" +fi + +# Make sure the user has a $HOME directory inside the Docker container. +mkdir -p "${BUILD_HOME}" +mkdir -p "${BUILD_OUTPUT}" + +# We use an array for the flags so they are easier to document. +docker_flags=( + # Grant the PTRACE capability to the Docker container running the build, + # this is needed by tools like AddressSanitizer. + "--cap-add" "SYS_PTRACE" + + # The name and version of the distribution, this is used to call + # define-docker-variables.sh and determine the Docker image built, and the + # output directory for any artifacts. + "--env" "DISTRO=${DISTRO}" + "--env" "DISTRO_VERSION=${DISTRO_VERSION}" + + # The C++ and C compiler, both Bazel and CMake use this environment variable + # to select the compiler binary. + "--env" "CXX=${CXX}" + "--env" "CC=${CC}" + + # If set to 'yes', the build script will run the style checks, including + # clang-format, cmake-format, and buildifier. + "--env" "CHECK_STYLE=${CHECK_STYLE:-}" + + # If set to 'yes', the build script will configure clang-tidy. Currently + # only the CMake builds use this flag. + "--env" "CLANG_TIDY=${CLANG_TIDY:-}" + + # If set to 'yes', run the integration tests. Currently only the Bazel + # builds use this flag. + "--env" "RUN_INTEGRATION_TESTS=${RUN_INTEGRATION_TESTS:-}" + + # If set to 'yes', run compile with code coverage flags. Currently only the + # CMake builds use this flag. + "--env" "CODE_COVERAGE=${CODE_COVERAGE:-}" + + # If set to 'yes', use Ninja as the CMake generator. Ninja is more strict + # that Make and can detect errors in your CMake files, it is also faster. + "--env" "USE_NINJA=${USE_NINJA:-}" + + # If set, pass -DGOOGLE_CLOUD_CPP_CXX_STANDARD=<value> to CMake. + "--env" "GOOGLE_CLOUD_CPP_CXX_STANDARD=${GOOGLE_CLOUD_CPP_CXX_STANDARD:-}" + + # When running the integration tests this directory contains the + # configuration files needed to run said tests. Make it available inside + # the Docker container. + "--volume" "${KOKORO_GFILE_DIR:-/dev/shm}:/c" + + # Let the Docker image script know what kind of terminal we are using, that + # produces properly colorized error messages. + "--env" "TERM=${TERM:-dumb}" + + # Run the docker script and this user id. Because the docker image gets to + # write in ${PWD} you typically want this to be your user id. + "--user" "${docker_uid}" + + # Bazel needs this environment variable to work correctly. + "--env" "USER=${docker_user}" + + # We give Bazel and CMake a fake $HOME inside the docker image. Bazel caches + # build byproducts in this directory. CMake (when ccache is enabled) uses + # it to store $HOME/.ccache + "--env" "HOME=/h" + "--volume" "${PWD}/${BUILD_HOME}:/h" + + # Mount the current directory (which is the top-level directory for the + # project) as `/v` inside the docker image, and move to that directory. + "--volume" "${PWD}:/v" + "--workdir" "/v" + + # Mask any other builds that may exist at the same time. That is, these + # directories appear as empty inside the Docker container, this prevents the + # container from writing into other builds, or to get confused by the output + # of other builds. In the CI system this does not matter, as each build runs + # on a completely separate VM. This is useful when running multiple builds + # in your workstation. + "--volume" "/v/cmake-out/home" + "--volume" "/v/cmake-out" + "--volume" "${PWD}/${BUILD_OUTPUT}:/v/${BUILD_OUTPUT}" +) + +# When running the builds from the command-line they get a tty, and the scripts +# running inside the Docker container can produce nicer output. On Kokoro the +# script does not get a tty, and Docker terminates the program if we pass the +# `-it` flag. +if [[ -t 0 ]]; then + docker_flags+=("-it") +fi + +docker run "${docker_flags[@]}" "${IMAGE}:latest" \ + "/v/${in_docker_script}" "${CMAKE_SOURCE_DIR}" \ + "${BUILD_OUTPUT}" diff --git a/t/t5100/empty b/third_party/cpp/googleapis/ci/kokoro/docker/clang-3.8-presubmit.cfg index e69de29bb2..e69de29bb2 100644 --- a/t/t5100/empty +++ b/third_party/cpp/googleapis/ci/kokoro/docker/clang-3.8-presubmit.cfg diff --git a/t/t5100/msg0013 b/third_party/cpp/googleapis/ci/kokoro/docker/clang-3.8.cfg index e69de29bb2..e69de29bb2 100644 --- a/t/t5100/msg0013 +++ b/third_party/cpp/googleapis/ci/kokoro/docker/clang-3.8.cfg diff --git a/t/t5100/msg0015 b/third_party/cpp/googleapis/ci/kokoro/docker/clang-tidy-presubmit.cfg index e69de29bb2..e69de29bb2 100644 --- a/t/t5100/msg0015 +++ b/third_party/cpp/googleapis/ci/kokoro/docker/clang-tidy-presubmit.cfg diff --git a/t/t5100/patch0007 b/third_party/cpp/googleapis/ci/kokoro/docker/clang-tidy.cfg index e69de29bb2..e69de29bb2 100644 --- a/t/t5100/patch0007 +++ b/third_party/cpp/googleapis/ci/kokoro/docker/clang-tidy.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/common.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/common.cfg new file mode 100644 index 0000000000..213d93419a --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/common.cfg @@ -0,0 +1,17 @@ +# Format: //devtools/kokoro/config/proto/build.proto +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +build_file: "cpp-cmakefiles/ci/kokoro/docker/build.sh" +timeout_mins: 120 diff --git a/t/t5100/patch0008 b/third_party/cpp/googleapis/ci/kokoro/docker/gcc-4.8-presubmit.cfg index e69de29bb2..e69de29bb2 100644 --- a/t/t5100/patch0008 +++ b/third_party/cpp/googleapis/ci/kokoro/docker/gcc-4.8-presubmit.cfg diff --git a/t/t5100/patch0013 b/third_party/cpp/googleapis/ci/kokoro/docker/gcc-4.8.cfg index e69de29bb2..e69de29bb2 100644 --- a/t/t5100/patch0013 +++ b/third_party/cpp/googleapis/ci/kokoro/docker/gcc-4.8.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/ninja-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/ninja-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/ninja-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/ninja.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/ninja.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/ninja.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-16.04-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-16.04-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-16.04-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-16.04.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-16.04.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-16.04.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-18.04-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-18.04-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-18.04-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-18.04.cfg b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-18.04.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/docker/ubuntu-18.04.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.centos-7 b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.centos-7 new file mode 100644 index 0000000000..21b8908134 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.centos-7 @@ -0,0 +1,105 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM centos:7 AS devtools + +# Please keep the formatting in these commands, it is optimized to cut & paste +# into the INSTALL.md file. + +## [START INSTALL.md] + +# First install the development tools and OpenSSL. The development tools +# distributed with CentOS (notably CMake) are too old to build +# `cpp-cmakefiles`. In these instructions, we use `cmake3` obtained from +# [Software Collections](https://www.softwarecollections.org/). + +# ```bash +RUN rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm +RUN yum install -y centos-release-scl +RUN yum-config-manager --enable rhel-server-rhscl-7-rpms +RUN yum makecache && \ + yum install -y automake cmake3 curl-devel gcc gcc-c++ git libtool \ + make openssl-devel pkgconfig tar wget which zlib-devel +RUN ln -sf /usr/bin/cmake3 /usr/bin/cmake && ln -sf /usr/bin/ctest3 /usr/bin/ctest +# ``` + +# #### Protobuf + +# Likewise, manually install protobuf: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/google/protobuf/archive/v3.9.0.tar.gz +RUN tar -xf v3.9.0.tar.gz +WORKDIR /var/tmp/build/protobuf-3.9.0/cmake +RUN cmake \ + -DCMAKE_BUILD_TYPE=Release \ + -DBUILD_SHARED_LIBS=yes \ + -Dprotobuf_BUILD_TESTS=OFF \ + -H. -Bcmake-out +RUN cmake --build cmake-out --target install -- -j $(nproc) +RUN ldconfig +# ``` + +# #### c-ares + +# Recent versions of gRPC require c-ares >= 1.11, while CentOS-7 +# distributes c-ares-1.10. Manually install a newer version: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/c-ares/c-ares/archive/cares-1_15_0.tar.gz +RUN tar -xf cares-1_15_0.tar.gz +WORKDIR /var/tmp/build/c-ares-cares-1_15_0 +RUN ./buildconf && ./configure && make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +# #### gRPC + +# Can be manually installed using: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/grpc/grpc/archive/v1.22.0.tar.gz +RUN tar -xf v1.22.0.tar.gz +WORKDIR /var/tmp/build/grpc-1.22.0 +ENV PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:/usr/local/lib64/pkgconfig +ENV LD_LIBRARY_PATH=/usr/local/lib:/usr/local/lib64 +ENV PATH=/usr/local/bin:${PATH} +RUN make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +FROM devtools AS install + +# #### googleapis + +# Finally we can install `googleapis`. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.fedora-30 b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.fedora-30 new file mode 100644 index 0000000000..d6e57b91e2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.fedora-30 @@ -0,0 +1,58 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM fedora:30 AS devtools + +# Please keep the formatting below, it is used by `extract-install.md` +# to generate the contents of the top-level INSTALL.md. + +## [START INSTALL.md] + +# Install the minimal development tools: + +# ```bash +RUN dnf makecache && \ + dnf install -y cmake gcc-c++ git make openssl-devel pkgconfig \ + zlib-devel +# ``` + +# Fedora includes packages for gRPC, libcurl, and OpenSSL that are recent enough +# for `cpp-cmakefiles`. Install these packages and additional development +# tools to compile the dependencies: + +# ```bash +RUN dnf makecache && \ + dnf install -y grpc-devel grpc-plugins \ + libcurl-devel protobuf-compiler tar wget zlib-devel +# ``` + +FROM devtools AS install + +# #### googleapis + +# We can now compile and install `googleapis`. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.fedora-30-shared b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.fedora-30-shared new file mode 100644 index 0000000000..572018f994 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.fedora-30-shared @@ -0,0 +1,62 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM fedora:30 AS devtools + +# Please keep the formatting below, it is used by `extract-install.md` +# to generate the contents of the top-level INSTALL.md. + +## [START INSTALL.md] + +# Install the minimal development tools: + +# ```bash +RUN dnf makecache && \ + dnf install -y cmake gcc-c++ git make openssl-devel pkgconfig \ + zlib-devel +# ``` + +# Fedora includes packages for gRPC, libcurl, and OpenSSL that are recent enough +# for `cpp-cmakefiles`. Install these packages and additional development +# tools to compile the dependencies: + +# ```bash +RUN dnf makecache && \ + dnf install -y grpc-devel grpc-plugins \ + libcurl-devel protobuf-compiler tar wget zlib-devel +# ``` + +FROM devtools AS install + +# #### googleapis + +# We can now compile and install `googleapis` as shared library. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out -DBUILD_SHARED_LIBS=yes +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# The share libraries will install in `/usr/local/lib64` we need that directory +# in the ld.so cache: +RUN echo "/usr/local/lib64" | tee /etc/ld.so.conf.d/local.conf +RUN ldconfig +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.opensuse-leap b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.opensuse-leap new file mode 100644 index 0000000000..ea2dda5ec4 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.opensuse-leap @@ -0,0 +1,114 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM opensuse/leap:latest AS devtools + +## [START INSTALL.md] + +# Install the minimal development tools: + +# ```bash +RUN zypper refresh && \ + zypper install --allow-downgrade -y cmake gcc gcc-c++ git gzip \ + libcurl-devel libopenssl-devel make tar wget +# ``` + +# #### Protobuf + +# OpenSUSE Leap includes a package for protobuf-2.6, but this is too old to +# support the Google Cloud Platform proto files, or to support gRPC for that +# matter. Manually install protobuf: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/google/protobuf/archive/v3.9.0.tar.gz +RUN tar -xf v3.9.0.tar.gz +WORKDIR /var/tmp/build/protobuf-3.9.0/cmake +RUN cmake \ + -DCMAKE_BUILD_TYPE=Release \ + -DBUILD_SHARED_LIBS=yes \ + -Dprotobuf_BUILD_TESTS=OFF \ + -H. -Bcmake-out +RUN cmake --build cmake-out --target install -- -j $(nproc) +RUN ldconfig +# ``` + +# #### c-ares + +# Recent versions of gRPC require c-ares >= 1.11, while OpenSUSE Leap +# distributes c-ares-1.9. We need some additional development tools to compile +# this library: + +# ```bash +RUN zypper refresh && \ + zypper install -y automake libtool +# ``` + +# Manually install a newer version: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/c-ares/c-ares/archive/cares-1_15_0.tar.gz +RUN tar -xf cares-1_15_0.tar.gz +WORKDIR /var/tmp/build/c-ares-cares-1_15_0 +RUN ./buildconf && ./configure && make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +# #### gRPC + +# The gRPC Makefile uses `which` to determine whether the compiler is available. +# Install this command for the extremely rare case where it may be missing from +# your workstation or build server: + +# ```bash +RUN zypper refresh && \ + zypper install -y which +# ``` + +# Then gRPC can be manually installed using: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/grpc/grpc/archive/v1.22.0.tar.gz +RUN tar -xf v1.22.0.tar.gz +WORKDIR /var/tmp/build/grpc-1.22.0 +ENV PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:/usr/local/lib64/pkgconfig +ENV LD_LIBRARY_PATH=/usr/local/lib:/usr/local/lib64 +ENV PATH=/usr/local/bin:${PATH} +RUN make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +FROM devtools AS install + +# #### googleapis + +# We can now compile and install `googleapis`. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.opensuse-tumbleweed b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.opensuse-tumbleweed new file mode 100644 index 0000000000..9a87337870 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.opensuse-tumbleweed @@ -0,0 +1,54 @@ +# Copyright 2018 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM opensuse/tumbleweed:latest AS devtools + +## [START INSTALL.md] + +# Install the minimal development tools: + +# ```bash +RUN zypper refresh && \ + zypper install --allow-downgrade -y cmake gcc gcc-c++ git gzip \ + libcurl-devel libopenssl-devel make tar wget zlib-devel +# ``` + +# OpenSUSE:tumbleweed provides packages for gRPC, libcurl, and protobuf, and the +# versions of these packages are recent enough to support the Google Cloud +# Platform proto files. + +# ```bash +RUN zypper refresh && \ + zypper install -y grpc-devel gzip libcurl-devel tar wget +# ``` + +FROM devtools AS install + +# #### googleapis + +# We can now compile and install `googleapis`. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.ubuntu-16.04 b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.ubuntu-16.04 new file mode 100644 index 0000000000..030ed4a2aa --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.ubuntu-16.04 @@ -0,0 +1,100 @@ +# Copyright 2018 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM ubuntu:16.04 AS devtools + +# Please keep the formatting in these commands, it is optimized to cut & paste +# into the README.md file. + +## [START INSTALL.md] + +# Install the minimal development tools: + +# ```bash +RUN apt update && \ + apt install -y automake build-essential cmake git gcc g++ cmake \ + libcurl4-openssl-dev libssl-dev libtool make pkg-config tar wget \ + zlib1g-dev +# ``` + +# #### c-ares + +# Recent versions of gRPC require c-ares >= 1.11, while Ubuntu-16.04 +# distributes c-ares-1.10. We can manually install a newer version +# of c-ares: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/c-ares/c-ares/archive/cares-1_15_0.tar.gz +RUN tar -xf cares-1_15_0.tar.gz +WORKDIR /var/tmp/build/c-ares-cares-1_15_0 +RUN ./buildconf && ./configure && make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +# #### Protobuf + +# While protobuf-3.0 is distributed with Ubuntu, the Google Cloud Plaform proto +# files require more recent versions (circa 3.4.x). To manually install a more +# recent version use: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/google/protobuf/archive/v3.9.0.tar.gz +RUN tar -xf v3.9.0.tar.gz +WORKDIR /var/tmp/build/protobuf-3.9.0/cmake +RUN cmake \ + -DCMAKE_BUILD_TYPE=Release \ + -DBUILD_SHARED_LIBS=yes \ + -Dprotobuf_BUILD_TESTS=OFF \ + -H. -Bcmake-out +RUN cmake --build cmake-out --target install -- -j $(nproc) +RUN ldconfig +# ``` + +# #### gRPC + +# Likewise, Ubuntu has packages for grpc-1.3.x, but this version is too old for +# the Google Cloud Platform APIs: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/grpc/grpc/archive/v1.22.0.tar.gz +RUN tar -xf v1.22.0.tar.gz +WORKDIR /var/tmp/build/grpc-1.22.0 +RUN make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +FROM devtools AS install + +# #### googleapis + +# Finally we can install `googleapis`. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.ubuntu-18.04 b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.ubuntu-18.04 new file mode 100644 index 0000000000..486d24aa47 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/Dockerfile.ubuntu-18.04 @@ -0,0 +1,84 @@ +# Copyright 2018 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +FROM ubuntu:18.04 AS devtools + +# Please keep the formatting in these commands, it is optimized to cut & paste +# into the README.md file. + +## [START INSTALL.md] + +# Install the minimal development tools: + +# ```bash +RUN apt update && \ + apt install -y build-essential cmake git gcc g++ cmake \ + libc-ares-dev libc-ares2 libcurl4-openssl-dev libssl-dev make \ + pkg-config tar wget zlib1g-dev +# ``` + +# #### Protobuf + +# While protobuf-3.0 is distributed with Ubuntu, the Google Cloud Plaform proto +# files require more recent versions (circa 3.4.x). To manually install a more +# recent version use: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/google/protobuf/archive/v3.9.0.tar.gz +RUN tar -xf v3.9.0.tar.gz +WORKDIR /var/tmp/build/protobuf-3.9.0/cmake +RUN cmake \ + -DCMAKE_BUILD_TYPE=Release \ + -DBUILD_SHARED_LIBS=yes \ + -Dprotobuf_BUILD_TESTS=OFF \ + -H. -Bcmake-out +RUN cmake --build cmake-out --target install -- -j $(nproc) +RUN ldconfig +# ``` + +# #### gRPC + +# Likewise, Ubuntu has packages for grpc-1.3.x, but this version is too old for +# the Google Cloud Platform APIs: + +# ```bash +WORKDIR /var/tmp/build +RUN wget -q https://github.com/grpc/grpc/archive/v1.22.0.tar.gz +RUN tar -xf v1.22.0.tar.gz +WORKDIR /var/tmp/build/grpc-1.22.0 +RUN make -j $(nproc) +RUN make install +RUN ldconfig +# ``` + +FROM devtools AS install + +# #### googleapis + +# Finally we can install `googleapis`. + +# ```bash +WORKDIR /home/build/cpp-cmakefiles +COPY . /home/build/cpp-cmakefiles +RUN cmake -H. -Bcmake-out +RUN cmake --build cmake-out -- -j $(nproc) +WORKDIR /home/build/cpp-cmakefiles/cmake-out +RUN cmake --build . --target install +# ``` + +## [END INSTALL.md] + +# Verify that the installed files are actually usable +RUN /home/build/cpp-cmakefiles/ci/test-install/compile-test-projects.sh diff --git a/third_party/cpp/googleapis/ci/kokoro/install/build.sh b/third_party/cpp/googleapis/ci/kokoro/install/build.sh new file mode 100755 index 0000000000..42e85f39b6 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/build.sh @@ -0,0 +1,106 @@ +#!/usr/bin/env bash +# +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -eu + +if [[ $# -eq 1 ]]; then + export TEST_TARGET="${1}" +elif [[ -n "${KOKORO_JOB_NAME:-}" ]]; then + # Kokoro injects the KOKORO_JOB_NAME environment variable, the value of this + # variable is cloud-cpp/spanner/<config-file-name-without-cfg> (or more + # generally <path/to/config-file-without-cfg>). By convention we name these + # files `$foo.cfg` for continuous builds and `$foo-presubmit.cfg` for + # presubmit builds. Here we extract the value of "foo" and use it as the build + # name. + TEST_TARGET="$(basename "${KOKORO_JOB_NAME}" "-presubmit")" + export TEST_TARGET +else + echo "Aborting build as the distribution name is not defined." + echo "If you are invoking this script via the command line use:" + echo " $0 <distro-name>" + echo + echo "If this script is invoked by Kokoro, the CI system is expected to set" + echo "the KOKORO_JOB_NAME environment variable." + exit 1 +fi + +echo "================================================================" +echo "Change working directory to project root $(date)." +cd "$(dirname "$0")/../../.." + +if [[ -z "${PROJECT_ID+x}" ]]; then + readonly PROJECT_ID="cloud-devrel-kokoro-resources" +fi + +readonly DEV_IMAGE="gcr.io/${PROJECT_ID}/cpp-cmakefiles/test-install-dev-${TEST_TARGET}" +readonly IMAGE="gcr.io/${PROJECT_ID}/cpp-cmakefiles/test-install-${TEST_TARGET}" + +has_cache="false" + +# We download the cached dev image for pull requests on kokoro. For continuous +# jobs, we don't download the cached image. This means we build from scratch and +# upload the image for future builds for pull requests. +if [[ -n "${KOKORO_JOB_NAME:-}" ]] \ + && [[ -n "${KOKORO_GITHUB_PULL_REQUEST_NUMBER:-}" ]]; then + echo "================================================================" + echo "Download existing image (if available) for ${TEST_TARGET} $(date)." + if docker pull "${DEV_IMAGE}:latest"; then + echo "Existing image successfully downloaded." + has_cache="true" + fi + echo "================================================================" +fi + +echo "================================================================" +echo "Build base image with minimal development tools for ${TEST_TARGET} $(date)." +update_cache="false" + +devtools_flags=( + # Only build up to the stage that installs the minimal development tools, but + # does not compile any of our code. + "--target" "devtools" + # Create the image with the same tag as the cache we are using, so we can + # upload it. + "-t" "${DEV_IMAGE}:latest" + "-f" "ci/kokoro/install/Dockerfile.${TEST_TARGET}" +) + +if "${has_cache}"; then + devtools_flags+=("--cache-from=${DEV_IMAGE}:latest") +fi + +echo "Running docker build with " "${devtools_flags[@]}" +if docker build "${devtools_flags[@]}" ci; then + update_cache="true" +fi + +# We upload the cached image for continuous builds. +if "${update_cache}" && [[ -z "${KOKORO_GITHUB_PULL_REQUEST_NUMBER:-}" ]] \ + && [[ -n "${KOKORO_JOB_NAME:-}" ]]; then + echo "================================================================" + echo "Uploading updated base image for ${TEST_TARGET} $(date)." + # Do not stop the build on a failure to update the cache. + docker push "${DEV_IMAGE}:latest" || true +fi + +echo "================================================================" +echo "Run validation script for INSTALL instructions on ${TEST_TARGET}." +docker build \ + "--cache-from=${DEV_IMAGE}:latest" \ + "--target=install" \ + -t "${IMAGE}" \ + -f "ci/kokoro/install/Dockerfile.${TEST_TARGET}" . +echo "================================================================" diff --git a/third_party/cpp/googleapis/ci/kokoro/install/centos-7-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/centos-7-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/centos-7-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/centos-7.cfg b/third_party/cpp/googleapis/ci/kokoro/install/centos-7.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/centos-7.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/common.cfg b/third_party/cpp/googleapis/ci/kokoro/install/common.cfg new file mode 100644 index 0000000000..77a3a1f9fe --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/common.cfg @@ -0,0 +1,17 @@ +# Format: //devtools/kokoro/config/proto/build.proto +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +build_file: "cpp-cmakefiles/ci/kokoro/install/build.sh" +timeout_mins: 120 diff --git a/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-shared-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-shared-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-shared-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-shared.cfg b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-shared.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30-shared.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/fedora-30.cfg b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/fedora-30.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/opensuse-leap-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-leap-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-leap-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/opensuse-leap.cfg b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-leap.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-leap.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/opensuse-tumbleweed-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-tumbleweed-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-tumbleweed-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/opensuse-tumbleweed.cfg b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-tumbleweed.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/opensuse-tumbleweed.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-16.04-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-16.04-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-16.04-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-16.04.cfg b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-16.04.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-16.04.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-18.04-presubmit.cfg b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-18.04-presubmit.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-18.04-presubmit.cfg diff --git a/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-18.04.cfg b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-18.04.cfg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/cpp/googleapis/ci/kokoro/install/ubuntu-18.04.cfg diff --git a/third_party/cpp/googleapis/ci/retry-command.sh b/third_party/cpp/googleapis/ci/retry-command.sh new file mode 100755 index 0000000000..190bce4817 --- /dev/null +++ b/third_party/cpp/googleapis/ci/retry-command.sh @@ -0,0 +1,48 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set -eu + +# Make three attempts to install the dependencies. It is rare, but from time to +# time the downloading the packages, building the Docker images, or an installer +# Bazel, or the Google Cloud SDK fails. To make the CI build more robust, try +# again when that happens. + +if (( $# < 1 )); then + echo "Usage: $(basename "$0") program [arguments]" + exit 1 +fi +readonly PROGRAM=${1} +shift + +# Initially, wait at least 2 minutes (the times are in seconds), because it +# makes no sense to try faster. This used to be 180 seconds, but that ends with +# sleeps close to 10 minutes, and Travis aborts builds that do not output in +# 10m. +min_wait=120 +# Do not exit on failures for this loop. +set +e +for i in 1 2 3; do + if "${PROGRAM}" "$@"; then + exit 0 + fi + # Sleep for a few minutes before trying again. + period=$(( (RANDOM % 60) + min_wait )) + echo "${PROGRAM} failed (attempt ${i}); trying again in ${period} seconds." + sleep ${period}s + min_wait=$(( min_wait * 2 )) +done + +exit 1 diff --git a/third_party/cpp/googleapis/ci/test-install/bigquery/CMakeLists.txt b/third_party/cpp/googleapis/ci/test-install/bigquery/CMakeLists.txt new file mode 100644 index 0000000000..3086ef4617 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/bigquery/CMakeLists.txt @@ -0,0 +1,28 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +cmake_minimum_required(VERSION 3.5) + +project(utilize-googleapis CXX C) + +# Configure the compiler options, we will be using C++11 features. +set(CMAKE_CXX_STANDARD 11) +set(CMAKE_CXX_STANDARD_REQUIRED ON) + +find_package(googleapis REQUIRED) + +add_executable(utilize-googleapis main.cc) +target_link_libraries(utilize-googleapis googleapis-c++::cloud_bigquery_protos) diff --git a/third_party/cpp/googleapis/ci/test-install/bigquery/Makefile b/third_party/cpp/googleapis/ci/test-install/bigquery/Makefile new file mode 100644 index 0000000000..bca2a7dc57 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/bigquery/Makefile @@ -0,0 +1,36 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# A simple Makefile to test the `install` target. +# +# This is not intended to be a demonstration of how to write good Makefiles, +# nor is it a general solution on how to build Makefiles for google-cloud-cpp. +# It is simply a minimal file to test the installed pkg-config support files. + +# The CXX, CXXFLAGS and CXXLD variables are hard-coded. These values work for +# our tests, but applications would typically make them configurable parameters. +CXX=g++ -std=c++11 +CXXLD=$(CXX) + +all: main + +# Configuration variables to compile and link against the library. +PROTOS := googleapis_cpp_cloud_bigquery_protos +CXXFLAGS := $(shell pkg-config $(PROTOS) --cflags) +CXXLDFLAGS := $(shell pkg-config $(PROTOS) --libs-only-L) +LIBS := $(shell pkg-config $(PROTOS) --libs-only-l) + +# A target using the Google Cloud Storage C++ client library. +main: main.cc + $(CXXLD) $(CXXFLAGS) $(CXXFLAGS) $(CXXLDFLAGS) -o $@ $^ $(LIBS) diff --git a/third_party/cpp/googleapis/ci/test-install/bigquery/main.cc b/third_party/cpp/googleapis/ci/test-install/bigquery/main.cc new file mode 100644 index 0000000000..bd00013edd --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/bigquery/main.cc @@ -0,0 +1,22 @@ +// Copyright 2019 Google LLC +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <google/cloud/bigquery/storage/v1beta1/storage.grpc.pb.h> +#include <grpcpp/grpcpp.h> + +int main() { + auto creds = grpc::InsecureChannelCredentials(); + auto channel = grpc::CreateChannel("localhost:12345", creds); + auto stub = google::cloud::bigquery::storage::v1beta1::BigQueryStorage::NewStub(channel); +} diff --git a/third_party/cpp/googleapis/ci/test-install/bigtable/CMakeLists.txt b/third_party/cpp/googleapis/ci/test-install/bigtable/CMakeLists.txt new file mode 100644 index 0000000000..7aed05ff1d --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/bigtable/CMakeLists.txt @@ -0,0 +1,28 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +cmake_minimum_required(VERSION 3.5) + +project(utilize-googleapis CXX C) + +# Configure the compiler options, we will be using C++11 features. +set(CMAKE_CXX_STANDARD 11) +set(CMAKE_CXX_STANDARD_REQUIRED ON) + +find_package(googleapis REQUIRED) + +add_executable(utilize-googleapis main.cc) +target_link_libraries(utilize-googleapis googleapis-c++::bigtable_protos) diff --git a/third_party/cpp/googleapis/ci/test-install/bigtable/Makefile b/third_party/cpp/googleapis/ci/test-install/bigtable/Makefile new file mode 100644 index 0000000000..5643b234d7 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/bigtable/Makefile @@ -0,0 +1,36 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# A simple Makefile to test the `install` target. +# +# This is not intended to be a demonstration of how to write good Makefiles, +# nor is it a general solution on how to build Makefiles for google-cloud-cpp. +# It is simply a minimal file to test the installed pkg-config support files. + +# The CXX, CXXFLAGS and CXXLD variables are hard-coded. These values work for +# our tests, but applications would typically make them configurable parameters. +CXX=g++ -std=c++11 +CXXLD=$(CXX) + +all: main + +# Configuration variables to compile and link against the library. +PROTOS := googleapis_cpp_bigtable_protos +CXXFLAGS := $(shell pkg-config $(PROTOS) --cflags) +CXXLDFLAGS := $(shell pkg-config $(PROTOS) --libs-only-L) +LIBS := $(shell pkg-config $(PROTOS) --libs-only-l) + +# A target using the Google Cloud Storage C++ client library. +main: main.cc + $(CXXLD) $(CXXFLAGS) $(CXXFLAGS) $(CXXLDFLAGS) -o $@ $^ $(LIBS) diff --git a/third_party/cpp/googleapis/ci/test-install/bigtable/main.cc b/third_party/cpp/googleapis/ci/test-install/bigtable/main.cc new file mode 100644 index 0000000000..08fce3c7bc --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/bigtable/main.cc @@ -0,0 +1,22 @@ +// Copyright 2019 Google LLC +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <google/bigtable/v2/bigtable.grpc.pb.h> +#include <grpcpp/grpcpp.h> + +int main() { + auto creds = grpc::InsecureChannelCredentials(); + auto channel = grpc::CreateChannel("localhost:12345", creds); + auto stub = google::bigtable::v2::Bigtable::NewStub(channel); +} diff --git a/third_party/cpp/googleapis/ci/test-install/compile-test-projects.sh b/third_party/cpp/googleapis/ci/test-install/compile-test-projects.sh new file mode 100755 index 0000000000..25eea82ffc --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/compile-test-projects.sh @@ -0,0 +1,47 @@ +#!/usr/bin/env bash +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# Compile projects that utilize the cpp-cmakefiles header files and libraries +# installed to the system. This script expects that the entire source tree is +# copied to /home/build/cpp-cmakefiles. Don't try to run this locally. + +set -eu + +# Verify the installed CMake config and pkgconfig files are actually usable. + +for subdir in bigquery bigtable pubsub spanner; do + # Compile a test program using CMake. + echo "================================================================" + echo "Testing ${subdir} $(date) with CMake" + echo "================================================================" + src_dir="/home/build/cpp-cmakefiles/ci/test-install/${subdir}" + cmake_dir="/home/build/test-cmake-${subdir}" + make_dir="/home/build/test-make-${subdir}" + cmake -H"${src_dir}" -B"${cmake_dir}" + cmake --build "${cmake_dir}" -- -j "$(nproc)" + # Verify the generated program is runnable + "${cmake_dir}/utilize-googleapis" + echo "================================================================" + echo "Testing ${subdir} $(date) with Make" + echo "================================================================" + cp -R "${src_dir}" "${make_dir}" + cd "${make_dir}" + # With Make we may need to set PKG_CONFIG_PATH because the code is installed + # in /usr/local and that is not a default search location in some distros. + env PKG_CONFIG_PATH=/usr/local/lib64/pkgconfig:/usr/local/lib/pkgconfig \ + make + # Verify the generated program is runnable + "${make_dir}/main" +done diff --git a/third_party/cpp/googleapis/ci/test-install/pubsub/CMakeLists.txt b/third_party/cpp/googleapis/ci/test-install/pubsub/CMakeLists.txt new file mode 100644 index 0000000000..cc8d59e187 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/pubsub/CMakeLists.txt @@ -0,0 +1,28 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +cmake_minimum_required(VERSION 3.5) + +project(utilize-googleapis CXX C) + +# Configure the compiler options, we will be using C++11 features. +set(CMAKE_CXX_STANDARD 11) +set(CMAKE_CXX_STANDARD_REQUIRED ON) + +find_package(googleapis REQUIRED) + +add_executable(utilize-googleapis main.cc) +target_link_libraries(utilize-googleapis googleapis-c++::pubsub_protos) diff --git a/third_party/cpp/googleapis/ci/test-install/pubsub/Makefile b/third_party/cpp/googleapis/ci/test-install/pubsub/Makefile new file mode 100644 index 0000000000..a5cbdcf789 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/pubsub/Makefile @@ -0,0 +1,36 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# A simple Makefile to test the `install` target. +# +# This is not intended to be a demonstration of how to write good Makefiles, +# nor is it a general solution on how to build Makefiles for google-cloud-cpp. +# It is simply a minimal file to test the installed pkg-config support files. + +# The CXX, CXXFLAGS and CXXLD variables are hard-coded. These values work for +# our tests, but applications would typically make them configurable parameters. +CXX=g++ -std=c++11 +CXXLD=$(CXX) + +all: main + +# Configuration variables to compile and link against the library. +PROTOS := googleapis_cpp_pubsub_protos +CXXFLAGS := $(shell pkg-config $(PROTOS) --cflags) +CXXLDFLAGS := $(shell pkg-config $(PROTOS) --libs-only-L) +LIBS := $(shell pkg-config $(PROTOS) --libs-only-l) + +# A target using the Google Cloud Storage C++ client library. +main: main.cc + $(CXXLD) $(CXXFLAGS) $(CXXFLAGS) $(CXXLDFLAGS) -o $@ $^ $(LIBS) diff --git a/third_party/cpp/googleapis/ci/test-install/pubsub/main.cc b/third_party/cpp/googleapis/ci/test-install/pubsub/main.cc new file mode 100644 index 0000000000..05549169da --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/pubsub/main.cc @@ -0,0 +1,22 @@ +// Copyright 2019 Google LLC +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <google/pubsub/v1/pubsub.grpc.pb.h> +#include <grpcpp/grpcpp.h> + +int main() { + auto creds = grpc::InsecureChannelCredentials(); + auto channel = grpc::CreateChannel("localhost:12345", creds); + auto stub = google::pubsub::v1::Publisher::NewStub(channel); +} diff --git a/third_party/cpp/googleapis/ci/test-install/spanner/CMakeLists.txt b/third_party/cpp/googleapis/ci/test-install/spanner/CMakeLists.txt new file mode 100644 index 0000000000..2a4577ace9 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/spanner/CMakeLists.txt @@ -0,0 +1,28 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +cmake_minimum_required(VERSION 3.5) + +project(utilize-googleapis CXX C) + +# Configure the compiler options, we will be using C++11 features. +set(CMAKE_CXX_STANDARD 11) +set(CMAKE_CXX_STANDARD_REQUIRED ON) + +find_package(googleapis REQUIRED) + +add_executable(utilize-googleapis main.cc) +target_link_libraries(utilize-googleapis googleapis-c++::spanner_protos) diff --git a/third_party/cpp/googleapis/ci/test-install/spanner/Makefile b/third_party/cpp/googleapis/ci/test-install/spanner/Makefile new file mode 100644 index 0000000000..74bf292ce6 --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/spanner/Makefile @@ -0,0 +1,36 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# A simple Makefile to test the `install` target. +# +# This is not intended to be a demonstration of how to write good Makefiles, +# nor is it a general solution on how to build Makefiles for google-cloud-cpp. +# It is simply a minimal file to test the installed pkg-config support files. + +# The CXX, CXXFLAGS and CXXLD variables are hard-coded. These values work for +# our tests, but applications would typically make them configurable parameters. +CXX=g++ -std=c++11 +CXXLD=$(CXX) + +all: main + +# Configuration variables to compile and link against the library. +PROTOS := googleapis_cpp_spanner_protos +CXXFLAGS := $(shell pkg-config $(PROTOS) --cflags) +CXXLDFLAGS := $(shell pkg-config $(PROTOS) --libs-only-L) +LIBS := $(shell pkg-config $(PROTOS) --libs-only-l) + +# A target using the Google Cloud Storage C++ client library. +main: main.cc + $(CXXLD) $(CXXFLAGS) $(CXXFLAGS) $(CXXLDFLAGS) -o $@ $^ $(LIBS) diff --git a/third_party/cpp/googleapis/ci/test-install/spanner/main.cc b/third_party/cpp/googleapis/ci/test-install/spanner/main.cc new file mode 100644 index 0000000000..f1866655ac --- /dev/null +++ b/third_party/cpp/googleapis/ci/test-install/spanner/main.cc @@ -0,0 +1,22 @@ +// Copyright 2019 Google LLC +// +// Licensed under the Apache License, Version 2.0 (the "License"); +// you may not use this file except in compliance with the License. +// You may obtain a copy of the License at +// +// http://www.apache.org/licenses/LICENSE-2.0 +// +// Unless required by applicable law or agreed to in writing, software +// distributed under the License is distributed on an "AS IS" BASIS, +// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +// See the License for the specific language governing permissions and +// limitations under the License. + +#include <google/spanner/v1/spanner.grpc.pb.h> +#include <grpcpp/grpcpp.h> + +int main() { + auto creds = grpc::InsecureChannelCredentials(); + auto channel = grpc::CreateChannel("localhost:12345", creds); + auto stub = google::spanner::v1::Spanner::NewStub(channel); +} diff --git a/third_party/cpp/googleapis/cmake/CompileProtos.cmake b/third_party/cpp/googleapis/cmake/CompileProtos.cmake new file mode 100644 index 0000000000..788267c8d9 --- /dev/null +++ b/third_party/cpp/googleapis/cmake/CompileProtos.cmake @@ -0,0 +1,271 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +# Introduce a new TARGET property to associate proto files with a target. +# +# We use a function to define the property so it can be called multiple times +# without introducing the property over and over. +function (google_cloud_cpp_add_protos_property) + set_property( + TARGET + PROPERTY PROTO_SOURCES BRIEF_DOCS + "The list of .proto files for a target." FULL_DOCS + "List of .proto files specified for a target.") +endfunction () + +# Generate C++ for .proto files preserving the directory hierarchy +# +# Receives a list of `.proto` file names and (a) creates the runs to convert +# these files to `.pb.h` and `.pb.cc` output files, (b) returns the list of +# `.pb.cc` files and `.pb.h` files in @p HDRS, and (c) creates the list of files +# preserving the directory hierarchy, such that if a `.proto` file says: +# +# import "foo/bar/baz.proto" +# +# the resulting C++ code says: +# +# #include <foo/bar/baz.pb.h> +# +# Use the `PROTO_PATH` option to provide one or more directories to search for +# proto files in the import. +# +# @par Example +# +# google_cloud_cpp_generate_proto( MY_PB_FILES "foo/bar/baz.proto" +# "foo/bar/qux.proto" PROTO_PATH_DIRECTORIES "another/dir/with/protos") +# +# Note that `protoc` the protocol buffer compiler requires your protos to be +# somewhere in the search path defined by the `--proto_path` (aka -I) options. +# For example, if you want to generate the `.pb.{h,cc}` files for +# `foo/bar/baz.proto` then the directory containing `foo` must be in the search +# path. +function (google_cloud_cpp_generate_proto SRCS) + cmake_parse_arguments(_opt "" "" "PROTO_PATH_DIRECTORIES" ${ARGN}) + if (NOT _opt_UNPARSED_ARGUMENTS) + message(SEND_ERROR "Error: google_cloud_cpp_generate_proto() called" + " without any proto files") + return() + endif () + + # Build the list of `--proto_path` options. Use the absolute path for each + # option given, and do not include any path more than once. + set(protobuf_include_path) + foreach (dir ${_opt_PROTO_PATH_DIRECTORIES}) + get_filename_component(absolute_path ${dir} ABSOLUTE) + list(FIND protobuf_include_path "${absolute_path}" + already_in_search_path) + if (${already_in_search_path} EQUAL -1) + list(APPEND protobuf_include_path "--proto_path" "${absolute_path}") + endif () + endforeach () + + set(${SRCS}) + foreach (filename ${_opt_UNPARSED_ARGUMENTS}) + get_filename_component(file_directory "${filename}" DIRECTORY) + # This gets the filename without the extension, analogous to $(basename + # "${filename}" .proto) + get_filename_component(file_stem "${filename}" NAME_WE) + + # Strip all the prefixes in ${_opt_PROTO_PATH_DIRECTORIES} from the + # source proto directory + set(D "${file_directory}") + if (DEFINED _opt_PROTO_PATH_DIRECTORIES) + foreach (P ${_opt_PROTO_PATH_DIRECTORIES}) + string(REGEX REPLACE "^${P}" "" T "${D}") + set(D ${T}) + endforeach () + endif () + set(pb_cc "${CMAKE_CURRENT_BINARY_DIR}/${D}/${file_stem}.pb.cc") + set(pb_h "${CMAKE_CURRENT_BINARY_DIR}/${D}/${file_stem}.pb.h") + list(APPEND ${SRCS} "${pb_cc}" "${pb_h}") + add_custom_command( + OUTPUT "${pb_cc}" "${pb_h}" + COMMAND + $<TARGET_FILE:protobuf::protoc> ARGS --cpp_out + "${CMAKE_CURRENT_BINARY_DIR}" ${protobuf_include_path} + "${filename}" + DEPENDS "${filename}" protobuf::protoc + COMMENT "Running C++ protocol buffer compiler on ${filename}" + VERBATIM) + endforeach () + + set_source_files_properties(${${SRCS}} PROPERTIES GENERATED TRUE) + set(${SRCS} + ${${SRCS}} + PARENT_SCOPE) +endfunction () + +# Generate gRPC C++ files from .proto files preserving the directory hierarchy. +# +# Receives a list of `.proto` file names and (a) creates the runs to convert +# these files to `.grpc.pb.h` and `.grpc.pb.cc` output files, (b) returns the +# list of `.grpc.pb.cc` and `.pb.h` files in @p SRCS, and (c) creates the list +# of files preserving the directory hierarchy, such that if a `.proto` file says +# +# import "foo/bar/baz.proto" +# +# the resulting C++ code says: +# +# #include <foo/bar/baz.pb.h> +# +# Use the `PROTO_PATH` option to provide one or more directories to search for +# proto files in the import. +# +# @par Example +# +# google_cloud_cpp_generate_grpc( MY_GRPC_PB_FILES "foo/bar/baz.proto" +# "foo/bar/qux.proto" PROTO_PATH_DIRECTORIES "another/dir/with/protos") +# +# Note that `protoc` the protocol buffer compiler requires your protos to be +# somewhere in the search path defined by the `--proto_path` (aka -I) options. +# For example, if you want to generate the `.pb.{h,cc}` files for +# `foo/bar/baz.proto` then the directory containing `foo` must be in the search +# path. +function (google_cloud_cpp_generate_grpcpp SRCS) + cmake_parse_arguments(_opt "" "" "PROTO_PATH_DIRECTORIES" ${ARGN}) + if (NOT _opt_UNPARSED_ARGUMENTS) + message( + SEND_ERROR "Error: google_cloud_cpp_generate_grpc() called without" + " any proto files") + return() + endif () + + # Build the list of `--proto_path` options. Use the absolute path for each + # option given, and do not include any path more than once. + set(protobuf_include_path) + foreach (dir ${_opt_PROTO_PATH_DIRECTORIES}) + get_filename_component(absolute_path ${dir} ABSOLUTE) + list(FIND protobuf_include_path "${absolute_path}" + already_in_search_path) + if (${already_in_search_path} EQUAL -1) + list(APPEND protobuf_include_path "--proto_path" "${absolute_path}") + endif () + endforeach () + + set(${SRCS}) + foreach (filename ${_opt_UNPARSED_ARGUMENTS}) + get_filename_component(file_directory "${filename}" DIRECTORY) + # This gets the filename without the extension, analogous to $(basename + # "${filename}" .proto) + get_filename_component(file_stem "${filename}" NAME_WE) + + # Strip all the prefixes in ${_opt_PROTO_PATH_DIRECTORIES} from the + # source proto directory + set(D "${file_directory}") + if (DEFINED _opt_PROTO_PATH_DIRECTORIES) + foreach (P ${_opt_PROTO_PATH_DIRECTORIES}) + string(REGEX REPLACE "^${P}" "" T "${D}") + set(D ${T}) + endforeach () + endif () + set(grpc_pb_cc + "${CMAKE_CURRENT_BINARY_DIR}/${D}/${file_stem}.grpc.pb.cc") + set(grpc_pb_h "${CMAKE_CURRENT_BINARY_DIR}/${D}/${file_stem}.grpc.pb.h") + list(APPEND ${SRCS} "${grpc_pb_cc}" "${grpc_pb_h}") + add_custom_command( + OUTPUT "${grpc_pb_cc}" "${grpc_pb_h}" + COMMAND + $<TARGET_FILE:protobuf::protoc> ARGS + --plugin=protoc-gen-grpc=$<TARGET_FILE:gRPC::grpc_cpp_plugin> + "--grpc_out=${CMAKE_CURRENT_BINARY_DIR}" + "--cpp_out=${CMAKE_CURRENT_BINARY_DIR}" ${protobuf_include_path} + "${filename}" + DEPENDS "${filename}" protobuf::protoc gRPC::grpc_cpp_plugin + COMMENT "Running gRPC C++ protocol buffer compiler on ${filename}" + VERBATIM) + endforeach () + + set_source_files_properties(${${SRCS}} PROPERTIES GENERATED TRUE) + set(${SRCS} + ${${SRCS}} + PARENT_SCOPE) +endfunction () + +include(GNUInstallDirs) + +# Install headers for a C++ proto library. +function (google_cloud_cpp_install_proto_library_headers target) + get_target_property(target_sources ${target} SOURCES) + foreach (header ${target_sources}) + # Skip anything that is not a header file. + if (NOT "${header}" MATCHES "\\.h$") + continue() + endif () + string(REPLACE "${CMAKE_CURRENT_BINARY_DIR}/" "" relative "${header}") + get_filename_component(dir "${relative}" DIRECTORY) + install(FILES "${header}" + DESTINATION "${CMAKE_INSTALL_INCLUDEDIR}/${dir}") + endforeach () +endfunction () + +# Install protos for a C++ proto library. +function (google_cloud_cpp_install_proto_library_protos target strip_prefix) + get_target_property(target_protos ${target} PROTO_SOURCES) + foreach (proto ${target_protos}) + # Skip anything that is not a header file. + if (NOT "${proto}" MATCHES "\\.proto$") + continue() + endif () + string(REPLACE "${strip_prefix}/" "" relative "${proto}") + get_filename_component(dir "${relative}" DIRECTORY) + # This is modeled after the Protobuf library, it installs the basic + # protos (think google/protobuf/any.proto) in the include directory for + # C/C++ code. :shrug: + install(FILES "${proto}" + DESTINATION "${CMAKE_INSTALL_INCLUDEDIR}/${dir}") + endforeach () +endfunction () + +function (google_cloud_cpp_proto_library libname) + cmake_parse_arguments(_opt "" "" "PROTO_PATH_DIRECTORIES" ${ARGN}) + if (NOT _opt_UNPARSED_ARGUMENTS) + message(SEND_ERROR "Error: google_cloud_cpp_proto_library() called" + " without any proto files") + return() + endif () + + google_cloud_cpp_generate_proto( + proto_sources ${_opt_UNPARSED_ARGUMENTS} PROTO_PATH_DIRECTORIES + ${_opt_PROTO_PATH_DIRECTORIES}) + + add_library(${libname} ${proto_sources}) + set_property(TARGET ${libname} PROPERTY PROTO_SOURCES + ${_opt_UNPARSED_ARGUMENTS}) + target_link_libraries(${libname} PUBLIC gRPC::grpc++ gRPC::grpc + protobuf::libprotobuf) + target_include_directories( + ${libname} + PUBLIC $<BUILD_INTERFACE:${CMAKE_CURRENT_BINARY_DIR}> + $<BUILD_INTERFACE:${PROJECT_SOURCE_DIR}> + $<INSTALL_INTERFACE:include>) +endfunction () + +function (google_cloud_cpp_grpcpp_library libname) + cmake_parse_arguments(_opt "" "" "PROTO_PATH_DIRECTORIES" ${ARGN}) + if (NOT _opt_UNPARSED_ARGUMENTS) + message(SEND_ERROR "Error: google_cloud_cpp_proto_library() called" + " without any proto files") + return() + endif () + + google_cloud_cpp_generate_grpcpp( + grpcpp_sources ${_opt_UNPARSED_ARGUMENTS} PROTO_PATH_DIRECTORIES + ${_opt_PROTO_PATH_DIRECTORIES}) + google_cloud_cpp_proto_library( + ${libname} ${_opt_UNPARSED_ARGUMENTS} PROTO_PATH_DIRECTORIES + ${_opt_PROTO_PATH_DIRECTORIES}) + target_sources(${libname} PRIVATE ${grpcpp_sources}) +endfunction () diff --git a/third_party/cpp/googleapis/cmake/FindProtobufTargets.cmake b/third_party/cpp/googleapis/cmake/FindProtobufTargets.cmake new file mode 100644 index 0000000000..ab196118d7 --- /dev/null +++ b/third_party/cpp/googleapis/cmake/FindProtobufTargets.cmake @@ -0,0 +1,204 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +#[=======================================================================[.rst: +FindProtobufTargets +------------------- + +A module to use `Protobuf` with less complications. + +Using ``find_package(Protobuf)`` should be simple, but it is not. + +CMake provides a ``FindProtobuf`` module. Unfortunately it does not generate +`protobuf::*` targets until CMake-3.9, and `protobuf::protoc` does not +appear until CMake-3.10. + +The CMake-config files generated by `protobuf` always create these targets, +but on some Linux distributions (e.g. Fedora>=29, and openSUSE-Tumbleweed) there +are system packages for protobuf, but these packages are installed without the +CMake-config files. One must either use the ``FindProtobuf`` module, find the +libraries via `pkg-config`, or find the libraries manually. + +When the CMake-config files are installed they produce the same targets as +recent versions of ``FindProtobuf``. However, they do not produce the +`Protobuf_LIBRARY`, `Protobuf_INCLUDE_DIR`, etc. that are generated by the +module. Furthermore, the `protobuf::protoc` library is not usable when loaded +from the CMake-config files: its ``IMPORTED_LOCATION`` variable is not defined. + +This module is designed to provide a single, uniform, ``find_package()`` +module that always produces the same outputs: + +- It always generates the ``protobuf::*`` targets. +- It always defines ``ProtobufTargets_FOUND`` and ``ProtobufTargets_VERSION``. +- It *prefers* using the CMake config files if they are available. +- It fallsback on the ``FindProtobuf`` module if the config files are not found. +- It populates any missing targets and their properties. + +The following :prop_tgt:`IMPORTED` targets are defined: + +``protobuf::libprotobuf`` + The protobuf library. +``protobuf::libprotobuf-lite`` + The protobuf lite library. +``protobuf::libprotoc`` + The protoc library. +``protobuf::protoc`` + The protoc compiler. + +Example: + +.. code-block:: cmake + + find_package(ProtobufTargets REQUIRED) + add_executable(bar bar.cc) + target_link_libraries(bar PRIVATE protobuf::libprotobuf) + +#]=======================================================================] + +if (protobuf_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "protobuf_USE_STATIC_LIBS = ${protobuf_USE_STATIC_LIBS}" + " ProtobufTargets = ${ProtobufTargets_FOUND}") +endif () + +# Always load thread support, even on Windows. +find_package(Threads REQUIRED) + +# First try to use the ``protobufConfig.cmake`` or ``protobuf-config.cmake`` +# file if it was installed. This is common on systems (or package managers) +# where protobuf was compiled and installed with `CMake`. Note that on Linux +# this *must* be all lowercase ``protobuf``, while on Windows it does not +# matter. +find_package(protobuf CONFIG) + +if (protobuf_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "protobuf_FOUND = ${protobuf_FOUND}" + " protobuf_VERSION = ${protobuf_VERSION}") +endif () + +if (protobuf_FOUND) + set(ProtobufTargets_FOUND 1) + set(ProtobufTargets_VERSION ${protobuf_VERSION}) + if (protobuf_DEBUG) + message( + STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "ProtobufTargets_FOUND = ${ProtobufTargets_FOUND}" + " ProtobufTargets_VERSION = ${ProtobufTargets_VERSION}") + endif () +else () + find_package(Protobuf QUIET) + if (Protobuf_FOUND) + set(ProtobufTargets_FOUND 1) + set(ProtobufTargets_VERSION ${Protobuf_VERSION}) + + if (NOT TARGET protobuf::libprotobuf) + add_library(protobuf::libprotobuf IMPORTED INTERFACE) + set_property( + TARGET protobuf::libprotobuf + PROPERTY INTERFACE_INCLUDE_DIRECTORIES ${Protobuf_INCLUDE_DIR}) + set_property( + TARGET protobuf::libprotobuf APPEND + PROPERTY INTERFACE_LINK_LIBRARIES ${Protobuf_LIBRARY} + Threads::Threads) + endif () + + if (NOT TARGET protobuf::libprotobuf-lite) + add_library(protobuf::libprotobuf-lite IMPORTED INTERFACE) + set_property( + TARGET protobuf::libprotobuf-lite + PROPERTY INTERFACE_INCLUDE_DIRECTORIES ${Protobuf_INCLUDE_DIR}) + set_property( + TARGET protobuf::libprotobuf-lite APPEND + PROPERTY INTERFACE_LINK_LIBRARIES ${Protobuf_LITE_LIBRARY} + Threads::Threads) + endif () + + if (NOT TARGET protobuf::libprotoc) + add_library(protobuf::libprotoc IMPORTED INTERFACE) + set_property( + TARGET protobuf::libprotoc + PROPERTY INTERFACE_INCLUDE_DIRECTORIES ${Protobuf_INCLUDE_DIR}) + set_property( + TARGET protobuf::libprotoc APPEND + PROPERTY INTERFACE_LINK_LIBRARIES ${Protobuf_PROTOC_LIBRARY} + Threads::Threads) + endif () + endif () +endif () + +if (protobuf_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "ProtobufTargets_FOUND = ${ProtobufTargets_FOUND}" + " ProtobufTargets_VERSION = ${ProtobufTargets_VERSION}") +endif () + +# We also should try to find the protobuf C++ plugin for the protocol buffers +# compiler. +if (ProtobufTargets_FOUND AND NOT TARGET protobuf::protoc) + add_executable(protobuf::protoc IMPORTED) + + # Discover the protoc compiler location. + find_program( + _protobuf_PROTOC_EXECUTABLE + NAMES protoc + DOC "The Google Protocol Buffers Compiler") + if (protobuf_DEBUG) + message( + STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "ProtobufTargets_FOUND = ${ProtobufTargets_FOUND}" + " ProtobufTargets_VERSION = ${ProtobufTargets_VERSION}" + " EXE = ${_protobuf_PROTOC_EXECUTABLE}") + endif () + set_property(TARGET protobuf::protoc + PROPERTY IMPORTED_LOCATION ${_protobuf_PROTOC_EXECUTABLE}) + set_property( + TARGET protobuf::protoc PROPERTY IMPORTED_LOCATION_DEBUG + ${_protobuf_PROTOC_EXECUTABLE}) + set_property( + TARGET protobuf::protoc PROPERTY IMPORTED_LOCATION_RELEASE + ${_protobuf_PROTOC_EXECUTABLE}) + unset(_protobuf_PROTOC_EXECUTABLE) + + if (protobuf_DEBUG) + get_target_property(_protobuf_PROTOC_EXECUTABLE protobuf::protoc + IMPORTED_LOCATION) + message( + STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "LOCATION=${_protobuf_PROTOC_EXECUTABLE}") + endif () +endif () + +if (protobuf_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "ProtobufTargets_FOUND = ${ProtobufTargets_FOUND}" + " ProtobufTargets_VERSION = ${ProtobufTargets_VERSION}") + if (ProtobufTargets_FOUND) + foreach (_target protobuf::libprotobuf protobuf::libprotobuf-lite + protobuf::libprotoc) + if (NOT TARGET ${_target}) + message( + STATUS + "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "target=${_target} is NOT a target") + endif () + endforeach () + unset(_target) + endif () +endif () + +find_package_handle_standard_args(ProtobufTargets REQUIRED_VARS + ProtobufTargets_FOUND ProtobufTargets_VERSION) diff --git a/third_party/cpp/googleapis/cmake/FindgRPC.cmake b/third_party/cpp/googleapis/cmake/FindgRPC.cmake new file mode 100644 index 0000000000..358285b620 --- /dev/null +++ b/third_party/cpp/googleapis/cmake/FindgRPC.cmake @@ -0,0 +1,333 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +#[=======================================================================[.rst: +FindgRPC +-------- + +Locate and configure the gRPC library. + +The following variables can be set and are optional: + +``gRPC_DEBUG`` + Show debug messages. +``gRPC_USE_STATIC_LIBS`` + Set to ON to force the use of the static libraries. + Default is OFF. + +Defines the following variables: + +``gRPC_FOUND`` + Found the gRPC library +``gRPC_VERSION`` + Version of package found. + +The following :prop_tgt:`IMPORTED` targets are also defined: + +``gRPC::grpc++`` + The gRPC C++ library. +``gRPC::grpc`` + The gRPC C core library. +``gRPC::cpp_plugin`` + The C++ plugin for the Protobuf protoc compiler. + +The following cache variables are also available to set or use: + +Example: + +.. code-block:: cmake + + find_package(gRPC REQUIRED) + add_executable(bar bar.cc) + target_link_libraries(bar PRIVATE gRPC::grpc++) + +#]=======================================================================] + +if (gRPC_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "gRPC_USE_STATIC_LIBS = ${gRPC_USE_STATIC_LIBS}" + " gRPC_FOUND = ${gRPC_FOUND}") +endif () + +# gRPC always requires Thread support. +find_package(Threads REQUIRED) + +# Load the module to find protobuf with proper targets. Do not use +# `find_package()` because we (have to) install this module in non-standard +# locations. +include(${CMAKE_CURRENT_LIST_DIR}/FindProtobufTargets.cmake) + +# The gRPC::grpc_cpp_plugin target is sometimes defined, but without a +# IMPORTED_LOCATION +function (_grpc_fix_grpc_cpp_plugin_target) + # The target may already exist, do not create it again if it does. + if (NOT TARGET gRPC::grpc_cpp_plugin) + add_executable(gRPC::grpc_cpp_plugin IMPORTED) + endif () + get_target_property(_gRPC_CPP_PLUGIN_EXECUTABLE gRPC::grpc_cpp_plugin + IMPORTED_LOCATION) + if (gRPC_DEBUG) + message( + STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "LOCATION=${_gRPC_CPP_PLUGIN_EXECUTABLE}") + endif () + # Even if the target exists, gRPC CMake support files do not define the + # executable for the imported target (at least they do not in v1.19.1), so + # we need to define it ourselves. + if (NOT _gRPC_CPP_PLUGIN_EXECUTABLE) + find_program(_gRPC_CPP_PLUGIN_EXECUTABLE grpc_cpp_plugin + DOC "The gRPC C++ plugin for protoc") + mark_as_advanced(_gRPC_CPP_PLUGIN_EXECUTABLE) + if (_gRPC_CPP_PLUGIN_EXECUTABLE) + set_property( + TARGET gRPC::grpc_cpp_plugin + PROPERTY IMPORTED_LOCATION ${_gRPC_CPP_PLUGIN_EXECUTABLE}) + else () + set(gRPC_FOUND "grpc_cpp_plugin-NOTFOUND") + endif () + endif () +endfunction () + +# The gRPC::* targets sometimes lack the right definitions to compile cleanly on +# WIN32 +function (_grpc_fix_grpc_target_definitions) + # Including gRPC headers without this definition results in a build error. + if (WIN32) + set_property(TARGET gRPC::grpc APPEND + PROPERTY INTERFACE_COMPILE_DEFINITIONS _WIN32_WINNT=0x600) + set_property(TARGET gRPC::grpc++ APPEND + PROPERTY INTERFACE_COMPILE_DEFINITIONS _WIN32_WINNT=0x600) + endif () +endfunction () + +# First try to use the `gRPCConfig.cmake` or `grpc-config.cmake` file if it was +# installed. This is common on systems (or package managers) where gRPC was +# compiled and installed with `CMake`. +find_package(gRPC NO_MODULE QUIET) + +if (gRPC_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "NO_MODULE result gRPC_FOUND = ${gRPC_FOUND}") +endif () + +if (gRPC_FOUND) + _grpc_fix_grpc_cpp_plugin_target() + _grpc_fix_grpc_target_definitions() + return() +endif () + +include(SelectLibraryConfigurations) + +# Internal function: search for normal library as well as a debug one if the +# debug one is specified also include debug/optimized keywords in *_LIBRARIES +# variable +function (_gRPC_find_library name filename) + if (${name}_LIBRARY) + # Use result recorded by a previous call. + return() + else () + find_library(${name}_LIBRARY_RELEASE NAMES ${filename}) + mark_as_advanced(${name}_LIBRARY_RELEASE) + + find_library(${name}_LIBRARY_DEBUG NAMES ${filename}d ${filename}) + mark_as_advanced(${name}_LIBRARY_DEBUG) + + select_library_configurations(${name}) + + if (gRPC_DEBUG) + message( + STATUS + "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "${name} ${filename} RELEASE=${${name}_LIBRARY}" + " DEBUG=${${name}_LIBRARY_DEBUG} DEFAULT=${${name}_LIBRARY}" + ) + endif () + + set(${name}_LIBRARY + "${${name}_LIBRARY}" + PARENT_SCOPE) + endif () +endfunction () + +# +# Main +# + +# Support preference of static libs by adjusting CMAKE_FIND_LIBRARY_SUFFIXES +if (_gRPC_USE_STATIC_LIBS) + set(_gRPC_ORIG_CMAKE_FIND_LIBRARY_SUFFIXES ${CMAKE_FIND_LIBRARY_SUFFIXES}) + if (WIN32) + set(CMAKE_FIND_LIBRARY_SUFFIXES .lib .a ${CMAKE_FIND_LIBRARY_SUFFIXES}) + else () + set(CMAKE_FIND_LIBRARY_SUFFIXES .a) + endif () +endif () + +_grpc_find_library(_gRPC_grpc grpc) +_grpc_find_library(_gRPC_grpc++ grpc++) + +if (NOT _gRPC_INCLUDE_DIR) + find_path(_gRPC_INCLUDE_DIR grpcpp/grpcpp.h) + mark_as_advanced(_gRPC_INCLUDE_DIR) +endif () + +if (gRPC_DEBUG) + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + " _gRPC_grpc_LIBRARY = ${_gRPC_grpc_LIBRARY}") + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + " _gRPC_grpc++_LIBRARY = ${_gRPC_grpc++_LIBRARY}") + message(STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + " _gRPC_INCLUDE_DIR = ${_gRPC_INCLUDE_DIR}") +endif () + +if (_gRPC_grpc_LIBRARY) + if (NOT TARGET gRPC::grpc) + add_library(gRPC::grpc IMPORTED UNKNOWN) + set_target_properties( + gRPC::grpc PROPERTIES INTERFACE_INCLUDE_DIRECTORIES + "${_gRPC_INCLUDE_DIR}") + if (EXISTS "${_gRPC_grpc_LIBRARY}") + set_target_properties(gRPC::grpc PROPERTIES IMPORTED_LOCATION + "${_gRPC_grpc_LIBRARY}") + endif () + if (EXISTS "${_gRPC_grpc_LIBRARY_RELEASE}") + set_property(TARGET gRPC::grpc APPEND + PROPERTY IMPORTED_CONFIGURATIONS RELEASE) + set_target_properties( + gRPC::grpc PROPERTIES IMPORTED_LOCATION_RELEASE + "${_gRPC_grpc_LIBRARY_RELEASE}") + endif () + if (EXISTS "${_gRPC_grpc_LIBRARY_DEBUG}") + set_property(TARGET gRPC::grpc APPEND + PROPERTY IMPORTED_CONFIGURATIONS DEBUG) + set_target_properties( + gRPC::grpc PROPERTIES IMPORTED_LOCATION_DEBUG + "${_gRPC_grpc_LIBRARY_DEBUG}") + endif () + set_property( + TARGET gRPC::grpc APPEND + PROPERTY INTERFACE_LINK_LIBRARIES protobuf::libprotobuf + Threads::Threads) + endif () +endif () + +if (_gRPC_grpc++_LIBRARY) + if (NOT TARGET gRPC::grpc++) + add_library(gRPC::grpc++ IMPORTED UNKNOWN) + set_target_properties( + gRPC::grpc++ PROPERTIES INTERFACE_INCLUDE_DIRECTORIES + "${_gRPC++_INCLUDE_DIR}") + if (EXISTS "${_gRPC_grpc++_LIBRARY}") + set_target_properties( + gRPC::grpc++ PROPERTIES IMPORTED_LOCATION + "${_gRPC_grpc++_LIBRARY}") + endif () + if (EXISTS "${_gRPC_grpc++_LIBRARY_RELEASE}") + set_property(TARGET gRPC::grpc++ APPEND + PROPERTY IMPORTED_CONFIGURATIONS RELEASE) + set_target_properties( + gRPC::grpc++ PROPERTIES IMPORTED_LOCATION_RELEASE + "${_gRPC_grpc++_LIBRARY_RELEASE}") + endif () + if (EXISTS "${_gRPC_grpc++_LIBRARY_DEBUG}") + set_property(TARGET gRPC::grpc++ APPEND + PROPERTY IMPORTED_CONFIGURATIONS DEBUG) + set_target_properties( + gRPC::grpc++ PROPERTIES IMPORTED_LOCATION_DEBUG + "${_gRPC_grpc++_LIBRARY_DEBUG}") + endif () + set_property( + TARGET gRPC::grpc++ APPEND + PROPERTY INTERFACE_LINK_LIBRARIES gRPC::grpc protobuf::libprotobuf + Threads::Threads) + if (CMAKE_VERSION VERSION_GREATER 3.8) + # gRPC++ requires C++11, but only CMake-3.8 introduced a target + # compiler feature to meet that requirement. + set_property(TARGET gRPC::grpc++ APPEND + PROPERTY INTERFACE_COMPILE_FEATURES cxx_std_11) + elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "GNU") + # CMake 3.5 is still alive and kicking in some older distros, use + # the compiler-specific versions in these cases. + set_property(TARGET gRPC::grpc++ APPEND + PROPERTY INTERFACE_COMPILE_OPTIONS "-std=c++11") + elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Clang") + set_property(TARGET gRPC::grpc++ APPEND + PROPERTY INTERFACE_COMPILE_OPTIONS "-std=c++11") + else () + message( + WARNING + "gRPC::grpc++ requires C++11, but this module" + " (${CMAKE_CURRENT_LIST_FILE})" + " cannot enable it for the library target in your CMake and" + " compiler versions. You need to enable C++11 in the" + " CMakeLists.txt for your project. Consider filing a bug" + " so we can fix this problem.") + endif () + endif () +endif () + +# Restore original find library prefixes +if (_gRPC_USE_STATIC_LIBS) + set(CMAKE_FIND_LIBRARY_PREFIXES "${_gRPC_ORIG_FIND_LIBRARY_PREFIXES}") +endif () + +file( + WRITE "${CMAKE_BINARY_DIR}/get_gRPC_version.cc" + [====[ +#include <grpcpp/grpcpp.h> +#include <iostream> +int main() { + std::cout << grpc::Version(); // no newline to simplify CMake module + return 0; +} + ]====]) + +try_run( + _gRPC_GET_VERSION_STATUS + _gRPC_GET_VERSION_COMPILE_STATUS + "${CMAKE_BINARY_DIR}" + "${CMAKE_BINARY_DIR}/get_gRPC_version.cc" + LINK_LIBRARIES + gRPC::grpc++ + gRPC::grpc + COMPILE_OUTPUT_VARIABLE _gRPC_GET_VERSION_COMPILE_OUTPUT + RUN_OUTPUT_VARIABLE gRPC_VERSION) + +file(REMOVE "${CMAKE_BINARY_DIR}/get_gRPC_version.cc") + +_grpc_fix_grpc_cpp_plugin_target() + +if (gRPC_DEBUG) + foreach ( + _var + _gRPC_CPP_PLUGIN_EXECUTABLE + _gRPC_VERSION_RAW + _gRPC_GET_VERSION_STATUS + _gRPC_GET_VERSION_COMPILE_STATUS + _gRPC_GET_VERSION_COMPILE_OUTPUT + _gRPC_grpc_LIBRARY + _gRPC_grpc++_LIBRARY + _gRPC_INCLUDE_DIR) + message( + STATUS "[ ${CMAKE_CURRENT_LIST_FILE}:${CMAKE_CURRENT_LIST_LINE} ] " + "${_var} = ${${_var}}") + endforeach () + unset(_var) +endif () + +include(FindPackageHandleStandardArgs) +find_package_handle_standard_args(gRPC REQUIRED_VARS _gRPC_grpc_LIBRARY + _gRPC_INCLUDE_DIR VERSION_VAR gRPC_VERSION) diff --git a/third_party/cpp/googleapis/cmake/SelectMSVCRuntime.cmake b/third_party/cpp/googleapis/cmake/SelectMSVCRuntime.cmake new file mode 100644 index 0000000000..feb2fe46c3 --- /dev/null +++ b/third_party/cpp/googleapis/cmake/SelectMSVCRuntime.cmake @@ -0,0 +1,39 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +# When compiling against *-static vcpkg packages we need to use the static C++ +# runtime with MSVC. The default is to use the dynamic runtime, which does not +# work in this case. This seems to be the recommended way to change the +# runtime: +# +# ~~~ +# https://gitlab.kitware.com/cmake/community/wikis/FAQ#how-can-i-build-my-msvc-application-with-a-static-runtime +# ~~~ +# +# Note that currently we use VCPKG_TARGET_TRIPLET to determine if the static +# runtime is needed. In the future we may need to use a more complex expression +# to determine this, but this is a good start. +# +if (MSVC AND VCPKG_TARGET_TRIPLET MATCHES "-static$") + foreach (flag_var + CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE + CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO) + if (${flag_var} MATCHES "/MD") + string(REGEX REPLACE "/MD" "/MT" ${flag_var} "${${flag_var}}") + endif () + endforeach (flag_var) + unset(flag_var) +endif () diff --git a/third_party/cpp/googleapis/cmake/config-version.cmake.in b/third_party/cpp/googleapis/cmake/config-version.cmake.in new file mode 100644 index 0000000000..29891a6bde --- /dev/null +++ b/third_party/cpp/googleapis/cmake/config-version.cmake.in @@ -0,0 +1,35 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +set(PACKAGE_VERSION @DOXYGEN_PROJECT_NUMBER@) + +# This package has not reached 1.0, there are no compatibility guarantees +# before then. +if (@GOOGLE_CLOUD_CPP_CONFIG_VERSION_MAJOR@ EQUAL 0) + if ("${PACKAGE_FIND_VERSION}" STREQUAL "") + set(PACKAGE_VERSION_COMPATIBLE TRUE) + elseif ("${PACKAGE_VERSION}" VERSION_EQUAL "${PACKAGE_FIND_VERSION}") + set(PACKAGE_VERSION_COMPATIBLE TRUE) + set(PACKAGE_VERSION_EXACT TRUE) + else () + set(PACKAGE_VERSION_UNSUITABLE TRUE) + endif () +elseif("${PACKAGE_VERSION}" VERSION_LESS "${PACKAGE_FIND_VERSION}") + set(PACKAGE_VERSION_COMPATIBLE FALSE) +else() + set(PACKAGE_VERSION_COMPATIBLE TRUE) + if ("${PACKAGE_VERSION}" VERSION_EQUAL "${PACKAGE_FIND_VERSION}") + set(PACKAGE_VERSION_EXACT TRUE) + endif() +endif() diff --git a/third_party/cpp/googleapis/cmake/config.cmake.in b/third_party/cpp/googleapis/cmake/config.cmake.in new file mode 100644 index 0000000000..25b324050c --- /dev/null +++ b/third_party/cpp/googleapis/cmake/config.cmake.in @@ -0,0 +1,52 @@ +# ~~~ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ~~~ + +include("${CMAKE_CURRENT_LIST_DIR}/FindProtobufTargets.cmake") +include("${CMAKE_CURRENT_LIST_DIR}/FindgRPC.cmake") + +include("${CMAKE_CURRENT_LIST_DIR}/googleapis-targets.cmake") + +foreach (_target + api_annotations + api_auth + api_client + api_field_behavior + api_http + api_resource + bigtable + cloud_bigquery + devtools_cloudtrace_v2_trace + devtools_cloudtrace_v2_tracing + iam_v1_iam_policy + iam_v1_options + iam_v1_policy + longrunning_operations + pubsub + rpc_error_details + rpc_status + spanner + storage + logging + type_expr) + set(scoped_name "googleapis-c++::${_target}_protos") + set(imported_name "googleapis_cpp_${_target}_protos") + if (NOT TARGET ${scoped_name}) + add_library(${scoped_name} IMPORTED INTERFACE) + set_target_properties(${scoped_name} + PROPERTIES INTERFACE_LINK_LIBRARIES + ${imported_name}) + endif () +endforeach () diff --git a/third_party/cpp/googleapis/cmake/config.pc.in b/third_party/cpp/googleapis/cmake/config.pc.in new file mode 100644 index 0000000000..af068beb74 --- /dev/null +++ b/third_party/cpp/googleapis/cmake/config.pc.in @@ -0,0 +1,26 @@ +# Copyright 2019 Google LLC +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +prefix=@CMAKE_INSTALL_PREFIX@ +exec_prefix=${prefix}/@CMAKE_INSTALL_BINDIR@ +libdir=${prefix}/@CMAKE_INSTALL_LIBDIR@ +includedir=${prefix}/@CMAKE_INSTALL_INCLUDEDIR@ + +Name: @GOOGLE_CLOUD_CPP_PC_NAME@ +Description: @GOOGLE_CLOUD_CPP_PC_DESCRIPTION@ +Requires: @GOOGLE_CLOUD_CPP_PC_REQUIRES@ +Version: @DOXYGEN_PROJECT_NUMBER@ + +Libs: -L${libdir} @GOOGLE_CLOUD_CPP_PC_LIBS@ +Cflags: -I${includedir} diff --git a/third_party/cpp/googleapis/default.nix b/third_party/cpp/googleapis/default.nix new file mode 100644 index 0000000000..76a1f7ed6e --- /dev/null +++ b/third_party/cpp/googleapis/default.nix @@ -0,0 +1,24 @@ +# This library contains generated gRPC implementations for Google's +# public libraries. +{ pkgs, ... }: + +let + inherit (pkgs) fetchFromGitHub; + stdenv = with pkgs; overrideCC pkgs.stdenv clang_9; +in stdenv.mkDerivation { + name = "googleapis-cpp"; + src = ./.; + + GOOGLEAPIS_DIR = fetchFromGitHub { + owner = "googleapis"; + repo = "googleapis"; + rev = "0aba1900ffef672ec5f0da677cf590ee5686e13b"; + sha256 = "1174mvipmzap4h8as1cl44y1kq7ikipdicnmnswv5yswgkwla84c"; + }; + + buildInputs = with pkgs; [ + c-ares c-ares.cmake-config grpc protobuf openssl zlib + ]; + + nativeBuildInputs = with pkgs; [ cmake pkgconfig ]; +} diff --git a/third_party/default.nix b/third_party/default.nix new file mode 100644 index 0000000000..0ef3d15d09 --- /dev/null +++ b/third_party/default.nix @@ -0,0 +1,160 @@ +# This file controls the import of external dependencies (i.e. +# third-party code) into my package tree. +# +# This includes *all packages needed from nixpkgs*. +{ ... }: + +let + # Tracking nixos-unstable as of 2020-05-21. + commit = "0f5ce2fac0c726036ca69a5524c59a49e2973dd4"; + nixpkgsSrc = fetchTarball { + url = "https://github.com/NixOS/nixpkgs-channels/archive/${commit}.tar.gz"; + sha256 = "0nkk492aa7pr0d30vv1aw192wc16wpa1j02925pldc09s9m9i0r3"; + }; + nixpkgs = import nixpkgsSrc { + config.allowUnfree = true; + config.allowBroken = true; + }; + + exposed = { + # Inherit the packages from nixpkgs that should be available inside + # of the repo. They become available under `pkgs.third_party.<name>` + inherit (nixpkgs) + age + autoconf + bashInteractive + bat + buildGoModule + buildGoPackage + bzip2 + c-ares + cacert + cachix + cairo + cargo + cgit + clang-tools + clangStdenv + clang_9 + cmake + coreutils + cudatoolkit + darwin + dockerTools + emacs26 + emacs26-nox + emacsPackages + emacsPackagesGen + fetchFromGitHub + fetchurl + fetchzip + fira + fira-code + fira-mono + fontconfig + freetype + gettext + glibc + gnutar + go + google-cloud-sdk + graphviz + grpc + gzip + haskell + iana-etc + imagemagickBig + jetbrains-mono + jq + kontemplate + lib + libredirect + llvmPackages + luajit + luatex + makeFontsConf + makeWrapper + mdbook + meson + mime-types + moreutils + nano + nginx + ninja + nix + openssh + openssl + overrideCC + pandoc + parallel + pkgconfig + pounce + protobuf + python3 + python3Packages + remarshal + rink + ripgrep + rsync + runCommand + runCommandNoCC + rustPlatform + rustc + sbcl + sqlite + stdenv + stern + symlinkJoin + systemd + tdlib + terraform_0_12 + texlive + thttpd + tree + writeShellScript + writeShellScriptBin + writeText + writeTextFile + xz + zlib + zstd; + + # Required by //third_party/nix + inherit (nixpkgs) + aws-sdk-cpp + bison + boehmgc + boost # urgh + brotli + busybox-sandbox-shell + curl + docbook5 + docbook_xsl_ns + editline + flex + libseccomp + libsodium + libxml2 + libxslt + mercurial + perl + perlPackages + utillinuxMinimal; + }; + +in exposed // { + callPackage = nixpkgs.lib.callPackageWith exposed; + + # Provide the source code of nixpkgs, but do not provide an imported + # version of it. + inherit nixpkgsSrc; + + # Packages to be overridden + originals = { + inherit (nixpkgs) abseil-cpp git glog notmuch; + ffmpeg = nixpkgs.ffmpeg-full; + }; + + # Make NixOS available + nixos = import "${nixpkgsSrc}/nixos"; +} diff --git a/third_party/emacs/carp-mode.nix b/third_party/emacs/carp-mode.nix new file mode 100644 index 0000000000..0ddf136542 --- /dev/null +++ b/third_party/emacs/carp-mode.nix @@ -0,0 +1,23 @@ +{ pkgs, ... }: + +with pkgs; +with emacsPackages; + +melpaBuild rec { + pname = "carp-mode"; + version = "3.0"; + packageRequires = [ clojure-mode ]; + + recipe = builtins.toFile "recipe" '' + (carp-mode :fetcher github + :repo "carp-lang/carp" + :files ("emacs/*.el")) + ''; + + src = fetchFromGitHub { + owner = "carp-lang"; + repo = "carp"; + rev = "6954642cadee730885717201c3180c7acfb1bfa9"; + sha256 = "1pz4x2qkwjbz789bwc6nkacrjpzlxawxhl2nv0xdp731y7q7xyk9"; + }; +} diff --git a/third_party/emacs/exwm.nix b/third_party/emacs/exwm.nix new file mode 100644 index 0000000000..5855205314 --- /dev/null +++ b/third_party/emacs/exwm.nix @@ -0,0 +1,13 @@ +# EXWM straight from GitHub. As of 2020-05-15, XELB in nixpkgs is +# already at a recent enough version and does not need to be +# overridden. +{ pkgs, ... }: + +pkgs.emacsPackages.exwm.overrideAttrs(_: { + src = pkgs.fetchFromGitHub { + owner = "ch11ng"; + repo = "exwm"; + rev = "48db94f48bea1137132345abfe8256cfc6219248"; + sha256 = "0jj12z6m5kvanq19gds3jpvid2mg8w28bbbq9iycl751y2sj4l1r"; + }; +}) diff --git a/third_party/emacs/rcirc/default.nix b/third_party/emacs/rcirc/default.nix new file mode 100644 index 0000000000..9d22c7cd86 --- /dev/null +++ b/third_party/emacs/rcirc/default.nix @@ -0,0 +1,7 @@ +{ pkgs, ... }: + +pkgs.emacsPackages.trivialBuild rec { + pname = "rcirc"; + version = "1"; + src = ./rcirc.el; +} diff --git a/third_party/emacs/rcirc/rcirc.el b/third_party/emacs/rcirc/rcirc.el new file mode 100644 index 0000000000..b59cb4e9af --- /dev/null +++ b/third_party/emacs/rcirc/rcirc.el @@ -0,0 +1,3133 @@ +;;; rcirc.el --- default, simple IRC client -*- lexical-binding: t; -*- + +;; Copyright (C) 2005-2019 Free Software Foundation, Inc. + +;; Author: Ryan Yeske <rcyeske@gmail.com> +;; Maintainers: Ryan Yeske <rcyeske@gmail.com>, +;; Leo Liu <sdl.web@gmail.com> +;; Keywords: comm + +;; This file is part of GNU Emacs. + +;; GNU Emacs is free software: you can redistribute it and/or modify +;; it under the terms of the GNU General Public License as published by +;; the Free Software Foundation, either version 3 of the License, or +;; (at your option) any later version. + +;; GNU Emacs is distributed in the hope that it will be useful, +;; but WITHOUT ANY WARRANTY; without even the implied warranty of +;; MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +;; GNU General Public License for more details. + +;; You should have received a copy of the GNU General Public License +;; along with GNU Emacs. If not, see <https://www.gnu.org/licenses/>. + +;;; Commentary: + +;; Internet Relay Chat (IRC) is a form of instant communication over +;; the Internet. It is mainly designed for group (many-to-many) +;; communication in discussion forums called channels, but also allows +;; one-to-one communication. + +;; Rcirc has simple defaults and clear and consistent behavior. +;; Message arrival timestamps, activity notification on the mode line, +;; message filling, nick completion, and keepalive pings are all +;; enabled by default, but can easily be adjusted or turned off. Each +;; discussion takes place in its own buffer and there is a single +;; server buffer per connection. + +;; Open a new irc connection with: +;; M-x irc RET + +;;; Todo: + +;;; Code: + +(require 'cl-lib) +(require 'ring) +(require 'time-date) +(require 'subr-x) + +(defgroup rcirc nil + "Simple IRC client." + :version "22.1" + :prefix "rcirc-" + :link '(custom-manual "(rcirc)") + :group 'applications) + +(defcustom rcirc-server-alist + '(("irc.freenode.net" :channels ("#rcirc") + ;; Don't use the TLS port by default, in case gnutls is not available. + ;; :port 7000 :encryption tls + )) + "An alist of IRC connections to establish when running `rcirc'. +Each element looks like (SERVER-NAME PARAMETERS). + +SERVER-NAME is a string describing the server to connect +to. + +The optional PARAMETERS come in pairs PARAMETER VALUE. + +The following parameters are recognized: + +`:nick' + +VALUE must be a string. If absent, `rcirc-default-nick' is used +for this connection. + +`:port' + +VALUE must be a number or string. If absent, +`rcirc-default-port' is used. + +`:user-name' + +VALUE must be a string. If absent, `rcirc-default-user-name' is +used. + +`:password' + +VALUE must be a string. If absent, no PASS command will be sent +to the server. + +`:full-name' + +VALUE must be a string. If absent, `rcirc-default-full-name' is +used. + +`:channels' + +VALUE must be a list of strings describing which channels to join +when connecting to this server. If absent, no channels will be +connected to automatically. + +`:encryption' + +VALUE must be `plain' (the default) for unencrypted connections, or `tls' +for connections using SSL/TLS. + +`:server-alias' + +VALUE must be a string that will be used instead of the server name for +display purposes. If absent, the real server name will be displayed instead." + :type '(alist :key-type string + :value-type (plist :options + ((:nick string) + (:port integer) + (:user-name string) + (:password string) + (:full-name string) + (:channels (repeat string)) + (:encryption (choice (const tls) + (const plain))) + (:server-alias string)))) + :group 'rcirc) + +(defcustom rcirc-default-port 6667 + "The default port to connect to." + :type 'integer + :group 'rcirc) + +(defcustom rcirc-default-nick (user-login-name) + "Your nick." + :type 'string + :group 'rcirc) + +(defcustom rcirc-default-user-name "user" + "Your user name sent to the server when connecting." + :version "24.1" ; changed default + :type 'string + :group 'rcirc) + +(defcustom rcirc-default-full-name "unknown" + "The full name sent to the server when connecting." + :version "24.1" ; changed default + :type 'string + :group 'rcirc) + +(defcustom rcirc-fill-flag t + "Non-nil means line-wrap messages printed in channel buffers." + :type 'boolean + :group 'rcirc) + +(defcustom rcirc-fill-column nil + "Column beyond which automatic line-wrapping should happen. +If nil, use value of `fill-column'. +If a function (e.g., `frame-text-width' or `window-text-width'), +call it to compute the number of columns." + :risky t ; can get funcalled + :type '(choice (const :tag "Value of `fill-column'" nil) + (integer :tag "Number of columns") + (function :tag "Function returning the number of columns")) + :group 'rcirc) + +(defcustom rcirc-fill-prefix nil + "Text to insert before filled lines. +If nil, calculate the prefix dynamically to line up text +underneath each nick." + :type '(choice (const :tag "Dynamic" nil) + (string :tag "Prefix text")) + :group 'rcirc) + +(defvar rcirc-ignore-buffer-activity-flag nil + "If non-nil, ignore activity in this buffer.") +(make-variable-buffer-local 'rcirc-ignore-buffer-activity-flag) + +(defvar rcirc-low-priority-flag nil + "If non-nil, activity in this buffer is considered low priority.") +(make-variable-buffer-local 'rcirc-low-priority-flag) + +(defcustom rcirc-omit-responses + '("JOIN" "PART" "QUIT" "NICK") + "Responses which will be hidden when `rcirc-omit-mode' is enabled." + :type '(repeat string) + :group 'rcirc) + +(defvar rcirc-prompt-start-marker nil) + +(define-minor-mode rcirc-omit-mode + "Toggle the hiding of \"uninteresting\" lines. +With a prefix argument ARG, enable Rcirc-Omit mode if ARG is +positive, and disable it otherwise. If called from Lisp, enable +the mode if ARG is omitted or nil. + +Uninteresting lines are those whose responses are listed in +`rcirc-omit-responses'." + nil " Omit" nil + (if rcirc-omit-mode + (progn + (add-to-invisibility-spec '(rcirc-omit . nil)) + (message "Rcirc-Omit mode enabled")) + (remove-from-invisibility-spec '(rcirc-omit . nil)) + (message "Rcirc-Omit mode disabled")) + (dolist (window (get-buffer-window-list (current-buffer))) + (with-selected-window window + (recenter (when (> (point) rcirc-prompt-start-marker) -1))))) + +(defcustom rcirc-time-format "%H:%M " + "Describes how timestamps are printed. +Used as the first arg to `format-time-string'." + :type 'string + :group 'rcirc) + +(defcustom rcirc-input-ring-size 1024 + "Size of input history ring." + :type 'integer + :group 'rcirc) + +(defcustom rcirc-read-only-flag t + "Non-nil means make text in IRC buffers read-only." + :type 'boolean + :group 'rcirc) + +(defcustom rcirc-buffer-maximum-lines nil + "The maximum size in lines for rcirc buffers. +Channel buffers are truncated from the top to be no greater than this +number. If zero or nil, no truncating is done." + :type '(choice (const :tag "No truncation" nil) + (integer :tag "Number of lines")) + :group 'rcirc) + +(defcustom rcirc-scroll-show-maximum-output t + "If non-nil, scroll buffer to keep the point at the bottom of +the window." + :type 'boolean + :group 'rcirc) + +(defcustom rcirc-authinfo nil + "List of authentication passwords. +Each element of the list is a list with a SERVER-REGEXP string +and a method symbol followed by method specific arguments. + +The valid METHOD symbols are `nickserv', `chanserv' and +`bitlbee'. + +The ARGUMENTS for each METHOD symbol are: + `nickserv': NICK PASSWORD [NICKSERV-NICK] + `chanserv': NICK CHANNEL PASSWORD + `bitlbee': NICK PASSWORD + `quakenet': ACCOUNT PASSWORD + +Examples: + ((\"freenode\" nickserv \"bob\" \"p455w0rd\") + (\"freenode\" chanserv \"bob\" \"#bobland\" \"passwd99\") + (\"bitlbee\" bitlbee \"robert\" \"sekrit\") + (\"dal.net\" nickserv \"bob\" \"sekrit\" \"NickServ@services.dal.net\") + (\"quakenet.org\" quakenet \"bobby\" \"sekrit\"))" + :type '(alist :key-type (string :tag "Server") + :value-type (choice (list :tag "NickServ" + (const nickserv) + (string :tag "Nick") + (string :tag "Password")) + (list :tag "ChanServ" + (const chanserv) + (string :tag "Nick") + (string :tag "Channel") + (string :tag "Password")) + (list :tag "BitlBee" + (const bitlbee) + (string :tag "Nick") + (string :tag "Password")) + (list :tag "QuakeNet" + (const quakenet) + (string :tag "Account") + (string :tag "Password")))) + :group 'rcirc) + +(defcustom rcirc-auto-authenticate-flag t + "Non-nil means automatically send authentication string to server. +See also `rcirc-authinfo'." + :type 'boolean + :group 'rcirc) + +(defcustom rcirc-authenticate-before-join t + "Non-nil means authenticate to services before joining channels. +Currently only works with NickServ on some networks." + :version "24.1" + :type 'boolean + :group 'rcirc) + +(defcustom rcirc-prompt "> " + "Prompt string to use in IRC buffers. + +The following replacements are made: +%n is your nick. +%s is the server. +%t is the buffer target, a channel or a user. + +Setting this alone will not affect the prompt; +use either M-x customize or also call `rcirc-update-prompt'." + :type 'string + :set 'rcirc-set-changed + :initialize 'custom-initialize-default + :group 'rcirc) + +(defcustom rcirc-keywords nil + "List of keywords to highlight in message text." + :type '(repeat string) + :group 'rcirc) + +(defcustom rcirc-ignore-list () + "List of ignored nicks. +Use /ignore to list them, use /ignore NICK to add or remove a nick." + :type '(repeat string) + :group 'rcirc) + +(defvar rcirc-ignore-list-automatic () + "List of ignored nicks added to `rcirc-ignore-list' because of renaming. +When an ignored person renames, their nick is added to both lists. +Nicks will be removed from the automatic list on follow-up renamings or +parts.") + +(defcustom rcirc-bright-nicks nil + "List of nicks to be emphasized. +See `rcirc-bright-nick' face." + :type '(repeat string) + :group 'rcirc) + +(defcustom rcirc-dim-nicks nil + "List of nicks to be deemphasized. +See `rcirc-dim-nick' face." + :type '(repeat string) + :group 'rcirc) + +(define-obsolete-variable-alias 'rcirc-print-hooks + 'rcirc-print-functions "24.3") +(defcustom rcirc-print-functions nil + "Hook run after text is printed. +Called with 5 arguments, PROCESS, SENDER, RESPONSE, TARGET and TEXT." + :type 'hook + :group 'rcirc) + +(defvar rcirc-authenticated-hook nil + "Hook run after successfully authenticated.") + +(defcustom rcirc-always-use-server-buffer-flag nil + "Non-nil means messages without a channel target will go to the server buffer." + :type 'boolean + :group 'rcirc) + +(defcustom rcirc-decode-coding-system 'utf-8 + "Coding system used to decode incoming irc messages. +Set to `undecided' if you want the encoding of the incoming +messages autodetected." + :type 'coding-system + :group 'rcirc) + +(defcustom rcirc-encode-coding-system 'utf-8 + "Coding system used to encode outgoing irc messages." + :type 'coding-system + :group 'rcirc) + +(defcustom rcirc-coding-system-alist nil + "Alist to decide a coding system to use for a channel I/O operation. +The format is ((PATTERN . VAL) ...). +PATTERN is either a string or a cons of strings. +If PATTERN is a string, it is used to match a target. +If PATTERN is a cons of strings, the car part is used to match a +target, and the cdr part is used to match a server. +VAL is either a coding system or a cons of coding systems. +If VAL is a coding system, it is used for both decoding and encoding +messages. +If VAL is a cons of coding systems, the car part is used for decoding, +and the cdr part is used for encoding." + :type '(alist :key-type (choice (string :tag "Channel Regexp") + (cons (string :tag "Channel Regexp") + (string :tag "Server Regexp"))) + :value-type (choice coding-system + (cons (coding-system :tag "Decode") + (coding-system :tag "Encode")))) + :group 'rcirc) + +(defcustom rcirc-multiline-major-mode 'fundamental-mode + "Major-mode function to use in multiline edit buffers." + :type 'function + :group 'rcirc) + +(defcustom rcirc-nick-completion-format "%s: " + "Format string to use in nick completions. + +The format string is only used when completing at the beginning +of a line. The string is passed as the first argument to +`format' with the nickname as the second argument." + :version "24.1" + :type 'string + :group 'rcirc) + +(defcustom rcirc-kill-channel-buffers nil + "When non-nil, kill channel buffers when the server buffer is killed. +Only the channel buffers associated with the server in question +will be killed." + :version "24.3" + :type 'boolean + :group 'rcirc) + +(defvar rcirc-nick nil) + +(defvar rcirc-prompt-end-marker nil) + +(defvar rcirc-nick-table nil) + +(defvar rcirc-recent-quit-alist nil + "Alist of nicks that have recently quit or parted the channel.") + +(defvar rcirc-nick-syntax-table + (let ((table (make-syntax-table text-mode-syntax-table))) + (mapc (lambda (c) (modify-syntax-entry c "w" table)) + "[]\\`_^{|}-") + (modify-syntax-entry ?' "_" table) + table) + "Syntax table which includes all nick characters as word constituents.") + +;; each process has an alist of (target . buffer) pairs +(defvar rcirc-buffer-alist nil) + +(defvar rcirc-activity nil + "List of buffers with unviewed activity.") + +(defvar rcirc-activity-string "" + "String displayed in mode line representing `rcirc-activity'.") +(put 'rcirc-activity-string 'risky-local-variable t) + +(defvar rcirc-server-buffer nil + "The server buffer associated with this channel buffer.") + +(defvar rcirc-target nil + "The channel or user associated with this buffer.") + +(defvar rcirc-urls nil + "List of URLs seen in the current buffer and their start positions.") +(put 'rcirc-urls 'permanent-local t) + +(defvar rcirc-timeout-seconds 600 + "Kill connection after this many seconds if there is no activity.") + +(defconst rcirc-id-string (concat "rcirc on GNU Emacs " emacs-version)) + +(defvar rcirc-startup-channels nil) + +(defvar rcirc-server-name-history nil + "History variable for \\[rcirc] call.") + +(defvar rcirc-server-port-history nil + "History variable for \\[rcirc] call.") + +(defvar rcirc-nick-name-history nil + "History variable for \\[rcirc] call.") + +(defvar rcirc-user-name-history nil + "History variable for \\[rcirc] call.") + +(defvar rcirc-last-message-time nil) + +;;;###autoload +(defun rcirc (arg) + "Connect to all servers in `rcirc-server-alist'. + +Do not connect to a server if it is already connected. + +If ARG is non-nil, instead prompt for connection parameters." + (interactive "P") + (if arg + (let* ((server (completing-read "IRC Server: " + rcirc-server-alist + nil nil + (caar rcirc-server-alist) + 'rcirc-server-name-history)) + (server-plist (cdr (assoc-string server rcirc-server-alist))) + (port (read-string "IRC Port: " + (number-to-string + (or (plist-get server-plist :port) + rcirc-default-port)) + 'rcirc-server-port-history)) + (nick (read-string "IRC Nick: " + (or (plist-get server-plist :nick) + rcirc-default-nick) + 'rcirc-nick-name-history)) + (user-name (read-string "IRC Username: " + (or (plist-get server-plist :user-name) + rcirc-default-user-name) + 'rcirc-user-name-history)) + (password (read-passwd "IRC Password: " nil + (plist-get server-plist :password))) + (channels (split-string + (read-string "IRC Channels: " + (mapconcat 'identity + (plist-get server-plist + :channels) + " ")) + "[, ]+" t)) + (encryption (rcirc-prompt-for-encryption server-plist))) + (rcirc-connect server port nick user-name + rcirc-default-full-name + channels password encryption)) + ;; connect to servers in `rcirc-server-alist' + (let (connected-servers) + (dolist (c rcirc-server-alist) + (let ((server (car c)) + (nick (or (plist-get (cdr c) :nick) rcirc-default-nick)) + (port (or (plist-get (cdr c) :port) rcirc-default-port)) + (user-name (or (plist-get (cdr c) :user-name) + rcirc-default-user-name)) + (full-name (or (plist-get (cdr c) :full-name) + rcirc-default-full-name)) + (channels (plist-get (cdr c) :channels)) + (password (plist-get (cdr c) :password)) + (encryption (plist-get (cdr c) :encryption)) + (server-alias (plist-get (cdr c) :server-alias)) + contact) + (when server + (let (connected) + (dolist (p (rcirc-process-list)) + (when (string= (or server-alias server) (process-name p)) + (setq connected p))) + (if (not connected) + (condition-case nil + (rcirc-connect server port nick user-name + full-name channels password encryption + server-alias) + (quit (message "Quit connecting to %s" + (or server-alias server)))) + (with-current-buffer (process-buffer connected) + (setq contact (process-contact + (get-buffer-process (current-buffer)) :name)) + (setq connected-servers + (cons (if (stringp contact) + contact (or server-alias server)) + connected-servers)))))))) + (when connected-servers + (message "Already connected to %s" + (if (cdr connected-servers) + (concat (mapconcat 'identity (butlast connected-servers) ", ") + ", and " + (car (last connected-servers))) + (car connected-servers))))))) + +;;;###autoload +(defalias 'irc 'rcirc) + + +(defvar rcirc-process-output nil) +(defvar rcirc-topic nil) +(defvar rcirc-keepalive-timer nil) +(defvar rcirc-last-server-message-time nil) +(defvar rcirc-server nil) ; server provided by server +(defvar rcirc-server-name nil) ; server name given by 001 response +(defvar rcirc-timeout-timer nil) +(defvar rcirc-user-authenticated nil) +(defvar rcirc-user-disconnect nil) +(defvar rcirc-connecting nil) +(defvar rcirc-connection-info nil) +(defvar rcirc-process nil) + +;;;###autoload +(defun rcirc-connect (server &optional port nick user-name + full-name startup-channels password encryption + server-alias) + (save-excursion + (message "Connecting to %s..." (or server-alias server)) + (let* ((inhibit-eol-conversion) + (port-number (if port + (if (stringp port) + (string-to-number port) + port) + rcirc-default-port)) + (nick (or nick rcirc-default-nick)) + (user-name (or user-name rcirc-default-user-name)) + (full-name (or full-name rcirc-default-full-name)) + (startup-channels startup-channels) + (process (open-network-stream + (or server-alias server) nil server port-number + :type (or encryption 'plain)))) + ;; set up process + (set-process-coding-system process 'raw-text 'raw-text) + (switch-to-buffer (rcirc-generate-new-buffer-name process nil)) + (set-process-buffer process (current-buffer)) + (rcirc-mode process nil) + (set-process-sentinel process 'rcirc-sentinel) + (set-process-filter process 'rcirc-filter) + + (setq-local rcirc-connection-info + (list server port nick user-name full-name startup-channels + password encryption server-alias)) + (setq-local rcirc-process process) + (setq-local rcirc-server server) + (setq-local rcirc-server-name + (or server-alias server)) ; Update when we get 001 response. + (setq-local rcirc-buffer-alist nil) + (setq-local rcirc-nick-table (make-hash-table :test 'equal)) + (setq-local rcirc-nick nick) + (setq-local rcirc-process-output nil) + (setq-local rcirc-startup-channels startup-channels) + (setq-local rcirc-last-server-message-time (current-time)) + + (setq-local rcirc-timeout-timer nil) + (setq-local rcirc-user-disconnect nil) + (setq-local rcirc-user-authenticated nil) + (setq-local rcirc-connecting t) + + (add-hook 'auto-save-hook 'rcirc-log-write) + + ;; identify + (unless (zerop (length password)) + (rcirc-send-string process (concat "PASS " password))) + (rcirc-send-string process (concat "NICK " nick)) + (rcirc-send-string process "CAP LS 302") + (rcirc-send-string process (concat "USER " user-name + " 0 * :" full-name)) + + ;; setup ping timer if necessary + (unless rcirc-keepalive-timer + (setq rcirc-keepalive-timer + (run-at-time 0 (/ rcirc-timeout-seconds 2) 'rcirc-keepalive))) + + (message "Connecting to %s...done" (or server-alias server)) + + ;; return process object + process))) + +(defmacro with-rcirc-process-buffer (process &rest body) + (declare (indent 1) (debug t)) + `(with-current-buffer (process-buffer ,process) + ,@body)) + +(defmacro with-rcirc-server-buffer (&rest body) + (declare (indent 0) (debug t)) + `(with-current-buffer rcirc-server-buffer + ,@body)) + +(define-obsolete-function-alias 'rcirc-float-time 'float-time "26.1") + +(defun rcirc-prompt-for-encryption (server-plist) + "Prompt the user for the encryption method to use. +SERVER-PLIST is the property list for the server." + (let ((msg "Encryption (default %s): ") + (choices '("plain" "tls")) + (default (or (plist-get server-plist :encryption) + 'plain))) + (intern + (completing-read (format msg default) + choices nil t nil nil (symbol-name default))))) + +(defun rcirc-keepalive () + "Send keep alive pings to active rcirc processes. +Kill processes that have not received a server message since the +last ping." + (if (rcirc-process-list) + (mapc (lambda (process) + (with-rcirc-process-buffer process + (when (not rcirc-connecting) + (rcirc-send-ctcp process + rcirc-nick + (format "KEEPALIVE %f" + (float-time)))))) + (rcirc-process-list)) + ;; no processes, clean up timer + (when (timerp rcirc-keepalive-timer) + (cancel-timer rcirc-keepalive-timer)) + (setq rcirc-keepalive-timer nil))) + +(defun rcirc-handler-ctcp-KEEPALIVE (process _target _sender message) + (with-rcirc-process-buffer process + (setq header-line-format (format "%f" (- (float-time) + (string-to-number message)))))) + +(defvar rcirc-debug-buffer "*rcirc debug*") +(defvar rcirc-debug-flag nil + "If non-nil, write information to `rcirc-debug-buffer'.") +(defun rcirc-debug (process text) + "Add an entry to the debug log including PROCESS and TEXT. +Debug text is written to `rcirc-debug-buffer' if `rcirc-debug-flag' +is non-nil." + (when rcirc-debug-flag + (with-current-buffer (get-buffer-create rcirc-debug-buffer) + (goto-char (point-max)) + (insert (concat + "[" + (format-time-string "%Y-%m-%dT%T ") (process-name process) + "] " + text))))) + +(define-obsolete-variable-alias 'rcirc-sentinel-hooks + 'rcirc-sentinel-functions "24.3") +(defvar rcirc-sentinel-functions nil + "Hook functions called when the process sentinel is called. +Functions are called with PROCESS and SENTINEL arguments.") + +(defcustom rcirc-reconnect-delay 0 + "The minimum interval in seconds between reconnect attempts. +When 0, do not auto-reconnect." + :version "25.1" + :type 'integer + :group 'rcirc) + +(defvar rcirc-last-connect-time nil + "The last time the buffer was connected.") + +(defun rcirc-sentinel (process sentinel) + "Called when PROCESS receives SENTINEL." + (let ((sentinel (replace-regexp-in-string "\n" "" sentinel))) + (rcirc-debug process (format "SENTINEL: %S %S\n" process sentinel)) + (with-rcirc-process-buffer process + (dolist (buffer (cons nil (mapcar 'cdr rcirc-buffer-alist))) + (with-current-buffer (or buffer (current-buffer)) + (rcirc-print process "rcirc.el" "ERROR" rcirc-target + (format "%s: %s (%S)" + (process-name process) + sentinel + (process-status process)) + (not rcirc-target)) + (rcirc-disconnect-buffer))) + (when (and (string= sentinel "deleted") + (< 0 rcirc-reconnect-delay)) + (let ((now (current-time))) + (when (or (null rcirc-last-connect-time) + (< rcirc-reconnect-delay + (float-time (time-subtract now rcirc-last-connect-time)))) + (setq rcirc-last-connect-time now) + (rcirc-cmd-reconnect nil)))) + (run-hook-with-args 'rcirc-sentinel-functions process sentinel)))) + +(defun rcirc-disconnect-buffer (&optional buffer) + (with-current-buffer (or buffer (current-buffer)) + ;; set rcirc-target to nil for each channel so cleanup + ;; doesn't happen when we reconnect + (setq rcirc-target nil) + (setq mode-line-process ":disconnected"))) + +(defun rcirc-process-list () + "Return a list of rcirc processes." + (let (ps) + (mapc (lambda (p) + (when (buffer-live-p (process-buffer p)) + (with-rcirc-process-buffer p + (when (eq major-mode 'rcirc-mode) + (setq ps (cons p ps)))))) + (process-list)) + ps)) + +(define-obsolete-variable-alias 'rcirc-receive-message-hooks + 'rcirc-receive-message-functions "24.3") +(defvar rcirc-receive-message-functions nil + "Hook functions run when a message is received from server. +Function is called with PROCESS, COMMAND, SENDER, ARGS and LINE.") +(defun rcirc-filter (process output) + "Called when PROCESS receives OUTPUT." + (rcirc-debug process output) + (rcirc-reschedule-timeout process) + (with-rcirc-process-buffer process + (setq rcirc-last-server-message-time (current-time)) + (setq rcirc-process-output (concat rcirc-process-output output)) + (when (= ?\n (aref rcirc-process-output + (1- (length rcirc-process-output)))) + (let ((lines (split-string rcirc-process-output "[\n\r]" t))) + (setq rcirc-process-output nil) + (dolist (line lines) + (rcirc-process-server-response process line)))))) + +(defun rcirc-reschedule-timeout (process) + (with-rcirc-process-buffer process + (when (not rcirc-connecting) + (with-rcirc-process-buffer process + (when rcirc-timeout-timer (cancel-timer rcirc-timeout-timer)) + (setq rcirc-timeout-timer (run-at-time rcirc-timeout-seconds nil + 'rcirc-delete-process + process)))))) + +(defun rcirc-delete-process (process) + (delete-process process)) + +(defvar rcirc-trap-errors-flag t) +(defun rcirc-process-server-response (process text) + (if rcirc-trap-errors-flag + (condition-case err + (rcirc-process-server-response-1 process text) + (error + (rcirc-print process "RCIRC" "ERROR" nil + (format "\"%s\" %s" text err) t))) + (rcirc-process-server-response-1 process text))) + +(defun rcirc-handle-message-tags (tags) + (if-let* ((time (cdr (assoc "time" tags))) + (timestamp (floor (float-time (date-to-time time))))) + (setq rcirc-last-message-time timestamp))) + +(defun rcirc-parse-tags (tags) + "Parse TAGS message prefix." + (mapcar (lambda (tag) + (let ((p (split-string tag "="))) + `(,(car p) . ,(cadr p)))) + (split-string tags ";"))) + +(defun rcirc-process-server-response-1 (process text) + + ;; attempt to extract and handle IRCv3 message tags (which contain server-time) + (if (string-match "^\\(@\\([^ ]+\\) \\)?\\(\\(:[^ ]+ \\)?[^ ]+ .+\\)$" text) + (let ((tags (match-string 2 text)) + (rest (match-string 3 text))) + (when tags + (rcirc-handle-message-tags (rcirc-parse-tags tags))) + (setq text rest))) + + (if (string-match "^\\(:\\([^ ]+\\) \\)?\\([^ ]+\\) \\(.+\\)$" text) + (let* ((user (match-string 2 text)) + (sender (rcirc-user-nick user)) + (cmd (match-string 3 text)) + (args (match-string 4 text)) + (handler (intern-soft (concat "rcirc-handler-" cmd)))) + (string-match "^\\([^:]*\\):?\\(.+\\)?$" args) + (let* ((args1 (match-string 1 args)) + (args2 (match-string 2 args)) + (args (delq nil (append (split-string args1 " " t) + (list args2))))) + (if (not (fboundp handler)) + (rcirc-handler-generic process cmd sender args text) + (funcall handler process sender args text)) + (run-hook-with-args 'rcirc-receive-message-functions + process cmd sender args text))) + (message "UNHANDLED: %s" text))) + +(defvar rcirc-responses-no-activity '("305" "306") + "Responses that don't trigger activity in the mode-line indicator.") + +(defun rcirc-handler-generic (process response sender args _text) + "Generic server response handler." + (rcirc-print process sender response nil + (mapconcat 'identity (cdr args) " ") + (not (member response rcirc-responses-no-activity)))) + +(defun rcirc--connection-open-p (process) + (memq (process-status process) '(run open))) + +(defun rcirc-send-string (process string) + "Send PROCESS a STRING plus a newline." + (let ((string (concat (encode-coding-string string rcirc-encode-coding-system) + "\n"))) + (unless (rcirc--connection-open-p process) + (error "Network connection to %s is not open" + (process-name process))) + (rcirc-debug process string) + (process-send-string process string))) + +(defun rcirc-send-privmsg (process target string) + (rcirc-send-string process (format "PRIVMSG %s :%s" target string))) + +(defun rcirc-send-ctcp (process target request &optional args) + (let ((args (if args (concat " " args) ""))) + (rcirc-send-privmsg process target + (format "\C-a%s%s\C-a" request args)))) + +(defun rcirc-buffer-process (&optional buffer) + "Return the process associated with channel BUFFER. +With no argument or nil as argument, use the current buffer." + (let ((buffer (or buffer (and (buffer-live-p rcirc-server-buffer) + rcirc-server-buffer)))) + (if buffer + (with-current-buffer buffer rcirc-process) + rcirc-process))) + +(defun rcirc-server-name (process) + "Return PROCESS server name, given by the 001 response." + (with-rcirc-process-buffer process + (or rcirc-server-name + (warn "server name for process %S unknown" process)))) + +(defun rcirc-nick (process) + "Return PROCESS nick." + (with-rcirc-process-buffer process + (or rcirc-nick rcirc-default-nick))) + +(defun rcirc-buffer-nick (&optional buffer) + "Return the nick associated with BUFFER. +With no argument or nil as argument, use the current buffer." + (with-current-buffer (or buffer (current-buffer)) + (with-current-buffer rcirc-server-buffer + (or rcirc-nick rcirc-default-nick)))) + +(defvar rcirc-max-message-length 420 + "Messages longer than this value will be split.") + +(defun rcirc-split-message (message) + "Split MESSAGE into chunks within `rcirc-max-message-length'." + ;; `rcirc-encode-coding-system' can have buffer-local value. + (let ((encoding rcirc-encode-coding-system)) + (with-temp-buffer + (insert message) + (goto-char (point-min)) + (let (result) + (while (not (eobp)) + (goto-char (or (byte-to-position rcirc-max-message-length) + (point-max))) + ;; max message length is 512 including CRLF + (while (and (not (bobp)) + (> (length (encode-coding-region + (point-min) (point) encoding t)) + rcirc-max-message-length)) + (forward-char -1)) + (push (delete-and-extract-region (point-min) (point)) result)) + (nreverse result))))) + +(defun rcirc-send-message (process target message &optional noticep silent) + "Send TARGET associated with PROCESS a privmsg with text MESSAGE. +If NOTICEP is non-nil, send a notice instead of privmsg. +If SILENT is non-nil, do not print the message in any irc buffer." + (let ((response (if noticep "NOTICE" "PRIVMSG"))) + (rcirc-get-buffer-create process target) + (dolist (msg (rcirc-split-message message)) + (rcirc-send-string process (concat response " " target " :" msg)) + (unless silent + (rcirc-print process (rcirc-nick process) response target msg))))) + +(defvar rcirc-input-ring nil) +(defvar rcirc-input-ring-index 0) + +(defun rcirc-prev-input-string (arg) + (ring-ref rcirc-input-ring (+ rcirc-input-ring-index arg))) + +(defun rcirc-insert-prev-input () + (interactive) + (when (<= rcirc-prompt-end-marker (point)) + (delete-region rcirc-prompt-end-marker (point-max)) + (insert (rcirc-prev-input-string 0)) + (setq rcirc-input-ring-index (1+ rcirc-input-ring-index)))) + +(defun rcirc-insert-next-input () + (interactive) + (when (<= rcirc-prompt-end-marker (point)) + (delete-region rcirc-prompt-end-marker (point-max)) + (setq rcirc-input-ring-index (1- rcirc-input-ring-index)) + (insert (rcirc-prev-input-string -1)))) + +(defvar rcirc-server-commands + '("/admin" "/away" "/connect" "/die" "/error" "/info" + "/invite" "/ison" "/join" "/kick" "/kill" "/links" + "/list" "/lusers" "/mode" "/motd" "/names" "/nick" + "/notice" "/oper" "/part" "/pass" "/ping" "/pong" + "/privmsg" "/quit" "/rehash" "/restart" "/service" "/servlist" + "/server" "/squery" "/squit" "/stats" "/summon" "/time" + "/topic" "/trace" "/user" "/userhost" "/users" "/version" + "/wallops" "/who" "/whois" "/whowas") + "A list of user commands by IRC server. +The value defaults to RFCs 1459 and 2812.") + +;; /me and /ctcp are not defined by `defun-rcirc-command'. +(defvar rcirc-client-commands '("/me" "/ctcp") + "A list of user commands defined by IRC client rcirc. +The list is updated automatically by `defun-rcirc-command'.") + +(defun rcirc-completion-at-point () + "Function used for `completion-at-point-functions' in `rcirc-mode'." + (and (rcirc-looking-at-input) + (let* ((beg (save-excursion + ;; On some networks it is common to message or + ;; mention someone using @nick instead of just + ;; nick. + (if (re-search-backward "[[:space:]@]" rcirc-prompt-end-marker t) + (1+ (point)) + rcirc-prompt-end-marker))) + (table (if (and (= beg rcirc-prompt-end-marker) + (eq (char-after beg) ?/)) + (delete-dups + (nconc (sort (copy-sequence rcirc-client-commands) + 'string-lessp) + (sort (copy-sequence rcirc-server-commands) + 'string-lessp))) + (rcirc-channel-nicks (rcirc-buffer-process) + rcirc-target)))) + (list beg (point) table)))) + +(defvar rcirc-completions nil) +(defvar rcirc-completion-start nil) + +(defun rcirc-complete () + "Cycle through completions from list of nicks in channel or IRC commands. +IRC command completion is performed only if `/' is the first input char." + (interactive) + (unless (rcirc-looking-at-input) + (error "Point not located after rcirc prompt")) + (if (eq last-command this-command) + (setq rcirc-completions + (append (cdr rcirc-completions) (list (car rcirc-completions)))) + (let ((completion-ignore-case t) + (table (rcirc-completion-at-point))) + (setq rcirc-completion-start (car table)) + (setq rcirc-completions + (and rcirc-completion-start + (all-completions (buffer-substring rcirc-completion-start + (cadr table)) + (nth 2 table)))))) + (let ((completion (car rcirc-completions))) + (when completion + (delete-region rcirc-completion-start (point)) + (insert + (cond + ((= (aref completion 0) ?/) (concat completion " ")) + ((= rcirc-completion-start rcirc-prompt-end-marker) + (format rcirc-nick-completion-format completion)) + (t completion)))))) + +(defun set-rcirc-decode-coding-system (coding-system) + "Set the decode coding system used in this channel." + (interactive "zCoding system for incoming messages: ") + (setq-local rcirc-decode-coding-system coding-system)) + +(defun set-rcirc-encode-coding-system (coding-system) + "Set the encode coding system used in this channel." + (interactive "zCoding system for outgoing messages: ") + (setq-local rcirc-encode-coding-system coding-system)) + +(defvar rcirc-mode-map + (let ((map (make-sparse-keymap))) + (define-key map (kbd "RET") 'rcirc-send-input) + (define-key map (kbd "M-p") 'rcirc-insert-prev-input) + (define-key map (kbd "M-n") 'rcirc-insert-next-input) + (define-key map (kbd "TAB") 'rcirc-complete) + (define-key map (kbd "C-c C-b") 'rcirc-browse-url) + (define-key map (kbd "C-c C-c") 'rcirc-edit-multiline) + (define-key map (kbd "C-c C-j") 'rcirc-cmd-join) + (define-key map (kbd "C-c C-k") 'rcirc-cmd-kick) + (define-key map (kbd "C-c C-l") 'rcirc-toggle-low-priority) + (define-key map (kbd "C-c C-d") 'rcirc-cmd-mode) + (define-key map (kbd "C-c C-m") 'rcirc-cmd-msg) + (define-key map (kbd "C-c C-r") 'rcirc-cmd-nick) ; rename + (define-key map (kbd "C-c C-o") 'rcirc-omit-mode) + (define-key map (kbd "C-c C-p") 'rcirc-cmd-part) + (define-key map (kbd "C-c C-q") 'rcirc-cmd-query) + (define-key map (kbd "C-c C-t") 'rcirc-cmd-topic) + (define-key map (kbd "C-c C-n") 'rcirc-cmd-names) + (define-key map (kbd "C-c C-w") 'rcirc-cmd-whois) + (define-key map (kbd "C-c C-x") 'rcirc-cmd-quit) + (define-key map (kbd "C-c TAB") ; C-i + 'rcirc-toggle-ignore-buffer-activity) + (define-key map (kbd "C-c C-s") 'rcirc-switch-to-server-buffer) + (define-key map (kbd "C-c C-a") 'rcirc-jump-to-first-unread-line) + map) + "Keymap for rcirc mode.") + +(defvar rcirc-short-buffer-name nil + "Generated abbreviation to use to indicate buffer activity.") + +(defvar rcirc-mode-hook nil + "Hook run when setting up rcirc buffer.") + +(defvar rcirc-last-post-time nil) + +(defvar rcirc-log-alist nil + "Alist of lines to log to disk when `rcirc-log-flag' is non-nil. +Each element looks like (FILENAME . TEXT).") + +(defvar rcirc-current-line 0 + "The current number of responses printed in this channel. +This number is independent of the number of lines in the buffer.") + +(defun rcirc-mode (process target) + ;; FIXME: Use define-derived-mode. + "Major mode for IRC channel buffers. + +\\{rcirc-mode-map}" + (kill-all-local-variables) + (use-local-map rcirc-mode-map) + (setq mode-name "rcirc") + (setq major-mode 'rcirc-mode) + (setq mode-line-process nil) + + (setq-local rcirc-input-ring + ;; If rcirc-input-ring is already a ring with desired + ;; size do not re-initialize. + (if (and (ring-p rcirc-input-ring) + (= (ring-size rcirc-input-ring) + rcirc-input-ring-size)) + rcirc-input-ring + (make-ring rcirc-input-ring-size))) + (setq-local rcirc-server-buffer (process-buffer process)) + (setq-local rcirc-target target) + (setq-local rcirc-topic nil) + (setq-local rcirc-last-post-time (current-time)) + (setq-local fill-paragraph-function 'rcirc-fill-paragraph) + (setq-local rcirc-recent-quit-alist nil) + (setq-local rcirc-current-line 0) + (setq-local rcirc-last-connect-time (current-time)) + + (use-hard-newlines t) + (setq-local rcirc-short-buffer-name nil) + (setq-local rcirc-urls nil) + + ;; setup for omitting responses + (setq buffer-invisibility-spec '()) + (setq buffer-display-table (make-display-table)) + (set-display-table-slot buffer-display-table 4 + (let ((glyph (make-glyph-code + ?. 'font-lock-keyword-face))) + (make-vector 3 glyph))) + + (dolist (i rcirc-coding-system-alist) + (let ((chan (if (consp (car i)) (caar i) (car i))) + (serv (if (consp (car i)) (cdar i) ""))) + (when (and (string-match chan (or target "")) + (string-match serv (rcirc-server-name process))) + (setq-local rcirc-decode-coding-system + (if (consp (cdr i)) (cadr i) (cdr i))) + (setq-local rcirc-encode-coding-system + (if (consp (cdr i)) (cddr i) (cdr i)))))) + + ;; setup the prompt and markers + (setq-local rcirc-prompt-start-marker (point-max-marker)) + (setq-local rcirc-prompt-end-marker (point-max-marker)) + (rcirc-update-prompt) + (goto-char rcirc-prompt-end-marker) + + (setq-local overlay-arrow-position (make-marker)) + + ;; if the user changes the major mode or kills the buffer, there is + ;; cleanup work to do + (add-hook 'change-major-mode-hook 'rcirc-change-major-mode-hook nil t) + (add-hook 'kill-buffer-hook 'rcirc-kill-buffer-hook nil t) + + ;; add to buffer list, and update buffer abbrevs + (when target ; skip server buffer + (let ((buffer (current-buffer))) + (with-rcirc-process-buffer process + (setq rcirc-buffer-alist (cons (cons target buffer) + rcirc-buffer-alist)))) + (rcirc-update-short-buffer-names)) + + (add-hook 'completion-at-point-functions + 'rcirc-completion-at-point nil 'local) + + (run-mode-hooks 'rcirc-mode-hook)) + +(defun rcirc-update-prompt (&optional all) + "Reset the prompt string in the current buffer. + +If ALL is non-nil, update prompts in all IRC buffers." + (if all + (mapc (lambda (process) + (mapc (lambda (buffer) + (with-current-buffer buffer + (rcirc-update-prompt))) + (with-rcirc-process-buffer process + (mapcar 'cdr rcirc-buffer-alist)))) + (rcirc-process-list)) + (let ((inhibit-read-only t) + (prompt (or rcirc-prompt ""))) + (mapc (lambda (rep) + (setq prompt + (replace-regexp-in-string (car rep) (cdr rep) prompt))) + (list (cons "%n" (rcirc-buffer-nick)) + (cons "%s" (with-rcirc-server-buffer rcirc-server-name)) + (cons "%t" (or rcirc-target "")))) + (save-excursion + (delete-region rcirc-prompt-start-marker rcirc-prompt-end-marker) + (goto-char rcirc-prompt-start-marker) + (let ((start (point))) + (insert-before-markers prompt) + (set-marker rcirc-prompt-start-marker start) + (when (not (zerop (- rcirc-prompt-end-marker + rcirc-prompt-start-marker))) + (add-text-properties rcirc-prompt-start-marker + rcirc-prompt-end-marker + (list 'face 'rcirc-prompt + 'read-only t 'field t + 'front-sticky t 'rear-nonsticky t)))))))) + +(defun rcirc-set-changed (option value) + "Set OPTION to VALUE and do updates after a customization change." + (set-default option value) + (cond ((eq option 'rcirc-prompt) + (rcirc-update-prompt 'all)) + (t + (error "Bad option %s" option)))) + +(defun rcirc-channel-p (target) + "Return t if TARGET is a channel name." + (and target + (not (zerop (length target))) + (or (eq (aref target 0) ?#) + (eq (aref target 0) ?&)))) + +(defcustom rcirc-log-directory "~/.emacs.d/rcirc-log" + "Directory to keep IRC logfiles." + :type 'directory + :group 'rcirc) + +(defcustom rcirc-log-flag nil + "Non-nil means log IRC activity to disk. +Logfiles are kept in `rcirc-log-directory'." + :type 'boolean + :group 'rcirc) + +(defun rcirc-kill-buffer-hook () + "Part the channel when killing an rcirc buffer. + +If `rcirc-kill-channel-buffers' is non-nil and the killed buffer +is a server buffer, kills all of the channel buffers associated +with it." + (when (eq major-mode 'rcirc-mode) + (when (and rcirc-log-flag + rcirc-log-directory) + (rcirc-log-write)) + (rcirc-clean-up-buffer "Killed buffer") + (when (and rcirc-buffer-alist ;; it's a server buffer + rcirc-kill-channel-buffers) + (dolist (channel rcirc-buffer-alist) + (kill-buffer (cdr channel)))))) + +(defun rcirc-change-major-mode-hook () + "Part the channel when changing the major-mode." + (rcirc-clean-up-buffer "Changed major mode")) + +(defun rcirc-clean-up-buffer (reason) + (let ((buffer (current-buffer))) + (rcirc-clear-activity buffer) + (when (and (rcirc-buffer-process) + (rcirc--connection-open-p (rcirc-buffer-process))) + (with-rcirc-server-buffer + (setq rcirc-buffer-alist + (rassq-delete-all buffer rcirc-buffer-alist))) + (rcirc-update-short-buffer-names) + (if (rcirc-channel-p rcirc-target) + (rcirc-send-string (rcirc-buffer-process) + (concat "PART " rcirc-target " :" reason)) + (when rcirc-target + (rcirc-remove-nick-channel (rcirc-buffer-process) + (rcirc-buffer-nick) + rcirc-target)))) + (setq rcirc-target nil))) + +(defun rcirc-generate-new-buffer-name (process target) + "Return a buffer name based on PROCESS and TARGET. +This is used for the initial name given to IRC buffers." + (substring-no-properties + (if target + (concat target "@" (process-name process)) + (concat "*" (process-name process) "*")))) + +(defun rcirc-get-buffer (process target &optional server) + "Return the buffer associated with the PROCESS and TARGET. + +If optional argument SERVER is non-nil, return the server buffer +if there is no existing buffer for TARGET, otherwise return nil." + (with-rcirc-process-buffer process + (if (null target) + (current-buffer) + (let ((buffer (cdr (assoc-string target rcirc-buffer-alist t)))) + (or buffer (when server (current-buffer))))))) + +(defun rcirc-get-buffer-create (process target) + "Return the buffer associated with the PROCESS and TARGET. +Create the buffer if it doesn't exist." + (let ((buffer (rcirc-get-buffer process target))) + (if (and buffer (buffer-live-p buffer)) + (with-current-buffer buffer + (when (not rcirc-target) + (setq rcirc-target target)) + buffer) + ;; create the buffer + (with-rcirc-process-buffer process + (let ((new-buffer (get-buffer-create + (rcirc-generate-new-buffer-name process target)))) + (with-current-buffer new-buffer + (rcirc-mode process target) + (rcirc-put-nick-channel process (rcirc-nick process) target + rcirc-current-line)) + new-buffer))))) + +(defun rcirc-send-input () + "Send input to target associated with the current buffer." + (interactive) + (if (< (point) rcirc-prompt-end-marker) + ;; copy the line down to the input area + (progn + (forward-line 0) + (let ((start (if (eq (point) (point-min)) + (point) + (if (get-text-property (1- (point)) 'hard) + (point) + (previous-single-property-change (point) 'hard)))) + (end (next-single-property-change (1+ (point)) 'hard))) + (goto-char (point-max)) + (insert (replace-regexp-in-string + "\n\\s-+" " " + (buffer-substring-no-properties start end))))) + ;; process input + (goto-char (point-max)) + (when (not (equal 0 (- (point) rcirc-prompt-end-marker))) + ;; delete a trailing newline + (when (eq (point) (point-at-bol)) + (delete-char -1)) + (let ((input (buffer-substring-no-properties + rcirc-prompt-end-marker (point)))) + (dolist (line (split-string input "\n")) + (rcirc-process-input-line line)) + ;; add to input-ring + (save-excursion + (ring-insert rcirc-input-ring input) + (setq rcirc-input-ring-index 0)))))) + +(defun rcirc-fill-paragraph (&optional justify) + (interactive "P") + (when (> (point) rcirc-prompt-end-marker) + (save-restriction + (narrow-to-region rcirc-prompt-end-marker (point-max)) + (let ((fill-column rcirc-max-message-length)) + (fill-region (point-min) (point-max) justify))))) + +(defun rcirc-process-input-line (line) + (if (string-match "^/\\([^ ]+\\) ?\\(.*\\)$" line) + (rcirc-process-command (match-string 1 line) + (match-string 2 line) + line) + (rcirc-process-message line))) + +(defun rcirc-process-message (line) + (if (not rcirc-target) + (message "Not joined (no target)") + (delete-region rcirc-prompt-end-marker (point)) + (rcirc-send-message (rcirc-buffer-process) rcirc-target line) + (setq rcirc-last-post-time (current-time)))) + +(defun rcirc-process-command (command args line) + (if (eq (aref command 0) ?/) + ;; "//text" will send "/text" as a message + (rcirc-process-message (substring line 1)) + (let ((fun (intern-soft (concat "rcirc-cmd-" command))) + (process (rcirc-buffer-process))) + (newline) + (with-current-buffer (current-buffer) + (delete-region rcirc-prompt-end-marker (point)) + (if (string= command "me") + (rcirc-print process (rcirc-buffer-nick) + "ACTION" rcirc-target args) + (rcirc-print process (rcirc-buffer-nick) + "COMMAND" rcirc-target line)) + (set-marker rcirc-prompt-end-marker (point)) + (if (fboundp fun) + (funcall fun args process rcirc-target) + (rcirc-send-string process + (concat command " :" args))))))) + +(defvar rcirc-parent-buffer nil) +(make-variable-buffer-local 'rcirc-parent-buffer) +(put 'rcirc-parent-buffer 'permanent-local t) +(defvar rcirc-window-configuration nil) +(defun rcirc-edit-multiline () + "Move current edit to a dedicated buffer." + (interactive) + (let ((pos (1+ (- (point) rcirc-prompt-end-marker)))) + (goto-char (point-max)) + (let ((text (buffer-substring-no-properties rcirc-prompt-end-marker + (point))) + (parent (buffer-name))) + (delete-region rcirc-prompt-end-marker (point)) + (setq rcirc-window-configuration (current-window-configuration)) + (pop-to-buffer (concat "*multiline " parent "*")) + (funcall rcirc-multiline-major-mode) + (rcirc-multiline-minor-mode 1) + (setq rcirc-parent-buffer parent) + (insert text) + (and (> pos 0) (goto-char pos)) + (message "Type C-c C-c to return text to %s, or C-c C-k to cancel" parent)))) + +(defvar rcirc-multiline-minor-mode-map + (let ((map (make-sparse-keymap))) + (define-key map (kbd "C-c C-c") 'rcirc-multiline-minor-submit) + (define-key map (kbd "C-x C-s") 'rcirc-multiline-minor-submit) + (define-key map (kbd "C-c C-k") 'rcirc-multiline-minor-cancel) + (define-key map (kbd "ESC ESC ESC") 'rcirc-multiline-minor-cancel) + map) + "Keymap for multiline mode in rcirc.") + +(define-minor-mode rcirc-multiline-minor-mode + "Minor mode for editing multiple lines in rcirc. +With a prefix argument ARG, enable the mode if ARG is positive, +and disable it otherwise. If called from Lisp, enable the mode +if ARG is omitted or nil." + :init-value nil + :lighter " rcirc-mline" + :keymap rcirc-multiline-minor-mode-map + :global nil + :group 'rcirc + (setq fill-column rcirc-max-message-length)) + +(defun rcirc-multiline-minor-submit () + "Send the text in buffer back to parent buffer." + (interactive) + (untabify (point-min) (point-max)) + (let ((text (buffer-substring (point-min) (point-max))) + (buffer (current-buffer)) + (pos (point))) + (set-buffer rcirc-parent-buffer) + (goto-char (point-max)) + (insert text) + (kill-buffer buffer) + (set-window-configuration rcirc-window-configuration) + (goto-char (+ rcirc-prompt-end-marker (1- pos))))) + +(defun rcirc-multiline-minor-cancel () + "Cancel the multiline edit." + (interactive) + (kill-buffer (current-buffer)) + (set-window-configuration rcirc-window-configuration)) + +(defun rcirc-any-buffer (process) + "Return a buffer for PROCESS, either the one selected or the process buffer." + (if rcirc-always-use-server-buffer-flag + (process-buffer process) + (let ((buffer (window-buffer))) + (if (and buffer + (with-current-buffer buffer + (and (eq major-mode 'rcirc-mode) + (eq (rcirc-buffer-process) process)))) + buffer + (process-buffer process))))) + +(defcustom rcirc-response-formats + '(("PRIVMSG" . "<%N> %m") + ("NOTICE" . "-%N- %m") + ("ACTION" . "[%N %m]") + ("COMMAND" . "%m") + ("ERROR" . "%fw!!! %m") + (t . "%fp*** %fs%n %r %m")) + "An alist of formats used for printing responses. +The format is looked up using the response-type as a key; +if no match is found, the default entry (with a key of t) is used. + +The entry's value part should be a string, which is inserted with +the of the following escape sequences replaced by the described values: + + %m The message text + %n The sender's nick + %N The sender's nick (with face `rcirc-my-nick' or `rcirc-other-nick') + %r The response-type + %t The target + %fw Following text uses the face `font-lock-warning-face' + %fp Following text uses the face `rcirc-server-prefix' + %fs Following text uses the face `rcirc-server' + %f[FACE] Following text uses the face FACE + %f- Following text uses the default face + %% A literal `%' character" + :type '(alist :key-type (choice (string :tag "Type") + (const :tag "Default" t)) + :value-type string) + :group 'rcirc) + +(defun rcirc-format-response-string (process sender response target text) + "Return a nicely-formatted response string, incorporating TEXT +\(and perhaps other arguments). The specific formatting used +is found by looking up RESPONSE in `rcirc-response-formats'." + (with-temp-buffer + (insert (or (cdr (assoc response rcirc-response-formats)) + (cdr (assq t rcirc-response-formats)))) + (goto-char (point-min)) + (let ((start (point-min)) + (sender (if (or (not sender) + (string= (rcirc-server-name process) sender)) + "" + sender)) + face) + (while (re-search-forward "%\\(\\(f\\(.\\)\\)\\|\\(.\\)\\)" nil t) + (rcirc-add-face start (match-beginning 0) face) + (setq start (match-beginning 0)) + (replace-match + (cl-case (aref (match-string 1) 0) + (?f (setq face + (cl-case (string-to-char (match-string 3)) + (?w 'font-lock-warning-face) + (?p 'rcirc-server-prefix) + (?s 'rcirc-server) + (t nil))) + "") + (?n sender) + (?N (let ((my-nick (rcirc-nick process))) + (save-match-data + (with-syntax-table rcirc-nick-syntax-table + (rcirc-facify sender + (cond ((string= sender my-nick) + 'rcirc-my-nick) + ((and rcirc-bright-nicks + (string-match + (regexp-opt rcirc-bright-nicks + 'words) + sender)) + 'rcirc-bright-nick) + ((and rcirc-dim-nicks + (string-match + (regexp-opt rcirc-dim-nicks + 'words) + sender)) + 'rcirc-dim-nick) + (t + 'rcirc-other-nick))))))) + (?m (propertize text 'rcirc-text text)) + (?r response) + (?t (or target "")) + (t (concat "UNKNOWN CODE:" (match-string 0)))) + t t nil 0) + (rcirc-add-face (match-beginning 0) (match-end 0) face)) + (rcirc-add-face start (match-beginning 0) face)) + (buffer-substring (point-min) (point-max)))) + +(defun rcirc-target-buffer (process sender response target _text) + "Return a buffer to print the server response." + (cl-assert (not (bufferp target))) + (with-rcirc-process-buffer process + (cond ((not target) + (rcirc-any-buffer process)) + ((not (rcirc-channel-p target)) + ;; message from another user + (if (or (string= response "PRIVMSG") + (string= response "ACTION")) + (rcirc-get-buffer-create process (if (string= sender rcirc-nick) + target + sender)) + (rcirc-get-buffer process target t))) + ((or (rcirc-get-buffer process target) + (rcirc-any-buffer process)))))) + +(defvar rcirc-activity-types nil) +(make-variable-buffer-local 'rcirc-activity-types) +(defvar rcirc-last-sender nil) +(make-variable-buffer-local 'rcirc-last-sender) + +(defcustom rcirc-omit-threshold 100 + "Number of lines since last activity from a nick before `rcirc-omit-responses' are omitted." + :type 'integer + :group 'rcirc) + +(defcustom rcirc-log-process-buffers nil + "Non-nil if rcirc process buffers should be logged to disk." + :group 'rcirc + :type 'boolean + :version "24.1") + +(defun rcirc-last-quit-line (process nick target) + "Return the line number where NICK left TARGET. +Returns nil if the information is not recorded." + (let ((chanbuf (rcirc-get-buffer process target))) + (when chanbuf + (cdr (assoc-string nick (with-current-buffer chanbuf + rcirc-recent-quit-alist)))))) + +(defun rcirc-last-line (process nick target) + "Return the line from the last activity from NICK in TARGET." + (let ((line (or (cdr (assoc-string target + (gethash nick (with-rcirc-server-buffer + rcirc-nick-table)) t)) + (rcirc-last-quit-line process nick target)))) + (if line + line + ;;(message "line is nil for %s in %s" nick target) + nil))) + +(defun rcirc-elapsed-lines (process nick target) + "Return the number of lines since activity from NICK in TARGET." + (let ((last-activity-line (rcirc-last-line process nick target))) + (when (and last-activity-line + (> last-activity-line 0)) + (- rcirc-current-line last-activity-line)))) + +(defvar rcirc-markup-text-functions + '(rcirc-markup-attributes + rcirc-markup-my-nick + rcirc-markup-urls + rcirc-markup-keywords + rcirc-markup-bright-nicks) + + "List of functions used to manipulate text before it is printed. + +Each function takes two arguments, SENDER, and RESPONSE. The +buffer is narrowed with the text to be printed and the point is +at the beginning of the `rcirc-text' propertized text.") + +(defun rcirc-print (process sender response target text &optional activity) + "Print TEXT in the buffer associated with TARGET. +Format based on SENDER and RESPONSE. If ACTIVITY is non-nil, +record activity." + (or text (setq text "")) + (unless (and (or (member sender rcirc-ignore-list) + (member (with-syntax-table rcirc-nick-syntax-table + (when (string-match "^\\([^/]\\w*\\)[:,]" text) + (match-string 1 text))) + rcirc-ignore-list)) + ;; do not ignore if we sent the message + (not (string= sender (rcirc-nick process)))) + (let* ((buffer (rcirc-target-buffer process sender response target text)) + (inhibit-read-only t)) + (with-current-buffer buffer + (let ((moving (= (point) rcirc-prompt-end-marker)) + (old-point (point-marker)) + (fill-start (marker-position rcirc-prompt-start-marker))) + + (setq text (decode-coding-string text rcirc-decode-coding-system)) + (unless (string= sender (rcirc-nick process)) + ;; mark the line with overlay arrow + (unless (or (marker-position overlay-arrow-position) + (get-buffer-window (current-buffer)) + (member response rcirc-omit-responses)) + (set-marker overlay-arrow-position + (marker-position rcirc-prompt-start-marker)))) + + ;; temporarily set the marker insertion-type because + ;; insert-before-markers results in hidden text in new buffers + (goto-char rcirc-prompt-start-marker) + (set-marker-insertion-type rcirc-prompt-start-marker t) + (set-marker-insertion-type rcirc-prompt-end-marker t) + + (let ((start (point))) + (insert (rcirc-format-response-string process sender response nil + text) + (propertize "\n" 'hard t)) + + ;; squeeze spaces out of text before rcirc-text + (fill-region fill-start + (1- (or (next-single-property-change fill-start + 'rcirc-text) + rcirc-prompt-end-marker))) + + ;; run markup functions + (save-excursion + (save-restriction + (narrow-to-region start rcirc-prompt-start-marker) + (goto-char (or (next-single-property-change start 'rcirc-text) + (point))) + (when (rcirc-buffer-process) + (save-excursion (rcirc-markup-timestamp sender response)) + (dolist (fn rcirc-markup-text-functions) + (save-excursion (funcall fn sender response))) + (when rcirc-fill-flag + (save-excursion (rcirc-markup-fill sender response)))) + + (when rcirc-read-only-flag + (add-text-properties (point-min) (point-max) + '(read-only t front-sticky t)))) + ;; make text omittable + (let ((last-activity-lines (rcirc-elapsed-lines process sender target))) + (if (and (not (string= (rcirc-nick process) sender)) + (member response rcirc-omit-responses) + (or (not last-activity-lines) + (< rcirc-omit-threshold last-activity-lines))) + (put-text-property (1- start) (1- rcirc-prompt-start-marker) + 'invisible 'rcirc-omit) + ;; otherwise increment the line count + (setq rcirc-current-line (1+ rcirc-current-line)))))) + + (set-marker-insertion-type rcirc-prompt-start-marker nil) + (set-marker-insertion-type rcirc-prompt-end-marker nil) + + ;; truncate buffer if it is very long + (save-excursion + (when (and rcirc-buffer-maximum-lines + (> rcirc-buffer-maximum-lines 0) + (= (forward-line (- rcirc-buffer-maximum-lines)) 0)) + (delete-region (point-min) (point)))) + + ;; set the window point for buffers show in windows + (walk-windows (lambda (w) + (when (and (not (eq (selected-window) w)) + (eq (current-buffer) + (window-buffer w)) + (>= (window-point w) + rcirc-prompt-end-marker)) + (set-window-point w (point-max)))) + nil t) + + ;; restore the point + (goto-char (if moving rcirc-prompt-end-marker old-point)) + + ;; keep window on bottom line if it was already there + (when rcirc-scroll-show-maximum-output + (let ((window (get-buffer-window))) + (when window + (with-selected-window window + (when (eq major-mode 'rcirc-mode) + (when (<= (- (window-height) + (count-screen-lines (window-point) + (window-start)) + 1) + 0) + (recenter -1))))))) + + ;; flush undo (can we do something smarter here?) + (buffer-disable-undo) + (buffer-enable-undo)) + + ;; record mode line activity + (when (and activity + (not rcirc-ignore-buffer-activity-flag) + (not (and rcirc-dim-nicks sender + (string-match (regexp-opt rcirc-dim-nicks) sender) + (rcirc-channel-p target)))) + (rcirc-record-activity (current-buffer) + (when (not (rcirc-channel-p rcirc-target)) + 'nick))) + + (when (and rcirc-log-flag + (or target + rcirc-log-process-buffers)) + (rcirc-log process sender response target text)) + + (sit-for 0) ; displayed text before hook + (run-hook-with-args 'rcirc-print-functions + process sender response target text))))) + +(defun rcirc-generate-log-filename (process target) + (if target + (rcirc-generate-new-buffer-name process target) + (process-name process))) + +(defcustom rcirc-log-filename-function 'rcirc-generate-log-filename + "A function to generate the filename used by rcirc's logging facility. + +It is called with two arguments, PROCESS and TARGET (see +`rcirc-generate-new-buffer-name' for their meaning), and should +return the filename, or nil if no logging is desired for this +session. + +If the returned filename is absolute (`file-name-absolute-p' +returns t), then it is used as-is, otherwise the resulting file +is put into `rcirc-log-directory'. + +The filename is then cleaned using `convert-standard-filename' to +guarantee valid filenames for the current OS." + :group 'rcirc + :type 'function) + +(defun rcirc-log (process sender response target text) + "Record line in `rcirc-log', to be later written to disk." + (let ((filename (funcall rcirc-log-filename-function process target))) + (unless (null filename) + (let ((cell (assoc-string filename rcirc-log-alist)) + (line (concat (format-time-string rcirc-time-format) + (substring-no-properties + (rcirc-format-response-string process sender + response target text)) + "\n"))) + (if cell + (setcdr cell (concat (cdr cell) line)) + (setq rcirc-log-alist + (cons (cons filename line) rcirc-log-alist))))))) + +(defun rcirc-log-write () + "Flush `rcirc-log-alist' data to disk. + +Log data is written to `rcirc-log-directory', except for +log-files with absolute names (see `rcirc-log-filename-function')." + (dolist (cell rcirc-log-alist) + (let ((filename (convert-standard-filename + (expand-file-name (car cell) + rcirc-log-directory))) + (coding-system-for-write 'utf-8)) + (make-directory (file-name-directory filename) t) + (with-temp-buffer + (insert (cdr cell)) + (write-region (point-min) (point-max) filename t 'quiet)))) + (setq rcirc-log-alist nil)) + +(defun rcirc-view-log-file () + "View logfile corresponding to the current buffer." + (interactive) + (find-file-other-window + (expand-file-name (funcall rcirc-log-filename-function + (rcirc-buffer-process) rcirc-target) + rcirc-log-directory))) + +(defun rcirc-join-channels (process channels) + "Join CHANNELS." + (save-window-excursion + (dolist (channel channels) + (with-rcirc-process-buffer process + (rcirc-cmd-join channel process))))) + +;;; nick management +(defvar rcirc-nick-prefix-chars "~&@%+") +(defun rcirc-user-nick (user) + "Return the nick from USER. Remove any non-nick junk." + (save-match-data + (if (string-match (concat "^[" rcirc-nick-prefix-chars + "]?\\([^! ]+\\)!?") (or user "")) + (match-string 1 user) + user))) + +(defun rcirc-nick-channels (process nick) + "Return list of channels for NICK." + (with-rcirc-process-buffer process + (mapcar (lambda (x) (car x)) + (gethash nick rcirc-nick-table)))) + +(defun rcirc-put-nick-channel (process nick channel &optional line) + "Add CHANNEL to list associated with NICK. +Update the associated linestamp if LINE is non-nil. + +If the record doesn't exist, and LINE is nil, set the linestamp +to zero." + (let ((nick (rcirc-user-nick nick))) + (with-rcirc-process-buffer process + (let* ((chans (gethash nick rcirc-nick-table)) + (record (assoc-string channel chans t))) + (if record + (when line (setcdr record line)) + (puthash nick (cons (cons channel (or line 0)) + chans) + rcirc-nick-table)))))) + +(defun rcirc-nick-remove (process nick) + "Remove NICK from table." + (with-rcirc-process-buffer process + (remhash nick rcirc-nick-table))) + +(defun rcirc-remove-nick-channel (process nick channel) + "Remove the CHANNEL from list associated with NICK." + (with-rcirc-process-buffer process + (let* ((chans (gethash nick rcirc-nick-table)) + (newchans + ;; instead of assoc-string-delete-all: + (let ((record (assoc-string channel chans t))) + (when record + (setcar record 'delete) + (assq-delete-all 'delete chans))))) + (if newchans + (puthash nick newchans rcirc-nick-table) + (remhash nick rcirc-nick-table))))) + +(defun rcirc-channel-nicks (process target) + "Return the list of nicks associated with TARGET sorted by last activity." + (when target + (if (rcirc-channel-p target) + (with-rcirc-process-buffer process + (let (nicks) + (maphash + (lambda (k v) + (let ((record (assoc-string target v t))) + (if record + (setq nicks (cons (cons k (cdr record)) nicks))))) + rcirc-nick-table) + (mapcar (lambda (x) (car x)) + (sort nicks (lambda (x y) + (let ((lx (or (cdr x) 0)) + (ly (or (cdr y) 0))) + (< ly lx))))))) + (list target)))) + +(defun rcirc-ignore-update-automatic (nick) + "Remove NICK from `rcirc-ignore-list' +if NICK is also on `rcirc-ignore-list-automatic'." + (when (member nick rcirc-ignore-list-automatic) + (setq rcirc-ignore-list-automatic + (delete nick rcirc-ignore-list-automatic) + rcirc-ignore-list + (delete nick rcirc-ignore-list)))) + +(defun rcirc-nickname< (s1 s2) + "Return t if IRC nickname S1 is less than S2, and nil otherwise. +Operator nicknames (@) are considered less than voiced +nicknames (+). Any other nicknames are greater than voiced +nicknames. The comparison is case-insensitive." + (setq s1 (downcase s1) + s2 (downcase s2)) + (let* ((s1-op (eq ?@ (string-to-char s1))) + (s2-op (eq ?@ (string-to-char s2)))) + (if s1-op + (if s2-op + (string< (substring s1 1) (substring s2 1)) + t) + (if s2-op + nil + (string< s1 s2))))) + +(defun rcirc-sort-nicknames-join (input sep) + "Return a string of sorted nicknames. +INPUT is a string containing nicknames separated by SEP. +This function does not alter the INPUT string." + (let* ((parts (split-string input sep t)) + (sorted (sort parts 'rcirc-nickname<))) + (mapconcat 'identity sorted sep))) + +;;; activity tracking +(defvar rcirc-track-minor-mode-map + (let ((map (make-sparse-keymap))) + (define-key map (kbd "C-c C-@") 'rcirc-next-active-buffer) + (define-key map (kbd "C-c C-SPC") 'rcirc-next-active-buffer) + map) + "Keymap for rcirc track minor mode.") + +;;;###autoload +(define-minor-mode rcirc-track-minor-mode + "Global minor mode for tracking activity in rcirc buffers. +With a prefix argument ARG, enable the mode if ARG is positive, +and disable it otherwise. If called from Lisp, enable the mode +if ARG is omitted or nil." + :init-value nil + :lighter "" + :keymap rcirc-track-minor-mode-map + :global t + :group 'rcirc + (or global-mode-string (setq global-mode-string '(""))) + ;; toggle the mode-line channel indicator + (if rcirc-track-minor-mode + (progn + (and (not (memq 'rcirc-activity-string global-mode-string)) + (setq global-mode-string + (append global-mode-string '(rcirc-activity-string)))) + (add-hook 'window-configuration-change-hook + 'rcirc-window-configuration-change)) + (setq global-mode-string + (delete 'rcirc-activity-string global-mode-string)) + (remove-hook 'window-configuration-change-hook + 'rcirc-window-configuration-change))) + +(or (assq 'rcirc-ignore-buffer-activity-flag minor-mode-alist) + (setq minor-mode-alist + (cons '(rcirc-ignore-buffer-activity-flag " Ignore") minor-mode-alist))) +(or (assq 'rcirc-low-priority-flag minor-mode-alist) + (setq minor-mode-alist + (cons '(rcirc-low-priority-flag " LowPri") minor-mode-alist))) + +(defun rcirc-toggle-ignore-buffer-activity () + "Toggle the value of `rcirc-ignore-buffer-activity-flag'." + (interactive) + (setq rcirc-ignore-buffer-activity-flag + (not rcirc-ignore-buffer-activity-flag)) + (message (if rcirc-ignore-buffer-activity-flag + "Ignore activity in this buffer" + "Notice activity in this buffer")) + (force-mode-line-update)) + +(defun rcirc-toggle-low-priority () + "Toggle the value of `rcirc-low-priority-flag'." + (interactive) + (setq rcirc-low-priority-flag + (not rcirc-low-priority-flag)) + (message (if rcirc-low-priority-flag + "Activity in this buffer is low priority" + "Activity in this buffer is normal priority")) + (force-mode-line-update)) + +(defun rcirc-switch-to-server-buffer () + "Switch to the server buffer associated with current channel buffer." + (interactive) + (unless (buffer-live-p rcirc-server-buffer) + (error "No such buffer")) + (switch-to-buffer rcirc-server-buffer)) + +(defun rcirc-jump-to-first-unread-line () + "Move the point to the first unread line in this buffer." + (interactive) + (if (marker-position overlay-arrow-position) + (goto-char overlay-arrow-position) + (message "No unread messages"))) + +(defun rcirc-bury-buffers () + "Bury all RCIRC buffers." + (interactive) + (dolist (buf (buffer-list)) + (when (eq 'rcirc-mode (with-current-buffer buf major-mode)) + (bury-buffer buf) ; buffers not shown + (quit-windows-on buf)))) ; buffers shown in a window + +(defun rcirc-next-active-buffer (arg) + "Switch to the next rcirc buffer with activity. +With prefix ARG, go to the next low priority buffer with activity." + (interactive "P") + (let* ((pair (rcirc-split-activity rcirc-activity)) + (lopri (car pair)) + (hipri (cdr pair))) + (if (or (and (not arg) hipri) + (and arg lopri)) + (progn + (switch-to-buffer (car (if arg lopri hipri))) + (when (> (point) rcirc-prompt-start-marker) + (recenter -1))) + (rcirc-bury-buffers) + (message "No IRC activity.%s" + (if lopri + (concat + " Type C-u " (key-description (this-command-keys)) + " for low priority activity.") + ""))))) + +(define-obsolete-variable-alias 'rcirc-activity-hooks + 'rcirc-activity-functions "24.3") +(defvar rcirc-activity-functions nil + "Hook to be run when there is channel activity. + +Functions are called with a single argument, the buffer with the +activity. Only run if the buffer is not visible and +`rcirc-ignore-buffer-activity-flag' is non-nil.") + +(defun rcirc-record-activity (buffer &optional type) + "Record BUFFER activity with TYPE." + (with-current-buffer buffer + (let ((old-activity rcirc-activity) + (old-types rcirc-activity-types)) + (when (not (get-buffer-window (current-buffer) t)) + (setq rcirc-activity + (sort (if (memq (current-buffer) rcirc-activity) rcirc-activity + (cons (current-buffer) rcirc-activity)) + (lambda (b1 b2) + (let ((t1 (with-current-buffer b1 rcirc-last-post-time)) + (t2 (with-current-buffer b2 rcirc-last-post-time))) + (time-less-p t2 t1))))) + (cl-pushnew type rcirc-activity-types) + (unless (and (equal rcirc-activity old-activity) + (member type old-types)) + (rcirc-update-activity-string))))) + (run-hook-with-args 'rcirc-activity-functions buffer)) + +(defun rcirc-clear-activity (buffer) + "Clear the BUFFER activity." + (setq rcirc-activity (remove buffer rcirc-activity)) + (with-current-buffer buffer + (setq rcirc-activity-types nil))) + +(defun rcirc-clear-unread (buffer) + "Erase the last read message arrow from BUFFER." + (when (buffer-live-p buffer) + (with-current-buffer buffer + (set-marker overlay-arrow-position nil)))) + +(defun rcirc-split-activity (activity) + "Return a cons cell with ACTIVITY split into (lopri . hipri)." + (let (lopri hipri) + (dolist (buf activity) + (with-current-buffer buf + (if (and rcirc-low-priority-flag + (not (member 'nick rcirc-activity-types))) + (push buf lopri) + (push buf hipri)))) + (cons (nreverse lopri) (nreverse hipri)))) + +(defvar rcirc-update-activity-string-hook nil + "Hook run whenever the activity string is updated.") + +;; TODO: add mouse properties +(defun rcirc-update-activity-string () + "Update mode-line string." + (let* ((pair (rcirc-split-activity rcirc-activity)) + (lopri (car pair)) + (hipri (cdr pair))) + (setq rcirc-activity-string + (cond ((or hipri lopri) + (concat (and hipri "[") + (rcirc-activity-string hipri) + (and hipri lopri ",") + (and lopri + (concat "(" + (rcirc-activity-string lopri) + ")")) + (and hipri "]"))) + ((not (null (rcirc-process-list))) + "[]") + (t "[]"))) + (run-hooks 'rcirc-update-activity-string-hook))) + +(defun rcirc-activity-string (buffers) + (mapconcat (lambda (b) + (let ((s (substring-no-properties (rcirc-short-buffer-name b)))) + (with-current-buffer b + (dolist (type rcirc-activity-types) + (rcirc-add-face 0 (length s) + (cl-case type + (nick 'rcirc-track-nick) + (keyword 'rcirc-track-keyword)) + s))) + s)) + buffers ",")) + +(defun rcirc-short-buffer-name (buffer) + "Return a short name for BUFFER to use in the mode line indicator." + (with-current-buffer buffer + (or rcirc-short-buffer-name (buffer-name)))) + +(defun rcirc-visible-buffers () + "Return a list of the visible buffers that are in rcirc-mode." + (let (acc) + (walk-windows (lambda (w) + (with-current-buffer (window-buffer w) + (when (eq major-mode 'rcirc-mode) + (push (current-buffer) acc))))) + acc)) + +(defvar rcirc-visible-buffers nil) +(defun rcirc-window-configuration-change () + (unless (minibuffer-window-active-p (minibuffer-window)) + ;; delay this until command has finished to make sure window is + ;; actually visible before clearing activity + (add-hook 'post-command-hook 'rcirc-window-configuration-change-1))) + +(defun rcirc-window-configuration-change-1 () + ;; clear activity and overlay arrows + (let* ((old-activity rcirc-activity) + (hidden-buffers rcirc-visible-buffers)) + + (setq rcirc-visible-buffers (rcirc-visible-buffers)) + + (dolist (vbuf rcirc-visible-buffers) + (setq hidden-buffers (delq vbuf hidden-buffers)) + ;; clear activity for all visible buffers + (rcirc-clear-activity vbuf)) + + ;; clear unread arrow from recently hidden buffers + (dolist (hbuf hidden-buffers) + (rcirc-clear-unread hbuf)) + + ;; remove any killed buffers from list + (setq rcirc-activity + (delq nil (mapcar (lambda (buf) (when (buffer-live-p buf) buf)) + rcirc-activity))) + ;; update the mode-line string + (unless (equal old-activity rcirc-activity) + (rcirc-update-activity-string))) + + (remove-hook 'post-command-hook 'rcirc-window-configuration-change-1)) + + +;;; buffer name abbreviation +(defun rcirc-update-short-buffer-names () + (let ((bufalist + (apply 'append (mapcar (lambda (process) + (with-rcirc-process-buffer process + rcirc-buffer-alist)) + (rcirc-process-list))))) + (dolist (i (rcirc-abbreviate bufalist)) + (when (buffer-live-p (cdr i)) + (with-current-buffer (cdr i) + (setq rcirc-short-buffer-name (car i))))))) + +(defun rcirc-abbreviate (pairs) + (apply 'append (mapcar 'rcirc-rebuild-tree (rcirc-make-trees pairs)))) + +(defun rcirc-rebuild-tree (tree &optional acc) + (let ((ch (char-to-string (car tree)))) + (dolist (x (cdr tree)) + (if (listp x) + (setq acc (append acc + (mapcar (lambda (y) + (cons (concat ch (car y)) + (cdr y))) + (rcirc-rebuild-tree x)))) + (setq acc (cons (cons ch x) acc)))) + acc)) + +(defun rcirc-make-trees (pairs) + (let (alist) + (mapc (lambda (pair) + (if (consp pair) + (let* ((str (car pair)) + (data (cdr pair)) + (char (unless (zerop (length str)) + (aref str 0))) + (rest (unless (zerop (length str)) + (substring str 1))) + (part (if char (assq char alist)))) + (if part + ;; existing partition + (setcdr part (cons (cons rest data) (cdr part))) + ;; new partition + (setq alist (cons (if char + (list char (cons rest data)) + data) + alist)))) + (setq alist (cons pair alist)))) + pairs) + ;; recurse into cdrs of alist + (mapc (lambda (x) + (when (and (listp x) (listp (cadr x))) + (setcdr x (if (> (length (cdr x)) 1) + (rcirc-make-trees (cdr x)) + (setcdr x (list (cl-cdadr x))))))) + alist))) + +;;; /commands these are called with 3 args: PROCESS, TARGET, which is +;; the current buffer/channel/user, and ARGS, which is a string +;; containing the text following the /cmd. + +(defmacro defun-rcirc-command (command argument docstring interactive-form + &rest body) + "Define a command." + `(progn + (add-to-list 'rcirc-client-commands ,(concat "/" (symbol-name command))) + (defun ,(intern (concat "rcirc-cmd-" (symbol-name command))) + (,@argument &optional process target) + ,(concat docstring "\n\nNote: If PROCESS or TARGET are nil, the values given" + "\nby `rcirc-buffer-process' and `rcirc-target' will be used.") + ,interactive-form + (let ((process (or process (rcirc-buffer-process))) + (target (or target rcirc-target))) + (ignore target) ; mark `target' variable as ignorable + ,@body)))) + +(defun-rcirc-command msg (message) + "Send private MESSAGE to TARGET." + (interactive "i") + (if (null message) + (progn + (setq target (completing-read "Message nick: " + (with-rcirc-server-buffer + rcirc-nick-table))) + (when (> (length target) 0) + (setq message (read-string (format "Message %s: " target))) + (when (> (length message) 0) + (rcirc-send-message process target message)))) + (if (not (string-match "\\([^ ]+\\) \\(.+\\)" message)) + (message "Not enough args, or something.") + (setq target (match-string 1 message) + message (match-string 2 message)) + (rcirc-send-message process target message)))) + +(defun-rcirc-command query (nick) + "Open a private chat buffer to NICK." + (interactive (list (completing-read "Query nick: " + (with-rcirc-server-buffer rcirc-nick-table)))) + (let ((existing-buffer (rcirc-get-buffer process nick))) + (switch-to-buffer (or existing-buffer + (rcirc-get-buffer-create process nick))) + (when (not existing-buffer) + (rcirc-cmd-whois nick)))) + +(defun-rcirc-command join (channels) + "Join CHANNELS. +CHANNELS is a comma- or space-separated string of channel names." + (interactive "sJoin channels: ") + (let* ((split-channels (split-string channels "[ ,]" t)) + (buffers (mapcar (lambda (ch) + (rcirc-get-buffer-create process ch)) + split-channels)) + (channels (mapconcat 'identity split-channels ","))) + (rcirc-send-string process (concat "JOIN " channels)) + (when (not (eq (selected-window) (minibuffer-window))) + (dolist (b buffers) ;; order the new channel buffers in the buffer list + (switch-to-buffer b))))) + +(defun-rcirc-command invite (nick-channel) + "Invite NICK to CHANNEL." + (interactive (list + (concat + (completing-read "Invite nick: " + (with-rcirc-server-buffer rcirc-nick-table)) + " " + (read-string "Channel: ")))) + (rcirc-send-string process (concat "INVITE " nick-channel))) + +;; TODO: /part #channel reason, or consider removing #channel altogether +(defun-rcirc-command part (channel) + "Part CHANNEL." + (interactive "sPart channel: ") + (let ((channel (if (> (length channel) 0) channel target))) + (rcirc-send-string process (concat "PART " channel " :" rcirc-id-string)))) + +(defun-rcirc-command quit (reason) + "Send a quit message to server with REASON." + (interactive "sQuit reason: ") + (rcirc-send-string process (concat "QUIT :" + (if (not (zerop (length reason))) + reason + rcirc-id-string)))) + +(defun-rcirc-command reconnect (_) + "Reconnect to current server." + (interactive "i") + (with-rcirc-server-buffer + (cond + (rcirc-connecting (message "Already connecting")) + ((process-live-p process) (message "Server process is alive")) + (t (let ((conn-info rcirc-connection-info)) + (setf (nth 5 conn-info) + (cl-remove-if-not #'rcirc-channel-p + (mapcar #'car rcirc-buffer-alist))) + (apply #'rcirc-connect conn-info)))))) + +(defun-rcirc-command nick (nick) + "Change nick to NICK." + (interactive "i") + (when (null nick) + (setq nick (read-string "New nick: " (rcirc-nick process)))) + (rcirc-send-string process (concat "NICK " nick))) + +(defun-rcirc-command names (channel) + "Display list of names in CHANNEL or in current channel if CHANNEL is nil. +If called interactively, prompt for a channel when prefix arg is supplied." + (interactive "P") + (if (called-interactively-p 'interactive) + (if channel + (setq channel (read-string "List names in channel: " target)))) + (let ((channel (if (> (length channel) 0) + channel + target))) + (rcirc-send-string process (concat "NAMES " channel)))) + +(defun-rcirc-command topic (topic) + "List TOPIC for the TARGET channel. +With a prefix arg, prompt for new topic." + (interactive "P") + (if (and (called-interactively-p 'interactive) topic) + (setq topic (read-string "New Topic: " rcirc-topic))) + (rcirc-send-string process (concat "TOPIC " target + (when (> (length topic) 0) + (concat " :" topic))))) + +(defun-rcirc-command whois (nick) + "Request information from server about NICK." + (interactive (list + (completing-read "Whois: " + (with-rcirc-server-buffer rcirc-nick-table)))) + (rcirc-send-string process (concat "WHOIS " nick))) + +(defun-rcirc-command mode (args) + "Set mode with ARGS." + (interactive (list (concat (read-string "Mode nick or channel: ") + " " (read-string "Mode: ")))) + (rcirc-send-string process (concat "MODE " args))) + +(defun-rcirc-command list (channels) + "Request information on CHANNELS from server." + (interactive "sList Channels: ") + (rcirc-send-string process (concat "LIST " channels))) + +(defun-rcirc-command oper (args) + "Send operator command to server." + (interactive "sOper args: ") + (rcirc-send-string process (concat "OPER " args))) + +(defun-rcirc-command quote (message) + "Send MESSAGE literally to server." + (interactive "sServer message: ") + (rcirc-send-string process message)) + +(defun-rcirc-command kick (arg) + "Kick NICK from current channel." + (interactive (list + (concat (completing-read "Kick nick: " + (rcirc-channel-nicks + (rcirc-buffer-process) + rcirc-target)) + (read-from-minibuffer "Kick reason: ")))) + (let* ((arglist (split-string arg)) + (argstring (concat (car arglist) " :" + (mapconcat 'identity (cdr arglist) " ")))) + (rcirc-send-string process (concat "KICK " target " " argstring)))) + +(defun rcirc-cmd-ctcp (args &optional process _target) + (if (string-match "^\\([^ ]+\\)\\s-+\\(.+\\)$" args) + (let* ((target (match-string 1 args)) + (request (upcase (match-string 2 args))) + (function (intern-soft (concat "rcirc-ctcp-sender-" request)))) + (if (fboundp function) ;; use special function if available + (funcall function process target request) + (rcirc-send-ctcp process target request))) + (rcirc-print process (rcirc-nick process) "ERROR" nil + "usage: /ctcp NICK REQUEST"))) + +(defun rcirc-ctcp-sender-PING (process target _request) + "Send a CTCP PING message to TARGET." + (let ((timestamp (format-time-string "%s"))) + (rcirc-send-ctcp process target "PING" timestamp))) + +(defun rcirc-cmd-me (args &optional process target) + (rcirc-send-ctcp process target "ACTION" args)) + +(defun rcirc-add-or-remove (set &rest elements) + (dolist (elt elements) + (if (and elt (not (string= "" elt))) + (setq set (if (member-ignore-case elt set) + (delete elt set) + (cons elt set))))) + set) + +(defun-rcirc-command ignore (nick) + "Manage the ignore list. +Ignore NICK, unignore NICK if already ignored, or list ignored +nicks when no NICK is given. When listing ignored nicks, the +ones added to the list automatically are marked with an asterisk." + (interactive "sToggle ignoring of nick: ") + (setq rcirc-ignore-list + (apply #'rcirc-add-or-remove rcirc-ignore-list + (split-string nick nil t))) + (rcirc-print process nil "IGNORE" target + (mapconcat + (lambda (nick) + (concat nick + (if (member nick rcirc-ignore-list-automatic) + "*" ""))) + rcirc-ignore-list " "))) + +(defun-rcirc-command bright (nick) + "Manage the bright nick list." + (interactive "sToggle emphasis of nick: ") + (setq rcirc-bright-nicks + (apply #'rcirc-add-or-remove rcirc-bright-nicks + (split-string nick nil t))) + (rcirc-print process nil "BRIGHT" target + (mapconcat 'identity rcirc-bright-nicks " "))) + +(defun-rcirc-command dim (nick) + "Manage the dim nick list." + (interactive "sToggle deemphasis of nick: ") + (setq rcirc-dim-nicks + (apply #'rcirc-add-or-remove rcirc-dim-nicks + (split-string nick nil t))) + (rcirc-print process nil "DIM" target + (mapconcat 'identity rcirc-dim-nicks " "))) + +(defun-rcirc-command keyword (keyword) + "Manage the keyword list. +Mark KEYWORD, unmark KEYWORD if already marked, or list marked +keywords when no KEYWORD is given." + (interactive "sToggle highlighting of keyword: ") + (setq rcirc-keywords + (apply #'rcirc-add-or-remove rcirc-keywords + (split-string keyword nil t))) + (rcirc-print process nil "KEYWORD" target + (mapconcat 'identity rcirc-keywords " "))) + + +(defun rcirc-add-face (start end name &optional object) + "Add face NAME to the face text property of the text from START to END." + (when name + (let ((pos start) + next prop) + (while (< pos end) + (setq prop (get-text-property pos 'font-lock-face object) + next (next-single-property-change pos 'font-lock-face object end)) + (unless (member name (get-text-property pos 'font-lock-face object)) + (add-text-properties pos next + (list 'font-lock-face (cons name prop)) object)) + (setq pos next))))) + +(defun rcirc-facify (string face) + "Return a copy of STRING with FACE property added." + (let ((string (or string ""))) + (rcirc-add-face 0 (length string) face string) + string)) + +(defvar rcirc-url-regexp + (concat + "\\b\\(\\(www\\.\\|\\(s?https?\\|ftp\\|file\\|gopher\\|" + "nntp\\|news\\|telnet\\|wais\\|mailto\\|info\\):\\)" + "\\(//[-a-z0-9_.]+:[0-9]*\\)?" + (if (string-match "[[:digit:]]" "1") ;; Support POSIX? + (let ((chars "-a-z0-9_=#$@~%&*+\\/[:word:]") + (punct "!?:;.,")) + (concat + "\\(?:" + ;; Match paired parentheses, e.g. in Wikipedia URLs: + "[" chars punct "]+" "(" "[" chars punct "]+" "[" chars "]*)" "[" chars "]" + "\\|" + "[" chars punct "]+" "[" chars "]" + "\\)")) + (concat ;; XEmacs 21.4 doesn't support POSIX. + "\\([-a-z0-9_=!?#$@~%&*+\\/:;.,]\\|\\w\\)+" + "\\([-a-z0-9_=#$@~%&*+\\/]\\|\\w\\)")) + "\\)") + "Regexp matching URLs. Set to nil to disable URL features in rcirc.") + +;; cf cl-remove-if-not +(defun rcirc-condition-filter (condp lst) + "Remove all items not satisfying condition CONDP in list LST. +CONDP is a function that takes a list element as argument and returns +non-nil if that element should be included. Returns a new list." + (delq nil (mapcar (lambda (x) (and (funcall condp x) x)) lst))) + +(defun rcirc-browse-url (&optional arg) + "Prompt for URL to browse based on URLs in buffer before point. + +If ARG is given, opens the URL in a new browser window." + (interactive "P") + (let* ((point (point)) + (filtered (rcirc-condition-filter + (lambda (x) (>= point (cdr x))) + rcirc-urls)) + (completions (mapcar (lambda (x) (car x)) filtered)) + (defaults (mapcar (lambda (x) (car x)) filtered))) + (browse-url (completing-read "Rcirc browse-url: " + completions nil nil (car defaults) nil defaults) + arg))) + +(defun rcirc-markup-timestamp (_sender _response) + (goto-char (point-min)) + (insert (rcirc-facify (format-time-string rcirc-time-format + (let ((time rcirc-last-message-time)) + (when time (setq rcirc-last-message-time nil)) + time)) + 'rcirc-timestamp))) + +(defun rcirc-markup-attributes (_sender _response) + (while (re-search-forward "\\([\C-b\C-_\C-v]\\).*?\\(\\1\\|\C-o\\)" nil t) + (rcirc-add-face (match-beginning 0) (match-end 0) + (cl-case (char-after (match-beginning 1)) + (?\C-b 'bold) + (?\C-v 'italic) + (?\C-_ 'underline))) + ;; keep the ^O since it could terminate other attributes + (when (not (eq ?\C-o (char-before (match-end 2)))) + (delete-region (match-beginning 2) (match-end 2))) + (delete-region (match-beginning 1) (match-end 1)) + (goto-char (match-beginning 1))) + ;; remove the ^O characters now + (goto-char (point-min)) + (while (re-search-forward "\C-o+" nil t) + (delete-region (match-beginning 0) (match-end 0)))) + +(defun rcirc-markup-my-nick (_sender response) + (with-syntax-table rcirc-nick-syntax-table + (while (re-search-forward (concat "\\b" + (regexp-quote (rcirc-nick + (rcirc-buffer-process))) + "\\b") + nil t) + (rcirc-add-face (match-beginning 0) (match-end 0) + 'rcirc-nick-in-message) + (when (string= response "PRIVMSG") + (rcirc-add-face (point-min) (point-max) + 'rcirc-nick-in-message-full-line) + (rcirc-record-activity (current-buffer) 'nick))))) + +(defun rcirc-markup-urls (_sender _response) + (while (and rcirc-url-regexp ;; nil means disable URL catching + (re-search-forward rcirc-url-regexp nil t)) + (let* ((start (match-beginning 0)) + (end (match-end 0)) + (url (match-string-no-properties 0)) + (link-text (buffer-substring-no-properties start end))) + ;; Add a button for the URL. Note that we use `make-text-button', + ;; rather than `make-button', as text-buttons are much faster in + ;; large buffers. + (make-text-button start end + 'face 'rcirc-url + 'follow-link t + 'rcirc-url url + 'action (lambda (button) + (browse-url (button-get button 'rcirc-url)))) + ;; record the url if it is not already the latest stored url + (when (not (string= link-text (caar rcirc-urls))) + (push (cons link-text start) rcirc-urls))))) + +(defun rcirc-markup-keywords (sender response) + (when (and (string= response "PRIVMSG") + (not (string= sender (rcirc-nick (rcirc-buffer-process))))) + (let* ((target (or rcirc-target "")) + (keywords (delq nil (mapcar (lambda (keyword) + (when (not (string-match keyword + target)) + keyword)) + rcirc-keywords)))) + (when keywords + (while (re-search-forward (regexp-opt keywords 'words) nil t) + (rcirc-add-face (match-beginning 0) (match-end 0) 'rcirc-keyword) + (rcirc-record-activity (current-buffer) 'keyword)))))) + +(defun rcirc-markup-bright-nicks (_sender response) + (when (and rcirc-bright-nicks + (string= response "NAMES")) + (with-syntax-table rcirc-nick-syntax-table + (while (re-search-forward (regexp-opt rcirc-bright-nicks 'words) nil t) + (rcirc-add-face (match-beginning 0) (match-end 0) + 'rcirc-bright-nick))))) + +(defun rcirc-markup-fill (_sender response) + (when (not (string= response "372")) ; /motd + (let ((fill-prefix + (or rcirc-fill-prefix + (make-string (- (point) (line-beginning-position)) ?\s))) + (fill-column (- (cond ((null rcirc-fill-column) fill-column) + ((functionp rcirc-fill-column) + (funcall rcirc-fill-column)) + (t rcirc-fill-column)) + ;; make sure ... doesn't cause line wrapping + 3))) + (fill-region (point) (point-max) nil t)))) + +;;; handlers +;; these are called with the server PROCESS, the SENDER, which is a +;; server or a user, depending on the command, the ARGS, which is a +;; list of strings, and the TEXT, which is the original server text, +;; verbatim +(defun rcirc-handler-001 (process sender args text) + (rcirc-handler-generic process "001" sender args text) + (with-rcirc-process-buffer process + (setq rcirc-connecting nil) + (rcirc-reschedule-timeout process) + (setq rcirc-server-name sender) + (setq rcirc-nick (car args)) + (rcirc-update-prompt) + (if rcirc-auto-authenticate-flag + (if (and rcirc-authenticate-before-join + ;; We have to ensure that there's an authentication + ;; entry for that server. Else, + ;; rcirc-authenticated-hook won't be triggered, and + ;; autojoin won't happen at all. + (let (auth-required) + (dolist (s rcirc-authinfo auth-required) + (when (string-match (car s) rcirc-server-name) + (setq auth-required t))))) + (progn + (add-hook 'rcirc-authenticated-hook 'rcirc-join-channels-post-auth t t) + (rcirc-authenticate)) + (rcirc-authenticate) + (rcirc-join-channels process rcirc-startup-channels)) + (rcirc-join-channels process rcirc-startup-channels)))) + +(defun rcirc-join-channels-post-auth (process) + "Join `rcirc-startup-channels' after authenticating." + (with-rcirc-process-buffer process + (rcirc-join-channels process rcirc-startup-channels))) + +(defun rcirc-handler-PRIVMSG (process sender args text) + (rcirc-check-auth-status process sender args text) + (let ((target (if (rcirc-channel-p (car args)) + (car args) + sender)) + (message (or (cadr args) ""))) + (if (string-match "^\C-a\\(.*\\)\C-a$" message) + (rcirc-handler-CTCP process target sender (match-string 1 message)) + (rcirc-print process sender "PRIVMSG" target message t)) + ;; update nick linestamp + (with-current-buffer (rcirc-get-buffer process target t) + (rcirc-put-nick-channel process sender target rcirc-current-line)))) + +(defun rcirc-handler-NOTICE (process sender args text) + (rcirc-check-auth-status process sender args text) + (let ((target (car args)) + (message (cadr args))) + (if (string-match "^\C-a\\(.*\\)\C-a$" message) + (rcirc-handler-CTCP-response process target sender + (match-string 1 message)) + (rcirc-print process sender "NOTICE" + (cond ((rcirc-channel-p target) + target) + ;;; -ChanServ- [#gnu] Welcome... + ((string-match "\\[\\(#[^] ]+\\)\\]" message) + (match-string 1 message)) + (sender + (if (string= sender (rcirc-server-name process)) + nil ; server notice + sender))) + message t)))) + +(defun rcirc-check-auth-status (process sender args _text) + "Check if the user just authenticated. +If authenticated, runs `rcirc-authenticated-hook' with PROCESS as +the only argument." + (with-rcirc-process-buffer process + (when (and (not rcirc-user-authenticated) + rcirc-authenticate-before-join + rcirc-auto-authenticate-flag) + (let ((target (car args)) + (message (cadr args))) + (when (or + (and ;; nickserv + (string= sender "NickServ") + (string= target rcirc-nick) + (member message + (list + (format "You are now identified for \C-b%s\C-b." rcirc-nick) + (format "You are successfully identified as \C-b%s\C-b." rcirc-nick) + "Password accepted - you are now recognized." + ))) + (and ;; quakenet + (string= sender "Q") + (string= target rcirc-nick) + (string-match "\\`You are now logged in as .+\\.\\'" message))) + (setq rcirc-user-authenticated t) + (run-hook-with-args 'rcirc-authenticated-hook process) + (remove-hook 'rcirc-authenticated-hook 'rcirc-join-channels-post-auth t)))))) + +(defun rcirc-handler-WALLOPS (process sender args _text) + (rcirc-print process sender "WALLOPS" sender (car args) t)) + +(defun rcirc-handler-JOIN (process sender args _text) + (let ((channel (car args))) + (with-current-buffer (rcirc-get-buffer-create process channel) + ;; when recently rejoining, restore the linestamp + (rcirc-put-nick-channel process sender channel + (let ((last-activity-lines + (rcirc-elapsed-lines process sender channel))) + (when (and last-activity-lines + (< last-activity-lines rcirc-omit-threshold)) + (rcirc-last-line process sender channel)))) + ;; reset mode-line-process in case joining a channel with an + ;; already open buffer (after getting kicked e.g.) + (setq mode-line-process nil)) + + (rcirc-print process sender "JOIN" channel "") + + ;; print in private chat buffer if it exists + (when (rcirc-get-buffer (rcirc-buffer-process) sender) + (rcirc-print process sender "JOIN" sender channel)))) + +;; PART and KICK are handled the same way +(defun rcirc-handler-PART-or-KICK (process _response channel _sender nick _args) + (rcirc-ignore-update-automatic nick) + (if (not (string= nick (rcirc-nick process))) + ;; this is someone else leaving + (progn + (rcirc-maybe-remember-nick-quit process nick channel) + (rcirc-remove-nick-channel process nick channel)) + ;; this is us leaving + (mapc (lambda (n) + (rcirc-remove-nick-channel process n channel)) + (rcirc-channel-nicks process channel)) + + ;; if the buffer is still around, make it inactive + (let ((buffer (rcirc-get-buffer process channel))) + (when buffer + (rcirc-disconnect-buffer buffer))))) + +(defun rcirc-handler-PART (process sender args _text) + (let* ((channel (car args)) + (reason (cadr args)) + (message (concat channel " " reason))) + (rcirc-print process sender "PART" channel message) + ;; print in private chat buffer if it exists + (when (rcirc-get-buffer (rcirc-buffer-process) sender) + (rcirc-print process sender "PART" sender message)) + + (rcirc-handler-PART-or-KICK process "PART" channel sender sender reason))) + +(defun rcirc-handler-KICK (process sender args _text) + (let* ((channel (car args)) + (nick (cadr args)) + (reason (nth 2 args)) + (message (concat nick " " channel " " reason))) + (rcirc-print process sender "KICK" channel message t) + ;; print in private chat buffer if it exists + (when (rcirc-get-buffer (rcirc-buffer-process) nick) + (rcirc-print process sender "KICK" nick message)) + + (rcirc-handler-PART-or-KICK process "KICK" channel sender nick reason))) + +(defun rcirc-maybe-remember-nick-quit (process nick channel) + "Remember NICK as leaving CHANNEL if they recently spoke." + (let ((elapsed-lines (rcirc-elapsed-lines process nick channel))) + (when (and elapsed-lines + (< elapsed-lines rcirc-omit-threshold)) + (let ((buffer (rcirc-get-buffer process channel))) + (when buffer + (with-current-buffer buffer + (let ((record (assoc-string nick rcirc-recent-quit-alist t)) + (line (rcirc-last-line process nick channel))) + (if record + (setcdr record line) + (setq rcirc-recent-quit-alist + (cons (cons nick line) + rcirc-recent-quit-alist)))))))))) + +(defun rcirc-handler-QUIT (process sender args _text) + (rcirc-ignore-update-automatic sender) + (mapc (lambda (channel) + ;; broadcast quit message each channel + (rcirc-print process sender "QUIT" channel (apply 'concat args)) + ;; record nick in quit table if they recently spoke + (rcirc-maybe-remember-nick-quit process sender channel)) + (rcirc-nick-channels process sender)) + (rcirc-nick-remove process sender)) + +(defun rcirc-handler-NICK (process sender args _text) + (let* ((old-nick sender) + (new-nick (car args)) + (channels (rcirc-nick-channels process old-nick))) + ;; update list of ignored nicks + (rcirc-ignore-update-automatic old-nick) + (when (member old-nick rcirc-ignore-list) + (add-to-list 'rcirc-ignore-list new-nick) + (add-to-list 'rcirc-ignore-list-automatic new-nick)) + ;; print message to nick's channels + (dolist (target channels) + (rcirc-print process sender "NICK" target new-nick)) + ;; update private chat buffer, if it exists + (let ((chat-buffer (rcirc-get-buffer process old-nick))) + (when chat-buffer + (with-current-buffer chat-buffer + (rcirc-print process sender "NICK" old-nick new-nick) + (setq rcirc-target new-nick) + (rename-buffer (rcirc-generate-new-buffer-name process new-nick))))) + ;; remove old nick and add new one + (with-rcirc-process-buffer process + (let ((v (gethash old-nick rcirc-nick-table))) + (remhash old-nick rcirc-nick-table) + (puthash new-nick v rcirc-nick-table)) + ;; if this is our nick... + (when (string= old-nick rcirc-nick) + (setq rcirc-nick new-nick) + (rcirc-update-prompt t) + ;; reauthenticate + (when rcirc-auto-authenticate-flag (rcirc-authenticate)))))) + +(defun rcirc-handler-PING (process _sender args _text) + (rcirc-send-string process (concat "PONG :" (car args)))) + +(defun rcirc-handler-PONG (_process _sender _args _text) + ;; do nothing + ) + +(defun rcirc-handler-TOPIC (process sender args _text) + (let ((topic (cadr args))) + (rcirc-print process sender "TOPIC" (car args) topic) + (with-current-buffer (rcirc-get-buffer process (car args)) + (setq rcirc-topic topic)))) + +(defvar rcirc-nick-away-alist nil) +(defun rcirc-handler-301 (process _sender args text) + "RPL_AWAY" + (let* ((nick (cadr args)) + (rec (assoc-string nick rcirc-nick-away-alist)) + (away-message (nth 2 args))) + (when (or (not rec) + (not (string= (cdr rec) away-message))) + ;; away message has changed + (rcirc-handler-generic process "AWAY" nick (cdr args) text) + (if rec + (setcdr rec away-message) + (setq rcirc-nick-away-alist (cons (cons nick away-message) + rcirc-nick-away-alist)))))) + +(defun rcirc-handler-317 (process sender args _text) + "RPL_WHOISIDLE" + (let* ((nick (nth 1 args)) + (idle-secs (string-to-number (nth 2 args))) + (idle-string + (if (< idle-secs most-positive-fixnum) + (format-seconds "%yy %dd %hh %mm %z%ss" idle-secs) + "a very long time")) + (signon-time (seconds-to-time (string-to-number (nth 3 args)))) + (signon-string (format-time-string "%c" signon-time)) + (message (format "%s idle for %s, signed on %s" + nick idle-string signon-string))) + (rcirc-print process sender "317" nil message t))) + +(defun rcirc-handler-332 (process _sender args _text) + "RPL_TOPIC" + (let ((buffer (or (rcirc-get-buffer process (cadr args)) + (rcirc-get-temp-buffer-create process (cadr args))))) + (with-current-buffer buffer + (setq rcirc-topic (nth 2 args))))) + +(defun rcirc-handler-333 (process sender args _text) + "333 says who set the topic and when. +Not in rfc1459.txt" + (let ((buffer (or (rcirc-get-buffer process (cadr args)) + (rcirc-get-temp-buffer-create process (cadr args))))) + (with-current-buffer buffer + (let ((setter (nth 2 args)) + (time (current-time-string + (seconds-to-time + (string-to-number (cl-cadddr args)))))) + (rcirc-print process sender "TOPIC" (cadr args) + (format "%s (%s on %s)" rcirc-topic setter time)))))) + +(defun rcirc-handler-477 (process sender args _text) + "ERR_NOCHANMODES" + (rcirc-print process sender "477" (cadr args) (nth 2 args))) + +(defun rcirc-handler-MODE (process sender args _text) + (let ((target (car args)) + (msg (mapconcat 'identity (cdr args) " "))) + (rcirc-print process sender "MODE" + (if (string= target (rcirc-nick process)) + nil + target) + msg) + + ;; print in private chat buffers if they exist + (mapc (lambda (nick) + (when (rcirc-get-buffer process nick) + (rcirc-print process sender "MODE" nick msg))) + (cddr args)))) + +(defun rcirc-get-temp-buffer-create (process channel) + "Return a buffer based on PROCESS and CHANNEL." + (let ((tmpnam (concat " " (downcase channel) "TMP" (process-name process)))) + (get-buffer-create tmpnam))) + +(defun rcirc-handler-353 (process _sender args _text) + "RPL_NAMREPLY" + (let ((channel (nth 2 args)) + (names (or (nth 3 args) ""))) + (mapc (lambda (nick) + (rcirc-put-nick-channel process nick channel)) + (split-string names " " t)) + ;; create a temporary buffer to insert the names into + ;; rcirc-handler-366 (RPL_ENDOFNAMES) will handle it + (with-current-buffer (rcirc-get-temp-buffer-create process channel) + (goto-char (point-max)) + (insert (car (last args)) " ")))) + +(defun rcirc-handler-366 (process sender args _text) + "RPL_ENDOFNAMES" + (let* ((channel (cadr args)) + (buffer (rcirc-get-temp-buffer-create process channel))) + (with-current-buffer buffer + (rcirc-print process sender "NAMES" channel + (let ((content (buffer-substring (point-min) (point-max)))) + (rcirc-sort-nicknames-join content " ")))) + (kill-buffer buffer))) + +(defun rcirc-handler-433 (process sender args text) + "ERR_NICKNAMEINUSE" + (rcirc-handler-generic process "433" sender args text) + (let* ((new-nick (concat (cadr args) "`"))) + (with-rcirc-process-buffer process + (rcirc-cmd-nick new-nick nil process)))) + +(defun rcirc-authenticate () + "Send authentication to process associated with current buffer. +Passwords are stored in `rcirc-authinfo' (which see)." + (interactive) + (with-rcirc-server-buffer + (dolist (i rcirc-authinfo) + (let ((process (rcirc-buffer-process)) + (server (car i)) + (nick (nth 2 i)) + (method (cadr i)) + (args (cl-cdddr i))) + (when (and (string-match server rcirc-server)) + (if (and (memq method '(nickserv chanserv bitlbee)) + (string-match nick rcirc-nick)) + ;; the following methods rely on the user's nickname. + (cl-case method + (nickserv + (rcirc-send-privmsg + process + (or (cadr args) "NickServ") + (concat "IDENTIFY " (car args)))) + (chanserv + (rcirc-send-privmsg + process + "ChanServ" + (format "IDENTIFY %s %s" (car args) (cadr args)))) + (bitlbee + (rcirc-send-privmsg + process + "&bitlbee" + (concat "IDENTIFY " (car args))))) + ;; quakenet authentication doesn't rely on the user's nickname. + ;; the variable `nick' here represents the Q account name. + (when (eq method 'quakenet) + (rcirc-send-privmsg + process + "Q@CServe.quakenet.org" + (format "AUTH %s %s" nick (car args)))))))))) + +(defun rcirc-handler-INVITE (process sender args _text) + (rcirc-print process sender "INVITE" nil (mapconcat 'identity args " ") t)) + +(defun rcirc-handler-ERROR (process sender args _text) + (rcirc-print process sender "ERROR" nil (mapconcat 'identity args " "))) + +(defun rcirc-handler-CTCP (process target sender text) + (if (string-match "^\\([^ ]+\\) *\\(.*\\)$" text) + (let* ((request (upcase (match-string 1 text))) + (args (match-string 2 text)) + (handler (intern-soft (concat "rcirc-handler-ctcp-" request)))) + (if (not (fboundp handler)) + (rcirc-print process sender "ERROR" target + (format "%s sent unsupported ctcp: %s" sender text) + t) + (funcall handler process target sender args) + (unless (or (string= request "ACTION") + (string= request "KEEPALIVE")) + (rcirc-print process sender "CTCP" target + (format "%s" text) t)))))) + +(defun rcirc-handler-ctcp-VERSION (process _target sender _args) + (rcirc-send-string process + (concat "NOTICE " sender + " :\C-aVERSION " rcirc-id-string + "\C-a"))) + +(defun rcirc-handler-ctcp-ACTION (process target sender args) + (rcirc-print process sender "ACTION" target args t)) + +(defun rcirc-handler-ctcp-TIME (process _target sender _args) + (rcirc-send-string process + (concat "NOTICE " sender + " :\C-aTIME " (current-time-string) "\C-a"))) + +(defun rcirc-handler-CTCP-response (process _target sender message) + (rcirc-print process sender "CTCP" nil message t)) + +(defun rcirc-handler-CAP (process _sender args _text) + (when (equal (cadr args) "LS") + (rcirc-send-string process "CAP REQ :server-time")) + + (when (or (equal (cadr args) "ACK") + (equal (cadr args) "NAK")) + ;; Capability negotiation is best-effort here, I know that my + ;; servers support server-time and thus we end negotiation + ;; immediately. + (rcirc-send-string process "CAP END"))) + +(defgroup rcirc-faces nil + "Faces for rcirc." + :group 'rcirc + :group 'faces) + +(defface rcirc-my-nick ; font-lock-function-name-face + '((((class color) (min-colors 88) (background light)) :foreground "Blue1") + (((class color) (min-colors 88) (background dark)) :foreground "LightSkyBlue") + (((class color) (min-colors 16) (background light)) :foreground "Blue") + (((class color) (min-colors 16) (background dark)) :foreground "LightSkyBlue") + (((class color) (min-colors 8)) :foreground "blue" :weight bold) + (t :inverse-video t :weight bold)) + "Rcirc face for my messages." + :group 'rcirc-faces) + +(defface rcirc-other-nick ; font-lock-variable-name-face + '((((class grayscale) (background light)) + :foreground "Gray90" :weight bold :slant italic) + (((class grayscale) (background dark)) + :foreground "DimGray" :weight bold :slant italic) + (((class color) (min-colors 88) (background light)) :foreground "DarkGoldenrod") + (((class color) (min-colors 88) (background dark)) :foreground "LightGoldenrod") + (((class color) (min-colors 16) (background light)) :foreground "DarkGoldenrod") + (((class color) (min-colors 16) (background dark)) :foreground "LightGoldenrod") + (((class color) (min-colors 8)) :foreground "yellow" :weight light) + (t :weight bold :slant italic)) + "Rcirc face for other users' messages." + :group 'rcirc-faces) + +(defface rcirc-bright-nick + '((((class grayscale) (background light)) + :foreground "LightGray" :weight bold :underline t) + (((class grayscale) (background dark)) + :foreground "Gray50" :weight bold :underline t) + (((class color) (min-colors 88) (background light)) :foreground "CadetBlue") + (((class color) (min-colors 88) (background dark)) :foreground "Aquamarine") + (((class color) (min-colors 16) (background light)) :foreground "CadetBlue") + (((class color) (min-colors 16) (background dark)) :foreground "Aquamarine") + (((class color) (min-colors 8)) :foreground "magenta") + (t :weight bold :underline t)) + "Rcirc face for nicks matched by `rcirc-bright-nicks'." + :group 'rcirc-faces) + +(defface rcirc-dim-nick + '((t :inherit default)) + "Rcirc face for nicks in `rcirc-dim-nicks'." + :group 'rcirc-faces) + +(defface rcirc-server ; font-lock-comment-face + '((((class grayscale) (background light)) + :foreground "DimGray" :weight bold :slant italic) + (((class grayscale) (background dark)) + :foreground "LightGray" :weight bold :slant italic) + (((class color) (min-colors 88) (background light)) + :foreground "Firebrick") + (((class color) (min-colors 88) (background dark)) + :foreground "chocolate1") + (((class color) (min-colors 16) (background light)) + :foreground "red") + (((class color) (min-colors 16) (background dark)) + :foreground "red1") + (((class color) (min-colors 8) (background light))) + (((class color) (min-colors 8) (background dark))) + (t :weight bold :slant italic)) + "Rcirc face for server messages." + :group 'rcirc-faces) + +(defface rcirc-server-prefix ; font-lock-comment-delimiter-face + '((default :inherit rcirc-server) + (((class grayscale))) + (((class color) (min-colors 16))) + (((class color) (min-colors 8) (background light)) + :foreground "red") + (((class color) (min-colors 8) (background dark)) + :foreground "red1")) + "Rcirc face for server prefixes." + :group 'rcirc-faces) + +(defface rcirc-timestamp + '((t :inherit default)) + "Rcirc face for timestamps." + :group 'rcirc-faces) + +(defface rcirc-nick-in-message ; font-lock-keyword-face + '((((class grayscale) (background light)) :foreground "LightGray" :weight bold) + (((class grayscale) (background dark)) :foreground "DimGray" :weight bold) + (((class color) (min-colors 88) (background light)) :foreground "Purple") + (((class color) (min-colors 88) (background dark)) :foreground "Cyan1") + (((class color) (min-colors 16) (background light)) :foreground "Purple") + (((class color) (min-colors 16) (background dark)) :foreground "Cyan") + (((class color) (min-colors 8)) :foreground "cyan" :weight bold) + (t :weight bold)) + "Rcirc face for instances of your nick within messages." + :group 'rcirc-faces) + +(defface rcirc-nick-in-message-full-line '((t :weight bold)) + "Rcirc face for emphasizing the entire message when your nick is mentioned." + :group 'rcirc-faces) + +(defface rcirc-prompt ; comint-highlight-prompt + '((((min-colors 88) (background dark)) :foreground "cyan1") + (((background dark)) :foreground "cyan") + (t :foreground "dark blue")) + "Rcirc face for prompts." + :group 'rcirc-faces) + +(defface rcirc-track-nick + '((((type tty)) :inherit default) + (t :inverse-video t)) + "Rcirc face used in the mode-line when your nick is mentioned." + :group 'rcirc-faces) + +(defface rcirc-track-keyword '((t :weight bold)) + "Rcirc face used in the mode-line when keywords are mentioned." + :group 'rcirc-faces) + +(defface rcirc-url '((t :weight bold)) + "Rcirc face used to highlight urls." + :group 'rcirc-faces) + +(defface rcirc-keyword '((t :inherit highlight)) + "Rcirc face used to highlight keywords." + :group 'rcirc-faces) + + +;; When using M-x flyspell-mode, only check words after the prompt +(put 'rcirc-mode 'flyspell-mode-predicate 'rcirc-looking-at-input) +(defun rcirc-looking-at-input () + "Returns true if point is past the input marker." + (>= (point) rcirc-prompt-end-marker)) + + +(provide 'rcirc) + +;;; rcirc.el ends here diff --git a/third_party/emacs/vterm.nix b/third_party/emacs/vterm.nix new file mode 100644 index 0000000000..674a919c99 --- /dev/null +++ b/third_party/emacs/vterm.nix @@ -0,0 +1,11 @@ +# Overridden vterm to fetch a newer version +{ pkgs, ... }: + +pkgs.emacsPackages.vterm.overrideAttrs(_: { + src = pkgs.fetchFromGitHub{ + owner = "akermu"; + repo = "emacs-libvterm"; + rev = "58b4cc40ee9872a08fc5cbfee78ad0e195a3306c"; + sha256 = "1w5yfl8nq4k7xyldf0ivzv36vhz3dwdzk6q2vs3xwpx6ljy52px6"; + }; +}) diff --git a/third_party/farmhash/default.nix b/third_party/farmhash/default.nix new file mode 100644 index 0000000000..d7431dbd01 --- /dev/null +++ b/third_party/farmhash/default.nix @@ -0,0 +1,13 @@ +# Google's farmhash family of hash functions +{ pkgs, ... }: + +pkgs.stdenv.mkDerivation { + name = "farmhash"; + + src = pkgs.fetchFromGitHub { + owner = "google"; + repo = "farmhash"; + rev = "0d859a811870d10f53a594927d0d0b97573ad06d"; + sha256 = "1w2583m5289hby0r91gds5yia6l8qpmzkl5b9bv58g5gacfj2h17"; + }; +} diff --git a/third_party/ffmpeg/default.nix b/third_party/ffmpeg/default.nix new file mode 100644 index 0000000000..e1b4d759da --- /dev/null +++ b/third_party/ffmpeg/default.nix @@ -0,0 +1,12 @@ +{ pkgs, ... }: + +pkgs.originals.ffmpeg.overrideAttrs(old: { + buildInputs = old.buildInputs ++ [ + pkgs.cudatoolkit.out + ]; + + configureFlags = old.configureFlags ++ [ + "--enable-libnpp" + "--enable-nonfree" + ]; +}) diff --git a/.cirrus.yml b/third_party/git/.cirrus.yml index c2f5fe385a..c2f5fe385a 100644 --- a/.cirrus.yml +++ b/third_party/git/.cirrus.yml diff --git a/.clang-format b/third_party/git/.clang-format index c592dda681..c592dda681 100644 --- a/.clang-format +++ b/third_party/git/.clang-format diff --git a/.editorconfig b/third_party/git/.editorconfig index f9d819623d..f9d819623d 100644 --- a/.editorconfig +++ b/third_party/git/.editorconfig diff --git a/.gitattributes b/third_party/git/.gitattributes index b08a1416d8..b08a1416d8 100644 --- a/.gitattributes +++ b/third_party/git/.gitattributes diff --git a/.github/CONTRIBUTING.md b/third_party/git/.github/CONTRIBUTING.md index e7b4e2f3c2..e7b4e2f3c2 100644 --- a/.github/CONTRIBUTING.md +++ b/third_party/git/.github/CONTRIBUTING.md diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/third_party/git/.github/PULL_REQUEST_TEMPLATE.md index 952c7c3a2a..952c7c3a2a 100644 --- a/.github/PULL_REQUEST_TEMPLATE.md +++ b/third_party/git/.github/PULL_REQUEST_TEMPLATE.md diff --git a/third_party/git/.gitignore b/third_party/git/.gitignore new file mode 100644 index 0000000000..aebe7c0908 --- /dev/null +++ b/third_party/git/.gitignore @@ -0,0 +1,241 @@ +/fuzz-commit-graph +/fuzz_corpora +/fuzz-pack-headers +/fuzz-pack-idx +/GIT-BUILD-OPTIONS +/GIT-CFLAGS +/GIT-LDFLAGS +/GIT-PREFIX +/GIT-PERL-DEFINES +/GIT-PERL-HEADER +/GIT-PYTHON-VARS +/GIT-SCRIPT-DEFINES +/GIT-USER-AGENT +/GIT-VERSION-FILE +/bin-wrappers/ +/git +/git-add +/git-add--interactive +/git-am +/git-annotate +/git-apply +/git-archimport +/git-archive +/git-bisect +/git-bisect--helper +/git-blame +/git-branch +/git-bundle +/git-cat-file +/git-check-attr +/git-check-ignore +/git-check-mailmap +/git-check-ref-format +/git-checkout +/git-checkout-index +/git-cherry +/git-cherry-pick +/git-clean +/git-clone +/git-column +/git-commit +/git-commit-graph +/git-commit-tree +/git-config +/git-count-objects +/git-credential +/git-credential-cache +/git-credential-cache--daemon +/git-credential-store +/git-cvsexportcommit +/git-cvsimport +/git-cvsserver +/git-daemon +/git-diff +/git-diff-files +/git-diff-index +/git-diff-tree +/git-difftool +/git-difftool--helper +/git-describe +/git-env--helper +/git-fast-export +/git-fast-import +/git-fetch +/git-fetch-pack +/git-filter-branch +/git-fmt-merge-msg +/git-for-each-ref +/git-format-patch +/git-fsck +/git-fsck-objects +/git-gc +/git-get-tar-commit-id +/git-grep +/git-hash-object +/git-help +/git-http-backend +/git-http-fetch +/git-http-push +/git-imap-send +/git-index-pack +/git-init +/git-init-db +/git-interpret-trailers +/git-instaweb +/git-legacy-stash +/git-log +/git-ls-files +/git-ls-remote +/git-ls-tree +/git-mailinfo +/git-mailsplit +/git-merge +/git-merge-base +/git-merge-index +/git-merge-file +/git-merge-tree +/git-merge-octopus +/git-merge-one-file +/git-merge-ours +/git-merge-recursive +/git-merge-resolve +/git-merge-subtree +/git-mergetool +/git-mergetool--lib +/git-mktag +/git-mktree +/git-multi-pack-index +/git-mv +/git-name-rev +/git-notes +/git-p4 +/git-pack-redundant +/git-pack-objects +/git-pack-refs +/git-parse-remote +/git-patch-id +/git-prune +/git-prune-packed +/git-pull +/git-push +/git-quiltimport +/git-range-diff +/git-read-tree +/git-rebase +/git-rebase--preserve-merges +/git-receive-pack +/git-reflog +/git-remote +/git-remote-http +/git-remote-https +/git-remote-ftp +/git-remote-ftps +/git-remote-fd +/git-remote-ext +/git-remote-testpy +/git-remote-testsvn +/git-repack +/git-replace +/git-request-pull +/git-rerere +/git-reset +/git-restore +/git-rev-list +/git-rev-parse +/git-revert +/git-rm +/git-send-email +/git-send-pack +/git-serve +/git-sh-i18n +/git-sh-i18n--envsubst +/git-sh-setup +/git-sh-i18n +/git-shell +/git-shortlog +/git-show +/git-show-branch +/git-show-index +/git-show-ref +/git-sparse-checkout +/git-stage +/git-stash +/git-status +/git-stripspace +/git-submodule +/git-submodule--helper +/git-svn +/git-switch +/git-symbolic-ref +/git-tag +/git-unpack-file +/git-unpack-objects +/git-update-index +/git-update-ref +/git-update-server-info +/git-upload-archive +/git-upload-pack +/git-var +/git-verify-commit +/git-verify-pack +/git-verify-tag +/git-web--browse +/git-whatchanged +/git-worktree +/git-write-tree +/git-core-*/?* +/gitweb/GITWEB-BUILD-OPTIONS +/gitweb/gitweb.cgi +/gitweb/static/gitweb.js +/gitweb/static/gitweb.min.* +/command-list.h +*.tar.gz +*.dsc +*.deb +/git.spec +*.exe +*.[aos] +*.py[co] +.depend/ +*.gcda +*.gcno +*.gcov +/coverage-untested-functions +/cover_db/ +/cover_db_html/ +*+ +/config.mak +/autom4te.cache +/config.cache +/config.log +/config.status +/config.mak.autogen +/config.mak.append +/configure +/.vscode/ +/tags +/TAGS +/cscope* +*.hcc +*.obj +*.lib +*.res +*.sln +*.suo +*.ncb +*.vcproj +*.user +*.idb +*.pdb +*.ilk +*.iobj +*.ipdb +*.dll +.vs/ +Debug/ +Release/ +/UpgradeLog*.htm +/git.VC.VC.opendb +/git.VC.db +*.dSYM diff --git a/.mailmap b/third_party/git/.mailmap index bde7aba756..bde7aba756 100644 --- a/.mailmap +++ b/third_party/git/.mailmap diff --git a/third_party/git/.skip-subtree b/third_party/git/.skip-subtree new file mode 100644 index 0000000000..2f5f854d72 --- /dev/null +++ b/third_party/git/.skip-subtree @@ -0,0 +1 @@ +Subtrees of this directory belong to git (third-party). diff --git a/.travis.yml b/third_party/git/.travis.yml index fc5730b085..fc5730b085 100644 --- a/.travis.yml +++ b/third_party/git/.travis.yml diff --git a/.tsan-suppressions b/third_party/git/.tsan-suppressions index 5ba86d6845..5ba86d6845 100644 --- a/.tsan-suppressions +++ b/third_party/git/.tsan-suppressions diff --git a/CODE_OF_CONDUCT.md b/third_party/git/CODE_OF_CONDUCT.md index fc4645d5c0..fc4645d5c0 100644 --- a/CODE_OF_CONDUCT.md +++ b/third_party/git/CODE_OF_CONDUCT.md diff --git a/COPYING b/third_party/git/COPYING index 536e55524d..536e55524d 100644 --- a/COPYING +++ b/third_party/git/COPYING diff --git a/Documentation/.gitattributes b/third_party/git/Documentation/.gitattributes index ddb030137d..ddb030137d 100644 --- a/Documentation/.gitattributes +++ b/third_party/git/Documentation/.gitattributes diff --git a/Documentation/.gitignore b/third_party/git/Documentation/.gitignore index 9022d48355..9022d48355 100644 --- a/Documentation/.gitignore +++ b/third_party/git/Documentation/.gitignore diff --git a/Documentation/CodingGuidelines b/third_party/git/Documentation/CodingGuidelines index ed4e443a3c..ed4e443a3c 100644 --- a/Documentation/CodingGuidelines +++ b/third_party/git/Documentation/CodingGuidelines diff --git a/Documentation/Makefile b/third_party/git/Documentation/Makefile index 8fe829cc1b..8fe829cc1b 100644 --- a/Documentation/Makefile +++ b/third_party/git/Documentation/Makefile diff --git a/Documentation/MyFirstContribution.txt b/third_party/git/Documentation/MyFirstContribution.txt index 427274df4d..427274df4d 100644 --- a/Documentation/MyFirstContribution.txt +++ b/third_party/git/Documentation/MyFirstContribution.txt diff --git a/Documentation/MyFirstObjectWalk.txt b/third_party/git/Documentation/MyFirstObjectWalk.txt index aa828dfdc4..aa828dfdc4 100644 --- a/Documentation/MyFirstObjectWalk.txt +++ b/third_party/git/Documentation/MyFirstObjectWalk.txt diff --git a/Documentation/RelNotes/1.5.0.1.txt b/third_party/git/Documentation/RelNotes/1.5.0.1.txt index fea3f9935b..fea3f9935b 100644 --- a/Documentation/RelNotes/1.5.0.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.1.txt diff --git a/Documentation/RelNotes/1.5.0.2.txt b/third_party/git/Documentation/RelNotes/1.5.0.2.txt index b061e50ff0..b061e50ff0 100644 --- a/Documentation/RelNotes/1.5.0.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.2.txt diff --git a/Documentation/RelNotes/1.5.0.3.txt b/third_party/git/Documentation/RelNotes/1.5.0.3.txt index cd500f96bf..cd500f96bf 100644 --- a/Documentation/RelNotes/1.5.0.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.3.txt diff --git a/Documentation/RelNotes/1.5.0.4.txt b/third_party/git/Documentation/RelNotes/1.5.0.4.txt index feefa5dfd4..feefa5dfd4 100644 --- a/Documentation/RelNotes/1.5.0.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.4.txt diff --git a/Documentation/RelNotes/1.5.0.5.txt b/third_party/git/Documentation/RelNotes/1.5.0.5.txt index eeec3d73d0..eeec3d73d0 100644 --- a/Documentation/RelNotes/1.5.0.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.5.txt diff --git a/Documentation/RelNotes/1.5.0.6.txt b/third_party/git/Documentation/RelNotes/1.5.0.6.txt index c02015ad5f..c02015ad5f 100644 --- a/Documentation/RelNotes/1.5.0.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.6.txt diff --git a/Documentation/RelNotes/1.5.0.7.txt b/third_party/git/Documentation/RelNotes/1.5.0.7.txt index 670ad32b85..670ad32b85 100644 --- a/Documentation/RelNotes/1.5.0.7.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.7.txt diff --git a/Documentation/RelNotes/1.5.0.txt b/third_party/git/Documentation/RelNotes/1.5.0.txt index d6d42f3183..d6d42f3183 100644 --- a/Documentation/RelNotes/1.5.0.txt +++ b/third_party/git/Documentation/RelNotes/1.5.0.txt diff --git a/Documentation/RelNotes/1.5.1.1.txt b/third_party/git/Documentation/RelNotes/1.5.1.1.txt index 91471213bd..91471213bd 100644 --- a/Documentation/RelNotes/1.5.1.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.1.txt diff --git a/Documentation/RelNotes/1.5.1.2.txt b/third_party/git/Documentation/RelNotes/1.5.1.2.txt index d88456306c..d88456306c 100644 --- a/Documentation/RelNotes/1.5.1.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.2.txt diff --git a/Documentation/RelNotes/1.5.1.3.txt b/third_party/git/Documentation/RelNotes/1.5.1.3.txt index 876408b65a..876408b65a 100644 --- a/Documentation/RelNotes/1.5.1.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.3.txt diff --git a/Documentation/RelNotes/1.5.1.4.txt b/third_party/git/Documentation/RelNotes/1.5.1.4.txt index df2f66ccb5..df2f66ccb5 100644 --- a/Documentation/RelNotes/1.5.1.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.4.txt diff --git a/Documentation/RelNotes/1.5.1.5.txt b/third_party/git/Documentation/RelNotes/1.5.1.5.txt index b0ab8eb371..b0ab8eb371 100644 --- a/Documentation/RelNotes/1.5.1.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.5.txt diff --git a/Documentation/RelNotes/1.5.1.6.txt b/third_party/git/Documentation/RelNotes/1.5.1.6.txt index 55f3ac13e3..55f3ac13e3 100644 --- a/Documentation/RelNotes/1.5.1.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.6.txt diff --git a/Documentation/RelNotes/1.5.1.txt b/third_party/git/Documentation/RelNotes/1.5.1.txt index daed367270..daed367270 100644 --- a/Documentation/RelNotes/1.5.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.1.txt diff --git a/Documentation/RelNotes/1.5.2.1.txt b/third_party/git/Documentation/RelNotes/1.5.2.1.txt index d41984df0b..d41984df0b 100644 --- a/Documentation/RelNotes/1.5.2.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.2.1.txt diff --git a/Documentation/RelNotes/1.5.2.2.txt b/third_party/git/Documentation/RelNotes/1.5.2.2.txt index 7bfa341750..7bfa341750 100644 --- a/Documentation/RelNotes/1.5.2.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.2.2.txt diff --git a/Documentation/RelNotes/1.5.2.3.txt b/third_party/git/Documentation/RelNotes/1.5.2.3.txt index addb22955b..addb22955b 100644 --- a/Documentation/RelNotes/1.5.2.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.2.3.txt diff --git a/Documentation/RelNotes/1.5.2.4.txt b/third_party/git/Documentation/RelNotes/1.5.2.4.txt index 75cff475f6..75cff475f6 100644 --- a/Documentation/RelNotes/1.5.2.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.2.4.txt diff --git a/Documentation/RelNotes/1.5.2.5.txt b/third_party/git/Documentation/RelNotes/1.5.2.5.txt index e8281c72a0..e8281c72a0 100644 --- a/Documentation/RelNotes/1.5.2.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.2.5.txt diff --git a/Documentation/RelNotes/1.5.2.txt b/third_party/git/Documentation/RelNotes/1.5.2.txt index e8328d090a..e8328d090a 100644 --- a/Documentation/RelNotes/1.5.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.2.txt diff --git a/Documentation/RelNotes/1.5.3.1.txt b/third_party/git/Documentation/RelNotes/1.5.3.1.txt index 7ff546c743..7ff546c743 100644 --- a/Documentation/RelNotes/1.5.3.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.1.txt diff --git a/Documentation/RelNotes/1.5.3.2.txt b/third_party/git/Documentation/RelNotes/1.5.3.2.txt index 4bbde3cab4..4bbde3cab4 100644 --- a/Documentation/RelNotes/1.5.3.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.2.txt diff --git a/Documentation/RelNotes/1.5.3.3.txt b/third_party/git/Documentation/RelNotes/1.5.3.3.txt index d213846951..d213846951 100644 --- a/Documentation/RelNotes/1.5.3.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.3.txt diff --git a/Documentation/RelNotes/1.5.3.4.txt b/third_party/git/Documentation/RelNotes/1.5.3.4.txt index b04b3a45a5..b04b3a45a5 100644 --- a/Documentation/RelNotes/1.5.3.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.4.txt diff --git a/Documentation/RelNotes/1.5.3.5.txt b/third_party/git/Documentation/RelNotes/1.5.3.5.txt index 7ff1d5d0d1..7ff1d5d0d1 100644 --- a/Documentation/RelNotes/1.5.3.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.5.txt diff --git a/Documentation/RelNotes/1.5.3.6.txt b/third_party/git/Documentation/RelNotes/1.5.3.6.txt index 069a2b2cf9..069a2b2cf9 100644 --- a/Documentation/RelNotes/1.5.3.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.6.txt diff --git a/Documentation/RelNotes/1.5.3.7.txt b/third_party/git/Documentation/RelNotes/1.5.3.7.txt index 2f690616c8..2f690616c8 100644 --- a/Documentation/RelNotes/1.5.3.7.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.7.txt diff --git a/Documentation/RelNotes/1.5.3.8.txt b/third_party/git/Documentation/RelNotes/1.5.3.8.txt index 0e3ff58a46..0e3ff58a46 100644 --- a/Documentation/RelNotes/1.5.3.8.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.8.txt diff --git a/Documentation/RelNotes/1.5.3.txt b/third_party/git/Documentation/RelNotes/1.5.3.txt index 0668d3c0ca..0668d3c0ca 100644 --- a/Documentation/RelNotes/1.5.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.3.txt diff --git a/Documentation/RelNotes/1.5.4.1.txt b/third_party/git/Documentation/RelNotes/1.5.4.1.txt index d4e44b8b09..d4e44b8b09 100644 --- a/Documentation/RelNotes/1.5.4.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.1.txt diff --git a/Documentation/RelNotes/1.5.4.2.txt b/third_party/git/Documentation/RelNotes/1.5.4.2.txt index 21d0df59fb..21d0df59fb 100644 --- a/Documentation/RelNotes/1.5.4.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.2.txt diff --git a/Documentation/RelNotes/1.5.4.3.txt b/third_party/git/Documentation/RelNotes/1.5.4.3.txt index b0fc67fb2a..b0fc67fb2a 100644 --- a/Documentation/RelNotes/1.5.4.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.3.txt diff --git a/Documentation/RelNotes/1.5.4.4.txt b/third_party/git/Documentation/RelNotes/1.5.4.4.txt index 323c1a88c7..323c1a88c7 100644 --- a/Documentation/RelNotes/1.5.4.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.4.txt diff --git a/Documentation/RelNotes/1.5.4.5.txt b/third_party/git/Documentation/RelNotes/1.5.4.5.txt index bbd130e36d..bbd130e36d 100644 --- a/Documentation/RelNotes/1.5.4.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.5.txt diff --git a/Documentation/RelNotes/1.5.4.6.txt b/third_party/git/Documentation/RelNotes/1.5.4.6.txt index 3e3c3e55a3..3e3c3e55a3 100644 --- a/Documentation/RelNotes/1.5.4.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.6.txt diff --git a/Documentation/RelNotes/1.5.4.7.txt b/third_party/git/Documentation/RelNotes/1.5.4.7.txt index 9065a0e273..9065a0e273 100644 --- a/Documentation/RelNotes/1.5.4.7.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.7.txt diff --git a/Documentation/RelNotes/1.5.4.txt b/third_party/git/Documentation/RelNotes/1.5.4.txt index f1323b6174..f1323b6174 100644 --- a/Documentation/RelNotes/1.5.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.4.txt diff --git a/Documentation/RelNotes/1.5.5.1.txt b/third_party/git/Documentation/RelNotes/1.5.5.1.txt index 7de419708f..7de419708f 100644 --- a/Documentation/RelNotes/1.5.5.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.1.txt diff --git a/Documentation/RelNotes/1.5.5.2.txt b/third_party/git/Documentation/RelNotes/1.5.5.2.txt index 391a7b02ea..391a7b02ea 100644 --- a/Documentation/RelNotes/1.5.5.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.2.txt diff --git a/Documentation/RelNotes/1.5.5.3.txt b/third_party/git/Documentation/RelNotes/1.5.5.3.txt index f22f98b734..f22f98b734 100644 --- a/Documentation/RelNotes/1.5.5.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.3.txt diff --git a/Documentation/RelNotes/1.5.5.4.txt b/third_party/git/Documentation/RelNotes/1.5.5.4.txt index 2d0279ecce..2d0279ecce 100644 --- a/Documentation/RelNotes/1.5.5.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.4.txt diff --git a/Documentation/RelNotes/1.5.5.5.txt b/third_party/git/Documentation/RelNotes/1.5.5.5.txt index 30fa3615c7..30fa3615c7 100644 --- a/Documentation/RelNotes/1.5.5.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.5.txt diff --git a/Documentation/RelNotes/1.5.5.6.txt b/third_party/git/Documentation/RelNotes/1.5.5.6.txt index d5e85cb70e..d5e85cb70e 100644 --- a/Documentation/RelNotes/1.5.5.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.6.txt diff --git a/Documentation/RelNotes/1.5.5.txt b/third_party/git/Documentation/RelNotes/1.5.5.txt index 2932212488..2932212488 100644 --- a/Documentation/RelNotes/1.5.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.5.txt diff --git a/Documentation/RelNotes/1.5.6.1.txt b/third_party/git/Documentation/RelNotes/1.5.6.1.txt index 4864b16445..4864b16445 100644 --- a/Documentation/RelNotes/1.5.6.1.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.1.txt diff --git a/Documentation/RelNotes/1.5.6.2.txt b/third_party/git/Documentation/RelNotes/1.5.6.2.txt index 5902a85a78..5902a85a78 100644 --- a/Documentation/RelNotes/1.5.6.2.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.2.txt diff --git a/Documentation/RelNotes/1.5.6.3.txt b/third_party/git/Documentation/RelNotes/1.5.6.3.txt index f61dd3504a..f61dd3504a 100644 --- a/Documentation/RelNotes/1.5.6.3.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.3.txt diff --git a/Documentation/RelNotes/1.5.6.4.txt b/third_party/git/Documentation/RelNotes/1.5.6.4.txt index d8968f1ecb..d8968f1ecb 100644 --- a/Documentation/RelNotes/1.5.6.4.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.4.txt diff --git a/Documentation/RelNotes/1.5.6.5.txt b/third_party/git/Documentation/RelNotes/1.5.6.5.txt index 47ca172462..47ca172462 100644 --- a/Documentation/RelNotes/1.5.6.5.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.5.txt diff --git a/Documentation/RelNotes/1.5.6.6.txt b/third_party/git/Documentation/RelNotes/1.5.6.6.txt index 79da23db5a..79da23db5a 100644 --- a/Documentation/RelNotes/1.5.6.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.6.txt diff --git a/Documentation/RelNotes/1.5.6.txt b/third_party/git/Documentation/RelNotes/1.5.6.txt index e143d8d61b..e143d8d61b 100644 --- a/Documentation/RelNotes/1.5.6.txt +++ b/third_party/git/Documentation/RelNotes/1.5.6.txt diff --git a/Documentation/RelNotes/1.6.0.1.txt b/third_party/git/Documentation/RelNotes/1.6.0.1.txt index 49d7a1cafa..49d7a1cafa 100644 --- a/Documentation/RelNotes/1.6.0.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.1.txt diff --git a/Documentation/RelNotes/1.6.0.2.txt b/third_party/git/Documentation/RelNotes/1.6.0.2.txt index 7d8fb85e1b..7d8fb85e1b 100644 --- a/Documentation/RelNotes/1.6.0.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.2.txt diff --git a/Documentation/RelNotes/1.6.0.3.txt b/third_party/git/Documentation/RelNotes/1.6.0.3.txt index ae0577836a..ae0577836a 100644 --- a/Documentation/RelNotes/1.6.0.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.3.txt diff --git a/Documentation/RelNotes/1.6.0.4.txt b/third_party/git/Documentation/RelNotes/1.6.0.4.txt index d522661d31..d522661d31 100644 --- a/Documentation/RelNotes/1.6.0.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.4.txt diff --git a/Documentation/RelNotes/1.6.0.5.txt b/third_party/git/Documentation/RelNotes/1.6.0.5.txt index a08bb96738..a08bb96738 100644 --- a/Documentation/RelNotes/1.6.0.5.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.5.txt diff --git a/Documentation/RelNotes/1.6.0.6.txt b/third_party/git/Documentation/RelNotes/1.6.0.6.txt index 64ece1ffd5..64ece1ffd5 100644 --- a/Documentation/RelNotes/1.6.0.6.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.6.txt diff --git a/Documentation/RelNotes/1.6.0.txt b/third_party/git/Documentation/RelNotes/1.6.0.txt index de7ef166b6..de7ef166b6 100644 --- a/Documentation/RelNotes/1.6.0.txt +++ b/third_party/git/Documentation/RelNotes/1.6.0.txt diff --git a/Documentation/RelNotes/1.6.1.1.txt b/third_party/git/Documentation/RelNotes/1.6.1.1.txt index 8c594ba02f..8c594ba02f 100644 --- a/Documentation/RelNotes/1.6.1.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.1.1.txt diff --git a/Documentation/RelNotes/1.6.1.2.txt b/third_party/git/Documentation/RelNotes/1.6.1.2.txt index be37cbb858..be37cbb858 100644 --- a/Documentation/RelNotes/1.6.1.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.1.2.txt diff --git a/Documentation/RelNotes/1.6.1.3.txt b/third_party/git/Documentation/RelNotes/1.6.1.3.txt index cd08d8174e..cd08d8174e 100644 --- a/Documentation/RelNotes/1.6.1.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.1.3.txt diff --git a/Documentation/RelNotes/1.6.1.4.txt b/third_party/git/Documentation/RelNotes/1.6.1.4.txt index ccbad794c0..ccbad794c0 100644 --- a/Documentation/RelNotes/1.6.1.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.1.4.txt diff --git a/Documentation/RelNotes/1.6.1.txt b/third_party/git/Documentation/RelNotes/1.6.1.txt index 7b152a6fdc..7b152a6fdc 100644 --- a/Documentation/RelNotes/1.6.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.1.txt diff --git a/Documentation/RelNotes/1.6.2.1.txt b/third_party/git/Documentation/RelNotes/1.6.2.1.txt index dfa36416af..dfa36416af 100644 --- a/Documentation/RelNotes/1.6.2.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.2.1.txt diff --git a/Documentation/RelNotes/1.6.2.2.txt b/third_party/git/Documentation/RelNotes/1.6.2.2.txt index fafa9986b0..fafa9986b0 100644 --- a/Documentation/RelNotes/1.6.2.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.2.2.txt diff --git a/Documentation/RelNotes/1.6.2.3.txt b/third_party/git/Documentation/RelNotes/1.6.2.3.txt index 4d3c1ac91c..4d3c1ac91c 100644 --- a/Documentation/RelNotes/1.6.2.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.2.3.txt diff --git a/Documentation/RelNotes/1.6.2.4.txt b/third_party/git/Documentation/RelNotes/1.6.2.4.txt index f4bf1d0986..f4bf1d0986 100644 --- a/Documentation/RelNotes/1.6.2.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.2.4.txt diff --git a/Documentation/RelNotes/1.6.2.5.txt b/third_party/git/Documentation/RelNotes/1.6.2.5.txt index b23f9e95d1..b23f9e95d1 100644 --- a/Documentation/RelNotes/1.6.2.5.txt +++ b/third_party/git/Documentation/RelNotes/1.6.2.5.txt diff --git a/Documentation/RelNotes/1.6.2.txt b/third_party/git/Documentation/RelNotes/1.6.2.txt index 980adfb315..980adfb315 100644 --- a/Documentation/RelNotes/1.6.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.2.txt diff --git a/Documentation/RelNotes/1.6.3.1.txt b/third_party/git/Documentation/RelNotes/1.6.3.1.txt index 2400b72ef7..2400b72ef7 100644 --- a/Documentation/RelNotes/1.6.3.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.3.1.txt diff --git a/Documentation/RelNotes/1.6.3.2.txt b/third_party/git/Documentation/RelNotes/1.6.3.2.txt index b2f3f0293c..b2f3f0293c 100644 --- a/Documentation/RelNotes/1.6.3.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.3.2.txt diff --git a/Documentation/RelNotes/1.6.3.3.txt b/third_party/git/Documentation/RelNotes/1.6.3.3.txt index 1c28398bb6..1c28398bb6 100644 --- a/Documentation/RelNotes/1.6.3.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.3.3.txt diff --git a/Documentation/RelNotes/1.6.3.4.txt b/third_party/git/Documentation/RelNotes/1.6.3.4.txt index cad461bc76..cad461bc76 100644 --- a/Documentation/RelNotes/1.6.3.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.3.4.txt diff --git a/Documentation/RelNotes/1.6.3.txt b/third_party/git/Documentation/RelNotes/1.6.3.txt index 4bcff945e0..4bcff945e0 100644 --- a/Documentation/RelNotes/1.6.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.3.txt diff --git a/Documentation/RelNotes/1.6.4.1.txt b/third_party/git/Documentation/RelNotes/1.6.4.1.txt index e439e45b96..e439e45b96 100644 --- a/Documentation/RelNotes/1.6.4.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.4.1.txt diff --git a/Documentation/RelNotes/1.6.4.2.txt b/third_party/git/Documentation/RelNotes/1.6.4.2.txt index c11ec0115c..c11ec0115c 100644 --- a/Documentation/RelNotes/1.6.4.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.4.2.txt diff --git a/Documentation/RelNotes/1.6.4.3.txt b/third_party/git/Documentation/RelNotes/1.6.4.3.txt index 5643e6537d..5643e6537d 100644 --- a/Documentation/RelNotes/1.6.4.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.4.3.txt diff --git a/Documentation/RelNotes/1.6.4.4.txt b/third_party/git/Documentation/RelNotes/1.6.4.4.txt index 0ead45fc72..0ead45fc72 100644 --- a/Documentation/RelNotes/1.6.4.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.4.4.txt diff --git a/Documentation/RelNotes/1.6.4.5.txt b/third_party/git/Documentation/RelNotes/1.6.4.5.txt index eb6307dcbb..eb6307dcbb 100644 --- a/Documentation/RelNotes/1.6.4.5.txt +++ b/third_party/git/Documentation/RelNotes/1.6.4.5.txt diff --git a/Documentation/RelNotes/1.6.4.txt b/third_party/git/Documentation/RelNotes/1.6.4.txt index a2a34b43a7..a2a34b43a7 100644 --- a/Documentation/RelNotes/1.6.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.4.txt diff --git a/Documentation/RelNotes/1.6.5.1.txt b/third_party/git/Documentation/RelNotes/1.6.5.1.txt index 309ba181b2..309ba181b2 100644 --- a/Documentation/RelNotes/1.6.5.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.1.txt diff --git a/Documentation/RelNotes/1.6.5.2.txt b/third_party/git/Documentation/RelNotes/1.6.5.2.txt index aa7ccce3a2..aa7ccce3a2 100644 --- a/Documentation/RelNotes/1.6.5.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.2.txt diff --git a/Documentation/RelNotes/1.6.5.3.txt b/third_party/git/Documentation/RelNotes/1.6.5.3.txt index b2fad1b22e..b2fad1b22e 100644 --- a/Documentation/RelNotes/1.6.5.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.3.txt diff --git a/Documentation/RelNotes/1.6.5.4.txt b/third_party/git/Documentation/RelNotes/1.6.5.4.txt index 344333de66..344333de66 100644 --- a/Documentation/RelNotes/1.6.5.4.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.4.txt diff --git a/Documentation/RelNotes/1.6.5.5.txt b/third_party/git/Documentation/RelNotes/1.6.5.5.txt index ecfc57d875..ecfc57d875 100644 --- a/Documentation/RelNotes/1.6.5.5.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.5.txt diff --git a/Documentation/RelNotes/1.6.5.6.txt b/third_party/git/Documentation/RelNotes/1.6.5.6.txt index a9eaf76f62..a9eaf76f62 100644 --- a/Documentation/RelNotes/1.6.5.6.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.6.txt diff --git a/Documentation/RelNotes/1.6.5.7.txt b/third_party/git/Documentation/RelNotes/1.6.5.7.txt index dc5302c21c..dc5302c21c 100644 --- a/Documentation/RelNotes/1.6.5.7.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.7.txt diff --git a/Documentation/RelNotes/1.6.5.8.txt b/third_party/git/Documentation/RelNotes/1.6.5.8.txt index 8b24bebb96..8b24bebb96 100644 --- a/Documentation/RelNotes/1.6.5.8.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.8.txt diff --git a/Documentation/RelNotes/1.6.5.9.txt b/third_party/git/Documentation/RelNotes/1.6.5.9.txt index bb469dd71e..bb469dd71e 100644 --- a/Documentation/RelNotes/1.6.5.9.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.9.txt diff --git a/Documentation/RelNotes/1.6.5.txt b/third_party/git/Documentation/RelNotes/1.6.5.txt index 6c7f7da7eb..6c7f7da7eb 100644 --- a/Documentation/RelNotes/1.6.5.txt +++ b/third_party/git/Documentation/RelNotes/1.6.5.txt diff --git a/Documentation/RelNotes/1.6.6.1.txt b/third_party/git/Documentation/RelNotes/1.6.6.1.txt index f1d0a4ae2d..f1d0a4ae2d 100644 --- a/Documentation/RelNotes/1.6.6.1.txt +++ b/third_party/git/Documentation/RelNotes/1.6.6.1.txt diff --git a/Documentation/RelNotes/1.6.6.2.txt b/third_party/git/Documentation/RelNotes/1.6.6.2.txt index 4eaddc0106..4eaddc0106 100644 --- a/Documentation/RelNotes/1.6.6.2.txt +++ b/third_party/git/Documentation/RelNotes/1.6.6.2.txt diff --git a/Documentation/RelNotes/1.6.6.3.txt b/third_party/git/Documentation/RelNotes/1.6.6.3.txt index 11483acaec..11483acaec 100644 --- a/Documentation/RelNotes/1.6.6.3.txt +++ b/third_party/git/Documentation/RelNotes/1.6.6.3.txt diff --git a/Documentation/RelNotes/1.6.6.txt b/third_party/git/Documentation/RelNotes/1.6.6.txt index 3ed1e01433..3ed1e01433 100644 --- a/Documentation/RelNotes/1.6.6.txt +++ b/third_party/git/Documentation/RelNotes/1.6.6.txt diff --git a/Documentation/RelNotes/1.7.0.1.txt b/third_party/git/Documentation/RelNotes/1.7.0.1.txt index 8ff5bcada8..8ff5bcada8 100644 --- a/Documentation/RelNotes/1.7.0.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.1.txt diff --git a/Documentation/RelNotes/1.7.0.2.txt b/third_party/git/Documentation/RelNotes/1.7.0.2.txt index 73ed2b5278..73ed2b5278 100644 --- a/Documentation/RelNotes/1.7.0.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.2.txt diff --git a/Documentation/RelNotes/1.7.0.3.txt b/third_party/git/Documentation/RelNotes/1.7.0.3.txt index 3b355737c0..3b355737c0 100644 --- a/Documentation/RelNotes/1.7.0.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.3.txt diff --git a/Documentation/RelNotes/1.7.0.4.txt b/third_party/git/Documentation/RelNotes/1.7.0.4.txt index cf7f60e60d..cf7f60e60d 100644 --- a/Documentation/RelNotes/1.7.0.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.4.txt diff --git a/Documentation/RelNotes/1.7.0.5.txt b/third_party/git/Documentation/RelNotes/1.7.0.5.txt index 3149c91b7b..3149c91b7b 100644 --- a/Documentation/RelNotes/1.7.0.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.5.txt diff --git a/Documentation/RelNotes/1.7.0.6.txt b/third_party/git/Documentation/RelNotes/1.7.0.6.txt index b2852b67d0..b2852b67d0 100644 --- a/Documentation/RelNotes/1.7.0.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.6.txt diff --git a/Documentation/RelNotes/1.7.0.7.txt b/third_party/git/Documentation/RelNotes/1.7.0.7.txt index d0cb7ca7e2..d0cb7ca7e2 100644 --- a/Documentation/RelNotes/1.7.0.7.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.7.txt diff --git a/Documentation/RelNotes/1.7.0.8.txt b/third_party/git/Documentation/RelNotes/1.7.0.8.txt index 7f05b48e17..7f05b48e17 100644 --- a/Documentation/RelNotes/1.7.0.8.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.8.txt diff --git a/Documentation/RelNotes/1.7.0.9.txt b/third_party/git/Documentation/RelNotes/1.7.0.9.txt index bfb3166387..bfb3166387 100644 --- a/Documentation/RelNotes/1.7.0.9.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.9.txt diff --git a/Documentation/RelNotes/1.7.0.txt b/third_party/git/Documentation/RelNotes/1.7.0.txt index 0bb8c0b2a2..0bb8c0b2a2 100644 --- a/Documentation/RelNotes/1.7.0.txt +++ b/third_party/git/Documentation/RelNotes/1.7.0.txt diff --git a/Documentation/RelNotes/1.7.1.1.txt b/third_party/git/Documentation/RelNotes/1.7.1.1.txt index 3f6b3148a3..3f6b3148a3 100644 --- a/Documentation/RelNotes/1.7.1.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.1.1.txt diff --git a/Documentation/RelNotes/1.7.1.2.txt b/third_party/git/Documentation/RelNotes/1.7.1.2.txt index 61ba14e262..61ba14e262 100644 --- a/Documentation/RelNotes/1.7.1.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.1.2.txt diff --git a/Documentation/RelNotes/1.7.1.3.txt b/third_party/git/Documentation/RelNotes/1.7.1.3.txt index 5b18518449..5b18518449 100644 --- a/Documentation/RelNotes/1.7.1.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.1.3.txt diff --git a/Documentation/RelNotes/1.7.1.4.txt b/third_party/git/Documentation/RelNotes/1.7.1.4.txt index 7c734b4f7b..7c734b4f7b 100644 --- a/Documentation/RelNotes/1.7.1.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.1.4.txt diff --git a/Documentation/RelNotes/1.7.1.txt b/third_party/git/Documentation/RelNotes/1.7.1.txt index 9d89fedb36..9d89fedb36 100644 --- a/Documentation/RelNotes/1.7.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.1.txt diff --git a/Documentation/RelNotes/1.7.10.1.txt b/third_party/git/Documentation/RelNotes/1.7.10.1.txt index 71a86cb7c6..71a86cb7c6 100644 --- a/Documentation/RelNotes/1.7.10.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.10.1.txt diff --git a/Documentation/RelNotes/1.7.10.2.txt b/third_party/git/Documentation/RelNotes/1.7.10.2.txt index 7a7e9d6fd1..7a7e9d6fd1 100644 --- a/Documentation/RelNotes/1.7.10.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.10.2.txt diff --git a/Documentation/RelNotes/1.7.10.3.txt b/third_party/git/Documentation/RelNotes/1.7.10.3.txt index 703fbf1d60..703fbf1d60 100644 --- a/Documentation/RelNotes/1.7.10.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.10.3.txt diff --git a/Documentation/RelNotes/1.7.10.4.txt b/third_party/git/Documentation/RelNotes/1.7.10.4.txt index 57597f2bf3..57597f2bf3 100644 --- a/Documentation/RelNotes/1.7.10.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.10.4.txt diff --git a/Documentation/RelNotes/1.7.10.5.txt b/third_party/git/Documentation/RelNotes/1.7.10.5.txt index 4db1770e38..4db1770e38 100644 --- a/Documentation/RelNotes/1.7.10.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.10.5.txt diff --git a/Documentation/RelNotes/1.7.10.txt b/third_party/git/Documentation/RelNotes/1.7.10.txt index 58100bf04e..58100bf04e 100644 --- a/Documentation/RelNotes/1.7.10.txt +++ b/third_party/git/Documentation/RelNotes/1.7.10.txt diff --git a/Documentation/RelNotes/1.7.11.1.txt b/third_party/git/Documentation/RelNotes/1.7.11.1.txt index 577eccaacd..577eccaacd 100644 --- a/Documentation/RelNotes/1.7.11.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.1.txt diff --git a/Documentation/RelNotes/1.7.11.2.txt b/third_party/git/Documentation/RelNotes/1.7.11.2.txt index f0cfd02d6f..f0cfd02d6f 100644 --- a/Documentation/RelNotes/1.7.11.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.2.txt diff --git a/Documentation/RelNotes/1.7.11.3.txt b/third_party/git/Documentation/RelNotes/1.7.11.3.txt index 64494f89d9..64494f89d9 100644 --- a/Documentation/RelNotes/1.7.11.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.3.txt diff --git a/Documentation/RelNotes/1.7.11.4.txt b/third_party/git/Documentation/RelNotes/1.7.11.4.txt index 3a640c2d4d..3a640c2d4d 100644 --- a/Documentation/RelNotes/1.7.11.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.4.txt diff --git a/Documentation/RelNotes/1.7.11.5.txt b/third_party/git/Documentation/RelNotes/1.7.11.5.txt index 0a2ed855c5..0a2ed855c5 100644 --- a/Documentation/RelNotes/1.7.11.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.5.txt diff --git a/Documentation/RelNotes/1.7.11.6.txt b/third_party/git/Documentation/RelNotes/1.7.11.6.txt index ba7d3c3966..ba7d3c3966 100644 --- a/Documentation/RelNotes/1.7.11.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.6.txt diff --git a/Documentation/RelNotes/1.7.11.7.txt b/third_party/git/Documentation/RelNotes/1.7.11.7.txt index e743a2a8e4..e743a2a8e4 100644 --- a/Documentation/RelNotes/1.7.11.7.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.7.txt diff --git a/Documentation/RelNotes/1.7.11.txt b/third_party/git/Documentation/RelNotes/1.7.11.txt index 15b954ca4b..15b954ca4b 100644 --- a/Documentation/RelNotes/1.7.11.txt +++ b/third_party/git/Documentation/RelNotes/1.7.11.txt diff --git a/Documentation/RelNotes/1.7.12.1.txt b/third_party/git/Documentation/RelNotes/1.7.12.1.txt index b8f04af19f..b8f04af19f 100644 --- a/Documentation/RelNotes/1.7.12.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.12.1.txt diff --git a/Documentation/RelNotes/1.7.12.2.txt b/third_party/git/Documentation/RelNotes/1.7.12.2.txt index 69255745e6..69255745e6 100644 --- a/Documentation/RelNotes/1.7.12.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.12.2.txt diff --git a/Documentation/RelNotes/1.7.12.3.txt b/third_party/git/Documentation/RelNotes/1.7.12.3.txt index 4b822976b8..4b822976b8 100644 --- a/Documentation/RelNotes/1.7.12.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.12.3.txt diff --git a/Documentation/RelNotes/1.7.12.4.txt b/third_party/git/Documentation/RelNotes/1.7.12.4.txt index c6da3cc939..c6da3cc939 100644 --- a/Documentation/RelNotes/1.7.12.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.12.4.txt diff --git a/Documentation/RelNotes/1.7.12.txt b/third_party/git/Documentation/RelNotes/1.7.12.txt index 010d8c7de4..010d8c7de4 100644 --- a/Documentation/RelNotes/1.7.12.txt +++ b/third_party/git/Documentation/RelNotes/1.7.12.txt diff --git a/Documentation/RelNotes/1.7.2.1.txt b/third_party/git/Documentation/RelNotes/1.7.2.1.txt index 1103c47a4f..1103c47a4f 100644 --- a/Documentation/RelNotes/1.7.2.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.2.1.txt diff --git a/Documentation/RelNotes/1.7.2.2.txt b/third_party/git/Documentation/RelNotes/1.7.2.2.txt index 71eb6a8b0a..71eb6a8b0a 100644 --- a/Documentation/RelNotes/1.7.2.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.2.2.txt diff --git a/Documentation/RelNotes/1.7.2.3.txt b/third_party/git/Documentation/RelNotes/1.7.2.3.txt index 610960cfe1..610960cfe1 100644 --- a/Documentation/RelNotes/1.7.2.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.2.3.txt diff --git a/Documentation/RelNotes/1.7.2.4.txt b/third_party/git/Documentation/RelNotes/1.7.2.4.txt index f7950a4c04..f7950a4c04 100644 --- a/Documentation/RelNotes/1.7.2.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.2.4.txt diff --git a/Documentation/RelNotes/1.7.2.5.txt b/third_party/git/Documentation/RelNotes/1.7.2.5.txt index bf976c40db..bf976c40db 100644 --- a/Documentation/RelNotes/1.7.2.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.2.5.txt diff --git a/Documentation/RelNotes/1.7.2.txt b/third_party/git/Documentation/RelNotes/1.7.2.txt index 15cf01178c..15cf01178c 100644 --- a/Documentation/RelNotes/1.7.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.2.txt diff --git a/Documentation/RelNotes/1.7.3.1.txt b/third_party/git/Documentation/RelNotes/1.7.3.1.txt index 002c93b961..002c93b961 100644 --- a/Documentation/RelNotes/1.7.3.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.3.1.txt diff --git a/Documentation/RelNotes/1.7.3.2.txt b/third_party/git/Documentation/RelNotes/1.7.3.2.txt index 5c93b85af4..5c93b85af4 100644 --- a/Documentation/RelNotes/1.7.3.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.3.2.txt diff --git a/Documentation/RelNotes/1.7.3.3.txt b/third_party/git/Documentation/RelNotes/1.7.3.3.txt index 9b2b2448df..9b2b2448df 100644 --- a/Documentation/RelNotes/1.7.3.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.3.3.txt diff --git a/Documentation/RelNotes/1.7.3.4.txt b/third_party/git/Documentation/RelNotes/1.7.3.4.txt index e57f7c176d..e57f7c176d 100644 --- a/Documentation/RelNotes/1.7.3.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.3.4.txt diff --git a/Documentation/RelNotes/1.7.3.5.txt b/third_party/git/Documentation/RelNotes/1.7.3.5.txt index 40f3ba5795..40f3ba5795 100644 --- a/Documentation/RelNotes/1.7.3.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.3.5.txt diff --git a/Documentation/RelNotes/1.7.3.txt b/third_party/git/Documentation/RelNotes/1.7.3.txt index 309c33181f..309c33181f 100644 --- a/Documentation/RelNotes/1.7.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.3.txt diff --git a/Documentation/RelNotes/1.7.4.1.txt b/third_party/git/Documentation/RelNotes/1.7.4.1.txt index 79923a6d2f..79923a6d2f 100644 --- a/Documentation/RelNotes/1.7.4.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.4.1.txt diff --git a/Documentation/RelNotes/1.7.4.2.txt b/third_party/git/Documentation/RelNotes/1.7.4.2.txt index ef4ce1fcd3..ef4ce1fcd3 100644 --- a/Documentation/RelNotes/1.7.4.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.4.2.txt diff --git a/Documentation/RelNotes/1.7.4.3.txt b/third_party/git/Documentation/RelNotes/1.7.4.3.txt index 02a3d5bdf6..02a3d5bdf6 100644 --- a/Documentation/RelNotes/1.7.4.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.4.3.txt diff --git a/Documentation/RelNotes/1.7.4.4.txt b/third_party/git/Documentation/RelNotes/1.7.4.4.txt index ff06e04a58..ff06e04a58 100644 --- a/Documentation/RelNotes/1.7.4.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.4.4.txt diff --git a/Documentation/RelNotes/1.7.4.5.txt b/third_party/git/Documentation/RelNotes/1.7.4.5.txt index b7a0eeb22f..b7a0eeb22f 100644 --- a/Documentation/RelNotes/1.7.4.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.4.5.txt diff --git a/Documentation/RelNotes/1.7.4.txt b/third_party/git/Documentation/RelNotes/1.7.4.txt index d5bca731b5..d5bca731b5 100644 --- a/Documentation/RelNotes/1.7.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.4.txt diff --git a/Documentation/RelNotes/1.7.5.1.txt b/third_party/git/Documentation/RelNotes/1.7.5.1.txt index c6ebd76d19..c6ebd76d19 100644 --- a/Documentation/RelNotes/1.7.5.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.5.1.txt diff --git a/Documentation/RelNotes/1.7.5.2.txt b/third_party/git/Documentation/RelNotes/1.7.5.2.txt index 951eb7cb08..951eb7cb08 100644 --- a/Documentation/RelNotes/1.7.5.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.5.2.txt diff --git a/Documentation/RelNotes/1.7.5.3.txt b/third_party/git/Documentation/RelNotes/1.7.5.3.txt index 1d24edcf2f..1d24edcf2f 100644 --- a/Documentation/RelNotes/1.7.5.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.5.3.txt diff --git a/Documentation/RelNotes/1.7.5.4.txt b/third_party/git/Documentation/RelNotes/1.7.5.4.txt index 7796df3fe4..7796df3fe4 100644 --- a/Documentation/RelNotes/1.7.5.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.5.4.txt diff --git a/Documentation/RelNotes/1.7.5.txt b/third_party/git/Documentation/RelNotes/1.7.5.txt index 987919c321..987919c321 100644 --- a/Documentation/RelNotes/1.7.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.5.txt diff --git a/Documentation/RelNotes/1.7.6.1.txt b/third_party/git/Documentation/RelNotes/1.7.6.1.txt index 42e46ab17f..42e46ab17f 100644 --- a/Documentation/RelNotes/1.7.6.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.1.txt diff --git a/Documentation/RelNotes/1.7.6.2.txt b/third_party/git/Documentation/RelNotes/1.7.6.2.txt index 67ae414965..67ae414965 100644 --- a/Documentation/RelNotes/1.7.6.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.2.txt diff --git a/Documentation/RelNotes/1.7.6.3.txt b/third_party/git/Documentation/RelNotes/1.7.6.3.txt index 95971831b9..95971831b9 100644 --- a/Documentation/RelNotes/1.7.6.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.3.txt diff --git a/Documentation/RelNotes/1.7.6.4.txt b/third_party/git/Documentation/RelNotes/1.7.6.4.txt index e19acac2da..e19acac2da 100644 --- a/Documentation/RelNotes/1.7.6.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.4.txt diff --git a/Documentation/RelNotes/1.7.6.5.txt b/third_party/git/Documentation/RelNotes/1.7.6.5.txt index 6713132a9e..6713132a9e 100644 --- a/Documentation/RelNotes/1.7.6.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.5.txt diff --git a/Documentation/RelNotes/1.7.6.6.txt b/third_party/git/Documentation/RelNotes/1.7.6.6.txt index 5343e00400..5343e00400 100644 --- a/Documentation/RelNotes/1.7.6.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.6.txt diff --git a/Documentation/RelNotes/1.7.6.txt b/third_party/git/Documentation/RelNotes/1.7.6.txt index 9ec498ea39..9ec498ea39 100644 --- a/Documentation/RelNotes/1.7.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.6.txt diff --git a/Documentation/RelNotes/1.7.7.1.txt b/third_party/git/Documentation/RelNotes/1.7.7.1.txt index ac9b838e25..ac9b838e25 100644 --- a/Documentation/RelNotes/1.7.7.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.1.txt diff --git a/Documentation/RelNotes/1.7.7.2.txt b/third_party/git/Documentation/RelNotes/1.7.7.2.txt index e6bbef2f01..e6bbef2f01 100644 --- a/Documentation/RelNotes/1.7.7.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.2.txt diff --git a/Documentation/RelNotes/1.7.7.3.txt b/third_party/git/Documentation/RelNotes/1.7.7.3.txt index 09301f0957..09301f0957 100644 --- a/Documentation/RelNotes/1.7.7.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.3.txt diff --git a/Documentation/RelNotes/1.7.7.4.txt b/third_party/git/Documentation/RelNotes/1.7.7.4.txt index e5234485e7..e5234485e7 100644 --- a/Documentation/RelNotes/1.7.7.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.4.txt diff --git a/Documentation/RelNotes/1.7.7.5.txt b/third_party/git/Documentation/RelNotes/1.7.7.5.txt index 7b0931987b..7b0931987b 100644 --- a/Documentation/RelNotes/1.7.7.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.5.txt diff --git a/Documentation/RelNotes/1.7.7.6.txt b/third_party/git/Documentation/RelNotes/1.7.7.6.txt index 8df606d452..8df606d452 100644 --- a/Documentation/RelNotes/1.7.7.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.6.txt diff --git a/Documentation/RelNotes/1.7.7.7.txt b/third_party/git/Documentation/RelNotes/1.7.7.7.txt index e79118d063..e79118d063 100644 --- a/Documentation/RelNotes/1.7.7.7.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.7.txt diff --git a/Documentation/RelNotes/1.7.7.txt b/third_party/git/Documentation/RelNotes/1.7.7.txt index 6eff128c80..6eff128c80 100644 --- a/Documentation/RelNotes/1.7.7.txt +++ b/third_party/git/Documentation/RelNotes/1.7.7.txt diff --git a/Documentation/RelNotes/1.7.8.1.txt b/third_party/git/Documentation/RelNotes/1.7.8.1.txt index 33dc948b94..33dc948b94 100644 --- a/Documentation/RelNotes/1.7.8.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.1.txt diff --git a/Documentation/RelNotes/1.7.8.2.txt b/third_party/git/Documentation/RelNotes/1.7.8.2.txt index b9c66aa1b7..b9c66aa1b7 100644 --- a/Documentation/RelNotes/1.7.8.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.2.txt diff --git a/Documentation/RelNotes/1.7.8.3.txt b/third_party/git/Documentation/RelNotes/1.7.8.3.txt index a92714c14b..a92714c14b 100644 --- a/Documentation/RelNotes/1.7.8.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.3.txt diff --git a/Documentation/RelNotes/1.7.8.4.txt b/third_party/git/Documentation/RelNotes/1.7.8.4.txt index 9bebdbf13d..9bebdbf13d 100644 --- a/Documentation/RelNotes/1.7.8.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.4.txt diff --git a/Documentation/RelNotes/1.7.8.5.txt b/third_party/git/Documentation/RelNotes/1.7.8.5.txt index 011fd2a428..011fd2a428 100644 --- a/Documentation/RelNotes/1.7.8.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.5.txt diff --git a/Documentation/RelNotes/1.7.8.6.txt b/third_party/git/Documentation/RelNotes/1.7.8.6.txt index d9bf2b741a..d9bf2b741a 100644 --- a/Documentation/RelNotes/1.7.8.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.6.txt diff --git a/Documentation/RelNotes/1.7.8.txt b/third_party/git/Documentation/RelNotes/1.7.8.txt index 249311361e..249311361e 100644 --- a/Documentation/RelNotes/1.7.8.txt +++ b/third_party/git/Documentation/RelNotes/1.7.8.txt diff --git a/Documentation/RelNotes/1.7.9.1.txt b/third_party/git/Documentation/RelNotes/1.7.9.1.txt index 6957183dbb..6957183dbb 100644 --- a/Documentation/RelNotes/1.7.9.1.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.1.txt diff --git a/Documentation/RelNotes/1.7.9.2.txt b/third_party/git/Documentation/RelNotes/1.7.9.2.txt index e500da75dd..e500da75dd 100644 --- a/Documentation/RelNotes/1.7.9.2.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.2.txt diff --git a/Documentation/RelNotes/1.7.9.3.txt b/third_party/git/Documentation/RelNotes/1.7.9.3.txt index 91c65012f9..91c65012f9 100644 --- a/Documentation/RelNotes/1.7.9.3.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.3.txt diff --git a/Documentation/RelNotes/1.7.9.4.txt b/third_party/git/Documentation/RelNotes/1.7.9.4.txt index e5217a1889..e5217a1889 100644 --- a/Documentation/RelNotes/1.7.9.4.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.4.txt diff --git a/Documentation/RelNotes/1.7.9.5.txt b/third_party/git/Documentation/RelNotes/1.7.9.5.txt index 95cc2bbf2c..95cc2bbf2c 100644 --- a/Documentation/RelNotes/1.7.9.5.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.5.txt diff --git a/Documentation/RelNotes/1.7.9.6.txt b/third_party/git/Documentation/RelNotes/1.7.9.6.txt index 74bf8825e2..74bf8825e2 100644 --- a/Documentation/RelNotes/1.7.9.6.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.6.txt diff --git a/Documentation/RelNotes/1.7.9.7.txt b/third_party/git/Documentation/RelNotes/1.7.9.7.txt index 59667d0f2a..59667d0f2a 100644 --- a/Documentation/RelNotes/1.7.9.7.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.7.txt diff --git a/Documentation/RelNotes/1.7.9.txt b/third_party/git/Documentation/RelNotes/1.7.9.txt index 95320aad5d..95320aad5d 100644 --- a/Documentation/RelNotes/1.7.9.txt +++ b/third_party/git/Documentation/RelNotes/1.7.9.txt diff --git a/Documentation/RelNotes/1.8.0.1.txt b/third_party/git/Documentation/RelNotes/1.8.0.1.txt index 1f372fa0b5..1f372fa0b5 100644 --- a/Documentation/RelNotes/1.8.0.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.0.1.txt diff --git a/Documentation/RelNotes/1.8.0.2.txt b/third_party/git/Documentation/RelNotes/1.8.0.2.txt index 8497e051de..8497e051de 100644 --- a/Documentation/RelNotes/1.8.0.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.0.2.txt diff --git a/Documentation/RelNotes/1.8.0.3.txt b/third_party/git/Documentation/RelNotes/1.8.0.3.txt index 92b1e4b363..92b1e4b363 100644 --- a/Documentation/RelNotes/1.8.0.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.0.3.txt diff --git a/Documentation/RelNotes/1.8.0.txt b/third_party/git/Documentation/RelNotes/1.8.0.txt index 63d6e4afa4..63d6e4afa4 100644 --- a/Documentation/RelNotes/1.8.0.txt +++ b/third_party/git/Documentation/RelNotes/1.8.0.txt diff --git a/Documentation/RelNotes/1.8.1.1.txt b/third_party/git/Documentation/RelNotes/1.8.1.1.txt index 6cde07ba29..6cde07ba29 100644 --- a/Documentation/RelNotes/1.8.1.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.1.txt diff --git a/Documentation/RelNotes/1.8.1.2.txt b/third_party/git/Documentation/RelNotes/1.8.1.2.txt index 5ab7b18906..5ab7b18906 100644 --- a/Documentation/RelNotes/1.8.1.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.2.txt diff --git a/Documentation/RelNotes/1.8.1.3.txt b/third_party/git/Documentation/RelNotes/1.8.1.3.txt index 681cb35c0a..681cb35c0a 100644 --- a/Documentation/RelNotes/1.8.1.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.3.txt diff --git a/Documentation/RelNotes/1.8.1.4.txt b/third_party/git/Documentation/RelNotes/1.8.1.4.txt index 22af1d1643..22af1d1643 100644 --- a/Documentation/RelNotes/1.8.1.4.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.4.txt diff --git a/Documentation/RelNotes/1.8.1.5.txt b/third_party/git/Documentation/RelNotes/1.8.1.5.txt index efa68aef22..efa68aef22 100644 --- a/Documentation/RelNotes/1.8.1.5.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.5.txt diff --git a/Documentation/RelNotes/1.8.1.6.txt b/third_party/git/Documentation/RelNotes/1.8.1.6.txt index c15cf2e805..c15cf2e805 100644 --- a/Documentation/RelNotes/1.8.1.6.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.6.txt diff --git a/Documentation/RelNotes/1.8.1.txt b/third_party/git/Documentation/RelNotes/1.8.1.txt index d6f9555923..d6f9555923 100644 --- a/Documentation/RelNotes/1.8.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.1.txt diff --git a/Documentation/RelNotes/1.8.2.1.txt b/third_party/git/Documentation/RelNotes/1.8.2.1.txt index 769a6fc06c..769a6fc06c 100644 --- a/Documentation/RelNotes/1.8.2.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.2.1.txt diff --git a/Documentation/RelNotes/1.8.2.2.txt b/third_party/git/Documentation/RelNotes/1.8.2.2.txt index 708df1ae19..708df1ae19 100644 --- a/Documentation/RelNotes/1.8.2.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.2.2.txt diff --git a/Documentation/RelNotes/1.8.2.3.txt b/third_party/git/Documentation/RelNotes/1.8.2.3.txt index 613948251a..613948251a 100644 --- a/Documentation/RelNotes/1.8.2.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.2.3.txt diff --git a/Documentation/RelNotes/1.8.2.txt b/third_party/git/Documentation/RelNotes/1.8.2.txt index fc606ae116..fc606ae116 100644 --- a/Documentation/RelNotes/1.8.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.2.txt diff --git a/Documentation/RelNotes/1.8.3.1.txt b/third_party/git/Documentation/RelNotes/1.8.3.1.txt index 986637b755..986637b755 100644 --- a/Documentation/RelNotes/1.8.3.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.3.1.txt diff --git a/Documentation/RelNotes/1.8.3.2.txt b/third_party/git/Documentation/RelNotes/1.8.3.2.txt index 26ae142c3d..26ae142c3d 100644 --- a/Documentation/RelNotes/1.8.3.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.3.2.txt diff --git a/Documentation/RelNotes/1.8.3.3.txt b/third_party/git/Documentation/RelNotes/1.8.3.3.txt index 9ba4f4da0f..9ba4f4da0f 100644 --- a/Documentation/RelNotes/1.8.3.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.3.3.txt diff --git a/Documentation/RelNotes/1.8.3.4.txt b/third_party/git/Documentation/RelNotes/1.8.3.4.txt index 56f106e262..56f106e262 100644 --- a/Documentation/RelNotes/1.8.3.4.txt +++ b/third_party/git/Documentation/RelNotes/1.8.3.4.txt diff --git a/Documentation/RelNotes/1.8.3.txt b/third_party/git/Documentation/RelNotes/1.8.3.txt index ead568e7f1..ead568e7f1 100644 --- a/Documentation/RelNotes/1.8.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.3.txt diff --git a/Documentation/RelNotes/1.8.4.1.txt b/third_party/git/Documentation/RelNotes/1.8.4.1.txt index c257beb114..c257beb114 100644 --- a/Documentation/RelNotes/1.8.4.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.4.1.txt diff --git a/Documentation/RelNotes/1.8.4.2.txt b/third_party/git/Documentation/RelNotes/1.8.4.2.txt index bf6fb1a023..bf6fb1a023 100644 --- a/Documentation/RelNotes/1.8.4.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.4.2.txt diff --git a/Documentation/RelNotes/1.8.4.3.txt b/third_party/git/Documentation/RelNotes/1.8.4.3.txt index 267a1b34b4..267a1b34b4 100644 --- a/Documentation/RelNotes/1.8.4.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.4.3.txt diff --git a/Documentation/RelNotes/1.8.4.4.txt b/third_party/git/Documentation/RelNotes/1.8.4.4.txt index a7c1ce15c0..a7c1ce15c0 100644 --- a/Documentation/RelNotes/1.8.4.4.txt +++ b/third_party/git/Documentation/RelNotes/1.8.4.4.txt diff --git a/Documentation/RelNotes/1.8.4.5.txt b/third_party/git/Documentation/RelNotes/1.8.4.5.txt index 215bd1a7a2..215bd1a7a2 100644 --- a/Documentation/RelNotes/1.8.4.5.txt +++ b/third_party/git/Documentation/RelNotes/1.8.4.5.txt diff --git a/Documentation/RelNotes/1.8.4.txt b/third_party/git/Documentation/RelNotes/1.8.4.txt index 255e185af6..255e185af6 100644 --- a/Documentation/RelNotes/1.8.4.txt +++ b/third_party/git/Documentation/RelNotes/1.8.4.txt diff --git a/Documentation/RelNotes/1.8.5.1.txt b/third_party/git/Documentation/RelNotes/1.8.5.1.txt index 7236aaf232..7236aaf232 100644 --- a/Documentation/RelNotes/1.8.5.1.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.1.txt diff --git a/Documentation/RelNotes/1.8.5.2.txt b/third_party/git/Documentation/RelNotes/1.8.5.2.txt index 3ac4984f10..3ac4984f10 100644 --- a/Documentation/RelNotes/1.8.5.2.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.2.txt diff --git a/Documentation/RelNotes/1.8.5.3.txt b/third_party/git/Documentation/RelNotes/1.8.5.3.txt index 3de2dd0f19..3de2dd0f19 100644 --- a/Documentation/RelNotes/1.8.5.3.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.3.txt diff --git a/Documentation/RelNotes/1.8.5.4.txt b/third_party/git/Documentation/RelNotes/1.8.5.4.txt index d18c40389e..d18c40389e 100644 --- a/Documentation/RelNotes/1.8.5.4.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.4.txt diff --git a/Documentation/RelNotes/1.8.5.5.txt b/third_party/git/Documentation/RelNotes/1.8.5.5.txt index 9191ce948f..9191ce948f 100644 --- a/Documentation/RelNotes/1.8.5.5.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.5.txt diff --git a/Documentation/RelNotes/1.8.5.6.txt b/third_party/git/Documentation/RelNotes/1.8.5.6.txt index 92ff92b1e6..92ff92b1e6 100644 --- a/Documentation/RelNotes/1.8.5.6.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.6.txt diff --git a/Documentation/RelNotes/1.8.5.txt b/third_party/git/Documentation/RelNotes/1.8.5.txt index 602df0cac2..602df0cac2 100644 --- a/Documentation/RelNotes/1.8.5.txt +++ b/third_party/git/Documentation/RelNotes/1.8.5.txt diff --git a/Documentation/RelNotes/1.9.0.txt b/third_party/git/Documentation/RelNotes/1.9.0.txt index 4e4b88aa5c..4e4b88aa5c 100644 --- a/Documentation/RelNotes/1.9.0.txt +++ b/third_party/git/Documentation/RelNotes/1.9.0.txt diff --git a/Documentation/RelNotes/1.9.1.txt b/third_party/git/Documentation/RelNotes/1.9.1.txt index 5b0602053c..5b0602053c 100644 --- a/Documentation/RelNotes/1.9.1.txt +++ b/third_party/git/Documentation/RelNotes/1.9.1.txt diff --git a/Documentation/RelNotes/1.9.2.txt b/third_party/git/Documentation/RelNotes/1.9.2.txt index 47a34ca964..47a34ca964 100644 --- a/Documentation/RelNotes/1.9.2.txt +++ b/third_party/git/Documentation/RelNotes/1.9.2.txt diff --git a/Documentation/RelNotes/1.9.3.txt b/third_party/git/Documentation/RelNotes/1.9.3.txt index 17b05ca7b5..17b05ca7b5 100644 --- a/Documentation/RelNotes/1.9.3.txt +++ b/third_party/git/Documentation/RelNotes/1.9.3.txt diff --git a/Documentation/RelNotes/1.9.4.txt b/third_party/git/Documentation/RelNotes/1.9.4.txt index e1d1835436..e1d1835436 100644 --- a/Documentation/RelNotes/1.9.4.txt +++ b/third_party/git/Documentation/RelNotes/1.9.4.txt diff --git a/Documentation/RelNotes/1.9.5.txt b/third_party/git/Documentation/RelNotes/1.9.5.txt index 8d6ac0cf53..8d6ac0cf53 100644 --- a/Documentation/RelNotes/1.9.5.txt +++ b/third_party/git/Documentation/RelNotes/1.9.5.txt diff --git a/Documentation/RelNotes/2.0.0.txt b/third_party/git/Documentation/RelNotes/2.0.0.txt index 2617372a0c..2617372a0c 100644 --- a/Documentation/RelNotes/2.0.0.txt +++ b/third_party/git/Documentation/RelNotes/2.0.0.txt diff --git a/Documentation/RelNotes/2.0.1.txt b/third_party/git/Documentation/RelNotes/2.0.1.txt index ce5579db3e..ce5579db3e 100644 --- a/Documentation/RelNotes/2.0.1.txt +++ b/third_party/git/Documentation/RelNotes/2.0.1.txt diff --git a/Documentation/RelNotes/2.0.2.txt b/third_party/git/Documentation/RelNotes/2.0.2.txt index 8e8321b2ef..8e8321b2ef 100644 --- a/Documentation/RelNotes/2.0.2.txt +++ b/third_party/git/Documentation/RelNotes/2.0.2.txt diff --git a/Documentation/RelNotes/2.0.3.txt b/third_party/git/Documentation/RelNotes/2.0.3.txt index 4047b46bbe..4047b46bbe 100644 --- a/Documentation/RelNotes/2.0.3.txt +++ b/third_party/git/Documentation/RelNotes/2.0.3.txt diff --git a/Documentation/RelNotes/2.0.4.txt b/third_party/git/Documentation/RelNotes/2.0.4.txt index 7e340921a2..7e340921a2 100644 --- a/Documentation/RelNotes/2.0.4.txt +++ b/third_party/git/Documentation/RelNotes/2.0.4.txt diff --git a/Documentation/RelNotes/2.0.5.txt b/third_party/git/Documentation/RelNotes/2.0.5.txt index 3a16f697e8..3a16f697e8 100644 --- a/Documentation/RelNotes/2.0.5.txt +++ b/third_party/git/Documentation/RelNotes/2.0.5.txt diff --git a/Documentation/RelNotes/2.1.0.txt b/third_party/git/Documentation/RelNotes/2.1.0.txt index ae4753728e..ae4753728e 100644 --- a/Documentation/RelNotes/2.1.0.txt +++ b/third_party/git/Documentation/RelNotes/2.1.0.txt diff --git a/Documentation/RelNotes/2.1.1.txt b/third_party/git/Documentation/RelNotes/2.1.1.txt index 830fc3cc6d..830fc3cc6d 100644 --- a/Documentation/RelNotes/2.1.1.txt +++ b/third_party/git/Documentation/RelNotes/2.1.1.txt diff --git a/Documentation/RelNotes/2.1.2.txt b/third_party/git/Documentation/RelNotes/2.1.2.txt index abc3b8928a..abc3b8928a 100644 --- a/Documentation/RelNotes/2.1.2.txt +++ b/third_party/git/Documentation/RelNotes/2.1.2.txt diff --git a/Documentation/RelNotes/2.1.3.txt b/third_party/git/Documentation/RelNotes/2.1.3.txt index 0dfb17c4fc..0dfb17c4fc 100644 --- a/Documentation/RelNotes/2.1.3.txt +++ b/third_party/git/Documentation/RelNotes/2.1.3.txt diff --git a/Documentation/RelNotes/2.1.4.txt b/third_party/git/Documentation/RelNotes/2.1.4.txt index d16e5f041f..d16e5f041f 100644 --- a/Documentation/RelNotes/2.1.4.txt +++ b/third_party/git/Documentation/RelNotes/2.1.4.txt diff --git a/Documentation/RelNotes/2.10.0.txt b/third_party/git/Documentation/RelNotes/2.10.0.txt index 3792b7d03d..3792b7d03d 100644 --- a/Documentation/RelNotes/2.10.0.txt +++ b/third_party/git/Documentation/RelNotes/2.10.0.txt diff --git a/Documentation/RelNotes/2.10.1.txt b/third_party/git/Documentation/RelNotes/2.10.1.txt index 70462f7f7e..70462f7f7e 100644 --- a/Documentation/RelNotes/2.10.1.txt +++ b/third_party/git/Documentation/RelNotes/2.10.1.txt diff --git a/Documentation/RelNotes/2.10.2.txt b/third_party/git/Documentation/RelNotes/2.10.2.txt index abbd331508..abbd331508 100644 --- a/Documentation/RelNotes/2.10.2.txt +++ b/third_party/git/Documentation/RelNotes/2.10.2.txt diff --git a/Documentation/RelNotes/2.10.3.txt b/third_party/git/Documentation/RelNotes/2.10.3.txt index ad6a01bf83..ad6a01bf83 100644 --- a/Documentation/RelNotes/2.10.3.txt +++ b/third_party/git/Documentation/RelNotes/2.10.3.txt diff --git a/Documentation/RelNotes/2.10.4.txt b/third_party/git/Documentation/RelNotes/2.10.4.txt index ee8142ad24..ee8142ad24 100644 --- a/Documentation/RelNotes/2.10.4.txt +++ b/third_party/git/Documentation/RelNotes/2.10.4.txt diff --git a/Documentation/RelNotes/2.10.5.txt b/third_party/git/Documentation/RelNotes/2.10.5.txt index a498fd6fdc..a498fd6fdc 100644 --- a/Documentation/RelNotes/2.10.5.txt +++ b/third_party/git/Documentation/RelNotes/2.10.5.txt diff --git a/Documentation/RelNotes/2.11.0.txt b/third_party/git/Documentation/RelNotes/2.11.0.txt index b7b7dd361e..b7b7dd361e 100644 --- a/Documentation/RelNotes/2.11.0.txt +++ b/third_party/git/Documentation/RelNotes/2.11.0.txt diff --git a/Documentation/RelNotes/2.11.1.txt b/third_party/git/Documentation/RelNotes/2.11.1.txt index 7d35cf186d..7d35cf186d 100644 --- a/Documentation/RelNotes/2.11.1.txt +++ b/third_party/git/Documentation/RelNotes/2.11.1.txt diff --git a/Documentation/RelNotes/2.11.2.txt b/third_party/git/Documentation/RelNotes/2.11.2.txt index 7428851168..7428851168 100644 --- a/Documentation/RelNotes/2.11.2.txt +++ b/third_party/git/Documentation/RelNotes/2.11.2.txt diff --git a/Documentation/RelNotes/2.11.3.txt b/third_party/git/Documentation/RelNotes/2.11.3.txt index 4e3b78d0e8..4e3b78d0e8 100644 --- a/Documentation/RelNotes/2.11.3.txt +++ b/third_party/git/Documentation/RelNotes/2.11.3.txt diff --git a/Documentation/RelNotes/2.11.4.txt b/third_party/git/Documentation/RelNotes/2.11.4.txt index ad4da8eb09..ad4da8eb09 100644 --- a/Documentation/RelNotes/2.11.4.txt +++ b/third_party/git/Documentation/RelNotes/2.11.4.txt diff --git a/Documentation/RelNotes/2.12.0.txt b/third_party/git/Documentation/RelNotes/2.12.0.txt index d2f6a83614..d2f6a83614 100644 --- a/Documentation/RelNotes/2.12.0.txt +++ b/third_party/git/Documentation/RelNotes/2.12.0.txt diff --git a/Documentation/RelNotes/2.12.1.txt b/third_party/git/Documentation/RelNotes/2.12.1.txt index a74f7db747..a74f7db747 100644 --- a/Documentation/RelNotes/2.12.1.txt +++ b/third_party/git/Documentation/RelNotes/2.12.1.txt diff --git a/Documentation/RelNotes/2.12.2.txt b/third_party/git/Documentation/RelNotes/2.12.2.txt index 441939709c..441939709c 100644 --- a/Documentation/RelNotes/2.12.2.txt +++ b/third_party/git/Documentation/RelNotes/2.12.2.txt diff --git a/Documentation/RelNotes/2.12.3.txt b/third_party/git/Documentation/RelNotes/2.12.3.txt index ebca846d5d..ebca846d5d 100644 --- a/Documentation/RelNotes/2.12.3.txt +++ b/third_party/git/Documentation/RelNotes/2.12.3.txt diff --git a/Documentation/RelNotes/2.12.4.txt b/third_party/git/Documentation/RelNotes/2.12.4.txt index 3f56938221..3f56938221 100644 --- a/Documentation/RelNotes/2.12.4.txt +++ b/third_party/git/Documentation/RelNotes/2.12.4.txt diff --git a/Documentation/RelNotes/2.12.5.txt b/third_party/git/Documentation/RelNotes/2.12.5.txt index 8fa73cfce7..8fa73cfce7 100644 --- a/Documentation/RelNotes/2.12.5.txt +++ b/third_party/git/Documentation/RelNotes/2.12.5.txt diff --git a/Documentation/RelNotes/2.13.0.txt b/third_party/git/Documentation/RelNotes/2.13.0.txt index 2a47b4cb0c..2a47b4cb0c 100644 --- a/Documentation/RelNotes/2.13.0.txt +++ b/third_party/git/Documentation/RelNotes/2.13.0.txt diff --git a/Documentation/RelNotes/2.13.1.txt b/third_party/git/Documentation/RelNotes/2.13.1.txt index ed7cd976d9..ed7cd976d9 100644 --- a/Documentation/RelNotes/2.13.1.txt +++ b/third_party/git/Documentation/RelNotes/2.13.1.txt diff --git a/Documentation/RelNotes/2.13.2.txt b/third_party/git/Documentation/RelNotes/2.13.2.txt index 8c2b20071e..8c2b20071e 100644 --- a/Documentation/RelNotes/2.13.2.txt +++ b/third_party/git/Documentation/RelNotes/2.13.2.txt diff --git a/Documentation/RelNotes/2.13.3.txt b/third_party/git/Documentation/RelNotes/2.13.3.txt index 384e4de265..384e4de265 100644 --- a/Documentation/RelNotes/2.13.3.txt +++ b/third_party/git/Documentation/RelNotes/2.13.3.txt diff --git a/Documentation/RelNotes/2.13.4.txt b/third_party/git/Documentation/RelNotes/2.13.4.txt index 9a9f8f9599..9a9f8f9599 100644 --- a/Documentation/RelNotes/2.13.4.txt +++ b/third_party/git/Documentation/RelNotes/2.13.4.txt diff --git a/Documentation/RelNotes/2.13.5.txt b/third_party/git/Documentation/RelNotes/2.13.5.txt index 6949fcda78..6949fcda78 100644 --- a/Documentation/RelNotes/2.13.5.txt +++ b/third_party/git/Documentation/RelNotes/2.13.5.txt diff --git a/Documentation/RelNotes/2.13.6.txt b/third_party/git/Documentation/RelNotes/2.13.6.txt index afcae9c808..afcae9c808 100644 --- a/Documentation/RelNotes/2.13.6.txt +++ b/third_party/git/Documentation/RelNotes/2.13.6.txt diff --git a/Documentation/RelNotes/2.13.7.txt b/third_party/git/Documentation/RelNotes/2.13.7.txt index 09fc01406c..09fc01406c 100644 --- a/Documentation/RelNotes/2.13.7.txt +++ b/third_party/git/Documentation/RelNotes/2.13.7.txt diff --git a/Documentation/RelNotes/2.14.0.txt b/third_party/git/Documentation/RelNotes/2.14.0.txt index 2711a2529d..2711a2529d 100644 --- a/Documentation/RelNotes/2.14.0.txt +++ b/third_party/git/Documentation/RelNotes/2.14.0.txt diff --git a/Documentation/RelNotes/2.14.1.txt b/third_party/git/Documentation/RelNotes/2.14.1.txt index 9403340f7f..9403340f7f 100644 --- a/Documentation/RelNotes/2.14.1.txt +++ b/third_party/git/Documentation/RelNotes/2.14.1.txt diff --git a/Documentation/RelNotes/2.14.2.txt b/third_party/git/Documentation/RelNotes/2.14.2.txt index bec9186ade..bec9186ade 100644 --- a/Documentation/RelNotes/2.14.2.txt +++ b/third_party/git/Documentation/RelNotes/2.14.2.txt diff --git a/Documentation/RelNotes/2.14.3.txt b/third_party/git/Documentation/RelNotes/2.14.3.txt index 977c9e857c..977c9e857c 100644 --- a/Documentation/RelNotes/2.14.3.txt +++ b/third_party/git/Documentation/RelNotes/2.14.3.txt diff --git a/Documentation/RelNotes/2.14.4.txt b/third_party/git/Documentation/RelNotes/2.14.4.txt index 97755a89d9..97755a89d9 100644 --- a/Documentation/RelNotes/2.14.4.txt +++ b/third_party/git/Documentation/RelNotes/2.14.4.txt diff --git a/Documentation/RelNotes/2.14.5.txt b/third_party/git/Documentation/RelNotes/2.14.5.txt index 130645fb29..130645fb29 100644 --- a/Documentation/RelNotes/2.14.5.txt +++ b/third_party/git/Documentation/RelNotes/2.14.5.txt diff --git a/Documentation/RelNotes/2.14.6.txt b/third_party/git/Documentation/RelNotes/2.14.6.txt index 72b7af6799..72b7af6799 100644 --- a/Documentation/RelNotes/2.14.6.txt +++ b/third_party/git/Documentation/RelNotes/2.14.6.txt diff --git a/Documentation/RelNotes/2.15.0.txt b/third_party/git/Documentation/RelNotes/2.15.0.txt index cdd761bcc2..cdd761bcc2 100644 --- a/Documentation/RelNotes/2.15.0.txt +++ b/third_party/git/Documentation/RelNotes/2.15.0.txt diff --git a/Documentation/RelNotes/2.15.1.txt b/third_party/git/Documentation/RelNotes/2.15.1.txt index ec06704e63..ec06704e63 100644 --- a/Documentation/RelNotes/2.15.1.txt +++ b/third_party/git/Documentation/RelNotes/2.15.1.txt diff --git a/Documentation/RelNotes/2.15.2.txt b/third_party/git/Documentation/RelNotes/2.15.2.txt index b480e56b68..b480e56b68 100644 --- a/Documentation/RelNotes/2.15.2.txt +++ b/third_party/git/Documentation/RelNotes/2.15.2.txt diff --git a/Documentation/RelNotes/2.15.3.txt b/third_party/git/Documentation/RelNotes/2.15.3.txt index fd2e6f8df7..fd2e6f8df7 100644 --- a/Documentation/RelNotes/2.15.3.txt +++ b/third_party/git/Documentation/RelNotes/2.15.3.txt diff --git a/Documentation/RelNotes/2.15.4.txt b/third_party/git/Documentation/RelNotes/2.15.4.txt index dc241cba34..dc241cba34 100644 --- a/Documentation/RelNotes/2.15.4.txt +++ b/third_party/git/Documentation/RelNotes/2.15.4.txt diff --git a/Documentation/RelNotes/2.16.0.txt b/third_party/git/Documentation/RelNotes/2.16.0.txt index b474781ed8..b474781ed8 100644 --- a/Documentation/RelNotes/2.16.0.txt +++ b/third_party/git/Documentation/RelNotes/2.16.0.txt diff --git a/Documentation/RelNotes/2.16.1.txt b/third_party/git/Documentation/RelNotes/2.16.1.txt index 66e64361fd..66e64361fd 100644 --- a/Documentation/RelNotes/2.16.1.txt +++ b/third_party/git/Documentation/RelNotes/2.16.1.txt diff --git a/Documentation/RelNotes/2.16.2.txt b/third_party/git/Documentation/RelNotes/2.16.2.txt index a216466d3d..a216466d3d 100644 --- a/Documentation/RelNotes/2.16.2.txt +++ b/third_party/git/Documentation/RelNotes/2.16.2.txt diff --git a/Documentation/RelNotes/2.16.3.txt b/third_party/git/Documentation/RelNotes/2.16.3.txt index f0121a8f2d..f0121a8f2d 100644 --- a/Documentation/RelNotes/2.16.3.txt +++ b/third_party/git/Documentation/RelNotes/2.16.3.txt diff --git a/Documentation/RelNotes/2.16.4.txt b/third_party/git/Documentation/RelNotes/2.16.4.txt index 6be538ba30..6be538ba30 100644 --- a/Documentation/RelNotes/2.16.4.txt +++ b/third_party/git/Documentation/RelNotes/2.16.4.txt diff --git a/Documentation/RelNotes/2.16.5.txt b/third_party/git/Documentation/RelNotes/2.16.5.txt index cb8ee02a9a..cb8ee02a9a 100644 --- a/Documentation/RelNotes/2.16.5.txt +++ b/third_party/git/Documentation/RelNotes/2.16.5.txt diff --git a/Documentation/RelNotes/2.16.6.txt b/third_party/git/Documentation/RelNotes/2.16.6.txt index 438306e60b..438306e60b 100644 --- a/Documentation/RelNotes/2.16.6.txt +++ b/third_party/git/Documentation/RelNotes/2.16.6.txt diff --git a/Documentation/RelNotes/2.17.0.txt b/third_party/git/Documentation/RelNotes/2.17.0.txt index 8b17c26033..8b17c26033 100644 --- a/Documentation/RelNotes/2.17.0.txt +++ b/third_party/git/Documentation/RelNotes/2.17.0.txt diff --git a/Documentation/RelNotes/2.17.1.txt b/third_party/git/Documentation/RelNotes/2.17.1.txt index e01384fe8e..e01384fe8e 100644 --- a/Documentation/RelNotes/2.17.1.txt +++ b/third_party/git/Documentation/RelNotes/2.17.1.txt diff --git a/Documentation/RelNotes/2.17.2.txt b/third_party/git/Documentation/RelNotes/2.17.2.txt index ef021be870..ef021be870 100644 --- a/Documentation/RelNotes/2.17.2.txt +++ b/third_party/git/Documentation/RelNotes/2.17.2.txt diff --git a/Documentation/RelNotes/2.17.3.txt b/third_party/git/Documentation/RelNotes/2.17.3.txt index 5a46c94271..5a46c94271 100644 --- a/Documentation/RelNotes/2.17.3.txt +++ b/third_party/git/Documentation/RelNotes/2.17.3.txt diff --git a/Documentation/RelNotes/2.17.4.txt b/third_party/git/Documentation/RelNotes/2.17.4.txt index 7d794ca01a..7d794ca01a 100644 --- a/Documentation/RelNotes/2.17.4.txt +++ b/third_party/git/Documentation/RelNotes/2.17.4.txt diff --git a/Documentation/RelNotes/2.17.5.txt b/third_party/git/Documentation/RelNotes/2.17.5.txt index 2abb821a73..2abb821a73 100644 --- a/Documentation/RelNotes/2.17.5.txt +++ b/third_party/git/Documentation/RelNotes/2.17.5.txt diff --git a/Documentation/RelNotes/2.18.0.txt b/third_party/git/Documentation/RelNotes/2.18.0.txt index 6c8a0e97c1..6c8a0e97c1 100644 --- a/Documentation/RelNotes/2.18.0.txt +++ b/third_party/git/Documentation/RelNotes/2.18.0.txt diff --git a/Documentation/RelNotes/2.18.1.txt b/third_party/git/Documentation/RelNotes/2.18.1.txt index 2098cdd776..2098cdd776 100644 --- a/Documentation/RelNotes/2.18.1.txt +++ b/third_party/git/Documentation/RelNotes/2.18.1.txt diff --git a/Documentation/RelNotes/2.18.2.txt b/third_party/git/Documentation/RelNotes/2.18.2.txt index 98b168aade..98b168aade 100644 --- a/Documentation/RelNotes/2.18.2.txt +++ b/third_party/git/Documentation/RelNotes/2.18.2.txt diff --git a/Documentation/RelNotes/2.18.3.txt b/third_party/git/Documentation/RelNotes/2.18.3.txt index 25143f0cec..25143f0cec 100644 --- a/Documentation/RelNotes/2.18.3.txt +++ b/third_party/git/Documentation/RelNotes/2.18.3.txt diff --git a/Documentation/RelNotes/2.18.4.txt b/third_party/git/Documentation/RelNotes/2.18.4.txt index e8ef858a00..e8ef858a00 100644 --- a/Documentation/RelNotes/2.18.4.txt +++ b/third_party/git/Documentation/RelNotes/2.18.4.txt diff --git a/Documentation/RelNotes/2.19.0.txt b/third_party/git/Documentation/RelNotes/2.19.0.txt index 891c79b9cb..891c79b9cb 100644 --- a/Documentation/RelNotes/2.19.0.txt +++ b/third_party/git/Documentation/RelNotes/2.19.0.txt diff --git a/Documentation/RelNotes/2.19.1.txt b/third_party/git/Documentation/RelNotes/2.19.1.txt index da7672674e..da7672674e 100644 --- a/Documentation/RelNotes/2.19.1.txt +++ b/third_party/git/Documentation/RelNotes/2.19.1.txt diff --git a/Documentation/RelNotes/2.19.2.txt b/third_party/git/Documentation/RelNotes/2.19.2.txt index 759e6ca957..759e6ca957 100644 --- a/Documentation/RelNotes/2.19.2.txt +++ b/third_party/git/Documentation/RelNotes/2.19.2.txt diff --git a/Documentation/RelNotes/2.19.3.txt b/third_party/git/Documentation/RelNotes/2.19.3.txt index 92d7f89de6..92d7f89de6 100644 --- a/Documentation/RelNotes/2.19.3.txt +++ b/third_party/git/Documentation/RelNotes/2.19.3.txt diff --git a/Documentation/RelNotes/2.19.4.txt b/third_party/git/Documentation/RelNotes/2.19.4.txt index 35d0ae561b..35d0ae561b 100644 --- a/Documentation/RelNotes/2.19.4.txt +++ b/third_party/git/Documentation/RelNotes/2.19.4.txt diff --git a/Documentation/RelNotes/2.19.5.txt b/third_party/git/Documentation/RelNotes/2.19.5.txt index 18a4dcbfd6..18a4dcbfd6 100644 --- a/Documentation/RelNotes/2.19.5.txt +++ b/third_party/git/Documentation/RelNotes/2.19.5.txt diff --git a/Documentation/RelNotes/2.2.0.txt b/third_party/git/Documentation/RelNotes/2.2.0.txt index e98ecbcff6..e98ecbcff6 100644 --- a/Documentation/RelNotes/2.2.0.txt +++ b/third_party/git/Documentation/RelNotes/2.2.0.txt diff --git a/Documentation/RelNotes/2.2.1.txt b/third_party/git/Documentation/RelNotes/2.2.1.txt index d5a3cd9e73..d5a3cd9e73 100644 --- a/Documentation/RelNotes/2.2.1.txt +++ b/third_party/git/Documentation/RelNotes/2.2.1.txt diff --git a/Documentation/RelNotes/2.2.2.txt b/third_party/git/Documentation/RelNotes/2.2.2.txt index b19a35d94f..b19a35d94f 100644 --- a/Documentation/RelNotes/2.2.2.txt +++ b/third_party/git/Documentation/RelNotes/2.2.2.txt diff --git a/Documentation/RelNotes/2.2.3.txt b/third_party/git/Documentation/RelNotes/2.2.3.txt index 5bfffa4106..5bfffa4106 100644 --- a/Documentation/RelNotes/2.2.3.txt +++ b/third_party/git/Documentation/RelNotes/2.2.3.txt diff --git a/Documentation/RelNotes/2.20.0.txt b/third_party/git/Documentation/RelNotes/2.20.0.txt index 3dd7e6e1fc..3dd7e6e1fc 100644 --- a/Documentation/RelNotes/2.20.0.txt +++ b/third_party/git/Documentation/RelNotes/2.20.0.txt diff --git a/Documentation/RelNotes/2.20.1.txt b/third_party/git/Documentation/RelNotes/2.20.1.txt index dcba888dba..dcba888dba 100644 --- a/Documentation/RelNotes/2.20.1.txt +++ b/third_party/git/Documentation/RelNotes/2.20.1.txt diff --git a/Documentation/RelNotes/2.20.2.txt b/third_party/git/Documentation/RelNotes/2.20.2.txt index 8e680cb9fb..8e680cb9fb 100644 --- a/Documentation/RelNotes/2.20.2.txt +++ b/third_party/git/Documentation/RelNotes/2.20.2.txt diff --git a/Documentation/RelNotes/2.20.3.txt b/third_party/git/Documentation/RelNotes/2.20.3.txt index f6eccd103b..f6eccd103b 100644 --- a/Documentation/RelNotes/2.20.3.txt +++ b/third_party/git/Documentation/RelNotes/2.20.3.txt diff --git a/Documentation/RelNotes/2.20.4.txt b/third_party/git/Documentation/RelNotes/2.20.4.txt index 5a9e24e470..5a9e24e470 100644 --- a/Documentation/RelNotes/2.20.4.txt +++ b/third_party/git/Documentation/RelNotes/2.20.4.txt diff --git a/Documentation/RelNotes/2.21.0.txt b/third_party/git/Documentation/RelNotes/2.21.0.txt index 7a49deddf3..7a49deddf3 100644 --- a/Documentation/RelNotes/2.21.0.txt +++ b/third_party/git/Documentation/RelNotes/2.21.0.txt diff --git a/Documentation/RelNotes/2.21.1.txt b/third_party/git/Documentation/RelNotes/2.21.1.txt index b7594151e4..b7594151e4 100644 --- a/Documentation/RelNotes/2.21.1.txt +++ b/third_party/git/Documentation/RelNotes/2.21.1.txt diff --git a/Documentation/RelNotes/2.21.2.txt b/third_party/git/Documentation/RelNotes/2.21.2.txt index a0fb83bb53..a0fb83bb53 100644 --- a/Documentation/RelNotes/2.21.2.txt +++ b/third_party/git/Documentation/RelNotes/2.21.2.txt diff --git a/Documentation/RelNotes/2.21.3.txt b/third_party/git/Documentation/RelNotes/2.21.3.txt index 2ca0aa5c62..2ca0aa5c62 100644 --- a/Documentation/RelNotes/2.21.3.txt +++ b/third_party/git/Documentation/RelNotes/2.21.3.txt diff --git a/Documentation/RelNotes/2.22.0.txt b/third_party/git/Documentation/RelNotes/2.22.0.txt index 91e6ae9887..91e6ae9887 100644 --- a/Documentation/RelNotes/2.22.0.txt +++ b/third_party/git/Documentation/RelNotes/2.22.0.txt diff --git a/Documentation/RelNotes/2.22.1.txt b/third_party/git/Documentation/RelNotes/2.22.1.txt index 432762f270..432762f270 100644 --- a/Documentation/RelNotes/2.22.1.txt +++ b/third_party/git/Documentation/RelNotes/2.22.1.txt diff --git a/Documentation/RelNotes/2.22.2.txt b/third_party/git/Documentation/RelNotes/2.22.2.txt index 940a23f0d9..940a23f0d9 100644 --- a/Documentation/RelNotes/2.22.2.txt +++ b/third_party/git/Documentation/RelNotes/2.22.2.txt diff --git a/Documentation/RelNotes/2.22.3.txt b/third_party/git/Documentation/RelNotes/2.22.3.txt index 57296f6d17..57296f6d17 100644 --- a/Documentation/RelNotes/2.22.3.txt +++ b/third_party/git/Documentation/RelNotes/2.22.3.txt diff --git a/Documentation/RelNotes/2.22.4.txt b/third_party/git/Documentation/RelNotes/2.22.4.txt index 8b5f3e3f37..8b5f3e3f37 100644 --- a/Documentation/RelNotes/2.22.4.txt +++ b/third_party/git/Documentation/RelNotes/2.22.4.txt diff --git a/Documentation/RelNotes/2.23.0.txt b/third_party/git/Documentation/RelNotes/2.23.0.txt index e3c4e78265..e3c4e78265 100644 --- a/Documentation/RelNotes/2.23.0.txt +++ b/third_party/git/Documentation/RelNotes/2.23.0.txt diff --git a/Documentation/RelNotes/2.23.1.txt b/third_party/git/Documentation/RelNotes/2.23.1.txt index 2083b492ce..2083b492ce 100644 --- a/Documentation/RelNotes/2.23.1.txt +++ b/third_party/git/Documentation/RelNotes/2.23.1.txt diff --git a/Documentation/RelNotes/2.23.2.txt b/third_party/git/Documentation/RelNotes/2.23.2.txt index b697cbe0e3..b697cbe0e3 100644 --- a/Documentation/RelNotes/2.23.2.txt +++ b/third_party/git/Documentation/RelNotes/2.23.2.txt diff --git a/Documentation/RelNotes/2.23.3.txt b/third_party/git/Documentation/RelNotes/2.23.3.txt index 2e35490137..2e35490137 100644 --- a/Documentation/RelNotes/2.23.3.txt +++ b/third_party/git/Documentation/RelNotes/2.23.3.txt diff --git a/Documentation/RelNotes/2.24.0.txt b/third_party/git/Documentation/RelNotes/2.24.0.txt index bde154124c..bde154124c 100644 --- a/Documentation/RelNotes/2.24.0.txt +++ b/third_party/git/Documentation/RelNotes/2.24.0.txt diff --git a/Documentation/RelNotes/2.24.1.txt b/third_party/git/Documentation/RelNotes/2.24.1.txt index 18104850fe..18104850fe 100644 --- a/Documentation/RelNotes/2.24.1.txt +++ b/third_party/git/Documentation/RelNotes/2.24.1.txt diff --git a/Documentation/RelNotes/2.24.2.txt b/third_party/git/Documentation/RelNotes/2.24.2.txt index 0049f65503..0049f65503 100644 --- a/Documentation/RelNotes/2.24.2.txt +++ b/third_party/git/Documentation/RelNotes/2.24.2.txt diff --git a/Documentation/RelNotes/2.24.3.txt b/third_party/git/Documentation/RelNotes/2.24.3.txt index 5302e0f73b..5302e0f73b 100644 --- a/Documentation/RelNotes/2.24.3.txt +++ b/third_party/git/Documentation/RelNotes/2.24.3.txt diff --git a/Documentation/RelNotes/2.25.0.txt b/third_party/git/Documentation/RelNotes/2.25.0.txt index 91ceb34927..91ceb34927 100644 --- a/Documentation/RelNotes/2.25.0.txt +++ b/third_party/git/Documentation/RelNotes/2.25.0.txt diff --git a/Documentation/RelNotes/2.25.1.txt b/third_party/git/Documentation/RelNotes/2.25.1.txt index cd869b02bb..cd869b02bb 100644 --- a/Documentation/RelNotes/2.25.1.txt +++ b/third_party/git/Documentation/RelNotes/2.25.1.txt diff --git a/Documentation/RelNotes/2.25.2.txt b/third_party/git/Documentation/RelNotes/2.25.2.txt index 303c53a17f..303c53a17f 100644 --- a/Documentation/RelNotes/2.25.2.txt +++ b/third_party/git/Documentation/RelNotes/2.25.2.txt diff --git a/Documentation/RelNotes/2.25.3.txt b/third_party/git/Documentation/RelNotes/2.25.3.txt index 15f7f21f10..15f7f21f10 100644 --- a/Documentation/RelNotes/2.25.3.txt +++ b/third_party/git/Documentation/RelNotes/2.25.3.txt diff --git a/Documentation/RelNotes/2.25.4.txt b/third_party/git/Documentation/RelNotes/2.25.4.txt index 0dbb5daeec..0dbb5daeec 100644 --- a/Documentation/RelNotes/2.25.4.txt +++ b/third_party/git/Documentation/RelNotes/2.25.4.txt diff --git a/Documentation/RelNotes/2.26.0.txt b/third_party/git/Documentation/RelNotes/2.26.0.txt index 3a7a734c26..3a7a734c26 100644 --- a/Documentation/RelNotes/2.26.0.txt +++ b/third_party/git/Documentation/RelNotes/2.26.0.txt diff --git a/Documentation/RelNotes/2.26.1.txt b/third_party/git/Documentation/RelNotes/2.26.1.txt index 1b4ecb3fdc..1b4ecb3fdc 100644 --- a/Documentation/RelNotes/2.26.1.txt +++ b/third_party/git/Documentation/RelNotes/2.26.1.txt diff --git a/Documentation/RelNotes/2.26.2.txt b/third_party/git/Documentation/RelNotes/2.26.2.txt index d434d0c695..d434d0c695 100644 --- a/Documentation/RelNotes/2.26.2.txt +++ b/third_party/git/Documentation/RelNotes/2.26.2.txt diff --git a/Documentation/RelNotes/2.3.0.txt b/third_party/git/Documentation/RelNotes/2.3.0.txt index e3c639c840..e3c639c840 100644 --- a/Documentation/RelNotes/2.3.0.txt +++ b/third_party/git/Documentation/RelNotes/2.3.0.txt diff --git a/Documentation/RelNotes/2.3.1.txt b/third_party/git/Documentation/RelNotes/2.3.1.txt index cf96186288..cf96186288 100644 --- a/Documentation/RelNotes/2.3.1.txt +++ b/third_party/git/Documentation/RelNotes/2.3.1.txt diff --git a/Documentation/RelNotes/2.3.10.txt b/third_party/git/Documentation/RelNotes/2.3.10.txt index 20c2d2cacc..20c2d2cacc 100644 --- a/Documentation/RelNotes/2.3.10.txt +++ b/third_party/git/Documentation/RelNotes/2.3.10.txt diff --git a/Documentation/RelNotes/2.3.2.txt b/third_party/git/Documentation/RelNotes/2.3.2.txt index 93462e45c2..93462e45c2 100644 --- a/Documentation/RelNotes/2.3.2.txt +++ b/third_party/git/Documentation/RelNotes/2.3.2.txt diff --git a/Documentation/RelNotes/2.3.3.txt b/third_party/git/Documentation/RelNotes/2.3.3.txt index 850dc68ede..850dc68ede 100644 --- a/Documentation/RelNotes/2.3.3.txt +++ b/third_party/git/Documentation/RelNotes/2.3.3.txt diff --git a/Documentation/RelNotes/2.3.4.txt b/third_party/git/Documentation/RelNotes/2.3.4.txt index 094c7b853b..094c7b853b 100644 --- a/Documentation/RelNotes/2.3.4.txt +++ b/third_party/git/Documentation/RelNotes/2.3.4.txt diff --git a/Documentation/RelNotes/2.3.5.txt b/third_party/git/Documentation/RelNotes/2.3.5.txt index 5b309db689..5b309db689 100644 --- a/Documentation/RelNotes/2.3.5.txt +++ b/third_party/git/Documentation/RelNotes/2.3.5.txt diff --git a/Documentation/RelNotes/2.3.6.txt b/third_party/git/Documentation/RelNotes/2.3.6.txt index 432f770ef3..432f770ef3 100644 --- a/Documentation/RelNotes/2.3.6.txt +++ b/third_party/git/Documentation/RelNotes/2.3.6.txt diff --git a/Documentation/RelNotes/2.3.7.txt b/third_party/git/Documentation/RelNotes/2.3.7.txt index 5769184081..5769184081 100644 --- a/Documentation/RelNotes/2.3.7.txt +++ b/third_party/git/Documentation/RelNotes/2.3.7.txt diff --git a/Documentation/RelNotes/2.3.8.txt b/third_party/git/Documentation/RelNotes/2.3.8.txt index 0b67268a96..0b67268a96 100644 --- a/Documentation/RelNotes/2.3.8.txt +++ b/third_party/git/Documentation/RelNotes/2.3.8.txt diff --git a/Documentation/RelNotes/2.3.9.txt b/third_party/git/Documentation/RelNotes/2.3.9.txt index 1a2ad3235a..1a2ad3235a 100644 --- a/Documentation/RelNotes/2.3.9.txt +++ b/third_party/git/Documentation/RelNotes/2.3.9.txt diff --git a/Documentation/RelNotes/2.4.0.txt b/third_party/git/Documentation/RelNotes/2.4.0.txt index cde64be535..cde64be535 100644 --- a/Documentation/RelNotes/2.4.0.txt +++ b/third_party/git/Documentation/RelNotes/2.4.0.txt diff --git a/Documentation/RelNotes/2.4.1.txt b/third_party/git/Documentation/RelNotes/2.4.1.txt index a65a6c5829..a65a6c5829 100644 --- a/Documentation/RelNotes/2.4.1.txt +++ b/third_party/git/Documentation/RelNotes/2.4.1.txt diff --git a/Documentation/RelNotes/2.4.10.txt b/third_party/git/Documentation/RelNotes/2.4.10.txt index 702d8d4e22..702d8d4e22 100644 --- a/Documentation/RelNotes/2.4.10.txt +++ b/third_party/git/Documentation/RelNotes/2.4.10.txt diff --git a/Documentation/RelNotes/2.4.11.txt b/third_party/git/Documentation/RelNotes/2.4.11.txt index 723360295c..723360295c 100644 --- a/Documentation/RelNotes/2.4.11.txt +++ b/third_party/git/Documentation/RelNotes/2.4.11.txt diff --git a/Documentation/RelNotes/2.4.12.txt b/third_party/git/Documentation/RelNotes/2.4.12.txt index 7d15f94725..7d15f94725 100644 --- a/Documentation/RelNotes/2.4.12.txt +++ b/third_party/git/Documentation/RelNotes/2.4.12.txt diff --git a/Documentation/RelNotes/2.4.2.txt b/third_party/git/Documentation/RelNotes/2.4.2.txt index 250cdc423c..250cdc423c 100644 --- a/Documentation/RelNotes/2.4.2.txt +++ b/third_party/git/Documentation/RelNotes/2.4.2.txt diff --git a/Documentation/RelNotes/2.4.3.txt b/third_party/git/Documentation/RelNotes/2.4.3.txt index 422e930aa2..422e930aa2 100644 --- a/Documentation/RelNotes/2.4.3.txt +++ b/third_party/git/Documentation/RelNotes/2.4.3.txt diff --git a/Documentation/RelNotes/2.4.4.txt b/third_party/git/Documentation/RelNotes/2.4.4.txt index f1ccd001be..f1ccd001be 100644 --- a/Documentation/RelNotes/2.4.4.txt +++ b/third_party/git/Documentation/RelNotes/2.4.4.txt diff --git a/Documentation/RelNotes/2.4.5.txt b/third_party/git/Documentation/RelNotes/2.4.5.txt index 568297ccb7..568297ccb7 100644 --- a/Documentation/RelNotes/2.4.5.txt +++ b/third_party/git/Documentation/RelNotes/2.4.5.txt diff --git a/Documentation/RelNotes/2.4.6.txt b/third_party/git/Documentation/RelNotes/2.4.6.txt index b53f353939..b53f353939 100644 --- a/Documentation/RelNotes/2.4.6.txt +++ b/third_party/git/Documentation/RelNotes/2.4.6.txt diff --git a/Documentation/RelNotes/2.4.7.txt b/third_party/git/Documentation/RelNotes/2.4.7.txt index b3ac412b82..b3ac412b82 100644 --- a/Documentation/RelNotes/2.4.7.txt +++ b/third_party/git/Documentation/RelNotes/2.4.7.txt diff --git a/Documentation/RelNotes/2.4.8.txt b/third_party/git/Documentation/RelNotes/2.4.8.txt index ad946b2673..ad946b2673 100644 --- a/Documentation/RelNotes/2.4.8.txt +++ b/third_party/git/Documentation/RelNotes/2.4.8.txt diff --git a/Documentation/RelNotes/2.4.9.txt b/third_party/git/Documentation/RelNotes/2.4.9.txt index 09af9ddbc7..09af9ddbc7 100644 --- a/Documentation/RelNotes/2.4.9.txt +++ b/third_party/git/Documentation/RelNotes/2.4.9.txt diff --git a/Documentation/RelNotes/2.5.0.txt b/third_party/git/Documentation/RelNotes/2.5.0.txt index 84723f912a..84723f912a 100644 --- a/Documentation/RelNotes/2.5.0.txt +++ b/third_party/git/Documentation/RelNotes/2.5.0.txt diff --git a/Documentation/RelNotes/2.5.1.txt b/third_party/git/Documentation/RelNotes/2.5.1.txt index b70553308a..b70553308a 100644 --- a/Documentation/RelNotes/2.5.1.txt +++ b/third_party/git/Documentation/RelNotes/2.5.1.txt diff --git a/Documentation/RelNotes/2.5.2.txt b/third_party/git/Documentation/RelNotes/2.5.2.txt index 3f749398bb..3f749398bb 100644 --- a/Documentation/RelNotes/2.5.2.txt +++ b/third_party/git/Documentation/RelNotes/2.5.2.txt diff --git a/Documentation/RelNotes/2.5.3.txt b/third_party/git/Documentation/RelNotes/2.5.3.txt index d1436857cb..d1436857cb 100644 --- a/Documentation/RelNotes/2.5.3.txt +++ b/third_party/git/Documentation/RelNotes/2.5.3.txt diff --git a/Documentation/RelNotes/2.5.4.txt b/third_party/git/Documentation/RelNotes/2.5.4.txt index b8a2f93ee7..b8a2f93ee7 100644 --- a/Documentation/RelNotes/2.5.4.txt +++ b/third_party/git/Documentation/RelNotes/2.5.4.txt diff --git a/Documentation/RelNotes/2.5.5.txt b/third_party/git/Documentation/RelNotes/2.5.5.txt index 37eae9a2d9..37eae9a2d9 100644 --- a/Documentation/RelNotes/2.5.5.txt +++ b/third_party/git/Documentation/RelNotes/2.5.5.txt diff --git a/Documentation/RelNotes/2.5.6.txt b/third_party/git/Documentation/RelNotes/2.5.6.txt index 9cd025bb1c..9cd025bb1c 100644 --- a/Documentation/RelNotes/2.5.6.txt +++ b/third_party/git/Documentation/RelNotes/2.5.6.txt diff --git a/Documentation/RelNotes/2.6.0.txt b/third_party/git/Documentation/RelNotes/2.6.0.txt index 7288aaf716..7288aaf716 100644 --- a/Documentation/RelNotes/2.6.0.txt +++ b/third_party/git/Documentation/RelNotes/2.6.0.txt diff --git a/Documentation/RelNotes/2.6.1.txt b/third_party/git/Documentation/RelNotes/2.6.1.txt index f37ea89cda..f37ea89cda 100644 --- a/Documentation/RelNotes/2.6.1.txt +++ b/third_party/git/Documentation/RelNotes/2.6.1.txt diff --git a/Documentation/RelNotes/2.6.2.txt b/third_party/git/Documentation/RelNotes/2.6.2.txt index 5b65e35245..5b65e35245 100644 --- a/Documentation/RelNotes/2.6.2.txt +++ b/third_party/git/Documentation/RelNotes/2.6.2.txt diff --git a/Documentation/RelNotes/2.6.3.txt b/third_party/git/Documentation/RelNotes/2.6.3.txt index fc6fe1711f..fc6fe1711f 100644 --- a/Documentation/RelNotes/2.6.3.txt +++ b/third_party/git/Documentation/RelNotes/2.6.3.txt diff --git a/Documentation/RelNotes/2.6.4.txt b/third_party/git/Documentation/RelNotes/2.6.4.txt index b0256a2dc9..b0256a2dc9 100644 --- a/Documentation/RelNotes/2.6.4.txt +++ b/third_party/git/Documentation/RelNotes/2.6.4.txt diff --git a/Documentation/RelNotes/2.6.5.txt b/third_party/git/Documentation/RelNotes/2.6.5.txt index f0924b62e0..f0924b62e0 100644 --- a/Documentation/RelNotes/2.6.5.txt +++ b/third_party/git/Documentation/RelNotes/2.6.5.txt diff --git a/Documentation/RelNotes/2.6.6.txt b/third_party/git/Documentation/RelNotes/2.6.6.txt index 023ad85ec6..023ad85ec6 100644 --- a/Documentation/RelNotes/2.6.6.txt +++ b/third_party/git/Documentation/RelNotes/2.6.6.txt diff --git a/Documentation/RelNotes/2.6.7.txt b/third_party/git/Documentation/RelNotes/2.6.7.txt index 1335de49a6..1335de49a6 100644 --- a/Documentation/RelNotes/2.6.7.txt +++ b/third_party/git/Documentation/RelNotes/2.6.7.txt diff --git a/Documentation/RelNotes/2.7.0.txt b/third_party/git/Documentation/RelNotes/2.7.0.txt index e3cbf3a73c..e3cbf3a73c 100644 --- a/Documentation/RelNotes/2.7.0.txt +++ b/third_party/git/Documentation/RelNotes/2.7.0.txt diff --git a/Documentation/RelNotes/2.7.1.txt b/third_party/git/Documentation/RelNotes/2.7.1.txt index 6323feaf64..6323feaf64 100644 --- a/Documentation/RelNotes/2.7.1.txt +++ b/third_party/git/Documentation/RelNotes/2.7.1.txt diff --git a/Documentation/RelNotes/2.7.2.txt b/third_party/git/Documentation/RelNotes/2.7.2.txt index 4feef76704..4feef76704 100644 --- a/Documentation/RelNotes/2.7.2.txt +++ b/third_party/git/Documentation/RelNotes/2.7.2.txt diff --git a/Documentation/RelNotes/2.7.3.txt b/third_party/git/Documentation/RelNotes/2.7.3.txt index f618d71efd..f618d71efd 100644 --- a/Documentation/RelNotes/2.7.3.txt +++ b/third_party/git/Documentation/RelNotes/2.7.3.txt diff --git a/Documentation/RelNotes/2.7.4.txt b/third_party/git/Documentation/RelNotes/2.7.4.txt index 883ae896fe..883ae896fe 100644 --- a/Documentation/RelNotes/2.7.4.txt +++ b/third_party/git/Documentation/RelNotes/2.7.4.txt diff --git a/Documentation/RelNotes/2.7.5.txt b/third_party/git/Documentation/RelNotes/2.7.5.txt index 83559ce3b2..83559ce3b2 100644 --- a/Documentation/RelNotes/2.7.5.txt +++ b/third_party/git/Documentation/RelNotes/2.7.5.txt diff --git a/Documentation/RelNotes/2.7.6.txt b/third_party/git/Documentation/RelNotes/2.7.6.txt index 4c6d1dcd4a..4c6d1dcd4a 100644 --- a/Documentation/RelNotes/2.7.6.txt +++ b/third_party/git/Documentation/RelNotes/2.7.6.txt diff --git a/Documentation/RelNotes/2.8.0.txt b/third_party/git/Documentation/RelNotes/2.8.0.txt index 27320b6a9f..27320b6a9f 100644 --- a/Documentation/RelNotes/2.8.0.txt +++ b/third_party/git/Documentation/RelNotes/2.8.0.txt diff --git a/Documentation/RelNotes/2.8.1.txt b/third_party/git/Documentation/RelNotes/2.8.1.txt index ef6d80b008..ef6d80b008 100644 --- a/Documentation/RelNotes/2.8.1.txt +++ b/third_party/git/Documentation/RelNotes/2.8.1.txt diff --git a/Documentation/RelNotes/2.8.2.txt b/third_party/git/Documentation/RelNotes/2.8.2.txt index 447b1933a8..447b1933a8 100644 --- a/Documentation/RelNotes/2.8.2.txt +++ b/third_party/git/Documentation/RelNotes/2.8.2.txt diff --git a/Documentation/RelNotes/2.8.3.txt b/third_party/git/Documentation/RelNotes/2.8.3.txt index a63825ed87..a63825ed87 100644 --- a/Documentation/RelNotes/2.8.3.txt +++ b/third_party/git/Documentation/RelNotes/2.8.3.txt diff --git a/Documentation/RelNotes/2.8.4.txt b/third_party/git/Documentation/RelNotes/2.8.4.txt index f4e2552836..f4e2552836 100644 --- a/Documentation/RelNotes/2.8.4.txt +++ b/third_party/git/Documentation/RelNotes/2.8.4.txt diff --git a/Documentation/RelNotes/2.8.5.txt b/third_party/git/Documentation/RelNotes/2.8.5.txt index 7bd179fa12..7bd179fa12 100644 --- a/Documentation/RelNotes/2.8.5.txt +++ b/third_party/git/Documentation/RelNotes/2.8.5.txt diff --git a/Documentation/RelNotes/2.8.6.txt b/third_party/git/Documentation/RelNotes/2.8.6.txt index d8db55d920..d8db55d920 100644 --- a/Documentation/RelNotes/2.8.6.txt +++ b/third_party/git/Documentation/RelNotes/2.8.6.txt diff --git a/Documentation/RelNotes/2.9.0.txt b/third_party/git/Documentation/RelNotes/2.9.0.txt index 991640119a..991640119a 100644 --- a/Documentation/RelNotes/2.9.0.txt +++ b/third_party/git/Documentation/RelNotes/2.9.0.txt diff --git a/Documentation/RelNotes/2.9.1.txt b/third_party/git/Documentation/RelNotes/2.9.1.txt index 338394097e..338394097e 100644 --- a/Documentation/RelNotes/2.9.1.txt +++ b/third_party/git/Documentation/RelNotes/2.9.1.txt diff --git a/Documentation/RelNotes/2.9.2.txt b/third_party/git/Documentation/RelNotes/2.9.2.txt index 2620003dcf..2620003dcf 100644 --- a/Documentation/RelNotes/2.9.2.txt +++ b/third_party/git/Documentation/RelNotes/2.9.2.txt diff --git a/Documentation/RelNotes/2.9.3.txt b/third_party/git/Documentation/RelNotes/2.9.3.txt index 305e08062b..305e08062b 100644 --- a/Documentation/RelNotes/2.9.3.txt +++ b/third_party/git/Documentation/RelNotes/2.9.3.txt diff --git a/Documentation/RelNotes/2.9.4.txt b/third_party/git/Documentation/RelNotes/2.9.4.txt index 9768293831..9768293831 100644 --- a/Documentation/RelNotes/2.9.4.txt +++ b/third_party/git/Documentation/RelNotes/2.9.4.txt diff --git a/Documentation/RelNotes/2.9.5.txt b/third_party/git/Documentation/RelNotes/2.9.5.txt index 668313ae55..668313ae55 100644 --- a/Documentation/RelNotes/2.9.5.txt +++ b/third_party/git/Documentation/RelNotes/2.9.5.txt diff --git a/Documentation/SubmittingPatches b/third_party/git/Documentation/SubmittingPatches index 4515cab519..4515cab519 100644 --- a/Documentation/SubmittingPatches +++ b/third_party/git/Documentation/SubmittingPatches diff --git a/Documentation/asciidoc.conf b/third_party/git/Documentation/asciidoc.conf index 8fc4b67081..8fc4b67081 100644 --- a/Documentation/asciidoc.conf +++ b/third_party/git/Documentation/asciidoc.conf diff --git a/Documentation/asciidoctor-extensions.rb b/third_party/git/Documentation/asciidoctor-extensions.rb index d906a00803..d906a00803 100644 --- a/Documentation/asciidoctor-extensions.rb +++ b/third_party/git/Documentation/asciidoctor-extensions.rb diff --git a/Documentation/blame-options.txt b/third_party/git/Documentation/blame-options.txt index 5d122db6e9..5d122db6e9 100644 --- a/Documentation/blame-options.txt +++ b/third_party/git/Documentation/blame-options.txt diff --git a/Documentation/build-docdep.perl b/third_party/git/Documentation/build-docdep.perl index ba4205e030..ba4205e030 100755 --- a/Documentation/build-docdep.perl +++ b/third_party/git/Documentation/build-docdep.perl diff --git a/Documentation/cat-texi.perl b/third_party/git/Documentation/cat-texi.perl index 14d2f83415..14d2f83415 100755 --- a/Documentation/cat-texi.perl +++ b/third_party/git/Documentation/cat-texi.perl diff --git a/Documentation/cmd-list.perl b/third_party/git/Documentation/cmd-list.perl index 5aa73cfe45..5aa73cfe45 100755 --- a/Documentation/cmd-list.perl +++ b/third_party/git/Documentation/cmd-list.perl diff --git a/Documentation/config.txt b/third_party/git/Documentation/config.txt index 08b13ba72b..08b13ba72b 100644 --- a/Documentation/config.txt +++ b/third_party/git/Documentation/config.txt diff --git a/Documentation/config/add.txt b/third_party/git/Documentation/config/add.txt index c9f748f81c..c9f748f81c 100644 --- a/Documentation/config/add.txt +++ b/third_party/git/Documentation/config/add.txt diff --git a/Documentation/config/advice.txt b/third_party/git/Documentation/config/advice.txt index bdd37c3eaa..bdd37c3eaa 100644 --- a/Documentation/config/advice.txt +++ b/third_party/git/Documentation/config/advice.txt diff --git a/Documentation/config/alias.txt b/third_party/git/Documentation/config/alias.txt index f1ca739d57..f1ca739d57 100644 --- a/Documentation/config/alias.txt +++ b/third_party/git/Documentation/config/alias.txt diff --git a/Documentation/config/am.txt b/third_party/git/Documentation/config/am.txt index 5bcad2efb1..5bcad2efb1 100644 --- a/Documentation/config/am.txt +++ b/third_party/git/Documentation/config/am.txt diff --git a/Documentation/config/apply.txt b/third_party/git/Documentation/config/apply.txt index 8fb8ef763d..8fb8ef763d 100644 --- a/Documentation/config/apply.txt +++ b/third_party/git/Documentation/config/apply.txt diff --git a/Documentation/config/blame.txt b/third_party/git/Documentation/config/blame.txt index 9468e8599c..9468e8599c 100644 --- a/Documentation/config/blame.txt +++ b/third_party/git/Documentation/config/blame.txt diff --git a/Documentation/config/branch.txt b/third_party/git/Documentation/config/branch.txt index cc5f3249fc..cc5f3249fc 100644 --- a/Documentation/config/branch.txt +++ b/third_party/git/Documentation/config/branch.txt diff --git a/Documentation/config/browser.txt b/third_party/git/Documentation/config/browser.txt index 195df207a6..195df207a6 100644 --- a/Documentation/config/browser.txt +++ b/third_party/git/Documentation/config/browser.txt diff --git a/Documentation/config/checkout.txt b/third_party/git/Documentation/config/checkout.txt index 6b646813ab..6b646813ab 100644 --- a/Documentation/config/checkout.txt +++ b/third_party/git/Documentation/config/checkout.txt diff --git a/Documentation/config/clean.txt b/third_party/git/Documentation/config/clean.txt index a807c925b9..a807c925b9 100644 --- a/Documentation/config/clean.txt +++ b/third_party/git/Documentation/config/clean.txt diff --git a/Documentation/config/color.txt b/third_party/git/Documentation/config/color.txt index d5daacb13a..d5daacb13a 100644 --- a/Documentation/config/color.txt +++ b/third_party/git/Documentation/config/color.txt diff --git a/Documentation/config/column.txt b/third_party/git/Documentation/config/column.txt index 76aa2f29dc..76aa2f29dc 100644 --- a/Documentation/config/column.txt +++ b/third_party/git/Documentation/config/column.txt diff --git a/Documentation/config/commit.txt b/third_party/git/Documentation/config/commit.txt index 2c95573930..2c95573930 100644 --- a/Documentation/config/commit.txt +++ b/third_party/git/Documentation/config/commit.txt diff --git a/Documentation/config/completion.txt b/third_party/git/Documentation/config/completion.txt index 4d99bf33c9..4d99bf33c9 100644 --- a/Documentation/config/completion.txt +++ b/third_party/git/Documentation/config/completion.txt diff --git a/Documentation/config/core.txt b/third_party/git/Documentation/config/core.txt index 74619a9c03..74619a9c03 100644 --- a/Documentation/config/core.txt +++ b/third_party/git/Documentation/config/core.txt diff --git a/Documentation/config/credential.txt b/third_party/git/Documentation/config/credential.txt index 60fb3189e1..60fb3189e1 100644 --- a/Documentation/config/credential.txt +++ b/third_party/git/Documentation/config/credential.txt diff --git a/Documentation/config/diff.txt b/third_party/git/Documentation/config/diff.txt index ff09f1cf73..ff09f1cf73 100644 --- a/Documentation/config/diff.txt +++ b/third_party/git/Documentation/config/diff.txt diff --git a/Documentation/config/difftool.txt b/third_party/git/Documentation/config/difftool.txt index 6762594480..6762594480 100644 --- a/Documentation/config/difftool.txt +++ b/third_party/git/Documentation/config/difftool.txt diff --git a/Documentation/config/fastimport.txt b/third_party/git/Documentation/config/fastimport.txt index c1166e330d..c1166e330d 100644 --- a/Documentation/config/fastimport.txt +++ b/third_party/git/Documentation/config/fastimport.txt diff --git a/Documentation/config/feature.txt b/third_party/git/Documentation/config/feature.txt index 875f8c8a66..875f8c8a66 100644 --- a/Documentation/config/feature.txt +++ b/third_party/git/Documentation/config/feature.txt diff --git a/Documentation/config/fetch.txt b/third_party/git/Documentation/config/fetch.txt index f11940280f..f11940280f 100644 --- a/Documentation/config/fetch.txt +++ b/third_party/git/Documentation/config/fetch.txt diff --git a/Documentation/config/filter.txt b/third_party/git/Documentation/config/filter.txt index 90dfe0ba5a..90dfe0ba5a 100644 --- a/Documentation/config/filter.txt +++ b/third_party/git/Documentation/config/filter.txt diff --git a/Documentation/config/fmt-merge-msg.txt b/third_party/git/Documentation/config/fmt-merge-msg.txt index c73cfa90b7..c73cfa90b7 100644 --- a/Documentation/config/fmt-merge-msg.txt +++ b/third_party/git/Documentation/config/fmt-merge-msg.txt diff --git a/Documentation/config/format.txt b/third_party/git/Documentation/config/format.txt index 45c7bd5a8f..45c7bd5a8f 100644 --- a/Documentation/config/format.txt +++ b/third_party/git/Documentation/config/format.txt diff --git a/Documentation/config/fsck.txt b/third_party/git/Documentation/config/fsck.txt index 450e8c38e3..450e8c38e3 100644 --- a/Documentation/config/fsck.txt +++ b/third_party/git/Documentation/config/fsck.txt diff --git a/Documentation/config/gc.txt b/third_party/git/Documentation/config/gc.txt index 00ea0a678e..00ea0a678e 100644 --- a/Documentation/config/gc.txt +++ b/third_party/git/Documentation/config/gc.txt diff --git a/Documentation/config/gitcvs.txt b/third_party/git/Documentation/config/gitcvs.txt index 02da427fd9..02da427fd9 100644 --- a/Documentation/config/gitcvs.txt +++ b/third_party/git/Documentation/config/gitcvs.txt diff --git a/Documentation/config/gitweb.txt b/third_party/git/Documentation/config/gitweb.txt index 1b51475108..1b51475108 100644 --- a/Documentation/config/gitweb.txt +++ b/third_party/git/Documentation/config/gitweb.txt diff --git a/Documentation/config/gpg.txt b/third_party/git/Documentation/config/gpg.txt index d94025cb36..d94025cb36 100644 --- a/Documentation/config/gpg.txt +++ b/third_party/git/Documentation/config/gpg.txt diff --git a/Documentation/config/grep.txt b/third_party/git/Documentation/config/grep.txt index 44abe45a7c..44abe45a7c 100644 --- a/Documentation/config/grep.txt +++ b/third_party/git/Documentation/config/grep.txt diff --git a/Documentation/config/gui.txt b/third_party/git/Documentation/config/gui.txt index d30831a130..d30831a130 100644 --- a/Documentation/config/gui.txt +++ b/third_party/git/Documentation/config/gui.txt diff --git a/Documentation/config/guitool.txt b/third_party/git/Documentation/config/guitool.txt index 43fb9466ff..43fb9466ff 100644 --- a/Documentation/config/guitool.txt +++ b/third_party/git/Documentation/config/guitool.txt diff --git a/Documentation/config/help.txt b/third_party/git/Documentation/config/help.txt index 224bbf5a28..224bbf5a28 100644 --- a/Documentation/config/help.txt +++ b/third_party/git/Documentation/config/help.txt diff --git a/Documentation/config/http.txt b/third_party/git/Documentation/config/http.txt index e806033aab..e806033aab 100644 --- a/Documentation/config/http.txt +++ b/third_party/git/Documentation/config/http.txt diff --git a/Documentation/config/i18n.txt b/third_party/git/Documentation/config/i18n.txt index cc25621731..cc25621731 100644 --- a/Documentation/config/i18n.txt +++ b/third_party/git/Documentation/config/i18n.txt diff --git a/Documentation/config/imap.txt b/third_party/git/Documentation/config/imap.txt index 06166fb5c0..06166fb5c0 100644 --- a/Documentation/config/imap.txt +++ b/third_party/git/Documentation/config/imap.txt diff --git a/Documentation/config/index.txt b/third_party/git/Documentation/config/index.txt index 7cb50b37e9..7cb50b37e9 100644 --- a/Documentation/config/index.txt +++ b/third_party/git/Documentation/config/index.txt diff --git a/Documentation/config/init.txt b/third_party/git/Documentation/config/init.txt index 46fa8c6a08..46fa8c6a08 100644 --- a/Documentation/config/init.txt +++ b/third_party/git/Documentation/config/init.txt diff --git a/Documentation/config/instaweb.txt b/third_party/git/Documentation/config/instaweb.txt index 50cb2f7d62..50cb2f7d62 100644 --- a/Documentation/config/instaweb.txt +++ b/third_party/git/Documentation/config/instaweb.txt diff --git a/Documentation/config/interactive.txt b/third_party/git/Documentation/config/interactive.txt index a2d3c7ec44..a2d3c7ec44 100644 --- a/Documentation/config/interactive.txt +++ b/third_party/git/Documentation/config/interactive.txt diff --git a/Documentation/config/log.txt b/third_party/git/Documentation/config/log.txt index e9e1e397f3..e9e1e397f3 100644 --- a/Documentation/config/log.txt +++ b/third_party/git/Documentation/config/log.txt diff --git a/Documentation/config/mailinfo.txt b/third_party/git/Documentation/config/mailinfo.txt index 3854d4ae37..3854d4ae37 100644 --- a/Documentation/config/mailinfo.txt +++ b/third_party/git/Documentation/config/mailinfo.txt diff --git a/Documentation/config/mailmap.txt b/third_party/git/Documentation/config/mailmap.txt index 48cbc30722..48cbc30722 100644 --- a/Documentation/config/mailmap.txt +++ b/third_party/git/Documentation/config/mailmap.txt diff --git a/Documentation/config/man.txt b/third_party/git/Documentation/config/man.txt index a727d987a8..a727d987a8 100644 --- a/Documentation/config/man.txt +++ b/third_party/git/Documentation/config/man.txt diff --git a/Documentation/config/merge.txt b/third_party/git/Documentation/config/merge.txt index 6a313937f8..6a313937f8 100644 --- a/Documentation/config/merge.txt +++ b/third_party/git/Documentation/config/merge.txt diff --git a/Documentation/config/mergetool.txt b/third_party/git/Documentation/config/mergetool.txt index 09ed31dbfa..09ed31dbfa 100644 --- a/Documentation/config/mergetool.txt +++ b/third_party/git/Documentation/config/mergetool.txt diff --git a/Documentation/config/notes.txt b/third_party/git/Documentation/config/notes.txt index aeef56d49a..aeef56d49a 100644 --- a/Documentation/config/notes.txt +++ b/third_party/git/Documentation/config/notes.txt diff --git a/Documentation/config/pack.txt b/third_party/git/Documentation/config/pack.txt index 0dac580581..0dac580581 100644 --- a/Documentation/config/pack.txt +++ b/third_party/git/Documentation/config/pack.txt diff --git a/Documentation/config/pager.txt b/third_party/git/Documentation/config/pager.txt index d3731cf66c..d3731cf66c 100644 --- a/Documentation/config/pager.txt +++ b/third_party/git/Documentation/config/pager.txt diff --git a/Documentation/config/pretty.txt b/third_party/git/Documentation/config/pretty.txt index 063c6b63d9..063c6b63d9 100644 --- a/Documentation/config/pretty.txt +++ b/third_party/git/Documentation/config/pretty.txt diff --git a/Documentation/config/protocol.txt b/third_party/git/Documentation/config/protocol.txt index 756591d77b..756591d77b 100644 --- a/Documentation/config/protocol.txt +++ b/third_party/git/Documentation/config/protocol.txt diff --git a/Documentation/config/pull.txt b/third_party/git/Documentation/config/pull.txt index 5404830609..5404830609 100644 --- a/Documentation/config/pull.txt +++ b/third_party/git/Documentation/config/pull.txt diff --git a/Documentation/config/push.txt b/third_party/git/Documentation/config/push.txt index 0a7aa322a9..0a7aa322a9 100644 --- a/Documentation/config/push.txt +++ b/third_party/git/Documentation/config/push.txt diff --git a/Documentation/config/rebase.txt b/third_party/git/Documentation/config/rebase.txt index 7f7a07d22f..7f7a07d22f 100644 --- a/Documentation/config/rebase.txt +++ b/third_party/git/Documentation/config/rebase.txt diff --git a/Documentation/config/receive.txt b/third_party/git/Documentation/config/receive.txt index 65f78aac37..65f78aac37 100644 --- a/Documentation/config/receive.txt +++ b/third_party/git/Documentation/config/receive.txt diff --git a/Documentation/config/remote.txt b/third_party/git/Documentation/config/remote.txt index a8e6437a90..a8e6437a90 100644 --- a/Documentation/config/remote.txt +++ b/third_party/git/Documentation/config/remote.txt diff --git a/Documentation/config/remotes.txt b/third_party/git/Documentation/config/remotes.txt index 4cfe03221e..4cfe03221e 100644 --- a/Documentation/config/remotes.txt +++ b/third_party/git/Documentation/config/remotes.txt diff --git a/Documentation/config/repack.txt b/third_party/git/Documentation/config/repack.txt index 9c413e177e..9c413e177e 100644 --- a/Documentation/config/repack.txt +++ b/third_party/git/Documentation/config/repack.txt diff --git a/Documentation/config/rerere.txt b/third_party/git/Documentation/config/rerere.txt index 40abdf6a6b..40abdf6a6b 100644 --- a/Documentation/config/rerere.txt +++ b/third_party/git/Documentation/config/rerere.txt diff --git a/Documentation/config/reset.txt b/third_party/git/Documentation/config/reset.txt index 63b7c45aac..63b7c45aac 100644 --- a/Documentation/config/reset.txt +++ b/third_party/git/Documentation/config/reset.txt diff --git a/Documentation/config/sendemail.txt b/third_party/git/Documentation/config/sendemail.txt index 0006faf800..0006faf800 100644 --- a/Documentation/config/sendemail.txt +++ b/third_party/git/Documentation/config/sendemail.txt diff --git a/Documentation/config/sequencer.txt b/third_party/git/Documentation/config/sequencer.txt index b48d532a96..b48d532a96 100644 --- a/Documentation/config/sequencer.txt +++ b/third_party/git/Documentation/config/sequencer.txt diff --git a/Documentation/config/showbranch.txt b/third_party/git/Documentation/config/showbranch.txt index e79ecd9ee9..e79ecd9ee9 100644 --- a/Documentation/config/showbranch.txt +++ b/third_party/git/Documentation/config/showbranch.txt diff --git a/Documentation/config/splitindex.txt b/third_party/git/Documentation/config/splitindex.txt index afdb186df8..afdb186df8 100644 --- a/Documentation/config/splitindex.txt +++ b/third_party/git/Documentation/config/splitindex.txt diff --git a/Documentation/config/ssh.txt b/third_party/git/Documentation/config/ssh.txt index 2ca4bf93e1..2ca4bf93e1 100644 --- a/Documentation/config/ssh.txt +++ b/third_party/git/Documentation/config/ssh.txt diff --git a/Documentation/config/stash.txt b/third_party/git/Documentation/config/stash.txt index abc7ef4a3a..abc7ef4a3a 100644 --- a/Documentation/config/stash.txt +++ b/third_party/git/Documentation/config/stash.txt diff --git a/Documentation/config/status.txt b/third_party/git/Documentation/config/status.txt index 0fc704ab80..0fc704ab80 100644 --- a/Documentation/config/status.txt +++ b/third_party/git/Documentation/config/status.txt diff --git a/Documentation/config/submodule.txt b/third_party/git/Documentation/config/submodule.txt index b33177151c..b33177151c 100644 --- a/Documentation/config/submodule.txt +++ b/third_party/git/Documentation/config/submodule.txt diff --git a/Documentation/config/tag.txt b/third_party/git/Documentation/config/tag.txt index 6d9110d84c..6d9110d84c 100644 --- a/Documentation/config/tag.txt +++ b/third_party/git/Documentation/config/tag.txt diff --git a/Documentation/config/trace2.txt b/third_party/git/Documentation/config/trace2.txt index 4ce0b9a6d1..4ce0b9a6d1 100644 --- a/Documentation/config/trace2.txt +++ b/third_party/git/Documentation/config/trace2.txt diff --git a/Documentation/config/transfer.txt b/third_party/git/Documentation/config/transfer.txt index f5b6245270..f5b6245270 100644 --- a/Documentation/config/transfer.txt +++ b/third_party/git/Documentation/config/transfer.txt diff --git a/Documentation/config/uploadarchive.txt b/third_party/git/Documentation/config/uploadarchive.txt index e0698e8c1d..e0698e8c1d 100644 --- a/Documentation/config/uploadarchive.txt +++ b/third_party/git/Documentation/config/uploadarchive.txt diff --git a/Documentation/config/uploadpack.txt b/third_party/git/Documentation/config/uploadpack.txt index ed1c835695..ed1c835695 100644 --- a/Documentation/config/uploadpack.txt +++ b/third_party/git/Documentation/config/uploadpack.txt diff --git a/Documentation/config/url.txt b/third_party/git/Documentation/config/url.txt index e5566c371d..e5566c371d 100644 --- a/Documentation/config/url.txt +++ b/third_party/git/Documentation/config/url.txt diff --git a/Documentation/config/user.txt b/third_party/git/Documentation/config/user.txt index 59aec7c3ae..59aec7c3ae 100644 --- a/Documentation/config/user.txt +++ b/third_party/git/Documentation/config/user.txt diff --git a/Documentation/config/versionsort.txt b/third_party/git/Documentation/config/versionsort.txt index 6c7cc054fa..6c7cc054fa 100644 --- a/Documentation/config/versionsort.txt +++ b/third_party/git/Documentation/config/versionsort.txt diff --git a/Documentation/config/web.txt b/third_party/git/Documentation/config/web.txt index beec8d1303..beec8d1303 100644 --- a/Documentation/config/web.txt +++ b/third_party/git/Documentation/config/web.txt diff --git a/Documentation/config/worktree.txt b/third_party/git/Documentation/config/worktree.txt index 048e349482..048e349482 100644 --- a/Documentation/config/worktree.txt +++ b/third_party/git/Documentation/config/worktree.txt diff --git a/Documentation/date-formats.txt b/third_party/git/Documentation/date-formats.txt index 6926e0a4c8..6926e0a4c8 100644 --- a/Documentation/date-formats.txt +++ b/third_party/git/Documentation/date-formats.txt diff --git a/Documentation/diff-format.txt b/third_party/git/Documentation/diff-format.txt index fbbd410a84..fbbd410a84 100644 --- a/Documentation/diff-format.txt +++ b/third_party/git/Documentation/diff-format.txt diff --git a/Documentation/diff-generate-patch.txt b/third_party/git/Documentation/diff-generate-patch.txt index e8ed6470fb..e8ed6470fb 100644 --- a/Documentation/diff-generate-patch.txt +++ b/third_party/git/Documentation/diff-generate-patch.txt diff --git a/Documentation/diff-options.txt b/third_party/git/Documentation/diff-options.txt index bb31f0c42b..bb31f0c42b 100644 --- a/Documentation/diff-options.txt +++ b/third_party/git/Documentation/diff-options.txt diff --git a/Documentation/doc-diff b/third_party/git/Documentation/doc-diff index 1694300e50..1694300e50 100755 --- a/Documentation/doc-diff +++ b/third_party/git/Documentation/doc-diff diff --git a/Documentation/docbook-xsl.css b/third_party/git/Documentation/docbook-xsl.css index e11c8f053a..e11c8f053a 100644 --- a/Documentation/docbook-xsl.css +++ b/third_party/git/Documentation/docbook-xsl.css diff --git a/Documentation/docbook.xsl b/third_party/git/Documentation/docbook.xsl index da8b05b922..da8b05b922 100644 --- a/Documentation/docbook.xsl +++ b/third_party/git/Documentation/docbook.xsl diff --git a/Documentation/everyday.txto b/third_party/git/Documentation/everyday.txto index ae555bd47e..ae555bd47e 100644 --- a/Documentation/everyday.txto +++ b/third_party/git/Documentation/everyday.txto diff --git a/Documentation/fetch-options.txt b/third_party/git/Documentation/fetch-options.txt index a115a1ae0e..a115a1ae0e 100644 --- a/Documentation/fetch-options.txt +++ b/third_party/git/Documentation/fetch-options.txt diff --git a/Documentation/fix-texi.perl b/third_party/git/Documentation/fix-texi.perl index ff7d78f620..ff7d78f620 100755 --- a/Documentation/fix-texi.perl +++ b/third_party/git/Documentation/fix-texi.perl diff --git a/Documentation/git-add.txt b/third_party/git/Documentation/git-add.txt index be5e3ac54b..be5e3ac54b 100644 --- a/Documentation/git-add.txt +++ b/third_party/git/Documentation/git-add.txt diff --git a/Documentation/git-am.txt b/third_party/git/Documentation/git-am.txt index ab5754e05d..ab5754e05d 100644 --- a/Documentation/git-am.txt +++ b/third_party/git/Documentation/git-am.txt diff --git a/Documentation/git-annotate.txt b/third_party/git/Documentation/git-annotate.txt index e44a831339..e44a831339 100644 --- a/Documentation/git-annotate.txt +++ b/third_party/git/Documentation/git-annotate.txt diff --git a/Documentation/git-apply.txt b/third_party/git/Documentation/git-apply.txt index b9aa39000f..b9aa39000f 100644 --- a/Documentation/git-apply.txt +++ b/third_party/git/Documentation/git-apply.txt diff --git a/Documentation/git-archimport.txt b/third_party/git/Documentation/git-archimport.txt index a595a0ffee..a595a0ffee 100644 --- a/Documentation/git-archimport.txt +++ b/third_party/git/Documentation/git-archimport.txt diff --git a/Documentation/git-archive.txt b/third_party/git/Documentation/git-archive.txt index cfa1e4ebe4..cfa1e4ebe4 100644 --- a/Documentation/git-archive.txt +++ b/third_party/git/Documentation/git-archive.txt diff --git a/Documentation/git-bisect-lk2009.txt b/third_party/git/Documentation/git-bisect-lk2009.txt index 3ba49e85b7..3ba49e85b7 100644 --- a/Documentation/git-bisect-lk2009.txt +++ b/third_party/git/Documentation/git-bisect-lk2009.txt diff --git a/Documentation/git-bisect.txt b/third_party/git/Documentation/git-bisect.txt index 7586c5a843..7586c5a843 100644 --- a/Documentation/git-bisect.txt +++ b/third_party/git/Documentation/git-bisect.txt diff --git a/Documentation/git-blame.txt b/third_party/git/Documentation/git-blame.txt index 7e81541996..7e81541996 100644 --- a/Documentation/git-blame.txt +++ b/third_party/git/Documentation/git-blame.txt diff --git a/Documentation/git-branch.txt b/third_party/git/Documentation/git-branch.txt index 135206ff4a..135206ff4a 100644 --- a/Documentation/git-branch.txt +++ b/third_party/git/Documentation/git-branch.txt diff --git a/Documentation/git-bundle.txt b/third_party/git/Documentation/git-bundle.txt index d34b0964be..d34b0964be 100644 --- a/Documentation/git-bundle.txt +++ b/third_party/git/Documentation/git-bundle.txt diff --git a/Documentation/git-cat-file.txt b/third_party/git/Documentation/git-cat-file.txt index 8eca671b82..8eca671b82 100644 --- a/Documentation/git-cat-file.txt +++ b/third_party/git/Documentation/git-cat-file.txt diff --git a/Documentation/git-check-attr.txt b/third_party/git/Documentation/git-check-attr.txt index 84f41a8e82..84f41a8e82 100644 --- a/Documentation/git-check-attr.txt +++ b/third_party/git/Documentation/git-check-attr.txt diff --git a/Documentation/git-check-ignore.txt b/third_party/git/Documentation/git-check-ignore.txt index 0c3924a63d..0c3924a63d 100644 --- a/Documentation/git-check-ignore.txt +++ b/third_party/git/Documentation/git-check-ignore.txt diff --git a/Documentation/git-check-mailmap.txt b/third_party/git/Documentation/git-check-mailmap.txt index aa2055dbeb..aa2055dbeb 100644 --- a/Documentation/git-check-mailmap.txt +++ b/third_party/git/Documentation/git-check-mailmap.txt diff --git a/Documentation/git-check-ref-format.txt b/third_party/git/Documentation/git-check-ref-format.txt index ee6a4144fb..ee6a4144fb 100644 --- a/Documentation/git-check-ref-format.txt +++ b/third_party/git/Documentation/git-check-ref-format.txt diff --git a/Documentation/git-checkout-index.txt b/third_party/git/Documentation/git-checkout-index.txt index 4d33e7be0f..4d33e7be0f 100644 --- a/Documentation/git-checkout-index.txt +++ b/third_party/git/Documentation/git-checkout-index.txt diff --git a/Documentation/git-checkout.txt b/third_party/git/Documentation/git-checkout.txt index c8fb995fa7..c8fb995fa7 100644 --- a/Documentation/git-checkout.txt +++ b/third_party/git/Documentation/git-checkout.txt diff --git a/Documentation/git-cherry-pick.txt b/third_party/git/Documentation/git-cherry-pick.txt index 83ce51aedf..83ce51aedf 100644 --- a/Documentation/git-cherry-pick.txt +++ b/third_party/git/Documentation/git-cherry-pick.txt diff --git a/Documentation/git-cherry.txt b/third_party/git/Documentation/git-cherry.txt index 0ea921a593..0ea921a593 100644 --- a/Documentation/git-cherry.txt +++ b/third_party/git/Documentation/git-cherry.txt diff --git a/Documentation/git-citool.txt b/third_party/git/Documentation/git-citool.txt index c7a11c36c1..c7a11c36c1 100644 --- a/Documentation/git-citool.txt +++ b/third_party/git/Documentation/git-citool.txt diff --git a/Documentation/git-clean.txt b/third_party/git/Documentation/git-clean.txt index a7f309dff5..a7f309dff5 100644 --- a/Documentation/git-clean.txt +++ b/third_party/git/Documentation/git-clean.txt diff --git a/Documentation/git-clone.txt b/third_party/git/Documentation/git-clone.txt index bf24f1813a..bf24f1813a 100644 --- a/Documentation/git-clone.txt +++ b/third_party/git/Documentation/git-clone.txt diff --git a/Documentation/git-column.txt b/third_party/git/Documentation/git-column.txt index f58e9c43e6..f58e9c43e6 100644 --- a/Documentation/git-column.txt +++ b/third_party/git/Documentation/git-column.txt diff --git a/Documentation/git-commit-graph.txt b/third_party/git/Documentation/git-commit-graph.txt index 28d1fee505..28d1fee505 100644 --- a/Documentation/git-commit-graph.txt +++ b/third_party/git/Documentation/git-commit-graph.txt diff --git a/Documentation/git-commit-tree.txt b/third_party/git/Documentation/git-commit-tree.txt index ec15ee8d6f..ec15ee8d6f 100644 --- a/Documentation/git-commit-tree.txt +++ b/third_party/git/Documentation/git-commit-tree.txt diff --git a/Documentation/git-commit.txt b/third_party/git/Documentation/git-commit.txt index 13f653989f..13f653989f 100644 --- a/Documentation/git-commit.txt +++ b/third_party/git/Documentation/git-commit.txt diff --git a/Documentation/git-config.txt b/third_party/git/Documentation/git-config.txt index 7573160f21..7573160f21 100644 --- a/Documentation/git-config.txt +++ b/third_party/git/Documentation/git-config.txt diff --git a/Documentation/git-count-objects.txt b/third_party/git/Documentation/git-count-objects.txt index cb9b4d2e46..cb9b4d2e46 100644 --- a/Documentation/git-count-objects.txt +++ b/third_party/git/Documentation/git-count-objects.txt diff --git a/Documentation/git-credential-cache--daemon.txt b/third_party/git/Documentation/git-credential-cache--daemon.txt index 7051c6bdf8..7051c6bdf8 100644 --- a/Documentation/git-credential-cache--daemon.txt +++ b/third_party/git/Documentation/git-credential-cache--daemon.txt diff --git a/Documentation/git-credential-cache.txt b/third_party/git/Documentation/git-credential-cache.txt index 0216c18ef8..0216c18ef8 100644 --- a/Documentation/git-credential-cache.txt +++ b/third_party/git/Documentation/git-credential-cache.txt diff --git a/Documentation/git-credential-store.txt b/third_party/git/Documentation/git-credential-store.txt index 693dd9d9d7..693dd9d9d7 100644 --- a/Documentation/git-credential-store.txt +++ b/third_party/git/Documentation/git-credential-store.txt diff --git a/Documentation/git-credential.txt b/third_party/git/Documentation/git-credential.txt index 6f0c7ca80f..6f0c7ca80f 100644 --- a/Documentation/git-credential.txt +++ b/third_party/git/Documentation/git-credential.txt diff --git a/Documentation/git-cvsexportcommit.txt b/third_party/git/Documentation/git-cvsexportcommit.txt index 00154b6c85..00154b6c85 100644 --- a/Documentation/git-cvsexportcommit.txt +++ b/third_party/git/Documentation/git-cvsexportcommit.txt diff --git a/Documentation/git-cvsimport.txt b/third_party/git/Documentation/git-cvsimport.txt index de1ebed67d..de1ebed67d 100644 --- a/Documentation/git-cvsimport.txt +++ b/third_party/git/Documentation/git-cvsimport.txt diff --git a/Documentation/git-cvsserver.txt b/third_party/git/Documentation/git-cvsserver.txt index 1b1c71ad9d..1b1c71ad9d 100644 --- a/Documentation/git-cvsserver.txt +++ b/third_party/git/Documentation/git-cvsserver.txt diff --git a/Documentation/git-daemon.txt b/third_party/git/Documentation/git-daemon.txt index fdc28c041c..fdc28c041c 100644 --- a/Documentation/git-daemon.txt +++ b/third_party/git/Documentation/git-daemon.txt diff --git a/Documentation/git-describe.txt b/third_party/git/Documentation/git-describe.txt index a88f6ae2c6..a88f6ae2c6 100644 --- a/Documentation/git-describe.txt +++ b/third_party/git/Documentation/git-describe.txt diff --git a/Documentation/git-diff-files.txt b/third_party/git/Documentation/git-diff-files.txt index 906774f0f7..906774f0f7 100644 --- a/Documentation/git-diff-files.txt +++ b/third_party/git/Documentation/git-diff-files.txt diff --git a/Documentation/git-diff-index.txt b/third_party/git/Documentation/git-diff-index.txt index f4bd8155c0..f4bd8155c0 100644 --- a/Documentation/git-diff-index.txt +++ b/third_party/git/Documentation/git-diff-index.txt diff --git a/Documentation/git-diff-tree.txt b/third_party/git/Documentation/git-diff-tree.txt index 5c8a2a5e97..5c8a2a5e97 100644 --- a/Documentation/git-diff-tree.txt +++ b/third_party/git/Documentation/git-diff-tree.txt diff --git a/Documentation/git-diff.txt b/third_party/git/Documentation/git-diff.txt index 37781cf175..37781cf175 100644 --- a/Documentation/git-diff.txt +++ b/third_party/git/Documentation/git-diff.txt diff --git a/Documentation/git-difftool.txt b/third_party/git/Documentation/git-difftool.txt index 484c485fd0..484c485fd0 100644 --- a/Documentation/git-difftool.txt +++ b/third_party/git/Documentation/git-difftool.txt diff --git a/Documentation/git-fast-export.txt b/third_party/git/Documentation/git-fast-export.txt index e8950de3ba..e8950de3ba 100644 --- a/Documentation/git-fast-export.txt +++ b/third_party/git/Documentation/git-fast-export.txt diff --git a/Documentation/git-fast-import.txt b/third_party/git/Documentation/git-fast-import.txt index 7889f95940..7889f95940 100644 --- a/Documentation/git-fast-import.txt +++ b/third_party/git/Documentation/git-fast-import.txt diff --git a/Documentation/git-fetch-pack.txt b/third_party/git/Documentation/git-fetch-pack.txt index c975884793..c975884793 100644 --- a/Documentation/git-fetch-pack.txt +++ b/third_party/git/Documentation/git-fetch-pack.txt diff --git a/Documentation/git-fetch.txt b/third_party/git/Documentation/git-fetch.txt index 5b1909fdf4..5b1909fdf4 100644 --- a/Documentation/git-fetch.txt +++ b/third_party/git/Documentation/git-fetch.txt diff --git a/Documentation/git-filter-branch.txt b/third_party/git/Documentation/git-filter-branch.txt index 40ba4aa3e6..40ba4aa3e6 100644 --- a/Documentation/git-filter-branch.txt +++ b/third_party/git/Documentation/git-filter-branch.txt diff --git a/Documentation/git-fmt-merge-msg.txt b/third_party/git/Documentation/git-fmt-merge-msg.txt index 6793d8fc05..6793d8fc05 100644 --- a/Documentation/git-fmt-merge-msg.txt +++ b/third_party/git/Documentation/git-fmt-merge-msg.txt diff --git a/Documentation/git-for-each-ref.txt b/third_party/git/Documentation/git-for-each-ref.txt index 6dcd39f6f6..6dcd39f6f6 100644 --- a/Documentation/git-for-each-ref.txt +++ b/third_party/git/Documentation/git-for-each-ref.txt diff --git a/Documentation/git-format-patch.txt b/third_party/git/Documentation/git-format-patch.txt index 0d4f8951bb..0d4f8951bb 100644 --- a/Documentation/git-format-patch.txt +++ b/third_party/git/Documentation/git-format-patch.txt diff --git a/Documentation/git-fsck-objects.txt b/third_party/git/Documentation/git-fsck-objects.txt index eec4bdb600..eec4bdb600 100644 --- a/Documentation/git-fsck-objects.txt +++ b/third_party/git/Documentation/git-fsck-objects.txt diff --git a/Documentation/git-fsck.txt b/third_party/git/Documentation/git-fsck.txt index d72d15be5b..d72d15be5b 100644 --- a/Documentation/git-fsck.txt +++ b/third_party/git/Documentation/git-fsck.txt diff --git a/Documentation/git-gc.txt b/third_party/git/Documentation/git-gc.txt index 0c114ad1ca..0c114ad1ca 100644 --- a/Documentation/git-gc.txt +++ b/third_party/git/Documentation/git-gc.txt diff --git a/Documentation/git-get-tar-commit-id.txt b/third_party/git/Documentation/git-get-tar-commit-id.txt index ac44d85b0b..ac44d85b0b 100644 --- a/Documentation/git-get-tar-commit-id.txt +++ b/third_party/git/Documentation/git-get-tar-commit-id.txt diff --git a/Documentation/git-grep.txt b/third_party/git/Documentation/git-grep.txt index ddb6acc025..ddb6acc025 100644 --- a/Documentation/git-grep.txt +++ b/third_party/git/Documentation/git-grep.txt diff --git a/Documentation/git-gui.txt b/third_party/git/Documentation/git-gui.txt index c9d7e96214..c9d7e96214 100644 --- a/Documentation/git-gui.txt +++ b/third_party/git/Documentation/git-gui.txt diff --git a/Documentation/git-hash-object.txt b/third_party/git/Documentation/git-hash-object.txt index df9e2c58bd..df9e2c58bd 100644 --- a/Documentation/git-hash-object.txt +++ b/third_party/git/Documentation/git-hash-object.txt diff --git a/Documentation/git-help.txt b/third_party/git/Documentation/git-help.txt index f71db0daa2..f71db0daa2 100644 --- a/Documentation/git-help.txt +++ b/third_party/git/Documentation/git-help.txt diff --git a/Documentation/git-http-backend.txt b/third_party/git/Documentation/git-http-backend.txt index 558966aa83..558966aa83 100644 --- a/Documentation/git-http-backend.txt +++ b/third_party/git/Documentation/git-http-backend.txt diff --git a/Documentation/git-http-fetch.txt b/third_party/git/Documentation/git-http-fetch.txt index 666b042679..666b042679 100644 --- a/Documentation/git-http-fetch.txt +++ b/third_party/git/Documentation/git-http-fetch.txt diff --git a/Documentation/git-http-push.txt b/third_party/git/Documentation/git-http-push.txt index ea03a4eeb0..ea03a4eeb0 100644 --- a/Documentation/git-http-push.txt +++ b/third_party/git/Documentation/git-http-push.txt diff --git a/Documentation/git-imap-send.txt b/third_party/git/Documentation/git-imap-send.txt index 65b53fcc47..65b53fcc47 100644 --- a/Documentation/git-imap-send.txt +++ b/third_party/git/Documentation/git-imap-send.txt diff --git a/Documentation/git-index-pack.txt b/third_party/git/Documentation/git-index-pack.txt index d5b7560bfe..d5b7560bfe 100644 --- a/Documentation/git-index-pack.txt +++ b/third_party/git/Documentation/git-index-pack.txt diff --git a/Documentation/git-init-db.txt b/third_party/git/Documentation/git-init-db.txt index 648a6cd78a..648a6cd78a 100644 --- a/Documentation/git-init-db.txt +++ b/third_party/git/Documentation/git-init-db.txt diff --git a/Documentation/git-init.txt b/third_party/git/Documentation/git-init.txt index 32880aafb0..32880aafb0 100644 --- a/Documentation/git-init.txt +++ b/third_party/git/Documentation/git-init.txt diff --git a/Documentation/git-instaweb.txt b/third_party/git/Documentation/git-instaweb.txt index a54fe4401b..a54fe4401b 100644 --- a/Documentation/git-instaweb.txt +++ b/third_party/git/Documentation/git-instaweb.txt diff --git a/Documentation/git-interpret-trailers.txt b/third_party/git/Documentation/git-interpret-trailers.txt index 96ec6499f0..96ec6499f0 100644 --- a/Documentation/git-interpret-trailers.txt +++ b/third_party/git/Documentation/git-interpret-trailers.txt diff --git a/Documentation/git-log.txt b/third_party/git/Documentation/git-log.txt index bed09bb09e..bed09bb09e 100644 --- a/Documentation/git-log.txt +++ b/third_party/git/Documentation/git-log.txt diff --git a/Documentation/git-ls-files.txt b/third_party/git/Documentation/git-ls-files.txt index 8461c0e83e..8461c0e83e 100644 --- a/Documentation/git-ls-files.txt +++ b/third_party/git/Documentation/git-ls-files.txt diff --git a/Documentation/git-ls-remote.txt b/third_party/git/Documentation/git-ls-remote.txt index 0a5c8b7d49..0a5c8b7d49 100644 --- a/Documentation/git-ls-remote.txt +++ b/third_party/git/Documentation/git-ls-remote.txt diff --git a/Documentation/git-ls-tree.txt b/third_party/git/Documentation/git-ls-tree.txt index a7515714da..a7515714da 100644 --- a/Documentation/git-ls-tree.txt +++ b/third_party/git/Documentation/git-ls-tree.txt diff --git a/Documentation/git-mailinfo.txt b/third_party/git/Documentation/git-mailinfo.txt index 3bbc731f67..3bbc731f67 100644 --- a/Documentation/git-mailinfo.txt +++ b/third_party/git/Documentation/git-mailinfo.txt diff --git a/Documentation/git-mailsplit.txt b/third_party/git/Documentation/git-mailsplit.txt index e3b2a88c4b..e3b2a88c4b 100644 --- a/Documentation/git-mailsplit.txt +++ b/third_party/git/Documentation/git-mailsplit.txt diff --git a/Documentation/git-merge-base.txt b/third_party/git/Documentation/git-merge-base.txt index 2d944e0851..2d944e0851 100644 --- a/Documentation/git-merge-base.txt +++ b/third_party/git/Documentation/git-merge-base.txt diff --git a/Documentation/git-merge-file.txt b/third_party/git/Documentation/git-merge-file.txt index f856032613..f856032613 100644 --- a/Documentation/git-merge-file.txt +++ b/third_party/git/Documentation/git-merge-file.txt diff --git a/Documentation/git-merge-index.txt b/third_party/git/Documentation/git-merge-index.txt index 2ab84a91e5..2ab84a91e5 100644 --- a/Documentation/git-merge-index.txt +++ b/third_party/git/Documentation/git-merge-index.txt diff --git a/Documentation/git-merge-one-file.txt b/third_party/git/Documentation/git-merge-one-file.txt index 04e803d5d3..04e803d5d3 100644 --- a/Documentation/git-merge-one-file.txt +++ b/third_party/git/Documentation/git-merge-one-file.txt diff --git a/Documentation/git-merge-tree.txt b/third_party/git/Documentation/git-merge-tree.txt index 58731c1942..58731c1942 100644 --- a/Documentation/git-merge-tree.txt +++ b/third_party/git/Documentation/git-merge-tree.txt diff --git a/Documentation/git-merge.txt b/third_party/git/Documentation/git-merge.txt index 092529c619..092529c619 100644 --- a/Documentation/git-merge.txt +++ b/third_party/git/Documentation/git-merge.txt diff --git a/Documentation/git-mergetool--lib.txt b/third_party/git/Documentation/git-mergetool--lib.txt index 4da9d24096..4da9d24096 100644 --- a/Documentation/git-mergetool--lib.txt +++ b/third_party/git/Documentation/git-mergetool--lib.txt diff --git a/Documentation/git-mergetool.txt b/third_party/git/Documentation/git-mergetool.txt index 6b14702e78..6b14702e78 100644 --- a/Documentation/git-mergetool.txt +++ b/third_party/git/Documentation/git-mergetool.txt diff --git a/Documentation/git-mktag.txt b/third_party/git/Documentation/git-mktag.txt index fa6a756123..fa6a756123 100644 --- a/Documentation/git-mktag.txt +++ b/third_party/git/Documentation/git-mktag.txt diff --git a/Documentation/git-mktree.txt b/third_party/git/Documentation/git-mktree.txt index 27fe2b32e1..27fe2b32e1 100644 --- a/Documentation/git-mktree.txt +++ b/third_party/git/Documentation/git-mktree.txt diff --git a/Documentation/git-multi-pack-index.txt b/third_party/git/Documentation/git-multi-pack-index.txt index 642d9ac5b7..642d9ac5b7 100644 --- a/Documentation/git-multi-pack-index.txt +++ b/third_party/git/Documentation/git-multi-pack-index.txt diff --git a/Documentation/git-mv.txt b/third_party/git/Documentation/git-mv.txt index 79449bf98f..79449bf98f 100644 --- a/Documentation/git-mv.txt +++ b/third_party/git/Documentation/git-mv.txt diff --git a/Documentation/git-name-rev.txt b/third_party/git/Documentation/git-name-rev.txt index 5cb0eb0855..5cb0eb0855 100644 --- a/Documentation/git-name-rev.txt +++ b/third_party/git/Documentation/git-name-rev.txt diff --git a/Documentation/git-notes.txt b/third_party/git/Documentation/git-notes.txt index ced2e8280e..ced2e8280e 100644 --- a/Documentation/git-notes.txt +++ b/third_party/git/Documentation/git-notes.txt diff --git a/Documentation/git-p4.txt b/third_party/git/Documentation/git-p4.txt index 3494a1db3e..3494a1db3e 100644 --- a/Documentation/git-p4.txt +++ b/third_party/git/Documentation/git-p4.txt diff --git a/Documentation/git-pack-objects.txt b/third_party/git/Documentation/git-pack-objects.txt index fecdf2600c..fecdf2600c 100644 --- a/Documentation/git-pack-objects.txt +++ b/third_party/git/Documentation/git-pack-objects.txt diff --git a/Documentation/git-pack-redundant.txt b/third_party/git/Documentation/git-pack-redundant.txt index f2869da572..f2869da572 100644 --- a/Documentation/git-pack-redundant.txt +++ b/third_party/git/Documentation/git-pack-redundant.txt diff --git a/Documentation/git-pack-refs.txt b/third_party/git/Documentation/git-pack-refs.txt index 154081f2de..154081f2de 100644 --- a/Documentation/git-pack-refs.txt +++ b/third_party/git/Documentation/git-pack-refs.txt diff --git a/Documentation/git-parse-remote.txt b/third_party/git/Documentation/git-parse-remote.txt index a45ea1ece8..a45ea1ece8 100644 --- a/Documentation/git-parse-remote.txt +++ b/third_party/git/Documentation/git-parse-remote.txt diff --git a/Documentation/git-patch-id.txt b/third_party/git/Documentation/git-patch-id.txt index 442caff8a9..442caff8a9 100644 --- a/Documentation/git-patch-id.txt +++ b/third_party/git/Documentation/git-patch-id.txt diff --git a/Documentation/git-prune-packed.txt b/third_party/git/Documentation/git-prune-packed.txt index 9fed59a317..9fed59a317 100644 --- a/Documentation/git-prune-packed.txt +++ b/third_party/git/Documentation/git-prune-packed.txt diff --git a/Documentation/git-prune.txt b/third_party/git/Documentation/git-prune.txt index 03552dd86f..03552dd86f 100644 --- a/Documentation/git-prune.txt +++ b/third_party/git/Documentation/git-prune.txt diff --git a/Documentation/git-pull.txt b/third_party/git/Documentation/git-pull.txt index dfb901f8b8..dfb901f8b8 100644 --- a/Documentation/git-pull.txt +++ b/third_party/git/Documentation/git-pull.txt diff --git a/Documentation/git-push.txt b/third_party/git/Documentation/git-push.txt index 3b8053447e..3b8053447e 100644 --- a/Documentation/git-push.txt +++ b/third_party/git/Documentation/git-push.txt diff --git a/Documentation/git-quiltimport.txt b/third_party/git/Documentation/git-quiltimport.txt index 70562dc4c0..70562dc4c0 100644 --- a/Documentation/git-quiltimport.txt +++ b/third_party/git/Documentation/git-quiltimport.txt diff --git a/Documentation/git-range-diff.txt b/third_party/git/Documentation/git-range-diff.txt index 9701c1e5fd..9701c1e5fd 100644 --- a/Documentation/git-range-diff.txt +++ b/third_party/git/Documentation/git-range-diff.txt diff --git a/Documentation/git-read-tree.txt b/third_party/git/Documentation/git-read-tree.txt index da33f84f33..da33f84f33 100644 --- a/Documentation/git-read-tree.txt +++ b/third_party/git/Documentation/git-read-tree.txt diff --git a/Documentation/git-rebase.txt b/third_party/git/Documentation/git-rebase.txt index f7a6033607..f7a6033607 100644 --- a/Documentation/git-rebase.txt +++ b/third_party/git/Documentation/git-rebase.txt diff --git a/Documentation/git-receive-pack.txt b/third_party/git/Documentation/git-receive-pack.txt index 25702ed730..25702ed730 100644 --- a/Documentation/git-receive-pack.txt +++ b/third_party/git/Documentation/git-receive-pack.txt diff --git a/Documentation/git-reflog.txt b/third_party/git/Documentation/git-reflog.txt index ff487ff77d..ff487ff77d 100644 --- a/Documentation/git-reflog.txt +++ b/third_party/git/Documentation/git-reflog.txt diff --git a/Documentation/git-remote-ext.txt b/third_party/git/Documentation/git-remote-ext.txt index 88ea7e1cc0..88ea7e1cc0 100644 --- a/Documentation/git-remote-ext.txt +++ b/third_party/git/Documentation/git-remote-ext.txt diff --git a/Documentation/git-remote-fd.txt b/third_party/git/Documentation/git-remote-fd.txt index 0451ceb8a2..0451ceb8a2 100644 --- a/Documentation/git-remote-fd.txt +++ b/third_party/git/Documentation/git-remote-fd.txt diff --git a/Documentation/git-remote-helpers.txto b/third_party/git/Documentation/git-remote-helpers.txto index 6f353ebfd3..6f353ebfd3 100644 --- a/Documentation/git-remote-helpers.txto +++ b/third_party/git/Documentation/git-remote-helpers.txto diff --git a/Documentation/git-remote.txt b/third_party/git/Documentation/git-remote.txt index 9659abbf8e..9659abbf8e 100644 --- a/Documentation/git-remote.txt +++ b/third_party/git/Documentation/git-remote.txt diff --git a/Documentation/git-repack.txt b/third_party/git/Documentation/git-repack.txt index 92f146d27d..92f146d27d 100644 --- a/Documentation/git-repack.txt +++ b/third_party/git/Documentation/git-repack.txt diff --git a/Documentation/git-replace.txt b/third_party/git/Documentation/git-replace.txt index f271d758c3..f271d758c3 100644 --- a/Documentation/git-replace.txt +++ b/third_party/git/Documentation/git-replace.txt diff --git a/Documentation/git-request-pull.txt b/third_party/git/Documentation/git-request-pull.txt index 4d4392d0f8..4d4392d0f8 100644 --- a/Documentation/git-request-pull.txt +++ b/third_party/git/Documentation/git-request-pull.txt diff --git a/Documentation/git-rerere.txt b/third_party/git/Documentation/git-rerere.txt index 4cfc883378..4cfc883378 100644 --- a/Documentation/git-rerere.txt +++ b/third_party/git/Documentation/git-rerere.txt diff --git a/Documentation/git-reset.txt b/third_party/git/Documentation/git-reset.txt index 932080c55d..932080c55d 100644 --- a/Documentation/git-reset.txt +++ b/third_party/git/Documentation/git-reset.txt diff --git a/Documentation/git-restore.txt b/third_party/git/Documentation/git-restore.txt index 5bf60d4943..5bf60d4943 100644 --- a/Documentation/git-restore.txt +++ b/third_party/git/Documentation/git-restore.txt diff --git a/Documentation/git-rev-list.txt b/third_party/git/Documentation/git-rev-list.txt index 025c911436..025c911436 100644 --- a/Documentation/git-rev-list.txt +++ b/third_party/git/Documentation/git-rev-list.txt diff --git a/Documentation/git-rev-parse.txt b/third_party/git/Documentation/git-rev-parse.txt index 19b12b6d43..19b12b6d43 100644 --- a/Documentation/git-rev-parse.txt +++ b/third_party/git/Documentation/git-rev-parse.txt diff --git a/Documentation/git-revert.txt b/third_party/git/Documentation/git-revert.txt index 9d22270757..9d22270757 100644 --- a/Documentation/git-revert.txt +++ b/third_party/git/Documentation/git-revert.txt diff --git a/Documentation/git-rm.txt b/third_party/git/Documentation/git-rm.txt index ab750367fd..ab750367fd 100644 --- a/Documentation/git-rm.txt +++ b/third_party/git/Documentation/git-rm.txt diff --git a/Documentation/git-send-email.txt b/third_party/git/Documentation/git-send-email.txt index 0a69810147..0a69810147 100644 --- a/Documentation/git-send-email.txt +++ b/third_party/git/Documentation/git-send-email.txt diff --git a/Documentation/git-send-pack.txt b/third_party/git/Documentation/git-send-pack.txt index 44fd146b91..44fd146b91 100644 --- a/Documentation/git-send-pack.txt +++ b/third_party/git/Documentation/git-send-pack.txt diff --git a/Documentation/git-sh-i18n--envsubst.txt b/third_party/git/Documentation/git-sh-i18n--envsubst.txt index 2ffaf9392e..2ffaf9392e 100644 --- a/Documentation/git-sh-i18n--envsubst.txt +++ b/third_party/git/Documentation/git-sh-i18n--envsubst.txt diff --git a/Documentation/git-sh-i18n.txt b/third_party/git/Documentation/git-sh-i18n.txt index 60cf49cb2a..60cf49cb2a 100644 --- a/Documentation/git-sh-i18n.txt +++ b/third_party/git/Documentation/git-sh-i18n.txt diff --git a/Documentation/git-sh-setup.txt b/third_party/git/Documentation/git-sh-setup.txt index 8632612c31..8632612c31 100644 --- a/Documentation/git-sh-setup.txt +++ b/third_party/git/Documentation/git-sh-setup.txt diff --git a/Documentation/git-shell.txt b/third_party/git/Documentation/git-shell.txt index 11361f33e9..11361f33e9 100644 --- a/Documentation/git-shell.txt +++ b/third_party/git/Documentation/git-shell.txt diff --git a/Documentation/git-shortlog.txt b/third_party/git/Documentation/git-shortlog.txt index a72ea7f7ba..a72ea7f7ba 100644 --- a/Documentation/git-shortlog.txt +++ b/third_party/git/Documentation/git-shortlog.txt diff --git a/Documentation/git-show-branch.txt b/third_party/git/Documentation/git-show-branch.txt index 5cc2fcefba..5cc2fcefba 100644 --- a/Documentation/git-show-branch.txt +++ b/third_party/git/Documentation/git-show-branch.txt diff --git a/Documentation/git-show-index.txt b/third_party/git/Documentation/git-show-index.txt index 424e4ba84c..424e4ba84c 100644 --- a/Documentation/git-show-index.txt +++ b/third_party/git/Documentation/git-show-index.txt diff --git a/Documentation/git-show-ref.txt b/third_party/git/Documentation/git-show-ref.txt index ab4d271925..ab4d271925 100644 --- a/Documentation/git-show-ref.txt +++ b/third_party/git/Documentation/git-show-ref.txt diff --git a/Documentation/git-show.txt b/third_party/git/Documentation/git-show.txt index fcf528c1b3..fcf528c1b3 100644 --- a/Documentation/git-show.txt +++ b/third_party/git/Documentation/git-show.txt diff --git a/Documentation/git-sparse-checkout.txt b/third_party/git/Documentation/git-sparse-checkout.txt index c0342e5393..c0342e5393 100644 --- a/Documentation/git-sparse-checkout.txt +++ b/third_party/git/Documentation/git-sparse-checkout.txt diff --git a/Documentation/git-stage.txt b/third_party/git/Documentation/git-stage.txt index 25bcda936d..25bcda936d 100644 --- a/Documentation/git-stage.txt +++ b/third_party/git/Documentation/git-stage.txt diff --git a/Documentation/git-stash.txt b/third_party/git/Documentation/git-stash.txt index 31f1beb65b..31f1beb65b 100644 --- a/Documentation/git-stash.txt +++ b/third_party/git/Documentation/git-stash.txt diff --git a/Documentation/git-status.txt b/third_party/git/Documentation/git-status.txt index 7731b45f07..7731b45f07 100644 --- a/Documentation/git-status.txt +++ b/third_party/git/Documentation/git-status.txt diff --git a/Documentation/git-stripspace.txt b/third_party/git/Documentation/git-stripspace.txt index 2438f76da0..2438f76da0 100644 --- a/Documentation/git-stripspace.txt +++ b/third_party/git/Documentation/git-stripspace.txt diff --git a/Documentation/git-submodule.txt b/third_party/git/Documentation/git-submodule.txt index c9ed2bf3d5..c9ed2bf3d5 100644 --- a/Documentation/git-submodule.txt +++ b/third_party/git/Documentation/git-submodule.txt diff --git a/Documentation/git-svn.txt b/third_party/git/Documentation/git-svn.txt index 6624a14fbd..6624a14fbd 100644 --- a/Documentation/git-svn.txt +++ b/third_party/git/Documentation/git-svn.txt diff --git a/Documentation/git-switch.txt b/third_party/git/Documentation/git-switch.txt index 197900363b..197900363b 100644 --- a/Documentation/git-switch.txt +++ b/third_party/git/Documentation/git-switch.txt diff --git a/Documentation/git-symbolic-ref.txt b/third_party/git/Documentation/git-symbolic-ref.txt index ef68ad2b71..ef68ad2b71 100644 --- a/Documentation/git-symbolic-ref.txt +++ b/third_party/git/Documentation/git-symbolic-ref.txt diff --git a/Documentation/git-tag.txt b/third_party/git/Documentation/git-tag.txt index f6d9791780..f6d9791780 100644 --- a/Documentation/git-tag.txt +++ b/third_party/git/Documentation/git-tag.txt diff --git a/Documentation/git-tools.txt b/third_party/git/Documentation/git-tools.txt index d0fec4cddd..d0fec4cddd 100644 --- a/Documentation/git-tools.txt +++ b/third_party/git/Documentation/git-tools.txt diff --git a/Documentation/git-unpack-file.txt b/third_party/git/Documentation/git-unpack-file.txt index e9f148a00d..e9f148a00d 100644 --- a/Documentation/git-unpack-file.txt +++ b/third_party/git/Documentation/git-unpack-file.txt diff --git a/Documentation/git-unpack-objects.txt b/third_party/git/Documentation/git-unpack-objects.txt index b3de50d710..b3de50d710 100644 --- a/Documentation/git-unpack-objects.txt +++ b/third_party/git/Documentation/git-unpack-objects.txt diff --git a/Documentation/git-update-index.txt b/third_party/git/Documentation/git-update-index.txt index 1489cb09a0..1489cb09a0 100644 --- a/Documentation/git-update-index.txt +++ b/third_party/git/Documentation/git-update-index.txt diff --git a/Documentation/git-update-ref.txt b/third_party/git/Documentation/git-update-ref.txt index 9671423117..9671423117 100644 --- a/Documentation/git-update-ref.txt +++ b/third_party/git/Documentation/git-update-ref.txt diff --git a/Documentation/git-update-server-info.txt b/third_party/git/Documentation/git-update-server-info.txt index 969bb2e15f..969bb2e15f 100644 --- a/Documentation/git-update-server-info.txt +++ b/third_party/git/Documentation/git-update-server-info.txt diff --git a/Documentation/git-upload-archive.txt b/third_party/git/Documentation/git-upload-archive.txt index fba0f1c1b2..fba0f1c1b2 100644 --- a/Documentation/git-upload-archive.txt +++ b/third_party/git/Documentation/git-upload-archive.txt diff --git a/Documentation/git-upload-pack.txt b/third_party/git/Documentation/git-upload-pack.txt index 9822c1eb1a..9822c1eb1a 100644 --- a/Documentation/git-upload-pack.txt +++ b/third_party/git/Documentation/git-upload-pack.txt diff --git a/Documentation/git-var.txt b/third_party/git/Documentation/git-var.txt index 6072f936ab..6072f936ab 100644 --- a/Documentation/git-var.txt +++ b/third_party/git/Documentation/git-var.txt diff --git a/Documentation/git-verify-commit.txt b/third_party/git/Documentation/git-verify-commit.txt index 92097f6673..92097f6673 100644 --- a/Documentation/git-verify-commit.txt +++ b/third_party/git/Documentation/git-verify-commit.txt diff --git a/Documentation/git-verify-pack.txt b/third_party/git/Documentation/git-verify-pack.txt index 61ca6d04c2..61ca6d04c2 100644 --- a/Documentation/git-verify-pack.txt +++ b/third_party/git/Documentation/git-verify-pack.txt diff --git a/Documentation/git-verify-tag.txt b/third_party/git/Documentation/git-verify-tag.txt index 0b8075dad9..0b8075dad9 100644 --- a/Documentation/git-verify-tag.txt +++ b/third_party/git/Documentation/git-verify-tag.txt diff --git a/Documentation/git-web--browse.txt b/third_party/git/Documentation/git-web--browse.txt index 8d162b56c5..8d162b56c5 100644 --- a/Documentation/git-web--browse.txt +++ b/third_party/git/Documentation/git-web--browse.txt diff --git a/Documentation/git-whatchanged.txt b/third_party/git/Documentation/git-whatchanged.txt index 8b63ceb00e..8b63ceb00e 100644 --- a/Documentation/git-whatchanged.txt +++ b/third_party/git/Documentation/git-whatchanged.txt diff --git a/Documentation/git-worktree.txt b/third_party/git/Documentation/git-worktree.txt index 85d92c9761..85d92c9761 100644 --- a/Documentation/git-worktree.txt +++ b/third_party/git/Documentation/git-worktree.txt diff --git a/Documentation/git-write-tree.txt b/third_party/git/Documentation/git-write-tree.txt index f22041a9dc..f22041a9dc 100644 --- a/Documentation/git-write-tree.txt +++ b/third_party/git/Documentation/git-write-tree.txt diff --git a/Documentation/git.txt b/third_party/git/Documentation/git.txt index b0672bd806..b0672bd806 100644 --- a/Documentation/git.txt +++ b/third_party/git/Documentation/git.txt diff --git a/Documentation/gitattributes.txt b/third_party/git/Documentation/gitattributes.txt index 508fe713c4..508fe713c4 100644 --- a/Documentation/gitattributes.txt +++ b/third_party/git/Documentation/gitattributes.txt diff --git a/Documentation/gitcli.txt b/third_party/git/Documentation/gitcli.txt index 92e4ba6a2f..92e4ba6a2f 100644 --- a/Documentation/gitcli.txt +++ b/third_party/git/Documentation/gitcli.txt diff --git a/Documentation/gitcore-tutorial.txt b/third_party/git/Documentation/gitcore-tutorial.txt index c0b95256cc..c0b95256cc 100644 --- a/Documentation/gitcore-tutorial.txt +++ b/third_party/git/Documentation/gitcore-tutorial.txt diff --git a/Documentation/gitcredentials.txt b/third_party/git/Documentation/gitcredentials.txt index 1814d2d23c..1814d2d23c 100644 --- a/Documentation/gitcredentials.txt +++ b/third_party/git/Documentation/gitcredentials.txt diff --git a/Documentation/gitcvs-migration.txt b/third_party/git/Documentation/gitcvs-migration.txt index 1cd1283d0f..1cd1283d0f 100644 --- a/Documentation/gitcvs-migration.txt +++ b/third_party/git/Documentation/gitcvs-migration.txt diff --git a/Documentation/gitdiffcore.txt b/third_party/git/Documentation/gitdiffcore.txt index c970d9fe43..c970d9fe43 100644 --- a/Documentation/gitdiffcore.txt +++ b/third_party/git/Documentation/gitdiffcore.txt diff --git a/Documentation/giteveryday.txt b/third_party/git/Documentation/giteveryday.txt index 1bd919f92b..1bd919f92b 100644 --- a/Documentation/giteveryday.txt +++ b/third_party/git/Documentation/giteveryday.txt diff --git a/Documentation/gitglossary.txt b/third_party/git/Documentation/gitglossary.txt index 571f640f5c..571f640f5c 100644 --- a/Documentation/gitglossary.txt +++ b/third_party/git/Documentation/gitglossary.txt diff --git a/Documentation/githooks.txt b/third_party/git/Documentation/githooks.txt index 3dccab5375..3dccab5375 100644 --- a/Documentation/githooks.txt +++ b/third_party/git/Documentation/githooks.txt diff --git a/Documentation/gitignore.txt b/third_party/git/Documentation/gitignore.txt index d47b1ae296..d47b1ae296 100644 --- a/Documentation/gitignore.txt +++ b/third_party/git/Documentation/gitignore.txt diff --git a/Documentation/gitk.txt b/third_party/git/Documentation/gitk.txt index c653ebb6a8..c653ebb6a8 100644 --- a/Documentation/gitk.txt +++ b/third_party/git/Documentation/gitk.txt diff --git a/Documentation/gitmodules.txt b/third_party/git/Documentation/gitmodules.txt index 67275fd187..67275fd187 100644 --- a/Documentation/gitmodules.txt +++ b/third_party/git/Documentation/gitmodules.txt diff --git a/Documentation/gitnamespaces.txt b/third_party/git/Documentation/gitnamespaces.txt index b614969ad2..b614969ad2 100644 --- a/Documentation/gitnamespaces.txt +++ b/third_party/git/Documentation/gitnamespaces.txt diff --git a/Documentation/gitremote-helpers.txt b/third_party/git/Documentation/gitremote-helpers.txt index f48a031dc3..f48a031dc3 100644 --- a/Documentation/gitremote-helpers.txt +++ b/third_party/git/Documentation/gitremote-helpers.txt diff --git a/Documentation/gitrepository-layout.txt b/third_party/git/Documentation/gitrepository-layout.txt index 1a2ef4c150..1a2ef4c150 100644 --- a/Documentation/gitrepository-layout.txt +++ b/third_party/git/Documentation/gitrepository-layout.txt diff --git a/Documentation/gitrevisions.txt b/third_party/git/Documentation/gitrevisions.txt index d407b7dee1..d407b7dee1 100644 --- a/Documentation/gitrevisions.txt +++ b/third_party/git/Documentation/gitrevisions.txt diff --git a/Documentation/gitsubmodules.txt b/third_party/git/Documentation/gitsubmodules.txt index c476f891b5..c476f891b5 100644 --- a/Documentation/gitsubmodules.txt +++ b/third_party/git/Documentation/gitsubmodules.txt diff --git a/Documentation/gittutorial-2.txt b/third_party/git/Documentation/gittutorial-2.txt index 8bdb7d0bd3..8bdb7d0bd3 100644 --- a/Documentation/gittutorial-2.txt +++ b/third_party/git/Documentation/gittutorial-2.txt diff --git a/Documentation/gittutorial.txt b/third_party/git/Documentation/gittutorial.txt index 59ef5cef1f..59ef5cef1f 100644 --- a/Documentation/gittutorial.txt +++ b/third_party/git/Documentation/gittutorial.txt diff --git a/Documentation/gitweb.conf.txt b/third_party/git/Documentation/gitweb.conf.txt index 7963a79ba9..7963a79ba9 100644 --- a/Documentation/gitweb.conf.txt +++ b/third_party/git/Documentation/gitweb.conf.txt diff --git a/Documentation/gitweb.txt b/third_party/git/Documentation/gitweb.txt index 3cc9b034c4..3cc9b034c4 100644 --- a/Documentation/gitweb.txt +++ b/third_party/git/Documentation/gitweb.txt diff --git a/Documentation/gitworkflows.txt b/third_party/git/Documentation/gitworkflows.txt index abc0dc6bc7..abc0dc6bc7 100644 --- a/Documentation/gitworkflows.txt +++ b/third_party/git/Documentation/gitworkflows.txt diff --git a/Documentation/glossary-content.txt b/third_party/git/Documentation/glossary-content.txt index 090c888335..090c888335 100644 --- a/Documentation/glossary-content.txt +++ b/third_party/git/Documentation/glossary-content.txt diff --git a/Documentation/howto-index.sh b/third_party/git/Documentation/howto-index.sh index 167b363668..167b363668 100755 --- a/Documentation/howto-index.sh +++ b/third_party/git/Documentation/howto-index.sh diff --git a/Documentation/howto/keep-canonical-history-correct.txt b/third_party/git/Documentation/howto/keep-canonical-history-correct.txt index 35d48ef714..35d48ef714 100644 --- a/Documentation/howto/keep-canonical-history-correct.txt +++ b/third_party/git/Documentation/howto/keep-canonical-history-correct.txt diff --git a/Documentation/howto/maintain-git.txt b/third_party/git/Documentation/howto/maintain-git.txt index ca4378740c..ca4378740c 100644 --- a/Documentation/howto/maintain-git.txt +++ b/third_party/git/Documentation/howto/maintain-git.txt diff --git a/Documentation/howto/new-command.txt b/third_party/git/Documentation/howto/new-command.txt index 15a4c8031f..15a4c8031f 100644 --- a/Documentation/howto/new-command.txt +++ b/third_party/git/Documentation/howto/new-command.txt diff --git a/Documentation/howto/rebase-from-internal-branch.txt b/third_party/git/Documentation/howto/rebase-from-internal-branch.txt index 02cb5f758d..02cb5f758d 100644 --- a/Documentation/howto/rebase-from-internal-branch.txt +++ b/third_party/git/Documentation/howto/rebase-from-internal-branch.txt diff --git a/Documentation/howto/rebuild-from-update-hook.txt b/third_party/git/Documentation/howto/rebuild-from-update-hook.txt index db219f5c07..db219f5c07 100644 --- a/Documentation/howto/rebuild-from-update-hook.txt +++ b/third_party/git/Documentation/howto/rebuild-from-update-hook.txt diff --git a/Documentation/howto/recover-corrupted-blob-object.txt b/third_party/git/Documentation/howto/recover-corrupted-blob-object.txt index 1b3b188d3c..1b3b188d3c 100644 --- a/Documentation/howto/recover-corrupted-blob-object.txt +++ b/third_party/git/Documentation/howto/recover-corrupted-blob-object.txt diff --git a/Documentation/howto/recover-corrupted-object-harder.txt b/third_party/git/Documentation/howto/recover-corrupted-object-harder.txt index 8994e2559e..8994e2559e 100644 --- a/Documentation/howto/recover-corrupted-object-harder.txt +++ b/third_party/git/Documentation/howto/recover-corrupted-object-harder.txt diff --git a/Documentation/howto/revert-a-faulty-merge.txt b/third_party/git/Documentation/howto/revert-a-faulty-merge.txt index 19f59cc888..19f59cc888 100644 --- a/Documentation/howto/revert-a-faulty-merge.txt +++ b/third_party/git/Documentation/howto/revert-a-faulty-merge.txt diff --git a/Documentation/howto/revert-branch-rebase.txt b/third_party/git/Documentation/howto/revert-branch-rebase.txt index 149508e13b..149508e13b 100644 --- a/Documentation/howto/revert-branch-rebase.txt +++ b/third_party/git/Documentation/howto/revert-branch-rebase.txt diff --git a/Documentation/howto/separating-topic-branches.txt b/third_party/git/Documentation/howto/separating-topic-branches.txt index 81be0d6115..81be0d6115 100644 --- a/Documentation/howto/separating-topic-branches.txt +++ b/third_party/git/Documentation/howto/separating-topic-branches.txt diff --git a/Documentation/howto/setup-git-server-over-http.txt b/third_party/git/Documentation/howto/setup-git-server-over-http.txt index bfe6f9b500..bfe6f9b500 100644 --- a/Documentation/howto/setup-git-server-over-http.txt +++ b/third_party/git/Documentation/howto/setup-git-server-over-http.txt diff --git a/Documentation/howto/update-hook-example.txt b/third_party/git/Documentation/howto/update-hook-example.txt index 89821ec74f..89821ec74f 100644 --- a/Documentation/howto/update-hook-example.txt +++ b/third_party/git/Documentation/howto/update-hook-example.txt diff --git a/Documentation/howto/use-git-daemon.txt b/third_party/git/Documentation/howto/use-git-daemon.txt index 7af2e52cf3..7af2e52cf3 100644 --- a/Documentation/howto/use-git-daemon.txt +++ b/third_party/git/Documentation/howto/use-git-daemon.txt diff --git a/Documentation/howto/using-merge-subtree.txt b/third_party/git/Documentation/howto/using-merge-subtree.txt index a499a94ac2..a499a94ac2 100644 --- a/Documentation/howto/using-merge-subtree.txt +++ b/third_party/git/Documentation/howto/using-merge-subtree.txt diff --git a/Documentation/howto/using-signed-tag-in-pull-request.txt b/third_party/git/Documentation/howto/using-signed-tag-in-pull-request.txt index bbf040eda8..bbf040eda8 100644 --- a/Documentation/howto/using-signed-tag-in-pull-request.txt +++ b/third_party/git/Documentation/howto/using-signed-tag-in-pull-request.txt diff --git a/Documentation/i18n.txt b/third_party/git/Documentation/i18n.txt index 7e36e5b55b..7e36e5b55b 100644 --- a/Documentation/i18n.txt +++ b/third_party/git/Documentation/i18n.txt diff --git a/Documentation/install-doc-quick.sh b/third_party/git/Documentation/install-doc-quick.sh index 17231d8e59..17231d8e59 100755 --- a/Documentation/install-doc-quick.sh +++ b/third_party/git/Documentation/install-doc-quick.sh diff --git a/Documentation/install-webdoc.sh b/third_party/git/Documentation/install-webdoc.sh index ed8b4ff3e5..ed8b4ff3e5 100755 --- a/Documentation/install-webdoc.sh +++ b/third_party/git/Documentation/install-webdoc.sh diff --git a/Documentation/line-range-format.txt b/third_party/git/Documentation/line-range-format.txt index 829676ff98..829676ff98 100644 --- a/Documentation/line-range-format.txt +++ b/third_party/git/Documentation/line-range-format.txt diff --git a/Documentation/lint-gitlink.perl b/third_party/git/Documentation/lint-gitlink.perl index 476cc30b83..476cc30b83 100755 --- a/Documentation/lint-gitlink.perl +++ b/third_party/git/Documentation/lint-gitlink.perl diff --git a/Documentation/mailmap.txt b/third_party/git/Documentation/mailmap.txt index 4a8c276529..4a8c276529 100644 --- a/Documentation/mailmap.txt +++ b/third_party/git/Documentation/mailmap.txt diff --git a/Documentation/manpage-1.72.xsl b/third_party/git/Documentation/manpage-1.72.xsl index b4d315cb8c..b4d315cb8c 100644 --- a/Documentation/manpage-1.72.xsl +++ b/third_party/git/Documentation/manpage-1.72.xsl diff --git a/Documentation/manpage-base-url.xsl.in b/third_party/git/Documentation/manpage-base-url.xsl.in index e800904df3..e800904df3 100644 --- a/Documentation/manpage-base-url.xsl.in +++ b/third_party/git/Documentation/manpage-base-url.xsl.in diff --git a/Documentation/manpage-base.xsl b/third_party/git/Documentation/manpage-base.xsl index a264fa6160..a264fa6160 100644 --- a/Documentation/manpage-base.xsl +++ b/third_party/git/Documentation/manpage-base.xsl diff --git a/Documentation/manpage-bold-literal.xsl b/third_party/git/Documentation/manpage-bold-literal.xsl index 94d6c1b545..94d6c1b545 100644 --- a/Documentation/manpage-bold-literal.xsl +++ b/third_party/git/Documentation/manpage-bold-literal.xsl diff --git a/Documentation/manpage-normal.xsl b/third_party/git/Documentation/manpage-normal.xsl index a48f5b11f3..a48f5b11f3 100644 --- a/Documentation/manpage-normal.xsl +++ b/third_party/git/Documentation/manpage-normal.xsl diff --git a/Documentation/manpage-quote-apos.xsl b/third_party/git/Documentation/manpage-quote-apos.xsl index aeb8839f33..aeb8839f33 100644 --- a/Documentation/manpage-quote-apos.xsl +++ b/third_party/git/Documentation/manpage-quote-apos.xsl diff --git a/Documentation/manpage-suppress-sp.xsl b/third_party/git/Documentation/manpage-suppress-sp.xsl index a63c7632a8..a63c7632a8 100644 --- a/Documentation/manpage-suppress-sp.xsl +++ b/third_party/git/Documentation/manpage-suppress-sp.xsl diff --git a/Documentation/manpage.xsl b/third_party/git/Documentation/manpage.xsl index ef64bab17a..ef64bab17a 100644 --- a/Documentation/manpage.xsl +++ b/third_party/git/Documentation/manpage.xsl diff --git a/Documentation/merge-options.txt b/third_party/git/Documentation/merge-options.txt index 40dc4f5e8c..40dc4f5e8c 100644 --- a/Documentation/merge-options.txt +++ b/third_party/git/Documentation/merge-options.txt diff --git a/Documentation/merge-strategies.txt b/third_party/git/Documentation/merge-strategies.txt index 2912de706b..2912de706b 100644 --- a/Documentation/merge-strategies.txt +++ b/third_party/git/Documentation/merge-strategies.txt diff --git a/Documentation/pretty-formats.txt b/third_party/git/Documentation/pretty-formats.txt index a4b6f49186..a4b6f49186 100644 --- a/Documentation/pretty-formats.txt +++ b/third_party/git/Documentation/pretty-formats.txt diff --git a/Documentation/pretty-options.txt b/third_party/git/Documentation/pretty-options.txt index 7a6da6db78..7a6da6db78 100644 --- a/Documentation/pretty-options.txt +++ b/third_party/git/Documentation/pretty-options.txt diff --git a/Documentation/pull-fetch-param.txt b/third_party/git/Documentation/pull-fetch-param.txt index 7d3a60f5b9..7d3a60f5b9 100644 --- a/Documentation/pull-fetch-param.txt +++ b/third_party/git/Documentation/pull-fetch-param.txt diff --git a/Documentation/rev-list-options.txt b/third_party/git/Documentation/rev-list-options.txt index bfd02ade99..0d49eb448f 100644 --- a/Documentation/rev-list-options.txt +++ b/third_party/git/Documentation/rev-list-options.txt @@ -890,6 +890,9 @@ omitted. 1970). As with `--raw`, this is always in UTC and therefore `-local` has no effect. +`--date=dottime` shows the date in dottime format (rendered as UTC, +but suffixed with the local timezone offset if given) + `--date=format:...` feeds the format `...` to your system `strftime`, except for %z and %Z, which are handled internally. Use `--date=format:%c` to show the date in your system locale's diff --git a/Documentation/revisions.txt b/third_party/git/Documentation/revisions.txt index 97f995e5a9..97f995e5a9 100644 --- a/Documentation/revisions.txt +++ b/third_party/git/Documentation/revisions.txt diff --git a/Documentation/sequencer.txt b/third_party/git/Documentation/sequencer.txt index 3bceb56474..3bceb56474 100644 --- a/Documentation/sequencer.txt +++ b/third_party/git/Documentation/sequencer.txt diff --git a/Documentation/technical/.gitignore b/third_party/git/Documentation/technical/.gitignore index 8aa891daee..8aa891daee 100644 --- a/Documentation/technical/.gitignore +++ b/third_party/git/Documentation/technical/.gitignore diff --git a/Documentation/technical/api-error-handling.txt b/third_party/git/Documentation/technical/api-error-handling.txt index ceeedd485c..ceeedd485c 100644 --- a/Documentation/technical/api-error-handling.txt +++ b/third_party/git/Documentation/technical/api-error-handling.txt diff --git a/Documentation/technical/api-index-skel.txt b/third_party/git/Documentation/technical/api-index-skel.txt index eda8c195c1..eda8c195c1 100644 --- a/Documentation/technical/api-index-skel.txt +++ b/third_party/git/Documentation/technical/api-index-skel.txt diff --git a/Documentation/technical/api-index.sh b/third_party/git/Documentation/technical/api-index.sh index 9c3f4131b8..9c3f4131b8 100755 --- a/Documentation/technical/api-index.sh +++ b/third_party/git/Documentation/technical/api-index.sh diff --git a/Documentation/technical/api-merge.txt b/third_party/git/Documentation/technical/api-merge.txt index 487d4d83ff..487d4d83ff 100644 --- a/Documentation/technical/api-merge.txt +++ b/third_party/git/Documentation/technical/api-merge.txt diff --git a/Documentation/technical/api-parse-options.txt b/third_party/git/Documentation/technical/api-parse-options.txt index 2e2e7c10c6..2e2e7c10c6 100644 --- a/Documentation/technical/api-parse-options.txt +++ b/third_party/git/Documentation/technical/api-parse-options.txt diff --git a/Documentation/technical/api-trace2.txt b/third_party/git/Documentation/technical/api-trace2.txt index 4f07ceadcb..4f07ceadcb 100644 --- a/Documentation/technical/api-trace2.txt +++ b/third_party/git/Documentation/technical/api-trace2.txt diff --git a/Documentation/technical/bitmap-format.txt b/third_party/git/Documentation/technical/bitmap-format.txt index f8c18a0f7a..f8c18a0f7a 100644 --- a/Documentation/technical/bitmap-format.txt +++ b/third_party/git/Documentation/technical/bitmap-format.txt diff --git a/Documentation/technical/bundle-format.txt b/third_party/git/Documentation/technical/bundle-format.txt index 0e828151a5..0e828151a5 100644 --- a/Documentation/technical/bundle-format.txt +++ b/third_party/git/Documentation/technical/bundle-format.txt diff --git a/Documentation/technical/commit-graph-format.txt b/third_party/git/Documentation/technical/commit-graph-format.txt index a4f17441ae..a4f17441ae 100644 --- a/Documentation/technical/commit-graph-format.txt +++ b/third_party/git/Documentation/technical/commit-graph-format.txt diff --git a/Documentation/technical/commit-graph.txt b/third_party/git/Documentation/technical/commit-graph.txt index 808fa30b99..808fa30b99 100644 --- a/Documentation/technical/commit-graph.txt +++ b/third_party/git/Documentation/technical/commit-graph.txt diff --git a/Documentation/technical/directory-rename-detection.txt b/third_party/git/Documentation/technical/directory-rename-detection.txt index 844629c8c4..844629c8c4 100644 --- a/Documentation/technical/directory-rename-detection.txt +++ b/third_party/git/Documentation/technical/directory-rename-detection.txt diff --git a/Documentation/technical/hash-function-transition.txt b/third_party/git/Documentation/technical/hash-function-transition.txt index 5b2db3be1e..5b2db3be1e 100644 --- a/Documentation/technical/hash-function-transition.txt +++ b/third_party/git/Documentation/technical/hash-function-transition.txt diff --git a/Documentation/technical/http-protocol.txt b/third_party/git/Documentation/technical/http-protocol.txt index 9c5b6f0fac..9c5b6f0fac 100644 --- a/Documentation/technical/http-protocol.txt +++ b/third_party/git/Documentation/technical/http-protocol.txt diff --git a/Documentation/technical/index-format.txt b/third_party/git/Documentation/technical/index-format.txt index faa25c5c52..faa25c5c52 100644 --- a/Documentation/technical/index-format.txt +++ b/third_party/git/Documentation/technical/index-format.txt diff --git a/Documentation/technical/long-running-process-protocol.txt b/third_party/git/Documentation/technical/long-running-process-protocol.txt index aa0aa9af1c..aa0aa9af1c 100644 --- a/Documentation/technical/long-running-process-protocol.txt +++ b/third_party/git/Documentation/technical/long-running-process-protocol.txt diff --git a/Documentation/technical/multi-pack-index.txt b/third_party/git/Documentation/technical/multi-pack-index.txt index 4e7631437a..4e7631437a 100644 --- a/Documentation/technical/multi-pack-index.txt +++ b/third_party/git/Documentation/technical/multi-pack-index.txt diff --git a/Documentation/technical/pack-format.txt b/third_party/git/Documentation/technical/pack-format.txt index d3a142c652..d3a142c652 100644 --- a/Documentation/technical/pack-format.txt +++ b/third_party/git/Documentation/technical/pack-format.txt diff --git a/Documentation/technical/pack-heuristics.txt b/third_party/git/Documentation/technical/pack-heuristics.txt index 95a07db6e8..95a07db6e8 100644 --- a/Documentation/technical/pack-heuristics.txt +++ b/third_party/git/Documentation/technical/pack-heuristics.txt diff --git a/Documentation/technical/pack-protocol.txt b/third_party/git/Documentation/technical/pack-protocol.txt index d5ce4eea8a..d5ce4eea8a 100644 --- a/Documentation/technical/pack-protocol.txt +++ b/third_party/git/Documentation/technical/pack-protocol.txt diff --git a/Documentation/technical/partial-clone.txt b/third_party/git/Documentation/technical/partial-clone.txt index b9e17e7a28..b9e17e7a28 100644 --- a/Documentation/technical/partial-clone.txt +++ b/third_party/git/Documentation/technical/partial-clone.txt diff --git a/Documentation/technical/protocol-capabilities.txt b/third_party/git/Documentation/technical/protocol-capabilities.txt index 2b267c0da6..2b267c0da6 100644 --- a/Documentation/technical/protocol-capabilities.txt +++ b/third_party/git/Documentation/technical/protocol-capabilities.txt diff --git a/Documentation/technical/protocol-common.txt b/third_party/git/Documentation/technical/protocol-common.txt index ecedb34bba..ecedb34bba 100644 --- a/Documentation/technical/protocol-common.txt +++ b/third_party/git/Documentation/technical/protocol-common.txt diff --git a/Documentation/technical/protocol-v2.txt b/third_party/git/Documentation/technical/protocol-v2.txt index 7e3766cafb..7e3766cafb 100644 --- a/Documentation/technical/protocol-v2.txt +++ b/third_party/git/Documentation/technical/protocol-v2.txt diff --git a/Documentation/technical/racy-git.txt b/third_party/git/Documentation/technical/racy-git.txt index ceda4bbfda..ceda4bbfda 100644 --- a/Documentation/technical/racy-git.txt +++ b/third_party/git/Documentation/technical/racy-git.txt diff --git a/Documentation/technical/repository-version.txt b/third_party/git/Documentation/technical/repository-version.txt index 7844ef30ff..7844ef30ff 100644 --- a/Documentation/technical/repository-version.txt +++ b/third_party/git/Documentation/technical/repository-version.txt diff --git a/Documentation/technical/rerere.txt b/third_party/git/Documentation/technical/rerere.txt index af5f9fc24f..af5f9fc24f 100644 --- a/Documentation/technical/rerere.txt +++ b/third_party/git/Documentation/technical/rerere.txt diff --git a/Documentation/technical/send-pack-pipeline.txt b/third_party/git/Documentation/technical/send-pack-pipeline.txt index 9b5a0bc186..9b5a0bc186 100644 --- a/Documentation/technical/send-pack-pipeline.txt +++ b/third_party/git/Documentation/technical/send-pack-pipeline.txt diff --git a/Documentation/technical/shallow.txt b/third_party/git/Documentation/technical/shallow.txt index 01dedfe9ff..01dedfe9ff 100644 --- a/Documentation/technical/shallow.txt +++ b/third_party/git/Documentation/technical/shallow.txt diff --git a/Documentation/technical/signature-format.txt b/third_party/git/Documentation/technical/signature-format.txt index 2c9406a56a..2c9406a56a 100644 --- a/Documentation/technical/signature-format.txt +++ b/third_party/git/Documentation/technical/signature-format.txt diff --git a/Documentation/technical/trivial-merge.txt b/third_party/git/Documentation/technical/trivial-merge.txt index 1f1c33d0da..1f1c33d0da 100644 --- a/Documentation/technical/trivial-merge.txt +++ b/third_party/git/Documentation/technical/trivial-merge.txt diff --git a/Documentation/texi.xsl b/third_party/git/Documentation/texi.xsl index 0f8ff07eca..0f8ff07eca 100644 --- a/Documentation/texi.xsl +++ b/third_party/git/Documentation/texi.xsl diff --git a/Documentation/trace2-target-values.txt b/third_party/git/Documentation/trace2-target-values.txt index 3985b6d3c2..3985b6d3c2 100644 --- a/Documentation/trace2-target-values.txt +++ b/third_party/git/Documentation/trace2-target-values.txt diff --git a/Documentation/transfer-data-leaks.txt b/third_party/git/Documentation/transfer-data-leaks.txt index 914bacc39e..914bacc39e 100644 --- a/Documentation/transfer-data-leaks.txt +++ b/third_party/git/Documentation/transfer-data-leaks.txt diff --git a/Documentation/urls-remotes.txt b/third_party/git/Documentation/urls-remotes.txt index bd184cd653..bd184cd653 100644 --- a/Documentation/urls-remotes.txt +++ b/third_party/git/Documentation/urls-remotes.txt diff --git a/Documentation/urls.txt b/third_party/git/Documentation/urls.txt index 1c229d7581..1c229d7581 100644 --- a/Documentation/urls.txt +++ b/third_party/git/Documentation/urls.txt diff --git a/Documentation/user-manual.conf b/third_party/git/Documentation/user-manual.conf index d87294de2f..d87294de2f 100644 --- a/Documentation/user-manual.conf +++ b/third_party/git/Documentation/user-manual.conf diff --git a/Documentation/user-manual.txt b/third_party/git/Documentation/user-manual.txt index 833652983f..833652983f 100644 --- a/Documentation/user-manual.txt +++ b/third_party/git/Documentation/user-manual.txt diff --git a/GIT-VERSION-GEN b/third_party/git/GIT-VERSION-GEN index dafe6d036a..dafe6d036a 100755 --- a/GIT-VERSION-GEN +++ b/third_party/git/GIT-VERSION-GEN diff --git a/INSTALL b/third_party/git/INSTALL index 22c364f34f..22c364f34f 100644 --- a/INSTALL +++ b/third_party/git/INSTALL diff --git a/LGPL-2.1 b/third_party/git/LGPL-2.1 index d38b1b92bd..d38b1b92bd 100644 --- a/LGPL-2.1 +++ b/third_party/git/LGPL-2.1 diff --git a/Makefile b/third_party/git/Makefile index 9804a0758b..9804a0758b 100644 --- a/Makefile +++ b/third_party/git/Makefile diff --git a/third_party/git/README.md b/third_party/git/README.md new file mode 100644 index 0000000000..9d4564c8aa --- /dev/null +++ b/third_party/git/README.md @@ -0,0 +1,66 @@ +[](https://dev.azure.com/git/git/_build/latest?definitionId=11) + +Git - fast, scalable, distributed revision control system +========================================================= + +Git is a fast, scalable, distributed revision control system with an +unusually rich command set that provides both high-level operations +and full access to internals. + +Git is an Open Source project covered by the GNU General Public +License version 2 (some parts of it are under different licenses, +compatible with the GPLv2). It was originally written by Linus +Torvalds with help of a group of hackers around the net. + +Please read the file [INSTALL][] for installation instructions. + +Many Git online resources are accessible from <https://git-scm.com/> +including full documentation and Git related tools. + +See [Documentation/gittutorial.txt][] to get started, then see +[Documentation/giteveryday.txt][] for a useful minimum set of commands, and +`Documentation/git-<commandname>.txt` for documentation of each command. +If git has been correctly installed, then the tutorial can also be +read with `man gittutorial` or `git help tutorial`, and the +documentation of each command with `man git-<commandname>` or `git help +<commandname>`. + +CVS users may also want to read [Documentation/gitcvs-migration.txt][] +(`man gitcvs-migration` or `git help cvs-migration` if git is +installed). + +The user discussion and development of Git take place on the Git +mailing list -- everyone is welcome to post bug reports, feature +requests, comments and patches to git@vger.kernel.org (read +[Documentation/SubmittingPatches][] for instructions on patch submission). +To subscribe to the list, send an email with just "subscribe git" in +the body to majordomo@vger.kernel.org. The mailing list archives are +available at <https://lore.kernel.org/git/>, +<http://marc.info/?l=git> and other archival sites. + +Issues which are security relevant should be disclosed privately to +the Git Security mailing list <git-security@googlegroups.com>. + +The maintainer frequently sends the "What's cooking" reports that +list the current status of various development topics to the mailing +list. The discussion following them give a good reference for +project status, development direction and remaining tasks. + +The name "git" was given by Linus Torvalds when he wrote the very +first version. He described the tool as "the stupid content tracker" +and the name as (depending on your mood): + + - random three-letter combination that is pronounceable, and not + actually used by any common UNIX command. The fact that it is a + mispronunciation of "get" may or may not be relevant. + - stupid. contemptible and despicable. simple. Take your pick from the + dictionary of slang. + - "global information tracker": you're in a good mood, and it actually + works for you. Angels sing, and a light suddenly fills the room. + - "goddamn idiotic truckload of sh*t": when it breaks + +[INSTALL]: INSTALL +[Documentation/gittutorial.txt]: Documentation/gittutorial.txt +[Documentation/giteveryday.txt]: Documentation/giteveryday.txt +[Documentation/gitcvs-migration.txt]: Documentation/gitcvs-migration.txt +[Documentation/SubmittingPatches]: Documentation/SubmittingPatches diff --git a/RelNotes b/third_party/git/RelNotes index 3427be6818..3427be6818 120000 --- a/RelNotes +++ b/third_party/git/RelNotes diff --git a/abspath.c b/third_party/git/abspath.c index 9857985329..9857985329 100644 --- a/abspath.c +++ b/third_party/git/abspath.c diff --git a/aclocal.m4 b/third_party/git/aclocal.m4 index f11bc7ed7d..f11bc7ed7d 100644 --- a/aclocal.m4 +++ b/third_party/git/aclocal.m4 diff --git a/add-interactive.c b/third_party/git/add-interactive.c index 4a9bf85cac..4a9bf85cac 100644 --- a/add-interactive.c +++ b/third_party/git/add-interactive.c diff --git a/add-interactive.h b/third_party/git/add-interactive.h index 693f125e8e..693f125e8e 100644 --- a/add-interactive.h +++ b/third_party/git/add-interactive.h diff --git a/add-patch.c b/third_party/git/add-patch.c index d8dafa8168..d8dafa8168 100644 --- a/add-patch.c +++ b/third_party/git/add-patch.c diff --git a/advice.c b/third_party/git/advice.c index 97f3f981b4..97f3f981b4 100644 --- a/advice.c +++ b/third_party/git/advice.c diff --git a/advice.h b/third_party/git/advice.h index 0e6e58d9f8..0e6e58d9f8 100644 --- a/advice.h +++ b/third_party/git/advice.h diff --git a/alias.c b/third_party/git/alias.c index c471538020..c471538020 100644 --- a/alias.c +++ b/third_party/git/alias.c diff --git a/alias.h b/third_party/git/alias.h index aef4843bb7..aef4843bb7 100644 --- a/alias.h +++ b/third_party/git/alias.h diff --git a/alloc.c b/third_party/git/alloc.c index 1c64c4dd16..1c64c4dd16 100644 --- a/alloc.c +++ b/third_party/git/alloc.c diff --git a/alloc.h b/third_party/git/alloc.h index ed1071c11e..ed1071c11e 100644 --- a/alloc.h +++ b/third_party/git/alloc.h diff --git a/apply.c b/third_party/git/apply.c index bdc008fae2..bdc008fae2 100644 --- a/apply.c +++ b/third_party/git/apply.c diff --git a/apply.h b/third_party/git/apply.h index da3d95fa50..da3d95fa50 100644 --- a/apply.h +++ b/third_party/git/apply.h diff --git a/archive-tar.c b/third_party/git/archive-tar.c index 5a77701a15..5a77701a15 100644 --- a/archive-tar.c +++ b/third_party/git/archive-tar.c diff --git a/archive-zip.c b/third_party/git/archive-zip.c index e9f426298b..e9f426298b 100644 --- a/archive-zip.c +++ b/third_party/git/archive-zip.c diff --git a/archive.c b/third_party/git/archive.c index a8da0fcc4f..a8da0fcc4f 100644 --- a/archive.c +++ b/third_party/git/archive.c diff --git a/archive.h b/third_party/git/archive.h index e60e3dd31c..e60e3dd31c 100644 --- a/archive.h +++ b/third_party/git/archive.h diff --git a/argv-array.c b/third_party/git/argv-array.c index 61ef8c0dfd..61ef8c0dfd 100644 --- a/argv-array.c +++ b/third_party/git/argv-array.c diff --git a/argv-array.h b/third_party/git/argv-array.h index a7d3b10707..a7d3b10707 100644 --- a/argv-array.h +++ b/third_party/git/argv-array.h diff --git a/attr.c b/third_party/git/attr.c index a826b2ef1f..a826b2ef1f 100644 --- a/attr.c +++ b/third_party/git/attr.c diff --git a/attr.h b/third_party/git/attr.h index 404548f028..404548f028 100644 --- a/attr.h +++ b/third_party/git/attr.h diff --git a/azure-pipelines.yml b/third_party/git/azure-pipelines.yml index 675c3a43c9..675c3a43c9 100644 --- a/azure-pipelines.yml +++ b/third_party/git/azure-pipelines.yml diff --git a/banned.h b/third_party/git/banned.h index 60a18d4403..60a18d4403 100644 --- a/banned.h +++ b/third_party/git/banned.h diff --git a/base85.c b/third_party/git/base85.c index 5ca601ee14..5ca601ee14 100644 --- a/base85.c +++ b/third_party/git/base85.c diff --git a/bisect.c b/third_party/git/bisect.c index 9154f810f7..9154f810f7 100644 --- a/bisect.c +++ b/third_party/git/bisect.c diff --git a/bisect.h b/third_party/git/bisect.h index 8bad8d8391..8bad8d8391 100644 --- a/bisect.h +++ b/third_party/git/bisect.h diff --git a/blame.c b/third_party/git/blame.c index 29770e5c81..29770e5c81 100644 --- a/blame.c +++ b/third_party/git/blame.c diff --git a/blame.h b/third_party/git/blame.h index 089b181ff2..089b181ff2 100644 --- a/blame.h +++ b/third_party/git/blame.h diff --git a/blob.c b/third_party/git/blob.c index 36f9abda19..36f9abda19 100644 --- a/blob.c +++ b/third_party/git/blob.c diff --git a/blob.h b/third_party/git/blob.h index 1664872055..1664872055 100644 --- a/blob.h +++ b/third_party/git/blob.h diff --git a/block-sha1/sha1.c b/third_party/git/block-sha1/sha1.c index 22b125cf8c..22b125cf8c 100644 --- a/block-sha1/sha1.c +++ b/third_party/git/block-sha1/sha1.c diff --git a/block-sha1/sha1.h b/third_party/git/block-sha1/sha1.h index 4df6747752..4df6747752 100644 --- a/block-sha1/sha1.h +++ b/third_party/git/block-sha1/sha1.h diff --git a/branch.c b/third_party/git/branch.c index 579494738a..579494738a 100644 --- a/branch.c +++ b/third_party/git/branch.c diff --git a/branch.h b/third_party/git/branch.h index df0be61506..df0be61506 100644 --- a/branch.h +++ b/third_party/git/branch.h diff --git a/builtin.h b/third_party/git/builtin.h index 2b25a80cde..2b25a80cde 100644 --- a/builtin.h +++ b/third_party/git/builtin.h diff --git a/builtin/add.c b/third_party/git/builtin/add.c index 18a0881ecf..18a0881ecf 100644 --- a/builtin/add.c +++ b/third_party/git/builtin/add.c diff --git a/builtin/am.c b/third_party/git/builtin/am.c index e3dfd93c25..e3dfd93c25 100644 --- a/builtin/am.c +++ b/third_party/git/builtin/am.c diff --git a/builtin/annotate.c b/third_party/git/builtin/annotate.c index da413ae0d1..da413ae0d1 100644 --- a/builtin/annotate.c +++ b/third_party/git/builtin/annotate.c diff --git a/builtin/apply.c b/third_party/git/builtin/apply.c index 3f099b9605..3f099b9605 100644 --- a/builtin/apply.c +++ b/third_party/git/builtin/apply.c diff --git a/builtin/archive.c b/third_party/git/builtin/archive.c index 45d11669aa..45d11669aa 100644 --- a/builtin/archive.c +++ b/third_party/git/builtin/archive.c diff --git a/builtin/bisect--helper.c b/third_party/git/builtin/bisect--helper.c index c1c40b516d..c1c40b516d 100644 --- a/builtin/bisect--helper.c +++ b/third_party/git/builtin/bisect--helper.c diff --git a/builtin/blame.c b/third_party/git/builtin/blame.c index bf1cecdf3f..edd4bf7e3b 100644 --- a/builtin/blame.c +++ b/third_party/git/builtin/blame.c @@ -981,6 +981,9 @@ parse_done: case DATE_STRFTIME: blame_date_width = strlen(show_date(0, 0, &blame_date_mode)) + 1; /* add the null */ break; + case DATE_DOTTIME: + blame_date_width = sizeof("2006-10-19T15·00-0700"); + break; } blame_date_width -= 1; /* strip the null */ diff --git a/builtin/branch.c b/third_party/git/builtin/branch.c index d8297f80ff..d8297f80ff 100644 --- a/builtin/branch.c +++ b/third_party/git/builtin/branch.c diff --git a/builtin/bundle.c b/third_party/git/builtin/bundle.c index f049d27a14..f049d27a14 100644 --- a/builtin/bundle.c +++ b/third_party/git/builtin/bundle.c diff --git a/builtin/cat-file.c b/third_party/git/builtin/cat-file.c index 272f9fc6d7..272f9fc6d7 100644 --- a/builtin/cat-file.c +++ b/third_party/git/builtin/cat-file.c diff --git a/builtin/check-attr.c b/third_party/git/builtin/check-attr.c index dd83397786..dd83397786 100644 --- a/builtin/check-attr.c +++ b/third_party/git/builtin/check-attr.c diff --git a/builtin/check-ignore.c b/third_party/git/builtin/check-ignore.c index ea5d0ae3a6..ea5d0ae3a6 100644 --- a/builtin/check-ignore.c +++ b/third_party/git/builtin/check-ignore.c diff --git a/builtin/check-mailmap.c b/third_party/git/builtin/check-mailmap.c index cdce144f3b..cdce144f3b 100644 --- a/builtin/check-mailmap.c +++ b/third_party/git/builtin/check-mailmap.c diff --git a/builtin/check-ref-format.c b/third_party/git/builtin/check-ref-format.c index bc67d3f0a8..bc67d3f0a8 100644 --- a/builtin/check-ref-format.c +++ b/third_party/git/builtin/check-ref-format.c diff --git a/builtin/checkout-index.c b/third_party/git/builtin/checkout-index.c index 1ac1cc290e..1ac1cc290e 100644 --- a/builtin/checkout-index.c +++ b/third_party/git/builtin/checkout-index.c diff --git a/builtin/checkout.c b/third_party/git/builtin/checkout.c index d6773818b8..d6773818b8 100644 --- a/builtin/checkout.c +++ b/third_party/git/builtin/checkout.c diff --git a/builtin/clean.c b/third_party/git/builtin/clean.c index 5abf087e7c..5abf087e7c 100644 --- a/builtin/clean.c +++ b/third_party/git/builtin/clean.c diff --git a/builtin/clone.c b/third_party/git/builtin/clone.c index 1ad26f4d8c..1ad26f4d8c 100644 --- a/builtin/clone.c +++ b/third_party/git/builtin/clone.c diff --git a/builtin/column.c b/third_party/git/builtin/column.c index e815e148aa..e815e148aa 100644 --- a/builtin/column.c +++ b/third_party/git/builtin/column.c diff --git a/builtin/commit-graph.c b/third_party/git/builtin/commit-graph.c index 4a70b33fb5..4a70b33fb5 100644 --- a/builtin/commit-graph.c +++ b/third_party/git/builtin/commit-graph.c diff --git a/builtin/commit-tree.c b/third_party/git/builtin/commit-tree.c index b866d83951..b866d83951 100644 --- a/builtin/commit-tree.c +++ b/third_party/git/builtin/commit-tree.c diff --git a/builtin/commit.c b/third_party/git/builtin/commit.c index 7ba33a3bec..7ba33a3bec 100644 --- a/builtin/commit.c +++ b/third_party/git/builtin/commit.c diff --git a/builtin/config.c b/third_party/git/builtin/config.c index ee4aef6a35..ee4aef6a35 100644 --- a/builtin/config.c +++ b/third_party/git/builtin/config.c diff --git a/builtin/count-objects.c b/third_party/git/builtin/count-objects.c index 3fae474f6f..3fae474f6f 100644 --- a/builtin/count-objects.c +++ b/third_party/git/builtin/count-objects.c diff --git a/builtin/credential.c b/third_party/git/builtin/credential.c index 879acfbcda..879acfbcda 100644 --- a/builtin/credential.c +++ b/third_party/git/builtin/credential.c diff --git a/builtin/describe.c b/third_party/git/builtin/describe.c index 420f4c6401..420f4c6401 100644 --- a/builtin/describe.c +++ b/third_party/git/builtin/describe.c diff --git a/builtin/diff-files.c b/third_party/git/builtin/diff-files.c index 86ae474fbf..86ae474fbf 100644 --- a/builtin/diff-files.c +++ b/third_party/git/builtin/diff-files.c diff --git a/builtin/diff-index.c b/third_party/git/builtin/diff-index.c index 93ec642423..93ec642423 100644 --- a/builtin/diff-index.c +++ b/third_party/git/builtin/diff-index.c diff --git a/builtin/diff-tree.c b/third_party/git/builtin/diff-tree.c index cb9ea79367..cb9ea79367 100644 --- a/builtin/diff-tree.c +++ b/third_party/git/builtin/diff-tree.c diff --git a/builtin/diff.c b/third_party/git/builtin/diff.c index 42ac803091..42ac803091 100644 --- a/builtin/diff.c +++ b/third_party/git/builtin/diff.c diff --git a/builtin/difftool.c b/third_party/git/builtin/difftool.c index c280e682b2..c280e682b2 100644 --- a/builtin/difftool.c +++ b/third_party/git/builtin/difftool.c diff --git a/builtin/env--helper.c b/third_party/git/builtin/env--helper.c index 23c214fff6..23c214fff6 100644 --- a/builtin/env--helper.c +++ b/third_party/git/builtin/env--helper.c diff --git a/builtin/fast-export.c b/third_party/git/builtin/fast-export.c index 85868162ee..85868162ee 100644 --- a/builtin/fast-export.c +++ b/third_party/git/builtin/fast-export.c diff --git a/builtin/fetch-pack.c b/third_party/git/builtin/fetch-pack.c index dc1485c8aa..dc1485c8aa 100644 --- a/builtin/fetch-pack.c +++ b/third_party/git/builtin/fetch-pack.c diff --git a/builtin/fetch.c b/third_party/git/builtin/fetch.c index bf6bab80fa..bf6bab80fa 100644 --- a/builtin/fetch.c +++ b/third_party/git/builtin/fetch.c diff --git a/builtin/fmt-merge-msg.c b/third_party/git/builtin/fmt-merge-msg.c index 736f666f64..736f666f64 100644 --- a/builtin/fmt-merge-msg.c +++ b/third_party/git/builtin/fmt-merge-msg.c diff --git a/builtin/for-each-ref.c b/third_party/git/builtin/for-each-ref.c index 465153e853..465153e853 100644 --- a/builtin/for-each-ref.c +++ b/third_party/git/builtin/for-each-ref.c diff --git a/builtin/fsck.c b/third_party/git/builtin/fsck.c index 8d13794b14..8d13794b14 100644 --- a/builtin/fsck.c +++ b/third_party/git/builtin/fsck.c diff --git a/builtin/gc.c b/third_party/git/builtin/gc.c index 8e0b9cf41b..8e0b9cf41b 100644 --- a/builtin/gc.c +++ b/third_party/git/builtin/gc.c diff --git a/builtin/get-tar-commit-id.c b/third_party/git/builtin/get-tar-commit-id.c index 491af9202d..491af9202d 100644 --- a/builtin/get-tar-commit-id.c +++ b/third_party/git/builtin/get-tar-commit-id.c diff --git a/builtin/grep.c b/third_party/git/builtin/grep.c index 99e2685090..99e2685090 100644 --- a/builtin/grep.c +++ b/third_party/git/builtin/grep.c diff --git a/builtin/hash-object.c b/third_party/git/builtin/hash-object.c index 640ef4ded5..640ef4ded5 100644 --- a/builtin/hash-object.c +++ b/third_party/git/builtin/hash-object.c diff --git a/builtin/help.c b/third_party/git/builtin/help.c index e5590d7787..e5590d7787 100644 --- a/builtin/help.c +++ b/third_party/git/builtin/help.c diff --git a/builtin/index-pack.c b/third_party/git/builtin/index-pack.c index d967d188a3..d967d188a3 100644 --- a/builtin/index-pack.c +++ b/third_party/git/builtin/index-pack.c diff --git a/builtin/init-db.c b/third_party/git/builtin/init-db.c index 944ec77fe1..944ec77fe1 100644 --- a/builtin/init-db.c +++ b/third_party/git/builtin/init-db.c diff --git a/builtin/interpret-trailers.c b/third_party/git/builtin/interpret-trailers.c index f101d092b8..f101d092b8 100644 --- a/builtin/interpret-trailers.c +++ b/third_party/git/builtin/interpret-trailers.c diff --git a/builtin/log.c b/third_party/git/builtin/log.c index 83a4a6188e..83a4a6188e 100644 --- a/builtin/log.c +++ b/third_party/git/builtin/log.c diff --git a/builtin/ls-files.c b/third_party/git/builtin/ls-files.c index f069a028ce..f069a028ce 100644 --- a/builtin/ls-files.c +++ b/third_party/git/builtin/ls-files.c diff --git a/builtin/ls-remote.c b/third_party/git/builtin/ls-remote.c index 6ef519514b..6ef519514b 100644 --- a/builtin/ls-remote.c +++ b/third_party/git/builtin/ls-remote.c diff --git a/builtin/ls-tree.c b/third_party/git/builtin/ls-tree.c index 7cad3f24eb..7cad3f24eb 100644 --- a/builtin/ls-tree.c +++ b/third_party/git/builtin/ls-tree.c diff --git a/builtin/mailinfo.c b/third_party/git/builtin/mailinfo.c index cfb667a594..cfb667a594 100644 --- a/builtin/mailinfo.c +++ b/third_party/git/builtin/mailinfo.c diff --git a/builtin/mailsplit.c b/third_party/git/builtin/mailsplit.c index 664400b816..664400b816 100644 --- a/builtin/mailsplit.c +++ b/third_party/git/builtin/mailsplit.c diff --git a/builtin/merge-base.c b/third_party/git/builtin/merge-base.c index e3f8da13b6..e3f8da13b6 100644 --- a/builtin/merge-base.c +++ b/third_party/git/builtin/merge-base.c diff --git a/builtin/merge-file.c b/third_party/git/builtin/merge-file.c index 06a2f90c48..06a2f90c48 100644 --- a/builtin/merge-file.c +++ b/third_party/git/builtin/merge-file.c diff --git a/builtin/merge-index.c b/third_party/git/builtin/merge-index.c index 38ea6ad6ca..38ea6ad6ca 100644 --- a/builtin/merge-index.c +++ b/third_party/git/builtin/merge-index.c diff --git a/builtin/merge-ours.c b/third_party/git/builtin/merge-ours.c index 4594507420..4594507420 100644 --- a/builtin/merge-ours.c +++ b/third_party/git/builtin/merge-ours.c diff --git a/builtin/merge-recursive.c b/third_party/git/builtin/merge-recursive.c index a4bfd8fc51..a4bfd8fc51 100644 --- a/builtin/merge-recursive.c +++ b/third_party/git/builtin/merge-recursive.c diff --git a/builtin/merge-tree.c b/third_party/git/builtin/merge-tree.c index e72714a5a8..e72714a5a8 100644 --- a/builtin/merge-tree.c +++ b/third_party/git/builtin/merge-tree.c diff --git a/builtin/merge.c b/third_party/git/builtin/merge.c index d127d2225f..d127d2225f 100644 --- a/builtin/merge.c +++ b/third_party/git/builtin/merge.c diff --git a/builtin/mktag.c b/third_party/git/builtin/mktag.c index 4982d3a93e..4982d3a93e 100644 --- a/builtin/mktag.c +++ b/third_party/git/builtin/mktag.c diff --git a/builtin/mktree.c b/third_party/git/builtin/mktree.c index 891991b00d..891991b00d 100644 --- a/builtin/mktree.c +++ b/third_party/git/builtin/mktree.c diff --git a/builtin/multi-pack-index.c b/third_party/git/builtin/multi-pack-index.c index 5bf88cd2a8..5bf88cd2a8 100644 --- a/builtin/multi-pack-index.c +++ b/third_party/git/builtin/multi-pack-index.c diff --git a/builtin/mv.c b/third_party/git/builtin/mv.c index be15ba7044..be15ba7044 100644 --- a/builtin/mv.c +++ b/third_party/git/builtin/mv.c diff --git a/builtin/name-rev.c b/third_party/git/builtin/name-rev.c index a9dcd25e46..a9dcd25e46 100644 --- a/builtin/name-rev.c +++ b/third_party/git/builtin/name-rev.c diff --git a/builtin/notes.c b/third_party/git/builtin/notes.c index 35e468ea2d..35e468ea2d 100644 --- a/builtin/notes.c +++ b/third_party/git/builtin/notes.c diff --git a/builtin/pack-objects.c b/third_party/git/builtin/pack-objects.c index 02aa6ee480..02aa6ee480 100644 --- a/builtin/pack-objects.c +++ b/third_party/git/builtin/pack-objects.c diff --git a/builtin/pack-redundant.c b/third_party/git/builtin/pack-redundant.c index 178e3409b7..178e3409b7 100644 --- a/builtin/pack-redundant.c +++ b/third_party/git/builtin/pack-redundant.c diff --git a/builtin/pack-refs.c b/third_party/git/builtin/pack-refs.c index cfbd5c36c7..cfbd5c36c7 100644 --- a/builtin/pack-refs.c +++ b/third_party/git/builtin/pack-refs.c diff --git a/builtin/patch-id.c b/third_party/git/builtin/patch-id.c index 822ffff51f..822ffff51f 100644 --- a/builtin/patch-id.c +++ b/third_party/git/builtin/patch-id.c diff --git a/builtin/prune-packed.c b/third_party/git/builtin/prune-packed.c index 48c5e78e33..48c5e78e33 100644 --- a/builtin/prune-packed.c +++ b/third_party/git/builtin/prune-packed.c diff --git a/builtin/prune.c b/third_party/git/builtin/prune.c index 2b76872ad2..2b76872ad2 100644 --- a/builtin/prune.c +++ b/third_party/git/builtin/prune.c diff --git a/builtin/pull.c b/third_party/git/builtin/pull.c index 3e624d1e00..3e624d1e00 100644 --- a/builtin/pull.c +++ b/third_party/git/builtin/pull.c diff --git a/builtin/push.c b/third_party/git/builtin/push.c index 6dbf0f0bb7..6dbf0f0bb7 100644 --- a/builtin/push.c +++ b/third_party/git/builtin/push.c diff --git a/builtin/range-diff.c b/third_party/git/builtin/range-diff.c index d8a4670629..d8a4670629 100644 --- a/builtin/range-diff.c +++ b/third_party/git/builtin/range-diff.c diff --git a/builtin/read-tree.c b/third_party/git/builtin/read-tree.c index af7424b94c..af7424b94c 100644 --- a/builtin/read-tree.c +++ b/third_party/git/builtin/read-tree.c diff --git a/builtin/rebase.c b/third_party/git/builtin/rebase.c index bff53d5d16..bff53d5d16 100644 --- a/builtin/rebase.c +++ b/third_party/git/builtin/rebase.c diff --git a/builtin/receive-pack.c b/third_party/git/builtin/receive-pack.c index 2cc18bbffd..2cc18bbffd 100644 --- a/builtin/receive-pack.c +++ b/third_party/git/builtin/receive-pack.c diff --git a/builtin/reflog.c b/third_party/git/builtin/reflog.c index 81dfd563c0..81dfd563c0 100644 --- a/builtin/reflog.c +++ b/third_party/git/builtin/reflog.c diff --git a/builtin/remote-ext.c b/third_party/git/builtin/remote-ext.c index 6a9127a33c..6a9127a33c 100644 --- a/builtin/remote-ext.c +++ b/third_party/git/builtin/remote-ext.c diff --git a/builtin/remote-fd.c b/third_party/git/builtin/remote-fd.c index 91dfe07e06..91dfe07e06 100644 --- a/builtin/remote-fd.c +++ b/third_party/git/builtin/remote-fd.c diff --git a/builtin/remote.c b/third_party/git/builtin/remote.c index 555d4c896c..555d4c896c 100644 --- a/builtin/remote.c +++ b/third_party/git/builtin/remote.c diff --git a/builtin/repack.c b/third_party/git/builtin/repack.c index 0781763b06..0781763b06 100644 --- a/builtin/repack.c +++ b/third_party/git/builtin/repack.c diff --git a/builtin/replace.c b/third_party/git/builtin/replace.c index b36d17a657..b36d17a657 100644 --- a/builtin/replace.c +++ b/third_party/git/builtin/replace.c diff --git a/builtin/rerere.c b/third_party/git/builtin/rerere.c index fd3be17b97..fd3be17b97 100644 --- a/builtin/rerere.c +++ b/third_party/git/builtin/rerere.c diff --git a/builtin/reset.c b/third_party/git/builtin/reset.c index 18228c312e..18228c312e 100644 --- a/builtin/reset.c +++ b/third_party/git/builtin/reset.c diff --git a/builtin/rev-list.c b/third_party/git/builtin/rev-list.c index f520111eda..f520111eda 100644 --- a/builtin/rev-list.c +++ b/third_party/git/builtin/rev-list.c diff --git a/builtin/rev-parse.c b/third_party/git/builtin/rev-parse.c index 7a00da8203..7a00da8203 100644 --- a/builtin/rev-parse.c +++ b/third_party/git/builtin/rev-parse.c diff --git a/builtin/revert.c b/third_party/git/builtin/revert.c index f61cc5d82c..f61cc5d82c 100644 --- a/builtin/revert.c +++ b/third_party/git/builtin/revert.c diff --git a/builtin/rm.c b/third_party/git/builtin/rm.c index 4858631e0f..4858631e0f 100644 --- a/builtin/rm.c +++ b/third_party/git/builtin/rm.c diff --git a/builtin/send-pack.c b/third_party/git/builtin/send-pack.c index 098ebf22d0..098ebf22d0 100644 --- a/builtin/send-pack.c +++ b/third_party/git/builtin/send-pack.c diff --git a/builtin/shortlog.c b/third_party/git/builtin/shortlog.c index 65cd41392c..65cd41392c 100644 --- a/builtin/shortlog.c +++ b/third_party/git/builtin/shortlog.c diff --git a/builtin/show-branch.c b/third_party/git/builtin/show-branch.c index 8c90cbb18f..8c90cbb18f 100644 --- a/builtin/show-branch.c +++ b/third_party/git/builtin/show-branch.c diff --git a/builtin/show-index.c b/third_party/git/builtin/show-index.c index 0826f6a5a2..0826f6a5a2 100644 --- a/builtin/show-index.c +++ b/third_party/git/builtin/show-index.c diff --git a/builtin/show-ref.c b/third_party/git/builtin/show-ref.c index 6456da70cc..6456da70cc 100644 --- a/builtin/show-ref.c +++ b/third_party/git/builtin/show-ref.c diff --git a/builtin/sparse-checkout.c b/third_party/git/builtin/sparse-checkout.c index 740da4b6d5..740da4b6d5 100644 --- a/builtin/sparse-checkout.c +++ b/third_party/git/builtin/sparse-checkout.c diff --git a/builtin/stash.c b/third_party/git/builtin/stash.c index 78af6ce564..78af6ce564 100644 --- a/builtin/stash.c +++ b/third_party/git/builtin/stash.c diff --git a/builtin/stripspace.c b/third_party/git/builtin/stripspace.c index be33eb83c1..be33eb83c1 100644 --- a/builtin/stripspace.c +++ b/third_party/git/builtin/stripspace.c diff --git a/builtin/submodule--helper.c b/third_party/git/builtin/submodule--helper.c index 86a608eec1..86a608eec1 100644 --- a/builtin/submodule--helper.c +++ b/third_party/git/builtin/submodule--helper.c diff --git a/builtin/symbolic-ref.c b/third_party/git/builtin/symbolic-ref.c index 80237f0df1..80237f0df1 100644 --- a/builtin/symbolic-ref.c +++ b/third_party/git/builtin/symbolic-ref.c diff --git a/builtin/tag.c b/third_party/git/builtin/tag.c index e0a4c25382..e0a4c25382 100644 --- a/builtin/tag.c +++ b/third_party/git/builtin/tag.c diff --git a/builtin/unpack-file.c b/third_party/git/builtin/unpack-file.c index 58652229f2..58652229f2 100644 --- a/builtin/unpack-file.c +++ b/third_party/git/builtin/unpack-file.c diff --git a/builtin/unpack-objects.c b/third_party/git/builtin/unpack-objects.c index dd4a75e030..dd4a75e030 100644 --- a/builtin/unpack-objects.c +++ b/third_party/git/builtin/unpack-objects.c diff --git a/builtin/update-index.c b/third_party/git/builtin/update-index.c index d527b8f106..d527b8f106 100644 --- a/builtin/update-index.c +++ b/third_party/git/builtin/update-index.c diff --git a/builtin/update-ref.c b/third_party/git/builtin/update-ref.c index 2d8f7f0578..2d8f7f0578 100644 --- a/builtin/update-ref.c +++ b/third_party/git/builtin/update-ref.c diff --git a/builtin/update-server-info.c b/third_party/git/builtin/update-server-info.c index 4321a34456..4321a34456 100644 --- a/builtin/update-server-info.c +++ b/third_party/git/builtin/update-server-info.c diff --git a/builtin/upload-archive.c b/third_party/git/builtin/upload-archive.c index 018879737a..018879737a 100644 --- a/builtin/upload-archive.c +++ b/third_party/git/builtin/upload-archive.c diff --git a/builtin/upload-pack.c b/third_party/git/builtin/upload-pack.c index 6da8fa2607..6da8fa2607 100644 --- a/builtin/upload-pack.c +++ b/third_party/git/builtin/upload-pack.c diff --git a/builtin/var.c b/third_party/git/builtin/var.c index 6c6f46b4ae..6c6f46b4ae 100644 --- a/builtin/var.c +++ b/third_party/git/builtin/var.c diff --git a/builtin/verify-commit.c b/third_party/git/builtin/verify-commit.c index 40c69a0bed..40c69a0bed 100644 --- a/builtin/verify-commit.c +++ b/third_party/git/builtin/verify-commit.c diff --git a/builtin/verify-pack.c b/third_party/git/builtin/verify-pack.c index c2a1a5c504..c2a1a5c504 100644 --- a/builtin/verify-pack.c +++ b/third_party/git/builtin/verify-pack.c diff --git a/builtin/verify-tag.c b/third_party/git/builtin/verify-tag.c index f45136a06b..f45136a06b 100644 --- a/builtin/verify-tag.c +++ b/third_party/git/builtin/verify-tag.c diff --git a/builtin/worktree.c b/third_party/git/builtin/worktree.c index 24f22800f3..24f22800f3 100644 --- a/builtin/worktree.c +++ b/third_party/git/builtin/worktree.c diff --git a/builtin/write-tree.c b/third_party/git/builtin/write-tree.c index 45d61707e7..45d61707e7 100644 --- a/builtin/write-tree.c +++ b/third_party/git/builtin/write-tree.c diff --git a/bulk-checkin.c b/third_party/git/bulk-checkin.c index 583aacb9e3..583aacb9e3 100644 --- a/bulk-checkin.c +++ b/third_party/git/bulk-checkin.c diff --git a/bulk-checkin.h b/third_party/git/bulk-checkin.h index b26f3dc3b7..b26f3dc3b7 100644 --- a/bulk-checkin.h +++ b/third_party/git/bulk-checkin.h diff --git a/bundle.c b/third_party/git/bundle.c index 99439e07a1..99439e07a1 100644 --- a/bundle.c +++ b/third_party/git/bundle.c diff --git a/bundle.h b/third_party/git/bundle.h index ceab0c7475..ceab0c7475 100644 --- a/bundle.h +++ b/third_party/git/bundle.h diff --git a/cache-tree.c b/third_party/git/cache-tree.c index a537a806c1..a537a806c1 100644 --- a/cache-tree.c +++ b/third_party/git/cache-tree.c diff --git a/cache-tree.h b/third_party/git/cache-tree.h index 639bfa5340..639bfa5340 100644 --- a/cache-tree.h +++ b/third_party/git/cache-tree.h diff --git a/cache.h b/third_party/git/cache.h index 37c899b53f..5c309b46c2 100644 --- a/cache.h +++ b/third_party/git/cache.h @@ -1581,7 +1581,8 @@ enum date_mode_type { DATE_RFC2822, DATE_STRFTIME, DATE_RAW, - DATE_UNIX + DATE_UNIX, + DATE_DOTTIME }; struct date_mode { diff --git a/chdir-notify.c b/third_party/git/chdir-notify.c index 5f7f2c2ac2..5f7f2c2ac2 100644 --- a/chdir-notify.c +++ b/third_party/git/chdir-notify.c diff --git a/chdir-notify.h b/third_party/git/chdir-notify.h index 366e4c1ee9..366e4c1ee9 100644 --- a/chdir-notify.h +++ b/third_party/git/chdir-notify.h diff --git a/check-builtins.sh b/third_party/git/check-builtins.sh index a0aaf3a347..a0aaf3a347 100755 --- a/check-builtins.sh +++ b/third_party/git/check-builtins.sh diff --git a/check_bindir b/third_party/git/check_bindir index 623eadcbb7..623eadcbb7 100755 --- a/check_bindir +++ b/third_party/git/check_bindir diff --git a/checkout.c b/third_party/git/checkout.c index c72e9f9773..c72e9f9773 100644 --- a/checkout.c +++ b/third_party/git/checkout.c diff --git a/checkout.h b/third_party/git/checkout.h index 1152133bd7..1152133bd7 100644 --- a/checkout.h +++ b/third_party/git/checkout.h diff --git a/ci/install-dependencies.sh b/third_party/git/ci/install-dependencies.sh index 497fd32ca8..497fd32ca8 100755 --- a/ci/install-dependencies.sh +++ b/third_party/git/ci/install-dependencies.sh diff --git a/ci/lib.sh b/third_party/git/ci/lib.sh index a90d0dc0fd..a90d0dc0fd 100755 --- a/ci/lib.sh +++ b/third_party/git/ci/lib.sh diff --git a/ci/make-test-artifacts.sh b/third_party/git/ci/make-test-artifacts.sh index 646967481f..646967481f 100755 --- a/ci/make-test-artifacts.sh +++ b/third_party/git/ci/make-test-artifacts.sh diff --git a/ci/mount-fileshare.sh b/third_party/git/ci/mount-fileshare.sh index 26b58a8096..26b58a8096 100755 --- a/ci/mount-fileshare.sh +++ b/third_party/git/ci/mount-fileshare.sh diff --git a/ci/print-test-failures.sh b/third_party/git/ci/print-test-failures.sh index e688a26f0d..e688a26f0d 100755 --- a/ci/print-test-failures.sh +++ b/third_party/git/ci/print-test-failures.sh diff --git a/ci/run-build-and-tests.sh b/third_party/git/ci/run-build-and-tests.sh index 4df54c4efe..4df54c4efe 100755 --- a/ci/run-build-and-tests.sh +++ b/third_party/git/ci/run-build-and-tests.sh diff --git a/ci/run-linux32-build.sh b/third_party/git/ci/run-linux32-build.sh index e3a193adbc..e3a193adbc 100755 --- a/ci/run-linux32-build.sh +++ b/third_party/git/ci/run-linux32-build.sh diff --git a/ci/run-linux32-docker.sh b/third_party/git/ci/run-linux32-docker.sh index 751acfcf8a..751acfcf8a 100755 --- a/ci/run-linux32-docker.sh +++ b/third_party/git/ci/run-linux32-docker.sh diff --git a/ci/run-static-analysis.sh b/third_party/git/ci/run-static-analysis.sh index 65bcebda41..65bcebda41 100755 --- a/ci/run-static-analysis.sh +++ b/third_party/git/ci/run-static-analysis.sh diff --git a/ci/run-test-slice.sh b/third_party/git/ci/run-test-slice.sh index f8c2c3106a..f8c2c3106a 100755 --- a/ci/run-test-slice.sh +++ b/third_party/git/ci/run-test-slice.sh diff --git a/ci/test-documentation.sh b/third_party/git/ci/test-documentation.sh index de41888430..de41888430 100755 --- a/ci/test-documentation.sh +++ b/third_party/git/ci/test-documentation.sh diff --git a/ci/util/extract-trash-dirs.sh b/third_party/git/ci/util/extract-trash-dirs.sh index 8e67bec21a..8e67bec21a 100755 --- a/ci/util/extract-trash-dirs.sh +++ b/third_party/git/ci/util/extract-trash-dirs.sh diff --git a/color.c b/third_party/git/color.c index 64f52a4f93..64f52a4f93 100644 --- a/color.c +++ b/third_party/git/color.c diff --git a/color.h b/third_party/git/color.h index 98894d6a17..98894d6a17 100644 --- a/color.h +++ b/third_party/git/color.h diff --git a/column.c b/third_party/git/column.c index 4a38eed322..4a38eed322 100644 --- a/column.c +++ b/third_party/git/column.c diff --git a/column.h b/third_party/git/column.h index 448c7440b3..448c7440b3 100644 --- a/column.h +++ b/third_party/git/column.h diff --git a/combine-diff.c b/third_party/git/combine-diff.c index d5c4d839dc..d5c4d839dc 100644 --- a/combine-diff.c +++ b/third_party/git/combine-diff.c diff --git a/command-list.txt b/third_party/git/command-list.txt index 2087894655..2087894655 100644 --- a/command-list.txt +++ b/third_party/git/command-list.txt diff --git a/commit-graph.c b/third_party/git/commit-graph.c index f013a84e29..f013a84e29 100644 --- a/commit-graph.c +++ b/third_party/git/commit-graph.c diff --git a/commit-graph.h b/third_party/git/commit-graph.h index e87a6f6360..e87a6f6360 100644 --- a/commit-graph.h +++ b/third_party/git/commit-graph.h diff --git a/commit-reach.c b/third_party/git/commit-reach.c index 4ca7e706a1..4ca7e706a1 100644 --- a/commit-reach.c +++ b/third_party/git/commit-reach.c diff --git a/commit-reach.h b/third_party/git/commit-reach.h index 99a43e8b64..99a43e8b64 100644 --- a/commit-reach.h +++ b/third_party/git/commit-reach.h diff --git a/commit-slab-decl.h b/third_party/git/commit-slab-decl.h index adc7b46c83..adc7b46c83 100644 --- a/commit-slab-decl.h +++ b/third_party/git/commit-slab-decl.h diff --git a/commit-slab-impl.h b/third_party/git/commit-slab-impl.h index 5c0eb91a5d..5c0eb91a5d 100644 --- a/commit-slab-impl.h +++ b/third_party/git/commit-slab-impl.h diff --git a/commit-slab.h b/third_party/git/commit-slab.h index 69bf0c807c..69bf0c807c 100644 --- a/commit-slab.h +++ b/third_party/git/commit-slab.h diff --git a/commit.c b/third_party/git/commit.c index a6cfa41a4e..a6cfa41a4e 100644 --- a/commit.c +++ b/third_party/git/commit.c diff --git a/commit.h b/third_party/git/commit.h index 008a0fa4a0..008a0fa4a0 100644 --- a/commit.h +++ b/third_party/git/commit.h diff --git a/common-main.c b/third_party/git/common-main.c index 71e21dd20a..71e21dd20a 100644 --- a/common-main.c +++ b/third_party/git/common-main.c diff --git a/compat/access.c b/third_party/git/compat/access.c index 19fda3e877..19fda3e877 100644 --- a/compat/access.c +++ b/third_party/git/compat/access.c diff --git a/compat/apple-common-crypto.h b/third_party/git/compat/apple-common-crypto.h index 11727f3e1e..11727f3e1e 100644 --- a/compat/apple-common-crypto.h +++ b/third_party/git/compat/apple-common-crypto.h diff --git a/compat/basename.c b/third_party/git/compat/basename.c index 96bd9533b4..96bd9533b4 100644 --- a/compat/basename.c +++ b/third_party/git/compat/basename.c diff --git a/compat/bswap.h b/third_party/git/compat/bswap.h index e4e25735ce..e4e25735ce 100644 --- a/compat/bswap.h +++ b/third_party/git/compat/bswap.h diff --git a/compat/fileno.c b/third_party/git/compat/fileno.c index 8e80ef335d..8e80ef335d 100644 --- a/compat/fileno.c +++ b/third_party/git/compat/fileno.c diff --git a/compat/fopen.c b/third_party/git/compat/fopen.c index 107b3e8182..107b3e8182 100644 --- a/compat/fopen.c +++ b/third_party/git/compat/fopen.c diff --git a/compat/gmtime.c b/third_party/git/compat/gmtime.c index e8362dd2b9..e8362dd2b9 100644 --- a/compat/gmtime.c +++ b/third_party/git/compat/gmtime.c diff --git a/compat/hstrerror.c b/third_party/git/compat/hstrerror.c index b85a2fa956..b85a2fa956 100644 --- a/compat/hstrerror.c +++ b/third_party/git/compat/hstrerror.c diff --git a/compat/inet_ntop.c b/third_party/git/compat/inet_ntop.c index 68307262be..68307262be 100644 --- a/compat/inet_ntop.c +++ b/third_party/git/compat/inet_ntop.c diff --git a/compat/inet_pton.c b/third_party/git/compat/inet_pton.c index 2b9a0a4e22..2b9a0a4e22 100644 --- a/compat/inet_pton.c +++ b/third_party/git/compat/inet_pton.c diff --git a/compat/memmem.c b/third_party/git/compat/memmem.c index 56bcb4277f..56bcb4277f 100644 --- a/compat/memmem.c +++ b/third_party/git/compat/memmem.c diff --git a/compat/mingw.c b/third_party/git/compat/mingw.c index d14065d60e..d14065d60e 100644 --- a/compat/mingw.c +++ b/third_party/git/compat/mingw.c diff --git a/compat/mingw.h b/third_party/git/compat/mingw.h index e6fe810ba9..e6fe810ba9 100644 --- a/compat/mingw.h +++ b/third_party/git/compat/mingw.h diff --git a/compat/mkdir.c b/third_party/git/compat/mkdir.c index 9e253fb72f..9e253fb72f 100644 --- a/compat/mkdir.c +++ b/third_party/git/compat/mkdir.c diff --git a/compat/mkdtemp.c b/third_party/git/compat/mkdtemp.c index 1136119592..1136119592 100644 --- a/compat/mkdtemp.c +++ b/third_party/git/compat/mkdtemp.c diff --git a/compat/mmap.c b/third_party/git/compat/mmap.c index 14d31010df..14d31010df 100644 --- a/compat/mmap.c +++ b/third_party/git/compat/mmap.c diff --git a/compat/msvc.c b/third_party/git/compat/msvc.c index 71843d7eef..71843d7eef 100644 --- a/compat/msvc.c +++ b/third_party/git/compat/msvc.c diff --git a/compat/msvc.h b/third_party/git/compat/msvc.h index 1d7a8c6145..1d7a8c6145 100644 --- a/compat/msvc.h +++ b/third_party/git/compat/msvc.h diff --git a/compat/nedmalloc/License.txt b/third_party/git/compat/nedmalloc/License.txt index 36b7cd93cd..36b7cd93cd 100644 --- a/compat/nedmalloc/License.txt +++ b/third_party/git/compat/nedmalloc/License.txt diff --git a/compat/nedmalloc/Readme.txt b/third_party/git/compat/nedmalloc/Readme.txt index 07cbf50c0f..07cbf50c0f 100644 --- a/compat/nedmalloc/Readme.txt +++ b/third_party/git/compat/nedmalloc/Readme.txt diff --git a/compat/nedmalloc/malloc.c.h b/third_party/git/compat/nedmalloc/malloc.c.h index 814845d4b3..814845d4b3 100644 --- a/compat/nedmalloc/malloc.c.h +++ b/third_party/git/compat/nedmalloc/malloc.c.h diff --git a/compat/nedmalloc/nedmalloc.c b/third_party/git/compat/nedmalloc/nedmalloc.c index 1cc31c3502..1cc31c3502 100644 --- a/compat/nedmalloc/nedmalloc.c +++ b/third_party/git/compat/nedmalloc/nedmalloc.c diff --git a/compat/nedmalloc/nedmalloc.h b/third_party/git/compat/nedmalloc/nedmalloc.h index f960e66063..f960e66063 100644 --- a/compat/nedmalloc/nedmalloc.h +++ b/third_party/git/compat/nedmalloc/nedmalloc.h diff --git a/compat/obstack.c b/third_party/git/compat/obstack.c index 27cd5c1ea1..27cd5c1ea1 100644 --- a/compat/obstack.c +++ b/third_party/git/compat/obstack.c diff --git a/compat/obstack.h b/third_party/git/compat/obstack.h index f90a46d9b9..f90a46d9b9 100644 --- a/compat/obstack.h +++ b/third_party/git/compat/obstack.h diff --git a/compat/poll/poll.c b/third_party/git/compat/poll/poll.c index afa6d24584..afa6d24584 100644 --- a/compat/poll/poll.c +++ b/third_party/git/compat/poll/poll.c diff --git a/compat/poll/poll.h b/third_party/git/compat/poll/poll.h index 1e1597360f..1e1597360f 100644 --- a/compat/poll/poll.h +++ b/third_party/git/compat/poll/poll.h diff --git a/compat/pread.c b/third_party/git/compat/pread.c index 978cac4ec9..978cac4ec9 100644 --- a/compat/pread.c +++ b/third_party/git/compat/pread.c diff --git a/compat/precompose_utf8.c b/third_party/git/compat/precompose_utf8.c index 136250fbf6..136250fbf6 100644 --- a/compat/precompose_utf8.c +++ b/third_party/git/compat/precompose_utf8.c diff --git a/compat/precompose_utf8.h b/third_party/git/compat/precompose_utf8.h index 6f843d3e1a..6f843d3e1a 100644 --- a/compat/precompose_utf8.h +++ b/third_party/git/compat/precompose_utf8.h diff --git a/compat/qsort_s.c b/third_party/git/compat/qsort_s.c index 52d1f0a73d..52d1f0a73d 100644 --- a/compat/qsort_s.c +++ b/third_party/git/compat/qsort_s.c diff --git a/compat/regex/regcomp.c b/third_party/git/compat/regex/regcomp.c index d1bc09e49b..d1bc09e49b 100644 --- a/compat/regex/regcomp.c +++ b/third_party/git/compat/regex/regcomp.c diff --git a/compat/regex/regex.c b/third_party/git/compat/regex/regex.c index f3e03a9eab..f3e03a9eab 100644 --- a/compat/regex/regex.c +++ b/third_party/git/compat/regex/regex.c diff --git a/compat/regex/regex.h b/third_party/git/compat/regex/regex.h index 2d3412860d..2d3412860d 100644 --- a/compat/regex/regex.h +++ b/third_party/git/compat/regex/regex.h diff --git a/compat/regex/regex_internal.c b/third_party/git/compat/regex/regex_internal.c index ec51cf3446..ec51cf3446 100644 --- a/compat/regex/regex_internal.c +++ b/third_party/git/compat/regex/regex_internal.c diff --git a/compat/regex/regex_internal.h b/third_party/git/compat/regex/regex_internal.h index 3ee8aae59d..3ee8aae59d 100644 --- a/compat/regex/regex_internal.h +++ b/third_party/git/compat/regex/regex_internal.h diff --git a/compat/regex/regexec.c b/third_party/git/compat/regex/regexec.c index 49358ae475..49358ae475 100644 --- a/compat/regex/regexec.c +++ b/third_party/git/compat/regex/regexec.c diff --git a/compat/setenv.c b/third_party/git/compat/setenv.c index 7849f258d2..7849f258d2 100644 --- a/compat/setenv.c +++ b/third_party/git/compat/setenv.c diff --git a/compat/sha1-chunked.c b/third_party/git/compat/sha1-chunked.c index 6adfcfd540..6adfcfd540 100644 --- a/compat/sha1-chunked.c +++ b/third_party/git/compat/sha1-chunked.c diff --git a/compat/sha1-chunked.h b/third_party/git/compat/sha1-chunked.h index 7b2df28eec..7b2df28eec 100644 --- a/compat/sha1-chunked.h +++ b/third_party/git/compat/sha1-chunked.h diff --git a/compat/snprintf.c b/third_party/git/compat/snprintf.c index 0b11688537..0b11688537 100644 --- a/compat/snprintf.c +++ b/third_party/git/compat/snprintf.c diff --git a/compat/stat.c b/third_party/git/compat/stat.c index a2d3931cb7..a2d3931cb7 100644 --- a/compat/stat.c +++ b/third_party/git/compat/stat.c diff --git a/compat/strcasestr.c b/third_party/git/compat/strcasestr.c index 26896deca6..26896deca6 100644 --- a/compat/strcasestr.c +++ b/third_party/git/compat/strcasestr.c diff --git a/compat/strdup.c b/third_party/git/compat/strdup.c index f3fb978eb3..f3fb978eb3 100644 --- a/compat/strdup.c +++ b/third_party/git/compat/strdup.c diff --git a/compat/strlcpy.c b/third_party/git/compat/strlcpy.c index 4024c36030..4024c36030 100644 --- a/compat/strlcpy.c +++ b/third_party/git/compat/strlcpy.c diff --git a/compat/strtoimax.c b/third_party/git/compat/strtoimax.c index ac09ed89e7..ac09ed89e7 100644 --- a/compat/strtoimax.c +++ b/third_party/git/compat/strtoimax.c diff --git a/compat/strtoumax.c b/third_party/git/compat/strtoumax.c index 5541353a77..5541353a77 100644 --- a/compat/strtoumax.c +++ b/third_party/git/compat/strtoumax.c diff --git a/compat/terminal.c b/third_party/git/compat/terminal.c index 35bca03d14..35bca03d14 100644 --- a/compat/terminal.c +++ b/third_party/git/compat/terminal.c diff --git a/compat/terminal.h b/third_party/git/compat/terminal.h index a9d52b8464..a9d52b8464 100644 --- a/compat/terminal.h +++ b/third_party/git/compat/terminal.h diff --git a/compat/unsetenv.c b/third_party/git/compat/unsetenv.c index bf5fd7063b..bf5fd7063b 100644 --- a/compat/unsetenv.c +++ b/third_party/git/compat/unsetenv.c diff --git a/compat/vcbuild/.gitignore b/third_party/git/compat/vcbuild/.gitignore index 8f8b794ef3..8f8b794ef3 100644 --- a/compat/vcbuild/.gitignore +++ b/third_party/git/compat/vcbuild/.gitignore diff --git a/compat/vcbuild/README b/third_party/git/compat/vcbuild/README index 1b6dabf5a2..1b6dabf5a2 100644 --- a/compat/vcbuild/README +++ b/third_party/git/compat/vcbuild/README diff --git a/compat/vcbuild/find_vs_env.bat b/third_party/git/compat/vcbuild/find_vs_env.bat index b35d264c0e..b35d264c0e 100644 --- a/compat/vcbuild/find_vs_env.bat +++ b/third_party/git/compat/vcbuild/find_vs_env.bat diff --git a/compat/vcbuild/include/sys/param.h b/third_party/git/compat/vcbuild/include/sys/param.h index 0d8552a2c6..0d8552a2c6 100644 --- a/compat/vcbuild/include/sys/param.h +++ b/third_party/git/compat/vcbuild/include/sys/param.h diff --git a/compat/vcbuild/include/sys/time.h b/third_party/git/compat/vcbuild/include/sys/time.h index 0d8552a2c6..0d8552a2c6 100644 --- a/compat/vcbuild/include/sys/time.h +++ b/third_party/git/compat/vcbuild/include/sys/time.h diff --git a/compat/vcbuild/include/sys/utime.h b/third_party/git/compat/vcbuild/include/sys/utime.h index 582589c70a..582589c70a 100644 --- a/compat/vcbuild/include/sys/utime.h +++ b/third_party/git/compat/vcbuild/include/sys/utime.h diff --git a/compat/vcbuild/include/unistd.h b/third_party/git/compat/vcbuild/include/unistd.h index 3a959d124c..3a959d124c 100644 --- a/compat/vcbuild/include/unistd.h +++ b/third_party/git/compat/vcbuild/include/unistd.h diff --git a/compat/vcbuild/include/utime.h b/third_party/git/compat/vcbuild/include/utime.h index 8285f38fde..8285f38fde 100644 --- a/compat/vcbuild/include/utime.h +++ b/third_party/git/compat/vcbuild/include/utime.h diff --git a/compat/vcbuild/scripts/clink.pl b/third_party/git/compat/vcbuild/scripts/clink.pl index d9f71b7cbb..d9f71b7cbb 100755 --- a/compat/vcbuild/scripts/clink.pl +++ b/third_party/git/compat/vcbuild/scripts/clink.pl diff --git a/compat/vcbuild/scripts/lib.pl b/third_party/git/compat/vcbuild/scripts/lib.pl index d8054e469f..d8054e469f 100755 --- a/compat/vcbuild/scripts/lib.pl +++ b/third_party/git/compat/vcbuild/scripts/lib.pl diff --git a/compat/vcbuild/vcpkg_copy_dlls.bat b/third_party/git/compat/vcbuild/vcpkg_copy_dlls.bat index 13661c14f8..13661c14f8 100644 --- a/compat/vcbuild/vcpkg_copy_dlls.bat +++ b/third_party/git/compat/vcbuild/vcpkg_copy_dlls.bat diff --git a/compat/vcbuild/vcpkg_install.bat b/third_party/git/compat/vcbuild/vcpkg_install.bat index ebd0bad242..ebd0bad242 100644 --- a/compat/vcbuild/vcpkg_install.bat +++ b/third_party/git/compat/vcbuild/vcpkg_install.bat diff --git a/compat/win32.h b/third_party/git/compat/win32.h index a97e880757..a97e880757 100644 --- a/compat/win32.h +++ b/third_party/git/compat/win32.h diff --git a/compat/win32/alloca.h b/third_party/git/compat/win32/alloca.h index c0d7985b7e..c0d7985b7e 100644 --- a/compat/win32/alloca.h +++ b/third_party/git/compat/win32/alloca.h diff --git a/compat/win32/dirent.c b/third_party/git/compat/win32/dirent.c index 52420ec7d4..52420ec7d4 100644 --- a/compat/win32/dirent.c +++ b/third_party/git/compat/win32/dirent.c diff --git a/compat/win32/dirent.h b/third_party/git/compat/win32/dirent.h index 058207e4bf..058207e4bf 100644 --- a/compat/win32/dirent.h +++ b/third_party/git/compat/win32/dirent.h diff --git a/compat/win32/git.manifest b/third_party/git/compat/win32/git.manifest index 771e3cce43..771e3cce43 100644 --- a/compat/win32/git.manifest +++ b/third_party/git/compat/win32/git.manifest diff --git a/compat/win32/lazyload.h b/third_party/git/compat/win32/lazyload.h index 9e631c8593..9e631c8593 100644 --- a/compat/win32/lazyload.h +++ b/third_party/git/compat/win32/lazyload.h diff --git a/compat/win32/path-utils.c b/third_party/git/compat/win32/path-utils.c index ebf2f12eb6..ebf2f12eb6 100644 --- a/compat/win32/path-utils.c +++ b/third_party/git/compat/win32/path-utils.c diff --git a/compat/win32/path-utils.h b/third_party/git/compat/win32/path-utils.h index f2e70872cd..f2e70872cd 100644 --- a/compat/win32/path-utils.h +++ b/third_party/git/compat/win32/path-utils.h diff --git a/compat/win32/pthread.c b/third_party/git/compat/win32/pthread.c index 2e7eead42c..2e7eead42c 100644 --- a/compat/win32/pthread.c +++ b/third_party/git/compat/win32/pthread.c diff --git a/compat/win32/pthread.h b/third_party/git/compat/win32/pthread.h index 737983d00b..737983d00b 100644 --- a/compat/win32/pthread.h +++ b/third_party/git/compat/win32/pthread.h diff --git a/compat/win32/syslog.c b/third_party/git/compat/win32/syslog.c index 161978d720..161978d720 100644 --- a/compat/win32/syslog.c +++ b/third_party/git/compat/win32/syslog.c diff --git a/compat/win32/syslog.h b/third_party/git/compat/win32/syslog.h index 70daa7c08b..70daa7c08b 100644 --- a/compat/win32/syslog.h +++ b/third_party/git/compat/win32/syslog.h diff --git a/compat/win32/trace2_win32_process_info.c b/third_party/git/compat/win32/trace2_win32_process_info.c index 8ccbd1c2c6..8ccbd1c2c6 100644 --- a/compat/win32/trace2_win32_process_info.c +++ b/third_party/git/compat/win32/trace2_win32_process_info.c diff --git a/compat/win32mmap.c b/third_party/git/compat/win32mmap.c index 519d51f2b6..519d51f2b6 100644 --- a/compat/win32mmap.c +++ b/third_party/git/compat/win32mmap.c diff --git a/compat/winansi.c b/third_party/git/compat/winansi.c index c27b20a79d..c27b20a79d 100644 --- a/compat/winansi.c +++ b/third_party/git/compat/winansi.c diff --git a/config.c b/third_party/git/config.c index d17d2bd9dc..d17d2bd9dc 100644 --- a/config.c +++ b/third_party/git/config.c diff --git a/config.h b/third_party/git/config.h index 9b3773f778..9b3773f778 100644 --- a/config.h +++ b/third_party/git/config.h diff --git a/config.mak.dev b/third_party/git/config.mak.dev index 89b218d11a..89b218d11a 100644 --- a/config.mak.dev +++ b/third_party/git/config.mak.dev diff --git a/config.mak.in b/third_party/git/config.mak.in index e6a6d0f941..e6a6d0f941 100644 --- a/config.mak.in +++ b/third_party/git/config.mak.in diff --git a/config.mak.uname b/third_party/git/config.mak.uname index 0ab8e00938..0ab8e00938 100644 --- a/config.mak.uname +++ b/third_party/git/config.mak.uname diff --git a/configure.ac b/third_party/git/configure.ac index 66aedb9288..66aedb9288 100644 --- a/configure.ac +++ b/third_party/git/configure.ac diff --git a/connect.c b/third_party/git/connect.c index b6451ab5e8..b6451ab5e8 100644 --- a/connect.c +++ b/third_party/git/connect.c diff --git a/connect.h b/third_party/git/connect.h index 5f2382e018..5f2382e018 100644 --- a/connect.h +++ b/third_party/git/connect.h diff --git a/connected.c b/third_party/git/connected.c index 7e9bd1bc62..7e9bd1bc62 100644 --- a/connected.c +++ b/third_party/git/connected.c diff --git a/connected.h b/third_party/git/connected.h index eba5c261ba..eba5c261ba 100644 --- a/connected.h +++ b/third_party/git/connected.h diff --git a/contrib/README b/third_party/git/contrib/README index 05f291c1f1..05f291c1f1 100644 --- a/contrib/README +++ b/third_party/git/contrib/README diff --git a/contrib/buildsystems/Generators.pm b/third_party/git/contrib/buildsystems/Generators.pm index aa4cbaa2ad..aa4cbaa2ad 100644 --- a/contrib/buildsystems/Generators.pm +++ b/third_party/git/contrib/buildsystems/Generators.pm diff --git a/contrib/buildsystems/Generators/QMake.pm b/third_party/git/contrib/buildsystems/Generators/QMake.pm index ff3b657e61..ff3b657e61 100644 --- a/contrib/buildsystems/Generators/QMake.pm +++ b/third_party/git/contrib/buildsystems/Generators/QMake.pm diff --git a/contrib/buildsystems/Generators/Vcproj.pm b/third_party/git/contrib/buildsystems/Generators/Vcproj.pm index 737647e76a..737647e76a 100644 --- a/contrib/buildsystems/Generators/Vcproj.pm +++ b/third_party/git/contrib/buildsystems/Generators/Vcproj.pm diff --git a/contrib/buildsystems/Generators/Vcxproj.pm b/third_party/git/contrib/buildsystems/Generators/Vcxproj.pm index 5c666f9ac0..5c666f9ac0 100644 --- a/contrib/buildsystems/Generators/Vcxproj.pm +++ b/third_party/git/contrib/buildsystems/Generators/Vcxproj.pm diff --git a/contrib/buildsystems/engine.pl b/third_party/git/contrib/buildsystems/engine.pl index 070978506a..070978506a 100755 --- a/contrib/buildsystems/engine.pl +++ b/third_party/git/contrib/buildsystems/engine.pl diff --git a/contrib/buildsystems/generate b/third_party/git/contrib/buildsystems/generate index bc10f25ff2..bc10f25ff2 100755 --- a/contrib/buildsystems/generate +++ b/third_party/git/contrib/buildsystems/generate diff --git a/contrib/buildsystems/parse.pl b/third_party/git/contrib/buildsystems/parse.pl index c9656ece99..c9656ece99 100755 --- a/contrib/buildsystems/parse.pl +++ b/third_party/git/contrib/buildsystems/parse.pl diff --git a/contrib/coccinelle/.gitignore b/third_party/git/contrib/coccinelle/.gitignore index d3f29646dc..d3f29646dc 100644 --- a/contrib/coccinelle/.gitignore +++ b/third_party/git/contrib/coccinelle/.gitignore diff --git a/contrib/coccinelle/README b/third_party/git/contrib/coccinelle/README index f0e80bd7f0..f0e80bd7f0 100644 --- a/contrib/coccinelle/README +++ b/third_party/git/contrib/coccinelle/README diff --git a/contrib/coccinelle/array.cocci b/third_party/git/contrib/coccinelle/array.cocci index 46b8d2ee11..46b8d2ee11 100644 --- a/contrib/coccinelle/array.cocci +++ b/third_party/git/contrib/coccinelle/array.cocci diff --git a/contrib/coccinelle/commit.cocci b/third_party/git/contrib/coccinelle/commit.cocci index 778e4704f6..778e4704f6 100644 --- a/contrib/coccinelle/commit.cocci +++ b/third_party/git/contrib/coccinelle/commit.cocci diff --git a/contrib/coccinelle/flex_alloc.cocci b/third_party/git/contrib/coccinelle/flex_alloc.cocci index e9f7f6d861..e9f7f6d861 100644 --- a/contrib/coccinelle/flex_alloc.cocci +++ b/third_party/git/contrib/coccinelle/flex_alloc.cocci diff --git a/contrib/coccinelle/free.cocci b/third_party/git/contrib/coccinelle/free.cocci index 4490069df9..4490069df9 100644 --- a/contrib/coccinelle/free.cocci +++ b/third_party/git/contrib/coccinelle/free.cocci diff --git a/contrib/coccinelle/hashmap.cocci b/third_party/git/contrib/coccinelle/hashmap.cocci index d69e120ccf..d69e120ccf 100644 --- a/contrib/coccinelle/hashmap.cocci +++ b/third_party/git/contrib/coccinelle/hashmap.cocci diff --git a/contrib/coccinelle/object_id.cocci b/third_party/git/contrib/coccinelle/object_id.cocci index ddf4f22bd7..ddf4f22bd7 100644 --- a/contrib/coccinelle/object_id.cocci +++ b/third_party/git/contrib/coccinelle/object_id.cocci diff --git a/contrib/coccinelle/preincr.cocci b/third_party/git/contrib/coccinelle/preincr.cocci index 7fe1e8d2d9..7fe1e8d2d9 100644 --- a/contrib/coccinelle/preincr.cocci +++ b/third_party/git/contrib/coccinelle/preincr.cocci diff --git a/contrib/coccinelle/qsort.cocci b/third_party/git/contrib/coccinelle/qsort.cocci index 22b93a9966..22b93a9966 100644 --- a/contrib/coccinelle/qsort.cocci +++ b/third_party/git/contrib/coccinelle/qsort.cocci diff --git a/contrib/coccinelle/strbuf.cocci b/third_party/git/contrib/coccinelle/strbuf.cocci index d9ada69b43..d9ada69b43 100644 --- a/contrib/coccinelle/strbuf.cocci +++ b/third_party/git/contrib/coccinelle/strbuf.cocci diff --git a/contrib/coccinelle/swap.cocci b/third_party/git/contrib/coccinelle/swap.cocci index a0934d1fda..a0934d1fda 100644 --- a/contrib/coccinelle/swap.cocci +++ b/third_party/git/contrib/coccinelle/swap.cocci diff --git a/contrib/coccinelle/the_repository.pending.cocci b/third_party/git/contrib/coccinelle/the_repository.pending.cocci index 2ee702ecf7..2ee702ecf7 100644 --- a/contrib/coccinelle/the_repository.pending.cocci +++ b/third_party/git/contrib/coccinelle/the_repository.pending.cocci diff --git a/contrib/coccinelle/xstrdup_or_null.cocci b/third_party/git/contrib/coccinelle/xstrdup_or_null.cocci index 8e05d1ca4b..8e05d1ca4b 100644 --- a/contrib/coccinelle/xstrdup_or_null.cocci +++ b/third_party/git/contrib/coccinelle/xstrdup_or_null.cocci diff --git a/contrib/completion/.gitattributes b/third_party/git/contrib/completion/.gitattributes index 19116944c1..19116944c1 100644 --- a/contrib/completion/.gitattributes +++ b/third_party/git/contrib/completion/.gitattributes diff --git a/contrib/completion/git-completion.bash b/third_party/git/contrib/completion/git-completion.bash index c21786f2fd..c21786f2fd 100644 --- a/contrib/completion/git-completion.bash +++ b/third_party/git/contrib/completion/git-completion.bash diff --git a/contrib/completion/git-completion.tcsh b/third_party/git/contrib/completion/git-completion.tcsh index 4a790d8f4e..4a790d8f4e 100644 --- a/contrib/completion/git-completion.tcsh +++ b/third_party/git/contrib/completion/git-completion.tcsh diff --git a/contrib/completion/git-completion.zsh b/third_party/git/contrib/completion/git-completion.zsh index eef4eff53d..eef4eff53d 100644 --- a/contrib/completion/git-completion.zsh +++ b/third_party/git/contrib/completion/git-completion.zsh diff --git a/contrib/completion/git-prompt.sh b/third_party/git/contrib/completion/git-prompt.sh index 014cd7c3cf..014cd7c3cf 100644 --- a/contrib/completion/git-prompt.sh +++ b/third_party/git/contrib/completion/git-prompt.sh diff --git a/contrib/contacts/.gitignore b/third_party/git/contrib/contacts/.gitignore index f385ee643c..f385ee643c 100644 --- a/contrib/contacts/.gitignore +++ b/third_party/git/contrib/contacts/.gitignore diff --git a/contrib/contacts/Makefile b/third_party/git/contrib/contacts/Makefile index a2990f0dcb..a2990f0dcb 100644 --- a/contrib/contacts/Makefile +++ b/third_party/git/contrib/contacts/Makefile diff --git a/contrib/contacts/git-contacts b/third_party/git/contrib/contacts/git-contacts index 85ad732fc0..85ad732fc0 100755 --- a/contrib/contacts/git-contacts +++ b/third_party/git/contrib/contacts/git-contacts diff --git a/contrib/contacts/git-contacts.txt b/third_party/git/contrib/contacts/git-contacts.txt index dd914d1261..dd914d1261 100644 --- a/contrib/contacts/git-contacts.txt +++ b/third_party/git/contrib/contacts/git-contacts.txt diff --git a/contrib/coverage-diff.sh b/third_party/git/contrib/coverage-diff.sh index 4ec419f900..4ec419f900 100755 --- a/contrib/coverage-diff.sh +++ b/third_party/git/contrib/coverage-diff.sh diff --git a/contrib/credential/gnome-keyring/.gitignore b/third_party/git/contrib/credential/gnome-keyring/.gitignore index 88d8fcdbce..88d8fcdbce 100644 --- a/contrib/credential/gnome-keyring/.gitignore +++ b/third_party/git/contrib/credential/gnome-keyring/.gitignore diff --git a/contrib/credential/gnome-keyring/Makefile b/third_party/git/contrib/credential/gnome-keyring/Makefile index 22c19df94b..22c19df94b 100644 --- a/contrib/credential/gnome-keyring/Makefile +++ b/third_party/git/contrib/credential/gnome-keyring/Makefile diff --git a/contrib/credential/gnome-keyring/git-credential-gnome-keyring.c b/third_party/git/contrib/credential/gnome-keyring/git-credential-gnome-keyring.c index d389bfadce..d389bfadce 100644 --- a/contrib/credential/gnome-keyring/git-credential-gnome-keyring.c +++ b/third_party/git/contrib/credential/gnome-keyring/git-credential-gnome-keyring.c diff --git a/contrib/credential/libsecret/Makefile b/third_party/git/contrib/credential/libsecret/Makefile index 3e67552cc5..3e67552cc5 100644 --- a/contrib/credential/libsecret/Makefile +++ b/third_party/git/contrib/credential/libsecret/Makefile diff --git a/contrib/credential/libsecret/git-credential-libsecret.c b/third_party/git/contrib/credential/libsecret/git-credential-libsecret.c index e6598b6383..e6598b6383 100644 --- a/contrib/credential/libsecret/git-credential-libsecret.c +++ b/third_party/git/contrib/credential/libsecret/git-credential-libsecret.c diff --git a/contrib/credential/netrc/.gitignore b/third_party/git/contrib/credential/netrc/.gitignore index d41cdde84b..d41cdde84b 100644 --- a/contrib/credential/netrc/.gitignore +++ b/third_party/git/contrib/credential/netrc/.gitignore diff --git a/contrib/credential/netrc/Makefile b/third_party/git/contrib/credential/netrc/Makefile index c284fb8ac4..c284fb8ac4 100644 --- a/contrib/credential/netrc/Makefile +++ b/third_party/git/contrib/credential/netrc/Makefile diff --git a/contrib/credential/netrc/git-credential-netrc.perl b/third_party/git/contrib/credential/netrc/git-credential-netrc.perl index bc57cc6588..bc57cc6588 100755 --- a/contrib/credential/netrc/git-credential-netrc.perl +++ b/third_party/git/contrib/credential/netrc/git-credential-netrc.perl diff --git a/contrib/credential/netrc/t-git-credential-netrc.sh b/third_party/git/contrib/credential/netrc/t-git-credential-netrc.sh index 07227d0228..07227d0228 100755 --- a/contrib/credential/netrc/t-git-credential-netrc.sh +++ b/third_party/git/contrib/credential/netrc/t-git-credential-netrc.sh diff --git a/contrib/credential/netrc/test.command-option-gpg b/third_party/git/contrib/credential/netrc/test.command-option-gpg index d8f1285d41..d8f1285d41 100755 --- a/contrib/credential/netrc/test.command-option-gpg +++ b/third_party/git/contrib/credential/netrc/test.command-option-gpg diff --git a/contrib/credential/netrc/test.git-config-gpg b/third_party/git/contrib/credential/netrc/test.git-config-gpg index 65cf594c20..65cf594c20 100755 --- a/contrib/credential/netrc/test.git-config-gpg +++ b/third_party/git/contrib/credential/netrc/test.git-config-gpg diff --git a/contrib/credential/netrc/test.netrc b/third_party/git/contrib/credential/netrc/test.netrc index ba119a937f..ba119a937f 100644 --- a/contrib/credential/netrc/test.netrc +++ b/third_party/git/contrib/credential/netrc/test.netrc diff --git a/third_party/git/contrib/credential/netrc/test.netrc.gpg b/third_party/git/contrib/credential/netrc/test.netrc.gpg new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/contrib/credential/netrc/test.netrc.gpg diff --git a/contrib/credential/netrc/test.pl b/third_party/git/contrib/credential/netrc/test.pl index c0fb3718b2..c0fb3718b2 100755 --- a/contrib/credential/netrc/test.pl +++ b/third_party/git/contrib/credential/netrc/test.pl diff --git a/contrib/credential/osxkeychain/.gitignore b/third_party/git/contrib/credential/osxkeychain/.gitignore index 6c5b7026c5..6c5b7026c5 100644 --- a/contrib/credential/osxkeychain/.gitignore +++ b/third_party/git/contrib/credential/osxkeychain/.gitignore diff --git a/contrib/credential/osxkeychain/Makefile b/third_party/git/contrib/credential/osxkeychain/Makefile index 4b3a08a2ba..4b3a08a2ba 100644 --- a/contrib/credential/osxkeychain/Makefile +++ b/third_party/git/contrib/credential/osxkeychain/Makefile diff --git a/contrib/credential/osxkeychain/git-credential-osxkeychain.c b/third_party/git/contrib/credential/osxkeychain/git-credential-osxkeychain.c index bcd3f575a3..bcd3f575a3 100644 --- a/contrib/credential/osxkeychain/git-credential-osxkeychain.c +++ b/third_party/git/contrib/credential/osxkeychain/git-credential-osxkeychain.c diff --git a/contrib/credential/wincred/Makefile b/third_party/git/contrib/credential/wincred/Makefile index 6e992c0866..6e992c0866 100644 --- a/contrib/credential/wincred/Makefile +++ b/third_party/git/contrib/credential/wincred/Makefile diff --git a/contrib/credential/wincred/git-credential-wincred.c b/third_party/git/contrib/credential/wincred/git-credential-wincred.c index 5bdad41de1..5bdad41de1 100644 --- a/contrib/credential/wincred/git-credential-wincred.c +++ b/third_party/git/contrib/credential/wincred/git-credential-wincred.c diff --git a/contrib/diff-highlight/.gitignore b/third_party/git/contrib/diff-highlight/.gitignore index c07454824e..c07454824e 100644 --- a/contrib/diff-highlight/.gitignore +++ b/third_party/git/contrib/diff-highlight/.gitignore diff --git a/contrib/diff-highlight/DiffHighlight.pm b/third_party/git/contrib/diff-highlight/DiffHighlight.pm index e2589922a6..e2589922a6 100644 --- a/contrib/diff-highlight/DiffHighlight.pm +++ b/third_party/git/contrib/diff-highlight/DiffHighlight.pm diff --git a/contrib/diff-highlight/Makefile b/third_party/git/contrib/diff-highlight/Makefile index f2be7cc924..f2be7cc924 100644 --- a/contrib/diff-highlight/Makefile +++ b/third_party/git/contrib/diff-highlight/Makefile diff --git a/contrib/diff-highlight/README b/third_party/git/contrib/diff-highlight/README index d4c2343175..d4c2343175 100644 --- a/contrib/diff-highlight/README +++ b/third_party/git/contrib/diff-highlight/README diff --git a/contrib/diff-highlight/diff-highlight.perl b/third_party/git/contrib/diff-highlight/diff-highlight.perl index 9b3e9c1f4d..9b3e9c1f4d 100644 --- a/contrib/diff-highlight/diff-highlight.perl +++ b/third_party/git/contrib/diff-highlight/diff-highlight.perl diff --git a/contrib/diff-highlight/t/.gitignore b/third_party/git/contrib/diff-highlight/t/.gitignore index 7dcbb232cd..7dcbb232cd 100644 --- a/contrib/diff-highlight/t/.gitignore +++ b/third_party/git/contrib/diff-highlight/t/.gitignore diff --git a/contrib/diff-highlight/t/Makefile b/third_party/git/contrib/diff-highlight/t/Makefile index 5ff5275496..5ff5275496 100644 --- a/contrib/diff-highlight/t/Makefile +++ b/third_party/git/contrib/diff-highlight/t/Makefile diff --git a/contrib/diff-highlight/t/t9400-diff-highlight.sh b/third_party/git/contrib/diff-highlight/t/t9400-diff-highlight.sh index f6f5195d00..f6f5195d00 100755 --- a/contrib/diff-highlight/t/t9400-diff-highlight.sh +++ b/third_party/git/contrib/diff-highlight/t/t9400-diff-highlight.sh diff --git a/contrib/emacs/README b/third_party/git/contrib/emacs/README index 977a16f1e3..977a16f1e3 100644 --- a/contrib/emacs/README +++ b/third_party/git/contrib/emacs/README diff --git a/contrib/emacs/git-blame.el b/third_party/git/contrib/emacs/git-blame.el index 6a8a2b8ff1..6a8a2b8ff1 100644 --- a/contrib/emacs/git-blame.el +++ b/third_party/git/contrib/emacs/git-blame.el diff --git a/contrib/emacs/git.el b/third_party/git/contrib/emacs/git.el index 03f926281f..03f926281f 100644 --- a/contrib/emacs/git.el +++ b/third_party/git/contrib/emacs/git.el diff --git a/contrib/examples/README b/third_party/git/contrib/examples/README index 18bc60b021..18bc60b021 100644 --- a/contrib/examples/README +++ b/third_party/git/contrib/examples/README diff --git a/contrib/fast-import/git-import.perl b/third_party/git/contrib/fast-import/git-import.perl index 0891b9e366..0891b9e366 100755 --- a/contrib/fast-import/git-import.perl +++ b/third_party/git/contrib/fast-import/git-import.perl diff --git a/contrib/fast-import/git-import.sh b/third_party/git/contrib/fast-import/git-import.sh index f8d803c5e2..f8d803c5e2 100755 --- a/contrib/fast-import/git-import.sh +++ b/third_party/git/contrib/fast-import/git-import.sh diff --git a/contrib/fast-import/git-p4.README b/third_party/git/contrib/fast-import/git-p4.README index cec5ecfa7c..cec5ecfa7c 100644 --- a/contrib/fast-import/git-p4.README +++ b/third_party/git/contrib/fast-import/git-p4.README diff --git a/contrib/fast-import/import-directories.perl b/third_party/git/contrib/fast-import/import-directories.perl index a16f79cfdc..a16f79cfdc 100755 --- a/contrib/fast-import/import-directories.perl +++ b/third_party/git/contrib/fast-import/import-directories.perl diff --git a/contrib/fast-import/import-tars.perl b/third_party/git/contrib/fast-import/import-tars.perl index e800d9f5c9..e800d9f5c9 100755 --- a/contrib/fast-import/import-tars.perl +++ b/third_party/git/contrib/fast-import/import-tars.perl diff --git a/contrib/fast-import/import-zips.py b/third_party/git/contrib/fast-import/import-zips.py index d12c296223..d12c296223 100755 --- a/contrib/fast-import/import-zips.py +++ b/third_party/git/contrib/fast-import/import-zips.py diff --git a/contrib/git-jump/README b/third_party/git/contrib/git-jump/README index 2f618a7f97..2f618a7f97 100644 --- a/contrib/git-jump/README +++ b/third_party/git/contrib/git-jump/README diff --git a/contrib/git-jump/git-jump b/third_party/git/contrib/git-jump/git-jump index 931b0fe3a9..931b0fe3a9 100755 --- a/contrib/git-jump/git-jump +++ b/third_party/git/contrib/git-jump/git-jump diff --git a/contrib/git-resurrect.sh b/third_party/git/contrib/git-resurrect.sh index 8c171dd959..8c171dd959 100755 --- a/contrib/git-resurrect.sh +++ b/third_party/git/contrib/git-resurrect.sh diff --git a/contrib/git-shell-commands/README b/third_party/git/contrib/git-shell-commands/README index 438463b160..438463b160 100644 --- a/contrib/git-shell-commands/README +++ b/third_party/git/contrib/git-shell-commands/README diff --git a/contrib/git-shell-commands/help b/third_party/git/contrib/git-shell-commands/help index 535770c6ec..535770c6ec 100755 --- a/contrib/git-shell-commands/help +++ b/third_party/git/contrib/git-shell-commands/help diff --git a/contrib/git-shell-commands/list b/third_party/git/contrib/git-shell-commands/list index 6f89938821..6f89938821 100755 --- a/contrib/git-shell-commands/list +++ b/third_party/git/contrib/git-shell-commands/list diff --git a/contrib/hg-to-git/hg-to-git.py b/third_party/git/contrib/hg-to-git/hg-to-git.py index 7eb1b24cc7..7eb1b24cc7 100755 --- a/contrib/hg-to-git/hg-to-git.py +++ b/third_party/git/contrib/hg-to-git/hg-to-git.py diff --git a/contrib/hg-to-git/hg-to-git.txt b/third_party/git/contrib/hg-to-git/hg-to-git.txt index 91f8fe6410..91f8fe6410 100644 --- a/contrib/hg-to-git/hg-to-git.txt +++ b/third_party/git/contrib/hg-to-git/hg-to-git.txt diff --git a/contrib/hooks/multimail/CHANGES b/third_party/git/contrib/hooks/multimail/CHANGES index 35791fd02c..35791fd02c 100644 --- a/contrib/hooks/multimail/CHANGES +++ b/third_party/git/contrib/hooks/multimail/CHANGES diff --git a/contrib/hooks/multimail/CONTRIBUTING.rst b/third_party/git/contrib/hooks/multimail/CONTRIBUTING.rst index de20a54287..de20a54287 100644 --- a/contrib/hooks/multimail/CONTRIBUTING.rst +++ b/third_party/git/contrib/hooks/multimail/CONTRIBUTING.rst diff --git a/contrib/hooks/multimail/README.Git b/third_party/git/contrib/hooks/multimail/README.Git index 044444245d..044444245d 100644 --- a/contrib/hooks/multimail/README.Git +++ b/third_party/git/contrib/hooks/multimail/README.Git diff --git a/contrib/hooks/multimail/README.migrate-from-post-receive-email b/third_party/git/contrib/hooks/multimail/README.migrate-from-post-receive-email index 1e6a976699..1e6a976699 100644 --- a/contrib/hooks/multimail/README.migrate-from-post-receive-email +++ b/third_party/git/contrib/hooks/multimail/README.migrate-from-post-receive-email diff --git a/contrib/hooks/multimail/README.rst b/third_party/git/contrib/hooks/multimail/README.rst index 7c0fc4a6ef..7c0fc4a6ef 100644 --- a/contrib/hooks/multimail/README.rst +++ b/third_party/git/contrib/hooks/multimail/README.rst diff --git a/contrib/hooks/multimail/doc/customizing-emails.rst b/third_party/git/contrib/hooks/multimail/doc/customizing-emails.rst index 3f5b67f768..3f5b67f768 100644 --- a/contrib/hooks/multimail/doc/customizing-emails.rst +++ b/third_party/git/contrib/hooks/multimail/doc/customizing-emails.rst diff --git a/contrib/hooks/multimail/doc/gerrit.rst b/third_party/git/contrib/hooks/multimail/doc/gerrit.rst index 8011d05dec..8011d05dec 100644 --- a/contrib/hooks/multimail/doc/gerrit.rst +++ b/third_party/git/contrib/hooks/multimail/doc/gerrit.rst diff --git a/contrib/hooks/multimail/doc/gitolite.rst b/third_party/git/contrib/hooks/multimail/doc/gitolite.rst index 5054833105..5054833105 100644 --- a/contrib/hooks/multimail/doc/gitolite.rst +++ b/third_party/git/contrib/hooks/multimail/doc/gitolite.rst diff --git a/contrib/hooks/multimail/doc/troubleshooting.rst b/third_party/git/contrib/hooks/multimail/doc/troubleshooting.rst index 651b509ee6..651b509ee6 100644 --- a/contrib/hooks/multimail/doc/troubleshooting.rst +++ b/third_party/git/contrib/hooks/multimail/doc/troubleshooting.rst diff --git a/contrib/hooks/multimail/git_multimail.py b/third_party/git/contrib/hooks/multimail/git_multimail.py index f563be82fc..f563be82fc 100755 --- a/contrib/hooks/multimail/git_multimail.py +++ b/third_party/git/contrib/hooks/multimail/git_multimail.py diff --git a/contrib/hooks/multimail/migrate-mailhook-config b/third_party/git/contrib/hooks/multimail/migrate-mailhook-config index 241ba22fa3..241ba22fa3 100755 --- a/contrib/hooks/multimail/migrate-mailhook-config +++ b/third_party/git/contrib/hooks/multimail/migrate-mailhook-config diff --git a/contrib/hooks/multimail/post-receive.example b/third_party/git/contrib/hooks/multimail/post-receive.example index 0f98c5a23d..0f98c5a23d 100755 --- a/contrib/hooks/multimail/post-receive.example +++ b/third_party/git/contrib/hooks/multimail/post-receive.example diff --git a/contrib/hooks/post-receive-email b/third_party/git/contrib/hooks/post-receive-email index ff565eb3d8..ff565eb3d8 100755 --- a/contrib/hooks/post-receive-email +++ b/third_party/git/contrib/hooks/post-receive-email diff --git a/contrib/hooks/pre-auto-gc-battery b/third_party/git/contrib/hooks/pre-auto-gc-battery index 7ba78c4dff..7ba78c4dff 100755 --- a/contrib/hooks/pre-auto-gc-battery +++ b/third_party/git/contrib/hooks/pre-auto-gc-battery diff --git a/contrib/hooks/setgitperms.perl b/third_party/git/contrib/hooks/setgitperms.perl index 2770a1b1d2..2770a1b1d2 100755 --- a/contrib/hooks/setgitperms.perl +++ b/third_party/git/contrib/hooks/setgitperms.perl diff --git a/contrib/hooks/update-paranoid b/third_party/git/contrib/hooks/update-paranoid index 0092d67b8a..0092d67b8a 100755 --- a/contrib/hooks/update-paranoid +++ b/third_party/git/contrib/hooks/update-paranoid diff --git a/contrib/long-running-filter/example.pl b/third_party/git/contrib/long-running-filter/example.pl index a677569ddd..a677569ddd 100755 --- a/contrib/long-running-filter/example.pl +++ b/third_party/git/contrib/long-running-filter/example.pl diff --git a/contrib/mw-to-git/.gitignore b/third_party/git/contrib/mw-to-git/.gitignore index ae545b013d..ae545b013d 100644 --- a/contrib/mw-to-git/.gitignore +++ b/third_party/git/contrib/mw-to-git/.gitignore diff --git a/contrib/mw-to-git/.perlcriticrc b/third_party/git/contrib/mw-to-git/.perlcriticrc index b7333267ad..b7333267ad 100644 --- a/contrib/mw-to-git/.perlcriticrc +++ b/third_party/git/contrib/mw-to-git/.perlcriticrc diff --git a/contrib/mw-to-git/Git/Mediawiki.pm b/third_party/git/contrib/mw-to-git/Git/Mediawiki.pm index 917d9e2d32..917d9e2d32 100644 --- a/contrib/mw-to-git/Git/Mediawiki.pm +++ b/third_party/git/contrib/mw-to-git/Git/Mediawiki.pm diff --git a/contrib/mw-to-git/Makefile b/third_party/git/contrib/mw-to-git/Makefile index 4e603512a3..4e603512a3 100644 --- a/contrib/mw-to-git/Makefile +++ b/third_party/git/contrib/mw-to-git/Makefile diff --git a/contrib/mw-to-git/bin-wrapper/git b/third_party/git/contrib/mw-to-git/bin-wrapper/git index 6663ae57e8..6663ae57e8 100755 --- a/contrib/mw-to-git/bin-wrapper/git +++ b/third_party/git/contrib/mw-to-git/bin-wrapper/git diff --git a/contrib/mw-to-git/git-mw.perl b/third_party/git/contrib/mw-to-git/git-mw.perl index 28df3ee321..28df3ee321 100755 --- a/contrib/mw-to-git/git-mw.perl +++ b/third_party/git/contrib/mw-to-git/git-mw.perl diff --git a/contrib/mw-to-git/git-remote-mediawiki.perl b/third_party/git/contrib/mw-to-git/git-remote-mediawiki.perl index d8ff2e69c4..d8ff2e69c4 100755 --- a/contrib/mw-to-git/git-remote-mediawiki.perl +++ b/third_party/git/contrib/mw-to-git/git-remote-mediawiki.perl diff --git a/contrib/mw-to-git/git-remote-mediawiki.txt b/third_party/git/contrib/mw-to-git/git-remote-mediawiki.txt index 23b7ef9f62..23b7ef9f62 100644 --- a/contrib/mw-to-git/git-remote-mediawiki.txt +++ b/third_party/git/contrib/mw-to-git/git-remote-mediawiki.txt diff --git a/contrib/mw-to-git/t/.gitignore b/third_party/git/contrib/mw-to-git/t/.gitignore index a7a40b4964..a7a40b4964 100644 --- a/contrib/mw-to-git/t/.gitignore +++ b/third_party/git/contrib/mw-to-git/t/.gitignore diff --git a/contrib/mw-to-git/t/Makefile b/third_party/git/contrib/mw-to-git/t/Makefile index f422203fa0..f422203fa0 100644 --- a/contrib/mw-to-git/t/Makefile +++ b/third_party/git/contrib/mw-to-git/t/Makefile diff --git a/contrib/mw-to-git/t/README b/third_party/git/contrib/mw-to-git/t/README index 2ee34be7e4..2ee34be7e4 100644 --- a/contrib/mw-to-git/t/README +++ b/third_party/git/contrib/mw-to-git/t/README diff --git a/contrib/mw-to-git/t/install-wiki.sh b/third_party/git/contrib/mw-to-git/t/install-wiki.sh index c215213c4b..c215213c4b 100755 --- a/contrib/mw-to-git/t/install-wiki.sh +++ b/third_party/git/contrib/mw-to-git/t/install-wiki.sh diff --git a/contrib/mw-to-git/t/install-wiki/.gitignore b/third_party/git/contrib/mw-to-git/t/install-wiki/.gitignore index b5a2a4408c..b5a2a4408c 100644 --- a/contrib/mw-to-git/t/install-wiki/.gitignore +++ b/third_party/git/contrib/mw-to-git/t/install-wiki/.gitignore diff --git a/contrib/mw-to-git/t/install-wiki/LocalSettings.php b/third_party/git/contrib/mw-to-git/t/install-wiki/LocalSettings.php index 745e47e881..745e47e881 100644 --- a/contrib/mw-to-git/t/install-wiki/LocalSettings.php +++ b/third_party/git/contrib/mw-to-git/t/install-wiki/LocalSettings.php diff --git a/contrib/mw-to-git/t/install-wiki/db_install.php b/third_party/git/contrib/mw-to-git/t/install-wiki/db_install.php index b033849800..b033849800 100644 --- a/contrib/mw-to-git/t/install-wiki/db_install.php +++ b/third_party/git/contrib/mw-to-git/t/install-wiki/db_install.php diff --git a/contrib/mw-to-git/t/push-pull-tests.sh b/third_party/git/contrib/mw-to-git/t/push-pull-tests.sh index 9da2dc5ff0..9da2dc5ff0 100644 --- a/contrib/mw-to-git/t/push-pull-tests.sh +++ b/third_party/git/contrib/mw-to-git/t/push-pull-tests.sh diff --git a/contrib/mw-to-git/t/t9360-mw-to-git-clone.sh b/third_party/git/contrib/mw-to-git/t/t9360-mw-to-git-clone.sh index 9106833578..9106833578 100755 --- a/contrib/mw-to-git/t/t9360-mw-to-git-clone.sh +++ b/third_party/git/contrib/mw-to-git/t/t9360-mw-to-git-clone.sh diff --git a/contrib/mw-to-git/t/t9361-mw-to-git-push-pull.sh b/third_party/git/contrib/mw-to-git/t/t9361-mw-to-git-push-pull.sh index 9ea201459b..9ea201459b 100755 --- a/contrib/mw-to-git/t/t9361-mw-to-git-push-pull.sh +++ b/third_party/git/contrib/mw-to-git/t/t9361-mw-to-git-push-pull.sh diff --git a/contrib/mw-to-git/t/t9362-mw-to-git-utf8.sh b/third_party/git/contrib/mw-to-git/t/t9362-mw-to-git-utf8.sh index 6b0dbdac4d..6b0dbdac4d 100755 --- a/contrib/mw-to-git/t/t9362-mw-to-git-utf8.sh +++ b/third_party/git/contrib/mw-to-git/t/t9362-mw-to-git-utf8.sh diff --git a/contrib/mw-to-git/t/t9363-mw-to-git-export-import.sh b/third_party/git/contrib/mw-to-git/t/t9363-mw-to-git-export-import.sh index 3ff3a09567..3ff3a09567 100755 --- a/contrib/mw-to-git/t/t9363-mw-to-git-export-import.sh +++ b/third_party/git/contrib/mw-to-git/t/t9363-mw-to-git-export-import.sh diff --git a/contrib/mw-to-git/t/t9364-pull-by-rev.sh b/third_party/git/contrib/mw-to-git/t/t9364-pull-by-rev.sh index 5c22457a0b..5c22457a0b 100755 --- a/contrib/mw-to-git/t/t9364-pull-by-rev.sh +++ b/third_party/git/contrib/mw-to-git/t/t9364-pull-by-rev.sh diff --git a/contrib/mw-to-git/t/t9365-continuing-queries.sh b/third_party/git/contrib/mw-to-git/t/t9365-continuing-queries.sh index 016454749f..016454749f 100755 --- a/contrib/mw-to-git/t/t9365-continuing-queries.sh +++ b/third_party/git/contrib/mw-to-git/t/t9365-continuing-queries.sh diff --git a/contrib/mw-to-git/t/test-gitmw-lib.sh b/third_party/git/contrib/mw-to-git/t/test-gitmw-lib.sh index 3948a00282..3948a00282 100755 --- a/contrib/mw-to-git/t/test-gitmw-lib.sh +++ b/third_party/git/contrib/mw-to-git/t/test-gitmw-lib.sh diff --git a/contrib/mw-to-git/t/test-gitmw.pl b/third_party/git/contrib/mw-to-git/t/test-gitmw.pl index 0ff76259fa..0ff76259fa 100755 --- a/contrib/mw-to-git/t/test-gitmw.pl +++ b/third_party/git/contrib/mw-to-git/t/test-gitmw.pl diff --git a/contrib/mw-to-git/t/test.config b/third_party/git/contrib/mw-to-git/t/test.config index 5ba0684162..5ba0684162 100644 --- a/contrib/mw-to-git/t/test.config +++ b/third_party/git/contrib/mw-to-git/t/test.config diff --git a/contrib/persistent-https/LICENSE b/third_party/git/contrib/persistent-https/LICENSE index d645695673..d645695673 100644 --- a/contrib/persistent-https/LICENSE +++ b/third_party/git/contrib/persistent-https/LICENSE diff --git a/contrib/persistent-https/Makefile b/third_party/git/contrib/persistent-https/Makefile index 52b84ba3d4..52b84ba3d4 100644 --- a/contrib/persistent-https/Makefile +++ b/third_party/git/contrib/persistent-https/Makefile diff --git a/contrib/persistent-https/README b/third_party/git/contrib/persistent-https/README index 7c4cd8d257..7c4cd8d257 100644 --- a/contrib/persistent-https/README +++ b/third_party/git/contrib/persistent-https/README diff --git a/contrib/persistent-https/client.go b/third_party/git/contrib/persistent-https/client.go index 71125b5832..71125b5832 100644 --- a/contrib/persistent-https/client.go +++ b/third_party/git/contrib/persistent-https/client.go diff --git a/contrib/persistent-https/main.go b/third_party/git/contrib/persistent-https/main.go index fd1b107743..fd1b107743 100644 --- a/contrib/persistent-https/main.go +++ b/third_party/git/contrib/persistent-https/main.go diff --git a/contrib/persistent-https/proxy.go b/third_party/git/contrib/persistent-https/proxy.go index bb0cdba386..bb0cdba386 100644 --- a/contrib/persistent-https/proxy.go +++ b/third_party/git/contrib/persistent-https/proxy.go diff --git a/contrib/persistent-https/socket.go b/third_party/git/contrib/persistent-https/socket.go index 193b911dd1..193b911dd1 100644 --- a/contrib/persistent-https/socket.go +++ b/third_party/git/contrib/persistent-https/socket.go diff --git a/contrib/remote-helpers/README b/third_party/git/contrib/remote-helpers/README index ac72332517..ac72332517 100644 --- a/contrib/remote-helpers/README +++ b/third_party/git/contrib/remote-helpers/README diff --git a/contrib/remote-helpers/git-remote-bzr b/third_party/git/contrib/remote-helpers/git-remote-bzr index 1c3d87f861..1c3d87f861 100755 --- a/contrib/remote-helpers/git-remote-bzr +++ b/third_party/git/contrib/remote-helpers/git-remote-bzr diff --git a/contrib/remote-helpers/git-remote-hg b/third_party/git/contrib/remote-helpers/git-remote-hg index 8e9188364c..8e9188364c 100755 --- a/contrib/remote-helpers/git-remote-hg +++ b/third_party/git/contrib/remote-helpers/git-remote-hg diff --git a/contrib/remotes2config.sh b/third_party/git/contrib/remotes2config.sh index 1cda19f66a..1cda19f66a 100755 --- a/contrib/remotes2config.sh +++ b/third_party/git/contrib/remotes2config.sh diff --git a/contrib/rerere-train.sh b/third_party/git/contrib/rerere-train.sh index eeee45dd34..eeee45dd34 100755 --- a/contrib/rerere-train.sh +++ b/third_party/git/contrib/rerere-train.sh diff --git a/contrib/stats/git-common-hash b/third_party/git/contrib/stats/git-common-hash index e27fd088be..e27fd088be 100755 --- a/contrib/stats/git-common-hash +++ b/third_party/git/contrib/stats/git-common-hash diff --git a/contrib/stats/mailmap.pl b/third_party/git/contrib/stats/mailmap.pl index 9513f5e35b..9513f5e35b 100755 --- a/contrib/stats/mailmap.pl +++ b/third_party/git/contrib/stats/mailmap.pl diff --git a/contrib/stats/packinfo.pl b/third_party/git/contrib/stats/packinfo.pl index be188c0f11..be188c0f11 100755 --- a/contrib/stats/packinfo.pl +++ b/third_party/git/contrib/stats/packinfo.pl diff --git a/contrib/subtree/.gitignore b/third_party/git/contrib/subtree/.gitignore index 0b9381abca..0b9381abca 100644 --- a/contrib/subtree/.gitignore +++ b/third_party/git/contrib/subtree/.gitignore diff --git a/contrib/subtree/COPYING b/third_party/git/contrib/subtree/COPYING index d511905c16..d511905c16 100644 --- a/contrib/subtree/COPYING +++ b/third_party/git/contrib/subtree/COPYING diff --git a/contrib/subtree/INSTALL b/third_party/git/contrib/subtree/INSTALL index 7ab0cf4509..7ab0cf4509 100644 --- a/contrib/subtree/INSTALL +++ b/third_party/git/contrib/subtree/INSTALL diff --git a/contrib/subtree/Makefile b/third_party/git/contrib/subtree/Makefile index 6906aae441..6906aae441 100644 --- a/contrib/subtree/Makefile +++ b/third_party/git/contrib/subtree/Makefile diff --git a/contrib/subtree/README b/third_party/git/contrib/subtree/README index c686b4a69b..c686b4a69b 100644 --- a/contrib/subtree/README +++ b/third_party/git/contrib/subtree/README diff --git a/contrib/subtree/git-subtree.sh b/third_party/git/contrib/subtree/git-subtree.sh index 868e18b9a1..868e18b9a1 100755 --- a/contrib/subtree/git-subtree.sh +++ b/third_party/git/contrib/subtree/git-subtree.sh diff --git a/contrib/subtree/git-subtree.txt b/third_party/git/contrib/subtree/git-subtree.txt index 352deda69d..352deda69d 100644 --- a/contrib/subtree/git-subtree.txt +++ b/third_party/git/contrib/subtree/git-subtree.txt diff --git a/contrib/subtree/t/Makefile b/third_party/git/contrib/subtree/t/Makefile index 276898eb6b..276898eb6b 100644 --- a/contrib/subtree/t/Makefile +++ b/third_party/git/contrib/subtree/t/Makefile diff --git a/contrib/subtree/t/t7900-subtree.sh b/third_party/git/contrib/subtree/t/t7900-subtree.sh index 57ff4b25c1..57ff4b25c1 100755 --- a/contrib/subtree/t/t7900-subtree.sh +++ b/third_party/git/contrib/subtree/t/t7900-subtree.sh diff --git a/contrib/subtree/todo b/third_party/git/contrib/subtree/todo index 0d0e777651..0d0e777651 100644 --- a/contrib/subtree/todo +++ b/third_party/git/contrib/subtree/todo diff --git a/contrib/svn-fe/.gitignore b/third_party/git/contrib/svn-fe/.gitignore index 02a7791585..02a7791585 100644 --- a/contrib/svn-fe/.gitignore +++ b/third_party/git/contrib/svn-fe/.gitignore diff --git a/contrib/svn-fe/Makefile b/third_party/git/contrib/svn-fe/Makefile index e8651aaf4b..e8651aaf4b 100644 --- a/contrib/svn-fe/Makefile +++ b/third_party/git/contrib/svn-fe/Makefile diff --git a/contrib/svn-fe/svn-fe.c b/third_party/git/contrib/svn-fe/svn-fe.c index f363505abb..f363505abb 100644 --- a/contrib/svn-fe/svn-fe.c +++ b/third_party/git/contrib/svn-fe/svn-fe.c diff --git a/contrib/svn-fe/svn-fe.txt b/third_party/git/contrib/svn-fe/svn-fe.txt index 19333fc8df..19333fc8df 100644 --- a/contrib/svn-fe/svn-fe.txt +++ b/third_party/git/contrib/svn-fe/svn-fe.txt diff --git a/contrib/svn-fe/svnrdump_sim.py b/third_party/git/contrib/svn-fe/svnrdump_sim.py index 8a3cee6175..8a3cee6175 100755 --- a/contrib/svn-fe/svnrdump_sim.py +++ b/third_party/git/contrib/svn-fe/svnrdump_sim.py diff --git a/contrib/thunderbird-patch-inline/README b/third_party/git/contrib/thunderbird-patch-inline/README index 000147bbe4..000147bbe4 100644 --- a/contrib/thunderbird-patch-inline/README +++ b/third_party/git/contrib/thunderbird-patch-inline/README diff --git a/contrib/thunderbird-patch-inline/appp.sh b/third_party/git/contrib/thunderbird-patch-inline/appp.sh index 1053872eea..1053872eea 100755 --- a/contrib/thunderbird-patch-inline/appp.sh +++ b/third_party/git/contrib/thunderbird-patch-inline/appp.sh diff --git a/contrib/update-unicode/.gitignore b/third_party/git/contrib/update-unicode/.gitignore index b0ebc6aad2..b0ebc6aad2 100644 --- a/contrib/update-unicode/.gitignore +++ b/third_party/git/contrib/update-unicode/.gitignore diff --git a/contrib/update-unicode/README b/third_party/git/contrib/update-unicode/README index 151a197041..151a197041 100644 --- a/contrib/update-unicode/README +++ b/third_party/git/contrib/update-unicode/README diff --git a/contrib/update-unicode/update_unicode.sh b/third_party/git/contrib/update-unicode/update_unicode.sh index aa90865bef..aa90865bef 100755 --- a/contrib/update-unicode/update_unicode.sh +++ b/third_party/git/contrib/update-unicode/update_unicode.sh diff --git a/contrib/vscode/.gitattributes b/third_party/git/contrib/vscode/.gitattributes index e89f2236ef..e89f2236ef 100644 --- a/contrib/vscode/.gitattributes +++ b/third_party/git/contrib/vscode/.gitattributes diff --git a/contrib/vscode/README.md b/third_party/git/contrib/vscode/README.md index 8202d62035..8202d62035 100644 --- a/contrib/vscode/README.md +++ b/third_party/git/contrib/vscode/README.md diff --git a/contrib/vscode/init.sh b/third_party/git/contrib/vscode/init.sh index 27de94994b..27de94994b 100755 --- a/contrib/vscode/init.sh +++ b/third_party/git/contrib/vscode/init.sh diff --git a/contrib/workdir/.gitattributes b/third_party/git/contrib/workdir/.gitattributes index 1f78c5d1bd..1f78c5d1bd 100644 --- a/contrib/workdir/.gitattributes +++ b/third_party/git/contrib/workdir/.gitattributes diff --git a/contrib/workdir/git-new-workdir b/third_party/git/contrib/workdir/git-new-workdir index 888c34a521..888c34a521 100755 --- a/contrib/workdir/git-new-workdir +++ b/third_party/git/contrib/workdir/git-new-workdir diff --git a/convert.c b/third_party/git/convert.c index 5ead3ce678..5ead3ce678 100644 --- a/convert.c +++ b/third_party/git/convert.c diff --git a/convert.h b/third_party/git/convert.h index 3710969d43..3710969d43 100644 --- a/convert.h +++ b/third_party/git/convert.h diff --git a/copy.c b/third_party/git/copy.c index 4de6a110f0..4de6a110f0 100644 --- a/copy.c +++ b/third_party/git/copy.c diff --git a/credential-cache--daemon.c b/third_party/git/credential-cache--daemon.c index ec1271f89c..ec1271f89c 100644 --- a/credential-cache--daemon.c +++ b/third_party/git/credential-cache--daemon.c diff --git a/credential-cache.c b/third_party/git/credential-cache.c index 1cccc3a0b9..1cccc3a0b9 100644 --- a/credential-cache.c +++ b/third_party/git/credential-cache.c diff --git a/credential-store.c b/third_party/git/credential-store.c index c010497cb2..c010497cb2 100644 --- a/credential-store.c +++ b/third_party/git/credential-store.c diff --git a/credential.c b/third_party/git/credential.c index 108d9e183a..108d9e183a 100644 --- a/credential.c +++ b/third_party/git/credential.c diff --git a/credential.h b/third_party/git/credential.h index d99ec42b2a..d99ec42b2a 100644 --- a/credential.h +++ b/third_party/git/credential.h diff --git a/csum-file.c b/third_party/git/csum-file.c index 53ce37f7ca..53ce37f7ca 100644 --- a/csum-file.c +++ b/third_party/git/csum-file.c diff --git a/csum-file.h b/third_party/git/csum-file.h index f9cbd317fb..f9cbd317fb 100644 --- a/csum-file.h +++ b/third_party/git/csum-file.h diff --git a/ctype.c b/third_party/git/ctype.c index fc0225cebd..fc0225cebd 100644 --- a/ctype.c +++ b/third_party/git/ctype.c diff --git a/daemon.c b/third_party/git/daemon.c index fd669ed3b4..fd669ed3b4 100644 --- a/daemon.c +++ b/third_party/git/daemon.c diff --git a/date.c b/third_party/git/date.c index b0d9a8421d..0355c0676b 100644 --- a/date.c +++ b/third_party/git/date.c @@ -347,6 +347,21 @@ const char *show_date(timestamp_t time, int tz, const struct date_mode *mode) tm->tm_mday, tm->tm_hour, tm->tm_min, tm->tm_sec, sign, tz / 100, tz % 100); + } else if (mode->type == DATE_DOTTIME) { + char sign = (tz >= 0) ? '+' : '-'; + tz = abs(tz); + + // Time is converted again without the timezone as the + // dottime format includes the zone only in offset + // position. + time_t t = gm_time_t(time, 0); + tm = gmtime(&t); + strbuf_addf(&timebuf, "%04d-%02d-%02dT%02d·%02d%c%02d%02d", + tm->tm_year + 1900, + tm->tm_mon + 1, + tm->tm_mday, + tm->tm_hour, tm->tm_min, + sign, tz / 100, tz % 100); } else if (mode->type == DATE_RFC2822) strbuf_addf(&timebuf, "%.3s, %d %.3s %d %02d:%02d:%02d %+05d", weekday_names[tm->tm_wday], tm->tm_mday, @@ -918,6 +933,8 @@ static enum date_mode_type parse_date_type(const char *format, const char **end) return DATE_UNIX; if (skip_prefix(format, "format", end)) return DATE_STRFTIME; + if (skip_prefix(format, "dottime", end)) + return DATE_DOTTIME; /* * Please update $__git_log_date_formats in * git-completion.bash when you add new formats. diff --git a/decorate.c b/third_party/git/decorate.c index a605b1b5f4..a605b1b5f4 100644 --- a/decorate.c +++ b/third_party/git/decorate.c diff --git a/decorate.h b/third_party/git/decorate.h index ee43dee1f0..ee43dee1f0 100644 --- a/decorate.h +++ b/third_party/git/decorate.h diff --git a/third_party/git/default.nix b/third_party/git/default.nix new file mode 100644 index 0000000000..10e47fea26 --- /dev/null +++ b/third_party/git/default.nix @@ -0,0 +1,16 @@ +# Use the upstream git derivation (there's a lot of stuff happening in +# there!) and just override the source: +{ depot, ... }: + +with depot.third_party; + +(originals.git.overrideAttrs(_: { + version = "2.23.0"; + src = ./.; + doInstallCheck = false; + preConfigure = '' + ${autoconf}/bin/autoreconf -i + ''; +})).override { + sendEmailSupport = true; +} diff --git a/delta-islands.c b/third_party/git/delta-islands.c index 09dbd3cf72..09dbd3cf72 100644 --- a/delta-islands.c +++ b/third_party/git/delta-islands.c diff --git a/delta-islands.h b/third_party/git/delta-islands.h index eb0f952629..eb0f952629 100644 --- a/delta-islands.h +++ b/third_party/git/delta-islands.h diff --git a/delta.h b/third_party/git/delta.h index 2df5fe13d9..2df5fe13d9 100644 --- a/delta.h +++ b/third_party/git/delta.h diff --git a/detect-compiler b/third_party/git/detect-compiler index 70b754481c..70b754481c 100755 --- a/detect-compiler +++ b/third_party/git/detect-compiler diff --git a/diff-delta.c b/third_party/git/diff-delta.c index 77fea08dfb..77fea08dfb 100644 --- a/diff-delta.c +++ b/third_party/git/diff-delta.c diff --git a/diff-lib.c b/third_party/git/diff-lib.c index 61812f48c2..61812f48c2 100644 --- a/diff-lib.c +++ b/third_party/git/diff-lib.c diff --git a/diff-no-index.c b/third_party/git/diff-no-index.c index 7814eabfe0..7814eabfe0 100644 --- a/diff-no-index.c +++ b/third_party/git/diff-no-index.c diff --git a/diff.c b/third_party/git/diff.c index f2cfbf2214..f2cfbf2214 100644 --- a/diff.c +++ b/third_party/git/diff.c diff --git a/diff.h b/third_party/git/diff.h index 6febe7e365..6febe7e365 100644 --- a/diff.h +++ b/third_party/git/diff.h diff --git a/diffcore-break.c b/third_party/git/diffcore-break.c index 9d20a6a6fc..9d20a6a6fc 100644 --- a/diffcore-break.c +++ b/third_party/git/diffcore-break.c diff --git a/diffcore-delta.c b/third_party/git/diffcore-delta.c index 5668ace60d..5668ace60d 100644 --- a/diffcore-delta.c +++ b/third_party/git/diffcore-delta.c diff --git a/diffcore-order.c b/third_party/git/diffcore-order.c index 19e73311f9..19e73311f9 100644 --- a/diffcore-order.c +++ b/third_party/git/diffcore-order.c diff --git a/diffcore-pickaxe.c b/third_party/git/diffcore-pickaxe.c index a9c6d60df2..a9c6d60df2 100644 --- a/diffcore-pickaxe.c +++ b/third_party/git/diffcore-pickaxe.c diff --git a/diffcore-rename.c b/third_party/git/diffcore-rename.c index e189f407af..e189f407af 100644 --- a/diffcore-rename.c +++ b/third_party/git/diffcore-rename.c diff --git a/diffcore.h b/third_party/git/diffcore.h index 7c07347e42..7c07347e42 100644 --- a/diffcore.h +++ b/third_party/git/diffcore.h diff --git a/dir-iterator.c b/third_party/git/dir-iterator.c index b17e9f970a..b17e9f970a 100644 --- a/dir-iterator.c +++ b/third_party/git/dir-iterator.c diff --git a/dir-iterator.h b/third_party/git/dir-iterator.h index 08229157c6..08229157c6 100644 --- a/dir-iterator.h +++ b/third_party/git/dir-iterator.h diff --git a/dir.c b/third_party/git/dir.c index 0ffb1b3302..0ffb1b3302 100644 --- a/dir.c +++ b/third_party/git/dir.c diff --git a/dir.h b/third_party/git/dir.h index 5855c065a6..5855c065a6 100644 --- a/dir.h +++ b/third_party/git/dir.h diff --git a/editor.c b/third_party/git/editor.c index f079abbf11..f079abbf11 100644 --- a/editor.c +++ b/third_party/git/editor.c diff --git a/entry.c b/third_party/git/entry.c index 53380bb614..53380bb614 100644 --- a/entry.c +++ b/third_party/git/entry.c diff --git a/environment.c b/third_party/git/environment.c index e72a02d0d5..e72a02d0d5 100644 --- a/environment.c +++ b/third_party/git/environment.c diff --git a/ewah/bitmap.c b/third_party/git/ewah/bitmap.c index d8cec585af..d8cec585af 100644 --- a/ewah/bitmap.c +++ b/third_party/git/ewah/bitmap.c diff --git a/ewah/ewah_bitmap.c b/third_party/git/ewah/ewah_bitmap.c index d59b1afe3d..d59b1afe3d 100644 --- a/ewah/ewah_bitmap.c +++ b/third_party/git/ewah/ewah_bitmap.c diff --git a/ewah/ewah_io.c b/third_party/git/ewah/ewah_io.c index 9035ee65ea..9035ee65ea 100644 --- a/ewah/ewah_io.c +++ b/third_party/git/ewah/ewah_io.c diff --git a/ewah/ewah_rlw.c b/third_party/git/ewah/ewah_rlw.c index 5093d43e2f..5093d43e2f 100644 --- a/ewah/ewah_rlw.c +++ b/third_party/git/ewah/ewah_rlw.c diff --git a/ewah/ewok.h b/third_party/git/ewah/ewok.h index 011852bef1..011852bef1 100644 --- a/ewah/ewok.h +++ b/third_party/git/ewah/ewok.h diff --git a/ewah/ewok_rlw.h b/third_party/git/ewah/ewok_rlw.h index bafa24f4c3..bafa24f4c3 100644 --- a/ewah/ewok_rlw.h +++ b/third_party/git/ewah/ewok_rlw.h diff --git a/exec-cmd.c b/third_party/git/exec-cmd.c index 7deeab3039..7deeab3039 100644 --- a/exec-cmd.c +++ b/third_party/git/exec-cmd.c diff --git a/exec-cmd.h b/third_party/git/exec-cmd.h index 8cd1df28d3..8cd1df28d3 100644 --- a/exec-cmd.h +++ b/third_party/git/exec-cmd.h diff --git a/fast-import.c b/third_party/git/fast-import.c index b8b65a801c..b8b65a801c 100644 --- a/fast-import.c +++ b/third_party/git/fast-import.c diff --git a/fetch-negotiator.c b/third_party/git/fetch-negotiator.c index 0a1357dc9d..0a1357dc9d 100644 --- a/fetch-negotiator.c +++ b/third_party/git/fetch-negotiator.c diff --git a/fetch-negotiator.h b/third_party/git/fetch-negotiator.h index ea78868504..ea78868504 100644 --- a/fetch-negotiator.h +++ b/third_party/git/fetch-negotiator.h diff --git a/fetch-pack.c b/third_party/git/fetch-pack.c index 1734a573b0..1734a573b0 100644 --- a/fetch-pack.c +++ b/third_party/git/fetch-pack.c diff --git a/fetch-pack.h b/third_party/git/fetch-pack.h index 67f684229a..67f684229a 100644 --- a/fetch-pack.h +++ b/third_party/git/fetch-pack.h diff --git a/fmt-merge-msg.h b/third_party/git/fmt-merge-msg.h index 01e3aa88c5..01e3aa88c5 100644 --- a/fmt-merge-msg.h +++ b/third_party/git/fmt-merge-msg.h diff --git a/fsck.c b/third_party/git/fsck.c index 73f30773f2..73f30773f2 100644 --- a/fsck.c +++ b/third_party/git/fsck.c diff --git a/fsck.h b/third_party/git/fsck.h index 69cf715e79..69cf715e79 100644 --- a/fsck.h +++ b/third_party/git/fsck.h diff --git a/fsmonitor.c b/third_party/git/fsmonitor.c index 932bd9012d..932bd9012d 100644 --- a/fsmonitor.c +++ b/third_party/git/fsmonitor.c diff --git a/fsmonitor.h b/third_party/git/fsmonitor.h index 739318ab6d..739318ab6d 100644 --- a/fsmonitor.h +++ b/third_party/git/fsmonitor.h diff --git a/fuzz-commit-graph.c b/third_party/git/fuzz-commit-graph.c index 0157acbf2e..0157acbf2e 100644 --- a/fuzz-commit-graph.c +++ b/third_party/git/fuzz-commit-graph.c diff --git a/fuzz-pack-headers.c b/third_party/git/fuzz-pack-headers.c index 99da1d0fd3..99da1d0fd3 100644 --- a/fuzz-pack-headers.c +++ b/third_party/git/fuzz-pack-headers.c diff --git a/fuzz-pack-idx.c b/third_party/git/fuzz-pack-idx.c index 0c3d777aac..0c3d777aac 100644 --- a/fuzz-pack-idx.c +++ b/third_party/git/fuzz-pack-idx.c diff --git a/generate-cmdlist.sh b/third_party/git/generate-cmdlist.sh index 71158f7d8b..71158f7d8b 100755 --- a/generate-cmdlist.sh +++ b/third_party/git/generate-cmdlist.sh diff --git a/gettext.c b/third_party/git/gettext.c index 35d2c1218d..35d2c1218d 100644 --- a/gettext.c +++ b/third_party/git/gettext.c diff --git a/gettext.h b/third_party/git/gettext.h index bee52eb113..bee52eb113 100644 --- a/gettext.h +++ b/third_party/git/gettext.h diff --git a/git-add--interactive.perl b/third_party/git/git-add--interactive.perl index 10fd30ae16..10fd30ae16 100755 --- a/git-add--interactive.perl +++ b/third_party/git/git-add--interactive.perl diff --git a/git-archimport.perl b/third_party/git/git-archimport.perl index b7c173c345..b7c173c345 100755 --- a/git-archimport.perl +++ b/third_party/git/git-archimport.perl diff --git a/git-bisect.sh b/third_party/git/git-bisect.sh index efee12b8b1..efee12b8b1 100755 --- a/git-bisect.sh +++ b/third_party/git/git-bisect.sh diff --git a/git-compat-util.h b/third_party/git/git-compat-util.h index aed0b5d4f9..aed0b5d4f9 100644 --- a/git-compat-util.h +++ b/third_party/git/git-compat-util.h diff --git a/git-cvsexportcommit.perl b/third_party/git/git-cvsexportcommit.perl index fc00d5946a..fc00d5946a 100755 --- a/git-cvsexportcommit.perl +++ b/third_party/git/git-cvsexportcommit.perl diff --git a/git-cvsimport.perl b/third_party/git/git-cvsimport.perl index 1057f389d3..1057f389d3 100755 --- a/git-cvsimport.perl +++ b/third_party/git/git-cvsimport.perl diff --git a/git-cvsserver.perl b/third_party/git/git-cvsserver.perl index ae1044273d..ae1044273d 100755 --- a/git-cvsserver.perl +++ b/third_party/git/git-cvsserver.perl diff --git a/git-difftool--helper.sh b/third_party/git/git-difftool--helper.sh index 46af3e60b7..46af3e60b7 100755 --- a/git-difftool--helper.sh +++ b/third_party/git/git-difftool--helper.sh diff --git a/git-filter-branch.sh b/third_party/git/git-filter-branch.sh index fea7964617..fea7964617 100755 --- a/git-filter-branch.sh +++ b/third_party/git/git-filter-branch.sh diff --git a/git-gui/.gitattributes b/third_party/git/git-gui/.gitattributes index 59cd41dbff..59cd41dbff 100644 --- a/git-gui/.gitattributes +++ b/third_party/git/git-gui/.gitattributes diff --git a/git-gui/.gitignore b/third_party/git/git-gui/.gitignore index 6483b21cbf..6483b21cbf 100644 --- a/git-gui/.gitignore +++ b/third_party/git/git-gui/.gitignore diff --git a/git-gui/GIT-VERSION-GEN b/third_party/git/git-gui/GIT-VERSION-GEN index 92373d251a..92373d251a 100755 --- a/git-gui/GIT-VERSION-GEN +++ b/third_party/git/git-gui/GIT-VERSION-GEN diff --git a/git-gui/Makefile b/third_party/git/git-gui/Makefile index f10caedaa7..f10caedaa7 100644 --- a/git-gui/Makefile +++ b/third_party/git/git-gui/Makefile diff --git a/git-gui/README.md b/third_party/git/git-gui/README.md index 5ce2122fbc..5ce2122fbc 100644 --- a/git-gui/README.md +++ b/third_party/git/git-gui/README.md diff --git a/git-gui/git-gui--askpass b/third_party/git/git-gui/git-gui--askpass index 1c99ee8ca2..1c99ee8ca2 100755 --- a/git-gui/git-gui--askpass +++ b/third_party/git/git-gui/git-gui--askpass diff --git a/git-gui/git-gui.sh b/third_party/git/git-gui/git-gui.sh index 4610e4ca72..4610e4ca72 100755 --- a/git-gui/git-gui.sh +++ b/third_party/git/git-gui/git-gui.sh diff --git a/git-gui/lib/about.tcl b/third_party/git/git-gui/lib/about.tcl index cfa50fca87..cfa50fca87 100644 --- a/git-gui/lib/about.tcl +++ b/third_party/git/git-gui/lib/about.tcl diff --git a/git-gui/lib/blame.tcl b/third_party/git/git-gui/lib/blame.tcl index 62ec083667..62ec083667 100644 --- a/git-gui/lib/blame.tcl +++ b/third_party/git/git-gui/lib/blame.tcl diff --git a/git-gui/lib/branch.tcl b/third_party/git/git-gui/lib/branch.tcl index 8b0c485889..8b0c485889 100644 --- a/git-gui/lib/branch.tcl +++ b/third_party/git/git-gui/lib/branch.tcl diff --git a/git-gui/lib/branch_checkout.tcl b/third_party/git/git-gui/lib/branch_checkout.tcl index d06037decc..d06037decc 100644 --- a/git-gui/lib/branch_checkout.tcl +++ b/third_party/git/git-gui/lib/branch_checkout.tcl diff --git a/git-gui/lib/branch_create.tcl b/third_party/git/git-gui/lib/branch_create.tcl index ba367d551d..ba367d551d 100644 --- a/git-gui/lib/branch_create.tcl +++ b/third_party/git/git-gui/lib/branch_create.tcl diff --git a/git-gui/lib/branch_delete.tcl b/third_party/git/git-gui/lib/branch_delete.tcl index a5051637bb..a5051637bb 100644 --- a/git-gui/lib/branch_delete.tcl +++ b/third_party/git/git-gui/lib/branch_delete.tcl diff --git a/git-gui/lib/branch_rename.tcl b/third_party/git/git-gui/lib/branch_rename.tcl index 3a2d79a9cc..3a2d79a9cc 100644 --- a/git-gui/lib/branch_rename.tcl +++ b/third_party/git/git-gui/lib/branch_rename.tcl diff --git a/git-gui/lib/browser.tcl b/third_party/git/git-gui/lib/browser.tcl index a982983667..a982983667 100644 --- a/git-gui/lib/browser.tcl +++ b/third_party/git/git-gui/lib/browser.tcl diff --git a/git-gui/lib/checkout_op.tcl b/third_party/git/git-gui/lib/checkout_op.tcl index 21ea768d80..21ea768d80 100644 --- a/git-gui/lib/checkout_op.tcl +++ b/third_party/git/git-gui/lib/checkout_op.tcl diff --git a/git-gui/lib/choose_font.tcl b/third_party/git/git-gui/lib/choose_font.tcl index ebe50bd7d0..ebe50bd7d0 100644 --- a/git-gui/lib/choose_font.tcl +++ b/third_party/git/git-gui/lib/choose_font.tcl diff --git a/git-gui/lib/choose_repository.tcl b/third_party/git/git-gui/lib/choose_repository.tcl index e54f3e66d8..e54f3e66d8 100644 --- a/git-gui/lib/choose_repository.tcl +++ b/third_party/git/git-gui/lib/choose_repository.tcl diff --git a/git-gui/lib/choose_rev.tcl b/third_party/git/git-gui/lib/choose_rev.tcl index 6dae7937d5..6dae7937d5 100644 --- a/git-gui/lib/choose_rev.tcl +++ b/third_party/git/git-gui/lib/choose_rev.tcl diff --git a/git-gui/lib/chord.tcl b/third_party/git/git-gui/lib/chord.tcl index e21e7d3d0b..e21e7d3d0b 100644 --- a/git-gui/lib/chord.tcl +++ b/third_party/git/git-gui/lib/chord.tcl diff --git a/git-gui/lib/class.tcl b/third_party/git/git-gui/lib/class.tcl index f08506f383..f08506f383 100644 --- a/git-gui/lib/class.tcl +++ b/third_party/git/git-gui/lib/class.tcl diff --git a/git-gui/lib/commit.tcl b/third_party/git/git-gui/lib/commit.tcl index b516aa2990..b516aa2990 100644 --- a/git-gui/lib/commit.tcl +++ b/third_party/git/git-gui/lib/commit.tcl diff --git a/git-gui/lib/console.tcl b/third_party/git/git-gui/lib/console.tcl index bb6b9c889e..bb6b9c889e 100644 --- a/git-gui/lib/console.tcl +++ b/third_party/git/git-gui/lib/console.tcl diff --git a/git-gui/lib/database.tcl b/third_party/git/git-gui/lib/database.tcl index 85783081e0..85783081e0 100644 --- a/git-gui/lib/database.tcl +++ b/third_party/git/git-gui/lib/database.tcl diff --git a/git-gui/lib/date.tcl b/third_party/git/git-gui/lib/date.tcl index abe82992b6..abe82992b6 100644 --- a/git-gui/lib/date.tcl +++ b/third_party/git/git-gui/lib/date.tcl diff --git a/git-gui/lib/diff.tcl b/third_party/git/git-gui/lib/diff.tcl index 871ad488c2..871ad488c2 100644 --- a/git-gui/lib/diff.tcl +++ b/third_party/git/git-gui/lib/diff.tcl diff --git a/git-gui/lib/encoding.tcl b/third_party/git/git-gui/lib/encoding.tcl index 32668fc9c6..32668fc9c6 100644 --- a/git-gui/lib/encoding.tcl +++ b/third_party/git/git-gui/lib/encoding.tcl diff --git a/git-gui/lib/error.tcl b/third_party/git/git-gui/lib/error.tcl index 8968a57f33..8968a57f33 100644 --- a/git-gui/lib/error.tcl +++ b/third_party/git/git-gui/lib/error.tcl diff --git a/git-gui/lib/git-gui.ico b/third_party/git/git-gui/lib/git-gui.ico index 334cfa5a1a..334cfa5a1a 100644 --- a/git-gui/lib/git-gui.ico +++ b/third_party/git/git-gui/lib/git-gui.ico Binary files differdiff --git a/git-gui/lib/index.tcl b/third_party/git/git-gui/lib/index.tcl index 1fc5b42300..1fc5b42300 100644 --- a/git-gui/lib/index.tcl +++ b/third_party/git/git-gui/lib/index.tcl diff --git a/git-gui/lib/line.tcl b/third_party/git/git-gui/lib/line.tcl index a026de954c..a026de954c 100644 --- a/git-gui/lib/line.tcl +++ b/third_party/git/git-gui/lib/line.tcl diff --git a/git-gui/lib/logo.tcl b/third_party/git/git-gui/lib/logo.tcl index 5ff76692f5..5ff76692f5 100644 --- a/git-gui/lib/logo.tcl +++ b/third_party/git/git-gui/lib/logo.tcl diff --git a/git-gui/lib/merge.tcl b/third_party/git/git-gui/lib/merge.tcl index 664803cf3f..664803cf3f 100644 --- a/git-gui/lib/merge.tcl +++ b/third_party/git/git-gui/lib/merge.tcl diff --git a/git-gui/lib/mergetool.tcl b/third_party/git/git-gui/lib/mergetool.tcl index 120bc4064b..120bc4064b 100644 --- a/git-gui/lib/mergetool.tcl +++ b/third_party/git/git-gui/lib/mergetool.tcl diff --git a/git-gui/lib/option.tcl b/third_party/git/git-gui/lib/option.tcl index e43971bfa3..e43971bfa3 100644 --- a/git-gui/lib/option.tcl +++ b/third_party/git/git-gui/lib/option.tcl diff --git a/git-gui/lib/remote.tcl b/third_party/git/git-gui/lib/remote.tcl index ef77ed7399..ef77ed7399 100644 --- a/git-gui/lib/remote.tcl +++ b/third_party/git/git-gui/lib/remote.tcl diff --git a/git-gui/lib/remote_add.tcl b/third_party/git/git-gui/lib/remote_add.tcl index 480a6b30d0..480a6b30d0 100644 --- a/git-gui/lib/remote_add.tcl +++ b/third_party/git/git-gui/lib/remote_add.tcl diff --git a/git-gui/lib/remote_branch_delete.tcl b/third_party/git/git-gui/lib/remote_branch_delete.tcl index 5ba9fcadd1..5ba9fcadd1 100644 --- a/git-gui/lib/remote_branch_delete.tcl +++ b/third_party/git/git-gui/lib/remote_branch_delete.tcl diff --git a/git-gui/lib/search.tcl b/third_party/git/git-gui/lib/search.tcl index ef1e55521d..ef1e55521d 100644 --- a/git-gui/lib/search.tcl +++ b/third_party/git/git-gui/lib/search.tcl diff --git a/git-gui/lib/shortcut.tcl b/third_party/git/git-gui/lib/shortcut.tcl index 97d1d7aa02..97d1d7aa02 100644 --- a/git-gui/lib/shortcut.tcl +++ b/third_party/git/git-gui/lib/shortcut.tcl diff --git a/git-gui/lib/spellcheck.tcl b/third_party/git/git-gui/lib/spellcheck.tcl index 538d61c792..538d61c792 100644 --- a/git-gui/lib/spellcheck.tcl +++ b/third_party/git/git-gui/lib/spellcheck.tcl diff --git a/git-gui/lib/sshkey.tcl b/third_party/git/git-gui/lib/sshkey.tcl index 589ff8f78a..589ff8f78a 100644 --- a/git-gui/lib/sshkey.tcl +++ b/third_party/git/git-gui/lib/sshkey.tcl diff --git a/git-gui/lib/status_bar.tcl b/third_party/git/git-gui/lib/status_bar.tcl index d32b14142f..d32b14142f 100644 --- a/git-gui/lib/status_bar.tcl +++ b/third_party/git/git-gui/lib/status_bar.tcl diff --git a/git-gui/lib/themed.tcl b/third_party/git/git-gui/lib/themed.tcl index 88b3119a75..88b3119a75 100644 --- a/git-gui/lib/themed.tcl +++ b/third_party/git/git-gui/lib/themed.tcl diff --git a/git-gui/lib/tools.tcl b/third_party/git/git-gui/lib/tools.tcl index 413f1a1700..413f1a1700 100644 --- a/git-gui/lib/tools.tcl +++ b/third_party/git/git-gui/lib/tools.tcl diff --git a/git-gui/lib/tools_dlg.tcl b/third_party/git/git-gui/lib/tools_dlg.tcl index c05413ce43..c05413ce43 100644 --- a/git-gui/lib/tools_dlg.tcl +++ b/third_party/git/git-gui/lib/tools_dlg.tcl diff --git a/git-gui/lib/transport.tcl b/third_party/git/git-gui/lib/transport.tcl index a1a424aab5..a1a424aab5 100644 --- a/git-gui/lib/transport.tcl +++ b/third_party/git/git-gui/lib/transport.tcl diff --git a/git-gui/lib/win32.tcl b/third_party/git/git-gui/lib/win32.tcl index db91ab84a5..db91ab84a5 100644 --- a/git-gui/lib/win32.tcl +++ b/third_party/git/git-gui/lib/win32.tcl diff --git a/git-gui/lib/win32_shortcut.js b/third_party/git/git-gui/lib/win32_shortcut.js index 117923f886..117923f886 100644 --- a/git-gui/lib/win32_shortcut.js +++ b/third_party/git/git-gui/lib/win32_shortcut.js diff --git a/git-gui/macosx/AppMain.tcl b/third_party/git/git-gui/macosx/AppMain.tcl index b6c6dc3500..b6c6dc3500 100644 --- a/git-gui/macosx/AppMain.tcl +++ b/third_party/git/git-gui/macosx/AppMain.tcl diff --git a/git-gui/macosx/Info.plist b/third_party/git/git-gui/macosx/Info.plist index 1ade121c4c..1ade121c4c 100644 --- a/git-gui/macosx/Info.plist +++ b/third_party/git/git-gui/macosx/Info.plist diff --git a/git-gui/macosx/git-gui.icns b/third_party/git/git-gui/macosx/git-gui.icns index 77d88a77a7..77d88a77a7 100644 --- a/git-gui/macosx/git-gui.icns +++ b/third_party/git/git-gui/macosx/git-gui.icns Binary files differdiff --git a/git-gui/po/.gitignore b/third_party/git/git-gui/po/.gitignore index a89cf44969..a89cf44969 100644 --- a/git-gui/po/.gitignore +++ b/third_party/git/git-gui/po/.gitignore diff --git a/git-gui/po/README b/third_party/git/git-gui/po/README index 2514bc22ab..2514bc22ab 100644 --- a/git-gui/po/README +++ b/third_party/git/git-gui/po/README diff --git a/git-gui/po/bg.po b/third_party/git/git-gui/po/bg.po index 5af78f15a8..5af78f15a8 100644 --- a/git-gui/po/bg.po +++ b/third_party/git/git-gui/po/bg.po diff --git a/git-gui/po/de.po b/third_party/git/git-gui/po/de.po index a8d5f61ca3..a8d5f61ca3 100644 --- a/git-gui/po/de.po +++ b/third_party/git/git-gui/po/de.po diff --git a/git-gui/po/el.po b/third_party/git/git-gui/po/el.po index 3634ba469d..3634ba469d 100644 --- a/git-gui/po/el.po +++ b/third_party/git/git-gui/po/el.po diff --git a/git-gui/po/fr.po b/third_party/git/git-gui/po/fr.po index 0aff18691d..0aff18691d 100644 --- a/git-gui/po/fr.po +++ b/third_party/git/git-gui/po/fr.po diff --git a/git-gui/po/git-gui.pot b/third_party/git/git-gui/po/git-gui.pot index b79ed4e133..b79ed4e133 100644 --- a/git-gui/po/git-gui.pot +++ b/third_party/git/git-gui/po/git-gui.pot diff --git a/git-gui/po/glossary/Makefile b/third_party/git/git-gui/po/glossary/Makefile index 749aa2e7ec..749aa2e7ec 100644 --- a/git-gui/po/glossary/Makefile +++ b/third_party/git/git-gui/po/glossary/Makefile diff --git a/git-gui/po/glossary/bg.po b/third_party/git/git-gui/po/glossary/bg.po index 8b71fad9a5..8b71fad9a5 100644 --- a/git-gui/po/glossary/bg.po +++ b/third_party/git/git-gui/po/glossary/bg.po diff --git a/git-gui/po/glossary/de.po b/third_party/git/git-gui/po/glossary/de.po index 4c5f233ee5..4c5f233ee5 100644 --- a/git-gui/po/glossary/de.po +++ b/third_party/git/git-gui/po/glossary/de.po diff --git a/git-gui/po/glossary/el.po b/third_party/git/git-gui/po/glossary/el.po index 1d3cc818d5..1d3cc818d5 100644 --- a/git-gui/po/glossary/el.po +++ b/third_party/git/git-gui/po/glossary/el.po diff --git a/git-gui/po/glossary/fr.po b/third_party/git/git-gui/po/glossary/fr.po index 27c006abb2..27c006abb2 100644 --- a/git-gui/po/glossary/fr.po +++ b/third_party/git/git-gui/po/glossary/fr.po diff --git a/git-gui/po/glossary/git-gui-glossary.pot b/third_party/git/git-gui/po/glossary/git-gui-glossary.pot index 4e66e0da3a..4e66e0da3a 100644 --- a/git-gui/po/glossary/git-gui-glossary.pot +++ b/third_party/git/git-gui/po/glossary/git-gui-glossary.pot diff --git a/git-gui/po/glossary/git-gui-glossary.txt b/third_party/git/git-gui/po/glossary/git-gui-glossary.txt index 48b9f10e57..48b9f10e57 100644 --- a/git-gui/po/glossary/git-gui-glossary.txt +++ b/third_party/git/git-gui/po/glossary/git-gui-glossary.txt diff --git a/git-gui/po/glossary/it.po b/third_party/git/git-gui/po/glossary/it.po index bb46b48d6b..bb46b48d6b 100644 --- a/git-gui/po/glossary/it.po +++ b/third_party/git/git-gui/po/glossary/it.po diff --git a/git-gui/po/glossary/pt_br.po b/third_party/git/git-gui/po/glossary/pt_br.po index eb039b2b49..eb039b2b49 100644 --- a/git-gui/po/glossary/pt_br.po +++ b/third_party/git/git-gui/po/glossary/pt_br.po diff --git a/git-gui/po/glossary/pt_pt.po b/third_party/git/git-gui/po/glossary/pt_pt.po index adc3b542a6..adc3b542a6 100644 --- a/git-gui/po/glossary/pt_pt.po +++ b/third_party/git/git-gui/po/glossary/pt_pt.po diff --git a/git-gui/po/glossary/txt-to-pot.sh b/third_party/git/git-gui/po/glossary/txt-to-pot.sh index 8249915d3c..8249915d3c 100755 --- a/git-gui/po/glossary/txt-to-pot.sh +++ b/third_party/git/git-gui/po/glossary/txt-to-pot.sh diff --git a/git-gui/po/glossary/zh_cn.po b/third_party/git/git-gui/po/glossary/zh_cn.po index 158835b5c1..158835b5c1 100644 --- a/git-gui/po/glossary/zh_cn.po +++ b/third_party/git/git-gui/po/glossary/zh_cn.po diff --git a/git-gui/po/hu.po b/third_party/git/git-gui/po/hu.po index d106dadac8..d106dadac8 100644 --- a/git-gui/po/hu.po +++ b/third_party/git/git-gui/po/hu.po diff --git a/git-gui/po/it.po b/third_party/git/git-gui/po/it.po index 1bd8b8e04f..1bd8b8e04f 100644 --- a/git-gui/po/it.po +++ b/third_party/git/git-gui/po/it.po diff --git a/git-gui/po/ja.po b/third_party/git/git-gui/po/ja.po index 2f61153ab9..2f61153ab9 100644 --- a/git-gui/po/ja.po +++ b/third_party/git/git-gui/po/ja.po diff --git a/git-gui/po/nb.po b/third_party/git/git-gui/po/nb.po index d66aa50263..d66aa50263 100644 --- a/git-gui/po/nb.po +++ b/third_party/git/git-gui/po/nb.po diff --git a/git-gui/po/po2msg.sh b/third_party/git/git-gui/po/po2msg.sh index 1e9f992528..1e9f992528 100755 --- a/git-gui/po/po2msg.sh +++ b/third_party/git/git-gui/po/po2msg.sh diff --git a/git-gui/po/pt_br.po b/third_party/git/git-gui/po/pt_br.po index bad116c780..bad116c780 100644 --- a/git-gui/po/pt_br.po +++ b/third_party/git/git-gui/po/pt_br.po diff --git a/git-gui/po/pt_pt.po b/third_party/git/git-gui/po/pt_pt.po index 0ef3c7927d..0ef3c7927d 100644 --- a/git-gui/po/pt_pt.po +++ b/third_party/git/git-gui/po/pt_pt.po diff --git a/git-gui/po/ru.po b/third_party/git/git-gui/po/ru.po index 9f5305c43e..9f5305c43e 100644 --- a/git-gui/po/ru.po +++ b/third_party/git/git-gui/po/ru.po diff --git a/git-gui/po/sv.po b/third_party/git/git-gui/po/sv.po index 1b4ad8368e..1b4ad8368e 100644 --- a/git-gui/po/sv.po +++ b/third_party/git/git-gui/po/sv.po diff --git a/git-gui/po/vi.po b/third_party/git/git-gui/po/vi.po index d956b59a9e..d956b59a9e 100644 --- a/git-gui/po/vi.po +++ b/third_party/git/git-gui/po/vi.po diff --git a/git-gui/po/zh_cn.po b/third_party/git/git-gui/po/zh_cn.po index 91c1be23c2..91c1be23c2 100644 --- a/git-gui/po/zh_cn.po +++ b/third_party/git/git-gui/po/zh_cn.po diff --git a/git-gui/windows/git-gui.sh b/third_party/git/git-gui/windows/git-gui.sh index b1845c5055..b1845c5055 100755 --- a/git-gui/windows/git-gui.sh +++ b/third_party/git/git-gui/windows/git-gui.sh diff --git a/git-instaweb.sh b/third_party/git/git-instaweb.sh index 7c55229773..7c55229773 100755 --- a/git-instaweb.sh +++ b/third_party/git/git-instaweb.sh diff --git a/git-legacy-stash.sh b/third_party/git/git-legacy-stash.sh index 4d4ebb4f2b..4d4ebb4f2b 100755 --- a/git-legacy-stash.sh +++ b/third_party/git/git-legacy-stash.sh diff --git a/git-merge-octopus.sh b/third_party/git/git-merge-octopus.sh index 7d19d37951..7d19d37951 100755 --- a/git-merge-octopus.sh +++ b/third_party/git/git-merge-octopus.sh diff --git a/git-merge-one-file.sh b/third_party/git/git-merge-one-file.sh index f6d9852d2f..f6d9852d2f 100755 --- a/git-merge-one-file.sh +++ b/third_party/git/git-merge-one-file.sh diff --git a/git-merge-resolve.sh b/third_party/git/git-merge-resolve.sh index 343fe7bccd..343fe7bccd 100755 --- a/git-merge-resolve.sh +++ b/third_party/git/git-merge-resolve.sh diff --git a/git-mergetool--lib.sh b/third_party/git/git-mergetool--lib.sh index 204a5acd66..204a5acd66 100644 --- a/git-mergetool--lib.sh +++ b/third_party/git/git-mergetool--lib.sh diff --git a/git-mergetool.sh b/third_party/git/git-mergetool.sh index e3f6d543fb..e3f6d543fb 100755 --- a/git-mergetool.sh +++ b/third_party/git/git-mergetool.sh diff --git a/git-p4.py b/third_party/git/git-p4.py index 9a71a6690d..9a71a6690d 100755 --- a/git-p4.py +++ b/third_party/git/git-p4.py diff --git a/git-parse-remote.sh b/third_party/git/git-parse-remote.sh index d3c39980f3..d3c39980f3 100644 --- a/git-parse-remote.sh +++ b/third_party/git/git-parse-remote.sh diff --git a/git-quiltimport.sh b/third_party/git/git-quiltimport.sh index e3d3909743..e3d3909743 100755 --- a/git-quiltimport.sh +++ b/third_party/git/git-quiltimport.sh diff --git a/git-rebase--preserve-merges.sh b/third_party/git/git-rebase--preserve-merges.sh index dec90e9af6..dec90e9af6 100644 --- a/git-rebase--preserve-merges.sh +++ b/third_party/git/git-rebase--preserve-merges.sh diff --git a/git-request-pull.sh b/third_party/git/git-request-pull.sh index 2d0e44656c..2d0e44656c 100755 --- a/git-request-pull.sh +++ b/third_party/git/git-request-pull.sh diff --git a/git-send-email.perl b/third_party/git/git-send-email.perl index dc95656f75..dc95656f75 100755 --- a/git-send-email.perl +++ b/third_party/git/git-send-email.perl diff --git a/git-sh-i18n.sh b/third_party/git/git-sh-i18n.sh index 8eef60b43f..8eef60b43f 100644 --- a/git-sh-i18n.sh +++ b/third_party/git/git-sh-i18n.sh diff --git a/git-sh-setup.sh b/third_party/git/git-sh-setup.sh index 10d9764185..10d9764185 100644 --- a/git-sh-setup.sh +++ b/third_party/git/git-sh-setup.sh diff --git a/git-submodule.sh b/third_party/git/git-submodule.sh index 89f915cae9..89f915cae9 100755 --- a/git-submodule.sh +++ b/third_party/git/git-submodule.sh diff --git a/git-svn.perl b/third_party/git/git-svn.perl index 4aa208ff5f..4aa208ff5f 100755 --- a/git-svn.perl +++ b/third_party/git/git-svn.perl diff --git a/git-web--browse.sh b/third_party/git/git-web--browse.sh index ae152534f5..ae152534f5 100755 --- a/git-web--browse.sh +++ b/third_party/git/git-web--browse.sh diff --git a/git.c b/third_party/git/git.c index 7be7ad34bd..7be7ad34bd 100644 --- a/git.c +++ b/third_party/git/git.c diff --git a/git.rc b/third_party/git/git.rc index cc3fdc6cc6..cc3fdc6cc6 100644 --- a/git.rc +++ b/third_party/git/git.rc diff --git a/gitk-git/.gitignore b/third_party/git/gitk-git/.gitignore index d7ebcaf366..d7ebcaf366 100644 --- a/gitk-git/.gitignore +++ b/third_party/git/gitk-git/.gitignore diff --git a/gitk-git/Makefile b/third_party/git/gitk-git/Makefile index 5bdd52a6eb..5bdd52a6eb 100644 --- a/gitk-git/Makefile +++ b/third_party/git/gitk-git/Makefile diff --git a/gitk-git/gitk b/third_party/git/gitk-git/gitk index abe4805ade..abe4805ade 100755 --- a/gitk-git/gitk +++ b/third_party/git/gitk-git/gitk diff --git a/gitk-git/po/.gitignore b/third_party/git/gitk-git/po/.gitignore index e358dd1903..e358dd1903 100644 --- a/gitk-git/po/.gitignore +++ b/third_party/git/gitk-git/po/.gitignore diff --git a/gitk-git/po/bg.po b/third_party/git/gitk-git/po/bg.po index 87ab1fac24..87ab1fac24 100644 --- a/gitk-git/po/bg.po +++ b/third_party/git/gitk-git/po/bg.po diff --git a/gitk-git/po/ca.po b/third_party/git/gitk-git/po/ca.po index 87dfc18b44..87dfc18b44 100644 --- a/gitk-git/po/ca.po +++ b/third_party/git/gitk-git/po/ca.po diff --git a/gitk-git/po/de.po b/third_party/git/gitk-git/po/de.po index 5db3824828..5db3824828 100644 --- a/gitk-git/po/de.po +++ b/third_party/git/gitk-git/po/de.po diff --git a/gitk-git/po/es.po b/third_party/git/gitk-git/po/es.po index fef3bbafee..fef3bbafee 100644 --- a/gitk-git/po/es.po +++ b/third_party/git/gitk-git/po/es.po diff --git a/gitk-git/po/fr.po b/third_party/git/gitk-git/po/fr.po index e4fac932e5..e4fac932e5 100644 --- a/gitk-git/po/fr.po +++ b/third_party/git/gitk-git/po/fr.po diff --git a/gitk-git/po/hu.po b/third_party/git/gitk-git/po/hu.po index 79ec5a5656..79ec5a5656 100644 --- a/gitk-git/po/hu.po +++ b/third_party/git/gitk-git/po/hu.po diff --git a/gitk-git/po/it.po b/third_party/git/gitk-git/po/it.po index b58d23eb2b..b58d23eb2b 100644 --- a/gitk-git/po/it.po +++ b/third_party/git/gitk-git/po/it.po diff --git a/gitk-git/po/ja.po b/third_party/git/gitk-git/po/ja.po index ca3c29b457..ca3c29b457 100644 --- a/gitk-git/po/ja.po +++ b/third_party/git/gitk-git/po/ja.po diff --git a/gitk-git/po/po2msg.sh b/third_party/git/gitk-git/po/po2msg.sh index c63248e375..c63248e375 100755 --- a/gitk-git/po/po2msg.sh +++ b/third_party/git/gitk-git/po/po2msg.sh diff --git a/gitk-git/po/pt_br.po b/third_party/git/gitk-git/po/pt_br.po index 1feb34854b..1feb34854b 100644 --- a/gitk-git/po/pt_br.po +++ b/third_party/git/gitk-git/po/pt_br.po diff --git a/gitk-git/po/pt_pt.po b/third_party/git/gitk-git/po/pt_pt.po index f680ea86aa..f680ea86aa 100644 --- a/gitk-git/po/pt_pt.po +++ b/third_party/git/gitk-git/po/pt_pt.po diff --git a/gitk-git/po/ru.po b/third_party/git/gitk-git/po/ru.po index 9b08c263ea..9b08c263ea 100644 --- a/gitk-git/po/ru.po +++ b/third_party/git/gitk-git/po/ru.po diff --git a/gitk-git/po/sv.po b/third_party/git/gitk-git/po/sv.po index 2a06fe5bbc..2a06fe5bbc 100644 --- a/gitk-git/po/sv.po +++ b/third_party/git/gitk-git/po/sv.po diff --git a/gitk-git/po/vi.po b/third_party/git/gitk-git/po/vi.po index 5967498660..5967498660 100644 --- a/gitk-git/po/vi.po +++ b/third_party/git/gitk-git/po/vi.po diff --git a/gitk-git/po/zh_cn.po b/third_party/git/gitk-git/po/zh_cn.po index 17b7f899da..17b7f899da 100644 --- a/gitk-git/po/zh_cn.po +++ b/third_party/git/gitk-git/po/zh_cn.po diff --git a/gitweb/INSTALL b/third_party/git/gitweb/INSTALL index a58e6b3c44..a58e6b3c44 100644 --- a/gitweb/INSTALL +++ b/third_party/git/gitweb/INSTALL diff --git a/gitweb/Makefile b/third_party/git/gitweb/Makefile index cd194d057f..cd194d057f 100644 --- a/gitweb/Makefile +++ b/third_party/git/gitweb/Makefile diff --git a/gitweb/README b/third_party/git/gitweb/README index 471dcfb691..471dcfb691 100644 --- a/gitweb/README +++ b/third_party/git/gitweb/README diff --git a/gitweb/gitweb.perl b/third_party/git/gitweb/gitweb.perl index 65a3a9e62e..65a3a9e62e 100755 --- a/gitweb/gitweb.perl +++ b/third_party/git/gitweb/gitweb.perl diff --git a/gitweb/static/git-favicon.png b/third_party/git/gitweb/static/git-favicon.png index aae35a70e7..aae35a70e7 100644 --- a/gitweb/static/git-favicon.png +++ b/third_party/git/gitweb/static/git-favicon.png Binary files differdiff --git a/gitweb/static/git-logo.png b/third_party/git/gitweb/static/git-logo.png index f4ede2e944..f4ede2e944 100644 --- a/gitweb/static/git-logo.png +++ b/third_party/git/gitweb/static/git-logo.png Binary files differdiff --git a/gitweb/static/gitweb.css b/third_party/git/gitweb/static/gitweb.css index 3212601032..3212601032 100644 --- a/gitweb/static/gitweb.css +++ b/third_party/git/gitweb/static/gitweb.css diff --git a/gitweb/static/js/README b/third_party/git/gitweb/static/js/README index f8460ed32f..f8460ed32f 100644 --- a/gitweb/static/js/README +++ b/third_party/git/gitweb/static/js/README diff --git a/gitweb/static/js/adjust-timezone.js b/third_party/git/gitweb/static/js/adjust-timezone.js index 0c67779500..0c67779500 100644 --- a/gitweb/static/js/adjust-timezone.js +++ b/third_party/git/gitweb/static/js/adjust-timezone.js diff --git a/gitweb/static/js/blame_incremental.js b/third_party/git/gitweb/static/js/blame_incremental.js index e100d8206b..e100d8206b 100644 --- a/gitweb/static/js/blame_incremental.js +++ b/third_party/git/gitweb/static/js/blame_incremental.js diff --git a/gitweb/static/js/javascript-detection.js b/third_party/git/gitweb/static/js/javascript-detection.js index fa2596f77c..fa2596f77c 100644 --- a/gitweb/static/js/javascript-detection.js +++ b/third_party/git/gitweb/static/js/javascript-detection.js diff --git a/gitweb/static/js/lib/common-lib.js b/third_party/git/gitweb/static/js/lib/common-lib.js index 018bbb7d4c..018bbb7d4c 100644 --- a/gitweb/static/js/lib/common-lib.js +++ b/third_party/git/gitweb/static/js/lib/common-lib.js diff --git a/gitweb/static/js/lib/cookies.js b/third_party/git/gitweb/static/js/lib/cookies.js index 66b9a072a4..66b9a072a4 100644 --- a/gitweb/static/js/lib/cookies.js +++ b/third_party/git/gitweb/static/js/lib/cookies.js diff --git a/gitweb/static/js/lib/datetime.js b/third_party/git/gitweb/static/js/lib/datetime.js index f78c60a912..f78c60a912 100644 --- a/gitweb/static/js/lib/datetime.js +++ b/third_party/git/gitweb/static/js/lib/datetime.js diff --git a/gpg-interface.c b/third_party/git/gpg-interface.c index 165274d74a..165274d74a 100644 --- a/gpg-interface.c +++ b/third_party/git/gpg-interface.c diff --git a/gpg-interface.h b/third_party/git/gpg-interface.h index 796571e9e9..796571e9e9 100644 --- a/gpg-interface.h +++ b/third_party/git/gpg-interface.h diff --git a/graph.c b/third_party/git/graph.c index 4fb25ad464..4fb25ad464 100644 --- a/graph.c +++ b/third_party/git/graph.c diff --git a/graph.h b/third_party/git/graph.h index 8313e293c7..8313e293c7 100644 --- a/graph.h +++ b/third_party/git/graph.h diff --git a/grep.c b/third_party/git/grep.c index 13232a904a..13232a904a 100644 --- a/grep.c +++ b/third_party/git/grep.c diff --git a/grep.h b/third_party/git/grep.h index 9115db8515..9115db8515 100644 --- a/grep.h +++ b/third_party/git/grep.h diff --git a/hash.h b/third_party/git/hash.h index 52a4f1a3f4..52a4f1a3f4 100644 --- a/hash.h +++ b/third_party/git/hash.h diff --git a/hashmap.c b/third_party/git/hashmap.c index 09813e1a46..09813e1a46 100644 --- a/hashmap.c +++ b/third_party/git/hashmap.c diff --git a/hashmap.h b/third_party/git/hashmap.h index 79ae9f80de..79ae9f80de 100644 --- a/hashmap.h +++ b/third_party/git/hashmap.h diff --git a/help.c b/third_party/git/help.c index cf67624a94..cf67624a94 100644 --- a/help.c +++ b/third_party/git/help.c diff --git a/help.h b/third_party/git/help.h index 7a455beeb7..7a455beeb7 100644 --- a/help.h +++ b/third_party/git/help.h diff --git a/hex.c b/third_party/git/hex.c index fd7f00c43f..fd7f00c43f 100644 --- a/hex.c +++ b/third_party/git/hex.c diff --git a/http-backend.c b/third_party/git/http-backend.c index ec3144b444..ec3144b444 100644 --- a/http-backend.c +++ b/third_party/git/http-backend.c diff --git a/http-fetch.c b/third_party/git/http-fetch.c index a32ac118d9..a32ac118d9 100644 --- a/http-fetch.c +++ b/third_party/git/http-fetch.c diff --git a/http-push.c b/third_party/git/http-push.c index 822f326599..822f326599 100644 --- a/http-push.c +++ b/third_party/git/http-push.c diff --git a/http-walker.c b/third_party/git/http-walker.c index fe15e325fa..fe15e325fa 100644 --- a/http-walker.c +++ b/third_party/git/http-walker.c diff --git a/http.c b/third_party/git/http.c index 5f71263482..5f71263482 100644 --- a/http.c +++ b/third_party/git/http.c diff --git a/http.h b/third_party/git/http.h index 5e0ad724f9..5e0ad724f9 100644 --- a/http.h +++ b/third_party/git/http.h diff --git a/ident.c b/third_party/git/ident.c index e666ee4e59..e666ee4e59 100644 --- a/ident.c +++ b/third_party/git/ident.c diff --git a/imap-send.c b/third_party/git/imap-send.c index 6c54d8c29d..6c54d8c29d 100644 --- a/imap-send.c +++ b/third_party/git/imap-send.c diff --git a/interdiff.c b/third_party/git/interdiff.c index c81d680a6c..c81d680a6c 100644 --- a/interdiff.c +++ b/third_party/git/interdiff.c diff --git a/interdiff.h b/third_party/git/interdiff.h index 01c730a5c9..01c730a5c9 100644 --- a/interdiff.h +++ b/third_party/git/interdiff.h diff --git a/iterator.h b/third_party/git/iterator.h index 0f6900e43a..0f6900e43a 100644 --- a/iterator.h +++ b/third_party/git/iterator.h diff --git a/json-writer.c b/third_party/git/json-writer.c index aadb9dbddc..aadb9dbddc 100644 --- a/json-writer.c +++ b/third_party/git/json-writer.c diff --git a/json-writer.h b/third_party/git/json-writer.h index 83906b09c1..83906b09c1 100644 --- a/json-writer.h +++ b/third_party/git/json-writer.h diff --git a/khash.h b/third_party/git/khash.h index 21c2095216..21c2095216 100644 --- a/khash.h +++ b/third_party/git/khash.h diff --git a/kwset.c b/third_party/git/kwset.c index fc439e0667..fc439e0667 100644 --- a/kwset.c +++ b/third_party/git/kwset.c diff --git a/kwset.h b/third_party/git/kwset.h index f50ecae573..f50ecae573 100644 --- a/kwset.h +++ b/third_party/git/kwset.h diff --git a/levenshtein.c b/third_party/git/levenshtein.c index d2632690d5..d2632690d5 100644 --- a/levenshtein.c +++ b/third_party/git/levenshtein.c diff --git a/levenshtein.h b/third_party/git/levenshtein.h index 4105bf3549..4105bf3549 100644 --- a/levenshtein.h +++ b/third_party/git/levenshtein.h diff --git a/line-log.c b/third_party/git/line-log.c index 9010e00950..9010e00950 100644 --- a/line-log.c +++ b/third_party/git/line-log.c diff --git a/line-log.h b/third_party/git/line-log.h index 8ee7a2bd4a..8ee7a2bd4a 100644 --- a/line-log.h +++ b/third_party/git/line-log.h diff --git a/line-range.c b/third_party/git/line-range.c index 9b50583dc0..9b50583dc0 100644 --- a/line-range.c +++ b/third_party/git/line-range.c diff --git a/line-range.h b/third_party/git/line-range.h index e69bf7c017..e69bf7c017 100644 --- a/line-range.h +++ b/third_party/git/line-range.h diff --git a/linear-assignment.c b/third_party/git/linear-assignment.c index ecffc09be6..ecffc09be6 100644 --- a/linear-assignment.c +++ b/third_party/git/linear-assignment.c diff --git a/linear-assignment.h b/third_party/git/linear-assignment.h index 1dfea76629..1dfea76629 100644 --- a/linear-assignment.h +++ b/third_party/git/linear-assignment.h diff --git a/list-objects-filter-options.c b/third_party/git/list-objects-filter-options.c index 256bcfbdfe..256bcfbdfe 100644 --- a/list-objects-filter-options.c +++ b/third_party/git/list-objects-filter-options.c diff --git a/list-objects-filter-options.h b/third_party/git/list-objects-filter-options.h index 2ffb39222c..2ffb39222c 100644 --- a/list-objects-filter-options.h +++ b/third_party/git/list-objects-filter-options.h diff --git a/list-objects-filter.c b/third_party/git/list-objects-filter.c index 1e8d4e763d..1e8d4e763d 100644 --- a/list-objects-filter.c +++ b/third_party/git/list-objects-filter.c diff --git a/list-objects-filter.h b/third_party/git/list-objects-filter.h index cfd784e203..cfd784e203 100644 --- a/list-objects-filter.h +++ b/third_party/git/list-objects-filter.h diff --git a/list-objects.c b/third_party/git/list-objects.c index e19589baa0..e19589baa0 100644 --- a/list-objects.c +++ b/third_party/git/list-objects.c diff --git a/list-objects.h b/third_party/git/list-objects.h index a952680e46..a952680e46 100644 --- a/list-objects.h +++ b/third_party/git/list-objects.h diff --git a/list.h b/third_party/git/list.h index eb601192f4..eb601192f4 100644 --- a/list.h +++ b/third_party/git/list.h diff --git a/ll-merge.c b/third_party/git/ll-merge.c index d65a8971db..d65a8971db 100644 --- a/ll-merge.c +++ b/third_party/git/ll-merge.c diff --git a/ll-merge.h b/third_party/git/ll-merge.h index aceb1b2413..aceb1b2413 100644 --- a/ll-merge.h +++ b/third_party/git/ll-merge.h diff --git a/lockfile.c b/third_party/git/lockfile.c index 8e8ab4f29f..8e8ab4f29f 100644 --- a/lockfile.c +++ b/third_party/git/lockfile.c diff --git a/lockfile.h b/third_party/git/lockfile.h index 9843053ce8..9843053ce8 100644 --- a/lockfile.h +++ b/third_party/git/lockfile.h diff --git a/log-tree.c b/third_party/git/log-tree.c index 52127427ff..52127427ff 100644 --- a/log-tree.c +++ b/third_party/git/log-tree.c diff --git a/log-tree.h b/third_party/git/log-tree.h index e668628074..e668628074 100644 --- a/log-tree.h +++ b/third_party/git/log-tree.h diff --git a/ls-refs.c b/third_party/git/ls-refs.c index 818aef70a0..818aef70a0 100644 --- a/ls-refs.c +++ b/third_party/git/ls-refs.c diff --git a/ls-refs.h b/third_party/git/ls-refs.h index 7e5646f5f6..7e5646f5f6 100644 --- a/ls-refs.h +++ b/third_party/git/ls-refs.h diff --git a/mailinfo.c b/third_party/git/mailinfo.c index 742fa376ab..742fa376ab 100644 --- a/mailinfo.c +++ b/third_party/git/mailinfo.c diff --git a/mailinfo.h b/third_party/git/mailinfo.h index 79b1d6774e..79b1d6774e 100644 --- a/mailinfo.h +++ b/third_party/git/mailinfo.h diff --git a/mailmap.c b/third_party/git/mailmap.c index 962fd86d6d..962fd86d6d 100644 --- a/mailmap.c +++ b/third_party/git/mailmap.c diff --git a/mailmap.h b/third_party/git/mailmap.h index d0e65646cb..d0e65646cb 100644 --- a/mailmap.h +++ b/third_party/git/mailmap.h diff --git a/match-trees.c b/third_party/git/match-trees.c index f6c194c1cc..f6c194c1cc 100644 --- a/match-trees.c +++ b/third_party/git/match-trees.c diff --git a/mem-pool.c b/third_party/git/mem-pool.c index a2841a4a9a..a2841a4a9a 100644 --- a/mem-pool.c +++ b/third_party/git/mem-pool.c diff --git a/mem-pool.h b/third_party/git/mem-pool.h index 999d3c3a52..999d3c3a52 100644 --- a/mem-pool.h +++ b/third_party/git/mem-pool.h diff --git a/merge-blobs.c b/third_party/git/merge-blobs.c index ee0a0e90c9..ee0a0e90c9 100644 --- a/merge-blobs.c +++ b/third_party/git/merge-blobs.c diff --git a/merge-blobs.h b/third_party/git/merge-blobs.h index 13cf9669e5..13cf9669e5 100644 --- a/merge-blobs.h +++ b/third_party/git/merge-blobs.h diff --git a/merge-recursive.c b/third_party/git/merge-recursive.c index 7a4e6f20fa..7a4e6f20fa 100644 --- a/merge-recursive.c +++ b/third_party/git/merge-recursive.c diff --git a/merge-recursive.h b/third_party/git/merge-recursive.h index 978847e672..978847e672 100644 --- a/merge-recursive.h +++ b/third_party/git/merge-recursive.h diff --git a/merge.c b/third_party/git/merge.c index 7c1d756c3f..7c1d756c3f 100644 --- a/merge.c +++ b/third_party/git/merge.c diff --git a/mergesort.c b/third_party/git/mergesort.c index e5fdf2ee4a..e5fdf2ee4a 100644 --- a/mergesort.c +++ b/third_party/git/mergesort.c diff --git a/mergesort.h b/third_party/git/mergesort.h index 644cff1f96..644cff1f96 100644 --- a/mergesort.h +++ b/third_party/git/mergesort.h diff --git a/mergetools/araxis b/third_party/git/mergetools/araxis index e2407b65b7..e2407b65b7 100644 --- a/mergetools/araxis +++ b/third_party/git/mergetools/araxis diff --git a/mergetools/bc b/third_party/git/mergetools/bc index 3a69e60faa..3a69e60faa 100644 --- a/mergetools/bc +++ b/third_party/git/mergetools/bc diff --git a/mergetools/bc3 b/third_party/git/mergetools/bc3 index 5d8dd48184..5d8dd48184 100644 --- a/mergetools/bc3 +++ b/third_party/git/mergetools/bc3 diff --git a/mergetools/codecompare b/third_party/git/mergetools/codecompare index 9f60e8da65..9f60e8da65 100644 --- a/mergetools/codecompare +++ b/third_party/git/mergetools/codecompare diff --git a/mergetools/deltawalker b/third_party/git/mergetools/deltawalker index ee6f374bce..ee6f374bce 100644 --- a/mergetools/deltawalker +++ b/third_party/git/mergetools/deltawalker diff --git a/mergetools/diffmerge b/third_party/git/mergetools/diffmerge index 9b6355b98a..9b6355b98a 100644 --- a/mergetools/diffmerge +++ b/third_party/git/mergetools/diffmerge diff --git a/mergetools/diffuse b/third_party/git/mergetools/diffuse index 5a3ae8b569..5a3ae8b569 100644 --- a/mergetools/diffuse +++ b/third_party/git/mergetools/diffuse diff --git a/mergetools/ecmerge b/third_party/git/mergetools/ecmerge index 6c5101c4f7..6c5101c4f7 100644 --- a/mergetools/ecmerge +++ b/third_party/git/mergetools/ecmerge diff --git a/mergetools/emerge b/third_party/git/mergetools/emerge index d1ce513ff5..d1ce513ff5 100644 --- a/mergetools/emerge +++ b/third_party/git/mergetools/emerge diff --git a/mergetools/examdiff b/third_party/git/mergetools/examdiff index e72b06fc4d..e72b06fc4d 100644 --- a/mergetools/examdiff +++ b/third_party/git/mergetools/examdiff diff --git a/mergetools/guiffy b/third_party/git/mergetools/guiffy index 8b23a13c41..8b23a13c41 100644 --- a/mergetools/guiffy +++ b/third_party/git/mergetools/guiffy diff --git a/mergetools/gvimdiff b/third_party/git/mergetools/gvimdiff index 04a5bb0ea8..04a5bb0ea8 100644 --- a/mergetools/gvimdiff +++ b/third_party/git/mergetools/gvimdiff diff --git a/mergetools/gvimdiff2 b/third_party/git/mergetools/gvimdiff2 index 04a5bb0ea8..04a5bb0ea8 100644 --- a/mergetools/gvimdiff2 +++ b/third_party/git/mergetools/gvimdiff2 diff --git a/mergetools/gvimdiff3 b/third_party/git/mergetools/gvimdiff3 index 04a5bb0ea8..04a5bb0ea8 100644 --- a/mergetools/gvimdiff3 +++ b/third_party/git/mergetools/gvimdiff3 diff --git a/mergetools/kdiff3 b/third_party/git/mergetools/kdiff3 index 0264ed5b20..0264ed5b20 100644 --- a/mergetools/kdiff3 +++ b/third_party/git/mergetools/kdiff3 diff --git a/mergetools/kompare b/third_party/git/mergetools/kompare index e8c0bfa678..e8c0bfa678 100644 --- a/mergetools/kompare +++ b/third_party/git/mergetools/kompare diff --git a/mergetools/meld b/third_party/git/mergetools/meld index 7a08470f88..7a08470f88 100644 --- a/mergetools/meld +++ b/third_party/git/mergetools/meld diff --git a/mergetools/opendiff b/third_party/git/mergetools/opendiff index b608dd6de3..b608dd6de3 100644 --- a/mergetools/opendiff +++ b/third_party/git/mergetools/opendiff diff --git a/mergetools/p4merge b/third_party/git/mergetools/p4merge index 7a5b291dd2..7a5b291dd2 100644 --- a/mergetools/p4merge +++ b/third_party/git/mergetools/p4merge diff --git a/mergetools/smerge b/third_party/git/mergetools/smerge index 9c2e6f6fd7..9c2e6f6fd7 100644 --- a/mergetools/smerge +++ b/third_party/git/mergetools/smerge diff --git a/mergetools/tkdiff b/third_party/git/mergetools/tkdiff index eee5cb57e3..eee5cb57e3 100644 --- a/mergetools/tkdiff +++ b/third_party/git/mergetools/tkdiff diff --git a/mergetools/tortoisemerge b/third_party/git/mergetools/tortoisemerge index d7ab666a59..d7ab666a59 100644 --- a/mergetools/tortoisemerge +++ b/third_party/git/mergetools/tortoisemerge diff --git a/mergetools/vimdiff b/third_party/git/mergetools/vimdiff index 10d86f3e19..10d86f3e19 100644 --- a/mergetools/vimdiff +++ b/third_party/git/mergetools/vimdiff diff --git a/mergetools/vimdiff2 b/third_party/git/mergetools/vimdiff2 index 04a5bb0ea8..04a5bb0ea8 100644 --- a/mergetools/vimdiff2 +++ b/third_party/git/mergetools/vimdiff2 diff --git a/mergetools/vimdiff3 b/third_party/git/mergetools/vimdiff3 index 04a5bb0ea8..04a5bb0ea8 100644 --- a/mergetools/vimdiff3 +++ b/third_party/git/mergetools/vimdiff3 diff --git a/mergetools/winmerge b/third_party/git/mergetools/winmerge index 74d03259fd..74d03259fd 100644 --- a/mergetools/winmerge +++ b/third_party/git/mergetools/winmerge diff --git a/mergetools/xxdiff b/third_party/git/mergetools/xxdiff index ce5b8e9f29..ce5b8e9f29 100644 --- a/mergetools/xxdiff +++ b/third_party/git/mergetools/xxdiff diff --git a/midx.c b/third_party/git/midx.c index 1527e464a7..1527e464a7 100644 --- a/midx.c +++ b/third_party/git/midx.c diff --git a/midx.h b/third_party/git/midx.h index e6fa356b5c..e6fa356b5c 100644 --- a/midx.h +++ b/third_party/git/midx.h diff --git a/name-hash.c b/third_party/git/name-hash.c index fb526a3775..fb526a3775 100644 --- a/name-hash.c +++ b/third_party/git/name-hash.c diff --git a/negotiator/default.c b/third_party/git/negotiator/default.c index 4b78f6bf36..4b78f6bf36 100644 --- a/negotiator/default.c +++ b/third_party/git/negotiator/default.c diff --git a/negotiator/default.h b/third_party/git/negotiator/default.h index d23a8f2fb8..d23a8f2fb8 100644 --- a/negotiator/default.h +++ b/third_party/git/negotiator/default.h diff --git a/negotiator/skipping.c b/third_party/git/negotiator/skipping.c index dffbc76c49..dffbc76c49 100644 --- a/negotiator/skipping.c +++ b/third_party/git/negotiator/skipping.c diff --git a/negotiator/skipping.h b/third_party/git/negotiator/skipping.h index d7dfa6c6e4..d7dfa6c6e4 100644 --- a/negotiator/skipping.h +++ b/third_party/git/negotiator/skipping.h diff --git a/notes-cache.c b/third_party/git/notes-cache.c index 2473314d68..2473314d68 100644 --- a/notes-cache.c +++ b/third_party/git/notes-cache.c diff --git a/notes-cache.h b/third_party/git/notes-cache.h index 56f8c98e24..56f8c98e24 100644 --- a/notes-cache.h +++ b/third_party/git/notes-cache.h diff --git a/notes-merge.c b/third_party/git/notes-merge.c index 2fe724f1cf..2fe724f1cf 100644 --- a/notes-merge.c +++ b/third_party/git/notes-merge.c diff --git a/notes-merge.h b/third_party/git/notes-merge.h index 99f9c709c5..99f9c709c5 100644 --- a/notes-merge.h +++ b/third_party/git/notes-merge.h diff --git a/notes-utils.c b/third_party/git/notes-utils.c index 4bf4888d8c..4bf4888d8c 100644 --- a/notes-utils.c +++ b/third_party/git/notes-utils.c diff --git a/notes-utils.h b/third_party/git/notes-utils.h index d9b3c09eaf..d9b3c09eaf 100644 --- a/notes-utils.h +++ b/third_party/git/notes-utils.h diff --git a/notes.c b/third_party/git/notes.c index 564baac64d..564baac64d 100644 --- a/notes.c +++ b/third_party/git/notes.c diff --git a/notes.h b/third_party/git/notes.h index c1682c39a9..c1682c39a9 100644 --- a/notes.h +++ b/third_party/git/notes.h diff --git a/object-store.h b/third_party/git/object-store.h index be72fee7d5..be72fee7d5 100644 --- a/object-store.h +++ b/third_party/git/object-store.h diff --git a/object.c b/third_party/git/object.c index 794c86650e..794c86650e 100644 --- a/object.c +++ b/third_party/git/object.c diff --git a/object.h b/third_party/git/object.h index 2dbabfca0a..2dbabfca0a 100644 --- a/object.h +++ b/third_party/git/object.h diff --git a/oidmap.c b/third_party/git/oidmap.c index 423aa014a3..423aa014a3 100644 --- a/oidmap.c +++ b/third_party/git/oidmap.c diff --git a/oidmap.h b/third_party/git/oidmap.h index c66a83ab1d..c66a83ab1d 100644 --- a/oidmap.h +++ b/third_party/git/oidmap.h diff --git a/oidset.c b/third_party/git/oidset.c index f63ce818f6..f63ce818f6 100644 --- a/oidset.c +++ b/third_party/git/oidset.c diff --git a/oidset.h b/third_party/git/oidset.h index 5346563b0b..5346563b0b 100644 --- a/oidset.h +++ b/third_party/git/oidset.h diff --git a/pack-bitmap-write.c b/third_party/git/pack-bitmap-write.c index a7a4964b50..a7a4964b50 100644 --- a/pack-bitmap-write.c +++ b/third_party/git/pack-bitmap-write.c diff --git a/pack-bitmap.c b/third_party/git/pack-bitmap.c index 49a8d10d0c..49a8d10d0c 100644 --- a/pack-bitmap.c +++ b/third_party/git/pack-bitmap.c diff --git a/pack-bitmap.h b/third_party/git/pack-bitmap.h index 1203120c43..1203120c43 100644 --- a/pack-bitmap.h +++ b/third_party/git/pack-bitmap.h diff --git a/pack-check.c b/third_party/git/pack-check.c index dad6d8ae7f..dad6d8ae7f 100644 --- a/pack-check.c +++ b/third_party/git/pack-check.c diff --git a/pack-objects.c b/third_party/git/pack-objects.c index f2a433885a..f2a433885a 100644 --- a/pack-objects.c +++ b/third_party/git/pack-objects.c diff --git a/pack-objects.h b/third_party/git/pack-objects.h index 9d88e3e518..9d88e3e518 100644 --- a/pack-objects.h +++ b/third_party/git/pack-objects.h diff --git a/pack-revindex.c b/third_party/git/pack-revindex.c index d28a7e43d0..d28a7e43d0 100644 --- a/pack-revindex.c +++ b/third_party/git/pack-revindex.c diff --git a/pack-revindex.h b/third_party/git/pack-revindex.h index 848331d5d6..848331d5d6 100644 --- a/pack-revindex.h +++ b/third_party/git/pack-revindex.h diff --git a/pack-write.c b/third_party/git/pack-write.c index f0017beb9d..f0017beb9d 100644 --- a/pack-write.c +++ b/third_party/git/pack-write.c diff --git a/pack.h b/third_party/git/pack.h index 9fc0945ac9..9fc0945ac9 100644 --- a/pack.h +++ b/third_party/git/pack.h diff --git a/packfile.c b/third_party/git/packfile.c index f4e752996d..f4e752996d 100644 --- a/packfile.c +++ b/third_party/git/packfile.c diff --git a/packfile.h b/third_party/git/packfile.h index 240aa73b95..240aa73b95 100644 --- a/packfile.h +++ b/third_party/git/packfile.h diff --git a/pager.c b/third_party/git/pager.c index 41446d4f05..41446d4f05 100644 --- a/pager.c +++ b/third_party/git/pager.c diff --git a/parse-options-cb.c b/third_party/git/parse-options-cb.c index a28b55be48..a28b55be48 100644 --- a/parse-options-cb.c +++ b/third_party/git/parse-options-cb.c diff --git a/parse-options.c b/third_party/git/parse-options.c index 63d6bab60c..63d6bab60c 100644 --- a/parse-options.c +++ b/third_party/git/parse-options.c diff --git a/parse-options.h b/third_party/git/parse-options.h index fece5ba628..fece5ba628 100644 --- a/parse-options.h +++ b/third_party/git/parse-options.h diff --git a/patch-delta.c b/third_party/git/patch-delta.c index b5c8594db6..b5c8594db6 100644 --- a/patch-delta.c +++ b/third_party/git/patch-delta.c diff --git a/patch-ids.c b/third_party/git/patch-ids.c index 12aa6d494b..12aa6d494b 100644 --- a/patch-ids.c +++ b/third_party/git/patch-ids.c diff --git a/patch-ids.h b/third_party/git/patch-ids.h index 03bb04e707..03bb04e707 100644 --- a/patch-ids.h +++ b/third_party/git/patch-ids.h diff --git a/path.c b/third_party/git/path.c index 88cf593007..88cf593007 100644 --- a/path.c +++ b/third_party/git/path.c diff --git a/path.h b/third_party/git/path.h index 14d6dcad16..14d6dcad16 100644 --- a/path.h +++ b/third_party/git/path.h diff --git a/pathspec.c b/third_party/git/pathspec.c index 8243e06eab..8243e06eab 100644 --- a/pathspec.c +++ b/third_party/git/pathspec.c diff --git a/pathspec.h b/third_party/git/pathspec.h index 454ce364fa..454ce364fa 100644 --- a/pathspec.h +++ b/third_party/git/pathspec.h diff --git a/perl/.gitignore b/third_party/git/perl/.gitignore index 84c048a73c..84c048a73c 100644 --- a/perl/.gitignore +++ b/third_party/git/perl/.gitignore diff --git a/perl/FromCPAN/.gitattributes b/third_party/git/perl/FromCPAN/.gitattributes index 8b64fc5e22..8b64fc5e22 100644 --- a/perl/FromCPAN/.gitattributes +++ b/third_party/git/perl/FromCPAN/.gitattributes diff --git a/perl/FromCPAN/Error.pm b/third_party/git/perl/FromCPAN/Error.pm index 8b95e2d73d..8b95e2d73d 100644 --- a/perl/FromCPAN/Error.pm +++ b/third_party/git/perl/FromCPAN/Error.pm diff --git a/perl/FromCPAN/Mail/Address.pm b/third_party/git/perl/FromCPAN/Mail/Address.pm index 683d490b2b..683d490b2b 100644 --- a/perl/FromCPAN/Mail/Address.pm +++ b/third_party/git/perl/FromCPAN/Mail/Address.pm diff --git a/perl/Git.pm b/third_party/git/perl/Git.pm index 54c9ed0dde..54c9ed0dde 100644 --- a/perl/Git.pm +++ b/third_party/git/perl/Git.pm diff --git a/perl/Git/I18N.pm b/third_party/git/perl/Git/I18N.pm index bfb4fb67a1..bfb4fb67a1 100644 --- a/perl/Git/I18N.pm +++ b/third_party/git/perl/Git/I18N.pm diff --git a/perl/Git/IndexInfo.pm b/third_party/git/perl/Git/IndexInfo.pm index a43108c985..a43108c985 100644 --- a/perl/Git/IndexInfo.pm +++ b/third_party/git/perl/Git/IndexInfo.pm diff --git a/perl/Git/LoadCPAN.pm b/third_party/git/perl/Git/LoadCPAN.pm index e5585e75e8..e5585e75e8 100644 --- a/perl/Git/LoadCPAN.pm +++ b/third_party/git/perl/Git/LoadCPAN.pm diff --git a/perl/Git/LoadCPAN/Error.pm b/third_party/git/perl/Git/LoadCPAN/Error.pm index c6d2c45d80..c6d2c45d80 100644 --- a/perl/Git/LoadCPAN/Error.pm +++ b/third_party/git/perl/Git/LoadCPAN/Error.pm diff --git a/perl/Git/LoadCPAN/Mail/Address.pm b/third_party/git/perl/Git/LoadCPAN/Mail/Address.pm index f70a4f064c..f70a4f064c 100644 --- a/perl/Git/LoadCPAN/Mail/Address.pm +++ b/third_party/git/perl/Git/LoadCPAN/Mail/Address.pm diff --git a/perl/Git/Packet.pm b/third_party/git/perl/Git/Packet.pm index b75738bed4..b75738bed4 100644 --- a/perl/Git/Packet.pm +++ b/third_party/git/perl/Git/Packet.pm diff --git a/perl/Git/SVN.pm b/third_party/git/perl/Git/SVN.pm index 4b28b87784..4b28b87784 100644 --- a/perl/Git/SVN.pm +++ b/third_party/git/perl/Git/SVN.pm diff --git a/perl/Git/SVN/Editor.pm b/third_party/git/perl/Git/SVN/Editor.pm index 0df16ed726..0df16ed726 100644 --- a/perl/Git/SVN/Editor.pm +++ b/third_party/git/perl/Git/SVN/Editor.pm diff --git a/perl/Git/SVN/Fetcher.pm b/third_party/git/perl/Git/SVN/Fetcher.pm index 64e900a0e9..64e900a0e9 100644 --- a/perl/Git/SVN/Fetcher.pm +++ b/third_party/git/perl/Git/SVN/Fetcher.pm diff --git a/perl/Git/SVN/GlobSpec.pm b/third_party/git/perl/Git/SVN/GlobSpec.pm index a0a8d17621..a0a8d17621 100644 --- a/perl/Git/SVN/GlobSpec.pm +++ b/third_party/git/perl/Git/SVN/GlobSpec.pm diff --git a/perl/Git/SVN/Log.pm b/third_party/git/perl/Git/SVN/Log.pm index 664105357c..664105357c 100644 --- a/perl/Git/SVN/Log.pm +++ b/third_party/git/perl/Git/SVN/Log.pm diff --git a/perl/Git/SVN/Memoize/YAML.pm b/third_party/git/perl/Git/SVN/Memoize/YAML.pm index 9676b8f2f7..9676b8f2f7 100644 --- a/perl/Git/SVN/Memoize/YAML.pm +++ b/third_party/git/perl/Git/SVN/Memoize/YAML.pm diff --git a/perl/Git/SVN/Migration.pm b/third_party/git/perl/Git/SVN/Migration.pm index dc90f6a621..dc90f6a621 100644 --- a/perl/Git/SVN/Migration.pm +++ b/third_party/git/perl/Git/SVN/Migration.pm diff --git a/perl/Git/SVN/Prompt.pm b/third_party/git/perl/Git/SVN/Prompt.pm index e940b08505..e940b08505 100644 --- a/perl/Git/SVN/Prompt.pm +++ b/third_party/git/perl/Git/SVN/Prompt.pm diff --git a/perl/Git/SVN/Ra.pm b/third_party/git/perl/Git/SVN/Ra.pm index 56ad9870bc..56ad9870bc 100644 --- a/perl/Git/SVN/Ra.pm +++ b/third_party/git/perl/Git/SVN/Ra.pm diff --git a/perl/Git/SVN/Utils.pm b/third_party/git/perl/Git/SVN/Utils.pm index 3d1a0933a2..3d1a0933a2 100644 --- a/perl/Git/SVN/Utils.pm +++ b/third_party/git/perl/Git/SVN/Utils.pm diff --git a/perl/header_templates/fixed_prefix.template.pl b/third_party/git/perl/header_templates/fixed_prefix.template.pl index 857b4391a4..857b4391a4 100644 --- a/perl/header_templates/fixed_prefix.template.pl +++ b/third_party/git/perl/header_templates/fixed_prefix.template.pl diff --git a/perl/header_templates/runtime_prefix.template.pl b/third_party/git/perl/header_templates/runtime_prefix.template.pl index 9d28b3d863..9d28b3d863 100644 --- a/perl/header_templates/runtime_prefix.template.pl +++ b/third_party/git/perl/header_templates/runtime_prefix.template.pl diff --git a/pkt-line.c b/third_party/git/pkt-line.c index a0e87b1e81..a0e87b1e81 100644 --- a/pkt-line.c +++ b/third_party/git/pkt-line.c diff --git a/pkt-line.h b/third_party/git/pkt-line.h index fef3a0d792..fef3a0d792 100644 --- a/pkt-line.h +++ b/third_party/git/pkt-line.h diff --git a/po/.gitignore b/third_party/git/po/.gitignore index 796b96d1c4..796b96d1c4 100644 --- a/po/.gitignore +++ b/third_party/git/po/.gitignore diff --git a/po/README b/third_party/git/po/README index 07595d369b..07595d369b 100644 --- a/po/README +++ b/third_party/git/po/README diff --git a/po/TEAMS b/third_party/git/po/TEAMS index dbcce4b40f..dbcce4b40f 100644 --- a/po/TEAMS +++ b/third_party/git/po/TEAMS diff --git a/po/bg.po b/third_party/git/po/bg.po index 79903137a4..79903137a4 100644 --- a/po/bg.po +++ b/third_party/git/po/bg.po diff --git a/po/ca.po b/third_party/git/po/ca.po index e324c80551..e324c80551 100644 --- a/po/ca.po +++ b/third_party/git/po/ca.po diff --git a/po/de.po b/third_party/git/po/de.po index cfe50c1055..cfe50c1055 100644 --- a/po/de.po +++ b/third_party/git/po/de.po diff --git a/po/el.po b/third_party/git/po/el.po index 703f46d0c7..703f46d0c7 100644 --- a/po/el.po +++ b/third_party/git/po/el.po diff --git a/po/es.po b/third_party/git/po/es.po index 4a94ee938f..4a94ee938f 100644 --- a/po/es.po +++ b/third_party/git/po/es.po diff --git a/po/fr.po b/third_party/git/po/fr.po index 314ff3747e..314ff3747e 100644 --- a/po/fr.po +++ b/third_party/git/po/fr.po diff --git a/po/git.pot b/third_party/git/po/git.pot index 7dd2e2bcf3..7dd2e2bcf3 100644 --- a/po/git.pot +++ b/third_party/git/po/git.pot diff --git a/po/is.po b/third_party/git/po/is.po index b8b34fd65e..b8b34fd65e 100644 --- a/po/is.po +++ b/third_party/git/po/is.po diff --git a/po/it.po b/third_party/git/po/it.po index e9f596b8fd..e9f596b8fd 100644 --- a/po/it.po +++ b/third_party/git/po/it.po diff --git a/po/ko.po b/third_party/git/po/ko.po index dcfe21c223..dcfe21c223 100644 --- a/po/ko.po +++ b/third_party/git/po/ko.po diff --git a/po/pt_PT.po b/third_party/git/po/pt_PT.po index 8a2d55a8b6..8a2d55a8b6 100644 --- a/po/pt_PT.po +++ b/third_party/git/po/pt_PT.po diff --git a/po/ru.po b/third_party/git/po/ru.po index a77b462e62..a77b462e62 100644 --- a/po/ru.po +++ b/third_party/git/po/ru.po diff --git a/po/sv.po b/third_party/git/po/sv.po index 06a586a215..06a586a215 100644 --- a/po/sv.po +++ b/third_party/git/po/sv.po diff --git a/po/tr.po b/third_party/git/po/tr.po index 1748297afb..1748297afb 100644 --- a/po/tr.po +++ b/third_party/git/po/tr.po diff --git a/po/vi.po b/third_party/git/po/vi.po index 5459484048..5459484048 100644 --- a/po/vi.po +++ b/third_party/git/po/vi.po diff --git a/po/zh_CN.po b/third_party/git/po/zh_CN.po index 5be52589bb..5be52589bb 100644 --- a/po/zh_CN.po +++ b/third_party/git/po/zh_CN.po diff --git a/po/zh_TW.po b/third_party/git/po/zh_TW.po index 5efe4966f7..5efe4966f7 100644 --- a/po/zh_TW.po +++ b/third_party/git/po/zh_TW.po diff --git a/ppc/sha1.c b/third_party/git/ppc/sha1.c index 1b705cee1f..1b705cee1f 100644 --- a/ppc/sha1.c +++ b/third_party/git/ppc/sha1.c diff --git a/ppc/sha1.h b/third_party/git/ppc/sha1.h index 9b24b32615..9b24b32615 100644 --- a/ppc/sha1.h +++ b/third_party/git/ppc/sha1.h diff --git a/ppc/sha1ppc.S b/third_party/git/ppc/sha1ppc.S index 1711eef6e7..1711eef6e7 100644 --- a/ppc/sha1ppc.S +++ b/third_party/git/ppc/sha1ppc.S diff --git a/preload-index.c b/third_party/git/preload-index.c index ed6eaa4738..ed6eaa4738 100644 --- a/preload-index.c +++ b/third_party/git/preload-index.c diff --git a/pretty.c b/third_party/git/pretty.c index 28afc701b6..28afc701b6 100644 --- a/pretty.c +++ b/third_party/git/pretty.c diff --git a/pretty.h b/third_party/git/pretty.h index 4ad1fc31ff..4ad1fc31ff 100644 --- a/pretty.h +++ b/third_party/git/pretty.h diff --git a/prio-queue.c b/third_party/git/prio-queue.c index d3f488cb05..d3f488cb05 100644 --- a/prio-queue.c +++ b/third_party/git/prio-queue.c diff --git a/prio-queue.h b/third_party/git/prio-queue.h index 4f9a37e6be..4f9a37e6be 100644 --- a/prio-queue.h +++ b/third_party/git/prio-queue.h diff --git a/progress.c b/third_party/git/progress.c index 19805ac646..19805ac646 100644 --- a/progress.c +++ b/third_party/git/progress.c diff --git a/progress.h b/third_party/git/progress.h index 847338911f..847338911f 100644 --- a/progress.h +++ b/third_party/git/progress.h diff --git a/promisor-remote.c b/third_party/git/promisor-remote.c index 9f338c945f..9f338c945f 100644 --- a/promisor-remote.c +++ b/third_party/git/promisor-remote.c diff --git a/promisor-remote.h b/third_party/git/promisor-remote.h index 737bac3a33..737bac3a33 100644 --- a/promisor-remote.h +++ b/third_party/git/promisor-remote.h diff --git a/prompt.c b/third_party/git/prompt.c index 6d5885d009..6d5885d009 100644 --- a/prompt.c +++ b/third_party/git/prompt.c diff --git a/prompt.h b/third_party/git/prompt.h index e04cced030..e04cced030 100644 --- a/prompt.h +++ b/third_party/git/prompt.h diff --git a/protocol.c b/third_party/git/protocol.c index 803bef5c87..803bef5c87 100644 --- a/protocol.c +++ b/third_party/git/protocol.c diff --git a/protocol.h b/third_party/git/protocol.h index cef1a4a01c..cef1a4a01c 100644 --- a/protocol.h +++ b/third_party/git/protocol.h diff --git a/quote.c b/third_party/git/quote.c index bcc0dbc50d..bcc0dbc50d 100644 --- a/quote.c +++ b/third_party/git/quote.c diff --git a/quote.h b/third_party/git/quote.h index ca8ee3144a..ca8ee3144a 100644 --- a/quote.h +++ b/third_party/git/quote.h diff --git a/range-diff.c b/third_party/git/range-diff.c index f745567cf6..f745567cf6 100644 --- a/range-diff.c +++ b/third_party/git/range-diff.c diff --git a/range-diff.h b/third_party/git/range-diff.h index e11976dc81..e11976dc81 100644 --- a/range-diff.h +++ b/third_party/git/range-diff.h diff --git a/reachable.c b/third_party/git/reachable.c index 77a60c70a5..77a60c70a5 100644 --- a/reachable.c +++ b/third_party/git/reachable.c diff --git a/reachable.h b/third_party/git/reachable.h index 5df932ad8f..5df932ad8f 100644 --- a/reachable.h +++ b/third_party/git/reachable.h diff --git a/read-cache.c b/third_party/git/read-cache.c index aa427c5c17..aa427c5c17 100644 --- a/read-cache.c +++ b/third_party/git/read-cache.c diff --git a/rebase-interactive.c b/third_party/git/rebase-interactive.c index 762853bc7e..762853bc7e 100644 --- a/rebase-interactive.c +++ b/third_party/git/rebase-interactive.c diff --git a/rebase-interactive.h b/third_party/git/rebase-interactive.h index dc2cf0ee12..dc2cf0ee12 100644 --- a/rebase-interactive.h +++ b/third_party/git/rebase-interactive.h diff --git a/rebase.c b/third_party/git/rebase.c index f8137d859b..f8137d859b 100644 --- a/rebase.c +++ b/third_party/git/rebase.c diff --git a/rebase.h b/third_party/git/rebase.h index cc723d4748..cc723d4748 100644 --- a/rebase.h +++ b/third_party/git/rebase.h diff --git a/ref-filter.c b/third_party/git/ref-filter.c index b1812cb69a..b1812cb69a 100644 --- a/ref-filter.c +++ b/third_party/git/ref-filter.c diff --git a/ref-filter.h b/third_party/git/ref-filter.h index f1dcff4c6e..f1dcff4c6e 100644 --- a/ref-filter.h +++ b/third_party/git/ref-filter.h diff --git a/reflog-walk.c b/third_party/git/reflog-walk.c index 3a25b27d8f..3a25b27d8f 100644 --- a/reflog-walk.c +++ b/third_party/git/reflog-walk.c diff --git a/reflog-walk.h b/third_party/git/reflog-walk.h index f26408f6cc..f26408f6cc 100644 --- a/reflog-walk.h +++ b/third_party/git/reflog-walk.h diff --git a/refs.c b/third_party/git/refs.c index 1ab0bb54d3..1ab0bb54d3 100644 --- a/refs.c +++ b/third_party/git/refs.c diff --git a/refs.h b/third_party/git/refs.h index 545029c6d8..545029c6d8 100644 --- a/refs.h +++ b/third_party/git/refs.h diff --git a/refs/files-backend.c b/third_party/git/refs/files-backend.c index 561c33ac8a..561c33ac8a 100644 --- a/refs/files-backend.c +++ b/third_party/git/refs/files-backend.c diff --git a/refs/iterator.c b/third_party/git/refs/iterator.c index 629e00a122..629e00a122 100644 --- a/refs/iterator.c +++ b/third_party/git/refs/iterator.c diff --git a/refs/packed-backend.c b/third_party/git/refs/packed-backend.c index 4458a0f69c..4458a0f69c 100644 --- a/refs/packed-backend.c +++ b/third_party/git/refs/packed-backend.c diff --git a/refs/packed-backend.h b/third_party/git/refs/packed-backend.h index a01a0aff9c..a01a0aff9c 100644 --- a/refs/packed-backend.h +++ b/third_party/git/refs/packed-backend.h diff --git a/refs/ref-cache.c b/third_party/git/refs/ref-cache.c index b7052f72e2..b7052f72e2 100644 --- a/refs/ref-cache.c +++ b/third_party/git/refs/ref-cache.c diff --git a/refs/ref-cache.h b/third_party/git/refs/ref-cache.h index 3bfb89d2b3..3bfb89d2b3 100644 --- a/refs/ref-cache.h +++ b/third_party/git/refs/ref-cache.h diff --git a/refs/refs-internal.h b/third_party/git/refs/refs-internal.h index ff2436c0fb..ff2436c0fb 100644 --- a/refs/refs-internal.h +++ b/third_party/git/refs/refs-internal.h diff --git a/refspec.c b/third_party/git/refspec.c index 9a9bf21934..9a9bf21934 100644 --- a/refspec.c +++ b/third_party/git/refspec.c diff --git a/refspec.h b/third_party/git/refspec.h index 3f2bd4aaa5..3f2bd4aaa5 100644 --- a/refspec.h +++ b/third_party/git/refspec.h diff --git a/remote-curl.c b/third_party/git/remote-curl.c index e4cd321844..e4cd321844 100644 --- a/remote-curl.c +++ b/third_party/git/remote-curl.c diff --git a/remote-testsvn.c b/third_party/git/remote-testsvn.c index 3af708c5b6..3af708c5b6 100644 --- a/remote-testsvn.c +++ b/third_party/git/remote-testsvn.c diff --git a/remote.c b/third_party/git/remote.c index c43196ec06..c43196ec06 100644 --- a/remote.c +++ b/third_party/git/remote.c diff --git a/remote.h b/third_party/git/remote.h index 11d8719b58..11d8719b58 100644 --- a/remote.h +++ b/third_party/git/remote.h diff --git a/replace-object.c b/third_party/git/replace-object.c index 7bd9aba6ee..7bd9aba6ee 100644 --- a/replace-object.c +++ b/third_party/git/replace-object.c diff --git a/replace-object.h b/third_party/git/replace-object.h index 3fbc32eb7b..3fbc32eb7b 100644 --- a/replace-object.h +++ b/third_party/git/replace-object.h diff --git a/repo-settings.c b/third_party/git/repo-settings.c index a703e407a3..a703e407a3 100644 --- a/repo-settings.c +++ b/third_party/git/repo-settings.c diff --git a/repository.c b/third_party/git/repository.c index a4174ddb06..a4174ddb06 100644 --- a/repository.c +++ b/third_party/git/repository.c diff --git a/repository.h b/third_party/git/repository.h index 040057dea6..040057dea6 100644 --- a/repository.h +++ b/third_party/git/repository.h diff --git a/rerere.c b/third_party/git/rerere.c index 9281131a9f..9281131a9f 100644 --- a/rerere.c +++ b/third_party/git/rerere.c diff --git a/rerere.h b/third_party/git/rerere.h index c32d79c3bd..c32d79c3bd 100644 --- a/rerere.h +++ b/third_party/git/rerere.h diff --git a/resolve-undo.c b/third_party/git/resolve-undo.c index 236320f179..236320f179 100644 --- a/resolve-undo.c +++ b/third_party/git/resolve-undo.c diff --git a/resolve-undo.h b/third_party/git/resolve-undo.h index 2b3f0f901e..2b3f0f901e 100644 --- a/resolve-undo.h +++ b/third_party/git/resolve-undo.h diff --git a/revision.c b/third_party/git/revision.c index 8136929e23..8136929e23 100644 --- a/revision.c +++ b/third_party/git/revision.c diff --git a/revision.h b/third_party/git/revision.h index 475f048fb6..475f048fb6 100644 --- a/revision.h +++ b/third_party/git/revision.h diff --git a/run-command.c b/third_party/git/run-command.c index f5e1149f9b..f5e1149f9b 100644 --- a/run-command.c +++ b/third_party/git/run-command.c diff --git a/run-command.h b/third_party/git/run-command.h index 0f3cc73ab6..0f3cc73ab6 100644 --- a/run-command.h +++ b/third_party/git/run-command.h diff --git a/send-pack.c b/third_party/git/send-pack.c index 0407841ae8..0407841ae8 100644 --- a/send-pack.c +++ b/third_party/git/send-pack.c diff --git a/send-pack.h b/third_party/git/send-pack.h index e148fcd960..e148fcd960 100644 --- a/send-pack.h +++ b/third_party/git/send-pack.h diff --git a/sequencer.c b/third_party/git/sequencer.c index e528225e78..e528225e78 100644 --- a/sequencer.c +++ b/third_party/git/sequencer.c diff --git a/sequencer.h b/third_party/git/sequencer.h index 718a07426d..718a07426d 100644 --- a/sequencer.h +++ b/third_party/git/sequencer.h diff --git a/serve.c b/third_party/git/serve.c index 317256c1a4..317256c1a4 100644 --- a/serve.c +++ b/third_party/git/serve.c diff --git a/serve.h b/third_party/git/serve.h index 42ddca7f8b..42ddca7f8b 100644 --- a/serve.h +++ b/third_party/git/serve.h diff --git a/server-info.c b/third_party/git/server-info.c index bae2cdfd51..bae2cdfd51 100644 --- a/server-info.c +++ b/third_party/git/server-info.c diff --git a/setup.c b/third_party/git/setup.c index 5ea9285a12..5ea9285a12 100644 --- a/setup.c +++ b/third_party/git/setup.c diff --git a/sh-i18n--envsubst.c b/third_party/git/sh-i18n--envsubst.c index e7430b9aa8..e7430b9aa8 100644 --- a/sh-i18n--envsubst.c +++ b/third_party/git/sh-i18n--envsubst.c diff --git a/sha1-array.c b/third_party/git/sha1-array.c index 3eeadfede9..3eeadfede9 100644 --- a/sha1-array.c +++ b/third_party/git/sha1-array.c diff --git a/sha1-array.h b/third_party/git/sha1-array.h index dc1bca9c9a..dc1bca9c9a 100644 --- a/sha1-array.h +++ b/third_party/git/sha1-array.h diff --git a/sha1-file.c b/third_party/git/sha1-file.c index 616886799e..616886799e 100644 --- a/sha1-file.c +++ b/third_party/git/sha1-file.c diff --git a/sha1-lookup.c b/third_party/git/sha1-lookup.c index 29185844ec..29185844ec 100644 --- a/sha1-lookup.c +++ b/third_party/git/sha1-lookup.c diff --git a/sha1-lookup.h b/third_party/git/sha1-lookup.h index 5afcd011c6..5afcd011c6 100644 --- a/sha1-lookup.h +++ b/third_party/git/sha1-lookup.h diff --git a/sha1-name.c b/third_party/git/sha1-name.c index 5bb006e5a9..5bb006e5a9 100644 --- a/sha1-name.c +++ b/third_party/git/sha1-name.c diff --git a/sha1dc/.gitattributes b/third_party/git/sha1dc/.gitattributes index da53f40548..da53f40548 100644 --- a/sha1dc/.gitattributes +++ b/third_party/git/sha1dc/.gitattributes diff --git a/sha1dc/LICENSE.txt b/third_party/git/sha1dc/LICENSE.txt index 4a3e6a1b15..4a3e6a1b15 100644 --- a/sha1dc/LICENSE.txt +++ b/third_party/git/sha1dc/LICENSE.txt diff --git a/sha1dc/sha1.c b/third_party/git/sha1dc/sha1.c index dede2cbddf..dede2cbddf 100644 --- a/sha1dc/sha1.c +++ b/third_party/git/sha1dc/sha1.c diff --git a/sha1dc/sha1.h b/third_party/git/sha1dc/sha1.h index 1e4e94be54..1e4e94be54 100644 --- a/sha1dc/sha1.h +++ b/third_party/git/sha1dc/sha1.h diff --git a/sha1dc/ubc_check.c b/third_party/git/sha1dc/ubc_check.c index b3beff2afb..b3beff2afb 100644 --- a/sha1dc/ubc_check.c +++ b/third_party/git/sha1dc/ubc_check.c diff --git a/sha1dc/ubc_check.h b/third_party/git/sha1dc/ubc_check.h index d7e17dc734..d7e17dc734 100644 --- a/sha1dc/ubc_check.h +++ b/third_party/git/sha1dc/ubc_check.h diff --git a/sha1dc_git.c b/third_party/git/sha1dc_git.c index 5c300e812e..5c300e812e 100644 --- a/sha1dc_git.c +++ b/third_party/git/sha1dc_git.c diff --git a/sha1dc_git.h b/third_party/git/sha1dc_git.h index 41e1c3fd3f..41e1c3fd3f 100644 --- a/sha1dc_git.h +++ b/third_party/git/sha1dc_git.h diff --git a/sha256/block/sha256.c b/third_party/git/sha256/block/sha256.c index 37850b4e52..37850b4e52 100644 --- a/sha256/block/sha256.c +++ b/third_party/git/sha256/block/sha256.c diff --git a/sha256/block/sha256.h b/third_party/git/sha256/block/sha256.h index 5099d6421d..5099d6421d 100644 --- a/sha256/block/sha256.h +++ b/third_party/git/sha256/block/sha256.h diff --git a/sha256/gcrypt.h b/third_party/git/sha256/gcrypt.h index 09bd8bb200..09bd8bb200 100644 --- a/sha256/gcrypt.h +++ b/third_party/git/sha256/gcrypt.h diff --git a/shallow.c b/third_party/git/shallow.c index 7fd04afed1..7fd04afed1 100644 --- a/shallow.c +++ b/third_party/git/shallow.c diff --git a/shell.c b/third_party/git/shell.c index 54cca7439d..54cca7439d 100644 --- a/shell.c +++ b/third_party/git/shell.c diff --git a/shortlog.h b/third_party/git/shortlog.h index 2fa61c4294..2fa61c4294 100644 --- a/shortlog.h +++ b/third_party/git/shortlog.h diff --git a/sideband.c b/third_party/git/sideband.c index ef851113c4..ef851113c4 100644 --- a/sideband.c +++ b/third_party/git/sideband.c diff --git a/sideband.h b/third_party/git/sideband.h index 227740a58e..227740a58e 100644 --- a/sideband.h +++ b/third_party/git/sideband.h diff --git a/sigchain.c b/third_party/git/sigchain.c index 022677b6ab..022677b6ab 100644 --- a/sigchain.c +++ b/third_party/git/sigchain.c diff --git a/sigchain.h b/third_party/git/sigchain.h index 8e6bada892..8e6bada892 100644 --- a/sigchain.h +++ b/third_party/git/sigchain.h diff --git a/split-index.c b/third_party/git/split-index.c index e6154e4ea9..e6154e4ea9 100644 --- a/split-index.c +++ b/third_party/git/split-index.c diff --git a/split-index.h b/third_party/git/split-index.h index 7a435ca2c9..7a435ca2c9 100644 --- a/split-index.h +++ b/third_party/git/split-index.h diff --git a/stable-qsort.c b/third_party/git/stable-qsort.c index 6cbaf39f7b..6cbaf39f7b 100644 --- a/stable-qsort.c +++ b/third_party/git/stable-qsort.c diff --git a/strbuf.c b/third_party/git/strbuf.c index bb0065ccaf..bb0065ccaf 100644 --- a/strbuf.c +++ b/third_party/git/strbuf.c diff --git a/strbuf.h b/third_party/git/strbuf.h index ce8e49c0b2..ce8e49c0b2 100644 --- a/strbuf.h +++ b/third_party/git/strbuf.h diff --git a/streaming.c b/third_party/git/streaming.c index 800f07a52c..800f07a52c 100644 --- a/streaming.c +++ b/third_party/git/streaming.c diff --git a/streaming.h b/third_party/git/streaming.h index 5e4e6acfd0..5e4e6acfd0 100644 --- a/streaming.h +++ b/third_party/git/streaming.h diff --git a/string-list.c b/third_party/git/string-list.c index a917955fbd..a917955fbd 100644 --- a/string-list.c +++ b/third_party/git/string-list.c diff --git a/string-list.h b/third_party/git/string-list.h index 6c5d274126..6c5d274126 100644 --- a/string-list.h +++ b/third_party/git/string-list.h diff --git a/sub-process.c b/third_party/git/sub-process.c index 1b1af9dcbd..1b1af9dcbd 100644 --- a/sub-process.c +++ b/third_party/git/sub-process.c diff --git a/sub-process.h b/third_party/git/sub-process.h index e85f21fa1a..e85f21fa1a 100644 --- a/sub-process.h +++ b/third_party/git/sub-process.h diff --git a/submodule-config.c b/third_party/git/submodule-config.c index 4d1c92d582..4d1c92d582 100644 --- a/submodule-config.c +++ b/third_party/git/submodule-config.c diff --git a/submodule-config.h b/third_party/git/submodule-config.h index c11e22cf50..c11e22cf50 100644 --- a/submodule-config.h +++ b/third_party/git/submodule-config.h diff --git a/submodule.c b/third_party/git/submodule.c index 31f391d7d2..31f391d7d2 100644 --- a/submodule.c +++ b/third_party/git/submodule.c diff --git a/submodule.h b/third_party/git/submodule.h index c81ec1a9b6..c81ec1a9b6 100644 --- a/submodule.h +++ b/third_party/git/submodule.h diff --git a/symlinks.c b/third_party/git/symlinks.c index 69d458a24d..69d458a24d 100644 --- a/symlinks.c +++ b/third_party/git/symlinks.c diff --git a/t/.gitattributes b/third_party/git/t/.gitattributes index df05434d32..df05434d32 100644 --- a/t/.gitattributes +++ b/third_party/git/t/.gitattributes diff --git a/t/.gitignore b/third_party/git/t/.gitignore index 91cf5772fe..91cf5772fe 100644 --- a/t/.gitignore +++ b/third_party/git/t/.gitignore diff --git a/t/Git-SVN/00compile.t b/third_party/git/t/Git-SVN/00compile.t index c92fee453f..c92fee453f 100755 --- a/t/Git-SVN/00compile.t +++ b/third_party/git/t/Git-SVN/00compile.t diff --git a/t/Git-SVN/Utils/add_path_to_url.t b/third_party/git/t/Git-SVN/Utils/add_path_to_url.t index bfbd87845f..bfbd87845f 100755 --- a/t/Git-SVN/Utils/add_path_to_url.t +++ b/third_party/git/t/Git-SVN/Utils/add_path_to_url.t diff --git a/t/Git-SVN/Utils/can_compress.t b/third_party/git/t/Git-SVN/Utils/can_compress.t index d7b49b8d54..d7b49b8d54 100755 --- a/t/Git-SVN/Utils/can_compress.t +++ b/third_party/git/t/Git-SVN/Utils/can_compress.t diff --git a/t/Git-SVN/Utils/canonicalize_url.t b/third_party/git/t/Git-SVN/Utils/canonicalize_url.t index 05795ab636..05795ab636 100755 --- a/t/Git-SVN/Utils/canonicalize_url.t +++ b/third_party/git/t/Git-SVN/Utils/canonicalize_url.t diff --git a/t/Git-SVN/Utils/collapse_dotdot.t b/third_party/git/t/Git-SVN/Utils/collapse_dotdot.t index 1da1cce156..1da1cce156 100755 --- a/t/Git-SVN/Utils/collapse_dotdot.t +++ b/third_party/git/t/Git-SVN/Utils/collapse_dotdot.t diff --git a/t/Git-SVN/Utils/fatal.t b/third_party/git/t/Git-SVN/Utils/fatal.t index 49e1438295..49e1438295 100755 --- a/t/Git-SVN/Utils/fatal.t +++ b/third_party/git/t/Git-SVN/Utils/fatal.t diff --git a/t/Git-SVN/Utils/join_paths.t b/third_party/git/t/Git-SVN/Utils/join_paths.t index d4488e7162..d4488e7162 100755 --- a/t/Git-SVN/Utils/join_paths.t +++ b/third_party/git/t/Git-SVN/Utils/join_paths.t diff --git a/t/Makefile b/third_party/git/t/Makefile index c83fd18861..c83fd18861 100644 --- a/t/Makefile +++ b/third_party/git/t/Makefile diff --git a/t/README b/third_party/git/t/README index 9afd61e3ca..9afd61e3ca 100644 --- a/t/README +++ b/third_party/git/t/README diff --git a/t/aggregate-results.sh b/third_party/git/t/aggregate-results.sh index 7913e206ed..7913e206ed 100755 --- a/t/aggregate-results.sh +++ b/third_party/git/t/aggregate-results.sh diff --git a/t/annotate-tests.sh b/third_party/git/t/annotate-tests.sh index d933af5714..d933af5714 100644 --- a/t/annotate-tests.sh +++ b/third_party/git/t/annotate-tests.sh diff --git a/t/chainlint.sed b/third_party/git/t/chainlint.sed index 70df40e34b..70df40e34b 100644 --- a/t/chainlint.sed +++ b/third_party/git/t/chainlint.sed diff --git a/t/chainlint/arithmetic-expansion.expect b/third_party/git/t/chainlint/arithmetic-expansion.expect index 09457d3196..09457d3196 100644 --- a/t/chainlint/arithmetic-expansion.expect +++ b/third_party/git/t/chainlint/arithmetic-expansion.expect diff --git a/t/chainlint/arithmetic-expansion.test b/third_party/git/t/chainlint/arithmetic-expansion.test index 16206960d8..16206960d8 100644 --- a/t/chainlint/arithmetic-expansion.test +++ b/third_party/git/t/chainlint/arithmetic-expansion.test diff --git a/t/chainlint/bash-array.expect b/third_party/git/t/chainlint/bash-array.expect index c4a830d1c1..c4a830d1c1 100644 --- a/t/chainlint/bash-array.expect +++ b/third_party/git/t/chainlint/bash-array.expect diff --git a/t/chainlint/bash-array.test b/third_party/git/t/chainlint/bash-array.test index 92bbb777b8..92bbb777b8 100644 --- a/t/chainlint/bash-array.test +++ b/third_party/git/t/chainlint/bash-array.test diff --git a/t/chainlint/blank-line.expect b/third_party/git/t/chainlint/blank-line.expect index 3be939ed38..3be939ed38 100644 --- a/t/chainlint/blank-line.expect +++ b/third_party/git/t/chainlint/blank-line.expect diff --git a/t/chainlint/blank-line.test b/third_party/git/t/chainlint/blank-line.test index f6dd14302b..f6dd14302b 100644 --- a/t/chainlint/blank-line.test +++ b/third_party/git/t/chainlint/blank-line.test diff --git a/t/chainlint/block.expect b/third_party/git/t/chainlint/block.expect index fed7e89ae8..fed7e89ae8 100644 --- a/t/chainlint/block.expect +++ b/third_party/git/t/chainlint/block.expect diff --git a/t/chainlint/block.test b/third_party/git/t/chainlint/block.test index d859151af1..d859151af1 100644 --- a/t/chainlint/block.test +++ b/third_party/git/t/chainlint/block.test diff --git a/t/chainlint/broken-chain.expect b/third_party/git/t/chainlint/broken-chain.expect index 55b0f42a53..55b0f42a53 100644 --- a/t/chainlint/broken-chain.expect +++ b/third_party/git/t/chainlint/broken-chain.expect diff --git a/t/chainlint/broken-chain.test b/third_party/git/t/chainlint/broken-chain.test index 3cc67b65d0..3cc67b65d0 100644 --- a/t/chainlint/broken-chain.test +++ b/third_party/git/t/chainlint/broken-chain.test diff --git a/t/chainlint/case.expect b/third_party/git/t/chainlint/case.expect index 41f121fbbf..41f121fbbf 100644 --- a/t/chainlint/case.expect +++ b/third_party/git/t/chainlint/case.expect diff --git a/t/chainlint/case.test b/third_party/git/t/chainlint/case.test index 5ef6ff7db5..5ef6ff7db5 100644 --- a/t/chainlint/case.test +++ b/third_party/git/t/chainlint/case.test diff --git a/t/chainlint/close-nested-and-parent-together.expect b/third_party/git/t/chainlint/close-nested-and-parent-together.expect index 2a910f9d66..2a910f9d66 100644 --- a/t/chainlint/close-nested-and-parent-together.expect +++ b/third_party/git/t/chainlint/close-nested-and-parent-together.expect diff --git a/t/chainlint/close-nested-and-parent-together.test b/third_party/git/t/chainlint/close-nested-and-parent-together.test index 72d482f76d..72d482f76d 100644 --- a/t/chainlint/close-nested-and-parent-together.test +++ b/third_party/git/t/chainlint/close-nested-and-parent-together.test diff --git a/t/chainlint/close-subshell.expect b/third_party/git/t/chainlint/close-subshell.expect index 184688718a..184688718a 100644 --- a/t/chainlint/close-subshell.expect +++ b/third_party/git/t/chainlint/close-subshell.expect diff --git a/t/chainlint/close-subshell.test b/third_party/git/t/chainlint/close-subshell.test index 508ca447fd..508ca447fd 100644 --- a/t/chainlint/close-subshell.test +++ b/third_party/git/t/chainlint/close-subshell.test diff --git a/t/chainlint/command-substitution.expect b/third_party/git/t/chainlint/command-substitution.expect index ad4118e537..ad4118e537 100644 --- a/t/chainlint/command-substitution.expect +++ b/third_party/git/t/chainlint/command-substitution.expect diff --git a/t/chainlint/command-substitution.test b/third_party/git/t/chainlint/command-substitution.test index 3bbb002a4c..3bbb002a4c 100644 --- a/t/chainlint/command-substitution.test +++ b/third_party/git/t/chainlint/command-substitution.test diff --git a/t/chainlint/comment.expect b/third_party/git/t/chainlint/comment.expect index 3be939ed38..3be939ed38 100644 --- a/t/chainlint/comment.expect +++ b/third_party/git/t/chainlint/comment.expect diff --git a/t/chainlint/comment.test b/third_party/git/t/chainlint/comment.test index 113c0c466f..113c0c466f 100644 --- a/t/chainlint/comment.test +++ b/third_party/git/t/chainlint/comment.test diff --git a/t/chainlint/complex-if-in-cuddled-loop.expect b/third_party/git/t/chainlint/complex-if-in-cuddled-loop.expect index 9674b88cf2..9674b88cf2 100644 --- a/t/chainlint/complex-if-in-cuddled-loop.expect +++ b/third_party/git/t/chainlint/complex-if-in-cuddled-loop.expect diff --git a/t/chainlint/complex-if-in-cuddled-loop.test b/third_party/git/t/chainlint/complex-if-in-cuddled-loop.test index 571bbd85cd..571bbd85cd 100644 --- a/t/chainlint/complex-if-in-cuddled-loop.test +++ b/third_party/git/t/chainlint/complex-if-in-cuddled-loop.test diff --git a/t/chainlint/cuddled-if-then-else.expect b/third_party/git/t/chainlint/cuddled-if-then-else.expect index ab2a026fbc..ab2a026fbc 100644 --- a/t/chainlint/cuddled-if-then-else.expect +++ b/third_party/git/t/chainlint/cuddled-if-then-else.expect diff --git a/t/chainlint/cuddled-if-then-else.test b/third_party/git/t/chainlint/cuddled-if-then-else.test index eed774a9d6..eed774a9d6 100644 --- a/t/chainlint/cuddled-if-then-else.test +++ b/third_party/git/t/chainlint/cuddled-if-then-else.test diff --git a/t/chainlint/cuddled-loop.expect b/third_party/git/t/chainlint/cuddled-loop.expect index 8c0260d7f1..8c0260d7f1 100644 --- a/t/chainlint/cuddled-loop.expect +++ b/third_party/git/t/chainlint/cuddled-loop.expect diff --git a/t/chainlint/cuddled-loop.test b/third_party/git/t/chainlint/cuddled-loop.test index a841d781f0..a841d781f0 100644 --- a/t/chainlint/cuddled-loop.test +++ b/third_party/git/t/chainlint/cuddled-loop.test diff --git a/t/chainlint/cuddled.expect b/third_party/git/t/chainlint/cuddled.expect index b506d46221..b506d46221 100644 --- a/t/chainlint/cuddled.expect +++ b/third_party/git/t/chainlint/cuddled.expect diff --git a/t/chainlint/cuddled.test b/third_party/git/t/chainlint/cuddled.test index 0499fa4180..0499fa4180 100644 --- a/t/chainlint/cuddled.test +++ b/third_party/git/t/chainlint/cuddled.test diff --git a/t/chainlint/exit-loop.expect b/third_party/git/t/chainlint/exit-loop.expect index 84d8bdebc0..84d8bdebc0 100644 --- a/t/chainlint/exit-loop.expect +++ b/third_party/git/t/chainlint/exit-loop.expect diff --git a/t/chainlint/exit-loop.test b/third_party/git/t/chainlint/exit-loop.test index 2f038207e1..2f038207e1 100644 --- a/t/chainlint/exit-loop.test +++ b/third_party/git/t/chainlint/exit-loop.test diff --git a/t/chainlint/exit-subshell.expect b/third_party/git/t/chainlint/exit-subshell.expect index bf78454f74..bf78454f74 100644 --- a/t/chainlint/exit-subshell.expect +++ b/third_party/git/t/chainlint/exit-subshell.expect diff --git a/t/chainlint/exit-subshell.test b/third_party/git/t/chainlint/exit-subshell.test index 4e6ab69b88..4e6ab69b88 100644 --- a/t/chainlint/exit-subshell.test +++ b/third_party/git/t/chainlint/exit-subshell.test diff --git a/t/chainlint/for-loop.expect b/third_party/git/t/chainlint/for-loop.expect index c33cf56ee7..c33cf56ee7 100644 --- a/t/chainlint/for-loop.expect +++ b/third_party/git/t/chainlint/for-loop.expect diff --git a/t/chainlint/for-loop.test b/third_party/git/t/chainlint/for-loop.test index 7db76262bc..7db76262bc 100644 --- a/t/chainlint/for-loop.test +++ b/third_party/git/t/chainlint/for-loop.test diff --git a/t/chainlint/here-doc-close-subshell.expect b/third_party/git/t/chainlint/here-doc-close-subshell.expect index f011e335e5..f011e335e5 100644 --- a/t/chainlint/here-doc-close-subshell.expect +++ b/third_party/git/t/chainlint/here-doc-close-subshell.expect diff --git a/t/chainlint/here-doc-close-subshell.test b/third_party/git/t/chainlint/here-doc-close-subshell.test index b857ff5467..b857ff5467 100644 --- a/t/chainlint/here-doc-close-subshell.test +++ b/third_party/git/t/chainlint/here-doc-close-subshell.test diff --git a/t/chainlint/here-doc-multi-line-command-subst.expect b/third_party/git/t/chainlint/here-doc-multi-line-command-subst.expect index e5fb752d2f..e5fb752d2f 100644 --- a/t/chainlint/here-doc-multi-line-command-subst.expect +++ b/third_party/git/t/chainlint/here-doc-multi-line-command-subst.expect diff --git a/t/chainlint/here-doc-multi-line-command-subst.test b/third_party/git/t/chainlint/here-doc-multi-line-command-subst.test index 899bc5de8b..899bc5de8b 100644 --- a/t/chainlint/here-doc-multi-line-command-subst.test +++ b/third_party/git/t/chainlint/here-doc-multi-line-command-subst.test diff --git a/t/chainlint/here-doc-multi-line-string.expect b/third_party/git/t/chainlint/here-doc-multi-line-string.expect index 32038a070c..32038a070c 100644 --- a/t/chainlint/here-doc-multi-line-string.expect +++ b/third_party/git/t/chainlint/here-doc-multi-line-string.expect diff --git a/t/chainlint/here-doc-multi-line-string.test b/third_party/git/t/chainlint/here-doc-multi-line-string.test index a53edbcc8d..a53edbcc8d 100644 --- a/t/chainlint/here-doc-multi-line-string.test +++ b/third_party/git/t/chainlint/here-doc-multi-line-string.test diff --git a/t/chainlint/here-doc.expect b/third_party/git/t/chainlint/here-doc.expect index 534b065e38..534b065e38 100644 --- a/t/chainlint/here-doc.expect +++ b/third_party/git/t/chainlint/here-doc.expect diff --git a/t/chainlint/here-doc.test b/third_party/git/t/chainlint/here-doc.test index ad4ce8afd9..ad4ce8afd9 100644 --- a/t/chainlint/here-doc.test +++ b/third_party/git/t/chainlint/here-doc.test diff --git a/t/chainlint/if-in-loop.expect b/third_party/git/t/chainlint/if-in-loop.expect index 03d3ceb22d..03d3ceb22d 100644 --- a/t/chainlint/if-in-loop.expect +++ b/third_party/git/t/chainlint/if-in-loop.expect diff --git a/t/chainlint/if-in-loop.test b/third_party/git/t/chainlint/if-in-loop.test index daf22da164..daf22da164 100644 --- a/t/chainlint/if-in-loop.test +++ b/third_party/git/t/chainlint/if-in-loop.test diff --git a/t/chainlint/if-then-else.expect b/third_party/git/t/chainlint/if-then-else.expect index 5953c7bfbc..5953c7bfbc 100644 --- a/t/chainlint/if-then-else.expect +++ b/third_party/git/t/chainlint/if-then-else.expect diff --git a/t/chainlint/if-then-else.test b/third_party/git/t/chainlint/if-then-else.test index 9bd8e9a4c6..9bd8e9a4c6 100644 --- a/t/chainlint/if-then-else.test +++ b/third_party/git/t/chainlint/if-then-else.test diff --git a/t/chainlint/incomplete-line.expect b/third_party/git/t/chainlint/incomplete-line.expect index 2f3ebabdc2..2f3ebabdc2 100644 --- a/t/chainlint/incomplete-line.expect +++ b/third_party/git/t/chainlint/incomplete-line.expect diff --git a/t/chainlint/incomplete-line.test b/third_party/git/t/chainlint/incomplete-line.test index d856658083..d856658083 100644 --- a/t/chainlint/incomplete-line.test +++ b/third_party/git/t/chainlint/incomplete-line.test diff --git a/t/chainlint/inline-comment.expect b/third_party/git/t/chainlint/inline-comment.expect index fc9f250ac4..fc9f250ac4 100644 --- a/t/chainlint/inline-comment.expect +++ b/third_party/git/t/chainlint/inline-comment.expect diff --git a/t/chainlint/inline-comment.test b/third_party/git/t/chainlint/inline-comment.test index 8f26856e77..8f26856e77 100644 --- a/t/chainlint/inline-comment.test +++ b/third_party/git/t/chainlint/inline-comment.test diff --git a/t/chainlint/loop-in-if.expect b/third_party/git/t/chainlint/loop-in-if.expect index 088e622c31..088e622c31 100644 --- a/t/chainlint/loop-in-if.expect +++ b/third_party/git/t/chainlint/loop-in-if.expect diff --git a/t/chainlint/loop-in-if.test b/third_party/git/t/chainlint/loop-in-if.test index 93e8ba8e4d..93e8ba8e4d 100644 --- a/t/chainlint/loop-in-if.test +++ b/third_party/git/t/chainlint/loop-in-if.test diff --git a/t/chainlint/multi-line-nested-command-substitution.expect b/third_party/git/t/chainlint/multi-line-nested-command-substitution.expect index 59b6c8b850..59b6c8b850 100644 --- a/t/chainlint/multi-line-nested-command-substitution.expect +++ b/third_party/git/t/chainlint/multi-line-nested-command-substitution.expect diff --git a/t/chainlint/multi-line-nested-command-substitution.test b/third_party/git/t/chainlint/multi-line-nested-command-substitution.test index 300058341b..300058341b 100644 --- a/t/chainlint/multi-line-nested-command-substitution.test +++ b/third_party/git/t/chainlint/multi-line-nested-command-substitution.test diff --git a/t/chainlint/multi-line-string.expect b/third_party/git/t/chainlint/multi-line-string.expect index 170cb59993..170cb59993 100644 --- a/t/chainlint/multi-line-string.expect +++ b/third_party/git/t/chainlint/multi-line-string.expect diff --git a/t/chainlint/multi-line-string.test b/third_party/git/t/chainlint/multi-line-string.test index 287ab89705..287ab89705 100644 --- a/t/chainlint/multi-line-string.test +++ b/third_party/git/t/chainlint/multi-line-string.test diff --git a/t/chainlint/negated-one-liner.expect b/third_party/git/t/chainlint/negated-one-liner.expect index cf18429d03..cf18429d03 100644 --- a/t/chainlint/negated-one-liner.expect +++ b/third_party/git/t/chainlint/negated-one-liner.expect diff --git a/t/chainlint/negated-one-liner.test b/third_party/git/t/chainlint/negated-one-liner.test index c9598e9153..c9598e9153 100644 --- a/t/chainlint/negated-one-liner.test +++ b/third_party/git/t/chainlint/negated-one-liner.test diff --git a/t/chainlint/nested-cuddled-subshell.expect b/third_party/git/t/chainlint/nested-cuddled-subshell.expect index c2a59ffc33..c2a59ffc33 100644 --- a/t/chainlint/nested-cuddled-subshell.expect +++ b/third_party/git/t/chainlint/nested-cuddled-subshell.expect diff --git a/t/chainlint/nested-cuddled-subshell.test b/third_party/git/t/chainlint/nested-cuddled-subshell.test index 8fd656c7b5..8fd656c7b5 100644 --- a/t/chainlint/nested-cuddled-subshell.test +++ b/third_party/git/t/chainlint/nested-cuddled-subshell.test diff --git a/t/chainlint/nested-here-doc.expect b/third_party/git/t/chainlint/nested-here-doc.expect index 0c9ef1cfc6..0c9ef1cfc6 100644 --- a/t/chainlint/nested-here-doc.expect +++ b/third_party/git/t/chainlint/nested-here-doc.expect diff --git a/t/chainlint/nested-here-doc.test b/third_party/git/t/chainlint/nested-here-doc.test index f35404bf0f..f35404bf0f 100644 --- a/t/chainlint/nested-here-doc.test +++ b/third_party/git/t/chainlint/nested-here-doc.test diff --git a/t/chainlint/nested-subshell-comment.expect b/third_party/git/t/chainlint/nested-subshell-comment.expect index 15b68d4373..15b68d4373 100644 --- a/t/chainlint/nested-subshell-comment.expect +++ b/third_party/git/t/chainlint/nested-subshell-comment.expect diff --git a/t/chainlint/nested-subshell-comment.test b/third_party/git/t/chainlint/nested-subshell-comment.test index 0ff136ab3c..0ff136ab3c 100644 --- a/t/chainlint/nested-subshell-comment.test +++ b/third_party/git/t/chainlint/nested-subshell-comment.test diff --git a/t/chainlint/nested-subshell.expect b/third_party/git/t/chainlint/nested-subshell.expect index c8165ad19e..c8165ad19e 100644 --- a/t/chainlint/nested-subshell.expect +++ b/third_party/git/t/chainlint/nested-subshell.expect diff --git a/t/chainlint/nested-subshell.test b/third_party/git/t/chainlint/nested-subshell.test index 998b05a47d..998b05a47d 100644 --- a/t/chainlint/nested-subshell.test +++ b/third_party/git/t/chainlint/nested-subshell.test diff --git a/t/chainlint/one-liner.expect b/third_party/git/t/chainlint/one-liner.expect index 237f227349..237f227349 100644 --- a/t/chainlint/one-liner.expect +++ b/third_party/git/t/chainlint/one-liner.expect diff --git a/t/chainlint/one-liner.test b/third_party/git/t/chainlint/one-liner.test index ec9acb9825..ec9acb9825 100644 --- a/t/chainlint/one-liner.test +++ b/third_party/git/t/chainlint/one-liner.test diff --git a/t/chainlint/p4-filespec.expect b/third_party/git/t/chainlint/p4-filespec.expect index 98b3d881fd..98b3d881fd 100644 --- a/t/chainlint/p4-filespec.expect +++ b/third_party/git/t/chainlint/p4-filespec.expect diff --git a/t/chainlint/p4-filespec.test b/third_party/git/t/chainlint/p4-filespec.test index 4fd2d6e2b8..4fd2d6e2b8 100644 --- a/t/chainlint/p4-filespec.test +++ b/third_party/git/t/chainlint/p4-filespec.test diff --git a/t/chainlint/pipe.expect b/third_party/git/t/chainlint/pipe.expect index 211b901dbc..211b901dbc 100644 --- a/t/chainlint/pipe.expect +++ b/third_party/git/t/chainlint/pipe.expect diff --git a/t/chainlint/pipe.test b/third_party/git/t/chainlint/pipe.test index e6af4de916..e6af4de916 100644 --- a/t/chainlint/pipe.test +++ b/third_party/git/t/chainlint/pipe.test diff --git a/t/chainlint/semicolon.expect b/third_party/git/t/chainlint/semicolon.expect index 1d79384606..1d79384606 100644 --- a/t/chainlint/semicolon.expect +++ b/third_party/git/t/chainlint/semicolon.expect diff --git a/t/chainlint/semicolon.test b/third_party/git/t/chainlint/semicolon.test index d82c8ebbc0..d82c8ebbc0 100644 --- a/t/chainlint/semicolon.test +++ b/third_party/git/t/chainlint/semicolon.test diff --git a/t/chainlint/subshell-here-doc.expect b/third_party/git/t/chainlint/subshell-here-doc.expect index 74723e7340..74723e7340 100644 --- a/t/chainlint/subshell-here-doc.expect +++ b/third_party/git/t/chainlint/subshell-here-doc.expect diff --git a/t/chainlint/subshell-here-doc.test b/third_party/git/t/chainlint/subshell-here-doc.test index f6b3ba4214..f6b3ba4214 100644 --- a/t/chainlint/subshell-here-doc.test +++ b/third_party/git/t/chainlint/subshell-here-doc.test diff --git a/t/chainlint/subshell-one-liner.expect b/third_party/git/t/chainlint/subshell-one-liner.expect index 51162821d7..51162821d7 100644 --- a/t/chainlint/subshell-one-liner.expect +++ b/third_party/git/t/chainlint/subshell-one-liner.expect diff --git a/t/chainlint/subshell-one-liner.test b/third_party/git/t/chainlint/subshell-one-liner.test index 37fa643c20..37fa643c20 100644 --- a/t/chainlint/subshell-one-liner.test +++ b/third_party/git/t/chainlint/subshell-one-liner.test diff --git a/t/chainlint/t7900-subtree.expect b/third_party/git/t/chainlint/t7900-subtree.expect index c9913429e6..c9913429e6 100644 --- a/t/chainlint/t7900-subtree.expect +++ b/third_party/git/t/chainlint/t7900-subtree.expect diff --git a/t/chainlint/t7900-subtree.test b/third_party/git/t/chainlint/t7900-subtree.test index 277d8358df..277d8358df 100644 --- a/t/chainlint/t7900-subtree.test +++ b/third_party/git/t/chainlint/t7900-subtree.test diff --git a/t/chainlint/while-loop.expect b/third_party/git/t/chainlint/while-loop.expect index 13cff2c0a5..13cff2c0a5 100644 --- a/t/chainlint/while-loop.expect +++ b/third_party/git/t/chainlint/while-loop.expect diff --git a/t/chainlint/while-loop.test b/third_party/git/t/chainlint/while-loop.test index f1df085bf0..f1df085bf0 100644 --- a/t/chainlint/while-loop.test +++ b/third_party/git/t/chainlint/while-loop.test diff --git a/t/check-non-portable-shell.pl b/third_party/git/t/check-non-portable-shell.pl index fd3303552b..fd3303552b 100755 --- a/t/check-non-portable-shell.pl +++ b/third_party/git/t/check-non-portable-shell.pl diff --git a/t/diff-lib.sh b/third_party/git/t/diff-lib.sh index 2de880f7a5..2de880f7a5 100644 --- a/t/diff-lib.sh +++ b/third_party/git/t/diff-lib.sh diff --git a/t/diff-lib/COPYING b/third_party/git/t/diff-lib/COPYING index 6ff87c4664..6ff87c4664 100644 --- a/t/diff-lib/COPYING +++ b/third_party/git/t/diff-lib/COPYING diff --git a/t/diff-lib/README b/third_party/git/t/diff-lib/README index 548142c327..548142c327 100644 --- a/t/diff-lib/README +++ b/third_party/git/t/diff-lib/README diff --git a/t/gitweb-lib.sh b/third_party/git/t/gitweb-lib.sh index 1f32ca66ea..1f32ca66ea 100644 --- a/t/gitweb-lib.sh +++ b/third_party/git/t/gitweb-lib.sh diff --git a/t/helper/.gitignore b/third_party/git/t/helper/.gitignore index 48c7bb0bbb..48c7bb0bbb 100644 --- a/t/helper/.gitignore +++ b/third_party/git/t/helper/.gitignore diff --git a/t/helper/test-chmtime.c b/third_party/git/t/helper/test-chmtime.c index aa22af48c2..aa22af48c2 100644 --- a/t/helper/test-chmtime.c +++ b/third_party/git/t/helper/test-chmtime.c diff --git a/t/helper/test-config.c b/third_party/git/t/helper/test-config.c index 234c722b48..234c722b48 100644 --- a/t/helper/test-config.c +++ b/third_party/git/t/helper/test-config.c diff --git a/t/helper/test-ctype.c b/third_party/git/t/helper/test-ctype.c index 92c4c2313e..92c4c2313e 100644 --- a/t/helper/test-ctype.c +++ b/third_party/git/t/helper/test-ctype.c diff --git a/t/helper/test-date.c b/third_party/git/t/helper/test-date.c index 099eff4f0f..099eff4f0f 100644 --- a/t/helper/test-date.c +++ b/third_party/git/t/helper/test-date.c diff --git a/t/helper/test-delta.c b/third_party/git/t/helper/test-delta.c index e749a49c88..e749a49c88 100644 --- a/t/helper/test-delta.c +++ b/third_party/git/t/helper/test-delta.c diff --git a/t/helper/test-dir-iterator.c b/third_party/git/t/helper/test-dir-iterator.c index 659b6bfa81..659b6bfa81 100644 --- a/t/helper/test-dir-iterator.c +++ b/third_party/git/t/helper/test-dir-iterator.c diff --git a/t/helper/test-drop-caches.c b/third_party/git/t/helper/test-drop-caches.c index 7b4278462b..7b4278462b 100644 --- a/t/helper/test-drop-caches.c +++ b/third_party/git/t/helper/test-drop-caches.c diff --git a/t/helper/test-dump-cache-tree.c b/third_party/git/t/helper/test-dump-cache-tree.c index 6a3f88f5f5..6a3f88f5f5 100644 --- a/t/helper/test-dump-cache-tree.c +++ b/third_party/git/t/helper/test-dump-cache-tree.c diff --git a/t/helper/test-dump-fsmonitor.c b/third_party/git/t/helper/test-dump-fsmonitor.c index 975f0ac890..975f0ac890 100644 --- a/t/helper/test-dump-fsmonitor.c +++ b/third_party/git/t/helper/test-dump-fsmonitor.c diff --git a/t/helper/test-dump-split-index.c b/third_party/git/t/helper/test-dump-split-index.c index 63c689d6ee..63c689d6ee 100644 --- a/t/helper/test-dump-split-index.c +++ b/third_party/git/t/helper/test-dump-split-index.c diff --git a/t/helper/test-dump-untracked-cache.c b/third_party/git/t/helper/test-dump-untracked-cache.c index cf0f2c7228..cf0f2c7228 100644 --- a/t/helper/test-dump-untracked-cache.c +++ b/third_party/git/t/helper/test-dump-untracked-cache.c diff --git a/t/helper/test-example-decorate.c b/third_party/git/t/helper/test-example-decorate.c index c8a1cde7d2..c8a1cde7d2 100644 --- a/t/helper/test-example-decorate.c +++ b/third_party/git/t/helper/test-example-decorate.c diff --git a/t/helper/test-fake-ssh.c b/third_party/git/t/helper/test-fake-ssh.c index 12beee99ad..12beee99ad 100644 --- a/t/helper/test-fake-ssh.c +++ b/third_party/git/t/helper/test-fake-ssh.c diff --git a/t/helper/test-genrandom.c b/third_party/git/t/helper/test-genrandom.c index 99b8dc1e2d..99b8dc1e2d 100644 --- a/t/helper/test-genrandom.c +++ b/third_party/git/t/helper/test-genrandom.c diff --git a/t/helper/test-genzeros.c b/third_party/git/t/helper/test-genzeros.c index 9532f5bac9..9532f5bac9 100644 --- a/t/helper/test-genzeros.c +++ b/third_party/git/t/helper/test-genzeros.c diff --git a/t/helper/test-hash-speed.c b/third_party/git/t/helper/test-hash-speed.c index 432233c7f0..432233c7f0 100644 --- a/t/helper/test-hash-speed.c +++ b/third_party/git/t/helper/test-hash-speed.c diff --git a/t/helper/test-hash.c b/third_party/git/t/helper/test-hash.c index 0a31de66f3..0a31de66f3 100644 --- a/t/helper/test-hash.c +++ b/third_party/git/t/helper/test-hash.c diff --git a/t/helper/test-hashmap.c b/third_party/git/t/helper/test-hashmap.c index f38706216f..f38706216f 100644 --- a/t/helper/test-hashmap.c +++ b/third_party/git/t/helper/test-hashmap.c diff --git a/t/helper/test-index-version.c b/third_party/git/t/helper/test-index-version.c index fcd10968cc..fcd10968cc 100644 --- a/t/helper/test-index-version.c +++ b/third_party/git/t/helper/test-index-version.c diff --git a/t/helper/test-json-writer.c b/third_party/git/t/helper/test-json-writer.c index 37c452535f..37c452535f 100644 --- a/t/helper/test-json-writer.c +++ b/third_party/git/t/helper/test-json-writer.c diff --git a/t/helper/test-lazy-init-name-hash.c b/third_party/git/t/helper/test-lazy-init-name-hash.c index cd1b4c9736..cd1b4c9736 100644 --- a/t/helper/test-lazy-init-name-hash.c +++ b/third_party/git/t/helper/test-lazy-init-name-hash.c diff --git a/t/helper/test-line-buffer.c b/third_party/git/t/helper/test-line-buffer.c index 078dd7e29d..078dd7e29d 100644 --- a/t/helper/test-line-buffer.c +++ b/third_party/git/t/helper/test-line-buffer.c diff --git a/t/helper/test-match-trees.c b/third_party/git/t/helper/test-match-trees.c index b9fd427571..b9fd427571 100644 --- a/t/helper/test-match-trees.c +++ b/third_party/git/t/helper/test-match-trees.c diff --git a/t/helper/test-mergesort.c b/third_party/git/t/helper/test-mergesort.c index c5cffaa4b7..c5cffaa4b7 100644 --- a/t/helper/test-mergesort.c +++ b/third_party/git/t/helper/test-mergesort.c diff --git a/t/helper/test-mktemp.c b/third_party/git/t/helper/test-mktemp.c index 2290688940..2290688940 100644 --- a/t/helper/test-mktemp.c +++ b/third_party/git/t/helper/test-mktemp.c diff --git a/t/helper/test-oidmap.c b/third_party/git/t/helper/test-oidmap.c index 0acf99931e..0acf99931e 100644 --- a/t/helper/test-oidmap.c +++ b/third_party/git/t/helper/test-oidmap.c diff --git a/t/helper/test-online-cpus.c b/third_party/git/t/helper/test-online-cpus.c index 8cb0d53840..8cb0d53840 100644 --- a/t/helper/test-online-cpus.c +++ b/third_party/git/t/helper/test-online-cpus.c diff --git a/t/helper/test-parse-options.c b/third_party/git/t/helper/test-parse-options.c index 2051ce57db..2051ce57db 100644 --- a/t/helper/test-parse-options.c +++ b/third_party/git/t/helper/test-parse-options.c diff --git a/t/helper/test-parse-pathspec-file.c b/third_party/git/t/helper/test-parse-pathspec-file.c index 02f4ccfd2a..02f4ccfd2a 100644 --- a/t/helper/test-parse-pathspec-file.c +++ b/third_party/git/t/helper/test-parse-pathspec-file.c diff --git a/t/helper/test-path-utils.c b/third_party/git/t/helper/test-path-utils.c index 409034cf4e..409034cf4e 100644 --- a/t/helper/test-path-utils.c +++ b/third_party/git/t/helper/test-path-utils.c diff --git a/t/helper/test-pkt-line.c b/third_party/git/t/helper/test-pkt-line.c index 282d536384..282d536384 100644 --- a/t/helper/test-pkt-line.c +++ b/third_party/git/t/helper/test-pkt-line.c diff --git a/t/helper/test-prio-queue.c b/third_party/git/t/helper/test-prio-queue.c index f4028442e3..f4028442e3 100644 --- a/t/helper/test-prio-queue.c +++ b/third_party/git/t/helper/test-prio-queue.c diff --git a/t/helper/test-progress.c b/third_party/git/t/helper/test-progress.c index 42b96cb103..42b96cb103 100644 --- a/t/helper/test-progress.c +++ b/third_party/git/t/helper/test-progress.c diff --git a/t/helper/test-reach.c b/third_party/git/t/helper/test-reach.c index a0272178b7..a0272178b7 100644 --- a/t/helper/test-reach.c +++ b/third_party/git/t/helper/test-reach.c diff --git a/t/helper/test-read-cache.c b/third_party/git/t/helper/test-read-cache.c index 244977a29b..244977a29b 100644 --- a/t/helper/test-read-cache.c +++ b/third_party/git/t/helper/test-read-cache.c diff --git a/t/helper/test-read-graph.c b/third_party/git/t/helper/test-read-graph.c index f8a461767c..f8a461767c 100644 --- a/t/helper/test-read-graph.c +++ b/third_party/git/t/helper/test-read-graph.c diff --git a/t/helper/test-read-midx.c b/third_party/git/t/helper/test-read-midx.c index 831b586d02..831b586d02 100644 --- a/t/helper/test-read-midx.c +++ b/third_party/git/t/helper/test-read-midx.c diff --git a/t/helper/test-ref-store.c b/third_party/git/t/helper/test-ref-store.c index 799fc00aa1..799fc00aa1 100644 --- a/t/helper/test-ref-store.c +++ b/third_party/git/t/helper/test-ref-store.c diff --git a/t/helper/test-regex.c b/third_party/git/t/helper/test-regex.c index 10284cc56f..10284cc56f 100644 --- a/t/helper/test-regex.c +++ b/third_party/git/t/helper/test-regex.c diff --git a/t/helper/test-repository.c b/third_party/git/t/helper/test-repository.c index f7f8618445..f7f8618445 100644 --- a/t/helper/test-repository.c +++ b/third_party/git/t/helper/test-repository.c diff --git a/t/helper/test-revision-walking.c b/third_party/git/t/helper/test-revision-walking.c index 625b2dbf82..625b2dbf82 100644 --- a/t/helper/test-revision-walking.c +++ b/third_party/git/t/helper/test-revision-walking.c diff --git a/t/helper/test-run-command.c b/third_party/git/t/helper/test-run-command.c index 1646aa25d8..1646aa25d8 100644 --- a/t/helper/test-run-command.c +++ b/third_party/git/t/helper/test-run-command.c diff --git a/t/helper/test-scrap-cache-tree.c b/third_party/git/t/helper/test-scrap-cache-tree.c index 393f1604ff..393f1604ff 100644 --- a/t/helper/test-scrap-cache-tree.c +++ b/third_party/git/t/helper/test-scrap-cache-tree.c diff --git a/t/helper/test-serve-v2.c b/third_party/git/t/helper/test-serve-v2.c index aee35e5aef..aee35e5aef 100644 --- a/t/helper/test-serve-v2.c +++ b/third_party/git/t/helper/test-serve-v2.c diff --git a/t/helper/test-sha1-array.c b/third_party/git/t/helper/test-sha1-array.c index ad5e69f9d3..ad5e69f9d3 100644 --- a/t/helper/test-sha1-array.c +++ b/third_party/git/t/helper/test-sha1-array.c diff --git a/t/helper/test-sha1.c b/third_party/git/t/helper/test-sha1.c index d860c387c3..d860c387c3 100644 --- a/t/helper/test-sha1.c +++ b/third_party/git/t/helper/test-sha1.c diff --git a/t/helper/test-sha1.sh b/third_party/git/t/helper/test-sha1.sh index 84594885c7..84594885c7 100755 --- a/t/helper/test-sha1.sh +++ b/third_party/git/t/helper/test-sha1.sh diff --git a/t/helper/test-sha256.c b/third_party/git/t/helper/test-sha256.c index 0ac6a99d5f..0ac6a99d5f 100644 --- a/t/helper/test-sha256.c +++ b/third_party/git/t/helper/test-sha256.c diff --git a/t/helper/test-sigchain.c b/third_party/git/t/helper/test-sigchain.c index d013bccdda..d013bccdda 100644 --- a/t/helper/test-sigchain.c +++ b/third_party/git/t/helper/test-sigchain.c diff --git a/t/helper/test-strcmp-offset.c b/third_party/git/t/helper/test-strcmp-offset.c index 44e4a6d143..44e4a6d143 100644 --- a/t/helper/test-strcmp-offset.c +++ b/third_party/git/t/helper/test-strcmp-offset.c diff --git a/t/helper/test-string-list.c b/third_party/git/t/helper/test-string-list.c index 2123dda85b..2123dda85b 100644 --- a/t/helper/test-string-list.c +++ b/third_party/git/t/helper/test-string-list.c diff --git a/t/helper/test-submodule-config.c b/third_party/git/t/helper/test-submodule-config.c index e2692746df..e2692746df 100644 --- a/t/helper/test-submodule-config.c +++ b/third_party/git/t/helper/test-submodule-config.c diff --git a/t/helper/test-submodule-nested-repo-config.c b/third_party/git/t/helper/test-submodule-nested-repo-config.c index bc97929bbc..bc97929bbc 100644 --- a/t/helper/test-submodule-nested-repo-config.c +++ b/third_party/git/t/helper/test-submodule-nested-repo-config.c diff --git a/t/helper/test-subprocess.c b/third_party/git/t/helper/test-subprocess.c index 92b69de635..92b69de635 100644 --- a/t/helper/test-subprocess.c +++ b/third_party/git/t/helper/test-subprocess.c diff --git a/t/helper/test-svn-fe.c b/third_party/git/t/helper/test-svn-fe.c index 7667c0803f..7667c0803f 100644 --- a/t/helper/test-svn-fe.c +++ b/third_party/git/t/helper/test-svn-fe.c diff --git a/t/helper/test-tool.c b/third_party/git/t/helper/test-tool.c index c9a232d238..c9a232d238 100644 --- a/t/helper/test-tool.c +++ b/third_party/git/t/helper/test-tool.c diff --git a/t/helper/test-tool.h b/third_party/git/t/helper/test-tool.h index c8549fd87f..c8549fd87f 100644 --- a/t/helper/test-tool.h +++ b/third_party/git/t/helper/test-tool.h diff --git a/t/helper/test-trace2.c b/third_party/git/t/helper/test-trace2.c index 197819c872..197819c872 100644 --- a/t/helper/test-trace2.c +++ b/third_party/git/t/helper/test-trace2.c diff --git a/t/helper/test-urlmatch-normalization.c b/third_party/git/t/helper/test-urlmatch-normalization.c index 8f4d67e646..8f4d67e646 100644 --- a/t/helper/test-urlmatch-normalization.c +++ b/third_party/git/t/helper/test-urlmatch-normalization.c diff --git a/t/helper/test-wildmatch.c b/third_party/git/t/helper/test-wildmatch.c index 2c103d1824..2c103d1824 100644 --- a/t/helper/test-wildmatch.c +++ b/third_party/git/t/helper/test-wildmatch.c diff --git a/t/helper/test-windows-named-pipe.c b/third_party/git/t/helper/test-windows-named-pipe.c index ae52183e63..ae52183e63 100644 --- a/t/helper/test-windows-named-pipe.c +++ b/third_party/git/t/helper/test-windows-named-pipe.c diff --git a/t/helper/test-write-cache.c b/third_party/git/t/helper/test-write-cache.c index 8837717d36..8837717d36 100644 --- a/t/helper/test-write-cache.c +++ b/third_party/git/t/helper/test-write-cache.c diff --git a/t/helper/test-xml-encode.c b/third_party/git/t/helper/test-xml-encode.c index a648bbd961..a648bbd961 100644 --- a/t/helper/test-xml-encode.c +++ b/third_party/git/t/helper/test-xml-encode.c diff --git a/t/interop/.gitignore b/third_party/git/t/interop/.gitignore index 49c78d3dba..49c78d3dba 100644 --- a/t/interop/.gitignore +++ b/third_party/git/t/interop/.gitignore diff --git a/t/interop/Makefile b/third_party/git/t/interop/Makefile index 31a4bbc716..31a4bbc716 100644 --- a/t/interop/Makefile +++ b/third_party/git/t/interop/Makefile diff --git a/t/interop/README b/third_party/git/t/interop/README index 72d42bd856..72d42bd856 100644 --- a/t/interop/README +++ b/third_party/git/t/interop/README diff --git a/t/interop/i0000-basic.sh b/third_party/git/t/interop/i0000-basic.sh index 903e9193f8..903e9193f8 100755 --- a/t/interop/i0000-basic.sh +++ b/third_party/git/t/interop/i0000-basic.sh diff --git a/t/interop/i5500-git-daemon.sh b/third_party/git/t/interop/i5500-git-daemon.sh index 4d22e42f84..4d22e42f84 100755 --- a/t/interop/i5500-git-daemon.sh +++ b/third_party/git/t/interop/i5500-git-daemon.sh diff --git a/t/interop/i5700-protocol-transition.sh b/third_party/git/t/interop/i5700-protocol-transition.sh index 97e8e580ef..97e8e580ef 100755 --- a/t/interop/i5700-protocol-transition.sh +++ b/third_party/git/t/interop/i5700-protocol-transition.sh diff --git a/t/interop/interop-lib.sh b/third_party/git/t/interop/interop-lib.sh index 3e0a2911d4..3e0a2911d4 100644 --- a/t/interop/interop-lib.sh +++ b/third_party/git/t/interop/interop-lib.sh diff --git a/t/lib-bash.sh b/third_party/git/t/lib-bash.sh index b0b6060929..b0b6060929 100644 --- a/t/lib-bash.sh +++ b/third_party/git/t/lib-bash.sh diff --git a/t/lib-credential.sh b/third_party/git/t/lib-credential.sh index bb88cc0108..bb88cc0108 100755 --- a/t/lib-credential.sh +++ b/third_party/git/t/lib-credential.sh diff --git a/t/lib-cvs.sh b/third_party/git/t/lib-cvs.sh index 9b2bcfb1b0..9b2bcfb1b0 100644 --- a/t/lib-cvs.sh +++ b/third_party/git/t/lib-cvs.sh diff --git a/t/lib-diff-alternative.sh b/third_party/git/t/lib-diff-alternative.sh index 8d1e408bb5..8d1e408bb5 100644 --- a/t/lib-diff-alternative.sh +++ b/third_party/git/t/lib-diff-alternative.sh diff --git a/t/lib-gettext.sh b/third_party/git/t/lib-gettext.sh index 2139b427ca..2139b427ca 100644 --- a/t/lib-gettext.sh +++ b/third_party/git/t/lib-gettext.sh diff --git a/t/lib-git-daemon.sh b/third_party/git/t/lib-git-daemon.sh index e62569222b..e62569222b 100644 --- a/t/lib-git-daemon.sh +++ b/third_party/git/t/lib-git-daemon.sh diff --git a/t/lib-git-p4.sh b/third_party/git/t/lib-git-p4.sh index 5aff2abe8b..5aff2abe8b 100644 --- a/t/lib-git-p4.sh +++ b/third_party/git/t/lib-git-p4.sh diff --git a/t/lib-git-svn.sh b/third_party/git/t/lib-git-svn.sh index 7d248e6588..7d248e6588 100644 --- a/t/lib-git-svn.sh +++ b/third_party/git/t/lib-git-svn.sh diff --git a/t/lib-gpg.sh b/third_party/git/t/lib-gpg.sh index 8d28652b72..8d28652b72 100755 --- a/t/lib-gpg.sh +++ b/third_party/git/t/lib-gpg.sh diff --git a/t/lib-gpg/gpgsm-gen-key.in b/third_party/git/t/lib-gpg/gpgsm-gen-key.in index a7fd87c069..a7fd87c069 100644 --- a/t/lib-gpg/gpgsm-gen-key.in +++ b/third_party/git/t/lib-gpg/gpgsm-gen-key.in diff --git a/t/lib-gpg/gpgsm_cert.p12 b/third_party/git/t/lib-gpg/gpgsm_cert.p12 index 94ffad0d31..94ffad0d31 100644 --- a/t/lib-gpg/gpgsm_cert.p12 +++ b/third_party/git/t/lib-gpg/gpgsm_cert.p12 Binary files differdiff --git a/t/lib-gpg/keyring.gpg b/third_party/git/t/lib-gpg/keyring.gpg index 918dfce332..918dfce332 100644 --- a/t/lib-gpg/keyring.gpg +++ b/third_party/git/t/lib-gpg/keyring.gpg diff --git a/t/lib-gpg/ownertrust b/third_party/git/t/lib-gpg/ownertrust index b3e3c4f1cd..b3e3c4f1cd 100644 --- a/t/lib-gpg/ownertrust +++ b/third_party/git/t/lib-gpg/ownertrust diff --git a/t/lib-httpd.sh b/third_party/git/t/lib-httpd.sh index 1449ee95e9..1449ee95e9 100644 --- a/t/lib-httpd.sh +++ b/third_party/git/t/lib-httpd.sh diff --git a/t/lib-httpd/apache.conf b/third_party/git/t/lib-httpd/apache.conf index 994e5290d6..994e5290d6 100644 --- a/t/lib-httpd/apache.conf +++ b/third_party/git/t/lib-httpd/apache.conf diff --git a/t/lib-httpd/apply-one-time-perl.sh b/third_party/git/t/lib-httpd/apply-one-time-perl.sh index 09a0abdff7..09a0abdff7 100644 --- a/t/lib-httpd/apply-one-time-perl.sh +++ b/third_party/git/t/lib-httpd/apply-one-time-perl.sh diff --git a/t/lib-httpd/broken-smart-http.sh b/third_party/git/t/lib-httpd/broken-smart-http.sh index 82cc610b0a..82cc610b0a 100644 --- a/t/lib-httpd/broken-smart-http.sh +++ b/third_party/git/t/lib-httpd/broken-smart-http.sh diff --git a/t/lib-httpd/error-smart-http.sh b/third_party/git/t/lib-httpd/error-smart-http.sh index e65d447fc4..e65d447fc4 100644 --- a/t/lib-httpd/error-smart-http.sh +++ b/third_party/git/t/lib-httpd/error-smart-http.sh diff --git a/t/lib-httpd/error.sh b/third_party/git/t/lib-httpd/error.sh index a77b8e5469..a77b8e5469 100755 --- a/t/lib-httpd/error.sh +++ b/third_party/git/t/lib-httpd/error.sh diff --git a/t/lib-httpd/passwd b/third_party/git/t/lib-httpd/passwd index 99a34d6487..99a34d6487 100644 --- a/t/lib-httpd/passwd +++ b/third_party/git/t/lib-httpd/passwd diff --git a/t/lib-httpd/ssl.cnf b/third_party/git/t/lib-httpd/ssl.cnf index 6dab2579cb..6dab2579cb 100644 --- a/t/lib-httpd/ssl.cnf +++ b/third_party/git/t/lib-httpd/ssl.cnf diff --git a/t/lib-log-graph.sh b/third_party/git/t/lib-log-graph.sh index 1184cceef2..1184cceef2 100755 --- a/t/lib-log-graph.sh +++ b/third_party/git/t/lib-log-graph.sh diff --git a/t/lib-pack.sh b/third_party/git/t/lib-pack.sh index f3463170b3..f3463170b3 100644 --- a/t/lib-pack.sh +++ b/third_party/git/t/lib-pack.sh diff --git a/t/lib-pager.sh b/third_party/git/t/lib-pager.sh index 3aa7a3ffd8..3aa7a3ffd8 100644 --- a/t/lib-pager.sh +++ b/third_party/git/t/lib-pager.sh diff --git a/t/lib-patch-mode.sh b/third_party/git/t/lib-patch-mode.sh index cfd76bf987..cfd76bf987 100644 --- a/t/lib-patch-mode.sh +++ b/third_party/git/t/lib-patch-mode.sh diff --git a/t/lib-proto-disable.sh b/third_party/git/t/lib-proto-disable.sh index 83babe57d9..83babe57d9 100644 --- a/t/lib-proto-disable.sh +++ b/third_party/git/t/lib-proto-disable.sh diff --git a/t/lib-read-tree-m-3way.sh b/third_party/git/t/lib-read-tree-m-3way.sh index 168329adbc..168329adbc 100644 --- a/t/lib-read-tree-m-3way.sh +++ b/third_party/git/t/lib-read-tree-m-3way.sh diff --git a/t/lib-read-tree.sh b/third_party/git/t/lib-read-tree.sh index b95f485606..b95f485606 100644 --- a/t/lib-read-tree.sh +++ b/third_party/git/t/lib-read-tree.sh diff --git a/t/lib-rebase.sh b/third_party/git/t/lib-rebase.sh index b72c051f47..b72c051f47 100644 --- a/t/lib-rebase.sh +++ b/third_party/git/t/lib-rebase.sh diff --git a/t/lib-submodule-update.sh b/third_party/git/t/lib-submodule-update.sh index 1dd17fc03e..1dd17fc03e 100755 --- a/t/lib-submodule-update.sh +++ b/third_party/git/t/lib-submodule-update.sh diff --git a/t/lib-t6000.sh b/third_party/git/t/lib-t6000.sh index b0ed4767e3..b0ed4767e3 100644 --- a/t/lib-t6000.sh +++ b/third_party/git/t/lib-t6000.sh diff --git a/t/lib-terminal.sh b/third_party/git/t/lib-terminal.sh index e3809dcead..e3809dcead 100644 --- a/t/lib-terminal.sh +++ b/third_party/git/t/lib-terminal.sh diff --git a/t/oid-info/README b/third_party/git/t/oid-info/README index 27f843fc00..27f843fc00 100644 --- a/t/oid-info/README +++ b/third_party/git/t/oid-info/README diff --git a/t/oid-info/hash-info b/third_party/git/t/oid-info/hash-info index d0736dd1a0..d0736dd1a0 100644 --- a/t/oid-info/hash-info +++ b/third_party/git/t/oid-info/hash-info diff --git a/t/oid-info/oid b/third_party/git/t/oid-info/oid index a754970523..a754970523 100644 --- a/t/oid-info/oid +++ b/third_party/git/t/oid-info/oid diff --git a/t/perf/.gitignore b/third_party/git/t/perf/.gitignore index 982eb8e3a9..982eb8e3a9 100644 --- a/t/perf/.gitignore +++ b/third_party/git/t/perf/.gitignore diff --git a/t/perf/Makefile b/third_party/git/t/perf/Makefile index 8c47155a7c..8c47155a7c 100644 --- a/t/perf/Makefile +++ b/third_party/git/t/perf/Makefile diff --git a/t/perf/README b/third_party/git/t/perf/README index c7b70e2d28..c7b70e2d28 100644 --- a/t/perf/README +++ b/third_party/git/t/perf/README diff --git a/t/perf/aggregate.perl b/third_party/git/t/perf/aggregate.perl index 14e4cda287..14e4cda287 100755 --- a/t/perf/aggregate.perl +++ b/third_party/git/t/perf/aggregate.perl diff --git a/t/perf/bisect_regression b/third_party/git/t/perf/bisect_regression index ce47e1662a..ce47e1662a 100755 --- a/t/perf/bisect_regression +++ b/third_party/git/t/perf/bisect_regression diff --git a/t/perf/bisect_run_script b/third_party/git/t/perf/bisect_run_script index 3ebaf15521..3ebaf15521 100755 --- a/t/perf/bisect_run_script +++ b/third_party/git/t/perf/bisect_run_script diff --git a/t/perf/lib-pack.sh b/third_party/git/t/perf/lib-pack.sh index d3865db286..d3865db286 100644 --- a/t/perf/lib-pack.sh +++ b/third_party/git/t/perf/lib-pack.sh diff --git a/t/perf/min_time.perl b/third_party/git/t/perf/min_time.perl index c1a2717e07..c1a2717e07 100755 --- a/t/perf/min_time.perl +++ b/third_party/git/t/perf/min_time.perl diff --git a/t/perf/p0000-perf-lib-sanity.sh b/third_party/git/t/perf/p0000-perf-lib-sanity.sh index 002c21e52a..002c21e52a 100755 --- a/t/perf/p0000-perf-lib-sanity.sh +++ b/third_party/git/t/perf/p0000-perf-lib-sanity.sh diff --git a/t/perf/p0001-rev-list.sh b/third_party/git/t/perf/p0001-rev-list.sh index 3042a85666..3042a85666 100755 --- a/t/perf/p0001-rev-list.sh +++ b/third_party/git/t/perf/p0001-rev-list.sh diff --git a/t/perf/p0002-read-cache.sh b/third_party/git/t/perf/p0002-read-cache.sh index cdd105a594..cdd105a594 100755 --- a/t/perf/p0002-read-cache.sh +++ b/third_party/git/t/perf/p0002-read-cache.sh diff --git a/t/perf/p0003-delta-base-cache.sh b/third_party/git/t/perf/p0003-delta-base-cache.sh index 62369eaaf0..62369eaaf0 100755 --- a/t/perf/p0003-delta-base-cache.sh +++ b/third_party/git/t/perf/p0003-delta-base-cache.sh diff --git a/t/perf/p0004-lazy-init-name-hash.sh b/third_party/git/t/perf/p0004-lazy-init-name-hash.sh index 1afc08fe7f..1afc08fe7f 100755 --- a/t/perf/p0004-lazy-init-name-hash.sh +++ b/third_party/git/t/perf/p0004-lazy-init-name-hash.sh diff --git a/t/perf/p0005-status.sh b/third_party/git/t/perf/p0005-status.sh index 0b0aa9858f..0b0aa9858f 100755 --- a/t/perf/p0005-status.sh +++ b/third_party/git/t/perf/p0005-status.sh diff --git a/t/perf/p0006-read-tree-checkout.sh b/third_party/git/t/perf/p0006-read-tree-checkout.sh index 78cc23fe2f..78cc23fe2f 100755 --- a/t/perf/p0006-read-tree-checkout.sh +++ b/third_party/git/t/perf/p0006-read-tree-checkout.sh diff --git a/t/perf/p0007-write-cache.sh b/third_party/git/t/perf/p0007-write-cache.sh index 09595264f0..09595264f0 100755 --- a/t/perf/p0007-write-cache.sh +++ b/third_party/git/t/perf/p0007-write-cache.sh diff --git a/t/perf/p0071-sort.sh b/third_party/git/t/perf/p0071-sort.sh index 6e924f5fa3..6e924f5fa3 100755 --- a/t/perf/p0071-sort.sh +++ b/third_party/git/t/perf/p0071-sort.sh diff --git a/t/perf/p0100-globbing.sh b/third_party/git/t/perf/p0100-globbing.sh index dd18a9ce2b..dd18a9ce2b 100755 --- a/t/perf/p0100-globbing.sh +++ b/third_party/git/t/perf/p0100-globbing.sh diff --git a/t/perf/p1450-fsck.sh b/third_party/git/t/perf/p1450-fsck.sh index ae1b84198b..ae1b84198b 100755 --- a/t/perf/p1450-fsck.sh +++ b/third_party/git/t/perf/p1450-fsck.sh diff --git a/t/perf/p1451-fsck-skip-list.sh b/third_party/git/t/perf/p1451-fsck-skip-list.sh index c2b97d2487..c2b97d2487 100755 --- a/t/perf/p1451-fsck-skip-list.sh +++ b/third_party/git/t/perf/p1451-fsck-skip-list.sh diff --git a/t/perf/p3400-rebase.sh b/third_party/git/t/perf/p3400-rebase.sh index d202aaed06..d202aaed06 100755 --- a/t/perf/p3400-rebase.sh +++ b/third_party/git/t/perf/p3400-rebase.sh diff --git a/t/perf/p3404-rebase-interactive.sh b/third_party/git/t/perf/p3404-rebase-interactive.sh index 88f47de282..88f47de282 100755 --- a/t/perf/p3404-rebase-interactive.sh +++ b/third_party/git/t/perf/p3404-rebase-interactive.sh diff --git a/t/perf/p4000-diff-algorithms.sh b/third_party/git/t/perf/p4000-diff-algorithms.sh index 7e00c9da47..7e00c9da47 100755 --- a/t/perf/p4000-diff-algorithms.sh +++ b/third_party/git/t/perf/p4000-diff-algorithms.sh diff --git a/t/perf/p4001-diff-no-index.sh b/third_party/git/t/perf/p4001-diff-no-index.sh index 683be6984f..683be6984f 100755 --- a/t/perf/p4001-diff-no-index.sh +++ b/third_party/git/t/perf/p4001-diff-no-index.sh diff --git a/t/perf/p4205-log-pretty-formats.sh b/third_party/git/t/perf/p4205-log-pretty-formats.sh index 7c26f4f337..7c26f4f337 100755 --- a/t/perf/p4205-log-pretty-formats.sh +++ b/third_party/git/t/perf/p4205-log-pretty-formats.sh diff --git a/t/perf/p4211-line-log.sh b/third_party/git/t/perf/p4211-line-log.sh index 392bcc0e51..392bcc0e51 100755 --- a/t/perf/p4211-line-log.sh +++ b/third_party/git/t/perf/p4211-line-log.sh diff --git a/t/perf/p4220-log-grep-engines.sh b/third_party/git/t/perf/p4220-log-grep-engines.sh index 2bc47ded4d..2bc47ded4d 100755 --- a/t/perf/p4220-log-grep-engines.sh +++ b/third_party/git/t/perf/p4220-log-grep-engines.sh diff --git a/t/perf/p4221-log-grep-engines-fixed.sh b/third_party/git/t/perf/p4221-log-grep-engines-fixed.sh index 060971265a..060971265a 100755 --- a/t/perf/p4221-log-grep-engines-fixed.sh +++ b/third_party/git/t/perf/p4221-log-grep-engines-fixed.sh diff --git a/t/perf/p5302-pack-index.sh b/third_party/git/t/perf/p5302-pack-index.sh index a9b3e112d9..a9b3e112d9 100755 --- a/t/perf/p5302-pack-index.sh +++ b/third_party/git/t/perf/p5302-pack-index.sh diff --git a/t/perf/p5303-many-packs.sh b/third_party/git/t/perf/p5303-many-packs.sh index 7ee791669a..7ee791669a 100755 --- a/t/perf/p5303-many-packs.sh +++ b/third_party/git/t/perf/p5303-many-packs.sh diff --git a/t/perf/p5304-prune.sh b/third_party/git/t/perf/p5304-prune.sh index 83baedb8a4..83baedb8a4 100755 --- a/t/perf/p5304-prune.sh +++ b/third_party/git/t/perf/p5304-prune.sh diff --git a/t/perf/p5310-pack-bitmaps.sh b/third_party/git/t/perf/p5310-pack-bitmaps.sh index 7743f4f4c9..7743f4f4c9 100755 --- a/t/perf/p5310-pack-bitmaps.sh +++ b/third_party/git/t/perf/p5310-pack-bitmaps.sh diff --git a/t/perf/p5311-pack-bitmaps-fetch.sh b/third_party/git/t/perf/p5311-pack-bitmaps-fetch.sh index 47c3fd7581..47c3fd7581 100755 --- a/t/perf/p5311-pack-bitmaps-fetch.sh +++ b/third_party/git/t/perf/p5311-pack-bitmaps-fetch.sh diff --git a/t/perf/p5550-fetch-tags.sh b/third_party/git/t/perf/p5550-fetch-tags.sh index d0e0e019ea..d0e0e019ea 100755 --- a/t/perf/p5550-fetch-tags.sh +++ b/third_party/git/t/perf/p5550-fetch-tags.sh diff --git a/t/perf/p5551-fetch-rescan.sh b/third_party/git/t/perf/p5551-fetch-rescan.sh index b99dc23e32..b99dc23e32 100755 --- a/t/perf/p5551-fetch-rescan.sh +++ b/third_party/git/t/perf/p5551-fetch-rescan.sh diff --git a/t/perf/p5600-partial-clone.sh b/third_party/git/t/perf/p5600-partial-clone.sh index 3e04bd2ae1..3e04bd2ae1 100755 --- a/t/perf/p5600-partial-clone.sh +++ b/third_party/git/t/perf/p5600-partial-clone.sh diff --git a/t/perf/p5601-clone-reference.sh b/third_party/git/t/perf/p5601-clone-reference.sh index 68fed66347..68fed66347 100755 --- a/t/perf/p5601-clone-reference.sh +++ b/third_party/git/t/perf/p5601-clone-reference.sh diff --git a/t/perf/p7000-filter-branch.sh b/third_party/git/t/perf/p7000-filter-branch.sh index b029586ccb..b029586ccb 100755 --- a/t/perf/p7000-filter-branch.sh +++ b/third_party/git/t/perf/p7000-filter-branch.sh diff --git a/t/perf/p7300-clean.sh b/third_party/git/t/perf/p7300-clean.sh index 7c1888a27e..7c1888a27e 100755 --- a/t/perf/p7300-clean.sh +++ b/third_party/git/t/perf/p7300-clean.sh diff --git a/t/perf/p7519-fsmonitor.sh b/third_party/git/t/perf/p7519-fsmonitor.sh index def7ecdbc7..def7ecdbc7 100755 --- a/t/perf/p7519-fsmonitor.sh +++ b/third_party/git/t/perf/p7519-fsmonitor.sh diff --git a/t/perf/p7810-grep.sh b/third_party/git/t/perf/p7810-grep.sh index 9f4ade639f..9f4ade639f 100755 --- a/t/perf/p7810-grep.sh +++ b/third_party/git/t/perf/p7810-grep.sh diff --git a/t/perf/p7820-grep-engines.sh b/third_party/git/t/perf/p7820-grep-engines.sh index 8b09c5bf32..8b09c5bf32 100755 --- a/t/perf/p7820-grep-engines.sh +++ b/third_party/git/t/perf/p7820-grep-engines.sh diff --git a/t/perf/p7821-grep-engines-fixed.sh b/third_party/git/t/perf/p7821-grep-engines-fixed.sh index 61e41b82cf..61e41b82cf 100755 --- a/t/perf/p7821-grep-engines-fixed.sh +++ b/third_party/git/t/perf/p7821-grep-engines-fixed.sh diff --git a/t/perf/perf-lib.sh b/third_party/git/t/perf/perf-lib.sh index 13e389367a..13e389367a 100644 --- a/t/perf/perf-lib.sh +++ b/third_party/git/t/perf/perf-lib.sh diff --git a/t/perf/repos/.gitignore b/third_party/git/t/perf/repos/.gitignore index 72e3dc3e19..72e3dc3e19 100644 --- a/t/perf/repos/.gitignore +++ b/third_party/git/t/perf/repos/.gitignore diff --git a/t/perf/repos/inflate-repo.sh b/third_party/git/t/perf/repos/inflate-repo.sh index fcfc992b5b..fcfc992b5b 100755 --- a/t/perf/repos/inflate-repo.sh +++ b/third_party/git/t/perf/repos/inflate-repo.sh diff --git a/t/perf/repos/many-files.sh b/third_party/git/t/perf/repos/many-files.sh index 28720e4e10..28720e4e10 100755 --- a/t/perf/repos/many-files.sh +++ b/third_party/git/t/perf/repos/many-files.sh diff --git a/t/perf/run b/third_party/git/t/perf/run index c7b86104e1..c7b86104e1 100755 --- a/t/perf/run +++ b/third_party/git/t/perf/run diff --git a/t/t0000-basic.sh b/third_party/git/t/t0000-basic.sh index 3e440c078d..3e440c078d 100755 --- a/t/t0000-basic.sh +++ b/third_party/git/t/t0000-basic.sh diff --git a/t/t0001-init.sh b/third_party/git/t/t0001-init.sh index 26f8206326..26f8206326 100755 --- a/t/t0001-init.sh +++ b/third_party/git/t/t0001-init.sh diff --git a/t/t0002-gitfile.sh b/third_party/git/t/t0002-gitfile.sh index 0aa9908ea1..0aa9908ea1 100755 --- a/t/t0002-gitfile.sh +++ b/third_party/git/t/t0002-gitfile.sh diff --git a/t/t0003-attributes.sh b/third_party/git/t/t0003-attributes.sh index b660593c20..b660593c20 100755 --- a/t/t0003-attributes.sh +++ b/third_party/git/t/t0003-attributes.sh diff --git a/t/t0004-unwritable.sh b/third_party/git/t/t0004-unwritable.sh index e3137d638e..e3137d638e 100755 --- a/t/t0004-unwritable.sh +++ b/third_party/git/t/t0004-unwritable.sh diff --git a/t/t0005-signals.sh b/third_party/git/t/t0005-signals.sh index 4c214bd11c..4c214bd11c 100755 --- a/t/t0005-signals.sh +++ b/third_party/git/t/t0005-signals.sh diff --git a/t/t0006-date.sh b/third_party/git/t/t0006-date.sh index d9fcc829a9..b723db1f76 100755 --- a/t/t0006-date.sh +++ b/third_party/git/t/t0006-date.sh @@ -49,9 +49,11 @@ check_show short "$TIME" '2016-06-15' check_show default "$TIME" 'Wed Jun 15 16:13:20 2016 +0200' check_show raw "$TIME" '1466000000 +0200' check_show unix "$TIME" '1466000000' +check_show dottime "$TIME" '2016-06-15T14·13+0200' check_show iso-local "$TIME" '2016-06-15 14:13:20 +0000' check_show raw-local "$TIME" '1466000000 +0000' check_show unix-local "$TIME" '1466000000' +check_show dottime-local "$TIME" '2016-06-15T14·13+0000' check_show 'format:%z' "$TIME" '+0200' check_show 'format-local:%z' "$TIME" '+0000' diff --git a/t/t0007-git-var.sh b/third_party/git/t/t0007-git-var.sh index 1f600e2cae..1f600e2cae 100755 --- a/t/t0007-git-var.sh +++ b/third_party/git/t/t0007-git-var.sh diff --git a/t/t0008-ignores.sh b/third_party/git/t/t0008-ignores.sh index 370a389e5c..370a389e5c 100755 --- a/t/t0008-ignores.sh +++ b/third_party/git/t/t0008-ignores.sh diff --git a/t/t0009-prio-queue.sh b/third_party/git/t/t0009-prio-queue.sh index 3941ad2528..3941ad2528 100755 --- a/t/t0009-prio-queue.sh +++ b/third_party/git/t/t0009-prio-queue.sh diff --git a/t/t0010-racy-git.sh b/third_party/git/t/t0010-racy-git.sh index 5657c5a87b..5657c5a87b 100755 --- a/t/t0010-racy-git.sh +++ b/third_party/git/t/t0010-racy-git.sh diff --git a/t/t0011-hashmap.sh b/third_party/git/t/t0011-hashmap.sh index 5343ffd3f9..5343ffd3f9 100755 --- a/t/t0011-hashmap.sh +++ b/third_party/git/t/t0011-hashmap.sh diff --git a/t/t0012-help.sh b/third_party/git/t/t0012-help.sh index e8ef7300ec..e8ef7300ec 100755 --- a/t/t0012-help.sh +++ b/third_party/git/t/t0012-help.sh diff --git a/t/t0013-sha1dc.sh b/third_party/git/t/t0013-sha1dc.sh index 419f31a8f7..419f31a8f7 100755 --- a/t/t0013-sha1dc.sh +++ b/third_party/git/t/t0013-sha1dc.sh diff --git a/t/t0013/shattered-1.pdf b/third_party/git/t/t0013/shattered-1.pdf index ba9aaa145c..ba9aaa145c 100644 --- a/t/t0013/shattered-1.pdf +++ b/third_party/git/t/t0013/shattered-1.pdf Binary files differdiff --git a/t/t0014-alias.sh b/third_party/git/t/t0014-alias.sh index 8d3d9144c0..8d3d9144c0 100755 --- a/t/t0014-alias.sh +++ b/third_party/git/t/t0014-alias.sh diff --git a/t/t0015-hash.sh b/third_party/git/t/t0015-hash.sh index 291e9061f3..291e9061f3 100755 --- a/t/t0015-hash.sh +++ b/third_party/git/t/t0015-hash.sh diff --git a/t/t0016-oidmap.sh b/third_party/git/t/t0016-oidmap.sh index 31f8276ba8..31f8276ba8 100755 --- a/t/t0016-oidmap.sh +++ b/third_party/git/t/t0016-oidmap.sh diff --git a/t/t0017-env-helper.sh b/third_party/git/t/t0017-env-helper.sh index c1ecf6aeac..c1ecf6aeac 100755 --- a/t/t0017-env-helper.sh +++ b/third_party/git/t/t0017-env-helper.sh diff --git a/t/t0019-json-writer.sh b/third_party/git/t/t0019-json-writer.sh index 3b0c336b38..3b0c336b38 100755 --- a/t/t0019-json-writer.sh +++ b/third_party/git/t/t0019-json-writer.sh diff --git a/t/t0019/parse_json.perl b/third_party/git/t/t0019/parse_json.perl index fea87fb81b..fea87fb81b 100644 --- a/t/t0019/parse_json.perl +++ b/third_party/git/t/t0019/parse_json.perl diff --git a/t/t0020-crlf.sh b/third_party/git/t/t0020-crlf.sh index b63ba62e5d..b63ba62e5d 100755 --- a/t/t0020-crlf.sh +++ b/third_party/git/t/t0020-crlf.sh diff --git a/t/t0021-conversion.sh b/third_party/git/t/t0021-conversion.sh index dc664da551..dc664da551 100755 --- a/t/t0021-conversion.sh +++ b/third_party/git/t/t0021-conversion.sh diff --git a/t/t0021/rot13-filter.pl b/third_party/git/t/t0021/rot13-filter.pl index 470107248e..470107248e 100644 --- a/t/t0021/rot13-filter.pl +++ b/third_party/git/t/t0021/rot13-filter.pl diff --git a/t/t0022-crlf-rename.sh b/third_party/git/t/t0022-crlf-rename.sh index 7af3fbcc7b..7af3fbcc7b 100755 --- a/t/t0022-crlf-rename.sh +++ b/third_party/git/t/t0022-crlf-rename.sh diff --git a/t/t0023-crlf-am.sh b/third_party/git/t/t0023-crlf-am.sh index f9bbb91f64..f9bbb91f64 100755 --- a/t/t0023-crlf-am.sh +++ b/third_party/git/t/t0023-crlf-am.sh diff --git a/t/t0024-crlf-archive.sh b/third_party/git/t/t0024-crlf-archive.sh index 4e9fa3cd68..4e9fa3cd68 100755 --- a/t/t0024-crlf-archive.sh +++ b/third_party/git/t/t0024-crlf-archive.sh diff --git a/t/t0025-crlf-renormalize.sh b/third_party/git/t/t0025-crlf-renormalize.sh index e13363ade5..e13363ade5 100755 --- a/t/t0025-crlf-renormalize.sh +++ b/third_party/git/t/t0025-crlf-renormalize.sh diff --git a/t/t0026-eol-config.sh b/third_party/git/t/t0026-eol-config.sh index c5203e232c..c5203e232c 100755 --- a/t/t0026-eol-config.sh +++ b/third_party/git/t/t0026-eol-config.sh diff --git a/t/t0027-auto-crlf.sh b/third_party/git/t/t0027-auto-crlf.sh index 9fcd56fab3..9fcd56fab3 100755 --- a/t/t0027-auto-crlf.sh +++ b/third_party/git/t/t0027-auto-crlf.sh diff --git a/t/t0028-working-tree-encoding.sh b/third_party/git/t/t0028-working-tree-encoding.sh index bfc4fb9af5..bfc4fb9af5 100755 --- a/t/t0028-working-tree-encoding.sh +++ b/third_party/git/t/t0028-working-tree-encoding.sh diff --git a/t/t0029-core-unsetenvvars.sh b/third_party/git/t/t0029-core-unsetenvvars.sh index 24ce46a6ea..24ce46a6ea 100755 --- a/t/t0029-core-unsetenvvars.sh +++ b/third_party/git/t/t0029-core-unsetenvvars.sh diff --git a/t/t0030-stripspace.sh b/third_party/git/t/t0030-stripspace.sh index 0c24a0f9a3..0c24a0f9a3 100755 --- a/t/t0030-stripspace.sh +++ b/third_party/git/t/t0030-stripspace.sh diff --git a/t/t0040-parse-options.sh b/third_party/git/t/t0040-parse-options.sh index 3483b72db4..3483b72db4 100755 --- a/t/t0040-parse-options.sh +++ b/third_party/git/t/t0040-parse-options.sh diff --git a/t/t0041-usage.sh b/third_party/git/t/t0041-usage.sh index 5b927b76fe..5b927b76fe 100755 --- a/t/t0041-usage.sh +++ b/third_party/git/t/t0041-usage.sh diff --git a/t/t0050-filesystem.sh b/third_party/git/t/t0050-filesystem.sh index 608673fb77..608673fb77 100755 --- a/t/t0050-filesystem.sh +++ b/third_party/git/t/t0050-filesystem.sh diff --git a/t/t0051-windows-named-pipe.sh b/third_party/git/t/t0051-windows-named-pipe.sh index 10ac92d225..10ac92d225 100755 --- a/t/t0051-windows-named-pipe.sh +++ b/third_party/git/t/t0051-windows-named-pipe.sh diff --git a/t/t0055-beyond-symlinks.sh b/third_party/git/t/t0055-beyond-symlinks.sh index 0c6ff567a1..0c6ff567a1 100755 --- a/t/t0055-beyond-symlinks.sh +++ b/third_party/git/t/t0055-beyond-symlinks.sh diff --git a/t/t0056-git-C.sh b/third_party/git/t/t0056-git-C.sh index 2630e756da..2630e756da 100755 --- a/t/t0056-git-C.sh +++ b/third_party/git/t/t0056-git-C.sh diff --git a/t/t0060-path-utils.sh b/third_party/git/t/t0060-path-utils.sh index 2ea2d00c39..2ea2d00c39 100755 --- a/t/t0060-path-utils.sh +++ b/third_party/git/t/t0060-path-utils.sh diff --git a/t/t0061-run-command.sh b/third_party/git/t/t0061-run-command.sh index 7d599675e3..7d599675e3 100755 --- a/t/t0061-run-command.sh +++ b/third_party/git/t/t0061-run-command.sh diff --git a/t/t0062-revision-walking.sh b/third_party/git/t/t0062-revision-walking.sh index 8e215867b8..8e215867b8 100755 --- a/t/t0062-revision-walking.sh +++ b/third_party/git/t/t0062-revision-walking.sh diff --git a/t/t0063-string-list.sh b/third_party/git/t/t0063-string-list.sh index c6ee9f66b1..c6ee9f66b1 100755 --- a/t/t0063-string-list.sh +++ b/third_party/git/t/t0063-string-list.sh diff --git a/t/t0064-sha1-array.sh b/third_party/git/t/t0064-sha1-array.sh index 5dda570b9a..5dda570b9a 100755 --- a/t/t0064-sha1-array.sh +++ b/third_party/git/t/t0064-sha1-array.sh diff --git a/t/t0065-strcmp-offset.sh b/third_party/git/t/t0065-strcmp-offset.sh index 91fa639c4a..91fa639c4a 100755 --- a/t/t0065-strcmp-offset.sh +++ b/third_party/git/t/t0065-strcmp-offset.sh diff --git a/t/t0066-dir-iterator.sh b/third_party/git/t/t0066-dir-iterator.sh index 92910e4e6c..92910e4e6c 100755 --- a/t/t0066-dir-iterator.sh +++ b/third_party/git/t/t0066-dir-iterator.sh diff --git a/t/t0067-parse_pathspec_file.sh b/third_party/git/t/t0067-parse_pathspec_file.sh index 7bab49f361..7bab49f361 100755 --- a/t/t0067-parse_pathspec_file.sh +++ b/third_party/git/t/t0067-parse_pathspec_file.sh diff --git a/t/t0070-fundamental.sh b/third_party/git/t/t0070-fundamental.sh index 7b111a56fd..7b111a56fd 100755 --- a/t/t0070-fundamental.sh +++ b/third_party/git/t/t0070-fundamental.sh diff --git a/t/t0081-line-buffer.sh b/third_party/git/t/t0081-line-buffer.sh index ce92e6acad..ce92e6acad 100755 --- a/t/t0081-line-buffer.sh +++ b/third_party/git/t/t0081-line-buffer.sh diff --git a/t/t0090-cache-tree.sh b/third_party/git/t/t0090-cache-tree.sh index 5a633690bf..5a633690bf 100755 --- a/t/t0090-cache-tree.sh +++ b/third_party/git/t/t0090-cache-tree.sh diff --git a/t/t0100-previous.sh b/third_party/git/t/t0100-previous.sh index 58c0b7e9b6..58c0b7e9b6 100755 --- a/t/t0100-previous.sh +++ b/third_party/git/t/t0100-previous.sh diff --git a/t/t0101-at-syntax.sh b/third_party/git/t/t0101-at-syntax.sh index a1998b558f..a1998b558f 100755 --- a/t/t0101-at-syntax.sh +++ b/third_party/git/t/t0101-at-syntax.sh diff --git a/t/t0110-urlmatch-normalization.sh b/third_party/git/t/t0110-urlmatch-normalization.sh index f99529d838..f99529d838 100755 --- a/t/t0110-urlmatch-normalization.sh +++ b/third_party/git/t/t0110-urlmatch-normalization.sh diff --git a/t/t0110/README b/third_party/git/t/t0110/README index ad4a50ecd8..ad4a50ecd8 100644 --- a/t/t0110/README +++ b/third_party/git/t/t0110/README diff --git a/t/t0110/url-1 b/third_party/git/t/t0110/url-1 index 519019c5ce..519019c5ce 100644 --- a/t/t0110/url-1 +++ b/third_party/git/t/t0110/url-1 diff --git a/t/t0110/url-10 b/third_party/git/t/t0110/url-10 index b9965de6a5..b9965de6a5 100644 --- a/t/t0110/url-10 +++ b/third_party/git/t/t0110/url-10 diff --git a/t/t0110/url-11 b/third_party/git/t/t0110/url-11 index f0a50f1009..f0a50f1009 100644 --- a/t/t0110/url-11 +++ b/third_party/git/t/t0110/url-11 diff --git a/t/t0110/url-2 b/third_party/git/t/t0110/url-2 index 43334b05b2..43334b05b2 100644 --- a/t/t0110/url-2 +++ b/third_party/git/t/t0110/url-2 diff --git a/t/t0110/url-3 b/third_party/git/t/t0110/url-3 index 7378c7bec2..7378c7bec2 100644 --- a/t/t0110/url-3 +++ b/third_party/git/t/t0110/url-3 diff --git a/t/t0110/url-4 b/third_party/git/t/t0110/url-4 index 220b198c97..220b198c97 100644 --- a/t/t0110/url-4 +++ b/third_party/git/t/t0110/url-4 diff --git a/t/t0110/url-5 b/third_party/git/t/t0110/url-5 index 1ccd927779..1ccd927779 100644 --- a/t/t0110/url-5 +++ b/third_party/git/t/t0110/url-5 diff --git a/t/t0110/url-6 b/third_party/git/t/t0110/url-6 index e8283aac6d..e8283aac6d 100644 --- a/t/t0110/url-6 +++ b/third_party/git/t/t0110/url-6 diff --git a/t/t0110/url-7 b/third_party/git/t/t0110/url-7 index fa7c10b615..fa7c10b615 100644 --- a/t/t0110/url-7 +++ b/third_party/git/t/t0110/url-7 diff --git a/t/t0110/url-8 b/third_party/git/t/t0110/url-8 index 79a0ba836f..79a0ba836f 100644 --- a/t/t0110/url-8 +++ b/third_party/git/t/t0110/url-8 diff --git a/t/t0110/url-9 b/third_party/git/t/t0110/url-9 index 8b44bec48b..8b44bec48b 100644 --- a/t/t0110/url-9 +++ b/third_party/git/t/t0110/url-9 diff --git a/t/t0200-gettext-basic.sh b/third_party/git/t/t0200-gettext-basic.sh index 8853d8afb9..8853d8afb9 100755 --- a/t/t0200-gettext-basic.sh +++ b/third_party/git/t/t0200-gettext-basic.sh diff --git a/t/t0200/test.c b/third_party/git/t/t0200/test.c index 584d45cf36..584d45cf36 100644 --- a/t/t0200/test.c +++ b/third_party/git/t/t0200/test.c diff --git a/t/t0200/test.perl b/third_party/git/t/t0200/test.perl index 36fba341ba..36fba341ba 100644 --- a/t/t0200/test.perl +++ b/third_party/git/t/t0200/test.perl diff --git a/t/t0200/test.sh b/third_party/git/t/t0200/test.sh index 022d607f4c..022d607f4c 100644 --- a/t/t0200/test.sh +++ b/third_party/git/t/t0200/test.sh diff --git a/t/t0201-gettext-fallbacks.sh b/third_party/git/t/t0201-gettext-fallbacks.sh index 90da1c7ddc..90da1c7ddc 100755 --- a/t/t0201-gettext-fallbacks.sh +++ b/third_party/git/t/t0201-gettext-fallbacks.sh diff --git a/t/t0202-gettext-perl.sh b/third_party/git/t/t0202-gettext-perl.sh index a29d166e00..a29d166e00 100755 --- a/t/t0202-gettext-perl.sh +++ b/third_party/git/t/t0202-gettext-perl.sh diff --git a/t/t0202/test.pl b/third_party/git/t/t0202/test.pl index 2cbf7b9590..2cbf7b9590 100755 --- a/t/t0202/test.pl +++ b/third_party/git/t/t0202/test.pl diff --git a/t/t0203-gettext-setlocale-sanity.sh b/third_party/git/t/t0203-gettext-setlocale-sanity.sh index 0ce1f22eff..0ce1f22eff 100755 --- a/t/t0203-gettext-setlocale-sanity.sh +++ b/third_party/git/t/t0203-gettext-setlocale-sanity.sh diff --git a/t/t0204-gettext-reencode-sanity.sh b/third_party/git/t/t0204-gettext-reencode-sanity.sh index 8437e51eb5..8437e51eb5 100755 --- a/t/t0204-gettext-reencode-sanity.sh +++ b/third_party/git/t/t0204-gettext-reencode-sanity.sh diff --git a/t/t0205-gettext-poison.sh b/third_party/git/t/t0205-gettext-poison.sh index f9fa16ad83..f9fa16ad83 100755 --- a/t/t0205-gettext-poison.sh +++ b/third_party/git/t/t0205-gettext-poison.sh diff --git a/t/t0210-trace2-normal.sh b/third_party/git/t/t0210-trace2-normal.sh index ce7574edb1..ce7574edb1 100755 --- a/t/t0210-trace2-normal.sh +++ b/third_party/git/t/t0210-trace2-normal.sh diff --git a/t/t0210/scrub_normal.perl b/third_party/git/t/t0210/scrub_normal.perl index c65d1a815e..c65d1a815e 100644 --- a/t/t0210/scrub_normal.perl +++ b/third_party/git/t/t0210/scrub_normal.perl diff --git a/t/t0211-trace2-perf.sh b/third_party/git/t/t0211-trace2-perf.sh index 6ee8ee3b67..6ee8ee3b67 100755 --- a/t/t0211-trace2-perf.sh +++ b/third_party/git/t/t0211-trace2-perf.sh diff --git a/t/t0211/scrub_perf.perl b/third_party/git/t/t0211/scrub_perf.perl index 351af7844e..351af7844e 100644 --- a/t/t0211/scrub_perf.perl +++ b/third_party/git/t/t0211/scrub_perf.perl diff --git a/t/t0212-trace2-event.sh b/third_party/git/t/t0212-trace2-event.sh index 7065a1b937..7065a1b937 100755 --- a/t/t0212-trace2-event.sh +++ b/third_party/git/t/t0212-trace2-event.sh diff --git a/t/t0212/parse_events.perl b/third_party/git/t/t0212/parse_events.perl index 6584bb5634..6584bb5634 100644 --- a/t/t0212/parse_events.perl +++ b/third_party/git/t/t0212/parse_events.perl diff --git a/t/t0300-credentials.sh b/third_party/git/t/t0300-credentials.sh index 5555a1524f..5555a1524f 100755 --- a/t/t0300-credentials.sh +++ b/third_party/git/t/t0300-credentials.sh diff --git a/t/t0301-credential-cache.sh b/third_party/git/t/t0301-credential-cache.sh index ebd5fa5249..ebd5fa5249 100755 --- a/t/t0301-credential-cache.sh +++ b/third_party/git/t/t0301-credential-cache.sh diff --git a/t/t0302-credential-store.sh b/third_party/git/t/t0302-credential-store.sh index d6b54e8c65..d6b54e8c65 100755 --- a/t/t0302-credential-store.sh +++ b/third_party/git/t/t0302-credential-store.sh diff --git a/t/t0303-credential-external.sh b/third_party/git/t/t0303-credential-external.sh index f028fd1418..f028fd1418 100755 --- a/t/t0303-credential-external.sh +++ b/third_party/git/t/t0303-credential-external.sh diff --git a/t/t0410-partial-clone.sh b/third_party/git/t/t0410-partial-clone.sh index a3988bd4b8..a3988bd4b8 100755 --- a/t/t0410-partial-clone.sh +++ b/third_party/git/t/t0410-partial-clone.sh diff --git a/t/t0500-progress-display.sh b/third_party/git/t/t0500-progress-display.sh index d2d088d9a0..d2d088d9a0 100755 --- a/t/t0500-progress-display.sh +++ b/third_party/git/t/t0500-progress-display.sh diff --git a/t/t1000-read-tree-m-3way.sh b/third_party/git/t/t1000-read-tree-m-3way.sh index 013c5a7bc3..013c5a7bc3 100755 --- a/t/t1000-read-tree-m-3way.sh +++ b/third_party/git/t/t1000-read-tree-m-3way.sh diff --git a/t/t1001-read-tree-m-2way.sh b/third_party/git/t/t1001-read-tree-m-2way.sh index 1057a96b24..1057a96b24 100755 --- a/t/t1001-read-tree-m-2way.sh +++ b/third_party/git/t/t1001-read-tree-m-2way.sh diff --git a/t/t1002-read-tree-m-u-2way.sh b/third_party/git/t/t1002-read-tree-m-u-2way.sh index 9c05f5e1f5..9c05f5e1f5 100755 --- a/t/t1002-read-tree-m-u-2way.sh +++ b/third_party/git/t/t1002-read-tree-m-u-2way.sh diff --git a/t/t1003-read-tree-prefix.sh b/third_party/git/t/t1003-read-tree-prefix.sh index b6111cd150..b6111cd150 100755 --- a/t/t1003-read-tree-prefix.sh +++ b/third_party/git/t/t1003-read-tree-prefix.sh diff --git a/t/t1004-read-tree-m-u-wf.sh b/third_party/git/t/t1004-read-tree-m-u-wf.sh index c13578a635..c13578a635 100755 --- a/t/t1004-read-tree-m-u-wf.sh +++ b/third_party/git/t/t1004-read-tree-m-u-wf.sh diff --git a/t/t1005-read-tree-reset.sh b/third_party/git/t/t1005-read-tree-reset.sh index 83b09e1310..83b09e1310 100755 --- a/t/t1005-read-tree-reset.sh +++ b/third_party/git/t/t1005-read-tree-reset.sh diff --git a/t/t1006-cat-file.sh b/third_party/git/t/t1006-cat-file.sh index 43c4be1e5e..43c4be1e5e 100755 --- a/t/t1006-cat-file.sh +++ b/third_party/git/t/t1006-cat-file.sh diff --git a/t/t1007-hash-object.sh b/third_party/git/t/t1007-hash-object.sh index 64b340f227..64b340f227 100755 --- a/t/t1007-hash-object.sh +++ b/third_party/git/t/t1007-hash-object.sh diff --git a/t/t1008-read-tree-overlay.sh b/third_party/git/t/t1008-read-tree-overlay.sh index cf96016844..cf96016844 100755 --- a/t/t1008-read-tree-overlay.sh +++ b/third_party/git/t/t1008-read-tree-overlay.sh diff --git a/t/t1009-read-tree-new-index.sh b/third_party/git/t/t1009-read-tree-new-index.sh index 59b3aa4bc4..59b3aa4bc4 100755 --- a/t/t1009-read-tree-new-index.sh +++ b/third_party/git/t/t1009-read-tree-new-index.sh diff --git a/t/t1010-mktree.sh b/third_party/git/t/t1010-mktree.sh index b946f87686..b946f87686 100755 --- a/t/t1010-mktree.sh +++ b/third_party/git/t/t1010-mktree.sh diff --git a/t/t1011-read-tree-sparse-checkout.sh b/third_party/git/t/t1011-read-tree-sparse-checkout.sh index eb44bafb59..eb44bafb59 100755 --- a/t/t1011-read-tree-sparse-checkout.sh +++ b/third_party/git/t/t1011-read-tree-sparse-checkout.sh diff --git a/t/t1012-read-tree-df.sh b/third_party/git/t/t1012-read-tree-df.sh index 57f0770df1..57f0770df1 100755 --- a/t/t1012-read-tree-df.sh +++ b/third_party/git/t/t1012-read-tree-df.sh diff --git a/t/t1013-read-tree-submodule.sh b/third_party/git/t/t1013-read-tree-submodule.sh index 91a6fafcb4..91a6fafcb4 100755 --- a/t/t1013-read-tree-submodule.sh +++ b/third_party/git/t/t1013-read-tree-submodule.sh diff --git a/t/t1014-read-tree-confusing.sh b/third_party/git/t/t1014-read-tree-confusing.sh index da3376b3bb..da3376b3bb 100755 --- a/t/t1014-read-tree-confusing.sh +++ b/third_party/git/t/t1014-read-tree-confusing.sh diff --git a/t/t1015-read-index-unmerged.sh b/third_party/git/t/t1015-read-index-unmerged.sh index 55d22da32c..55d22da32c 100755 --- a/t/t1015-read-index-unmerged.sh +++ b/third_party/git/t/t1015-read-index-unmerged.sh diff --git a/t/t1020-subdirectory.sh b/third_party/git/t/t1020-subdirectory.sh index c2df75e495..c2df75e495 100755 --- a/t/t1020-subdirectory.sh +++ b/third_party/git/t/t1020-subdirectory.sh diff --git a/t/t1021-rerere-in-workdir.sh b/third_party/git/t/t1021-rerere-in-workdir.sh index 301e071ff7..301e071ff7 100755 --- a/t/t1021-rerere-in-workdir.sh +++ b/third_party/git/t/t1021-rerere-in-workdir.sh diff --git a/t/t1050-large.sh b/third_party/git/t/t1050-large.sh index 184b479a21..184b479a21 100755 --- a/t/t1050-large.sh +++ b/third_party/git/t/t1050-large.sh diff --git a/t/t1051-large-conversion.sh b/third_party/git/t/t1051-large-conversion.sh index 8b7640b3ba..8b7640b3ba 100755 --- a/t/t1051-large-conversion.sh +++ b/third_party/git/t/t1051-large-conversion.sh diff --git a/t/t1060-object-corruption.sh b/third_party/git/t/t1060-object-corruption.sh index bc89371f53..bc89371f53 100755 --- a/t/t1060-object-corruption.sh +++ b/third_party/git/t/t1060-object-corruption.sh diff --git a/t/t1090-sparse-checkout-scope.sh b/third_party/git/t/t1090-sparse-checkout-scope.sh index 40cc004326..40cc004326 100755 --- a/t/t1090-sparse-checkout-scope.sh +++ b/third_party/git/t/t1090-sparse-checkout-scope.sh diff --git a/t/t1091-sparse-checkout-builtin.sh b/third_party/git/t/t1091-sparse-checkout-builtin.sh index 44a91205d6..44a91205d6 100755 --- a/t/t1091-sparse-checkout-builtin.sh +++ b/third_party/git/t/t1091-sparse-checkout-builtin.sh diff --git a/t/t1100-commit-tree-options.sh b/third_party/git/t/t1100-commit-tree-options.sh index ae66ba5bab..ae66ba5bab 100755 --- a/t/t1100-commit-tree-options.sh +++ b/third_party/git/t/t1100-commit-tree-options.sh diff --git a/t/t1300-config.sh b/third_party/git/t/t1300-config.sh index 97ebfe1f9d..97ebfe1f9d 100755 --- a/t/t1300-config.sh +++ b/third_party/git/t/t1300-config.sh diff --git a/t/t1301-shared-repo.sh b/third_party/git/t/t1301-shared-repo.sh index 2dc853d1be..2dc853d1be 100755 --- a/t/t1301-shared-repo.sh +++ b/third_party/git/t/t1301-shared-repo.sh diff --git a/t/t1302-repo-version.sh b/third_party/git/t/t1302-repo-version.sh index ce4cff13bb..ce4cff13bb 100755 --- a/t/t1302-repo-version.sh +++ b/third_party/git/t/t1302-repo-version.sh diff --git a/t/t1303-wacky-config.sh b/third_party/git/t/t1303-wacky-config.sh index 0000e664e7..0000e664e7 100755 --- a/t/t1303-wacky-config.sh +++ b/third_party/git/t/t1303-wacky-config.sh diff --git a/t/t1304-default-acl.sh b/third_party/git/t/t1304-default-acl.sh index 335d3f3211..335d3f3211 100755 --- a/t/t1304-default-acl.sh +++ b/third_party/git/t/t1304-default-acl.sh diff --git a/t/t1305-config-include.sh b/third_party/git/t/t1305-config-include.sh index f1e1b289f9..f1e1b289f9 100755 --- a/t/t1305-config-include.sh +++ b/third_party/git/t/t1305-config-include.sh diff --git a/t/t1306-xdg-files.sh b/third_party/git/t/t1306-xdg-files.sh index dd87b43be1..dd87b43be1 100755 --- a/t/t1306-xdg-files.sh +++ b/third_party/git/t/t1306-xdg-files.sh diff --git a/t/t1307-config-blob.sh b/third_party/git/t/t1307-config-blob.sh index 002e6d3388..002e6d3388 100755 --- a/t/t1307-config-blob.sh +++ b/third_party/git/t/t1307-config-blob.sh diff --git a/t/t1308-config-set.sh b/third_party/git/t/t1308-config-set.sh index 3a527e3a84..3a527e3a84 100755 --- a/t/t1308-config-set.sh +++ b/third_party/git/t/t1308-config-set.sh diff --git a/t/t1309-early-config.sh b/third_party/git/t/t1309-early-config.sh index ebb8e1aecb..ebb8e1aecb 100755 --- a/t/t1309-early-config.sh +++ b/third_party/git/t/t1309-early-config.sh diff --git a/t/t1310-config-default.sh b/third_party/git/t/t1310-config-default.sh index 6049d91708..6049d91708 100755 --- a/t/t1310-config-default.sh +++ b/third_party/git/t/t1310-config-default.sh diff --git a/t/t1350-config-hooks-path.sh b/third_party/git/t/t1350-config-hooks-path.sh index f1f9aee9f5..f1f9aee9f5 100755 --- a/t/t1350-config-hooks-path.sh +++ b/third_party/git/t/t1350-config-hooks-path.sh diff --git a/t/t1400-update-ref.sh b/third_party/git/t/t1400-update-ref.sh index a6224ef65f..a6224ef65f 100755 --- a/t/t1400-update-ref.sh +++ b/third_party/git/t/t1400-update-ref.sh diff --git a/t/t1401-symbolic-ref.sh b/third_party/git/t/t1401-symbolic-ref.sh index a4ebb0b65f..a4ebb0b65f 100755 --- a/t/t1401-symbolic-ref.sh +++ b/third_party/git/t/t1401-symbolic-ref.sh diff --git a/t/t1402-check-ref-format.sh b/third_party/git/t/t1402-check-ref-format.sh index 98e4a8613b..98e4a8613b 100755 --- a/t/t1402-check-ref-format.sh +++ b/third_party/git/t/t1402-check-ref-format.sh diff --git a/t/t1403-show-ref.sh b/third_party/git/t/t1403-show-ref.sh index 5d955c3bff..5d955c3bff 100755 --- a/t/t1403-show-ref.sh +++ b/third_party/git/t/t1403-show-ref.sh diff --git a/t/t1404-update-ref-errors.sh b/third_party/git/t/t1404-update-ref-errors.sh index 2d142e5535..2d142e5535 100755 --- a/t/t1404-update-ref-errors.sh +++ b/third_party/git/t/t1404-update-ref-errors.sh diff --git a/t/t1405-main-ref-store.sh b/third_party/git/t/t1405-main-ref-store.sh index 331899ddc4..331899ddc4 100755 --- a/t/t1405-main-ref-store.sh +++ b/third_party/git/t/t1405-main-ref-store.sh diff --git a/t/t1406-submodule-ref-store.sh b/third_party/git/t/t1406-submodule-ref-store.sh index 36b7ef5046..36b7ef5046 100755 --- a/t/t1406-submodule-ref-store.sh +++ b/third_party/git/t/t1406-submodule-ref-store.sh diff --git a/t/t1407-worktree-ref-store.sh b/third_party/git/t/t1407-worktree-ref-store.sh index 9a84858118..9a84858118 100755 --- a/t/t1407-worktree-ref-store.sh +++ b/third_party/git/t/t1407-worktree-ref-store.sh diff --git a/t/t1408-packed-refs.sh b/third_party/git/t/t1408-packed-refs.sh index 1e44a17eea..1e44a17eea 100755 --- a/t/t1408-packed-refs.sh +++ b/third_party/git/t/t1408-packed-refs.sh diff --git a/t/t1409-avoid-packing-refs.sh b/third_party/git/t/t1409-avoid-packing-refs.sh index be12fb6350..be12fb6350 100755 --- a/t/t1409-avoid-packing-refs.sh +++ b/third_party/git/t/t1409-avoid-packing-refs.sh diff --git a/t/t1410-reflog.sh b/third_party/git/t/t1410-reflog.sh index 76d9b744a6..76d9b744a6 100755 --- a/t/t1410-reflog.sh +++ b/third_party/git/t/t1410-reflog.sh diff --git a/t/t1411-reflog-show.sh b/third_party/git/t/t1411-reflog-show.sh index 985daf1def..985daf1def 100755 --- a/t/t1411-reflog-show.sh +++ b/third_party/git/t/t1411-reflog-show.sh diff --git a/t/t1412-reflog-loop.sh b/third_party/git/t/t1412-reflog-loop.sh index 3acd895afb..3acd895afb 100755 --- a/t/t1412-reflog-loop.sh +++ b/third_party/git/t/t1412-reflog-loop.sh diff --git a/t/t1413-reflog-detach.sh b/third_party/git/t/t1413-reflog-detach.sh index c730600d8a..c730600d8a 100755 --- a/t/t1413-reflog-detach.sh +++ b/third_party/git/t/t1413-reflog-detach.sh diff --git a/t/t1414-reflog-walk.sh b/third_party/git/t/t1414-reflog-walk.sh index 1181a9fb28..1181a9fb28 100755 --- a/t/t1414-reflog-walk.sh +++ b/third_party/git/t/t1414-reflog-walk.sh diff --git a/t/t1415-worktree-refs.sh b/third_party/git/t/t1415-worktree-refs.sh index bb2c7572a3..bb2c7572a3 100755 --- a/t/t1415-worktree-refs.sh +++ b/third_party/git/t/t1415-worktree-refs.sh diff --git a/t/t1420-lost-found.sh b/third_party/git/t/t1420-lost-found.sh index dc9e402c55..dc9e402c55 100755 --- a/t/t1420-lost-found.sh +++ b/third_party/git/t/t1420-lost-found.sh diff --git a/t/t1430-bad-ref-name.sh b/third_party/git/t/t1430-bad-ref-name.sh index c7878a60ed..c7878a60ed 100755 --- a/t/t1430-bad-ref-name.sh +++ b/third_party/git/t/t1430-bad-ref-name.sh diff --git a/t/t1450-fsck.sh b/third_party/git/t/t1450-fsck.sh index d09eff503c..d09eff503c 100755 --- a/t/t1450-fsck.sh +++ b/third_party/git/t/t1450-fsck.sh diff --git a/t/t1500-rev-parse.sh b/third_party/git/t/t1500-rev-parse.sh index 603019b541..603019b541 100755 --- a/t/t1500-rev-parse.sh +++ b/third_party/git/t/t1500-rev-parse.sh diff --git a/t/t1501-work-tree.sh b/third_party/git/t/t1501-work-tree.sh index b75558040f..b75558040f 100755 --- a/t/t1501-work-tree.sh +++ b/third_party/git/t/t1501-work-tree.sh diff --git a/t/t1502-rev-parse-parseopt.sh b/third_party/git/t/t1502-rev-parse-parseopt.sh index a859abedf5..a859abedf5 100755 --- a/t/t1502-rev-parse-parseopt.sh +++ b/third_party/git/t/t1502-rev-parse-parseopt.sh diff --git a/t/t1503-rev-parse-verify.sh b/third_party/git/t/t1503-rev-parse-verify.sh index 492edffa9c..492edffa9c 100755 --- a/t/t1503-rev-parse-verify.sh +++ b/third_party/git/t/t1503-rev-parse-verify.sh diff --git a/t/t1504-ceiling-dirs.sh b/third_party/git/t/t1504-ceiling-dirs.sh index 3d51615e42..3d51615e42 100755 --- a/t/t1504-ceiling-dirs.sh +++ b/third_party/git/t/t1504-ceiling-dirs.sh diff --git a/t/t1505-rev-parse-last.sh b/third_party/git/t/t1505-rev-parse-last.sh index 4969edb314..4969edb314 100755 --- a/t/t1505-rev-parse-last.sh +++ b/third_party/git/t/t1505-rev-parse-last.sh diff --git a/t/t1506-rev-parse-diagnosis.sh b/third_party/git/t/t1506-rev-parse-diagnosis.sh index 52edcbdcc3..52edcbdcc3 100755 --- a/t/t1506-rev-parse-diagnosis.sh +++ b/third_party/git/t/t1506-rev-parse-diagnosis.sh diff --git a/t/t1507-rev-parse-upstream.sh b/third_party/git/t/t1507-rev-parse-upstream.sh index dfc0d96d8a..dfc0d96d8a 100755 --- a/t/t1507-rev-parse-upstream.sh +++ b/third_party/git/t/t1507-rev-parse-upstream.sh diff --git a/t/t1508-at-combinations.sh b/third_party/git/t/t1508-at-combinations.sh index 4a9964e9dc..4a9964e9dc 100755 --- a/t/t1508-at-combinations.sh +++ b/third_party/git/t/t1508-at-combinations.sh diff --git a/t/t1509-root-work-tree.sh b/third_party/git/t/t1509-root-work-tree.sh index 553a3f601b..553a3f601b 100755 --- a/t/t1509-root-work-tree.sh +++ b/third_party/git/t/t1509-root-work-tree.sh diff --git a/t/t1509/excludes b/third_party/git/t/t1509/excludes index d4d21d31a9..d4d21d31a9 100644 --- a/t/t1509/excludes +++ b/third_party/git/t/t1509/excludes diff --git a/t/t1509/prepare-chroot.sh b/third_party/git/t/t1509/prepare-chroot.sh index 6d47e2c725..6d47e2c725 100755 --- a/t/t1509/prepare-chroot.sh +++ b/third_party/git/t/t1509/prepare-chroot.sh diff --git a/t/t1510-repo-setup.sh b/third_party/git/t/t1510-repo-setup.sh index 9974457f56..9974457f56 100755 --- a/t/t1510-repo-setup.sh +++ b/third_party/git/t/t1510-repo-setup.sh diff --git a/t/t1511-rev-parse-caret.sh b/third_party/git/t/t1511-rev-parse-caret.sh index e0a49a651f..e0a49a651f 100755 --- a/t/t1511-rev-parse-caret.sh +++ b/third_party/git/t/t1511-rev-parse-caret.sh diff --git a/t/t1512-rev-parse-disambiguation.sh b/third_party/git/t/t1512-rev-parse-disambiguation.sh index 18fa6cf40d..18fa6cf40d 100755 --- a/t/t1512-rev-parse-disambiguation.sh +++ b/third_party/git/t/t1512-rev-parse-disambiguation.sh diff --git a/t/t1513-rev-parse-prefix.sh b/third_party/git/t/t1513-rev-parse-prefix.sh index 87ec3ae714..87ec3ae714 100755 --- a/t/t1513-rev-parse-prefix.sh +++ b/third_party/git/t/t1513-rev-parse-prefix.sh diff --git a/t/t1514-rev-parse-push.sh b/third_party/git/t/t1514-rev-parse-push.sh index 788cc91e45..788cc91e45 100755 --- a/t/t1514-rev-parse-push.sh +++ b/third_party/git/t/t1514-rev-parse-push.sh diff --git a/t/t1515-rev-parse-outside-repo.sh b/third_party/git/t/t1515-rev-parse-outside-repo.sh index 3ec2971ee5..3ec2971ee5 100755 --- a/t/t1515-rev-parse-outside-repo.sh +++ b/third_party/git/t/t1515-rev-parse-outside-repo.sh diff --git a/t/t1600-index.sh b/third_party/git/t/t1600-index.sh index b7c31aa86a..b7c31aa86a 100755 --- a/t/t1600-index.sh +++ b/third_party/git/t/t1600-index.sh diff --git a/t/t1601-index-bogus.sh b/third_party/git/t/t1601-index-bogus.sh index 4171f1e141..4171f1e141 100755 --- a/t/t1601-index-bogus.sh +++ b/third_party/git/t/t1601-index-bogus.sh diff --git a/t/t1700-split-index.sh b/third_party/git/t/t1700-split-index.sh index 12a5568844..12a5568844 100755 --- a/t/t1700-split-index.sh +++ b/third_party/git/t/t1700-split-index.sh diff --git a/t/t1701-racy-split-index.sh b/third_party/git/t/t1701-racy-split-index.sh index 5dc221ef38..5dc221ef38 100755 --- a/t/t1701-racy-split-index.sh +++ b/third_party/git/t/t1701-racy-split-index.sh diff --git a/t/t2000-conflict-when-checking-files-out.sh b/third_party/git/t/t2000-conflict-when-checking-files-out.sh index f18616ad2b..f18616ad2b 100755 --- a/t/t2000-conflict-when-checking-files-out.sh +++ b/third_party/git/t/t2000-conflict-when-checking-files-out.sh diff --git a/t/t2002-checkout-cache-u.sh b/third_party/git/t/t2002-checkout-cache-u.sh index 70361c806e..70361c806e 100755 --- a/t/t2002-checkout-cache-u.sh +++ b/third_party/git/t/t2002-checkout-cache-u.sh diff --git a/t/t2003-checkout-cache-mkdir.sh b/third_party/git/t/t2003-checkout-cache-mkdir.sh index ff163cf675..ff163cf675 100755 --- a/t/t2003-checkout-cache-mkdir.sh +++ b/third_party/git/t/t2003-checkout-cache-mkdir.sh diff --git a/t/t2004-checkout-cache-temp.sh b/third_party/git/t/t2004-checkout-cache-temp.sh index a12afe93f3..a12afe93f3 100755 --- a/t/t2004-checkout-cache-temp.sh +++ b/third_party/git/t/t2004-checkout-cache-temp.sh diff --git a/t/t2005-checkout-index-symlinks.sh b/third_party/git/t/t2005-checkout-index-symlinks.sh index 9fa5610474..9fa5610474 100755 --- a/t/t2005-checkout-index-symlinks.sh +++ b/third_party/git/t/t2005-checkout-index-symlinks.sh diff --git a/t/t2006-checkout-index-basic.sh b/third_party/git/t/t2006-checkout-index-basic.sh index 57cbdfe9bc..57cbdfe9bc 100755 --- a/t/t2006-checkout-index-basic.sh +++ b/third_party/git/t/t2006-checkout-index-basic.sh diff --git a/t/t2007-checkout-symlink.sh b/third_party/git/t/t2007-checkout-symlink.sh index fc9aad530e..fc9aad530e 100755 --- a/t/t2007-checkout-symlink.sh +++ b/third_party/git/t/t2007-checkout-symlink.sh diff --git a/t/t2008-checkout-subdir.sh b/third_party/git/t/t2008-checkout-subdir.sh index eadb9434ae..eadb9434ae 100755 --- a/t/t2008-checkout-subdir.sh +++ b/third_party/git/t/t2008-checkout-subdir.sh diff --git a/t/t2009-checkout-statinfo.sh b/third_party/git/t/t2009-checkout-statinfo.sh index f3c2152087..f3c2152087 100755 --- a/t/t2009-checkout-statinfo.sh +++ b/third_party/git/t/t2009-checkout-statinfo.sh diff --git a/t/t2010-checkout-ambiguous.sh b/third_party/git/t/t2010-checkout-ambiguous.sh index 2e47fe01cf..2e47fe01cf 100755 --- a/t/t2010-checkout-ambiguous.sh +++ b/third_party/git/t/t2010-checkout-ambiguous.sh diff --git a/t/t2011-checkout-invalid-head.sh b/third_party/git/t/t2011-checkout-invalid-head.sh index 0e8d56aa76..0e8d56aa76 100755 --- a/t/t2011-checkout-invalid-head.sh +++ b/third_party/git/t/t2011-checkout-invalid-head.sh diff --git a/t/t2012-checkout-last.sh b/third_party/git/t/t2012-checkout-last.sh index e7ba8c505f..e7ba8c505f 100755 --- a/t/t2012-checkout-last.sh +++ b/third_party/git/t/t2012-checkout-last.sh diff --git a/t/t2013-checkout-submodule.sh b/third_party/git/t/t2013-checkout-submodule.sh index 8f86b5f4b2..8f86b5f4b2 100755 --- a/t/t2013-checkout-submodule.sh +++ b/third_party/git/t/t2013-checkout-submodule.sh diff --git a/t/t2014-checkout-switch.sh b/third_party/git/t/t2014-checkout-switch.sh index ccfb147113..ccfb147113 100755 --- a/t/t2014-checkout-switch.sh +++ b/third_party/git/t/t2014-checkout-switch.sh diff --git a/t/t2015-checkout-unborn.sh b/third_party/git/t/t2015-checkout-unborn.sh index 37bdcedcc9..37bdcedcc9 100755 --- a/t/t2015-checkout-unborn.sh +++ b/third_party/git/t/t2015-checkout-unborn.sh diff --git a/t/t2016-checkout-patch.sh b/third_party/git/t/t2016-checkout-patch.sh index 47aeb0b167..47aeb0b167 100755 --- a/t/t2016-checkout-patch.sh +++ b/third_party/git/t/t2016-checkout-patch.sh diff --git a/t/t2017-checkout-orphan.sh b/third_party/git/t/t2017-checkout-orphan.sh index 655f278c5f..655f278c5f 100755 --- a/t/t2017-checkout-orphan.sh +++ b/third_party/git/t/t2017-checkout-orphan.sh diff --git a/t/t2018-checkout-branch.sh b/third_party/git/t/t2018-checkout-branch.sh index bbca7ef8da..bbca7ef8da 100755 --- a/t/t2018-checkout-branch.sh +++ b/third_party/git/t/t2018-checkout-branch.sh diff --git a/t/t2019-checkout-ambiguous-ref.sh b/third_party/git/t/t2019-checkout-ambiguous-ref.sh index b99d5192a9..b99d5192a9 100755 --- a/t/t2019-checkout-ambiguous-ref.sh +++ b/third_party/git/t/t2019-checkout-ambiguous-ref.sh diff --git a/t/t2020-checkout-detach.sh b/third_party/git/t/t2020-checkout-detach.sh index b748db9946..b748db9946 100755 --- a/t/t2020-checkout-detach.sh +++ b/third_party/git/t/t2020-checkout-detach.sh diff --git a/t/t2021-checkout-overwrite.sh b/third_party/git/t/t2021-checkout-overwrite.sh index c2ada7de37..c2ada7de37 100755 --- a/t/t2021-checkout-overwrite.sh +++ b/third_party/git/t/t2021-checkout-overwrite.sh diff --git a/t/t2022-checkout-paths.sh b/third_party/git/t/t2022-checkout-paths.sh index 6844afafc0..6844afafc0 100755 --- a/t/t2022-checkout-paths.sh +++ b/third_party/git/t/t2022-checkout-paths.sh diff --git a/t/t2023-checkout-m.sh b/third_party/git/t/t2023-checkout-m.sh index fca3f85824..fca3f85824 100755 --- a/t/t2023-checkout-m.sh +++ b/third_party/git/t/t2023-checkout-m.sh diff --git a/t/t2024-checkout-dwim.sh b/third_party/git/t/t2024-checkout-dwim.sh index accfa9aa4b..accfa9aa4b 100755 --- a/t/t2024-checkout-dwim.sh +++ b/third_party/git/t/t2024-checkout-dwim.sh diff --git a/t/t2025-checkout-no-overlay.sh b/third_party/git/t/t2025-checkout-no-overlay.sh index 76330cb5ab..76330cb5ab 100755 --- a/t/t2025-checkout-no-overlay.sh +++ b/third_party/git/t/t2025-checkout-no-overlay.sh diff --git a/t/t2026-checkout-pathspec-file.sh b/third_party/git/t/t2026-checkout-pathspec-file.sh index 43d31d7948..43d31d7948 100755 --- a/t/t2026-checkout-pathspec-file.sh +++ b/third_party/git/t/t2026-checkout-pathspec-file.sh diff --git a/t/t2030-unresolve-info.sh b/third_party/git/t/t2030-unresolve-info.sh index 309199bca2..309199bca2 100755 --- a/t/t2030-unresolve-info.sh +++ b/third_party/git/t/t2030-unresolve-info.sh diff --git a/t/t2050-git-dir-relative.sh b/third_party/git/t/t2050-git-dir-relative.sh index 21f4659a9d..21f4659a9d 100755 --- a/t/t2050-git-dir-relative.sh +++ b/third_party/git/t/t2050-git-dir-relative.sh diff --git a/t/t2060-switch.sh b/third_party/git/t/t2060-switch.sh index f9efa29dfb..f9efa29dfb 100755 --- a/t/t2060-switch.sh +++ b/third_party/git/t/t2060-switch.sh diff --git a/t/t2070-restore.sh b/third_party/git/t/t2070-restore.sh index 076d0df7fc..076d0df7fc 100755 --- a/t/t2070-restore.sh +++ b/third_party/git/t/t2070-restore.sh diff --git a/t/t2071-restore-patch.sh b/third_party/git/t/t2071-restore-patch.sh index 98b2476e7c..98b2476e7c 100755 --- a/t/t2071-restore-patch.sh +++ b/third_party/git/t/t2071-restore-patch.sh diff --git a/t/t2072-restore-pathspec-file.sh b/third_party/git/t/t2072-restore-pathspec-file.sh index 0d47946e8a..0d47946e8a 100755 --- a/t/t2072-restore-pathspec-file.sh +++ b/third_party/git/t/t2072-restore-pathspec-file.sh diff --git a/t/t2100-update-cache-badpath.sh b/third_party/git/t/t2100-update-cache-badpath.sh index 2df3fdde8b..2df3fdde8b 100755 --- a/t/t2100-update-cache-badpath.sh +++ b/third_party/git/t/t2100-update-cache-badpath.sh diff --git a/t/t2101-update-index-reupdate.sh b/third_party/git/t/t2101-update-index-reupdate.sh index 6c32d42c8c..6c32d42c8c 100755 --- a/t/t2101-update-index-reupdate.sh +++ b/third_party/git/t/t2101-update-index-reupdate.sh diff --git a/t/t2102-update-index-symlinks.sh b/third_party/git/t/t2102-update-index-symlinks.sh index 22f2c730ae..22f2c730ae 100755 --- a/t/t2102-update-index-symlinks.sh +++ b/third_party/git/t/t2102-update-index-symlinks.sh diff --git a/t/t2103-update-index-ignore-missing.sh b/third_party/git/t/t2103-update-index-ignore-missing.sh index 0114f05228..0114f05228 100755 --- a/t/t2103-update-index-ignore-missing.sh +++ b/third_party/git/t/t2103-update-index-ignore-missing.sh diff --git a/t/t2104-update-index-skip-worktree.sh b/third_party/git/t/t2104-update-index-skip-worktree.sh index 7e2e7dd4ae..7e2e7dd4ae 100755 --- a/t/t2104-update-index-skip-worktree.sh +++ b/third_party/git/t/t2104-update-index-skip-worktree.sh diff --git a/t/t2105-update-index-gitfile.sh b/third_party/git/t/t2105-update-index-gitfile.sh index a7f3d47aec..a7f3d47aec 100755 --- a/t/t2105-update-index-gitfile.sh +++ b/third_party/git/t/t2105-update-index-gitfile.sh diff --git a/t/t2106-update-index-assume-unchanged.sh b/third_party/git/t/t2106-update-index-assume-unchanged.sh index 99d858c6b7..99d858c6b7 100755 --- a/t/t2106-update-index-assume-unchanged.sh +++ b/third_party/git/t/t2106-update-index-assume-unchanged.sh diff --git a/t/t2107-update-index-basic.sh b/third_party/git/t/t2107-update-index-basic.sh index a30b7ca6bc..a30b7ca6bc 100755 --- a/t/t2107-update-index-basic.sh +++ b/third_party/git/t/t2107-update-index-basic.sh diff --git a/t/t2200-add-update.sh b/third_party/git/t/t2200-add-update.sh index f764b7e3f5..f764b7e3f5 100755 --- a/t/t2200-add-update.sh +++ b/third_party/git/t/t2200-add-update.sh diff --git a/t/t2201-add-update-typechange.sh b/third_party/git/t/t2201-add-update-typechange.sh index a4eec0a346..a4eec0a346 100755 --- a/t/t2201-add-update-typechange.sh +++ b/third_party/git/t/t2201-add-update-typechange.sh diff --git a/t/t2202-add-addremove.sh b/third_party/git/t/t2202-add-addremove.sh index 9ee659098c..9ee659098c 100755 --- a/t/t2202-add-addremove.sh +++ b/third_party/git/t/t2202-add-addremove.sh diff --git a/t/t2203-add-intent.sh b/third_party/git/t/t2203-add-intent.sh index 5bbe8dcce4..5bbe8dcce4 100755 --- a/t/t2203-add-intent.sh +++ b/third_party/git/t/t2203-add-intent.sh diff --git a/t/t2204-add-ignored.sh b/third_party/git/t/t2204-add-ignored.sh index 2e07365bbb..2e07365bbb 100755 --- a/t/t2204-add-ignored.sh +++ b/third_party/git/t/t2204-add-ignored.sh diff --git a/t/t2300-cd-to-toplevel.sh b/third_party/git/t/t2300-cd-to-toplevel.sh index c8de6d8a19..c8de6d8a19 100755 --- a/t/t2300-cd-to-toplevel.sh +++ b/third_party/git/t/t2300-cd-to-toplevel.sh diff --git a/t/t2400-worktree-add.sh b/third_party/git/t/t2400-worktree-add.sh index 5a7495474a..5a7495474a 100755 --- a/t/t2400-worktree-add.sh +++ b/third_party/git/t/t2400-worktree-add.sh diff --git a/t/t2401-worktree-prune.sh b/third_party/git/t/t2401-worktree-prune.sh index b7d6d5d45a..b7d6d5d45a 100755 --- a/t/t2401-worktree-prune.sh +++ b/third_party/git/t/t2401-worktree-prune.sh diff --git a/t/t2402-worktree-list.sh b/third_party/git/t/t2402-worktree-list.sh index 69ffe865b4..69ffe865b4 100755 --- a/t/t2402-worktree-list.sh +++ b/third_party/git/t/t2402-worktree-list.sh diff --git a/t/t2403-worktree-move.sh b/third_party/git/t/t2403-worktree-move.sh index 939d18d728..939d18d728 100755 --- a/t/t2403-worktree-move.sh +++ b/third_party/git/t/t2403-worktree-move.sh diff --git a/t/t2404-worktree-config.sh b/third_party/git/t/t2404-worktree-config.sh index 286121d8de..286121d8de 100755 --- a/t/t2404-worktree-config.sh +++ b/third_party/git/t/t2404-worktree-config.sh diff --git a/t/t2405-worktree-submodule.sh b/third_party/git/t/t2405-worktree-submodule.sh index e1b2bfd87e..e1b2bfd87e 100755 --- a/t/t2405-worktree-submodule.sh +++ b/third_party/git/t/t2405-worktree-submodule.sh diff --git a/t/t3000-ls-files-others.sh b/third_party/git/t/t3000-ls-files-others.sh index 0aefadacb0..0aefadacb0 100755 --- a/t/t3000-ls-files-others.sh +++ b/third_party/git/t/t3000-ls-files-others.sh diff --git a/t/t3001-ls-files-others-exclude.sh b/third_party/git/t/t3001-ls-files-others-exclude.sh index 1ec7cb57c7..1ec7cb57c7 100755 --- a/t/t3001-ls-files-others-exclude.sh +++ b/third_party/git/t/t3001-ls-files-others-exclude.sh diff --git a/t/t3002-ls-files-dashpath.sh b/third_party/git/t/t3002-ls-files-dashpath.sh index 8704b04e1b..8704b04e1b 100755 --- a/t/t3002-ls-files-dashpath.sh +++ b/third_party/git/t/t3002-ls-files-dashpath.sh diff --git a/t/t3003-ls-files-exclude.sh b/third_party/git/t/t3003-ls-files-exclude.sh index d5ec333131..d5ec333131 100755 --- a/t/t3003-ls-files-exclude.sh +++ b/third_party/git/t/t3003-ls-files-exclude.sh diff --git a/t/t3004-ls-files-basic.sh b/third_party/git/t/t3004-ls-files-basic.sh index 9fd5a1f188..9fd5a1f188 100755 --- a/t/t3004-ls-files-basic.sh +++ b/third_party/git/t/t3004-ls-files-basic.sh diff --git a/t/t3005-ls-files-relative.sh b/third_party/git/t/t3005-ls-files-relative.sh index 2ec69a8a26..2ec69a8a26 100755 --- a/t/t3005-ls-files-relative.sh +++ b/third_party/git/t/t3005-ls-files-relative.sh diff --git a/t/t3006-ls-files-long.sh b/third_party/git/t/t3006-ls-files-long.sh index e109c3fbfb..e109c3fbfb 100755 --- a/t/t3006-ls-files-long.sh +++ b/third_party/git/t/t3006-ls-files-long.sh diff --git a/t/t3007-ls-files-recurse-submodules.sh b/third_party/git/t/t3007-ls-files-recurse-submodules.sh index 4a08000713..4a08000713 100755 --- a/t/t3007-ls-files-recurse-submodules.sh +++ b/third_party/git/t/t3007-ls-files-recurse-submodules.sh diff --git a/t/t3008-ls-files-lazy-init-name-hash.sh b/third_party/git/t/t3008-ls-files-lazy-init-name-hash.sh index 85f3704958..85f3704958 100755 --- a/t/t3008-ls-files-lazy-init-name-hash.sh +++ b/third_party/git/t/t3008-ls-files-lazy-init-name-hash.sh diff --git a/t/t3009-ls-files-others-nonsubmodule.sh b/third_party/git/t/t3009-ls-files-others-nonsubmodule.sh index 963f3462b7..963f3462b7 100755 --- a/t/t3009-ls-files-others-nonsubmodule.sh +++ b/third_party/git/t/t3009-ls-files-others-nonsubmodule.sh diff --git a/t/t3010-ls-files-killed-modified.sh b/third_party/git/t/t3010-ls-files-killed-modified.sh index 580e158f99..580e158f99 100755 --- a/t/t3010-ls-files-killed-modified.sh +++ b/third_party/git/t/t3010-ls-files-killed-modified.sh diff --git a/t/t3011-common-prefixes-and-directory-traversal.sh b/third_party/git/t/t3011-common-prefixes-and-directory-traversal.sh index 3da5b2b6e7..3da5b2b6e7 100755 --- a/t/t3011-common-prefixes-and-directory-traversal.sh +++ b/third_party/git/t/t3011-common-prefixes-and-directory-traversal.sh diff --git a/t/t3020-ls-files-error-unmatch.sh b/third_party/git/t/t3020-ls-files-error-unmatch.sh index 124e73b8e6..124e73b8e6 100755 --- a/t/t3020-ls-files-error-unmatch.sh +++ b/third_party/git/t/t3020-ls-files-error-unmatch.sh diff --git a/t/t3030-merge-recursive.sh b/third_party/git/t/t3030-merge-recursive.sh index d48d211a95..d48d211a95 100755 --- a/t/t3030-merge-recursive.sh +++ b/third_party/git/t/t3030-merge-recursive.sh diff --git a/t/t3031-merge-criscross.sh b/third_party/git/t/t3031-merge-criscross.sh index 3824756a02..3824756a02 100755 --- a/t/t3031-merge-criscross.sh +++ b/third_party/git/t/t3031-merge-criscross.sh diff --git a/t/t3032-merge-recursive-space-options.sh b/third_party/git/t/t3032-merge-recursive-space-options.sh index b56180ee4a..b56180ee4a 100755 --- a/t/t3032-merge-recursive-space-options.sh +++ b/third_party/git/t/t3032-merge-recursive-space-options.sh diff --git a/t/t3033-merge-toplevel.sh b/third_party/git/t/t3033-merge-toplevel.sh index d314599428..d314599428 100755 --- a/t/t3033-merge-toplevel.sh +++ b/third_party/git/t/t3033-merge-toplevel.sh diff --git a/t/t3034-merge-recursive-rename-options.sh b/third_party/git/t/t3034-merge-recursive-rename-options.sh index 3d9fae68c4..3d9fae68c4 100755 --- a/t/t3034-merge-recursive-rename-options.sh +++ b/third_party/git/t/t3034-merge-recursive-rename-options.sh diff --git a/t/t3035-merge-sparse.sh b/third_party/git/t/t3035-merge-sparse.sh index 74562e1235..74562e1235 100755 --- a/t/t3035-merge-sparse.sh +++ b/third_party/git/t/t3035-merge-sparse.sh diff --git a/t/t3040-subprojects-basic.sh b/third_party/git/t/t3040-subprojects-basic.sh index b81eb5fd6f..b81eb5fd6f 100755 --- a/t/t3040-subprojects-basic.sh +++ b/third_party/git/t/t3040-subprojects-basic.sh diff --git a/t/t3050-subprojects-fetch.sh b/third_party/git/t/t3050-subprojects-fetch.sh index f1f09abdd9..f1f09abdd9 100755 --- a/t/t3050-subprojects-fetch.sh +++ b/third_party/git/t/t3050-subprojects-fetch.sh diff --git a/t/t3060-ls-files-with-tree.sh b/third_party/git/t/t3060-ls-files-with-tree.sh index 52ed665fcd..52ed665fcd 100755 --- a/t/t3060-ls-files-with-tree.sh +++ b/third_party/git/t/t3060-ls-files-with-tree.sh diff --git a/t/t3070-wildmatch.sh b/third_party/git/t/t3070-wildmatch.sh index 891d4d7cb9..891d4d7cb9 100755 --- a/t/t3070-wildmatch.sh +++ b/third_party/git/t/t3070-wildmatch.sh diff --git a/t/t3100-ls-tree-restrict.sh b/third_party/git/t/t3100-ls-tree-restrict.sh index 18baf49a49..18baf49a49 100755 --- a/t/t3100-ls-tree-restrict.sh +++ b/third_party/git/t/t3100-ls-tree-restrict.sh diff --git a/t/t3101-ls-tree-dirname.sh b/third_party/git/t/t3101-ls-tree-dirname.sh index 12bf31022a..12bf31022a 100755 --- a/t/t3101-ls-tree-dirname.sh +++ b/third_party/git/t/t3101-ls-tree-dirname.sh diff --git a/t/t3102-ls-tree-wildcards.sh b/third_party/git/t/t3102-ls-tree-wildcards.sh index 1e16c6b8ea..1e16c6b8ea 100755 --- a/t/t3102-ls-tree-wildcards.sh +++ b/third_party/git/t/t3102-ls-tree-wildcards.sh diff --git a/t/t3103-ls-tree-misc.sh b/third_party/git/t/t3103-ls-tree-misc.sh index 14520913af..14520913af 100755 --- a/t/t3103-ls-tree-misc.sh +++ b/third_party/git/t/t3103-ls-tree-misc.sh diff --git a/t/t3200-branch.sh b/third_party/git/t/t3200-branch.sh index 411a70b0ce..411a70b0ce 100755 --- a/t/t3200-branch.sh +++ b/third_party/git/t/t3200-branch.sh diff --git a/t/t3201-branch-contains.sh b/third_party/git/t/t3201-branch-contains.sh index 40251c9f8f..40251c9f8f 100755 --- a/t/t3201-branch-contains.sh +++ b/third_party/git/t/t3201-branch-contains.sh diff --git a/t/t3202-show-branch-octopus.sh b/third_party/git/t/t3202-show-branch-octopus.sh index 6adf47869c..6adf47869c 100755 --- a/t/t3202-show-branch-octopus.sh +++ b/third_party/git/t/t3202-show-branch-octopus.sh diff --git a/t/t3203-branch-output.sh b/third_party/git/t/t3203-branch-output.sh index 71818b90f0..71818b90f0 100755 --- a/t/t3203-branch-output.sh +++ b/third_party/git/t/t3203-branch-output.sh diff --git a/t/t3204-branch-name-interpretation.sh b/third_party/git/t/t3204-branch-name-interpretation.sh index 698d9cc4f3..698d9cc4f3 100755 --- a/t/t3204-branch-name-interpretation.sh +++ b/third_party/git/t/t3204-branch-name-interpretation.sh diff --git a/t/t3205-branch-color.sh b/third_party/git/t/t3205-branch-color.sh index 4f1e16bb44..4f1e16bb44 100755 --- a/t/t3205-branch-color.sh +++ b/third_party/git/t/t3205-branch-color.sh diff --git a/t/t3206-range-diff.sh b/third_party/git/t/t3206-range-diff.sh index bd808f87ed..bd808f87ed 100755 --- a/t/t3206-range-diff.sh +++ b/third_party/git/t/t3206-range-diff.sh diff --git a/t/t3206/history.export b/third_party/git/t/t3206/history.export index 4c808e5b3b..4c808e5b3b 100644 --- a/t/t3206/history.export +++ b/third_party/git/t/t3206/history.export diff --git a/t/t3210-pack-refs.sh b/third_party/git/t/t3210-pack-refs.sh index f41b2afb99..f41b2afb99 100755 --- a/t/t3210-pack-refs.sh +++ b/third_party/git/t/t3210-pack-refs.sh diff --git a/t/t3211-peel-ref.sh b/third_party/git/t/t3211-peel-ref.sh index 3b7caca421..3b7caca421 100755 --- a/t/t3211-peel-ref.sh +++ b/third_party/git/t/t3211-peel-ref.sh diff --git a/t/t3300-funny-names.sh b/third_party/git/t/t3300-funny-names.sh index 04de03cad0..04de03cad0 100755 --- a/t/t3300-funny-names.sh +++ b/third_party/git/t/t3300-funny-names.sh diff --git a/t/t3301-notes.sh b/third_party/git/t/t3301-notes.sh index 8f43303007..8f43303007 100755 --- a/t/t3301-notes.sh +++ b/third_party/git/t/t3301-notes.sh diff --git a/t/t3302-notes-index-expensive.sh b/third_party/git/t/t3302-notes-index-expensive.sh index 7217c5e222..7217c5e222 100755 --- a/t/t3302-notes-index-expensive.sh +++ b/third_party/git/t/t3302-notes-index-expensive.sh diff --git a/t/t3303-notes-subtrees.sh b/third_party/git/t/t3303-notes-subtrees.sh index 704aee81ef..704aee81ef 100755 --- a/t/t3303-notes-subtrees.sh +++ b/third_party/git/t/t3303-notes-subtrees.sh diff --git a/t/t3304-notes-mixed.sh b/third_party/git/t/t3304-notes-mixed.sh index 1709e8c00b..1709e8c00b 100755 --- a/t/t3304-notes-mixed.sh +++ b/third_party/git/t/t3304-notes-mixed.sh diff --git a/t/t3305-notes-fanout.sh b/third_party/git/t/t3305-notes-fanout.sh index 3b4753e1b4..3b4753e1b4 100755 --- a/t/t3305-notes-fanout.sh +++ b/third_party/git/t/t3305-notes-fanout.sh diff --git a/t/t3306-notes-prune.sh b/third_party/git/t/t3306-notes-prune.sh index 8f4102ff9e..8f4102ff9e 100755 --- a/t/t3306-notes-prune.sh +++ b/third_party/git/t/t3306-notes-prune.sh diff --git a/t/t3307-notes-man.sh b/third_party/git/t/t3307-notes-man.sh index 1aa366a410..1aa366a410 100755 --- a/t/t3307-notes-man.sh +++ b/third_party/git/t/t3307-notes-man.sh diff --git a/t/t3308-notes-merge.sh b/third_party/git/t/t3308-notes-merge.sh index 790e292966..790e292966 100755 --- a/t/t3308-notes-merge.sh +++ b/third_party/git/t/t3308-notes-merge.sh diff --git a/t/t3309-notes-merge-auto-resolve.sh b/third_party/git/t/t3309-notes-merge-auto-resolve.sh index 141d3e4ca4..141d3e4ca4 100755 --- a/t/t3309-notes-merge-auto-resolve.sh +++ b/third_party/git/t/t3309-notes-merge-auto-resolve.sh diff --git a/t/t3310-notes-merge-manual-resolve.sh b/third_party/git/t/t3310-notes-merge-manual-resolve.sh index d3d72e25fe..d3d72e25fe 100755 --- a/t/t3310-notes-merge-manual-resolve.sh +++ b/third_party/git/t/t3310-notes-merge-manual-resolve.sh diff --git a/t/t3311-notes-merge-fanout.sh b/third_party/git/t/t3311-notes-merge-fanout.sh index 5b675417e9..5b675417e9 100755 --- a/t/t3311-notes-merge-fanout.sh +++ b/third_party/git/t/t3311-notes-merge-fanout.sh diff --git a/t/t3320-notes-merge-worktrees.sh b/third_party/git/t/t3320-notes-merge-worktrees.sh index 823fdbda1f..823fdbda1f 100755 --- a/t/t3320-notes-merge-worktrees.sh +++ b/third_party/git/t/t3320-notes-merge-worktrees.sh diff --git a/t/t3400-rebase.sh b/third_party/git/t/t3400-rebase.sh index 40d2975995..40d2975995 100755 --- a/t/t3400-rebase.sh +++ b/third_party/git/t/t3400-rebase.sh diff --git a/t/t3401-rebase-and-am-rename.sh b/third_party/git/t/t3401-rebase-and-am-rename.sh index f18bae9450..f18bae9450 100755 --- a/t/t3401-rebase-and-am-rename.sh +++ b/third_party/git/t/t3401-rebase-and-am-rename.sh diff --git a/t/t3402-rebase-merge.sh b/third_party/git/t/t3402-rebase-merge.sh index a1ec501a87..a1ec501a87 100755 --- a/t/t3402-rebase-merge.sh +++ b/third_party/git/t/t3402-rebase-merge.sh diff --git a/t/t3403-rebase-skip.sh b/third_party/git/t/t3403-rebase-skip.sh index ee8a8dba52..ee8a8dba52 100755 --- a/t/t3403-rebase-skip.sh +++ b/third_party/git/t/t3403-rebase-skip.sh diff --git a/t/t3404-rebase-interactive.sh b/third_party/git/t/t3404-rebase-interactive.sh index c5ce3ab760..c5ce3ab760 100755 --- a/t/t3404-rebase-interactive.sh +++ b/third_party/git/t/t3404-rebase-interactive.sh diff --git a/t/t3405-rebase-malformed.sh b/third_party/git/t/t3405-rebase-malformed.sh index 860e63e444..860e63e444 100755 --- a/t/t3405-rebase-malformed.sh +++ b/third_party/git/t/t3405-rebase-malformed.sh diff --git a/t/t3406-rebase-message.sh b/third_party/git/t/t3406-rebase-message.sh index 61b76f3301..61b76f3301 100755 --- a/t/t3406-rebase-message.sh +++ b/third_party/git/t/t3406-rebase-message.sh diff --git a/t/t3407-rebase-abort.sh b/third_party/git/t/t3407-rebase-abort.sh index 97efea0f56..97efea0f56 100755 --- a/t/t3407-rebase-abort.sh +++ b/third_party/git/t/t3407-rebase-abort.sh diff --git a/t/t3408-rebase-multi-line.sh b/third_party/git/t/t3408-rebase-multi-line.sh index d2bd7c17b0..d2bd7c17b0 100755 --- a/t/t3408-rebase-multi-line.sh +++ b/third_party/git/t/t3408-rebase-multi-line.sh diff --git a/t/t3409-rebase-preserve-merges.sh b/third_party/git/t/t3409-rebase-preserve-merges.sh index 3b340f1ece..3b340f1ece 100755 --- a/t/t3409-rebase-preserve-merges.sh +++ b/third_party/git/t/t3409-rebase-preserve-merges.sh diff --git a/t/t3410-rebase-preserve-dropped-merges.sh b/third_party/git/t/t3410-rebase-preserve-dropped-merges.sh index 2e29866993..2e29866993 100755 --- a/t/t3410-rebase-preserve-dropped-merges.sh +++ b/third_party/git/t/t3410-rebase-preserve-dropped-merges.sh diff --git a/t/t3411-rebase-preserve-around-merges.sh b/third_party/git/t/t3411-rebase-preserve-around-merges.sh index fb45e7bf7b..fb45e7bf7b 100755 --- a/t/t3411-rebase-preserve-around-merges.sh +++ b/third_party/git/t/t3411-rebase-preserve-around-merges.sh diff --git a/t/t3412-rebase-root.sh b/third_party/git/t/t3412-rebase-root.sh index 21632a984e..21632a984e 100755 --- a/t/t3412-rebase-root.sh +++ b/third_party/git/t/t3412-rebase-root.sh diff --git a/t/t3413-rebase-hook.sh b/third_party/git/t/t3413-rebase-hook.sh index b6833e9a5f..b6833e9a5f 100755 --- a/t/t3413-rebase-hook.sh +++ b/third_party/git/t/t3413-rebase-hook.sh diff --git a/t/t3414-rebase-preserve-onto.sh b/third_party/git/t/t3414-rebase-preserve-onto.sh index 72e04b5386..72e04b5386 100755 --- a/t/t3414-rebase-preserve-onto.sh +++ b/third_party/git/t/t3414-rebase-preserve-onto.sh diff --git a/t/t3415-rebase-autosquash.sh b/third_party/git/t/t3415-rebase-autosquash.sh index 093de9005b..093de9005b 100755 --- a/t/t3415-rebase-autosquash.sh +++ b/third_party/git/t/t3415-rebase-autosquash.sh diff --git a/t/t3416-rebase-onto-threedots.sh b/third_party/git/t/t3416-rebase-onto-threedots.sh index 9c2548423b..9c2548423b 100755 --- a/t/t3416-rebase-onto-threedots.sh +++ b/third_party/git/t/t3416-rebase-onto-threedots.sh diff --git a/t/t3417-rebase-whitespace-fix.sh b/third_party/git/t/t3417-rebase-whitespace-fix.sh index e85cdc7037..e85cdc7037 100755 --- a/t/t3417-rebase-whitespace-fix.sh +++ b/third_party/git/t/t3417-rebase-whitespace-fix.sh diff --git a/t/t3418-rebase-continue.sh b/third_party/git/t/t3418-rebase-continue.sh index 7a2da972fd..7a2da972fd 100755 --- a/t/t3418-rebase-continue.sh +++ b/third_party/git/t/t3418-rebase-continue.sh diff --git a/t/t3419-rebase-patch-id.sh b/third_party/git/t/t3419-rebase-patch-id.sh index d934583776..d934583776 100755 --- a/t/t3419-rebase-patch-id.sh +++ b/third_party/git/t/t3419-rebase-patch-id.sh diff --git a/t/t3420-rebase-autostash.sh b/third_party/git/t/t3420-rebase-autostash.sh index b97ea62363..b97ea62363 100755 --- a/t/t3420-rebase-autostash.sh +++ b/third_party/git/t/t3420-rebase-autostash.sh diff --git a/t/t3421-rebase-topology-linear.sh b/third_party/git/t/t3421-rebase-topology-linear.sh index cf8dfd6c20..cf8dfd6c20 100755 --- a/t/t3421-rebase-topology-linear.sh +++ b/third_party/git/t/t3421-rebase-topology-linear.sh diff --git a/t/t3422-rebase-incompatible-options.sh b/third_party/git/t/t3422-rebase-incompatible-options.sh index 50e7960702..50e7960702 100755 --- a/t/t3422-rebase-incompatible-options.sh +++ b/third_party/git/t/t3422-rebase-incompatible-options.sh diff --git a/t/t3423-rebase-reword.sh b/third_party/git/t/t3423-rebase-reword.sh index 6963750794..6963750794 100755 --- a/t/t3423-rebase-reword.sh +++ b/third_party/git/t/t3423-rebase-reword.sh diff --git a/t/t3424-rebase-empty.sh b/third_party/git/t/t3424-rebase-empty.sh index e1e30517ea..e1e30517ea 100755 --- a/t/t3424-rebase-empty.sh +++ b/third_party/git/t/t3424-rebase-empty.sh diff --git a/t/t3425-rebase-topology-merges.sh b/third_party/git/t/t3425-rebase-topology-merges.sh index e42faa44e7..e42faa44e7 100755 --- a/t/t3425-rebase-topology-merges.sh +++ b/third_party/git/t/t3425-rebase-topology-merges.sh diff --git a/t/t3426-rebase-submodule.sh b/third_party/git/t/t3426-rebase-submodule.sh index a2bba04ba9..a2bba04ba9 100755 --- a/t/t3426-rebase-submodule.sh +++ b/third_party/git/t/t3426-rebase-submodule.sh diff --git a/t/t3427-rebase-subtree.sh b/third_party/git/t/t3427-rebase-subtree.sh index 79e43a370b..79e43a370b 100755 --- a/t/t3427-rebase-subtree.sh +++ b/third_party/git/t/t3427-rebase-subtree.sh diff --git a/t/t3428-rebase-signoff.sh b/third_party/git/t/t3428-rebase-signoff.sh index f6993b7e14..f6993b7e14 100755 --- a/t/t3428-rebase-signoff.sh +++ b/third_party/git/t/t3428-rebase-signoff.sh diff --git a/t/t3429-rebase-edit-todo.sh b/third_party/git/t/t3429-rebase-edit-todo.sh index 7024d49ae7..7024d49ae7 100755 --- a/t/t3429-rebase-edit-todo.sh +++ b/third_party/git/t/t3429-rebase-edit-todo.sh diff --git a/t/t3430-rebase-merges.sh b/third_party/git/t/t3430-rebase-merges.sh index a1bc3e2001..a1bc3e2001 100755 --- a/t/t3430-rebase-merges.sh +++ b/third_party/git/t/t3430-rebase-merges.sh diff --git a/t/t3431-rebase-fork-point.sh b/third_party/git/t/t3431-rebase-fork-point.sh index 78851b9a2a..78851b9a2a 100755 --- a/t/t3431-rebase-fork-point.sh +++ b/third_party/git/t/t3431-rebase-fork-point.sh diff --git a/t/t3432-rebase-fast-forward.sh b/third_party/git/t/t3432-rebase-fast-forward.sh index 6c9d4a1375..6c9d4a1375 100755 --- a/t/t3432-rebase-fast-forward.sh +++ b/third_party/git/t/t3432-rebase-fast-forward.sh diff --git a/t/t3433-rebase-across-mode-change.sh b/third_party/git/t/t3433-rebase-across-mode-change.sh index 05df964670..05df964670 100755 --- a/t/t3433-rebase-across-mode-change.sh +++ b/third_party/git/t/t3433-rebase-across-mode-change.sh diff --git a/t/t3434-rebase-i18n.sh b/third_party/git/t/t3434-rebase-i18n.sh index c7c835cde9..c7c835cde9 100755 --- a/t/t3434-rebase-i18n.sh +++ b/third_party/git/t/t3434-rebase-i18n.sh diff --git a/t/t3434/ISO8859-1.txt b/third_party/git/t/t3434/ISO8859-1.txt index 7cbef0ee6f..7cbef0ee6f 100644 --- a/t/t3434/ISO8859-1.txt +++ b/third_party/git/t/t3434/ISO8859-1.txt diff --git a/t/t3434/eucJP.txt b/third_party/git/t/t3434/eucJP.txt index 546f2aac01..546f2aac01 100644 --- a/t/t3434/eucJP.txt +++ b/third_party/git/t/t3434/eucJP.txt diff --git a/t/t3500-cherry.sh b/third_party/git/t/t3500-cherry.sh index f038f34b7c..f038f34b7c 100755 --- a/t/t3500-cherry.sh +++ b/third_party/git/t/t3500-cherry.sh diff --git a/t/t3501-revert-cherry-pick.sh b/third_party/git/t/t3501-revert-cherry-pick.sh index 7c1da21df1..7c1da21df1 100755 --- a/t/t3501-revert-cherry-pick.sh +++ b/third_party/git/t/t3501-revert-cherry-pick.sh diff --git a/t/t3502-cherry-pick-merge.sh b/third_party/git/t/t3502-cherry-pick-merge.sh index 8b635a196d..8b635a196d 100755 --- a/t/t3502-cherry-pick-merge.sh +++ b/third_party/git/t/t3502-cherry-pick-merge.sh diff --git a/t/t3503-cherry-pick-root.sh b/third_party/git/t/t3503-cherry-pick-root.sh index e27f39d1e5..e27f39d1e5 100755 --- a/t/t3503-cherry-pick-root.sh +++ b/third_party/git/t/t3503-cherry-pick-root.sh diff --git a/t/t3504-cherry-pick-rerere.sh b/third_party/git/t/t3504-cherry-pick-rerere.sh index 80a0d08706..80a0d08706 100755 --- a/t/t3504-cherry-pick-rerere.sh +++ b/third_party/git/t/t3504-cherry-pick-rerere.sh diff --git a/t/t3505-cherry-pick-empty.sh b/third_party/git/t/t3505-cherry-pick-empty.sh index 5f911bb529..5f911bb529 100755 --- a/t/t3505-cherry-pick-empty.sh +++ b/third_party/git/t/t3505-cherry-pick-empty.sh diff --git a/t/t3506-cherry-pick-ff.sh b/third_party/git/t/t3506-cherry-pick-ff.sh index 9d5adbc130..9d5adbc130 100755 --- a/t/t3506-cherry-pick-ff.sh +++ b/third_party/git/t/t3506-cherry-pick-ff.sh diff --git a/t/t3507-cherry-pick-conflict.sh b/third_party/git/t/t3507-cherry-pick-conflict.sh index 9bd482ce3b..9bd482ce3b 100755 --- a/t/t3507-cherry-pick-conflict.sh +++ b/third_party/git/t/t3507-cherry-pick-conflict.sh diff --git a/t/t3508-cherry-pick-many-commits.sh b/third_party/git/t/t3508-cherry-pick-many-commits.sh index 23070a7b73..23070a7b73 100755 --- a/t/t3508-cherry-pick-many-commits.sh +++ b/third_party/git/t/t3508-cherry-pick-many-commits.sh diff --git a/t/t3509-cherry-pick-merge-df.sh b/third_party/git/t/t3509-cherry-pick-merge-df.sh index 1e5b3948df..1e5b3948df 100755 --- a/t/t3509-cherry-pick-merge-df.sh +++ b/third_party/git/t/t3509-cherry-pick-merge-df.sh diff --git a/t/t3510-cherry-pick-sequence.sh b/third_party/git/t/t3510-cherry-pick-sequence.sh index 793bcc7fe3..793bcc7fe3 100755 --- a/t/t3510-cherry-pick-sequence.sh +++ b/third_party/git/t/t3510-cherry-pick-sequence.sh diff --git a/t/t3511-cherry-pick-x.sh b/third_party/git/t/t3511-cherry-pick-x.sh index 84a587daf3..84a587daf3 100755 --- a/t/t3511-cherry-pick-x.sh +++ b/third_party/git/t/t3511-cherry-pick-x.sh diff --git a/t/t3512-cherry-pick-submodule.sh b/third_party/git/t/t3512-cherry-pick-submodule.sh index bd78287841..bd78287841 100755 --- a/t/t3512-cherry-pick-submodule.sh +++ b/third_party/git/t/t3512-cherry-pick-submodule.sh diff --git a/t/t3513-revert-submodule.sh b/third_party/git/t/t3513-revert-submodule.sh index 5e39fcdb66..5e39fcdb66 100755 --- a/t/t3513-revert-submodule.sh +++ b/third_party/git/t/t3513-revert-submodule.sh diff --git a/t/t3600-rm.sh b/third_party/git/t/t3600-rm.sh index f2c0168941..f2c0168941 100755 --- a/t/t3600-rm.sh +++ b/third_party/git/t/t3600-rm.sh diff --git a/t/t3601-rm-pathspec-file.sh b/third_party/git/t/t3601-rm-pathspec-file.sh index 7de21f8bcf..7de21f8bcf 100755 --- a/t/t3601-rm-pathspec-file.sh +++ b/third_party/git/t/t3601-rm-pathspec-file.sh diff --git a/t/t3700-add.sh b/third_party/git/t/t3700-add.sh index 88bc799807..88bc799807 100755 --- a/t/t3700-add.sh +++ b/third_party/git/t/t3700-add.sh diff --git a/t/t3701-add-interactive.sh b/third_party/git/t/t3701-add-interactive.sh index 5bae6e50f1..5bae6e50f1 100755 --- a/t/t3701-add-interactive.sh +++ b/third_party/git/t/t3701-add-interactive.sh diff --git a/t/t3702-add-edit.sh b/third_party/git/t/t3702-add-edit.sh index 6c676645d8..6c676645d8 100755 --- a/t/t3702-add-edit.sh +++ b/third_party/git/t/t3702-add-edit.sh diff --git a/t/t3703-add-magic-pathspec.sh b/third_party/git/t/t3703-add-magic-pathspec.sh index 3ef525a559..3ef525a559 100755 --- a/t/t3703-add-magic-pathspec.sh +++ b/third_party/git/t/t3703-add-magic-pathspec.sh diff --git a/t/t3704-add-pathspec-file.sh b/third_party/git/t/t3704-add-pathspec-file.sh index 9e35c1fbca..9e35c1fbca 100755 --- a/t/t3704-add-pathspec-file.sh +++ b/third_party/git/t/t3704-add-pathspec-file.sh diff --git a/t/t3800-mktag.sh b/third_party/git/t/t3800-mktag.sh index 64dcc5ec28..64dcc5ec28 100755 --- a/t/t3800-mktag.sh +++ b/third_party/git/t/t3800-mktag.sh diff --git a/t/t3900-i18n-commit.sh b/third_party/git/t/t3900-i18n-commit.sh index d277a9f4b7..d277a9f4b7 100755 --- a/t/t3900-i18n-commit.sh +++ b/third_party/git/t/t3900-i18n-commit.sh diff --git a/t/t3900/1-UTF-8.txt b/third_party/git/t/t3900/1-UTF-8.txt index ee31e19738..ee31e19738 100644 --- a/t/t3900/1-UTF-8.txt +++ b/third_party/git/t/t3900/1-UTF-8.txt diff --git a/t/t3900/2-UTF-8.txt b/third_party/git/t/t3900/2-UTF-8.txt index 63f4f8f121..63f4f8f121 100644 --- a/t/t3900/2-UTF-8.txt +++ b/third_party/git/t/t3900/2-UTF-8.txt diff --git a/t/t3900/ISO-2022-JP.txt b/third_party/git/t/t3900/ISO-2022-JP.txt index 74b533042f..74b533042f 100644 --- a/t/t3900/ISO-2022-JP.txt +++ b/third_party/git/t/t3900/ISO-2022-JP.txt diff --git a/t/t3900/ISO8859-1.txt b/third_party/git/t/t3900/ISO8859-1.txt index 7cbef0ee6f..7cbef0ee6f 100644 --- a/t/t3900/ISO8859-1.txt +++ b/third_party/git/t/t3900/ISO8859-1.txt diff --git a/t/t3900/UTF-16.txt b/third_party/git/t/t3900/UTF-16.txt index 2257f05a99..2257f05a99 100644 --- a/t/t3900/UTF-16.txt +++ b/third_party/git/t/t3900/UTF-16.txt Binary files differdiff --git a/t/t3900/eucJP.txt b/third_party/git/t/t3900/eucJP.txt index 546f2aac01..546f2aac01 100644 --- a/t/t3900/eucJP.txt +++ b/third_party/git/t/t3900/eucJP.txt diff --git a/t/t3901-i18n-patch.sh b/third_party/git/t/t3901-i18n-patch.sh index 923eb01f0e..923eb01f0e 100755 --- a/t/t3901-i18n-patch.sh +++ b/third_party/git/t/t3901-i18n-patch.sh diff --git a/t/t3901/8859-1.txt b/third_party/git/t/t3901/8859-1.txt index 38c21a6a7f..38c21a6a7f 100755 --- a/t/t3901/8859-1.txt +++ b/third_party/git/t/t3901/8859-1.txt diff --git a/t/t3901/utf8.txt b/third_party/git/t/t3901/utf8.txt index 5f5205cd02..5f5205cd02 100755 --- a/t/t3901/utf8.txt +++ b/third_party/git/t/t3901/utf8.txt diff --git a/t/t3902-quoted.sh b/third_party/git/t/t3902-quoted.sh index f528008c36..f528008c36 100755 --- a/t/t3902-quoted.sh +++ b/third_party/git/t/t3902-quoted.sh diff --git a/t/t3903-stash.sh b/third_party/git/t/t3903-stash.sh index 3ad23e2502..3ad23e2502 100755 --- a/t/t3903-stash.sh +++ b/third_party/git/t/t3903-stash.sh diff --git a/t/t3904-stash-patch.sh b/third_party/git/t/t3904-stash-patch.sh index 9546b6f8a4..9546b6f8a4 100755 --- a/t/t3904-stash-patch.sh +++ b/third_party/git/t/t3904-stash-patch.sh diff --git a/t/t3905-stash-include-untracked.sh b/third_party/git/t/t3905-stash-include-untracked.sh index f075c7f1f3..f075c7f1f3 100755 --- a/t/t3905-stash-include-untracked.sh +++ b/third_party/git/t/t3905-stash-include-untracked.sh diff --git a/t/t3906-stash-submodule.sh b/third_party/git/t/t3906-stash-submodule.sh index b93d1d74da..b93d1d74da 100755 --- a/t/t3906-stash-submodule.sh +++ b/third_party/git/t/t3906-stash-submodule.sh diff --git a/t/t3907-stash-show-config.sh b/third_party/git/t/t3907-stash-show-config.sh index 10914bba7b..10914bba7b 100755 --- a/t/t3907-stash-show-config.sh +++ b/third_party/git/t/t3907-stash-show-config.sh diff --git a/t/t3908-stash-in-worktree.sh b/third_party/git/t/t3908-stash-in-worktree.sh index 2b2b366ef9..2b2b366ef9 100755 --- a/t/t3908-stash-in-worktree.sh +++ b/third_party/git/t/t3908-stash-in-worktree.sh diff --git a/t/t3909-stash-pathspec-file.sh b/third_party/git/t/t3909-stash-pathspec-file.sh index 55e050cfd4..55e050cfd4 100755 --- a/t/t3909-stash-pathspec-file.sh +++ b/third_party/git/t/t3909-stash-pathspec-file.sh diff --git a/t/t3910-mac-os-precompose.sh b/third_party/git/t/t3910-mac-os-precompose.sh index 54ce19e353..54ce19e353 100755 --- a/t/t3910-mac-os-precompose.sh +++ b/third_party/git/t/t3910-mac-os-precompose.sh diff --git a/t/t4000-diff-format.sh b/third_party/git/t/t4000-diff-format.sh index e5116a76a1..e5116a76a1 100755 --- a/t/t4000-diff-format.sh +++ b/third_party/git/t/t4000-diff-format.sh diff --git a/t/t4001-diff-rename.sh b/third_party/git/t/t4001-diff-rename.sh index c16486a9d4..c16486a9d4 100755 --- a/t/t4001-diff-rename.sh +++ b/third_party/git/t/t4001-diff-rename.sh diff --git a/t/t4002-diff-basic.sh b/third_party/git/t/t4002-diff-basic.sh index cbcdd10464..cbcdd10464 100755 --- a/t/t4002-diff-basic.sh +++ b/third_party/git/t/t4002-diff-basic.sh diff --git a/t/t4003-diff-rename-1.sh b/third_party/git/t/t4003-diff-rename-1.sh index df2accb655..df2accb655 100755 --- a/t/t4003-diff-rename-1.sh +++ b/third_party/git/t/t4003-diff-rename-1.sh diff --git a/t/t4004-diff-rename-symlink.sh b/third_party/git/t/t4004-diff-rename-symlink.sh index 6e562c80d1..6e562c80d1 100755 --- a/t/t4004-diff-rename-symlink.sh +++ b/third_party/git/t/t4004-diff-rename-symlink.sh diff --git a/t/t4005-diff-rename-2.sh b/third_party/git/t/t4005-diff-rename-2.sh index f542d2929d..f542d2929d 100755 --- a/t/t4005-diff-rename-2.sh +++ b/third_party/git/t/t4005-diff-rename-2.sh diff --git a/t/t4006-diff-mode.sh b/third_party/git/t/t4006-diff-mode.sh index 03489aff14..03489aff14 100755 --- a/t/t4006-diff-mode.sh +++ b/third_party/git/t/t4006-diff-mode.sh diff --git a/t/t4007-rename-3.sh b/third_party/git/t/t4007-rename-3.sh index b187b7f6c6..b187b7f6c6 100755 --- a/t/t4007-rename-3.sh +++ b/third_party/git/t/t4007-rename-3.sh diff --git a/t/t4008-diff-break-rewrite.sh b/third_party/git/t/t4008-diff-break-rewrite.sh index b1ccd4102e..b1ccd4102e 100755 --- a/t/t4008-diff-break-rewrite.sh +++ b/third_party/git/t/t4008-diff-break-rewrite.sh diff --git a/t/t4009-diff-rename-4.sh b/third_party/git/t/t4009-diff-rename-4.sh index b63bdf031f..b63bdf031f 100755 --- a/t/t4009-diff-rename-4.sh +++ b/third_party/git/t/t4009-diff-rename-4.sh diff --git a/t/t4010-diff-pathspec.sh b/third_party/git/t/t4010-diff-pathspec.sh index e5ca359edf..e5ca359edf 100755 --- a/t/t4010-diff-pathspec.sh +++ b/third_party/git/t/t4010-diff-pathspec.sh diff --git a/t/t4011-diff-symlink.sh b/third_party/git/t/t4011-diff-symlink.sh index 717034bb50..717034bb50 100755 --- a/t/t4011-diff-symlink.sh +++ b/third_party/git/t/t4011-diff-symlink.sh diff --git a/t/t4012-diff-binary.sh b/third_party/git/t/t4012-diff-binary.sh index 6579c81216..6579c81216 100755 --- a/t/t4012-diff-binary.sh +++ b/third_party/git/t/t4012-diff-binary.sh diff --git a/t/t4013-diff-various.sh b/third_party/git/t/t4013-diff-various.sh index dde3f11fec..dde3f11fec 100755 --- a/t/t4013-diff-various.sh +++ b/third_party/git/t/t4013-diff-various.sh diff --git a/t/t4013/diff.config_format.subjectprefix_DIFFERENT_PREFIX b/third_party/git/t/t4013/diff.config_format.subjectprefix_DIFFERENT_PREFIX index 78f8970e2b..78f8970e2b 100644 --- a/t/t4013/diff.config_format.subjectprefix_DIFFERENT_PREFIX +++ b/third_party/git/t/t4013/diff.config_format.subjectprefix_DIFFERENT_PREFIX diff --git a/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_master index 9951e3677d..9951e3677d 100644 --- a/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_side b/third_party/git/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_side index cec33fa3f0..cec33fa3f0 100644 --- a/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_side +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--patch-with-stat_--summary_side diff --git a/t/t4013/diff.diff-tree_--cc_--patch-with-stat_master b/third_party/git/t/t4013/diff.diff-tree_--cc_--patch-with-stat_master index db3c0a7b2c..db3c0a7b2c 100644 --- a/t/t4013/diff.diff-tree_--cc_--patch-with-stat_master +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--patch-with-stat_master diff --git a/t/t4013/diff.diff-tree_--cc_--shortstat_master b/third_party/git/t/t4013/diff.diff-tree_--cc_--shortstat_master index a4ca42df2a..a4ca42df2a 100644 --- a/t/t4013/diff.diff-tree_--cc_--shortstat_master +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--shortstat_master diff --git a/t/t4013/diff.diff-tree_--cc_--stat_--summary_master b/third_party/git/t/t4013/diff.diff-tree_--cc_--stat_--summary_master index d019867dd9..d019867dd9 100644 --- a/t/t4013/diff.diff-tree_--cc_--stat_--summary_master +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--stat_--summary_master diff --git a/t/t4013/diff.diff-tree_--cc_--stat_--summary_side b/third_party/git/t/t4013/diff.diff-tree_--cc_--stat_--summary_side index 12b2eee17e..12b2eee17e 100644 --- a/t/t4013/diff.diff-tree_--cc_--stat_--summary_side +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--stat_--summary_side diff --git a/t/t4013/diff.diff-tree_--cc_--stat_master b/third_party/git/t/t4013/diff.diff-tree_--cc_--stat_master index 40b91796b3..40b91796b3 100644 --- a/t/t4013/diff.diff-tree_--cc_--stat_master +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--stat_master diff --git a/t/t4013/diff.diff-tree_--cc_--summary_REVERSE b/third_party/git/t/t4013/diff.diff-tree_--cc_--summary_REVERSE index e208dd5682..e208dd5682 100644 --- a/t/t4013/diff.diff-tree_--cc_--summary_REVERSE +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_--summary_REVERSE diff --git a/t/t4013/diff.diff-tree_--cc_master b/third_party/git/t/t4013/diff.diff-tree_--cc_master index 5ecb4e14ae..5ecb4e14ae 100644 --- a/t/t4013/diff.diff-tree_--cc_master +++ b/third_party/git/t/t4013/diff.diff-tree_--cc_master diff --git a/t/t4013/diff.diff-tree_--patch-with-raw_initial b/third_party/git/t/t4013/diff.diff-tree_--patch-with-raw_initial index fc177ab3f2..fc177ab3f2 100644 --- a/t/t4013/diff.diff-tree_--patch-with-raw_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--patch-with-raw_initial diff --git a/t/t4013/diff.diff-tree_--patch-with-stat_initial b/third_party/git/t/t4013/diff.diff-tree_--patch-with-stat_initial index bd905b1c57..bd905b1c57 100644 --- a/t/t4013/diff.diff-tree_--patch-with-stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--patch-with-stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-raw_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-raw_initial index 7bb8b45e3e..7bb8b45e3e 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-raw_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-raw_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-stat_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-stat_initial index cbdde4f400..cbdde4f400 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--patch-with-stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-raw_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-raw_initial index cd79f1a0ff..cd79f1a0ff 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-raw_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-raw_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-stat_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-stat_initial index 817ed06f82..817ed06f82 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_--patch-with-stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_--root_-p_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_-p_initial index 3c5092c699..3c5092c699 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_--root_-p_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_-p_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_--root_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_initial index 08920ac658..08920ac658 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_--root_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_--root_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_-p_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_-p_initial index 94b76bfef1..94b76bfef1 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_-p_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_-p_initial diff --git a/t/t4013/diff.diff-tree_--pretty=oneline_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_initial index d50970d574..d50970d574 100644 --- a/t/t4013/diff.diff-tree_--pretty=oneline_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty=oneline_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--patch-with-raw_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--patch-with-raw_initial index 3a85316d8a..3a85316d8a 100644 --- a/t/t4013/diff.diff-tree_--pretty_--patch-with-raw_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--patch-with-raw_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_initial index 2e08239a46..2e08239a46 100644 --- a/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_side b/third_party/git/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_side index fe3f6b7c7e..fe3f6b7c7e 100644 --- a/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_side +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--patch-with-stat_side diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-raw_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-raw_initial index a3203bd19b..a3203bd19b 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-raw_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-raw_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-stat_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-stat_initial index 06eb77e386..06eb77e386 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--patch-with-stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--stat_--compact-summary_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--stat_--compact-summary_initial index d6451ff7cc..d6451ff7cc 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--stat_--compact-summary_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--stat_--compact-summary_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--stat_--summary_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--stat_--summary_initial index 680eab5f27..680eab5f27 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--stat_--summary_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--stat_--summary_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--stat_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--stat_initial index 9722d1b3a7..9722d1b3a7 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--summary_-r_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--summary_-r_initial index ccdaafb377..ccdaafb377 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--summary_-r_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--summary_-r_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_--summary_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--summary_initial index 58e5f74aea..58e5f74aea 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_--summary_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_--summary_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_-p_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_-p_initial index d0411f64ec..d0411f64ec 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_-p_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_-p_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--root_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_initial index 94e32eabb1..94e32eabb1 100644 --- a/t/t4013/diff.diff-tree_--pretty_--root_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--root_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--stat_--summary_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--stat_--summary_initial index c22983ac4a..c22983ac4a 100644 --- a/t/t4013/diff.diff-tree_--pretty_--stat_--summary_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--stat_--summary_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--stat_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--stat_initial index 8fdcfb4c0a..8fdcfb4c0a 100644 --- a/t/t4013/diff.diff-tree_--pretty_--stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--stat_initial diff --git a/t/t4013/diff.diff-tree_--pretty_--summary_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_--summary_initial index 9bc2c4fbad..9bc2c4fbad 100644 --- a/t/t4013/diff.diff-tree_--pretty_--summary_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_--summary_initial diff --git a/t/t4013/diff.diff-tree_--pretty_-R_--root_--stat_--compact-summary_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_-R_--root_--stat_--compact-summary_initial index 1989e55cd0..1989e55cd0 100644 --- a/t/t4013/diff.diff-tree_--pretty_-R_--root_--stat_--compact-summary_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_-R_--root_--stat_--compact-summary_initial diff --git a/t/t4013/diff.diff-tree_--pretty_-p_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_-p_initial index 3c9942faf4..3c9942faf4 100644 --- a/t/t4013/diff.diff-tree_--pretty_-p_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_-p_initial diff --git a/t/t4013/diff.diff-tree_--pretty_-p_side b/third_party/git/t/t4013/diff.diff-tree_--pretty_-p_side index b993aa7b89..b993aa7b89 100644 --- a/t/t4013/diff.diff-tree_--pretty_-p_side +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_-p_side diff --git a/t/t4013/diff.diff-tree_--pretty_initial b/third_party/git/t/t4013/diff.diff-tree_--pretty_initial index 14715bf7d0..14715bf7d0 100644 --- a/t/t4013/diff.diff-tree_--pretty_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_initial diff --git a/t/t4013/diff.diff-tree_--pretty_side b/third_party/git/t/t4013/diff.diff-tree_--pretty_side index e9b6e1c102..e9b6e1c102 100644 --- a/t/t4013/diff.diff-tree_--pretty_side +++ b/third_party/git/t/t4013/diff.diff-tree_--pretty_side diff --git a/t/t4013/diff.diff-tree_--root_--abbrev_initial b/third_party/git/t/t4013/diff.diff-tree_--root_--abbrev_initial index 5aa84b2a86..5aa84b2a86 100644 --- a/t/t4013/diff.diff-tree_--root_--abbrev_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_--abbrev_initial diff --git a/t/t4013/diff.diff-tree_--root_--patch-with-raw_initial b/third_party/git/t/t4013/diff.diff-tree_--root_--patch-with-raw_initial index d295e475dd..d295e475dd 100644 --- a/t/t4013/diff.diff-tree_--root_--patch-with-raw_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_--patch-with-raw_initial diff --git a/t/t4013/diff.diff-tree_--root_--patch-with-stat_initial b/third_party/git/t/t4013/diff.diff-tree_--root_--patch-with-stat_initial index ad69ffe647..ad69ffe647 100644 --- a/t/t4013/diff.diff-tree_--root_--patch-with-stat_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_--patch-with-stat_initial diff --git a/t/t4013/diff.diff-tree_--root_-p_initial b/third_party/git/t/t4013/diff.diff-tree_--root_-p_initial index 3219c72fcb..3219c72fcb 100644 --- a/t/t4013/diff.diff-tree_--root_-p_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_-p_initial diff --git a/t/t4013/diff.diff-tree_--root_-r_--abbrev=4_initial b/third_party/git/t/t4013/diff.diff-tree_--root_-r_--abbrev=4_initial index 0c5361688c..0c5361688c 100644 --- a/t/t4013/diff.diff-tree_--root_-r_--abbrev=4_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_-r_--abbrev=4_initial diff --git a/t/t4013/diff.diff-tree_--root_-r_--abbrev_initial b/third_party/git/t/t4013/diff.diff-tree_--root_-r_--abbrev_initial index c7b460faf6..c7b460faf6 100644 --- a/t/t4013/diff.diff-tree_--root_-r_--abbrev_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_-r_--abbrev_initial diff --git a/t/t4013/diff.diff-tree_--root_-r_initial b/third_party/git/t/t4013/diff.diff-tree_--root_-r_initial index eed435e175..eed435e175 100644 --- a/t/t4013/diff.diff-tree_--root_-r_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_-r_initial diff --git a/t/t4013/diff.diff-tree_--root_initial b/third_party/git/t/t4013/diff.diff-tree_--root_initial index ddf6b068ab..ddf6b068ab 100644 --- a/t/t4013/diff.diff-tree_--root_initial +++ b/third_party/git/t/t4013/diff.diff-tree_--root_initial diff --git a/t/t4013/diff.diff-tree_--stat_--compact-summary_initial_mode b/third_party/git/t/t4013/diff.diff-tree_--stat_--compact-summary_initial_mode index 9c7c8f63af..9c7c8f63af 100644 --- a/t/t4013/diff.diff-tree_--stat_--compact-summary_initial_mode +++ b/third_party/git/t/t4013/diff.diff-tree_--stat_--compact-summary_initial_mode diff --git a/t/t4013/diff.diff-tree_--stat_initial_mode b/third_party/git/t/t4013/diff.diff-tree_--stat_initial_mode index 0e5943c2c6..0e5943c2c6 100644 --- a/t/t4013/diff.diff-tree_--stat_initial_mode +++ b/third_party/git/t/t4013/diff.diff-tree_--stat_initial_mode diff --git a/t/t4013/diff.diff-tree_--summary_initial_mode b/third_party/git/t/t4013/diff.diff-tree_--summary_initial_mode index 25846b6af8..25846b6af8 100644 --- a/t/t4013/diff.diff-tree_--summary_initial_mode +++ b/third_party/git/t/t4013/diff.diff-tree_--summary_initial_mode diff --git a/t/t4013/diff.diff-tree_-R_--stat_--compact-summary_initial_mode b/third_party/git/t/t4013/diff.diff-tree_-R_--stat_--compact-summary_initial_mode index e38f3d3bfb..e38f3d3bfb 100644 --- a/t/t4013/diff.diff-tree_-R_--stat_--compact-summary_initial_mode +++ b/third_party/git/t/t4013/diff.diff-tree_-R_--stat_--compact-summary_initial_mode diff --git a/t/t4013/diff.diff-tree_-c_--abbrev_master b/third_party/git/t/t4013/diff.diff-tree_-c_--abbrev_master index b8e4aa2530..b8e4aa2530 100644 --- a/t/t4013/diff.diff-tree_-c_--abbrev_master +++ b/third_party/git/t/t4013/diff.diff-tree_-c_--abbrev_master diff --git a/t/t4013/diff.diff-tree_-c_--stat_--summary_master b/third_party/git/t/t4013/diff.diff-tree_-c_--stat_--summary_master index 81c3021541..81c3021541 100644 --- a/t/t4013/diff.diff-tree_-c_--stat_--summary_master +++ b/third_party/git/t/t4013/diff.diff-tree_-c_--stat_--summary_master diff --git a/t/t4013/diff.diff-tree_-c_--stat_--summary_side b/third_party/git/t/t4013/diff.diff-tree_-c_--stat_--summary_side index e8dc12bfbf..e8dc12bfbf 100644 --- a/t/t4013/diff.diff-tree_-c_--stat_--summary_side +++ b/third_party/git/t/t4013/diff.diff-tree_-c_--stat_--summary_side diff --git a/t/t4013/diff.diff-tree_-c_--stat_master b/third_party/git/t/t4013/diff.diff-tree_-c_--stat_master index 89d59b1548..89d59b1548 100644 --- a/t/t4013/diff.diff-tree_-c_--stat_master +++ b/third_party/git/t/t4013/diff.diff-tree_-c_--stat_master diff --git a/t/t4013/diff.diff-tree_-c_master b/third_party/git/t/t4013/diff.diff-tree_-c_master index e2d2bb2611..e2d2bb2611 100644 --- a/t/t4013/diff.diff-tree_-c_master +++ b/third_party/git/t/t4013/diff.diff-tree_-c_master diff --git a/t/t4013/diff.diff-tree_-p_-m_master b/third_party/git/t/t4013/diff.diff-tree_-p_-m_master index b60bea039d..b60bea039d 100644 --- a/t/t4013/diff.diff-tree_-p_-m_master +++ b/third_party/git/t/t4013/diff.diff-tree_-p_-m_master diff --git a/t/t4013/diff.diff-tree_-p_initial b/third_party/git/t/t4013/diff.diff-tree_-p_initial index e20ce88370..e20ce88370 100644 --- a/t/t4013/diff.diff-tree_-p_initial +++ b/third_party/git/t/t4013/diff.diff-tree_-p_initial diff --git a/t/t4013/diff.diff-tree_-p_master b/third_party/git/t/t4013/diff.diff-tree_-p_master index b182875fb2..b182875fb2 100644 --- a/t/t4013/diff.diff-tree_-p_master +++ b/third_party/git/t/t4013/diff.diff-tree_-p_master diff --git a/t/t4013/diff.diff-tree_-r_--abbrev=4_initial b/third_party/git/t/t4013/diff.diff-tree_-r_--abbrev=4_initial index c5a3aa5aa4..c5a3aa5aa4 100644 --- a/t/t4013/diff.diff-tree_-r_--abbrev=4_initial +++ b/third_party/git/t/t4013/diff.diff-tree_-r_--abbrev=4_initial diff --git a/t/t4013/diff.diff-tree_-r_--abbrev_initial b/third_party/git/t/t4013/diff.diff-tree_-r_--abbrev_initial index 0b689b773c..0b689b773c 100644 --- a/t/t4013/diff.diff-tree_-r_--abbrev_initial +++ b/third_party/git/t/t4013/diff.diff-tree_-r_--abbrev_initial diff --git a/t/t4013/diff.diff-tree_-r_initial b/third_party/git/t/t4013/diff.diff-tree_-r_initial index 1765d83ce4..1765d83ce4 100644 --- a/t/t4013/diff.diff-tree_-r_initial +++ b/third_party/git/t/t4013/diff.diff-tree_-r_initial diff --git a/t/t4013/diff.diff-tree_initial b/third_party/git/t/t4013/diff.diff-tree_initial index b49fc53457..b49fc53457 100644 --- a/t/t4013/diff.diff-tree_initial +++ b/third_party/git/t/t4013/diff.diff-tree_initial diff --git a/t/t4013/diff.diff-tree_initial_mode b/third_party/git/t/t4013/diff.diff-tree_initial_mode index c47c09423e..c47c09423e 100644 --- a/t/t4013/diff.diff-tree_initial_mode +++ b/third_party/git/t/t4013/diff.diff-tree_initial_mode diff --git a/t/t4013/diff.diff-tree_master b/third_party/git/t/t4013/diff.diff-tree_master index fe9226f8a1..fe9226f8a1 100644 --- a/t/t4013/diff.diff-tree_master +++ b/third_party/git/t/t4013/diff.diff-tree_master diff --git a/t/t4013/diff.diff_--abbrev_initial..side b/third_party/git/t/t4013/diff.diff_--abbrev_initial..side index a88e66f817..a88e66f817 100644 --- a/t/t4013/diff.diff_--abbrev_initial..side +++ b/third_party/git/t/t4013/diff.diff_--abbrev_initial..side diff --git a/t/t4013/diff.diff_--cached b/third_party/git/t/t4013/diff.diff_--cached index ff16e83e7c..ff16e83e7c 100644 --- a/t/t4013/diff.diff_--cached +++ b/third_party/git/t/t4013/diff.diff_--cached diff --git a/t/t4013/diff.diff_--cached_--_file0 b/third_party/git/t/t4013/diff.diff_--cached_--_file0 index b9bb858a03..b9bb858a03 100644 --- a/t/t4013/diff.diff_--cached_--_file0 +++ b/third_party/git/t/t4013/diff.diff_--cached_--_file0 diff --git a/t/t4013/diff.diff_--dirstat-by-file_initial_rearrange b/third_party/git/t/t4013/diff.diff_--dirstat-by-file_initial_rearrange index e48e33f678..e48e33f678 100644 --- a/t/t4013/diff.diff_--dirstat-by-file_initial_rearrange +++ b/third_party/git/t/t4013/diff.diff_--dirstat-by-file_initial_rearrange diff --git a/t/t4013/diff.diff_--dirstat_--cc_master~1_master b/third_party/git/t/t4013/diff.diff_--dirstat_--cc_master~1_master index fba4e34175..fba4e34175 100644 --- a/t/t4013/diff.diff_--dirstat_--cc_master~1_master +++ b/third_party/git/t/t4013/diff.diff_--dirstat_--cc_master~1_master diff --git a/t/t4013/diff.diff_--dirstat_initial_rearrange b/third_party/git/t/t4013/diff.diff_--dirstat_initial_rearrange index 5fb02c13bc..5fb02c13bc 100644 --- a/t/t4013/diff.diff_--dirstat_initial_rearrange +++ b/third_party/git/t/t4013/diff.diff_--dirstat_initial_rearrange diff --git a/t/t4013/diff.diff_--dirstat_master~1_master~2 b/third_party/git/t/t4013/diff.diff_--dirstat_master~1_master~2 index b672e1ca63..b672e1ca63 100644 --- a/t/t4013/diff.diff_--dirstat_master~1_master~2 +++ b/third_party/git/t/t4013/diff.diff_--dirstat_master~1_master~2 diff --git a/t/t4013/diff.diff_--line-prefix=abc_master_master^_side b/third_party/git/t/t4013/diff.diff_--line-prefix=abc_master_master^_side index 99f91e7f0e..99f91e7f0e 100644 --- a/t/t4013/diff.diff_--line-prefix=abc_master_master^_side +++ b/third_party/git/t/t4013/diff.diff_--line-prefix=abc_master_master^_side diff --git a/t/t4013/diff.diff_--line-prefix_--cached_--_file0 b/third_party/git/t/t4013/diff.diff_--line-prefix_--cached_--_file0 index f41ba4d36a..f41ba4d36a 100644 --- a/t/t4013/diff.diff_--line-prefix_--cached_--_file0 +++ b/third_party/git/t/t4013/diff.diff_--line-prefix_--cached_--_file0 diff --git a/t/t4013/diff.diff_--name-status_dir2_dir b/third_party/git/t/t4013/diff.diff_--name-status_dir2_dir index d0d96aaa91..d0d96aaa91 100644 --- a/t/t4013/diff.diff_--name-status_dir2_dir +++ b/third_party/git/t/t4013/diff.diff_--name-status_dir2_dir diff --git a/t/t4013/diff.diff_--no-index_--name-status_--_dir2_dir b/third_party/git/t/t4013/diff.diff_--no-index_--name-status_--_dir2_dir index 6756f8de67..6756f8de67 100644 --- a/t/t4013/diff.diff_--no-index_--name-status_--_dir2_dir +++ b/third_party/git/t/t4013/diff.diff_--no-index_--name-status_--_dir2_dir diff --git a/t/t4013/diff.diff_--no-index_--name-status_dir2_dir b/third_party/git/t/t4013/diff.diff_--no-index_--name-status_dir2_dir index 6a47584777..6a47584777 100644 --- a/t/t4013/diff.diff_--no-index_--name-status_dir2_dir +++ b/third_party/git/t/t4013/diff.diff_--no-index_--name-status_dir2_dir diff --git a/t/t4013/diff.diff_--no-index_--raw_--abbrev=4_dir2_dir b/third_party/git/t/t4013/diff.diff_--no-index_--raw_--abbrev=4_dir2_dir index a71b38a833..a71b38a833 100644 --- a/t/t4013/diff.diff_--no-index_--raw_--abbrev=4_dir2_dir +++ b/third_party/git/t/t4013/diff.diff_--no-index_--raw_--abbrev=4_dir2_dir diff --git a/t/t4013/diff.diff_--no-index_--raw_--no-abbrev_dir2_dir b/third_party/git/t/t4013/diff.diff_--no-index_--raw_--no-abbrev_dir2_dir index e0f00977c8..e0f00977c8 100644 --- a/t/t4013/diff.diff_--no-index_--raw_--no-abbrev_dir2_dir +++ b/third_party/git/t/t4013/diff.diff_--no-index_--raw_--no-abbrev_dir2_dir diff --git a/t/t4013/diff.diff_--no-index_--raw_dir2_dir b/third_party/git/t/t4013/diff.diff_--no-index_--raw_dir2_dir index 3cb4ee7a9a..3cb4ee7a9a 100644 --- a/t/t4013/diff.diff_--no-index_--raw_dir2_dir +++ b/third_party/git/t/t4013/diff.diff_--no-index_--raw_dir2_dir diff --git a/t/t4013/diff.diff_--no-index_dir_dir3 b/third_party/git/t/t4013/diff.diff_--no-index_dir_dir3 index 2142c2b9ad..2142c2b9ad 100644 --- a/t/t4013/diff.diff_--no-index_dir_dir3 +++ b/third_party/git/t/t4013/diff.diff_--no-index_dir_dir3 diff --git a/t/t4013/diff.diff_--patch-with-raw_-r_initial..side b/third_party/git/t/t4013/diff.diff_--patch-with-raw_-r_initial..side index 3590dc79a6..3590dc79a6 100644 --- a/t/t4013/diff.diff_--patch-with-raw_-r_initial..side +++ b/third_party/git/t/t4013/diff.diff_--patch-with-raw_-r_initial..side diff --git a/t/t4013/diff.diff_--patch-with-raw_initial..side b/third_party/git/t/t4013/diff.diff_--patch-with-raw_initial..side index b21d5dc6f3..b21d5dc6f3 100644 --- a/t/t4013/diff.diff_--patch-with-raw_initial..side +++ b/third_party/git/t/t4013/diff.diff_--patch-with-raw_initial..side diff --git a/t/t4013/diff.diff_--patch-with-stat_-r_initial..side b/third_party/git/t/t4013/diff.diff_--patch-with-stat_-r_initial..side index be8d1ea1bd..be8d1ea1bd 100644 --- a/t/t4013/diff.diff_--patch-with-stat_-r_initial..side +++ b/third_party/git/t/t4013/diff.diff_--patch-with-stat_-r_initial..side diff --git a/t/t4013/diff.diff_--patch-with-stat_initial..side b/third_party/git/t/t4013/diff.diff_--patch-with-stat_initial..side index 5424e6d566..5424e6d566 100644 --- a/t/t4013/diff.diff_--patch-with-stat_initial..side +++ b/third_party/git/t/t4013/diff.diff_--patch-with-stat_initial..side diff --git a/t/t4013/diff.diff_--raw_--abbrev=4_initial b/third_party/git/t/t4013/diff.diff_--raw_--abbrev=4_initial index c3641db31d..c3641db31d 100644 --- a/t/t4013/diff.diff_--raw_--abbrev=4_initial +++ b/third_party/git/t/t4013/diff.diff_--raw_--abbrev=4_initial diff --git a/t/t4013/diff.diff_--raw_--no-abbrev_initial b/third_party/git/t/t4013/diff.diff_--raw_--no-abbrev_initial index c87a1258e3..c87a1258e3 100644 --- a/t/t4013/diff.diff_--raw_--no-abbrev_initial +++ b/third_party/git/t/t4013/diff.diff_--raw_--no-abbrev_initial diff --git a/t/t4013/diff.diff_--raw_initial b/third_party/git/t/t4013/diff.diff_--raw_initial index a3e978040d..a3e978040d 100644 --- a/t/t4013/diff.diff_--raw_initial +++ b/third_party/git/t/t4013/diff.diff_--raw_initial diff --git a/t/t4013/diff.diff_--stat_initial..side b/third_party/git/t/t4013/diff.diff_--stat_initial..side index b7741e2b83..b7741e2b83 100644 --- a/t/t4013/diff.diff_--stat_initial..side +++ b/third_party/git/t/t4013/diff.diff_--stat_initial..side diff --git a/t/t4013/diff.diff_-U1_initial..side b/third_party/git/t/t4013/diff.diff_-U1_initial..side index b69f8f048a..b69f8f048a 100644 --- a/t/t4013/diff.diff_-U1_initial..side +++ b/third_party/git/t/t4013/diff.diff_-U1_initial..side diff --git a/t/t4013/diff.diff_-U2_initial..side b/third_party/git/t/t4013/diff.diff_-U2_initial..side index 8ffe04f203..8ffe04f203 100644 --- a/t/t4013/diff.diff_-U2_initial..side +++ b/third_party/git/t/t4013/diff.diff_-U2_initial..side diff --git a/t/t4013/diff.diff_-U_initial..side b/third_party/git/t/t4013/diff.diff_-U_initial..side index c66c0dd5c6..c66c0dd5c6 100644 --- a/t/t4013/diff.diff_-U_initial..side +++ b/third_party/git/t/t4013/diff.diff_-U_initial..side diff --git a/t/t4013/diff.diff_-r_--stat_initial..side b/third_party/git/t/t4013/diff.diff_-r_--stat_initial..side index 5d514f55b9..5d514f55b9 100644 --- a/t/t4013/diff.diff_-r_--stat_initial..side +++ b/third_party/git/t/t4013/diff.diff_-r_--stat_initial..side diff --git a/t/t4013/diff.diff_-r_initial..side b/third_party/git/t/t4013/diff.diff_-r_initial..side index 5bb2fe2f28..5bb2fe2f28 100644 --- a/t/t4013/diff.diff_-r_initial..side +++ b/third_party/git/t/t4013/diff.diff_-r_initial..side diff --git a/t/t4013/diff.diff_initial..side b/third_party/git/t/t4013/diff.diff_initial..side index c8adaf5958..c8adaf5958 100644 --- a/t/t4013/diff.diff_initial..side +++ b/third_party/git/t/t4013/diff.diff_initial..side diff --git a/t/t4013/diff.diff_master_master^_side b/third_party/git/t/t4013/diff.diff_master_master^_side index 50ec9cadd6..50ec9cadd6 100644 --- a/t/t4013/diff.diff_master_master^_side +++ b/third_party/git/t/t4013/diff.diff_master_master^_side diff --git a/t/t4013/diff.format-patch_--attach_--stdout_--suffix=.diff_initial..side b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_--suffix=.diff_initial..side index 547ca065a5..547ca065a5 100644 --- a/t/t4013/diff.format-patch_--attach_--stdout_--suffix=.diff_initial..side +++ b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_--suffix=.diff_initial..side diff --git a/t/t4013/diff.format-patch_--attach_--stdout_initial..master b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_initial..master index 52fedc179e..52fedc179e 100644 --- a/t/t4013/diff.format-patch_--attach_--stdout_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_initial..master diff --git a/t/t4013/diff.format-patch_--attach_--stdout_initial..master^ b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_initial..master^ index 1c3cde251b..1c3cde251b 100644 --- a/t/t4013/diff.format-patch_--attach_--stdout_initial..master^ +++ b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_initial..master^ diff --git a/t/t4013/diff.format-patch_--attach_--stdout_initial..side b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_initial..side index 4717bd8313..4717bd8313 100644 --- a/t/t4013/diff.format-patch_--attach_--stdout_initial..side +++ b/third_party/git/t/t4013/diff.format-patch_--attach_--stdout_initial..side diff --git a/t/t4013/diff.format-patch_--inline_--stdout_--numbered-files_initial..master b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_--numbered-files_initial..master index 02c4db7ec5..02c4db7ec5 100644 --- a/t/t4013/diff.format-patch_--inline_--stdout_--numbered-files_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_--numbered-files_initial..master diff --git a/t/t4013/diff.format-patch_--inline_--stdout_--subject-prefix=TESTCASE_initial..master b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_--subject-prefix=TESTCASE_initial..master index c7677c5951..c7677c5951 100644 --- a/t/t4013/diff.format-patch_--inline_--stdout_--subject-prefix=TESTCASE_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_--subject-prefix=TESTCASE_initial..master diff --git a/t/t4013/diff.format-patch_--inline_--stdout_initial..master b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..master index 5b3e34e2c0..5b3e34e2c0 100644 --- a/t/t4013/diff.format-patch_--inline_--stdout_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..master diff --git a/t/t4013/diff.format-patch_--inline_--stdout_initial..master^ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..master^ index d13f8a8128..d13f8a8128 100644 --- a/t/t4013/diff.format-patch_--inline_--stdout_initial..master^ +++ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..master^ diff --git a/t/t4013/diff.format-patch_--inline_--stdout_initial..master^^ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..master^^ index caec5537de..caec5537de 100644 --- a/t/t4013/diff.format-patch_--inline_--stdout_initial..master^^ +++ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..master^^ diff --git a/t/t4013/diff.format-patch_--inline_--stdout_initial..side b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..side index d3a6762130..d3a6762130 100644 --- a/t/t4013/diff.format-patch_--inline_--stdout_initial..side +++ b/third_party/git/t/t4013/diff.format-patch_--inline_--stdout_initial..side diff --git a/t/t4013/diff.format-patch_--stdout_--cover-letter_-n_initial..master^ b/third_party/git/t/t4013/diff.format-patch_--stdout_--cover-letter_-n_initial..master^ index 244d964fc6..244d964fc6 100644 --- a/t/t4013/diff.format-patch_--stdout_--cover-letter_-n_initial..master^ +++ b/third_party/git/t/t4013/diff.format-patch_--stdout_--cover-letter_-n_initial..master^ diff --git a/t/t4013/diff.format-patch_--stdout_--no-numbered_initial..master b/third_party/git/t/t4013/diff.format-patch_--stdout_--no-numbered_initial..master index bfc287a147..bfc287a147 100644 --- a/t/t4013/diff.format-patch_--stdout_--no-numbered_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--stdout_--no-numbered_initial..master diff --git a/t/t4013/diff.format-patch_--stdout_--numbered_initial..master b/third_party/git/t/t4013/diff.format-patch_--stdout_--numbered_initial..master index 568f6f584e..568f6f584e 100644 --- a/t/t4013/diff.format-patch_--stdout_--numbered_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--stdout_--numbered_initial..master diff --git a/t/t4013/diff.format-patch_--stdout_initial..master b/third_party/git/t/t4013/diff.format-patch_--stdout_initial..master index 5f0352f9f7..5f0352f9f7 100644 --- a/t/t4013/diff.format-patch_--stdout_initial..master +++ b/third_party/git/t/t4013/diff.format-patch_--stdout_initial..master diff --git a/t/t4013/diff.format-patch_--stdout_initial..master^ b/third_party/git/t/t4013/diff.format-patch_--stdout_initial..master^ index 2ae454d807..2ae454d807 100644 --- a/t/t4013/diff.format-patch_--stdout_initial..master^ +++ b/third_party/git/t/t4013/diff.format-patch_--stdout_initial..master^ diff --git a/t/t4013/diff.format-patch_--stdout_initial..side b/third_party/git/t/t4013/diff.format-patch_--stdout_initial..side index a7d52fbeea..a7d52fbeea 100644 --- a/t/t4013/diff.format-patch_--stdout_initial..side +++ b/third_party/git/t/t4013/diff.format-patch_--stdout_initial..side diff --git a/t/t4013/diff.log_--decorate=full_--all b/third_party/git/t/t4013/diff.log_--decorate=full_--all index 2afe91f116..2afe91f116 100644 --- a/t/t4013/diff.log_--decorate=full_--all +++ b/third_party/git/t/t4013/diff.log_--decorate=full_--all diff --git a/t/t4013/diff.log_--decorate_--all b/third_party/git/t/t4013/diff.log_--decorate_--all index d0f308ab2b..d0f308ab2b 100644 --- a/t/t4013/diff.log_--decorate_--all +++ b/third_party/git/t/t4013/diff.log_--decorate_--all diff --git a/t/t4013/diff.log_--patch-with-stat_--summary_master_--_dir_ b/third_party/git/t/t4013/diff.log_--patch-with-stat_--summary_master_--_dir_ index a18f1472a9..a18f1472a9 100644 --- a/t/t4013/diff.log_--patch-with-stat_--summary_master_--_dir_ +++ b/third_party/git/t/t4013/diff.log_--patch-with-stat_--summary_master_--_dir_ diff --git a/t/t4013/diff.log_--patch-with-stat_master b/third_party/git/t/t4013/diff.log_--patch-with-stat_master index ae425c4672..ae425c4672 100644 --- a/t/t4013/diff.log_--patch-with-stat_master +++ b/third_party/git/t/t4013/diff.log_--patch-with-stat_master diff --git a/t/t4013/diff.log_--patch-with-stat_master_--_dir_ b/third_party/git/t/t4013/diff.log_--patch-with-stat_master_--_dir_ index d5207cadf4..d5207cadf4 100644 --- a/t/t4013/diff.log_--patch-with-stat_master_--_dir_ +++ b/third_party/git/t/t4013/diff.log_--patch-with-stat_master_--_dir_ diff --git a/t/t4013/diff.log_--root_--cc_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.log_--root_--cc_--patch-with-stat_--summary_master index 0fc1e8cd71..0fc1e8cd71 100644 --- a/t/t4013/diff.log_--root_--cc_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.log_--root_--cc_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.log_--root_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.log_--root_--patch-with-stat_--summary_master index dffc09dde9..dffc09dde9 100644 --- a/t/t4013/diff.log_--root_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.log_--root_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.log_--root_--patch-with-stat_master b/third_party/git/t/t4013/diff.log_--root_--patch-with-stat_master index 55aa98012d..55aa98012d 100644 --- a/t/t4013/diff.log_--root_--patch-with-stat_master +++ b/third_party/git/t/t4013/diff.log_--root_--patch-with-stat_master diff --git a/t/t4013/diff.log_--root_-c_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.log_--root_-c_--patch-with-stat_--summary_master index 019d85f7de..019d85f7de 100644 --- a/t/t4013/diff.log_--root_-c_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.log_--root_-c_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.log_--root_-p_master b/third_party/git/t/t4013/diff.log_--root_-p_master index b42c334439..b42c334439 100644 --- a/t/t4013/diff.log_--root_-p_master +++ b/third_party/git/t/t4013/diff.log_--root_-p_master diff --git a/t/t4013/diff.log_--root_master b/third_party/git/t/t4013/diff.log_--root_master index e8f46159da..e8f46159da 100644 --- a/t/t4013/diff.log_--root_master +++ b/third_party/git/t/t4013/diff.log_--root_master diff --git a/t/t4013/diff.log_-GF_-p_--pickaxe-all_master b/third_party/git/t/t4013/diff.log_-GF_-p_--pickaxe-all_master index d36f88098b..d36f88098b 100644 --- a/t/t4013/diff.log_-GF_-p_--pickaxe-all_master +++ b/third_party/git/t/t4013/diff.log_-GF_-p_--pickaxe-all_master diff --git a/t/t4013/diff.log_-GF_-p_master b/third_party/git/t/t4013/diff.log_-GF_-p_master index 9d93f2c23a..9d93f2c23a 100644 --- a/t/t4013/diff.log_-GF_-p_master +++ b/third_party/git/t/t4013/diff.log_-GF_-p_master diff --git a/t/t4013/diff.log_-GF_master b/third_party/git/t/t4013/diff.log_-GF_master index 4c6708d2d0..4c6708d2d0 100644 --- a/t/t4013/diff.log_-GF_master +++ b/third_party/git/t/t4013/diff.log_-GF_master diff --git a/t/t4013/diff.log_-SF_-p_master b/third_party/git/t/t4013/diff.log_-SF_-p_master index 5e32438972..5e32438972 100644 --- a/t/t4013/diff.log_-SF_-p_master +++ b/third_party/git/t/t4013/diff.log_-SF_-p_master diff --git a/t/t4013/diff.log_-SF_master b/third_party/git/t/t4013/diff.log_-SF_master index c1599f2f52..c1599f2f52 100644 --- a/t/t4013/diff.log_-SF_master +++ b/third_party/git/t/t4013/diff.log_-SF_master diff --git a/t/t4013/diff.log_-SF_master_--max-count=0 b/third_party/git/t/t4013/diff.log_-SF_master_--max-count=0 index c1fc6c8731..c1fc6c8731 100644 --- a/t/t4013/diff.log_-SF_master_--max-count=0 +++ b/third_party/git/t/t4013/diff.log_-SF_master_--max-count=0 diff --git a/t/t4013/diff.log_-SF_master_--max-count=1 b/third_party/git/t/t4013/diff.log_-SF_master_--max-count=1 index c981a03814..c981a03814 100644 --- a/t/t4013/diff.log_-SF_master_--max-count=1 +++ b/third_party/git/t/t4013/diff.log_-SF_master_--max-count=1 diff --git a/t/t4013/diff.log_-SF_master_--max-count=2 b/third_party/git/t/t4013/diff.log_-SF_master_--max-count=2 index a6c55fd482..a6c55fd482 100644 --- a/t/t4013/diff.log_-SF_master_--max-count=2 +++ b/third_party/git/t/t4013/diff.log_-SF_master_--max-count=2 diff --git a/t/t4013/diff.log_-S_F_master b/third_party/git/t/t4013/diff.log_-S_F_master index 978d2b4118..978d2b4118 100644 --- a/t/t4013/diff.log_-S_F_master +++ b/third_party/git/t/t4013/diff.log_-S_F_master diff --git a/t/t4013/diff.log_-m_-p_--first-parent_master b/third_party/git/t/t4013/diff.log_-m_-p_--first-parent_master index 7a0073f529..7a0073f529 100644 --- a/t/t4013/diff.log_-m_-p_--first-parent_master +++ b/third_party/git/t/t4013/diff.log_-m_-p_--first-parent_master diff --git a/t/t4013/diff.log_-m_-p_master b/third_party/git/t/t4013/diff.log_-m_-p_master index 9ca62a01ed..9ca62a01ed 100644 --- a/t/t4013/diff.log_-m_-p_master +++ b/third_party/git/t/t4013/diff.log_-m_-p_master diff --git a/t/t4013/diff.log_-p_--first-parent_master b/third_party/git/t/t4013/diff.log_-p_--first-parent_master index 3fc896d424..3fc896d424 100644 --- a/t/t4013/diff.log_-p_--first-parent_master +++ b/third_party/git/t/t4013/diff.log_-p_--first-parent_master diff --git a/t/t4013/diff.log_-p_master b/third_party/git/t/t4013/diff.log_-p_master index bf1326dc36..bf1326dc36 100644 --- a/t/t4013/diff.log_-p_master +++ b/third_party/git/t/t4013/diff.log_-p_master diff --git a/t/t4013/diff.log_master b/third_party/git/t/t4013/diff.log_master index a8f6ce5abd..a8f6ce5abd 100644 --- a/t/t4013/diff.log_master +++ b/third_party/git/t/t4013/diff.log_master diff --git a/t/t4013/diff.noellipses-diff-tree_--root_--abbrev_initial b/third_party/git/t/t4013/diff.noellipses-diff-tree_--root_--abbrev_initial index 4bdad4072e..4bdad4072e 100644 --- a/t/t4013/diff.noellipses-diff-tree_--root_--abbrev_initial +++ b/third_party/git/t/t4013/diff.noellipses-diff-tree_--root_--abbrev_initial diff --git a/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev=4_initial b/third_party/git/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev=4_initial index 26fbfeb177..26fbfeb177 100644 --- a/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev=4_initial +++ b/third_party/git/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev=4_initial diff --git a/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev_initial b/third_party/git/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev_initial index 2ac8561191..2ac8561191 100644 --- a/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev_initial +++ b/third_party/git/t/t4013/diff.noellipses-diff-tree_--root_-r_--abbrev_initial diff --git a/t/t4013/diff.noellipses-diff-tree_-c_--abbrev_master b/third_party/git/t/t4013/diff.noellipses-diff-tree_-c_--abbrev_master index bb80f013b3..bb80f013b3 100644 --- a/t/t4013/diff.noellipses-diff-tree_-c_--abbrev_master +++ b/third_party/git/t/t4013/diff.noellipses-diff-tree_-c_--abbrev_master diff --git a/t/t4013/diff.noellipses-diff_--no-index_--raw_--abbrev=4_dir2_dir b/third_party/git/t/t4013/diff.noellipses-diff_--no-index_--raw_--abbrev=4_dir2_dir index 41b7baf0a5..41b7baf0a5 100644 --- a/t/t4013/diff.noellipses-diff_--no-index_--raw_--abbrev=4_dir2_dir +++ b/third_party/git/t/t4013/diff.noellipses-diff_--no-index_--raw_--abbrev=4_dir2_dir diff --git a/t/t4013/diff.noellipses-diff_--no-index_--raw_dir2_dir b/third_party/git/t/t4013/diff.noellipses-diff_--no-index_--raw_dir2_dir index 0cf3a3efea..0cf3a3efea 100644 --- a/t/t4013/diff.noellipses-diff_--no-index_--raw_dir2_dir +++ b/third_party/git/t/t4013/diff.noellipses-diff_--no-index_--raw_dir2_dir diff --git a/t/t4013/diff.noellipses-diff_--patch-with-raw_-r_initial..side b/third_party/git/t/t4013/diff.noellipses-diff_--patch-with-raw_-r_initial..side index 8d1f1e3721..8d1f1e3721 100644 --- a/t/t4013/diff.noellipses-diff_--patch-with-raw_-r_initial..side +++ b/third_party/git/t/t4013/diff.noellipses-diff_--patch-with-raw_-r_initial..side diff --git a/t/t4013/diff.noellipses-diff_--patch-with-raw_initial..side b/third_party/git/t/t4013/diff.noellipses-diff_--patch-with-raw_initial..side index 50d8aee4f7..50d8aee4f7 100644 --- a/t/t4013/diff.noellipses-diff_--patch-with-raw_initial..side +++ b/third_party/git/t/t4013/diff.noellipses-diff_--patch-with-raw_initial..side diff --git a/t/t4013/diff.noellipses-diff_--raw_--abbrev=4_initial b/third_party/git/t/t4013/diff.noellipses-diff_--raw_--abbrev=4_initial index 8ae44d6c83..8ae44d6c83 100644 --- a/t/t4013/diff.noellipses-diff_--raw_--abbrev=4_initial +++ b/third_party/git/t/t4013/diff.noellipses-diff_--raw_--abbrev=4_initial diff --git a/t/t4013/diff.noellipses-diff_--raw_initial b/third_party/git/t/t4013/diff.noellipses-diff_--raw_initial index 0175bfb281..0175bfb281 100644 --- a/t/t4013/diff.noellipses-diff_--raw_initial +++ b/third_party/git/t/t4013/diff.noellipses-diff_--raw_initial diff --git a/t/t4013/diff.noellipses-show_--patch-with-raw_side b/third_party/git/t/t4013/diff.noellipses-show_--patch-with-raw_side index 32fed3d576..32fed3d576 100644 --- a/t/t4013/diff.noellipses-show_--patch-with-raw_side +++ b/third_party/git/t/t4013/diff.noellipses-show_--patch-with-raw_side diff --git a/t/t4013/diff.noellipses-whatchanged_--root_master b/third_party/git/t/t4013/diff.noellipses-whatchanged_--root_master index c2cfd4e729..c2cfd4e729 100644 --- a/t/t4013/diff.noellipses-whatchanged_--root_master +++ b/third_party/git/t/t4013/diff.noellipses-whatchanged_--root_master diff --git a/t/t4013/diff.noellipses-whatchanged_-SF_master b/third_party/git/t/t4013/diff.noellipses-whatchanged_-SF_master index b36ce5886e..b36ce5886e 100644 --- a/t/t4013/diff.noellipses-whatchanged_-SF_master +++ b/third_party/git/t/t4013/diff.noellipses-whatchanged_-SF_master diff --git a/t/t4013/diff.noellipses-whatchanged_master b/third_party/git/t/t4013/diff.noellipses-whatchanged_master index 55e500f2ed..55e500f2ed 100644 --- a/t/t4013/diff.noellipses-whatchanged_master +++ b/third_party/git/t/t4013/diff.noellipses-whatchanged_master diff --git a/t/t4013/diff.rev-list_--children_HEAD b/third_party/git/t/t4013/diff.rev-list_--children_HEAD index e7f17d5aa0..e7f17d5aa0 100644 --- a/t/t4013/diff.rev-list_--children_HEAD +++ b/third_party/git/t/t4013/diff.rev-list_--children_HEAD diff --git a/t/t4013/diff.rev-list_--parents_HEAD b/third_party/git/t/t4013/diff.rev-list_--parents_HEAD index 65d2a80208..65d2a80208 100644 --- a/t/t4013/diff.rev-list_--parents_HEAD +++ b/third_party/git/t/t4013/diff.rev-list_--parents_HEAD diff --git a/t/t4013/diff.show_--first-parent_master b/third_party/git/t/t4013/diff.show_--first-parent_master index 3dcbe473a0..3dcbe473a0 100644 --- a/t/t4013/diff.show_--first-parent_master +++ b/third_party/git/t/t4013/diff.show_--first-parent_master diff --git a/t/t4013/diff.show_--patch-with-raw_side b/third_party/git/t/t4013/diff.show_--patch-with-raw_side index 221b46a7cc..221b46a7cc 100644 --- a/t/t4013/diff.show_--patch-with-raw_side +++ b/third_party/git/t/t4013/diff.show_--patch-with-raw_side diff --git a/t/t4013/diff.show_--patch-with-stat_--summary_side b/third_party/git/t/t4013/diff.show_--patch-with-stat_--summary_side index 95a474ef1d..95a474ef1d 100644 --- a/t/t4013/diff.show_--patch-with-stat_--summary_side +++ b/third_party/git/t/t4013/diff.show_--patch-with-stat_--summary_side diff --git a/t/t4013/diff.show_--patch-with-stat_side b/third_party/git/t/t4013/diff.show_--patch-with-stat_side index 974e99be82..974e99be82 100644 --- a/t/t4013/diff.show_--patch-with-stat_side +++ b/third_party/git/t/t4013/diff.show_--patch-with-stat_side diff --git a/t/t4013/diff.show_--root_initial b/third_party/git/t/t4013/diff.show_--root_initial index 8c89136c4d..8c89136c4d 100644 --- a/t/t4013/diff.show_--root_initial +++ b/third_party/git/t/t4013/diff.show_--root_initial diff --git a/t/t4013/diff.show_--stat_--summary_side b/third_party/git/t/t4013/diff.show_--stat_--summary_side index a71492f9bf..a71492f9bf 100644 --- a/t/t4013/diff.show_--stat_--summary_side +++ b/third_party/git/t/t4013/diff.show_--stat_--summary_side diff --git a/t/t4013/diff.show_--stat_side b/third_party/git/t/t4013/diff.show_--stat_side index 9be712458f..9be712458f 100644 --- a/t/t4013/diff.show_--stat_side +++ b/third_party/git/t/t4013/diff.show_--stat_side diff --git a/t/t4013/diff.show_-c_master b/third_party/git/t/t4013/diff.show_-c_master index 81aba8da96..81aba8da96 100644 --- a/t/t4013/diff.show_-c_master +++ b/third_party/git/t/t4013/diff.show_-c_master diff --git a/t/t4013/diff.show_-m_master b/third_party/git/t/t4013/diff.show_-m_master index 4ea2ee453d..4ea2ee453d 100644 --- a/t/t4013/diff.show_-m_master +++ b/third_party/git/t/t4013/diff.show_-m_master diff --git a/t/t4013/diff.show_initial b/third_party/git/t/t4013/diff.show_initial index 4c4066ae48..4c4066ae48 100644 --- a/t/t4013/diff.show_initial +++ b/third_party/git/t/t4013/diff.show_initial diff --git a/t/t4013/diff.show_master b/third_party/git/t/t4013/diff.show_master index fb08ce0e46..fb08ce0e46 100644 --- a/t/t4013/diff.show_master +++ b/third_party/git/t/t4013/diff.show_master diff --git a/t/t4013/diff.show_side b/third_party/git/t/t4013/diff.show_side index 530a073b19..530a073b19 100644 --- a/t/t4013/diff.show_side +++ b/third_party/git/t/t4013/diff.show_side diff --git a/t/t4013/diff.whatchanged_--patch-with-stat_--summary_master_--_dir_ b/third_party/git/t/t4013/diff.whatchanged_--patch-with-stat_--summary_master_--_dir_ index c8b6af2f43..c8b6af2f43 100644 --- a/t/t4013/diff.whatchanged_--patch-with-stat_--summary_master_--_dir_ +++ b/third_party/git/t/t4013/diff.whatchanged_--patch-with-stat_--summary_master_--_dir_ diff --git a/t/t4013/diff.whatchanged_--patch-with-stat_master b/third_party/git/t/t4013/diff.whatchanged_--patch-with-stat_master index 1ac431ba92..1ac431ba92 100644 --- a/t/t4013/diff.whatchanged_--patch-with-stat_master +++ b/third_party/git/t/t4013/diff.whatchanged_--patch-with-stat_master diff --git a/t/t4013/diff.whatchanged_--patch-with-stat_master_--_dir_ b/third_party/git/t/t4013/diff.whatchanged_--patch-with-stat_master_--_dir_ index b30c28588f..b30c28588f 100644 --- a/t/t4013/diff.whatchanged_--patch-with-stat_master_--_dir_ +++ b/third_party/git/t/t4013/diff.whatchanged_--patch-with-stat_master_--_dir_ diff --git a/t/t4013/diff.whatchanged_--root_--cc_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.whatchanged_--root_--cc_--patch-with-stat_--summary_master index 30aae7817b..30aae7817b 100644 --- a/t/t4013/diff.whatchanged_--root_--cc_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.whatchanged_--root_--cc_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.whatchanged_--root_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.whatchanged_--root_--patch-with-stat_--summary_master index db90e51525..db90e51525 100644 --- a/t/t4013/diff.whatchanged_--root_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.whatchanged_--root_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.whatchanged_--root_--patch-with-stat_master b/third_party/git/t/t4013/diff.whatchanged_--root_--patch-with-stat_master index 9a6cc92ce7..9a6cc92ce7 100644 --- a/t/t4013/diff.whatchanged_--root_--patch-with-stat_master +++ b/third_party/git/t/t4013/diff.whatchanged_--root_--patch-with-stat_master diff --git a/t/t4013/diff.whatchanged_--root_-c_--patch-with-stat_--summary_master b/third_party/git/t/t4013/diff.whatchanged_--root_-c_--patch-with-stat_--summary_master index d1d32bd34c..d1d32bd34c 100644 --- a/t/t4013/diff.whatchanged_--root_-c_--patch-with-stat_--summary_master +++ b/third_party/git/t/t4013/diff.whatchanged_--root_-c_--patch-with-stat_--summary_master diff --git a/t/t4013/diff.whatchanged_--root_-p_master b/third_party/git/t/t4013/diff.whatchanged_--root_-p_master index ebf1f0661e..ebf1f0661e 100644 --- a/t/t4013/diff.whatchanged_--root_-p_master +++ b/third_party/git/t/t4013/diff.whatchanged_--root_-p_master diff --git a/t/t4013/diff.whatchanged_--root_master b/third_party/git/t/t4013/diff.whatchanged_--root_master index a405cb6138..a405cb6138 100644 --- a/t/t4013/diff.whatchanged_--root_master +++ b/third_party/git/t/t4013/diff.whatchanged_--root_master diff --git a/t/t4013/diff.whatchanged_-SF_-p_master b/third_party/git/t/t4013/diff.whatchanged_-SF_-p_master index f39da84822..f39da84822 100644 --- a/t/t4013/diff.whatchanged_-SF_-p_master +++ b/third_party/git/t/t4013/diff.whatchanged_-SF_-p_master diff --git a/t/t4013/diff.whatchanged_-SF_master b/third_party/git/t/t4013/diff.whatchanged_-SF_master index 0499321d0e..0499321d0e 100644 --- a/t/t4013/diff.whatchanged_-SF_master +++ b/third_party/git/t/t4013/diff.whatchanged_-SF_master diff --git a/t/t4013/diff.whatchanged_-p_master b/third_party/git/t/t4013/diff.whatchanged_-p_master index f18d43209c..f18d43209c 100644 --- a/t/t4013/diff.whatchanged_-p_master +++ b/third_party/git/t/t4013/diff.whatchanged_-p_master diff --git a/t/t4013/diff.whatchanged_master b/third_party/git/t/t4013/diff.whatchanged_master index cd3bcc2c72..cd3bcc2c72 100644 --- a/t/t4013/diff.whatchanged_master +++ b/third_party/git/t/t4013/diff.whatchanged_master diff --git a/t/t4014-format-patch.sh b/third_party/git/t/t4014-format-patch.sh index b653dd7d44..b653dd7d44 100755 --- a/t/t4014-format-patch.sh +++ b/third_party/git/t/t4014-format-patch.sh diff --git a/t/t4015-diff-whitespace.sh b/third_party/git/t/t4015-diff-whitespace.sh index 88d3026894..88d3026894 100755 --- a/t/t4015-diff-whitespace.sh +++ b/third_party/git/t/t4015-diff-whitespace.sh diff --git a/t/t4016-diff-quote.sh b/third_party/git/t/t4016-diff-quote.sh index 9c48e5c2c9..9c48e5c2c9 100755 --- a/t/t4016-diff-quote.sh +++ b/third_party/git/t/t4016-diff-quote.sh diff --git a/t/t4017-diff-retval.sh b/third_party/git/t/t4017-diff-retval.sh index 95a7ca7070..95a7ca7070 100755 --- a/t/t4017-diff-retval.sh +++ b/third_party/git/t/t4017-diff-retval.sh diff --git a/t/t4018-diff-funcname.sh b/third_party/git/t/t4018-diff-funcname.sh index 02255a08bf..02255a08bf 100755 --- a/t/t4018-diff-funcname.sh +++ b/third_party/git/t/t4018-diff-funcname.sh diff --git a/t/t4018/README b/third_party/git/t/t4018/README index 283e01cca1..283e01cca1 100644 --- a/t/t4018/README +++ b/third_party/git/t/t4018/README diff --git a/t/t4018/cpp-c++-function b/third_party/git/t/t4018/cpp-c++-function index 9ee6bbef55..9ee6bbef55 100644 --- a/t/t4018/cpp-c++-function +++ b/third_party/git/t/t4018/cpp-c++-function diff --git a/t/t4018/cpp-class-constructor b/third_party/git/t/t4018/cpp-class-constructor index ec4f115c25..ec4f115c25 100644 --- a/t/t4018/cpp-class-constructor +++ b/third_party/git/t/t4018/cpp-class-constructor diff --git a/t/t4018/cpp-class-constructor-mem-init b/third_party/git/t/t4018/cpp-class-constructor-mem-init index 49a69f37e1..49a69f37e1 100644 --- a/t/t4018/cpp-class-constructor-mem-init +++ b/third_party/git/t/t4018/cpp-class-constructor-mem-init diff --git a/t/t4018/cpp-class-definition b/third_party/git/t/t4018/cpp-class-definition index 11b61da3b7..11b61da3b7 100644 --- a/t/t4018/cpp-class-definition +++ b/third_party/git/t/t4018/cpp-class-definition diff --git a/t/t4018/cpp-class-definition-derived b/third_party/git/t/t4018/cpp-class-definition-derived index 3b98cd09ab..3b98cd09ab 100644 --- a/t/t4018/cpp-class-definition-derived +++ b/third_party/git/t/t4018/cpp-class-definition-derived diff --git a/t/t4018/cpp-class-destructor b/third_party/git/t/t4018/cpp-class-destructor index 5487665096..5487665096 100644 --- a/t/t4018/cpp-class-destructor +++ b/third_party/git/t/t4018/cpp-class-destructor diff --git a/t/t4018/cpp-function-returning-global-type b/third_party/git/t/t4018/cpp-function-returning-global-type index 1084d5990e..1084d5990e 100644 --- a/t/t4018/cpp-function-returning-global-type +++ b/third_party/git/t/t4018/cpp-function-returning-global-type diff --git a/t/t4018/cpp-function-returning-nested b/third_party/git/t/t4018/cpp-function-returning-nested index d9750aa61a..d9750aa61a 100644 --- a/t/t4018/cpp-function-returning-nested +++ b/third_party/git/t/t4018/cpp-function-returning-nested diff --git a/t/t4018/cpp-function-returning-pointer b/third_party/git/t/t4018/cpp-function-returning-pointer index ef15657ea8..ef15657ea8 100644 --- a/t/t4018/cpp-function-returning-pointer +++ b/third_party/git/t/t4018/cpp-function-returning-pointer diff --git a/t/t4018/cpp-function-returning-reference b/third_party/git/t/t4018/cpp-function-returning-reference index 01b051df70..01b051df70 100644 --- a/t/t4018/cpp-function-returning-reference +++ b/third_party/git/t/t4018/cpp-function-returning-reference diff --git a/t/t4018/cpp-gnu-style-function b/third_party/git/t/t4018/cpp-gnu-style-function index 08c7c7565a..08c7c7565a 100644 --- a/t/t4018/cpp-gnu-style-function +++ b/third_party/git/t/t4018/cpp-gnu-style-function diff --git a/t/t4018/cpp-namespace-definition b/third_party/git/t/t4018/cpp-namespace-definition index 6749980241..6749980241 100644 --- a/t/t4018/cpp-namespace-definition +++ b/third_party/git/t/t4018/cpp-namespace-definition diff --git a/t/t4018/cpp-operator-definition b/third_party/git/t/t4018/cpp-operator-definition index 1acd827159..1acd827159 100644 --- a/t/t4018/cpp-operator-definition +++ b/third_party/git/t/t4018/cpp-operator-definition diff --git a/t/t4018/cpp-skip-access-specifiers b/third_party/git/t/t4018/cpp-skip-access-specifiers index 4d4a9dbb9d..4d4a9dbb9d 100644 --- a/t/t4018/cpp-skip-access-specifiers +++ b/third_party/git/t/t4018/cpp-skip-access-specifiers diff --git a/t/t4018/cpp-skip-comment-block b/third_party/git/t/t4018/cpp-skip-comment-block index 3800b9967a..3800b9967a 100644 --- a/t/t4018/cpp-skip-comment-block +++ b/third_party/git/t/t4018/cpp-skip-comment-block diff --git a/t/t4018/cpp-skip-labels b/third_party/git/t/t4018/cpp-skip-labels index b9c10aba22..b9c10aba22 100644 --- a/t/t4018/cpp-skip-labels +++ b/third_party/git/t/t4018/cpp-skip-labels diff --git a/t/t4018/cpp-struct-definition b/third_party/git/t/t4018/cpp-struct-definition index 521c59fd15..521c59fd15 100644 --- a/t/t4018/cpp-struct-definition +++ b/third_party/git/t/t4018/cpp-struct-definition diff --git a/t/t4018/cpp-struct-single-line b/third_party/git/t/t4018/cpp-struct-single-line index a0de5fb800..a0de5fb800 100644 --- a/t/t4018/cpp-struct-single-line +++ b/third_party/git/t/t4018/cpp-struct-single-line diff --git a/t/t4018/cpp-template-function-definition b/third_party/git/t/t4018/cpp-template-function-definition index 0cdf5ba5bd..0cdf5ba5bd 100644 --- a/t/t4018/cpp-template-function-definition +++ b/third_party/git/t/t4018/cpp-template-function-definition diff --git a/t/t4018/cpp-union-definition b/third_party/git/t/t4018/cpp-union-definition index 7ec94df697..7ec94df697 100644 --- a/t/t4018/cpp-union-definition +++ b/third_party/git/t/t4018/cpp-union-definition diff --git a/t/t4018/cpp-void-c-function b/third_party/git/t/t4018/cpp-void-c-function index 153081e872..153081e872 100644 --- a/t/t4018/cpp-void-c-function +++ b/third_party/git/t/t4018/cpp-void-c-function diff --git a/t/t4018/css-brace-in-col-1 b/third_party/git/t/t4018/css-brace-in-col-1 index 7831577506..7831577506 100644 --- a/t/t4018/css-brace-in-col-1 +++ b/third_party/git/t/t4018/css-brace-in-col-1 diff --git a/t/t4018/css-colon-eol b/third_party/git/t/t4018/css-colon-eol index 5a30553d29..5a30553d29 100644 --- a/t/t4018/css-colon-eol +++ b/third_party/git/t/t4018/css-colon-eol diff --git a/t/t4018/css-colon-selector b/third_party/git/t/t4018/css-colon-selector index c6d71fb42d..c6d71fb42d 100644 --- a/t/t4018/css-colon-selector +++ b/third_party/git/t/t4018/css-colon-selector diff --git a/t/t4018/css-common b/third_party/git/t/t4018/css-common index 84ed754b33..84ed754b33 100644 --- a/t/t4018/css-common +++ b/third_party/git/t/t4018/css-common diff --git a/t/t4018/css-long-selector-list b/third_party/git/t/t4018/css-long-selector-list index 7ccd25d9ed..7ccd25d9ed 100644 --- a/t/t4018/css-long-selector-list +++ b/third_party/git/t/t4018/css-long-selector-list diff --git a/t/t4018/css-prop-sans-indent b/third_party/git/t/t4018/css-prop-sans-indent index a9e3c86b3c..a9e3c86b3c 100644 --- a/t/t4018/css-prop-sans-indent +++ b/third_party/git/t/t4018/css-prop-sans-indent diff --git a/t/t4018/css-short-selector-list b/third_party/git/t/t4018/css-short-selector-list index 6a0bdee336..6a0bdee336 100644 --- a/t/t4018/css-short-selector-list +++ b/third_party/git/t/t4018/css-short-selector-list diff --git a/t/t4018/css-trailing-space b/third_party/git/t/t4018/css-trailing-space index 32b5606c70..32b5606c70 100644 --- a/t/t4018/css-trailing-space +++ b/third_party/git/t/t4018/css-trailing-space diff --git a/t/t4018/custom1-pattern b/third_party/git/t/t4018/custom1-pattern index e8fd59f884..e8fd59f884 100644 --- a/t/t4018/custom1-pattern +++ b/third_party/git/t/t4018/custom1-pattern diff --git a/t/t4018/custom2-match-to-end-of-line b/third_party/git/t/t4018/custom2-match-to-end-of-line index f88ac318b7..f88ac318b7 100644 --- a/t/t4018/custom2-match-to-end-of-line +++ b/third_party/git/t/t4018/custom2-match-to-end-of-line diff --git a/t/t4018/custom3-alternation-in-pattern b/third_party/git/t/t4018/custom3-alternation-in-pattern index 5f3769c64f..5f3769c64f 100644 --- a/t/t4018/custom3-alternation-in-pattern +++ b/third_party/git/t/t4018/custom3-alternation-in-pattern diff --git a/t/t4018/dts-labels b/third_party/git/t/t4018/dts-labels index b21ef8737b..b21ef8737b 100644 --- a/t/t4018/dts-labels +++ b/third_party/git/t/t4018/dts-labels diff --git a/t/t4018/dts-node-unitless b/third_party/git/t/t4018/dts-node-unitless index c5287d9141..c5287d9141 100644 --- a/t/t4018/dts-node-unitless +++ b/third_party/git/t/t4018/dts-node-unitless diff --git a/t/t4018/dts-nodes b/third_party/git/t/t4018/dts-nodes index 5a4334bb16..5a4334bb16 100644 --- a/t/t4018/dts-nodes +++ b/third_party/git/t/t4018/dts-nodes diff --git a/t/t4018/dts-nodes-boolean-prop b/third_party/git/t/t4018/dts-nodes-boolean-prop index afc6b5b404..afc6b5b404 100644 --- a/t/t4018/dts-nodes-boolean-prop +++ b/third_party/git/t/t4018/dts-nodes-boolean-prop diff --git a/t/t4018/dts-nodes-comment1 b/third_party/git/t/t4018/dts-nodes-comment1 index 559dfce9b3..559dfce9b3 100644 --- a/t/t4018/dts-nodes-comment1 +++ b/third_party/git/t/t4018/dts-nodes-comment1 diff --git a/t/t4018/dts-nodes-comment2 b/third_party/git/t/t4018/dts-nodes-comment2 index 27e9718b31..27e9718b31 100644 --- a/t/t4018/dts-nodes-comment2 +++ b/third_party/git/t/t4018/dts-nodes-comment2 diff --git a/t/t4018/dts-nodes-multiline-prop b/third_party/git/t/t4018/dts-nodes-multiline-prop index 072d58b69d..072d58b69d 100644 --- a/t/t4018/dts-nodes-multiline-prop +++ b/third_party/git/t/t4018/dts-nodes-multiline-prop diff --git a/t/t4018/dts-reference b/third_party/git/t/t4018/dts-reference index 8f0c87d863..8f0c87d863 100644 --- a/t/t4018/dts-reference +++ b/third_party/git/t/t4018/dts-reference diff --git a/t/t4018/dts-root b/third_party/git/t/t4018/dts-root index 4353b8220c..4353b8220c 100644 --- a/t/t4018/dts-root +++ b/third_party/git/t/t4018/dts-root diff --git a/t/t4018/dts-root-comment b/third_party/git/t/t4018/dts-root-comment index 333a625c70..333a625c70 100644 --- a/t/t4018/dts-root-comment +++ b/third_party/git/t/t4018/dts-root-comment diff --git a/t/t4018/elixir-do-not-pick-end b/third_party/git/t/t4018/elixir-do-not-pick-end index fae08ba7e8..fae08ba7e8 100644 --- a/t/t4018/elixir-do-not-pick-end +++ b/third_party/git/t/t4018/elixir-do-not-pick-end diff --git a/t/t4018/elixir-ex-unit-test b/third_party/git/t/t4018/elixir-ex-unit-test index 0560a2b697..0560a2b697 100644 --- a/t/t4018/elixir-ex-unit-test +++ b/third_party/git/t/t4018/elixir-ex-unit-test diff --git a/t/t4018/elixir-function b/third_party/git/t/t4018/elixir-function index d452f495a7..d452f495a7 100644 --- a/t/t4018/elixir-function +++ b/third_party/git/t/t4018/elixir-function diff --git a/t/t4018/elixir-macro b/third_party/git/t/t4018/elixir-macro index 4f925e9ad4..4f925e9ad4 100644 --- a/t/t4018/elixir-macro +++ b/third_party/git/t/t4018/elixir-macro diff --git a/t/t4018/elixir-module b/third_party/git/t/t4018/elixir-module index 91a4e7aa20..91a4e7aa20 100644 --- a/t/t4018/elixir-module +++ b/third_party/git/t/t4018/elixir-module diff --git a/t/t4018/elixir-module-func b/third_party/git/t/t4018/elixir-module-func index c9910d0675..c9910d0675 100644 --- a/t/t4018/elixir-module-func +++ b/third_party/git/t/t4018/elixir-module-func diff --git a/t/t4018/elixir-nested-module b/third_party/git/t/t4018/elixir-nested-module index 771ebc5c42..771ebc5c42 100644 --- a/t/t4018/elixir-nested-module +++ b/third_party/git/t/t4018/elixir-nested-module diff --git a/t/t4018/elixir-private-function b/third_party/git/t/t4018/elixir-private-function index 1aabe33b7a..1aabe33b7a 100644 --- a/t/t4018/elixir-private-function +++ b/third_party/git/t/t4018/elixir-private-function diff --git a/t/t4018/elixir-protocol b/third_party/git/t/t4018/elixir-protocol index 7d9173691e..7d9173691e 100644 --- a/t/t4018/elixir-protocol +++ b/third_party/git/t/t4018/elixir-protocol diff --git a/t/t4018/elixir-protocol-implementation b/third_party/git/t/t4018/elixir-protocol-implementation index f9234bbfc4..f9234bbfc4 100644 --- a/t/t4018/elixir-protocol-implementation +++ b/third_party/git/t/t4018/elixir-protocol-implementation diff --git a/t/t4018/fountain-scene b/third_party/git/t/t4018/fountain-scene index 6b3257d680..6b3257d680 100644 --- a/t/t4018/fountain-scene +++ b/third_party/git/t/t4018/fountain-scene diff --git a/t/t4018/golang-complex-function b/third_party/git/t/t4018/golang-complex-function index e057dcefed..e057dcefed 100644 --- a/t/t4018/golang-complex-function +++ b/third_party/git/t/t4018/golang-complex-function diff --git a/t/t4018/golang-func b/third_party/git/t/t4018/golang-func index 8e9c9ac7c3..8e9c9ac7c3 100644 --- a/t/t4018/golang-func +++ b/third_party/git/t/t4018/golang-func diff --git a/t/t4018/golang-interface b/third_party/git/t/t4018/golang-interface index 553bedec96..553bedec96 100644 --- a/t/t4018/golang-interface +++ b/third_party/git/t/t4018/golang-interface diff --git a/t/t4018/golang-long-func b/third_party/git/t/t4018/golang-long-func index ac3a77b5c4..ac3a77b5c4 100644 --- a/t/t4018/golang-long-func +++ b/third_party/git/t/t4018/golang-long-func diff --git a/t/t4018/golang-struct b/third_party/git/t/t4018/golang-struct index 5deda77fee..5deda77fee 100644 --- a/t/t4018/golang-struct +++ b/third_party/git/t/t4018/golang-struct diff --git a/t/t4018/java-class-member-function b/third_party/git/t/t4018/java-class-member-function index 298bc7a71b..298bc7a71b 100644 --- a/t/t4018/java-class-member-function +++ b/third_party/git/t/t4018/java-class-member-function diff --git a/t/t4018/matlab-class-definition b/third_party/git/t/t4018/matlab-class-definition index 84daedfb4e..84daedfb4e 100644 --- a/t/t4018/matlab-class-definition +++ b/third_party/git/t/t4018/matlab-class-definition diff --git a/t/t4018/matlab-function b/third_party/git/t/t4018/matlab-function index 897a9b13ff..897a9b13ff 100644 --- a/t/t4018/matlab-function +++ b/third_party/git/t/t4018/matlab-function diff --git a/t/t4018/matlab-octave-section-1 b/third_party/git/t/t4018/matlab-octave-section-1 index 3bb6c4670e..3bb6c4670e 100644 --- a/t/t4018/matlab-octave-section-1 +++ b/third_party/git/t/t4018/matlab-octave-section-1 diff --git a/t/t4018/matlab-octave-section-2 b/third_party/git/t/t4018/matlab-octave-section-2 index ab2980f7f2..ab2980f7f2 100644 --- a/t/t4018/matlab-octave-section-2 +++ b/third_party/git/t/t4018/matlab-octave-section-2 diff --git a/t/t4018/matlab-section b/third_party/git/t/t4018/matlab-section index 5ea59a5de0..5ea59a5de0 100644 --- a/t/t4018/matlab-section +++ b/third_party/git/t/t4018/matlab-section diff --git a/t/t4018/perl-skip-end-of-heredoc b/third_party/git/t/t4018/perl-skip-end-of-heredoc index c22d39b256..c22d39b256 100644 --- a/t/t4018/perl-skip-end-of-heredoc +++ b/third_party/git/t/t4018/perl-skip-end-of-heredoc diff --git a/t/t4018/perl-skip-forward-decl b/third_party/git/t/t4018/perl-skip-forward-decl index a98cb8bdad..a98cb8bdad 100644 --- a/t/t4018/perl-skip-forward-decl +++ b/third_party/git/t/t4018/perl-skip-forward-decl diff --git a/t/t4018/perl-skip-sub-in-pod b/third_party/git/t/t4018/perl-skip-sub-in-pod index e39f02462e..e39f02462e 100644 --- a/t/t4018/perl-skip-sub-in-pod +++ b/third_party/git/t/t4018/perl-skip-sub-in-pod diff --git a/t/t4018/perl-sub-definition b/third_party/git/t/t4018/perl-sub-definition index a507d1f645..a507d1f645 100644 --- a/t/t4018/perl-sub-definition +++ b/third_party/git/t/t4018/perl-sub-definition diff --git a/t/t4018/perl-sub-definition-kr-brace b/third_party/git/t/t4018/perl-sub-definition-kr-brace index 330b3df114..330b3df114 100644 --- a/t/t4018/perl-sub-definition-kr-brace +++ b/third_party/git/t/t4018/perl-sub-definition-kr-brace diff --git a/t/t4018/php-abstract-class b/third_party/git/t/t4018/php-abstract-class index 5213e12494..5213e12494 100644 --- a/t/t4018/php-abstract-class +++ b/third_party/git/t/t4018/php-abstract-class diff --git a/t/t4018/php-class b/third_party/git/t/t4018/php-class index 7785b6303c..7785b6303c 100644 --- a/t/t4018/php-class +++ b/third_party/git/t/t4018/php-class diff --git a/t/t4018/php-final-class b/third_party/git/t/t4018/php-final-class index 69f5710552..69f5710552 100644 --- a/t/t4018/php-final-class +++ b/third_party/git/t/t4018/php-final-class diff --git a/t/t4018/php-function b/third_party/git/t/t4018/php-function index 35717c51c3..35717c51c3 100644 --- a/t/t4018/php-function +++ b/third_party/git/t/t4018/php-function diff --git a/t/t4018/php-interface b/third_party/git/t/t4018/php-interface index 86b49ad5d9..86b49ad5d9 100644 --- a/t/t4018/php-interface +++ b/third_party/git/t/t4018/php-interface diff --git a/t/t4018/php-method b/third_party/git/t/t4018/php-method index 03af1a6d9d..03af1a6d9d 100644 --- a/t/t4018/php-method +++ b/third_party/git/t/t4018/php-method diff --git a/t/t4018/php-trait b/third_party/git/t/t4018/php-trait index 65b8c82a61..65b8c82a61 100644 --- a/t/t4018/php-trait +++ b/third_party/git/t/t4018/php-trait diff --git a/t/t4018/python-async-def b/third_party/git/t/t4018/python-async-def index 87640e03d2..87640e03d2 100644 --- a/t/t4018/python-async-def +++ b/third_party/git/t/t4018/python-async-def diff --git a/t/t4018/python-class b/third_party/git/t/t4018/python-class index ba9e741430..ba9e741430 100644 --- a/t/t4018/python-class +++ b/third_party/git/t/t4018/python-class diff --git a/t/t4018/python-def b/third_party/git/t/t4018/python-def index e50b31b0ad..e50b31b0ad 100644 --- a/t/t4018/python-def +++ b/third_party/git/t/t4018/python-def diff --git a/t/t4018/python-indented-async-def b/third_party/git/t/t4018/python-indented-async-def index f5d03258af..f5d03258af 100644 --- a/t/t4018/python-indented-async-def +++ b/third_party/git/t/t4018/python-indented-async-def diff --git a/t/t4018/python-indented-class b/third_party/git/t/t4018/python-indented-class index 19b4f35c4c..19b4f35c4c 100644 --- a/t/t4018/python-indented-class +++ b/third_party/git/t/t4018/python-indented-class diff --git a/t/t4018/python-indented-def b/third_party/git/t/t4018/python-indented-def index 208fbadd2b..208fbadd2b 100644 --- a/t/t4018/python-indented-def +++ b/third_party/git/t/t4018/python-indented-def diff --git a/t/t4018/rust-fn b/third_party/git/t/t4018/rust-fn index cbe02155f1..cbe02155f1 100644 --- a/t/t4018/rust-fn +++ b/third_party/git/t/t4018/rust-fn diff --git a/t/t4018/rust-impl b/third_party/git/t/t4018/rust-impl index 09df3cd93b..09df3cd93b 100644 --- a/t/t4018/rust-impl +++ b/third_party/git/t/t4018/rust-impl diff --git a/t/t4018/rust-struct b/third_party/git/t/t4018/rust-struct index 76aff1c0d8..76aff1c0d8 100644 --- a/t/t4018/rust-struct +++ b/third_party/git/t/t4018/rust-struct diff --git a/t/t4018/rust-trait b/third_party/git/t/t4018/rust-trait index ea397f09ed..ea397f09ed 100644 --- a/t/t4018/rust-trait +++ b/third_party/git/t/t4018/rust-trait diff --git a/t/t4019-diff-wserror.sh b/third_party/git/t/t4019-diff-wserror.sh index c6135c7548..c6135c7548 100755 --- a/t/t4019-diff-wserror.sh +++ b/third_party/git/t/t4019-diff-wserror.sh diff --git a/t/t4020-diff-external.sh b/third_party/git/t/t4020-diff-external.sh index e009826fcb..e009826fcb 100755 --- a/t/t4020-diff-external.sh +++ b/third_party/git/t/t4020-diff-external.sh diff --git a/t/t4020/diff.NUL b/third_party/git/t/t4020/diff.NUL index db2f89090c..db2f89090c 100644 --- a/t/t4020/diff.NUL +++ b/third_party/git/t/t4020/diff.NUL Binary files differdiff --git a/t/t4021-format-patch-numbered.sh b/third_party/git/t/t4021-format-patch-numbered.sh index 9be65fd444..9be65fd444 100755 --- a/t/t4021-format-patch-numbered.sh +++ b/third_party/git/t/t4021-format-patch-numbered.sh diff --git a/t/t4022-diff-rewrite.sh b/third_party/git/t/t4022-diff-rewrite.sh index 6d1c3d949c..6d1c3d949c 100755 --- a/t/t4022-diff-rewrite.sh +++ b/third_party/git/t/t4022-diff-rewrite.sh diff --git a/t/t4023-diff-rename-typechange.sh b/third_party/git/t/t4023-diff-rename-typechange.sh index 8c9823765e..8c9823765e 100755 --- a/t/t4023-diff-rename-typechange.sh +++ b/third_party/git/t/t4023-diff-rename-typechange.sh diff --git a/t/t4024-diff-optimize-common.sh b/third_party/git/t/t4024-diff-optimize-common.sh index 6b44ce1493..6b44ce1493 100755 --- a/t/t4024-diff-optimize-common.sh +++ b/third_party/git/t/t4024-diff-optimize-common.sh diff --git a/t/t4025-hunk-header.sh b/third_party/git/t/t4025-hunk-header.sh index 35578f2bb9..35578f2bb9 100755 --- a/t/t4025-hunk-header.sh +++ b/third_party/git/t/t4025-hunk-header.sh diff --git a/t/t4026-color.sh b/third_party/git/t/t4026-color.sh index c0b642c1ab..c0b642c1ab 100755 --- a/t/t4026-color.sh +++ b/third_party/git/t/t4026-color.sh diff --git a/t/t4027-diff-submodule.sh b/third_party/git/t/t4027-diff-submodule.sh index e29deaf4a5..e29deaf4a5 100755 --- a/t/t4027-diff-submodule.sh +++ b/third_party/git/t/t4027-diff-submodule.sh diff --git a/t/t4028-format-patch-mime-headers.sh b/third_party/git/t/t4028-format-patch-mime-headers.sh index 204ba673cb..204ba673cb 100755 --- a/t/t4028-format-patch-mime-headers.sh +++ b/third_party/git/t/t4028-format-patch-mime-headers.sh diff --git a/t/t4029-diff-trailing-space.sh b/third_party/git/t/t4029-diff-trailing-space.sh index 32b6e9a4e7..32b6e9a4e7 100755 --- a/t/t4029-diff-trailing-space.sh +++ b/third_party/git/t/t4029-diff-trailing-space.sh diff --git a/t/t4030-diff-textconv.sh b/third_party/git/t/t4030-diff-textconv.sh index 4cb9f0e523..4cb9f0e523 100755 --- a/t/t4030-diff-textconv.sh +++ b/third_party/git/t/t4030-diff-textconv.sh diff --git a/t/t4031-diff-rewrite-binary.sh b/third_party/git/t/t4031-diff-rewrite-binary.sh index eacc6694f7..eacc6694f7 100755 --- a/t/t4031-diff-rewrite-binary.sh +++ b/third_party/git/t/t4031-diff-rewrite-binary.sh diff --git a/t/t4032-diff-inter-hunk-context.sh b/third_party/git/t/t4032-diff-inter-hunk-context.sh index bada0cbd32..bada0cbd32 100755 --- a/t/t4032-diff-inter-hunk-context.sh +++ b/third_party/git/t/t4032-diff-inter-hunk-context.sh diff --git a/t/t4033-diff-patience.sh b/third_party/git/t/t4033-diff-patience.sh index 113304dc59..113304dc59 100755 --- a/t/t4033-diff-patience.sh +++ b/third_party/git/t/t4033-diff-patience.sh diff --git a/t/t4034-diff-words.sh b/third_party/git/t/t4034-diff-words.sh index fb145aa173..fb145aa173 100755 --- a/t/t4034-diff-words.sh +++ b/third_party/git/t/t4034-diff-words.sh diff --git a/t/t4034/ada/expect b/third_party/git/t/t4034/ada/expect index a682d288b2..a682d288b2 100644 --- a/t/t4034/ada/expect +++ b/third_party/git/t/t4034/ada/expect diff --git a/t/t4034/ada/post b/third_party/git/t/t4034/ada/post index df21bb044f..df21bb044f 100644 --- a/t/t4034/ada/post +++ b/third_party/git/t/t4034/ada/post diff --git a/t/t4034/ada/pre b/third_party/git/t/t4034/ada/pre index d96fdd1e8e..d96fdd1e8e 100644 --- a/t/t4034/ada/pre +++ b/third_party/git/t/t4034/ada/pre diff --git a/t/t4034/bibtex/expect b/third_party/git/t/t4034/bibtex/expect index a157774f9d..a157774f9d 100644 --- a/t/t4034/bibtex/expect +++ b/third_party/git/t/t4034/bibtex/expect diff --git a/t/t4034/bibtex/post b/third_party/git/t/t4034/bibtex/post index ddcba9b2fc..ddcba9b2fc 100644 --- a/t/t4034/bibtex/post +++ b/third_party/git/t/t4034/bibtex/post diff --git a/t/t4034/bibtex/pre b/third_party/git/t/t4034/bibtex/pre index 95cd55bd7b..95cd55bd7b 100644 --- a/t/t4034/bibtex/pre +++ b/third_party/git/t/t4034/bibtex/pre diff --git a/t/t4034/cpp/expect b/third_party/git/t/t4034/cpp/expect index 37d1ea2587..37d1ea2587 100644 --- a/t/t4034/cpp/expect +++ b/third_party/git/t/t4034/cpp/expect diff --git a/t/t4034/cpp/post b/third_party/git/t/t4034/cpp/post index 7e8c026cef..7e8c026cef 100644 --- a/t/t4034/cpp/post +++ b/third_party/git/t/t4034/cpp/post diff --git a/t/t4034/cpp/pre b/third_party/git/t/t4034/cpp/pre index 23d5c8adf5..23d5c8adf5 100644 --- a/t/t4034/cpp/pre +++ b/third_party/git/t/t4034/cpp/pre diff --git a/t/t4034/csharp/expect b/third_party/git/t/t4034/csharp/expect index e5d1dd2b3d..e5d1dd2b3d 100644 --- a/t/t4034/csharp/expect +++ b/third_party/git/t/t4034/csharp/expect diff --git a/t/t4034/csharp/post b/third_party/git/t/t4034/csharp/post index dd5f4218a6..dd5f4218a6 100644 --- a/t/t4034/csharp/post +++ b/third_party/git/t/t4034/csharp/post diff --git a/t/t4034/csharp/pre b/third_party/git/t/t4034/csharp/pre index 9106d63e87..9106d63e87 100644 --- a/t/t4034/csharp/pre +++ b/third_party/git/t/t4034/csharp/pre diff --git a/t/t4034/css/expect b/third_party/git/t/t4034/css/expect index ed10393bda..ed10393bda 100644 --- a/t/t4034/css/expect +++ b/third_party/git/t/t4034/css/expect diff --git a/t/t4034/css/post b/third_party/git/t/t4034/css/post index fe500b7a4f..fe500b7a4f 100644 --- a/t/t4034/css/post +++ b/third_party/git/t/t4034/css/post diff --git a/t/t4034/css/pre b/third_party/git/t/t4034/css/pre index b8ae0bb48f..b8ae0bb48f 100644 --- a/t/t4034/css/pre +++ b/third_party/git/t/t4034/css/pre diff --git a/t/t4034/dts/expect b/third_party/git/t/t4034/dts/expect index 560fc99184..560fc99184 100644 --- a/t/t4034/dts/expect +++ b/third_party/git/t/t4034/dts/expect diff --git a/t/t4034/dts/post b/third_party/git/t/t4034/dts/post index 7803aee280..7803aee280 100644 --- a/t/t4034/dts/post +++ b/third_party/git/t/t4034/dts/post diff --git a/t/t4034/dts/pre b/third_party/git/t/t4034/dts/pre index b6a905113c..b6a905113c 100644 --- a/t/t4034/dts/pre +++ b/third_party/git/t/t4034/dts/pre diff --git a/t/t4034/fortran/expect b/third_party/git/t/t4034/fortran/expect index b233dbd621..b233dbd621 100644 --- a/t/t4034/fortran/expect +++ b/third_party/git/t/t4034/fortran/expect diff --git a/t/t4034/fortran/post b/third_party/git/t/t4034/fortran/post index d308da2ad2..d308da2ad2 100644 --- a/t/t4034/fortran/post +++ b/third_party/git/t/t4034/fortran/post diff --git a/t/t4034/fortran/pre b/third_party/git/t/t4034/fortran/pre index 87f0d0b031..87f0d0b031 100644 --- a/t/t4034/fortran/pre +++ b/third_party/git/t/t4034/fortran/pre diff --git a/t/t4034/html/expect b/third_party/git/t/t4034/html/expect index 447b49ab6d..447b49ab6d 100644 --- a/t/t4034/html/expect +++ b/third_party/git/t/t4034/html/expect diff --git a/t/t4034/html/post b/third_party/git/t/t4034/html/post index 46921e586c..46921e586c 100644 --- a/t/t4034/html/post +++ b/third_party/git/t/t4034/html/post diff --git a/t/t4034/html/pre b/third_party/git/t/t4034/html/pre index 8ca4aeae83..8ca4aeae83 100644 --- a/t/t4034/html/pre +++ b/third_party/git/t/t4034/html/pre diff --git a/t/t4034/java/expect b/third_party/git/t/t4034/java/expect index 37d1ea2587..37d1ea2587 100644 --- a/t/t4034/java/expect +++ b/third_party/git/t/t4034/java/expect diff --git a/t/t4034/java/post b/third_party/git/t/t4034/java/post index 7e8c026cef..7e8c026cef 100644 --- a/t/t4034/java/post +++ b/third_party/git/t/t4034/java/post diff --git a/t/t4034/java/pre b/third_party/git/t/t4034/java/pre index 23d5c8adf5..23d5c8adf5 100644 --- a/t/t4034/java/pre +++ b/third_party/git/t/t4034/java/pre diff --git a/t/t4034/matlab/expect b/third_party/git/t/t4034/matlab/expect index 72cf3e93a2..72cf3e93a2 100644 --- a/t/t4034/matlab/expect +++ b/third_party/git/t/t4034/matlab/expect diff --git a/t/t4034/matlab/post b/third_party/git/t/t4034/matlab/post index 70e05f0753..70e05f0753 100644 --- a/t/t4034/matlab/post +++ b/third_party/git/t/t4034/matlab/post diff --git a/t/t4034/matlab/pre b/third_party/git/t/t4034/matlab/pre index dc204db486..dc204db486 100644 --- a/t/t4034/matlab/pre +++ b/third_party/git/t/t4034/matlab/pre diff --git a/t/t4034/objc/expect b/third_party/git/t/t4034/objc/expect index e5d1dd2b3d..e5d1dd2b3d 100644 --- a/t/t4034/objc/expect +++ b/third_party/git/t/t4034/objc/expect diff --git a/t/t4034/objc/post b/third_party/git/t/t4034/objc/post index dd5f4218a6..dd5f4218a6 100644 --- a/t/t4034/objc/post +++ b/third_party/git/t/t4034/objc/post diff --git a/t/t4034/objc/pre b/third_party/git/t/t4034/objc/pre index 9106d63e87..9106d63e87 100644 --- a/t/t4034/objc/pre +++ b/third_party/git/t/t4034/objc/pre diff --git a/t/t4034/pascal/expect b/third_party/git/t/t4034/pascal/expect index 2ce4230954..2ce4230954 100644 --- a/t/t4034/pascal/expect +++ b/third_party/git/t/t4034/pascal/expect diff --git a/t/t4034/pascal/post b/third_party/git/t/t4034/pascal/post index 8865e6bddd..8865e6bddd 100644 --- a/t/t4034/pascal/post +++ b/third_party/git/t/t4034/pascal/post diff --git a/t/t4034/pascal/pre b/third_party/git/t/t4034/pascal/pre index 077046c832..077046c832 100644 --- a/t/t4034/pascal/pre +++ b/third_party/git/t/t4034/pascal/pre diff --git a/t/t4034/perl/expect b/third_party/git/t/t4034/perl/expect index a1deb6b6ad..a1deb6b6ad 100644 --- a/t/t4034/perl/expect +++ b/third_party/git/t/t4034/perl/expect diff --git a/t/t4034/perl/post b/third_party/git/t/t4034/perl/post index e8b72ef5dc..e8b72ef5dc 100644 --- a/t/t4034/perl/post +++ b/third_party/git/t/t4034/perl/post diff --git a/t/t4034/perl/pre b/third_party/git/t/t4034/perl/pre index f6610d37b8..f6610d37b8 100644 --- a/t/t4034/perl/pre +++ b/third_party/git/t/t4034/perl/pre diff --git a/t/t4034/php/expect b/third_party/git/t/t4034/php/expect index 040440860a..040440860a 100644 --- a/t/t4034/php/expect +++ b/third_party/git/t/t4034/php/expect diff --git a/t/t4034/php/post b/third_party/git/t/t4034/php/post index 4420a49192..4420a49192 100644 --- a/t/t4034/php/post +++ b/third_party/git/t/t4034/php/post diff --git a/t/t4034/php/pre b/third_party/git/t/t4034/php/pre index cf6e06bc22..cf6e06bc22 100644 --- a/t/t4034/php/pre +++ b/third_party/git/t/t4034/php/pre diff --git a/t/t4034/python/expect b/third_party/git/t/t4034/python/expect index 8abb8a48b4..8abb8a48b4 100644 --- a/t/t4034/python/expect +++ b/third_party/git/t/t4034/python/expect diff --git a/t/t4034/python/post b/third_party/git/t/t4034/python/post index 68baf34f0e..68baf34f0e 100644 --- a/t/t4034/python/post +++ b/third_party/git/t/t4034/python/post diff --git a/t/t4034/python/pre b/third_party/git/t/t4034/python/pre index 438f776875..438f776875 100644 --- a/t/t4034/python/pre +++ b/third_party/git/t/t4034/python/pre diff --git a/t/t4034/ruby/expect b/third_party/git/t/t4034/ruby/expect index 16e1dd5674..16e1dd5674 100644 --- a/t/t4034/ruby/expect +++ b/third_party/git/t/t4034/ruby/expect diff --git a/t/t4034/ruby/post b/third_party/git/t/t4034/ruby/post index 7678f14e14..7678f14e14 100644 --- a/t/t4034/ruby/post +++ b/third_party/git/t/t4034/ruby/post diff --git a/t/t4034/ruby/pre b/third_party/git/t/t4034/ruby/pre index 30ed9a1595..30ed9a1595 100644 --- a/t/t4034/ruby/pre +++ b/third_party/git/t/t4034/ruby/pre diff --git a/t/t4034/tex/expect b/third_party/git/t/t4034/tex/expect index 604969bcde..604969bcde 100644 --- a/t/t4034/tex/expect +++ b/third_party/git/t/t4034/tex/expect diff --git a/t/t4034/tex/post b/third_party/git/t/t4034/tex/post index 65cab61a10..65cab61a10 100644 --- a/t/t4034/tex/post +++ b/third_party/git/t/t4034/tex/post diff --git a/t/t4034/tex/pre b/third_party/git/t/t4034/tex/pre index 2b2dfcb65c..2b2dfcb65c 100644 --- a/t/t4034/tex/pre +++ b/third_party/git/t/t4034/tex/pre diff --git a/t/t4035-diff-quiet.sh b/third_party/git/t/t4035-diff-quiet.sh index 0352bf81a9..0352bf81a9 100755 --- a/t/t4035-diff-quiet.sh +++ b/third_party/git/t/t4035-diff-quiet.sh diff --git a/t/t4036-format-patch-signer-mime.sh b/third_party/git/t/t4036-format-patch-signer-mime.sh index 98d9713d8b..98d9713d8b 100755 --- a/t/t4036-format-patch-signer-mime.sh +++ b/third_party/git/t/t4036-format-patch-signer-mime.sh diff --git a/t/t4037-diff-r-t-dirs.sh b/third_party/git/t/t4037-diff-r-t-dirs.sh index f5ce3b29a2..f5ce3b29a2 100755 --- a/t/t4037-diff-r-t-dirs.sh +++ b/third_party/git/t/t4037-diff-r-t-dirs.sh diff --git a/t/t4038-diff-combined.sh b/third_party/git/t/t4038-diff-combined.sh index 94680836ce..94680836ce 100755 --- a/t/t4038-diff-combined.sh +++ b/third_party/git/t/t4038-diff-combined.sh diff --git a/t/t4039-diff-assume-unchanged.sh b/third_party/git/t/t4039-diff-assume-unchanged.sh index 0eb0314a8b..0eb0314a8b 100755 --- a/t/t4039-diff-assume-unchanged.sh +++ b/third_party/git/t/t4039-diff-assume-unchanged.sh diff --git a/t/t4040-whitespace-status.sh b/third_party/git/t/t4040-whitespace-status.sh index 3c728a3ebf..3c728a3ebf 100755 --- a/t/t4040-whitespace-status.sh +++ b/third_party/git/t/t4040-whitespace-status.sh diff --git a/t/t4041-diff-submodule-option.sh b/third_party/git/t/t4041-diff-submodule-option.sh index f852136585..f852136585 100755 --- a/t/t4041-diff-submodule-option.sh +++ b/third_party/git/t/t4041-diff-submodule-option.sh diff --git a/t/t4042-diff-textconv-caching.sh b/third_party/git/t/t4042-diff-textconv-caching.sh index bf33aedf4b..bf33aedf4b 100755 --- a/t/t4042-diff-textconv-caching.sh +++ b/third_party/git/t/t4042-diff-textconv-caching.sh diff --git a/t/t4043-diff-rename-binary.sh b/third_party/git/t/t4043-diff-rename-binary.sh index 2a2cf91352..2a2cf91352 100755 --- a/t/t4043-diff-rename-binary.sh +++ b/third_party/git/t/t4043-diff-rename-binary.sh diff --git a/t/t4044-diff-index-unique-abbrev.sh b/third_party/git/t/t4044-diff-index-unique-abbrev.sh index 4701796d10..4701796d10 100755 --- a/t/t4044-diff-index-unique-abbrev.sh +++ b/third_party/git/t/t4044-diff-index-unique-abbrev.sh diff --git a/t/t4045-diff-relative.sh b/third_party/git/t/t4045-diff-relative.sh index 258808708e..258808708e 100755 --- a/t/t4045-diff-relative.sh +++ b/third_party/git/t/t4045-diff-relative.sh diff --git a/t/t4046-diff-unmerged.sh b/third_party/git/t/t4046-diff-unmerged.sh index ff7cfd884a..ff7cfd884a 100755 --- a/t/t4046-diff-unmerged.sh +++ b/third_party/git/t/t4046-diff-unmerged.sh diff --git a/t/t4047-diff-dirstat.sh b/third_party/git/t/t4047-diff-dirstat.sh index 7fec2cb9cd..7fec2cb9cd 100755 --- a/t/t4047-diff-dirstat.sh +++ b/third_party/git/t/t4047-diff-dirstat.sh diff --git a/t/t4048-diff-combined-binary.sh b/third_party/git/t/t4048-diff-combined-binary.sh index 7f9ad9fa3d..7f9ad9fa3d 100755 --- a/t/t4048-diff-combined-binary.sh +++ b/third_party/git/t/t4048-diff-combined-binary.sh diff --git a/t/t4049-diff-stat-count.sh b/third_party/git/t/t4049-diff-stat-count.sh index a34121740a..a34121740a 100755 --- a/t/t4049-diff-stat-count.sh +++ b/third_party/git/t/t4049-diff-stat-count.sh diff --git a/t/t4050-diff-histogram.sh b/third_party/git/t/t4050-diff-histogram.sh index fd3e86a74f..fd3e86a74f 100755 --- a/t/t4050-diff-histogram.sh +++ b/third_party/git/t/t4050-diff-histogram.sh diff --git a/t/t4051-diff-function-context.sh b/third_party/git/t/t4051-diff-function-context.sh index 4838a1df8b..4838a1df8b 100755 --- a/t/t4051-diff-function-context.sh +++ b/third_party/git/t/t4051-diff-function-context.sh diff --git a/t/t4051/appended1.c b/third_party/git/t/t4051/appended1.c index a9f56f11db..a9f56f11db 100644 --- a/t/t4051/appended1.c +++ b/third_party/git/t/t4051/appended1.c diff --git a/t/t4051/appended2.c b/third_party/git/t/t4051/appended2.c index e651f7147b..e651f7147b 100644 --- a/t/t4051/appended2.c +++ b/third_party/git/t/t4051/appended2.c diff --git a/t/t4051/dummy.c b/third_party/git/t/t4051/dummy.c index a43016e870..a43016e870 100644 --- a/t/t4051/dummy.c +++ b/third_party/git/t/t4051/dummy.c diff --git a/t/t4051/hello.c b/third_party/git/t/t4051/hello.c index 73e767e178..73e767e178 100644 --- a/t/t4051/hello.c +++ b/third_party/git/t/t4051/hello.c diff --git a/t/t4051/includes.c b/third_party/git/t/t4051/includes.c index efc68f8bf6..efc68f8bf6 100644 --- a/t/t4051/includes.c +++ b/third_party/git/t/t4051/includes.c diff --git a/t/t4052-stat-output.sh b/third_party/git/t/t4052-stat-output.sh index 28c053849a..28c053849a 100755 --- a/t/t4052-stat-output.sh +++ b/third_party/git/t/t4052-stat-output.sh diff --git a/t/t4053-diff-no-index.sh b/third_party/git/t/t4053-diff-no-index.sh index 0168946b63..0168946b63 100755 --- a/t/t4053-diff-no-index.sh +++ b/third_party/git/t/t4053-diff-no-index.sh diff --git a/t/t4054-diff-bogus-tree.sh b/third_party/git/t/t4054-diff-bogus-tree.sh index 8c95f152b2..8c95f152b2 100755 --- a/t/t4054-diff-bogus-tree.sh +++ b/third_party/git/t/t4054-diff-bogus-tree.sh diff --git a/t/t4055-diff-context.sh b/third_party/git/t/t4055-diff-context.sh index 741e0803c1..741e0803c1 100755 --- a/t/t4055-diff-context.sh +++ b/third_party/git/t/t4055-diff-context.sh diff --git a/t/t4056-diff-order.sh b/third_party/git/t/t4056-diff-order.sh index 43dd474a12..43dd474a12 100755 --- a/t/t4056-diff-order.sh +++ b/third_party/git/t/t4056-diff-order.sh diff --git a/t/t4057-diff-combined-paths.sh b/third_party/git/t/t4057-diff-combined-paths.sh index 4f4b541658..4f4b541658 100755 --- a/t/t4057-diff-combined-paths.sh +++ b/third_party/git/t/t4057-diff-combined-paths.sh diff --git a/t/t4058-diff-duplicates.sh b/third_party/git/t/t4058-diff-duplicates.sh index c24ee175ef..c24ee175ef 100755 --- a/t/t4058-diff-duplicates.sh +++ b/third_party/git/t/t4058-diff-duplicates.sh diff --git a/t/t4059-diff-submodule-not-initialized.sh b/third_party/git/t/t4059-diff-submodule-not-initialized.sh index 49bca7b48d..49bca7b48d 100755 --- a/t/t4059-diff-submodule-not-initialized.sh +++ b/third_party/git/t/t4059-diff-submodule-not-initialized.sh diff --git a/t/t4060-diff-submodule-option-diff-format.sh b/third_party/git/t/t4060-diff-submodule-option-diff-format.sh index fc8229c726..fc8229c726 100755 --- a/t/t4060-diff-submodule-option-diff-format.sh +++ b/third_party/git/t/t4060-diff-submodule-option-diff-format.sh diff --git a/t/t4061-diff-indent.sh b/third_party/git/t/t4061-diff-indent.sh index 2affd7a100..2affd7a100 100755 --- a/t/t4061-diff-indent.sh +++ b/third_party/git/t/t4061-diff-indent.sh diff --git a/t/t4062-diff-pickaxe.sh b/third_party/git/t/t4062-diff-pickaxe.sh index 1130c8019b..1130c8019b 100755 --- a/t/t4062-diff-pickaxe.sh +++ b/third_party/git/t/t4062-diff-pickaxe.sh diff --git a/t/t4063-diff-blobs.sh b/third_party/git/t/t4063-diff-blobs.sh index bc69e26c52..bc69e26c52 100755 --- a/t/t4063-diff-blobs.sh +++ b/third_party/git/t/t4063-diff-blobs.sh diff --git a/t/t4064-diff-oidfind.sh b/third_party/git/t/t4064-diff-oidfind.sh index 3bdf317af8..3bdf317af8 100755 --- a/t/t4064-diff-oidfind.sh +++ b/third_party/git/t/t4064-diff-oidfind.sh diff --git a/t/t4065-diff-anchored.sh b/third_party/git/t/t4065-diff-anchored.sh index b3f510f040..b3f510f040 100755 --- a/t/t4065-diff-anchored.sh +++ b/third_party/git/t/t4065-diff-anchored.sh diff --git a/t/t4066-diff-emit-delay.sh b/third_party/git/t/t4066-diff-emit-delay.sh index 6331f63b12..6331f63b12 100755 --- a/t/t4066-diff-emit-delay.sh +++ b/third_party/git/t/t4066-diff-emit-delay.sh diff --git a/t/t4067-diff-partial-clone.sh b/third_party/git/t/t4067-diff-partial-clone.sh index 4831ad35e6..4831ad35e6 100755 --- a/t/t4067-diff-partial-clone.sh +++ b/third_party/git/t/t4067-diff-partial-clone.sh diff --git a/t/t4100-apply-stat.sh b/third_party/git/t/t4100-apply-stat.sh index 744b8e51be..744b8e51be 100755 --- a/t/t4100-apply-stat.sh +++ b/third_party/git/t/t4100-apply-stat.sh diff --git a/t/t4100/t-apply-1.expect b/third_party/git/t/t4100/t-apply-1.expect index 540e64db85..540e64db85 100644 --- a/t/t4100/t-apply-1.expect +++ b/third_party/git/t/t4100/t-apply-1.expect diff --git a/t/t4100/t-apply-1.patch b/third_party/git/t/t4100/t-apply-1.patch index 43394f8285..43394f8285 100644 --- a/t/t4100/t-apply-1.patch +++ b/third_party/git/t/t4100/t-apply-1.patch diff --git a/t/t4100/t-apply-2.expect b/third_party/git/t/t4100/t-apply-2.expect index d1e6459749..d1e6459749 100644 --- a/t/t4100/t-apply-2.expect +++ b/third_party/git/t/t4100/t-apply-2.expect diff --git a/t/t4100/t-apply-2.patch b/third_party/git/t/t4100/t-apply-2.patch index f5c7d601fc..f5c7d601fc 100644 --- a/t/t4100/t-apply-2.patch +++ b/third_party/git/t/t4100/t-apply-2.patch diff --git a/t/t4100/t-apply-3.expect b/third_party/git/t/t4100/t-apply-3.expect index 912a552a7a..912a552a7a 100644 --- a/t/t4100/t-apply-3.expect +++ b/third_party/git/t/t4100/t-apply-3.expect diff --git a/t/t4100/t-apply-3.patch b/third_party/git/t/t4100/t-apply-3.patch index cac172e779..cac172e779 100644 --- a/t/t4100/t-apply-3.patch +++ b/third_party/git/t/t4100/t-apply-3.patch diff --git a/t/t4100/t-apply-4.expect b/third_party/git/t/t4100/t-apply-4.expect index 1ec028b3d0..1ec028b3d0 100644 --- a/t/t4100/t-apply-4.expect +++ b/third_party/git/t/t4100/t-apply-4.expect diff --git a/t/t4100/t-apply-4.patch b/third_party/git/t/t4100/t-apply-4.patch index 4a56ab5cf4..4a56ab5cf4 100644 --- a/t/t4100/t-apply-4.patch +++ b/third_party/git/t/t4100/t-apply-4.patch diff --git a/t/t4100/t-apply-5.expect b/third_party/git/t/t4100/t-apply-5.expect index b387df15d4..b387df15d4 100644 --- a/t/t4100/t-apply-5.expect +++ b/third_party/git/t/t4100/t-apply-5.expect diff --git a/t/t4100/t-apply-5.patch b/third_party/git/t/t4100/t-apply-5.patch index 57ec79d887..57ec79d887 100644 --- a/t/t4100/t-apply-5.patch +++ b/third_party/git/t/t4100/t-apply-5.patch diff --git a/t/t4100/t-apply-6.expect b/third_party/git/t/t4100/t-apply-6.expect index 1c343d459e..1c343d459e 100644 --- a/t/t4100/t-apply-6.expect +++ b/third_party/git/t/t4100/t-apply-6.expect diff --git a/t/t4100/t-apply-6.patch b/third_party/git/t/t4100/t-apply-6.patch index a72729a712..a72729a712 100644 --- a/t/t4100/t-apply-6.patch +++ b/third_party/git/t/t4100/t-apply-6.patch diff --git a/t/t4100/t-apply-7.expect b/third_party/git/t/t4100/t-apply-7.expect index 1283164d99..1283164d99 100644 --- a/t/t4100/t-apply-7.expect +++ b/third_party/git/t/t4100/t-apply-7.expect diff --git a/t/t4100/t-apply-7.patch b/third_party/git/t/t4100/t-apply-7.patch index fa24305108..fa24305108 100644 --- a/t/t4100/t-apply-7.patch +++ b/third_party/git/t/t4100/t-apply-7.patch diff --git a/t/t4100/t-apply-8.expect b/third_party/git/t/t4100/t-apply-8.expect index 55a55c3cc7..55a55c3cc7 100644 --- a/t/t4100/t-apply-8.expect +++ b/third_party/git/t/t4100/t-apply-8.expect diff --git a/t/t4100/t-apply-8.patch b/third_party/git/t/t4100/t-apply-8.patch index 5ca13e6594..5ca13e6594 100644 --- a/t/t4100/t-apply-8.patch +++ b/third_party/git/t/t4100/t-apply-8.patch diff --git a/t/t4100/t-apply-9.expect b/third_party/git/t/t4100/t-apply-9.expect index 55a55c3cc7..55a55c3cc7 100644 --- a/t/t4100/t-apply-9.expect +++ b/third_party/git/t/t4100/t-apply-9.expect diff --git a/t/t4100/t-apply-9.patch b/third_party/git/t/t4100/t-apply-9.patch index 875d57d567..875d57d567 100644 --- a/t/t4100/t-apply-9.patch +++ b/third_party/git/t/t4100/t-apply-9.patch diff --git a/t/t4101-apply-nonl.sh b/third_party/git/t/t4101-apply-nonl.sh index e3443d004d..e3443d004d 100755 --- a/t/t4101-apply-nonl.sh +++ b/third_party/git/t/t4101-apply-nonl.sh diff --git a/t/t4101/diff.0-1 b/third_party/git/t/t4101/diff.0-1 index 1010a88f47..1010a88f47 100644 --- a/t/t4101/diff.0-1 +++ b/third_party/git/t/t4101/diff.0-1 diff --git a/t/t4101/diff.0-2 b/third_party/git/t/t4101/diff.0-2 index 36460a243a..36460a243a 100644 --- a/t/t4101/diff.0-2 +++ b/third_party/git/t/t4101/diff.0-2 diff --git a/t/t4101/diff.0-3 b/third_party/git/t/t4101/diff.0-3 index b281c43e5b..b281c43e5b 100644 --- a/t/t4101/diff.0-3 +++ b/third_party/git/t/t4101/diff.0-3 diff --git a/t/t4101/diff.1-0 b/third_party/git/t/t4101/diff.1-0 index f0a2e92770..f0a2e92770 100644 --- a/t/t4101/diff.1-0 +++ b/third_party/git/t/t4101/diff.1-0 diff --git a/t/t4101/diff.1-2 b/third_party/git/t/t4101/diff.1-2 index 2a440a5ce2..2a440a5ce2 100644 --- a/t/t4101/diff.1-2 +++ b/third_party/git/t/t4101/diff.1-2 diff --git a/t/t4101/diff.1-3 b/third_party/git/t/t4101/diff.1-3 index 61aff975b6..61aff975b6 100644 --- a/t/t4101/diff.1-3 +++ b/third_party/git/t/t4101/diff.1-3 diff --git a/t/t4101/diff.2-0 b/third_party/git/t/t4101/diff.2-0 index c2e71ee344..c2e71ee344 100644 --- a/t/t4101/diff.2-0 +++ b/third_party/git/t/t4101/diff.2-0 diff --git a/t/t4101/diff.2-1 b/third_party/git/t/t4101/diff.2-1 index a66d9fd3a1..a66d9fd3a1 100644 --- a/t/t4101/diff.2-1 +++ b/third_party/git/t/t4101/diff.2-1 diff --git a/t/t4101/diff.2-3 b/third_party/git/t/t4101/diff.2-3 index 5633c831de..5633c831de 100644 --- a/t/t4101/diff.2-3 +++ b/third_party/git/t/t4101/diff.2-3 diff --git a/t/t4101/diff.3-0 b/third_party/git/t/t4101/diff.3-0 index 10b1a41edf..10b1a41edf 100644 --- a/t/t4101/diff.3-0 +++ b/third_party/git/t/t4101/diff.3-0 diff --git a/t/t4101/diff.3-1 b/third_party/git/t/t4101/diff.3-1 index c799c60fb9..c799c60fb9 100644 --- a/t/t4101/diff.3-1 +++ b/third_party/git/t/t4101/diff.3-1 diff --git a/t/t4101/diff.3-2 b/third_party/git/t/t4101/diff.3-2 index f8d1ba6dc2..f8d1ba6dc2 100644 --- a/t/t4101/diff.3-2 +++ b/third_party/git/t/t4101/diff.3-2 diff --git a/t/t4102-apply-rename.sh b/third_party/git/t/t4102-apply-rename.sh index fae305979a..fae305979a 100755 --- a/t/t4102-apply-rename.sh +++ b/third_party/git/t/t4102-apply-rename.sh diff --git a/t/t4103-apply-binary.sh b/third_party/git/t/t4103-apply-binary.sh index 1b420e3b5f..1b420e3b5f 100755 --- a/t/t4103-apply-binary.sh +++ b/third_party/git/t/t4103-apply-binary.sh diff --git a/t/t4104-apply-boundary.sh b/third_party/git/t/t4104-apply-boundary.sh index 32e3b0ee0b..32e3b0ee0b 100755 --- a/t/t4104-apply-boundary.sh +++ b/third_party/git/t/t4104-apply-boundary.sh diff --git a/t/t4105-apply-fuzz.sh b/third_party/git/t/t4105-apply-fuzz.sh index 3266e39400..3266e39400 100755 --- a/t/t4105-apply-fuzz.sh +++ b/third_party/git/t/t4105-apply-fuzz.sh diff --git a/t/t4106-apply-stdin.sh b/third_party/git/t/t4106-apply-stdin.sh index 72467a1e8e..72467a1e8e 100755 --- a/t/t4106-apply-stdin.sh +++ b/third_party/git/t/t4106-apply-stdin.sh diff --git a/t/t4107-apply-ignore-whitespace.sh b/third_party/git/t/t4107-apply-ignore-whitespace.sh index ac72eeaf27..ac72eeaf27 100755 --- a/t/t4107-apply-ignore-whitespace.sh +++ b/third_party/git/t/t4107-apply-ignore-whitespace.sh diff --git a/t/t4108-apply-threeway.sh b/third_party/git/t/t4108-apply-threeway.sh index d7349ced6b..d7349ced6b 100755 --- a/t/t4108-apply-threeway.sh +++ b/third_party/git/t/t4108-apply-threeway.sh diff --git a/t/t4109-apply-multifrag.sh b/third_party/git/t/t4109-apply-multifrag.sh index ac58083fe2..ac58083fe2 100755 --- a/t/t4109-apply-multifrag.sh +++ b/third_party/git/t/t4109-apply-multifrag.sh diff --git a/t/t4109/expect-1 b/third_party/git/t/t4109/expect-1 index 1db5ff1050..1db5ff1050 100644 --- a/t/t4109/expect-1 +++ b/third_party/git/t/t4109/expect-1 diff --git a/t/t4109/expect-2 b/third_party/git/t/t4109/expect-2 index bc52924112..bc52924112 100644 --- a/t/t4109/expect-2 +++ b/third_party/git/t/t4109/expect-2 diff --git a/t/t4109/expect-3 b/third_party/git/t/t4109/expect-3 index cd2a475feb..cd2a475feb 100644 --- a/t/t4109/expect-3 +++ b/third_party/git/t/t4109/expect-3 diff --git a/t/t4109/patch1.patch b/third_party/git/t/t4109/patch1.patch index 1d411fc3cc..1d411fc3cc 100644 --- a/t/t4109/patch1.patch +++ b/third_party/git/t/t4109/patch1.patch diff --git a/t/t4109/patch2.patch b/third_party/git/t/t4109/patch2.patch index 8c6b06d536..8c6b06d536 100644 --- a/t/t4109/patch2.patch +++ b/third_party/git/t/t4109/patch2.patch diff --git a/t/t4109/patch3.patch b/third_party/git/t/t4109/patch3.patch index d696c55a75..d696c55a75 100644 --- a/t/t4109/patch3.patch +++ b/third_party/git/t/t4109/patch3.patch diff --git a/t/t4109/patch4.patch b/third_party/git/t/t4109/patch4.patch index 4b085909b1..4b085909b1 100644 --- a/t/t4109/patch4.patch +++ b/third_party/git/t/t4109/patch4.patch diff --git a/t/t4110-apply-scan.sh b/third_party/git/t/t4110-apply-scan.sh index 09f58112e0..09f58112e0 100755 --- a/t/t4110-apply-scan.sh +++ b/third_party/git/t/t4110-apply-scan.sh diff --git a/t/t4110/expect b/third_party/git/t/t4110/expect index 87cc493ec8..87cc493ec8 100644 --- a/t/t4110/expect +++ b/third_party/git/t/t4110/expect diff --git a/t/t4110/patch1.patch b/third_party/git/t/t4110/patch1.patch index 56139080dc..56139080dc 100644 --- a/t/t4110/patch1.patch +++ b/third_party/git/t/t4110/patch1.patch diff --git a/t/t4110/patch2.patch b/third_party/git/t/t4110/patch2.patch index 04974247ec..04974247ec 100644 --- a/t/t4110/patch2.patch +++ b/third_party/git/t/t4110/patch2.patch diff --git a/t/t4110/patch3.patch b/third_party/git/t/t4110/patch3.patch index 26bd4427f8..26bd4427f8 100644 --- a/t/t4110/patch3.patch +++ b/third_party/git/t/t4110/patch3.patch diff --git a/t/t4110/patch4.patch b/third_party/git/t/t4110/patch4.patch index 9ffb9c2d7e..9ffb9c2d7e 100644 --- a/t/t4110/patch4.patch +++ b/third_party/git/t/t4110/patch4.patch diff --git a/t/t4110/patch5.patch b/third_party/git/t/t4110/patch5.patch index c5ac6914f9..c5ac6914f9 100644 --- a/t/t4110/patch5.patch +++ b/third_party/git/t/t4110/patch5.patch diff --git a/t/t4111-apply-subdir.sh b/third_party/git/t/t4111-apply-subdir.sh index 1618a6dbc7..1618a6dbc7 100755 --- a/t/t4111-apply-subdir.sh +++ b/third_party/git/t/t4111-apply-subdir.sh diff --git a/t/t4112-apply-renames.sh b/third_party/git/t/t4112-apply-renames.sh index f9ad183758..f9ad183758 100755 --- a/t/t4112-apply-renames.sh +++ b/third_party/git/t/t4112-apply-renames.sh diff --git a/t/t4113-apply-ending.sh b/third_party/git/t/t4113-apply-ending.sh index 66fa51591e..66fa51591e 100755 --- a/t/t4113-apply-ending.sh +++ b/third_party/git/t/t4113-apply-ending.sh diff --git a/t/t4114-apply-typechange.sh b/third_party/git/t/t4114-apply-typechange.sh index ebadbc347f..ebadbc347f 100755 --- a/t/t4114-apply-typechange.sh +++ b/third_party/git/t/t4114-apply-typechange.sh diff --git a/t/t4115-apply-symlink.sh b/third_party/git/t/t4115-apply-symlink.sh index 872fcda6cb..872fcda6cb 100755 --- a/t/t4115-apply-symlink.sh +++ b/third_party/git/t/t4115-apply-symlink.sh diff --git a/t/t4116-apply-reverse.sh b/third_party/git/t/t4116-apply-reverse.sh index b99e65c086..b99e65c086 100755 --- a/t/t4116-apply-reverse.sh +++ b/third_party/git/t/t4116-apply-reverse.sh diff --git a/t/t4117-apply-reject.sh b/third_party/git/t/t4117-apply-reject.sh index 0ee93fe845..0ee93fe845 100755 --- a/t/t4117-apply-reject.sh +++ b/third_party/git/t/t4117-apply-reject.sh diff --git a/t/t4118-apply-empty-context.sh b/third_party/git/t/t4118-apply-empty-context.sh index 65f2e4c3ef..65f2e4c3ef 100755 --- a/t/t4118-apply-empty-context.sh +++ b/third_party/git/t/t4118-apply-empty-context.sh diff --git a/t/t4119-apply-config.sh b/third_party/git/t/t4119-apply-config.sh index a9a0583811..a9a0583811 100755 --- a/t/t4119-apply-config.sh +++ b/third_party/git/t/t4119-apply-config.sh diff --git a/t/t4120-apply-popt.sh b/third_party/git/t/t4120-apply-popt.sh index 497b62868d..497b62868d 100755 --- a/t/t4120-apply-popt.sh +++ b/third_party/git/t/t4120-apply-popt.sh diff --git a/t/t4121-apply-diffs.sh b/third_party/git/t/t4121-apply-diffs.sh index 66368effd5..66368effd5 100755 --- a/t/t4121-apply-diffs.sh +++ b/third_party/git/t/t4121-apply-diffs.sh diff --git a/t/t4122-apply-symlink-inside.sh b/third_party/git/t/t4122-apply-symlink-inside.sh index 4acb3f336e..4acb3f336e 100755 --- a/t/t4122-apply-symlink-inside.sh +++ b/third_party/git/t/t4122-apply-symlink-inside.sh diff --git a/t/t4123-apply-shrink.sh b/third_party/git/t/t4123-apply-shrink.sh index 984157f03b..984157f03b 100755 --- a/t/t4123-apply-shrink.sh +++ b/third_party/git/t/t4123-apply-shrink.sh diff --git a/t/t4124-apply-ws-rule.sh b/third_party/git/t/t4124-apply-ws-rule.sh index 971a5a7512..971a5a7512 100755 --- a/t/t4124-apply-ws-rule.sh +++ b/third_party/git/t/t4124-apply-ws-rule.sh diff --git a/t/t4125-apply-ws-fuzz.sh b/third_party/git/t/t4125-apply-ws-fuzz.sh index 9671de7999..9671de7999 100755 --- a/t/t4125-apply-ws-fuzz.sh +++ b/third_party/git/t/t4125-apply-ws-fuzz.sh diff --git a/t/t4126-apply-empty.sh b/third_party/git/t/t4126-apply-empty.sh index ceb6a79fe0..ceb6a79fe0 100755 --- a/t/t4126-apply-empty.sh +++ b/third_party/git/t/t4126-apply-empty.sh diff --git a/t/t4127-apply-same-fn.sh b/third_party/git/t/t4127-apply-same-fn.sh index 972946c174..972946c174 100755 --- a/t/t4127-apply-same-fn.sh +++ b/third_party/git/t/t4127-apply-same-fn.sh diff --git a/t/t4128-apply-root.sh b/third_party/git/t/t4128-apply-root.sh index 6cc741a634..6cc741a634 100755 --- a/t/t4128-apply-root.sh +++ b/third_party/git/t/t4128-apply-root.sh diff --git a/t/t4129-apply-samemode.sh b/third_party/git/t/t4129-apply-samemode.sh index 5cdd76dfa7..5cdd76dfa7 100755 --- a/t/t4129-apply-samemode.sh +++ b/third_party/git/t/t4129-apply-samemode.sh diff --git a/t/t4130-apply-criss-cross-rename.sh b/third_party/git/t/t4130-apply-criss-cross-rename.sh index f8a313bcb9..f8a313bcb9 100755 --- a/t/t4130-apply-criss-cross-rename.sh +++ b/third_party/git/t/t4130-apply-criss-cross-rename.sh diff --git a/t/t4131-apply-fake-ancestor.sh b/third_party/git/t/t4131-apply-fake-ancestor.sh index b1361ce546..b1361ce546 100755 --- a/t/t4131-apply-fake-ancestor.sh +++ b/third_party/git/t/t4131-apply-fake-ancestor.sh diff --git a/t/t4132-apply-removal.sh b/third_party/git/t/t4132-apply-removal.sh index fec1d6fa51..fec1d6fa51 100755 --- a/t/t4132-apply-removal.sh +++ b/third_party/git/t/t4132-apply-removal.sh diff --git a/t/t4133-apply-filenames.sh b/third_party/git/t/t4133-apply-filenames.sh index c5ed3b17c4..c5ed3b17c4 100755 --- a/t/t4133-apply-filenames.sh +++ b/third_party/git/t/t4133-apply-filenames.sh diff --git a/t/t4134-apply-submodule.sh b/third_party/git/t/t4134-apply-submodule.sh index 99ed4cc546..99ed4cc546 100755 --- a/t/t4134-apply-submodule.sh +++ b/third_party/git/t/t4134-apply-submodule.sh diff --git a/t/t4135-apply-weird-filenames.sh b/third_party/git/t/t4135-apply-weird-filenames.sh index 6bc3fb97a7..6bc3fb97a7 100755 --- a/t/t4135-apply-weird-filenames.sh +++ b/third_party/git/t/t4135-apply-weird-filenames.sh diff --git a/t/t4135/.gitignore b/third_party/git/t/t4135/.gitignore index 3e58e65f57..3e58e65f57 100644 --- a/t/t4135/.gitignore +++ b/third_party/git/t/t4135/.gitignore diff --git a/t/t4135/add-plain.diff b/third_party/git/t/t4135/add-plain.diff index cf5970a089..cf5970a089 100644 --- a/t/t4135/add-plain.diff +++ b/third_party/git/t/t4135/add-plain.diff diff --git a/t/t4135/add-with backslash.diff b/third_party/git/t/t4135/add-with backslash.diff index c6861e1966..c6861e1966 100644 --- a/t/t4135/add-with backslash.diff +++ b/third_party/git/t/t4135/add-with backslash.diff diff --git a/t/t4135/add-with quote.diff b/third_party/git/t/t4135/add-with quote.diff index 866de78ca1..866de78ca1 100644 --- a/t/t4135/add-with quote.diff +++ b/third_party/git/t/t4135/add-with quote.diff diff --git a/t/t4135/add-with spaces.diff b/third_party/git/t/t4135/add-with spaces.diff index a9a1212a21..a9a1212a21 100644 --- a/t/t4135/add-with spaces.diff +++ b/third_party/git/t/t4135/add-with spaces.diff diff --git a/t/t4135/add-with tab.diff b/third_party/git/t/t4135/add-with tab.diff index bb67cb7930..bb67cb7930 100644 --- a/t/t4135/add-with tab.diff +++ b/third_party/git/t/t4135/add-with tab.diff diff --git a/t/t4135/damaged-tz.diff b/third_party/git/t/t4135/damaged-tz.diff index 07aaf08370..07aaf08370 100644 --- a/t/t4135/damaged-tz.diff +++ b/third_party/git/t/t4135/damaged-tz.diff diff --git a/t/t4135/damaged.diff b/third_party/git/t/t4135/damaged.diff index 68f7ededf9..68f7ededf9 100644 --- a/t/t4135/damaged.diff +++ b/third_party/git/t/t4135/damaged.diff diff --git a/t/t4135/diff-plain.diff b/third_party/git/t/t4135/diff-plain.diff index acedcfa612..acedcfa612 100644 --- a/t/t4135/diff-plain.diff +++ b/third_party/git/t/t4135/diff-plain.diff diff --git a/t/t4135/diff-with backslash.diff b/third_party/git/t/t4135/diff-with backslash.diff index 9068a61bd9..9068a61bd9 100644 --- a/t/t4135/diff-with backslash.diff +++ b/third_party/git/t/t4135/diff-with backslash.diff diff --git a/t/t4135/diff-with quote.diff b/third_party/git/t/t4135/diff-with quote.diff index c8e8cc1a8d..c8e8cc1a8d 100644 --- a/t/t4135/diff-with quote.diff +++ b/third_party/git/t/t4135/diff-with quote.diff diff --git a/t/t4135/diff-with spaces.diff b/third_party/git/t/t4135/diff-with spaces.diff index 3512056f21..3512056f21 100644 --- a/t/t4135/diff-with spaces.diff +++ b/third_party/git/t/t4135/diff-with spaces.diff diff --git a/t/t4135/diff-with tab.diff b/third_party/git/t/t4135/diff-with tab.diff index 4e6d9b2941..4e6d9b2941 100644 --- a/t/t4135/diff-with tab.diff +++ b/third_party/git/t/t4135/diff-with tab.diff diff --git a/t/t4135/funny-tz.diff b/third_party/git/t/t4135/funny-tz.diff index 998e3a867e..998e3a867e 100644 --- a/t/t4135/funny-tz.diff +++ b/third_party/git/t/t4135/funny-tz.diff diff --git a/t/t4135/git-plain.diff b/third_party/git/t/t4135/git-plain.diff index db47d1a693..db47d1a693 100644 --- a/t/t4135/git-plain.diff +++ b/third_party/git/t/t4135/git-plain.diff diff --git a/t/t4135/git-with backslash.diff b/third_party/git/t/t4135/git-with backslash.diff index 0e84a10e93..0e84a10e93 100644 --- a/t/t4135/git-with backslash.diff +++ b/third_party/git/t/t4135/git-with backslash.diff diff --git a/t/t4135/git-with quote.diff b/third_party/git/t/t4135/git-with quote.diff index bdbea8af35..bdbea8af35 100644 --- a/t/t4135/git-with quote.diff +++ b/third_party/git/t/t4135/git-with quote.diff diff --git a/t/t4135/git-with spaces.diff b/third_party/git/t/t4135/git-with spaces.diff index baaa810de0..baaa810de0 100644 --- a/t/t4135/git-with spaces.diff +++ b/third_party/git/t/t4135/git-with spaces.diff diff --git a/t/t4135/git-with tab.diff b/third_party/git/t/t4135/git-with tab.diff index cca3c9287b..cca3c9287b 100644 --- a/t/t4135/git-with tab.diff +++ b/third_party/git/t/t4135/git-with tab.diff diff --git a/t/t4135/make-patches b/third_party/git/t/t4135/make-patches index f5f45ddd09..f5f45ddd09 100755 --- a/t/t4135/make-patches +++ b/third_party/git/t/t4135/make-patches diff --git a/t/t4136-apply-check.sh b/third_party/git/t/t4136-apply-check.sh index 4c3f264a63..4c3f264a63 100755 --- a/t/t4136-apply-check.sh +++ b/third_party/git/t/t4136-apply-check.sh diff --git a/t/t4137-apply-submodule.sh b/third_party/git/t/t4137-apply-submodule.sh index a9bd40a6d0..a9bd40a6d0 100755 --- a/t/t4137-apply-submodule.sh +++ b/third_party/git/t/t4137-apply-submodule.sh diff --git a/t/t4138-apply-ws-expansion.sh b/third_party/git/t/t4138-apply-ws-expansion.sh index b19faeb67a..b19faeb67a 100755 --- a/t/t4138-apply-ws-expansion.sh +++ b/third_party/git/t/t4138-apply-ws-expansion.sh diff --git a/t/t4139-apply-escape.sh b/third_party/git/t/t4139-apply-escape.sh index 45b5660a47..45b5660a47 100755 --- a/t/t4139-apply-escape.sh +++ b/third_party/git/t/t4139-apply-escape.sh diff --git a/t/t4150-am.sh b/third_party/git/t/t4150-am.sh index cb45271457..cb45271457 100755 --- a/t/t4150-am.sh +++ b/third_party/git/t/t4150-am.sh diff --git a/t/t4151-am-abort.sh b/third_party/git/t/t4151-am-abort.sh index 9d8d3c72e7..9d8d3c72e7 100755 --- a/t/t4151-am-abort.sh +++ b/third_party/git/t/t4151-am-abort.sh diff --git a/t/t4152-am-subjects.sh b/third_party/git/t/t4152-am-subjects.sh index 4c68245aca..4c68245aca 100755 --- a/t/t4152-am-subjects.sh +++ b/third_party/git/t/t4152-am-subjects.sh diff --git a/t/t4153-am-resume-override-opts.sh b/third_party/git/t/t4153-am-resume-override-opts.sh index 8ea22d1bcb..8ea22d1bcb 100755 --- a/t/t4153-am-resume-override-opts.sh +++ b/third_party/git/t/t4153-am-resume-override-opts.sh diff --git a/t/t4200-rerere.sh b/third_party/git/t/t4200-rerere.sh index 831d424c47..831d424c47 100755 --- a/t/t4200-rerere.sh +++ b/third_party/git/t/t4200-rerere.sh diff --git a/t/t4201-shortlog.sh b/third_party/git/t/t4201-shortlog.sh index d3a7ce6bbb..d3a7ce6bbb 100755 --- a/t/t4201-shortlog.sh +++ b/third_party/git/t/t4201-shortlog.sh diff --git a/t/t4202-log.sh b/third_party/git/t/t4202-log.sh index 0f766ba65f..0f766ba65f 100755 --- a/t/t4202-log.sh +++ b/third_party/git/t/t4202-log.sh diff --git a/t/t4203-mailmap.sh b/third_party/git/t/t4203-mailmap.sh index 586c3a86b1..586c3a86b1 100755 --- a/t/t4203-mailmap.sh +++ b/third_party/git/t/t4203-mailmap.sh diff --git a/t/t4204-patch-id.sh b/third_party/git/t/t4204-patch-id.sh index 8ff8bd84c7..8ff8bd84c7 100755 --- a/t/t4204-patch-id.sh +++ b/third_party/git/t/t4204-patch-id.sh diff --git a/t/t4205-log-pretty-formats.sh b/third_party/git/t/t4205-log-pretty-formats.sh index 204c149d5a..204c149d5a 100755 --- a/t/t4205-log-pretty-formats.sh +++ b/third_party/git/t/t4205-log-pretty-formats.sh diff --git a/t/t4206-log-follow-harder-copies.sh b/third_party/git/t/t4206-log-follow-harder-copies.sh index ad29e65fcb..ad29e65fcb 100755 --- a/t/t4206-log-follow-harder-copies.sh +++ b/third_party/git/t/t4206-log-follow-harder-copies.sh diff --git a/t/t4207-log-decoration-colors.sh b/third_party/git/t/t4207-log-decoration-colors.sh index 60f040cab8..60f040cab8 100755 --- a/t/t4207-log-decoration-colors.sh +++ b/third_party/git/t/t4207-log-decoration-colors.sh diff --git a/t/t4208-log-magic-pathspec.sh b/third_party/git/t/t4208-log-magic-pathspec.sh index 4c8f3b8e1b..4c8f3b8e1b 100755 --- a/t/t4208-log-magic-pathspec.sh +++ b/third_party/git/t/t4208-log-magic-pathspec.sh diff --git a/t/t4209-log-pickaxe.sh b/third_party/git/t/t4209-log-pickaxe.sh index 5d06f5f45e..5d06f5f45e 100755 --- a/t/t4209-log-pickaxe.sh +++ b/third_party/git/t/t4209-log-pickaxe.sh diff --git a/t/t4210-log-i18n.sh b/third_party/git/t/t4210-log-i18n.sh index c3792081e6..c3792081e6 100755 --- a/t/t4210-log-i18n.sh +++ b/third_party/git/t/t4210-log-i18n.sh diff --git a/t/t4211-line-log.sh b/third_party/git/t/t4211-line-log.sh index cda58186c2..cda58186c2 100755 --- a/t/t4211-line-log.sh +++ b/third_party/git/t/t4211-line-log.sh diff --git a/t/t4211/history.export b/third_party/git/t/t4211/history.export index f9f41e211e..f9f41e211e 100644 --- a/t/t4211/history.export +++ b/third_party/git/t/t4211/history.export diff --git a/t/t4211/sha1/expect.beginning-of-file b/third_party/git/t/t4211/sha1/expect.beginning-of-file index 91b4054898..91b4054898 100644 --- a/t/t4211/sha1/expect.beginning-of-file +++ b/third_party/git/t/t4211/sha1/expect.beginning-of-file diff --git a/t/t4211/sha1/expect.end-of-file b/third_party/git/t/t4211/sha1/expect.end-of-file index bd25bb2f59..bd25bb2f59 100644 --- a/t/t4211/sha1/expect.end-of-file +++ b/third_party/git/t/t4211/sha1/expect.end-of-file diff --git a/t/t4211/sha1/expect.move-support-f b/third_party/git/t/t4211/sha1/expect.move-support-f index c905e01bc2..c905e01bc2 100644 --- a/t/t4211/sha1/expect.move-support-f +++ b/third_party/git/t/t4211/sha1/expect.move-support-f diff --git a/t/t4211/sha1/expect.multiple b/third_party/git/t/t4211/sha1/expect.multiple index 76ad5b598c..76ad5b598c 100644 --- a/t/t4211/sha1/expect.multiple +++ b/third_party/git/t/t4211/sha1/expect.multiple diff --git a/t/t4211/sha1/expect.multiple-overlapping b/third_party/git/t/t4211/sha1/expect.multiple-overlapping index d930b6eec4..d930b6eec4 100644 --- a/t/t4211/sha1/expect.multiple-overlapping +++ b/third_party/git/t/t4211/sha1/expect.multiple-overlapping diff --git a/t/t4211/sha1/expect.multiple-superset b/third_party/git/t/t4211/sha1/expect.multiple-superset index d930b6eec4..d930b6eec4 100644 --- a/t/t4211/sha1/expect.multiple-superset +++ b/third_party/git/t/t4211/sha1/expect.multiple-superset diff --git a/t/t4211/sha1/expect.parallel-change-f-to-main b/third_party/git/t/t4211/sha1/expect.parallel-change-f-to-main index 052def8074..052def8074 100644 --- a/t/t4211/sha1/expect.parallel-change-f-to-main +++ b/third_party/git/t/t4211/sha1/expect.parallel-change-f-to-main diff --git a/t/t4211/sha1/expect.simple-f b/third_party/git/t/t4211/sha1/expect.simple-f index a1f5bc49c8..a1f5bc49c8 100644 --- a/t/t4211/sha1/expect.simple-f +++ b/third_party/git/t/t4211/sha1/expect.simple-f diff --git a/t/t4211/sha1/expect.simple-f-to-main b/third_party/git/t/t4211/sha1/expect.simple-f-to-main index a475768710..a475768710 100644 --- a/t/t4211/sha1/expect.simple-f-to-main +++ b/third_party/git/t/t4211/sha1/expect.simple-f-to-main diff --git a/t/t4211/sha1/expect.simple-main b/third_party/git/t/t4211/sha1/expect.simple-main index 39ce39bebe..39ce39bebe 100644 --- a/t/t4211/sha1/expect.simple-main +++ b/third_party/git/t/t4211/sha1/expect.simple-main diff --git a/t/t4211/sha1/expect.simple-main-to-end b/third_party/git/t/t4211/sha1/expect.simple-main-to-end index 8480bd9cc4..8480bd9cc4 100644 --- a/t/t4211/sha1/expect.simple-main-to-end +++ b/third_party/git/t/t4211/sha1/expect.simple-main-to-end diff --git a/t/t4211/sha1/expect.two-ranges b/third_party/git/t/t4211/sha1/expect.two-ranges index 6109aa0dce..6109aa0dce 100644 --- a/t/t4211/sha1/expect.two-ranges +++ b/third_party/git/t/t4211/sha1/expect.two-ranges diff --git a/t/t4211/sha1/expect.vanishes-early b/third_party/git/t/t4211/sha1/expect.vanishes-early index 1f7cd06941..1f7cd06941 100644 --- a/t/t4211/sha1/expect.vanishes-early +++ b/third_party/git/t/t4211/sha1/expect.vanishes-early diff --git a/t/t4211/sha256/expect.beginning-of-file b/third_party/git/t/t4211/sha256/expect.beginning-of-file index 5adfdfc1a1..5adfdfc1a1 100644 --- a/t/t4211/sha256/expect.beginning-of-file +++ b/third_party/git/t/t4211/sha256/expect.beginning-of-file diff --git a/t/t4211/sha256/expect.end-of-file b/third_party/git/t/t4211/sha256/expect.end-of-file index 03ab5c1784..03ab5c1784 100644 --- a/t/t4211/sha256/expect.end-of-file +++ b/third_party/git/t/t4211/sha256/expect.end-of-file diff --git a/t/t4211/sha256/expect.move-support-f b/third_party/git/t/t4211/sha256/expect.move-support-f index 223b4ed2a0..223b4ed2a0 100644 --- a/t/t4211/sha256/expect.move-support-f +++ b/third_party/git/t/t4211/sha256/expect.move-support-f diff --git a/t/t4211/sha256/expect.multiple b/third_party/git/t/t4211/sha256/expect.multiple index ca00409b9a..ca00409b9a 100644 --- a/t/t4211/sha256/expect.multiple +++ b/third_party/git/t/t4211/sha256/expect.multiple diff --git a/t/t4211/sha256/expect.multiple-overlapping b/third_party/git/t/t4211/sha256/expect.multiple-overlapping index 9015a45a25..9015a45a25 100644 --- a/t/t4211/sha256/expect.multiple-overlapping +++ b/third_party/git/t/t4211/sha256/expect.multiple-overlapping diff --git a/t/t4211/sha256/expect.multiple-superset b/third_party/git/t/t4211/sha256/expect.multiple-superset index 9015a45a25..9015a45a25 100644 --- a/t/t4211/sha256/expect.multiple-superset +++ b/third_party/git/t/t4211/sha256/expect.multiple-superset diff --git a/t/t4211/sha256/expect.parallel-change-f-to-main b/third_party/git/t/t4211/sha256/expect.parallel-change-f-to-main index e68f8928ea..e68f8928ea 100644 --- a/t/t4211/sha256/expect.parallel-change-f-to-main +++ b/third_party/git/t/t4211/sha256/expect.parallel-change-f-to-main diff --git a/t/t4211/sha256/expect.simple-f b/third_party/git/t/t4211/sha256/expect.simple-f index 65508d7c0b..65508d7c0b 100644 --- a/t/t4211/sha256/expect.simple-f +++ b/third_party/git/t/t4211/sha256/expect.simple-f diff --git a/t/t4211/sha256/expect.simple-f-to-main b/third_party/git/t/t4211/sha256/expect.simple-f-to-main index 77b721c196..77b721c196 100644 --- a/t/t4211/sha256/expect.simple-f-to-main +++ b/third_party/git/t/t4211/sha256/expect.simple-f-to-main diff --git a/t/t4211/sha256/expect.simple-main b/third_party/git/t/t4211/sha256/expect.simple-main index d20708c9f9..d20708c9f9 100644 --- a/t/t4211/sha256/expect.simple-main +++ b/third_party/git/t/t4211/sha256/expect.simple-main diff --git a/t/t4211/sha256/expect.simple-main-to-end b/third_party/git/t/t4211/sha256/expect.simple-main-to-end index 617cdf3481..617cdf3481 100644 --- a/t/t4211/sha256/expect.simple-main-to-end +++ b/third_party/git/t/t4211/sha256/expect.simple-main-to-end diff --git a/t/t4211/sha256/expect.two-ranges b/third_party/git/t/t4211/sha256/expect.two-ranges index af57c8b997..af57c8b997 100644 --- a/t/t4211/sha256/expect.two-ranges +++ b/third_party/git/t/t4211/sha256/expect.two-ranges diff --git a/t/t4211/sha256/expect.vanishes-early b/third_party/git/t/t4211/sha256/expect.vanishes-early index 11ec9bdecf..11ec9bdecf 100644 --- a/t/t4211/sha256/expect.vanishes-early +++ b/third_party/git/t/t4211/sha256/expect.vanishes-early diff --git a/t/t4212-log-corrupt.sh b/third_party/git/t/t4212-log-corrupt.sh index 03b952c90d..03b952c90d 100755 --- a/t/t4212-log-corrupt.sh +++ b/third_party/git/t/t4212-log-corrupt.sh diff --git a/t/t4213-log-tabexpand.sh b/third_party/git/t/t4213-log-tabexpand.sh index 53a4af3244..53a4af3244 100755 --- a/t/t4213-log-tabexpand.sh +++ b/third_party/git/t/t4213-log-tabexpand.sh diff --git a/t/t4214-log-graph-octopus.sh b/third_party/git/t/t4214-log-graph-octopus.sh index a080325098..a080325098 100755 --- a/t/t4214-log-graph-octopus.sh +++ b/third_party/git/t/t4214-log-graph-octopus.sh diff --git a/t/t4215-log-skewed-merges.sh b/third_party/git/t/t4215-log-skewed-merges.sh index 28d0779a8c..28d0779a8c 100755 --- a/t/t4215-log-skewed-merges.sh +++ b/third_party/git/t/t4215-log-skewed-merges.sh diff --git a/t/t4252-am-options.sh b/third_party/git/t/t4252-am-options.sh index e758e634a3..e758e634a3 100755 --- a/t/t4252-am-options.sh +++ b/third_party/git/t/t4252-am-options.sh diff --git a/t/t4252/am-test-1-1 b/third_party/git/t/t4252/am-test-1-1 index b0c09dc965..b0c09dc965 100644 --- a/t/t4252/am-test-1-1 +++ b/third_party/git/t/t4252/am-test-1-1 diff --git a/t/t4252/am-test-1-2 b/third_party/git/t/t4252/am-test-1-2 index 1b874ae115..1b874ae115 100644 --- a/t/t4252/am-test-1-2 +++ b/third_party/git/t/t4252/am-test-1-2 diff --git a/t/t4252/am-test-2-1 b/third_party/git/t/t4252/am-test-2-1 index feda94a0cc..feda94a0cc 100644 --- a/t/t4252/am-test-2-1 +++ b/third_party/git/t/t4252/am-test-2-1 diff --git a/t/t4252/am-test-2-2 b/third_party/git/t/t4252/am-test-2-2 index 2ac6600976..2ac6600976 100644 --- a/t/t4252/am-test-2-2 +++ b/third_party/git/t/t4252/am-test-2-2 diff --git a/t/t4252/am-test-3-1 b/third_party/git/t/t4252/am-test-3-1 index 608e5abba4..608e5abba4 100644 --- a/t/t4252/am-test-3-1 +++ b/third_party/git/t/t4252/am-test-3-1 diff --git a/t/t4252/am-test-3-2 b/third_party/git/t/t4252/am-test-3-2 index 0081b96f2a..0081b96f2a 100644 --- a/t/t4252/am-test-3-2 +++ b/third_party/git/t/t4252/am-test-3-2 diff --git a/t/t4252/am-test-4-1 b/third_party/git/t/t4252/am-test-4-1 index e48cd6cbde..e48cd6cbde 100644 --- a/t/t4252/am-test-4-1 +++ b/third_party/git/t/t4252/am-test-4-1 diff --git a/t/t4252/am-test-4-2 b/third_party/git/t/t4252/am-test-4-2 index 0e69bfa55b..0e69bfa55b 100644 --- a/t/t4252/am-test-4-2 +++ b/third_party/git/t/t4252/am-test-4-2 diff --git a/t/t4252/am-test-5-1 b/third_party/git/t/t4252/am-test-5-1 index da7bf29cbe..da7bf29cbe 100644 --- a/t/t4252/am-test-5-1 +++ b/third_party/git/t/t4252/am-test-5-1 diff --git a/t/t4252/am-test-5-2 b/third_party/git/t/t4252/am-test-5-2 index 373025bcf6..373025bcf6 100644 --- a/t/t4252/am-test-5-2 +++ b/third_party/git/t/t4252/am-test-5-2 diff --git a/t/t4252/am-test-6-1 b/third_party/git/t/t4252/am-test-6-1 index a8859e9b8f..a8859e9b8f 100644 --- a/t/t4252/am-test-6-1 +++ b/third_party/git/t/t4252/am-test-6-1 diff --git a/t/t4252/file-1-0 b/third_party/git/t/t4252/file-1-0 index 06e567b11d..06e567b11d 100644 --- a/t/t4252/file-1-0 +++ b/third_party/git/t/t4252/file-1-0 diff --git a/t/t4252/file-2-0 b/third_party/git/t/t4252/file-2-0 index 06e567b11d..06e567b11d 100644 --- a/t/t4252/file-2-0 +++ b/third_party/git/t/t4252/file-2-0 diff --git a/t/t4253-am-keep-cr-dos.sh b/third_party/git/t/t4253-am-keep-cr-dos.sh index 6e1b73ec3a..6e1b73ec3a 100755 --- a/t/t4253-am-keep-cr-dos.sh +++ b/third_party/git/t/t4253-am-keep-cr-dos.sh diff --git a/t/t4254-am-corrupt.sh b/third_party/git/t/t4254-am-corrupt.sh index fd3bdbfe2c..fd3bdbfe2c 100755 --- a/t/t4254-am-corrupt.sh +++ b/third_party/git/t/t4254-am-corrupt.sh diff --git a/t/t4255-am-submodule.sh b/third_party/git/t/t4255-am-submodule.sh index 0ba8194403..0ba8194403 100755 --- a/t/t4255-am-submodule.sh +++ b/third_party/git/t/t4255-am-submodule.sh diff --git a/t/t4256-am-format-flowed.sh b/third_party/git/t/t4256-am-format-flowed.sh index 2369c4e17a..2369c4e17a 100755 --- a/t/t4256-am-format-flowed.sh +++ b/third_party/git/t/t4256-am-format-flowed.sh diff --git a/t/t4256/1/mailinfo.c b/third_party/git/t/t4256/1/mailinfo.c index b395adbdf2..b395adbdf2 100644 --- a/t/t4256/1/mailinfo.c +++ b/third_party/git/t/t4256/1/mailinfo.c diff --git a/t/t4256/1/mailinfo.c.orig b/third_party/git/t/t4256/1/mailinfo.c.orig index 3281a37d51..3281a37d51 100644 --- a/t/t4256/1/mailinfo.c.orig +++ b/third_party/git/t/t4256/1/mailinfo.c.orig diff --git a/t/t4256/1/patch b/third_party/git/t/t4256/1/patch index bd0d8b0251..bd0d8b0251 100644 --- a/t/t4256/1/patch +++ b/third_party/git/t/t4256/1/patch diff --git a/t/t4257-am-interactive.sh b/third_party/git/t/t4257-am-interactive.sh index 5344bd248a..5344bd248a 100755 --- a/t/t4257-am-interactive.sh +++ b/third_party/git/t/t4257-am-interactive.sh diff --git a/t/t4300-merge-tree.sh b/third_party/git/t/t4300-merge-tree.sh index e59601e5fe..e59601e5fe 100755 --- a/t/t4300-merge-tree.sh +++ b/third_party/git/t/t4300-merge-tree.sh diff --git a/t/t5000-tar-tree.sh b/third_party/git/t/t5000-tar-tree.sh index 37655a237c..37655a237c 100755 --- a/t/t5000-tar-tree.sh +++ b/third_party/git/t/t5000-tar-tree.sh diff --git a/t/t5000/huge-and-future.tar b/third_party/git/t/t5000/huge-and-future.tar index 63155e1855..63155e1855 100644 --- a/t/t5000/huge-and-future.tar +++ b/third_party/git/t/t5000/huge-and-future.tar Binary files differdiff --git a/t/t5000/huge-object b/third_party/git/t/t5000/huge-object index 5cbe9ec312..5cbe9ec312 100644 --- a/t/t5000/huge-object +++ b/third_party/git/t/t5000/huge-object Binary files differdiff --git a/t/t5000/pax.tar b/third_party/git/t/t5000/pax.tar index d911737149..d911737149 100644 --- a/t/t5000/pax.tar +++ b/third_party/git/t/t5000/pax.tar Binary files differdiff --git a/t/t5001-archive-attr.sh b/third_party/git/t/t5001-archive-attr.sh index e9aa97117a..e9aa97117a 100755 --- a/t/t5001-archive-attr.sh +++ b/third_party/git/t/t5001-archive-attr.sh diff --git a/t/t5002-archive-attr-pattern.sh b/third_party/git/t/t5002-archive-attr-pattern.sh index bda6d7d7e9..bda6d7d7e9 100755 --- a/t/t5002-archive-attr-pattern.sh +++ b/third_party/git/t/t5002-archive-attr-pattern.sh diff --git a/t/t5003-archive-zip.sh b/third_party/git/t/t5003-archive-zip.sh index 106eddbd85..106eddbd85 100755 --- a/t/t5003-archive-zip.sh +++ b/third_party/git/t/t5003-archive-zip.sh diff --git a/t/t5003/infozip-symlinks.zip b/third_party/git/t/t5003/infozip-symlinks.zip index 065728c631..065728c631 100644 --- a/t/t5003/infozip-symlinks.zip +++ b/third_party/git/t/t5003/infozip-symlinks.zip Binary files differdiff --git a/t/t5004-archive-corner-cases.sh b/third_party/git/t/t5004-archive-corner-cases.sh index 3e7b23cb32..3e7b23cb32 100755 --- a/t/t5004-archive-corner-cases.sh +++ b/third_party/git/t/t5004-archive-corner-cases.sh diff --git a/t/t5004/big-pack.zip b/third_party/git/t/t5004/big-pack.zip index caaf614eee..caaf614eee 100644 --- a/t/t5004/big-pack.zip +++ b/third_party/git/t/t5004/big-pack.zip Binary files differdiff --git a/t/t5004/empty-with-pax-header.tar b/third_party/git/t/t5004/empty-with-pax-header.tar index da9e39e6cf..da9e39e6cf 100644 --- a/t/t5004/empty-with-pax-header.tar +++ b/third_party/git/t/t5004/empty-with-pax-header.tar Binary files differdiff --git a/t/t5004/empty.zip b/third_party/git/t/t5004/empty.zip index 1a76bb6005..1a76bb6005 100644 --- a/t/t5004/empty.zip +++ b/third_party/git/t/t5004/empty.zip Binary files differdiff --git a/t/t5100-mailinfo.sh b/third_party/git/t/t5100-mailinfo.sh index 147e616533..147e616533 100755 --- a/t/t5100-mailinfo.sh +++ b/third_party/git/t/t5100-mailinfo.sh diff --git a/t/t5100/.gitattributes b/third_party/git/t/t5100/.gitattributes index c93f5142fa..c93f5142fa 100644 --- a/t/t5100/.gitattributes +++ b/third_party/git/t/t5100/.gitattributes diff --git a/t/t5100/0001mboxrd b/third_party/git/t/t5100/0001mboxrd index 494ec554b9..494ec554b9 100644 --- a/t/t5100/0001mboxrd +++ b/third_party/git/t/t5100/0001mboxrd diff --git a/t/t5100/0002mboxrd b/third_party/git/t/t5100/0002mboxrd index 71343d41f2..71343d41f2 100644 --- a/t/t5100/0002mboxrd +++ b/third_party/git/t/t5100/0002mboxrd diff --git a/t/t5100/comment.expect b/third_party/git/t/t5100/comment.expect index 7228177984..7228177984 100644 --- a/t/t5100/comment.expect +++ b/third_party/git/t/t5100/comment.expect diff --git a/t/t5100/comment.in b/third_party/git/t/t5100/comment.in index c53a192dfe..c53a192dfe 100644 --- a/t/t5100/comment.in +++ b/third_party/git/t/t5100/comment.in diff --git a/t/t5100/embed-from.expect b/third_party/git/t/t5100/embed-from.expect index 06a3a3859a..06a3a3859a 100644 --- a/t/t5100/embed-from.expect +++ b/third_party/git/t/t5100/embed-from.expect diff --git a/t/t5100/embed-from.in b/third_party/git/t/t5100/embed-from.in index 5f3f84e508..5f3f84e508 100644 --- a/t/t5100/embed-from.in +++ b/third_party/git/t/t5100/embed-from.in diff --git a/third_party/git/t/t5100/empty b/third_party/git/t/t5100/empty new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/t/t5100/empty diff --git a/t/t5100/info-from.expect b/third_party/git/t/t5100/info-from.expect index c31d2eb550..c31d2eb550 100644 --- a/t/t5100/info-from.expect +++ b/third_party/git/t/t5100/info-from.expect diff --git a/t/t5100/info-from.in b/third_party/git/t/t5100/info-from.in index 4f082093fc..4f082093fc 100644 --- a/t/t5100/info-from.in +++ b/third_party/git/t/t5100/info-from.in diff --git a/t/t5100/info0001 b/third_party/git/t/t5100/info0001 index f951538acc..f951538acc 100644 --- a/t/t5100/info0001 +++ b/third_party/git/t/t5100/info0001 diff --git a/t/t5100/info0002 b/third_party/git/t/t5100/info0002 index 49bb0fec85..49bb0fec85 100644 --- a/t/t5100/info0002 +++ b/third_party/git/t/t5100/info0002 diff --git a/t/t5100/info0003 b/third_party/git/t/t5100/info0003 index bd0d1221aa..bd0d1221aa 100644 --- a/t/t5100/info0003 +++ b/third_party/git/t/t5100/info0003 diff --git a/t/t5100/info0004 b/third_party/git/t/t5100/info0004 index 616c3092a2..616c3092a2 100644 --- a/t/t5100/info0004 +++ b/third_party/git/t/t5100/info0004 diff --git a/t/t5100/info0005 b/third_party/git/t/t5100/info0005 index 46a46fc772..46a46fc772 100644 --- a/t/t5100/info0005 +++ b/third_party/git/t/t5100/info0005 diff --git a/t/t5100/info0006 b/third_party/git/t/t5100/info0006 index 8c052777e0..8c052777e0 100644 --- a/t/t5100/info0006 +++ b/third_party/git/t/t5100/info0006 diff --git a/t/t5100/info0007 b/third_party/git/t/t5100/info0007 index 49bb0fec85..49bb0fec85 100644 --- a/t/t5100/info0007 +++ b/third_party/git/t/t5100/info0007 diff --git a/t/t5100/info0008 b/third_party/git/t/t5100/info0008 index e8a2951383..e8a2951383 100644 --- a/t/t5100/info0008 +++ b/third_party/git/t/t5100/info0008 diff --git a/t/t5100/info0009 b/third_party/git/t/t5100/info0009 index 2a66321c80..2a66321c80 100644 --- a/t/t5100/info0009 +++ b/third_party/git/t/t5100/info0009 diff --git a/t/t5100/info0010 b/third_party/git/t/t5100/info0010 index 1791241e46..1791241e46 100644 --- a/t/t5100/info0010 +++ b/third_party/git/t/t5100/info0010 diff --git a/t/t5100/info0011 b/third_party/git/t/t5100/info0011 index da5a605a12..da5a605a12 100644 --- a/t/t5100/info0011 +++ b/third_party/git/t/t5100/info0011 diff --git a/t/t5100/info0012 b/third_party/git/t/t5100/info0012 index ac1216ff75..ac1216ff75 100644 --- a/t/t5100/info0012 +++ b/third_party/git/t/t5100/info0012 diff --git a/t/t5100/info0012--message-id b/third_party/git/t/t5100/info0012--message-id index ac1216ff75..ac1216ff75 100644 --- a/t/t5100/info0012--message-id +++ b/third_party/git/t/t5100/info0012--message-id diff --git a/t/t5100/info0013 b/third_party/git/t/t5100/info0013 index bbe049e20e..bbe049e20e 100644 --- a/t/t5100/info0013 +++ b/third_party/git/t/t5100/info0013 diff --git a/t/t5100/info0014 b/third_party/git/t/t5100/info0014 index 08566b34b9..08566b34b9 100644 --- a/t/t5100/info0014 +++ b/third_party/git/t/t5100/info0014 diff --git a/t/t5100/info0014--scissors b/third_party/git/t/t5100/info0014--scissors index ab9c8d0905..ab9c8d0905 100644 --- a/t/t5100/info0014--scissors +++ b/third_party/git/t/t5100/info0014--scissors diff --git a/t/t5100/info0015 b/third_party/git/t/t5100/info0015 index 0114f106c5..0114f106c5 100644 --- a/t/t5100/info0015 +++ b/third_party/git/t/t5100/info0015 diff --git a/t/t5100/info0015--no-inbody-headers b/third_party/git/t/t5100/info0015--no-inbody-headers index c4d8d7720e..c4d8d7720e 100644 --- a/t/t5100/info0015--no-inbody-headers +++ b/third_party/git/t/t5100/info0015--no-inbody-headers diff --git a/t/t5100/info0016 b/third_party/git/t/t5100/info0016 index 38ccd0dcf2..38ccd0dcf2 100644 --- a/t/t5100/info0016 +++ b/third_party/git/t/t5100/info0016 diff --git a/t/t5100/info0016--no-inbody-headers b/third_party/git/t/t5100/info0016--no-inbody-headers index f4857d45df..f4857d45df 100644 --- a/t/t5100/info0016--no-inbody-headers +++ b/third_party/git/t/t5100/info0016--no-inbody-headers diff --git a/t/t5100/info0017 b/third_party/git/t/t5100/info0017 index d2bc89ffe9..d2bc89ffe9 100644 --- a/t/t5100/info0017 +++ b/third_party/git/t/t5100/info0017 diff --git a/t/t5100/info0018 b/third_party/git/t/t5100/info0018 index d53e7491c7..d53e7491c7 100644 --- a/t/t5100/info0018 +++ b/third_party/git/t/t5100/info0018 diff --git a/t/t5100/info0018--no-inbody-headers b/third_party/git/t/t5100/info0018--no-inbody-headers index 30b17bd913..30b17bd913 100644 --- a/t/t5100/info0018--no-inbody-headers +++ b/third_party/git/t/t5100/info0018--no-inbody-headers diff --git a/t/t5100/msg0001 b/third_party/git/t/t5100/msg0001 index b275a9a9b2..b275a9a9b2 100644 --- a/t/t5100/msg0001 +++ b/third_party/git/t/t5100/msg0001 diff --git a/t/t5100/msg0002 b/third_party/git/t/t5100/msg0002 index e2546ec733..e2546ec733 100644 --- a/t/t5100/msg0002 +++ b/third_party/git/t/t5100/msg0002 diff --git a/t/t5100/msg0003 b/third_party/git/t/t5100/msg0003 index 1ac68101b1..1ac68101b1 100644 --- a/t/t5100/msg0003 +++ b/third_party/git/t/t5100/msg0003 diff --git a/t/t5100/msg0004 b/third_party/git/t/t5100/msg0004 index 6f8ba3b8e0..6f8ba3b8e0 100644 --- a/t/t5100/msg0004 +++ b/third_party/git/t/t5100/msg0004 diff --git a/t/t5100/msg0005 b/third_party/git/t/t5100/msg0005 index dd94cd7b9f..dd94cd7b9f 100644 --- a/t/t5100/msg0005 +++ b/third_party/git/t/t5100/msg0005 diff --git a/t/t5100/msg0006 b/third_party/git/t/t5100/msg0006 index b275a9a9b2..b275a9a9b2 100644 --- a/t/t5100/msg0006 +++ b/third_party/git/t/t5100/msg0006 diff --git a/t/t5100/msg0007 b/third_party/git/t/t5100/msg0007 index 71b23c0236..71b23c0236 100644 --- a/t/t5100/msg0007 +++ b/third_party/git/t/t5100/msg0007 diff --git a/t/t5100/msg0008 b/third_party/git/t/t5100/msg0008 index a80ecb97ef..a80ecb97ef 100644 --- a/t/t5100/msg0008 +++ b/third_party/git/t/t5100/msg0008 diff --git a/t/t5100/msg0009 b/third_party/git/t/t5100/msg0009 index 9ffe131489..9ffe131489 100644 --- a/t/t5100/msg0009 +++ b/third_party/git/t/t5100/msg0009 diff --git a/t/t5100/msg0010 b/third_party/git/t/t5100/msg0010 index a96c230092..a96c230092 100644 --- a/t/t5100/msg0010 +++ b/third_party/git/t/t5100/msg0010 diff --git a/t/t5100/msg0011 b/third_party/git/t/t5100/msg0011 index 4667f21007..4667f21007 100644 --- a/t/t5100/msg0011 +++ b/third_party/git/t/t5100/msg0011 diff --git a/t/t5100/msg0012 b/third_party/git/t/t5100/msg0012 index 1dc2bf7f7f..1dc2bf7f7f 100644 --- a/t/t5100/msg0012 +++ b/third_party/git/t/t5100/msg0012 diff --git a/t/t5100/msg0012--message-id b/third_party/git/t/t5100/msg0012--message-id index 376e26e9ae..376e26e9ae 100644 --- a/t/t5100/msg0012--message-id +++ b/third_party/git/t/t5100/msg0012--message-id diff --git a/third_party/git/t/t5100/msg0013 b/third_party/git/t/t5100/msg0013 new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/t/t5100/msg0013 diff --git a/t/t5100/msg0014 b/third_party/git/t/t5100/msg0014 index 62e5cd2ecd..62e5cd2ecd 100644 --- a/t/t5100/msg0014 +++ b/third_party/git/t/t5100/msg0014 diff --git a/t/t5100/msg0014--scissors b/third_party/git/t/t5100/msg0014--scissors index 259c6a46d2..259c6a46d2 100644 --- a/t/t5100/msg0014--scissors +++ b/third_party/git/t/t5100/msg0014--scissors diff --git a/third_party/git/t/t5100/msg0015 b/third_party/git/t/t5100/msg0015 new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/t/t5100/msg0015 diff --git a/t/t5100/msg0015--no-inbody-headers b/third_party/git/t/t5100/msg0015--no-inbody-headers index be5115b1c1..be5115b1c1 100644 --- a/t/t5100/msg0015--no-inbody-headers +++ b/third_party/git/t/t5100/msg0015--no-inbody-headers diff --git a/t/t5100/msg0016 b/third_party/git/t/t5100/msg0016 index 0d9adada96..0d9adada96 100644 --- a/t/t5100/msg0016 +++ b/third_party/git/t/t5100/msg0016 diff --git a/t/t5100/msg0016--no-inbody-headers b/third_party/git/t/t5100/msg0016--no-inbody-headers index 1063f51178..1063f51178 100644 --- a/t/t5100/msg0016--no-inbody-headers +++ b/third_party/git/t/t5100/msg0016--no-inbody-headers diff --git a/t/t5100/msg0017 b/third_party/git/t/t5100/msg0017 index 2ee0900850..2ee0900850 100644 --- a/t/t5100/msg0017 +++ b/third_party/git/t/t5100/msg0017 diff --git a/t/t5100/msg0018 b/third_party/git/t/t5100/msg0018 index 56de83d7fc..56de83d7fc 100644 --- a/t/t5100/msg0018 +++ b/third_party/git/t/t5100/msg0018 diff --git a/t/t5100/msg0018--no-inbody-headers b/third_party/git/t/t5100/msg0018--no-inbody-headers index b1e05d3862..b1e05d3862 100644 --- a/t/t5100/msg0018--no-inbody-headers +++ b/third_party/git/t/t5100/msg0018--no-inbody-headers diff --git a/t/t5100/nul-b64.expect b/third_party/git/t/t5100/nul-b64.expect index d7d680f631..d7d680f631 100644 --- a/t/t5100/nul-b64.expect +++ b/third_party/git/t/t5100/nul-b64.expect Binary files differdiff --git a/t/t5100/nul-b64.in b/third_party/git/t/t5100/nul-b64.in index 16540d961f..16540d961f 100644 --- a/t/t5100/nul-b64.in +++ b/third_party/git/t/t5100/nul-b64.in diff --git a/t/t5100/nul-plain b/third_party/git/t/t5100/nul-plain index 3d40691787..3d40691787 100644 --- a/t/t5100/nul-plain +++ b/third_party/git/t/t5100/nul-plain Binary files differdiff --git a/t/t5100/patch0001 b/third_party/git/t/t5100/patch0001 index 02c97746d6..02c97746d6 100644 --- a/t/t5100/patch0001 +++ b/third_party/git/t/t5100/patch0001 diff --git a/t/t5100/patch0002 b/third_party/git/t/t5100/patch0002 index 02c97746d6..02c97746d6 100644 --- a/t/t5100/patch0002 +++ b/third_party/git/t/t5100/patch0002 diff --git a/t/t5100/patch0003 b/third_party/git/t/t5100/patch0003 index 02c97746d6..02c97746d6 100644 --- a/t/t5100/patch0003 +++ b/third_party/git/t/t5100/patch0003 diff --git a/t/t5100/patch0004 b/third_party/git/t/t5100/patch0004 index 196458e44e..196458e44e 100644 --- a/t/t5100/patch0004 +++ b/third_party/git/t/t5100/patch0004 diff --git a/t/t5100/patch0005 b/third_party/git/t/t5100/patch0005 index ab7a38373b..ab7a38373b 100644 --- a/t/t5100/patch0005 +++ b/third_party/git/t/t5100/patch0005 diff --git a/t/t5100/patch0006 b/third_party/git/t/t5100/patch0006 index 02c97746d6..02c97746d6 100644 --- a/t/t5100/patch0006 +++ b/third_party/git/t/t5100/patch0006 diff --git a/third_party/git/t/t5100/patch0007 b/third_party/git/t/t5100/patch0007 new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/t/t5100/patch0007 diff --git a/third_party/git/t/t5100/patch0008 b/third_party/git/t/t5100/patch0008 new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/t/t5100/patch0008 diff --git a/t/t5100/patch0009 b/third_party/git/t/t5100/patch0009 index 65615c34af..65615c34af 100644 --- a/t/t5100/patch0009 +++ b/third_party/git/t/t5100/patch0009 diff --git a/t/t5100/patch0010 b/third_party/git/t/t5100/patch0010 index 436821c97a..436821c97a 100644 --- a/t/t5100/patch0010 +++ b/third_party/git/t/t5100/patch0010 diff --git a/t/t5100/patch0011 b/third_party/git/t/t5100/patch0011 index 0988713761..0988713761 100644 --- a/t/t5100/patch0011 +++ b/third_party/git/t/t5100/patch0011 diff --git a/t/t5100/patch0012 b/third_party/git/t/t5100/patch0012 index 36a0b68161..36a0b68161 100644 --- a/t/t5100/patch0012 +++ b/third_party/git/t/t5100/patch0012 diff --git a/t/t5100/patch0012--message-id b/third_party/git/t/t5100/patch0012--message-id index 36a0b68161..36a0b68161 100644 --- a/t/t5100/patch0012--message-id +++ b/third_party/git/t/t5100/patch0012--message-id diff --git a/third_party/git/t/t5100/patch0013 b/third_party/git/t/t5100/patch0013 new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/git/t/t5100/patch0013 diff --git a/t/t5100/patch0014 b/third_party/git/t/t5100/patch0014 index 3f3825f9f2..3f3825f9f2 100644 --- a/t/t5100/patch0014 +++ b/third_party/git/t/t5100/patch0014 diff --git a/t/t5100/patch0014--scissors b/third_party/git/t/t5100/patch0014--scissors index 3f3825f9f2..3f3825f9f2 100644 --- a/t/t5100/patch0014--scissors +++ b/third_party/git/t/t5100/patch0014--scissors diff --git a/t/t5100/patch0015 b/third_party/git/t/t5100/patch0015 index ad64848873..ad64848873 100644 --- a/t/t5100/patch0015 +++ b/third_party/git/t/t5100/patch0015 diff --git a/t/t5100/patch0015--no-inbody-headers b/third_party/git/t/t5100/patch0015--no-inbody-headers index ad64848873..ad64848873 100644 --- a/t/t5100/patch0015--no-inbody-headers +++ b/third_party/git/t/t5100/patch0015--no-inbody-headers diff --git a/t/t5100/patch0016 b/third_party/git/t/t5100/patch0016 index ad64848873..ad64848873 100644 --- a/t/t5100/patch0016 +++ b/third_party/git/t/t5100/patch0016 diff --git a/t/t5100/patch0016--no-inbody-headers b/third_party/git/t/t5100/patch0016--no-inbody-headers index ad64848873..ad64848873 100644 --- a/t/t5100/patch0016--no-inbody-headers +++ b/third_party/git/t/t5100/patch0016--no-inbody-headers diff --git a/t/t5100/patch0017 b/third_party/git/t/t5100/patch0017 index 35cf84c9a1..35cf84c9a1 100644 --- a/t/t5100/patch0017 +++ b/third_party/git/t/t5100/patch0017 diff --git a/t/t5100/patch0018 b/third_party/git/t/t5100/patch0018 index 789df6d030..789df6d030 100644 --- a/t/t5100/patch0018 +++ b/third_party/git/t/t5100/patch0018 diff --git a/t/t5100/patch0018--no-inbody-headers b/third_party/git/t/t5100/patch0018--no-inbody-headers index 789df6d030..789df6d030 100644 --- a/t/t5100/patch0018--no-inbody-headers +++ b/third_party/git/t/t5100/patch0018--no-inbody-headers diff --git a/t/t5100/quoted-from.expect b/third_party/git/t/t5100/quoted-from.expect index 8c9d48c852..8c9d48c852 100644 --- a/t/t5100/quoted-from.expect +++ b/third_party/git/t/t5100/quoted-from.expect diff --git a/t/t5100/quoted-from.in b/third_party/git/t/t5100/quoted-from.in index 847e1c4d3e..847e1c4d3e 100644 --- a/t/t5100/quoted-from.in +++ b/third_party/git/t/t5100/quoted-from.in diff --git a/t/t5100/quoted-string.expect b/third_party/git/t/t5100/quoted-string.expect index cab1bcebf9..cab1bcebf9 100644 --- a/t/t5100/quoted-string.expect +++ b/third_party/git/t/t5100/quoted-string.expect diff --git a/t/t5100/quoted-string.in b/third_party/git/t/t5100/quoted-string.in index e2e627ae23..e2e627ae23 100644 --- a/t/t5100/quoted-string.in +++ b/third_party/git/t/t5100/quoted-string.in diff --git a/t/t5100/rfc2047-info-0001 b/third_party/git/t/t5100/rfc2047-info-0001 index 0a383b07e3..0a383b07e3 100644 --- a/t/t5100/rfc2047-info-0001 +++ b/third_party/git/t/t5100/rfc2047-info-0001 diff --git a/t/t5100/rfc2047-info-0002 b/third_party/git/t/t5100/rfc2047-info-0002 index 881be75d6f..881be75d6f 100644 --- a/t/t5100/rfc2047-info-0002 +++ b/third_party/git/t/t5100/rfc2047-info-0002 diff --git a/t/t5100/rfc2047-info-0003 b/third_party/git/t/t5100/rfc2047-info-0003 index d0f789177c..d0f789177c 100644 --- a/t/t5100/rfc2047-info-0003 +++ b/third_party/git/t/t5100/rfc2047-info-0003 diff --git a/t/t5100/rfc2047-info-0004 b/third_party/git/t/t5100/rfc2047-info-0004 index f67a90a974..f67a90a974 100644 --- a/t/t5100/rfc2047-info-0004 +++ b/third_party/git/t/t5100/rfc2047-info-0004 diff --git a/t/t5100/rfc2047-info-0005 b/third_party/git/t/t5100/rfc2047-info-0005 index c27be3bf24..c27be3bf24 100644 --- a/t/t5100/rfc2047-info-0005 +++ b/third_party/git/t/t5100/rfc2047-info-0005 diff --git a/t/t5100/rfc2047-info-0006 b/third_party/git/t/t5100/rfc2047-info-0006 index 9dad474456..9dad474456 100644 --- a/t/t5100/rfc2047-info-0006 +++ b/third_party/git/t/t5100/rfc2047-info-0006 diff --git a/t/t5100/rfc2047-info-0007 b/third_party/git/t/t5100/rfc2047-info-0007 index 294f195a57..294f195a57 100644 --- a/t/t5100/rfc2047-info-0007 +++ b/third_party/git/t/t5100/rfc2047-info-0007 diff --git a/t/t5100/rfc2047-info-0008 b/third_party/git/t/t5100/rfc2047-info-0008 index 294f195a57..294f195a57 100644 --- a/t/t5100/rfc2047-info-0008 +++ b/third_party/git/t/t5100/rfc2047-info-0008 diff --git a/t/t5100/rfc2047-info-0009 b/third_party/git/t/t5100/rfc2047-info-0009 index 294f195a57..294f195a57 100644 --- a/t/t5100/rfc2047-info-0009 +++ b/third_party/git/t/t5100/rfc2047-info-0009 diff --git a/t/t5100/rfc2047-info-0010 b/third_party/git/t/t5100/rfc2047-info-0010 index 9dad474456..9dad474456 100644 --- a/t/t5100/rfc2047-info-0010 +++ b/third_party/git/t/t5100/rfc2047-info-0010 diff --git a/t/t5100/rfc2047-info-0011 b/third_party/git/t/t5100/rfc2047-info-0011 index 9dad474456..9dad474456 100644 --- a/t/t5100/rfc2047-info-0011 +++ b/third_party/git/t/t5100/rfc2047-info-0011 diff --git a/t/t5100/rfc2047-samples.mbox b/third_party/git/t/t5100/rfc2047-samples.mbox index 1fc224810d..1fc224810d 100644 --- a/t/t5100/rfc2047-samples.mbox +++ b/third_party/git/t/t5100/rfc2047-samples.mbox diff --git a/t/t5100/sample.mbox b/third_party/git/t/t5100/sample.mbox index 6d4d0e4474..6d4d0e4474 100644 --- a/t/t5100/sample.mbox +++ b/third_party/git/t/t5100/sample.mbox diff --git a/t/t5100/sample.mboxrd b/third_party/git/t/t5100/sample.mboxrd index 79ad5ae0e7..79ad5ae0e7 100644 --- a/t/t5100/sample.mboxrd +++ b/third_party/git/t/t5100/sample.mboxrd diff --git a/t/t5150-request-pull.sh b/third_party/git/t/t5150-request-pull.sh index c1811ea0f4..c1811ea0f4 100755 --- a/t/t5150-request-pull.sh +++ b/third_party/git/t/t5150-request-pull.sh diff --git a/t/t5200-update-server-info.sh b/third_party/git/t/t5200-update-server-info.sh index 21a58eecb9..21a58eecb9 100755 --- a/t/t5200-update-server-info.sh +++ b/third_party/git/t/t5200-update-server-info.sh diff --git a/t/t5300-pack-object.sh b/third_party/git/t/t5300-pack-object.sh index 410a09b0dd..410a09b0dd 100755 --- a/t/t5300-pack-object.sh +++ b/third_party/git/t/t5300-pack-object.sh diff --git a/t/t5301-sliding-window.sh b/third_party/git/t/t5301-sliding-window.sh index 76f9798ab9..76f9798ab9 100755 --- a/t/t5301-sliding-window.sh +++ b/third_party/git/t/t5301-sliding-window.sh diff --git a/t/t5302-pack-index.sh b/third_party/git/t/t5302-pack-index.sh index ad07f2f7fc..ad07f2f7fc 100755 --- a/t/t5302-pack-index.sh +++ b/third_party/git/t/t5302-pack-index.sh diff --git a/t/t5303-pack-corruption-resilience.sh b/third_party/git/t/t5303-pack-corruption-resilience.sh index 41e6dc4dcf..41e6dc4dcf 100755 --- a/t/t5303-pack-corruption-resilience.sh +++ b/third_party/git/t/t5303-pack-corruption-resilience.sh diff --git a/t/t5304-prune.sh b/third_party/git/t/t5304-prune.sh index df60f18fb8..df60f18fb8 100755 --- a/t/t5304-prune.sh +++ b/third_party/git/t/t5304-prune.sh diff --git a/t/t5305-include-tag.sh b/third_party/git/t/t5305-include-tag.sh index a5eca210b8..a5eca210b8 100755 --- a/t/t5305-include-tag.sh +++ b/third_party/git/t/t5305-include-tag.sh diff --git a/t/t5306-pack-nobase.sh b/third_party/git/t/t5306-pack-nobase.sh index f4931c0c2a..f4931c0c2a 100755 --- a/t/t5306-pack-nobase.sh +++ b/third_party/git/t/t5306-pack-nobase.sh diff --git a/t/t5307-pack-missing-commit.sh b/third_party/git/t/t5307-pack-missing-commit.sh index f4338abb78..f4338abb78 100755 --- a/t/t5307-pack-missing-commit.sh +++ b/third_party/git/t/t5307-pack-missing-commit.sh diff --git a/t/t5308-pack-detect-duplicates.sh b/third_party/git/t/t5308-pack-detect-duplicates.sh index 6845c1f3c3..6845c1f3c3 100755 --- a/t/t5308-pack-detect-duplicates.sh +++ b/third_party/git/t/t5308-pack-detect-duplicates.sh diff --git a/t/t5309-pack-delta-cycles.sh b/third_party/git/t/t5309-pack-delta-cycles.sh index 55b787630f..55b787630f 100755 --- a/t/t5309-pack-delta-cycles.sh +++ b/third_party/git/t/t5309-pack-delta-cycles.sh diff --git a/t/t5310-pack-bitmaps.sh b/third_party/git/t/t5310-pack-bitmaps.sh index 8318781d2b..8318781d2b 100755 --- a/t/t5310-pack-bitmaps.sh +++ b/third_party/git/t/t5310-pack-bitmaps.sh diff --git a/t/t5311-pack-bitmaps-shallow.sh b/third_party/git/t/t5311-pack-bitmaps-shallow.sh index 872a95df33..872a95df33 100755 --- a/t/t5311-pack-bitmaps-shallow.sh +++ b/third_party/git/t/t5311-pack-bitmaps-shallow.sh diff --git a/t/t5312-prune-corruption.sh b/third_party/git/t/t5312-prune-corruption.sh index da9d59940d..da9d59940d 100755 --- a/t/t5312-prune-corruption.sh +++ b/third_party/git/t/t5312-prune-corruption.sh diff --git a/t/t5313-pack-bounds-checks.sh b/third_party/git/t/t5313-pack-bounds-checks.sh index 2a4557efc2..2a4557efc2 100755 --- a/t/t5313-pack-bounds-checks.sh +++ b/third_party/git/t/t5313-pack-bounds-checks.sh diff --git a/t/t5314-pack-cycle-detection.sh b/third_party/git/t/t5314-pack-cycle-detection.sh index 0aec8619e2..0aec8619e2 100755 --- a/t/t5314-pack-cycle-detection.sh +++ b/third_party/git/t/t5314-pack-cycle-detection.sh diff --git a/t/t5315-pack-objects-compression.sh b/third_party/git/t/t5315-pack-objects-compression.sh index df970d7584..df970d7584 100755 --- a/t/t5315-pack-objects-compression.sh +++ b/third_party/git/t/t5315-pack-objects-compression.sh diff --git a/t/t5316-pack-delta-depth.sh b/third_party/git/t/t5316-pack-delta-depth.sh index 0f06c40eb1..0f06c40eb1 100755 --- a/t/t5316-pack-delta-depth.sh +++ b/third_party/git/t/t5316-pack-delta-depth.sh diff --git a/t/t5317-pack-objects-filter-objects.sh b/third_party/git/t/t5317-pack-objects-filter-objects.sh index dc0446574b..dc0446574b 100755 --- a/t/t5317-pack-objects-filter-objects.sh +++ b/third_party/git/t/t5317-pack-objects-filter-objects.sh diff --git a/t/t5318-commit-graph.sh b/third_party/git/t/t5318-commit-graph.sh index 9bf920ae17..9bf920ae17 100755 --- a/t/t5318-commit-graph.sh +++ b/third_party/git/t/t5318-commit-graph.sh diff --git a/t/t5319-multi-pack-index.sh b/third_party/git/t/t5319-multi-pack-index.sh index 43a7a66c9d..43a7a66c9d 100755 --- a/t/t5319-multi-pack-index.sh +++ b/third_party/git/t/t5319-multi-pack-index.sh diff --git a/t/t5320-delta-islands.sh b/third_party/git/t/t5320-delta-islands.sh index fea92a5777..fea92a5777 100755 --- a/t/t5320-delta-islands.sh +++ b/third_party/git/t/t5320-delta-islands.sh diff --git a/t/t5321-pack-large-objects.sh b/third_party/git/t/t5321-pack-large-objects.sh index 8a56d98a0e..8a56d98a0e 100755 --- a/t/t5321-pack-large-objects.sh +++ b/third_party/git/t/t5321-pack-large-objects.sh diff --git a/t/t5322-pack-objects-sparse.sh b/third_party/git/t/t5322-pack-objects-sparse.sh index 7124b5581a..7124b5581a 100755 --- a/t/t5322-pack-objects-sparse.sh +++ b/third_party/git/t/t5322-pack-objects-sparse.sh diff --git a/t/t5323-pack-redundant.sh b/third_party/git/t/t5323-pack-redundant.sh index 6b4d1ca353..6b4d1ca353 100755 --- a/t/t5323-pack-redundant.sh +++ b/third_party/git/t/t5323-pack-redundant.sh diff --git a/t/t5324-split-commit-graph.sh b/third_party/git/t/t5324-split-commit-graph.sh index 53b2e6b455..53b2e6b455 100755 --- a/t/t5324-split-commit-graph.sh +++ b/third_party/git/t/t5324-split-commit-graph.sh diff --git a/t/t5400-send-pack.sh b/third_party/git/t/t5400-send-pack.sh index b84618c925..b84618c925 100755 --- a/t/t5400-send-pack.sh +++ b/third_party/git/t/t5400-send-pack.sh diff --git a/t/t5401-update-hooks.sh b/third_party/git/t/t5401-update-hooks.sh index 956d69f5b1..956d69f5b1 100755 --- a/t/t5401-update-hooks.sh +++ b/third_party/git/t/t5401-update-hooks.sh diff --git a/t/t5402-post-merge-hook.sh b/third_party/git/t/t5402-post-merge-hook.sh index 6eb2ffd6ec..6eb2ffd6ec 100755 --- a/t/t5402-post-merge-hook.sh +++ b/third_party/git/t/t5402-post-merge-hook.sh diff --git a/t/t5403-post-checkout-hook.sh b/third_party/git/t/t5403-post-checkout-hook.sh index a39b3b5c78..a39b3b5c78 100755 --- a/t/t5403-post-checkout-hook.sh +++ b/third_party/git/t/t5403-post-checkout-hook.sh diff --git a/t/t5404-tracking-branches.sh b/third_party/git/t/t5404-tracking-branches.sh index 2762f420bc..2762f420bc 100755 --- a/t/t5404-tracking-branches.sh +++ b/third_party/git/t/t5404-tracking-branches.sh diff --git a/t/t5405-send-pack-rewind.sh b/third_party/git/t/t5405-send-pack-rewind.sh index 235fb7686a..235fb7686a 100755 --- a/t/t5405-send-pack-rewind.sh +++ b/third_party/git/t/t5405-send-pack-rewind.sh diff --git a/t/t5406-remote-rejects.sh b/third_party/git/t/t5406-remote-rejects.sh index ff06f99649..ff06f99649 100755 --- a/t/t5406-remote-rejects.sh +++ b/third_party/git/t/t5406-remote-rejects.sh diff --git a/t/t5407-post-rewrite-hook.sh b/third_party/git/t/t5407-post-rewrite-hook.sh index 80750a817e..80750a817e 100755 --- a/t/t5407-post-rewrite-hook.sh +++ b/third_party/git/t/t5407-post-rewrite-hook.sh diff --git a/t/t5408-send-pack-stdin.sh b/third_party/git/t/t5408-send-pack-stdin.sh index e8737df6f9..e8737df6f9 100755 --- a/t/t5408-send-pack-stdin.sh +++ b/third_party/git/t/t5408-send-pack-stdin.sh diff --git a/t/t5409-colorize-remote-messages.sh b/third_party/git/t/t5409-colorize-remote-messages.sh index 5d8f401d8e..5d8f401d8e 100755 --- a/t/t5409-colorize-remote-messages.sh +++ b/third_party/git/t/t5409-colorize-remote-messages.sh diff --git a/t/t5410-receive-pack-alternates.sh b/third_party/git/t/t5410-receive-pack-alternates.sh index f00d0da860..f00d0da860 100755 --- a/t/t5410-receive-pack-alternates.sh +++ b/third_party/git/t/t5410-receive-pack-alternates.sh diff --git a/t/t5500-fetch-pack.sh b/third_party/git/t/t5500-fetch-pack.sh index baa1a99f45..baa1a99f45 100755 --- a/t/t5500-fetch-pack.sh +++ b/third_party/git/t/t5500-fetch-pack.sh diff --git a/t/t5501-fetch-push-alternates.sh b/third_party/git/t/t5501-fetch-push-alternates.sh index 1bc57ac03f..1bc57ac03f 100755 --- a/t/t5501-fetch-push-alternates.sh +++ b/third_party/git/t/t5501-fetch-push-alternates.sh diff --git a/t/t5502-quickfetch.sh b/third_party/git/t/t5502-quickfetch.sh index 7a46cbdbe6..7a46cbdbe6 100755 --- a/t/t5502-quickfetch.sh +++ b/third_party/git/t/t5502-quickfetch.sh diff --git a/t/t5503-tagfollow.sh b/third_party/git/t/t5503-tagfollow.sh index 6041a4dd32..6041a4dd32 100755 --- a/t/t5503-tagfollow.sh +++ b/third_party/git/t/t5503-tagfollow.sh diff --git a/t/t5504-fetch-receive-strict.sh b/third_party/git/t/t5504-fetch-receive-strict.sh index 645b4c78d3..645b4c78d3 100755 --- a/t/t5504-fetch-receive-strict.sh +++ b/third_party/git/t/t5504-fetch-receive-strict.sh diff --git a/t/t5505-remote.sh b/third_party/git/t/t5505-remote.sh index dda81b7d07..dda81b7d07 100755 --- a/t/t5505-remote.sh +++ b/third_party/git/t/t5505-remote.sh diff --git a/t/t5506-remote-groups.sh b/third_party/git/t/t5506-remote-groups.sh index 83d5558c0e..83d5558c0e 100755 --- a/t/t5506-remote-groups.sh +++ b/third_party/git/t/t5506-remote-groups.sh diff --git a/t/t5507-remote-environment.sh b/third_party/git/t/t5507-remote-environment.sh index e6149295b1..e6149295b1 100755 --- a/t/t5507-remote-environment.sh +++ b/third_party/git/t/t5507-remote-environment.sh diff --git a/t/t5509-fetch-push-namespaces.sh b/third_party/git/t/t5509-fetch-push-namespaces.sh index a67f792adf..a67f792adf 100755 --- a/t/t5509-fetch-push-namespaces.sh +++ b/third_party/git/t/t5509-fetch-push-namespaces.sh diff --git a/t/t5510-fetch.sh b/third_party/git/t/t5510-fetch.sh index a66dbe0bde..a66dbe0bde 100755 --- a/t/t5510-fetch.sh +++ b/third_party/git/t/t5510-fetch.sh diff --git a/t/t5511-refspec.sh b/third_party/git/t/t5511-refspec.sh index f541f30bc2..f541f30bc2 100755 --- a/t/t5511-refspec.sh +++ b/third_party/git/t/t5511-refspec.sh diff --git a/t/t5512-ls-remote.sh b/third_party/git/t/t5512-ls-remote.sh index 04b35402c7..04b35402c7 100755 --- a/t/t5512-ls-remote.sh +++ b/third_party/git/t/t5512-ls-remote.sh diff --git a/t/t5513-fetch-track.sh b/third_party/git/t/t5513-fetch-track.sh index 65d1e05bd6..65d1e05bd6 100755 --- a/t/t5513-fetch-track.sh +++ b/third_party/git/t/t5513-fetch-track.sh diff --git a/t/t5514-fetch-multiple.sh b/third_party/git/t/t5514-fetch-multiple.sh index de8e2f1531..de8e2f1531 100755 --- a/t/t5514-fetch-multiple.sh +++ b/third_party/git/t/t5514-fetch-multiple.sh diff --git a/t/t5515-fetch-merge-logic.sh b/third_party/git/t/t5515-fetch-merge-logic.sh index 9d6a46ff56..9d6a46ff56 100755 --- a/t/t5515-fetch-merge-logic.sh +++ b/third_party/git/t/t5515-fetch-merge-logic.sh diff --git a/t/t5515/fetch.br-branches-default b/third_party/git/t/t5515/fetch.br-branches-default index a1bc3d53a6..a1bc3d53a6 100644 --- a/t/t5515/fetch.br-branches-default +++ b/third_party/git/t/t5515/fetch.br-branches-default diff --git a/t/t5515/fetch.br-branches-default-merge b/third_party/git/t/t5515/fetch.br-branches-default-merge index 12ab08e8ac..12ab08e8ac 100644 --- a/t/t5515/fetch.br-branches-default-merge +++ b/third_party/git/t/t5515/fetch.br-branches-default-merge diff --git a/t/t5515/fetch.br-branches-default-merge_branches-default b/third_party/git/t/t5515/fetch.br-branches-default-merge_branches-default index 54427522dd..54427522dd 100644 --- a/t/t5515/fetch.br-branches-default-merge_branches-default +++ b/third_party/git/t/t5515/fetch.br-branches-default-merge_branches-default diff --git a/t/t5515/fetch.br-branches-default-octopus b/third_party/git/t/t5515/fetch.br-branches-default-octopus index 498a761aae..498a761aae 100644 --- a/t/t5515/fetch.br-branches-default-octopus +++ b/third_party/git/t/t5515/fetch.br-branches-default-octopus diff --git a/t/t5515/fetch.br-branches-default-octopus_branches-default b/third_party/git/t/t5515/fetch.br-branches-default-octopus_branches-default index 0857f134e1..0857f134e1 100644 --- a/t/t5515/fetch.br-branches-default-octopus_branches-default +++ b/third_party/git/t/t5515/fetch.br-branches-default-octopus_branches-default diff --git a/t/t5515/fetch.br-branches-default_branches-default b/third_party/git/t/t5515/fetch.br-branches-default_branches-default index 8cbd718936..8cbd718936 100644 --- a/t/t5515/fetch.br-branches-default_branches-default +++ b/third_party/git/t/t5515/fetch.br-branches-default_branches-default diff --git a/t/t5515/fetch.br-branches-one b/third_party/git/t/t5515/fetch.br-branches-one index c98f670526..c98f670526 100644 --- a/t/t5515/fetch.br-branches-one +++ b/third_party/git/t/t5515/fetch.br-branches-one diff --git a/t/t5515/fetch.br-branches-one-merge b/third_party/git/t/t5515/fetch.br-branches-one-merge index 54a77420d5..54a77420d5 100644 --- a/t/t5515/fetch.br-branches-one-merge +++ b/third_party/git/t/t5515/fetch.br-branches-one-merge diff --git a/t/t5515/fetch.br-branches-one-merge_branches-one b/third_party/git/t/t5515/fetch.br-branches-one-merge_branches-one index b4d1bb0b0b..b4d1bb0b0b 100644 --- a/t/t5515/fetch.br-branches-one-merge_branches-one +++ b/third_party/git/t/t5515/fetch.br-branches-one-merge_branches-one diff --git a/t/t5515/fetch.br-branches-one-octopus b/third_party/git/t/t5515/fetch.br-branches-one-octopus index 97c4b544b8..97c4b544b8 100644 --- a/t/t5515/fetch.br-branches-one-octopus +++ b/third_party/git/t/t5515/fetch.br-branches-one-octopus diff --git a/t/t5515/fetch.br-branches-one-octopus_branches-one b/third_party/git/t/t5515/fetch.br-branches-one-octopus_branches-one index df705f74c7..df705f74c7 100644 --- a/t/t5515/fetch.br-branches-one-octopus_branches-one +++ b/third_party/git/t/t5515/fetch.br-branches-one-octopus_branches-one diff --git a/t/t5515/fetch.br-branches-one_branches-one b/third_party/git/t/t5515/fetch.br-branches-one_branches-one index 96890e5bd9..96890e5bd9 100644 --- a/t/t5515/fetch.br-branches-one_branches-one +++ b/third_party/git/t/t5515/fetch.br-branches-one_branches-one diff --git a/t/t5515/fetch.br-config-explicit b/third_party/git/t/t5515/fetch.br-config-explicit index 68fc927263..68fc927263 100644 --- a/t/t5515/fetch.br-config-explicit +++ b/third_party/git/t/t5515/fetch.br-config-explicit diff --git a/t/t5515/fetch.br-config-explicit-merge b/third_party/git/t/t5515/fetch.br-config-explicit-merge index 5ce764a06e..5ce764a06e 100644 --- a/t/t5515/fetch.br-config-explicit-merge +++ b/third_party/git/t/t5515/fetch.br-config-explicit-merge diff --git a/t/t5515/fetch.br-config-explicit-merge_config-explicit b/third_party/git/t/t5515/fetch.br-config-explicit-merge_config-explicit index b1152b76dc..b1152b76dc 100644 --- a/t/t5515/fetch.br-config-explicit-merge_config-explicit +++ b/third_party/git/t/t5515/fetch.br-config-explicit-merge_config-explicit diff --git a/t/t5515/fetch.br-config-explicit-octopus b/third_party/git/t/t5515/fetch.br-config-explicit-octopus index 110577bb67..110577bb67 100644 --- a/t/t5515/fetch.br-config-explicit-octopus +++ b/third_party/git/t/t5515/fetch.br-config-explicit-octopus diff --git a/t/t5515/fetch.br-config-explicit-octopus_config-explicit b/third_party/git/t/t5515/fetch.br-config-explicit-octopus_config-explicit index a29dd8baba..a29dd8baba 100644 --- a/t/t5515/fetch.br-config-explicit-octopus_config-explicit +++ b/third_party/git/t/t5515/fetch.br-config-explicit-octopus_config-explicit diff --git a/t/t5515/fetch.br-config-explicit_config-explicit b/third_party/git/t/t5515/fetch.br-config-explicit_config-explicit index b19b0162e1..b19b0162e1 100644 --- a/t/t5515/fetch.br-config-explicit_config-explicit +++ b/third_party/git/t/t5515/fetch.br-config-explicit_config-explicit diff --git a/t/t5515/fetch.br-config-glob b/third_party/git/t/t5515/fetch.br-config-glob index 946d70ca07..946d70ca07 100644 --- a/t/t5515/fetch.br-config-glob +++ b/third_party/git/t/t5515/fetch.br-config-glob diff --git a/t/t5515/fetch.br-config-glob-merge b/third_party/git/t/t5515/fetch.br-config-glob-merge index 89f2596cb9..89f2596cb9 100644 --- a/t/t5515/fetch.br-config-glob-merge +++ b/third_party/git/t/t5515/fetch.br-config-glob-merge diff --git a/t/t5515/fetch.br-config-glob-merge_config-glob b/third_party/git/t/t5515/fetch.br-config-glob-merge_config-glob index 2ba4832160..2ba4832160 100644 --- a/t/t5515/fetch.br-config-glob-merge_config-glob +++ b/third_party/git/t/t5515/fetch.br-config-glob-merge_config-glob diff --git a/t/t5515/fetch.br-config-glob-octopus b/third_party/git/t/t5515/fetch.br-config-glob-octopus index 64994df7e2..64994df7e2 100644 --- a/t/t5515/fetch.br-config-glob-octopus +++ b/third_party/git/t/t5515/fetch.br-config-glob-octopus diff --git a/t/t5515/fetch.br-config-glob-octopus_config-glob b/third_party/git/t/t5515/fetch.br-config-glob-octopus_config-glob index 681a725adc..681a725adc 100644 --- a/t/t5515/fetch.br-config-glob-octopus_config-glob +++ b/third_party/git/t/t5515/fetch.br-config-glob-octopus_config-glob diff --git a/t/t5515/fetch.br-config-glob_config-glob b/third_party/git/t/t5515/fetch.br-config-glob_config-glob index 19daf0cb77..19daf0cb77 100644 --- a/t/t5515/fetch.br-config-glob_config-glob +++ b/third_party/git/t/t5515/fetch.br-config-glob_config-glob diff --git a/t/t5515/fetch.br-remote-explicit b/third_party/git/t/t5515/fetch.br-remote-explicit index ab44bc5519..ab44bc5519 100644 --- a/t/t5515/fetch.br-remote-explicit +++ b/third_party/git/t/t5515/fetch.br-remote-explicit diff --git a/t/t5515/fetch.br-remote-explicit-merge b/third_party/git/t/t5515/fetch.br-remote-explicit-merge index d018b3515f..d018b3515f 100644 --- a/t/t5515/fetch.br-remote-explicit-merge +++ b/third_party/git/t/t5515/fetch.br-remote-explicit-merge diff --git a/t/t5515/fetch.br-remote-explicit-merge_remote-explicit b/third_party/git/t/t5515/fetch.br-remote-explicit-merge_remote-explicit index 0d3d780dd0..0d3d780dd0 100644 --- a/t/t5515/fetch.br-remote-explicit-merge_remote-explicit +++ b/third_party/git/t/t5515/fetch.br-remote-explicit-merge_remote-explicit diff --git a/t/t5515/fetch.br-remote-explicit-octopus b/third_party/git/t/t5515/fetch.br-remote-explicit-octopus index 6f843044ed..6f843044ed 100644 --- a/t/t5515/fetch.br-remote-explicit-octopus +++ b/third_party/git/t/t5515/fetch.br-remote-explicit-octopus diff --git a/t/t5515/fetch.br-remote-explicit-octopus_remote-explicit b/third_party/git/t/t5515/fetch.br-remote-explicit-octopus_remote-explicit index 3546a83713..3546a83713 100644 --- a/t/t5515/fetch.br-remote-explicit-octopus_remote-explicit +++ b/third_party/git/t/t5515/fetch.br-remote-explicit-octopus_remote-explicit diff --git a/t/t5515/fetch.br-remote-explicit_remote-explicit b/third_party/git/t/t5515/fetch.br-remote-explicit_remote-explicit index 01e014e6a0..01e014e6a0 100644 --- a/t/t5515/fetch.br-remote-explicit_remote-explicit +++ b/third_party/git/t/t5515/fetch.br-remote-explicit_remote-explicit diff --git a/t/t5515/fetch.br-remote-glob b/third_party/git/t/t5515/fetch.br-remote-glob index 09bfcee00f..09bfcee00f 100644 --- a/t/t5515/fetch.br-remote-glob +++ b/third_party/git/t/t5515/fetch.br-remote-glob diff --git a/t/t5515/fetch.br-remote-glob-merge b/third_party/git/t/t5515/fetch.br-remote-glob-merge index 7e1a433a64..7e1a433a64 100644 --- a/t/t5515/fetch.br-remote-glob-merge +++ b/third_party/git/t/t5515/fetch.br-remote-glob-merge diff --git a/t/t5515/fetch.br-remote-glob-merge_remote-glob b/third_party/git/t/t5515/fetch.br-remote-glob-merge_remote-glob index 53571bb4ec..53571bb4ec 100644 --- a/t/t5515/fetch.br-remote-glob-merge_remote-glob +++ b/third_party/git/t/t5515/fetch.br-remote-glob-merge_remote-glob diff --git a/t/t5515/fetch.br-remote-glob-octopus b/third_party/git/t/t5515/fetch.br-remote-glob-octopus index c7c8b6d7f4..c7c8b6d7f4 100644 --- a/t/t5515/fetch.br-remote-glob-octopus +++ b/third_party/git/t/t5515/fetch.br-remote-glob-octopus diff --git a/t/t5515/fetch.br-remote-glob-octopus_remote-glob b/third_party/git/t/t5515/fetch.br-remote-glob-octopus_remote-glob index 36076fba0c..36076fba0c 100644 --- a/t/t5515/fetch.br-remote-glob-octopus_remote-glob +++ b/third_party/git/t/t5515/fetch.br-remote-glob-octopus_remote-glob diff --git a/t/t5515/fetch.br-remote-glob_remote-glob b/third_party/git/t/t5515/fetch.br-remote-glob_remote-glob index 20ba5cb172..20ba5cb172 100644 --- a/t/t5515/fetch.br-remote-glob_remote-glob +++ b/third_party/git/t/t5515/fetch.br-remote-glob_remote-glob diff --git a/t/t5515/fetch.br-unconfig b/third_party/git/t/t5515/fetch.br-unconfig index 887ccfc41f..887ccfc41f 100644 --- a/t/t5515/fetch.br-unconfig +++ b/third_party/git/t/t5515/fetch.br-unconfig diff --git a/t/t5515/fetch.br-unconfig_--tags_.._.git b/third_party/git/t/t5515/fetch.br-unconfig_--tags_.._.git index 0f70f66c70..0f70f66c70 100644 --- a/t/t5515/fetch.br-unconfig_--tags_.._.git +++ b/third_party/git/t/t5515/fetch.br-unconfig_--tags_.._.git diff --git a/t/t5515/fetch.br-unconfig_.._.git b/third_party/git/t/t5515/fetch.br-unconfig_.._.git index 284bb1fb61..284bb1fb61 100644 --- a/t/t5515/fetch.br-unconfig_.._.git +++ b/third_party/git/t/t5515/fetch.br-unconfig_.._.git diff --git a/t/t5515/fetch.br-unconfig_.._.git_one b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_one index 11eb5a6ef2..11eb5a6ef2 100644 --- a/t/t5515/fetch.br-unconfig_.._.git_one +++ b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_one diff --git a/t/t5515/fetch.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file index 74115361ba..74115361ba 100644 --- a/t/t5515/fetch.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file +++ b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file diff --git a/t/t5515/fetch.br-unconfig_.._.git_one_two b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_one_two index 3f1be224b8..3f1be224b8 100644 --- a/t/t5515/fetch.br-unconfig_.._.git_one_two +++ b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_one_two diff --git a/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file index 7726983818..7726983818 100644 --- a/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file +++ b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file diff --git a/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one_tag_tag-three b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one_tag_tag-three index 7b3750ce5c..7b3750ce5c 100644 --- a/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one_tag_tag-three +++ b/third_party/git/t/t5515/fetch.br-unconfig_.._.git_tag_tag-one_tag_tag-three diff --git a/t/t5515/fetch.br-unconfig_branches-default b/third_party/git/t/t5515/fetch.br-unconfig_branches-default index da30e3c62c..da30e3c62c 100644 --- a/t/t5515/fetch.br-unconfig_branches-default +++ b/third_party/git/t/t5515/fetch.br-unconfig_branches-default diff --git a/t/t5515/fetch.br-unconfig_branches-one b/third_party/git/t/t5515/fetch.br-unconfig_branches-one index e4614314c5..e4614314c5 100644 --- a/t/t5515/fetch.br-unconfig_branches-one +++ b/third_party/git/t/t5515/fetch.br-unconfig_branches-one diff --git a/t/t5515/fetch.br-unconfig_config-explicit b/third_party/git/t/t5515/fetch.br-unconfig_config-explicit index ed323c9871..ed323c9871 100644 --- a/t/t5515/fetch.br-unconfig_config-explicit +++ b/third_party/git/t/t5515/fetch.br-unconfig_config-explicit diff --git a/t/t5515/fetch.br-unconfig_config-glob b/third_party/git/t/t5515/fetch.br-unconfig_config-glob index 2372ed03c5..2372ed03c5 100644 --- a/t/t5515/fetch.br-unconfig_config-glob +++ b/third_party/git/t/t5515/fetch.br-unconfig_config-glob diff --git a/t/t5515/fetch.br-unconfig_remote-explicit b/third_party/git/t/t5515/fetch.br-unconfig_remote-explicit index 6318dd11b4..6318dd11b4 100644 --- a/t/t5515/fetch.br-unconfig_remote-explicit +++ b/third_party/git/t/t5515/fetch.br-unconfig_remote-explicit diff --git a/t/t5515/fetch.br-unconfig_remote-glob b/third_party/git/t/t5515/fetch.br-unconfig_remote-glob index 1d9afad7d8..1d9afad7d8 100644 --- a/t/t5515/fetch.br-unconfig_remote-glob +++ b/third_party/git/t/t5515/fetch.br-unconfig_remote-glob diff --git a/t/t5515/fetch.master b/third_party/git/t/t5515/fetch.master index 9b29d67200..9b29d67200 100644 --- a/t/t5515/fetch.master +++ b/third_party/git/t/t5515/fetch.master diff --git a/t/t5515/fetch.master_--tags_.._.git b/third_party/git/t/t5515/fetch.master_--tags_.._.git index ab473a6e1f..ab473a6e1f 100644 --- a/t/t5515/fetch.master_--tags_.._.git +++ b/third_party/git/t/t5515/fetch.master_--tags_.._.git diff --git a/t/t5515/fetch.master_.._.git b/third_party/git/t/t5515/fetch.master_.._.git index 66d1aaddae..66d1aaddae 100644 --- a/t/t5515/fetch.master_.._.git +++ b/third_party/git/t/t5515/fetch.master_.._.git diff --git a/t/t5515/fetch.master_.._.git_one b/third_party/git/t/t5515/fetch.master_.._.git_one index 35deddbd2c..35deddbd2c 100644 --- a/t/t5515/fetch.master_.._.git_one +++ b/third_party/git/t/t5515/fetch.master_.._.git_one diff --git a/t/t5515/fetch.master_.._.git_one_tag_tag-one_tag_tag-three-file b/third_party/git/t/t5515/fetch.master_.._.git_one_tag_tag-one_tag_tag-three-file index 0672d1292f..0672d1292f 100644 --- a/t/t5515/fetch.master_.._.git_one_tag_tag-one_tag_tag-three-file +++ b/third_party/git/t/t5515/fetch.master_.._.git_one_tag_tag-one_tag_tag-three-file diff --git a/t/t5515/fetch.master_.._.git_one_two b/third_party/git/t/t5515/fetch.master_.._.git_one_two index 35ec5782c8..35ec5782c8 100644 --- a/t/t5515/fetch.master_.._.git_one_two +++ b/third_party/git/t/t5515/fetch.master_.._.git_one_two diff --git a/t/t5515/fetch.master_.._.git_tag_tag-one-tree_tag_tag-three-file b/third_party/git/t/t5515/fetch.master_.._.git_tag_tag-one-tree_tag_tag-three-file index 0fd737cf81..0fd737cf81 100644 --- a/t/t5515/fetch.master_.._.git_tag_tag-one-tree_tag_tag-three-file +++ b/third_party/git/t/t5515/fetch.master_.._.git_tag_tag-one-tree_tag_tag-three-file diff --git a/t/t5515/fetch.master_.._.git_tag_tag-one_tag_tag-three b/third_party/git/t/t5515/fetch.master_.._.git_tag_tag-one_tag_tag-three index e488986653..e488986653 100644 --- a/t/t5515/fetch.master_.._.git_tag_tag-one_tag_tag-three +++ b/third_party/git/t/t5515/fetch.master_.._.git_tag_tag-one_tag_tag-three diff --git a/t/t5515/fetch.master_branches-default b/third_party/git/t/t5515/fetch.master_branches-default index 2eedd3bfa4..2eedd3bfa4 100644 --- a/t/t5515/fetch.master_branches-default +++ b/third_party/git/t/t5515/fetch.master_branches-default diff --git a/t/t5515/fetch.master_branches-one b/third_party/git/t/t5515/fetch.master_branches-one index 901ce21d33..901ce21d33 100644 --- a/t/t5515/fetch.master_branches-one +++ b/third_party/git/t/t5515/fetch.master_branches-one diff --git a/t/t5515/fetch.master_config-explicit b/third_party/git/t/t5515/fetch.master_config-explicit index 251c826aa9..251c826aa9 100644 --- a/t/t5515/fetch.master_config-explicit +++ b/third_party/git/t/t5515/fetch.master_config-explicit diff --git a/t/t5515/fetch.master_config-glob b/third_party/git/t/t5515/fetch.master_config-glob index 27c158e332..27c158e332 100644 --- a/t/t5515/fetch.master_config-glob +++ b/third_party/git/t/t5515/fetch.master_config-glob diff --git a/t/t5515/fetch.master_remote-explicit b/third_party/git/t/t5515/fetch.master_remote-explicit index b3cfe6b98b..b3cfe6b98b 100644 --- a/t/t5515/fetch.master_remote-explicit +++ b/third_party/git/t/t5515/fetch.master_remote-explicit diff --git a/t/t5515/fetch.master_remote-glob b/third_party/git/t/t5515/fetch.master_remote-glob index 118befd1e4..118befd1e4 100644 --- a/t/t5515/fetch.master_remote-glob +++ b/third_party/git/t/t5515/fetch.master_remote-glob diff --git a/t/t5515/refs.br-branches-default b/third_party/git/t/t5515/refs.br-branches-default index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-branches-default +++ b/third_party/git/t/t5515/refs.br-branches-default diff --git a/t/t5515/refs.br-branches-default-merge b/third_party/git/t/t5515/refs.br-branches-default-merge index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-branches-default-merge +++ b/third_party/git/t/t5515/refs.br-branches-default-merge diff --git a/t/t5515/refs.br-branches-default-merge_branches-default b/third_party/git/t/t5515/refs.br-branches-default-merge_branches-default index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-branches-default-merge_branches-default +++ b/third_party/git/t/t5515/refs.br-branches-default-merge_branches-default diff --git a/t/t5515/refs.br-branches-default-octopus b/third_party/git/t/t5515/refs.br-branches-default-octopus index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-branches-default-octopus +++ b/third_party/git/t/t5515/refs.br-branches-default-octopus diff --git a/t/t5515/refs.br-branches-default-octopus_branches-default b/third_party/git/t/t5515/refs.br-branches-default-octopus_branches-default index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-branches-default-octopus_branches-default +++ b/third_party/git/t/t5515/refs.br-branches-default-octopus_branches-default diff --git a/t/t5515/refs.br-branches-default_branches-default b/third_party/git/t/t5515/refs.br-branches-default_branches-default index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-branches-default_branches-default +++ b/third_party/git/t/t5515/refs.br-branches-default_branches-default diff --git a/t/t5515/refs.br-branches-one b/third_party/git/t/t5515/refs.br-branches-one index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-branches-one +++ b/third_party/git/t/t5515/refs.br-branches-one diff --git a/t/t5515/refs.br-branches-one-merge b/third_party/git/t/t5515/refs.br-branches-one-merge index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-branches-one-merge +++ b/third_party/git/t/t5515/refs.br-branches-one-merge diff --git a/t/t5515/refs.br-branches-one-merge_branches-one b/third_party/git/t/t5515/refs.br-branches-one-merge_branches-one index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-branches-one-merge_branches-one +++ b/third_party/git/t/t5515/refs.br-branches-one-merge_branches-one diff --git a/t/t5515/refs.br-branches-one-octopus b/third_party/git/t/t5515/refs.br-branches-one-octopus index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-branches-one-octopus +++ b/third_party/git/t/t5515/refs.br-branches-one-octopus diff --git a/t/t5515/refs.br-branches-one-octopus_branches-one b/third_party/git/t/t5515/refs.br-branches-one-octopus_branches-one index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-branches-one-octopus_branches-one +++ b/third_party/git/t/t5515/refs.br-branches-one-octopus_branches-one diff --git a/t/t5515/refs.br-branches-one_branches-one b/third_party/git/t/t5515/refs.br-branches-one_branches-one index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-branches-one_branches-one +++ b/third_party/git/t/t5515/refs.br-branches-one_branches-one diff --git a/t/t5515/refs.br-config-explicit b/third_party/git/t/t5515/refs.br-config-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-explicit +++ b/third_party/git/t/t5515/refs.br-config-explicit diff --git a/t/t5515/refs.br-config-explicit-merge b/third_party/git/t/t5515/refs.br-config-explicit-merge index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-explicit-merge +++ b/third_party/git/t/t5515/refs.br-config-explicit-merge diff --git a/t/t5515/refs.br-config-explicit-merge_config-explicit b/third_party/git/t/t5515/refs.br-config-explicit-merge_config-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-explicit-merge_config-explicit +++ b/third_party/git/t/t5515/refs.br-config-explicit-merge_config-explicit diff --git a/t/t5515/refs.br-config-explicit-octopus b/third_party/git/t/t5515/refs.br-config-explicit-octopus index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-explicit-octopus +++ b/third_party/git/t/t5515/refs.br-config-explicit-octopus diff --git a/t/t5515/refs.br-config-explicit-octopus_config-explicit b/third_party/git/t/t5515/refs.br-config-explicit-octopus_config-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-explicit-octopus_config-explicit +++ b/third_party/git/t/t5515/refs.br-config-explicit-octopus_config-explicit diff --git a/t/t5515/refs.br-config-explicit_config-explicit b/third_party/git/t/t5515/refs.br-config-explicit_config-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-explicit_config-explicit +++ b/third_party/git/t/t5515/refs.br-config-explicit_config-explicit diff --git a/t/t5515/refs.br-config-glob b/third_party/git/t/t5515/refs.br-config-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-glob +++ b/third_party/git/t/t5515/refs.br-config-glob diff --git a/t/t5515/refs.br-config-glob-merge b/third_party/git/t/t5515/refs.br-config-glob-merge index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-glob-merge +++ b/third_party/git/t/t5515/refs.br-config-glob-merge diff --git a/t/t5515/refs.br-config-glob-merge_config-glob b/third_party/git/t/t5515/refs.br-config-glob-merge_config-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-glob-merge_config-glob +++ b/third_party/git/t/t5515/refs.br-config-glob-merge_config-glob diff --git a/t/t5515/refs.br-config-glob-octopus b/third_party/git/t/t5515/refs.br-config-glob-octopus index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-glob-octopus +++ b/third_party/git/t/t5515/refs.br-config-glob-octopus diff --git a/t/t5515/refs.br-config-glob-octopus_config-glob b/third_party/git/t/t5515/refs.br-config-glob-octopus_config-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-glob-octopus_config-glob +++ b/third_party/git/t/t5515/refs.br-config-glob-octopus_config-glob diff --git a/t/t5515/refs.br-config-glob_config-glob b/third_party/git/t/t5515/refs.br-config-glob_config-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-config-glob_config-glob +++ b/third_party/git/t/t5515/refs.br-config-glob_config-glob diff --git a/t/t5515/refs.br-remote-explicit b/third_party/git/t/t5515/refs.br-remote-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-explicit +++ b/third_party/git/t/t5515/refs.br-remote-explicit diff --git a/t/t5515/refs.br-remote-explicit-merge b/third_party/git/t/t5515/refs.br-remote-explicit-merge index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-explicit-merge +++ b/third_party/git/t/t5515/refs.br-remote-explicit-merge diff --git a/t/t5515/refs.br-remote-explicit-merge_remote-explicit b/third_party/git/t/t5515/refs.br-remote-explicit-merge_remote-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-explicit-merge_remote-explicit +++ b/third_party/git/t/t5515/refs.br-remote-explicit-merge_remote-explicit diff --git a/t/t5515/refs.br-remote-explicit-octopus b/third_party/git/t/t5515/refs.br-remote-explicit-octopus index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-explicit-octopus +++ b/third_party/git/t/t5515/refs.br-remote-explicit-octopus diff --git a/t/t5515/refs.br-remote-explicit-octopus_remote-explicit b/third_party/git/t/t5515/refs.br-remote-explicit-octopus_remote-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-explicit-octopus_remote-explicit +++ b/third_party/git/t/t5515/refs.br-remote-explicit-octopus_remote-explicit diff --git a/t/t5515/refs.br-remote-explicit_remote-explicit b/third_party/git/t/t5515/refs.br-remote-explicit_remote-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-explicit_remote-explicit +++ b/third_party/git/t/t5515/refs.br-remote-explicit_remote-explicit diff --git a/t/t5515/refs.br-remote-glob b/third_party/git/t/t5515/refs.br-remote-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-glob +++ b/third_party/git/t/t5515/refs.br-remote-glob diff --git a/t/t5515/refs.br-remote-glob-merge b/third_party/git/t/t5515/refs.br-remote-glob-merge index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-glob-merge +++ b/third_party/git/t/t5515/refs.br-remote-glob-merge diff --git a/t/t5515/refs.br-remote-glob-merge_remote-glob b/third_party/git/t/t5515/refs.br-remote-glob-merge_remote-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-glob-merge_remote-glob +++ b/third_party/git/t/t5515/refs.br-remote-glob-merge_remote-glob diff --git a/t/t5515/refs.br-remote-glob-octopus b/third_party/git/t/t5515/refs.br-remote-glob-octopus index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-glob-octopus +++ b/third_party/git/t/t5515/refs.br-remote-glob-octopus diff --git a/t/t5515/refs.br-remote-glob-octopus_remote-glob b/third_party/git/t/t5515/refs.br-remote-glob-octopus_remote-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-glob-octopus_remote-glob +++ b/third_party/git/t/t5515/refs.br-remote-glob-octopus_remote-glob diff --git a/t/t5515/refs.br-remote-glob_remote-glob b/third_party/git/t/t5515/refs.br-remote-glob_remote-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-remote-glob_remote-glob +++ b/third_party/git/t/t5515/refs.br-remote-glob_remote-glob diff --git a/t/t5515/refs.br-unconfig b/third_party/git/t/t5515/refs.br-unconfig index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.br-unconfig +++ b/third_party/git/t/t5515/refs.br-unconfig diff --git a/t/t5515/refs.br-unconfig_--tags_.._.git b/third_party/git/t/t5515/refs.br-unconfig_--tags_.._.git index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.br-unconfig_--tags_.._.git +++ b/third_party/git/t/t5515/refs.br-unconfig_--tags_.._.git diff --git a/t/t5515/refs.br-unconfig_.._.git b/third_party/git/t/t5515/refs.br-unconfig_.._.git index 70962eaac1..70962eaac1 100644 --- a/t/t5515/refs.br-unconfig_.._.git +++ b/third_party/git/t/t5515/refs.br-unconfig_.._.git diff --git a/t/t5515/refs.br-unconfig_.._.git_one b/third_party/git/t/t5515/refs.br-unconfig_.._.git_one index 70962eaac1..70962eaac1 100644 --- a/t/t5515/refs.br-unconfig_.._.git_one +++ b/third_party/git/t/t5515/refs.br-unconfig_.._.git_one diff --git a/t/t5515/refs.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file b/third_party/git/t/t5515/refs.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file +++ b/third_party/git/t/t5515/refs.br-unconfig_.._.git_one_tag_tag-one_tag_tag-three-file diff --git a/t/t5515/refs.br-unconfig_.._.git_one_two b/third_party/git/t/t5515/refs.br-unconfig_.._.git_one_two index 70962eaac1..70962eaac1 100644 --- a/t/t5515/refs.br-unconfig_.._.git_one_two +++ b/third_party/git/t/t5515/refs.br-unconfig_.._.git_one_two diff --git a/t/t5515/refs.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file b/third_party/git/t/t5515/refs.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file +++ b/third_party/git/t/t5515/refs.br-unconfig_.._.git_tag_tag-one-tree_tag_tag-three-file diff --git a/t/t5515/refs.br-unconfig_.._.git_tag_tag-one_tag_tag-three b/third_party/git/t/t5515/refs.br-unconfig_.._.git_tag_tag-one_tag_tag-three index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.br-unconfig_.._.git_tag_tag-one_tag_tag-three +++ b/third_party/git/t/t5515/refs.br-unconfig_.._.git_tag_tag-one_tag_tag-three diff --git a/t/t5515/refs.br-unconfig_branches-default b/third_party/git/t/t5515/refs.br-unconfig_branches-default index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.br-unconfig_branches-default +++ b/third_party/git/t/t5515/refs.br-unconfig_branches-default diff --git a/t/t5515/refs.br-unconfig_branches-one b/third_party/git/t/t5515/refs.br-unconfig_branches-one index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.br-unconfig_branches-one +++ b/third_party/git/t/t5515/refs.br-unconfig_branches-one diff --git a/t/t5515/refs.br-unconfig_config-explicit b/third_party/git/t/t5515/refs.br-unconfig_config-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-unconfig_config-explicit +++ b/third_party/git/t/t5515/refs.br-unconfig_config-explicit diff --git a/t/t5515/refs.br-unconfig_config-glob b/third_party/git/t/t5515/refs.br-unconfig_config-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-unconfig_config-glob +++ b/third_party/git/t/t5515/refs.br-unconfig_config-glob diff --git a/t/t5515/refs.br-unconfig_remote-explicit b/third_party/git/t/t5515/refs.br-unconfig_remote-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-unconfig_remote-explicit +++ b/third_party/git/t/t5515/refs.br-unconfig_remote-explicit diff --git a/t/t5515/refs.br-unconfig_remote-glob b/third_party/git/t/t5515/refs.br-unconfig_remote-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.br-unconfig_remote-glob +++ b/third_party/git/t/t5515/refs.br-unconfig_remote-glob diff --git a/t/t5515/refs.master b/third_party/git/t/t5515/refs.master index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.master +++ b/third_party/git/t/t5515/refs.master diff --git a/t/t5515/refs.master_--tags_.._.git b/third_party/git/t/t5515/refs.master_--tags_.._.git index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.master_--tags_.._.git +++ b/third_party/git/t/t5515/refs.master_--tags_.._.git diff --git a/t/t5515/refs.master_.._.git b/third_party/git/t/t5515/refs.master_.._.git index 70962eaac1..70962eaac1 100644 --- a/t/t5515/refs.master_.._.git +++ b/third_party/git/t/t5515/refs.master_.._.git diff --git a/t/t5515/refs.master_.._.git_one b/third_party/git/t/t5515/refs.master_.._.git_one index 70962eaac1..70962eaac1 100644 --- a/t/t5515/refs.master_.._.git_one +++ b/third_party/git/t/t5515/refs.master_.._.git_one diff --git a/t/t5515/refs.master_.._.git_one_tag_tag-one_tag_tag-three-file b/third_party/git/t/t5515/refs.master_.._.git_one_tag_tag-one_tag_tag-three-file index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.master_.._.git_one_tag_tag-one_tag_tag-three-file +++ b/third_party/git/t/t5515/refs.master_.._.git_one_tag_tag-one_tag_tag-three-file diff --git a/t/t5515/refs.master_.._.git_one_two b/third_party/git/t/t5515/refs.master_.._.git_one_two index 70962eaac1..70962eaac1 100644 --- a/t/t5515/refs.master_.._.git_one_two +++ b/third_party/git/t/t5515/refs.master_.._.git_one_two diff --git a/t/t5515/refs.master_.._.git_tag_tag-one-tree_tag_tag-three-file b/third_party/git/t/t5515/refs.master_.._.git_tag_tag-one-tree_tag_tag-three-file index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.master_.._.git_tag_tag-one-tree_tag_tag-three-file +++ b/third_party/git/t/t5515/refs.master_.._.git_tag_tag-one-tree_tag_tag-three-file diff --git a/t/t5515/refs.master_.._.git_tag_tag-one_tag_tag-three b/third_party/git/t/t5515/refs.master_.._.git_tag_tag-one_tag_tag-three index 13e4ad2e46..13e4ad2e46 100644 --- a/t/t5515/refs.master_.._.git_tag_tag-one_tag_tag-three +++ b/third_party/git/t/t5515/refs.master_.._.git_tag_tag-one_tag_tag-three diff --git a/t/t5515/refs.master_branches-default b/third_party/git/t/t5515/refs.master_branches-default index 21917c1e5d..21917c1e5d 100644 --- a/t/t5515/refs.master_branches-default +++ b/third_party/git/t/t5515/refs.master_branches-default diff --git a/t/t5515/refs.master_branches-one b/third_party/git/t/t5515/refs.master_branches-one index 8a705a5df2..8a705a5df2 100644 --- a/t/t5515/refs.master_branches-one +++ b/third_party/git/t/t5515/refs.master_branches-one diff --git a/t/t5515/refs.master_config-explicit b/third_party/git/t/t5515/refs.master_config-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.master_config-explicit +++ b/third_party/git/t/t5515/refs.master_config-explicit diff --git a/t/t5515/refs.master_config-glob b/third_party/git/t/t5515/refs.master_config-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.master_config-glob +++ b/third_party/git/t/t5515/refs.master_config-glob diff --git a/t/t5515/refs.master_remote-explicit b/third_party/git/t/t5515/refs.master_remote-explicit index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.master_remote-explicit +++ b/third_party/git/t/t5515/refs.master_remote-explicit diff --git a/t/t5515/refs.master_remote-glob b/third_party/git/t/t5515/refs.master_remote-glob index 9bbbfd9fc5..9bbbfd9fc5 100644 --- a/t/t5515/refs.master_remote-glob +++ b/third_party/git/t/t5515/refs.master_remote-glob diff --git a/t/t5516-fetch-push.sh b/third_party/git/t/t5516-fetch-push.sh index 9ff041a093..9ff041a093 100755 --- a/t/t5516-fetch-push.sh +++ b/third_party/git/t/t5516-fetch-push.sh diff --git a/t/t5517-push-mirror.sh b/third_party/git/t/t5517-push-mirror.sh index e4edd56404..e4edd56404 100755 --- a/t/t5517-push-mirror.sh +++ b/third_party/git/t/t5517-push-mirror.sh diff --git a/t/t5518-fetch-exit-status.sh b/third_party/git/t/t5518-fetch-exit-status.sh index c2060bb870..c2060bb870 100755 --- a/t/t5518-fetch-exit-status.sh +++ b/third_party/git/t/t5518-fetch-exit-status.sh diff --git a/t/t5519-push-alternates.sh b/third_party/git/t/t5519-push-alternates.sh index 11fcd37700..11fcd37700 100755 --- a/t/t5519-push-alternates.sh +++ b/third_party/git/t/t5519-push-alternates.sh diff --git a/t/t5520-pull.sh b/third_party/git/t/t5520-pull.sh index 2f86fca042..2f86fca042 100755 --- a/t/t5520-pull.sh +++ b/third_party/git/t/t5520-pull.sh diff --git a/t/t5521-pull-options.sh b/third_party/git/t/t5521-pull-options.sh index ccde8ba491..ccde8ba491 100755 --- a/t/t5521-pull-options.sh +++ b/third_party/git/t/t5521-pull-options.sh diff --git a/t/t5522-pull-symlink.sh b/third_party/git/t/t5522-pull-symlink.sh index bcff460d0a..bcff460d0a 100755 --- a/t/t5522-pull-symlink.sh +++ b/third_party/git/t/t5522-pull-symlink.sh diff --git a/t/t5523-push-upstream.sh b/third_party/git/t/t5523-push-upstream.sh index c0df81a014..c0df81a014 100755 --- a/t/t5523-push-upstream.sh +++ b/third_party/git/t/t5523-push-upstream.sh diff --git a/t/t5524-pull-msg.sh b/third_party/git/t/t5524-pull-msg.sh index c278adaa5a..c278adaa5a 100755 --- a/t/t5524-pull-msg.sh +++ b/third_party/git/t/t5524-pull-msg.sh diff --git a/t/t5525-fetch-tagopt.sh b/third_party/git/t/t5525-fetch-tagopt.sh index 45815f7378..45815f7378 100755 --- a/t/t5525-fetch-tagopt.sh +++ b/third_party/git/t/t5525-fetch-tagopt.sh diff --git a/t/t5526-fetch-submodules.sh b/third_party/git/t/t5526-fetch-submodules.sh index 63205dfdf9..63205dfdf9 100755 --- a/t/t5526-fetch-submodules.sh +++ b/third_party/git/t/t5526-fetch-submodules.sh diff --git a/t/t5527-fetch-odd-refs.sh b/third_party/git/t/t5527-fetch-odd-refs.sh index 3b0cb98422..3b0cb98422 100755 --- a/t/t5527-fetch-odd-refs.sh +++ b/third_party/git/t/t5527-fetch-odd-refs.sh diff --git a/t/t5528-push-default.sh b/third_party/git/t/t5528-push-default.sh index 4d1e0c363e..4d1e0c363e 100755 --- a/t/t5528-push-default.sh +++ b/third_party/git/t/t5528-push-default.sh diff --git a/t/t5529-push-errors.sh b/third_party/git/t/t5529-push-errors.sh index 9871307fd4..9871307fd4 100755 --- a/t/t5529-push-errors.sh +++ b/third_party/git/t/t5529-push-errors.sh diff --git a/t/t5530-upload-pack-error.sh b/third_party/git/t/t5530-upload-pack-error.sh index 4ce9a9f704..4ce9a9f704 100755 --- a/t/t5530-upload-pack-error.sh +++ b/third_party/git/t/t5530-upload-pack-error.sh diff --git a/t/t5531-deep-submodule-push.sh b/third_party/git/t/t5531-deep-submodule-push.sh index 4ad059e6be..4ad059e6be 100755 --- a/t/t5531-deep-submodule-push.sh +++ b/third_party/git/t/t5531-deep-submodule-push.sh diff --git a/t/t5532-fetch-proxy.sh b/third_party/git/t/t5532-fetch-proxy.sh index 9c2798603b..9c2798603b 100755 --- a/t/t5532-fetch-proxy.sh +++ b/third_party/git/t/t5532-fetch-proxy.sh diff --git a/t/t5533-push-cas.sh b/third_party/git/t/t5533-push-cas.sh index 0b0eb1d025..0b0eb1d025 100755 --- a/t/t5533-push-cas.sh +++ b/third_party/git/t/t5533-push-cas.sh diff --git a/t/t5534-push-signed.sh b/third_party/git/t/t5534-push-signed.sh index 030331f1c5..030331f1c5 100755 --- a/t/t5534-push-signed.sh +++ b/third_party/git/t/t5534-push-signed.sh diff --git a/t/t5535-fetch-push-symref.sh b/third_party/git/t/t5535-fetch-push-symref.sh index e8f6d233ff..e8f6d233ff 100755 --- a/t/t5535-fetch-push-symref.sh +++ b/third_party/git/t/t5535-fetch-push-symref.sh diff --git a/t/t5536-fetch-conflicts.sh b/third_party/git/t/t5536-fetch-conflicts.sh index 91f28c2f78..91f28c2f78 100755 --- a/t/t5536-fetch-conflicts.sh +++ b/third_party/git/t/t5536-fetch-conflicts.sh diff --git a/t/t5537-fetch-shallow.sh b/third_party/git/t/t5537-fetch-shallow.sh index 4f681dbbe1..4f681dbbe1 100755 --- a/t/t5537-fetch-shallow.sh +++ b/third_party/git/t/t5537-fetch-shallow.sh diff --git a/t/t5538-push-shallow.sh b/third_party/git/t/t5538-push-shallow.sh index ecbf84d21c..ecbf84d21c 100755 --- a/t/t5538-push-shallow.sh +++ b/third_party/git/t/t5538-push-shallow.sh diff --git a/t/t5539-fetch-http-shallow.sh b/third_party/git/t/t5539-fetch-http-shallow.sh index c0d02dee89..c0d02dee89 100755 --- a/t/t5539-fetch-http-shallow.sh +++ b/third_party/git/t/t5539-fetch-http-shallow.sh diff --git a/t/t5540-http-push-webdav.sh b/third_party/git/t/t5540-http-push-webdav.sh index d476c33509..d476c33509 100755 --- a/t/t5540-http-push-webdav.sh +++ b/third_party/git/t/t5540-http-push-webdav.sh diff --git a/t/t5541-http-push-smart.sh b/third_party/git/t/t5541-http-push-smart.sh index 23be8ce92d..23be8ce92d 100755 --- a/t/t5541-http-push-smart.sh +++ b/third_party/git/t/t5541-http-push-smart.sh diff --git a/t/t5542-push-http-shallow.sh b/third_party/git/t/t5542-push-http-shallow.sh index ddc1db722d..ddc1db722d 100755 --- a/t/t5542-push-http-shallow.sh +++ b/third_party/git/t/t5542-push-http-shallow.sh diff --git a/t/t5543-atomic-push.sh b/third_party/git/t/t5543-atomic-push.sh index 7079bcf9a0..7079bcf9a0 100755 --- a/t/t5543-atomic-push.sh +++ b/third_party/git/t/t5543-atomic-push.sh diff --git a/t/t5544-pack-objects-hook.sh b/third_party/git/t/t5544-pack-objects-hook.sh index 4357af1525..4357af1525 100755 --- a/t/t5544-pack-objects-hook.sh +++ b/third_party/git/t/t5544-pack-objects-hook.sh diff --git a/t/t5545-push-options.sh b/third_party/git/t/t5545-push-options.sh index 38e6f7340e..38e6f7340e 100755 --- a/t/t5545-push-options.sh +++ b/third_party/git/t/t5545-push-options.sh diff --git a/t/t5546-receive-limits.sh b/third_party/git/t/t5546-receive-limits.sh index 0b0e987fdb..0b0e987fdb 100755 --- a/t/t5546-receive-limits.sh +++ b/third_party/git/t/t5546-receive-limits.sh diff --git a/t/t5547-push-quarantine.sh b/third_party/git/t/t5547-push-quarantine.sh index faaa51ccc5..faaa51ccc5 100755 --- a/t/t5547-push-quarantine.sh +++ b/third_party/git/t/t5547-push-quarantine.sh diff --git a/t/t5550-http-fetch-dumb.sh b/third_party/git/t/t5550-http-fetch-dumb.sh index ea2688bde5..ea2688bde5 100755 --- a/t/t5550-http-fetch-dumb.sh +++ b/third_party/git/t/t5550-http-fetch-dumb.sh diff --git a/t/t5551-http-fetch-smart.sh b/third_party/git/t/t5551-http-fetch-smart.sh index 6788aeface..6788aeface 100755 --- a/t/t5551-http-fetch-smart.sh +++ b/third_party/git/t/t5551-http-fetch-smart.sh diff --git a/t/t5552-skipping-fetch-negotiator.sh b/third_party/git/t/t5552-skipping-fetch-negotiator.sh index 156c704040..156c704040 100755 --- a/t/t5552-skipping-fetch-negotiator.sh +++ b/third_party/git/t/t5552-skipping-fetch-negotiator.sh diff --git a/t/t5553-set-upstream.sh b/third_party/git/t/t5553-set-upstream.sh index 81975ad8f9..81975ad8f9 100755 --- a/t/t5553-set-upstream.sh +++ b/third_party/git/t/t5553-set-upstream.sh diff --git a/t/t5560-http-backend-noserver.sh b/third_party/git/t/t5560-http-backend-noserver.sh index 9fafcf1945..9fafcf1945 100755 --- a/t/t5560-http-backend-noserver.sh +++ b/third_party/git/t/t5560-http-backend-noserver.sh diff --git a/t/t5561-http-backend.sh b/third_party/git/t/t5561-http-backend.sh index 6eb0294978..6eb0294978 100755 --- a/t/t5561-http-backend.sh +++ b/third_party/git/t/t5561-http-backend.sh diff --git a/t/t5562-http-backend-content-length.sh b/third_party/git/t/t5562-http-backend-content-length.sh index 4a110b307e..4a110b307e 100755 --- a/t/t5562-http-backend-content-length.sh +++ b/third_party/git/t/t5562-http-backend-content-length.sh diff --git a/t/t5562/invoke-with-content-length.pl b/third_party/git/t/t5562/invoke-with-content-length.pl index 0943474af2..0943474af2 100644 --- a/t/t5562/invoke-with-content-length.pl +++ b/third_party/git/t/t5562/invoke-with-content-length.pl diff --git a/t/t556x_common b/third_party/git/t/t556x_common index 359fcfe32b..359fcfe32b 100755 --- a/t/t556x_common +++ b/third_party/git/t/t556x_common diff --git a/t/t5570-git-daemon.sh b/third_party/git/t/t5570-git-daemon.sh index 34487bbb8c..34487bbb8c 100755 --- a/t/t5570-git-daemon.sh +++ b/third_party/git/t/t5570-git-daemon.sh diff --git a/t/t5571-pre-push-hook.sh b/third_party/git/t/t5571-pre-push-hook.sh index ac53d63869..ac53d63869 100755 --- a/t/t5571-pre-push-hook.sh +++ b/third_party/git/t/t5571-pre-push-hook.sh diff --git a/t/t5572-pull-submodule.sh b/third_party/git/t/t5572-pull-submodule.sh index f916729a12..f916729a12 100755 --- a/t/t5572-pull-submodule.sh +++ b/third_party/git/t/t5572-pull-submodule.sh diff --git a/t/t5573-pull-verify-signatures.sh b/third_party/git/t/t5573-pull-verify-signatures.sh index a53dd8550d..a53dd8550d 100755 --- a/t/t5573-pull-verify-signatures.sh +++ b/third_party/git/t/t5573-pull-verify-signatures.sh diff --git a/t/t5580-unc-paths.sh b/third_party/git/t/t5580-unc-paths.sh index cf768b3a27..cf768b3a27 100755 --- a/t/t5580-unc-paths.sh +++ b/third_party/git/t/t5580-unc-paths.sh diff --git a/t/t5581-http-curl-verbose.sh b/third_party/git/t/t5581-http-curl-verbose.sh index 5129b0724f..5129b0724f 100755 --- a/t/t5581-http-curl-verbose.sh +++ b/third_party/git/t/t5581-http-curl-verbose.sh diff --git a/t/t5600-clone-fail-cleanup.sh b/third_party/git/t/t5600-clone-fail-cleanup.sh index 4a1a912e03..4a1a912e03 100755 --- a/t/t5600-clone-fail-cleanup.sh +++ b/third_party/git/t/t5600-clone-fail-cleanup.sh diff --git a/t/t5601-clone.sh b/third_party/git/t/t5601-clone.sh index 84ea2a3eb7..84ea2a3eb7 100755 --- a/t/t5601-clone.sh +++ b/third_party/git/t/t5601-clone.sh diff --git a/t/t5602-clone-remote-exec.sh b/third_party/git/t/t5602-clone-remote-exec.sh index cbcceab9d5..cbcceab9d5 100755 --- a/t/t5602-clone-remote-exec.sh +++ b/third_party/git/t/t5602-clone-remote-exec.sh diff --git a/t/t5603-clone-dirname.sh b/third_party/git/t/t5603-clone-dirname.sh index 13b5e5eb9b..13b5e5eb9b 100755 --- a/t/t5603-clone-dirname.sh +++ b/third_party/git/t/t5603-clone-dirname.sh diff --git a/t/t5604-clone-reference.sh b/third_party/git/t/t5604-clone-reference.sh index 0c74b4e21a..0c74b4e21a 100755 --- a/t/t5604-clone-reference.sh +++ b/third_party/git/t/t5604-clone-reference.sh diff --git a/t/t5605-clone-local.sh b/third_party/git/t/t5605-clone-local.sh index af23419ebf..af23419ebf 100755 --- a/t/t5605-clone-local.sh +++ b/third_party/git/t/t5605-clone-local.sh diff --git a/t/t5606-clone-options.sh b/third_party/git/t/t5606-clone-options.sh index 9e24ec88e6..9e24ec88e6 100755 --- a/t/t5606-clone-options.sh +++ b/third_party/git/t/t5606-clone-options.sh diff --git a/t/t5607-clone-bundle.sh b/third_party/git/t/t5607-clone-bundle.sh index 9108ff6fbd..9108ff6fbd 100755 --- a/t/t5607-clone-bundle.sh +++ b/third_party/git/t/t5607-clone-bundle.sh diff --git a/t/t5608-clone-2gb.sh b/third_party/git/t/t5608-clone-2gb.sh index eee0842888..eee0842888 100755 --- a/t/t5608-clone-2gb.sh +++ b/third_party/git/t/t5608-clone-2gb.sh diff --git a/t/t5609-clone-branch.sh b/third_party/git/t/t5609-clone-branch.sh index 6e7a7be052..6e7a7be052 100755 --- a/t/t5609-clone-branch.sh +++ b/third_party/git/t/t5609-clone-branch.sh diff --git a/t/t5610-clone-detached.sh b/third_party/git/t/t5610-clone-detached.sh index 8b0d607df1..8b0d607df1 100755 --- a/t/t5610-clone-detached.sh +++ b/third_party/git/t/t5610-clone-detached.sh diff --git a/t/t5611-clone-config.sh b/third_party/git/t/t5611-clone-config.sh index 60c1ba951b..60c1ba951b 100755 --- a/t/t5611-clone-config.sh +++ b/third_party/git/t/t5611-clone-config.sh diff --git a/t/t5612-clone-refspec.sh b/third_party/git/t/t5612-clone-refspec.sh index e36ac01661..e36ac01661 100755 --- a/t/t5612-clone-refspec.sh +++ b/third_party/git/t/t5612-clone-refspec.sh diff --git a/t/t5613-info-alternate.sh b/third_party/git/t/t5613-info-alternate.sh index 895f46bb91..895f46bb91 100755 --- a/t/t5613-info-alternate.sh +++ b/third_party/git/t/t5613-info-alternate.sh diff --git a/t/t5614-clone-submodules-shallow.sh b/third_party/git/t/t5614-clone-submodules-shallow.sh index e4e6ea4d52..e4e6ea4d52 100755 --- a/t/t5614-clone-submodules-shallow.sh +++ b/third_party/git/t/t5614-clone-submodules-shallow.sh diff --git a/t/t5615-alternate-env.sh b/third_party/git/t/t5615-alternate-env.sh index b4905b822c..b4905b822c 100755 --- a/t/t5615-alternate-env.sh +++ b/third_party/git/t/t5615-alternate-env.sh diff --git a/t/t5616-partial-clone.sh b/third_party/git/t/t5616-partial-clone.sh index 77bb91e976..77bb91e976 100755 --- a/t/t5616-partial-clone.sh +++ b/third_party/git/t/t5616-partial-clone.sh diff --git a/t/t5617-clone-submodules-remote.sh b/third_party/git/t/t5617-clone-submodules-remote.sh index 1a041df10b..1a041df10b 100755 --- a/t/t5617-clone-submodules-remote.sh +++ b/third_party/git/t/t5617-clone-submodules-remote.sh diff --git a/t/t5618-alternate-refs.sh b/third_party/git/t/t5618-alternate-refs.sh index 3353216f09..3353216f09 100755 --- a/t/t5618-alternate-refs.sh +++ b/third_party/git/t/t5618-alternate-refs.sh diff --git a/t/t5700-protocol-v1.sh b/third_party/git/t/t5700-protocol-v1.sh index 022901b9eb..022901b9eb 100755 --- a/t/t5700-protocol-v1.sh +++ b/third_party/git/t/t5700-protocol-v1.sh diff --git a/t/t5701-git-serve.sh b/third_party/git/t/t5701-git-serve.sh index ffb9613885..ffb9613885 100755 --- a/t/t5701-git-serve.sh +++ b/third_party/git/t/t5701-git-serve.sh diff --git a/t/t5702-protocol-v2.sh b/third_party/git/t/t5702-protocol-v2.sh index 5039e66dc4..5039e66dc4 100755 --- a/t/t5702-protocol-v2.sh +++ b/third_party/git/t/t5702-protocol-v2.sh diff --git a/t/t5703-upload-pack-ref-in-want.sh b/third_party/git/t/t5703-upload-pack-ref-in-want.sh index 7fba3063bf..7fba3063bf 100755 --- a/t/t5703-upload-pack-ref-in-want.sh +++ b/third_party/git/t/t5703-upload-pack-ref-in-want.sh diff --git a/t/t5801-remote-helpers.sh b/third_party/git/t/t5801-remote-helpers.sh index 121e5c6edb..121e5c6edb 100755 --- a/t/t5801-remote-helpers.sh +++ b/third_party/git/t/t5801-remote-helpers.sh diff --git a/t/t5801/git-remote-testgit b/third_party/git/t/t5801/git-remote-testgit index 6b9f0b5dc7..6b9f0b5dc7 100755 --- a/t/t5801/git-remote-testgit +++ b/third_party/git/t/t5801/git-remote-testgit diff --git a/t/t5802-connect-helper.sh b/third_party/git/t/t5802-connect-helper.sh index c6c2661878..c6c2661878 100755 --- a/t/t5802-connect-helper.sh +++ b/third_party/git/t/t5802-connect-helper.sh diff --git a/t/t5810-proto-disable-local.sh b/third_party/git/t/t5810-proto-disable-local.sh index c1ef99b85c..c1ef99b85c 100755 --- a/t/t5810-proto-disable-local.sh +++ b/third_party/git/t/t5810-proto-disable-local.sh diff --git a/t/t5811-proto-disable-git.sh b/third_party/git/t/t5811-proto-disable-git.sh index 8ac6b2a1d0..8ac6b2a1d0 100755 --- a/t/t5811-proto-disable-git.sh +++ b/third_party/git/t/t5811-proto-disable-git.sh diff --git a/t/t5812-proto-disable-http.sh b/third_party/git/t/t5812-proto-disable-http.sh index af8772fada..af8772fada 100755 --- a/t/t5812-proto-disable-http.sh +++ b/third_party/git/t/t5812-proto-disable-http.sh diff --git a/t/t5813-proto-disable-ssh.sh b/third_party/git/t/t5813-proto-disable-ssh.sh index 3f084ee306..3f084ee306 100755 --- a/t/t5813-proto-disable-ssh.sh +++ b/third_party/git/t/t5813-proto-disable-ssh.sh diff --git a/t/t5814-proto-disable-ext.sh b/third_party/git/t/t5814-proto-disable-ext.sh index 9d6f7dfa2c..9d6f7dfa2c 100755 --- a/t/t5814-proto-disable-ext.sh +++ b/third_party/git/t/t5814-proto-disable-ext.sh diff --git a/t/t5815-submodule-protos.sh b/third_party/git/t/t5815-submodule-protos.sh index 06f55a1b8a..06f55a1b8a 100755 --- a/t/t5815-submodule-protos.sh +++ b/third_party/git/t/t5815-submodule-protos.sh diff --git a/t/t5900-repo-selection.sh b/third_party/git/t/t5900-repo-selection.sh index 14e59c5b3e..14e59c5b3e 100755 --- a/t/t5900-repo-selection.sh +++ b/third_party/git/t/t5900-repo-selection.sh diff --git a/t/t6000-rev-list-misc.sh b/third_party/git/t/t6000-rev-list-misc.sh index 3dc1ad8f71..3dc1ad8f71 100755 --- a/t/t6000-rev-list-misc.sh +++ b/third_party/git/t/t6000-rev-list-misc.sh diff --git a/t/t6001-rev-list-graft.sh b/third_party/git/t/t6001-rev-list-graft.sh index 7504ba4751..7504ba4751 100755 --- a/t/t6001-rev-list-graft.sh +++ b/third_party/git/t/t6001-rev-list-graft.sh diff --git a/t/t6002-rev-list-bisect.sh b/third_party/git/t/t6002-rev-list-bisect.sh index a661408038..a661408038 100755 --- a/t/t6002-rev-list-bisect.sh +++ b/third_party/git/t/t6002-rev-list-bisect.sh diff --git a/t/t6003-rev-list-topo-order.sh b/third_party/git/t/t6003-rev-list-topo-order.sh index 24d1836f41..24d1836f41 100755 --- a/t/t6003-rev-list-topo-order.sh +++ b/third_party/git/t/t6003-rev-list-topo-order.sh diff --git a/t/t6004-rev-list-path-optim.sh b/third_party/git/t/t6004-rev-list-path-optim.sh index 3e8c42ee0b..3e8c42ee0b 100755 --- a/t/t6004-rev-list-path-optim.sh +++ b/third_party/git/t/t6004-rev-list-path-optim.sh diff --git a/t/t6005-rev-list-count.sh b/third_party/git/t/t6005-rev-list-count.sh index 0b64822bf6..0b64822bf6 100755 --- a/t/t6005-rev-list-count.sh +++ b/third_party/git/t/t6005-rev-list-count.sh diff --git a/t/t6006-rev-list-format.sh b/third_party/git/t/t6006-rev-list-format.sh index 7e82e43a63..7e82e43a63 100755 --- a/t/t6006-rev-list-format.sh +++ b/third_party/git/t/t6006-rev-list-format.sh diff --git a/t/t6007-rev-list-cherry-pick-file.sh b/third_party/git/t/t6007-rev-list-cherry-pick-file.sh index f0268372d2..f0268372d2 100755 --- a/t/t6007-rev-list-cherry-pick-file.sh +++ b/third_party/git/t/t6007-rev-list-cherry-pick-file.sh diff --git a/t/t6008-rev-list-submodule.sh b/third_party/git/t/t6008-rev-list-submodule.sh index c4af9ca0a7..c4af9ca0a7 100755 --- a/t/t6008-rev-list-submodule.sh +++ b/third_party/git/t/t6008-rev-list-submodule.sh diff --git a/t/t6009-rev-list-parent.sh b/third_party/git/t/t6009-rev-list-parent.sh index 916d9692bc..916d9692bc 100755 --- a/t/t6009-rev-list-parent.sh +++ b/third_party/git/t/t6009-rev-list-parent.sh diff --git a/t/t6010-merge-base.sh b/third_party/git/t/t6010-merge-base.sh index 44c726ea39..44c726ea39 100755 --- a/t/t6010-merge-base.sh +++ b/third_party/git/t/t6010-merge-base.sh diff --git a/t/t6011-rev-list-with-bad-commit.sh b/third_party/git/t/t6011-rev-list-with-bad-commit.sh index bad02cf5b8..bad02cf5b8 100755 --- a/t/t6011-rev-list-with-bad-commit.sh +++ b/third_party/git/t/t6011-rev-list-with-bad-commit.sh diff --git a/t/t6012-rev-list-simplify.sh b/third_party/git/t/t6012-rev-list-simplify.sh index a10f0df02b..a10f0df02b 100755 --- a/t/t6012-rev-list-simplify.sh +++ b/third_party/git/t/t6012-rev-list-simplify.sh diff --git a/t/t6013-rev-list-reverse-parents.sh b/third_party/git/t/t6013-rev-list-reverse-parents.sh index 89458d370f..89458d370f 100755 --- a/t/t6013-rev-list-reverse-parents.sh +++ b/third_party/git/t/t6013-rev-list-reverse-parents.sh diff --git a/t/t6014-rev-list-all.sh b/third_party/git/t/t6014-rev-list-all.sh index c9bedd29cb..c9bedd29cb 100755 --- a/t/t6014-rev-list-all.sh +++ b/third_party/git/t/t6014-rev-list-all.sh diff --git a/t/t6016-rev-list-graph-simplify-history.sh b/third_party/git/t/t6016-rev-list-graph-simplify-history.sh index f5e6e92f5b..f5e6e92f5b 100755 --- a/t/t6016-rev-list-graph-simplify-history.sh +++ b/third_party/git/t/t6016-rev-list-graph-simplify-history.sh diff --git a/t/t6017-rev-list-stdin.sh b/third_party/git/t/t6017-rev-list-stdin.sh index 667b37564e..667b37564e 100755 --- a/t/t6017-rev-list-stdin.sh +++ b/third_party/git/t/t6017-rev-list-stdin.sh diff --git a/t/t6018-rev-list-glob.sh b/third_party/git/t/t6018-rev-list-glob.sh index bb5aeac07f..bb5aeac07f 100755 --- a/t/t6018-rev-list-glob.sh +++ b/third_party/git/t/t6018-rev-list-glob.sh diff --git a/t/t6019-rev-list-ancestry-path.sh b/third_party/git/t/t6019-rev-list-ancestry-path.sh index 353f84313f..353f84313f 100755 --- a/t/t6019-rev-list-ancestry-path.sh +++ b/third_party/git/t/t6019-rev-list-ancestry-path.sh diff --git a/t/t6020-merge-df.sh b/third_party/git/t/t6020-merge-df.sh index 400a4cd139..400a4cd139 100755 --- a/t/t6020-merge-df.sh +++ b/third_party/git/t/t6020-merge-df.sh diff --git a/t/t6021-merge-criss-cross.sh b/third_party/git/t/t6021-merge-criss-cross.sh index 9d5e992878..9d5e992878 100755 --- a/t/t6021-merge-criss-cross.sh +++ b/third_party/git/t/t6021-merge-criss-cross.sh diff --git a/t/t6022-merge-rename.sh b/third_party/git/t/t6022-merge-rename.sh index bbbba3dcbf..bbbba3dcbf 100755 --- a/t/t6022-merge-rename.sh +++ b/third_party/git/t/t6022-merge-rename.sh diff --git a/t/t6023-merge-file.sh b/third_party/git/t/t6023-merge-file.sh index 2f421d967a..2f421d967a 100755 --- a/t/t6023-merge-file.sh +++ b/third_party/git/t/t6023-merge-file.sh diff --git a/t/t6024-recursive-merge.sh b/third_party/git/t/t6024-recursive-merge.sh index 332cfc53fd..332cfc53fd 100755 --- a/t/t6024-recursive-merge.sh +++ b/third_party/git/t/t6024-recursive-merge.sh diff --git a/t/t6025-merge-symlinks.sh b/third_party/git/t/t6025-merge-symlinks.sh index 6c0a90d044..6c0a90d044 100755 --- a/t/t6025-merge-symlinks.sh +++ b/third_party/git/t/t6025-merge-symlinks.sh diff --git a/t/t6026-merge-attr.sh b/third_party/git/t/t6026-merge-attr.sh index 5900358ce9..5900358ce9 100755 --- a/t/t6026-merge-attr.sh +++ b/third_party/git/t/t6026-merge-attr.sh diff --git a/t/t6027-merge-binary.sh b/third_party/git/t/t6027-merge-binary.sh index 4e6c7cb77e..4e6c7cb77e 100755 --- a/t/t6027-merge-binary.sh +++ b/third_party/git/t/t6027-merge-binary.sh diff --git a/t/t6028-merge-up-to-date.sh b/third_party/git/t/t6028-merge-up-to-date.sh index 7763c1ba98..7763c1ba98 100755 --- a/t/t6028-merge-up-to-date.sh +++ b/third_party/git/t/t6028-merge-up-to-date.sh diff --git a/t/t6029-merge-subtree.sh b/third_party/git/t/t6029-merge-subtree.sh index 793f0c8bf3..793f0c8bf3 100755 --- a/t/t6029-merge-subtree.sh +++ b/third_party/git/t/t6029-merge-subtree.sh diff --git a/t/t6030-bisect-porcelain.sh b/third_party/git/t/t6030-bisect-porcelain.sh index 821a0c88cf..821a0c88cf 100755 --- a/t/t6030-bisect-porcelain.sh +++ b/third_party/git/t/t6030-bisect-porcelain.sh diff --git a/t/t6031-merge-filemode.sh b/third_party/git/t/t6031-merge-filemode.sh index 87741efad3..87741efad3 100755 --- a/t/t6031-merge-filemode.sh +++ b/third_party/git/t/t6031-merge-filemode.sh diff --git a/t/t6032-merge-large-rename.sh b/third_party/git/t/t6032-merge-large-rename.sh index 80777386dc..80777386dc 100755 --- a/t/t6032-merge-large-rename.sh +++ b/third_party/git/t/t6032-merge-large-rename.sh diff --git a/t/t6033-merge-crlf.sh b/third_party/git/t/t6033-merge-crlf.sh index e8d65eefb5..e8d65eefb5 100755 --- a/t/t6033-merge-crlf.sh +++ b/third_party/git/t/t6033-merge-crlf.sh diff --git a/t/t6034-merge-rename-nocruft.sh b/third_party/git/t/t6034-merge-rename-nocruft.sh index a25e730460..a25e730460 100755 --- a/t/t6034-merge-rename-nocruft.sh +++ b/third_party/git/t/t6034-merge-rename-nocruft.sh diff --git a/t/t6035-merge-dir-to-symlink.sh b/third_party/git/t/t6035-merge-dir-to-symlink.sh index 2eddcc7664..2eddcc7664 100755 --- a/t/t6035-merge-dir-to-symlink.sh +++ b/third_party/git/t/t6035-merge-dir-to-symlink.sh diff --git a/t/t6036-recursive-corner-cases.sh b/third_party/git/t/t6036-recursive-corner-cases.sh index b3bf462617..b3bf462617 100755 --- a/t/t6036-recursive-corner-cases.sh +++ b/third_party/git/t/t6036-recursive-corner-cases.sh diff --git a/t/t6037-merge-ours-theirs.sh b/third_party/git/t/t6037-merge-ours-theirs.sh index 0aebc6c028..0aebc6c028 100755 --- a/t/t6037-merge-ours-theirs.sh +++ b/third_party/git/t/t6037-merge-ours-theirs.sh diff --git a/t/t6038-merge-text-auto.sh b/third_party/git/t/t6038-merge-text-auto.sh index 5e8d5fa50c..5e8d5fa50c 100755 --- a/t/t6038-merge-text-auto.sh +++ b/third_party/git/t/t6038-merge-text-auto.sh diff --git a/t/t6039-merge-ignorecase.sh b/third_party/git/t/t6039-merge-ignorecase.sh index 531850d834..531850d834 100755 --- a/t/t6039-merge-ignorecase.sh +++ b/third_party/git/t/t6039-merge-ignorecase.sh diff --git a/t/t6040-tracking-info.sh b/third_party/git/t/t6040-tracking-info.sh index ad1922b999..ad1922b999 100755 --- a/t/t6040-tracking-info.sh +++ b/third_party/git/t/t6040-tracking-info.sh diff --git a/t/t6041-bisect-submodule.sh b/third_party/git/t/t6041-bisect-submodule.sh index 62b8a2e7bb..62b8a2e7bb 100755 --- a/t/t6041-bisect-submodule.sh +++ b/third_party/git/t/t6041-bisect-submodule.sh diff --git a/t/t6042-merge-rename-corner-cases.sh b/third_party/git/t/t6042-merge-rename-corner-cases.sh index b047cf1c1c..b047cf1c1c 100755 --- a/t/t6042-merge-rename-corner-cases.sh +++ b/third_party/git/t/t6042-merge-rename-corner-cases.sh diff --git a/t/t6043-merge-rename-directories.sh b/third_party/git/t/t6043-merge-rename-directories.sh index 83792c5ef1..83792c5ef1 100755 --- a/t/t6043-merge-rename-directories.sh +++ b/third_party/git/t/t6043-merge-rename-directories.sh diff --git a/t/t6044-merge-unrelated-index-changes.sh b/third_party/git/t/t6044-merge-unrelated-index-changes.sh index 5e3779ebc9..5e3779ebc9 100755 --- a/t/t6044-merge-unrelated-index-changes.sh +++ b/third_party/git/t/t6044-merge-unrelated-index-changes.sh diff --git a/t/t6045-merge-rename-delete.sh b/third_party/git/t/t6045-merge-rename-delete.sh index 5d33577d2f..5d33577d2f 100755 --- a/t/t6045-merge-rename-delete.sh +++ b/third_party/git/t/t6045-merge-rename-delete.sh diff --git a/t/t6046-merge-skip-unneeded-updates.sh b/third_party/git/t/t6046-merge-skip-unneeded-updates.sh index 1ddc9e6626..1ddc9e6626 100755 --- a/t/t6046-merge-skip-unneeded-updates.sh +++ b/third_party/git/t/t6046-merge-skip-unneeded-updates.sh diff --git a/t/t6047-diff3-conflict-markers.sh b/third_party/git/t/t6047-diff3-conflict-markers.sh index f4655bb358..f4655bb358 100755 --- a/t/t6047-diff3-conflict-markers.sh +++ b/third_party/git/t/t6047-diff3-conflict-markers.sh diff --git a/t/t6050-replace.sh b/third_party/git/t/t6050-replace.sh index e7e64e085d..e7e64e085d 100755 --- a/t/t6050-replace.sh +++ b/third_party/git/t/t6050-replace.sh diff --git a/t/t6060-merge-index.sh b/third_party/git/t/t6060-merge-index.sh index ddf34f0115..ddf34f0115 100755 --- a/t/t6060-merge-index.sh +++ b/third_party/git/t/t6060-merge-index.sh diff --git a/t/t6100-rev-list-in-order.sh b/third_party/git/t/t6100-rev-list-in-order.sh index b2bb0a7f61..b2bb0a7f61 100755 --- a/t/t6100-rev-list-in-order.sh +++ b/third_party/git/t/t6100-rev-list-in-order.sh diff --git a/t/t6101-rev-parse-parents.sh b/third_party/git/t/t6101-rev-parse-parents.sh index 7683e4a114..7683e4a114 100755 --- a/t/t6101-rev-parse-parents.sh +++ b/third_party/git/t/t6101-rev-parse-parents.sh diff --git a/t/t6102-rev-list-unexpected-objects.sh b/third_party/git/t/t6102-rev-list-unexpected-objects.sh index 52cde097dd..52cde097dd 100755 --- a/t/t6102-rev-list-unexpected-objects.sh +++ b/third_party/git/t/t6102-rev-list-unexpected-objects.sh diff --git a/t/t6110-rev-list-sparse.sh b/third_party/git/t/t6110-rev-list-sparse.sh index 656ac7fe9d..656ac7fe9d 100755 --- a/t/t6110-rev-list-sparse.sh +++ b/third_party/git/t/t6110-rev-list-sparse.sh diff --git a/t/t6111-rev-list-treesame.sh b/third_party/git/t/t6111-rev-list-treesame.sh index 4244638285..4244638285 100755 --- a/t/t6111-rev-list-treesame.sh +++ b/third_party/git/t/t6111-rev-list-treesame.sh diff --git a/t/t6112-rev-list-filters-objects.sh b/third_party/git/t/t6112-rev-list-filters-objects.sh index de0e5a5d36..de0e5a5d36 100755 --- a/t/t6112-rev-list-filters-objects.sh +++ b/third_party/git/t/t6112-rev-list-filters-objects.sh diff --git a/t/t6113-rev-list-bitmap-filters.sh b/third_party/git/t/t6113-rev-list-bitmap-filters.sh index 145603f124..145603f124 100755 --- a/t/t6113-rev-list-bitmap-filters.sh +++ b/third_party/git/t/t6113-rev-list-bitmap-filters.sh diff --git a/t/t6120-describe.sh b/third_party/git/t/t6120-describe.sh index 34502e3a50..34502e3a50 100755 --- a/t/t6120-describe.sh +++ b/third_party/git/t/t6120-describe.sh diff --git a/t/t6130-pathspec-noglob.sh b/third_party/git/t/t6130-pathspec-noglob.sh index ba7902c9cd..ba7902c9cd 100755 --- a/t/t6130-pathspec-noglob.sh +++ b/third_party/git/t/t6130-pathspec-noglob.sh diff --git a/t/t6131-pathspec-icase.sh b/third_party/git/t/t6131-pathspec-icase.sh index 39fc3f6769..39fc3f6769 100755 --- a/t/t6131-pathspec-icase.sh +++ b/third_party/git/t/t6131-pathspec-icase.sh diff --git a/t/t6132-pathspec-exclude.sh b/third_party/git/t/t6132-pathspec-exclude.sh index 2462b19ddd..2462b19ddd 100755 --- a/t/t6132-pathspec-exclude.sh +++ b/third_party/git/t/t6132-pathspec-exclude.sh diff --git a/t/t6133-pathspec-rev-dwim.sh b/third_party/git/t/t6133-pathspec-rev-dwim.sh index a290ffca0d..a290ffca0d 100755 --- a/t/t6133-pathspec-rev-dwim.sh +++ b/third_party/git/t/t6133-pathspec-rev-dwim.sh diff --git a/t/t6134-pathspec-in-submodule.sh b/third_party/git/t/t6134-pathspec-in-submodule.sh index c670668409..c670668409 100755 --- a/t/t6134-pathspec-in-submodule.sh +++ b/third_party/git/t/t6134-pathspec-in-submodule.sh diff --git a/t/t6135-pathspec-with-attrs.sh b/third_party/git/t/t6135-pathspec-with-attrs.sh index 457cc167c7..457cc167c7 100755 --- a/t/t6135-pathspec-with-attrs.sh +++ b/third_party/git/t/t6135-pathspec-with-attrs.sh diff --git a/t/t6136-pathspec-in-bare.sh b/third_party/git/t/t6136-pathspec-in-bare.sh index b117251366..b117251366 100755 --- a/t/t6136-pathspec-in-bare.sh +++ b/third_party/git/t/t6136-pathspec-in-bare.sh diff --git a/t/t6200-fmt-merge-msg.sh b/third_party/git/t/t6200-fmt-merge-msg.sh index 8a72b4c43a..8a72b4c43a 100755 --- a/t/t6200-fmt-merge-msg.sh +++ b/third_party/git/t/t6200-fmt-merge-msg.sh diff --git a/t/t6300-for-each-ref.sh b/third_party/git/t/t6300-for-each-ref.sh index 9c910ce746..9c910ce746 100755 --- a/t/t6300-for-each-ref.sh +++ b/third_party/git/t/t6300-for-each-ref.sh diff --git a/t/t6301-for-each-ref-errors.sh b/third_party/git/t/t6301-for-each-ref-errors.sh index 49cc65bb58..49cc65bb58 100755 --- a/t/t6301-for-each-ref-errors.sh +++ b/third_party/git/t/t6301-for-each-ref-errors.sh diff --git a/t/t6302-for-each-ref-filter.sh b/third_party/git/t/t6302-for-each-ref-filter.sh index 35408d53fd..35408d53fd 100755 --- a/t/t6302-for-each-ref-filter.sh +++ b/third_party/git/t/t6302-for-each-ref-filter.sh diff --git a/t/t6500-gc.sh b/third_party/git/t/t6500-gc.sh index 0a69a67117..0a69a67117 100755 --- a/t/t6500-gc.sh +++ b/third_party/git/t/t6500-gc.sh diff --git a/t/t6501-freshen-objects.sh b/third_party/git/t/t6501-freshen-objects.sh index f30b4849b6..f30b4849b6 100755 --- a/t/t6501-freshen-objects.sh +++ b/third_party/git/t/t6501-freshen-objects.sh diff --git a/t/t6600-test-reach.sh b/third_party/git/t/t6600-test-reach.sh index b24d850036..b24d850036 100755 --- a/t/t6600-test-reach.sh +++ b/third_party/git/t/t6600-test-reach.sh diff --git a/t/t7001-mv.sh b/third_party/git/t/t7001-mv.sh index 36b50d0b4c..36b50d0b4c 100755 --- a/t/t7001-mv.sh +++ b/third_party/git/t/t7001-mv.sh diff --git a/t/t7003-filter-branch.sh b/third_party/git/t/t7003-filter-branch.sh index e23de7d0b5..e23de7d0b5 100755 --- a/t/t7003-filter-branch.sh +++ b/third_party/git/t/t7003-filter-branch.sh diff --git a/t/t7004-tag.sh b/third_party/git/t/t7004-tag.sh index 6db92bd3ba..6db92bd3ba 100755 --- a/t/t7004-tag.sh +++ b/third_party/git/t/t7004-tag.sh diff --git a/t/t7005-editor.sh b/third_party/git/t/t7005-editor.sh index 5fcf281dfb..5fcf281dfb 100755 --- a/t/t7005-editor.sh +++ b/third_party/git/t/t7005-editor.sh diff --git a/t/t7006-pager.sh b/third_party/git/t/t7006-pager.sh index 00e09a375c..00e09a375c 100755 --- a/t/t7006-pager.sh +++ b/third_party/git/t/t7006-pager.sh diff --git a/t/t7007-show.sh b/third_party/git/t/t7007-show.sh index 42d3db6246..42d3db6246 100755 --- a/t/t7007-show.sh +++ b/third_party/git/t/t7007-show.sh diff --git a/t/t7008-filter-branch-null-sha1.sh b/third_party/git/t/t7008-filter-branch-null-sha1.sh index 9ba9f24ad2..9ba9f24ad2 100755 --- a/t/t7008-filter-branch-null-sha1.sh +++ b/third_party/git/t/t7008-filter-branch-null-sha1.sh diff --git a/t/t7010-setup.sh b/third_party/git/t/t7010-setup.sh index 0335a9a158..0335a9a158 100755 --- a/t/t7010-setup.sh +++ b/third_party/git/t/t7010-setup.sh diff --git a/t/t7011-skip-worktree-reading.sh b/third_party/git/t/t7011-skip-worktree-reading.sh index 37525cae3a..37525cae3a 100755 --- a/t/t7011-skip-worktree-reading.sh +++ b/third_party/git/t/t7011-skip-worktree-reading.sh diff --git a/t/t7012-skip-worktree-writing.sh b/third_party/git/t/t7012-skip-worktree-writing.sh index 7476781979..7476781979 100755 --- a/t/t7012-skip-worktree-writing.sh +++ b/third_party/git/t/t7012-skip-worktree-writing.sh diff --git a/t/t7030-verify-tag.sh b/third_party/git/t/t7030-verify-tag.sh index 5c5bc32ccb..5c5bc32ccb 100755 --- a/t/t7030-verify-tag.sh +++ b/third_party/git/t/t7030-verify-tag.sh diff --git a/t/t7060-wtstatus.sh b/third_party/git/t/t7060-wtstatus.sh index d5218743e9..d5218743e9 100755 --- a/t/t7060-wtstatus.sh +++ b/third_party/git/t/t7060-wtstatus.sh diff --git a/t/t7061-wtstatus-ignore.sh b/third_party/git/t/t7061-wtstatus-ignore.sh index e4cf5484f9..e4cf5484f9 100755 --- a/t/t7061-wtstatus-ignore.sh +++ b/third_party/git/t/t7061-wtstatus-ignore.sh diff --git a/t/t7062-wtstatus-ignorecase.sh b/third_party/git/t/t7062-wtstatus-ignorecase.sh index 73709dbeee..73709dbeee 100755 --- a/t/t7062-wtstatus-ignorecase.sh +++ b/third_party/git/t/t7062-wtstatus-ignorecase.sh diff --git a/t/t7063-status-untracked-cache.sh b/third_party/git/t/t7063-status-untracked-cache.sh index 190ae149cf..190ae149cf 100755 --- a/t/t7063-status-untracked-cache.sh +++ b/third_party/git/t/t7063-status-untracked-cache.sh diff --git a/t/t7064-wtstatus-pv2.sh b/third_party/git/t/t7064-wtstatus-pv2.sh index 537787e598..537787e598 100755 --- a/t/t7064-wtstatus-pv2.sh +++ b/third_party/git/t/t7064-wtstatus-pv2.sh diff --git a/t/t7101-reset-empty-subdirs.sh b/third_party/git/t/t7101-reset-empty-subdirs.sh index 96e163f084..96e163f084 100755 --- a/t/t7101-reset-empty-subdirs.sh +++ b/third_party/git/t/t7101-reset-empty-subdirs.sh diff --git a/t/t7102-reset.sh b/third_party/git/t/t7102-reset.sh index 97be0d968d..97be0d968d 100755 --- a/t/t7102-reset.sh +++ b/third_party/git/t/t7102-reset.sh diff --git a/t/t7103-reset-bare.sh b/third_party/git/t/t7103-reset-bare.sh index afe36a533c..afe36a533c 100755 --- a/t/t7103-reset-bare.sh +++ b/third_party/git/t/t7103-reset-bare.sh diff --git a/t/t7104-reset-hard.sh b/third_party/git/t/t7104-reset-hard.sh index 16faa07813..16faa07813 100755 --- a/t/t7104-reset-hard.sh +++ b/third_party/git/t/t7104-reset-hard.sh diff --git a/t/t7105-reset-patch.sh b/third_party/git/t/t7105-reset-patch.sh index fc2a6cf5c7..fc2a6cf5c7 100755 --- a/t/t7105-reset-patch.sh +++ b/third_party/git/t/t7105-reset-patch.sh diff --git a/t/t7106-reset-unborn-branch.sh b/third_party/git/t/t7106-reset-unborn-branch.sh index ecb85c3b82..ecb85c3b82 100755 --- a/t/t7106-reset-unborn-branch.sh +++ b/third_party/git/t/t7106-reset-unborn-branch.sh diff --git a/t/t7107-reset-pathspec-file.sh b/third_party/git/t/t7107-reset-pathspec-file.sh index cad3a9de9e..cad3a9de9e 100755 --- a/t/t7107-reset-pathspec-file.sh +++ b/third_party/git/t/t7107-reset-pathspec-file.sh diff --git a/t/t7110-reset-merge.sh b/third_party/git/t/t7110-reset-merge.sh index a82a07a04a..a82a07a04a 100755 --- a/t/t7110-reset-merge.sh +++ b/third_party/git/t/t7110-reset-merge.sh diff --git a/t/t7111-reset-table.sh b/third_party/git/t/t7111-reset-table.sh index ce421ad5ac..ce421ad5ac 100755 --- a/t/t7111-reset-table.sh +++ b/third_party/git/t/t7111-reset-table.sh diff --git a/t/t7112-reset-submodule.sh b/third_party/git/t/t7112-reset-submodule.sh index a1cb9ff858..a1cb9ff858 100755 --- a/t/t7112-reset-submodule.sh +++ b/third_party/git/t/t7112-reset-submodule.sh diff --git a/t/t7113-post-index-change-hook.sh b/third_party/git/t/t7113-post-index-change-hook.sh index f011ad7eec..f011ad7eec 100755 --- a/t/t7113-post-index-change-hook.sh +++ b/third_party/git/t/t7113-post-index-change-hook.sh diff --git a/t/t7201-co.sh b/third_party/git/t/t7201-co.sh index b696bae5f5..b696bae5f5 100755 --- a/t/t7201-co.sh +++ b/third_party/git/t/t7201-co.sh diff --git a/t/t7300-clean.sh b/third_party/git/t/t7300-clean.sh index cb5e34d94c..cb5e34d94c 100755 --- a/t/t7300-clean.sh +++ b/third_party/git/t/t7300-clean.sh diff --git a/t/t7301-clean-interactive.sh b/third_party/git/t/t7301-clean-interactive.sh index a07e8b86de..a07e8b86de 100755 --- a/t/t7301-clean-interactive.sh +++ b/third_party/git/t/t7301-clean-interactive.sh diff --git a/t/t7400-submodule-basic.sh b/third_party/git/t/t7400-submodule-basic.sh index e3e2aab3b0..e3e2aab3b0 100755 --- a/t/t7400-submodule-basic.sh +++ b/third_party/git/t/t7400-submodule-basic.sh diff --git a/t/t7401-submodule-summary.sh b/third_party/git/t/t7401-submodule-summary.sh index 9bc841d085..9bc841d085 100755 --- a/t/t7401-submodule-summary.sh +++ b/third_party/git/t/t7401-submodule-summary.sh diff --git a/t/t7402-submodule-rebase.sh b/third_party/git/t/t7402-submodule-rebase.sh index 8e32f19007..8e32f19007 100755 --- a/t/t7402-submodule-rebase.sh +++ b/third_party/git/t/t7402-submodule-rebase.sh diff --git a/t/t7403-submodule-sync.sh b/third_party/git/t/t7403-submodule-sync.sh index 0726799e74..0726799e74 100755 --- a/t/t7403-submodule-sync.sh +++ b/third_party/git/t/t7403-submodule-sync.sh diff --git a/t/t7405-submodule-merge.sh b/third_party/git/t/t7405-submodule-merge.sh index aa33978ed2..aa33978ed2 100755 --- a/t/t7405-submodule-merge.sh +++ b/third_party/git/t/t7405-submodule-merge.sh diff --git a/t/t7406-submodule-update.sh b/third_party/git/t/t7406-submodule-update.sh index 4fb447a143..4fb447a143 100755 --- a/t/t7406-submodule-update.sh +++ b/third_party/git/t/t7406-submodule-update.sh diff --git a/t/t7407-submodule-foreach.sh b/third_party/git/t/t7407-submodule-foreach.sh index 6b2aa917e1..6b2aa917e1 100755 --- a/t/t7407-submodule-foreach.sh +++ b/third_party/git/t/t7407-submodule-foreach.sh diff --git a/t/t7408-submodule-reference.sh b/third_party/git/t/t7408-submodule-reference.sh index 34ac28c056..34ac28c056 100755 --- a/t/t7408-submodule-reference.sh +++ b/third_party/git/t/t7408-submodule-reference.sh diff --git a/t/t7409-submodule-detached-work-tree.sh b/third_party/git/t/t7409-submodule-detached-work-tree.sh index fc018e3638..fc018e3638 100755 --- a/t/t7409-submodule-detached-work-tree.sh +++ b/third_party/git/t/t7409-submodule-detached-work-tree.sh diff --git a/t/t7411-submodule-config.sh b/third_party/git/t/t7411-submodule-config.sh index ad28e93880..ad28e93880 100755 --- a/t/t7411-submodule-config.sh +++ b/third_party/git/t/t7411-submodule-config.sh diff --git a/t/t7412-submodule-absorbgitdirs.sh b/third_party/git/t/t7412-submodule-absorbgitdirs.sh index 1cfa150768..1cfa150768 100755 --- a/t/t7412-submodule-absorbgitdirs.sh +++ b/third_party/git/t/t7412-submodule-absorbgitdirs.sh diff --git a/t/t7413-submodule-is-active.sh b/third_party/git/t/t7413-submodule-is-active.sh index c8e7e98331..c8e7e98331 100755 --- a/t/t7413-submodule-is-active.sh +++ b/third_party/git/t/t7413-submodule-is-active.sh diff --git a/t/t7414-submodule-mistakes.sh b/third_party/git/t/t7414-submodule-mistakes.sh index f2e7df59cf..f2e7df59cf 100755 --- a/t/t7414-submodule-mistakes.sh +++ b/third_party/git/t/t7414-submodule-mistakes.sh diff --git a/t/t7415-submodule-names.sh b/third_party/git/t/t7415-submodule-names.sh index f70368bc2e..f70368bc2e 100755 --- a/t/t7415-submodule-names.sh +++ b/third_party/git/t/t7415-submodule-names.sh diff --git a/t/t7416-submodule-dash-url.sh b/third_party/git/t/t7416-submodule-dash-url.sh index eec96e0ba9..eec96e0ba9 100755 --- a/t/t7416-submodule-dash-url.sh +++ b/third_party/git/t/t7416-submodule-dash-url.sh diff --git a/t/t7417-submodule-path-url.sh b/third_party/git/t/t7417-submodule-path-url.sh index f7e7e94d7b..f7e7e94d7b 100755 --- a/t/t7417-submodule-path-url.sh +++ b/third_party/git/t/t7417-submodule-path-url.sh diff --git a/t/t7418-submodule-sparse-gitmodules.sh b/third_party/git/t/t7418-submodule-sparse-gitmodules.sh index 3f7f271883..3f7f271883 100755 --- a/t/t7418-submodule-sparse-gitmodules.sh +++ b/third_party/git/t/t7418-submodule-sparse-gitmodules.sh diff --git a/t/t7419-submodule-set-branch.sh b/third_party/git/t/t7419-submodule-set-branch.sh index fd25f786a3..fd25f786a3 100755 --- a/t/t7419-submodule-set-branch.sh +++ b/third_party/git/t/t7419-submodule-set-branch.sh diff --git a/t/t7420-submodule-set-url.sh b/third_party/git/t/t7420-submodule-set-url.sh index ef0cb6e8e1..ef0cb6e8e1 100755 --- a/t/t7420-submodule-set-url.sh +++ b/third_party/git/t/t7420-submodule-set-url.sh diff --git a/t/t7500-commit-template-squash-signoff.sh b/third_party/git/t/t7500-commit-template-squash-signoff.sh index 6d19ece05d..6d19ece05d 100755 --- a/t/t7500-commit-template-squash-signoff.sh +++ b/third_party/git/t/t7500-commit-template-squash-signoff.sh diff --git a/t/t7500/add-comments b/third_party/git/t/t7500/add-comments index a72e65c891..a72e65c891 100755 --- a/t/t7500/add-comments +++ b/third_party/git/t/t7500/add-comments diff --git a/t/t7500/add-content b/third_party/git/t/t7500/add-content index 2fa3d86a10..2fa3d86a10 100755 --- a/t/t7500/add-content +++ b/third_party/git/t/t7500/add-content diff --git a/t/t7500/add-content-and-comment b/third_party/git/t/t7500/add-content-and-comment index c4dccff13a..c4dccff13a 100755 --- a/t/t7500/add-content-and-comment +++ b/third_party/git/t/t7500/add-content-and-comment diff --git a/t/t7500/add-signed-off b/third_party/git/t/t7500/add-signed-off index e1d856af6d..e1d856af6d 100755 --- a/t/t7500/add-signed-off +++ b/third_party/git/t/t7500/add-signed-off diff --git a/t/t7500/add-whitespaced-content b/third_party/git/t/t7500/add-whitespaced-content index ccf07c61a4..ccf07c61a4 100755 --- a/t/t7500/add-whitespaced-content +++ b/third_party/git/t/t7500/add-whitespaced-content diff --git a/t/t7500/edit-content b/third_party/git/t/t7500/edit-content index 08db9fdd2e..08db9fdd2e 100755 --- a/t/t7500/edit-content +++ b/third_party/git/t/t7500/edit-content diff --git a/t/t7501-commit-basic-functionality.sh b/third_party/git/t/t7501-commit-basic-functionality.sh index 110b4bf459..110b4bf459 100755 --- a/t/t7501-commit-basic-functionality.sh +++ b/third_party/git/t/t7501-commit-basic-functionality.sh diff --git a/t/t7502-commit-porcelain.sh b/third_party/git/t/t7502-commit-porcelain.sh index 14c92e4c25..14c92e4c25 100755 --- a/t/t7502-commit-porcelain.sh +++ b/third_party/git/t/t7502-commit-porcelain.sh diff --git a/t/t7503-pre-commit-and-pre-merge-commit-hooks.sh b/third_party/git/t/t7503-pre-commit-and-pre-merge-commit-hooks.sh index b3485450a2..b3485450a2 100755 --- a/t/t7503-pre-commit-and-pre-merge-commit-hooks.sh +++ b/third_party/git/t/t7503-pre-commit-and-pre-merge-commit-hooks.sh diff --git a/t/t7504-commit-msg-hook.sh b/third_party/git/t/t7504-commit-msg-hook.sh index 31b9c6a2c1..31b9c6a2c1 100755 --- a/t/t7504-commit-msg-hook.sh +++ b/third_party/git/t/t7504-commit-msg-hook.sh diff --git a/t/t7505-prepare-commit-msg-hook.sh b/third_party/git/t/t7505-prepare-commit-msg-hook.sh index 94f85cdf83..94f85cdf83 100755 --- a/t/t7505-prepare-commit-msg-hook.sh +++ b/third_party/git/t/t7505-prepare-commit-msg-hook.sh diff --git a/t/t7505/expected-rebase-i b/third_party/git/t/t7505/expected-rebase-i index 93bada596e..93bada596e 100644 --- a/t/t7505/expected-rebase-i +++ b/third_party/git/t/t7505/expected-rebase-i diff --git a/t/t7505/expected-rebase-p b/third_party/git/t/t7505/expected-rebase-p index 93bada596e..93bada596e 100644 --- a/t/t7505/expected-rebase-p +++ b/third_party/git/t/t7505/expected-rebase-p diff --git a/t/t7506-status-submodule.sh b/third_party/git/t/t7506-status-submodule.sh index 08629a6e70..08629a6e70 100755 --- a/t/t7506-status-submodule.sh +++ b/third_party/git/t/t7506-status-submodule.sh diff --git a/t/t7507-commit-verbose.sh b/third_party/git/t/t7507-commit-verbose.sh index ed2653d46f..ed2653d46f 100755 --- a/t/t7507-commit-verbose.sh +++ b/third_party/git/t/t7507-commit-verbose.sh diff --git a/t/t7508-status.sh b/third_party/git/t/t7508-status.sh index 482ce3510e..482ce3510e 100755 --- a/t/t7508-status.sh +++ b/third_party/git/t/t7508-status.sh diff --git a/t/t7509-commit-authorship.sh b/third_party/git/t/t7509-commit-authorship.sh index 500ab2fe72..500ab2fe72 100755 --- a/t/t7509-commit-authorship.sh +++ b/third_party/git/t/t7509-commit-authorship.sh diff --git a/t/t7510-signed-commit.sh b/third_party/git/t/t7510-signed-commit.sh index 0c06d22a00..0c06d22a00 100755 --- a/t/t7510-signed-commit.sh +++ b/third_party/git/t/t7510-signed-commit.sh diff --git a/t/t7511-status-index.sh b/third_party/git/t/t7511-status-index.sh index b5fdc048a5..b5fdc048a5 100755 --- a/t/t7511-status-index.sh +++ b/third_party/git/t/t7511-status-index.sh diff --git a/t/t7512-status-help.sh b/third_party/git/t/t7512-status-help.sh index 29518e0949..29518e0949 100755 --- a/t/t7512-status-help.sh +++ b/third_party/git/t/t7512-status-help.sh diff --git a/t/t7513-interpret-trailers.sh b/third_party/git/t/t7513-interpret-trailers.sh index 6602790b5f..6602790b5f 100755 --- a/t/t7513-interpret-trailers.sh +++ b/third_party/git/t/t7513-interpret-trailers.sh diff --git a/t/t7514-commit-patch.sh b/third_party/git/t/t7514-commit-patch.sh index 998a2103c7..998a2103c7 100755 --- a/t/t7514-commit-patch.sh +++ b/third_party/git/t/t7514-commit-patch.sh diff --git a/t/t7515-status-symlinks.sh b/third_party/git/t/t7515-status-symlinks.sh index 9f989be01b..9f989be01b 100755 --- a/t/t7515-status-symlinks.sh +++ b/third_party/git/t/t7515-status-symlinks.sh diff --git a/t/t7516-commit-races.sh b/third_party/git/t/t7516-commit-races.sh index f2ce14e907..f2ce14e907 100755 --- a/t/t7516-commit-races.sh +++ b/third_party/git/t/t7516-commit-races.sh diff --git a/t/t7517-per-repo-email.sh b/third_party/git/t/t7517-per-repo-email.sh index b2401cec3e..b2401cec3e 100755 --- a/t/t7517-per-repo-email.sh +++ b/third_party/git/t/t7517-per-repo-email.sh diff --git a/t/t7518-ident-corner-cases.sh b/third_party/git/t/t7518-ident-corner-cases.sh index b22f631261..b22f631261 100755 --- a/t/t7518-ident-corner-cases.sh +++ b/third_party/git/t/t7518-ident-corner-cases.sh diff --git a/t/t7519-status-fsmonitor.sh b/third_party/git/t/t7519-status-fsmonitor.sh index fbfdcca000..fbfdcca000 100755 --- a/t/t7519-status-fsmonitor.sh +++ b/third_party/git/t/t7519-status-fsmonitor.sh diff --git a/t/t7519/fsmonitor-all b/third_party/git/t/t7519/fsmonitor-all index 94ab66bd3d..94ab66bd3d 100755 --- a/t/t7519/fsmonitor-all +++ b/third_party/git/t/t7519/fsmonitor-all diff --git a/t/t7519/fsmonitor-all-v2 b/third_party/git/t/t7519/fsmonitor-all-v2 index 061907e88b..061907e88b 100755 --- a/t/t7519/fsmonitor-all-v2 +++ b/third_party/git/t/t7519/fsmonitor-all-v2 diff --git a/t/t7519/fsmonitor-env b/third_party/git/t/t7519/fsmonitor-env index 8f1f7ab164..8f1f7ab164 100755 --- a/t/t7519/fsmonitor-env +++ b/third_party/git/t/t7519/fsmonitor-env diff --git a/t/t7519/fsmonitor-none b/third_party/git/t/t7519/fsmonitor-none index ed9cf5a6a9..ed9cf5a6a9 100755 --- a/t/t7519/fsmonitor-none +++ b/third_party/git/t/t7519/fsmonitor-none diff --git a/t/t7519/fsmonitor-watchman b/third_party/git/t/t7519/fsmonitor-watchman index 264b9daf83..264b9daf83 100755 --- a/t/t7519/fsmonitor-watchman +++ b/third_party/git/t/t7519/fsmonitor-watchman diff --git a/t/t7519/fsmonitor-watchman-v2 b/third_party/git/t/t7519/fsmonitor-watchman-v2 index 14ed0aa42d..14ed0aa42d 100755 --- a/t/t7519/fsmonitor-watchman-v2 +++ b/third_party/git/t/t7519/fsmonitor-watchman-v2 diff --git a/t/t7520-ignored-hook-warning.sh b/third_party/git/t/t7520-ignored-hook-warning.sh index 634fb7f23a..634fb7f23a 100755 --- a/t/t7520-ignored-hook-warning.sh +++ b/third_party/git/t/t7520-ignored-hook-warning.sh diff --git a/t/t7521-ignored-mode.sh b/third_party/git/t/t7521-ignored-mode.sh index 91790943c3..91790943c3 100755 --- a/t/t7521-ignored-mode.sh +++ b/third_party/git/t/t7521-ignored-mode.sh diff --git a/t/t7525-status-rename.sh b/third_party/git/t/t7525-status-rename.sh index a62736dce0..a62736dce0 100755 --- a/t/t7525-status-rename.sh +++ b/third_party/git/t/t7525-status-rename.sh diff --git a/t/t7526-commit-pathspec-file.sh b/third_party/git/t/t7526-commit-pathspec-file.sh index 5fbe47ebcd..5fbe47ebcd 100755 --- a/t/t7526-commit-pathspec-file.sh +++ b/third_party/git/t/t7526-commit-pathspec-file.sh diff --git a/t/t7600-merge.sh b/third_party/git/t/t7600-merge.sh index 132608879a..132608879a 100755 --- a/t/t7600-merge.sh +++ b/third_party/git/t/t7600-merge.sh diff --git a/t/t7601-merge-pull-config.sh b/third_party/git/t/t7601-merge-pull-config.sh index c6c44ec570..c6c44ec570 100755 --- a/t/t7601-merge-pull-config.sh +++ b/third_party/git/t/t7601-merge-pull-config.sh diff --git a/t/t7602-merge-octopus-many.sh b/third_party/git/t/t7602-merge-octopus-many.sh index 6abe441ae3..6abe441ae3 100755 --- a/t/t7602-merge-octopus-many.sh +++ b/third_party/git/t/t7602-merge-octopus-many.sh diff --git a/t/t7603-merge-reduce-heads.sh b/third_party/git/t/t7603-merge-reduce-heads.sh index 98948955ae..98948955ae 100755 --- a/t/t7603-merge-reduce-heads.sh +++ b/third_party/git/t/t7603-merge-reduce-heads.sh diff --git a/t/t7604-merge-custom-message.sh b/third_party/git/t/t7604-merge-custom-message.sh index cd4f9607dc..cd4f9607dc 100755 --- a/t/t7604-merge-custom-message.sh +++ b/third_party/git/t/t7604-merge-custom-message.sh diff --git a/t/t7605-merge-resolve.sh b/third_party/git/t/t7605-merge-resolve.sh index 5d56c38546..5d56c38546 100755 --- a/t/t7605-merge-resolve.sh +++ b/third_party/git/t/t7605-merge-resolve.sh diff --git a/t/t7606-merge-custom.sh b/third_party/git/t/t7606-merge-custom.sh index 8e8c4d7246..8e8c4d7246 100755 --- a/t/t7606-merge-custom.sh +++ b/third_party/git/t/t7606-merge-custom.sh diff --git a/t/t7607-merge-overwrite.sh b/third_party/git/t/t7607-merge-overwrite.sh index dd8ab7ede1..dd8ab7ede1 100755 --- a/t/t7607-merge-overwrite.sh +++ b/third_party/git/t/t7607-merge-overwrite.sh diff --git a/t/t7608-merge-messages.sh b/third_party/git/t/t7608-merge-messages.sh index 8e7e0a5865..8e7e0a5865 100755 --- a/t/t7608-merge-messages.sh +++ b/third_party/git/t/t7608-merge-messages.sh diff --git a/t/t7609-merge-co-error-msgs.sh b/third_party/git/t/t7609-merge-co-error-msgs.sh index e90413204e..e90413204e 100755 --- a/t/t7609-merge-co-error-msgs.sh +++ b/third_party/git/t/t7609-merge-co-error-msgs.sh diff --git a/t/t7610-mergetool.sh b/third_party/git/t/t7610-mergetool.sh index ad288ddc69..ad288ddc69 100755 --- a/t/t7610-mergetool.sh +++ b/third_party/git/t/t7610-mergetool.sh diff --git a/t/t7611-merge-abort.sh b/third_party/git/t/t7611-merge-abort.sh index 7c84a518aa..7c84a518aa 100755 --- a/t/t7611-merge-abort.sh +++ b/third_party/git/t/t7611-merge-abort.sh diff --git a/t/t7612-merge-verify-signatures.sh b/third_party/git/t/t7612-merge-verify-signatures.sh index a426f3a89a..a426f3a89a 100755 --- a/t/t7612-merge-verify-signatures.sh +++ b/third_party/git/t/t7612-merge-verify-signatures.sh diff --git a/t/t7613-merge-submodule.sh b/third_party/git/t/t7613-merge-submodule.sh index d1e9fcc781..d1e9fcc781 100755 --- a/t/t7613-merge-submodule.sh +++ b/third_party/git/t/t7613-merge-submodule.sh diff --git a/t/t7614-merge-signoff.sh b/third_party/git/t/t7614-merge-signoff.sh index c1b8446f49..c1b8446f49 100755 --- a/t/t7614-merge-signoff.sh +++ b/third_party/git/t/t7614-merge-signoff.sh diff --git a/t/t7700-repack.sh b/third_party/git/t/t7700-repack.sh index 25b235c063..25b235c063 100755 --- a/t/t7700-repack.sh +++ b/third_party/git/t/t7700-repack.sh diff --git a/t/t7701-repack-unpack-unreachable.sh b/third_party/git/t/t7701-repack-unpack-unreachable.sh index 48261ba080..48261ba080 100755 --- a/t/t7701-repack-unpack-unreachable.sh +++ b/third_party/git/t/t7701-repack-unpack-unreachable.sh diff --git a/t/t7702-repack-cyclic-alternate.sh b/third_party/git/t/t7702-repack-cyclic-alternate.sh index 93b74867ac..93b74867ac 100755 --- a/t/t7702-repack-cyclic-alternate.sh +++ b/third_party/git/t/t7702-repack-cyclic-alternate.sh diff --git a/t/t7800-difftool.sh b/third_party/git/t/t7800-difftool.sh index 29b92907e2..29b92907e2 100755 --- a/t/t7800-difftool.sh +++ b/third_party/git/t/t7800-difftool.sh diff --git a/t/t7810-grep.sh b/third_party/git/t/t7810-grep.sh index 7d7b396c23..7d7b396c23 100755 --- a/t/t7810-grep.sh +++ b/third_party/git/t/t7810-grep.sh diff --git a/t/t7811-grep-open.sh b/third_party/git/t/t7811-grep-open.sh index a98785da79..a98785da79 100755 --- a/t/t7811-grep-open.sh +++ b/third_party/git/t/t7811-grep-open.sh diff --git a/t/t7812-grep-icase-non-ascii.sh b/third_party/git/t/t7812-grep-icase-non-ascii.sh index 03dba6685a..03dba6685a 100755 --- a/t/t7812-grep-icase-non-ascii.sh +++ b/third_party/git/t/t7812-grep-icase-non-ascii.sh diff --git a/t/t7813-grep-icase-iso.sh b/third_party/git/t/t7813-grep-icase-iso.sh index 701e08a8e5..701e08a8e5 100755 --- a/t/t7813-grep-icase-iso.sh +++ b/third_party/git/t/t7813-grep-icase-iso.sh diff --git a/t/t7814-grep-recurse-submodules.sh b/third_party/git/t/t7814-grep-recurse-submodules.sh index 828cb3ba58..828cb3ba58 100755 --- a/t/t7814-grep-recurse-submodules.sh +++ b/third_party/git/t/t7814-grep-recurse-submodules.sh diff --git a/t/t7815-grep-binary.sh b/third_party/git/t/t7815-grep-binary.sh index 90ebb64f46..90ebb64f46 100755 --- a/t/t7815-grep-binary.sh +++ b/third_party/git/t/t7815-grep-binary.sh diff --git a/t/t7816-grep-binary-pattern.sh b/third_party/git/t/t7816-grep-binary-pattern.sh index 60bab291e4..60bab291e4 100755 --- a/t/t7816-grep-binary-pattern.sh +++ b/third_party/git/t/t7816-grep-binary-pattern.sh diff --git a/t/t8001-annotate.sh b/third_party/git/t/t8001-annotate.sh index 72176e42c1..72176e42c1 100755 --- a/t/t8001-annotate.sh +++ b/third_party/git/t/t8001-annotate.sh diff --git a/t/t8002-blame.sh b/third_party/git/t/t8002-blame.sh index eea048e52c..eea048e52c 100755 --- a/t/t8002-blame.sh +++ b/third_party/git/t/t8002-blame.sh diff --git a/t/t8003-blame-corner-cases.sh b/third_party/git/t/t8003-blame-corner-cases.sh index 9130b887d2..9130b887d2 100755 --- a/t/t8003-blame-corner-cases.sh +++ b/third_party/git/t/t8003-blame-corner-cases.sh diff --git a/t/t8004-blame-with-conflicts.sh b/third_party/git/t/t8004-blame-with-conflicts.sh index 9c353ab222..9c353ab222 100755 --- a/t/t8004-blame-with-conflicts.sh +++ b/third_party/git/t/t8004-blame-with-conflicts.sh diff --git a/t/t8005-blame-i18n.sh b/third_party/git/t/t8005-blame-i18n.sh index 75da219ed1..75da219ed1 100755 --- a/t/t8005-blame-i18n.sh +++ b/third_party/git/t/t8005-blame-i18n.sh diff --git a/t/t8005/euc-japan.txt b/third_party/git/t/t8005/euc-japan.txt index 288f040c99..288f040c99 100644 --- a/t/t8005/euc-japan.txt +++ b/third_party/git/t/t8005/euc-japan.txt diff --git a/t/t8005/sjis.txt b/third_party/git/t/t8005/sjis.txt index bbdefeaced..bbdefeaced 100644 --- a/t/t8005/sjis.txt +++ b/third_party/git/t/t8005/sjis.txt diff --git a/t/t8005/utf8.txt b/third_party/git/t/t8005/utf8.txt index 4d00dbea76..4d00dbea76 100644 --- a/t/t8005/utf8.txt +++ b/third_party/git/t/t8005/utf8.txt diff --git a/t/t8006-blame-textconv.sh b/third_party/git/t/t8006-blame-textconv.sh index 7683515155..7683515155 100755 --- a/t/t8006-blame-textconv.sh +++ b/third_party/git/t/t8006-blame-textconv.sh diff --git a/t/t8007-cat-file-textconv.sh b/third_party/git/t/t8007-cat-file-textconv.sh index eacd49ade6..eacd49ade6 100755 --- a/t/t8007-cat-file-textconv.sh +++ b/third_party/git/t/t8007-cat-file-textconv.sh diff --git a/t/t8008-blame-formats.sh b/third_party/git/t/t8008-blame-formats.sh index ae4b579d24..ae4b579d24 100755 --- a/t/t8008-blame-formats.sh +++ b/third_party/git/t/t8008-blame-formats.sh diff --git a/t/t8009-blame-vs-topicbranches.sh b/third_party/git/t/t8009-blame-vs-topicbranches.sh index 72596e38b2..72596e38b2 100755 --- a/t/t8009-blame-vs-topicbranches.sh +++ b/third_party/git/t/t8009-blame-vs-topicbranches.sh diff --git a/t/t8010-cat-file-filters.sh b/third_party/git/t/t8010-cat-file-filters.sh index 31de4b64dc..31de4b64dc 100755 --- a/t/t8010-cat-file-filters.sh +++ b/third_party/git/t/t8010-cat-file-filters.sh diff --git a/t/t8011-blame-split-file.sh b/third_party/git/t/t8011-blame-split-file.sh index 831125047b..831125047b 100755 --- a/t/t8011-blame-split-file.sh +++ b/third_party/git/t/t8011-blame-split-file.sh diff --git a/t/t8012-blame-colors.sh b/third_party/git/t/t8012-blame-colors.sh index ed38f74de9..ed38f74de9 100755 --- a/t/t8012-blame-colors.sh +++ b/third_party/git/t/t8012-blame-colors.sh diff --git a/t/t8013-blame-ignore-revs.sh b/third_party/git/t/t8013-blame-ignore-revs.sh index 36dc31eb39..36dc31eb39 100755 --- a/t/t8013-blame-ignore-revs.sh +++ b/third_party/git/t/t8013-blame-ignore-revs.sh diff --git a/t/t8014-blame-ignore-fuzzy.sh b/third_party/git/t/t8014-blame-ignore-fuzzy.sh index 6e61882b6f..6e61882b6f 100755 --- a/t/t8014-blame-ignore-fuzzy.sh +++ b/third_party/git/t/t8014-blame-ignore-fuzzy.sh diff --git a/t/t9001-send-email.sh b/third_party/git/t/t9001-send-email.sh index 90f61c3400..90f61c3400 100755 --- a/t/t9001-send-email.sh +++ b/third_party/git/t/t9001-send-email.sh diff --git a/t/t9002-column.sh b/third_party/git/t/t9002-column.sh index 89983527b6..89983527b6 100755 --- a/t/t9002-column.sh +++ b/third_party/git/t/t9002-column.sh diff --git a/t/t9003-help-autocorrect.sh b/third_party/git/t/t9003-help-autocorrect.sh index b1c7919c4a..b1c7919c4a 100755 --- a/t/t9003-help-autocorrect.sh +++ b/third_party/git/t/t9003-help-autocorrect.sh diff --git a/t/t9004-example.sh b/third_party/git/t/t9004-example.sh index 7e8894a4a7..7e8894a4a7 100755 --- a/t/t9004-example.sh +++ b/third_party/git/t/t9004-example.sh diff --git a/t/t9010-svn-fe.sh b/third_party/git/t/t9010-svn-fe.sh index c90fdc5c89..c90fdc5c89 100755 --- a/t/t9010-svn-fe.sh +++ b/third_party/git/t/t9010-svn-fe.sh diff --git a/t/t9011-svn-da.sh b/third_party/git/t/t9011-svn-da.sh index ab1ef28fd9..ab1ef28fd9 100755 --- a/t/t9011-svn-da.sh +++ b/third_party/git/t/t9011-svn-da.sh diff --git a/t/t9020-remote-svn.sh b/third_party/git/t/t9020-remote-svn.sh index 6fca08e5e3..6fca08e5e3 100755 --- a/t/t9020-remote-svn.sh +++ b/third_party/git/t/t9020-remote-svn.sh diff --git a/t/t9100-git-svn-basic.sh b/third_party/git/t/t9100-git-svn-basic.sh index 2c309a57d9..2c309a57d9 100755 --- a/t/t9100-git-svn-basic.sh +++ b/third_party/git/t/t9100-git-svn-basic.sh diff --git a/t/t9101-git-svn-props.sh b/third_party/git/t/t9101-git-svn-props.sh index c26c4b0927..c26c4b0927 100755 --- a/t/t9101-git-svn-props.sh +++ b/third_party/git/t/t9101-git-svn-props.sh diff --git a/t/t9102-git-svn-deep-rmdir.sh b/third_party/git/t/t9102-git-svn-deep-rmdir.sh index 66cd51102c..66cd51102c 100755 --- a/t/t9102-git-svn-deep-rmdir.sh +++ b/third_party/git/t/t9102-git-svn-deep-rmdir.sh diff --git a/t/t9103-git-svn-tracked-directory-removed.sh b/third_party/git/t/t9103-git-svn-tracked-directory-removed.sh index b28271345c..b28271345c 100755 --- a/t/t9103-git-svn-tracked-directory-removed.sh +++ b/third_party/git/t/t9103-git-svn-tracked-directory-removed.sh diff --git a/t/t9104-git-svn-follow-parent.sh b/third_party/git/t/t9104-git-svn-follow-parent.sh index 5e0ad19177..5e0ad19177 100755 --- a/t/t9104-git-svn-follow-parent.sh +++ b/third_party/git/t/t9104-git-svn-follow-parent.sh diff --git a/t/t9105-git-svn-commit-diff.sh b/third_party/git/t/t9105-git-svn-commit-diff.sh index 6ed5f74e25..6ed5f74e25 100755 --- a/t/t9105-git-svn-commit-diff.sh +++ b/third_party/git/t/t9105-git-svn-commit-diff.sh diff --git a/t/t9106-git-svn-commit-diff-clobber.sh b/third_party/git/t/t9106-git-svn-commit-diff-clobber.sh index aec45bca3b..aec45bca3b 100755 --- a/t/t9106-git-svn-commit-diff-clobber.sh +++ b/third_party/git/t/t9106-git-svn-commit-diff-clobber.sh diff --git a/t/t9107-git-svn-migrate.sh b/third_party/git/t/t9107-git-svn-migrate.sh index ceaa5bad10..ceaa5bad10 100755 --- a/t/t9107-git-svn-migrate.sh +++ b/third_party/git/t/t9107-git-svn-migrate.sh diff --git a/t/t9108-git-svn-glob.sh b/third_party/git/t/t9108-git-svn-glob.sh index 6990f64364..6990f64364 100755 --- a/t/t9108-git-svn-glob.sh +++ b/third_party/git/t/t9108-git-svn-glob.sh diff --git a/t/t9109-git-svn-multi-glob.sh b/third_party/git/t/t9109-git-svn-multi-glob.sh index c1e7542a37..c1e7542a37 100755 --- a/t/t9109-git-svn-multi-glob.sh +++ b/third_party/git/t/t9109-git-svn-multi-glob.sh diff --git a/t/t9110-git-svn-use-svm-props.sh b/third_party/git/t/t9110-git-svn-use-svm-props.sh index ad37d980c9..ad37d980c9 100755 --- a/t/t9110-git-svn-use-svm-props.sh +++ b/third_party/git/t/t9110-git-svn-use-svm-props.sh diff --git a/t/t9110/svm.dump b/third_party/git/t/t9110/svm.dump index cc799c238d..cc799c238d 100644 --- a/t/t9110/svm.dump +++ b/third_party/git/t/t9110/svm.dump diff --git a/t/t9111-git-svn-use-svnsync-props.sh b/third_party/git/t/t9111-git-svn-use-svnsync-props.sh index 6c93073551..6c93073551 100755 --- a/t/t9111-git-svn-use-svnsync-props.sh +++ b/third_party/git/t/t9111-git-svn-use-svnsync-props.sh diff --git a/t/t9111/svnsync.dump b/third_party/git/t/t9111/svnsync.dump index 499fa9594f..499fa9594f 100644 --- a/t/t9111/svnsync.dump +++ b/third_party/git/t/t9111/svnsync.dump diff --git a/t/t9112-git-svn-md5less-file.sh b/third_party/git/t/t9112-git-svn-md5less-file.sh index 9861c719f8..9861c719f8 100755 --- a/t/t9112-git-svn-md5less-file.sh +++ b/third_party/git/t/t9112-git-svn-md5less-file.sh diff --git a/t/t9113-git-svn-dcommit-new-file.sh b/third_party/git/t/t9113-git-svn-dcommit-new-file.sh index e8479cec7a..e8479cec7a 100755 --- a/t/t9113-git-svn-dcommit-new-file.sh +++ b/third_party/git/t/t9113-git-svn-dcommit-new-file.sh diff --git a/t/t9114-git-svn-dcommit-merge.sh b/third_party/git/t/t9114-git-svn-dcommit-merge.sh index 32317d6bca..32317d6bca 100755 --- a/t/t9114-git-svn-dcommit-merge.sh +++ b/third_party/git/t/t9114-git-svn-dcommit-merge.sh diff --git a/t/t9115-git-svn-dcommit-funky-renames.sh b/third_party/git/t/t9115-git-svn-dcommit-funky-renames.sh index 9b44a44bc1..9b44a44bc1 100755 --- a/t/t9115-git-svn-dcommit-funky-renames.sh +++ b/third_party/git/t/t9115-git-svn-dcommit-funky-renames.sh diff --git a/t/t9115/funky-names.dump b/third_party/git/t/t9115/funky-names.dump index 42422f791e..42422f791e 100644 --- a/t/t9115/funky-names.dump +++ b/third_party/git/t/t9115/funky-names.dump diff --git a/t/t9116-git-svn-log.sh b/third_party/git/t/t9116-git-svn-log.sh index 0a9f1ef366..0a9f1ef366 100755 --- a/t/t9116-git-svn-log.sh +++ b/third_party/git/t/t9116-git-svn-log.sh diff --git a/t/t9117-git-svn-init-clone.sh b/third_party/git/t/t9117-git-svn-init-clone.sh index 044f65e916..044f65e916 100755 --- a/t/t9117-git-svn-init-clone.sh +++ b/third_party/git/t/t9117-git-svn-init-clone.sh diff --git a/t/t9118-git-svn-funky-branch-names.sh b/third_party/git/t/t9118-git-svn-funky-branch-names.sh index a159ff96b7..a159ff96b7 100755 --- a/t/t9118-git-svn-funky-branch-names.sh +++ b/third_party/git/t/t9118-git-svn-funky-branch-names.sh diff --git a/t/t9119-git-svn-info.sh b/third_party/git/t/t9119-git-svn-info.sh index 8201c3e808..8201c3e808 100755 --- a/t/t9119-git-svn-info.sh +++ b/third_party/git/t/t9119-git-svn-info.sh diff --git a/t/t9120-git-svn-clone-with-percent-escapes.sh b/third_party/git/t/t9120-git-svn-clone-with-percent-escapes.sh index 40b714df31..40b714df31 100755 --- a/t/t9120-git-svn-clone-with-percent-escapes.sh +++ b/third_party/git/t/t9120-git-svn-clone-with-percent-escapes.sh diff --git a/t/t9121-git-svn-fetch-renamed-dir.sh b/third_party/git/t/t9121-git-svn-fetch-renamed-dir.sh index 000cad37c6..000cad37c6 100755 --- a/t/t9121-git-svn-fetch-renamed-dir.sh +++ b/third_party/git/t/t9121-git-svn-fetch-renamed-dir.sh diff --git a/t/t9121/renamed-dir.dump b/third_party/git/t/t9121/renamed-dir.dump index 5f9127be92..5f9127be92 100644 --- a/t/t9121/renamed-dir.dump +++ b/third_party/git/t/t9121/renamed-dir.dump diff --git a/t/t9122-git-svn-author.sh b/third_party/git/t/t9122-git-svn-author.sh index 9e8fe38e7e..9e8fe38e7e 100755 --- a/t/t9122-git-svn-author.sh +++ b/third_party/git/t/t9122-git-svn-author.sh diff --git a/t/t9123-git-svn-rebuild-with-rewriteroot.sh b/third_party/git/t/t9123-git-svn-rebuild-with-rewriteroot.sh index ead404589e..ead404589e 100755 --- a/t/t9123-git-svn-rebuild-with-rewriteroot.sh +++ b/third_party/git/t/t9123-git-svn-rebuild-with-rewriteroot.sh diff --git a/t/t9124-git-svn-dcommit-auto-props.sh b/third_party/git/t/t9124-git-svn-dcommit-auto-props.sh index 9f7231d5b7..9f7231d5b7 100755 --- a/t/t9124-git-svn-dcommit-auto-props.sh +++ b/third_party/git/t/t9124-git-svn-dcommit-auto-props.sh diff --git a/t/t9125-git-svn-multi-glob-branch-names.sh b/third_party/git/t/t9125-git-svn-multi-glob-branch-names.sh index 0d53fc9014..0d53fc9014 100755 --- a/t/t9125-git-svn-multi-glob-branch-names.sh +++ b/third_party/git/t/t9125-git-svn-multi-glob-branch-names.sh diff --git a/t/t9126-git-svn-follow-deleted-readded-directory.sh b/third_party/git/t/t9126-git-svn-follow-deleted-readded-directory.sh index edec640e97..edec640e97 100755 --- a/t/t9126-git-svn-follow-deleted-readded-directory.sh +++ b/third_party/git/t/t9126-git-svn-follow-deleted-readded-directory.sh diff --git a/t/t9126/follow-deleted-readded.dump b/third_party/git/t/t9126/follow-deleted-readded.dump index 19da5d1ddc..19da5d1ddc 100644 --- a/t/t9126/follow-deleted-readded.dump +++ b/third_party/git/t/t9126/follow-deleted-readded.dump diff --git a/t/t9127-git-svn-partial-rebuild.sh b/third_party/git/t/t9127-git-svn-partial-rebuild.sh index 2e4789d061..2e4789d061 100755 --- a/t/t9127-git-svn-partial-rebuild.sh +++ b/third_party/git/t/t9127-git-svn-partial-rebuild.sh diff --git a/t/t9128-git-svn-cmd-branch.sh b/third_party/git/t/t9128-git-svn-cmd-branch.sh index 4e95f791db..4e95f791db 100755 --- a/t/t9128-git-svn-cmd-branch.sh +++ b/third_party/git/t/t9128-git-svn-cmd-branch.sh diff --git a/t/t9129-git-svn-i18n-commitencoding.sh b/third_party/git/t/t9129-git-svn-i18n-commitencoding.sh index 2c213ae654..2c213ae654 100755 --- a/t/t9129-git-svn-i18n-commitencoding.sh +++ b/third_party/git/t/t9129-git-svn-i18n-commitencoding.sh diff --git a/t/t9130-git-svn-authors-file.sh b/third_party/git/t/t9130-git-svn-authors-file.sh index cb764bcadc..cb764bcadc 100755 --- a/t/t9130-git-svn-authors-file.sh +++ b/third_party/git/t/t9130-git-svn-authors-file.sh diff --git a/t/t9131-git-svn-empty-symlink.sh b/third_party/git/t/t9131-git-svn-empty-symlink.sh index 3bf4255aa3..3bf4255aa3 100755 --- a/t/t9131-git-svn-empty-symlink.sh +++ b/third_party/git/t/t9131-git-svn-empty-symlink.sh diff --git a/t/t9132-git-svn-broken-symlink.sh b/third_party/git/t/t9132-git-svn-broken-symlink.sh index aeceffaf7b..aeceffaf7b 100755 --- a/t/t9132-git-svn-broken-symlink.sh +++ b/third_party/git/t/t9132-git-svn-broken-symlink.sh diff --git a/t/t9133-git-svn-nested-git-repo.sh b/third_party/git/t/t9133-git-svn-nested-git-repo.sh index f894860867..f894860867 100755 --- a/t/t9133-git-svn-nested-git-repo.sh +++ b/third_party/git/t/t9133-git-svn-nested-git-repo.sh diff --git a/t/t9134-git-svn-ignore-paths.sh b/third_party/git/t/t9134-git-svn-ignore-paths.sh index fff49c4100..fff49c4100 100755 --- a/t/t9134-git-svn-ignore-paths.sh +++ b/third_party/git/t/t9134-git-svn-ignore-paths.sh diff --git a/t/t9135-git-svn-moved-branch-empty-file.sh b/third_party/git/t/t9135-git-svn-moved-branch-empty-file.sh index 2f80b216fe..2f80b216fe 100755 --- a/t/t9135-git-svn-moved-branch-empty-file.sh +++ b/third_party/git/t/t9135-git-svn-moved-branch-empty-file.sh diff --git a/t/t9135/svn.dump b/third_party/git/t/t9135/svn.dump index b51c0ccceb..b51c0ccceb 100644 --- a/t/t9135/svn.dump +++ b/third_party/git/t/t9135/svn.dump diff --git a/t/t9136-git-svn-recreated-branch-empty-file.sh b/third_party/git/t/t9136-git-svn-recreated-branch-empty-file.sh index 733d16e0b2..733d16e0b2 100755 --- a/t/t9136-git-svn-recreated-branch-empty-file.sh +++ b/third_party/git/t/t9136-git-svn-recreated-branch-empty-file.sh diff --git a/t/t9136/svn.dump b/third_party/git/t/t9136/svn.dump index 6b1ce0b2e8..6b1ce0b2e8 100644 --- a/t/t9136/svn.dump +++ b/third_party/git/t/t9136/svn.dump diff --git a/t/t9137-git-svn-dcommit-clobber-series.sh b/third_party/git/t/t9137-git-svn-dcommit-clobber-series.sh index 067b15bad2..067b15bad2 100755 --- a/t/t9137-git-svn-dcommit-clobber-series.sh +++ b/third_party/git/t/t9137-git-svn-dcommit-clobber-series.sh diff --git a/t/t9138-git-svn-authors-prog.sh b/third_party/git/t/t9138-git-svn-authors-prog.sh index 027b416720..027b416720 100755 --- a/t/t9138-git-svn-authors-prog.sh +++ b/third_party/git/t/t9138-git-svn-authors-prog.sh diff --git a/t/t9139-git-svn-non-utf8-commitencoding.sh b/third_party/git/t/t9139-git-svn-non-utf8-commitencoding.sh index 22d80b0be2..22d80b0be2 100755 --- a/t/t9139-git-svn-non-utf8-commitencoding.sh +++ b/third_party/git/t/t9139-git-svn-non-utf8-commitencoding.sh diff --git a/t/t9140-git-svn-reset.sh b/third_party/git/t/t9140-git-svn-reset.sh index e855904629..e855904629 100755 --- a/t/t9140-git-svn-reset.sh +++ b/third_party/git/t/t9140-git-svn-reset.sh diff --git a/t/t9141-git-svn-multiple-branches.sh b/third_party/git/t/t9141-git-svn-multiple-branches.sh index 8e7f7d68b7..8e7f7d68b7 100755 --- a/t/t9141-git-svn-multiple-branches.sh +++ b/third_party/git/t/t9141-git-svn-multiple-branches.sh diff --git a/t/t9142-git-svn-shallow-clone.sh b/third_party/git/t/t9142-git-svn-shallow-clone.sh index a30730502d..a30730502d 100755 --- a/t/t9142-git-svn-shallow-clone.sh +++ b/third_party/git/t/t9142-git-svn-shallow-clone.sh diff --git a/t/t9143-git-svn-gc.sh b/third_party/git/t/t9143-git-svn-gc.sh index 4594e1ae2f..4594e1ae2f 100755 --- a/t/t9143-git-svn-gc.sh +++ b/third_party/git/t/t9143-git-svn-gc.sh diff --git a/t/t9144-git-svn-old-rev_map.sh b/third_party/git/t/t9144-git-svn-old-rev_map.sh index 7600a35cd4..7600a35cd4 100755 --- a/t/t9144-git-svn-old-rev_map.sh +++ b/third_party/git/t/t9144-git-svn-old-rev_map.sh diff --git a/t/t9145-git-svn-master-branch.sh b/third_party/git/t/t9145-git-svn-master-branch.sh index 3bbf341f6a..3bbf341f6a 100755 --- a/t/t9145-git-svn-master-branch.sh +++ b/third_party/git/t/t9145-git-svn-master-branch.sh diff --git a/t/t9146-git-svn-empty-dirs.sh b/third_party/git/t/t9146-git-svn-empty-dirs.sh index 5f91c0d68b..5f91c0d68b 100755 --- a/t/t9146-git-svn-empty-dirs.sh +++ b/third_party/git/t/t9146-git-svn-empty-dirs.sh diff --git a/t/t9147-git-svn-include-paths.sh b/third_party/git/t/t9147-git-svn-include-paths.sh index d292bf9f55..d292bf9f55 100755 --- a/t/t9147-git-svn-include-paths.sh +++ b/third_party/git/t/t9147-git-svn-include-paths.sh diff --git a/t/t9148-git-svn-propset.sh b/third_party/git/t/t9148-git-svn-propset.sh index 102639090c..102639090c 100755 --- a/t/t9148-git-svn-propset.sh +++ b/third_party/git/t/t9148-git-svn-propset.sh diff --git a/t/t9150-svk-mergetickets.sh b/third_party/git/t/t9150-svk-mergetickets.sh index 1bb676bede..1bb676bede 100755 --- a/t/t9150-svk-mergetickets.sh +++ b/third_party/git/t/t9150-svk-mergetickets.sh diff --git a/t/t9150/make-svk-dump b/third_party/git/t/t9150/make-svk-dump index 2242f14ebe..2242f14ebe 100755 --- a/t/t9150/make-svk-dump +++ b/third_party/git/t/t9150/make-svk-dump diff --git a/t/t9150/svk-merge.dump b/third_party/git/t/t9150/svk-merge.dump index 42f70dbec7..42f70dbec7 100644 --- a/t/t9150/svk-merge.dump +++ b/third_party/git/t/t9150/svk-merge.dump diff --git a/t/t9151-svn-mergeinfo.sh b/third_party/git/t/t9151-svn-mergeinfo.sh index 4f6c06ecb2..4f6c06ecb2 100755 --- a/t/t9151-svn-mergeinfo.sh +++ b/third_party/git/t/t9151-svn-mergeinfo.sh diff --git a/t/t9151/.gitignore b/third_party/git/t/t9151/.gitignore index 587c37dba3..587c37dba3 100644 --- a/t/t9151/.gitignore +++ b/third_party/git/t/t9151/.gitignore diff --git a/t/t9151/make-svnmerge-dump b/third_party/git/t/t9151/make-svnmerge-dump index e1e138cb1a..e1e138cb1a 100755 --- a/t/t9151/make-svnmerge-dump +++ b/third_party/git/t/t9151/make-svnmerge-dump diff --git a/t/t9151/svn-mergeinfo.dump b/third_party/git/t/t9151/svn-mergeinfo.dump index 47cafcf528..47cafcf528 100644 --- a/t/t9151/svn-mergeinfo.dump +++ b/third_party/git/t/t9151/svn-mergeinfo.dump diff --git a/t/t9152-svn-empty-dirs-after-gc.sh b/third_party/git/t/t9152-svn-empty-dirs-after-gc.sh index 89f285d082..89f285d082 100755 --- a/t/t9152-svn-empty-dirs-after-gc.sh +++ b/third_party/git/t/t9152-svn-empty-dirs-after-gc.sh diff --git a/t/t9153-git-svn-rewrite-uuid.sh b/third_party/git/t/t9153-git-svn-rewrite-uuid.sh index 8cb2b5c69c..8cb2b5c69c 100755 --- a/t/t9153-git-svn-rewrite-uuid.sh +++ b/third_party/git/t/t9153-git-svn-rewrite-uuid.sh diff --git a/t/t9153/svn.dump b/third_party/git/t/t9153/svn.dump index 0ddfe7025d..0ddfe7025d 100644 --- a/t/t9153/svn.dump +++ b/third_party/git/t/t9153/svn.dump diff --git a/t/t9154-git-svn-fancy-glob.sh b/third_party/git/t/t9154-git-svn-fancy-glob.sh index a0150f057d..a0150f057d 100755 --- a/t/t9154-git-svn-fancy-glob.sh +++ b/third_party/git/t/t9154-git-svn-fancy-glob.sh diff --git a/t/t9154/svn.dump b/third_party/git/t/t9154/svn.dump index 3dfabb67db..3dfabb67db 100644 --- a/t/t9154/svn.dump +++ b/third_party/git/t/t9154/svn.dump diff --git a/t/t9155-git-svn-fetch-deleted-tag.sh b/third_party/git/t/t9155-git-svn-fetch-deleted-tag.sh index 184336f346..184336f346 100755 --- a/t/t9155-git-svn-fetch-deleted-tag.sh +++ b/third_party/git/t/t9155-git-svn-fetch-deleted-tag.sh diff --git a/t/t9156-git-svn-fetch-deleted-tag-2.sh b/third_party/git/t/t9156-git-svn-fetch-deleted-tag-2.sh index 7a6e33ba3c..7a6e33ba3c 100755 --- a/t/t9156-git-svn-fetch-deleted-tag-2.sh +++ b/third_party/git/t/t9156-git-svn-fetch-deleted-tag-2.sh diff --git a/t/t9157-git-svn-fetch-merge.sh b/third_party/git/t/t9157-git-svn-fetch-merge.sh index 991d2aa1be..991d2aa1be 100755 --- a/t/t9157-git-svn-fetch-merge.sh +++ b/third_party/git/t/t9157-git-svn-fetch-merge.sh diff --git a/t/t9158-git-svn-mergeinfo.sh b/third_party/git/t/t9158-git-svn-mergeinfo.sh index a875b45102..a875b45102 100755 --- a/t/t9158-git-svn-mergeinfo.sh +++ b/third_party/git/t/t9158-git-svn-mergeinfo.sh diff --git a/t/t9159-git-svn-no-parent-mergeinfo.sh b/third_party/git/t/t9159-git-svn-no-parent-mergeinfo.sh index 69e4815781..69e4815781 100755 --- a/t/t9159-git-svn-no-parent-mergeinfo.sh +++ b/third_party/git/t/t9159-git-svn-no-parent-mergeinfo.sh diff --git a/t/t9160-git-svn-preserve-empty-dirs.sh b/third_party/git/t/t9160-git-svn-preserve-empty-dirs.sh index 0ede3cfedb..0ede3cfedb 100755 --- a/t/t9160-git-svn-preserve-empty-dirs.sh +++ b/third_party/git/t/t9160-git-svn-preserve-empty-dirs.sh diff --git a/t/t9161-git-svn-mergeinfo-push.sh b/third_party/git/t/t9161-git-svn-mergeinfo-push.sh index f113acaa6c..f113acaa6c 100755 --- a/t/t9161-git-svn-mergeinfo-push.sh +++ b/third_party/git/t/t9161-git-svn-mergeinfo-push.sh diff --git a/t/t9161/branches.dump b/third_party/git/t/t9161/branches.dump index e61c3e7236..e61c3e7236 100644 --- a/t/t9161/branches.dump +++ b/third_party/git/t/t9161/branches.dump diff --git a/t/t9162-git-svn-dcommit-interactive.sh b/third_party/git/t/t9162-git-svn-dcommit-interactive.sh index e38d9fa37b..e38d9fa37b 100755 --- a/t/t9162-git-svn-dcommit-interactive.sh +++ b/third_party/git/t/t9162-git-svn-dcommit-interactive.sh diff --git a/t/t9163-git-svn-reset-clears-caches.sh b/third_party/git/t/t9163-git-svn-reset-clears-caches.sh index d6245cee08..d6245cee08 100755 --- a/t/t9163-git-svn-reset-clears-caches.sh +++ b/third_party/git/t/t9163-git-svn-reset-clears-caches.sh diff --git a/t/t9164-git-svn-dcommit-concurrent.sh b/third_party/git/t/t9164-git-svn-dcommit-concurrent.sh index 90346ff4e9..90346ff4e9 100755 --- a/t/t9164-git-svn-dcommit-concurrent.sh +++ b/third_party/git/t/t9164-git-svn-dcommit-concurrent.sh diff --git a/t/t9165-git-svn-fetch-merge-branch-of-branch.sh b/third_party/git/t/t9165-git-svn-fetch-merge-branch-of-branch.sh index a4813c2b09..a4813c2b09 100755 --- a/t/t9165-git-svn-fetch-merge-branch-of-branch.sh +++ b/third_party/git/t/t9165-git-svn-fetch-merge-branch-of-branch.sh diff --git a/t/t9166-git-svn-fetch-merge-branch-of-branch2.sh b/third_party/git/t/t9166-git-svn-fetch-merge-branch-of-branch2.sh index 52f2e46a5b..52f2e46a5b 100755 --- a/t/t9166-git-svn-fetch-merge-branch-of-branch2.sh +++ b/third_party/git/t/t9166-git-svn-fetch-merge-branch-of-branch2.sh diff --git a/t/t9167-git-svn-cmd-branch-subproject.sh b/third_party/git/t/t9167-git-svn-cmd-branch-subproject.sh index ba35fc06fc..ba35fc06fc 100755 --- a/t/t9167-git-svn-cmd-branch-subproject.sh +++ b/third_party/git/t/t9167-git-svn-cmd-branch-subproject.sh diff --git a/t/t9168-git-svn-partially-globbed-names.sh b/third_party/git/t/t9168-git-svn-partially-globbed-names.sh index bdf6e84999..bdf6e84999 100755 --- a/t/t9168-git-svn-partially-globbed-names.sh +++ b/third_party/git/t/t9168-git-svn-partially-globbed-names.sh diff --git a/t/t9169-git-svn-dcommit-crlf.sh b/third_party/git/t/t9169-git-svn-dcommit-crlf.sh index 54b1f61a2a..54b1f61a2a 100755 --- a/t/t9169-git-svn-dcommit-crlf.sh +++ b/third_party/git/t/t9169-git-svn-dcommit-crlf.sh diff --git a/t/t9200-git-cvsexportcommit.sh b/third_party/git/t/t9200-git-cvsexportcommit.sh index c5946cb0b8..c5946cb0b8 100755 --- a/t/t9200-git-cvsexportcommit.sh +++ b/third_party/git/t/t9200-git-cvsexportcommit.sh diff --git a/t/t9300-fast-import.sh b/third_party/git/t/t9300-fast-import.sh index 3e41c58a13..3e41c58a13 100755 --- a/t/t9300-fast-import.sh +++ b/third_party/git/t/t9300-fast-import.sh diff --git a/t/t9301-fast-import-notes.sh b/third_party/git/t/t9301-fast-import-notes.sh index ca223dca98..ca223dca98 100755 --- a/t/t9301-fast-import-notes.sh +++ b/third_party/git/t/t9301-fast-import-notes.sh diff --git a/t/t9302-fast-import-unpack-limit.sh b/third_party/git/t/t9302-fast-import-unpack-limit.sh index bb1c39cfcc..bb1c39cfcc 100755 --- a/t/t9302-fast-import-unpack-limit.sh +++ b/third_party/git/t/t9302-fast-import-unpack-limit.sh diff --git a/t/t9303-fast-import-compression.sh b/third_party/git/t/t9303-fast-import-compression.sh index 5045f02a53..5045f02a53 100755 --- a/t/t9303-fast-import-compression.sh +++ b/third_party/git/t/t9303-fast-import-compression.sh diff --git a/t/t9350-fast-export.sh b/third_party/git/t/t9350-fast-export.sh index 690c90fb82..690c90fb82 100755 --- a/t/t9350-fast-export.sh +++ b/third_party/git/t/t9350-fast-export.sh diff --git a/t/t9350/broken-iso-8859-7-commit-message.txt b/third_party/git/t/t9350/broken-iso-8859-7-commit-message.txt index d06ad75b44..d06ad75b44 100644 --- a/t/t9350/broken-iso-8859-7-commit-message.txt +++ b/third_party/git/t/t9350/broken-iso-8859-7-commit-message.txt diff --git a/t/t9350/simple-iso-8859-7-commit-message.txt b/third_party/git/t/t9350/simple-iso-8859-7-commit-message.txt index 8b3f0c3dba..8b3f0c3dba 100644 --- a/t/t9350/simple-iso-8859-7-commit-message.txt +++ b/third_party/git/t/t9350/simple-iso-8859-7-commit-message.txt diff --git a/t/t9351-fast-export-anonymize.sh b/third_party/git/t/t9351-fast-export-anonymize.sh index 897dc50907..897dc50907 100755 --- a/t/t9351-fast-export-anonymize.sh +++ b/third_party/git/t/t9351-fast-export-anonymize.sh diff --git a/t/t9400-git-cvsserver-server.sh b/third_party/git/t/t9400-git-cvsserver-server.sh index a5e5dca753..a5e5dca753 100755 --- a/t/t9400-git-cvsserver-server.sh +++ b/third_party/git/t/t9400-git-cvsserver-server.sh diff --git a/t/t9401-git-cvsserver-crlf.sh b/third_party/git/t/t9401-git-cvsserver-crlf.sh index 84787eee9a..84787eee9a 100755 --- a/t/t9401-git-cvsserver-crlf.sh +++ b/third_party/git/t/t9401-git-cvsserver-crlf.sh diff --git a/t/t9402-git-cvsserver-refs.sh b/third_party/git/t/t9402-git-cvsserver-refs.sh index cf31ace667..cf31ace667 100755 --- a/t/t9402-git-cvsserver-refs.sh +++ b/third_party/git/t/t9402-git-cvsserver-refs.sh diff --git a/t/t9500-gitweb-standalone-no-errors.sh b/third_party/git/t/t9500-gitweb-standalone-no-errors.sh index cc8d463e01..cc8d463e01 100755 --- a/t/t9500-gitweb-standalone-no-errors.sh +++ b/third_party/git/t/t9500-gitweb-standalone-no-errors.sh diff --git a/t/t9501-gitweb-standalone-http-status.sh b/third_party/git/t/t9501-gitweb-standalone-http-status.sh index 2a0ffed870..2a0ffed870 100755 --- a/t/t9501-gitweb-standalone-http-status.sh +++ b/third_party/git/t/t9501-gitweb-standalone-http-status.sh diff --git a/t/t9502-gitweb-standalone-parse-output.sh b/third_party/git/t/t9502-gitweb-standalone-parse-output.sh index e38cbc97d3..e38cbc97d3 100755 --- a/t/t9502-gitweb-standalone-parse-output.sh +++ b/third_party/git/t/t9502-gitweb-standalone-parse-output.sh diff --git a/t/t9600-cvsimport.sh b/third_party/git/t/t9600-cvsimport.sh index 251fdd66c4..251fdd66c4 100755 --- a/t/t9600-cvsimport.sh +++ b/third_party/git/t/t9600-cvsimport.sh diff --git a/t/t9601-cvsimport-vendor-branch.sh b/third_party/git/t/t9601-cvsimport-vendor-branch.sh index 827d39f5bf..827d39f5bf 100755 --- a/t/t9601-cvsimport-vendor-branch.sh +++ b/third_party/git/t/t9601-cvsimport-vendor-branch.sh diff --git a/t/t9601/cvsroot/.gitattributes b/third_party/git/t/t9601/cvsroot/.gitattributes index 562b12e16e..562b12e16e 100644 --- a/t/t9601/cvsroot/.gitattributes +++ b/third_party/git/t/t9601/cvsroot/.gitattributes diff --git a/t/t9601/cvsroot/CVSROOT/.gitignore b/third_party/git/t/t9601/cvsroot/CVSROOT/.gitignore index 3bb9b34173..3bb9b34173 100644 --- a/t/t9601/cvsroot/CVSROOT/.gitignore +++ b/third_party/git/t/t9601/cvsroot/CVSROOT/.gitignore diff --git a/t/t9601/cvsroot/module/added-imported.txt,v b/third_party/git/t/t9601/cvsroot/module/added-imported.txt,v index 5f83072ea4..5f83072ea4 100644 --- a/t/t9601/cvsroot/module/added-imported.txt,v +++ b/third_party/git/t/t9601/cvsroot/module/added-imported.txt,v diff --git a/t/t9601/cvsroot/module/imported-anonymously.txt,v b/third_party/git/t/t9601/cvsroot/module/imported-anonymously.txt,v index 55e1b0ca5d..55e1b0ca5d 100644 --- a/t/t9601/cvsroot/module/imported-anonymously.txt,v +++ b/third_party/git/t/t9601/cvsroot/module/imported-anonymously.txt,v diff --git a/t/t9601/cvsroot/module/imported-modified-imported.txt,v b/third_party/git/t/t9601/cvsroot/module/imported-modified-imported.txt,v index e5830aeb37..e5830aeb37 100644 --- a/t/t9601/cvsroot/module/imported-modified-imported.txt,v +++ b/third_party/git/t/t9601/cvsroot/module/imported-modified-imported.txt,v diff --git a/t/t9601/cvsroot/module/imported-modified.txt,v b/third_party/git/t/t9601/cvsroot/module/imported-modified.txt,v index bbcfe447b9..bbcfe447b9 100644 --- a/t/t9601/cvsroot/module/imported-modified.txt,v +++ b/third_party/git/t/t9601/cvsroot/module/imported-modified.txt,v diff --git a/t/t9601/cvsroot/module/imported-once.txt,v b/third_party/git/t/t9601/cvsroot/module/imported-once.txt,v index c5dd82b12d..c5dd82b12d 100644 --- a/t/t9601/cvsroot/module/imported-once.txt,v +++ b/third_party/git/t/t9601/cvsroot/module/imported-once.txt,v diff --git a/t/t9601/cvsroot/module/imported-twice.txt,v b/third_party/git/t/t9601/cvsroot/module/imported-twice.txt,v index d1f3f1b344..d1f3f1b344 100644 --- a/t/t9601/cvsroot/module/imported-twice.txt,v +++ b/third_party/git/t/t9601/cvsroot/module/imported-twice.txt,v diff --git a/t/t9602-cvsimport-branches-tags.sh b/third_party/git/t/t9602-cvsimport-branches-tags.sh index e1db323f54..e1db323f54 100755 --- a/t/t9602-cvsimport-branches-tags.sh +++ b/third_party/git/t/t9602-cvsimport-branches-tags.sh diff --git a/t/t9602/README b/third_party/git/t/t9602/README index c231e0f26f..c231e0f26f 100644 --- a/t/t9602/README +++ b/third_party/git/t/t9602/README diff --git a/t/t9602/cvsroot/.gitattributes b/third_party/git/t/t9602/cvsroot/.gitattributes index 562b12e16e..562b12e16e 100644 --- a/t/t9602/cvsroot/.gitattributes +++ b/third_party/git/t/t9602/cvsroot/.gitattributes diff --git a/t/t9602/cvsroot/CVSROOT/.gitignore b/third_party/git/t/t9602/cvsroot/CVSROOT/.gitignore index 3bb9b34173..3bb9b34173 100644 --- a/t/t9602/cvsroot/CVSROOT/.gitignore +++ b/third_party/git/t/t9602/cvsroot/CVSROOT/.gitignore diff --git a/t/t9602/cvsroot/module/default,v b/third_party/git/t/t9602/cvsroot/module/default,v index 3b68382a3b..3b68382a3b 100644 --- a/t/t9602/cvsroot/module/default,v +++ b/third_party/git/t/t9602/cvsroot/module/default,v diff --git a/t/t9602/cvsroot/module/sub1/default,v b/third_party/git/t/t9602/cvsroot/module/sub1/default,v index b7fdccdfdf..b7fdccdfdf 100644 --- a/t/t9602/cvsroot/module/sub1/default,v +++ b/third_party/git/t/t9602/cvsroot/module/sub1/default,v diff --git a/t/t9602/cvsroot/module/sub1/subsubA/default,v b/third_party/git/t/t9602/cvsroot/module/sub1/subsubA/default,v index 472b7b2bd9..472b7b2bd9 100644 --- a/t/t9602/cvsroot/module/sub1/subsubA/default,v +++ b/third_party/git/t/t9602/cvsroot/module/sub1/subsubA/default,v diff --git a/t/t9602/cvsroot/module/sub1/subsubB/default,v b/third_party/git/t/t9602/cvsroot/module/sub1/subsubB/default,v index fe6efa4554..fe6efa4554 100644 --- a/t/t9602/cvsroot/module/sub1/subsubB/default,v +++ b/third_party/git/t/t9602/cvsroot/module/sub1/subsubB/default,v diff --git a/t/t9602/cvsroot/module/sub2/Attic/branch_B_MIXED_only,v b/third_party/git/t/t9602/cvsroot/module/sub2/Attic/branch_B_MIXED_only,v index 34c9789f2f..34c9789f2f 100644 --- a/t/t9602/cvsroot/module/sub2/Attic/branch_B_MIXED_only,v +++ b/third_party/git/t/t9602/cvsroot/module/sub2/Attic/branch_B_MIXED_only,v diff --git a/t/t9602/cvsroot/module/sub2/default,v b/third_party/git/t/t9602/cvsroot/module/sub2/default,v index 018f7f8ece..018f7f8ece 100644 --- a/t/t9602/cvsroot/module/sub2/default,v +++ b/third_party/git/t/t9602/cvsroot/module/sub2/default,v diff --git a/t/t9602/cvsroot/module/sub2/subsubA/default,v b/third_party/git/t/t9602/cvsroot/module/sub2/subsubA/default,v index d13242cb09..d13242cb09 100644 --- a/t/t9602/cvsroot/module/sub2/subsubA/default,v +++ b/third_party/git/t/t9602/cvsroot/module/sub2/subsubA/default,v diff --git a/t/t9602/cvsroot/module/sub3/default,v b/third_party/git/t/t9602/cvsroot/module/sub3/default,v index 88e4567434..88e4567434 100644 --- a/t/t9602/cvsroot/module/sub3/default,v +++ b/third_party/git/t/t9602/cvsroot/module/sub3/default,v diff --git a/t/t9603-cvsimport-patchsets.sh b/third_party/git/t/t9603-cvsimport-patchsets.sh index 3e64b11eac..3e64b11eac 100755 --- a/t/t9603-cvsimport-patchsets.sh +++ b/third_party/git/t/t9603-cvsimport-patchsets.sh diff --git a/t/t9603/cvsroot/.gitattributes b/third_party/git/t/t9603/cvsroot/.gitattributes index 562b12e16e..562b12e16e 100644 --- a/t/t9603/cvsroot/.gitattributes +++ b/third_party/git/t/t9603/cvsroot/.gitattributes diff --git a/t/t9603/cvsroot/CVSROOT/.gitignore b/third_party/git/t/t9603/cvsroot/CVSROOT/.gitignore index 3bb9b34173..3bb9b34173 100644 --- a/t/t9603/cvsroot/CVSROOT/.gitignore +++ b/third_party/git/t/t9603/cvsroot/CVSROOT/.gitignore diff --git a/t/t9603/cvsroot/module/a,v b/third_party/git/t/t9603/cvsroot/module/a,v index ba8fd5af23..ba8fd5af23 100644 --- a/t/t9603/cvsroot/module/a,v +++ b/third_party/git/t/t9603/cvsroot/module/a,v diff --git a/t/t9603/cvsroot/module/b,v b/third_party/git/t/t9603/cvsroot/module/b,v index d26885518a..d26885518a 100644 --- a/t/t9603/cvsroot/module/b,v +++ b/third_party/git/t/t9603/cvsroot/module/b,v diff --git a/t/t9604-cvsimport-timestamps.sh b/third_party/git/t/t9604-cvsimport-timestamps.sh index 2ff4aa932d..2ff4aa932d 100755 --- a/t/t9604-cvsimport-timestamps.sh +++ b/third_party/git/t/t9604-cvsimport-timestamps.sh diff --git a/t/t9604/cvsroot/.gitattributes b/third_party/git/t/t9604/cvsroot/.gitattributes index 562b12e16e..562b12e16e 100644 --- a/t/t9604/cvsroot/.gitattributes +++ b/third_party/git/t/t9604/cvsroot/.gitattributes diff --git a/t/t9604/cvsroot/CVSROOT/.gitignore b/third_party/git/t/t9604/cvsroot/CVSROOT/.gitignore index 3bb9b34173..3bb9b34173 100644 --- a/t/t9604/cvsroot/CVSROOT/.gitignore +++ b/third_party/git/t/t9604/cvsroot/CVSROOT/.gitignore diff --git a/t/t9604/cvsroot/module/a,v b/third_party/git/t/t9604/cvsroot/module/a,v index 80658c3c8d..80658c3c8d 100644 --- a/t/t9604/cvsroot/module/a,v +++ b/third_party/git/t/t9604/cvsroot/module/a,v diff --git a/t/t9700-perl-git.sh b/third_party/git/t/t9700-perl-git.sh index 102c133112..102c133112 100755 --- a/t/t9700-perl-git.sh +++ b/third_party/git/t/t9700-perl-git.sh diff --git a/t/t9700/test.pl b/third_party/git/t/t9700/test.pl index 34cd01366f..34cd01366f 100755 --- a/t/t9700/test.pl +++ b/third_party/git/t/t9700/test.pl diff --git a/t/t9800-git-p4-basic.sh b/third_party/git/t/t9800-git-p4-basic.sh index c98c1dfc23..c98c1dfc23 100755 --- a/t/t9800-git-p4-basic.sh +++ b/third_party/git/t/t9800-git-p4-basic.sh diff --git a/t/t9801-git-p4-branch.sh b/third_party/git/t/t9801-git-p4-branch.sh index 67ff2711f5..67ff2711f5 100755 --- a/t/t9801-git-p4-branch.sh +++ b/third_party/git/t/t9801-git-p4-branch.sh diff --git a/t/t9802-git-p4-filetype.sh b/third_party/git/t/t9802-git-p4-filetype.sh index 94edebe272..94edebe272 100755 --- a/t/t9802-git-p4-filetype.sh +++ b/third_party/git/t/t9802-git-p4-filetype.sh diff --git a/t/t9803-git-p4-shell-metachars.sh b/third_party/git/t/t9803-git-p4-shell-metachars.sh index 2913277013..2913277013 100755 --- a/t/t9803-git-p4-shell-metachars.sh +++ b/third_party/git/t/t9803-git-p4-shell-metachars.sh diff --git a/t/t9804-git-p4-label.sh b/third_party/git/t/t9804-git-p4-label.sh index 3236457106..3236457106 100755 --- a/t/t9804-git-p4-label.sh +++ b/third_party/git/t/t9804-git-p4-label.sh diff --git a/t/t9805-git-p4-skip-submit-edit.sh b/third_party/git/t/t9805-git-p4-skip-submit-edit.sh index 90ef647db7..90ef647db7 100755 --- a/t/t9805-git-p4-skip-submit-edit.sh +++ b/third_party/git/t/t9805-git-p4-skip-submit-edit.sh diff --git a/t/t9806-git-p4-options.sh b/third_party/git/t/t9806-git-p4-options.sh index 4e794a01bf..4e794a01bf 100755 --- a/t/t9806-git-p4-options.sh +++ b/third_party/git/t/t9806-git-p4-options.sh diff --git a/t/t9807-git-p4-submit.sh b/third_party/git/t/t9807-git-p4-submit.sh index eaaae414a1..eaaae414a1 100755 --- a/t/t9807-git-p4-submit.sh +++ b/third_party/git/t/t9807-git-p4-submit.sh diff --git a/t/t9808-git-p4-chdir.sh b/third_party/git/t/t9808-git-p4-chdir.sh index 58a9b3b71e..58a9b3b71e 100755 --- a/t/t9808-git-p4-chdir.sh +++ b/third_party/git/t/t9808-git-p4-chdir.sh diff --git a/t/t9809-git-p4-client-view.sh b/third_party/git/t/t9809-git-p4-client-view.sh index 9c9710d8c7..9c9710d8c7 100755 --- a/t/t9809-git-p4-client-view.sh +++ b/third_party/git/t/t9809-git-p4-client-view.sh diff --git a/t/t9810-git-p4-rcs.sh b/third_party/git/t/t9810-git-p4-rcs.sh index e3836888ec..e3836888ec 100755 --- a/t/t9810-git-p4-rcs.sh +++ b/third_party/git/t/t9810-git-p4-rcs.sh diff --git a/t/t9811-git-p4-label-import.sh b/third_party/git/t/t9811-git-p4-label-import.sh index c1446f26ab..c1446f26ab 100755 --- a/t/t9811-git-p4-label-import.sh +++ b/third_party/git/t/t9811-git-p4-label-import.sh diff --git a/t/t9812-git-p4-wildcards.sh b/third_party/git/t/t9812-git-p4-wildcards.sh index 254a7c2446..254a7c2446 100755 --- a/t/t9812-git-p4-wildcards.sh +++ b/third_party/git/t/t9812-git-p4-wildcards.sh diff --git a/t/t9813-git-p4-preserve-users.sh b/third_party/git/t/t9813-git-p4-preserve-users.sh index fd018c87a8..fd018c87a8 100755 --- a/t/t9813-git-p4-preserve-users.sh +++ b/third_party/git/t/t9813-git-p4-preserve-users.sh diff --git a/t/t9814-git-p4-rename.sh b/third_party/git/t/t9814-git-p4-rename.sh index 468767cbf4..468767cbf4 100755 --- a/t/t9814-git-p4-rename.sh +++ b/third_party/git/t/t9814-git-p4-rename.sh diff --git a/t/t9815-git-p4-submit-fail.sh b/third_party/git/t/t9815-git-p4-submit-fail.sh index 9779dc0d11..9779dc0d11 100755 --- a/t/t9815-git-p4-submit-fail.sh +++ b/third_party/git/t/t9815-git-p4-submit-fail.sh diff --git a/t/t9816-git-p4-locked.sh b/third_party/git/t/t9816-git-p4-locked.sh index 932841003c..932841003c 100755 --- a/t/t9816-git-p4-locked.sh +++ b/third_party/git/t/t9816-git-p4-locked.sh diff --git a/t/t9817-git-p4-exclude.sh b/third_party/git/t/t9817-git-p4-exclude.sh index ec3d937c6a..ec3d937c6a 100755 --- a/t/t9817-git-p4-exclude.sh +++ b/third_party/git/t/t9817-git-p4-exclude.sh diff --git a/t/t9818-git-p4-block.sh b/third_party/git/t/t9818-git-p4-block.sh index 0db7ab9918..0db7ab9918 100755 --- a/t/t9818-git-p4-block.sh +++ b/third_party/git/t/t9818-git-p4-block.sh diff --git a/t/t9819-git-p4-case-folding.sh b/third_party/git/t/t9819-git-p4-case-folding.sh index 600ce1e0b0..600ce1e0b0 100755 --- a/t/t9819-git-p4-case-folding.sh +++ b/third_party/git/t/t9819-git-p4-case-folding.sh diff --git a/t/t9820-git-p4-editor-handling.sh b/third_party/git/t/t9820-git-p4-editor-handling.sh index fa1bba1dd9..fa1bba1dd9 100755 --- a/t/t9820-git-p4-editor-handling.sh +++ b/third_party/git/t/t9820-git-p4-editor-handling.sh diff --git a/t/t9821-git-p4-path-variations.sh b/third_party/git/t/t9821-git-p4-path-variations.sh index ef80f1690b..ef80f1690b 100755 --- a/t/t9821-git-p4-path-variations.sh +++ b/third_party/git/t/t9821-git-p4-path-variations.sh diff --git a/t/t9822-git-p4-path-encoding.sh b/third_party/git/t/t9822-git-p4-path-encoding.sh index 572d395498..572d395498 100755 --- a/t/t9822-git-p4-path-encoding.sh +++ b/third_party/git/t/t9822-git-p4-path-encoding.sh diff --git a/t/t9823-git-p4-mock-lfs.sh b/third_party/git/t/t9823-git-p4-mock-lfs.sh index 88b76dc4d6..88b76dc4d6 100755 --- a/t/t9823-git-p4-mock-lfs.sh +++ b/third_party/git/t/t9823-git-p4-mock-lfs.sh diff --git a/t/t9824-git-p4-git-lfs.sh b/third_party/git/t/t9824-git-p4-git-lfs.sh index a28dbbdd56..a28dbbdd56 100755 --- a/t/t9824-git-p4-git-lfs.sh +++ b/third_party/git/t/t9824-git-p4-git-lfs.sh diff --git a/t/t9825-git-p4-handle-utf16-without-bom.sh b/third_party/git/t/t9825-git-p4-handle-utf16-without-bom.sh index f049ff8229..f049ff8229 100755 --- a/t/t9825-git-p4-handle-utf16-without-bom.sh +++ b/third_party/git/t/t9825-git-p4-handle-utf16-without-bom.sh diff --git a/t/t9826-git-p4-keep-empty-commits.sh b/third_party/git/t/t9826-git-p4-keep-empty-commits.sh index fd64afe064..fd64afe064 100755 --- a/t/t9826-git-p4-keep-empty-commits.sh +++ b/third_party/git/t/t9826-git-p4-keep-empty-commits.sh diff --git a/t/t9827-git-p4-change-filetype.sh b/third_party/git/t/t9827-git-p4-change-filetype.sh index d3670bd7a2..d3670bd7a2 100755 --- a/t/t9827-git-p4-change-filetype.sh +++ b/third_party/git/t/t9827-git-p4-change-filetype.sh diff --git a/t/t9828-git-p4-map-user.sh b/third_party/git/t/t9828-git-p4-map-user.sh index ca6c2942bd..ca6c2942bd 100755 --- a/t/t9828-git-p4-map-user.sh +++ b/third_party/git/t/t9828-git-p4-map-user.sh diff --git a/t/t9829-git-p4-jobs.sh b/third_party/git/t/t9829-git-p4-jobs.sh index 88cfb1fcd3..88cfb1fcd3 100755 --- a/t/t9829-git-p4-jobs.sh +++ b/third_party/git/t/t9829-git-p4-jobs.sh diff --git a/t/t9830-git-p4-symlink-dir.sh b/third_party/git/t/t9830-git-p4-symlink-dir.sh index 3fb6960c18..3fb6960c18 100755 --- a/t/t9830-git-p4-symlink-dir.sh +++ b/third_party/git/t/t9830-git-p4-symlink-dir.sh diff --git a/t/t9831-git-p4-triggers.sh b/third_party/git/t/t9831-git-p4-triggers.sh index d743ca33ee..d743ca33ee 100755 --- a/t/t9831-git-p4-triggers.sh +++ b/third_party/git/t/t9831-git-p4-triggers.sh diff --git a/t/t9832-unshelve.sh b/third_party/git/t/t9832-unshelve.sh index e9276c48f4..e9276c48f4 100755 --- a/t/t9832-unshelve.sh +++ b/third_party/git/t/t9832-unshelve.sh diff --git a/t/t9833-errors.sh b/third_party/git/t/t9833-errors.sh index e22369ccdf..e22369ccdf 100755 --- a/t/t9833-errors.sh +++ b/third_party/git/t/t9833-errors.sh diff --git a/t/t9901-git-web--browse.sh b/third_party/git/t/t9901-git-web--browse.sh index de7152f827..de7152f827 100755 --- a/t/t9901-git-web--browse.sh +++ b/third_party/git/t/t9901-git-web--browse.sh diff --git a/t/t9902-completion.sh b/third_party/git/t/t9902-completion.sh index 5505e5aa24..5505e5aa24 100755 --- a/t/t9902-completion.sh +++ b/third_party/git/t/t9902-completion.sh diff --git a/t/t9903-bash-prompt.sh b/third_party/git/t/t9903-bash-prompt.sh index ab5da2cabc..ab5da2cabc 100755 --- a/t/t9903-bash-prompt.sh +++ b/third_party/git/t/t9903-bash-prompt.sh diff --git a/t/test-binary-1.png b/third_party/git/t/test-binary-1.png index 7b181d15ce..7b181d15ce 100644 --- a/t/test-binary-1.png +++ b/third_party/git/t/test-binary-1.png Binary files differdiff --git a/t/test-binary-2.png b/third_party/git/t/test-binary-2.png index ac22ccbd3e..ac22ccbd3e 100644 --- a/t/test-binary-2.png +++ b/third_party/git/t/test-binary-2.png Binary files differdiff --git a/t/test-lib-functions.sh b/third_party/git/t/test-lib-functions.sh index 352c213d52..352c213d52 100644 --- a/t/test-lib-functions.sh +++ b/third_party/git/t/test-lib-functions.sh diff --git a/t/test-lib.sh b/third_party/git/t/test-lib.sh index 0ea1e5a05e..0ea1e5a05e 100644 --- a/t/test-lib.sh +++ b/third_party/git/t/test-lib.sh diff --git a/t/test-terminal.perl b/third_party/git/t/test-terminal.perl index 46bf618479..46bf618479 100755 --- a/t/test-terminal.perl +++ b/third_party/git/t/test-terminal.perl diff --git a/t/valgrind/.gitignore b/third_party/git/t/valgrind/.gitignore index d4ae6676d1..d4ae6676d1 100644 --- a/t/valgrind/.gitignore +++ b/third_party/git/t/valgrind/.gitignore diff --git a/t/valgrind/analyze.sh b/third_party/git/t/valgrind/analyze.sh index 2ffc80f721..2ffc80f721 100755 --- a/t/valgrind/analyze.sh +++ b/third_party/git/t/valgrind/analyze.sh diff --git a/t/valgrind/default.supp b/third_party/git/t/valgrind/default.supp index 0a6724fcc4..0a6724fcc4 100644 --- a/t/valgrind/default.supp +++ b/third_party/git/t/valgrind/default.supp diff --git a/t/valgrind/valgrind.sh b/third_party/git/t/valgrind/valgrind.sh index 669ebaf68b..669ebaf68b 100755 --- a/t/valgrind/valgrind.sh +++ b/third_party/git/t/valgrind/valgrind.sh diff --git a/tag.c b/third_party/git/tag.c index 71b544467e..71b544467e 100644 --- a/tag.c +++ b/third_party/git/tag.c diff --git a/tag.h b/third_party/git/tag.h index 3ce8e72192..3ce8e72192 100644 --- a/tag.h +++ b/third_party/git/tag.h diff --git a/tar.h b/third_party/git/tar.h index 6b258c4d4a..6b258c4d4a 100644 --- a/tar.h +++ b/third_party/git/tar.h diff --git a/tempfile.c b/third_party/git/tempfile.c index d43ad8c191..d43ad8c191 100644 --- a/tempfile.c +++ b/third_party/git/tempfile.c diff --git a/tempfile.h b/third_party/git/tempfile.h index cddda0a33c..cddda0a33c 100644 --- a/tempfile.h +++ b/third_party/git/tempfile.h diff --git a/templates/.gitignore b/third_party/git/templates/.gitignore index 6759ecbf98..6759ecbf98 100644 --- a/templates/.gitignore +++ b/third_party/git/templates/.gitignore diff --git a/templates/Makefile b/third_party/git/templates/Makefile index d22a71a399..d22a71a399 100644 --- a/templates/Makefile +++ b/third_party/git/templates/Makefile diff --git a/templates/branches-- b/third_party/git/templates/branches-- index fae88709a6..fae88709a6 100644 --- a/templates/branches-- +++ b/third_party/git/templates/branches-- diff --git a/templates/hooks--applypatch-msg.sample b/third_party/git/templates/hooks--applypatch-msg.sample index a5d7b84a67..a5d7b84a67 100755 --- a/templates/hooks--applypatch-msg.sample +++ b/third_party/git/templates/hooks--applypatch-msg.sample diff --git a/templates/hooks--commit-msg.sample b/third_party/git/templates/hooks--commit-msg.sample index b58d1184a9..b58d1184a9 100755 --- a/templates/hooks--commit-msg.sample +++ b/third_party/git/templates/hooks--commit-msg.sample diff --git a/templates/hooks--fsmonitor-watchman.sample b/third_party/git/templates/hooks--fsmonitor-watchman.sample index 14ed0aa42d..14ed0aa42d 100755 --- a/templates/hooks--fsmonitor-watchman.sample +++ b/third_party/git/templates/hooks--fsmonitor-watchman.sample diff --git a/templates/hooks--post-update.sample b/third_party/git/templates/hooks--post-update.sample index ec17ec1939..ec17ec1939 100755 --- a/templates/hooks--post-update.sample +++ b/third_party/git/templates/hooks--post-update.sample diff --git a/templates/hooks--pre-applypatch.sample b/third_party/git/templates/hooks--pre-applypatch.sample index 4142082bcb..4142082bcb 100755 --- a/templates/hooks--pre-applypatch.sample +++ b/third_party/git/templates/hooks--pre-applypatch.sample diff --git a/templates/hooks--pre-commit.sample b/third_party/git/templates/hooks--pre-commit.sample index e144712c85..e144712c85 100755 --- a/templates/hooks--pre-commit.sample +++ b/third_party/git/templates/hooks--pre-commit.sample diff --git a/templates/hooks--pre-merge-commit.sample b/third_party/git/templates/hooks--pre-merge-commit.sample index 399eab1924..399eab1924 100755 --- a/templates/hooks--pre-merge-commit.sample +++ b/third_party/git/templates/hooks--pre-merge-commit.sample diff --git a/templates/hooks--pre-push.sample b/third_party/git/templates/hooks--pre-push.sample index 6187dbf439..6187dbf439 100755 --- a/templates/hooks--pre-push.sample +++ b/third_party/git/templates/hooks--pre-push.sample diff --git a/templates/hooks--pre-rebase.sample b/third_party/git/templates/hooks--pre-rebase.sample index db5feab8a1..db5feab8a1 100755 --- a/templates/hooks--pre-rebase.sample +++ b/third_party/git/templates/hooks--pre-rebase.sample diff --git a/templates/hooks--pre-receive.sample b/third_party/git/templates/hooks--pre-receive.sample index a1fd29ec14..a1fd29ec14 100755 --- a/templates/hooks--pre-receive.sample +++ b/third_party/git/templates/hooks--pre-receive.sample diff --git a/templates/hooks--prepare-commit-msg.sample b/third_party/git/templates/hooks--prepare-commit-msg.sample index 318afe3fd8..318afe3fd8 100755 --- a/templates/hooks--prepare-commit-msg.sample +++ b/third_party/git/templates/hooks--prepare-commit-msg.sample diff --git a/templates/hooks--update.sample b/third_party/git/templates/hooks--update.sample index 5014c4b31c..5014c4b31c 100755 --- a/templates/hooks--update.sample +++ b/third_party/git/templates/hooks--update.sample diff --git a/templates/info--exclude b/third_party/git/templates/info--exclude index a5196d1be8..a5196d1be8 100644 --- a/templates/info--exclude +++ b/third_party/git/templates/info--exclude diff --git a/templates/this--description b/third_party/git/templates/this--description index 498b267a8c..498b267a8c 100644 --- a/templates/this--description +++ b/third_party/git/templates/this--description diff --git a/thread-utils.c b/third_party/git/thread-utils.c index 5329845691..5329845691 100644 --- a/thread-utils.c +++ b/third_party/git/thread-utils.c diff --git a/thread-utils.h b/third_party/git/thread-utils.h index 4961487ed9..4961487ed9 100644 --- a/thread-utils.h +++ b/third_party/git/thread-utils.h diff --git a/tmp-objdir.c b/third_party/git/tmp-objdir.c index 91c00567f4..91c00567f4 100644 --- a/tmp-objdir.c +++ b/third_party/git/tmp-objdir.c diff --git a/tmp-objdir.h b/third_party/git/tmp-objdir.h index b1e45b4c75..b1e45b4c75 100644 --- a/tmp-objdir.h +++ b/third_party/git/tmp-objdir.h diff --git a/trace.c b/third_party/git/trace.c index b3ef0e627f..b3ef0e627f 100644 --- a/trace.c +++ b/third_party/git/trace.c diff --git a/trace.h b/third_party/git/trace.h index 9826618b33..9826618b33 100644 --- a/trace.h +++ b/third_party/git/trace.h diff --git a/trace2.c b/third_party/git/trace2.c index c7b4f14d29..c7b4f14d29 100644 --- a/trace2.c +++ b/third_party/git/trace2.c diff --git a/trace2.h b/third_party/git/trace2.h index e5e81c0533..e5e81c0533 100644 --- a/trace2.h +++ b/third_party/git/trace2.h diff --git a/trace2/tr2_cfg.c b/third_party/git/trace2/tr2_cfg.c index caa7f06948..caa7f06948 100644 --- a/trace2/tr2_cfg.c +++ b/third_party/git/trace2/tr2_cfg.c diff --git a/trace2/tr2_cfg.h b/third_party/git/trace2/tr2_cfg.h index d9c98f64dd..d9c98f64dd 100644 --- a/trace2/tr2_cfg.h +++ b/third_party/git/trace2/tr2_cfg.h diff --git a/trace2/tr2_cmd_name.c b/third_party/git/trace2/tr2_cmd_name.c index dd313204f5..dd313204f5 100644 --- a/trace2/tr2_cmd_name.c +++ b/third_party/git/trace2/tr2_cmd_name.c diff --git a/trace2/tr2_cmd_name.h b/third_party/git/trace2/tr2_cmd_name.h index ab70b67a8e..ab70b67a8e 100644 --- a/trace2/tr2_cmd_name.h +++ b/third_party/git/trace2/tr2_cmd_name.h diff --git a/trace2/tr2_dst.c b/third_party/git/trace2/tr2_dst.c index ae052a07fe..ae052a07fe 100644 --- a/trace2/tr2_dst.c +++ b/third_party/git/trace2/tr2_dst.c diff --git a/trace2/tr2_dst.h b/third_party/git/trace2/tr2_dst.h index b1a8c144e0..b1a8c144e0 100644 --- a/trace2/tr2_dst.h +++ b/third_party/git/trace2/tr2_dst.h diff --git a/trace2/tr2_sid.c b/third_party/git/trace2/tr2_sid.c index dc6e75ef13..dc6e75ef13 100644 --- a/trace2/tr2_sid.c +++ b/third_party/git/trace2/tr2_sid.c diff --git a/trace2/tr2_sid.h b/third_party/git/trace2/tr2_sid.h index 9bef321708..9bef321708 100644 --- a/trace2/tr2_sid.h +++ b/third_party/git/trace2/tr2_sid.h diff --git a/trace2/tr2_sysenv.c b/third_party/git/trace2/tr2_sysenv.c index 3c3792eca2..3c3792eca2 100644 --- a/trace2/tr2_sysenv.c +++ b/third_party/git/trace2/tr2_sysenv.c diff --git a/trace2/tr2_sysenv.h b/third_party/git/trace2/tr2_sysenv.h index d4364a7b85..d4364a7b85 100644 --- a/trace2/tr2_sysenv.h +++ b/third_party/git/trace2/tr2_sysenv.h diff --git a/trace2/tr2_tbuf.c b/third_party/git/trace2/tr2_tbuf.c index 2498482d9a..2498482d9a 100644 --- a/trace2/tr2_tbuf.c +++ b/third_party/git/trace2/tr2_tbuf.c diff --git a/trace2/tr2_tbuf.h b/third_party/git/trace2/tr2_tbuf.h index fa853d8f42..fa853d8f42 100644 --- a/trace2/tr2_tbuf.h +++ b/third_party/git/trace2/tr2_tbuf.h diff --git a/trace2/tr2_tgt.h b/third_party/git/trace2/tr2_tgt.h index 7b90469212..7b90469212 100644 --- a/trace2/tr2_tgt.h +++ b/third_party/git/trace2/tr2_tgt.h diff --git a/trace2/tr2_tgt_event.c b/third_party/git/trace2/tr2_tgt_event.c index 6353e8ad91..6353e8ad91 100644 --- a/trace2/tr2_tgt_event.c +++ b/third_party/git/trace2/tr2_tgt_event.c diff --git a/trace2/tr2_tgt_normal.c b/third_party/git/trace2/tr2_tgt_normal.c index 31b602c171..31b602c171 100644 --- a/trace2/tr2_tgt_normal.c +++ b/third_party/git/trace2/tr2_tgt_normal.c diff --git a/trace2/tr2_tgt_perf.c b/third_party/git/trace2/tr2_tgt_perf.c index a8018f18cc..a8018f18cc 100644 --- a/trace2/tr2_tgt_perf.c +++ b/third_party/git/trace2/tr2_tgt_perf.c diff --git a/trace2/tr2_tls.c b/third_party/git/trace2/tr2_tls.c index 067c23755f..067c23755f 100644 --- a/trace2/tr2_tls.c +++ b/third_party/git/trace2/tr2_tls.c diff --git a/trace2/tr2_tls.h b/third_party/git/trace2/tr2_tls.h index b1e327a928..b1e327a928 100644 --- a/trace2/tr2_tls.h +++ b/third_party/git/trace2/tr2_tls.h diff --git a/trailer.c b/third_party/git/trailer.c index 0c414f2fed..0c414f2fed 100644 --- a/trailer.c +++ b/third_party/git/trailer.c diff --git a/trailer.h b/third_party/git/trailer.h index 203acf4ee1..203acf4ee1 100644 --- a/trailer.h +++ b/third_party/git/trailer.h diff --git a/transport-helper.c b/third_party/git/transport-helper.c index 20a7185ec4..20a7185ec4 100644 --- a/transport-helper.c +++ b/third_party/git/transport-helper.c diff --git a/transport-internal.h b/third_party/git/transport-internal.h index 1cde6258a7..1cde6258a7 100644 --- a/transport-internal.h +++ b/third_party/git/transport-internal.h diff --git a/transport.c b/third_party/git/transport.c index 1fdc7dac1a..1fdc7dac1a 100644 --- a/transport.c +++ b/third_party/git/transport.c diff --git a/transport.h b/third_party/git/transport.h index e0131daab9..e0131daab9 100644 --- a/transport.h +++ b/third_party/git/transport.h diff --git a/tree-diff.c b/third_party/git/tree-diff.c index 33ded7f8b3..33ded7f8b3 100644 --- a/tree-diff.c +++ b/third_party/git/tree-diff.c diff --git a/tree-walk.c b/third_party/git/tree-walk.c index bb0ad34c54..bb0ad34c54 100644 --- a/tree-walk.c +++ b/third_party/git/tree-walk.c diff --git a/tree-walk.h b/third_party/git/tree-walk.h index a5058469e9..a5058469e9 100644 --- a/tree-walk.h +++ b/third_party/git/tree-walk.h diff --git a/tree.c b/third_party/git/tree.c index 1466bcc6a8..1466bcc6a8 100644 --- a/tree.c +++ b/third_party/git/tree.c diff --git a/tree.h b/third_party/git/tree.h index 9383745073..9383745073 100644 --- a/tree.h +++ b/third_party/git/tree.h diff --git a/unicode-width.h b/third_party/git/unicode-width.h index b50e686bae..b50e686bae 100644 --- a/unicode-width.h +++ b/third_party/git/unicode-width.h diff --git a/unimplemented.sh b/third_party/git/unimplemented.sh index fee21d24e8..fee21d24e8 100644 --- a/unimplemented.sh +++ b/third_party/git/unimplemented.sh diff --git a/unix-socket.c b/third_party/git/unix-socket.c index 19ed48be99..19ed48be99 100644 --- a/unix-socket.c +++ b/third_party/git/unix-socket.c diff --git a/unix-socket.h b/third_party/git/unix-socket.h index e271aeec5a..e271aeec5a 100644 --- a/unix-socket.h +++ b/third_party/git/unix-socket.h diff --git a/unpack-trees.c b/third_party/git/unpack-trees.c index 1ecdab3304..1ecdab3304 100644 --- a/unpack-trees.c +++ b/third_party/git/unpack-trees.c diff --git a/unpack-trees.h b/third_party/git/unpack-trees.h index ae1557fb80..ae1557fb80 100644 --- a/unpack-trees.h +++ b/third_party/git/unpack-trees.h diff --git a/upload-pack.c b/third_party/git/upload-pack.c index c53249cac1..c53249cac1 100644 --- a/upload-pack.c +++ b/third_party/git/upload-pack.c diff --git a/upload-pack.h b/third_party/git/upload-pack.h index 4bafe16a22..4bafe16a22 100644 --- a/upload-pack.h +++ b/third_party/git/upload-pack.h diff --git a/url.c b/third_party/git/url.c index e04bd60b6b..e04bd60b6b 100644 --- a/url.c +++ b/third_party/git/url.c diff --git a/url.h b/third_party/git/url.h index 2a27c34277..2a27c34277 100644 --- a/url.h +++ b/third_party/git/url.h diff --git a/urlmatch.c b/third_party/git/urlmatch.c index 29272a5c4f..29272a5c4f 100644 --- a/urlmatch.c +++ b/third_party/git/urlmatch.c diff --git a/urlmatch.h b/third_party/git/urlmatch.h index 2407520731..2407520731 100644 --- a/urlmatch.h +++ b/third_party/git/urlmatch.h diff --git a/usage.c b/third_party/git/usage.c index 58fb5fff5f..58fb5fff5f 100644 --- a/usage.c +++ b/third_party/git/usage.c diff --git a/userdiff.c b/third_party/git/userdiff.c index efbe05e5a5..efbe05e5a5 100644 --- a/userdiff.c +++ b/third_party/git/userdiff.c diff --git a/userdiff.h b/third_party/git/userdiff.h index 203057e13e..203057e13e 100644 --- a/userdiff.h +++ b/third_party/git/userdiff.h diff --git a/utf8.c b/third_party/git/utf8.c index 5b39361ada..5b39361ada 100644 --- a/utf8.c +++ b/third_party/git/utf8.c diff --git a/utf8.h b/third_party/git/utf8.h index fcd5167baf..fcd5167baf 100644 --- a/utf8.h +++ b/third_party/git/utf8.h diff --git a/varint.c b/third_party/git/varint.c index 409c4977a1..409c4977a1 100644 --- a/varint.c +++ b/third_party/git/varint.c diff --git a/varint.h b/third_party/git/varint.h index f78bb0ca52..f78bb0ca52 100644 --- a/varint.h +++ b/third_party/git/varint.h diff --git a/vcs-svn/LICENSE b/third_party/git/vcs-svn/LICENSE index eb91858b82..eb91858b82 100644 --- a/vcs-svn/LICENSE +++ b/third_party/git/vcs-svn/LICENSE diff --git a/vcs-svn/fast_export.c b/third_party/git/vcs-svn/fast_export.c index b5b8913cb0..b5b8913cb0 100644 --- a/vcs-svn/fast_export.c +++ b/third_party/git/vcs-svn/fast_export.c diff --git a/vcs-svn/fast_export.h b/third_party/git/vcs-svn/fast_export.h index 9dcf9337c1..9dcf9337c1 100644 --- a/vcs-svn/fast_export.h +++ b/third_party/git/vcs-svn/fast_export.h diff --git a/vcs-svn/line_buffer.c b/third_party/git/vcs-svn/line_buffer.c index e416caf8a4..e416caf8a4 100644 --- a/vcs-svn/line_buffer.c +++ b/third_party/git/vcs-svn/line_buffer.c diff --git a/vcs-svn/line_buffer.h b/third_party/git/vcs-svn/line_buffer.h index e192aedea2..e192aedea2 100644 --- a/vcs-svn/line_buffer.h +++ b/third_party/git/vcs-svn/line_buffer.h diff --git a/vcs-svn/line_buffer.txt b/third_party/git/vcs-svn/line_buffer.txt index 8e139eb22d..8e139eb22d 100644 --- a/vcs-svn/line_buffer.txt +++ b/third_party/git/vcs-svn/line_buffer.txt diff --git a/vcs-svn/sliding_window.c b/third_party/git/vcs-svn/sliding_window.c index 06d273c9e8..06d273c9e8 100644 --- a/vcs-svn/sliding_window.c +++ b/third_party/git/vcs-svn/sliding_window.c diff --git a/vcs-svn/sliding_window.h b/third_party/git/vcs-svn/sliding_window.h index a7fc0999cb..a7fc0999cb 100644 --- a/vcs-svn/sliding_window.h +++ b/third_party/git/vcs-svn/sliding_window.h diff --git a/vcs-svn/svndiff.c b/third_party/git/vcs-svn/svndiff.c index 75c753162a..75c753162a 100644 --- a/vcs-svn/svndiff.c +++ b/third_party/git/vcs-svn/svndiff.c diff --git a/vcs-svn/svndiff.h b/third_party/git/vcs-svn/svndiff.h index 625d950bb8..625d950bb8 100644 --- a/vcs-svn/svndiff.h +++ b/third_party/git/vcs-svn/svndiff.h diff --git a/vcs-svn/svndump.c b/third_party/git/vcs-svn/svndump.c index 08d136b8cc..08d136b8cc 100644 --- a/vcs-svn/svndump.c +++ b/third_party/git/vcs-svn/svndump.c diff --git a/vcs-svn/svndump.h b/third_party/git/vcs-svn/svndump.h index 26faed5968..26faed5968 100644 --- a/vcs-svn/svndump.h +++ b/third_party/git/vcs-svn/svndump.h diff --git a/version.c b/third_party/git/version.c index 41b718c29e..41b718c29e 100644 --- a/version.c +++ b/third_party/git/version.c diff --git a/version.h b/third_party/git/version.h index 7c62e80577..7c62e80577 100644 --- a/version.h +++ b/third_party/git/version.h diff --git a/versioncmp.c b/third_party/git/versioncmp.c index 069ee94a4d..069ee94a4d 100644 --- a/versioncmp.c +++ b/third_party/git/versioncmp.c diff --git a/walker.c b/third_party/git/walker.c index 4984bf8b3d..4984bf8b3d 100644 --- a/walker.c +++ b/third_party/git/walker.c diff --git a/walker.h b/third_party/git/walker.h index d40b016bab..d40b016bab 100644 --- a/walker.h +++ b/third_party/git/walker.h diff --git a/wildmatch.c b/third_party/git/wildmatch.c index 9e9e2a2f95..9e9e2a2f95 100644 --- a/wildmatch.c +++ b/third_party/git/wildmatch.c diff --git a/wildmatch.h b/third_party/git/wildmatch.h index 5993696298..5993696298 100644 --- a/wildmatch.h +++ b/third_party/git/wildmatch.h diff --git a/worktree.c b/third_party/git/worktree.c index eba4fd3a03..eba4fd3a03 100644 --- a/worktree.c +++ b/third_party/git/worktree.c diff --git a/worktree.h b/third_party/git/worktree.h index d242a6e71c..d242a6e71c 100644 --- a/worktree.h +++ b/third_party/git/worktree.h diff --git a/wrap-for-bin.sh b/third_party/git/wrap-for-bin.sh index 95851b85b6..95851b85b6 100644 --- a/wrap-for-bin.sh +++ b/third_party/git/wrap-for-bin.sh diff --git a/wrapper.c b/third_party/git/wrapper.c index e1eaef2e16..e1eaef2e16 100644 --- a/wrapper.c +++ b/third_party/git/wrapper.c diff --git a/write-or-die.c b/third_party/git/write-or-die.c index eab8c8d0b9..eab8c8d0b9 100644 --- a/write-or-die.c +++ b/third_party/git/write-or-die.c diff --git a/ws.c b/third_party/git/ws.c index 6e69877f25..6e69877f25 100644 --- a/ws.c +++ b/third_party/git/ws.c diff --git a/wt-status.c b/third_party/git/wt-status.c index cc6f94504d..cc6f94504d 100644 --- a/wt-status.c +++ b/third_party/git/wt-status.c diff --git a/wt-status.h b/third_party/git/wt-status.h index 71c3f25f43..71c3f25f43 100644 --- a/wt-status.h +++ b/third_party/git/wt-status.h diff --git a/xdiff-interface.c b/third_party/git/xdiff-interface.c index 4d20069302..4d20069302 100644 --- a/xdiff-interface.c +++ b/third_party/git/xdiff-interface.c diff --git a/xdiff-interface.h b/third_party/git/xdiff-interface.h index 93df26900c..93df26900c 100644 --- a/xdiff-interface.h +++ b/third_party/git/xdiff-interface.h diff --git a/xdiff/xdiff.h b/third_party/git/xdiff/xdiff.h index 032e3a9f41..032e3a9f41 100644 --- a/xdiff/xdiff.h +++ b/third_party/git/xdiff/xdiff.h diff --git a/xdiff/xdiffi.c b/third_party/git/xdiff/xdiffi.c index bd035139f9..bd035139f9 100644 --- a/xdiff/xdiffi.c +++ b/third_party/git/xdiff/xdiffi.c diff --git a/xdiff/xdiffi.h b/third_party/git/xdiff/xdiffi.h index 8f1c7c8b04..8f1c7c8b04 100644 --- a/xdiff/xdiffi.h +++ b/third_party/git/xdiff/xdiffi.h diff --git a/xdiff/xemit.c b/third_party/git/xdiff/xemit.c index 9d7d6c5087..9d7d6c5087 100644 --- a/xdiff/xemit.c +++ b/third_party/git/xdiff/xemit.c diff --git a/xdiff/xemit.h b/third_party/git/xdiff/xemit.h index 1b9887e670..1b9887e670 100644 --- a/xdiff/xemit.h +++ b/third_party/git/xdiff/xemit.h diff --git a/xdiff/xhistogram.c b/third_party/git/xdiff/xhistogram.c index c7b35a9667..c7b35a9667 100644 --- a/xdiff/xhistogram.c +++ b/third_party/git/xdiff/xhistogram.c diff --git a/xdiff/xinclude.h b/third_party/git/xdiff/xinclude.h index a4285ac0eb..a4285ac0eb 100644 --- a/xdiff/xinclude.h +++ b/third_party/git/xdiff/xinclude.h diff --git a/xdiff/xmacros.h b/third_party/git/xdiff/xmacros.h index 2809a28ca9..2809a28ca9 100644 --- a/xdiff/xmacros.h +++ b/third_party/git/xdiff/xmacros.h diff --git a/xdiff/xmerge.c b/third_party/git/xdiff/xmerge.c index 1659edb453..1659edb453 100644 --- a/xdiff/xmerge.c +++ b/third_party/git/xdiff/xmerge.c diff --git a/xdiff/xpatience.c b/third_party/git/xdiff/xpatience.c index 3c5601b602..3c5601b602 100644 --- a/xdiff/xpatience.c +++ b/third_party/git/xdiff/xpatience.c diff --git a/xdiff/xprepare.c b/third_party/git/xdiff/xprepare.c index abeb8fb84e..abeb8fb84e 100644 --- a/xdiff/xprepare.c +++ b/third_party/git/xdiff/xprepare.c diff --git a/xdiff/xprepare.h b/third_party/git/xdiff/xprepare.h index 947d9fc1bb..947d9fc1bb 100644 --- a/xdiff/xprepare.h +++ b/third_party/git/xdiff/xprepare.h diff --git a/xdiff/xtypes.h b/third_party/git/xdiff/xtypes.h index 8442bd436e..8442bd436e 100644 --- a/xdiff/xtypes.h +++ b/third_party/git/xdiff/xtypes.h diff --git a/xdiff/xutils.c b/third_party/git/xdiff/xutils.c index cfa6e2220f..cfa6e2220f 100644 --- a/xdiff/xutils.c +++ b/third_party/git/xdiff/xutils.c diff --git a/xdiff/xutils.h b/third_party/git/xdiff/xutils.h index fba7bae03c..fba7bae03c 100644 --- a/xdiff/xutils.h +++ b/third_party/git/xdiff/xutils.h diff --git a/zlib.c b/third_party/git/zlib.c index d594cba3fc..d594cba3fc 100644 --- a/zlib.c +++ b/third_party/git/zlib.c diff --git a/third_party/glog/default.nix b/third_party/glog/default.nix new file mode 100644 index 0000000000..c51724e27b --- /dev/null +++ b/third_party/glog/default.nix @@ -0,0 +1,15 @@ +{ pkgs, ... }: + +pkgs.originals.glog.overrideAttrs(old: { + version = "master-20200518"; + + # packaged version has a patch that is now in master. + patches = []; + + src = pkgs.fetchFromGitHub { + owner = "google"; + repo = "glog"; + rev = "0a2e5931bd5ff22fd3bf8999eb8ce776f159cda6"; + sha256 = "08yih0hc63j02p0ms4ydbgf2c13v2c7knjzp3qdin0v3sng896wg"; + }; +}) diff --git a/third_party/gopkgs/cloud.google.com/go/default.nix b/third_party/gopkgs/cloud.google.com/go/default.nix new file mode 100644 index 0000000000..d6c897f15e --- /dev/null +++ b/third_party/gopkgs/cloud.google.com/go/default.nix @@ -0,0 +1,9 @@ +{ pkgs, ... }: + +depot.buildGo.external { + path = "cloud.google.com/go"; + src = builtins.fetchGit { + url = "https://code.googlesource.com/gocloud"; + rev = "4f03f8e4ba168c636e1c218da7ab41a1c8c0d8cf"; + }; +} diff --git a/third_party/gopkgs/github.com/emirpasic/gods/default.nix b/third_party/gopkgs/github.com/emirpasic/gods/default.nix new file mode 100644 index 0000000000..c43485ee5f --- /dev/null +++ b/third_party/gopkgs/github.com/emirpasic/gods/default.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/emirpasic/gods"; + + src = depot.third_party.fetchFromGitHub { + owner = "emirpasic"; + repo = "gods"; + rev = "4e23915b9a82f35f320a68a395a7a5045c826932"; + sha256 = "00f8ch1rccakc62f9nj97hapvnx84z7wbcdmbmz7p802b9mxk5nl"; + }; +} diff --git a/third_party/gopkgs/github.com/golang/groupcache/default.nix b/third_party/gopkgs/github.com/golang/groupcache/default.nix new file mode 100644 index 0000000000..8c0a639a32 --- /dev/null +++ b/third_party/gopkgs/github.com/golang/groupcache/default.nix @@ -0,0 +1,9 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/golang/groupcache"; + src = builtins.fetchGit { + url = "https://github.com/golang/groupcache"; + rev = "611e8accdfc92c4187d399e95ce826046d4c8d73"; + }; +} diff --git a/third_party/gopkgs/github.com/golang/protobuf/default.nix b/third_party/gopkgs/github.com/golang/protobuf/default.nix new file mode 100644 index 0000000000..3a405181b2 --- /dev/null +++ b/third_party/gopkgs/github.com/golang/protobuf/default.nix @@ -0,0 +1,9 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/golang/protobuf"; + src = builtins.fetchGit { + url = "https://github.com/golang/protobuf"; + rev = "ed6926b37a637426117ccab59282c3839528a700"; + }; +} diff --git a/third_party/gopkgs/github.com/google/uuid/default.nix b/third_party/gopkgs/github.com/google/uuid/default.nix new file mode 100644 index 0000000000..f590b5749b --- /dev/null +++ b/third_party/gopkgs/github.com/google/uuid/default.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/google/uuid"; + + src = depot.third_party.fetchFromGitHub { + owner = "google"; + repo = "uuid"; + rev = "c2e93f3ae59f2904160ceaab466009f965df46d6"; + sha256 = "0zw8fvl6jqg0fmv6kmvhss0g4gkrbvgyvl2zgy5wdbdlgp4fja0h"; + }; +} diff --git a/third_party/gopkgs/github.com/googleapis/gax-go/default.nix b/third_party/gopkgs/github.com/googleapis/gax-go/default.nix new file mode 100644 index 0000000000..d897e155e9 --- /dev/null +++ b/third_party/gopkgs/github.com/googleapis/gax-go/default.nix @@ -0,0 +1,19 @@ +{ depot, ... }: + +let + inherit (depot) buildGo; + inherit (builtins) fetchGit; +in depot.buildGo.external { + path = "github.com/googleapis/gax-go"; + src = fetchGit { + url = "https://github.com/googleapis/gax-go"; + rev = "b443e5a67ec8eeac76f5f384004931878cab24b3"; + }; + + deps = with depot.third_party; [ + gopkgs."golang.org".x.net.trace.gopkg + gopkgs."google.golang.org".grpc.gopkg + gopkgs."google.golang.org".grpc.codes.gopkg + gopkgs."google.golang.org".grpc.status.gopkg + ]; +} diff --git a/third_party/gopkgs/github.com/hashicorp/golang-lru/default.nix b/third_party/gopkgs/github.com/hashicorp/golang-lru/default.nix new file mode 100644 index 0000000000..4e8073f93a --- /dev/null +++ b/third_party/gopkgs/github.com/hashicorp/golang-lru/default.nix @@ -0,0 +1,14 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/hashicorp/golang-lru"; + src = builtins.fetchGit { + url = "https://github.com/hashicorp/golang-lru"; + rev = "7f827b33c0f158ec5dfbba01bb0b14a4541fd81d"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."golang.org".x.net.context.ctxhttp + gopkgs."cloud.google.com".go.compute.metadata + ]; +} diff --git a/third_party/gopkgs/github.com/jbenet/go-context/default.nix b/third_party/gopkgs/github.com/jbenet/go-context/default.nix new file mode 100644 index 0000000000..4092f8ecff --- /dev/null +++ b/third_party/gopkgs/github.com/jbenet/go-context/default.nix @@ -0,0 +1,16 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/jbenet/go-context"; + + src = depot.third_party.fetchFromGitHub { + owner = "jbenet"; + repo = "go-context"; + rev = "d14ea06fba99483203c19d92cfcd13ebe73135f4"; + sha256 = "0q91f5549n81w3z5927n4a1mdh220bdmgl42zi3h992dcc4ls0sl"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."golang.org".x.net.context + ]; +} diff --git a/third_party/gopkgs/github.com/kevinburke/ssh_config/default.nix b/third_party/gopkgs/github.com/kevinburke/ssh_config/default.nix new file mode 100644 index 0000000000..a3371dea22 --- /dev/null +++ b/third_party/gopkgs/github.com/kevinburke/ssh_config/default.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/kevinburke/ssh_config"; + + src = depot.third_party.fetchFromGitHub { + owner = "kevinburke"; + repo = "ssh_config"; + rev = "01f96b0aa0cdcaa93f9495f89bbc6cb5a992ce6e"; + sha256 = "1bxfjkjl3ibzdkwyvgdwawmd0skz30ah1ha10rg6fkxvj7lgg4jz"; + }; +} diff --git a/third_party/gopkgs/github.com/mitchellh/go-homedir/default.nix b/third_party/gopkgs/github.com/mitchellh/go-homedir/default.nix new file mode 100644 index 0000000000..974f39c919 --- /dev/null +++ b/third_party/gopkgs/github.com/mitchellh/go-homedir/default.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/mitchellh/go-homedir"; + + src = depot.third_party.fetchFromGitHub { + owner = "mitchellh"; + repo = "go-homedir"; + rev = "af06845cf3004701891bf4fdb884bfe4920b3727"; + sha256 = "0ydzkipf28hwj2bfxqmwlww47khyk6d152xax4bnyh60f4lq3nx1"; + }; +} diff --git a/third_party/gopkgs/github.com/sergi/go-diff/default.nix b/third_party/gopkgs/github.com/sergi/go-diff/default.nix new file mode 100644 index 0000000000..c789fc5815 --- /dev/null +++ b/third_party/gopkgs/github.com/sergi/go-diff/default.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/sergi/go-diff"; + + src = depot.third_party.fetchFromGitHub { + owner = "sergi"; + repo = "go-diff"; + rev = "58c5cb1602ee9676b5d3590d782bedde80706fcc"; + sha256 = "0ir8ali2vx0j7pipmlfd6k8c973akyy2nmbjrf008fm800zcp7z2"; + }; +} diff --git a/third_party/gopkgs/github.com/src-d/gcfg/default.nix b/third_party/gopkgs/github.com/src-d/gcfg/default.nix new file mode 100644 index 0000000000..2906063428 --- /dev/null +++ b/third_party/gopkgs/github.com/src-d/gcfg/default.nix @@ -0,0 +1,16 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/src-d/gcfg"; + + src = depot.third_party.fetchFromGitHub { + owner = "src-d"; + repo = "gcfg"; + rev = "1ac3a1ac202429a54835fe8408a92880156b489d"; + sha256 = "044j95skmyrwjw5fwjk6ka32rjgsg0ar0mfp9np19sh1acwv4x4r"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."gopkg.in".warnings + ]; +} diff --git a/third_party/gopkgs/github.com/xanzy/ssh-agent/default.nix b/third_party/gopkgs/github.com/xanzy/ssh-agent/default.nix new file mode 100644 index 0000000000..b52165efe3 --- /dev/null +++ b/third_party/gopkgs/github.com/xanzy/ssh-agent/default.nix @@ -0,0 +1,16 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "github.com/xanzy/ssh-agent"; + + src = depot.third_party.fetchFromGitHub { + owner = "xanzy"; + repo = "ssh-agent"; + rev = "6a3e2ff9e7c564f36873c2e36413f634534f1c44"; + sha256 = "1chjlnv5d6svpymxgsr62d992m2xi6jb5lybjc5zn1h3hv1m01av"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."golang.org".x.crypto.ssh.agent + ]; +} diff --git a/third_party/gopkgs/go.opencensus.io/default.nix b/third_party/gopkgs/go.opencensus.io/default.nix new file mode 100644 index 0000000000..af9690880f --- /dev/null +++ b/third_party/gopkgs/go.opencensus.io/default.nix @@ -0,0 +1,14 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "go.opencensus.io"; + src = builtins.fetchGit { + url = "https://github.com/census-instrumentation/opencensus-go"; + rev = "643eada29081047b355cfaa1ceb9bc307a10423c"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."github.com".hashicorp.golang-lru.simplelru + gopkgs."github.com".golang.groupcache.lru + ]; +} diff --git a/third_party/gopkgs/golang.org/x/crypto/default.nix b/third_party/gopkgs/golang.org/x/crypto/default.nix new file mode 100644 index 0000000000..2129f8b538 --- /dev/null +++ b/third_party/gopkgs/golang.org/x/crypto/default.nix @@ -0,0 +1,13 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "golang.org/x/crypto"; + src = builtins.fetchGit { + url = "https://go.googlesource.com/crypto"; + rev = "e9b2fee46413994441b28dfca259d911d963dfed"; + }; + + deps = with depot.third_party; [ + gopkgs."golang.org".x.sys.unix.gopkg + ]; +} diff --git a/third_party/gopkgs/golang.org/x/net/default.nix b/third_party/gopkgs/golang.org/x/net/default.nix new file mode 100644 index 0000000000..450369d694 --- /dev/null +++ b/third_party/gopkgs/golang.org/x/net/default.nix @@ -0,0 +1,15 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "golang.org/x/net"; + src = builtins.fetchGit { + url = "https://go.googlesource.com/net"; + rev = "c0dbc17a35534bf2e581d7a942408dc936316da4"; + }; + + deps = with depot.third_party; [ + gopkgs."golang.org".x.text.secure.bidirule.gopkg + gopkgs."golang.org".x.text.unicode.bidi.gopkg + gopkgs."golang.org".x.text.unicode.norm.gopkg + ]; +} diff --git a/third_party/gopkgs/golang.org/x/oauth2/default.nix b/third_party/gopkgs/golang.org/x/oauth2/default.nix new file mode 100644 index 0000000000..230e629672 --- /dev/null +++ b/third_party/gopkgs/golang.org/x/oauth2/default.nix @@ -0,0 +1,14 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "golang.org/x/oauth2"; + src = builtins.fetchGit { + url = "https://go.googlesource.com/oauth2"; + rev = "858c2ad4c8b6c5d10852cb89079f6ca1c7309787"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."golang.org".x.net.context.ctxhttp + gopkgs."cloud.google.com".go.compute.metadata + ]; +} diff --git a/third_party/gopkgs/golang.org/x/sys/default.nix b/third_party/gopkgs/golang.org/x/sys/default.nix new file mode 100644 index 0000000000..2d45b6286d --- /dev/null +++ b/third_party/gopkgs/golang.org/x/sys/default.nix @@ -0,0 +1,9 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "golang.org/x/sys"; + src = builtins.fetchGit { + url = "https://go.googlesource.com/sys"; + rev = "ac6580df4449443a05718fd7858c1f91ad5f8d20"; + }; +} diff --git a/third_party/gopkgs/golang.org/x/text/default.nix b/third_party/gopkgs/golang.org/x/text/default.nix new file mode 100644 index 0000000000..84753e5362 --- /dev/null +++ b/third_party/gopkgs/golang.org/x/text/default.nix @@ -0,0 +1,9 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "golang.org/x/text"; + src = builtins.fetchGit { + url = "https://go.googlesource.com/text"; + rev = "cbf43d21aaebfdfeb81d91a5f444d13a3046e686"; + }; +} diff --git a/third_party/gopkgs/golang.org/x/time/default.nix b/third_party/gopkgs/golang.org/x/time/default.nix new file mode 100644 index 0000000000..0c8aaeab98 --- /dev/null +++ b/third_party/gopkgs/golang.org/x/time/default.nix @@ -0,0 +1,10 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "golang.org/x/time"; + + src = builtins.fetchGit { + url = "https://go.googlesource.com/time"; + rev = "555d28b269f0569763d25dbe1a237ae74c6bcc82"; + }; +} diff --git a/third_party/gopkgs/google.golang.org/api/default.nix b/third_party/gopkgs/google.golang.org/api/default.nix new file mode 100644 index 0000000000..333b9df157 --- /dev/null +++ b/third_party/gopkgs/google.golang.org/api/default.nix @@ -0,0 +1,20 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "google.golang.org/api"; + src = builtins.fetchGit { + url = "https://code.googlesource.com/google-api-go-client"; + rev = "8b4e46d953bd748a9ff098644a42389b3d8dab41"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."github.com".googleapis.gax-go.v2 + gopkgs."golang.org".x.oauth2.google + gopkgs."golang.org".x.oauth2 + gopkgs."google.golang.org".grpc + gopkgs."google.golang.org".grpc.naming + gopkgs."go.opencensus.io".plugin.ochttp + gopkgs."go.opencensus.io".trace + gopkgs."go.opencensus.io".trace.propagation + ]; +} diff --git a/third_party/gopkgs/google.golang.org/genproto/default.nix b/third_party/gopkgs/google.golang.org/genproto/default.nix new file mode 100644 index 0000000000..e3b0a2065a --- /dev/null +++ b/third_party/gopkgs/google.golang.org/genproto/default.nix @@ -0,0 +1,14 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "google.golang.org/genproto"; + src = builtins.fetchGit { + url = "https://github.com/google/go-genproto"; + rev = "0243a4be9c8f1264d238fdc2895620b4d9baf9e1"; + }; + + deps = with depot.third_party; [ + gopkgs."github.com".golang.protobuf.proto.gopkg + gopkgs."github.com".golang.protobuf.ptypes.any.gopkg + ]; +} diff --git a/third_party/gopkgs/google.golang.org/grpc/default.nix b/third_party/gopkgs/google.golang.org/grpc/default.nix new file mode 100644 index 0000000000..8b533c9077 --- /dev/null +++ b/third_party/gopkgs/google.golang.org/grpc/default.nix @@ -0,0 +1,21 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "google.golang.org/grpc"; + src = builtins.fetchGit { + url = "https://github.com/grpc/grpc-go"; + rev = "085c980048876e2735d4aba8f0d5bca4d7acaaa5"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."golang.org".x.net.trace + gopkgs."golang.org".x.net.http2 + gopkgs."golang.org".x.net.http2.hpack + gopkgs."golang.org".x.sys.unix + gopkgs."github.com".golang.protobuf.proto + gopkgs."github.com".golang.protobuf.ptypes + gopkgs."github.com".golang.protobuf.ptypes.duration + gopkgs."github.com".golang.protobuf.ptypes.timestamp + gopkgs."google.golang.org".genproto.googleapis.rpc.status + ]; +} diff --git a/third_party/gopkgs/googlemaps.github.io/maps.nix b/third_party/gopkgs/googlemaps.github.io/maps.nix new file mode 100644 index 0000000000..20db836aa7 --- /dev/null +++ b/third_party/gopkgs/googlemaps.github.io/maps.nix @@ -0,0 +1,17 @@ +{ depot, ... }: + +depot.nix.buildGo.external { + path = "googlemaps.github.io/maps"; + + src = depot.third_party.fetchFromGitHub { + owner = "googlemaps"; + repo = "google-maps-services-go"; + rev = "a46d9fca56ac82caa79408b2417ea93a75e3b986"; + sha256 = "1zpl85yd3m417060isdlhxzakqkf4f59jgpz3kcjp2i0mkrskkjs"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."github.com".google.uuid + gopkgs."golang.org".x.time.rate + ]; +} diff --git a/third_party/gopkgs/gopkg.in/src-d/go-billy/default.nix b/third_party/gopkgs/gopkg.in/src-d/go-billy/default.nix new file mode 100644 index 0000000000..0ed4e343e1 --- /dev/null +++ b/third_party/gopkgs/gopkg.in/src-d/go-billy/default.nix @@ -0,0 +1,16 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "gopkg.in/src-d/go-billy.v4"; + + src = depot.third_party.fetchFromGitHub { + owner = "src-d"; + repo = "go-billy"; + rev = "fd409ff12f33d0d60af0ce0abeb8d93df360af49"; + sha256 = "1j0pl6ggzmd2lrqj71vmsnl6cqm43145h7yg6sy3j5n7hhd592qv"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."golang.org".x.sys.unix + ]; +} diff --git a/third_party/gopkgs/gopkg.in/src-d/go-git/default.nix b/third_party/gopkgs/gopkg.in/src-d/go-git/default.nix new file mode 100644 index 0000000000..a39b7e82b7 --- /dev/null +++ b/third_party/gopkgs/gopkg.in/src-d/go-git/default.nix @@ -0,0 +1,31 @@ +{ depot, ... }: + +depot.buildGo.external { + # .v4 is used throughout the codebase and I can't be bothered to do + # anything else about it other than using that package path here. + path = "gopkg.in/src-d/go-git.v4"; + + src = depot.third_party.fetchFromGitHub { + owner = "src-d"; + repo = "go-git"; + rev = "1a7db85bca7027d90afdb5ce711622aaac9feaed"; + sha256 = "08jl4ljrzzil7c3qcl2y1859nhpgw9ixxy1g40ff7kmq989yhs6v"; + }; + + deps = with depot.third_party; map (p: p.gopkg) [ + gopkgs."github.com".emirpasic.gods.trees.binaryheap + gopkgs."github.com".jbenet.go-context.io + gopkgs."github.com".kevinburke.ssh_config + gopkgs."github.com".mitchellh.go-homedir + gopkgs."github.com".sergi.go-diff.diffmatchpatch + gopkgs."github.com".src-d.gcfg + gopkgs."github.com".xanzy.ssh-agent + gopkgs."golang.org".x.crypto.openpgp + gopkgs."golang.org".x.crypto.ssh + gopkgs."golang.org".x.crypto.ssh.knownhosts + gopkgs."golang.org".x.net.proxy + gopkgs."gopkg.in".src-d.go-billy + gopkgs."gopkg.in".src-d.go-billy.osfs + gopkgs."gopkg.in".src-d.go-billy.util + ]; +} diff --git a/third_party/gopkgs/gopkg.in/warnings/default.nix b/third_party/gopkgs/gopkg.in/warnings/default.nix new file mode 100644 index 0000000000..0ea28cce57 --- /dev/null +++ b/third_party/gopkgs/gopkg.in/warnings/default.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +depot.buildGo.external { + path = "gopkg.in/warnings.v0"; + + src = depot.third_party.fetchFromGitHub { + owner = "go-warnings"; + repo = "warnings"; + rev = "27b9fabbdaf131d2169ec3ff7db8ffc4d839635e"; + sha256 = "1y276jd9gwvjriz8yd98k3srgbnmbja8f7f7m6lvr0h5sbq3g3w9"; + }; +} diff --git a/third_party/honk/default.nix b/third_party/honk/default.nix new file mode 100644 index 0000000000..fb3e80c452 --- /dev/null +++ b/third_party/honk/default.nix @@ -0,0 +1,26 @@ +{ pkgs, ... }: + +pkgs.stdenv.mkDerivation rec { + name = "honk-${version}"; + version = "0.9.0"; + nativeBuildInputs = [ pkgs.go ]; + buildInputs = [ pkgs.sqlite ]; + + src = builtins.fetchTarball { + url = "https://humungus.tedunangst.com/r/honk/d/honk-${version}.tgz"; + sha256 = "0fj1ybhsra626q5vy1sy9aigxx5rjda5mgq74m7kzw7an4z2a67m"; + }; + + # Go tooling needs $HOME to exist because, well, who knows. + preBuild = '' + mkdir home && export HOME=$PWD/home + ''; + + installPhase = '' + install -D honk $out/bin/honk + install -D docs/honk.1 $out/share/man/man1/honk.1 + install -D docs/honk.3 $out/share/man/man3/honk.3 + install -D docs/honk.5 $out/share/man/man5/honk.5 + install -D docs/honk.8 $out/share/man/man8/honk.8 + ''; +} diff --git a/third_party/lieer/api_client.patch b/third_party/lieer/api_client.patch new file mode 100644 index 0000000000..cbde914a6b --- /dev/null +++ b/third_party/lieer/api_client.patch @@ -0,0 +1,20 @@ +diff --git a/lieer/remote.py b/lieer/remote.py +index 6e3973a..62728f7 100644 +--- a/lieer/remote.py ++++ b/lieer/remote.py +@@ -25,12 +25,12 @@ class Remote: + # * https://stackoverflow.com/questions/19615372/client-secret-in-oauth-2-0?rq=1 + # + OAUTH2_CLIENT_SECRET = { +- "client_id":"753933720722-ju82fu305lii0v9rdo6mf9hj40l5juv0.apps.googleusercontent.com", +- "project_id":"capable-pixel-160614", ++ "client_id":"${CLIENT_ID}", ++ "project_id":"${PROJECT_ID}", + "auth_uri":"https://accounts.google.com/o/oauth2/auth", + "token_uri":"https://accounts.google.com/o/oauth2/token", + "auth_provider_x509_cert_url":"https://www.googleapis.com/oauth2/v1/certs", +- "client_secret":"8oudEG0Tvb7YI2V0ykp2Pzz9", ++ "client_secret":"${CLIENT_SECRET}", + "redirect_uris":["urn:ietf:wg:oauth:2.0:oob", "http://localhost"] + } + diff --git a/third_party/lieer/default.nix b/third_party/lieer/default.nix new file mode 100644 index 0000000000..6dd4cecd1d --- /dev/null +++ b/third_party/lieer/default.nix @@ -0,0 +1,51 @@ +# Lieer is a small tool to synchronise a Gmail account with a local +# maildir. +# +# Lieer is packaged in nixpkgs, but as of 2019-12-23 it is an old +# version using the previous branding (gmailieer). +{ pkgs, ... }: + +# For a variety of reasons (specific to my setup), custom OAuth2 +# scopes are used. +# +# The below client ID is the default for *@tazj.in and is overridden +# in a private repository for my work account. Publishing it here is +# not a security issue. +{ + clientId ? "515965513093-7b4bo4gm0q09ccsmikkuaas9a40j0jcj.apps.googleusercontent.com", + clientSecret ? "3jVbpfT4GmubFD64svctJSdQ", + project ? "tazjins-infrastructure" +}: + +with pkgs; + +let + authPatch = runCommand "client_secret.patch" {} '' + export CLIENT_ID='${clientId}' + export CLIENT_SECRET='${clientSecret}' + export PROJECT_ID='${project}' + cat ${./api_client.patch} | ${gettext}/bin/envsubst > $out + ''; +in python3Packages.buildPythonApplication rec { + name = "lieer-${version}"; + version = "1.0"; + + src = fetchFromGitHub { + owner = "gauteh"; + repo = "lieer"; + rev = "v${version}"; + sha256 = "1zzylv8xbcrh34bz0s29dawzcyx39lai8y8wk0bl4x75v1jfynvf"; + }; + + patches = [ + authPatch + ./send_scope.patch + ]; + + propagatedBuildInputs = with python3Packages; [ + notmuch + oauth2client + google_api_python_client + tqdm + ]; +} diff --git a/third_party/lieer/send_scope.patch b/third_party/lieer/send_scope.patch new file mode 100644 index 0000000000..c882a79ac5 --- /dev/null +++ b/third_party/lieer/send_scope.patch @@ -0,0 +1,13 @@ +diff --git a/lieer/remote.py b/lieer/remote.py +index 6e3973a..ade1082 100644 +--- a/lieer/remote.py ++++ b/lieer/remote.py +@@ -9,7 +9,7 @@ from oauth2client.file import Storage + from pathlib import Path + + class Remote: +- SCOPES = 'https://www.googleapis.com/auth/gmail.readonly https://www.googleapis.com/auth/gmail.labels https://www.googleapis.com/auth/gmail.modify' ++ SCOPES = 'https://www.googleapis.com/auth/gmail.readonly https://www.googleapis.com/auth/gmail.labels https://www.googleapis.com/auth/gmail.modify https://mail.google.com/' + APPLICATION_NAME = 'Lieer' + CLIENT_SECRET_FILE = None + authorized = False diff --git a/third_party/lisp/alexandria/.boring b/third_party/lisp/alexandria/.boring new file mode 100644 index 0000000000..dfa9e6dd7b --- /dev/null +++ b/third_party/lisp/alexandria/.boring @@ -0,0 +1,13 @@ +# Boring file regexps: +~$ +^_darcs +^\{arch\} +^.arch-ids +\# +\.dfsl$ +\.ppcf$ +\.fasl$ +\.x86f$ +\.fas$ +\.lib$ +^public_html diff --git a/third_party/lisp/alexandria/.gitignore b/third_party/lisp/alexandria/.gitignore new file mode 100644 index 0000000000..e832e94718 --- /dev/null +++ b/third_party/lisp/alexandria/.gitignore @@ -0,0 +1,4 @@ +*.fasl +*~ +\#* +*.patch diff --git a/third_party/lisp/alexandria/AUTHORS b/third_party/lisp/alexandria/AUTHORS new file mode 100644 index 0000000000..b550ea5032 --- /dev/null +++ b/third_party/lisp/alexandria/AUTHORS @@ -0,0 +1,9 @@ + +ACTA EST FABULA PLAUDITE + +Nikodemus Siivola +Attila Lendvai +Marco Baringer +Robert Strandh +Luis Oliveira +Tobias C. Rittweiler \ No newline at end of file diff --git a/third_party/lisp/alexandria/LICENCE b/third_party/lisp/alexandria/LICENCE new file mode 100644 index 0000000000..b5140fbb24 --- /dev/null +++ b/third_party/lisp/alexandria/LICENCE @@ -0,0 +1,37 @@ +Alexandria software and associated documentation are in the public +domain: + + Authors dedicate this work to public domain, for the benefit of the + public at large and to the detriment of the authors' heirs and + successors. Authors intends this dedication to be an overt act of + relinquishment in perpetuity of all present and future rights under + copyright law, whether vested or contingent, in the work. Authors + understands that such relinquishment of all rights includes the + relinquishment of all rights to enforce (by lawsuit or otherwise) + those copyrights in the work. + + Authors recognize that, once placed in the public domain, the work + may be freely reproduced, distributed, transmitted, used, modified, + built upon, or otherwise exploited by anyone for any purpose, + commercial or non-commercial, and in any way, including by methods + that have not yet been invented or conceived. + +In those legislations where public domain dedications are not +recognized or possible, Alexandria is distributed under the following +terms and conditions: + + Permission is hereby granted, free of charge, to any person + obtaining a copy of this software and associated documentation files + (the "Software"), to deal in the Software without restriction, + including without limitation the rights to use, copy, modify, merge, + publish, distribute, sublicense, and/or sell copies of the Software, + and to permit persons to whom the Software is furnished to do so, + subject to the following conditions: + + THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, + EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF + MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. + IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY + CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, + TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE + SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. diff --git a/third_party/lisp/alexandria/README b/third_party/lisp/alexandria/README new file mode 100644 index 0000000000..a5dae9ed1a --- /dev/null +++ b/third_party/lisp/alexandria/README @@ -0,0 +1,52 @@ +Alexandria is a collection of portable public domain utilities that +meet the following constraints: + + * Utilities, not extensions: Alexandria will not contain conceptual + extensions to Common Lisp, instead limiting itself to tools and + utilities that fit well within the framework of standard ANSI + Common Lisp. Test-frameworks, system definitions, logging + facilities, serialization layers, etc. are all outside the scope of + Alexandria as a library, though well within the scope of Alexandria + as a project. + + * Conservative: Alexandria limits itself to what project members + consider conservative utilities. Alexandria does not and will not + include anaphoric constructs, loop-like binding macros, etc. + + * Portable: Alexandria limits itself to portable parts of Common + Lisp. Even apparently conservative and useful functions remain + outside the scope of Alexandria if they cannot be implemented + portably. Portability is here defined as portable within a + conforming implementation: implementation bugs are not considered + portability issues. + +Homepage: + + http://common-lisp.net/project/alexandria/ + +Mailing lists: + + http://lists.common-lisp.net/mailman/listinfo/alexandria-devel + http://lists.common-lisp.net/mailman/listinfo/alexandria-cvs + +Repository: + + git://gitlab.common-lisp.net/alexandria/alexandria.git + +Documentation: + + http://common-lisp.net/project/alexandria/draft/alexandria.html + + (To build docs locally: cd doc && make html pdf info) + +Patches: + + Patches are always welcome! Please send them to the mailing list as + attachments, generated by "git format-patch -1". + + Patches should include a commit message that explains what's being + done and /why/, and when fixing a bug or adding a feature you should + also include a test-case. + + Be advised though that right now new features are unlikely to be + accepted until 1.0 is officially out of the door. diff --git a/third_party/lisp/alexandria/alexandria-tests.asd b/third_party/lisp/alexandria/alexandria-tests.asd new file mode 100644 index 0000000000..445c18cf7f --- /dev/null +++ b/third_party/lisp/alexandria/alexandria-tests.asd @@ -0,0 +1,11 @@ +(defsystem "alexandria-tests" + :licence "Public Domain / 0-clause MIT" + :description "Tests for Alexandria, which is a collection of portable public domain utilities." + :author "Nikodemus Siivola <nikodemus@sb-studio.net>, and others." + :depends-on (:alexandria #+sbcl :sb-rt #-sbcl :rt) + :components ((:file "tests")) + :perform (test-op (o c) + (flet ((run-tests (&rest args) + (apply (intern (string '#:run-tests) '#:alexandria-tests) args))) + (run-tests :compiled nil) + (run-tests :compiled t)))) diff --git a/third_party/lisp/alexandria/alexandria.asd b/third_party/lisp/alexandria/alexandria.asd new file mode 100644 index 0000000000..db10e4f537 --- /dev/null +++ b/third_party/lisp/alexandria/alexandria.asd @@ -0,0 +1,62 @@ +(defsystem "alexandria" + :version "1.0.0" + :licence "Public Domain / 0-clause MIT" + :description "Alexandria is a collection of portable public domain utilities." + :author "Nikodemus Siivola and others." + :long-description + "Alexandria is a project and a library. + +As a project Alexandria's goal is to reduce duplication of effort and improve +portability of Common Lisp code according to its own idiosyncratic and rather +conservative aesthetic. + +As a library Alexandria is one of the means by which the project strives for +its goals. + +Alexandria is a collection of portable public domain utilities that meet +the following constraints: + + * Utilities, not extensions: Alexandria will not contain conceptual + extensions to Common Lisp, instead limiting itself to tools and utilities + that fit well within the framework of standard ANSI Common Lisp. + Test-frameworks, system definitions, logging facilities, serialization + layers, etc. are all outside the scope of Alexandria as a library, though + well within the scope of Alexandria as a project. + + * Conservative: Alexandria limits itself to what project members consider + conservative utilities. Alexandria does not and will not include anaphoric + constructs, loop-like binding macros, etc. + Also, its exported symbols are being imported by many other packages + already, so each new export carries the danger of causing conflicts. + + * Portable: Alexandria limits itself to portable parts of Common Lisp. Even + apparently conservative and useful functions remain outside the scope of + Alexandria if they cannot be implemented portably. Portability is here + defined as portable within a conforming implementation: implementation bugs + are not considered portability issues. + + * Team player: Alexandria will not (initially, at least) subsume or provide + functionality for which good-quality special-purpose packages exist, like + split-sequence. Instead, third party packages such as that may be + \"blessed\"." + :components + ((:static-file "LICENCE") + (:static-file "tests.lisp") + (:file "package") + (:file "definitions" :depends-on ("package")) + (:file "binding" :depends-on ("package")) + (:file "strings" :depends-on ("package")) + (:file "conditions" :depends-on ("package")) + (:file "io" :depends-on ("package" "macros" "lists" "types")) + (:file "macros" :depends-on ("package" "strings" "symbols")) + (:file "hash-tables" :depends-on ("package" "macros")) + (:file "control-flow" :depends-on ("package" "definitions" "macros")) + (:file "symbols" :depends-on ("package")) + (:file "functions" :depends-on ("package" "symbols" "macros")) + (:file "lists" :depends-on ("package" "functions")) + (:file "types" :depends-on ("package" "symbols" "lists")) + (:file "arrays" :depends-on ("package" "types")) + (:file "sequences" :depends-on ("package" "lists" "types")) + (:file "numbers" :depends-on ("package" "sequences")) + (:file "features" :depends-on ("package" "control-flow"))) + :in-order-to ((test-op (test-op "alexandria-tests")))) diff --git a/third_party/lisp/alexandria/arrays.lisp b/third_party/lisp/alexandria/arrays.lisp new file mode 100644 index 0000000000..76c18791ad --- /dev/null +++ b/third_party/lisp/alexandria/arrays.lisp @@ -0,0 +1,18 @@ +(in-package :alexandria) + +(defun copy-array (array &key (element-type (array-element-type array)) + (fill-pointer (and (array-has-fill-pointer-p array) + (fill-pointer array))) + (adjustable (adjustable-array-p array))) + "Returns an undisplaced copy of ARRAY, with same fill-pointer and +adjustability (if any) as the original, unless overridden by the keyword +arguments." + (let* ((dimensions (array-dimensions array)) + (new-array (make-array dimensions + :element-type element-type + :adjustable adjustable + :fill-pointer fill-pointer))) + (dotimes (i (array-total-size array)) + (setf (row-major-aref new-array i) + (row-major-aref array i))) + new-array)) diff --git a/third_party/lisp/alexandria/binding.lisp b/third_party/lisp/alexandria/binding.lisp new file mode 100644 index 0000000000..37a3d52fb9 --- /dev/null +++ b/third_party/lisp/alexandria/binding.lisp @@ -0,0 +1,90 @@ +(in-package :alexandria) + +(defmacro if-let (bindings &body (then-form &optional else-form)) + "Creates new variable bindings, and conditionally executes either +THEN-FORM or ELSE-FORM. ELSE-FORM defaults to NIL. + +BINDINGS must be either single binding of the form: + + (variable initial-form) + +or a list of bindings of the form: + + ((variable-1 initial-form-1) + (variable-2 initial-form-2) + ... + (variable-n initial-form-n)) + +All initial-forms are executed sequentially in the specified order. Then all +the variables are bound to the corresponding values. + +If all variables were bound to true values, the THEN-FORM is executed with the +bindings in effect, otherwise the ELSE-FORM is executed with the bindings in +effect." + (let* ((binding-list (if (and (consp bindings) (symbolp (car bindings))) + (list bindings) + bindings)) + (variables (mapcar #'car binding-list))) + `(let ,binding-list + (if (and ,@variables) + ,then-form + ,else-form)))) + +(defmacro when-let (bindings &body forms) + "Creates new variable bindings, and conditionally executes FORMS. + +BINDINGS must be either single binding of the form: + + (variable initial-form) + +or a list of bindings of the form: + + ((variable-1 initial-form-1) + (variable-2 initial-form-2) + ... + (variable-n initial-form-n)) + +All initial-forms are executed sequentially in the specified order. Then all +the variables are bound to the corresponding values. + +If all variables were bound to true values, then FORMS are executed as an +implicit PROGN." + (let* ((binding-list (if (and (consp bindings) (symbolp (car bindings))) + (list bindings) + bindings)) + (variables (mapcar #'car binding-list))) + `(let ,binding-list + (when (and ,@variables) + ,@forms)))) + +(defmacro when-let* (bindings &body body) + "Creates new variable bindings, and conditionally executes BODY. + +BINDINGS must be either single binding of the form: + + (variable initial-form) + +or a list of bindings of the form: + + ((variable-1 initial-form-1) + (variable-2 initial-form-2) + ... + (variable-n initial-form-n)) + +Each INITIAL-FORM is executed in turn, and the variable bound to the +corresponding value. INITIAL-FORM expressions can refer to variables +previously bound by the WHEN-LET*. + +Execution of WHEN-LET* stops immediately if any INITIAL-FORM evaluates to NIL. +If all INITIAL-FORMs evaluate to true, then BODY is executed as an implicit +PROGN." + (let ((binding-list (if (and (consp bindings) (symbolp (car bindings))) + (list bindings) + bindings))) + (labels ((bind (bindings body) + (if bindings + `(let (,(car bindings)) + (when ,(caar bindings) + ,(bind (cdr bindings) body))) + `(progn ,@body)))) + (bind binding-list body)))) diff --git a/third_party/lisp/alexandria/conditions.lisp b/third_party/lisp/alexandria/conditions.lisp new file mode 100644 index 0000000000..ac471cca7e --- /dev/null +++ b/third_party/lisp/alexandria/conditions.lisp @@ -0,0 +1,91 @@ +(in-package :alexandria) + +(defun required-argument (&optional name) + "Signals an error for a missing argument of NAME. Intended for +use as an initialization form for structure and class-slots, and +a default value for required keyword arguments." + (error "Required argument ~@[~S ~]missing." name)) + +(define-condition simple-style-warning (simple-warning style-warning) + ()) + +(defun simple-style-warning (message &rest args) + (warn 'simple-style-warning :format-control message :format-arguments args)) + +;; We don't specify a :report for simple-reader-error to let the +;; underlying implementation report the line and column position for +;; us. Unfortunately this way the message from simple-error is not +;; displayed, unless there's special support for that in the +;; implementation. But even then it's still inspectable from the +;; debugger... +(define-condition simple-reader-error + #-sbcl(simple-error reader-error) + #+sbcl(sb-int:simple-reader-error) + ()) + +(defun simple-reader-error (stream message &rest args) + (error 'simple-reader-error + :stream stream + :format-control message + :format-arguments args)) + +(define-condition simple-parse-error (simple-error parse-error) + ()) + +(defun simple-parse-error (message &rest args) + (error 'simple-parse-error + :format-control message + :format-arguments args)) + +(define-condition simple-program-error (simple-error program-error) + ()) + +(defun simple-program-error (message &rest args) + (error 'simple-program-error + :format-control message + :format-arguments args)) + +(defmacro ignore-some-conditions ((&rest conditions) &body body) + "Similar to CL:IGNORE-ERRORS but the (unevaluated) CONDITIONS +list determines which specific conditions are to be ignored." + `(handler-case + (progn ,@body) + ,@(loop for condition in conditions collect + `(,condition (c) (values nil c))))) + +(defmacro unwind-protect-case ((&optional abort-flag) protected-form &body clauses) + "Like CL:UNWIND-PROTECT, but you can specify the circumstances that +the cleanup CLAUSES are run. + + clauses ::= (:NORMAL form*)* | (:ABORT form*)* | (:ALWAYS form*)* + +Clauses can be given in any order, and more than one clause can be +given for each circumstance. The clauses whose denoted circumstance +occured, are executed in the order the clauses appear. + +ABORT-FLAG is the name of a variable that will be bound to T in +CLAUSES if the PROTECTED-FORM aborted preemptively, and to NIL +otherwise. + +Examples: + + (unwind-protect-case () + (protected-form) + (:normal (format t \"This is only evaluated if PROTECTED-FORM executed normally.~%\")) + (:abort (format t \"This is only evaluated if PROTECTED-FORM aborted preemptively.~%\")) + (:always (format t \"This is evaluated in either case.~%\"))) + + (unwind-protect-case (aborted-p) + (protected-form) + (:always (perform-cleanup-if aborted-p))) +" + (check-type abort-flag (or null symbol)) + (let ((gflag (gensym "FLAG+"))) + `(let ((,gflag t)) + (unwind-protect (multiple-value-prog1 ,protected-form (setf ,gflag nil)) + (let ,(and abort-flag `((,abort-flag ,gflag))) + ,@(loop for (cleanup-kind . forms) in clauses + collect (ecase cleanup-kind + (:normal `(when (not ,gflag) ,@forms)) + (:abort `(when ,gflag ,@forms)) + (:always `(progn ,@forms))))))))) \ No newline at end of file diff --git a/third_party/lisp/alexandria/control-flow.lisp b/third_party/lisp/alexandria/control-flow.lisp new file mode 100644 index 0000000000..dd00df3e16 --- /dev/null +++ b/third_party/lisp/alexandria/control-flow.lisp @@ -0,0 +1,106 @@ +(in-package :alexandria) + +(defun extract-function-name (spec) + "Useful for macros that want to mimic the functional interface for functions +like #'eq and 'eq." + (if (and (consp spec) + (member (first spec) '(quote function))) + (second spec) + spec)) + +(defun generate-switch-body (whole object clauses test key &optional default) + (with-gensyms (value) + (setf test (extract-function-name test)) + (setf key (extract-function-name key)) + (when (and (consp default) + (member (first default) '(error cerror))) + (setf default `(,@default "No keys match in SWITCH. Testing against ~S with ~S." + ,value ',test))) + `(let ((,value (,key ,object))) + (cond ,@(mapcar (lambda (clause) + (if (member (first clause) '(t otherwise)) + (progn + (when default + (error "Multiple default clauses or illegal use of a default clause in ~S." + whole)) + (setf default `(progn ,@(rest clause))) + '(())) + (destructuring-bind (key-form &body forms) clause + `((,test ,value ,key-form) + ,@forms)))) + clauses) + (t ,default))))) + +(defmacro switch (&whole whole (object &key (test 'eql) (key 'identity)) + &body clauses) + "Evaluates first matching clause, returning its values, or evaluates and +returns the values of T or OTHERWISE if no keys match." + (generate-switch-body whole object clauses test key)) + +(defmacro eswitch (&whole whole (object &key (test 'eql) (key 'identity)) + &body clauses) + "Like SWITCH, but signals an error if no key matches." + (generate-switch-body whole object clauses test key '(error))) + +(defmacro cswitch (&whole whole (object &key (test 'eql) (key 'identity)) + &body clauses) + "Like SWITCH, but signals a continuable error if no key matches." + (generate-switch-body whole object clauses test key '(cerror "Return NIL from CSWITCH."))) + +(defmacro whichever (&rest possibilities &environment env) + "Evaluates exactly one of POSSIBILITIES, chosen at random." + (setf possibilities (mapcar (lambda (p) (macroexpand p env)) possibilities)) + (if (every (lambda (p) (constantp p)) possibilities) + `(svref (load-time-value (vector ,@possibilities)) (random ,(length possibilities))) + (labels ((expand (possibilities position random-number) + (if (null (cdr possibilities)) + (car possibilities) + (let* ((length (length possibilities)) + (half (truncate length 2)) + (second-half (nthcdr half possibilities)) + (first-half (butlast possibilities (- length half)))) + `(if (< ,random-number ,(+ position half)) + ,(expand first-half position random-number) + ,(expand second-half (+ position half) random-number)))))) + (with-gensyms (random-number) + (let ((length (length possibilities))) + `(let ((,random-number (random ,length))) + ,(expand possibilities 0 random-number))))))) + +(defmacro xor (&rest datums) + "Evaluates its arguments one at a time, from left to right. If more than one +argument evaluates to a true value no further DATUMS are evaluated, and NIL is +returned as both primary and secondary value. If exactly one argument +evaluates to true, its value is returned as the primary value after all the +arguments have been evaluated, and T is returned as the secondary value. If no +arguments evaluate to true NIL is retuned as primary, and T as secondary +value." + (with-gensyms (xor tmp true) + `(let (,tmp ,true) + (block ,xor + ,@(mapcar (lambda (datum) + `(if (setf ,tmp ,datum) + (if ,true + (return-from ,xor (values nil nil)) + (setf ,true ,tmp)))) + datums) + (return-from ,xor (values ,true t)))))) + +(defmacro nth-value-or (nth-value &body forms) + "Evaluates FORM arguments one at a time, until the NTH-VALUE returned by one +of the forms is true. It then returns all the values returned by evaluating +that form. If none of the forms return a true nth value, this form returns +NIL." + (once-only (nth-value) + (with-gensyms (values) + `(let ((,values (multiple-value-list ,(first forms)))) + (if (nth ,nth-value ,values) + (values-list ,values) + ,(if (rest forms) + `(nth-value-or ,nth-value ,@(rest forms)) + nil)))))) + +(defmacro multiple-value-prog2 (first-form second-form &body forms) + "Evaluates FIRST-FORM, then SECOND-FORM, and then FORMS. Yields as its value +all the value returned by SECOND-FORM." + `(progn ,first-form (multiple-value-prog1 ,second-form ,@forms))) diff --git a/third_party/lisp/alexandria/default.nix b/third_party/lisp/alexandria/default.nix new file mode 100644 index 0000000000..2358c898b3 --- /dev/null +++ b/third_party/lisp/alexandria/default.nix @@ -0,0 +1,28 @@ +# Alexandria is one of the foundational Common Lisp libraries that +# pretty much everything depends on: +# +# Imported from https://common-lisp.net/project/alexandria/ +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "alexandria"; + srcs = [ + ./package.lisp + ./definitions.lisp + ./binding.lisp + ./strings.lisp + ./conditions.lisp + ./symbols.lisp + ./macros.lisp + ./functions.lisp + ./io.lisp + ./hash-tables.lisp + ./control-flow.lisp + ./lists.lisp + ./types.lisp + ./arrays.lisp + ./sequences.lisp + ./numbers.lisp + ./features.lisp + ]; +} diff --git a/third_party/lisp/alexandria/definitions.lisp b/third_party/lisp/alexandria/definitions.lisp new file mode 100644 index 0000000000..863e1f6962 --- /dev/null +++ b/third_party/lisp/alexandria/definitions.lisp @@ -0,0 +1,37 @@ +(in-package :alexandria) + +(defun %reevaluate-constant (name value test) + (if (not (boundp name)) + value + (let ((old (symbol-value name)) + (new value)) + (if (not (constantp name)) + (prog1 new + (cerror "Try to redefine the variable as a constant." + "~@<~S is an already bound non-constant variable ~ + whose value is ~S.~:@>" name old)) + (if (funcall test old new) + old + (restart-case + (error "~@<~S is an already defined constant whose value ~ + ~S is not equal to the provided initial value ~S ~ + under ~S.~:@>" name old new test) + (ignore () + :report "Retain the current value." + old) + (continue () + :report "Try to redefine the constant." + new))))))) + +(defmacro define-constant (name initial-value &key (test ''eql) documentation) + "Ensures that the global variable named by NAME is a constant with a value +that is equal under TEST to the result of evaluating INITIAL-VALUE. TEST is a +/function designator/ that defaults to EQL. If DOCUMENTATION is given, it +becomes the documentation string of the constant. + +Signals an error if NAME is already a bound non-constant variable. + +Signals an error if NAME is already a constant variable whose value is not +equal under TEST to result of evaluating INITIAL-VALUE." + `(defconstant ,name (%reevaluate-constant ',name ,initial-value ,test) + ,@(when documentation `(,documentation)))) diff --git a/third_party/lisp/alexandria/doc/.gitignore b/third_party/lisp/alexandria/doc/.gitignore new file mode 100644 index 0000000000..f22577b3ac --- /dev/null +++ b/third_party/lisp/alexandria/doc/.gitignore @@ -0,0 +1,3 @@ +alexandria +include + diff --git a/third_party/lisp/alexandria/doc/Makefile b/third_party/lisp/alexandria/doc/Makefile new file mode 100644 index 0000000000..85eb818220 --- /dev/null +++ b/third_party/lisp/alexandria/doc/Makefile @@ -0,0 +1,28 @@ +.PHONY: clean html pdf include clean-include clean-crap info doc + +doc: pdf html info clean-crap + +clean-include: + rm -rf include + +clean-crap: + rm -f *.aux *.cp *.fn *.fns *.ky *.log *.pg *.toc *.tp *.tps *.vr + +clean: clean-include + rm -f *.pdf *.html *.info + +include: + sbcl --no-userinit --eval '(require :asdf)' \ + --eval '(let ((asdf:*central-registry* (list "../"))) (require :alexandria))' \ + --load docstrings.lisp \ + --eval '(sb-texinfo:generate-includes "include/" (list :alexandria) :base-package :alexandria)' \ + --eval '(quit)' + +pdf: include + texi2pdf alexandria.texinfo + +html: include + makeinfo --html --no-split alexandria.texinfo + +info: include + makeinfo alexandria.texinfo diff --git a/third_party/lisp/alexandria/doc/alexandria.texinfo b/third_party/lisp/alexandria/doc/alexandria.texinfo new file mode 100644 index 0000000000..89b03ac349 --- /dev/null +++ b/third_party/lisp/alexandria/doc/alexandria.texinfo @@ -0,0 +1,277 @@ +\input texinfo @c -*-texinfo-*- +@c %**start of header +@setfilename alexandria.info +@settitle Alexandria Manual +@c %**end of header + +@settitle Alexandria Manual -- draft version + +@c for install-info +@dircategory Software development +@direntry +* alexandria: Common Lisp utilities. +@end direntry + +@copying +Alexandria software and associated documentation are in the public +domain: + +@quotation + Authors dedicate this work to public domain, for the benefit of the + public at large and to the detriment of the authors' heirs and + successors. Authors intends this dedication to be an overt act of + relinquishment in perpetuity of all present and future rights under + copyright law, whether vested or contingent, in the work. Authors + understands that such relinquishment of all rights includes the + relinquishment of all rights to enforce (by lawsuit or otherwise) + those copyrights in the work. + + Authors recognize that, once placed in the public domain, the work + may be freely reproduced, distributed, transmitted, used, modified, + built upon, or otherwise exploited by anyone for any purpose, + commercial or non-commercial, and in any way, including by methods + that have not yet been invented or conceived. +@end quotation + +In those legislations where public domain dedications are not +recognized or possible, Alexandria is distributed under the following +terms and conditions: + +@quotation + Permission is hereby granted, free of charge, to any person + obtaining a copy of this software and associated documentation files + (the "Software"), to deal in the Software without restriction, + including without limitation the rights to use, copy, modify, merge, + publish, distribute, sublicense, and/or sell copies of the Software, + and to permit persons to whom the Software is furnished to do so, + subject to the following conditions: + + THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, + EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF + MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. + IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY + CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, + TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE + SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. +@end quotation +@end copying + +@titlepage + +@title Alexandria Manual +@subtitle draft version + +@c The following two commands start the copyright page. +@page +@vskip 0pt plus 1filll +@insertcopying + +@end titlepage + +@contents + +@ifnottex + +@include include/ifnottex.texinfo + +@node Top +@comment node-name, next, previous, up +@top Alexandria + +@insertcopying + +@menu +* Hash Tables:: +* Data and Control Flow:: +* Conses:: +* Sequences:: +* IO:: +* Macro Writing:: +* Symbols:: +* Arrays:: +* Types:: +* Numbers:: +@end menu + +@end ifnottex + +@node Hash Tables +@comment node-name, next, previous, up +@chapter Hash Tables + +@include include/macro-alexandria-ensure-gethash.texinfo +@include include/fun-alexandria-copy-hash-table.texinfo +@include include/fun-alexandria-maphash-keys.texinfo +@include include/fun-alexandria-maphash-values.texinfo +@include include/fun-alexandria-hash-table-keys.texinfo +@include include/fun-alexandria-hash-table-values.texinfo +@include include/fun-alexandria-hash-table-alist.texinfo +@include include/fun-alexandria-hash-table-plist.texinfo +@include include/fun-alexandria-alist-hash-table.texinfo +@include include/fun-alexandria-plist-hash-table.texinfo + +@node Data and Control Flow +@comment node-name, next, previous, up +@chapter Data and Control Flow + +@include include/macro-alexandria-define-constant.texinfo +@include include/macro-alexandria-destructuring-case.texinfo +@include include/macro-alexandria-ensure-functionf.texinfo +@include include/macro-alexandria-multiple-value-prog2.texinfo +@include include/macro-alexandria-named-lambda.texinfo +@include include/macro-alexandria-nth-value-or.texinfo +@include include/macro-alexandria-if-let.texinfo +@include include/macro-alexandria-when-let.texinfo +@include include/macro-alexandria-when-let-star.texinfo +@include include/macro-alexandria-switch.texinfo +@include include/macro-alexandria-cswitch.texinfo +@include include/macro-alexandria-eswitch.texinfo +@include include/macro-alexandria-whichever.texinfo +@include include/macro-alexandria-xor.texinfo + +@include include/fun-alexandria-disjoin.texinfo +@include include/fun-alexandria-conjoin.texinfo +@include include/fun-alexandria-compose.texinfo +@include include/fun-alexandria-ensure-function.texinfo +@include include/fun-alexandria-multiple-value-compose.texinfo +@include include/fun-alexandria-curry.texinfo +@include include/fun-alexandria-rcurry.texinfo + +@node Conses +@comment node-name, next, previous, up +@chapter Conses + +@include include/type-alexandria-proper-list.texinfo +@include include/type-alexandria-circular-list.texinfo + +@include include/macro-alexandria-appendf.texinfo +@include include/macro-alexandria-nconcf.texinfo +@include include/macro-alexandria-remove-from-plistf.texinfo +@include include/macro-alexandria-delete-from-plistf.texinfo +@include include/macro-alexandria-reversef.texinfo +@include include/macro-alexandria-nreversef.texinfo +@include include/macro-alexandria-unionf.texinfo +@include include/macro-alexandria-nunionf.texinfo + +@include include/macro-alexandria-doplist.texinfo + +@include include/fun-alexandria-circular-list-p.texinfo +@include include/fun-alexandria-circular-tree-p.texinfo +@include include/fun-alexandria-proper-list-p.texinfo + +@include include/fun-alexandria-alist-plist.texinfo +@include include/fun-alexandria-plist-alist.texinfo +@include include/fun-alexandria-circular-list.texinfo +@include include/fun-alexandria-make-circular-list.texinfo +@include include/fun-alexandria-ensure-car.texinfo +@include include/fun-alexandria-ensure-cons.texinfo +@include include/fun-alexandria-ensure-list.texinfo +@include include/fun-alexandria-flatten.texinfo +@include include/fun-alexandria-lastcar.texinfo +@include include/fun-alexandria-setf-lastcar.texinfo +@include include/fun-alexandria-proper-list-length.texinfo +@include include/fun-alexandria-mappend.texinfo +@include include/fun-alexandria-map-product.texinfo +@include include/fun-alexandria-remove-from-plist.texinfo +@include include/fun-alexandria-delete-from-plist.texinfo +@include include/fun-alexandria-set-equal.texinfo +@include include/fun-alexandria-setp.texinfo + +@node Sequences +@comment node-name, next, previous, up +@chapter Sequences + +@include include/type-alexandria-proper-sequence.texinfo + +@include include/macro-alexandria-deletef.texinfo +@include include/macro-alexandria-removef.texinfo + +@include include/fun-alexandria-rotate.texinfo +@include include/fun-alexandria-shuffle.texinfo +@include include/fun-alexandria-random-elt.texinfo +@include include/fun-alexandria-emptyp.texinfo +@include include/fun-alexandria-sequence-of-length-p.texinfo +@include include/fun-alexandria-length-equals.texinfo +@include include/fun-alexandria-copy-sequence.texinfo +@include include/fun-alexandria-first-elt.texinfo +@include include/fun-alexandria-setf-first-elt.texinfo +@include include/fun-alexandria-last-elt.texinfo +@include include/fun-alexandria-setf-last-elt.texinfo +@include include/fun-alexandria-starts-with.texinfo +@include include/fun-alexandria-starts-with-subseq.texinfo +@include include/fun-alexandria-ends-with.texinfo +@include include/fun-alexandria-ends-with-subseq.texinfo +@include include/fun-alexandria-map-combinations.texinfo +@include include/fun-alexandria-map-derangements.texinfo +@include include/fun-alexandria-map-permutations.texinfo + +@node IO +@comment node-name, next, previous, up +@chapter IO + +@include include/fun-alexandria-read-stream-content-into-string.texinfo +@include include/fun-alexandria-read-file-into-string.texinfo +@include include/fun-alexandria-read-stream-content-into-byte-vector.texinfo +@include include/fun-alexandria-read-file-into-byte-vector.texinfo + +@node Macro Writing +@comment node-name, next, previous, up +@chapter Macro Writing + +@include include/macro-alexandria-once-only.texinfo +@include include/macro-alexandria-with-gensyms.texinfo +@include include/macro-alexandria-with-unique-names.texinfo +@include include/fun-alexandria-featurep.texinfo +@include include/fun-alexandria-parse-body.texinfo +@include include/fun-alexandria-parse-ordinary-lambda-list.texinfo + +@node Symbols +@comment node-name, next, previous, up +@chapter Symbols + +@include include/fun-alexandria-ensure-symbol.texinfo +@include include/fun-alexandria-format-symbol.texinfo +@include include/fun-alexandria-make-keyword.texinfo +@include include/fun-alexandria-make-gensym.texinfo +@include include/fun-alexandria-make-gensym-list.texinfo +@include include/fun-alexandria-symbolicate.texinfo + +@node Arrays +@comment node-name, next, previous, up +@chapter Arrays + +@include include/type-alexandria-array-index.texinfo +@include include/type-alexandria-array-length.texinfo +@include include/fun-alexandria-copy-array.texinfo + +@node Types +@comment node-name, next, previous, up +@chapter Types + +@include include/type-alexandria-string-designator.texinfo +@include include/macro-alexandria-coercef.texinfo +@include include/fun-alexandria-of-type.texinfo +@include include/fun-alexandria-type-equals.texinfo + +@node Numbers +@comment node-name, next, previous, up +@chapter Numbers + +@include include/macro-alexandria-maxf.texinfo +@include include/macro-alexandria-minf.texinfo + +@include include/fun-alexandria-binomial-coefficient.texinfo +@include include/fun-alexandria-count-permutations.texinfo +@include include/fun-alexandria-clamp.texinfo +@include include/fun-alexandria-lerp.texinfo +@include include/fun-alexandria-factorial.texinfo +@include include/fun-alexandria-subfactorial.texinfo +@include include/fun-alexandria-gaussian-random.texinfo +@include include/fun-alexandria-iota.texinfo +@include include/fun-alexandria-map-iota.texinfo +@include include/fun-alexandria-mean.texinfo +@include include/fun-alexandria-median.texinfo +@include include/fun-alexandria-variance.texinfo +@include include/fun-alexandria-standard-deviation.texinfo + +@bye diff --git a/third_party/lisp/alexandria/doc/docstrings.lisp b/third_party/lisp/alexandria/doc/docstrings.lisp new file mode 100644 index 0000000000..51dda07d09 --- /dev/null +++ b/third_party/lisp/alexandria/doc/docstrings.lisp @@ -0,0 +1,881 @@ +;;; -*- lisp -*- + +;;;; A docstring extractor for the sbcl manual. Creates +;;;; @include-ready documentation from the docstrings of exported +;;;; symbols of specified packages. + +;;;; This software is part of the SBCL software system. SBCL is in the +;;;; public domain and is provided with absolutely no warranty. See +;;;; the COPYING file for more information. +;;;; +;;;; Written by Rudi Schlatte <rudi@constantly.at>, mangled +;;;; by Nikodemus Siivola. + +;;;; TODO +;;;; * Verbatim text +;;;; * Quotations +;;;; * Method documentation untested +;;;; * Method sorting, somehow +;;;; * Index for macros & constants? +;;;; * This is getting complicated enough that tests would be good +;;;; * Nesting (currently only nested itemizations work) +;;;; * doc -> internal form -> texinfo (so that non-texinfo format are also +;;;; easily generated) + +;;;; FIXME: The description below is no longer complete. This +;;;; should possibly be turned into a contrib with proper documentation. + +;;;; Formatting heuristics (tweaked to format SAVE-LISP-AND-DIE sanely): +;;;; +;;;; Formats SYMBOL as @code{symbol}, or @var{symbol} if symbol is in +;;;; the argument list of the defun / defmacro. +;;;; +;;;; Lines starting with * or - that are followed by intented lines +;;;; are marked up with @itemize. +;;;; +;;;; Lines containing only a SYMBOL that are followed by indented +;;;; lines are marked up as @table @code, with the SYMBOL as the item. + +(eval-when (:compile-toplevel :load-toplevel :execute) + (require 'sb-introspect)) + +(defpackage :sb-texinfo + (:use :cl :sb-mop) + (:shadow #:documentation) + (:export #:generate-includes #:document-package) + (:documentation + "Tools to generate TexInfo documentation from docstrings.")) + +(in-package :sb-texinfo) + +;;;; various specials and parameters + +(defvar *texinfo-output*) +(defvar *texinfo-variables*) +(defvar *documentation-package*) +(defvar *base-package*) + +(defparameter *undocumented-packages* '(sb-pcl sb-int sb-kernel sb-sys sb-c)) + +(defparameter *documentation-types* + '(compiler-macro + function + method-combination + setf + ;;structure ; also handled by `type' + type + variable) + "A list of symbols accepted as second argument of `documentation'") + +(defparameter *character-replacements* + '((#\* . "star") (#\/ . "slash") (#\+ . "plus") + (#\< . "lt") (#\> . "gt") + (#\= . "equals")) + "Characters and their replacement names that `alphanumize' uses. If +the replacements contain any of the chars they're supposed to replace, +you deserve to lose.") + +(defparameter *characters-to-drop* '(#\\ #\` #\') + "Characters that should be removed by `alphanumize'.") + +(defparameter *texinfo-escaped-chars* "@{}" + "Characters that must be escaped with #\@ for Texinfo.") + +(defparameter *itemize-start-characters* '(#\* #\-) + "Characters that might start an itemization in docstrings when + at the start of a line.") + +(defparameter *symbol-characters* "ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890*:-+&#'" + "List of characters that make up symbols in a docstring.") + +(defparameter *symbol-delimiters* " ,.!?;") + +(defparameter *ordered-documentation-kinds* + '(package type structure condition class macro)) + +;;;; utilities + +(defun flatten (list) + (cond ((null list) + nil) + ((consp (car list)) + (nconc (flatten (car list)) (flatten (cdr list)))) + ((null (cdr list)) + (cons (car list) nil)) + (t + (cons (car list) (flatten (cdr list)))))) + +(defun whitespacep (char) + (find char #(#\tab #\space #\page))) + +(defun setf-name-p (name) + (or (symbolp name) + (and (listp name) (= 2 (length name)) (eq (car name) 'setf)))) + +(defgeneric specializer-name (specializer)) + +(defmethod specializer-name ((specializer eql-specializer)) + (list 'eql (eql-specializer-object specializer))) + +(defmethod specializer-name ((specializer class)) + (class-name specializer)) + +(defun ensure-class-precedence-list (class) + (unless (class-finalized-p class) + (finalize-inheritance class)) + (class-precedence-list class)) + +(defun specialized-lambda-list (method) + ;; courtecy of AMOP p. 61 + (let* ((specializers (method-specializers method)) + (lambda-list (method-lambda-list method)) + (n-required (length specializers))) + (append (mapcar (lambda (arg specializer) + (if (eq specializer (find-class 't)) + arg + `(,arg ,(specializer-name specializer)))) + (subseq lambda-list 0 n-required) + specializers) + (subseq lambda-list n-required)))) + +(defun string-lines (string) + "Lines in STRING as a vector." + (coerce (with-input-from-string (s string) + (loop for line = (read-line s nil nil) + while line collect line)) + 'vector)) + +(defun indentation (line) + "Position of first non-SPACE character in LINE." + (position-if-not (lambda (c) (char= c #\Space)) line)) + +(defun docstring (x doc-type) + (cl:documentation x doc-type)) + +(defun flatten-to-string (list) + (format nil "~{~A~^-~}" (flatten list))) + +(defun alphanumize (original) + "Construct a string without characters like *`' that will f-star-ck +up filename handling. See `*character-replacements*' and +`*characters-to-drop*' for customization." + (let ((name (remove-if (lambda (x) (member x *characters-to-drop*)) + (if (listp original) + (flatten-to-string original) + (string original)))) + (chars-to-replace (mapcar #'car *character-replacements*))) + (flet ((replacement-delimiter (index) + (cond ((or (< index 0) (>= index (length name))) "") + ((alphanumericp (char name index)) "-") + (t "")))) + (loop for index = (position-if #'(lambda (x) (member x chars-to-replace)) + name) + while index + do (setf name (concatenate 'string (subseq name 0 index) + (replacement-delimiter (1- index)) + (cdr (assoc (aref name index) + *character-replacements*)) + (replacement-delimiter (1+ index)) + (subseq name (1+ index)))))) + name)) + +;;;; generating various names + +(defgeneric name (thing) + (:documentation "Name for a documented thing. Names are either +symbols or lists of symbols.")) + +(defmethod name ((symbol symbol)) + symbol) + +(defmethod name ((cons cons)) + cons) + +(defmethod name ((package package)) + (short-package-name package)) + +(defmethod name ((method method)) + (list + (generic-function-name (method-generic-function method)) + (method-qualifiers method) + (specialized-lambda-list method))) + +;;; Node names for DOCUMENTATION instances + +(defgeneric name-using-kind/name (kind name doc)) + +(defmethod name-using-kind/name (kind (name string) doc) + (declare (ignore kind doc)) + name) + +(defmethod name-using-kind/name (kind (name symbol) doc) + (declare (ignore kind)) + (format nil "~@[~A:~]~A" (short-package-name (get-package doc)) name)) + +(defmethod name-using-kind/name (kind (name list) doc) + (declare (ignore kind)) + (assert (setf-name-p name)) + (format nil "(setf ~@[~A:~]~A)" (short-package-name (get-package doc)) (second name))) + +(defmethod name-using-kind/name ((kind (eql 'method)) name doc) + (format nil "~A~{ ~A~} ~A" + (name-using-kind/name nil (first name) doc) + (second name) + (third name))) + +(defun node-name (doc) + "Returns TexInfo node name as a string for a DOCUMENTATION instance." + (let ((kind (get-kind doc))) + (format nil "~:(~A~) ~(~A~)" kind (name-using-kind/name kind (get-name doc) doc)))) + +(defun short-package-name (package) + (unless (eq package *base-package*) + (car (sort (copy-list (cons (package-name package) (package-nicknames package))) + #'< :key #'length)))) + +;;; Definition titles for DOCUMENTATION instances + +(defgeneric title-using-kind/name (kind name doc)) + +(defmethod title-using-kind/name (kind (name string) doc) + (declare (ignore kind doc)) + name) + +(defmethod title-using-kind/name (kind (name symbol) doc) + (declare (ignore kind)) + (format nil "~@[~A:~]~A" (short-package-name (get-package doc)) name)) + +(defmethod title-using-kind/name (kind (name list) doc) + (declare (ignore kind)) + (assert (setf-name-p name)) + (format nil "(setf ~@[~A:~]~A)" (short-package-name (get-package doc)) (second name))) + +(defmethod title-using-kind/name ((kind (eql 'method)) name doc) + (format nil "~{~A ~}~A" + (second name) + (title-using-kind/name nil (first name) doc))) + +(defun title-name (doc) + "Returns a string to be used as name of the definition." + (string-downcase (title-using-kind/name (get-kind doc) (get-name doc) doc))) + +(defun include-pathname (doc) + (let* ((kind (get-kind doc)) + (name (nstring-downcase + (if (eq 'package kind) + (format nil "package-~A" (alphanumize (get-name doc))) + (format nil "~A-~A-~A" + (case (get-kind doc) + ((function generic-function) "fun") + (structure "struct") + (variable "var") + (otherwise (symbol-name (get-kind doc)))) + (alphanumize (let ((*base-package* nil)) + (short-package-name (get-package doc)))) + (alphanumize (get-name doc))))))) + (make-pathname :name name :type "texinfo"))) + +;;;; documentation class and related methods + +(defclass documentation () + ((name :initarg :name :reader get-name) + (kind :initarg :kind :reader get-kind) + (string :initarg :string :reader get-string) + (children :initarg :children :initform nil :reader get-children) + (package :initform *documentation-package* :reader get-package))) + +(defmethod print-object ((documentation documentation) stream) + (print-unreadable-object (documentation stream :type t) + (princ (list (get-kind documentation) (get-name documentation)) stream))) + +(defgeneric make-documentation (x doc-type string)) + +(defmethod make-documentation ((x package) doc-type string) + (declare (ignore doc-type)) + (make-instance 'documentation + :name (name x) + :kind 'package + :string string)) + +(defmethod make-documentation (x (doc-type (eql 'function)) string) + (declare (ignore doc-type)) + (let* ((fdef (and (fboundp x) (fdefinition x))) + (name x) + (kind (cond ((and (symbolp x) (special-operator-p x)) + 'special-operator) + ((and (symbolp x) (macro-function x)) + 'macro) + ((typep fdef 'generic-function) + (assert (or (symbolp name) (setf-name-p name))) + 'generic-function) + (fdef + (assert (or (symbolp name) (setf-name-p name))) + 'function))) + (children (when (eq kind 'generic-function) + (collect-gf-documentation fdef)))) + (make-instance 'documentation + :name (name x) + :string string + :kind kind + :children children))) + +(defmethod make-documentation ((x method) doc-type string) + (declare (ignore doc-type)) + (make-instance 'documentation + :name (name x) + :kind 'method + :string string)) + +(defmethod make-documentation (x (doc-type (eql 'type)) string) + (make-instance 'documentation + :name (name x) + :string string + :kind (etypecase (find-class x nil) + (structure-class 'structure) + (standard-class 'class) + (sb-pcl::condition-class 'condition) + ((or built-in-class null) 'type)))) + +(defmethod make-documentation (x (doc-type (eql 'variable)) string) + (make-instance 'documentation + :name (name x) + :string string + :kind (if (constantp x) + 'constant + 'variable))) + +(defmethod make-documentation (x (doc-type (eql 'setf)) string) + (declare (ignore doc-type)) + (make-instance 'documentation + :name (name x) + :kind 'setf-expander + :string string)) + +(defmethod make-documentation (x doc-type string) + (make-instance 'documentation + :name (name x) + :kind doc-type + :string string)) + +(defun maybe-documentation (x doc-type) + "Returns a DOCUMENTATION instance for X and DOC-TYPE, or NIL if +there is no corresponding docstring." + (let ((docstring (docstring x doc-type))) + (when docstring + (make-documentation x doc-type docstring)))) + +(defun lambda-list (doc) + (case (get-kind doc) + ((package constant variable type structure class condition nil) + nil) + (method + (third (get-name doc))) + (t + ;; KLUDGE: Eugh. + ;; + ;; believe it or not, the above comment was written before CSR + ;; came along and obfuscated this. (2005-07-04) + (when (symbolp (get-name doc)) + (labels ((clean (x &key optional key) + (typecase x + (atom x) + ((cons (member &optional)) + (cons (car x) (clean (cdr x) :optional t))) + ((cons (member &key)) + (cons (car x) (clean (cdr x) :key t))) + ((cons (member &whole &environment)) + ;; Skip these + (clean (cdr x) :optional optional :key key)) + ((cons cons) + (cons + (cond (key (if (consp (caar x)) + (caaar x) + (caar x))) + (optional (caar x)) + (t (clean (car x)))) + (clean (cdr x) :key key :optional optional))) + (cons + (cons + (cond ((or key optional) (car x)) + (t (clean (car x)))) + (clean (cdr x) :key key :optional optional)))))) + (clean (sb-introspect:function-lambda-list (get-name doc)))))))) + +(defun get-string-name (x) + (let ((name (get-name x))) + (cond ((symbolp name) + (symbol-name name)) + ((and (consp name) (eq 'setf (car name))) + (symbol-name (second name))) + ((stringp name) + name) + (t + (error "Don't know which symbol to use for name ~S" name))))) + +(defun documentation< (x y) + (let ((p1 (position (get-kind x) *ordered-documentation-kinds*)) + (p2 (position (get-kind y) *ordered-documentation-kinds*))) + (if (or (not (and p1 p2)) (= p1 p2)) + (string< (get-string-name x) (get-string-name y)) + (< p1 p2)))) + +;;;; turning text into texinfo + +(defun escape-for-texinfo (string &optional downcasep) + "Return STRING with characters in *TEXINFO-ESCAPED-CHARS* escaped +with #\@. Optionally downcase the result." + (let ((result (with-output-to-string (s) + (loop for char across string + when (find char *texinfo-escaped-chars*) + do (write-char #\@ s) + do (write-char char s))))) + (if downcasep (nstring-downcase result) result))) + +(defun empty-p (line-number lines) + (and (< -1 line-number (length lines)) + (not (indentation (svref lines line-number))))) + +;;; line markups + +(defvar *not-symbols* '("ANSI" "CLHS")) + +(defun locate-symbols (line) + "Return a list of index pairs of symbol-like parts of LINE." + ;; This would be a good application for a regex ... + (let (result) + (flet ((grab (start end) + (unless (member (subseq line start end) '("ANSI" "CLHS")) + (push (list start end) result)))) + (do ((begin nil) + (maybe-begin t) + (i 0 (1+ i))) + ((= i (length line)) + ;; symbol at end of line + (when (and begin (or (> i (1+ begin)) + (not (member (char line begin) '(#\A #\I))))) + (grab begin i)) + (nreverse result)) + (cond + ((and begin (find (char line i) *symbol-delimiters*)) + ;; symbol end; remember it if it's not "A" or "I" + (when (or (> i (1+ begin)) (not (member (char line begin) '(#\A #\I)))) + (grab begin i)) + (setf begin nil + maybe-begin t)) + ((and begin (not (find (char line i) *symbol-characters*))) + ;; Not a symbol: abort + (setf begin nil)) + ((and maybe-begin (not begin) (find (char line i) *symbol-characters*)) + ;; potential symbol begin at this position + (setf begin i + maybe-begin nil)) + ((find (char line i) *symbol-delimiters*) + ;; potential symbol begin after this position + (setf maybe-begin t)) + (t + ;; Not reading a symbol, not at potential start of symbol + (setf maybe-begin nil))))))) + +(defun texinfo-line (line) + "Format symbols in LINE texinfo-style: either as code or as +variables if the symbol in question is contained in symbols +*TEXINFO-VARIABLES*." + (with-output-to-string (result) + (let ((last 0)) + (dolist (symbol/index (locate-symbols line)) + (write-string (subseq line last (first symbol/index)) result) + (let ((symbol-name (apply #'subseq line symbol/index))) + (format result (if (member symbol-name *texinfo-variables* + :test #'string=) + "@var{~A}" + "@code{~A}") + (string-downcase symbol-name))) + (setf last (second symbol/index))) + (write-string (subseq line last) result)))) + +;;; lisp sections + +(defun lisp-section-p (line line-number lines) + "Returns T if the given LINE looks like start of lisp code -- +ie. if it starts with whitespace followed by a paren or +semicolon, and the previous line is empty" + (let ((offset (indentation line))) + (and offset + (plusp offset) + (find (find-if-not #'whitespacep line) "(;") + (empty-p (1- line-number) lines)))) + +(defun collect-lisp-section (lines line-number) + (let ((lisp (loop for index = line-number then (1+ index) + for line = (and (< index (length lines)) (svref lines index)) + while (indentation line) + collect line))) + (values (length lisp) `("@lisp" ,@lisp "@end lisp")))) + +;;; itemized sections + +(defun maybe-itemize-offset (line) + "Return NIL or the indentation offset if LINE looks like it starts +an item in an itemization." + (let* ((offset (indentation line)) + (char (when offset (char line offset)))) + (and offset + (member char *itemize-start-characters* :test #'char=) + (char= #\Space (find-if-not (lambda (c) (char= c char)) + line :start offset)) + offset))) + +(defun collect-maybe-itemized-section (lines starting-line) + ;; Return index of next line to be processed outside + (let ((this-offset (maybe-itemize-offset (svref lines starting-line))) + (result nil) + (lines-consumed 0)) + (loop for line-number from starting-line below (length lines) + for line = (svref lines line-number) + for indentation = (indentation line) + for offset = (maybe-itemize-offset line) + do (cond + ((not indentation) + ;; empty line -- inserts paragraph. + (push "" result) + (incf lines-consumed)) + ((and offset (> indentation this-offset)) + ;; nested itemization -- handle recursively + ;; FIXME: tables in itemizations go wrong + (multiple-value-bind (sub-lines-consumed sub-itemization) + (collect-maybe-itemized-section lines line-number) + (when sub-lines-consumed + (incf line-number (1- sub-lines-consumed)) ; +1 on next loop + (incf lines-consumed sub-lines-consumed) + (setf result (nconc (nreverse sub-itemization) result))))) + ((and offset (= indentation this-offset)) + ;; start of new item + (push (format nil "@item ~A" + (texinfo-line (subseq line (1+ offset)))) + result) + (incf lines-consumed)) + ((and (not offset) (> indentation this-offset)) + ;; continued item from previous line + (push (texinfo-line line) result) + (incf lines-consumed)) + (t + ;; end of itemization + (loop-finish)))) + ;; a single-line itemization isn't. + (if (> (count-if (lambda (line) (> (length line) 0)) result) 1) + (values lines-consumed `("@itemize" ,@(reverse result) "@end itemize")) + nil))) + +;;; table sections + +(defun tabulation-body-p (offset line-number lines) + (when (< line-number (length lines)) + (let ((offset2 (indentation (svref lines line-number)))) + (and offset2 (< offset offset2))))) + +(defun tabulation-p (offset line-number lines direction) + (let ((step (ecase direction + (:backwards (1- line-number)) + (:forwards (1+ line-number))))) + (when (and (plusp line-number) (< line-number (length lines))) + (and (eql offset (indentation (svref lines line-number))) + (or (when (eq direction :backwards) + (empty-p step lines)) + (tabulation-p offset step lines direction) + (tabulation-body-p offset step lines)))))) + +(defun maybe-table-offset (line-number lines) + "Return NIL or the indentation offset if LINE looks like it starts +an item in a tabulation. Ie, if it is (1) indented, (2) preceded by an +empty line, another tabulation label, or a tabulation body, (3) and +followed another tabulation label or a tabulation body." + (let* ((line (svref lines line-number)) + (offset (indentation line)) + (prev (1- line-number)) + (next (1+ line-number))) + (when (and offset (plusp offset)) + (and (or (empty-p prev lines) + (tabulation-body-p offset prev lines) + (tabulation-p offset prev lines :backwards)) + (or (tabulation-body-p offset next lines) + (tabulation-p offset next lines :forwards)) + offset)))) + +;;; FIXME: This and itemization are very similar: could they share +;;; some code, mayhap? + +(defun collect-maybe-table-section (lines starting-line) + ;; Return index of next line to be processed outside + (let ((this-offset (maybe-table-offset starting-line lines)) + (result nil) + (lines-consumed 0)) + (loop for line-number from starting-line below (length lines) + for line = (svref lines line-number) + for indentation = (indentation line) + for offset = (maybe-table-offset line-number lines) + do (cond + ((not indentation) + ;; empty line -- inserts paragraph. + (push "" result) + (incf lines-consumed)) + ((and offset (= indentation this-offset)) + ;; start of new item, or continuation of previous item + (if (and result (search "@item" (car result) :test #'char=)) + (push (format nil "@itemx ~A" (texinfo-line line)) + result) + (progn + (push "" result) + (push (format nil "@item ~A" (texinfo-line line)) + result))) + (incf lines-consumed)) + ((> indentation this-offset) + ;; continued item from previous line + (push (texinfo-line line) result) + (incf lines-consumed)) + (t + ;; end of itemization + (loop-finish)))) + ;; a single-line table isn't. + (if (> (count-if (lambda (line) (> (length line) 0)) result) 1) + (values lines-consumed + `("" "@table @emph" ,@(reverse result) "@end table" "")) + nil))) + +;;; section markup + +(defmacro with-maybe-section (index &rest forms) + `(multiple-value-bind (count collected) (progn ,@forms) + (when count + (dolist (line collected) + (write-line line *texinfo-output*)) + (incf ,index (1- count))))) + +(defun write-texinfo-string (string &optional lambda-list) + "Try to guess as much formatting for a raw docstring as possible." + (let ((*texinfo-variables* (flatten lambda-list)) + (lines (string-lines (escape-for-texinfo string nil)))) + (loop for line-number from 0 below (length lines) + for line = (svref lines line-number) + do (cond + ((with-maybe-section line-number + (and (lisp-section-p line line-number lines) + (collect-lisp-section lines line-number)))) + ((with-maybe-section line-number + (and (maybe-itemize-offset line) + (collect-maybe-itemized-section lines line-number)))) + ((with-maybe-section line-number + (and (maybe-table-offset line-number lines) + (collect-maybe-table-section lines line-number)))) + (t + (write-line (texinfo-line line) *texinfo-output*)))))) + +;;;; texinfo formatting tools + +(defun hide-superclass-p (class-name super-name) + (let ((super-package (symbol-package super-name))) + (or + ;; KLUDGE: We assume that we don't want to advertise internal + ;; classes in CP-lists, unless the symbol we're documenting is + ;; internal as well. + (and (member super-package #.'(mapcar #'find-package *undocumented-packages*)) + (not (eq super-package (symbol-package class-name)))) + ;; KLUDGE: We don't generally want to advertise SIMPLE-ERROR or + ;; SIMPLE-CONDITION in the CPLs of conditions that inherit them + ;; simply as a matter of convenience. The assumption here is that + ;; the inheritance is incidental unless the name of the condition + ;; begins with SIMPLE-. + (and (member super-name '(simple-error simple-condition)) + (let ((prefix "SIMPLE-")) + (mismatch prefix (string class-name) :end2 (length prefix))) + t ; don't return number from MISMATCH + )))) + +(defun hide-slot-p (symbol slot) + ;; FIXME: There is no pricipal reason to avoid the slot docs fo + ;; structures and conditions, but their DOCUMENTATION T doesn't + ;; currently work with them the way we'd like. + (not (and (typep (find-class symbol nil) 'standard-class) + (docstring slot t)))) + +(defun texinfo-anchor (doc) + (format *texinfo-output* "@anchor{~A}~%" (node-name doc))) + +;;; KLUDGE: &AUX *PRINT-PRETTY* here means "no linebreaks please" +(defun texinfo-begin (doc &aux *print-pretty*) + (let ((kind (get-kind doc))) + (format *texinfo-output* "@~A {~:(~A~)} ~({~A}~@[ ~{~A~^ ~}~]~)~%" + (case kind + ((package constant variable) + "defvr") + ((structure class condition type) + "deftp") + (t + "deffn")) + (map 'string (lambda (char) (if (eql char #\-) #\Space char)) (string kind)) + (title-name doc) + ;; &foo would be amusingly bold in the pdf thanks to TeX/Texinfo + ;; interactions,so we escape the ampersand -- amusingly for TeX. + ;; sbcl.texinfo defines macros that expand @&key and friends to &key. + (mapcar (lambda (name) + (if (member name lambda-list-keywords) + (format nil "@~A" name) + name)) + (lambda-list doc))))) + +(defun texinfo-index (doc) + (let ((title (title-name doc))) + (case (get-kind doc) + ((structure type class condition) + (format *texinfo-output* "@tindex ~A~%" title)) + ((variable constant) + (format *texinfo-output* "@vindex ~A~%" title)) + ((compiler-macro function method-combination macro generic-function) + (format *texinfo-output* "@findex ~A~%" title))))) + +(defun texinfo-inferred-body (doc) + (when (member (get-kind doc) '(class structure condition)) + (let ((name (get-name doc))) + ;; class precedence list + (format *texinfo-output* "Class precedence list: @code{~(~{@lw{~A}~^, ~}~)}~%~%" + (remove-if (lambda (class) (hide-superclass-p name class)) + (mapcar #'class-name (ensure-class-precedence-list (find-class name))))) + ;; slots + (let ((slots (remove-if (lambda (slot) (hide-slot-p name slot)) + (class-direct-slots (find-class name))))) + (when slots + (format *texinfo-output* "Slots:~%@itemize~%") + (dolist (slot slots) + (format *texinfo-output* + "@item ~(@code{~A}~#[~:; --- ~]~ + ~:{~2*~@[~2:*~A~P: ~{@code{@w{~S}}~^, ~}~]~:^; ~}~)~%~%" + (slot-definition-name slot) + (remove + nil + (mapcar + (lambda (name things) + (if things + (list name (length things) things))) + '("initarg" "reader" "writer") + (list + (slot-definition-initargs slot) + (slot-definition-readers slot) + (slot-definition-writers slot))))) + ;; FIXME: Would be neater to handler as children + (write-texinfo-string (docstring slot t))) + (format *texinfo-output* "@end itemize~%~%")))))) + +(defun texinfo-body (doc) + (write-texinfo-string (get-string doc))) + +(defun texinfo-end (doc) + (write-line (case (get-kind doc) + ((package variable constant) "@end defvr") + ((structure type class condition) "@end deftp") + (t "@end deffn")) + *texinfo-output*)) + +(defun write-texinfo (doc) + "Writes TexInfo for a DOCUMENTATION instance to *TEXINFO-OUTPUT*." + (texinfo-anchor doc) + (texinfo-begin doc) + (texinfo-index doc) + (texinfo-inferred-body doc) + (texinfo-body doc) + (texinfo-end doc) + ;; FIXME: Children should be sorted one way or another + (mapc #'write-texinfo (get-children doc))) + +;;;; main logic + +(defun collect-gf-documentation (gf) + "Collects method documentation for the generic function GF" + (loop for method in (generic-function-methods gf) + for doc = (maybe-documentation method t) + when doc + collect doc)) + +(defun collect-name-documentation (name) + (loop for type in *documentation-types* + for doc = (maybe-documentation name type) + when doc + collect doc)) + +(defun collect-symbol-documentation (symbol) + "Collects all docs for a SYMBOL and (SETF SYMBOL), returns a list of +the form DOC instances. See `*documentation-types*' for the possible +values of doc-type." + (nconc (collect-name-documentation symbol) + (collect-name-documentation (list 'setf symbol)))) + +(defun collect-documentation (package) + "Collects all documentation for all external symbols of the given +package, as well as for the package itself." + (let* ((*documentation-package* (find-package package)) + (docs nil)) + (check-type package package) + (do-external-symbols (symbol package) + (setf docs (nconc (collect-symbol-documentation symbol) docs))) + (let ((doc (maybe-documentation *documentation-package* t))) + (when doc + (push doc docs))) + docs)) + +(defmacro with-texinfo-file (pathname &body forms) + `(with-open-file (*texinfo-output* ,pathname + :direction :output + :if-does-not-exist :create + :if-exists :supersede) + ,@forms)) + +(defun write-ifnottex () + ;; We use @&key, etc to escape & from TeX in lambda lists -- so we need to + ;; define them for info as well. + (flet ((macro (name) + (let ((string (string-downcase name))) + (format *texinfo-output* "@macro ~A~%~A~%@end macro~%" string string)))) + (macro '&allow-other-keys) + (macro '&optional) + (macro '&rest) + (macro '&key) + (macro '&body))) + +(defun generate-includes (directory packages &key (base-package :cl-user)) + "Create files in `directory' containing Texinfo markup of all +docstrings of each exported symbol in `packages'. `directory' is +created if necessary. If you supply a namestring that doesn't end in a +slash, you lose. The generated files are of the form +\"<doc-type>_<packagename>_<symbol-name>.texinfo\" and can be included +via @include statements. Texinfo syntax-significant characters are +escaped in symbol names, but if a docstring contains invalid Texinfo +markup, you lose." + (handler-bind ((warning #'muffle-warning)) + (let ((directory (merge-pathnames (pathname directory))) + (*base-package* (find-package base-package))) + (ensure-directories-exist directory) + (dolist (package packages) + (dolist (doc (collect-documentation (find-package package))) + (with-texinfo-file (merge-pathnames (include-pathname doc) directory) + (write-texinfo doc)))) + (with-texinfo-file (merge-pathnames "ifnottex.texinfo" directory) + (write-ifnottex)) + directory))) + +(defun document-package (package &optional filename) + "Create a file containing all available documentation for the +exported symbols of `package' in Texinfo format. If `filename' is not +supplied, a file \"<packagename>.texinfo\" is generated. + +The definitions can be referenced using Texinfo statements like +@ref{<doc-type>_<packagename>_<symbol-name>.texinfo}. Texinfo +syntax-significant characters are escaped in symbol names, but if a +docstring contains invalid Texinfo markup, you lose." + (handler-bind ((warning #'muffle-warning)) + (let* ((package (find-package package)) + (filename (or filename (make-pathname + :name (string-downcase (short-package-name package)) + :type "texinfo"))) + (docs (sort (collect-documentation package) #'documentation<))) + (with-texinfo-file filename + (dolist (doc docs) + (write-texinfo doc))) + filename))) diff --git a/third_party/lisp/alexandria/features.lisp b/third_party/lisp/alexandria/features.lisp new file mode 100644 index 0000000000..67348dbba4 --- /dev/null +++ b/third_party/lisp/alexandria/features.lisp @@ -0,0 +1,14 @@ +(in-package :alexandria) + +(defun featurep (feature-expression) + "Returns T if the argument matches the state of the *FEATURES* +list and NIL if it does not. FEATURE-EXPRESSION can be any atom +or list acceptable to the reader macros #+ and #-." + (etypecase feature-expression + (symbol (not (null (member feature-expression *features*)))) + (cons (check-type (first feature-expression) symbol) + (eswitch ((first feature-expression) :test 'string=) + (:and (every #'featurep (rest feature-expression))) + (:or (some #'featurep (rest feature-expression))) + (:not (assert (= 2 (length feature-expression))) + (not (featurep (second feature-expression)))))))) diff --git a/third_party/lisp/alexandria/functions.lisp b/third_party/lisp/alexandria/functions.lisp new file mode 100644 index 0000000000..dd83e38b4e --- /dev/null +++ b/third_party/lisp/alexandria/functions.lisp @@ -0,0 +1,161 @@ +(in-package :alexandria) + +;;; To propagate return type and allow the compiler to eliminate the IF when +;;; it is known if the argument is function or not. +(declaim (inline ensure-function)) + +(declaim (ftype (function (t) (values function &optional)) + ensure-function)) +(defun ensure-function (function-designator) + "Returns the function designated by FUNCTION-DESIGNATOR: +if FUNCTION-DESIGNATOR is a function, it is returned, otherwise +it must be a function name and its FDEFINITION is returned." + (if (functionp function-designator) + function-designator + (fdefinition function-designator))) + +(define-modify-macro ensure-functionf/1 () ensure-function) + +(defmacro ensure-functionf (&rest places) + "Multiple-place modify macro for ENSURE-FUNCTION: ensures that each of +PLACES contains a function." + `(progn ,@(mapcar (lambda (x) `(ensure-functionf/1 ,x)) places))) + +(defun disjoin (predicate &rest more-predicates) + "Returns a function that applies each of PREDICATE and MORE-PREDICATE +functions in turn to its arguments, returning the primary value of the first +predicate that returns true, without calling the remaining predicates. +If none of the predicates returns true, NIL is returned." + (declare (optimize (speed 3) (safety 1) (debug 1))) + (let ((predicate (ensure-function predicate)) + (more-predicates (mapcar #'ensure-function more-predicates))) + (lambda (&rest arguments) + (or (apply predicate arguments) + (some (lambda (p) + (declare (type function p)) + (apply p arguments)) + more-predicates))))) + +(defun conjoin (predicate &rest more-predicates) + "Returns a function that applies each of PREDICATE and MORE-PREDICATE +functions in turn to its arguments, returning NIL if any of the predicates +returns false, without calling the remaining predicates. If none of the +predicates returns false, returns the primary value of the last predicate." + (if (null more-predicates) + predicate + (lambda (&rest arguments) + (and (apply predicate arguments) + ;; Cannot simply use CL:EVERY because we want to return the + ;; non-NIL value of the last predicate if all succeed. + (do ((tail (cdr more-predicates) (cdr tail)) + (head (car more-predicates) (car tail))) + ((not tail) + (apply head arguments)) + (unless (apply head arguments) + (return nil))))))) + + +(defun compose (function &rest more-functions) + "Returns a function composed of FUNCTION and MORE-FUNCTIONS that applies its +arguments to to each in turn, starting from the rightmost of MORE-FUNCTIONS, +and then calling the next one with the primary value of the last." + (declare (optimize (speed 3) (safety 1) (debug 1))) + (reduce (lambda (f g) + (let ((f (ensure-function f)) + (g (ensure-function g))) + (lambda (&rest arguments) + (declare (dynamic-extent arguments)) + (funcall f (apply g arguments))))) + more-functions + :initial-value function)) + +(define-compiler-macro compose (function &rest more-functions) + (labels ((compose-1 (funs) + (if (cdr funs) + `(funcall ,(car funs) ,(compose-1 (cdr funs))) + `(apply ,(car funs) arguments)))) + (let* ((args (cons function more-functions)) + (funs (make-gensym-list (length args) "COMPOSE"))) + `(let ,(loop for f in funs for arg in args + collect `(,f (ensure-function ,arg))) + (declare (optimize (speed 3) (safety 1) (debug 1))) + (lambda (&rest arguments) + (declare (dynamic-extent arguments)) + ,(compose-1 funs)))))) + +(defun multiple-value-compose (function &rest more-functions) + "Returns a function composed of FUNCTION and MORE-FUNCTIONS that applies +its arguments to each in turn, starting from the rightmost of +MORE-FUNCTIONS, and then calling the next one with all the return values of +the last." + (declare (optimize (speed 3) (safety 1) (debug 1))) + (reduce (lambda (f g) + (let ((f (ensure-function f)) + (g (ensure-function g))) + (lambda (&rest arguments) + (declare (dynamic-extent arguments)) + (multiple-value-call f (apply g arguments))))) + more-functions + :initial-value function)) + +(define-compiler-macro multiple-value-compose (function &rest more-functions) + (labels ((compose-1 (funs) + (if (cdr funs) + `(multiple-value-call ,(car funs) ,(compose-1 (cdr funs))) + `(apply ,(car funs) arguments)))) + (let* ((args (cons function more-functions)) + (funs (make-gensym-list (length args) "MV-COMPOSE"))) + `(let ,(mapcar #'list funs args) + (declare (optimize (speed 3) (safety 1) (debug 1))) + (lambda (&rest arguments) + (declare (dynamic-extent arguments)) + ,(compose-1 funs)))))) + +(declaim (inline curry rcurry)) + +(defun curry (function &rest arguments) + "Returns a function that applies ARGUMENTS and the arguments +it is called with to FUNCTION." + (declare (optimize (speed 3) (safety 1))) + (let ((fn (ensure-function function))) + (lambda (&rest more) + (declare (dynamic-extent more)) + ;; Using M-V-C we don't need to append the arguments. + (multiple-value-call fn (values-list arguments) (values-list more))))) + +(define-compiler-macro curry (function &rest arguments) + (let ((curries (make-gensym-list (length arguments) "CURRY")) + (fun (gensym "FUN"))) + `(let ((,fun (ensure-function ,function)) + ,@(mapcar #'list curries arguments)) + (declare (optimize (speed 3) (safety 1))) + (lambda (&rest more) + (declare (dynamic-extent more)) + (apply ,fun ,@curries more))))) + +(defun rcurry (function &rest arguments) + "Returns a function that applies the arguments it is called +with and ARGUMENTS to FUNCTION." + (declare (optimize (speed 3) (safety 1))) + (let ((fn (ensure-function function))) + (lambda (&rest more) + (declare (dynamic-extent more)) + (multiple-value-call fn (values-list more) (values-list arguments))))) + +(define-compiler-macro rcurry (function &rest arguments) + (let ((rcurries (make-gensym-list (length arguments) "RCURRY")) + (fun (gensym "FUN"))) + `(let ((,fun (ensure-function ,function)) + ,@(mapcar #'list rcurries arguments)) + (declare (optimize (speed 3) (safety 1))) + (lambda (&rest more) + (declare (dynamic-extent more)) + (multiple-value-call ,fun (values-list more) ,@rcurries))))) + +(declaim (notinline curry rcurry)) + +(defmacro named-lambda (name lambda-list &body body) + "Expands into a lambda-expression within whose BODY NAME denotes the +corresponding function." + `(labels ((,name ,lambda-list ,@body)) + #',name)) diff --git a/third_party/lisp/alexandria/hash-tables.lisp b/third_party/lisp/alexandria/hash-tables.lisp new file mode 100644 index 0000000000..a9f7902204 --- /dev/null +++ b/third_party/lisp/alexandria/hash-tables.lisp @@ -0,0 +1,101 @@ +(in-package :alexandria) + +(defmacro ensure-gethash (key hash-table &optional default) + "Like GETHASH, but if KEY is not found in the HASH-TABLE saves the DEFAULT +under key before returning it. Secondary return value is true if key was +already in the table." + (once-only (key hash-table) + (with-unique-names (value presentp) + `(multiple-value-bind (,value ,presentp) (gethash ,key ,hash-table) + (if ,presentp + (values ,value ,presentp) + (values (setf (gethash ,key ,hash-table) ,default) nil)))))) + +(defun copy-hash-table (table &key key test size + rehash-size rehash-threshold) + "Returns a copy of hash table TABLE, with the same keys and values +as the TABLE. The copy has the same properties as the original, unless +overridden by the keyword arguments. + +Before each of the original values is set into the new hash-table, KEY +is invoked on the value. As KEY defaults to CL:IDENTITY, a shallow +copy is returned by default." + (setf key (or key 'identity)) + (setf test (or test (hash-table-test table))) + (setf size (or size (hash-table-size table))) + (setf rehash-size (or rehash-size (hash-table-rehash-size table))) + (setf rehash-threshold (or rehash-threshold (hash-table-rehash-threshold table))) + (let ((copy (make-hash-table :test test :size size + :rehash-size rehash-size + :rehash-threshold rehash-threshold))) + (maphash (lambda (k v) + (setf (gethash k copy) (funcall key v))) + table) + copy)) + +(declaim (inline maphash-keys)) +(defun maphash-keys (function table) + "Like MAPHASH, but calls FUNCTION with each key in the hash table TABLE." + (maphash (lambda (k v) + (declare (ignore v)) + (funcall function k)) + table)) + +(declaim (inline maphash-values)) +(defun maphash-values (function table) + "Like MAPHASH, but calls FUNCTION with each value in the hash table TABLE." + (maphash (lambda (k v) + (declare (ignore k)) + (funcall function v)) + table)) + +(defun hash-table-keys (table) + "Returns a list containing the keys of hash table TABLE." + (let ((keys nil)) + (maphash-keys (lambda (k) + (push k keys)) + table) + keys)) + +(defun hash-table-values (table) + "Returns a list containing the values of hash table TABLE." + (let ((values nil)) + (maphash-values (lambda (v) + (push v values)) + table) + values)) + +(defun hash-table-alist (table) + "Returns an association list containing the keys and values of hash table +TABLE." + (let ((alist nil)) + (maphash (lambda (k v) + (push (cons k v) alist)) + table) + alist)) + +(defun hash-table-plist (table) + "Returns a property list containing the keys and values of hash table +TABLE." + (let ((plist nil)) + (maphash (lambda (k v) + (setf plist (list* k v plist))) + table) + plist)) + +(defun alist-hash-table (alist &rest hash-table-initargs) + "Returns a hash table containing the keys and values of the association list +ALIST. Hash table is initialized using the HASH-TABLE-INITARGS." + (let ((table (apply #'make-hash-table hash-table-initargs))) + (dolist (cons alist) + (ensure-gethash (car cons) table (cdr cons))) + table)) + +(defun plist-hash-table (plist &rest hash-table-initargs) + "Returns a hash table containing the keys and values of the property list +PLIST. Hash table is initialized using the HASH-TABLE-INITARGS." + (let ((table (apply #'make-hash-table hash-table-initargs))) + (do ((tail plist (cddr tail))) + ((not tail)) + (ensure-gethash (car tail) table (cadr tail))) + table)) diff --git a/third_party/lisp/alexandria/io.lisp b/third_party/lisp/alexandria/io.lisp new file mode 100644 index 0000000000..28bf5e6d82 --- /dev/null +++ b/third_party/lisp/alexandria/io.lisp @@ -0,0 +1,172 @@ +;; Copyright (c) 2002-2006, Edward Marco Baringer +;; All rights reserved. + +(in-package :alexandria) + +(defmacro with-open-file* ((stream filespec &key direction element-type + if-exists if-does-not-exist external-format) + &body body) + "Just like WITH-OPEN-FILE, but NIL values in the keyword arguments mean to use +the default value specified for OPEN." + (once-only (direction element-type if-exists if-does-not-exist external-format) + `(with-open-stream + (,stream (apply #'open ,filespec + (append + (when ,direction + (list :direction ,direction)) + (when ,element-type + (list :element-type ,element-type)) + (when ,if-exists + (list :if-exists ,if-exists)) + (when ,if-does-not-exist + (list :if-does-not-exist ,if-does-not-exist)) + (when ,external-format + (list :external-format ,external-format))))) + ,@body))) + +(defmacro with-input-from-file ((stream-name file-name &rest args + &key (direction nil direction-p) + &allow-other-keys) + &body body) + "Evaluate BODY with STREAM-NAME to an input stream on the file +FILE-NAME. ARGS is sent as is to the call to OPEN except EXTERNAL-FORMAT, +which is only sent to WITH-OPEN-FILE when it's not NIL." + (declare (ignore direction)) + (when direction-p + (error "Can't specify :DIRECTION for WITH-INPUT-FROM-FILE.")) + `(with-open-file* (,stream-name ,file-name :direction :input ,@args) + ,@body)) + +(defmacro with-output-to-file ((stream-name file-name &rest args + &key (direction nil direction-p) + &allow-other-keys) + &body body) + "Evaluate BODY with STREAM-NAME to an output stream on the file +FILE-NAME. ARGS is sent as is to the call to OPEN except EXTERNAL-FORMAT, +which is only sent to WITH-OPEN-FILE when it's not NIL." + (declare (ignore direction)) + (when direction-p + (error "Can't specify :DIRECTION for WITH-OUTPUT-TO-FILE.")) + `(with-open-file* (,stream-name ,file-name :direction :output ,@args) + ,@body)) + +(defun read-stream-content-into-string (stream &key (buffer-size 4096)) + "Return the \"content\" of STREAM as a fresh string." + (check-type buffer-size positive-integer) + (let ((*print-pretty* nil)) + (with-output-to-string (datum) + (let ((buffer (make-array buffer-size :element-type 'character))) + (loop + :for bytes-read = (read-sequence buffer stream) + :do (write-sequence buffer datum :start 0 :end bytes-read) + :while (= bytes-read buffer-size)))))) + +(defun read-file-into-string (pathname &key (buffer-size 4096) external-format) + "Return the contents of the file denoted by PATHNAME as a fresh string. + +The EXTERNAL-FORMAT parameter will be passed directly to WITH-OPEN-FILE +unless it's NIL, which means the system default." + (with-input-from-file + (file-stream pathname :external-format external-format) + (read-stream-content-into-string file-stream :buffer-size buffer-size))) + +(defun write-string-into-file (string pathname &key (if-exists :error) + if-does-not-exist + external-format) + "Write STRING to PATHNAME. + +The EXTERNAL-FORMAT parameter will be passed directly to WITH-OPEN-FILE +unless it's NIL, which means the system default." + (with-output-to-file (file-stream pathname :if-exists if-exists + :if-does-not-exist if-does-not-exist + :external-format external-format) + (write-sequence string file-stream))) + +(defun read-stream-content-into-byte-vector (stream &key ((%length length)) + (initial-size 4096)) + "Return \"content\" of STREAM as freshly allocated (unsigned-byte 8) vector." + (check-type length (or null non-negative-integer)) + (check-type initial-size positive-integer) + (do ((buffer (make-array (or length initial-size) + :element-type '(unsigned-byte 8))) + (offset 0) + (offset-wanted 0)) + ((or (/= offset-wanted offset) + (and length (>= offset length))) + (if (= offset (length buffer)) + buffer + (subseq buffer 0 offset))) + (unless (zerop offset) + (let ((new-buffer (make-array (* 2 (length buffer)) + :element-type '(unsigned-byte 8)))) + (replace new-buffer buffer) + (setf buffer new-buffer))) + (setf offset-wanted (length buffer) + offset (read-sequence buffer stream :start offset)))) + +(defun read-file-into-byte-vector (pathname) + "Read PATHNAME into a freshly allocated (unsigned-byte 8) vector." + (with-input-from-file (stream pathname :element-type '(unsigned-byte 8)) + (read-stream-content-into-byte-vector stream '%length (file-length stream)))) + +(defun write-byte-vector-into-file (bytes pathname &key (if-exists :error) + if-does-not-exist) + "Write BYTES to PATHNAME." + (check-type bytes (vector (unsigned-byte 8))) + (with-output-to-file (stream pathname :if-exists if-exists + :if-does-not-exist if-does-not-exist + :element-type '(unsigned-byte 8)) + (write-sequence bytes stream))) + +(defun copy-file (from to &key (if-to-exists :supersede) + (element-type '(unsigned-byte 8)) finish-output) + (with-input-from-file (input from :element-type element-type) + (with-output-to-file (output to :element-type element-type + :if-exists if-to-exists) + (copy-stream input output + :element-type element-type + :finish-output finish-output)))) + +(defun copy-stream (input output &key (element-type (stream-element-type input)) + (buffer-size 4096) + (buffer (make-array buffer-size :element-type element-type)) + (start 0) end + finish-output) + "Reads data from INPUT and writes it to OUTPUT. Both INPUT and OUTPUT must +be streams, they will be passed to READ-SEQUENCE and WRITE-SEQUENCE and must have +compatible element-types." + (check-type start non-negative-integer) + (check-type end (or null non-negative-integer)) + (check-type buffer-size positive-integer) + (when (and end + (< end start)) + (error "END is smaller than START in ~S" 'copy-stream)) + (let ((output-position 0) + (input-position 0)) + (unless (zerop start) + ;; FIXME add platform specific optimization to skip seekable streams + (loop while (< input-position start) + do (let ((n (read-sequence buffer input + :end (min (length buffer) + (- start input-position))))) + (when (zerop n) + (error "~@<Could not read enough bytes from the input to fulfill ~ + the :START ~S requirement in ~S.~:@>" 'copy-stream start)) + (incf input-position n)))) + (assert (= input-position start)) + (loop while (or (null end) (< input-position end)) + do (let ((n (read-sequence buffer input + :end (when end + (min (length buffer) + (- end input-position)))))) + (when (zerop n) + (if end + (error "~@<Could not read enough bytes from the input to fulfill ~ + the :END ~S requirement in ~S.~:@>" 'copy-stream end) + (return))) + (incf input-position n) + (write-sequence buffer output :end n) + (incf output-position n))) + (when finish-output + (finish-output output)) + output-position)) diff --git a/third_party/lisp/alexandria/lists.lisp b/third_party/lisp/alexandria/lists.lisp new file mode 100644 index 0000000000..51286071eb --- /dev/null +++ b/third_party/lisp/alexandria/lists.lisp @@ -0,0 +1,367 @@ +(in-package :alexandria) + +(declaim (inline safe-endp)) +(defun safe-endp (x) + (declare (optimize safety)) + (endp x)) + +(defun alist-plist (alist) + "Returns a property list containing the same keys and values as the +association list ALIST in the same order." + (let (plist) + (dolist (pair alist) + (push (car pair) plist) + (push (cdr pair) plist)) + (nreverse plist))) + +(defun plist-alist (plist) + "Returns an association list containing the same keys and values as the +property list PLIST in the same order." + (let (alist) + (do ((tail plist (cddr tail))) + ((safe-endp tail) (nreverse alist)) + (push (cons (car tail) (cadr tail)) alist)))) + +(declaim (inline racons)) +(defun racons (key value ralist) + (acons value key ralist)) + +(macrolet + ((define-alist-get (name get-entry get-value-from-entry add doc) + `(progn + (declaim (inline ,name)) + (defun ,name (alist key &key (test 'eql)) + ,doc + (let ((entry (,get-entry key alist :test test))) + (values (,get-value-from-entry entry) entry))) + (define-setf-expander ,name (place key &key (test ''eql) + &environment env) + (multiple-value-bind + (temporary-variables initforms newvals setter getter) + (get-setf-expansion place env) + (when (cdr newvals) + (error "~A cannot store multiple values in one place" ',name)) + (with-unique-names (new-value key-val test-val alist entry) + (values + (append temporary-variables + (list alist + key-val + test-val + entry)) + (append initforms + (list getter + key + test + `(,',get-entry ,key-val ,alist :test ,test-val))) + `(,new-value) + `(cond + (,entry + (setf (,',get-value-from-entry ,entry) ,new-value)) + (t + (let ,newvals + (setf ,(first newvals) (,',add ,key ,new-value ,alist)) + ,setter + ,new-value))) + `(,',get-value-from-entry ,entry)))))))) + (define-alist-get assoc-value assoc cdr acons +"ASSOC-VALUE is an alist accessor very much like ASSOC, but it can +be used with SETF.") + (define-alist-get rassoc-value rassoc car racons +"RASSOC-VALUE is an alist accessor very much like RASSOC, but it can +be used with SETF.")) + +(defun malformed-plist (plist) + (error "Malformed plist: ~S" plist)) + +(defmacro doplist ((key val plist &optional values) &body body) + "Iterates over elements of PLIST. BODY can be preceded by +declarations, and is like a TAGBODY. RETURN may be used to terminate +the iteration early. If RETURN is not used, returns VALUES." + (multiple-value-bind (forms declarations) (parse-body body) + (with-gensyms (tail loop results) + `(block nil + (flet ((,results () + (let (,key ,val) + (declare (ignorable ,key ,val)) + (return ,values)))) + (let* ((,tail ,plist) + (,key (if ,tail + (pop ,tail) + (,results))) + (,val (if ,tail + (pop ,tail) + (malformed-plist ',plist)))) + (declare (ignorable ,key ,val)) + ,@declarations + (tagbody + ,loop + ,@forms + (setf ,key (if ,tail + (pop ,tail) + (,results)) + ,val (if ,tail + (pop ,tail) + (malformed-plist ',plist))) + (go ,loop)))))))) + +(define-modify-macro appendf (&rest lists) append + "Modify-macro for APPEND. Appends LISTS to the place designated by the first +argument.") + +(define-modify-macro nconcf (&rest lists) nconc + "Modify-macro for NCONC. Concatenates LISTS to place designated by the first +argument.") + +(define-modify-macro unionf (list &rest args) union + "Modify-macro for UNION. Saves the union of LIST and the contents of the +place designated by the first argument to the designated place.") + +(define-modify-macro nunionf (list &rest args) nunion + "Modify-macro for NUNION. Saves the union of LIST and the contents of the +place designated by the first argument to the designated place. May modify +either argument.") + +(define-modify-macro reversef () reverse + "Modify-macro for REVERSE. Copies and reverses the list stored in the given +place and saves back the result into the place.") + +(define-modify-macro nreversef () nreverse + "Modify-macro for NREVERSE. Reverses the list stored in the given place by +destructively modifying it and saves back the result into the place.") + +(defun circular-list (&rest elements) + "Creates a circular list of ELEMENTS." + (let ((cycle (copy-list elements))) + (nconc cycle cycle))) + +(defun circular-list-p (object) + "Returns true if OBJECT is a circular list, NIL otherwise." + (and (listp object) + (do ((fast object (cddr fast)) + (slow (cons (car object) (cdr object)) (cdr slow))) + (nil) + (unless (and (consp fast) (listp (cdr fast))) + (return nil)) + (when (eq fast slow) + (return t))))) + +(defun circular-tree-p (object) + "Returns true if OBJECT is a circular tree, NIL otherwise." + (labels ((circularp (object seen) + (and (consp object) + (do ((fast (cons (car object) (cdr object)) (cddr fast)) + (slow object (cdr slow))) + (nil) + (when (or (eq fast slow) (member slow seen)) + (return-from circular-tree-p t)) + (when (or (not (consp fast)) (not (consp (cdr slow)))) + (return + (do ((tail object (cdr tail))) + ((not (consp tail)) + nil) + (let ((elt (car tail))) + (circularp elt (cons object seen)))))))))) + (circularp object nil))) + +(defun proper-list-p (object) + "Returns true if OBJECT is a proper list." + (cond ((not object) + t) + ((consp object) + (do ((fast object (cddr fast)) + (slow (cons (car object) (cdr object)) (cdr slow))) + (nil) + (unless (and (listp fast) (consp (cdr fast))) + (return (and (listp fast) (not (cdr fast))))) + (when (eq fast slow) + (return nil)))) + (t + nil))) + +(deftype proper-list () + "Type designator for proper lists. Implemented as a SATISFIES type, hence +not recommended for performance intensive use. Main usefullness as a type +designator of the expected type in a TYPE-ERROR." + `(and list (satisfies proper-list-p))) + +(defun circular-list-error (list) + (error 'type-error + :datum list + :expected-type '(and list (not circular-list)))) + +(macrolet ((def (name lambda-list doc step declare ret1 ret2) + (assert (member 'list lambda-list)) + `(defun ,name ,lambda-list + ,doc + (do ((last list fast) + (fast list (cddr fast)) + (slow (cons (car list) (cdr list)) (cdr slow)) + ,@(when step (list step))) + (nil) + (declare (dynamic-extent slow) ,@(when declare (list declare)) + (ignorable last)) + (when (safe-endp fast) + (return ,ret1)) + (when (safe-endp (cdr fast)) + (return ,ret2)) + (when (eq fast slow) + (circular-list-error list)))))) + (def proper-list-length (list) + "Returns length of LIST, signalling an error if it is not a proper list." + (n 1 (+ n 2)) + ;; KLUDGE: Most implementations don't actually support lists with bignum + ;; elements -- and this is WAY faster on most implementations then declaring + ;; N to be an UNSIGNED-BYTE. + (fixnum n) + (1- n) + n) + + (def lastcar (list) + "Returns the last element of LIST. Signals a type-error if LIST is not a +proper list." + nil + nil + (cadr last) + (car fast)) + + (def (setf lastcar) (object list) + "Sets the last element of LIST. Signals a type-error if LIST is not a proper +list." + nil + nil + (setf (cadr last) object) + (setf (car fast) object))) + +(defun make-circular-list (length &key initial-element) + "Creates a circular list of LENGTH with the given INITIAL-ELEMENT." + (let ((cycle (make-list length :initial-element initial-element))) + (nconc cycle cycle))) + +(deftype circular-list () + "Type designator for circular lists. Implemented as a SATISFIES type, so not +recommended for performance intensive use. Main usefullness as the +expected-type designator of a TYPE-ERROR." + `(satisfies circular-list-p)) + +(defun ensure-car (thing) + "If THING is a CONS, its CAR is returned. Otherwise THING is returned." + (if (consp thing) + (car thing) + thing)) + +(defun ensure-cons (cons) + "If CONS is a cons, it is returned. Otherwise returns a fresh cons with CONS + in the car, and NIL in the cdr." + (if (consp cons) + cons + (cons cons nil))) + +(defun ensure-list (list) + "If LIST is a list, it is returned. Otherwise returns the list designated by LIST." + (if (listp list) + list + (list list))) + +(defun remove-from-plist (plist &rest keys) + "Returns a propery-list with same keys and values as PLIST, except that keys +in the list designated by KEYS and values corresponding to them are removed. +The returned property-list may share structure with the PLIST, but PLIST is +not destructively modified. Keys are compared using EQ." + (declare (optimize (speed 3))) + ;; FIXME: possible optimization: (remove-from-plist '(:x 0 :a 1 :b 2) :a) + ;; could return the tail without consing up a new list. + (loop for (key . rest) on plist by #'cddr + do (assert rest () "Expected a proper plist, got ~S" plist) + unless (member key keys :test #'eq) + collect key and collect (first rest))) + +(defun delete-from-plist (plist &rest keys) + "Just like REMOVE-FROM-PLIST, but this version may destructively modify the +provided PLIST." + (declare (optimize speed)) + (loop with head = plist + with tail = nil ; a nil tail means an empty result so far + for (key . rest) on plist by #'cddr + do (assert rest () "Expected a proper plist, got ~S" plist) + (if (member key keys :test #'eq) + ;; skip over this pair + (let ((next (cdr rest))) + (if tail + (setf (cdr tail) next) + (setf head next))) + ;; keep this pair + (setf tail rest)) + finally (return head))) + +(define-modify-macro remove-from-plistf (&rest keys) remove-from-plist + "Modify macro for REMOVE-FROM-PLIST.") +(define-modify-macro delete-from-plistf (&rest keys) delete-from-plist + "Modify macro for DELETE-FROM-PLIST.") + +(declaim (inline sans)) +(defun sans (plist &rest keys) + "Alias of REMOVE-FROM-PLIST for backward compatibility." + (apply #'remove-from-plist plist keys)) + +(defun mappend (function &rest lists) + "Applies FUNCTION to respective element(s) of each LIST, appending all the +all the result list to a single list. FUNCTION must return a list." + (loop for results in (apply #'mapcar function lists) + append results)) + +(defun setp (object &key (test #'eql) (key #'identity)) + "Returns true if OBJECT is a list that denotes a set, NIL otherwise. A list +denotes a set if each element of the list is unique under KEY and TEST." + (and (listp object) + (let (seen) + (dolist (elt object t) + (let ((key (funcall key elt))) + (if (member key seen :test test) + (return nil) + (push key seen))))))) + +(defun set-equal (list1 list2 &key (test #'eql) (key nil keyp)) + "Returns true if every element of LIST1 matches some element of LIST2 and +every element of LIST2 matches some element of LIST1. Otherwise returns false." + (let ((keylist1 (if keyp (mapcar key list1) list1)) + (keylist2 (if keyp (mapcar key list2) list2))) + (and (dolist (elt keylist1 t) + (or (member elt keylist2 :test test) + (return nil))) + (dolist (elt keylist2 t) + (or (member elt keylist1 :test test) + (return nil)))))) + +(defun map-product (function list &rest more-lists) + "Returns a list containing the results of calling FUNCTION with one argument +from LIST, and one from each of MORE-LISTS for each combination of arguments. +In other words, returns the product of LIST and MORE-LISTS using FUNCTION. + +Example: + + (map-product 'list '(1 2) '(3 4) '(5 6)) + => ((1 3 5) (1 3 6) (1 4 5) (1 4 6) + (2 3 5) (2 3 6) (2 4 5) (2 4 6)) +" + (labels ((%map-product (f lists) + (let ((more (cdr lists)) + (one (car lists))) + (if (not more) + (mapcar f one) + (mappend (lambda (x) + (%map-product (curry f x) more)) + one))))) + (%map-product (ensure-function function) (cons list more-lists)))) + +(defun flatten (tree) + "Traverses the tree in order, collecting non-null leaves into a list." + (let (list) + (labels ((traverse (subtree) + (when subtree + (if (consp subtree) + (progn + (traverse (car subtree)) + (traverse (cdr subtree))) + (push subtree list))))) + (traverse tree)) + (nreverse list))) diff --git a/third_party/lisp/alexandria/macros.lisp b/third_party/lisp/alexandria/macros.lisp new file mode 100644 index 0000000000..4364ad63b8 --- /dev/null +++ b/third_party/lisp/alexandria/macros.lisp @@ -0,0 +1,370 @@ +(in-package :alexandria) + +(defmacro with-gensyms (names &body forms) + "Binds a set of variables to gensyms and evaluates the implicit progn FORMS. + +Each element within NAMES is either a symbol SYMBOL or a pair (SYMBOL +STRING-DESIGNATOR). Bare symbols are equivalent to the pair (SYMBOL SYMBOL). + +Each pair (SYMBOL STRING-DESIGNATOR) specifies that the variable named by SYMBOL +should be bound to a symbol constructed using GENSYM with the string designated +by STRING-DESIGNATOR being its first argument." + `(let ,(mapcar (lambda (name) + (multiple-value-bind (symbol string) + (etypecase name + (symbol + (values name (symbol-name name))) + ((cons symbol (cons string-designator null)) + (values (first name) (string (second name))))) + `(,symbol (gensym ,string)))) + names) + ,@forms)) + +(defmacro with-unique-names (names &body forms) + "Alias for WITH-GENSYMS." + `(with-gensyms ,names ,@forms)) + +(defmacro once-only (specs &body forms) + "Constructs code whose primary goal is to help automate the handling of +multiple evaluation within macros. Multiple evaluation is handled by introducing +intermediate variables, in order to reuse the result of an expression. + +The returned value is a list of the form + + (let ((<gensym-1> <expr-1>) + ... + (<gensym-n> <expr-n>)) + <res>) + +where GENSYM-1, ..., GENSYM-N are the intermediate variables introduced in order +to evaluate EXPR-1, ..., EXPR-N once, only. RES is code that is the result of +evaluating the implicit progn FORMS within a special context determined by +SPECS. RES should make use of (reference) the intermediate variables. + +Each element within SPECS is either a symbol SYMBOL or a pair (SYMBOL INITFORM). +Bare symbols are equivalent to the pair (SYMBOL SYMBOL). + +Each pair (SYMBOL INITFORM) specifies a single intermediate variable: + +- INITFORM is an expression evaluated to produce EXPR-i + +- SYMBOL is the name of the variable that will be bound around FORMS to the + corresponding gensym GENSYM-i, in order for FORMS to generate RES that + references the intermediate variable + +The evaluation of INITFORMs and binding of SYMBOLs resembles LET. INITFORMs of +all the pairs are evaluated before binding SYMBOLs and evaluating FORMS. + +Example: + + The following expression + + (let ((x '(incf y))) + (once-only (x) + `(cons ,x ,x))) + + ;;; => + ;;; (let ((#1=#:X123 (incf y))) + ;;; (cons #1# #1#)) + + could be used within a macro to avoid multiple evaluation like so + + (defmacro cons1 (x) + (once-only (x) + `(cons ,x ,x))) + + (let ((y 0)) + (cons1 (incf y))) + + ;;; => (1 . 1) + +Example: + + The following expression demonstrates the usage of the INITFORM field + + (let ((expr '(incf y))) + (once-only ((var `(1+ ,expr))) + `(list ',expr ,var ,var))) + + ;;; => + ;;; (let ((#1=#:VAR123 (1+ (incf y)))) + ;;; (list '(incf y) #1# #1)) + + which could be used like so + + (defmacro print-succ-twice (expr) + (once-only ((var `(1+ ,expr))) + `(format t \"Expr: ~s, Once: ~s, Twice: ~s~%\" ',expr ,var ,var))) + + (let ((y 10)) + (print-succ-twice (incf y))) + + ;;; >> + ;;; Expr: (INCF Y), Once: 12, Twice: 12" + (let ((gensyms (make-gensym-list (length specs) "ONCE-ONLY")) + (names-and-forms (mapcar (lambda (spec) + (etypecase spec + (list + (destructuring-bind (name form) spec + (cons name form))) + (symbol + (cons spec spec)))) + specs))) + ;; bind in user-macro + `(let ,(mapcar (lambda (g n) (list g `(gensym ,(string (car n))))) + gensyms names-and-forms) + ;; bind in final expansion + `(let (,,@(mapcar (lambda (g n) + ``(,,g ,,(cdr n))) + gensyms names-and-forms)) + ;; bind in user-macro + ,(let ,(mapcar (lambda (n g) (list (car n) g)) + names-and-forms gensyms) + ,@forms))))) + +(defun parse-body (body &key documentation whole) + "Parses BODY into (values remaining-forms declarations doc-string). +Documentation strings are recognized only if DOCUMENTATION is true. +Syntax errors in body are signalled and WHOLE is used in the signal +arguments when given." + (let ((doc nil) + (decls nil) + (current nil)) + (tagbody + :declarations + (setf current (car body)) + (when (and documentation (stringp current) (cdr body)) + (if doc + (error "Too many documentation strings in ~S." (or whole body)) + (setf doc (pop body))) + (go :declarations)) + (when (and (listp current) (eql (first current) 'declare)) + (push (pop body) decls) + (go :declarations))) + (values body (nreverse decls) doc))) + +(defun parse-ordinary-lambda-list (lambda-list &key (normalize t) + allow-specializers + (normalize-optional normalize) + (normalize-keyword normalize) + (normalize-auxilary normalize)) + "Parses an ordinary lambda-list, returning as multiple values: + +1. Required parameters. + +2. Optional parameter specifications, normalized into form: + + (name init suppliedp) + +3. Name of the rest parameter, or NIL. + +4. Keyword parameter specifications, normalized into form: + + ((keyword-name name) init suppliedp) + +5. Boolean indicating &ALLOW-OTHER-KEYS presence. + +6. &AUX parameter specifications, normalized into form + + (name init). + +7. Existence of &KEY in the lambda-list. + +Signals a PROGRAM-ERROR is the lambda-list is malformed." + (let ((state :required) + (allow-other-keys nil) + (auxp nil) + (required nil) + (optional nil) + (rest nil) + (keys nil) + (keyp nil) + (aux nil)) + (labels ((fail (elt) + (simple-program-error "Misplaced ~S in ordinary lambda-list:~% ~S" + elt lambda-list)) + (check-variable (elt what &optional (allow-specializers allow-specializers)) + (unless (and (or (symbolp elt) + (and allow-specializers + (consp elt) (= 2 (length elt)) (symbolp (first elt)))) + (not (constantp elt))) + (simple-program-error "Invalid ~A ~S in ordinary lambda-list:~% ~S" + what elt lambda-list))) + (check-spec (spec what) + (destructuring-bind (init suppliedp) spec + (declare (ignore init)) + (check-variable suppliedp what nil)))) + (dolist (elt lambda-list) + (case elt + (&optional + (if (eq state :required) + (setf state elt) + (fail elt))) + (&rest + (if (member state '(:required &optional)) + (setf state elt) + (fail elt))) + (&key + (if (member state '(:required &optional :after-rest)) + (setf state elt) + (fail elt)) + (setf keyp t)) + (&allow-other-keys + (if (eq state '&key) + (setf allow-other-keys t + state elt) + (fail elt))) + (&aux + (cond ((eq state '&rest) + (fail elt)) + (auxp + (simple-program-error "Multiple ~S in ordinary lambda-list:~% ~S" + elt lambda-list)) + (t + (setf auxp t + state elt)) + )) + (otherwise + (when (member elt '#.(set-difference lambda-list-keywords + '(&optional &rest &key &allow-other-keys &aux))) + (simple-program-error + "Bad lambda-list keyword ~S in ordinary lambda-list:~% ~S" + elt lambda-list)) + (case state + (:required + (check-variable elt "required parameter") + (push elt required)) + (&optional + (cond ((consp elt) + (destructuring-bind (name &rest tail) elt + (check-variable name "optional parameter") + (cond ((cdr tail) + (check-spec tail "optional-supplied-p parameter")) + ((and normalize-optional tail) + (setf elt (append elt '(nil)))) + (normalize-optional + (setf elt (append elt '(nil nil))))))) + (t + (check-variable elt "optional parameter") + (when normalize-optional + (setf elt (cons elt '(nil nil)))))) + (push (ensure-list elt) optional)) + (&rest + (check-variable elt "rest parameter") + (setf rest elt + state :after-rest)) + (&key + (cond ((consp elt) + (destructuring-bind (var-or-kv &rest tail) elt + (cond ((consp var-or-kv) + (destructuring-bind (keyword var) var-or-kv + (unless (symbolp keyword) + (simple-program-error "Invalid keyword name ~S in ordinary ~ + lambda-list:~% ~S" + keyword lambda-list)) + (check-variable var "keyword parameter"))) + (t + (check-variable var-or-kv "keyword parameter") + (when normalize-keyword + (setf var-or-kv (list (make-keyword var-or-kv) var-or-kv))))) + (cond ((cdr tail) + (check-spec tail "keyword-supplied-p parameter")) + ((and normalize-keyword tail) + (setf tail (append tail '(nil)))) + (normalize-keyword + (setf tail '(nil nil)))) + (setf elt (cons var-or-kv tail)))) + (t + (check-variable elt "keyword parameter") + (setf elt (if normalize-keyword + (list (list (make-keyword elt) elt) nil nil) + elt)))) + (push elt keys)) + (&aux + (if (consp elt) + (destructuring-bind (var &optional init) elt + (declare (ignore init)) + (check-variable var "&aux parameter")) + (progn + (check-variable elt "&aux parameter") + (setf elt (list* elt (when normalize-auxilary + '(nil)))))) + (push elt aux)) + (t + (simple-program-error "Invalid ordinary lambda-list:~% ~S" lambda-list))))))) + (values (nreverse required) (nreverse optional) rest (nreverse keys) + allow-other-keys (nreverse aux) keyp))) + +;;;; DESTRUCTURING-*CASE + +(defun expand-destructuring-case (key clauses case) + (once-only (key) + `(if (typep ,key 'cons) + (,case (car ,key) + ,@(mapcar (lambda (clause) + (destructuring-bind ((keys . lambda-list) &body body) clause + `(,keys + (destructuring-bind ,lambda-list (cdr ,key) + ,@body)))) + clauses)) + (error "Invalid key to DESTRUCTURING-~S: ~S" ',case ,key)))) + +(defmacro destructuring-case (keyform &body clauses) + "DESTRUCTURING-CASE, -CCASE, and -ECASE are a combination of CASE and DESTRUCTURING-BIND. +KEYFORM must evaluate to a CONS. + +Clauses are of the form: + + ((CASE-KEYS . DESTRUCTURING-LAMBDA-LIST) FORM*) + +The clause whose CASE-KEYS matches CAR of KEY, as if by CASE, CCASE, or ECASE, +is selected, and FORMs are then executed with CDR of KEY is destructured and +bound by the DESTRUCTURING-LAMBDA-LIST. + +Example: + + (defun dcase (x) + (destructuring-case x + ((:foo a b) + (format nil \"foo: ~S, ~S\" a b)) + ((:bar &key a b) + (format nil \"bar: ~S, ~S\" a b)) + (((:alt1 :alt2) a) + (format nil \"alt: ~S\" a)) + ((t &rest rest) + (format nil \"unknown: ~S\" rest)))) + + (dcase (list :foo 1 2)) ; => \"foo: 1, 2\" + (dcase (list :bar :a 1 :b 2)) ; => \"bar: 1, 2\" + (dcase (list :alt1 1)) ; => \"alt: 1\" + (dcase (list :alt2 2)) ; => \"alt: 2\" + (dcase (list :quux 1 2 3)) ; => \"unknown: 1, 2, 3\" + + (defun decase (x) + (destructuring-case x + ((:foo a b) + (format nil \"foo: ~S, ~S\" a b)) + ((:bar &key a b) + (format nil \"bar: ~S, ~S\" a b)) + (((:alt1 :alt2) a) + (format nil \"alt: ~S\" a)))) + + (decase (list :foo 1 2)) ; => \"foo: 1, 2\" + (decase (list :bar :a 1 :b 2)) ; => \"bar: 1, 2\" + (decase (list :alt1 1)) ; => \"alt: 1\" + (decase (list :alt2 2)) ; => \"alt: 2\" + (decase (list :quux 1 2 3)) ; =| error +" + (expand-destructuring-case keyform clauses 'case)) + +(defmacro destructuring-ccase (keyform &body clauses) + (expand-destructuring-case keyform clauses 'ccase)) + +(defmacro destructuring-ecase (keyform &body clauses) + (expand-destructuring-case keyform clauses 'ecase)) + +(dolist (name '(destructuring-ccase destructuring-ecase)) + (setf (documentation name 'function) (documentation 'destructuring-case 'function))) + + + diff --git a/third_party/lisp/alexandria/numbers.lisp b/third_party/lisp/alexandria/numbers.lisp new file mode 100644 index 0000000000..1c06f71d50 --- /dev/null +++ b/third_party/lisp/alexandria/numbers.lisp @@ -0,0 +1,295 @@ +(in-package :alexandria) + +(declaim (inline clamp)) +(defun clamp (number min max) + "Clamps the NUMBER into [min, max] range. Returns MIN if NUMBER is lesser then +MIN and MAX if NUMBER is greater then MAX, otherwise returns NUMBER." + (if (< number min) + min + (if (> number max) + max + number))) + +(defun gaussian-random (&optional min max) + "Returns two gaussian random double floats as the primary and secondary value, +optionally constrained by MIN and MAX. Gaussian random numbers form a standard +normal distribution around 0.0d0. + +Sufficiently positive MIN or negative MAX will cause the algorithm used to +take a very long time. If MIN is positive it should be close to zero, and +similarly if MAX is negative it should be close to zero." + (macrolet + ((valid (x) + `(<= (or min ,x) ,x (or max ,x)) )) + (labels + ((gauss () + (loop + for x1 = (- (random 2.0d0) 1.0d0) + for x2 = (- (random 2.0d0) 1.0d0) + for w = (+ (expt x1 2) (expt x2 2)) + when (< w 1.0d0) + do (let ((v (sqrt (/ (* -2.0d0 (log w)) w)))) + (return (values (* x1 v) (* x2 v)))))) + (guard (x) + (unless (valid x) + (tagbody + :retry + (multiple-value-bind (x1 x2) (gauss) + (when (valid x1) + (setf x x1) + (go :done)) + (when (valid x2) + (setf x x2) + (go :done)) + (go :retry)) + :done)) + x)) + (multiple-value-bind + (g1 g2) (gauss) + (values (guard g1) (guard g2)))))) + +(declaim (inline iota)) +(defun iota (n &key (start 0) (step 1)) + "Return a list of n numbers, starting from START (with numeric contagion +from STEP applied), each consequtive number being the sum of the previous one +and STEP. START defaults to 0 and STEP to 1. + +Examples: + + (iota 4) => (0 1 2 3) + (iota 3 :start 1 :step 1.0) => (1.0 2.0 3.0) + (iota 3 :start -1 :step -1/2) => (-1 -3/2 -2) +" + (declare (type (integer 0) n) (number start step)) + (loop ;; KLUDGE: get numeric contagion right for the first element too + for i = (+ (- (+ start step) step)) then (+ i step) + repeat n + collect i)) + +(declaim (inline map-iota)) +(defun map-iota (function n &key (start 0) (step 1)) + "Calls FUNCTION with N numbers, starting from START (with numeric contagion +from STEP applied), each consequtive number being the sum of the previous one +and STEP. START defaults to 0 and STEP to 1. Returns N. + +Examples: + + (map-iota #'print 3 :start 1 :step 1.0) => 3 + ;;; 1.0 + ;;; 2.0 + ;;; 3.0 +" + (declare (type (integer 0) n) (number start step)) + (loop ;; KLUDGE: get numeric contagion right for the first element too + for i = (+ start (- step step)) then (+ i step) + repeat n + do (funcall function i)) + n) + +(declaim (inline lerp)) +(defun lerp (v a b) + "Returns the result of linear interpolation between A and B, using the +interpolation coefficient V." + ;; The correct version is numerically stable, at the expense of an + ;; extra multiply. See (lerp 0.1 4 25) with (+ a (* v (- b a))). The + ;; unstable version can often be converted to a fast instruction on + ;; a lot of machines, though this is machine/implementation + ;; specific. As alexandria is more about correct code, than + ;; efficiency, and we're only talking about a single extra multiply, + ;; many would prefer the stable version + (+ (* (- 1.0 v) a) (* v b))) + +(declaim (inline mean)) +(defun mean (sample) + "Returns the mean of SAMPLE. SAMPLE must be a sequence of numbers." + (/ (reduce #'+ sample) (length sample))) + +(defun median (sample) + "Returns median of SAMPLE. SAMPLE must be a sequence of real numbers." + ;; Implements and uses the quick-select algorithm to find the median + ;; https://en.wikipedia.org/wiki/Quickselect + + (labels ((randint-in-range (start-int end-int) + "Returns a random integer in the specified range, inclusive" + (+ start-int (random (1+ (- end-int start-int))))) + (partition (vec start-i end-i) + "Implements the partition function, which performs a partial + sort of vec around the (randomly) chosen pivot. + Returns the index where the pivot element would be located + in a correctly-sorted array" + (if (= start-i end-i) + start-i + (let ((pivot-i (randint-in-range start-i end-i))) + (rotatef (aref vec start-i) (aref vec pivot-i)) + (let ((swap-i end-i)) + (loop for i from swap-i downto (1+ start-i) do + (when (>= (aref vec i) (aref vec start-i)) + (rotatef (aref vec i) (aref vec swap-i)) + (decf swap-i))) + (rotatef (aref vec swap-i) (aref vec start-i)) + swap-i))))) + + (let* ((vector (copy-sequence 'vector sample)) + (len (length vector)) + (mid-i (ash len -1)) + (i 0) + (j (1- len))) + + (loop for correct-pos = (partition vector i j) + while (/= correct-pos mid-i) do + (if (< correct-pos mid-i) + (setf i (1+ correct-pos)) + (setf j (1- correct-pos)))) + + (if (oddp len) + (aref vector mid-i) + (* 1/2 + (+ (aref vector mid-i) + (reduce #'max (make-array + mid-i + :displaced-to vector)))))))) + +(declaim (inline variance)) +(defun variance (sample &key (biased t)) + "Variance of SAMPLE. Returns the biased variance if BIASED is true (the default), +and the unbiased estimator of variance if BIASED is false. SAMPLE must be a +sequence of numbers." + (let ((mean (mean sample))) + (/ (reduce (lambda (a b) + (+ a (expt (- b mean) 2))) + sample + :initial-value 0) + (- (length sample) (if biased 0 1))))) + +(declaim (inline standard-deviation)) +(defun standard-deviation (sample &key (biased t)) + "Standard deviation of SAMPLE. Returns the biased standard deviation if +BIASED is true (the default), and the square root of the unbiased estimator +for variance if BIASED is false (which is not the same as the unbiased +estimator for standard deviation). SAMPLE must be a sequence of numbers." + (sqrt (variance sample :biased biased))) + +(define-modify-macro maxf (&rest numbers) max + "Modify-macro for MAX. Sets place designated by the first argument to the +maximum of its original value and NUMBERS.") + +(define-modify-macro minf (&rest numbers) min + "Modify-macro for MIN. Sets place designated by the first argument to the +minimum of its original value and NUMBERS.") + +;;;; Factorial + +;;; KLUDGE: This is really dependant on the numbers in question: for +;;; small numbers this is larger, and vice versa. Ideally instead of a +;;; constant we would have RANGE-FAST-TO-MULTIPLY-DIRECTLY-P. +(defconstant +factorial-bisection-range-limit+ 8) + +;;; KLUDGE: This is really platform dependant: ideally we would use +;;; (load-time-value (find-good-direct-multiplication-limit)) instead. +(defconstant +factorial-direct-multiplication-limit+ 13) + +(defun %multiply-range (i j) + ;; We use a a bit of cleverness here: + ;; + ;; 1. For large factorials we bisect in order to avoid expensive bignum + ;; multiplications: 1 x 2 x 3 x ... runs into bignums pretty soon, + ;; and once it does that all further multiplications will be with bignums. + ;; + ;; By instead doing the multiplication in a tree like + ;; ((1 x 2) x (3 x 4)) x ((5 x 6) x (7 x 8)) + ;; we manage to get less bignums. + ;; + ;; 2. Division isn't exactly free either, however, so we don't bisect + ;; all the way down, but multiply ranges of integers close to each + ;; other directly. + ;; + ;; For even better results it should be possible to use prime + ;; factorization magic, but Nikodemus ran out of steam. + ;; + ;; KLUDGE: We support factorials of bignums, but it seems quite + ;; unlikely anyone would ever be able to use them on a modern lisp, + ;; since the resulting numbers are unlikely to fit in memory... but + ;; it would be extremely unelegant to define FACTORIAL only on + ;; fixnums, _and_ on lisps with 16 bit fixnums this can actually be + ;; needed. + (labels ((bisect (j k) + (declare (type (integer 1 #.most-positive-fixnum) j k)) + (if (< (- k j) +factorial-bisection-range-limit+) + (multiply-range j k) + (let ((middle (+ j (truncate (- k j) 2)))) + (* (bisect j middle) + (bisect (+ middle 1) k))))) + (bisect-big (j k) + (declare (type (integer 1) j k)) + (if (= j k) + j + (let ((middle (+ j (truncate (- k j) 2)))) + (* (if (<= middle most-positive-fixnum) + (bisect j middle) + (bisect-big j middle)) + (bisect-big (+ middle 1) k))))) + (multiply-range (j k) + (declare (type (integer 1 #.most-positive-fixnum) j k)) + (do ((f k (* f m)) + (m (1- k) (1- m))) + ((< m j) f) + (declare (type (integer 0 (#.most-positive-fixnum)) m) + (type unsigned-byte f))))) + (if (and (typep i 'fixnum) (typep j 'fixnum)) + (bisect i j) + (bisect-big i j)))) + +(declaim (inline factorial)) +(defun %factorial (n) + (if (< n 2) + 1 + (%multiply-range 1 n))) + +(defun factorial (n) + "Factorial of non-negative integer N." + (check-type n (integer 0)) + (%factorial n)) + +;;;; Combinatorics + +(defun binomial-coefficient (n k) + "Binomial coefficient of N and K, also expressed as N choose K. This is the +number of K element combinations given N choises. N must be equal to or +greater then K." + (check-type n (integer 0)) + (check-type k (integer 0)) + (assert (>= n k)) + (if (or (zerop k) (= n k)) + 1 + (let ((n-k (- n k))) + ;; Swaps K and N-K if K < N-K because the algorithm + ;; below is faster for bigger K and smaller N-K + (when (< k n-k) + (rotatef k n-k)) + (if (= 1 n-k) + n + ;; General case, avoid computing the 1x...xK twice: + ;; + ;; N! 1x...xN (K+1)x...xN + ;; -------- = ---------------- = ------------, N>1 + ;; K!(N-K)! 1x...xK x (N-K)! (N-K)! + (/ (%multiply-range (+ k 1) n) + (%factorial n-k)))))) + +(defun subfactorial (n) + "Subfactorial of the non-negative integer N." + (check-type n (integer 0)) + (if (zerop n) + 1 + (do ((x 1 (1+ x)) + (a 0 (* x (+ a b))) + (b 1 a)) + ((= n x) a)))) + +(defun count-permutations (n &optional (k n)) + "Number of K element permutations for a sequence of N objects. +K defaults to N" + (check-type n (integer 0)) + (check-type k (integer 0)) + (assert (>= n k)) + (%multiply-range (1+ (- n k)) n)) diff --git a/third_party/lisp/alexandria/package.lisp b/third_party/lisp/alexandria/package.lisp new file mode 100644 index 0000000000..f9d2014cd7 --- /dev/null +++ b/third_party/lisp/alexandria/package.lisp @@ -0,0 +1,243 @@ +(defpackage :alexandria.1.0.0 + (:nicknames :alexandria) + (:use :cl) + #+sb-package-locks + (:lock t) + (:export + ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; + ;; BLESSED + ;; + ;; Binding constructs + #:if-let + #:when-let + #:when-let* + ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; + ;; REVIEW IN PROGRESS + ;; + ;; Control flow + ;; + ;; -- no clear consensus yet -- + #:cswitch + #:eswitch + #:switch + ;; -- problem free? -- + #:multiple-value-prog2 + #:nth-value-or + #:whichever + #:xor + ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; + ;; REVIEW PENDING + ;; + ;; Definitions + #:define-constant + ;; Hash tables + #:alist-hash-table + #:copy-hash-table + #:ensure-gethash + #:hash-table-alist + #:hash-table-keys + #:hash-table-plist + #:hash-table-values + #:maphash-keys + #:maphash-values + #:plist-hash-table + ;; Functions + #:compose + #:conjoin + #:curry + #:disjoin + #:ensure-function + #:ensure-functionf + #:multiple-value-compose + #:named-lambda + #:rcurry + ;; Lists + #:alist-plist + #:appendf + #:nconcf + #:reversef + #:nreversef + #:circular-list + #:circular-list-p + #:circular-tree-p + #:doplist + #:ensure-car + #:ensure-cons + #:ensure-list + #:flatten + #:lastcar + #:make-circular-list + #:map-product + #:mappend + #:nunionf + #:plist-alist + #:proper-list + #:proper-list-length + #:proper-list-p + #:remove-from-plist + #:remove-from-plistf + #:delete-from-plist + #:delete-from-plistf + #:set-equal + #:setp + #:unionf + ;; Numbers + #:binomial-coefficient + #:clamp + #:count-permutations + #:factorial + #:gaussian-random + #:iota + #:lerp + #:map-iota + #:maxf + #:mean + #:median + #:minf + #:standard-deviation + #:subfactorial + #:variance + ;; Arrays + #:array-index + #:array-length + #:copy-array + ;; Sequences + #:copy-sequence + #:deletef + #:emptyp + #:ends-with + #:ends-with-subseq + #:extremum + #:first-elt + #:last-elt + #:length= + #:map-combinations + #:map-derangements + #:map-permutations + #:proper-sequence + #:random-elt + #:removef + #:rotate + #:sequence-of-length-p + #:shuffle + #:starts-with + #:starts-with-subseq + ;; Macros + #:once-only + #:parse-body + #:parse-ordinary-lambda-list + #:with-gensyms + #:with-unique-names + ;; Symbols + #:ensure-symbol + #:format-symbol + #:make-gensym + #:make-gensym-list + #:make-keyword + ;; Strings + #:string-designator + ;; Types + #:negative-double-float + #:negative-fixnum-p + #:negative-float + #:negative-float-p + #:negative-long-float + #:negative-long-float-p + #:negative-rational + #:negative-rational-p + #:negative-real + #:negative-single-float-p + #:non-negative-double-float + #:non-negative-double-float-p + #:non-negative-fixnum + #:non-negative-fixnum-p + #:non-negative-float + #:non-negative-float-p + #:non-negative-integer-p + #:non-negative-long-float + #:non-negative-rational + #:non-negative-real-p + #:non-negative-short-float-p + #:non-negative-single-float + #:non-negative-single-float-p + #:non-positive-double-float + #:non-positive-double-float-p + #:non-positive-fixnum + #:non-positive-fixnum-p + #:non-positive-float + #:non-positive-float-p + #:non-positive-integer + #:non-positive-rational + #:non-positive-real + #:non-positive-real-p + #:non-positive-short-float + #:non-positive-short-float-p + #:non-positive-single-float-p + #:positive-double-float + #:positive-double-float-p + #:positive-fixnum + #:positive-fixnum-p + #:positive-float + #:positive-float-p + #:positive-integer + #:positive-rational + #:positive-real + #:positive-real-p + #:positive-short-float + #:positive-short-float-p + #:positive-single-float + #:positive-single-float-p + #:coercef + #:negative-double-float-p + #:negative-fixnum + #:negative-integer + #:negative-integer-p + #:negative-real-p + #:negative-short-float + #:negative-short-float-p + #:negative-single-float + #:non-negative-integer + #:non-negative-long-float-p + #:non-negative-rational-p + #:non-negative-real + #:non-negative-short-float + #:non-positive-integer-p + #:non-positive-long-float + #:non-positive-long-float-p + #:non-positive-rational-p + #:non-positive-single-float + #:of-type + #:positive-integer-p + #:positive-long-float + #:positive-long-float-p + #:positive-rational-p + #:type= + ;; Conditions + #:required-argument + #:ignore-some-conditions + #:simple-style-warning + #:simple-reader-error + #:simple-parse-error + #:simple-program-error + #:unwind-protect-case + ;; Features + #:featurep + ;; io + #:with-input-from-file + #:with-output-to-file + #:read-stream-content-into-string + #:read-file-into-string + #:write-string-into-file + #:read-stream-content-into-byte-vector + #:read-file-into-byte-vector + #:write-byte-vector-into-file + #:copy-stream + #:copy-file + ;; new additions collected at the end (subject to removal or further changes) + #:symbolicate + #:assoc-value + #:rassoc-value + #:destructuring-case + #:destructuring-ccase + #:destructuring-ecase + )) diff --git a/third_party/lisp/alexandria/sequences.lisp b/third_party/lisp/alexandria/sequences.lisp new file mode 100644 index 0000000000..21464f5376 --- /dev/null +++ b/third_party/lisp/alexandria/sequences.lisp @@ -0,0 +1,555 @@ +(in-package :alexandria) + +;; Make these inlinable by declaiming them INLINE here and some of them +;; NOTINLINE at the end of the file. Exclude functions that have a compiler +;; macro, because NOTINLINE is required to prevent compiler-macro expansion. +(declaim (inline copy-sequence sequence-of-length-p)) + +(defun sequence-of-length-p (sequence length) + "Return true if SEQUENCE is a sequence of length LENGTH. Signals an error if +SEQUENCE is not a sequence. Returns FALSE for circular lists." + (declare (type array-index length) + #-lispworks (inline length) + (optimize speed)) + (etypecase sequence + (null + (zerop length)) + (cons + (let ((n (1- length))) + (unless (minusp n) + (let ((tail (nthcdr n sequence))) + (and tail + (null (cdr tail))))))) + (vector + (= length (length sequence))) + (sequence + (= length (length sequence))))) + +(defun rotate-tail-to-head (sequence n) + (declare (type (integer 1) n)) + (if (listp sequence) + (let ((m (mod n (proper-list-length sequence)))) + (if (null (cdr sequence)) + sequence + (let* ((tail (last sequence (+ m 1))) + (last (cdr tail))) + (setf (cdr tail) nil) + (nconc last sequence)))) + (let* ((len (length sequence)) + (m (mod n len)) + (tail (subseq sequence (- len m)))) + (replace sequence sequence :start1 m :start2 0) + (replace sequence tail) + sequence))) + +(defun rotate-head-to-tail (sequence n) + (declare (type (integer 1) n)) + (if (listp sequence) + (let ((m (mod (1- n) (proper-list-length sequence)))) + (if (null (cdr sequence)) + sequence + (let* ((headtail (nthcdr m sequence)) + (tail (cdr headtail))) + (setf (cdr headtail) nil) + (nconc tail sequence)))) + (let* ((len (length sequence)) + (m (mod n len)) + (head (subseq sequence 0 m))) + (replace sequence sequence :start1 0 :start2 m) + (replace sequence head :start1 (- len m)) + sequence))) + +(defun rotate (sequence &optional (n 1)) + "Returns a sequence of the same type as SEQUENCE, with the elements of +SEQUENCE rotated by N: N elements are moved from the end of the sequence to +the front if N is positive, and -N elements moved from the front to the end if +N is negative. SEQUENCE must be a proper sequence. N must be an integer, +defaulting to 1. + +If absolute value of N is greater then the length of the sequence, the results +are identical to calling ROTATE with + + (* (signum n) (mod n (length sequence))). + +Note: the original sequence may be destructively altered, and result sequence may +share structure with it." + (if (plusp n) + (rotate-tail-to-head sequence n) + (if (minusp n) + (rotate-head-to-tail sequence (- n)) + sequence))) + +(defun shuffle (sequence &key (start 0) end) + "Returns a random permutation of SEQUENCE bounded by START and END. +Original sequence may be destructively modified, and (if it contains +CONS or lists themselv) share storage with the original one. +Signals an error if SEQUENCE is not a proper sequence." + (declare (type fixnum start) + (type (or fixnum null) end)) + (etypecase sequence + (list + (let* ((end (or end (proper-list-length sequence))) + (n (- end start))) + (do ((tail (nthcdr start sequence) (cdr tail))) + ((zerop n)) + (rotatef (car tail) (car (nthcdr (random n) tail))) + (decf n)))) + (vector + (let ((end (or end (length sequence)))) + (loop for i from start below end + do (rotatef (aref sequence i) + (aref sequence (+ i (random (- end i)))))))) + (sequence + (let ((end (or end (length sequence)))) + (loop for i from (- end 1) downto start + do (rotatef (elt sequence i) + (elt sequence (+ i (random (- end i))))))))) + sequence) + +(defun random-elt (sequence &key (start 0) end) + "Returns a random element from SEQUENCE bounded by START and END. Signals an +error if the SEQUENCE is not a proper non-empty sequence, or if END and START +are not proper bounding index designators for SEQUENCE." + (declare (sequence sequence) (fixnum start) (type (or fixnum null) end)) + (let* ((size (if (listp sequence) + (proper-list-length sequence) + (length sequence))) + (end2 (or end size))) + (cond ((zerop size) + (error 'type-error + :datum sequence + :expected-type `(and sequence (not (satisfies emptyp))))) + ((not (and (<= 0 start) (< start end2) (<= end2 size))) + (error 'simple-type-error + :datum (cons start end) + :expected-type `(cons (integer 0 (,end2)) + (or null (integer (,start) ,size))) + :format-control "~@<~S and ~S are not valid bounding index designators for ~ + a sequence of length ~S.~:@>" + :format-arguments (list start end size))) + (t + (let ((index (+ start (random (- end2 start))))) + (elt sequence index)))))) + +(declaim (inline remove/swapped-arguments)) +(defun remove/swapped-arguments (sequence item &rest keyword-arguments) + (apply #'remove item sequence keyword-arguments)) + +(define-modify-macro removef (item &rest keyword-arguments) + remove/swapped-arguments + "Modify-macro for REMOVE. Sets place designated by the first argument to +the result of calling REMOVE with ITEM, place, and the KEYWORD-ARGUMENTS.") + +(declaim (inline delete/swapped-arguments)) +(defun delete/swapped-arguments (sequence item &rest keyword-arguments) + (apply #'delete item sequence keyword-arguments)) + +(define-modify-macro deletef (item &rest keyword-arguments) + delete/swapped-arguments + "Modify-macro for DELETE. Sets place designated by the first argument to +the result of calling DELETE with ITEM, place, and the KEYWORD-ARGUMENTS.") + +(deftype proper-sequence () + "Type designator for proper sequences, that is proper lists and sequences +that are not lists." + `(or proper-list + (and (not list) sequence))) + +(eval-when (:compile-toplevel :load-toplevel :execute) + (when (and (find-package '#:sequence) + (find-symbol (string '#:emptyp) '#:sequence)) + (pushnew 'sequence-emptyp *features*))) + +#-alexandria::sequence-emptyp +(defun emptyp (sequence) + "Returns true if SEQUENCE is an empty sequence. Signals an error if SEQUENCE +is not a sequence." + (etypecase sequence + (list (null sequence)) + (sequence (zerop (length sequence))))) + +#+alexandria::sequence-emptyp +(declaim (ftype (function (sequence) (values boolean &optional)) emptyp)) +#+alexandria::sequence-emptyp +(setf (symbol-function 'emptyp) (symbol-function 'sequence:emptyp)) +#+alexandria::sequence-emptyp +(define-compiler-macro emptyp (sequence) + `(sequence:emptyp ,sequence)) + +(defun length= (&rest sequences) + "Takes any number of sequences or integers in any order. Returns true iff +the length of all the sequences and the integers are equal. Hint: there's a +compiler macro that expands into more efficient code if the first argument +is a literal integer." + (declare (dynamic-extent sequences) + (inline sequence-of-length-p) + (optimize speed)) + (unless (cdr sequences) + (error "You must call LENGTH= with at least two arguments")) + ;; There's room for optimization here: multiple list arguments could be + ;; traversed in parallel. + (let* ((first (pop sequences)) + (current (if (integerp first) + first + (length first)))) + (declare (type array-index current)) + (dolist (el sequences) + (if (integerp el) + (unless (= el current) + (return-from length= nil)) + (unless (sequence-of-length-p el current) + (return-from length= nil))))) + t) + +(define-compiler-macro length= (&whole form length &rest sequences) + (cond + ((zerop (length sequences)) + form) + (t + (let ((optimizedp (integerp length))) + (with-unique-names (tmp current) + (declare (ignorable current)) + `(locally + (declare (inline sequence-of-length-p)) + (let ((,tmp) + ,@(unless optimizedp + `((,current ,length)))) + ,@(unless optimizedp + `((unless (integerp ,current) + (setf ,current (length ,current))))) + (and + ,@(loop + :for sequence :in sequences + :collect `(progn + (setf ,tmp ,sequence) + (if (integerp ,tmp) + (= ,tmp ,(if optimizedp + length + current)) + (sequence-of-length-p ,tmp ,(if optimizedp + length + current))))))))))))) + +(defun copy-sequence (type sequence) + "Returns a fresh sequence of TYPE, which has the same elements as +SEQUENCE." + (if (typep sequence type) + (copy-seq sequence) + (coerce sequence type))) + +(defun first-elt (sequence) + "Returns the first element of SEQUENCE. Signals a type-error if SEQUENCE is +not a sequence, or is an empty sequence." + ;; Can't just directly use ELT, as it is not guaranteed to signal the + ;; type-error. + (cond ((consp sequence) + (car sequence)) + ((and (typep sequence 'sequence) (not (emptyp sequence))) + (elt sequence 0)) + (t + (error 'type-error + :datum sequence + :expected-type '(and sequence (not (satisfies emptyp))))))) + +(defun (setf first-elt) (object sequence) + "Sets the first element of SEQUENCE. Signals a type-error if SEQUENCE is +not a sequence, is an empty sequence, or if OBJECT cannot be stored in SEQUENCE." + ;; Can't just directly use ELT, as it is not guaranteed to signal the + ;; type-error. + (cond ((consp sequence) + (setf (car sequence) object)) + ((and (typep sequence 'sequence) (not (emptyp sequence))) + (setf (elt sequence 0) object)) + (t + (error 'type-error + :datum sequence + :expected-type '(and sequence (not (satisfies emptyp))))))) + +(defun last-elt (sequence) + "Returns the last element of SEQUENCE. Signals a type-error if SEQUENCE is +not a proper sequence, or is an empty sequence." + ;; Can't just directly use ELT, as it is not guaranteed to signal the + ;; type-error. + (let ((len 0)) + (cond ((consp sequence) + (lastcar sequence)) + ((and (typep sequence '(and sequence (not list))) (plusp (setf len (length sequence)))) + (elt sequence (1- len))) + (t + (error 'type-error + :datum sequence + :expected-type '(and proper-sequence (not (satisfies emptyp)))))))) + +(defun (setf last-elt) (object sequence) + "Sets the last element of SEQUENCE. Signals a type-error if SEQUENCE is not a proper +sequence, is an empty sequence, or if OBJECT cannot be stored in SEQUENCE." + (let ((len 0)) + (cond ((consp sequence) + (setf (lastcar sequence) object)) + ((and (typep sequence '(and sequence (not list))) (plusp (setf len (length sequence)))) + (setf (elt sequence (1- len)) object)) + (t + (error 'type-error + :datum sequence + :expected-type '(and proper-sequence (not (satisfies emptyp)))))))) + +(defun starts-with-subseq (prefix sequence &rest args + &key + (return-suffix nil return-suffix-supplied-p) + &allow-other-keys) + "Test whether the first elements of SEQUENCE are the same (as per TEST) as the elements of PREFIX. + +If RETURN-SUFFIX is T the function returns, as a second value, a +sub-sequence or displaced array pointing to the sequence after PREFIX." + (declare (dynamic-extent args)) + (let ((sequence-length (length sequence)) + (prefix-length (length prefix))) + (when (< sequence-length prefix-length) + (return-from starts-with-subseq (values nil nil))) + (flet ((make-suffix (start) + (when return-suffix + (cond + ((not (arrayp sequence)) + (if start + (subseq sequence start) + (subseq sequence 0 0))) + ((not start) + (make-array 0 + :element-type (array-element-type sequence) + :adjustable nil)) + (t + (make-array (- sequence-length start) + :element-type (array-element-type sequence) + :displaced-to sequence + :displaced-index-offset start + :adjustable nil)))))) + (let ((mismatch (apply #'mismatch prefix sequence + (if return-suffix-supplied-p + (remove-from-plist args :return-suffix) + args)))) + (cond + ((not mismatch) + (values t (make-suffix nil))) + ((= mismatch prefix-length) + (values t (make-suffix mismatch))) + (t + (values nil nil))))))) + +(defun ends-with-subseq (suffix sequence &key (test #'eql)) + "Test whether SEQUENCE ends with SUFFIX. In other words: return true if +the last (length SUFFIX) elements of SEQUENCE are equal to SUFFIX." + (let ((sequence-length (length sequence)) + (suffix-length (length suffix))) + (when (< sequence-length suffix-length) + ;; if SEQUENCE is shorter than SUFFIX, then SEQUENCE can't end with SUFFIX. + (return-from ends-with-subseq nil)) + (loop for sequence-index from (- sequence-length suffix-length) below sequence-length + for suffix-index from 0 below suffix-length + when (not (funcall test (elt sequence sequence-index) (elt suffix suffix-index))) + do (return-from ends-with-subseq nil) + finally (return t)))) + +(defun starts-with (object sequence &key (test #'eql) (key #'identity)) + "Returns true if SEQUENCE is a sequence whose first element is EQL to OBJECT. +Returns NIL if the SEQUENCE is not a sequence or is an empty sequence." + (let ((first-elt (typecase sequence + (cons (car sequence)) + (sequence + (if (emptyp sequence) + (return-from starts-with nil) + (elt sequence 0))) + (t + (return-from starts-with nil))))) + (funcall test (funcall key first-elt) object))) + +(defun ends-with (object sequence &key (test #'eql) (key #'identity)) + "Returns true if SEQUENCE is a sequence whose last element is EQL to OBJECT. +Returns NIL if the SEQUENCE is not a sequence or is an empty sequence. Signals +an error if SEQUENCE is an improper list." + (let ((last-elt (typecase sequence + (cons + (lastcar sequence)) ; signals for improper lists + (sequence + ;; Can't use last-elt, as that signals an error + ;; for empty sequences + (let ((len (length sequence))) + (if (plusp len) + (elt sequence (1- len)) + (return-from ends-with nil)))) + (t + (return-from ends-with nil))))) + (funcall test (funcall key last-elt) object))) + +(defun map-combinations (function sequence &key (start 0) end length (copy t)) + "Calls FUNCTION with each combination of LENGTH constructable from the +elements of the subsequence of SEQUENCE delimited by START and END. START +defaults to 0, END to length of SEQUENCE, and LENGTH to the length of the +delimited subsequence. (So unless LENGTH is specified there is only a single +combination, which has the same elements as the delimited subsequence.) If +COPY is true (the default) each combination is freshly allocated. If COPY is +false all combinations are EQ to each other, in which case consequences are +unspecified if a combination is modified by FUNCTION." + (let* ((end (or end (length sequence))) + (size (- end start)) + (length (or length size)) + (combination (subseq sequence 0 length)) + (function (ensure-function function))) + (if (= length size) + (funcall function combination) + (flet ((call () + (funcall function (if copy + (copy-seq combination) + combination)))) + (etypecase sequence + ;; When dealing with lists we prefer walking back and + ;; forth instead of using indexes. + (list + (labels ((combine-list (c-tail o-tail) + (if (not c-tail) + (call) + (do ((tail o-tail (cdr tail))) + ((not tail)) + (setf (car c-tail) (car tail)) + (combine-list (cdr c-tail) (cdr tail)))))) + (combine-list combination (nthcdr start sequence)))) + (vector + (labels ((combine (count start) + (if (zerop count) + (call) + (loop for i from start below end + do (let ((j (- count 1))) + (setf (aref combination j) (aref sequence i)) + (combine j (+ i 1))))))) + (combine length start))) + (sequence + (labels ((combine (count start) + (if (zerop count) + (call) + (loop for i from start below end + do (let ((j (- count 1))) + (setf (elt combination j) (elt sequence i)) + (combine j (+ i 1))))))) + (combine length start))))))) + sequence) + +(defun map-permutations (function sequence &key (start 0) end length (copy t)) + "Calls function with each permutation of LENGTH constructable +from the subsequence of SEQUENCE delimited by START and END. START +defaults to 0, END to length of the sequence, and LENGTH to the +length of the delimited subsequence." + (let* ((end (or end (length sequence))) + (size (- end start)) + (length (or length size))) + (labels ((permute (seq n) + (let ((n-1 (- n 1))) + (if (zerop n-1) + (funcall function (if copy + (copy-seq seq) + seq)) + (loop for i from 0 upto n-1 + do (permute seq n-1) + (if (evenp n-1) + (rotatef (elt seq 0) (elt seq n-1)) + (rotatef (elt seq i) (elt seq n-1))))))) + (permute-sequence (seq) + (permute seq length))) + (if (= length size) + ;; Things are simple if we need to just permute the + ;; full START-END range. + (permute-sequence (subseq sequence start end)) + ;; Otherwise we need to generate all the combinations + ;; of LENGTH in the START-END range, and then permute + ;; a copy of the result: can't permute the combination + ;; directly, as they share structure with each other. + (let ((permutation (subseq sequence 0 length))) + (flet ((permute-combination (combination) + (permute-sequence (replace permutation combination)))) + (declare (dynamic-extent #'permute-combination)) + (map-combinations #'permute-combination sequence + :start start + :end end + :length length + :copy nil))))))) + +(defun map-derangements (function sequence &key (start 0) end (copy t)) + "Calls FUNCTION with each derangement of the subsequence of SEQUENCE denoted +by the bounding index designators START and END. Derangement is a permutation +of the sequence where no element remains in place. SEQUENCE is not modified, +but individual derangements are EQ to each other. Consequences are unspecified +if calling FUNCTION modifies either the derangement or SEQUENCE." + (let* ((end (or end (length sequence))) + (size (- end start)) + ;; We don't really care about the elements here. + (derangement (subseq sequence 0 size)) + ;; Bitvector that has 1 for elements that have been deranged. + (mask (make-array size :element-type 'bit :initial-element 0))) + (declare (dynamic-extent mask)) + ;; ad hoc algorith + (labels ((derange (place n) + ;; Perform one recursive step in deranging the + ;; sequence: PLACE is index of the original sequence + ;; to derange to another index, and N is the number of + ;; indexes not yet deranged. + (if (zerop n) + (funcall function (if copy + (copy-seq derangement) + derangement)) + ;; Itarate over the indexes I of the subsequence to + ;; derange: if I != PLACE and I has not yet been + ;; deranged by an earlier call put the element from + ;; PLACE to I, mark I as deranged, and recurse, + ;; finally removing the mark. + (loop for i from 0 below size + do + (unless (or (= place (+ i start)) (not (zerop (bit mask i)))) + (setf (elt derangement i) (elt sequence place) + (bit mask i) 1) + (derange (1+ place) (1- n)) + (setf (bit mask i) 0)))))) + (derange start size) + sequence))) + +(declaim (notinline sequence-of-length-p)) + +(defun extremum (sequence predicate &key key (start 0) end) + "Returns the element of SEQUENCE that would appear first if the subsequence +bounded by START and END was sorted using PREDICATE and KEY. + +EXTREMUM determines the relationship between two elements of SEQUENCE by using +the PREDICATE function. PREDICATE should return true if and only if the first +argument is strictly less than the second one (in some appropriate sense). Two +arguments X and Y are considered to be equal if (FUNCALL PREDICATE X Y) +and (FUNCALL PREDICATE Y X) are both false. + +The arguments to the PREDICATE function are computed from elements of SEQUENCE +using the KEY function, if supplied. If KEY is not supplied or is NIL, the +sequence element itself is used. + +If SEQUENCE is empty, NIL is returned." + (let* ((pred-fun (ensure-function predicate)) + (key-fun (unless (or (not key) (eq key 'identity) (eq key #'identity)) + (ensure-function key))) + (real-end (or end (length sequence)))) + (cond ((> real-end start) + (if key-fun + (flet ((reduce-keys (a b) + (if (funcall pred-fun + (funcall key-fun a) + (funcall key-fun b)) + a + b))) + (declare (dynamic-extent #'reduce-keys)) + (reduce #'reduce-keys sequence :start start :end real-end)) + (flet ((reduce-elts (a b) + (if (funcall pred-fun a b) + a + b))) + (declare (dynamic-extent #'reduce-elts)) + (reduce #'reduce-elts sequence :start start :end real-end)))) + ((= real-end start) + nil) + (t + (error "Invalid bounding indexes for sequence of length ~S: ~S ~S, ~S ~S" + (length sequence) + :start start + :end end))))) diff --git a/third_party/lisp/alexandria/strings.lisp b/third_party/lisp/alexandria/strings.lisp new file mode 100644 index 0000000000..e9fd91c961 --- /dev/null +++ b/third_party/lisp/alexandria/strings.lisp @@ -0,0 +1,6 @@ +(in-package :alexandria) + +(deftype string-designator () + "A string designator type. A string designator is either a string, a symbol, +or a character." + `(or symbol string character)) diff --git a/third_party/lisp/alexandria/symbols.lisp b/third_party/lisp/alexandria/symbols.lisp new file mode 100644 index 0000000000..5733d3e1cc --- /dev/null +++ b/third_party/lisp/alexandria/symbols.lisp @@ -0,0 +1,65 @@ +(in-package :alexandria) + +(declaim (inline ensure-symbol)) +(defun ensure-symbol (name &optional (package *package*)) + "Returns a symbol with name designated by NAME, accessible in package +designated by PACKAGE. If symbol is not already accessible in PACKAGE, it is +interned there. Returns a secondary value reflecting the status of the symbol +in the package, which matches the secondary return value of INTERN. + +Example: + + (ensure-symbol :cons :cl) => cl:cons, :external +" + (intern (string name) package)) + +(defun maybe-intern (name package) + (values + (if package + (intern name (if (eq t package) *package* package)) + (make-symbol name)))) + +(declaim (inline format-symbol)) +(defun format-symbol (package control &rest arguments) + "Constructs a string by applying ARGUMENTS to string designator CONTROL as +if by FORMAT within WITH-STANDARD-IO-SYNTAX, and then creates a symbol named +by that string. + +If PACKAGE is NIL, returns an uninterned symbol, if package is T, returns a +symbol interned in the current package, and otherwise returns a symbol +interned in the package designated by PACKAGE." + (maybe-intern (with-standard-io-syntax + (apply #'format nil (string control) arguments)) + package)) + +(defun make-keyword (name) + "Interns the string designated by NAME in the KEYWORD package." + (intern (string name) :keyword)) + +(defun make-gensym (name) + "If NAME is a non-negative integer, calls GENSYM using it. Otherwise NAME +must be a string designator, in which case calls GENSYM using the designated +string as the argument." + (gensym (if (typep name '(integer 0)) + name + (string name)))) + +(defun make-gensym-list (length &optional (x "G")) + "Returns a list of LENGTH gensyms, each generated as if with a call to MAKE-GENSYM, +using the second (optional, defaulting to \"G\") argument." + (let ((g (if (typep x '(integer 0)) x (string x)))) + (loop repeat length + collect (gensym g)))) + +(defun symbolicate (&rest things) + "Concatenate together the names of some strings and symbols, +producing a symbol in the current package." + (let* ((length (reduce #'+ things + :key (lambda (x) (length (string x))))) + (name (make-array length :element-type 'character))) + (let ((index 0)) + (dolist (thing things (values (intern name))) + (let* ((x (string thing)) + (len (length x))) + (replace name x :start1 index) + (incf index len)))))) diff --git a/third_party/lisp/alexandria/tests.lisp b/third_party/lisp/alexandria/tests.lisp new file mode 100644 index 0000000000..b70ef0475e --- /dev/null +++ b/third_party/lisp/alexandria/tests.lisp @@ -0,0 +1,2047 @@ +(in-package :cl-user) + +(defpackage :alexandria-tests + (:use :cl :alexandria #+sbcl :sb-rt #-sbcl :rtest) + (:import-from #+sbcl :sb-rt #-sbcl :rtest + #:*compile-tests* #:*expected-failures*)) + +(in-package :alexandria-tests) + +(defun run-tests (&key ((:compiled *compile-tests*))) + (do-tests)) + +(defun hash-table-test-name (name) + ;; Workaround for Clisp calling EQL in a hash-table FASTHASH-EQL. + (hash-table-test (make-hash-table :test name))) + +;;;; Arrays + +(deftest copy-array.1 + (let* ((orig (vector 1 2 3)) + (copy (copy-array orig))) + (values (eq orig copy) (equalp orig copy))) + nil t) + +(deftest copy-array.2 + (let ((orig (make-array 1024 :fill-pointer 0))) + (vector-push-extend 1 orig) + (vector-push-extend 2 orig) + (vector-push-extend 3 orig) + (let ((copy (copy-array orig))) + (values (eq orig copy) (equalp orig copy) + (array-has-fill-pointer-p copy) + (eql (fill-pointer orig) (fill-pointer copy))))) + nil t t t) + +(deftest copy-array.3 + (let* ((orig (vector 1 2 3)) + (copy (copy-array orig))) + (typep copy 'simple-array)) + t) + +(deftest copy-array.4 + (let ((orig (make-array 21 + :adjustable t + :fill-pointer 0))) + (dotimes (n 42) + (vector-push-extend n orig)) + (let ((copy (copy-array orig + :adjustable nil + :fill-pointer nil))) + (typep copy 'simple-array))) + t) + +(deftest array-index.1 + (typep 0 'array-index) + t) + +;;;; Conditions + +(deftest unwind-protect-case.1 + (let (result) + (unwind-protect-case () + (random 10) + (:normal (push :normal result)) + (:abort (push :abort result)) + (:always (push :always result))) + result) + (:always :normal)) + +(deftest unwind-protect-case.2 + (let (result) + (unwind-protect-case () + (random 10) + (:always (push :always result)) + (:normal (push :normal result)) + (:abort (push :abort result))) + result) + (:normal :always)) + +(deftest unwind-protect-case.3 + (let (result1 result2 result3) + (ignore-errors + (unwind-protect-case () + (error "FOOF!") + (:normal (push :normal result1)) + (:abort (push :abort result1)) + (:always (push :always result1)))) + (catch 'foof + (unwind-protect-case () + (throw 'foof 42) + (:normal (push :normal result2)) + (:abort (push :abort result2)) + (:always (push :always result2)))) + (block foof + (unwind-protect-case () + (return-from foof 42) + (:normal (push :normal result3)) + (:abort (push :abort result3)) + (:always (push :always result3)))) + (values result1 result2 result3)) + (:always :abort) + (:always :abort) + (:always :abort)) + +(deftest unwind-protect-case.4 + (let (result) + (unwind-protect-case (aborted-p) + (random 42) + (:always (setq result aborted-p))) + result) + nil) + +(deftest unwind-protect-case.5 + (let (result) + (block foof + (unwind-protect-case (aborted-p) + (return-from foof) + (:always (setq result aborted-p)))) + result) + t) + +;;;; Control flow + +(deftest switch.1 + (switch (13 :test =) + (12 :oops) + (13.0 :yay)) + :yay) + +(deftest switch.2 + (switch (13) + ((+ 12 2) :oops) + ((- 13 1) :oops2) + (t :yay)) + :yay) + +(deftest eswitch.1 + (let ((x 13)) + (eswitch (x :test =) + (12 :oops) + (13.0 :yay))) + :yay) + +(deftest eswitch.2 + (let ((x 13)) + (eswitch (x :key 1+) + (11 :oops) + (14 :yay))) + :yay) + +(deftest cswitch.1 + (cswitch (13 :test =) + (12 :oops) + (13.0 :yay)) + :yay) + +(deftest cswitch.2 + (cswitch (13 :key 1-) + (12 :yay) + (13.0 :oops)) + :yay) + +(deftest multiple-value-prog2.1 + (multiple-value-prog2 + (values 1 1 1) + (values 2 20 200) + (values 3 3 3)) + 2 20 200) + +(deftest nth-value-or.1 + (multiple-value-bind (a b c) + (nth-value-or 1 + (values 1 nil 1) + (values 2 2 2)) + (= a b c 2)) + t) + +(deftest whichever.1 + (let ((x (whichever 1 2 3))) + (and (member x '(1 2 3)) t)) + t) + +(deftest whichever.2 + (let* ((a 1) + (b 2) + (c 3) + (x (whichever a b c))) + (and (member x '(1 2 3)) t)) + t) + +(deftest xor.1 + (xor nil nil 1 nil) + 1 + t) + +(deftest xor.2 + (xor nil nil 1 2) + nil + nil) + +(deftest xor.3 + (xor nil nil nil) + nil + t) + +;;;; Definitions + +(deftest define-constant.1 + (let ((name (gensym))) + (eval `(define-constant ,name "FOO" :test 'equal)) + (eval `(define-constant ,name "FOO" :test 'equal)) + (values (equal "FOO" (symbol-value name)) + (constantp name))) + t + t) + +(deftest define-constant.2 + (let ((name (gensym))) + (eval `(define-constant ,name 13)) + (eval `(define-constant ,name 13)) + (values (eql 13 (symbol-value name)) + (constantp name))) + t + t) + +;;;; Errors + +;;; TYPEP is specified to return a generalized boolean and, for +;;; example, ECL exploits this by returning the superclasses of ERROR +;;; in this case. +(defun errorp (x) + (not (null (typep x 'error)))) + +(deftest required-argument.1 + (multiple-value-bind (res err) + (ignore-errors (required-argument)) + (errorp err)) + t) + +;;;; Hash tables + +(deftest ensure-gethash.1 + (let ((table (make-hash-table)) + (x (list 1))) + (multiple-value-bind (value already-there) + (ensure-gethash x table 42) + (and (= value 42) + (not already-there) + (= 42 (gethash x table)) + (multiple-value-bind (value2 already-there2) + (ensure-gethash x table 13) + (and (= value2 42) + already-there2 + (= 42 (gethash x table))))))) + t) + +(deftest ensure-gethash.2 + (let ((table (make-hash-table)) + (count 0)) + (multiple-value-call #'values + (ensure-gethash (progn (incf count) :foo) + (progn (incf count) table) + (progn (incf count) :bar)) + (gethash :foo table) + count)) + :bar nil :bar t 3) + +(deftest copy-hash-table.1 + (let ((orig (make-hash-table :test 'eq :size 123)) + (foo "foo")) + (setf (gethash orig orig) t + (gethash foo orig) t) + (let ((eq-copy (copy-hash-table orig)) + (eql-copy (copy-hash-table orig :test 'eql)) + (equal-copy (copy-hash-table orig :test 'equal)) + (equalp-copy (copy-hash-table orig :test 'equalp))) + (list (eql (hash-table-size eq-copy) (hash-table-size orig)) + (eql (hash-table-rehash-size eq-copy) + (hash-table-rehash-size orig)) + (hash-table-count eql-copy) + (gethash orig eq-copy) + (gethash (copy-seq foo) eql-copy) + (gethash foo eql-copy) + (gethash (copy-seq foo) equal-copy) + (gethash "FOO" equal-copy) + (gethash "FOO" equalp-copy)))) + (t t 2 t nil t t nil t)) + +(deftest copy-hash-table.2 + (let ((ht (make-hash-table)) + (list (list :list (vector :A :B :C)))) + (setf (gethash 'list ht) list) + (let* ((shallow-copy (copy-hash-table ht)) + (deep1-copy (copy-hash-table ht :key 'copy-list)) + (list (gethash 'list ht)) + (shallow-list (gethash 'list shallow-copy)) + (deep1-list (gethash 'list deep1-copy))) + (list (eq ht shallow-copy) + (eq ht deep1-copy) + (eq list shallow-list) + (eq list deep1-list) ; outer list was copied. + (eq (second list) (second shallow-list)) + (eq (second list) (second deep1-list)) ; inner vector wasn't copied. + ))) + (nil nil t nil t t)) + +(deftest maphash-keys.1 + (let ((keys nil) + (table (make-hash-table))) + (declare (notinline maphash-keys)) + (dotimes (i 10) + (setf (gethash i table) t)) + (maphash-keys (lambda (k) (push k keys)) table) + (set-equal keys '(0 1 2 3 4 5 6 7 8 9))) + t) + +(deftest maphash-values.1 + (let ((vals nil) + (table (make-hash-table))) + (declare (notinline maphash-values)) + (dotimes (i 10) + (setf (gethash i table) (- i))) + (maphash-values (lambda (v) (push v vals)) table) + (set-equal vals '(0 -1 -2 -3 -4 -5 -6 -7 -8 -9))) + t) + +(deftest hash-table-keys.1 + (let ((table (make-hash-table))) + (dotimes (i 10) + (setf (gethash i table) t)) + (set-equal (hash-table-keys table) '(0 1 2 3 4 5 6 7 8 9))) + t) + +(deftest hash-table-values.1 + (let ((table (make-hash-table))) + (dotimes (i 10) + (setf (gethash (gensym) table) i)) + (set-equal (hash-table-values table) '(0 1 2 3 4 5 6 7 8 9))) + t) + +(deftest hash-table-alist.1 + (let ((table (make-hash-table))) + (dotimes (i 10) + (setf (gethash i table) (- i))) + (let ((alist (hash-table-alist table))) + (list (length alist) + (assoc 0 alist) + (assoc 3 alist) + (assoc 9 alist) + (assoc nil alist)))) + (10 (0 . 0) (3 . -3) (9 . -9) nil)) + +(deftest hash-table-plist.1 + (let ((table (make-hash-table))) + (dotimes (i 10) + (setf (gethash i table) (- i))) + (let ((plist (hash-table-plist table))) + (list (length plist) + (getf plist 0) + (getf plist 2) + (getf plist 7) + (getf plist nil)))) + (20 0 -2 -7 nil)) + +(deftest alist-hash-table.1 + (let* ((alist '((0 a) (1 b) (2 c))) + (table (alist-hash-table alist))) + (list (hash-table-count table) + (gethash 0 table) + (gethash 1 table) + (gethash 2 table) + (eq (hash-table-test-name 'eql) + (hash-table-test table)))) + (3 (a) (b) (c) t)) + +(deftest alist-hash-table.duplicate-keys + (let* ((alist '((0 a) (1 b) (0 c) (1 d) (2 e))) + (table (alist-hash-table alist))) + (list (hash-table-count table) + (gethash 0 table) + (gethash 1 table) + (gethash 2 table))) + (3 (a) (b) (e))) + +(deftest plist-hash-table.1 + (let* ((plist '(:a 1 :b 2 :c 3)) + (table (plist-hash-table plist :test 'eq))) + (list (hash-table-count table) + (gethash :a table) + (gethash :b table) + (gethash :c table) + (gethash 2 table) + (gethash nil table) + (eq (hash-table-test-name 'eq) + (hash-table-test table)))) + (3 1 2 3 nil nil t)) + +(deftest plist-hash-table.duplicate-keys + (let* ((plist '(:a 1 :b 2 :a 3 :b 4 :c 5)) + (table (plist-hash-table plist))) + (list (hash-table-count table) + (gethash :a table) + (gethash :b table) + (gethash :c table))) + (3 1 2 5)) + +;;;; Functions + +(deftest disjoin.1 + (let ((disjunction (disjoin (lambda (x) + (and (consp x) :cons)) + (lambda (x) + (and (stringp x) :string))))) + (list (funcall disjunction 'zot) + (funcall disjunction '(foo bar)) + (funcall disjunction "test"))) + (nil :cons :string)) + +(deftest disjoin.2 + (let ((disjunction (disjoin #'zerop))) + (list (funcall disjunction 0) + (funcall disjunction 1))) + (t nil)) + +(deftest conjoin.1 + (let ((conjunction (conjoin #'consp + (lambda (x) + (stringp (car x))) + (lambda (x) + (char (car x) 0))))) + (list (funcall conjunction 'zot) + (funcall conjunction '(foo)) + (funcall conjunction '("foo")))) + (nil nil #\f)) + +(deftest conjoin.2 + (let ((conjunction (conjoin #'zerop))) + (list (funcall conjunction 0) + (funcall conjunction 1))) + (t nil)) + +(deftest compose.1 + (let ((composite (compose '1+ + (lambda (x) + (* x 2)) + #'read-from-string))) + (funcall composite "1")) + 3) + +(deftest compose.2 + (let ((composite + (locally (declare (notinline compose)) + (compose '1+ + (lambda (x) + (* x 2)) + #'read-from-string)))) + (funcall composite "2")) + 5) + +(deftest compose.3 + (let ((compose-form (funcall (compiler-macro-function 'compose) + '(compose '1+ + (lambda (x) + (* x 2)) + #'read-from-string) + nil))) + (let ((fun (funcall (compile nil `(lambda () ,compose-form))))) + (funcall fun "3"))) + 7) + +(deftest compose.4 + (let ((composite (compose #'zerop))) + (list (funcall composite 0) + (funcall composite 1))) + (t nil)) + +(deftest multiple-value-compose.1 + (let ((composite (multiple-value-compose + #'truncate + (lambda (x y) + (values y x)) + (lambda (x) + (with-input-from-string (s x) + (values (read s) (read s))))))) + (multiple-value-list (funcall composite "2 7"))) + (3 1)) + +(deftest multiple-value-compose.2 + (let ((composite (locally (declare (notinline multiple-value-compose)) + (multiple-value-compose + #'truncate + (lambda (x y) + (values y x)) + (lambda (x) + (with-input-from-string (s x) + (values (read s) (read s)))))))) + (multiple-value-list (funcall composite "2 11"))) + (5 1)) + +(deftest multiple-value-compose.3 + (let ((compose-form (funcall (compiler-macro-function 'multiple-value-compose) + '(multiple-value-compose + #'truncate + (lambda (x y) + (values y x)) + (lambda (x) + (with-input-from-string (s x) + (values (read s) (read s))))) + nil))) + (let ((fun (funcall (compile nil `(lambda () ,compose-form))))) + (multiple-value-list (funcall fun "2 9")))) + (4 1)) + +(deftest multiple-value-compose.4 + (let ((composite (multiple-value-compose #'truncate))) + (multiple-value-list (funcall composite 9 2))) + (4 1)) + +(deftest curry.1 + (let ((curried (curry '+ 3))) + (funcall curried 1 5)) + 9) + +(deftest curry.2 + (let ((curried (locally (declare (notinline curry)) + (curry '* 2 3)))) + (funcall curried 7)) + 42) + +(deftest curry.3 + (let ((curried-form (funcall (compiler-macro-function 'curry) + '(curry '/ 8) + nil))) + (let ((fun (funcall (compile nil `(lambda () ,curried-form))))) + (funcall fun 2))) + 4) + +(deftest curry.4 + (let* ((x 1) + (curried (curry (progn + (incf x) + (lambda (y z) (* x y z))) + 3))) + (list (funcall curried 7) + (funcall curried 7) + x)) + (42 42 2)) + +(deftest rcurry.1 + (let ((r (rcurry '/ 2))) + (funcall r 8)) + 4) + +(deftest rcurry.2 + (let* ((x 1) + (curried (rcurry (progn + (incf x) + (lambda (y z) (* x y z))) + 3))) + (list (funcall curried 7) + (funcall curried 7) + x)) + (42 42 2)) + +(deftest named-lambda.1 + (let ((fac (named-lambda fac (x) + (if (> x 1) + (* x (fac (- x 1))) + x)))) + (funcall fac 5)) + 120) + +(deftest named-lambda.2 + (let ((fac (named-lambda fac (&key x) + (if (> x 1) + (* x (fac :x (- x 1))) + x)))) + (funcall fac :x 5)) + 120) + +;;;; Lists + +(deftest alist-plist.1 + (alist-plist '((a . 1) (b . 2) (c . 3))) + (a 1 b 2 c 3)) + +(deftest plist-alist.1 + (plist-alist '(a 1 b 2 c 3)) + ((a . 1) (b . 2) (c . 3))) + +(deftest unionf.1 + (let* ((list (list 1 2 3)) + (orig list)) + (unionf list (list 1 2 4)) + (values (equal orig (list 1 2 3)) + (eql (length list) 4) + (set-difference list (list 1 2 3 4)) + (set-difference (list 1 2 3 4) list))) + t + t + nil + nil) + +(deftest nunionf.1 + (let ((list (list 1 2 3))) + (nunionf list (list 1 2 4)) + (values (eql (length list) 4) + (set-difference (list 1 2 3 4) list) + (set-difference list (list 1 2 3 4)))) + t + nil + nil) + +(deftest appendf.1 + (let* ((list (list 1 2 3)) + (orig list)) + (appendf list '(4 5 6) '(7 8)) + (list list (eq list orig))) + ((1 2 3 4 5 6 7 8) nil)) + +(deftest nconcf.1 + (let ((list1 (list 1 2 3)) + (list2 (list 4 5 6))) + (nconcf list1 list2 (list 7 8 9)) + list1) + (1 2 3 4 5 6 7 8 9)) + +(deftest circular-list.1 + (let ((circle (circular-list 1 2 3))) + (list (first circle) + (second circle) + (third circle) + (fourth circle) + (eq circle (nthcdr 3 circle)))) + (1 2 3 1 t)) + +(deftest circular-list-p.1 + (let* ((circle (circular-list 1 2 3 4)) + (tree (list circle circle)) + (dotted (cons circle t)) + (proper (list 1 2 3 circle)) + (tailcirc (list* 1 2 3 circle))) + (list (circular-list-p circle) + (circular-list-p tree) + (circular-list-p dotted) + (circular-list-p proper) + (circular-list-p tailcirc))) + (t nil nil nil t)) + +(deftest circular-list-p.2 + (circular-list-p 'foo) + nil) + +(deftest circular-tree-p.1 + (let* ((circle (circular-list 1 2 3 4)) + (tree1 (list circle circle)) + (tree2 (let* ((level2 (list 1 nil 2)) + (level1 (list level2))) + (setf (second level2) level1) + level1)) + (dotted (cons circle t)) + (proper (list 1 2 3 circle)) + (tailcirc (list* 1 2 3 circle)) + (quite-proper (list 1 2 3)) + (quite-dotted (list 1 (cons 2 3)))) + (list (circular-tree-p circle) + (circular-tree-p tree1) + (circular-tree-p tree2) + (circular-tree-p dotted) + (circular-tree-p proper) + (circular-tree-p tailcirc) + (circular-tree-p quite-proper) + (circular-tree-p quite-dotted))) + (t t t t t t nil nil)) + +(deftest circular-tree-p.2 + (alexandria:circular-tree-p '#1=(#1#)) + t) + +(deftest proper-list-p.1 + (let ((l1 (list 1)) + (l2 (list 1 2)) + (l3 (cons 1 2)) + (l4 (list (cons 1 2) 3)) + (l5 (circular-list 1 2))) + (list (proper-list-p l1) + (proper-list-p l2) + (proper-list-p l3) + (proper-list-p l4) + (proper-list-p l5))) + (t t nil t nil)) + +(deftest proper-list-p.2 + (proper-list-p '(1 2 . 3)) + nil) + +(deftest proper-list.type.1 + (let ((l1 (list 1)) + (l2 (list 1 2)) + (l3 (cons 1 2)) + (l4 (list (cons 1 2) 3)) + (l5 (circular-list 1 2))) + (list (typep l1 'proper-list) + (typep l2 'proper-list) + (typep l3 'proper-list) + (typep l4 'proper-list) + (typep l5 'proper-list))) + (t t nil t nil)) + +(deftest proper-list-length.1 + (values + (proper-list-length nil) + (proper-list-length (list 1)) + (proper-list-length (list 2 2)) + (proper-list-length (list 3 3 3)) + (proper-list-length (list 4 4 4 4)) + (proper-list-length (list 5 5 5 5 5)) + (proper-list-length (list 6 6 6 6 6 6)) + (proper-list-length (list 7 7 7 7 7 7 7)) + (proper-list-length (list 8 8 8 8 8 8 8 8)) + (proper-list-length (list 9 9 9 9 9 9 9 9 9))) + 0 1 2 3 4 5 6 7 8 9) + +(deftest proper-list-length.2 + (flet ((plength (x) + (handler-case + (proper-list-length x) + (type-error () + :ok)))) + (values + (plength (list* 1)) + (plength (list* 2 2)) + (plength (list* 3 3 3)) + (plength (list* 4 4 4 4)) + (plength (list* 5 5 5 5 5)) + (plength (list* 6 6 6 6 6 6)) + (plength (list* 7 7 7 7 7 7 7)) + (plength (list* 8 8 8 8 8 8 8 8)) + (plength (list* 9 9 9 9 9 9 9 9 9)))) + :ok :ok :ok + :ok :ok :ok + :ok :ok :ok) + +(deftest lastcar.1 + (let ((l1 (list 1)) + (l2 (list 1 2))) + (list (lastcar l1) + (lastcar l2))) + (1 2)) + +(deftest lastcar.error.2 + (handler-case + (progn + (lastcar (circular-list 1 2 3)) + nil) + (error () + t)) + t) + +(deftest setf-lastcar.1 + (let ((l (list 1 2 3 4))) + (values (lastcar l) + (progn + (setf (lastcar l) 42) + (lastcar l)))) + 4 + 42) + +(deftest setf-lastcar.2 + (let ((l (circular-list 1 2 3))) + (multiple-value-bind (res err) + (ignore-errors (setf (lastcar l) 4)) + (typep err 'type-error))) + t) + +(deftest make-circular-list.1 + (let ((l (make-circular-list 3 :initial-element :x))) + (setf (car l) :y) + (list (eq l (nthcdr 3 l)) + (first l) + (second l) + (third l) + (fourth l))) + (t :y :x :x :y)) + +(deftest circular-list.type.1 + (let* ((l1 (list 1 2 3)) + (l2 (circular-list 1 2 3)) + (l3 (list* 1 2 3 l2))) + (list (typep l1 'circular-list) + (typep l2 'circular-list) + (typep l3 'circular-list))) + (nil t t)) + +(deftest ensure-list.1 + (let ((x (list 1)) + (y 2)) + (list (ensure-list x) + (ensure-list y))) + ((1) (2))) + +(deftest ensure-cons.1 + (let ((x (cons 1 2)) + (y nil) + (z "foo")) + (values (ensure-cons x) + (ensure-cons y) + (ensure-cons z))) + (1 . 2) + (nil) + ("foo")) + +(deftest setp.1 + (setp '(1)) + t) + +(deftest setp.2 + (setp nil) + t) + +(deftest setp.3 + (setp "foo") + nil) + +(deftest setp.4 + (setp '(1 2 3 1)) + nil) + +(deftest setp.5 + (setp '(1 2 3)) + t) + +(deftest setp.6 + (setp '(a :a)) + t) + +(deftest setp.7 + (setp '(a :a) :key 'character) + nil) + +(deftest setp.8 + (setp '(a :a) :key 'character :test (constantly nil)) + t) + +(deftest set-equal.1 + (set-equal '(1 2 3) '(3 1 2)) + t) + +(deftest set-equal.2 + (set-equal '("Xa") '("Xb") + :test (lambda (a b) (eql (char a 0) (char b 0)))) + t) + +(deftest set-equal.3 + (set-equal '(1 2) '(4 2)) + nil) + +(deftest set-equal.4 + (set-equal '(a b c) '(:a :b :c) :key 'string :test 'equal) + t) + +(deftest set-equal.5 + (set-equal '(a d c) '(:a :b :c) :key 'string :test 'equal) + nil) + +(deftest set-equal.6 + (set-equal '(a b c) '(a b c d)) + nil) + +(deftest map-product.1 + (map-product 'cons '(2 3) '(1 4)) + ((2 . 1) (2 . 4) (3 . 1) (3 . 4))) + +(deftest map-product.2 + (map-product #'cons '(2 3) '(1 4)) + ((2 . 1) (2 . 4) (3 . 1) (3 . 4))) + +(deftest flatten.1 + (flatten '((1) 2 (((3 4))) ((((5)) 6)) 7)) + (1 2 3 4 5 6 7)) + +(deftest remove-from-plist.1 + (let ((orig '(a 1 b 2 c 3 d 4))) + (list (remove-from-plist orig 'a 'c) + (remove-from-plist orig 'b 'd) + (remove-from-plist orig 'b) + (remove-from-plist orig 'a) + (remove-from-plist orig 'd 42 "zot") + (remove-from-plist orig 'a 'b 'c 'd) + (remove-from-plist orig 'a 'b 'c 'd 'x) + (equal orig '(a 1 b 2 c 3 d 4)))) + ((b 2 d 4) + (a 1 c 3) + (a 1 c 3 d 4) + (b 2 c 3 d 4) + (a 1 b 2 c 3) + nil + nil + t)) + +(deftest delete-from-plist.1 + (let ((orig '(a 1 b 2 c 3 d 4 d 5))) + (list (delete-from-plist (copy-list orig) 'a 'c) + (delete-from-plist (copy-list orig) 'b 'd) + (delete-from-plist (copy-list orig) 'b) + (delete-from-plist (copy-list orig) 'a) + (delete-from-plist (copy-list orig) 'd 42 "zot") + (delete-from-plist (copy-list orig) 'a 'b 'c 'd) + (delete-from-plist (copy-list orig) 'a 'b 'c 'd 'x) + (equal orig (delete-from-plist orig)) + (eq orig (delete-from-plist orig)))) + ((b 2 d 4 d 5) + (a 1 c 3) + (a 1 c 3 d 4 d 5) + (b 2 c 3 d 4 d 5) + (a 1 b 2 c 3) + nil + nil + t + t)) + +(deftest mappend.1 + (mappend (compose 'list '*) '(1 2 3) '(1 2 3)) + (1 4 9)) + +(deftest assoc-value.1 + (let ((key1 '(complex key)) + (key2 'simple-key) + (alist '()) + (result '())) + (push 1 (assoc-value alist key1 :test #'equal)) + (push 2 (assoc-value alist key1 :test 'equal)) + (push 42 (assoc-value alist key2)) + (push 43 (assoc-value alist key2 :test 'eq)) + (push (assoc-value alist key1 :test #'equal) result) + (push (assoc-value alist key2) result) + + (push 'very (rassoc-value alist (list 2 1) :test #'equal)) + (push (cdr (assoc '(very complex key) alist :test #'equal)) result) + result) + ((2 1) (43 42) (2 1))) + +;;;; Numbers + +(deftest clamp.1 + (list (clamp 1.5 1 2) + (clamp 2.0 1 2) + (clamp 1.0 1 2) + (clamp 3 1 2) + (clamp 0 1 2)) + (1.5 2.0 1.0 2 1)) + +(deftest gaussian-random.1 + (let ((min -0.2) + (max +0.2)) + (multiple-value-bind (g1 g2) + (gaussian-random min max) + (values (<= min g1 max) + (<= min g2 max) + (/= g1 g2) ;uh + ))) + t + t + t) + +#+sbcl +(deftest gaussian-random.2 + (handler-case + (sb-ext:with-timeout 2 + (progn + (loop + :repeat 10000 + :do (gaussian-random 0 nil)) + 'done)) + (sb-ext:timeout () + 'timed-out)) + done) + +(deftest iota.1 + (iota 3) + (0 1 2)) + +(deftest iota.2 + (iota 3 :start 0.0d0) + (0.0d0 1.0d0 2.0d0)) + +(deftest iota.3 + (iota 3 :start 2 :step 3.0) + (2.0 5.0 8.0)) + +(deftest map-iota.1 + (let (all) + (declare (notinline map-iota)) + (values (map-iota (lambda (x) (push x all)) + 3 + :start 2 + :step 1.1d0) + all)) + 3 + (4.2d0 3.1d0 2.0d0)) + +(deftest lerp.1 + (lerp 0.5 1 2) + 1.5) + +(deftest lerp.2 + (lerp 0.1 1 2) + 1.1) + +(deftest lerp.3 + (lerp 0.1 4 25) + 6.1) + +(deftest mean.1 + (mean '(1 2 3)) + 2) + +(deftest mean.2 + (mean '(1 2 3 4)) + 5/2) + +(deftest mean.3 + (mean '(1 2 10)) + 13/3) + +(deftest median.1 + (median '(100 0 99 1 98 2 97)) + 97) + +(deftest median.2 + (median '(100 0 99 1 98 2 97 96)) + 193/2) + +(deftest variance.1 + (variance (list 1 2 3)) + 2/3) + +(deftest standard-deviation.1 + (< 0 (standard-deviation (list 1 2 3)) 1) + t) + +(deftest maxf.1 + (let ((x 1)) + (maxf x 2) + x) + 2) + +(deftest maxf.2 + (let ((x 1)) + (maxf x 0) + x) + 1) + +(deftest maxf.3 + (let ((x 1) + (c 0)) + (maxf x (incf c)) + (list x c)) + (1 1)) + +(deftest maxf.4 + (let ((xv (vector 0 0 0)) + (p 0)) + (maxf (svref xv (incf p)) (incf p)) + (list p xv)) + (2 #(0 2 0))) + +(deftest minf.1 + (let ((y 1)) + (minf y 0) + y) + 0) + +(deftest minf.2 + (let ((xv (vector 10 10 10)) + (p 0)) + (minf (svref xv (incf p)) (incf p)) + (list p xv)) + (2 #(10 2 10))) + +(deftest subfactorial.1 + (mapcar #'subfactorial (iota 22)) + (1 + 0 + 1 + 2 + 9 + 44 + 265 + 1854 + 14833 + 133496 + 1334961 + 14684570 + 176214841 + 2290792932 + 32071101049 + 481066515734 + 7697064251745 + 130850092279664 + 2355301661033953 + 44750731559645106 + 895014631192902121 + 18795307255050944540)) + +;;;; Arrays + +#+nil +(deftest array-index.type) + +#+nil +(deftest copy-array) + +;;;; Sequences + +(deftest rotate.1 + (list (rotate (list 1 2 3) 0) + (rotate (list 1 2 3) 1) + (rotate (list 1 2 3) 2) + (rotate (list 1 2 3) 3) + (rotate (list 1 2 3) 4)) + ((1 2 3) + (3 1 2) + (2 3 1) + (1 2 3) + (3 1 2))) + +(deftest rotate.2 + (list (rotate (vector 1 2 3 4) 0) + (rotate (vector 1 2 3 4)) + (rotate (vector 1 2 3 4) 2) + (rotate (vector 1 2 3 4) 3) + (rotate (vector 1 2 3 4) 4) + (rotate (vector 1 2 3 4) 5)) + (#(1 2 3 4) + #(4 1 2 3) + #(3 4 1 2) + #(2 3 4 1) + #(1 2 3 4) + #(4 1 2 3))) + +(deftest rotate.3 + (list (rotate (list 1 2 3) 0) + (rotate (list 1 2 3) -1) + (rotate (list 1 2 3) -2) + (rotate (list 1 2 3) -3) + (rotate (list 1 2 3) -4)) + ((1 2 3) + (2 3 1) + (3 1 2) + (1 2 3) + (2 3 1))) + +(deftest rotate.4 + (list (rotate (vector 1 2 3 4) 0) + (rotate (vector 1 2 3 4) -1) + (rotate (vector 1 2 3 4) -2) + (rotate (vector 1 2 3 4) -3) + (rotate (vector 1 2 3 4) -4) + (rotate (vector 1 2 3 4) -5)) + (#(1 2 3 4) + #(2 3 4 1) + #(3 4 1 2) + #(4 1 2 3) + #(1 2 3 4) + #(2 3 4 1))) + +(deftest rotate.5 + (values (rotate (list 1) 17) + (rotate (list 1) -5)) + (1) + (1)) + +(deftest shuffle.1 + (let ((s (shuffle (iota 100)))) + (list (equal s (iota 100)) + (every (lambda (x) + (member x s)) + (iota 100)) + (every (lambda (x) + (typep x '(integer 0 99))) + s))) + (nil t t)) + +(deftest shuffle.2 + (let ((s (shuffle (coerce (iota 100) 'vector)))) + (list (equal s (coerce (iota 100) 'vector)) + (every (lambda (x) + (find x s)) + (iota 100)) + (every (lambda (x) + (typep x '(integer 0 99))) + s))) + (nil t t)) + +(deftest shuffle.3 + (let* ((orig (coerce (iota 21) 'vector)) + (copy (copy-seq orig))) + (shuffle copy :start 10 :end 15) + (list (every #'eql (subseq copy 0 10) (subseq orig 0 10)) + (every #'eql (subseq copy 15) (subseq orig 15)))) + (t t)) + +(deftest random-elt.1 + (let ((s1 #(1 2 3 4)) + (s2 '(1 2 3 4))) + (list (dotimes (i 1000 nil) + (unless (member (random-elt s1) s2) + (return nil)) + (when (/= (random-elt s1) (random-elt s1)) + (return t))) + (dotimes (i 1000 nil) + (unless (member (random-elt s2) s2) + (return nil)) + (when (/= (random-elt s2) (random-elt s2)) + (return t))))) + (t t)) + +(deftest removef.1 + (let* ((x '(1 2 3)) + (x* x) + (y #(1 2 3)) + (y* y)) + (removef x 1) + (removef y 3) + (list x x* y y*)) + ((2 3) + (1 2 3) + #(1 2) + #(1 2 3))) + +(deftest deletef.1 + (let* ((x (list 1 2 3)) + (x* x) + (y (vector 1 2 3))) + (deletef x 2) + (deletef y 1) + (list x x* y)) + ((1 3) + (1 3) + #(2 3))) + +(deftest map-permutations.1 + (let ((seq (list 1 2 3)) + (seen nil) + (ok t)) + (map-permutations (lambda (s) + (unless (set-equal s seq) + (setf ok nil)) + (when (member s seen :test 'equal) + (setf ok nil)) + (push s seen)) + seq + :copy t) + (values ok (length seen))) + t + 6) + +(deftest proper-sequence.type.1 + (mapcar (lambda (x) + (typep x 'proper-sequence)) + (list (list 1 2 3) + (vector 1 2 3) + #2a((1 2) (3 4)) + (circular-list 1 2 3 4))) + (t t nil nil)) + +(deftest emptyp.1 + (mapcar #'emptyp + (list (list 1) + (circular-list 1) + nil + (vector) + (vector 1))) + (nil nil t t nil)) + +(deftest sequence-of-length-p.1 + (mapcar #'sequence-of-length-p + (list nil + #() + (list 1) + (vector 1) + (list 1 2) + (vector 1 2) + (list 1 2) + (vector 1 2) + (list 1 2) + (vector 1 2)) + (list 0 + 0 + 1 + 1 + 2 + 2 + 1 + 1 + 4 + 4)) + (t t t t t t nil nil nil nil)) + +(deftest length=.1 + (mapcar #'length= + (list nil + #() + (list 1) + (vector 1) + (list 1 2) + (vector 1 2) + (list 1 2) + (vector 1 2) + (list 1 2) + (vector 1 2)) + (list 0 + 0 + 1 + 1 + 2 + 2 + 1 + 1 + 4 + 4)) + (t t t t t t nil nil nil nil)) + +(deftest length=.2 + ;; test the compiler macro + (macrolet ((x (&rest args) + (funcall + (compile nil + `(lambda () + (length= ,@args)))))) + (list (x 2 '(1 2)) + (x '(1 2) '(3 4)) + (x '(1 2) 2) + (x '(1 2) 2 '(3 4)) + (x 1 2 3))) + (t t t t nil)) + +(deftest copy-sequence.1 + (let ((l (list 1 2 3)) + (v (vector #\a #\b #\c))) + (declare (notinline copy-sequence)) + (let ((l.list (copy-sequence 'list l)) + (l.vector (copy-sequence 'vector l)) + (l.spec-v (copy-sequence '(vector fixnum) l)) + (v.vector (copy-sequence 'vector v)) + (v.list (copy-sequence 'list v)) + (v.string (copy-sequence 'string v))) + (list (member l (list l.list l.vector l.spec-v)) + (member v (list v.vector v.list v.string)) + (equal l.list l) + (equalp l.vector #(1 2 3)) + (type= (upgraded-array-element-type 'fixnum) + (array-element-type l.spec-v)) + (equalp v.vector v) + (equal v.list '(#\a #\b #\c)) + (equal "abc" v.string)))) + (nil nil t t t t t t)) + +(deftest first-elt.1 + (mapcar #'first-elt + (list (list 1 2 3) + "abc" + (vector :a :b :c))) + (1 #\a :a)) + +(deftest first-elt.error.1 + (mapcar (lambda (x) + (handler-case + (first-elt x) + (type-error () + :type-error))) + (list nil + #() + 12 + :zot)) + (:type-error + :type-error + :type-error + :type-error)) + +(deftest setf-first-elt.1 + (let ((l (list 1 2 3)) + (s (copy-seq "foobar")) + (v (vector :a :b :c))) + (setf (first-elt l) -1 + (first-elt s) #\x + (first-elt v) 'zot) + (values l s v)) + (-1 2 3) + "xoobar" + #(zot :b :c)) + +(deftest setf-first-elt.error.1 + (let ((l 'foo)) + (multiple-value-bind (res err) + (ignore-errors (setf (first-elt l) 4)) + (typep err 'type-error))) + t) + +(deftest last-elt.1 + (mapcar #'last-elt + (list (list 1 2 3) + (vector :a :b :c) + "FOOBAR" + #*001 + #*010)) + (3 :c #\R 1 0)) + +(deftest last-elt.error.1 + (mapcar (lambda (x) + (handler-case + (last-elt x) + (type-error () + :type-error))) + (list nil + #() + 12 + :zot + (circular-list 1 2 3) + (list* 1 2 3 (circular-list 4 5)))) + (:type-error + :type-error + :type-error + :type-error + :type-error + :type-error)) + +(deftest setf-last-elt.1 + (let ((l (list 1 2 3)) + (s (copy-seq "foobar")) + (b (copy-seq #*010101001))) + (setf (last-elt l) '??? + (last-elt s) #\? + (last-elt b) 0) + (values l s b)) + (1 2 ???) + "fooba?" + #*010101000) + +(deftest setf-last-elt.error.1 + (handler-case + (setf (last-elt 'foo) 13) + (type-error () + :type-error)) + :type-error) + +(deftest starts-with.1 + (list (starts-with 1 '(1 2 3)) + (starts-with 1 #(1 2 3)) + (starts-with #\x "xyz") + (starts-with 2 '(1 2 3)) + (starts-with 3 #(1 2 3)) + (starts-with 1 1) + (starts-with nil nil)) + (t t t nil nil nil nil)) + +(deftest starts-with.2 + (values (starts-with 1 '(-1 2 3) :key '-) + (starts-with "foo" '("foo" "bar") :test 'equal) + (starts-with "f" '(#\f) :key 'string :test 'equal) + (starts-with -1 '(0 1 2) :key #'1+) + (starts-with "zot" '("ZOT") :test 'equal)) + t + t + t + nil + nil) + +(deftest ends-with.1 + (list (ends-with 3 '(1 2 3)) + (ends-with 3 #(1 2 3)) + (ends-with #\z "xyz") + (ends-with 2 '(1 2 3)) + (ends-with 1 #(1 2 3)) + (ends-with 1 1) + (ends-with nil nil)) + (t t t nil nil nil nil)) + +(deftest ends-with.2 + (values (ends-with 2 '(0 13 1) :key '1+) + (ends-with "foo" (vector "bar" "foo") :test 'equal) + (ends-with "X" (vector 1 2 #\X) :key 'string :test 'equal) + (ends-with "foo" "foo" :test 'equal)) + t + t + t + nil) + +(deftest ends-with.error.1 + (handler-case + (ends-with 3 (circular-list 3 3 3 1 3 3)) + (type-error () + :type-error)) + :type-error) + +(deftest sequences.passing-improper-lists + (macrolet ((signals-error-p (form) + `(handler-case + (progn ,form nil) + (type-error (e) + t))) + (cut (fn &rest args) + (with-gensyms (arg) + (print`(lambda (,arg) + (apply ,fn (list ,@(substitute arg '_ args)))))))) + (let ((circular-list (make-circular-list 5 :initial-element :foo)) + (dotted-list (list* 'a 'b 'c 'd))) + (loop for nth from 0 + for fn in (list + (cut #'lastcar _) + (cut #'rotate _ 3) + (cut #'rotate _ -3) + (cut #'shuffle _) + (cut #'random-elt _) + (cut #'last-elt _) + (cut #'ends-with :foo _)) + nconcing + (let ((on-circular-p (signals-error-p (funcall fn circular-list))) + (on-dotted-p (signals-error-p (funcall fn dotted-list)))) + (when (or (not on-circular-p) (not on-dotted-p)) + (append + (unless on-circular-p + (let ((*print-circle* t)) + (list + (format nil + "No appropriate error signalled when passing ~S to ~Ath entry." + circular-list nth)))) + (unless on-dotted-p + (list + (format nil + "No appropriate error signalled when passing ~S to ~Ath entry." + dotted-list nth))))))))) + nil) + +;;;; IO + +(deftest read-stream-content-into-string.1 + (values (with-input-from-string (stream "foo bar") + (read-stream-content-into-string stream)) + (with-input-from-string (stream "foo bar") + (read-stream-content-into-string stream :buffer-size 1)) + (with-input-from-string (stream "foo bar") + (read-stream-content-into-string stream :buffer-size 6)) + (with-input-from-string (stream "foo bar") + (read-stream-content-into-string stream :buffer-size 7))) + "foo bar" + "foo bar" + "foo bar" + "foo bar") + +(deftest read-stream-content-into-string.2 + (handler-case + (let ((stream (make-broadcast-stream))) + (read-stream-content-into-string stream :buffer-size 0)) + (type-error () + :type-error)) + :type-error) + +#+(or) +(defvar *octets* + (map '(simple-array (unsigned-byte 8) (7)) #'char-code "foo bar")) + +#+(or) +(deftest read-stream-content-into-byte-vector.1 + (values (with-input-from-byte-vector (stream *octets*) + (read-stream-content-into-byte-vector stream)) + (with-input-from-byte-vector (stream *octets*) + (read-stream-content-into-byte-vector stream :initial-size 1)) + (with-input-from-byte-vector (stream *octets*) + (read-stream-content-into-byte-vector stream 'alexandria::%length 6)) + (with-input-from-byte-vector (stream *octets*) + (read-stream-content-into-byte-vector stream 'alexandria::%length 3))) + *octets* + *octets* + *octets* + (subseq *octets* 0 3)) + +(deftest read-stream-content-into-byte-vector.2 + (handler-case + (let ((stream (make-broadcast-stream))) + (read-stream-content-into-byte-vector stream :initial-size 0)) + (type-error () + :type-error)) + :type-error) + +;;;; Macros + +(deftest with-unique-names.1 + (let ((*gensym-counter* 0)) + (let ((syms (with-unique-names (foo bar quux) + (list foo bar quux)))) + (list (find-if #'symbol-package syms) + (equal '("FOO0" "BAR1" "QUUX2") + (mapcar #'symbol-name syms))))) + (nil t)) + +(deftest with-unique-names.2 + (let ((*gensym-counter* 0)) + (let ((syms (with-unique-names ((foo "_foo_") (bar -bar-) (quux #\q)) + (list foo bar quux)))) + (list (find-if #'symbol-package syms) + (equal '("_foo_0" "-BAR-1" "q2") + (mapcar #'symbol-name syms))))) + (nil t)) + +(deftest with-unique-names.3 + (let ((*gensym-counter* 0)) + (multiple-value-bind (res err) + (ignore-errors + (eval + '(let ((syms + (with-unique-names ((foo "_foo_") (bar -bar-) (quux 42)) + (list foo bar quux)))) + (list (find-if #'symbol-package syms) + (equal '("_foo_0" "-BAR-1" "q2") + (mapcar #'symbol-name syms)))))) + (errorp err))) + t) + +(deftest once-only.1 + (macrolet ((cons1.good (x) + (once-only (x) + `(cons ,x ,x))) + (cons1.bad (x) + `(cons ,x ,x))) + (let ((y 0)) + (list (cons1.good (incf y)) + y + (cons1.bad (incf y)) + y))) + ((1 . 1) 1 (2 . 3) 3)) + +(deftest once-only.2 + (macrolet ((cons1 (x) + (once-only ((y x)) + `(cons ,y ,y)))) + (let ((z 0)) + (list (cons1 (incf z)) + z + (cons1 (incf z))))) + ((1 . 1) 1 (2 . 2))) + +(deftest parse-body.1 + (parse-body '("doc" "body") :documentation t) + ("body") + nil + "doc") + +(deftest parse-body.2 + (parse-body '("body") :documentation t) + ("body") + nil + nil) + +(deftest parse-body.3 + (parse-body '("doc" "body")) + ("doc" "body") + nil + nil) + +(deftest parse-body.4 + (parse-body '((declare (foo)) "doc" (declare (bar)) body) :documentation t) + (body) + ((declare (foo)) (declare (bar))) + "doc") + +(deftest parse-body.5 + (parse-body '((declare (foo)) "doc" (declare (bar)) body)) + ("doc" (declare (bar)) body) + ((declare (foo))) + nil) + +(deftest parse-body.6 + (multiple-value-bind (res err) + (ignore-errors + (parse-body '("foo" "bar" "quux") + :documentation t)) + (errorp err)) + t) + +;;;; Symbols + +(deftest ensure-symbol.1 + (ensure-symbol :cons :cl) + cons + :external) + +(deftest ensure-symbol.2 + (ensure-symbol "CONS" :alexandria) + cons + :inherited) + +(deftest ensure-symbol.3 + (ensure-symbol 'foo :keyword) + :foo + :external) + +(deftest ensure-symbol.4 + (ensure-symbol #\* :alexandria) + * + :inherited) + +(deftest format-symbol.1 + (let ((s (format-symbol nil '#:x-~d 13))) + (list (symbol-package s) + (string= (string '#:x-13) (symbol-name s)))) + (nil t)) + +(deftest format-symbol.2 + (format-symbol :keyword '#:sym-~a (string :bolic)) + :sym-bolic) + +(deftest format-symbol.3 + (let ((*package* (find-package :cl))) + (format-symbol t '#:find-~a (string 'package))) + find-package) + +(deftest make-keyword.1 + (list (make-keyword 'zot) + (make-keyword "FOO") + (make-keyword #\Q)) + (:zot :foo :q)) + +(deftest make-gensym-list.1 + (let ((*gensym-counter* 0)) + (let ((syms (make-gensym-list 3 "FOO"))) + (list (find-if 'symbol-package syms) + (equal '("FOO0" "FOO1" "FOO2") + (mapcar 'symbol-name syms))))) + (nil t)) + +(deftest make-gensym-list.2 + (let ((*gensym-counter* 0)) + (let ((syms (make-gensym-list 3))) + (list (find-if 'symbol-package syms) + (equal '("G0" "G1" "G2") + (mapcar 'symbol-name syms))))) + (nil t)) + +;;;; Type-system + +(deftest of-type.1 + (locally + (declare (notinline of-type)) + (let ((f (of-type 'string))) + (list (funcall f "foo") + (funcall f 'bar)))) + (t nil)) + +(deftest type=.1 + (type= 'string 'string) + t + t) + +(deftest type=.2 + (type= 'list '(or null cons)) + t + t) + +(deftest type=.3 + (type= 'null '(and symbol list)) + t + t) + +(deftest type=.4 + (type= 'string '(satisfies emptyp)) + nil + nil) + +(deftest type=.5 + (type= 'string 'list) + nil + t) + +(macrolet + ((test (type numbers) + `(deftest ,(format-symbol t '#:cdr5.~a (string type)) + (let ((numbers ,numbers)) + (values (mapcar (of-type ',(format-symbol t '#:negative-~a (string type))) numbers) + (mapcar (of-type ',(format-symbol t '#:non-positive-~a (string type))) numbers) + (mapcar (of-type ',(format-symbol t '#:non-negative-~a (string type))) numbers) + (mapcar (of-type ',(format-symbol t '#:positive-~a (string type))) numbers))) + (t t t nil nil nil nil) + (t t t t nil nil nil) + (nil nil nil t t t t) + (nil nil nil nil t t t)))) + (test fixnum (list most-negative-fixnum -42 -1 0 1 42 most-positive-fixnum)) + (test integer (list (1- most-negative-fixnum) -42 -1 0 1 42 (1+ most-positive-fixnum))) + (test rational (list (1- most-negative-fixnum) -42/13 -1 0 1 42/13 (1+ most-positive-fixnum))) + (test real (list most-negative-long-float -42/13 -1 0 1 42/13 most-positive-long-float)) + (test float (list most-negative-short-float -42.02 -1.0 0.0 1.0 42.02 most-positive-short-float)) + (test short-float (list most-negative-short-float -42.02s0 -1.0s0 0.0s0 1.0s0 42.02s0 most-positive-short-float)) + (test single-float (list most-negative-single-float -42.02f0 -1.0f0 0.0f0 1.0f0 42.02f0 most-positive-single-float)) + (test double-float (list most-negative-double-float -42.02d0 -1.0d0 0.0d0 1.0d0 42.02d0 most-positive-double-float)) + (test long-float (list most-negative-long-float -42.02l0 -1.0l0 0.0l0 1.0l0 42.02l0 most-positive-long-float))) + +;;;; Bindings + +(declaim (notinline opaque)) +(defun opaque (x) + x) + +(deftest if-let.1 + (if-let (x (opaque :ok)) + x + :bad) + :ok) + +(deftest if-let.2 + (if-let (x (opaque nil)) + :bad + (and (not x) :ok)) + :ok) + +(deftest if-let.3 + (let ((x 1)) + (if-let ((x 2) + (y x)) + (+ x y) + :oops)) + 3) + +(deftest if-let.4 + (if-let ((x 1) + (y nil)) + :oops + (and (not y) x)) + 1) + +(deftest if-let.5 + (if-let (x) + :oops + (not x)) + t) + +(deftest if-let.error.1 + (handler-case + (eval '(if-let x + :oops + :oops)) + (type-error () + :type-error)) + :type-error) + +(deftest when-let.1 + (when-let (x (opaque :ok)) + (setf x (cons x x)) + x) + (:ok . :ok)) + +(deftest when-let.2 + (when-let ((x 1) + (y nil) + (z 3)) + :oops) + nil) + +(deftest when-let.3 + (let ((x 1)) + (when-let ((x 2) + (y x)) + (+ x y))) + 3) + +(deftest when-let.error.1 + (handler-case + (eval '(when-let x :oops)) + (type-error () + :type-error)) + :type-error) + +(deftest when-let*.1 + (let ((x 1)) + (when-let* ((x 2) + (y x)) + (+ x y))) + 4) + +(deftest when-let*.2 + (let ((y 1)) + (when-let* (x y) + (1+ x))) + 2) + +(deftest when-let*.3 + (when-let* ((x t) + (y (consp x)) + (z (error "OOPS"))) + t) + nil) + +(deftest when-let*.error.1 + (handler-case + (eval '(when-let* x :oops)) + (type-error () + :type-error)) + :type-error) + +(deftest doplist.1 + (let (keys values) + (doplist (k v '(a 1 b 2 c 3) (values t (reverse keys) (reverse values) k v)) + (push k keys) + (push v values))) + t + (a b c) + (1 2 3) + nil + nil) + +(deftest count-permutations.1 + (values (count-permutations 31 7) + (count-permutations 1 1) + (count-permutations 2 1) + (count-permutations 2 2) + (count-permutations 3 2) + (count-permutations 3 1)) + 13253058000 + 1 + 2 + 2 + 6 + 3) + +(deftest binomial-coefficient.1 + (alexandria:binomial-coefficient 1239 139) + 28794902202288970200771694600561826718847179309929858835480006683522184441358211423695124921058123706380656375919763349913245306834194782172712255592710204598527867804110129489943080460154) + +;; Exercise bignum case (at least on x86). +(deftest binomial-coefficient.2 + (alexandria:binomial-coefficient 2000000000000 20) + 430998041177272843950422879590338454856322722740402365741730748431530623813012487773080486408378680853987520854296499536311275320016878730999689934464711239072435565454954447356845336730100919970769793030177499999999900000000000) + +(deftest copy-stream.1 + (let ((data "sdkfjhsakfh weior763495ewofhsdfk sdfadlkfjhsadf woif sdlkjfhslkdfh sdklfjh")) + (values (equal data + (with-input-from-string (in data) + (with-output-to-string (out) + (alexandria:copy-stream in out)))) + (equal (subseq data 10 20) + (with-input-from-string (in data) + (with-output-to-string (out) + (alexandria:copy-stream in out :start 10 :end 20)))) + (equal (subseq data 10) + (with-input-from-string (in data) + (with-output-to-string (out) + (alexandria:copy-stream in out :start 10)))) + (equal (subseq data 0 20) + (with-input-from-string (in data) + (with-output-to-string (out) + (alexandria:copy-stream in out :end 20)))))) + t + t + t + t) + +(deftest extremum.1 + (let ((n 0)) + (dotimes (i 10) + (let ((data (shuffle (coerce (iota 10000 :start i) 'vector))) + (ok t)) + (unless (eql i (extremum data #'<)) + (setf ok nil)) + (unless (eql i (extremum (coerce data 'list) #'<)) + (setf ok nil)) + (unless (eql (+ 9999 i) (extremum data #'>)) + (setf ok nil)) + (unless (eql (+ 9999 i) (extremum (coerce data 'list) #'>)) + (setf ok nil)) + (when ok + (incf n)))) + (when (eql 10 (extremum #(100 1 10 1000) #'> :start 1 :end 3)) + (incf n)) + (when (eql -1000 (extremum #(100 1 10 -1000) #'> :key 'abs)) + (incf n)) + (when (eq nil (extremum "" (lambda (a b) (error "wtf? ~S, ~S" a b)))) + (incf n)) + n) + 13) + +(deftest starts-with-subseq.string + (starts-with-subseq "f" "foo" :return-suffix t) + t + "oo") + +(deftest starts-with-subseq.vector + (starts-with-subseq #(1) #(1 2 3) :return-suffix t) + t + #(2 3)) + +(deftest starts-with-subseq.list + (starts-with-subseq '(1) '(1 2 3) :return-suffix t) + t + (2 3)) + +(deftest starts-with-subseq.start1 + (starts-with-subseq "foo" "oop" :start1 1) + t + nil) + +(deftest starts-with-subseq.start2 + (starts-with-subseq "foo" "xfoop" :start2 1) + t + nil) + +(deftest format-symbol.print-case-bound + (let ((upper (intern "FOO-BAR")) + (lower (intern "foo-bar")) + (*print-escape* nil)) + (values + (let ((*print-case* :downcase)) + (and (eq upper (format-symbol t "~A" upper)) + (eq lower (format-symbol t "~A" lower)))) + (let ((*print-case* :upcase)) + (and (eq upper (format-symbol t "~A" upper)) + (eq lower (format-symbol t "~A" lower)))) + (let ((*print-case* :capitalize)) + (and (eq upper (format-symbol t "~A" upper)) + (eq lower (format-symbol t "~A" lower)))))) + t + t + t) + +(deftest iota.fp-start-and-complex-integer-step + (equal '(#C(0.0 0.0) #C(0.0 2.0) #C(0.0 4.0)) + (iota 3 :start 0.0 :step #C(0 2))) + t) + +(deftest parse-ordinary-lambda-list.1 + (multiple-value-bind (req opt rest keys allowp aux keyp) + (parse-ordinary-lambda-list '(a b c + &optional o1 (o2 42) (o3 42 o3-supplied?) + &key (k1) ((:key k2)) (k3 42 k3-supplied?)) + :normalize t) + (and (equal '(a b c) req) + (equal '((o1 nil nil) + (o2 42 nil) + (o3 42 o3-supplied?)) + opt) + (equal '(((:k1 k1) nil nil) + ((:key k2) nil nil) + ((:k3 k3) 42 k3-supplied?)) + keys) + (not allowp) + (not aux) + (eq t keyp))) + t) diff --git a/third_party/lisp/alexandria/types.lisp b/third_party/lisp/alexandria/types.lisp new file mode 100644 index 0000000000..1942d0ecdf --- /dev/null +++ b/third_party/lisp/alexandria/types.lisp @@ -0,0 +1,137 @@ +(in-package :alexandria) + +(deftype array-index (&optional (length (1- array-dimension-limit))) + "Type designator for an index into array of LENGTH: an integer between +0 (inclusive) and LENGTH (exclusive). LENGTH defaults to one less than +ARRAY-DIMENSION-LIMIT." + `(integer 0 (,length))) + +(deftype array-length (&optional (length (1- array-dimension-limit))) + "Type designator for a dimension of an array of LENGTH: an integer between +0 (inclusive) and LENGTH (inclusive). LENGTH defaults to one less than +ARRAY-DIMENSION-LIMIT." + `(integer 0 ,length)) + +;; This MACROLET will generate most of CDR5 (http://cdr.eurolisp.org/document/5/) +;; except the RATIO related definitions and ARRAY-INDEX. +(macrolet + ((frob (type &optional (base-type type)) + (let ((subtype-names (list)) + (predicate-names (list))) + (flet ((make-subtype-name (format-control) + (let ((result (format-symbol :alexandria format-control + (symbol-name type)))) + (push result subtype-names) + result)) + (make-predicate-name (sybtype-name) + (let ((result (format-symbol :alexandria '#:~A-p + (symbol-name sybtype-name)))) + (push result predicate-names) + result)) + (make-docstring (range-beg range-end range-type) + (let ((inf (ecase range-type (:negative "-inf") (:positive "+inf")))) + (format nil "Type specifier denoting the ~(~A~) range from ~A to ~A." + type + (if (equal range-beg ''*) inf (ensure-car range-beg)) + (if (equal range-end ''*) inf (ensure-car range-end)))))) + (let* ((negative-name (make-subtype-name '#:negative-~a)) + (non-positive-name (make-subtype-name '#:non-positive-~a)) + (non-negative-name (make-subtype-name '#:non-negative-~a)) + (positive-name (make-subtype-name '#:positive-~a)) + (negative-p-name (make-predicate-name negative-name)) + (non-positive-p-name (make-predicate-name non-positive-name)) + (non-negative-p-name (make-predicate-name non-negative-name)) + (positive-p-name (make-predicate-name positive-name)) + (negative-extremum) + (positive-extremum) + (below-zero) + (above-zero) + (zero)) + (setf (values negative-extremum below-zero + above-zero positive-extremum zero) + (ecase type + (fixnum (values 'most-negative-fixnum -1 1 'most-positive-fixnum 0)) + (integer (values ''* -1 1 ''* 0)) + (rational (values ''* '(0) '(0) ''* 0)) + (real (values ''* '(0) '(0) ''* 0)) + (float (values ''* '(0.0E0) '(0.0E0) ''* 0.0E0)) + (short-float (values ''* '(0.0S0) '(0.0S0) ''* 0.0S0)) + (single-float (values ''* '(0.0F0) '(0.0F0) ''* 0.0F0)) + (double-float (values ''* '(0.0D0) '(0.0D0) ''* 0.0D0)) + (long-float (values ''* '(0.0L0) '(0.0L0) ''* 0.0L0)))) + `(progn + (deftype ,negative-name () + ,(make-docstring negative-extremum below-zero :negative) + `(,',base-type ,,negative-extremum ,',below-zero)) + + (deftype ,non-positive-name () + ,(make-docstring negative-extremum zero :negative) + `(,',base-type ,,negative-extremum ,',zero)) + + (deftype ,non-negative-name () + ,(make-docstring zero positive-extremum :positive) + `(,',base-type ,',zero ,,positive-extremum)) + + (deftype ,positive-name () + ,(make-docstring above-zero positive-extremum :positive) + `(,',base-type ,',above-zero ,,positive-extremum)) + + (declaim (inline ,@predicate-names)) + + (defun ,negative-p-name (n) + (and (typep n ',type) + (< n ,zero))) + + (defun ,non-positive-p-name (n) + (and (typep n ',type) + (<= n ,zero))) + + (defun ,non-negative-p-name (n) + (and (typep n ',type) + (<= ,zero n))) + + (defun ,positive-p-name (n) + (and (typep n ',type) + (< ,zero n))))))))) + (frob fixnum integer) + (frob integer) + (frob rational) + (frob real) + (frob float) + (frob short-float) + (frob single-float) + (frob double-float) + (frob long-float)) + +(defun of-type (type) + "Returns a function of one argument, which returns true when its argument is +of TYPE." + (lambda (thing) (typep thing type))) + +(define-compiler-macro of-type (&whole form type &environment env) + ;; This can yeild a big benefit, but no point inlining the function + ;; all over the place if TYPE is not constant. + (if (constantp type env) + (with-gensyms (thing) + `(lambda (,thing) + (typep ,thing ,type))) + form)) + +(declaim (inline type=)) +(defun type= (type1 type2) + "Returns a primary value of T is TYPE1 and TYPE2 are the same type, +and a secondary value that is true is the type equality could be reliably +determined: primary value of NIL and secondary value of T indicates that the +types are not equivalent." + (multiple-value-bind (sub ok) (subtypep type1 type2) + (cond ((and ok sub) + (subtypep type2 type1)) + (ok + (values nil ok)) + (t + (multiple-value-bind (sub ok) (subtypep type2 type1) + (declare (ignore sub)) + (values nil ok)))))) + +(define-modify-macro coercef (type-spec) coerce + "Modify-macro for COERCE.") diff --git a/third_party/lisp/asdf-flv/.gitattributes b/third_party/lisp/asdf-flv/.gitattributes new file mode 100644 index 0000000000..2b45716e47 --- /dev/null +++ b/third_party/lisp/asdf-flv/.gitattributes @@ -0,0 +1,2 @@ +.gitignore export-ignore +.gitattributes export-ignore diff --git a/third_party/lisp/asdf-flv/.gitignore b/third_party/lisp/asdf-flv/.gitignore new file mode 100644 index 0000000000..bdf4ad2ae6 --- /dev/null +++ b/third_party/lisp/asdf-flv/.gitignore @@ -0,0 +1,3 @@ +sbcl-*/ +cmu-*/ +openmcl-*/ diff --git a/third_party/lisp/asdf-flv/Makefile b/third_party/lisp/asdf-flv/Makefile new file mode 100644 index 0000000000..b4c74feefe --- /dev/null +++ b/third_party/lisp/asdf-flv/Makefile @@ -0,0 +1,77 @@ +### Makefile --- Toplevel directory + +## Copyright (C) 2011, 2015 Didier Verna + +## Author: Didier Verna <didier@didierverna.net> + +## This file is part of ASDF-FLV. + +## Copying and distribution of this file, with or without modification, +## are permitted in any medium without royalty provided the copyright +## notice and this notice are preserved. This file is offered as-is, +## without any warranty. + + +### Commentary: + +## Contents management by FCM version 0.1. + + +### Code: + +PROJECT := asdf-flv +VERSION := 2.1 + +W3DIR := $(HOME)/www/software/lisp/$(PROJECT) + +DIST_NAME := $(PROJECT)-$(VERSION) +TARBALL := $(DIST_NAME).tar.gz +SIGNATURE := $(TARBALL).asc + + +all: + +clean: + -rm *~ + +distclean: clean + -rm *.tar.gz *.tar.gz.asc + +tag: + git tag -a -m 'Version $(VERSION)' 'version-$(VERSION)' + +tar: $(TARBALL) +gpg: $(SIGNATURE) +dist: tar gpg + +install-www: dist + -install -m 644 $(TARBALL) "$(W3DIR)/attic/" + -install -m 644 $(SIGNATURE) "$(W3DIR)/attic/" + echo "\ +<? lref (\"$(PROJECT)/attic/$(PROJECT)-$(VERSION).tar.gz\", \ + contents (\"Derni�re version\", \"Latest version\")); ?> \ +| \ +<? lref (\"$(PROJECT)/attic/$(PROJECT)-$(VERSION).tar.gz.asc\", \ + contents (\"Signature GPG\", \"GPG Signature\")); ?>" \ + > "$(W3DIR)/latest.txt" + chmod 644 "$(W3DIR)/latest.txt" + cd "$(W3DIR)" \ + && ln -fs attic/$(TARBALL) latest.tar.gz \ + && ln -fs attic/$(SIGNATURE) latest.tar.gz.asc + +update-version: + perl -pi -e 's/:version ".*"/:version "$(VERSION)"/' \ + net.didierverna.$(PROJECT).asd + +$(TARBALL): + git archive --format=tar --prefix=$(DIST_NAME)/ \ + --worktree-attributes HEAD \ + | gzip -c > $@ + +$(SIGNATURE): $(TARBALL) + gpg -b -a $< + + +.PHONY: all clean distclean tag tar gpg dist install-www update-version + +### Makefile ends here diff --git a/third_party/lisp/asdf-flv/README.md b/third_party/lisp/asdf-flv/README.md new file mode 100644 index 0000000000..7ccdd18881 --- /dev/null +++ b/third_party/lisp/asdf-flv/README.md @@ -0,0 +1,7 @@ +ASDF-FLV provides support for file-local variables through ASDF. A file-local +variable behaves like `*PACKAGE*` and `*READTABLE*` with respect to `LOAD` and +`COMPILE-FILE`: a new dynamic binding is created before processing the file, +so that any modification to the variable essentially becomes file-local. + +In order to make one or several variables file-local, use the macros +`SET-FILE-LOCAL-VARIABLE(S)`. diff --git a/third_party/lisp/asdf-flv/asdf-flv.lisp b/third_party/lisp/asdf-flv/asdf-flv.lisp new file mode 100644 index 0000000000..76c6845b82 --- /dev/null +++ b/third_party/lisp/asdf-flv/asdf-flv.lisp @@ -0,0 +1,64 @@ +;;; asdf-flv.lisp --- Implementation + +;; Copyright (C) 2011, 2015 Didier Verna + +;; Author: Didier Verna <didier@didierverna.net> + +;; This file is part of ASDF-FLV. + +;; Copying and distribution of this file, with or without modification, +;; are permitted in any medium without royalty provided the copyright +;; notice and this notice are preserved. This file is offered as-is, +;; without any warranty. + + +;;; Commentary: + +;; Contents management by FCM version 0.1. + + +;;; Code: + +(in-package :net.didierverna.asdf-flv) + + +(defvar *file-local-variables* () + "List of file-local special variables.") + + +(defun make-variable-file-local (symbol) + "Make special variable named by SYMBOL have a file-local value." + (pushnew symbol *file-local-variables*)) + +(defmacro set-file-local-variable (symbol) + "Set special variable named by SYMBOL as file-local. +SYMBOL need not be quoted." + `(make-variable-file-local ',symbol)) + +(defun make-variables-file-local (&rest symbols) + "Make special variables named by SYMBOLS have a file-local value." + (dolist (symbol symbols) + (pushnew symbol *file-local-variables*))) + +(defmacro set-file-local-variables (&rest symbols) + "Set special variables named by SYMBOLS as file-local. +SYMBOLS need not be quoted." + `(make-variables-file-local ,@(mapcar (lambda (symbol) (list 'quote symbol)) + symbols))) + + +(defmethod asdf:perform :around + ((operation asdf:load-op) (file asdf:cl-source-file)) + "Establish new dynamic bindings for file-local variables." + (progv *file-local-variables* + (mapcar #'symbol-value *file-local-variables*) + (call-next-method))) + +(defmethod asdf:perform :around + ((operation asdf:compile-op) (file asdf:cl-source-file)) + "Establish new dynamic bindings for file-local variables." + (progv *file-local-variables* + (mapcar #'symbol-value *file-local-variables*) + (call-next-method))) + +;;; asdf-flv.lisp ends here diff --git a/third_party/lisp/asdf-flv/default.nix b/third_party/lisp/asdf-flv/default.nix new file mode 100644 index 0000000000..e8ec4aa8f8 --- /dev/null +++ b/third_party/lisp/asdf-flv/default.nix @@ -0,0 +1,13 @@ +# Imported from https://github.com/didierverna/asdf-flv +{ depot, ... }: + +with depot.nix; +buildLisp.library { + name = "asdf-flv"; + deps = [ (buildLisp.bundled "asdf") ]; + + srcs = [ + ./package.lisp + ./asdf-flv.lisp + ]; +} diff --git a/third_party/lisp/asdf-flv/net.didierverna.asdf-flv.asd b/third_party/lisp/asdf-flv/net.didierverna.asdf-flv.asd new file mode 100644 index 0000000000..41202746d0 --- /dev/null +++ b/third_party/lisp/asdf-flv/net.didierverna.asdf-flv.asd @@ -0,0 +1,43 @@ +;;; net.didierverna.asdf-flv.asd --- ASDF system definition + +;; Copyright (C) 2011, 2015 Didier Verna + +;; Author: Didier Verna <didier@didierverna.net> + +;; This file is part of ASDF-FLV. + +;; Copying and distribution of this file, with or without modification, +;; are permitted in any medium without royalty provided the copyright +;; notice and this notice are preserved. This file is offered as-is, +;; without any warranty. + + +;;; Commentary: + +;; Contents management by FCM version 0.1. + + +;;; Code: + +(asdf:defsystem :net.didierverna.asdf-flv + :long-name "ASDF File Local Variables" + :description "ASDF extension to provide support for file-local variables." + :long-description "\ +ASDF-FLV provides support for file-local variables through ASDF. A file-local +variable behaves like *PACKAGE* and *READTABLE* with respect to LOAD and +COMPILE-FILE: a new dynamic binding is created before processing the file, so +that any modification to the variable becomes essentially file-local. + +In order to make one or several variables file-local, use the macros +SET-FILE-LOCAL-VARIABLE(S)." + :author "Didier Verna" + :mailto "didier@didierverna.net" + :homepage "http://www.lrde.epita.fr/~didier/software/lisp/misc.php#asdf-flv" + :source-control "https://github.com/didierverna/asdf-flv" + :license "GNU All Permissive" + :version "2.1" + :serial t + :components ((:file "package") + (:file "asdf-flv"))) + +;;; net.didierverna.asdf-flv.asd ends here diff --git a/third_party/lisp/asdf-flv/package.lisp b/third_party/lisp/asdf-flv/package.lisp new file mode 100644 index 0000000000..1d7fb2bab4 --- /dev/null +++ b/third_party/lisp/asdf-flv/package.lisp @@ -0,0 +1,28 @@ +;;; package.lisp --- Package definition + +;; Copyright (C) 2011, 2015 Didier Verna + +;; Author: Didier Verna <didier@didierverna.net> + +;; This file is part of ASDF-FLV. + +;; Copying and distribution of this file, with or without modification, +;; are permitted in any medium without royalty provided the copyright +;; notice and this notice are preserved. This file is offered as-is, +;; without any warranty. + + +;;; Commentary: + +;; Contents management by FCM version 0.1. + + +;;; Code: + +(in-package :cl-user) + +(defpackage :net.didierverna.asdf-flv + (:use :cl) + (:export :set-file-local-variable :set-file-local-variables)) + +;;; package.lisp ends here diff --git a/third_party/lisp/babel.nix b/third_party/lisp/babel.nix new file mode 100644 index 0000000000..7c066904fe --- /dev/null +++ b/third_party/lisp/babel.nix @@ -0,0 +1,31 @@ +# Babel is an encoding conversion library for Common Lisp. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/cl-babel/babel.git"; + rev = "ec9a17cdbdba3c1dd39609fc7961cfb3f0aa260e"; +}; +in depot.nix.buildLisp.library { + name = "babel"; + deps = [ depot.third_party.lisp.alexandria ]; + + srcs = map (f: src + ("/src/" + f)) [ + "packages.lisp" + "encodings.lisp" + "enc-ascii.lisp" + "enc-ebcdic.lisp" + "enc-ebcdic-int.lisp" + "enc-iso-8859.lisp" + "enc-unicode.lisp" + "enc-cp1251.lisp" + "enc-cp1252.lisp" + "jpn-table.lisp" + "enc-jpn.lisp" + "enc-gbk.lisp" + "enc-koi8.lisp" + "external-format.lisp" + "strings.lisp" + "gbk-map.lisp" + "sharp-backslash.lisp" + ]; +} diff --git a/third_party/lisp/bordeaux-threads.nix b/third_party/lisp/bordeaux-threads.nix new file mode 100644 index 0000000000..b2596672ba --- /dev/null +++ b/third_party/lisp/bordeaux-threads.nix @@ -0,0 +1,19 @@ +# This library is meant to make writing portable multi-threaded apps +# in Common Lisp simple. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/sionescu/bordeaux-threads.git"; + rev = "499b6d3f0ce635417d6096acf0a671d8bf3f6e5f"; +}; +in depot.nix.buildLisp.library { + name = "bordeaux-threads"; + deps = [ depot.third_party.lisp.alexandria ]; + + srcs = map (f: src + ("/src/" + f)) [ + "pkgdcl.lisp" + "bordeaux-threads.lisp" + "impl-sbcl.lisp" + "default-implementations.lisp" + ]; +} diff --git a/third_party/lisp/cffi.nix b/third_party/lisp/cffi.nix new file mode 100644 index 0000000000..62c1f81da7 --- /dev/null +++ b/third_party/lisp/cffi.nix @@ -0,0 +1,33 @@ +# CFFI purports to be the Common Foreign Function Interface. +{ depot, ... }: + +with depot.nix; +let src = builtins.fetchGit { + url = "https://github.com/cffi/cffi.git"; + rev = "5e838bf46d0089c43ebd3ea014a207c403e29c61"; +}; +in buildLisp.library { + name = "cffi"; + deps = with depot.third_party.lisp; [ + alexandria + babel + trivial-features + (buildLisp.bundled "asdf") + (buildLisp.bundled "uiop") + ]; + + srcs = map (f: src + ("/src/" + f)) [ + "cffi-sbcl.lisp" + "package.lisp" + "utils.lisp" + "libraries.lisp" + "early-types.lisp" + "types.lisp" + "enum.lisp" + "strings.lisp" + "structures.lisp" + "functions.lisp" + "foreign-vars.lisp" + "features.lisp" + ]; +} diff --git a/third_party/lisp/chipz.nix b/third_party/lisp/chipz.nix new file mode 100644 index 0000000000..dfbf32b094 --- /dev/null +++ b/third_party/lisp/chipz.nix @@ -0,0 +1,33 @@ +# Common Lisp library for decompressing deflate, zlib, gzip, and bzip2 data +{ depot, ... }: + +with depot.nix; + +let src = depot.third_party.fetchFromGitHub { + owner = "froydnj"; + repo = "chipz"; + rev = "75dfbc660a5a28161c57f115adf74c8a926bfc4d"; + sha256 = "0plx4rs39zbs4gjk77h4a2q11zpy75fh9v8hnxrvsf8fnakajhwg"; +}; +in buildLisp.library { + name = "chipz"; + deps = [ (buildLisp.bundled "asdf") ]; + + srcs = map (f: src + ("/" + f)) [ + "chipz.asd" + "package.lisp" + "constants.lisp" + "conditions.lisp" + "dstate.lisp" + "types-and-tables.lisp" + "crc32.lisp" + "adler32.lisp" + "inflate-state.lisp" + "gzip.lisp" + "zlib.lisp" + "inflate.lisp" + "bzip2.lisp" + "decompress.lisp" + "stream.lisp" + ]; +} diff --git a/third_party/lisp/chunga.nix b/third_party/lisp/chunga.nix new file mode 100644 index 0000000000..f787981887 --- /dev/null +++ b/third_party/lisp/chunga.nix @@ -0,0 +1,27 @@ +# Portable chunked streams for Common Lisp +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "edicl"; + repo = "chunga"; + rev = "16330852d01dfde4dd97dee7cd985a88ea571e7e"; + sha256 = "0jzn3nyb3f22gm983rfk99smqs3mhb9ivjmasvhq9qla5cl9pyhd"; +}; +in depot.nix.buildLisp.library { + name = "chunga"; + deps = with depot.third_party.lisp; [ + trivial-gray-streams + ]; + + srcs = map (f: src + ("/" + f)) [ + "packages.lisp" + "specials.lisp" + "util.lisp" + "known-words.lisp" + "conditions.lisp" + "read.lisp" + "streams.lisp" + "input.lisp" + "output.lisp" + ]; +} diff --git a/third_party/lisp/cl-ansi-text.nix b/third_party/lisp/cl-ansi-text.nix new file mode 100644 index 0000000000..5c01e02326 --- /dev/null +++ b/third_party/lisp/cl-ansi-text.nix @@ -0,0 +1,19 @@ +# Enables ANSI colors for printing. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/pnathan/cl-ansi-text.git"; + rev = "257a5f19a2dc92d22f8fd772c0a78923b99b36a8"; +}; +in depot.nix.buildLisp.library { + name = "cl-ansi-text"; + deps = with depot.third_party.lisp; [ + alexandria + cl-colors2 + ]; + + srcs = map (f: src + ("/src/" + f)) [ + "cl-ansi-text.lisp" + "define-colors.lisp" + ]; +} diff --git a/third_party/lisp/cl-base64.nix b/third_party/lisp/cl-base64.nix new file mode 100644 index 0000000000..1152601a81 --- /dev/null +++ b/third_party/lisp/cl-base64.nix @@ -0,0 +1,17 @@ +# Base64 encoding for Common Lisp +{ depot, ... }: + +let src = builtins.fetchGit { + url = "http://git.kpe.io/cl-base64.git"; + rev = "fc62a5342445d4ec1dd44e95f7dc513473a8c89a"; +}; +in depot.nix.buildLisp.library { + name = "cl-base64"; + srcs = [ + (src + "/package.lisp") + (src + "/encode.lisp") + (src + "/decode.lisp") + ]; +} + + diff --git a/third_party/lisp/cl-colors2.nix b/third_party/lisp/cl-colors2.nix new file mode 100644 index 0000000000..c90b8eae01 --- /dev/null +++ b/third_party/lisp/cl-colors2.nix @@ -0,0 +1,21 @@ + +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://notabug.org/cage/cl-colors2.git"; + rev = "795aedee593b095fecde574bd999b520dd03ed24"; +}; +in depot.nix.buildLisp.library { + name = "cl-colors2"; + deps = with depot.third_party.lisp; [ + alexandria + cl-ppcre + ]; + + srcs = map (f: src + ("/" + f)) [ + "package.lisp" + "colors.lisp" + "colornames.lisp" + "hexcolors.lisp" + ]; +} diff --git a/third_party/lisp/cl-fad.nix b/third_party/lisp/cl-fad.nix new file mode 100644 index 0000000000..8131bf31be --- /dev/null +++ b/third_party/lisp/cl-fad.nix @@ -0,0 +1,27 @@ +# Portable pathname library +{ depot, ...}: + +with depot.nix; + +let src = depot.third_party.fetchFromGitHub { + owner = "edicl"; + repo = "cl-fad"; + rev = "c13d81c4bd9ba3a172631fd05dd213ab90e7d4cb"; + sha256 = "1gc8i82v6gks7g0lnm54r4prk2mklidv2flm5fvbr0a7rsys0vpa"; +}; +in buildLisp.library { + name = "cl-fad"; + + deps = with depot.third_party.lisp; [ + alexandria + bordeaux-threads + (buildLisp.bundled "sb-posix") + ]; + + srcs = map (f: src + ("/" + f)) [ + "packages.lisp" + "fad.lisp" + "path.lisp" + "temporary-files.lisp" + ]; +} diff --git a/third_party/lisp/cl-json.nix b/third_party/lisp/cl-json.nix new file mode 100644 index 0000000000..3652bd0793 --- /dev/null +++ b/third_party/lisp/cl-json.nix @@ -0,0 +1,26 @@ +# JSON encoder & decoder +{ depot, ... }: + +with depot.nix; +let src = depot.third_party.fetchFromGitHub { + owner = "hankhero"; + repo = "cl-json"; + rev = "6dfebb9540bfc3cc33582d0c03c9ec27cb913e79"; + sha256 = "0fx3m3x3s5ji950yzpazz4s0img3l6b3d6l3jrfjv0lr702496lh"; +}; +in buildLisp.library { + name = "cl-json"; + deps = [ (buildLisp.bundled "asdf") ]; + + srcs = [ "${src}/cl-json.asd" ] ++ + (map (f: src + ("/src/" + f)) [ + "package.lisp" + "common.lisp" + "objects.lisp" + "camel-case.lisp" + "decoder.lisp" + "encoder.lisp" + "utils.lisp" + "json-rpc.lisp" + ]); +} diff --git a/third_party/lisp/cl-plus-ssl.nix b/third_party/lisp/cl-plus-ssl.nix new file mode 100644 index 0000000000..63c21aa6ba --- /dev/null +++ b/third_party/lisp/cl-plus-ssl.nix @@ -0,0 +1,40 @@ +# Common Lisp bindings to OpenSSL +{ depot, ... }: + +with depot.nix; + +let src = builtins.fetchGit { + url = "https://github.com/cl-plus-ssl/cl-plus-ssl.git"; + rev = "29081992f6d7b4e3aa2c5eeece4cd92b745071f4"; +}; +in buildLisp.library { + name = "cl-plus-ssl"; + deps = with depot.third_party.lisp; [ + alexandria + bordeaux-threads + cffi + flexi-streams + trivial-features + trivial-garbage + trivial-gray-streams + (buildLisp.bundled "uiop") + (buildLisp.bundled "sb-posix") + ]; + + native = [ depot.third_party.openssl ]; + + srcs = map (f: src + ("/src/" + f)) [ + "package.lisp" + "reload.lisp" + "conditions.lisp" + "ffi.lisp" + "x509.lisp" + "ffi-buffer-all.lisp" + "ffi-buffer.lisp" + "streams.lisp" + "bio.lisp" + "random.lisp" + "context.lisp" + "verify-hostname.lisp" + ]; +} diff --git a/third_party/lisp/cl-ppcre.nix b/third_party/lisp/cl-ppcre.nix new file mode 100644 index 0000000000..1dc9eb5531 --- /dev/null +++ b/third_party/lisp/cl-ppcre.nix @@ -0,0 +1,30 @@ +# cl-ppcre is a Common Lisp regular expression library. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/edicl/cl-ppcre"; + rev = "1ca0cd9ca0d161acd49c463d6cb5fff897596e2f"; +}; +in depot.nix.buildLisp.library { + name = "cl-ppcre"; + + srcs = map (f: src + ("/" + f)) [ + "packages.lisp" + "specials.lisp" + "util.lisp" + "errors.lisp" + "charset.lisp" + "charmap.lisp" + "chartest.lisp" + "lexer.lisp" + "parser.lisp" + "regex-class.lisp" + "regex-class-util.lisp" + "convert.lisp" + "optimize.lisp" + "closures.lisp" + "repetition-closures.lisp" + "scanner.lisp" + "api.lisp" + ]; +} diff --git a/third_party/lisp/cl-prevalence.nix b/third_party/lisp/cl-prevalence.nix new file mode 100644 index 0000000000..c024db0924 --- /dev/null +++ b/third_party/lisp/cl-prevalence.nix @@ -0,0 +1,29 @@ +# cl-prevalence is an implementation of object prevalence for CL (i.e. +# an in-memory database) +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "40ants"; + repo = "cl-prevalence"; + rev = "da3ed6c4594b1c2fca90c178c1993973c4bf16c9"; + sha256 = "0bq905hv1626dl6b7s0zn4lbdh608g1pxaljl1fda6pwp9hmj95a"; +}; +in depot.nix.buildLisp.library { + name = "cl-prevalence"; + + deps = with depot.third_party.lisp; [ + s-xml + s-sysdeps + ]; + + srcs = map (f: src + ("/src/" + f)) [ + "package.lisp" + "serialization/serialization.lisp" + "serialization/xml.lisp" + "serialization/sexp.lisp" + "prevalence.lisp" + "managed-prevalence.lisp" + "master-slave.lisp" + "blob.lisp" + ]; +} diff --git a/third_party/lisp/closer-mop.nix b/third_party/lisp/closer-mop.nix new file mode 100644 index 0000000000..ab7e33e59b --- /dev/null +++ b/third_party/lisp/closer-mop.nix @@ -0,0 +1,20 @@ +# Closer to MOP is a compatibility layer that rectifies many of the +# absent or incorrect CLOS MOP features across a broad range of Common +# Lisp implementations +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "pcostanza"; + repo = "closer-mop"; + rev = "e1d1430524086709a7ea8e0eede6849aa29d6276"; + sha256 = "1zda6927379pmrsxpg29jnj6azjpa2pms9h7n1iwhy6q9d3w06rf"; +}; +in depot.nix.buildLisp.library { + name = "closer-mop"; + + srcs = [ + "${src}/closer-mop-packages.lisp" + "${src}/closer-mop-shared.lisp" + "${src}/closer-sbcl.lisp" + ]; +} diff --git a/third_party/lisp/drakma.nix b/third_party/lisp/drakma.nix new file mode 100644 index 0000000000..8b8b9f1c90 --- /dev/null +++ b/third_party/lisp/drakma.nix @@ -0,0 +1,37 @@ +# Drakma is an HTTP client for Common Lisp. +{ depot, ... }: + +with depot.nix; + +let src = depot.third_party.fetchFromGitHub { + owner = "edicl"; + repo = "drakma"; + rev = "87feb02bef00b11a753d5fb21a5fec526b0d0bbb"; + sha256 = "01b80am2vrw94xmdj7f21qm7p5ys08mmpzv4nc4icql81hqr1w2m"; +}; +in buildLisp.library { + name = "drakma"; + deps = with depot.third_party.lisp; [ + chipz + chunga + cl-base64 + cl-plus-ssl + cl-ppcre + flexi-streams + puri + usocket + (buildLisp.bundled "asdf") + ]; + + srcs = map (f: src + ("/" + f)) [ + "drakma.asd" # Required because the system definition is used + "packages.lisp" + "specials.lisp" + "conditions.lisp" + "util.lisp" + "read.lisp" + "cookies.lisp" + "encoding.lisp" + "request.lisp" + ]; +} diff --git a/third_party/lisp/fiveam/.boring b/third_party/lisp/fiveam/.boring new file mode 100644 index 0000000000..662944f765 --- /dev/null +++ b/third_party/lisp/fiveam/.boring @@ -0,0 +1,14 @@ +# Boring file regexps: +\# +~$ +(^|/)_darcs($|/) +\.dfsl$ +\.ppcf$ +\.fasl$ +\.x86f$ +\.fas$ +\.lib$ +^docs/html($|/) +^docs/pdf($|/) +^\{arch\}$ +(^|/).arch-ids($|/) diff --git a/third_party/lisp/fiveam/.travis.yml b/third_party/lisp/fiveam/.travis.yml new file mode 100644 index 0000000000..6f6559189f --- /dev/null +++ b/third_party/lisp/fiveam/.travis.yml @@ -0,0 +1,47 @@ +dist: bionic +language: lisp + +env: + matrix: + - LISP=abcl + - LISP=allegro + - LISP=ccl + - LISP=ccl32 + - LISP=ecl + - LISP=sbcl + - LISP=sbcl32 + - LISP=cmucl + +matrix: + allow_failures: + - env: LISP=allegro + - env: LISP=ccl32 + - env: LISP=cmucl + - env: LISP=sbcl32 + +notifications: + email: + on_success: change + on_failure: always + irc: + channels: + - "chat.freenode.net#iolib" + on_success: change + on_failure: always + use_notice: true + skip_join: true + +install: + - curl -L https://raw.githubusercontent.com/sionescu/cl-travis/master/install.sh | sh + - cl -e "(cl:in-package :cl-user) + (dolist (p '(:alexandria)) + (ql:quickload p :verbose t))" + +script: + - cl -e "(cl:in-package :cl-user) + (ql:quickload :fiveam/test :verbose t) + (uiop:quit (if (some (lambda (x) (typep x '5am::test-failure)) + (5am:run :it.bese.fiveam)) + 1 0))" + +sudo: required diff --git a/third_party/lisp/fiveam/COPYING b/third_party/lisp/fiveam/COPYING new file mode 100644 index 0000000000..91adf85a5a --- /dev/null +++ b/third_party/lisp/fiveam/COPYING @@ -0,0 +1,30 @@ +Copyright (c) 2003-2006, Edward Marco Baringer +All rights reserved. + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are +met: + +- Redistributions of source code must retain the above copyright +notice, this list of conditions and the following disclaimer. + +- Redistributions in binary form must reproduce the above copyright +notice, this list of conditions and the following disclaimer in the +documentation and/or other materials provided with the distribution. + +- Neither the name of Edward Marco Baringer, nor BESE, nor the names +of its contributors may be used to endorse or promote products derived +from this software without specific prior written permission. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. + diff --git a/third_party/lisp/fiveam/README b/third_party/lisp/fiveam/README new file mode 100644 index 0000000000..32a205fa5f --- /dev/null +++ b/third_party/lisp/fiveam/README @@ -0,0 +1,8 @@ +This is FiveAM, a common lisp testing framework. + +The documentation can be found in the docstrings, start with the +package :it.bese.fiveam (nicknamed 5AM). + +The mailing list for FiveAM is fiveam-devel@common-lisp.net + +All the code is Copyright (C) 2002-2006 Edward Marco Baringer. diff --git a/third_party/lisp/fiveam/default.nix b/third_party/lisp/fiveam/default.nix new file mode 100644 index 0000000000..4236b93bc9 --- /dev/null +++ b/third_party/lisp/fiveam/default.nix @@ -0,0 +1,28 @@ +# FiveAM is a Common Lisp testing framework. +# +# Imported from https://github.com/sionescu/fiveam.git + +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "fiveam"; + + deps = with depot.third_party.lisp; [ + alexandria + asdf-flv + trivial-backtrace + ]; + + srcs = [ + ./src/package.lisp + ./src/utils.lisp + ./src/check.lisp + ./src/fixture.lisp + ./src/classes.lisp + ./src/random.lisp + ./src/test.lisp + ./src/explain.lisp + ./src/suite.lisp + ./src/run.lisp + ]; +} diff --git a/third_party/lisp/fiveam/docs/make-qbook.lisp b/third_party/lisp/fiveam/docs/make-qbook.lisp new file mode 100644 index 0000000000..8144c94f02 --- /dev/null +++ b/third_party/lisp/fiveam/docs/make-qbook.lisp @@ -0,0 +1,13 @@ +(asdf:oos 'asdf:load-op :FiveAM) +(asdf:oos 'asdf:load-op :qbook) + +(asdf:oos 'qbook:publish-op :FiveAM + :generator (make-instance 'qbook:html-generator + :title "FiveAM" + :output-directory + (merge-pathnames + (make-pathname :directory '(:relative "docs" "html")) + (asdf:component-pathname (asdf:find-system :FiveAM))))) + + + diff --git a/third_party/lisp/fiveam/fiveam.asd b/third_party/lisp/fiveam/fiveam.asd new file mode 100644 index 0000000000..7607e33372 --- /dev/null +++ b/third_party/lisp/fiveam/fiveam.asd @@ -0,0 +1,36 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +#.(unless (or #+asdf3.1 (version<= "3.1" (asdf-version))) + (error "You need ASDF >= 3.1 to load this system correctly.")) + +(defsystem :fiveam + :author "Edward Marco Baringer <mb@bese.it>" + :version (:read-file-form "version.sexp") + :description "A simple regression testing framework" + :license "BSD" + :depends-on (:alexandria :net.didierverna.asdf-flv :trivial-backtrace) + :pathname "src/" + :components ((:file "package") + (:file "utils" :depends-on ("package")) + (:file "check" :depends-on ("package" "utils")) + (:file "fixture" :depends-on ("package")) + (:file "classes" :depends-on ("package")) + (:file "random" :depends-on ("package" "check")) + (:file "test" :depends-on ("package" "fixture" "classes")) + (:file "explain" :depends-on ("package" "utils" "check" "classes" "random")) + (:file "suite" :depends-on ("package" "test" "classes")) + (:file "run" :depends-on ("package" "check" "classes" "test" "explain" "suite"))) + :in-order-to ((test-op (test-op :fiveam/test)))) + +(defsystem :fiveam/test + :author "Edward Marco Baringer <mb@bese.it>" + :description "FiveAM's own test suite" + :license "BSD" + :depends-on (:fiveam) + :pathname "t/" + :components ((:file "tests")) + :perform (test-op (o c) (symbol-call :5am :run! :it.bese.fiveam))) + +;;;;@include "src/package.lisp" + +;;;;@include "t/example.lisp" diff --git a/third_party/lisp/fiveam/src/check.lisp b/third_party/lisp/fiveam/src/check.lisp new file mode 100644 index 0000000000..b3808c5cf0 --- /dev/null +++ b/third_party/lisp/fiveam/src/check.lisp @@ -0,0 +1,311 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +;;;; * Checks + +;;;; At the lowest level testing the system requires that certain +;;;; forms be evaluated and that certain post conditions are met: the +;;;; value returned must satisfy a certain predicate, the form must +;;;; (or must not) signal a certain condition, etc. In FiveAM these +;;;; low level operations are called 'checks' and are defined using +;;;; the various checking macros. + +;;;; Checks are the basic operators for collecting results. Tests and +;;;; test suites on the other hand allow grouping multiple checks into +;;;; logic collections. + +(defvar *test-dribble* t) + +(defmacro with-*test-dribble* (stream &body body) + `(let ((*test-dribble* ,stream)) + (declare (special *test-dribble*)) + ,@body)) + +(eval-when (:compile-toplevel :load-toplevel :execute) + (def-special-environment run-state () + result-list + current-test)) + +;;;; ** Types of test results + +;;;; Every check produces a result object. + +(defclass test-result () + ((reason :accessor reason :initarg :reason :initform "no reason given") + (test-case :accessor test-case :initarg :test-case) + (test-expr :accessor test-expr :initarg :test-expr)) + (:documentation "All checking macros will generate an object of + type TEST-RESULT.")) + +(defclass test-passed (test-result) + () + (:documentation "Class for successful checks.")) + +(defgeneric test-passed-p (object) + (:method ((o t)) nil) + (:method ((o test-passed)) t)) + +(define-condition check-failure (error) + ((reason :accessor reason :initarg :reason :initform "no reason given") + (test-case :accessor test-case :initarg :test-case) + (test-expr :accessor test-expr :initarg :test-expr)) + (:documentation "Signaled when a check fails.") + (:report (lambda (c stream) + (format stream "The following check failed: ~S~%~A." + (test-expr c) + (reason c))))) + +(defun process-failure (test-expr &optional reason-format &rest format-args) + (let ((reason (and reason-format + (apply #'format nil reason-format format-args)))) + (with-simple-restart (ignore-failure "Continue the test run.") + (error 'check-failure :test-expr test-expr + :reason reason)) + (add-result 'test-failure :test-expr test-expr + :reason reason))) + +(defclass test-failure (test-result) + () + (:documentation "Class for unsuccessful checks.")) + +(defgeneric test-failure-p (object) + (:method ((o t)) nil) + (:method ((o test-failure)) t)) + +(defclass unexpected-test-failure (test-failure) + ((actual-condition :accessor actual-condition :initarg :condition)) + (:documentation "Represents the result of a test which neither +passed nor failed, but signaled an error we couldn't deal +with. + +Note: This is very different than a SIGNALS check which instead +creates a TEST-PASSED or TEST-FAILURE object.")) + +(defclass test-skipped (test-result) + () + (:documentation "A test which was not run. Usually this is due to +unsatisfied dependencies, but users can decide to skip the test when +appropriate.")) + +(defgeneric test-skipped-p (object) + (:method ((o t)) nil) + (:method ((o test-skipped)) t)) + +(defun add-result (result-type &rest make-instance-args) + "Create a TEST-RESULT object of type RESULT-TYPE passing it the + initialize args MAKE-INSTANCE-ARGS and add the resulting + object to the list of test results." + (with-run-state (result-list current-test) + (let ((result (apply #'make-instance result-type + (append make-instance-args (list :test-case current-test))))) + (etypecase result + (test-passed (format *test-dribble* ".")) + (unexpected-test-failure (format *test-dribble* "X")) + (test-failure (format *test-dribble* "f")) + (test-skipped (format *test-dribble* "s"))) + (push result result-list)))) + +;;;; ** The check operators + +;;;; *** The IS check + +(defmacro is (test &rest reason-args) + "The DWIM checking operator. + +If TEST returns a true value a test-passed result is generated, +otherwise a test-failure result is generated. The reason, unless +REASON-ARGS is provided, is generated based on the form of TEST: + + (predicate expected actual) - Means that we want to check + whether, according to PREDICATE, the ACTUAL value is + in fact what we EXPECTED. + + (predicate value) - Means that we want to ensure that VALUE + satisfies PREDICATE. + + Wrapping the TEST form in a NOT simply produces a negated reason + string." + (assert (listp test) + (test) + "Argument to IS must be a list, not ~S" test) + (let (bindings effective-test default-reason-args) + (with-gensyms (e a v) + (flet ((process-entry (predicate expected actual &optional negatedp) + ;; make sure EXPECTED is holding the entry that starts with 'values + (when (and (consp actual) + (eq (car actual) 'values)) + (assert (not (and (consp expected) + (eq (car expected) 'values))) () + "Both the expected and actual part is a values expression.") + (rotatef expected actual)) + (let ((setf-forms)) + (if (and (consp expected) + (eq (car expected) 'values)) + (progn + (setf expected (copy-list expected)) + (setf setf-forms (loop for cell = (rest expected) then (cdr cell) + for i from 0 + while cell + when (eq (car cell) '*) + collect `(setf (elt ,a ,i) nil) + and do (setf (car cell) nil))) + (setf bindings (list (list e `(list ,@(rest expected))) + (list a `(multiple-value-list ,actual))))) + (setf bindings (list (list e expected) + (list a actual)))) + (setf effective-test `(progn + ,@setf-forms + ,(if negatedp + `(not (,predicate ,e ,a)) + `(,predicate ,e ,a))))))) + (list-match-case test + ((not (?predicate ?expected ?actual)) + (process-entry ?predicate ?expected ?actual t) + (setf default-reason-args + (list "~2&~S~2% evaluated to ~2&~S~2% which is ~2&~S~2%to ~2&~S~2% (it should not be)" + `',?actual a `',?predicate e))) + ((not (?satisfies ?value)) + (setf bindings (list (list v ?value)) + effective-test `(not (,?satisfies ,v)) + default-reason-args + (list "~2&~S~2% evaluated to ~2&~S~2% which satisfies ~2&~S~2% (it should not)" + `',?value v `',?satisfies))) + ((?predicate ?expected ?actual) + (process-entry ?predicate ?expected ?actual) + (setf default-reason-args + (list "~2&~S~2% evaluated to ~2&~S~2% which is not ~2&~S~2% to ~2&~S~2%." + `',?actual a `',?predicate e))) + ((?satisfies ?value) + (setf bindings (list (list v ?value)) + effective-test `(,?satisfies ,v) + default-reason-args + (list "~2&~S~2% evaluated to ~2&~S~2% which does not satisfy ~2&~S~2%" + `',?value v `',?satisfies))) + (?_ + (setf bindings '() + effective-test test + default-reason-args (list "~2&~S~2% was NIL." `',test))))) + `(let ,bindings + (if ,effective-test + (add-result 'test-passed :test-expr ',test) + (process-failure ',test + ,@(or reason-args default-reason-args))))))) + +;;;; *** Other checks + +(defmacro skip (&rest reason) + "Generates a TEST-SKIPPED result." + `(progn + (format *test-dribble* "s") + (add-result 'test-skipped :reason (format nil ,@reason)))) + +(defmacro is-every (predicate &body clauses) + "The input is either a list of lists, or a list of pairs. Generates (is (,predicate ,expr ,value)) + for each pair of elements or (is (,predicate ,expr ,value) ,@reason) for each list." + `(progn + ,@(if (every #'consp clauses) + (loop for (expected actual . reason) in clauses + collect `(is (,predicate ,expected ,actual) ,@reason)) + (progn + (assert (evenp (list-length clauses))) + (loop for (expr value) on clauses by #'cddr + collect `(is (,predicate ,expr ,value))))))) + +(defmacro is-true (condition &rest reason-args) + "Like IS this check generates a pass if CONDITION returns true + and a failure if CONDITION returns false. Unlike IS this check + does not inspect CONDITION to determine how to report the + failure." + `(if ,condition + (add-result 'test-passed :test-expr ',condition) + (process-failure ',condition + ,@(or reason-args + `("~S did not return a true value" ',condition))))) + +(defmacro is-false (condition &rest reason-args) + "Generates a pass if CONDITION returns false, generates a + failure otherwise. Like IS-TRUE, and unlike IS, IS-FALSE does + not inspect CONDITION to determine what reason to give it case + of test failure" + (with-gensyms (value) + `(let ((,value ,condition)) + (if ,value + (process-failure ',condition + ,@(or reason-args + `("~S returned the value ~S, which is true" ',condition ,value))) + (add-result 'test-passed :test-expr ',condition))))) + +(defmacro signals (condition-spec + &body body) + "Generates a pass if BODY signals a condition of type +CONDITION. BODY is evaluated in a block named NIL, CONDITION is +not evaluated." + (let ((block-name (gensym))) + (destructuring-bind (condition &optional reason-control reason-args) + (ensure-list condition-spec) + `(block ,block-name + (handler-bind ((,condition (lambda (c) + (declare (ignore c)) + ;; ok, body threw condition + (add-result 'test-passed + :test-expr ',condition) + (return-from ,block-name t)))) + (block nil + ,@body)) + (process-failure + ',condition + ,@(if reason-control + `(,reason-control ,@reason-args) + `("Failed to signal a ~S" ',condition))) + (return-from ,block-name nil))))) + +(defmacro finishes (&body body) + "Generates a pass if BODY executes to normal completion. In +other words if body does signal, return-from or throw this test +fails." + `(unwind-protect-case () (progn ,@body) + (:normal (add-result 'test-passed :test-expr ',body)) + (:abort (process-failure ',body "Test didn't finish")))) + +(defmacro pass (&rest message-args) + "Simply generate a PASS." + `(add-result 'test-passed + :test-expr ',message-args + ,@(when message-args + `(:reason (format nil ,@message-args))))) + +(defmacro fail (&rest message-args) + "Simply generate a FAIL." + `(process-failure ',message-args + ,@message-args)) + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE diff --git a/third_party/lisp/fiveam/src/classes.lisp b/third_party/lisp/fiveam/src/classes.lisp new file mode 100644 index 0000000000..fc4dc782e8 --- /dev/null +++ b/third_party/lisp/fiveam/src/classes.lisp @@ -0,0 +1,128 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +(defclass testable-object () + ((name :initarg :name :accessor name + :documentation "A symbol naming this test object.") + (description :initarg :description :accessor description :initform nil + :documentation "The textual description of this test object.") + (depends-on :initarg :depends-on :accessor depends-on :initform nil + :documentation "The list of AND, OR, NOT forms specifying when to run this test.") + (status :initarg :status :accessor status :initform :unknown + :documentation "A symbol specifying the current status + of this test. Either: T - this test (and all its + dependencies, have passed. NIL - this test + failed (either it failed or its dependecies weren't + met. :circular this test has a circular dependency + and was skipped. Or :depends-not-satisfied or :resolving") + (profiling-info :accessor profiling-info + :initform nil + :documentation "An object representing how + much time and memory where used by the + test.") + (collect-profiling-info :accessor collect-profiling-info + :initarg :collect-profiling-info + :initform nil + :documentation "When T profiling + information will be collected when the + test is run."))) + +(defmethod print-object ((test testable-object) stream) + (print-unreadable-object (test stream :type t :identity t) + (format stream "~S" (name test)))) + +(defclass test-suite (testable-object) + ((tests :accessor tests :initform (make-hash-table :test 'eql) + :documentation "The hash table mapping names to test + objects in this suite. The values in this hash table + can be either test-cases or other test-suites.")) + (:documentation "A test suite is a collection of tests or test suites. + +Test suites serve to organize tests into groups so that the +developer can chose to run some tests and not just one or +all. Like tests test suites have a name and a description. + +Test suites, like tests, can be part of other test suites, this +allows the developer to create a hierarchy of tests where sub +trees can be singularly run. + +Running a test suite has the effect of running every test (or +suite) in the suite.")) + +(defclass test-case (testable-object) + ((test-lambda :initarg :test-lambda :accessor test-lambda + :documentation "The function to run.") + (runtime-package :initarg :runtime-package :accessor runtime-package + :documentation "By default it stores *package* from the time this test was defined (macroexpanded).")) + (:documentation "A test case is a single, named, collection of +checks. + +A test case is the smallest organizational element which can be +run individually. Every test case has a name, which is a symbol, +a description and a test lambda. The test lambda is a regular +funcall'able function which should use the various checking +macros to collect results. + +Every test case is part of a suite, when a suite is not +explicitly specified (either via the :SUITE parameter to the TEST +macro or the global variable *SUITE*) the test is inserted into +the global suite named NIL. + +Sometimes we want to run a certain test only if another test has +passed. FiveAM allows us to specify the ways in which one test is +dependent on another. + +- AND Run this test only if all the named tests passed. + +- OR Run this test if at least one of the named tests passed. + +- NOT Run this test only if another test has failed. + +FiveAM considers a test to have passed if all the checks executed +were successful, otherwise we consider the test a failure. + +When a test is not run due to it's dependencies having failed a +test-skipped result is added to the results.")) + +(defclass explainer () + ()) + +(defclass text-explainer (explainer) + ()) + +(defclass simple-text-explainer (text-explainer) + ()) + +(defclass detailed-text-explainer (text-explainer) + ()) + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE diff --git a/third_party/lisp/fiveam/src/explain.lisp b/third_party/lisp/fiveam/src/explain.lisp new file mode 100644 index 0000000000..015cdf4552 --- /dev/null +++ b/third_party/lisp/fiveam/src/explain.lisp @@ -0,0 +1,133 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +;;;; * Analyzing the results + +(defparameter *verbose-failures* nil + "T if we should print the expression failing, NIL otherwise.") + +;;;; Just as important as defining and runnig the tests is +;;;; understanding the results. FiveAM provides the function EXPLAIN +;;;; which prints a human readable summary (number passed, number +;;;; failed, what failed and why, etc.) of a list of test results. + +(defgeneric explain (explainer results &optional stream recursive-depth) + (:documentation "Given a list of test results report write to stream detailed + human readable statistics regarding the results.")) + +(defmethod explain ((exp detailed-text-explainer) results + &optional (stream *test-dribble*) (recursive-depth 0)) + (multiple-value-bind (num-checks passed num-passed passed% + skipped num-skipped skipped% + failed num-failed failed% + unknown num-unknown unknown%) + (partition-results results) + (declare (ignore passed)) + (flet ((output (&rest format-args) + (format stream "~&~vT" recursive-depth) + (apply #'format stream format-args))) + + (when (zerop num-checks) + (output "Didn't run anything...huh?") + (return-from explain nil)) + (output "Did ~D check~P.~%" num-checks num-checks) + (output " Pass: ~D (~2D%)~%" num-passed passed%) + (output " Skip: ~D (~2D%)~%" num-skipped skipped%) + (output " Fail: ~D (~2D%)~%" num-failed failed%) + (when unknown + (output " UNKNOWN RESULTS: ~D (~2D)~%" num-unknown unknown%)) + (terpri stream) + (when failed + (output "Failure Details:~%") + (dolist (f (reverse failed)) + (output "--------------------------------~%") + (output "~A ~@{[~A]~}: ~%" + (name (test-case f)) + (description (test-case f))) + (output " ~A.~%" (reason f)) + (when (for-all-test-failed-p f) + (output "Results collected with failure data:~%") + (explain exp (slot-value f 'result-list) + stream (+ 4 recursive-depth))) + (when (and *verbose-failures* (test-expr f)) + (output " ~S~%" (test-expr f))) + (output "--------------------------------~%")) + (terpri stream)) + (when skipped + (output "Skip Details:~%") + (dolist (f skipped) + (output "~A ~@{[~A]~}: ~%" + (name (test-case f)) + (description (test-case f))) + (output " ~A.~%" (reason f))) + (terpri stream))))) + +(defmethod explain ((exp simple-text-explainer) results + &optional (stream *test-dribble*) (recursive-depth 0)) + (multiple-value-bind (num-checks passed num-passed passed% + skipped num-skipped skipped% + failed num-failed failed% + unknown num-unknown unknown%) + (partition-results results) + (declare (ignore passed passed% skipped skipped% failed failed% unknown unknown%)) + (format stream "~&~vTRan ~D checks, ~D passed" recursive-depth num-checks num-passed) + (when (plusp num-skipped) + (format stream ", ~D skipped " num-skipped)) + (format stream " and ~D failed.~%" num-failed) + (when (plusp num-unknown) + (format stream "~vT~D UNKNOWN RESULTS.~%" recursive-depth num-unknown)))) + +(defun partition-results (results-list) + (let ((num-checks (length results-list))) + (destructuring-bind (passed skipped failed unknown) + (partitionx results-list + (lambda (res) + (typep res 'test-passed)) + (lambda (res) + (typep res 'test-skipped)) + (lambda (res) + (typep res 'test-failure)) + t) + (if (zerop num-checks) + (values 0 + nil 0 0 + nil 0 0 + nil 0 0 + nil 0 0) + (values + num-checks + passed (length passed) (floor (* 100 (/ (length passed) num-checks))) + skipped (length skipped) (floor (* 100 (/ (length skipped) num-checks))) + failed (length failed) (floor (* 100 (/ (length failed) num-checks))) + unknown (length unknown) (floor (* 100 (/ (length failed) num-checks)))))))) + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE diff --git a/third_party/lisp/fiveam/src/fixture.lisp b/third_party/lisp/fiveam/src/fixture.lisp new file mode 100644 index 0000000000..26e993304f --- /dev/null +++ b/third_party/lisp/fiveam/src/fixture.lisp @@ -0,0 +1,82 @@ +;; -*- lisp -*- + +(in-package :it.bese.fiveam) + +;;;; ** Fixtures + +;;;; When running tests we often need to setup some kind of context +;;;; (create dummy db connections, simulate an http request, +;;;; etc.). Fixtures provide a way to conviently hide this context +;;;; into a macro and allow the test to focus on testing. + +;;;; NB: A FiveAM fixture is nothing more than a macro. Since the term +;;;; 'fixture' is so common in testing frameworks we've provided a +;;;; wrapper around defmacro for this purpose. + +(defvar *fixture* + (make-hash-table :test 'eql) + "Lookup table mapping fixture names to fixture + objects.") + +(defun get-fixture (key &optional default) + (gethash key *fixture* default)) + +(defun (setf get-fixture) (value key) + (setf (gethash key *fixture*) value)) + +(defun rem-fixture (key) + (remhash key *fixture*)) + +(defmacro def-fixture (name (&rest args) &body body) + "Defines a fixture named NAME. A fixture is very much like a +macro but is used only for simple templating. A fixture created +with DEF-FIXTURE is a macro which can use the special macrolet +&BODY to specify where the body should go. + +See Also: WITH-FIXTURE +" + `(eval-when (:compile-toplevel :load-toplevel :execute) + (setf (get-fixture ',name) (cons ',args ',body)) + ',name)) + +(defmacro with-fixture (fixture-name (&rest args) &body body) + "Insert BODY into the fixture named FIXTURE-NAME. + +See Also: DEF-FIXTURE" + (assert (get-fixture fixture-name) + (fixture-name) + "Unknown fixture ~S." fixture-name) + (destructuring-bind ((&rest largs) &rest lbody) + (get-fixture fixture-name) + `(macrolet ((&body () '(progn ,@body))) + (funcall (lambda (,@largs) ,@lbody) ,@args)))) + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. diff --git a/third_party/lisp/fiveam/src/package.lisp b/third_party/lisp/fiveam/src/package.lisp new file mode 100644 index 0000000000..3279a9a4f7 --- /dev/null +++ b/third_party/lisp/fiveam/src/package.lisp @@ -0,0 +1,139 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +;;;; * Introduction + +;;;; FiveAM is a testing framework. It takes care of all the boring +;;;; bookkeeping associated with managing a test framework allowing +;;;; the developer to focus on writing tests and code. + +;;;; FiveAM was designed with the following premises: + +;;;; - Defining tests should be about writing tests, not +;;;; infrastructure. The developer should be able to focus on what +;;;; they're testing, not the testing framework. + +;;;; - Interactive testing is the norm. Common Lisp is an interactive +;;;; development environment, the testing environment should allow the +;;;; developer to quickly and easily redefine, change, remove and run +;;;; tests. + +(defpackage :it.bese.fiveam + (:use :common-lisp :alexandria) + (:nicknames :5am :fiveam) + #+sb-package-locks + (:lock t) + (:export + ;; creating tests and test-suites + #:make-suite + #:def-suite + #:def-suite* + #:in-suite + #:in-suite* + #:test + #:def-test + #:get-test + #:rem-test + #:test-names + #:*default-test-compilation-time* + ;; fixtures + #:def-fixture + #:with-fixture + #:get-fixture + #:rem-fixture + ;; running checks + #:is + #:is-every + #:is-true + #:is-false + #:signals + #:finishes + #:skip + #:pass + #:fail + #:*test-dribble* + #:for-all + #:*num-trials* + #:*max-trials* + #:gen-integer + #:gen-float + #:gen-character + #:gen-string + #:gen-list + #:gen-tree + #:gen-buffer + #:gen-one-element + ;; running tests + #:run + #:run-all-tests + #:explain + #:explain! + #:run! + #:debug! + #:! + #:!! + #:!!! + #:*run-test-when-defined* + #:*debug-on-error* + #:*debug-on-failure* + #:*on-error* + #:*on-failure* + #:*verbose-failures* + #:*print-names* + #:results-status)) + +;;;; You can use #+5am to put your test-defining code inline with your +;;;; other code - and not require people to have fiveam to run your +;;;; package. + +(pushnew :5am *features*) + +;;;;@include "check.lisp" + +;;;;@include "random.lisp" + +;;;;@include "fixture.lisp" + +;;;;@include "test.lisp" + +;;;;@include "suite.lisp" + +;;;;@include "run.lisp" + +;;;;@include "explain.lisp" + +;;;; * Colophon + +;;;; This documentaion was written by Edward Marco Baringer +;;;; <mb@bese.it> and generated by qbook. + +;;;; ** COPYRIGHT + +;;;; Copyright (c) 2002-2003, Edward Marco Baringer +;;;; All rights reserved. + +;;;; Redistribution and use in source and binary forms, with or without +;;;; modification, are permitted provided that the following conditions are +;;;; met: + +;;;; - Redistributions of source code must retain the above copyright +;;;; notice, this list of conditions and the following disclaimer. + +;;;; - Redistributions in binary form must reproduce the above copyright +;;;; notice, this list of conditions and the following disclaimer in the +;;;; documentation and/or other materials provided with the distribution. + +;;;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;;;; of its contributors may be used to endorse or promote products +;;;; derived from this software without specific prior written permission. + +;;;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;;;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;;;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;;;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;;;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;;;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;;;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;;;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;;;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;;;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;;;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE diff --git a/third_party/lisp/fiveam/src/random.lisp b/third_party/lisp/fiveam/src/random.lisp new file mode 100644 index 0000000000..49e14bc8a8 --- /dev/null +++ b/third_party/lisp/fiveam/src/random.lisp @@ -0,0 +1,265 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +;;;; ** Random (QuickCheck-ish) testing + +;;;; FiveAM provides the ability to automatically generate a +;;;; collection of random input data for a specific test and run a +;;;; test multiple times. + +;;;; Specification testing is done through the FOR-ALL macro. This +;;;; macro will bind variables to random data and run a test body a +;;;; certain number of times. Should the test body ever signal a +;;;; failure we stop running and report what values of the variables +;;;; caused the code to fail. + +;;;; The generation of the random data is done using "generator +;;;; functions" (see below for details). A generator function is a +;;;; function which creates, based on user supplied parameters, a +;;;; function which returns random data. In order to facilitate +;;;; generating good random data the FOR-ALL macro also supports guard +;;;; conditions and creating one random input based on the values of +;;;; another (see the FOR-ALL macro for details). + +;;;; *** Public Interface to the Random Tester + +(defparameter *num-trials* 100 + "Number of times we attempt to run the body of the FOR-ALL test.") + +(defparameter *max-trials* 10000 + "Number of total times we attempt to run the body of the + FOR-ALL test including when the body is skipped due to failed + guard conditions. + +Since we have guard conditions we may get into infinite loops +where the test code is never run due to the guards never +returning true. This second run limit prevents that.") + +(defmacro for-all (bindings &body body) + "Bind BINDINGS to random variables and test BODY *num-trials* times. + +BINDINGS is a list of binding forms, each element is a list +of (BINDING VALUE &optional GUARD). Value, which is evaluated +once when the for-all is evaluated, must return a generator which +be called each time BODY is evaluated. BINDING is either a symbol +or a list which will be passed to destructuring-bind. GUARD is a +form which, if present, stops BODY from executing when IT returns +NIL. The GUARDS are evaluated after all the random data has been +generated and they can refer to the current value of any +binding. NB: Generator forms, unlike guard forms, can not contain +references to the bound variables. + +Examples: + + (for-all ((a (gen-integer))) + (is (integerp a))) + + (for-all ((a (gen-integer) (plusp a))) + (is (integerp a)) + (is (plusp a))) + + (for-all ((less (gen-integer)) + (more (gen-integer) (< less more))) + (is (<= less more))) + + (for-all (((a b) (gen-two-integers))) + (is (integerp a)) + (is (integerp b)))" + (with-gensyms (test-lambda-args) + `(perform-random-testing + (list ,@(mapcar #'second bindings)) + (lambda (,test-lambda-args) + (destructuring-bind ,(mapcar #'first bindings) + ,test-lambda-args + (if (and ,@(delete-if #'null (mapcar #'third bindings))) + (progn ,@body) + (throw 'run-once + (list :guard-conditions-failed)))))))) + +;;;; *** Implementation + +;;;; We could just make FOR-ALL a monster macro, but having FOR-ALL be +;;;; a preproccessor for the perform-random-testing function is +;;;; actually much easier. + +(defun perform-random-testing (generators body) + (loop + with random-state = *random-state* + with total-counter = *max-trials* + with counter = *num-trials* + with run-at-least-once = nil + until (or (zerop total-counter) + (zerop counter)) + do (let ((result (perform-random-testing/run-once generators body))) + (ecase (first result) + (:pass + (decf counter) + (decf total-counter) + (setf run-at-least-once t)) + (:no-tests + (add-result 'for-all-test-no-tests + :reason "No tests" + :random-state random-state) + (return-from perform-random-testing nil)) + (:guard-conditions-failed + (decf total-counter)) + (:fail + (add-result 'for-all-test-failed + :reason "Found failing test data" + :random-state random-state + :failure-values (second result) + :result-list (third result)) + (return-from perform-random-testing nil)))) + finally (if run-at-least-once + (add-result 'for-all-test-passed) + (add-result 'for-all-test-never-run + :reason "Guard conditions never passed")))) + +(defun perform-random-testing/run-once (generators body) + (catch 'run-once + (bind-run-state ((result-list '())) + (let ((values (mapcar #'funcall generators))) + (funcall body values) + (cond + ((null result-list) + (throw 'run-once (list :no-tests))) + ((every #'test-passed-p result-list) + (throw 'run-once (list :pass))) + ((notevery #'test-passed-p result-list) + (throw 'run-once (list :fail values result-list)))))))) + +(defclass for-all-test-result () + ((random-state :initarg :random-state))) + +(defclass for-all-test-passed (test-passed for-all-test-result) + ()) + +(defclass for-all-test-failed (test-failure for-all-test-result) + ((failure-values :initarg :failure-values) + (result-list :initarg :result-list))) + +(defgeneric for-all-test-failed-p (object) + (:method ((object for-all-test-failed)) t) + (:method ((object t)) nil)) + +(defmethod reason ((result for-all-test-failed)) + (format nil "Falsifiable with ~S" (slot-value result 'failure-values))) + +(defclass for-all-test-no-tests (test-failure for-all-test-result) + ()) + +(defclass for-all-test-never-run (test-failure for-all-test-result) + ()) + +;;;; *** Generators + +;;;; Since this is random testing we need some way of creating random +;;;; data to feed to our code. Generators are regular functions which +;;;; create this random data. + +;;;; We provide a set of built-in generators. + +(defun gen-integer (&key (max (1+ most-positive-fixnum)) + (min (1- most-negative-fixnum))) + "Returns a generator which produces random integers greater +than or equal to MIN and less than or equal to MAX." + (lambda () + (+ min (random (1+ (- max min)))))) + +(defun gen-float (&key bound (type 'short-float)) + "Returns a generator which produces floats of type TYPE. BOUND, +if specified, constrains the results to be in the range (-BOUND, +BOUND)." + (lambda () + (let* ((most-negative (ecase type + (short-float most-negative-short-float) + (single-float most-negative-single-float) + (double-float most-negative-double-float) + (long-float most-negative-long-float))) + (most-positive (ecase type + (short-float most-positive-short-float) + (single-float most-positive-single-float) + (double-float most-positive-double-float) + (long-float most-positive-long-float))) + (bound (or bound (max most-positive (- most-negative))))) + (coerce + (ecase (random 2) + (0 ;; generate a positive number + (random (min most-positive bound))) + (1 ;; generate a negative number + (- (random (min (- most-negative) bound))))) + type)))) + +(defun gen-character (&key (code-limit char-code-limit) + (code (gen-integer :min 0 :max (1- code-limit))) + (alphanumericp nil)) + "Returns a generator of characters. + +CODE must be a generator of random integers. ALPHANUMERICP, if +non-NIL, limits the returned chars to those which pass +alphanumericp." + (lambda () + (loop + for count upfrom 0 + for char = (code-char (funcall code)) + until (and char + (or (not alphanumericp) + (alphanumericp char))) + when (= 1000 count) + do (error "After 1000 iterations ~S has still not generated ~:[a valid~;an alphanumeric~] character :(." + code alphanumericp) + finally (return char)))) + +(defun gen-string (&key (length (gen-integer :min 0 :max 80)) + (elements (gen-character)) + (element-type 'character)) + "Returns a generator which produces random strings. LENGTH must +be a generator which produces integers, ELEMENTS must be a +generator which produces characters of type ELEMENT-TYPE." + (lambda () + (loop + with length = (funcall length) + with string = (make-string length :element-type element-type) + for index below length + do (setf (aref string index) (funcall elements)) + finally (return string)))) + +(defun gen-list (&key (length (gen-integer :min 0 :max 10)) + (elements (gen-integer :min -10 :max 10))) + "Returns a generator which produces random lists. LENGTH must be +an integer generator and ELEMENTS must be a generator which +produces objects." + (lambda () + (loop + repeat (funcall length) + collect (funcall elements)))) + +(defun gen-tree (&key (size 20) + (elements (gen-integer :min -10 :max 10))) + "Returns a generator which produces random trees. SIZE controls +the approximate size of the tree, but don't try anything above + 30, you have been warned. ELEMENTS must be a generator which +will produce the elements." + (labels ((rec (&optional (current-depth 0)) + (let ((key (random (+ 3 (- size current-depth))))) + (cond ((> key 2) + (list (rec (+ current-depth 1)) + (rec (+ current-depth 1)))) + (t (funcall elements)))))) + (lambda () + (rec)))) + +(defun gen-buffer (&key (length (gen-integer :min 0 :max 50)) + (element-type '(unsigned-byte 8)) + (elements (gen-integer :min 0 :max (1- (expt 2 8))))) + (lambda () + (let ((buffer (make-array (funcall length) :element-type element-type))) + (map-into buffer elements)))) + +(defun gen-one-element (&rest elements) + (lambda () + (nth (random (length elements)) elements))) + +;;;; The trivial always-produce-the-same-thing generator is done using +;;;; cl:constantly. diff --git a/third_party/lisp/fiveam/src/run.lisp b/third_party/lisp/fiveam/src/run.lisp new file mode 100644 index 0000000000..89c5223515 --- /dev/null +++ b/third_party/lisp/fiveam/src/run.lisp @@ -0,0 +1,385 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +;;;; * Running Tests + +;;;; Once the programmer has defined what the tests are these need to +;;;; be run and the expected effects should be compared with the +;;;; actual effects. FiveAM provides the function RUN for this +;;;; purpose, RUN executes a number of tests and collects the results +;;;; of each individual check into a list which is then +;;;; returned. There are three types of test results: passed, failed +;;;; and skipped, these are represented by TEST-RESULT objects. + +;;;; Generally running a test will return normally, but there are two +;;;; exceptional situations which can occur: + +;;;; - An exception is signaled while running the test. If the +;;;; variable *on-error* is :DEBUG than FiveAM will enter the +;;;; debugger, otherwise a test failure (of type +;;;; unexpected-test-failure) is returned. When entering the +;;;; debugger two restarts are made available, one simply reruns the +;;;; current test and another signals a test-failure and continues +;;;; with the remaining tests. + +;;;; - A circular dependency is detected. An error is signaled and a +;;;; restart is made available which signals a test-skipped and +;;;; continues with the remaining tests. This restart also sets the +;;;; dependency status of the test to nil, so any tests which depend +;;;; on this one (even if the dependency is not circular) will be +;;;; skipped. + +;;;; The functions RUN!, !, !! and !!! are convenient wrappers around +;;;; RUN and EXPLAIN. + +(deftype on-problem-action () + '(member :debug :backtrace nil)) + +(declaim (type on-problem-action *on-error* *on-failure*)) + +(defvar *on-error* nil + "The action to perform on error: +- :DEBUG if we should drop into the debugger +- :BACKTRACE to print a backtrace +- NIL to simply continue") + +(defvar *on-failure* nil + "The action to perform on check failure: +- :DEBUG if we should drop into the debugger +- :BACKTRACE to print a backtrace +- NIL to simply continue") + +(defvar *debug-on-error* nil + "T if we should drop into the debugger on error, NIL otherwise. +OBSOLETE: superseded by *ON-ERROR*") + +(defvar *debug-on-failure* nil + "T if we should drop into the debugger on a failing check, NIL otherwise. +OBSOLETE: superseded by *ON-FAILURE*") + +(defparameter *print-names* t + "T if we should print test running progress, NIL otherwise.") + +(defparameter *test-dribble-indent* (make-array 0 + :element-type 'character + :fill-pointer 0 + :adjustable t) + "Used to indent tests and test suites in their parent suite") + +(defun import-testing-symbols (package-designator) + (import '(5am::is 5am::is-true 5am::is-false 5am::signals 5am::finishes) + package-designator)) + +(defparameter *run-queue* '() + "List of test waiting to be run.") + +(define-condition circular-dependency (error) + ((test-case :initarg :test-case)) + (:report (lambda (cd stream) + (format stream "A circular dependency wes detected in ~S." (slot-value cd 'test-case)))) + (:documentation "Condition signaled when a circular dependency +between test-cases has been detected.")) + +(defgeneric run-resolving-dependencies (test) + (:documentation "Given a dependency spec determine if the spec +is satisfied or not, this will generally involve running other +tests. If the dependency spec can be satisfied the test is also +run.")) + +(defmethod run-resolving-dependencies ((test test-case)) + "Return true if this test, and its dependencies, are satisfied, + NIL otherwise." + (case (status test) + (:unknown + (setf (status test) :resolving) + (if (or (not (depends-on test)) + (eql t (resolve-dependencies (depends-on test)))) + (progn + (run-test-lambda test) + (status test)) + (with-run-state (result-list) + (unless (eql :circular (status test)) + (push (make-instance 'test-skipped + :test-case test + :reason "Dependencies not satisfied") + result-list) + (setf (status test) :depends-not-satisfied))))) + (:resolving + (restart-case + (error 'circular-dependency :test-case test) + (skip () + :report (lambda (s) + (format s "Skip the test ~S and all its dependencies." (name test))) + (with-run-state (result-list) + (push (make-instance 'test-skipped :reason "Circular dependencies" :test-case test) + result-list)) + (setf (status test) :circular)))) + (t (status test)))) + +(defgeneric resolve-dependencies (depends-on)) + +(defmethod resolve-dependencies ((depends-on symbol)) + "A test which depends on a symbol is interpreted as `(AND + ,DEPENDS-ON)." + (run-resolving-dependencies (get-test depends-on))) + +(defmethod resolve-dependencies ((depends-on list)) + "Return true if the dependency spec DEPENDS-ON is satisfied, + nil otherwise." + (if (null depends-on) + t + (flet ((satisfies-depends-p (test) + (funcall test (lambda (dep) + (eql t (resolve-dependencies dep))) + (cdr depends-on)))) + (ecase (car depends-on) + (and (satisfies-depends-p #'every)) + (or (satisfies-depends-p #'some)) + (not (satisfies-depends-p #'notany)) + (:before (every #'(lambda (dep) + (let ((status (status (get-test dep)))) + (if (eql :unknown status) + (run-resolving-dependencies (get-test dep)) + status))) + (cdr depends-on))))))) + +(defun results-status (result-list) + "Given a list of test results (generated while running a test) + return true if no results are of type TEST-FAILURE. Returns second + and third values, which are the set of failed tests and skipped + tests respectively." + (let ((failed-tests + (remove-if-not #'test-failure-p result-list)) + (skipped-tests + (remove-if-not #'test-skipped-p result-list))) + (values (null failed-tests) + failed-tests + skipped-tests))) + +(defun return-result-list (test-lambda) + "Run the test function TEST-LAMBDA and return a list of all + test results generated, does not modify the special environment + variable RESULT-LIST." + (bind-run-state ((result-list '())) + (funcall test-lambda) + result-list)) + +(defgeneric run-test-lambda (test)) + +(defmethod run-test-lambda ((test test-case)) + (with-run-state (result-list) + (bind-run-state ((current-test test)) + (labels ((abort-test (e &optional (reason (format nil "Unexpected Error: ~S~%~A." e e))) + (add-result 'unexpected-test-failure + :test-expr nil + :test-case test + :reason reason + :condition e)) + (run-it () + (let ((result-list '())) + (declare (special result-list)) + (handler-bind ((check-failure (lambda (e) + (declare (ignore e)) + (cond + ((eql *on-failure* :debug) + nil) + (t + (when (eql *on-failure* :backtrace) + (trivial-backtrace:print-backtrace-to-stream + *test-dribble*)) + (invoke-restart + (find-restart 'ignore-failure)))))) + (error (lambda (e) + (unless (or (eql *on-error* :debug) + (typep e 'check-failure)) + (when (eql *on-error* :backtrace) + (trivial-backtrace:print-backtrace-to-stream + *test-dribble*)) + (abort-test e) + (return-from run-it result-list))))) + (restart-case + (handler-case + (let ((*readtable* (copy-readtable)) + (*package* (runtime-package test))) + (when *print-names* + (format *test-dribble* "~%~ARunning test ~A " *test-dribble-indent* (name test))) + (if (collect-profiling-info test) + ;; Timing info doesn't get collected ATM, we need a portable library + ;; (setf (profiling-info test) (collect-timing (test-lambda test))) + (funcall (test-lambda test)) + (funcall (test-lambda test)))) + (storage-condition (e) + ;; heap-exhausted/constrol-stack-exhausted + ;; handler-case unwinds the stack (unlike handler-bind) + (abort-test e (format nil "STORAGE-CONDITION: aborted for safety. ~S~%~A." e e)) + (return-from run-it result-list))) + (retest () + :report (lambda (stream) + (format stream "~@<Rerun the test ~S~@:>" test)) + (return-from run-it (run-it))) + (ignore () + :report (lambda (stream) + (format stream "~@<Signal an exceptional test failure and abort the test ~S.~@:>" test)) + (abort-test (make-instance 'test-failure :test-case test + :reason "Failure restart.")))) + result-list)))) + (let ((results (run-it))) + (setf (status test) (results-status results) + result-list (nconc result-list results))))))) + +(defgeneric %run (test-spec) + (:documentation "Internal method for running a test. Does not + update the status of the tests nor the special variables !, + !!, !!!")) + +(defmethod %run ((test test-case)) + (run-resolving-dependencies test)) + +(defmethod %run ((tests list)) + (mapc #'%run tests)) + +(defmethod %run ((suite test-suite)) + (when *print-names* + (format *test-dribble* "~%~ARunning test suite ~A" *test-dribble-indent* (name suite))) + (let ((suite-results '())) + (flet ((run-tests () + (loop + for test being the hash-values of (tests suite) + do (%run test)))) + (vector-push-extend #\space *test-dribble-indent*) + (unwind-protect + (bind-run-state ((result-list '())) + (unwind-protect + (if (collect-profiling-info suite) + ;; Timing info doesn't get collected ATM, we need a portable library + ;; (setf (profiling-info suite) (collect-timing #'run-tests)) + (run-tests) + (run-tests))) + (setf suite-results result-list + (status suite) (every #'test-passed-p suite-results))) + (vector-pop *test-dribble-indent*) + (with-run-state (result-list) + (setf result-list (nconc result-list suite-results))))))) + +(defmethod %run ((test-name symbol)) + (when-let (test (get-test test-name)) + (%run test))) + +(defvar *initial-!* (lambda () (format t "Haven't run that many tests yet.~%"))) + +(defvar *!* *initial-!*) +(defvar *!!* *initial-!*) +(defvar *!!!* *initial-!*) + +;;;; ** Public entry points + +(defun run! (&optional (test-spec *suite*) + &key ((:print-names *print-names*) *print-names*)) + "Equivalent to (explain! (run TEST-SPEC))." + (explain! (run test-spec))) + +(defun explain! (result-list) + "Explain the results of RESULT-LIST using a +detailed-text-explainer with output going to *test-dribble*. +Return a boolean indicating whether no tests failed." + (explain (make-instance 'detailed-text-explainer) result-list *test-dribble*) + (results-status result-list)) + +(defun debug! (&optional (test-spec *suite*)) + "Calls (run! test-spec) but enters the debugger if any kind of error happens." + (let ((*on-error* :debug) + (*on-failure* :debug)) + (run! test-spec))) + +(defun run (test-spec &key ((:print-names *print-names*) *print-names*)) + "Run the test specified by TEST-SPEC. + +TEST-SPEC can be either a symbol naming a test or test suite, or +a testable-object object. This function changes the operations +performed by the !, !! and !!! functions." + (psetf *!* (lambda () + (loop :for test :being :the :hash-keys :of *test* + :do (setf (status (get-test test)) :unknown)) + (bind-run-state ((result-list '())) + (with-simple-restart (explain "Ignore the rest of the tests and explain current results") + (%run test-spec)) + result-list)) + *!!* *!* + *!!!* *!!*) + (let ((*on-error* + (or *on-error* (cond + (*debug-on-error* + (format *test-dribble* "*DEBUG-ON-ERROR* is obsolete. Use *ON-ERROR*.") + :debug) + (t nil)))) + (*on-failure* + (or *on-failure* (cond + (*debug-on-failure* + (format *test-dribble* "*DEBUG-ON-FAILURE* is obsolete. Use *ON-FAILURE*.") + :debug) + (t nil))))) + (funcall *!*))) + +(defun ! () + "Rerun the most recently run test and explain the results." + (explain! (funcall *!*))) + +(defun !! () + "Rerun the second most recently run test and explain the results." + (explain! (funcall *!!*))) + +(defun !!! () + "Rerun the third most recently run test and explain the results." + (explain! (funcall *!!!*))) + +(defun run-all-tests (&key (summary :end)) + "Runs all defined test suites, T if all tests passed and NIL otherwise. +SUMMARY can be :END to print a summary at the end, :SUITE to print it +after each suite or NIL to skip explanations." + (check-type summary (member nil :suite :end)) + (loop :for suite :in (cons 'nil (sort (copy-list *toplevel-suites*) #'string<=)) + :for results := (if (suite-emptyp suite) nil (run suite)) + :when (consp results) + :collect results :into all-results + :do (cond + ((not (eql summary :suite)) + nil) + (results + (explain! results)) + (suite + (format *test-dribble* "Suite ~A is empty~%" suite))) + :finally (progn + (when (eql summary :end) + (explain! (alexandria:flatten all-results))) + (return (every #'results-status all-results))))) + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. diff --git a/third_party/lisp/fiveam/src/style.css b/third_party/lisp/fiveam/src/style.css new file mode 100644 index 0000000000..4a1e6010dc --- /dev/null +++ b/third_party/lisp/fiveam/src/style.css @@ -0,0 +1,64 @@ +body { + background-color: #FFFFFF; + color: #000000; + padding: 0px; margin: 0px; +} + +.qbook { width: 600px; background-color: #FFFFFF; margin: 0px; + border-left: 3em solid #660000; padding: 3px; } + +h1 { text-align: center; margin: 0px; + color: #333333; + border-bottom: 0.3em solid #660000; +} + +p { padding-left: 1em; } + +h2 { border-bottom: 0.2em solid #000000; font-family: verdana; } + +h3 { border-bottom: 0.1em solid #000000; } + +pre.code { + background-color: #eeeeee; + border: solid 1px #d0d0d0; + overflow: auto; +} + +pre.code * .paren { color: #666666; } + +pre.code a:active { color: #000000; } +pre.code a:link { color: #000000; } +pre.code a:visited { color: #000000; } + +pre.code .first-line { font-weight: bold; } + +div.contents { font-family: verdana; } + +div.contents a:active { color: #000000; } +div.contents a:link { color: #000000; } +div.contents a:visited { color: #000000; } + +div.contents div.contents-heading-1 { padding-left: 0.5em; font-weight: bold; } +div.contents div.contents-heading-1 a:active { color: #660000; } +div.contents div.contents-heading-1 a:link { color: #660000; } +div.contents div.contents-heading-1 a:visited { color: #660000; } + +div.contents div.contents-heading-2 { padding-left: 1.0em; } +div.contents div.contents-heading-2 a:active { color: #660000; } +div.contents div.contents-heading-2 a:link { color: #660000; } +div.contents div.contents-heading-2 a:visited { color: #660000; } + +div.contents div.contents-heading-3 { padding-left: 1.5em; } +div.contents div.contents-heading-3 a:active { color: #660000; } +div.contents div.contents-heading-3 a:link { color: #660000; } +div.contents div.contents-heading-3 a:visited { color: #660000; } + +div.contents div.contents-heading-4 { padding-left: 2em; } +div.contents div.contents-heading-4 a:active { color: #660000; } +div.contents div.contents-heading-4 a:link { color: #660000; } +div.contents div.contents-heading-4 a:visited { color: #660000; } + +div.contents div.contents-heading-5 { padding-left: 2.5em; } +div.contents div.contents-heading-5 a:active { color: #660000; } +div.contents div.contents-heading-5 a:link { color: #660000; } +div.contents div.contents-heading-5 a:visited { color: #660000; } diff --git a/third_party/lisp/fiveam/src/suite.lisp b/third_party/lisp/fiveam/src/suite.lisp new file mode 100644 index 0000000000..8497a9d12d --- /dev/null +++ b/third_party/lisp/fiveam/src/suite.lisp @@ -0,0 +1,140 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +;;;; * Test Suites + +;;;; Test suites allow us to collect multiple tests into a single +;;;; object and run them all using asingle name. Test suites do not +;;;; affect the way test are run nor the way the results are handled, +;;;; they are simply a test organizing group. + +;;;; Test suites can contain both tests and other test suites. Running +;;;; a test suite causes all of its tests and test suites to be +;;;; run. Suites do not affect test dependencies, running a test suite +;;;; can cause tests which are not in the suite to be run. + +;;;; ** Current Suite + +(defvar *suite* nil + "The current test suite object") +(net.didierverna.asdf-flv:set-file-local-variable *suite*) + +;;;; ** Creating Suits + +;; Suites that have no parent suites. +(defvar *toplevel-suites* nil) + +(defgeneric suite-emptyp (suite) + (:method ((suite symbol)) + (suite-emptyp (get-test suite))) + (:method ((suite test-suite)) + (= 0 (hash-table-count (tests suite))))) + +(defmacro def-suite (name &key description in) + "Define a new test-suite named NAME. + +IN (a symbol), if provided, causes this suite te be nested in the +suite named by IN. NB: This macro is built on top of make-suite, +as such it, like make-suite, will overrwrite any existing suite +named NAME." + `(eval-when (:compile-toplevel :load-toplevel :execute) + (make-suite ',name + ,@(when description `(:description ,description)) + ,@(when in `(:in ',in))) + ',name)) + +(defmacro def-suite* (name &rest def-suite-args) + `(progn + (def-suite ,name ,@def-suite-args) + (in-suite ,name))) + +(defun make-suite (name &key description ((:in parent-suite))) + "Create a new test suite object. + +Overrides any existing suite named NAME." + (let ((suite (make-instance 'test-suite :name name))) + (when description + (setf (description suite) description)) + (when (and name + (null (name *suite*)) + (null parent-suite)) + (pushnew name *toplevel-suites*)) + (loop for i in (ensure-list parent-suite) + for in-suite = (get-test i) + do (progn + (when (null in-suite) + (cerror "Create a new suite named ~A." "Unknown suite ~A." i) + (setf (get-test in-suite) (make-suite i) + in-suite (get-test in-suite))) + (setf (gethash name (tests in-suite)) suite))) + (setf (get-test name) suite) + suite)) + +(eval-when (:load-toplevel :execute) + (setf *suite* + (setf (get-test 'nil) + (make-suite 'nil :description "Global Suite")))) + +(defun list-all-suites () + "Returns an unordered LIST of all suites." + (hash-table-values *suite*)) + +;;;; ** Managing the Current Suite + +(defmacro in-suite (suite-name) + "Set the *suite* special variable so that all tests defined +after the execution of this form are, unless specified otherwise, +in the test-suite named SUITE-NAME. + +See also: DEF-SUITE *SUITE*" + `(eval-when (:compile-toplevel :load-toplevel :execute) + (%in-suite ,suite-name))) + +(defmacro in-suite* (suite-name &key in) + "Just like in-suite, but silently creates missing suites." + `(eval-when (:compile-toplevel :load-toplevel :execute) + (%in-suite ,suite-name :in ,in :fail-on-error nil))) + +(defmacro %in-suite (suite-name &key (fail-on-error t) in) + (with-gensyms (suite) + `(progn + (if-let (,suite (get-test ',suite-name)) + (setf *suite* ,suite) + (progn + (when ,fail-on-error + (cerror "Create a new suite named ~A." + "Unknown suite ~A." ',suite-name)) + (setf (get-test ',suite-name) (make-suite ',suite-name :in ',in) + *suite* (get-test ',suite-name)))) + ',suite-name))) + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE diff --git a/third_party/lisp/fiveam/src/test.lisp b/third_party/lisp/fiveam/src/test.lisp new file mode 100644 index 0000000000..4a6f2fee9a --- /dev/null +++ b/third_party/lisp/fiveam/src/test.lisp @@ -0,0 +1,167 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +;;;; * Tests + +;;;; While executing checks and collecting the results is the core job +;;;; of a testing framework it is also important to be able to +;;;; organize checks into groups, fiveam provides two mechanisms for +;;;; organizing checks: tests and test suites. A test is a named +;;;; collection of checks which can be run and a test suite is a named +;;;; collection of tests and test suites. + +(declaim (special *suite*)) + +(defvar *test* + (make-hash-table :test 'eql) + "Lookup table mapping test (and test suite) + names to objects.") + +(defun get-test (key &optional default) + (gethash key *test* default)) + +(defun (setf get-test) (value key) + (setf (gethash key *test*) value)) + +(defun rem-test (key) + (remhash key *test*)) + +(defun test-names () + (hash-table-keys *test*)) + +(defmacro test (name &body body) + "Create a test named NAME. If NAME is a list it must be of the +form: + + (name &key depends-on suite fixture compile-at profile) + +NAME is the symbol which names the test. + +DEPENDS-ON is a list of the form: + + (AND . test-names) - This test is run only if all of the tests + in TEST-NAMES have passed, otherwise a single test-skipped + result is generated. + + (OR . test-names) - If any of TEST-NAMES has passed this test is + run, otherwise a test-skipped result is generated. + + (NOT test-name) - This is test is run only if TEST-NAME failed. + +AND, OR and NOT can be combined to produce complex dependencies. + +If DEPENDS-ON is a symbol it is interpreted as `(AND +,depends-on), this is accomadate the common case of one test +depending on another. + +FIXTURE specifies a fixture to wrap the body in. + +If PROFILE is T profiling information will be collected as well." + (destructuring-bind (name &rest args) + (ensure-list name) + `(def-test ,name (,@args) ,@body))) + +(defvar *default-test-compilation-time* :definition-time) + +(defmacro def-test (name (&key depends-on (suite '*suite* suite-p) fixture + (compile-at *default-test-compilation-time*) profile) + &body body) + "Create a test named NAME. + +NAME is the symbol which names the test. + +DEPENDS-ON is a list of the form: + + (AND . test-names) - This test is run only if all of the tests + in TEST-NAMES have passed, otherwise a single test-skipped + result is generated. + + (OR . test-names) - If any of TEST-NAMES has passed this test is + run, otherwise a test-skipped result is generated. + + (NOT test-name) - This is test is run only if TEST-NAME failed. + +AND, OR and NOT can be combined to produce complex dependencies. + +If DEPENDS-ON is a symbol it is interpreted as `(AND +,depends-on), this is accomadate the common case of one test +depending on another. + +FIXTURE specifies a fixture to wrap the body in. + +If PROFILE is T profiling information will be collected as well." + (check-type compile-at (member :run-time :definition-time)) + (multiple-value-bind (forms decls docstring) + (parse-body body :documentation t :whole name) + (let* ((description (or docstring "")) + (body-forms (append decls forms)) + (suite-form (if suite-p + `(get-test ',suite) + (or suite '*suite*))) + (effective-body (if fixture + (destructuring-bind (name &rest args) + (ensure-list fixture) + `((with-fixture ,name ,args ,@body-forms))) + body-forms))) + `(progn + (register-test ',name ,description ',effective-body ,suite-form ',depends-on ,compile-at ,profile) + (when *run-test-when-defined* + (run! ',name)) + ',name)))) + +(defun register-test (name description body suite depends-on compile-at profile) + (let ((lambda-name + (format-symbol t "%~A-~A" '#:test name)) + (inner-lambda-name + (format-symbol t "%~A-~A" '#:inner-test name))) + (setf (get-test name) + (make-instance 'test-case + :name name + :runtime-package (find-package (package-name *package*)) + :test-lambda + (eval + `(named-lambda ,lambda-name () + ,@(ecase compile-at + (:run-time `((funcall + (let ((*package* (find-package ',(package-name *package*)))) + (compile ',inner-lambda-name + '(lambda () ,@body)))))) + (:definition-time body)))) + :description description + :depends-on depends-on + :collect-profiling-info profile)) + (setf (gethash name (tests suite)) name))) + +(defvar *run-test-when-defined* nil + "When non-NIL tests are run as soon as they are defined.") + +;; Copyright (c) 2002-2003, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. diff --git a/third_party/lisp/fiveam/src/utils.lisp b/third_party/lisp/fiveam/src/utils.lisp new file mode 100644 index 0000000000..49d552fa00 --- /dev/null +++ b/third_party/lisp/fiveam/src/utils.lisp @@ -0,0 +1,226 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +(defmacro dolist* ((iterator list &optional return-value) &body body) + "Like DOLIST but destructuring-binds the elements of LIST. + +If ITERATOR is a symbol then dolist* is just like dolist EXCEPT +that it creates a fresh binding." + (if (listp iterator) + (let ((i (gensym "DOLIST*-I-"))) + `(dolist (,i ,list ,return-value) + (destructuring-bind ,iterator ,i + ,@body))) + `(dolist (,iterator ,list ,return-value) + (let ((,iterator ,iterator)) + ,@body)))) + +(defun make-collector (&optional initial-value) + "Create a collector function. + +A Collector function will collect, into a list, all the values +passed to it in the order in which they were passed. If the +callector function is called without arguments it returns the +current list of values." + (let ((value initial-value) + (cdr (last initial-value))) + (lambda (&rest items) + (if items + (progn + (if value + (if cdr + (setf (cdr cdr) items + cdr (last items)) + (setf cdr (last items))) + (setf value items + cdr (last items))) + items) + value)))) + +(defun partitionx (list &rest lambdas) + (let ((collectors (mapcar (lambda (l) + (cons (if (and (symbolp l) + (member l (list :otherwise t) + :test #'string=)) + (constantly t) + l) + (make-collector))) + lambdas))) + (dolist (item list) + (block item + (dolist* ((test-func . collector-func) collectors) + (when (funcall test-func item) + (funcall collector-func item) + (return-from item))))) + (mapcar #'funcall (mapcar #'cdr collectors)))) + +;;;; ** Anaphoric conditionals + +(defmacro if-bind (var test &body then/else) + "Anaphoric IF control structure. + +VAR (a symbol) will be bound to the primary value of TEST. If +TEST returns a true value then THEN will be executed, otherwise +ELSE will be executed." + (assert (first then/else) + (then/else) + "IF-BIND missing THEN clause.") + (destructuring-bind (then &optional else) + then/else + `(let ((,var ,test)) + (if ,var ,then ,else)))) + +(defmacro aif (test then &optional else) + "Just like IF-BIND but the var is always IT." + `(if-bind it ,test ,then ,else)) + +;;;; ** Simple list matching based on code from Paul Graham's On Lisp. + +(defmacro acond2 (&rest clauses) + (if (null clauses) + nil + (with-gensyms (val foundp) + (destructuring-bind ((test &rest progn) &rest others) + clauses + `(multiple-value-bind (,val ,foundp) + ,test + (if (or ,val ,foundp) + (let ((it ,val)) + (declare (ignorable it)) + ,@progn) + (acond2 ,@others))))))) + +(defun varsymp (x) + (and (symbolp x) + (let ((name (symbol-name x))) + (and (>= (length name) 2) + (char= (char name 0) #\?))))) + +(defun binding (x binds) + (labels ((recbind (x binds) + (aif (assoc x binds) + (or (recbind (cdr it) binds) + it)))) + (let ((b (recbind x binds))) + (values (cdr b) b)))) + +(defun list-match (x y &optional binds) + (acond2 + ((or (eql x y) (eql x '_) (eql y '_)) + (values binds t)) + ((binding x binds) (list-match it y binds)) + ((binding y binds) (list-match x it binds)) + ((varsymp x) (values (cons (cons x y) binds) t)) + ((varsymp y) (values (cons (cons y x) binds) t)) + ((and (consp x) (consp y) (list-match (car x) (car y) binds)) + (list-match (cdr x) (cdr y) it)) + (t (values nil nil)))) + +(defun vars (match-spec) + (let ((vars nil)) + (labels ((find-vars (spec) + (cond + ((null spec) nil) + ((varsymp spec) (push spec vars)) + ((consp spec) + (find-vars (car spec)) + (find-vars (cdr spec)))))) + (find-vars match-spec)) + (delete-duplicates vars))) + +(defmacro list-match-case (target &body clauses) + (if clauses + (destructuring-bind ((test &rest progn) &rest others) + clauses + (with-gensyms (tgt binds success) + `(let ((,tgt ,target)) + (multiple-value-bind (,binds ,success) + (list-match ,tgt ',test) + (declare (ignorable ,binds)) + (if ,success + (let ,(mapcar (lambda (var) + `(,var (cdr (assoc ',var ,binds)))) + (vars test)) + (declare (ignorable ,@(vars test))) + ,@progn) + (list-match-case ,tgt ,@others)))))) + nil)) + +;;;; * def-special-environment + +(defun check-required (name vars required) + (dolist (var required) + (assert (member var vars) + (var) + "Unrecognized symbol ~S in ~S." var name))) + +(defmacro def-special-environment (name (&key accessor binder binder*) + &rest vars) + "Define two macros for dealing with groups or related special variables. + +ACCESSOR is defined as a macro: (defmacro ACCESSOR (VARS &rest +BODY)). Each element of VARS will be bound to the +current (dynamic) value of the special variable. + +BINDER is defined as a macro for introducing (and binding new) +special variables. It is basically a readable LET form with the +prorpe declarations appended to the body. The first argument to +BINDER must be a form suitable as the first argument to LET. + +ACCESSOR defaults to a new symbol in the same package as NAME +which is the concatenation of \"WITH-\" NAME. BINDER is built as +\"BIND-\" and BINDER* is BINDER \"*\"." + (unless accessor + (setf accessor (format-symbol (symbol-package name) "~A-~A" '#:with name))) + (unless binder + (setf binder (format-symbol (symbol-package name) "~A-~A" '#:bind name))) + (unless binder* + (setf binder* (format-symbol (symbol-package binder) "~A~A" binder '#:*))) + `(eval-when (:compile-toplevel :load-toplevel :execute) + (flet () + (defmacro ,binder (requested-vars &body body) + (check-required ',name ',vars (mapcar #'car requested-vars)) + `(let ,requested-vars + (declare (special ,@(mapcar #'car requested-vars))) + ,@body)) + (defmacro ,binder* (requested-vars &body body) + (check-required ',name ',vars (mapcar #'car requested-vars)) + `(let* ,requested-vars + (declare (special ,@(mapcar #'car requested-vars))) + ,@body)) + (defmacro ,accessor (requested-vars &body body) + (check-required ',name ',vars requested-vars) + `(locally (declare (special ,@requested-vars)) + ,@body)) + ',name))) + +;; Copyright (c) 2002-2006, Edward Marco Baringer +;; All rights reserved. +;; +;; Redistribution and use in source and binary forms, with or without +;; modification, are permitted provided that the following conditions are +;; met: +;; +;; - Redistributions of source code must retain the above copyright +;; notice, this list of conditions and the following disclaimer. +;; +;; - Redistributions in binary form must reproduce the above copyright +;; notice, this list of conditions and the following disclaimer in the +;; documentation and/or other materials provided with the distribution. +;; +;; - Neither the name of Edward Marco Baringer, nor BESE, nor the names +;; of its contributors may be used to endorse or promote products +;; derived from this software without specific prior written permission. +;; +;; THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS +;; "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT +;; LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR +;; A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT +;; OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, +;; SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT +;; LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, +;; DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY +;; THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +;; (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE +;; OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE diff --git a/third_party/lisp/fiveam/t/example.lisp b/third_party/lisp/fiveam/t/example.lisp new file mode 100644 index 0000000000..c949511a28 --- /dev/null +++ b/third_party/lisp/fiveam/t/example.lisp @@ -0,0 +1,126 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +;;;; * FiveAM Example (poor man's tutorial) + +(asdf:oos 'asdf:load-op :fiveam) + +(defpackage :it.bese.fiveam.example + (:use :common-lisp + :it.bese.fiveam)) + +(in-package :it.bese.fiveam.example) + +;;;; First we need some functions to test. + +(defun add-2 (n) + (+ n 2)) + +(defun add-4 (n) + (+ n 4)) + +;;;; Now we need to create a test which makes sure that add-2 and add-4 +;;;; work as specified. + +;;;; we create a test named ADD-2 and supply a short description. +(test add-2 + "Test the ADD-2 function" ;; a short description + ;; the checks + (is (= 2 (add-2 0))) + (is (= 0 (add-2 -2)))) + +;;;; we can already run add-2. This will return the list of test +;;;; results, it should be a list of two test-passed objects. + +(run 'add-2) + +;;;; since we'd like to have some kind of readbale output we'll explain +;;;; the results + +(explain! (run 'add-2)) + +;;;; or we could do both at once: + +(run! 'add-2) + +;;;; So now we've defined and run a single test. Since we plan on +;;;; having more than one test and we'd like to run them together let's +;;;; create a simple test suite. + +(def-suite example-suite :description "The example test suite.") + +;;;; we could explictly specify that every test we create is in the the +;;;; example-suite suite, but it's easier to just change the default +;;;; suite: + +(in-suite example-suite) + +;;;; now we'll create a new test for the add-4 function. + +(test add-4 + (is (= 0 (add-4 -4)))) + +;;;; now let's run the test + +(run! 'add-4) + +;;;; we can get the same effect by running the suite: + +(run! 'example-suite) + +;;;; since we'd like both add-2 and add-4 to be in the same suite, let's +;;;; redefine add-2 to be in this suite: + +(test add-2 "Test the ADD-2 function" + (is (= 2 (add-2 0))) + (is (= 0 (add-2 -2)))) + +;;;; now we can run the suite and we'll see that both add-2 and add-4 +;;;; have been run (we know this since we no get 4 checks as opposed to +;;;; 2 as before. + +(run! 'example-suite) + +;;;; Just for fun let's see what happens when a test fails. Again we'll +;;;; redefine add-2, but add in a third, failing, check: + +(test add-2 "Test the ADD-2 function" + (is (= 2 (add-2 0))) + (is (= 0 (add-2 -2))) + (is (= 0 (add-2 0)))) + +;;;; Finally let's try out the specification based testing. + +(defun dummy-add (a b) + (+ a b)) + +(defun dummy-strcat (a b) + (concatenate 'string a b)) + +(test dummy-add + (for-all ((a (gen-integer)) + (b (gen-integer))) + ;; assuming we have an "oracle" to compare our function results to + ;; we can use it: + (is (= (+ a b) (dummy-add a b))) + ;; if we don't have an oracle (as in most cases) we just ensure + ;; that certain properties hold: + (is (= (dummy-add a b) + (dummy-add b a))) + (is (= a (dummy-add a 0))) + (is (= 0 (dummy-add a (- a)))) + (is (< a (dummy-add a 1))) + (is (= (* 2 a) (dummy-add a a))))) + +(test dummy-strcat + (for-all ((result (gen-string)) + (split-point (gen-integer :min 0 :max 10000) + (< split-point (length result)))) + (is (string= result (dummy-strcat (subseq result 0 split-point) + (subseq result split-point)))))) + +(test random-failure + (for-all ((result (gen-integer :min 0 :max 1))) + (is (plusp result)) + (is (= result 0)))) + +(run! 'example-suite) diff --git a/third_party/lisp/fiveam/t/tests.lisp b/third_party/lisp/fiveam/t/tests.lisp new file mode 100644 index 0000000000..ed1c565e7d --- /dev/null +++ b/third_party/lisp/fiveam/t/tests.lisp @@ -0,0 +1,280 @@ +;;;; -*- Mode: Lisp; indent-tabs-mode: nil -*- + +(in-package :it.bese.fiveam) + +(in-suite* :it.bese.fiveam) + +(def-suite test-suite :description "Suite for tests which should fail.") + +(defmacro with-test-results ((results test-name) &body body) + `(let ((,results (with-*test-dribble* nil (run ',test-name)))) + ,@body)) + +(def-fixture null-fixture () + `(progn ,@(&body))) + +;;;; Test the checks + +(def-test is1 (:suite test-suite) + (is (plusp 1)) + (is (< 0 1)) + (is (not (plusp -1))) + (is (not (< 1 0))) + (is-true t) + (is-false nil)) + +(def-test is2 (:suite test-suite :fixture null-fixture) + (is (plusp 0)) + (is (< 0 -1)) + (is (not (plusp 1))) + (is (not (< 0 1))) + (is-true nil) + (is-false t)) + +(def-test is (:profile t) + (with-test-results (results is1) + (is (= 6 (length results))) + (is (every #'test-passed-p results))) + (with-test-results (results is2) + (is (= 6 (length results))) + (is (every #'test-failure-p results)))) + +(def-test signals/finishes () + (signals error + (error "an error")) + (finishes + (signals error + (error "an error")))) + +(def-test pass () + (pass)) + +(def-test fail1 (:suite test-suite) + (fail "This is supposed to fail")) + +(def-test fail () + (with-test-results (results fail1) + (is (= 1 (length results))) + (is (test-failure-p (first results))))) + +;;;; non top level checks + +(def-test foo-bar () + (let ((state 0)) + (is (= 0 state)) + (is (= 1 (incf state))))) + +;;;; Test dependencies + +(def-test ok (:suite test-suite) + (pass)) + +(def-test not-ok (:suite test-suite) + (fail "This is supposed to fail.")) + +(def-test and1 (:depends-on (and ok not-ok) :suite test-suite) + (fail)) + +(def-test and2 (:depends-on (and ok) :suite test-suite) + (pass)) + +(def-test dep-and () + (with-test-results (results and1) + (is (= 3 (length results))) + ;; we should have one skippedw one failed and one passed + (is (some #'test-passed-p results)) + (is (some #'test-skipped-p results)) + (is (some #'test-failure-p results))) + (with-test-results (results and2) + (is (= 2 (length results))) + (is (every #'test-passed-p results)))) + +(def-test or1 (:depends-on (or ok not-ok) :suite test-suite) + (pass)) + +(def-test or2 (:depends-on (or not-ok ok) :suite test-suite) + (pass)) + +(def-test dep-or () + (with-test-results (results or1) + (is (= 2 (length results))) + (is (every #'test-passed-p results))) + (with-test-results (results or2) + (is (= 3 (length results))) + (is (= 2 (length (remove-if-not #'test-passed-p results)))))) + +(def-test not1 (:depends-on (not not-ok) :suite test-suite) + (pass)) + +(def-test not2 (:depends-on (not ok) :suite test-suite) + (fail)) + +(def-test not () + (with-test-results (results not1) + (is (= 2 (length results))) + (is (some #'test-passed-p results)) + (is (some #'test-failure-p results))) + (with-test-results (results not2) + (is (= 2 (length results))) + (is (some #'test-passed-p results)) + (is (some #'test-skipped-p results)))) + +(def-test nested-logic (:depends-on (and ok (not not-ok) (not not-ok)) + :suite test-suite) + (pass)) + +(def-test dep-nested () + (with-test-results (results nested-logic) + (is (= 3 (length results))) + (is (= 2 (length (remove-if-not #'test-passed-p results)))) + (is (= 1 (length (remove-if-not #'test-failure-p results)))))) + +(def-test circular-0 (:depends-on (and circular-1 circular-2 or1) + :suite test-suite) + (fail "we depend on a circular dependency, we should not be tested.")) + +(def-test circular-1 (:depends-on (and circular-2) + :suite test-suite) + (fail "we have a circular depednency, we should not be tested.")) + +(def-test circular-2 (:depends-on (and circular-1) + :suite test-suite) + (fail "we have a circular depednency, we should not be tested.")) + +(def-test circular () + (signals circular-dependency + (run 'circular-0)) + (signals circular-dependency + (run 'circular-1)) + (signals circular-dependency + (run 'circular-2))) + + +(defun stack-exhaust () + (declare (optimize (debug 3) (speed 0) (space 0) (safety 3))) + (cons 42 (stack-exhaust))) + +;; Disable until we determine on which implementations it's actually safe +;; to exhaust the stack. +#| +(def-test stack-exhaust (:suite test-suite) + (stack-exhaust)) + +(def-test test-stack-exhaust () + (with-test-results (results stack-exhaust) + (is (= 1 (length results))) + (is (test-failure-p (first results))))) +|# + +(def-suite before-test-suite :description "Suite for before test") + +(def-test before-0 (:suite before-test-suite) + (fail)) + +(def-test before-1 (:depends-on (:before before-0) + :suite before-test-suite) + (pass)) + +(def-suite before-test-suite-2 :description "Suite for before test") + +(def-test before-2 (:depends-on (:before before-3) + :suite before-test-suite-2) + (pass)) + +(def-test before-3 (:suite before-test-suite-2) + (pass)) + +(def-test before () + (with-test-results (results before-test-suite) + (is (some #'test-skipped-p results))) + + (with-test-results (results before-test-suite-2) + (is (every #'test-passed-p results)))) + + +;;;; dependencies with symbol +(def-test dep-with-symbol-first (:suite test-suite) + (pass)) + +(def-test dep-with-symbol-dependencies-not-met (:depends-on (not dep-with-symbol-first) + :suite test-suite) + (fail "Error in the test of the test, this should not ever happen")) + +(def-test dep-with-symbol-depends-on-ok (:depends-on dep-with-symbol-first :suite test-suite) + (pass)) + +(def-test dep-with-symbol-depends-on-failed-dependency (:depends-on dep-with-symbol-dependencies-not-met + :suite test-suite) + (fail "No, I should not be tested because I depend on a test that in its turn has a failed dependecy.")) + +(def-test dependencies-with-symbol () + (with-test-results (results dep-with-symbol-first) + (is (some #'test-passed-p results))) + + (with-test-results (results dep-with-symbol-depends-on-ok) + (is (some #'test-passed-p results))) + + (with-test-results (results dep-with-symbol-dependencies-not-met) + (is (some #'test-skipped-p results))) + + ;; No failure here, because it means the test was run. + (with-test-results (results dep-with-symbol-depends-on-failed-dependency) + (is (not (some #'test-failure-p results))))) + + +;;;; test for-all + +(def-test gen-integer () + (for-all ((a (gen-integer))) + (is (integerp a)))) + +(def-test for-all-guarded () + (for-all ((less (gen-integer)) + (more (gen-integer) (< less more))) + (is (< less more)))) + +(def-test gen-float () + (macrolet ((test-gen-float (type) + `(for-all ((unbounded (gen-float :type ',type)) + (bounded (gen-float :type ',type :bound 42))) + (is (typep unbounded ',type)) + (is (typep bounded ',type)) + (is (<= (abs bounded) 42))))) + (test-gen-float single-float) + (test-gen-float short-float) + (test-gen-float double-float) + (test-gen-float long-float))) + +(def-test gen-character () + (for-all ((c (gen-character))) + (is (characterp c))) + (for-all ((c (gen-character :code (gen-integer :min 32 :max 40)))) + (is (characterp c)) + (member c (list #\Space #\! #\" #\# #\$ #\% #\& #\' #\()))) + +(def-test gen-string () + (for-all ((s (gen-string))) + (is (stringp s))) + (for-all ((s (gen-string :length (gen-integer :min 0 :max 2)))) + (is (<= (length s) 2))) + (for-all ((s (gen-string :elements (gen-character :code (gen-integer :min 0 :max 0)) + :length (constantly 2)))) + (is (= 2 (length s))) + (is (every (curry #'char= #\Null) s)))) + +(defun dummy-mv-generator () + (lambda () + (list 1 1))) + +(def-test for-all-destructuring-bind () + (for-all (((a b) (dummy-mv-generator))) + (is (= 1 a)) + (is (= 1 b)))) + +(def-test return-values () + "Return values indicate test failures." + (is-true (with-*test-dribble* nil (explain! (run 'is1)))) + (is-true (with-*test-dribble* nil (run! 'is1))) + + (is-false (with-*test-dribble* nil (explain! (run 'is2)))) + (is-false (with-*test-dribble* nil (run! 'is2)))) diff --git a/third_party/lisp/fiveam/version.sexp b/third_party/lisp/fiveam/version.sexp new file mode 100644 index 0000000000..e0e0284e67 --- /dev/null +++ b/third_party/lisp/fiveam/version.sexp @@ -0,0 +1,2 @@ +;; -*- lisp -*- +"1.4.1" diff --git a/third_party/lisp/flexi-streams.nix b/third_party/lisp/flexi-streams.nix new file mode 100644 index 0000000000..8cdf062f1c --- /dev/null +++ b/third_party/lisp/flexi-streams.nix @@ -0,0 +1,34 @@ +# Flexible bivalent streams for Common Lisp +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/edicl/flexi-streams.git"; + rev = "0fd872ae32022e834ef861a67d86879cf33a6b64"; +}; +in depot.nix.buildLisp.library { + name = "flexi-streams"; + deps = [ depot.third_party.lisp.trivial-gray-streams ]; + + srcs = map (f: src + ("/" + f)) [ + "packages.lisp" + "mapping.lisp" + "ascii.lisp" + "koi8-r.lisp" + "iso-8859.lisp" + "code-pages.lisp" + "specials.lisp" + "util.lisp" + "conditions.lisp" + "external-format.lisp" + "length.lisp" + "encode.lisp" + "decode.lisp" + "in-memory.lisp" + "stream.lisp" + "output.lisp" + "input.lisp" + "io.lisp" + "strings.lisp" + ]; +} + diff --git a/third_party/lisp/hunchentoot.nix b/third_party/lisp/hunchentoot.nix new file mode 100644 index 0000000000..9977405c65 --- /dev/null +++ b/third_party/lisp/hunchentoot.nix @@ -0,0 +1,61 @@ +# Hunchentoot is a web framework for Common Lisp. +{ depot, ...}: + +let + src = depot.third_party.fetchFromGitHub { + owner = "edicl"; + repo = "hunchentoot"; + rev = "585b45b6b873f2da421fdf456b61860ab5868207"; + sha256 = "13nazwix067mdclq9vgjhsi2vpr57a8dz51dd5d3h99ccsq4mik5"; + }; + url-rewrite = depot.nix.buildLisp.library { + name = "url-rewrite"; + + srcs = map (f: src + ("/url-rewrite/" + f)) [ + "packages.lisp" + "specials.lisp" + "primitives.lisp" + "util.lisp" + "url-rewrite.lisp" + ]; + }; +in depot.nix.buildLisp.library { + name = "hunchentoot"; + + deps = with depot.third_party.lisp; [ + alexandria + bordeaux-threads + chunga + cl-base64 + cl-fad + rfc2388 + cl-plus-ssl + cl-ppcre + flexi-streams + md5 + trivial-backtrace + usocket + url-rewrite + ]; + + srcs = map (f: src + ("/" + f)) [ + "hunchentoot.asd" + "packages.lisp" + "compat.lisp" + "specials.lisp" + "conditions.lisp" + "mime-types.lisp" + "util.lisp" + "log.lisp" + "cookie.lisp" + "reply.lisp" + "request.lisp" + "session.lisp" + "misc.lisp" + "headers.lisp" + "set-timeouts.lisp" + "taskmaster.lisp" + "acceptor.lisp" + "easy-handlers.lisp" + ]; +} diff --git a/third_party/lisp/iterate.nix b/third_party/lisp/iterate.nix new file mode 100644 index 0000000000..2e6873885f --- /dev/null +++ b/third_party/lisp/iterate.nix @@ -0,0 +1,15 @@ +# iterate is an iteration construct for Common Lisp, similar to the +# LOOP macro. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://gitlab.common-lisp.net/iterate/iterate.git"; + rev = "a1c47b2b74f6c96149d717be90c07a1b273ced69"; +}; +in depot.nix.buildLisp.library { + name = "iterate"; + srcs = [ + "${src}/package.lisp" + "${src}/iterate.lisp" + ]; +} diff --git a/third_party/lisp/lisp-binary.nix b/third_party/lisp/lisp-binary.nix new file mode 100644 index 0000000000..f2dab565c2 --- /dev/null +++ b/third_party/lisp/lisp-binary.nix @@ -0,0 +1,30 @@ +# A library to easily read and write complex binary formats. +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "j3pic"; + repo = "lisp-binary"; + rev = "1aefc8618b7734f68697ddf59bc93cb8522aa0bf"; + sha256 = "1hflzn3mjp32jz9fxx9wayp3c3x58s77cgjfbs06nrynqkv0c6df"; +}; +in depot.nix.buildLisp.library { + name = "lisp-binary"; + + deps = with depot.third_party.lisp; [ + cffi + quasiquote_2 + moptilities + flexi-streams + closer-mop + ]; + + srcs = map (f: src + ("/" + f)) [ + "utils.lisp" + "integer.lisp" + "float.lisp" + "simple-bit-stream.lisp" + "reverse-stream.lisp" + "binary-1.lisp" + "binary-2.lisp" + ]; +} diff --git a/third_party/lisp/local-time.nix b/third_party/lisp/local-time.nix new file mode 100644 index 0000000000..52e7c257e4 --- /dev/null +++ b/third_party/lisp/local-time.nix @@ -0,0 +1,18 @@ +# Library for manipulating dates & times +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "dlowe-net"; + repo = "local-time"; + rev = "dc54f61415c76ee755a6f69d4154a3a282f2789f"; + sha256 = "1l9v07ghx7g9p2gp003fki4j8bsa1w2gbm40qc41i94mdzikc0ry"; +}; +in depot.nix.buildLisp.library { + name = "local-time"; + deps = [ depot.third_party.lisp.cl-fad ]; + + srcs = [ + "${src}/src/package.lisp" + "${src}/src/local-time.lisp" + ]; +} diff --git a/third_party/lisp/md5.nix b/third_party/lisp/md5.nix new file mode 100644 index 0000000000..3f2ed371de --- /dev/null +++ b/third_party/lisp/md5.nix @@ -0,0 +1,16 @@ +# MD5 hash implementation +{ depot, ... }: + +with depot.nix; + +let src = depot.third_party.fetchFromGitHub { + owner = "pmai"; + repo = "md5"; + rev = "b1412600f60d526ee34a7ba1596ec483da7894ab"; + sha256 = "0lzip6b6xg7gd70xl1xmqp24fvxqj6ywjnz9lmx7988zpj20nhl2"; +}; +in buildLisp.library { + name = "md5"; + deps = [ (buildLisp.bundled "sb-rotate-byte") ]; + srcs = [ (src + "/md5.lisp") ]; +} diff --git a/third_party/lisp/moptilities.nix b/third_party/lisp/moptilities.nix new file mode 100644 index 0000000000..24a7f2c06d --- /dev/null +++ b/third_party/lisp/moptilities.nix @@ -0,0 +1,14 @@ +# Compatibility layer for minor MOP implementation differences +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "gwkkwg"; + repo = "moptilities"; + rev = "a436f16b357c96b82397ec018ea469574c10dd41"; + sha256 = "1q12bqjbj47lx98yim1kfnnhgfhkl80102fkgp9pdqxg0fp6g5fc"; +}; +in depot.nix.buildLisp.library { + name = "moptilities"; + deps = [ depot.third_party.lisp.closer-mop ]; + srcs = [ "${src}/dev/moptilities.lisp" ]; +} diff --git a/third_party/lisp/puri.nix b/third_party/lisp/puri.nix new file mode 100644 index 0000000000..51728c7646 --- /dev/null +++ b/third_party/lisp/puri.nix @@ -0,0 +1,15 @@ +# Portable URI library +{ depot, ... }: + +let src = builtins.fetchGit { + url = "http://git.kpe.io/puri.git"; + rev = "ef5afb9e5286c8e952d4344f019c1a636a717b97"; +}; +in depot.nix.buildLisp.library { + name = "puri"; + srcs = [ + (src + "/src.lisp") + ]; +} + + diff --git a/third_party/lisp/quasiquote_2/README.md b/third_party/lisp/quasiquote_2/README.md new file mode 100644 index 0000000000..2d590a0564 --- /dev/null +++ b/third_party/lisp/quasiquote_2/README.md @@ -0,0 +1,258 @@ +quasiquote-2.0 +============== + +Why should it be hard to write macros that write other macros? +Well, it shouldn't! + +quasiquote-2.0 defines slightly different rules for quasiquotation, +that make writing macro-writing macros very smooth experience. + +NOTE: quasiquote-2.0 does horrible things to shared structure!!! +(it does a lot of COPY-TREE's, so shared-ness is destroyed). +So, it's indeed a tool to construct code (where it does not matter much if the +structure is shared or not) and not the data (or, at least, not the data with shared structure) + + +```lisp +(quasiquote-2.0:enable-quasiquote-2.0) + +(defmacro define-my-macro (name args &body body) + `(defmacro ,name ,args + `(sample-thing-to-expand-to + ,,@body))) ; note the difference from usual way + +(define-my-macro foo (x y) + ,x ; now here injections of quotation constructs work + ,y) + +(define-my-macro bar (&body body) + ,@body) ; splicing is also easy +``` + +The "injections" in macros FOO and BAR work as naively expected, as if I had written +```lisp +(defmacro foo (x y) + `(sample-thing-to-expand-to ,x ,y)) + +(defmacro bar (&body body) + `(sample-thing-to-expand-to ,@body)) + +(macroexpand-1 '(foo a b)) + + '(SAMPLE-THING-TO-EXPAND-TO A B) + +(macroexpand-1 '(bar a b c)) + + '(SAMPLE-THING-TO-EXPAND-TO A B C) +``` + + +So, how is this effect achieved? + + +DIG, INJECT and SPLICE +------------------------- + +The transformations of backquote occur at macroexpansion-time and not at read-time. +It is totally possible not to use any special reader syntax, but just +underlying macros directly! + +At the core is a macro DIG, which expands to the code that generates the +expression according to the rules, which are roughly these: + * each DIG increases "depth" by one (hence the name) + * each INJECT or SPLICE decreases "depth" by one + * if depth is 0, evaluation is turned on + * if depth if not zero (even if it's negative!) evaluation is off + * SPLICE splices the form, similarly to ordinary `,@`, INJECT simply injects, same as `,` + +```lisp +;; The example using macros, without special reader syntax + +(dig ; depth is 1 here + (a b + (dig ; depth is 2 here + ((inject c) ; this inject is not evaluated, because depth is nonzero + (inject (d ;depth becomes 1 here again + (inject e) ; and this inject is evaluated, because depth becomes zero + )) + (inject 2 f) ; this inject with level specification is evaluated, because it + ; decreases depth by 2 + )))) + + +;; the same example using ENABLE-QUASIQUOTE-2.0 syntax is written as +`(a b `(,c ,(d ,e) ,,f)) ; note double comma acts different than usually +``` + + +The ENABLE-QUASIQUOTE-2.0 macro just installs reader that reads +`FORM as (DIG FORM), ,FORM as (INJECT FORM) and ,@FORM as (SPLICE FORM). +You can just as well type DIG's, INJECT's and SPLICE's directly, +(in particular, when writing utility functions that generate macro-generating code) +or roll your own convenient reader syntax (pull requests are welcome). + +So, these two lines (with ENABLE-QUASIQUOTE-2.0) read the same +```lisp +`(a (,b `,,c) d) + +(dig (a ((inject b) (dig (inject 2 c))) d)) +``` + +You may notice the (INJECT 2 ...) form appearing, which is described below. + + +At "level 1", i.e. when only \` , and ,@ are used, and not, say \`\` ,, ,', ,,@ ,',@ +this behaves exactly as usual quasiquotation. + + +The optional N argument +-------------- + +All quasiquote-2.0 operators accept optional "depth" argument, +which goes before the form for human readability. + +Namely, (DIG N FORM) increases depth by N instead of one and +(INJECT N FORM) decreases depth by N instead of one. + +```lisp +(DIG 2 (INJECT 2 A)) + +; gives the same result as + +(DIG (INJECT A)) +``` + + +In fact, with ENABLE-QUASIQUOTE-2.0, say, ,,,,,FORM (5 quotes) reads as (INJECT 5 FORM) +and ,,,,,@FORM as (SPLICE 5 FORM) + + +More examples +------------- + +For fairly complicated example, which uses ,,,@ and OINJECT (see below), + see DEFINE-BINOP-DEFINER macro +in CG-LLVM (https://github.com/mabragor/cg-llvm/src/basics.lisp), +desire to write which was the initial impulse for this project. + + +For macro, that is not a macro-writing macro, yet benefits from +ability to inject using `,` and `,@`, consider JOINING-WITH-COMMA-SPACE macro +(also from CG-LLVM) + +```lisp +(defmacro joining-with-comma-space (&body body) + ;; joinl just joins strings in the list with specified string + `(joinl ", " (mapcar #'emit-text-repr + (remove-if-not #'identity `(,,@body))))) + +;; the macro can be then used uniformly over strings and lists of strings +(defun foo (x y &rest z) + (joining-with-comma-space ,x ,y ,@z)) + +(foo "a" "b" "c" "d") + ;; produces + "a, b, c, d" +``` + + +ODIG and OINJECT and OSPLICE +---------------------------- + +Sometimes you don't want DIG's macroexpansion to look further into the structure of +some INJECT or SPLICE or DIG in its subform, +if the depth does not match. In these cases you need "opaque" versions of +DIG, INJECT and SPLICE, named, respectively, ODIG, OINJECT and OSPLICE. + +```lisp +;; here injection of B would occur +(defun foo (b) + (dig (dig (inject (a (inject b)))))) + +;; and here not, because macroexpansion does not look into OINJECT form +(defun bar (b) + (dig (dig (oinject (a (inject b)))))) + +(foo 1) + + '(DIG (INJECT (A 1))) + +(bar 1) + + '(DIG (OINJECT (A (INJECT B)))) +``` + +MACRO-INJECT and MACRO-SPLICE +----------------------------- + +Sometimes you just want to abstract-out some common injection patterns... +That is, you want macros, that expand into common injection patterns. +However, you want this only sometimes, and only in special circumstances. +So it won't do, if INJECT and SPLICE just expanded something, whenever it +turned out to be macro. For that, use MACRO-INJECT and MACRO-SPLICE. + +```lisp +;; with quasiquote-2.0 syntax turned on +(defmacro inject-n-times (form n) + (make-list n :initial-element `(inject ,form))) + +(let (x 0) + `(dig (a (macro-inject (inject-n-times (incf x) 3))))) +;; yields +'(a (1 2 3)) + +;;and same with MACRO-SPLICE +(let (x 0) + `(dig (a (macro-splice (inject-n-times (incf x) 3))))) +;; yields +'(a 1 2 3) +``` + +OMACRO-INJECT and OMACRO-SPLICE are, as usual, opaque variants of MACRO-INJECT and MACRO-SPLICE. + +Both MACRO-INJECT and MACRO-SPLICE expand their subform exactly once (using MACROEXPAND-1), +before plugging it into list. +If you want to expand as much as it's possible, use MACRO-INJECT-ALL and MACRO-SPLICE-ALL, +which expand using MACROEXPAND before injecting/splicing, respectively. +That implies, that while subform of MACRO-INJECT and MACRO-SPLICE is checked to be +macro-form, the subform of MACRO-INJECT-ALL is not. + + +Terse syntax of the ENABLE-QUASIQUOTE-2.0 +----------------------------------------- + +Of course, typing all those MACRO-INJECT-ALL, or OMACRO-SPLICE-ALL or whatever explicitly +every time you want this special things is kind of clumsy. For that, default reader +of quasiquote-2.0 provides extended syntax + +```lisp +',,,,!oma@x + +;; reads as +'(OMACRO-SPLICE-ALL 4 X) +``` + +That is, the regexp of the syntax is +[,]+![o][m][a][@]<whatever> + +As usual, number of commas determine the anti-depth of the injector, exclamation mark +turns on the syntax, if `o` is present, opaque version of injector will be used, +if `m` is present, macro-expanding version of injector will be used and if +`a` is present, macro-all version of injector will be used. + +Note: it's possible to write ,!ax, which will read as (INJECT-ALL X), but +this will not correspond to the actual macro name. + +Note: it was necessary to introduce special escape-char for extended syntax, +since usual idioms like `,args` would otherwise be completely screwed. + + +TODO +---- + +* WITH-QUASIQUOTE-2.0 read-macro-token for local enabling of ` and , overloading +* wrappers for convenient definition of custom overloading schemes +* some syntax for opaque operations + +P.S. Name "quasiquote-2.0" comes from "patronus 2.0" spell from www.hpmor.com + and has nothing to do with being "the 2.0" version of quasiquote. \ No newline at end of file diff --git a/third_party/lisp/quasiquote_2/default.nix b/third_party/lisp/quasiquote_2/default.nix new file mode 100644 index 0000000000..521c384787 --- /dev/null +++ b/third_party/lisp/quasiquote_2/default.nix @@ -0,0 +1,17 @@ +# Quasiquote more suitable for macros that define other macros +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "quasiquote-2.0"; + + deps = [ + depot.third_party.lisp.iterate + ]; + + srcs = [ + ./package.lisp + ./quasiquote-2.0.lisp + ./macros.lisp + ./readers.lisp + ]; +} diff --git a/third_party/lisp/quasiquote_2/macros.lisp b/third_party/lisp/quasiquote_2/macros.lisp new file mode 100644 index 0000000000..6ebeb47d08 --- /dev/null +++ b/third_party/lisp/quasiquote_2/macros.lisp @@ -0,0 +1,15 @@ + +(in-package #:quasiquote-2.0) + +(defmacro define-dig-like-macro (name) + `(defmacro ,name (n-or-form &optional (form nil form-p) &environment env) + (if (not form-p) + `(,',name 1 ,n-or-form) + (let ((*env* env)) + (transform-dig-form `(,',name ,n-or-form ,form)))))) + + +(define-dig-like-macro dig) +(define-dig-like-macro odig) + + diff --git a/third_party/lisp/quasiquote_2/package.lisp b/third_party/lisp/quasiquote_2/package.lisp new file mode 100644 index 0000000000..9b140ef84c --- /dev/null +++ b/third_party/lisp/quasiquote_2/package.lisp @@ -0,0 +1,11 @@ +;;;; package.lisp + +(defpackage #:quasiquote-2.0 + (:use #:cl #:iterate) + (:export #:%codewalk-dig-form #:transform-dig-form + #:dig #:inject #:splice #:odig #:oinject #:osplice + #:macro-inject #:omacro-inject #:macro-splice #:omacro-splice + #:macro-inject-all #:omacro-inject-all #:macro-splice-all #:omacro-splice-all + #:enable-quasiquote-2.0 #:disable-quasiquote-2.0)) + + diff --git a/third_party/lisp/quasiquote_2/quasiquote-2.0.asd b/third_party/lisp/quasiquote_2/quasiquote-2.0.asd new file mode 100644 index 0000000000..3acfd32b80 --- /dev/null +++ b/third_party/lisp/quasiquote_2/quasiquote-2.0.asd @@ -0,0 +1,30 @@ +;;;; quasiquote-2.0.asd + +(defpackage :quasiquote-2.0-system + (:use :cl :asdf)) + +(in-package quasiquote-2.0-system) + +(asdf:defsystem #:quasiquote-2.0 + :serial t + :description "Writing macros that write macros. Effortless." + :author "Alexandr Popolitov <popolit@gmail.com>" + :license "MIT" + :version "0.3" + :depends-on (#:iterate) + :components ((:file "package") + (:file "quasiquote-2.0") + (:file "macros") + (:file "readers"))) + +(defsystem :quasiquote-2.0-tests + :description "Tests for QUASIQUOTE-2.0" + :licence "MIT" + :depends-on (:quasiquote-2.0 :fiveam) + :components ((:file "tests") + (:file "tests-macro") + )) + +(defmethod perform ((op test-op) (sys (eql (find-system :quasiquote-2.0)))) + (load-system :quasiquote-2.0) + (funcall (intern "RUN-TESTS" :quasiquote-2.0))) diff --git a/third_party/lisp/quasiquote_2/quasiquote-2.0.lisp b/third_party/lisp/quasiquote_2/quasiquote-2.0.lisp new file mode 100644 index 0000000000..10043fe0ec --- /dev/null +++ b/third_party/lisp/quasiquote_2/quasiquote-2.0.lisp @@ -0,0 +1,340 @@ +;;;; quasiquote-2.0.lisp + +(in-package #:quasiquote-2.0) + +(defparameter *env* nil) + +(defmacro nonsense-error (str) + `(error ,(concatenate 'string + str + " appears as a bare, non DIG-enclosed form. " + "For now I don't know how to make sense of this."))) + +(defmacro define-nonsense-when-bare (name) + `(defmacro ,name (n-or-form &optional form) + (declare (ignore n-or-form form)) + (nonsense-error ,(string name)))) + +(define-nonsense-when-bare inject) +(define-nonsense-when-bare oinject) +(define-nonsense-when-bare splice) +(define-nonsense-when-bare osplice) +(define-nonsense-when-bare macro-inject) + +(defparameter *depth* 0) + + +(defparameter *injectors* nil) + +(defparameter *void-elt* nil) +(defparameter *void-filter-needed* nil) + +;; (defmacro with-injector-parsed (form) +;; `(let ((kwd (intern (string + +(defun reset-injectors () + (setf *injectors* nil)) + +(defparameter *known-injectors* '(inject splice oinject osplice + macro-inject omacro-inject + macro-splice omacro-splice + macro-inject-all omacro-inject-all + macro-splice-all omacro-splice-all)) + +(defun injector-form-p (form) + (and (consp form) + (find (car form) *known-injectors* :test #'eq))) + +(defun injector-level (form) + (if (equal 2 (length form)) + 1 + (cadr form))) + +(defun injector-subform (form) + (if (equal 2 (length form)) + (values (cdr form) '(cdr)) + (values (cddr form) '(cddr)))) + +(defparameter *opaque-injectors* '(odig oinject osplice omacro-inject)) + +(defun transparent-p (form) + (not (find (car form) *opaque-injectors* :test #'eq))) + +(defun look-into-injector (form path) + (let ((*depth* (- *depth* (injector-level form)))) + (multiple-value-bind (subform subpath) (injector-subform form) + (search-all-active-sites subform (append subpath path) nil)))) + +(defparameter *known-diggers* '(dig odig)) + +(defun dig-form-p (form) + (and (consp form) + (find (car form) *known-diggers* :test #'eq))) + +(defun look-into-dig (form path) + (let ((*depth* (+ *depth* (injector-level form)))) + (multiple-value-bind (subform subpath) (injector-subform form) + (search-all-active-sites subform (append subpath path) nil)))) + +(defun handle-macro-1 (form) + (if (atom form) + (error "Sorry, symbol-macros are not implemented for now") + (let ((fun (macro-function (car form) *env*))) + (if (not fun) + (error "The subform of MACRO-1 injector is supposed to be macro, perhaps, something went wrong...")) + (macroexpand-1 form *env*)))) + +(defun handle-macro-all (form) + (if (atom form) + (error "Sorry, symbol-macros are not implemented for now") + (macroexpand form *env*))) + + +(defparameter *macro-handlers* `((macro-inject . ,#'handle-macro-1) + (omacro-inject . ,#'handle-macro-1) + (macro-splice . ,#'handle-macro-1) + (omacro-splice . ,#'handle-macro-1) + (macro-inject-all . ,#'handle-macro-all) + (omacro-inject-all . ,#'handle-macro-all) + (macro-splice-all . ,#'handle-macro-all) + (omacro-splice-all . ,#'handle-macro-all))) + +(defun get-macro-handler (sym) + (or (cdr (assoc sym *macro-handlers*)) + (error "Don't know how to handle this macro injector: ~a" sym))) + + + +(defun macroexpand-macroinjector (place) + (if (not (splicing-injector (car place))) + (progn (setf (car place) (funcall (get-macro-handler (caar place)) + (car (injector-subform (car place))))) + nil) + (let ((new-forms (funcall (get-macro-handler (caar place)) + (car (injector-subform (car place)))))) + (cond ((not new-forms) + (setf *void-filter-needed* t + (car place) *void-elt*)) + ((atom new-forms) (error "We need to splice the macroexpansion, but got atom: ~a" new-forms)) + (t (setf (car place) (car new-forms)) + (let ((tail (cdr place))) + (setf (cdr place) (cdr new-forms) + (cdr (last new-forms)) tail)))) + t))) + + +(defun search-all-active-sites (form path toplevel-p) + ;; (format t "SEARCH-ALL-ACTIVE-SITES: got form ~a~%" form) + (if (not form) + nil + (if toplevel-p + (cond ((atom (car form)) :just-quote-it!) + ((injector-form-p (car form)) (if (equal *depth* (injector-level (car form))) + :just-form-it! + (if (transparent-p (car form)) + (look-into-injector (car form) (cons 'car path))))) + ((dig-form-p (car form)) + ;; (format t "Got dig form ~a~%" form) + (if (transparent-p (car form)) + (look-into-dig (car form) (cons 'car path)))) + (t (search-all-active-sites (car form) (cons 'car path) nil) + (search-all-active-sites (cdr form) (cons 'cdr path) nil))) + (when (consp form) + (cond ((dig-form-p (car form)) + ;; (format t "Got dig form ~a~%" form) + (if (transparent-p (car form)) + (look-into-dig (car form) (cons 'car path)))) + ((injector-form-p (car form)) + ;; (format t "Got injector form ~a ~a ~a~%" form *depth* (injector-level (car form))) + (if (equal *depth* (injector-level (car form))) + (if (macro-injector-p (car form)) + (progn (macroexpand-macroinjector form) + (return-from search-all-active-sites + (search-all-active-sites form path nil))) + (progn (push (cons form (cons 'car path)) *injectors*) + nil)) + (if (transparent-p (car form)) + (look-into-injector (car form) (cons 'car path))))) + (t (search-all-active-sites (car form) (cons 'car path) nil))) + (search-all-active-sites (cdr form) (cons 'cdr path) nil))))) + + + +(defun codewalk-dig-form (form) + (reset-injectors) + (let ((it (search-all-active-sites form nil t))) + (values (nreverse *injectors*) it))) + +(defun %codewalk-dig-form (form) + (if (not (dig-form-p form)) + (error "Supposed to be called on dig form") + (let ((*depth* (+ (injector-level form) *depth*))) + (codewalk-dig-form (injector-subform form))))) + +(defun path->setfable (path var) + (let ((res var)) + ;; First element is artifact of extra CAR-ing + (dolist (spec (cdr (reverse path))) + (setf res (list spec res))) + res)) + +(defun tree->cons-code (tree) + (if (atom tree) + `(quote ,tree) + `(cons ,(tree->cons-code (car tree)) + ,(tree->cons-code (cdr tree))))) + +(defparameter *known-splicers* '(splice osplice + macro-splice omacro-splice + macro-splice-all omacro-splice-all)) + +(defun splicing-injector (form) + (and (consp form) + (find (car form) *known-splicers* :test #'eq))) + +(defparameter *known-macro-injectors* '(macro-inject omacro-inject + macro-splice omacro-splice + macro-inject-all omacro-inject-all + macro-splice-all omacro-splice-all + )) + +(defun macro-injector-p (form) + (and (consp form) + (find (car form) *known-macro-injectors* :test #'eq))) + +(defun filter-out-voids (lst void-sym) + (let (caars cadrs cdars cddrs) + ;; search for all occurences of VOID + (labels ((rec (x) + (if (consp x) + (progn (cond ((consp (car x)) + (cond ((eq void-sym (caar x)) (push x caars)) + ((eq void-sym (cdar x)) (push x cdars)))) + ((consp (cdr x)) + (cond ((eq void-sym (cadr x)) (push x cadrs)) + ((eq void-sym (cddr x)) (push x cddrs))))) + (rec (car x)) + (rec (cdr x)))))) + (rec lst)) + (if (or cdars cddrs) + (error "Void sym found on CDR position, which should not have happened")) + ;; destructively transform LST + (dolist (elt caars) + (setf (car elt) (cdar elt))) + (dolist (elt cadrs) + (setf (cdr elt) (cddr elt))) + ;; check that we indeed filtered-out all VOIDs + (labels ((rec (x) + (if (not (atom x)) + (progn (rec (car x)) + (rec (cdr x))) + (if (eq void-sym x) + (error "Not all VOIDs were filtered"))))) + (rec lst)) + lst)) + +(defun transform-dig-form (form) + (let ((the-form (copy-tree form))) + (let ((*void-filter-needed* nil) + (*void-elt* (gensym "VOID"))) + (multiple-value-bind (site-paths cmd) (%codewalk-dig-form the-form) + (cond ((eq cmd :just-quote-it!) + `(quote ,(car (injector-subform the-form)))) + ((eq cmd :just-form-it!) + (car (injector-subform (car (injector-subform the-form))))) + (t (let ((cons-code (if (not site-paths) + (tree->cons-code (car (injector-subform the-form))) + (really-transform-dig-form the-form site-paths)))) + (if (not *void-filter-needed*) + cons-code + `(filter-out-voids ,cons-code ',*void-elt*))))))))) + +(defmacro make-list-form (o!-n form) + (let ((g!-n (gensym "N")) + (g!-i (gensym "I")) + (g!-res (gensym "RES"))) + `(let ((,g!-n ,o!-n) + (,g!-res nil)) + (dotimes (,g!-i ,g!-n) + (push ,form ,g!-res)) + (nreverse ,g!-res)))) + +(defun mk-splicing-injector-let (x) + `(let ((it ,(car (injector-subform x)))) + (assert (listp it)) + (copy-list it))) + + + +(defun mk-splicing-injector-setf (path g!-list g!-splicee) + (assert (eq 'car (car path))) + (let ((g!-rest (gensym "REST"))) + `(let ((,g!-rest ,(path->setfable (cons 'cdr (cdr path)) g!-list))) + (assert (or (not ,g!-rest) (consp ,g!-rest))) + (if (not ,g!-splicee) + (setf ,(path->setfable (cdr path) g!-list) + ,g!-rest) + (progn (setf ,(path->setfable (cdr path) g!-list) ,g!-splicee) + (setf (cdr (last ,g!-splicee)) ,g!-rest)))))) + + +(defun really-transform-dig-form (the-form site-paths) + (let ((gensyms (make-list-form (length site-paths) (gensym "INJECTEE")))) + (let ((g!-list (gensym "LIST"))) + (let ((lets nil) + (splicing-setfs nil) + (setfs nil)) + (do ((site-path site-paths (cdr site-path)) + (gensym gensyms (cdr gensym))) + ((not site-path)) + (destructuring-bind (site . path) (car site-path) + (push `(,(car gensym) ,(if (not (splicing-injector (car site))) + (car (injector-subform (car site))) + (mk-splicing-injector-let (car site)))) + lets) + (if (not (splicing-injector (car site))) + (push `(setf ,(path->setfable path g!-list) ,(car gensym)) setfs) + (push (mk-splicing-injector-setf path g!-list (car gensym)) splicing-setfs)) + (setf (car site) nil))) + `(let ,(nreverse lets) + (let ((,g!-list ,(tree->cons-code (car (injector-subform the-form))))) + ,@(nreverse setfs) + ;; we apply splicing setf in reverse order for them not to bork the paths of each other + ,@splicing-setfs + ,g!-list)))))) + + +;; There are few types of recursive injection that may happen: +;; * compile-time injection: +;; (dig (inject (dig (inject a)))) -- this type will be handled automatically by subsequent macroexpansions +;; * run-time injection: +;; (dig (dig (inject 2 a))) +;; and A is '(dig (inject 3 'foo)) -- this one we guard against ? (probably, first we just ignore it +;; -- do not warn about it, and then it wont really happen. +;; * macroexpanded compile-time injection: +;; (dig (inject (my-macro a b c))), +;; where MY-MACRO expands into, say (splice (list 'a 'b 'c)) +;; This is *not* handled automatically, and therefore we must do it by hand. + + +;; OK, now how to implement splicing ? +;; (dig (a (splice (list b c)) d)) +;; should transform into code that yields +;; (a b c d) +;; what this code is? +;; (let ((#:a (copy-list (list b c)))) +;; (let ((#:res (cons 'a nil 'd))) +;; ;; all non-splicing injects go here, as they do not spoil the path-structure +;; (setf (cdr #:res) #:a) +;; (setf (cdr (last #:a)) (cdr (cdr #:res))) +;; #:res))) + + +;; How this macroexpansion should work in general? +;; * We go over the cons-tree, keeping track of the depth level, which is +;; controlled by DIG's +;; * Once we find the INJECT with matching level, we remember the place, where +;; this happens +;; * We have two special cases: +;; * cons-tree is an atom +;; * cons-tree is just a single INJECT diff --git a/third_party/lisp/quasiquote_2/readers.lisp b/third_party/lisp/quasiquote_2/readers.lisp new file mode 100644 index 0000000000..7c4c5a30c9 --- /dev/null +++ b/third_party/lisp/quasiquote_2/readers.lisp @@ -0,0 +1,77 @@ + + +(in-package #:quasiquote-2.0) + +(defun read-n-chars (stream char) + (let (new-char + (n 0)) + (loop + (setf new-char (read-char stream nil :eof t)) + (if (not (char= new-char char)) + (progn (unread-char new-char stream) + (return n)) + (incf n))))) + +(defmacro define-dig-reader (name symbol) + `(defun ,name (stream char) + (let ((depth (1+ (read-n-chars stream char)))) + (if (equal 1 depth) + (list ',symbol (read stream t nil t)) + (list ',symbol + depth + (read stream t nil t)))))) + +(define-dig-reader dig-reader dig) +(define-dig-reader odig-reader odig) + +(defun expect-char (char stream) + (let ((new-char (read-char stream t nil t))) + (if (char= char new-char) + t + (unread-char new-char stream)))) + +(defun guess-injector-name (opaque-p macro-p all-p splicing-p) + (intern (concatenate 'string + (if opaque-p "O" "") + (if macro-p "MACRO-" "") + (if splicing-p "SPLICE" "INJECT") + (if all-p "-ALL" "")) + "QUASIQUOTE-2.0")) + +(defun inject-reader (stream char) + (let ((anti-depth (1+ (read-n-chars stream char))) + (extended-syntax (expect-char #\! stream))) + (let ((injector-name (if (not extended-syntax) + (guess-injector-name nil nil nil (expect-char #\@ stream)) + (guess-injector-name (expect-char #\o stream) + (expect-char #\m stream) + (expect-char #\a stream) + (expect-char #\@ stream))))) + `(,injector-name ,@(if (not (equal 1 anti-depth)) `(,anti-depth)) + ,(read stream t nil t))))) + + + +(defvar *previous-readtables* nil) + +(defun %enable-quasiquote-2.0 () + (push *readtable* + *previous-readtables*) + (setq *readtable* (copy-readtable)) + (set-macro-character #\` #'dig-reader) + (set-macro-character #\, #'inject-reader) + (values)) + +(defun %disable-quasiquote-2.0 () + (if *previous-readtables* + (setf *readtable* (pop *previous-readtables*)) + (setf *readtable* (copy-readtable nil))) + (values)) + +(defmacro enable-quasiquote-2.0 () + `(eval-when (:compile-toplevel :load-toplevel :execute) + (%enable-quasiquote-2.0))) +(defmacro disable-quasiquote-2.0 () + `(eval-when (:compile-toplevel :load-toplevel :execute) + (%disable-quasiquote-2.0))) + diff --git a/third_party/lisp/quasiquote_2/tests-macro.lisp b/third_party/lisp/quasiquote_2/tests-macro.lisp new file mode 100644 index 0000000000..df6c43e21d --- /dev/null +++ b/third_party/lisp/quasiquote_2/tests-macro.lisp @@ -0,0 +1,21 @@ + +(in-package #:quasiquote-2.0-tests) + +(in-suite quasiquote-2.0) + +(enable-quasiquote-2.0) + +(defmacro define-sample-macro (name args &body body) + `(defmacro ,name ,args + `(sample-thing-to-macroexpand-to + ,,@body))) + +(define-sample-macro sample-macro-1 (x y) + ,x ,y) + +(define-sample-macro sample-macro-2 (&body body) + ,@body) + +(test macro-defined-macroexpansions + (is (equal '(sample-thing-to-macroexpand-to a b) (macroexpand-1 '(sample-macro-1 a b)))) + (is (equal '(sample-thing-to-macroexpand-to a b c) (macroexpand-1 '(sample-macro-2 a b c))))) \ No newline at end of file diff --git a/third_party/lisp/quasiquote_2/tests.lisp b/third_party/lisp/quasiquote_2/tests.lisp new file mode 100644 index 0000000000..6c8ab08cc1 --- /dev/null +++ b/third_party/lisp/quasiquote_2/tests.lisp @@ -0,0 +1,143 @@ +(in-package :cl-user) + +(defpackage :quasiquote-2.0-tests + (:use :cl :quasiquote-2.0 :fiveam) + (:export #:run-tests)) + +(in-package :quasiquote-2.0-tests) + +(def-suite quasiquote-2.0) +(in-suite quasiquote-2.0) + +(defun run-tests () + (let ((results (run 'quasiquote-2.0))) + (fiveam:explain! results) + (unless (fiveam:results-status results) + (error "Tests failed.")))) + +(test basic + (is (equal '(nil :just-quote-it!) (multiple-value-list (%codewalk-dig-form '(dig nil))))) + (is (equal '(nil :just-form-it!) (multiple-value-list (%codewalk-dig-form '(dig (inject a)))))) + (is (equal '(nil :just-form-it!) (multiple-value-list (%codewalk-dig-form '(dig 2 (inject 2 a)))))) + (is (equal '(((((inject b) c (inject d)) car cdr car) (((inject d)) car cdr cdr cdr car)) nil) + (multiple-value-list (%codewalk-dig-form '(dig (a (inject b) c (inject d))))))) + (is (equal '(nil nil) + (multiple-value-list (%codewalk-dig-form '(dig (dig (a (inject b) c (inject d)))))))) + (is (equal '(((((inject 2 d)) car cdr cdr cdr car cdr car)) nil) + (multiple-value-list (%codewalk-dig-form '(dig (dig (a (inject b) c (inject 2 d))))))))) + +(test transform + (is (equal '(quote a) (transform-dig-form '(dig a)))) + (is (equal '(quote a) (transform-dig-form '(dig 2 a)))) + (is (equal 'a (transform-dig-form '(dig (inject a))))) + (is (equal 'a (transform-dig-form '(dig 2 (inject 2 a)))))) + +(defun foo (b d) + (dig (a (inject b) c (inject d)))) + +(defun foo1-transparent (x) + (declare (ignorable x)) + (dig (dig (a (inject (b (inject x) c)))))) + +(defun foo1-opaque (x) + (declare (ignorable x)) + (dig (dig (a (oinject (b (inject x) c)))))) + +(defun foo-recursive (x y) + (dig (a (inject (list x (dig (c (inject y)))))))) + + +(test foos + (is (equal '(a 1 c 2) (foo 1 2))) + (is (equal '(a 100 c 200) (foo 100 200)))) + +(test opaque-vs-transparent + (is (equal '(quote a) (transform-dig-form '(odig a)))) + (is (equal '(quote a) (transform-dig-form '(odig 2 a)))) + (is (equal 'a (transform-dig-form '(odig (inject a))))) + (is (equal 'a (transform-dig-form '(odig 2 (inject 2 a))))) + (is (equal '(odig (inject 2 a)) (eval (transform-dig-form '(dig (odig (inject 2 a))))))) + (is (equal '(dig (a (inject (b 3 c)))) (foo1-transparent 3))) + (is (equal '(dig (a (oinject (b (inject x) c)))) (foo1-opaque 3)))) + +(test recursive-compile-time + (is (equal '(a (1 (c 2))) (foo-recursive 1 2)))) + + +(test splicing + (is (equal '(a b c d) (eval (transform-dig-form '(dig (a (splice '(b c)) d)))))) + (is (equal '(b c d) (eval (transform-dig-form '(dig ((splice '(b c)) d)))))) + (is (equal '(a b c) (eval (transform-dig-form '(dig (a (splice '(b c)))))))) + (is (equal '(a b) (eval (transform-dig-form '(dig (a (splice nil) b)))))) + (is (equal '(b) (eval (transform-dig-form '(dig ((splice nil) b)))))) + (is (equal '(a) (eval (transform-dig-form '(dig (a (splice nil))))))) + (is (equal '() (eval (transform-dig-form '(dig ((splice nil))))))) + (is (equal '(a b) (eval (transform-dig-form '(dig ((splice '(a b))))))))) + + +(test are-they-macro + (is (not (equal '(dig (a b)) (macroexpand-1 '(dig (a b)))))) + (is (not (equal '(odig (a b)) (macroexpand-1 '(odig (a b))))))) + + +(defmacro triple-var (x) + `((inject ,x) (inject ,x) (inject ,x))) + +(test correct-order-of-effects + (is (equal '(a 1 2 3) (let ((x 0)) + (dig (a (inject (incf x)) (inject (incf x)) (inject (incf x))))))) + (is (equal '(a (((1))) 2) + (let ((x 0)) + (dig (a ((((inject (incf x))))) (inject (incf x)))))))) + +(test macro-injects + (is (equal '(a (3 3 3)) (let ((x 3)) + (dig (a (macro-inject (triple-var x))))))) + (is (equal '(a (1 2 3)) (let ((x 0)) + (dig (a (macro-inject (triple-var (incf x)))))))) + (macrolet ((frob (form n) + (mapcar (lambda (x) + `(inject ,x)) + (make-list n :initial-element form))) + (frob1 (form) + `(frob ,form 4))) + (is (equal '(a (1 2 3 4 5)) + (let ((x 0)) + (dig (a (macro-inject (frob (incf x) 5))))))) + (is (equal '(a 1 2 3 4 5) + (let ((x 0)) + (dig (a (macro-splice (frob (incf x) 5))))))) + (is (equal '(a) + (let ((x 0)) + (declare (ignorable x)) + (dig (a (macro-splice (frob (incf x) 0))))))) + (is (equal '(a frob (incf x) 4) + (let ((x 0)) + (declare (ignorable x)) + (dig (a (macro-splice (frob1 (incf x)))))))) + (is (equal '(a 1 2 3 4) + (let ((x 0)) + (dig (a (macro-splice-all (frob1 (incf x)))))))))) + + +(quasiquote-2.0:enable-quasiquote-2.0) + +(test reader + (is (equal '(inject x) ',x)) + (is (equal '(inject 3 x) ',,,x)) + (is (equal '(splice x) ',@x)) + (is (equal '(splice 3 x) ',,,@x)) + (is (equal '(omacro-splice-all 4 x) ',,,,!oma@x)) + (is (equal '(inject 4 oma@x) ',,,,oma@x))) + +(test macro-splices + (macrolet ((splicer (x) + ``(splice ,x))) + (is (equal '(a 1 2 3) (let ((x '(1 2 3))) + `(a ,!m(splicer x))))))) + +(test repeated-splices + (is (equal '(a) `(a ,@nil ,@nil ,@nil ,@nil))) + (is (equal '(a b c d e f g) `(a ,@(list 'b 'c) ,@(list 'd 'e) ,@nil ,@(list 'f 'g))))) + + \ No newline at end of file diff --git a/third_party/lisp/rfc2388.nix b/third_party/lisp/rfc2388.nix new file mode 100644 index 0000000000..8288094904 --- /dev/null +++ b/third_party/lisp/rfc2388.nix @@ -0,0 +1,17 @@ +# Implementation of RFC2388 (multipart/form-data) +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "jdz"; + repo = "rfc2388"; + rev = "591bcf7e77f2c222c43953a80f8c297751dc0c4e"; + sha256 = "0phh5n3clhl9ji8jaxrajidn22d3f0aq87mlbfkkxlnx2pnw694k"; +}; +in depot.nix.buildLisp.library { + name = "rfc2388"; + + srcs = map (f: src + ("/" + f)) [ + "packages.lisp" + "rfc2388.lisp" + ]; +} diff --git a/third_party/lisp/s-sysdeps.nix b/third_party/lisp/s-sysdeps.nix new file mode 100644 index 0000000000..aebd7c3f7b --- /dev/null +++ b/third_party/lisp/s-sysdeps.nix @@ -0,0 +1,17 @@ +# A Common Lisp abstraction layer over platform dependent functionality. +{ depot, ... }: + +let src = depot.third_party.fetchFromGitHub { + owner = "svenvc"; + repo = "s-sysdeps"; + rev = "d28246b5dffef9e73a0e0e6cfbc4e878006fe34d"; + sha256 = "14b69b81yrxmjlvmm3lfxk04x5v7hqz4fql121334wh72czznfh9"; +}; +in depot.nix.buildLisp.library { + name = "s-sysdeps"; + + srcs = [ + "${src}/src/package.lisp" + "${src}/src/sysdeps.lisp" + ]; +} diff --git a/third_party/lisp/s-xml/.gitignore b/third_party/lisp/s-xml/.gitignore new file mode 100644 index 0000000000..40caffa8e2 --- /dev/null +++ b/third_party/lisp/s-xml/.gitignore @@ -0,0 +1,28 @@ +# CVS default ignores begin +tags +TAGS +.make.state +.nse_depinfo +*~ +#* +.#* +,* +_$* +*$ +*.old +*.bak +*.BAK +*.orig +*.rej +.del-* +*.a +*.olb +*.o +*.obj +*.so +*.exe +*.Z +*.elc +*.ln +core +# CVS default ignores end diff --git a/third_party/lisp/s-xml/ChangeLog b/third_party/lisp/s-xml/ChangeLog new file mode 100644 index 0000000000..ac196619c0 --- /dev/null +++ b/third_party/lisp/s-xml/ChangeLog @@ -0,0 +1,66 @@ +2006-01-19 Sven Van Caekenberghe <svc@mac.com> + + * added a set of patches contributed by David Tolpin dvd@davidashen.net : we're now using char of type + Character and #\Null instead of null, read/unread instead of peek/read and some more declarations for + more efficiency - added hooks for customizing parsing attribute names and values + +2005-11-20 Sven Van Caekenberghe <svc@mac.com> + + * added xml prefix namespace as per REC-xml-names-19990114 (by Rudi Schlatte) + +2005-11-06 Sven Van Caekenberghe <svc@mac.com> + + * removed Debian packaging directory (on Luca's request) + * added CDATA support (patch contributed by Peter Van Eynde pvaneynd@mailworks.org) + +2005-08-30 Sven Van Caekenberghe <svc@mac.com> + + * added Debian packaging directory (contributed by Luca Capello luca@pca.it) + * added experimental XML namespace support + +2005-02-03 Sven Van Caekenberghe <svc@mac.com> + + * release 5 (cvs tag RELEASE_5) + * added :start and :end keywords to print-string-xml + * fixed a bug: in a tag containing whitespace, like <foo> </foo> the parser collapsed + and ingnored all whitespace and considered the tag to be empty! + this is now fixed and a unit test has been added + * cleaned up xml character escaping a bit: single quotes and all normal whitespace + (newline, return and tab) is preserved a unit test for this has been added + * IE doesn't understand the ' XML entity, so I've commented that out for now. + Also, using actual newlines for newlines is probably better than using #xA, + which won't get any end of line conversion by the server or user agent. + +June 2004 Sven Van Caekenberghe <svc@mac.com> + + * release 4 + * project moved to common-lisp.net, renamed to s-xml, + * added examples counter, tracer and remove-markup, improved documentation + +13 Jan 2004 Sven Van Caekenberghe <svc@mac.com> + + * release 3 + * added ASDF systems + * optimized print-string-xml + +10 Jun 2003 Sven Van Caekenberghe <svc@mac.com> + + * release 2 + * added echo-xml function: we are no longer taking the car when + the last seed is returned from start-parse-xml + +25 May 2003 Sven Van Caekenberghe <svc@mac.com> + + * release 1 + * first public release of working code + * tested on OpenMCL + * rewritten to be event-based, to improve efficiency and + to optionally use different DOM representations + * more documentation + +end of 2002 Sven Van Caekenberghe <svc@mac.com> + + * release 0 + * as part of an XML-RPC implementation + +$Id: ChangeLog,v 1.5 2005/11/20 14:24:33 scaekenberghe Exp $ diff --git a/third_party/lisp/s-xml/Makefile b/third_party/lisp/s-xml/Makefile new file mode 100644 index 0000000000..0c7292ea9f --- /dev/null +++ b/third_party/lisp/s-xml/Makefile @@ -0,0 +1,35 @@ +# $Id: Makefile,v 1.2 2004/06/11 13:46:48 scaekenberghe Exp $ + +default: + @echo Possible targets: + @echo clean-openmcl --- remove all '*.dfsl' recursively + @echo clean-lw --- remove all '*.nfasl' recursively + @echo clean-emacs --- remove all '*~' recursively + @echo clean --- all of the above + +clean-openmcl: + find . -name "*.dfsl" | xargs rm + +clean-lw: + find . -name "*.nfasl" | xargs rm + +clean-emacs: + find . -name "*~" | xargs rm + +clean: clean-openmcl clean-lw clean-emacs + +# +# This can obviously only be done by a specific person in a very specific context ;-) +# + +PRJ=s-xml +ACCOUNT=scaekenberghe +CVSRT=:ext:$(ACCOUNT)@common-lisp.net:/project/$(PRJ)/cvsroot + +release: + rm -rf /tmp/$(PRJ) /tmp/public_html /tmp/$(PRJ).tgz /tmp/$(PRJ).tgz.asc + cd /tmp; cvs -d$(CVSRT) export -r HEAD $(PRJ); cvs -d$(CVSRT) export -r HEAD public_html + mv /tmp/public_html /tmp/$(PRJ)/doc + cd /tmp; gnutar cvfz $(PRJ).tgz $(PRJ); gpg -a -b $(PRJ).tgz + scp /tmp/$(PRJ).tgz $(ACCOUNT)@common-lisp.net:/project/$(PRJ)/public_html + scp /tmp/$(PRJ).tgz.asc $(ACCOUNT)@common-lisp.net:/project/$(PRJ)/public_html diff --git a/third_party/lisp/s-xml/default.nix b/third_party/lisp/s-xml/default.nix new file mode 100644 index 0000000000..82b6317f37 --- /dev/null +++ b/third_party/lisp/s-xml/default.nix @@ -0,0 +1,17 @@ +# XML serialiser for Common Lisp. +# +# This system was imported from a Quicklisp tarball at 's-xml-20150608'. +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "s-xml"; + + srcs = [ + ./src/package.lisp + ./src/xml.lisp + ./src/dom.lisp + ./src/lxml-dom.lisp + ./src/sxml-dom.lisp + ./src/xml-struct-dom.lisp + ]; +} diff --git a/third_party/lisp/s-xml/examples/counter.lisp b/third_party/lisp/s-xml/examples/counter.lisp new file mode 100644 index 0000000000..b26453e6ea --- /dev/null +++ b/third_party/lisp/s-xml/examples/counter.lisp @@ -0,0 +1,47 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: counter.lisp,v 1.2 2004/06/11 11:14:43 scaekenberghe Exp $ +;;;; +;;;; A simple SSAX counter example that can be used as a performance test +;;;; +;;;; Copyright (C) 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(defclass count-xml-seed () + ((elements :initform 0) + (attributes :initform 0) + (characters :initform 0))) + +(defun count-xml-new-element-hook (name attributes seed) + (declare (ignore name)) + (incf (slot-value seed 'elements)) + (incf (slot-value seed 'attributes) (length attributes)) + seed) + +(defun count-xml-text-hook (string seed) + (incf (slot-value seed 'characters) (length string)) + seed) + +(defun count-xml (in) + "Parse a toplevel XML element from stream in, counting elements, attributes and characters" + (start-parse-xml in + (make-instance 'xml-parser-state + :seed (make-instance 'count-xml-seed) + :new-element-hook #'count-xml-new-element-hook + :text-hook #'count-xml-text-hook))) + +(defun count-xml-file (pathname) + "Parse XMl from the file at pathname, counting elements, attributes and characters" + (with-open-file (in pathname) + (let ((result (count-xml in))) + (with-slots (elements attributes characters) result + (format t + "~a contains ~d XML elements, ~d attributes and ~d characters.~%" + pathname elements attributes characters))))) + +;;;; eof diff --git a/third_party/lisp/s-xml/examples/echo.lisp b/third_party/lisp/s-xml/examples/echo.lisp new file mode 100644 index 0000000000..a0befe2cbb --- /dev/null +++ b/third_party/lisp/s-xml/examples/echo.lisp @@ -0,0 +1,64 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: echo.lisp,v 1.1 2005/08/17 13:44:30 scaekenberghe Exp $ +;;;; +;;;; A simple example as well as a useful tool: parse, echo and pretty print XML +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(defun indent (stream count) + (loop :repeat (* count 2) :do (write-char #\space stream))) + +(defclass echo-xml-seed () + ((stream :initarg :stream) + (level :initarg :level :initform 0))) + +#+NIL +(defmethod print-object ((seed echo-xml-seed) stream) + (with-slots (stream level) seed + (print-unreadable-object (seed stream :type t) + (format stream "level=~d" level)))) + +(defun echo-xml-new-element-hook (name attributes seed) + (with-slots (stream level) seed + (indent stream level) + (format stream "<~a" name) + (dolist (attribute (reverse attributes)) + (format stream " ~a=\'" (car attribute)) + (print-string-xml (cdr attribute) stream) + (write-char #\' stream)) + (format stream ">~%") + (incf level) + seed)) + +(defun echo-xml-finish-element-hook (name attributes parent-seed seed) + (declare (ignore attributes parent-seed)) + (with-slots (stream level) seed + (decf level) + (indent stream level) + (format stream "</~a>~%" name) + seed)) + +(defun echo-xml-text-hook (string seed) + (with-slots (stream level) seed + (indent stream level) + (print-string-xml string stream) + (terpri stream) + seed)) + +(defun echo-xml (in out) + "Parse a toplevel XML element from stream in, echoing and pretty printing the result to stream out" + (start-parse-xml in + (make-instance 'xml-parser-state + :seed (make-instance 'echo-xml-seed :stream out) + :new-element-hook #'echo-xml-new-element-hook + :finish-element-hook #'echo-xml-finish-element-hook + :text-hook #'echo-xml-text-hook))) + +;;;; eof diff --git a/third_party/lisp/s-xml/examples/remove-markup.lisp b/third_party/lisp/s-xml/examples/remove-markup.lisp new file mode 100644 index 0000000000..41d858b4a8 --- /dev/null +++ b/third_party/lisp/s-xml/examples/remove-markup.lisp @@ -0,0 +1,21 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: remove-markup.lisp,v 1.1 2004/06/11 11:14:43 scaekenberghe Exp $ +;;;; +;;;; Remove markup from an XML document using the SSAX interface +;;;; +;;;; Copyright (C) 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(defun remove-xml-markup (in) + (let* ((state (make-instance 'xml-parser-state + :text-hook #'(lambda (string seed) (cons string seed)))) + (result (start-parse-xml in state))) + (apply #'concatenate 'string (nreverse result)))) + +;;;; eof \ No newline at end of file diff --git a/third_party/lisp/s-xml/examples/tracer.lisp b/third_party/lisp/s-xml/examples/tracer.lisp new file mode 100644 index 0000000000..c8a3eaec1f --- /dev/null +++ b/third_party/lisp/s-xml/examples/tracer.lisp @@ -0,0 +1,57 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: tracer.lisp,v 1.2 2004/06/11 11:14:43 scaekenberghe Exp $ +;;;; +;;;; A simple SSAX tracer example that can be used to understand how the hooks are called +;;;; +;;;; Copyright (C) 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(defun trace-xml-log (level msg &rest args) + (indent *standard-output* level) + (apply #'format *standard-output* msg args) + (terpri *standard-output*)) + +(defun trace-xml-new-element-hook (name attributes seed) + (let ((new-seed (cons (1+ (car seed)) (1+ (cdr seed))))) + (trace-xml-log (car seed) + "(new-element :name ~s :attributes ~:[()~;~:*~s~] :seed ~s) => ~s" + name attributes seed new-seed) + new-seed)) + +(defun trace-xml-finish-element-hook (name attributes parent-seed seed) + (let ((new-seed (cons (1- (car seed)) (1+ (cdr seed))))) + (trace-xml-log (car parent-seed) + "(finish-element :name ~s :attributes ~:[()~;~:*~s~] :parent-seed ~s :seed ~s) => ~s" + name attributes parent-seed seed new-seed) + new-seed)) + +(defun trace-xml-text-hook (string seed) + (let ((new-seed (cons (car seed) (1+ (cdr seed))))) + (trace-xml-log (car seed) + "(text :string ~s :seed ~s) => ~s" + string seed new-seed) + new-seed)) + +(defun trace-xml (in) + "Parse and trace a toplevel XML element from stream in" + (start-parse-xml in + (make-instance 'xml-parser-state + :seed (cons 0 0) + ;; seed car is xml element nesting level + ;; seed cdr is ever increasing from element to element + :new-element-hook #'trace-xml-new-element-hook + :finish-element-hook #'trace-xml-finish-element-hook + :text-hook #'trace-xml-text-hook))) + +(defun trace-xml-file (pathname) + "Parse and trace XMl from the file at pathname" + (with-open-file (in pathname) + (trace-xml in))) + +;;;; eof diff --git a/third_party/lisp/s-xml/s-xml.asd b/third_party/lisp/s-xml/s-xml.asd new file mode 100644 index 0000000000..651f5e5844 --- /dev/null +++ b/third_party/lisp/s-xml/s-xml.asd @@ -0,0 +1,49 @@ +;;;; -*- Mode: LISP -*- +;;;; +;;;; $Id: s-xml.asd,v 1.2 2005/12/14 21:49:04 scaekenberghe Exp $ +;;;; +;;;; The S-XML ASDF system definition +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :asdf) + +(defsystem :s-xml + :name "S-XML" + :author "Sven Van Caekenberghe <svc@mac.com>" + :version "3" + :maintainer "Sven Van Caekenberghe <svc@mac.com>, Brian Mastenbrook <>, Rudi Schlatte <>" + :licence "Lisp Lesser General Public License (LLGPL)" + :description "Simple Common Lisp XML Parser" + :long-description "S-XML is a Common Lisp implementation of a simple XML parser, with a SAX-like and DOM interface" + + :components + ((:module + :src + :components ((:file "package") + (:file "xml" :depends-on ("package")) + (:file "dom" :depends-on ("package" "xml")) + (:file "lxml-dom" :depends-on ("dom")) + (:file "sxml-dom" :depends-on ("dom")) + (:file "xml-struct-dom" :depends-on ("dom")))))) + +(defsystem :s-xml.test + :depends-on (:s-xml) + :components ((:module :test + :components ((:file "test-xml") + (:file "test-xml-struct-dom") + (:file "test-lxml-dom") + (:file "test-sxml-dom"))))) + +(defsystem :s-xml.examples + :depends-on (:s-xml) + :components ((:module :examples + :components ((:file "counter") + (:file "echo") + (:file "remove-markup") + (:file "tracer"))))) +;;;; eof diff --git a/third_party/lisp/s-xml/src/dom.lisp b/third_party/lisp/s-xml/src/dom.lisp new file mode 100644 index 0000000000..74d1c371db --- /dev/null +++ b/third_party/lisp/s-xml/src/dom.lisp @@ -0,0 +1,75 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: dom.lisp,v 1.1.1.1 2004/06/07 18:49:56 scaekenberghe Exp $ +;;;; +;;;; This is the generic simple DOM parser and printer interface. +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +;;; top level DOM parser interface + +(defgeneric parse-xml-dom (stream output-type) + (:documentation "Parse a character stream as XML and generate a DOM of output-type")) + +(defun parse-xml (stream &key (output-type :lxml)) + "Parse a character stream as XML and generate a DOM of output-type, defaulting to :lxml" + (parse-xml-dom stream output-type)) + +(defun parse-xml-string (string &key (output-type :lxml)) + "Parse a string as XML and generate a DOM of output-type, defaulting to :lxml" + (with-input-from-string (stream string) + (parse-xml-dom stream output-type))) + +(defun parse-xml-file (filename &key (output-type :lxml)) + "Parse a character file as XML and generate a DOM of output-type, defaulting to :lxml" + (with-open-file (in filename :direction :input) + (parse-xml-dom in output-type))) + +;;; top level DOM printer interface + +(defgeneric print-xml-dom (dom input-type stream pretty level) + (:documentation "Generate XML output on a character stream from a DOM of input-type, optionally pretty printing using level")) + +(defun print-xml (dom &key (stream t) (pretty nil) (input-type :lxml) (header)) + "Generate XML output on a character stream (t by default) from a DOM of input-type (:lxml by default), optionally pretty printing (off by default), or adding a header (none by default)" + (when header (format stream header)) + (when pretty (terpri stream)) + (print-xml-dom dom input-type stream pretty 1)) + +(defun print-xml-string (dom &key (pretty nil) (input-type :lxml)) + "Generate XML output to a string from a DOM of input-type (:lxml by default), optionally pretty printing (off by default)" + (with-output-to-string (stream) + (print-xml dom :stream stream :pretty pretty :input-type input-type))) + +;;; shared/common support functions + +(defun print-spaces (n stream &optional (preceding-newline t)) + (when preceding-newline + (terpri stream)) + (loop :repeat n + :do (write-char #\Space stream))) + +(defun print-solitary-tag (tag stream) + (write-char #\< stream) + (print-identifier tag stream) + (write-string "/>" stream)) + +(defun print-closing-tag (tag stream) + (write-string "</" stream) + (print-identifier tag stream) + (write-char #\> stream)) + +(defun print-attribute (name value stream) + (write-char #\space stream) + (print-identifier name stream t) + (write-string "=\"" stream) + (print-string-xml value stream) + (write-char #\" stream)) + +;;;; eof diff --git a/third_party/lisp/s-xml/src/lxml-dom.lisp b/third_party/lisp/s-xml/src/lxml-dom.lisp new file mode 100644 index 0000000000..d43df6cf81 --- /dev/null +++ b/third_party/lisp/s-xml/src/lxml-dom.lisp @@ -0,0 +1,83 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: lxml-dom.lisp,v 1.5 2005/09/20 09:57:44 scaekenberghe Exp $ +;;;; +;;;; LXML implementation of the generic DOM parser and printer. +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +;;; the lxml hooks to generate lxml + +(defun lxml-new-element-hook (name attributes seed) + (declare (ignore name attributes seed)) + '()) + +(defun lxml-finish-element-hook (name attributes parent-seed seed) + (let ((xml-element + (cond ((and (null seed) (null attributes)) + name) + (attributes + `((,name ,@(let (list) + (dolist (attribute attributes list) + (push (cdr attribute) list) + (push (car attribute) list)))) + ,@(nreverse seed))) + (t + `(,name ,@(nreverse seed)))))) + (cons xml-element parent-seed))) + +(defun lxml-text-hook (string seed) + (cons string seed)) + +;;; standard DOM interfaces + +(defmethod parse-xml-dom (stream (output-type (eql :lxml))) + (car (start-parse-xml stream + (make-instance 'xml-parser-state + :new-element-hook #'lxml-new-element-hook + :finish-element-hook #'lxml-finish-element-hook + :text-hook #'lxml-text-hook)))) + +(defun plist->alist (plist) + (when plist + (cons (cons (first plist) (second plist)) + (plist->alist (rest (rest plist)))))) + +(defmethod print-xml-dom (dom (input-type (eql :lxml)) stream pretty level) + (declare (special *namespaces*)) + (cond ((symbolp dom) (print-solitary-tag dom stream)) + ((stringp dom) (print-string-xml dom stream)) + ((consp dom) + (let (tag attributes) + (cond ((symbolp (first dom)) (setf tag (first dom))) + ((consp (first dom)) (setf tag (first (first dom)) + attributes (plist->alist (rest (first dom))))) + (t (error "Input not recognized as LXML ~s" dom))) + (let ((*namespaces* (extend-namespaces attributes *namespaces*))) + (write-char #\< stream) + (print-identifier tag stream) + (loop :for (name . value) :in attributes + :do (print-attribute name value stream)) + (if (rest dom) + (let ((children (rest dom))) + (write-char #\> stream) + (if (and (= (length children) 1) (stringp (first children))) + (print-string-xml (first children) stream) + (progn + (dolist (child children) + (when pretty (print-spaces (* 2 level) stream)) + (if (stringp child) + (print-string-xml child stream) + (print-xml-dom child input-type stream pretty (1+ level)))) + (when pretty (print-spaces (* 2 (1- level)) stream)))) + (print-closing-tag tag stream)) + (write-string "/>" stream))))) + (t (error "Input not recognized as LXML ~s" dom)))) + +;;;; eof \ No newline at end of file diff --git a/third_party/lisp/s-xml/src/package.lisp b/third_party/lisp/s-xml/src/package.lisp new file mode 100644 index 0000000000..f90f0f49a1 --- /dev/null +++ b/third_party/lisp/s-xml/src/package.lisp @@ -0,0 +1,46 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: package.lisp,v 1.7 2006/01/19 20:00:06 scaekenberghe Exp $ +;;;; +;;;; This is a Common Lisp implementation of a very basic XML parser. +;;;; The parser is non-validating. +;;;; The API into the parser is pure functional parser hook model that comes from SSAX, +;;;; see also http://pobox.com/~oleg/ftp/Scheme/xml.html or http://ssax.sourceforge.net +;;;; Different DOM models are provided, an XSML, an LXML and a xml-element struct based one. +;;;; +;;;; Copyright (C) 2002, 2003, 2004, 2005, 2006 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(defpackage s-xml + (:use common-lisp) + (:export + ;; main parser interface + #:start-parse-xml + #:print-string-xml + #:xml-parser-error #:xml-parser-error-message #:xml-parser-error-args #:xml-parser-error-stream + #:xml-parser-state #:get-entities #:get-seed + #:get-new-element-hook #:get-finish-element-hook #:get-text-hook + ;; callbacks + #:*attribute-name-parser* + #:*attribute-value-parser* + #:parse-attribute-name + #:parse-attribute-value + ;; dom parser and printer + #:parse-xml-dom #:parse-xml #:parse-xml-string #:parse-xml-file + #:print-xml-dom #:print-xml #:print-xml-string + ;; xml-element structure + #:make-xml-element #:xml-element-children #:xml-element-name + #:xml-element-attribute #:xml-element-attributes + #:xml-element-p #:new-xml-element #:first-xml-element-child + ;; namespaces + #:*ignore-namespaces* #:*local-namespace* #:*namespaces* + #:*require-existing-symbols* #:*auto-export-symbols* #:*auto-create-namespace-packages* + #:find-namespace #:register-namespace #:get-prefix #:get-uri #:get-package + #:resolve-identifier #:extend-namespaces #:print-identifier #:split-identifier) + (:documentation + "A simple XML parser with an efficient, purely functional, event-based interface as well as a DOM interface")) + +;;;; eof diff --git a/third_party/lisp/s-xml/src/sxml-dom.lisp b/third_party/lisp/s-xml/src/sxml-dom.lisp new file mode 100644 index 0000000000..c9e0f9e0db --- /dev/null +++ b/third_party/lisp/s-xml/src/sxml-dom.lisp @@ -0,0 +1,76 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: sxml-dom.lisp,v 1.4 2005/09/20 09:57:48 scaekenberghe Exp $ +;;;; +;;;; LXML implementation of the generic DOM parser and printer. +;;;; +;;;; Copyright (C) 2003, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +;;; the sxml hooks to generate sxml + +(defun sxml-new-element-hook (name attributes seed) + (declare (ignore name attributes seed)) + '()) + +(defun sxml-finish-element-hook (name attributes parent-seed seed) + (let ((xml-element (append (list name) + (when attributes + (list (let (list) + (dolist (attribute attributes (cons :@ list)) + (push (list (car attribute) (cdr attribute)) list))))) + (nreverse seed)))) + (cons xml-element parent-seed))) + +(defun sxml-text-hook (string seed) + (cons string seed)) + +;;; the standard DOM interfaces + +(defmethod parse-xml-dom (stream (output-type (eql :sxml))) + (car (start-parse-xml stream + (make-instance 'xml-parser-state + :new-element-hook #'sxml-new-element-hook + :finish-element-hook #'sxml-finish-element-hook + :text-hook #'sxml-text-hook)))) + +(defmethod print-xml-dom (dom (input-type (eql :sxml)) stream pretty level) + (declare (special *namespaces*)) + (cond ((stringp dom) (print-string-xml dom stream)) + ((consp dom) + (let ((tag (first dom)) + attributes + children) + (if (and (consp (second dom)) (eq (first (second dom)) :@)) + (setf attributes (rest (second dom)) + children (rest (rest dom))) + (setf children (rest dom))) + (let ((*namespaces* (extend-namespaces (loop :for (name value) :in attributes + :collect (cons name value)) + *namespaces*))) + (write-char #\< stream) + (print-identifier tag stream) + (loop :for (name value) :in attributes + :do (print-attribute name value stream)) + (if children + (progn + (write-char #\> stream) + (if (and (= (length children) 1) (stringp (first children))) + (print-string-xml (first children) stream) + (progn + (dolist (child children) + (when pretty (print-spaces (* 2 level) stream)) + (if (stringp child) + (print-string-xml child stream) + (print-xml-dom child input-type stream pretty (1+ level)))) + (when pretty (print-spaces (* 2 (1- level)) stream)))) + (print-closing-tag tag stream)) + (write-string "/>" stream))))) + (t (error "Input not recognized as SXML ~s" dom)))) + +;;;; eof diff --git a/third_party/lisp/s-xml/src/xml-struct-dom.lisp b/third_party/lisp/s-xml/src/xml-struct-dom.lisp new file mode 100644 index 0000000000..7037388915 --- /dev/null +++ b/third_party/lisp/s-xml/src/xml-struct-dom.lisp @@ -0,0 +1,125 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: xml-struct-dom.lisp,v 1.2 2005/08/29 15:01:47 scaekenberghe Exp $ +;;;; +;;;; XML-STRUCT implementation of the generic DOM parser and printer. +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +;;; xml-element struct datastructure and API + +(defstruct xml-element + name ; :tag-name + attributes ; a assoc list of (:attribute-name . "attribute-value") + children ; a list of children/content either text strings or xml-elements + ) + +(setf (documentation 'xml-element-p 'function) + "Return T when the argument is an xml-element struct" + (documentation 'xml-element-attributes 'function) + "Return the alist of attribute names and values dotted pairs from an xml-element struct" + (documentation 'xml-element-children 'function) + "Return the list of children from an xml-element struct" + (documentation 'xml-element-name 'function) + "Return the name from an xml-element struct" + (documentation 'make-xml-element 'function) + "Make and return a new xml-element struct") + +(defun xml-element-attribute (xml-element key) + "Return the string value of the attribute with name the keyword :key + of xml-element if any, return null if not found" + (let ((pair (assoc key (xml-element-attributes xml-element) :test #'eq))) + (when pair (cdr pair)))) + +(defun (setf xml-element-attribute) (value xml-element key) + "Set the string value of the attribute with name the keyword :key of + xml-element, creating a new attribute if necessary or overwriting an + existing one, returning the value" + (let ((attributes (xml-element-attributes xml-element))) + (if (null attributes) + (push (cons key value) (xml-element-attributes xml-element)) + (let ((pair (assoc key attributes :test #'eq))) + (if pair + (setf (cdr pair) value) + (push (cons key value) (xml-element-attributes xml-element))))) + value)) + +(defun new-xml-element (name &rest children) + "Make a new xml-element with name and children" + (make-xml-element :name name :children children)) + +(defun first-xml-element-child (xml-element) + "Get the first child of an xml-element" + (first (xml-element-children xml-element))) + +(defun xml-equal (xml-1 xml-2) + (and (xml-element-p xml-1) + (xml-element-p xml-2) + (eq (xml-element-name xml-1) + (xml-element-name xml-2)) + (equal (xml-element-attributes xml-1) + (xml-element-attributes xml-2)) + (reduce #'(lambda (&optional (x t) (y t)) (and x y)) + (mapcar #'(lambda (x y) + (or (and (stringp x) (stringp y) (string= x y)) + (xml-equal x y))) + (xml-element-children xml-1) + (xml-element-children xml-2))))) + +;;; printing xml structures + +(defmethod print-xml-dom (xml-element (input-type (eql :xml-struct)) stream pretty level) + (declare (special *namespaces*)) + (let ((*namespaces* (extend-namespaces (xml-element-attributes xml-element) + *namespaces*))) + (write-char #\< stream) + (print-identifier (xml-element-name xml-element) stream) + (loop :for (name . value) :in (xml-element-attributes xml-element) + :do (print-attribute name value stream)) + (let ((children (xml-element-children xml-element))) + (if children + (progn + (write-char #\> stream) + (if (and (= (length children) 1) (stringp (first children))) + (print-string-xml (first children) stream) + (progn + (dolist (child children) + (when pretty (print-spaces (* 2 level) stream)) + (if (stringp child) + (print-string-xml child stream) + (print-xml-dom child input-type stream pretty (1+ level)))) + (when pretty (print-spaces (* 2 (1- level)) stream)))) + (print-closing-tag (xml-element-name xml-element) stream)) + (write-string "/>" stream))))) + +;;; the standard hooks to generate xml-element structs + +(defun standard-new-element-hook (name attributes seed) + (declare (ignore name attributes seed)) + '()) + +(defun standard-finish-element-hook (name attributes parent-seed seed) + (let ((xml-element (make-xml-element :name name + :attributes attributes + :children (nreverse seed)))) + (cons xml-element parent-seed))) + +(defun standard-text-hook (string seed) + (cons string seed)) + +;;; top level standard parser interfaces + +(defmethod parse-xml-dom (stream (output-type (eql :xml-struct))) + (car (start-parse-xml stream + (make-instance 'xml-parser-state + :new-element-hook #'standard-new-element-hook + :finish-element-hook #'standard-finish-element-hook + :text-hook #'standard-text-hook)))) + +;;;; eof diff --git a/third_party/lisp/s-xml/src/xml.lisp b/third_party/lisp/s-xml/src/xml.lisp new file mode 100644 index 0000000000..8a2076985a --- /dev/null +++ b/third_party/lisp/s-xml/src/xml.lisp @@ -0,0 +1,702 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: xml.lisp,v 1.15 2006/01/19 20:00:06 scaekenberghe Exp $ +;;;; +;;;; This is a Common Lisp implementation of a basic but usable XML parser. +;;;; The parser is non-validating and not complete (no PI). +;;;; Namespace and entities are handled. +;;;; The API into the parser is a pure functional parser hook model that comes from SSAX, +;;;; see also http://pobox.com/~oleg/ftp/Scheme/xml.html or http://ssax.sourceforge.net +;;;; Different DOM models are provided, an XSML, an LXML and a xml-element struct based one. +;;;; +;;;; Copyright (C) 2002, 2003, 2004, 2005, 2006 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +;;; (tazjin): moved up here because something was wonky with the +;;; definition order +(defvar *ignore-namespaces* nil + "When t, namespaces are ignored like in the old version of S-XML") + +;;; error reporting + +(define-condition xml-parser-error (error) + ((message :initarg :message :reader xml-parser-error-message) + (args :initarg :args :reader xml-parser-error-args) + (stream :initarg :stream :reader xml-parser-error-stream :initform nil)) + (:report (lambda (condition stream) + (format stream + "XML parser ~?~@[ near stream position ~d~]." + (xml-parser-error-message condition) + (xml-parser-error-args condition) + (and (xml-parser-error-stream condition) + (file-position (xml-parser-error-stream condition)))))) + (:documentation "Thrown by the XML parser to indicate errorneous input")) + +(setf (documentation 'xml-parser-error-message 'function) + "Get the message from an XML parser error" + (documentation 'xml-parser-error-args 'function) + "Get the error arguments from an XML parser error" + (documentation 'xml-parser-error-stream 'function) + "Get the stream from an XML parser error") + +(defun parser-error (message &optional args stream) + (make-condition 'xml-parser-error + :message message + :args args + :stream stream)) + +;; attribute parsing hooks +;; this is a bit complicated, refer to the mailing lists for a more detailed explanation + +(defun parse-attribute-name (string) + "Default parser for the attribute name" + (declare (special *namespaces*)) + (resolve-identifier string *namespaces* t)) + +(defun parse-attribute-value (name string) + "Default parser for the attribute value" + (declare (ignore name) + (special *ignore-namespace*)) + (if *ignore-namespaces* + (copy-seq string) + string)) + +(defparameter *attribute-name-parser* #'parse-attribute-name + "Called to compute interned attribute name from a buffer that will be reused") + +(defparameter *attribute-value-parser* #'parse-attribute-value + "Called to compute an element of an attribute list from a buffer that will be reused") + +;;; utilities + +(defun whitespace-char-p (char) + "Is char an XML whitespace character ?" + (declare (type character char)) + (or (char= char #\space) + (char= char #\tab) + (char= char #\return) + (char= char #\linefeed))) + +(defun identifier-char-p (char) + "Is char an XML identifier character ?" + (declare (type character char)) + (or (and (char<= #\A char) (char<= char #\Z)) + (and (char<= #\a char) (char<= char #\z)) + (and (char<= #\0 char) (char<= char #\9)) + (char= char #\-) + (char= char #\_) + (char= char #\.) + (char= char #\:))) + +(defun skip-whitespace (stream) + "Skip over XML whitespace in stream, return first non-whitespace + character which was peeked but not read, return nil on eof" + (loop + (let ((char (peek-char nil stream nil #\Null))) + (declare (type character char)) + (if (whitespace-char-p char) + (read-char stream) + (return char))))) + +(defun make-extendable-string (&optional (size 10)) + "Make an extendable string which is a one-dimensional character + array which is adjustable and has a fill pointer" + (make-array size + :element-type 'character + :adjustable t + :fill-pointer 0)) + +(defun print-string-xml (string stream &key (start 0) end) + "Write the characters of string to stream using basic XML conventions" + (loop for offset upfrom start below (or end (length string)) + for char = (char string offset) + do (case char + (#\& (write-string "&" stream)) + (#\< (write-string "<" stream)) + (#\> (write-string ">" stream)) + (#\" (write-string """ stream)) + ((#\newline #\return #\tab) (write-char char stream)) + (t (if (and (<= 32 (char-code char)) + (<= (char-code char) 126)) + (write-char char stream) + (progn + (write-string "&#x" stream) + (write (char-code char) :stream stream :base 16) + (write-char #\; stream))))))) + +(defun make-standard-entities () + "A hashtable mapping XML entity names to their replacement strings, + filled with the standard set" + (let ((entities (make-hash-table :test #'equal))) + (setf (gethash "amp" entities) (string #\&) + (gethash "quot" entities) (string #\") + (gethash "apos" entities) (string #\') + (gethash "lt" entities) (string #\<) + (gethash "gt" entities) (string #\>) + (gethash "nbsp" entities) (string #\space)) + entities)) + +(defun resolve-entity (stream extendable-string entities entity) + "Read and resolve an XML entity from stream, positioned after the '&' entity marker, + accepting &name; &#DEC; and &#xHEX; formats, + destructively modifying string, which is also returned, + destructively modifying entity, incorrect entity formats result in errors" + (declare (type (vector character) entity)) + (loop + (let ((char (read-char stream nil #\Null))) + (declare (type character char)) + (cond ((char= char #\Null) (error (parser-error "encountered eof before end of entity"))) + ((char= #\; char) (return)) + (t (vector-push-extend char entity))))) + (if (char= (char entity 0) #\#) + (let ((code (if (char= (char entity 1) #\x) + (parse-integer entity :start 2 :radix 16 :junk-allowed t) + (parse-integer entity :start 1 :radix 10 :junk-allowed t)))) + (when (null code) + (error (parser-error "encountered incorrect entity &~s;" (list entity) stream))) + (vector-push-extend (code-char code) extendable-string)) + (let ((value (gethash entity entities))) + (if value + (loop :for char :across value + :do (vector-push-extend char extendable-string)) + (error (parser-error "encountered unknown entity &~s;" (list entity) stream))))) + extendable-string) + +;;; namespace support + +(defclass xml-namespace () + ((uri :documentation "The URI used to identify this namespace" + :accessor get-uri + :initarg :uri) + (prefix :documentation "The preferred prefix assigned to this namespace" + :accessor get-prefix + :initarg :prefix + :initform nil) + (package :documentation "The Common Lisp package where this namespace's symbols are interned" + :accessor get-package + :initarg :package + :initform nil)) + (:documentation "Describes an XML namespace and how it is handled")) + +(setf (documentation 'get-uri 'function) + "The URI used to identify this namespace" + (documentation 'get-prefix 'function) + "The preferred prefix assigned to this namespace" + (documentation 'get-package 'function) + "The Common Lisp package where this namespace's symbols are interned") + +(defmethod print-object ((object xml-namespace) stream) + (print-unreadable-object (object stream :type t :identity t) + (format stream "~A - ~A" (get-prefix object) (get-uri object)))) + +(defvar *local-namespace* (make-instance 'xml-namespace + :uri "local" + :prefix "" + :package (find-package :keyword)) + "The local (global default) XML namespace") + +(defvar *xml-namespace* (make-instance 'xml-namespace + :uri "http://www.w3.org/XML/1998/namespace" + :prefix "xml" + :package (or (find-package :xml) + (make-package :xml :nicknames '("XML")))) + "REC-xml-names-19990114 says the prefix xml is bound to the namespace http://www.w3.org/XML/1998/namespace.") + +(defvar *known-namespaces* (list *local-namespace* *xml-namespace*) + "The list of known/defined namespaces") + +(defvar *namespaces* `(("xml" . ,*xml-namespace*) ("" . ,*local-namespace*)) + "Ordered list of (prefix . XML-namespace) bindings currently in effect - special variable") + +(defun find-namespace (uri) + "Find a registered XML namespace identified by uri" + (find uri *known-namespaces* :key #'get-uri :test #'string-equal)) + +(defun register-namespace (uri prefix package) + "Register a new or redefine an existing XML namespace defined by uri with prefix and package" + (let ((namespace (find-namespace uri))) + (if namespace + (setf (get-prefix namespace) prefix + (get-package namespace) (find-package package)) + (push (setf namespace (make-instance 'xml-namespace + :uri uri + :prefix prefix + :package (find-package package))) + *known-namespaces*)) + namespace)) + +(defun find-namespace-binding (prefix namespaces) + "Find the XML namespace currently bound to prefix in the namespaces bindings" + (cdr (assoc prefix namespaces :test #'string-equal))) + +(defun split-identifier (identifier) + "Split an identifier 'prefix:name' and return (values prefix name)" + (when (symbolp identifier) + (setf identifier (symbol-name identifier))) + (let ((colon-position (position #\: identifier :test #'char=))) + (if colon-position + (values (subseq identifier 0 colon-position) + (subseq identifier (1+ colon-position))) + (values nil identifier)))) + +(defvar *require-existing-symbols* nil + "If t, each XML identifier must exist as symbol already") + +(defvar *auto-export-symbols* t + "If t, export newly interned symbols form their packages") + +(defun resolve-identifier (identifier namespaces &optional as-attribute) + "Resolve the string identifier in the list of namespace bindings" + (if *ignore-namespaces* + (intern identifier :keyword) + (flet ((intern-symbol (string package) ; intern string as a symbol in package + (if *require-existing-symbols* + (let ((symbol (find-symbol string package))) + (or symbol + (error "Symbol ~s does not exist in ~s" string package))) + (let ((symbol (intern string package))) + (when (and *auto-export-symbols* + (not (eql package (find-package :keyword)))) + (export symbol package)) + symbol)))) + (multiple-value-bind (prefix name) + (split-identifier identifier) + (if (or (null prefix) (string= prefix "xmlns")) + (if as-attribute + (intern (if (string= prefix "xmlns") identifier name) (get-package *local-namespace*)) + (let ((default-namespace (find-namespace-binding "" namespaces))) + (intern-symbol name (get-package default-namespace)))) + (let ((namespace (find-namespace-binding prefix namespaces))) + (if namespace + (intern-symbol name (get-package namespace)) + (error "namespace not found for prefix ~s" prefix)))))))) + +(defvar *auto-create-namespace-packages* t + "If t, new packages will be created for namespaces, if needed, named by the prefix") + +(defun new-namespace (uri &optional prefix) + "Register a new namespace for uri and prefix, creating a package if necessary" + (if prefix + (register-namespace uri + prefix + (or (find-package prefix) + (if *auto-create-namespace-packages* + (make-package prefix :nicknames `(,(string-upcase prefix))) + (error "Cannot find or create package ~s" prefix)))) + (let ((unique-name (loop :for i :upfrom 0 + :do (let ((name (format nil "ns-~d" i))) + (when (not (find-package name)) + (return name)))))) + (register-namespace uri + unique-name + (if *auto-create-namespace-packages* + (make-package (string-upcase unique-name) :nicknames `(,unique-name)) + (error "Cannot create package ~s" unique-name)))))) + +(defun extend-namespaces (attributes namespaces) + "Given possible 'xmlns[:prefix]' attributes, extend the namespaces bindings" + (unless *ignore-namespaces* + (let (default-namespace-uri) + (loop :for (key . value) :in attributes + :do (if (string= key "xmlns") + (setf default-namespace-uri value) + (multiple-value-bind (prefix name) + (split-identifier key) + (when (string= prefix "xmlns") + (let* ((uri value) + (prefix name) + (namespace (find-namespace uri))) + (unless namespace + (setf namespace (new-namespace uri prefix))) + (push `(,prefix . ,namespace) namespaces)))))) + (when default-namespace-uri + (let ((namespace (find-namespace default-namespace-uri))) + (unless namespace + (setf namespace (new-namespace default-namespace-uri))) + (push `("" . ,namespace) namespaces))))) + namespaces) + +(defun print-identifier (identifier stream &optional as-attribute) + "Print identifier on stream using namespace conventions" + (declare (ignore as-attribute) (special *namespaces*)) + (if *ignore-namespaces* + (princ identifier stream) + (if (symbolp identifier) + (let ((package (symbol-package identifier)) + (name (symbol-name identifier))) + (let* ((namespace (find package *known-namespaces* :key #'get-package)) + (prefix (or (car (find namespace *namespaces* :key #'cdr)) + (get-prefix namespace)))) + (if (string= prefix "") + (princ name stream) + (format stream "~a:~a" prefix name)))) + (princ identifier stream)))) + +;;; the parser state + +(defclass xml-parser-state () + ((entities :documentation "A hashtable mapping XML entity names to their replacement stings" + :accessor get-entities + :initarg :entities + :initform (make-standard-entities)) + (seed :documentation "The user seed object" + :accessor get-seed + :initarg :seed + :initform nil) + (buffer :documentation "The main reusable character buffer" + :accessor get-buffer + :initform (make-extendable-string)) + (mini-buffer :documentation "The secondary, smaller reusable character buffer" + :accessor get-mini-buffer + :initform (make-extendable-string)) + (new-element-hook :documentation "Called when new element starts" + ;; Handle the start of a new xml element with name and attributes, + ;; receiving seed from previous element (sibling or parent) + ;; return seed to be used for first child (content) + ;; or directly to finish-element-hook + :accessor get-new-element-hook + :initarg :new-element-hook + :initform #'(lambda (name attributes seed) + (declare (ignore name attributes)) + seed)) + (finish-element-hook :documentation "Called when element ends" + ;; Handle the end of an xml element with name and attributes, + ;; receiving parent-seed, the seed passed to us when this element started, + ;; i.e. passed to our corresponding new-element-hook + ;; and receiving seed from last child (content) + ;; or directly from new-element-hook + ;; return final seed for this element to next element (sibling or parent) + :accessor get-finish-element-hook + :initarg :finish-element-hook + :initform #'(lambda (name attributes parent-seed seed) + (declare (ignore name attributes parent-seed)) + seed)) + (text-hook :documentation "Called when text is found" + ;; Handle text in string, found as contents, + ;; receiving seed from previous element (sibling or parent), + ;; return final seed for this element to next element (sibling or parent) + :accessor get-text-hook + :initarg :text-hook + :initform #'(lambda (string seed) + (declare (ignore string)) + seed))) + (:documentation "The XML parser state passed along all code making up the parser")) + +(setf (documentation 'get-seed 'function) + "Get the initial user seed of an XML parser state" + (documentation 'get-entities 'function) + "Get the entities hashtable of an XML parser state" + (documentation 'get-new-element-hook 'function) + "Get the new element hook of an XML parser state" + (documentation 'get-finish-element-hook 'function) + "Get the finish element hook of an XML parser state" + (documentation 'get-text-hook 'function) + "Get the text hook of an XML parser state") + +#-allegro +(setf (documentation '(setf get-seed) 'function) + "Set the initial user seed of an XML parser state" + (documentation '(setf get-entities) 'function) + "Set the entities hashtable of an XML parser state" + (documentation '(setf get-new-element-hook) 'function) + "Set the new element hook of an XML parser state" + (documentation '(setf get-finish-element-hook) 'function) + "Set the finish element hook of an XML parser state" + (documentation '(setf get-text-hook) 'function) + "Set the text hook of an XML parser state") + +(defmethod get-mini-buffer :after ((state xml-parser-state)) + "Reset and return the reusable mini buffer" + (with-slots (mini-buffer) state + (setf (fill-pointer mini-buffer) 0))) + +(defmethod get-buffer :after ((state xml-parser-state)) + "Reset and return the main reusable buffer" + (with-slots (buffer) state + (setf (fill-pointer buffer) 0))) + +;;; parser support + +(defun parse-whitespace (stream extendable-string) + "Read and collect XML whitespace from stream in string which is + destructively modified, return first non-whitespace character which + was peeked but not read, return #\Null on eof" + (declare (type (vector character) extendable-string)) + (loop + (let ((char (peek-char nil stream nil #\Null))) + (declare (type character char)) + (if (whitespace-char-p char) + (vector-push-extend (read-char stream) extendable-string) + (return char))))) + +(defun parse-string (stream state string) + "Read and return an XML string from stream, delimited by either + single or double quotes, the stream is expected to be on the opening + delimiter, at the end the closing delimiter is also read, entities + are resolved, eof before end of string is an error" + (declare (type (vector character) string)) + (let ((delimiter (read-char stream nil #\Null)) + (char #\Null)) + (declare (type character delimiter char)) + (unless (or (char= delimiter #\') (char= delimiter #\")) + (error (parser-error "expected string delimiter" nil stream))) + (loop + (setf char (read-char stream nil #\Null)) + (cond ((char= char #\Null) (error (parser-error "encountered eof before end of string"))) + ((char= char delimiter) (return)) + ((char= char #\&) (resolve-entity stream string (get-entities state) (get-mini-buffer state))) + (t (vector-push-extend char string)))) + string)) + +(defun parse-text (stream state extendable-string) + "Read and collect XML text from stream in string which is + destructively modified, the text ends with a '<', which is peeked and + returned, entities are resolved, eof is considered an error" + (declare (type (vector character) extendable-string)) + (let ((char #\Null)) + (declare (type character char)) + (loop + (setf char (peek-char nil stream nil #\Null)) + (when (char= char #\Null) (error (parser-error "encountered unexpected eof in text"))) + (when (char= char #\<) (return)) + (read-char stream) + (if (char= char #\&) + (resolve-entity stream extendable-string (get-entities state) (get-mini-buffer state)) + (vector-push-extend char extendable-string))) + char)) + +(defun parse-identifier (stream identifier) + "Read and returns an XML identifier from stream, positioned at the + start of the identifier, ending with the first non-identifier + character, which is peeked, the identifier is written destructively + into identifier which is also returned" + (declare (type (vector character) identifier)) + (loop + (let ((char (read-char stream nil #\Null))) + (declare (type character char)) + (cond ((identifier-char-p char) + (vector-push-extend char identifier)) + (t + (when (char/= char #\Null) (unread-char char stream)) + (return identifier)))))) + +(defun skip-comment (stream) + "Skip an XML comment in stream, positioned after the opening '<!--', + consumes the closing '-->' sequence, unexpected eof or a malformed + closing sequence result in a error" + (let ((dashes-to-read 2)) + (loop + (if (zerop dashes-to-read) (return)) + (let ((char (read-char stream nil #\Null))) + (declare (type character char)) + (if (char= char #\Null) + (error (parser-error "encountered unexpected eof for comment"))) + (if (char= char #\-) + (decf dashes-to-read) + (setf dashes-to-read 2))))) + (if (char/= (read-char stream nil #\Null) #\>) + (error (parser-error "expected > ending comment" nil stream)))) + +(defun read-cdata (stream state string) + "Reads in the CDATA and calls the callback for CDATA if it exists" + ;; we already read the <![CDATA[ stuff + ;; continue to read until we hit ]]> + (let ((char #\space) + (last-3-characters (list #\[ #\A #\T)) + (pattern (list #\> #\] #\]))) + (declare (type character char)) + (loop + (setf char (read-char stream nil #\Null)) + (when (char= char #\Null) (error (parser-error "encountered unexpected eof in text"))) + (push char last-3-characters) + (setf (cdddr last-3-characters) nil) + (cond + ((equal last-3-characters + pattern) + (setf (fill-pointer string) + (- (fill-pointer string) 2)) + (setf (get-seed state) + (funcall (get-text-hook state) + (copy-seq string) + (get-seed state))) + (return-from read-cdata)) + (t + (vector-push-extend char string)))))) + +(defun skip-special-tag (stream state) + "Skip an XML special tag (comments and processing instructions) in + stream, positioned after the opening '<', unexpected eof is an error" + ;; opening < has been read, consume ? or ! + (read-char stream) + (let ((char (read-char stream nil #\Null))) + (declare (type character char)) + ;; see if we are dealing with a comment + (when (char= char #\-) + (setf char (read-char stream nil #\Null)) + (when (char= char #\-) + (skip-comment stream) + (return-from skip-special-tag))) + ;; maybe we are dealing with CDATA? + (when (and (char= char #\[) + (loop :for pattern :across "CDATA[" + :for char = (read-char stream nil #\Null) + :when (char= char #\Null) :do + (error (parser-error "encountered unexpected eof in cdata")) + :always (char= char pattern))) + (read-cdata stream state (get-buffer state)) + (return-from skip-special-tag)) + ;; loop over chars, dealing with strings (skipping their content) + ;; and counting opening and closing < and > chars + (let ((taglevel 1) + (string-delimiter #\Null)) + (declare (type character string-delimiter)) + (loop + (when (zerop taglevel) (return)) + (setf char (read-char stream nil #\Null)) + (when (char= char #\Null) + (error (parser-error "encountered unexpected eof for special (! or ?) tag" nil stream))) + (if (char/= string-delimiter #\Null) + ;; inside a string we only look for a closing string delimiter + (when (char= char string-delimiter) + (setf string-delimiter #\Null)) + ;; outside a string we count < and > and watch out for strings + (cond ((or (char= char #\') (char= char #\")) (setf string-delimiter char)) + ((char= char #\<) (incf taglevel)) + ((char= char #\>) (decf taglevel)))))))) + +;;; the XML parser proper + +(defun parse-xml-element-attributes (stream state) + "Parse XML element attributes from stream positioned after the tag + identifier, returning the attributes as an assoc list, ending at + either a '>' or a '/' which is peeked and also returned" + (declare (special *namespaces*)) + (let ((char #\Null) attributes) + (declare (type character char)) + (loop + ;; skip whitespace separating items + (setf char (skip-whitespace stream)) + ;; start tag attributes ends with > or /> + (when (or (char= char #\>) (char= char #\/)) (return)) + ;; read the attribute key + (let ((key (let ((string (parse-identifier stream (get-mini-buffer state)))) + (if *ignore-namespaces* + (funcall *attribute-name-parser* string) + (copy-seq string))))) + ;; skip separating whitespace + (setf char (skip-whitespace stream)) + ;; require = sign (and consume it if present) + (if (char= char #\=) + (read-char stream) + (error (parser-error "expected =" nil stream))) + ;; skip separating whitespace + (skip-whitespace stream) + ;; read the attribute value as a string + (push (cons key (let ((string (parse-string stream state (get-buffer state)))) + (if *ignore-namespaces* + (funcall *attribute-value-parser* key string) + (copy-seq string)))) + attributes))) + ;; return attributes peek char ending loop + (values attributes char))) + +(defun parse-xml-element (stream state) + "Parse and return an XML element from stream, positioned after the opening '<'" + (declare (special *namespaces*)) + ;; opening < has been read + (when (char= (peek-char nil stream nil #\Null) #\!) + (skip-special-tag stream state) + (return-from parse-xml-element)) + (let ((char #\Null) buffer open-tag parent-seed has-children) + (declare (type character char)) + (setf parent-seed (get-seed state)) + ;; read tag name (no whitespace between < and name ?) + (setf open-tag (copy-seq (parse-identifier stream (get-mini-buffer state)))) + ;; tag has been read, read attributes if any + (multiple-value-bind (attributes peeked-char) + (parse-xml-element-attributes stream state) + (let ((*namespaces* (extend-namespaces attributes *namespaces*))) + (setf open-tag (resolve-identifier open-tag *namespaces*)) + (unless *ignore-namespaces* + (dolist (attribute attributes) + (setf (car attribute) (funcall *attribute-name-parser* (car attribute)) + (cdr attribute) (funcall *attribute-value-parser* (car attribute) (cdr attribute))))) + (setf (get-seed state) (funcall (get-new-element-hook state) + open-tag attributes (get-seed state))) + (setf char peeked-char) + (when (char= char #\/) + ;; handle solitary tag of the form <tag .. /> + (read-char stream) + (setf char (read-char stream nil #\Null)) + (if (char= #\> char) + (progn + (setf (get-seed state) (funcall (get-finish-element-hook state) + open-tag attributes parent-seed (get-seed state))) + (return-from parse-xml-element)) + (error (parser-error "expected >" nil stream)))) + ;; consume > + (read-char stream) + (loop + (setf buffer (get-buffer state)) + ;; read whitespace into buffer + (setf char (parse-whitespace stream buffer)) + ;; see what ended the whitespace scan + (cond ((char= char #\Null) (error (parser-error "encountered unexpected eof handling ~a" + (list open-tag)))) + ((char= char #\<) + ;; consume the < + (read-char stream) + (if (char= (peek-char nil stream nil #\Null) #\/) + (progn + ;; handle the matching closing tag </tag> and done + ;; if we read whitespace as this (leaf) element's contents, it is significant + (when (and (not has-children) (plusp (length buffer))) + (setf (get-seed state) (funcall (get-text-hook state) + (copy-seq buffer) (get-seed state)))) + (read-char stream) + (let ((close-tag (resolve-identifier (parse-identifier stream (get-mini-buffer state)) + *namespaces*))) + (unless (eq open-tag close-tag) + (error (parser-error "found <~a> not matched by </~a> but by <~a>" + (list open-tag open-tag close-tag) stream))) + (unless (char= (read-char stream nil #\Null) #\>) + (error (parser-error "expected >" nil stream))) + (setf (get-seed state) (funcall (get-finish-element-hook state) + open-tag attributes parent-seed (get-seed state)))) + (return)) + ;; handle child tag and loop, no hooks to call here + ;; whitespace between child elements is skipped + (progn + (setf has-children t) + (parse-xml-element stream state)))) + (t + ;; no child tag, concatenate text to whitespace in buffer + ;; handle text content and loop + (setf char (parse-text stream state buffer)) + (setf (get-seed state) (funcall (get-text-hook state) + (copy-seq buffer) (get-seed state)))))))))) + +(defun start-parse-xml (stream &optional (state (make-instance 'xml-parser-state))) + "Parse and return a toplevel XML element from stream, using parser state" + (loop + (let ((char (skip-whitespace stream))) + (when (char= char #\Null) (return-from start-parse-xml)) + ;; skip whitespace until start tag + (unless (char= char #\<) + (error (parser-error "expected <" nil stream))) + (read-char stream) ; consume peeked char + (setf char (peek-char nil stream nil #\Null)) + (if (or (char= char #\!) (char= char #\?)) + ;; deal with special tags + (skip-special-tag stream state) + (progn + ;; read the main element + (parse-xml-element stream state) + (return-from start-parse-xml (get-seed state))))))) + +;;;; eof diff --git a/third_party/lisp/s-xml/test/ant-build-file.xml b/third_party/lisp/s-xml/test/ant-build-file.xml new file mode 100644 index 0000000000..91d78707b8 --- /dev/null +++ b/third_party/lisp/s-xml/test/ant-build-file.xml @@ -0,0 +1,252 @@ +<!-- $Id: ant-build-file.xml,v 1.1 2003/03/18 08:22:09 sven Exp $ --> +<!-- Ant 1.2 build file --> + +<project name="Libretto" default="compile" basedir="."> + + <!-- set global properties for this build --> + <property name="src" value="${basedir}/src" /> + <property name="rsrc" value="${basedir}/rsrc" /> + <property name="build" value="${basedir}/bin" /> + <property name="api" value="${basedir}/api" /> + <property name="lib" value="${basedir}/lib" /> + <property name="junit" value="${basedir}/junit" /> + <property name="rsrc" value="${basedir}/rsrc" /> + + <target name="prepare"> + <!-- Create the time stamp --> + <tstamp/> + <!-- Create the build directory structure used by compile --> + <mkdir dir="${build}" /> + <mkdir dir="${api}" /> + <mkdir dir="${junit}" /> + <copy file="${rsrc}/build/build.version" tofile="${build}/build.properties"/> + <replace file="${build}/build.properties" token="@@@BUILD_ID@@@" value="${DSTAMP}-${TSTAMP}"/> + </target> + + <target name="compile" depends="copy-rsrc"> + <!-- Compile the java code from ${src} into ${build} --> + <javac srcdir="${src}" destdir="${build}" debug="on"> + <classpath> + <fileset dir="${lib}"> + <include name="log4j-core.jar" /> + <include name="jaxp.jar" /> + <include name="crimson.jar" /> + <include name="jdom.jar" /> + <include name="beanshell.jar" /> + </fileset> + </classpath> + </javac> + </target> + + <target name="compile-junit" depends="copy-rsrc"> + <!-- Compile the java code from ${src} into ${build} --> + <javac srcdir="${junit}" destdir="${build}" debug="on"> + <classpath> + <fileset dir="${lib}"> + <include name="*.jar" /> + </fileset> + </classpath> + </javac> + </target> + + <target name="copy-rsrc" depends="prepare"> + <!-- Copy various resource files into ${build} --> + <copy todir="${build}"> + <fileset + dir="${basedir}" + includes="images/*.gif, images/*.jpg" /> + </copy> + <copy todir="${build}"> + <fileset + dir="${src}" + includes="be/beta9/libretto/data/*.txt" /> + </copy> + <copy todir="${build}"> + <fileset + dir="${rsrc}/log4j" + includes="log4j.properties" /> + </copy> + </target> + + <target name="c-header" depends="compile"> + <javah destdir="${rsrc}/VC_source" class="be.beta9.libretto.io.ParallelPort"> + <classpath> + <pathelement location="${build}" /> + </classpath> + </javah> + </target> + + <target name="test-parport" depends="compile"> + <java + classname="be.beta9.libretto.io.ParallelPortWriter" + fork="yes"> + <classpath> + <pathelement location="${build}" /> + <fileset dir="${lib}"> + <include name="*.jar" /> + </fileset> + </classpath> + </java> + </target> + + <target name="jar-simple" depends="compile"> + <!-- Put everything in ${build} into the a jar file --> + <jar + jarfile="${basedir}/libretto.jar" + basedir="${build}" + manifest="${rsrc}/manifest/libretto.mf"/> + </target> + + <target name="jar" depends="compile"> + <!-- Put everything in ${build} into the a jar file including all dependecies --> + <unjar src="${lib}/jaxp.jar" dest="${build}" /> + <unjar src="${lib}/crimson.jar" dest="${build}" /> + <unjar src="${lib}/jdom.jar" dest="${build}" /> + <unjar src="${lib}/log4j-core.jar" dest="${build}" /> + <jar + jarfile="${basedir}/libretto.jar" + basedir="${build}" + manifest="${rsrc}/manifest/libretto.mf"/> + </target> + + <target name="client-jar" depends="background-jar"> + <!-- Put everything in ${build} into the a jar file including all dependecies --> + <unjar src="${lib}/log4j-core.jar" dest="${build}" /> + <jar jarfile="${basedir}/libretto-client.jar" manifest="${rsrc}/manifest/libretto-client.mf"> + <fileset dir="${build}"> + <include name="build.properties"/> + <include name="log4j.properties"/> + <include name="be/beta9/libretto/io/*.class"/> + <include name="be/beta9/libretto/application/Build.class"/> + <include name="be/beta9/libretto/net/LibrettoTextClient*.class"/> + <include name="be/beta9/libretto/net/TestClientMessage.class"/> + <include name="be/beta9/libretto/net/ClientStatusMessageResult.class"/> + <include name="be/beta9/libretto/net/Client*.class"/> + <include name="be/beta9/libretto/net/Constants.class"/> + <include name="be/beta9/libretto/net/TextMessage.class"/> + <include name="be/beta9/libretto/net/MessageResult.class"/> + <include name="be/beta9/libretto/net/MessageException.class"/> + <include name="be/beta9/libretto/net/SingleTextMessage.class"/> + <include name="be/beta9/libretto/net/Message.class"/> + <include name="be/beta9/libretto/net/Util.class"/> + <include name="be/beta9/libretto/gui/ShowSingleTextFrame*.class"/> + <include name="be/beta9/libretto/gui/AWTTextView*.class"/> + <include name="be/beta9/libretto/model/AttributedString*.class"/> + <include name="be/beta9/libretto/model/AWTTextStyle.class"/> + <include name="be/beta9/libretto/model/LTextStyle.class"/> + <include name="be/beta9/libretto/model/AWTCharacterAttributes.class"/> + <include name="be/beta9/libretto/model/Java2DTextStyle.class"/> + <include name="be/beta9/libretto/model/LCharacterAttributes.class"/> + <include name="be/beta9/libretto/model/Java2DCharacterAttributes.class"/> + <include name="be/beta9/libretto/util/TextStyleManager.class"/> + <include name="be/beta9/libretto/util/Bean.class"/> + <include name="be/beta9/libretto/util/LibrettoSaxReader.class"/> + <include name="be/beta9/libretto/util/Preferences.class"/> + <include name="be/beta9/libretto/util/Utilities.class"/> + <include name="org/apache/log4j/**"/> + </fileset> + </jar> + </target> + + <target name="background-jar" depends="compile"> + <!-- Put everything in ${build} into the a jar file including all dependecies --> + <jar jarfile="${basedir}/background.jar" manifest="${rsrc}/manifest/background-black-window.mf"> + <fileset dir="${build}"> + <include name="be/beta9/libretto/gui/BackgroundBlackWindow.class"/> + </fileset> + </jar> + </target> + + <target name="run" depends="compile"> + <!-- Execute the main application --> + <java + classname="be.beta9.libretto.application.Libretto" + fork="yes"> + <classpath> + <pathelement location="${build}" /> + <fileset dir="${lib}"> + <include name="log4j-core.jar" /> + <include name="jaxp.jar" /> + <include name="crimson.jar" /> + <include name="jdom.jar" /> + </fileset> + </classpath> + </java> + </target> + + <target name="debug" depends="compile"> + <!-- Execute the main application in debug mode --> + <java + classname="be.beta9.libretto.application.LibrettoDebug" + fork="yes"> + <classpath> + <pathelement location="${build}" /> + <fileset dir="${lib}"> + <include name="*.jar" /> + </fileset> + </classpath> + </java> + </target> + + <target name="junit" depends="compile-junit"> + <!-- Execute all junit tests --> + <java + classname="be.beta9.libretto.AllTests" + fork="yes"> + <classpath> + <pathelement location="${build}" /> + <fileset dir="${lib}"> + <include name="*.jar" /> + </fileset> + </classpath> + </java> + </target> + + <target name="clean"> + <!-- Delete the ${build} directory trees --> + <delete dir="${build}" /> + <delete dir="${api}" /> + </target> + + <target name="api" depends="prepare"> + <!-- Generate javadoc --> + <javadoc + packagenames="be.beta9.libretto.*" + sourcepath="${src}" + destdir="${api}" + windowtitle="Libretto" + author="true" + version="true" + use="true"/> + </target> + + <target name="zip-all" depends="jar, client-jar"> + <zip zipfile="libretto.zip"> + <fileset dir="${basedir}"> + <include name="libretto.jar"/> + <include name="libretto-client.jar"/> + </fileset> + </zip> + </target> + + <target name="upload" depends="clean, zip-all"> + <ftp + server="users.pandora.be" + userid="a002458" + password="bast0s" + remotedir="libretto" + verbose="true" + passive="true"> + <fileset dir="${basedir}"> + <include name="libretto.jar" /> + <include name="libretto-client.jar" /> + <include name="libretto.zip" /> + </fileset> + </ftp> + </target> + +</project> + + + + diff --git a/third_party/lisp/s-xml/test/plist.xml b/third_party/lisp/s-xml/test/plist.xml new file mode 100644 index 0000000000..910e6326ea --- /dev/null +++ b/third_party/lisp/s-xml/test/plist.xml @@ -0,0 +1,38 @@ +<?xml version="1.0" encoding="UTF-8"?> +<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> +<plist version="1.0"> +<dict> + <key>AppleDockIconEnabled</key> + <true/> + <key>AppleNavServices:GetFile:0:Path</key> + <string>file://localhost/Users/sven/Pictures/</string> + <key>AppleNavServices:GetFile:0:Position</key> + <data> + AOUBXw== + </data> + <key>AppleNavServices:GetFile:0:Size</key> + <data> + AAAAAAFeAcI= + </data> + <key>AppleNavServices:PutFile:0:Disclosure</key> + <data> + AQ== + </data> + <key>AppleNavServices:PutFile:0:Path</key> + <string>file://localhost/Users/sven/Desktop/</string> + <key>AppleNavServices:PutFile:0:Position</key> + <data> + AUIBVQ== + </data> + <key>AppleNavServices:PutFile:0:Size</key> + <data> + AAAAAACkAdY= + </data> + <key>AppleSavePanelExpanded</key> + <string>YES</string> + <key>NSDefaultOpenDirectory</key> + <string>~/Desktop</string> + <key>NSNoBigString</key> + <true/> +</dict> +</plist> diff --git a/third_party/lisp/s-xml/test/simple.xml b/third_party/lisp/s-xml/test/simple.xml new file mode 100644 index 0000000000..08ad9424e3 --- /dev/null +++ b/third_party/lisp/s-xml/test/simple.xml @@ -0,0 +1,5 @@ +<?xml version="1.0"?> +<!-- This is a very simple XML document --> +<root id="123"> + <text>Hello World!</text> +</root> diff --git a/third_party/lisp/s-xml/test/test-lxml-dom.lisp b/third_party/lisp/s-xml/test/test-lxml-dom.lisp new file mode 100644 index 0000000000..248e1e4b90 --- /dev/null +++ b/third_party/lisp/s-xml/test/test-lxml-dom.lisp @@ -0,0 +1,86 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: test-lxml-dom.lisp,v 1.2 2005/11/06 12:44:48 scaekenberghe Exp $ +;;;; +;;;; Unit and functional tests for lxml-dom.lisp +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(assert + (equal (with-input-from-string (stream " <foo/>") + (parse-xml stream :output-type :lxml)) + :|foo|)) + +(assert + (equal (parse-xml-string "<tag1><tag2 att1='one'/>this is some text</tag1>" + :output-type :lxml) + '(:|tag1| + ((:|tag2| :|att1| "one")) + "this is some text"))) + +(assert + (equal (parse-xml-string "<TAG><foo></TAG>" + :output-type :lxml) + '(:TAG "<foo>"))) + +(assert + (equal (parse-xml-string + "<P><INDEX ITEM='one'/> This is some <B>bold</B> text, with a leading & trailing space </P>" + :output-type :lxml) + '(:p + ((:index :item "one")) + " This is some " + (:b "bold") + " text, with a leading & trailing space "))) + +(assert + (consp (parse-xml-file (merge-pathnames "test/xhtml-page.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :lxml))) + +(assert + (consp (parse-xml-file (merge-pathnames "test/ant-build-file.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :lxml))) + +(assert + (consp (parse-xml-file (merge-pathnames "test/plist.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :lxml))) + +(assert + (string-equal (print-xml-string :|foo| :input-type :lxml) + "<foo/>")) + +(assert + (string-equal (print-xml-string '((:|foo| :|bar| "1")) :input-type :lxml) + "<foo bar=\"1\"/>")) + +(assert + (string-equal (print-xml-string '(:foo "some text") :input-type :lxml) + "<FOO>some text</FOO>")) + +(assert + (string-equal (print-xml-string '(:|foo| :|bar|) :input-type :lxml) + "<foo><bar/></foo>")) + +(assert (string-equal (second + (with-input-from-string (stream "<foo><![CDATA[<greeting>Hello, world!</greeting>]]></foo>") + (parse-xml stream :output-type :lxml))) + "<greeting>Hello, world!</greeting>")) + +(assert (string-equal (second + (with-input-from-string (stream "<foo><![CDATA[<greeting>Hello, < world!</greeting>]]></foo>") + (parse-xml stream :output-type :lxml))) + "<greeting>Hello, < world!</greeting>")) + +;;;; eof diff --git a/third_party/lisp/s-xml/test/test-sxml-dom.lisp b/third_party/lisp/s-xml/test/test-sxml-dom.lisp new file mode 100644 index 0000000000..7164d5ef0d --- /dev/null +++ b/third_party/lisp/s-xml/test/test-sxml-dom.lisp @@ -0,0 +1,76 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: test-sxml-dom.lisp,v 1.1.1.1 2004/06/07 18:49:59 scaekenberghe Exp $ +;;;; +;;;; Unit and functional tests for sxml-dom.lisp +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(assert + (equal (with-input-from-string (stream " <foo/>") + (parse-xml stream :output-type :sxml)) + '(:|foo|))) + +(assert + (equal (parse-xml-string "<tag1><tag2 att1='one'/>this is some text</tag1>" + :output-type :sxml) + '(:|tag1| + (:|tag2| (:@ (:|att1| "one"))) + "this is some text"))) + +(assert + (equal (parse-xml-string "<TAG><foo></TAG>" + :output-type :sxml) + '(:TAG "<foo>"))) + +(assert + (equal (parse-xml-string + "<P><INDEX ITEM='one'/> This is some <B>bold</B> text, with a leading & trailing space </P>" + :output-type :sxml) + '(:p + (:index (:@ (:item "one"))) + " This is some " + (:b "bold") + " text, with a leading & trailing space "))) + +(assert + (consp (parse-xml-file (merge-pathnames "test/xhtml-page.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :sxml))) + +(assert + (consp (parse-xml-file (merge-pathnames "test/ant-build-file.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :sxml))) + +(assert + (consp (parse-xml-file (merge-pathnames "test/plist.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :sxml))) + +(assert + (string-equal (print-xml-string '(:|foo|) :input-type :sxml) + "<foo/>")) + +(assert + (string-equal (print-xml-string '(:|foo| (:@ (:|bar| "1"))) :input-type :sxml) + "<foo bar=\"1\"/>")) + +(assert + (string-equal (print-xml-string '(:foo "some text") :input-type :sxml) + "<FOO>some text</FOO>")) + +(assert + (string-equal (print-xml-string '(:|foo| (:|bar|)) :input-type :sxml) + "<foo><bar/></foo>")) + +;;;; eof \ No newline at end of file diff --git a/third_party/lisp/s-xml/test/test-xml-struct-dom.lisp b/third_party/lisp/s-xml/test/test-xml-struct-dom.lisp new file mode 100644 index 0000000000..f5ee1cc925 --- /dev/null +++ b/third_party/lisp/s-xml/test/test-xml-struct-dom.lisp @@ -0,0 +1,84 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: test-xml-struct-dom.lisp,v 1.2 2005/08/29 15:01:49 scaekenberghe Exp $ +;;;; +;;;; Unit and functional tests for xml-struct-dom.lisp +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(assert + (xml-equal (with-input-from-string (stream " <foo/>") + (parse-xml stream :output-type :xml-struct)) + (make-xml-element :name :|foo|))) + +(assert + (xml-equal (parse-xml-string "<tag1><tag2 att1='one'/>this is some text</tag1>" + :output-type :xml-struct) + (make-xml-element :name :|tag1| + :children (list (make-xml-element :name :|tag2| + :attributes '((:|att1| . "one"))) + "this is some text")))) + +(assert + (xml-equal (parse-xml-string "<tag><foo></tag>" + :output-type :xml-struct) + (make-xml-element :name :|tag| + :children (list "<foo>")))) + +(assert + (xml-equal (parse-xml-string + "<P><INDEX ITEM='one'/> This is some <B>bold</B> text, with a leading & trailing space </P>" + :output-type :xml-struct) + (make-xml-element :name :p + :children (list (make-xml-element :name :index + :attributes '((:item . "one"))) + " This is some " + (make-xml-element :name :b + :children (list "bold")) + " text, with a leading & trailing space ")))) + +(assert + (xml-element-p (parse-xml-file (merge-pathnames "test/xhtml-page.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :xml-struct))) + +(assert + (xml-element-p (parse-xml-file (merge-pathnames "test/ant-build-file.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :xml-struct))) + +(assert + (xml-element-p (parse-xml-file (merge-pathnames "test/plist.xml" + (asdf:component-pathname + (asdf:find-system :s-xml.test))) + :output-type :xml-struct))) + +(assert + (string-equal (print-xml-string (make-xml-element :name "foo") + :input-type :xml-struct) + "<foo/>")) + +(assert + (string-equal (print-xml-string (make-xml-element :name "foo" :attributes '((:|bar| . "1"))) + :input-type :xml-struct) + "<foo bar=\"1\"/>")) + +(assert + (string-equal (print-xml-string (make-xml-element :name "foo" :children (list "some text")) + :input-type :xml-struct) + "<foo>some text</foo>")) + +(assert + (string-equal (print-xml-string (make-xml-element :name "foo" :children (list (make-xml-element :name "bar"))) + :input-type :xml-struct) + "<foo><bar/></foo>")) + +;;;; eof \ No newline at end of file diff --git a/third_party/lisp/s-xml/test/test-xml.lisp b/third_party/lisp/s-xml/test/test-xml.lisp new file mode 100644 index 0000000000..daef58ea46 --- /dev/null +++ b/third_party/lisp/s-xml/test/test-xml.lisp @@ -0,0 +1,86 @@ +;;;; -*- mode: lisp -*- +;;;; +;;;; $Id: test-xml.lisp,v 1.3 2005/11/06 12:44:48 scaekenberghe Exp $ +;;;; +;;;; Unit and functional tests for xml.lisp +;;;; +;;;; Copyright (C) 2002, 2004 Sven Van Caekenberghe, Beta Nine BVBA. +;;;; +;;;; You are granted the rights to distribute and use this software +;;;; as governed by the terms of the Lisp Lesser General Public License +;;;; (http://opensource.franz.com/preamble.html), also known as the LLGPL. + +(in-package :s-xml) + +(assert + (whitespace-char-p (character " "))) + +(assert + (whitespace-char-p (character " "))) + +(assert + (whitespace-char-p (code-char 10))) + +(assert + (whitespace-char-p (code-char 13))) + +(assert + (not (whitespace-char-p #\A))) + +(assert + (char= (with-input-from-string (stream " ABC") + (skip-whitespace stream)) + #\A)) + +(assert + (char= (with-input-from-string (stream "ABC") + (skip-whitespace stream)) + #\A)) + +(assert + (string-equal (with-output-to-string (stream) (print-string-xml "<foo>" stream)) + "<foo>")) + +(assert + (string-equal (with-output-to-string (stream) (print-string-xml "' '" stream)) + "' '")) + +(assert + (let ((string (map 'string #'identity '(#\return #\tab #\newline)))) + (string-equal (with-output-to-string (stream) (print-string-xml string stream)) + string))) + +(defun simple-echo-xml (in out) + (start-parse-xml + in + (make-instance 'xml-parser-state + :new-element-hook #'(lambda (name attributes seed) + (declare (ignore seed)) + (format out "<~a~:{ ~a='~a'~}>" + name + (mapcar #'(lambda (p) (list (car p) (cdr p))) + (reverse attributes)))) + :finish-element-hook #'(lambda (name attributes parent-seed seed) + (declare (ignore attributes parent-seed seed)) + (format out "</~a>" name)) + :text-hook #'(lambda (string seed) + (declare (ignore seed)) + (princ string out))))) + +(defun simple-echo-xml-string (string) + (with-input-from-string (in string) + (with-output-to-string (out) + (simple-echo-xml in out)))) + +(dolist (*ignore-namespaces* '(nil t)) + (assert + (let ((xml "<FOO ATT1='1' ATT2='2'><B>Text</B><EMPTY></EMPTY>More text!<SUB><SUB></SUB></SUB></FOO>")) + (equal (simple-echo-xml-string xml) + xml)))) + +(assert + (let ((xml "<p> </p>")) + (equal (simple-echo-xml-string xml) + xml))) + +;;;; eof \ No newline at end of file diff --git a/third_party/lisp/s-xml/test/xhtml-page.xml b/third_party/lisp/s-xml/test/xhtml-page.xml new file mode 100644 index 0000000000..79f3ae3bad --- /dev/null +++ b/third_party/lisp/s-xml/test/xhtml-page.xml @@ -0,0 +1,271 @@ +<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> + +<html> +<head> + +<title>XHTML Tutorial</title> +<meta http-equiv="Content-Type" content="text/html; charset=windows-1252" /> +<meta name="Keywords" content="XML,tutorial,HTML,DHTML,CSS,XSL,XHTML,JavaScript,ASP,ADO,VBScript,DOM,authoring,programming,learning,beginner's guide,primer,lessons,school,howto,reference,examples,samples,source code,demos,tips,links,FAQ,tag list,forms,frames,color table,W3C,Cascading Style Sheets,Active Server Pages,Dynamic HTML,Internet database development,Webbuilder,Sitebuilder,Webmaster,HTMLGuide,SiteExpert" /> +<meta name="Description" content="HTML,CSS,JavaScript,DHTML,XML,XHTML,ASP,ADO and VBScript tutorial from W3Schools." /> +<meta http-equiv="pragma" content="no-cache" /> +<meta http-equiv="cache-control" content="no-cache" /> + +<link rel="stylesheet" type="text/css" href="../stdtheme.css" /> + +</head> +<body> + +<table border="0" cellpadding="0" cellspacing="0" width="775"> +<tr> +<td width="140" class="content" valign="top"> +<br /> +<a class="left" href="../default.asp" target="_top"><b>HOME</b></a><br /> +<br /> +<b>XHTML Tutorial</b><br /> +<a class="left" target="_top" href="default.asp" style='font-weight:bold;color:#000000;background-color:transparent;'>XHTML HOME</a><br /> +<a class="left" target="_top" href="xhtml_intro.asp" >XHTML Introduction</a><br /> +<a class="left" target="_top" href="xhtml_why.asp" >XHTML Why</a><br /> +<a class="left" target="_top" href="xhtml_html.asp" >XHTML v HTML</a><br /> +<a class="left" target="_top" href="xhtml_syntax.asp" >XHTML Syntax</a><br /> +<a class="left" target="_top" href="xhtml_dtd.asp" >XHTML DTD</a><br /> +<a class="left" target="_top" href="xhtml_howto.asp" >XHTML HowTo</a><br /> +<a class="left" target="_top" href="xhtml_validate.asp" >XHTML Validation</a><br /> +<br /> +<b>Quiz</b> +<br /> +<a class="left" target="_top" href="xhtml_quiz.asp" >XHTML Quiz</a><br /> +<br /> +<b>References</b> +<br /> +<a class="left" target="_top" href="xhtml_reference.asp" >XHTML Tag List</a><br /> +<a class="left" target="_top" href="xhtml_standardattributes.asp" >XHTML Attributes</a><br /> +<a class="left" target="_top" href="xhtml_eventattributes.asp" >XHTML Events</a><br /> +</td> +<td width="490" valign="top"> +<table width="100%" bgcolor="#FFFFFF" border="1" cellpadding="7" cellspacing="0"> +<tr> +<td> +<center> +<a href="http://ad.doubleclick.net/jump/N1951.w3schools/B1097963;sz=468x60;ord=[timestamp]?" target="_new"> +<img src="http://ad.doubleclick.net/ad/N1951.w3schools/B1097963;sz=468x60;ord=[timestamp]?" +border="0" width="468" height="60" alt="Corel XMetal 3" /></a> + + +<br />Please Visit Our Sponsors ! +</center> +<h1>XHTML Tutorial</h1> +<a href="../default.asp"><img border="0" src="../images/btn_previous.gif" alt="Previous" /></a> +<a href="xhtml_intro.asp"><img border="0" src="../images/btn_next.gif" width="100" height="20" alt="Next" /></a> + +<hr /> + +<h2>XHTML Tutorial</h2> +<p>XHTML is the next generation of HTML! In our XHTML tutorial you will learn the difference between HTML and XHTML, and how to use XHTML in your future +applications. You will also see how we converted this Web site into XHTML. <a href="xhtml_intro.asp">Start Learning +XHTML!</a></p> + +<h2>XHTML Quiz Test</h2> +<p>Test your XHTML skills at W3Schools! <a href="xhtml_quiz.asp">Start XHTML +Quiz!</a> </p> + +<h2>XHTML References</h2> +<p>At W3Schools you will find complete XHTML references about tags, attributes +and events. <a href="xhtml_reference.asp">XHTML 1.0 References</a>.</p> +<hr /> +<h2>Table of Contents</h2> +<p><a href="xhtml_intro.asp">Introduction to XHTML</a><br /> +This chapter gives a brief introduction to XHTML and explains what XHTML is.</p> +<p><a href="xhtml_why.asp">XHTML - Why?</a><br /> +This chapter explains why we needed a new language like XHTML.</p> +<p><a href="xhtml_html.asp">Differences between XHTML and HTML</a><br /> +This chapter explains the main differences in syntax between XHTML and HTML.</p> +<p><a href="xhtml_syntax.asp">XHTML Syntax</a> <br /> +This chapter explains the basic syntax of XHTML.</p> +<p><a href="xhtml_dtd.asp">XHTML DTD</a> <br /> +This chapter explains the three different XHTML Document Type Definitions.</p> +<p><a href="xhtml_howto.asp">XHTML HowTo</a><br /> +This chapter explains how this web site was converted from HTML to XHTML.</p> +<p><a href="xhtml_validate.asp">XHTML Validation</a><br /> +This chapter explains how to validate XHTML documents.</p> +<hr /> +<h2>XHTML References</h2> +<p><a href="xhtml_reference.asp">XHTML 1.0 Reference<br /> +</a>Our complete XHTML 1.0 reference is an alphabetical list of all XHTML tags +with lots of examples and tips.</p> +<p><a href="xhtml_standardattributes.asp">XHTML 1.0 Standard Attributes<br /> +</a>All the tags have attributes. The attributes for each tag are listed in the +examples in the "XHTML 1.0 Reference" page. The attributes listed here +are the core and language attributes all the tags has as standard (with +few exceptions). This reference describes the attributes, and shows possible +values for each.</p> +<p><a href="xhtml_eventattributes.asp">XHTML 1.0 Event Attributes<br /> +</a>All the standard event attributes of the tags. This reference describes the attributes, and shows possible +values for each.</p> +<hr /> +<a href="../default.asp"><img border="0" src="../images/btn_previous.gif" width="100" height="20" alt="Previous" /></a> +<a href="xhtml_intro.asp"><img border="0" src="../images/btn_next.gif" width="100" height="20" alt="Next" /></a> + + +<hr /> +<p> +Jump to: <a href="#top" target="_top"><b>Top of Page</b></a> +or <a href="/" target="_top"><b>HOME</b></a> or +<a href='/xhtml/default.asp?output=print' target="_blank"> +<img src="../images/print.gif" alt="Printer Friendly" border="0" /> +<b>Printer friendly page</b></a> +</p> +<hr /> + +<h2>Search W3Schools:</h2> +<form method="get" name="searchform" action="http://www.google.com/search" target="_blank"> +<input type="hidden" name="as_sitesearch" value="www.w3schools.com" /> +<input type="text" size="30" name="as_q" /> +<input type="submit" value=" Go! " /> +</form> + +<hr /> +<h2>What Others Say About Us</h2> +<p>Does the world know about us? Check out these places:</p> +<p> +<a href="http://search.dogpile.com/texis/search?q=W3schools" target="_blank">Dogpile</a> +<a href="http://www.altavista.com/cgi-bin/query?q=W3Schools" target="_blank">Alta Vista</a> +<a href="http://search.msn.com/results.asp?q=W3Schools" target="_blank">MSN</a> +<a href="http://www.google.com/search?q=W3Schools" target="_blank">Google</a> +<a href="http://search.excite.com/search.gw?search=W3Schools" target="_blank">Excite</a> +<a href="http://search.lycos.com/main/?query=W3Schools" target="_blank">Lycos</a> +<a href="http://search.yahoo.com/search?p=w3schools" target="_blank">Yahoo</a> +<a href="http://www.ask.com/main/askJeeves.asp?ask=W3Schools" target="_blank">Ask Jeeves</a> +</p> +<hr /> +<h2>We Help You For Free. You Can Help Us!</h2> +<ul> +<li><a href="../tellyourgroup.htm" target="blank">Tell your newsgroup or mailing list</a></li> +<li><a href="../about/about_linking.asp">Link to us from your pages</a></li> +<li><a href="../about/about_helpers.asp">Help us correct errors and broken links</a></li> +<li><a href="../about/about_helpers.asp">Help us with spelling and grammar</a></li> +<li><a href="http://validator.w3.org/check/referer" target="_blank">Validate the XHTML code of this page</a></li> +</ul> + +<hr /> +<p> +W3Schools is for training only. We do not warrant its correctness or its fitness for use. +The risk of using it remains entirely with the user. While using this site, you agree to have read and accepted our +<a href="../about/about_copyright.asp">terms of use</a> and +<a href="../about/about_privacy.asp">privacy policy</a>.</p> +<p> +<a href="../about/about_copyright.asp">Copyright 1999-2002</a> by Refsnes Data. All Rights Reserved</p> +<hr /> +<table border="0" width="100%" cellspacing="0" cellpadding="0"><tr> +<td width="25%" align="left"> +<a href="http://validator.w3.org/check/referer" target="_blank"> +<img src="../images/vxhtml.gif" alt="Validate" width="88" height="31" border="0" /></a> +</td> +<td width="50%" align="center"> +<a href="../xhtml/" target="_top">How we converted to XHTML</a> +</td> +<td width="25%" align="right"> +<a href="http://jigsaw.w3.org/css-validator/check/referer" target="_blank"> +<img src="../images/vcss.gif" alt="Validate" width="88" height="31" border="0" /></a> +</td> +</tr></table> +</td> +</tr> +</table> +</td> + + + +<td width="144" align="center" valign="top"> + +<table border="1" width="100%" bgcolor="#ffffff" cellpadding="0" cellspacing="0"><tr> +<td align="center" class="right"><br /> + +<a href="http://www.dotnetcharting.com" target="_blank"><img src="../images/dnc-icon.gif" alt="Web charting" border="0" /></a> +<br /> +<a class="right" href="http://www.dotnetcharting.com" target="_blank">Web based charting<br />for ASP.NET</a> + +<br /><br /> +</td></tr></table> + +<table border="1" width="100%" bgcolor="#ffffff" cellpadding="0" cellspacing="0"><tr> +<td align="center" class="right"> +<br /> +<a href="../hosting/default.asp"> +Your own Web Site?<br /> +<br />Read W3Schools +<br />Hosting Tutorial</a> +<br /> +<br /> +</td></tr></table> + +<table border="1" width="100%" bgcolor="#ffffff" cellpadding="0" cellspacing="0"><tr> +<td align="center" class="right"> +<br /> +<a class="red" href="http://www.dotdnr.com" target="_blank">$15 Domain Name<br />Registration<br />Save $20 / year!</a> +<br /> +<br /> +</td></tr></table> + + + +<table border="1" width="100%" bgcolor="#ffffff" cellpadding="0" cellspacing="0"> +<tr><td align="center" class="right"> +<br /> +<b>SELECTED LINKS</b> +<br /><br /> +<a class="right" href="http://opogee.com/clk/dangtingcentiaonie" target="_blank">University Online<br /> +Master Degree<br />Bachelor Degree</a> +<br /><br /> +<a class="right" href="../software/default.asp" target="_top">Web Software</a> +<br /><br /> +<a class="right" href="../appml/default.asp" target="_top">The Future of<br />Web Development</a> +<br /><br /> +<a class="right" href="../careers/default.asp" target="_top">Jobs and Careers</a> +<br /><br /> +<a class="right" href="../site/site_security.asp" target="_top">Web Security</a> +<br /> +<a class="right" href="../browsers/browsers_stats.asp" target="_top">Web Statistics</a> +<br /> +<a class="right" href="../w3c" target="_top">Web Standards</a> +<br /><br /> +</td></tr></table> + + +<table border="1" width="100%" bgcolor="#ffffff" cellpadding="0" cellspacing="0"><tr> +<td align="center" class="right"> +<br /> + +<b>Recommended<br /> +Reading:</b><br /><br /> + +<a class="right" target="_blank" +href="http://www.amazon.com/exec/obidos/ASIN/059600026X/w3schools03"> +<img src="../images/book_amazon_xhtml.jpg" border="0" alt="HTML XHTML" /></a> + + +<br /><br /></td> +</tr></table> + +<table border="1" width="100%" bgcolor="#ffffff" cellpadding="0" cellspacing="0"><tr> +<td align="center" class="right"> +<br /> +<b>PARTNERS</b><br /> +<br /> +<a class="right" href="http://www.W3Schools.com" target="_blank">W3Schools</a><br /> +<a class="right" href="http://www.topxml.com" target="_blank">TopXML</a><br /> +<a class="right" href="http://www.visualbuilder.com" target="_blank">VisualBuilder</a><br /> +<a class="right" href="http://www.xmlpitstop.com" target="_blank">XMLPitstop</a><br /> +<a class="right" href="http://www.developersdex.com" target="_blank">DevelopersDex</a><br /> +<a class="right" href="http://www.devguru.com" target="_blank">DevGuru</a><br /> +<a class="right" href="http://www.programmersheaven.com/" target="_blank">Programmers Heaven</a><br /> +<a class="right" href="http://www.codeproject.com" target="_blank">The Code Project</a><br /> +<a class="right" href="http://www.tek-tips.com" target="_blank">Tek Tips Forum</a><br /> +<a class="right" href="http://www.zvon.ORG/" target="_blank">ZVON.ORG</a><br /> +<a class="right" href="http://www.topxml.com/search.asp" target="_blank">TopXML Search</a><br /> +<br /> +</td> +</tr></table> +</td></tr></table> + +</body> +</html> diff --git a/third_party/lisp/split-sequence.nix b/third_party/lisp/split-sequence.nix new file mode 100644 index 0000000000..105646386f --- /dev/null +++ b/third_party/lisp/split-sequence.nix @@ -0,0 +1,18 @@ +# split-sequence is a library for, well, splitting sequences apparently. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/sharplispers/split-sequence.git"; + rev = "41c0fc79a5a2871d16e5727969a8f699ef44d791"; +}; +in depot.nix.buildLisp.library { + name = "split-sequence"; + srcs = map (f: src + ("/" + f)) [ + "package.lisp" + "vector.lisp" + "list.lisp" + "extended-sequence.lisp" + "api.lisp" + "documentation.lisp" + ]; +} diff --git a/third_party/lisp/trivial-backtrace/.gitignore b/third_party/lisp/trivial-backtrace/.gitignore new file mode 100644 index 0000000000..391b10e5db --- /dev/null +++ b/third_party/lisp/trivial-backtrace/.gitignore @@ -0,0 +1,15 @@ +# really this is private to my build process +make/ +common-lisp.net +.vcs +GNUmakefile +init-lisp.lisp +website/changelog.xml + + +trivial-backtrace.tar.gz +website/output/ +test-results/ +lift-local.config +*.dribble +*.fasl diff --git a/third_party/lisp/trivial-backtrace/COPYING b/third_party/lisp/trivial-backtrace/COPYING new file mode 100644 index 0000000000..3798a6664a --- /dev/null +++ b/third_party/lisp/trivial-backtrace/COPYING @@ -0,0 +1,25 @@ +Copyright (c) 2008-2008 Gary Warren King (gwking@metabang.com) + +Permission is hereby granted, free of charge, to any person obtaining a +copy of this software and associated documentation files (the "Software"), +to deal in the Software without restriction, including without limitation +the rights to use, copy, modify, merge, publish, distribute, sublicense, +and/or sell copies of the Software, and to permit persons to whom the +Software is furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in +all copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL +THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING +FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER +DEALINGS IN THE SOFTWARE. + + + +Copyright (c) 2005-2007 Dr. Edi Weitz + +BSD style license: http://www.opensource.org/licenses/bsd-license.php diff --git a/third_party/lisp/trivial-backtrace/default.nix b/third_party/lisp/trivial-backtrace/default.nix new file mode 100644 index 0000000000..bdd057cade --- /dev/null +++ b/third_party/lisp/trivial-backtrace/default.nix @@ -0,0 +1,14 @@ +# Imported from http://common-lisp.net/project/trivial-backtrace/trivial-backtrace.git +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "trivial-backtrace"; + + srcs = [ + ./dev/packages.lisp + ./dev/utilities.lisp + ./dev/backtrace.lisp + ./dev/map-backtrace.lisp + ./dev/fallback.lisp + ]; +} diff --git a/third_party/lisp/trivial-backtrace/dev/backtrace.lisp b/third_party/lisp/trivial-backtrace/dev/backtrace.lisp new file mode 100644 index 0000000000..aa3951e30f --- /dev/null +++ b/third_party/lisp/trivial-backtrace/dev/backtrace.lisp @@ -0,0 +1,127 @@ +(in-package #:trivial-backtrace) + +(defun print-condition (condition stream) + "Print `condition` to `stream` using the pretty printer." + (format + stream + "~@<An unhandled error condition has been signalled:~3I ~a~I~:@>~%~%" + condition)) + +(defun print-backtrace (error &key (output *debug-io*) + (if-exists :append) + (verbose nil)) + "Send a backtrace for the error `error` to `output`. + +The keywords arguments are: + + * :output - where to send the output. This can be: + + * a string (which is assumed to designate a pathname) + * an open stream + * nil to indicate that the backtrace information should be + returned as a string + + * if-exists - what to do if output designates a pathname and + the pathname already exists. Defaults to :append. + + * verbose - if true, then a message about the backtrace is sent + to \\*terminal-io\\*. Defaults to `nil`. + +If the `output` is nil, the returns the backtrace output as a +string. Otherwise, returns nil. +" + (when verbose + (print-condition error *terminal-io*)) + (multiple-value-bind (stream close?) + (typecase output + (null (values (make-string-output-stream) nil)) + (string (values (open output :if-exists if-exists + :if-does-not-exist :create + :direction :output) t)) + (stream (values output nil))) + (unwind-protect + (progn + (format stream "~&Date/time: ~a" (date-time-string)) + (print-condition error stream) + (terpri stream) + (print-backtrace-to-stream stream) + (terpri stream) + (when (typep stream 'string-stream) + (get-output-stream-string stream))) + ;; cleanup + (when close? + (close stream))))) + +#+(or mcl ccl) +(defun print-backtrace-to-stream (stream) + (let ((*debug-io* stream)) + (ccl:print-call-history :detailed-p nil))) + +#+allegro +(defun print-backtrace-to-stream (stream) + (with-standard-io-syntax + (let ((*print-readably* nil) + (*print-miser-width* 40) + (*print-pretty* t) + (tpl:*zoom-print-circle* t) + (tpl:*zoom-print-level* nil) + (tpl:*zoom-print-length* nil)) + (cl:ignore-errors + (let ((*terminal-io* stream) + (*standard-output* stream)) + (tpl:do-command "zoom" + :from-read-eval-print-loop nil + :count t + :all t)))))) + +#+lispworks +(defun print-backtrace-to-stream (stream) + (let ((dbg::*debugger-stack* + (dbg::grab-stack nil :how-many most-positive-fixnum)) + (*debug-io* stream) + (dbg:*debug-print-level* nil) + (dbg:*debug-print-length* nil)) + (dbg:bug-backtrace nil))) + +#+sbcl +;; determine how we're going to access the backtrace in the next +;; function +(eval-when (:compile-toplevel :load-toplevel :execute) + (when (find-symbol "*DEBUG-PRINT-VARIABLE-ALIST*" :sb-debug) + (pushnew :sbcl-debug-print-variable-alist *features*))) + +#+sbcl +(defun print-backtrace-to-stream (stream) + (let (#+:sbcl-debug-print-variable-alist + (sb-debug:*debug-print-variable-alist* + (list* '(*print-level* . nil) + '(*print-length* . nil) + sb-debug:*debug-print-variable-alist*)) + #-:sbcl-debug-print-variable-alist + (sb-debug:*debug-print-level* nil) + #-:sbcl-debug-print-variable-alist + (sb-debug:*debug-print-length* nil)) + (sb-debug:backtrace most-positive-fixnum stream))) + +#+clisp +(defun print-backtrace-to-stream (stream) + (system::print-backtrace :out stream)) + +#+(or cmucl scl) +(defun print-backtrace-to-stream (stream) + (let ((debug:*debug-print-level* nil) + (debug:*debug-print-length* nil)) + (debug:backtrace most-positive-fixnum stream))) + + +;; must be after the defun above or the docstring may be wiped out +(setf (documentation 'print-backtrace-to-stream 'function) + "Send a backtrace of the current error to stream. + +Stream is assumed to be an open writable file stream or a +string-output-stream. Note that `print-backtrace-to-stream` +will print a backtrace for whatever the Lisp deems to be the +*current* error. +") + + diff --git a/third_party/lisp/trivial-backtrace/dev/fallback.lisp b/third_party/lisp/trivial-backtrace/dev/fallback.lisp new file mode 100644 index 0000000000..40a5219824 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/dev/fallback.lisp @@ -0,0 +1,10 @@ +(in-package #:trivial-backtrace) + +(eval-when (:compile-toplevel :load-toplevel :execute) + (unless (fboundp 'map-backtrace) + (defun map-backtrace (func) + (declare (ignore func)))) + + (unless (fboundp 'print-backtrace-to-stream) + (defun print-backtrace-to-stream (stream) + (format stream "~&backtrace output unavailable.~%")))) diff --git a/third_party/lisp/trivial-backtrace/dev/map-backtrace.lisp b/third_party/lisp/trivial-backtrace/dev/map-backtrace.lisp new file mode 100644 index 0000000000..43eddda475 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/dev/map-backtrace.lisp @@ -0,0 +1,105 @@ +(in-package #:trivial-backtrace) + +(defstruct frame + func + source-filename + source-pos + vars) + +(defstruct var + name + value) + +(defstruct pos-form-number + number) + +(defmethod print-object ((pos-form-number pos-form-number) stream) + (cond + (*print-readably* (call-next-method)) + (t + (format stream "f~A" (pos-form-number-number pos-form-number))))) + + +(defvar *trivial-backtrace-frame-print-specials* + '((*print-length* . 100) + (*print-level* . 20) + (*print-lines* . 5) + (*print-pretty* . t) + (*print-readably* . nil))) + +(defun print-frame (frame stream) + (format stream "~A:~@[~A:~] ~A: ~%" + (or (ignore-errors (translate-logical-pathname (frame-source-filename frame))) (frame-source-filename frame) "<unknown>") + (frame-source-pos frame) + (frame-func frame)) + (loop for var in (frame-vars frame) + do + (format stream " ~A = ~A~%" (var-name var) + (or (ignore-errors + (progv + (mapcar #'car *trivial-backtrace-frame-print-specials*) + (mapcar #'cdr *trivial-backtrace-frame-print-specials*) + (prin1-to-string + (var-value var)))) + "<error>")))) + +(defun map-backtrace (function) + (impl-map-backtrace function)) + +(defun print-map-backtrace (&optional (stream *debug-io*) &rest args) + (apply 'map-backtrace + (lambda (frame) + (print-frame frame stream)) args)) + +(defun backtrace-string (&rest args) + (with-output-to-string (stream) + (apply 'print-map-backtrace stream args))) + + +#+ccl +(defun impl-map-backtrace (func) + (ccl::map-call-frames (lambda (ptr) + (multiple-value-bind (lfun pc) + (ccl::cfp-lfun ptr) + (let ((source-note (ccl:function-source-note lfun))) + (funcall func + (make-frame :func (ccl::lfun-name lfun) + :source-filename (ccl:source-note-filename source-note) + :source-pos (let ((form-number (ccl:source-note-start-pos source-note))) + (when form-number (make-pos-form-number :number form-number))) + :vars (loop for (name . value) in (ccl::arguments-and-locals nil ptr lfun pc) + collect (make-var :name name :value value))))))))) + +#+sbcl +(defun impl-map-backtrace (func) + (loop for f = (or sb-debug:*stack-top-hint* (sb-di:top-frame)) then (sb-di:frame-down f) + while f + do (funcall func + (make-frame :func + (ignore-errors + (sb-di:debug-fun-name + (sb-di:frame-debug-fun f))) + :source-filename + (ignore-errors + (sb-di:debug-source-namestring (sb-di:code-location-debug-source (sb-di:frame-code-location f)))) + :source-pos + (ignore-errors ;;; XXX does not work + (let ((cloc (sb-di:frame-code-location f))) + (unless (sb-di:code-location-unknown-p cloc) + (format nil "tlf~Dfn~D" + (sb-di:code-location-toplevel-form-offset cloc) + (sb-di:code-location-form-number cloc))))) + :vars + (remove-if 'not + (map 'list (lambda(v) + (ignore-errors + (when (eq :valid + (sb-di:debug-var-validity v (sb-di:frame-code-location f))) + (make-var :name (sb-di:debug-var-symbol v) + :value (sb-di:debug-var-value v f))))) + (ignore-errors (sb-di::debug-fun-debug-vars (sb-di:frame-debug-fun f))))))))) + +#-(or ccl sbcl) +(defun impl-map-backtrace (func) + (declare (ignore func)) + (warn "unable to map backtrace for ~a" (lisp-implementation-type))) \ No newline at end of file diff --git a/third_party/lisp/trivial-backtrace/dev/mucking.lisp b/third_party/lisp/trivial-backtrace/dev/mucking.lisp new file mode 100644 index 0000000000..2be26a5a87 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/dev/mucking.lisp @@ -0,0 +1,75 @@ +(in-package #:metabang.gsn) + +#| +Need to account for different kinds of links + in gsn-nodes-from-json, need to return pairs of node and attributes + +hash-table for nodes to prevent duplicates +queue or stack for nodes to expand +hash-table for links (triples of A link B?) to handle duplicates +|# + +(defgeneric expand-node (context node) + ) + +(defgeneric find-neighbors (context node) + ) + +(defgeneric expand-node-p (context node) + ) + +(defgeneric add-node (context node) + ) + +(defgeneric add-link (context node neighbor direction) + ) + +(defgeneric update-node-data (context node data) + ) + +(defclass abstract-context () + ()) + +(defclass gsn-context (abstract-context) + ()) + +(defparameter +gsn-root+ "http://socialgraph.apis.google.com/") + +(defmethod expand-node ((context abstract-context) node) + (bind (((to from) (find-neighbors context node))) + (dolist (neighbor to) + (add-node context neighbor) + (add-link context node neighbor :to)) + (dolist (neighbor from) + (add-node context neighbor) + (add-link context node neighbor :from)))) + + + +(defmethod find-neighbors ((context gsn-context) node) + (bind (((result headers stream) + (http-get + (format nil "~alookup?edo=1&edi=1&pretty=1&q=~a" + +gsn-root+ node))) + json) + (unwind-protect + (setf json (json:decode-json stream)) + (close strea)) + (update-node-data context node json) + (list (gsn-nodes-from-json json :to) + (gsn-nodes-from-json json :from)))) + +(gsn-nodes-from-json x :from) + +(defun gsn-test (who) + (destructuring-bind (result headers stream) + (http-get + (format nil "http://socialgraph.apis.google.com/lookup?edo=1&edi=1&pretty=1&q=~a" who)) + (declare (ignore result headers)) + (json:decode-json stream))) + +(assoc :nodes_referenced + (assoc :nodes (gsn-test "TWITTER.COM/GWKING") :key #'first)) + + +(setf x (gsn-test "TWITTER.COM/GWKING")) diff --git a/third_party/lisp/trivial-backtrace/dev/packages.lisp b/third_party/lisp/trivial-backtrace/dev/packages.lisp new file mode 100644 index 0000000000..2da49d3d9b --- /dev/null +++ b/third_party/lisp/trivial-backtrace/dev/packages.lisp @@ -0,0 +1,13 @@ +(in-package #:common-lisp-user) + +(defpackage #:trivial-backtrace + (:use #:common-lisp) + (:export #:print-backtrace + #:print-backtrace-to-stream + #:print-condition + #:*date-time-format* + + + #:backtrace-string + #:map-backtrace)) + diff --git a/third_party/lisp/trivial-backtrace/dev/utilities.lisp b/third_party/lisp/trivial-backtrace/dev/utilities.lisp new file mode 100644 index 0000000000..b0a249867a --- /dev/null +++ b/third_party/lisp/trivial-backtrace/dev/utilities.lisp @@ -0,0 +1,104 @@ +(in-package #:trivial-backtrace) + +(defparameter *date-time-format* "%Y-%m-%d-%H:%M" + "The default format to use when printing dates and times. + +* %% - A '%' character +* %d - Day of the month as a decimal number [01-31] +* %e - Same as %d but does not print the leading 0 for days 1 through 9 + [unlike strftime[], does not print a leading space] +* %H - Hour based on a 24-hour clock as a decimal number [00-23] +*%I - Hour based on a 12-hour clock as a decimal number [01-12] +* %m - Month as a decimal number [01-12] +* %M - Minute as a decimal number [00-59] +* %S - Second as a decimal number [00-59] +* %w - Weekday as a decimal number [0-6], where Sunday is 0 +* %y - Year without century [00-99] +* %Y - Year with century [such as 1990] + +This code is borrowed from the `format-date` function in +[metatilities-base][].") + +;; modified from metatilities-base +(eval-when (:compile-toplevel :load-toplevel :execute) + (defmacro generate-time-part-function (part-name position) + (let ((function-name + (intern + (concatenate 'string + (symbol-name 'time) "-" (symbol-name part-name)) + :trivial-backtrace))) + `(eval-when (:compile-toplevel :load-toplevel :execute) + (defun ,function-name + (&optional (universal-time (get-universal-time)) + (time-zone nil)) + ,(format nil "Returns the ~(~A~) part of the given time." part-name) + (nth-value ,position + (apply #'decode-universal-time + universal-time time-zone)))))) + + (generate-time-part-function second 0) + (generate-time-part-function minute 1) + (generate-time-part-function hour 2) + (generate-time-part-function date 3) + (generate-time-part-function month 4) + (generate-time-part-function year 5) + (generate-time-part-function day-of-week 6) + (generate-time-part-function daylight-savings-time-p 7)) + +(defun date-time-string (&key (date/time (get-universal-time)) + (format *date-time-format*)) + (format-date format date/time nil)) + +(defun format-date (format date &optional stream time-zone) + (declare (ignore time-zone)) + (let ((format-length (length format))) + (format + stream "~{~A~}" + (loop for index = 0 then (1+ index) + while (< index format-length) collect + (let ((char (aref format index))) + (cond + ((char= #\% char) + (setf char (aref format (incf index))) + (cond + ;; %% - A '%' character + ((char= char #\%) #\%) + + ;; %d - Day of the month as a decimal number [01-31] + ((char= char #\d) (format nil "~2,'0D" (time-date date))) + + ;; %e - Same as %d but does not print the leading 0 for + ;; days 1 through 9. Unlike strftime, does not print a + ;; leading space + ((char= char #\e) (format nil "~D" (time-date date))) + + ;; %H - Hour based on a 24-hour clock as a decimal number [00-23] + ((char= char #\H) (format nil "~2,'0D" (time-hour date))) + + ;; %I - Hour based on a 12-hour clock as a decimal number [01-12] + ((char= char #\I) (format nil "~2,'0D" + (1+ (mod (time-hour date) 12)))) + + ;; %m - Month as a decimal number [01-12] + ((char= char #\m) (format nil "~2,'0D" (time-month date))) + + ;; %M - Minute as a decimal number [00-59] + ((char= char #\M) (format nil "~2,'0D" (time-minute date))) + + ;; %S - Second as a decimal number [00-59] + ((char= char #\S) (format nil "~2,'0D" (time-second date))) + + ;; %w - Weekday as a decimal number [0-6], where Sunday is 0 + ((char= char #\w) (format nil "~D" (time-day-of-week date))) + + ;; %y - Year without century [00-99] + ((char= char #\y) + (let ((year-string (format nil "~,2A" (time-year date)))) + (subseq year-string (- (length year-string) 2)))) + + ;; %Y - Year with century [such as 1990] + ((char= char #\Y) (format nil "~D" (time-year date))) + + (t + (error "Ouch - unknown formatter '%~c" char)))) + (t char))))))) diff --git a/third_party/lisp/trivial-backtrace/lift-standard.config b/third_party/lisp/trivial-backtrace/lift-standard.config new file mode 100644 index 0000000000..0f22312080 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/lift-standard.config @@ -0,0 +1,35 @@ +;;; configuration for LIFT tests + +;; settings +(:if-dribble-exists :supersede) +(:dribble "lift.dribble") +(:print-length 10) +(:print-level 5) +(:print-test-case-names t) + +;; suites to run +(trivial-backtrace-test) + +;; report properties +(:report-property :title "Trivial-Backtrace | Test results") +(:report-property :relative-to trivial-backtrace-test) + +(:report-property :style-sheet "test-style.css") +(:report-property :if-exists :supersede) +(:report-property :format :html) +(:report-property :full-pathname "test-results/test-report.html") +(:report-property :unique-name t) +(:build-report) + +(:report-property :unique-name t) +(:report-property :format :describe) +(:report-property :full-pathname "test-results/test-report.txt") +(:build-report) + +(:report-property :format :save) +(:report-property :full-pathname "test-results/test-report.sav") +(:build-report) + +(:report-property :format :describe) +(:report-property :full-pathname *standard-output*) +(:build-report) diff --git a/third_party/lisp/trivial-backtrace/test/packages.lisp b/third_party/lisp/trivial-backtrace/test/packages.lisp new file mode 100644 index 0000000000..7dc3eae576 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/test/packages.lisp @@ -0,0 +1,5 @@ +(in-package #:common-lisp-user) + +(defpackage #:trivial-backtrace-test + (:use #:common-lisp #:lift #:trivial-backtrace)) + diff --git a/third_party/lisp/trivial-backtrace/test/test-setup.lisp b/third_party/lisp/trivial-backtrace/test/test-setup.lisp new file mode 100644 index 0000000000..a46b3a1966 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/test/test-setup.lisp @@ -0,0 +1,4 @@ +(in-package #:trivial-backtrace-test) + +(deftestsuite trivial-backtrace-test () + ()) diff --git a/third_party/lisp/trivial-backtrace/test/tests.lisp b/third_party/lisp/trivial-backtrace/test/tests.lisp new file mode 100644 index 0000000000..9b32090f13 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/test/tests.lisp @@ -0,0 +1,17 @@ +(in-package #:trivial-backtrace-test) + +(deftestsuite generates-backtrace (trivial-backtrace-test) + ()) + +(addtest (generates-backtrace) + test-1 + (let ((output nil)) + (handler-case + (let ((x 1)) + (let ((y (- x (expt 1024 0)))) + (declare (optimize (safety 3))) + (/ 2 y))) + (error (c) + (setf output (print-backtrace c :output nil)))) + (ensure (stringp output)) + (ensure (plusp (length output))))) diff --git a/third_party/lisp/trivial-backtrace/trivial-backtrace-test.asd b/third_party/lisp/trivial-backtrace/trivial-backtrace-test.asd new file mode 100644 index 0000000000..cb088434a2 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/trivial-backtrace-test.asd @@ -0,0 +1,22 @@ +(defpackage #:trivial-backtrace-test-system (:use #:asdf #:cl)) +(in-package #:trivial-backtrace-test-system) + +(defsystem trivial-backtrace-test + :author "Gary Warren King <gwking@metabang.com>" + :maintainer "Gary Warren King <gwking@metabang.com>" + :licence "MIT Style License; see file COPYING for details" + :components ((:module + "setup" + :pathname "test/" + :components ((:file "packages") + (:file "test-setup" + :depends-on ("packages")))) + (:module + "test" + :pathname "test/" + :depends-on ("setup") + :components ((:file "tests")))) + :depends-on (:lift :trivial-backtrace)) + + + diff --git a/third_party/lisp/trivial-backtrace/trivial-backtrace.asd b/third_party/lisp/trivial-backtrace/trivial-backtrace.asd new file mode 100644 index 0000000000..843b6cc39a --- /dev/null +++ b/third_party/lisp/trivial-backtrace/trivial-backtrace.asd @@ -0,0 +1,35 @@ +(in-package #:common-lisp-user) + +(defpackage #:trivial-backtrace-system (:use #:asdf #:cl)) +(in-package #:trivial-backtrace-system) + +(defsystem trivial-backtrace + :version "1.1.0" + :author "Gary Warren King <gwking@metabang.com> and contributors" + :maintainer "Gary Warren King <gwking@metabang.com> and contributors" + :licence "MIT Style license " + :description "trivial-backtrace" + :depends-on () + :components + ((:static-file "COPYING") + (:module + "setup" + :pathname "dev/" + :components ((:file "packages"))) + (:module + "dev" + :depends-on ("setup") + :components ((:file "utilities") + (:file "backtrace") + (:file "map-backtrace") + (:file "fallback" :depends-on ("backtrace" "map-backtrace"))))) + :in-order-to ((test-op (load-op trivial-backtrace-test))) + :perform (test-op :after (op c) + (funcall + (intern (symbol-name '#:run-tests) :lift) + :config :generic))) + +(defmethod operation-done-p + ((o test-op) + (c (eql (find-system 'trivial-backtrace)))) + (values nil)) diff --git a/third_party/lisp/trivial-backtrace/website/source/index.md b/third_party/lisp/trivial-backtrace/website/source/index.md new file mode 100644 index 0000000000..93a5df3b91 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/website/source/index.md @@ -0,0 +1,88 @@ +{include resources/header.md} + +<div class="contents"> +<div class="system-links"> + + * [Mailing Lists][mailing-list] + * [Getting it][downloads] + * [Documentation][] + * [News][] + * [Test results][tr] + * [Changelog][] + +</div> +<div class="system-description"> + +### What it is + +On of the many things that didn't quite get into the Common +Lisp standard was how to get a Lisp to output its call stack +when something has gone wrong. As such, each Lisp has +developed its own notion of what to display, how to display +it, and what sort of arguments can be used to customize it. +`trivial-backtrace` is a simple solution to generating a +backtrace portably. As of {today}, it supports Allegro Common +Lisp, LispWorks, ECL, MCL, SCL, SBCL and CMUCL. Its +interface consists of three functions and one variable: + + * print-backtrace + * print-backtrace-to-stream + * print-condition + * \*date-time-format\* + +You can probably already guess what they do, but they are +described in more detail below. + +{anchor mailing-lists} + +### Mailing Lists + + * [trivial-backtrace-devel][devel-list]: A list for + announcements, questions, patches, bug reports, and so + on; It's for anything and everything + +### API + +{set-property docs-package trivial-backtrace} +{docs print-backtrace} +{docs print-backtrace-to-stream} +{docs print-condition} +{docs *date-time-format*} + +{anchor downloads} + +### Where is it + +A [git][] repository is available using + + git clone http://common-lisp.net/project/trivial-backtrace/trivial-backtrace.git + +The [darcs][] repository is still around but is **not** being updated. +The command to get it is below: + + ;;; WARNING: out of date + darcs get http://common-lisp.net/project/trivial-backtrace/ + +trivial-backtrace is also [ASDF installable][asdf-install]. +Its CLiki home is right [where][cliki-home] you'd expect. + +There's also a handy [gzipped tar file][tarball]. + +{anchor news} + +### What is happening + +<dl> + <dt>14 May 2009</dt> + <dd>Moved to [git][]; John Fremlin adds map-backtrace + </dd> + +<dt>1 June 2008</dt> +<dd>Release version 1.0 + </dd> + </dl> +</div> +</div> + +{include resources/footer.md} + diff --git a/third_party/lisp/trivial-backtrace/website/source/resources/footer.md b/third_party/lisp/trivial-backtrace/website/source/resources/footer.md new file mode 100644 index 0000000000..c5bf3c4ec3 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/website/source/resources/footer.md @@ -0,0 +1,15 @@ +<div id="footer" class="footer"> +<div id="buttons"> +<a class="nav" href="http://validator.w3.org/check/referer" title="xhtml1.1"><img src="http://common-lisp.net/project/cl-containers/shared/buttons/xhtml.gif" width="80" height="15" title="valid xhtml button" alt="valid xhtml" /></a> +<a class="nav" href="http://common-lisp.net/project/cl-markdown/" title="Mark with CL-Markdown"><img src="http://common-lisp.net/project/cl-containers/shared/buttons/cl-markdown.png" width="80" height="15" title="Made with CL-Markdown" alt="CL-Markdown" /></a> +<a class="nav" href="http://www.catb.org/hacker-emblem/" title="hacker"><img src="http://common-lisp.net/project/cl-containers/shared/buttons/hacker.png" width="80" height="15" title="hacker emblem" alt="hacker button" /></a> +<a class="nav" href="http://www.lisp.org/" title="Association of Lisp Users"><img src="http://common-lisp.net/project/cl-containers/shared/buttons/lambda-lisp.png" width="80" height="15" title="ALU emblem" alt="ALU button" /></a> +<a class="nav" href="http://common-lisp.net/" title="Common-Lisp.net"><img src="http://common-lisp.net/project/cl-containers/shared/buttons/lisp-lizard.png" width="80" height="15" title="Common-Lisp.net" alt="Common-Lisp.net button" /></a> +</div> + +### Copyright (c) 2009 - 2011 Gary Warren King (gwking@metabang.com) + +trivial-backtrace has an [MIT style][mit-license] license + +<div id="timestamp">Last updated {today} at {now}</div> +</div> diff --git a/third_party/lisp/trivial-backtrace/website/source/resources/header.md b/third_party/lisp/trivial-backtrace/website/source/resources/header.md new file mode 100644 index 0000000000..2738c47137 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/website/source/resources/header.md @@ -0,0 +1,19 @@ +{include shared-links.md} + +{set-property html yes} +{set-property style-sheet "styles.css"} +{set-property author "Gary Warren King"} +{set-property title "trivial-backtrace | watch where you've been"} + + [devel-list]: http://common-lisp.net/cgi-bin/mailman/listinfo/trivial-backtrace-devel + [cliki-home]: http://www.cliki.net//trivial-backtrace + [tarball]: http://common-lisp.net/project/trivial-backtrace/trivial-backtrace.tar.gz + +<div id="header"> + <span class="logo"><a href="http://www.metabang.com/" title="metabang.com"><img src="http://common-lisp.net/project/cl-containers/shared/metabang-2.png" title="metabang.com" width="100" alt="Metabang Logo" /></a></span> + +## trivial-backtrace + +#### watch where you've been + +</div> diff --git a/third_party/lisp/trivial-backtrace/website/source/resources/navigation.md b/third_party/lisp/trivial-backtrace/website/source/resources/navigation.md new file mode 100644 index 0000000000..a734edfb83 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/website/source/resources/navigation.md @@ -0,0 +1,2 @@ +<div id="navigation"> +</div> diff --git a/third_party/lisp/trivial-backtrace/website/website.tmproj b/third_party/lisp/trivial-backtrace/website/website.tmproj new file mode 100644 index 0000000000..01b745ba44 --- /dev/null +++ b/third_party/lisp/trivial-backtrace/website/website.tmproj @@ -0,0 +1,93 @@ +<?xml version="1.0" encoding="UTF-8"?> +<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> +<plist version="1.0"> +<dict> + <key>currentDocument</key> + <string>source/resources/header.md</string> + <key>documents</key> + <array> + <dict> + <key>expanded</key> + <true/> + <key>name</key> + <string>source</string> + <key>regexFolderFilter</key> + <string>!.*/(\.[^/]*|CVS|_darcs|_MTN|\{arch\}|blib|.*~\.nib|.*\.(framework|app|pbproj|pbxproj|xcode(proj)?|bundle))$</string> + <key>sourceDirectory</key> + <string>source</string> + </dict> + </array> + <key>fileHierarchyDrawerWidth</key> + <integer>190</integer> + <key>metaData</key> + <dict> + <key>source/index.md</key> + <dict> + <key>caret</key> + <dict> + <key>column</key> + <integer>0</integer> + <key>line</key> + <integer>0</integer> + </dict> + <key>firstVisibleColumn</key> + <integer>0</integer> + <key>firstVisibleLine</key> + <integer>0</integer> + </dict> + <key>source/resources/footer.md</key> + <dict> + <key>caret</key> + <dict> + <key>column</key> + <integer>29</integer> + <key>line</key> + <integer>9</integer> + </dict> + <key>firstVisibleColumn</key> + <integer>0</integer> + <key>firstVisibleLine</key> + <integer>0</integer> + </dict> + <key>source/resources/header.md</key> + <dict> + <key>caret</key> + <dict> + <key>column</key> + <integer>27</integer> + <key>line</key> + <integer>3</integer> + </dict> + <key>firstVisibleColumn</key> + <integer>0</integer> + <key>firstVisibleLine</key> + <integer>0</integer> + </dict> + <key>source/resources/navigation.md</key> + <dict> + <key>caret</key> + <dict> + <key>column</key> + <integer>0</integer> + <key>line</key> + <integer>1</integer> + </dict> + <key>firstVisibleColumn</key> + <integer>0</integer> + <key>firstVisibleLine</key> + <integer>0</integer> + </dict> + </dict> + <key>openDocuments</key> + <array> + <string>source/resources/header.md</string> + <string>source/index.md</string> + <string>source/resources/navigation.md</string> + <string>source/resources/footer.md</string> + </array> + <key>showFileHierarchyDrawer</key> + <true/> + <key>windowFrame</key> + <string>{{615, 0}, {578, 778}}</string> +</dict> +</plist> diff --git a/third_party/lisp/trivial-features.nix b/third_party/lisp/trivial-features.nix new file mode 100644 index 0000000000..b7808a2364 --- /dev/null +++ b/third_party/lisp/trivial-features.nix @@ -0,0 +1,12 @@ +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/trivial-features/trivial-features.git"; + rev = "b78b2df5d75bdf8fdfc69f0deec0a187d9664b0b"; +}; +in depot.nix.buildLisp.library { + name = "trivial-features"; + srcs = [ + (src + "/src/tf-sbcl.lisp") + ]; +} diff --git a/third_party/lisp/trivial-garbage.nix b/third_party/lisp/trivial-garbage.nix new file mode 100644 index 0000000000..e5b3550de7 --- /dev/null +++ b/third_party/lisp/trivial-garbage.nix @@ -0,0 +1,12 @@ +# trivial-garbage provides a portable API to finalizers, weak +# hash-tables and weak pointers +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/trivial-garbage/trivial-garbage.git"; + rev = "dbc8e35acb0176b9a14fdc1027f5ebea93435a84"; +}; +in depot.nix.buildLisp.library { + name = "trivial-garbage"; + srcs = [ (src + "/trivial-garbage.lisp") ]; +} diff --git a/third_party/lisp/trivial-gray-streams.nix b/third_party/lisp/trivial-gray-streams.nix new file mode 100644 index 0000000000..b5722f9a68 --- /dev/null +++ b/third_party/lisp/trivial-gray-streams.nix @@ -0,0 +1,16 @@ +# Portability library for CL gray streams. +{ depot, ... }: + +let src = builtins.fetchGit { + url = "https://github.com/trivial-gray-streams/trivial-gray-streams.git"; + rev = "ebd59b1afed03b9dc8544320f8f432fdf92ab010"; +}; +in depot.nix.buildLisp.library { + name = "trivial-gray-streams"; + srcs = [ + (src + "/package.lisp") + (src + "/streams.lisp") + ]; +} + + diff --git a/third_party/lisp/unix-opts.nix b/third_party/lisp/unix-opts.nix new file mode 100644 index 0000000000..99117d8beb --- /dev/null +++ b/third_party/lisp/unix-opts.nix @@ -0,0 +1,17 @@ +# unix-opts is a portable command line argument parser +{ depot, ...}: + +let + src = depot.third_party.fetchFromGitHub { + owner = "libre-man"; + repo = "unix-opts"; + rev = "b805050b074bd860edd18cfc8776fdec666ec36e"; + sha256 = "0j93dkc9f77wz1zfspm7q1scx6wwbm6jhk8vl2rm6bfd0n8scxla"; + }; +in depot.nix.buildLisp.library { + name = "unix-opts"; + + srcs = [ + "${src}/unix-opts.lisp" + ]; +} diff --git a/third_party/lisp/usocket.nix b/third_party/lisp/usocket.nix new file mode 100644 index 0000000000..920c41c58d --- /dev/null +++ b/third_party/lisp/usocket.nix @@ -0,0 +1,37 @@ +# Usocket is a portable socket library +{ depot, ... }: + +with depot.nix; + +let src = depot.third_party.fetchFromGitHub { + owner = "usocket"; + repo = "usocket"; + rev = "fdf4fd1e0051ce83340ccfbbc8a43a462bb19cf2"; + sha256 = "0x746wr2324l6bn7skqzgkzcbj5kd0zp2ck0c8rldrw0rzabg826"; +}; +in buildLisp.library { + name = "usocket"; + deps = with depot.third_party.lisp; [ + (buildLisp.bundled "asdf") + (buildLisp.bundled "sb-bsd-sockets") + split-sequence + ]; + + srcs = [ + # usocket also reads its version from ASDF, but there's further + # shenanigans happening there that I don't intend to support right + # now. Behold: + (builtins.toFile "usocket.asd" '' + (in-package :asdf) + (defsystem usocket + :version "0.8.3") + '') + ] ++ + # Now for the regularly scheduled programming: + (map (f: src + ("/" + f)) [ + "package.lisp" + "usocket.lisp" + "condition.lisp" + "backend/sbcl.lisp" + ]); +} diff --git a/third_party/naersk/default.nix b/third_party/naersk/default.nix new file mode 100644 index 0000000000..0b86f9a64f --- /dev/null +++ b/third_party/naersk/default.nix @@ -0,0 +1,9 @@ +{ depot, ... }: + +let inherit (depot.third_party) callPackage fetchFromGitHub; +in callPackage (fetchFromGitHub { + owner = "nmattia"; + repo = "naersk"; + rev = "551a2a63399589f97f503ddd8919f27bb2406354"; + sha256 = "1jrrj4qjwgqa3yjyr0apsz8hlq28rv77ll2w4xmjg2wf4z2fgj0h"; +}) {} diff --git a/third_party/nix/.clang-format b/third_party/nix/.clang-format new file mode 100644 index 0000000000..b8c36e122b --- /dev/null +++ b/third_party/nix/.clang-format @@ -0,0 +1,11 @@ +# Use the Google style in this project. +BasedOnStyle: Google +DerivePointerAlignment: false +PointerAlignment: Left +IncludeCategories: + - Regex: '^<.*\.h>' + Priority: 2 + - Regex: '^<.*' + Priority: 1 + - Regex: '.*' + Priority: 3 diff --git a/third_party/nix/.dir-locals.el b/third_party/nix/.dir-locals.el new file mode 100644 index 0000000000..92aa816f10 --- /dev/null +++ b/third_party/nix/.dir-locals.el @@ -0,0 +1 @@ +((c++-mode . ((c-file-style . "google")))) diff --git a/third_party/nix/.github/ISSUE_TEMPLATE.md b/third_party/nix/.github/ISSUE_TEMPLATE.md new file mode 100644 index 0000000000..3372b1f03f --- /dev/null +++ b/third_party/nix/.github/ISSUE_TEMPLATE.md @@ -0,0 +1,27 @@ +<!-- + +# Filing a Nix issue + +*WAIT* Are you sure you're filing your issue in the right repository? + +We appreciate you taking the time to tell us about issues you encounter, but routing the issue to the right place will get you help sooner and save everyone time. + +This is the Nix repository, and issues here should be about Nix the build and package management *_tool_*. + +If you have a problem with a specific package on NixOS or when using Nix, you probably want to file an issue with _nixpkgs_, whose issue tracker is over at https://github.com/NixOS/nixpkgs/issues. + +Examples of _Nix_ issues: + +- Nix segfaults when I run `nix-build -A blahblah` +- The Nix language needs a new builtin: `builtins.foobar` +- Regression in the behavior of `nix-env` in Nix 2.0 + +Examples of _nixpkgs_ issues: + +- glibc is b0rked on aarch64 +- chromium in NixOS doesn't support U2F but google-chrome does! +- The OpenJDK package on macOS is missing a key component + +Chances are if you're a newcomer to the Nix world, you'll probably want the [nixpkgs tracker](https://github.com/NixOS/nixpkgs/issues). It also gets a lot more eyeball traffic so you'll probably get a response a lot more quickly. + +--> diff --git a/third_party/nix/.gitignore b/third_party/nix/.gitignore new file mode 100644 index 0000000000..6009737eec --- /dev/null +++ b/third_party/nix/.gitignore @@ -0,0 +1,120 @@ +Makefile.config +perl/Makefile.config + +# / +/aclocal.m4 +/autom4te.cache +/config.* +/configure +/nix.spec +/stamp-h1 +/svn-revision +/build-gcc +/libtool + +/corepkgs/config.nix + +# /corepkgs/channels/ +/corepkgs/channels/unpack.sh + +# /corepkgs/nar/ +/corepkgs/nar/nar.sh +/corepkgs/nar/unnar.sh + +# /doc/manual/ +/doc/manual/manual.html +/doc/manual/manual.xmli +/doc/manual/manual.pdf +/doc/manual/manual.is-valid +/doc/manual/*.1 +/doc/manual/*.5 +/doc/manual/*.8 +/doc/manual/version.txt + +# /scripts/ +/scripts/nix-profile.sh +/scripts/nix-copy-closure +/scripts/nix-reduce-build +/scripts/nix-http-export.cgi +/scripts/nix-profile-daemon.sh + +# /src/libexpr/ +/src/libexpr/lexer-tab.cc +/src/libexpr/lexer-tab.hh +/src/libexpr/parser-tab.cc +/src/libexpr/parser-tab.hh +/src/libexpr/parser-tab.output +/src/libexpr/nix.tbl + +# /src/libstore/ +/src/libstore/*.gen.hh + +/src/nix/nix + +# /src/nix-env/ +/src/nix-env/nix-env + +# /src/nix-instantiate/ +/src/nix-instantiate/nix-instantiate + +# /src/nix-store/ +/src/nix-store/nix-store + +/src/nix-prefetch-url/nix-prefetch-url + +# /src/nix-daemon/ +/src/nix-daemon/nix-daemon + +/src/nix-collect-garbage/nix-collect-garbage + +# /src/nix-channel/ +/src/nix-channel/nix-channel + +# /src/nix-build/ +/src/nix-build/nix-build + +/src/nix-copy-closure/nix-copy-closure + +/src/build-remote/build-remote + +# /tests/ +/tests/test-tmp +/tests/common.sh +/tests/dummy +/tests/result* +/tests/restricted-innocent +/tests/shell +/tests/shell.drv + +# /tests/lang/ +/tests/lang/*.out +/tests/lang/*.out.xml +/tests/lang/*.ast + +/perl/lib/Nix/Config.pm +/perl/lib/Nix/Store.cc + +/misc/systemd/nix-daemon.service +/misc/systemd/nix-daemon.socket +/misc/upstart/nix-daemon.conf + +/src/resolve-system-dependencies/resolve-system-dependencies + +inst/ + +*.a +*.o +*.so +*.dylib +*.dll +*.exe +*.dep +*~ +*.pc +*.plist + +# GNU Global +GPATH +GRTAGS +GSYMS +GTAGS diff --git a/third_party/nix/.travis.yml b/third_party/nix/.travis.yml new file mode 100644 index 0000000000..99218a963c --- /dev/null +++ b/third_party/nix/.travis.yml @@ -0,0 +1,2 @@ +os: osx +script: ./tests/install-darwin.sh diff --git a/third_party/nix/.version b/third_party/nix/.version new file mode 100644 index 0000000000..fd06a9268d --- /dev/null +++ b/third_party/nix/.version @@ -0,0 +1 @@ +2.3.4 \ No newline at end of file diff --git a/third_party/nix/COPYING b/third_party/nix/COPYING new file mode 100644 index 0000000000..5ab7695ab8 --- /dev/null +++ b/third_party/nix/COPYING @@ -0,0 +1,504 @@ + GNU LESSER GENERAL PUBLIC LICENSE + Version 2.1, February 1999 + + Copyright (C) 1991, 1999 Free Software Foundation, Inc. + 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + +[This is the first released version of the Lesser GPL. It also counts + as the successor of the GNU Library Public License, version 2, hence + the version number 2.1.] + + Preamble + + The licenses for most software are designed to take away your +freedom to share and change it. By contrast, the GNU General Public +Licenses are intended to guarantee your freedom to share and change +free software--to make sure the software is free for all its users. + + This license, the Lesser General Public License, applies to some +specially designated software packages--typically libraries--of the +Free Software Foundation and other authors who decide to use it. You +can use it too, but we suggest you first think carefully about whether +this license or the ordinary General Public License is the better +strategy to use in any particular case, based on the explanations below. + + When we speak of free software, we are referring to freedom of use, +not price. Our General Public Licenses are designed to make sure that +you have the freedom to distribute copies of free software (and charge +for this service if you wish); that you receive source code or can get +it if you want it; that you can change the software and use pieces of +it in new free programs; and that you are informed that you can do +these things. + + To protect your rights, we need to make restrictions that forbid +distributors to deny you these rights or to ask you to surrender these +rights. These restrictions translate to certain responsibilities for +you if you distribute copies of the library or if you modify it. + + For example, if you distribute copies of the library, whether gratis +or for a fee, you must give the recipients all the rights that we gave +you. You must make sure that they, too, receive or can get the source +code. If you link other code with the library, you must provide +complete object files to the recipients, so that they can relink them +with the library after making changes to the library and recompiling +it. And you must show them these terms so they know their rights. + + We protect your rights with a two-step method: (1) we copyright the +library, and (2) we offer you this license, which gives you legal +permission to copy, distribute and/or modify the library. + + To protect each distributor, we want to make it very clear that +there is no warranty for the free library. Also, if the library is +modified by someone else and passed on, the recipients should know +that what they have is not the original version, so that the original +author's reputation will not be affected by problems that might be +introduced by others. + + Finally, software patents pose a constant threat to the existence of +any free program. We wish to make sure that a company cannot +effectively restrict the users of a free program by obtaining a +restrictive license from a patent holder. Therefore, we insist that +any patent license obtained for a version of the library must be +consistent with the full freedom of use specified in this license. + + Most GNU software, including some libraries, is covered by the +ordinary GNU General Public License. This license, the GNU Lesser +General Public License, applies to certain designated libraries, and +is quite different from the ordinary General Public License. We use +this license for certain libraries in order to permit linking those +libraries into non-free programs. + + When a program is linked with a library, whether statically or using +a shared library, the combination of the two is legally speaking a +combined work, a derivative of the original library. The ordinary +General Public License therefore permits such linking only if the +entire combination fits its criteria of freedom. The Lesser General +Public License permits more lax criteria for linking other code with +the library. + + We call this license the "Lesser" General Public License because it +does Less to protect the user's freedom than the ordinary General +Public License. It also provides other free software developers Less +of an advantage over competing non-free programs. These disadvantages +are the reason we use the ordinary General Public License for many +libraries. However, the Lesser license provides advantages in certain +special circumstances. + + For example, on rare occasions, there may be a special need to +encourage the widest possible use of a certain library, so that it becomes +a de-facto standard. To achieve this, non-free programs must be +allowed to use the library. A more frequent case is that a free +library does the same job as widely used non-free libraries. In this +case, there is little to gain by limiting the free library to free +software only, so we use the Lesser General Public License. + + In other cases, permission to use a particular library in non-free +programs enables a greater number of people to use a large body of +free software. For example, permission to use the GNU C Library in +non-free programs enables many more people to use the whole GNU +operating system, as well as its variant, the GNU/Linux operating +system. + + Although the Lesser General Public License is Less protective of the +users' freedom, it does ensure that the user of a program that is +linked with the Library has the freedom and the wherewithal to run +that program using a modified version of the Library. + + The precise terms and conditions for copying, distribution and +modification follow. Pay close attention to the difference between a +"work based on the library" and a "work that uses the library". The +former contains code derived from the library, whereas the latter must +be combined with the library in order to run. + + GNU LESSER GENERAL PUBLIC LICENSE + TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION + + 0. This License Agreement applies to any software library or other +program which contains a notice placed by the copyright holder or +other authorized party saying it may be distributed under the terms of +this Lesser General Public License (also called "this License"). +Each licensee is addressed as "you". + + A "library" means a collection of software functions and/or data +prepared so as to be conveniently linked with application programs +(which use some of those functions and data) to form executables. + + The "Library", below, refers to any such software library or work +which has been distributed under these terms. A "work based on the +Library" means either the Library or any derivative work under +copyright law: that is to say, a work containing the Library or a +portion of it, either verbatim or with modifications and/or translated +straightforwardly into another language. (Hereinafter, translation is +included without limitation in the term "modification".) + + "Source code" for a work means the preferred form of the work for +making modifications to it. For a library, complete source code means +all the source code for all modules it contains, plus any associated +interface definition files, plus the scripts used to control compilation +and installation of the library. + + Activities other than copying, distribution and modification are not +covered by this License; they are outside its scope. The act of +running a program using the Library is not restricted, and output from +such a program is covered only if its contents constitute a work based +on the Library (independent of the use of the Library in a tool for +writing it). Whether that is true depends on what the Library does +and what the program that uses the Library does. + + 1. You may copy and distribute verbatim copies of the Library's +complete source code as you receive it, in any medium, provided that +you conspicuously and appropriately publish on each copy an +appropriate copyright notice and disclaimer of warranty; keep intact +all the notices that refer to this License and to the absence of any +warranty; and distribute a copy of this License along with the +Library. + + You may charge a fee for the physical act of transferring a copy, +and you may at your option offer warranty protection in exchange for a +fee. + + 2. You may modify your copy or copies of the Library or any portion +of it, thus forming a work based on the Library, and copy and +distribute such modifications or work under the terms of Section 1 +above, provided that you also meet all of these conditions: + + a) The modified work must itself be a software library. + + b) You must cause the files modified to carry prominent notices + stating that you changed the files and the date of any change. + + c) You must cause the whole of the work to be licensed at no + charge to all third parties under the terms of this License. + + d) If a facility in the modified Library refers to a function or a + table of data to be supplied by an application program that uses + the facility, other than as an argument passed when the facility + is invoked, then you must make a good faith effort to ensure that, + in the event an application does not supply such function or + table, the facility still operates, and performs whatever part of + its purpose remains meaningful. + + (For example, a function in a library to compute square roots has + a purpose that is entirely well-defined independent of the + application. Therefore, Subsection 2d requires that any + application-supplied function or table used by this function must + be optional: if the application does not supply it, the square + root function must still compute square roots.) + +These requirements apply to the modified work as a whole. If +identifiable sections of that work are not derived from the Library, +and can be reasonably considered independent and separate works in +themselves, then this License, and its terms, do not apply to those +sections when you distribute them as separate works. But when you +distribute the same sections as part of a whole which is a work based +on the Library, the distribution of the whole must be on the terms of +this License, whose permissions for other licensees extend to the +entire whole, and thus to each and every part regardless of who wrote +it. + +Thus, it is not the intent of this section to claim rights or contest +your rights to work written entirely by you; rather, the intent is to +exercise the right to control the distribution of derivative or +collective works based on the Library. + +In addition, mere aggregation of another work not based on the Library +with the Library (or with a work based on the Library) on a volume of +a storage or distribution medium does not bring the other work under +the scope of this License. + + 3. You may opt to apply the terms of the ordinary GNU General Public +License instead of this License to a given copy of the Library. To do +this, you must alter all the notices that refer to this License, so +that they refer to the ordinary GNU General Public License, version 2, +instead of to this License. (If a newer version than version 2 of the +ordinary GNU General Public License has appeared, then you can specify +that version instead if you wish.) Do not make any other change in +these notices. + + Once this change is made in a given copy, it is irreversible for +that copy, so the ordinary GNU General Public License applies to all +subsequent copies and derivative works made from that copy. + + This option is useful when you wish to copy part of the code of +the Library into a program that is not a library. + + 4. You may copy and distribute the Library (or a portion or +derivative of it, under Section 2) in object code or executable form +under the terms of Sections 1 and 2 above provided that you accompany +it with the complete corresponding machine-readable source code, which +must be distributed under the terms of Sections 1 and 2 above on a +medium customarily used for software interchange. + + If distribution of object code is made by offering access to copy +from a designated place, then offering equivalent access to copy the +source code from the same place satisfies the requirement to +distribute the source code, even though third parties are not +compelled to copy the source along with the object code. + + 5. A program that contains no derivative of any portion of the +Library, but is designed to work with the Library by being compiled or +linked with it, is called a "work that uses the Library". Such a +work, in isolation, is not a derivative work of the Library, and +therefore falls outside the scope of this License. + + However, linking a "work that uses the Library" with the Library +creates an executable that is a derivative of the Library (because it +contains portions of the Library), rather than a "work that uses the +library". The executable is therefore covered by this License. +Section 6 states terms for distribution of such executables. + + When a "work that uses the Library" uses material from a header file +that is part of the Library, the object code for the work may be a +derivative work of the Library even though the source code is not. +Whether this is true is especially significant if the work can be +linked without the Library, or if the work is itself a library. The +threshold for this to be true is not precisely defined by law. + + If such an object file uses only numerical parameters, data +structure layouts and accessors, and small macros and small inline +functions (ten lines or less in length), then the use of the object +file is unrestricted, regardless of whether it is legally a derivative +work. (Executables containing this object code plus portions of the +Library will still fall under Section 6.) + + Otherwise, if the work is a derivative of the Library, you may +distribute the object code for the work under the terms of Section 6. +Any executables containing that work also fall under Section 6, +whether or not they are linked directly with the Library itself. + + 6. As an exception to the Sections above, you may also combine or +link a "work that uses the Library" with the Library to produce a +work containing portions of the Library, and distribute that work +under terms of your choice, provided that the terms permit +modification of the work for the customer's own use and reverse +engineering for debugging such modifications. + + You must give prominent notice with each copy of the work that the +Library is used in it and that the Library and its use are covered by +this License. You must supply a copy of this License. If the work +during execution displays copyright notices, you must include the +copyright notice for the Library among them, as well as a reference +directing the user to the copy of this License. Also, you must do one +of these things: + + a) Accompany the work with the complete corresponding + machine-readable source code for the Library including whatever + changes were used in the work (which must be distributed under + Sections 1 and 2 above); and, if the work is an executable linked + with the Library, with the complete machine-readable "work that + uses the Library", as object code and/or source code, so that the + user can modify the Library and then relink to produce a modified + executable containing the modified Library. (It is understood + that the user who changes the contents of definitions files in the + Library will not necessarily be able to recompile the application + to use the modified definitions.) + + b) Use a suitable shared library mechanism for linking with the + Library. A suitable mechanism is one that (1) uses at run time a + copy of the library already present on the user's computer system, + rather than copying library functions into the executable, and (2) + will operate properly with a modified version of the library, if + the user installs one, as long as the modified version is + interface-compatible with the version that the work was made with. + + c) Accompany the work with a written offer, valid for at + least three years, to give the same user the materials + specified in Subsection 6a, above, for a charge no more + than the cost of performing this distribution. + + d) If distribution of the work is made by offering access to copy + from a designated place, offer equivalent access to copy the above + specified materials from the same place. + + e) Verify that the user has already received a copy of these + materials or that you have already sent this user a copy. + + For an executable, the required form of the "work that uses the +Library" must include any data and utility programs needed for +reproducing the executable from it. However, as a special exception, +the materials to be distributed need not include anything that is +normally distributed (in either source or binary form) with the major +components (compiler, kernel, and so on) of the operating system on +which the executable runs, unless that component itself accompanies +the executable. + + It may happen that this requirement contradicts the license +restrictions of other proprietary libraries that do not normally +accompany the operating system. Such a contradiction means you cannot +use both them and the Library together in an executable that you +distribute. + + 7. You may place library facilities that are a work based on the +Library side-by-side in a single library together with other library +facilities not covered by this License, and distribute such a combined +library, provided that the separate distribution of the work based on +the Library and of the other library facilities is otherwise +permitted, and provided that you do these two things: + + a) Accompany the combined library with a copy of the same work + based on the Library, uncombined with any other library + facilities. This must be distributed under the terms of the + Sections above. + + b) Give prominent notice with the combined library of the fact + that part of it is a work based on the Library, and explaining + where to find the accompanying uncombined form of the same work. + + 8. You may not copy, modify, sublicense, link with, or distribute +the Library except as expressly provided under this License. Any +attempt otherwise to copy, modify, sublicense, link with, or +distribute the Library is void, and will automatically terminate your +rights under this License. However, parties who have received copies, +or rights, from you under this License will not have their licenses +terminated so long as such parties remain in full compliance. + + 9. You are not required to accept this License, since you have not +signed it. However, nothing else grants you permission to modify or +distribute the Library or its derivative works. These actions are +prohibited by law if you do not accept this License. Therefore, by +modifying or distributing the Library (or any work based on the +Library), you indicate your acceptance of this License to do so, and +all its terms and conditions for copying, distributing or modifying +the Library or works based on it. + + 10. Each time you redistribute the Library (or any work based on the +Library), the recipient automatically receives a license from the +original licensor to copy, distribute, link with or modify the Library +subject to these terms and conditions. You may not impose any further +restrictions on the recipients' exercise of the rights granted herein. +You are not responsible for enforcing compliance by third parties with +this License. + + 11. If, as a consequence of a court judgment or allegation of patent +infringement or for any other reason (not limited to patent issues), +conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot +distribute so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you +may not distribute the Library at all. For example, if a patent +license would not permit royalty-free redistribution of the Library by +all those who receive copies directly or indirectly through you, then +the only way you could satisfy both it and this License would be to +refrain entirely from distribution of the Library. + +If any portion of this section is held invalid or unenforceable under any +particular circumstance, the balance of the section is intended to apply, +and the section as a whole is intended to apply in other circumstances. + +It is not the purpose of this section to induce you to infringe any +patents or other property right claims or to contest validity of any +such claims; this section has the sole purpose of protecting the +integrity of the free software distribution system which is +implemented by public license practices. Many people have made +generous contributions to the wide range of software distributed +through that system in reliance on consistent application of that +system; it is up to the author/donor to decide if he or she is willing +to distribute software through any other system and a licensee cannot +impose that choice. + +This section is intended to make thoroughly clear what is believed to +be a consequence of the rest of this License. + + 12. If the distribution and/or use of the Library is restricted in +certain countries either by patents or by copyrighted interfaces, the +original copyright holder who places the Library under this License may add +an explicit geographical distribution limitation excluding those countries, +so that distribution is permitted only in or among countries not thus +excluded. In such case, this License incorporates the limitation as if +written in the body of this License. + + 13. The Free Software Foundation may publish revised and/or new +versions of the Lesser General Public License from time to time. +Such new versions will be similar in spirit to the present version, +but may differ in detail to address new problems or concerns. + +Each version is given a distinguishing version number. If the Library +specifies a version number of this License which applies to it and +"any later version", you have the option of following the terms and +conditions either of that version or of any later version published by +the Free Software Foundation. If the Library does not specify a +license version number, you may choose any version ever published by +the Free Software Foundation. + + 14. If you wish to incorporate parts of the Library into other free +programs whose distribution conditions are incompatible with these, +write to the author to ask for permission. For software which is +copyrighted by the Free Software Foundation, write to the Free +Software Foundation; we sometimes make exceptions for this. Our +decision will be guided by the two goals of preserving the free status +of all derivatives of our free software and of promoting the sharing +and reuse of software generally. + + NO WARRANTY + + 15. BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO +WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW. +EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR +OTHER PARTIES PROVIDE THE LIBRARY "AS IS" WITHOUT WARRANTY OF ANY +KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE +IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR +PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE +LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME +THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION. + + 16. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN +WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY +AND/OR REDISTRIBUTE THE LIBRARY AS PERMITTED ABOVE, BE LIABLE TO YOU +FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR +CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE +LIBRARY (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING +RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A +FAILURE OF THE LIBRARY TO OPERATE WITH ANY OTHER SOFTWARE), EVEN IF +SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH +DAMAGES. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Libraries + + If you develop a new library, and you want it to be of the greatest +possible use to the public, we recommend making it free software that +everyone can redistribute and change. You can do so by permitting +redistribution under these terms (or, alternatively, under the terms of the +ordinary General Public License). + + To apply these terms, attach the following notices to the library. It is +safest to attach them to the start of each source file to most effectively +convey the exclusion of warranty; and each file should have at least the +"copyright" line and a pointer to where the full notice is found. + + <one line to give the library's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This library is free software; you can redistribute it and/or + modify it under the terms of the GNU Lesser General Public + License as published by the Free Software Foundation; either + version 2.1 of the License, or (at your option) any later version. + + This library is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU + Lesser General Public License for more details. + + You should have received a copy of the GNU Lesser General Public + License along with this library; if not, write to the Free Software + Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA + +Also add information on how to contact you by electronic and paper mail. + +You should also get your employer (if you work as a programmer) or your +school, if any, to sign a "copyright disclaimer" for the library, if +necessary. Here is a sample; alter the names: + + Yoyodyne, Inc., hereby disclaims all copyright interest in the + library `Frob' (a library for tweaking knobs) written by James Random Hacker. + + <signature of Ty Coon>, 1 April 1990 + Ty Coon, President of Vice + +That's all there is to it! + + diff --git a/third_party/nix/README.md b/third_party/nix/README.md new file mode 100644 index 0000000000..48cb1685c7 --- /dev/null +++ b/third_party/nix/README.md @@ -0,0 +1,24 @@ +[](https://opencollective.com/nixos) + +Nix, the purely functional package manager +------------------------------------------ + +Nix is a new take on package management that is fairly unique. Because of its +purity aspects, a lot of issues found in traditional package managers don't +appear with Nix. + +To find out more about the tool, usage and installation instructions, please +read the manual, which is available on the Nix website at +<http://nixos.org/nix/manual>. + +## Contributing + +Take a look at the [Hacking Section](http://nixos.org/nix/manual/#chap-hacking) +of the manual. It helps you to get started with building Nix from source. + +## License + +Nix is released under the LGPL v2.1 + +This product includes software developed by the OpenSSL Project for +use in the [OpenSSL Toolkit](http://www.OpenSSL.org/). diff --git a/third_party/nix/config/config.guess b/third_party/nix/config/config.guess new file mode 100755 index 0000000000..d4fb3213ec --- /dev/null +++ b/third_party/nix/config/config.guess @@ -0,0 +1,1486 @@ +#! /bin/sh +# Attempt to guess a canonical system name. +# Copyright 1992-2018 Free Software Foundation, Inc. + +timestamp='2018-08-02' + +# This file is free software; you can redistribute it and/or modify it +# under the terms of the GNU General Public License as published by +# the Free Software Foundation; either version 3 of the License, or +# (at your option) any later version. +# +# This program is distributed in the hope that it will be useful, but +# WITHOUT ANY WARRANTY; without even the implied warranty of +# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU +# General Public License for more details. +# +# You should have received a copy of the GNU General Public License +# along with this program; if not, see <https://www.gnu.org/licenses/>. +# +# As a special exception to the GNU General Public License, if you +# distribute this file as part of a program that contains a +# configuration script generated by Autoconf, you may include it under +# the same distribution terms that you use for the rest of that +# program. This Exception is an additional permission under section 7 +# of the GNU General Public License, version 3 ("GPLv3"). +# +# Originally written by Per Bothner; maintained since 2000 by Ben Elliston. +# +# You can get the latest version of this script from: +# https://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.guess +# +# Please send patches to <config-patches@gnu.org>. + + +me=`echo "$0" | sed -e 's,.*/,,'` + +usage="\ +Usage: $0 [OPTION] + +Output the configuration name of the system \`$me' is run on. + +Options: + -h, --help print this help, then exit + -t, --time-stamp print date of last modification, then exit + -v, --version print version number, then exit + +Report bugs and patches to <config-patches@gnu.org>." + +version="\ +GNU config.guess ($timestamp) + +Originally written by Per Bothner. +Copyright 1992-2018 Free Software Foundation, Inc. + +This is free software; see the source for copying conditions. There is NO +warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE." + +help=" +Try \`$me --help' for more information." + +# Parse command line +while test $# -gt 0 ; do + case $1 in + --time-stamp | --time* | -t ) + echo "$timestamp" ; exit ;; + --version | -v ) + echo "$version" ; exit ;; + --help | --h* | -h ) + echo "$usage"; exit ;; + -- ) # Stop option processing + shift; break ;; + - ) # Use stdin as input. + break ;; + -* ) + echo "$me: invalid option $1$help" >&2 + exit 1 ;; + * ) + break ;; + esac +done + +if test $# != 0; then + echo "$me: too many arguments$help" >&2 + exit 1 +fi + +# CC_FOR_BUILD -- compiler used by this script. Note that the use of a +# compiler to aid in system detection is discouraged as it requires +# temporary files to be created and, as you can see below, it is a +# headache to deal with in a portable fashion. + +# Historically, `CC_FOR_BUILD' used to be named `HOST_CC'. We still +# use `HOST_CC' if defined, but it is deprecated. + +# Portable tmp directory creation inspired by the Autoconf team. + +tmp= +# shellcheck disable=SC2172 +trap 'test -z "$tmp" || rm -fr "$tmp"' 1 2 13 15 +trap 'exitcode=$?; test -z "$tmp" || rm -fr "$tmp"; exit $exitcode' 0 + +set_cc_for_build() { + : "${TMPDIR=/tmp}" + # shellcheck disable=SC2039 + { tmp=`(umask 077 && mktemp -d "$TMPDIR/cgXXXXXX") 2>/dev/null` && test -n "$tmp" && test -d "$tmp" ; } || + { test -n "$RANDOM" && tmp=$TMPDIR/cg$$-$RANDOM && (umask 077 && mkdir "$tmp" 2>/dev/null) ; } || + { tmp=$TMPDIR/cg-$$ && (umask 077 && mkdir "$tmp" 2>/dev/null) && echo "Warning: creating insecure temp directory" >&2 ; } || + { echo "$me: cannot create a temporary directory in $TMPDIR" >&2 ; exit 1 ; } + dummy=$tmp/dummy + case ${CC_FOR_BUILD-},${HOST_CC-},${CC-} in + ,,) echo "int x;" > "$dummy.c" + for driver in cc gcc c89 c99 ; do + if ($driver -c -o "$dummy.o" "$dummy.c") >/dev/null 2>&1 ; then + CC_FOR_BUILD="$driver" + break + fi + done + if test x"$CC_FOR_BUILD" = x ; then + CC_FOR_BUILD=no_compiler_found + fi + ;; + ,,*) CC_FOR_BUILD=$CC ;; + ,*,*) CC_FOR_BUILD=$HOST_CC ;; + esac +} + +# This is needed to find uname on a Pyramid OSx when run in the BSD universe. +# (ghazi@noc.rutgers.edu 1994-08-24) +if test -f /.attbin/uname ; then + PATH=$PATH:/.attbin ; export PATH +fi + +UNAME_MACHINE=`(uname -m) 2>/dev/null` || UNAME_MACHINE=unknown +UNAME_RELEASE=`(uname -r) 2>/dev/null` || UNAME_RELEASE=unknown +UNAME_SYSTEM=`(uname -s) 2>/dev/null` || UNAME_SYSTEM=unknown +UNAME_VERSION=`(uname -v) 2>/dev/null` || UNAME_VERSION=unknown + +case "$UNAME_SYSTEM" in +Linux|GNU|GNU/*) + # If the system lacks a compiler, then just pick glibc. + # We could probably try harder. + LIBC=gnu + + set_cc_for_build + cat <<-EOF > "$dummy.c" + #include <features.h> + #if defined(__UCLIBC__) + LIBC=uclibc + #elif defined(__dietlibc__) + LIBC=dietlibc + #else + LIBC=gnu + #endif + EOF + eval "`$CC_FOR_BUILD -E "$dummy.c" 2>/dev/null | grep '^LIBC' | sed 's, ,,g'`" + + # If ldd exists, use it to detect musl libc. + if command -v ldd >/dev/null && \ + ldd --version 2>&1 | grep -q ^musl + then + LIBC=musl + fi + ;; +esac + +# Note: order is significant - the case branches are not exclusive. + +case "$UNAME_MACHINE:$UNAME_SYSTEM:$UNAME_RELEASE:$UNAME_VERSION" in + *:NetBSD:*:*) + # NetBSD (nbsd) targets should (where applicable) match one or + # more of the tuples: *-*-netbsdelf*, *-*-netbsdaout*, + # *-*-netbsdecoff* and *-*-netbsd*. For targets that recently + # switched to ELF, *-*-netbsd* would select the old + # object file format. This provides both forward + # compatibility and a consistent mechanism for selecting the + # object file format. + # + # Note: NetBSD doesn't particularly care about the vendor + # portion of the name. We always set it to "unknown". + sysctl="sysctl -n hw.machine_arch" + UNAME_MACHINE_ARCH=`(uname -p 2>/dev/null || \ + "/sbin/$sysctl" 2>/dev/null || \ + "/usr/sbin/$sysctl" 2>/dev/null || \ + echo unknown)` + case "$UNAME_MACHINE_ARCH" in + armeb) machine=armeb-unknown ;; + arm*) machine=arm-unknown ;; + sh3el) machine=shl-unknown ;; + sh3eb) machine=sh-unknown ;; + sh5el) machine=sh5le-unknown ;; + earmv*) + arch=`echo "$UNAME_MACHINE_ARCH" | sed -e 's,^e\(armv[0-9]\).*$,\1,'` + endian=`echo "$UNAME_MACHINE_ARCH" | sed -ne 's,^.*\(eb\)$,\1,p'` + machine="${arch}${endian}"-unknown + ;; + *) machine="$UNAME_MACHINE_ARCH"-unknown ;; + esac + # The Operating System including object format, if it has switched + # to ELF recently (or will in the future) and ABI. + case "$UNAME_MACHINE_ARCH" in + earm*) + os=netbsdelf + ;; + arm*|i386|m68k|ns32k|sh3*|sparc|vax) + set_cc_for_build + if echo __ELF__ | $CC_FOR_BUILD -E - 2>/dev/null \ + | grep -q __ELF__ + then + # Once all utilities can be ECOFF (netbsdecoff) or a.out (netbsdaout). + # Return netbsd for either. FIX? + os=netbsd + else + os=netbsdelf + fi + ;; + *) + os=netbsd + ;; + esac + # Determine ABI tags. + case "$UNAME_MACHINE_ARCH" in + earm*) + expr='s/^earmv[0-9]/-eabi/;s/eb$//' + abi=`echo "$UNAME_MACHINE_ARCH" | sed -e "$expr"` + ;; + esac + # The OS release + # Debian GNU/NetBSD machines have a different userland, and + # thus, need a distinct triplet. However, they do not need + # kernel version information, so it can be replaced with a + # suitable tag, in the style of linux-gnu. + case "$UNAME_VERSION" in + Debian*) + release='-gnu' + ;; + *) + release=`echo "$UNAME_RELEASE" | sed -e 's/[-_].*//' | cut -d. -f1,2` + ;; + esac + # Since CPU_TYPE-MANUFACTURER-KERNEL-OPERATING_SYSTEM: + # contains redundant information, the shorter form: + # CPU_TYPE-MANUFACTURER-OPERATING_SYSTEM is used. + echo "$machine-${os}${release}${abi-}" + exit ;; + *:Bitrig:*:*) + UNAME_MACHINE_ARCH=`arch | sed 's/Bitrig.//'` + echo "$UNAME_MACHINE_ARCH"-unknown-bitrig"$UNAME_RELEASE" + exit ;; + *:OpenBSD:*:*) + UNAME_MACHINE_ARCH=`arch | sed 's/OpenBSD.//'` + echo "$UNAME_MACHINE_ARCH"-unknown-openbsd"$UNAME_RELEASE" + exit ;; + *:LibertyBSD:*:*) + UNAME_MACHINE_ARCH=`arch | sed 's/^.*BSD\.//'` + echo "$UNAME_MACHINE_ARCH"-unknown-libertybsd"$UNAME_RELEASE" + exit ;; + *:MidnightBSD:*:*) + echo "$UNAME_MACHINE"-unknown-midnightbsd"$UNAME_RELEASE" + exit ;; + *:ekkoBSD:*:*) + echo "$UNAME_MACHINE"-unknown-ekkobsd"$UNAME_RELEASE" + exit ;; + *:SolidBSD:*:*) + echo "$UNAME_MACHINE"-unknown-solidbsd"$UNAME_RELEASE" + exit ;; + macppc:MirBSD:*:*) + echo powerpc-unknown-mirbsd"$UNAME_RELEASE" + exit ;; + *:MirBSD:*:*) + echo "$UNAME_MACHINE"-unknown-mirbsd"$UNAME_RELEASE" + exit ;; + *:Sortix:*:*) + echo "$UNAME_MACHINE"-unknown-sortix + exit ;; + *:Redox:*:*) + echo "$UNAME_MACHINE"-unknown-redox + exit ;; + mips:OSF1:*.*) + echo mips-dec-osf1 + exit ;; + alpha:OSF1:*:*) + case $UNAME_RELEASE in + *4.0) + UNAME_RELEASE=`/usr/sbin/sizer -v | awk '{print $3}'` + ;; + *5.*) + UNAME_RELEASE=`/usr/sbin/sizer -v | awk '{print $4}'` + ;; + esac + # According to Compaq, /usr/sbin/psrinfo has been available on + # OSF/1 and Tru64 systems produced since 1995. I hope that + # covers most systems running today. This code pipes the CPU + # types through head -n 1, so we only detect the type of CPU 0. + ALPHA_CPU_TYPE=`/usr/sbin/psrinfo -v | sed -n -e 's/^ The alpha \(.*\) processor.*$/\1/p' | head -n 1` + case "$ALPHA_CPU_TYPE" in + "EV4 (21064)") + UNAME_MACHINE=alpha ;; + "EV4.5 (21064)") + UNAME_MACHINE=alpha ;; + "LCA4 (21066/21068)") + UNAME_MACHINE=alpha ;; + "EV5 (21164)") + UNAME_MACHINE=alphaev5 ;; + "EV5.6 (21164A)") + UNAME_MACHINE=alphaev56 ;; + "EV5.6 (21164PC)") + UNAME_MACHINE=alphapca56 ;; + "EV5.7 (21164PC)") + UNAME_MACHINE=alphapca57 ;; + "EV6 (21264)") + UNAME_MACHINE=alphaev6 ;; + "EV6.7 (21264A)") + UNAME_MACHINE=alphaev67 ;; + "EV6.8CB (21264C)") + UNAME_MACHINE=alphaev68 ;; + "EV6.8AL (21264B)") + UNAME_MACHINE=alphaev68 ;; + "EV6.8CX (21264D)") + UNAME_MACHINE=alphaev68 ;; + "EV6.9A (21264/EV69A)") + UNAME_MACHINE=alphaev69 ;; + "EV7 (21364)") + UNAME_MACHINE=alphaev7 ;; + "EV7.9 (21364A)") + UNAME_MACHINE=alphaev79 ;; + esac + # A Pn.n version is a patched version. + # A Vn.n version is a released version. + # A Tn.n version is a released field test version. + # A Xn.n version is an unreleased experimental baselevel. + # 1.2 uses "1.2" for uname -r. + echo "$UNAME_MACHINE"-dec-osf"`echo "$UNAME_RELEASE" | sed -e 's/^[PVTX]//' | tr ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz`" + # Reset EXIT trap before exiting to avoid spurious non-zero exit code. + exitcode=$? + trap '' 0 + exit $exitcode ;; + Amiga*:UNIX_System_V:4.0:*) + echo m68k-unknown-sysv4 + exit ;; + *:[Aa]miga[Oo][Ss]:*:*) + echo "$UNAME_MACHINE"-unknown-amigaos + exit ;; + *:[Mm]orph[Oo][Ss]:*:*) + echo "$UNAME_MACHINE"-unknown-morphos + exit ;; + *:OS/390:*:*) + echo i370-ibm-openedition + exit ;; + *:z/VM:*:*) + echo s390-ibm-zvmoe + exit ;; + *:OS400:*:*) + echo powerpc-ibm-os400 + exit ;; + arm:RISC*:1.[012]*:*|arm:riscix:1.[012]*:*) + echo arm-acorn-riscix"$UNAME_RELEASE" + exit ;; + arm*:riscos:*:*|arm*:RISCOS:*:*) + echo arm-unknown-riscos + exit ;; + SR2?01:HI-UX/MPP:*:* | SR8000:HI-UX/MPP:*:*) + echo hppa1.1-hitachi-hiuxmpp + exit ;; + Pyramid*:OSx*:*:* | MIS*:OSx*:*:* | MIS*:SMP_DC-OSx*:*:*) + # akee@wpdis03.wpafb.af.mil (Earle F. Ake) contributed MIS and NILE. + if test "`(/bin/universe) 2>/dev/null`" = att ; then + echo pyramid-pyramid-sysv3 + else + echo pyramid-pyramid-bsd + fi + exit ;; + NILE*:*:*:dcosx) + echo pyramid-pyramid-svr4 + exit ;; + DRS?6000:unix:4.0:6*) + echo sparc-icl-nx6 + exit ;; + DRS?6000:UNIX_SV:4.2*:7* | DRS?6000:isis:4.2*:7*) + case `/usr/bin/uname -p` in + sparc) echo sparc-icl-nx7; exit ;; + esac ;; + s390x:SunOS:*:*) + echo "$UNAME_MACHINE"-ibm-solaris2"`echo "$UNAME_RELEASE" | sed -e 's/[^.]*//'`" + exit ;; + sun4H:SunOS:5.*:*) + echo sparc-hal-solaris2"`echo "$UNAME_RELEASE"|sed -e 's/[^.]*//'`" + exit ;; + sun4*:SunOS:5.*:* | tadpole*:SunOS:5.*:*) + echo sparc-sun-solaris2"`echo "$UNAME_RELEASE" | sed -e 's/[^.]*//'`" + exit ;; + i86pc:AuroraUX:5.*:* | i86xen:AuroraUX:5.*:*) + echo i386-pc-auroraux"$UNAME_RELEASE" + exit ;; + i86pc:SunOS:5.*:* | i86xen:SunOS:5.*:*) + UNAME_REL="`echo "$UNAME_RELEASE" | sed -e 's/[^.]*//'`" + case `isainfo -b` in + 32) + echo i386-pc-solaris2"$UNAME_REL" + ;; + 64) + echo x86_64-pc-solaris2"$UNAME_REL" + ;; + esac + exit ;; + sun4*:SunOS:6*:*) + # According to config.sub, this is the proper way to canonicalize + # SunOS6. Hard to guess exactly what SunOS6 will be like, but + # it's likely to be more like Solaris than SunOS4. + echo sparc-sun-solaris3"`echo "$UNAME_RELEASE"|sed -e 's/[^.]*//'`" + exit ;; + sun4*:SunOS:*:*) + case "`/usr/bin/arch -k`" in + Series*|S4*) + UNAME_RELEASE=`uname -v` + ;; + esac + # Japanese Language versions have a version number like `4.1.3-JL'. + echo sparc-sun-sunos"`echo "$UNAME_RELEASE"|sed -e 's/-/_/'`" + exit ;; + sun3*:SunOS:*:*) + echo m68k-sun-sunos"$UNAME_RELEASE" + exit ;; + sun*:*:4.2BSD:*) + UNAME_RELEASE=`(sed 1q /etc/motd | awk '{print substr($5,1,3)}') 2>/dev/null` + test "x$UNAME_RELEASE" = x && UNAME_RELEASE=3 + case "`/bin/arch`" in + sun3) + echo m68k-sun-sunos"$UNAME_RELEASE" + ;; + sun4) + echo sparc-sun-sunos"$UNAME_RELEASE" + ;; + esac + exit ;; + aushp:SunOS:*:*) + echo sparc-auspex-sunos"$UNAME_RELEASE" + exit ;; + # The situation for MiNT is a little confusing. The machine name + # can be virtually everything (everything which is not + # "atarist" or "atariste" at least should have a processor + # > m68000). The system name ranges from "MiNT" over "FreeMiNT" + # to the lowercase version "mint" (or "freemint"). Finally + # the system name "TOS" denotes a system which is actually not + # MiNT. But MiNT is downward compatible to TOS, so this should + # be no problem. + atarist[e]:*MiNT:*:* | atarist[e]:*mint:*:* | atarist[e]:*TOS:*:*) + echo m68k-atari-mint"$UNAME_RELEASE" + exit ;; + atari*:*MiNT:*:* | atari*:*mint:*:* | atarist[e]:*TOS:*:*) + echo m68k-atari-mint"$UNAME_RELEASE" + exit ;; + *falcon*:*MiNT:*:* | *falcon*:*mint:*:* | *falcon*:*TOS:*:*) + echo m68k-atari-mint"$UNAME_RELEASE" + exit ;; + milan*:*MiNT:*:* | milan*:*mint:*:* | *milan*:*TOS:*:*) + echo m68k-milan-mint"$UNAME_RELEASE" + exit ;; + hades*:*MiNT:*:* | hades*:*mint:*:* | *hades*:*TOS:*:*) + echo m68k-hades-mint"$UNAME_RELEASE" + exit ;; + *:*MiNT:*:* | *:*mint:*:* | *:*TOS:*:*) + echo m68k-unknown-mint"$UNAME_RELEASE" + exit ;; + m68k:machten:*:*) + echo m68k-apple-machten"$UNAME_RELEASE" + exit ;; + powerpc:machten:*:*) + echo powerpc-apple-machten"$UNAME_RELEASE" + exit ;; + RISC*:Mach:*:*) + echo mips-dec-mach_bsd4.3 + exit ;; + RISC*:ULTRIX:*:*) + echo mips-dec-ultrix"$UNAME_RELEASE" + exit ;; + VAX*:ULTRIX*:*:*) + echo vax-dec-ultrix"$UNAME_RELEASE" + exit ;; + 2020:CLIX:*:* | 2430:CLIX:*:*) + echo clipper-intergraph-clix"$UNAME_RELEASE" + exit ;; + mips:*:*:UMIPS | mips:*:*:RISCos) + set_cc_for_build + sed 's/^ //' << EOF > "$dummy.c" +#ifdef __cplusplus +#include <stdio.h> /* for printf() prototype */ + int main (int argc, char *argv[]) { +#else + int main (argc, argv) int argc; char *argv[]; { +#endif + #if defined (host_mips) && defined (MIPSEB) + #if defined (SYSTYPE_SYSV) + printf ("mips-mips-riscos%ssysv\\n", argv[1]); exit (0); + #endif + #if defined (SYSTYPE_SVR4) + printf ("mips-mips-riscos%ssvr4\\n", argv[1]); exit (0); + #endif + #if defined (SYSTYPE_BSD43) || defined(SYSTYPE_BSD) + printf ("mips-mips-riscos%sbsd\\n", argv[1]); exit (0); + #endif + #endif + exit (-1); + } +EOF + $CC_FOR_BUILD -o "$dummy" "$dummy.c" && + dummyarg=`echo "$UNAME_RELEASE" | sed -n 's/\([0-9]*\).*/\1/p'` && + SYSTEM_NAME=`"$dummy" "$dummyarg"` && + { echo "$SYSTEM_NAME"; exit; } + echo mips-mips-riscos"$UNAME_RELEASE" + exit ;; + Motorola:PowerMAX_OS:*:*) + echo powerpc-motorola-powermax + exit ;; + Motorola:*:4.3:PL8-*) + echo powerpc-harris-powermax + exit ;; + Night_Hawk:*:*:PowerMAX_OS | Synergy:PowerMAX_OS:*:*) + echo powerpc-harris-powermax + exit ;; + Night_Hawk:Power_UNIX:*:*) + echo powerpc-harris-powerunix + exit ;; + m88k:CX/UX:7*:*) + echo m88k-harris-cxux7 + exit ;; + m88k:*:4*:R4*) + echo m88k-motorola-sysv4 + exit ;; + m88k:*:3*:R3*) + echo m88k-motorola-sysv3 + exit ;; + AViiON:dgux:*:*) + # DG/UX returns AViiON for all architectures + UNAME_PROCESSOR=`/usr/bin/uname -p` + if [ "$UNAME_PROCESSOR" = mc88100 ] || [ "$UNAME_PROCESSOR" = mc88110 ] + then + if [ "$TARGET_BINARY_INTERFACE"x = m88kdguxelfx ] || \ + [ "$TARGET_BINARY_INTERFACE"x = x ] + then + echo m88k-dg-dgux"$UNAME_RELEASE" + else + echo m88k-dg-dguxbcs"$UNAME_RELEASE" + fi + else + echo i586-dg-dgux"$UNAME_RELEASE" + fi + exit ;; + M88*:DolphinOS:*:*) # DolphinOS (SVR3) + echo m88k-dolphin-sysv3 + exit ;; + M88*:*:R3*:*) + # Delta 88k system running SVR3 + echo m88k-motorola-sysv3 + exit ;; + XD88*:*:*:*) # Tektronix XD88 system running UTekV (SVR3) + echo m88k-tektronix-sysv3 + exit ;; + Tek43[0-9][0-9]:UTek:*:*) # Tektronix 4300 system running UTek (BSD) + echo m68k-tektronix-bsd + exit ;; + *:IRIX*:*:*) + echo mips-sgi-irix"`echo "$UNAME_RELEASE"|sed -e 's/-/_/g'`" + exit ;; + ????????:AIX?:[12].1:2) # AIX 2.2.1 or AIX 2.1.1 is RT/PC AIX. + echo romp-ibm-aix # uname -m gives an 8 hex-code CPU id + exit ;; # Note that: echo "'`uname -s`'" gives 'AIX ' + i*86:AIX:*:*) + echo i386-ibm-aix + exit ;; + ia64:AIX:*:*) + if [ -x /usr/bin/oslevel ] ; then + IBM_REV=`/usr/bin/oslevel` + else + IBM_REV="$UNAME_VERSION.$UNAME_RELEASE" + fi + echo "$UNAME_MACHINE"-ibm-aix"$IBM_REV" + exit ;; + *:AIX:2:3) + if grep bos325 /usr/include/stdio.h >/dev/null 2>&1; then + set_cc_for_build + sed 's/^ //' << EOF > "$dummy.c" + #include <sys/systemcfg.h> + + main() + { + if (!__power_pc()) + exit(1); + puts("powerpc-ibm-aix3.2.5"); + exit(0); + } +EOF + if $CC_FOR_BUILD -o "$dummy" "$dummy.c" && SYSTEM_NAME=`"$dummy"` + then + echo "$SYSTEM_NAME" + else + echo rs6000-ibm-aix3.2.5 + fi + elif grep bos324 /usr/include/stdio.h >/dev/null 2>&1; then + echo rs6000-ibm-aix3.2.4 + else + echo rs6000-ibm-aix3.2 + fi + exit ;; + *:AIX:*:[4567]) + IBM_CPU_ID=`/usr/sbin/lsdev -C -c processor -S available | sed 1q | awk '{ print $1 }'` + if /usr/sbin/lsattr -El "$IBM_CPU_ID" | grep ' POWER' >/dev/null 2>&1; then + IBM_ARCH=rs6000 + else + IBM_ARCH=powerpc + fi + if [ -x /usr/bin/lslpp ] ; then + IBM_REV=`/usr/bin/lslpp -Lqc bos.rte.libc | + awk -F: '{ print $3 }' | sed s/[0-9]*$/0/` + else + IBM_REV="$UNAME_VERSION.$UNAME_RELEASE" + fi + echo "$IBM_ARCH"-ibm-aix"$IBM_REV" + exit ;; + *:AIX:*:*) + echo rs6000-ibm-aix + exit ;; + ibmrt:4.4BSD:*|romp-ibm:4.4BSD:*) + echo romp-ibm-bsd4.4 + exit ;; + ibmrt:*BSD:*|romp-ibm:BSD:*) # covers RT/PC BSD and + echo romp-ibm-bsd"$UNAME_RELEASE" # 4.3 with uname added to + exit ;; # report: romp-ibm BSD 4.3 + *:BOSX:*:*) + echo rs6000-bull-bosx + exit ;; + DPX/2?00:B.O.S.:*:*) + echo m68k-bull-sysv3 + exit ;; + 9000/[34]??:4.3bsd:1.*:*) + echo m68k-hp-bsd + exit ;; + hp300:4.4BSD:*:* | 9000/[34]??:4.3bsd:2.*:*) + echo m68k-hp-bsd4.4 + exit ;; + 9000/[34678]??:HP-UX:*:*) + HPUX_REV=`echo "$UNAME_RELEASE"|sed -e 's/[^.]*.[0B]*//'` + case "$UNAME_MACHINE" in + 9000/31?) HP_ARCH=m68000 ;; + 9000/[34]??) HP_ARCH=m68k ;; + 9000/[678][0-9][0-9]) + if [ -x /usr/bin/getconf ]; then + sc_cpu_version=`/usr/bin/getconf SC_CPU_VERSION 2>/dev/null` + sc_kernel_bits=`/usr/bin/getconf SC_KERNEL_BITS 2>/dev/null` + case "$sc_cpu_version" in + 523) HP_ARCH=hppa1.0 ;; # CPU_PA_RISC1_0 + 528) HP_ARCH=hppa1.1 ;; # CPU_PA_RISC1_1 + 532) # CPU_PA_RISC2_0 + case "$sc_kernel_bits" in + 32) HP_ARCH=hppa2.0n ;; + 64) HP_ARCH=hppa2.0w ;; + '') HP_ARCH=hppa2.0 ;; # HP-UX 10.20 + esac ;; + esac + fi + if [ "$HP_ARCH" = "" ]; then + set_cc_for_build + sed 's/^ //' << EOF > "$dummy.c" + + #define _HPUX_SOURCE + #include <stdlib.h> + #include <unistd.h> + + int main () + { + #if defined(_SC_KERNEL_BITS) + long bits = sysconf(_SC_KERNEL_BITS); + #endif + long cpu = sysconf (_SC_CPU_VERSION); + + switch (cpu) + { + case CPU_PA_RISC1_0: puts ("hppa1.0"); break; + case CPU_PA_RISC1_1: puts ("hppa1.1"); break; + case CPU_PA_RISC2_0: + #if defined(_SC_KERNEL_BITS) + switch (bits) + { + case 64: puts ("hppa2.0w"); break; + case 32: puts ("hppa2.0n"); break; + default: puts ("hppa2.0"); break; + } break; + #else /* !defined(_SC_KERNEL_BITS) */ + puts ("hppa2.0"); break; + #endif + default: puts ("hppa1.0"); break; + } + exit (0); + } +EOF + (CCOPTS="" $CC_FOR_BUILD -o "$dummy" "$dummy.c" 2>/dev/null) && HP_ARCH=`"$dummy"` + test -z "$HP_ARCH" && HP_ARCH=hppa + fi ;; + esac + if [ "$HP_ARCH" = hppa2.0w ] + then + set_cc_for_build + + # hppa2.0w-hp-hpux* has a 64-bit kernel and a compiler generating + # 32-bit code. hppa64-hp-hpux* has the same kernel and a compiler + # generating 64-bit code. GNU and HP use different nomenclature: + # + # $ CC_FOR_BUILD=cc ./config.guess + # => hppa2.0w-hp-hpux11.23 + # $ CC_FOR_BUILD="cc +DA2.0w" ./config.guess + # => hppa64-hp-hpux11.23 + + if echo __LP64__ | (CCOPTS="" $CC_FOR_BUILD -E - 2>/dev/null) | + grep -q __LP64__ + then + HP_ARCH=hppa2.0w + else + HP_ARCH=hppa64 + fi + fi + echo "$HP_ARCH"-hp-hpux"$HPUX_REV" + exit ;; + ia64:HP-UX:*:*) + HPUX_REV=`echo "$UNAME_RELEASE"|sed -e 's/[^.]*.[0B]*//'` + echo ia64-hp-hpux"$HPUX_REV" + exit ;; + 3050*:HI-UX:*:*) + set_cc_for_build + sed 's/^ //' << EOF > "$dummy.c" + #include <unistd.h> + int + main () + { + long cpu = sysconf (_SC_CPU_VERSION); + /* The order matters, because CPU_IS_HP_MC68K erroneously returns + true for CPU_PA_RISC1_0. CPU_IS_PA_RISC returns correct + results, however. */ + if (CPU_IS_PA_RISC (cpu)) + { + switch (cpu) + { + case CPU_PA_RISC1_0: puts ("hppa1.0-hitachi-hiuxwe2"); break; + case CPU_PA_RISC1_1: puts ("hppa1.1-hitachi-hiuxwe2"); break; + case CPU_PA_RISC2_0: puts ("hppa2.0-hitachi-hiuxwe2"); break; + default: puts ("hppa-hitachi-hiuxwe2"); break; + } + } + else if (CPU_IS_HP_MC68K (cpu)) + puts ("m68k-hitachi-hiuxwe2"); + else puts ("unknown-hitachi-hiuxwe2"); + exit (0); + } +EOF + $CC_FOR_BUILD -o "$dummy" "$dummy.c" && SYSTEM_NAME=`"$dummy"` && + { echo "$SYSTEM_NAME"; exit; } + echo unknown-hitachi-hiuxwe2 + exit ;; + 9000/7??:4.3bsd:*:* | 9000/8?[79]:4.3bsd:*:*) + echo hppa1.1-hp-bsd + exit ;; + 9000/8??:4.3bsd:*:*) + echo hppa1.0-hp-bsd + exit ;; + *9??*:MPE/iX:*:* | *3000*:MPE/iX:*:*) + echo hppa1.0-hp-mpeix + exit ;; + hp7??:OSF1:*:* | hp8?[79]:OSF1:*:*) + echo hppa1.1-hp-osf + exit ;; + hp8??:OSF1:*:*) + echo hppa1.0-hp-osf + exit ;; + i*86:OSF1:*:*) + if [ -x /usr/sbin/sysversion ] ; then + echo "$UNAME_MACHINE"-unknown-osf1mk + else + echo "$UNAME_MACHINE"-unknown-osf1 + fi + exit ;; + parisc*:Lites*:*:*) + echo hppa1.1-hp-lites + exit ;; + C1*:ConvexOS:*:* | convex:ConvexOS:C1*:*) + echo c1-convex-bsd + exit ;; + C2*:ConvexOS:*:* | convex:ConvexOS:C2*:*) + if getsysinfo -f scalar_acc + then echo c32-convex-bsd + else echo c2-convex-bsd + fi + exit ;; + C34*:ConvexOS:*:* | convex:ConvexOS:C34*:*) + echo c34-convex-bsd + exit ;; + C38*:ConvexOS:*:* | convex:ConvexOS:C38*:*) + echo c38-convex-bsd + exit ;; + C4*:ConvexOS:*:* | convex:ConvexOS:C4*:*) + echo c4-convex-bsd + exit ;; + CRAY*Y-MP:*:*:*) + echo ymp-cray-unicos"$UNAME_RELEASE" | sed -e 's/\.[^.]*$/.X/' + exit ;; + CRAY*[A-Z]90:*:*:*) + echo "$UNAME_MACHINE"-cray-unicos"$UNAME_RELEASE" \ + | sed -e 's/CRAY.*\([A-Z]90\)/\1/' \ + -e y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/ \ + -e 's/\.[^.]*$/.X/' + exit ;; + CRAY*TS:*:*:*) + echo t90-cray-unicos"$UNAME_RELEASE" | sed -e 's/\.[^.]*$/.X/' + exit ;; + CRAY*T3E:*:*:*) + echo alphaev5-cray-unicosmk"$UNAME_RELEASE" | sed -e 's/\.[^.]*$/.X/' + exit ;; + CRAY*SV1:*:*:*) + echo sv1-cray-unicos"$UNAME_RELEASE" | sed -e 's/\.[^.]*$/.X/' + exit ;; + *:UNICOS/mp:*:*) + echo craynv-cray-unicosmp"$UNAME_RELEASE" | sed -e 's/\.[^.]*$/.X/' + exit ;; + F30[01]:UNIX_System_V:*:* | F700:UNIX_System_V:*:*) + FUJITSU_PROC=`uname -m | tr ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz` + FUJITSU_SYS=`uname -p | tr ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz | sed -e 's/\///'` + FUJITSU_REL=`echo "$UNAME_RELEASE" | sed -e 's/ /_/'` + echo "${FUJITSU_PROC}-fujitsu-${FUJITSU_SYS}${FUJITSU_REL}" + exit ;; + 5000:UNIX_System_V:4.*:*) + FUJITSU_SYS=`uname -p | tr ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz | sed -e 's/\///'` + FUJITSU_REL=`echo "$UNAME_RELEASE" | tr ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz | sed -e 's/ /_/'` + echo "sparc-fujitsu-${FUJITSU_SYS}${FUJITSU_REL}" + exit ;; + i*86:BSD/386:*:* | i*86:BSD/OS:*:* | *:Ascend\ Embedded/OS:*:*) + echo "$UNAME_MACHINE"-pc-bsdi"$UNAME_RELEASE" + exit ;; + sparc*:BSD/OS:*:*) + echo sparc-unknown-bsdi"$UNAME_RELEASE" + exit ;; + *:BSD/OS:*:*) + echo "$UNAME_MACHINE"-unknown-bsdi"$UNAME_RELEASE" + exit ;; + arm*:FreeBSD:*:*) + UNAME_PROCESSOR=`uname -p` + set_cc_for_build + if echo __ARM_PCS_VFP | $CC_FOR_BUILD -E - 2>/dev/null \ + | grep -q __ARM_PCS_VFP + then + echo "${UNAME_PROCESSOR}"-unknown-freebsd"`echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'`"-gnueabi + else + echo "${UNAME_PROCESSOR}"-unknown-freebsd"`echo ${UNAME_RELEASE}|sed -e 's/[-(].*//'`"-gnueabihf + fi + exit ;; + *:FreeBSD:*:*) + UNAME_PROCESSOR=`/usr/bin/uname -p` + case "$UNAME_PROCESSOR" in + amd64) + UNAME_PROCESSOR=x86_64 ;; + i386) + UNAME_PROCESSOR=i586 ;; + esac + echo "$UNAME_PROCESSOR"-unknown-freebsd"`echo "$UNAME_RELEASE"|sed -e 's/[-(].*//'`" + exit ;; + i*:CYGWIN*:*) + echo "$UNAME_MACHINE"-pc-cygwin + exit ;; + *:MINGW64*:*) + echo "$UNAME_MACHINE"-pc-mingw64 + exit ;; + *:MINGW*:*) + echo "$UNAME_MACHINE"-pc-mingw32 + exit ;; + *:MSYS*:*) + echo "$UNAME_MACHINE"-pc-msys + exit ;; + i*:PW*:*) + echo "$UNAME_MACHINE"-pc-pw32 + exit ;; + *:Interix*:*) + case "$UNAME_MACHINE" in + x86) + echo i586-pc-interix"$UNAME_RELEASE" + exit ;; + authenticamd | genuineintel | EM64T) + echo x86_64-unknown-interix"$UNAME_RELEASE" + exit ;; + IA64) + echo ia64-unknown-interix"$UNAME_RELEASE" + exit ;; + esac ;; + i*:UWIN*:*) + echo "$UNAME_MACHINE"-pc-uwin + exit ;; + amd64:CYGWIN*:*:* | x86_64:CYGWIN*:*:*) + echo x86_64-unknown-cygwin + exit ;; + prep*:SunOS:5.*:*) + echo powerpcle-unknown-solaris2"`echo "$UNAME_RELEASE"|sed -e 's/[^.]*//'`" + exit ;; + *:GNU:*:*) + # the GNU system + echo "`echo "$UNAME_MACHINE"|sed -e 's,[-/].*$,,'`-unknown-$LIBC`echo "$UNAME_RELEASE"|sed -e 's,/.*$,,'`" + exit ;; + *:GNU/*:*:*) + # other systems with GNU libc and userland + echo "$UNAME_MACHINE-unknown-`echo "$UNAME_SYSTEM" | sed 's,^[^/]*/,,' | tr "[:upper:]" "[:lower:]"``echo "$UNAME_RELEASE"|sed -e 's/[-(].*//'`-$LIBC" + exit ;; + *:Minix:*:*) + echo "$UNAME_MACHINE"-unknown-minix + exit ;; + aarch64:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + aarch64_be:Linux:*:*) + UNAME_MACHINE=aarch64_be + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + alpha:Linux:*:*) + case `sed -n '/^cpu model/s/^.*: \(.*\)/\1/p' < /proc/cpuinfo` in + EV5) UNAME_MACHINE=alphaev5 ;; + EV56) UNAME_MACHINE=alphaev56 ;; + PCA56) UNAME_MACHINE=alphapca56 ;; + PCA57) UNAME_MACHINE=alphapca56 ;; + EV6) UNAME_MACHINE=alphaev6 ;; + EV67) UNAME_MACHINE=alphaev67 ;; + EV68*) UNAME_MACHINE=alphaev68 ;; + esac + objdump --private-headers /bin/sh | grep -q ld.so.1 + if test "$?" = 0 ; then LIBC=gnulibc1 ; fi + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + arc:Linux:*:* | arceb:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + arm*:Linux:*:*) + set_cc_for_build + if echo __ARM_EABI__ | $CC_FOR_BUILD -E - 2>/dev/null \ + | grep -q __ARM_EABI__ + then + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + else + if echo __ARM_PCS_VFP | $CC_FOR_BUILD -E - 2>/dev/null \ + | grep -q __ARM_PCS_VFP + then + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC"eabi + else + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC"eabihf + fi + fi + exit ;; + avr32*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + cris:Linux:*:*) + echo "$UNAME_MACHINE"-axis-linux-"$LIBC" + exit ;; + crisv32:Linux:*:*) + echo "$UNAME_MACHINE"-axis-linux-"$LIBC" + exit ;; + e2k:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + frv:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + hexagon:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + i*86:Linux:*:*) + echo "$UNAME_MACHINE"-pc-linux-"$LIBC" + exit ;; + ia64:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + k1om:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + m32r*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + m68*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + mips:Linux:*:* | mips64:Linux:*:*) + set_cc_for_build + sed 's/^ //' << EOF > "$dummy.c" + #undef CPU + #undef ${UNAME_MACHINE} + #undef ${UNAME_MACHINE}el + #if defined(__MIPSEL__) || defined(__MIPSEL) || defined(_MIPSEL) || defined(MIPSEL) + CPU=${UNAME_MACHINE}el + #else + #if defined(__MIPSEB__) || defined(__MIPSEB) || defined(_MIPSEB) || defined(MIPSEB) + CPU=${UNAME_MACHINE} + #else + CPU= + #endif + #endif +EOF + eval "`$CC_FOR_BUILD -E "$dummy.c" 2>/dev/null | grep '^CPU'`" + test "x$CPU" != x && { echo "$CPU-unknown-linux-$LIBC"; exit; } + ;; + mips64el:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + openrisc*:Linux:*:*) + echo or1k-unknown-linux-"$LIBC" + exit ;; + or32:Linux:*:* | or1k*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + padre:Linux:*:*) + echo sparc-unknown-linux-"$LIBC" + exit ;; + parisc64:Linux:*:* | hppa64:Linux:*:*) + echo hppa64-unknown-linux-"$LIBC" + exit ;; + parisc:Linux:*:* | hppa:Linux:*:*) + # Look for CPU level + case `grep '^cpu[^a-z]*:' /proc/cpuinfo 2>/dev/null | cut -d' ' -f2` in + PA7*) echo hppa1.1-unknown-linux-"$LIBC" ;; + PA8*) echo hppa2.0-unknown-linux-"$LIBC" ;; + *) echo hppa-unknown-linux-"$LIBC" ;; + esac + exit ;; + ppc64:Linux:*:*) + echo powerpc64-unknown-linux-"$LIBC" + exit ;; + ppc:Linux:*:*) + echo powerpc-unknown-linux-"$LIBC" + exit ;; + ppc64le:Linux:*:*) + echo powerpc64le-unknown-linux-"$LIBC" + exit ;; + ppcle:Linux:*:*) + echo powerpcle-unknown-linux-"$LIBC" + exit ;; + riscv32:Linux:*:* | riscv64:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + s390:Linux:*:* | s390x:Linux:*:*) + echo "$UNAME_MACHINE"-ibm-linux-"$LIBC" + exit ;; + sh64*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + sh*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + sparc:Linux:*:* | sparc64:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + tile*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + vax:Linux:*:*) + echo "$UNAME_MACHINE"-dec-linux-"$LIBC" + exit ;; + x86_64:Linux:*:*) + echo "$UNAME_MACHINE"-pc-linux-"$LIBC" + exit ;; + xtensa*:Linux:*:*) + echo "$UNAME_MACHINE"-unknown-linux-"$LIBC" + exit ;; + i*86:DYNIX/ptx:4*:*) + # ptx 4.0 does uname -s correctly, with DYNIX/ptx in there. + # earlier versions are messed up and put the nodename in both + # sysname and nodename. + echo i386-sequent-sysv4 + exit ;; + i*86:UNIX_SV:4.2MP:2.*) + # Unixware is an offshoot of SVR4, but it has its own version + # number series starting with 2... + # I am not positive that other SVR4 systems won't match this, + # I just have to hope. -- rms. + # Use sysv4.2uw... so that sysv4* matches it. + echo "$UNAME_MACHINE"-pc-sysv4.2uw"$UNAME_VERSION" + exit ;; + i*86:OS/2:*:*) + # If we were able to find `uname', then EMX Unix compatibility + # is probably installed. + echo "$UNAME_MACHINE"-pc-os2-emx + exit ;; + i*86:XTS-300:*:STOP) + echo "$UNAME_MACHINE"-unknown-stop + exit ;; + i*86:atheos:*:*) + echo "$UNAME_MACHINE"-unknown-atheos + exit ;; + i*86:syllable:*:*) + echo "$UNAME_MACHINE"-pc-syllable + exit ;; + i*86:LynxOS:2.*:* | i*86:LynxOS:3.[01]*:* | i*86:LynxOS:4.[02]*:*) + echo i386-unknown-lynxos"$UNAME_RELEASE" + exit ;; + i*86:*DOS:*:*) + echo "$UNAME_MACHINE"-pc-msdosdjgpp + exit ;; + i*86:*:4.*:*) + UNAME_REL=`echo "$UNAME_RELEASE" | sed 's/\/MP$//'` + if grep Novell /usr/include/link.h >/dev/null 2>/dev/null; then + echo "$UNAME_MACHINE"-univel-sysv"$UNAME_REL" + else + echo "$UNAME_MACHINE"-pc-sysv"$UNAME_REL" + fi + exit ;; + i*86:*:5:[678]*) + # UnixWare 7.x, OpenUNIX and OpenServer 6. + case `/bin/uname -X | grep "^Machine"` in + *486*) UNAME_MACHINE=i486 ;; + *Pentium) UNAME_MACHINE=i586 ;; + *Pent*|*Celeron) UNAME_MACHINE=i686 ;; + esac + echo "$UNAME_MACHINE-unknown-sysv${UNAME_RELEASE}${UNAME_SYSTEM}{$UNAME_VERSION}" + exit ;; + i*86:*:3.2:*) + if test -f /usr/options/cb.name; then + UNAME_REL=`sed -n 's/.*Version //p' </usr/options/cb.name` + echo "$UNAME_MACHINE"-pc-isc"$UNAME_REL" + elif /bin/uname -X 2>/dev/null >/dev/null ; then + UNAME_REL=`(/bin/uname -X|grep Release|sed -e 's/.*= //')` + (/bin/uname -X|grep i80486 >/dev/null) && UNAME_MACHINE=i486 + (/bin/uname -X|grep '^Machine.*Pentium' >/dev/null) \ + && UNAME_MACHINE=i586 + (/bin/uname -X|grep '^Machine.*Pent *II' >/dev/null) \ + && UNAME_MACHINE=i686 + (/bin/uname -X|grep '^Machine.*Pentium Pro' >/dev/null) \ + && UNAME_MACHINE=i686 + echo "$UNAME_MACHINE"-pc-sco"$UNAME_REL" + else + echo "$UNAME_MACHINE"-pc-sysv32 + fi + exit ;; + pc:*:*:*) + # Left here for compatibility: + # uname -m prints for DJGPP always 'pc', but it prints nothing about + # the processor, so we play safe by assuming i586. + # Note: whatever this is, it MUST be the same as what config.sub + # prints for the "djgpp" host, or else GDB configure will decide that + # this is a cross-build. + echo i586-pc-msdosdjgpp + exit ;; + Intel:Mach:3*:*) + echo i386-pc-mach3 + exit ;; + paragon:*:*:*) + echo i860-intel-osf1 + exit ;; + i860:*:4.*:*) # i860-SVR4 + if grep Stardent /usr/include/sys/uadmin.h >/dev/null 2>&1 ; then + echo i860-stardent-sysv"$UNAME_RELEASE" # Stardent Vistra i860-SVR4 + else # Add other i860-SVR4 vendors below as they are discovered. + echo i860-unknown-sysv"$UNAME_RELEASE" # Unknown i860-SVR4 + fi + exit ;; + mini*:CTIX:SYS*5:*) + # "miniframe" + echo m68010-convergent-sysv + exit ;; + mc68k:UNIX:SYSTEM5:3.51m) + echo m68k-convergent-sysv + exit ;; + M680?0:D-NIX:5.3:*) + echo m68k-diab-dnix + exit ;; + M68*:*:R3V[5678]*:*) + test -r /sysV68 && { echo 'm68k-motorola-sysv'; exit; } ;; + 3[345]??:*:4.0:3.0 | 3[34]??A:*:4.0:3.0 | 3[34]??,*:*:4.0:3.0 | 3[34]??/*:*:4.0:3.0 | 4400:*:4.0:3.0 | 4850:*:4.0:3.0 | SKA40:*:4.0:3.0 | SDS2:*:4.0:3.0 | SHG2:*:4.0:3.0 | S7501*:*:4.0:3.0) + OS_REL='' + test -r /etc/.relid \ + && OS_REL=.`sed -n 's/[^ ]* [^ ]* \([0-9][0-9]\).*/\1/p' < /etc/.relid` + /bin/uname -p 2>/dev/null | grep 86 >/dev/null \ + && { echo i486-ncr-sysv4.3"$OS_REL"; exit; } + /bin/uname -p 2>/dev/null | /bin/grep entium >/dev/null \ + && { echo i586-ncr-sysv4.3"$OS_REL"; exit; } ;; + 3[34]??:*:4.0:* | 3[34]??,*:*:4.0:*) + /bin/uname -p 2>/dev/null | grep 86 >/dev/null \ + && { echo i486-ncr-sysv4; exit; } ;; + NCR*:*:4.2:* | MPRAS*:*:4.2:*) + OS_REL='.3' + test -r /etc/.relid \ + && OS_REL=.`sed -n 's/[^ ]* [^ ]* \([0-9][0-9]\).*/\1/p' < /etc/.relid` + /bin/uname -p 2>/dev/null | grep 86 >/dev/null \ + && { echo i486-ncr-sysv4.3"$OS_REL"; exit; } + /bin/uname -p 2>/dev/null | /bin/grep entium >/dev/null \ + && { echo i586-ncr-sysv4.3"$OS_REL"; exit; } + /bin/uname -p 2>/dev/null | /bin/grep pteron >/dev/null \ + && { echo i586-ncr-sysv4.3"$OS_REL"; exit; } ;; + m68*:LynxOS:2.*:* | m68*:LynxOS:3.0*:*) + echo m68k-unknown-lynxos"$UNAME_RELEASE" + exit ;; + mc68030:UNIX_System_V:4.*:*) + echo m68k-atari-sysv4 + exit ;; + TSUNAMI:LynxOS:2.*:*) + echo sparc-unknown-lynxos"$UNAME_RELEASE" + exit ;; + rs6000:LynxOS:2.*:*) + echo rs6000-unknown-lynxos"$UNAME_RELEASE" + exit ;; + PowerPC:LynxOS:2.*:* | PowerPC:LynxOS:3.[01]*:* | PowerPC:LynxOS:4.[02]*:*) + echo powerpc-unknown-lynxos"$UNAME_RELEASE" + exit ;; + SM[BE]S:UNIX_SV:*:*) + echo mips-dde-sysv"$UNAME_RELEASE" + exit ;; + RM*:ReliantUNIX-*:*:*) + echo mips-sni-sysv4 + exit ;; + RM*:SINIX-*:*:*) + echo mips-sni-sysv4 + exit ;; + *:SINIX-*:*:*) + if uname -p 2>/dev/null >/dev/null ; then + UNAME_MACHINE=`(uname -p) 2>/dev/null` + echo "$UNAME_MACHINE"-sni-sysv4 + else + echo ns32k-sni-sysv + fi + exit ;; + PENTIUM:*:4.0*:*) # Unisys `ClearPath HMP IX 4000' SVR4/MP effort + # says <Richard.M.Bartel@ccMail.Census.GOV> + echo i586-unisys-sysv4 + exit ;; + *:UNIX_System_V:4*:FTX*) + # From Gerald Hewes <hewes@openmarket.com>. + # How about differentiating between stratus architectures? -djm + echo hppa1.1-stratus-sysv4 + exit ;; + *:*:*:FTX*) + # From seanf@swdc.stratus.com. + echo i860-stratus-sysv4 + exit ;; + i*86:VOS:*:*) + # From Paul.Green@stratus.com. + echo "$UNAME_MACHINE"-stratus-vos + exit ;; + *:VOS:*:*) + # From Paul.Green@stratus.com. + echo hppa1.1-stratus-vos + exit ;; + mc68*:A/UX:*:*) + echo m68k-apple-aux"$UNAME_RELEASE" + exit ;; + news*:NEWS-OS:6*:*) + echo mips-sony-newsos6 + exit ;; + R[34]000:*System_V*:*:* | R4000:UNIX_SYSV:*:* | R*000:UNIX_SV:*:*) + if [ -d /usr/nec ]; then + echo mips-nec-sysv"$UNAME_RELEASE" + else + echo mips-unknown-sysv"$UNAME_RELEASE" + fi + exit ;; + BeBox:BeOS:*:*) # BeOS running on hardware made by Be, PPC only. + echo powerpc-be-beos + exit ;; + BeMac:BeOS:*:*) # BeOS running on Mac or Mac clone, PPC only. + echo powerpc-apple-beos + exit ;; + BePC:BeOS:*:*) # BeOS running on Intel PC compatible. + echo i586-pc-beos + exit ;; + BePC:Haiku:*:*) # Haiku running on Intel PC compatible. + echo i586-pc-haiku + exit ;; + x86_64:Haiku:*:*) + echo x86_64-unknown-haiku + exit ;; + SX-4:SUPER-UX:*:*) + echo sx4-nec-superux"$UNAME_RELEASE" + exit ;; + SX-5:SUPER-UX:*:*) + echo sx5-nec-superux"$UNAME_RELEASE" + exit ;; + SX-6:SUPER-UX:*:*) + echo sx6-nec-superux"$UNAME_RELEASE" + exit ;; + SX-7:SUPER-UX:*:*) + echo sx7-nec-superux"$UNAME_RELEASE" + exit ;; + SX-8:SUPER-UX:*:*) + echo sx8-nec-superux"$UNAME_RELEASE" + exit ;; + SX-8R:SUPER-UX:*:*) + echo sx8r-nec-superux"$UNAME_RELEASE" + exit ;; + SX-ACE:SUPER-UX:*:*) + echo sxace-nec-superux"$UNAME_RELEASE" + exit ;; + Power*:Rhapsody:*:*) + echo powerpc-apple-rhapsody"$UNAME_RELEASE" + exit ;; + *:Rhapsody:*:*) + echo "$UNAME_MACHINE"-apple-rhapsody"$UNAME_RELEASE" + exit ;; + *:Darwin:*:*) + UNAME_PROCESSOR=`uname -p` || UNAME_PROCESSOR=unknown + set_cc_for_build + if test "$UNAME_PROCESSOR" = unknown ; then + UNAME_PROCESSOR=powerpc + fi + if test "`echo "$UNAME_RELEASE" | sed -e 's/\..*//'`" -le 10 ; then + if [ "$CC_FOR_BUILD" != no_compiler_found ]; then + if (echo '#ifdef __LP64__'; echo IS_64BIT_ARCH; echo '#endif') | \ + (CCOPTS="" $CC_FOR_BUILD -E - 2>/dev/null) | \ + grep IS_64BIT_ARCH >/dev/null + then + case $UNAME_PROCESSOR in + i386) UNAME_PROCESSOR=x86_64 ;; + powerpc) UNAME_PROCESSOR=powerpc64 ;; + esac + fi + # On 10.4-10.6 one might compile for PowerPC via gcc -arch ppc + if (echo '#ifdef __POWERPC__'; echo IS_PPC; echo '#endif') | \ + (CCOPTS="" $CC_FOR_BUILD -E - 2>/dev/null) | \ + grep IS_PPC >/dev/null + then + UNAME_PROCESSOR=powerpc + fi + fi + elif test "$UNAME_PROCESSOR" = i386 ; then + # Avoid executing cc on OS X 10.9, as it ships with a stub + # that puts up a graphical alert prompting to install + # developer tools. Any system running Mac OS X 10.7 or + # later (Darwin 11 and later) is required to have a 64-bit + # processor. This is not true of the ARM version of Darwin + # that Apple uses in portable devices. + UNAME_PROCESSOR=x86_64 + fi + echo "$UNAME_PROCESSOR"-apple-darwin"$UNAME_RELEASE" + exit ;; + *:procnto*:*:* | *:QNX:[0123456789]*:*) + UNAME_PROCESSOR=`uname -p` + if test "$UNAME_PROCESSOR" = x86; then + UNAME_PROCESSOR=i386 + UNAME_MACHINE=pc + fi + echo "$UNAME_PROCESSOR"-"$UNAME_MACHINE"-nto-qnx"$UNAME_RELEASE" + exit ;; + *:QNX:*:4*) + echo i386-pc-qnx + exit ;; + NEO-*:NONSTOP_KERNEL:*:*) + echo neo-tandem-nsk"$UNAME_RELEASE" + exit ;; + NSE-*:NONSTOP_KERNEL:*:*) + echo nse-tandem-nsk"$UNAME_RELEASE" + exit ;; + NSR-*:NONSTOP_KERNEL:*:*) + echo nsr-tandem-nsk"$UNAME_RELEASE" + exit ;; + NSV-*:NONSTOP_KERNEL:*:*) + echo nsv-tandem-nsk"$UNAME_RELEASE" + exit ;; + NSX-*:NONSTOP_KERNEL:*:*) + echo nsx-tandem-nsk"$UNAME_RELEASE" + exit ;; + *:NonStop-UX:*:*) + echo mips-compaq-nonstopux + exit ;; + BS2000:POSIX*:*:*) + echo bs2000-siemens-sysv + exit ;; + DS/*:UNIX_System_V:*:*) + echo "$UNAME_MACHINE"-"$UNAME_SYSTEM"-"$UNAME_RELEASE" + exit ;; + *:Plan9:*:*) + # "uname -m" is not consistent, so use $cputype instead. 386 + # is converted to i386 for consistency with other x86 + # operating systems. + # shellcheck disable=SC2154 + if test "$cputype" = 386; then + UNAME_MACHINE=i386 + else + UNAME_MACHINE="$cputype" + fi + echo "$UNAME_MACHINE"-unknown-plan9 + exit ;; + *:TOPS-10:*:*) + echo pdp10-unknown-tops10 + exit ;; + *:TENEX:*:*) + echo pdp10-unknown-tenex + exit ;; + KS10:TOPS-20:*:* | KL10:TOPS-20:*:* | TYPE4:TOPS-20:*:*) + echo pdp10-dec-tops20 + exit ;; + XKL-1:TOPS-20:*:* | TYPE5:TOPS-20:*:*) + echo pdp10-xkl-tops20 + exit ;; + *:TOPS-20:*:*) + echo pdp10-unknown-tops20 + exit ;; + *:ITS:*:*) + echo pdp10-unknown-its + exit ;; + SEI:*:*:SEIUX) + echo mips-sei-seiux"$UNAME_RELEASE" + exit ;; + *:DragonFly:*:*) + echo "$UNAME_MACHINE"-unknown-dragonfly"`echo "$UNAME_RELEASE"|sed -e 's/[-(].*//'`" + exit ;; + *:*VMS:*:*) + UNAME_MACHINE=`(uname -p) 2>/dev/null` + case "$UNAME_MACHINE" in + A*) echo alpha-dec-vms ; exit ;; + I*) echo ia64-dec-vms ; exit ;; + V*) echo vax-dec-vms ; exit ;; + esac ;; + *:XENIX:*:SysV) + echo i386-pc-xenix + exit ;; + i*86:skyos:*:*) + echo "$UNAME_MACHINE"-pc-skyos"`echo "$UNAME_RELEASE" | sed -e 's/ .*$//'`" + exit ;; + i*86:rdos:*:*) + echo "$UNAME_MACHINE"-pc-rdos + exit ;; + i*86:AROS:*:*) + echo "$UNAME_MACHINE"-pc-aros + exit ;; + x86_64:VMkernel:*:*) + echo "$UNAME_MACHINE"-unknown-esx + exit ;; + amd64:Isilon\ OneFS:*:*) + echo x86_64-unknown-onefs + exit ;; +esac + +echo "$0: unable to guess system type" >&2 + +case "$UNAME_MACHINE:$UNAME_SYSTEM" in + mips:Linux | mips64:Linux) + # If we got here on MIPS GNU/Linux, output extra information. + cat >&2 <<EOF + +NOTE: MIPS GNU/Linux systems require a C compiler to fully recognize +the system type. Please install a C compiler and try again. +EOF + ;; +esac + +cat >&2 <<EOF + +This script (version $timestamp), has failed to recognize the +operating system you are using. If your script is old, overwrite *all* +copies of config.guess and config.sub with the latest versions from: + + https://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.guess +and + https://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.sub + +If $0 has already been updated, send the following data and any +information you think might be pertinent to config-patches@gnu.org to +provide the necessary information to handle your system. + +config.guess timestamp = $timestamp + +uname -m = `(uname -m) 2>/dev/null || echo unknown` +uname -r = `(uname -r) 2>/dev/null || echo unknown` +uname -s = `(uname -s) 2>/dev/null || echo unknown` +uname -v = `(uname -v) 2>/dev/null || echo unknown` + +/usr/bin/uname -p = `(/usr/bin/uname -p) 2>/dev/null` +/bin/uname -X = `(/bin/uname -X) 2>/dev/null` + +hostinfo = `(hostinfo) 2>/dev/null` +/bin/universe = `(/bin/universe) 2>/dev/null` +/usr/bin/arch -k = `(/usr/bin/arch -k) 2>/dev/null` +/bin/arch = `(/bin/arch) 2>/dev/null` +/usr/bin/oslevel = `(/usr/bin/oslevel) 2>/dev/null` +/usr/convex/getsysinfo = `(/usr/convex/getsysinfo) 2>/dev/null` + +UNAME_MACHINE = "$UNAME_MACHINE" +UNAME_RELEASE = "$UNAME_RELEASE" +UNAME_SYSTEM = "$UNAME_SYSTEM" +UNAME_VERSION = "$UNAME_VERSION" +EOF + +exit 1 + +# Local variables: +# eval: (add-hook 'before-save-hook 'time-stamp) +# time-stamp-start: "timestamp='" +# time-stamp-format: "%:y-%02m-%02d" +# time-stamp-end: "'" +# End: diff --git a/third_party/nix/config/config.sub b/third_party/nix/config/config.sub new file mode 100755 index 0000000000..c19e671805 --- /dev/null +++ b/third_party/nix/config/config.sub @@ -0,0 +1,1818 @@ +#! /bin/sh +# Configuration validation subroutine script. +# Copyright 1992-2018 Free Software Foundation, Inc. + +timestamp='2018-08-13' + +# This file is free software; you can redistribute it and/or modify it +# under the terms of the GNU General Public License as published by +# the Free Software Foundation; either version 3 of the License, or +# (at your option) any later version. +# +# This program is distributed in the hope that it will be useful, but +# WITHOUT ANY WARRANTY; without even the implied warranty of +# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU +# General Public License for more details. +# +# You should have received a copy of the GNU General Public License +# along with this program; if not, see <https://www.gnu.org/licenses/>. +# +# As a special exception to the GNU General Public License, if you +# distribute this file as part of a program that contains a +# configuration script generated by Autoconf, you may include it under +# the same distribution terms that you use for the rest of that +# program. This Exception is an additional permission under section 7 +# of the GNU General Public License, version 3 ("GPLv3"). + + +# Please send patches to <config-patches@gnu.org>. +# +# Configuration subroutine to validate and canonicalize a configuration type. +# Supply the specified configuration type as an argument. +# If it is invalid, we print an error message on stderr and exit with code 1. +# Otherwise, we print the canonical config type on stdout and succeed. + +# You can get the latest version of this script from: +# https://git.savannah.gnu.org/gitweb/?p=config.git;a=blob_plain;f=config.sub + +# This file is supposed to be the same for all GNU packages +# and recognize all the CPU types, system types and aliases +# that are meaningful with *any* GNU software. +# Each package is responsible for reporting which valid configurations +# it does not support. The user should be able to distinguish +# a failure to support a valid configuration from a meaningless +# configuration. + +# The goal of this file is to map all the various variations of a given +# machine specification into a single specification in the form: +# CPU_TYPE-MANUFACTURER-OPERATING_SYSTEM +# or in some cases, the newer four-part form: +# CPU_TYPE-MANUFACTURER-KERNEL-OPERATING_SYSTEM +# It is wrong to echo any other type of specification. + +me=`echo "$0" | sed -e 's,.*/,,'` + +usage="\ +Usage: $0 [OPTION] CPU-MFR-OPSYS or ALIAS + +Canonicalize a configuration name. + +Options: + -h, --help print this help, then exit + -t, --time-stamp print date of last modification, then exit + -v, --version print version number, then exit + +Report bugs and patches to <config-patches@gnu.org>." + +version="\ +GNU config.sub ($timestamp) + +Copyright 1992-2018 Free Software Foundation, Inc. + +This is free software; see the source for copying conditions. There is NO +warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE." + +help=" +Try \`$me --help' for more information." + +# Parse command line +while test $# -gt 0 ; do + case $1 in + --time-stamp | --time* | -t ) + echo "$timestamp" ; exit ;; + --version | -v ) + echo "$version" ; exit ;; + --help | --h* | -h ) + echo "$usage"; exit ;; + -- ) # Stop option processing + shift; break ;; + - ) # Use stdin as input. + break ;; + -* ) + echo "$me: invalid option $1$help" + exit 1 ;; + + *local*) + # First pass through any local machine types. + echo "$1" + exit ;; + + * ) + break ;; + esac +done + +case $# in + 0) echo "$me: missing argument$help" >&2 + exit 1;; + 1) ;; + *) echo "$me: too many arguments$help" >&2 + exit 1;; +esac + +# Split fields of configuration type +IFS="-" read -r field1 field2 field3 field4 <<EOF +$1 +EOF + +# Separate into logical components for further validation +case $1 in + *-*-*-*-*) + echo Invalid configuration \`"$1"\': more than four components >&2 + exit 1 + ;; + *-*-*-*) + basic_machine=$field1-$field2 + os=$field3-$field4 + ;; + *-*-*) + # Ambiguous whether COMPANY is present, or skipped and KERNEL-OS is two + # parts + maybe_os=$field2-$field3 + case $maybe_os in + nto-qnx* | linux-gnu* | linux-android* | linux-dietlibc \ + | linux-newlib* | linux-musl* | linux-uclibc* | uclinux-uclibc* \ + | uclinux-gnu* | kfreebsd*-gnu* | knetbsd*-gnu* | netbsd*-gnu* \ + | netbsd*-eabi* | kopensolaris*-gnu* | cloudabi*-eabi* \ + | storm-chaos* | os2-emx* | rtmk-nova*) + basic_machine=$field1 + os=$maybe_os + ;; + android-linux) + basic_machine=$field1-unknown + os=linux-android + ;; + *) + basic_machine=$field1-$field2 + os=$field3 + ;; + esac + ;; + *-*) + # Second component is usually, but not always the OS + case $field2 in + # Prevent following clause from handling this valid os + sun*os*) + basic_machine=$field1 + os=$field2 + ;; + # Manufacturers + dec* | mips* | sequent* | encore* | pc532* | sgi* | sony* \ + | att* | 7300* | 3300* | delta* | motorola* | sun[234]* \ + | unicom* | ibm* | next | hp | isi* | apollo | altos* \ + | convergent* | ncr* | news | 32* | 3600* | 3100* | hitachi* \ + | c[123]* | convex* | sun | crds | omron* | dg | ultra | tti* \ + | harris | dolphin | highlevel | gould | cbm | ns | masscomp \ + | apple | axis | knuth | cray | microblaze* \ + | sim | cisco | oki | wec | wrs | winbond) + basic_machine=$field1-$field2 + os= + ;; + *) + basic_machine=$field1 + os=$field2 + ;; + esac + ;; + *) + # Convert single-component short-hands not valid as part of + # multi-component configurations. + case $field1 in + 386bsd) + basic_machine=i386-pc + os=bsd + ;; + a29khif) + basic_machine=a29k-amd + os=udi + ;; + adobe68k) + basic_machine=m68010-adobe + os=scout + ;; + alliant) + basic_machine=fx80-alliant + os= + ;; + altos | altos3068) + basic_machine=m68k-altos + os= + ;; + am29k) + basic_machine=a29k-none + os=bsd + ;; + amdahl) + basic_machine=580-amdahl + os=sysv + ;; + amigaos | amigados) + basic_machine=m68k-unknown + os=amigaos + ;; + amigaunix | amix) + basic_machine=m68k-unknown + os=sysv4 + ;; + apollo68) + basic_machine=m68k-apollo + os=sysv + ;; + apollo68bsd) + basic_machine=m68k-apollo + os=bsd + ;; + aros) + basic_machine=i386-pc + os=aros + ;; + aux) + basic_machine=m68k-apple + os=aux + ;; + balance) + basic_machine=ns32k-sequent + os=dynix + ;; + blackfin) + basic_machine=bfin-unknown + os=linux + ;; + cegcc) + basic_machine=arm-unknown + os=cegcc + ;; + convex-c1) + basic_machine=c1-convex + os=bsd + ;; + convex-c2) + basic_machine=c2-convex + os=bsd + ;; + convex-c32) + basic_machine=c32-convex + os=bsd + ;; + convex-c34) + basic_machine=c34-convex + os=bsd + ;; + convex-c38) + basic_machine=c38-convex + os=bsd + ;; + cray) + basic_machine=j90-cray + os=unicos + ;; + crds | unos) + basic_machine=m68k-crds + os= + ;; + delta88) + basic_machine=m88k-motorola + os=sysv3 + ;; + dicos) + basic_machine=i686-pc + os=dicos + ;; + djgpp) + basic_machine=i586-pc + os=msdosdjgpp + ;; + ebmon29k) + basic_machine=a29k-amd + os=ebmon + ;; + es1800 | OSE68k | ose68k | ose | OSE) + basic_machine=m68k-ericsson + os=ose + ;; + gmicro) + basic_machine=tron-gmicro + os=sysv + ;; + go32) + basic_machine=i386-pc + os=go32 + ;; + h8300hms) + basic_machine=h8300-hitachi + os=hms + ;; + h8300xray) + basic_machine=h8300-hitachi + os=xray + ;; + h8500hms) + basic_machine=h8500-hitachi + os=hms + ;; + harris) + basic_machine=m88k-harris + os=sysv3 + ;; + hp300bsd) + basic_machine=m68k-hp + os=bsd + ;; + hp300hpux) + basic_machine=m68k-hp + os=hpux + ;; + hppaosf) + basic_machine=hppa1.1-hp + os=osf + ;; + hppro) + basic_machine=hppa1.1-hp + os=proelf + ;; + i386mach) + basic_machine=i386-mach + os=mach + ;; + vsta) + basic_machine=i386-pc + os=vsta + ;; + isi68 | isi) + basic_machine=m68k-isi + os=sysv + ;; + m68knommu) + basic_machine=m68k-unknown + os=linux + ;; + magnum | m3230) + basic_machine=mips-mips + os=sysv + ;; + merlin) + basic_machine=ns32k-utek + os=sysv + ;; + mingw64) + basic_machine=x86_64-pc + os=mingw64 + ;; + mingw32) + basic_machine=i686-pc + os=mingw32 + ;; + mingw32ce) + basic_machine=arm-unknown + os=mingw32ce + ;; + monitor) + basic_machine=m68k-rom68k + os=coff + ;; + morphos) + basic_machine=powerpc-unknown + os=morphos + ;; + moxiebox) + basic_machine=moxie-unknown + os=moxiebox + ;; + msdos) + basic_machine=i386-pc + os=msdos + ;; + msys) + basic_machine=i686-pc + os=msys + ;; + mvs) + basic_machine=i370-ibm + os=mvs + ;; + nacl) + basic_machine=le32-unknown + os=nacl + ;; + ncr3000) + basic_machine=i486-ncr + os=sysv4 + ;; + netbsd386) + basic_machine=i386-pc + os=netbsd + ;; + netwinder) + basic_machine=armv4l-rebel + os=linux + ;; + news | news700 | news800 | news900) + basic_machine=m68k-sony + os=newsos + ;; + news1000) + basic_machine=m68030-sony + os=newsos + ;; + necv70) + basic_machine=v70-nec + os=sysv + ;; + nh3000) + basic_machine=m68k-harris + os=cxux + ;; + nh[45]000) + basic_machine=m88k-harris + os=cxux + ;; + nindy960) + basic_machine=i960-intel + os=nindy + ;; + mon960) + basic_machine=i960-intel + os=mon960 + ;; + nonstopux) + basic_machine=mips-compaq + os=nonstopux + ;; + os400) + basic_machine=powerpc-ibm + os=os400 + ;; + OSE68000 | ose68000) + basic_machine=m68000-ericsson + os=ose + ;; + os68k) + basic_machine=m68k-none + os=os68k + ;; + paragon) + basic_machine=i860-intel + os=osf + ;; + parisc) + basic_machine=hppa-unknown + os=linux + ;; + pw32) + basic_machine=i586-unknown + os=pw32 + ;; + rdos | rdos64) + basic_machine=x86_64-pc + os=rdos + ;; + rdos32) + basic_machine=i386-pc + os=rdos + ;; + rom68k) + basic_machine=m68k-rom68k + os=coff + ;; + sa29200) + basic_machine=a29k-amd + os=udi + ;; + sei) + basic_machine=mips-sei + os=seiux + ;; + sps7) + basic_machine=m68k-bull + os=sysv2 + ;; + st2000) + basic_machine=m68k-tandem + os= + ;; + stratus) + basic_machine=i860-stratus + os=sysv4 + ;; + sun2) + basic_machine=m68000-sun + os= + ;; + sun2os3) + basic_machine=m68000-sun + os=sunos3 + ;; + sun2os4) + basic_machine=m68000-sun + os=sunos4 + ;; + sun3) + basic_machine=m68k-sun + os= + ;; + sun3os3) + basic_machine=m68k-sun + os=sunos3 + ;; + sun3os4) + basic_machine=m68k-sun + os=sunos4 + ;; + sun4) + basic_machine=sparc-sun + os= + ;; + sun4os3) + basic_machine=sparc-sun + os=sunos3 + ;; + sun4os4) + basic_machine=sparc-sun + os=sunos4 + ;; + sun4sol2) + basic_machine=sparc-sun + os=solaris2 + ;; + sun386 | sun386i | roadrunner) + basic_machine=i386-sun + os= + ;; + sv1) + basic_machine=sv1-cray + os=unicos + ;; + symmetry) + basic_machine=i386-sequent + os=dynix + ;; + t3e) + basic_machine=alphaev5-cray + os=unicos + ;; + t90) + basic_machine=t90-cray + os=unicos + ;; + toad1) + basic_machine=pdp10-xkl + os=tops20 + ;; + tpf) + basic_machine=s390x-ibm + os=tpf + ;; + udi29k) + basic_machine=a29k-amd + os=udi + ;; + ultra3) + basic_machine=a29k-nyu + os=sym1 + ;; + v810 | necv810) + basic_machine=v810-nec + os=none + ;; + vaxv) + basic_machine=vax-dec + os=sysv + ;; + vms) + basic_machine=vax-dec + os=vms + ;; + vxworks960) + basic_machine=i960-wrs + os=vxworks + ;; + vxworks68) + basic_machine=m68k-wrs + os=vxworks + ;; + vxworks29k) + basic_machine=a29k-wrs + os=vxworks + ;; + xbox) + basic_machine=i686-pc + os=mingw32 + ;; + ymp) + basic_machine=ymp-cray + os=unicos + ;; + *) + basic_machine=$1 + os= + ;; + esac + ;; +esac + +# Decode aliases for certain CPU-COMPANY combinations. +case $basic_machine in + # Here we handle the default manufacturer of certain CPU types. It is in + # some cases the only manufacturer, in others, it is the most popular. + craynv) + basic_machine=craynv-cray + os=${os:-unicosmp} + ;; + fx80) + basic_machine=fx80-alliant + ;; + w89k) + basic_machine=hppa1.1-winbond + ;; + op50n) + basic_machine=hppa1.1-oki + ;; + op60c) + basic_machine=hppa1.1-oki + ;; + romp) + basic_machine=romp-ibm + ;; + mmix) + basic_machine=mmix-knuth + ;; + rs6000) + basic_machine=rs6000-ibm + ;; + vax) + basic_machine=vax-dec + ;; + pdp11) + basic_machine=pdp11-dec + ;; + we32k) + basic_machine=we32k-att + ;; + cydra) + basic_machine=cydra-cydrome + ;; + i370-ibm* | ibm*) + basic_machine=i370-ibm + ;; + orion) + basic_machine=orion-highlevel + ;; + orion105) + basic_machine=clipper-highlevel + ;; + mac | mpw | mac-mpw) + basic_machine=m68k-apple + ;; + pmac | pmac-mpw) + basic_machine=powerpc-apple + ;; + xps | xps100) + basic_machine=xps100-honeywell + ;; + + # Recognize the basic CPU types without company name. + # Some are omitted here because they have special meanings below. + 1750a | 580 \ + | a29k \ + | aarch64 | aarch64_be \ + | abacus \ + | alpha | alphaev[4-8] | alphaev56 | alphaev6[78] | alphapca5[67] \ + | alpha64 | alpha64ev[4-8] | alpha64ev56 | alpha64ev6[78] | alpha64pca5[67] \ + | am33_2.0 \ + | arc | arceb \ + | arm | arm[bl]e | arme[lb] | armv[2-8] | armv[3-8][lb] | armv6m | armv[78][arm] \ + | avr | avr32 \ + | asmjs \ + | ba \ + | be32 | be64 \ + | bfin \ + | c4x | c8051 | clipper | csky \ + | d10v | d30v | dlx | dsp16xx \ + | e2k | epiphany \ + | fido | fr30 | frv | ft32 \ + | h8300 | h8500 | hppa | hppa1.[01] | hppa2.0 | hppa2.0[nw] | hppa64 \ + | hexagon \ + | i370 | i860 | i960 | ia16 | ia64 \ + | ip2k | iq2000 \ + | k1om \ + | le32 | le64 \ + | lm32 \ + | m32c | m32r | m32rle | m68000 | m68k | m88k \ + | m6811 | m68hc11 | m6812 | m68hc12 | m68hcs12x | nvptx | picochip \ + | maxq | mb | microblaze | microblazeel | mcore | mep | metag \ + | mips | mipsbe | mipseb | mipsel | mipsle \ + | mips16 \ + | mips64 | mips64el \ + | mips64octeon | mips64octeonel \ + | mips64orion | mips64orionel \ + | mips64r5900 | mips64r5900el \ + | mips64vr | mips64vrel \ + | mips64vr4100 | mips64vr4100el \ + | mips64vr4300 | mips64vr4300el \ + | mips64vr5000 | mips64vr5000el \ + | mips64vr5900 | mips64vr5900el \ + | mipsisa32 | mipsisa32el \ + | mipsisa32r2 | mipsisa32r2el \ + | mipsisa32r6 | mipsisa32r6el \ + | mipsisa64 | mipsisa64el \ + | mipsisa64r2 | mipsisa64r2el \ + | mipsisa64r6 | mipsisa64r6el \ + | mipsisa64sb1 | mipsisa64sb1el \ + | mipsisa64sr71k | mipsisa64sr71kel \ + | mipsr5900 | mipsr5900el \ + | mipstx39 | mipstx39el \ + | mn10200 | mn10300 \ + | moxie \ + | mt \ + | msp430 \ + | nds32 | nds32le | nds32be \ + | nfp \ + | nios | nios2 | nios2eb | nios2el \ + | ns16k | ns32k \ + | open8 | or1k | or1knd | or32 \ + | pdp10 | pj | pjl \ + | powerpc | powerpc64 | powerpc64le | powerpcle \ + | pru \ + | pyramid \ + | riscv | riscv32 | riscv64 \ + | rl78 | rx \ + | score \ + | sh | sh[1234] | sh[24]a | sh[24]aeb | sh[23]e | sh[234]eb | sheb | shbe | shle | sh[1234]le | sh[23]ele \ + | sh64 | sh64le \ + | sparc | sparc64 | sparc64b | sparc64v | sparc86x | sparclet | sparclite \ + | sparcv8 | sparcv9 | sparcv9b | sparcv9v \ + | spu \ + | tahoe | tic4x | tic54x | tic55x | tic6x | tic80 | tron \ + | ubicom32 \ + | v850 | v850e | v850e1 | v850e2 | v850es | v850e2v3 \ + | visium \ + | wasm32 \ + | x86 | xc16x | xstormy16 | xgate | xtensa \ + | z8k | z80) + basic_machine=$basic_machine-unknown + ;; + c54x) + basic_machine=tic54x-unknown + ;; + c55x) + basic_machine=tic55x-unknown + ;; + c6x) + basic_machine=tic6x-unknown + ;; + leon|leon[3-9]) + basic_machine=sparc-$basic_machine + ;; + m88110 | m680[12346]0 | m683?2 | m68360 | m5200 | v70 | w65) + ;; + m9s12z | m68hcs12z | hcs12z | s12z) + basic_machine=s12z-unknown + ;; + m9s12z-* | m68hcs12z-* | hcs12z-* | s12z-*) + basic_machine=s12z-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + ms1) + basic_machine=mt-unknown + ;; + strongarm | thumb | xscale) + basic_machine=arm-unknown + ;; + xscaleeb) + basic_machine=armeb-unknown + ;; + + xscaleel) + basic_machine=armel-unknown + ;; + + # We use `pc' rather than `unknown' + # because (1) that's what they normally are, and + # (2) the word "unknown" tends to confuse beginning users. + i*86 | x86_64) + basic_machine=$basic_machine-pc + ;; + # Recognize the basic CPU types with company name. + 1750a-* | 580-* \ + | a29k-* \ + | aarch64-* | aarch64_be-* \ + | abacus-* \ + | alpha-* | alphaev[4-8]-* | alphaev56-* | alphaev6[78]-* \ + | alpha64-* | alpha64ev[4-8]-* | alpha64ev56-* | alpha64ev6[78]-* \ + | alphapca5[67]-* | alpha64pca5[67]-* \ + | am33_2.0-* \ + | arc-* | arceb-* \ + | arm-* | arm[lb]e-* | arme[lb]-* | armv*-* \ + | avr-* | avr32-* \ + | asmjs-* \ + | ba-* \ + | be32-* | be64-* \ + | bfin-* | bs2000-* \ + | c[123]* | c30-* | [cjt]90-* | c4x-* \ + | c8051-* | clipper-* | craynv-* | csky-* | cydra-* \ + | d10v-* | d30v-* | dlx-* | dsp16xx-* \ + | e2k-* | elxsi-* | epiphany-* \ + | f30[01]-* | f700-* | fido-* | fr30-* | frv-* | ft32-* | fx80-* \ + | h8300-* | h8500-* \ + | hppa-* | hppa1.[01]-* | hppa2.0-* | hppa2.0[nw]-* | hppa64-* \ + | hexagon-* \ + | i370-* | i*86-* | i860-* | i960-* | ia16-* | ia64-* \ + | ip2k-* | iq2000-* \ + | k1om-* \ + | le32-* | le64-* \ + | lm32-* \ + | m32c-* | m32r-* | m32rle-* \ + | m5200-* | m68000-* | m680[012346]0-* | m68360-* | m683?2-* | m68k-* | v70-* | w65-* \ + | m6811-* | m68hc11-* | m6812-* | m68hc12-* | m68hcs12x-* | nvptx-* | picochip-* \ + | m88110-* | m88k-* | maxq-* | mb-* | mcore-* | mep-* | metag-* \ + | microblaze-* | microblazeel-* \ + | mips-* | mipsbe-* | mipseb-* | mipsel-* | mipsle-* \ + | mips16-* \ + | mips64-* | mips64el-* \ + | mips64octeon-* | mips64octeonel-* \ + | mips64orion-* | mips64orionel-* \ + | mips64r5900-* | mips64r5900el-* \ + | mips64vr-* | mips64vrel-* \ + | mips64vr4100-* | mips64vr4100el-* \ + | mips64vr4300-* | mips64vr4300el-* \ + | mips64vr5000-* | mips64vr5000el-* \ + | mips64vr5900-* | mips64vr5900el-* \ + | mipsisa32-* | mipsisa32el-* \ + | mipsisa32r2-* | mipsisa32r2el-* \ + | mipsisa32r6-* | mipsisa32r6el-* \ + | mipsisa64-* | mipsisa64el-* \ + | mipsisa64r2-* | mipsisa64r2el-* \ + | mipsisa64r6-* | mipsisa64r6el-* \ + | mipsisa64sb1-* | mipsisa64sb1el-* \ + | mipsisa64sr71k-* | mipsisa64sr71kel-* \ + | mipsr5900-* | mipsr5900el-* \ + | mipstx39-* | mipstx39el-* \ + | mmix-* \ + | mn10200-* | mn10300-* \ + | moxie-* \ + | mt-* \ + | msp430-* \ + | nds32-* | nds32le-* | nds32be-* \ + | nfp-* \ + | nios-* | nios2-* | nios2eb-* | nios2el-* \ + | none-* | np1-* | ns16k-* | ns32k-* \ + | open8-* \ + | or1k*-* \ + | or32-* \ + | orion-* \ + | pdp10-* | pdp11-* | pj-* | pjl-* | pn-* | power-* \ + | powerpc-* | powerpc64-* | powerpc64le-* | powerpcle-* \ + | pru-* \ + | pyramid-* \ + | riscv-* | riscv32-* | riscv64-* \ + | rl78-* | romp-* | rs6000-* | rx-* \ + | score-* \ + | sh-* | sh[1234]-* | sh[24]a-* | sh[24]ae[lb]-* | sh[23]e-* | she[lb]-* | sh[lb]e-* \ + | sh[1234]e[lb]-* | sh[12345][lb]e-* | sh[23]ele-* | sh64-* | sh64le-* \ + | sparc-* | sparc64-* | sparc64b-* | sparc64v-* | sparc86x-* | sparclet-* \ + | sparclite-* \ + | sparcv8-* | sparcv9-* | sparcv9b-* | sparcv9v-* | sv1-* | sx*-* \ + | spu-* \ + | tahoe-* \ + | tic30-* | tic4x-* | tic54x-* | tic55x-* | tic6x-* | tic80-* \ + | tron-* \ + | ubicom32-* \ + | v850-* | v850e-* | v850e1-* | v850es-* | v850e2-* | v850e2v3-* \ + | vax-* \ + | visium-* \ + | wasm32-* \ + | we32k-* \ + | x86-* | x86_64-* | xc16x-* | xgate-* | xps100-* \ + | xstormy16-* | xtensa*-* \ + | ymp-* \ + | z8k-* | z80-*) + ;; + # Recognize the basic CPU types without company name, with glob match. + xtensa*) + basic_machine=$basic_machine-unknown + ;; + # Recognize the various machine names and aliases which stand + # for a CPU type and a company and sometimes even an OS. + 3b1 | 7300 | 7300-att | att-7300 | pc7300 | safari | unixpc) + basic_machine=m68000-att + ;; + 3b*) + basic_machine=we32k-att + ;; + amd64) + basic_machine=x86_64-pc + ;; + amd64-*) + basic_machine=x86_64-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + amiga | amiga-*) + basic_machine=m68k-unknown + ;; + blackfin-*) + basic_machine=bfin-`echo "$basic_machine" | sed 's/^[^-]*-//'` + os=linux + ;; + bluegene*) + basic_machine=powerpc-ibm + os=cnk + ;; + c54x-*) + basic_machine=tic54x-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + c55x-*) + basic_machine=tic55x-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + c6x-*) + basic_machine=tic6x-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + c90) + basic_machine=c90-cray + os=${os:-unicos} + ;; + cr16 | cr16-*) + basic_machine=cr16-unknown + os=${os:-elf} + ;; + crisv32 | crisv32-* | etraxfs*) + basic_machine=crisv32-axis + ;; + cris | cris-* | etrax*) + basic_machine=cris-axis + ;; + crx) + basic_machine=crx-unknown + os=${os:-elf} + ;; + da30 | da30-*) + basic_machine=m68k-da30 + ;; + decstation | decstation-3100 | pmax | pmax-* | pmin | dec3100 | decstatn) + basic_machine=mips-dec + ;; + decsystem10* | dec10*) + basic_machine=pdp10-dec + os=tops10 + ;; + decsystem20* | dec20*) + basic_machine=pdp10-dec + os=tops20 + ;; + delta | 3300 | motorola-3300 | motorola-delta \ + | 3300-motorola | delta-motorola) + basic_machine=m68k-motorola + ;; + dpx20 | dpx20-*) + basic_machine=rs6000-bull + os=${os:-bosx} + ;; + dpx2*) + basic_machine=m68k-bull + os=sysv3 + ;; + e500v[12]) + basic_machine=powerpc-unknown + os=$os"spe" + ;; + e500v[12]-*) + basic_machine=powerpc-`echo "$basic_machine" | sed 's/^[^-]*-//'` + os=$os"spe" + ;; + encore | umax | mmax) + basic_machine=ns32k-encore + ;; + elxsi) + basic_machine=elxsi-elxsi + os=${os:-bsd} + ;; + fx2800) + basic_machine=i860-alliant + ;; + genix) + basic_machine=ns32k-ns + ;; + h3050r* | hiux*) + basic_machine=hppa1.1-hitachi + os=hiuxwe2 + ;; + hp300-*) + basic_machine=m68k-hp + ;; + hp3k9[0-9][0-9] | hp9[0-9][0-9]) + basic_machine=hppa1.0-hp + ;; + hp9k2[0-9][0-9] | hp9k31[0-9]) + basic_machine=m68000-hp + ;; + hp9k3[2-9][0-9]) + basic_machine=m68k-hp + ;; + hp9k6[0-9][0-9] | hp6[0-9][0-9]) + basic_machine=hppa1.0-hp + ;; + hp9k7[0-79][0-9] | hp7[0-79][0-9]) + basic_machine=hppa1.1-hp + ;; + hp9k78[0-9] | hp78[0-9]) + # FIXME: really hppa2.0-hp + basic_machine=hppa1.1-hp + ;; + hp9k8[67]1 | hp8[67]1 | hp9k80[24] | hp80[24] | hp9k8[78]9 | hp8[78]9 | hp9k893 | hp893) + # FIXME: really hppa2.0-hp + basic_machine=hppa1.1-hp + ;; + hp9k8[0-9][13679] | hp8[0-9][13679]) + basic_machine=hppa1.1-hp + ;; + hp9k8[0-9][0-9] | hp8[0-9][0-9]) + basic_machine=hppa1.0-hp + ;; + i*86v32) + basic_machine=`echo "$1" | sed -e 's/86.*/86-pc/'` + os=sysv32 + ;; + i*86v4*) + basic_machine=`echo "$1" | sed -e 's/86.*/86-pc/'` + os=sysv4 + ;; + i*86v) + basic_machine=`echo "$1" | sed -e 's/86.*/86-pc/'` + os=sysv + ;; + i*86sol2) + basic_machine=`echo "$1" | sed -e 's/86.*/86-pc/'` + os=solaris2 + ;; + j90 | j90-cray) + basic_machine=j90-cray + os=${os:-unicos} + ;; + iris | iris4d) + basic_machine=mips-sgi + case $os in + irix*) + ;; + *) + os=irix4 + ;; + esac + ;; + leon-*|leon[3-9]-*) + basic_machine=sparc-`echo "$basic_machine" | sed 's/-.*//'` + ;; + m68knommu-*) + basic_machine=m68k-`echo "$basic_machine" | sed 's/^[^-]*-//'` + os=linux + ;; + microblaze*) + basic_machine=microblaze-xilinx + ;; + miniframe) + basic_machine=m68000-convergent + ;; + *mint | mint[0-9]* | *MiNT | *MiNT[0-9]*) + basic_machine=m68k-atari + os=mint + ;; + mips3*-*) + basic_machine=`echo "$basic_machine" | sed -e 's/mips3/mips64/'` + ;; + mips3*) + basic_machine=`echo "$basic_machine" | sed -e 's/mips3/mips64/'`-unknown + ;; + ms1-*) + basic_machine=`echo "$basic_machine" | sed -e 's/ms1-/mt-/'` + ;; + news-3600 | risc-news) + basic_machine=mips-sony + os=newsos + ;; + next | m*-next) + basic_machine=m68k-next + case $os in + nextstep* ) + ;; + ns2*) + os=nextstep2 + ;; + *) + os=nextstep3 + ;; + esac + ;; + np1) + basic_machine=np1-gould + ;; + neo-tandem) + basic_machine=neo-tandem + ;; + nse-tandem) + basic_machine=nse-tandem + ;; + nsr-tandem) + basic_machine=nsr-tandem + ;; + nsv-tandem) + basic_machine=nsv-tandem + ;; + nsx-tandem) + basic_machine=nsx-tandem + ;; + op50n-* | op60c-*) + basic_machine=hppa1.1-oki + os=proelf + ;; + openrisc | openrisc-*) + basic_machine=or32-unknown + ;; + pa-hitachi) + basic_machine=hppa1.1-hitachi + os=hiuxwe2 + ;; + parisc-*) + basic_machine=hppa-`echo "$basic_machine" | sed 's/^[^-]*-//'` + os=linux + ;; + pbd) + basic_machine=sparc-tti + ;; + pbb) + basic_machine=m68k-tti + ;; + pc532 | pc532-*) + basic_machine=ns32k-pc532 + ;; + pc98) + basic_machine=i386-pc + ;; + pc98-*) + basic_machine=i386-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + pentium | p5 | k5 | k6 | nexgen | viac3) + basic_machine=i586-pc + ;; + pentiumpro | p6 | 6x86 | athlon | athlon_*) + basic_machine=i686-pc + ;; + pentiumii | pentium2 | pentiumiii | pentium3) + basic_machine=i686-pc + ;; + pentium4) + basic_machine=i786-pc + ;; + pentium-* | p5-* | k5-* | k6-* | nexgen-* | viac3-*) + basic_machine=i586-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + pentiumpro-* | p6-* | 6x86-* | athlon-*) + basic_machine=i686-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + pentiumii-* | pentium2-* | pentiumiii-* | pentium3-*) + basic_machine=i686-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + pentium4-*) + basic_machine=i786-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + pn) + basic_machine=pn-gould + ;; + power) basic_machine=power-ibm + ;; + ppc | ppcbe) basic_machine=powerpc-unknown + ;; + ppc-* | ppcbe-*) + basic_machine=powerpc-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + ppcle | powerpclittle) + basic_machine=powerpcle-unknown + ;; + ppcle-* | powerpclittle-*) + basic_machine=powerpcle-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + ppc64) basic_machine=powerpc64-unknown + ;; + ppc64-*) basic_machine=powerpc64-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + ppc64le | powerpc64little) + basic_machine=powerpc64le-unknown + ;; + ppc64le-* | powerpc64little-*) + basic_machine=powerpc64le-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + ps2) + basic_machine=i386-ibm + ;; + rm[46]00) + basic_machine=mips-siemens + ;; + rtpc | rtpc-*) + basic_machine=romp-ibm + ;; + s390 | s390-*) + basic_machine=s390-ibm + ;; + s390x | s390x-*) + basic_machine=s390x-ibm + ;; + sb1) + basic_machine=mipsisa64sb1-unknown + ;; + sb1el) + basic_machine=mipsisa64sb1el-unknown + ;; + sde) + basic_machine=mipsisa32-sde + os=${os:-elf} + ;; + sequent) + basic_machine=i386-sequent + ;; + sh5el) + basic_machine=sh5le-unknown + ;; + sh5el-*) + basic_machine=sh5le-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + simso-wrs) + basic_machine=sparclite-wrs + os=vxworks + ;; + spur) + basic_machine=spur-unknown + ;; + strongarm-* | thumb-*) + basic_machine=arm-`echo "$basic_machine" | sed 's/^[^-]*-//'` + ;; + tile*-*) + ;; + tile*) + basic_machine=$basic_machine-unknown + os=${os:-linux-gnu} + ;; + tx39) + basic_machine=mipstx39-unknown + ;; + tx39el) + basic_machine=mipstx39el-unknown + ;; + tower | tower-32) + basic_machine=m68k-ncr + ;; + vpp*|vx|vx-*) + basic_machine=f301-fujitsu + ;; + w65*) + basic_machine=w65-wdc + os=none + ;; + w89k-*) + basic_machine=hppa1.1-winbond + os=proelf + ;; + x64) + basic_machine=x86_64-pc + ;; + xscale-* | xscalee[bl]-*) + basic_machine=`echo "$basic_machine" | sed 's/^xscale/arm/'` + ;; + none) + basic_machine=none-none + ;; + + *) + echo Invalid configuration \`"$1"\': machine \`"$basic_machine"\' not recognized 1>&2 + exit 1 + ;; +esac + +# Here we canonicalize certain aliases for manufacturers. +case $basic_machine in + *-digital*) + basic_machine=`echo "$basic_machine" | sed 's/digital.*/dec/'` + ;; + *-commodore*) + basic_machine=`echo "$basic_machine" | sed 's/commodore.*/cbm/'` + ;; + *) + ;; +esac + +# Decode manufacturer-specific aliases for certain operating systems. + +if [ x$os != x ] +then +case $os in + # First match some system type aliases that might get confused + # with valid system types. + # solaris* is a basic system type, with this one exception. + auroraux) + os=auroraux + ;; + bluegene*) + os=cnk + ;; + solaris1 | solaris1.*) + os=`echo $os | sed -e 's|solaris1|sunos4|'` + ;; + solaris) + os=solaris2 + ;; + unixware*) + os=sysv4.2uw + ;; + gnu/linux*) + os=`echo $os | sed -e 's|gnu/linux|linux-gnu|'` + ;; + # es1800 is here to avoid being matched by es* (a different OS) + es1800*) + os=ose + ;; + # Some version numbers need modification + chorusos*) + os=chorusos + ;; + isc) + os=isc2.2 + ;; + sco6) + os=sco5v6 + ;; + sco5) + os=sco3.2v5 + ;; + sco4) + os=sco3.2v4 + ;; + sco3.2.[4-9]*) + os=`echo $os | sed -e 's/sco3.2./sco3.2v/'` + ;; + sco3.2v[4-9]* | sco5v6*) + # Don't forget version if it is 3.2v4 or newer. + ;; + scout) + # Don't match below + ;; + sco*) + os=sco3.2v2 + ;; + psos*) + os=psos + ;; + # Now accept the basic system types. + # The portable systems comes first. + # Each alternative MUST end in a * to match a version number. + # sysv* is not here because it comes later, after sysvr4. + gnu* | bsd* | mach* | minix* | genix* | ultrix* | irix* \ + | *vms* | esix* | aix* | cnk* | sunos | sunos[34]*\ + | hpux* | unos* | osf* | luna* | dgux* | auroraux* | solaris* \ + | sym* | kopensolaris* | plan9* \ + | amigaos* | amigados* | msdos* | newsos* | unicos* | aof* \ + | aos* | aros* | cloudabi* | sortix* \ + | nindy* | vxsim* | vxworks* | ebmon* | hms* | mvs* \ + | clix* | riscos* | uniplus* | iris* | isc* | rtu* | xenix* \ + | knetbsd* | mirbsd* | netbsd* \ + | bitrig* | openbsd* | solidbsd* | libertybsd* \ + | ekkobsd* | kfreebsd* | freebsd* | riscix* | lynxos* \ + | bosx* | nextstep* | cxux* | aout* | elf* | oabi* \ + | ptx* | coff* | ecoff* | winnt* | domain* | vsta* \ + | udi* | eabi* | lites* | ieee* | go32* | aux* | hcos* \ + | chorusrdb* | cegcc* | glidix* \ + | cygwin* | msys* | pe* | moss* | proelf* | rtems* \ + | midipix* | mingw32* | mingw64* | linux-gnu* | linux-android* \ + | linux-newlib* | linux-musl* | linux-uclibc* \ + | uxpv* | beos* | mpeix* | udk* | moxiebox* \ + | interix* | uwin* | mks* | rhapsody* | darwin* \ + | openstep* | oskit* | conix* | pw32* | nonstopux* \ + | storm-chaos* | tops10* | tenex* | tops20* | its* \ + | os2* | vos* | palmos* | uclinux* | nucleus* \ + | morphos* | superux* | rtmk* | windiss* \ + | powermax* | dnix* | nx6 | nx7 | sei* | dragonfly* \ + | skyos* | haiku* | rdos* | toppers* | drops* | es* \ + | onefs* | tirtos* | phoenix* | fuchsia* | redox* | bme* \ + | midnightbsd*) + # Remember, each alternative MUST END IN *, to match a version number. + ;; + qnx*) + case $basic_machine in + x86-* | i*86-*) + ;; + *) + os=nto-$os + ;; + esac + ;; + hiux*) + os=hiuxwe2 + ;; + nto-qnx*) + ;; + nto*) + os=`echo $os | sed -e 's|nto|nto-qnx|'` + ;; + sim | xray | os68k* | v88r* \ + | windows* | osx | abug | netware* | os9* \ + | macos* | mpw* | magic* | mmixware* | mon960* | lnews*) + ;; + linux-dietlibc) + os=linux-dietlibc + ;; + linux*) + os=`echo $os | sed -e 's|linux|linux-gnu|'` + ;; + lynx*178) + os=lynxos178 + ;; + lynx*5) + os=lynxos5 + ;; + lynx*) + os=lynxos + ;; + mac*) + os=`echo "$os" | sed -e 's|mac|macos|'` + ;; + opened*) + os=openedition + ;; + os400*) + os=os400 + ;; + sunos5*) + os=`echo "$os" | sed -e 's|sunos5|solaris2|'` + ;; + sunos6*) + os=`echo "$os" | sed -e 's|sunos6|solaris3|'` + ;; + wince*) + os=wince + ;; + utek*) + os=bsd + ;; + dynix*) + os=bsd + ;; + acis*) + os=aos + ;; + atheos*) + os=atheos + ;; + syllable*) + os=syllable + ;; + 386bsd) + os=bsd + ;; + ctix* | uts*) + os=sysv + ;; + nova*) + os=rtmk-nova + ;; + ns2) + os=nextstep2 + ;; + nsk*) + os=nsk + ;; + # Preserve the version number of sinix5. + sinix5.*) + os=`echo $os | sed -e 's|sinix|sysv|'` + ;; + sinix*) + os=sysv4 + ;; + tpf*) + os=tpf + ;; + triton*) + os=sysv3 + ;; + oss*) + os=sysv3 + ;; + svr4*) + os=sysv4 + ;; + svr3) + os=sysv3 + ;; + sysvr4) + os=sysv4 + ;; + # This must come after sysvr4. + sysv*) + ;; + ose*) + os=ose + ;; + *mint | mint[0-9]* | *MiNT | MiNT[0-9]*) + os=mint + ;; + zvmoe) + os=zvmoe + ;; + dicos*) + os=dicos + ;; + pikeos*) + # Until real need of OS specific support for + # particular features comes up, bare metal + # configurations are quite functional. + case $basic_machine in + arm*) + os=eabi + ;; + *) + os=elf + ;; + esac + ;; + nacl*) + ;; + ios) + ;; + none) + ;; + *-eabi) + ;; + *) + echo Invalid configuration \`"$1"\': system \`"$os"\' not recognized 1>&2 + exit 1 + ;; +esac +else + +# Here we handle the default operating systems that come with various machines. +# The value should be what the vendor currently ships out the door with their +# machine or put another way, the most popular os provided with the machine. + +# Note that if you're going to try to match "-MANUFACTURER" here (say, +# "-sun"), then you have to tell the case statement up towards the top +# that MANUFACTURER isn't an operating system. Otherwise, code above +# will signal an error saying that MANUFACTURER isn't an operating +# system, and we'll never get to this point. + +case $basic_machine in + score-*) + os=elf + ;; + spu-*) + os=elf + ;; + *-acorn) + os=riscix1.2 + ;; + arm*-rebel) + os=linux + ;; + arm*-semi) + os=aout + ;; + c4x-* | tic4x-*) + os=coff + ;; + c8051-*) + os=elf + ;; + clipper-intergraph) + os=clix + ;; + hexagon-*) + os=elf + ;; + tic54x-*) + os=coff + ;; + tic55x-*) + os=coff + ;; + tic6x-*) + os=coff + ;; + # This must come before the *-dec entry. + pdp10-*) + os=tops20 + ;; + pdp11-*) + os=none + ;; + *-dec | vax-*) + os=ultrix4.2 + ;; + m68*-apollo) + os=domain + ;; + i386-sun) + os=sunos4.0.2 + ;; + m68000-sun) + os=sunos3 + ;; + m68*-cisco) + os=aout + ;; + mep-*) + os=elf + ;; + mips*-cisco) + os=elf + ;; + mips*-*) + os=elf + ;; + or32-*) + os=coff + ;; + *-tti) # must be before sparc entry or we get the wrong os. + os=sysv3 + ;; + sparc-* | *-sun) + os=sunos4.1.1 + ;; + pru-*) + os=elf + ;; + *-be) + os=beos + ;; + *-ibm) + os=aix + ;; + *-knuth) + os=mmixware + ;; + *-wec) + os=proelf + ;; + *-winbond) + os=proelf + ;; + *-oki) + os=proelf + ;; + *-hp) + os=hpux + ;; + *-hitachi) + os=hiux + ;; + i860-* | *-att | *-ncr | *-altos | *-motorola | *-convergent) + os=sysv + ;; + *-cbm) + os=amigaos + ;; + *-dg) + os=dgux + ;; + *-dolphin) + os=sysv3 + ;; + m68k-ccur) + os=rtu + ;; + m88k-omron*) + os=luna + ;; + *-next) + os=nextstep + ;; + *-sequent) + os=ptx + ;; + *-crds) + os=unos + ;; + *-ns) + os=genix + ;; + i370-*) + os=mvs + ;; + *-gould) + os=sysv + ;; + *-highlevel) + os=bsd + ;; + *-encore) + os=bsd + ;; + *-sgi) + os=irix + ;; + *-siemens) + os=sysv4 + ;; + *-masscomp) + os=rtu + ;; + f30[01]-fujitsu | f700-fujitsu) + os=uxpv + ;; + *-rom68k) + os=coff + ;; + *-*bug) + os=coff + ;; + *-apple) + os=macos + ;; + *-atari*) + os=mint + ;; + *-wrs) + os=vxworks + ;; + *) + os=none + ;; +esac +fi + +# Here we handle the case where we know the os, and the CPU type, but not the +# manufacturer. We pick the logical manufacturer. +vendor=unknown +case $basic_machine in + *-unknown) + case $os in + riscix*) + vendor=acorn + ;; + sunos*) + vendor=sun + ;; + cnk*|-aix*) + vendor=ibm + ;; + beos*) + vendor=be + ;; + hpux*) + vendor=hp + ;; + mpeix*) + vendor=hp + ;; + hiux*) + vendor=hitachi + ;; + unos*) + vendor=crds + ;; + dgux*) + vendor=dg + ;; + luna*) + vendor=omron + ;; + genix*) + vendor=ns + ;; + clix*) + vendor=intergraph + ;; + mvs* | opened*) + vendor=ibm + ;; + os400*) + vendor=ibm + ;; + ptx*) + vendor=sequent + ;; + tpf*) + vendor=ibm + ;; + vxsim* | vxworks* | windiss*) + vendor=wrs + ;; + aux*) + vendor=apple + ;; + hms*) + vendor=hitachi + ;; + mpw* | macos*) + vendor=apple + ;; + *mint | mint[0-9]* | *MiNT | MiNT[0-9]*) + vendor=atari + ;; + vos*) + vendor=stratus + ;; + esac + basic_machine=`echo "$basic_machine" | sed "s/unknown/$vendor/"` + ;; +esac + +echo "$basic_machine-$os" +exit + +# Local variables: +# eval: (add-hook 'before-save-hook 'time-stamp) +# time-stamp-start: "timestamp='" +# time-stamp-format: "%:y-%02m-%02d" +# time-stamp-end: "'" +# End: diff --git a/third_party/nix/config/install-sh b/third_party/nix/config/install-sh new file mode 100755 index 0000000000..377bb8687f --- /dev/null +++ b/third_party/nix/config/install-sh @@ -0,0 +1,527 @@ +#!/bin/sh +# install - install a program, script, or datafile + +scriptversion=2011-11-20.07; # UTC + +# This originates from X11R5 (mit/util/scripts/install.sh), which was +# later released in X11R6 (xc/config/util/install.sh) with the +# following copyright and license. +# +# Copyright (C) 1994 X Consortium +# +# Permission is hereby granted, free of charge, to any person obtaining a copy +# of this software and associated documentation files (the "Software"), to +# deal in the Software without restriction, including without limitation the +# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or +# sell copies of the Software, and to permit persons to whom the Software is +# furnished to do so, subject to the following conditions: +# +# The above copyright notice and this permission notice shall be included in +# all copies or substantial portions of the Software. +# +# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +# X CONSORTIUM BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN +# AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNEC- +# TION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. +# +# Except as contained in this notice, the name of the X Consortium shall not +# be used in advertising or otherwise to promote the sale, use or other deal- +# ings in this Software without prior written authorization from the X Consor- +# tium. +# +# +# FSF changes to this file are in the public domain. +# +# Calling this script install-sh is preferred over install.sh, to prevent +# 'make' implicit rules from creating a file called install from it +# when there is no Makefile. +# +# This script is compatible with the BSD install script, but was written +# from scratch. + +nl=' +' +IFS=" "" $nl" + +# set DOITPROG to echo to test this script + +# Don't use :- since 4.3BSD and earlier shells don't like it. +doit=${DOITPROG-} +if test -z "$doit"; then + doit_exec=exec +else + doit_exec=$doit +fi + +# Put in absolute file names if you don't have them in your path; +# or use environment vars. + +chgrpprog=${CHGRPPROG-chgrp} +chmodprog=${CHMODPROG-chmod} +chownprog=${CHOWNPROG-chown} +cmpprog=${CMPPROG-cmp} +cpprog=${CPPROG-cp} +mkdirprog=${MKDIRPROG-mkdir} +mvprog=${MVPROG-mv} +rmprog=${RMPROG-rm} +stripprog=${STRIPPROG-strip} + +posix_glob='?' +initialize_posix_glob=' + test "$posix_glob" != "?" || { + if (set -f) 2>/dev/null; then + posix_glob= + else + posix_glob=: + fi + } +' + +posix_mkdir= + +# Desired mode of installed file. +mode=0755 + +chgrpcmd= +chmodcmd=$chmodprog +chowncmd= +mvcmd=$mvprog +rmcmd="$rmprog -f" +stripcmd= + +src= +dst= +dir_arg= +dst_arg= + +copy_on_change=false +no_target_directory= + +usage="\ +Usage: $0 [OPTION]... [-T] SRCFILE DSTFILE + or: $0 [OPTION]... SRCFILES... DIRECTORY + or: $0 [OPTION]... -t DIRECTORY SRCFILES... + or: $0 [OPTION]... -d DIRECTORIES... + +In the 1st form, copy SRCFILE to DSTFILE. +In the 2nd and 3rd, copy all SRCFILES to DIRECTORY. +In the 4th, create DIRECTORIES. + +Options: + --help display this help and exit. + --version display version info and exit. + + -c (ignored) + -C install only if different (preserve the last data modification time) + -d create directories instead of installing files. + -g GROUP $chgrpprog installed files to GROUP. + -m MODE $chmodprog installed files to MODE. + -o USER $chownprog installed files to USER. + -s $stripprog installed files. + -t DIRECTORY install into DIRECTORY. + -T report an error if DSTFILE is a directory. + +Environment variables override the default commands: + CHGRPPROG CHMODPROG CHOWNPROG CMPPROG CPPROG MKDIRPROG MVPROG + RMPROG STRIPPROG +" + +while test $# -ne 0; do + case $1 in + -c) ;; + + -C) copy_on_change=true;; + + -d) dir_arg=true;; + + -g) chgrpcmd="$chgrpprog $2" + shift;; + + --help) echo "$usage"; exit $?;; + + -m) mode=$2 + case $mode in + *' '* | *' '* | *' +'* | *'*'* | *'?'* | *'['*) + echo "$0: invalid mode: $mode" >&2 + exit 1;; + esac + shift;; + + -o) chowncmd="$chownprog $2" + shift;; + + -s) stripcmd=$stripprog;; + + -t) dst_arg=$2 + # Protect names problematic for 'test' and other utilities. + case $dst_arg in + -* | [=\(\)!]) dst_arg=./$dst_arg;; + esac + shift;; + + -T) no_target_directory=true;; + + --version) echo "$0 $scriptversion"; exit $?;; + + --) shift + break;; + + -*) echo "$0: invalid option: $1" >&2 + exit 1;; + + *) break;; + esac + shift +done + +if test $# -ne 0 && test -z "$dir_arg$dst_arg"; then + # When -d is used, all remaining arguments are directories to create. + # When -t is used, the destination is already specified. + # Otherwise, the last argument is the destination. Remove it from $@. + for arg + do + if test -n "$dst_arg"; then + # $@ is not empty: it contains at least $arg. + set fnord "$@" "$dst_arg" + shift # fnord + fi + shift # arg + dst_arg=$arg + # Protect names problematic for 'test' and other utilities. + case $dst_arg in + -* | [=\(\)!]) dst_arg=./$dst_arg;; + esac + done +fi + +if test $# -eq 0; then + if test -z "$dir_arg"; then + echo "$0: no input file specified." >&2 + exit 1 + fi + # It's OK to call 'install-sh -d' without argument. + # This can happen when creating conditional directories. + exit 0 +fi + +if test -z "$dir_arg"; then + do_exit='(exit $ret); exit $ret' + trap "ret=129; $do_exit" 1 + trap "ret=130; $do_exit" 2 + trap "ret=141; $do_exit" 13 + trap "ret=143; $do_exit" 15 + + # Set umask so as not to create temps with too-generous modes. + # However, 'strip' requires both read and write access to temps. + case $mode in + # Optimize common cases. + *644) cp_umask=133;; + *755) cp_umask=22;; + + *[0-7]) + if test -z "$stripcmd"; then + u_plus_rw= + else + u_plus_rw='% 200' + fi + cp_umask=`expr '(' 777 - $mode % 1000 ')' $u_plus_rw`;; + *) + if test -z "$stripcmd"; then + u_plus_rw= + else + u_plus_rw=,u+rw + fi + cp_umask=$mode$u_plus_rw;; + esac +fi + +for src +do + # Protect names problematic for 'test' and other utilities. + case $src in + -* | [=\(\)!]) src=./$src;; + esac + + if test -n "$dir_arg"; then + dst=$src + dstdir=$dst + test -d "$dstdir" + dstdir_status=$? + else + + # Waiting for this to be detected by the "$cpprog $src $dsttmp" command + # might cause directories to be created, which would be especially bad + # if $src (and thus $dsttmp) contains '*'. + if test ! -f "$src" && test ! -d "$src"; then + echo "$0: $src does not exist." >&2 + exit 1 + fi + + if test -z "$dst_arg"; then + echo "$0: no destination specified." >&2 + exit 1 + fi + dst=$dst_arg + + # If destination is a directory, append the input filename; won't work + # if double slashes aren't ignored. + if test -d "$dst"; then + if test -n "$no_target_directory"; then + echo "$0: $dst_arg: Is a directory" >&2 + exit 1 + fi + dstdir=$dst + dst=$dstdir/`basename "$src"` + dstdir_status=0 + else + # Prefer dirname, but fall back on a substitute if dirname fails. + dstdir=` + (dirname "$dst") 2>/dev/null || + expr X"$dst" : 'X\(.*[^/]\)//*[^/][^/]*/*$' \| \ + X"$dst" : 'X\(//\)[^/]' \| \ + X"$dst" : 'X\(//\)$' \| \ + X"$dst" : 'X\(/\)' \| . 2>/dev/null || + echo X"$dst" | + sed '/^X\(.*[^/]\)\/\/*[^/][^/]*\/*$/{ + s//\1/ + q + } + /^X\(\/\/\)[^/].*/{ + s//\1/ + q + } + /^X\(\/\/\)$/{ + s//\1/ + q + } + /^X\(\/\).*/{ + s//\1/ + q + } + s/.*/./; q' + ` + + test -d "$dstdir" + dstdir_status=$? + fi + fi + + obsolete_mkdir_used=false + + if test $dstdir_status != 0; then + case $posix_mkdir in + '') + # Create intermediate dirs using mode 755 as modified by the umask. + # This is like FreeBSD 'install' as of 1997-10-28. + umask=`umask` + case $stripcmd.$umask in + # Optimize common cases. + *[2367][2367]) mkdir_umask=$umask;; + .*0[02][02] | .[02][02] | .[02]) mkdir_umask=22;; + + *[0-7]) + mkdir_umask=`expr $umask + 22 \ + - $umask % 100 % 40 + $umask % 20 \ + - $umask % 10 % 4 + $umask % 2 + `;; + *) mkdir_umask=$umask,go-w;; + esac + + # With -d, create the new directory with the user-specified mode. + # Otherwise, rely on $mkdir_umask. + if test -n "$dir_arg"; then + mkdir_mode=-m$mode + else + mkdir_mode= + fi + + posix_mkdir=false + case $umask in + *[123567][0-7][0-7]) + # POSIX mkdir -p sets u+wx bits regardless of umask, which + # is incompatible with FreeBSD 'install' when (umask & 300) != 0. + ;; + *) + tmpdir=${TMPDIR-/tmp}/ins$RANDOM-$$ + trap 'ret=$?; rmdir "$tmpdir/d" "$tmpdir" 2>/dev/null; exit $ret' 0 + + if (umask $mkdir_umask && + exec $mkdirprog $mkdir_mode -p -- "$tmpdir/d") >/dev/null 2>&1 + then + if test -z "$dir_arg" || { + # Check for POSIX incompatibilities with -m. + # HP-UX 11.23 and IRIX 6.5 mkdir -m -p sets group- or + # other-writable bit of parent directory when it shouldn't. + # FreeBSD 6.1 mkdir -m -p sets mode of existing directory. + ls_ld_tmpdir=`ls -ld "$tmpdir"` + case $ls_ld_tmpdir in + d????-?r-*) different_mode=700;; + d????-?--*) different_mode=755;; + *) false;; + esac && + $mkdirprog -m$different_mode -p -- "$tmpdir" && { + ls_ld_tmpdir_1=`ls -ld "$tmpdir"` + test "$ls_ld_tmpdir" = "$ls_ld_tmpdir_1" + } + } + then posix_mkdir=: + fi + rmdir "$tmpdir/d" "$tmpdir" + else + # Remove any dirs left behind by ancient mkdir implementations. + rmdir ./$mkdir_mode ./-p ./-- 2>/dev/null + fi + trap '' 0;; + esac;; + esac + + if + $posix_mkdir && ( + umask $mkdir_umask && + $doit_exec $mkdirprog $mkdir_mode -p -- "$dstdir" + ) + then : + else + + # The umask is ridiculous, or mkdir does not conform to POSIX, + # or it failed possibly due to a race condition. Create the + # directory the slow way, step by step, checking for races as we go. + + case $dstdir in + /*) prefix='/';; + [-=\(\)!]*) prefix='./';; + *) prefix='';; + esac + + eval "$initialize_posix_glob" + + oIFS=$IFS + IFS=/ + $posix_glob set -f + set fnord $dstdir + shift + $posix_glob set +f + IFS=$oIFS + + prefixes= + + for d + do + test X"$d" = X && continue + + prefix=$prefix$d + if test -d "$prefix"; then + prefixes= + else + if $posix_mkdir; then + (umask=$mkdir_umask && + $doit_exec $mkdirprog $mkdir_mode -p -- "$dstdir") && break + # Don't fail if two instances are running concurrently. + test -d "$prefix" || exit 1 + else + case $prefix in + *\'*) qprefix=`echo "$prefix" | sed "s/'/'\\\\\\\\''/g"`;; + *) qprefix=$prefix;; + esac + prefixes="$prefixes '$qprefix'" + fi + fi + prefix=$prefix/ + done + + if test -n "$prefixes"; then + # Don't fail if two instances are running concurrently. + (umask $mkdir_umask && + eval "\$doit_exec \$mkdirprog $prefixes") || + test -d "$dstdir" || exit 1 + obsolete_mkdir_used=true + fi + fi + fi + + if test -n "$dir_arg"; then + { test -z "$chowncmd" || $doit $chowncmd "$dst"; } && + { test -z "$chgrpcmd" || $doit $chgrpcmd "$dst"; } && + { test "$obsolete_mkdir_used$chowncmd$chgrpcmd" = false || + test -z "$chmodcmd" || $doit $chmodcmd $mode "$dst"; } || exit 1 + else + + # Make a couple of temp file names in the proper directory. + dsttmp=$dstdir/_inst.$$_ + rmtmp=$dstdir/_rm.$$_ + + # Trap to clean up those temp files at exit. + trap 'ret=$?; rm -f "$dsttmp" "$rmtmp" && exit $ret' 0 + + # Copy the file name to the temp name. + (umask $cp_umask && $doit_exec $cpprog "$src" "$dsttmp") && + + # and set any options; do chmod last to preserve setuid bits. + # + # If any of these fail, we abort the whole thing. If we want to + # ignore errors from any of these, just make sure not to ignore + # errors from the above "$doit $cpprog $src $dsttmp" command. + # + { test -z "$chowncmd" || $doit $chowncmd "$dsttmp"; } && + { test -z "$chgrpcmd" || $doit $chgrpcmd "$dsttmp"; } && + { test -z "$stripcmd" || $doit $stripcmd "$dsttmp"; } && + { test -z "$chmodcmd" || $doit $chmodcmd $mode "$dsttmp"; } && + + # If -C, don't bother to copy if it wouldn't change the file. + if $copy_on_change && + old=`LC_ALL=C ls -dlL "$dst" 2>/dev/null` && + new=`LC_ALL=C ls -dlL "$dsttmp" 2>/dev/null` && + + eval "$initialize_posix_glob" && + $posix_glob set -f && + set X $old && old=:$2:$4:$5:$6 && + set X $new && new=:$2:$4:$5:$6 && + $posix_glob set +f && + + test "$old" = "$new" && + $cmpprog "$dst" "$dsttmp" >/dev/null 2>&1 + then + rm -f "$dsttmp" + else + # Rename the file to the real destination. + $doit $mvcmd -f "$dsttmp" "$dst" 2>/dev/null || + + # The rename failed, perhaps because mv can't rename something else + # to itself, or perhaps because mv is so ancient that it does not + # support -f. + { + # Now remove or move aside any old file at destination location. + # We try this two ways since rm can't unlink itself on some + # systems and the destination file might be busy for other + # reasons. In this case, the final cleanup might fail but the new + # file should still install successfully. + { + test ! -f "$dst" || + $doit $rmcmd -f "$dst" 2>/dev/null || + { $doit $mvcmd -f "$dst" "$rmtmp" 2>/dev/null && + { $doit $rmcmd -f "$rmtmp" 2>/dev/null; :; } + } || + { echo "$0: cannot unlink or rename $dst" >&2 + (exit 1); exit 1 + } + } && + + # Now rename the file to the real destination. + $doit $mvcmd "$dsttmp" "$dst" + } + fi || exit 1 + + trap '' 0 + fi +done + +# Local variables: +# eval: (add-hook 'write-file-hooks 'time-stamp) +# time-stamp-start: "scriptversion=" +# time-stamp-format: "%:y-%02m-%02d.%02H" +# time-stamp-time-zone: "UTC" +# time-stamp-end: "; # UTC" +# End: diff --git a/third_party/nix/contrib/stack-collapse.py b/third_party/nix/contrib/stack-collapse.py new file mode 100755 index 0000000000..f5602c95c4 --- /dev/null +++ b/third_party/nix/contrib/stack-collapse.py @@ -0,0 +1,38 @@ +#!/usr/bin/env nix-shell +#!nix-shell -i python3 -p python3 --pure + +# To be used with `--trace-function-calls` and `flamegraph.pl`. +# +# For example: +# +# nix-instantiate --trace-function-calls '<nixpkgs>' -A hello 2> nix-function-calls.trace +# ./contrib/stack-collapse.py nix-function-calls.trace > nix-function-calls.folded +# nix-shell -p flamegraph --run "flamegraph.pl nix-function-calls.folded > nix-function-calls.svg" + +import sys +from pprint import pprint +import fileinput + +stack = [] +timestack = [] + +for line in fileinput.input(): + components = line.strip().split(" ", 2) + if components[0] != "function-trace": + continue + + direction = components[1] + components = components[2].rsplit(" ", 2) + + loc = components[0] + _at = components[1] + time = int(components[2]) + + if direction == "entered": + stack.append(loc) + timestack.append(time) + elif direction == "exited": + dur = time - timestack.pop() + vst = ";".join(stack) + print(f"{vst} {dur}") + stack.pop() diff --git a/third_party/nix/corepkgs/buildenv.nix b/third_party/nix/corepkgs/buildenv.nix new file mode 100644 index 0000000000..0bac4c44b4 --- /dev/null +++ b/third_party/nix/corepkgs/buildenv.nix @@ -0,0 +1,25 @@ +{ derivations, manifest }: + +derivation { + name = "user-environment"; + system = "builtin"; + builder = "builtin:buildenv"; + + inherit manifest; + + # !!! grmbl, need structured data for passing this in a clean way. + derivations = + map (d: + [ (d.meta.active or "true") + (d.meta.priority or 5) + (builtins.length d.outputs) + ] ++ map (output: builtins.getAttr output d) d.outputs) + derivations; + + # Building user environments remotely just causes huge amounts of + # network traffic, so don't do that. + preferLocalBuild = true; + + # Also don't bother substituting. + allowSubstitutes = false; +} diff --git a/third_party/nix/corepkgs/config.nix.in b/third_party/nix/corepkgs/config.nix.in new file mode 100644 index 0000000000..32ce6b399f --- /dev/null +++ b/third_party/nix/corepkgs/config.nix.in @@ -0,0 +1,29 @@ +let + fromEnv = var: def: + let val = builtins.getEnv var; in + if val != "" then val else def; +in rec { + shell = "@bash@"; + coreutils = "@coreutils@"; + bzip2 = "@bzip2@"; + gzip = "@gzip@"; + xz = "@xz@"; + tar = "@tar@"; + tarFlags = "@tarFlags@"; + tr = "@tr@"; + nixBinDir = fromEnv "NIX_BIN_DIR" "@bindir@"; + nixPrefix = "@prefix@"; + nixLibexecDir = fromEnv "NIX_LIBEXEC_DIR" "@libexecdir@"; + nixLocalstateDir = "@localstatedir@"; + nixSysconfDir = "@sysconfdir@"; + nixStoreDir = fromEnv "NIX_STORE_DIR" "@storedir@"; + + # If Nix is installed in the Nix store, then automatically add it as + # a dependency to the core packages. This ensures that they work + # properly in a chroot. + chrootDeps = + if dirOf nixPrefix == builtins.storeDir then + [ (builtins.storePath nixPrefix) ] + else + [ ]; +} diff --git a/third_party/nix/corepkgs/derivation.nix b/third_party/nix/corepkgs/derivation.nix new file mode 100644 index 0000000000..c0fbe8082c --- /dev/null +++ b/third_party/nix/corepkgs/derivation.nix @@ -0,0 +1,27 @@ +/* This is the implementation of the ‘derivation’ builtin function. + It's actually a wrapper around the ‘derivationStrict’ primop. */ + +drvAttrs @ { outputs ? [ "out" ], ... }: + +let + + strict = derivationStrict drvAttrs; + + commonAttrs = drvAttrs // (builtins.listToAttrs outputsList) // + { all = map (x: x.value) outputsList; + inherit drvAttrs; + }; + + outputToAttrListElement = outputName: + { name = outputName; + value = commonAttrs // { + outPath = builtins.getAttr outputName strict; + drvPath = strict.drvPath; + type = "derivation"; + inherit outputName; + }; + }; + + outputsList = map outputToAttrListElement outputs; + +in (builtins.head outputsList).value diff --git a/third_party/nix/corepkgs/fetchurl.nix b/third_party/nix/corepkgs/fetchurl.nix new file mode 100644 index 0000000000..a84777f574 --- /dev/null +++ b/third_party/nix/corepkgs/fetchurl.nix @@ -0,0 +1,41 @@ +{ system ? "" # obsolete +, url +, hash ? "" # an SRI ash + +# Legacy hash specification +, md5 ? "", sha1 ? "", sha256 ? "", sha512 ? "" +, outputHash ? + if hash != "" then hash else if sha512 != "" then sha512 else if sha1 != "" then sha1 else if md5 != "" then md5 else sha256 +, outputHashAlgo ? + if hash != "" then "" else if sha512 != "" then "sha512" else if sha1 != "" then "sha1" else if md5 != "" then "md5" else "sha256" + +, executable ? false +, unpack ? false +, name ? baseNameOf (toString url) +}: + +derivation { + builder = "builtin:fetchurl"; + + # New-style output content requirements. + inherit outputHashAlgo outputHash; + outputHashMode = if unpack || executable then "recursive" else "flat"; + + inherit name url executable unpack; + + system = "builtin"; + + # No need to double the amount of network traffic + preferLocalBuild = true; + + impureEnvVars = [ + # We borrow these environment variables from the caller to allow + # easy proxy configuration. This is impure, but a fixed-output + # derivation like fetchurl is allowed to do so since its result is + # by definition pure. + "http_proxy" "https_proxy" "ftp_proxy" "all_proxy" "no_proxy" + ]; + + # To make "nix-prefetch-url" work. + urls = [ url ]; +} diff --git a/third_party/nix/corepkgs/imported-drv-to-derivation.nix b/third_party/nix/corepkgs/imported-drv-to-derivation.nix new file mode 100644 index 0000000000..eab8b050e8 --- /dev/null +++ b/third_party/nix/corepkgs/imported-drv-to-derivation.nix @@ -0,0 +1,21 @@ +attrs @ { drvPath, outputs, name, ... }: + +let + + commonAttrs = (builtins.listToAttrs outputsList) // + { all = map (x: x.value) outputsList; + inherit drvPath name; + type = "derivation"; + }; + + outputToAttrListElement = outputName: + { name = outputName; + value = commonAttrs // { + outPath = builtins.getAttr outputName attrs; + inherit outputName; + }; + }; + + outputsList = map outputToAttrListElement outputs; + +in (builtins.head outputsList).value diff --git a/third_party/nix/corepkgs/meson.build b/third_party/nix/corepkgs/meson.build new file mode 100644 index 0000000000..383909b0f7 --- /dev/null +++ b/third_party/nix/corepkgs/meson.build @@ -0,0 +1,32 @@ +corepkgs_data = files( + join_paths(meson.source_root(), 'corepkgs/buildenv.nix'), + join_paths(meson.source_root(), 'corepkgs/derivation.nix'), + join_paths(meson.source_root(), 'corepkgs/fetchurl.nix'), + join_paths(meson.source_root(), 'corepkgs/imported-drv-to-derivation.nix'), + join_paths(meson.source_root(), 'corepkgs/unpack-channel.nix')) + +config_nix = configuration_data() +config_nix.set('bash', bash.path()) +config_nix.set('coreutils', coreutils) +config_nix.set('bzip2', bzip2.path()) +config_nix.set('gzip', gzip.path()) +config_nix.set('xz', xz.path()) +config_nix.set('tar', tar.path()) +config_nix.set('tarFlags', '') +config_nix.set('tr', tr.path()) +config_nix.set('bindir', bindir) +config_nix.set('prefix', prefix) +config_nix.set('libexecdir', libexecdir) +config_nix.set('localstatedir', localstatedir) +config_nix.set('sysconfdir', sysconfdir) +config_nix.set('storedir', nixstoredir) + +corepkgs_data += configure_file( + input : 'config.nix.in', + output : 'config.nix', + configuration : config_nix) + +install_data( + corepkgs_data, + install_mode : 'rwxr-xr-x', + install_dir : join_paths(datadir, 'nix/corepkgs')) diff --git a/third_party/nix/corepkgs/unpack-channel.nix b/third_party/nix/corepkgs/unpack-channel.nix new file mode 100644 index 0000000000..d39a206378 --- /dev/null +++ b/third_party/nix/corepkgs/unpack-channel.nix @@ -0,0 +1,39 @@ +with import <nix/config.nix>; + +let + + builder = builtins.toFile "unpack-channel.sh" + '' + mkdir $out + cd $out + xzpat="\.xz\$" + gzpat="\.gz\$" + if [[ "$src" =~ $xzpat ]]; then + ${xz} -d < $src | ${tar} xf - ${tarFlags} + elif [[ "$src" =~ $gzpat ]]; then + ${gzip} -d < $src | ${tar} xf - ${tarFlags} + else + ${bzip2} -d < $src | ${tar} xf - ${tarFlags} + fi + if [ * != $channelName ]; then + mv * $out/$channelName + fi + ''; + +in + +{ name, channelName, src }: + +derivation { + system = builtins.currentSystem; + builder = shell; + args = [ "-e" builder ]; + inherit name channelName src; + + PATH = "${nixBinDir}:${coreutils}"; + + # No point in doing this remotely. + preferLocalBuild = true; + + inherit chrootDeps; +} diff --git a/third_party/nix/default.nix b/third_party/nix/default.nix new file mode 100644 index 0000000000..d7a85bb612 --- /dev/null +++ b/third_party/nix/default.nix @@ -0,0 +1,86 @@ +{ pkgs ? (import <nixpkgs> {}).third_party, ... }: + +let + stdenv = with pkgs; overrideCC clangStdenv clang_9; + + aws-s3-cpp = pkgs.aws-sdk-cpp.override { + apis = ["s3" "transfer"]; + customMemoryManagement = false; + }; + + # TODO(tazjin): this is copied from the original derivation, but what + # is it for? + largeBoehm = pkgs.boehmgc.override { + enableLargeConfig = true; + }; +in stdenv.mkDerivation { + pname = "nix"; + version = "2.3.4"; + src = ./.; + + # Abseil's sources need to be linked into a subproject. + postUnpack = '' + ln -fs ${pkgs.abseil_cpp.src} nix/subprojects/abseil_cpp + ''; + + nativeBuildInputs = with pkgs; [ + bison + clang-tools + cmake + meson + ninja + pkgconfig + libxml2 + libxslt + ]; + + # TODO(tazjin): Some of these might only be required for native inputs + buildInputs = with pkgs; [ + # TODO(tazjin): Figure out why meson can't make the Abseil headers visible + abseil_cpp + aws-s3-cpp + boost + brotli + bzip2 + curl + editline + flex + glog + largeBoehm + libseccomp + libsodium + openssl + sqlite + xz + ]; + + mesonFlags = [ + "-Dsandbox_shell=${pkgs.busybox-sandbox-shell}/bin/busybox" + ]; + + # cmake is only included to build Abseil and its hook should not run + dontUseCmakeConfigure = true; + + # Install the various symlinks to the Nix binary which users expect + # to exist. + postInstall = '' + ln -s $out/bin/nix $out/bin/nix-build + ln -s $out/bin/nix $out/bin/nix-channel + ln -s $out/bin/nix $out/bin/nix-collect-garbage + ln -s $out/bin/nix $out/bin/nix-copy-closure + ln -s $out/bin/nix $out/bin/nix-daemon + ln -s $out/bin/nix $out/bin/nix-env + ln -s $out/bin/nix $out/bin/nix-hash + ln -s $out/bin/nix $out/bin/nix-instantiate + ln -s $out/bin/nix $out/bin/nix-prefetch-url + ln -s $out/bin/nix $out/bin/nix-shell + ln -s $out/bin/nix $out/bin/nix-store + + mkdir -p $out/libexec/nix + ln -s $out/bin/nix $out/libexec/nix/build-remote + ''; + + # TODO(tazjin): equivalent of --enable-gc + # TODO(tazjin): integration test setup? + # TODO(tazjin): docs generation? +} diff --git a/third_party/nix/doc/manual/advanced-topics/advanced-topics.xml b/third_party/nix/doc/manual/advanced-topics/advanced-topics.xml new file mode 100644 index 0000000000..871b7eb1d3 --- /dev/null +++ b/third_party/nix/doc/manual/advanced-topics/advanced-topics.xml @@ -0,0 +1,14 @@ +<part xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + xml:id="part-advanced-topics" + version="5.0"> + +<title>Advanced Topics</title> + +<xi:include href="distributed-builds.xml" /> +<xi:include href="cores-vs-jobs.xml" /> +<xi:include href="diff-hook.xml" /> +<xi:include href="post-build-hook.xml" /> + +</part> diff --git a/third_party/nix/doc/manual/advanced-topics/cores-vs-jobs.xml b/third_party/nix/doc/manual/advanced-topics/cores-vs-jobs.xml new file mode 100644 index 0000000000..eba645faf8 --- /dev/null +++ b/third_party/nix/doc/manual/advanced-topics/cores-vs-jobs.xml @@ -0,0 +1,121 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="chap-tuning-cores-and-jobs"> + +<title>Tuning Cores and Jobs</title> + +<para>Nix has two relevant settings with regards to how your CPU cores +will be utilized: <xref linkend="conf-cores" /> and +<xref linkend="conf-max-jobs" />. This chapter will talk about what +they are, how they interact, and their configuration trade-offs.</para> + +<variablelist> + <varlistentry> + <term><xref linkend="conf-max-jobs" /></term> + <listitem><para> + Dictates how many separate derivations will be built at the same + time. If you set this to zero, the local machine will do no + builds. Nix will still substitute from binary caches, and build + remotely if remote builders are configured. + </para></listitem> + </varlistentry> + <varlistentry> + <term><xref linkend="conf-cores" /></term> + <listitem><para> + Suggests how many cores each derivation should use. Similar to + <command>make -j</command>. + </para></listitem> + </varlistentry> +</variablelist> + +<para>The <xref linkend="conf-cores" /> setting determines the value of +<envar>NIX_BUILD_CORES</envar>. <envar>NIX_BUILD_CORES</envar> is equal +to <xref linkend="conf-cores" />, unless <xref linkend="conf-cores" /> +equals <literal>0</literal>, in which case <envar>NIX_BUILD_CORES</envar> +will be the total number of cores in the system.</para> + +<para>The total number of consumed cores is a simple multiplication, +<xref linkend="conf-cores" /> * <envar>NIX_BUILD_CORES</envar>.</para> + +<para>The balance on how to set these two independent variables depends +upon each builder's workload and hardware. Here are a few example +scenarios on a machine with 24 cores:</para> + +<table> + <caption>Balancing 24 Build Cores</caption> + <thead> + <tr> + <th><xref linkend="conf-max-jobs" /></th> + <th><xref linkend="conf-cores" /></th> + <th><envar>NIX_BUILD_CORES</envar></th> + <th>Maximum Processes</th> + <th>Result</th> + </tr> + </thead> + <tbody> + <tr> + <td>1</td> + <td>24</td> + <td>24</td> + <td>24</td> + <td> + One derivation will be built at a time, each one can use 24 + cores. Undersold if a job can’t use 24 cores. + </td> + </tr> + + <tr> + <td>4</td> + <td>6</td> + <td>6</td> + <td>24</td> + <td> + Four derivations will be built at once, each given access to + six cores. + </td> + </tr> + <tr> + <td>12</td> + <td>6</td> + <td>6</td> + <td>72</td> + <td> + 12 derivations will be built at once, each given access to six + cores. This configuration is over-sold. If all 12 derivations + being built simultaneously try to use all six cores, the + machine's performance will be degraded due to extensive context + switching between the 12 builds. + </td> + </tr> + <tr> + <td>24</td> + <td>1</td> + <td>1</td> + <td>24</td> + <td> + 24 derivations can build at the same time, each using a single + core. Never oversold, but derivations which require many cores + will be very slow to compile. + </td> + </tr> + <tr> + <td>24</td> + <td>0</td> + <td>24</td> + <td>576</td> + <td> + 24 derivations can build at the same time, each using all the + available cores of the machine. Very likely to be oversold, + and very likely to suffer context switches. + </td> + </tr> + </tbody> +</table> + +<para>It is up to the derivations' build script to respect +host's requested cores-per-build by following the value of the +<envar>NIX_BUILD_CORES</envar> environment variable.</para> + +</chapter> diff --git a/third_party/nix/doc/manual/advanced-topics/diff-hook.xml b/third_party/nix/doc/manual/advanced-topics/diff-hook.xml new file mode 100644 index 0000000000..fb4bf819f9 --- /dev/null +++ b/third_party/nix/doc/manual/advanced-topics/diff-hook.xml @@ -0,0 +1,205 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + xml:id="chap-diff-hook" + version="5.0" + > + +<title>Verifying Build Reproducibility with <option linkend="conf-diff-hook">diff-hook</option></title> + +<subtitle>Check build reproducibility by running builds multiple times +and comparing their results.</subtitle> + +<para>Specify a program with Nix's <xref linkend="conf-diff-hook" /> to +compare build results when two builds produce different results. Note: +this hook is only executed if the results are not the same, this hook +is not used for determining if the results are the same.</para> + +<para>For purposes of demonstration, we'll use the following Nix file, +<filename>deterministic.nix</filename> for testing:</para> + +<programlisting> +let + inherit (import <nixpkgs> {}) runCommand; +in { + stable = runCommand "stable" {} '' + touch $out + ''; + + unstable = runCommand "unstable" {} '' + echo $RANDOM > $out + ''; +} +</programlisting> + +<para>Additionally, <filename>nix.conf</filename> contains: + +<programlisting> +diff-hook = /etc/nix/my-diff-hook +run-diff-hook = true +</programlisting> + +where <filename>/etc/nix/my-diff-hook</filename> is an executable +file containing: + +<programlisting> +#!/bin/sh +exec >&2 +echo "For derivation $3:" +/run/current-system/sw/bin/diff -r "$1" "$2" +</programlisting> + +</para> + +<para>The diff hook is executed by the same user and group who ran the +build. However, the diff hook does not have write access to the store +path just built.</para> + +<section> + <title> + Spot-Checking Build Determinism + </title> + + <para> + Verify a path which already exists in the Nix store by passing + <option>--check</option> to the build command. + </para> + + <para>If the build passes and is deterministic, Nix will exit with a + status code of 0:</para> + + <screen> +$ nix-build ./deterministic.nix -A stable +these derivations will be built: + /nix/store/z98fasz2jqy9gs0xbvdj939p27jwda38-stable.drv +building '/nix/store/z98fasz2jqy9gs0xbvdj939p27jwda38-stable.drv'... +/nix/store/yyxlzw3vqaas7wfp04g0b1xg51f2czgq-stable + +$ nix-build ./deterministic.nix -A stable --check +checking outputs of '/nix/store/z98fasz2jqy9gs0xbvdj939p27jwda38-stable.drv'... +/nix/store/yyxlzw3vqaas7wfp04g0b1xg51f2czgq-stable +</screen> + + <para>If the build is not deterministic, Nix will exit with a status + code of 1:</para> + + <screen> +$ nix-build ./deterministic.nix -A unstable +these derivations will be built: + /nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv +building '/nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv'... +/nix/store/krpqk0l9ib0ibi1d2w52z293zw455cap-unstable + +$ nix-build ./deterministic.nix -A unstable --check +checking outputs of '/nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv'... +error: derivation '/nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv' may not be deterministic: output '/nix/store/krpqk0l9ib0ibi1d2w52z293zw455cap-unstable' differs +</screen> + +<para>In the Nix daemon's log, we will now see: +<screen> +For derivation /nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv: +1c1 +< 8108 +--- +> 30204 +</screen> +</para> + + <para>Using <option>--check</option> with <option>--keep-failed</option> + will cause Nix to keep the second build's output in a special, + <literal>.check</literal> path:</para> + + <screen> +$ nix-build ./deterministic.nix -A unstable --check --keep-failed +checking outputs of '/nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv'... +note: keeping build directory '/tmp/nix-build-unstable.drv-0' +error: derivation '/nix/store/cgl13lbj1w368r5z8gywipl1ifli7dhk-unstable.drv' may not be deterministic: output '/nix/store/krpqk0l9ib0ibi1d2w52z293zw455cap-unstable' differs from '/nix/store/krpqk0l9ib0ibi1d2w52z293zw455cap-unstable.check' +</screen> + + <para>In particular, notice the + <literal>/nix/store/krpqk0l9ib0ibi1d2w52z293zw455cap-unstable.check</literal> + output. Nix has copied the build results to that directory where you + can examine it.</para> + + <note xml:id="check-dirs-are-unregistered"> + <title><literal>.check</literal> paths are not registered store paths</title> + + <para>Check paths are not protected against garbage collection, + and this path will be deleted on the next garbage collection.</para> + + <para>The path is guaranteed to be alive for the duration of + <xref linkend="conf-diff-hook" />'s execution, but may be deleted + any time after.</para> + + <para>If the comparison is performed as part of automated tooling, + please use the diff-hook or author your tooling to handle the case + where the build was not deterministic and also a check path does + not exist.</para> + </note> + + <para> + <option>--check</option> is only usable if the derivation has + been built on the system already. If the derivation has not been + built Nix will fail with the error: + <screen> +error: some outputs of '/nix/store/hzi1h60z2qf0nb85iwnpvrai3j2w7rr6-unstable.drv' are not valid, so checking is not possible +</screen> + + Run the build without <option>--check</option>, and then try with + <option>--check</option> again. + </para> +</section> + +<section> + <title> + Automatic and Optionally Enforced Determinism Verification + </title> + + <para> + Automatically verify every build at build time by executing the + build multiple times. + </para> + + <para> + Setting <xref linkend="conf-repeat" /> and + <xref linkend="conf-enforce-determinism" /> in your + <filename>nix.conf</filename> permits the automated verification + of every build Nix performs. + </para> + + <para> + The following configuration will run each build three times, and + will require the build to be deterministic: + + <programlisting> +enforce-determinism = true +repeat = 2 +</programlisting> + </para> + + <para> + Setting <xref linkend="conf-enforce-determinism" /> to false as in + the following configuration will run the build multiple times, + execute the build hook, but will allow the build to succeed even + if it does not build reproducibly: + + <programlisting> +enforce-determinism = false +repeat = 1 +</programlisting> + </para> + + <para> + An example output of this configuration: + <screen> +$ nix-build ./test.nix -A unstable +these derivations will be built: + /nix/store/ch6llwpr2h8c3jmnf3f2ghkhx59aa97f-unstable.drv +building '/nix/store/ch6llwpr2h8c3jmnf3f2ghkhx59aa97f-unstable.drv' (round 1/2)... +building '/nix/store/ch6llwpr2h8c3jmnf3f2ghkhx59aa97f-unstable.drv' (round 2/2)... +output '/nix/store/6xg356v9gl03hpbbg8gws77n19qanh02-unstable' of '/nix/store/ch6llwpr2h8c3jmnf3f2ghkhx59aa97f-unstable.drv' differs from '/nix/store/6xg356v9gl03hpbbg8gws77n19qanh02-unstable.check' from previous round +/nix/store/6xg356v9gl03hpbbg8gws77n19qanh02-unstable +</screen> + </para> +</section> +</chapter> diff --git a/third_party/nix/doc/manual/advanced-topics/distributed-builds.xml b/third_party/nix/doc/manual/advanced-topics/distributed-builds.xml new file mode 100644 index 0000000000..9ac4a92cd5 --- /dev/null +++ b/third_party/nix/doc/manual/advanced-topics/distributed-builds.xml @@ -0,0 +1,190 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='chap-distributed-builds'> + +<title>Remote Builds</title> + +<para>Nix supports remote builds, where a local Nix installation can +forward Nix builds to other machines. This allows multiple builds to +be performed in parallel and allows Nix to perform multi-platform +builds in a semi-transparent way. For instance, if you perform a +build for a <literal>x86_64-darwin</literal> on an +<literal>i686-linux</literal> machine, Nix can automatically forward +the build to a <literal>x86_64-darwin</literal> machine, if +available.</para> + +<para>To forward a build to a remote machine, it’s required that the +remote machine is accessible via SSH and that it has Nix +installed. You can test whether connecting to the remote Nix instance +works, e.g. + +<screen> +$ nix ping-store --store ssh://mac +</screen> + +will try to connect to the machine named <literal>mac</literal>. It is +possible to specify an SSH identity file as part of the remote store +URI, e.g. + +<screen> +$ nix ping-store --store ssh://mac?ssh-key=/home/alice/my-key +</screen> + +Since builds should be non-interactive, the key should not have a +passphrase. Alternatively, you can load identities ahead of time into +<command>ssh-agent</command> or <command>gpg-agent</command>.</para> + +<para>If you get the error + +<screen> +bash: nix-store: command not found +error: cannot connect to 'mac' +</screen> + +then you need to ensure that the <envar>PATH</envar> of +non-interactive login shells contains Nix.</para> + +<warning><para>If you are building via the Nix daemon, it is the Nix +daemon user account (that is, <literal>root</literal>) that should +have SSH access to the remote machine. If you can’t or don’t want to +configure <literal>root</literal> to be able to access to remote +machine, you can use a private Nix store instead by passing +e.g. <literal>--store ~/my-nix</literal>.</para></warning> + +<para>The list of remote machines can be specified on the command line +or in the Nix configuration file. The former is convenient for +testing. For example, the following command allows you to build a +derivation for <literal>x86_64-darwin</literal> on a Linux machine: + +<screen> +$ uname +Linux + +$ nix build \ + '(with import <nixpkgs> { system = "x86_64-darwin"; }; runCommand "foo" {} "uname > $out")' \ + --builders 'ssh://mac x86_64-darwin' +[1/0/1 built, 0.0 MiB DL] building foo on ssh://mac + +$ cat ./result +Darwin +</screen> + +It is possible to specify multiple builders separated by a semicolon +or a newline, e.g. + +<screen> + --builders 'ssh://mac x86_64-darwin ; ssh://beastie x86_64-freebsd' +</screen> +</para> + +<para>Each machine specification consists of the following elements, +separated by spaces. Only the first element is required. +To leave a field at its default, set it to <literal>-</literal>. + +<orderedlist> + + <listitem><para>The URI of the remote store in the format + <literal>ssh://[<replaceable>username</replaceable>@]<replaceable>hostname</replaceable></literal>, + e.g. <literal>ssh://nix@mac</literal> or + <literal>ssh://mac</literal>. For backward compatibility, + <literal>ssh://</literal> may be omitted. The hostname may be an + alias defined in your + <filename>~/.ssh/config</filename>.</para></listitem> + + <listitem><para>A comma-separated list of Nix platform type + identifiers, such as <literal>x86_64-darwin</literal>. It is + possible for a machine to support multiple platform types, e.g., + <literal>i686-linux,x86_64-linux</literal>. If omitted, this + defaults to the local platform type.</para></listitem> + + <listitem><para>The SSH identity file to be used to log in to the + remote machine. If omitted, SSH will use its regular + identities.</para></listitem> + + <listitem><para>The maximum number of builds that Nix will execute + in parallel on the machine. Typically this should be equal to the + number of CPU cores. For instance, the machine + <literal>itchy</literal> in the example will execute up to 8 builds + in parallel.</para></listitem> + + <listitem><para>The “speed factor”, indicating the relative speed of + the machine. If there are multiple machines of the right type, Nix + will prefer the fastest, taking load into account.</para></listitem> + + <listitem><para>A comma-separated list of <emphasis>supported + features</emphasis>. If a derivation has the + <varname>requiredSystemFeatures</varname> attribute, then Nix will + only perform the derivation on a machine that has the specified + features. For instance, the attribute + +<programlisting> +requiredSystemFeatures = [ "kvm" ]; +</programlisting> + + will cause the build to be performed on a machine that has the + <literal>kvm</literal> feature.</para></listitem> + + <listitem><para>A comma-separated list of <emphasis>mandatory + features</emphasis>. A machine will only be used to build a + derivation if all of the machine’s mandatory features appear in the + derivation’s <varname>requiredSystemFeatures</varname> + attribute..</para></listitem> + +</orderedlist> + +For example, the machine specification + +<programlisting> +nix@scratchy.labs.cs.uu.nl i686-linux /home/nix/.ssh/id_scratchy_auto 8 1 kvm +nix@itchy.labs.cs.uu.nl i686-linux /home/nix/.ssh/id_scratchy_auto 8 2 +nix@poochie.labs.cs.uu.nl i686-linux /home/nix/.ssh/id_scratchy_auto 1 2 kvm benchmark +</programlisting> + +specifies several machines that can perform +<literal>i686-linux</literal> builds. However, +<literal>poochie</literal> will only do builds that have the attribute + +<programlisting> +requiredSystemFeatures = [ "benchmark" ]; +</programlisting> + +or + +<programlisting> +requiredSystemFeatures = [ "benchmark" "kvm" ]; +</programlisting> + +<literal>itchy</literal> cannot do builds that require +<literal>kvm</literal>, but <literal>scratchy</literal> does support +such builds. For regular builds, <literal>itchy</literal> will be +preferred over <literal>scratchy</literal> because it has a higher +speed factor.</para> + +<para>Remote builders can also be configured in +<filename>nix.conf</filename>, e.g. + +<programlisting> +builders = ssh://mac x86_64-darwin ; ssh://beastie x86_64-freebsd +</programlisting> + +Finally, remote builders can be configured in a separate configuration +file included in <option>builders</option> via the syntax +<literal>@<replaceable>file</replaceable></literal>. For example, + +<programlisting> +builders = @/etc/nix/machines +</programlisting> + +causes the list of machines in <filename>/etc/nix/machines</filename> +to be included. (This is the default.)</para> + +<para>If you want the builders to use caches, you likely want to set +the option <link linkend='conf-builders-use-substitutes'><literal>builders-use-substitutes</literal></link> +in your local <filename>nix.conf</filename>.</para> + +<para>To build only on remote builders and disable building on the local machine, +you can use the option <option>--max-jobs 0</option>.</para> + +</chapter> diff --git a/third_party/nix/doc/manual/advanced-topics/post-build-hook.xml b/third_party/nix/doc/manual/advanced-topics/post-build-hook.xml new file mode 100644 index 0000000000..3dc43ee795 --- /dev/null +++ b/third_party/nix/doc/manual/advanced-topics/post-build-hook.xml @@ -0,0 +1,160 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + xml:id="chap-post-build-hook" + version="5.0" + > + +<title>Using the <xref linkend="conf-post-build-hook" /></title> +<subtitle>Uploading to an S3-compatible binary cache after each build</subtitle> + + +<section xml:id="chap-post-build-hook-caveats"> + <title>Implementation Caveats</title> + <para>Here we use the post-build hook to upload to a binary cache. + This is a simple and working example, but it is not suitable for all + use cases.</para> + + <para>The post build hook program runs after each executed build, + and blocks the build loop. The build loop exits if the hook program + fails.</para> + + <para>Concretely, this implementation will make Nix slow or unusable + when the internet is slow or unreliable.</para> + + <para>A more advanced implementation might pass the store paths to a + user-supplied daemon or queue for processing the store paths outside + of the build loop.</para> +</section> + +<section> + <title>Prerequisites</title> + + <para> + This tutorial assumes you have configured an S3-compatible binary cache + according to the instructions at + <xref linkend="ssec-s3-substituter-authenticated-writes" />, and + that the <literal>root</literal> user's default AWS profile can + upload to the bucket. + </para> +</section> + +<section> + <title>Set up a Signing Key</title> + <para>Use <command>nix-store --generate-binary-cache-key</command> to + create our public and private signing keys. We will sign paths + with the private key, and distribute the public key for verifying + the authenticity of the paths.</para> + + <screen> +# nix-store --generate-binary-cache-key example-nix-cache-1 /etc/nix/key.private /etc/nix/key.public +# cat /etc/nix/key.public +example-nix-cache-1:1/cKDz3QCCOmwcztD2eV6Coggp6rqc9DGjWv7C0G+rM= +</screen> + +<para>Then, add the public key and the cache URL to your +<filename>nix.conf</filename>'s <xref linkend="conf-trusted-public-keys" /> +and <xref linkend="conf-substituters" /> like:</para> + +<programlisting> +substituters = https://cache.nixos.org/ s3://example-nix-cache +trusted-public-keys = cache.nixos.org-1:6NCHdD59X431o0gWypbMrAURkbJ16ZPMQFGspcDShjY= example-nix-cache-1:1/cKDz3QCCOmwcztD2eV6Coggp6rqc9DGjWv7C0G+rM= +</programlisting> + +<para>we will restart the Nix daemon a later step.</para> +</section> + +<section> + <title>Implementing the build hook</title> + <para>Write the following script to + <filename>/etc/nix/upload-to-cache.sh</filename>: + </para> + + <programlisting> +#!/bin/sh + +set -eu +set -f # disable globbing +export IFS=' ' + +echo "Signing paths" $OUT_PATHS +nix sign-paths --key-file /etc/nix/key.private $OUT_PATHS +echo "Uploading paths" $OUT_PATHS +exec nix copy --to 's3://example-nix-cache' $OUT_PATHS +</programlisting> + + <note> + <title>Should <literal>$OUT_PATHS</literal> be quoted?</title> + <para> + The <literal>$OUT_PATHS</literal> variable is a space-separated + list of Nix store paths. In this case, we expect and want the + shell to perform word splitting to make each output path its + own argument to <command>nix sign-paths</command>. Nix guarantees + the paths will not contain any spaces, however a store path + might contain glob characters. The <command>set -f</command> + disables globbing in the shell. + </para> + </note> + <para> + Then make sure the hook program is executable by the <literal>root</literal> user: + <screen> +# chmod +x /etc/nix/upload-to-cache.sh +</screen></para> +</section> + +<section> + <title>Updating Nix Configuration</title> + + <para>Edit <filename>/etc/nix/nix.conf</filename> to run our hook, + by adding the following configuration snippet at the end:</para> + + <programlisting> +post-build-hook = /etc/nix/upload-to-cache.sh +</programlisting> + +<para>Then, restart the <command>nix-daemon</command>.</para> +</section> + +<section> + <title>Testing</title> + + <para>Build any derivation, for example:</para> + + <screen> +$ nix-build -E '(import <nixpkgs> {}).writeText "example" (builtins.toString builtins.currentTime)' +these derivations will be built: + /nix/store/s4pnfbkalzy5qz57qs6yybna8wylkig6-example.drv +building '/nix/store/s4pnfbkalzy5qz57qs6yybna8wylkig6-example.drv'... +running post-build-hook '/home/grahamc/projects/github.com/NixOS/nix/post-hook.sh'... +post-build-hook: Signing paths /nix/store/ibcyipq5gf91838ldx40mjsp0b8w9n18-example +post-build-hook: Uploading paths /nix/store/ibcyipq5gf91838ldx40mjsp0b8w9n18-example +/nix/store/ibcyipq5gf91838ldx40mjsp0b8w9n18-example +</screen> + + <para>Then delete the path from the store, and try substituting it from the binary cache:</para> + <screen> +$ rm ./result +$ nix-store --delete /nix/store/ibcyipq5gf91838ldx40mjsp0b8w9n18-example +</screen> + +<para>Now, copy the path back from the cache:</para> +<screen> +$ nix store --realize /nix/store/ibcyipq5gf91838ldx40mjsp0b8w9n18-example +copying path '/nix/store/m8bmqwrch6l3h8s0k3d673xpmipcdpsa-example from 's3://example-nix-cache'... +warning: you did not specify '--add-root'; the result might be removed by the garbage collector +/nix/store/m8bmqwrch6l3h8s0k3d673xpmipcdpsa-example +</screen> +</section> +<section> + <title>Conclusion</title> + <para> + We now have a Nix installation configured to automatically sign and + upload every local build to a remote binary cache. + </para> + + <para> + Before deploying this to production, be sure to consider the + implementation caveats in <xref linkend="chap-post-build-hook-caveats" />. + </para> +</section> +</chapter> diff --git a/third_party/nix/doc/manual/command-ref/command-ref.xml b/third_party/nix/doc/manual/command-ref/command-ref.xml new file mode 100644 index 0000000000..cfad9b7d79 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/command-ref.xml @@ -0,0 +1,20 @@ +<part xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='part-command-ref'> + +<title>Command Reference</title> + +<partintro> +<para>This section lists commands and options that you can use when you +work with Nix.</para> +</partintro> + +<xi:include href="opt-common.xml" /> +<xi:include href="env-common.xml" /> +<xi:include href="main-commands.xml" /> +<xi:include href="utilities.xml" /> +<xi:include href="files.xml" /> + +</part> diff --git a/third_party/nix/doc/manual/command-ref/conf-file.xml b/third_party/nix/doc/manual/command-ref/conf-file.xml new file mode 100644 index 0000000000..48dce7c950 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/conf-file.xml @@ -0,0 +1,1233 @@ +<?xml version="1.0" encoding="utf-8"?> +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + xml:id="sec-conf-file" + version="5"> + +<refmeta> + <refentrytitle>nix.conf</refentrytitle> + <manvolnum>5</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix.conf</refname> + <refpurpose>Nix configuration file</refpurpose> +</refnamediv> + +<refsection><title>Description</title> + +<para>Nix reads settings from two configuration files:</para> + +<itemizedlist> + + <listitem> + <para>The system-wide configuration file + <filename><replaceable>sysconfdir</replaceable>/nix/nix.conf</filename> + (i.e. <filename>/etc/nix/nix.conf</filename> on most systems), or + <filename>$NIX_CONF_DIR/nix.conf</filename> if + <envar>NIX_CONF_DIR</envar> is set.</para> + </listitem> + + <listitem> + <para>The user configuration file + <filename>$XDG_CONFIG_HOME/nix/nix.conf</filename>, or + <filename>~/.config/nix/nix.conf</filename> if + <envar>XDG_CONFIG_HOME</envar> is not set.</para> + </listitem> + +</itemizedlist> + +<para>The configuration files consist of +<literal><replaceable>name</replaceable> = +<replaceable>value</replaceable></literal> pairs, one per line. Other +files can be included with a line like <literal>include +<replaceable>path</replaceable></literal>, where +<replaceable>path</replaceable> is interpreted relative to the current +conf file and a missing file is an error unless +<literal>!include</literal> is used instead. +Comments start with a <literal>#</literal> character. Here is an +example configuration file:</para> + +<programlisting> +keep-outputs = true # Nice for developers +keep-derivations = true # Idem +</programlisting> + +<para>You can override settings on the command line using the +<option>--option</option> flag, e.g. <literal>--option keep-outputs +false</literal>.</para> + +<para>The following settings are currently available: + +<variablelist> + + + <varlistentry xml:id="conf-allowed-uris"><term><literal>allowed-uris</literal></term> + + <listitem> + + <para>A list of URI prefixes to which access is allowed in + restricted evaluation mode. For example, when set to + <literal>https://github.com/NixOS</literal>, builtin functions + such as <function>fetchGit</function> are allowed to access + <literal>https://github.com/NixOS/patchelf.git</literal>.</para> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-allow-import-from-derivation"><term><literal>allow-import-from-derivation</literal></term> + + <listitem><para>By default, Nix allows you to <function>import</function> from a derivation, + allowing building at evaluation time. With this option set to false, Nix will throw an error + when evaluating an expression that uses this feature, allowing users to ensure their evaluation + will not require any builds to take place.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-allow-new-privileges"><term><literal>allow-new-privileges</literal></term> + + <listitem><para>(Linux-specific.) By default, builders on Linux + cannot acquire new privileges by calling setuid/setgid programs or + programs that have file capabilities. For example, programs such + as <command>sudo</command> or <command>ping</command> will + fail. (Note that in sandbox builds, no such programs are available + unless you bind-mount them into the sandbox via the + <option>sandbox-paths</option> option.) You can allow the + use of such programs by enabling this option. This is impure and + usually undesirable, but may be useful in certain scenarios + (e.g. to spin up containers or set up userspace network interfaces + in tests).</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-allowed-users"><term><literal>allowed-users</literal></term> + + <listitem> + + <para>A list of names of users (separated by whitespace) that + are allowed to connect to the Nix daemon. As with the + <option>trusted-users</option> option, you can specify groups by + prefixing them with <literal>@</literal>. Also, you can allow + all users by specifying <literal>*</literal>. The default is + <literal>*</literal>.</para> + + <para>Note that trusted users are always allowed to connect.</para> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-auto-optimise-store"><term><literal>auto-optimise-store</literal></term> + + <listitem><para>If set to <literal>true</literal>, Nix + automatically detects files in the store that have identical + contents, and replaces them with hard links to a single copy. + This saves disk space. If set to <literal>false</literal> (the + default), you can still run <command>nix-store + --optimise</command> to get rid of duplicate + files.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-builders"> + <term><literal>builders</literal></term> + <listitem> + <para>A list of machines on which to perform builds. <phrase + condition="manual">See <xref linkend="chap-distributed-builds" + /> for details.</phrase></para> + </listitem> + </varlistentry> + + + <varlistentry xml:id="conf-builders-use-substitutes"><term><literal>builders-use-substitutes</literal></term> + + <listitem><para>If set to <literal>true</literal>, Nix will instruct + remote build machines to use their own binary substitutes if available. In + practical terms, this means that remote hosts will fetch as many build + dependencies as possible from their own substitutes (e.g, from + <literal>cache.nixos.org</literal>), instead of waiting for this host to + upload them all. This can drastically reduce build times if the network + connection between this computer and the remote build host is slow. Defaults + to <literal>false</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-build-users-group"><term><literal>build-users-group</literal></term> + + <listitem><para>This options specifies the Unix group containing + the Nix build user accounts. In multi-user Nix installations, + builds should not be performed by the Nix account since that would + allow users to arbitrarily modify the Nix store and database by + supplying specially crafted builders; and they cannot be performed + by the calling user since that would allow him/her to influence + the build result.</para> + + <para>Therefore, if this option is non-empty and specifies a valid + group, builds will be performed under the user accounts that are a + member of the group specified here (as listed in + <filename>/etc/group</filename>). Those user accounts should not + be used for any other purpose!</para> + + <para>Nix will never run two builds under the same user account at + the same time. This is to prevent an obvious security hole: a + malicious user writing a Nix expression that modifies the build + result of a legitimate Nix expression being built by another user. + Therefore it is good to have as many Nix build user accounts as + you can spare. (Remember: uids are cheap.)</para> + + <para>The build users should have permission to create files in + the Nix store, but not delete them. Therefore, + <filename>/nix/store</filename> should be owned by the Nix + account, its group should be the group specified here, and its + mode should be <literal>1775</literal>.</para> + + <para>If the build users group is empty, builds will be performed + under the uid of the Nix process (that is, the uid of the caller + if <envar>NIX_REMOTE</envar> is empty, the uid under which the Nix + daemon runs if <envar>NIX_REMOTE</envar> is + <literal>daemon</literal>). Obviously, this should not be used in + multi-user settings with untrusted users.</para> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-compress-build-log"><term><literal>compress-build-log</literal></term> + + <listitem><para>If set to <literal>true</literal> (the default), + build logs written to <filename>/nix/var/log/nix/drvs</filename> + will be compressed on the fly using bzip2. Otherwise, they will + not be compressed.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-connect-timeout"><term><literal>connect-timeout</literal></term> + + <listitem> + + <para>The timeout (in seconds) for establishing connections in + the binary cache substituter. It corresponds to + <command>curl</command>’s <option>--connect-timeout</option> + option.</para> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-cores"><term><literal>cores</literal></term> + + <listitem><para>Sets the value of the + <envar>NIX_BUILD_CORES</envar> environment variable in the + invocation of builders. Builders can use this variable at their + discretion to control the maximum amount of parallelism. For + instance, in Nixpkgs, if the derivation attribute + <varname>enableParallelBuilding</varname> is set to + <literal>true</literal>, the builder passes the + <option>-j<replaceable>N</replaceable></option> flag to GNU Make. + It can be overridden using the <option + linkend='opt-cores'>--cores</option> command line switch and + defaults to <literal>1</literal>. The value <literal>0</literal> + means that the builder should use all available CPU cores in the + system.</para> + + <para>See also <xref linkend="chap-tuning-cores-and-jobs" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-diff-hook"><term><literal>diff-hook</literal></term> + <listitem> + <para> + Absolute path to an executable capable of diffing build results. + The hook executes if <xref linkend="conf-run-diff-hook" /> is + true, and the output of a build is known to not be the same. + This program is not executed to determine if two results are the + same. + </para> + + <para> + The diff hook is executed by the same user and group who ran the + build. However, the diff hook does not have write access to the + store path just built. + </para> + + <para>The diff hook program receives three parameters:</para> + + <orderedlist> + <listitem> + <para> + A path to the previous build's results + </para> + </listitem> + + <listitem> + <para> + A path to the current build's results + </para> + </listitem> + + <listitem> + <para> + The path to the build's derivation + </para> + </listitem> + + <listitem> + <para> + The path to the build's scratch directory. This directory + will exist only if the build was run with + <option>--keep-failed</option>. + </para> + </listitem> + </orderedlist> + + <para> + The stderr and stdout output from the diff hook will not be + displayed to the user. Instead, it will print to the nix-daemon's + log. + </para> + + <para>When using the Nix daemon, <literal>diff-hook</literal> must + be set in the <filename>nix.conf</filename> configuration file, and + cannot be passed at the command line. + </para> + </listitem> + </varlistentry> + + <varlistentry xml:id="conf-enforce-determinism"> + <term><literal>enforce-determinism</literal></term> + + <listitem><para>See <xref linkend="conf-repeat" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-extra-sandbox-paths"> + <term><literal>extra-sandbox-paths</literal></term> + + <listitem><para>A list of additional paths appended to + <option>sandbox-paths</option>. Useful if you want to extend + its default value.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-extra-platforms"><term><literal>extra-platforms</literal></term> + + <listitem><para>Platforms other than the native one which + this machine is capable of building for. This can be useful for + supporting additional architectures on compatible machines: + i686-linux can be built on x86_64-linux machines (and the default + for this setting reflects this); armv7 is backwards-compatible with + armv6 and armv5tel; some aarch64 machines can also natively run + 32-bit ARM code; and qemu-user may be used to support non-native + platforms (though this may be slow and buggy). Most values for this + are not enabled by default because build systems will often + misdetect the target platform and generate incompatible code, so you + may wish to cross-check the results of using this option against + proper natively-built versions of your + derivations.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-extra-substituters"><term><literal>extra-substituters</literal></term> + + <listitem><para>Additional binary caches appended to those + specified in <option>substituters</option>. When used by + unprivileged users, untrusted substituters (i.e. those not listed + in <option>trusted-substituters</option>) are silently + ignored.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-fallback"><term><literal>fallback</literal></term> + + <listitem><para>If set to <literal>true</literal>, Nix will fall + back to building from source if a binary substitute fails. This + is equivalent to the <option>--fallback</option> flag. The + default is <literal>false</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-fsync-metadata"><term><literal>fsync-metadata</literal></term> + + <listitem><para>If set to <literal>true</literal>, changes to the + Nix store metadata (in <filename>/nix/var/nix/db</filename>) are + synchronously flushed to disk. This improves robustness in case + of system crashes, but reduces performance. The default is + <literal>true</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-hashed-mirrors"><term><literal>hashed-mirrors</literal></term> + + <listitem><para>A list of web servers used by + <function>builtins.fetchurl</function> to obtain files by + hash. The default is + <literal>http://tarballs.nixos.org/</literal>. Given a hash type + <replaceable>ht</replaceable> and a base-16 hash + <replaceable>h</replaceable>, Nix will try to download the file + from + <literal>hashed-mirror/<replaceable>ht</replaceable>/<replaceable>h</replaceable></literal>. + This allows files to be downloaded even if they have disappeared + from their original URI. For example, given the default mirror + <literal>http://tarballs.nixos.org/</literal>, when building the derivation + +<programlisting> +builtins.fetchurl { + url = https://example.org/foo-1.2.3.tar.xz; + sha256 = "2c26b46b68ffc68ff99b453c1d30413413422d706483bfa0f98a5e886266e7ae"; +} +</programlisting> + + Nix will attempt to download this file from + <literal>http://tarballs.nixos.org/sha256/2c26b46b68ffc68ff99b453c1d30413413422d706483bfa0f98a5e886266e7ae</literal> + first. If it is not available there, if will try the original URI.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-http-connections"><term><literal>http-connections</literal></term> + + <listitem><para>The maximum number of parallel TCP connections + used to fetch files from binary caches and by other downloads. It + defaults to 25. 0 means no limit.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-keep-build-log"><term><literal>keep-build-log</literal></term> + + <listitem><para>If set to <literal>true</literal> (the default), + Nix will write the build log of a derivation (i.e. the standard + output and error of its builder) to the directory + <filename>/nix/var/log/nix/drvs</filename>. The build log can be + retrieved using the command <command>nix-store -l + <replaceable>path</replaceable></command>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-keep-derivations"><term><literal>keep-derivations</literal></term> + + <listitem><para>If <literal>true</literal> (default), the garbage + collector will keep the derivations from which non-garbage store + paths were built. If <literal>false</literal>, they will be + deleted unless explicitly registered as a root (or reachable from + other roots).</para> + + <para>Keeping derivation around is useful for querying and + traceability (e.g., it allows you to ask with what dependencies or + options a store path was built), so by default this option is on. + Turn it off to save a bit of disk space (or a lot if + <literal>keep-outputs</literal> is also turned on).</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-keep-env-derivations"><term><literal>keep-env-derivations</literal></term> + + <listitem><para>If <literal>false</literal> (default), derivations + are not stored in Nix user environments. That is, the derivations of + any build-time-only dependencies may be garbage-collected.</para> + + <para>If <literal>true</literal>, when you add a Nix derivation to + a user environment, the path of the derivation is stored in the + user environment. Thus, the derivation will not be + garbage-collected until the user environment generation is deleted + (<command>nix-env --delete-generations</command>). To prevent + build-time-only dependencies from being collected, you should also + turn on <literal>keep-outputs</literal>.</para> + + <para>The difference between this option and + <literal>keep-derivations</literal> is that this one is + “sticky”: it applies to any user environment created while this + option was enabled, while <literal>keep-derivations</literal> + only applies at the moment the garbage collector is + run.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-keep-outputs"><term><literal>keep-outputs</literal></term> + + <listitem><para>If <literal>true</literal>, the garbage collector + will keep the outputs of non-garbage derivations. If + <literal>false</literal> (default), outputs will be deleted unless + they are GC roots themselves (or reachable from other roots).</para> + + <para>In general, outputs must be registered as roots separately. + However, even if the output of a derivation is registered as a + root, the collector will still delete store paths that are used + only at build time (e.g., the C compiler, or source tarballs + downloaded from the network). To prevent it from doing so, set + this option to <literal>true</literal>.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-max-build-log-size"><term><literal>max-build-log-size</literal></term> + + <listitem> + + <para>This option defines the maximum number of bytes that a + builder can write to its stdout/stderr. If the builder exceeds + this limit, it’s killed. A value of <literal>0</literal> (the + default) means that there is no limit.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-max-free"><term><literal>max-free</literal></term> + + <listitem><para>When a garbage collection is triggered by the + <literal>min-free</literal> option, it stops as soon as + <literal>max-free</literal> bytes are available. The default is + infinity (i.e. delete all garbage).</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-max-jobs"><term><literal>max-jobs</literal></term> + + <listitem><para>This option defines the maximum number of jobs + that Nix will try to build in parallel. The default is + <literal>1</literal>. The special value <literal>auto</literal> + causes Nix to use the number of CPUs in your system. <literal>0</literal> + is useful when using remote builders to prevent any local builds (except for + <literal>preferLocalBuild</literal> derivation attribute which executes locally + regardless). It can be + overridden using the <option + linkend='opt-max-jobs'>--max-jobs</option> (<option>-j</option>) + command line switch.</para> + + <para>See also <xref linkend="chap-tuning-cores-and-jobs" />.</para> + </listitem> + </varlistentry> + + <varlistentry xml:id="conf-max-silent-time"><term><literal>max-silent-time</literal></term> + + <listitem> + + <para>This option defines the maximum number of seconds that a + builder can go without producing any data on standard output or + standard error. This is useful (for instance in an automated + build system) to catch builds that are stuck in an infinite + loop, or to catch remote builds that are hanging due to network + problems. It can be overridden using the <option + linkend="opt-max-silent-time">--max-silent-time</option> command + line switch.</para> + + <para>The value <literal>0</literal> means that there is no + timeout. This is also the default.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-min-free"><term><literal>min-free</literal></term> + + <listitem> + <para>When free disk space in <filename>/nix/store</filename> + drops below <literal>min-free</literal> during a build, Nix + performs a garbage-collection until <literal>max-free</literal> + bytes are available or there is no more garbage. A value of + <literal>0</literal> (the default) disables this feature.</para> + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-narinfo-cache-negative-ttl"><term><literal>narinfo-cache-negative-ttl</literal></term> + + <listitem> + + <para>The TTL in seconds for negative lookups. If a store path is + queried from a substituter but was not found, there will be a + negative lookup cached in the local disk cache database for the + specified duration.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-narinfo-cache-positive-ttl"><term><literal>narinfo-cache-positive-ttl</literal></term> + + <listitem> + + <para>The TTL in seconds for positive lookups. If a store path is + queried from a substituter, the result of the query will be cached + in the local disk cache database including some of the NAR + metadata. The default TTL is a month, setting a shorter TTL for + positive lookups can be useful for binary caches that have + frequent garbage collection, in which case having a more frequent + cache invalidation would prevent trying to pull the path again and + failing with a hash mismatch if the build isn't reproducible. + </para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-netrc-file"><term><literal>netrc-file</literal></term> + + <listitem><para>If set to an absolute path to a <filename>netrc</filename> + file, Nix will use the HTTP authentication credentials in this file when + trying to download from a remote host through HTTP or HTTPS. Defaults to + <filename>$NIX_CONF_DIR/netrc</filename>.</para> + + <para>The <filename>netrc</filename> file consists of a list of + accounts in the following format: + +<screen> +machine <replaceable>my-machine</replaceable> +login <replaceable>my-username</replaceable> +password <replaceable>my-password</replaceable> +</screen> + + For the exact syntax, see <link + xlink:href="https://ec.haxx.se/usingcurl-netrc.html">the + <literal>curl</literal> documentation.</link></para> + + <note><para>This must be an absolute path, and <literal>~</literal> + is not resolved. For example, <filename>~/.netrc</filename> won't + resolve to your home directory's <filename>.netrc</filename>.</para></note> + </listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-plugin-files"> + <term><literal>plugin-files</literal></term> + <listitem> + <para> + A list of plugin files to be loaded by Nix. Each of these + files will be dlopened by Nix, allowing them to affect + execution through static initialization. In particular, these + plugins may construct static instances of RegisterPrimOp to + add new primops or constants to the expression language, + RegisterStoreImplementation to add new store implementations, + RegisterCommand to add new subcommands to the + <literal>nix</literal> command, and RegisterSetting to add new + nix config settings. See the constructors for those types for + more details. + </para> + <para> + Since these files are loaded into the same address space as + Nix itself, they must be DSOs compatible with the instance of + Nix running at the time (i.e. compiled against the same + headers, not linked to any incompatible libraries). They + should not be linked to any Nix libs directly, as those will + be available already at load time. + </para> + <para> + If an entry in the list is a directory, all files in the + directory are loaded as plugins (non-recursively). + </para> + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-pre-build-hook"><term><literal>pre-build-hook</literal></term> + + <listitem> + + + <para>If set, the path to a program that can set extra + derivation-specific settings for this system. This is used for settings + that can't be captured by the derivation model itself and are too variable + between different versions of the same system to be hard-coded into nix. + </para> + + <para>The hook is passed the derivation path and, if sandboxes are enabled, + the sandbox directory. It can then modify the sandbox and send a series of + commands to modify various settings to stdout. The currently recognized + commands are:</para> + + <variablelist> + <varlistentry xml:id="extra-sandbox-paths"> + <term><literal>extra-sandbox-paths</literal></term> + + <listitem> + + <para>Pass a list of files and directories to be included in the + sandbox for this build. One entry per line, terminated by an empty + line. Entries have the same format as + <literal>sandbox-paths</literal>.</para> + + </listitem> + + </varlistentry> + </variablelist> + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-post-build-hook"> + <term><literal>post-build-hook</literal></term> + <listitem> + <para>Optional. The path to a program to execute after each build.</para> + + <para>This option is only settable in the global + <filename>nix.conf</filename>, or on the command line by trusted + users.</para> + + <para>When using the nix-daemon, the daemon executes the hook as + <literal>root</literal>. If the nix-daemon is not involved, the + hook runs as the user executing the nix-build.</para> + + <itemizedlist> + <listitem><para>The hook executes after an evaluation-time build.</para></listitem> + <listitem><para>The hook does not execute on substituted paths.</para></listitem> + <listitem><para>The hook's output always goes to the user's terminal.</para></listitem> + <listitem><para>If the hook fails, the build succeeds but no further builds execute.</para></listitem> + <listitem><para>The hook executes synchronously, and blocks other builds from progressing while it runs.</para></listitem> + </itemizedlist> + + <para>The program executes with no arguments. The program's environment + contains the following environment variables:</para> + + <variablelist> + <varlistentry> + <term><envar>DRV_PATH</envar></term> + <listitem> + <para>The derivation for the built paths.</para> + <para>Example: + <literal>/nix/store/5nihn1a7pa8b25l9zafqaqibznlvvp3f-bash-4.4-p23.drv</literal> + </para> + </listitem> + </varlistentry> + + <varlistentry> + <term><envar>OUT_PATHS</envar></term> + <listitem> + <para>Output paths of the built derivation, separated by a space character.</para> + <para>Example: + <literal>/nix/store/zf5lbh336mnzf1nlswdn11g4n2m8zh3g-bash-4.4-p23-dev + /nix/store/rjxwxwv1fpn9wa2x5ssk5phzwlcv4mna-bash-4.4-p23-doc + /nix/store/6bqvbzjkcp9695dq0dpl5y43nvy37pq1-bash-4.4-p23-info + /nix/store/r7fng3kk3vlpdlh2idnrbn37vh4imlj2-bash-4.4-p23-man + /nix/store/xfghy8ixrhz3kyy6p724iv3cxji088dx-bash-4.4-p23</literal>. + </para> + </listitem> + </varlistentry> + </variablelist> + + <para>See <xref linkend="chap-post-build-hook" /> for an example + implementation.</para> + + </listitem> + </varlistentry> + + <varlistentry xml:id="conf-repeat"><term><literal>repeat</literal></term> + + <listitem><para>How many times to repeat builds to check whether + they are deterministic. The default value is 0. If the value is + non-zero, every build is repeated the specified number of + times. If the contents of any of the runs differs from the + previous ones and <xref linkend="conf-enforce-determinism" /> is + true, the build is rejected and the resulting store paths are not + registered as “valid” in Nix’s database.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-require-sigs"><term><literal>require-sigs</literal></term> + + <listitem><para>If set to <literal>true</literal> (the default), + any non-content-addressed path added or copied to the Nix store + (e.g. when substituting from a binary cache) must have a valid + signature, that is, be signed using one of the keys listed in + <option>trusted-public-keys</option> or + <option>secret-key-files</option>. Set to <literal>false</literal> + to disable signature checking.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-restrict-eval"><term><literal>restrict-eval</literal></term> + + <listitem> + + <para>If set to <literal>true</literal>, the Nix evaluator will + not allow access to any files outside of the Nix search path (as + set via the <envar>NIX_PATH</envar> environment variable or the + <option>-I</option> option), or to URIs outside of + <option>allowed-uri</option>. The default is + <literal>false</literal>.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-run-diff-hook"><term><literal>run-diff-hook</literal></term> + <listitem> + <para> + If true, enable the execution of <xref linkend="conf-diff-hook" />. + </para> + + <para> + When using the Nix daemon, <literal>run-diff-hook</literal> must + be set in the <filename>nix.conf</filename> configuration file, + and cannot be passed at the command line. + </para> + </listitem> + </varlistentry> + + <varlistentry xml:id="conf-sandbox"><term><literal>sandbox</literal></term> + + <listitem><para>If set to <literal>true</literal>, builds will be + performed in a <emphasis>sandboxed environment</emphasis>, i.e., + they’re isolated from the normal file system hierarchy and will + only see their dependencies in the Nix store, the temporary build + directory, private versions of <filename>/proc</filename>, + <filename>/dev</filename>, <filename>/dev/shm</filename> and + <filename>/dev/pts</filename> (on Linux), and the paths configured with the + <link linkend='conf-sandbox-paths'><literal>sandbox-paths</literal> + option</link>. This is useful to prevent undeclared dependencies + on files in directories such as <filename>/usr/bin</filename>. In + addition, on Linux, builds run in private PID, mount, network, IPC + and UTS namespaces to isolate them from other processes in the + system (except that fixed-output derivations do not run in private + network namespace to ensure they can access the network).</para> + + <para>Currently, sandboxing only work on Linux and macOS. The use + of a sandbox requires that Nix is run as root (so you should use + the <link linkend='conf-build-users-group'>“build users” + feature</link> to perform the actual builds under different users + than root).</para> + + <para>If this option is set to <literal>relaxed</literal>, then + fixed-output derivations and derivations that have the + <varname>__noChroot</varname> attribute set to + <literal>true</literal> do not run in sandboxes.</para> + + <para>The default is <literal>true</literal> on Linux and + <literal>false</literal> on all other platforms.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-sandbox-dev-shm-size"><term><literal>sandbox-dev-shm-size</literal></term> + + <listitem><para>This option determines the maximum size of the + <literal>tmpfs</literal> filesystem mounted on + <filename>/dev/shm</filename> in Linux sandboxes. For the format, + see the description of the <option>size</option> option of + <literal>tmpfs</literal> in + <citerefentry><refentrytitle>mount</refentrytitle><manvolnum>8</manvolnum></citerefentry>. The + default is <literal>50%</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-sandbox-paths"> + <term><literal>sandbox-paths</literal></term> + + <listitem><para>A list of paths bind-mounted into Nix sandbox + environments. You can use the syntax + <literal><replaceable>target</replaceable>=<replaceable>source</replaceable></literal> + to mount a path in a different location in the sandbox; for + instance, <literal>/bin=/nix-bin</literal> will mount the path + <literal>/nix-bin</literal> as <literal>/bin</literal> inside the + sandbox. If <replaceable>source</replaceable> is followed by + <literal>?</literal>, then it is not an error if + <replaceable>source</replaceable> does not exist; for example, + <literal>/dev/nvidiactl?</literal> specifies that + <filename>/dev/nvidiactl</filename> will only be mounted in the + sandbox if it exists in the host filesystem.</para> + + <para>Depending on how Nix was built, the default value for this option + may be empty or provide <filename>/bin/sh</filename> as a + bind-mount of <command>bash</command>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-secret-key-files"><term><literal>secret-key-files</literal></term> + + <listitem><para>A whitespace-separated list of files containing + secret (private) keys. These are used to sign locally-built + paths. They can be generated using <command>nix-store + --generate-binary-cache-key</command>. The corresponding public + key can be distributed to other users, who can add it to + <option>trusted-public-keys</option> in their + <filename>nix.conf</filename>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-show-trace"><term><literal>show-trace</literal></term> + + <listitem><para>Causes Nix to print out a stack trace in case of Nix + expression evaluation errors.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-substitute"><term><literal>substitute</literal></term> + + <listitem><para>If set to <literal>true</literal> (default), Nix + will use binary substitutes if available. This option can be + disabled to force building from source.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-stalled-download-timeout"><term><literal>stalled-download-timeout</literal></term> + <listitem> + <para>The timeout (in seconds) for receiving data from servers + during download. Nix cancels idle downloads after this timeout's + duration.</para> + </listitem> + </varlistentry> + + <varlistentry xml:id="conf-substituters"><term><literal>substituters</literal></term> + + <listitem><para>A list of URLs of substituters, separated by + whitespace. The default is + <literal>https://cache.nixos.org</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-system"><term><literal>system</literal></term> + + <listitem><para>This option specifies the canonical Nix system + name of the current installation, such as + <literal>i686-linux</literal> or + <literal>x86_64-darwin</literal>. Nix can only build derivations + whose <literal>system</literal> attribute equals the value + specified here. In general, it never makes sense to modify this + value from its default, since you can use it to ‘lie’ about the + platform you are building on (e.g., perform a Mac OS build on a + Linux machine; the result would obviously be wrong). It only + makes sense if the Nix binaries can run on multiple platforms, + e.g., ‘universal binaries’ that run on <literal>x86_64-linux</literal> and + <literal>i686-linux</literal>.</para> + + <para>It defaults to the canonical Nix system name detected by + <filename>configure</filename> at build time.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id="conf-system-features"><term><literal>system-features</literal></term> + + <listitem><para>A set of system “features” supported by this + machine, e.g. <literal>kvm</literal>. Derivations can express a + dependency on such features through the derivation attribute + <varname>requiredSystemFeatures</varname>. For example, the + attribute + +<programlisting> +requiredSystemFeatures = [ "kvm" ]; +</programlisting> + + ensures that the derivation can only be built on a machine with + the <literal>kvm</literal> feature.</para> + + <para>This setting by default includes <literal>kvm</literal> if + <filename>/dev/kvm</filename> is accessible, and the + pseudo-features <literal>nixos-test</literal>, + <literal>benchmark</literal> and <literal>big-parallel</literal> + that are used in Nixpkgs to route builds to specific + machines.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-tarball-ttl"><term><literal>tarball-ttl</literal></term> + + <listitem> + <para>Default: <literal>3600</literal> seconds.</para> + + <para>The number of seconds a downloaded tarball is considered + fresh. If the cached tarball is stale, Nix will check whether + it is still up to date using the ETag header. Nix will download + a new version if the ETag header is unsupported, or the + cached ETag doesn't match. + </para> + + <para>Setting the TTL to <literal>0</literal> forces Nix to always + check if the tarball is up to date.</para> + + <para>Nix caches tarballs in + <filename>$XDG_CACHE_HOME/nix/tarballs</filename>.</para> + + <para>Files fetched via <envar>NIX_PATH</envar>, + <function>fetchGit</function>, <function>fetchMercurial</function>, + <function>fetchTarball</function>, and <function>fetchurl</function> + respect this TTL. + </para> + </listitem> + </varlistentry> + + <varlistentry xml:id="conf-timeout"><term><literal>timeout</literal></term> + + <listitem> + + <para>This option defines the maximum number of seconds that a + builder can run. This is useful (for instance in an automated + build system) to catch builds that are stuck in an infinite loop + but keep writing to their standard output or standard error. It + can be overridden using the <option + linkend="opt-timeout">--timeout</option> command line + switch.</para> + + <para>The value <literal>0</literal> means that there is no + timeout. This is also the default.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-trace-function-calls"><term><literal>trace-function-calls</literal></term> + + <listitem> + + <para>Default: <literal>false</literal>.</para> + + <para>If set to <literal>true</literal>, the Nix evaluator will + trace every function call. Nix will print a log message at the + "vomit" level for every function entrance and function exit.</para> + + <informalexample><screen> +function-trace entered undefined position at 1565795816999559622 +function-trace exited undefined position at 1565795816999581277 +function-trace entered /nix/store/.../example.nix:226:41 at 1565795253249935150 +function-trace exited /nix/store/.../example.nix:226:41 at 1565795253249941684 +</screen></informalexample> + + <para>The <literal>undefined position</literal> means the function + call is a builtin.</para> + + <para>Use the <literal>contrib/stack-collapse.py</literal> script + distributed with the Nix source code to convert the trace logs + in to a format suitable for <command>flamegraph.pl</command>.</para> + + </listitem> + + </varlistentry> + + <varlistentry xml:id="conf-trusted-public-keys"><term><literal>trusted-public-keys</literal></term> + + <listitem><para>A whitespace-separated list of public keys. When + paths are copied from another Nix store (such as a binary cache), + they must be signed with one of these keys. For example: + <literal>cache.nixos.org-1:6NCHdD59X431o0gWypbMrAURkbJ16ZPMQFGspcDShjY= + hydra.nixos.org-1:CNHJZBh9K4tP3EKF6FkkgeVYsS3ohTl+oS0Qa8bezVs=</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-trusted-substituters"><term><literal>trusted-substituters</literal></term> + + <listitem><para>A list of URLs of substituters, separated by + whitespace. These are not used by default, but can be enabled by + users of the Nix daemon by specifying <literal>--option + substituters <replaceable>urls</replaceable></literal> on the + command line. Unprivileged users are only allowed to pass a + subset of the URLs listed in <literal>substituters</literal> and + <literal>trusted-substituters</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id="conf-trusted-users"><term><literal>trusted-users</literal></term> + + <listitem> + + <para>A list of names of users (separated by whitespace) that + have additional rights when connecting to the Nix daemon, such + as the ability to specify additional binary caches, or to import + unsigned NARs. You can also specify groups by prefixing them + with <literal>@</literal>; for instance, + <literal>@wheel</literal> means all users in the + <literal>wheel</literal> group. The default is + <literal>root</literal>.</para> + + <warning><para>Adding a user to <option>trusted-users</option> + is essentially equivalent to giving that user root access to the + system. For example, the user can set + <option>sandbox-paths</option> and thereby obtain read access to + directories that are otherwise inacessible to + them.</para></warning> + + </listitem> + + </varlistentry> + +</variablelist> +</para> + +<refsection> + <title>Deprecated Settings</title> + +<para> + +<variablelist> + + <varlistentry xml:id="conf-binary-caches"> + <term><literal>binary-caches</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>binary-caches</literal> is now an alias to + <xref linkend="conf-substituters" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-binary-cache-public-keys"> + <term><literal>binary-cache-public-keys</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>binary-cache-public-keys</literal> is now an alias to + <xref linkend="conf-trusted-public-keys" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-compress-log"> + <term><literal>build-compress-log</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-compress-log</literal> is now an alias to + <xref linkend="conf-compress-build-log" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-cores"> + <term><literal>build-cores</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-cores</literal> is now an alias to + <xref linkend="conf-cores" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-extra-chroot-dirs"> + <term><literal>build-extra-chroot-dirs</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-extra-chroot-dirs</literal> is now an alias to + <xref linkend="conf-extra-sandbox-paths" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-extra-sandbox-paths"> + <term><literal>build-extra-sandbox-paths</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-extra-sandbox-paths</literal> is now an alias to + <xref linkend="conf-extra-sandbox-paths" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-fallback"> + <term><literal>build-fallback</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-fallback</literal> is now an alias to + <xref linkend="conf-fallback" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-max-jobs"> + <term><literal>build-max-jobs</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-max-jobs</literal> is now an alias to + <xref linkend="conf-max-jobs" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-max-log-size"> + <term><literal>build-max-log-size</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-max-log-size</literal> is now an alias to + <xref linkend="conf-max-build-log-size" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-max-silent-time"> + <term><literal>build-max-silent-time</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-max-silent-time</literal> is now an alias to + <xref linkend="conf-max-silent-time" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-repeat"> + <term><literal>build-repeat</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-repeat</literal> is now an alias to + <xref linkend="conf-repeat" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-timeout"> + <term><literal>build-timeout</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-timeout</literal> is now an alias to + <xref linkend="conf-timeout" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-use-chroot"> + <term><literal>build-use-chroot</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-use-chroot</literal> is now an alias to + <xref linkend="conf-sandbox" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-use-sandbox"> + <term><literal>build-use-sandbox</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-use-sandbox</literal> is now an alias to + <xref linkend="conf-sandbox" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-build-use-substitutes"> + <term><literal>build-use-substitutes</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>build-use-substitutes</literal> is now an alias to + <xref linkend="conf-substitute" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-gc-keep-derivations"> + <term><literal>gc-keep-derivations</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>gc-keep-derivations</literal> is now an alias to + <xref linkend="conf-keep-derivations" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-gc-keep-outputs"> + <term><literal>gc-keep-outputs</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>gc-keep-outputs</literal> is now an alias to + <xref linkend="conf-keep-outputs" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-env-keep-derivations"> + <term><literal>env-keep-derivations</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>env-keep-derivations</literal> is now an alias to + <xref linkend="conf-keep-env-derivations" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-extra-binary-caches"> + <term><literal>extra-binary-caches</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>extra-binary-caches</literal> is now an alias to + <xref linkend="conf-extra-substituters" />.</para></listitem> + </varlistentry> + + <varlistentry xml:id="conf-trusted-binary-caches"> + <term><literal>trusted-binary-caches</literal></term> + + <listitem><para><emphasis>Deprecated:</emphasis> + <literal>trusted-binary-caches</literal> is now an alias to + <xref linkend="conf-trusted-substituters" />.</para></listitem> + </varlistentry> +</variablelist> +</para> +</refsection> + +</refsection> + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/env-common.xml b/third_party/nix/doc/manual/command-ref/env-common.xml new file mode 100644 index 0000000000..696d68c345 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/env-common.xml @@ -0,0 +1,202 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-common-env"> + +<title>Common Environment Variables</title> + + +<para>Most Nix commands interpret the following environment variables:</para> + +<variablelist xml:id="env-common"> + +<varlistentry><term><envar>IN_NIX_SHELL</envar></term> + + <listitem><para>Indicator that tells if the current environment was set up by + <command>nix-shell</command>. Since Nix 2.0 the values are + <literal>"pure"</literal> and <literal>"impure"</literal></para></listitem> + +</varlistentry> + +<varlistentry xml:id="env-NIX_PATH"><term><envar>NIX_PATH</envar></term> + + <listitem> + + <para>A colon-separated list of directories used to look up Nix + expressions enclosed in angle brackets (i.e., + <literal><<replaceable>path</replaceable>></literal>). For + instance, the value + + <screen> +/home/eelco/Dev:/etc/nixos</screen> + + will cause Nix to look for paths relative to + <filename>/home/eelco/Dev</filename> and + <filename>/etc/nixos</filename>, in that order. It is also + possible to match paths against a prefix. For example, the value + + <screen> +nixpkgs=/home/eelco/Dev/nixpkgs-branch:/etc/nixos</screen> + + will cause Nix to search for + <literal><nixpkgs/<replaceable>path</replaceable>></literal> in + <filename>/home/eelco/Dev/nixpkgs-branch/<replaceable>path</replaceable></filename> + and + <filename>/etc/nixos/nixpkgs/<replaceable>path</replaceable></filename>.</para> + + <para>If a path in the Nix search path starts with + <literal>http://</literal> or <literal>https://</literal>, it is + interpreted as the URL of a tarball that will be downloaded and + unpacked to a temporary location. The tarball must consist of a + single top-level directory. For example, setting + <envar>NIX_PATH</envar> to + + <screen> +nixpkgs=https://github.com/NixOS/nixpkgs-channels/archive/nixos-15.09.tar.gz</screen> + + tells Nix to download the latest revision in the Nixpkgs/NixOS + 15.09 channel.</para> + + <para>A following shorthand can be used to refer to the official channels: + + <screen>nixpkgs=channel:nixos-15.09</screen> + </para> + + <para>The search path can be extended using the <option + linkend="opt-I">-I</option> option, which takes precedence over + <envar>NIX_PATH</envar>.</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_IGNORE_SYMLINK_STORE</envar></term> + + <listitem> + + <para>Normally, the Nix store directory (typically + <filename>/nix/store</filename>) is not allowed to contain any + symlink components. This is to prevent “impure” builds. Builders + sometimes “canonicalise” paths by resolving all symlink components. + Thus, builds on different machines (with + <filename>/nix/store</filename> resolving to different locations) + could yield different results. This is generally not a problem, + except when builds are deployed to machines where + <filename>/nix/store</filename> resolves differently. If you are + sure that you’re not going to do that, you can set + <envar>NIX_IGNORE_SYMLINK_STORE</envar> to <envar>1</envar>.</para> + + <para>Note that if you’re symlinking the Nix store so that you can + put it on another file system than the root file system, on Linux + you’re better off using <literal>bind</literal> mount points, e.g., + + <screen> +$ mkdir /nix +$ mount -o bind /mnt/otherdisk/nix /nix</screen> + + Consult the <citerefentry><refentrytitle>mount</refentrytitle> + <manvolnum>8</manvolnum></citerefentry> manual page for details.</para> + + </listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_STORE_DIR</envar></term> + + <listitem><para>Overrides the location of the Nix store (default + <filename><replaceable>prefix</replaceable>/store</filename>).</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_DATA_DIR</envar></term> + + <listitem><para>Overrides the location of the Nix static data + directory (default + <filename><replaceable>prefix</replaceable>/share</filename>).</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_LOG_DIR</envar></term> + + <listitem><para>Overrides the location of the Nix log directory + (default <filename><replaceable>prefix</replaceable>/var/log/nix</filename>).</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_STATE_DIR</envar></term> + + <listitem><para>Overrides the location of the Nix state directory + (default <filename><replaceable>prefix</replaceable>/var/nix</filename>).</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_CONF_DIR</envar></term> + + <listitem><para>Overrides the location of the Nix configuration + directory (default + <filename><replaceable>prefix</replaceable>/etc/nix</filename>).</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>TMPDIR</envar></term> + + <listitem><para>Use the specified directory to store temporary + files. In particular, this includes temporary build directories; + these can take up substantial amounts of disk space. The default is + <filename>/tmp</filename>.</para></listitem> + +</varlistentry> + + +<varlistentry xml:id="envar-remote"><term><envar>NIX_REMOTE</envar></term> + + <listitem><para>This variable should be set to + <literal>daemon</literal> if you want to use the Nix daemon to + execute Nix operations. This is necessary in <link + linkend="ssec-multi-user">multi-user Nix installations</link>. + If the Nix daemon's Unix socket is at some non-standard path, + this variable should be set to <literal>unix://path/to/socket</literal>. + Otherwise, it should be left unset.</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_SHOW_STATS</envar></term> + + <listitem><para>If set to <literal>1</literal>, Nix will print some + evaluation statistics, such as the number of values + allocated.</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>NIX_COUNT_CALLS</envar></term> + + <listitem><para>If set to <literal>1</literal>, Nix will print how + often functions were called during Nix expression evaluation. This + is useful for profiling your Nix expressions.</para></listitem> + +</varlistentry> + + +<varlistentry><term><envar>GC_INITIAL_HEAP_SIZE</envar></term> + + <listitem><para>If Nix has been configured to use the Boehm garbage + collector, this variable sets the initial size of the heap in bytes. + It defaults to 384 MiB. Setting it to a low value reduces memory + consumption, but will increase runtime due to the overhead of + garbage collection.</para></listitem> + +</varlistentry> + + +</variablelist> + + +</chapter> diff --git a/third_party/nix/doc/manual/command-ref/files.xml b/third_party/nix/doc/manual/command-ref/files.xml new file mode 100644 index 0000000000..7bbc96e899 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/files.xml @@ -0,0 +1,14 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='ch-files'> + +<title>Files</title> + +<para>This section lists configuration files that you can use when you +work with Nix.</para> + +<xi:include href="conf-file.xml" /> + +</chapter> \ No newline at end of file diff --git a/third_party/nix/doc/manual/command-ref/main-commands.xml b/third_party/nix/doc/manual/command-ref/main-commands.xml new file mode 100644 index 0000000000..0f4169243c --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/main-commands.xml @@ -0,0 +1,17 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='ch-main-commands'> + +<title>Main Commands</title> + +<para>This section lists commands and options that you can use when you +work with Nix.</para> + +<xi:include href="nix-env.xml" /> +<xi:include href="nix-build.xml" /> +<xi:include href="nix-shell.xml" /> +<xi:include href="nix-store.xml" /> + +</chapter> \ No newline at end of file diff --git a/third_party/nix/doc/manual/command-ref/nix-build.xml b/third_party/nix/doc/manual/command-ref/nix-build.xml new file mode 100644 index 0000000000..c1b783c87d --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-build.xml @@ -0,0 +1,190 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-build"> + +<refmeta> + <refentrytitle>nix-build</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-build</refname> + <refpurpose>build a Nix expression</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-build</command> + <xi:include xmlns:xi="http://www.w3.org/2001/XInclude" href="opt-common-syn.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(/db:nop/*)" /> + <arg><option>--arg</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg><option>--argstr</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--attr</option></arg> + <arg choice='plain'><option>-A</option></arg> + </group> + <replaceable>attrPath</replaceable> + </arg> + <arg><option>--no-out-link</option></arg> + <arg><option>--dry-run</option></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--out-link</option></arg> + <arg choice='plain'><option>-o</option></arg> + </group> + <replaceable>outlink</replaceable> + </arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + +<refsection><title>Description</title> + +<para>The <command>nix-build</command> command builds the derivations +described by the Nix expressions in <replaceable>paths</replaceable>. +If the build succeeds, it places a symlink to the result in the +current directory. The symlink is called <filename>result</filename>. +If there are multiple Nix expressions, or the Nix expressions evaluate +to multiple derivations, multiple sequentially numbered symlinks are +created (<filename>result</filename>, <filename>result-2</filename>, +and so on).</para> + +<para>If no <replaceable>paths</replaceable> are specified, then +<command>nix-build</command> will use <filename>default.nix</filename> +in the current directory, if it exists.</para> + +<para>If an element of <replaceable>paths</replaceable> starts with +<literal>http://</literal> or <literal>https://</literal>, it is +interpreted as the URL of a tarball that will be downloaded and +unpacked to a temporary location. The tarball must include a single +top-level directory containing at least a file named +<filename>default.nix</filename>.</para> + +<para><command>nix-build</command> is essentially a wrapper around +<link +linkend="sec-nix-instantiate"><command>nix-instantiate</command></link> +(to translate a high-level Nix expression to a low-level store +derivation) and <link +linkend="rsec-nix-store-realise"><command>nix-store +--realise</command></link> (to build the store derivation).</para> + +<warning><para>The result of the build is automatically registered as +a root of the Nix garbage collector. This root disappears +automatically when the <filename>result</filename> symlink is deleted +or renamed. So don’t rename the symlink.</para></warning> + +</refsection> + + +<refsection><title>Options</title> + +<para>All options not listed here are passed to <command>nix-store +--realise</command>, except for <option>--arg</option> and +<option>--attr</option> / <option>-A</option> which are passed to +<command>nix-instantiate</command>. <phrase condition="manual">See +also <xref linkend="sec-common-options" />.</phrase></para> + +<variablelist> + + <varlistentry><term><option>--no-out-link</option></term> + + <listitem><para>Do not create a symlink to the output path. Note + that as a result the output does not become a root of the garbage + collector, and so might be deleted by <command>nix-store + --gc</command>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--dry-run</option></term> + <listitem><para>Show what store paths would be built or downloaded</para></listitem> + </varlistentry> + + <varlistentry xml:id='opt-out-link'><term><option>--out-link</option> / + <option>-o</option> <replaceable>outlink</replaceable></term> + + <listitem><para>Change the name of the symlink to the output path + created from <filename>result</filename> to + <replaceable>outlink</replaceable>.</para></listitem> + + </varlistentry> + +</variablelist> + +<para>The following common options are supported:</para> + +<variablelist condition="manpage"> + <xi:include href="opt-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='opt-common']/*)" /> +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<screen> +$ nix-build '<nixpkgs>' -A firefox +store derivation is /nix/store/qybprl8sz2lc...-firefox-1.5.0.7.drv +/nix/store/d18hyl92g30l...-firefox-1.5.0.7 + +$ ls -l result +lrwxrwxrwx <replaceable>...</replaceable> result -> /nix/store/d18hyl92g30l...-firefox-1.5.0.7 + +$ ls ./result/bin/ +firefox firefox-config</screen> + +<para>If a derivation has multiple outputs, +<command>nix-build</command> will build the default (first) output. +You can also build all outputs: +<screen> +$ nix-build '<nixpkgs>' -A openssl.all +</screen> +This will create a symlink for each output named +<filename>result-<replaceable>outputname</replaceable></filename>. +The suffix is omitted if the output name is <literal>out</literal>. +So if <literal>openssl</literal> has outputs <literal>out</literal>, +<literal>bin</literal> and <literal>man</literal>, +<command>nix-build</command> will create symlinks +<literal>result</literal>, <literal>result-bin</literal> and +<literal>result-man</literal>. It’s also possible to build a specific +output: +<screen> +$ nix-build '<nixpkgs>' -A openssl.man +</screen> +This will create a symlink <literal>result-man</literal>.</para> + +<para>Build a Nix expression given on the command line: + +<screen> +$ nix-build -E 'with import <nixpkgs> { }; runCommand "foo" { } "echo bar > $out"' +$ cat ./result +bar +</screen> + +</para> + +<para>Build the GNU Hello package from the latest revision of the +master branch of Nixpkgs: + +<screen> +$ nix-build https://github.com/NixOS/nixpkgs/archive/master.tar.gz -A hello +</screen> + +</para> + +</refsection> + + +<refsection condition="manpage"><title>Environment variables</title> + +<variablelist> + <xi:include href="env-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='env-common']/*)" /> +</variablelist> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-channel.xml b/third_party/nix/doc/manual/command-ref/nix-channel.xml new file mode 100644 index 0000000000..5a2866e6bc --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-channel.xml @@ -0,0 +1,178 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-channel"> + +<refmeta> + <refentrytitle>nix-channel</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-channel</refname> + <refpurpose>manage Nix channels</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-channel</command> + <group choice='req'> + <arg choice='plain'><option>--add</option> <replaceable>url</replaceable> <arg choice='opt'><replaceable>name</replaceable></arg></arg> + <arg choice='plain'><option>--remove</option> <replaceable>name</replaceable></arg> + <arg choice='plain'><option>--list</option></arg> + <arg choice='plain'><option>--update</option> <arg rep='repeat'><replaceable>names</replaceable></arg></arg> + <arg choice='plain'><option>--rollback</option> <arg choice='opt'><replaceable>generation</replaceable></arg></arg> + </group> + </cmdsynopsis> +</refsynopsisdiv> + +<refsection><title>Description</title> + +<para>A Nix channel is a mechanism that allows you to automatically +stay up-to-date with a set of pre-built Nix expressions. A Nix +channel is just a URL that points to a place containing a set of Nix +expressions. <phrase condition="manual">See also <xref +linkend="sec-channels" />.</phrase></para> + +<para>This command has the following operations: + +<variablelist> + + <varlistentry><term><option>--add</option> <replaceable>url</replaceable> [<replaceable>name</replaceable>]</term> + + <listitem><para>Adds a channel named + <replaceable>name</replaceable> with URL + <replaceable>url</replaceable> to the list of subscribed channels. + If <replaceable>name</replaceable> is omitted, it defaults to the + last component of <replaceable>url</replaceable>, with the + suffixes <literal>-stable</literal> or + <literal>-unstable</literal> removed.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--remove</option> <replaceable>name</replaceable></term> + + <listitem><para>Removes the channel named + <replaceable>name</replaceable> from the list of subscribed + channels.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--list</option></term> + + <listitem><para>Prints the names and URLs of all subscribed + channels on standard output.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--update</option> [<replaceable>names</replaceable>…]</term> + + <listitem><para>Downloads the Nix expressions of all subscribed + channels (or only those included in + <replaceable>names</replaceable> if specified) and makes them the + default for <command>nix-env</command> operations (by symlinking + them from the directory + <filename>~/.nix-defexpr</filename>).</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--rollback</option> [<replaceable>generation</replaceable>]</term> + + <listitem><para>Reverts the previous call to <command>nix-channel + --update</command>. Optionally, you can specify a specific channel + generation number to restore.</para></listitem> + + </varlistentry> + +</variablelist> + +</para> + +<para>Note that <option>--add</option> does not automatically perform +an update.</para> + +<para>The list of subscribed channels is stored in +<filename>~/.nix-channels</filename>.</para> + +</refsection> + +<refsection><title>Examples</title> + +<para>To subscribe to the Nixpkgs channel and install the GNU Hello package:</para> + +<screen> +$ nix-channel --add https://nixos.org/channels/nixpkgs-unstable +$ nix-channel --update +$ nix-env -iA nixpkgs.hello</screen> + +<para>You can revert channel updates using <option>--rollback</option>:</para> + +<screen> +$ nix-instantiate --eval -E '(import <nixpkgs> {}).lib.nixpkgsVersion' +"14.04.527.0e935f1" + +$ nix-channel --rollback +switching from generation 483 to 482 + +$ nix-instantiate --eval -E '(import <nixpkgs> {}).lib.nixpkgsVersion' +"14.04.526.dbadfad" +</screen> + +</refsection> + +<refsection><title>Files</title> + +<variablelist> + + <varlistentry><term><filename>/nix/var/nix/profiles/per-user/<replaceable>username</replaceable>/channels</filename></term> + + <listitem><para><command>nix-channel</command> uses a + <command>nix-env</command> profile to keep track of previous + versions of the subscribed channels. Every time you run + <command>nix-channel --update</command>, a new channel generation + (that is, a symlink to the channel Nix expressions in the Nix store) + is created. This enables <command>nix-channel --rollback</command> + to revert to previous versions.</para></listitem> + + </varlistentry> + + <varlistentry><term><filename>~/.nix-defexpr/channels</filename></term> + + <listitem><para>This is a symlink to + <filename>/nix/var/nix/profiles/per-user/<replaceable>username</replaceable>/channels</filename>. It + ensures that <command>nix-env</command> can find your channels. In + a multi-user installation, you may also have + <filename>~/.nix-defexpr/channels_root</filename>, which links to + the channels of the root user.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + +<refsection><title>Channel format</title> + +<para>A channel URL should point to a directory containing the +following files:</para> + +<variablelist> + + <varlistentry><term><filename>nixexprs.tar.xz</filename></term> + + <listitem><para>A tarball containing Nix expressions and files + referenced by them (such as build scripts and patches). At the + top level, the tarball should contain a single directory. That + directory must contain a file <filename>default.nix</filename> + that serves as the channel’s “entry point”.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-collect-garbage.xml b/third_party/nix/doc/manual/command-ref/nix-collect-garbage.xml new file mode 100644 index 0000000000..43e0687969 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-collect-garbage.xml @@ -0,0 +1,63 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-collect-garbage"> + +<refmeta> + <refentrytitle>nix-collect-garbage</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-collect-garbage</refname> + <refpurpose>delete unreachable store paths</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-collect-garbage</command> + <arg><option>--delete-old</option></arg> + <arg><option>-d</option></arg> + <arg><option>--delete-older-than</option> <replaceable>period</replaceable></arg> + <arg><option>--max-freed</option> <replaceable>bytes</replaceable></arg> + <arg><option>--dry-run</option></arg> + </cmdsynopsis> +</refsynopsisdiv> + +<refsection><title>Description</title> + +<para>The command <command>nix-collect-garbage</command> is mostly an +alias of <link linkend="rsec-nix-store-gc"><command>nix-store +--gc</command></link>, that is, it deletes all unreachable paths in +the Nix store to clean up your system. However, it provides two +additional options: <option>-d</option> (<option>--delete-old</option>), +which deletes all old generations of all profiles in +<filename>/nix/var/nix/profiles</filename> by invoking +<literal>nix-env --delete-generations old</literal> on all profiles +(of course, this makes rollbacks to previous configurations +impossible); and +<option>--delete-older-than</option> <replaceable>period</replaceable>, +where period is a value such as <literal>30d</literal>, which deletes +all generations older than the specified number of days in all profiles +in <filename>/nix/var/nix/profiles</filename> (except for the generations +that were active at that point in time). +</para> + +</refsection> + +<refsection><title>Example</title> + +<para>To delete from the Nix store everything that is not used by the +current generations of each profile, do + +<screen> +$ nix-collect-garbage -d</screen> + +</para> + +</refsection> + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-copy-closure.xml b/third_party/nix/doc/manual/command-ref/nix-copy-closure.xml new file mode 100644 index 0000000000..e6dcf180ad --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-copy-closure.xml @@ -0,0 +1,169 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + xml:id="sec-nix-copy-closure"> + +<refmeta> + <refentrytitle>nix-copy-closure</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-copy-closure</refname> + <refpurpose>copy a closure to or from a remote machine via SSH</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-copy-closure</command> + <group> + <arg choice='plain'><option>--to</option></arg> + <arg choice='plain'><option>--from</option></arg> + </group> + <arg><option>--gzip</option></arg> + <!-- + <arg><option>- -show-progress</option></arg> + --> + <arg><option>--include-outputs</option></arg> + <group> + <arg choice='plain'><option>--use-substitutes</option></arg> + <arg choice='plain'><option>-s</option></arg> + </group> + <arg><option>-v</option></arg> + <arg choice='plain'> + <replaceable>user@</replaceable><replaceable>machine</replaceable> + </arg> + <arg choice='plain'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + + +<refsection><title>Description</title> + +<para><command>nix-copy-closure</command> gives you an easy and +efficient way to exchange software between machines. Given one or +more Nix store <replaceable>paths</replaceable> on the local +machine, <command>nix-copy-closure</command> computes the closure of +those paths (i.e. all their dependencies in the Nix store), and copies +all paths in the closure to the remote machine via the +<command>ssh</command> (Secure Shell) command. With the +<option>--from</option>, the direction is reversed: +the closure of <replaceable>paths</replaceable> on a remote machine is +copied to the Nix store on the local machine.</para> + +<para>This command is efficient because it only sends the store paths +that are missing on the target machine.</para> + +<para>Since <command>nix-copy-closure</command> calls +<command>ssh</command>, you may be asked to type in the appropriate +password or passphrase. In fact, you may be asked +<emphasis>twice</emphasis> because <command>nix-copy-closure</command> +currently connects twice to the remote machine, first to get the set +of paths missing on the target machine, and second to send the dump of +those paths. If this bothers you, use +<command>ssh-agent</command>.</para> + + +<refsection><title>Options</title> + +<variablelist> + + <varlistentry><term><option>--to</option></term> + + <listitem><para>Copy the closure of + <replaceable>paths</replaceable> from the local Nix store to the + Nix store on <replaceable>machine</replaceable>. This is the + default.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--from</option></term> + + <listitem><para>Copy the closure of + <replaceable>paths</replaceable> from the Nix store on + <replaceable>machine</replaceable> to the local Nix + store.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--gzip</option></term> + + <listitem><para>Enable compression of the SSH + connection.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--include-outputs</option></term> + + <listitem><para>Also copy the outputs of store derivations + included in the closure.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--use-substitutes</option> / <option>-s</option></term> + + <listitem><para>Attempt to download missing paths on the target + machine using Nix’s substitute mechanism. Any paths that cannot + be substituted on the target are still copied normally from the + source. This is useful, for instance, if the connection between + the source and target machine is slow, but the connection between + the target machine and <literal>nixos.org</literal> (the default + binary cache server) is fast.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>-v</option></term> + + <listitem><para>Show verbose output.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Environment variables</title> + +<variablelist> + + <varlistentry><term><envar>NIX_SSHOPTS</envar></term> + + <listitem><para>Additional options to be passed to + <command>ssh</command> on the command line.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>Copy Firefox with all its dependencies to a remote machine: + +<screen> +$ nix-copy-closure --to alice@itchy.labs $(type -tP firefox)</screen> + +</para> + +<para>Copy Subversion from a remote machine and then install it into a +user environment: + +<screen> +$ nix-copy-closure --from alice@itchy.labs \ + /nix/store/0dj0503hjxy5mbwlafv1rsbdiyx1gkdy-subversion-1.4.4 +$ nix-env -i /nix/store/0dj0503hjxy5mbwlafv1rsbdiyx1gkdy-subversion-1.4.4 +</screen> + +</para> + +</refsection> + + +</refsection> + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-daemon.xml b/third_party/nix/doc/manual/command-ref/nix-daemon.xml new file mode 100644 index 0000000000..a2161f0334 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-daemon.xml @@ -0,0 +1,35 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-daemon"> + +<refmeta> + <refentrytitle>nix-daemon</refentrytitle> + <manvolnum>8</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-daemon</refname> + <refpurpose>Nix multi-user support daemon</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-daemon</command> + </cmdsynopsis> +</refsynopsisdiv> + + +<refsection><title>Description</title> + +<para>The Nix daemon is necessary in multi-user Nix installations. It +performs build actions and other operations on the Nix store on behalf +of unprivileged users.</para> + + +</refsection> + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-env.xml b/third_party/nix/doc/manual/command-ref/nix-env.xml new file mode 100644 index 0000000000..d257a5e49c --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-env.xml @@ -0,0 +1,1505 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-env"> + +<refmeta> + <refentrytitle>nix-env</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-env</refname> + <refpurpose>manipulate or query Nix user environments</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-env</command> + <xi:include href="opt-common-syn.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(/db:nop/*)" /> + <arg><option>--arg</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg><option>--argstr</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--file</option></arg> + <arg choice='plain'><option>-f</option></arg> + </group> + <replaceable>path</replaceable> + </arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--profile</option></arg> + <arg choice='plain'><option>-p</option></arg> + </group> + <replaceable>path</replaceable> + </arg> + <arg> + <arg choice='plain'><option>--system-filter</option></arg> + <replaceable>system</replaceable> + </arg> + <arg><option>--dry-run</option></arg> + <arg choice='plain'><replaceable>operation</replaceable></arg> + <arg rep='repeat'><replaceable>options</replaceable></arg> + <arg rep='repeat'><replaceable>arguments</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + + +<refsection><title>Description</title> + +<para>The command <command>nix-env</command> is used to manipulate Nix +user environments. User environments are sets of software packages +available to a user at some point in time. In other words, they are a +synthesised view of the programs available in the Nix store. There +may be many user environments: different users can have different +environments, and individual users can switch between different +environments.</para> + +<para><command>nix-env</command> takes exactly one +<emphasis>operation</emphasis> flag which indicates the subcommand to +be performed. These are documented below.</para> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Selectors</title> + +<para>Several commands, such as <command>nix-env -q</command> and +<command>nix-env -i</command>, take a list of arguments that specify +the packages on which to operate. These are extended regular +expressions that must match the entire name of the package. (For +details on regular expressions, see +<citerefentry><refentrytitle>regex</refentrytitle><manvolnum>7</manvolnum></citerefentry>.) +The match is case-sensitive. The regular expression can optionally be +followed by a dash and a version number; if omitted, any version of +the package will match. Here are some examples: + +<variablelist> + + <varlistentry> + <term><literal>firefox</literal></term> + <listitem><para>Matches the package name + <literal>firefox</literal> and any version.</para></listitem> + </varlistentry> + + <varlistentry> + <term><literal>firefox-32.0</literal></term> + <listitem><para>Matches the package name + <literal>firefox</literal> and version + <literal>32.0</literal>.</para></listitem> + </varlistentry> + + <varlistentry> + <term><literal>gtk\\+</literal></term> + <listitem><para>Matches the package name + <literal>gtk+</literal>. The <literal>+</literal> character must + be escaped using a backslash to prevent it from being interpreted + as a quantifier, and the backslash must be escaped in turn with + another backslash to ensure that the shell passes it + on.</para></listitem> + </varlistentry> + + <varlistentry> + <term><literal>.\*</literal></term> + <listitem><para>Matches any package name. This is the default for + most commands.</para></listitem> + </varlistentry> + + <varlistentry> + <term><literal>'.*zip.*'</literal></term> + <listitem><para>Matches any package name containing the string + <literal>zip</literal>. Note the dots: <literal>'*zip*'</literal> + does not work, because in a regular expression, the character + <literal>*</literal> is interpreted as a + quantifier.</para></listitem> + </varlistentry> + + <varlistentry> + <term><literal>'.*(firefox|chromium).*'</literal></term> + <listitem><para>Matches any package name containing the strings + <literal>firefox</literal> or + <literal>chromium</literal>.</para></listitem> + </varlistentry> + +</variablelist> + +</para> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Common options</title> + +<para>This section lists the options that are common to all +operations. These options are allowed for every subcommand, though +they may not always have an effect. <phrase condition="manual">See +also <xref linkend="sec-common-options" />.</phrase></para> + +<variablelist> + + <varlistentry><term><option>--file</option> / <option>-f</option> <replaceable>path</replaceable></term> + + <listitem><para>Specifies the Nix expression (designated below as + the <emphasis>active Nix expression</emphasis>) used by the + <option>--install</option>, <option>--upgrade</option>, and + <option>--query --available</option> operations to obtain + derivations. The default is + <filename>~/.nix-defexpr</filename>.</para> + + <para>If the argument starts with <literal>http://</literal> or + <literal>https://</literal>, it is interpreted as the URL of a + tarball that will be downloaded and unpacked to a temporary + location. The tarball must include a single top-level directory + containing at least a file named <filename>default.nix</filename>.</para> + + </listitem> + + </varlistentry> + + <varlistentry><term><option>--profile</option> / <option>-p</option> <replaceable>path</replaceable></term> + + <listitem><para>Specifies the profile to be used by those + operations that operate on a profile (designated below as the + <emphasis>active profile</emphasis>). A profile is a sequence of + user environments called <emphasis>generations</emphasis>, one of + which is the <emphasis>current + generation</emphasis>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--dry-run</option></term> + + <listitem><para>For the <option>--install</option>, + <option>--upgrade</option>, <option>--uninstall</option>, + <option>--switch-generation</option>, + <option>--delete-generations</option> and + <option>--rollback</option> operations, this flag will cause + <command>nix-env</command> to print what + <emphasis>would</emphasis> be done if this flag had not been + specified, without actually doing it.</para> + + <para><option>--dry-run</option> also prints out which paths will + be <link linkend="gloss-substitute">substituted</link> (i.e., + downloaded) and which paths will be built from source (because no + substitute is available).</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--system-filter</option> <replaceable>system</replaceable></term> + + <listitem><para>By default, operations such as <option>--query + --available</option> show derivations matching any platform. This + option allows you to use derivations for the specified platform + <replaceable>system</replaceable>.</para></listitem> + + </varlistentry> + +</variablelist> + +<variablelist condition="manpage"> + <xi:include href="opt-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='opt-common']/*)" /> +</variablelist> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Files</title> + +<variablelist> + + <varlistentry><term><filename>~/.nix-defexpr</filename></term> + + <listitem><para>The source for the default Nix + expressions used by the <option>--install</option>, + <option>--upgrade</option>, and <option>--query + --available</option> operations to obtain derivations. The + <option>--file</option> option may be used to override this + default.</para> + + <para>If <filename>~/.nix-defexpr</filename> is a file, + it is loaded as a Nix expression. If the expression + is a set, it is used as the default Nix expression. + If the expression is a function, an empty set is passed + as argument and the return value is used as + the default Nix expression.</para> + + <para>If <filename>~/.nix-defexpr</filename> is a directory + containing a <filename>default.nix</filename> file, that file + is loaded as in the above paragraph.</para> + + <para>If <filename>~/.nix-defexpr</filename> is a directory without + a <filename>default.nix</filename> file, then its contents + (both files and subdirectories) are loaded as Nix expressions. + The expressions are combined into a single set, each expression + under an attribute with the same name as the original file + or subdirectory. + </para> + + <para>For example, if <filename>~/.nix-defexpr</filename> contains + two files, <filename>foo.nix</filename> and <filename>bar.nix</filename>, + then the default Nix expression will essentially be + +<programlisting> +{ + foo = import ~/.nix-defexpr/foo.nix; + bar = import ~/.nix-defexpr/bar.nix; +}</programlisting> + + </para> + + <para>The file <filename>manifest.nix</filename> is always ignored. + Subdirectories without a <filename>default.nix</filename> file + are traversed recursively in search of more Nix expressions, + but the names of these intermediate directories are not + added to the attribute paths of the default Nix expression.</para> + + <para>The command <command>nix-channel</command> places symlinks + to the downloaded Nix expressions from each subscribed channel in + this directory.</para> + </listitem> + + </varlistentry> + + <varlistentry><term><filename>~/.nix-profile</filename></term> + + <listitem><para>A symbolic link to the user's current profile. By + default, this symlink points to + <filename><replaceable>prefix</replaceable>/var/nix/profiles/default</filename>. + The <envar>PATH</envar> environment variable should include + <filename>~/.nix-profile/bin</filename> for the user environment + to be visible to the user.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id="rsec-nix-env-install"><title>Operation <option>--install</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <group choice='req'> + <arg choice='plain'><option>--install</option></arg> + <arg choice='plain'><option>-i</option></arg> + </group> + <xi:include xmlns:xi="http://www.w3.org/2001/XInclude" href="opt-inst-syn.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(/db:nop/*)" /> + <group choice='opt'> + <arg choice='plain'><option>--preserve-installed</option></arg> + <arg choice='plain'><option>-P</option></arg> + </group> + <group choice='opt'> + <arg choice='plain'><option>--remove-all</option></arg> + <arg choice='plain'><option>-r</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>args</replaceable></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>The install operation creates a new user environment, based on +the current generation of the active profile, to which a set of store +paths described by <replaceable>args</replaceable> is added. The +arguments <replaceable>args</replaceable> map to store paths in a +number of possible ways: + +<itemizedlist> + + <listitem><para>By default, <replaceable>args</replaceable> is a set + of derivation names denoting derivations in the active Nix + expression. These are realised, and the resulting output paths are + installed. Currently installed derivations with a name equal to the + name of a derivation being added are removed unless the option + <option>--preserve-installed</option> is + specified.</para> + + <para>If there are multiple derivations matching a name in + <replaceable>args</replaceable> that have the same name (e.g., + <literal>gcc-3.3.6</literal> and <literal>gcc-4.1.1</literal>), then + the derivation with the highest <emphasis>priority</emphasis> is + used. A derivation can define a priority by declaring the + <varname>meta.priority</varname> attribute. This attribute should + be a number, with a higher value denoting a lower priority. The + default priority is <literal>0</literal>.</para> + + <para>If there are multiple matching derivations with the same + priority, then the derivation with the highest version will be + installed.</para> + + <para>You can force the installation of multiple derivations with + the same name by being specific about the versions. For instance, + <literal>nix-env -i gcc-3.3.6 gcc-4.1.1</literal> will install both + version of GCC (and will probably cause a user environment + conflict!).</para></listitem> + + <listitem><para>If <link + linkend='opt-attr'><option>--attr</option></link> + (<option>-A</option>) is specified, the arguments are + <emphasis>attribute paths</emphasis> that select attributes from the + top-level Nix expression. This is faster than using derivation + names and unambiguous. To find out the attribute paths of available + packages, use <literal>nix-env -qaP</literal>.</para></listitem> + + <listitem><para>If <option>--from-profile</option> + <replaceable>path</replaceable> is given, + <replaceable>args</replaceable> is a set of names denoting installed + store paths in the profile <replaceable>path</replaceable>. This is + an easy way to copy user environment elements from one profile to + another.</para></listitem> + + <listitem><para>If <option>--from-expression</option> is given, + <replaceable>args</replaceable> are Nix <link + linkend="ss-functions">functions</link> that are called with the + active Nix expression as their single argument. The derivations + returned by those function calls are installed. This allows + derivations to be specified in an unambiguous way, which is necessary + if there are multiple derivations with the same + name.</para></listitem> + + <listitem><para>If <replaceable>args</replaceable> are store + derivations, then these are <link + linkend="rsec-nix-store-realise">realised</link>, and the resulting + output paths are installed.</para></listitem> + + <listitem><para>If <replaceable>args</replaceable> are store paths + that are not store derivations, then these are <link + linkend="rsec-nix-store-realise">realised</link> and + installed.</para></listitem> + + <listitem><para>By default all outputs are installed for each derivation. + That can be reduced by setting <literal>meta.outputsToInstall</literal>. + </para></listitem> <!-- TODO: link nixpkgs docs on the ability to override those. --> + +</itemizedlist> + +</para> + +</refsection> + + +<refsection><title>Flags</title> + +<variablelist> + + <varlistentry><term><option>--prebuilt-only</option> / <option>-b</option></term> + + <listitem><para>Use only derivations for which a substitute is + registered, i.e., there is a pre-built binary available that can + be downloaded in lieu of building the derivation. Thus, no + packages will be built from source.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--preserve-installed</option></term> + <term><option>-P</option></term> + + <listitem><para>Do not remove derivations with a name matching one + of the derivations being installed. Usually, trying to have two + versions of the same package installed in the same generation of a + profile will lead to an error in building the generation, due to + file name clashes between the two versions. However, this is not + the case for all packages.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--remove-all</option></term> + <term><option>-r</option></term> + + <listitem><para>Remove all previously installed packages first. + This is equivalent to running <literal>nix-env -e '.*'</literal> + first, except that everything happens in a single + transaction.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection xml:id='refsec-nix-env-install-examples'><title>Examples</title> + +<para>To install a specific version of <command>gcc</command> from the +active Nix expression: + +<screen> +$ nix-env --install gcc-3.3.2 +installing `gcc-3.3.2' +uninstalling `gcc-3.1'</screen> + +Note the previously installed version is removed, since +<option>--preserve-installed</option> was not specified.</para> + +<para>To install an arbitrary version: + +<screen> +$ nix-env --install gcc +installing `gcc-3.3.2'</screen> + +</para> + +<para>To install using a specific attribute: + +<screen> +$ nix-env -i -A gcc40mips +$ nix-env -i -A xorg.xorgserver</screen> + +</para> + +<para>To install all derivations in the Nix expression <filename>foo.nix</filename>: + +<screen> +$ nix-env -f ~/foo.nix -i '.*'</screen> + +</para> + +<para>To copy the store path with symbolic name <literal>gcc</literal> +from another profile: + +<screen> +$ nix-env -i --from-profile /nix/var/nix/profiles/foo gcc</screen> + +</para> + +<para>To install a specific store derivation (typically created by +<command>nix-instantiate</command>): + +<screen> +$ nix-env -i /nix/store/fibjb1bfbpm5mrsxc4mh2d8n37sxh91i-gcc-3.4.3.drv</screen> + +</para> + +<para>To install a specific output path: + +<screen> +$ nix-env -i /nix/store/y3cgx0xj1p4iv9x0pnnmdhr8iyg741vk-gcc-3.4.3</screen> + +</para> + +<para>To install from a Nix expression specified on the command-line: + +<screen> +$ nix-env -f ./foo.nix -i -E \ + 'f: (f {system = "i686-linux";}).subversionWithJava'</screen> + +I.e., this evaluates to <literal>(f: (f {system = +"i686-linux";}).subversionWithJava) (import ./foo.nix)</literal>, thus +selecting the <literal>subversionWithJava</literal> attribute from the +set returned by calling the function defined in +<filename>./foo.nix</filename>.</para> + +<para>A dry-run tells you which paths will be downloaded or built from +source: + +<screen> +$ nix-env -f '<nixpkgs>' -iA hello --dry-run +(dry run; not doing anything) +installing ‘hello-2.10’ +these paths will be fetched (0.04 MiB download, 0.19 MiB unpacked): + /nix/store/wkhdf9jinag5750mqlax6z2zbwhqb76n-hello-2.10 + <replaceable>...</replaceable></screen> + +</para> + +<para>To install Firefox from the latest revision in the Nixpkgs/NixOS +14.12 channel: + +<screen> +$ nix-env -f https://github.com/NixOS/nixpkgs-channels/archive/nixos-14.12.tar.gz -iA firefox +</screen> + +(The GitHub repository <literal>nixpkgs-channels</literal> is updated +automatically from the main <literal>nixpkgs</literal> repository +after certain tests have succeeded and binaries have been built and +uploaded to the binary cache at <uri>cache.nixos.org</uri>.)</para> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id="rsec-nix-env-upgrade"><title>Operation <option>--upgrade</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <group choice='req'> + <arg choice='plain'><option>--upgrade</option></arg> + <arg choice='plain'><option>-u</option></arg> + </group> + <xi:include xmlns:xi="http://www.w3.org/2001/XInclude" href="opt-inst-syn.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(/db:nop/*)" /> + <group choice='opt'> + <arg choice='plain'><option>--lt</option></arg> + <arg choice='plain'><option>--leq</option></arg> + <arg choice='plain'><option>--eq</option></arg> + <arg choice='plain'><option>--always</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>args</replaceable></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>The upgrade operation creates a new user environment, based on +the current generation of the active profile, in which all store paths +are replaced for which there are newer versions in the set of paths +described by <replaceable>args</replaceable>. Paths for which there +are no newer versions are left untouched; this is not an error. It is +also not an error if an element of <replaceable>args</replaceable> +matches no installed derivations.</para> + +<para>For a description of how <replaceable>args</replaceable> is +mapped to a set of store paths, see <link +linkend="rsec-nix-env-install"><option>--install</option></link>. If +<replaceable>args</replaceable> describes multiple store paths with +the same symbolic name, only the one with the highest version is +installed.</para> + +</refsection> + +<refsection><title>Flags</title> + +<variablelist> + + <varlistentry><term><option>--lt</option></term> + + <listitem><para>Only upgrade a derivation to newer versions. This + is the default.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--leq</option></term> + + <listitem><para>In addition to upgrading to newer versions, also + “upgrade” to derivations that have the same version. Version are + not a unique identification of a derivation, so there may be many + derivations that have the same version. This flag may be useful + to force “synchronisation” between the installed and available + derivations.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--eq</option></term> + + <listitem><para><emphasis>Only</emphasis> “upgrade” to derivations + that have the same version. This may not seem very useful, but it + actually is, e.g., when there is a new release of Nixpkgs and you + want to replace installed applications with the same versions + built against newer dependencies (to reduce the number of + dependencies floating around on your system).</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--always</option></term> + + <listitem><para>In addition to upgrading to newer versions, also + “upgrade” to derivations that have the same or a lower version. + I.e., derivations may actually be downgraded depending on what is + available in the active Nix expression.</para></listitem> + + </varlistentry> + +</variablelist> + +<para>For the other flags, see <option +linkend="rsec-nix-env-install">--install</option>.</para> + +</refsection> + +<refsection><title>Examples</title> + +<screen> +$ nix-env --upgrade gcc +upgrading `gcc-3.3.1' to `gcc-3.4' + +$ nix-env -u gcc-3.3.2 --always <lineannotation>(switch to a specific version)</lineannotation> +upgrading `gcc-3.4' to `gcc-3.3.2' + +$ nix-env --upgrade pan +<lineannotation>(no upgrades available, so nothing happens)</lineannotation> + +$ nix-env -u <lineannotation>(try to upgrade everything)</lineannotation> +upgrading `hello-2.1.2' to `hello-2.1.3' +upgrading `mozilla-1.2' to `mozilla-1.4'</screen> + +</refsection> + +<refsection xml:id="ssec-version-comparisons"><title>Versions</title> + +<para>The upgrade operation determines whether a derivation +<varname>y</varname> is an upgrade of a derivation +<varname>x</varname> by looking at their respective +<literal>name</literal> attributes. The names (e.g., +<literal>gcc-3.3.1</literal> are split into two parts: the package +name (<literal>gcc</literal>), and the version +(<literal>3.3.1</literal>). The version part starts after the first +dash not followed by a letter. <varname>x</varname> is considered an +upgrade of <varname>y</varname> if their package names match, and the +version of <varname>y</varname> is higher that that of +<varname>x</varname>.</para> + +<para>The versions are compared by splitting them into contiguous +components of numbers and letters. E.g., <literal>3.3.1pre5</literal> +is split into <literal>[3, 3, 1, "pre", 5]</literal>. These lists are +then compared lexicographically (from left to right). Corresponding +components <varname>a</varname> and <varname>b</varname> are compared +as follows. If they are both numbers, integer comparison is used. If +<varname>a</varname> is an empty string and <varname>b</varname> is a +number, <varname>a</varname> is considered less than +<varname>b</varname>. The special string component +<literal>pre</literal> (for <emphasis>pre-release</emphasis>) is +considered to be less than other components. String components are +considered less than number components. Otherwise, they are compared +lexicographically (i.e., using case-sensitive string comparison).</para> + +<para>This is illustrated by the following examples: + +<screen> +1.0 < 2.3 +2.1 < 2.3 +2.3 = 2.3 +2.5 > 2.3 +3.1 > 2.3 +2.3.1 > 2.3 +2.3.1 > 2.3a +2.3pre1 < 2.3 +2.3pre3 < 2.3pre12 +2.3a < 2.3c +2.3pre1 < 2.3c +2.3pre1 < 2.3q</screen> + +</para> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--uninstall</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <group choice='req'> + <arg choice='plain'><option>--uninstall</option></arg> + <arg choice='plain'><option>-e</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>drvnames</replaceable></arg> +</cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The uninstall operation creates a new user environment, based on +the current generation of the active profile, from which the store +paths designated by the symbolic names +<replaceable>names</replaceable> are removed.</para> + +</refsection> + +<refsection><title>Examples</title> + +<screen> +$ nix-env --uninstall gcc +$ nix-env -e '.*' <lineannotation>(remove everything)</lineannotation></screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id="rsec-nix-env-set"><title>Operation <option>--set</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <arg choice='plain'><option>--set</option></arg> + <arg choice='plain'><replaceable>drvname</replaceable></arg> +</cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The <option>--set</option> operation modifies the current generation of a +profile so that it contains exactly the specified derivation, and nothing else. +</para> + +</refsection> + +<refsection><title>Examples</title> + +<para> +The following updates a profile such that its current generation will contain +just Firefox: + +<screen> +$ nix-env -p /nix/var/nix/profiles/browser --set firefox</screen> + +</para> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id="rsec-nix-env-set-flag"><title>Operation <option>--set-flag</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <arg choice='plain'><option>--set-flag</option></arg> + <arg choice='plain'><replaceable>name</replaceable></arg> + <arg choice='plain'><replaceable>value</replaceable></arg> + <arg choice='plain' rep='repeat'><replaceable>drvnames</replaceable></arg> +</cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The <option>--set-flag</option> operation allows meta attributes +of installed packages to be modified. There are several attributes +that can be usefully modified, because they affect the behaviour of +<command>nix-env</command> or the user environment build +script: + +<itemizedlist> + + <listitem><para><varname>priority</varname> can be changed to + resolve filename clashes. The user environment build script uses + the <varname>meta.priority</varname> attribute of derivations to + resolve filename collisions between packages. Lower priority values + denote a higher priority. For instance, the GCC wrapper package and + the Binutils package in Nixpkgs both have a file + <filename>bin/ld</filename>, so previously if you tried to install + both you would get a collision. Now, on the other hand, the GCC + wrapper declares a higher priority than Binutils, so the former’s + <filename>bin/ld</filename> is symlinked in the user + environment.</para></listitem> + + <listitem><para><varname>keep</varname> can be set to + <literal>true</literal> to prevent the package from being upgraded + or replaced. This is useful if you want to hang on to an older + version of a package.</para></listitem> + + <listitem><para><varname>active</varname> can be set to + <literal>false</literal> to “disable” the package. That is, no + symlinks will be generated to the files of the package, but it + remains part of the profile (so it won’t be garbage-collected). It + can be set back to <literal>true</literal> to re-enable the + package.</para></listitem> + +</itemizedlist> + +</para> + +</refsection> + +<refsection><title>Examples</title> + +<para>To prevent the currently installed Firefox from being upgraded: + +<screen> +$ nix-env --set-flag keep true firefox</screen> + +After this, <command>nix-env -u</command> will ignore Firefox.</para> + +<para>To disable the currently installed Firefox, then install a new +Firefox while the old remains part of the profile: + +<screen> +$ nix-env -q +firefox-2.0.0.9 <lineannotation>(the current one)</lineannotation> + +$ nix-env --preserve-installed -i firefox-2.0.0.11 +installing `firefox-2.0.0.11' +building path(s) `/nix/store/myy0y59q3ig70dgq37jqwg1j0rsapzsl-user-environment' +collision between `/nix/store/<replaceable>...</replaceable>-firefox-2.0.0.11/bin/firefox' + and `/nix/store/<replaceable>...</replaceable>-firefox-2.0.0.9/bin/firefox'. +<lineannotation>(i.e., can’t have two active at the same time)</lineannotation> + +$ nix-env --set-flag active false firefox +setting flag on `firefox-2.0.0.9' + +$ nix-env --preserve-installed -i firefox-2.0.0.11 +installing `firefox-2.0.0.11' + +$ nix-env -q +firefox-2.0.0.11 <lineannotation>(the enabled one)</lineannotation> +firefox-2.0.0.9 <lineannotation>(the disabled one)</lineannotation></screen> + +</para> + +<para>To make files from <literal>binutils</literal> take precedence +over files from <literal>gcc</literal>: + +<screen> +$ nix-env --set-flag priority 5 binutils +$ nix-env --set-flag priority 10 gcc</screen> + +</para> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--query</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <group choice='req'> + <arg choice='plain'><option>--query</option></arg> + <arg choice='plain'><option>-q</option></arg> + </group> + <group choice='opt'> + <arg choice='plain'><option>--installed</option></arg> + <arg choice='plain'><option>--available</option></arg> + <arg choice='plain'><option>-a</option></arg> + </group> + + <sbr /> + + <arg> + <group choice='req'> + <arg choice='plain'><option>--status</option></arg> + <arg choice='plain'><option>-s</option></arg> + </group> + </arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--attr-path</option></arg> + <arg choice='plain'><option>-P</option></arg> + </group> + </arg> + <arg><option>--no-name</option></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--compare-versions</option></arg> + <arg choice='plain'><option>-c</option></arg> + </group> + </arg> + <arg><option>--system</option></arg> + <arg><option>--drv-path</option></arg> + <arg><option>--out-path</option></arg> + <arg><option>--description</option></arg> + <arg><option>--meta</option></arg> + + <sbr /> + + <arg><option>--xml</option></arg> + <arg><option>--json</option></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--prebuilt-only</option></arg> + <arg choice='plain'><option>-b</option></arg> + </group> + </arg> + + <arg> + <group choice='req'> + <arg choice='plain'><option>--attr</option></arg> + <arg choice='plain'><option>-A</option></arg> + </group> + <replaceable>attribute-path</replaceable> + </arg> + + <sbr /> + + <arg choice='plain' rep='repeat'><replaceable>names</replaceable></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>The query operation displays information about either the store +paths that are installed in the current generation of the active +profile (<option>--installed</option>), or the derivations that are +available for installation in the active Nix expression +(<option>--available</option>). It only prints information about +derivations whose symbolic name matches one of +<replaceable>names</replaceable>.</para> + +<para>The derivations are sorted by their <literal>name</literal> +attributes.</para> + +</refsection> + + +<refsection><title>Source selection</title> + +<para>The following flags specify the set of things on which the query +operates.</para> + +<variablelist> + + <varlistentry><term><option>--installed</option></term> + + <listitem><para>The query operates on the store paths that are + installed in the current generation of the active profile. This + is the default.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--available</option></term> + <term><option>-a</option></term> + + <listitem><para>The query operates on the derivations that are + available in the active Nix expression.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Queries</title> + +<para>The following flags specify what information to display about +the selected derivations. Multiple flags may be specified, in which +case the information is shown in the order given here. Note that the +name of the derivation is shown unless <option>--no-name</option> is +specified.</para> + +<!-- TODO: fix the terminology here; i.e., derivations, store paths, +user environment elements, etc. --> + +<variablelist> + + <varlistentry><term><option>--xml</option></term> + + <listitem><para>Print the result in an XML representation suitable + for automatic processing by other tools. The root element is + called <literal>items</literal>, which contains a + <literal>item</literal> element for each available or installed + derivation. The fields discussed below are all stored in + attributes of the <literal>item</literal> + elements.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--json</option></term> + + <listitem><para>Print the result in a JSON representation suitable + for automatic processing by other tools.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--prebuilt-only</option> / <option>-b</option></term> + + <listitem><para>Show only derivations for which a substitute is + registered, i.e., there is a pre-built binary available that can + be downloaded in lieu of building the derivation. Thus, this + shows all packages that probably can be installed + quickly.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--status</option></term> + <term><option>-s</option></term> + + <listitem><para>Print the <emphasis>status</emphasis> of the + derivation. The status consists of three characters. The first + is <literal>I</literal> or <literal>-</literal>, indicating + whether the derivation is currently installed in the current + generation of the active profile. This is by definition the case + for <option>--installed</option>, but not for + <option>--available</option>. The second is <literal>P</literal> + or <literal>-</literal>, indicating whether the derivation is + present on the system. This indicates whether installation of an + available derivation will require the derivation to be built. The + third is <literal>S</literal> or <literal>-</literal>, indicating + whether a substitute is available for the + derivation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--attr-path</option></term> + <term><option>-P</option></term> + + <listitem><para>Print the <emphasis>attribute path</emphasis> of + the derivation, which can be used to unambiguously select it using + the <link linkend="opt-attr"><option>--attr</option> option</link> + available in commands that install derivations like + <literal>nix-env --install</literal>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--no-name</option></term> + + <listitem><para>Suppress printing of the <literal>name</literal> + attribute of each derivation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--compare-versions</option> / + <option>-c</option></term> + + <listitem><para>Compare installed versions to available versions, + or vice versa (if <option>--available</option> is given). This is + useful for quickly seeing whether upgrades for installed + packages are available in a Nix expression. A column is added + with the following meaning: + + <variablelist> + + <varlistentry><term><literal><</literal> <replaceable>version</replaceable></term> + + <listitem><para>A newer version of the package is available + or installed.</para></listitem> + + </varlistentry> + + <varlistentry><term><literal>=</literal> <replaceable>version</replaceable></term> + + <listitem><para>At most the same version of the package is + available or installed.</para></listitem> + + </varlistentry> + + <varlistentry><term><literal>></literal> <replaceable>version</replaceable></term> + + <listitem><para>Only older versions of the package are + available or installed.</para></listitem> + + </varlistentry> + + <varlistentry><term><literal>- ?</literal></term> + + <listitem><para>No version of the package is available or + installed.</para></listitem> + + </varlistentry> + + </variablelist> + + </para></listitem> + + </varlistentry> + + <varlistentry><term><option>--system</option></term> + + <listitem><para>Print the <literal>system</literal> attribute of + the derivation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--drv-path</option></term> + + <listitem><para>Print the path of the store + derivation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--out-path</option></term> + + <listitem><para>Print the output path of the + derivation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--description</option></term> + + <listitem><para>Print a short (one-line) description of the + derivation, if available. The description is taken from the + <literal>meta.description</literal> attribute of the + derivation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--meta</option></term> + + <listitem><para>Print all of the meta-attributes of the + derivation. This option is only available with + <option>--xml</option> or <option>--json</option>.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>To show installed packages: + +<screen> +$ nix-env -q +bison-1.875c +docbook-xml-4.2 +firefox-1.0.4 +MPlayer-1.0pre7 +ORBit2-2.8.3 +<replaceable>…</replaceable> +</screen> + +</para> + +<para>To show available packages: + +<screen> +$ nix-env -qa +firefox-1.0.7 +GConf-2.4.0.1 +MPlayer-1.0pre7 +ORBit2-2.8.3 +<replaceable>…</replaceable> +</screen> + +</para> + +<para>To show the status of available packages: + +<screen> +$ nix-env -qas +-P- firefox-1.0.7 <lineannotation>(not installed but present)</lineannotation> +--S GConf-2.4.0.1 <lineannotation>(not present, but there is a substitute for fast installation)</lineannotation> +--S MPlayer-1.0pre3 <lineannotation>(i.e., this is not the installed MPlayer, even though the version is the same!)</lineannotation> +IP- ORBit2-2.8.3 <lineannotation>(installed and by definition present)</lineannotation> +<replaceable>…</replaceable> +</screen> + +</para> + +<para>To show available packages in the Nix expression <filename>foo.nix</filename>: + +<screen> +$ nix-env -f ./foo.nix -qa +foo-1.2.3 +</screen> + +</para> + +<para>To compare installed versions to what’s available: + +<screen> +$ nix-env -qc +<replaceable>...</replaceable> +acrobat-reader-7.0 - ? <lineannotation>(package is not available at all)</lineannotation> +autoconf-2.59 = 2.59 <lineannotation>(same version)</lineannotation> +firefox-1.0.4 < 1.0.7 <lineannotation>(a more recent version is available)</lineannotation> +<replaceable>...</replaceable> +</screen> + +</para> + +<para>To show all packages with “<literal>zip</literal>” in the name: + +<screen> +$ nix-env -qa '.*zip.*' +bzip2-1.0.6 +gzip-1.6 +zip-3.0 +<replaceable>…</replaceable> +</screen> + +</para> + +<para>To show all packages with “<literal>firefox</literal>” or +“<literal>chromium</literal>” in the name: + +<screen> +$ nix-env -qa '.*(firefox|chromium).*' +chromium-37.0.2062.94 +chromium-beta-38.0.2125.24 +firefox-32.0.3 +firefox-with-plugins-13.0.1 +<replaceable>…</replaceable> +</screen> + +</para> + +<para>To show all packages in the latest revision of the Nixpkgs +repository: + +<screen> +$ nix-env -f https://github.com/NixOS/nixpkgs/archive/master.tar.gz -qa +</screen> + +</para> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--switch-profile</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <group choice='req'> + <arg choice='plain'><option>--switch-profile</option></arg> + <arg choice='plain'><option>-S</option></arg> + </group> + <arg choice='req'><replaceable>path</replaceable></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>This operation makes <replaceable>path</replaceable> the current +profile for the user. That is, the symlink +<filename>~/.nix-profile</filename> is made to point to +<replaceable>path</replaceable>.</para> + +</refsection> + +<refsection><title>Examples</title> + +<screen> +$ nix-env -S ~/my-profile</screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--list-generations</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <arg choice='plain'><option>--list-generations</option></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>This operation print a list of all the currently existing +generations for the active profile. These may be switched to using +the <option>--switch-generation</option> operation. It also prints +the creation date of the generation, and indicates the current +generation.</para> + +</refsection> + + +<refsection><title>Examples</title> + +<screen> +$ nix-env --list-generations + 95 2004-02-06 11:48:24 + 96 2004-02-06 11:49:01 + 97 2004-02-06 16:22:45 + 98 2004-02-06 16:24:33 (current)</screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--delete-generations</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <arg choice='plain'><option>--delete-generations</option></arg> + <arg choice='plain' rep='repeat'><replaceable>generations</replaceable></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>This operation deletes the specified generations of the current +profile. The generations can be a list of generation numbers, the +special value <literal>old</literal> to delete all non-current +generations, a value such as <literal>30d</literal> to delete all +generations older than the specified number of days (except for the +generation that was active at that point in time), or a value such as +<literal>+5</literal> to keep the last <literal>5</literal> generations +ignoring any newer than current, e.g., if <literal>30</literal> is the current +generation <literal>+5</literal> will delete generation <literal>25</literal> +and all older generations. +Periodically deleting old generations is important to make garbage collection +effective.</para> + +</refsection> + +<refsection><title>Examples</title> + +<screen> +$ nix-env --delete-generations 3 4 8 + +$ nix-env --delete-generations +5 + +$ nix-env --delete-generations 30d + +$ nix-env -p other_profile --delete-generations old</screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--switch-generation</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <group choice='req'> + <arg choice='plain'><option>--switch-generation</option></arg> + <arg choice='plain'><option>-G</option></arg> + </group> + <arg choice='req'><replaceable>generation</replaceable></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>This operation makes generation number +<replaceable>generation</replaceable> the current generation of the +active profile. That is, if the +<filename><replaceable>profile</replaceable></filename> is the path to +the active profile, then the symlink +<filename><replaceable>profile</replaceable></filename> is made to +point to +<filename><replaceable>profile</replaceable>-<replaceable>generation</replaceable>-link</filename>, +which is in turn a symlink to the actual user environment in the Nix +store.</para> + +<para>Switching will fail if the specified generation does not exist.</para> + +</refsection> + + +<refsection><title>Examples</title> + +<screen> +$ nix-env -G 42 +switching from generation 50 to 42</screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--rollback</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-env</command> + <arg choice='plain'><option>--rollback</option></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>This operation switches to the “previous” generation of the +active profile, that is, the highest numbered generation lower than +the current generation, if it exists. It is just a convenience +wrapper around <option>--list-generations</option> and +<option>--switch-generation</option>.</para> + +</refsection> + + +<refsection><title>Examples</title> + +<screen> +$ nix-env --rollback +switching from generation 92 to 91 + +$ nix-env --rollback +error: no generation older than the current (91) exists</screen> + +</refsection> + +</refsection> + + +<refsection condition="manpage"><title>Environment variables</title> + +<variablelist> + + <varlistentry><term><envar>NIX_PROFILE</envar></term> + + <listitem><para>Location of the Nix profile. Defaults to the + target of the symlink <filename>~/.nix-profile</filename>, if it + exists, or <filename>/nix/var/nix/profiles/default</filename> + otherwise.</para></listitem> + + </varlistentry> + + <xi:include href="env-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='env-common']/*)" /> +</variablelist> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-hash.xml b/third_party/nix/doc/manual/command-ref/nix-hash.xml new file mode 100644 index 0000000000..80263e18e3 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-hash.xml @@ -0,0 +1,176 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-hash"> + +<refmeta> + <refentrytitle>nix-hash</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-hash</refname> + <refpurpose>compute the cryptographic hash of a path</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-hash</command> + <arg><option>--flat</option></arg> + <arg><option>--base32</option></arg> + <arg><option>--truncate</option></arg> + <arg><option>--type</option> <replaceable>hashAlgo</replaceable></arg> + <arg choice='plain' rep='repeat'><replaceable>path</replaceable></arg> + </cmdsynopsis> + <cmdsynopsis> + <command>nix-hash</command> + <arg choice='plain'><option>--to-base16</option></arg> + <arg choice='plain' rep='repeat'><replaceable>hash</replaceable></arg> + </cmdsynopsis> + <cmdsynopsis> + <command>nix-hash</command> + <arg choice='plain'><option>--to-base32</option></arg> + <arg choice='plain' rep='repeat'><replaceable>hash</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + + +<refsection><title>Description</title> + +<para>The command <command>nix-hash</command> computes the +cryptographic hash of the contents of each +<replaceable>path</replaceable> and prints it on standard output. By +default, it computes an MD5 hash, but other hash algorithms are +available as well. The hash is printed in hexadecimal. To generate +the same hash as <command>nix-prefetch-url</command> you have to +specify multiple arguments, see below for an example.</para> + +<para>The hash is computed over a <emphasis>serialisation</emphasis> +of each path: a dump of the file system tree rooted at the path. This +allows directories and symlinks to be hashed as well as regular files. +The dump is in the <emphasis>NAR format</emphasis> produced by <link +linkend="refsec-nix-store-dump"><command>nix-store</command> +<option>--dump</option></link>. Thus, <literal>nix-hash +<replaceable>path</replaceable></literal> yields the same +cryptographic hash as <literal>nix-store --dump +<replaceable>path</replaceable> | md5sum</literal>.</para> + +</refsection> + + +<refsection><title>Options</title> + +<variablelist> + + <varlistentry><term><option>--flat</option></term> + + <listitem><para>Print the cryptographic hash of the contents of + each regular file <replaceable>path</replaceable>. That is, do + not compute the hash over the dump of + <replaceable>path</replaceable>. The result is identical to that + produced by the GNU commands <command>md5sum</command> and + <command>sha1sum</command>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--base32</option></term> + + <listitem><para>Print the hash in a base-32 representation rather + than hexadecimal. This base-32 representation is more compact and + can be used in Nix expressions (such as in calls to + <function>fetchurl</function>).</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--truncate</option></term> + + <listitem><para>Truncate hashes longer than 160 bits (such as + SHA-256) to 160 bits.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--type</option> <replaceable>hashAlgo</replaceable></term> + + <listitem><para>Use the specified cryptographic hash algorithm, + which can be one of <literal>md5</literal>, + <literal>sha1</literal>, and + <literal>sha256</literal>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--to-base16</option></term> + + <listitem><para>Don’t hash anything, but convert the base-32 hash + representation <replaceable>hash</replaceable> to + hexadecimal.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--to-base32</option></term> + + <listitem><para>Don’t hash anything, but convert the hexadecimal + hash representation <replaceable>hash</replaceable> to + base-32.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>Computing the same hash as <command>nix-prefetch-url</command>: +<screen> +$ nix-prefetch-url file://<(echo test) +1lkgqb6fclns49861dwk9rzb6xnfkxbpws74mxnx01z9qyv1pjpj +$ nix-hash --type sha256 --flat --base32 <(echo test) +1lkgqb6fclns49861dwk9rzb6xnfkxbpws74mxnx01z9qyv1pjpj +</screen> +</para> + +<para>Computing hashes: + +<screen> +$ mkdir test +$ echo "hello" > test/world + +$ nix-hash test/ <lineannotation>(MD5 hash; default)</lineannotation> +8179d3caeff1869b5ba1744e5a245c04 + +$ nix-store --dump test/ | md5sum <lineannotation>(for comparison)</lineannotation> +8179d3caeff1869b5ba1744e5a245c04 - + +$ nix-hash --type sha1 test/ +e4fd8ba5f7bbeaea5ace89fe10255536cd60dab6 + +$ nix-hash --type sha1 --base32 test/ +nvd61k9nalji1zl9rrdfmsmvyyjqpzg4 + +$ nix-hash --type sha256 --flat test/ +error: reading file `test/': Is a directory + +$ nix-hash --type sha256 --flat test/world +5891b5b522d5df086d0ff0b110fbd9d21bb4fc7163af34d08286a2e846f6be03</screen> + +</para> + +<para>Converting between hexadecimal and base-32: + +<screen> +$ nix-hash --type sha1 --to-base32 e4fd8ba5f7bbeaea5ace89fe10255536cd60dab6 +nvd61k9nalji1zl9rrdfmsmvyyjqpzg4 + +$ nix-hash --type sha1 --to-base16 nvd61k9nalji1zl9rrdfmsmvyyjqpzg4 +e4fd8ba5f7bbeaea5ace89fe10255536cd60dab6</screen> + +</para> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-instantiate.xml b/third_party/nix/doc/manual/command-ref/nix-instantiate.xml new file mode 100644 index 0000000000..53f06aed12 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-instantiate.xml @@ -0,0 +1,266 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-instantiate"> + +<refmeta> + <refentrytitle>nix-instantiate</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-instantiate</refname> + <refpurpose>instantiate store derivations from Nix expressions</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-instantiate</command> + <group> + <arg choice='plain'><option>--parse</option></arg> + <arg choice='plain'> + <option>--eval</option> + <arg><option>--strict</option></arg> + <arg><option>--json</option></arg> + <arg><option>--xml</option></arg> + </arg> + </group> + <arg><option>--read-write-mode</option></arg> + <arg><option>--arg</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--attr</option></arg> + <arg choice='plain'><option>-A</option></arg> + </group> + <replaceable>attrPath</replaceable> + </arg> + <arg><option>--add-root</option> <replaceable>path</replaceable></arg> + <arg><option>--indirect</option></arg> + <group> + <arg choice='plain'><option>--expr</option></arg> + <arg choice='plain'><option>-E</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>files</replaceable></arg> + </cmdsynopsis> + <cmdsynopsis> + <command>nix-instantiate</command> + <arg choice='plain'><option>--find-file</option></arg> + <arg choice='plain' rep='repeat'><replaceable>files</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + + +<refsection><title>Description</title> + +<para>The command <command>nix-instantiate</command> generates <link +linkend="gloss-derivation">store derivations</link> from (high-level) +Nix expressions. It evaluates the Nix expressions in each of +<replaceable>files</replaceable> (which defaults to +<replaceable>./default.nix</replaceable>). Each top-level expression +should evaluate to a derivation, a list of derivations, or a set of +derivations. The paths of the resulting store derivations are printed +on standard output.</para> + +<para>If <replaceable>files</replaceable> is the character +<literal>-</literal>, then a Nix expression will be read from standard +input.</para> + +<para condition="manual">See also <xref linkend="sec-common-options" +/> for a list of common options.</para> + +</refsection> + + +<refsection><title>Options</title> + +<variablelist> + + <varlistentry> + <term><option>--add-root</option> <replaceable>path</replaceable></term> + <term><option>--indirect</option></term> + + <listitem><para>See the <link linkend="opt-add-root">corresponding + options</link> in <command>nix-store</command>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--parse</option></term> + + <listitem><para>Just parse the input files, and print their + abstract syntax trees on standard output in ATerm + format.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--eval</option></term> + + <listitem><para>Just parse and evaluate the input files, and print + the resulting values on standard output. No instantiation of + store derivations takes place.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--find-file</option></term> + + <listitem><para>Look up the given files in Nix’s search path (as + specified by the <envar linkend="env-NIX_PATH">NIX_PATH</envar> + environment variable). If found, print the corresponding absolute + paths on standard output. For instance, if + <envar>NIX_PATH</envar> is + <literal>nixpkgs=/home/alice/nixpkgs</literal>, then + <literal>nix-instantiate --find-file nixpkgs/default.nix</literal> + will print + <literal>/home/alice/nixpkgs/default.nix</literal>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--strict</option></term> + + <listitem><para>When used with <option>--eval</option>, + recursively evaluate list elements and attributes. Normally, such + sub-expressions are left unevaluated (since the Nix expression + language is lazy).</para> + + <warning><para>This option can cause non-termination, because lazy + data structures can be infinitely large.</para></warning> + + </listitem> + + </varlistentry> + + <varlistentry><term><option>--json</option></term> + + <listitem><para>When used with <option>--eval</option>, print the resulting + value as an JSON representation of the abstract syntax tree rather + than as an ATerm.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--xml</option></term> + + <listitem><para>When used with <option>--eval</option>, print the resulting + value as an XML representation of the abstract syntax tree rather than as + an ATerm. The schema is the same as that used by the <link + linkend="builtin-toXML"><function>toXML</function> built-in</link>. + </para></listitem> + + </varlistentry> + + <varlistentry><term><option>--read-write-mode</option></term> + + <listitem><para>When used with <option>--eval</option>, perform + evaluation in read/write mode so nix language features that + require it will still work (at the cost of needing to do + instantiation of every evaluated derivation). If this option is + not enabled, there may be uninstantiated store paths in the final + output.</para> + + </listitem> + + </varlistentry> + +</variablelist> + +<variablelist condition="manpage"> + <xi:include href="opt-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='opt-common']/*)" /> +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>Instantiating store derivations from a Nix expression, and +building them using <command>nix-store</command>: + +<screen> +$ nix-instantiate test.nix <lineannotation>(instantiate)</lineannotation> +/nix/store/cigxbmvy6dzix98dxxh9b6shg7ar5bvs-perl-BerkeleyDB-0.26.drv + +$ nix-store -r $(nix-instantiate test.nix) <lineannotation>(build)</lineannotation> +<replaceable>...</replaceable> +/nix/store/qhqk4n8ci095g3sdp93x7rgwyh9rdvgk-perl-BerkeleyDB-0.26 <lineannotation>(output path)</lineannotation> + +$ ls -l /nix/store/qhqk4n8ci095g3sdp93x7rgwyh9rdvgk-perl-BerkeleyDB-0.26 +dr-xr-xr-x 2 eelco users 4096 1970-01-01 01:00 lib +...</screen> + +</para> + +<para>You can also give a Nix expression on the command line: + +<screen> +$ nix-instantiate -E 'with import <nixpkgs> { }; hello' +/nix/store/j8s4zyv75a724q38cb0r87rlczaiag4y-hello-2.8.drv +</screen> + +This is equivalent to: + +<screen> +$ nix-instantiate '<nixpkgs>' -A hello +</screen> + +</para> + +<para>Parsing and evaluating Nix expressions: + +<screen> +$ nix-instantiate --parse -E '1 + 2' +1 + 2 + +$ nix-instantiate --eval -E '1 + 2' +3 + +$ nix-instantiate --eval --xml -E '1 + 2' +<![CDATA[<?xml version='1.0' encoding='utf-8'?> +<expr> + <int value="3" /> +</expr>]]></screen> + +</para> + +<para>The difference between non-strict and strict evaluation: + +<screen> +$ nix-instantiate --eval --xml -E 'rec { x = "foo"; y = x; }' +<replaceable>...</replaceable><![CDATA[ + <attr name="x"> + <string value="foo" /> + </attr> + <attr name="y"> + <unevaluated /> + </attr>]]> +<replaceable>...</replaceable></screen> + +Note that <varname>y</varname> is left unevaluated (the XML +representation doesn’t attempt to show non-normal forms). + +<screen> +$ nix-instantiate --eval --xml --strict -E 'rec { x = "foo"; y = x; }' +<replaceable>...</replaceable><![CDATA[ + <attr name="x"> + <string value="foo" /> + </attr> + <attr name="y"> + <string value="foo" /> + </attr>]]> +<replaceable>...</replaceable></screen> + +</para> + +</refsection> + + +<refsection condition="manpage"><title>Environment variables</title> + +<variablelist> + <xi:include href="env-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='env-common']/*)" /> +</variablelist> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-prefetch-url.xml b/third_party/nix/doc/manual/command-ref/nix-prefetch-url.xml new file mode 100644 index 0000000000..621ded72ec --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-prefetch-url.xml @@ -0,0 +1,131 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-prefetch-url"> + +<refmeta> + <refentrytitle>nix-prefetch-url</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-prefetch-url</refname> + <refpurpose>copy a file from a URL into the store and print its hash</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-prefetch-url</command> + <arg><option>--version</option></arg> + <arg><option>--type</option> <replaceable>hashAlgo</replaceable></arg> + <arg><option>--print-path</option></arg> + <arg><option>--unpack</option></arg> + <arg><option>--name</option> <replaceable>name</replaceable></arg> + <arg choice='plain'><replaceable>url</replaceable></arg> + <arg><replaceable>hash</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + +<refsection><title>Description</title> + +<para>The command <command>nix-prefetch-url</command> downloads the +file referenced by the URL <replaceable>url</replaceable>, prints its +cryptographic hash, and copies it into the Nix store. The file name +in the store is +<filename><replaceable>hash</replaceable>-<replaceable>baseName</replaceable></filename>, +where <replaceable>baseName</replaceable> is everything following the +final slash in <replaceable>url</replaceable>.</para> + +<para>This command is just a convenience for Nix expression writers. +Often a Nix expression fetches some source distribution from the +network using the <literal>fetchurl</literal> expression contained in +Nixpkgs. However, <literal>fetchurl</literal> requires a +cryptographic hash. If you don't know the hash, you would have to +download the file first, and then <literal>fetchurl</literal> would +download it again when you build your Nix expression. Since +<literal>fetchurl</literal> uses the same name for the downloaded file +as <command>nix-prefetch-url</command>, the redundant download can be +avoided.</para> + +<para>If <replaceable>hash</replaceable> is specified, then a download +is not performed if the Nix store already contains a file with the +same hash and base name. Otherwise, the file is downloaded, and an +error is signaled if the actual hash of the file does not match the +specified hash.</para> + +<para>This command prints the hash on standard output. Additionally, +if the option <option>--print-path</option> is used, the path of the +downloaded file in the Nix store is also printed.</para> + +</refsection> + + +<refsection><title>Options</title> + +<variablelist> + + <varlistentry><term><option>--type</option> <replaceable>hashAlgo</replaceable></term> + + <listitem><para>Use the specified cryptographic hash algorithm, + which can be one of <literal>md5</literal>, + <literal>sha1</literal>, and + <literal>sha256</literal>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--print-path</option></term> + + <listitem><para>Print the store path of the downloaded file on + standard output.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--unpack</option></term> + + <listitem><para>Unpack the archive (which must be a tarball or zip + file) and add the result to the Nix store. The resulting hash can + be used with functions such as Nixpkgs’s + <varname>fetchzip</varname> or + <varname>fetchFromGitHub</varname>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--name</option> <replaceable>name</replaceable></term> + + <listitem><para>Override the name of the file in the Nix store. By + default, this is + <literal><replaceable>hash</replaceable>-<replaceable>basename</replaceable></literal>, + where <replaceable>basename</replaceable> is the last component of + <replaceable>url</replaceable>. Overriding the name is necessary + when <replaceable>basename</replaceable> contains characters that + are not allowed in Nix store paths.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<screen> +$ nix-prefetch-url ftp://ftp.gnu.org/pub/gnu/hello/hello-2.10.tar.gz +0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i + +$ nix-prefetch-url --print-path mirror://gnu/hello/hello-2.10.tar.gz +0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i +/nix/store/3x7dwzq014bblazs7kq20p9hyzz0qh8g-hello-2.10.tar.gz + +$ nix-prefetch-url --unpack --print-path https://github.com/NixOS/patchelf/archive/0.8.tar.gz +079agjlv0hrv7fxnx9ngipx14gyncbkllxrp9cccnh3a50fxcmy7 +/nix/store/19zrmhm3m40xxaw81c8cqm6aljgrnwj2-0.8.tar.gz +</screen> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-shell.xml b/third_party/nix/doc/manual/command-ref/nix-shell.xml new file mode 100644 index 0000000000..bb4a4e4201 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-shell.xml @@ -0,0 +1,397 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-shell"> + +<refmeta> + <refentrytitle>nix-shell</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-shell</refname> + <refpurpose>start an interactive shell based on a Nix expression</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-shell</command> + <arg><option>--arg</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg><option>--argstr</option> <replaceable>name</replaceable> <replaceable>value</replaceable></arg> + <arg> + <group choice='req'> + <arg choice='plain'><option>--attr</option></arg> + <arg choice='plain'><option>-A</option></arg> + </group> + <replaceable>attrPath</replaceable> + </arg> + <arg><option>--command</option> <replaceable>cmd</replaceable></arg> + <arg><option>--run</option> <replaceable>cmd</replaceable></arg> + <arg><option>--exclude</option> <replaceable>regexp</replaceable></arg> + <arg><option>--pure</option></arg> + <arg><option>--keep</option> <replaceable>name</replaceable></arg> + <group choice='req'> + <arg choice='plain'> + <group choice='req'> + <arg choice='plain'><option>--packages</option></arg> + <arg choice='plain'><option>-p</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>packages</replaceable></arg> + </arg> + <arg><replaceable>path</replaceable></arg> + </group> + </cmdsynopsis> +</refsynopsisdiv> + +<refsection><title>Description</title> + +<para>The command <command>nix-shell</command> will build the +dependencies of the specified derivation, but not the derivation +itself. It will then start an interactive shell in which all +environment variables defined by the derivation +<replaceable>path</replaceable> have been set to their corresponding +values, and the script <literal>$stdenv/setup</literal> has been +sourced. This is useful for reproducing the environment of a +derivation for development.</para> + +<para>If <replaceable>path</replaceable> is not given, +<command>nix-shell</command> defaults to +<filename>shell.nix</filename> if it exists, and +<filename>default.nix</filename> otherwise.</para> + +<para>If <replaceable>path</replaceable> starts with +<literal>http://</literal> or <literal>https://</literal>, it is +interpreted as the URL of a tarball that will be downloaded and +unpacked to a temporary location. The tarball must include a single +top-level directory containing at least a file named +<filename>default.nix</filename>.</para> + +<para>If the derivation defines the variable +<varname>shellHook</varname>, it will be evaluated after +<literal>$stdenv/setup</literal> has been sourced. Since this hook is +not executed by regular Nix builds, it allows you to perform +initialisation specific to <command>nix-shell</command>. For example, +the derivation attribute + +<programlisting> +shellHook = + '' + echo "Hello shell" + ''; +</programlisting> + +will cause <command>nix-shell</command> to print <literal>Hello shell</literal>.</para> + +</refsection> + + +<refsection><title>Options</title> + +<para>All options not listed here are passed to <command>nix-store +--realise</command>, except for <option>--arg</option> and +<option>--attr</option> / <option>-A</option> which are passed to +<command>nix-instantiate</command>. <phrase condition="manual">See +also <xref linkend="sec-common-options" />.</phrase></para> + +<variablelist> + + <varlistentry><term><option>--command</option> <replaceable>cmd</replaceable></term> + + <listitem><para>In the environment of the derivation, run the + shell command <replaceable>cmd</replaceable>. This command is + executed in an interactive shell. (Use <option>--run</option> to + use a non-interactive shell instead.) However, a call to + <literal>exit</literal> is implicitly added to the command, so the + shell will exit after running the command. To prevent this, add + <literal>return</literal> at the end; e.g. <literal>--command + "echo Hello; return"</literal> will print <literal>Hello</literal> + and then drop you into the interactive shell. This can be useful + for doing any additional initialisation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--run</option> <replaceable>cmd</replaceable></term> + + <listitem><para>Like <option>--command</option>, but executes the + command in a non-interactive shell. This means (among other + things) that if you hit Ctrl-C while the command is running, the + shell exits.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--exclude</option> <replaceable>regexp</replaceable></term> + + <listitem><para>Do not build any dependencies whose store path + matches the regular expression <replaceable>regexp</replaceable>. + This option may be specified multiple times.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--pure</option></term> + + <listitem><para>If this flag is specified, the environment is + almost entirely cleared before the interactive shell is started, + so you get an environment that more closely corresponds to the + “real” Nix build. A few variables, in particular + <envar>HOME</envar>, <envar>USER</envar> and + <envar>DISPLAY</envar>, are retained. Note that + <filename>~/.bashrc</filename> and (depending on your Bash + installation) <filename>/etc/bashrc</filename> are still sourced, + so any variables set there will affect the interactive + shell.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--packages</option> / <option>-p</option> <replaceable>packages</replaceable>…</term> + + <listitem><para>Set up an environment in which the specified + packages are present. The command line arguments are interpreted + as attribute names inside the Nix Packages collection. Thus, + <literal>nix-shell -p libjpeg openjdk</literal> will start a shell + in which the packages denoted by the attribute names + <varname>libjpeg</varname> and <varname>openjdk</varname> are + present.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>-i</option> <replaceable>interpreter</replaceable></term> + + <listitem><para>The chained script interpreter to be invoked by + <command>nix-shell</command>. Only applicable in + <literal>#!</literal>-scripts (described <link + linkend="ssec-nix-shell-shebang">below</link>).</para> + + </listitem></varlistentry> + + <varlistentry><term><option>--keep</option> <replaceable>name</replaceable></term> + + <listitem><para>When a <option>--pure</option> shell is started, + keep the listed environment variables.</para></listitem> + + </varlistentry> + +</variablelist> + +<para>The following common options are supported:</para> + +<variablelist condition="manpage"> + <xi:include href="opt-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='opt-common']/*)" /> +</variablelist> + +</refsection> + + +<refsection><title>Environment variables</title> + +<variablelist> + + <varlistentry><term><envar>NIX_BUILD_SHELL</envar></term> + + <listitem><para>Shell used to start the interactive environment. + Defaults to the <command>bash</command> found in <envar>PATH</envar>.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>To build the dependencies of the package Pan, and start an +interactive shell in which to build it: + +<screen> +$ nix-shell '<nixpkgs>' -A pan +[nix-shell]$ unpackPhase +[nix-shell]$ cd pan-* +[nix-shell]$ configurePhase +[nix-shell]$ buildPhase +[nix-shell]$ ./pan/gui/pan +</screen> + +To clear the environment first, and do some additional automatic +initialisation of the interactive shell: + +<screen> +$ nix-shell '<nixpkgs>' -A pan --pure \ + --command 'export NIX_DEBUG=1; export NIX_CORES=8; return' +</screen> + +Nix expressions can also be given on the command line. For instance, +the following starts a shell containing the packages +<literal>sqlite</literal> and <literal>libX11</literal>: + +<screen> +$ nix-shell -E 'with import <nixpkgs> { }; runCommand "dummy" { buildInputs = [ sqlite xorg.libX11 ]; } ""' +</screen> + +A shorter way to do the same is: + +<screen> +$ nix-shell -p sqlite xorg.libX11 +[nix-shell]$ echo $NIX_LDFLAGS +… -L/nix/store/j1zg5v…-sqlite-3.8.0.2/lib -L/nix/store/0gmcz9…-libX11-1.6.1/lib … +</screen> + +The <command>-p</command> flag looks up Nixpkgs in the Nix search +path. You can override it by passing <option>-I</option> or setting +<envar>NIX_PATH</envar>. For example, the following gives you a shell +containing the Pan package from a specific revision of Nixpkgs: + +<screen> +$ nix-shell -p pan -I nixpkgs=https://github.com/NixOS/nixpkgs-channels/archive/8a3eea054838b55aca962c3fbde9c83c102b8bf2.tar.gz + +[nix-shell:~]$ pan --version +Pan 0.139 +</screen> + +</para> + +</refsection> + + +<refsection xml:id="ssec-nix-shell-shebang"><title>Use as a <literal>#!</literal>-interpreter</title> + +<para>You can use <command>nix-shell</command> as a script interpreter +to allow scripts written in arbitrary languages to obtain their own +dependencies via Nix. This is done by starting the script with the +following lines: + +<programlisting> +#! /usr/bin/env nix-shell +#! nix-shell -i <replaceable>real-interpreter</replaceable> -p <replaceable>packages</replaceable> +</programlisting> + +where <replaceable>real-interpreter</replaceable> is the “real” script +interpreter that will be invoked by <command>nix-shell</command> after +it has obtained the dependencies and initialised the environment, and +<replaceable>packages</replaceable> are the attribute names of the +dependencies in Nixpkgs.</para> + +<para>The lines starting with <literal>#! nix-shell</literal> specify +<command>nix-shell</command> options (see above). Note that you cannot +write <literal>#! /usr/bin/env nix-shell -i ...</literal> because +many operating systems only allow one argument in +<literal>#!</literal> lines.</para> + +<para>For example, here is a Python script that depends on Python and +the <literal>prettytable</literal> package: + +<programlisting> +#! /usr/bin/env nix-shell +#! nix-shell -i python -p python pythonPackages.prettytable + +import prettytable + +# Print a simple table. +t = prettytable.PrettyTable(["N", "N^2"]) +for n in range(1, 10): t.add_row([n, n * n]) +print t +</programlisting> + +</para> + +<para>Similarly, the following is a Perl script that specifies that it +requires Perl and the <literal>HTML::TokeParser::Simple</literal> and +<literal>LWP</literal> packages: + +<programlisting> +#! /usr/bin/env nix-shell +#! nix-shell -i perl -p perl perlPackages.HTMLTokeParserSimple perlPackages.LWP + +use HTML::TokeParser::Simple; + +# Fetch nixos.org and print all hrefs. +my $p = HTML::TokeParser::Simple->new(url => 'http://nixos.org/'); + +while (my $token = $p->get_tag("a")) { + my $href = $token->get_attr("href"); + print "$href\n" if $href; +} +</programlisting> + +</para> + +<para>Sometimes you need to pass a simple Nix expression to customize +a package like Terraform: + +<programlisting><![CDATA[ +#! /usr/bin/env nix-shell +#! nix-shell -i bash -p "terraform.withPlugins (plugins: [ plugins.openstack ])" + +terraform apply +]]></programlisting> + +<note><para>You must use double quotes (<literal>"</literal>) when +passing a simple Nix expression in a nix-shell shebang.</para></note> +</para> + +<para>Finally, using the merging of multiple nix-shell shebangs the +following Haskell script uses a specific branch of Nixpkgs/NixOS (the +18.03 stable branch): + +<programlisting><![CDATA[ +#! /usr/bin/env nix-shell +#! nix-shell -i runghc -p "haskellPackages.ghcWithPackages (ps: [ps.HTTP ps.tagsoup])" +#! nix-shell -I nixpkgs=https://github.com/NixOS/nixpkgs-channels/archive/nixos-18.03.tar.gz + +import Network.HTTP +import Text.HTML.TagSoup + +-- Fetch nixos.org and print all hrefs. +main = do + resp <- Network.HTTP.simpleHTTP (getRequest "http://nixos.org/") + body <- getResponseBody resp + let tags = filter (isTagOpenName "a") $ parseTags body + let tags' = map (fromAttrib "href") tags + mapM_ putStrLn $ filter (/= "") tags' +]]></programlisting> + +If you want to be even more precise, you can specify a specific +revision of Nixpkgs: + +<programlisting> +#! nix-shell -I nixpkgs=https://github.com/NixOS/nixpkgs-channels/archive/0672315759b3e15e2121365f067c1c8c56bb4722.tar.gz +</programlisting> + +</para> + +<para>The examples above all used <option>-p</option> to get +dependencies from Nixpkgs. You can also use a Nix expression to build +your own dependencies. For example, the Python example could have been +written as: + +<programlisting> +#! /usr/bin/env nix-shell +#! nix-shell deps.nix -i python +</programlisting> + +where the file <filename>deps.nix</filename> in the same directory +as the <literal>#!</literal>-script contains: + +<programlisting> +with import <nixpkgs> {}; + +runCommand "dummy" { buildInputs = [ python pythonPackages.prettytable ]; } "" +</programlisting> + +</para> + +</refsection> + + +<refsection condition="manpage"><title>Environment variables</title> + +<variablelist> + <xi:include href="env-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='env-common']/*)" /> +</variablelist> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/nix-store.xml b/third_party/nix/doc/manual/command-ref/nix-store.xml new file mode 100644 index 0000000000..113a3c2e41 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/nix-store.xml @@ -0,0 +1,1525 @@ +<refentry xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-nix-store"> + +<refmeta> + <refentrytitle>nix-store</refentrytitle> + <manvolnum>1</manvolnum> + <refmiscinfo class="source">Nix</refmiscinfo> + <refmiscinfo class="version"><xi:include href="../version.txt" parse="text"/></refmiscinfo> +</refmeta> + +<refnamediv> + <refname>nix-store</refname> + <refpurpose>manipulate or query the Nix store</refpurpose> +</refnamediv> + +<refsynopsisdiv> + <cmdsynopsis> + <command>nix-store</command> + <xi:include xmlns:xi="http://www.w3.org/2001/XInclude" href="opt-common-syn.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(/db:nop/*)" /> + <arg><option>--add-root</option> <replaceable>path</replaceable></arg> + <arg><option>--indirect</option></arg> + <arg choice='plain'><replaceable>operation</replaceable></arg> + <arg rep='repeat'><replaceable>options</replaceable></arg> + <arg rep='repeat'><replaceable>arguments</replaceable></arg> + </cmdsynopsis> +</refsynopsisdiv> + + +<refsection><title>Description</title> + +<para>The command <command>nix-store</command> performs primitive +operations on the Nix store. You generally do not need to run this +command manually.</para> + +<para><command>nix-store</command> takes exactly one +<emphasis>operation</emphasis> flag which indicates the subcommand to +be performed. These are documented below.</para> + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Common options</title> + +<para>This section lists the options that are common to all +operations. These options are allowed for every subcommand, though +they may not always have an effect. <phrase condition="manual">See +also <xref linkend="sec-common-options" /> for a list of common +options.</phrase></para> + +<variablelist> + + <varlistentry xml:id="opt-add-root"><term><option>--add-root</option> <replaceable>path</replaceable></term> + + <listitem><para>Causes the result of a realisation + (<option>--realise</option> and <option>--force-realise</option>) + to be registered as a root of the garbage collector<phrase + condition="manual"> (see <xref linkend="ssec-gc-roots" + />)</phrase>. The root is stored in + <replaceable>path</replaceable>, which must be inside a directory + that is scanned for roots by the garbage collector (i.e., + typically in a subdirectory of + <filename>/nix/var/nix/gcroots/</filename>) + <emphasis>unless</emphasis> the <option>--indirect</option> flag + is used.</para> + + <para>If there are multiple results, then multiple symlinks will + be created by sequentially numbering symlinks beyond the first one + (e.g., <filename>foo</filename>, <filename>foo-2</filename>, + <filename>foo-3</filename>, and so on).</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--indirect</option></term> + + <listitem> + + <para>In conjunction with <option>--add-root</option>, this option + allows roots to be stored <emphasis>outside</emphasis> of the GC + roots directory. This is useful for commands such as + <command>nix-build</command> that place a symlink to the build + result in the current directory; such a build result should not be + garbage-collected unless the symlink is removed.</para> + + <para>The <option>--indirect</option> flag causes a uniquely named + symlink to <replaceable>path</replaceable> to be stored in + <filename>/nix/var/nix/gcroots/auto/</filename>. For instance, + + <screen> +$ nix-store --add-root /home/eelco/bla/result --indirect -r <replaceable>...</replaceable> + +$ ls -l /nix/var/nix/gcroots/auto +lrwxrwxrwx 1 ... 2005-03-13 21:10 dn54lcypm8f8... -> /home/eelco/bla/result + +$ ls -l /home/eelco/bla/result +lrwxrwxrwx 1 ... 2005-03-13 21:10 /home/eelco/bla/result -> /nix/store/1r11343n6qd4...-f-spot-0.0.10</screen> + + Thus, when <filename>/home/eelco/bla/result</filename> is removed, + the GC root in the <filename>auto</filename> directory becomes a + dangling symlink and will be ignored by the collector.</para> + + <warning><para>Note that it is not possible to move or rename + indirect GC roots, since the symlink in the + <filename>auto</filename> directory will still point to the old + location.</para></warning> + + </listitem> + + </varlistentry> + +</variablelist> + +<variablelist condition="manpage"> + <xi:include href="opt-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='opt-common']/*)" /> +</variablelist> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id='rsec-nix-store-realise'><title>Operation <option>--realise</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <group choice='req'> + <arg choice='plain'><option>--realise</option></arg> + <arg choice='plain'><option>-r</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> + <arg><option>--dry-run</option></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--realise</option> essentially “builds” +the specified store paths. Realisation is a somewhat overloaded term: + +<itemizedlist> + + <listitem><para>If the store path is a + <emphasis>derivation</emphasis>, realisation ensures that the output + paths of the derivation are <link + linkend="gloss-validity">valid</link> (i.e., the output path and its + closure exist in the file system). This can be done in several + ways. First, it is possible that the outputs are already valid, in + which case we are done immediately. Otherwise, there may be <link + linkend="gloss-substitute">substitutes</link> that produce the + outputs (e.g., by downloading them). Finally, the outputs can be + produced by performing the build action described by the + derivation.</para></listitem> + + <listitem><para>If the store path is not a derivation, realisation + ensures that the specified path is valid (i.e., it and its closure + exist in the file system). If the path is already valid, we are + done immediately. Otherwise, the path and any missing paths in its + closure may be produced through substitutes. If there are no + (successful) subsitutes, realisation fails.</para></listitem> + +</itemizedlist> + +</para> + +<para>The output path of each derivation is printed on standard +output. (For non-derivations argument, the argument itself is +printed.)</para> + +<para>The following flags are available:</para> + +<variablelist> + + <varlistentry><term><option>--dry-run</option></term> + + <listitem><para>Print on standard error a description of what + packages would be built or downloaded, without actually performing + the operation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--ignore-unknown</option></term> + + <listitem><para>If a non-derivation path does not have a + substitute, then silently ignore it.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--check</option></term> + + <listitem><para>This option allows you to check whether a + derivation is deterministic. It rebuilds the specified derivation + and checks whether the result is bitwise-identical with the + existing outputs, printing an error if that’s not the case. The + outputs of the specified derivation must already exist. When used + with <option>-K</option>, if an output path is not identical to + the corresponding output from the previous build, the new output + path is left in + <filename>/nix/store/<replaceable>name</replaceable>.check.</filename></para> + + <para>See also the <option>build-repeat</option> configuration + option, which repeats a derivation a number of times and prevents + its outputs from being registered as “valid” in the Nix store + unless they are identical.</para></listitem> + + </varlistentry> + +</variablelist> + +<para>Special exit codes:</para> + +<variablelist> + + <varlistentry><term><literal>100</literal></term> + <listitem><para>Generic build failure, the builder process + returned with a non-zero exit code.</para></listitem> + </varlistentry> + + <varlistentry><term><literal>101</literal></term> + <listitem><para>Build timeout, the build was aborted because it + did not complete within the specified <link + linkend='conf-timeout'><literal>timeout</literal></link>. + </para></listitem> + </varlistentry> + + <varlistentry><term><literal>102</literal></term> + <listitem><para>Hash mismatch, the build output was rejected + because it does not match the specified <link + linkend="fixed-output-drvs"><varname>outputHash</varname></link>. + </para></listitem> + </varlistentry> + + <varlistentry><term><literal>104</literal></term> + <listitem><para>Not deterministic, the build succeeded in check + mode but the resulting output is not binary reproducable.</para> + </listitem> + </varlistentry> + +</variablelist> + +<para>With the <option>--keep-going</option> flag it's possible for +multiple failures to occur, in this case the 1xx status codes are or combined +using binary or. <screen> +1100100 + ^^^^ + |||`- timeout + ||`-- output hash mismatch + |`--- build failure + `---- not deterministic +</screen></para> + +</refsection> + + +<refsection><title>Examples</title> + +<para>This operation is typically used to build store derivations +produced by <link +linkend="sec-nix-instantiate"><command>nix-instantiate</command></link>: + +<screen> +$ nix-store -r $(nix-instantiate ./test.nix) +/nix/store/31axcgrlbfsxzmfff1gyj1bf62hvkby2-aterm-2.3.1</screen> + +This is essentially what <link +linkend="sec-nix-build"><command>nix-build</command></link> does.</para> + +<para>To test whether a previously-built derivation is deterministic: + +<screen> +$ nix-build '<nixpkgs>' -A hello --check -K +</screen> + +</para> + +</refsection> + + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id='rsec-nix-store-serve'><title>Operation <option>--serve</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--serve</option></arg> + <arg><option>--write</option></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--serve</option> provides access to +the Nix store over stdin and stdout, and is intended to be used +as a means of providing Nix store access to a restricted ssh user. +</para> + +<para>The following flags are available:</para> + +<variablelist> + + <varlistentry><term><option>--write</option></term> + + <listitem><para>Allow the connected client to request the realization + of derivations. In effect, this can be used to make the host act + as a remote builder.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>To turn a host into a build server, the +<filename>authorized_keys</filename> file can be used to provide build +access to a given SSH public key: + +<screen> +$ cat <<EOF >>/root/.ssh/authorized_keys +command="nice -n20 nix-store --serve --write" ssh-rsa AAAAB3NzaC1yc2EAAAA... +EOF +</screen> + +</para> + +</refsection> + + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id='rsec-nix-store-gc'><title>Operation <option>--gc</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--gc</option></arg> + <group> + <arg choice='plain'><option>--print-roots</option></arg> + <arg choice='plain'><option>--print-live</option></arg> + <arg choice='plain'><option>--print-dead</option></arg> + <arg choice='plain'><option>--delete</option></arg> + </group> + <arg><option>--max-freed</option> <replaceable>bytes</replaceable></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>Without additional flags, the operation <option>--gc</option> +performs a garbage collection on the Nix store. That is, all paths in +the Nix store not reachable via file system references from a set of +“roots”, are deleted.</para> + +<para>The following suboperations may be specified:</para> + +<variablelist> + + <varlistentry><term><option>--print-roots</option></term> + + <listitem><para>This operation prints on standard output the set + of roots used by the garbage collector. What constitutes a root + is described in <xref linkend="ssec-gc-roots" + />.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--print-live</option></term> + + <listitem><para>This operation prints on standard output the set + of “live” store paths, which are all the store paths reachable + from the roots. Live paths should never be deleted, since that + would break consistency — it would become possible that + applications are installed that reference things that are no + longer present in the store.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--print-dead</option></term> + + <listitem><para>This operation prints out on standard output the + set of “dead” store paths, which is just the opposite of the set + of live paths: any path in the store that is not live (with + respect to the roots) is dead.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--delete</option></term> + + <listitem><para>This operation performs an actual garbage + collection. All dead paths are removed from the + store. This is the default.</para></listitem> + + </varlistentry> + +</variablelist> + +<para>By default, all unreachable paths are deleted. The following +options control what gets deleted and in what order: + +<variablelist> + + <varlistentry><term><option>--max-freed</option> <replaceable>bytes</replaceable></term> + + <listitem><para>Keep deleting paths until at least + <replaceable>bytes</replaceable> bytes have been deleted, then + stop. The argument <replaceable>bytes</replaceable> can be + followed by the multiplicative suffix <literal>K</literal>, + <literal>M</literal>, <literal>G</literal> or + <literal>T</literal>, denoting KiB, MiB, GiB or TiB + units.</para></listitem> + + </varlistentry> + +</variablelist> + +</para> + +<para>The behaviour of the collector is also influenced by the <link +linkend="conf-keep-outputs"><literal>keep-outputs</literal></link> +and <link +linkend="conf-keep-derivations"><literal>keep-derivations</literal></link> +variables in the Nix configuration file.</para> + +<para>With <option>--delete</option>, the collector prints the total +number of freed bytes when it finishes (or when it is interrupted). +With <option>--print-dead</option>, it prints the number of bytes that +would be freed.</para> + +</refsection> + + +<refsection><title>Examples</title> + +<para>To delete all unreachable paths, just do: + +<screen> +$ nix-store --gc +deleting `/nix/store/kq82idx6g0nyzsp2s14gfsc38npai7lf-cairo-1.0.4.tar.gz.drv' +<replaceable>...</replaceable> +8825586 bytes freed (8.42 MiB)</screen> + +</para> + +<para>To delete at least 100 MiBs of unreachable paths: + +<screen> +$ nix-store --gc --max-freed $((100 * 1024 * 1024))</screen> + +</para> + +</refsection> + + +</refsection> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--delete</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--delete</option></arg> + <arg><option>--ignore-liveness</option></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--delete</option> deletes the store paths +<replaceable>paths</replaceable> from the Nix store, but only if it is +safe to do so; that is, when the path is not reachable from a root of +the garbage collector. This means that you can only delete paths that +would also be deleted by <literal>nix-store --gc</literal>. Thus, +<literal>--delete</literal> is a more targeted version of +<literal>--gc</literal>.</para> + +<para>With the option <option>--ignore-liveness</option>, reachability +from the roots is ignored. However, the path still won’t be deleted +if there are other paths in the store that refer to it (i.e., depend +on it).</para> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store --delete /nix/store/zq0h41l75vlb4z45kzgjjmsjxvcv1qk7-mesa-6.4 +0 bytes freed (0.00 MiB) +error: cannot delete path `/nix/store/zq0h41l75vlb4z45kzgjjmsjxvcv1qk7-mesa-6.4' since it is still alive</screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id='refsec-nix-store-query'><title>Operation <option>--query</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <group choice='req'> + <arg choice='plain'><option>--query</option></arg> + <arg choice='plain'><option>-q</option></arg> + </group> + <group choice='req'> + <arg choice='plain'><option>--outputs</option></arg> + <arg choice='plain'><option>--requisites</option></arg> + <arg choice='plain'><option>-R</option></arg> + <arg choice='plain'><option>--references</option></arg> + <arg choice='plain'><option>--referrers</option></arg> + <arg choice='plain'><option>--referrers-closure</option></arg> + <arg choice='plain'><option>--deriver</option></arg> + <arg choice='plain'><option>-d</option></arg> + <arg choice='plain'><option>--graph</option></arg> + <arg choice='plain'><option>--tree</option></arg> + <arg choice='plain'><option>--binding</option> <replaceable>name</replaceable></arg> + <arg choice='plain'><option>-b</option> <replaceable>name</replaceable></arg> + <arg choice='plain'><option>--hash</option></arg> + <arg choice='plain'><option>--size</option></arg> + <arg choice='plain'><option>--roots</option></arg> + </group> + <arg><option>--use-output</option></arg> + <arg><option>-u</option></arg> + <arg><option>--force-realise</option></arg> + <arg><option>-f</option></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> +</cmdsynopsis> + +</refsection> + + +<refsection><title>Description</title> + +<para>The operation <option>--query</option> displays various bits of +information about the store paths . The queries are described below. At +most one query can be specified. The default query is +<option>--outputs</option>.</para> + +<para>The paths <replaceable>paths</replaceable> may also be symlinks +from outside of the Nix store, to the Nix store. In that case, the +query is applied to the target of the symlink.</para> + + +</refsection> + + +<refsection><title>Common query options</title> + +<variablelist> + + <varlistentry><term><option>--use-output</option></term> + <term><option>-u</option></term> + + <listitem><para>For each argument to the query that is a store + derivation, apply the query to the output path of the derivation + instead.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--force-realise</option></term> + <term><option>-f</option></term> + + <listitem><para>Realise each argument to the query first (see + <link linkend="rsec-nix-store-realise"><command>nix-store + --realise</command></link>).</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection xml:id='nixref-queries'><title>Queries</title> + +<variablelist> + + <varlistentry><term><option>--outputs</option></term> + + <listitem><para>Prints out the <link + linkend="gloss-output-path">output paths</link> of the store + derivations <replaceable>paths</replaceable>. These are the paths + that will be produced when the derivation is + built.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--requisites</option></term> + <term><option>-R</option></term> + + <listitem><para>Prints out the <link + linkend="gloss-closure">closure</link> of the store path + <replaceable>paths</replaceable>.</para> + + <para>This query has one option:</para> + + <variablelist> + + <varlistentry><term><option>--include-outputs</option></term> + + <listitem><para>Also include the output path of store + derivations, and their closures.</para></listitem> + + </varlistentry> + + </variablelist> + + <para>This query can be used to implement various kinds of + deployment. A <emphasis>source deployment</emphasis> is obtained + by distributing the closure of a store derivation. A + <emphasis>binary deployment</emphasis> is obtained by distributing + the closure of an output path. A <emphasis>cache + deployment</emphasis> (combined source/binary deployment, + including binaries of build-time-only dependencies) is obtained by + distributing the closure of a store derivation and specifying the + option <option>--include-outputs</option>.</para> + + </listitem> + + </varlistentry> + + <varlistentry><term><option>--references</option></term> + + <listitem><para>Prints the set of <link + linkend="gloss-reference">references</link> of the store paths + <replaceable>paths</replaceable>, that is, their immediate + dependencies. (For <emphasis>all</emphasis> dependencies, use + <option>--requisites</option>.)</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--referrers</option></term> + + <listitem><para>Prints the set of <emphasis>referrers</emphasis> of + the store paths <replaceable>paths</replaceable>, that is, the + store paths currently existing in the Nix store that refer to one + of <replaceable>paths</replaceable>. Note that contrary to the + references, the set of referrers is not constant; it can change as + store paths are added or removed.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--referrers-closure</option></term> + + <listitem><para>Prints the closure of the set of store paths + <replaceable>paths</replaceable> under the referrers relation; that + is, all store paths that directly or indirectly refer to one of + <replaceable>paths</replaceable>. These are all the path currently + in the Nix store that are dependent on + <replaceable>paths</replaceable>.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--deriver</option></term> + <term><option>-d</option></term> + + <listitem><para>Prints the <link + linkend="gloss-deriver">deriver</link> of the store paths + <replaceable>paths</replaceable>. If the path has no deriver + (e.g., if it is a source file), or if the deriver is not known + (e.g., in the case of a binary-only deployment), the string + <literal>unknown-deriver</literal> is printed.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--graph</option></term> + + <listitem><para>Prints the references graph of the store paths + <replaceable>paths</replaceable> in the format of the + <command>dot</command> tool of AT&T's <link + xlink:href="http://www.graphviz.org/">Graphviz package</link>. + This can be used to visualise dependency graphs. To obtain a + build-time dependency graph, apply this to a store derivation. To + obtain a runtime dependency graph, apply it to an output + path.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--tree</option></term> + + <listitem><para>Prints the references graph of the store paths + <replaceable>paths</replaceable> as a nested ASCII tree. + References are ordered by descending closure size; this tends to + flatten the tree, making it more readable. The query only + recurses into a store path when it is first encountered; this + prevents a blowup of the tree representation of the + graph.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--graphml</option></term> + + <listitem><para>Prints the references graph of the store paths + <replaceable>paths</replaceable> in the <link + xlink:href="http://graphml.graphdrawing.org/">GraphML</link> file format. + This can be used to visualise dependency graphs. To obtain a + build-time dependency graph, apply this to a store derivation. To + obtain a runtime dependency graph, apply it to an output + path.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--binding</option> <replaceable>name</replaceable></term> + <term><option>-b</option> <replaceable>name</replaceable></term> + + <listitem><para>Prints the value of the attribute + <replaceable>name</replaceable> (i.e., environment variable) of + the store derivations <replaceable>paths</replaceable>. It is an + error for a derivation to not have the specified + attribute.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--hash</option></term> + + <listitem><para>Prints the SHA-256 hash of the contents of the + store paths <replaceable>paths</replaceable> (that is, the hash of + the output of <command>nix-store --dump</command> on the given + paths). Since the hash is stored in the Nix database, this is a + fast operation.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--size</option></term> + + <listitem><para>Prints the size in bytes of the contents of the + store paths <replaceable>paths</replaceable> — to be precise, the + size of the output of <command>nix-store --dump</command> on the + given paths. Note that the actual disk space required by the + store paths may be higher, especially on filesystems with large + cluster sizes.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--roots</option></term> + + <listitem><para>Prints the garbage collector roots that point, + directly or indirectly, at the store paths + <replaceable>paths</replaceable>.</para></listitem> + + </varlistentry> + +</variablelist> + +</refsection> + + +<refsection><title>Examples</title> + +<para>Print the closure (runtime dependencies) of the +<command>svn</command> program in the current user environment: + +<screen> +$ nix-store -qR $(which svn) +/nix/store/5mbglq5ldqld8sj57273aljwkfvj22mc-subversion-1.1.4 +/nix/store/9lz9yc6zgmc0vlqmn2ipcpkjlmbi51vv-glibc-2.3.4 +<replaceable>...</replaceable></screen> + +</para> + +<para>Print the build-time dependencies of <command>svn</command>: + +<screen> +$ nix-store -qR $(nix-store -qd $(which svn)) +/nix/store/02iizgn86m42q905rddvg4ja975bk2i4-grep-2.5.1.tar.bz2.drv +/nix/store/07a2bzxmzwz5hp58nf03pahrv2ygwgs3-gcc-wrapper.sh +/nix/store/0ma7c9wsbaxahwwl04gbw3fcd806ski4-glibc-2.3.4.drv +<replaceable>... lots of other paths ...</replaceable></screen> + +The difference with the previous example is that we ask the closure of +the derivation (<option>-qd</option>), not the closure of the output +path that contains <command>svn</command>.</para> + +<para>Show the build-time dependencies as a tree: + +<screen> +$ nix-store -q --tree $(nix-store -qd $(which svn)) +/nix/store/7i5082kfb6yjbqdbiwdhhza0am2xvh6c-subversion-1.1.4.drv ++---/nix/store/d8afh10z72n8l1cr5w42366abiblgn54-builder.sh ++---/nix/store/fmzxmpjx2lh849ph0l36snfj9zdibw67-bash-3.0.drv +| +---/nix/store/570hmhmx3v57605cqg9yfvvyh0nnb8k8-bash +| +---/nix/store/p3srsbd8dx44v2pg6nbnszab5mcwx03v-builder.sh +<replaceable>...</replaceable></screen> + +</para> + +<para>Show all paths that depend on the same OpenSSL library as +<command>svn</command>: + +<screen> +$ nix-store -q --referrers $(nix-store -q --binding openssl $(nix-store -qd $(which svn))) +/nix/store/23ny9l9wixx21632y2wi4p585qhva1q8-sylpheed-1.0.0 +/nix/store/5mbglq5ldqld8sj57273aljwkfvj22mc-subversion-1.1.4 +/nix/store/dpmvp969yhdqs7lm2r1a3gng7pyq6vy4-subversion-1.1.3 +/nix/store/l51240xqsgg8a7yrbqdx1rfzyv6l26fx-lynx-2.8.5</screen> + +</para> + +<para>Show all paths that directly or indirectly depend on the Glibc +(C library) used by <command>svn</command>: + +<screen> +$ nix-store -q --referrers-closure $(ldd $(which svn) | grep /libc.so | awk '{print $3}') +/nix/store/034a6h4vpz9kds5r6kzb9lhh81mscw43-libgnomeprintui-2.8.2 +/nix/store/15l3yi0d45prm7a82pcrknxdh6nzmxza-gawk-3.1.4 +<replaceable>...</replaceable></screen> + +Note that <command>ldd</command> is a command that prints out the +dynamic libraries used by an ELF executable.</para> + +<para>Make a picture of the runtime dependency graph of the current +user environment: + +<screen> +$ nix-store -q --graph ~/.nix-profile | dot -Tps > graph.ps +$ gv graph.ps</screen> + +</para> + +<para>Show every garbage collector root that points to a store path +that depends on <command>svn</command>: + +<screen> +$ nix-store -q --roots $(which svn) +/nix/var/nix/profiles/default-81-link +/nix/var/nix/profiles/default-82-link +/nix/var/nix/profiles/per-user/eelco/profile-97-link +</screen> + +</para> + +</refsection> + + +</refsection> + + + +<!--######################################################################--> + +<!-- +<refsection xml:id="rsec-nix-store-reg-val"><title>Operation <option>-XXX-register-validity</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>-XXX-register-validity</option></arg> +</cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>TODO</para> + +</refsection> + +</refsection> +--> + + + +<!--######################################################################--> + +<refsection><title>Operation <option>--add</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--add</option></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--add</option> adds the specified paths to +the Nix store. It prints the resulting paths in the Nix store on +standard output.</para> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store --add ./foo.c +/nix/store/m7lrha58ph6rcnv109yzx1nk1cj7k7zf-foo.c</screen> + +</refsection> + +</refsection> + +<!--######################################################################--> + +<refsection><title>Operation <option>--add-fixed</option></title> + +<refsection><title>Synopsis</title> + +<cmdsynopsis> + <command>nix-store</command> + <arg><option>--recursive</option></arg> + <arg choice='plain'><option>--add-fixed</option></arg> + <arg choice='plain'><replaceable>algorithm</replaceable></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> +</cmdsynopsis> + +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--add-fixed</option> adds the specified paths to +the Nix store. Unlike <option>--add</option> paths are registered using the +specified hashing algorithm, resulting in the same output path as a fixed output +derivation. This can be used for sources that are not available from a public +url or broke since the download expression was written. +</para> + +<para>This operation has the following options: + +<variablelist> + + <varlistentry><term><option>--recursive</option></term> + + <listitem><para> + Use recursive instead of flat hashing mode, used when adding directories + to the store. + </para></listitem> + + </varlistentry> + +</variablelist> + +</para> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store --add-fixed sha256 ./hello-2.10.tar.gz +/nix/store/3x7dwzq014bblazs7kq20p9hyzz0qh8g-hello-2.10.tar.gz</screen> + +</refsection> + +</refsection> + + + +<!--######################################################################--> + +<refsection xml:id='refsec-nix-store-verify'><title>Operation <option>--verify</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--verify</option></arg> + <arg><option>--check-contents</option></arg> + <arg><option>--repair</option></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--verify</option> verifies the internal +consistency of the Nix database, and the consistency between the Nix +database and the Nix store. Any inconsistencies encountered are +automatically repaired. Inconsistencies are generally the result of +the Nix store or database being modified by non-Nix tools, or of bugs +in Nix itself.</para> + +<para>This operation has the following options: + +<variablelist> + + <varlistentry><term><option>--check-contents</option></term> + + <listitem><para>Checks that the contents of every valid store path + has not been altered by computing a SHA-256 hash of the contents + and comparing it with the hash stored in the Nix database at build + time. Paths that have been modified are printed out. For large + stores, <option>--check-contents</option> is obviously quite + slow.</para></listitem> + + </varlistentry> + + <varlistentry><term><option>--repair</option></term> + + <listitem><para>If any valid path is missing from the store, or + (if <option>--check-contents</option> is given) the contents of a + valid path has been modified, then try to repair the path by + redownloading it. See <command>nix-store --repair-path</command> + for details.</para></listitem> + + </varlistentry> + +</variablelist> + +</para> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--verify-path</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--verify-path</option></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--verify-path</option> compares the +contents of the given store paths to their cryptographic hashes stored +in Nix’s database. For every changed path, it prints a warning +message. The exit status is 0 if no path has changed, and 1 +otherwise.</para> + +</refsection> + +<refsection><title>Example</title> + +<para>To verify the integrity of the <command>svn</command> command and all its dependencies: + +<screen> +$ nix-store --verify-path $(nix-store -qR $(which svn)) +</screen> + +</para> + +</refsection> + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--repair-path</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--repair-path</option></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--repair-path</option> attempts to +“repair” the specified paths by redownloading them using the available +substituters. If no substitutes are available, then repair is not +possible.</para> + +<warning><para>During repair, there is a very small time window during +which the old path (if it exists) is moved out of the way and replaced +with the new path. If repair is interrupted in between, then the +system may be left in a broken state (e.g., if the path contains a +critical system component like the GNU C Library).</para></warning> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store --verify-path /nix/store/dj7a81wsm1ijwwpkks3725661h3263p5-glibc-2.13 +path `/nix/store/dj7a81wsm1ijwwpkks3725661h3263p5-glibc-2.13' was modified! + expected hash `2db57715ae90b7e31ff1f2ecb8c12ec1cc43da920efcbe3b22763f36a1861588', + got `481c5aa5483ebc97c20457bb8bca24deea56550d3985cda0027f67fe54b808e4' + +$ nix-store --repair-path /nix/store/dj7a81wsm1ijwwpkks3725661h3263p5-glibc-2.13 +fetching path `/nix/store/d7a81wsm1ijwwpkks3725661h3263p5-glibc-2.13'... +… +</screen> + +</refsection> + +</refsection> + + +<!--######################################################################--> + +<refsection xml:id='refsec-nix-store-dump'><title>Operation <option>--dump</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--dump</option></arg> + <arg choice='plain'><replaceable>path</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--dump</option> produces a NAR (Nix +ARchive) file containing the contents of the file system tree rooted +at <replaceable>path</replaceable>. The archive is written to +standard output.</para> + +<para>A NAR archive is like a TAR or Zip archive, but it contains only +the information that Nix considers important. For instance, +timestamps are elided because all files in the Nix store have their +timestamp set to 0 anyway. Likewise, all permissions are left out +except for the execute bit, because all files in the Nix store have +644 or 755 permission.</para> + +<para>Also, a NAR archive is <emphasis>canonical</emphasis>, meaning +that “equal” paths always produce the same NAR archive. For instance, +directory entries are always sorted so that the actual on-disk order +doesn’t influence the result. This means that the cryptographic hash +of a NAR dump of a path is usable as a fingerprint of the contents of +the path. Indeed, the hashes of store paths stored in Nix’s database +(see <link linkend="refsec-nix-store-query"><literal>nix-store -q +--hash</literal></link>) are SHA-256 hashes of the NAR dump of each +store path.</para> + +<para>NAR archives support filenames of unlimited length and 64-bit +file sizes. They can contain regular files, directories, and symbolic +links, but not other types of files (such as device nodes).</para> + +<para>A Nix archive can be unpacked using <literal>nix-store +--restore</literal>.</para> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--restore</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--restore</option></arg> + <arg choice='plain'><replaceable>path</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--restore</option> unpacks a NAR archive +to <replaceable>path</replaceable>, which must not already exist. The +archive is read from standard input.</para> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection xml:id='refsec-nix-store-export'><title>Operation <option>--export</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--export</option></arg> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--export</option> writes a serialisation +of the specified store paths to standard output in a format that can +be imported into another Nix store with <command +linkend="refsec-nix-store-import">nix-store --import</command>. This +is like <command linkend="refsec-nix-store-dump">nix-store +--dump</command>, except that the NAR archive produced by that command +doesn’t contain the necessary meta-information to allow it to be +imported into another Nix store (namely, the set of references of the +path).</para> + +<para>This command does not produce a <emphasis>closure</emphasis> of +the specified paths, so if a store path references other store paths +that are missing in the target Nix store, the import will fail. To +copy a whole closure, do something like: + +<screen> +$ nix-store --export $(nix-store -qR <replaceable>paths</replaceable>) > out</screen> + +To import the whole closure again, run: + +<screen> +$ nix-store --import < out</screen> + +</para> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection xml:id='refsec-nix-store-import'><title>Operation <option>--import</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--import</option></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--import</option> reads a serialisation of +a set of store paths produced by <command +linkend="refsec-nix-store-export">nix-store --export</command> from +standard input and adds those store paths to the Nix store. Paths +that already exist in the Nix store are ignored. If a path refers to +another path that doesn’t exist in the Nix store, the import +fails.</para> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--optimise</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--optimise</option></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--optimise</option> reduces Nix store disk +space usage by finding identical files in the store and hard-linking +them to each other. It typically reduces the size of the store by +something like 25-35%. Only regular files and symlinks are +hard-linked in this manner. Files are considered identical when they +have the same NAR archive serialisation: that is, regular files must +have the same contents and permission (executable or non-executable), +and symlinks must have the same contents.</para> + +<para>After completion, or when the command is interrupted, a report +on the achieved savings is printed on standard error.</para> + +<para>Use <option>-vv</option> or <option>-vvv</option> to get some +progress indication.</para> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store --optimise +hashing files in `/nix/store/qhqx7l2f1kmwihc9bnxs7rc159hsxnf3-gcc-4.1.1' +<replaceable>...</replaceable> +541838819 bytes (516.74 MiB) freed by hard-linking 54143 files; +there are 114486 files with equal contents out of 215894 files in total +</screen> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--read-log</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <group choice='req'> + <arg choice='plain'><option>--read-log</option></arg> + <arg choice='plain'><option>-l</option></arg> + </group> + <arg choice='plain' rep='repeat'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--read-log</option> prints the build log +of the specified store paths on standard output. The build log is +whatever the builder of a derivation wrote to standard output and +standard error. If a store path is not a derivation, the deriver of +the store path is used.</para> + +<para>Build logs are kept in +<filename>/nix/var/log/nix/drvs</filename>. However, there is no +guarantee that a build log is available for any particular store path. +For instance, if the path was downloaded as a pre-built binary through +a substitute, then the log is unavailable.</para> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store -l $(which ktorrent) +building /nix/store/dhc73pvzpnzxhdgpimsd9sw39di66ph1-ktorrent-2.2.1 +unpacking sources +unpacking source archive /nix/store/p8n1jpqs27mgkjw07pb5269717nzf5f8-ktorrent-2.2.1.tar.gz +ktorrent-2.2.1/ +ktorrent-2.2.1/NEWS +<replaceable>...</replaceable> +</screen> + +</refsection> + + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--dump-db</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--dump-db</option></arg> + <arg rep='repeat'><replaceable>paths</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--dump-db</option> writes a dump of the +Nix database to standard output. It can be loaded into an empty Nix +store using <option>--load-db</option>. This is useful for making +backups and when migrating to different database schemas.</para> + +<para>By default, <option>--dump-db</option> will dump the entire Nix +database. When one or more store paths is passed, only the subset of +the Nix database for those store paths is dumped. As with +<option>--export</option>, the user is responsible for passing all the +store paths for a closure. See <option>--export</option> for an +example.</para> + +</refsection> + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--load-db</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--load-db</option></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--load-db</option> reads a dump of the Nix +database created by <option>--dump-db</option> from standard input and +loads it into the Nix database.</para> + +</refsection> + +</refsection> + + +<!--######################################################################--> + +<refsection><title>Operation <option>--print-env</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'><option>--print-env</option></arg> + <arg choice='plain'><replaceable>drvpath</replaceable></arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>The operation <option>--print-env</option> prints out the +environment of a derivation in a format that can be evaluated by a +shell. The command line arguments of the builder are placed in the +variable <envar>_args</envar>.</para> + +</refsection> + +<refsection><title>Example</title> + +<screen> +$ nix-store --print-env $(nix-instantiate '<nixpkgs>' -A firefox) +<replaceable>…</replaceable> +export src; src='/nix/store/plpj7qrwcz94z2psh6fchsi7s8yihc7k-firefox-12.0.source.tar.bz2' +export stdenv; stdenv='/nix/store/7c8asx3yfrg5dg1gzhzyq2236zfgibnn-stdenv' +export system; system='x86_64-linux' +export _args; _args='-e /nix/store/9krlzvny65gdc8s7kpb6lkx8cd02c25c-default-builder.sh' +</screen> + +</refsection> + +</refsection> + + +<!--######################################################################--> + +<refsection xml:id='rsec-nix-store-generate-binary-cache-key'><title>Operation <option>--generate-binary-cache-key</option></title> + +<refsection> + <title>Synopsis</title> + <cmdsynopsis> + <command>nix-store</command> + <arg choice='plain'> + <option>--generate-binary-cache-key</option> + <option>key-name</option> + <option>secret-key-file</option> + <option>public-key-file</option> + </arg> + </cmdsynopsis> +</refsection> + +<refsection><title>Description</title> + +<para>This command generates an <link +xlink:href="http://ed25519.cr.yp.to/">Ed25519 key pair</link> that can +be used to create a signed binary cache. It takes three mandatory +parameters: + +<orderedlist> + + <listitem><para>A key name, such as + <literal>cache.example.org-1</literal>, that is used to look up keys + on the client when it verifies signatures. It can be anything, but + it’s suggested to use the host name of your cache + (e.g. <literal>cache.example.org</literal>) with a suffix denoting + the number of the key (to be incremented every time you need to + revoke a key).</para></listitem> + + <listitem><para>The file name where the secret key is to be + stored.</para></listitem> + + <listitem><para>The file name where the public key is to be + stored.</para></listitem> + +</orderedlist> + +</para> + +</refsection> + +</refsection> + + +<!--######################################################################--> + +<refsection condition="manpage"><title>Environment variables</title> + +<variablelist> + <xi:include href="env-common.xml#xmlns(db=http://docbook.org/ns/docbook)xpointer(//db:variablelist[@xml:id='env-common']/*)" /> +</variablelist> + +</refsection> + + +</refentry> diff --git a/third_party/nix/doc/manual/command-ref/opt-common-syn.xml b/third_party/nix/doc/manual/command-ref/opt-common-syn.xml new file mode 100644 index 0000000000..b610b54b96 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/opt-common-syn.xml @@ -0,0 +1,64 @@ +<nop xmlns="http://docbook.org/ns/docbook"> + +<arg><option>--help</option></arg> +<arg><option>--version</option></arg> +<arg rep='repeat'> + <group choice='req'> + <arg choice='plain'><option>--verbose</option></arg> + <arg choice='plain'><option>-v</option></arg> + </group> +</arg> +<arg> + <arg choice='plain'><option>--quiet</option></arg> +</arg> +<arg> + <group choice='plain'> + <arg choice='plain'><option>--no-build-output</option></arg> + <arg choice='plain'><option>-Q</option></arg> + </group> +</arg> +<arg> + <group choice='req'> + <arg choice='plain'><option>--max-jobs</option></arg> + <arg choice='plain'><option>-j</option></arg> + </group> + <replaceable>number</replaceable> +</arg> +<arg> + <option>--cores</option> + <replaceable>number</replaceable> +</arg> +<arg> + <option>--max-silent-time</option> + <replaceable>number</replaceable> +</arg> +<arg> + <option>--timeout</option> + <replaceable>number</replaceable> +</arg> +<arg> + <group choice='plain'> + <arg choice='plain'><option>--keep-going</option></arg> + <arg choice='plain'><option>-k</option></arg> + </group> +</arg> +<arg> + <group choice='plain'> + <arg choice='plain'><option>--keep-failed</option></arg> + <arg choice='plain'><option>-K</option></arg> + </group> +</arg> +<arg><option>--fallback</option></arg> +<arg><option>--readonly-mode</option></arg> +<arg> + <option>-I</option> + <replaceable>path</replaceable> +</arg> +<arg> + <option>--option</option> + <replaceable>name</replaceable> + <replaceable>value</replaceable> +</arg> +<sbr /> + +</nop> diff --git a/third_party/nix/doc/manual/command-ref/opt-common.xml b/third_party/nix/doc/manual/command-ref/opt-common.xml new file mode 100644 index 0000000000..b8a2f260e8 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/opt-common.xml @@ -0,0 +1,366 @@ +<chapter xmlns="http://docbook.org/ns/docbook" xml:id="sec-common-options"> + +<title>Common Options</title> + + +<para>Most Nix commands accept the following command-line options:</para> + +<variablelist xml:id="opt-common"> + +<varlistentry><term><option>--help</option></term> + + <listitem><para>Prints out a summary of the command syntax and + exits.</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--version</option></term> + + <listitem><para>Prints out the Nix version number on standard output + and exits.</para></listitem> +</varlistentry> + + +<varlistentry><term><option>--verbose</option> / <option>-v</option></term> + + <listitem> + + <para>Increases the level of verbosity of diagnostic messages + printed on standard error. For each Nix operation, the information + printed on standard output is well-defined; any diagnostic + information is printed on standard error, never on standard + output.</para> + + <para>This option may be specified repeatedly. Currently, the + following verbosity levels exist:</para> + + <variablelist> + + <varlistentry><term>0</term> + <listitem><para>“Errors only”: only print messages + explaining why the Nix invocation failed.</para></listitem> + </varlistentry> + + <varlistentry><term>1</term> + <listitem><para>“Informational”: print + <emphasis>useful</emphasis> messages about what Nix is doing. + This is the default.</para></listitem> + </varlistentry> + + <varlistentry><term>2</term> + <listitem><para>“Talkative”: print more informational + messages.</para></listitem> + </varlistentry> + + <varlistentry><term>3</term> + <listitem><para>“Chatty”: print even more + informational messages.</para></listitem> + </varlistentry> + + <varlistentry><term>4</term> + <listitem><para>“Debug”: print debug + information.</para></listitem> + </varlistentry> + + <varlistentry><term>5</term> + <listitem><para>“Vomit”: print vast amounts of debug + information.</para></listitem> + </varlistentry> + + </variablelist> + + </listitem> + +</varlistentry> + + +<varlistentry><term><option>--quiet</option></term> + + <listitem> + + <para>Decreases the level of verbosity of diagnostic messages + printed on standard error. This is the inverse option to + <option>-v</option> / <option>--verbose</option>. + </para> + + <para>This option may be specified repeatedly. See the previous + verbosity levels list.</para> + + </listitem> + +</varlistentry> + + +<varlistentry><term><option>--no-build-output</option> / <option>-Q</option></term> + + <listitem><para>By default, output written by builders to standard + output and standard error is echoed to the Nix command's standard + error. This option suppresses this behaviour. Note that the + builder's standard output and error are always written to a log file + in + <filename><replaceable>prefix</replaceable>/nix/var/log/nix</filename>.</para></listitem> + +</varlistentry> + + +<varlistentry xml:id="opt-max-jobs"><term><option>--max-jobs</option> / <option>-j</option> +<replaceable>number</replaceable></term> + + <listitem> + + <para>Sets the maximum number of build jobs that Nix will + perform in parallel to the specified number. Specify + <literal>auto</literal> to use the number of CPUs in the system. + The default is specified by the <link + linkend='conf-max-jobs'><literal>max-jobs</literal></link> + configuration setting, which itself defaults to + <literal>1</literal>. A higher value is useful on SMP systems or to + exploit I/O latency.</para> + + <para> Setting it to <literal>0</literal> disallows building on the local + machine, which is useful when you want builds to happen only on remote + builders.</para> + + </listitem> + +</varlistentry> + + +<varlistentry xml:id="opt-cores"><term><option>--cores</option></term> + + <listitem><para>Sets the value of the <envar>NIX_BUILD_CORES</envar> + environment variable in the invocation of builders. Builders can + use this variable at their discretion to control the maximum amount + of parallelism. For instance, in Nixpkgs, if the derivation + attribute <varname>enableParallelBuilding</varname> is set to + <literal>true</literal>, the builder passes the + <option>-j<replaceable>N</replaceable></option> flag to GNU Make. + It defaults to the value of the <link + linkend='conf-cores'><literal>cores</literal></link> + configuration setting, if set, or <literal>1</literal> otherwise. + The value <literal>0</literal> means that the builder should use all + available CPU cores in the system.</para></listitem> + +</varlistentry> + + +<varlistentry xml:id="opt-max-silent-time"><term><option>--max-silent-time</option></term> + + <listitem><para>Sets the maximum number of seconds that a builder + can go without producing any data on standard output or standard + error. The default is specified by the <link + linkend='conf-max-silent-time'><literal>max-silent-time</literal></link> + configuration setting. <literal>0</literal> means no + time-out.</para></listitem> + +</varlistentry> + +<varlistentry xml:id="opt-timeout"><term><option>--timeout</option></term> + + <listitem><para>Sets the maximum number of seconds that a builder + can run. The default is specified by the <link + linkend='conf-timeout'><literal>timeout</literal></link> + configuration setting. <literal>0</literal> means no + timeout.</para></listitem> + +</varlistentry> + +<varlistentry><term><option>--keep-going</option> / <option>-k</option></term> + + <listitem><para>Keep going in case of failed builds, to the + greatest extent possible. That is, if building an input of some + derivation fails, Nix will still build the other inputs, but not the + derivation itself. Without this option, Nix stops if any build + fails (except for builds of substitutes), possibly killing builds in + progress (in case of parallel or distributed builds).</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--keep-failed</option> / <option>-K</option></term> + + <listitem><para>Specifies that in case of a build failure, the + temporary directory (usually in <filename>/tmp</filename>) in which + the build takes place should not be deleted. The path of the build + directory is printed as an informational message. + </para> + </listitem> +</varlistentry> + + +<varlistentry><term><option>--fallback</option></term> + + <listitem> + + <para>Whenever Nix attempts to build a derivation for which + substitutes are known for each output path, but realising the output + paths through the substitutes fails, fall back on building the + derivation.</para> + + <para>The most common scenario in which this is useful is when we + have registered substitutes in order to perform binary distribution + from, say, a network repository. If the repository is down, the + realisation of the derivation will fail. When this option is + specified, Nix will build the derivation instead. Thus, + installation from binaries falls back on installation from source. + This option is not the default since it is generally not desirable + for a transient failure in obtaining the substitutes to lead to a + full build from source (with the related consumption of + resources).</para> + + </listitem> + +</varlistentry> + +<varlistentry><term><option>--no-build-hook</option></term> + + <listitem> + + <para>Disables the build hook mechanism. This allows to ignore remote + builders if they are setup on the machine.</para> + + <para>It's useful in cases where the bandwidth between the client and the + remote builder is too low. In that case it can take more time to upload the + sources to the remote builder and fetch back the result than to do the + computation locally.</para> + + </listitem> + +</varlistentry> + + + +<varlistentry><term><option>--readonly-mode</option></term> + + <listitem><para>When this option is used, no attempt is made to open + the Nix database. Most Nix operations do need database access, so + those operations will fail.</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--arg</option> <replaceable>name</replaceable> <replaceable>value</replaceable></term> + + <listitem><para>This option is accepted by + <command>nix-env</command>, <command>nix-instantiate</command> and + <command>nix-build</command>. When evaluating Nix expressions, the + expression evaluator will automatically try to call functions that + it encounters. It can automatically call functions for which every + argument has a <link linkend='ss-functions'>default value</link> + (e.g., <literal>{ <replaceable>argName</replaceable> ? + <replaceable>defaultValue</replaceable> }: + <replaceable>...</replaceable></literal>). With + <option>--arg</option>, you can also call functions that have + arguments without a default value (or override a default value). + That is, if the evaluator encounters a function with an argument + named <replaceable>name</replaceable>, it will call it with value + <replaceable>value</replaceable>.</para> + + <para>For instance, the top-level <literal>default.nix</literal> in + Nixpkgs is actually a function: + +<programlisting> +{ # The system (e.g., `i686-linux') for which to build the packages. + system ? builtins.currentSystem + <replaceable>...</replaceable> +}: <replaceable>...</replaceable></programlisting> + + So if you call this Nix expression (e.g., when you do + <literal>nix-env -i <replaceable>pkgname</replaceable></literal>), + the function will be called automatically using the value <link + linkend='builtin-currentSystem'><literal>builtins.currentSystem</literal></link> + for the <literal>system</literal> argument. You can override this + using <option>--arg</option>, e.g., <literal>nix-env -i + <replaceable>pkgname</replaceable> --arg system + \"i686-freebsd\"</literal>. (Note that since the argument is a Nix + string literal, you have to escape the quotes.)</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--argstr</option> <replaceable>name</replaceable> <replaceable>value</replaceable></term> + + <listitem><para>This option is like <option>--arg</option>, only the + value is not a Nix expression but a string. So instead of + <literal>--arg system \"i686-linux\"</literal> (the outer quotes are + to keep the shell happy) you can say <literal>--argstr system + i686-linux</literal>.</para></listitem> + +</varlistentry> + + +<varlistentry xml:id="opt-attr"><term><option>--attr</option> / <option>-A</option> +<replaceable>attrPath</replaceable></term> + + <listitem><para>Select an attribute from the top-level Nix + expression being evaluated. (<command>nix-env</command>, + <command>nix-instantiate</command>, <command>nix-build</command> and + <command>nix-shell</command> only.) The <emphasis>attribute + path</emphasis> <replaceable>attrPath</replaceable> is a sequence of + attribute names separated by dots. For instance, given a top-level + Nix expression <replaceable>e</replaceable>, the attribute path + <literal>xorg.xorgserver</literal> would cause the expression + <literal><replaceable>e</replaceable>.xorg.xorgserver</literal> to + be used. See <link + linkend='refsec-nix-env-install-examples'><command>nix-env + --install</command></link> for some concrete examples.</para> + + <para>In addition to attribute names, you can also specify array + indices. For instance, the attribute path + <literal>foo.3.bar</literal> selects the <literal>bar</literal> + attribute of the fourth element of the array in the + <literal>foo</literal> attribute of the top-level + expression.</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--expr</option> / <option>-E</option></term> + + <listitem><para>Interpret the command line arguments as a list of + Nix expressions to be parsed and evaluated, rather than as a list + of file names of Nix expressions. + (<command>nix-instantiate</command>, <command>nix-build</command> + and <command>nix-shell</command> only.)</para></listitem> + +</varlistentry> + + +<varlistentry xml:id="opt-I"><term><option>-I</option> <replaceable>path</replaceable></term> + + <listitem><para>Add a path to the Nix expression search path. This + option may be given multiple times. See the <envar + linkend="env-NIX_PATH">NIX_PATH</envar> environment variable for + information on the semantics of the Nix search path. Paths added + through <option>-I</option> take precedence over + <envar>NIX_PATH</envar>.</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--option</option> <replaceable>name</replaceable> <replaceable>value</replaceable></term> + + <listitem><para>Set the Nix configuration option + <replaceable>name</replaceable> to <replaceable>value</replaceable>. + This overrides settings in the Nix configuration file (see + <citerefentry><refentrytitle>nix.conf</refentrytitle><manvolnum>5</manvolnum></citerefentry>).</para></listitem> + +</varlistentry> + + +<varlistentry><term><option>--repair</option></term> + + <listitem><para>Fix corrupted or missing store paths by + redownloading or rebuilding them. Note that this is slow because it + requires computing a cryptographic hash of the contents of every + path in the closure of the build. Also note the warning under + <command>nix-store --repair-path</command>.</para></listitem> + +</varlistentry> + + +</variablelist> + + +</chapter> diff --git a/third_party/nix/doc/manual/command-ref/opt-inst-syn.xml b/third_party/nix/doc/manual/command-ref/opt-inst-syn.xml new file mode 100644 index 0000000000..e8c3f1ec6f --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/opt-inst-syn.xml @@ -0,0 +1,22 @@ +<nop xmlns="http://docbook.org/ns/docbook"> + + <arg> + <group choice='req'> + <arg choice='plain'><option>--prebuilt-only</option></arg> + <arg choice='plain'><option>-b</option></arg> + </group> + </arg> + + <arg> + <group choice='req'> + <arg choice='plain'><option>--attr</option></arg> + <arg choice='plain'><option>-A</option></arg> + </group> + </arg> + + <arg><option>--from-expression</option></arg> + <arg><option>-E</option></arg> + + <arg><option>--from-profile</option> <replaceable>path</replaceable></arg> + +</nop> diff --git a/third_party/nix/doc/manual/command-ref/utilities.xml b/third_party/nix/doc/manual/command-ref/utilities.xml new file mode 100644 index 0000000000..893f5b5b52 --- /dev/null +++ b/third_party/nix/doc/manual/command-ref/utilities.xml @@ -0,0 +1,20 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='ch-utilities'> + +<title>Utilities</title> + +<para>This section lists utilities that you can use when you +work with Nix.</para> + +<xi:include href="nix-channel.xml" /> +<xi:include href="nix-collect-garbage.xml" /> +<xi:include href="nix-copy-closure.xml" /> +<xi:include href="nix-daemon.xml" /> +<xi:include href="nix-hash.xml" /> +<xi:include href="nix-instantiate.xml" /> +<xi:include href="nix-prefetch-url.xml" /> + +</chapter> diff --git a/third_party/nix/doc/manual/expressions/advanced-attributes.xml b/third_party/nix/doc/manual/expressions/advanced-attributes.xml new file mode 100644 index 0000000000..07b0d97d3f --- /dev/null +++ b/third_party/nix/doc/manual/expressions/advanced-attributes.xml @@ -0,0 +1,340 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-advanced-attributes"> + +<title>Advanced Attributes</title> + +<para>Derivations can declare some infrequently used optional +attributes.</para> + +<variablelist> + + <varlistentry><term><varname>allowedReferences</varname></term> + + <listitem><para>The optional attribute + <varname>allowedReferences</varname> specifies a list of legal + references (dependencies) of the output of the builder. For + example, + +<programlisting> +allowedReferences = []; +</programlisting> + + enforces that the output of a derivation cannot have any runtime + dependencies on its inputs. To allow an output to have a runtime + dependency on itself, use <literal>"out"</literal> as a list item. + This is used in NixOS to check that generated files such as + initial ramdisks for booting Linux don’t have accidental + dependencies on other paths in the Nix store.</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>allowedRequisites</varname></term> + + <listitem><para>This attribute is similar to + <varname>allowedReferences</varname>, but it specifies the legal + requisites of the whole closure, so all the dependencies + recursively. For example, + +<programlisting> +allowedRequisites = [ foobar ]; +</programlisting> + + enforces that the output of a derivation cannot have any other + runtime dependency than <varname>foobar</varname>, and in addition + it enforces that <varname>foobar</varname> itself doesn't + introduce any other dependency itself.</para></listitem> + + </varlistentry> + + <varlistentry><term><varname>disallowedReferences</varname></term> + + <listitem><para>The optional attribute + <varname>disallowedReferences</varname> specifies a list of illegal + references (dependencies) of the output of the builder. For + example, + +<programlisting> +disallowedReferences = [ foo ]; +</programlisting> + + enforces that the output of a derivation cannot have a direct runtime + dependencies on the derivation <varname>foo</varname>.</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>disallowedRequisites</varname></term> + + <listitem><para>This attribute is similar to + <varname>disallowedReferences</varname>, but it specifies illegal + requisites for the whole closure, so all the dependencies + recursively. For example, + +<programlisting> +disallowedRequisites = [ foobar ]; +</programlisting> + + enforces that the output of a derivation cannot have any + runtime dependency on <varname>foobar</varname> or any other derivation + depending recursively on <varname>foobar</varname>.</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>exportReferencesGraph</varname></term> + + <listitem><para>This attribute allows builders access to the + references graph of their inputs. The attribute is a list of + inputs in the Nix store whose references graph the builder needs + to know. The value of this attribute should be a list of pairs + <literal>[ <replaceable>name1</replaceable> + <replaceable>path1</replaceable> <replaceable>name2</replaceable> + <replaceable>path2</replaceable> <replaceable>...</replaceable> + ]</literal>. The references graph of each + <replaceable>pathN</replaceable> will be stored in a text file + <replaceable>nameN</replaceable> in the temporary build directory. + The text files have the format used by <command>nix-store + --register-validity</command> (with the deriver fields left + empty). For example, when the following derivation is built: + +<programlisting> +derivation { + ... + exportReferencesGraph = [ "libfoo-graph" libfoo ]; +}; +</programlisting> + + the references graph of <literal>libfoo</literal> is placed in the + file <filename>libfoo-graph</filename> in the temporary build + directory.</para> + + <para><varname>exportReferencesGraph</varname> is useful for + builders that want to do something with the closure of a store + path. Examples include the builders in NixOS that generate the + initial ramdisk for booting Linux (a <command>cpio</command> + archive containing the closure of the boot script) and the + ISO-9660 image for the installation CD (which is populated with a + Nix store containing the closure of a bootable NixOS + configuration).</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>impureEnvVars</varname></term> + + <listitem><para>This attribute allows you to specify a list of + environment variables that should be passed from the environment + of the calling user to the builder. Usually, the environment is + cleared completely when the builder is executed, but with this + attribute you can allow specific environment variables to be + passed unmodified. For example, <function>fetchurl</function> in + Nixpkgs has the line + +<programlisting> +impureEnvVars = [ "http_proxy" "https_proxy" <replaceable>...</replaceable> ]; +</programlisting> + + to make it use the proxy server configuration specified by the + user in the environment variables <envar>http_proxy</envar> and + friends.</para> + + <para>This attribute is only allowed in <link + linkend="fixed-output-drvs">fixed-output derivations</link>, where + impurities such as these are okay since (the hash of) the output + is known in advance. It is ignored for all other + derivations.</para> + + <warning><para><varname>impureEnvVars</varname> implementation takes + environment variables from the current builder process. When a daemon is + building its environmental variables are used. Without the daemon, the + environmental variables come from the environment of the + <command>nix-build</command>.</para></warning></listitem> + + </varlistentry> + + + <varlistentry xml:id="fixed-output-drvs"> + <term><varname>outputHash</varname></term> + <term><varname>outputHashAlgo</varname></term> + <term><varname>outputHashMode</varname></term> + + <listitem><para>These attributes declare that the derivation is a + so-called <emphasis>fixed-output derivation</emphasis>, which + means that a cryptographic hash of the output is already known in + advance. When the build of a fixed-output derivation finishes, + Nix computes the cryptographic hash of the output and compares it + to the hash declared with these attributes. If there is a + mismatch, the build fails.</para> + + <para>The rationale for fixed-output derivations is derivations + such as those produced by the <function>fetchurl</function> + function. This function downloads a file from a given URL. To + ensure that the downloaded file has not been modified, the caller + must also specify a cryptographic hash of the file. For example, + +<programlisting> +fetchurl { + url = http://ftp.gnu.org/pub/gnu/hello/hello-2.1.1.tar.gz; + sha256 = "1md7jsfd8pa45z73bz1kszpp01yw6x5ljkjk2hx7wl800any6465"; +} +</programlisting> + + It sometimes happens that the URL of the file changes, e.g., + because servers are reorganised or no longer available. We then + must update the call to <function>fetchurl</function>, e.g., + +<programlisting> +fetchurl { + url = ftp://ftp.nluug.nl/pub/gnu/hello/hello-2.1.1.tar.gz; + sha256 = "1md7jsfd8pa45z73bz1kszpp01yw6x5ljkjk2hx7wl800any6465"; +} +</programlisting> + + If a <function>fetchurl</function> derivation was treated like a + normal derivation, the output paths of the derivation and + <emphasis>all derivations depending on it</emphasis> would change. + For instance, if we were to change the URL of the Glibc source + distribution in Nixpkgs (a package on which almost all other + packages depend) massive rebuilds would be needed. This is + unfortunate for a change which we know cannot have a real effect + as it propagates upwards through the dependency graph.</para> + + <para>For fixed-output derivations, on the other hand, the name of + the output path only depends on the <varname>outputHash*</varname> + and <varname>name</varname> attributes, while all other attributes + are ignored for the purpose of computing the output path. (The + <varname>name</varname> attribute is included because it is part + of the path.)</para> + + <para>As an example, here is the (simplified) Nix expression for + <varname>fetchurl</varname>: + +<programlisting> +{ stdenv, curl }: # The <command>curl</command> program is used for downloading. + +{ url, sha256 }: + +stdenv.mkDerivation { + name = baseNameOf (toString url); + builder = ./builder.sh; + buildInputs = [ curl ]; + + # This is a fixed-output derivation; the output must be a regular + # file with SHA256 hash <varname>sha256</varname>. + outputHashMode = "flat"; + outputHashAlgo = "sha256"; + outputHash = sha256; + + inherit url; +} +</programlisting> + + </para> + + <para>The <varname>outputHashAlgo</varname> attribute specifies + the hash algorithm used to compute the hash. It can currently be + <literal>"sha1"</literal>, <literal>"sha256"</literal> or + <literal>"sha512"</literal>.</para> + + <para>The <varname>outputHashMode</varname> attribute determines + how the hash is computed. It must be one of the following two + values: + + <variablelist> + + <varlistentry><term><literal>"flat"</literal></term> + + <listitem><para>The output must be a non-executable regular + file. If it isn’t, the build fails. The hash is simply + computed over the contents of that file (so it’s equal to what + Unix commands like <command>sha256sum</command> or + <command>sha1sum</command> produce).</para> + + <para>This is the default.</para></listitem> + + </varlistentry> + + <varlistentry><term><literal>"recursive"</literal></term> + + <listitem><para>The hash is computed over the NAR archive dump + of the output (i.e., the result of <link + linkend="refsec-nix-store-dump"><command>nix-store + --dump</command></link>). In this case, the output can be + anything, including a directory tree.</para></listitem> + + </varlistentry> + + </variablelist> + + </para> + + <para>The <varname>outputHash</varname> attribute, finally, must + be a string containing the hash in either hexadecimal or base-32 + notation. (See the <link + linkend="sec-nix-hash"><command>nix-hash</command> command</link> + for information about converting to and from base-32 + notation.)</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>passAsFile</varname></term> + + <listitem><para>A list of names of attributes that should be + passed via files rather than environment variables. For example, + if you have + + <programlisting> +passAsFile = ["big"]; +big = "a very long string"; + </programlisting> + + then when the builder runs, the environment variable + <envar>bigPath</envar> will contain the absolute path to a + temporary file containing <literal>a very long + string</literal>. That is, for any attribute + <replaceable>x</replaceable> listed in + <varname>passAsFile</varname>, Nix will pass an environment + variable <envar><replaceable>x</replaceable>Path</envar> holding + the path of the file containing the value of attribute + <replaceable>x</replaceable>. This is useful when you need to pass + large strings to a builder, since most operating systems impose a + limit on the size of the environment (typically, a few hundred + kilobyte).</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>preferLocalBuild</varname></term> + + <listitem><para>If this attribute is set to + <literal>true</literal> and <link + linkend="chap-distributed-builds">distributed building is + enabled</link>, then, if possible, the derivaton will be built + locally instead of forwarded to a remote machine. This is + appropriate for trivial builders where the cost of doing a + download or remote build would exceed the cost of building + locally.</para></listitem> + + </varlistentry> + + + <varlistentry><term><varname>allowSubstitutes</varname></term> + + <listitem><para>If this attribute is set to + <literal>false</literal>, then Nix will always build this + derivation; it will not try to substitute its outputs. This is + useful for very trivial derivations (such as + <function>writeText</function> in Nixpkgs) that are cheaper to + build than to substitute from a binary cache.</para></listitem> + + </varlistentry> + + +</variablelist> + +</section> diff --git a/third_party/nix/doc/manual/expressions/arguments-variables.xml b/third_party/nix/doc/manual/expressions/arguments-variables.xml new file mode 100644 index 0000000000..bf60cb7eef --- /dev/null +++ b/third_party/nix/doc/manual/expressions/arguments-variables.xml @@ -0,0 +1,121 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-arguments'> + +<title>Arguments and Variables</title> + +<example xml:id='ex-hello-composition'> + +<title>Composing GNU Hello +(<filename>all-packages.nix</filename>)</title> +<programlisting> +... + +rec { <co xml:id='ex-hello-composition-co-1' /> + + hello = import ../applications/misc/hello/ex-1 <co xml:id='ex-hello-composition-co-2' /> { <co xml:id='ex-hello-composition-co-3' /> + inherit fetchurl stdenv perl; + }; + + perl = import ../development/interpreters/perl { <co xml:id='ex-hello-composition-co-4' /> + inherit fetchurl stdenv; + }; + + fetchurl = import ../build-support/fetchurl { + inherit stdenv; ... + }; + + stdenv = ...; + +} +</programlisting> +</example> + +<para>The Nix expression in <xref linkend='ex-hello-nix' /> is a +function; it is missing some arguments that have to be filled in +somewhere. In the Nix Packages collection this is done in the file +<filename>pkgs/top-level/all-packages.nix</filename>, where all +Nix expressions for packages are imported and called with the +appropriate arguments. <xref linkend='ex-hello-composition' /> shows +some fragments of +<filename>all-packages.nix</filename>.</para> + +<calloutlist> + + <callout arearefs='ex-hello-composition-co-1'> + + <para>This file defines a set of attributes, all of which are + concrete derivations (i.e., not functions). In fact, we define a + <emphasis>mutually recursive</emphasis> set of attributes. That + is, the attributes can refer to each other. This is precisely + what we want since we want to <quote>plug</quote> the + various packages into each other.</para> + + </callout> + + <callout arearefs='ex-hello-composition-co-2'> + + <para>Here we <emphasis>import</emphasis> the Nix expression for + GNU Hello. The import operation just loads and returns the + specified Nix expression. In fact, we could just have put the + contents of <xref linkend='ex-hello-nix' /> in + <filename>all-packages.nix</filename> at this point. That + would be completely equivalent, but it would make the file rather + bulky.</para> + + <para>Note that we refer to + <filename>../applications/misc/hello/ex-1</filename>, not + <filename>../applications/misc/hello/ex-1/default.nix</filename>. + When you try to import a directory, Nix automatically appends + <filename>/default.nix</filename> to the file name.</para> + + </callout> + + <callout arearefs='ex-hello-composition-co-3'> + + <para>This is where the actual composition takes place. Here we + <emphasis>call</emphasis> the function imported from + <filename>../applications/misc/hello/ex-1</filename> with a set + containing the things that the function expects, namely + <varname>fetchurl</varname>, <varname>stdenv</varname>, and + <varname>perl</varname>. We use inherit again to use the + attributes defined in the surrounding scope (we could also have + written <literal>fetchurl = fetchurl;</literal>, etc.).</para> + + <para>The result of this function call is an actual derivation + that can be built by Nix (since when we fill in the arguments of + the function, what we get is its body, which is the call to + <varname>stdenv.mkDerivation</varname> in <xref + linkend='ex-hello-nix' />).</para> + + <note><para>Nixpkgs has a convenience function + <function>callPackage</function> that imports and calls a + function, filling in any missing arguments by passing the + corresponding attribute from the Nixpkgs set, like this: + +<programlisting> +hello = callPackage ../applications/misc/hello/ex-1 { }; +</programlisting> + + If necessary, you can set or override arguments: + +<programlisting> +hello = callPackage ../applications/misc/hello/ex-1 { stdenv = myStdenv; }; +</programlisting> + + </para></note> + + </callout> + + <callout arearefs='ex-hello-composition-co-4'> + + <para>Likewise, we have to instantiate Perl, + <varname>fetchurl</varname>, and the standard environment.</para> + + </callout> + +</calloutlist> + +</section> \ No newline at end of file diff --git a/third_party/nix/doc/manual/expressions/build-script.xml b/third_party/nix/doc/manual/expressions/build-script.xml new file mode 100644 index 0000000000..7bad8f808d --- /dev/null +++ b/third_party/nix/doc/manual/expressions/build-script.xml @@ -0,0 +1,119 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-build-script'> + +<title>Build Script</title> + +<example xml:id='ex-hello-builder'><title>Build script for GNU Hello +(<filename>builder.sh</filename>)</title> +<programlisting> +source $stdenv/setup <co xml:id='ex-hello-builder-co-1' /> + +PATH=$perl/bin:$PATH <co xml:id='ex-hello-builder-co-2' /> + +tar xvfz $src <co xml:id='ex-hello-builder-co-3' /> +cd hello-* +./configure --prefix=$out <co xml:id='ex-hello-builder-co-4' /> +make <co xml:id='ex-hello-builder-co-5' /> +make install</programlisting> +</example> + +<para><xref linkend='ex-hello-builder' /> shows the builder referenced +from Hello's Nix expression (stored in +<filename>pkgs/applications/misc/hello/ex-1/builder.sh</filename>). +The builder can actually be made a lot shorter by using the +<emphasis>generic builder</emphasis> functions provided by +<varname>stdenv</varname>, but here we write out the build steps to +elucidate what a builder does. It performs the following +steps:</para> + +<calloutlist> + + <callout arearefs='ex-hello-builder-co-1'> + + <para>When Nix runs a builder, it initially completely clears the + environment (except for the attributes declared in the + derivation). For instance, the <envar>PATH</envar> variable is + empty<footnote><para>Actually, it's initialised to + <filename>/path-not-set</filename> to prevent Bash from setting it + to a default value.</para></footnote>. This is done to prevent + undeclared inputs from being used in the build process. If for + example the <envar>PATH</envar> contained + <filename>/usr/bin</filename>, then you might accidentally use + <filename>/usr/bin/gcc</filename>.</para> + + <para>So the first step is to set up the environment. This is + done by calling the <filename>setup</filename> script of the + standard environment. The environment variable + <envar>stdenv</envar> points to the location of the standard + environment being used. (It wasn't specified explicitly as an + attribute in <xref linkend='ex-hello-nix' />, but + <varname>mkDerivation</varname> adds it automatically.)</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-2'> + + <para>Since Hello needs Perl, we have to make sure that Perl is in + the <envar>PATH</envar>. The <envar>perl</envar> environment + variable points to the location of the Perl package (since it + was passed in as an attribute to the derivation), so + <filename><replaceable>$perl</replaceable>/bin</filename> is the + directory containing the Perl interpreter.</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-3'> + + <para>Now we have to unpack the sources. The + <varname>src</varname> attribute was bound to the result of + fetching the Hello source tarball from the network, so the + <envar>src</envar> environment variable points to the location in + the Nix store to which the tarball was downloaded. After + unpacking, we <command>cd</command> to the resulting source + directory.</para> + + <para>The whole build is performed in a temporary directory + created in <varname>/tmp</varname>, by the way. This directory is + removed after the builder finishes, so there is no need to clean + up the sources afterwards. Also, the temporary directory is + always newly created, so you don't have to worry about files from + previous builds interfering with the current build.</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-4'> + + <para>GNU Hello is a typical Autoconf-based package, so we first + have to run its <filename>configure</filename> script. In Nix + every package is stored in a separate location in the Nix store, + for instance + <filename>/nix/store/9a54ba97fb71b65fda531012d0443ce2-hello-2.1.1</filename>. + Nix computes this path by cryptographically hashing all attributes + of the derivation. The path is passed to the builder through the + <envar>out</envar> environment variable. So here we give + <filename>configure</filename> the parameter + <literal>--prefix=$out</literal> to cause Hello to be installed in + the expected location.</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-5'> + + <para>Finally we build Hello (<literal>make</literal>) and install + it into the location specified by <envar>out</envar> + (<literal>make install</literal>).</para> + + </callout> + +</calloutlist> + +<para>If you are wondering about the absence of error checking on the +result of various commands called in the builder: this is because the +shell script is evaluated with Bash's <option>-e</option> option, +which causes the script to be aborted if any command fails without an +error check.</para> + +</section> \ No newline at end of file diff --git a/third_party/nix/doc/manual/expressions/builder-syntax.xml b/third_party/nix/doc/manual/expressions/builder-syntax.xml new file mode 100644 index 0000000000..e51bade44e --- /dev/null +++ b/third_party/nix/doc/manual/expressions/builder-syntax.xml @@ -0,0 +1,119 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-builder-syntax'> + +<title>Builder Syntax</title> + +<example xml:id='ex-hello-builder'><title>Build script for GNU Hello +(<filename>builder.sh</filename>)</title> +<programlisting> +source $stdenv/setup <co xml:id='ex-hello-builder-co-1' /> + +PATH=$perl/bin:$PATH <co xml:id='ex-hello-builder-co-2' /> + +tar xvfz $src <co xml:id='ex-hello-builder-co-3' /> +cd hello-* +./configure --prefix=$out <co xml:id='ex-hello-builder-co-4' /> +make <co xml:id='ex-hello-builder-co-5' /> +make install</programlisting> +</example> + +<para><xref linkend='ex-hello-builder' /> shows the builder referenced +from Hello's Nix expression (stored in +<filename>pkgs/applications/misc/hello/ex-1/builder.sh</filename>). +The builder can actually be made a lot shorter by using the +<emphasis>generic builder</emphasis> functions provided by +<varname>stdenv</varname>, but here we write out the build steps to +elucidate what a builder does. It performs the following +steps:</para> + +<calloutlist> + + <callout arearefs='ex-hello-builder-co-1'> + + <para>When Nix runs a builder, it initially completely clears the + environment (except for the attributes declared in the + derivation). For instance, the <envar>PATH</envar> variable is + empty<footnote><para>Actually, it's initialised to + <filename>/path-not-set</filename> to prevent Bash from setting it + to a default value.</para></footnote>. This is done to prevent + undeclared inputs from being used in the build process. If for + example the <envar>PATH</envar> contained + <filename>/usr/bin</filename>, then you might accidentally use + <filename>/usr/bin/gcc</filename>.</para> + + <para>So the first step is to set up the environment. This is + done by calling the <filename>setup</filename> script of the + standard environment. The environment variable + <envar>stdenv</envar> points to the location of the standard + environment being used. (It wasn't specified explicitly as an + attribute in <xref linkend='ex-hello-nix' />, but + <varname>mkDerivation</varname> adds it automatically.)</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-2'> + + <para>Since Hello needs Perl, we have to make sure that Perl is in + the <envar>PATH</envar>. The <envar>perl</envar> environment + variable points to the location of the Perl package (since it + was passed in as an attribute to the derivation), so + <filename><replaceable>$perl</replaceable>/bin</filename> is the + directory containing the Perl interpreter.</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-3'> + + <para>Now we have to unpack the sources. The + <varname>src</varname> attribute was bound to the result of + fetching the Hello source tarball from the network, so the + <envar>src</envar> environment variable points to the location in + the Nix store to which the tarball was downloaded. After + unpacking, we <command>cd</command> to the resulting source + directory.</para> + + <para>The whole build is performed in a temporary directory + created in <varname>/tmp</varname>, by the way. This directory is + removed after the builder finishes, so there is no need to clean + up the sources afterwards. Also, the temporary directory is + always newly created, so you don't have to worry about files from + previous builds interfering with the current build.</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-4'> + + <para>GNU Hello is a typical Autoconf-based package, so we first + have to run its <filename>configure</filename> script. In Nix + every package is stored in a separate location in the Nix store, + for instance + <filename>/nix/store/9a54ba97fb71b65fda531012d0443ce2-hello-2.1.1</filename>. + Nix computes this path by cryptographically hashing all attributes + of the derivation. The path is passed to the builder through the + <envar>out</envar> environment variable. So here we give + <filename>configure</filename> the parameter + <literal>--prefix=$out</literal> to cause Hello to be installed in + the expected location.</para> + + </callout> + + <callout arearefs='ex-hello-builder-co-5'> + + <para>Finally we build Hello (<literal>make</literal>) and install + it into the location specified by <envar>out</envar> + (<literal>make install</literal>).</para> + + </callout> + +</calloutlist> + +<para>If you are wondering about the absence of error checking on the +result of various commands called in the builder: this is because the +shell script is evaluated with Bash's <option>-e</option> option, +which causes the script to be aborted if any command fails without an +error check.</para> + +</section> \ No newline at end of file diff --git a/third_party/nix/doc/manual/expressions/builtins.xml b/third_party/nix/doc/manual/expressions/builtins.xml new file mode 100644 index 0000000000..394e1fc32c --- /dev/null +++ b/third_party/nix/doc/manual/expressions/builtins.xml @@ -0,0 +1,1658 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='ssec-builtins'> + +<title>Built-in Functions</title> + +<para>This section lists the functions and constants built into the +Nix expression evaluator. (The built-in function +<function>derivation</function> is discussed above.) Some built-ins, +such as <function>derivation</function>, are always in scope of every +Nix expression; you can just access them right away. But to prevent +polluting the namespace too much, most built-ins are not in scope. +Instead, you can access them through the <varname>builtins</varname> +built-in value, which is a set that contains all built-in functions +and values. For instance, <function>derivation</function> is also +available as <function>builtins.derivation</function>.</para> + + +<variablelist> + + + <varlistentry xml:id='builtin-abort'> + <term><function>abort</function> <replaceable>s</replaceable></term> + <term><function>builtins.abort</function> <replaceable>s</replaceable></term> + + <listitem><para>Abort Nix expression evaluation, print error + message <replaceable>s</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-add'> + <term><function>builtins.add</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable> + </term> + + <listitem><para>Return the sum of the numbers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-all'> + <term><function>builtins.all</function> + <replaceable>pred</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Return <literal>true</literal> if the function + <replaceable>pred</replaceable> returns <literal>true</literal> + for all elements of <replaceable>list</replaceable>, + and <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-any'> + <term><function>builtins.any</function> + <replaceable>pred</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Return <literal>true</literal> if the function + <replaceable>pred</replaceable> returns <literal>true</literal> + for at least one element of <replaceable>list</replaceable>, + and <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-attrNames'> + <term><function>builtins.attrNames</function> + <replaceable>set</replaceable></term> + + <listitem><para>Return the names of the attributes in the set + <replaceable>set</replaceable> in an alphabetically sorted list. For instance, + <literal>builtins.attrNames { y = 1; x = "foo"; }</literal> + evaluates to <literal>[ "x" "y" ]</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-attrValues'> + <term><function>builtins.attrValues</function> + <replaceable>set</replaceable></term> + + <listitem><para>Return the values of the attributes in the set + <replaceable>set</replaceable> in the order corresponding to the + sorted attribute names.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-baseNameOf'> + <term><function>baseNameOf</function> <replaceable>s</replaceable></term> + + <listitem><para>Return the <emphasis>base name</emphasis> of the + string <replaceable>s</replaceable>, that is, everything following + the final slash in the string. This is similar to the GNU + <command>basename</command> command.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-bitAnd'> + <term><function>builtins.bitAnd</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return the bitwise AND of the integers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-bitOr'> + <term><function>builtins.bitOr</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return the bitwise OR of the integers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-bitXor'> + <term><function>builtins.bitXor</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return the bitwise XOR of the integers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-builtins'> + <term><varname>builtins</varname></term> + + <listitem><para>The set <varname>builtins</varname> contains all + the built-in functions and values. You can use + <varname>builtins</varname> to test for the availability of + features in the Nix installation, e.g., + +<programlisting> +if builtins ? getEnv then builtins.getEnv "PATH" else ""</programlisting> + + This allows a Nix expression to fall back gracefully on older Nix + installations that don’t have the desired built-in + function.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-compareVersions'> + <term><function>builtins.compareVersions</function> + <replaceable>s1</replaceable> <replaceable>s2</replaceable></term> + + <listitem><para>Compare two strings representing versions and + return <literal>-1</literal> if version + <replaceable>s1</replaceable> is older than version + <replaceable>s2</replaceable>, <literal>0</literal> if they are + the same, and <literal>1</literal> if + <replaceable>s1</replaceable> is newer than + <replaceable>s2</replaceable>. The version comparison algorithm + is the same as the one used by <link + linkend="ssec-version-comparisons"><command>nix-env + -u</command></link>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-concatLists'> + <term><function>builtins.concatLists</function> + <replaceable>lists</replaceable></term> + + <listitem><para>Concatenate a list of lists into a single + list.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-concatStringsSep'> + <term><function>builtins.concatStringsSep</function> + <replaceable>separator</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Concatenate a list of strings with a separator + between each element, e.g. <literal>concatStringsSep "/" + ["usr" "local" "bin"] == "usr/local/bin"</literal></para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-currentSystem'> + <term><varname>builtins.currentSystem</varname></term> + + <listitem><para>The built-in value <varname>currentSystem</varname> + evaluates to the Nix platform identifier for the Nix installation + on which the expression is being evaluated, such as + <literal>"i686-linux"</literal> or + <literal>"x86_64-darwin"</literal>.</para></listitem> + + </varlistentry> + + + <!-- + <varlistentry><term><function>currentTime</function></term> + + <listitem><para>The built-in value <varname>currentTime</varname> + returns the current system time in seconds since 00:00:00 1/1/1970 + UTC. Due to the evaluation model of Nix expressions + (<emphasis>maximal laziness</emphasis>), it always yields the same + value within an execution of Nix.</para></listitem> + + </varlistentry> + --> + + + <!-- + <varlistentry><term><function>dependencyClosure</function></term> + + <listitem><para>TODO</para></listitem> + + </varlistentry> + --> + + + <varlistentry xml:id='builtin-deepSeq'> + <term><function>builtins.deepSeq</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>This is like <literal>seq + <replaceable>e1</replaceable> + <replaceable>e2</replaceable></literal>, except that + <replaceable>e1</replaceable> is evaluated + <emphasis>deeply</emphasis>: if it’s a list or set, its elements + or attributes are also evaluated recursively.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-derivation'> + <term><function>derivation</function> + <replaceable>attrs</replaceable></term> + <term><function>builtins.derivation</function> + <replaceable>attrs</replaceable></term> + + <listitem><para><function>derivation</function> is described in + <xref linkend='ssec-derivation' />.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-dirOf'> + <term><function>dirOf</function> <replaceable>s</replaceable></term> + <term><function>builtins.dirOf</function> <replaceable>s</replaceable></term> + + <listitem><para>Return the directory part of the string + <replaceable>s</replaceable>, that is, everything before the final + slash in the string. This is similar to the GNU + <command>dirname</command> command.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-div'> + <term><function>builtins.div</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return the quotient of the numbers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-elem'> + <term><function>builtins.elem</function> + <replaceable>x</replaceable> <replaceable>xs</replaceable></term> + + <listitem><para>Return <literal>true</literal> if a value equal to + <replaceable>x</replaceable> occurs in the list + <replaceable>xs</replaceable>, and <literal>false</literal> + otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-elemAt'> + <term><function>builtins.elemAt</function> + <replaceable>xs</replaceable> <replaceable>n</replaceable></term> + + <listitem><para>Return element <replaceable>n</replaceable> from + the list <replaceable>xs</replaceable>. Elements are counted + starting from 0. A fatal error occurs if the index is out of + bounds.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-fetchurl'> + <term><function>builtins.fetchurl</function> + <replaceable>url</replaceable></term> + + <listitem><para>Download the specified URL and return the path of + the downloaded file. This function is not available if <link + linkend="conf-restrict-eval">restricted evaluation mode</link> is + enabled.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-fetchTarball'> + <term><function>fetchTarball</function> + <replaceable>url</replaceable></term> + <term><function>builtins.fetchTarball</function> + <replaceable>url</replaceable></term> + + <listitem><para>Download the specified URL, unpack it and return + the path of the unpacked tree. The file must be a tape archive + (<filename>.tar</filename>) compressed with + <literal>gzip</literal>, <literal>bzip2</literal> or + <literal>xz</literal>. The top-level path component of the files + in the tarball is removed, so it is best if the tarball contains a + single directory at top level. The typical use of the function is + to obtain external Nix expression dependencies, such as a + particular version of Nixpkgs, e.g. + +<programlisting> +with import (fetchTarball https://github.com/NixOS/nixpkgs-channels/archive/nixos-14.12.tar.gz) {}; + +stdenv.mkDerivation { … } +</programlisting> + </para> + + <para>The fetched tarball is cached for a certain amount of time + (1 hour by default) in <filename>~/.cache/nix/tarballs/</filename>. + You can change the cache timeout either on the command line with + <option>--option tarball-ttl <replaceable>number of seconds</replaceable></option> or + in the Nix configuration file with this option: + <literal><xref linkend="conf-tarball-ttl" /> <replaceable>number of seconds to cache</replaceable></literal>. + </para> + + <para>Note that when obtaining the hash with <varname>nix-prefetch-url + </varname> the option <varname>--unpack</varname> is required. + </para> + + <para>This function can also verify the contents against a hash. + In that case, the function takes a set instead of a URL. The set + requires the attribute <varname>url</varname> and the attribute + <varname>sha256</varname>, e.g. + +<programlisting> +with import (fetchTarball { + url = https://github.com/NixOS/nixpkgs-channels/archive/nixos-14.12.tar.gz; + sha256 = "1jppksrfvbk5ypiqdz4cddxdl8z6zyzdb2srq8fcffr327ld5jj2"; +}) {}; + +stdenv.mkDerivation { … } +</programlisting> + + </para> + + <para>This function is not available if <link + linkend="conf-restrict-eval">restricted evaluation mode</link> is + enabled.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-fetchGit'> + <term> + <function>builtins.fetchGit</function> + <replaceable>args</replaceable> + </term> + + <listitem> + <para> + Fetch a path from git. <replaceable>args</replaceable> can be + a URL, in which case the HEAD of the repo at that URL is + fetched. Otherwise, it can be an attribute with the following + attributes (all except <varname>url</varname> optional): + </para> + + <variablelist> + <varlistentry> + <term>url</term> + <listitem> + <para> + The URL of the repo. + </para> + </listitem> + </varlistentry> + <varlistentry> + <term>name</term> + <listitem> + <para> + The name of the directory the repo should be exported to + in the store. Defaults to the basename of the URL. + </para> + </listitem> + </varlistentry> + <varlistentry> + <term>rev</term> + <listitem> + <para> + The git revision to fetch. Defaults to the tip of + <varname>ref</varname>. + </para> + </listitem> + </varlistentry> + <varlistentry> + <term>ref</term> + <listitem> + <para> + The git ref to look for the requested revision under. + This is often a branch or tag name. Defaults to + <literal>HEAD</literal>. + </para> + + <para> + By default, the <varname>ref</varname> value is prefixed + with <literal>refs/heads/</literal>. As of Nix 2.3.0 + Nix will not prefix <literal>refs/heads/</literal> if + <varname>ref</varname> starts with <literal>refs/</literal>. + </para> + </listitem> + </varlistentry> + </variablelist> + + <example> + <title>Fetching a private repository over SSH</title> + <programlisting>builtins.fetchGit { + url = "git@github.com:my-secret/repository.git"; + ref = "master"; + rev = "adab8b916a45068c044658c4158d81878f9ed1c3"; +}</programlisting> + </example> + + <example> + <title>Fetching an arbitrary ref</title> + <programlisting>builtins.fetchGit { + url = "https://github.com/NixOS/nix.git"; + ref = "refs/heads/0.5-release"; +}</programlisting> + </example> + + <example> + <title>Fetching a repository's specific commit on an arbitrary branch</title> + <para> + If the revision you're looking for is in the default branch + of the git repository you don't strictly need to specify + the branch name in the <varname>ref</varname> attribute. + </para> + <para> + However, if the revision you're looking for is in a future + branch for the non-default branch you will need to specify + the the <varname>ref</varname> attribute as well. + </para> + <programlisting>builtins.fetchGit { + url = "https://github.com/nixos/nix.git"; + rev = "841fcbd04755c7a2865c51c1e2d3b045976b7452"; + ref = "1.11-maintenance"; +}</programlisting> + <note> + <para> + It is nice to always specify the branch which a revision + belongs to. Without the branch being specified, the + fetcher might fail if the default branch changes. + Additionally, it can be confusing to try a commit from a + non-default branch and see the fetch fail. If the branch + is specified the fault is much more obvious. + </para> + </note> + </example> + + <example> + <title>Fetching a repository's specific commit on the default branch</title> + <para> + If the revision you're looking for is in the default branch + of the git repository you may omit the + <varname>ref</varname> attribute. + </para> + <programlisting>builtins.fetchGit { + url = "https://github.com/nixos/nix.git"; + rev = "841fcbd04755c7a2865c51c1e2d3b045976b7452"; +}</programlisting> + </example> + + <example> + <title>Fetching a tag</title> + <programlisting>builtins.fetchGit { + url = "https://github.com/nixos/nix.git"; + ref = "refs/tags/1.9"; +}</programlisting> + </example> + + <example> + <title>Fetching the latest version of a remote branch</title> + <para> + <function>builtins.fetchGit</function> can behave impurely + fetch the latest version of a remote branch. + </para> + <note><para>Nix will refetch the branch in accordance to + <xref linkend="conf-tarball-ttl" />.</para></note> + <note><para>This behavior is disabled in + <emphasis>Pure evaluation mode</emphasis>.</para></note> + <programlisting>builtins.fetchGit { + url = "ssh://git@github.com/nixos/nix.git"; + ref = "master"; +}</programlisting> + </example> + </listitem> + </varlistentry> + + + <varlistentry><term><function>builtins.filter</function> + <replaceable>f</replaceable> <replaceable>xs</replaceable></term> + + <listitem><para>Return a list consisting of the elements of + <replaceable>xs</replaceable> for which the function + <replaceable>f</replaceable> returns + <literal>true</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-filterSource'> + <term><function>builtins.filterSource</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem> + + <para>This function allows you to copy sources into the Nix + store while filtering certain files. For instance, suppose that + you want to use the directory <filename>source-dir</filename> as + an input to a Nix expression, e.g. + +<programlisting> +stdenv.mkDerivation { + ... + src = ./source-dir; +} +</programlisting> + + However, if <filename>source-dir</filename> is a Subversion + working copy, then all those annoying <filename>.svn</filename> + subdirectories will also be copied to the store. Worse, the + contents of those directories may change a lot, causing lots of + spurious rebuilds. With <function>filterSource</function> you + can filter out the <filename>.svn</filename> directories: + +<programlisting> + src = builtins.filterSource + (path: type: type != "directory" || baseNameOf path != ".svn") + ./source-dir; +</programlisting> + + </para> + + <para>Thus, the first argument <replaceable>e1</replaceable> + must be a predicate function that is called for each regular + file, directory or symlink in the source tree + <replaceable>e2</replaceable>. If the function returns + <literal>true</literal>, the file is copied to the Nix store, + otherwise it is omitted. The function is called with two + arguments. The first is the full path of the file. The second + is a string that identifies the type of the file, which is + either <literal>"regular"</literal>, + <literal>"directory"</literal>, <literal>"symlink"</literal> or + <literal>"unknown"</literal> (for other kinds of files such as + device nodes or fifos — but note that those cannot be copied to + the Nix store, so if the predicate returns + <literal>true</literal> for them, the copy will fail). If you + exclude a directory, the entire corresponding subtree of + <replaceable>e2</replaceable> will be excluded.</para> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-foldl-prime'> + <term><function>builtins.foldl’</function> + <replaceable>op</replaceable> <replaceable>nul</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Reduce a list by applying a binary operator, from + left to right, e.g. <literal>foldl’ op nul [x0 x1 x2 ...] = op (op + (op nul x0) x1) x2) ...</literal>. The operator is applied + strictly, i.e., its arguments are evaluated first. For example, + <literal>foldl’ (x: y: x + y) 0 [1 2 3]</literal> evaluates to + 6.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-functionArgs'> + <term><function>builtins.functionArgs</function> + <replaceable>f</replaceable></term> + + <listitem><para> + Return a set containing the names of the formal arguments expected + by the function <replaceable>f</replaceable>. + The value of each attribute is a Boolean denoting whether the corresponding + argument has a default value. For instance, + <literal>functionArgs ({ x, y ? 123}: ...) = { x = false; y = true; }</literal>. + </para> + + <para>"Formal argument" here refers to the attributes pattern-matched by + the function. Plain lambdas are not included, e.g. + <literal>functionArgs (x: ...) = { }</literal>. + </para></listitem> + </varlistentry> + + + <varlistentry xml:id='builtin-fromJSON'> + <term><function>builtins.fromJSON</function> <replaceable>e</replaceable></term> + + <listitem><para>Convert a JSON string to a Nix + value. For example, + +<programlisting> +builtins.fromJSON ''{"x": [1, 2, 3], "y": null}'' +</programlisting> + + returns the value <literal>{ x = [ 1 2 3 ]; y = null; + }</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-genList'> + <term><function>builtins.genList</function> + <replaceable>generator</replaceable> <replaceable>length</replaceable></term> + + <listitem><para>Generate list of size + <replaceable>length</replaceable>, with each element + <replaceable>i</replaceable> equal to the value returned by + <replaceable>generator</replaceable> <literal>i</literal>. For + example, + +<programlisting> +builtins.genList (x: x * x) 5 +</programlisting> + + returns the list <literal>[ 0 1 4 9 16 ]</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-getAttr'> + <term><function>builtins.getAttr</function> + <replaceable>s</replaceable> <replaceable>set</replaceable></term> + + <listitem><para><function>getAttr</function> returns the attribute + named <replaceable>s</replaceable> from + <replaceable>set</replaceable>. Evaluation aborts if the + attribute doesn’t exist. This is a dynamic version of the + <literal>.</literal> operator, since <replaceable>s</replaceable> + is an expression rather than an identifier.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-getEnv'> + <term><function>builtins.getEnv</function> + <replaceable>s</replaceable></term> + + <listitem><para><function>getEnv</function> returns the value of + the environment variable <replaceable>s</replaceable>, or an empty + string if the variable doesn’t exist. This function should be + used with care, as it can introduce all sorts of nasty environment + dependencies in your Nix expression.</para> + + <para><function>getEnv</function> is used in Nix Packages to + locate the file <filename>~/.nixpkgs/config.nix</filename>, which + contains user-local settings for Nix Packages. (That is, it does + a <literal>getEnv "HOME"</literal> to locate the user’s home + directory.)</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-hasAttr'> + <term><function>builtins.hasAttr</function> + <replaceable>s</replaceable> <replaceable>set</replaceable></term> + + <listitem><para><function>hasAttr</function> returns + <literal>true</literal> if <replaceable>set</replaceable> has an + attribute named <replaceable>s</replaceable>, and + <literal>false</literal> otherwise. This is a dynamic version of + the <literal>?</literal> operator, since + <replaceable>s</replaceable> is an expression rather than an + identifier.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-hashString'> + <term><function>builtins.hashString</function> + <replaceable>type</replaceable> <replaceable>s</replaceable></term> + + <listitem><para>Return a base-16 representation of the + cryptographic hash of string <replaceable>s</replaceable>. The + hash algorithm specified by <replaceable>type</replaceable> must + be one of <literal>"md5"</literal>, <literal>"sha1"</literal>, + <literal>"sha256"</literal> or <literal>"sha512"</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-hashFile'> + <term><function>builtins.hashFile</function> + <replaceable>type</replaceable> <replaceable>p</replaceable></term> + + <listitem><para>Return a base-16 representation of the + cryptographic hash of the file at path <replaceable>p</replaceable>. The + hash algorithm specified by <replaceable>type</replaceable> must + be one of <literal>"md5"</literal>, <literal>"sha1"</literal>, + <literal>"sha256"</literal> or <literal>"sha512"</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-head'> + <term><function>builtins.head</function> + <replaceable>list</replaceable></term> + + <listitem><para>Return the first element of a list; abort + evaluation if the argument isn’t a list or is an empty list. You + can test whether a list is empty by comparing it with + <literal>[]</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-import'> + <term><function>import</function> + <replaceable>path</replaceable></term> + <term><function>builtins.import</function> + <replaceable>path</replaceable></term> + + <listitem><para>Load, parse and return the Nix expression in the + file <replaceable>path</replaceable>. If <replaceable>path + </replaceable> is a directory, the file <filename>default.nix + </filename> in that directory is loaded. Evaluation aborts if the + file doesn’t exist or contains an incorrect Nix expression. + <function>import</function> implements Nix’s module system: you + can put any Nix expression (such as a set or a function) in a + separate file, and use it from Nix expressions in other + files.</para> + + <note><para>Unlike some languages, <function>import</function> is a regular + function in Nix. Paths using the angle bracket syntax (e.g., <function> + import</function> <replaceable><foo></replaceable>) are normal path + values (see <xref linkend='ssec-values' />).</para></note> + + <para>A Nix expression loaded by <function>import</function> must + not contain any <emphasis>free variables</emphasis> (identifiers + that are not defined in the Nix expression itself and are not + built-in). Therefore, it cannot refer to variables that are in + scope at the call site. For instance, if you have a calling + expression + +<programlisting> +rec { + x = 123; + y = import ./foo.nix; +}</programlisting> + + then the following <filename>foo.nix</filename> will give an + error: + +<programlisting> +x + 456</programlisting> + + since <varname>x</varname> is not in scope in + <filename>foo.nix</filename>. If you want <varname>x</varname> + to be available in <filename>foo.nix</filename>, you should pass + it as a function argument: + +<programlisting> +rec { + x = 123; + y = import ./foo.nix x; +}</programlisting> + + and + +<programlisting> +x: x + 456</programlisting> + + (The function argument doesn’t have to be called + <varname>x</varname> in <filename>foo.nix</filename>; any name + would work.)</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-intersectAttrs'> + <term><function>builtins.intersectAttrs</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return a set consisting of the attributes in the + set <replaceable>e2</replaceable> that also exist in the set + <replaceable>e1</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isAttrs'> + <term><function>builtins.isAttrs</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a set, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isList'> + <term><function>builtins.isList</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a list, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isFunction'><term><function>builtins.isFunction</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a function, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isString'> + <term><function>builtins.isString</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a string, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isInt'> + <term><function>builtins.isInt</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to an int, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isFloat'> + <term><function>builtins.isFloat</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a float, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-isBool'> + <term><function>builtins.isBool</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a bool, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + <varlistentry><term><function>builtins.isPath</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to a path, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-isNull'> + <term><function>isNull</function> + <replaceable>e</replaceable></term> + <term><function>builtins.isNull</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return <literal>true</literal> if + <replaceable>e</replaceable> evaluates to <literal>null</literal>, + and <literal>false</literal> otherwise.</para> + + <warning><para>This function is <emphasis>deprecated</emphasis>; + just write <literal>e == null</literal> instead.</para></warning> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-length'> + <term><function>builtins.length</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return the length of the list + <replaceable>e</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-lessThan'> + <term><function>builtins.lessThan</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return <literal>true</literal> if the number + <replaceable>e1</replaceable> is less than the number + <replaceable>e2</replaceable>, and <literal>false</literal> + otherwise. Evaluation aborts if either + <replaceable>e1</replaceable> or <replaceable>e2</replaceable> + does not evaluate to a number.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-listToAttrs'> + <term><function>builtins.listToAttrs</function> + <replaceable>e</replaceable></term> + + <listitem><para>Construct a set from a list specifying the names + and values of each attribute. Each element of the list should be + a set consisting of a string-valued attribute + <varname>name</varname> specifying the name of the attribute, and + an attribute <varname>value</varname> specifying its value. + Example: + +<programlisting> +builtins.listToAttrs + [ { name = "foo"; value = 123; } + { name = "bar"; value = 456; } + ] +</programlisting> + + evaluates to + +<programlisting> +{ foo = 123; bar = 456; } +</programlisting> + + </para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-map'> + <term><function>map</function> + <replaceable>f</replaceable> <replaceable>list</replaceable></term> + <term><function>builtins.map</function> + <replaceable>f</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Apply the function <replaceable>f</replaceable> to + each element in the list <replaceable>list</replaceable>. For + example, + +<programlisting> +map (x: "foo" + x) [ "bar" "bla" "abc" ]</programlisting> + + evaluates to <literal>[ "foobar" "foobla" "fooabc" + ]</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-match'> + <term><function>builtins.match</function> + <replaceable>regex</replaceable> <replaceable>str</replaceable></term> + + <listitem><para>Returns a list if the <link + xlink:href="http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04">extended + POSIX regular expression</link> <replaceable>regex</replaceable> + matches <replaceable>str</replaceable> precisely, otherwise returns + <literal>null</literal>. Each item in the list is a regex group. + +<programlisting> +builtins.match "ab" "abc" +</programlisting> + +Evaluates to <literal>null</literal>. + +<programlisting> +builtins.match "abc" "abc" +</programlisting> + +Evaluates to <literal>[ ]</literal>. + +<programlisting> +builtins.match "a(b)(c)" "abc" +</programlisting> + +Evaluates to <literal>[ "b" "c" ]</literal>. + +<programlisting> +builtins.match "[[:space:]]+([[:upper:]]+)[[:space:]]+" " FOO " +</programlisting> + +Evaluates to <literal>[ "foo" ]</literal>. + + </para></listitem> + </varlistentry> + + <varlistentry xml:id='builtin-mul'> + <term><function>builtins.mul</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return the product of the numbers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-parseDrvName'> + <term><function>builtins.parseDrvName</function> + <replaceable>s</replaceable></term> + + <listitem><para>Split the string <replaceable>s</replaceable> into + a package name and version. The package name is everything up to + but not including the first dash followed by a digit, and the + version is everything following that dash. The result is returned + in a set <literal>{ name, version }</literal>. Thus, + <literal>builtins.parseDrvName "nix-0.12pre12876"</literal> + returns <literal>{ name = "nix"; version = "0.12pre12876"; + }</literal>.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-path'> + <term> + <function>builtins.path</function> + <replaceable>args</replaceable> + </term> + + <listitem> + <para> + An enrichment of the built-in path type, based on the attributes + present in <replaceable>args</replaceable>. All are optional + except <varname>path</varname>: + </para> + + <variablelist> + <varlistentry> + <term>path</term> + <listitem> + <para>The underlying path.</para> + </listitem> + </varlistentry> + <varlistentry> + <term>name</term> + <listitem> + <para> + The name of the path when added to the store. This can + used to reference paths that have nix-illegal characters + in their names, like <literal>@</literal>. + </para> + </listitem> + </varlistentry> + <varlistentry> + <term>filter</term> + <listitem> + <para> + A function of the type expected by + <link linkend="builtin-filterSource">builtins.filterSource</link>, + with the same semantics. + </para> + </listitem> + </varlistentry> + <varlistentry> + <term>recursive</term> + <listitem> + <para> + When <literal>false</literal>, when + <varname>path</varname> is added to the store it is with a + flat hash, rather than a hash of the NAR serialization of + the file. Thus, <varname>path</varname> must refer to a + regular file, not a directory. This allows similar + behavior to <literal>fetchurl</literal>. Defaults to + <literal>true</literal>. + </para> + </listitem> + </varlistentry> + <varlistentry> + <term>sha256</term> + <listitem> + <para> + When provided, this is the expected hash of the file at + the path. Evaluation will fail if the hash is incorrect, + and providing a hash allows + <literal>builtins.path</literal> to be used even when the + <literal>pure-eval</literal> nix config option is on. + </para> + </listitem> + </varlistentry> + </variablelist> + </listitem> + </varlistentry> + + <varlistentry xml:id='builtin-pathExists'> + <term><function>builtins.pathExists</function> + <replaceable>path</replaceable></term> + + <listitem><para>Return <literal>true</literal> if the path + <replaceable>path</replaceable> exists at evaluation time, and + <literal>false</literal> otherwise.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-placeholder'> + <term><function>builtins.placeholder</function> + <replaceable>output</replaceable></term> + + <listitem><para>Return a placeholder string for the specified + <replaceable>output</replaceable> that will be substituted by the + corresponding output path at build time. Typical outputs would be + <literal>"out"</literal>, <literal>"bin"</literal> or + <literal>"dev"</literal>.</para></listitem> + </varlistentry> + + <varlistentry xml:id='builtin-readDir'> + <term><function>builtins.readDir</function> + <replaceable>path</replaceable></term> + + <listitem><para>Return the contents of the directory + <replaceable>path</replaceable> as a set mapping directory entries + to the corresponding file type. For instance, if directory + <filename>A</filename> contains a regular file + <filename>B</filename> and another directory + <filename>C</filename>, then <literal>builtins.readDir + ./A</literal> will return the set + +<programlisting> +{ B = "regular"; C = "directory"; }</programlisting> + + The possible values for the file type are + <literal>"regular"</literal>, <literal>"directory"</literal>, + <literal>"symlink"</literal> and + <literal>"unknown"</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-readFile'> + <term><function>builtins.readFile</function> + <replaceable>path</replaceable></term> + + <listitem><para>Return the contents of the file + <replaceable>path</replaceable> as a string.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-removeAttrs'> + <term><function>removeAttrs</function> + <replaceable>set</replaceable> <replaceable>list</replaceable></term> + <term><function>builtins.removeAttrs</function> + <replaceable>set</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Remove the attributes listed in + <replaceable>list</replaceable> from + <replaceable>set</replaceable>. The attributes don’t have to + exist in <replaceable>set</replaceable>. For instance, + +<programlisting> +removeAttrs { x = 1; y = 2; z = 3; } [ "a" "x" "z" ]</programlisting> + + evaluates to <literal>{ y = 2; }</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-replaceStrings'> + <term><function>builtins.replaceStrings</function> + <replaceable>from</replaceable> <replaceable>to</replaceable> <replaceable>s</replaceable></term> + + <listitem><para>Given string <replaceable>s</replaceable>, replace + every occurrence of the strings in <replaceable>from</replaceable> + with the corresponding string in + <replaceable>to</replaceable>. For example, + +<programlisting> +builtins.replaceStrings ["oo" "a"] ["a" "i"] "foobar" +</programlisting> + + evaluates to <literal>"fabir"</literal>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-seq'> + <term><function>builtins.seq</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Evaluate <replaceable>e1</replaceable>, then + evaluate and return <replaceable>e2</replaceable>. This ensures + that a computation is strict in the value of + <replaceable>e1</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-sort'> + <term><function>builtins.sort</function> + <replaceable>comparator</replaceable> <replaceable>list</replaceable></term> + + <listitem><para>Return <replaceable>list</replaceable> in sorted + order. It repeatedly calls the function + <replaceable>comparator</replaceable> with two elements. The + comparator should return <literal>true</literal> if the first + element is less than the second, and <literal>false</literal> + otherwise. For example, + +<programlisting> +builtins.sort builtins.lessThan [ 483 249 526 147 42 77 ] +</programlisting> + + produces the list <literal>[ 42 77 147 249 483 526 + ]</literal>.</para> + + <para>This is a stable sort: it preserves the relative order of + elements deemed equal by the comparator.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-split'> + <term><function>builtins.split</function> + <replaceable>regex</replaceable> <replaceable>str</replaceable></term> + + <listitem><para>Returns a list composed of non matched strings interleaved + with the lists of the <link + xlink:href="http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04">extended + POSIX regular expression</link> <replaceable>regex</replaceable> matches + of <replaceable>str</replaceable>. Each item in the lists of matched + sequences is a regex group. + +<programlisting> +builtins.split "(a)b" "abc" +</programlisting> + +Evaluates to <literal>[ "" [ "a" ] "c" ]</literal>. + +<programlisting> +builtins.split "([ac])" "abc" +</programlisting> + +Evaluates to <literal>[ "" [ "a" ] "b" [ "c" ] "" ]</literal>. + +<programlisting> +builtins.split "(a)|(c)" "abc" +</programlisting> + +Evaluates to <literal>[ "" [ "a" null ] "b" [ null "c" ] "" ]</literal>. + +<programlisting> +builtins.split "([[:upper:]]+)" " FOO " +</programlisting> + +Evaluates to <literal>[ " " [ "FOO" ] " " ]</literal>. + + </para></listitem> + </varlistentry> + + + <varlistentry xml:id='builtin-splitVersion'> + <term><function>builtins.splitVersion</function> + <replaceable>s</replaceable></term> + + <listitem><para>Split a string representing a version into its + components, by the same version splitting logic underlying the + version comparison in <link linkend="ssec-version-comparisons"> + <command>nix-env -u</command></link>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-stringLength'> + <term><function>builtins.stringLength</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return the length of the string + <replaceable>e</replaceable>. If <replaceable>e</replaceable> is + not a string, evaluation is aborted.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-sub'> + <term><function>builtins.sub</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Return the difference between the numbers + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable>.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-substring'> + <term><function>builtins.substring</function> + <replaceable>start</replaceable> <replaceable>len</replaceable> + <replaceable>s</replaceable></term> + + <listitem><para>Return the substring of + <replaceable>s</replaceable> from character position + <replaceable>start</replaceable> (zero-based) up to but not + including <replaceable>start + len</replaceable>. If + <replaceable>start</replaceable> is greater than the length of the + string, an empty string is returned, and if <replaceable>start + + len</replaceable> lies beyond the end of the string, only the + substring up to the end of the string is returned. + <replaceable>start</replaceable> must be + non-negative. For example, + +<programlisting> +builtins.substring 0 3 "nixos" +</programlisting> + + evaluates to <literal>"nix"</literal>. + </para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-tail'> + <term><function>builtins.tail</function> + <replaceable>list</replaceable></term> + + <listitem><para>Return the second to last elements of a list; + abort evaluation if the argument isn’t a list or is an empty + list.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-throw'> + <term><function>throw</function> + <replaceable>s</replaceable></term> + <term><function>builtins.throw</function> + <replaceable>s</replaceable></term> + + <listitem><para>Throw an error message + <replaceable>s</replaceable>. This usually aborts Nix expression + evaluation, but in <command>nix-env -qa</command> and other + commands that try to evaluate a set of derivations to get + information about those derivations, a derivation that throws an + error is silently skipped (which is not the case for + <function>abort</function>).</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-toFile'> + <term><function>builtins.toFile</function> + <replaceable>name</replaceable> + <replaceable>s</replaceable></term> + + <listitem><para>Store the string <replaceable>s</replaceable> in a + file in the Nix store and return its path. The file has suffix + <replaceable>name</replaceable>. This file can be used as an + input to derivations. One application is to write builders + “inline”. For instance, the following Nix expression combines + <xref linkend='ex-hello-nix' /> and <xref + linkend='ex-hello-builder' /> into one file: + +<programlisting> +{ stdenv, fetchurl, perl }: + +stdenv.mkDerivation { + name = "hello-2.1.1"; + + builder = builtins.toFile "builder.sh" " + source $stdenv/setup + + PATH=$perl/bin:$PATH + + tar xvfz $src + cd hello-* + ./configure --prefix=$out + make + make install + "; + + src = fetchurl { + url = http://ftp.nluug.nl/pub/gnu/hello/hello-2.1.1.tar.gz; + sha256 = "1md7jsfd8pa45z73bz1kszpp01yw6x5ljkjk2hx7wl800any6465"; + }; + inherit perl; +}</programlisting> + + </para> + + <para>It is even possible for one file to refer to another, e.g., + +<programlisting> + builder = let + configFile = builtins.toFile "foo.conf" " + # This is some dummy configuration file. + <replaceable>...</replaceable> + "; + in builtins.toFile "builder.sh" " + source $stdenv/setup + <replaceable>...</replaceable> + cp ${configFile} $out/etc/foo.conf + ";</programlisting> + + Note that <literal>${configFile}</literal> is an antiquotation + (see <xref linkend='ssec-values' />), so the result of the + expression <literal>configFile</literal> (i.e., a path like + <filename>/nix/store/m7p7jfny445k...-foo.conf</filename>) will be + spliced into the resulting string.</para> + + <para>It is however <emphasis>not</emphasis> allowed to have files + mutually referring to each other, like so: + +<programlisting> +let + foo = builtins.toFile "foo" "...${bar}..."; + bar = builtins.toFile "bar" "...${foo}..."; +in foo</programlisting> + + This is not allowed because it would cause a cyclic dependency in + the computation of the cryptographic hashes for + <varname>foo</varname> and <varname>bar</varname>.</para> + <para>It is also not possible to reference the result of a derivation. + If you are using Nixpkgs, the <literal>writeTextFile</literal> function is able to + do that.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-toJSON'> + <term><function>builtins.toJSON</function> <replaceable>e</replaceable></term> + + <listitem><para>Return a string containing a JSON representation + of <replaceable>e</replaceable>. Strings, integers, floats, booleans, + nulls and lists are mapped to their JSON equivalents. Sets + (except derivations) are represented as objects. Derivations are + translated to a JSON string containing the derivation’s output + path. Paths are copied to the store and represented as a JSON + string of the resulting store path.</para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-toPath'> + <term><function>builtins.toPath</function> <replaceable>s</replaceable></term> + + <listitem><para> DEPRECATED. Use <literal>/. + "/path"</literal> + to convert a string into an absolute path. For relative paths, + use <literal>./. + "/path"</literal>. + </para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-toString'> + <term><function>toString</function> <replaceable>e</replaceable></term> + <term><function>builtins.toString</function> <replaceable>e</replaceable></term> + + <listitem><para>Convert the expression + <replaceable>e</replaceable> to a string. + <replaceable>e</replaceable> can be:</para> + <itemizedlist> + <listitem><para>A string (in which case the string is returned unmodified).</para></listitem> + <listitem><para>A path (e.g., <literal>toString /foo/bar</literal> yields <literal>"/foo/bar"</literal>.</para></listitem> + <listitem><para>A set containing <literal>{ __toString = self: ...; }</literal>.</para></listitem> + <listitem><para>An integer.</para></listitem> + <listitem><para>A list, in which case the string representations of its elements are joined with spaces.</para></listitem> + <listitem><para>A Boolean (<literal>false</literal> yields <literal>""</literal>, <literal>true</literal> yields <literal>"1"</literal>).</para></listitem> + <listitem><para><literal>null</literal>, which yields the empty string.</para></listitem> + </itemizedlist> + </listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-toXML'> + <term><function>builtins.toXML</function> <replaceable>e</replaceable></term> + + <listitem><para>Return a string containing an XML representation + of <replaceable>e</replaceable>. The main application for + <function>toXML</function> is to communicate information with the + builder in a more structured format than plain environment + variables.</para> + + <!-- TODO: more formally describe the schema of the XML + representation --> + + <para><xref linkend='ex-toxml' /> shows an example where this is + the case. The builder is supposed to generate the configuration + file for a <link xlink:href='http://jetty.mortbay.org/'>Jetty + servlet container</link>. A servlet container contains a number + of servlets (<filename>*.war</filename> files) each exported under + a specific URI prefix. So the servlet configuration is a list of + sets containing the <varname>path</varname> and + <varname>war</varname> of the servlet (<xref + linkend='ex-toxml-co-servlets' />). This kind of information is + difficult to communicate with the normal method of passing + information through an environment variable, which just + concatenates everything together into a string (which might just + work in this case, but wouldn’t work if fields are optional or + contain lists themselves). Instead the Nix expression is + converted to an XML representation with + <function>toXML</function>, which is unambiguous and can easily be + processed with the appropriate tools. For instance, in the + example an XSLT stylesheet (<xref linkend='ex-toxml-co-stylesheet' + />) is applied to it (<xref linkend='ex-toxml-co-apply' />) to + generate the XML configuration file for the Jetty server. The XML + representation produced from <xref linkend='ex-toxml-co-servlets' + /> by <function>toXML</function> is shown in <xref + linkend='ex-toxml-result' />.</para> + + <para>Note that <xref linkend='ex-toxml' /> uses the <function + linkend='builtin-toFile'>toFile</function> built-in to write the + builder and the stylesheet “inline” in the Nix expression. The + path of the stylesheet is spliced into the builder at + <literal>xsltproc ${stylesheet} + <replaceable>...</replaceable></literal>.</para> + + <example xml:id='ex-toxml'><title>Passing information to a builder + using <function>toXML</function></title> + +<programlisting><![CDATA[ +{ stdenv, fetchurl, libxslt, jira, uberwiki }: + +stdenv.mkDerivation (rec { + name = "web-server"; + + buildInputs = [ libxslt ]; + + builder = builtins.toFile "builder.sh" " + source $stdenv/setup + mkdir $out + echo "$servlets" | xsltproc ${stylesheet} - > $out/server-conf.xml]]> <co xml:id='ex-toxml-co-apply' /> <![CDATA[ + "; + + stylesheet = builtins.toFile "stylesheet.xsl"]]> <co xml:id='ex-toxml-co-stylesheet' /> <![CDATA[ + "<?xml version='1.0' encoding='UTF-8'?> + <xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version='1.0'> + <xsl:template match='/'> + <Configure> + <xsl:for-each select='/expr/list/attrs'> + <Call name='addWebApplication'> + <Arg><xsl:value-of select=\"attr[@name = 'path']/string/@value\" /></Arg> + <Arg><xsl:value-of select=\"attr[@name = 'war']/path/@value\" /></Arg> + </Call> + </xsl:for-each> + </Configure> + </xsl:template> + </xsl:stylesheet> + "; + + servlets = builtins.toXML []]> <co xml:id='ex-toxml-co-servlets' /> <![CDATA[ + { path = "/bugtracker"; war = jira + "/lib/atlassian-jira.war"; } + { path = "/wiki"; war = uberwiki + "/uberwiki.war"; } + ]; +})]]></programlisting> + + </example> + + <example xml:id='ex-toxml-result'><title>XML representation produced by + <function>toXML</function></title> + +<programlisting><![CDATA[<?xml version='1.0' encoding='utf-8'?> +<expr> + <list> + <attrs> + <attr name="path"> + <string value="/bugtracker" /> + </attr> + <attr name="war"> + <path value="/nix/store/d1jh9pasa7k2...-jira/lib/atlassian-jira.war" /> + </attr> + </attrs> + <attrs> + <attr name="path"> + <string value="/wiki" /> + </attr> + <attr name="war"> + <path value="/nix/store/y6423b1yi4sx...-uberwiki/uberwiki.war" /> + </attr> + </attrs> + </list> +</expr>]]></programlisting> + + </example> + + </listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-trace'> + <term><function>builtins.trace</function> + <replaceable>e1</replaceable> <replaceable>e2</replaceable></term> + + <listitem><para>Evaluate <replaceable>e1</replaceable> and print its + abstract syntax representation on standard error. Then return + <replaceable>e2</replaceable>. This function is useful for + debugging.</para></listitem> + + </varlistentry> + + <varlistentry xml:id='builtin-tryEval'> + <term><function>builtins.tryEval</function> + <replaceable>e</replaceable></term> + + <listitem><para>Try to shallowly evaluate <replaceable>e</replaceable>. + Return a set containing the attributes <literal>success</literal> + (<literal>true</literal> if <replaceable>e</replaceable> evaluated + successfully, <literal>false</literal> if an error was thrown) and + <literal>value</literal>, equalling <replaceable>e</replaceable> + if successful and <literal>false</literal> otherwise. Note that this + doesn't evaluate <replaceable>e</replaceable> deeply, so + <literal>let e = { x = throw ""; }; in (builtins.tryEval e).success + </literal> will be <literal>true</literal>. Using <literal>builtins.deepSeq + </literal> one can get the expected result: <literal>let e = { x = throw ""; + }; in (builtins.tryEval (builtins.deepSeq e e)).success</literal> will be + <literal>false</literal>. + </para></listitem> + + </varlistentry> + + + <varlistentry xml:id='builtin-typeOf'> + <term><function>builtins.typeOf</function> + <replaceable>e</replaceable></term> + + <listitem><para>Return a string representing the type of the value + <replaceable>e</replaceable>, namely <literal>"int"</literal>, + <literal>"bool"</literal>, <literal>"string"</literal>, + <literal>"path"</literal>, <literal>"null"</literal>, + <literal>"set"</literal>, <literal>"list"</literal>, + <literal>"lambda"</literal> or + <literal>"float"</literal>.</para></listitem> + + </varlistentry> + + +</variablelist> + + +</section> diff --git a/third_party/nix/doc/manual/expressions/derivations.xml b/third_party/nix/doc/manual/expressions/derivations.xml new file mode 100644 index 0000000000..6f6297565c --- /dev/null +++ b/third_party/nix/doc/manual/expressions/derivations.xml @@ -0,0 +1,211 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-derivation"> + +<title>Derivations</title> + +<para>The most important built-in function is +<function>derivation</function>, which is used to describe a single +derivation (a build action). It takes as input a set, the attributes +of which specify the inputs of the build.</para> + +<itemizedlist> + + <listitem xml:id="attr-system"><para>There must be an attribute named + <varname>system</varname> whose value must be a string specifying a + Nix platform identifier, such as <literal>"i686-linux"</literal> or + <literal>"x86_64-darwin"</literal><footnote><para>To figure out + your platform identifier, look at the line <quote>Checking for the + canonical Nix system name</quote> in the output of Nix's + <filename>configure</filename> script.</para></footnote> The build + can only be performed on a machine and operating system matching the + platform identifier. (Nix can automatically forward builds for + other platforms by forwarding them to other machines; see <xref + linkend='chap-distributed-builds' />.)</para></listitem> + + <listitem><para>There must be an attribute named + <varname>name</varname> whose value must be a string. This is used + as a symbolic name for the package by <command>nix-env</command>, + and it is appended to the output paths of the + derivation.</para></listitem> + + <listitem><para>There must be an attribute named + <varname>builder</varname> that identifies the program that is + executed to perform the build. It can be either a derivation or a + source (a local file reference, e.g., + <filename>./builder.sh</filename>).</para></listitem> + + <listitem><para>Every attribute is passed as an environment variable + to the builder. Attribute values are translated to environment + variables as follows: + + <itemizedlist> + + <listitem><para>Strings and numbers are just passed + verbatim.</para></listitem> + + <listitem><para>A <emphasis>path</emphasis> (e.g., + <filename>../foo/sources.tar</filename>) causes the referenced + file to be copied to the store; its location in the store is put + in the environment variable. The idea is that all sources + should reside in the Nix store, since all inputs to a derivation + should reside in the Nix store.</para></listitem> + + <listitem><para>A <emphasis>derivation</emphasis> causes that + derivation to be built prior to the present derivation; its + default output path is put in the environment + variable.</para></listitem> + + <listitem><para>Lists of the previous types are also allowed. + They are simply concatenated, separated by + spaces.</para></listitem> + + <listitem><para><literal>true</literal> is passed as the string + <literal>1</literal>, <literal>false</literal> and + <literal>null</literal> are passed as an empty string. + </para></listitem> + </itemizedlist> + + </para></listitem> + + <listitem><para>The optional attribute <varname>args</varname> + specifies command-line arguments to be passed to the builder. It + should be a list.</para></listitem> + + <listitem><para>The optional attribute <varname>outputs</varname> + specifies a list of symbolic outputs of the derivation. By default, + a derivation produces a single output path, denoted as + <literal>out</literal>. However, derivations can produce multiple + output paths. This is useful because it allows outputs to be + downloaded or garbage-collected separately. For instance, imagine a + library package that provides a dynamic library, header files, and + documentation. A program that links against the library doesn’t + need the header files and documentation at runtime, and it doesn’t + need the documentation at build time. Thus, the library package + could specify: +<programlisting> +outputs = [ "lib" "headers" "doc" ]; +</programlisting> + This will cause Nix to pass environment variables + <literal>lib</literal>, <literal>headers</literal> and + <literal>doc</literal> to the builder containing the intended store + paths of each output. The builder would typically do something like +<programlisting> +./configure --libdir=$lib/lib --includedir=$headers/include --docdir=$doc/share/doc +</programlisting> + for an Autoconf-style package. You can refer to each output of a + derivation by selecting it as an attribute, e.g. +<programlisting> +buildInputs = [ pkg.lib pkg.headers ]; +</programlisting> + The first element of <varname>outputs</varname> determines the + <emphasis>default output</emphasis>. Thus, you could also write +<programlisting> +buildInputs = [ pkg pkg.headers ]; +</programlisting> + since <literal>pkg</literal> is equivalent to + <literal>pkg.lib</literal>.</para></listitem> + +</itemizedlist> + +<para>The function <function>mkDerivation</function> in the Nixpkgs +standard environment is a wrapper around +<function>derivation</function> that adds a default value for +<varname>system</varname> and always uses Bash as the builder, to +which the supplied builder is passed as a command-line argument. See +the Nixpkgs manual for details.</para> + +<para>The builder is executed as follows: + +<itemizedlist> + + <listitem><para>A temporary directory is created under the directory + specified by <envar>TMPDIR</envar> (default + <filename>/tmp</filename>) where the build will take place. The + current directory is changed to this directory.</para></listitem> + + <listitem><para>The environment is cleared and set to the derivation + attributes, as specified above.</para></listitem> + + <listitem><para>In addition, the following variables are set: + + <itemizedlist> + + <listitem><para><envar>NIX_BUILD_TOP</envar> contains the path of + the temporary directory for this build.</para></listitem> + + <listitem><para>Also, <envar>TMPDIR</envar>, + <envar>TEMPDIR</envar>, <envar>TMP</envar>, <envar>TEMP</envar> + are set to point to the temporary directory. This is to prevent + the builder from accidentally writing temporary files anywhere + else. Doing so might cause interference by other + processes.</para></listitem> + + <listitem><para><envar>PATH</envar> is set to + <filename>/path-not-set</filename> to prevent shells from + initialising it to their built-in default value.</para></listitem> + + <listitem><para><envar>HOME</envar> is set to + <filename>/homeless-shelter</filename> to prevent programs from + using <filename>/etc/passwd</filename> or the like to find the + user's home directory, which could cause impurity. Usually, when + <envar>HOME</envar> is set, it is used as the location of the home + directory, even if it points to a non-existent + path.</para></listitem> + + <listitem><para><envar>NIX_STORE</envar> is set to the path of the + top-level Nix store directory (typically, + <filename>/nix/store</filename>).</para></listitem> + + <listitem><para>For each output declared in + <varname>outputs</varname>, the corresponding environment variable + is set to point to the intended path in the Nix store for that + output. Each output path is a concatenation of the cryptographic + hash of all build inputs, the <varname>name</varname> attribute + and the output name. (The output name is omitted if it’s + <literal>out</literal>.)</para></listitem> + + </itemizedlist> + + </para></listitem> + + <listitem><para>If an output path already exists, it is removed. + Also, locks are acquired to prevent multiple Nix instances from + performing the same build at the same time.</para></listitem> + + <listitem><para>A log of the combined standard output and error is + written to <filename>/nix/var/log/nix</filename>.</para></listitem> + + <listitem><para>The builder is executed with the arguments specified + by the attribute <varname>args</varname>. If it exits with exit + code 0, it is considered to have succeeded.</para></listitem> + + <listitem><para>The temporary directory is removed (unless the + <option>-K</option> option was specified).</para></listitem> + + <listitem><para>If the build was successful, Nix scans each output + path for references to input paths by looking for the hash parts of + the input paths. Since these are potential runtime dependencies, + Nix registers them as dependencies of the output + paths.</para></listitem> + + <listitem><para>After the build, Nix sets the last-modified + timestamp on all files in the build result to 1 (00:00:01 1/1/1970 + UTC), sets the group to the default group, and sets the mode of the + file to 0444 or 0555 (i.e., read-only, with execute permission + enabled if the file was originally executable). Note that possible + <literal>setuid</literal> and <literal>setgid</literal> bits are + cleared. Setuid and setgid programs are not currently supported by + Nix. This is because the Nix archives used in deployment have no + concept of ownership information, and because it makes the build + result dependent on the user performing the build.</para></listitem> + +</itemizedlist> + +</para> + +<xi:include href="advanced-attributes.xml" /> + +</section> diff --git a/third_party/nix/doc/manual/expressions/expression-language.xml b/third_party/nix/doc/manual/expressions/expression-language.xml new file mode 100644 index 0000000000..240ef80f14 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/expression-language.xml @@ -0,0 +1,30 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-expression-language"> + +<title>Nix Expression Language</title> + +<para>The Nix expression language is a pure, lazy, functional +language. Purity means that operations in the language don't have +side-effects (for instance, there is no variable assignment). +Laziness means that arguments to functions are evaluated only when +they are needed. Functional means that functions are +<quote>normal</quote> values that can be passed around and manipulated +in interesting ways. The language is not a full-featured, general +purpose language. Its main job is to describe packages, +compositions of packages, and the variability within +packages.</para> + +<para>This section presents the various features of the +language.</para> + +<xi:include href="language-values.xml" /> +<xi:include href="language-constructs.xml" /> +<xi:include href="language-operators.xml" /> +<xi:include href="derivations.xml" /> +<xi:include href="builtins.xml" /> + + +</chapter> diff --git a/third_party/nix/doc/manual/expressions/expression-syntax.xml b/third_party/nix/doc/manual/expressions/expression-syntax.xml new file mode 100644 index 0000000000..42b9dca362 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/expression-syntax.xml @@ -0,0 +1,148 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-expression-syntax'> + +<title>Expression Syntax</title> + +<example xml:id='ex-hello-nix'><title>Nix expression for GNU Hello +(<filename>default.nix</filename>)</title> +<programlisting> +{ stdenv, fetchurl, perl }: <co xml:id='ex-hello-nix-co-1' /> + +stdenv.mkDerivation { <co xml:id='ex-hello-nix-co-2' /> + name = "hello-2.1.1"; <co xml:id='ex-hello-nix-co-3' /> + builder = ./builder.sh; <co xml:id='ex-hello-nix-co-4' /> + src = fetchurl { <co xml:id='ex-hello-nix-co-5' /> + url = ftp://ftp.nluug.nl/pub/gnu/hello/hello-2.1.1.tar.gz; + sha256 = "1md7jsfd8pa45z73bz1kszpp01yw6x5ljkjk2hx7wl800any6465"; + }; + inherit perl; <co xml:id='ex-hello-nix-co-6' /> +}</programlisting> +</example> + +<para><xref linkend='ex-hello-nix' /> shows a Nix expression for GNU +Hello. It's actually already in the Nix Packages collection in +<filename>pkgs/applications/misc/hello/ex-1/default.nix</filename>. +It is customary to place each package in a separate directory and call +the single Nix expression in that directory +<filename>default.nix</filename>. The file has the following elements +(referenced from the figure by number): + +<calloutlist> + + <callout arearefs='ex-hello-nix-co-1'> + + <para>This states that the expression is a + <emphasis>function</emphasis> that expects to be called with three + arguments: <varname>stdenv</varname>, <varname>fetchurl</varname>, + and <varname>perl</varname>. They are needed to build Hello, but + we don't know how to build them here; that's why they are function + arguments. <varname>stdenv</varname> is a package that is used + by almost all Nix Packages packages; it provides a + <quote>standard</quote> environment consisting of the things you + would expect in a basic Unix environment: a C/C++ compiler (GCC, + to be precise), the Bash shell, fundamental Unix tools such as + <command>cp</command>, <command>grep</command>, + <command>tar</command>, etc. <varname>fetchurl</varname> is a + function that downloads files. <varname>perl</varname> is the + Perl interpreter.</para> + + <para>Nix functions generally have the form <literal>{ x, y, ..., + z }: e</literal> where <varname>x</varname>, <varname>y</varname>, + etc. are the names of the expected arguments, and where + <replaceable>e</replaceable> is the body of the function. So + here, the entire remainder of the file is the body of the + function; when given the required arguments, the body should + describe how to build an instance of the Hello package.</para> + + </callout> + + <callout arearefs='ex-hello-nix-co-2'> + + <para>So we have to build a package. Building something from + other stuff is called a <emphasis>derivation</emphasis> in Nix (as + opposed to sources, which are built by humans instead of + computers). We perform a derivation by calling + <varname>stdenv.mkDerivation</varname>. + <varname>mkDerivation</varname> is a function provided by + <varname>stdenv</varname> that builds a package from a set of + <emphasis>attributes</emphasis>. A set is just a list of + key/value pairs where each key is a string and each value is an + arbitrary Nix expression. They take the general form <literal>{ + <replaceable>name1</replaceable> = + <replaceable>expr1</replaceable>; <replaceable>...</replaceable> + <replaceable>nameN</replaceable> = + <replaceable>exprN</replaceable>; }</literal>.</para> + + </callout> + + <callout arearefs='ex-hello-nix-co-3'> + + <para>The attribute <varname>name</varname> specifies the symbolic + name and version of the package. Nix doesn't really care about + these things, but they are used by for instance <command>nix-env + -q</command> to show a <quote>human-readable</quote> name for + packages. This attribute is required by + <varname>mkDerivation</varname>.</para> + + </callout> + + <callout arearefs='ex-hello-nix-co-4'> + + <para>The attribute <varname>builder</varname> specifies the + builder. This attribute can sometimes be omitted, in which case + <varname>mkDerivation</varname> will fill in a default builder + (which does a <literal>configure; make; make install</literal>, in + essence). Hello is sufficiently simple that the default builder + would suffice, but in this case, we will show an actual builder + for educational purposes. The value + <command>./builder.sh</command> refers to the shell script shown + in <xref linkend='ex-hello-builder' />, discussed below.</para> + + </callout> + + <callout arearefs='ex-hello-nix-co-5'> + + <para>The builder has to know what the sources of the package + are. Here, the attribute <varname>src</varname> is bound to the + result of a call to the <command>fetchurl</command> function. + Given a URL and a SHA-256 hash of the expected contents of the file + at that URL, this function builds a derivation that downloads the + file and checks its hash. So the sources are a dependency that + like all other dependencies is built before Hello itself is + built.</para> + + <para>Instead of <varname>src</varname> any other name could have + been used, and in fact there can be any number of sources (bound + to different attributes). However, <varname>src</varname> is + customary, and it's also expected by the default builder (which we + don't use in this example).</para> + + </callout> + + <callout arearefs='ex-hello-nix-co-6'> + + <para>Since the derivation requires Perl, we have to pass the + value of the <varname>perl</varname> function argument to the + builder. All attributes in the set are actually passed as + environment variables to the builder, so declaring an attribute + + <programlisting> +perl = perl;</programlisting> + + will do the trick: it binds an attribute <varname>perl</varname> + to the function argument which also happens to be called + <varname>perl</varname>. However, it looks a bit silly, so there + is a shorter syntax. The <literal>inherit</literal> keyword + causes the specified attributes to be bound to whatever variables + with the same name happen to be in scope.</para> + + </callout> + +</calloutlist> + +</para> + +</section> diff --git a/third_party/nix/doc/manual/expressions/generic-builder.xml b/third_party/nix/doc/manual/expressions/generic-builder.xml new file mode 100644 index 0000000000..db7ff405d8 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/generic-builder.xml @@ -0,0 +1,98 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-generic-builder'> + +<title>Generic Builder Syntax</title> + +<para>Recall from <xref linkend='ex-hello-builder' /> that the builder +looked something like this: + +<programlisting> +PATH=$perl/bin:$PATH +tar xvfz $src +cd hello-* +./configure --prefix=$out +make +make install</programlisting> + +The builders for almost all Unix packages look like this — set up some +environment variables, unpack the sources, configure, build, and +install. For this reason the standard environment provides some Bash +functions that automate the build process. A builder using the +generic build facilities in shown in <xref linkend='ex-hello-builder2' +/>.</para> + +<example xml:id='ex-hello-builder2'><title>Build script using the generic +build functions</title> +<programlisting> +buildInputs="$perl" <co xml:id='ex-hello-builder2-co-1' /> + +source $stdenv/setup <co xml:id='ex-hello-builder2-co-2' /> + +genericBuild <co xml:id='ex-hello-builder2-co-3' /></programlisting> +</example> + +<calloutlist> + + <callout arearefs='ex-hello-builder2-co-1'> + + <para>The <envar>buildInputs</envar> variable tells + <filename>setup</filename> to use the indicated packages as + <quote>inputs</quote>. This means that if a package provides a + <filename>bin</filename> subdirectory, it's added to + <envar>PATH</envar>; if it has a <filename>include</filename> + subdirectory, it's added to GCC's header search path; and so + on.<footnote><para>How does it work? <filename>setup</filename> + tries to source the file + <filename><replaceable>pkg</replaceable>/nix-support/setup-hook</filename> + of all dependencies. These “setup hooks” can then set up whatever + environment variables they want; for instance, the setup hook for + Perl sets the <envar>PERL5LIB</envar> environment variable to + contain the <filename>lib/site_perl</filename> directories of all + inputs.</para></footnote> + </para> + + </callout> + + <callout arearefs='ex-hello-builder2-co-2'> + + <para>The function <function>genericBuild</function> is defined in + the file <literal>$stdenv/setup</literal>.</para> + + </callout> + + <callout arearefs='ex-hello-builder2-co-3'> + + <para>The final step calls the shell function + <function>genericBuild</function>, which performs the steps that + were done explicitly in <xref linkend='ex-hello-builder' />. The + generic builder is smart enough to figure out whether to unpack + the sources using <command>gzip</command>, + <command>bzip2</command>, etc. It can be customised in many ways; + see the Nixpkgs manual for details.</para> + + </callout> + +</calloutlist> + +<para>Discerning readers will note that the +<envar>buildInputs</envar> could just as well have been set in the Nix +expression, like this: + +<programlisting> + buildInputs = [ perl ];</programlisting> + +The <varname>perl</varname> attribute can then be removed, and the +builder becomes even shorter: + +<programlisting> +source $stdenv/setup +genericBuild</programlisting> + +In fact, <varname>mkDerivation</varname> provides a default builder +that looks exactly like that, so it is actually possible to omit the +builder for Hello entirely.</para> + +</section> diff --git a/third_party/nix/doc/manual/expressions/language-constructs.xml b/third_party/nix/doc/manual/expressions/language-constructs.xml new file mode 100644 index 0000000000..0d0cbbe155 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/language-constructs.xml @@ -0,0 +1,409 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-constructs"> + +<title>Language Constructs</title> + +<simplesect><title>Recursive sets</title> + +<para>Recursive sets are just normal sets, but the attributes can +refer to each other. For example, + +<programlisting> +rec { + x = y; + y = 123; +}.x +</programlisting> + +evaluates to <literal>123</literal>. Note that without +<literal>rec</literal> the binding <literal>x = y;</literal> would +refer to the variable <varname>y</varname> in the surrounding scope, +if one exists, and would be invalid if no such variable exists. That +is, in a normal (non-recursive) set, attributes are not added to the +lexical scope; in a recursive set, they are.</para> + +<para>Recursive sets of course introduce the danger of infinite +recursion. For example, + +<programlisting> +rec { + x = y; + y = x; +}.x</programlisting> + +does not terminate<footnote><para>Actually, Nix detects infinite +recursion in this case and aborts (<quote>infinite recursion +encountered</quote>).</para></footnote>.</para> + +</simplesect> + + +<simplesect xml:id="sect-let-expressions"><title>Let-expressions</title> + +<para>A let-expression allows you to define local variables for an +expression. For instance, + +<programlisting> +let + x = "foo"; + y = "bar"; +in x + y</programlisting> + +evaluates to <literal>"foobar"</literal>. + +</para> + +</simplesect> + + +<simplesect><title>Inheriting attributes</title> + +<para>When defining a set or in a let-expression it is often convenient to copy variables +from the surrounding lexical scope (e.g., when you want to propagate +attributes). This can be shortened using the +<literal>inherit</literal> keyword. For instance, + +<programlisting> +let x = 123; in +{ inherit x; + y = 456; +}</programlisting> + +is equivalent to + +<programlisting> +let x = 123; in +{ x = x; + y = 456; +}</programlisting> + +and both evaluate to <literal>{ x = 123; y = 456; }</literal>. (Note that +this works because <varname>x</varname> is added to the lexical scope +by the <literal>let</literal> construct.) It is also possible to +inherit attributes from another set. For instance, in this fragment +from <filename>all-packages.nix</filename>, + +<programlisting> + graphviz = (import ../tools/graphics/graphviz) { + inherit fetchurl stdenv libpng libjpeg expat x11 yacc; + inherit (xlibs) libXaw; + }; + + xlibs = { + libX11 = ...; + libXaw = ...; + ... + } + + libpng = ...; + libjpg = ...; + ...</programlisting> + +the set used in the function call to the function defined in +<filename>../tools/graphics/graphviz</filename> inherits a number of +variables from the surrounding scope (<varname>fetchurl</varname> +... <varname>yacc</varname>), but also inherits +<varname>libXaw</varname> (the X Athena Widgets) from the +<varname>xlibs</varname> (X11 client-side libraries) set.</para> + +<para> +Summarizing the fragment + +<programlisting> +... +inherit x y z; +inherit (src-set) a b c; +...</programlisting> + +is equivalent to + +<programlisting> +... +x = x; y = y; z = z; +a = src-set.a; b = src-set.b; c = src-set.c; +...</programlisting> + +when used while defining local variables in a let-expression or +while defining a set.</para> + +</simplesect> + + +<simplesect xml:id="ss-functions"><title>Functions</title> + +<para>Functions have the following form: + +<programlisting> +<replaceable>pattern</replaceable>: <replaceable>body</replaceable></programlisting> + +The pattern specifies what the argument of the function must look +like, and binds variables in the body to (parts of) the +argument. There are three kinds of patterns:</para> + +<itemizedlist> + + + <listitem><para>If a pattern is a single identifier, then the + function matches any argument. Example: + + <programlisting> +let negate = x: !x; + concat = x: y: x + y; +in if negate true then concat "foo" "bar" else ""</programlisting> + + Note that <function>concat</function> is a function that takes one + argument and returns a function that takes another argument. This + allows partial parameterisation (i.e., only filling some of the + arguments of a function); e.g., + + <programlisting> +map (concat "foo") [ "bar" "bla" "abc" ]</programlisting> + + evaluates to <literal>[ "foobar" "foobla" + "fooabc" ]</literal>.</para></listitem> + + + <listitem><para>A <emphasis>set pattern</emphasis> of the form + <literal>{ name1, name2, …, nameN }</literal> matches a set + containing the listed attributes, and binds the values of those + attributes to variables in the function body. For example, the + function + +<programlisting> +{ x, y, z }: z + y + x</programlisting> + + can only be called with a set containing exactly the attributes + <varname>x</varname>, <varname>y</varname> and + <varname>z</varname>. No other attributes are allowed. If you want + to allow additional arguments, you can use an ellipsis + (<literal>...</literal>): + +<programlisting> +{ x, y, z, ... }: z + y + x</programlisting> + + This works on any set that contains at least the three named + attributes.</para> + + <para>It is possible to provide <emphasis>default values</emphasis> + for attributes, in which case they are allowed to be missing. A + default value is specified by writing + <literal><replaceable>name</replaceable> ? + <replaceable>e</replaceable></literal>, where + <replaceable>e</replaceable> is an arbitrary expression. For example, + +<programlisting> +{ x, y ? "foo", z ? "bar" }: z + y + x</programlisting> + + specifies a function that only requires an attribute named + <varname>x</varname>, but optionally accepts <varname>y</varname> + and <varname>z</varname>.</para></listitem> + + + <listitem><para>An <literal>@</literal>-pattern provides a means of referring + to the whole value being matched: + +<programlisting> args@{ x, y, z, ... }: z + y + x + args.a</programlisting> + +but can also be written as: + +<programlisting> { x, y, z, ... } @ args: z + y + x + args.a</programlisting> + + Here <varname>args</varname> is bound to the entire argument, which + is further matched against the pattern <literal>{ x, y, z, + ... }</literal>. <literal>@</literal>-pattern makes mainly sense with an + ellipsis(<literal>...</literal>) as you can access attribute names as + <literal>a</literal>, using <literal>args.a</literal>, which was given as an + additional attribute to the function. + </para> + + <warning> + <para> + The <literal>args@</literal> expression is bound to the argument passed to the function which + means that attributes with defaults that aren't explicitly specified in the function call + won't cause an evaluation error, but won't exist in <literal>args</literal>. + </para> + <para> + For instance +<programlisting> +let + function = args@{ a ? 23, ... }: args; +in + function {} +</programlisting> + will evaluate to an empty attribute set. + </para> + </warning></listitem> + +</itemizedlist> + +<para>Note that functions do not have names. If you want to give them +a name, you can bind them to an attribute, e.g., + +<programlisting> +let concat = { x, y }: x + y; +in concat { x = "foo"; y = "bar"; }</programlisting> + +</para> + +</simplesect> + + +<simplesect><title>Conditionals</title> + +<para>Conditionals look like this: + +<programlisting> +if <replaceable>e1</replaceable> then <replaceable>e2</replaceable> else <replaceable>e3</replaceable></programlisting> + +where <replaceable>e1</replaceable> is an expression that should +evaluate to a Boolean value (<literal>true</literal> or +<literal>false</literal>).</para> + +</simplesect> + + +<simplesect><title>Assertions</title> + +<para>Assertions are generally used to check that certain requirements +on or between features and dependencies hold. They look like this: + +<programlisting> +assert <replaceable>e1</replaceable>; <replaceable>e2</replaceable></programlisting> + +where <replaceable>e1</replaceable> is an expression that should +evaluate to a Boolean value. If it evaluates to +<literal>true</literal>, <replaceable>e2</replaceable> is returned; +otherwise expression evaluation is aborted and a backtrace is printed.</para> + +<example xml:id='ex-subversion-nix'><title>Nix expression for Subversion</title> +<programlisting> +{ localServer ? false +, httpServer ? false +, sslSupport ? false +, pythonBindings ? false +, javaSwigBindings ? false +, javahlBindings ? false +, stdenv, fetchurl +, openssl ? null, httpd ? null, db4 ? null, expat, swig ? null, j2sdk ? null +}: + +assert localServer -> db4 != null; <co xml:id='ex-subversion-nix-co-1' /> +assert httpServer -> httpd != null && httpd.expat == expat; <co xml:id='ex-subversion-nix-co-2' /> +assert sslSupport -> openssl != null && (httpServer -> httpd.openssl == openssl); <co xml:id='ex-subversion-nix-co-3' /> +assert pythonBindings -> swig != null && swig.pythonSupport; +assert javaSwigBindings -> swig != null && swig.javaSupport; +assert javahlBindings -> j2sdk != null; + +stdenv.mkDerivation { + name = "subversion-1.1.1"; + ... + openssl = if sslSupport then openssl else null; <co xml:id='ex-subversion-nix-co-4' /> + ... +}</programlisting> +</example> + +<para><xref linkend='ex-subversion-nix' /> show how assertions are +used in the Nix expression for Subversion.</para> + +<calloutlist> + + <callout arearefs='ex-subversion-nix-co-1'> + <para>This assertion states that if Subversion is to have support + for local repositories, then Berkeley DB is needed. So if the + Subversion function is called with the + <varname>localServer</varname> argument set to + <literal>true</literal> but the <varname>db4</varname> argument + set to <literal>null</literal>, then the evaluation fails.</para> + </callout> + + <callout arearefs='ex-subversion-nix-co-2'> + <para>This is a more subtle condition: if Subversion is built with + Apache (<literal>httpServer</literal>) support, then the Expat + library (an XML library) used by Subversion should be same as the + one used by Apache. This is because in this configuration + Subversion code ends up being linked with Apache code, and if the + Expat libraries do not match, a build- or runtime link error or + incompatibility might occur.</para> + </callout> + + <callout arearefs='ex-subversion-nix-co-3'> + <para>This assertion says that in order for Subversion to have SSL + support (so that it can access <literal>https</literal> URLs), an + OpenSSL library must be passed. Additionally, it says that + <emphasis>if</emphasis> Apache support is enabled, then Apache's + OpenSSL should match Subversion's. (Note that if Apache support + is not enabled, we don't care about Apache's OpenSSL.)</para> + </callout> + + <callout arearefs='ex-subversion-nix-co-4'> + <para>The conditional here is not really related to assertions, + but is worth pointing out: it ensures that if SSL support is + disabled, then the Subversion derivation is not dependent on + OpenSSL, even if a non-<literal>null</literal> value was passed. + This prevents an unnecessary rebuild of Subversion if OpenSSL + changes.</para> + </callout> + +</calloutlist> + +</simplesect> + + + +<simplesect><title>With-expressions</title> + +<para>A <emphasis>with-expression</emphasis>, + +<programlisting> +with <replaceable>e1</replaceable>; <replaceable>e2</replaceable></programlisting> + +introduces the set <replaceable>e1</replaceable> into the lexical +scope of the expression <replaceable>e2</replaceable>. For instance, + +<programlisting> +let as = { x = "foo"; y = "bar"; }; +in with as; x + y</programlisting> + +evaluates to <literal>"foobar"</literal> since the +<literal>with</literal> adds the <varname>x</varname> and +<varname>y</varname> attributes of <varname>as</varname> to the +lexical scope in the expression <literal>x + y</literal>. The most +common use of <literal>with</literal> is in conjunction with the +<function>import</function> function. E.g., + +<programlisting> +with (import ./definitions.nix); ...</programlisting> + +makes all attributes defined in the file +<filename>definitions.nix</filename> available as if they were defined +locally in a <literal>let</literal>-expression.</para> + +<para>The bindings introduced by <literal>with</literal> do not shadow bindings +introduced by other means, e.g. + +<programlisting> +let a = 3; in with { a = 1; }; let a = 4; in with { a = 2; }; ...</programlisting> + +establishes the same scope as + +<programlisting> +let a = 1; in let a = 2; in let a = 3; in let a = 4; in ...</programlisting> + +</para> + +</simplesect> + + +<simplesect><title>Comments</title> + +<para>Comments can be single-line, started with a <literal>#</literal> +character, or inline/multi-line, enclosed within <literal>/* +... */</literal>.</para> + +</simplesect> + + +</section> diff --git a/third_party/nix/doc/manual/expressions/language-operators.xml b/third_party/nix/doc/manual/expressions/language-operators.xml new file mode 100644 index 0000000000..4f11bf5293 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/language-operators.xml @@ -0,0 +1,222 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-language-operators"> + +<title>Operators</title> + +<para><xref linkend='table-operators' /> lists the operators in the +Nix expression language, in order of precedence (from strongest to +weakest binding).</para> + +<table xml:id='table-operators'> + <title>Operators</title> + <tgroup cols='3'> + <thead> + <row> + <entry>Name</entry> + <entry>Syntax</entry> + <entry>Associativity</entry> + <entry>Description</entry> + <entry>Precedence</entry> + </row> + </thead> + <tbody> + <row> + <entry>Select</entry> + <entry><replaceable>e</replaceable> <literal>.</literal> + <replaceable>attrpath</replaceable> + [ <literal>or</literal> <replaceable>def</replaceable> ] + </entry> + <entry>none</entry> + <entry>Select attribute denoted by the attribute path + <replaceable>attrpath</replaceable> from set + <replaceable>e</replaceable>. (An attribute path is a + dot-separated list of attribute names.) If the attribute + doesn’t exist, return <replaceable>def</replaceable> if + provided, otherwise abort evaluation.</entry> + <entry>1</entry> + </row> + <row> + <entry>Application</entry> + <entry><replaceable>e1</replaceable> <replaceable>e2</replaceable></entry> + <entry>left</entry> + <entry>Call function <replaceable>e1</replaceable> with + argument <replaceable>e2</replaceable>.</entry> + <entry>2</entry> + </row> + <row> + <entry>Arithmetic Negation</entry> + <entry><literal>-</literal> <replaceable>e</replaceable></entry> + <entry>none</entry> + <entry>Arithmetic negation.</entry> + <entry>3</entry> + </row> + <row> + <entry>Has Attribute</entry> + <entry><replaceable>e</replaceable> <literal>?</literal> + <replaceable>attrpath</replaceable></entry> + <entry>none</entry> + <entry>Test whether set <replaceable>e</replaceable> contains + the attribute denoted by <replaceable>attrpath</replaceable>; + return <literal>true</literal> or + <literal>false</literal>.</entry> + <entry>4</entry> + </row> + <row> + <entry>List Concatenation</entry> + <entry><replaceable>e1</replaceable> <literal>++</literal> <replaceable>e2</replaceable></entry> + <entry>right</entry> + <entry>List concatenation.</entry> + <entry>5</entry> + </row> + <row> + <entry>Multiplication</entry> + <entry> + <replaceable>e1</replaceable> <literal>*</literal> <replaceable>e2</replaceable>, + </entry> + <entry>left</entry> + <entry>Arithmetic multiplication.</entry> + <entry>6</entry> + </row> + <row> + <entry>Division</entry> + <entry> + <replaceable>e1</replaceable> <literal>/</literal> <replaceable>e2</replaceable> + </entry> + <entry>left</entry> + <entry>Arithmetic division.</entry> + <entry>6</entry> + </row> + <row> + <entry>Addition</entry> + <entry> + <replaceable>e1</replaceable> <literal>+</literal> <replaceable>e2</replaceable> + </entry> + <entry>left</entry> + <entry>Arithmetic addition.</entry> + <entry>7</entry> + </row> + <row> + <entry>Subtraction</entry> + <entry> + <replaceable>e1</replaceable> <literal>-</literal> <replaceable>e2</replaceable> + </entry> + <entry>left</entry> + <entry>Arithmetic subtraction.</entry> + <entry>7</entry> + </row> + <row> + <entry>String Concatenation</entry> + <entry> + <replaceable>string1</replaceable> <literal>+</literal> <replaceable>string2</replaceable> + </entry> + <entry>left</entry> + <entry>String concatenation.</entry> + <entry>7</entry> + </row> + <row> + <entry>Not</entry> + <entry><literal>!</literal> <replaceable>e</replaceable></entry> + <entry>none</entry> + <entry>Boolean negation.</entry> + <entry>8</entry> + </row> + <row> + <entry>Update</entry> + <entry><replaceable>e1</replaceable> <literal>//</literal> + <replaceable>e2</replaceable></entry> + <entry>right</entry> + <entry>Return a set consisting of the attributes in + <replaceable>e1</replaceable> and + <replaceable>e2</replaceable> (with the latter taking + precedence over the former in case of equally named + attributes).</entry> + <entry>9</entry> + </row> + <row> + <entry>Less Than</entry> + <entry> + <replaceable>e1</replaceable> <literal><</literal> <replaceable>e2</replaceable>, + </entry> + <entry>none</entry> + <entry>Arithmetic comparison.</entry> + <entry>10</entry> + </row> + <row> + <entry>Less Than or Equal To</entry> + <entry> + <replaceable>e1</replaceable> <literal><=</literal> <replaceable>e2</replaceable> + </entry> + <entry>none</entry> + <entry>Arithmetic comparison.</entry> + <entry>10</entry> + </row> + <row> + <entry>Greater Than</entry> + <entry> + <replaceable>e1</replaceable> <literal>></literal> <replaceable>e2</replaceable> + </entry> + <entry>none</entry> + <entry>Arithmetic comparison.</entry> + <entry>10</entry> + </row> + <row> + <entry>Greater Than or Equal To</entry> + <entry> + <replaceable>e1</replaceable> <literal>>=</literal> <replaceable>e2</replaceable> + </entry> + <entry>none</entry> + <entry>Arithmetic comparison.</entry> + <entry>10</entry> + </row> + <row> + <entry>Equality</entry> + <entry> + <replaceable>e1</replaceable> <literal>==</literal> <replaceable>e2</replaceable> + </entry> + <entry>none</entry> + <entry>Equality.</entry> + <entry>11</entry> + </row> + <row> + <entry>Inequality</entry> + <entry> + <replaceable>e1</replaceable> <literal>!=</literal> <replaceable>e2</replaceable> + </entry> + <entry>none</entry> + <entry>Inequality.</entry> + <entry>11</entry> + </row> + <row> + <entry>Logical AND</entry> + <entry><replaceable>e1</replaceable> <literal>&&</literal> + <replaceable>e2</replaceable></entry> + <entry>left</entry> + <entry>Logical AND.</entry> + <entry>12</entry> + </row> + <row> + <entry>Logical OR</entry> + <entry><replaceable>e1</replaceable> <literal>||</literal> + <replaceable>e2</replaceable></entry> + <entry>left</entry> + <entry>Logical OR.</entry> + <entry>13</entry> + </row> + <row> + <entry>Logical Implication</entry> + <entry><replaceable>e1</replaceable> <literal>-></literal> + <replaceable>e2</replaceable></entry> + <entry>none</entry> + <entry>Logical implication (equivalent to + <literal>!<replaceable>e1</replaceable> || + <replaceable>e2</replaceable></literal>).</entry> + <entry>14</entry> + </row> + </tbody> + </tgroup> +</table> + +</section> diff --git a/third_party/nix/doc/manual/expressions/language-values.xml b/third_party/nix/doc/manual/expressions/language-values.xml new file mode 100644 index 0000000000..bb2090c881 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/language-values.xml @@ -0,0 +1,313 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='ssec-values'> + +<title>Values</title> + + +<simplesect><title>Simple Values</title> + +<para>Nix has the following basic data types: + +<itemizedlist> + + <listitem> + + <para><emphasis>Strings</emphasis> can be written in three + ways.</para> + + <para>The most common way is to enclose the string between double + quotes, e.g., <literal>"foo bar"</literal>. Strings can span + multiple lines. The special characters <literal>"</literal> and + <literal>\</literal> and the character sequence + <literal>${</literal> must be escaped by prefixing them with a + backslash (<literal>\</literal>). Newlines, carriage returns and + tabs can be written as <literal>\n</literal>, + <literal>\r</literal> and <literal>\t</literal>, + respectively.</para> + + <para>You can include the result of an expression into a string by + enclosing it in + <literal>${<replaceable>...</replaceable>}</literal>, a feature + known as <emphasis>antiquotation</emphasis>. The enclosed + expression must evaluate to something that can be coerced into a + string (meaning that it must be a string, a path, or a + derivation). For instance, rather than writing + +<programlisting> +"--with-freetype2-library=" + freetype + "/lib"</programlisting> + + (where <varname>freetype</varname> is a derivation), you can + instead write the more natural + +<programlisting> +"--with-freetype2-library=${freetype}/lib"</programlisting> + + The latter is automatically translated to the former. A more + complicated example (from the Nix expression for <link + xlink:href='http://www.trolltech.com/products/qt'>Qt</link>): + +<programlisting> +configureFlags = " + -system-zlib -system-libpng -system-libjpeg + ${if openglSupport then "-dlopen-opengl + -L${mesa}/lib -I${mesa}/include + -L${libXmu}/lib -I${libXmu}/include" else ""} + ${if threadSupport then "-thread" else "-no-thread"} +";</programlisting> + + Note that Nix expressions and strings can be arbitrarily nested; + in this case the outer string contains various antiquotations that + themselves contain strings (e.g., <literal>"-thread"</literal>), + some of which in turn contain expressions (e.g., + <literal>${mesa}</literal>).</para> + + <para>The second way to write string literals is as an + <emphasis>indented string</emphasis>, which is enclosed between + pairs of <emphasis>double single-quotes</emphasis>, like so: + +<programlisting> +'' + This is the first line. + This is the second line. + This is the third line. +''</programlisting> + + This kind of string literal intelligently strips indentation from + the start of each line. To be precise, it strips from each line a + number of spaces equal to the minimal indentation of the string as + a whole (disregarding the indentation of empty lines). For + instance, the first and second line are indented two space, while + the third line is indented four spaces. Thus, two spaces are + stripped from each line, so the resulting string is + +<programlisting> +"This is the first line.\nThis is the second line.\n This is the third line.\n"</programlisting> + + </para> + + <para>Note that the whitespace and newline following the opening + <literal>''</literal> is ignored if there is no non-whitespace + text on the initial line.</para> + + <para>Antiquotation + (<literal>${<replaceable>expr</replaceable>}</literal>) is + supported in indented strings.</para> + + <para>Since <literal>${</literal> and <literal>''</literal> have + special meaning in indented strings, you need a way to quote them. + <literal>$</literal> can be escaped by prefixing it with + <literal>''</literal> (that is, two single quotes), i.e., + <literal>''$</literal>. <literal>''</literal> can be escaped by + prefixing it with <literal>'</literal>, i.e., + <literal>'''</literal>. <literal>$</literal> removes any special meaning + from the following <literal>$</literal>. Linefeed, carriage-return and tab + characters can be written as <literal>''\n</literal>, + <literal>''\r</literal>, <literal>''\t</literal>, and <literal>''\</literal> + escapes any other character. + + </para> + + <para>Indented strings are primarily useful in that they allow + multi-line string literals to follow the indentation of the + enclosing Nix expression, and that less escaping is typically + necessary for strings representing languages such as shell scripts + and configuration files because <literal>''</literal> is much less + common than <literal>"</literal>. Example: + +<programlisting> +stdenv.mkDerivation { + <replaceable>...</replaceable> + postInstall = + '' + mkdir $out/bin $out/etc + cp foo $out/bin + echo "Hello World" > $out/etc/foo.conf + ${if enableBar then "cp bar $out/bin" else ""} + ''; + <replaceable>...</replaceable> +} +</programlisting> + + </para> + + <para>Finally, as a convenience, <emphasis>URIs</emphasis> as + defined in appendix B of <link + xlink:href='http://www.ietf.org/rfc/rfc2396.txt'>RFC 2396</link> + can be written <emphasis>as is</emphasis>, without quotes. For + instance, the string + <literal>"http://example.org/foo.tar.bz2"</literal> + can also be written as + <literal>http://example.org/foo.tar.bz2</literal>.</para> + + </listitem> + + <listitem><para>Numbers, which can be <emphasis>integers</emphasis> (like + <literal>123</literal>) or <emphasis>floating point</emphasis> (like + <literal>123.43</literal> or <literal>.27e13</literal>).</para> + + <para>Numbers are type-compatible: pure integer operations will always + return integers, whereas any operation involving at least one floating point + number will have a floating point number as a result.</para></listitem> + + <listitem><para><emphasis>Paths</emphasis>, e.g., + <filename>/bin/sh</filename> or <filename>./builder.sh</filename>. + A path must contain at least one slash to be recognised as such; for + instance, <filename>builder.sh</filename> is not a + path<footnote><para>It's parsed as an expression that selects the + attribute <varname>sh</varname> from the variable + <varname>builder</varname>.</para></footnote>. If the file name is + relative, i.e., if it does not begin with a slash, it is made + absolute at parse time relative to the directory of the Nix + expression that contained it. For instance, if a Nix expression in + <filename>/foo/bar/bla.nix</filename> refers to + <filename>../xyzzy/fnord.nix</filename>, the absolute path is + <filename>/foo/xyzzy/fnord.nix</filename>.</para> + + <para>If the first component of a path is a <literal>~</literal>, + it is interpreted as if the rest of the path were relative to the + user's home directory. e.g. <filename>~/foo</filename> would be + equivalent to <filename>/home/edolstra/foo</filename> for a user + whose home directory is <filename>/home/edolstra</filename>. + </para> + + <para>Paths can also be specified between angle brackets, e.g. + <literal><nixpkgs></literal>. This means that the directories + listed in the environment variable + <envar linkend="env-NIX_PATH">NIX_PATH</envar> will be searched + for the given file or directory name. + </para> + + </listitem> + + <listitem><para><emphasis>Booleans</emphasis> with values + <literal>true</literal> and + <literal>false</literal>.</para></listitem> + + <listitem><para>The null value, denoted as + <literal>null</literal>.</para></listitem> + +</itemizedlist> + +</para> + +</simplesect> + + +<simplesect><title>Lists</title> + +<para>Lists are formed by enclosing a whitespace-separated list of +values between square brackets. For example, + +<programlisting> +[ 123 ./foo.nix "abc" (f { x = y; }) ]</programlisting> + +defines a list of four elements, the last being the result of a call +to the function <varname>f</varname>. Note that function calls have +to be enclosed in parentheses. If they had been omitted, e.g., + +<programlisting> +[ 123 ./foo.nix "abc" f { x = y; } ]</programlisting> + +the result would be a list of five elements, the fourth one being a +function and the fifth being a set.</para> + +<para>Note that lists are only lazy in values, and they are strict in length. +</para> + +</simplesect> + + +<simplesect><title>Sets</title> + +<para>Sets are really the core of the language, since ultimately the +Nix language is all about creating derivations, which are really just +sets of attributes to be passed to build scripts.</para> + +<para>Sets are just a list of name/value pairs (called +<emphasis>attributes</emphasis>) enclosed in curly brackets, where +each value is an arbitrary expression terminated by a semicolon. For +example: + +<programlisting> +{ x = 123; + text = "Hello"; + y = f { bla = 456; }; +}</programlisting> + +This defines a set with attributes named <varname>x</varname>, +<varname>text</varname>, <varname>y</varname>. The order of the +attributes is irrelevant. An attribute name may only occur +once.</para> + +<para>Attributes can be selected from a set using the +<literal>.</literal> operator. For instance, + +<programlisting> +{ a = "Foo"; b = "Bar"; }.a</programlisting> + +evaluates to <literal>"Foo"</literal>. It is possible to provide a +default value in an attribute selection using the +<literal>or</literal> keyword. For example, + +<programlisting> +{ a = "Foo"; b = "Bar"; }.c or "Xyzzy"</programlisting> + +will evaluate to <literal>"Xyzzy"</literal> because there is no +<varname>c</varname> attribute in the set.</para> + +<para>You can use arbitrary double-quoted strings as attribute +names: + +<programlisting> +{ "foo ${bar}" = 123; "nix-1.0" = 456; }."foo ${bar}" +</programlisting> + +This will evaluate to <literal>123</literal> (Assuming +<literal>bar</literal> is antiquotable). In the case where an +attribute name is just a single antiquotation, the quotes can be +dropped: + +<programlisting> +{ foo = 123; }.${bar} or 456 </programlisting> + +This will evaluate to <literal>123</literal> if +<literal>bar</literal> evaluates to <literal>"foo"</literal> when +coerced to a string and <literal>456</literal> otherwise (again +assuming <literal>bar</literal> is antiquotable).</para> + +<para>In the special case where an attribute name inside of a set declaration +evaluates to <literal>null</literal> (which is normally an error, as +<literal>null</literal> is not antiquotable), that attribute is simply not +added to the set: + +<programlisting> +{ ${if foo then "bar" else null} = true; }</programlisting> + +This will evaluate to <literal>{}</literal> if <literal>foo</literal> +evaluates to <literal>false</literal>.</para> + +<para>A set that has a <literal>__functor</literal> attribute whose value +is callable (i.e. is itself a function or a set with a +<literal>__functor</literal> attribute whose value is callable) can be +applied as if it were a function, with the set itself passed in first +, e.g., + +<programlisting> +let add = { __functor = self: x: x + self.x; }; + inc = add // { x = 1; }; +in inc 1 +</programlisting> + +evaluates to <literal>2</literal>. This can be used to attach metadata to a +function without the caller needing to treat it specially, or to implement +a form of object-oriented programming, for example. + +</para> + +</simplesect> + + +</section> diff --git a/third_party/nix/doc/manual/expressions/simple-building-testing.xml b/third_party/nix/doc/manual/expressions/simple-building-testing.xml new file mode 100644 index 0000000000..7326a3e76a --- /dev/null +++ b/third_party/nix/doc/manual/expressions/simple-building-testing.xml @@ -0,0 +1,84 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-building-simple'> + +<title>Building and Testing</title> + +<para>You can now try to build Hello. Of course, you could do +<literal>nix-env -i hello</literal>, but you may not want to install a +possibly broken package just yet. The best way to test the package is by +using the command <command linkend="sec-nix-build">nix-build</command>, +which builds a Nix expression and creates a symlink named +<filename>result</filename> in the current directory: + +<screen> +$ nix-build -A hello +building path `/nix/store/632d2b22514d...-hello-2.1.1' +hello-2.1.1/ +hello-2.1.1/intl/ +hello-2.1.1/intl/ChangeLog +<replaceable>...</replaceable> + +$ ls -l result +lrwxrwxrwx ... 2006-09-29 10:43 result -> /nix/store/632d2b22514d...-hello-2.1.1 + +$ ./result/bin/hello +Hello, world!</screen> + +The <link linkend='opt-attr'><option>-A</option></link> option selects +the <literal>hello</literal> attribute. This is faster than using the +symbolic package name specified by the <literal>name</literal> +attribute (which also happens to be <literal>hello</literal>) and is +unambiguous (there can be multiple packages with the symbolic name +<literal>hello</literal>, but there can be only one attribute in a set +named <literal>hello</literal>).</para> + +<para><command>nix-build</command> registers the +<filename>./result</filename> symlink as a garbage collection root, so +unless and until you delete the <filename>./result</filename> symlink, +the output of the build will be safely kept on your system. You can +use <command>nix-build</command>’s <option +linkend='opt-out-link'>-o</option> switch to give the symlink another +name.</para> + +<para>Nix has transactional semantics. Once a build finishes +successfully, Nix makes a note of this in its database: it registers +that the path denoted by <envar>out</envar> is now +<quote>valid</quote>. If you try to build the derivation again, Nix +will see that the path is already valid and finish immediately. If a +build fails, either because it returns a non-zero exit code, because +Nix or the builder are killed, or because the machine crashes, then +the output paths will not be registered as valid. If you try to build +the derivation again, Nix will remove the output paths if they exist +(e.g., because the builder died half-way through <literal>make +install</literal>) and try again. Note that there is no +<quote>negative caching</quote>: Nix doesn't remember that a build +failed, and so a failed build can always be repeated. This is because +Nix cannot distinguish between permanent failures (e.g., a compiler +error due to a syntax error in the source) and transient failures +(e.g., a disk full condition).</para> + +<para>Nix also performs locking. If you run multiple Nix builds +simultaneously, and they try to build the same derivation, the first +Nix instance that gets there will perform the build, while the others +block (or perform other derivations if available) until the build +finishes: + +<screen> +$ nix-build -A hello +waiting for lock on `/nix/store/0h5b7hp8d4hqfrw8igvx97x1xawrjnac-hello-2.1.1x'</screen> + +So it is always safe to run multiple instances of Nix in parallel +(which isn’t the case with, say, <command>make</command>).</para> + +<para>If you have a system with multiple CPUs, you may want to have +Nix build different derivations in parallel (insofar as possible). +Just pass the option <link linkend='opt-max-jobs'><option>-j +<replaceable>N</replaceable></option></link>, where +<replaceable>N</replaceable> is the maximum number of jobs to be run +in parallel, or set. Typically this should be the number of +CPUs.</para> + +</section> diff --git a/third_party/nix/doc/manual/expressions/simple-expression.xml b/third_party/nix/doc/manual/expressions/simple-expression.xml new file mode 100644 index 0000000000..29fd872eea --- /dev/null +++ b/third_party/nix/doc/manual/expressions/simple-expression.xml @@ -0,0 +1,47 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-simple-expression"> + +<title>A Simple Nix Expression</title> + +<para>This section shows how to add and test the <link +xlink:href='http://www.gnu.org/software/hello/hello.html'>GNU Hello +package</link> to the Nix Packages collection. Hello is a program +that prints out the text <quote>Hello, world!</quote>.</para> + +<para>To add a package to the Nix Packages collection, you generally +need to do three things: + +<orderedlist> + + <listitem><para>Write a Nix expression for the package. This is a + file that describes all the inputs involved in building the package, + such as dependencies, sources, and so on.</para></listitem> + + <listitem><para>Write a <emphasis>builder</emphasis>. This is a + shell script<footnote><para>In fact, it can be written in any + language, but typically it's a <command>bash</command> shell + script.</para></footnote> that actually builds the package from + the inputs.</para></listitem> + + <listitem><para>Add the package to the file + <filename>pkgs/top-level/all-packages.nix</filename>. The Nix + expression written in the first step is a + <emphasis>function</emphasis>; it requires other packages in order + to build it. In this step you put it all together, i.e., you call + the function with the right arguments to build the actual + package.</para></listitem> + +</orderedlist> + +</para> + +<xi:include href="expression-syntax.xml" /> +<xi:include href="build-script.xml" /> +<xi:include href="arguments-variables.xml" /> +<xi:include href="simple-building-testing.xml" /> +<xi:include href="generic-builder.xml" /> + +</chapter> diff --git a/third_party/nix/doc/manual/expressions/writing-nix-expressions.xml b/third_party/nix/doc/manual/expressions/writing-nix-expressions.xml new file mode 100644 index 0000000000..6646dddf08 --- /dev/null +++ b/third_party/nix/doc/manual/expressions/writing-nix-expressions.xml @@ -0,0 +1,26 @@ +<part xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='chap-writing-nix-expressions'> + +<title>Writing Nix Expressions</title> + +<partintro> +<para>This chapter shows you how to write Nix expressions, which +instruct Nix how to build packages. It starts with a +simple example (a Nix expression for GNU Hello), and then moves +on to a more in-depth look at the Nix expression language.</para> + +<note><para>This chapter is mostly about the Nix expression language. +For more extensive information on adding packages to the Nix Packages +collection (such as functions in the standard environment and coding +conventions), please consult <link +xlink:href="http://nixos.org/nixpkgs/manual/">its +manual</link>.</para></note> +</partintro> + +<xi:include href="simple-expression.xml" /> +<xi:include href="expression-language.xml" /> + +</part> diff --git a/third_party/nix/doc/manual/figures/user-environments.png b/third_party/nix/doc/manual/figures/user-environments.png new file mode 100644 index 0000000000..1f781cf23c --- /dev/null +++ b/third_party/nix/doc/manual/figures/user-environments.png Binary files differdiff --git a/third_party/nix/doc/manual/figures/user-environments.sxd b/third_party/nix/doc/manual/figures/user-environments.sxd new file mode 100644 index 0000000000..bc661b6406 --- /dev/null +++ b/third_party/nix/doc/manual/figures/user-environments.sxd Binary files differdiff --git a/third_party/nix/doc/manual/glossary/glossary.xml b/third_party/nix/doc/manual/glossary/glossary.xml new file mode 100644 index 0000000000..e3162ed8d4 --- /dev/null +++ b/third_party/nix/doc/manual/glossary/glossary.xml @@ -0,0 +1,199 @@ +<appendix xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xml:id="part-glossary"> + +<title>Glossary</title> + + +<glosslist> + + +<glossentry xml:id="gloss-derivation"><glossterm>derivation</glossterm> + + <glossdef><para>A description of a build action. The result of a + derivation is a store object. Derivations are typically specified + in Nix expressions using the <link + linkend="ssec-derivation"><function>derivation</function> + primitive</link>. These are translated into low-level + <emphasis>store derivations</emphasis> (implicitly by + <command>nix-env</command> and <command>nix-build</command>, or + explicitly by <command>nix-instantiate</command>).</para></glossdef> + +</glossentry> + + +<glossentry><glossterm>store</glossterm> + + <glossdef><para>The location in the file system where store objects + live. Typically <filename>/nix/store</filename>.</para></glossdef> + +</glossentry> + + +<glossentry><glossterm>store path</glossterm> + + <glossdef><para>The location in the file system of a store object, + i.e., an immediate child of the Nix store + directory.</para></glossdef> + +</glossentry> + + +<glossentry><glossterm>store object</glossterm> + + <glossdef><para>A file that is an immediate child of the Nix store + directory. These can be regular files, but also entire directory + trees. Store objects can be sources (objects copied from outside of + the store), derivation outputs (objects produced by running a build + action), or derivations (files describing a build + action).</para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-substitute"><glossterm>substitute</glossterm> + + <glossdef><para>A substitute is a command invocation stored in the + Nix database that describes how to build a store object, bypassing + the normal build mechanism (i.e., derivations). Typically, the + substitute builds the store object by downloading a pre-built + version of the store object from some server.</para></glossdef> + +</glossentry> + + +<glossentry><glossterm>purity</glossterm> + + <glossdef><para>The assumption that equal Nix derivations when run + always produce the same output. This cannot be guaranteed in + general (e.g., a builder can rely on external inputs such as the + network or the system time) but the Nix model assumes + it.</para></glossdef> + +</glossentry> + + +<glossentry><glossterm>Nix expression</glossterm> + + <glossdef><para>A high-level description of software packages and + compositions thereof. Deploying software using Nix entails writing + Nix expressions for your packages. Nix expressions are translated + to derivations that are stored in the Nix store. These derivations + can then be built.</para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-reference"><glossterm>reference</glossterm> + + <glossdef> + <para>A store path <varname>P</varname> is said to have a + reference to a store path <varname>Q</varname> if the store object + at <varname>P</varname> contains the path <varname>Q</varname> + somewhere. The <emphasis>references</emphasis> of a store path are + the set of store paths to which it has a reference. + </para> + <para>A derivation can reference other derivations and sources + (but not output paths), whereas an output path only references other + output paths. + </para> + </glossdef> + +</glossentry> + +<glossentry xml:id="gloss-reachable"><glossterm>reachable</glossterm> + + <glossdef><para>A store path <varname>Q</varname> is reachable from + another store path <varname>P</varname> if <varname>Q</varname> is in the + <link linkend="gloss-closure">closure</link> of the + <link linkend="gloss-reference">references</link> relation. + </para></glossdef> +</glossentry> + +<glossentry xml:id="gloss-closure"><glossterm>closure</glossterm> + + <glossdef><para>The closure of a store path is the set of store + paths that are directly or indirectly “reachable” from that store + path; that is, it’s the closure of the path under the <link + linkend="gloss-reference">references</link> relation. For a package, the + closure of its derivation is equivalent to the build-time + dependencies, while the closure of its output path is equivalent to its + runtime dependencies. For correct deployment it is necessary to deploy whole + closures, since otherwise at runtime files could be missing. The command + <command>nix-store -qR</command> prints out closures of store paths. + </para> + <para>As an example, if the store object at path <varname>P</varname> contains + a reference to path <varname>Q</varname>, then <varname>Q</varname> is + in the closure of <varname>P</varname>. Further, if <varname>Q</varname> + references <varname>R</varname> then <varname>R</varname> is also in + the closure of <varname>P</varname>. + </para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-output-path"><glossterm>output path</glossterm> + + <glossdef><para>A store path produced by a derivation.</para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-deriver"><glossterm>deriver</glossterm> + + <glossdef><para>The deriver of an <link + linkend="gloss-output-path">output path</link> is the store + derivation that built it.</para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-validity"><glossterm>validity</glossterm> + + <glossdef><para>A store path is considered + <emphasis>valid</emphasis> if it exists in the file system, is + listed in the Nix database as being valid, and if all paths in its + closure are also valid.</para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-user-env"><glossterm>user environment</glossterm> + + <glossdef><para>An automatically generated store object that + consists of a set of symlinks to “active” applications, i.e., other + store paths. These are generated automatically by <link + linkend="sec-nix-env"><command>nix-env</command></link>. See <xref + linkend="sec-profiles" />.</para> + + </glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-profile"><glossterm>profile</glossterm> + + <glossdef><para>A symlink to the current <link + linkend="gloss-user-env">user environment</link> of a user, e.g., + <filename>/nix/var/nix/profiles/default</filename>.</para></glossdef> + +</glossentry> + + +<glossentry xml:id="gloss-nar"><glossterm>NAR</glossterm> + + <glossdef><para>A <emphasis>N</emphasis>ix + <emphasis>AR</emphasis>chive. This is a serialisation of a path in + the Nix store. It can contain regular files, directories and + symbolic links. NARs are generated and unpacked using + <command>nix-store --dump</command> and <command>nix-store + --restore</command>.</para></glossdef> + +</glossentry> + + + +</glosslist> + + +</appendix> diff --git a/third_party/nix/doc/manual/hacking.xml b/third_party/nix/doc/manual/hacking.xml new file mode 100644 index 0000000000..b671811d3a --- /dev/null +++ b/third_party/nix/doc/manual/hacking.xml @@ -0,0 +1,41 @@ +<appendix xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xml:id="chap-hacking"> + +<title>Hacking</title> + +<para>This section provides some notes on how to hack on Nix. To get +the latest version of Nix from GitHub: +<screen> +$ git clone git://github.com/NixOS/nix.git +$ cd nix +</screen> +</para> + +<para>To build it and its dependencies: +<screen> +$ nix-build release.nix -A build.x86_64-linux +</screen> +</para> + +<para>To build all dependencies and start a shell in which all +environment variables are set up so that those dependencies can be +found: +<screen> +$ nix-shell +</screen> +To build Nix itself in this shell: +<screen> +[nix-shell]$ ./bootstrap.sh +[nix-shell]$ configurePhase +[nix-shell]$ make +</screen> +To install it in <literal>$(pwd)/inst</literal> and test it: +<screen> +[nix-shell]$ make install +[nix-shell]$ make installcheck +</screen> + +</para> + +</appendix> diff --git a/third_party/nix/doc/manual/images/callouts/1.gif b/third_party/nix/doc/manual/images/callouts/1.gif new file mode 100644 index 0000000000..9e7a87f754 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/1.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/10.gif b/third_party/nix/doc/manual/images/callouts/10.gif new file mode 100644 index 0000000000..e80f7f8e63 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/10.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/11.gif b/third_party/nix/doc/manual/images/callouts/11.gif new file mode 100644 index 0000000000..67f91a239d --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/11.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/12.gif b/third_party/nix/doc/manual/images/callouts/12.gif new file mode 100644 index 0000000000..54c4b42f19 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/12.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/13.gif b/third_party/nix/doc/manual/images/callouts/13.gif new file mode 100644 index 0000000000..dd5d7d9b64 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/13.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/14.gif b/third_party/nix/doc/manual/images/callouts/14.gif new file mode 100644 index 0000000000..3d7a952a31 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/14.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/15.gif b/third_party/nix/doc/manual/images/callouts/15.gif new file mode 100644 index 0000000000..1c9183d5bb --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/15.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/2.gif b/third_party/nix/doc/manual/images/callouts/2.gif new file mode 100644 index 0000000000..94d42a30f9 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/2.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/3.gif b/third_party/nix/doc/manual/images/callouts/3.gif new file mode 100644 index 0000000000..dd3541a1bc --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/3.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/4.gif b/third_party/nix/doc/manual/images/callouts/4.gif new file mode 100644 index 0000000000..4bcbf7e31a --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/4.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/5.gif b/third_party/nix/doc/manual/images/callouts/5.gif new file mode 100644 index 0000000000..1c62b4f920 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/5.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/6.gif b/third_party/nix/doc/manual/images/callouts/6.gif new file mode 100644 index 0000000000..23bc5555d2 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/6.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/7.gif b/third_party/nix/doc/manual/images/callouts/7.gif new file mode 100644 index 0000000000..e55ce89585 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/7.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/8.gif b/third_party/nix/doc/manual/images/callouts/8.gif new file mode 100644 index 0000000000..49375e09f4 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/8.gif Binary files differdiff --git a/third_party/nix/doc/manual/images/callouts/9.gif b/third_party/nix/doc/manual/images/callouts/9.gif new file mode 100644 index 0000000000..da12a4fe28 --- /dev/null +++ b/third_party/nix/doc/manual/images/callouts/9.gif Binary files differdiff --git a/third_party/nix/doc/manual/installation/building-source.xml b/third_party/nix/doc/manual/installation/building-source.xml new file mode 100644 index 0000000000..772cda9cc3 --- /dev/null +++ b/third_party/nix/doc/manual/installation/building-source.xml @@ -0,0 +1,49 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-building-source"> + +<title>Building Nix from Source</title> + +<para>After unpacking or checking out the Nix sources, issue the +following commands: + +<screen> +$ ./configure <replaceable>options...</replaceable> +$ make +$ make install</screen> + +Nix requires GNU Make so you may need to invoke +<command>gmake</command> instead.</para> + +<para>When building from the Git repository, these should be preceded +by the command: + +<screen> +$ ./bootstrap.sh</screen> + +</para> + +<para>The installation path can be specified by passing the +<option>--prefix=<replaceable>prefix</replaceable></option> to +<command>configure</command>. The default installation directory is +<filename>/usr/local</filename>. You can change this to any location +you like. You must have write permission to the +<replaceable>prefix</replaceable> path.</para> + +<para>Nix keeps its <emphasis>store</emphasis> (the place where +packages are stored) in <filename>/nix/store</filename> by default. +This can be changed using +<option>--with-store-dir=<replaceable>path</replaceable></option>.</para> + +<warning><para>It is best <emphasis>not</emphasis> to change the Nix +store from its default, since doing so makes it impossible to use +pre-built binaries from the standard Nixpkgs channels — that is, all +packages will need to be built from source.</para></warning> + +<para>Nix keeps state (such as its database and log files) in +<filename>/nix/var</filename> by default. This can be changed using +<option>--localstatedir=<replaceable>path</replaceable></option>.</para> + +</section> diff --git a/third_party/nix/doc/manual/installation/env-variables.xml b/third_party/nix/doc/manual/installation/env-variables.xml new file mode 100644 index 0000000000..e2b8fc867c --- /dev/null +++ b/third_party/nix/doc/manual/installation/env-variables.xml @@ -0,0 +1,89 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-env-variables"> + +<title>Environment Variables</title> + +<para>To use Nix, some environment variables should be set. In +particular, <envar>PATH</envar> should contain the directories +<filename><replaceable>prefix</replaceable>/bin</filename> and +<filename>~/.nix-profile/bin</filename>. The first directory contains +the Nix tools themselves, while <filename>~/.nix-profile</filename> is +a symbolic link to the current <emphasis>user environment</emphasis> +(an automatically generated package consisting of symlinks to +installed packages). The simplest way to set the required environment +variables is to include the file +<filename><replaceable>prefix</replaceable>/etc/profile.d/nix.sh</filename> +in your <filename>~/.profile</filename> (or similar), like this:</para> + +<screen> +source <replaceable>prefix</replaceable>/etc/profile.d/nix.sh</screen> + +<section xml:id="sec-nix-ssl-cert-file"> + +<title><envar>NIX_SSL_CERT_FILE</envar></title> + +<para>If you need to specify a custom certificate bundle to account +for an HTTPS-intercepting man in the middle proxy, you must specify +the path to the certificate bundle in the environment variable +<envar>NIX_SSL_CERT_FILE</envar>.</para> + + +<para>If you don't specify a <envar>NIX_SSL_CERT_FILE</envar> +manually, Nix will install and use its own certificate +bundle.</para> + +<procedure> + <step><para>Set the environment variable and install Nix</para> + <screen> +$ export NIX_SSL_CERT_FILE=/etc/ssl/my-certificate-bundle.crt +$ sh <(curl https://nixos.org/nix/install) +</screen></step> + + <step><para>In the shell profile and rc files (for example, + <filename>/etc/bashrc</filename>, <filename>/etc/zshrc</filename>), + add the following line:</para> +<programlisting> +export NIX_SSL_CERT_FILE=/etc/ssl/my-certificate-bundle.crt +</programlisting> +</step> +</procedure> + +<note><para>You must not add the export and then do the install, as +the Nix installer will detect the presense of Nix configuration, and +abort.</para></note> + +<section xml:id="sec-nix-ssl-cert-file-with-nix-daemon-and-macos"> +<title><envar>NIX_SSL_CERT_FILE</envar> with macOS and the Nix daemon</title> + +<para>On macOS you must specify the environment variable for the Nix +daemon service, then restart it:</para> + +<screen> +$ sudo launchctl setenv NIX_SSL_CERT_FILE /etc/ssl/my-certificate-bundle.crt +$ sudo launchctl kickstart -k system/org.nixos.nix-daemon +</screen> +</section> + +<section xml:id="sec-installer-proxy-settings"> + +<title>Proxy Environment Variables</title> + +<para>The Nix installer has special handling for these proxy-related +environment variables: +<varname>http_proxy</varname>, <varname>https_proxy</varname>, +<varname>ftp_proxy</varname>, <varname>no_proxy</varname>, +<varname>HTTP_PROXY</varname>, <varname>HTTPS_PROXY</varname>, +<varname>FTP_PROXY</varname>, <varname>NO_PROXY</varname>. +</para> +<para>If any of these variables are set when running the Nix installer, +then the installer will create an override file at +<filename>/etc/systemd/system/nix-daemon.service.d/override.conf</filename> +so <command>nix-daemon</command> will use them. +</para> +</section> + +</section> +</chapter> diff --git a/third_party/nix/doc/manual/installation/installation.xml b/third_party/nix/doc/manual/installation/installation.xml new file mode 100644 index 0000000000..8789593528 --- /dev/null +++ b/third_party/nix/doc/manual/installation/installation.xml @@ -0,0 +1,34 @@ +<part xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="chap-installation"> + +<title>Installation</title> + +<partintro> +<para>This section describes how to install and configure Nix for first-time use.</para> +</partintro> + +<xi:include href="supported-platforms.xml" /> +<xi:include href="installing-binary.xml" /> +<xi:include href="installing-source.xml" /> +<xi:include href="nix-security.xml" /> +<xi:include href="env-variables.xml" /> + +<!-- TODO: should be updated +<section><title>Upgrading Nix through Nix</title> + +<para>You can install the latest stable version of Nix through Nix +itself by subscribing to the channel <link +xlink:href="http://nixos.org/releases/nix/channels/nix-stable" />, +or the latest unstable version by subscribing to the channel <link +xlink:href="http://nixos.org/releases/nix/channels/nix-unstable" />. +You can also do a <link linkend="sec-one-click">one-click +installation</link> by clicking on the package links at <link +xlink:href="http://nixos.org/releases/full-index-nix.html" />.</para> + +</section> +--> + +</part> diff --git a/third_party/nix/doc/manual/installation/installing-binary.xml b/third_party/nix/doc/manual/installation/installing-binary.xml new file mode 100644 index 0000000000..394d8053b9 --- /dev/null +++ b/third_party/nix/doc/manual/installation/installing-binary.xml @@ -0,0 +1,190 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-installing-binary"> + +<title>Installing a Binary Distribution</title> + +<para>If you are using Linux or macOS, the easiest way to install Nix +is to run the following command: + +<screen> + $ sh <(curl https://nixos.org/nix/install) +</screen> + +As of Nix 2.1.0, the Nix installer will always default to creating a +single-user installation, however opting in to the multi-user +installation is highly recommended. +</para> + +<section xml:id="sect-single-user-installation"> + <title>Single User Installation</title> + + <para> + To explicitly select a single-user installation on your system: + + <screen> + sh <(curl https://nixos.org/nix/install) --no-daemon +</screen> + </para> + +<para> +This will perform a single-user installation of Nix, meaning that +<filename>/nix</filename> is owned by the invoking user. You should +run this under your usual user account, <emphasis>not</emphasis> as +root. The script will invoke <command>sudo</command> to create +<filename>/nix</filename> if it doesn’t already exist. If you don’t +have <command>sudo</command>, you should manually create +<command>/nix</command> first as root, e.g.: + +<screen> +$ mkdir /nix +$ chown alice /nix +</screen> + +The install script will modify the first writable file from amongst +<filename>.bash_profile</filename>, <filename>.bash_login</filename> +and <filename>.profile</filename> to source +<filename>~/.nix-profile/etc/profile.d/nix.sh</filename>. You can set +the <command>NIX_INSTALLER_NO_MODIFY_PROFILE</command> environment +variable before executing the install script to disable this +behaviour. +</para> + + +<para>You can uninstall Nix simply by running: + +<screen> +$ rm -rf /nix +</screen> + +</para> +</section> + +<section xml:id="sect-multi-user-installation"> + <title>Multi User Installation</title> + <para> + The multi-user Nix installation creates system users, and a system + service for the Nix daemon. + </para> + + <itemizedlist> + <title>Supported Systems</title> + + <listitem> + <para>Linux running systemd, with SELinux disabled</para> + </listitem> + <listitem><para>macOS</para></listitem> + </itemizedlist> + + <para> + You can instruct the installer to perform a multi-user + installation on your system: + + <screen> + sh <(curl https://nixos.org/nix/install) --daemon +</screen> + </para> + + <para> + The multi-user installation of Nix will create build users between + the user IDs 30001 and 30032, and a group with the group ID 30000. + + You should run this under your usual user account, + <emphasis>not</emphasis> as root. The script will invoke + <command>sudo</command> as needed. + </para> + + <note><para> + If you need Nix to use a different group ID or user ID set, you + will have to download the tarball manually and <link + linkend="sect-nix-install-binary-tarball">edit the install + script</link>. + </para></note> + + <para> + The installer will modify <filename>/etc/bashrc</filename>, and + <filename>/etc/zshrc</filename> if they exist. The installer will + first back up these files with a + <literal>.backup-before-nix</literal> extension. The installer + will also create <filename>/etc/profile.d/nix.sh</filename>. + </para> + + <para>You can uninstall Nix with the following commands: + +<screen> +sudo rm -rf /etc/profile/nix.sh /etc/nix /nix ~root/.nix-profile ~root/.nix-defexpr ~root/.nix-channels ~/.nix-profile ~/.nix-defexpr ~/.nix-channels + +# If you are on Linux with systemd, you will need to run: +sudo systemctl stop nix-daemon.socket +sudo systemctl stop nix-daemon.service +sudo systemctl disable nix-daemon.socket +sudo systemctl disable nix-daemon.service +sudo systemctl daemon-reload + +# If you are on macOS, you will need to run: +sudo launchctl unload /Library/LaunchDaemons/org.nixos.nix-daemon.plist +sudo rm /Library/LaunchDaemons/org.nixos.nix-daemon.plist +</screen> + + There may also be references to Nix in + <filename>/etc/profile</filename>, + <filename>/etc/bashrc</filename>, and + <filename>/etc/zshrc</filename> which you may remove. + </para> + +</section> + +<section xml:id="sect-nix-install-pinned-version-url"> + <title>Installing a pinned Nix version from a URL</title> + + <para> + NixOS.org hosts version-specific installation URLs for all Nix + versions since 1.11.16, at + <literal>https://nixos.org/releases/nix/nix-VERSION/install</literal>. + </para> + + <para> + These install scripts can be used the same as the main + NixOS.org installation script: + + <screen> + sh <(curl https://nixos.org/nix/install) +</screen> + </para> + + <para> + In the same directory of the install script are sha256 sums, and + gpg signature files. + </para> +</section> + +<section xml:id="sect-nix-install-binary-tarball"> + <title>Installing from a binary tarball</title> + + <para> + You can also download a binary tarball that contains Nix and all + its dependencies. (This is what the install script at + <uri>https://nixos.org/nix/install</uri> does automatically.) You + should unpack it somewhere (e.g. in <filename>/tmp</filename>), + and then run the script named <command>install</command> inside + the binary tarball: + + +<screen> +alice$ cd /tmp +alice$ tar xfj nix-1.8-x86_64-darwin.tar.bz2 +alice$ cd nix-1.8-x86_64-darwin +alice$ ./install +</screen> + </para> + + <para> + If you need to edit the multi-user installation script to use + different group ID or a different user ID range, modify the + variables set in the file named + <filename>install-multi-user</filename>. + </para> +</section> +</chapter> diff --git a/third_party/nix/doc/manual/installation/installing-source.xml b/third_party/nix/doc/manual/installation/installing-source.xml new file mode 100644 index 0000000000..c261a109d6 --- /dev/null +++ b/third_party/nix/doc/manual/installation/installing-source.xml @@ -0,0 +1,16 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-installing-source"> + +<title>Installing Nix from Source</title> + +<para>If no binary package is available, you can download and compile +a source distribution.</para> + +<xi:include href="prerequisites-source.xml" /> +<xi:include href="obtaining-source.xml" /> +<xi:include href="building-source.xml" /> + +</chapter> diff --git a/third_party/nix/doc/manual/installation/multi-user.xml b/third_party/nix/doc/manual/installation/multi-user.xml new file mode 100644 index 0000000000..69ae1ef270 --- /dev/null +++ b/third_party/nix/doc/manual/installation/multi-user.xml @@ -0,0 +1,107 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-multi-user"> + +<title>Multi-User Mode</title> + +<para>To allow a Nix store to be shared safely among multiple users, +it is important that users are not able to run builders that modify +the Nix store or database in arbitrary ways, or that interfere with +builds started by other users. If they could do so, they could +install a Trojan horse in some package and compromise the accounts of +other users.</para> + +<para>To prevent this, the Nix store and database are owned by some +privileged user (usually <literal>root</literal>) and builders are +executed under special user accounts (usually named +<literal>nixbld1</literal>, <literal>nixbld2</literal>, etc.). When a +unprivileged user runs a Nix command, actions that operate on the Nix +store (such as builds) are forwarded to a <emphasis>Nix +daemon</emphasis> running under the owner of the Nix store/database +that performs the operation.</para> + +<note><para>Multi-user mode has one important limitation: only +<systemitem class="username">root</systemitem> and a set of trusted +users specified in <filename>nix.conf</filename> can specify arbitrary +binary caches. So while unprivileged users may install packages from +arbitrary Nix expressions, they may not get pre-built +binaries.</para></note> + + +<simplesect> + +<title>Setting up the build users</title> + +<para>The <emphasis>build users</emphasis> are the special UIDs under +which builds are performed. They should all be members of the +<emphasis>build users group</emphasis> <literal>nixbld</literal>. +This group should have no other members. The build users should not +be members of any other group. On Linux, you can create the group and +users as follows: + +<screen> +$ groupadd -r nixbld +$ for n in $(seq 1 10); do useradd -c "Nix build user $n" \ + -d /var/empty -g nixbld -G nixbld -M -N -r -s "$(which nologin)" \ + nixbld$n; done +</screen> + +This creates 10 build users. There can never be more concurrent builds +than the number of build users, so you may want to increase this if +you expect to do many builds at the same time.</para> + +</simplesect> + + +<simplesect> + +<title>Running the daemon</title> + +<para>The <link linkend="sec-nix-daemon">Nix daemon</link> should be +started as follows (as <literal>root</literal>): + +<screen> +$ nix-daemon</screen> + +You’ll want to put that line somewhere in your system’s boot +scripts.</para> + +<para>To let unprivileged users use the daemon, they should set the +<link linkend="envar-remote"><envar>NIX_REMOTE</envar> environment +variable</link> to <literal>daemon</literal>. So you should put a +line like + +<programlisting> +export NIX_REMOTE=daemon</programlisting> + +into the users’ login scripts.</para> + +</simplesect> + + +<simplesect> + +<title>Restricting access</title> + +<para>To limit which users can perform Nix operations, you can use the +permissions on the directory +<filename>/nix/var/nix/daemon-socket</filename>. For instance, if you +want to restrict the use of Nix to the members of a group called +<literal>nix-users</literal>, do + +<screen> +$ chgrp nix-users /nix/var/nix/daemon-socket +$ chmod ug=rwx,o= /nix/var/nix/daemon-socket +</screen> + +This way, users who are not in the <literal>nix-users</literal> group +cannot connect to the Unix domain socket +<filename>/nix/var/nix/daemon-socket/socket</filename>, so they cannot +perform Nix operations.</para> + +</simplesect> + + +</section> diff --git a/third_party/nix/doc/manual/installation/nix-security.xml b/third_party/nix/doc/manual/installation/nix-security.xml new file mode 100644 index 0000000000..d888ff14d4 --- /dev/null +++ b/third_party/nix/doc/manual/installation/nix-security.xml @@ -0,0 +1,27 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-nix-security"> + +<title>Security</title> + +<para>Nix has two basic security models. First, it can be used in +“single-user mode”, which is similar to what most other package +management tools do: there is a single user (typically <systemitem +class="username">root</systemitem>) who performs all package +management operations. All other users can then use the installed +packages, but they cannot perform package management operations +themselves.</para> + +<para>Alternatively, you can configure Nix in “multi-user mode”. In +this model, all users can perform package management operations — for +instance, every user can install software without requiring root +privileges. Nix ensures that this is secure. For instance, it’s not +possible for one user to overwrite a package used by another user with +a Trojan horse.</para> + +<xi:include href="single-user.xml" /> +<xi:include href="multi-user.xml" /> + +</chapter> \ No newline at end of file diff --git a/third_party/nix/doc/manual/installation/obtaining-source.xml b/third_party/nix/doc/manual/installation/obtaining-source.xml new file mode 100644 index 0000000000..968822cc06 --- /dev/null +++ b/third_party/nix/doc/manual/installation/obtaining-source.xml @@ -0,0 +1,30 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-obtaining-source"> + +<title>Obtaining a Source Distribution</title> + +<para>The source tarball of the most recent stable release can be +downloaded from the <link +xlink:href="http://nixos.org/nix/download.html">Nix homepage</link>. +You can also grab the <link +xlink:href="http://hydra.nixos.org/job/nix/master/release/latest-finished#tabs-constituents">most +recent development release</link>.</para> + +<para>Alternatively, the most recent sources of Nix can be obtained +from its <link +xlink:href="https://github.com/NixOS/nix">Git +repository</link>. For example, the following command will check out +the latest revision into a directory called +<filename>nix</filename>:</para> + +<screen> +$ git clone https://github.com/NixOS/nix</screen> + +<para>Likewise, specific releases can be obtained from the <link +xlink:href="https://github.com/NixOS/nix/tags">tags</link> of the +repository.</para> + +</section> \ No newline at end of file diff --git a/third_party/nix/doc/manual/installation/prerequisites-source.xml b/third_party/nix/doc/manual/installation/prerequisites-source.xml new file mode 100644 index 0000000000..e7bdcf966c --- /dev/null +++ b/third_party/nix/doc/manual/installation/prerequisites-source.xml @@ -0,0 +1,105 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-prerequisites-source"> + +<title>Prerequisites</title> + +<itemizedlist> + + <listitem><para>GNU Make.</para></listitem> + + <listitem><para>Bash Shell. The <literal>./configure</literal> script + relies on bashisms, so Bash is required.</para></listitem> + + <listitem><para>A version of GCC or Clang that supports C++17.</para></listitem> + + <listitem><para><command>pkg-config</command> to locate + dependencies. If your distribution does not provide it, you can get + it from <link + xlink:href="http://www.freedesktop.org/wiki/Software/pkg-config" + />.</para></listitem> + + <listitem><para>The OpenSSL library to calculate cryptographic hashes. + If your distribution does not provide it, you can get it from <link + xlink:href="https://www.openssl.org"/>.</para></listitem> + + <listitem><para>The <literal>libbrotlienc</literal> and + <literal>libbrotlidec</literal> libraries to provide implementation + of the Brotli compression algorithm. They are available for download + from the official repository <link + xlink:href="https://github.com/google/brotli" />.</para></listitem> + + <listitem><para>The bzip2 compressor program and the + <literal>libbz2</literal> library. Thus you must have bzip2 + installed, including development headers and libraries. If your + distribution does not provide these, you can obtain bzip2 from <link + xlink:href="https://web.archive.org/web/20180624184756/http://www.bzip.org/" + />.</para></listitem> + + <listitem><para><literal>liblzma</literal>, which is provided by + XZ Utils. If your distribution does not provide this, you can + get it from <link xlink:href="https://tukaani.org/xz/"/>.</para></listitem> + + <listitem><para>cURL and its library. If your distribution does not + provide it, you can get it from <link + xlink:href="https://curl.haxx.se/"/>.</para></listitem> + + <listitem><para>The SQLite embedded database library, version 3.6.19 + or higher. If your distribution does not provide it, please install + it from <link xlink:href="http://www.sqlite.org/" />.</para></listitem> + + <listitem><para>The <link + xlink:href="http://www.hboehm.info/gc/">Boehm + garbage collector</link> to reduce the evaluator’s memory + consumption (optional). To enable it, install + <literal>pkgconfig</literal> and the Boehm garbage collector, and + pass the flag <option>--enable-gc</option> to + <command>configure</command>.</para></listitem> + + <listitem><para>The <literal>boost</literal> library of version + 1.66.0 or higher. It can be obtained from the official web site + <link xlink:href="https://www.boost.org/" />.</para></listitem> + + <listitem><para>The <literal>editline</literal> library of version + 1.14.0 or higher. It can be obtained from the its repository + <link xlink:href="https://github.com/troglobit/editline" />.</para></listitem> + + <listitem><para>The <command>xmllint</command> and + <command>xsltproc</command> programs to build this manual and the + man-pages. These are part of the <literal>libxml2</literal> and + <literal>libxslt</literal> packages, respectively. You also need + the <link + xlink:href="http://docbook.sourceforge.net/projects/xsl/">DocBook + XSL stylesheets</link> and optionally the <link + xlink:href="http://www.docbook.org/schemas/5x"> DocBook 5.0 RELAX NG + schemas</link>. Note that these are only required if you modify the + manual sources or when you are building from the Git + repository.</para></listitem> + + <listitem><para>Recent versions of Bison and Flex to build the + parser. (This is because Nix needs GLR support in Bison and + reentrancy support in Flex.) For Bison, you need version 2.6, which + can be obtained from the <link + xlink:href="ftp://alpha.gnu.org/pub/gnu/bison">GNU FTP + server</link>. For Flex, you need version 2.5.35, which is + available on <link + xlink:href="http://lex.sourceforge.net/">SourceForge</link>. + Slightly older versions may also work, but ancient versions like the + ubiquitous 2.5.4a won't. Note that these are only required if you + modify the parser or when you are building from the Git + repository.</para></listitem> + + <listitem><para>The <literal>libseccomp</literal> is used to provide + syscall filtering on Linux. This is an optional dependency and can + be disabled passing a <option>--disable-seccomp-sandboxing</option> + option to the <command>configure</command> script (Not recommended + unless your system doesn't support + <literal>libseccomp</literal>). To get the library, visit <link + xlink:href="https://github.com/seccomp/libseccomp" + />.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/installation/single-user.xml b/third_party/nix/doc/manual/installation/single-user.xml new file mode 100644 index 0000000000..09cdaa5d48 --- /dev/null +++ b/third_party/nix/doc/manual/installation/single-user.xml @@ -0,0 +1,21 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-single-user"> + +<title>Single-User Mode</title> + +<para>In single-user mode, all Nix operations that access the database +in <filename><replaceable>prefix</replaceable>/var/nix/db</filename> +or modify the Nix store in +<filename><replaceable>prefix</replaceable>/store</filename> must be +performed under the user ID that owns those directories. This is +typically <systemitem class="username">root</systemitem>. (If you +install from RPM packages, that’s in fact the default ownership.) +However, on single-user machines, it is often convenient to +<command>chown</command> those directories to your normal user account +so that you don’t have to <command>su</command> to <systemitem +class="username">root</systemitem> all the time.</para> + +</section> \ No newline at end of file diff --git a/third_party/nix/doc/manual/installation/supported-platforms.xml b/third_party/nix/doc/manual/installation/supported-platforms.xml new file mode 100644 index 0000000000..3e74be49d1 --- /dev/null +++ b/third_party/nix/doc/manual/installation/supported-platforms.xml @@ -0,0 +1,36 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-supported-platforms"> + +<title>Supported Platforms</title> + +<para>Nix is currently supported on the following platforms: + +<itemizedlist> + + <listitem><para>Linux (i686, x86_64, aarch64).</para></listitem> + + <listitem><para>macOS (x86_64).</para></listitem> + + <!-- + <listitem><para>FreeBSD (only tested on Intel).</para></listitem> + --> + + <!-- + <listitem><para>Windows through <link + xlink:href="http://www.cygwin.com/">Cygwin</link>.</para> + + <warning><para>On Cygwin, Nix <emphasis>must</emphasis> be installed + on an NTFS partition. It will not work correctly on a FAT + partition.</para></warning> + + </listitem> + --> + +</itemizedlist> + +</para> + +</chapter> diff --git a/third_party/nix/doc/manual/installation/upgrading.xml b/third_party/nix/doc/manual/installation/upgrading.xml new file mode 100644 index 0000000000..30670d7fec --- /dev/null +++ b/third_party/nix/doc/manual/installation/upgrading.xml @@ -0,0 +1,22 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-upgrading-nix"> + + <title>Upgrading Nix</title> + + <para> + Multi-user Nix users on macOS can upgrade Nix by running: + <command>sudo -i sh -c 'nix-channel --update && + nix-env -iA nixpkgs.nix && + launchctl remove org.nixos.nix-daemon && + launchctl load /Library/LaunchDaemons/org.nixos.nix-daemon.plist'</command> + </para> + + + <para> + Single-user installations of Nix should run this: + <command>nix-channel --update; nix-env -iA nixpkgs.nix</command> + </para> +</chapter> diff --git a/third_party/nix/doc/manual/introduction/about-nix.xml b/third_party/nix/doc/manual/introduction/about-nix.xml new file mode 100644 index 0000000000..c21ed34ddc --- /dev/null +++ b/third_party/nix/doc/manual/introduction/about-nix.xml @@ -0,0 +1,268 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-about-nix"> + +<title>About Nix</title> + +<para>Nix is a <emphasis>purely functional package manager</emphasis>. +This means that it treats packages like values in purely functional +programming languages such as Haskell — they are built by functions +that don’t have side-effects, and they never change after they have +been built. Nix stores packages in the <emphasis>Nix +store</emphasis>, usually the directory +<filename>/nix/store</filename>, where each package has its own unique +subdirectory such as + +<programlisting> +/nix/store/b6gvzjyb2pg0kjfwrjmg1vfhh54ad73z-firefox-33.1/ +</programlisting> + +where <literal>b6gvzjyb2pg0…</literal> is a unique identifier for the +package that captures all its dependencies (it’s a cryptographic hash +of the package’s build dependency graph). This enables many powerful +features.</para> + + +<simplesect><title>Multiple versions</title> + +<para>You can have multiple versions or variants of a package +installed at the same time. This is especially important when +different applications have dependencies on different versions of the +same package — it prevents the “DLL hell”. Because of the hashing +scheme, different versions of a package end up in different paths in +the Nix store, so they don’t interfere with each other.</para> + +<para>An important consequence is that operations like upgrading or +uninstalling an application cannot break other applications, since +these operations never “destructively” update or delete files that are +used by other packages.</para> + +</simplesect> + + +<simplesect><title>Complete dependencies</title> + +<para>Nix helps you make sure that package dependency specifications +are complete. In general, when you’re making a package for a package +management system like RPM, you have to specify for each package what +its dependencies are, but there are no guarantees that this +specification is complete. If you forget a dependency, then the +package will build and work correctly on <emphasis>your</emphasis> +machine if you have the dependency installed, but not on the end +user's machine if it's not there.</para> + +<para>Since Nix on the other hand doesn’t install packages in “global” +locations like <filename>/usr/bin</filename> but in package-specific +directories, the risk of incomplete dependencies is greatly reduced. +This is because tools such as compilers don’t search in per-packages +directories such as +<filename>/nix/store/5lbfaxb722zp…-openssl-0.9.8d/include</filename>, +so if a package builds correctly on your system, this is because you +specified the dependency explicitly. This takes care of the build-time +dependencies.</para> + +<para>Once a package is built, runtime dependencies are found by +scanning binaries for the hash parts of Nix store paths (such as +<literal>r8vvq9kq…</literal>). This sounds risky, but it works +extremely well.</para> + +</simplesect> + + +<simplesect><title>Multi-user support</title> + +<para>Nix has multi-user support. This means that non-privileged +users can securely install software. Each user can have a different +<emphasis>profile</emphasis>, a set of packages in the Nix store that +appear in the user’s <envar>PATH</envar>. If a user installs a +package that another user has already installed previously, the +package won’t be built or downloaded a second time. At the same time, +it is not possible for one user to inject a Trojan horse into a +package that might be used by another user.</para> + +</simplesect> + + +<simplesect><title>Atomic upgrades and rollbacks</title> + +<para>Since package management operations never overwrite packages in +the Nix store but just add new versions in different paths, they are +<emphasis>atomic</emphasis>. So during a package upgrade, there is no +time window in which the package has some files from the old version +and some files from the new version — which would be bad because a +program might well crash if it’s started during that period.</para> + +<para>And since packages aren’t overwritten, the old versions are still +there after an upgrade. This means that you can <emphasis>roll +back</emphasis> to the old version:</para> + +<screen> +$ nix-env --upgrade <replaceable>some-packages</replaceable> +$ nix-env --rollback +</screen> + +</simplesect> + + +<simplesect><title>Garbage collection</title> + +<para>When you uninstall a package like this… + +<screen> +$ nix-env --uninstall firefox +</screen> + +the package isn’t deleted from the system right away (after all, you +might want to do a rollback, or it might be in the profiles of other +users). Instead, unused packages can be deleted safely by running the +<emphasis>garbage collector</emphasis>: + +<screen> +$ nix-collect-garbage +</screen> + +This deletes all packages that aren’t in use by any user profile or by +a currently running program.</para> + +</simplesect> + + +<simplesect><title>Functional package language</title> + +<para>Packages are built from <emphasis>Nix expressions</emphasis>, +which is a simple functional language. A Nix expression describes +everything that goes into a package build action (a “derivation”): +other packages, sources, the build script, environment variables for +the build script, etc. Nix tries very hard to ensure that Nix +expressions are <emphasis>deterministic</emphasis>: building a Nix +expression twice should yield the same result.</para> + +<para>Because it’s a functional language, it’s easy to support +building variants of a package: turn the Nix expression into a +function and call it any number of times with the appropriate +arguments. Due to the hashing scheme, variants don’t conflict with +each other in the Nix store.</para> + +</simplesect> + + +<simplesect><title>Transparent source/binary deployment</title> + +<para>Nix expressions generally describe how to build a package from +source, so an installation action like + +<screen> +$ nix-env --install firefox +</screen> + +<emphasis>could</emphasis> cause quite a bit of build activity, as not +only Firefox but also all its dependencies (all the way up to the C +library and the compiler) would have to built, at least if they are +not already in the Nix store. This is a <emphasis>source deployment +model</emphasis>. For most users, building from source is not very +pleasant as it takes far too long. However, Nix can automatically +skip building from source and instead use a <emphasis>binary +cache</emphasis>, a web server that provides pre-built binaries. For +instance, when asked to build +<literal>/nix/store/b6gvzjyb2pg0…-firefox-33.1</literal> from source, +Nix would first check if the file +<uri>https://cache.nixos.org/b6gvzjyb2pg0….narinfo</uri> exists, and +if so, fetch the pre-built binary referenced from there; otherwise, it +would fall back to building from source.</para> + +</simplesect> + + +<!-- +<simplesect><title>Binary patching</title> + +<para>In addition to downloading binaries automatically if they’re +available, Nix can download binary deltas that patch an existing +package in the Nix store into a new version. This speeds up +upgrades.</para> + +</simplesect> +--> + + +<simplesect><title>Nix Packages collection</title> + +<para>We provide a large set of Nix expressions containing hundreds of +existing Unix packages, the <emphasis>Nix Packages +collection</emphasis> (Nixpkgs).</para> + +</simplesect> + + +<simplesect><title>Managing build environments</title> + +<para>Nix is extremely useful for developers as it makes it easy to +automatically set up the build environment for a package. Given a +Nix expression that describes the dependencies of your package, the +command <command>nix-shell</command> will build or download those +dependencies if they’re not already in your Nix store, and then start +a Bash shell in which all necessary environment variables (such as +compiler search paths) are set.</para> + +<para>For example, the following command gets all dependencies of the +Pan newsreader, as described by <link +xlink:href="https://github.com/NixOS/nixpkgs/blob/master/pkgs/applications/networking/newsreaders/pan/default.nix">its +Nix expression</link>:</para> + +<screen> +$ nix-shell '<nixpkgs>' -A pan +</screen> + +<para>You’re then dropped into a shell where you can edit, build and test +the package:</para> + +<screen> +[nix-shell]$ tar xf $src +[nix-shell]$ cd pan-* +[nix-shell]$ ./configure +[nix-shell]$ make +[nix-shell]$ ./pan/gui/pan +</screen> + +<!-- +<para>Since Nix packages are reproducible and have complete dependency +specifications, Nix makes an excellent basis for <a +href="[%root%]hydra">a continuous build system</a>.</para> +--> + +</simplesect> + + +<simplesect><title>Portability</title> + +<para>Nix runs on Linux and macOS.</para> + +</simplesect> + + +<simplesect><title>NixOS</title> + +<para>NixOS is a Linux distribution based on Nix. It uses Nix not +just for package management but also to manage the system +configuration (e.g., to build configuration files in +<filename>/etc</filename>). This means, among other things, that it +is easy to roll back the entire configuration of the system to an +earlier state. Also, users can install software without root +privileges. For more information and downloads, see the <link +xlink:href="http://nixos.org/">NixOS homepage</link>.</para> + +</simplesect> + + +<simplesect><title>License</title> + +<para>Nix is released under the terms of the <link +xlink:href="http://www.gnu.org/licenses/old-licenses/lgpl-2.1.html">GNU +LGPLv2.1 or (at your option) any later version</link>.</para> + +</simplesect> + + +</chapter> diff --git a/third_party/nix/doc/manual/introduction/introduction.xml b/third_party/nix/doc/manual/introduction/introduction.xml new file mode 100644 index 0000000000..12b2cc7610 --- /dev/null +++ b/third_party/nix/doc/manual/introduction/introduction.xml @@ -0,0 +1,12 @@ +<part xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="chap-introduction"> + +<title>Introduction</title> + +<xi:include href="about-nix.xml" /> +<xi:include href="quick-start.xml" /> + +</part> diff --git a/third_party/nix/doc/manual/introduction/quick-start.xml b/third_party/nix/doc/manual/introduction/quick-start.xml new file mode 100644 index 0000000000..1ce6c8d50a --- /dev/null +++ b/third_party/nix/doc/manual/introduction/quick-start.xml @@ -0,0 +1,124 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="chap-quick-start"> + +<title>Quick Start</title> + +<para>This chapter is for impatient people who don't like reading +documentation. For more in-depth information you are kindly referred +to subsequent chapters.</para> + +<procedure> + +<step><para>Install single-user Nix by running the following: + +<screen> +$ bash <(curl https://nixos.org/nix/install) +</screen> + +This will install Nix in <filename>/nix</filename>. The install script +will create <filename>/nix</filename> using <command>sudo</command>, +so make sure you have sufficient rights. (For other installation +methods, see <xref linkend="chap-installation"/>.)</para></step> + +<step><para>See what installable packages are currently available +in the channel: + +<screen> +$ nix-env -qa +docbook-xml-4.3 +docbook-xml-4.5 +firefox-33.0.2 +hello-2.9 +libxslt-1.1.28 +<replaceable>...</replaceable></screen> + +</para></step> + +<step><para>Install some packages from the channel: + +<screen> +$ nix-env -i hello</screen> + +This should download pre-built packages; it should not build them +locally (if it does, something went wrong).</para></step> + +<step><para>Test that they work: + +<screen> +$ which hello +/home/eelco/.nix-profile/bin/hello +$ hello +Hello, world! +</screen> + +</para></step> + +<step><para>Uninstall a package: + +<screen> +$ nix-env -e hello</screen> + +</para></step> + +<step><para>You can also test a package without installing it: + +<screen> +$ nix-shell -p hello +</screen> + +This builds or downloads GNU Hello and its dependencies, then drops +you into a Bash shell where the <command>hello</command> command is +present, all without affecting your normal environment: + +<screen> +[nix-shell:~]$ hello +Hello, world! + +[nix-shell:~]$ exit + +$ hello +hello: command not found +</screen> + +</para></step> + +<step><para>To keep up-to-date with the channel, do: + +<screen> +$ nix-channel --update nixpkgs +$ nix-env -u '*'</screen> + +The latter command will upgrade each installed package for which there +is a “newer” version (as determined by comparing the version +numbers).</para></step> + +<step><para>If you're unhappy with the result of a +<command>nix-env</command> action (e.g., an upgraded package turned +out not to work properly), you can go back: + +<screen> +$ nix-env --rollback</screen> + +</para></step> + +<step><para>You should periodically run the Nix garbage collector +to get rid of unused packages, since uninstalls or upgrades don't +actually delete them: + +<screen> +$ nix-collect-garbage -d</screen> + +<!-- +The first command deletes old “generations” of your profile (making +rollbacks impossible, but also making the packages in those old +generations available for garbage collection), while the second +command actually deletes them.--> + +</para></step> + +</procedure> + +</chapter> diff --git a/third_party/nix/doc/manual/manual.xml b/third_party/nix/doc/manual/manual.xml new file mode 100644 index 0000000000..87d9de28ab --- /dev/null +++ b/third_party/nix/doc/manual/manual.xml @@ -0,0 +1,52 @@ +<book xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0"> + + <info> + <title>Nix Package Manager Guide</title> + <subtitle>Version <xi:include href="version.txt" parse="text" /></subtitle> + + <author> + <personname> + <firstname>Eelco</firstname> + <surname>Dolstra</surname> + </personname> + <contrib>Author</contrib> + </author> + + <copyright> + <year>2004-2018</year> + <holder>Eelco Dolstra</holder> + </copyright> + + </info> + + <!-- + <preface> + <title>Preface</title> + <para>This manual describes how to set up and use the Nix package + manager.</para> + </preface> + --> + + <xi:include href="introduction/introduction.xml" /> + <xi:include href="installation/installation.xml" /> + <xi:include href="installation/upgrading.xml" /> + <xi:include href="packages/package-management.xml" /> + <xi:include href="expressions/writing-nix-expressions.xml" /> + <xi:include href="advanced-topics/advanced-topics.xml" /> + <xi:include href="command-ref/command-ref.xml" /> + <xi:include href="glossary/glossary.xml" /> + <xi:include href="hacking.xml" /> + <xi:include href="release-notes/release-notes.xml" /> + +<!-- +<appendix> + <title>Nix Release Notes</title> + <xi:include href="release-notes/release-notes.xml" + xpointer="xmlns(x=http://docbook.org/ns/docbook)xpointer(x:article/x:section)" /> + </appendix> +--> + +</book> diff --git a/third_party/nix/doc/manual/meson.build b/third_party/nix/doc/manual/meson.build new file mode 100644 index 0000000000..42e0695a9a --- /dev/null +++ b/third_party/nix/doc/manual/meson.build @@ -0,0 +1,5 @@ +# nix manual build file +#============================================================================ + + +# TODO: generate the manual diff --git a/third_party/nix/doc/manual/nix-lang-ref.xml b/third_party/nix/doc/manual/nix-lang-ref.xml new file mode 100644 index 0000000000..86273ac3d0 --- /dev/null +++ b/third_party/nix/doc/manual/nix-lang-ref.xml @@ -0,0 +1,182 @@ +<appendix> + <title>Nix Language Reference</title> + + <sect1> + <title>Grammar</title> + + <productionset> + <title>Expressions</title> + + <production id="nix.expr"> + <lhs>Expr</lhs> + <rhs> + <nonterminal def="#nix.expr_function" /> + </rhs> + </production> + + <production id="nix.expr_function"> + <lhs>ExprFunction</lhs> + <rhs> + '{' <nonterminal def="#nix.formals" /> '}' ':' <nonterminal def="#nix.expr_function" /> + <sbr />| + <nonterminal def="#nix.expr_assert" /> + </rhs> + </production> + + <production id="nix.expr_assert"> + <lhs>ExprAssert</lhs> + <rhs> + 'assert' <nonterminal def="#nix.expr" /> ';' <nonterminal def="#nix.expr_assert" /> + <sbr />| + <nonterminal def="#nix.expr_if" /> + </rhs> + </production> + + <production id="nix.expr_if"> + <lhs>ExprIf</lhs> + <rhs> + 'if' <nonterminal def="#nix.expr" /> 'then' <nonterminal def="#nix.expr" /> + 'else' <nonterminal def="#nix.expr" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> + </rhs> + </production> + + <production id="nix.expr_op"> + <lhs>ExprOp</lhs> + <rhs> + '!' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '==' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '!=' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '&&' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '||' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '->' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '//' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '~' <nonterminal def="#nix.expr_op" /> + <sbr />| + <nonterminal def="#nix.expr_op" /> '?' <nonterminal def="#nix.id" /> + <sbr />| + <nonterminal def="#nix.expr_app" /> + </rhs> + </production> + + <production id="nix.expr_app"> + <lhs>ExprApp</lhs> + <rhs> + <nonterminal def="#nix.expr_app" /> '.' <nonterminal def="#nix.expr_select" /> + <sbr />| + <nonterminal def="#nix.expr_select" /> + </rhs> + </production> + + <production id="nix.expr_select"> + <lhs>ExprSelect</lhs> + <rhs> + <nonterminal def="#nix.expr_select" /> <nonterminal def="#nix.id" /> + <sbr />| + <nonterminal def="#nix.expr_simple" /> + </rhs> + </production> + + <production id="nix.expr_simple"> + <lhs>ExprSimple</lhs> + <rhs> + <nonterminal def="#nix.id" /> | + <nonterminal def="#nix.int" /> | + <nonterminal def="#nix.str" /> | + <nonterminal def="#nix.path" /> | + <nonterminal def="#nix.uri" /> + <sbr />| + 'true' | 'false' | 'null' + <sbr />| + '(' <nonterminal def="#nix.expr" /> ')' + <sbr />| + '{' <nonterminal def="#nix.bind" />* '}' + <sbr />| + 'let' '{' <nonterminal def="#nix.bind" />* '}' + <sbr />| + 'rec' '{' <nonterminal def="#nix.bind" />* '}' + <sbr />| + '[' <nonterminal def="#nix.expr_select" />* ']' + </rhs> + </production> + + <production id="nix.bind"> + <lhs>Bind</lhs> + <rhs> + <nonterminal def="#nix.id" /> '=' <nonterminal def="#nix.expr" /> ';' + <sbr />| + 'inherit' ('(' <nonterminal def="#nix.expr" /> ')')? <nonterminal def="#nix.id" />* ';' + </rhs> + </production> + + <production id="nix.formals"> + <lhs>Formals</lhs> + <rhs> + <nonterminal def="#nix.formal" /> ',' <nonterminal def="#nix.formals" /> + | <nonterminal def="#nix.formal" /> + </rhs> + </production> + + <production id="nix.formal"> + <lhs>Formal</lhs> + <rhs> + <nonterminal def="#nix.id" /> + <sbr />| + <nonterminal def="#nix.id" /> '?' <nonterminal def="#nix.expr" /> + </rhs> + </production> + + </productionset> + + <productionset> + <title>Terminals</title> + + <production id="nix.id"> + <lhs>Id</lhs> + <rhs>[a-zA-Z\_][a-zA-Z0-9\_\']*</rhs> + </production> + + <production id="nix.int"> + <lhs>Int</lhs> + <rhs>[0-9]+</rhs> + </production> + + <production id="nix.str"> + <lhs>Str</lhs> + <rhs>\"[^\n\"]*\"</rhs> + </production> + + <production id="nix.path"> + <lhs>Path</lhs> + <rhs>[a-zA-Z0-9\.\_\-\+]*(\/[a-zA-Z0-9\.\_\-\+]+)+</rhs> + </production> + + <production id="nix.uri"> + <lhs>Uri</lhs> + <rhs>[a-zA-Z][a-zA-Z0-9\+\-\.]*\:[a-zA-Z0-9\%\/\?\:\@\&\=\+\$\,\-\_\.\!\~\*\']+</rhs> + </production> + + <production id="nix.ws"> + <lhs>Whitespace</lhs> + <rhs> + [ \t\n]+ + <sbr />| + \#[^\n]* + <sbr />| + \/\*(.|\n)*\*\/ + </rhs> + </production> + + </productionset> + + </sect1> + +</appendix> diff --git a/third_party/nix/doc/manual/packages/basic-package-mgmt.xml b/third_party/nix/doc/manual/packages/basic-package-mgmt.xml new file mode 100644 index 0000000000..0f21297f31 --- /dev/null +++ b/third_party/nix/doc/manual/packages/basic-package-mgmt.xml @@ -0,0 +1,194 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-basic-package-mgmt"> + +<title>Basic Package Management</title> + +<para>The main command for package management is <link +linkend="sec-nix-env"><command>nix-env</command></link>. You can use +it to install, upgrade, and erase packages, and to query what +packages are installed or are available for installation.</para> + +<para>In Nix, different users can have different “views” +on the set of installed applications. That is, there might be lots of +applications present on the system (possibly in many different +versions), but users can have a specific selection of those active — +where “active” just means that it appears in a directory +in the user’s <envar>PATH</envar>. Such a view on the set of +installed applications is called a <emphasis>user +environment</emphasis>, which is just a directory tree consisting of +symlinks to the files of the active applications. </para> + +<para>Components are installed from a set of <emphasis>Nix +expressions</emphasis> that tell Nix how to build those packages, +including, if necessary, their dependencies. There is a collection of +Nix expressions called the Nixpkgs package collection that contains +packages ranging from basic development stuff such as GCC and Glibc, +to end-user applications like Mozilla Firefox. (Nix is however not +tied to the Nixpkgs package collection; you could write your own Nix +expressions based on Nixpkgs, or completely new ones.)</para> + +<para>You can manually download the latest version of Nixpkgs from +<link xlink:href='http://nixos.org/nixpkgs/download.html'/>. However, +it’s much more convenient to use the Nixpkgs +<emphasis>channel</emphasis>, since it makes it easy to stay up to +date with new versions of Nixpkgs. (Channels are described in more +detail in <xref linkend="sec-channels"/>.) Nixpkgs is automatically +added to your list of “subscribed” channels when you install +Nix. If this is not the case for some reason, you can add it as +follows: + +<screen> +$ nix-channel --add https://nixos.org/channels/nixpkgs-unstable +$ nix-channel --update +</screen> + +</para> + +<note><para>On NixOS, you’re automatically subscribed to a NixOS +channel corresponding to your NixOS major release +(e.g. <uri>http://nixos.org/channels/nixos-14.12</uri>). A NixOS +channel is identical to the Nixpkgs channel, except that it contains +only Linux binaries and is updated only if a set of regression tests +succeed.</para></note> + +<para>You can view the set of available packages in Nixpkgs: + +<screen> +$ nix-env -qa +aterm-2.2 +bash-3.0 +binutils-2.15 +bison-1.875d +blackdown-1.4.2 +bzip2-1.0.2 +…</screen> + +The flag <option>-q</option> specifies a query operation, and +<option>-a</option> means that you want to show the “available” (i.e., +installable) packages, as opposed to the installed packages. If you +downloaded Nixpkgs yourself, or if you checked it out from GitHub, +then you need to pass the path to your Nixpkgs tree using the +<option>-f</option> flag: + +<screen> +$ nix-env -qaf <replaceable>/path/to/nixpkgs</replaceable> +</screen> + +where <replaceable>/path/to/nixpkgs</replaceable> is where you’ve +unpacked or checked out Nixpkgs.</para> + +<para>You can select specific packages by name: + +<screen> +$ nix-env -qa firefox +firefox-34.0.5 +firefox-with-plugins-34.0.5 +</screen> + +and using regular expressions: + +<screen> +$ nix-env -qa 'firefox.*' +</screen> + +</para> + +<para>It is also possible to see the <emphasis>status</emphasis> of +available packages, i.e., whether they are installed into the user +environment and/or present in the system: + +<screen> +$ nix-env -qas +… +-PS bash-3.0 +--S binutils-2.15 +IPS bison-1.875d +…</screen> + +The first character (<literal>I</literal>) indicates whether the +package is installed in your current user environment. The second +(<literal>P</literal>) indicates whether it is present on your system +(in which case installing it into your user environment would be a +very quick operation). The last one (<literal>S</literal>) indicates +whether there is a so-called <emphasis>substitute</emphasis> for the +package, which is Nix’s mechanism for doing binary deployment. It +just means that Nix knows that it can fetch a pre-built package from +somewhere (typically a network server) instead of building it +locally.</para> + +<para>You can install a package using <literal>nix-env -i</literal>. +For instance, + +<screen> +$ nix-env -i subversion</screen> + +will install the package called <literal>subversion</literal> (which +is, of course, the <link +xlink:href='http://subversion.tigris.org/'>Subversion version +management system</link>).</para> + +<note><para>When you ask Nix to install a package, it will first try +to get it in pre-compiled form from a <emphasis>binary +cache</emphasis>. By default, Nix will use the binary cache +<uri>https://cache.nixos.org</uri>; it contains binaries for most +packages in Nixpkgs. Only if no binary is available in the binary +cache, Nix will build the package from source. So if <literal>nix-env +-i subversion</literal> results in Nix building stuff from source, +then either the package is not built for your platform by the Nixpkgs +build servers, or your version of Nixpkgs is too old or too new. For +instance, if you have a very recent checkout of Nixpkgs, then the +Nixpkgs build servers may not have had a chance to build everything +and upload the resulting binaries to +<uri>https://cache.nixos.org</uri>. The Nixpkgs channel is only +updated after all binaries have been uploaded to the cache, so if you +stick to the Nixpkgs channel (rather than using a Git checkout of the +Nixpkgs tree), you will get binaries for most packages.</para></note> + +<para>Naturally, packages can also be uninstalled: + +<screen> +$ nix-env -e subversion</screen> + +</para> + +<para>Upgrading to a new version is just as easy. If you have a new +release of Nix Packages, you can do: + +<screen> +$ nix-env -u subversion</screen> + +This will <emphasis>only</emphasis> upgrade Subversion if there is a +“newer” version in the new set of Nix expressions, as +defined by some pretty arbitrary rules regarding ordering of version +numbers (which generally do what you’d expect of them). To just +unconditionally replace Subversion with whatever version is in the Nix +expressions, use <parameter>-i</parameter> instead of +<parameter>-u</parameter>; <parameter>-i</parameter> will remove +whatever version is already installed.</para> + +<para>You can also upgrade all packages for which there are newer +versions: + +<screen> +$ nix-env -u</screen> + +</para> + +<para>Sometimes it’s useful to be able to ask what +<command>nix-env</command> would do, without actually doing it. For +instance, to find out what packages would be upgraded by +<literal>nix-env -u</literal>, you can do + +<screen> +$ nix-env -u --dry-run +(dry run; not doing anything) +upgrading `libxslt-1.1.0' to `libxslt-1.1.10' +upgrading `graphviz-1.10' to `graphviz-1.12' +upgrading `coreutils-5.0' to `coreutils-5.2.1'</screen> + +</para> + +</chapter> diff --git a/third_party/nix/doc/manual/packages/binary-cache-substituter.xml b/third_party/nix/doc/manual/packages/binary-cache-substituter.xml new file mode 100644 index 0000000000..c6ceb9c806 --- /dev/null +++ b/third_party/nix/doc/manual/packages/binary-cache-substituter.xml @@ -0,0 +1,70 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-binary-cache-substituter"> + +<title>Serving a Nix store via HTTP</title> + +<para>You can easily share the Nix store of a machine via HTTP. This +allows other machines to fetch store paths from that machine to speed +up installations. It uses the same <emphasis>binary cache</emphasis> +mechanism that Nix usually uses to fetch pre-built binaries from +<uri>https://cache.nixos.org</uri>.</para> + +<para>The daemon that handles binary cache requests via HTTP, +<command>nix-serve</command>, is not part of the Nix distribution, but +you can install it from Nixpkgs: + +<screen> +$ nix-env -i nix-serve +</screen> + +You can then start the server, listening for HTTP connections on +whatever port you like: + +<screen> +$ nix-serve -p 8080 +</screen> + +To check whether it works, try the following on the client: + +<screen> +$ curl http://avalon:8080/nix-cache-info +</screen> + +which should print something like: + +<screen> +StoreDir: /nix/store +WantMassQuery: 1 +Priority: 30 +</screen> + +</para> + +<para>On the client side, you can tell Nix to use your binary cache +using <option>--option extra-binary-caches</option>, e.g.: + +<screen> +$ nix-env -i firefox --option extra-binary-caches http://avalon:8080/ +</screen> + +The option <option>extra-binary-caches</option> tells Nix to use this +binary cache in addition to your default caches, such as +<uri>https://cache.nixos.org</uri>. Thus, for any path in the closure +of Firefox, Nix will first check if the path is available on the +server <literal>avalon</literal> or another binary caches. If not, it +will fall back to building from source.</para> + +<para>You can also tell Nix to always use your binary cache by adding +a line to the <filename linkend="sec-conf-file">nix.conf</filename> +configuration file like this: + +<programlisting> +binary-caches = http://avalon:8080/ https://cache.nixos.org/ +</programlisting> + +</para> + +</section> diff --git a/third_party/nix/doc/manual/packages/channels.xml b/third_party/nix/doc/manual/packages/channels.xml new file mode 100644 index 0000000000..15c119fcb1 --- /dev/null +++ b/third_party/nix/doc/manual/packages/channels.xml @@ -0,0 +1,57 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-channels"> + +<title>Channels</title> + +<para>If you want to stay up to date with a set of packages, it’s not +very convenient to manually download the latest set of Nix expressions +for those packages and upgrade using <command>nix-env</command>. +Fortunately, there’s a better way: <emphasis>Nix +channels</emphasis>.</para> + +<para>A Nix channel is just a URL that points to a place that contains +a set of Nix expressions and a manifest. Using the command <link +linkend="sec-nix-channel"><command>nix-channel</command></link> you +can automatically stay up to date with whatever is available at that +URL.</para> + +<para>You can “subscribe” to a channel using +<command>nix-channel --add</command>, e.g., + +<screen> +$ nix-channel --add https://nixos.org/channels/nixpkgs-unstable</screen> + +subscribes you to a channel that always contains that latest version +of the Nix Packages collection. (Subscribing really just means that +the URL is added to the file <filename>~/.nix-channels</filename>, +where it is read by subsequent calls to <command>nix-channel +--update</command>.) You can “unsubscribe” using <command>nix-channel +--remove</command>: + +<screen> +$ nix-channel --remove nixpkgs +</screen> +</para> + +<para>To obtain the latest Nix expressions available in a channel, do + +<screen> +$ nix-channel --update</screen> + +This downloads and unpacks the Nix expressions in every channel +(downloaded from <literal><replaceable>url</replaceable>/nixexprs.tar.bz2</literal>). +It also makes the union of each channel’s Nix expressions available by +default to <command>nix-env</command> operations (via the symlink +<filename>~/.nix-defexpr/channels</filename>). Consequently, you can +then say + +<screen> +$ nix-env -u</screen> + +to upgrade all packages in your profile to the latest versions +available in the subscribed channels.</para> + +</chapter> diff --git a/third_party/nix/doc/manual/packages/copy-closure.xml b/third_party/nix/doc/manual/packages/copy-closure.xml new file mode 100644 index 0000000000..012030e3eb --- /dev/null +++ b/third_party/nix/doc/manual/packages/copy-closure.xml @@ -0,0 +1,50 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-copy-closure"> + +<title>Copying Closures Via SSH</title> + +<para>The command <command +linkend="sec-nix-copy-closure">nix-copy-closure</command> copies a Nix +store path along with all its dependencies to or from another machine +via the SSH protocol. It doesn’t copy store paths that are already +present on the target machine. For example, the following command +copies Firefox with all its dependencies: + +<screen> +$ nix-copy-closure --to alice@itchy.example.org $(type -p firefox)</screen> + +See <xref linkend='sec-nix-copy-closure' /> for details.</para> + +<para>With <command linkend='refsec-nix-store-export'>nix-store +--export</command> and <command +linkend='refsec-nix-store-import'>nix-store --import</command> you can +write the closure of a store path (that is, the path and all its +dependencies) to a file, and then unpack that file into another Nix +store. For example, + +<screen> +$ nix-store --export $(nix-store -qR $(type -p firefox)) > firefox.closure</screen> + +writes the closure of Firefox to a file. You can then copy this file +to another machine and install the closure: + +<screen> +$ nix-store --import < firefox.closure</screen> + +Any store paths in the closure that are already present in the target +store are ignored. It is also possible to pipe the export into +another command, e.g. to copy and install a closure directly to/on +another machine: + +<screen> +$ nix-store --export $(nix-store -qR $(type -p firefox)) | bzip2 | \ + ssh alice@itchy.example.org "bunzip2 | nix-store --import"</screen> + +However, <command>nix-copy-closure</command> is generally more +efficient because it only copies paths that are not already present in +the target Nix store.</para> + +</section> diff --git a/third_party/nix/doc/manual/packages/garbage-collection.xml b/third_party/nix/doc/manual/packages/garbage-collection.xml new file mode 100644 index 0000000000..b506f22b03 --- /dev/null +++ b/third_party/nix/doc/manual/packages/garbage-collection.xml @@ -0,0 +1,86 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='sec-garbage-collection'> + +<title>Garbage Collection</title> + +<para><command>nix-env</command> operations such as upgrades +(<option>-u</option>) and uninstall (<option>-e</option>) never +actually delete packages from the system. All they do (as shown +above) is to create a new user environment that no longer contains +symlinks to the “deleted” packages.</para> + +<para>Of course, since disk space is not infinite, unused packages +should be removed at some point. You can do this by running the Nix +garbage collector. It will remove from the Nix store any package +not used (directly or indirectly) by any generation of any +profile.</para> + +<para>Note however that as long as old generations reference a +package, it will not be deleted. After all, we wouldn’t be able to +do a rollback otherwise. So in order for garbage collection to be +effective, you should also delete (some) old generations. Of course, +this should only be done if you are certain that you will not need to +roll back.</para> + +<para>To delete all old (non-current) generations of your current +profile: + +<screen> +$ nix-env --delete-generations old</screen> + +Instead of <literal>old</literal> you can also specify a list of +generations, e.g., + +<screen> +$ nix-env --delete-generations 10 11 14</screen> + +To delete all generations older than a specified number of days +(except the current generation), use the <literal>d</literal> +suffix. For example, + +<screen> +$ nix-env --delete-generations 14d</screen> + +deletes all generations older than two weeks.</para> + +<para>After removing appropriate old generations you can run the +garbage collector as follows: + +<screen> +$ nix-store --gc</screen> + +The behaviour of the gargage collector is affected by the +<literal>keep-derivations</literal> (default: true) and <literal>keep-outputs</literal> +(default: false) options in the Nix configuration file. The defaults will ensure +that all derivations that are build-time dependencies of garbage collector roots +will be kept and that all output paths that are runtime dependencies +will be kept as well. All other derivations or paths will be collected. +(This is usually what you want, but while you are developing +it may make sense to keep outputs to ensure that rebuild times are quick.) + +If you are feeling uncertain, you can also first view what files would +be deleted: + +<screen> +$ nix-store --gc --print-dead</screen> + +Likewise, the option <option>--print-live</option> will show the paths +that <emphasis>won’t</emphasis> be deleted.</para> + +<para>There is also a convenient little utility +<command>nix-collect-garbage</command>, which when invoked with the +<option>-d</option> (<option>--delete-old</option>) switch deletes all +old generations of all profiles in +<filename>/nix/var/nix/profiles</filename>. So + +<screen> +$ nix-collect-garbage -d</screen> + +is a quick and easy way to clean up your system.</para> + +<xi:include href="garbage-collector-roots.xml" /> + +</chapter> diff --git a/third_party/nix/doc/manual/packages/garbage-collector-roots.xml b/third_party/nix/doc/manual/packages/garbage-collector-roots.xml new file mode 100644 index 0000000000..8338e53920 --- /dev/null +++ b/third_party/nix/doc/manual/packages/garbage-collector-roots.xml @@ -0,0 +1,29 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-gc-roots"> + +<title>Garbage Collector Roots</title> + +<para>The roots of the garbage collector are all store paths to which +there are symlinks in the directory +<filename><replaceable>prefix</replaceable>/nix/var/nix/gcroots</filename>. +For instance, the following command makes the path +<filename>/nix/store/d718ef...-foo</filename> a root of the collector: + +<screen> +$ ln -s /nix/store/d718ef...-foo /nix/var/nix/gcroots/bar</screen> + +That is, after this command, the garbage collector will not remove +<filename>/nix/store/d718ef...-foo</filename> or any of its +dependencies.</para> + +<para>Subdirectories of +<filename><replaceable>prefix</replaceable>/nix/var/nix/gcroots</filename> +are also searched for symlinks. Symlinks to non-store paths are +followed and searched for roots, but symlinks to non-store paths +<emphasis>inside</emphasis> the paths reached in that way are not +followed to prevent infinite recursion.</para> + +</section> \ No newline at end of file diff --git a/third_party/nix/doc/manual/packages/package-management.xml b/third_party/nix/doc/manual/packages/package-management.xml new file mode 100644 index 0000000000..61e55faeb3 --- /dev/null +++ b/third_party/nix/doc/manual/packages/package-management.xml @@ -0,0 +1,23 @@ +<part xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id='chap-package-management'> + +<title>Package Management</title> + +<partintro> +<para>This chapter discusses how to do package management with Nix, +i.e., how to obtain, install, upgrade, and erase packages. This is +the “user’s” perspective of the Nix system — people +who want to <emphasis>create</emphasis> packages should consult +<xref linkend='chap-writing-nix-expressions' />.</para> +</partintro> + +<xi:include href="basic-package-mgmt.xml" /> +<xi:include href="profiles.xml" /> +<xi:include href="garbage-collection.xml" /> +<xi:include href="channels.xml" /> +<xi:include href="sharing-packages.xml" /> + +</part> diff --git a/third_party/nix/doc/manual/packages/profiles.xml b/third_party/nix/doc/manual/packages/profiles.xml new file mode 100644 index 0000000000..4d10319abe --- /dev/null +++ b/third_party/nix/doc/manual/packages/profiles.xml @@ -0,0 +1,158 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-profiles"> + +<title>Profiles</title> + +<para>Profiles and user environments are Nix’s mechanism for +implementing the ability to allow different users to have different +configurations, and to do atomic upgrades and rollbacks. To +understand how they work, it’s useful to know a bit about how Nix +works. In Nix, packages are stored in unique locations in the +<emphasis>Nix store</emphasis> (typically, +<filename>/nix/store</filename>). For instance, a particular version +of the Subversion package might be stored in a directory +<filename>/nix/store/dpmvp969yhdqs7lm2r1a3gng7pyq6vy4-subversion-1.1.3/</filename>, +while another version might be stored in +<filename>/nix/store/5mq2jcn36ldlmh93yj1n8s9c95pj7c5s-subversion-1.1.2</filename>. +The long strings prefixed to the directory names are cryptographic +hashes<footnote><para>160-bit truncations of SHA-256 hashes encoded in +a base-32 notation, to be precise.</para></footnote> of +<emphasis>all</emphasis> inputs involved in building the package — +sources, dependencies, compiler flags, and so on. So if two +packages differ in any way, they end up in different locations in +the file system, so they don’t interfere with each other. <xref +linkend='fig-user-environments' /> shows a part of a typical Nix +store.</para> + +<figure xml:id='fig-user-environments'><title>User environments</title> + <mediaobject> + <imageobject> + <imagedata fileref='../figures/user-environments.png' format='PNG' /> + </imageobject> + </mediaobject> +</figure> + +<para>Of course, you wouldn’t want to type + +<screen> +$ /nix/store/dpmvp969yhdq...-subversion-1.1.3/bin/svn</screen> + +every time you want to run Subversion. Of course we could set up the +<envar>PATH</envar> environment variable to include the +<filename>bin</filename> directory of every package we want to use, +but this is not very convenient since changing <envar>PATH</envar> +doesn’t take effect for already existing processes. The solution Nix +uses is to create directory trees of symlinks to +<emphasis>activated</emphasis> packages. These are called +<emphasis>user environments</emphasis> and they are packages +themselves (though automatically generated by +<command>nix-env</command>), so they too reside in the Nix store. For +instance, in <xref linkend='fig-user-environments' /> the user +environment <filename>/nix/store/0c1p5z4kda11...-user-env</filename> +contains a symlink to just Subversion 1.1.2 (arrows in the figure +indicate symlinks). This would be what we would obtain if we had done + +<screen> +$ nix-env -i subversion</screen> + +on a set of Nix expressions that contained Subversion 1.1.2.</para> + +<para>This doesn’t in itself solve the problem, of course; you +wouldn’t want to type +<filename>/nix/store/0c1p5z4kda11...-user-env/bin/svn</filename> +either. That’s why there are symlinks outside of the store that point +to the user environments in the store; for instance, the symlinks +<filename>default-42-link</filename> and +<filename>default-43-link</filename> in the example. These are called +<emphasis>generations</emphasis> since every time you perform a +<command>nix-env</command> operation, a new user environment is +generated based on the current one. For instance, generation 43 was +created from generation 42 when we did + +<screen> +$ nix-env -i subversion firefox</screen> + +on a set of Nix expressions that contained Firefox and a new version +of Subversion.</para> + +<para>Generations are grouped together into +<emphasis>profiles</emphasis> so that different users don’t interfere +with each other if they don’t want to. For example: + +<screen> +$ ls -l /nix/var/nix/profiles/ +... +lrwxrwxrwx 1 eelco ... default-42-link -> /nix/store/0c1p5z4kda11...-user-env +lrwxrwxrwx 1 eelco ... default-43-link -> /nix/store/3aw2pdyx2jfc...-user-env +lrwxrwxrwx 1 eelco ... default -> default-43-link</screen> + +This shows a profile called <filename>default</filename>. The file +<filename>default</filename> itself is actually a symlink that points +to the current generation. When we do a <command>nix-env</command> +operation, a new user environment and generation link are created +based on the current one, and finally the <filename>default</filename> +symlink is made to point at the new generation. This last step is +atomic on Unix, which explains how we can do atomic upgrades. (Note +that the building/installing of new packages doesn’t interfere in +any way with old packages, since they are stored in different +locations in the Nix store.)</para> + +<para>If you find that you want to undo a <command>nix-env</command> +operation, you can just do + +<screen> +$ nix-env --rollback</screen> + +which will just make the current generation link point at the previous +link. E.g., <filename>default</filename> would be made to point at +<filename>default-42-link</filename>. You can also switch to a +specific generation: + +<screen> +$ nix-env --switch-generation 43</screen> + +which in this example would roll forward to generation 43 again. You +can also see all available generations: + +<screen> +$ nix-env --list-generations</screen></para> + +<para>You generally wouldn’t have +<filename>/nix/var/nix/profiles/<replaceable>some-profile</replaceable>/bin</filename> +in your <envar>PATH</envar>. Rather, there is a symlink +<filename>~/.nix-profile</filename> that points to your current +profile. This means that you should put +<filename>~/.nix-profile/bin</filename> in your <envar>PATH</envar> +(and indeed, that’s what the initialisation script +<filename>/nix/etc/profile.d/nix.sh</filename> does). This makes it +easier to switch to a different profile. You can do that using the +command <command>nix-env --switch-profile</command>: + +<screen> +$ nix-env --switch-profile /nix/var/nix/profiles/my-profile + +$ nix-env --switch-profile /nix/var/nix/profiles/default</screen> + +These commands switch to the <filename>my-profile</filename> and +default profile, respectively. If the profile doesn’t exist, it will +be created automatically. You should be careful about storing a +profile in another location than the <filename>profiles</filename> +directory, since otherwise it might not be used as a root of the +garbage collector (see <xref linkend='sec-garbage-collection' +/>).</para> + +<para>All <command>nix-env</command> operations work on the profile +pointed to by <command>~/.nix-profile</command>, but you can override +this using the <option>--profile</option> option (abbreviation +<option>-p</option>): + +<screen> +$ nix-env -p /nix/var/nix/profiles/other-profile -i subversion</screen> + +This will <emphasis>not</emphasis> change the +<command>~/.nix-profile</command> symlink.</para> + +</chapter> diff --git a/third_party/nix/doc/manual/packages/s3-substituter.xml b/third_party/nix/doc/manual/packages/s3-substituter.xml new file mode 100644 index 0000000000..868b5a66dc --- /dev/null +++ b/third_party/nix/doc/manual/packages/s3-substituter.xml @@ -0,0 +1,182 @@ +<?xml version="1.0" encoding="utf-8"?> +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-s3-substituter"> + +<title>Serving a Nix store via AWS S3 or S3-compatible Service</title> + +<para>Nix has built-in support for storing and fetching store paths +from Amazon S3 and S3 compatible services. This uses the same +<emphasis>binary</emphasis> cache mechanism that Nix usually uses to +fetch prebuilt binaries from <uri>cache.nixos.org</uri>.</para> + +<para>The following options can be specified as URL parameters to +the S3 URL:</para> + +<variablelist> + <varlistentry><term><literal>profile</literal></term> + <listitem> + <para> + The name of the AWS configuration profile to use. By default + Nix will use the <literal>default</literal> profile. + </para> + </listitem> + </varlistentry> + + <varlistentry><term><literal>region</literal></term> + <listitem> + <para> + The region of the S3 bucket. <literal>us–east-1</literal> by + default. + </para> + + <para> + If your bucket is not in <literal>us–east-1</literal>, you + should always explicitly specify the region parameter. + </para> + </listitem> + </varlistentry> + + <varlistentry><term><literal>endpoint</literal></term> + <listitem> + <para> + The URL to your S3-compatible service, for when not using + Amazon S3. Do not specify this value if you're using Amazon + S3. + </para> + <note><para>This endpoint must support HTTPS and will use + path-based addressing instead of virtual host based + addressing.</para></note> + </listitem> + </varlistentry> + + <varlistentry><term><literal>scheme</literal></term> + <listitem> + <para> + The scheme used for S3 requests, <literal>https</literal> + (default) or <literal>http</literal>. This option allows you to + disable HTTPS for binary caches which don't support it. + </para> + <note><para>HTTPS should be used if the cache might contain + sensitive information.</para></note> + </listitem> + </varlistentry> +</variablelist> + +<para>In this example we will use the bucket named +<literal>example-nix-cache</literal>.</para> + +<section xml:id="ssec-s3-substituter-anonymous-reads"> + <title>Anonymous Reads to your S3-compatible binary cache</title> + + <para>If your binary cache is publicly accessible and does not + require authentication, the simplest and easiest way to use Nix with + your S3 compatible binary cache is to use the HTTP URL for that + cache.</para> + + <para>For AWS S3 the binary cache URL for example bucket will be + exactly <uri>https://example-nix-cache.s3.amazonaws.com</uri> or + <uri>s3://example-nix-cache</uri>. For S3 compatible binary caches, + consult that cache's documentation.</para> + + <para>Your bucket will need the following bucket policy:</para> + + <programlisting><![CDATA[ +{ + "Id": "DirectReads", + "Version": "2012-10-17", + "Statement": [ + { + "Sid": "AllowDirectReads", + "Action": [ + "s3:GetObject", + "s3:GetBucketLocation" + ], + "Effect": "Allow", + "Resource": [ + "arn:aws:s3:::example-nix-cache", + "arn:aws:s3:::example-nix-cache/*" + ], + "Principal": "*" + } + ] +} +]]></programlisting> +</section> + +<section xml:id="ssec-s3-substituter-authenticated-reads"> + <title>Authenticated Reads to your S3 binary cache</title> + + <para>For AWS S3 the binary cache URL for example bucket will be + exactly <uri>s3://example-nix-cache</uri>.</para> + + <para>Nix will use the <link + xlink:href="https://docs.aws.amazon.com/sdk-for-cpp/v1/developer-guide/credentials.html">default + credential provider chain</link> for authenticating requests to + Amazon S3.</para> + + <para>Nix supports authenticated reads from Amazon S3 and S3 + compatible binary caches.</para> + + <para>Your bucket will need a bucket policy allowing the desired + users to perform the <literal>s3:GetObject</literal> and + <literal>s3:GetBucketLocation</literal> action on all objects in the + bucket. The anonymous policy in <xref + linkend="ssec-s3-substituter-anonymous-reads" /> can be updated to + have a restricted <literal>Principal</literal> to support + this.</para> +</section> + + +<section xml:id="ssec-s3-substituter-authenticated-writes"> + <title>Authenticated Writes to your S3-compatible binary cache</title> + + <para>Nix support fully supports writing to Amazon S3 and S3 + compatible buckets. The binary cache URL for our example bucket will + be <uri>s3://example-nix-cache</uri>.</para> + + <para>Nix will use the <link + xlink:href="https://docs.aws.amazon.com/sdk-for-cpp/v1/developer-guide/credentials.html">default + credential provider chain</link> for authenticating requests to + Amazon S3.</para> + + <para>Your account will need the following IAM policy to + upload to the cache:</para> + + <programlisting><![CDATA[ +{ + "Version": "2012-10-17", + "Statement": [ + { + "Sid": "UploadToCache", + "Effect": "Allow", + "Action": [ + "s3:AbortMultipartUpload", + "s3:GetBucketLocation", + "s3:GetObject", + "s3:ListBucket", + "s3:ListBucketMultipartUploads", + "s3:ListMultipartUploadParts", + "s3:PutObject" + ], + "Resource": [ + "arn:aws:s3:::example-nix-cache", + "arn:aws:s3:::example-nix-cache/*" + ] + } + ] +} +]]></programlisting> + + + <example><title>Uploading with a specific credential profile for Amazon S3</title> + <para><command>nix copy --to 's3://example-nix-cache?profile=cache-upload&region=eu-west-2' nixpkgs.hello</command></para> + </example> + + <example><title>Uploading to an S3-Compatible Binary Cache</title> + <para><command>nix copy --to 's3://example-nix-cache?profile=cache-upload&scheme=https&endpoint=minio.example.com' nixpkgs.hello</command></para> + </example> +</section> +</section> diff --git a/third_party/nix/doc/manual/packages/sharing-packages.xml b/third_party/nix/doc/manual/packages/sharing-packages.xml new file mode 100644 index 0000000000..bb6c52b8f8 --- /dev/null +++ b/third_party/nix/doc/manual/packages/sharing-packages.xml @@ -0,0 +1,20 @@ +<chapter xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-sharing-packages"> + +<title>Sharing Packages Between Machines</title> + +<para>Sometimes you want to copy a package from one machine to +another. Or, you want to install some packages and you know that +another machine already has some or all of those packages or their +dependencies. In that case there are mechanisms to quickly copy +packages between machines.</para> + +<xi:include href="binary-cache-substituter.xml" /> +<xi:include href="copy-closure.xml" /> +<xi:include href="ssh-substituter.xml" /> +<xi:include href="s3-substituter.xml" /> + +</chapter> diff --git a/third_party/nix/doc/manual/packages/ssh-substituter.xml b/third_party/nix/doc/manual/packages/ssh-substituter.xml new file mode 100644 index 0000000000..8db3f96625 --- /dev/null +++ b/third_party/nix/doc/manual/packages/ssh-substituter.xml @@ -0,0 +1,73 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-ssh-substituter"> + +<title>Serving a Nix store via SSH</title> + +<para>You can tell Nix to automatically fetch needed binaries from a +remote Nix store via SSH. For example, the following installs Firefox, +automatically fetching any store paths in Firefox’s closure if they +are available on the server <literal>avalon</literal>: + +<screen> +$ nix-env -i firefox --substituters ssh://alice@avalon +</screen> + +This works similar to the binary cache substituter that Nix usually +uses, only using SSH instead of HTTP: if a store path +<literal>P</literal> is needed, Nix will first check if it’s available +in the Nix store on <literal>avalon</literal>. If not, it will fall +back to using the binary cache substituter, and then to building from +source.</para> + +<note><para>The SSH substituter currently does not allow you to enter +an SSH passphrase interactively. Therefore, you should use +<command>ssh-add</command> to load the decrypted private key into +<command>ssh-agent</command>.</para></note> + +<para>You can also copy the closure of some store path, without +installing it into your profile, e.g. + +<screen> +$ nix-store -r /nix/store/m85bxg…-firefox-34.0.5 --substituters ssh://alice@avalon +</screen> + +This is essentially equivalent to doing + +<screen> +$ nix-copy-closure --from alice@avalon /nix/store/m85bxg…-firefox-34.0.5 +</screen> + +</para> + +<para>You can use SSH’s <emphasis>forced command</emphasis> feature to +set up a restricted user account for SSH substituter access, allowing +read-only access to the local Nix store, but nothing more. For +example, add the following lines to <filename>sshd_config</filename> +to restrict the user <literal>nix-ssh</literal>: + +<programlisting> +Match User nix-ssh + AllowAgentForwarding no + AllowTcpForwarding no + PermitTTY no + PermitTunnel no + X11Forwarding no + ForceCommand nix-store --serve +Match All +</programlisting> + +On NixOS, you can accomplish the same by adding the following to your +<filename>configuration.nix</filename>: + +<programlisting> +nix.sshServe.enable = true; +nix.sshServe.keys = [ "ssh-dss AAAAB3NzaC1k... bob@example.org" ]; +</programlisting> + +where the latter line lists the public keys of users that are allowed +to connect.</para> + +</section> diff --git a/third_party/nix/doc/manual/quote-literals.xsl b/third_party/nix/doc/manual/quote-literals.xsl new file mode 100644 index 0000000000..5002643dbd --- /dev/null +++ b/third_party/nix/doc/manual/quote-literals.xsl @@ -0,0 +1,40 @@ +<?xml version="1.0"?> + +<xsl:stylesheet + version="1.0" + xmlns:xsl="http://www.w3.org/1999/XSL/Transform" + xmlns:str="http://exslt.org/strings" + extension-element-prefixes="str"> + + <xsl:output method="xml"/> + + <xsl:template match="function|command|literal|varname|filename|option|quote">`<xsl:apply-templates/>'</xsl:template> + + <xsl:template match="token"><xsl:text> </xsl:text><xsl:apply-templates /><xsl:text> +</xsl:text></xsl:template> + + <xsl:template match="screen|programlisting"> + <screen><xsl:apply-templates select="str:split(., '
')" /></screen> + </xsl:template> + + <xsl:template match="section[following::section]"> + <section> + <xsl:apply-templates /> + <screen><xsl:text> + </xsl:text></screen> + </section> + </xsl:template> + + <xsl:template match="*"> + <xsl:element name="{name(.)}" namespace="{namespace-uri(.)}"> + <xsl:copy-of select="namespace::*" /> + <xsl:for-each select="@*"> + <xsl:attribute name="{name(.)}" namespace="{namespace-uri(.)}"> + <xsl:value-of select="."/> + </xsl:attribute> + </xsl:for-each> + <xsl:apply-templates/> + </xsl:element> + </xsl:template> + +</xsl:stylesheet> diff --git a/third_party/nix/doc/manual/release-notes/release-notes.xml b/third_party/nix/doc/manual/release-notes/release-notes.xml new file mode 100644 index 0000000000..2655d68e35 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/release-notes.xml @@ -0,0 +1,51 @@ +<appendix xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="sec-relnotes"> + +<title>Nix Release Notes</title> + +<!-- +<partintro> +<para>This section lists the release notes for each stable version of Nix.</para> +</partintro> +--> + +<xi:include href="rl-2.3.xml" /> +<xi:include href="rl-2.2.xml" /> +<xi:include href="rl-2.1.xml" /> +<xi:include href="rl-2.0.xml" /> +<xi:include href="rl-1.11.10.xml" /> +<xi:include href="rl-1.11.xml" /> +<xi:include href="rl-1.10.xml" /> +<xi:include href="rl-1.9.xml" /> +<xi:include href="rl-1.8.xml" /> +<xi:include href="rl-1.7.xml" /> +<xi:include href="rl-1.6.1.xml" /> +<xi:include href="rl-1.6.xml" /> +<xi:include href="rl-1.5.2.xml" /> +<xi:include href="rl-1.5.xml" /> +<xi:include href="rl-1.4.xml" /> +<xi:include href="rl-1.3.xml" /> +<xi:include href="rl-1.2.xml" /> +<xi:include href="rl-1.1.xml" /> +<xi:include href="rl-1.0.xml" /> +<xi:include href="rl-0.16.xml" /> +<xi:include href="rl-0.15.xml" /> +<xi:include href="rl-0.14.xml" /> +<xi:include href="rl-0.13.xml" /> +<xi:include href="rl-0.12.xml" /> +<xi:include href="rl-0.11.xml" /> +<xi:include href="rl-0.10.1.xml" /> +<xi:include href="rl-0.10.xml" /> +<xi:include href="rl-0.9.2.xml" /> +<xi:include href="rl-0.9.1.xml" /> +<xi:include href="rl-0.9.xml" /> +<xi:include href="rl-0.8.1.xml" /> +<xi:include href="rl-0.8.xml" /> +<xi:include href="rl-0.7.xml" /> +<xi:include href="rl-0.6.xml" /> +<xi:include href="rl-0.5.xml" /> + +</appendix> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.10.1.xml b/third_party/nix/doc/manual/release-notes/rl-0.10.1.xml new file mode 100644 index 0000000000..95829323d4 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.10.1.xml @@ -0,0 +1,13 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.10.1"> + +<title>Release 0.10.1 (2006-10-11)</title> + +<para>This release fixes two somewhat obscure bugs that occur when +evaluating Nix expressions that are stored inside the Nix store +(<literal>NIX-67</literal>). These do not affect most users.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.10.xml b/third_party/nix/doc/manual/release-notes/rl-0.10.xml new file mode 100644 index 0000000000..9afec4de94 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.10.xml @@ -0,0 +1,323 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.10"> + +<title>Release 0.10 (2006-10-06)</title> + +<note><para>This version of Nix uses Berkeley DB 4.4 instead of 4.3. +The database is upgraded automatically, but you should be careful not +to use old versions of Nix that still use Berkeley DB 4.3. In +particular, if you use a Nix installed through Nix, you should run + +<screen> +$ nix-store --clear-substitutes</screen> + +first.</para></note> + +<warning><para>Also, the database schema has changed slighted to fix a +performance issue (see below). When you run any Nix 0.10 command for +the first time, the database will be upgraded automatically. This is +irreversible.</para></warning> + +<itemizedlist> + + + <!-- Usability / features --> + + + <listitem><para><command>nix-env</command> usability improvements: + + <itemizedlist> + + <listitem><para>An option <option>--compare-versions</option> + (or <option>-c</option>) has been added to <command>nix-env + --query</command> to allow you to compare installed versions of + packages to available versions, or vice versa. An easy way to + see if you are up to date with what’s in your subscribed + channels is <literal>nix-env -qc \*</literal>.</para></listitem> + + <listitem><para><literal>nix-env --query</literal> now takes as + arguments a list of package names about which to show + information, just like <option>--install</option>, etc.: for + example, <literal>nix-env -q gcc</literal>. Note that to show + all derivations, you need to specify + <literal>\*</literal>.</para></listitem> + + <listitem><para><literal>nix-env -i + <replaceable>pkgname</replaceable></literal> will now install + the highest available version of + <replaceable>pkgname</replaceable>, rather than installing all + available versions (which would probably give collisions) + (<literal>NIX-31</literal>).</para></listitem> + + <listitem><para><literal>nix-env (-i|-u) --dry-run</literal> now + shows exactly which missing paths will be built or + substituted.</para></listitem> + + <listitem><para><literal>nix-env -qa --description</literal> + shows human-readable descriptions of packages, provided that + they have a <literal>meta.description</literal> attribute (which + most packages in Nixpkgs don’t have yet).</para></listitem> + + </itemizedlist> + + </para></listitem> + + + <listitem><para>New language features: + + <itemizedlist> + + <listitem><para>Reference scanning (which happens after each + build) is much faster and takes a constant amount of + memory.</para></listitem> + + <listitem><para>String interpolation. Expressions like + +<programlisting> +"--with-freetype2-library=" + freetype + "/lib"</programlisting> + + can now be written as + +<programlisting> +"--with-freetype2-library=${freetype}/lib"</programlisting> + + You can write arbitrary expressions within + <literal>${<replaceable>...</replaceable>}</literal>, not just + identifiers.</para></listitem> + + <listitem><para>Multi-line string literals.</para></listitem> + + <listitem><para>String concatenations can now involve + derivations, as in the example <code>"--with-freetype2-library=" + + freetype + "/lib"</code>. This was not previously possible + because we need to register that a derivation that uses such a + string is dependent on <literal>freetype</literal>. The + evaluator now properly propagates this information. + Consequently, the subpath operator (<literal>~</literal>) has + been deprecated.</para></listitem> + + <listitem><para>Default values of function arguments can now + refer to other function arguments; that is, all arguments are in + scope in the default values + (<literal>NIX-45</literal>).</para></listitem> + + <!-- + <listitem><para>TODO: domain checks (r5895).</para></listitem> + --> + + <listitem><para>Lots of new built-in primitives, such as + functions for list manipulation and integer arithmetic. See the + manual for a complete list. All primops are now available in + the set <varname>builtins</varname>, allowing one to test for + the availability of primop in a backwards-compatible + way.</para></listitem> + + <listitem><para>Real let-expressions: <literal>let x = ...; + ... z = ...; in ...</literal>.</para></listitem> + + </itemizedlist> + + </para></listitem> + + + <listitem><para>New commands <command>nix-pack-closure</command> and + <command>nix-unpack-closure</command> than can be used to easily + transfer a store path with all its dependencies to another machine. + Very convenient whenever you have some package on your machine and + you want to copy it somewhere else.</para></listitem> + + + <listitem><para>XML support: + + <itemizedlist> + + <listitem><para><literal>nix-env -q --xml</literal> prints the + installed or available packages in an XML representation for + easy processing by other tools.</para></listitem> + + <listitem><para><literal>nix-instantiate --eval-only + --xml</literal> prints an XML representation of the resulting + term. (The new flag <option>--strict</option> forces ‘deep’ + evaluation of the result, i.e., list elements and attributes are + evaluated recursively.)</para></listitem> + + <listitem><para>In Nix expressions, the primop + <function>builtins.toXML</function> converts a term to an XML + representation. This is primarily useful for passing structured + information to builders.</para></listitem> + + </itemizedlist> + + </para></listitem> + + + <listitem><para>You can now unambiguously specify which derivation to + build or install in <command>nix-env</command>, + <command>nix-instantiate</command> and <command>nix-build</command> + using the <option>--attr</option> / <option>-A</option> flags, which + takes an attribute name as argument. (Unlike symbolic package names + such as <literal>subversion-1.4.0</literal>, attribute names in an + attribute set are unique.) For instance, a quick way to perform a + test build of a package in Nixpkgs is <literal>nix-build + pkgs/top-level/all-packages.nix -A + <replaceable>foo</replaceable></literal>. <literal>nix-env -q + --attr</literal> shows the attribute names corresponding to each + derivation.</para></listitem> + + + <listitem><para>If the top-level Nix expression used by + <command>nix-env</command>, <command>nix-instantiate</command> or + <command>nix-build</command> evaluates to a function whose arguments + all have default values, the function will be called automatically. + Also, the new command-line switch <option>--arg + <replaceable>name</replaceable> + <replaceable>value</replaceable></option> can be used to specify + function arguments on the command line.</para></listitem> + + + <listitem><para><literal>nix-install-package --url + <replaceable>URL</replaceable></literal> allows a package to be + installed directly from the given URL.</para></listitem> + + + <listitem><para>Nix now works behind an HTTP proxy server; just set + the standard environment variables <envar>http_proxy</envar>, + <envar>https_proxy</envar>, <envar>ftp_proxy</envar> or + <envar>all_proxy</envar> appropriately. Functions such as + <function>fetchurl</function> in Nixpkgs also respect these + variables.</para></listitem> + + + <listitem><para><literal>nix-build -o + <replaceable>symlink</replaceable></literal> allows the symlink to + the build result to be named something other than + <literal>result</literal>.</para></listitem> + + + <!-- Stability / performance / etc. --> + + + <listitem><para>Platform support: + + <itemizedlist> + + <listitem><para>Support for 64-bit platforms, provided a <link + xlink:href="http://bugzilla.sen.cwi.nl:8080/show_bug.cgi?id=606">suitably + patched ATerm library</link> is used. Also, files larger than 2 + GiB are now supported.</para></listitem> + + <listitem><para>Added support for Cygwin (Windows, + <literal>i686-cygwin</literal>), Mac OS X on Intel + (<literal>i686-darwin</literal>) and Linux on PowerPC + (<literal>powerpc-linux</literal>).</para></listitem> + + <listitem><para>Users of SMP and multicore machines will + appreciate that the number of builds to be performed in parallel + can now be specified in the configuration file in the + <literal>build-max-jobs</literal> setting.</para></listitem> + + </itemizedlist> + + </para></listitem> + + + <listitem><para>Garbage collector improvements: + + <itemizedlist> + + <listitem><para>Open files (such as running programs) are now + used as roots of the garbage collector. This prevents programs + that have been uninstalled from being garbage collected while + they are still running. The script that detects these + additional runtime roots + (<filename>find-runtime-roots.pl</filename>) is inherently + system-specific, but it should work on Linux and on all + platforms that have the <command>lsof</command> + utility.</para></listitem> + + <listitem><para><literal>nix-store --gc</literal> + (a.k.a. <command>nix-collect-garbage</command>) prints out the + number of bytes freed on standard output. <literal>nix-store + --gc --print-dead</literal> shows how many bytes would be freed + by an actual garbage collection.</para></listitem> + + <listitem><para><literal>nix-collect-garbage -d</literal> + removes all old generations of <emphasis>all</emphasis> profiles + before calling the actual garbage collector (<literal>nix-store + --gc</literal>). This is an easy way to get rid of all old + packages in the Nix store.</para></listitem> + + <listitem><para><command>nix-store</command> now has an + operation <option>--delete</option> to delete specific paths + from the Nix store. It won’t delete reachable (non-garbage) + paths unless <option>--ignore-liveness</option> is + specified.</para></listitem> + + </itemizedlist> + + </para></listitem> + + + <listitem><para>Berkeley DB 4.4’s process registry feature is used + to recover from crashed Nix processes.</para></listitem> + + <!-- <listitem><para>TODO: shared stores.</para></listitem> --> + + <listitem><para>A performance issue has been fixed with the + <literal>referer</literal> table, which stores the inverse of the + <literal>references</literal> table (i.e., it tells you what store + paths refer to a given path). Maintaining this table could take a + quadratic amount of time, as well as a quadratic amount of Berkeley + DB log file space (in particular when running the garbage collector) + (<literal>NIX-23</literal>).</para></listitem> + + <listitem><para>Nix now catches the <literal>TERM</literal> and + <literal>HUP</literal> signals in addition to the + <literal>INT</literal> signal. So you can now do a <literal>killall + nix-store</literal> without triggering a database + recovery.</para></listitem> + + <listitem><para><command>bsdiff</command> updated to version + 4.3.</para></listitem> + + <listitem><para>Substantial performance improvements in expression + evaluation and <literal>nix-env -qa</literal>, all thanks to <link + xlink:href="http://valgrind.org/">Valgrind</link>. Memory use has + been reduced by a factor 8 or so. Big speedup by memoisation of + path hashing.</para></listitem> + + <listitem><para>Lots of bug fixes, notably: + + <itemizedlist> + + <listitem><para>Make sure that the garbage collector can run + successfully when the disk is full + (<literal>NIX-18</literal>).</para></listitem> + + <listitem><para><command>nix-env</command> now locks the profile + to prevent races between concurrent <command>nix-env</command> + operations on the same profile + (<literal>NIX-7</literal>).</para></listitem> + + <listitem><para>Removed misleading messages from + <literal>nix-env -i</literal> (e.g., <literal>installing + `foo'</literal> followed by <literal>uninstalling + `foo'</literal>) (<literal>NIX-17</literal>).</para></listitem> + + </itemizedlist> + + </para></listitem> + + <listitem><para>Nix source distributions are a lot smaller now since + we no longer include a full copy of the Berkeley DB source + distribution (but only the bits we need).</para></listitem> + + <listitem><para>Header files are now installed so that external + programs can use the Nix libraries.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.11.xml b/third_party/nix/doc/manual/release-notes/rl-0.11.xml new file mode 100644 index 0000000000..7ad0ab5b71 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.11.xml @@ -0,0 +1,261 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-0.11"> + +<title>Release 0.11 (2007-12-31)</title> + +<para>Nix 0.11 has many improvements over the previous stable release. +The most important improvement is secure multi-user support. It also +features many usability enhancements and language extensions, many of +them prompted by NixOS, the purely functional Linux distribution based +on Nix. Here is an (incomplete) list:</para> + + +<itemizedlist> + + + <listitem><para>Secure multi-user support. A single Nix store can + now be shared between multiple (possible untrusted) users. This is + an important feature for NixOS, where it allows non-root users to + install software. The old setuid method for sharing a store between + multiple users has been removed. Details for setting up a + multi-user store can be found in the manual.</para></listitem> + + + <listitem><para>The new command <command>nix-copy-closure</command> + gives you an easy and efficient way to exchange software between + machines. It copies the missing parts of the closure of a set of + store path to or from a remote machine via + <command>ssh</command>.</para></listitem> + + + <listitem><para>A new kind of string literal: strings between double + single-quotes (<literal>''</literal>) have indentation + “intelligently” removed. This allows large strings (such as shell + scripts or configuration file fragments in NixOS) to cleanly follow + the indentation of the surrounding expression. It also requires + much less escaping, since <literal>''</literal> is less common in + most languages than <literal>"</literal>.</para></listitem> + + + <listitem><para><command>nix-env</command> <option>--set</option> + modifies the current generation of a profile so that it contains + exactly the specified derivation, and nothing else. For example, + <literal>nix-env -p /nix/var/nix/profiles/browser --set + firefox</literal> lets the profile named + <filename>browser</filename> contain just Firefox.</para></listitem> + + + <listitem><para><command>nix-env</command> now maintains + meta-information about installed packages in profiles. The + meta-information is the contents of the <varname>meta</varname> + attribute of derivations, such as <varname>description</varname> or + <varname>homepage</varname>. The command <literal>nix-env -q --xml + --meta</literal> shows all meta-information.</para></listitem> + + + <listitem><para><command>nix-env</command> now uses the + <varname>meta.priority</varname> attribute of derivations to resolve + filename collisions between packages. Lower priority values denote + a higher priority. For instance, the GCC wrapper package and the + Binutils package in Nixpkgs both have a file + <filename>bin/ld</filename>, so previously if you tried to install + both you would get a collision. Now, on the other hand, the GCC + wrapper declares a higher priority than Binutils, so the former’s + <filename>bin/ld</filename> is symlinked in the user + environment.</para></listitem> + + + <listitem><para><command>nix-env -i / -u</command>: instead of + breaking package ties by version, break them by priority and version + number. That is, if there are multiple packages with the same name, + then pick the package with the highest priority, and only use the + version if there are multiple packages with the same + priority.</para> + + <para>This makes it possible to mark specific versions/variant in + Nixpkgs more or less desirable than others. A typical example would + be a beta version of some package (e.g., + <literal>gcc-4.2.0rc1</literal>) which should not be installed even + though it is the highest version, except when it is explicitly + selected (e.g., <literal>nix-env -i + gcc-4.2.0rc1</literal>).</para></listitem> + + + <listitem><para><command>nix-env --set-flag</command> allows meta + attributes of installed packages to be modified. There are several + attributes that can be usefully modified, because they affect the + behaviour of <command>nix-env</command> or the user environment + build script: + + <itemizedlist> + + <listitem><para><varname>meta.priority</varname> can be changed + to resolve filename clashes (see above).</para></listitem> + + <listitem><para><varname>meta.keep</varname> can be set to + <literal>true</literal> to prevent the package from being + upgraded or replaced. Useful if you want to hang on to an older + version of a package.</para></listitem> + + <listitem><para><varname>meta.active</varname> can be set to + <literal>false</literal> to “disable” the package. That is, no + symlinks will be generated to the files of the package, but it + remains part of the profile (so it won’t be garbage-collected). + Set it back to <literal>true</literal> to re-enable the + package.</para></listitem> + + </itemizedlist> + + </para></listitem> + + + <listitem><para><command>nix-env -q</command> now has a flag + <option>--prebuilt-only</option> (<option>-b</option>) that causes + <command>nix-env</command> to show only those derivations whose + output is already in the Nix store or that can be substituted (i.e., + downloaded from somewhere). In other words, it shows the packages + that can be installed “quickly”, i.e., don’t need to be built from + source. The <option>-b</option> flag is also available in + <command>nix-env -i</command> and <command>nix-env -u</command> to + filter out derivations for which no pre-built binary is + available.</para></listitem> + + + <listitem><para>The new option <option>--argstr</option> (in + <command>nix-env</command>, <command>nix-instantiate</command> and + <command>nix-build</command>) is like <option>--arg</option>, except + that the value is a string. For example, <literal>--argstr system + i686-linux</literal> is equivalent to <literal>--arg system + \"i686-linux\"</literal> (note that <option>--argstr</option> + prevents annoying quoting around shell arguments).</para></listitem> + + + <listitem><para><command>nix-store</command> has a new operation + <option>--read-log</option> (<option>-l</option>) + <parameter>paths</parameter> that shows the build log of the given + paths.</para></listitem> + + + <!-- + <listitem><para>TODO: semantic cleanups of string concatenation + etc. (mostly in r6740).</para></listitem> + --> + + + <listitem><para>Nix now uses Berkeley DB 4.5. The database is + upgraded automatically, but you should be careful not to use old + versions of Nix that still use Berkeley DB 4.4.</para></listitem> + + + <!-- foo + <listitem><para>TODO: option <option>- -reregister</option> in + <command>nix-store - -register-validity</command>.</para></listitem> + --> + + + <listitem><para>The option <option>--max-silent-time</option> + (corresponding to the configuration setting + <literal>build-max-silent-time</literal>) allows you to set a + timeout on builds — if a build produces no output on + <literal>stdout</literal> or <literal>stderr</literal> for the given + number of seconds, it is terminated. This is useful for recovering + automatically from builds that are stuck in an infinite + loop.</para></listitem> + + + <listitem><para><command>nix-channel</command>: each subscribed + channel is its own attribute in the top-level expression generated + for the channel. This allows disambiguation (e.g. <literal>nix-env + -i -A nixpkgs_unstable.firefox</literal>).</para></listitem> + + + <listitem><para>The substitutes table has been removed from the + database. This makes operations such as <command>nix-pull</command> + and <command>nix-channel --update</command> much, much + faster.</para></listitem> + + + <listitem><para><command>nix-pull</command> now supports + bzip2-compressed manifests. This speeds up + channels.</para></listitem> + + + <listitem><para><command>nix-prefetch-url</command> now has a + limited form of caching. This is used by + <command>nix-channel</command> to prevent unnecessary downloads when + the channel hasn’t changed.</para></listitem> + + + <listitem><para><command>nix-prefetch-url</command> now by default + computes the SHA-256 hash of the file instead of the MD5 hash. In + calls to <function>fetchurl</function> you should pass the + <literal>sha256</literal> attribute instead of + <literal>md5</literal>. You can pass either a hexadecimal or a + base-32 encoding of the hash.</para></listitem> + + + <listitem><para>Nix can now perform builds in an automatically + generated “chroot”. This prevents a builder from accessing stuff + outside of the Nix store, and thus helps ensure purity. This is an + experimental feature.</para></listitem> + + + <listitem><para>The new command <command>nix-store + --optimise</command> reduces Nix store disk space usage by finding + identical files in the store and hard-linking them to each other. + It typically reduces the size of the store by something like + 25-35%.</para></listitem> + + + <listitem><para><filename>~/.nix-defexpr</filename> can now be a + directory, in which case the Nix expressions in that directory are + combined into an attribute set, with the file names used as the + names of the attributes. The command <command>nix-env + --import</command> (which set the + <filename>~/.nix-defexpr</filename> symlink) is + removed.</para></listitem> + + + <listitem><para>Derivations can specify the new special attribute + <varname>allowedReferences</varname> to enforce that the references + in the output of a derivation are a subset of a declared set of + paths. For example, if <varname>allowedReferences</varname> is an + empty list, then the output must not have any references. This is + used in NixOS to check that generated files such as initial ramdisks + for booting Linux don’t have any dependencies.</para></listitem> + + + <listitem><para>The new attribute + <varname>exportReferencesGraph</varname> allows builders access to + the references graph of their inputs. This is used in NixOS for + tasks such as generating ISO-9660 images that contain a Nix store + populated with the closure of certain paths.</para></listitem> + + + <listitem><para>Fixed-output derivations (like + <function>fetchurl</function>) can define the attribute + <varname>impureEnvVars</varname> to allow external environment + variables to be passed to builders. This is used in Nixpkgs to + support proxy configuration, among other things.</para></listitem> + + + <listitem><para>Several new built-in functions: + <function>builtins.attrNames</function>, + <function>builtins.filterSource</function>, + <function>builtins.isAttrs</function>, + <function>builtins.isFunction</function>, + <function>builtins.listToAttrs</function>, + <function>builtins.stringLength</function>, + <function>builtins.sub</function>, + <function>builtins.substring</function>, + <function>throw</function>, + <function>builtins.trace</function>, + <function>builtins.readFile</function>.</para></listitem> + + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.12.xml b/third_party/nix/doc/manual/release-notes/rl-0.12.xml new file mode 100644 index 0000000000..fdba8c4d57 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.12.xml @@ -0,0 +1,175 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-0.12"> + +<title>Release 0.12 (2008-11-20)</title> + +<itemizedlist> + + <listitem> + <para>Nix no longer uses Berkeley DB to store Nix store metadata. + The principal advantages of the new storage scheme are: it works + properly over decent implementations of NFS (allowing Nix stores + to be shared between multiple machines); no recovery is needed + when a Nix process crashes; no write access is needed for + read-only operations; no more running out of Berkeley DB locks on + certain operations.</para> + + <para>You still need to compile Nix with Berkeley DB support if + you want Nix to automatically convert your old Nix store to the + new schema. If you don’t need this, you can build Nix with the + <filename>configure</filename> option + <option>--disable-old-db-compat</option>.</para> + + <para>After the automatic conversion to the new schema, you can + delete the old Berkeley DB files: + + <screen> +$ cd /nix/var/nix/db +$ rm __db* log.* derivers references referrers reserved validpaths DB_CONFIG</screen> + + The new metadata is stored in the directories + <filename>/nix/var/nix/db/info</filename> and + <filename>/nix/var/nix/db/referrer</filename>. Though the + metadata is stored in human-readable plain-text files, they are + not intended to be human-editable, as Nix is rather strict about + the format.</para> + + <para>The new storage schema may or may not require less disk + space than the Berkeley DB environment, mostly depending on the + cluster size of your file system. With 1 KiB clusters (which + seems to be the <literal>ext3</literal> default nowadays) it + usually takes up much less space.</para> + </listitem> + + <listitem><para>There is a new substituter that copies paths + directly from other (remote) Nix stores mounted somewhere in the + filesystem. For instance, you can speed up an installation by + mounting some remote Nix store that already has the packages in + question via NFS or <literal>sshfs</literal>. The environment + variable <envar>NIX_OTHER_STORES</envar> specifies the locations of + the remote Nix directories, + e.g. <literal>/mnt/remote-fs/nix</literal>.</para></listitem> + + <listitem><para>New <command>nix-store</command> operations + <option>--dump-db</option> and <option>--load-db</option> to dump + and reload the Nix database.</para></listitem> + + <listitem><para>The garbage collector has a number of new options to + allow only some of the garbage to be deleted. The option + <option>--max-freed <replaceable>N</replaceable></option> tells the + collector to stop after at least <replaceable>N</replaceable> bytes + have been deleted. The option <option>--max-links + <replaceable>N</replaceable></option> tells it to stop after the + link count on <filename>/nix/store</filename> has dropped below + <replaceable>N</replaceable>. This is useful for very large Nix + stores on filesystems with a 32000 subdirectories limit (like + <literal>ext3</literal>). The option <option>--use-atime</option> + causes store paths to be deleted in order of ascending last access + time. This allows non-recently used stuff to be deleted. The + option <option>--max-atime <replaceable>time</replaceable></option> + specifies an upper limit to the last accessed time of paths that may + be deleted. For instance, + + <screen> + $ nix-store --gc -v --max-atime $(date +%s -d "2 months ago")</screen> + + deletes everything that hasn’t been accessed in two months.</para></listitem> + + <listitem><para><command>nix-env</command> now uses optimistic + profile locking when performing an operation like installing or + upgrading, instead of setting an exclusive lock on the profile. + This allows multiple <command>nix-env -i / -u / -e</command> + operations on the same profile in parallel. If a + <command>nix-env</command> operation sees at the end that the profile + was changed in the meantime by another process, it will just + restart. This is generally cheap because the build results are + still in the Nix store.</para></listitem> + + <listitem><para>The option <option>--dry-run</option> is now + supported by <command>nix-store -r</command> and + <command>nix-build</command>.</para></listitem> + + <listitem><para>The information previously shown by + <option>--dry-run</option> (i.e., which derivations will be built + and which paths will be substituted) is now always shown by + <command>nix-env</command>, <command>nix-store -r</command> and + <command>nix-build</command>. The total download size of + substitutable paths is now also shown. For instance, a build will + show something like + + <screen> +the following derivations will be built: + /nix/store/129sbxnk5n466zg6r1qmq1xjv9zymyy7-activate-configuration.sh.drv + /nix/store/7mzy971rdm8l566ch8hgxaf89x7lr7ik-upstart-jobs.drv + ... +the following paths will be downloaded/copied (30.02 MiB): + /nix/store/4m8pvgy2dcjgppf5b4cj5l6wyshjhalj-samba-3.2.4 + /nix/store/7h1kwcj29ip8vk26rhmx6bfjraxp0g4l-libunwind-0.98.6 + ...</screen> + + </para></listitem> + + <listitem><para>Language features: + + <itemizedlist> + + <listitem><para>@-patterns as in Haskell. For instance, in a + function definition + + <programlisting>f = args @ {x, y, z}: <replaceable>...</replaceable>;</programlisting> + + <varname>args</varname> refers to the argument as a whole, which + is further pattern-matched against the attribute set pattern + <literal>{x, y, z}</literal>.</para></listitem> + + <listitem><para>“<literal>...</literal>” (ellipsis) patterns. + An attribute set pattern can now say <literal>...</literal> at + the end of the attribute name list to specify that the function + takes <emphasis>at least</emphasis> the listed attributes, while + ignoring additional attributes. For instance, + + <programlisting>{stdenv, fetchurl, fuse, ...}: <replaceable>...</replaceable></programlisting> + + defines a function that accepts any attribute set that includes + at least the three listed attributes.</para></listitem> + + <listitem><para>New primops: + <varname>builtins.parseDrvName</varname> (split a package name + string like <literal>"nix-0.12pre12876"</literal> into its name + and version components, e.g. <literal>"nix"</literal> and + <literal>"0.12pre12876"</literal>), + <varname>builtins.compareVersions</varname> (compare two version + strings using the same algorithm that <command>nix-env</command> + uses), <varname>builtins.length</varname> (efficiently compute + the length of a list), <varname>builtins.mul</varname> (integer + multiplication), <varname>builtins.div</varname> (integer + division). + <!-- <varname>builtins.genericClosure</varname> --> + </para></listitem> + + </itemizedlist> + + </para></listitem> + + <listitem><para><command>nix-prefetch-url</command> now supports + <literal>mirror://</literal> URLs, provided that the environment + variable <envar>NIXPKGS_ALL</envar> points at a Nixpkgs + tree.</para></listitem> + + <listitem><para>Removed the commands + <command>nix-pack-closure</command> and + <command>nix-unpack-closure</command>. You can do almost the same + thing but much more efficiently by doing <literal>nix-store --export + $(nix-store -qR <replaceable>paths</replaceable>) > closure</literal> and + <literal>nix-store --import < + closure</literal>.</para></listitem> + + <listitem><para>Lots of bug fixes, including a big performance bug in + the handling of <literal>with</literal>-expressions.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.13.xml b/third_party/nix/doc/manual/release-notes/rl-0.13.xml new file mode 100644 index 0000000000..cce2e4a26b --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.13.xml @@ -0,0 +1,106 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-0.13"> + +<title>Release 0.13 (2009-11-05)</title> + +<para>This is primarily a bug fix release. It has some new +features:</para> + +<itemizedlist> + + <listitem> + <para>Syntactic sugar for writing nested attribute sets. Instead of + +<programlisting> +{ + foo = { + bar = 123; + xyzzy = true; + }; + a = { b = { c = "d"; }; }; +} +</programlisting> + + you can write + +<programlisting> +{ + foo.bar = 123; + foo.xyzzy = true; + a.b.c = "d"; +} +</programlisting> + + This is useful, for instance, in NixOS configuration files.</para> + + </listitem> + + <listitem> + <para>Support for Nix channels generated by Hydra, the Nix-based + continuous build system. (Hydra generates NAR archives on the + fly, so the size and hash of these archives isn’t known in + advance.)</para> + </listitem> + + <listitem> + <para>Support <literal>i686-linux</literal> builds directly on + <literal>x86_64-linux</literal> Nix installations. This is + implemented using the <function>personality()</function> syscall, + which causes <command>uname</command> to return + <literal>i686</literal> in child processes.</para> + </listitem> + + <listitem> + <para>Various improvements to the <literal>chroot</literal> + support. Building in a <literal>chroot</literal> works quite well + now.</para> + </listitem> + + <listitem> + <para>Nix no longer blocks if it tries to build a path and another + process is already building the same path. Instead it tries to + build another buildable path first. This improves + parallelism.</para> + </listitem> + + <listitem> + <para>Support for large (> 4 GiB) files in NAR archives.</para> + </listitem> + + <listitem> + <para>Various (performance) improvements to the remote build + mechanism.</para> + </listitem> + + <listitem> + <para>New primops: <varname>builtins.addErrorContext</varname> (to + add a string to stack traces — useful for debugging), + <varname>builtins.isBool</varname>, + <varname>builtins.isString</varname>, + <varname>builtins.isInt</varname>, + <varname>builtins.intersectAttrs</varname>.</para> + </listitem> + + <listitem> + <para>OpenSolaris support (Sander van der Burg).</para> + </listitem> + + <listitem> + <para>Stack traces are no longer displayed unless the + <option>--show-trace</option> option is used.</para> + </listitem> + + <listitem> + <para>The scoping rules for <literal>inherit + (<replaceable>e</replaceable>) ...</literal> in recursive + attribute sets have changed. The expression + <replaceable>e</replaceable> can now refer to the attributes + defined in the containing set.</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.14.xml b/third_party/nix/doc/manual/release-notes/rl-0.14.xml new file mode 100644 index 0000000000..e5fe9da78e --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.14.xml @@ -0,0 +1,46 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-0.14"> + +<title>Release 0.14 (2010-02-04)</title> + +<para>This release has the following improvements:</para> + +<itemizedlist> + + <listitem> + <para>The garbage collector now starts deleting garbage much + faster than before. It no longer determines liveness of all paths + in the store, but does so on demand.</para> + </listitem> + + <listitem> + <para>Added a new operation, <command>nix-store --query + --roots</command>, that shows the garbage collector roots that + directly or indirectly point to the given store paths.</para> + </listitem> + + <listitem> + <para>Removed support for converting Berkeley DB-based Nix + databases to the new schema.</para> + </listitem> + + <listitem> + <para>Removed the <option>--use-atime</option> and + <option>--max-atime</option> garbage collector options. They were + not very useful in practice.</para> + </listitem> + + <listitem> + <para>On Windows, Nix now requires Cygwin 1.7.x.</para> + </listitem> + + <listitem> + <para>A few bug fixes.</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.15.xml b/third_party/nix/doc/manual/release-notes/rl-0.15.xml new file mode 100644 index 0000000000..9f58a8efc5 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.15.xml @@ -0,0 +1,14 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-0.15"> + +<title>Release 0.15 (2010-03-17)</title> + +<para>This is a bug-fix release. Among other things, it fixes +building on Mac OS X (Snow Leopard), and improves the contents of +<filename>/etc/passwd</filename> and <filename>/etc/group</filename> +in <literal>chroot</literal> builds.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.16.xml b/third_party/nix/doc/manual/release-notes/rl-0.16.xml new file mode 100644 index 0000000000..af1edc0ebb --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.16.xml @@ -0,0 +1,55 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-0.16"> + +<title>Release 0.16 (2010-08-17)</title> + +<para>This release has the following improvements:</para> + +<itemizedlist> + + <listitem> + <para>The Nix expression evaluator is now much faster in most + cases: typically, <link + xlink:href="http://www.mail-archive.com/nix-dev@cs.uu.nl/msg04113.html">3 + to 8 times compared to the old implementation</link>. It also + uses less memory. It no longer depends on the ATerm + library.</para> + </listitem> + + <listitem> + <para> + Support for configurable parallelism inside builders. Build + scripts have always had the ability to perform multiple build + actions in parallel (for instance, by running <command>make -j + 2</command>), but this was not desirable because the number of + actions to be performed in parallel was not configurable. Nix + now has an option <option>--cores + <replaceable>N</replaceable></option> as well as a configuration + setting <varname>build-cores = + <replaceable>N</replaceable></varname> that causes the + environment variable <envar>NIX_BUILD_CORES</envar> to be set to + <replaceable>N</replaceable> when the builder is invoked. The + builder can use this at its discretion to perform a parallel + build, e.g., by calling <command>make -j + <replaceable>N</replaceable></command>. In Nixpkgs, this can be + enabled on a per-package basis by setting the derivation + attribute <varname>enableParallelBuilding</varname> to + <literal>true</literal>. + </para> + </listitem> + + <listitem> + <para><command>nix-store -q</command> now supports XML output + through the <option>--xml</option> flag.</para> + </listitem> + + <listitem> + <para>Several bug fixes.</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.5.xml b/third_party/nix/doc/manual/release-notes/rl-0.5.xml new file mode 100644 index 0000000000..e9f8bf2701 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.5.xml @@ -0,0 +1,11 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.5"> + +<title>Release 0.5 and earlier</title> + +<para>Please refer to the Subversion commit log messages.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.6.xml b/third_party/nix/doc/manual/release-notes/rl-0.6.xml new file mode 100644 index 0000000000..6dc6521d3c --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.6.xml @@ -0,0 +1,122 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.6"> + +<title>Release 0.6 (2004-11-14)</title> + +<itemizedlist> + + <listitem> + <para>Rewrite of the normalisation engine. + + <itemizedlist> + + <listitem><para>Multiple builds can now be performed in parallel + (option <option>-j</option>).</para></listitem> + + <listitem><para>Distributed builds. Nix can now call a shell + script to forward builds to Nix installations on remote + machines, which may or may not be of the same platform + type.</para></listitem> + + <listitem><para>Option <option>--fallback</option> allows + recovery from broken substitutes.</para></listitem> + + <listitem><para>Option <option>--keep-going</option> causes + building of other (unaffected) derivations to continue if one + failed.</para></listitem> + + </itemizedlist> + + </para> + + </listitem> + + <listitem><para>Improvements to the garbage collector (i.e., it + should actually work now).</para></listitem> + + <listitem><para>Setuid Nix installations allow a Nix store to be + shared among multiple users.</para></listitem> + + <listitem><para>Substitute registration is much faster + now.</para></listitem> + + <listitem><para>A utility <command>nix-build</command> to build a + Nix expression and create a symlink to the result int the current + directory; useful for testing Nix derivations.</para></listitem> + + <listitem><para>Manual updates.</para></listitem> + + <listitem> + + <para><command>nix-env</command> changes: + + <itemizedlist> + + <listitem><para>Derivations for other platforms are filtered out + (which can be overridden using + <option>--system-filter</option>).</para></listitem> + + <listitem><para><option>--install</option> by default now + uninstall previous derivations with the same + name.</para></listitem> + + <listitem><para><option>--upgrade</option> allows upgrading to a + specific version.</para></listitem> + + <listitem><para>New operation + <option>--delete-generations</option> to remove profile + generations (necessary for effective garbage + collection).</para></listitem> + + <listitem><para>Nicer output (sorted, + columnised).</para></listitem> + + </itemizedlist> + + </para> + + </listitem> + + <listitem><para>More sensible verbosity levels all around (builder + output is now shown always, unless <option>-Q</option> is + given).</para></listitem> + + <listitem> + + <para>Nix expression language changes: + + <itemizedlist> + + <listitem><para>New language construct: <literal>with + <replaceable>E1</replaceable>; + <replaceable>E2</replaceable></literal> brings all attributes + defined in the attribute set <replaceable>E1</replaceable> in + scope in <replaceable>E2</replaceable>.</para></listitem> + + <listitem><para>Added a <function>map</function> + function.</para></listitem> + + <listitem><para>Various new operators (e.g., string + concatenation).</para></listitem> + + </itemizedlist> + + </para> + + </listitem> + + <listitem><para>Expression evaluation is much + faster.</para></listitem> + + <listitem><para>An Emacs mode for editing Nix expressions (with + syntax highlighting and indentation) has been + added.</para></listitem> + + <listitem><para>Many bug fixes.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.7.xml b/third_party/nix/doc/manual/release-notes/rl-0.7.xml new file mode 100644 index 0000000000..6f95db4367 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.7.xml @@ -0,0 +1,35 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.7"> + +<title>Release 0.7 (2005-01-12)</title> + +<itemizedlist> + + <listitem><para>Binary patching. When upgrading components using + pre-built binaries (through nix-pull / nix-channel), Nix can + automatically download and apply binary patches to already installed + components instead of full downloads. Patching is “smart”: if there + is a <emphasis>sequence</emphasis> of patches to an installed + component, Nix will use it. Patches are currently generated + automatically between Nixpkgs (pre-)releases.</para></listitem> + + <listitem><para>Simplifications to the substitute + mechanism.</para></listitem> + + <listitem><para>Nix-pull now stores downloaded manifests in + <filename>/nix/var/nix/manifests</filename>.</para></listitem> + + <listitem><para>Metadata on files in the Nix store is canonicalised + after builds: the last-modified timestamp is set to 0 (00:00:00 + 1/1/1970), the mode is set to 0444 or 0555 (readable and possibly + executable by all; setuid/setgid bits are dropped), and the group is + set to the default. This ensures that the result of a build and an + installation through a substitute is the same; and that timestamp + dependencies are revealed.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.8.1.xml b/third_party/nix/doc/manual/release-notes/rl-0.8.1.xml new file mode 100644 index 0000000000..f7ffca0f8d --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.8.1.xml @@ -0,0 +1,21 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.8.1"> + +<title>Release 0.8.1 (2005-04-13)</title> + +<para>This is a bug fix release.</para> + +<itemizedlist> + + <listitem><para>Patch downloading was broken.</para></listitem> + + <listitem><para>The garbage collector would not delete paths that + had references from invalid (but substitutable) + paths.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.8.xml b/third_party/nix/doc/manual/release-notes/rl-0.8.xml new file mode 100644 index 0000000000..784b26c6b7 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.8.xml @@ -0,0 +1,246 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.8"> + +<title>Release 0.8 (2005-04-11)</title> + +<para>NOTE: the hashing scheme in Nix 0.8 changed (as detailed below). +As a result, <command>nix-pull</command> manifests and channels built +for Nix 0.7 and below will now work anymore. However, the Nix +expression language has not changed, so you can still build from +source. Also, existing user environments continue to work. Nix 0.8 +will automatically upgrade the database schema of previous +installations when it is first run.</para> + +<para>If you get the error message + +<screen> +you have an old-style manifest `/nix/var/nix/manifests/[...]'; please +delete it</screen> + +you should delete previously downloaded manifests: + +<screen> +$ rm /nix/var/nix/manifests/*</screen> + +If <command>nix-channel</command> gives the error message + +<screen> +manifest `http://catamaran.labs.cs.uu.nl/dist/nix/channels/[channel]/MANIFEST' +is too old (i.e., for Nix <= 0.7)</screen> + +then you should unsubscribe from the offending channel +(<command>nix-channel --remove +<replaceable>URL</replaceable></command>; leave out +<literal>/MANIFEST</literal>), and subscribe to the same URL, with +<literal>channels</literal> replaced by <literal>channels-v3</literal> +(e.g., <link +xlink:href='http://catamaran.labs.cs.uu.nl/dist/nix/channels-v3/nixpkgs-unstable' +/>).</para> + +<para>Nix 0.8 has the following improvements: + +<itemizedlist> + + <listitem><para>The cryptographic hashes used in store paths are now + 160 bits long, but encoded in base-32 so that they are still only 32 + characters long (e.g., + <filename>/nix/store/csw87wag8bqlqk7ipllbwypb14xainap-atk-1.9.0</filename>). + (This is actually a 160 bit truncation of a SHA-256 + hash.)</para></listitem> + + <listitem><para>Big cleanups and simplifications of the basic store + semantics. The notion of “closure store expressions” is gone (and + so is the notion of “successors”); the file system references of a + store path are now just stored in the database.</para> + + <para>For instance, given any store path, you can query its closure: + + <screen> +$ nix-store -qR $(which firefox) +... lots of paths ...</screen> + + Also, Nix now remembers for each store path the derivation that + built it (the “deriver”): + + <screen> +$ nix-store -qR $(which firefox) +/nix/store/4b0jx7vq80l9aqcnkszxhymsf1ffa5jd-firefox-1.0.1.drv</screen> + + So to see the build-time dependencies, you can do + + <screen> +$ nix-store -qR $(nix-store -qd $(which firefox))</screen> + + or, in a nicer format: + + <screen> +$ nix-store -q --tree $(nix-store -qd $(which firefox))</screen> + + </para> + + <para>File system references are also stored in reverse. For + instance, you can query all paths that directly or indirectly use a + certain Glibc: + + <screen> +$ nix-store -q --referrers-closure \ + /nix/store/8lz9yc6zgmc0vlqmn2ipcpkjlmbi51vv-glibc-2.3.4</screen> + + </para> + + </listitem> + + <listitem><para>The concept of fixed-output derivations has been + formalised. Previously, functions such as + <function>fetchurl</function> in Nixpkgs used a hack (namely, + explicitly specifying a store path hash) to prevent changes to, say, + the URL of the file from propagating upwards through the dependency + graph, causing rebuilds of everything. This can now be done cleanly + by specifying the <varname>outputHash</varname> and + <varname>outputHashAlgo</varname> attributes. Nix itself checks + that the content of the output has the specified hash. (This is + important for maintaining certain invariants necessary for future + work on secure shared stores.)</para></listitem> + + <listitem><para>One-click installation :-) It is now possible to + install any top-level component in Nixpkgs directly, through the web + — see, e.g., <link + xlink:href='http://catamaran.labs.cs.uu.nl/dist/nixpkgs-0.8/' />. + All you have to do is associate + <filename>/nix/bin/nix-install-package</filename> with the MIME type + <literal>application/nix-package</literal> (or the extension + <filename>.nixpkg</filename>), and clicking on a package link will + cause it to be installed, with all appropriate dependencies. If you + just want to install some specific application, this is easier than + subscribing to a channel.</para></listitem> + + <listitem><para><command>nix-store -r + <replaceable>PATHS</replaceable></command> now builds all the + derivations PATHS in parallel. Previously it did them sequentially + (though exploiting possible parallelism between subderivations). + This is nice for build farms.</para></listitem> + + <listitem><para><command>nix-channel</command> has new operations + <option>--list</option> and + <option>--remove</option>.</para></listitem> + + <listitem><para>New ways of installing components into user + environments: + + <itemizedlist> + + <listitem><para>Copy from another user environment: + + <screen> +$ nix-env -i --from-profile .../other-profile firefox</screen> + + </para></listitem> + + <listitem><para>Install a store derivation directly (bypassing the + Nix expression language entirely): + + <screen> +$ nix-env -i /nix/store/z58v41v21xd3...-aterm-2.3.1.drv</screen> + + (This is used to implement <command>nix-install-package</command>, + which is therefore immune to evolution in the Nix expression + language.)</para></listitem> + + <listitem><para>Install an already built store path directly: + + <screen> +$ nix-env -i /nix/store/hsyj5pbn0d9i...-aterm-2.3.1</screen> + + </para></listitem> + + <listitem><para>Install the result of a Nix expression specified + as a command-line argument: + + <screen> +$ nix-env -f .../i686-linux.nix -i -E 'x: x.firefoxWrapper'</screen> + + The difference with the normal installation mode is that + <option>-E</option> does not use the <varname>name</varname> + attributes of derivations. Therefore, this can be used to + disambiguate multiple derivations with the same + name.</para></listitem> + + </itemizedlist></para></listitem> + + <listitem><para>A hash of the contents of a store path is now stored + in the database after a successful build. This allows you to check + whether store paths have been tampered with: <command>nix-store + --verify --check-contents</command>.</para></listitem> + + <listitem> + + <para>Implemented a concurrent garbage collector. It is now + always safe to run the garbage collector, even if other Nix + operations are happening simultaneously.</para> + + <para>However, there can still be GC races if you use + <command>nix-instantiate</command> and <command>nix-store + --realise</command> directly to build things. To prevent races, + use the <option>--add-root</option> flag of those commands.</para> + + </listitem> + + <listitem><para>The garbage collector now finally deletes paths in + the right order (i.e., topologically sorted under the “references” + relation), thus making it safe to interrupt the collector without + risking a store that violates the closure + invariant.</para></listitem> + + <listitem><para>Likewise, the substitute mechanism now downloads + files in the right order, thus preserving the closure invariant at + all times.</para></listitem> + + <listitem><para>The result of <command>nix-build</command> is now + registered as a root of the garbage collector. If the + <filename>./result</filename> link is deleted, the GC root + disappears automatically.</para></listitem> + + <listitem> + + <para>The behaviour of the garbage collector can be changed + globally by setting options in + <filename>/nix/etc/nix/nix.conf</filename>. + + <itemizedlist> + + <listitem><para><literal>gc-keep-derivations</literal> specifies + whether deriver links should be followed when searching for live + paths.</para></listitem> + + <listitem><para><literal>gc-keep-outputs</literal> specifies + whether outputs of derivations should be followed when searching + for live paths.</para></listitem> + + <listitem><para><literal>env-keep-derivations</literal> + specifies whether user environments should store the paths of + derivations when they are added (thus keeping the derivations + alive).</para></listitem> + + </itemizedlist> + + </para></listitem> + + <listitem><para>New <command>nix-env</command> query flags + <option>--drv-path</option> and + <option>--out-path</option>.</para></listitem> + + <listitem><para><command>fetchurl</command> allows SHA-1 and SHA-256 + in addition to MD5. Just specify the attribute + <varname>sha1</varname> or <varname>sha256</varname> instead of + <varname>md5</varname>.</para></listitem> + + <listitem><para>Manual updates.</para></listitem> + +</itemizedlist> + +</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.9.1.xml b/third_party/nix/doc/manual/release-notes/rl-0.9.1.xml new file mode 100644 index 0000000000..85d11f4168 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.9.1.xml @@ -0,0 +1,13 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.9.1"> + +<title>Release 0.9.1 (2005-09-20)</title> + +<para>This bug fix release addresses a problem with the ATerm library +when the <option>--with-aterm</option> flag in +<command>configure</command> was <emphasis>not</emphasis> used.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.9.2.xml b/third_party/nix/doc/manual/release-notes/rl-0.9.2.xml new file mode 100644 index 0000000000..cb705e98ac --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.9.2.xml @@ -0,0 +1,28 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.9.2"> + +<title>Release 0.9.2 (2005-09-21)</title> + +<para>This bug fix release fixes two problems on Mac OS X: + +<itemizedlist> + + <listitem><para>If Nix was linked against statically linked versions + of the ATerm or Berkeley DB library, there would be dynamic link + errors at runtime.</para></listitem> + + <listitem><para><command>nix-pull</command> and + <command>nix-push</command> intermittently failed due to race + conditions involving pipes and child processes with error messages + such as <literal>open2: open(GLOB(0x180b2e4), >&=9) failed: Bad + file descriptor at /nix/bin/nix-pull line 77</literal> (issue + <literal>NIX-14</literal>).</para></listitem> + +</itemizedlist> + +</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-0.9.xml b/third_party/nix/doc/manual/release-notes/rl-0.9.xml new file mode 100644 index 0000000000..fd1e633f78 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-0.9.xml @@ -0,0 +1,98 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ch-relnotes-0.9"> + +<title>Release 0.9 (2005-09-16)</title> + +<para>NOTE: this version of Nix uses Berkeley DB 4.3 instead of 4.2. +The database is upgraded automatically, but you should be careful not +to use old versions of Nix that still use Berkeley DB 4.2. In +particular, if you use a Nix installed through Nix, you should run + +<screen> +$ nix-store --clear-substitutes</screen> + +first.</para> + + +<itemizedlist> + + <listitem><para>Unpacking of patch sequences is much faster now + since we no longer do redundant unpacking and repacking of + intermediate paths.</para></listitem> + + <listitem><para>Nix now uses Berkeley DB 4.3.</para></listitem> + + <listitem><para>The <function>derivation</function> primitive is + lazier. Attributes of dependent derivations can mutually refer to + each other (as long as there are no data dependencies on the + <varname>outPath</varname> and <varname>drvPath</varname> attributes + computed by <function>derivation</function>).</para> + + <para>For example, the expression <literal>derivation + attrs</literal> now evaluates to (essentially) + + <programlisting> +attrs // { + type = "derivation"; + outPath = derivation! attrs; + drvPath = derivation! attrs; +}</programlisting> + + where <function>derivation!</function> is a primop that does the + actual derivation instantiation (i.e., it does what + <function>derivation</function> used to do). The advantage is that + it allows commands such as <command>nix-env -qa</command> and + <command>nix-env -i</command> to be much faster since they no longer + need to instantiate all derivations, just the + <varname>name</varname> attribute.</para> + + <para>Also, it allows derivations to cyclically reference each + other, for example, + + <programlisting> +webServer = derivation { + ... + hostName = "svn.cs.uu.nl"; + services = [svnService]; +}; +  +svnService = derivation { + ... + hostName = webServer.hostName; +};</programlisting> + + Previously, this would yield a black hole (infinite recursion).</para> + + </listitem> + + <listitem><para><command>nix-build</command> now defaults to using + <filename>./default.nix</filename> if no Nix expression is + specified.</para></listitem> + + <listitem><para><command>nix-instantiate</command>, when applied to + a Nix expression that evaluates to a function, will call the + function automatically if all its arguments have + defaults.</para></listitem> + + <listitem><para>Nix now uses libtool to build dynamic libraries. + This reduces the size of executables.</para></listitem> + + <listitem><para>A new list concatenation operator + <literal>++</literal>. For example, <literal>[1 2 3] ++ [4 5 + 6]</literal> evaluates to <literal>[1 2 3 4 5 + 6]</literal>.</para></listitem> + + <listitem><para>Some currently undocumented primops to support + low-level build management using Nix (i.e., using Nix as a Make + replacement). See the commit messages for <literal>r3578</literal> + and <literal>r3580</literal>.</para></listitem> + + <listitem><para>Various bug fixes and performance + improvements.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.0.xml b/third_party/nix/doc/manual/release-notes/rl-1.0.xml new file mode 100644 index 0000000000..ff11168d09 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.0.xml @@ -0,0 +1,119 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.0"> + +<title>Release 1.0 (2012-05-11)</title> + +<para>There have been numerous improvements and bug fixes since the +previous release. Here are the most significant:</para> + +<itemizedlist> + + <listitem> + <para>Nix can now optionally use the Boehm garbage collector. + This significantly reduces the Nix evaluator’s memory footprint, + especially when evaluating large NixOS system configurations. It + can be enabled using the <option>--enable-gc</option> configure + option.</para> + </listitem> + + <listitem> + <para>Nix now uses SQLite for its database. This is faster and + more flexible than the old <emphasis>ad hoc</emphasis> format. + SQLite is also used to cache the manifests in + <filename>/nix/var/nix/manifests</filename>, resulting in a + significant speedup.</para> + </listitem> + + <listitem> + <para>Nix now has an search path for expressions. The search path + is set using the environment variable <envar>NIX_PATH</envar> and + the <option>-I</option> command line option. In Nix expressions, + paths between angle brackets are used to specify files that must + be looked up in the search path. For instance, the expression + <literal><nixpkgs/default.nix></literal> looks for a file + <filename>nixpkgs/default.nix</filename> relative to every element + in the search path.</para> + </listitem> + + <listitem> + <para>The new command <command>nix-build --run-env</command> + builds all dependencies of a derivation, then starts a shell in an + environment containing all variables from the derivation. This is + useful for reproducing the environment of a derivation for + development.</para> + </listitem> + + <listitem> + <para>The new command <command>nix-store --verify-path</command> + verifies that the contents of a store path have not + changed.</para> + </listitem> + + <listitem> + <para>The new command <command>nix-store --print-env</command> + prints out the environment of a derivation in a format that can be + evaluated by a shell.</para> + </listitem> + + <listitem> + <para>Attribute names can now be arbitrary strings. For instance, + you can write <literal>{ "foo-1.2" = …; "bla bla" = …; }."bla + bla"</literal>.</para> + </listitem> + + <listitem> + <para>Attribute selection can now provide a default value using + the <literal>or</literal> operator. For instance, the expression + <literal>x.y.z or e</literal> evaluates to the attribute + <literal>x.y.z</literal> if it exists, and <literal>e</literal> + otherwise.</para> + </listitem> + + <listitem> + <para>The right-hand side of the <literal>?</literal> operator can + now be an attribute path, e.g., <literal>attrs ? + a.b.c</literal>.</para> + </listitem> + + <listitem> + <para>On Linux, Nix will now make files in the Nix store immutable + on filesystems that support it. This prevents accidental + modification of files in the store by the root user.</para> + </listitem> + + <listitem> + <para>Nix has preliminary support for derivations with multiple + outputs. This is useful because it allows parts of a package to + be deployed and garbage-collected separately. For instance, + development parts of a package such as header files or static + libraries would typically not be part of the closure of an + application, resulting in reduced disk usage and installation + time.</para> + </listitem> + + <listitem> + <para>The Nix store garbage collector is faster and holds the + global lock for a shorter amount of time.</para> + </listitem> + + <listitem> + <para>The option <option>--timeout</option> (corresponding to the + configuration setting <literal>build-timeout</literal>) allows you + to set an absolute timeout on builds — if a build runs for more than + the given number of seconds, it is terminated. This is useful for + recovering automatically from builds that are stuck in an infinite + loop but keep producing output, and for which + <literal>--max-silent-time</literal> is ineffective.</para> + </listitem> + + <listitem> + <para>Nix development has moved to GitHub (<link + xlink:href="https://github.com/NixOS/nix" />).</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.1.xml b/third_party/nix/doc/manual/release-notes/rl-1.1.xml new file mode 100644 index 0000000000..2f26e7a242 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.1.xml @@ -0,0 +1,100 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.1"> + +<title>Release 1.1 (2012-07-18)</title> + +<para>This release has the following improvements:</para> + +<itemizedlist> + + <listitem> + <para>On Linux, when doing a chroot build, Nix now uses various + namespace features provided by the Linux kernel to improve + build isolation. Namely: + <itemizedlist> + <listitem><para>The private network namespace ensures that + builders cannot talk to the outside world (or vice versa): each + build only sees a private loopback interface. This also means + that two concurrent builds can listen on the same port (e.g. as + part of a test) without conflicting with each + other.</para></listitem> + <listitem><para>The PID namespace causes each build to start as + PID 1. Processes outside of the chroot are not visible to those + on the inside. On the other hand, processes inside the chroot + <emphasis>are</emphasis> visible from the outside (though with + different PIDs).</para></listitem> + <listitem><para>The IPC namespace prevents the builder from + communicating with outside processes using SysV IPC mechanisms + (shared memory, message queues, semaphores). It also ensures + that all IPC objects are destroyed when the builder + exits.</para></listitem> + <listitem><para>The UTS namespace ensures that builders see a + hostname of <literal>localhost</literal> rather than the actual + hostname.</para></listitem> + <listitem><para>The private mount namespace was already used by + Nix to ensure that the bind-mounts used to set up the chroot are + cleaned up automatically.</para></listitem> + </itemizedlist> + </para> + </listitem> + + <listitem> + <para>Build logs are now compressed using + <command>bzip2</command>. The command <command>nix-store + -l</command> decompresses them on the fly. This can be disabled + by setting the option <literal>build-compress-log</literal> to + <literal>false</literal>.</para> + </listitem> + + <listitem> + <para>The creation of build logs in + <filename>/nix/var/log/nix/drvs</filename> can be disabled by + setting the new option <literal>build-keep-log</literal> to + <literal>false</literal>. This is useful, for instance, for Hydra + build machines.</para> + </listitem> + + <listitem> + <para>Nix now reserves some space in + <filename>/nix/var/nix/db/reserved</filename> to ensure that the + garbage collector can run successfully if the disk is full. This + is necessary because SQLite transactions fail if the disk is + full.</para> + </listitem> + + <listitem> + <para>Added a basic <function>fetchurl</function> function. This + is not intended to replace the <function>fetchurl</function> in + Nixpkgs, but is useful for bootstrapping; e.g., it will allow us + to get rid of the bootstrap binaries in the Nixpkgs source tree + and download them instead. You can use it by doing + <literal>import <nix/fetchurl.nix> { url = + <replaceable>url</replaceable>; sha256 = + "<replaceable>hash</replaceable>"; }</literal>. (Shea Levy)</para> + </listitem> + + <listitem> + <para>Improved RPM spec file. (Michel Alexandre Salim)</para> + </listitem> + + <listitem> + <para>Support for on-demand socket-based activation in the Nix + daemon with <command>systemd</command>.</para> + </listitem> + + <listitem> + <para>Added a manpage for + <citerefentry><refentrytitle>nix.conf</refentrytitle><manvolnum>5</manvolnum></citerefentry>.</para> + </listitem> + + <listitem> + <para>When using the Nix daemon, the <option>-s</option> flag in + <command>nix-env -qa</command> is now much faster.</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.10.xml b/third_party/nix/doc/manual/release-notes/rl-1.10.xml new file mode 100644 index 0000000000..689a954663 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.10.xml @@ -0,0 +1,64 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.10"> + +<title>Release 1.10 (2015-09-03)</title> + +<para>This is primarily a bug fix release. It also has a number of new +features:</para> + +<itemizedlist> + + <listitem> + <para>A number of builtin functions have been added to reduce + Nixpkgs/NixOS evaluation time and memory consumption: + <function>all</function>, + <function>any</function>, + <function>concatStringsSep</function>, + <function>foldl’</function>, + <function>genList</function>, + <function>replaceStrings</function>, + <function>sort</function>. + </para> + </listitem> + + <listitem> + <para>The garbage collector is more robust when the disk is full.</para> + </listitem> + + <listitem> + <para>Nix supports a new API for building derivations that doesn’t + require a <literal>.drv</literal> file to be present on disk; it + only requires an in-memory representation of the derivation. This + is used by the Hydra continuous build system to make remote builds + more efficient.</para> + </listitem> + + <listitem> + <para>The function <literal><nix/fetchurl.nix></literal> now + uses a <emphasis>builtin</emphasis> builder (i.e. it doesn’t + require starting an external process; the download is performed by + Nix itself). This ensures that derivation paths don’t change when + Nix is upgraded, and obviates the need for ugly hacks to support + chroot execution.</para> + </listitem> + + <listitem> + <para><option>--version -v</option> now prints some configuration + information, in particular what compile-time optional features are + enabled, and the paths of various directories.</para> + </listitem> + + <listitem> + <para>Build users have their supplementary groups set correctly.</para> + </listitem> + +</itemizedlist> + +<para>This release has contributions from Eelco Dolstra, Guillaume +Maudoux, Iwan Aucamp, Jaka Hudoklin, Kirill Elagin, Ludovic Courtès, +Manolis Ragkousis, Nicolas B. Pierron and Shea Levy.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.11.10.xml b/third_party/nix/doc/manual/release-notes/rl-1.11.10.xml new file mode 100644 index 0000000000..415388b3e2 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.11.10.xml @@ -0,0 +1,31 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.11.10"> + +<title>Release 1.11.10 (2017-06-12)</title> + +<para>This release fixes a security bug in Nix’s “build user” build +isolation mechanism. Previously, Nix builders had the ability to +create setuid binaries owned by a <literal>nixbld</literal> +user. Such a binary could then be used by an attacker to assume a +<literal>nixbld</literal> identity and interfere with subsequent +builds running under the same UID.</para> + +<para>To prevent this issue, Nix now disallows builders to create +setuid and setgid binaries. On Linux, this is done using a seccomp BPF +filter. Note that this imposes a small performance penalty (e.g. 1% +when building GNU Hello). Using seccomp, we now also prevent the +creation of extended attributes and POSIX ACLs since these cannot be +represented in the NAR format and (in the case of POSIX ACLs) allow +bypassing regular Nix store permissions. On macOS, the restriction is +implemented using the existing sandbox mechanism, which now uses a +minimal “allow all except the creation of setuid/setgid binaries” +profile when regular sandboxing is disabled. On other platforms, the +“build user” mechanism is now disabled.</para> + +<para>Thanks go to Linus Heckemann for discovering and reporting this +bug.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.11.xml b/third_party/nix/doc/manual/release-notes/rl-1.11.xml new file mode 100644 index 0000000000..fe422dd1f8 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.11.xml @@ -0,0 +1,141 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.11"> + +<title>Release 1.11 (2016-01-19)</title> + +<para>This is primarily a bug fix release. It also has a number of new +features:</para> + +<itemizedlist> + + <listitem> + <para><command>nix-prefetch-url</command> can now download URLs + specified in a Nix expression. For example, + +<screen> +$ nix-prefetch-url -A hello.src +</screen> + + will prefetch the file specified by the + <function>fetchurl</function> call in the attribute + <literal>hello.src</literal> from the Nix expression in the + current directory, and print the cryptographic hash of the + resulting file on stdout. This differs from <literal>nix-build -A + hello.src</literal> in that it doesn't verify the hash, and is + thus useful when you’re updating a Nix expression.</para> + + <para>You can also prefetch the result of functions that unpack a + tarball, such as <function>fetchFromGitHub</function>. For example: + +<screen> +$ nix-prefetch-url --unpack https://github.com/NixOS/patchelf/archive/0.8.tar.gz +</screen> + + or from a Nix expression: + +<screen> +$ nix-prefetch-url -A nix-repl.src +</screen> + + </para> + + </listitem> + + <listitem> + <para>The builtin function + <function><nix/fetchurl.nix></function> now supports + downloading and unpacking NARs. This removes the need to have + multiple downloads in the Nixpkgs stdenv bootstrap process (like a + separate busybox binary for Linux, or curl/mkdir/sh/bzip2 for + Darwin). Now all those files can be combined into a single NAR, + optionally compressed using <command>xz</command>.</para> + </listitem> + + <listitem> + <para>Nix now supports SHA-512 hashes for verifying fixed-output + derivations, and in <function>builtins.hashString</function>.</para> + </listitem> + + <listitem> + <para> + The new flag <option>--option build-repeat + <replaceable>N</replaceable></option> will cause every build to + be executed <replaceable>N</replaceable>+1 times. If the build + output differs between any round, the build is rejected, and the + output paths are not registered as valid. This is primarily + useful to verify build determinism. (We already had a + <option>--check</option> option to repeat a previously succeeded + build. However, with <option>--check</option>, non-deterministic + builds are registered in the DB. Preventing that is useful for + Hydra to ensure that non-deterministic builds don't end up + getting published to the binary cache.) + </para> + </listitem> + + <listitem> + <para> + The options <option>--check</option> and <option>--option + build-repeat <replaceable>N</replaceable></option>, if they + detect a difference between two runs of the same derivation and + <option>-K</option> is given, will make the output of the other + run available under + <filename><replaceable>store-path</replaceable>-check</filename>. This + makes it easier to investigate the non-determinism using tools + like <command>diffoscope</command>, e.g., + +<screen> +$ nix-build pkgs/stdenv/linux -A stage1.pkgs.zlib --check -K +error: derivation ‘/nix/store/l54i8wlw2265…-zlib-1.2.8.drv’ may not +be deterministic: output ‘/nix/store/11a27shh6n2i…-zlib-1.2.8’ +differs from ‘/nix/store/11a27shh6n2i…-zlib-1.2.8-check’ + +$ diffoscope /nix/store/11a27shh6n2i…-zlib-1.2.8 /nix/store/11a27shh6n2i…-zlib-1.2.8-check +… +├── lib/libz.a +│ ├── metadata +│ │ @@ -1,15 +1,15 @@ +│ │ -rw-r--r-- 30001/30000 3096 Jan 12 15:20 2016 adler32.o +… +│ │ +rw-r--r-- 30001/30000 3096 Jan 12 15:28 2016 adler32.o +… +</screen> + + </para></listitem> + + <listitem> + <para>Improved FreeBSD support.</para> + </listitem> + + <listitem> + <para><command>nix-env -qa --xml --meta</command> now prints + license information.</para> + </listitem> + + <listitem> + <para>The maximum number of parallel TCP connections that the + binary cache substituter will use has been decreased from 150 to + 25. This should prevent upsetting some broken NAT routers, and + also improves performance.</para> + </listitem> + + <listitem> + <para>All "chroot"-containing strings got renamed to "sandbox". + In particular, some Nix options got renamed, but the old names + are still accepted as lower-priority aliases. + </para> + </listitem> + +</itemizedlist> + +<para>This release has contributions from Anders Claesson, Anthony +Cowley, Bjørn Forsman, Brian McKenna, Danny Wilson, davidak, Eelco Dolstra, +Fabian Schmitthenner, FrankHB, Ilya Novoselov, janus, Jim Garrison, John +Ericson, Jude Taylor, Ludovic Courtès, Manuel Jacob, Mathnerd314, +Pascal Wittmann, Peter Simons, Philip Potter, Preston Bennes, Rommel +M. Martinez, Sander van der Burg, Shea Levy, Tim Cuthbertson, Tuomas +Tynkkynen, Utku Demir and Vladimír Čunát.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.2.xml b/third_party/nix/doc/manual/release-notes/rl-1.2.xml new file mode 100644 index 0000000000..748fd9e670 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.2.xml @@ -0,0 +1,157 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.2"> + +<title>Release 1.2 (2012-12-06)</title> + +<para>This release has the following improvements and changes:</para> + +<itemizedlist> + + <listitem> + <para>Nix has a new binary substituter mechanism: the + <emphasis>binary cache</emphasis>. A binary cache contains + pre-built binaries of Nix packages. Whenever Nix wants to build a + missing Nix store path, it will check a set of binary caches to + see if any of them has a pre-built binary of that path. The + configuration setting <option>binary-caches</option> contains a + list of URLs of binary caches. For instance, doing +<screen> +$ nix-env -i thunderbird --option binary-caches http://cache.nixos.org +</screen> + will install Thunderbird and its dependencies, using the available + pre-built binaries in <uri>http://cache.nixos.org</uri>. + The main advantage over the old “manifest”-based method of getting + pre-built binaries is that you don’t have to worry about your + manifest being in sync with the Nix expressions you’re installing + from; i.e., you don’t need to run <command>nix-pull</command> to + update your manifest. It’s also more scalable because you don’t + need to redownload a giant manifest file every time. + </para> + + <para>A Nix channel can provide a binary cache URL that will be + used automatically if you subscribe to that channel. If you use + the Nixpkgs or NixOS channels + (<uri>http://nixos.org/channels</uri>) you automatically get the + cache <uri>http://cache.nixos.org</uri>.</para> + + <para>Binary caches are created using <command>nix-push</command>. + For details on the operation and format of binary caches, see the + <command>nix-push</command> manpage. More details are provided in + <link xlink:href="https://nixos.org/nix-dev/2012-September/009826.html">this + nix-dev posting</link>.</para> + </listitem> + + <listitem> + <para>Multiple output support should now be usable. A derivation + can declare that it wants to produce multiple store paths by + saying something like +<programlisting> +outputs = [ "lib" "headers" "doc" ]; +</programlisting> + This will cause Nix to pass the intended store path of each output + to the builder through the environment variables + <literal>lib</literal>, <literal>headers</literal> and + <literal>doc</literal>. Other packages can refer to a specific + output by referring to + <literal><replaceable>pkg</replaceable>.<replaceable>output</replaceable></literal>, + e.g. +<programlisting> +buildInputs = [ pkg.lib pkg.headers ]; +</programlisting> + If you install a package with multiple outputs using + <command>nix-env</command>, each output path will be symlinked + into the user environment.</para> + </listitem> + + <listitem> + <para>Dashes are now valid as part of identifiers and attribute + names.</para> + </listitem> + + <listitem> + <para>The new operation <command>nix-store --repair-path</command> + allows corrupted or missing store paths to be repaired by + redownloading them. <command>nix-store --verify --check-contents + --repair</command> will scan and repair all paths in the Nix + store. Similarly, <command>nix-env</command>, + <command>nix-build</command>, <command>nix-instantiate</command> + and <command>nix-store --realise</command> have a + <option>--repair</option> flag to detect and fix bad paths by + rebuilding or redownloading them.</para> + </listitem> + + <listitem> + <para>Nix no longer sets the immutable bit on files in the Nix + store. Instead, the recommended way to guard the Nix store + against accidental modification on Linux is to make it a read-only + bind mount, like this: + +<screen> +$ mount --bind /nix/store /nix/store +$ mount -o remount,ro,bind /nix/store +</screen> + + Nix will automatically make <filename>/nix/store</filename> + writable as needed (using a private mount namespace) to allow + modifications.</para> + </listitem> + + <listitem> + <para>Store optimisation (replacing identical files in the store + with hard links) can now be done automatically every time a path + is added to the store. This is enabled by setting the + configuration option <literal>auto-optimise-store</literal> to + <literal>true</literal> (disabled by default).</para> + </listitem> + + <listitem> + <para>Nix now supports <command>xz</command> compression for NARs + in addition to <command>bzip2</command>. It compresses about 30% + better on typical archives and decompresses about twice as + fast.</para> + </listitem> + + <listitem> + <para>Basic Nix expression evaluation profiling: setting the + environment variable <envar>NIX_COUNT_CALLS</envar> to + <literal>1</literal> will cause Nix to print how many times each + primop or function was executed.</para> + </listitem> + + <listitem> + <para>New primops: <varname>concatLists</varname>, + <varname>elem</varname>, <varname>elemAt</varname> and + <varname>filter</varname>.</para> + </listitem> + + <listitem> + <para>The command <command>nix-copy-closure</command> has a new + flag <option>--use-substitutes</option> (<option>-s</option>) to + download missing paths on the target machine using the substitute + mechanism.</para> + </listitem> + + <listitem> + <para>The command <command>nix-worker</command> has been renamed + to <command>nix-daemon</command>. Support for running the Nix + worker in “slave” mode has been removed.</para> + </listitem> + + <listitem> + <para>The <option>--help</option> flag of every Nix command now + invokes <command>man</command>.</para> + </listitem> + + <listitem> + <para>Chroot builds are now supported on systemd machines.</para> + </listitem> + +</itemizedlist> + +<para>This release has contributions from Eelco Dolstra, Florian +Friesdorf, Mats Erik Andersson and Shea Levy.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.3.xml b/third_party/nix/doc/manual/release-notes/rl-1.3.xml new file mode 100644 index 0000000000..e2009ee3ba --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.3.xml @@ -0,0 +1,19 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.3"> + +<title>Release 1.3 (2013-01-04)</title> + +<para>This is primarily a bug fix release. When this version is first +run on Linux, it removes any immutable bits from the Nix store and +increases the schema version of the Nix store. (The previous release +removed support for setting the immutable bit; this release clears any +remaining immutable bits to make certain operations more +efficient.)</para> + +<para>This release has contributions from Eelco Dolstra and Stuart +Pernsteiner.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.4.xml b/third_party/nix/doc/manual/release-notes/rl-1.4.xml new file mode 100644 index 0000000000..aefb22f2b9 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.4.xml @@ -0,0 +1,39 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.4"> + +<title>Release 1.4 (2013-02-26)</title> + +<para>This release fixes a security bug in multi-user operation. It +was possible for derivations to cause the mode of files outside of the +Nix store to be changed to 444 (read-only but world-readable) by +creating hard links to those files (<link +xlink:href="https://github.com/NixOS/nix/commit/5526a282b5b44e9296e61e07d7d2626a79141ac4">details</link>).</para> + +<para>There are also the following improvements:</para> + +<itemizedlist> + + <listitem><para>New built-in function: + <function>builtins.hashString</function>.</para></listitem> + + <listitem><para>Build logs are now stored in + <filename>/nix/var/log/nix/drvs/<replaceable>XX</replaceable>/</filename>, + where <replaceable>XX</replaceable> is the first two characters of + the derivation. This is useful on machines that keep a lot of build + logs (such as Hydra servers).</para></listitem> + + <listitem><para>The function <function>corepkgs/fetchurl</function> + can now make the downloaded file executable. This will allow + getting rid of all bootstrap binaries in the Nixpkgs source + tree.</para></listitem> + + <listitem><para>Language change: The expression <literal>"${./path} + ..."</literal> now evaluates to a string instead of a + path.</para></listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.5.1.xml b/third_party/nix/doc/manual/release-notes/rl-1.5.1.xml new file mode 100644 index 0000000000..035c8dbcbb --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.5.1.xml @@ -0,0 +1,12 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.5.1"> + +<title>Release 1.5.1 (2013-02-28)</title> + +<para>The bug fix to the bug fix had a bug itself, of course. But +this time it will work for sure!</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.5.2.xml b/third_party/nix/doc/manual/release-notes/rl-1.5.2.xml new file mode 100644 index 0000000000..7e81dd2432 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.5.2.xml @@ -0,0 +1,12 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.5.2"> + +<title>Release 1.5.2 (2013-05-13)</title> + +<para>This is primarily a bug fix release. It has contributions from +Eelco Dolstra, Lluís Batlle i Rossell and Shea Levy.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.5.xml b/third_party/nix/doc/manual/release-notes/rl-1.5.xml new file mode 100644 index 0000000000..8e279d7693 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.5.xml @@ -0,0 +1,12 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.5"> + +<title>Release 1.5 (2013-02-27)</title> + +<para>This is a brown paper bag release to fix a regression introduced +by the hard link security fix in 1.4.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.6.1.xml b/third_party/nix/doc/manual/release-notes/rl-1.6.1.xml new file mode 100644 index 0000000000..9ecc527347 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.6.1.xml @@ -0,0 +1,69 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.6.1"> + +<title>Release 1.6.1 (2013-10-28)</title> + +<para>This is primarily a bug fix release. Changes of interest +are:</para> + +<itemizedlist> + + <listitem> + <para>Nix 1.6 accidentally changed the semantics of antiquoted + paths in strings, such as <literal>"${/foo}/bar"</literal>. This + release reverts to the Nix 1.5.3 behaviour.</para> + </listitem> + + <listitem> + <para>Previously, Nix optimised expressions such as + <literal>"${<replaceable>expr</replaceable>}"</literal> to + <replaceable>expr</replaceable>. Thus it neither checked whether + <replaceable>expr</replaceable> could be coerced to a string, nor + applied such coercions. This meant that + <literal>"${123}"</literal> evaluatued to <literal>123</literal>, + and <literal>"${./foo}"</literal> evaluated to + <literal>./foo</literal> (even though + <literal>"${./foo} "</literal> evaluates to + <literal>"/nix/store/<replaceable>hash</replaceable>-foo "</literal>). + Nix now checks the type of antiquoted expressions and + applies coercions.</para> + </listitem> + + <listitem> + <para>Nix now shows the exact position of undefined variables. In + particular, undefined variable errors in a <literal>with</literal> + previously didn't show <emphasis>any</emphasis> position + information, so this makes it a lot easier to fix such + errors.</para> + </listitem> + + <listitem> + <para>Undefined variables are now treated consistently. + Previously, the <function>tryEval</function> function would catch + undefined variables inside a <literal>with</literal> but not + outside. Now <function>tryEval</function> never catches undefined + variables.</para> + </listitem> + + <listitem> + <para>Bash completion in <command>nix-shell</command> now works + correctly.</para> + </listitem> + + <listitem> + <para>Stack traces are less verbose: they no longer show calls to + builtin functions and only show a single line for each derivation + on the call stack.</para> + </listitem> + + <listitem> + <para>New built-in function: <function>builtins.typeOf</function>, + which returns the type of its argument as a string.</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.6.xml b/third_party/nix/doc/manual/release-notes/rl-1.6.xml new file mode 100644 index 0000000000..5805634209 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.6.xml @@ -0,0 +1,127 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.6.0"> + +<title>Release 1.6 (2013-09-10)</title> + +<para>In addition to the usual bug fixes, this release has several new +features:</para> + +<itemizedlist> + + <listitem> + <para>The command <command>nix-build --run-env</command> has been + renamed to <command>nix-shell</command>.</para> + </listitem> + + <listitem> + <para><command>nix-shell</command> now sources + <filename>$stdenv/setup</filename> <emphasis>inside</emphasis> the + interactive shell, rather than in a parent shell. This ensures + that shell functions defined by <literal>stdenv</literal> can be + used in the interactive shell.</para> + </listitem> + + <listitem> + <para><command>nix-shell</command> has a new flag + <option>--pure</option> to clear the environment, so you get an + environment that more closely corresponds to the “real” Nix build. + </para> + </listitem> + + <listitem> + <para><command>nix-shell</command> now sets the shell prompt + (<envar>PS1</envar>) to ensure that Nix shells are distinguishable + from your regular shells.</para> + </listitem> + + <listitem> + <para><command>nix-env</command> no longer requires a + <literal>*</literal> argument to match all packages, so + <literal>nix-env -qa</literal> is equivalent to <literal>nix-env + -qa '*'</literal>.</para> + </listitem> + + <listitem> + <para><command>nix-env -i</command> has a new flag + <option>--remove-all</option> (<option>-r</option>) to remove all + previous packages from the profile. This makes it easier to do + declarative package management similar to NixOS’s + <option>environment.systemPackages</option>. For instance, if you + have a specification <filename>my-packages.nix</filename> like this: + +<programlisting> +with import <nixpkgs> {}; +[ thunderbird + geeqie + ... +] +</programlisting> + + then after any change to this file, you can run: + +<screen> +$ nix-env -f my-packages.nix -ir +</screen> + + to update your profile to match the specification.</para> + </listitem> + + <listitem> + <para>The ‘<literal>with</literal>’ language construct is now more + lazy. It only evaluates its argument if a variable might actually + refer to an attribute in the argument. For instance, this now + works: + +<programlisting> +let + pkgs = with pkgs; { foo = "old"; bar = foo; } // overrides; + overrides = { foo = "new"; }; +in pkgs.bar +</programlisting> + + This evaluates to <literal>"new"</literal>, while previously it + gave an “infinite recursion” error.</para> + </listitem> + + <listitem> + <para>Nix now has proper integer arithmetic operators. For + instance, you can write <literal>x + y</literal> instead of + <literal>builtins.add x y</literal>, or <literal>x < + y</literal> instead of <literal>builtins.lessThan x y</literal>. + The comparison operators also work on strings.</para> + </listitem> + + <listitem> + <para>On 64-bit systems, Nix integers are now 64 bits rather than + 32 bits.</para> + </listitem> + + <listitem> + <para>When using the Nix daemon, the <command>nix-daemon</command> + worker process now runs on the same CPU as the client, on systems + that support setting CPU affinity. This gives a significant speedup + on some systems.</para> + </listitem> + + <listitem> + <para>If a stack overflow occurs in the Nix evaluator, you now get + a proper error message (rather than “Segmentation fault”) on some + systems.</para> + </listitem> + + <listitem> + <para>In addition to directories, you can now bind-mount regular + files in chroots through the (now misnamed) option + <option>build-chroot-dirs</option>.</para> + </listitem> + +</itemizedlist> + +<para>This release has contributions from Domen Kožar, Eelco Dolstra, +Florian Friesdorf, Gergely Risko, Ivan Kozik, Ludovic Courtès and Shea +Levy.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.7.xml b/third_party/nix/doc/manual/release-notes/rl-1.7.xml new file mode 100644 index 0000000000..44ecaa78da --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.7.xml @@ -0,0 +1,263 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.7"> + +<title>Release 1.7 (2014-04-11)</title> + +<para>In addition to the usual bug fixes, this release has the +following new features:</para> + +<itemizedlist> + + <listitem> + <para>Antiquotation is now allowed inside of quoted attribute + names (e.g. <literal>set."${foo}"</literal>). In the case where + the attribute name is just a single antiquotation, the quotes can + be dropped (e.g. the above example can be written + <literal>set.${foo}</literal>). If an attribute name inside of a + set declaration evaluates to <literal>null</literal> (e.g. + <literal>{ ${null} = false; }</literal>), then that attribute is + not added to the set.</para> + </listitem> + + <listitem> + <para>Experimental support for cryptographically signed binary + caches. See <link + xlink:href="https://github.com/NixOS/nix/commit/0fdf4da0e979f992db75cc17376e455ddc5a96d8">the + commit for details</link>.</para> + </listitem> + + <listitem> + <para>An experimental new substituter, + <command>download-via-ssh</command>, that fetches binaries from + remote machines via SSH. Specifying the flags <literal>--option + use-ssh-substituter true --option ssh-substituter-hosts + <replaceable>user@hostname</replaceable></literal> will cause Nix + to download binaries from the specified machine, if it has + them.</para> + </listitem> + + <listitem> + <para><command>nix-store -r</command> and + <command>nix-build</command> have a new flag, + <option>--check</option>, that builds a previously built + derivation again, and prints an error message if the output is not + exactly the same. This helps to verify whether a derivation is + truly deterministic. For example: + +<screen> +$ nix-build '<nixpkgs>' -A patchelf +<replaceable>…</replaceable> +$ nix-build '<nixpkgs>' -A patchelf --check +<replaceable>…</replaceable> +error: derivation `/nix/store/1ipvxs…-patchelf-0.6' may not be deterministic: + hash mismatch in output `/nix/store/4pc1dm…-patchelf-0.6.drv' +</screen> + + </para> + + </listitem> + + <listitem> + <para>The <command>nix-instantiate</command> flags + <option>--eval-only</option> and <option>--parse-only</option> + have been renamed to <option>--eval</option> and + <option>--parse</option>, respectively.</para> + </listitem> + + <listitem> + <para><command>nix-instantiate</command>, + <command>nix-build</command> and <command>nix-shell</command> now + have a flag <option>--expr</option> (or <option>-E</option>) that + allows you to specify the expression to be evaluated as a command + line argument. For instance, <literal>nix-instantiate --eval -E + '1 + 2'</literal> will print <literal>3</literal>.</para> + </listitem> + + <listitem> + <para><command>nix-shell</command> improvements:</para> + + <itemizedlist> + + <listitem> + <para>It has a new flag, <option>--packages</option> (or + <option>-p</option>), that sets up a build environment + containing the specified packages from Nixpkgs. For example, + the command + +<screen> +$ nix-shell -p sqlite xorg.libX11 hello +</screen> + + will start a shell in which the given packages are + present.</para> + </listitem> + + <listitem> + <para>It now uses <filename>shell.nix</filename> as the + default expression, falling back to + <filename>default.nix</filename> if the former doesn’t + exist. This makes it convenient to have a + <filename>shell.nix</filename> in your project to set up a + nice development environment.</para> + </listitem> + + <listitem> + <para>It evaluates the derivation attribute + <varname>shellHook</varname>, if set. Since + <literal>stdenv</literal> does not normally execute this hook, + it allows you to do <command>nix-shell</command>-specific + setup.</para> + </listitem> + + <listitem> + <para>It preserves the user’s timezone setting.</para> + </listitem> + + </itemizedlist> + + </listitem> + + <listitem> + <para>In chroots, Nix now sets up a <filename>/dev</filename> + containing only a minimal set of devices (such as + <filename>/dev/null</filename>). Note that it only does this if + you <emphasis>don’t</emphasis> have <filename>/dev</filename> + listed in your <option>build-chroot-dirs</option> setting; + otherwise, it will bind-mount the <literal>/dev</literal> from + outside the chroot.</para> + + <para>Similarly, if you don’t have <filename>/dev/pts</filename> listed + in <option>build-chroot-dirs</option>, Nix will mount a private + <literal>devpts</literal> filesystem on the chroot’s + <filename>/dev/pts</filename>.</para> + + </listitem> + + <listitem> + <para>New built-in function: <function>builtins.toJSON</function>, + which returns a JSON representation of a value.</para> + </listitem> + + <listitem> + <para><command>nix-env -q</command> has a new flag + <option>--json</option> to print a JSON representation of the + installed or available packages.</para> + </listitem> + + <listitem> + <para><command>nix-env</command> now supports meta attributes with + more complex values, such as attribute sets.</para> + </listitem> + + <listitem> + <para>The <option>-A</option> flag now allows attribute names with + dots in them, e.g. + +<screen> +$ nix-instantiate --eval '<nixos>' -A 'config.systemd.units."nscd.service".text' +</screen> + + </para> + </listitem> + + <listitem> + <para>The <option>--max-freed</option> option to + <command>nix-store --gc</command> now accepts a unit + specifier. For example, <literal>nix-store --gc --max-freed + 1G</literal> will free up to 1 gigabyte of disk space.</para> + </listitem> + + <listitem> + <para><command>nix-collect-garbage</command> has a new flag + <option>--delete-older-than</option> + <replaceable>N</replaceable><literal>d</literal>, which deletes + all user environment generations older than + <replaceable>N</replaceable> days. Likewise, <command>nix-env + --delete-generations</command> accepts a + <replaceable>N</replaceable><literal>d</literal> age limit.</para> + </listitem> + + <listitem> + <para>Nix now heuristically detects whether a build failure was + due to a disk-full condition. In that case, the build is not + flagged as “permanently failed”. This is mostly useful for Hydra, + which needs to distinguish between permanent and transient build + failures.</para> + </listitem> + + <listitem> + <para>There is a new symbol <literal>__curPos</literal> that + expands to an attribute set containing its file name and line and + column numbers, e.g. <literal>{ file = "foo.nix"; line = 10; + column = 5; }</literal>. There also is a new builtin function, + <varname>unsafeGetAttrPos</varname>, that returns the position of + an attribute. This is used by Nixpkgs to provide location + information in error messages, e.g. + +<screen> +$ nix-build '<nixpkgs>' -A libreoffice --argstr system x86_64-darwin +error: the package ‘libreoffice-4.0.5.2’ in ‘.../applications/office/libreoffice/default.nix:263’ + is not supported on ‘x86_64-darwin’ +</screen> + + </para> + </listitem> + + <listitem> + <para>The garbage collector is now more concurrent with other Nix + processes because it releases certain locks earlier.</para> + </listitem> + + <listitem> + <para>The binary tarball installer has been improved. You can now + install Nix by running: + +<screen> +$ bash <(curl https://nixos.org/nix/install) +</screen> + + </para> + </listitem> + + <listitem> + <para>More evaluation errors include position information. For + instance, selecting a missing attribute will print something like + +<screen> +error: attribute `nixUnstabl' missing, at /etc/nixos/configurations/misc/eelco/mandark.nix:216:15 +</screen> + + </para> + </listitem> + + <listitem> + <para>The command <command>nix-setuid-helper</command> is + gone.</para> + </listitem> + + <listitem> + <para>Nix no longer uses Automake, but instead has a + non-recursive, GNU Make-based build system.</para> + </listitem> + + <listitem> + <para>All installed libraries now have the prefix + <literal>libnix</literal>. In particular, this gets rid of + <literal>libutil</literal>, which could clash with libraries with + the same name from other packages.</para> + </listitem> + + <listitem> + <para>Nix now requires a compiler that supports C++11.</para> + </listitem> + +</itemizedlist> + +<para>This release has contributions from Danny Wilson, Domen Kožar, +Eelco Dolstra, Ian-Woo Kim, Ludovic Courtès, Maxim Ivanov, Petr +Rockai, Ricardo M. Correia and Shea Levy.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.8.xml b/third_party/nix/doc/manual/release-notes/rl-1.8.xml new file mode 100644 index 0000000000..c854c5c5f8 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.8.xml @@ -0,0 +1,123 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.8"> + +<title>Release 1.8 (2014-12-14)</title> + +<itemizedlist> + + <listitem><para>Breaking change: to address a race condition, the + remote build hook mechanism now uses <command>nix-store + --serve</command> on the remote machine. This requires build slaves + to be updated to Nix 1.8.</para></listitem> + + <listitem><para>Nix now uses HTTPS instead of HTTP to access the + default binary cache, + <literal>cache.nixos.org</literal>.</para></listitem> + + <listitem><para><command>nix-env</command> selectors are now regular + expressions. For instance, you can do + +<screen> +$ nix-env -qa '.*zip.*' +</screen> + + to query all packages with a name containing + <literal>zip</literal>.</para></listitem> + + <listitem><para><command>nix-store --read-log</command> can now + fetch remote build logs. If a build log is not available locally, + then ‘nix-store -l’ will now try to download it from the servers + listed in the ‘log-servers’ option in nix.conf. For instance, if you + have the configuration option + +<programlisting> +log-servers = http://hydra.nixos.org/log +</programlisting> + +then it will try to get logs from +<literal>http://hydra.nixos.org/log/<replaceable>base name of the +store path</replaceable></literal>. This allows you to do things like: + +<screen> +$ nix-store -l $(which xterm) +</screen> + + and get a log even if <command>xterm</command> wasn't built + locally.</para></listitem> + + <listitem><para>New builtin functions: + <function>attrValues</function>, <function>deepSeq</function>, + <function>fromJSON</function>, <function>readDir</function>, + <function>seq</function>.</para></listitem> + + <listitem><para><command>nix-instantiate --eval</command> now has a + <option>--json</option> flag to print the resulting value in JSON + format.</para></listitem> + + <listitem><para><command>nix-copy-closure</command> now uses + <command>nix-store --serve</command> on the remote side to send or + receive closures. This fixes a race condition between + <command>nix-copy-closure</command> and the garbage + collector.</para></listitem> + + <listitem><para>Derivations can specify the new special attribute + <varname>allowedRequisites</varname>, which has a similar meaning to + <varname>allowedReferences</varname>. But instead of only enforcing + to explicitly specify the immediate references, it requires the + derivation to specify all the dependencies recursively (hence the + name, requisites) that are used by the resulting + output.</para></listitem> + + <listitem><para>On Mac OS X, Nix now handles case collisions when + importing closures from case-sensitive file systems. This is mostly + useful for running NixOps on Mac OS X.</para></listitem> + + <listitem><para>The Nix daemon has new configuration options + <option>allowed-users</option> (specifying the users and groups that + are allowed to connect to the daemon) and + <option>trusted-users</option> (specifying the users and groups that + can perform privileged operations like specifying untrusted binary + caches).</para></listitem> + + <listitem><para>The configuration option + <option>build-cores</option> now defaults to the number of available + CPU cores.</para></listitem> + + <listitem><para>Build users are now used by default when Nix is + invoked as root. This prevents builds from accidentally running as + root.</para></listitem> + + <listitem><para>Nix now includes systemd units and Upstart + jobs.</para></listitem> + + <listitem><para>Speed improvements to <command>nix-store + --optimise</command>.</para></listitem> + + <listitem><para>Language change: the <literal>==</literal> operator + now ignores string contexts (the “dependencies” of a + string).</para></listitem> + + <listitem><para>Nix now filters out Nix-specific ANSI escape + sequences on standard error. They are supposed to be invisible, but + some terminals show them anyway.</para></listitem> + + <listitem><para>Various commands now automatically pipe their output + into the pager as specified by the <envar>PAGER</envar> environment + variable.</para></listitem> + + <listitem><para>Several improvements to reduce memory consumption in + the evaluator.</para></listitem> + +</itemizedlist> + +<para>This release has contributions from Adam Szkoda, Aristid +Breitkreuz, Bob van der Linden, Charles Strahan, darealshinji, Eelco +Dolstra, Gergely Risko, Joel Taylor, Ludovic Courtès, Marko Durkovic, +Mikey Ariel, Paul Colomiets, Ricardo M. Correia, Ricky Elrod, Robert +Helgesson, Rob Vermaas, Russell O'Connor, Shea Levy, Shell Turner, +Sönke Hahn, Steve Purcell, Vladimír Čunát and Wout Mertens.</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-1.9.xml b/third_party/nix/doc/manual/release-notes/rl-1.9.xml new file mode 100644 index 0000000000..c8406bd207 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-1.9.xml @@ -0,0 +1,216 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-1.9"> + +<title>Release 1.9 (2015-06-12)</title> + +<para>In addition to the usual bug fixes, this release has the +following new features:</para> + +<itemizedlist> + + <listitem> + <para>Signed binary cache support. You can enable signature + checking by adding the following to <filename>nix.conf</filename>: + +<programlisting> +signed-binary-caches = * +binary-cache-public-keys = cache.nixos.org-1:6NCHdD59X431o0gWypbMrAURkbJ16ZPMQFGspcDShjY= +</programlisting> + + This will prevent Nix from downloading any binary from the cache + that is not signed by one of the keys listed in + <option>binary-cache-public-keys</option>.</para> + + <para>Signature checking is only supported if you built Nix with + the <literal>libsodium</literal> package.</para> + + <para>Note that while Nix has had experimental support for signed + binary caches since version 1.7, this release changes the + signature format in a backwards-incompatible way.</para> + + </listitem> + + <listitem> + + <para>Automatic downloading of Nix expression tarballs. In various + places, you can now specify the URL of a tarball containing Nix + expressions (such as Nixpkgs), which will be downloaded and + unpacked automatically. For example:</para> + + <itemizedlist> + + <listitem><para>In <command>nix-env</command>: + +<screen> +$ nix-env -f https://github.com/NixOS/nixpkgs-channels/archive/nixos-14.12.tar.gz -iA firefox +</screen> + + This installs Firefox from the latest tested and built revision + of the NixOS 14.12 channel.</para></listitem> + + <listitem><para>In <command>nix-build</command> and + <command>nix-shell</command>: + +<screen> +$ nix-build https://github.com/NixOS/nixpkgs/archive/master.tar.gz -A hello +</screen> + + This builds GNU Hello from the latest revision of the Nixpkgs + master branch.</para></listitem> + + <listitem><para>In the Nix search path (as specified via + <envar>NIX_PATH</envar> or <option>-I</option>). For example, to + start a shell containing the Pan package from a specific version + of Nixpkgs: + +<screen> +$ nix-shell -p pan -I nixpkgs=https://github.com/NixOS/nixpkgs-channels/archive/8a3eea054838b55aca962c3fbde9c83c102b8bf2.tar.gz +</screen> + + </para></listitem> + + <listitem><para>In <command>nixos-rebuild</command> (on NixOS): + +<screen> +$ nixos-rebuild test -I nixpkgs=https://github.com/NixOS/nixpkgs-channels/archive/nixos-unstable.tar.gz +</screen> + + </para></listitem> + + <listitem><para>In Nix expressions, via the new builtin function <function>fetchTarball</function>: + +<programlisting> +with import (fetchTarball https://github.com/NixOS/nixpkgs-channels/archive/nixos-14.12.tar.gz) {}; … +</programlisting> + + (This is not allowed in restricted mode.)</para></listitem> + + </itemizedlist> + + </listitem> + + <listitem> + + <para><command>nix-shell</command> improvements:</para> + + <itemizedlist> + + <listitem><para><command>nix-shell</command> now has a flag + <option>--run</option> to execute a command in the + <command>nix-shell</command> environment, + e.g. <literal>nix-shell --run make</literal>. This is like + the existing <option>--command</option> flag, except that it + uses a non-interactive shell (ensuring that hitting Ctrl-C won’t + drop you into the child shell).</para></listitem> + + <listitem><para><command>nix-shell</command> can now be used as + a <literal>#!</literal>-interpreter. This allows you to write + scripts that dynamically fetch their own dependencies. For + example, here is a Haskell script that, when invoked, first + downloads GHC and the Haskell packages on which it depends: + +<programlisting> +#! /usr/bin/env nix-shell +#! nix-shell -i runghc -p haskellPackages.ghc haskellPackages.HTTP + +import Network.HTTP + +main = do + resp <- Network.HTTP.simpleHTTP (getRequest "http://nixos.org/") + body <- getResponseBody resp + print (take 100 body) +</programlisting> + + Of course, the dependencies are cached in the Nix store, so the + second invocation of this script will be much + faster.</para></listitem> + + </itemizedlist> + + </listitem> + + <listitem> + + <para>Chroot improvements:</para> + + <itemizedlist> + + <listitem><para>Chroot builds are now supported on Mac OS X + (using its sandbox mechanism).</para></listitem> + + <listitem><para>If chroots are enabled, they are now used for + all derivations, including fixed-output derivations (such as + <function>fetchurl</function>). The latter do have network + access, but can no longer access the host filesystem. If you + need the old behaviour, you can set the option + <option>build-use-chroot</option> to + <literal>relaxed</literal>.</para></listitem> + + <listitem><para>On Linux, if chroots are enabled, builds are + performed in a private PID namespace once again. (This + functionality was lost in Nix 1.8.)</para></listitem> + + <listitem><para>Store paths listed in + <option>build-chroot-dirs</option> are now automatically + expanded to their closure. For instance, if you want + <filename>/nix/store/…-bash/bin/sh</filename> mounted in your + chroot as <filename>/bin/sh</filename>, you only need to say + <literal>build-chroot-dirs = + /bin/sh=/nix/store/…-bash/bin/sh</literal>; it is no longer + necessary to specify the dependencies of Bash.</para></listitem> + + </itemizedlist> + + </listitem> + + <listitem><para>The new derivation attribute + <varname>passAsFile</varname> allows you to specify that the + contents of derivation attributes should be passed via files rather + than environment variables. This is useful if you need to pass very + long strings that exceed the size limit of the environment. The + Nixpkgs function <function>writeTextFile</function> uses + this.</para></listitem> + + <listitem><para>You can now use <literal>~</literal> in Nix file + names to refer to your home directory, e.g. <literal>import + ~/.nixpkgs/config.nix</literal>.</para></listitem> + + <listitem><para>Nix has a new option <option>restrict-eval</option> + that allows limiting what paths the Nix evaluator has access to. By + passing <literal>--option restrict-eval true</literal> to Nix, the + evaluator will throw an exception if an attempt is made to access + any file outside of the Nix search path. This is primarily intended + for Hydra to ensure that a Hydra jobset only refers to its declared + inputs (and is therefore reproducible).</para></listitem> + + <listitem><para><command>nix-env</command> now only creates a new + “generation” symlink in <filename>/nix/var/nix/profiles</filename> + if something actually changed.</para></listitem> + + <listitem><para>The environment variable <envar>NIX_PAGER</envar> + can now be set to override <envar>PAGER</envar>. You can set it to + <literal>cat</literal> to disable paging for Nix commands + only.</para></listitem> + + <listitem><para>Failing <literal><...></literal> + lookups now show position information.</para></listitem> + + <listitem><para>Improved Boehm GC use: we disabled scanning for + interior pointers, which should reduce the “<literal>Repeated + allocation of very large block</literal>” warnings and associated + retention of memory.</para></listitem> + +</itemizedlist> + +<para>This release has contributions from aszlig, Benjamin Staffin, +Charles Strahan, Christian Theune, Daniel Hahler, Danylo Hlynskyi +Daniel Peebles, Dan Peebles, Domen Kožar, Eelco Dolstra, Harald van +Dijk, Hoang Xuan Phu, Jaka Hudoklin, Jeff Ramnani, j-keck, Linquize, +Luca Bruno, Michael Merickel, Oliver Dunkl, Rob Vermaas, Rok Garbas, +Shea Levy, Tobias Geerinckx-Rice and William A. Kennington III.</para> + +</section> + diff --git a/third_party/nix/doc/manual/release-notes/rl-2.0.xml b/third_party/nix/doc/manual/release-notes/rl-2.0.xml new file mode 100644 index 0000000000..fc9a77b08b --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-2.0.xml @@ -0,0 +1,1012 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-2.0"> + +<title>Release 2.0 (2018-02-22)</title> + +<para>The following incompatible changes have been made:</para> + +<itemizedlist> + + <listitem> + <para>The manifest-based substituter mechanism + (<command>download-using-manifests</command>) has been <link + xlink:href="https://github.com/NixOS/nix/commit/867967265b80946dfe1db72d40324b4f9af988ed">removed</link>. It + has been superseded by the binary cache substituter mechanism + since several years. As a result, the following programs have been + removed: + + <itemizedlist> + <listitem><para><command>nix-pull</command></para></listitem> + <listitem><para><command>nix-generate-patches</command></para></listitem> + <listitem><para><command>bsdiff</command></para></listitem> + <listitem><para><command>bspatch</command></para></listitem> + </itemizedlist> + </para> + </listitem> + + <listitem> + <para>The “copy from other stores” substituter mechanism + (<command>copy-from-other-stores</command> and the + <envar>NIX_OTHER_STORES</envar> environment variable) has been + removed. It was primarily used by the NixOS installer to copy + available paths from the installation medium. The replacement is + to use a chroot store as a substituter + (e.g. <literal>--substituters /mnt</literal>), or to build into a + chroot store (e.g. <literal>--store /mnt --substituters /</literal>).</para> + </listitem> + + <listitem> + <para>The command <command>nix-push</command> has been removed as + part of the effort to eliminate Nix's dependency on Perl. You can + use <command>nix copy</command> instead, e.g. <literal>nix copy + --to file:///tmp/my-binary-cache <replaceable>paths…</replaceable></literal></para> + </listitem> + + <listitem> + <para>The “nested” log output feature (<option>--log-type + pretty</option>) has been removed. As a result, + <command>nix-log2xml</command> was also removed.</para> + </listitem> + + <listitem> + <para>OpenSSL-based signing has been <link + xlink:href="https://github.com/NixOS/nix/commit/f435f8247553656774dd1b2c88e9de5d59cab203">removed</link>. This + feature was never well-supported. A better alternative is provided + by the <option>secret-key-files</option> and + <option>trusted-public-keys</option> options.</para> + </listitem> + + <listitem> + <para>Failed build caching has been <link + xlink:href="https://github.com/NixOS/nix/commit/8cffec84859cec8b610a2a22ab0c4d462a9351ff">removed</link>. This + feature was introduced to support the Hydra continuous build + system, but Hydra no longer uses it.</para> + </listitem> + + <listitem> + <para><filename>nix-mode.el</filename> has been removed from + Nix. It is now <link + xlink:href="https://github.com/NixOS/nix-mode">a separate + repository</link> and can be installed through the MELPA package + repository.</para> + </listitem> + +</itemizedlist> + +<para>This release has the following new features:</para> + +<itemizedlist> + + <listitem> + <para>It introduces a new command named <command>nix</command>, + which is intended to eventually replace all + <command>nix-*</command> commands with a more consistent and + better designed user interface. It currently provides replacements + for some (but not all) of the functionality provided by + <command>nix-store</command>, <command>nix-build</command>, + <command>nix-shell -p</command>, <command>nix-env -qa</command>, + <command>nix-instantiate --eval</command>, + <command>nix-push</command> and + <command>nix-copy-closure</command>. It has the following major + features:</para> + + <itemizedlist> + + <listitem> + <para>Unlike the legacy commands, it has a consistent way to + refer to packages and package-like arguments (like store + paths). For example, the following commands all copy the GNU + Hello package to a remote machine: + + <screen>nix copy --to ssh://machine nixpkgs.hello</screen> + <screen>nix copy --to ssh://machine /nix/store/0i2jd68mp5g6h2sa5k9c85rb80sn8hi9-hello-2.10</screen> + <screen>nix copy --to ssh://machine '(with import <nixpkgs> {}; hello)'</screen> + + By contrast, <command>nix-copy-closure</command> only accepted + store paths as arguments.</para> + </listitem> + + <listitem> + <para>It is self-documenting: <option>--help</option> shows + all available command-line arguments. If + <option>--help</option> is given after a subcommand, it shows + examples for that subcommand. <command>nix + --help-config</command> shows all configuration + options.</para> + </listitem> + + <listitem> + <para>It is much less verbose. By default, it displays a + single-line progress indicator that shows how many packages + are left to be built or downloaded, and (if there are running + builds) the most recent line of builder output. If a build + fails, it shows the last few lines of builder output. The full + build log can be retrieved using <command>nix + log</command>.</para> + </listitem> + + <listitem> + <para>It <link + xlink:href="https://github.com/NixOS/nix/commit/b8283773bd64d7da6859ed520ee19867742a03ba">provides</link> + all <filename>nix.conf</filename> configuration options as + command line flags. For example, instead of <literal>--option + http-connections 100</literal> you can write + <literal>--http-connections 100</literal>. Boolean options can + be written as + <literal>--<replaceable>foo</replaceable></literal> or + <literal>--no-<replaceable>foo</replaceable></literal> + (e.g. <option>--no-auto-optimise-store</option>).</para> + </listitem> + + <listitem> + <para>Many subcommands have a <option>--json</option> flag to + write results to stdout in JSON format.</para> + </listitem> + + </itemizedlist> + + <warning><para>Please note that the <command>nix</command> command + is a work in progress and the interface is subject to + change.</para></warning> + + <para>It provides the following high-level (“porcelain”) + subcommands:</para> + + <itemizedlist> + + <listitem> + <para><command>nix build</command> is a replacement for + <command>nix-build</command>.</para> + </listitem> + + <listitem> + <para><command>nix run</command> executes a command in an + environment in which the specified packages are available. It + is (roughly) a replacement for <command>nix-shell + -p</command>. Unlike that command, it does not execute the + command in a shell, and has a flag (<command>-c</command>) + that specifies the unquoted command line to be + executed.</para> + + <para>It is particularly useful in conjunction with chroot + stores, allowing Linux users who do not have permission to + install Nix in <command>/nix/store</command> to still use + binary substitutes that assume + <command>/nix/store</command>. For example, + + <screen>nix run --store ~/my-nix nixpkgs.hello -c hello --greeting 'Hi everybody!'</screen> + + downloads (or if not substitutes are available, builds) the + GNU Hello package into + <filename>~/my-nix/nix/store</filename>, then runs + <command>hello</command> in a mount namespace where + <filename>~/my-nix/nix/store</filename> is mounted onto + <command>/nix/store</command>.</para> + </listitem> + + <listitem> + <para><command>nix search</command> replaces <command>nix-env + -qa</command>. It searches the available packages for + occurrences of a search string in the attribute name, package + name or description. Unlike <command>nix-env -qa</command>, it + has a cache to speed up subsequent searches.</para> + </listitem> + + <listitem> + <para><command>nix copy</command> copies paths between + arbitrary Nix stores, generalising + <command>nix-copy-closure</command> and + <command>nix-push</command>.</para> + </listitem> + + <listitem> + <para><command>nix repl</command> replaces the external + program <command>nix-repl</command>. It provides an + interactive environment for evaluating and building Nix + expressions. Note that it uses <literal>linenoise-ng</literal> + instead of GNU Readline.</para> + </listitem> + + <listitem> + <para><command>nix upgrade-nix</command> upgrades Nix to the + latest stable version. This requires that Nix is installed in + a profile. (Thus it won’t work on NixOS, or if it’s installed + outside of the Nix store.)</para> + </listitem> + + <listitem> + <para><command>nix verify</command> checks whether store paths + are unmodified and/or “trusted” (see below). It replaces + <command>nix-store --verify</command> and <command>nix-store + --verify-path</command>.</para> + </listitem> + + <listitem> + <para><command>nix log</command> shows the build log of a + package or path. If the build log is not available locally, it + will try to obtain it from the configured substituters (such + as <uri>cache.nixos.org</uri>, which now provides build + logs).</para> + </listitem> + + <listitem> + <para><command>nix edit</command> opens the source code of a + package in your editor.</para> + </listitem> + + <listitem> + <para><command>nix eval</command> replaces + <command>nix-instantiate --eval</command>.</para> + </listitem> + + <listitem> + <para><command + xlink:href="https://github.com/NixOS/nix/commit/d41c5eb13f4f3a37d80dbc6d3888644170c3b44a">nix + why-depends</command> shows why one store path has another in + its closure. This is primarily useful to finding the causes of + closure bloat. For example, + + <screen>nix why-depends nixpkgs.vlc nixpkgs.libdrm.dev</screen> + + shows a chain of files and fragments of file contents that + cause the VLC package to have the “dev” output of + <literal>libdrm</literal> in its closure — an undesirable + situation.</para> + </listitem> + + <listitem> + <para><command>nix path-info</command> shows information about + store paths, replacing <command>nix-store -q</command>. A + useful feature is the option <option>--closure-size</option> + (<option>-S</option>). For example, the following command show + the closure sizes of every path in the current NixOS system + closure, sorted by size: + + <screen>nix path-info -rS /run/current-system | sort -nk2</screen> + + </para> + </listitem> + + <listitem> + <para><command>nix optimise-store</command> replaces + <command>nix-store --optimise</command>. The main difference + is that it has a progress indicator.</para> + </listitem> + + </itemizedlist> + + <para>A number of low-level (“plumbing”) commands are also + available:</para> + + <itemizedlist> + + <listitem> + <para><command>nix ls-store</command> and <command>nix + ls-nar</command> list the contents of a store path or NAR + file. The former is primarily useful in conjunction with + remote stores, e.g. + + <screen>nix ls-store --store https://cache.nixos.org/ -lR /nix/store/0i2jd68mp5g6h2sa5k9c85rb80sn8hi9-hello-2.10</screen> + + lists the contents of path in a binary cache.</para> + </listitem> + + <listitem> + <para><command>nix cat-store</command> and <command>nix + cat-nar</command> allow extracting a file from a store path or + NAR file.</para> + </listitem> + + <listitem> + <para><command>nix dump-path</command> writes the contents of + a store path to stdout in NAR format. This replaces + <command>nix-store --dump</command>.</para> + </listitem> + + <listitem> + <para><command + xlink:href="https://github.com/NixOS/nix/commit/e8d6ee7c1b90a2fe6d824f1a875acc56799ae6e2">nix + show-derivation</command> displays a store derivation in JSON + format. This is an alternative to + <command>pp-aterm</command>.</para> + </listitem> + + <listitem> + <para><command + xlink:href="https://github.com/NixOS/nix/commit/970366266b8df712f5f9cedb45af183ef5a8357f">nix + add-to-store</command> replaces <command>nix-store + --add</command>.</para> + </listitem> + + <listitem> + <para><command>nix sign-paths</command> signs store + paths.</para> + </listitem> + + <listitem> + <para><command>nix copy-sigs</command> copies signatures from + one store to another.</para> + </listitem> + + <listitem> + <para><command>nix show-config</command> shows all + configuration options and their current values.</para> + </listitem> + + </itemizedlist> + + </listitem> + + <listitem> + <para>The store abstraction that Nix has had for a long time to + support store access via the Nix daemon has been extended + significantly. In particular, substituters (which used to be + external programs such as + <command>download-from-binary-cache</command>) are now subclasses + of the abstract <classname>Store</classname> class. This allows + many Nix commands to operate on such store types. For example, + <command>nix path-info</command> shows information about paths in + your local Nix store, while <command>nix path-info --store + https://cache.nixos.org/</command> shows information about paths + in the specified binary cache. Similarly, + <command>nix-copy-closure</command>, <command>nix-push</command> + and substitution are all instances of the general notion of + copying paths between different kinds of Nix stores.</para> + + <para>Stores are specified using an URI-like syntax, + e.g. <uri>https://cache.nixos.org/</uri> or + <uri>ssh://machine</uri>. The following store types are supported: + + <itemizedlist> + + <listitem> + + <para><classname>LocalStore</classname> (stori URI + <literal>local</literal> or an absolute path) and the misnamed + <classname>RemoteStore</classname> (<literal>daemon</literal>) + provide access to a local Nix store, the latter via the Nix + daemon. You can use <literal>auto</literal> or the empty + string to auto-select a local or daemon store depending on + whether you have write permission to the Nix store. It is no + longer necessary to set the <envar>NIX_REMOTE</envar> + environment variable to use the Nix daemon.</para> + + <para>As noted above, <classname>LocalStore</classname> now + supports chroot builds, allowing the “physical” location of + the Nix store + (e.g. <filename>/home/alice/nix/store</filename>) to differ + from its “logical” location (typically + <filename>/nix/store</filename>). This allows non-root users + to use Nix while still getting the benefits from prebuilt + binaries from <uri>cache.nixos.org</uri>.</para> + + </listitem> + + <listitem> + + <para><classname>BinaryCacheStore</classname> is the abstract + superclass of all binary cache stores. It supports writing + build logs and NAR content listings in JSON format.</para> + + </listitem> + + <listitem> + + <para><classname>HttpBinaryCacheStore</classname> + (<literal>http://</literal>, <literal>https://</literal>) + supports binary caches via HTTP or HTTPS. If the server + supports <literal>PUT</literal> requests, it supports + uploading store paths via commands such as <command>nix + copy</command>.</para> + + </listitem> + + <listitem> + + <para><classname>LocalBinaryCacheStore</classname> + (<literal>file://</literal>) supports binary caches in the + local filesystem.</para> + + </listitem> + + <listitem> + + <para><classname>S3BinaryCacheStore</classname> + (<literal>s3://</literal>) supports binary caches stored in + Amazon S3, if enabled at compile time.</para> + + </listitem> + + <listitem> + + <para><classname>LegacySSHStore</classname> (<literal>ssh://</literal>) + is used to implement remote builds and + <command>nix-copy-closure</command>.</para> + + </listitem> + + <listitem> + + <para><classname>SSHStore</classname> + (<literal>ssh-ng://</literal>) supports arbitrary Nix + operations on a remote machine via the same protocol used by + <command>nix-daemon</command>.</para> + + </listitem> + + </itemizedlist> + + </para> + + </listitem> + + <listitem> + + <para>Security has been improved in various ways: + + <itemizedlist> + + <listitem> + <para>Nix now stores signatures for local store + paths. When paths are copied between stores (e.g., copied from + a binary cache to a local store), signatures are + propagated.</para> + + <para>Locally-built paths are signed automatically using the + secret keys specified by the <option>secret-key-files</option> + store option. Secret/public key pairs can be generated using + <command>nix-store + --generate-binary-cache-key</command>.</para> + + <para>In addition, locally-built store paths are marked as + “ultimately trusted”, but this bit is not propagated when + paths are copied between stores.</para> + </listitem> + + <listitem> + <para>Content-addressable store paths no longer require + signatures — they can be imported into a store by unprivileged + users even if they lack signatures.</para> + </listitem> + + <listitem> + <para>The command <command>nix verify</command> checks whether + the specified paths are trusted, i.e., have a certain number + of trusted signatures, are ultimately trusted, or are + content-addressed.</para> + </listitem> + + <listitem> + <para>Substitutions from binary caches <link + xlink:href="https://github.com/NixOS/nix/commit/ecbc3fedd3d5bdc5a0e1a0a51b29062f2874ac8b">now</link> + require signatures by default. This was already the case on + NixOS.</para> + </listitem> + + <listitem> + <para>In Linux sandbox builds, we <link + xlink:href="https://github.com/NixOS/nix/commit/eba840c8a13b465ace90172ff76a0db2899ab11b">now</link> + use <filename>/build</filename> instead of + <filename>/tmp</filename> as the temporary build + directory. This fixes potential security problems when a build + accidentally stores its <envar>TMPDIR</envar> in some + security-sensitive place, such as an RPATH.</para> + </listitem> + + </itemizedlist> + + </para> + + </listitem> + + <listitem> + <para><emphasis>Pure evaluation mode</emphasis>. This is a variant + of the existing restricted evaluation mode. In pure mode, the Nix + evaluator forbids access to anything that could cause different + evaluations of the same command line arguments to produce a + different result. This includes builtin functions such as + <function>builtins.getEnv</function>, but more importantly, + <emphasis>all</emphasis> filesystem or network access unless a + content hash or commit hash is specified. For example, calls to + <function>builtins.fetchGit</function> are only allowed if a + <varname>rev</varname> attribute is specified.</para> + + <para>The goal of this feature is to enable true reproducibility + and traceability of builds (including NixOS system configurations) + at the evaluation level. For example, in the future, + <command>nixos-rebuild</command> might build configurations from a + Nix expression in a Git repository in pure mode. That expression + might fetch other repositories such as Nixpkgs via + <function>builtins.fetchGit</function>. The commit hash of the + top-level repository then uniquely identifies a running system, + and, in conjunction with that repository, allows it to be + reproduced or modified.</para> + + </listitem> + + <listitem> + <para>There are several new features to support binary + reproducibility (i.e. to help ensure that multiple builds of the + same derivation produce exactly the same output). When + <option>enforce-determinism</option> is set to + <literal>false</literal>, it’s <link + xlink:href="https://github.com/NixOS/nix/commit/8bdf83f936adae6f2c907a6d2541e80d4120f051">no + longer</link> a fatal error if build rounds produce different + output. Also, a hook named <option>diff-hook</option> is <link + xlink:href="https://github.com/NixOS/nix/commit/9a313469a4bdea2d1e8df24d16289dc2a172a169">provided</link> + to allow you to run tools such as <command>diffoscope</command> + when build rounds produce different output.</para> + </listitem> + + <listitem> + <para>Configuring remote builds is a lot easier now. Provided you + are not using the Nix daemon, you can now just specify a remote + build machine on the command line, e.g. <literal>--option builders + 'ssh://my-mac x86_64-darwin'</literal>. The environment variable + <envar>NIX_BUILD_HOOK</envar> has been removed and is no longer + needed. The environment variable <envar>NIX_REMOTE_SYSTEMS</envar> + is still supported for compatibility, but it is also possible to + specify builders in <command>nix.conf</command> by setting the + option <literal>builders = + @<replaceable>path</replaceable></literal>.</para> + </listitem> + + <listitem> + <para>If a fixed-output derivation produces a result with an + incorrect hash, the output path is moved to the location + corresponding to the actual hash and registered as valid. Thus, a + subsequent build of the fixed-output derivation with the correct + hash is unnecessary.</para> + </listitem> + + <listitem> + <para><command>nix-shell</command> <link + xlink:href="https://github.com/NixOS/nix/commit/ea59f39326c8e9dc42dfed4bcbf597fbce58797c">now</link> + sets the <varname>IN_NIX_SHELL</varname> environment variable + during evaluation and in the shell itself. This can be used to + perform different actions depending on whether you’re in a Nix + shell or in a regular build. Nixpkgs provides + <varname>lib.inNixShell</varname> to check this variable during + evaluation.</para> + </listitem> + + <listitem> + <para><envar>NIX_PATH</envar> is now lazy, so URIs in the path are + only downloaded if they are needed for evaluation.</para> + </listitem> + + <listitem> + <para>You can now use + <uri>channel:<replaceable>channel-name</replaceable></uri> as a + short-hand for + <uri>https://nixos.org/channels/<replaceable>channel-name</replaceable>/nixexprs.tar.xz</uri>. For + example, <literal>nix-build channel:nixos-15.09 -A hello</literal> + will build the GNU Hello package from the + <literal>nixos-15.09</literal> channel. In the future, this may + use Git to fetch updates more efficiently.</para> + </listitem> + + <listitem> + <para>When <option>--no-build-output</option> is given, the last + 10 lines of the build log will be shown if a build + fails.</para> + </listitem> + + <listitem> + <para>Networking has been improved: + + <itemizedlist> + + <listitem> + <para>HTTP/2 is now supported. This makes binary cache lookups + <link + xlink:href="https://github.com/NixOS/nix/commit/90ad02bf626b885a5dd8967894e2eafc953bdf92">much + more efficient</link>.</para> + </listitem> + + <listitem> + <para>We now retry downloads on many HTTP errors, making + binary caches substituters more resilient to temporary + failures.</para> + </listitem> + + <listitem> + <para>HTTP credentials can now be configured via the standard + <filename>netrc</filename> mechanism.</para> + </listitem> + + <listitem> + <para>If S3 support is enabled at compile time, + <uri>s3://</uri> URIs are <link + xlink:href="https://github.com/NixOS/nix/commit/9ff9c3f2f80ba4108e9c945bbfda2c64735f987b">supported</link> + in all places where Nix allows URIs.</para> + </listitem> + + <listitem> + <para>Brotli compression is now supported. In particular, + <uri>cache.nixos.org</uri> build logs are now compressed using + Brotli.</para> + </listitem> + + </itemizedlist> + + </para> + + </listitem> + + <listitem> + <para><command>nix-env</command> <link + xlink:href="https://github.com/NixOS/nix/commit/b0cb11722626e906a73f10dd9a0c9eea29faf43a">now</link> + ignores packages with bad derivation names (in particular those + starting with a digit or containing a dot).</para> + </listitem> + + <listitem> + <para>Many configuration options have been renamed, either because + they were unnecessarily verbose + (e.g. <option>build-use-sandbox</option> is now just + <option>sandbox</option>) or to reflect generalised behaviour + (e.g. <option>binary-caches</option> is now + <option>substituters</option> because it allows arbitrary store + URIs). The old names are still supported for compatibility.</para> + </listitem> + + <listitem> + <para>The <option>max-jobs</option> option can <link + xlink:href="https://github.com/NixOS/nix/commit/7251d048fa812d2551b7003bc9f13a8f5d4c95a5">now</link> + be set to <literal>auto</literal> to use the number of CPUs in the + system.</para> + </listitem> + + <listitem> + <para>Hashes can <link + xlink:href="https://github.com/NixOS/nix/commit/c0015e87af70f539f24d2aa2bc224a9d8b84276b">now</link> + be specified in base-64 format, in addition to base-16 and the + non-standard base-32.</para> + </listitem> + + <listitem> + <para><command>nix-shell</command> now uses + <varname>bashInteractive</varname> from Nixpkgs, rather than the + <command>bash</command> command that happens to be in the caller’s + <envar>PATH</envar>. This is especially important on macOS where + the <command>bash</command> provided by the system is seriously + outdated and cannot execute <literal>stdenv</literal>’s setup + script.</para> + </listitem> + + <listitem> + <para>Nix can now automatically trigger a garbage collection if + free disk space drops below a certain level during a build. This + is configured using the <option>min-free</option> and + <option>max-free</option> options.</para> + </listitem> + + <listitem> + <para><command>nix-store -q --roots</command> and + <command>nix-store --gc --print-roots</command> now show temporary + and in-memory roots.</para> + </listitem> + + <listitem> + <para> + Nix can now be extended with plugins. See the documentation of + the <option>plugin-files</option> option for more details. + </para> + </listitem> + +</itemizedlist> + +<para>The Nix language has the following new features: + +<itemizedlist> + + <listitem> + <para>It supports floating point numbers. They are based on the + C++ <literal>float</literal> type and are supported by the + existing numerical operators. Export and import to and from JSON + and XML works, too.</para> + </listitem> + + <listitem> + <para>Derivation attributes can now reference the outputs of the + derivation using the <function>placeholder</function> builtin + function. For example, the attribute + +<programlisting> +configureFlags = "--prefix=${placeholder "out"} --includedir=${placeholder "dev"}"; +</programlisting> + + will cause the <envar>configureFlags</envar> environment variable + to contain the actual store paths corresponding to the + <literal>out</literal> and <literal>dev</literal> outputs.</para> + </listitem> + +</itemizedlist> + +</para> + +<para>The following builtin functions are new or extended: + +<itemizedlist> + + <listitem> + <para><function + xlink:href="https://github.com/NixOS/nix/commit/38539b943a060d9cdfc24d6e5d997c0885b8aa2f">builtins.fetchGit</function> + allows Git repositories to be fetched at evaluation time. Thus it + differs from the <function>fetchgit</function> function in + Nixpkgs, which fetches at build time and cannot be used to fetch + Nix expressions during evaluation. A typical use case is to import + external NixOS modules from your configuration, e.g. + + <programlisting>imports = [ (builtins.fetchGit https://github.com/edolstra/dwarffs + "/module.nix") ];</programlisting> + + </para> + </listitem> + + <listitem> + <para>Similarly, <function>builtins.fetchMercurial</function> + allows you to fetch Mercurial repositories.</para> + </listitem> + + <listitem> + <para><function>builtins.path</function> generalises + <function>builtins.filterSource</function> and path literals + (e.g. <literal>./foo</literal>). It allows specifying a store path + name that differs from the source path name + (e.g. <literal>builtins.path { path = ./foo; name = "bar"; + }</literal>) and also supports filtering out unwanted + files.</para> + </listitem> + + <listitem> + <para><function>builtins.fetchurl</function> and + <function>builtins.fetchTarball</function> now support + <varname>sha256</varname> and <varname>name</varname> + attributes.</para> + </listitem> + + <listitem> + <para><function + xlink:href="https://github.com/NixOS/nix/commit/b8867a0239b1930a16f9ef3f7f3e864b01416dff">builtins.split</function> + splits a string using a POSIX extended regular expression as the + separator.</para> + </listitem> + + <listitem> + <para><function + xlink:href="https://github.com/NixOS/nix/commit/26d92017d3b36cff940dcb7d1611c42232edb81a">builtins.partition</function> + partitions the elements of a list into two lists, depending on a + Boolean predicate.</para> + </listitem> + + <listitem> + <para><literal><nix/fetchurl.nix></literal> now uses the + content-addressable tarball cache at + <uri>http://tarballs.nixos.org/</uri>, just like + <function>fetchurl</function> in + Nixpkgs. (f2682e6e18a76ecbfb8a12c17e3a0ca15c084197)</para> + </listitem> + + <listitem> + <para>In restricted and pure evaluation mode, builtin functions + that download from the network (such as + <function>fetchGit</function>) are permitted to fetch underneath a + list of URI prefixes specified in the option + <option>allowed-uris</option>.</para> + </listitem> + +</itemizedlist> + +</para> + +<para>The Nix build environment has the following changes: + +<itemizedlist> + + <listitem> + <para>Values such as Booleans, integers, (nested) lists and + attribute sets can <link + xlink:href="https://github.com/NixOS/nix/commit/6de33a9c675b187437a2e1abbcb290981a89ecb1">now</link> + be passed to builders in a non-lossy way. If the special attribute + <varname>__structuredAttrs</varname> is set to + <literal>true</literal>, the other derivation attributes are + serialised in JSON format and made available to the builder via + the file <envar>.attrs.json</envar> in the builder’s temporary + directory. This obviates the need for + <varname>passAsFile</varname> since JSON files have no size + restrictions, unlike process environments.</para> + + <para><link + xlink:href="https://github.com/NixOS/nix/commit/2d5b1b24bf70a498e4c0b378704cfdb6471cc699">As + a convenience to Bash builders</link>, Nix writes a script named + <envar>.attrs.sh</envar> to the builder’s directory that + initialises shell variables corresponding to all attributes that + are representable in Bash. This includes non-nested (associative) + arrays. For example, the attribute <literal>hardening.format = + true</literal> ends up as the Bash associative array element + <literal>${hardening[format]}</literal>.</para> + </listitem> + + <listitem> + <para>Builders can <link + xlink:href="https://github.com/NixOS/nix/commit/88e6bb76de5564b3217be9688677d1c89101b2a3">now</link> + communicate what build phase they are in by writing messages to + the file descriptor specified in <envar>NIX_LOG_FD</envar>. The + current phase is shown by the <command>nix</command> progress + indicator. + </para> + </listitem> + + <listitem> + <para>In Linux sandbox builds, we <link + xlink:href="https://github.com/NixOS/nix/commit/a2d92bb20e82a0957067ede60e91fab256948b41">now</link> + provide a default <filename>/bin/sh</filename> (namely + <filename>ash</filename> from BusyBox).</para> + </listitem> + + <listitem> + <para>In structured attribute mode, + <varname>exportReferencesGraph</varname> <link + xlink:href="https://github.com/NixOS/nix/commit/c2b0d8749f7e77afc1c4b3e8dd36b7ee9720af4a">exports</link> + extended information about closures in JSON format. In particular, + it includes the sizes and hashes of paths. This is primarily + useful for NixOS image builders.</para> + </listitem> + + <listitem> + <para>Builds are <link + xlink:href="https://github.com/NixOS/nix/commit/21948deed99a3295e4d5666e027a6ca42dc00b40">now</link> + killed as soon as Nix receives EOF on the builder’s stdout or + stderr. This fixes a bug that allowed builds to hang Nix + indefinitely, regardless of + timeouts.</para> + </listitem> + + <listitem> + <para>The <option>sandbox-paths</option> configuration + option can now specify optional paths by appending a + <literal>?</literal>, e.g. <literal>/dev/nvidiactl?</literal> will + bind-mount <varname>/dev/nvidiactl</varname> only if it + exists.</para> + </listitem> + + <listitem> + <para>On Linux, builds are now executed in a user + namespace with UID 1000 and GID 100.</para> + </listitem> + +</itemizedlist> + +</para> + +<para>A number of significant internal changes were made: + +<itemizedlist> + + <listitem> + <para>Nix no longer depends on Perl and all Perl components have + been rewritten in C++ or removed. The Perl bindings that used to + be part of Nix have been moved to a separate package, + <literal>nix-perl</literal>.</para> + </listitem> + + <listitem> + <para>All <classname>Store</classname> classes are now + thread-safe. <classname>RemoteStore</classname> supports multiple + concurrent connections to the daemon. This is primarily useful in + multi-threaded programs such as + <command>hydra-queue-runner</command>.</para> + </listitem> + +</itemizedlist> + +</para> + +<para>This release has contributions from + +Adrien Devresse, +Alexander Ried, +Alex Cruice, +Alexey Shmalko, +AmineChikhaoui, +Andy Wingo, +Aneesh Agrawal, +Anthony Cowley, +Armijn Hemel, +aszlig, +Ben Gamari, +Benjamin Hipple, +Benjamin Staffin, +Benno Fünfstück, +Bjørn Forsman, +Brian McKenna, +Charles Strahan, +Chase Adams, +Chris Martin, +Christian Theune, +Chris Warburton, +Daiderd Jordan, +Dan Connolly, +Daniel Peebles, +Dan Peebles, +davidak, +David McFarland, +Dmitry Kalinkin, +Domen Kožar, +Eelco Dolstra, +Emery Hemingway, +Eric Litak, +Eric Wolf, +Fabian Schmitthenner, +Frederik Rietdijk, +Gabriel Gonzalez, +Giorgio Gallo, +Graham Christensen, +Guillaume Maudoux, +Harmen, +Iavael, +James Broadhead, +James Earl Douglas, +Janus Troelsen, +Jeremy Shaw, +Joachim Schiele, +Joe Hermaszewski, +Joel Moberg, +Johannes 'fish' Ziemke, +Jörg Thalheim, +Jude Taylor, +kballou, +Keshav Kini, +Kjetil Orbekk, +Langston Barrett, +Linus Heckemann, +Ludovic Courtès, +Manav Rathi, +Marc Scholten, +Markus Hauck, +Matt Audesse, +Matthew Bauer, +Matthias Beyer, +Matthieu Coudron, +N1X, +Nathan Zadoks, +Neil Mayhew, +Nicolas B. Pierron, +Niklas Hambüchen, +Nikolay Amiantov, +Ole Jørgen Brønner, +Orivej Desh, +Peter Simons, +Peter Stuart, +Pyry Jahkola, +regnat, +Renzo Carbonara, +Rhys, +Robert Vollmert, +Scott Olson, +Scott R. Parish, +Sergei Trofimovich, +Shea Levy, +Sheena Artrip, +Spencer Baugh, +Stefan Junker, +Susan Potter, +Thomas Tuegel, +Timothy Allen, +Tristan Hume, +Tuomas Tynkkynen, +tv, +Tyson Whitehead, +Vladimír Čunát, +Will Dietz, +wmertens, +Wout Mertens, +zimbatm and +Zoran Plesivčak. +</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-2.1.xml b/third_party/nix/doc/manual/release-notes/rl-2.1.xml new file mode 100644 index 0000000000..16c243fc19 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-2.1.xml @@ -0,0 +1,133 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-2.1"> + +<title>Release 2.1 (2018-09-02)</title> + +<para>This is primarily a bug fix release. It also reduces memory +consumption in certain situations. In addition, it has the following +new features:</para> + +<itemizedlist> + + <listitem> + <para>The Nix installer will no longer default to the Multi-User + installation for macOS. You can still <link + linkend="sect-multi-user-installation">instruct the installer to + run in multi-user mode</link>. + </para> + </listitem> + + <listitem> + <para>The Nix installer now supports performing a Multi-User + installation for Linux computers which are running systemd. You + can <link + linkend="sect-multi-user-installation">select a Multi-User installation</link> by passing the + <option>--daemon</option> flag to the installer: <command>sh <(curl + https://nixos.org/nix/install) --daemon</command>. + </para> + + <para>The multi-user installer cannot handle systems with SELinux. + If your system has SELinux enabled, you can <link + linkend="sect-single-user-installation">force the installer to run + in single-user mode</link>.</para> + </listitem> + + <listitem> + <para>New builtin functions: + <literal>builtins.bitAnd</literal>, + <literal>builtins.bitOr</literal>, + <literal>builtins.bitXor</literal>, + <literal>builtins.fromTOML</literal>, + <literal>builtins.concatMap</literal>, + <literal>builtins.mapAttrs</literal>. + </para> + </listitem> + + <listitem> + <para>The S3 binary cache store now supports uploading NARs larger + than 5 GiB.</para> + </listitem> + + <listitem> + <para>The S3 binary cache store now supports uploading to + S3-compatible services with the <literal>endpoint</literal> + option.</para> + </listitem> + + <listitem> + <para>The flag <option>--fallback</option> is no longer required + to recover from disappeared NARs in binary caches.</para> + </listitem> + + <listitem> + <para><command>nix-daemon</command> now respects + <option>--store</option>.</para> + </listitem> + + <listitem> + <para><command>nix run</command> now respects + <varname>nix-support/propagated-user-env-packages</varname>.</para> + </listitem> + +</itemizedlist> + +<para>This release has contributions from + +Adrien Devresse, +Aleksandr Pashkov, +Alexandre Esteves, +Amine Chikhaoui, +Andrew Dunham, +Asad Saeeduddin, +aszlig, +Ben Challenor, +Ben Gamari, +Benjamin Hipple, +Bogdan Seniuc, +Corey O'Connor, +Daiderd Jordan, +Daniel Peebles, +Daniel Poelzleithner, +Danylo Hlynskyi, +Dmitry Kalinkin, +Domen Kožar, +Doug Beardsley, +Eelco Dolstra, +Erik Arvstedt, +Félix Baylac-Jacqué, +Gleb Peregud, +Graham Christensen, +Guillaume Maudoux, +Ivan Kozik, +John Arnold, +Justin Humm, +Linus Heckemann, +Lorenzo Manacorda, +Matthew Justin Bauer, +Matthew O'Gorman, +Maximilian Bosch, +Michael Bishop, +Michael Fiano, +Michael Mercier, +Michael Raskin, +Michael Weiss, +Nicolas Dudebout, +Peter Simons, +Ryan Trinkle, +Samuel Dionne-Riel, +Sean Seefried, +Shea Levy, +Symphorien Gibol, +Tim Engler, +Tim Sears, +Tuomas Tynkkynen, +volth, +Will Dietz, +Yorick van Pelt and +zimbatm. +</para> + +</section> diff --git a/third_party/nix/doc/manual/release-notes/rl-2.2.xml b/third_party/nix/doc/manual/release-notes/rl-2.2.xml new file mode 100644 index 0000000000..d29eb87e82 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-2.2.xml @@ -0,0 +1,143 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-2.2"> + +<title>Release 2.2 (2019-01-11)</title> + +<para>This is primarily a bug fix release. It also has the following +changes:</para> + +<itemizedlist> + + <listitem> + <para>In derivations that use structured attributes (i.e. that + specify set the <varname>__structuredAttrs</varname> attribute to + <literal>true</literal> to cause all attributes to be passed to + the builder in JSON format), you can now specify closure checks + per output, e.g.: + +<programlisting> +outputChecks."out" = { + # The closure of 'out' must not be larger than 256 MiB. + maxClosureSize = 256 * 1024 * 1024; + + # It must not refer to C compiler or to the 'dev' output. + disallowedRequisites = [ stdenv.cc "dev" ]; +}; + +outputChecks."dev" = { + # The 'dev' output must not be larger than 128 KiB. + maxSize = 128 * 1024; +}; +</programlisting> + + </para> + </listitem> + + + <listitem> + <para>The derivation attribute + <varname>requiredSystemFeatures</varname> is now enforced for + local builds, and not just to route builds to remote builders. + The supported features of a machine can be specified through the + configuration setting <varname>system-features</varname>.</para> + + <para>By default, <varname>system-features</varname> includes + <literal>kvm</literal> if <filename>/dev/kvm</filename> + exists. For compatibility, it also includes the pseudo-features + <literal>nixos-test</literal>, <literal>benchmark</literal> and + <literal>big-parallel</literal> which are used by Nixpkgs to route + builds to particular Hydra build machines.</para> + + </listitem> + + <listitem> + <para>Sandbox builds are now enabled by default on Linux.</para> + </listitem> + + <listitem> + <para>The new command <command>nix doctor</command> shows + potential issues with your Nix installation.</para> + </listitem> + + <listitem> + <para>The <literal>fetchGit</literal> builtin function now uses a + caching scheme that puts different remote repositories in distinct + local repositories, rather than a single shared repository. This + may require more disk space but is faster.</para> + </listitem> + + <listitem> + <para>The <literal>dirOf</literal> builtin function now works on + relative paths.</para> + </listitem> + + <listitem> + <para>Nix now supports <link + xlink:href="https://www.w3.org/TR/SRI/">SRI hashes</link>, + allowing the hash algorithm and hash to be specified in a single + string. For example, you can write: + +<programlisting> +import <nix/fetchurl.nix> { + url = https://nixos.org/releases/nix/nix-2.1.3/nix-2.1.3.tar.xz; + hash = "sha256-XSLa0FjVyADWWhFfkZ2iKTjFDda6mMXjoYMXLRSYQKQ="; +}; +</programlisting> + + instead of + +<programlisting> +import <nix/fetchurl.nix> { + url = https://nixos.org/releases/nix/nix-2.1.3/nix-2.1.3.tar.xz; + sha256 = "5d22dad058d5c800d65a115f919da22938c50dd6ba98c5e3a183172d149840a4"; +}; +</programlisting> + + </para> + + <para>In fixed-output derivations, the + <varname>outputHashAlgo</varname> attribute is no longer mandatory + if <varname>outputHash</varname> specifies the hash.</para> + + <para><command>nix hash-file</command> and <command>nix + hash-path</command> now print hashes in SRI format by + default. They also use SHA-256 by default instead of SHA-512 + because that's what we use most of the time in Nixpkgs.</para> + </listitem> + + <listitem> + <para>Integers are now 64 bits on all platforms.</para> + </listitem> + + <listitem> + <para>The evaluator now prints profiling statistics (enabled via + the <envar>NIX_SHOW_STATS</envar> and + <envar>NIX_COUNT_CALLS</envar> environment variables) in JSON + format.</para> + </listitem> + + <listitem> + <para>The option <option>--xml</option> in <command>nix-store + --query</command> has been removed. Instead, there now is an + option <option>--graphml</option> to output the dependency graph + in GraphML format.</para> + </listitem> + + <listitem> + <para>All <filename>nix-*</filename> commands are now symlinks to + <filename>nix</filename>. This saves a bit of disk space.</para> + </listitem> + + <listitem> + <para><command>nix repl</command> now uses + <literal>libeditline</literal> or + <literal>libreadline</literal>.</para> + </listitem> + +</itemizedlist> + +</section> + diff --git a/third_party/nix/doc/manual/release-notes/rl-2.3.xml b/third_party/nix/doc/manual/release-notes/rl-2.3.xml new file mode 100644 index 0000000000..0ad7d641f8 --- /dev/null +++ b/third_party/nix/doc/manual/release-notes/rl-2.3.xml @@ -0,0 +1,91 @@ +<section xmlns="http://docbook.org/ns/docbook" + xmlns:xlink="http://www.w3.org/1999/xlink" + xmlns:xi="http://www.w3.org/2001/XInclude" + version="5.0" + xml:id="ssec-relnotes-2.3"> + +<title>Release 2.3 (2019-09-04)</title> + +<para>This is primarily a bug fix release. However, it makes some +incompatible changes:</para> + +<itemizedlist> + + <listitem> + <para>Nix now uses BSD file locks instead of POSIX file + locks. Because of this, you should not use Nix 2.3 and previous + releases at the same time on a Nix store.</para> + </listitem> + +</itemizedlist> + +<para>It also has the following changes:</para> + +<itemizedlist> + + <listitem> + <para><function>builtins.fetchGit</function>'s <varname>ref</varname> + argument now allows specifying an absolute remote ref. + Nix will automatically prefix <varname>ref</varname> with + <literal>refs/heads</literal> only if <varname>ref</varname> doesn't + already begin with <literal>refs/</literal>. + </para> + </listitem> + + <listitem> + <para>The installer now enables sandboxing by default on Linux when the + system has the necessary kernel support. + </para> + </listitem> + + <listitem> + <para>The <literal>max-jobs</literal> setting now defaults to 1.</para> + </listitem> + + <listitem> + <para>New builtin functions: + <literal>builtins.isPath</literal>, + <literal>builtins.hashFile</literal>. + </para> + </listitem> + + <listitem> + <para>The <command>nix</command> command has a new + <option>--print-build-logs</option> (<option>-L</option>) flag to + print build log output to stderr, rather than showing the last log + line in the progress bar. To distinguish between concurrent + builds, log lines are prefixed by the name of the package. + </para> + </listitem> + + <listitem> + <para>Builds are now executed in a pseudo-terminal, and the + <envar>TERM</envar> environment variable is set to + <literal>xterm-256color</literal>. This allows many programs + (e.g. <command>gcc</command>, <command>clang</command>, + <command>cmake</command>) to print colorized log output.</para> + </listitem> + + <listitem> + <para>Add <option>--no-net</option> convenience flag. This flag + disables substituters; sets the <literal>tarball-ttl</literal> + setting to infinity (ensuring that any previously downloaded files + are considered current); and disables retrying downloads and sets + the connection timeout to the minimum. This flag is enabled + automatically if there are no configured non-loopback network + interfaces.</para> + </listitem> + + <listitem> + <para>Add a <literal>post-build-hook</literal> setting to run a + program after a build has succeeded.</para> + </listitem> + + <listitem> + <para>Add a <literal>trace-function-calls</literal> setting to log + the duration of Nix function calls to stderr.</para> + </listitem> + +</itemizedlist> + +</section> diff --git a/third_party/nix/doc/manual/schemas.xml b/third_party/nix/doc/manual/schemas.xml new file mode 100644 index 0000000000..691a517b9c --- /dev/null +++ b/third_party/nix/doc/manual/schemas.xml @@ -0,0 +1,4 @@ +<?xml version="1.0"?> +<locatingRules xmlns="http://thaiopensource.com/ns/locating-rules/1.0"> + <uri pattern="*.xml" typeId="DocBook"/> +</locatingRules> diff --git a/third_party/nix/doc/meson.build b/third_party/nix/doc/meson.build new file mode 100644 index 0000000000..6d90b784a5 --- /dev/null +++ b/third_party/nix/doc/meson.build @@ -0,0 +1,13 @@ +# nix doc build file +#============================================================================ + +doc_dirs = [ + 'manual' +] + +if (not get_option('disable_doc_gen')) + xsltproc = find_program('xsltproc', required : true) + foreach dir : doc_dirs + subdir(dir) + endforeach +endif \ No newline at end of file diff --git a/third_party/nix/maintainers/upload-release.pl b/third_party/nix/maintainers/upload-release.pl new file mode 100755 index 0000000000..1cdf5ed16d --- /dev/null +++ b/third_party/nix/maintainers/upload-release.pl @@ -0,0 +1,156 @@ +#! /usr/bin/env nix-shell +#! nix-shell -i perl -p perl perlPackages.LWPUserAgent perlPackages.LWPProtocolHttps perlPackages.FileSlurp gnupg1 + +use strict; +use Data::Dumper; +use File::Basename; +use File::Path; +use File::Slurp; +use File::Copy; +use JSON::PP; +use LWP::UserAgent; + +my $evalId = $ARGV[0] or die "Usage: $0 EVAL-ID\n"; + +my $releasesDir = "/home/eelco/mnt/releases"; +my $nixpkgsDir = "/home/eelco/Dev/nixpkgs-pristine"; + +# FIXME: cut&paste from nixos-channel-scripts. +sub fetch { + my ($url, $type) = @_; + + my $ua = LWP::UserAgent->new; + $ua->default_header('Accept', $type) if defined $type; + + my $response = $ua->get($url); + die "could not download $url: ", $response->status_line, "\n" unless $response->is_success; + + return $response->decoded_content; +} + +my $evalUrl = "https://hydra.nixos.org/eval/$evalId"; +my $evalInfo = decode_json(fetch($evalUrl, 'application/json')); +#print Dumper($evalInfo); + +my $nixRev = $evalInfo->{jobsetevalinputs}->{nix}->{revision} or die; + +my $tarballInfo = decode_json(fetch("$evalUrl/job/tarball", 'application/json')); + +my $releaseName = $tarballInfo->{releasename}; +$releaseName =~ /nix-(.*)$/ or die; +my $version = $1; + +print STDERR "Nix revision is $nixRev, version is $version\n"; + +File::Path::make_path($releasesDir); +if (system("mountpoint -q $releasesDir") != 0) { + system("sshfs hydra-mirror:/releases $releasesDir") == 0 or die; +} + +my $releaseDir = "$releasesDir/nix/$releaseName"; +File::Path::make_path($releaseDir); + +sub downloadFile { + my ($jobName, $productNr, $dstName) = @_; + + my $buildInfo = decode_json(fetch("$evalUrl/job/$jobName", 'application/json')); + + my $srcFile = $buildInfo->{buildproducts}->{$productNr}->{path} or die "job '$jobName' lacks product $productNr\n"; + $dstName //= basename($srcFile); + my $dstFile = "$releaseDir/" . $dstName; + + if (! -e $dstFile) { + print STDERR "downloading $srcFile to $dstFile...\n"; + system("NIX_REMOTE=https://cache.nixos.org/ nix cat-store '$srcFile' > '$dstFile.tmp'") == 0 + or die "unable to fetch $srcFile\n"; + rename("$dstFile.tmp", $dstFile) or die; + } + + my $sha256_expected = $buildInfo->{buildproducts}->{$productNr}->{sha256hash} or die; + my $sha256_actual = `nix hash-file --base16 --type sha256 '$dstFile'`; + chomp $sha256_actual; + if ($sha256_expected ne $sha256_actual) { + print STDERR "file $dstFile is corrupt, got $sha256_actual, expected $sha256_expected\n"; + exit 1; + } + + write_file("$dstFile.sha256", $sha256_expected); + + if (! -e "$dstFile.asc") { + system("gpg2 --detach-sign --armor $dstFile") == 0 or die "unable to sign $dstFile\n"; + } + + return ($dstFile, $sha256_expected); +} + +downloadFile("tarball", "2"); # .tar.bz2 +my ($tarball, $tarballHash) = downloadFile("tarball", "3"); # .tar.xz +downloadFile("binaryTarball.i686-linux", "1"); +downloadFile("binaryTarball.x86_64-linux", "1"); +downloadFile("binaryTarball.aarch64-linux", "1"); +downloadFile("binaryTarball.x86_64-darwin", "1"); +downloadFile("installerScript", "1"); + +exit if $version =~ /pre/; + +# Update Nixpkgs in a very hacky way. +system("cd $nixpkgsDir && git pull") == 0 or die; +my $oldName = `nix-instantiate --eval $nixpkgsDir -A nix.name`; chomp $oldName; +my $oldHash = `nix-instantiate --eval $nixpkgsDir -A nix.src.outputHash`; chomp $oldHash; +print STDERR "old stable version in Nixpkgs = $oldName / $oldHash\n"; + +my $fn = "$nixpkgsDir/pkgs/tools/package-management/nix/default.nix"; +my $oldFile = read_file($fn); +$oldFile =~ s/$oldName/"$releaseName"/g; +$oldFile =~ s/$oldHash/"$tarballHash"/g; +write_file($fn, $oldFile); + +$oldName =~ s/nix-//g; +$oldName =~ s/"//g; + +sub getStorePath { + my ($jobName) = @_; + my $buildInfo = decode_json(fetch("$evalUrl/job/$jobName", 'application/json')); + die unless $buildInfo->{buildproducts}->{1}->{type} eq "nix-build"; + return $buildInfo->{buildproducts}->{1}->{path}; +} + +write_file("$nixpkgsDir/nixos/modules/installer/tools/nix-fallback-paths.nix", + "{\n" . + " x86_64-linux = \"" . getStorePath("build.x86_64-linux") . "\";\n" . + " i686-linux = \"" . getStorePath("build.i686-linux") . "\";\n" . + " aarch64-linux = \"" . getStorePath("build.aarch64-linux") . "\";\n" . + " x86_64-darwin = \"" . getStorePath("build.x86_64-darwin") . "\";\n" . + "}\n"); + +system("cd $nixpkgsDir && git commit -a -m 'nix: $oldName -> $version'") == 0 or die; + +# Extract the HTML manual. +File::Path::make_path("$releaseDir/manual"); + +system("tar xvf $tarball --strip-components=3 -C $releaseDir/manual --wildcards '*/doc/manual/*.html' '*/doc/manual/*.css' '*/doc/manual/*.gif' '*/doc/manual/*.png'") == 0 or die; + +if (! -e "$releaseDir/manual/index.html") { + symlink("manual.html", "$releaseDir/manual/index.html") or die; +} + +# Update the "latest" symlink. +symlink("$releaseName", "$releasesDir/nix/latest-tmp") or die; +rename("$releasesDir/nix/latest-tmp", "$releasesDir/nix/latest") or die; + +# Tag the release in Git. +chdir("/home/eelco/Dev/nix-pristine") or die; +system("git remote update origin") == 0 or die; +system("git tag --force --sign $version $nixRev -m 'Tagging release $version'") == 0 or die; + +# Update the website. +my $siteDir = "/home/eelco/Dev/nixos-homepage-pristine"; + +system("cd $siteDir && git pull") == 0 or die; + +write_file("$siteDir/nix-release.tt", + "[%-\n" . + "latestNixVersion = \"$version\"\n" . + "-%]\n"); + +system("cd $siteDir && git commit -a -m 'Nix $version released'") == 0 or die; diff --git a/third_party/nix/meson.build b/third_party/nix/meson.build new file mode 100644 index 0000000000..8e845c20e2 --- /dev/null +++ b/third_party/nix/meson.build @@ -0,0 +1,580 @@ +project( + 'nix', + 'cpp', + + default_options : [ + 'cpp_std=c++17', + 'warning_level=3', + 'optimization=3', + 'debug=true' + ], + version : run_command('cat', './.version').stdout().strip(), + license : 'MIT' +) + +# init compiler +cpp = meson.get_compiler('cpp') + +add_project_arguments(get_option('cxxflags'), language : 'cpp') +add_project_link_arguments(get_option('ldflags'), language: 'cpp') + +pkg = import('pkgconfig') +cmake = import('cmake') + +config_h = configuration_data() + +config_h.set( + 'HAVE_CXX17', 1, + description : 'Define if the compiler supports basic C++17 syntax') + +package_name = meson.project_name() +config_h.set_quoted( + 'PACKAGE_NAME', package_name, + description : 'Define to the full name of this package.' + ) + +package_tarname = meson.project_name() +config_h.set_quoted( + 'PACKAGE_TARNAME', package_tarname, + description : 'Define to the one symbol short name of this package.') + +package_version = meson.project_version() +config_h.set_quoted( + 'PACKAGE_VERSION', package_version, + description : 'Define to the version of this package.') + +package_string = '@0@ @1@'.format(package_name, package_version) +config_h.set_quoted( + 'PACKAGE_STRING', package_string, + description : 'Define to the full name and version of this package.') + +package_url = 'https://nixos.org/nix/' +config_h.set_quoted( + 'PACKAGE_URL', package_url, + description : 'Define to the home page for this package.') + +package_bug_url = 'https://github.com/nixos/nix/issues' +config_h.set_quoted( + 'PACKAGE_BUGREPORT', package_bug_url, + description : 'Define to the address where bug reports for this package should be sent.') + +# env + +# set install directories +#------------------------------------------------- +prefix = get_option('prefix') +libdir = join_paths(prefix, get_option('libdir')) +bindir = join_paths(prefix, get_option('bindir')) +datadir = join_paths(prefix, get_option('datadir')) +sysconfdir = join_paths(prefix, get_option('sysconfdir')) +libexecdir = join_paths(prefix, get_option('libexecdir')) +mandir = join_paths(prefix, get_option('mandir')) +includedir = join_paths(prefix, get_option('includedir')) + +# set nix directories + +# State should be stored in /nix/var, unless the user overrides it explicitly. +if get_option('normal_var') + localstatedir = '/nix/var' +else + localstatedir = join_paths(prefix, get_option('localstatedir')) +endif + +nixstoredir = get_option('nixstoredir') + +profiledir = join_paths(sysconfdir, 'profile.d') + +# Construct a Nix system name (like "i686-linux"). +#------------------------------------------------- +machine_name = host_machine.cpu() +sys_name = host_machine.system().to_lower() + +cpu_archs = ['x86_64', 'armv6', 'armv7', ''] + +foreach cpu : cpu_archs + if (host_machine.cpu().contains(cpu)) + if cpu.contains('armv') + machine_name = cpu + '1' + else + machine_name = cpu + endif + break + endif +endforeach + +system= '"' + machine_name + '-' + sys_name + '"' +message('system name: ' + system) +config_h.set( + 'SYSTEM', system, + description : 'platform identifier (`cpu-os`)') + +# checking headers +#============================================================================ + +if (cpp.has_header('sys/stat.h')) + config_h.set( + 'HAVE_SYS_STAT_H', 1, + description : 'Define to 1 if you have the <sys/stat.h> header file.') +endif + +if (cpp.has_header('sys/types.h')) + config_h.set( + 'HAVE_SYS_TYPES_H', 1, + description : 'Define to 1 if you have the <sys/types.h> header file.') +endif + +if (cpp.has_header('sys/dir.h')) + config_h.set( + 'HAVE_DIR_H', 1, + description : 'Define to 1 if you have the <sys/dir.h> header file, and it defines `DIR`') +endif + +if (cpp.has_header('sys/ndir.h')) + config_h.set( + 'HAVE_NDIR_H', 1, + description : 'Define to 1 if you have the <sys/ndir.h> header file, and it defines `DIR`') +endif + +has_dirent_h = cpp.has_header('dirent.h') +if (has_dirent_h) + config_h.set( + 'HAVE_DIRENT_H', 1, + description : 'Define to 1 if you have the <dirent.h> header file, and it defines `DIR`') +endif + +if (cpp.has_header('locale.h')) + config_h.set( + 'HAVE_LOCALE', 1, + description : 'Define to 1 if you have the <locale.h> header file.') +endif + +if (cpp.has_header('unistd.h')) + config_h.set( + 'HAVE_UNISTD_H', 1, + description: 'Define to 1 if you have the <unistd.h> header file.') +endif + +if (cpp.has_header('stdint.h')) + config_h.set( + 'HAVE_STDINT_H', 1, + description: 'Define to 1 if you have the <stdint.h> header file.') +endif + +if (cpp.has_header('stdlib.h')) + config_h.set( + 'HAVE_STDLIB_H', 1, + description: 'Define to 1 if you have the <stdlib.h> header file.') +endif + +if (cpp.has_header('strings.h')) + config_h.set( + 'HAVE_STRINGS_H', 1, + description: 'Define to 1 if you have the <strings.h> header file.') +endif + +if (cpp.has_header('string.h')) + config_h.set( + 'HAVE_STRING_H', 1, + description: 'Define to 1 if you have the <strings.h> header file.') +endif + +if (cpp.has_header('bzlib.h')) + config_h.set( + 'HAVE_BZLIB_H', 1, + description : 'Define to 1 if you have the <bzlib.h> header file.') +endif + +if (cpp.has_header('inttypes.h')) + config_h.set( + 'HAVE_INTTYPES_H', 1, + description : 'Define to 1 if you have the <inttypes.h> header file.') +endif + +if (cpp.has_header('memory.h')) + config_h.set( + 'HAVE_MEMORY_H', 1, + description : 'Define to 1 if you have the <memory.h> header file.') +endif + +if (cpp.has_header('editline.h')) + config_h.set( + 'HAVE_EDITLINE_H', 1, + description : 'Define to 1 if you have the <editline.h> header file.') +else + error('Nix requires editline.h; however the header was not found.') +endif + + + + +# checking functions +#============================================================================ + + +if (cpp.has_function('lutimes')) + config_h.set( + 'HAVE_LUTIMES', 1, + description : 'Define to 1 if you have the `lutimes` function.') +endif + +if (cpp.has_function('lchown')) + config_h.set( + 'HAVE_LCHOWN', 1, + description : 'Define to 1 if you have the `lchown` function.') +endif + +if (cpp.has_function('pipe2')) + config_h.set( + 'HAVE_PIPE2', 1, + description : 'Define to 1 if you have the `pipe2` function.') +endif + +if (cpp.has_function('posix_fallocate')) + config_h.set( + 'HAVE_POSIX_FALLOCATE', 1, + description : 'Define to 1 if you have the `posix_fallocate` function.') +endif + +if (cpp.has_function('setresuid')) + config_h.set( + 'HAVE_SETRESUID', 1, + description : 'Define to 1 if you have the `setresuid` function.') +endif + +if (cpp.has_function('setreuid')) + config_h.set( + 'HAVE_SETREUID', 1, + description : 'Define to 1 if you have the `setreuid` function.') +endif + +if (cpp.has_function('statvfs')) + config_h.set( + 'HAVE_STATVFS', 1, + description : 'Define to 1 if you have the `statvfs` function.') +endif + +if (cpp.has_function('strsignal')) + config_h.set( + 'HAVE_STRSIGNAL', 1, + description : 'Define to 1 if you have the `strsignal` function.') +endif + +if (cpp.has_function('sysconf')) + config_h.set( + 'HAVE_SYSCONF', 1, + description : 'Define to 1 if you have the `sysconf` function.') +endif + +pubsetbuff_c = ''' + #include <iostream> + using namespace std; + static char buf[1024]; + void func() { + cerr.rdbuf()->pubsetbuf(buf, sizeof(buf)); + }''' + +if meson.get_compiler('cpp').compiles( + pubsetbuff_c, + name : 'pubsetbuf' + ) + config_h.set( + 'HAVE_PUBSETBUF', 1, + description : 'Define to 1 if you have the `pubsetbuf` function.') +endif + + + +# checking data types +#============================================================================ + + +dirent_h_prefix = ''' + #include <sys/types.h> + #include <dirent.h> +''' + +if has_dirent_h and meson.get_compiler('cpp').has_member('struct dirent', 'd_type', prefix: dirent_h_prefix) + config_h.set('HAVE_STRUCT_DIRENT_D_TYPE', 1) +endif + +# required dependancies +#============================================================================ + + +# look for required programs +#-------------------------------------------------- +cat = find_program('cat', required : true) +ln = find_program('ln', required : true) +cp = find_program('cp', required : true) +rm = find_program('rm', required : true) +bash = find_program('bash', required : true) +echo = find_program('echo', required : true) +patch = find_program('patch', required : true) +xmllint = find_program('xmllint', required : true) +flex = find_program('flex', required : true) +bison = find_program('bison', required : true) +sed = find_program('sed', required : true) +tar = find_program('tar', required : true) +bzip2 = find_program('bzip2', required : true) +gzip = find_program('gzip', required : true) +xz = find_program('xz', required : true) +dot = find_program('dot', required : false) +lsof = find_program('lsof', required : false) +tr = find_program('tr', required : true) +coreutils = run_command('dirname', cat.path()).stdout().strip() + + +# Check whether the store optimiser can optimise symlinks. +#------------------------------------------------- +gen_header = ''' +ln -s bla tmp_link +if ln tmp_link tmp_link2 2> /dev/null; then + echo 1 +else + echo 0 +fi +''' + +run_command('sh', '-c', 'rm tmp_link*') +can_link_symlink = run_command('sh', '-c', gen_header).stdout().strip() +if can_link_symlink.to_int() == 1 + run_command('sh', '-c', 'rm tmp_link*') +endif + +config_h.set('CAN_LINK_SYMLINK', can_link_symlink, +description : 'Whether link() works on symlinks') + +# Import the Abseil cmake project from the (symlinked) depot sources. +absl = cmake.subproject('abseil_cpp') + +# Bundle all relevant Abseil libraries. Meson is not able to resolve +# the internal dependencies of Abseil, and reconstructing them is more +# work than I am willing to invest at the moment. +absl_deps = [ + absl.dependency('algorithm_container'), + absl.dependency('base'), + absl.dependency('bits'), + absl.dependency('btree'), + absl.dependency('city'), + absl.dependency('config'), + absl.dependency('container_common'), + absl.dependency('container_memory'), + absl.dependency('core_headers'), + absl.dependency('debugging_internal'), + absl.dependency('demangle_internal'), + absl.dependency('dynamic_annotations'), + absl.dependency('endian'), + absl.dependency('fixed_array'), + absl.dependency('graphcycles_internal'), + absl.dependency('hash'), + absl.dependency('hash_function_defaults'), + absl.dependency('hashtablez_sampler'), + absl.dependency('int128'), + absl.dependency('malloc_internal'), + absl.dependency('memory'), + absl.dependency('meta'), + absl.dependency('node_hash_policy'), + absl.dependency('node_hash_set'), + absl.dependency('optional'), + absl.dependency('raw_hash_set'), + absl.dependency('raw_logging_internal'), + absl.dependency('spinlock_wait'), + absl.dependency('stacktrace'), + absl.dependency('strings'), + absl.dependency('symbolize'), + absl.dependency('synchronization'), + absl.dependency('throw_delegate'), + absl.dependency('time'), + absl.dependency('time_zone'), + absl.dependency('type_traits'), + absl.dependency('utility'), + absl.dependency('variant'), +] + +# Look for boost, a required dependency. +#-------------------------------------------------- +boost_dep = declare_dependency( + dependencies : [ + cpp.find_library('boost_system'), + cpp.find_library('boost_context'), + cpp.find_library('boost_thread')], + link_args : get_option('boost_link_args')) + +if (boost_dep.found()) + config_h.set('HAVE_BOOST', 1, description : 'Define if the Boost library is available.') +endif + + +# Look for liblzma, a required dependency. +#-------------------------------------------------- +liblzma_dep = declare_dependency( + dependencies: dependency('liblzma'), + link_args : get_option('lzma_link_args')) + + +# Look for libbrotli{enc,dec}. +#-------------------------------------------------- +libbrotli_dep = declare_dependency( + dependencies: [ + dependency('libbrotlienc'), + dependency('libbrotlidec')], + link_args : get_option('brotli_link_args')) + + +# Look for OpenSSL, a required dependency. +#-------------------------------------------------- +openssl_dep = declare_dependency( + dependencies: cpp.find_library('ssl'), + link_args : get_option('openssl_link_args')) + + +# Look for SQLite, a required dependency. +#-------------------------------------------------- +sqlite3_dep = declare_dependency( + dependencies : dependency('sqlite3', version : '>= 3.6.19'), + link_args : get_option('sqlite3_link_args')) + + +# Look for libcurl, a required dependency. +#-------------------------------------------------- +libcurl_dep = declare_dependency( + dependencies : dependency('libcurl'), + link_args : get_option('curl_link_args')) + + +# Look for pthread, a required dependency. +#-------------------------------------------------- +pthread_dep = declare_dependency( + dependencies : dependency('threads'), + link_args : get_option('pthread_link_args')) + + +# Look for libdl, a required dependency. +#-------------------------------------------------- +libdl_dep = declare_dependency( + dependencies : cpp.find_library('dl'), + link_args : get_option('dl_link_args')) + + +# Look for libbz2, a required dependency. +#-------------------------------------------------- +libbz2_dep = declare_dependency( + dependencies : cpp.find_library('bz2'), + link_args : get_option('bz2_link_args')) + +# Look for glog, a required dependency. +#-------------------------------------- +glog_dep = declare_dependency( + dependencies : cpp.find_library('glog'), + link_args : get_option('glog_link_args')) + +# Look for editline, a required dependency. +#-------------------------------------------------- +# NOTE: The the libeditline.pc file was added only in libeditline >= 1.15.2, see +# https://github.com/troglobit/editline/commit/0a8f2ef4203c3a4a4726b9dd1336869cd0da8607, +# but e.g. Ubuntu 16.04 has an older version, so we fall back to searching for +# editline.h when the pkg-config approach fails. + +editline_dep = declare_dependency( + dependencies : cpp.find_library('editline'), + link_args : get_option('editline_link_args')) + +if not ( + cpp.has_function( + 'read_history', + prefix : '#include <stdio.h>\n#include "editline.h"', + args : '-lreadline')) + warning('Nix requires libeditline; However, required functions do not work. Maybe ' +\ + 'it is too old? >= 1.14 is required.') +endif + +# Look for libsodium, an optional dependency. +#-------------------------------------------------- +libsodium_lib = cpp.find_library('sodium', required: get_option('with_libsodium')) +if (libsodium_lib.found()) + libsodium_dep = declare_dependency( + dependencies : libsodium_lib, + link_args : get_option('sodium_link_args')) + config_h.set('HAVE_SODIUM', 1, description : 'Whether to use libsodium for cryptography.') +else + libsodium_dep = dependency('', required: false) +endif + + +# Look for Boehm garbage collector, a required dependency. +# TODO(tazjin): Remove option to disable GC +gc_dep = declare_dependency( + dependencies : dependency('bdw-gc'), + link_args : get_option('gc_link_args')) +config_h.set( + 'HAVE_BOEHMGC', 1, + description : 'Whether to use the Boehm garbage collector.') + +# Look for aws-cpp-sdk-s3. +#-------------------------------------------------- +if (get_option('with_s3')) + enable_s3 = meson.get_compiler('cpp').check_header('aws/s3/S3Client.h') + + aws_version = meson.get_compiler('cpp').get_define( + 'AWS_SDK_VERSION_STRING', + prefix : '#include <aws/core/VersionConfig.h>' + ).strip('"').split('.') + + conf_data.set('ENABLE_S3', 1, description : 'Whether to enable S3 support via aws-sdk-cpp.') + conf_data.set('AWS_VERSION_MAJOR', aws_version[0], description : 'Major version of aws-sdk-cpp.') + conf_data.set('AWS_VERSION_MINOR', aws_version[1], description : 'Minor version of aws-sdk-cpp.') +endif + + +# OS Specific checks +#============================================================================ +# Look for libsecppomp, required for Linux sandboxing. +if sys_name.contains('linux') + libseccomp_dep = dependency( + 'libseccomp', + version : '>= 2.3.1', + not_found_message : 'Nix requires libseccomp on a linux host system') + config_h.set( + 'HAVE_SECCOMP', 1, + description : 'Whether seccomp is available and should be used for sandboxing.') +else + libseccomp_dep = dependency('', required: false) +endif + +if (sys_name.contains('freebsd')) + add_project_arguments('-D_GNU_SOURCE', language : 'cpp') + config_h.set('_GNU_SOURCE', 1) +endif + +if (sys_name.contains('sunos')) + # Solaris requires -lsocket -lnsl for network functions +endif + + +# build +#============================================================================ + +conf = configure_file( + output : 'config.h', + configuration : config_h) + +install_headers( + conf, + install_dir : join_paths(includedir, 'nix')) + +add_project_arguments('-include', 'config.h', language : 'cpp') +src_inc = [include_directories('.', 'src')] + +project_dirs = [ + 'src', + 'scripts', + 'corepkgs', + 'misc', + 'doc', + 'tests' +] + + +foreach dir : project_dirs + subdir(dir) +endforeach diff --git a/third_party/nix/meson_options.txt b/third_party/nix/meson_options.txt new file mode 100644 index 0000000000..1b1efffe48 --- /dev/null +++ b/third_party/nix/meson_options.txt @@ -0,0 +1,202 @@ +# Nix project build options +#============================================================================ + +# dirs +#============================================================================ + +option( + 'nixstoredir', + type : 'string', + value : '/nix/store', + description : 'path of the Nix store (defaults to /nix/store)') + + +# compiler args +#============================================================================ + +option( + 'ldflags', + type : 'array', + value : [ + '-L/usr/local/lib', + '-L/usr/lib', + '-L/lib'], + description : 'Link flags') + + +option( + 'cxxflags', + type : 'array', + value : [ + '-Wdeprecated', + '-Wno-non-virtual-dtor', + '-Wno-unused-parameter'], + description : 'C build flags') + + + + +# link args +#============================================================================ + +option( + 'boost_link_args', + type : 'array', + value : [ + '-L/usr/lib64', + '-lboost_system', + '-lboost_context', + '-lboost_thread'], + description : 'link args for boost') + +option( + 'brotli_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lbrotlienc', + '-lbrotlidec'], + description : 'link args for libbrotli') + +option( + 'bz2_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lbz2'], + description : 'link args for libbz2') + +option( + 'curl_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lcurl'], + description : 'link args for libcurl') + +option( + 'dl_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-ldl'], + description : 'link args for libdl') + +option( + 'editline_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-leditline'], + description : 'link args for editline_link_args') + +option( + 'lzma_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-llzma'], + description : 'link args for liblzma') + +option( + 'openssl_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lcrypto'], + description : 'link args for openssl') + +option( + 'pthread_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-pthread'], + description : 'link args for pthread') + +option( + 'sodium_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lsodium'], + description : 'link args for libsodium') + +option( + 'sqlite3_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lsqlite3'], + description : 'link args for sqlite3') + +option( + 'gc_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lgc'], + description : 'link args for boehm garbage collector') + +option( + 'glog_link_args', + type : 'array', + value : [ + '-L/usr/local/lib', + '-lglog'], + description : 'link args for glog') + + +# optional dependancies +#============================================================================ + +option( + 'with_gc', + type : 'boolean', + value : 'false', + description : 'Build nix with Boehm garbage collector') + +option( + 'with_libsodium', + type : 'feature', + value : 'auto', + description : 'Build nix with libsodium') + +option( + 'with_s3', + type : 'boolean', + value : 'false', + description : 'Build nix with s3') + +option( + 'with_coreutils_bin', + type : 'string', + description : 'path of cat, mkdir, etc.') + + + +# misc +#============================================================================ +option( + 'disable_doc_gen', + type : 'boolean', + value : 'false', + description : 'disable documentation generation') + +option( + 'build_shared_libs', + type : 'boolean', + value : 'false', + description : 'Build nix with shared libs') + +option( + 'sandbox_shell', + type : 'string', + value : '/usr/bin/busybox', + description : 'path of a statically-linked shell to use as /bin/sh in sandboxes') + +option( + 'normal_var', + type : 'boolean', + value : 'true', + description : 'Whether to use `/nix/var` or the user-overridable `localstatedir`.') diff --git a/third_party/nix/misc/meson.build b/third_party/nix/misc/meson.build new file mode 100644 index 0000000000..1b381de5a1 --- /dev/null +++ b/third_party/nix/misc/meson.build @@ -0,0 +1,7 @@ +misc_dirs = [ + 'systemd', +] + +foreach dir : misc_dirs + subdir(dir) +endforeach diff --git a/third_party/nix/misc/systemd/meson.build b/third_party/nix/misc/systemd/meson.build new file mode 100644 index 0000000000..588f0b3d9d --- /dev/null +++ b/third_party/nix/misc/systemd/meson.build @@ -0,0 +1,26 @@ +# nix systemd build file +#============================================================================ + +if (sys_name.contains('linux')) + + systemd_data = [] + + systemd_nix_daemon = configuration_data() + systemd_nix_daemon.set('bindir', bindir) + systemd_nix_daemon.set('storedir', nixstoredir) + systemd_nix_daemon.set('localstatedir', localstatedir) + + systemd_data += configure_file( + input : 'nix-daemon.socket.in', + output : 'nix-daemon.socket', + configuration : systemd_nix_daemon) + + systemd_data += configure_file( + input : 'nix-daemon.service.in', + output : 'nix-daemon.service', + configuration : systemd_nix_daemon) + + install_data( + systemd_data, + install_dir : join_paths(prefix, 'lib/systemd/system')) +endif diff --git a/third_party/nix/misc/systemd/nix-daemon.service.in b/third_party/nix/misc/systemd/nix-daemon.service.in new file mode 100644 index 0000000000..25655204d4 --- /dev/null +++ b/third_party/nix/misc/systemd/nix-daemon.service.in @@ -0,0 +1,12 @@ +[Unit] +Description=Nix Daemon +RequiresMountsFor=@storedir@ +RequiresMountsFor=@localstatedir@ +ConditionPathIsReadWrite=@localstatedir@/nix/daemon-socket + +[Service] +ExecStart=@@bindir@/nix-daemon nix-daemon --daemon +KillMode=process + +[Install] +WantedBy=multi-user.target diff --git a/third_party/nix/misc/systemd/nix-daemon.socket.in b/third_party/nix/misc/systemd/nix-daemon.socket.in new file mode 100644 index 0000000000..9ed39ffe6e --- /dev/null +++ b/third_party/nix/misc/systemd/nix-daemon.socket.in @@ -0,0 +1,11 @@ +[Unit] +Description=Nix Daemon Socket +Before=multi-user.target +RequiresMountsFor=@storedir@ +ConditionPathIsReadWrite=@localstatedir@/nix/daemon-socket + +[Socket] +ListenStream=@localstatedir@/nix/daemon-socket/socket + +[Install] +WantedBy=sockets.target diff --git a/third_party/nix/scripts/install-darwin-multi-user.sh b/third_party/nix/scripts/install-darwin-multi-user.sh new file mode 100644 index 0000000000..49076bd5c0 --- /dev/null +++ b/third_party/nix/scripts/install-darwin-multi-user.sh @@ -0,0 +1,144 @@ +#!/usr/bin/env bash + +set -eu +set -o pipefail + +readonly PLIST_DEST=/Library/LaunchDaemons/org.nixos.nix-daemon.plist + +dsclattr() { + /usr/bin/dscl . -read "$1" \ + | awk "/$2/ { print \$2 }" +} + +poly_validate_assumptions() { + if [ "$(uname -s)" != "Darwin" ]; then + failure "This script is for use with macOS!" + fi +} + +poly_service_installed_check() { + [ -e "$PLIST_DEST" ] +} + +poly_service_uninstall_directions() { + cat <<EOF +$1. Delete $PLIST_DEST + + sudo launchctl unload $PLIST_DEST + sudo rm $PLIST_DEST + +EOF +} + +poly_service_setup_note() { + cat <<EOF + - load and start a LaunchDaemon (at $PLIST_DEST) for nix-daemon + +EOF +} + +poly_configure_nix_daemon_service() { + _sudo "to set up the nix-daemon as a LaunchDaemon" \ + cp -f "/nix/var/nix/profiles/default$PLIST_DEST" "$PLIST_DEST" + + _sudo "to load the LaunchDaemon plist for nix-daemon" \ + launchctl load /Library/LaunchDaemons/org.nixos.nix-daemon.plist + + _sudo "to start the nix-daemon" \ + launchctl start org.nixos.nix-daemon + +} + +poly_group_exists() { + /usr/bin/dscl . -read "/Groups/$1" > /dev/null 2>&1 +} + +poly_group_id_get() { + dsclattr "/Groups/$1" "PrimaryGroupID" +} + +poly_create_build_group() { + _sudo "Create the Nix build group, $NIX_BUILD_GROUP_NAME" \ + /usr/sbin/dseditgroup -o create \ + -r "Nix build group for nix-daemon" \ + -i "$NIX_BUILD_GROUP_ID" \ + "$NIX_BUILD_GROUP_NAME" >&2 +} + +poly_user_exists() { + /usr/bin/dscl . -read "/Users/$1" > /dev/null 2>&1 +} + +poly_user_id_get() { + dsclattr "/Users/$1" "UniqueID" +} + +poly_user_hidden_get() { + dsclattr "/Users/$1" "IsHidden" +} + +poly_user_hidden_set() { + _sudo "in order to make $1 a hidden user" \ + /usr/bin/dscl . -create "/Users/$1" "IsHidden" "1" +} + +poly_user_home_get() { + dsclattr "/Users/$1" "NFSHomeDirectory" +} + +poly_user_home_set() { + _sudo "in order to give $1 a safe home directory" \ + /usr/bin/dscl . -create "/Users/$1" "NFSHomeDirectory" "$2" +} + +poly_user_note_get() { + dsclattr "/Users/$1" "RealName" +} + +poly_user_note_set() { + _sudo "in order to give $username a useful note" \ + /usr/bin/dscl . -create "/Users/$1" "RealName" "$2" +} + +poly_user_shell_get() { + dsclattr "/Users/$1" "UserShell" +} + +poly_user_shell_set() { + _sudo "in order to give $1 a safe home directory" \ + /usr/bin/dscl . -create "/Users/$1" "UserShell" "$2" +} + +poly_user_in_group_check() { + username=$1 + group=$2 + dseditgroup -o checkmember -m "$username" "$group" > /dev/null 2>&1 +} + +poly_user_in_group_set() { + username=$1 + group=$2 + + _sudo "Add $username to the $group group"\ + /usr/sbin/dseditgroup -o edit -t user \ + -a "$username" "$group" +} + +poly_user_primary_group_get() { + dsclattr "/Users/$1" "PrimaryGroupID" +} + +poly_user_primary_group_set() { + _sudo "to let the nix daemon use this user for builds (this might seem redundant, but there are two concepts of group membership)" \ + /usr/bin/dscl . -create "/Users/$1" "PrimaryGroupID" "$2" +} + +poly_create_build_user() { + username=$1 + uid=$2 + builder_num=$3 + + _sudo "Creating the Nix build user (#$builder_num), $username" \ + /usr/bin/dscl . create "/Users/$username" \ + UniqueID "${uid}" +} diff --git a/third_party/nix/scripts/install-multi-user.sh b/third_party/nix/scripts/install-multi-user.sh new file mode 100644 index 0000000000..5233762fa6 --- /dev/null +++ b/third_party/nix/scripts/install-multi-user.sh @@ -0,0 +1,798 @@ +#!/usr/bin/env bash + +set -eu +set -o pipefail + +# Sourced from: +# - https://github.com/LnL7/nix-darwin/blob/8c29d0985d74b4a990238497c47a2542a5616b3c/bootstrap.sh +# - https://gist.github.com/expipiplus1/e571ce88c608a1e83547c918591b149f/ac504c6c1b96e65505fbda437a28ce563408ecb0 +# - https://github.com/NixOS/nixos-org-configurations/blob/a122f418797713d519aadf02e677fce0dc1cb446/delft/scripts/nix-mac-installer.sh +# - https://github.com/matthewbauer/macNixOS/blob/f6045394f9153edea417be90c216788e754feaba/install-macNixOS.sh +# - https://gist.github.com/LnL7/9717bd6cdcb30b086fd7f2093e5f8494/86b26f852ce563e973acd30f796a9a416248c34a +# +# however tracking which bits came from which would be impossible. + +readonly ESC='\033[0m' +readonly BOLD='\033[1m' +readonly BLUE='\033[34m' +readonly BLUE_UL='\033[4;34m' +readonly GREEN='\033[32m' +readonly GREEN_UL='\033[4;32m' +readonly RED='\033[31m' + +readonly NIX_USER_COUNT="32" +readonly NIX_BUILD_GROUP_ID="30000" +readonly NIX_BUILD_GROUP_NAME="nixbld" +readonly NIX_FIRST_BUILD_UID="30001" +# Please don't change this. We don't support it, because the +# default shell profile that comes with Nix doesn't support it. +readonly NIX_ROOT="/nix" + +readonly PROFILE_TARGETS=("/etc/bashrc" "/etc/profile.d/nix.sh" "/etc/zshrc") +readonly PROFILE_BACKUP_SUFFIX=".backup-before-nix" +readonly PROFILE_NIX_FILE="$NIX_ROOT/var/nix/profiles/default/etc/profile.d/nix-daemon.sh" + +readonly NIX_INSTALLED_NIX="@nix@" +readonly NIX_INSTALLED_CACERT="@cacert@" +readonly EXTRACTED_NIX_PATH="$(dirname "$0")" + +readonly ROOT_HOME=$(echo ~root) + +if [ -t 0 ]; then + readonly IS_HEADLESS='no' +else + readonly IS_HEADLESS='yes' +fi + +headless() { + if [ "$IS_HEADLESS" = "yes" ]; then + return 0 + else + return 1 + fi +} + +contactme() { + echo "We'd love to help if you need it." + echo "" + echo "If you can, open an issue at https://github.com/nixos/nix/issues" + echo "" + echo "Or feel free to contact the team," + echo " - on IRC #nixos on irc.freenode.net" + echo " - on twitter @nixos_org" +} + +uninstall_directions() { + subheader "Uninstalling nix:" + local step=0 + + if poly_service_installed_check; then + step=$((step + 1)) + poly_service_uninstall_directions "$step" + fi + + for profile_target in "${PROFILE_TARGETS[@]}"; do + if [ -e "$profile_target" ] && [ -e "$profile_target$PROFILE_BACKUP_SUFFIX" ]; then + step=$((step + 1)) + cat <<EOF +$step. Restore $profile_target$PROFILE_BACKUP_SUFFIX back to $profile_target + + sudo mv $profile_target$PROFILE_BACKUP_SUFFIX $profile_target + +(after this one, you may need to re-open any terminals that were +opened while it existed.) + +EOF + fi + done + + step=$((step + 1)) + cat <<EOF +$step. Delete the files Nix added to your system: + + sudo rm -rf /etc/nix $NIX_ROOT $ROOT_HOME/.nix-profile $ROOT_HOME/.nix-defexpr $ROOT_HOME/.nix-channels $HOME/.nix-profile $HOME/.nix-defexpr $HOME/.nix-channels + +and that is it. + +EOF + +} + +nix_user_for_core() { + printf "nixbld%d" "$1" +} + +nix_uid_for_core() { + echo $((NIX_FIRST_BUILD_UID + $1 - 1)) +} + +_textout() { + echo -en "$1" + shift + if [ "$*" = "" ]; then + cat + else + echo "$@" + fi + echo -en "$ESC" +} + +header() { + follow="---------------------------------------------------------" + header=$(echo "---- $* $follow$follow$follow" | head -c 80) + echo "" + _textout "$BLUE" "$header" +} + +warningheader() { + follow="---------------------------------------------------------" + header=$(echo "---- $* $follow$follow$follow" | head -c 80) + echo "" + _textout "$RED" "$header" +} + +subheader() { + echo "" + _textout "$BLUE_UL" "$*" +} + +row() { + printf "$BOLD%s$ESC:\\t%s\\n" "$1" "$2" +} + +task() { + echo "" + ok "~~> $1" +} + +bold() { + echo "$BOLD$*$ESC" +} + +ok() { + _textout "$GREEN" "$@" +} + +warning() { + warningheader "warning!" + cat + echo "" +} + +failure() { + header "oh no!" + _textout "$RED" "$@" + echo "" + _textout "$RED" "$(contactme)" + trap finish_cleanup EXIT + exit 1 +} + +ui_confirm() { + _textout "$GREEN$GREEN_UL" "$1" + + if headless; then + echo "No TTY, assuming you would say yes :)" + return 0 + fi + + local prompt="[y/n] " + echo -n "$prompt" + while read -r y; do + if [ "$y" = "y" ]; then + echo "" + return 0 + elif [ "$y" = "n" ]; then + echo "" + return 1 + else + _textout "$RED" "Sorry, I didn't understand. I can only understand answers of y or n" + echo -n "$prompt" + fi + done + echo "" + return 1 +} + +__sudo() { + local expl="$1" + local cmd="$2" + shift + header "sudo execution" + + echo "I am executing:" + echo "" + printf " $ sudo %s\\n" "$cmd" + echo "" + echo "$expl" + echo "" + + return 0 +} + +_sudo() { + local expl="$1" + shift + if ! headless; then + __sudo "$expl" "$*" + fi + sudo "$@" +} + + +readonly SCRATCH=$(mktemp -d -t tmp.XXXXXXXXXX) +function finish_cleanup { + rm -rf "$SCRATCH" +} + +function finish_fail { + finish_cleanup + + failure <<EOF +Jeeze, something went wrong. If you can take all the output and open +an issue, we'd love to fix the problem so nobody else has this issue. + +:( +EOF +} +trap finish_fail EXIT + +channel_update_failed=0 +function finish_success { + finish_cleanup + + ok "Alright! We're done!" + if [ "x$channel_update_failed" = x1 ]; then + echo "" + echo "But fetching the nixpkgs channel failed. (Are you offline?)" + echo "To try again later, run \"sudo -i nix-channel --update nixpkgs\"." + fi + cat <<EOF + +Before Nix will work in your existing shells, you'll need to close +them and open them again. Other than that, you should be ready to go. + +Try it! Open a new terminal, and type: + + $ nix-shell -p nix-info --run "nix-info -m" + +Thank you for using this installer. If you have any feedback, don't +hesitate: + +$(contactme) +EOF +} + + +validate_starting_assumptions() { + poly_validate_assumptions + + if [ $EUID -eq 0 ]; then + failure <<EOF +Please do not run this script with root privileges. We will call sudo +when we need to. +EOF + fi + + if type nix-env 2> /dev/null >&2; then + failure <<EOF +Nix already appears to be installed, and this tool assumes it is +_not_ yet installed. + +$(uninstall_directions) +EOF + fi + + if [ "${NIX_REMOTE:-}" != "" ]; then + failure <<EOF +For some reason, \$NIX_REMOTE is set. It really should not be set +before this installer runs, and it hints that Nix is currently +installed. Please delete the old Nix installation and start again. + +Note: You might need to close your shell window and open a new shell +to clear the variable. +EOF + fi + + if echo "${SSL_CERT_FILE:-}" | grep -qE "(nix/var/nix|nix-profile)"; then + failure <<EOF +It looks like \$SSL_CERT_FILE is set to a path that used to be part of +the old Nix installation. Please unset that variable and try again: + + $ unset SSL_CERT_FILE + +EOF + fi + + for file in ~/.bash_profile ~/.bash_login ~/.profile ~/.zshenv ~/.zprofile ~/.zshrc ~/.zlogin; do + if [ -f "$file" ]; then + if grep -l "^[^#].*.nix-profile" "$file"; then + failure <<EOF +I found a reference to a ".nix-profile" in $file. +This has a high chance of breaking a new nix installation. It was most +likely put there by a previous Nix installer. + +Please remove this reference and try running this again. You should +also look for similar references in: + + - ~/.bash_profile + - ~/.bash_login + - ~/.profile + +or other shell init files that you may have. + +$(uninstall_directions) +EOF + fi + fi + done + + if [ -d /nix/store ] || [ -d /nix/var ]; then + failure <<EOF +There are some relics of a previous installation of Nix at /nix, and +this scripts assumes Nix is _not_ yet installed. Please delete the old +Nix installation and start again. + +$(uninstall_directions) +EOF + fi + + if [ -d /etc/nix ]; then + failure <<EOF +There are some relics of a previous installation of Nix at /etc/nix, and +this scripts assumes Nix is _not_ yet installed. Please delete the old +Nix installation and start again. + +$(uninstall_directions) +EOF + fi + + for profile_target in "${PROFILE_TARGETS[@]}"; do + if [ -e "$profile_target$PROFILE_BACKUP_SUFFIX" ]; then + failure <<EOF +When this script runs, it backs up the current $profile_target to +$profile_target$PROFILE_BACKUP_SUFFIX. This backup file already exists, though. + +Please follow these instructions to clean up the old backup file: + +1. Copy $profile_target and $profile_target$PROFILE_BACKUP_SUFFIX to another place, just +in case. + +2. Take care to make sure that $profile_target$PROFILE_BACKUP_SUFFIX doesn't look like +it has anything nix-related in it. If it does, something is probably +quite wrong. Please open an issue or get in touch immediately. + +3. Take care to make sure that $profile_target doesn't look like it has +anything nix-related in it. If it does, and $profile_target _did not_, +run: + + $ /usr/bin/sudo /bin/mv $profile_target$PROFILE_BACKUP_SUFFIX $profile_target + +and try again. +EOF + fi + + if [ -e "$profile_target" ] && grep -qi "nix" "$profile_target"; then + failure <<EOF +It looks like $profile_target already has some Nix configuration in +there. There should be no reason to run this again. If you're having +trouble, please open an issue. +EOF + fi + done + + danger_paths=("$ROOT_HOME/.nix-defexpr" "$ROOT_HOME/.nix-channels" "$ROOT_HOME/.nix-profile") + for danger_path in "${danger_paths[@]}"; do + if _sudo "making sure that $danger_path doesn't exist" \ + test -e "$danger_path"; then + failure <<EOF +I found a file at $danger_path, which is a relic of a previous +installation. You must first delete this file before continuing. + +$(uninstall_directions) +EOF + fi + done +} + +setup_report() { + header "Nix config report" + row " Temp Dir" "$SCRATCH" + row " Nix Root" "$NIX_ROOT" + row " Build Users" "$NIX_USER_COUNT" + row " Build Group ID" "$NIX_BUILD_GROUP_ID" + row "Build Group Name" "$NIX_BUILD_GROUP_NAME" + if [ "${ALLOW_PREEXISTING_INSTALLATION:-}" != "" ]; then + row "Preexisting Install" "Allowed" + fi + + subheader "build users:" + + row " Username" "UID" + for i in $(seq 1 "$NIX_USER_COUNT"); do + row " $(nix_user_for_core "$i")" "$(nix_uid_for_core "$i")" + done + echo "" +} + +create_build_group() { + local primary_group_id + + task "Setting up the build group $NIX_BUILD_GROUP_NAME" + if ! poly_group_exists "$NIX_BUILD_GROUP_NAME"; then + poly_create_build_group + row " Created" "Yes" + else + primary_group_id=$(poly_group_id_get "$NIX_BUILD_GROUP_NAME") + if [ "$primary_group_id" -ne "$NIX_BUILD_GROUP_ID" ]; then + failure <<EOF +It seems the build group $NIX_BUILD_GROUP_NAME already exists, but +with the UID $primary_group_id. This script can't really handle +that right now, so I'm going to give up. + +You can fix this by editing this script and changing the +NIX_BUILD_GROUP_ID variable near the top to from $NIX_BUILD_GROUP_ID +to $primary_group_id and re-run. +EOF + else + row " Exists" "Yes" + fi + fi +} + +create_build_user_for_core() { + local coreid + local username + local uid + + coreid="$1" + username=$(nix_user_for_core "$coreid") + uid=$(nix_uid_for_core "$coreid") + + task "Setting up the build user $username" + + if ! poly_user_exists "$username"; then + poly_create_build_user "$username" "$uid" "$coreid" + row " Created" "Yes" + else + actual_uid=$(poly_user_id_get "$username") + if [ "$actual_uid" != "$uid" ]; then + failure <<EOF +It seems the build user $username already exists, but with the UID +with the UID '$actual_uid'. This script can't really handle that right +now, so I'm going to give up. + +If you already created the users and you know they start from +$actual_uid and go up from there, you can edit this script and change +NIX_FIRST_BUILD_UID near the top of the file to $actual_uid and try +again. +EOF + else + row " Exists" "Yes" + fi + fi + + if [ "$(poly_user_hidden_get "$username")" = "1" ]; then + row " Hidden" "Yes" + else + poly_user_hidden_set "$username" + row " Hidden" "Yes" + fi + + if [ "$(poly_user_home_get "$username")" = "/var/empty" ]; then + row " Home Directory" "/var/empty" + else + poly_user_home_set "$username" "/var/empty" + row " Home Directory" "/var/empty" + fi + + # We use grep instead of an equality check because it is difficult + # to extract _just_ the user's note, instead it is prefixed with + # some plist junk. This was causing the user note to always be set, + # even if there was no reason for it. + if ! poly_user_note_get "$username" | grep -q "Nix build user $coreid"; then + row " Note" "Nix build user $coreid" + else + poly_user_note_set "$username" "Nix build user $coreid" + row " Note" "Nix build user $coreid" + fi + + if [ "$(poly_user_shell_get "$username")" = "/sbin/nologin" ]; then + row " Logins Disabled" "Yes" + else + poly_user_shell_set "$username" "/sbin/nologin" + row " Logins Disabled" "Yes" + fi + + if poly_user_in_group_check "$username" "$NIX_BUILD_GROUP_NAME"; then + row " Member of $NIX_BUILD_GROUP_NAME" "Yes" + else + poly_user_in_group_set "$username" "$NIX_BUILD_GROUP_NAME" + row " Member of $NIX_BUILD_GROUP_NAME" "Yes" + fi + + if [ "$(poly_user_primary_group_get "$username")" = "$NIX_BUILD_GROUP_ID" ]; then + row " PrimaryGroupID" "$NIX_BUILD_GROUP_ID" + else + poly_user_primary_group_set "$username" "$NIX_BUILD_GROUP_ID" + row " PrimaryGroupID" "$NIX_BUILD_GROUP_ID" + fi +} + +create_build_users() { + for i in $(seq 1 "$NIX_USER_COUNT"); do + create_build_user_for_core "$i" + done +} + +create_directories() { + # FIXME: remove all of this because it duplicates LocalStore::LocalStore(). + + _sudo "to make the basic directory structure of Nix (part 1)" \ + mkdir -pv -m 0755 /nix /nix/var /nix/var/log /nix/var/log/nix /nix/var/log/nix/drvs /nix/var/nix{,/db,/gcroots,/profiles,/temproots,/userpool} /nix/var/nix/{gcroots,profiles}/per-user + + _sudo "to make the basic directory structure of Nix (part 2)" \ + mkdir -pv -m 1775 /nix/store + + _sudo "to make the basic directory structure of Nix (part 3)" \ + chgrp "$NIX_BUILD_GROUP_NAME" /nix/store + + _sudo "to place the default nix daemon configuration (part 1)" \ + mkdir -pv -m 0555 /etc/nix +} + +place_channel_configuration() { + echo "https://nixos.org/channels/nixpkgs-unstable nixpkgs" > "$SCRATCH/.nix-channels" + _sudo "to set up the default system channel (part 1)" \ + install -m 0664 "$SCRATCH/.nix-channels" "$ROOT_HOME/.nix-channels" +} + +welcome_to_nix() { + ok "Welcome to the Multi-User Nix Installation" + + cat <<EOF + +This installation tool will set up your computer with the Nix package +manager. This will happen in a few stages: + +1. Make sure your computer doesn't already have Nix. If it does, I + will show you instructions on how to clean up your old one. + +2. Show you what we are going to install and where. Then we will ask + if you are ready to continue. + +3. Create the system users and groups that the Nix daemon uses to run + builds. + +4. Perform the basic installation of the Nix files daemon. + +5. Configure your shell to import special Nix Profile files, so you + can use Nix. + +6. Start the Nix daemon. + +EOF + + if ui_confirm "Would you like to see a more detailed list of what we will do?"; then + cat <<EOF + +We will: + + - make sure your computer doesn't already have Nix files + (if it does, I will tell you how to clean them up.) + - create local users (see the list above for the users we'll make) + - create a local group ($NIX_BUILD_GROUP_NAME) + - install Nix in to $NIX_ROOT + - create a configuration file in /etc/nix + - set up the "default profile" by creating some Nix-related files in + $ROOT_HOME +EOF + for profile_target in "${PROFILE_TARGETS[@]}"; do + if [ -e "$profile_target" ]; then + cat <<EOF + - back up $profile_target to $profile_target$PROFILE_BACKUP_SUFFIX + - update $profile_target to include some Nix configuration +EOF + fi + done + poly_service_setup_note + if ! ui_confirm "Ready to continue?"; then + failure <<EOF +Okay, maybe you would like to talk to the team. +EOF + fi + fi +} + +chat_about_sudo() { + header "let's talk about sudo" + + if headless; then + cat <<EOF +This script is going to call sudo a lot. Normally, it would show you +exactly what commands it is running and why. However, the script is +run in a headless fashion, like this: + + $ curl https://nixos.org/nix/install | sh + +or maybe in a CI pipeline. Because of that, we're going to skip the +verbose output in the interest of brevity. + +If you would like to +see the output, try like this: + + $ curl -o install-nix https://nixos.org/nix/install + $ sh ./install-nix + +EOF + return 0 + fi + + cat <<EOF +This script is going to call sudo a lot. Every time we do, it'll +output exactly what it'll do, and why. + +Just like this: +EOF + + __sudo "to demonstrate how our sudo prompts look" \ + echo "this is a sudo prompt" + + cat <<EOF + +This might look scary, but everything can be undone by running just a +few commands. We used to ask you to confirm each time sudo ran, but it +was too many times. Instead, I'll just ask you this one time: + +EOF + if ui_confirm "Can we use sudo?"; then + ok "Yay! Thanks! Let's get going!" + else + failure <<EOF +That is okay, but we can't install. +EOF + fi +} + +install_from_extracted_nix() { + ( + cd "$EXTRACTED_NIX_PATH" + + _sudo "to copy the basic Nix files to the new store at $NIX_ROOT/store" \ + rsync -rlpt ./store/* "$NIX_ROOT/store/" + + if [ -d "$NIX_INSTALLED_NIX" ]; then + echo " Alright! We have our first nix at $NIX_INSTALLED_NIX" + else + failure <<EOF +Something went wrong, and I didn't find Nix installed at +$NIX_INSTALLED_NIX. +EOF + fi + + cat ./.reginfo \ + | _sudo "to load data for the first time in to the Nix Database" \ + "$NIX_INSTALLED_NIX/bin/nix-store" --load-db + + echo " Just finished getting the nix database ready." + ) +} + +shell_source_lines() { + cat <<EOF + +# Nix +if [ -e '$PROFILE_NIX_FILE' ]; then + . '$PROFILE_NIX_FILE' +fi +# End Nix + +EOF +} + +configure_shell_profile() { + # If there is an /etc/profile.d directory, we want to ensure there + # is a nix.sh within it, so we can use the following loop to add + # the source lines to it. Note that I'm _not_ adding the source + # lines here, because we want to be using the regular machinery. + # + # If we go around that machinery, it becomes more complicated and + # adds complications to the uninstall instruction generator and + # old instruction sniffer as well. + if [ -d /etc/profile.d ]; then + _sudo "create a stub /etc/profile.d/nix.sh which will be updated" \ + touch /etc/profile.d/nix.sh + fi + + for profile_target in "${PROFILE_TARGETS[@]}"; do + if [ -e "$profile_target" ]; then + _sudo "to back up your current $profile_target to $profile_target$PROFILE_BACKUP_SUFFIX" \ + cp "$profile_target" "$profile_target$PROFILE_BACKUP_SUFFIX" + + shell_source_lines \ + | _sudo "extend your $profile_target with nix-daemon settings" \ + tee -a "$profile_target" + fi + done +} + +setup_default_profile() { + _sudo "to installing a bootstrapping Nix in to the default Profile" \ + HOME="$ROOT_HOME" "$NIX_INSTALLED_NIX/bin/nix-env" -i "$NIX_INSTALLED_NIX" + + if [ -z "${NIX_SSL_CERT_FILE:-}" ] || ! [ -f "${NIX_SSL_CERT_FILE:-}" ]; then + _sudo "to installing a bootstrapping SSL certificate just for Nix in to the default Profile" \ + HOME="$ROOT_HOME" "$NIX_INSTALLED_NIX/bin/nix-env" -i "$NIX_INSTALLED_CACERT" + export NIX_SSL_CERT_FILE=/nix/var/nix/profiles/default/etc/ssl/certs/ca-bundle.crt + fi + + # Have to explicitly pass NIX_SSL_CERT_FILE as part of the sudo call, + # otherwise it will be lost in environments where sudo doesn't pass + # all the environment variables by default. + _sudo "to update the default channel in the default profile" \ + HOME="$ROOT_HOME" NIX_SSL_CERT_FILE="$NIX_SSL_CERT_FILE" "$NIX_INSTALLED_NIX/bin/nix-channel" --update nixpkgs \ + || channel_update_failed=1 + +} + + +place_nix_configuration() { + cat <<EOF > "$SCRATCH/nix.conf" +build-users-group = $NIX_BUILD_GROUP_NAME +EOF + _sudo "to place the default nix daemon configuration (part 2)" \ + install -m 0664 "$SCRATCH/nix.conf" /etc/nix/nix.conf +} + +main() { + if [ "$(uname -s)" = "Darwin" ]; then + # shellcheck source=./install-darwin-multi-user.sh + . "$EXTRACTED_NIX_PATH/install-darwin-multi-user.sh" + elif [ "$(uname -s)" = "Linux" ]; then + if [ -e /run/systemd/system ]; then + # shellcheck source=./install-systemd-multi-user.sh + . "$EXTRACTED_NIX_PATH/install-systemd-multi-user.sh" + else + failure "Sorry, the multi-user installation requires systemd on Linux (detected using /run/systemd/system)" + fi + else + failure "Sorry, I don't know what to do on $(uname)" + fi + + welcome_to_nix + chat_about_sudo + + if [ "${ALLOW_PREEXISTING_INSTALLATION:-}" = "" ]; then + validate_starting_assumptions + fi + + setup_report + + if ! ui_confirm "Ready to continue?"; then + ok "Alright, no changes have been made :)" + contactme + trap finish_cleanup EXIT + exit 1 + fi + + create_build_group + create_build_users + create_directories + place_channel_configuration + install_from_extracted_nix + + configure_shell_profile + + set +eu + . /etc/profile + set -eu + + setup_default_profile + place_nix_configuration + poly_configure_nix_daemon_service + + trap finish_success EXIT +} + + +main diff --git a/third_party/nix/scripts/install-nix-from-closure.sh b/third_party/nix/scripts/install-nix-from-closure.sh new file mode 100644 index 0000000000..3f15818547 --- /dev/null +++ b/third_party/nix/scripts/install-nix-from-closure.sh @@ -0,0 +1,180 @@ +#!/bin/sh + +set -e + +dest="/nix" +self="$(dirname "$0")" +nix="@nix@" +cacert="@cacert@" + + +if ! [ -e "$self/.reginfo" ]; then + echo "$0: incomplete installer (.reginfo is missing)" >&2 +fi + +if [ -z "$USER" ] && ! USER=$(id -u -n); then + echo "$0: \$USER is not set" >&2 + exit 1 +fi + +if [ -z "$HOME" ]; then + echo "$0: \$HOME is not set" >&2 + exit 1 +fi + +# macOS support for 10.12.6 or higher +if [ "$(uname -s)" = "Darwin" ]; then + macos_major=$(sw_vers -productVersion | cut -d '.' -f 2) + macos_minor=$(sw_vers -productVersion | cut -d '.' -f 3) + if [ "$macos_major" -lt 12 ] || { [ "$macos_major" -eq 12 ] && [ "$macos_minor" -lt 6 ]; }; then + echo "$0: macOS $(sw_vers -productVersion) is not supported, upgrade to 10.12.6 or higher" + exit 1 + fi +fi + +# Determine if we could use the multi-user installer or not +if [ "$(uname -s)" = "Darwin" ]; then + echo "Note: a multi-user installation is possible. See https://nixos.org/nix/manual/#sect-multi-user-installation" >&2 +elif [ "$(uname -s)" = "Linux" ] && [ -e /run/systemd/system ]; then + echo "Note: a multi-user installation is possible. See https://nixos.org/nix/manual/#sect-multi-user-installation" >&2 +fi + +INSTALL_MODE=no-daemon +# Trivially handle the --daemon / --no-daemon options +if [ "x${1:-}" = "x--no-daemon" ]; then + INSTALL_MODE=no-daemon +elif [ "x${1:-}" = "x--daemon" ]; then + INSTALL_MODE=daemon +elif [ "x${1:-}" != "x" ]; then + ( + echo "Nix Installer [--daemon|--no-daemon]" + + echo "Choose installation method." + echo "" + echo " --daemon: Installs and configures a background daemon that manages the store," + echo " providing multi-user support and better isolation for local builds." + echo " Both for security and reproducibility, this method is recommended if" + echo " supported on your platform." + echo " See https://nixos.org/nix/manual/#sect-multi-user-installation" + echo "" + echo " --no-daemon: Simple, single-user installation that does not require root and is" + echo " trivial to uninstall." + echo " (default)" + echo "" + ) >&2 + exit +fi + +if [ "$INSTALL_MODE" = "daemon" ]; then + printf '\e[1;31mSwitching to the Daemon-based Installer\e[0m\n' + exec "$self/install-multi-user" + exit 0 +fi + +if [ "$(id -u)" -eq 0 ]; then + printf '\e[1;31mwarning: installing Nix as root is not supported by this script!\e[0m\n' +fi + +echo "performing a single-user installation of Nix..." >&2 + +if ! [ -e $dest ]; then + cmd="mkdir -m 0755 $dest && chown $USER $dest" + echo "directory $dest does not exist; creating it by running '$cmd' using sudo" >&2 + if ! sudo sh -c "$cmd"; then + echo "$0: please manually run '$cmd' as root to create $dest" >&2 + exit 1 + fi +fi + +if ! [ -w $dest ]; then + echo "$0: directory $dest exists, but is not writable by you. This could indicate that another user has already performed a single-user installation of Nix on this system. If you wish to enable multi-user support see http://nixos.org/nix/manual/#ssec-multi-user. If you wish to continue with a single-user install for $USER please run 'chown -R $USER $dest' as root." >&2 + exit 1 +fi + +mkdir -p $dest/store + +printf "copying Nix to %s..." "${dest}/store" >&2 + +for i in $(cd "$self/store" >/dev/null && echo ./*); do + printf "." >&2 + i_tmp="$dest/store/$i.$$" + if [ -e "$i_tmp" ]; then + rm -rf "$i_tmp" + fi + if ! [ -e "$dest/store/$i" ]; then + cp -Rp "$self/store/$i" "$i_tmp" + chmod -R a-w "$i_tmp" + chmod +w "$i_tmp" + mv "$i_tmp" "$dest/store/$i" + chmod -w "$dest/store/$i" + fi +done +echo "" >&2 + +if ! "$nix/bin/nix-store" --load-db < "$self/.reginfo"; then + echo "$0: unable to register valid paths" >&2 + exit 1 +fi + +. "$nix/etc/profile.d/nix.sh" + +if ! "$nix/bin/nix-env" -i "$nix"; then + echo "$0: unable to install Nix into your default profile" >&2 + exit 1 +fi + +# Install an SSL certificate bundle. +if [ -z "$NIX_SSL_CERT_FILE" ] || ! [ -f "$NIX_SSL_CERT_FILE" ]; then + $nix/bin/nix-env -i "$cacert" + export NIX_SSL_CERT_FILE="$HOME/.nix-profile/etc/ssl/certs/ca-bundle.crt" +fi + +# Subscribe the user to the Nixpkgs channel and fetch it. +if ! $nix/bin/nix-channel --list | grep -q "^nixpkgs "; then + $nix/bin/nix-channel --add https://nixos.org/channels/nixpkgs-unstable +fi +if [ -z "$_NIX_INSTALLER_TEST" ]; then + if ! $nix/bin/nix-channel --update nixpkgs; then + echo "Fetching the nixpkgs channel failed. (Are you offline?)" + echo "To try again later, run \"nix-channel --update nixpkgs\"." + fi +fi + +added= +p=$HOME/.nix-profile/etc/profile.d/nix.sh +if [ -z "$NIX_INSTALLER_NO_MODIFY_PROFILE" ]; then + # Make the shell source nix.sh during login. + for i in .bash_profile .bash_login .profile; do + fn="$HOME/$i" + if [ -w "$fn" ]; then + if ! grep -q "$p" "$fn"; then + echo "modifying $fn..." >&2 + echo "if [ -e $p ]; then . $p; fi # added by Nix installer" >> "$fn" + fi + added=1 + break + fi + done +fi + +if [ -z "$added" ]; then + cat >&2 <<EOF + +Installation finished! To ensure that the necessary environment +variables are set, please add the line + + . $p + +to your shell profile (e.g. ~/.profile). +EOF +else + cat >&2 <<EOF + +Installation finished! To ensure that the necessary environment +variables are set, either log in again, or type + + . $p + +in your shell. +EOF +fi diff --git a/third_party/nix/scripts/install-systemd-multi-user.sh b/third_party/nix/scripts/install-systemd-multi-user.sh new file mode 100755 index 0000000000..bef3ac4f99 --- /dev/null +++ b/third_party/nix/scripts/install-systemd-multi-user.sh @@ -0,0 +1,188 @@ +#!/usr/bin/env bash + +set -eu +set -o pipefail + +readonly SERVICE_SRC=/lib/systemd/system/nix-daemon.service +readonly SERVICE_DEST=/etc/systemd/system/nix-daemon.service + +readonly SOCKET_SRC=/lib/systemd/system/nix-daemon.socket +readonly SOCKET_DEST=/etc/systemd/system/nix-daemon.socket + + +# Path for the systemd override unit file to contain the proxy settings +readonly SERVICE_OVERRIDE=${SERVICE_DEST}.d/override.conf + +create_systemd_override() { + header "Configuring proxy for the nix-daemon service" + _sudo "create directory for systemd unit override" mkdir -p "$(dirname $SERVICE_OVERRIDE)" + cat <<EOF | _sudo "create systemd unit override" tee "$SERVICE_OVERRIDE" +[Service] +$1 +EOF +} + +# Gather all non-empty proxy environment variables into a string +create_systemd_proxy_env() { + vars="http_proxy https_proxy ftp_proxy no_proxy HTTP_PROXY HTTPS_PROXY FTP_PROXY NO_PROXY" + for v in $vars; do + if [ "x${!v:-}" != "x" ]; then + echo "Environment=${v}=${!v}" + fi + done +} + +handle_network_proxy() { + # Create a systemd unit override with proxy environment variables + # if any proxy environment variables are not empty. + PROXY_ENV_STRING=$(create_systemd_proxy_env) + if [ -n "${PROXY_ENV_STRING}" ]; then + create_systemd_override "${PROXY_ENV_STRING}" + fi +} + +poly_validate_assumptions() { + if [ "$(uname -s)" != "Linux" ]; then + failure "This script is for use with Linux!" + fi +} + +poly_service_installed_check() { + [ "$(systemctl is-enabled nix-daemon.service)" = "linked" ] \ + || [ "$(systemctl is-enabled nix-daemon.socket)" = "enabled" ] +} + +poly_service_uninstall_directions() { + cat <<EOF +$1. Delete the systemd service and socket units + + sudo systemctl stop nix-daemon.socket + sudo systemctl stop nix-daemon.service + sudo systemctl disable nix-daemon.socket + sudo systemctl disable nix-daemon.service + sudo systemctl daemon-reload +EOF +} + +poly_service_setup_note() { + cat <<EOF + - load and start a service (at $SERVICE_DEST + and $SOCKET_DEST) for nix-daemon + +EOF +} + +poly_configure_nix_daemon_service() { + _sudo "to set up the nix-daemon service" \ + systemctl link "/nix/var/nix/profiles/default$SERVICE_SRC" + + _sudo "to set up the nix-daemon socket service" \ + systemctl enable "/nix/var/nix/profiles/default$SOCKET_SRC" + + handle_network_proxy + + _sudo "to load the systemd unit for nix-daemon" \ + systemctl daemon-reload + + _sudo "to start the nix-daemon.socket" \ + systemctl start nix-daemon.socket + + _sudo "to start the nix-daemon.service" \ + systemctl start nix-daemon.service + +} + +poly_group_exists() { + getent group "$1" > /dev/null 2>&1 +} + +poly_group_id_get() { + getent group "$1" | cut -d: -f3 +} + +poly_create_build_group() { + _sudo "Create the Nix build group, $NIX_BUILD_GROUP_NAME" \ + groupadd -g "$NIX_BUILD_GROUP_ID" --system \ + "$NIX_BUILD_GROUP_NAME" >&2 +} + +poly_user_exists() { + getent passwd "$1" > /dev/null 2>&1 +} + +poly_user_id_get() { + getent passwd "$1" | cut -d: -f3 +} + +poly_user_hidden_get() { + echo "1" +} + +poly_user_hidden_set() { + true +} + +poly_user_home_get() { + getent passwd "$1" | cut -d: -f6 +} + +poly_user_home_set() { + _sudo "in order to give $1 a safe home directory" \ + usermod --home "$2" "$1" +} + +poly_user_note_get() { + getent passwd "$1" | cut -d: -f5 +} + +poly_user_note_set() { + _sudo "in order to give $1 a useful comment" \ + usermod --comment "$2" "$1" +} + +poly_user_shell_get() { + getent passwd "$1" | cut -d: -f7 +} + +poly_user_shell_set() { + _sudo "in order to prevent $1 from logging in" \ + usermod --shell "$2" "$1" +} + +poly_user_in_group_check() { + groups "$1" | grep -q "$2" > /dev/null 2>&1 +} + +poly_user_in_group_set() { + _sudo "Add $1 to the $2 group"\ + usermod --append --groups "$2" "$1" +} + +poly_user_primary_group_get() { + getent passwd "$1" | cut -d: -f4 +} + +poly_user_primary_group_set() { + _sudo "to let the nix daemon use this user for builds (this might seem redundant, but there are two concepts of group membership)" \ + usermod --gid "$2" "$1" + +} + +poly_create_build_user() { + username=$1 + uid=$2 + builder_num=$3 + + _sudo "Creating the Nix build user, $username" \ + useradd \ + --home-dir /var/empty \ + --comment "Nix build user $builder_num" \ + --gid "$NIX_BUILD_GROUP_ID" \ + --groups "$NIX_BUILD_GROUP_NAME" \ + --no-user-group \ + --system \ + --shell /sbin/nologin \ + --uid "$uid" \ + --password "!" \ + "$username" +} diff --git a/third_party/nix/scripts/install.in b/third_party/nix/scripts/install.in new file mode 100644 index 0000000000..902758b138 --- /dev/null +++ b/third_party/nix/scripts/install.in @@ -0,0 +1,66 @@ +#!/bin/sh + +# This script installs the Nix package manager on your system by +# downloading a binary distribution and running its installer script +# (which in turn creates and populates /nix). + +{ # Prevent execution if this script was only partially downloaded +oops() { + echo "$0:" "$@" >&2 + exit 1 +} + +tmpDir="$(mktemp -d -t nix-binary-tarball-unpack.XXXXXXXXXX || \ + oops "Can't create temporary directory for downloading the Nix binary tarball")" +cleanup() { + rm -rf "$tmpDir" +} +trap cleanup EXIT INT QUIT TERM + +require_util() { + command -v "$1" > /dev/null 2>&1 || + oops "you do not have '$1' installed, which I need to $2" +} + +case "$(uname -s).$(uname -m)" in + Linux.x86_64) system=x86_64-linux; hash=@binaryTarball_x86_64-linux@;; + Linux.i?86) system=i686-linux; hash=@binaryTarball_i686-linux@;; + Linux.aarch64) system=aarch64-linux; hash=@binaryTarball_aarch64-linux@;; + Darwin.x86_64) system=x86_64-darwin; hash=@binaryTarball_x86_64-darwin@;; + *) oops "sorry, there is no binary distribution of Nix for your platform";; +esac + +url="https://nixos.org/releases/nix/nix-@nixVersion@/nix-@nixVersion@-$system.tar.xz" + +tarball="$tmpDir/$(basename "$tmpDir/nix-@nixVersion@-$system.tar.xz")" + +require_util curl "download the binary tarball" +require_util tar "unpack the binary tarball" + +echo "downloading Nix @nixVersion@ binary tarball for $system from '$url' to '$tmpDir'..." +curl -L "$url" -o "$tarball" || oops "failed to download '$url'" + +if command -v sha256sum > /dev/null 2>&1; then + hash2="$(sha256sum -b "$tarball" | cut -c1-64)" +elif command -v shasum > /dev/null 2>&1; then + hash2="$(shasum -a 256 -b "$tarball" | cut -c1-64)" +elif command -v openssl > /dev/null 2>&1; then + hash2="$(openssl dgst -r -sha256 "$tarball" | cut -c1-64)" +else + oops "cannot verify the SHA-256 hash of '$url'; you need one of 'shasum', 'sha256sum', or 'openssl'" +fi + +if [ "$hash" != "$hash2" ]; then + oops "SHA-256 hash mismatch in '$url'; expected $hash, got $hash2" +fi + +unpack=$tmpDir/unpack +mkdir -p "$unpack" +tar -xf "$tarball" -C "$unpack" || oops "failed to unpack '$url'" + +script=$(echo "$unpack"/*/install) + +[ -e "$script" ] || oops "installation script is missing from the binary tarball!" +"$script" "$@" + +} # End of wrapping diff --git a/third_party/nix/scripts/meson.build b/third_party/nix/scripts/meson.build new file mode 100644 index 0000000000..8787a185d0 --- /dev/null +++ b/third_party/nix/scripts/meson.build @@ -0,0 +1,74 @@ +# Nix corepkgs build file +#============================================================================ + + + + +# src files +#============================================================================ + +scripts_data = files( + join_paths(meson.source_root(), 'scripts/install-darwin-multi-user.sh'), + join_paths(meson.source_root(), 'scripts/install-multi-user.sh')) + + + + + +# targets +#============================================================================ + +nix_profile_sh = configuration_data() +nix_profile_sh.set('localstatedir', localstatedir) +nix_profile_sh.set('coreutils', coreutils) + +nix_http_export_cgi = configuration_data() +nix_http_export_cgi.set('bindir', bindir) +nix_http_export_cgi.set('localstatedir', localstatedir) +nix_http_export_cgi.set('coreutils', coreutils) +nix_http_export_cgi.set('gzip', gzip.path()) + +nix_reduce_build = configuration_data() +nix_reduce_build.set('bash', bash.path()) +nix_reduce_build.set('bindir', bindir) +nix_reduce_build.set('localstatedir', localstatedir) + + +# TODO: make these work +nix_install = configuration_data() +nix_install.set('nixVersion', package_version) +nix_install.set('binaryTarball_x86_64-linux', '') +nix_install.set('binaryTarball_i686-linux', '') +nix_install.set('binaryTarball_aarch64-linux', '') +nix_install.set('binaryTarball_x86_64-darwin', '') + + + + +# build +#============================================================================ + +scripts_data += configure_file( + input : 'nix-profile.sh.in', + output : 'nix.sh', + configuration : nix_profile_sh) + +scripts_data += configure_file( + input : 'nix-profile-daemon.sh.in', + output : 'nix-daemon.sh', + configuration : nix_profile_sh) + +scripts_data += configure_file( + input : 'nix-http-export.cgi.in', + output : 'nix-http-export.cgi', + configuration : nix_http_export_cgi) + +scripts_data += configure_file( + input : 'nix-reduce-build.in', + output : 'nix-reduce-build', + configuration : nix_reduce_build) + +install_data( + scripts_data, + install_mode : 'rwxr-xr-x', + install_dir : profiledir) diff --git a/third_party/nix/scripts/nix-http-export.cgi.in b/third_party/nix/scripts/nix-http-export.cgi.in new file mode 100755 index 0000000000..19a505af1c --- /dev/null +++ b/third_party/nix/scripts/nix-http-export.cgi.in @@ -0,0 +1,51 @@ +#! /bin/sh + +export HOME=/tmp +export NIX_REMOTE=daemon + +TMP_DIR="${TMP_DIR:-/tmp/nix-export}" + +@coreutils@/mkdir -p "$TMP_DIR" || true +@coreutils@/chmod a+r "$TMP_DIR" + +needed_path="?$QUERY_STRING" +needed_path="${needed_path#*[?&]needed_path=}" +needed_path="${needed_path%%&*}" +#needed_path="$(echo $needed_path | ./unhttp)" +needed_path="${needed_path//%2B/+}" +needed_path="${needed_path//%3D/=}" + +echo needed_path: "$needed_path" >&2 + +NIX_STORE="${NIX_STORE_DIR:-/nix/store}" + +echo NIX_STORE: "${NIX_STORE}" >&2 + +full_path="${NIX_STORE}"/"$needed_path" + +if [ "$needed_path" != "${needed_path%.drv}" ]; then + echo "Status: 403 You should create the derivation file yourself" + echo "Content-Type: text/plain" + echo + echo "Refusing to disclose derivation contents" + exit +fi + +if @bindir@/nix-store --check-validity "$full_path"; then + if ! [ -e nix-export/"$needed_path".nar.gz ]; then + @bindir@/nix-store --export "$full_path" | @gzip@ > "$TMP_DIR"/"$needed_path".nar.gz + @coreutils@/ln -fs "$TMP_DIR"/"$needed_path".nar.gz nix-export/"$needed_path".nar.gz + fi; + echo "Status: 301 Moved" + echo "Location: nix-export/"$needed_path".nar.gz" + echo +else + echo "Status: 404 No such path found" + echo "Content-Type: text/plain" + echo + echo "Path not found:" + echo "$needed_path" + echo "checked:" + echo "$full_path" +fi + diff --git a/third_party/nix/scripts/nix-profile-daemon.sh.in b/third_party/nix/scripts/nix-profile-daemon.sh.in new file mode 100644 index 0000000000..47655080a6 --- /dev/null +++ b/third_party/nix/scripts/nix-profile-daemon.sh.in @@ -0,0 +1,29 @@ +# Only execute this file once per shell. +if [ -n "${__ETC_PROFILE_NIX_SOURCED:-}" ]; then return; fi +__ETC_PROFILE_NIX_SOURCED=1 + +export NIX_USER_PROFILE_DIR="@localstatedir@/nix/profiles/per-user/$USER" +export NIX_PROFILES="@localstatedir@/nix/profiles/default $HOME/.nix-profile" + +# Set $NIX_SSL_CERT_FILE so that Nixpkgs applications like curl work. +if [ ! -z "${NIX_SSL_CERT_FILE:-}" ]; then + : # Allow users to override the NIX_SSL_CERT_FILE +elif [ -e /etc/ssl/certs/ca-certificates.crt ]; then # NixOS, Ubuntu, Debian, Gentoo, Arch + export NIX_SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt +elif [ -e /etc/ssl/ca-bundle.pem ]; then # openSUSE Tumbleweed + export NIX_SSL_CERT_FILE=/etc/ssl/ca-bundle.pem +elif [ -e /etc/ssl/certs/ca-bundle.crt ]; then # Old NixOS + export NIX_SSL_CERT_FILE=/etc/ssl/certs/ca-bundle.crt +elif [ -e /etc/pki/tls/certs/ca-bundle.crt ]; then # Fedora, CentOS + export NIX_SSL_CERT_FILE=/etc/pki/tls/certs/ca-bundle.crt +else + # Fall back to what is in the nix profiles, favouring whatever is defined last. + for i in $NIX_PROFILES; do + if [ -e $i/etc/ssl/certs/ca-bundle.crt ]; then + export NIX_SSL_CERT_FILE=$i/etc/ssl/certs/ca-bundle.crt + fi + done +fi + +export NIX_PATH="nixpkgs=@localstatedir@/nix/profiles/per-user/root/channels/nixpkgs:@localstatedir@/nix/profiles/per-user/root/channels" +export PATH="$HOME/.nix-profile/bin:@localstatedir@/nix/profiles/default/bin:$PATH" diff --git a/third_party/nix/scripts/nix-profile.sh.in b/third_party/nix/scripts/nix-profile.sh.in new file mode 100644 index 0000000000..e15f7cd46b --- /dev/null +++ b/third_party/nix/scripts/nix-profile.sh.in @@ -0,0 +1,39 @@ +if [ -n "$HOME" ] && [ -n "$USER" ]; then + + # Set up the per-user profile. + # This part should be kept in sync with nixpkgs:nixos/modules/programs/shell.nix + + NIX_LINK=$HOME/.nix-profile + + NIX_USER_PROFILE_DIR=@localstatedir@/nix/profiles/per-user/$USER + + # Append ~/.nix-defexpr/channels to $NIX_PATH so that <nixpkgs> + # paths work when the user has fetched the Nixpkgs channel. + export NIX_PATH=${NIX_PATH:+$NIX_PATH:}$HOME/.nix-defexpr/channels + + # Set up environment. + # This part should be kept in sync with nixpkgs:nixos/modules/programs/environment.nix + export NIX_PROFILES="@localstatedir@/nix/profiles/default $HOME/.nix-profile" + + # Set $NIX_SSL_CERT_FILE so that Nixpkgs applications like curl work. + if [ -e /etc/ssl/certs/ca-certificates.crt ]; then # NixOS, Ubuntu, Debian, Gentoo, Arch + export NIX_SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt + elif [ -e /etc/ssl/ca-bundle.pem ]; then # openSUSE Tumbleweed + export NIX_SSL_CERT_FILE=/etc/ssl/ca-bundle.pem + elif [ -e /etc/ssl/certs/ca-bundle.crt ]; then # Old NixOS + export NIX_SSL_CERT_FILE=/etc/ssl/certs/ca-bundle.crt + elif [ -e /etc/pki/tls/certs/ca-bundle.crt ]; then # Fedora, CentOS + export NIX_SSL_CERT_FILE=/etc/pki/tls/certs/ca-bundle.crt + elif [ -e "$NIX_LINK/etc/ssl/certs/ca-bundle.crt" ]; then # fall back to cacert in Nix profile + export NIX_SSL_CERT_FILE="$NIX_LINK/etc/ssl/certs/ca-bundle.crt" + elif [ -e "$NIX_LINK/etc/ca-bundle.crt" ]; then # old cacert in Nix profile + export NIX_SSL_CERT_FILE="$NIX_LINK/etc/ca-bundle.crt" + fi + + if [ -n "${MANPATH-}" ]; then + export MANPATH="$NIX_LINK/share/man:$MANPATH" + fi + + export PATH="$NIX_LINK/bin:$PATH" + unset NIX_LINK NIX_USER_PROFILE_DIR +fi diff --git a/third_party/nix/scripts/nix-reduce-build.in b/third_party/nix/scripts/nix-reduce-build.in new file mode 100755 index 0000000000..50beb9d10b --- /dev/null +++ b/third_party/nix/scripts/nix-reduce-build.in @@ -0,0 +1,171 @@ +#! @bash@ + +WORKING_DIRECTORY=$(mktemp -d "${TMPDIR:-/tmp}"/nix-reduce-build-XXXXXX); +cd "$WORKING_DIRECTORY"; + +if test -z "$1" || test "a--help" = "a$1" ; then + echo 'nix-reduce-build (paths or Nix expressions) -- (package sources)' >&2 + echo As in: >&2 + echo nix-reduce-build /etc/nixos/nixos -- ssh://user@somewhere.nowhere.example.org >&2 + echo nix-reduce-build /etc/nixos/nixos -- \\ + echo " " \''http://somewhere.nowhere.example.org/nix/nix-http-export.cgi?needed_path='\' >&2 + echo " store path name will be added into the end of the URL" >&2 + echo nix-reduce-build /etc/nixos/nixos -- file://home/user/nar/ >&2 + echo " that should be a directory where gzipped 'nix-store --export' ">&2 + echo " files are located (they should have .nar.gz extension)" >&2 + echo " Or all together: " >&2 + echo -e nix-reduce-build /expr.nix /e2.nix -- \\\\\\\n\ + " ssh://a@b.example.com http://n.example.com/get-nar?q= file://nar/" >&2 + echo " Also supports best-effort local builds of failing expression set:" >&2 + echo "nix-reduce-build /e.nix -- nix-daemon:// nix-self://" >&2 + echo " nix-daemon:// builds using daemon" + echo " nix-self:// builds directly using nix-store from current installation" >&2 + echo " nix-daemon-fixed:// and nix-self-fixed:// do the same, but only for" >&2; + echo "derivations with specified output hash (sha256, sha1 or md5)." >&2 + echo " nix-daemon-substitute:// and nix-self-substitute:// try to substitute" >&2; + echo "maximum amount of paths" >&2; + echo " nix-daemon-build:// and nix-self-build:// try to build (not substitute)" >&2; + echo "maximum amount of paths" >&2; + echo " If no package sources are specified, required paths are listed." >&2; + exit; +fi; + +while ! test "$1" = "--" || test "$1" = "" ; do + echo "$1" >> initial; >&2 + shift; +done +shift; +echo Will work on $(cat initial | wc -l) targets. >&2 + +while read ; do + case "$REPLY" in + ${NIX_STORE_DIR:-/nix/store}/*) + echo "$REPLY" >> paths; >&2 + ;; + *) + ( + IFS=: ; + nix-instantiate $REPLY >> paths; + ); + ;; + esac; +done < initial; +echo Proceeding $(cat paths | wc -l) paths. >&2 + +while read; do + case "$REPLY" in + *.drv) + echo "$REPLY" >> derivers; >&2 + ;; + *) + nix-store --query --deriver "$REPLY" >>derivers; + ;; + esac; +done < paths; +echo Found $(cat derivers | wc -l) derivers. >&2 + +cat derivers | xargs nix-store --query -R > derivers-closure; +echo Proceeding at most $(cat derivers-closure | wc -l) derivers. >&2 + +cat derivers-closure | egrep '[.]drv$' | xargs nix-store --query --outputs > wanted-paths; +cat derivers-closure | egrep -v '[.]drv$' >> wanted-paths; +echo Prepared $(cat wanted-paths | wc -l) paths to get. >&2 + +cat wanted-paths | xargs nix-store --check-validity --print-invalid > needed-paths; +echo We need $(cat needed-paths | wc -l) paths. >&2 + +egrep '[.]drv$' derivers-closure > critical-derivers; + +if test -z "$1" ; then + cat needed-paths; +fi; + +refresh_critical_derivers() { + echo "Finding needed derivers..." >&2; + cat critical-derivers | while read; do + if ! (nix-store --query --outputs "$REPLY" | xargs nix-store --check-validity &> /dev/null;); then + echo "$REPLY"; + fi; + done > new-critical-derivers; + mv new-critical-derivers critical-derivers; + echo The needed paths are realized by $(cat critical-derivers | wc -l) derivers. >&2 +} + +build_here() { + cat critical-derivers | while read; do + echo "Realising $REPLY using nix-daemon" >&2 + @bindir@/nix-store -r "${REPLY}" + done; +} + +try_to_substitute(){ + cat needed-paths | while read ; do + echo "Building $REPLY using nix-daemon" >&2 + @bindir@/nix-store -r "${NIX_STORE_DIR:-/nix/store}/${REPLY##*/}" + done; +} + +for i in "$@"; do + sshHost="${i#ssh://}"; + httpHost="${i#http://}"; + httpsHost="${i#https://}"; + filePath="${i#file:/}"; + if [ "$i" != "$sshHost" ]; then + cat needed-paths | while read; do + echo "Getting $REPLY and its closure over ssh" >&2 + nix-copy-closure --from "$sshHost" --gzip "$REPLY" </dev/null || true; + done; + elif [ "$i" != "$httpHost" ] || [ "$i" != "$httpsHost" ]; then + cat needed-paths | while read; do + echo "Getting $REPLY over http/https" >&2 + curl ${BAD_CERTIFICATE:+-k} -L "$i${REPLY##*/}" | gunzip | nix-store --import; + done; + elif [ "$i" != "$filePath" ] ; then + cat needed-paths | while read; do + echo "Installing $REPLY from file" >&2 + gunzip < "$filePath/${REPLY##*/}".nar.gz | nix-store --import; + done; + elif [ "$i" = "nix-daemon://" ] ; then + NIX_REMOTE=daemon try_to_substitute; + refresh_critical_derivers; + NIX_REMOTE=daemon build_here; + elif [ "$i" = "nix-self://" ] ; then + NIX_REMOTE= try_to_substitute; + refresh_critical_derivers; + NIX_REMOTE= build_here; + elif [ "$i" = "nix-daemon-fixed://" ] ; then + refresh_critical_derivers; + + cat critical-derivers | while read; do + if egrep '"(md5|sha1|sha256)"' "$REPLY" &>/dev/null; then + echo "Realising $REPLY using nix-daemon" >&2 + NIX_REMOTE=daemon @bindir@/nix-store -r "${REPLY}" + fi; + done; + elif [ "$i" = "nix-self-fixed://" ] ; then + refresh_critical_derivers; + + cat critical-derivers | while read; do + if egrep '"(md5|sha1|sha256)"' "$REPLY" &>/dev/null; then + echo "Realising $REPLY using direct Nix build" >&2 + NIX_REMOTE= @bindir@/nix-store -r "${REPLY}" + fi; + done; + elif [ "$i" = "nix-daemon-substitute://" ] ; then + NIX_REMOTE=daemon try_to_substitute; + elif [ "$i" = "nix-self-substitute://" ] ; then + NIX_REMOTE= try_to_substitute; + elif [ "$i" = "nix-daemon-build://" ] ; then + refresh_critical_derivers; + NIX_REMOTE=daemon build_here; + elif [ "$i" = "nix-self-build://" ] ; then + refresh_critical_derivers; + NIX_REMOTE= build_here; + fi; + mv needed-paths wanted-paths; + cat wanted-paths | xargs nix-store --check-validity --print-invalid > needed-paths; + echo We still need $(cat needed-paths | wc -l) paths. >&2 +done; + +cd / +rm -r "$WORKING_DIRECTORY" diff --git a/third_party/nix/src/build-remote/build-remote.cc b/third_party/nix/src/build-remote/build-remote.cc new file mode 100644 index 0000000000..2802b49ac8 --- /dev/null +++ b/third_party/nix/src/build-remote/build-remote.cc @@ -0,0 +1,283 @@ +#include <algorithm> +#include <cstdlib> +#include <cstring> +#include <iomanip> +#include <memory> +#include <set> +#include <tuple> + +#include <glog/logging.h> +#if __APPLE__ +#include <sys/time.h> +#endif + +#include "derivations.hh" +#include "globals.hh" +#include "legacy.hh" +#include "local-store.hh" +#include "machines.hh" +#include "pathlocks.hh" +#include "serialise.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; +using std::cin; + +static void handleAlarm(int sig) {} + +std::string escapeUri(std::string uri) { + std::replace(uri.begin(), uri.end(), '/', '_'); + return uri; +} + +static string currentLoad; + +static AutoCloseFD openSlotLock(const Machine& m, unsigned long long slot) { + return openLockFile(fmt("%s/%s-%d", currentLoad, escapeUri(m.storeUri), slot), + true); +} + +static bool allSupportedLocally(const std::set<std::string>& requiredFeatures) { + for (auto& feature : requiredFeatures) { + if (settings.systemFeatures.get().count(feature) == 0u) { + return false; + } + } + return true; +} + +static int _main(int argc, char* argv[]) { + { + /* Ensure we don't get any SSH passphrase or host key popups. */ + unsetenv("DISPLAY"); + unsetenv("SSH_ASKPASS"); + + if (argc != 2) { + throw UsageError("called without required arguments"); + } + + FdSource source(STDIN_FILENO); + + /* Read the parent's settings. */ + while (readInt(source) != 0u) { + auto name = readString(source); + auto value = readString(source); + settings.set(name, value); + } + + settings.maxBuildJobs.set("1"); // hack to make tests with local?root= work + + initPlugins(); + + auto store = openStore().cast<LocalStore>(); + + /* It would be more appropriate to use $XDG_RUNTIME_DIR, since + that gets cleared on reboot, but it wouldn't work on macOS. */ + currentLoad = store->stateDir + "/current-load"; + + std::shared_ptr<Store> sshStore; + AutoCloseFD bestSlotLock; + + auto machines = getMachines(); + DLOG(INFO) << "got " << machines.size() << " remote builders"; + + if (machines.empty()) { + std::cerr << "# decline-permanently\n"; + return 0; + } + + string drvPath; + string storeUri; + + while (true) { + try { + auto s = readString(source); + if (s != "try") { + return 0; + } + } catch (EndOfFile&) { + return 0; + } + + auto amWilling = readInt(source); + auto neededSystem = readString(source); + source >> drvPath; + auto requiredFeatures = readStrings<std::set<std::string>>(source); + + auto canBuildLocally = + (amWilling != 0u) && + (neededSystem == settings.thisSystem || + settings.extraPlatforms.get().count(neededSystem) > 0) && + allSupportedLocally(requiredFeatures); + + /* Error ignored here, will be caught later */ + mkdir(currentLoad.c_str(), 0777); + + while (true) { + bestSlotLock = -1; + AutoCloseFD lock = openLockFile(currentLoad + "/main-lock", true); + lockFile(lock.get(), ltWrite, true); + + bool rightType = false; + + Machine* bestMachine = nullptr; + unsigned long long bestLoad = 0; + for (auto& m : machines) { + DLOG(INFO) << "considering building on remote machine '" << m.storeUri + << "'"; + + if (m.enabled && + std::find(m.systemTypes.begin(), m.systemTypes.end(), + neededSystem) != m.systemTypes.end() && + m.allSupported(requiredFeatures) && + m.mandatoryMet(requiredFeatures)) { + rightType = true; + AutoCloseFD free; + unsigned long long load = 0; + for (unsigned long long slot = 0; slot < m.maxJobs; ++slot) { + auto slotLock = openSlotLock(m, slot); + if (lockFile(slotLock.get(), ltWrite, false)) { + if (!free) { + free = std::move(slotLock); + } + } else { + ++load; + } + } + if (!free) { + continue; + } + bool best = false; + if (!bestSlotLock) { + best = true; + } else if (load / m.speedFactor < + bestLoad / bestMachine->speedFactor) { + best = true; + } else if (load / m.speedFactor == + bestLoad / bestMachine->speedFactor) { + if (m.speedFactor > bestMachine->speedFactor) { + best = true; + } else if (m.speedFactor == bestMachine->speedFactor) { + if (load < bestLoad) { + best = true; + } + } + } + if (best) { + bestLoad = load; + bestSlotLock = std::move(free); + bestMachine = &m; + } + } + } + + if (!bestSlotLock) { + if (rightType && !canBuildLocally) { + std::cerr << "# postpone\n"; + } else { + std::cerr << "# decline\n"; + } + break; + } + +#if __APPLE__ + futimes(bestSlotLock.get(), NULL); +#else + futimens(bestSlotLock.get(), nullptr); +#endif + + lock = -1; + + try { + DLOG(INFO) << "connecting to '" << bestMachine->storeUri << "'"; + + Store::Params storeParams; + if (hasPrefix(bestMachine->storeUri, "ssh://")) { + storeParams["max-connections"] = "1"; + storeParams["log-fd"] = "4"; + if (!bestMachine->sshKey.empty()) { + storeParams["ssh-key"] = bestMachine->sshKey; + } + } + + sshStore = openStore(bestMachine->storeUri, storeParams); + sshStore->connect(); + storeUri = bestMachine->storeUri; + + } catch (std::exception& e) { + auto msg = chomp(drainFD(5, false)); + LOG(ERROR) << "cannot build on '" << bestMachine->storeUri + << "': " << e.what() << (msg.empty() ? "" : ": " + msg); + bestMachine->enabled = false; + continue; + } + + goto connected; + } + } + + connected: + close(5); + + std::cerr << "# accept\n" << storeUri << "\n"; + + auto inputs = readStrings<PathSet>(source); + auto outputs = readStrings<PathSet>(source); + + AutoCloseFD uploadLock = openLockFile( + currentLoad + "/" + escapeUri(storeUri) + ".upload-lock", true); + + { + DLOG(INFO) << "waiting for the upload lock to '" << storeUri << "'"; + + auto old = signal(SIGALRM, handleAlarm); + alarm(15 * 60); + if (!lockFile(uploadLock.get(), ltWrite, true)) { + LOG(ERROR) << "somebody is hogging the upload lock, continuing..."; + } + alarm(0); + signal(SIGALRM, old); + } + + auto substitute = + settings.buildersUseSubstitutes ? Substitute : NoSubstitute; + + { + DLOG(INFO) << "copying dependencies to '" << storeUri << "'"; + copyPaths(store, ref<Store>(sshStore), inputs, NoRepair, NoCheckSigs, + substitute); + } + + uploadLock = -1; + + BasicDerivation drv( + readDerivation(store->realStoreDir + "/" + baseNameOf(drvPath))); + drv.inputSrcs = inputs; + + auto result = sshStore->buildDerivation(drvPath, drv); + + if (!result.success()) { + throw Error("build of '%s' on '%s' failed: %s", drvPath, storeUri, + result.errorMsg); + } + + PathSet missing; + for (auto& path : outputs) { + if (!store->isValidPath(path)) { + missing.insert(path); + } + } + + if (!missing.empty()) { + DLOG(INFO) << "copying outputs from '" << storeUri << "'"; + store->locksHeld.insert(missing.begin(), missing.end()); /* FIXME: ugly */ + copyPaths(ref<Store>(sshStore), store, missing, NoRepair, NoCheckSigs, + NoSubstitute); + } + + return 0; + } +} + +static RegisterLegacyCommand s1("build-remote", _main); diff --git a/third_party/nix/src/cpptoml/LICENSE b/third_party/nix/src/cpptoml/LICENSE new file mode 100644 index 0000000000..8802c4fa5a --- /dev/null +++ b/third_party/nix/src/cpptoml/LICENSE @@ -0,0 +1,18 @@ +Copyright (c) 2014 Chase Geigle + +Permission is hereby granted, free of charge, to any person obtaining a copy of +this software and associated documentation files (the "Software"), to deal in +the Software without restriction, including without limitation the rights to +use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of +the Software, and to permit persons to whom the Software is furnished to do so, +subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS +FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR +COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER +IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN +CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. diff --git a/third_party/nix/src/cpptoml/cpptoml.h b/third_party/nix/src/cpptoml/cpptoml.h new file mode 100644 index 0000000000..5a00da3b4c --- /dev/null +++ b/third_party/nix/src/cpptoml/cpptoml.h @@ -0,0 +1,3668 @@ +/** + * @file cpptoml.h + * @author Chase Geigle + * @date May 2013 + */ + +#ifndef CPPTOML_H +#define CPPTOML_H + +#include <algorithm> +#include <cassert> +#include <clocale> +#include <cstdint> +#include <cstring> +#include <fstream> +#include <iomanip> +#include <map> +#include <memory> +#include <sstream> +#include <stdexcept> +#include <string> +#include <unordered_map> +#include <vector> + +#if __cplusplus > 201103L +#define CPPTOML_DEPRECATED(reason) [[deprecated(reason)]] +#elif defined(__clang__) +#define CPPTOML_DEPRECATED(reason) __attribute__((deprecated(reason))) +#elif defined(__GNUG__) +#define CPPTOML_DEPRECATED(reason) __attribute__((deprecated)) +#elif defined(_MSC_VER) +#if _MSC_VER < 1910 +#define CPPTOML_DEPRECATED(reason) __declspec(deprecated) +#else +#define CPPTOML_DEPRECATED(reason) [[deprecated(reason)]] +#endif +#endif + +namespace cpptoml +{ +class writer; // forward declaration +class base; // forward declaration +#if defined(CPPTOML_USE_MAP) +// a std::map will ensure that entries a sorted, albeit at a slight +// performance penalty relative to the (default) unordered_map +using string_to_base_map = std::map<std::string, std::shared_ptr<base>>; +#else +// by default an unordered_map is used for best performance as the +// toml specification does not require entries to be sorted +using string_to_base_map + = std::unordered_map<std::string, std::shared_ptr<base>>; +#endif + +// if defined, `base` will retain type information in form of an enum class +// such that static_cast can be used instead of dynamic_cast +// #define CPPTOML_NO_RTTI + +template <class T> +class option +{ + public: + option() : empty_{true} + { + // nothing + } + + option(T value) : empty_{false}, value_(std::move(value)) + { + // nothing + } + + explicit operator bool() const + { + return !empty_; + } + + const T& operator*() const + { + return value_; + } + + const T* operator->() const + { + return &value_; + } + + template <class U> + T value_or(U&& alternative) const + { + if (!empty_) + return value_; + return static_cast<T>(std::forward<U>(alternative)); + } + + private: + bool empty_; + T value_; +}; + +struct local_date +{ + int year = 0; + int month = 0; + int day = 0; +}; + +struct local_time +{ + int hour = 0; + int minute = 0; + int second = 0; + int microsecond = 0; +}; + +struct zone_offset +{ + int hour_offset = 0; + int minute_offset = 0; +}; + +struct local_datetime : local_date, local_time +{ +}; + +struct offset_datetime : local_datetime, zone_offset +{ + static inline struct offset_datetime from_zoned(const struct tm& t) + { + offset_datetime dt; + dt.year = t.tm_year + 1900; + dt.month = t.tm_mon + 1; + dt.day = t.tm_mday; + dt.hour = t.tm_hour; + dt.minute = t.tm_min; + dt.second = t.tm_sec; + + char buf[16]; + strftime(buf, 16, "%z", &t); + + int offset = std::stoi(buf); + dt.hour_offset = offset / 100; + dt.minute_offset = offset % 100; + return dt; + } + + CPPTOML_DEPRECATED("from_local has been renamed to from_zoned") + static inline struct offset_datetime from_local(const struct tm& t) + { + return from_zoned(t); + } + + static inline struct offset_datetime from_utc(const struct tm& t) + { + offset_datetime dt; + dt.year = t.tm_year + 1900; + dt.month = t.tm_mon + 1; + dt.day = t.tm_mday; + dt.hour = t.tm_hour; + dt.minute = t.tm_min; + dt.second = t.tm_sec; + return dt; + } +}; + +CPPTOML_DEPRECATED("datetime has been renamed to offset_datetime") +typedef offset_datetime datetime; + +class fill_guard +{ + public: + fill_guard(std::ostream& os) : os_(os), fill_{os.fill()} + { + // nothing + } + + ~fill_guard() + { + os_.fill(fill_); + } + + private: + std::ostream& os_; + std::ostream::char_type fill_; +}; + +inline std::ostream& operator<<(std::ostream& os, const local_date& dt) +{ + fill_guard g{os}; + os.fill('0'); + + using std::setw; + os << setw(4) << dt.year << "-" << setw(2) << dt.month << "-" << setw(2) + << dt.day; + + return os; +} + +inline std::ostream& operator<<(std::ostream& os, const local_time& ltime) +{ + fill_guard g{os}; + os.fill('0'); + + using std::setw; + os << setw(2) << ltime.hour << ":" << setw(2) << ltime.minute << ":" + << setw(2) << ltime.second; + + if (ltime.microsecond > 0) + { + os << "."; + int power = 100000; + for (int curr_us = ltime.microsecond; curr_us; power /= 10) + { + auto num = curr_us / power; + os << num; + curr_us -= num * power; + } + } + + return os; +} + +inline std::ostream& operator<<(std::ostream& os, const zone_offset& zo) +{ + fill_guard g{os}; + os.fill('0'); + + using std::setw; + + if (zo.hour_offset != 0 || zo.minute_offset != 0) + { + if (zo.hour_offset > 0) + { + os << "+"; + } + else + { + os << "-"; + } + os << setw(2) << std::abs(zo.hour_offset) << ":" << setw(2) + << std::abs(zo.minute_offset); + } + else + { + os << "Z"; + } + + return os; +} + +inline std::ostream& operator<<(std::ostream& os, const local_datetime& dt) +{ + return os << static_cast<const local_date&>(dt) << "T" + << static_cast<const local_time&>(dt); +} + +inline std::ostream& operator<<(std::ostream& os, const offset_datetime& dt) +{ + return os << static_cast<const local_datetime&>(dt) + << static_cast<const zone_offset&>(dt); +} + +template <class T, class... Ts> +struct is_one_of; + +template <class T, class V> +struct is_one_of<T, V> : std::is_same<T, V> +{ +}; + +template <class T, class V, class... Ts> +struct is_one_of<T, V, Ts...> +{ + const static bool value + = std::is_same<T, V>::value || is_one_of<T, Ts...>::value; +}; + +template <class T> +class value; + +template <class T> +struct valid_value + : is_one_of<T, std::string, int64_t, double, bool, local_date, local_time, + local_datetime, offset_datetime> +{ +}; + +template <class T, class Enable = void> +struct value_traits; + +template <class T> +struct valid_value_or_string_convertible +{ + + const static bool value = valid_value<typename std::decay<T>::type>::value + || std::is_convertible<T, std::string>::value; +}; + +template <class T> +struct value_traits<T, typename std::enable_if< + valid_value_or_string_convertible<T>::value>::type> +{ + using value_type = typename std::conditional< + valid_value<typename std::decay<T>::type>::value, + typename std::decay<T>::type, std::string>::type; + + using type = value<value_type>; + + static value_type construct(T&& val) + { + return value_type(val); + } +}; + +template <class T> +struct value_traits< + T, + typename std::enable_if< + !valid_value_or_string_convertible<T>::value + && std::is_floating_point<typename std::decay<T>::type>::value>::type> +{ + using value_type = typename std::decay<T>::type; + + using type = value<double>; + + static value_type construct(T&& val) + { + return value_type(val); + } +}; + +template <class T> +struct value_traits< + T, typename std::enable_if< + !valid_value_or_string_convertible<T>::value + && !std::is_floating_point<typename std::decay<T>::type>::value + && std::is_signed<typename std::decay<T>::type>::value>::type> +{ + using value_type = int64_t; + + using type = value<int64_t>; + + static value_type construct(T&& val) + { + if (val < (std::numeric_limits<int64_t>::min)()) + throw std::underflow_error{"constructed value cannot be " + "represented by a 64-bit signed " + "integer"}; + + if (val > (std::numeric_limits<int64_t>::max)()) + throw std::overflow_error{"constructed value cannot be represented " + "by a 64-bit signed integer"}; + + return static_cast<int64_t>(val); + } +}; + +template <class T> +struct value_traits< + T, typename std::enable_if< + !valid_value_or_string_convertible<T>::value + && std::is_unsigned<typename std::decay<T>::type>::value>::type> +{ + using value_type = int64_t; + + using type = value<int64_t>; + + static value_type construct(T&& val) + { + if (val > static_cast<uint64_t>((std::numeric_limits<int64_t>::max)())) + throw std::overflow_error{"constructed value cannot be represented " + "by a 64-bit signed integer"}; + + return static_cast<int64_t>(val); + } +}; + +class array; +class table; +class table_array; + +template <class T> +struct array_of_trait +{ + using return_type = option<std::vector<T>>; +}; + +template <> +struct array_of_trait<array> +{ + using return_type = option<std::vector<std::shared_ptr<array>>>; +}; + +template <class T> +inline std::shared_ptr<typename value_traits<T>::type> make_value(T&& val); +inline std::shared_ptr<array> make_array(); + +namespace detail +{ +template <class T> +inline std::shared_ptr<T> make_element(); +} + +inline std::shared_ptr<table> make_table(); +inline std::shared_ptr<table_array> make_table_array(bool is_inline = false); + +#if defined(CPPTOML_NO_RTTI) +/// Base type used to store underlying data type explicitly if RTTI is disabled +enum class base_type +{ + NONE, + STRING, + LOCAL_TIME, + LOCAL_DATE, + LOCAL_DATETIME, + OFFSET_DATETIME, + INT, + FLOAT, + BOOL, + TABLE, + ARRAY, + TABLE_ARRAY +}; + +/// Type traits class to convert C++ types to enum member +template <class T> +struct base_type_traits; + +template <> +struct base_type_traits<std::string> +{ + static const base_type type = base_type::STRING; +}; + +template <> +struct base_type_traits<local_time> +{ + static const base_type type = base_type::LOCAL_TIME; +}; + +template <> +struct base_type_traits<local_date> +{ + static const base_type type = base_type::LOCAL_DATE; +}; + +template <> +struct base_type_traits<local_datetime> +{ + static const base_type type = base_type::LOCAL_DATETIME; +}; + +template <> +struct base_type_traits<offset_datetime> +{ + static const base_type type = base_type::OFFSET_DATETIME; +}; + +template <> +struct base_type_traits<int64_t> +{ + static const base_type type = base_type::INT; +}; + +template <> +struct base_type_traits<double> +{ + static const base_type type = base_type::FLOAT; +}; + +template <> +struct base_type_traits<bool> +{ + static const base_type type = base_type::BOOL; +}; + +template <> +struct base_type_traits<table> +{ + static const base_type type = base_type::TABLE; +}; + +template <> +struct base_type_traits<array> +{ + static const base_type type = base_type::ARRAY; +}; + +template <> +struct base_type_traits<table_array> +{ + static const base_type type = base_type::TABLE_ARRAY; +}; +#endif + +/** + * A generic base TOML value used for type erasure. + */ +class base : public std::enable_shared_from_this<base> +{ + public: + virtual ~base() = default; + + virtual std::shared_ptr<base> clone() const = 0; + + /** + * Determines if the given TOML element is a value. + */ + virtual bool is_value() const + { + return false; + } + + /** + * Determines if the given TOML element is a table. + */ + virtual bool is_table() const + { + return false; + } + + /** + * Converts the TOML element into a table. + */ + std::shared_ptr<table> as_table() + { + if (is_table()) + return std::static_pointer_cast<table>(shared_from_this()); + return nullptr; + } + /** + * Determines if the TOML element is an array of "leaf" elements. + */ + virtual bool is_array() const + { + return false; + } + + /** + * Converts the TOML element to an array. + */ + std::shared_ptr<array> as_array() + { + if (is_array()) + return std::static_pointer_cast<array>(shared_from_this()); + return nullptr; + } + + /** + * Determines if the given TOML element is an array of tables. + */ + virtual bool is_table_array() const + { + return false; + } + + /** + * Converts the TOML element into a table array. + */ + std::shared_ptr<table_array> as_table_array() + { + if (is_table_array()) + return std::static_pointer_cast<table_array>(shared_from_this()); + return nullptr; + } + + /** + * Attempts to coerce the TOML element into a concrete TOML value + * of type T. + */ + template <class T> + std::shared_ptr<value<T>> as(); + + template <class T> + std::shared_ptr<const value<T>> as() const; + + template <class Visitor, class... Args> + void accept(Visitor&& visitor, Args&&... args) const; + +#if defined(CPPTOML_NO_RTTI) + base_type type() const + { + return type_; + } + + protected: + base(const base_type t) : type_(t) + { + // nothing + } + + private: + const base_type type_ = base_type::NONE; + +#else + protected: + base() + { + // nothing + } +#endif +}; + +/** + * A concrete TOML value representing the "leaves" of the "tree". + */ +template <class T> +class value : public base +{ + struct make_shared_enabler + { + // nothing; this is a private key accessible only to friends + }; + + template <class U> + friend std::shared_ptr<typename value_traits<U>::type> + cpptoml::make_value(U&& val); + + public: + static_assert(valid_value<T>::value, "invalid value type"); + + std::shared_ptr<base> clone() const override; + + value(const make_shared_enabler&, const T& val) : value(val) + { + // nothing; note that users cannot actually invoke this function + // because they lack access to the make_shared_enabler. + } + + bool is_value() const override + { + return true; + } + + /** + * Gets the data associated with this value. + */ + T& get() + { + return data_; + } + + /** + * Gets the data associated with this value. Const version. + */ + const T& get() const + { + return data_; + } + + private: + T data_; + + /** + * Constructs a value from the given data. + */ +#if defined(CPPTOML_NO_RTTI) + value(const T& val) : base(base_type_traits<T>::type), data_(val) + { + } +#else + value(const T& val) : data_(val) + { + } +#endif + + value(const value& val) = delete; + value& operator=(const value& val) = delete; +}; + +template <class T> +std::shared_ptr<typename value_traits<T>::type> make_value(T&& val) +{ + using value_type = typename value_traits<T>::type; + using enabler = typename value_type::make_shared_enabler; + return std::make_shared<value_type>( + enabler{}, value_traits<T>::construct(std::forward<T>(val))); +} + +template <class T> +inline std::shared_ptr<value<T>> base::as() +{ +#if defined(CPPTOML_NO_RTTI) + if (type() == base_type_traits<T>::type) + return std::static_pointer_cast<value<T>>(shared_from_this()); + else + return nullptr; +#else + return std::dynamic_pointer_cast<value<T>>(shared_from_this()); +#endif +} + +// special case value<double> to allow getting an integer parameter as a +// double value +template <> +inline std::shared_ptr<value<double>> base::as() +{ +#if defined(CPPTOML_NO_RTTI) + if (type() == base_type::FLOAT) + return std::static_pointer_cast<value<double>>(shared_from_this()); + + if (type() == base_type::INT) + { + auto v = std::static_pointer_cast<value<int64_t>>(shared_from_this()); + return make_value<double>(static_cast<double>(v->get())); + } +#else + if (auto v = std::dynamic_pointer_cast<value<double>>(shared_from_this())) + return v; + + if (auto v = std::dynamic_pointer_cast<value<int64_t>>(shared_from_this())) + return make_value<double>(static_cast<double>(v->get())); +#endif + + return nullptr; +} + +template <class T> +inline std::shared_ptr<const value<T>> base::as() const +{ +#if defined(CPPTOML_NO_RTTI) + if (type() == base_type_traits<T>::type) + return std::static_pointer_cast<const value<T>>(shared_from_this()); + else + return nullptr; +#else + return std::dynamic_pointer_cast<const value<T>>(shared_from_this()); +#endif +} + +// special case value<double> to allow getting an integer parameter as a +// double value +template <> +inline std::shared_ptr<const value<double>> base::as() const +{ +#if defined(CPPTOML_NO_RTTI) + if (type() == base_type::FLOAT) + return std::static_pointer_cast<const value<double>>( + shared_from_this()); + + if (type() == base_type::INT) + { + auto v = as<int64_t>(); + // the below has to be a non-const value<double> due to a bug in + // libc++: https://llvm.org/bugs/show_bug.cgi?id=18843 + return make_value<double>(static_cast<double>(v->get())); + } +#else + if (auto v + = std::dynamic_pointer_cast<const value<double>>(shared_from_this())) + return v; + + if (auto v = as<int64_t>()) + { + // the below has to be a non-const value<double> due to a bug in + // libc++: https://llvm.org/bugs/show_bug.cgi?id=18843 + return make_value<double>(static_cast<double>(v->get())); + } +#endif + + return nullptr; +} + +/** + * Exception class for array insertion errors. + */ +class array_exception : public std::runtime_error +{ + public: + array_exception(const std::string& err) : std::runtime_error{err} + { + } +}; + +class array : public base +{ + public: + friend std::shared_ptr<array> make_array(); + + std::shared_ptr<base> clone() const override; + + virtual bool is_array() const override + { + return true; + } + + using size_type = std::size_t; + + /** + * arrays can be iterated over + */ + using iterator = std::vector<std::shared_ptr<base>>::iterator; + + /** + * arrays can be iterated over. Const version. + */ + using const_iterator = std::vector<std::shared_ptr<base>>::const_iterator; + + iterator begin() + { + return values_.begin(); + } + + const_iterator begin() const + { + return values_.begin(); + } + + iterator end() + { + return values_.end(); + } + + const_iterator end() const + { + return values_.end(); + } + + /** + * Obtains the array (vector) of base values. + */ + std::vector<std::shared_ptr<base>>& get() + { + return values_; + } + + /** + * Obtains the array (vector) of base values. Const version. + */ + const std::vector<std::shared_ptr<base>>& get() const + { + return values_; + } + + std::shared_ptr<base> at(size_t idx) const + { + return values_.at(idx); + } + + /** + * Obtains an array of value<T>s. Note that elements may be + * nullptr if they cannot be converted to a value<T>. + */ + template <class T> + std::vector<std::shared_ptr<value<T>>> array_of() const + { + std::vector<std::shared_ptr<value<T>>> result(values_.size()); + + std::transform(values_.begin(), values_.end(), result.begin(), + [&](std::shared_ptr<base> v) { return v->as<T>(); }); + + return result; + } + + /** + * Obtains a option<vector<T>>. The option will be empty if the array + * contains values that are not of type T. + */ + template <class T> + inline typename array_of_trait<T>::return_type get_array_of() const + { + std::vector<T> result; + result.reserve(values_.size()); + + for (const auto& val : values_) + { + if (auto v = val->as<T>()) + result.push_back(v->get()); + else + return {}; + } + + return {std::move(result)}; + } + + /** + * Obtains an array of arrays. Note that elements may be nullptr + * if they cannot be converted to a array. + */ + std::vector<std::shared_ptr<array>> nested_array() const + { + std::vector<std::shared_ptr<array>> result(values_.size()); + + std::transform(values_.begin(), values_.end(), result.begin(), + [&](std::shared_ptr<base> v) -> std::shared_ptr<array> { + if (v->is_array()) + return std::static_pointer_cast<array>(v); + return std::shared_ptr<array>{}; + }); + + return result; + } + + /** + * Add a value to the end of the array + */ + template <class T> + void push_back(const std::shared_ptr<value<T>>& val) + { + if (values_.empty() || values_[0]->as<T>()) + { + values_.push_back(val); + } + else + { + throw array_exception{"Arrays must be homogenous."}; + } + } + + /** + * Add an array to the end of the array + */ + void push_back(const std::shared_ptr<array>& val) + { + if (values_.empty() || values_[0]->is_array()) + { + values_.push_back(val); + } + else + { + throw array_exception{"Arrays must be homogenous."}; + } + } + + /** + * Convenience function for adding a simple element to the end + * of the array. + */ + template <class T> + void push_back(T&& val, typename value_traits<T>::type* = 0) + { + push_back(make_value(std::forward<T>(val))); + } + + /** + * Insert a value into the array + */ + template <class T> + iterator insert(iterator position, const std::shared_ptr<value<T>>& value) + { + if (values_.empty() || values_[0]->as<T>()) + { + return values_.insert(position, value); + } + else + { + throw array_exception{"Arrays must be homogenous."}; + } + } + + /** + * Insert an array into the array + */ + iterator insert(iterator position, const std::shared_ptr<array>& value) + { + if (values_.empty() || values_[0]->is_array()) + { + return values_.insert(position, value); + } + else + { + throw array_exception{"Arrays must be homogenous."}; + } + } + + /** + * Convenience function for inserting a simple element in the array + */ + template <class T> + iterator insert(iterator position, T&& val, + typename value_traits<T>::type* = 0) + { + return insert(position, make_value(std::forward<T>(val))); + } + + /** + * Erase an element from the array + */ + iterator erase(iterator position) + { + return values_.erase(position); + } + + /** + * Clear the array + */ + void clear() + { + values_.clear(); + } + + /** + * Reserve space for n values. + */ + void reserve(size_type n) + { + values_.reserve(n); + } + + private: +#if defined(CPPTOML_NO_RTTI) + array() : base(base_type::ARRAY) + { + // empty + } +#else + array() = default; +#endif + + template <class InputIterator> + array(InputIterator begin, InputIterator end) : values_{begin, end} + { + // nothing + } + + array(const array& obj) = delete; + array& operator=(const array& obj) = delete; + + std::vector<std::shared_ptr<base>> values_; +}; + +inline std::shared_ptr<array> make_array() +{ + struct make_shared_enabler : public array + { + make_shared_enabler() + { + // nothing + } + }; + + return std::make_shared<make_shared_enabler>(); +} + +namespace detail +{ +template <> +inline std::shared_ptr<array> make_element<array>() +{ + return make_array(); +} +} // namespace detail + +/** + * Obtains a option<vector<T>>. The option will be empty if the array + * contains values that are not of type T. + */ +template <> +inline typename array_of_trait<array>::return_type +array::get_array_of<array>() const +{ + std::vector<std::shared_ptr<array>> result; + result.reserve(values_.size()); + + for (const auto& val : values_) + { + if (auto v = val->as_array()) + result.push_back(v); + else + return {}; + } + + return {std::move(result)}; +} + +class table; + +class table_array : public base +{ + friend class table; + friend std::shared_ptr<table_array> make_table_array(bool); + + public: + std::shared_ptr<base> clone() const override; + + using size_type = std::size_t; + + /** + * arrays can be iterated over + */ + using iterator = std::vector<std::shared_ptr<table>>::iterator; + + /** + * arrays can be iterated over. Const version. + */ + using const_iterator = std::vector<std::shared_ptr<table>>::const_iterator; + + iterator begin() + { + return array_.begin(); + } + + const_iterator begin() const + { + return array_.begin(); + } + + iterator end() + { + return array_.end(); + } + + const_iterator end() const + { + return array_.end(); + } + + virtual bool is_table_array() const override + { + return true; + } + + std::vector<std::shared_ptr<table>>& get() + { + return array_; + } + + const std::vector<std::shared_ptr<table>>& get() const + { + return array_; + } + + /** + * Add a table to the end of the array + */ + void push_back(const std::shared_ptr<table>& val) + { + array_.push_back(val); + } + + /** + * Insert a table into the array + */ + iterator insert(iterator position, const std::shared_ptr<table>& value) + { + return array_.insert(position, value); + } + + /** + * Erase an element from the array + */ + iterator erase(iterator position) + { + return array_.erase(position); + } + + /** + * Clear the array + */ + void clear() + { + array_.clear(); + } + + /** + * Reserve space for n tables. + */ + void reserve(size_type n) + { + array_.reserve(n); + } + + /** + * Whether or not the table array is declared inline. This mostly + * matters for parsing, where statically defined arrays cannot be + * appended to using the array-of-table syntax. + */ + bool is_inline() const + { + return is_inline_; + } + + private: +#if defined(CPPTOML_NO_RTTI) + table_array(bool is_inline = false) + : base(base_type::TABLE_ARRAY), is_inline_(is_inline) + { + // nothing + } +#else + table_array(bool is_inline = false) : is_inline_(is_inline) + { + // nothing + } +#endif + + table_array(const table_array& obj) = delete; + table_array& operator=(const table_array& rhs) = delete; + + std::vector<std::shared_ptr<table>> array_; + const bool is_inline_ = false; +}; + +inline std::shared_ptr<table_array> make_table_array(bool is_inline) +{ + struct make_shared_enabler : public table_array + { + make_shared_enabler(bool mse_is_inline) : table_array(mse_is_inline) + { + // nothing + } + }; + + return std::make_shared<make_shared_enabler>(is_inline); +} + +namespace detail +{ +template <> +inline std::shared_ptr<table_array> make_element<table_array>() +{ + return make_table_array(true); +} +} // namespace detail + +// The below are overloads for fetching specific value types out of a value +// where special casting behavior (like bounds checking) is desired + +template <class T> +typename std::enable_if<!std::is_floating_point<T>::value + && std::is_signed<T>::value, + option<T>>::type +get_impl(const std::shared_ptr<base>& elem) +{ + if (auto v = elem->as<int64_t>()) + { + if (v->get() < (std::numeric_limits<T>::min)()) + throw std::underflow_error{ + "T cannot represent the value requested in get"}; + + if (v->get() > (std::numeric_limits<T>::max)()) + throw std::overflow_error{ + "T cannot represent the value requested in get"}; + + return {static_cast<T>(v->get())}; + } + else + { + return {}; + } +} + +template <class T> +typename std::enable_if<!std::is_same<T, bool>::value + && std::is_unsigned<T>::value, + option<T>>::type +get_impl(const std::shared_ptr<base>& elem) +{ + if (auto v = elem->as<int64_t>()) + { + if (v->get() < 0) + throw std::underflow_error{"T cannot store negative value in get"}; + + if (static_cast<uint64_t>(v->get()) > (std::numeric_limits<T>::max)()) + throw std::overflow_error{ + "T cannot represent the value requested in get"}; + + return {static_cast<T>(v->get())}; + } + else + { + return {}; + } +} + +template <class T> +typename std::enable_if<!std::is_integral<T>::value + || std::is_same<T, bool>::value, + option<T>>::type +get_impl(const std::shared_ptr<base>& elem) +{ + if (auto v = elem->as<T>()) + { + return {v->get()}; + } + else + { + return {}; + } +} + +/** + * Represents a TOML keytable. + */ +class table : public base +{ + public: + friend class table_array; + friend std::shared_ptr<table> make_table(); + + std::shared_ptr<base> clone() const override; + + /** + * tables can be iterated over. + */ + using iterator = string_to_base_map::iterator; + + /** + * tables can be iterated over. Const version. + */ + using const_iterator = string_to_base_map::const_iterator; + + iterator begin() + { + return map_.begin(); + } + + const_iterator begin() const + { + return map_.begin(); + } + + iterator end() + { + return map_.end(); + } + + const_iterator end() const + { + return map_.end(); + } + + bool is_table() const override + { + return true; + } + + bool empty() const + { + return map_.empty(); + } + + /** + * Determines if this key table contains the given key. + */ + bool contains(const std::string& key) const + { + return map_.find(key) != map_.end(); + } + + /** + * Determines if this key table contains the given key. Will + * resolve "qualified keys". Qualified keys are the full access + * path separated with dots like "grandparent.parent.child". + */ + bool contains_qualified(const std::string& key) const + { + return resolve_qualified(key); + } + + /** + * Obtains the base for a given key. + * @throw std::out_of_range if the key does not exist + */ + std::shared_ptr<base> get(const std::string& key) const + { + return map_.at(key); + } + + /** + * Obtains the base for a given key. Will resolve "qualified + * keys". Qualified keys are the full access path separated with + * dots like "grandparent.parent.child". + * + * @throw std::out_of_range if the key does not exist + */ + std::shared_ptr<base> get_qualified(const std::string& key) const + { + std::shared_ptr<base> p; + resolve_qualified(key, &p); + return p; + } + + /** + * Obtains a table for a given key, if possible. + */ + std::shared_ptr<table> get_table(const std::string& key) const + { + if (contains(key) && get(key)->is_table()) + return std::static_pointer_cast<table>(get(key)); + return nullptr; + } + + /** + * Obtains a table for a given key, if possible. Will resolve + * "qualified keys". + */ + std::shared_ptr<table> get_table_qualified(const std::string& key) const + { + if (contains_qualified(key) && get_qualified(key)->is_table()) + return std::static_pointer_cast<table>(get_qualified(key)); + return nullptr; + } + + /** + * Obtains an array for a given key. + */ + std::shared_ptr<array> get_array(const std::string& key) const + { + if (!contains(key)) + return nullptr; + return get(key)->as_array(); + } + + /** + * Obtains an array for a given key. Will resolve "qualified keys". + */ + std::shared_ptr<array> get_array_qualified(const std::string& key) const + { + if (!contains_qualified(key)) + return nullptr; + return get_qualified(key)->as_array(); + } + + /** + * Obtains a table_array for a given key, if possible. + */ + std::shared_ptr<table_array> get_table_array(const std::string& key) const + { + if (!contains(key)) + return nullptr; + return get(key)->as_table_array(); + } + + /** + * Obtains a table_array for a given key, if possible. Will resolve + * "qualified keys". + */ + std::shared_ptr<table_array> + get_table_array_qualified(const std::string& key) const + { + if (!contains_qualified(key)) + return nullptr; + return get_qualified(key)->as_table_array(); + } + + /** + * Helper function that attempts to get a value corresponding + * to the template parameter from a given key. + */ + template <class T> + option<T> get_as(const std::string& key) const + { + try + { + return get_impl<T>(get(key)); + } + catch (const std::out_of_range&) + { + return {}; + } + } + + /** + * Helper function that attempts to get a value corresponding + * to the template parameter from a given key. Will resolve "qualified + * keys". + */ + template <class T> + option<T> get_qualified_as(const std::string& key) const + { + try + { + return get_impl<T>(get_qualified(key)); + } + catch (const std::out_of_range&) + { + return {}; + } + } + + /** + * Helper function that attempts to get an array of values of a given + * type corresponding to the template parameter for a given key. + * + * If the key doesn't exist, doesn't exist as an array type, or one or + * more keys inside the array type are not of type T, an empty option + * is returned. Otherwise, an option containing a vector of the values + * is returned. + */ + template <class T> + inline typename array_of_trait<T>::return_type + get_array_of(const std::string& key) const + { + if (auto v = get_array(key)) + { + std::vector<T> result; + result.reserve(v->get().size()); + + for (const auto& b : v->get()) + { + if (auto val = b->as<T>()) + result.push_back(val->get()); + else + return {}; + } + return {std::move(result)}; + } + + return {}; + } + + /** + * Helper function that attempts to get an array of values of a given + * type corresponding to the template parameter for a given key. Will + * resolve "qualified keys". + * + * If the key doesn't exist, doesn't exist as an array type, or one or + * more keys inside the array type are not of type T, an empty option + * is returned. Otherwise, an option containing a vector of the values + * is returned. + */ + template <class T> + inline typename array_of_trait<T>::return_type + get_qualified_array_of(const std::string& key) const + { + if (auto v = get_array_qualified(key)) + { + std::vector<T> result; + result.reserve(v->get().size()); + + for (const auto& b : v->get()) + { + if (auto val = b->as<T>()) + result.push_back(val->get()); + else + return {}; + } + return {std::move(result)}; + } + + return {}; + } + + /** + * Adds an element to the keytable. + */ + void insert(const std::string& key, const std::shared_ptr<base>& value) + { + map_[key] = value; + } + + /** + * Convenience shorthand for adding a simple element to the + * keytable. + */ + template <class T> + void insert(const std::string& key, T&& val, + typename value_traits<T>::type* = 0) + { + insert(key, make_value(std::forward<T>(val))); + } + + /** + * Removes an element from the table. + */ + void erase(const std::string& key) + { + map_.erase(key); + } + + private: +#if defined(CPPTOML_NO_RTTI) + table() : base(base_type::TABLE) + { + // nothing + } +#else + table() + { + // nothing + } +#endif + + table(const table& obj) = delete; + table& operator=(const table& rhs) = delete; + + std::vector<std::string> split(const std::string& value, + char separator) const + { + std::vector<std::string> result; + std::string::size_type p = 0; + std::string::size_type q; + while ((q = value.find(separator, p)) != std::string::npos) + { + result.emplace_back(value, p, q - p); + p = q + 1; + } + result.emplace_back(value, p); + return result; + } + + // If output parameter p is specified, fill it with the pointer to the + // specified entry and throw std::out_of_range if it couldn't be found. + // + // Otherwise, just return true if the entry could be found or false + // otherwise and do not throw. + bool resolve_qualified(const std::string& key, + std::shared_ptr<base>* p = nullptr) const + { + auto parts = split(key, '.'); + auto last_key = parts.back(); + parts.pop_back(); + + auto cur_table = this; + for (const auto& part : parts) + { + cur_table = cur_table->get_table(part).get(); + if (!cur_table) + { + if (!p) + return false; + + throw std::out_of_range{key + " is not a valid key"}; + } + } + + if (!p) + return cur_table->map_.count(last_key) != 0; + + *p = cur_table->map_.at(last_key); + return true; + } + + string_to_base_map map_; +}; + +/** + * Helper function that attempts to get an array of arrays for a given + * key. + * + * If the key doesn't exist, doesn't exist as an array type, or one or + * more keys inside the array type are not of type T, an empty option + * is returned. Otherwise, an option containing a vector of the values + * is returned. + */ +template <> +inline typename array_of_trait<array>::return_type +table::get_array_of<array>(const std::string& key) const +{ + if (auto v = get_array(key)) + { + std::vector<std::shared_ptr<array>> result; + result.reserve(v->get().size()); + + for (const auto& b : v->get()) + { + if (auto val = b->as_array()) + result.push_back(val); + else + return {}; + } + + return {std::move(result)}; + } + + return {}; +} + +/** + * Helper function that attempts to get an array of arrays for a given + * key. Will resolve "qualified keys". + * + * If the key doesn't exist, doesn't exist as an array type, or one or + * more keys inside the array type are not of type T, an empty option + * is returned. Otherwise, an option containing a vector of the values + * is returned. + */ +template <> +inline typename array_of_trait<array>::return_type +table::get_qualified_array_of<array>(const std::string& key) const +{ + if (auto v = get_array_qualified(key)) + { + std::vector<std::shared_ptr<array>> result; + result.reserve(v->get().size()); + + for (const auto& b : v->get()) + { + if (auto val = b->as_array()) + result.push_back(val); + else + return {}; + } + + return {std::move(result)}; + } + + return {}; +} + +std::shared_ptr<table> make_table() +{ + struct make_shared_enabler : public table + { + make_shared_enabler() + { + // nothing + } + }; + + return std::make_shared<make_shared_enabler>(); +} + +namespace detail +{ +template <> +inline std::shared_ptr<table> make_element<table>() +{ + return make_table(); +} +} // namespace detail + +template <class T> +std::shared_ptr<base> value<T>::clone() const +{ + return make_value(data_); +} + +inline std::shared_ptr<base> array::clone() const +{ + auto result = make_array(); + result->reserve(values_.size()); + for (const auto& ptr : values_) + result->values_.push_back(ptr->clone()); + return result; +} + +inline std::shared_ptr<base> table_array::clone() const +{ + auto result = make_table_array(is_inline()); + result->reserve(array_.size()); + for (const auto& ptr : array_) + result->array_.push_back(ptr->clone()->as_table()); + return result; +} + +inline std::shared_ptr<base> table::clone() const +{ + auto result = make_table(); + for (const auto& pr : map_) + result->insert(pr.first, pr.second->clone()); + return result; +} + +/** + * Exception class for all TOML parsing errors. + */ +class parse_exception : public std::runtime_error +{ + public: + parse_exception(const std::string& err) : std::runtime_error{err} + { + } + + parse_exception(const std::string& err, std::size_t line_number) + : std::runtime_error{err + " at line " + std::to_string(line_number)} + { + } +}; + +inline bool is_number(char c) +{ + return c >= '0' && c <= '9'; +} + +inline bool is_hex(char c) +{ + return is_number(c) || (c >= 'a' && c <= 'f') || (c >= 'A' && c <= 'F'); +} + +/** + * Helper object for consuming expected characters. + */ +template <class OnError> +class consumer +{ + public: + consumer(std::string::iterator& it, const std::string::iterator& end, + OnError&& on_error) + : it_(it), end_(end), on_error_(std::forward<OnError>(on_error)) + { + // nothing + } + + void operator()(char c) + { + if (it_ == end_ || *it_ != c) + on_error_(); + ++it_; + } + + template <std::size_t N> + void operator()(const char (&str)[N]) + { + std::for_each(std::begin(str), std::end(str) - 1, + [&](char c) { (*this)(c); }); + } + + void eat_or(char a, char b) + { + if (it_ == end_ || (*it_ != a && *it_ != b)) + on_error_(); + ++it_; + } + + int eat_digits(int len) + { + int val = 0; + for (int i = 0; i < len; ++i) + { + if (!is_number(*it_) || it_ == end_) + on_error_(); + val = 10 * val + (*it_++ - '0'); + } + return val; + } + + void error() + { + on_error_(); + } + + private: + std::string::iterator& it_; + const std::string::iterator& end_; + OnError on_error_; +}; + +template <class OnError> +consumer<OnError> make_consumer(std::string::iterator& it, + const std::string::iterator& end, + OnError&& on_error) +{ + return consumer<OnError>(it, end, std::forward<OnError>(on_error)); +} + +// replacement for std::getline to handle incorrectly line-ended files +// https://stackoverflow.com/questions/6089231/getting-std-ifstream-to-handle-lf-cr-and-crlf +namespace detail +{ +inline std::istream& getline(std::istream& input, std::string& line) +{ + line.clear(); + + std::istream::sentry sentry{input, true}; + auto sb = input.rdbuf(); + + while (true) + { + auto c = sb->sbumpc(); + if (c == '\r') + { + if (sb->sgetc() == '\n') + c = sb->sbumpc(); + } + + if (c == '\n') + return input; + + if (c == std::istream::traits_type::eof()) + { + if (line.empty()) + input.setstate(std::ios::eofbit); + return input; + } + + line.push_back(static_cast<char>(c)); + } +} +} // namespace detail + +/** + * The parser class. + */ +class parser +{ + public: + /** + * Parsers are constructed from streams. + */ + parser(std::istream& stream) : input_(stream) + { + // nothing + } + + parser& operator=(const parser& parser) = delete; + + /** + * Parses the stream this parser was created on until EOF. + * @throw parse_exception if there are errors in parsing + */ + std::shared_ptr<table> parse() + { + std::shared_ptr<table> root = make_table(); + + table* curr_table = root.get(); + + while (detail::getline(input_, line_)) + { + line_number_++; + auto it = line_.begin(); + auto end = line_.end(); + consume_whitespace(it, end); + if (it == end || *it == '#') + continue; + if (*it == '[') + { + curr_table = root.get(); + parse_table(it, end, curr_table); + } + else + { + parse_key_value(it, end, curr_table); + consume_whitespace(it, end); + eol_or_comment(it, end); + } + } + return root; + } + + private: +#if defined _MSC_VER + __declspec(noreturn) +#elif defined __GNUC__ + __attribute__((noreturn)) +#endif + void throw_parse_exception(const std::string& err) + { + throw parse_exception{err, line_number_}; + } + + void parse_table(std::string::iterator& it, + const std::string::iterator& end, table*& curr_table) + { + // remove the beginning keytable marker + ++it; + if (it == end) + throw_parse_exception("Unexpected end of table"); + if (*it == '[') + parse_table_array(it, end, curr_table); + else + parse_single_table(it, end, curr_table); + } + + void parse_single_table(std::string::iterator& it, + const std::string::iterator& end, + table*& curr_table) + { + if (it == end || *it == ']') + throw_parse_exception("Table name cannot be empty"); + + std::string full_table_name; + bool inserted = false; + + auto key_end = [](char c) { return c == ']'; }; + + auto key_part_handler = [&](const std::string& part) { + if (part.empty()) + throw_parse_exception("Empty component of table name"); + + if (!full_table_name.empty()) + full_table_name += '.'; + full_table_name += part; + + if (curr_table->contains(part)) + { +#if !defined(__PGI) + auto b = curr_table->get(part); +#else + // Workaround for PGI compiler + std::shared_ptr<base> b = curr_table->get(part); +#endif + if (b->is_table()) + curr_table = static_cast<table*>(b.get()); + else if (b->is_table_array()) + curr_table = std::static_pointer_cast<table_array>(b) + ->get() + .back() + .get(); + else + throw_parse_exception("Key " + full_table_name + + "already exists as a value"); + } + else + { + inserted = true; + curr_table->insert(part, make_table()); + curr_table = static_cast<table*>(curr_table->get(part).get()); + } + }; + + key_part_handler(parse_key(it, end, key_end, key_part_handler)); + + if (it == end) + throw_parse_exception( + "Unterminated table declaration; did you forget a ']'?"); + + if (*it != ']') + { + std::string errmsg{"Unexpected character in table definition: "}; + errmsg += '"'; + errmsg += *it; + errmsg += '"'; + throw_parse_exception(errmsg); + } + + // table already existed + if (!inserted) + { + auto is_value + = [](const std::pair<const std::string&, + const std::shared_ptr<base>&>& p) { + return p.second->is_value(); + }; + + // if there are any values, we can't add values to this table + // since it has already been defined. If there aren't any + // values, then it was implicitly created by something like + // [a.b] + if (curr_table->empty() + || std::any_of(curr_table->begin(), curr_table->end(), + is_value)) + { + throw_parse_exception("Redefinition of table " + + full_table_name); + } + } + + ++it; + consume_whitespace(it, end); + eol_or_comment(it, end); + } + + void parse_table_array(std::string::iterator& it, + const std::string::iterator& end, table*& curr_table) + { + ++it; + if (it == end || *it == ']') + throw_parse_exception("Table array name cannot be empty"); + + auto key_end = [](char c) { return c == ']'; }; + + std::string full_ta_name; + auto key_part_handler = [&](const std::string& part) { + if (part.empty()) + throw_parse_exception("Empty component of table array name"); + + if (!full_ta_name.empty()) + full_ta_name += '.'; + full_ta_name += part; + + if (curr_table->contains(part)) + { +#if !defined(__PGI) + auto b = curr_table->get(part); +#else + // Workaround for PGI compiler + std::shared_ptr<base> b = curr_table->get(part); +#endif + + // if this is the end of the table array name, add an + // element to the table array that we just looked up, + // provided it was not declared inline + if (it != end && *it == ']') + { + if (!b->is_table_array()) + { + throw_parse_exception("Key " + full_ta_name + + " is not a table array"); + } + + auto v = b->as_table_array(); + + if (v->is_inline()) + { + throw_parse_exception("Static array " + full_ta_name + + " cannot be appended to"); + } + + v->get().push_back(make_table()); + curr_table = v->get().back().get(); + } + // otherwise, just keep traversing down the key name + else + { + if (b->is_table()) + curr_table = static_cast<table*>(b.get()); + else if (b->is_table_array()) + curr_table = std::static_pointer_cast<table_array>(b) + ->get() + .back() + .get(); + else + throw_parse_exception("Key " + full_ta_name + + " already exists as a value"); + } + } + else + { + // if this is the end of the table array name, add a new + // table array and a new table inside that array for us to + // add keys to next + if (it != end && *it == ']') + { + curr_table->insert(part, make_table_array()); + auto arr = std::static_pointer_cast<table_array>( + curr_table->get(part)); + arr->get().push_back(make_table()); + curr_table = arr->get().back().get(); + } + // otherwise, create the implicitly defined table and move + // down to it + else + { + curr_table->insert(part, make_table()); + curr_table + = static_cast<table*>(curr_table->get(part).get()); + } + } + }; + + key_part_handler(parse_key(it, end, key_end, key_part_handler)); + + // consume the last "]]" + auto eat = make_consumer(it, end, [this]() { + throw_parse_exception("Unterminated table array name"); + }); + eat(']'); + eat(']'); + + consume_whitespace(it, end); + eol_or_comment(it, end); + } + + void parse_key_value(std::string::iterator& it, std::string::iterator& end, + table* curr_table) + { + auto key_end = [](char c) { return c == '='; }; + + auto key_part_handler = [&](const std::string& part) { + // two cases: this key part exists already, in which case it must + // be a table, or it doesn't exist in which case we must create + // an implicitly defined table + if (curr_table->contains(part)) + { + auto val = curr_table->get(part); + if (val->is_table()) + { + curr_table = static_cast<table*>(val.get()); + } + else + { + throw_parse_exception("Key " + part + + " already exists as a value"); + } + } + else + { + auto newtable = make_table(); + curr_table->insert(part, newtable); + curr_table = newtable.get(); + } + }; + + auto key = parse_key(it, end, key_end, key_part_handler); + + if (curr_table->contains(key)) + throw_parse_exception("Key " + key + " already present"); + if (it == end || *it != '=') + throw_parse_exception("Value must follow after a '='"); + ++it; + consume_whitespace(it, end); + curr_table->insert(key, parse_value(it, end)); + consume_whitespace(it, end); + } + + template <class KeyEndFinder, class KeyPartHandler> + std::string + parse_key(std::string::iterator& it, const std::string::iterator& end, + KeyEndFinder&& key_end, KeyPartHandler&& key_part_handler) + { + // parse the key as a series of one or more simple-keys joined with '.' + while (it != end && !key_end(*it)) + { + auto part = parse_simple_key(it, end); + consume_whitespace(it, end); + + if (it == end || key_end(*it)) + { + return part; + } + + if (*it != '.') + { + std::string errmsg{"Unexpected character in key: "}; + errmsg += '"'; + errmsg += *it; + errmsg += '"'; + throw_parse_exception(errmsg); + } + + key_part_handler(part); + + // consume the dot + ++it; + } + + throw_parse_exception("Unexpected end of key"); + } + + std::string parse_simple_key(std::string::iterator& it, + const std::string::iterator& end) + { + consume_whitespace(it, end); + + if (it == end) + throw_parse_exception("Unexpected end of key (blank key?)"); + + if (*it == '"' || *it == '\'') + { + return string_literal(it, end, *it); + } + else + { + auto bke = std::find_if(it, end, [](char c) { + return c == '.' || c == '=' || c == ']'; + }); + return parse_bare_key(it, bke); + } + } + + std::string parse_bare_key(std::string::iterator& it, + const std::string::iterator& end) + { + if (it == end) + { + throw_parse_exception("Bare key missing name"); + } + + auto key_end = end; + --key_end; + consume_backwards_whitespace(key_end, it); + ++key_end; + std::string key{it, key_end}; + + if (std::find(it, key_end, '#') != key_end) + { + throw_parse_exception("Bare key " + key + " cannot contain #"); + } + + if (std::find_if(it, key_end, + [](char c) { return c == ' ' || c == '\t'; }) + != key_end) + { + throw_parse_exception("Bare key " + key + + " cannot contain whitespace"); + } + + if (std::find_if(it, key_end, + [](char c) { return c == '[' || c == ']'; }) + != key_end) + { + throw_parse_exception("Bare key " + key + + " cannot contain '[' or ']'"); + } + + it = end; + return key; + } + + enum class parse_type + { + STRING = 1, + LOCAL_TIME, + LOCAL_DATE, + LOCAL_DATETIME, + OFFSET_DATETIME, + INT, + FLOAT, + BOOL, + ARRAY, + INLINE_TABLE + }; + + std::shared_ptr<base> parse_value(std::string::iterator& it, + std::string::iterator& end) + { + parse_type type = determine_value_type(it, end); + switch (type) + { + case parse_type::STRING: + return parse_string(it, end); + case parse_type::LOCAL_TIME: + return parse_time(it, end); + case parse_type::LOCAL_DATE: + case parse_type::LOCAL_DATETIME: + case parse_type::OFFSET_DATETIME: + return parse_date(it, end); + case parse_type::INT: + case parse_type::FLOAT: + return parse_number(it, end); + case parse_type::BOOL: + return parse_bool(it, end); + case parse_type::ARRAY: + return parse_array(it, end); + case parse_type::INLINE_TABLE: + return parse_inline_table(it, end); + default: + throw_parse_exception("Failed to parse value"); + } + } + + parse_type determine_value_type(const std::string::iterator& it, + const std::string::iterator& end) + { + if (it == end) + { + throw_parse_exception("Failed to parse value type"); + } + if (*it == '"' || *it == '\'') + { + return parse_type::STRING; + } + else if (is_time(it, end)) + { + return parse_type::LOCAL_TIME; + } + else if (auto dtype = date_type(it, end)) + { + return *dtype; + } + else if (is_number(*it) || *it == '-' || *it == '+' + || (*it == 'i' && it + 1 != end && it[1] == 'n' + && it + 2 != end && it[2] == 'f') + || (*it == 'n' && it + 1 != end && it[1] == 'a' + && it + 2 != end && it[2] == 'n')) + { + return determine_number_type(it, end); + } + else if (*it == 't' || *it == 'f') + { + return parse_type::BOOL; + } + else if (*it == '[') + { + return parse_type::ARRAY; + } + else if (*it == '{') + { + return parse_type::INLINE_TABLE; + } + throw_parse_exception("Failed to parse value type"); + } + + parse_type determine_number_type(const std::string::iterator& it, + const std::string::iterator& end) + { + // determine if we are an integer or a float + auto check_it = it; + if (*check_it == '-' || *check_it == '+') + ++check_it; + + if (check_it == end) + throw_parse_exception("Malformed number"); + + if (*check_it == 'i' || *check_it == 'n') + return parse_type::FLOAT; + + while (check_it != end && is_number(*check_it)) + ++check_it; + if (check_it != end && *check_it == '.') + { + ++check_it; + while (check_it != end && is_number(*check_it)) + ++check_it; + return parse_type::FLOAT; + } + else + { + return parse_type::INT; + } + } + + std::shared_ptr<value<std::string>> parse_string(std::string::iterator& it, + std::string::iterator& end) + { + auto delim = *it; + assert(delim == '"' || delim == '\''); + + // end is non-const here because we have to be able to potentially + // parse multiple lines in a string, not just one + auto check_it = it; + ++check_it; + if (check_it != end && *check_it == delim) + { + ++check_it; + if (check_it != end && *check_it == delim) + { + it = ++check_it; + return parse_multiline_string(it, end, delim); + } + } + return make_value<std::string>(string_literal(it, end, delim)); + } + + std::shared_ptr<value<std::string>> + parse_multiline_string(std::string::iterator& it, + std::string::iterator& end, char delim) + { + std::stringstream ss; + + auto is_ws = [](char c) { return c == ' ' || c == '\t'; }; + + bool consuming = false; + std::shared_ptr<value<std::string>> ret; + + auto handle_line = [&](std::string::iterator& local_it, + std::string::iterator& local_end) { + if (consuming) + { + local_it = std::find_if_not(local_it, local_end, is_ws); + + // whole line is whitespace + if (local_it == local_end) + return; + } + + consuming = false; + + while (local_it != local_end) + { + // handle escaped characters + if (delim == '"' && *local_it == '\\') + { + auto check = local_it; + // check if this is an actual escape sequence or a + // whitespace escaping backslash + ++check; + consume_whitespace(check, local_end); + if (check == local_end) + { + consuming = true; + break; + } + + ss << parse_escape_code(local_it, local_end); + continue; + } + + // if we can end the string + if (std::distance(local_it, local_end) >= 3) + { + auto check = local_it; + // check for """ + if (*check++ == delim && *check++ == delim + && *check++ == delim) + { + local_it = check; + ret = make_value<std::string>(ss.str()); + break; + } + } + + ss << *local_it++; + } + }; + + // handle the remainder of the current line + handle_line(it, end); + if (ret) + return ret; + + // start eating lines + while (detail::getline(input_, line_)) + { + ++line_number_; + + it = line_.begin(); + end = line_.end(); + + handle_line(it, end); + + if (ret) + return ret; + + if (!consuming) + ss << std::endl; + } + + throw_parse_exception("Unterminated multi-line basic string"); + } + + std::string string_literal(std::string::iterator& it, + const std::string::iterator& end, char delim) + { + ++it; + std::string val; + while (it != end) + { + // handle escaped characters + if (delim == '"' && *it == '\\') + { + val += parse_escape_code(it, end); + } + else if (*it == delim) + { + ++it; + consume_whitespace(it, end); + return val; + } + else + { + val += *it++; + } + } + throw_parse_exception("Unterminated string literal"); + } + + std::string parse_escape_code(std::string::iterator& it, + const std::string::iterator& end) + { + ++it; + if (it == end) + throw_parse_exception("Invalid escape sequence"); + char value; + if (*it == 'b') + { + value = '\b'; + } + else if (*it == 't') + { + value = '\t'; + } + else if (*it == 'n') + { + value = '\n'; + } + else if (*it == 'f') + { + value = '\f'; + } + else if (*it == 'r') + { + value = '\r'; + } + else if (*it == '"') + { + value = '"'; + } + else if (*it == '\\') + { + value = '\\'; + } + else if (*it == 'u' || *it == 'U') + { + return parse_unicode(it, end); + } + else + { + throw_parse_exception("Invalid escape sequence"); + } + ++it; + return std::string(1, value); + } + + std::string parse_unicode(std::string::iterator& it, + const std::string::iterator& end) + { + bool large = *it++ == 'U'; + auto codepoint = parse_hex(it, end, large ? 0x10000000 : 0x1000); + + if ((codepoint > 0xd7ff && codepoint < 0xe000) || codepoint > 0x10ffff) + { + throw_parse_exception( + "Unicode escape sequence is not a Unicode scalar value"); + } + + std::string result; + // See Table 3-6 of the Unicode standard + if (codepoint <= 0x7f) + { + // 1-byte codepoints: 00000000 0xxxxxxx + // repr: 0xxxxxxx + result += static_cast<char>(codepoint & 0x7f); + } + else if (codepoint <= 0x7ff) + { + // 2-byte codepoints: 00000yyy yyxxxxxx + // repr: 110yyyyy 10xxxxxx + // + // 0x1f = 00011111 + // 0xc0 = 11000000 + // + result += static_cast<char>(0xc0 | ((codepoint >> 6) & 0x1f)); + // + // 0x80 = 10000000 + // 0x3f = 00111111 + // + result += static_cast<char>(0x80 | (codepoint & 0x3f)); + } + else if (codepoint <= 0xffff) + { + // 3-byte codepoints: zzzzyyyy yyxxxxxx + // repr: 1110zzzz 10yyyyyy 10xxxxxx + // + // 0xe0 = 11100000 + // 0x0f = 00001111 + // + result += static_cast<char>(0xe0 | ((codepoint >> 12) & 0x0f)); + result += static_cast<char>(0x80 | ((codepoint >> 6) & 0x1f)); + result += static_cast<char>(0x80 | (codepoint & 0x3f)); + } + else + { + // 4-byte codepoints: 000uuuuu zzzzyyyy yyxxxxxx + // repr: 11110uuu 10uuzzzz 10yyyyyy 10xxxxxx + // + // 0xf0 = 11110000 + // 0x07 = 00000111 + // + result += static_cast<char>(0xf0 | ((codepoint >> 18) & 0x07)); + result += static_cast<char>(0x80 | ((codepoint >> 12) & 0x3f)); + result += static_cast<char>(0x80 | ((codepoint >> 6) & 0x3f)); + result += static_cast<char>(0x80 | (codepoint & 0x3f)); + } + return result; + } + + uint32_t parse_hex(std::string::iterator& it, + const std::string::iterator& end, uint32_t place) + { + uint32_t value = 0; + while (place > 0) + { + if (it == end) + throw_parse_exception("Unexpected end of unicode sequence"); + + if (!is_hex(*it)) + throw_parse_exception("Invalid unicode escape sequence"); + + value += place * hex_to_digit(*it++); + place /= 16; + } + return value; + } + + uint32_t hex_to_digit(char c) + { + if (is_number(c)) + return static_cast<uint32_t>(c - '0'); + return 10 + + static_cast<uint32_t>(c + - ((c >= 'a' && c <= 'f') ? 'a' : 'A')); + } + + std::shared_ptr<base> parse_number(std::string::iterator& it, + const std::string::iterator& end) + { + auto check_it = it; + auto check_end = find_end_of_number(it, end); + + auto eat_sign = [&]() { + if (check_it != end && (*check_it == '-' || *check_it == '+')) + ++check_it; + }; + + auto check_no_leading_zero = [&]() { + if (check_it != end && *check_it == '0' && check_it + 1 != check_end + && check_it[1] != '.') + { + throw_parse_exception("Numbers may not have leading zeros"); + } + }; + + auto eat_digits = [&](bool (*check_char)(char)) { + auto beg = check_it; + while (check_it != end && check_char(*check_it)) + { + ++check_it; + if (check_it != end && *check_it == '_') + { + ++check_it; + if (check_it == end || !check_char(*check_it)) + throw_parse_exception("Malformed number"); + } + } + + if (check_it == beg) + throw_parse_exception("Malformed number"); + }; + + auto eat_hex = [&]() { eat_digits(&is_hex); }; + + auto eat_numbers = [&]() { eat_digits(&is_number); }; + + if (check_it != end && *check_it == '0' && check_it + 1 != check_end + && (check_it[1] == 'x' || check_it[1] == 'o' || check_it[1] == 'b')) + { + ++check_it; + char base = *check_it; + ++check_it; + if (base == 'x') + { + eat_hex(); + return parse_int(it, check_it, 16); + } + else if (base == 'o') + { + auto start = check_it; + eat_numbers(); + auto val = parse_int(start, check_it, 8, "0"); + it = start; + return val; + } + else // if (base == 'b') + { + auto start = check_it; + eat_numbers(); + auto val = parse_int(start, check_it, 2); + it = start; + return val; + } + } + + eat_sign(); + check_no_leading_zero(); + + if (check_it != end && check_it + 1 != end && check_it + 2 != end) + { + if (check_it[0] == 'i' && check_it[1] == 'n' && check_it[2] == 'f') + { + auto val = std::numeric_limits<double>::infinity(); + if (*it == '-') + val = -val; + it = check_it + 3; + return make_value(val); + } + else if (check_it[0] == 'n' && check_it[1] == 'a' + && check_it[2] == 'n') + { + auto val = std::numeric_limits<double>::quiet_NaN(); + if (*it == '-') + val = -val; + it = check_it + 3; + return make_value(val); + } + } + + eat_numbers(); + + if (check_it != end + && (*check_it == '.' || *check_it == 'e' || *check_it == 'E')) + { + bool is_exp = *check_it == 'e' || *check_it == 'E'; + + ++check_it; + if (check_it == end) + throw_parse_exception("Floats must have trailing digits"); + + auto eat_exp = [&]() { + eat_sign(); + check_no_leading_zero(); + eat_numbers(); + }; + + if (is_exp) + eat_exp(); + else + eat_numbers(); + + if (!is_exp && check_it != end + && (*check_it == 'e' || *check_it == 'E')) + { + ++check_it; + eat_exp(); + } + + return parse_float(it, check_it); + } + else + { + return parse_int(it, check_it); + } + } + + std::shared_ptr<value<int64_t>> parse_int(std::string::iterator& it, + const std::string::iterator& end, + int base = 10, + const char* prefix = "") + { + std::string v{it, end}; + v = prefix + v; + v.erase(std::remove(v.begin(), v.end(), '_'), v.end()); + it = end; + try + { + return make_value<int64_t>(std::stoll(v, nullptr, base)); + } + catch (const std::invalid_argument& ex) + { + throw_parse_exception("Malformed number (invalid argument: " + + std::string{ex.what()} + ")"); + } + catch (const std::out_of_range& ex) + { + throw_parse_exception("Malformed number (out of range: " + + std::string{ex.what()} + ")"); + } + } + + std::shared_ptr<value<double>> parse_float(std::string::iterator& it, + const std::string::iterator& end) + { + std::string v{it, end}; + v.erase(std::remove(v.begin(), v.end(), '_'), v.end()); + it = end; + char decimal_point = std::localeconv()->decimal_point[0]; + std::replace(v.begin(), v.end(), '.', decimal_point); + try + { + return make_value<double>(std::stod(v)); + } + catch (const std::invalid_argument& ex) + { + throw_parse_exception("Malformed number (invalid argument: " + + std::string{ex.what()} + ")"); + } + catch (const std::out_of_range& ex) + { + throw_parse_exception("Malformed number (out of range: " + + std::string{ex.what()} + ")"); + } + } + + std::shared_ptr<value<bool>> parse_bool(std::string::iterator& it, + const std::string::iterator& end) + { + auto eat = make_consumer(it, end, [this]() { + throw_parse_exception("Attempted to parse invalid boolean value"); + }); + + if (*it == 't') + { + eat("true"); + return make_value<bool>(true); + } + else if (*it == 'f') + { + eat("false"); + return make_value<bool>(false); + } + + eat.error(); + return nullptr; + } + + std::string::iterator find_end_of_number(std::string::iterator it, + std::string::iterator end) + { + auto ret = std::find_if(it, end, [](char c) { + return !is_number(c) && c != '_' && c != '.' && c != 'e' && c != 'E' + && c != '-' && c != '+' && c != 'x' && c != 'o' && c != 'b'; + }); + if (ret != end && ret + 1 != end && ret + 2 != end) + { + if ((ret[0] == 'i' && ret[1] == 'n' && ret[2] == 'f') + || (ret[0] == 'n' && ret[1] == 'a' && ret[2] == 'n')) + { + ret = ret + 3; + } + } + return ret; + } + + std::string::iterator find_end_of_date(std::string::iterator it, + std::string::iterator end) + { + auto end_of_date = std::find_if(it, end, [](char c) { + return !is_number(c) && c != '-'; + }); + if (end_of_date != end && *end_of_date == ' ' && end_of_date + 1 != end + && is_number(end_of_date[1])) + end_of_date++; + return std::find_if(end_of_date, end, [](char c) { + return !is_number(c) && c != 'T' && c != 'Z' && c != ':' + && c != '-' && c != '+' && c != '.'; + }); + } + + std::string::iterator find_end_of_time(std::string::iterator it, + std::string::iterator end) + { + return std::find_if(it, end, [](char c) { + return !is_number(c) && c != ':' && c != '.'; + }); + } + + local_time read_time(std::string::iterator& it, + const std::string::iterator& end) + { + auto time_end = find_end_of_time(it, end); + + auto eat = make_consumer( + it, time_end, [&]() { throw_parse_exception("Malformed time"); }); + + local_time ltime; + + ltime.hour = eat.eat_digits(2); + eat(':'); + ltime.minute = eat.eat_digits(2); + eat(':'); + ltime.second = eat.eat_digits(2); + + int power = 100000; + if (it != time_end && *it == '.') + { + ++it; + while (it != time_end && is_number(*it)) + { + ltime.microsecond += power * (*it++ - '0'); + power /= 10; + } + } + + if (it != time_end) + throw_parse_exception("Malformed time"); + + return ltime; + } + + std::shared_ptr<value<local_time>> + parse_time(std::string::iterator& it, const std::string::iterator& end) + { + return make_value(read_time(it, end)); + } + + std::shared_ptr<base> parse_date(std::string::iterator& it, + const std::string::iterator& end) + { + auto date_end = find_end_of_date(it, end); + + auto eat = make_consumer( + it, date_end, [&]() { throw_parse_exception("Malformed date"); }); + + local_date ldate; + ldate.year = eat.eat_digits(4); + eat('-'); + ldate.month = eat.eat_digits(2); + eat('-'); + ldate.day = eat.eat_digits(2); + + if (it == date_end) + return make_value(ldate); + + eat.eat_or('T', ' '); + + local_datetime ldt; + static_cast<local_date&>(ldt) = ldate; + static_cast<local_time&>(ldt) = read_time(it, date_end); + + if (it == date_end) + return make_value(ldt); + + offset_datetime dt; + static_cast<local_datetime&>(dt) = ldt; + + int hoff = 0; + int moff = 0; + if (*it == '+' || *it == '-') + { + auto plus = *it == '+'; + ++it; + + hoff = eat.eat_digits(2); + dt.hour_offset = (plus) ? hoff : -hoff; + eat(':'); + moff = eat.eat_digits(2); + dt.minute_offset = (plus) ? moff : -moff; + } + else if (*it == 'Z') + { + ++it; + } + + if (it != date_end) + throw_parse_exception("Malformed date"); + + return make_value(dt); + } + + std::shared_ptr<base> parse_array(std::string::iterator& it, + std::string::iterator& end) + { + // this gets ugly because of the "homogeneity" restriction: + // arrays can either be of only one type, or contain arrays + // (each of those arrays could be of different types, though) + // + // because of the latter portion, we don't really have a choice + // but to represent them as arrays of base values... + ++it; + + // ugh---have to read the first value to determine array type... + skip_whitespace_and_comments(it, end); + + // edge case---empty array + if (*it == ']') + { + ++it; + return make_array(); + } + + auto val_end = std::find_if( + it, end, [](char c) { return c == ',' || c == ']' || c == '#'; }); + parse_type type = determine_value_type(it, val_end); + switch (type) + { + case parse_type::STRING: + return parse_value_array<std::string>(it, end); + case parse_type::LOCAL_TIME: + return parse_value_array<local_time>(it, end); + case parse_type::LOCAL_DATE: + return parse_value_array<local_date>(it, end); + case parse_type::LOCAL_DATETIME: + return parse_value_array<local_datetime>(it, end); + case parse_type::OFFSET_DATETIME: + return parse_value_array<offset_datetime>(it, end); + case parse_type::INT: + return parse_value_array<int64_t>(it, end); + case parse_type::FLOAT: + return parse_value_array<double>(it, end); + case parse_type::BOOL: + return parse_value_array<bool>(it, end); + case parse_type::ARRAY: + return parse_object_array<array>(&parser::parse_array, '[', it, + end); + case parse_type::INLINE_TABLE: + return parse_object_array<table_array>( + &parser::parse_inline_table, '{', it, end); + default: + throw_parse_exception("Unable to parse array"); + } + } + + template <class Value> + std::shared_ptr<array> parse_value_array(std::string::iterator& it, + std::string::iterator& end) + { + auto arr = make_array(); + while (it != end && *it != ']') + { + auto val = parse_value(it, end); + if (auto v = val->as<Value>()) + arr->get().push_back(val); + else + throw_parse_exception("Arrays must be homogeneous"); + skip_whitespace_and_comments(it, end); + if (*it != ',') + break; + ++it; + skip_whitespace_and_comments(it, end); + } + if (it != end) + ++it; + return arr; + } + + template <class Object, class Function> + std::shared_ptr<Object> parse_object_array(Function&& fun, char delim, + std::string::iterator& it, + std::string::iterator& end) + { + auto arr = detail::make_element<Object>(); + + while (it != end && *it != ']') + { + if (*it != delim) + throw_parse_exception("Unexpected character in array"); + + arr->get().push_back(((*this).*fun)(it, end)); + skip_whitespace_and_comments(it, end); + + if (it == end || *it != ',') + break; + + ++it; + skip_whitespace_and_comments(it, end); + } + + if (it == end || *it != ']') + throw_parse_exception("Unterminated array"); + + ++it; + return arr; + } + + std::shared_ptr<table> parse_inline_table(std::string::iterator& it, + std::string::iterator& end) + { + auto tbl = make_table(); + do + { + ++it; + if (it == end) + throw_parse_exception("Unterminated inline table"); + + consume_whitespace(it, end); + if (it != end && *it != '}') + { + parse_key_value(it, end, tbl.get()); + consume_whitespace(it, end); + } + } while (*it == ','); + + if (it == end || *it != '}') + throw_parse_exception("Unterminated inline table"); + + ++it; + consume_whitespace(it, end); + + return tbl; + } + + void skip_whitespace_and_comments(std::string::iterator& start, + std::string::iterator& end) + { + consume_whitespace(start, end); + while (start == end || *start == '#') + { + if (!detail::getline(input_, line_)) + throw_parse_exception("Unclosed array"); + line_number_++; + start = line_.begin(); + end = line_.end(); + consume_whitespace(start, end); + } + } + + void consume_whitespace(std::string::iterator& it, + const std::string::iterator& end) + { + while (it != end && (*it == ' ' || *it == '\t')) + ++it; + } + + void consume_backwards_whitespace(std::string::iterator& back, + const std::string::iterator& front) + { + while (back != front && (*back == ' ' || *back == '\t')) + --back; + } + + void eol_or_comment(const std::string::iterator& it, + const std::string::iterator& end) + { + if (it != end && *it != '#') + throw_parse_exception("Unidentified trailing character '" + + std::string{*it} + + "'---did you forget a '#'?"); + } + + bool is_time(const std::string::iterator& it, + const std::string::iterator& end) + { + auto time_end = find_end_of_time(it, end); + auto len = std::distance(it, time_end); + + if (len < 8) + return false; + + if (it[2] != ':' || it[5] != ':') + return false; + + if (len > 8) + return it[8] == '.' && len > 9; + + return true; + } + + option<parse_type> date_type(const std::string::iterator& it, + const std::string::iterator& end) + { + auto date_end = find_end_of_date(it, end); + auto len = std::distance(it, date_end); + + if (len < 10) + return {}; + + if (it[4] != '-' || it[7] != '-') + return {}; + + if (len >= 19 && (it[10] == 'T' || it[10] == ' ') + && is_time(it + 11, date_end)) + { + // datetime type + auto time_end = find_end_of_time(it + 11, date_end); + if (time_end == date_end) + return {parse_type::LOCAL_DATETIME}; + else + return {parse_type::OFFSET_DATETIME}; + } + else if (len == 10) + { + // just a regular date + return {parse_type::LOCAL_DATE}; + } + + return {}; + } + + std::istream& input_; + std::string line_; + std::size_t line_number_ = 0; +}; + +/** + * Utility function to parse a file as a TOML file. Returns the root table. + * Throws a parse_exception if the file cannot be opened. + */ +inline std::shared_ptr<table> parse_file(const std::string& filename) +{ +#if defined(BOOST_NOWIDE_FSTREAM_INCLUDED_HPP) + boost::nowide::ifstream file{filename.c_str()}; +#elif defined(NOWIDE_FSTREAM_INCLUDED_HPP) + nowide::ifstream file{filename.c_str()}; +#else + std::ifstream file{filename}; +#endif + if (!file.is_open()) + throw parse_exception{filename + " could not be opened for parsing"}; + parser p{file}; + return p.parse(); +} + +template <class... Ts> +struct value_accept; + +template <> +struct value_accept<> +{ + template <class Visitor, class... Args> + static void accept(const base&, Visitor&&, Args&&...) + { + // nothing + } +}; + +template <class T, class... Ts> +struct value_accept<T, Ts...> +{ + template <class Visitor, class... Args> + static void accept(const base& b, Visitor&& visitor, Args&&... args) + { + if (auto v = b.as<T>()) + { + visitor.visit(*v, std::forward<Args>(args)...); + } + else + { + value_accept<Ts...>::accept(b, std::forward<Visitor>(visitor), + std::forward<Args>(args)...); + } + } +}; + +/** + * base implementation of accept() that calls visitor.visit() on the concrete + * class. + */ +template <class Visitor, class... Args> +void base::accept(Visitor&& visitor, Args&&... args) const +{ + if (is_value()) + { + using value_acceptor + = value_accept<std::string, int64_t, double, bool, local_date, + local_time, local_datetime, offset_datetime>; + value_acceptor::accept(*this, std::forward<Visitor>(visitor), + std::forward<Args>(args)...); + } + else if (is_table()) + { + visitor.visit(static_cast<const table&>(*this), + std::forward<Args>(args)...); + } + else if (is_array()) + { + visitor.visit(static_cast<const array&>(*this), + std::forward<Args>(args)...); + } + else if (is_table_array()) + { + visitor.visit(static_cast<const table_array&>(*this), + std::forward<Args>(args)...); + } +} + +/** + * Writer that can be passed to accept() functions of cpptoml objects and + * will output valid TOML to a stream. + */ +class toml_writer +{ + public: + /** + * Construct a toml_writer that will write to the given stream + */ + toml_writer(std::ostream& s, const std::string& indent_space = "\t") + : stream_(s), indent_(indent_space), has_naked_endline_(false) + { + // nothing + } + + public: + /** + * Output a base value of the TOML tree. + */ + template <class T> + void visit(const value<T>& v, bool = false) + { + write(v); + } + + /** + * Output a table element of the TOML tree + */ + void visit(const table& t, bool in_array = false) + { + write_table_header(in_array); + std::vector<std::string> values; + std::vector<std::string> tables; + + for (const auto& i : t) + { + if (i.second->is_table() || i.second->is_table_array()) + { + tables.push_back(i.first); + } + else + { + values.push_back(i.first); + } + } + + for (unsigned int i = 0; i < values.size(); ++i) + { + path_.push_back(values[i]); + + if (i > 0) + endline(); + + write_table_item_header(*t.get(values[i])); + t.get(values[i])->accept(*this, false); + path_.pop_back(); + } + + for (unsigned int i = 0; i < tables.size(); ++i) + { + path_.push_back(tables[i]); + + if (values.size() > 0 || i > 0) + endline(); + + write_table_item_header(*t.get(tables[i])); + t.get(tables[i])->accept(*this, false); + path_.pop_back(); + } + + endline(); + } + + /** + * Output an array element of the TOML tree + */ + void visit(const array& a, bool = false) + { + write("["); + + for (unsigned int i = 0; i < a.get().size(); ++i) + { + if (i > 0) + write(", "); + + if (a.get()[i]->is_array()) + { + a.get()[i]->as_array()->accept(*this, true); + } + else + { + a.get()[i]->accept(*this, true); + } + } + + write("]"); + } + + /** + * Output a table_array element of the TOML tree + */ + void visit(const table_array& t, bool = false) + { + for (unsigned int j = 0; j < t.get().size(); ++j) + { + if (j > 0) + endline(); + + t.get()[j]->accept(*this, true); + } + + endline(); + } + + /** + * Escape a string for output. + */ + static std::string escape_string(const std::string& str) + { + std::string res; + for (auto it = str.begin(); it != str.end(); ++it) + { + if (*it == '\b') + { + res += "\\b"; + } + else if (*it == '\t') + { + res += "\\t"; + } + else if (*it == '\n') + { + res += "\\n"; + } + else if (*it == '\f') + { + res += "\\f"; + } + else if (*it == '\r') + { + res += "\\r"; + } + else if (*it == '"') + { + res += "\\\""; + } + else if (*it == '\\') + { + res += "\\\\"; + } + else if (static_cast<uint32_t>(*it) <= UINT32_C(0x001f)) + { + res += "\\u"; + std::stringstream ss; + ss << std::hex << static_cast<uint32_t>(*it); + res += ss.str(); + } + else + { + res += *it; + } + } + return res; + } + + protected: + /** + * Write out a string. + */ + void write(const value<std::string>& v) + { + write("\""); + write(escape_string(v.get())); + write("\""); + } + + /** + * Write out a double. + */ + void write(const value<double>& v) + { + std::stringstream ss; + ss << std::showpoint + << std::setprecision(std::numeric_limits<double>::max_digits10) + << v.get(); + + auto double_str = ss.str(); + auto pos = double_str.find("e0"); + if (pos != std::string::npos) + double_str.replace(pos, 2, "e"); + pos = double_str.find("e-0"); + if (pos != std::string::npos) + double_str.replace(pos, 3, "e-"); + + stream_ << double_str; + has_naked_endline_ = false; + } + + /** + * Write out an integer, local_date, local_time, local_datetime, or + * offset_datetime. + */ + template <class T> + typename std::enable_if< + is_one_of<T, int64_t, local_date, local_time, local_datetime, + offset_datetime>::value>::type + write(const value<T>& v) + { + write(v.get()); + } + + /** + * Write out a boolean. + */ + void write(const value<bool>& v) + { + write((v.get() ? "true" : "false")); + } + + /** + * Write out the header of a table. + */ + void write_table_header(bool in_array = false) + { + if (!path_.empty()) + { + indent(); + + write("["); + + if (in_array) + { + write("["); + } + + for (unsigned int i = 0; i < path_.size(); ++i) + { + if (i > 0) + { + write("."); + } + + if (path_[i].find_first_not_of("ABCDEFGHIJKLMNOPQRSTUVWXYZabcde" + "fghijklmnopqrstuvwxyz0123456789" + "_-") + == std::string::npos) + { + write(path_[i]); + } + else + { + write("\""); + write(escape_string(path_[i])); + write("\""); + } + } + + if (in_array) + { + write("]"); + } + + write("]"); + endline(); + } + } + + /** + * Write out the identifier for an item in a table. + */ + void write_table_item_header(const base& b) + { + if (!b.is_table() && !b.is_table_array()) + { + indent(); + + if (path_.back().find_first_not_of("ABCDEFGHIJKLMNOPQRSTUVWXYZabcde" + "fghijklmnopqrstuvwxyz0123456789" + "_-") + == std::string::npos) + { + write(path_.back()); + } + else + { + write("\""); + write(escape_string(path_.back())); + write("\""); + } + + write(" = "); + } + } + + private: + /** + * Indent the proper number of tabs given the size of + * the path. + */ + void indent() + { + for (std::size_t i = 1; i < path_.size(); ++i) + write(indent_); + } + + /** + * Write a value out to the stream. + */ + template <class T> + void write(const T& v) + { + stream_ << v; + has_naked_endline_ = false; + } + + /** + * Write an endline out to the stream + */ + void endline() + { + if (!has_naked_endline_) + { + stream_ << "\n"; + has_naked_endline_ = true; + } + } + + private: + std::ostream& stream_; + const std::string indent_; + std::vector<std::string> path_; + bool has_naked_endline_; +}; + +inline std::ostream& operator<<(std::ostream& stream, const base& b) +{ + toml_writer writer{stream}; + b.accept(writer); + return stream; +} + +template <class T> +std::ostream& operator<<(std::ostream& stream, const value<T>& v) +{ + toml_writer writer{stream}; + v.accept(writer); + return stream; +} + +inline std::ostream& operator<<(std::ostream& stream, const table& t) +{ + toml_writer writer{stream}; + t.accept(writer); + return stream; +} + +inline std::ostream& operator<<(std::ostream& stream, const table_array& t) +{ + toml_writer writer{stream}; + t.accept(writer); + return stream; +} + +inline std::ostream& operator<<(std::ostream& stream, const array& a) +{ + toml_writer writer{stream}; + a.accept(writer); + return stream; +} +} // namespace cpptoml +#endif // CPPTOML_H diff --git a/third_party/nix/src/libexpr/attr-path.cc b/third_party/nix/src/libexpr/attr-path.cc new file mode 100644 index 0000000000..1815b5e510 --- /dev/null +++ b/third_party/nix/src/libexpr/attr-path.cc @@ -0,0 +1,107 @@ +#include "attr-path.hh" + +#include "eval-inline.hh" +#include "util.hh" + +namespace nix { + +static Strings parseAttrPath(const std::string& s) { + Strings res; + std::string cur; + string::const_iterator i = s.begin(); + while (i != s.end()) { + if (*i == '.') { + res.push_back(cur); + cur.clear(); + } else if (*i == '"') { + ++i; + while (true) { + if (i == s.end()) { + throw Error(format("missing closing quote in selection path '%1%'") % + s); + } + if (*i == '"') { + break; + } + cur.push_back(*i++); + } + } else { + cur.push_back(*i); + } + ++i; + } + if (!cur.empty()) { + res.push_back(cur); + } + return res; +} + +Value* findAlongAttrPath(EvalState& state, const std::string& attrPath, + Bindings& autoArgs, Value& vIn) { + Strings tokens = parseAttrPath(attrPath); + + Error attrError = + Error(format("attribute selection path '%1%' does not match expression") % + attrPath); + + Value* v = &vIn; + + for (auto& attr : tokens) { + /* Is i an index (integer) or a normal attribute name? */ + enum { apAttr, apIndex } apType = apAttr; + unsigned int attrIndex; + if (string2Int(attr, attrIndex)) { + apType = apIndex; + } + + /* Evaluate the expression. */ + Value* vNew = state.allocValue(); + state.autoCallFunction(autoArgs, *v, *vNew); + v = vNew; + state.forceValue(*v); + + /* It should evaluate to either a set or an expression, + according to what is specified in the attrPath. */ + + if (apType == apAttr) { + if (v->type != tAttrs) { + throw TypeError(format("the expression selected by the selection path " + "'%1%' should be a set but is %2%") % + attrPath % showType(*v)); + } + + if (attr.empty()) { + throw Error(format("empty attribute name in selection path '%1%'") % + attrPath); + } + + Bindings::iterator a = v->attrs->find(state.symbols.Create(attr)); + if (a == v->attrs->end()) { + throw Error( + format("attribute '%1%' in selection path '%2%' not found") % attr % + attrPath); + } + v = &*(a->second).value; + } + + else if (apType == apIndex) { + if (!v->isList()) { + throw TypeError(format("the expression selected by the selection path " + "'%1%' should be a list but is %2%") % + attrPath % showType(*v)); + } + + if (attrIndex >= v->listSize()) { + throw Error( + format("list index %1% in selection path '%2%' is out of range") % + attrIndex % attrPath); + } + + v = v->listElems()[attrIndex]; + } + } + + return v; +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/attr-path.hh b/third_party/nix/src/libexpr/attr-path.hh new file mode 100644 index 0000000000..889c2158d7 --- /dev/null +++ b/third_party/nix/src/libexpr/attr-path.hh @@ -0,0 +1,13 @@ +#pragma once + +#include <map> +#include <string> + +#include "eval.hh" + +namespace nix { + +Value* findAlongAttrPath(EvalState& state, const std::string& attrPath, + Bindings& autoArgs, Value& vIn); + +} diff --git a/third_party/nix/src/libexpr/attr-set.cc b/third_party/nix/src/libexpr/attr-set.cc new file mode 100644 index 0000000000..e961156487 --- /dev/null +++ b/third_party/nix/src/libexpr/attr-set.cc @@ -0,0 +1,75 @@ +#include "attr-set.hh" + +#include <new> + +#include <absl/container/btree_map.h> +#include <gc/gc_cpp.h> + +#include "eval-inline.hh" + +namespace nix { + +// TODO: using insert_or_assign might break existing Nix code because +// of the weird ordering situation. Need to investigate. +void Bindings::push_back(const Attr& attr) { + attributes_.insert_or_assign(attr.name, attr); +} + +size_t Bindings::size() { return attributes_.size(); } + +size_t Bindings::capacity() { return 0; } + +bool Bindings::empty() { return attributes_.empty(); } + +std::vector<const Attr*> Bindings::lexicographicOrder() { + std::vector<const Attr*> res; + res.reserve(attributes_.size()); + + for (const auto& [key, value] : attributes_) { + res.emplace_back(&value); + } + + return res; +} + +Bindings::iterator Bindings::find(const Symbol& name) { + return attributes_.find(name); +} + +Bindings::iterator Bindings::begin() { return attributes_.begin(); } + +Bindings::iterator Bindings::end() { return attributes_.end(); } + +void Bindings::merge(Bindings* other) { + // We want the values from the other attribute set to take + // precedence, but .merge() works the other way around. + // + // To work around that, we merge and then swap. + other->attributes_.merge(attributes_); + attributes_.swap(other->attributes_); +} + +Bindings* Bindings::NewGC() { return new (GC) Bindings; } + +void EvalState::mkAttrs(Value& v, size_t capacity) { + if (capacity == 0) { + v = vEmptySet; + return; + } + clearValue(v); + v.type = tAttrs; + v.attrs = Bindings::NewGC(); + nrAttrsets++; + nrAttrsInAttrsets += capacity; +} + +/* Create a new attribute named 'name' on an existing attribute set stored + in 'vAttrs' and return the newly allocated Value which is associated with + this attribute. */ +Value* EvalState::allocAttr(Value& vAttrs, const Symbol& name) { + Value* v = allocValue(); + vAttrs.attrs->push_back(Attr(name, v)); + return v; +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/attr-set.hh b/third_party/nix/src/libexpr/attr-set.hh new file mode 100644 index 0000000000..caddc6bebd --- /dev/null +++ b/third_party/nix/src/libexpr/attr-set.hh @@ -0,0 +1,76 @@ +// This file implements the underlying structure of Nix attribute sets. +#pragma once + +#include <absl/container/btree_map.h> + +#include "nixexpr.hh" +#include "symbol-table.hh" +#include "types.hh" // TODO(tazjin): audit this include + +namespace nix { // TODO(tazjin): ::expr + +class EvalState; +struct Value; + +/* Map one attribute name to its value. */ +struct Attr { + Symbol name; + Value* value; // TODO(tazjin): Who owns this? + Pos* pos; // TODO(tazjin): Who owns this? + Attr(Symbol name, Value* value, Pos* pos = &noPos) + : name(name), value(value), pos(pos){}; + Attr() : pos(&noPos){}; + bool operator<(const Attr& a) const { return name < a.name; } +}; + +// TODO: remove this, it only exists briefly while I get rid of the +// current Attr struct +inline bool operator==(const Attr& lhs, const Attr& rhs) { + return lhs.name == rhs.name; +} + +class Bindings { + public: + typedef absl::btree_map<Symbol, Attr>::iterator iterator; + + // Allocate a new attribute set that is visible to the garbage + // collector. + static Bindings* NewGC(); + + // Return the number of contained elements. + size_t size(); + + // Is this attribute set empty? + bool empty(); + + // TODO(tazjin): rename + // TODO(tazjin): does this need to copy? + void push_back(const Attr& attr); + + // Look up a specific element of the attribute set. + iterator find(const Symbol& name); + + // TODO + iterator begin(); + iterator end(); + + // Merge values from other into the current attribute + void merge(Bindings* other); + + // ??? + [[deprecated]] size_t capacity(); + + // oh no + // Attr& operator[](size_t pos); // { return attrs[pos]; } + + // TODO: can callers just iterate? + [[deprecated]] std::vector<const Attr*> lexicographicOrder(); + + // oh no + friend class EvalState; + + private: + absl::btree_map<Symbol, Attr> attributes_; +}; + +} // namespace nix diff --git a/third_party/nix/src/libexpr/common-eval-args.cc b/third_party/nix/src/libexpr/common-eval-args.cc new file mode 100644 index 0000000000..2059d53741 --- /dev/null +++ b/third_party/nix/src/libexpr/common-eval-args.cc @@ -0,0 +1,64 @@ +#include "common-eval-args.hh" + +#include "download.hh" +#include "eval.hh" +#include "shared.hh" +#include "util.hh" + +namespace nix { + +MixEvalArgs::MixEvalArgs() { + mkFlag() + .longName("arg") + .description("argument to be passed to Nix functions") + .labels({"name", "expr"}) + .handler( + [&](std::vector<std::string> ss) { autoArgs[ss[0]] = 'E' + ss[1]; }); + + mkFlag() + .longName("argstr") + .description("string-valued argument to be passed to Nix functions") + .labels({"name", "string"}) + .handler( + [&](std::vector<std::string> ss) { autoArgs[ss[0]] = 'S' + ss[1]; }); + + mkFlag() + .shortName('I') + .longName("include") + .description( + "add a path to the list of locations used to look up <...> file " + "names") + .label("path") + .handler([&](const std::string& s) { searchPath.push_back(s); }); +} + +Bindings* MixEvalArgs::getAutoArgs(EvalState& state) { + Bindings* res = Bindings::NewGC(); + for (auto& i : autoArgs) { + Value* v = state.allocValue(); + if (i.second[0] == 'E') { + state.mkThunk_( + *v, state.parseExprFromString(string(i.second, 1), absPath("."))); + } else { + mkString(*v, string(i.second, 1)); + } + res->push_back(Attr(state.symbols.Create(i.first), v)); + } + return res; +} + +Path lookupFileArg(EvalState& state, std::string s) { + if (isUri(s)) { + CachedDownloadRequest request(s); + request.unpack = true; + return getDownloader()->downloadCached(state.store, request).path; + } + if (s.size() > 2 && s.at(0) == '<' && s.at(s.size() - 1) == '>') { + Path p = s.substr(1, s.size() - 2); + return state.findFile(p); + } else { + return absPath(s); + } +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/common-eval-args.hh b/third_party/nix/src/libexpr/common-eval-args.hh new file mode 100644 index 0000000000..dad30daf6b --- /dev/null +++ b/third_party/nix/src/libexpr/common-eval-args.hh @@ -0,0 +1,24 @@ +#pragma once + +#include "args.hh" + +namespace nix { + +class Store; +class EvalState; +class Bindings; + +struct MixEvalArgs : virtual Args { + MixEvalArgs(); + + Bindings* getAutoArgs(EvalState& state); + + Strings searchPath; + + private: + std::map<std::string, std::string> autoArgs; +}; + +Path lookupFileArg(EvalState& state, std::string s); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/eval-inline.hh b/third_party/nix/src/libexpr/eval-inline.hh new file mode 100644 index 0000000000..ca0cf2a360 --- /dev/null +++ b/third_party/nix/src/libexpr/eval-inline.hh @@ -0,0 +1,90 @@ +#pragma once + +#include "eval.hh" + +#define LocalNoInline(f) \ + static f __attribute__((noinline)); \ + f +#define LocalNoInlineNoReturn(f) \ + static f __attribute__((noinline, noreturn)); \ + f + +namespace nix { + +LocalNoInlineNoReturn(void throwEvalError(const char* s, const Pos& pos)) { + throw EvalError(format(s) % pos); +} + +LocalNoInlineNoReturn(void throwTypeError(const char* s, const Value& v)) { + throw TypeError(format(s) % showType(v)); +} + +LocalNoInlineNoReturn(void throwTypeError(const char* s, const Value& v, + const Pos& pos)) { + throw TypeError(format(s) % showType(v) % pos); +} + +void EvalState::forceValue(Value& v, const Pos& pos) { + if (v.type == tThunk) { + Env* env = v.thunk.env; + Expr* expr = v.thunk.expr; + try { + v.type = tBlackhole; + // checkInterrupt(); + expr->eval(*this, *env, v); + } catch (...) { + v.type = tThunk; + v.thunk.env = env; + v.thunk.expr = expr; + throw; + } + } else if (v.type == tApp) { + callFunction(*v.app.left, *v.app.right, v, noPos); + } else if (v.type == tBlackhole) { + throwEvalError("infinite recursion encountered, at %1%", pos); + } +} + +inline void EvalState::forceAttrs(Value& v) { + forceValue(v); + if (v.type != tAttrs) { + throwTypeError("value is %1% while a set was expected", v); + } +} + +inline void EvalState::forceAttrs(Value& v, const Pos& pos) { + forceValue(v); + if (v.type != tAttrs) { + throwTypeError("value is %1% while a set was expected, at %2%", v, pos); + } +} + +inline void EvalState::forceList(Value& v) { + forceValue(v); + if (!v.isList()) { + throwTypeError("value is %1% while a list was expected", v); + } +} + +inline void EvalState::forceList(Value& v, const Pos& pos) { + forceValue(v); + if (!v.isList()) { + throwTypeError("value is %1% while a list was expected, at %2%", v, pos); + } +} + +/* Note: Various places expect the allocated memory to be zeroed. */ +inline void* allocBytes(size_t n) { + void* p; +#if HAVE_BOEHMGC + p = GC_MALLOC(n); +#else + p = calloc(n, 1); +#endif + if (!p) { + throw std::bad_alloc(); + } + return p; +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/eval.cc b/third_party/nix/src/libexpr/eval.cc new file mode 100644 index 0000000000..0abf94c874 --- /dev/null +++ b/third_party/nix/src/libexpr/eval.cc @@ -0,0 +1,2001 @@ +#include "eval.hh" + +#include <algorithm> +#include <chrono> +#include <cstring> +#include <fstream> +#include <iostream> +#include <new> + +#include <gc/gc.h> +#include <gc/gc_cpp.h> +#include <glog/logging.h> +#include <sys/resource.h> +#include <sys/time.h> +#include <unistd.h> + +#include "derivations.hh" +#include "download.hh" +#include "eval-inline.hh" +#include "function-trace.hh" +#include "globals.hh" +#include "hash.hh" +#include "json.hh" +#include "store-api.hh" +#include "util.hh" + +namespace nix { + +static char* dupString(const char* s) { + char* t; + t = GC_STRDUP(s); + if (t == nullptr) { + throw std::bad_alloc(); + } + return t; +} + +static void printValue(std::ostream& str, std::set<const Value*>& active, + const Value& v) { + checkInterrupt(); + + if (active.find(&v) != active.end()) { + str << "<CYCLE>"; + return; + } + active.insert(&v); + + switch (v.type) { + case tInt: + str << v.integer; + break; + case tBool: + str << (v.boolean ? "true" : "false"); + break; + case tString: + str << "\""; + for (const char* i = v.string.s; *i != 0; i++) { + if (*i == '\"' || *i == '\\') { + str << "\\" << *i; + } else if (*i == '\n') { + str << "\\n"; + } else if (*i == '\r') { + str << "\\r"; + } else if (*i == '\t') { + str << "\\t"; + } else { + str << *i; + } + } + str << "\""; + break; + case tPath: + str << v.path; // !!! escaping? + break; + case tNull: + str << "null"; + break; + case tAttrs: { + str << "{ "; + for (auto& i : v.attrs->lexicographicOrder()) { + str << i->name << " = "; + printValue(str, active, *i->value); + str << "; "; + } + str << "}"; + break; + } + case tList1: + case tList2: + case tListN: + str << "[ "; + for (unsigned int n = 0; n < v.listSize(); ++n) { + printValue(str, active, *v.listElems()[n]); + str << " "; + } + str << "]"; + break; + case tThunk: + case tApp: + str << "<CODE>"; + break; + case tLambda: + str << "<LAMBDA>"; + break; + case tPrimOp: + str << "<PRIMOP>"; + break; + case tPrimOpApp: + str << "<PRIMOP-APP>"; + break; + case tExternal: + str << *v.external; + break; + case tFloat: + str << v.fpoint; + break; + default: + throw Error("invalid value"); + } + + active.erase(&v); +} + +std::ostream& operator<<(std::ostream& str, const Value& v) { + std::set<const Value*> active; + printValue(str, active, v); + return str; +} + +const Value* getPrimOp(const Value& v) { + const Value* primOp = &v; + while (primOp->type == tPrimOpApp) { + primOp = primOp->primOpApp.left; + } + assert(primOp->type == tPrimOp); + return primOp; +} + +string showType(const Value& v) { + switch (v.type) { + case tInt: + return "an integer"; + case tBool: + return "a boolean"; + case tString: + return v.string.context != nullptr ? "a string with context" : "a string"; + case tPath: + return "a path"; + case tNull: + return "null"; + case tAttrs: + return "a set"; + case tList1: + case tList2: + case tListN: + return "a list"; + case tThunk: + return "a thunk"; + case tApp: + return "a function application"; + case tLambda: + return "a function"; + case tBlackhole: + return "a black hole"; + case tPrimOp: + return fmt("the built-in function '%s'", string(v.primOp->name)); + case tPrimOpApp: + return fmt("the partially applied built-in function '%s'", + string(getPrimOp(v)->primOp->name)); + case tExternal: + return v.external->showType(); + case tFloat: + return "a float"; + } + abort(); +} + +#if HAVE_BOEHMGC +/* Called when the Boehm GC runs out of memory. */ +static void* oomHandler(size_t requested) { + /* Convert this to a proper C++ exception. */ + throw std::bad_alloc(); +} +#endif + +static Symbol getName(const AttrName& name, EvalState& state, Env& env) { + if (name.symbol.set()) { + return name.symbol; + } + Value nameValue; + name.expr->eval(state, env, nameValue); + state.forceStringNoCtx(nameValue); + return state.symbols.Create(nameValue.string.s); +} + +static bool gcInitialised = false; + +void initGC() { + if (gcInitialised) { + return; + } + +#if HAVE_BOEHMGC + /* Initialise the Boehm garbage collector. */ + + /* Don't look for interior pointers. This reduces the odds of + misdetection a bit. */ + GC_set_all_interior_pointers(0); + + /* We don't have any roots in data segments, so don't scan from + there. */ + GC_set_no_dls(1); + + GC_INIT(); + + GC_set_oom_fn(oomHandler); + + /* Set the initial heap size to something fairly big (25% of + physical RAM, up to a maximum of 384 MiB) so that in most cases + we don't need to garbage collect at all. (Collection has a + fairly significant overhead.) The heap size can be overridden + through libgc's GC_INITIAL_HEAP_SIZE environment variable. We + should probably also provide a nix.conf setting for this. Note + that GC_expand_hp() causes a lot of virtual, but not physical + (resident) memory to be allocated. This might be a problem on + systems that don't overcommit. */ + if (getenv("GC_INITIAL_HEAP_SIZE") == nullptr) { + size_t size = 32 * 1024 * 1024; +#if HAVE_SYSCONF && defined(_SC_PAGESIZE) && defined(_SC_PHYS_PAGES) + size_t maxSize = 384 * 1024 * 1024; + long pageSize = sysconf(_SC_PAGESIZE); + long pages = sysconf(_SC_PHYS_PAGES); + if (pageSize != -1) { + size = (pageSize * pages) / 4; + } // 25% of RAM + if (size > maxSize) { + size = maxSize; + } +#endif + DLOG(INFO) << "setting initial heap size to " << size << " bytes"; + GC_expand_hp(size); + } + +#endif + + gcInitialised = true; +} + +/* Very hacky way to parse $NIX_PATH, which is colon-separated, but + can contain URLs (e.g. "nixpkgs=https://bla...:foo=https://"). */ +static Strings parseNixPath(const std::string& s) { + Strings res; + + auto p = s.begin(); + + while (p != s.end()) { + auto start = p; + auto start2 = p; + + while (p != s.end() && *p != ':') { + if (*p == '=') { + start2 = p + 1; + } + ++p; + } + + if (p == s.end()) { + if (p != start) { + res.push_back(std::string(start, p)); + } + break; + } + + if (*p == ':') { + if (isUri(std::string(start2, s.end()))) { + ++p; + while (p != s.end() && *p != ':') { + ++p; + } + } + res.push_back(std::string(start, p)); + if (p == s.end()) { + break; + } + } + + ++p; + } + + return res; +} + +EvalState::EvalState(const Strings& _searchPath, const ref<Store>& store) + : sWith(symbols.Create("<with>")), + sOutPath(symbols.Create("outPath")), + sDrvPath(symbols.Create("drvPath")), + sType(symbols.Create("type")), + sMeta(symbols.Create("meta")), + sName(symbols.Create("name")), + sValue(symbols.Create("value")), + sSystem(symbols.Create("system")), + sOverrides(symbols.Create("__overrides")), + sOutputs(symbols.Create("outputs")), + sOutputName(symbols.Create("outputName")), + sIgnoreNulls(symbols.Create("__ignoreNulls")), + sFile(symbols.Create("file")), + sLine(symbols.Create("line")), + sColumn(symbols.Create("column")), + sFunctor(symbols.Create("__functor")), + sToString(symbols.Create("__toString")), + sRight(symbols.Create("right")), + sWrong(symbols.Create("wrong")), + sStructuredAttrs(symbols.Create("__structuredAttrs")), + sBuilder(symbols.Create("builder")), + sArgs(symbols.Create("args")), + sOutputHash(symbols.Create("outputHash")), + sOutputHashAlgo(symbols.Create("outputHashAlgo")), + sOutputHashMode(symbols.Create("outputHashMode")), + repair(NoRepair), + store(store), + baseEnv(allocEnv(128)), + staticBaseEnv(false, nullptr) { + countCalls = getEnv("NIX_COUNT_CALLS", "0") != "0"; + + assert(gcInitialised); + + static_assert(sizeof(Env) <= 16, "environment must be <= 16 bytes"); + + /* Initialise the Nix expression search path. */ + if (!evalSettings.pureEval) { + Strings paths = parseNixPath(getEnv("NIX_PATH", "")); + for (auto& i : _searchPath) { + addToSearchPath(i); + } + for (auto& i : paths) { + addToSearchPath(i); + } + } + addToSearchPath("nix=" + + canonPath(settings.nixDataDir + "/nix/corepkgs", true)); + + if (evalSettings.restrictEval || evalSettings.pureEval) { + allowedPaths = PathSet(); + + for (auto& i : searchPath) { + auto r = resolveSearchPathElem(i); + if (!r.first) { + continue; + } + + auto path = r.second; + + if (store->isInStore(r.second)) { + PathSet closure; + store->computeFSClosure(store->toStorePath(r.second), closure); + for (auto& path : closure) { + allowedPaths->insert(path); + } + } else { + allowedPaths->insert(r.second); + } + } + } + + clearValue(vEmptySet); + vEmptySet.type = tAttrs; + vEmptySet.attrs = Bindings::NewGC(); + + createBaseEnv(); +} + +EvalState::~EvalState() = default; + +Path EvalState::checkSourcePath(const Path& path_) { + if (!allowedPaths) { + return path_; + } + + auto i = resolvedPaths.find(path_); + if (i != resolvedPaths.end()) { + return i->second; + } + + bool found = false; + + /* First canonicalize the path without symlinks, so we make sure an + * attacker can't append ../../... to a path that would be in allowedPaths + * and thus leak symlink targets. + */ + Path abspath = canonPath(path_); + + for (auto& i : *allowedPaths) { + if (isDirOrInDir(abspath, i)) { + found = true; + break; + } + } + + if (!found) { + throw RestrictedPathError( + "access to path '%1%' is forbidden in restricted mode", abspath); + } + + /* Resolve symlinks. */ + DLOG(INFO) << "checking access to '" << abspath << "'"; + Path path = canonPath(abspath, true); + + for (auto& i : *allowedPaths) { + if (isDirOrInDir(path, i)) { + resolvedPaths[path_] = path; + return path; + } + } + + throw RestrictedPathError( + "access to path '%1%' is forbidden in restricted mode", path); +} + +void EvalState::checkURI(const std::string& uri) { + if (!evalSettings.restrictEval) { + return; + } + + /* 'uri' should be equal to a prefix, or in a subdirectory of a + prefix. Thus, the prefix https://github.co does not permit + access to https://github.com. Note: this allows 'http://' and + 'https://' as prefixes for any http/https URI. */ + for (auto& prefix : evalSettings.allowedUris.get()) { + if (uri == prefix || + (uri.size() > prefix.size() && !prefix.empty() && + hasPrefix(uri, prefix) && + (prefix[prefix.size() - 1] == '/' || uri[prefix.size()] == '/'))) { + return; + } + } + + /* If the URI is a path, then check it against allowedPaths as + well. */ + if (hasPrefix(uri, "/")) { + checkSourcePath(uri); + return; + } + + if (hasPrefix(uri, "file://")) { + checkSourcePath(std::string(uri, 7)); + return; + } + + throw RestrictedPathError( + "access to URI '%s' is forbidden in restricted mode", uri); +} + +Path EvalState::toRealPath(const Path& path, const PathSet& context) { + // FIXME: check whether 'path' is in 'context'. + return !context.empty() && store->isInStore(path) ? store->toRealPath(path) + : path; +}; + +Value* EvalState::addConstant(const std::string& name, Value& v) { + Value* v2 = allocValue(); + *v2 = v; + staticBaseEnv.vars[symbols.Create(name)] = baseEnvDispl; + baseEnv.values[baseEnvDispl++] = v2; + std::string name2 = string(name, 0, 2) == "__" ? string(name, 2) : name; + baseEnv.values[0]->attrs->push_back(Attr(symbols.Create(name2), v2)); + return v2; +} + +Value* EvalState::addPrimOp(const std::string& name, size_t arity, + PrimOpFun primOp) { + if (arity == 0) { + Value v; + primOp(*this, noPos, nullptr, v); + return addConstant(name, v); + } + Value* v = allocValue(); + std::string name2 = string(name, 0, 2) == "__" ? string(name, 2) : name; + Symbol sym = symbols.Create(name2); + v->type = tPrimOp; + v->primOp = new PrimOp(primOp, arity, sym); + staticBaseEnv.vars[symbols.Create(name)] = baseEnvDispl; + baseEnv.values[baseEnvDispl++] = v; + baseEnv.values[0]->attrs->push_back(Attr(sym, v)); + return v; +} + +Value& EvalState::getBuiltin(const std::string& name) { + return *baseEnv.values[0]->attrs->find(symbols.Create(name))->second.value; +} + +/* Every "format" object (even temporary) takes up a few hundred bytes + of stack space, which is a real killer in the recursive + evaluator. So here are some helper functions for throwing + exceptions. */ + +LocalNoInlineNoReturn(void throwEvalError(const char* s, + const std::string& s2)) { + throw EvalError(format(s) % s2); +} + +LocalNoInlineNoReturn(void throwEvalError(const char* s, const std::string& s2, + const Pos& pos)) { + throw EvalError(format(s) % s2 % pos); +} + +LocalNoInlineNoReturn(void throwEvalError(const char* s, const std::string& s2, + const std::string& s3)) { + throw EvalError(format(s) % s2 % s3); +} + +LocalNoInlineNoReturn(void throwEvalError(const char* s, const std::string& s2, + const std::string& s3, + const Pos& pos)) { + throw EvalError(format(s) % s2 % s3 % pos); +} + +LocalNoInlineNoReturn(void throwEvalError(const char* s, const Symbol& sym, + const Pos& p1, const Pos& p2)) { + throw EvalError(format(s) % sym % p1 % p2); +} + +LocalNoInlineNoReturn(void throwTypeError(const char* s, const Pos& pos)) { + throw TypeError(format(s) % pos); +} + +LocalNoInlineNoReturn(void throwTypeError(const char* s, + const std::string& s1)) { + throw TypeError(format(s) % s1); +} + +LocalNoInlineNoReturn(void throwTypeError(const char* s, const ExprLambda& fun, + const Symbol& s2, const Pos& pos)) { + throw TypeError(format(s) % fun.showNamePos() % s2 % pos); +} + +LocalNoInlineNoReturn(void throwAssertionError(const char* s, + const std::string& s1, + const Pos& pos)) { + throw AssertionError(format(s) % s1 % pos); +} + +LocalNoInlineNoReturn(void throwUndefinedVarError(const char* s, + const std::string& s1, + const Pos& pos)) { + throw UndefinedVarError(format(s) % s1 % pos); +} + +LocalNoInline(void addErrorPrefix(Error& e, const char* s, + const std::string& s2)) { + e.addPrefix(format(s) % s2); +} + +LocalNoInline(void addErrorPrefix(Error& e, const char* s, + const ExprLambda& fun, const Pos& pos)) { + e.addPrefix(format(s) % fun.showNamePos() % pos); +} + +LocalNoInline(void addErrorPrefix(Error& e, const char* s, + const std::string& s2, const Pos& pos)) { + e.addPrefix(format(s) % s2 % pos); +} + +void mkString(Value& v, const char* s) { mkStringNoCopy(v, dupString(s)); } + +Value& mkString(Value& v, const std::string& s, const PathSet& context) { + mkString(v, s.c_str()); + if (!context.empty()) { + size_t n = 0; + v.string.context = + (const char**)allocBytes((context.size() + 1) * sizeof(char*)); + for (auto& i : context) { + v.string.context[n++] = dupString(i.c_str()); + } + v.string.context[n] = nullptr; + } + return v; +} + +void mkPath(Value& v, const char* s) { mkPathNoCopy(v, dupString(s)); } + +inline Value* EvalState::lookupVar(Env* env, const ExprVar& var, bool noEval) { + for (size_t l = var.level; l != 0u; --l, env = env->up) { + ; + } + + if (!var.fromWith) { + return env->values[var.displ]; + } + + while (true) { + if (env->type == Env::HasWithExpr) { + if (noEval) { + return nullptr; + } + Value* v = allocValue(); + evalAttrs(*env->up, (Expr*)env->values[0], *v); + env->values[0] = v; + env->type = Env::HasWithAttrs; + } + Bindings::iterator j = env->values[0]->attrs->find(var.name); + if (j != env->values[0]->attrs->end()) { + if (countCalls && (j->second.pos != nullptr)) { + attrSelects[*j->second.pos]++; + } + return j->second.value; + } + if (env->prevWith == 0u) { + throwUndefinedVarError("undefined variable '%1%' at %2%", var.name, + var.pos); + } + for (size_t l = env->prevWith; l != 0u; --l, env = env->up) { + } + } +} + +Value* EvalState::allocValue() { + nrValues++; + return new (GC) Value; +} + +Env& EvalState::allocEnv(size_t size) { + if (size > std::numeric_limits<decltype(Env::size)>::max()) { + throw Error("environment size %d is too big", size); + } + + nrEnvs++; + nrValuesInEnvs += size; + Env* env = (Env*)allocBytes(sizeof(Env) + size * sizeof(Value*)); + env->size = (decltype(Env::size))size; + env->type = Env::Plain; + + /* We assume that env->values has been cleared by the allocator; maybeThunk() + * and lookupVar fromWith expect this. */ + + return *env; +} + +void EvalState::mkList(Value& v, size_t size) { + clearValue(v); + if (size == 1) { + v.type = tList1; + } else if (size == 2) { + v.type = tList2; + } else { + v.type = tListN; + v.bigList.size = size; + v.bigList.elems = + size != 0u ? (Value**)allocBytes(size * sizeof(Value*)) : nullptr; + } + nrListElems += size; +} + +unsigned long nrThunks = 0; + +static inline void mkThunk(Value& v, Env& env, Expr* expr) { + v.type = tThunk; + v.thunk.env = &env; + v.thunk.expr = expr; + nrThunks++; +} + +void EvalState::mkThunk_(Value& v, Expr* expr) { mkThunk(v, baseEnv, expr); } + +void EvalState::mkPos(Value& v, Pos* pos) { + if ((pos != nullptr) && pos->file.set()) { + mkAttrs(v, 3); + mkString(*allocAttr(v, sFile), pos->file); + mkInt(*allocAttr(v, sLine), pos->line); + mkInt(*allocAttr(v, sColumn), pos->column); + } else { + mkNull(v); + } +} + +/* Create a thunk for the delayed computation of the given expression + in the given environment. But if the expression is a variable, + then look it up right away. This significantly reduces the number + of thunks allocated. */ +Value* Expr::maybeThunk(EvalState& state, Env& env) { + Value* v = state.allocValue(); + mkThunk(*v, env, this); + return v; +} + +unsigned long nrAvoided = 0; + +Value* ExprVar::maybeThunk(EvalState& state, Env& env) { + Value* v = state.lookupVar(&env, *this, true); + /* The value might not be initialised in the environment yet. + In that case, ignore it. */ + if (v != nullptr) { + nrAvoided++; + return v; + } + return Expr::maybeThunk(state, env); +} + +Value* ExprString::maybeThunk(EvalState& state, Env& env) { + nrAvoided++; + return &v; +} + +Value* ExprInt::maybeThunk(EvalState& state, Env& env) { + nrAvoided++; + return &v; +} + +Value* ExprFloat::maybeThunk(EvalState& state, Env& env) { + nrAvoided++; + return &v; +} + +Value* ExprPath::maybeThunk(EvalState& state, Env& env) { + nrAvoided++; + return &v; +} + +void EvalState::evalFile(const Path& path_, Value& v) { + auto path = checkSourcePath(path_); + + FileEvalCache::iterator i; + if ((i = fileEvalCache.find(path)) != fileEvalCache.end()) { + v = i->second; + return; + } + + Path path2 = resolveExprPath(path); + if ((i = fileEvalCache.find(path2)) != fileEvalCache.end()) { + v = i->second; + return; + } + + DLOG(INFO) << "evaluating file '" << path2 << "'"; + Expr* e = nullptr; + + auto j = fileParseCache.find(path2); + if (j != fileParseCache.end()) { + e = j->second; + } + + if (e == nullptr) { + e = parseExprFromFile(checkSourcePath(path2)); + } + + fileParseCache[path2] = e; + + try { + eval(e, v); + } catch (Error& e) { + addErrorPrefix(e, "while evaluating the file '%1%':\n", path2); + throw; + } + + fileEvalCache[path2] = v; + if (path != path2) { + fileEvalCache[path] = v; + } +} + +void EvalState::resetFileCache() { + fileEvalCache.clear(); + fileParseCache.clear(); +} + +void EvalState::eval(Expr* e, Value& v) { e->eval(*this, baseEnv, v); } + +inline bool EvalState::evalBool(Env& env, Expr* e) { + Value v; + e->eval(*this, env, v); + if (v.type != tBool) { + throwTypeError("value is %1% while a Boolean was expected", v); + } + return v.boolean; +} + +inline bool EvalState::evalBool(Env& env, Expr* e, const Pos& pos) { + Value v; + e->eval(*this, env, v); + if (v.type != tBool) { + throwTypeError("value is %1% while a Boolean was expected, at %2%", v, pos); + } + return v.boolean; +} + +inline void EvalState::evalAttrs(Env& env, Expr* e, Value& v) { + e->eval(*this, env, v); + if (v.type != tAttrs) { + throwTypeError("value is %1% while a set was expected", v); + } +} + +void Expr::eval(EvalState& state, Env& env, Value& v) { abort(); } + +void ExprInt::eval(EvalState& state, Env& env, Value& v) { v = this->v; } + +void ExprFloat::eval(EvalState& state, Env& env, Value& v) { v = this->v; } + +void ExprString::eval(EvalState& state, Env& env, Value& v) { v = this->v; } + +void ExprPath::eval(EvalState& state, Env& env, Value& v) { v = this->v; } + +void ExprAttrs::eval(EvalState& state, Env& env, Value& v) { + state.mkAttrs(v, attrs.size() + dynamicAttrs.size()); + Env* dynamicEnv = &env; + + if (recursive) { + /* Create a new environment that contains the attributes in + this `rec'. */ + Env& env2(state.allocEnv(attrs.size())); + env2.up = &env; + dynamicEnv = &env2; + + // TODO(tazjin): contains? + AttrDefs::iterator overrides = attrs.find(state.sOverrides); + bool hasOverrides = overrides != attrs.end(); + + /* The recursive attributes are evaluated in the new + environment, while the inherited attributes are evaluated + in the original environment. */ + size_t displ = 0; + for (auto& i : attrs) { + Value* vAttr; + if (hasOverrides && !i.second.inherited) { + vAttr = state.allocValue(); + mkThunk(*vAttr, env2, i.second.e); + } else { + vAttr = i.second.e->maybeThunk(state, i.second.inherited ? env : env2); + } + env2.values[displ++] = vAttr; + v.attrs->push_back(Attr(i.first, vAttr, &i.second.pos)); + } + + /* If the rec contains an attribute called `__overrides', then + evaluate it, and add the attributes in that set to the rec. + This allows overriding of recursive attributes, which is + otherwise not possible. (You can use the // operator to + replace an attribute, but other attributes in the rec will + still reference the original value, because that value has + been substituted into the bodies of the other attributes. + Hence we need __overrides.) */ + if (hasOverrides) { + Value* vOverrides = v.attrs->find(overrides->first)->second.value; + state.forceAttrs(*vOverrides); + Bindings* newBnds = Bindings::NewGC(); + for (auto& i : *v.attrs) { // TODO(tazjin): copy constructor? + newBnds->push_back(i.second); + } + for (auto& i : *vOverrides->attrs) { + auto j = attrs.find(i.second.name); + if (j != attrs.end()) { + newBnds->push_back(i.second); + env2.values[j->second.displ] = i.second.value; + } else { + newBnds->push_back(i.second); + } + } + v.attrs = newBnds; + } + } else { + // TODO(tazjin): insert range + for (auto& i : attrs) { + v.attrs->push_back( + Attr(i.first, i.second.e->maybeThunk(state, env), &i.second.pos)); + } + } + + /* Dynamic attrs apply *after* rec and __overrides. */ + for (auto& i : dynamicAttrs) { + Value nameVal; + i.nameExpr->eval(state, *dynamicEnv, nameVal); + state.forceValue(nameVal, i.pos); + if (nameVal.type == tNull) { + continue; + } + state.forceStringNoCtx(nameVal); + Symbol nameSym = state.symbols.Create(nameVal.string.s); + Bindings::iterator j = v.attrs->find(nameSym); + if (j != v.attrs->end()) { + throwEvalError("dynamic attribute '%1%' at %2% already defined at %3%", + nameSym, i.pos, *j->second.pos); + } + + i.valueExpr->setName(nameSym); + v.attrs->push_back( + Attr(nameSym, i.valueExpr->maybeThunk(state, *dynamicEnv), &i.pos)); + } +} + +void ExprLet::eval(EvalState& state, Env& env, Value& v) { + /* Create a new environment that contains the attributes in this + `let'. */ + Env& env2(state.allocEnv(attrs->attrs.size())); + env2.up = &env; + + /* The recursive attributes are evaluated in the new environment, + while the inherited attributes are evaluated in the original + environment. */ + size_t displ = 0; + for (auto& i : attrs->attrs) { + env2.values[displ++] = + i.second.e->maybeThunk(state, i.second.inherited ? env : env2); + } + + body->eval(state, env2, v); +} + +void ExprList::eval(EvalState& state, Env& env, Value& v) { + state.mkList(v, elems.size()); + for (size_t n = 0; n < elems.size(); ++n) { + v.listElems()[n] = elems[n]->maybeThunk(state, env); + } +} + +void ExprVar::eval(EvalState& state, Env& env, Value& v) { + Value* v2 = state.lookupVar(&env, *this, false); + state.forceValue(*v2, pos); + v = *v2; +} + +static std::string showAttrPath(EvalState& state, Env& env, + const AttrPath& attrPath) { + std::ostringstream out; + bool first = true; + for (auto& i : attrPath) { + if (!first) { + out << '.'; + } else { + first = false; + } + try { + out << getName(i, state, env); + } catch (Error& e) { + assert(!i.symbol.set()); + out << "\"${" << *i.expr << "}\""; + } + } + return out.str(); +} + +unsigned long nrLookups = 0; + +void ExprSelect::eval(EvalState& state, Env& env, Value& v) { + Value vTmp; + Pos* pos2 = nullptr; + Value* vAttrs = &vTmp; + + e->eval(state, env, vTmp); + + try { + for (auto& i : attrPath) { + nrLookups++; + Bindings::iterator j; + Symbol name = getName(i, state, env); + if (def != nullptr) { + state.forceValue(*vAttrs, pos); + if (vAttrs->type != tAttrs || + (j = vAttrs->attrs->find(name)) == vAttrs->attrs->end()) { + def->eval(state, env, v); + return; + } + } else { + state.forceAttrs(*vAttrs, pos); + if ((j = vAttrs->attrs->find(name)) == vAttrs->attrs->end()) { + throwEvalError("attribute '%1%' missing, at %2%", name, pos); + } + } + vAttrs = j->second.value; + pos2 = j->second.pos; + if (state.countCalls && (pos2 != nullptr)) { + state.attrSelects[*pos2]++; + } + } + + state.forceValue(*vAttrs, (pos2 != nullptr ? *pos2 : this->pos)); + + } catch (Error& e) { + if ((pos2 != nullptr) && pos2->file != state.sDerivationNix) { + addErrorPrefix(e, "while evaluating the attribute '%1%' at %2%:\n", + showAttrPath(state, env, attrPath), *pos2); + } + throw; + } + + v = *vAttrs; +} + +void ExprOpHasAttr::eval(EvalState& state, Env& env, Value& v) { + Value vTmp; + Value* vAttrs = &vTmp; + + e->eval(state, env, vTmp); + + for (auto& i : attrPath) { + state.forceValue(*vAttrs); + Bindings::iterator j; + Symbol name = getName(i, state, env); + if (vAttrs->type != tAttrs || + (j = vAttrs->attrs->find(name)) == vAttrs->attrs->end()) { + mkBool(v, false); + return; + } + vAttrs = j->second.value; + } + + mkBool(v, true); +} + +void ExprLambda::eval(EvalState& state, Env& env, Value& v) { + v.type = tLambda; + v.lambda.env = &env; + v.lambda.fun = this; +} + +void ExprApp::eval(EvalState& state, Env& env, Value& v) { + /* FIXME: vFun prevents GCC from doing tail call optimisation. */ + Value vFun; + e1->eval(state, env, vFun); + state.callFunction(vFun, *(e2->maybeThunk(state, env)), v, pos); +} + +void EvalState::callPrimOp(Value& fun, Value& arg, Value& v, const Pos& pos) { + /* Figure out the number of arguments still needed. */ + size_t argsDone = 0; + Value* primOp = &fun; + while (primOp->type == tPrimOpApp) { + argsDone++; + primOp = primOp->primOpApp.left; + } + assert(primOp->type == tPrimOp); + auto arity = primOp->primOp->arity; + auto argsLeft = arity - argsDone; + + if (argsLeft == 1) { + /* We have all the arguments, so call the primop. */ + + /* Put all the arguments in an array. */ + Value* vArgs[arity]; + auto n = arity - 1; + vArgs[n--] = &arg; + for (Value* arg = &fun; arg->type == tPrimOpApp; + arg = arg->primOpApp.left) { + vArgs[n--] = arg->primOpApp.right; + } + + /* And call the primop. */ + nrPrimOpCalls++; + if (countCalls) { + primOpCalls[primOp->primOp->name]++; + } + primOp->primOp->fun(*this, pos, vArgs, v); + } else { + Value* fun2 = allocValue(); + *fun2 = fun; + v.type = tPrimOpApp; + v.primOpApp.left = fun2; + v.primOpApp.right = &arg; + } +} + +void EvalState::callFunction(Value& fun, Value& arg, Value& v, const Pos& pos) { + auto trace = evalSettings.traceFunctionCalls + ? std::make_unique<FunctionCallTrace>(pos) + : nullptr; + + forceValue(fun, pos); + + if (fun.type == tPrimOp || fun.type == tPrimOpApp) { + callPrimOp(fun, arg, v, pos); + return; + } + + if (fun.type == tAttrs) { + auto found = fun.attrs->find(sFunctor); + if (found != fun.attrs->end()) { + /* fun may be allocated on the stack of the calling function, + * but for functors we may keep a reference, so heap-allocate + * a copy and use that instead. + */ + auto& fun2 = *allocValue(); + fun2 = fun; + /* !!! Should we use the attr pos here? */ + Value v2; + callFunction(*found->second.value, fun2, v2, pos); + return callFunction(v2, arg, v, pos); + } + } + + if (fun.type != tLambda) { + throwTypeError( + "attempt to call something which is not a function but %1%, at %2%", + fun, pos); + } + + ExprLambda& lambda(*fun.lambda.fun); + + auto size = (lambda.arg.empty() ? 0 : 1) + + (lambda.matchAttrs ? lambda.formals->formals.size() : 0); + Env& env2(allocEnv(size)); + env2.up = fun.lambda.env; + + size_t displ = 0; + + if (!lambda.matchAttrs) { + env2.values[displ++] = &arg; + + } else { + forceAttrs(arg, pos); + + if (!lambda.arg.empty()) { + env2.values[displ++] = &arg; + } + + /* For each formal argument, get the actual argument. If + there is no matching actual argument but the formal + argument has a default, use the default. */ + size_t attrsUsed = 0; + for (auto& i : lambda.formals->formals) { + Bindings::iterator j = arg.attrs->find(i.name); + if (j == arg.attrs->end()) { + if (i.def == nullptr) { + throwTypeError("%1% called without required argument '%2%', at %3%", + lambda, i.name, pos); + } + env2.values[displ++] = i.def->maybeThunk(*this, env2); + } else { + attrsUsed++; + env2.values[displ++] = j->second.value; + } + } + + /* Check that each actual argument is listed as a formal + argument (unless the attribute match specifies a `...'). */ + if (!lambda.formals->ellipsis && attrsUsed != arg.attrs->size()) { + /* Nope, so show the first unexpected argument to the + user. */ + for (auto& i : *arg.attrs) { + if (lambda.formals->argNames.find(i.second.name) == + lambda.formals->argNames.end()) { + throwTypeError("%1% called with unexpected argument '%2%', at %3%", + lambda, i.second.name, pos); + } + } + abort(); // can't happen + } + } + + nrFunctionCalls++; + if (countCalls) { + incrFunctionCall(&lambda); + } + + /* Evaluate the body. This is conditional on showTrace, because + catching exceptions makes this function not tail-recursive. */ + if (settings.showTrace) { + try { + lambda.body->eval(*this, env2, v); + } catch (Error& e) { + addErrorPrefix(e, "while evaluating %1%, called from %2%:\n", lambda, + pos); + throw; + } + } else { + fun.lambda.fun->body->eval(*this, env2, v); + } +} + +// Lifted out of callFunction() because it creates a temporary that +// prevents tail-call optimisation. +void EvalState::incrFunctionCall(ExprLambda* fun) { functionCalls[fun]++; } + +void EvalState::autoCallFunction(Bindings& args, Value& fun, Value& res) { + forceValue(fun); + + if (fun.type == tAttrs) { + auto found = fun.attrs->find(sFunctor); + if (found != fun.attrs->end()) { + Value* v = allocValue(); + callFunction(*found->second.value, fun, *v, noPos); + forceValue(*v); + return autoCallFunction(args, *v, res); + } + } + + if (fun.type != tLambda || !fun.lambda.fun->matchAttrs) { + res = fun; + return; + } + + Value* actualArgs = allocValue(); + mkAttrs(*actualArgs, fun.lambda.fun->formals->formals.size()); + + for (auto& i : fun.lambda.fun->formals->formals) { + Bindings::iterator j = args.find(i.name); + if (j != args.end()) { + actualArgs->attrs->push_back(j->second); + } else if (i.def == nullptr) { + throwTypeError( + "cannot auto-call a function that has an argument without a default " + "value ('%1%')", + i.name); + } + } + + callFunction(fun, *actualArgs, res, noPos); +} + +void ExprWith::eval(EvalState& state, Env& env, Value& v) { + Env& env2(state.allocEnv(1)); + env2.up = &env; + env2.prevWith = prevWith; + env2.type = Env::HasWithExpr; + env2.values[0] = (Value*)attrs; + + body->eval(state, env2, v); +} + +void ExprIf::eval(EvalState& state, Env& env, Value& v) { + (state.evalBool(env, cond) ? then : else_)->eval(state, env, v); +} + +void ExprAssert::eval(EvalState& state, Env& env, Value& v) { + if (!state.evalBool(env, cond, pos)) { + std::ostringstream out; + cond->show(out); + throwAssertionError("assertion %1% failed at %2%", out.str(), pos); + } + body->eval(state, env, v); +} + +void ExprOpNot::eval(EvalState& state, Env& env, Value& v) { + mkBool(v, !state.evalBool(env, e)); +} + +void ExprOpEq::eval(EvalState& state, Env& env, Value& v) { + Value v1; + e1->eval(state, env, v1); + Value v2; + e2->eval(state, env, v2); + mkBool(v, state.eqValues(v1, v2)); +} + +void ExprOpNEq::eval(EvalState& state, Env& env, Value& v) { + Value v1; + e1->eval(state, env, v1); + Value v2; + e2->eval(state, env, v2); + mkBool(v, !state.eqValues(v1, v2)); +} + +void ExprOpAnd::eval(EvalState& state, Env& env, Value& v) { + mkBool(v, state.evalBool(env, e1, pos) && state.evalBool(env, e2, pos)); +} + +void ExprOpOr::eval(EvalState& state, Env& env, Value& v) { + mkBool(v, state.evalBool(env, e1, pos) || state.evalBool(env, e2, pos)); +} + +void ExprOpImpl::eval(EvalState& state, Env& env, Value& v) { + mkBool(v, !state.evalBool(env, e1, pos) || state.evalBool(env, e2, pos)); +} + +void ExprOpUpdate::eval(EvalState& state, Env& env, Value& v) { + Value v1; + Value v2; + state.evalAttrs(env, e1, v1); + state.evalAttrs(env, e2, v2); + + state.nrOpUpdates++; + + if (v1.attrs->empty()) { + v = v2; + return; + } + if (v2.attrs->empty()) { + v = v1; + return; + } + + state.mkAttrs(v, /* capacity = */ 0); + + /* Merge the sets, preferring values from the second set. Make + sure to keep the resulting vector in sorted order. */ + v.attrs->merge(v1.attrs); + v.attrs->merge(v2.attrs); + + state.nrOpUpdateValuesCopied += v.attrs->size(); +} + +void ExprOpConcatLists::eval(EvalState& state, Env& env, Value& v) { + Value v1; + e1->eval(state, env, v1); + Value v2; + e2->eval(state, env, v2); + Value* lists[2] = {&v1, &v2}; + state.concatLists(v, 2, lists, pos); +} + +void EvalState::concatLists(Value& v, size_t nrLists, Value** lists, + const Pos& pos) { + nrListConcats++; + + Value* nonEmpty = nullptr; + size_t len = 0; + for (size_t n = 0; n < nrLists; ++n) { + forceList(*lists[n], pos); + auto l = lists[n]->listSize(); + len += l; + if (l != 0u) { + nonEmpty = lists[n]; + } + } + + if ((nonEmpty != nullptr) && len == nonEmpty->listSize()) { + v = *nonEmpty; + return; + } + + mkList(v, len); + auto out = v.listElems(); + for (size_t n = 0, pos = 0; n < nrLists; ++n) { + auto l = lists[n]->listSize(); + if (l != 0u) { + memcpy(out + pos, lists[n]->listElems(), l * sizeof(Value*)); + } + pos += l; + } +} + +void ExprConcatStrings::eval(EvalState& state, Env& env, Value& v) { + PathSet context; + std::ostringstream s; + NixInt n = 0; + NixFloat nf = 0; + + bool first = !forceString; + ValueType firstType = tString; + + for (auto& i : *es) { + Value vTmp; + i->eval(state, env, vTmp); + + /* If the first element is a path, then the result will also + be a path, we don't copy anything (yet - that's done later, + since paths are copied when they are used in a derivation), + and none of the strings are allowed to have contexts. */ + if (first) { + firstType = vTmp.type; + first = false; + } + + if (firstType == tInt) { + if (vTmp.type == tInt) { + n += vTmp.integer; + } else if (vTmp.type == tFloat) { + // Upgrade the type from int to float; + firstType = tFloat; + nf = n; + nf += vTmp.fpoint; + } else { + throwEvalError("cannot add %1% to an integer, at %2%", showType(vTmp), + pos); + } + } else if (firstType == tFloat) { + if (vTmp.type == tInt) { + nf += vTmp.integer; + } else if (vTmp.type == tFloat) { + nf += vTmp.fpoint; + } else { + throwEvalError("cannot add %1% to a float, at %2%", showType(vTmp), + pos); + } + } else { + s << state.coerceToString(pos, vTmp, context, false, + firstType == tString); + } + } + + if (firstType == tInt) { + mkInt(v, n); + } else if (firstType == tFloat) { + mkFloat(v, nf); + } else if (firstType == tPath) { + if (!context.empty()) { + throwEvalError( + "a string that refers to a store path cannot be appended to a path, " + "at %1%", + pos); + } + auto path = canonPath(s.str()); + mkPath(v, path.c_str()); + } else { + mkString(v, s.str(), context); + } +} + +void ExprPos::eval(EvalState& state, Env& env, Value& v) { + state.mkPos(v, &pos); +} + +void EvalState::forceValueDeep(Value& v) { + std::set<const Value*> seen; + + std::function<void(Value & v)> recurse; + + recurse = [&](Value& v) { + if (seen.find(&v) != seen.end()) { + return; + } + seen.insert(&v); + + forceValue(v); + + if (v.type == tAttrs) { + for (auto& i : *v.attrs) { + try { + recurse(*i.second.value); + } catch (Error& e) { + addErrorPrefix(e, "while evaluating the attribute '%1%' at %2%:\n", + i.second.name, *i.second.pos); + throw; + } + } + } else if (v.isList()) { + for (size_t n = 0; n < v.listSize(); ++n) { + recurse(*v.listElems()[n]); + } + } + }; + + recurse(v); +} + +NixInt EvalState::forceInt(Value& v, const Pos& pos) { + forceValue(v, pos); + if (v.type != tInt) { + throwTypeError("value is %1% while an integer was expected, at %2%", v, + pos); + } + return v.integer; +} + +NixFloat EvalState::forceFloat(Value& v, const Pos& pos) { + forceValue(v, pos); + if (v.type == tInt) { + return v.integer; + } + if (v.type != tFloat) { + throwTypeError("value is %1% while a float was expected, at %2%", v, pos); + } + return v.fpoint; +} + +bool EvalState::forceBool(Value& v, const Pos& pos) { + forceValue(v); + if (v.type != tBool) { + throwTypeError("value is %1% while a Boolean was expected, at %2%", v, pos); + } + return v.boolean; +} + +bool EvalState::isFunctor(Value& fun) { + return fun.type == tAttrs && fun.attrs->find(sFunctor) != fun.attrs->end(); +} + +void EvalState::forceFunction(Value& v, const Pos& pos) { + forceValue(v); + if (v.type != tLambda && v.type != tPrimOp && v.type != tPrimOpApp && + !isFunctor(v)) { + throwTypeError("value is %1% while a function was expected, at %2%", v, + pos); + } +} + +string EvalState::forceString(Value& v, const Pos& pos) { + forceValue(v, pos); + if (v.type != tString) { + if (pos) { + throwTypeError("value is %1% while a string was expected, at %2%", v, + pos); + } else { + throwTypeError("value is %1% while a string was expected", v); + } + } + return string(v.string.s); +} + +void copyContext(const Value& v, PathSet& context) { + if (v.string.context != nullptr) { + for (const char** p = v.string.context; *p != nullptr; ++p) { + context.insert(*p); + } + } +} + +string EvalState::forceString(Value& v, PathSet& context, const Pos& pos) { + std::string s = forceString(v, pos); + copyContext(v, context); + return s; +} + +string EvalState::forceStringNoCtx(Value& v, const Pos& pos) { + std::string s = forceString(v, pos); + if (v.string.context != nullptr) { + if (pos) { + throwEvalError( + "the string '%1%' is not allowed to refer to a store path (such as " + "'%2%'), at %3%", + v.string.s, v.string.context[0], pos); + } else { + throwEvalError( + "the string '%1%' is not allowed to refer to a store path (such as " + "'%2%')", + v.string.s, v.string.context[0]); + } + } + return s; +} + +bool EvalState::isDerivation(Value& v) { + if (v.type != tAttrs) { + return false; + } + Bindings::iterator i = v.attrs->find(sType); + if (i == v.attrs->end()) { + return false; + } + forceValue(*i->second.value); + if (i->second.value->type != tString) { + return false; + } + return strcmp(i->second.value->string.s, "derivation") == 0; +} + +std::optional<string> EvalState::tryAttrsToString(const Pos& pos, Value& v, + PathSet& context, + bool coerceMore, + bool copyToStore) { + auto i = v.attrs->find(sToString); + if (i != v.attrs->end()) { + Value v1; + callFunction(*i->second.value, v, v1, pos); + return coerceToString(pos, v1, context, coerceMore, copyToStore); + } + + return {}; +} + +string EvalState::coerceToString(const Pos& pos, Value& v, PathSet& context, + bool coerceMore, bool copyToStore) { + forceValue(v); + + std::string s; + + if (v.type == tString) { + copyContext(v, context); + return v.string.s; + } + + if (v.type == tPath) { + Path path(canonPath(v.path)); + return copyToStore ? copyPathToStore(context, path) : path; + } + + if (v.type == tAttrs) { + auto maybeString = + tryAttrsToString(pos, v, context, coerceMore, copyToStore); + if (maybeString) { + return *maybeString; + } + auto i = v.attrs->find(sOutPath); + if (i == v.attrs->end()) { + throwTypeError("cannot coerce a set to a string, at %1%", pos); + } + return coerceToString(pos, *i->second.value, context, coerceMore, + copyToStore); + } + + if (v.type == tExternal) { + return v.external->coerceToString(pos, context, coerceMore, copyToStore); + } + + if (coerceMore) { + /* Note that `false' is represented as an empty string for + shell scripting convenience, just like `null'. */ + if (v.type == tBool && v.boolean) { + return "1"; + } + if (v.type == tBool && !v.boolean) { + return ""; + } + if (v.type == tInt) { + return std::to_string(v.integer); + } + if (v.type == tFloat) { + return std::to_string(v.fpoint); + } + if (v.type == tNull) { + return ""; + } + + if (v.isList()) { + std::string result; + for (size_t n = 0; n < v.listSize(); ++n) { + result += coerceToString(pos, *v.listElems()[n], context, coerceMore, + copyToStore); + if (n < v.listSize() - 1 + /* !!! not quite correct */ + && (!v.listElems()[n]->isList() || + v.listElems()[n]->listSize() != 0)) { + result += " "; + } + } + return result; + } + } + + throwTypeError("cannot coerce %1% to a string, at %2%", v, pos); +} + +string EvalState::copyPathToStore(PathSet& context, const Path& path) { + if (nix::isDerivation(path)) { + throwEvalError("file names are not allowed to end in '%1%'", drvExtension); + } + + Path dstPath; + if (!srcToStore[path].empty()) { + dstPath = srcToStore[path]; + } else { + dstPath = + settings.readOnlyMode + ? store + ->computeStorePathForPath(baseNameOf(path), + checkSourcePath(path)) + .first + : store->addToStore(baseNameOf(path), checkSourcePath(path), true, + htSHA256, defaultPathFilter, repair); + srcToStore[path] = dstPath; + DLOG(INFO) << "copied source '" << path << "' -> '" << dstPath << "'"; + } + + context.insert(dstPath); + return dstPath; +} + +Path EvalState::coerceToPath(const Pos& pos, Value& v, PathSet& context) { + std::string path = coerceToString(pos, v, context, false, false); + if (path.empty() || path[0] != '/') { + throwEvalError("string '%1%' doesn't represent an absolute path, at %2%", + path, pos); + } + return path; +} + +bool EvalState::eqValues(Value& v1, Value& v2) { + forceValue(v1); + forceValue(v2); + + /* !!! Hack to support some old broken code that relies on pointer + equality tests between sets. (Specifically, builderDefs calls + uniqList on a list of sets.) Will remove this eventually. */ + if (&v1 == &v2) { + return true; + } + + // Special case type-compatibility between float and int + if (v1.type == tInt && v2.type == tFloat) { + return v1.integer == v2.fpoint; + } + if (v1.type == tFloat && v2.type == tInt) { + return v1.fpoint == v2.integer; + } + + // All other types are not compatible with each other. + if (v1.type != v2.type) { + return false; + } + + switch (v1.type) { + case tInt: + return v1.integer == v2.integer; + + case tBool: + return v1.boolean == v2.boolean; + + case tString: + return strcmp(v1.string.s, v2.string.s) == 0; + + case tPath: + return strcmp(v1.path, v2.path) == 0; + + case tNull: + return true; + + case tList1: + case tList2: + case tListN: + if (v1.listSize() != v2.listSize()) { + return false; + } + for (size_t n = 0; n < v1.listSize(); ++n) { + if (!eqValues(*v1.listElems()[n], *v2.listElems()[n])) { + return false; + } + } + return true; + + case tAttrs: { + /* If both sets denote a derivation (type = "derivation"), + then compare their outPaths. */ + if (isDerivation(v1) && isDerivation(v2)) { + Bindings::iterator i = v1.attrs->find(sOutPath); + Bindings::iterator j = v2.attrs->find(sOutPath); + if (i != v1.attrs->end() && j != v2.attrs->end()) { + return eqValues(*i->second.value, *j->second.value); + } + } + + if (v1.attrs->size() != v2.attrs->size()) { + return false; + } + + /* Otherwise, compare the attributes one by one. */ + Bindings::iterator i; + Bindings::iterator j; + for (i = v1.attrs->begin(), j = v2.attrs->begin(); i != v1.attrs->end(); + ++i, ++j) { + if (i->second.name != j->second.name || + !eqValues(*i->second.value, *j->second.value)) { + return false; + } + } + + return true; + } + + /* Functions are incomparable. */ + case tLambda: + case tPrimOp: + case tPrimOpApp: + return false; + + case tExternal: + return *v1.external == *v2.external; + + case tFloat: + return v1.fpoint == v2.fpoint; + + default: + throwEvalError("cannot compare %1% with %2%", showType(v1), showType(v2)); + } +} + +void EvalState::printStats() { + bool showStats = getEnv("NIX_SHOW_STATS", "0") != "0"; + + struct rusage buf; + getrusage(RUSAGE_SELF, &buf); + float cpuTime = buf.ru_utime.tv_sec + ((float)buf.ru_utime.tv_usec / 1000000); + + uint64_t bEnvs = nrEnvs * sizeof(Env) + nrValuesInEnvs * sizeof(Value*); + uint64_t bLists = nrListElems * sizeof(Value*); + uint64_t bValues = nrValues * sizeof(Value); + uint64_t bAttrsets = + nrAttrsets * sizeof(Bindings) + nrAttrsInAttrsets * sizeof(Attr); + +#if HAVE_BOEHMGC + GC_word heapSize; + GC_word totalBytes; + GC_get_heap_usage_safe(&heapSize, nullptr, nullptr, nullptr, &totalBytes); +#endif + if (showStats) { + auto outPath = getEnv("NIX_SHOW_STATS_PATH", "-"); + std::fstream fs; + if (outPath != "-") { + fs.open(outPath, std::fstream::out); + } + JSONObject topObj(outPath == "-" ? std::cerr : fs, true); + topObj.attr("cpuTime", cpuTime); + { + auto envs = topObj.object("envs"); + envs.attr("number", nrEnvs); + envs.attr("elements", nrValuesInEnvs); + envs.attr("bytes", bEnvs); + } + { + auto lists = topObj.object("list"); + lists.attr("elements", nrListElems); + lists.attr("bytes", bLists); + lists.attr("concats", nrListConcats); + } + { + auto values = topObj.object("values"); + values.attr("number", nrValues); + values.attr("bytes", bValues); + } + { + auto syms = topObj.object("symbols"); + syms.attr("number", symbols.Size()); + syms.attr("bytes", symbols.TotalSize()); + } + { + auto sets = topObj.object("sets"); + sets.attr("number", nrAttrsets); + sets.attr("bytes", bAttrsets); + sets.attr("elements", nrAttrsInAttrsets); + } + { + auto sizes = topObj.object("sizes"); + sizes.attr("Env", sizeof(Env)); + sizes.attr("Value", sizeof(Value)); + sizes.attr("Bindings", sizeof(Bindings)); + sizes.attr("Attr", sizeof(Attr)); + } + topObj.attr("nrOpUpdates", nrOpUpdates); + topObj.attr("nrOpUpdateValuesCopied", nrOpUpdateValuesCopied); + topObj.attr("nrThunks", nrThunks); + topObj.attr("nrAvoided", nrAvoided); + topObj.attr("nrLookups", nrLookups); + topObj.attr("nrPrimOpCalls", nrPrimOpCalls); + topObj.attr("nrFunctionCalls", nrFunctionCalls); +#if HAVE_BOEHMGC + { + auto gc = topObj.object("gc"); + gc.attr("heapSize", heapSize); + gc.attr("totalBytes", totalBytes); + } +#endif + + if (countCalls) { + { + auto obj = topObj.object("primops"); + for (auto& i : primOpCalls) { + obj.attr(i.first, i.second); + } + } + { + auto list = topObj.list("functions"); + for (auto& i : functionCalls) { + auto obj = list.object(); + if (i.first->name.set()) { + obj.attr("name", (const std::string&)i.first->name); + } else { + obj.attr("name", nullptr); + } + if (i.first->pos) { + obj.attr("file", (const std::string&)i.first->pos.file); + obj.attr("line", i.first->pos.line); + obj.attr("column", i.first->pos.column); + } + obj.attr("count", i.second); + } + } + { + auto list = topObj.list("attributes"); + for (auto& i : attrSelects) { + auto obj = list.object(); + if (i.first) { + obj.attr("file", (const std::string&)i.first.file); + obj.attr("line", i.first.line); + obj.attr("column", i.first.column); + } + obj.attr("count", i.second); + } + } + } + + // TODO(tazjin): what is this? commented out because .dump() is gone. + // if (getEnv("NIX_SHOW_SYMBOLS", "0") != "0") { + // auto list = topObj.list("symbols"); + // symbols.dump([&](const std::string& s) { list.elem(s); }); + // } + } +} + +size_t valueSize(Value& v) { + std::set<const void*> seen; + + auto doString = [&](const char* s) -> size_t { + if (seen.find(s) != seen.end()) { + return 0; + } + seen.insert(s); + return strlen(s) + 1; + }; + + std::function<size_t(Value & v)> doValue; + std::function<size_t(Env & v)> doEnv; + + doValue = [&](Value& v) -> size_t { + if (seen.find(&v) != seen.end()) { + return 0; + } + seen.insert(&v); + + size_t sz = sizeof(Value); + + switch (v.type) { + case tString: + sz += doString(v.string.s); + if (v.string.context != nullptr) { + for (const char** p = v.string.context; *p != nullptr; ++p) { + sz += doString(*p); + } + } + break; + case tPath: + sz += doString(v.path); + break; + case tAttrs: + if (seen.find(v.attrs) == seen.end()) { + seen.insert(v.attrs); + sz += sizeof(Bindings) + sizeof(Attr) * v.attrs->capacity(); + for (auto& i : *v.attrs) { + sz += doValue(*i.second.value); + } + } + break; + case tList1: + case tList2: + case tListN: + if (seen.find(v.listElems()) == seen.end()) { + seen.insert(v.listElems()); + sz += v.listSize() * sizeof(Value*); + for (size_t n = 0; n < v.listSize(); ++n) { + sz += doValue(*v.listElems()[n]); + } + } + break; + case tThunk: + sz += doEnv(*v.thunk.env); + break; + case tApp: + sz += doValue(*v.app.left); + sz += doValue(*v.app.right); + break; + case tLambda: + sz += doEnv(*v.lambda.env); + break; + case tPrimOpApp: + sz += doValue(*v.primOpApp.left); + sz += doValue(*v.primOpApp.right); + break; + case tExternal: + if (seen.find(v.external) != seen.end()) { + break; + } + seen.insert(v.external); + sz += v.external->valueSize(seen); + break; + default:; + } + + return sz; + }; + + doEnv = [&](Env& env) -> size_t { + if (seen.find(&env) != seen.end()) { + return 0; + } + seen.insert(&env); + + size_t sz = sizeof(Env) + sizeof(Value*) * env.size; + + if (env.type != Env::HasWithExpr) { + for (size_t i = 0; i < env.size; ++i) { + if (env.values[i] != nullptr) { + sz += doValue(*env.values[i]); + } + } + } + + if (env.up != nullptr) { + sz += doEnv(*env.up); + } + + return sz; + }; + + return doValue(v); +} + +string ExternalValueBase::coerceToString(const Pos& pos, PathSet& context, + bool copyMore, + bool copyToStore) const { + throw TypeError(format("cannot coerce %1% to a string, at %2%") % showType() % + pos); +} + +bool ExternalValueBase::operator==(const ExternalValueBase& b) const { + return false; +} + +std::ostream& operator<<(std::ostream& str, const ExternalValueBase& v) { + return v.print(str); +} + +EvalSettings evalSettings; + +static GlobalConfig::Register r1(&evalSettings); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/eval.hh b/third_party/nix/src/libexpr/eval.hh new file mode 100644 index 0000000000..73e35c9b2c --- /dev/null +++ b/third_party/nix/src/libexpr/eval.hh @@ -0,0 +1,357 @@ +#pragma once + +#include <map> +#include <optional> +#include <unordered_map> + +#include "attr-set.hh" +#include "config.hh" +#include "hash.hh" +#include "nixexpr.hh" +#include "symbol-table.hh" +#include "value.hh" + +namespace nix { + +class Store; +class EvalState; +enum RepairFlag : bool; + +typedef void (*PrimOpFun)(EvalState& state, const Pos& pos, Value** args, + Value& v); + +struct PrimOp { + PrimOpFun fun; + size_t arity; + Symbol name; + PrimOp(PrimOpFun fun, size_t arity, Symbol name) + : fun(fun), arity(arity), name(name) {} +}; + +struct Env { + Env* up; + unsigned short size; // used by ‘valueSize’ + unsigned short prevWith : 14; // nr of levels up to next `with' environment + enum { Plain = 0, HasWithExpr, HasWithAttrs } type : 2; + Value* values[0]; +}; + +Value& mkString(Value& v, const std::string& s, + const PathSet& context = PathSet()); + +void copyContext(const Value& v, PathSet& context); + +/* Cache for calls to addToStore(); maps source paths to the store + paths. */ +typedef std::map<Path, Path> SrcToStore; + +std::ostream& operator<<(std::ostream& str, const Value& v); + +typedef std::pair<std::string, std::string> SearchPathElem; +typedef std::list<SearchPathElem> SearchPath; + +/* Initialise the Boehm GC, if applicable. */ +void initGC(); + +class EvalState { + public: + SymbolTable symbols; + + const Symbol sWith, sOutPath, sDrvPath, sType, sMeta, sName, sValue, sSystem, + sOverrides, sOutputs, sOutputName, sIgnoreNulls, sFile, sLine, sColumn, + sFunctor, sToString, sRight, sWrong, sStructuredAttrs, sBuilder, sArgs, + sOutputHash, sOutputHashAlgo, sOutputHashMode; + Symbol sDerivationNix; + + /* If set, force copying files to the Nix store even if they + already exist there. */ + RepairFlag repair; + + /* The allowed filesystem paths in restricted or pure evaluation + mode. */ + std::optional<PathSet> allowedPaths; + + Value vEmptySet; + + const ref<Store> store; + + private: + SrcToStore srcToStore; + + /* A cache from path names to parse trees. */ +#if HAVE_BOEHMGC + typedef std::map<Path, Expr*, std::less<Path>, + traceable_allocator<std::pair<const Path, Expr*>>> + FileParseCache; +#else + typedef std::map<Path, Expr*> FileParseCache; +#endif + FileParseCache fileParseCache; + + /* A cache from path names to values. */ +#if HAVE_BOEHMGC + typedef std::map<Path, Value, std::less<Path>, + traceable_allocator<std::pair<const Path, Value>>> + FileEvalCache; +#else + typedef std::map<Path, Value> FileEvalCache; +#endif + FileEvalCache fileEvalCache; + + SearchPath searchPath; + + std::map<std::string, std::pair<bool, std::string>> searchPathResolved; + + /* Cache used by checkSourcePath(). */ + std::unordered_map<Path, Path> resolvedPaths; + + public: + EvalState(const Strings& _searchPath, const ref<Store>& store); + ~EvalState(); + + void addToSearchPath(const std::string& s); + + SearchPath getSearchPath() { return searchPath; } + + Path checkSourcePath(const Path& path); + + void checkURI(const std::string& uri); + + /* When using a diverted store and 'path' is in the Nix store, map + 'path' to the diverted location (e.g. /nix/store/foo is mapped + to /home/alice/my-nix/nix/store/foo). However, this is only + done if the context is not empty, since otherwise we're + probably trying to read from the actual /nix/store. This is + intended to distinguish between import-from-derivation and + sources stored in the actual /nix/store. */ + Path toRealPath(const Path& path, const PathSet& context); + + /* Parse a Nix expression from the specified file. */ + Expr* parseExprFromFile(const Path& path); + Expr* parseExprFromFile(const Path& path, StaticEnv& staticEnv); + + /* Parse a Nix expression from the specified string. */ + Expr* parseExprFromString(const std::string& s, const Path& basePath, + StaticEnv& staticEnv); + Expr* parseExprFromString(const std::string& s, const Path& basePath); + + Expr* parseStdin(); + + /* Evaluate an expression read from the given file to normal + form. */ + void evalFile(const Path& path, Value& v); + + void resetFileCache(); + + /* Look up a file in the search path. */ + Path findFile(const std::string& path); + Path findFile(SearchPath& searchPath, const std::string& path, + const Pos& pos = noPos); + + /* If the specified search path element is a URI, download it. */ + std::pair<bool, std::string> resolveSearchPathElem( + const SearchPathElem& elem); + + /* Evaluate an expression to normal form, storing the result in + value `v'. */ + void eval(Expr* e, Value& v); + + /* Evaluation the expression, then verify that it has the expected + type. */ + inline bool evalBool(Env& env, Expr* e); + inline bool evalBool(Env& env, Expr* e, const Pos& pos); + inline void evalAttrs(Env& env, Expr* e, Value& v); + + /* If `v' is a thunk, enter it and overwrite `v' with the result + of the evaluation of the thunk. If `v' is a delayed function + application, call the function and overwrite `v' with the + result. Otherwise, this is a no-op. */ + inline void forceValue(Value& v, const Pos& pos = noPos); + + /* Force a value, then recursively force list elements and + attributes. */ + void forceValueDeep(Value& v); + + /* Force `v', and then verify that it has the expected type. */ + NixInt forceInt(Value& v, const Pos& pos); + NixFloat forceFloat(Value& v, const Pos& pos); + bool forceBool(Value& v, const Pos& pos); + inline void forceAttrs(Value& v); + inline void forceAttrs(Value& v, const Pos& pos); + inline void forceList(Value& v); + inline void forceList(Value& v, const Pos& pos); + void forceFunction(Value& v, const Pos& pos); // either lambda or primop + std::string forceString(Value& v, const Pos& pos = noPos); + std::string forceString(Value& v, PathSet& context, const Pos& pos = noPos); + std::string forceStringNoCtx(Value& v, const Pos& pos = noPos); + + /* Return true iff the value `v' denotes a derivation (i.e. a + set with attribute `type = "derivation"'). */ + bool isDerivation(Value& v); + + std::optional<string> tryAttrsToString(const Pos& pos, Value& v, + PathSet& context, + bool coerceMore = false, + bool copyToStore = true); + + /* String coercion. Converts strings, paths and derivations to a + string. If `coerceMore' is set, also converts nulls, integers, + booleans and lists to a string. If `copyToStore' is set, + referenced paths are copied to the Nix store as a side effect. */ + std::string coerceToString(const Pos& pos, Value& v, PathSet& context, + bool coerceMore = false, bool copyToStore = true); + + std::string copyPathToStore(PathSet& context, const Path& path); + + /* Path coercion. Converts strings, paths and derivations to a + path. The result is guaranteed to be a canonicalised, absolute + path. Nothing is copied to the store. */ + Path coerceToPath(const Pos& pos, Value& v, PathSet& context); + + public: + /* The base environment, containing the builtin functions and + values. */ + Env& baseEnv; + + /* The same, but used during parsing to resolve variables. */ + StaticEnv staticBaseEnv; // !!! should be private + + private: + unsigned int baseEnvDispl = 0; + + void createBaseEnv(); + + Value* addConstant(const std::string& name, Value& v); + + Value* addPrimOp(const std::string& name, size_t arity, PrimOpFun primOp); + + public: + Value& getBuiltin(const std::string& name); + + private: + inline Value* lookupVar(Env* env, const ExprVar& var, bool noEval); + + friend struct ExprVar; + friend struct ExprAttrs; + friend struct ExprLet; + + Expr* parse(const char* text, const Path& path, const Path& basePath, + StaticEnv& staticEnv); + + public: + /* Do a deep equality test between two values. That is, list + elements and attributes are compared recursively. */ + bool eqValues(Value& v1, Value& v2); + + bool isFunctor(Value& fun); + + void callFunction(Value& fun, Value& arg, Value& v, const Pos& pos); + void callPrimOp(Value& fun, Value& arg, Value& v, const Pos& pos); + + /* Automatically call a function for which each argument has a + default value or has a binding in the `args' map. */ + void autoCallFunction(Bindings& args, Value& fun, Value& res); + + /* Allocation primitives. */ + Value* allocValue(); + Env& allocEnv(size_t size); + + Value* allocAttr(Value& vAttrs, const Symbol& name); + + void mkList(Value& v, size_t size); + void mkAttrs(Value& v, size_t capacity); + void mkThunk_(Value& v, Expr* expr); + void mkPos(Value& v, Pos* pos); + + void concatLists(Value& v, size_t nrLists, Value** lists, const Pos& pos); + + /* Print statistics. */ + void printStats(); + + void realiseContext(const PathSet& context); + + private: + unsigned long nrEnvs = 0; + unsigned long nrValuesInEnvs = 0; + unsigned long nrValues = 0; + unsigned long nrListElems = 0; + unsigned long nrAttrsets = 0; + unsigned long nrAttrsInAttrsets = 0; + unsigned long nrOpUpdates = 0; + unsigned long nrOpUpdateValuesCopied = 0; + unsigned long nrListConcats = 0; + unsigned long nrPrimOpCalls = 0; + unsigned long nrFunctionCalls = 0; + + bool countCalls; + + typedef std::map<Symbol, size_t> PrimOpCalls; + PrimOpCalls primOpCalls; + + typedef std::map<ExprLambda*, size_t> FunctionCalls; + FunctionCalls functionCalls; + + void incrFunctionCall(ExprLambda* fun); + + typedef std::map<Pos, size_t> AttrSelects; + AttrSelects attrSelects; + + friend struct ExprOpUpdate; + friend struct ExprOpConcatLists; + friend struct ExprSelect; + friend void prim_getAttr(EvalState& state, const Pos& pos, Value** args, + Value& v); +}; + +/* Return a string representing the type of the value `v'. */ +string showType(const Value& v); + +/* Decode a context string ‘!<name>!<path>’ into a pair <path, + name>. */ +std::pair<string, string> decodeContext(const std::string& s); + +/* If `path' refers to a directory, then append "/default.nix". */ +Path resolveExprPath(Path path); + +struct InvalidPathError : EvalError { + Path path; + InvalidPathError(const Path& path); +#ifdef EXCEPTION_NEEDS_THROW_SPEC + ~InvalidPathError() noexcept {}; +#endif +}; + +struct EvalSettings : Config { + Setting<bool> enableNativeCode{this, false, + "allow-unsafe-native-code-during-evaluation", + "Whether builtin functions that allow " + "executing native code should be enabled."}; + + Setting<bool> restrictEval{ + this, false, "restrict-eval", + "Whether to restrict file system access to paths in $NIX_PATH, " + "and network access to the URI prefixes listed in 'allowed-uris'."}; + + Setting<bool> pureEval{this, false, "pure-eval", + "Whether to restrict file system and network access " + "to files specified by cryptographic hash."}; + + Setting<bool> enableImportFromDerivation{ + this, true, "allow-import-from-derivation", + "Whether the evaluator allows importing the result of a derivation."}; + + Setting<Strings> allowedUris{ + this, + {}, + "allowed-uris", + "Prefixes of URIs that builtin functions such as fetchurl and fetchGit " + "are allowed to fetch."}; + + Setting<bool> traceFunctionCalls{this, false, "trace-function-calls", + "Emit log messages for each function entry " + "and exit at the 'vomit' log level (-vvvv)"}; +}; + +extern EvalSettings evalSettings; + +} // namespace nix diff --git a/third_party/nix/src/libexpr/function-trace.cc b/third_party/nix/src/libexpr/function-trace.cc new file mode 100644 index 0000000000..8b0d60fab8 --- /dev/null +++ b/third_party/nix/src/libexpr/function-trace.cc @@ -0,0 +1,19 @@ +#include "function-trace.hh" + +#include <glog/logging.h> + +namespace nix { + +FunctionCallTrace::FunctionCallTrace(const Pos& pos) : pos(pos) { + auto duration = std::chrono::high_resolution_clock::now().time_since_epoch(); + auto ns = std::chrono::duration_cast<std::chrono::nanoseconds>(duration); + LOG(INFO) << "function-trace entered " << pos << " at " << ns.count(); +} + +FunctionCallTrace::~FunctionCallTrace() { + auto duration = std::chrono::high_resolution_clock::now().time_since_epoch(); + auto ns = std::chrono::duration_cast<std::chrono::nanoseconds>(duration); + LOG(INFO) << "function-trace exited " << pos << " at " << ns.count(); +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/function-trace.hh b/third_party/nix/src/libexpr/function-trace.hh new file mode 100644 index 0000000000..93d70862ed --- /dev/null +++ b/third_party/nix/src/libexpr/function-trace.hh @@ -0,0 +1,14 @@ +#pragma once + +#include <chrono> + +#include "eval.hh" + +namespace nix { + +struct FunctionCallTrace { + const Pos& pos; + FunctionCallTrace(const Pos& pos); + ~FunctionCallTrace(); +}; +} // namespace nix diff --git a/third_party/nix/src/libexpr/get-drvs.cc b/third_party/nix/src/libexpr/get-drvs.cc new file mode 100644 index 0000000000..6d4ad33be0 --- /dev/null +++ b/third_party/nix/src/libexpr/get-drvs.cc @@ -0,0 +1,444 @@ +#include "get-drvs.hh" + +#include <cstring> +#include <regex> +#include <utility> + +#include <glog/logging.h> + +#include "derivations.hh" +#include "eval-inline.hh" +#include "util.hh" + +namespace nix { + +DrvInfo::DrvInfo(EvalState& state, std::string attrPath, Bindings* attrs) + : state(&state), attrs(attrs), attrPath(std::move(attrPath)) {} + +DrvInfo::DrvInfo(EvalState& state, const ref<Store>& store, + const std::string& drvPathWithOutputs) + : state(&state), attrPath("") { + auto spec = parseDrvPathWithOutputs(drvPathWithOutputs); + + drvPath = spec.first; + + auto drv = store->derivationFromPath(drvPath); + + name = storePathToName(drvPath); + + if (spec.second.size() > 1) { + throw Error( + "building more than one derivation output is not supported, in '%s'", + drvPathWithOutputs); + } + + outputName = spec.second.empty() ? get(drv.env, "outputName", "out") + : *spec.second.begin(); + + auto i = drv.outputs.find(outputName); + if (i == drv.outputs.end()) { + throw Error("derivation '%s' does not have output '%s'", drvPath, + outputName); + } + + outPath = i->second.path; +} + +string DrvInfo::queryName() const { + if (name.empty() && (attrs != nullptr)) { + auto i = attrs->find(state->sName); + if (i == attrs->end()) { + throw TypeError("derivation name missing"); + } + name = state->forceStringNoCtx(*i->second.value); + } + return name; +} + +string DrvInfo::querySystem() const { + if (system.empty() && (attrs != nullptr)) { + auto i = attrs->find(state->sSystem); + system = i == attrs->end() + ? "unknown" + : state->forceStringNoCtx(*i->second.value, *i->second.pos); + } + return system; +} + +string DrvInfo::queryDrvPath() const { + if (drvPath.empty() && (attrs != nullptr)) { + Bindings::iterator i = attrs->find(state->sDrvPath); + PathSet context; + drvPath = i != attrs->end() ? state->coerceToPath(*i->second.pos, + *i->second.value, context) + : ""; + } + return drvPath; +} + +string DrvInfo::queryOutPath() const { + if (outPath.empty() && (attrs != nullptr)) { + Bindings::iterator i = attrs->find(state->sOutPath); + PathSet context; + outPath = i != attrs->end() ? state->coerceToPath(*i->second.pos, + *i->second.value, context) + : ""; + } + return outPath; +} + +DrvInfo::Outputs DrvInfo::queryOutputs(bool onlyOutputsToInstall) { + if (outputs.empty()) { + /* Get the ‘outputs’ list. */ + Bindings::iterator i; + if ((attrs != nullptr) && + (i = attrs->find(state->sOutputs)) != attrs->end()) { + state->forceList(*i->second.value, *i->second.pos); + + /* For each output... */ + for (unsigned int j = 0; j < i->second.value->listSize(); ++j) { + /* Evaluate the corresponding set. */ + std::string name = state->forceStringNoCtx( + *i->second.value->listElems()[j], *i->second.pos); + Bindings::iterator out = attrs->find(state->symbols.Create(name)); + if (out == attrs->end()) { + continue; // FIXME: throw error? + } + state->forceAttrs(*out->second.value); + + /* And evaluate its ‘outPath’ attribute. */ + Bindings::iterator outPath = + out->second.value->attrs->find(state->sOutPath); + if (outPath == out->second.value->attrs->end()) { + continue; // FIXME: throw error? + } + PathSet context; + outputs[name] = state->coerceToPath(*outPath->second.pos, + *outPath->second.value, context); + } + } else { + outputs["out"] = queryOutPath(); + } + } + if (!onlyOutputsToInstall || (attrs == nullptr)) { + return outputs; + } + + /* Check for `meta.outputsToInstall` and return `outputs` reduced to that. */ + const Value* outTI = queryMeta("outputsToInstall"); + if (outTI == nullptr) { + return outputs; + } + const auto errMsg = Error("this derivation has bad 'meta.outputsToInstall'"); + /* ^ this shows during `nix-env -i` right under the bad derivation */ + if (!outTI->isList()) { + throw errMsg; + } + Outputs result; + for (auto i = outTI->listElems(); i != outTI->listElems() + outTI->listSize(); + ++i) { + if ((*i)->type != tString) { + throw errMsg; + } + auto out = outputs.find((*i)->string.s); + if (out == outputs.end()) { + throw errMsg; + } + result.insert(*out); + } + return result; +} + +string DrvInfo::queryOutputName() const { + if (outputName.empty() && (attrs != nullptr)) { + Bindings::iterator i = attrs->find(state->sOutputName); + outputName = + i != attrs->end() ? state->forceStringNoCtx(*i->second.value) : ""; + } + return outputName; +} + +Bindings* DrvInfo::getMeta() { + if (meta != nullptr) { + return meta; + } + if (attrs == nullptr) { + return nullptr; + } + Bindings::iterator a = attrs->find(state->sMeta); + if (a == attrs->end()) { + return nullptr; + } + state->forceAttrs(*a->second.value, *a->second.pos); + meta = a->second.value->attrs; + return meta; +} + +StringSet DrvInfo::queryMetaNames() { + StringSet res; + if (getMeta() == nullptr) { + return res; + } + for (auto& i : *meta) { + res.insert(i.second.name); + } + return res; +} + +bool DrvInfo::checkMeta(Value& v) { + state->forceValue(v); + if (v.isList()) { + for (unsigned int n = 0; n < v.listSize(); ++n) { + if (!checkMeta(*v.listElems()[n])) { + return false; + } + } + return true; + } + if (v.type == tAttrs) { + Bindings::iterator i = v.attrs->find(state->sOutPath); + if (i != v.attrs->end()) { + return false; + } + for (auto& i : *v.attrs) { + if (!checkMeta(*i.second.value)) { + return false; + } + } + return true; + } else { + return v.type == tInt || v.type == tBool || v.type == tString || + v.type == tFloat; + } +} + +Value* DrvInfo::queryMeta(const std::string& name) { + if (getMeta() == nullptr) { + return nullptr; + } + Bindings::iterator a = meta->find(state->symbols.Create(name)); + if (a == meta->end() || !checkMeta(*a->second.value)) { + return nullptr; + } + return a->second.value; +} + +string DrvInfo::queryMetaString(const std::string& name) { + Value* v = queryMeta(name); + if ((v == nullptr) || v->type != tString) { + return ""; + } + return v->string.s; +} + +NixInt DrvInfo::queryMetaInt(const std::string& name, NixInt def) { + Value* v = queryMeta(name); + if (v == nullptr) { + return def; + } + if (v->type == tInt) { + return v->integer; + } + if (v->type == tString) { + /* Backwards compatibility with before we had support for + integer meta fields. */ + NixInt n; + if (string2Int(v->string.s, n)) { + return n; + } + } + return def; +} + +NixFloat DrvInfo::queryMetaFloat(const std::string& name, NixFloat def) { + Value* v = queryMeta(name); + if (v == nullptr) { + return def; + } + if (v->type == tFloat) { + return v->fpoint; + } + if (v->type == tString) { + /* Backwards compatibility with before we had support for + float meta fields. */ + NixFloat n; + if (string2Float(v->string.s, n)) { + return n; + } + } + return def; +} + +bool DrvInfo::queryMetaBool(const std::string& name, bool def) { + Value* v = queryMeta(name); + if (v == nullptr) { + return def; + } + if (v->type == tBool) { + return v->boolean; + } + if (v->type == tString) { + /* Backwards compatibility with before we had support for + Boolean meta fields. */ + if (strcmp(v->string.s, "true") == 0) { + return true; + } + if (strcmp(v->string.s, "false") == 0) { + return false; + } + } + return def; +} + +void DrvInfo::setMeta(const std::string& name, Value* v) { + getMeta(); + Bindings* old = meta; + meta = Bindings::NewGC(); + Symbol sym = state->symbols.Create(name); + if (old != nullptr) { + for (auto i : *old) { + if (i.second.name != sym) { + meta->push_back(i.second); + } + } + } + if (v != nullptr) { + meta->push_back(Attr(sym, v)); + } +} + +/* Cache for already considered attrsets. */ +using Done = set<Bindings*>; + +/* Evaluate value `v'. If it evaluates to a set of type `derivation', + then put information about it in `drvs' (unless it's already in `done'). + The result boolean indicates whether it makes sense + for the caller to recursively search for derivations in `v'. */ +static bool getDerivation(EvalState& state, Value& v, + const std::string& attrPath, DrvInfos& drvs, + Done& done, bool ignoreAssertionFailures) { + try { + state.forceValue(v); + if (!state.isDerivation(v)) { + return true; + } + + /* Remove spurious duplicates (e.g., a set like `rec { x = + derivation {...}; y = x;}'. */ + if (done.find(v.attrs) != done.end()) { + return false; + } + done.insert(v.attrs); + + DrvInfo drv(state, attrPath, v.attrs); + + drv.queryName(); + + drvs.push_back(drv); + + return false; + + } catch (AssertionError& e) { + if (ignoreAssertionFailures) { + return false; + } + throw; + } +} + +std::optional<DrvInfo> getDerivation(EvalState& state, Value& v, + bool ignoreAssertionFailures) { + Done done; + DrvInfos drvs; + getDerivation(state, v, "", drvs, done, ignoreAssertionFailures); + if (drvs.size() != 1) { + return {}; + } + return std::move(drvs.front()); +} + +static std::string addToPath(const std::string& s1, const std::string& s2) { + return s1.empty() ? s2 : s1 + "." + s2; +} + +static std::regex attrRegex("[A-Za-z_][A-Za-z0-9-_+]*"); + +static void getDerivations(EvalState& state, Value& vIn, + const std::string& pathPrefix, Bindings& autoArgs, + DrvInfos& drvs, Done& done, + bool ignoreAssertionFailures) { + Value v; + state.autoCallFunction(autoArgs, vIn, v); + + /* Process the expression. */ + if (!getDerivation(state, v, pathPrefix, drvs, done, + ignoreAssertionFailures)) { + ; + + } else if (v.type == tAttrs) { + /* !!! undocumented hackery to support combining channels in + nix-env.cc. */ + bool combineChannels = + v.attrs->find(state.symbols.Create("_combineChannels")) != + v.attrs->end(); + + /* Consider the attributes in sorted order to get more + deterministic behaviour in nix-env operations (e.g. when + there are names clashes between derivations, the derivation + bound to the attribute with the "lower" name should take + precedence). */ + for (auto& i : v.attrs->lexicographicOrder()) { + DLOG(INFO) << "evaluating attribute '" << i->name << "'"; + if (!std::regex_match(std::string(i->name), attrRegex)) { + continue; + } + std::string pathPrefix2 = addToPath(pathPrefix, i->name); + if (combineChannels) { + getDerivations(state, *i->value, pathPrefix2, autoArgs, drvs, done, + ignoreAssertionFailures); + } else if (getDerivation(state, *i->value, pathPrefix2, drvs, done, + ignoreAssertionFailures)) { + /* If the value of this attribute is itself a set, + should we recurse into it? => Only if it has a + `recurseForDerivations = true' attribute. */ + if (i->value->type == tAttrs) { + Bindings::iterator j = i->value->attrs->find( + state.symbols.Create("recurseForDerivations")); + if (j != i->value->attrs->end() && + state.forceBool(*j->second.value, *j->second.pos)) { + getDerivations(state, *i->value, pathPrefix2, autoArgs, drvs, done, + ignoreAssertionFailures); + } + } + } + } + } + + else if (v.isList()) { + for (unsigned int n = 0; n < v.listSize(); ++n) { + std::string pathPrefix2 = + addToPath(pathPrefix, (format("%1%") % n).str()); + if (getDerivation(state, *v.listElems()[n], pathPrefix2, drvs, done, + ignoreAssertionFailures)) { + getDerivations(state, *v.listElems()[n], pathPrefix2, autoArgs, drvs, + done, ignoreAssertionFailures); + } + } + } + + else { + throw TypeError( + "expression does not evaluate to a derivation (or a set or list of " + "those)"); + } +} + +void getDerivations(EvalState& state, Value& v, const std::string& pathPrefix, + Bindings& autoArgs, DrvInfos& drvs, + bool ignoreAssertionFailures) { + Done done; + getDerivations(state, v, pathPrefix, autoArgs, drvs, done, + ignoreAssertionFailures); +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/get-drvs.hh b/third_party/nix/src/libexpr/get-drvs.hh new file mode 100644 index 0000000000..3da2319461 --- /dev/null +++ b/third_party/nix/src/libexpr/get-drvs.hh @@ -0,0 +1,85 @@ +#pragma once + +#include <map> +#include <string> + +#include "eval.hh" + +namespace nix { + +struct DrvInfo { + public: + typedef std::map<string, Path> Outputs; + + private: + EvalState* state; + + mutable std::string name; + mutable std::string system; + mutable std::string drvPath; + mutable std::string outPath; + mutable std::string outputName; + Outputs outputs; + + bool failed = false; // set if we get an AssertionError + + Bindings *attrs = nullptr, *meta = nullptr; + + Bindings* getMeta(); + + bool checkMeta(Value& v); + + public: + std::string attrPath; /* path towards the derivation */ + + DrvInfo(EvalState& state) : state(&state){}; + DrvInfo(EvalState& state, std::string attrPath, Bindings* attrs); + DrvInfo(EvalState& state, const ref<Store>& store, + const std::string& drvPathWithOutputs); + + std::string queryName() const; + std::string querySystem() const; + std::string queryDrvPath() const; + std::string queryOutPath() const; + std::string queryOutputName() const; + /** Return the list of outputs. The "outputs to install" are determined by + * `meta.outputsToInstall`. */ + Outputs queryOutputs(bool onlyOutputsToInstall = false); + + StringSet queryMetaNames(); + Value* queryMeta(const std::string& name); + std::string queryMetaString(const std::string& name); + NixInt queryMetaInt(const std::string& name, NixInt def); + NixFloat queryMetaFloat(const std::string& name, NixFloat def); + bool queryMetaBool(const std::string& name, bool def); + void setMeta(const std::string& name, Value* v); + + /* + MetaInfo queryMetaInfo(EvalState & state) const; + MetaValue queryMetaInfo(EvalState & state, const std::string & name) const; + */ + + void setName(const std::string& s) { name = s; } + void setDrvPath(const std::string& s) { drvPath = s; } + void setOutPath(const std::string& s) { outPath = s; } + + void setFailed() { failed = true; }; + bool hasFailed() { return failed; }; +}; + +#if HAVE_BOEHMGC +typedef list<DrvInfo, traceable_allocator<DrvInfo> > DrvInfos; +#else +typedef list<DrvInfo> DrvInfos; +#endif + +/* If value `v' denotes a derivation, return a DrvInfo object + describing it. Otherwise return nothing. */ +std::optional<DrvInfo> getDerivation(EvalState& state, Value& v, + bool ignoreAssertionFailures); + +void getDerivations(EvalState& state, Value& v, const std::string& pathPrefix, + Bindings& autoArgs, DrvInfos& drvs, + bool ignoreAssertionFailures); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/json-to-value.cc b/third_party/nix/src/libexpr/json-to-value.cc new file mode 100644 index 0000000000..d46e6f268e --- /dev/null +++ b/third_party/nix/src/libexpr/json-to-value.cc @@ -0,0 +1,185 @@ +#include "json-to-value.hh" + +#include <cstring> + +namespace nix { + +static void skipWhitespace(const char*& s) { + while (*s == ' ' || *s == '\t' || *s == '\n' || *s == '\r') { + s++; + } +} + +static std::string parseJSONString(const char*& s) { + std::string res; + if (*s++ != '"') { + throw JSONParseError("expected JSON string"); + } + while (*s != '"') { + if (*s == 0) { + throw JSONParseError("got end-of-string in JSON string"); + } + if (*s == '\\') { + s++; + if (*s == '"') { + res += '"'; + } else if (*s == '\\') { + res += '\\'; + } else if (*s == '/') { + res += '/'; + } else if (*s == '/') { + res += '/'; + } else if (*s == 'b') { + res += '\b'; + } else if (*s == 'f') { + res += '\f'; + } else if (*s == 'n') { + res += '\n'; + } else if (*s == 'r') { + res += '\r'; + } else if (*s == 't') { + res += '\t'; + } else if (*s == 'u') { + throw JSONParseError( + "\\u characters in JSON strings are currently not supported"); + } else { + throw JSONParseError("invalid escaped character in JSON string"); + } + s++; + } else { + res += *s++; + } + } + s++; + return res; +} + +static void parseJSON(EvalState& state, const char*& s, Value& v) { + skipWhitespace(s); + + if (*s == 0) { + throw JSONParseError("expected JSON value"); + } + + if (*s == '[') { + s++; + ValueVector values; + values.reserve(128); + skipWhitespace(s); + while (true) { + if (values.empty() && *s == ']') { + break; + } + Value* v2 = state.allocValue(); + parseJSON(state, s, *v2); + values.push_back(v2); + skipWhitespace(s); + if (*s == ']') { + break; + } + if (*s != ',') { + throw JSONParseError("expected ',' or ']' after JSON array element"); + } + s++; + } + s++; + state.mkList(v, values.size()); + for (size_t n = 0; n < values.size(); ++n) { + v.listElems()[n] = values[n]; + } + } + + else if (*s == '{') { + s++; + ValueMap attrs; + while (true) { + skipWhitespace(s); + if (attrs.empty() && *s == '}') { + break; + } + std::string name = parseJSONString(s); + skipWhitespace(s); + if (*s != ':') { + throw JSONParseError("expected ':' in JSON object"); + } + s++; + Value* v2 = state.allocValue(); + parseJSON(state, s, *v2); + attrs[state.symbols.Create(name)] = v2; + skipWhitespace(s); + if (*s == '}') { + break; + } + if (*s != ',') { + throw JSONParseError("expected ',' or '}' after JSON member"); + } + s++; + } + state.mkAttrs(v, attrs.size()); + for (auto& i : attrs) { + v.attrs->push_back(Attr(i.first, i.second)); + } + s++; + } + + else if (*s == '"') { + mkString(v, parseJSONString(s)); + } + + else if ((isdigit(*s) != 0) || *s == '-' || *s == '.') { + // Buffer into a std::string first, then use built-in C++ conversions + std::string tmp_number; + ValueType number_type = tInt; + + while ((isdigit(*s) != 0) || *s == '-' || *s == '.' || *s == 'e' || + *s == 'E') { + if (*s == '.' || *s == 'e' || *s == 'E') { + number_type = tFloat; + } + tmp_number += *s++; + } + + try { + if (number_type == tFloat) { + mkFloat(v, stod(tmp_number)); + } else { + mkInt(v, stol(tmp_number)); + } + } catch (std::invalid_argument& e) { + throw JSONParseError("invalid JSON number"); + } catch (std::out_of_range& e) { + throw JSONParseError("out-of-range JSON number"); + } + } + + else if (strncmp(s, "true", 4) == 0) { + s += 4; + mkBool(v, true); + } + + else if (strncmp(s, "false", 5) == 0) { + s += 5; + mkBool(v, false); + } + + else if (strncmp(s, "null", 4) == 0) { + s += 4; + mkNull(v); + } + + else { + throw JSONParseError("unrecognised JSON value"); + } +} + +void parseJSON(EvalState& state, const std::string& s_, Value& v) { + const char* s = s_.c_str(); + parseJSON(state, s, v); + skipWhitespace(s); + if (*s != 0) { + throw JSONParseError( + format("expected end-of-string while parsing JSON value: %1%") % s); + } +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/json-to-value.hh b/third_party/nix/src/libexpr/json-to-value.hh new file mode 100644 index 0000000000..f416dfbb38 --- /dev/null +++ b/third_party/nix/src/libexpr/json-to-value.hh @@ -0,0 +1,13 @@ +#pragma once + +#include <string> + +#include "eval.hh" + +namespace nix { + +MakeError(JSONParseError, EvalError) + + void parseJSON(EvalState& state, const std::string& s, Value& v); + +} diff --git a/third_party/nix/src/libexpr/lexer.l b/third_party/nix/src/libexpr/lexer.l new file mode 100644 index 0000000000..9cdb2bd97e --- /dev/null +++ b/third_party/nix/src/libexpr/lexer.l @@ -0,0 +1,222 @@ +%option reentrant bison-bridge bison-locations +%option noyywrap +%option never-interactive +%option stack +%option nodefault +%option nounput noyy_top_state + + +%s DEFAULT +%x STRING +%x IND_STRING + + +%{ +#include <boost/lexical_cast.hpp> + +#include "nixexpr.hh" +#include "parser-tab.hh" + +using namespace nix; + +namespace nix { + + +static void initLoc(YYLTYPE * loc) +{ + loc->first_line = loc->last_line = 1; + loc->first_column = loc->last_column = 1; +} + + +static void adjustLoc(YYLTYPE * loc, const char * s, size_t len) +{ + loc->first_line = loc->last_line; + loc->first_column = loc->last_column; + + while (len--) { + switch (*s++) { + case '\r': + if (*s == '\n') /* cr/lf */ + s++; + /* fall through */ + case '\n': + ++loc->last_line; + loc->last_column = 1; + break; + default: + ++loc->last_column; + } + } +} + + +static Expr * unescapeStr(SymbolTable & symbols, const char * s, size_t length) +{ + std::string t; + t.reserve(length); + char c; + while ((c = *s++)) { + if (c == '\\') { + assert(*s); + c = *s++; + if (c == 'n') { t += '\n'; } + else if (c == 'r') { t += '\r'; } + else if (c == 't') { t += '\t'; } + else t += c; + } + else if (c == '\r') { + /* Normalise CR and CR/LF into LF. */ + t += '\n'; + if (*s == '\n') { s++; } /* cr/lf */ + } + else t += c; + } + return new ExprString(symbols.Create(t)); +} + + +} + +#define YY_USER_INIT initLoc(yylloc) +#define YY_USER_ACTION adjustLoc(yylloc, yytext, yyleng); + +#define PUSH_STATE(state) yy_push_state(state, yyscanner) +#define POP_STATE() yy_pop_state(yyscanner) + +%} + + +ANY .|\n +ID [a-zA-Z\_][a-zA-Z0-9\_\'\-]* +INT [0-9]+ +FLOAT (([1-9][0-9]*\.[0-9]*)|(0?\.[0-9]+))([Ee][+-]?[0-9]+)? +PATH [a-zA-Z0-9\.\_\-\+]*(\/[a-zA-Z0-9\.\_\-\+]+)+\/? +HPATH \~(\/[a-zA-Z0-9\.\_\-\+]+)+\/? +SPATH \<[a-zA-Z0-9\.\_\-\+]+(\/[a-zA-Z0-9\.\_\-\+]+)*\> +URI [a-zA-Z][a-zA-Z0-9\+\-\.]*\:[a-zA-Z0-9\%\/\?\:\@\&\=\+\$\,\-\_\.\!\~\*\']+ + + +%% + + +if { return IF; } +then { return THEN; } +else { return ELSE; } +assert { return ASSERT; } +with { return WITH; } +let { return LET; } +in { return IN; } +rec { return REC; } +inherit { return INHERIT; } +or { return OR_KW; } +\.\.\. { return ELLIPSIS; } + +\=\= { return EQ; } +\!\= { return NEQ; } +\<\= { return LEQ; } +\>\= { return GEQ; } +\&\& { return AND; } +\|\| { return OR; } +\-\> { return IMPL; } +\/\/ { return UPDATE; } +\+\+ { return CONCAT; } + +{ID} { yylval->id = strdup(yytext); return ID; } +{INT} { errno = 0; + try { + yylval->n = boost::lexical_cast<int64_t>(yytext); + } catch (const boost::bad_lexical_cast &) { + throw ParseError(format("invalid integer '%1%'") % yytext); + } + return INT; + } +{FLOAT} { errno = 0; + yylval->nf = strtod(yytext, 0); + if (errno != 0) + throw ParseError(format("invalid float '%1%'") % yytext); + return FLOAT; + } + +\$\{ { PUSH_STATE(DEFAULT); return DOLLAR_CURLY; } + +\} { /* State INITIAL only exists at the bottom of the stack and is + used as a marker. DEFAULT replaces it everywhere else. + Popping when in INITIAL state causes an empty stack exception, + so don't */ + if (YYSTATE != INITIAL) + POP_STATE(); + return '}'; + } +\{ { PUSH_STATE(DEFAULT); return '{'; } + +\" { PUSH_STATE(STRING); return '"'; } +<STRING>([^\$\"\\]|\$[^\{\"\\]|\\{ANY}|\$\\{ANY})*\$/\" | +<STRING>([^\$\"\\]|\$[^\{\"\\]|\\{ANY}|\$\\{ANY})+ { + /* It is impossible to match strings ending with '$' with one + regex because trailing contexts are only valid at the end + of a rule. (A sane but undocumented limitation.) */ + yylval->e = unescapeStr(data->symbols, yytext, yyleng); + return STR; + } +<STRING>\$\{ { PUSH_STATE(DEFAULT); return DOLLAR_CURLY; } +<STRING>\" { POP_STATE(); return '"'; } +<STRING>\$|\\|\$\\ { + /* This can only occur when we reach EOF, otherwise the above + (...|\$[^\{\"\\]|\\.|\$\\.)+ would have triggered. + This is technically invalid, but we leave the problem to the + parser who fails with exact location. */ + return STR; + } + +\'\'(\ *\n)? { PUSH_STATE(IND_STRING); return IND_STRING_OPEN; } +<IND_STRING>([^\$\']|\$[^\{\']|\'[^\'\$])+ { + yylval->e = new ExprIndStr(yytext); + return IND_STR; + } +<IND_STRING>\'\'\$ | +<IND_STRING>\$ { + yylval->e = new ExprIndStr("$"); + return IND_STR; + } +<IND_STRING>\'\'\' { + yylval->e = new ExprIndStr("''"); + return IND_STR; + } +<IND_STRING>\'\'\\{ANY} { + yylval->e = unescapeStr(data->symbols, yytext + 2, yyleng - 2); + return IND_STR; + } +<IND_STRING>\$\{ { PUSH_STATE(DEFAULT); return DOLLAR_CURLY; } +<IND_STRING>\'\' { POP_STATE(); return IND_STRING_CLOSE; } +<IND_STRING>\' { + yylval->e = new ExprIndStr("'"); + return IND_STR; + } + + +{PATH} { if (yytext[yyleng-1] == '/') + throw ParseError("path '%s' has a trailing slash", yytext); + yylval->path = strdup(yytext); + return PATH; + } +{HPATH} { if (yytext[yyleng-1] == '/') + throw ParseError("path '%s' has a trailing slash", yytext); + yylval->path = strdup(yytext); + return HPATH; + } +{SPATH} { yylval->path = strdup(yytext); return SPATH; } +{URI} { yylval->uri = strdup(yytext); return URI; } + +[ \t\r\n]+ /* eat up whitespace */ +\#[^\r\n]* /* single-line comments */ +\/\*([^*]|\*+[^*/])*\*+\/ /* long comments */ + +{ANY} { + /* Don't return a negative number, as this will cause + Bison to stop parsing without an error. */ + return (unsigned char) yytext[0]; + } + +%% + diff --git a/third_party/nix/src/libexpr/meson.build b/third_party/nix/src/libexpr/meson.build new file mode 100644 index 0000000000..ce50838b97 --- /dev/null +++ b/third_party/nix/src/libexpr/meson.build @@ -0,0 +1,97 @@ +src_inc += include_directories('.', 'primops') + +libexpr_src = files( + join_paths(meson.source_root(), 'src/libexpr/primops/context.cc'), + join_paths(meson.source_root(), 'src/libexpr/primops/fetchGit.cc'), + join_paths(meson.source_root(), 'src/libexpr/primops/fetchMercurial.cc'), + join_paths(meson.source_root(), 'src/libexpr/primops/fromTOML.cc'), + + join_paths(meson.source_root(), 'src/libexpr/attr-path.cc'), + join_paths(meson.source_root(), 'src/libexpr/attr-set.cc'), + join_paths(meson.source_root(), 'src/libexpr/common-eval-args.cc'), + join_paths(meson.source_root(), 'src/libexpr/eval.cc'), + join_paths(meson.source_root(), 'src/libexpr/function-trace.cc'), + join_paths(meson.source_root(), 'src/libexpr/get-drvs.cc'), + join_paths(meson.source_root(), 'src/libexpr/json-to-value.cc'), + join_paths(meson.source_root(), 'src/libexpr/names.cc'), + join_paths(meson.source_root(), 'src/libexpr/nixexpr.cc'), + join_paths(meson.source_root(), 'src/libexpr/primops.cc'), + join_paths(meson.source_root(), 'src/libexpr/symbol-table.cc'), + join_paths(meson.source_root(), 'src/libexpr/value-to-json.cc'), + join_paths(meson.source_root(), 'src/libexpr/value-to-xml.cc'), +) + +libexpr_headers = files( + join_paths(meson.source_root(), 'src/libexpr/attr-path.hh'), + join_paths(meson.source_root(), 'src/libexpr/attr-set.hh'), + join_paths(meson.source_root(), 'src/libexpr/common-eval-args.hh'), + join_paths(meson.source_root(), 'src/libexpr/eval.hh'), + join_paths(meson.source_root(), 'src/libexpr/eval-inline.hh'), + join_paths(meson.source_root(), 'src/libexpr/function-trace.hh'), + join_paths(meson.source_root(), 'src/libexpr/get-drvs.hh'), + join_paths(meson.source_root(), 'src/libexpr/json-to-value.hh'), + join_paths(meson.source_root(), 'src/libexpr/names.hh'), + join_paths(meson.source_root(), 'src/libexpr/nixexpr.hh'), + join_paths(meson.source_root(), 'src/libexpr/primops.hh'), + join_paths(meson.source_root(), 'src/libexpr/symbol-table.hh'), + join_paths(meson.source_root(), 'src/libexpr/value.hh'), + join_paths(meson.source_root(), 'src/libexpr/value-to-json.hh'), + join_paths(meson.source_root(), 'src/libexpr/value-to-xml.hh')) + +libexpr_dep_list = [ + gc_dep, + glog_dep, + libdl_dep, + libsodium_dep, +] + absl_deps + +libexpr_link_list = [ + libutil_lib, + libstore_lib, + libmain_lib, +] + +libexpr_link_args = [ + '-lpthread', + '-lgccpp', +] + +libexpr_cxx_args = [] + +libexpr_src += custom_target( + 'parser_tab.[cchh]', + output : [ + 'parser-tab.cc', + 'parser-tab.hh'], + input : 'parser.y', + command : [ + bison, + '-v', + '--output=@OUTPUT0@', + '@INPUT@', + '-d']) + +libexpr_src += custom_target( + 'lexer_tab.[cchh]', + output : ['lexer-tab.cc', 'lexer-tab.hh'], + input : 'lexer.l', + command : [ + flex, + '--outfile=@OUTPUT0@', + '--header-file=@OUTPUT1@', + '@INPUT@']) + +libexpr_lib = library( + 'nixexpr', + install : true, + install_mode : 'rwxr-xr-x', + install_dir : libdir, + include_directories : src_inc, + link_with : libexpr_link_list, + sources : libexpr_src, + link_args : libexpr_link_args, + dependencies : libexpr_dep_list) + +install_headers( + libexpr_headers, + install_dir : join_paths(includedir, 'nix')) diff --git a/third_party/nix/src/libexpr/names.cc b/third_party/nix/src/libexpr/names.cc new file mode 100644 index 0000000000..ac8150532f --- /dev/null +++ b/third_party/nix/src/libexpr/names.cc @@ -0,0 +1,119 @@ +#include "names.hh" + +#include <memory> + +#include "util.hh" + +namespace nix { + +DrvName::DrvName() { name = ""; } + +/* Parse a derivation name. The `name' part of a derivation name is + everything up to but not including the first dash *not* followed by + a letter. The `version' part is the rest (excluding the separating + dash). E.g., `apache-httpd-2.0.48' is parsed to (`apache-httpd', + '2.0.48'). */ +DrvName::DrvName(const std::string& s) : hits(0) { + name = fullName = s; + for (unsigned int i = 0; i < s.size(); ++i) { + /* !!! isalpha/isdigit are affected by the locale. */ + if (s[i] == '-' && i + 1 < s.size() && (isalpha(s[i + 1]) == 0)) { + name = string(s, 0, i); + version = string(s, i + 1); + break; + } + } +} + +bool DrvName::matches(DrvName& n) { + if (name != "*") { + if (!regex) { + regex = std::make_unique<std::regex>(name, std::regex::extended); + } + if (!std::regex_match(n.name, *regex)) { + return false; + } + } + return !(!version.empty() && version != n.version); +} + +string nextComponent(string::const_iterator& p, + const string::const_iterator end) { + /* Skip any dots and dashes (component separators). */ + while (p != end && (*p == '.' || *p == '-')) { + ++p; + } + + if (p == end) { + return ""; + } + + /* If the first character is a digit, consume the longest sequence + of digits. Otherwise, consume the longest sequence of + non-digit, non-separator characters. */ + std::string s; + if (isdigit(*p) != 0) { + while (p != end && (isdigit(*p) != 0)) { + s += *p++; + } + } else { + while (p != end && ((isdigit(*p) == 0) && *p != '.' && *p != '-')) { + s += *p++; + } + } + + return s; +} + +static bool componentsLT(const std::string& c1, const std::string& c2) { + int n1; + int n2; + bool c1Num = string2Int(c1, n1); + bool c2Num = string2Int(c2, n2); + + if (c1Num && c2Num) { + return n1 < n2; + } + if (c1.empty() && c2Num) { + return true; + } else if (c1 == "pre" && c2 != "pre") { + return true; + } else if (c2 == "pre") { + return false; + /* Assume that `2.3a' < `2.3.1'. */ + } else if (c2Num) { + return true; + } else if (c1Num) { + return false; + } else { + return c1 < c2; + } +} + +int compareVersions(const std::string& v1, const std::string& v2) { + string::const_iterator p1 = v1.begin(); + string::const_iterator p2 = v2.begin(); + + while (p1 != v1.end() || p2 != v2.end()) { + std::string c1 = nextComponent(p1, v1.end()); + std::string c2 = nextComponent(p2, v2.end()); + if (componentsLT(c1, c2)) { + return -1; + } + if (componentsLT(c2, c1)) { + return 1; + } + } + + return 0; +} + +DrvNames drvNamesFromArgs(const Strings& opArgs) { + DrvNames result; + for (auto& i : opArgs) { + result.push_back(DrvName(i)); + } + return result; +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/names.hh b/third_party/nix/src/libexpr/names.hh new file mode 100644 index 0000000000..e2ddb5cb99 --- /dev/null +++ b/third_party/nix/src/libexpr/names.hh @@ -0,0 +1,31 @@ +#pragma once + +#include <memory> +#include <regex> + +#include "types.hh" + +namespace nix { + +struct DrvName { + std::string fullName; + std::string name; + std::string version; + unsigned int hits; + + DrvName(); + DrvName(const std::string& s); + bool matches(DrvName& n); + + private: + std::unique_ptr<std::regex> regex; +}; + +typedef list<DrvName> DrvNames; + +string nextComponent(string::const_iterator& p, + const string::const_iterator end); +int compareVersions(const std::string& v1, const std::string& v2); +DrvNames drvNamesFromArgs(const Strings& opArgs); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/nix-expr.pc.in b/third_party/nix/src/libexpr/nix-expr.pc.in new file mode 100644 index 0000000000..80f7a492b1 --- /dev/null +++ b/third_party/nix/src/libexpr/nix-expr.pc.in @@ -0,0 +1,10 @@ +prefix=@prefix@ +libdir=@libdir@ +includedir=@includedir@ + +Name: Nix +Description: Nix Package Manager +Version: @PACKAGE_VERSION@ +Requires: nix-store bdw-gc +Libs: -L${libdir} -lnixexpr +Cflags: -I${includedir}/nix -std=c++17 diff --git a/third_party/nix/src/libexpr/nixexpr.cc b/third_party/nix/src/libexpr/nixexpr.cc new file mode 100644 index 0000000000..3d454d266f --- /dev/null +++ b/third_party/nix/src/libexpr/nixexpr.cc @@ -0,0 +1,416 @@ +#include "nixexpr.hh" + +#include <cstdlib> + +#include "derivations.hh" +#include "util.hh" + +namespace nix { + +/* Displaying abstract syntax trees. */ + +std::ostream& operator<<(std::ostream& str, const Expr& e) { + e.show(str); + return str; +} + +static void showString(std::ostream& str, const std::string& s) { + str << '"'; + for (auto c : (string)s) { + if (c == '"' || c == '\\' || c == '$') { + str << "\\" << c; + } else if (c == '\n') { + str << "\\n"; + } else if (c == '\r') { + str << "\\r"; + } else if (c == '\t') { + str << "\\t"; + } else { + str << c; + } + } + str << '"'; +} + +static void showId(std::ostream& str, const std::string& s) { + if (s.empty()) { + str << "\"\""; + } else if (s == "if") { // FIXME: handle other keywords + str << '"' << s << '"'; + } else { + char c = s[0]; + if (!((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_')) { + showString(str, s); + return; + } + for (auto c : s) { + if (!((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || + (c >= '0' && c <= '9') || c == '_' || c == '\'' || c == '-')) { + showString(str, s); + return; + } + } + str << s; + } +} + +std::ostream& operator<<(std::ostream& str, const Symbol& sym) { + showId(str, *sym.s); + return str; +} + +void Expr::show(std::ostream& str) const { abort(); } + +void ExprInt::show(std::ostream& str) const { str << n; } + +void ExprFloat::show(std::ostream& str) const { str << nf; } + +void ExprString::show(std::ostream& str) const { showString(str, s); } + +void ExprPath::show(std::ostream& str) const { str << s; } + +void ExprVar::show(std::ostream& str) const { str << name; } + +void ExprSelect::show(std::ostream& str) const { + str << "(" << *e << ")." << showAttrPath(attrPath); + if (def != nullptr) { + str << " or (" << *def << ")"; + } +} + +void ExprOpHasAttr::show(std::ostream& str) const { + str << "((" << *e << ") ? " << showAttrPath(attrPath) << ")"; +} + +void ExprAttrs::show(std::ostream& str) const { + if (recursive) { + str << "rec "; + } + str << "{ "; + for (auto& i : attrs) { + if (i.second.inherited) { + str << "inherit " << i.first << " " + << "; "; + } else { + str << i.first << " = " << *i.second.e << "; "; + } + } + for (auto& i : dynamicAttrs) { + str << "\"${" << *i.nameExpr << "}\" = " << *i.valueExpr << "; "; + } + str << "}"; +} + +void ExprList::show(std::ostream& str) const { + str << "[ "; + for (auto& i : elems) { + str << "(" << *i << ") "; + } + str << "]"; +} + +void ExprLambda::show(std::ostream& str) const { + str << "("; + if (matchAttrs) { + str << "{ "; + bool first = true; + for (auto& i : formals->formals) { + if (first) { + first = false; + } else { + str << ", "; + } + str << i.name; + if (i.def != nullptr) { + str << " ? " << *i.def; + } + } + if (formals->ellipsis) { + if (!first) { + str << ", "; + } + str << "..."; + } + str << " }"; + if (!arg.empty()) { + str << " @ "; + } + } + if (!arg.empty()) { + str << arg; + } + str << ": " << *body << ")"; +} + +void ExprLet::show(std::ostream& str) const { + str << "(let "; + for (auto& i : attrs->attrs) { + if (i.second.inherited) { + str << "inherit " << i.first << "; "; + } else { + str << i.first << " = " << *i.second.e << "; "; + } + } + str << "in " << *body << ")"; +} + +void ExprWith::show(std::ostream& str) const { + str << "(with " << *attrs << "; " << *body << ")"; +} + +void ExprIf::show(std::ostream& str) const { + str << "(if " << *cond << " then " << *then << " else " << *else_ << ")"; +} + +void ExprAssert::show(std::ostream& str) const { + str << "assert " << *cond << "; " << *body; +} + +void ExprOpNot::show(std::ostream& str) const { str << "(! " << *e << ")"; } + +void ExprConcatStrings::show(std::ostream& str) const { + bool first = true; + str << "("; + for (auto& i : *es) { + if (first) { + first = false; + } else { + str << " + "; + } + str << *i; + } + str << ")"; +} + +void ExprPos::show(std::ostream& str) const { str << "__curPos"; } + +std::ostream& operator<<(std::ostream& str, const Pos& pos) { + if (!pos) { + str << "undefined position"; + } else { + str << (format(ANSI_BOLD "%1%" ANSI_NORMAL ":%2%:%3%") % (string)pos.file % + pos.line % pos.column) + .str(); + } + return str; +} + +string showAttrPath(const AttrPath& attrPath) { + std::ostringstream out; + bool first = true; + for (auto& i : attrPath) { + if (!first) { + out << '.'; + } else { + first = false; + } + if (i.symbol.set()) { + out << i.symbol; + } else { + out << "\"${" << *i.expr << "}\""; + } + } + return out.str(); +} + +Pos noPos; + +/* Computing levels/displacements for variables. */ + +void Expr::bindVars(const StaticEnv& env) { abort(); } + +void ExprInt::bindVars(const StaticEnv& env) {} + +void ExprFloat::bindVars(const StaticEnv& env) {} + +void ExprString::bindVars(const StaticEnv& env) {} + +void ExprPath::bindVars(const StaticEnv& env) {} + +void ExprVar::bindVars(const StaticEnv& env) { + /* Check whether the variable appears in the environment. If so, + set its level and displacement. */ + const StaticEnv* curEnv; + unsigned int level; + int withLevel = -1; + for (curEnv = &env, level = 0; curEnv != nullptr; + curEnv = curEnv->up, level++) { + if (curEnv->isWith) { + if (withLevel == -1) { + withLevel = level; + } + } else { + auto i = curEnv->vars.find(name); + if (i != curEnv->vars.end()) { + fromWith = false; + this->level = level; + displ = i->second; + return; + } + } + } + + /* Otherwise, the variable must be obtained from the nearest + enclosing `with'. If there is no `with', then we can issue an + "undefined variable" error now. */ + if (withLevel == -1) { + throw UndefinedVarError(format("undefined variable '%1%' at %2%") % name % + pos); + } + + fromWith = true; + this->level = withLevel; +} + +void ExprSelect::bindVars(const StaticEnv& env) { + e->bindVars(env); + if (def != nullptr) { + def->bindVars(env); + } + for (auto& i : attrPath) { + if (!i.symbol.set()) { + i.expr->bindVars(env); + } + } +} + +void ExprOpHasAttr::bindVars(const StaticEnv& env) { + e->bindVars(env); + for (auto& i : attrPath) { + if (!i.symbol.set()) { + i.expr->bindVars(env); + } + } +} + +void ExprAttrs::bindVars(const StaticEnv& env) { + const StaticEnv* dynamicEnv = &env; + StaticEnv newEnv(/* isWith = */ false, &env); + + if (recursive) { + dynamicEnv = &newEnv; + + unsigned int displ = 0; + for (auto& i : attrs) { + newEnv.vars[i.first] = i.second.displ = displ++; + } + + for (auto& i : attrs) { + i.second.e->bindVars(i.second.inherited ? env : newEnv); + } + } + + else { + for (auto& i : attrs) { + i.second.e->bindVars(env); + } + } + + for (auto& i : dynamicAttrs) { + i.nameExpr->bindVars(*dynamicEnv); + i.valueExpr->bindVars(*dynamicEnv); + } +} + +void ExprList::bindVars(const StaticEnv& env) { + for (auto& i : elems) { + i->bindVars(env); + } +} + +void ExprLambda::bindVars(const StaticEnv& env) { + StaticEnv newEnv(false, &env); + + unsigned int displ = 0; + + if (!arg.empty()) { + newEnv.vars[arg] = displ++; + } + + if (matchAttrs) { + for (auto& i : formals->formals) { + newEnv.vars[i.name] = displ++; + } + + for (auto& i : formals->formals) { + if (i.def != nullptr) { + i.def->bindVars(newEnv); + } + } + } + + body->bindVars(newEnv); +} + +void ExprLet::bindVars(const StaticEnv& env) { + StaticEnv newEnv(false, &env); + + unsigned int displ = 0; + for (auto& i : attrs->attrs) { + newEnv.vars[i.first] = i.second.displ = displ++; + } + + for (auto& i : attrs->attrs) { + i.second.e->bindVars(i.second.inherited ? env : newEnv); + } + + body->bindVars(newEnv); +} + +void ExprWith::bindVars(const StaticEnv& env) { + /* Does this `with' have an enclosing `with'? If so, record its + level so that `lookupVar' can look up variables in the previous + `with' if this one doesn't contain the desired attribute. */ + const StaticEnv* curEnv; + unsigned int level; + prevWith = 0; + for (curEnv = &env, level = 1; curEnv != nullptr; + curEnv = curEnv->up, level++) { + if (curEnv->isWith) { + prevWith = level; + break; + } + } + + attrs->bindVars(env); + StaticEnv newEnv(true, &env); + body->bindVars(newEnv); +} + +void ExprIf::bindVars(const StaticEnv& env) { + cond->bindVars(env); + then->bindVars(env); + else_->bindVars(env); +} + +void ExprAssert::bindVars(const StaticEnv& env) { + cond->bindVars(env); + body->bindVars(env); +} + +void ExprOpNot::bindVars(const StaticEnv& env) { e->bindVars(env); } + +void ExprConcatStrings::bindVars(const StaticEnv& env) { + for (auto& i : *es) { + i->bindVars(env); + } +} + +void ExprPos::bindVars(const StaticEnv& env) {} + +/* Storing function names. */ + +void Expr::setName(Symbol& name) {} + +void ExprLambda::setName(Symbol& name) { + this->name = name; + body->setName(name); +} + +string ExprLambda::showNamePos() const { + return (format("%1% at %2%") % + (name.set() ? "'" + (string)name + "'" : "anonymous function") % pos) + .str(); +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/nixexpr.hh b/third_party/nix/src/libexpr/nixexpr.hh new file mode 100644 index 0000000000..715dbd8d59 --- /dev/null +++ b/third_party/nix/src/libexpr/nixexpr.hh @@ -0,0 +1,323 @@ +#pragma once + +#include <map> + +#include "symbol-table.hh" +#include "types.hh" // TODO(tazjin): audit this include +#include "value.hh" + +namespace nix { + +MakeError(EvalError, Error) MakeError(ParseError, Error) + MakeError(AssertionError, EvalError) MakeError(ThrownError, AssertionError) + MakeError(Abort, EvalError) MakeError(TypeError, EvalError) + MakeError(UndefinedVarError, Error) + MakeError(RestrictedPathError, Error) + + /* Position objects. */ + + struct Pos { + Symbol file; + unsigned int line, column; + Pos() : line(0), column(0){}; + Pos(const Symbol& file, unsigned int line, unsigned int column) + : file(file), line(line), column(column){}; + operator bool() const { return line != 0; } + bool operator<(const Pos& p2) const { + if (!line) { + return p2.line; + } + if (!p2.line) { + return false; + } + int d = ((string)file).compare((string)p2.file); + if (d < 0) { + return true; + } + if (d > 0) { + return false; + } + if (line < p2.line) { + return true; + } + if (line > p2.line) { + return false; + } + return column < p2.column; + } +}; + +extern Pos noPos; + +std::ostream& operator<<(std::ostream& str, const Pos& pos); + +struct Env; +struct Value; +class EvalState; +struct StaticEnv; + +/* An attribute path is a sequence of attribute names. */ +struct AttrName { + Symbol symbol; + Expr* expr; + AttrName(const Symbol& s) : symbol(s){}; + AttrName(Expr* e) : expr(e){}; +}; + +typedef std::vector<AttrName> AttrPath; + +string showAttrPath(const AttrPath& attrPath); + +/* Abstract syntax of Nix expressions. */ + +struct Expr { + virtual ~Expr(){}; + virtual void show(std::ostream& str) const; + virtual void bindVars(const StaticEnv& env); + virtual void eval(EvalState& state, Env& env, Value& v); + virtual Value* maybeThunk(EvalState& state, Env& env); + virtual void setName(Symbol& name); +}; + +std::ostream& operator<<(std::ostream& str, const Expr& e); + +#define COMMON_METHODS \ + void show(std::ostream& str) const; \ + void eval(EvalState& state, Env& env, Value& v); \ + void bindVars(const StaticEnv& env); + +struct ExprInt : Expr { + NixInt n; + Value v; + ExprInt(NixInt n) : n(n) { mkInt(v, n); }; + COMMON_METHODS + Value* maybeThunk(EvalState& state, Env& env); +}; + +struct ExprFloat : Expr { + NixFloat nf; + Value v; + ExprFloat(NixFloat nf) : nf(nf) { mkFloat(v, nf); }; + COMMON_METHODS + Value* maybeThunk(EvalState& state, Env& env); +}; + +struct ExprString : Expr { + Symbol s; + Value v; + ExprString(const Symbol& s) : s(s) { mkString(v, s); }; + COMMON_METHODS + Value* maybeThunk(EvalState& state, Env& env); +}; + +/* Temporary class used during parsing of indented strings. */ +struct ExprIndStr : Expr { + std::string s; + ExprIndStr(const std::string& s) : s(s){}; +}; + +struct ExprPath : Expr { + std::string s; + Value v; + ExprPath(const std::string& s) : s(s) { mkPathNoCopy(v, this->s.c_str()); }; + COMMON_METHODS + Value* maybeThunk(EvalState& state, Env& env); +}; + +struct ExprVar : Expr { + Pos pos; + Symbol name; + + /* Whether the variable comes from an environment (e.g. a rec, let + or function argument) or from a "with". */ + bool fromWith; + + /* In the former case, the value is obtained by going `level' + levels up from the current environment and getting the + `displ'th value in that environment. In the latter case, the + value is obtained by getting the attribute named `name' from + the set stored in the environment that is `level' levels up + from the current one.*/ + unsigned int level; + unsigned int displ; + + ExprVar(const Symbol& name) : name(name){}; + ExprVar(const Pos& pos, const Symbol& name) : pos(pos), name(name){}; + COMMON_METHODS + Value* maybeThunk(EvalState& state, Env& env); +}; + +struct ExprSelect : Expr { + Pos pos; + Expr *e, *def; + AttrPath attrPath; + ExprSelect(const Pos& pos, Expr* e, const AttrPath& attrPath, Expr* def) + : pos(pos), e(e), def(def), attrPath(attrPath){}; + ExprSelect(const Pos& pos, Expr* e, const Symbol& name) + : pos(pos), e(e), def(0) { + attrPath.push_back(AttrName(name)); + }; + COMMON_METHODS +}; + +struct ExprOpHasAttr : Expr { + Expr* e; + AttrPath attrPath; + ExprOpHasAttr(Expr* e, const AttrPath& attrPath) : e(e), attrPath(attrPath){}; + COMMON_METHODS +}; + +struct ExprAttrs : Expr { + bool recursive; + struct AttrDef { + bool inherited; + Expr* e; + Pos pos; + unsigned int displ; // displacement + AttrDef(Expr* e, const Pos& pos, bool inherited = false) + : inherited(inherited), e(e), pos(pos){}; + AttrDef(){}; + }; + typedef std::map<Symbol, AttrDef> AttrDefs; + AttrDefs attrs; + struct DynamicAttrDef { + Expr *nameExpr, *valueExpr; + Pos pos; + DynamicAttrDef(Expr* nameExpr, Expr* valueExpr, const Pos& pos) + : nameExpr(nameExpr), valueExpr(valueExpr), pos(pos){}; + }; + typedef std::vector<DynamicAttrDef> DynamicAttrDefs; + DynamicAttrDefs dynamicAttrs; + ExprAttrs() : recursive(false){}; + COMMON_METHODS +}; + +struct ExprList : Expr { + std::vector<Expr*> elems; + ExprList(){}; + COMMON_METHODS +}; + +struct Formal { + Symbol name; + Expr* def; + Formal(const Symbol& name, Expr* def) : name(name), def(def){}; +}; + +struct Formals { + typedef std::list<Formal> Formals_; + Formals_ formals; + std::set<Symbol> argNames; // used during parsing + bool ellipsis; +}; + +struct ExprLambda : Expr { + Pos pos; + Symbol name; + Symbol arg; + bool matchAttrs; + Formals* formals; + Expr* body; + ExprLambda(const Pos& pos, const Symbol& arg, bool matchAttrs, + Formals* formals, Expr* body) + : pos(pos), + arg(arg), + matchAttrs(matchAttrs), + formals(formals), + body(body) { + if (!arg.empty() && formals && + formals->argNames.find(arg) != formals->argNames.end()) + throw ParseError( + format("duplicate formal function argument '%1%' at %2%") % arg % + pos); + }; + void setName(Symbol& name); + std::string showNamePos() const; + COMMON_METHODS +}; + +struct ExprLet : Expr { + ExprAttrs* attrs; + Expr* body; + ExprLet(ExprAttrs* attrs, Expr* body) : attrs(attrs), body(body){}; + COMMON_METHODS +}; + +struct ExprWith : Expr { + Pos pos; + Expr *attrs, *body; + size_t prevWith; + ExprWith(const Pos& pos, Expr* attrs, Expr* body) + : pos(pos), attrs(attrs), body(body){}; + COMMON_METHODS +}; + +struct ExprIf : Expr { + Expr *cond, *then, *else_; + ExprIf(Expr* cond, Expr* then, Expr* else_) + : cond(cond), then(then), else_(else_){}; + COMMON_METHODS +}; + +struct ExprAssert : Expr { + Pos pos; + Expr *cond, *body; + ExprAssert(const Pos& pos, Expr* cond, Expr* body) + : pos(pos), cond(cond), body(body){}; + COMMON_METHODS +}; + +struct ExprOpNot : Expr { + Expr* e; + ExprOpNot(Expr* e) : e(e){}; + COMMON_METHODS +}; + +#define MakeBinOp(name, s) \ + struct name : Expr { \ + Pos pos; \ + Expr *e1, *e2; \ + name(Expr* e1, Expr* e2) : e1(e1), e2(e2){}; \ + name(const Pos& pos, Expr* e1, Expr* e2) : pos(pos), e1(e1), e2(e2){}; \ + void show(std::ostream& str) const { \ + str << "(" << *e1 << " " s " " << *e2 << ")"; \ + } \ + void bindVars(const StaticEnv& env) { \ + e1->bindVars(env); \ + e2->bindVars(env); \ + } \ + void eval(EvalState& state, Env& env, Value& v); \ + }; + +MakeBinOp(ExprApp, "") MakeBinOp(ExprOpEq, "==") MakeBinOp(ExprOpNEq, "!=") + MakeBinOp(ExprOpAnd, "&&") MakeBinOp(ExprOpOr, "||") + MakeBinOp(ExprOpImpl, "->") MakeBinOp(ExprOpUpdate, "//") + MakeBinOp(ExprOpConcatLists, "++") + + struct ExprConcatStrings : Expr { + Pos pos; + bool forceString; + vector<Expr*>* es; + ExprConcatStrings(const Pos& pos, bool forceString, vector<Expr*>* es) + : pos(pos), forceString(forceString), es(es){}; + COMMON_METHODS +}; + +struct ExprPos : Expr { + Pos pos; + ExprPos(const Pos& pos) : pos(pos){}; + COMMON_METHODS +}; + +/* Static environments are used to map variable names onto (level, + displacement) pairs used to obtain the value of the variable at + runtime. */ +struct StaticEnv { + bool isWith; + const StaticEnv* up; + typedef std::map<Symbol, unsigned int> Vars; + Vars vars; + StaticEnv(bool isWith, const StaticEnv* up) : isWith(isWith), up(up){}; +}; + +} // namespace nix diff --git a/third_party/nix/src/libexpr/parser.y b/third_party/nix/src/libexpr/parser.y new file mode 100644 index 0000000000..bd62a7fd0f --- /dev/null +++ b/third_party/nix/src/libexpr/parser.y @@ -0,0 +1,703 @@ +%glr-parser +%pure-parser +%locations +%define parse.error verbose +%defines +/* %no-lines */ +%parse-param { void * scanner } +%parse-param { nix::ParseData * data } +%lex-param { void * scanner } +%lex-param { nix::ParseData * data } +%expect 1 +%expect-rr 1 + +%code requires { + +#ifndef BISON_HEADER +#define BISON_HEADER + +#include "util.hh" +#include "nixexpr.hh" +#include "eval.hh" +#include <glog/logging.h> + +namespace nix { + + struct ParseData + { + EvalState & state; + SymbolTable & symbols; + Expr * result; + Path basePath; + Symbol path; + std::string error; + Symbol sLetBody; + ParseData(EvalState & state) + : state(state) + , symbols(state.symbols) + , sLetBody(symbols.Create("<let-body>")) + { }; + }; + +} + +#define YY_DECL int yylex \ + (YYSTYPE * yylval_param, YYLTYPE * yylloc_param, yyscan_t yyscanner, nix::ParseData * data) + +#endif + +} + +%{ + +#include "parser-tab.hh" +#include "lexer-tab.hh" + +YY_DECL; + +using namespace nix; + + +namespace nix { + + +static void dupAttr(const AttrPath & attrPath, const Pos & pos, const Pos & prevPos) +{ + throw ParseError(format("attribute '%1%' at %2% already defined at %3%") + % showAttrPath(attrPath) % pos % prevPos); +} + + +static void dupAttr(Symbol attr, const Pos & pos, const Pos & prevPos) +{ + throw ParseError(format("attribute '%1%' at %2% already defined at %3%") + % attr % pos % prevPos); +} + + +static void addAttr(ExprAttrs * attrs, AttrPath & attrPath, + Expr * e, const Pos & pos) +{ + AttrPath::iterator i; + // All attrpaths have at least one attr + assert(!attrPath.empty()); + // Checking attrPath validity. + // =========================== + for (i = attrPath.begin(); i + 1 < attrPath.end(); i++) { + if (i->symbol.set()) { + ExprAttrs::AttrDefs::iterator j = attrs->attrs.find(i->symbol); + if (j != attrs->attrs.end()) { + if (!j->second.inherited) { + ExprAttrs * attrs2 = dynamic_cast<ExprAttrs *>(j->second.e); + if (!attrs2) { dupAttr(attrPath, pos, j->second.pos); } + attrs = attrs2; + } else + dupAttr(attrPath, pos, j->second.pos); + } else { + ExprAttrs * nested = new ExprAttrs; + attrs->attrs[i->symbol] = ExprAttrs::AttrDef(nested, pos); + attrs = nested; + } + } else { + ExprAttrs *nested = new ExprAttrs; + attrs->dynamicAttrs.push_back(ExprAttrs::DynamicAttrDef(i->expr, nested, pos)); + attrs = nested; + } + } + // Expr insertion. + // ========================== + if (i->symbol.set()) { + ExprAttrs::AttrDefs::iterator j = attrs->attrs.find(i->symbol); + if (j != attrs->attrs.end()) { + // This attr path is already defined. However, if both + // e and the expr pointed by the attr path are two attribute sets, + // we want to merge them. + // Otherwise, throw an error. + auto ae = dynamic_cast<ExprAttrs *>(e); + auto jAttrs = dynamic_cast<ExprAttrs *>(j->second.e); + if (jAttrs && ae) { + for (auto & ad : ae->attrs) { + auto j2 = jAttrs->attrs.find(ad.first); + if (j2 != jAttrs->attrs.end()) // Attr already defined in iAttrs, error. + dupAttr(ad.first, j2->second.pos, ad.second.pos); + jAttrs->attrs[ad.first] = ad.second; + } + } else { + dupAttr(attrPath, pos, j->second.pos); + } + } else { + // This attr path is not defined. Let's create it. + attrs->attrs[i->symbol] = ExprAttrs::AttrDef(e, pos); + e->setName(i->symbol); + } + } else { + attrs->dynamicAttrs.push_back(ExprAttrs::DynamicAttrDef(i->expr, e, pos)); + } +} + + +static void addFormal(const Pos & pos, Formals * formals, const Formal & formal) +{ + if (formals->argNames.find(formal.name) != formals->argNames.end()) + throw ParseError(format("duplicate formal function argument '%1%' at %2%") + % formal.name % pos); + formals->formals.push_front(formal); + formals->argNames.insert(formal.name); +} + + +static Expr * stripIndentation(const Pos & pos, SymbolTable & symbols, vector<Expr *> & es) +{ + if (es.empty()) { return new ExprString(symbols.Create("")); } + + /* Figure out the minimum indentation. Note that by design + whitespace-only final lines are not taken into account. (So + the " " in "\n ''" is ignored, but the " " in "\n foo''" is.) */ + bool atStartOfLine = true; /* = seen only whitespace in the current line */ + size_t minIndent = 1000000; + size_t curIndent = 0; + for (auto & i : es) { + ExprIndStr * e = dynamic_cast<ExprIndStr *>(i); + if (!e) { + /* Anti-quotations end the current start-of-line whitespace. */ + if (atStartOfLine) { + atStartOfLine = false; + if (curIndent < minIndent) { minIndent = curIndent; } + } + continue; + } + for (size_t j = 0; j < e->s.size(); ++j) { + if (atStartOfLine) { + if (e->s[j] == ' ') + curIndent++; + else if (e->s[j] == '\n') { + /* Empty line, doesn't influence minimum + indentation. */ + curIndent = 0; + } else { + atStartOfLine = false; + if (curIndent < minIndent) { minIndent = curIndent; } + } + } else if (e->s[j] == '\n') { + atStartOfLine = true; + curIndent = 0; + } + } + } + + /* Strip spaces from each line. */ + vector<Expr *> * es2 = new vector<Expr *>; + atStartOfLine = true; + size_t curDropped = 0; + size_t n = es.size(); + for (vector<Expr *>::iterator i = es.begin(); i != es.end(); ++i, --n) { + ExprIndStr * e = dynamic_cast<ExprIndStr *>(*i); + if (!e) { + atStartOfLine = false; + curDropped = 0; + es2->push_back(*i); + continue; + } + + std::string s2; + for (size_t j = 0; j < e->s.size(); ++j) { + if (atStartOfLine) { + if (e->s[j] == ' ') { + if (curDropped++ >= minIndent) + s2 += e->s[j]; + } + else if (e->s[j] == '\n') { + curDropped = 0; + s2 += e->s[j]; + } else { + atStartOfLine = false; + curDropped = 0; + s2 += e->s[j]; + } + } else { + s2 += e->s[j]; + if (e->s[j] == '\n') { atStartOfLine = true; } + } + } + + /* Remove the last line if it is empty and consists only of + spaces. */ + if (n == 1) { + string::size_type p = s2.find_last_of('\n'); + if (p != string::npos && s2.find_first_not_of(' ', p + 1) == string::npos) + s2 = string(s2, 0, p + 1); + } + + es2->push_back(new ExprString(symbols.Create(s2))); + } + + /* If this is a single string, then don't do a concatenation. */ + return es2->size() == 1 && dynamic_cast<ExprString *>((*es2)[0]) ? (*es2)[0] : new ExprConcatStrings(pos, true, es2); +} + + +static inline Pos makeCurPos(const YYLTYPE & loc, ParseData * data) +{ + return Pos(data->path, loc.first_line, loc.first_column); +} + +#define CUR_POS makeCurPos(*yylocp, data) + + +} + + +void yyerror(YYLTYPE * loc, yyscan_t scanner, ParseData * data, const char * error) +{ + data->error = (format("%1%, at %2%") + % error % makeCurPos(*loc, data)).str(); +} + + +%} + +%union { + // !!! We're probably leaking stuff here. + nix::Expr * e; + nix::ExprList * list; + nix::ExprAttrs * attrs; + nix::Formals * formals; + nix::Formal * formal; + nix::NixInt n; + nix::NixFloat nf; + const char * id; // !!! -> Symbol + char * path; + char * uri; + std::vector<nix::AttrName> * attrNames; + std::vector<nix::Expr *> * string_parts; +} + +%type <e> start expr expr_function expr_if expr_op +%type <e> expr_app expr_select expr_simple +%type <list> expr_list +%type <attrs> binds +%type <formals> formals +%type <formal> formal +%type <attrNames> attrs attrpath +%type <string_parts> string_parts_interpolated ind_string_parts +%type <e> string_parts string_attr +%type <id> attr +%token <id> ID ATTRPATH +%token <e> STR IND_STR +%token <n> INT +%token <nf> FLOAT +%token <path> PATH HPATH SPATH +%token <uri> URI +%token IF THEN ELSE ASSERT WITH LET IN REC INHERIT EQ NEQ AND OR IMPL OR_KW +%token DOLLAR_CURLY /* == ${ */ +%token IND_STRING_OPEN IND_STRING_CLOSE +%token ELLIPSIS + +%right IMPL +%left OR +%left AND +%nonassoc EQ NEQ +%nonassoc '<' '>' LEQ GEQ +%right UPDATE +%left NOT +%left '+' '-' +%left '*' '/' +%right CONCAT +%nonassoc '?' +%nonassoc NEGATE + +%% + +start: expr { data->result = $1; }; + +expr: expr_function; + +expr_function + : ID ':' expr_function + { $$ = new ExprLambda(CUR_POS, data->symbols.Create($1), false, 0, $3); } + | '{' formals '}' ':' expr_function + { $$ = new ExprLambda(CUR_POS, data->symbols.Create(""), true, $2, $5); } + | '{' formals '}' '@' ID ':' expr_function + { $$ = new ExprLambda(CUR_POS, data->symbols.Create($5), true, $2, $7); } + | ID '@' '{' formals '}' ':' expr_function + { $$ = new ExprLambda(CUR_POS, data->symbols.Create($1), true, $4, $7); } + | ASSERT expr ';' expr_function + { $$ = new ExprAssert(CUR_POS, $2, $4); } + | WITH expr ';' expr_function + { $$ = new ExprWith(CUR_POS, $2, $4); } + | LET binds IN expr_function + { if (!$2->dynamicAttrs.empty()) + throw ParseError(format("dynamic attributes not allowed in let at %1%") + % CUR_POS); + $$ = new ExprLet($2, $4); + } + | expr_if + ; + +expr_if + : IF expr THEN expr ELSE expr { $$ = new ExprIf($2, $4, $6); } + | expr_op + ; + +expr_op + : '!' expr_op %prec NOT { $$ = new ExprOpNot($2); } + | '-' expr_op %prec NEGATE { $$ = new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__sub")), new ExprInt(0)), $2); } + | expr_op EQ expr_op { $$ = new ExprOpEq($1, $3); } + | expr_op NEQ expr_op { $$ = new ExprOpNEq($1, $3); } + | expr_op '<' expr_op { $$ = new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__lessThan")), $1), $3); } + | expr_op LEQ expr_op { $$ = new ExprOpNot(new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__lessThan")), $3), $1)); } + | expr_op '>' expr_op { $$ = new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__lessThan")), $3), $1); } + | expr_op GEQ expr_op { $$ = new ExprOpNot(new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__lessThan")), $1), $3)); } + | expr_op AND expr_op { $$ = new ExprOpAnd(CUR_POS, $1, $3); } + | expr_op OR expr_op { $$ = new ExprOpOr(CUR_POS, $1, $3); } + | expr_op IMPL expr_op { $$ = new ExprOpImpl(CUR_POS, $1, $3); } + | expr_op UPDATE expr_op { $$ = new ExprOpUpdate(CUR_POS, $1, $3); } + | expr_op '?' attrpath { $$ = new ExprOpHasAttr($1, *$3); } + | expr_op '+' expr_op + { $$ = new ExprConcatStrings(CUR_POS, false, new vector<Expr *>({$1, $3})); } + | expr_op '-' expr_op { $$ = new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__sub")), $1), $3); } + | expr_op '*' expr_op { $$ = new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__mul")), $1), $3); } + | expr_op '/' expr_op { $$ = new ExprApp(CUR_POS, new ExprApp(new ExprVar(data->symbols.Create("__div")), $1), $3); } + | expr_op CONCAT expr_op { $$ = new ExprOpConcatLists(CUR_POS, $1, $3); } + | expr_app + ; + +expr_app + : expr_app expr_select + { $$ = new ExprApp(CUR_POS, $1, $2); } + | expr_select { $$ = $1; } + ; + +expr_select + : expr_simple '.' attrpath + { $$ = new ExprSelect(CUR_POS, $1, *$3, 0); } + | expr_simple '.' attrpath OR_KW expr_select + { $$ = new ExprSelect(CUR_POS, $1, *$3, $5); } + | /* Backwards compatibility: because Nixpkgs has a rarely used + function named ‘or’, allow stuff like ‘map or [...]’. */ + expr_simple OR_KW + { $$ = new ExprApp(CUR_POS, $1, new ExprVar(CUR_POS, data->symbols.Create("or"))); } + | expr_simple { $$ = $1; } + ; + +expr_simple + : ID { + if (strcmp($1, "__curPos") == 0) + $$ = new ExprPos(CUR_POS); + else + $$ = new ExprVar(CUR_POS, data->symbols.Create($1)); + } + | INT { $$ = new ExprInt($1); } + | FLOAT { $$ = new ExprFloat($1); } + | '"' string_parts '"' { $$ = $2; } + | IND_STRING_OPEN ind_string_parts IND_STRING_CLOSE { + $$ = stripIndentation(CUR_POS, data->symbols, *$2); + } + | PATH { $$ = new ExprPath(absPath($1, data->basePath)); } + | HPATH { $$ = new ExprPath(getHome() + string{$1 + 1}); } + | SPATH { + std::string path($1 + 1, strlen($1) - 2); + $$ = new ExprApp(CUR_POS, + new ExprApp(new ExprVar(data->symbols.Create("__findFile")), + new ExprVar(data->symbols.Create("__nixPath"))), + new ExprString(data->symbols.Create(path))); + } + | URI { $$ = new ExprString(data->symbols.Create($1)); } + | '(' expr ')' { $$ = $2; } + /* Let expressions `let {..., body = ...}' are just desugared + into `(rec {..., body = ...}).body'. */ + | LET '{' binds '}' + { $3->recursive = true; $$ = new ExprSelect(noPos, $3, data->symbols.Create("body")); } + | REC '{' binds '}' + { $3->recursive = true; $$ = $3; } + | '{' binds '}' + { $$ = $2; } + | '[' expr_list ']' { $$ = $2; } + ; + +string_parts + : STR + | string_parts_interpolated { $$ = new ExprConcatStrings(CUR_POS, true, $1); } + | { $$ = new ExprString(data->symbols.Create("")); } + ; + +string_parts_interpolated + : string_parts_interpolated STR { $$ = $1; $1->push_back($2); } + | string_parts_interpolated DOLLAR_CURLY expr '}' { $$ = $1; $1->push_back($3); } + | DOLLAR_CURLY expr '}' { $$ = new vector<Expr *>; $$->push_back($2); } + | STR DOLLAR_CURLY expr '}' { + $$ = new vector<Expr *>; + $$->push_back($1); + $$->push_back($3); + } + ; + +ind_string_parts + : ind_string_parts IND_STR { $$ = $1; $1->push_back($2); } + | ind_string_parts DOLLAR_CURLY expr '}' { $$ = $1; $1->push_back($3); } + | { $$ = new vector<Expr *>; } + ; + +binds + : binds attrpath '=' expr ';' { $$ = $1; addAttr($$, *$2, $4, makeCurPos(@2, data)); } + | binds INHERIT attrs ';' + { $$ = $1; + for (auto & i : *$3) { + if ($$->attrs.find(i.symbol) != $$->attrs.end()) + dupAttr(i.symbol, makeCurPos(@3, data), $$->attrs[i.symbol].pos); + Pos pos = makeCurPos(@3, data); + $$->attrs[i.symbol] = ExprAttrs::AttrDef(new ExprVar(CUR_POS, i.symbol), pos, true); + } + } + | binds INHERIT '(' expr ')' attrs ';' + { $$ = $1; + /* !!! Should ensure sharing of the expression in $4. */ + for (auto & i : *$6) { + if ($$->attrs.find(i.symbol) != $$->attrs.end()) + dupAttr(i.symbol, makeCurPos(@6, data), $$->attrs[i.symbol].pos); + $$->attrs[i.symbol] = ExprAttrs::AttrDef(new ExprSelect(CUR_POS, $4, i.symbol), makeCurPos(@6, data)); + } + } + | { $$ = new ExprAttrs; } + ; + +attrs + : attrs attr { $$ = $1; $1->push_back(AttrName(data->symbols.Create($2))); } + | attrs string_attr + { $$ = $1; + ExprString * str = dynamic_cast<ExprString *>($2); + if (str) { + $$->push_back(AttrName(str->s)); + delete str; + } else + throw ParseError(format("dynamic attributes not allowed in inherit at %1%") + % makeCurPos(@2, data)); + } + | { $$ = new AttrPath; } + ; + +attrpath + : attrpath '.' attr { $$ = $1; $1->push_back(AttrName(data->symbols.Create($3))); } + | attrpath '.' string_attr + { $$ = $1; + ExprString * str = dynamic_cast<ExprString *>($3); + if (str) { + $$->push_back(AttrName(str->s)); + delete str; + } else + $$->push_back(AttrName($3)); + } + | attr { $$ = new vector<AttrName>; $$->push_back(AttrName(data->symbols.Create($1))); } + | string_attr + { $$ = new vector<AttrName>; + ExprString *str = dynamic_cast<ExprString *>($1); + if (str) { + $$->push_back(AttrName(str->s)); + delete str; + } else + $$->push_back(AttrName($1)); + } + ; + +attr + : ID { $$ = $1; } + | OR_KW { $$ = "or"; } + ; + +string_attr + : '"' string_parts '"' { $$ = $2; } + | DOLLAR_CURLY expr '}' { $$ = $2; } + ; + +expr_list + : expr_list expr_select { $$ = $1; $1->elems.push_back($2); /* !!! dangerous */ } + | { $$ = new ExprList; } + ; + +formals + : formal ',' formals + { $$ = $3; addFormal(CUR_POS, $$, *$1); } + | formal + { $$ = new Formals; addFormal(CUR_POS, $$, *$1); $$->ellipsis = false; } + | + { $$ = new Formals; $$->ellipsis = false; } + | ELLIPSIS + { $$ = new Formals; $$->ellipsis = true; } + ; + +formal + : ID { $$ = new Formal(data->symbols.Create($1), 0); } + | ID '?' expr { $$ = new Formal(data->symbols.Create($1), $3); } + ; + +%% + + +#include <sys/types.h> +#include <sys/stat.h> +#include <fcntl.h> +#include <unistd.h> + +#include "eval.hh" +#include "download.hh" +#include "store-api.hh" + + +namespace nix { + + +Expr * EvalState::parse(const char * text, + const Path & path, const Path & basePath, StaticEnv & staticEnv) +{ + yyscan_t scanner; + ParseData data(*this); + data.basePath = basePath; + data.path = data.symbols.Create(path); + + yylex_init(&scanner); + yy_scan_string(text, scanner); + int res = yyparse(scanner, &data); + yylex_destroy(scanner); + + if (res) { throw ParseError(data.error); } + + data.result->bindVars(staticEnv); + + return data.result; +} + + +Path resolveExprPath(Path path) +{ + assert(path[0] == '/'); + + /* If `path' is a symlink, follow it. This is so that relative + path references work. */ + struct stat st; + while (true) { + if (lstat(path.c_str(), &st)) + throw SysError(format("getting status of '%1%'") % path); + if (!S_ISLNK(st.st_mode)) { break; } + path = absPath(readLink(path), dirOf(path)); + } + + /* If `path' refers to a directory, append `/default.nix'. */ + if (S_ISDIR(st.st_mode)) + path = canonPath(path + "/default.nix"); + + return path; +} + + +Expr * EvalState::parseExprFromFile(const Path & path) +{ + return parseExprFromFile(path, staticBaseEnv); +} + + +Expr * EvalState::parseExprFromFile(const Path & path, StaticEnv & staticEnv) +{ + return parse(readFile(path).c_str(), path, dirOf(path), staticEnv); +} + + +Expr * EvalState::parseExprFromString(const std::string & s, const Path & basePath, StaticEnv & staticEnv) +{ + return parse(s.c_str(), "(string)", basePath, staticEnv); +} + + +Expr * EvalState::parseExprFromString(const std::string & s, const Path & basePath) +{ + return parseExprFromString(s, basePath, staticBaseEnv); +} + + +Expr * EvalState::parseStdin() +{ + //Activity act(*logger, lvlTalkative, format("parsing standard input")); + return parseExprFromString(drainFD(0), absPath(".")); +} + + +void EvalState::addToSearchPath(const std::string & s) +{ + size_t pos = s.find('='); + std::string prefix; + Path path; + if (pos == string::npos) { + path = s; + } else { + prefix = string(s, 0, pos); + path = string(s, pos + 1); + } + + searchPath.emplace_back(prefix, path); +} + + +Path EvalState::findFile(const std::string & path) +{ + return findFile(searchPath, path); +} + + +Path EvalState::findFile(SearchPath & searchPath, const std::string & path, const Pos & pos) +{ + for (auto & i : searchPath) { + std::string suffix; + if (i.first.empty()) + suffix = "/" + path; + else { + auto s = i.first.size(); + if (path.compare(0, s, i.first) != 0 || + (path.size() > s && path[s] != '/')) + continue; + suffix = path.size() == s ? "" : "/" + string(path, s); + } + auto r = resolveSearchPathElem(i); + if (!r.first) { continue; } + Path res = r.second + suffix; + if (pathExists(res)) { return canonPath(res); } + } + format f = format( + "file '%1%' was not found in the Nix search path (add it using $NIX_PATH or -I)" + + string(pos ? ", at %2%" : "")); + f.exceptions(boost::io::all_error_bits ^ boost::io::too_many_args_bit); + throw ThrownError(f % path % pos); +} + + +std::pair<bool, std::string> EvalState::resolveSearchPathElem(const SearchPathElem & elem) +{ + auto i = searchPathResolved.find(elem.second); + if (i != searchPathResolved.end()) { return i->second; } + + std::pair<bool, std::string> res; + + if (isUri(elem.second)) { + try { + CachedDownloadRequest request(elem.second); + request.unpack = true; + res = { true, getDownloader()->downloadCached(store, request).path }; + } catch (DownloadError & e) { + LOG(WARNING) << "Nix search path entry '" << elem.second << "' cannot be downloaded, ignoring"; + res = { false, "" }; + } + } else { + auto path = absPath(elem.second); + if (pathExists(path)) { + res = { true, path }; + } else { + LOG(WARNING) << "Nix search path entry '" << elem.second << "' does not exist, ignoring"; + res = { false, "" }; + } + } + + DLOG(INFO) << "resolved search path element '" << elem.second << "' to '" << res.second << "'"; + + searchPathResolved[elem.second] = res; + return res; +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/primops.cc b/third_party/nix/src/libexpr/primops.cc new file mode 100644 index 0000000000..713c31e4fa --- /dev/null +++ b/third_party/nix/src/libexpr/primops.cc @@ -0,0 +1,2456 @@ +#include "primops.hh" + +#include <algorithm> +#include <cstring> +#include <regex> + +#include <dlfcn.h> +#include <glog/logging.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include "archive.hh" +#include "derivations.hh" +#include "download.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "globals.hh" +#include "json-to-value.hh" +#include "json.hh" +#include "names.hh" +#include "store-api.hh" +#include "util.hh" +#include "value-to-json.hh" +#include "value-to-xml.hh" + +namespace nix { + +/************************************************************* + * Miscellaneous + *************************************************************/ + +/* Decode a context string ‘!<name>!<path>’ into a pair <path, + name>. */ +std::pair<string, string> decodeContext(const std::string& s) { + if (s.at(0) == '!') { + size_t index = s.find('!', 1); + return std::pair<string, string>(string(s, index + 1), + string(s, 1, index - 1)); + } + return std::pair<string, string>(s.at(0) == '/' ? s : string(s, 1), ""); +} + +InvalidPathError::InvalidPathError(const Path& path) + : EvalError(format("path '%1%' is not valid") % path), path(path) {} + +void EvalState::realiseContext(const PathSet& context) { + PathSet drvs; + + for (auto& i : context) { + std::pair<string, string> decoded = decodeContext(i); + Path ctx = decoded.first; + assert(store->isStorePath(ctx)); + if (!store->isValidPath(ctx)) { + throw InvalidPathError(ctx); + } + if (!decoded.second.empty() && nix::isDerivation(ctx)) { + drvs.insert(decoded.first + "!" + decoded.second); + + /* Add the output of this derivation to the allowed + paths. */ + if (allowedPaths) { + auto drv = store->derivationFromPath(decoded.first); + auto i = drv.outputs.find(decoded.second); + if (i == drv.outputs.end()) { + throw Error("derivation '%s' does not have an output named '%s'", + decoded.first, decoded.second); + } + allowedPaths->insert(i->second.path); + } + } + } + + if (drvs.empty()) { + return; + } + + if (!evalSettings.enableImportFromDerivation) { + throw EvalError(format("attempted to realize '%1%' during evaluation but " + "'allow-import-from-derivation' is false") % + *(drvs.begin())); + } + + /* For performance, prefetch all substitute info. */ + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + unsigned long long downloadSize; + unsigned long long narSize; + store->queryMissing(drvs, willBuild, willSubstitute, unknown, downloadSize, + narSize); + store->buildPaths(drvs); +} + +/* Load and evaluate an expression from path specified by the + argument. */ +static void prim_scopedImport(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.coerceToPath(pos, *args[1], context); + + try { + state.realiseContext(context); + } catch (InvalidPathError& e) { + throw EvalError( + format("cannot import '%1%', since path '%2%' is not valid, at %3%") % + path % e.path % pos); + } + + Path realPath = state.checkSourcePath(state.toRealPath(path, context)); + + if (state.store->isStorePath(path) && state.store->isValidPath(path) && + isDerivation(path)) { + Derivation drv = readDerivation(realPath); + Value& w = *state.allocValue(); + state.mkAttrs(w, 3 + drv.outputs.size()); + Value* v2 = state.allocAttr(w, state.sDrvPath); + mkString(*v2, path, {"=" + path}); + v2 = state.allocAttr(w, state.sName); + mkString(*v2, drv.env["name"]); + Value* outputsVal = state.allocAttr(w, state.symbols.Create("outputs")); + state.mkList(*outputsVal, drv.outputs.size()); + unsigned int outputs_index = 0; + + for (const auto& o : drv.outputs) { + v2 = state.allocAttr(w, state.symbols.Create(o.first)); + mkString(*v2, o.second.path, {"!" + o.first + "!" + path}); + outputsVal->listElems()[outputs_index] = state.allocValue(); + mkString(*(outputsVal->listElems()[outputs_index++]), o.first); + } + Value fun; + state.evalFile( + settings.nixDataDir + "/nix/corepkgs/imported-drv-to-derivation.nix", + fun); + state.forceFunction(fun, pos); + mkApp(v, fun, w); + state.forceAttrs(v, pos); + } else { + state.forceAttrs(*args[0]); + if (args[0]->attrs->empty()) { + state.evalFile(realPath, v); + } else { + Env* env = &state.allocEnv(args[0]->attrs->size()); + env->up = &state.baseEnv; + + StaticEnv staticEnv(false, &state.staticBaseEnv); + + unsigned int displ = 0; + for (auto& attr : *args[0]->attrs) { + staticEnv.vars[attr.second.name] = displ; + env->values[displ++] = attr.second.value; + } + + DLOG(INFO) << "evaluating file '" << realPath << "'"; + Expr* e = state.parseExprFromFile(resolveExprPath(realPath), staticEnv); + + e->eval(state, *env, v); + } + } +} + +/* Want reasonable symbol names, so extern C */ +/* !!! Should we pass the Pos or the file name too? */ +extern "C" using ValueInitializer = void(*)(EvalState&, Value&); + +/* Load a ValueInitializer from a DSO and return whatever it initializes */ +void prim_importNative(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.coerceToPath(pos, *args[0], context); + + try { + state.realiseContext(context); + } catch (InvalidPathError& e) { + throw EvalError( + format("cannot import '%1%', since path '%2%' is not valid, at %3%") % + path % e.path % pos); + } + + path = state.checkSourcePath(path); + + std::string sym = state.forceStringNoCtx(*args[1], pos); + + void* handle = dlopen(path.c_str(), RTLD_LAZY | RTLD_LOCAL); + if (handle == nullptr) { + throw EvalError(format("could not open '%1%': %2%") % path % dlerror()); + } + + dlerror(); + auto func = (ValueInitializer)dlsym(handle, sym.c_str()); + if (func == nullptr) { + char* message = dlerror(); + if (message != nullptr) { + throw EvalError(format("could not load symbol '%1%' from '%2%': %3%") % + sym % path % message); + } + throw EvalError(format("symbol '%1%' from '%2%' resolved to NULL when a " + "function pointer was expected") % + sym % path); + } + + (func)(state, v); + + /* We don't dlclose because v may be a primop referencing a function in the + * shared object file */ +} + +/* Execute a program and parse its output */ +void prim_exec(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceList(*args[0], pos); + auto elems = args[0]->listElems(); + auto count = args[0]->listSize(); + if (count == 0) { + throw EvalError(format("at least one argument to 'exec' required, at %1%") % + pos); + } + PathSet context; + auto program = state.coerceToString(pos, *elems[0], context, false, false); + Strings commandArgs; + for (unsigned int i = 1; i < args[0]->listSize(); ++i) { + commandArgs.emplace_back( + state.coerceToString(pos, *elems[i], context, false, false)); + } + try { + state.realiseContext(context); + } catch (InvalidPathError& e) { + throw EvalError( + format("cannot execute '%1%', since path '%2%' is not valid, at %3%") % + program % e.path % pos); + } + + auto output = runProgram(program, true, commandArgs); + Expr* parsed; + try { + parsed = state.parseExprFromString(output, pos.file); + } catch (Error& e) { + e.addPrefix(format("While parsing the output from '%1%', at %2%\n") % + program % pos); + throw; + } + try { + state.eval(parsed, v); + } catch (Error& e) { + e.addPrefix(format("While evaluating the output from '%1%', at %2%\n") % + program % pos); + throw; + } +} + +/* Return a string representing the type of the expression. */ +static void prim_typeOf(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + std::string t; + switch (args[0]->type) { + case tInt: + t = "int"; + break; + case tBool: + t = "bool"; + break; + case tString: + t = "string"; + break; + case tPath: + t = "path"; + break; + case tNull: + t = "null"; + break; + case tAttrs: + t = "set"; + break; + case tList1: + case tList2: + case tListN: + t = "list"; + break; + case tLambda: + case tPrimOp: + case tPrimOpApp: + t = "lambda"; + break; + case tExternal: + t = args[0]->external->typeOf(); + break; + case tFloat: + t = "float"; + break; + default: + abort(); + } + mkString(v, state.symbols.Create(t)); +} + +/* Determine whether the argument is the null value. */ +static void prim_isNull(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tNull); +} + +/* Determine whether the argument is a function. */ +static void prim_isFunction(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + bool res; + switch (args[0]->type) { + case tLambda: + case tPrimOp: + case tPrimOpApp: + res = true; + break; + default: + res = false; + break; + } + mkBool(v, res); +} + +/* Determine whether the argument is an integer. */ +static void prim_isInt(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tInt); +} + +/* Determine whether the argument is a float. */ +static void prim_isFloat(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tFloat); +} + +/* Determine whether the argument is a string. */ +static void prim_isString(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tString); +} + +/* Determine whether the argument is a Boolean. */ +static void prim_isBool(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tBool); +} + +/* Determine whether the argument is a path. */ +static void prim_isPath(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tPath); +} + +struct CompareValues { + bool operator()(const Value* v1, const Value* v2) const { + if (v1->type == tFloat && v2->type == tInt) { + return v1->fpoint < v2->integer; + } + if (v1->type == tInt && v2->type == tFloat) { + return v1->integer < v2->fpoint; + } + if (v1->type != v2->type) { + throw EvalError(format("cannot compare %1% with %2%") % showType(*v1) % + showType(*v2)); + } + switch (v1->type) { + case tInt: + return v1->integer < v2->integer; + case tFloat: + return v1->fpoint < v2->fpoint; + case tString: + return strcmp(v1->string.s, v2->string.s) < 0; + case tPath: + return strcmp(v1->path, v2->path) < 0; + default: + throw EvalError(format("cannot compare %1% with %2%") % showType(*v1) % + showType(*v2)); + } + } +}; + +#if HAVE_BOEHMGC +typedef list<Value*, gc_allocator<Value*>> ValueList; +#else +typedef list<Value*> ValueList; +#endif + +static void prim_genericClosure(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[0], pos); + + /* Get the start set. */ + Bindings::iterator startSet = + args[0]->attrs->find(state.symbols.Create("startSet")); + if (startSet == args[0]->attrs->end()) { + throw EvalError(format("attribute 'startSet' required, at %1%") % pos); + } + state.forceList(*startSet->second.value, pos); + + ValueList workSet; + for (unsigned int n = 0; n < startSet->second.value->listSize(); ++n) { + workSet.push_back(startSet->second.value->listElems()[n]); + } + + /* Get the operator. */ + Bindings::iterator op = + args[0]->attrs->find(state.symbols.Create("operator")); + if (op == args[0]->attrs->end()) { + throw EvalError(format("attribute 'operator' required, at %1%") % pos); + } + state.forceValue(*op->second.value); + + /* Construct the closure by applying the operator to element of + `workSet', adding the result to `workSet', continuing until + no new elements are found. */ + ValueList res; + // `doneKeys' doesn't need to be a GC root, because its values are + // reachable from res. + set<Value*, CompareValues> doneKeys; + while (!workSet.empty()) { + Value* e = *(workSet.begin()); + workSet.pop_front(); + + state.forceAttrs(*e, pos); + + Bindings::iterator key = e->attrs->find(state.symbols.Create("key")); + if (key == e->attrs->end()) { + throw EvalError(format("attribute 'key' required, at %1%") % pos); + } + state.forceValue(*key->second.value); + + if (doneKeys.find(key->second.value) != doneKeys.end()) { + continue; + } + doneKeys.insert(key->second.value); + res.push_back(e); + + /* Call the `operator' function with `e' as argument. */ + Value call; + mkApp(call, *op->second.value, *e); + state.forceList(call, pos); + + /* Add the values returned by the operator to the work set. */ + for (unsigned int n = 0; n < call.listSize(); ++n) { + state.forceValue(*call.listElems()[n]); + workSet.push_back(call.listElems()[n]); + } + } + + /* Create the result list. */ + state.mkList(v, res.size()); + unsigned int n = 0; + for (auto& i : res) { + v.listElems()[n++] = i; + } +} + +static void prim_abort(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + std::string s = state.coerceToString(pos, *args[0], context); + throw Abort( + format("evaluation aborted with the following error message: '%1%'") % s); +} + +static void prim_throw(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + std::string s = state.coerceToString(pos, *args[0], context); + throw ThrownError(s); +} + +static void prim_addErrorContext(EvalState& state, const Pos& pos, Value** args, + Value& v) { + try { + state.forceValue(*args[1]); + v = *args[1]; + } catch (Error& e) { + PathSet context; + e.addPrefix(format("%1%\n") % state.coerceToString(pos, *args[0], context)); + throw; + } +} + +/* Try evaluating the argument. Success => {success=true; value=something;}, + * else => {success=false; value=false;} */ +static void prim_tryEval(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.mkAttrs(v, 2); + try { + state.forceValue(*args[0]); + v.attrs->push_back(Attr(state.sValue, args[0])); + mkBool(*state.allocAttr(v, state.symbols.Create("success")), true); + } catch (AssertionError& e) { + mkBool(*state.allocAttr(v, state.sValue), false); + mkBool(*state.allocAttr(v, state.symbols.Create("success")), false); + } +} + +/* Return an environment variable. Use with care. */ +static void prim_getEnv(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string name = state.forceStringNoCtx(*args[0], pos); + mkString(v, evalSettings.restrictEval || evalSettings.pureEval + ? "" + : getEnv(name)); +} + +/* Evaluate the first argument, then return the second argument. */ +static void prim_seq(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceValue(*args[0]); + state.forceValue(*args[1]); + v = *args[1]; +} + +/* Evaluate the first argument deeply (i.e. recursing into lists and + attrsets), then return the second argument. */ +static void prim_deepSeq(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValueDeep(*args[0]); + state.forceValue(*args[1]); + v = *args[1]; +} + +/* Evaluate the first expression and print it on standard error. Then + return the second expression. Useful for debugging. */ +static void prim_trace(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + if (args[0]->type == tString) { + DLOG(INFO) << "trace: " << args[0]->string.s; + } else { + DLOG(INFO) << "trace: " << *args[0]; + } + state.forceValue(*args[1]); + v = *args[1]; +} + +void prim_valueSize(EvalState& state, const Pos& pos, Value** args, Value& v) { + /* We're not forcing the argument on purpose. */ + mkInt(v, valueSize(*args[0])); +} + +/************************************************************* + * Derivations + *************************************************************/ + +/* Construct (as a unobservable side effect) a Nix derivation + expression that performs the derivation described by the argument + set. Returns the original set extended with the following + attributes: `outPath' containing the primary output path of the + derivation; `drvPath' containing the path of the Nix expression; + and `type' set to `derivation' to indicate that this is a + derivation. */ +static void prim_derivationStrict(EvalState& state, const Pos& pos, + Value** args, Value& v) { + state.forceAttrs(*args[0], pos); + + /* Figure out the name first (for stack backtraces). */ + Bindings::iterator attr = args[0]->attrs->find(state.sName); + if (attr == args[0]->attrs->end()) { + throw EvalError(format("required attribute 'name' missing, at %1%") % pos); + } + std::string drvName; + Pos& posDrvName(*attr->second.pos); + try { + drvName = state.forceStringNoCtx(*attr->second.value, pos); + } catch (Error& e) { + e.addPrefix( + format("while evaluating the derivation attribute 'name' at %1%:\n") % + posDrvName); + throw; + } + + /* Check whether attributes should be passed as a JSON file. */ + std::ostringstream jsonBuf; + std::unique_ptr<JSONObject> jsonObject; + attr = args[0]->attrs->find(state.sStructuredAttrs); + if (attr != args[0]->attrs->end() && + state.forceBool(*attr->second.value, pos)) { + jsonObject = std::make_unique<JSONObject>(jsonBuf); + } + + /* Check whether null attributes should be ignored. */ + bool ignoreNulls = false; + attr = args[0]->attrs->find(state.sIgnoreNulls); + if (attr != args[0]->attrs->end()) { + ignoreNulls = state.forceBool(*attr->second.value, pos); + } + + /* Build the derivation expression by processing the attributes. */ + Derivation drv; + + PathSet context; + + std::optional<std::string> outputHash; + std::string outputHashAlgo; + bool outputHashRecursive = false; + + StringSet outputs; + outputs.insert("out"); + + for (auto& i : args[0]->attrs->lexicographicOrder()) { + if (i->name == state.sIgnoreNulls) { + continue; + } + const std::string& key = i->name; + + auto handleHashMode = [&](const std::string& s) { + if (s == "recursive") { + outputHashRecursive = true; + } else if (s == "flat") { + outputHashRecursive = false; + } else { + throw EvalError( + "invalid value '%s' for 'outputHashMode' attribute, at %s", s, + posDrvName); + } + }; + + auto handleOutputs = [&](const Strings& ss) { + outputs.clear(); + for (auto& j : ss) { + if (outputs.find(j) != outputs.end()) { + throw EvalError(format("duplicate derivation output '%1%', at %2%") % + j % posDrvName); + } + /* !!! Check whether j is a valid attribute + name. */ + /* Derivations cannot be named ‘drv’, because + then we'd have an attribute ‘drvPath’ in + the resulting set. */ + if (j == "drv") { + throw EvalError( + format("invalid derivation output name 'drv', at %1%") % + posDrvName); + } + outputs.insert(j); + } + if (outputs.empty()) { + throw EvalError( + format("derivation cannot have an empty set of outputs, at %1%") % + posDrvName); + } + }; + + try { + if (ignoreNulls) { + state.forceValue(*i->value); + if (i->value->type == tNull) { + continue; + } + } + + /* The `args' attribute is special: it supplies the + command-line arguments to the builder. */ + if (i->name == state.sArgs) { + state.forceList(*i->value, pos); + for (unsigned int n = 0; n < i->value->listSize(); ++n) { + std::string s = state.coerceToString( + posDrvName, *i->value->listElems()[n], context, true); + drv.args.push_back(s); + } + } + + /* All other attributes are passed to the builder through + the environment. */ + else { + if (jsonObject) { + if (i->name == state.sStructuredAttrs) { + continue; + } + + auto placeholder(jsonObject->placeholder(key)); + printValueAsJSON(state, true, *i->value, placeholder, context); + + if (i->name == state.sBuilder) { + drv.builder = state.forceString(*i->value, context, posDrvName); + } else if (i->name == state.sSystem) { + drv.platform = state.forceStringNoCtx(*i->value, posDrvName); + } else if (i->name == state.sOutputHash) { + outputHash = state.forceStringNoCtx(*i->value, posDrvName); + } else if (i->name == state.sOutputHashAlgo) { + outputHashAlgo = state.forceStringNoCtx(*i->value, posDrvName); + } else if (i->name == state.sOutputHashMode) { + handleHashMode(state.forceStringNoCtx(*i->value, posDrvName)); + } else if (i->name == state.sOutputs) { + /* Require ‘outputs’ to be a list of strings. */ + state.forceList(*i->value, posDrvName); + Strings ss; + for (unsigned int n = 0; n < i->value->listSize(); ++n) { + ss.emplace_back(state.forceStringNoCtx(*i->value->listElems()[n], + posDrvName)); + } + handleOutputs(ss); + } + + } else { + auto s = state.coerceToString(posDrvName, *i->value, context, true); + drv.env.emplace(key, s); + if (i->name == state.sBuilder) { + drv.builder = s; + } else if (i->name == state.sSystem) { + drv.platform = s; + } else if (i->name == state.sOutputHash) { + outputHash = s; + } else if (i->name == state.sOutputHashAlgo) { + outputHashAlgo = s; + } else if (i->name == state.sOutputHashMode) { + handleHashMode(s); + } else if (i->name == state.sOutputs) { + handleOutputs(tokenizeString<Strings>(s)); + } + } + } + + } catch (Error& e) { + e.addPrefix(format("while evaluating the attribute '%1%' of the " + "derivation '%2%' at %3%:\n") % + key % drvName % posDrvName); + throw; + } + } + + if (jsonObject) { + jsonObject.reset(); + drv.env.emplace("__json", jsonBuf.str()); + } + + /* Everything in the context of the strings in the derivation + attributes should be added as dependencies of the resulting + derivation. */ + for (auto& path : context) { + /* Paths marked with `=' denote that the path of a derivation + is explicitly passed to the builder. Since that allows the + builder to gain access to every path in the dependency + graph of the derivation (including all outputs), all paths + in the graph must be added to this derivation's list of + inputs to ensure that they are available when the builder + runs. */ + if (path.at(0) == '=') { + /* !!! This doesn't work if readOnlyMode is set. */ + PathSet refs; + state.store->computeFSClosure(string(path, 1), refs); + for (auto& j : refs) { + drv.inputSrcs.insert(j); + if (isDerivation(j)) { + drv.inputDrvs[j] = state.store->queryDerivationOutputNames(j); + } + } + } + + /* Handle derivation outputs of the form ‘!<name>!<path>’. */ + else if (path.at(0) == '!') { + std::pair<string, string> ctx = decodeContext(path); + drv.inputDrvs[ctx.first].insert(ctx.second); + } + + /* Otherwise it's a source file. */ + else { + drv.inputSrcs.insert(path); + } + } + + /* Do we have all required attributes? */ + if (drv.builder.empty()) { + throw EvalError(format("required attribute 'builder' missing, at %1%") % + posDrvName); + } + if (drv.platform.empty()) { + throw EvalError(format("required attribute 'system' missing, at %1%") % + posDrvName); + } + + /* Check whether the derivation name is valid. */ + checkStoreName(drvName); + if (isDerivation(drvName)) { + throw EvalError( + format("derivation names are not allowed to end in '%1%', at %2%") % + drvExtension % posDrvName); + } + + if (outputHash) { + /* Handle fixed-output derivations. */ + if (outputs.size() != 1 || *(outputs.begin()) != "out") { + throw Error(format("multiple outputs are not supported in fixed-output " + "derivations, at %1%") % + posDrvName); + } + + HashType ht = + outputHashAlgo.empty() ? htUnknown : parseHashType(outputHashAlgo); + Hash h(*outputHash, ht); + + Path outPath = + state.store->makeFixedOutputPath(outputHashRecursive, h, drvName); + if (!jsonObject) { + drv.env["out"] = outPath; + } + drv.outputs["out"] = DerivationOutput( + outPath, (outputHashRecursive ? "r:" : "") + printHashType(h.type), + h.to_string(Base16, false)); + } + + else { + /* Construct the "masked" store derivation, which is the final + one except that in the list of outputs, the output paths + are empty, and the corresponding environment variables have + an empty value. This ensures that changes in the set of + output names do get reflected in the hash. */ + for (auto& i : outputs) { + if (!jsonObject) { + drv.env[i] = ""; + } + drv.outputs[i] = DerivationOutput("", "", ""); + } + + /* Use the masked derivation expression to compute the output + path. */ + Hash h = hashDerivationModulo(*state.store, drv); + + for (auto& i : drv.outputs) { + if (i.second.path.empty()) { + Path outPath = state.store->makeOutputPath(i.first, h, drvName); + if (!jsonObject) { + drv.env[i.first] = outPath; + } + i.second.path = outPath; + } + } + } + + /* Write the resulting term into the Nix store directory. */ + Path drvPath = writeDerivation(state.store, drv, drvName, state.repair); + + DLOG(INFO) << "instantiated '" << drvName << "' -> '" << drvPath << "'"; + + /* Optimisation, but required in read-only mode! because in that + case we don't actually write store derivations, so we can't + read them later. */ + drvHashes[drvPath] = hashDerivationModulo(*state.store, drv); + + state.mkAttrs(v, 1 + drv.outputs.size()); + mkString(*state.allocAttr(v, state.sDrvPath), drvPath, {"=" + drvPath}); + for (auto& i : drv.outputs) { + mkString(*state.allocAttr(v, state.symbols.Create(i.first)), i.second.path, + {"!" + i.first + "!" + drvPath}); + } +} + +/* Return a placeholder string for the specified output that will be + substituted by the corresponding output path at build time. For + example, 'placeholder "out"' returns the string + /1rz4g4znpzjwh1xymhjpm42vipw92pr73vdgl6xs1hycac8kf2n9. At build + time, any occurence of this string in an derivation attribute will + be replaced with the concrete path in the Nix store of the output + ‘out’. */ +static void prim_placeholder(EvalState& state, const Pos& pos, Value** args, + Value& v) { + mkString(v, hashPlaceholder(state.forceStringNoCtx(*args[0], pos))); +} + +/************************************************************* + * Paths + *************************************************************/ + +/* Convert the argument to a path. !!! obsolete? */ +static void prim_toPath(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.coerceToPath(pos, *args[0], context); + mkString(v, canonPath(path), context); +} + +/* Allow a valid store path to be used in an expression. This is + useful in some generated expressions such as in nix-push, which + generates a call to a function with an already existing store path + as argument. You don't want to use `toPath' here because it copies + the path to the Nix store, which yields a copy like + /nix/store/newhash-oldhash-oldname. In the past, `toPath' had + special case behaviour for store paths, but that created weird + corner cases. */ +static void prim_storePath(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.checkSourcePath(state.coerceToPath(pos, *args[0], context)); + /* Resolve symlinks in ‘path’, unless ‘path’ itself is a symlink + directly in the store. The latter condition is necessary so + e.g. nix-push does the right thing. */ + if (!state.store->isStorePath(path)) { + path = canonPath(path, true); + } + if (!state.store->isInStore(path)) { + throw EvalError(format("path '%1%' is not in the Nix store, at %2%") % + path % pos); + } + Path path2 = state.store->toStorePath(path); + if (!settings.readOnlyMode) { + state.store->ensurePath(path2); + } + context.insert(path2); + mkString(v, path, context); +} + +static void prim_pathExists(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.coerceToPath(pos, *args[0], context); + try { + state.realiseContext(context); + } catch (InvalidPathError& e) { + throw EvalError(format("cannot check the existence of '%1%', since path " + "'%2%' is not valid, at %3%") % + path % e.path % pos); + } + + try { + mkBool(v, pathExists(state.checkSourcePath(path))); + } catch (SysError& e) { + /* Don't give away info from errors while canonicalising + ‘path’ in restricted mode. */ + mkBool(v, false); + } catch (RestrictedPathError& e) { + mkBool(v, false); + } +} + +/* Return the base name of the given string, i.e., everything + following the last slash. */ +static void prim_baseNameOf(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + mkString( + v, baseNameOf(state.coerceToString(pos, *args[0], context, false, false)), + context); +} + +/* Return the directory of the given path, i.e., everything before the + last slash. Return either a path or a string depending on the type + of the argument. */ +static void prim_dirOf(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path dir = dirOf(state.coerceToString(pos, *args[0], context, false, false)); + if (args[0]->type == tPath) { + mkPath(v, dir.c_str()); + } else { + mkString(v, dir, context); + } +} + +/* Return the contents of a file as a string. */ +static void prim_readFile(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.coerceToPath(pos, *args[0], context); + try { + state.realiseContext(context); + } catch (InvalidPathError& e) { + throw EvalError( + format("cannot read '%1%', since path '%2%' is not valid, at %3%") % + path % e.path % pos); + } + std::string s = + readFile(state.checkSourcePath(state.toRealPath(path, context))); + if (s.find((char)0) != string::npos) { + throw Error(format("the contents of the file '%1%' cannot be represented " + "as a Nix string") % + path); + } + mkString(v, s.c_str()); +} + +/* Find a file in the Nix search path. Used to implement <x> paths, + which are desugared to 'findFile __nixPath "x"'. */ +static void prim_findFile(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceList(*args[0], pos); + + SearchPath searchPath; + + for (unsigned int n = 0; n < args[0]->listSize(); ++n) { + Value& v2(*args[0]->listElems()[n]); + state.forceAttrs(v2, pos); + + std::string prefix; + Bindings::iterator i = v2.attrs->find(state.symbols.Create("prefix")); + if (i != v2.attrs->end()) { + prefix = state.forceStringNoCtx(*i->second.value, pos); + } + + i = v2.attrs->find(state.symbols.Create("path")); + if (i == v2.attrs->end()) { + throw EvalError(format("attribute 'path' missing, at %1%") % pos); + } + + PathSet context; + std::string path = + state.coerceToString(pos, *i->second.value, context, false, false); + + try { + state.realiseContext(context); + } catch (InvalidPathError& e) { + throw EvalError( + format("cannot find '%1%', since path '%2%' is not valid, at %3%") % + path % e.path % pos); + } + + searchPath.emplace_back(prefix, path); + } + + std::string path = state.forceStringNoCtx(*args[1], pos); + + mkPath(v, + state.checkSourcePath(state.findFile(searchPath, path, pos)).c_str()); +} + +/* Return the cryptographic hash of a file in base-16. */ +static void prim_hashFile(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string type = state.forceStringNoCtx(*args[0], pos); + HashType ht = parseHashType(type); + if (ht == htUnknown) { + throw Error(format("unknown hash type '%1%', at %2%") % type % pos); + } + + PathSet context; // discarded + Path p = state.coerceToPath(pos, *args[1], context); + + mkString(v, hashFile(ht, state.checkSourcePath(p)).to_string(Base16, false), + context); +} + +/* Read a directory (without . or ..) */ +static void prim_readDir(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet ctx; + Path path = state.coerceToPath(pos, *args[0], ctx); + try { + state.realiseContext(ctx); + } catch (InvalidPathError& e) { + throw EvalError( + format("cannot read '%1%', since path '%2%' is not valid, at %3%") % + path % e.path % pos); + } + + DirEntries entries = readDirectory(state.checkSourcePath(path)); + state.mkAttrs(v, entries.size()); + + for (auto& ent : entries) { + Value* ent_val = state.allocAttr(v, state.symbols.Create(ent.name)); + if (ent.type == DT_UNKNOWN) { + ent.type = getFileType(path + "/" + ent.name); + } + mkStringNoCopy(*ent_val, + ent.type == DT_REG + ? "regular" + : ent.type == DT_DIR + ? "directory" + : ent.type == DT_LNK ? "symlink" : "unknown"); + } +} + +/************************************************************* + * Creating files + *************************************************************/ + +/* Convert the argument (which can be any Nix expression) to an XML + representation returned in a string. Not all Nix expressions can + be sensibly or completely represented (e.g., functions). */ +static void prim_toXML(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::ostringstream out; + PathSet context; + printValueAsXML(state, true, false, *args[0], out, context); + mkString(v, out.str(), context); +} + +/* Convert the argument (which can be any Nix expression) to a JSON + string. Not all Nix expressions can be sensibly or completely + represented (e.g., functions). */ +static void prim_toJSON(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::ostringstream out; + PathSet context; + printValueAsJSON(state, true, *args[0], out, context); + mkString(v, out.str(), context); +} + +/* Parse a JSON string to a value. */ +static void prim_fromJSON(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string s = state.forceStringNoCtx(*args[0], pos); + parseJSON(state, s, v); +} + +/* Store a string in the Nix store as a source file that can be used + as an input by derivations. */ +static void prim_toFile(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + std::string name = state.forceStringNoCtx(*args[0], pos); + std::string contents = state.forceString(*args[1], context, pos); + + PathSet refs; + + for (auto path : context) { + if (path.at(0) != '/') { + throw EvalError(format("in 'toFile': the file '%1%' cannot refer to " + "derivation outputs, at %2%") % + name % pos); + } + refs.insert(path); + } + + Path storePath = + settings.readOnlyMode + ? state.store->computeStorePathForText(name, contents, refs) + : state.store->addTextToStore(name, contents, refs, state.repair); + + /* Note: we don't need to add `context' to the context of the + result, since `storePath' itself has references to the paths + used in args[1]. */ + + mkString(v, storePath, {storePath}); +} + +static void addPath(EvalState& state, const Pos& pos, const std::string& name, + const Path& path_, Value* filterFun, bool recursive, + const Hash& expectedHash, Value& v) { + const auto path = evalSettings.pureEval && expectedHash + ? path_ + : state.checkSourcePath(path_); + PathFilter filter = filterFun != nullptr ? ([&](const Path& path) { + auto st = lstat(path); + + /* Call the filter function. The first argument is the path, + the second is a string indicating the type of the file. */ + Value arg1; + mkString(arg1, path); + + Value fun2; + state.callFunction(*filterFun, arg1, fun2, noPos); + + Value arg2; + mkString(arg2, S_ISREG(st.st_mode) + ? "regular" + : S_ISDIR(st.st_mode) + ? "directory" + : S_ISLNK(st.st_mode) + ? "symlink" + : "unknown" /* not supported, will fail! */); + + Value res; + state.callFunction(fun2, arg2, res, noPos); + + return state.forceBool(res, pos); + }) + : defaultPathFilter; + + Path expectedStorePath; + if (expectedHash) { + expectedStorePath = + state.store->makeFixedOutputPath(recursive, expectedHash, name); + } + Path dstPath; + if (!expectedHash || !state.store->isValidPath(expectedStorePath)) { + dstPath = settings.readOnlyMode + ? state.store + ->computeStorePathForPath(name, path, recursive, + htSHA256, filter) + .first + : state.store->addToStore(name, path, recursive, htSHA256, + filter, state.repair); + if (expectedHash && expectedStorePath != dstPath) { + throw Error(format("store path mismatch in (possibly filtered) path " + "added from '%1%'") % + path); + } + } else { + dstPath = expectedStorePath; + } + + mkString(v, dstPath, {dstPath}); +} + +static void prim_filterSource(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + Path path = state.coerceToPath(pos, *args[1], context); + if (!context.empty()) { + throw EvalError(format("string '%1%' cannot refer to other paths, at %2%") % + path % pos); + } + + state.forceValue(*args[0]); + if (args[0]->type != tLambda) { + throw TypeError(format("first argument in call to 'filterSource' is not a " + "function but %1%, at %2%") % + showType(*args[0]) % pos); + } + + addPath(state, pos, baseNameOf(path), path, args[0], true, Hash(), v); +} + +static void prim_path(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[0], pos); + Path path; + std::string name; + Value* filterFun = nullptr; + auto recursive = true; + Hash expectedHash; + + for (auto& attr : *args[0]->attrs) { + const std::string& n(attr.second.name); + if (n == "path") { + PathSet context; + path = state.coerceToPath(*attr.second.pos, *attr.second.value, context); + if (!context.empty()) { + throw EvalError( + format("string '%1%' cannot refer to other paths, at %2%") % path % + *attr.second.pos); + } + } else if (attr.second.name == state.sName) { + name = state.forceStringNoCtx(*attr.second.value, *attr.second.pos); + } else if (n == "filter") { + state.forceValue(*attr.second.value); + filterFun = attr.second.value; + } else if (n == "recursive") { + recursive = state.forceBool(*attr.second.value, *attr.second.pos); + } else if (n == "sha256") { + expectedHash = + Hash(state.forceStringNoCtx(*attr.second.value, *attr.second.pos), + htSHA256); + } else { + throw EvalError( + format("unsupported argument '%1%' to 'addPath', at %2%") % + attr.second.name % *attr.second.pos); + } + } + if (path.empty()) { + throw EvalError(format("'path' required, at %1%") % pos); + } + if (name.empty()) { + name = baseNameOf(path); + } + + addPath(state, pos, name, path, filterFun, recursive, expectedHash, v); +} + +/************************************************************* + * Sets + *************************************************************/ + +/* Return the names of the attributes in a set as a sorted list of + strings. */ +static void prim_attrNames(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[0], pos); + + state.mkList(v, args[0]->attrs->size()); + + size_t n = 0; + for (auto& i : *args[0]->attrs) { + mkString(*(v.listElems()[n++] = state.allocValue()), i.second.name); + } + + std::sort(v.listElems(), v.listElems() + n, [](Value* v1, Value* v2) { + return strcmp(v1->string.s, v2->string.s) < 0; + }); +} + +/* Return the values of the attributes in a set as a list, in the same + order as attrNames. */ +static void prim_attrValues(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[0], pos); + + state.mkList(v, args[0]->attrs->size()); + + unsigned int n = 0; + for (auto& i : *args[0]->attrs) { + v.listElems()[n++] = (Value*)&i; + } + + std::sort(v.listElems(), v.listElems() + n, [](Value* v1, Value* v2) { + return (string)((Attr*)v1)->name < (string)((Attr*)v2)->name; + }); + + for (unsigned int i = 0; i < n; ++i) { + v.listElems()[i] = ((Attr*)v.listElems()[i])->value; + } +} + +/* Dynamic version of the `.' operator. */ +void prim_getAttr(EvalState& state, const Pos& pos, Value** args, Value& v) { + std::string attr = state.forceStringNoCtx(*args[0], pos); + state.forceAttrs(*args[1], pos); + // !!! Should we create a symbol here or just do a lookup? + Bindings::iterator i = args[1]->attrs->find(state.symbols.Create(attr)); + if (i == args[1]->attrs->end()) { + throw EvalError(format("attribute '%1%' missing, at %2%") % attr % pos); + } + // !!! add to stack trace? + if (state.countCalls && (i->second.pos != nullptr)) { + state.attrSelects[*i->second.pos]++; + } + state.forceValue(*i->second.value); + v = *i->second.value; +} + +/* Return position information of the specified attribute. */ +void prim_unsafeGetAttrPos(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string attr = state.forceStringNoCtx(*args[0], pos); + state.forceAttrs(*args[1], pos); + Bindings::iterator i = args[1]->attrs->find(state.symbols.Create(attr)); + if (i == args[1]->attrs->end()) { + mkNull(v); + } else { + state.mkPos(v, i->second.pos); + } +} + +/* Dynamic version of the `?' operator. */ +static void prim_hasAttr(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string attr = state.forceStringNoCtx(*args[0], pos); + state.forceAttrs(*args[1], pos); + mkBool(v, args[1]->attrs->find(state.symbols.Create(attr)) != + args[1]->attrs->end()); +} + +/* Determine whether the argument is a set. */ +static void prim_isAttrs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->type == tAttrs); +} + +static void prim_removeAttrs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[0], pos); + state.forceList(*args[1], pos); + + /* Get the attribute names to be removed. */ + std::set<Symbol> names; + for (unsigned int i = 0; i < args[1]->listSize(); ++i) { + state.forceStringNoCtx(*args[1]->listElems()[i], pos); + names.insert(state.symbols.Create(args[1]->listElems()[i]->string.s)); + } + + /* Copy all attributes not in that set. Note that we don't need + to sort v.attrs because it's a subset of an already sorted + vector. */ + state.mkAttrs(v, args[0]->attrs->size()); + for (auto& i : *args[0]->attrs) { + if (names.find(i.second.name) == names.end()) { + v.attrs->push_back(i.second); + } + } +} + +/* Builds a set from a list specifying (name, value) pairs. To be + precise, a list [{name = "name1"; value = value1;} ... {name = + "nameN"; value = valueN;}] is transformed to {name1 = value1; + ... nameN = valueN;}. In case of duplicate occurences of the same + name, the first takes precedence. */ +static void prim_listToAttrs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceList(*args[0], pos); + + state.mkAttrs(v, args[0]->listSize()); + + std::set<Symbol> seen; + + for (unsigned int i = 0; i < args[0]->listSize(); ++i) { + Value& v2(*args[0]->listElems()[i]); + state.forceAttrs(v2, pos); + + Bindings::iterator j = v2.attrs->find(state.sName); + if (j == v2.attrs->end()) { + throw TypeError( + format( + "'name' attribute missing in a call to 'listToAttrs', at %1%") % + pos); + } + std::string name = state.forceStringNoCtx(*j->second.value, pos); + + Symbol sym = state.symbols.Create(name); + if (seen.find(sym) == seen.end()) { + Bindings::iterator j2 = + // TODO(tazjin): this line used to construct the symbol again: + // state.symbols.Create(state.sValue)); + // Why? + v2.attrs->find(state.sValue); + if (j2 == v2.attrs->end()) { + throw TypeError(format("'value' attribute missing in a call to " + "'listToAttrs', at %1%") % + pos); + } + + v.attrs->push_back(Attr(sym, j2->second.value, j2->second.pos)); + seen.insert(sym); + } + } +} + +/* Return the right-biased intersection of two sets as1 and as2, + i.e. a set that contains every attribute from as2 that is also a + member of as1. */ +static void prim_intersectAttrs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[0], pos); + state.forceAttrs(*args[1], pos); + + state.mkAttrs(v, std::min(args[0]->attrs->size(), args[1]->attrs->size())); + + for (auto& i : *args[0]->attrs) { + Bindings::iterator j = args[1]->attrs->find(i.second.name); + if (j != args[1]->attrs->end()) { + v.attrs->push_back(j->second); + } + } +} + +/* Collect each attribute named `attr' from a list of attribute sets. + Sets that don't contain the named attribute are ignored. + + Example: + catAttrs "a" [{a = 1;} {b = 0;} {a = 2;}] + => [1 2] +*/ +static void prim_catAttrs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + Symbol attrName = state.symbols.Create(state.forceStringNoCtx(*args[0], pos)); + state.forceList(*args[1], pos); + + Value* res[args[1]->listSize()]; + unsigned int found = 0; + + for (unsigned int n = 0; n < args[1]->listSize(); ++n) { + Value& v2(*args[1]->listElems()[n]); + state.forceAttrs(v2, pos); + Bindings::iterator i = v2.attrs->find(attrName); + if (i != v2.attrs->end()) { + res[found++] = i->second.value; + } + } + + state.mkList(v, found); + for (unsigned int n = 0; n < found; ++n) { + v.listElems()[n] = res[n]; + } +} + +/* Return a set containing the names of the formal arguments expected + by the function `f'. The value of each attribute is a Boolean + denoting whether the corresponding argument has a default value. For + instance, + + functionArgs ({ x, y ? 123}: ...) + => { x = false; y = true; } + + "Formal argument" here refers to the attributes pattern-matched by + the function. Plain lambdas are not included, e.g. + + functionArgs (x: ...) + => { } +*/ +static void prim_functionArgs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + if (args[0]->type != tLambda) { + throw TypeError(format("'functionArgs' requires a function, at %1%") % pos); + } + + if (!args[0]->lambda.fun->matchAttrs) { + state.mkAttrs(v, 0); + return; + } + + state.mkAttrs(v, args[0]->lambda.fun->formals->formals.size()); + for (auto& i : args[0]->lambda.fun->formals->formals) { + // !!! should optimise booleans (allocate only once) + // TODO(tazjin): figure out what the above comment means + mkBool(*state.allocAttr(v, i.name), i.def != nullptr); + } +} + +/* Apply a function to every element of an attribute set. */ +static void prim_mapAttrs(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceAttrs(*args[1], pos); + + state.mkAttrs(v, args[1]->attrs->size()); + + for (auto& i : *args[1]->attrs) { + Value* vName = state.allocValue(); + Value* vFun2 = state.allocValue(); + mkString(*vName, i.second.name); + mkApp(*vFun2, *args[0], *vName); + mkApp(*state.allocAttr(v, i.second.name), *vFun2, *i.second.value); + } +} + +/************************************************************* + * Lists + *************************************************************/ + +/* Determine whether the argument is a list. */ +static void prim_isList(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + mkBool(v, args[0]->isList()); +} + +static void elemAt(EvalState& state, const Pos& pos, Value& list, int n, + Value& v) { + state.forceList(list, pos); + if (n < 0 || (unsigned int)n >= list.listSize()) { + throw Error(format("list index %1% is out of bounds, at %2%") % n % pos); + } + state.forceValue(*list.listElems()[n]); + v = *list.listElems()[n]; +} + +/* Return the n-1'th element of a list. */ +static void prim_elemAt(EvalState& state, const Pos& pos, Value** args, + Value& v) { + elemAt(state, pos, *args[0], state.forceInt(*args[1], pos), v); +} + +/* Return the first element of a list. */ +static void prim_head(EvalState& state, const Pos& pos, Value** args, + Value& v) { + elemAt(state, pos, *args[0], 0, v); +} + +/* Return a list consisting of everything but the first element of + a list. Warning: this function takes O(n) time, so you probably + don't want to use it! */ +static void prim_tail(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceList(*args[0], pos); + if (args[0]->listSize() == 0) { + throw Error(format("'tail' called on an empty list, at %1%") % pos); + } + state.mkList(v, args[0]->listSize() - 1); + for (unsigned int n = 0; n < v.listSize(); ++n) { + v.listElems()[n] = args[0]->listElems()[n + 1]; + } +} + +/* Apply a function to every element of a list. */ +static void prim_map(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceList(*args[1], pos); + + state.mkList(v, args[1]->listSize()); + + for (unsigned int n = 0; n < v.listSize(); ++n) { + mkApp(*(v.listElems()[n] = state.allocValue()), *args[0], + *args[1]->listElems()[n]); + } +} + +/* Filter a list using a predicate; that is, return a list containing + every element from the list for which the predicate function + returns true. */ +static void prim_filter(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceFunction(*args[0], pos); + state.forceList(*args[1], pos); + + // FIXME: putting this on the stack is risky. + Value* vs[args[1]->listSize()]; + unsigned int k = 0; + + bool same = true; + for (unsigned int n = 0; n < args[1]->listSize(); ++n) { + Value res; + state.callFunction(*args[0], *args[1]->listElems()[n], res, noPos); + if (state.forceBool(res, pos)) { + vs[k++] = args[1]->listElems()[n]; + } else { + same = false; + } + } + + if (same) { + v = *args[1]; + } else { + state.mkList(v, k); + for (unsigned int n = 0; n < k; ++n) { + v.listElems()[n] = vs[n]; + } + } +} + +/* Return true if a list contains a given element. */ +static void prim_elem(EvalState& state, const Pos& pos, Value** args, + Value& v) { + bool res = false; + state.forceList(*args[1], pos); + for (unsigned int n = 0; n < args[1]->listSize(); ++n) { + if (state.eqValues(*args[0], *args[1]->listElems()[n])) { + res = true; + break; + } + } + mkBool(v, res); +} + +/* Concatenate a list of lists. */ +static void prim_concatLists(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceList(*args[0], pos); + state.concatLists(v, args[0]->listSize(), args[0]->listElems(), pos); +} + +/* Return the length of a list. This is an O(1) time operation. */ +static void prim_length(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceList(*args[0], pos); + mkInt(v, args[0]->listSize()); +} + +/* Reduce a list by applying a binary operator, from left to + right. The operator is applied strictly. */ +static void prim_foldlStrict(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceFunction(*args[0], pos); + state.forceList(*args[2], pos); + + if (args[2]->listSize() != 0u) { + Value* vCur = args[1]; + + for (unsigned int n = 0; n < args[2]->listSize(); ++n) { + Value vTmp; + state.callFunction(*args[0], *vCur, vTmp, pos); + vCur = n == args[2]->listSize() - 1 ? &v : state.allocValue(); + state.callFunction(vTmp, *args[2]->listElems()[n], *vCur, pos); + } + state.forceValue(v); + } else { + state.forceValue(*args[1]); + v = *args[1]; + } +} + +static void anyOrAll(bool any, EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceFunction(*args[0], pos); + state.forceList(*args[1], pos); + + Value vTmp; + for (unsigned int n = 0; n < args[1]->listSize(); ++n) { + state.callFunction(*args[0], *args[1]->listElems()[n], vTmp, pos); + bool res = state.forceBool(vTmp, pos); + if (res == any) { + mkBool(v, any); + return; + } + } + + mkBool(v, !any); +} + +static void prim_any(EvalState& state, const Pos& pos, Value** args, Value& v) { + anyOrAll(true, state, pos, args, v); +} + +static void prim_all(EvalState& state, const Pos& pos, Value** args, Value& v) { + anyOrAll(false, state, pos, args, v); +} + +static void prim_genList(EvalState& state, const Pos& pos, Value** args, + Value& v) { + auto len = state.forceInt(*args[1], pos); + + if (len < 0) { + throw EvalError(format("cannot create list of size %1%, at %2%") % len % + pos); + } + + state.mkList(v, len); + + for (unsigned int n = 0; n < (unsigned int)len; ++n) { + Value* arg = state.allocValue(); + mkInt(*arg, n); + mkApp(*(v.listElems()[n] = state.allocValue()), *args[0], *arg); + } +} + +static void prim_lessThan(EvalState& state, const Pos& pos, Value** args, + Value& v); + +static void prim_sort(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceFunction(*args[0], pos); + state.forceList(*args[1], pos); + + auto len = args[1]->listSize(); + state.mkList(v, len); + for (unsigned int n = 0; n < len; ++n) { + state.forceValue(*args[1]->listElems()[n]); + v.listElems()[n] = args[1]->listElems()[n]; + } + + auto comparator = [&](Value* a, Value* b) { + /* Optimization: if the comparator is lessThan, bypass + callFunction. */ + if (args[0]->type == tPrimOp && args[0]->primOp->fun == prim_lessThan) { + return CompareValues()(a, b); + } + + Value vTmp1; + Value vTmp2; + state.callFunction(*args[0], *a, vTmp1, pos); + state.callFunction(vTmp1, *b, vTmp2, pos); + return state.forceBool(vTmp2, pos); + }; + + /* FIXME: std::sort can segfault if the comparator is not a strict + weak ordering. What to do? std::stable_sort() seems more + resilient, but no guarantees... */ + std::stable_sort(v.listElems(), v.listElems() + len, comparator); +} + +static void prim_partition(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceFunction(*args[0], pos); + state.forceList(*args[1], pos); + + auto len = args[1]->listSize(); + + ValueVector right; + ValueVector wrong; + + for (unsigned int n = 0; n < len; ++n) { + auto vElem = args[1]->listElems()[n]; + state.forceValue(*vElem); + Value res; + state.callFunction(*args[0], *vElem, res, pos); + if (state.forceBool(res, pos)) { + right.push_back(vElem); + } else { + wrong.push_back(vElem); + } + } + + state.mkAttrs(v, 2); + + Value* vRight = state.allocAttr(v, state.sRight); + auto rsize = right.size(); + state.mkList(*vRight, rsize); + if (rsize != 0u) { + memcpy(vRight->listElems(), right.data(), sizeof(Value*) * rsize); + } + + Value* vWrong = state.allocAttr(v, state.sWrong); + auto wsize = wrong.size(); + state.mkList(*vWrong, wsize); + if (wsize != 0u) { + memcpy(vWrong->listElems(), wrong.data(), sizeof(Value*) * wsize); + } +} + +/* concatMap = f: list: concatLists (map f list); */ +/* C++-version is to avoid allocating `mkApp', call `f' eagerly */ +static void prim_concatMap(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceFunction(*args[0], pos); + state.forceList(*args[1], pos); + auto nrLists = args[1]->listSize(); + + Value lists[nrLists]; + size_t len = 0; + + for (unsigned int n = 0; n < nrLists; ++n) { + Value* vElem = args[1]->listElems()[n]; + state.callFunction(*args[0], *vElem, lists[n], pos); + state.forceList(lists[n], pos); + len += lists[n].listSize(); + } + + state.mkList(v, len); + auto out = v.listElems(); + for (unsigned int n = 0, pos = 0; n < nrLists; ++n) { + auto l = lists[n].listSize(); + if (l != 0u) { + memcpy(out + pos, lists[n].listElems(), l * sizeof(Value*)); + } + pos += l; + } +} + +/************************************************************* + * Integer arithmetic + *************************************************************/ + +static void prim_add(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceValue(*args[0], pos); + state.forceValue(*args[1], pos); + if (args[0]->type == tFloat || args[1]->type == tFloat) { + mkFloat(v, + state.forceFloat(*args[0], pos) + state.forceFloat(*args[1], pos)); + } else { + mkInt(v, state.forceInt(*args[0], pos) + state.forceInt(*args[1], pos)); + } +} + +static void prim_sub(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceValue(*args[0], pos); + state.forceValue(*args[1], pos); + if (args[0]->type == tFloat || args[1]->type == tFloat) { + mkFloat(v, + state.forceFloat(*args[0], pos) - state.forceFloat(*args[1], pos)); + } else { + mkInt(v, state.forceInt(*args[0], pos) - state.forceInt(*args[1], pos)); + } +} + +static void prim_mul(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceValue(*args[0], pos); + state.forceValue(*args[1], pos); + if (args[0]->type == tFloat || args[1]->type == tFloat) { + mkFloat(v, + state.forceFloat(*args[0], pos) * state.forceFloat(*args[1], pos)); + } else { + mkInt(v, state.forceInt(*args[0], pos) * state.forceInt(*args[1], pos)); + } +} + +static void prim_div(EvalState& state, const Pos& pos, Value** args, Value& v) { + state.forceValue(*args[0], pos); + state.forceValue(*args[1], pos); + + NixFloat f2 = state.forceFloat(*args[1], pos); + if (f2 == 0) { + throw EvalError(format("division by zero, at %1%") % pos); + } + + if (args[0]->type == tFloat || args[1]->type == tFloat) { + mkFloat(v, + state.forceFloat(*args[0], pos) / state.forceFloat(*args[1], pos)); + } else { + NixInt i1 = state.forceInt(*args[0], pos); + NixInt i2 = state.forceInt(*args[1], pos); + /* Avoid division overflow as it might raise SIGFPE. */ + if (i1 == std::numeric_limits<NixInt>::min() && i2 == -1) { + throw EvalError(format("overflow in integer division, at %1%") % pos); + } + mkInt(v, i1 / i2); + } +} + +static void prim_bitAnd(EvalState& state, const Pos& pos, Value** args, + Value& v) { + mkInt(v, state.forceInt(*args[0], pos) & state.forceInt(*args[1], pos)); +} + +static void prim_bitOr(EvalState& state, const Pos& pos, Value** args, + Value& v) { + mkInt(v, state.forceInt(*args[0], pos) | state.forceInt(*args[1], pos)); +} + +static void prim_bitXor(EvalState& state, const Pos& pos, Value** args, + Value& v) { + mkInt(v, state.forceInt(*args[0], pos) ^ state.forceInt(*args[1], pos)); +} + +static void prim_lessThan(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceValue(*args[0]); + state.forceValue(*args[1]); + CompareValues comp; + mkBool(v, comp(args[0], args[1])); +} + +/************************************************************* + * String manipulation + *************************************************************/ + +/* Convert the argument to a string. Paths are *not* copied to the + store, so `toString /foo/bar' yields `"/foo/bar"', not + `"/nix/store/whatever..."'. */ +static void prim_toString(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + std::string s = state.coerceToString(pos, *args[0], context, true, false); + mkString(v, s, context); +} + +/* `substring start len str' returns the substring of `str' starting + at character position `min(start, stringLength str)' inclusive and + ending at `min(start + len, stringLength str)'. `start' must be + non-negative. */ +static void prim_substring(EvalState& state, const Pos& pos, Value** args, + Value& v) { + int start = state.forceInt(*args[0], pos); + int len = state.forceInt(*args[1], pos); + PathSet context; + std::string s = state.coerceToString(pos, *args[2], context); + + if (start < 0) { + throw EvalError(format("negative start position in 'substring', at %1%") % + pos); + } + + mkString(v, (unsigned int)start >= s.size() ? "" : string(s, start, len), + context); +} + +static void prim_stringLength(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + std::string s = state.coerceToString(pos, *args[0], context); + mkInt(v, s.size()); +} + +/* Return the cryptographic hash of a string in base-16. */ +static void prim_hashString(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string type = state.forceStringNoCtx(*args[0], pos); + HashType ht = parseHashType(type); + if (ht == htUnknown) { + throw Error(format("unknown hash type '%1%', at %2%") % type % pos); + } + + PathSet context; // discarded + std::string s = state.forceString(*args[1], context, pos); + + mkString(v, hashString(ht, s).to_string(Base16, false), context); +} + +/* Match a regular expression against a string and return either + ‘null’ or a list containing substring matches. */ +static void prim_match(EvalState& state, const Pos& pos, Value** args, + Value& v) { + auto re = state.forceStringNoCtx(*args[0], pos); + + try { + std::regex regex(re, std::regex::extended); + + PathSet context; + const std::string str = state.forceString(*args[1], context, pos); + + std::smatch match; + if (!std::regex_match(str, match, regex)) { + mkNull(v); + return; + } + + // the first match is the whole string + const size_t len = match.size() - 1; + state.mkList(v, len); + for (size_t i = 0; i < len; ++i) { + if (!match[i + 1].matched) { + mkNull(*(v.listElems()[i] = state.allocValue())); + } else { + mkString(*(v.listElems()[i] = state.allocValue()), + match[i + 1].str().c_str()); + } + } + + } catch (std::regex_error& e) { + if (e.code() == std::regex_constants::error_space) { + // limit is _GLIBCXX_REGEX_STATE_LIMIT for libstdc++ + throw EvalError("memory limit exceeded by regular expression '%s', at %s", + re, pos); + } + throw EvalError("invalid regular expression '%s', at %s", re, pos); + } +} + +/* Split a std::string with a regular expression, and return a list of the + non-matching parts interleaved by the lists of the matching groups. */ +static void prim_split(EvalState& state, const Pos& pos, Value** args, + Value& v) { + auto re = state.forceStringNoCtx(*args[0], pos); + + try { + std::regex regex(re, std::regex::extended); + + PathSet context; + const std::string str = state.forceString(*args[1], context, pos); + + auto begin = std::sregex_iterator(str.begin(), str.end(), regex); + auto end = std::sregex_iterator(); + + // Any matches results are surrounded by non-matching results. + const size_t len = std::distance(begin, end); + state.mkList(v, 2 * len + 1); + size_t idx = 0; + Value* elem; + + if (len == 0) { + v.listElems()[idx++] = args[1]; + return; + } + + for (std::sregex_iterator i = begin; i != end; ++i) { + assert(idx <= 2 * len + 1 - 3); + std::smatch match = *i; + + // Add a string for non-matched characters. + elem = v.listElems()[idx++] = state.allocValue(); + mkString(*elem, match.prefix().str().c_str()); + + // Add a list for matched substrings. + const size_t slen = match.size() - 1; + elem = v.listElems()[idx++] = state.allocValue(); + + // Start at 1, beacause the first match is the whole string. + state.mkList(*elem, slen); + for (size_t si = 0; si < slen; ++si) { + if (!match[si + 1].matched) { + mkNull(*(elem->listElems()[si] = state.allocValue())); + } else { + mkString(*(elem->listElems()[si] = state.allocValue()), + match[si + 1].str().c_str()); + } + } + + // Add a string for non-matched suffix characters. + if (idx == 2 * len) { + elem = v.listElems()[idx++] = state.allocValue(); + mkString(*elem, match.suffix().str().c_str()); + } + } + assert(idx == 2 * len + 1); + + } catch (std::regex_error& e) { + if (e.code() == std::regex_constants::error_space) { + // limit is _GLIBCXX_REGEX_STATE_LIMIT for libstdc++ + throw EvalError("memory limit exceeded by regular expression '%s', at %s", + re, pos); + } + throw EvalError("invalid regular expression '%s', at %s", re, pos); + } +} + +static void prim_concatStringSep(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + + auto sep = state.forceString(*args[0], context, pos); + state.forceList(*args[1], pos); + + std::string res; + res.reserve((args[1]->listSize() + 32) * sep.size()); + bool first = true; + + for (unsigned int n = 0; n < args[1]->listSize(); ++n) { + if (first) { + first = false; + } else { + res += sep; + } + + res += state.coerceToString(pos, *args[1]->listElems()[n], context); + } + + mkString(v, res, context); +} + +static void prim_replaceStrings(EvalState& state, const Pos& pos, Value** args, + Value& v) { + state.forceList(*args[0], pos); + state.forceList(*args[1], pos); + if (args[0]->listSize() != args[1]->listSize()) { + throw EvalError(format("'from' and 'to' arguments to 'replaceStrings' have " + "different lengths, at %1%") % + pos); + } + + vector<string> from; + from.reserve(args[0]->listSize()); + for (unsigned int n = 0; n < args[0]->listSize(); ++n) { + from.push_back(state.forceString(*args[0]->listElems()[n], pos)); + } + + vector<std::pair<string, PathSet>> to; + to.reserve(args[1]->listSize()); + for (unsigned int n = 0; n < args[1]->listSize(); ++n) { + PathSet ctx; + auto s = state.forceString(*args[1]->listElems()[n], ctx, pos); + to.emplace_back(std::move(s), std::move(ctx)); + } + + PathSet context; + auto s = state.forceString(*args[2], context, pos); + + std::string res; + // Loops one past last character to handle the case where 'from' contains an + // empty string. + for (size_t p = 0; p <= s.size();) { + bool found = false; + auto i = from.begin(); + auto j = to.begin(); + for (; i != from.end(); ++i, ++j) { + if (s.compare(p, i->size(), *i) == 0) { + found = true; + res += j->first; + if (i->empty()) { + if (p < s.size()) { + res += s[p]; + } + p++; + } else { + p += i->size(); + } + for (auto& path : j->second) { + context.insert(path); + } + j->second.clear(); + break; + } + } + if (!found) { + if (p < s.size()) { + res += s[p]; + } + p++; + } + } + + mkString(v, res, context); +} + +/************************************************************* + * Versions + *************************************************************/ + +static void prim_parseDrvName(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string name = state.forceStringNoCtx(*args[0], pos); + DrvName parsed(name); + state.mkAttrs(v, 2); + mkString(*state.allocAttr(v, state.sName), parsed.name); + mkString(*state.allocAttr(v, state.symbols.Create("version")), + parsed.version); +} + +static void prim_compareVersions(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string version1 = state.forceStringNoCtx(*args[0], pos); + std::string version2 = state.forceStringNoCtx(*args[1], pos); + mkInt(v, compareVersions(version1, version2)); +} + +static void prim_splitVersion(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string version = state.forceStringNoCtx(*args[0], pos); + auto iter = version.cbegin(); + Strings components; + while (iter != version.cend()) { + auto component = nextComponent(iter, version.cend()); + if (component.empty()) { + break; + } + components.emplace_back(std::move(component)); + } + state.mkList(v, components.size()); + unsigned int n = 0; + for (auto& component : components) { + auto listElem = v.listElems()[n++] = state.allocValue(); + mkString(*listElem, component); + } +} + +/************************************************************* + * Networking + *************************************************************/ + +void fetch(EvalState& state, const Pos& pos, Value** args, Value& v, + const std::string& who, bool unpack, + const std::string& defaultName) { + CachedDownloadRequest request(""); + request.unpack = unpack; + request.name = defaultName; + + state.forceValue(*args[0]); + + if (args[0]->type == tAttrs) { + state.forceAttrs(*args[0], pos); + + for (auto& attr : *args[0]->attrs) { + std::string n(attr.second.name); + if (n == "url") { + request.uri = + state.forceStringNoCtx(*attr.second.value, *attr.second.pos); + } else if (n == "sha256") { + request.expectedHash = + Hash(state.forceStringNoCtx(*attr.second.value, *attr.second.pos), + htSHA256); + } else if (n == "name") { + request.name = + state.forceStringNoCtx(*attr.second.value, *attr.second.pos); + } else { + throw EvalError(format("unsupported argument '%1%' to '%2%', at %3%") % + attr.second.name % who % attr.second.pos); + } + } + + if (request.uri.empty()) { + throw EvalError(format("'url' argument required, at %1%") % pos); + } + + } else { + request.uri = state.forceStringNoCtx(*args[0], pos); + } + + state.checkURI(request.uri); + + if (evalSettings.pureEval && !request.expectedHash) { + throw Error("in pure evaluation mode, '%s' requires a 'sha256' argument", + who); + } + + auto res = getDownloader()->downloadCached(state.store, request); + + if (state.allowedPaths) { + state.allowedPaths->insert(res.path); + } + + mkString(v, res.storePath, PathSet({res.storePath})); +} + +static void prim_fetchurl(EvalState& state, const Pos& pos, Value** args, + Value& v) { + fetch(state, pos, args, v, "fetchurl", false, ""); +} + +static void prim_fetchTarball(EvalState& state, const Pos& pos, Value** args, + Value& v) { + fetch(state, pos, args, v, "fetchTarball", true, "source"); +} + +/************************************************************* + * Primop registration + *************************************************************/ + +RegisterPrimOp::PrimOps* RegisterPrimOp::primOps; + +RegisterPrimOp::RegisterPrimOp(const std::string& name, size_t arity, + PrimOpFun fun) { + if (primOps == nullptr) { + primOps = new PrimOps; + } + primOps->emplace_back(name, arity, fun); +} + +void EvalState::createBaseEnv() { + baseEnv.up = nullptr; + + /* Add global constants such as `true' to the base environment. */ + Value v; + + /* `builtins' must be first! */ + mkAttrs(v, 128); + addConstant("builtins", v); + + mkBool(v, true); + addConstant("true", v); + + mkBool(v, false); + addConstant("false", v); + + mkNull(v); + addConstant("null", v); + + auto vThrow = addPrimOp("throw", 1, prim_throw); + + auto addPurityError = [&](const std::string& name) { + Value* v2 = allocValue(); + mkString(*v2, fmt("'%s' is not allowed in pure evaluation mode", name)); + mkApp(v, *vThrow, *v2); + addConstant(name, v); + }; + + if (!evalSettings.pureEval) { + mkInt(v, time(nullptr)); + addConstant("__currentTime", v); + } + + if (!evalSettings.pureEval) { + mkString(v, settings.thisSystem); + addConstant("__currentSystem", v); + } + + mkString(v, nixVersion); + addConstant("__nixVersion", v); + + mkString(v, store->storeDir); + addConstant("__storeDir", v); + + /* Language version. This should be increased every time a new + language feature gets added. It's not necessary to increase it + when primops get added, because you can just use `builtins ? + primOp' to check. */ + mkInt(v, 5); + addConstant("__langVersion", v); + + // Miscellaneous + auto vScopedImport = addPrimOp("scopedImport", 2, prim_scopedImport); + Value* v2 = allocValue(); + mkAttrs(*v2, 0); + mkApp(v, *vScopedImport, *v2); + forceValue(v); + addConstant("import", v); + if (evalSettings.enableNativeCode) { + addPrimOp("__importNative", 2, prim_importNative); + addPrimOp("__exec", 1, prim_exec); + } + addPrimOp("__typeOf", 1, prim_typeOf); + addPrimOp("isNull", 1, prim_isNull); + addPrimOp("__isFunction", 1, prim_isFunction); + addPrimOp("__isString", 1, prim_isString); + addPrimOp("__isInt", 1, prim_isInt); + addPrimOp("__isFloat", 1, prim_isFloat); + addPrimOp("__isBool", 1, prim_isBool); + addPrimOp("__isPath", 1, prim_isPath); + addPrimOp("__genericClosure", 1, prim_genericClosure); + addPrimOp("abort", 1, prim_abort); + addPrimOp("__addErrorContext", 2, prim_addErrorContext); + addPrimOp("__tryEval", 1, prim_tryEval); + addPrimOp("__getEnv", 1, prim_getEnv); + + // Strictness + addPrimOp("__seq", 2, prim_seq); + addPrimOp("__deepSeq", 2, prim_deepSeq); + + // Debugging + addPrimOp("__trace", 2, prim_trace); + addPrimOp("__valueSize", 1, prim_valueSize); + + // Paths + addPrimOp("__toPath", 1, prim_toPath); + if (evalSettings.pureEval) { + addPurityError("__storePath"); + } else { + addPrimOp("__storePath", 1, prim_storePath); + } + addPrimOp("__pathExists", 1, prim_pathExists); + addPrimOp("baseNameOf", 1, prim_baseNameOf); + addPrimOp("dirOf", 1, prim_dirOf); + addPrimOp("__readFile", 1, prim_readFile); + addPrimOp("__readDir", 1, prim_readDir); + addPrimOp("__findFile", 2, prim_findFile); + addPrimOp("__hashFile", 2, prim_hashFile); + + // Creating files + addPrimOp("__toXML", 1, prim_toXML); + addPrimOp("__toJSON", 1, prim_toJSON); + addPrimOp("__fromJSON", 1, prim_fromJSON); + addPrimOp("__toFile", 2, prim_toFile); + addPrimOp("__filterSource", 2, prim_filterSource); + addPrimOp("__path", 1, prim_path); + + // Sets + addPrimOp("__attrNames", 1, prim_attrNames); + addPrimOp("__attrValues", 1, prim_attrValues); + addPrimOp("__getAttr", 2, prim_getAttr); + addPrimOp("__unsafeGetAttrPos", 2, prim_unsafeGetAttrPos); + addPrimOp("__hasAttr", 2, prim_hasAttr); + addPrimOp("__isAttrs", 1, prim_isAttrs); + addPrimOp("removeAttrs", 2, prim_removeAttrs); + addPrimOp("__listToAttrs", 1, prim_listToAttrs); + addPrimOp("__intersectAttrs", 2, prim_intersectAttrs); + addPrimOp("__catAttrs", 2, prim_catAttrs); + addPrimOp("__functionArgs", 1, prim_functionArgs); + addPrimOp("__mapAttrs", 2, prim_mapAttrs); + + // Lists + addPrimOp("__isList", 1, prim_isList); + addPrimOp("__elemAt", 2, prim_elemAt); + addPrimOp("__head", 1, prim_head); + addPrimOp("__tail", 1, prim_tail); + addPrimOp("map", 2, prim_map); + addPrimOp("__filter", 2, prim_filter); + addPrimOp("__elem", 2, prim_elem); + addPrimOp("__concatLists", 1, prim_concatLists); + addPrimOp("__length", 1, prim_length); + addPrimOp("__foldl'", 3, prim_foldlStrict); + addPrimOp("__any", 2, prim_any); + addPrimOp("__all", 2, prim_all); + addPrimOp("__genList", 2, prim_genList); + addPrimOp("__sort", 2, prim_sort); + addPrimOp("__partition", 2, prim_partition); + addPrimOp("__concatMap", 2, prim_concatMap); + + // Integer arithmetic + addPrimOp("__add", 2, prim_add); + addPrimOp("__sub", 2, prim_sub); + addPrimOp("__mul", 2, prim_mul); + addPrimOp("__div", 2, prim_div); + addPrimOp("__bitAnd", 2, prim_bitAnd); + addPrimOp("__bitOr", 2, prim_bitOr); + addPrimOp("__bitXor", 2, prim_bitXor); + addPrimOp("__lessThan", 2, prim_lessThan); + + // String manipulation + addPrimOp("toString", 1, prim_toString); + addPrimOp("__substring", 3, prim_substring); + addPrimOp("__stringLength", 1, prim_stringLength); + addPrimOp("__hashString", 2, prim_hashString); + addPrimOp("__match", 2, prim_match); + addPrimOp("__split", 2, prim_split); + addPrimOp("__concatStringsSep", 2, prim_concatStringSep); + addPrimOp("__replaceStrings", 3, prim_replaceStrings); + + // Versions + addPrimOp("__parseDrvName", 1, prim_parseDrvName); + addPrimOp("__compareVersions", 2, prim_compareVersions); + addPrimOp("__splitVersion", 1, prim_splitVersion); + + // Derivations + addPrimOp("derivationStrict", 1, prim_derivationStrict); + addPrimOp("placeholder", 1, prim_placeholder); + + // Networking + addPrimOp("__fetchurl", 1, prim_fetchurl); + addPrimOp("fetchTarball", 1, prim_fetchTarball); + + /* Add a wrapper around the derivation primop that computes the + `drvPath' and `outPath' attributes lazily. */ + std::string path = + canonPath(settings.nixDataDir + "/nix/corepkgs/derivation.nix", true); + sDerivationNix = symbols.Create(path); + evalFile(path, v); + addConstant("derivation", v); + + /* Add a value containing the current Nix expression search path. */ + mkList(v, searchPath.size()); + int n = 0; + for (auto& i : searchPath) { + v2 = v.listElems()[n++] = allocValue(); + mkAttrs(*v2, 2); + mkString(*allocAttr(*v2, symbols.Create("path")), i.second); + mkString(*allocAttr(*v2, symbols.Create("prefix")), i.first); + } + addConstant("__nixPath", v); + + if (RegisterPrimOp::primOps != nullptr) { + for (auto& primOp : *RegisterPrimOp::primOps) { + addPrimOp(std::get<0>(primOp), std::get<1>(primOp), std::get<2>(primOp)); + } + } +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/primops.hh b/third_party/nix/src/libexpr/primops.hh new file mode 100644 index 0000000000..6abd0508a0 --- /dev/null +++ b/third_party/nix/src/libexpr/primops.hh @@ -0,0 +1,26 @@ +#include <tuple> +#include <vector> + +#include "eval.hh" + +namespace nix { + +struct RegisterPrimOp { + typedef std::vector<std::tuple<std::string, size_t, PrimOpFun>> PrimOps; + static PrimOps* primOps; + /* You can register a constant by passing an arity of 0. fun + will get called during EvalState initialization, so there + may be primops not yet added and builtins is not yet sorted. */ + RegisterPrimOp(const std::string& name, size_t arity, PrimOpFun fun); +}; + +/* These primops are disabled without enableNativeCode, but plugins + may wish to use them in limited contexts without globally enabling + them. */ +/* Load a ValueInitializer from a DSO and return whatever it initializes */ +void prim_importNative(EvalState& state, const Pos& pos, Value** args, + Value& v); +/* Execute a program and parse its output */ +void prim_exec(EvalState& state, const Pos& pos, Value** args, Value& v); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/primops/context.cc b/third_party/nix/src/libexpr/primops/context.cc new file mode 100644 index 0000000000..2ae8ba8aa9 --- /dev/null +++ b/third_party/nix/src/libexpr/primops/context.cc @@ -0,0 +1,199 @@ +#include "derivations.hh" +#include "eval-inline.hh" +#include "primops.hh" + +namespace nix { + +static void prim_unsafeDiscardStringContext(EvalState& state, const Pos& pos, + Value** args, Value& v) { + PathSet context; + std::string s = state.coerceToString(pos, *args[0], context); + mkString(v, s, PathSet()); +} + +static RegisterPrimOp r1("__unsafeDiscardStringContext", 1, + prim_unsafeDiscardStringContext); + +static void prim_hasContext(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + state.forceString(*args[0], context, pos); + mkBool(v, !context.empty()); +} + +static RegisterPrimOp r2("__hasContext", 1, prim_hasContext); + +/* Sometimes we want to pass a derivation path (i.e. pkg.drvPath) to a + builder without causing the derivation to be built (for instance, + in the derivation that builds NARs in nix-push, when doing + source-only deployment). This primop marks the string context so + that builtins.derivation adds the path to drv.inputSrcs rather than + drv.inputDrvs. */ +static void prim_unsafeDiscardOutputDependency(EvalState& state, const Pos& pos, + Value** args, Value& v) { + PathSet context; + std::string s = state.coerceToString(pos, *args[0], context); + + PathSet context2; + for (auto& p : context) { + context2.insert(p.at(0) == '=' ? string(p, 1) : p); + } + + mkString(v, s, context2); +} + +static RegisterPrimOp r3("__unsafeDiscardOutputDependency", 1, + prim_unsafeDiscardOutputDependency); + +/* Extract the context of a string as a structured Nix value. + + The context is represented as an attribute set whose keys are the + paths in the context set and whose values are attribute sets with + the following keys: + path: True if the relevant path is in the context as a plain store + path (i.e. the kind of context you get when interpolating + a Nix path (e.g. ./.) into a string). False if missing. + allOutputs: True if the relevant path is a derivation and it is + in the context as a drv file with all of its outputs + (i.e. the kind of context you get when referencing + .drvPath of some derivation). False if missing. + outputs: If a non-empty list, the relevant path is a derivation + and the provided outputs are referenced in the context + (i.e. the kind of context you get when referencing + .outPath of some derivation). Empty list if missing. + Note that for a given path any combination of the above attributes + may be present. +*/ +static void prim_getContext(EvalState& state, const Pos& pos, Value** args, + Value& v) { + struct ContextInfo { + bool path = false; + bool allOutputs = false; + Strings outputs; + }; + PathSet context; + state.forceString(*args[0], context, pos); + auto contextInfos = std::map<Path, ContextInfo>(); + for (const auto& p : context) { + Path drv; + std::string output; + const Path* path = &p; + if (p.at(0) == '=') { + drv = string(p, 1); + path = &drv; + } else if (p.at(0) == '!') { + std::pair<string, string> ctx = decodeContext(p); + drv = ctx.first; + output = ctx.second; + path = &drv; + } + auto isPath = drv.empty(); + auto isAllOutputs = (!drv.empty()) && output.empty(); + + auto iter = contextInfos.find(*path); + if (iter == contextInfos.end()) { + contextInfos.emplace( + *path, + ContextInfo{isPath, isAllOutputs, + output.empty() ? Strings{} : Strings{std::move(output)}}); + } else { + if (isPath) + iter->second.path = true; + else if (isAllOutputs) + iter->second.allOutputs = true; + else + iter->second.outputs.emplace_back(std::move(output)); + } + } + + state.mkAttrs(v, contextInfos.size()); + + auto sPath = state.symbols.Create("path"); + auto sAllOutputs = state.symbols.Create("allOutputs"); + for (const auto& info : contextInfos) { + auto& infoVal = *state.allocAttr(v, state.symbols.Create(info.first)); + state.mkAttrs(infoVal, 3); + if (info.second.path) { + mkBool(*state.allocAttr(infoVal, sPath), true); + } + if (info.second.allOutputs) + mkBool(*state.allocAttr(infoVal, sAllOutputs), true); + if (!info.second.outputs.empty()) { + auto& outputsVal = *state.allocAttr(infoVal, state.sOutputs); + state.mkList(outputsVal, info.second.outputs.size()); + size_t i = 0; + for (const auto& output : info.second.outputs) { + mkString(*(outputsVal.listElems()[i++] = state.allocValue()), output); + } + } + } +} + +static RegisterPrimOp r4("__getContext", 1, prim_getContext); + +/* Append the given context to a given string. + + See the commentary above unsafeGetContext for details of the + context representation. +*/ +static void prim_appendContext(EvalState& state, const Pos& pos, Value** args, + Value& v) { + PathSet context; + auto orig = state.forceString(*args[0], context, pos); + + state.forceAttrs(*args[1], pos); + + auto sPath = state.symbols.Create("path"); + auto sAllOutputs = state.symbols.Create("allOutputs"); + for (const auto& attr_iter : *args[1]->attrs) { + const Attr* i = &attr_iter.second; // TODO(tazjin): get rid of this + if (!state.store->isStorePath(i->name)) + throw EvalError("Context key '%s' is not a store path, at %s", i->name, + i->pos); + if (!settings.readOnlyMode) { + state.store->ensurePath(i->name); + } + state.forceAttrs(*i->value, *i->pos); + auto iter = i->value->attrs->find(sPath); + if (iter != i->value->attrs->end()) { + if (state.forceBool(*iter->second.value, *iter->second.pos)) { + context.insert(i->name); + } + } + + iter = i->value->attrs->find(sAllOutputs); + if (iter != i->value->attrs->end()) { + if (state.forceBool(*iter->second.value, *iter->second.pos)) { + if (!isDerivation(i->name)) { + throw EvalError( + "Tried to add all-outputs context of %s, which is not a " + "derivation, to a string, at %s", + i->name, i->pos); + } + context.insert("=" + string(i->name)); + } + } + + iter = i->value->attrs->find(state.sOutputs); + if (iter != i->value->attrs->end()) { + state.forceList(*iter->second.value, *iter->second.pos); + if (iter->second.value->listSize() && !isDerivation(i->name)) { + throw EvalError( + "Tried to add derivation output context of %s, which is not a " + "derivation, to a string, at %s", + i->name, i->pos); + } + for (unsigned int n = 0; n < iter->second.value->listSize(); ++n) { + auto name = state.forceStringNoCtx(*iter->second.value->listElems()[n], + *iter->second.pos); + context.insert("!" + name + "!" + string(i->name)); + } + } + } + + mkString(v, orig, context); +} + +static RegisterPrimOp r5("__appendContext", 2, prim_appendContext); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/primops/fetchGit.cc b/third_party/nix/src/libexpr/primops/fetchGit.cc new file mode 100644 index 0000000000..67641258d5 --- /dev/null +++ b/third_party/nix/src/libexpr/primops/fetchGit.cc @@ -0,0 +1,263 @@ +#include <nlohmann/json.hpp> +#include <regex> + +#include <glog/logging.h> +#include <sys/time.h> + +#include "download.hh" +#include "eval-inline.hh" +#include "hash.hh" +#include "pathlocks.hh" +#include "primops.hh" +#include "store-api.hh" + +using namespace std::string_literals; + +namespace nix { + +struct GitInfo { + Path storePath; + std::string rev; + std::string shortRev; + uint64_t revCount = 0; +}; + +std::regex revRegex("^[0-9a-fA-F]{40}$"); + +GitInfo exportGit(ref<Store> store, const std::string& uri, + std::optional<std::string> ref, std::string rev, + const std::string& name) { + if (evalSettings.pureEval && rev == "") + throw Error("in pure evaluation mode, 'fetchGit' requires a Git revision"); + + if (!ref && rev == "" && hasPrefix(uri, "/") && pathExists(uri + "/.git")) { + bool clean = true; + + try { + runProgram("git", true, + {"-C", uri, "diff-index", "--quiet", "HEAD", "--"}); + } catch (ExecError& e) { + if (!WIFEXITED(e.status) || WEXITSTATUS(e.status) != 1) { + throw; + } + clean = false; + } + + if (!clean) { + /* This is an unclean working tree. So copy all tracked + files. */ + + GitInfo gitInfo; + gitInfo.rev = "0000000000000000000000000000000000000000"; + gitInfo.shortRev = std::string(gitInfo.rev, 0, 7); + + auto files = tokenizeString<std::set<std::string>>( + runProgram("git", true, {"-C", uri, "ls-files", "-z"}), "\0"s); + + PathFilter filter = [&](const Path& p) -> bool { + assert(hasPrefix(p, uri)); + std::string file(p, uri.size() + 1); + + auto st = lstat(p); + + if (S_ISDIR(st.st_mode)) { + auto prefix = file + "/"; + auto i = files.lower_bound(prefix); + return i != files.end() && hasPrefix(*i, prefix); + } + + return files.count(file); + }; + + gitInfo.storePath = + store->addToStore("source", uri, true, htSHA256, filter); + + return gitInfo; + } + + // clean working tree, but no ref or rev specified. Use 'HEAD'. + rev = chomp(runProgram("git", true, {"-C", uri, "rev-parse", "HEAD"})); + ref = "HEAD"s; + } + + if (!ref) { + ref = "HEAD"s; + } + + if (rev != "" && !std::regex_match(rev, revRegex)) + throw Error("invalid Git revision '%s'", rev); + + deletePath(getCacheDir() + "/nix/git"); + + Path cacheDir = getCacheDir() + "/nix/gitv2/" + + hashString(htSHA256, uri).to_string(Base32, false); + + if (!pathExists(cacheDir)) { + createDirs(dirOf(cacheDir)); + runProgram("git", true, {"init", "--bare", cacheDir}); + } + + Path localRefFile; + if (ref->compare(0, 5, "refs/") == 0) + localRefFile = cacheDir + "/" + *ref; + else + localRefFile = cacheDir + "/refs/heads/" + *ref; + + bool doFetch; + time_t now = time(0); + /* If a rev was specified, we need to fetch if it's not in the + repo. */ + if (rev != "") { + try { + runProgram("git", true, {"-C", cacheDir, "cat-file", "-e", rev}); + doFetch = false; + } catch (ExecError& e) { + if (WIFEXITED(e.status)) { + doFetch = true; + } else { + throw; + } + } + } else { + /* If the local ref is older than ‘tarball-ttl’ seconds, do a + git fetch to update the local ref to the remote ref. */ + struct stat st; + doFetch = stat(localRefFile.c_str(), &st) != 0 || + (uint64_t)st.st_mtime + settings.tarballTtl <= (uint64_t)now; + } + if (doFetch) { + DLOG(INFO) << "fetching Git repository '" << uri << "'"; + + // FIXME: git stderr messes up our progress indicator, so + // we're using --quiet for now. Should process its stderr. + runProgram("git", true, + {"-C", cacheDir, "fetch", "--quiet", "--force", "--", uri, + fmt("%s:%s", *ref, *ref)}); + + struct timeval times[2]; + times[0].tv_sec = now; + times[0].tv_usec = 0; + times[1].tv_sec = now; + times[1].tv_usec = 0; + + utimes(localRefFile.c_str(), times); + } + + // FIXME: check whether rev is an ancestor of ref. + GitInfo gitInfo; + gitInfo.rev = rev != "" ? rev : chomp(readFile(localRefFile)); + gitInfo.shortRev = std::string(gitInfo.rev, 0, 7); + + DLOG(INFO) << "using revision " << gitInfo.rev << " of repo '" << uri << "'"; + + std::string storeLinkName = + hashString(htSHA512, name + std::string("\0"s) + gitInfo.rev) + .to_string(Base32, false); + Path storeLink = cacheDir + "/" + storeLinkName + ".link"; + PathLocks storeLinkLock({storeLink}, fmt("waiting for lock on '%1%'...", + storeLink)); // FIXME: broken + + try { + auto json = nlohmann::json::parse(readFile(storeLink)); + + assert(json["name"] == name && json["rev"] == gitInfo.rev); + + gitInfo.storePath = json["storePath"]; + + if (store->isValidPath(gitInfo.storePath)) { + gitInfo.revCount = json["revCount"]; + return gitInfo; + } + + } catch (SysError& e) { + if (e.errNo != ENOENT) { + throw; + } + } + + // FIXME: should pipe this, or find some better way to extract a + // revision. + auto tar = runProgram("git", true, {"-C", cacheDir, "archive", gitInfo.rev}); + + Path tmpDir = createTempDir(); + AutoDelete delTmpDir(tmpDir, true); + + runProgram("tar", true, {"x", "-C", tmpDir}, tar); + + gitInfo.storePath = store->addToStore(name, tmpDir); + + gitInfo.revCount = std::stoull(runProgram( + "git", true, {"-C", cacheDir, "rev-list", "--count", gitInfo.rev})); + + nlohmann::json json; + json["storePath"] = gitInfo.storePath; + json["uri"] = uri; + json["name"] = name; + json["rev"] = gitInfo.rev; + json["revCount"] = gitInfo.revCount; + + writeFile(storeLink, json.dump()); + + return gitInfo; +} + +static void prim_fetchGit(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string url; + std::optional<std::string> ref; + std::string rev; + std::string name = "source"; + PathSet context; + + state.forceValue(*args[0]); + + if (args[0]->type == tAttrs) { + state.forceAttrs(*args[0], pos); + + for (auto& attr_iter : *args[0]->attrs) { + auto& attr = attr_iter.second; + std::string n(attr.name); + if (n == "url") + url = + state.coerceToString(*attr.pos, *attr.value, context, false, false); + else if (n == "ref") + ref = state.forceStringNoCtx(*attr.value, *attr.pos); + else if (n == "rev") + rev = state.forceStringNoCtx(*attr.value, *attr.pos); + else if (n == "name") + name = state.forceStringNoCtx(*attr.value, *attr.pos); + else + throw EvalError("unsupported argument '%s' to 'fetchGit', at %s", + attr.name, *attr.pos); + } + + if (url.empty()) + throw EvalError(format("'url' argument required, at %1%") % pos); + + } else { + url = state.coerceToString(pos, *args[0], context, false, false); + } + + // FIXME: git externals probably can be used to bypass the URI + // whitelist. Ah well. + state.checkURI(url); + + auto gitInfo = exportGit(state.store, url, ref, rev, name); + + state.mkAttrs(v, 8); + mkString(*state.allocAttr(v, state.sOutPath), gitInfo.storePath, + PathSet({gitInfo.storePath})); + mkString(*state.allocAttr(v, state.symbols.Create("rev")), gitInfo.rev); + mkString(*state.allocAttr(v, state.symbols.Create("shortRev")), + gitInfo.shortRev); + mkInt(*state.allocAttr(v, state.symbols.Create("revCount")), + gitInfo.revCount); + + if (state.allowedPaths) { + state.allowedPaths->insert(state.store->toRealPath(gitInfo.storePath)); + } +} + +static RegisterPrimOp r("fetchGit", 1, prim_fetchGit); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/primops/fetchMercurial.cc b/third_party/nix/src/libexpr/primops/fetchMercurial.cc new file mode 100644 index 0000000000..9223f1c3ca --- /dev/null +++ b/third_party/nix/src/libexpr/primops/fetchMercurial.cc @@ -0,0 +1,237 @@ +#include <nlohmann/json.hpp> +#include <regex> + +#include <glog/logging.h> +#include <sys/time.h> + +#include "download.hh" +#include "eval-inline.hh" +#include "pathlocks.hh" +#include "primops.hh" +#include "store-api.hh" + +using namespace std::string_literals; + +namespace nix { + +struct HgInfo { + Path storePath; + std::string branch; + std::string rev; + uint64_t revCount = 0; +}; + +std::regex commitHashRegex("^[0-9a-fA-F]{40}$"); + +HgInfo exportMercurial(ref<Store> store, const std::string& uri, + std::string rev, const std::string& name) { + if (evalSettings.pureEval && rev == "") + throw Error( + "in pure evaluation mode, 'fetchMercurial' requires a Mercurial " + "revision"); + + if (rev == "" && hasPrefix(uri, "/") && pathExists(uri + "/.hg")) { + bool clean = runProgram("hg", true, + {"status", "-R", uri, "--modified", "--added", + "--removed"}) == ""; + + if (!clean) { + /* This is an unclean working tree. So copy all tracked + files. */ + + DLOG(INFO) << "copying unclean Mercurial working tree '" << uri << "'"; + + HgInfo hgInfo; + hgInfo.rev = "0000000000000000000000000000000000000000"; + hgInfo.branch = chomp(runProgram("hg", true, {"branch", "-R", uri})); + + auto files = tokenizeString<std::set<std::string>>( + runProgram("hg", true, + {"status", "-R", uri, "--clean", "--modified", "--added", + "--no-status", "--print0"}), + "\0"s); + + PathFilter filter = [&](const Path& p) -> bool { + assert(hasPrefix(p, uri)); + std::string file(p, uri.size() + 1); + + auto st = lstat(p); + + if (S_ISDIR(st.st_mode)) { + auto prefix = file + "/"; + auto i = files.lower_bound(prefix); + return i != files.end() && hasPrefix(*i, prefix); + } + + return files.count(file); + }; + + hgInfo.storePath = + store->addToStore("source", uri, true, htSHA256, filter); + + return hgInfo; + } + } + + if (rev == "") { + rev = "default"; + } + + Path cacheDir = fmt("%s/nix/hg/%s", getCacheDir(), + hashString(htSHA256, uri).to_string(Base32, false)); + + Path stampFile = fmt("%s/.hg/%s.stamp", cacheDir, + hashString(htSHA512, rev).to_string(Base32, false)); + + /* If we haven't pulled this repo less than ‘tarball-ttl’ seconds, + do so now. */ + time_t now = time(0); + struct stat st; + if (stat(stampFile.c_str(), &st) != 0 || + (uint64_t)st.st_mtime + settings.tarballTtl <= (uint64_t)now) { + /* Except that if this is a commit hash that we already have, + we don't have to pull again. */ + if (!(std::regex_match(rev, commitHashRegex) && pathExists(cacheDir) && + runProgram(RunOptions("hg", {"log", "-R", cacheDir, "-r", rev, + "--template", "1"}) + .killStderr(true)) + .second == "1")) { + DLOG(INFO) << "fetching Mercurial repository '" << uri << "'"; + + if (pathExists(cacheDir)) { + try { + runProgram("hg", true, {"pull", "-R", cacheDir, "--", uri}); + } catch (ExecError& e) { + std::string transJournal = cacheDir + "/.hg/store/journal"; + /* hg throws "abandoned transaction" error only if this file exists */ + if (pathExists(transJournal)) { + runProgram("hg", true, {"recover", "-R", cacheDir}); + runProgram("hg", true, {"pull", "-R", cacheDir, "--", uri}); + } else { + throw ExecError(e.status, + fmt("'hg pull' %s", statusToString(e.status))); + } + } + } else { + createDirs(dirOf(cacheDir)); + runProgram("hg", true, {"clone", "--noupdate", "--", uri, cacheDir}); + } + } + + writeFile(stampFile, ""); + } + + auto tokens = tokenizeString<std::vector<std::string>>( + runProgram("hg", true, + {"log", "-R", cacheDir, "-r", rev, "--template", + "{node} {rev} {branch}"})); + assert(tokens.size() == 3); + + HgInfo hgInfo; + hgInfo.rev = tokens[0]; + hgInfo.revCount = std::stoull(tokens[1]); + hgInfo.branch = tokens[2]; + + std::string storeLinkName = + hashString(htSHA512, name + std::string("\0"s) + hgInfo.rev) + .to_string(Base32, false); + Path storeLink = fmt("%s/.hg/%s.link", cacheDir, storeLinkName); + + try { + auto json = nlohmann::json::parse(readFile(storeLink)); + + assert(json["name"] == name && json["rev"] == hgInfo.rev); + + hgInfo.storePath = json["storePath"]; + + if (store->isValidPath(hgInfo.storePath)) { + DLOG(INFO) << "using cached Mercurial store path '" << hgInfo.storePath + << "'"; + return hgInfo; + } + + } catch (SysError& e) { + if (e.errNo != ENOENT) { + throw; + } + } + + Path tmpDir = createTempDir(); + AutoDelete delTmpDir(tmpDir, true); + + runProgram("hg", true, {"archive", "-R", cacheDir, "-r", rev, tmpDir}); + + deletePath(tmpDir + "/.hg_archival.txt"); + + hgInfo.storePath = store->addToStore(name, tmpDir); + + nlohmann::json json; + json["storePath"] = hgInfo.storePath; + json["uri"] = uri; + json["name"] = name; + json["branch"] = hgInfo.branch; + json["rev"] = hgInfo.rev; + json["revCount"] = hgInfo.revCount; + + writeFile(storeLink, json.dump()); + + return hgInfo; +} + +static void prim_fetchMercurial(EvalState& state, const Pos& pos, Value** args, + Value& v) { + std::string url; + std::string rev; + std::string name = "source"; + PathSet context; + + state.forceValue(*args[0]); + + if (args[0]->type == tAttrs) { + state.forceAttrs(*args[0], pos); + + for (auto& attr_iter : *args[0]->attrs) { + auto& attr = attr_iter.second; + std::string n(attr.name); + if (n == "url") + url = + state.coerceToString(*attr.pos, *attr.value, context, false, false); + else if (n == "rev") + rev = state.forceStringNoCtx(*attr.value, *attr.pos); + else if (n == "name") + name = state.forceStringNoCtx(*attr.value, *attr.pos); + else + throw EvalError("unsupported argument '%s' to 'fetchMercurial', at %s", + attr.name, *attr.pos); + } + + if (url.empty()) + throw EvalError(format("'url' argument required, at %1%") % pos); + + } else { + url = state.coerceToString(pos, *args[0], context, false, false); + } + + // FIXME: git externals probably can be used to bypass the URI + // whitelist. Ah well. + state.checkURI(url); + + auto hgInfo = exportMercurial(state.store, url, rev, name); + + state.mkAttrs(v, 8); + mkString(*state.allocAttr(v, state.sOutPath), hgInfo.storePath, + PathSet({hgInfo.storePath})); + mkString(*state.allocAttr(v, state.symbols.Create("branch")), hgInfo.branch); + mkString(*state.allocAttr(v, state.symbols.Create("rev")), hgInfo.rev); + mkString(*state.allocAttr(v, state.symbols.Create("shortRev")), + std::string(hgInfo.rev, 0, 12)); + mkInt(*state.allocAttr(v, state.symbols.Create("revCount")), hgInfo.revCount); + + if (state.allowedPaths) { + state.allowedPaths->insert(state.store->toRealPath(hgInfo.storePath)); + } +} + +static RegisterPrimOp r("fetchMercurial", 1, prim_fetchMercurial); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/primops/fromTOML.cc b/third_party/nix/src/libexpr/primops/fromTOML.cc new file mode 100644 index 0000000000..cc7b3cfcc3 --- /dev/null +++ b/third_party/nix/src/libexpr/primops/fromTOML.cc @@ -0,0 +1,88 @@ +#include "cpptoml/cpptoml.h" +#include "eval-inline.hh" +#include "primops.hh" + +namespace nix { + +static void prim_fromTOML(EvalState& state, const Pos& pos, Value** args, + Value& v) { + using namespace cpptoml; + + auto toml = state.forceStringNoCtx(*args[0], pos); + + std::istringstream tomlStream(toml); + + std::function<void(Value&, std::shared_ptr<base>)> visit; + + visit = [&](Value& v, std::shared_ptr<base> t) { + if (auto t2 = t->as_table()) { + size_t size = 0; + for (auto& i : *t2) { + (void)i; + size++; + } + + state.mkAttrs(v, size); + + for (auto& i : *t2) { + auto& v2 = *state.allocAttr(v, state.symbols.Create(i.first)); + + if (auto i2 = i.second->as_table_array()) { + size_t size2 = i2->get().size(); + state.mkList(v2, size2); + for (size_t j = 0; j < size2; ++j) + visit(*(v2.listElems()[j] = state.allocValue()), i2->get()[j]); + } else + visit(v2, i.second); + } + } + + else if (auto t2 = t->as_array()) { + size_t size = t2->get().size(); + + state.mkList(v, size); + + for (size_t i = 0; i < size; ++i) + visit(*(v.listElems()[i] = state.allocValue()), t2->get()[i]); + } + + // Handle cases like 'a = [[{ a = true }]]', which IMHO should be + // parsed as a array containing an array containing a table, + // but instead are parsed as an array containing a table array + // containing a table. + else if (auto t2 = t->as_table_array()) { + size_t size = t2->get().size(); + + state.mkList(v, size); + + for (size_t j = 0; j < size; ++j) + visit(*(v.listElems()[j] = state.allocValue()), t2->get()[j]); + } + + else if (t->is_value()) { + if (auto val = t->as<int64_t>()) + mkInt(v, val->get()); + else if (auto val = t->as<NixFloat>()) + mkFloat(v, val->get()); + else if (auto val = t->as<bool>()) + mkBool(v, val->get()); + else if (auto val = t->as<std::string>()) + mkString(v, val->get()); + else + throw EvalError("unsupported value type in TOML"); + } + + else + abort(); + }; + + try { + visit(v, parser(tomlStream).parse()); + } catch (std::runtime_error& e) { + throw EvalError("while parsing a TOML string at %s: %s", pos, e.what()); + } +} + +static RegisterPrimOp r("fromTOML", 1, prim_fromTOML); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/symbol-table.cc b/third_party/nix/src/libexpr/symbol-table.cc new file mode 100644 index 0000000000..6abaedc517 --- /dev/null +++ b/third_party/nix/src/libexpr/symbol-table.cc @@ -0,0 +1,24 @@ +#include "symbol-table.hh" + +#include <absl/container/node_hash_set.h> +#include <absl/strings/string_view.h> + +namespace nix { + +Symbol SymbolTable::Create(absl::string_view sym) { + auto it = symbols_.emplace(sym); + const std::string* ptr = &(*it.first); + return Symbol(ptr); +} + +size_t SymbolTable::Size() const { return symbols_.size(); } + +size_t SymbolTable::TotalSize() const { + size_t n = 0; + for (auto& i : symbols_) { + n += i.size(); + } + return n; +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/symbol-table.hh b/third_party/nix/src/libexpr/symbol-table.hh new file mode 100644 index 0000000000..df696c9e1a --- /dev/null +++ b/third_party/nix/src/libexpr/symbol-table.hh @@ -0,0 +1,66 @@ +#pragma once + +#include <absl/container/node_hash_set.h> +#include <absl/strings/string_view.h> + +namespace nix { // TODO(tazjin): ::expr + +// TODO(tazjin): Replace with a simpler struct, or get rid of. +class Symbol { + private: + const std::string* s; // pointer into SymbolTable + Symbol(const std::string* s) : s(s){}; + friend class SymbolTable; + + public: + Symbol() : s(0){}; + + bool operator==(const Symbol& s2) const { return s == s2.s; } + + bool operator!=(const Symbol& s2) const { return s != s2.s; } + + bool operator<(const Symbol& s2) const { return s < s2.s; } + + operator const std::string&() const { return *s; } + + bool set() const { return s; } + + bool empty() const { return s->empty(); } + + friend std::ostream& operator<<(std::ostream& str, const Symbol& sym); +}; + +// SymbolTable is a hash-set based symbol-interning mechanism. +// +// TODO(tazjin): Figure out which things use this. AttrSets, ...? +// Is it possible this only exists because AttrSet wasn't a map? +// +// Original comment: +// +// Symbol table used by the parser and evaluator to represent and look +// up identifiers and attributes efficiently. SymbolTable::create() +// converts a string into a symbol. Symbols have the property that +// they can be compared efficiently (using a pointer equality test), +// because the symbol table stores only one copy of each string. +class SymbolTable { + public: + // Create a new symbol in this table by emplacing the provided + // string into it. + // + // The symbol will reference an existing symbol if the symbol is + // already interned. + Symbol Create(absl::string_view sym); + + // Return the number of symbols interned. + size_t Size() const; + + // Return the total size (in bytes) + size_t TotalSize() const; + + private: + // flat_hash_set does not retain pointer stability on rehashing, + // hence "interned" strings/symbols are stored on the heap. + absl::node_hash_set<std::string> symbols_; +}; + +} // namespace nix diff --git a/third_party/nix/src/libexpr/value-to-json.cc b/third_party/nix/src/libexpr/value-to-json.cc new file mode 100644 index 0000000000..0b641a41b5 --- /dev/null +++ b/third_party/nix/src/libexpr/value-to-json.cc @@ -0,0 +1,104 @@ +#include "value-to-json.hh" + +#include <cstdlib> +#include <iomanip> + +#include "eval-inline.hh" +#include "json.hh" +#include "util.hh" + +namespace nix { + +void printValueAsJSON(EvalState& state, bool strict, Value& v, + JSONPlaceholder& out, PathSet& context) { + checkInterrupt(); + + if (strict) { + state.forceValue(v); + } + + switch (v.type) { + case tInt: + out.write(v.integer); + break; + + case tBool: + out.write(v.boolean); + break; + + case tString: + copyContext(v, context); + out.write(v.string.s); + break; + + case tPath: + out.write(state.copyPathToStore(context, v.path)); + break; + + case tNull: + out.write(nullptr); + break; + + case tAttrs: { + auto maybeString = + state.tryAttrsToString(noPos, v, context, false, false); + if (maybeString) { + out.write(*maybeString); + break; + } + auto i = v.attrs->find(state.sOutPath); + if (i == v.attrs->end()) { + auto obj(out.object()); + StringSet names; + for (auto& j : *v.attrs) { + names.insert(j.second.name); + } + for (auto& j : names) { + auto [_, a] = *v.attrs->find(state.symbols.Create(j)); + auto placeholder(obj.placeholder(j)); + printValueAsJSON(state, strict, *a.value, placeholder, context); + } + } else { + printValueAsJSON(state, strict, *i->second.value, out, context); + } + break; + } + + case tList1: + case tList2: + case tListN: { + auto list(out.list()); + for (unsigned int n = 0; n < v.listSize(); ++n) { + auto placeholder(list.placeholder()); + printValueAsJSON(state, strict, *v.listElems()[n], placeholder, + context); + } + break; + } + + case tExternal: + v.external->printValueAsJSON(state, strict, out, context); + break; + + case tFloat: + out.write(v.fpoint); + break; + + default: + throw TypeError(format("cannot convert %1% to JSON") % showType(v)); + } +} + +void printValueAsJSON(EvalState& state, bool strict, Value& v, + std::ostream& str, PathSet& context) { + JSONPlaceholder out(str); + printValueAsJSON(state, strict, v, out, context); +} + +void ExternalValueBase::printValueAsJSON(EvalState& state, bool strict, + JSONPlaceholder& out, + PathSet& context) const { + throw TypeError(format("cannot convert %1% to JSON") % showType()); +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/value-to-json.hh b/third_party/nix/src/libexpr/value-to-json.hh new file mode 100644 index 0000000000..6ec36c829d --- /dev/null +++ b/third_party/nix/src/libexpr/value-to-json.hh @@ -0,0 +1,19 @@ +#pragma once + +#include <map> +#include <string> + +#include "eval.hh" +#include "nixexpr.hh" + +namespace nix { + +class JSONPlaceholder; + +void printValueAsJSON(EvalState& state, bool strict, Value& v, + JSONPlaceholder& out, PathSet& context); + +void printValueAsJSON(EvalState& state, bool strict, Value& v, + std::ostream& str, PathSet& context); + +} // namespace nix diff --git a/third_party/nix/src/libexpr/value-to-xml.cc b/third_party/nix/src/libexpr/value-to-xml.cc new file mode 100644 index 0000000000..149bf764f0 --- /dev/null +++ b/third_party/nix/src/libexpr/value-to-xml.cc @@ -0,0 +1,198 @@ +#include "value-to-xml.hh" + +#include <cstdlib> + +#include "eval-inline.hh" +#include "util.hh" +#include "xml-writer.hh" + +namespace nix { + +static XMLAttrs singletonAttrs(const std::string& name, + const std::string& value) { + XMLAttrs attrs; + attrs[name] = value; + return attrs; +} + +static void printValueAsXML(EvalState& state, bool strict, bool location, + Value& v, XMLWriter& doc, PathSet& context, + PathSet& drvsSeen); + +static void posToXML(XMLAttrs& xmlAttrs, const Pos& pos) { + xmlAttrs["path"] = pos.file; + xmlAttrs["line"] = (format("%1%") % pos.line).str(); + xmlAttrs["column"] = (format("%1%") % pos.column).str(); +} + +static void showAttrs(EvalState& state, bool strict, bool location, + Bindings& attrs, XMLWriter& doc, PathSet& context, + PathSet& drvsSeen) { + StringSet names; + + for (auto& i : attrs) { + names.insert(i.second.name); + } + + for (auto& i : names) { + auto& [_, a] = *attrs.find(state.symbols.Create(i)); + + XMLAttrs xmlAttrs; + xmlAttrs["name"] = i; + if (location && a.pos != &noPos) { + posToXML(xmlAttrs, *a.pos); + } + + XMLOpenElement elem(doc, "attr", xmlAttrs); + printValueAsXML(state, strict, location, *a.value, doc, context, drvsSeen); + } +} + +static void printValueAsXML(EvalState& state, bool strict, bool location, + Value& v, XMLWriter& doc, PathSet& context, + PathSet& drvsSeen) { + checkInterrupt(); + + if (strict) { + state.forceValue(v); + } + + switch (v.type) { + case tInt: + doc.writeEmptyElement( + "int", singletonAttrs("value", (format("%1%") % v.integer).str())); + break; + + case tBool: + doc.writeEmptyElement( + "bool", singletonAttrs("value", v.boolean ? "true" : "false")); + break; + + case tString: + /* !!! show the context? */ + copyContext(v, context); + doc.writeEmptyElement("string", singletonAttrs("value", v.string.s)); + break; + + case tPath: + doc.writeEmptyElement("path", singletonAttrs("value", v.path)); + break; + + case tNull: + doc.writeEmptyElement("null"); + break; + + case tAttrs: + if (state.isDerivation(v)) { + XMLAttrs xmlAttrs; + + Bindings::iterator a = + v.attrs->find(state.symbols.Create("derivation")); + + Path drvPath; + a = v.attrs->find(state.sDrvPath); + if (a != v.attrs->end()) { + if (strict) { + state.forceValue(*a->second.value); + } + if (a->second.value->type == tString) { + xmlAttrs["drvPath"] = drvPath = a->second.value->string.s; + } + } + + a = v.attrs->find(state.sOutPath); + if (a != v.attrs->end()) { + if (strict) { + state.forceValue(*a->second.value); + } + if (a->second.value->type == tString) { + xmlAttrs["outPath"] = a->second.value->string.s; + } + } + + XMLOpenElement _(doc, "derivation", xmlAttrs); + + if (!drvPath.empty() && drvsSeen.find(drvPath) == drvsSeen.end()) { + drvsSeen.insert(drvPath); + showAttrs(state, strict, location, *v.attrs, doc, context, drvsSeen); + } else { + doc.writeEmptyElement("repeated"); + } + } + + else { + XMLOpenElement _(doc, "attrs"); + showAttrs(state, strict, location, *v.attrs, doc, context, drvsSeen); + } + + break; + + case tList1: + case tList2: + case tListN: { + XMLOpenElement _(doc, "list"); + for (unsigned int n = 0; n < v.listSize(); ++n) { + printValueAsXML(state, strict, location, *v.listElems()[n], doc, + context, drvsSeen); + } + break; + } + + case tLambda: { + XMLAttrs xmlAttrs; + if (location) { + posToXML(xmlAttrs, v.lambda.fun->pos); + } + XMLOpenElement _(doc, "function", xmlAttrs); + + if (v.lambda.fun->matchAttrs) { + XMLAttrs attrs; + if (!v.lambda.fun->arg.empty()) { + attrs["name"] = v.lambda.fun->arg; + } + if (v.lambda.fun->formals->ellipsis) { + attrs["ellipsis"] = "1"; + } + XMLOpenElement _(doc, "attrspat", attrs); + for (auto& i : v.lambda.fun->formals->formals) { + doc.writeEmptyElement("attr", singletonAttrs("name", i.name)); + } + } else { + doc.writeEmptyElement("varpat", + singletonAttrs("name", v.lambda.fun->arg)); + } + + break; + } + + case tExternal: + v.external->printValueAsXML(state, strict, location, doc, context, + drvsSeen); + break; + + case tFloat: + doc.writeEmptyElement( + "float", singletonAttrs("value", (format("%1%") % v.fpoint).str())); + break; + + default: + doc.writeEmptyElement("unevaluated"); + } +} + +void ExternalValueBase::printValueAsXML(EvalState& state, bool strict, + bool location, XMLWriter& doc, + PathSet& context, + PathSet& drvsSeen) const { + doc.writeEmptyElement("unevaluated"); +} + +void printValueAsXML(EvalState& state, bool strict, bool location, Value& v, + std::ostream& out, PathSet& context) { + XMLWriter doc(true, out); + XMLOpenElement root(doc, "expr"); + PathSet drvsSeen; + printValueAsXML(state, strict, location, v, doc, context, drvsSeen); +} + +} // namespace nix diff --git a/third_party/nix/src/libexpr/value-to-xml.hh b/third_party/nix/src/libexpr/value-to-xml.hh new file mode 100644 index 0000000000..e7749dd7ae --- /dev/null +++ b/third_party/nix/src/libexpr/value-to-xml.hh @@ -0,0 +1,14 @@ +#pragma once + +#include <map> +#include <string> + +#include "eval.hh" +#include "nixexpr.hh" + +namespace nix { + +void printValueAsXML(EvalState& state, bool strict, bool location, Value& v, + std::ostream& out, PathSet& context); + +} diff --git a/third_party/nix/src/libexpr/value.hh b/third_party/nix/src/libexpr/value.hh new file mode 100644 index 0000000000..892c11220e --- /dev/null +++ b/third_party/nix/src/libexpr/value.hh @@ -0,0 +1,257 @@ +#pragma once + +#include "symbol-table.hh" +#include "types.hh" + +#if HAVE_BOEHMGC +#include <gc/gc_allocator.h> +#endif + +namespace nix { + +typedef enum { + tInt = 1, + tBool, + tString, + tPath, + tNull, + tAttrs, + tList1, + tList2, + tListN, + tThunk, + tApp, + tLambda, + tBlackhole, + tPrimOp, + tPrimOpApp, + tExternal, + tFloat +} ValueType; + +class Bindings; +struct Env; +struct Expr; +struct ExprLambda; +struct PrimOp; +struct PrimOp; +class Symbol; +struct Pos; +class EvalState; +class XMLWriter; +class JSONPlaceholder; + +typedef int64_t NixInt; +typedef double NixFloat; + +/* External values must descend from ExternalValueBase, so that + * type-agnostic nix functions (e.g. showType) can be implemented + */ +class ExternalValueBase { + friend std::ostream& operator<<(std::ostream& str, + const ExternalValueBase& v); + + protected: + /* Print out the value */ + virtual std::ostream& print(std::ostream& str) const = 0; + + public: + /* Return a simple string describing the type */ + virtual std::string showType() const = 0; + + /* Return a string to be used in builtins.typeOf */ + virtual std::string typeOf() const = 0; + + /* How much space does this value take up */ + virtual size_t valueSize(std::set<const void*>& seen) const = 0; + + /* Coerce the value to a string. Defaults to uncoercable, i.e. throws an + * error + */ + virtual std::string coerceToString(const Pos& pos, PathSet& context, + bool copyMore, bool copyToStore) const; + + /* Compare to another value of the same type. Defaults to uncomparable, + * i.e. always false. + */ + virtual bool operator==(const ExternalValueBase& b) const; + + /* Print the value as JSON. Defaults to unconvertable, i.e. throws an error */ + virtual void printValueAsJSON(EvalState& state, bool strict, + JSONPlaceholder& out, PathSet& context) const; + + /* Print the value as XML. Defaults to unevaluated */ + virtual void printValueAsXML(EvalState& state, bool strict, bool location, + XMLWriter& doc, PathSet& context, + PathSet& drvsSeen) const; + + virtual ~ExternalValueBase(){}; +}; + +std::ostream& operator<<(std::ostream& str, const ExternalValueBase& v); + +// Forward declaration of Value is required because the following +// types are mutually recursive. +// +// TODO(tazjin): Really, these types need some serious refactoring. +struct Value; + +/* Strings in the evaluator carry a so-called `context' which + is a list of strings representing store paths. This is to + allow users to write things like + + "--with-freetype2-library=" + freetype + "/lib" + + where `freetype' is a derivation (or a source to be copied + to the store). If we just concatenated the strings without + keeping track of the referenced store paths, then if the + string is used as a derivation attribute, the derivation + will not have the correct dependencies in its inputDrvs and + inputSrcs. + + The semantics of the context is as follows: when a string + with context C is used as a derivation attribute, then the + derivations in C will be added to the inputDrvs of the + derivation, and the other store paths in C will be added to + the inputSrcs of the derivations. + + For canonicity, the store paths should be in sorted order. */ +struct NixString { + const char* s; + const char** context; // must be in sorted order +}; + +struct NixBigList { + size_t size; + Value** elems; +}; + +struct NixThunk { + Env* env; + Expr* expr; +}; + +struct NixApp { + Value *left, *right; +}; + +struct NixLambda { + Env* env; + ExprLambda* fun; +}; + +struct NixPrimOpApp { + Value *left, *right; +}; + +struct Value { + ValueType type; + union { // TODO(tazjin): std::variant + NixInt integer; + bool boolean; + NixString string; + const char* path; + Bindings* attrs; + NixBigList bigList; + Value* smallList[2]; + NixThunk thunk; + NixApp app; // TODO(tazjin): "app"? + NixLambda lambda; + PrimOp* primOp; + NixPrimOpApp primOpApp; + ExternalValueBase* external; + NixFloat fpoint; + }; + + bool isList() const { + return type == tList1 || type == tList2 || type == tListN; + } + + Value** listElems() { + return type == tList1 || type == tList2 ? smallList : bigList.elems; + } + + const Value* const* listElems() const { + return type == tList1 || type == tList2 ? smallList : bigList.elems; + } + + size_t listSize() const { + return type == tList1 ? 1 : type == tList2 ? 2 : bigList.size; + } +}; + +/* After overwriting an app node, be sure to clear pointers in the + Value to ensure that the target isn't kept alive unnecessarily. */ +static inline void clearValue(Value& v) { v.app.left = v.app.right = 0; } + +static inline void mkInt(Value& v, NixInt n) { + clearValue(v); + v.type = tInt; + v.integer = n; +} + +static inline void mkFloat(Value& v, NixFloat n) { + clearValue(v); + v.type = tFloat; + v.fpoint = n; +} + +static inline void mkBool(Value& v, bool b) { + clearValue(v); + v.type = tBool; + v.boolean = b; +} + +static inline void mkNull(Value& v) { + clearValue(v); + v.type = tNull; +} + +static inline void mkApp(Value& v, Value& left, Value& right) { + v.type = tApp; + v.app.left = &left; + v.app.right = &right; +} + +static inline void mkPrimOpApp(Value& v, Value& left, Value& right) { + v.type = tPrimOpApp; + v.app.left = &left; + v.app.right = &right; +} + +static inline void mkStringNoCopy(Value& v, const char* s) { + v.type = tString; + v.string.s = s; + v.string.context = 0; +} + +static inline void mkString(Value& v, const Symbol& s) { + mkStringNoCopy(v, ((const std::string&)s).c_str()); +} + +void mkString(Value& v, const char* s); + +static inline void mkPathNoCopy(Value& v, const char* s) { + clearValue(v); + v.type = tPath; + v.path = s; +} + +void mkPath(Value& v, const char* s); + +/* Compute the size in bytes of the given value, including all values + and environments reachable from it. Static expressions (Exprs) are + not included. */ +size_t valueSize(Value& v); + +#if HAVE_BOEHMGC +typedef std::vector<Value*, gc_allocator<Value*> > ValueVector; +typedef std::map<Symbol, Value*, std::less<Symbol>, + gc_allocator<std::pair<const Symbol, Value*> > > + ValueMap; +#else +typedef std::vector<Value*> ValueVector; +typedef std::map<Symbol, Value*> ValueMap; +#endif + +} // namespace nix diff --git a/third_party/nix/src/libmain/common-args.cc b/third_party/nix/src/libmain/common-args.cc new file mode 100644 index 0000000000..3d9b8ebfae --- /dev/null +++ b/third_party/nix/src/libmain/common-args.cc @@ -0,0 +1,42 @@ +#include "common-args.hh" + +#include <glog/logging.h> + +#include "globals.hh" + +namespace nix { + +MixCommonArgs::MixCommonArgs(const string& programName) + : programName(programName) { + mkFlag() + .longName("option") + .labels({"name", "value"}) + .description("set a Nix configuration option (overriding nix.conf)") + .arity(2) + .handler([](std::vector<std::string> ss) { + try { + globalConfig.set(ss[0], ss[1]); + } catch (UsageError& e) { + LOG(WARNING) << e.what(); + } + }); + + mkFlag() + .longName("max-jobs") + .shortName('j') + .label("jobs") + .description("maximum number of parallel builds") + .handler([=](const std::string& s) { settings.set("max-jobs", s); }); + + std::string cat = "config"; + globalConfig.convertToArgs(*this, cat); + + // Backward compatibility hack: nix-env already had a --system flag. + if (programName == "nix-env") { + longFlags.erase("system"); + } + + hiddenCategories.insert(cat); +} + +} // namespace nix diff --git a/third_party/nix/src/libmain/common-args.hh b/third_party/nix/src/libmain/common-args.hh new file mode 100644 index 0000000000..d8917b8367 --- /dev/null +++ b/third_party/nix/src/libmain/common-args.hh @@ -0,0 +1,27 @@ +#pragma once + +#include "args.hh" + +namespace nix { + +struct MixCommonArgs : virtual Args { + string programName; + MixCommonArgs(const string& programName); +}; + +struct MixDryRun : virtual Args { + bool dryRun = false; + + MixDryRun() { + mkFlag(0, "dry-run", "show what this command would do without doing it", + &dryRun); + } +}; + +struct MixJSON : virtual Args { + bool json = false; + + MixJSON() { mkFlag(0, "json", "produce JSON output", &json); } +}; + +} // namespace nix diff --git a/third_party/nix/src/libmain/meson.build b/third_party/nix/src/libmain/meson.build new file mode 100644 index 0000000000..0524301059 --- /dev/null +++ b/third_party/nix/src/libmain/meson.build @@ -0,0 +1,40 @@ +src_inc += include_directories('.') + +libmain_src = files( + join_paths(meson.source_root(), 'src/libmain/common-args.cc'), + join_paths(meson.source_root(), 'src/libmain/shared.cc'), + join_paths(meson.source_root(), 'src/libmain/stack.cc')) + +libmain_headers = files( + join_paths(meson.source_root(), 'src/libmain/common-args.hh'), + join_paths(meson.source_root(), 'src/libmain/shared.hh')) + +libmain_dep_list = [ + glog_dep, + pthread_dep, + openssl_dep, + libsodium_dep, +] + +libmain_link_list = [ + libutil_lib, + libstore_lib, +] + +libmain_link_args = [] +libstore_cxx_args = [] + +libmain_lib = library( + 'nixmain', + install : true, + install_mode : 'rwxr-xr-x', + install_dir : libdir, + include_directories : src_inc, + link_with : libmain_link_list, + sources : libmain_src, + link_args : libmain_link_args, + dependencies : libmain_dep_list) + +install_headers( + libmain_headers, + install_dir : join_paths(includedir, 'nix')) diff --git a/third_party/nix/src/libmain/nix-main.pc.in b/third_party/nix/src/libmain/nix-main.pc.in new file mode 100644 index 0000000000..37b03dcd42 --- /dev/null +++ b/third_party/nix/src/libmain/nix-main.pc.in @@ -0,0 +1,9 @@ +prefix=@prefix@ +libdir=@libdir@ +includedir=@includedir@ + +Name: Nix +Description: Nix Package Manager +Version: @PACKAGE_VERSION@ +Libs: -L${libdir} -lnixmain +Cflags: -I${includedir}/nix -std=c++17 diff --git a/third_party/nix/src/libmain/shared.cc b/third_party/nix/src/libmain/shared.cc new file mode 100644 index 0000000000..f6c80cae30 --- /dev/null +++ b/third_party/nix/src/libmain/shared.cc @@ -0,0 +1,406 @@ +#include "shared.hh" + +#include <algorithm> +#include <cctype> +#include <csignal> +#include <cstdlib> +#include <exception> +#include <iostream> +#include <mutex> +#include <utility> + +#include <glog/logging.h> +#include <openssl/crypto.h> +#include <sys/stat.h> +#include <sys/time.h> +#include <unistd.h> + +#include "globals.hh" +#include "store-api.hh" +#include "util.hh" + +namespace nix { + +static bool gcWarning = true; + +void printGCWarning() { + if (!gcWarning) { + return; + } + + static bool haveWarned = false; + if (!haveWarned) { + haveWarned = true; + LOG(WARNING) << "you did not specify '--add-root'; " + << "the result might be removed by the garbage collector"; + } +} + +void printMissing(const ref<Store>& store, const PathSet& paths) { + unsigned long long downloadSize; + unsigned long long narSize; + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + store->queryMissing(paths, willBuild, willSubstitute, unknown, downloadSize, + narSize); + printMissing(store, willBuild, willSubstitute, unknown, downloadSize, + narSize); +} + +void printMissing(const ref<Store>& store, const PathSet& willBuild, + const PathSet& willSubstitute, const PathSet& unknown, + unsigned long long downloadSize, unsigned long long narSize) { + if (!willBuild.empty()) { + LOG(INFO) << "these derivations will be built:"; + Paths sorted = store->topoSortPaths(willBuild); + reverse(sorted.begin(), sorted.end()); + for (auto& i : sorted) { + LOG(INFO) << " " << i; + } + } + + if (!willSubstitute.empty()) { + LOG(INFO) << "these paths will be fetched (" + << (downloadSize / (1024.0 * 1024.0)) << " MiB download, " + << (narSize / (1024.0 * 1024.0)) << "MiB unpacked):"; + + for (auto& i : willSubstitute) { + LOG(INFO) << i; + } + } + + if (!unknown.empty()) { + LOG(INFO) << "don't know how to build these paths" + << (settings.readOnlyMode + ? " (may be caused by read-only store access)" + : "") + << ":"; + + for (auto& i : unknown) { + LOG(INFO) << i; + } + } +} + +string getArg(const string& opt, Strings::iterator& i, + const Strings::iterator& end) { + ++i; + if (i == end) { + throw UsageError(format("'%1%' requires an argument") % opt); + } + + return *i; +} + +#if OPENSSL_VERSION_NUMBER < 0x10101000L +/* OpenSSL is not thread-safe by default - it will randomly crash + unless the user supplies a mutex locking function. So let's do + that. */ +static std::vector<std::mutex> opensslLocks; + +static void opensslLockCallback(int mode, int type, const char* file, + int line) { + if (mode & CRYPTO_LOCK) + opensslLocks[type].lock(); + else + opensslLocks[type].unlock(); +} +#endif + +static void sigHandler(int signo) {} + +void initNix() { + /* Turn on buffering for cerr. */ +#if HAVE_PUBSETBUF + static char buf[1024]; + std::cerr.rdbuf()->pubsetbuf(buf, sizeof(buf)); +#endif + +#if OPENSSL_VERSION_NUMBER < 0x10101000L + /* Initialise OpenSSL locking. */ + opensslLocks = std::vector<std::mutex>(CRYPTO_num_locks()); + CRYPTO_set_locking_callback(opensslLockCallback); +#endif + + loadConfFile(); + + startSignalHandlerThread(); + + /* Reset SIGCHLD to its default. */ + struct sigaction act; + sigemptyset(&act.sa_mask); + act.sa_handler = SIG_DFL; + act.sa_flags = 0; + if (sigaction(SIGCHLD, &act, nullptr) != 0) { + throw SysError("resetting SIGCHLD"); + } + + /* Install a dummy SIGUSR1 handler for use with pthread_kill(). */ + act.sa_handler = sigHandler; + if (sigaction(SIGUSR1, &act, nullptr) != 0) { + throw SysError("handling SIGUSR1"); + } + +#if __APPLE__ + /* HACK: on darwin, we need can’t use sigprocmask with SIGWINCH. + * Instead, add a dummy sigaction handler, and signalHandlerThread + * can handle the rest. */ + struct sigaction sa; + sa.sa_handler = sigHandler; + if (sigaction(SIGWINCH, &sa, 0)) { + throw SysError("handling SIGWINCH"); + } +#endif + + /* Register a SIGSEGV handler to detect stack overflows. */ + detectStackOverflow(); + + /* There is no privacy in the Nix system ;-) At least not for + now. In particular, store objects should be readable by + everybody. */ + umask(0022); + + /* Initialise the PRNG. */ + struct timeval tv; + gettimeofday(&tv, nullptr); + srandom(tv.tv_usec); + + /* On macOS, don't use the per-session TMPDIR (as set e.g. by + sshd). This breaks build users because they don't have access + to the TMPDIR, in particular in ‘nix-store --serve’. */ +#if __APPLE__ + if (getuid() == 0 && hasPrefix(getEnv("TMPDIR"), "/var/folders/")) + unsetenv("TMPDIR"); +#endif +} + +LegacyArgs::LegacyArgs( + const std::string& programName, + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg) + : MixCommonArgs(programName), parseArg(std::move(parseArg)) { + mkFlag() + .longName("no-build-output") + .shortName('Q') + .description("do not show build output") + .set(&settings.verboseBuild, false); + + mkFlag() + .longName("keep-failed") + .shortName('K') + .description("keep temporary directories of failed builds") + .set(&(bool&)settings.keepFailed, true); + + mkFlag() + .longName("keep-going") + .shortName('k') + .description("keep going after a build fails") + .set(&(bool&)settings.keepGoing, true); + + mkFlag() + .longName("fallback") + .description("build from source if substitution fails") + .set(&(bool&)settings.tryFallback, true); + + auto intSettingAlias = [&](char shortName, const std::string& longName, + const std::string& description, + const std::string& dest) { + mkFlag<unsigned int>(shortName, longName, description, [=](unsigned int n) { + settings.set(dest, std::to_string(n)); + }); + }; + + intSettingAlias(0, "cores", + "maximum number of CPU cores to use inside a build", "cores"); + intSettingAlias(0, "max-silent-time", + "number of seconds of silence before a build is killed", + "max-silent-time"); + intSettingAlias(0, "timeout", "number of seconds before a build is killed", + "timeout"); + + mkFlag(0, "readonly-mode", "do not write to the Nix store", + &settings.readOnlyMode); + + mkFlag(0, "no-gc-warning", "disable warning about not using '--add-root'", + &gcWarning, false); + + mkFlag() + .longName("store") + .label("store-uri") + .description("URI of the Nix store to use") + .dest(&(std::string&)settings.storeUri); +} + +bool LegacyArgs::processFlag(Strings::iterator& pos, Strings::iterator end) { + if (MixCommonArgs::processFlag(pos, end)) { + return true; + } + bool res = parseArg(pos, end); + if (res) { + ++pos; + } + return res; +} + +bool LegacyArgs::processArgs(const Strings& args, bool finish) { + if (args.empty()) { + return true; + } + assert(args.size() == 1); + Strings ss(args); + auto pos = ss.begin(); + if (!parseArg(pos, ss.end())) { + throw UsageError(format("unexpected argument '%1%'") % args.front()); + } + return true; +} + +void parseCmdLine( + int argc, char** argv, + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg) { + parseCmdLine(baseNameOf(argv[0]), argvToStrings(argc, argv), + std::move(parseArg)); +} + +void parseCmdLine( + const string& programName, const Strings& args, + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg) { + LegacyArgs(programName, std::move(parseArg)).parseCmdline(args); +} + +void printVersion(const string& programName) { + std::cout << format("%1% (Nix) %2%") % programName % nixVersion << std::endl; + + // TODO(tazjin): figure out what the fuck this is + /*if (verbosity > lvlInfo) { + Strings cfg; +#if HAVE_BOEHMGC + cfg.push_back("gc"); +#endif +#if HAVE_SODIUM + cfg.push_back("signed-caches"); +#endif + std::cout << "Features: " << concatStringsSep(", ", cfg) << "\n"; + std::cout << "Configuration file: " << settings.nixConfDir + "/nix.conf" + << "\n"; + std::cout << "Store directory: " << settings.nixStore << "\n"; + std::cout << "State directory: " << settings.nixStateDir << "\n"; + } */ + throw Exit(); +} + +void showManPage(const string& name) { + restoreSignals(); + setenv("MANPATH", settings.nixManDir.c_str(), 1); + execlp("man", "man", name.c_str(), nullptr); + throw SysError(format("command 'man %1%' failed") % name.c_str()); +} + +int handleExceptions(const string& programName, + const std::function<void()>& fun) { + ReceiveInterrupts receiveInterrupts; // FIXME: need better place for this + + string error = ANSI_RED "error:" ANSI_NORMAL " "; + try { + try { + fun(); + } catch (...) { + /* Subtle: we have to make sure that any `interrupted' + condition is discharged before we reach printMsg() + below, since otherwise it will throw an (uncaught) + exception. */ + setInterruptThrown(); + throw; + } + } catch (Exit& e) { + return e.status; + } catch (UsageError& e) { + LOG(INFO) << e.what(); + LOG(INFO) << "Try '" << programName << " " + << " --help' for more information."; + return 1; + } catch (BaseError& e) { + LOG(ERROR) << error << (settings.showTrace ? e.prefix() : "") << e.msg(); + if (!e.prefix().empty() && !settings.showTrace) { + LOG(INFO) << "(use '--show-trace' to show detailed location information)"; + } + return e.status; + } catch (std::bad_alloc& e) { + LOG(ERROR) << error << "failed to allocate: " << e.what(); + return 1; + } catch (std::exception& e) { + LOG(ERROR) << error << e.what(); + return 1; + } + + return 0; +} + +RunPager::RunPager() { + if (isatty(STDOUT_FILENO) == 0) { + return; + } + char* pager = getenv("NIX_PAGER"); + if (pager == nullptr) { + pager = getenv("PAGER"); + } + if (pager && ((string)pager == "" || (string)pager == "cat")) { + return; + } + + Pipe toPager; + toPager.create(); + + pid = startProcess([&]() { + if (dup2(toPager.readSide.get(), STDIN_FILENO) == -1) { + throw SysError("dupping stdin"); + } + if (getenv("LESS") == nullptr) { + setenv("LESS", "FRSXMK", 1); + } + restoreSignals(); + if (pager != nullptr) { + execl("/bin/sh", "sh", "-c", pager, nullptr); + } + execlp("pager", "pager", nullptr); + execlp("less", "less", nullptr); + execlp("more", "more", nullptr); + throw SysError(format("executing '%1%'") % pager); + }); + + pid.setKillSignal(SIGINT); + + if (dup2(toPager.writeSide.get(), STDOUT_FILENO) == -1) { + throw SysError("dupping stdout"); + } +} + +RunPager::~RunPager() { + try { + if (pid != -1) { + std::cout.flush(); + close(STDOUT_FILENO); + pid.wait(); + } + } catch (...) { + ignoreException(); + } +} + +string showBytes(unsigned long long bytes) { + return (format("%.2f MiB") % (bytes / (1024.0 * 1024.0))).str(); +} + +PrintFreed::~PrintFreed() { + if (show) { + std::cout << format("%1% store paths deleted, %2% freed\n") % + results.paths.size() % showBytes(results.bytesFreed); + } +} + +Exit::~Exit() = default; + +} // namespace nix diff --git a/third_party/nix/src/libmain/shared.hh b/third_party/nix/src/libmain/shared.hh new file mode 100644 index 0000000000..da1c9cc66a --- /dev/null +++ b/third_party/nix/src/libmain/shared.hh @@ -0,0 +1,133 @@ +#pragma once + +#include <locale> + +#include <signal.h> + +#include "args.hh" +#include "common-args.hh" +#include "util.hh" + +namespace nix { + +class Exit : public std::exception { + public: + int status; + Exit() : status(0) {} + Exit(int status) : status(status) {} + virtual ~Exit(); +}; + +int handleExceptions(const string& programName, + const std::function<void()>& fun); + +/* Don't forget to call initPlugins() after settings are initialized! */ +void initNix(); + +void parseCmdLine( + int argc, char** argv, + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg); + +void parseCmdLine( + const string& programName, const Strings& args, + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg); + +void printVersion(const string& programName); + +/* Ugh. No better place to put this. */ +void printGCWarning(); + +class Store; + +void printMissing(const ref<Store>& store, const PathSet& paths); + +void printMissing(const ref<Store>& store, const PathSet& willBuild, + const PathSet& willSubstitute, const PathSet& unknown, + unsigned long long downloadSize, unsigned long long narSize); + +string getArg(const string& opt, Strings::iterator& i, + const Strings::iterator& end); + +template <class N> +N getIntArg(const string& opt, Strings::iterator& i, + const Strings::iterator& end, bool allowUnit) { + ++i; + if (i == end) { + throw UsageError(format("'%1%' requires an argument") % opt); + } + string s = *i; + N multiplier = 1; + if (allowUnit && !s.empty()) { + char u = std::toupper(*s.rbegin()); + if (std::isalpha(u)) { + if (u == 'K') { + multiplier = 1ULL << 10; + } else if (u == 'M') { + multiplier = 1ULL << 20; + } else if (u == 'G') { + multiplier = 1ULL << 30; + } else if (u == 'T') { + multiplier = 1ULL << 40; + } else { + throw UsageError(format("invalid unit specifier '%1%'") % u); + } + + s.resize(s.size() - 1); + } + } + N n; + if (!string2Int(s, n)) + throw UsageError(format("'%1%' requires an integer argument") % opt); + return n * multiplier; +} + +struct LegacyArgs : public MixCommonArgs { + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg; + + LegacyArgs( + const std::string& programName, + std::function<bool(Strings::iterator& arg, const Strings::iterator& end)> + parseArg); + + bool processFlag(Strings::iterator& pos, Strings::iterator end) override; + + bool processArgs(const Strings& args, bool finish) override; +}; + +/* Show the manual page for the specified program. */ +void showManPage(const string& name); + +/* The constructor of this class starts a pager if stdout is a + terminal and $PAGER is set. Stdout is redirected to the pager. */ +class RunPager { + public: + RunPager(); + ~RunPager(); + + private: + Pid pid; +}; + +extern volatile ::sig_atomic_t blockInt; + +/* GC helpers. */ + +string showBytes(unsigned long long bytes); + +struct GCResults; + +struct PrintFreed { + bool show; + const GCResults& results; + PrintFreed(bool show, const GCResults& results) + : show(show), results(results) {} + ~PrintFreed(); +}; + +/* Install a SIGSEGV handler to detect stack overflows. */ +void detectStackOverflow(); + +} // namespace nix diff --git a/third_party/nix/src/libmain/stack.cc b/third_party/nix/src/libmain/stack.cc new file mode 100644 index 0000000000..f100b39156 --- /dev/null +++ b/third_party/nix/src/libmain/stack.cc @@ -0,0 +1,75 @@ +#include <csignal> +#include <cstddef> +#include <cstdlib> +#include <cstring> + +#include <unistd.h> + +#include "types.hh" + +namespace nix { + +static void sigsegvHandler(int signo, siginfo_t* info, void* ctx) { + /* Detect stack overflows by comparing the faulting address with + the stack pointer. Unfortunately, getting the stack pointer is + not portable. */ + bool haveSP = true; + char* sp = nullptr; +#if defined(__x86_64__) && defined(REG_RSP) + sp = (char*)((ucontext_t*)ctx)->uc_mcontext.gregs[REG_RSP]; +#elif defined(REG_ESP) + sp = (char*)((ucontext_t*)ctx)->uc_mcontext.gregs[REG_ESP]; +#else + haveSP = false; +#endif + + if (haveSP) { + ptrdiff_t diff = (char*)info->si_addr - sp; + if (diff < 0) { + diff = -diff; + } + if (diff < 4096) { + char msg[] = "error: stack overflow (possible infinite recursion)\n"; + [[gnu::unused]] auto res = write(2, msg, strlen(msg)); + _exit(1); // maybe abort instead? + } + } + + /* Restore default behaviour (i.e. segfault and dump core). */ + struct sigaction act; + sigfillset(&act.sa_mask); + act.sa_handler = SIG_DFL; + act.sa_flags = 0; + if (sigaction(SIGSEGV, &act, nullptr) != 0) { + abort(); + } +} + +void detectStackOverflow() { +#if defined(SA_SIGINFO) && defined(SA_ONSTACK) + /* Install a SIGSEGV handler to detect stack overflows. This + requires an alternative stack, otherwise the signal cannot be + delivered when we're out of stack space. */ + stack_t stack; + stack.ss_size = 4096 * 4 + MINSIGSTKSZ; + static auto stackBuf = std::make_unique<std::vector<char>>(stack.ss_size); + stack.ss_sp = stackBuf->data(); + if (stack.ss_sp == nullptr) { + throw Error("cannot allocate alternative stack"); + } + stack.ss_flags = 0; + if (sigaltstack(&stack, nullptr) == -1) { + throw SysError("cannot set alternative stack"); + } + + struct sigaction act; + sigfillset(&act.sa_mask); + act.sa_sigaction = sigsegvHandler; + act.sa_flags = SA_SIGINFO | SA_ONSTACK; + if (sigaction(SIGSEGV, &act, nullptr) != 0) { + throw SysError("resetting SIGSEGV"); + } +#endif +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/binary-cache-store.cc b/third_party/nix/src/libstore/binary-cache-store.cc new file mode 100644 index 0000000000..487c12b531 --- /dev/null +++ b/third_party/nix/src/libstore/binary-cache-store.cc @@ -0,0 +1,382 @@ +#include "binary-cache-store.hh" + +#include <chrono> +#include <future> +#include <memory> + +#include "archive.hh" +#include "compression.hh" +#include "derivations.hh" +#include "fs-accessor.hh" +#include "globals.hh" +#include "glog/logging.h" +#include "json.hh" +#include "nar-accessor.hh" +#include "nar-info-disk-cache.hh" +#include "nar-info.hh" +#include "remote-fs-accessor.hh" +#include "sync.hh" + +namespace nix { + +BinaryCacheStore::BinaryCacheStore(const Params& params) : Store(params) { + if (secretKeyFile != "") { + secretKey = std::make_unique<SecretKey>(readFile(secretKeyFile)); + } + + StringSink sink; + sink << narVersionMagic1; + narMagic = *sink.s; +} + +void BinaryCacheStore::init() { + std::string cacheInfoFile = "nix-cache-info"; + + auto cacheInfo = getFile(cacheInfoFile); + if (!cacheInfo) { + upsertFile(cacheInfoFile, "StoreDir: " + storeDir + "\n", + "text/x-nix-cache-info"); + } else { + for (auto& line : tokenizeString<Strings>(*cacheInfo, "\n")) { + size_t colon = line.find(':'); + if (colon == std::string::npos) { + continue; + } + auto name = line.substr(0, colon); + auto value = trim(line.substr(colon + 1, std::string::npos)); + if (name == "StoreDir") { + if (value != storeDir) { + throw Error(format("binary cache '%s' is for Nix stores with prefix " + "'%s', not '%s'") % + getUri() % value % storeDir); + } + } else if (name == "WantMassQuery") { + wantMassQuery_ = value == "1"; + } else if (name == "Priority") { + string2Int(value, priority); + } + } + } +} + +void BinaryCacheStore::getFile( + const std::string& path, + Callback<std::shared_ptr<std::string>> callback) noexcept { + try { + callback(getFile(path)); + } catch (...) { + callback.rethrow(); + } +} + +void BinaryCacheStore::getFile(const std::string& path, Sink& sink) { + std::promise<std::shared_ptr<std::string>> promise; + getFile(path, {[&](std::future<std::shared_ptr<std::string>> result) { + try { + promise.set_value(result.get()); + } catch (...) { + promise.set_exception(std::current_exception()); + } + }}); + auto data = promise.get_future().get(); + sink((unsigned char*)data->data(), data->size()); +} + +std::shared_ptr<std::string> BinaryCacheStore::getFile( + const std::string& path) { + StringSink sink; + try { + getFile(path, sink); + } catch (NoSuchBinaryCacheFile&) { + return nullptr; + } + return sink.s; +} + +Path BinaryCacheStore::narInfoFileFor(const Path& storePath) { + assertStorePath(storePath); + return storePathToHash(storePath) + ".narinfo"; +} + +void BinaryCacheStore::writeNarInfo(const ref<NarInfo>& narInfo) { + auto narInfoFile = narInfoFileFor(narInfo->path); + + upsertFile(narInfoFile, narInfo->to_string(), "text/x-nix-narinfo"); + + auto hashPart = storePathToHash(narInfo->path); + + { + auto state_(state.lock()); + state_->pathInfoCache.upsert(hashPart, std::shared_ptr<NarInfo>(narInfo)); + } + + if (diskCache) { + diskCache->upsertNarInfo(getUri(), hashPart, + std::shared_ptr<NarInfo>(narInfo)); + } +} + +void BinaryCacheStore::addToStore(const ValidPathInfo& info, + const ref<std::string>& nar, + RepairFlag repair, CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) { + if ((repair == 0u) && isValidPath(info.path)) { + return; + } + + /* Verify that all references are valid. This may do some .narinfo + reads, but typically they'll already be cached. */ + for (auto& ref : info.references) { + try { + if (ref != info.path) { + queryPathInfo(ref); + } + } catch (InvalidPath&) { + throw Error(format("cannot add '%s' to the binary cache because the " + "reference '%s' is not valid") % + info.path % ref); + } + } + + assert(nar->compare(0, narMagic.size(), narMagic) == 0); + + auto narInfo = make_ref<NarInfo>(info); + + narInfo->narSize = nar->size(); + narInfo->narHash = hashString(htSHA256, *nar); + + if (info.narHash && info.narHash != narInfo->narHash) { + throw Error( + format("refusing to copy corrupted path '%1%' to binary cache") % + info.path); + } + + auto accessor_ = std::dynamic_pointer_cast<RemoteFSAccessor>(accessor); + + /* Optionally write a JSON file containing a listing of the + contents of the NAR. */ + if (writeNARListing) { + std::ostringstream jsonOut; + + { + JSONObject jsonRoot(jsonOut); + jsonRoot.attr("version", 1); + + auto narAccessor = makeNarAccessor(nar); + + if (accessor_) { + accessor_->addToCache(info.path, *nar, narAccessor); + } + + { + auto res = jsonRoot.placeholder("root"); + listNar(res, narAccessor, "", true); + } + } + + upsertFile(storePathToHash(info.path) + ".ls", jsonOut.str(), + "application/json"); + } + + else { + if (accessor_) { + accessor_->addToCache(info.path, *nar, makeNarAccessor(nar)); + } + } + + /* Compress the NAR. */ + narInfo->compression = compression; + auto now1 = std::chrono::steady_clock::now(); + auto narCompressed = compress(compression, *nar, parallelCompression); + auto now2 = std::chrono::steady_clock::now(); + narInfo->fileHash = hashString(htSHA256, *narCompressed); + narInfo->fileSize = narCompressed->size(); + + auto duration = + std::chrono::duration_cast<std::chrono::milliseconds>(now2 - now1) + .count(); + DLOG(INFO) << "copying path '" << narInfo->path << "' (" << narInfo->narSize + << " bytes, compressed " + << ((1.0 - (double)narCompressed->size() / nar->size()) * 100.0) + << "% in " << duration << "ms) to binary cache"; + + /* Atomically write the NAR file. */ + narInfo->url = "nar/" + narInfo->fileHash.to_string(Base32, false) + ".nar" + + (compression == "xz" ? ".xz" + : compression == "bzip2" + ? ".bz2" + : compression == "br" ? ".br" : ""); + if ((repair != 0u) || !fileExists(narInfo->url)) { + stats.narWrite++; + upsertFile(narInfo->url, *narCompressed, "application/x-nix-nar"); + } else { + stats.narWriteAverted++; + } + + stats.narWriteBytes += nar->size(); + stats.narWriteCompressedBytes += narCompressed->size(); + stats.narWriteCompressionTimeMs += duration; + + /* Atomically write the NAR info file.*/ + if (secretKey) { + narInfo->sign(*secretKey); + } + + writeNarInfo(narInfo); + + stats.narInfoWrite++; +} + +bool BinaryCacheStore::isValidPathUncached(const Path& storePath) { + // FIXME: this only checks whether a .narinfo with a matching hash + // part exists. So ‘f4kb...-foo’ matches ‘f4kb...-bar’, even + // though they shouldn't. Not easily fixed. + return fileExists(narInfoFileFor(storePath)); +} + +void BinaryCacheStore::narFromPath(const Path& storePath, Sink& sink) { + auto info = queryPathInfo(storePath).cast<const NarInfo>(); + + uint64_t narSize = 0; + + LambdaSink wrapperSink([&](const unsigned char* data, size_t len) { + sink(data, len); + narSize += len; + }); + + auto decompressor = makeDecompressionSink(info->compression, wrapperSink); + + try { + getFile(info->url, *decompressor); + } catch (NoSuchBinaryCacheFile& e) { + throw SubstituteGone(e.what()); + } + + decompressor->finish(); + + stats.narRead++; + // stats.narReadCompressedBytes += nar->size(); // FIXME + stats.narReadBytes += narSize; +} + +void BinaryCacheStore::queryPathInfoUncached( + const Path& storePath, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept { + auto uri = getUri(); + LOG(INFO) << "querying info about '" << storePath << "' on '" << uri << "'"; + + auto narInfoFile = narInfoFileFor(storePath); + + auto callbackPtr = std::make_shared<decltype(callback)>(std::move(callback)); + + getFile(narInfoFile, {[=](std::future<std::shared_ptr<std::string>> fut) { + try { + auto data = fut.get(); + + if (!data) { + return (*callbackPtr)(nullptr); + } + + stats.narInfoRead++; + + (*callbackPtr)( + (std::shared_ptr<ValidPathInfo>)std::make_shared<NarInfo>( + *this, *data, narInfoFile)); + + } catch (...) { + callbackPtr->rethrow(); + } + }}); +} + +Path BinaryCacheStore::addToStore(const string& name, const Path& srcPath, + bool recursive, HashType hashAlgo, + PathFilter& filter, RepairFlag repair) { + // FIXME: some cut&paste from LocalStore::addToStore(). + + /* Read the whole path into memory. This is not a very scalable + method for very large paths, but `copyPath' is mainly used for + small files. */ + StringSink sink; + Hash h; + if (recursive) { + dumpPath(srcPath, sink, filter); + h = hashString(hashAlgo, *sink.s); + } else { + auto s = readFile(srcPath); + dumpString(s, sink); + h = hashString(hashAlgo, s); + } + + ValidPathInfo info; + info.path = makeFixedOutputPath(recursive, h, name); + + addToStore(info, sink.s, repair, CheckSigs, nullptr); + + return info.path; +} + +Path BinaryCacheStore::addTextToStore(const string& name, const string& s, + const PathSet& references, + RepairFlag repair) { + ValidPathInfo info; + info.path = computeStorePathForText(name, s, references); + info.references = references; + + if ((repair != 0u) || !isValidPath(info.path)) { + StringSink sink; + dumpString(s, sink); + addToStore(info, sink.s, repair, CheckSigs, nullptr); + } + + return info.path; +} + +ref<FSAccessor> BinaryCacheStore::getFSAccessor() { + return make_ref<RemoteFSAccessor>(ref<Store>(shared_from_this()), + localNarCache); +} + +void BinaryCacheStore::addSignatures(const Path& storePath, + const StringSet& sigs) { + /* Note: this is inherently racy since there is no locking on + binary caches. In particular, with S3 this unreliable, even + when addSignatures() is called sequentially on a path, because + S3 might return an outdated cached version. */ + + auto narInfo = make_ref<NarInfo>((NarInfo&)*queryPathInfo(storePath)); + + narInfo->sigs.insert(sigs.begin(), sigs.end()); + + auto narInfoFile = narInfoFileFor(narInfo->path); + + writeNarInfo(narInfo); +} + +std::shared_ptr<std::string> BinaryCacheStore::getBuildLog(const Path& path) { + Path drvPath; + + if (isDerivation(path)) { + drvPath = path; + } else { + try { + auto info = queryPathInfo(path); + // FIXME: add a "Log" field to .narinfo + if (info->deriver.empty()) { + return nullptr; + } + drvPath = info->deriver; + } catch (InvalidPath&) { + return nullptr; + } + } + + auto logPath = "log/" + baseNameOf(drvPath); + + DLOG(INFO) << "fetching build log from binary cache '" << getUri() << "/" + << logPath << "'"; + + return getFile(logPath); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/binary-cache-store.hh b/third_party/nix/src/libstore/binary-cache-store.hh new file mode 100644 index 0000000000..f5bd66bbd6 --- /dev/null +++ b/third_party/nix/src/libstore/binary-cache-store.hh @@ -0,0 +1,114 @@ +#pragma once + +#include <atomic> + +#include "crypto.hh" +#include "pool.hh" +#include "store-api.hh" + +namespace nix { + +struct NarInfo; + +class BinaryCacheStore : public Store { + public: + const Setting<std::string> compression{ + this, "xz", "compression", + "NAR compression method ('xz', 'bzip2', or 'none')"}; + const Setting<bool> writeNARListing{ + this, false, "write-nar-listing", + "whether to write a JSON file listing the files in each NAR"}; + const Setting<Path> secretKeyFile{ + this, "", "secret-key", + "path to secret key used to sign the binary cache"}; + const Setting<Path> localNarCache{this, "", "local-nar-cache", + "path to a local cache of NARs"}; + const Setting<bool> parallelCompression{ + this, false, "parallel-compression", + "enable multi-threading compression, available for xz only currently"}; + + private: + std::unique_ptr<SecretKey> secretKey; + + protected: + BinaryCacheStore(const Params& params); + + public: + virtual bool fileExists(const std::string& path) = 0; + + virtual void upsertFile(const std::string& path, const std::string& data, + const std::string& mimeType) = 0; + + /* Note: subclasses must implement at least one of the two + following getFile() methods. */ + + /* Dump the contents of the specified file to a sink. */ + virtual void getFile(const std::string& path, Sink& sink); + + /* Fetch the specified file and call the specified callback with + the result. A subclass may implement this asynchronously. */ + virtual void getFile( + const std::string& path, + Callback<std::shared_ptr<std::string>> callback) noexcept; + + std::shared_ptr<std::string> getFile(const std::string& path); + + protected: + bool wantMassQuery_ = false; + int priority = 50; + + public: + virtual void init(); + + private: + std::string narMagic; + + std::string narInfoFileFor(const Path& storePath); + + void writeNarInfo(const ref<NarInfo>& narInfo); + + public: + bool isValidPathUncached(const Path& path) override; + + void queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept override; + + Path queryPathFromHashPart(const string& hashPart) override { + unsupported("queryPathFromHashPart"); + } + + bool wantMassQuery() override { return wantMassQuery_; } + + void addToStore(const ValidPathInfo& info, const ref<std::string>& nar, + RepairFlag repair, CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) override; + + Path addToStore(const string& name, const Path& srcPath, bool recursive, + HashType hashAlgo, PathFilter& filter, + RepairFlag repair) override; + + Path addTextToStore(const string& name, const string& s, + const PathSet& references, RepairFlag repair) override; + + void narFromPath(const Path& path, Sink& sink) override; + + BuildResult buildDerivation(const Path& drvPath, const BasicDerivation& drv, + BuildMode buildMode) override { + unsupported("buildDerivation"); + } + + void ensurePath(const Path& path) override { unsupported("ensurePath"); } + + ref<FSAccessor> getFSAccessor() override; + + void addSignatures(const Path& storePath, const StringSet& sigs) override; + + std::shared_ptr<std::string> getBuildLog(const Path& path) override; + + int getPriority() override { return priority; } +}; + +MakeError(NoSuchBinaryCacheFile, Error); + +} // namespace nix diff --git a/third_party/nix/src/libstore/build.cc b/third_party/nix/src/libstore/build.cc new file mode 100644 index 0000000000..fe64635847 --- /dev/null +++ b/third_party/nix/src/libstore/build.cc @@ -0,0 +1,4955 @@ +#include <algorithm> +#include <cerrno> +#include <chrono> +#include <climits> +#include <cstring> +#include <future> +#include <iostream> +#include <map> +#include <memory> +#include <queue> +#include <regex> +#include <sstream> +#include <thread> + +#include <fcntl.h> +#include <grp.h> +#include <netdb.h> +#include <pwd.h> +#include <sys/resource.h> +#include <sys/select.h> +#include <sys/socket.h> +#include <sys/stat.h> +#include <sys/time.h> +#include <sys/types.h> +#include <sys/utsname.h> +#include <sys/wait.h> +#include <termios.h> +#include <unistd.h> + +#include "affinity.hh" +#include "archive.hh" +#include "builtins.hh" +#include "compression.hh" +#include "download.hh" +#include "finally.hh" +#include "globals.hh" +#include "glog/logging.h" +#include "json.hh" +#include "local-store.hh" +#include "machines.hh" +#include "nar-info.hh" +#include "parsed-derivations.hh" +#include "pathlocks.hh" +#include "references.hh" +#include "util.hh" + +/* Includes required for chroot support. */ +#if __linux__ +#include <net/if.h> +#include <netinet/ip.h> +#include <sched.h> +#include <sys/ioctl.h> +#include <sys/mman.h> +#include <sys/mount.h> +#include <sys/param.h> +#include <sys/personality.h> +#include <sys/socket.h> +#include <sys/syscall.h> +#if HAVE_SECCOMP +#include <seccomp.h> +#endif +#define pivot_root(new_root, put_old) \ + (syscall(SYS_pivot_root, new_root, put_old)) +#endif + +#if HAVE_STATVFS +#include <sys/statvfs.h> +#endif + +#include <nlohmann/json.hpp> +#include <utility> + +namespace nix { + +using std::map; + +static string pathNullDevice = "/dev/null"; + +/* Forward definition. */ +class Worker; +struct HookInstance; + +/* A pointer to a goal. */ +class Goal; +class DerivationGoal; +using GoalPtr = std::shared_ptr<Goal>; +using WeakGoalPtr = std::weak_ptr<Goal>; + +struct CompareGoalPtrs { + bool operator()(const GoalPtr& a, const GoalPtr& b) const; +}; + +/* Set of goals. */ +typedef set<GoalPtr, CompareGoalPtrs> Goals; +using WeakGoals = list<WeakGoalPtr>; + +/* A map of paths to goals (and the other way around). */ +typedef map<Path, WeakGoalPtr> WeakGoalMap; + +class Goal : public std::enable_shared_from_this<Goal> { + public: + typedef enum { + ecBusy, + ecSuccess, + ecFailed, + ecNoSubstituters, + ecIncompleteClosure + } ExitCode; + + protected: + /* Backlink to the worker. */ + Worker& worker; + + /* Goals that this goal is waiting for. */ + Goals waitees; + + /* Goals waiting for this one to finish. Must use weak pointers + here to prevent cycles. */ + WeakGoals waiters; + + /* Number of goals we are/were waiting for that have failed. */ + unsigned int nrFailed; + + /* Number of substitution goals we are/were waiting for that + failed because there are no substituters. */ + unsigned int nrNoSubstituters; + + /* Number of substitution goals we are/were waiting for that + failed because othey had unsubstitutable references. */ + unsigned int nrIncompleteClosure; + + /* Name of this goal for debugging purposes. */ + string name; + + /* Whether the goal is finished. */ + ExitCode exitCode; + + explicit Goal(Worker& worker) : worker(worker) { + nrFailed = nrNoSubstituters = nrIncompleteClosure = 0; + exitCode = ecBusy; + } + + virtual ~Goal() { trace("goal destroyed"); } + + public: + virtual void work() = 0; + + void addWaitee(const GoalPtr& waitee); + + virtual void waiteeDone(GoalPtr waitee, ExitCode result); + + virtual void handleChildOutput(int fd, const string& data) { abort(); } + + virtual void handleEOF(int fd) { abort(); } + + void trace(const FormatOrString& fs); + + string getName() { return name; } + + ExitCode getExitCode() { return exitCode; } + + /* Callback in case of a timeout. It should wake up its waiters, + get rid of any running child processes that are being monitored + by the worker (important!), etc. */ + virtual void timedOut() = 0; + + virtual string key() = 0; + + protected: + virtual void amDone(ExitCode result); +}; + +bool CompareGoalPtrs::operator()(const GoalPtr& a, const GoalPtr& b) const { + string s1 = a->key(); + string s2 = b->key(); + return s1 < s2; +} + +using steady_time_point = std::chrono::time_point<std::chrono::steady_clock>; + +/* A mapping used to remember for each child process to what goal it + belongs, and file descriptors for receiving log data and output + path creation commands. */ +struct Child { + WeakGoalPtr goal; + Goal* goal2; // ugly hackery + set<int> fds; + bool respectTimeouts; + bool inBuildSlot; + steady_time_point lastOutput; /* time we last got output on stdout/stderr */ + steady_time_point timeStarted; +}; + +/* The worker class. */ +class Worker { + private: + /* Note: the worker should only have strong pointers to the + top-level goals. */ + + /* The top-level goals of the worker. */ + Goals topGoals; + + /* Goals that are ready to do some work. */ + WeakGoals awake; + + /* Goals waiting for a build slot. */ + WeakGoals wantingToBuild; + + /* Child processes currently running. */ + std::list<Child> children; + + /* Number of build slots occupied. This includes local builds and + substitutions but not remote builds via the build hook. */ + unsigned int nrLocalBuilds; + + /* Maps used to prevent multiple instantiations of a goal for the + same derivation / path. */ + WeakGoalMap derivationGoals; + WeakGoalMap substitutionGoals; + + /* Goals waiting for busy paths to be unlocked. */ + WeakGoals waitingForAnyGoal; + + /* Goals sleeping for a few seconds (polling a lock). */ + WeakGoals waitingForAWhile; + + /* Last time the goals in `waitingForAWhile' where woken up. */ + steady_time_point lastWokenUp; + + /* Cache for pathContentsGood(). */ + std::map<Path, bool> pathContentsGoodCache; + + public: + /* Set if at least one derivation had a BuildError (i.e. permanent + failure). */ + bool permanentFailure; + + /* Set if at least one derivation had a timeout. */ + bool timedOut; + + /* Set if at least one derivation fails with a hash mismatch. */ + bool hashMismatch; + + /* Set if at least one derivation is not deterministic in check mode. */ + bool checkMismatch; + + LocalStore& store; + + std::unique_ptr<HookInstance> hook; + + uint64_t expectedBuilds = 0; + uint64_t doneBuilds = 0; + uint64_t failedBuilds = 0; + uint64_t runningBuilds = 0; + + uint64_t expectedSubstitutions = 0; + uint64_t doneSubstitutions = 0; + uint64_t failedSubstitutions = 0; + uint64_t runningSubstitutions = 0; + uint64_t expectedDownloadSize = 0; + uint64_t doneDownloadSize = 0; + uint64_t expectedNarSize = 0; + uint64_t doneNarSize = 0; + + /* Whether to ask the build hook if it can build a derivation. If + it answers with "decline-permanently", we don't try again. */ + bool tryBuildHook = true; + + explicit Worker(LocalStore& store); + ~Worker(); + + /* Make a goal (with caching). */ + GoalPtr makeDerivationGoal(const Path& drvPath, + const StringSet& wantedOutputs, + BuildMode buildMode = bmNormal); + std::shared_ptr<DerivationGoal> makeBasicDerivationGoal( + const Path& drvPath, const BasicDerivation& drv, + BuildMode buildMode = bmNormal); + GoalPtr makeSubstitutionGoal(const Path& storePath, + RepairFlag repair = NoRepair); + + /* Remove a dead goal. */ + void removeGoal(const GoalPtr& goal); + + /* Wake up a goal (i.e., there is something for it to do). */ + void wakeUp(const GoalPtr& goal); + + /* Return the number of local build and substitution processes + currently running (but not remote builds via the build + hook). */ + unsigned int getNrLocalBuilds(); + + /* Registers a running child process. `inBuildSlot' means that + the process counts towards the jobs limit. */ + void childStarted(const GoalPtr& goal, const set<int>& fds, bool inBuildSlot, + bool respectTimeouts); + + /* Unregisters a running child process. `wakeSleepers' should be + false if there is no sense in waking up goals that are sleeping + because they can't run yet (e.g., there is no free build slot, + or the hook would still say `postpone'). */ + void childTerminated(Goal* goal, bool wakeSleepers = true); + + /* Put `goal' to sleep until a build slot becomes available (which + might be right away). */ + void waitForBuildSlot(const GoalPtr& goal); + + /* Wait for any goal to finish. Pretty indiscriminate way to + wait for some resource that some other goal is holding. */ + void waitForAnyGoal(GoalPtr goal); + + /* Wait for a few seconds and then retry this goal. Used when + waiting for a lock held by another process. This kind of + polling is inefficient, but POSIX doesn't really provide a way + to wait for multiple locks in the main select() loop. */ + void waitForAWhile(GoalPtr goal); + + /* Loop until the specified top-level goals have finished. */ + void run(const Goals& topGoals); + + /* Wait for input to become available. */ + void waitForInput(); + + unsigned int exitStatus(); + + /* Check whether the given valid path exists and has the right + contents. */ + bool pathContentsGood(const Path& path); + + void markContentsGood(const Path& path); +}; + +////////////////////////////////////////////////////////////////////// + +void addToWeakGoals(WeakGoals& goals, const GoalPtr& p) { + // FIXME: necessary? + // FIXME: O(n) + for (auto& i : goals) { + if (i.lock() == p) { + return; + } + } + goals.push_back(p); +} + +void Goal::addWaitee(const GoalPtr& waitee) { + waitees.insert(waitee); + addToWeakGoals(waitee->waiters, shared_from_this()); +} + +void Goal::waiteeDone(GoalPtr waitee, ExitCode result) { + assert(waitees.find(waitee) != waitees.end()); + waitees.erase(waitee); + + trace(format("waitee '%1%' done; %2% left") % waitee->name % waitees.size()); + + if (result == ecFailed || result == ecNoSubstituters || + result == ecIncompleteClosure) { + ++nrFailed; + } + + if (result == ecNoSubstituters) { + ++nrNoSubstituters; + } + + if (result == ecIncompleteClosure) { + ++nrIncompleteClosure; + } + + if (waitees.empty() || (result == ecFailed && !settings.keepGoing)) { + /* If we failed and keepGoing is not set, we remove all + remaining waitees. */ + for (auto& goal : waitees) { + WeakGoals waiters2; + for (auto& j : goal->waiters) { + if (j.lock() != shared_from_this()) { + waiters2.push_back(j); + } + } + goal->waiters = waiters2; + } + waitees.clear(); + + worker.wakeUp(shared_from_this()); + } +} + +void Goal::amDone(ExitCode result) { + trace("done"); + assert(exitCode == ecBusy); + assert(result == ecSuccess || result == ecFailed || + result == ecNoSubstituters || result == ecIncompleteClosure); + exitCode = result; + for (auto& i : waiters) { + GoalPtr goal = i.lock(); + if (goal) { + goal->waiteeDone(shared_from_this(), result); + } + } + waiters.clear(); + worker.removeGoal(shared_from_this()); +} + +void Goal::trace(const FormatOrString& fs) { + DLOG(INFO) << name << ": " << fs.s; +} + +////////////////////////////////////////////////////////////////////// + +/* Common initialisation performed in child processes. */ +static void commonChildInit(Pipe& logPipe) { + restoreSignals(); + + /* Put the child in a separate session (and thus a separate + process group) so that it has no controlling terminal (meaning + that e.g. ssh cannot open /dev/tty) and it doesn't receive + terminal signals. */ + if (setsid() == -1) { + throw SysError(format("creating a new session")); + } + + /* Dup the write side of the logger pipe into stderr. */ + if (dup2(logPipe.writeSide.get(), STDERR_FILENO) == -1) { + throw SysError("cannot pipe standard error into log file"); + } + + /* Dup stderr to stdout. */ + if (dup2(STDERR_FILENO, STDOUT_FILENO) == -1) { + throw SysError("cannot dup stderr into stdout"); + } + + /* Reroute stdin to /dev/null. */ + int fdDevNull = open(pathNullDevice.c_str(), O_RDWR); + if (fdDevNull == -1) { + throw SysError(format("cannot open '%1%'") % pathNullDevice); + } + if (dup2(fdDevNull, STDIN_FILENO) == -1) { + throw SysError("cannot dup null device into stdin"); + } + close(fdDevNull); +} + +void handleDiffHook(uid_t uid, uid_t gid, Path tryA, Path tryB, Path drvPath, + Path tmpDir) { + auto diffHook = settings.diffHook; + if (diffHook != "" && settings.runDiffHook) { + try { + RunOptions diffHookOptions( + diffHook, {std::move(tryA), std::move(tryB), std::move(drvPath), + std::move(tmpDir)}); + diffHookOptions.searchPath = true; + diffHookOptions.uid = uid; + diffHookOptions.gid = gid; + diffHookOptions.chdir = "/"; + + auto diffRes = runProgram(diffHookOptions); + if (!statusOk(diffRes.first)) { + throw ExecError(diffRes.first, + fmt("diff-hook program '%1%' %2%", diffHook, + statusToString(diffRes.first))); + } + + if (!diffRes.second.empty()) { + LOG(ERROR) << chomp(diffRes.second); + } + } catch (Error& error) { + LOG(ERROR) << "diff hook execution failed: " << error.what(); + } + } +} + +////////////////////////////////////////////////////////////////////// + +class UserLock { + private: + /* POSIX locks suck. If we have a lock on a file, and we open and + close that file again (without closing the original file + descriptor), we lose the lock. So we have to be *very* careful + not to open a lock file on which we are holding a lock. */ + static Sync<PathSet> lockedPaths_; + + Path fnUserLock; + AutoCloseFD fdUserLock; + + string user; + uid_t uid; + gid_t gid; + std::vector<gid_t> supplementaryGIDs; + + public: + UserLock(); + ~UserLock(); + + void kill(); + + string getUser() { return user; } + uid_t getUID() { + assert(uid); + return uid; + } + uid_t getGID() { + assert(gid); + return gid; + } + std::vector<gid_t> getSupplementaryGIDs() { return supplementaryGIDs; } + + bool enabled() { return uid != 0; } +}; + +Sync<PathSet> UserLock::lockedPaths_; + +UserLock::UserLock() { + assert(settings.buildUsersGroup != ""); + + /* Get the members of the build-users-group. */ + struct group* gr = getgrnam(settings.buildUsersGroup.get().c_str()); + if (gr == nullptr) { + throw Error( + format( + "the group '%1%' specified in 'build-users-group' does not exist") % + settings.buildUsersGroup); + } + gid = gr->gr_gid; + + /* Copy the result of getgrnam. */ + Strings users; + for (char** p = gr->gr_mem; *p != nullptr; ++p) { + DLOG(INFO) << "found build user " << *p; + users.push_back(*p); + } + + if (users.empty()) { + throw Error(format("the build users group '%1%' has no members") % + settings.buildUsersGroup); + } + + /* Find a user account that isn't currently in use for another + build. */ + for (auto& i : users) { + DLOG(INFO) << "trying user " << i; + + struct passwd* pw = getpwnam(i.c_str()); + if (pw == nullptr) { + throw Error(format("the user '%1%' in the group '%2%' does not exist") % + i % settings.buildUsersGroup); + } + + createDirs(settings.nixStateDir + "/userpool"); + + fnUserLock = + (format("%1%/userpool/%2%") % settings.nixStateDir % pw->pw_uid).str(); + + { + auto lockedPaths(lockedPaths_.lock()); + if (lockedPaths->count(fnUserLock) != 0u) { + /* We already have a lock on this one. */ + continue; + } + lockedPaths->insert(fnUserLock); + } + + try { + AutoCloseFD fd = + open(fnUserLock.c_str(), O_RDWR | O_CREAT | O_CLOEXEC, 0600); + if (!fd) { + throw SysError(format("opening user lock '%1%'") % fnUserLock); + } + + if (lockFile(fd.get(), ltWrite, false)) { + fdUserLock = std::move(fd); + user = i; + uid = pw->pw_uid; + + /* Sanity check... */ + if (uid == getuid() || uid == geteuid()) { + throw Error(format("the Nix user should not be a member of '%1%'") % + settings.buildUsersGroup); + } + +#if __linux__ + /* Get the list of supplementary groups of this build user. This + is usually either empty or contains a group such as "kvm". */ + supplementaryGIDs.resize(10); + int ngroups = supplementaryGIDs.size(); + int err = getgrouplist(pw->pw_name, pw->pw_gid, + supplementaryGIDs.data(), &ngroups); + if (err == -1) { + throw Error( + format("failed to get list of supplementary groups for '%1%'") % + pw->pw_name); + } + + supplementaryGIDs.resize(ngroups); +#endif + + return; + } + + } catch (...) { + lockedPaths_.lock()->erase(fnUserLock); + } + } + + throw Error(format("all build users are currently in use; " + "consider creating additional users and adding them to " + "the '%1%' group") % + settings.buildUsersGroup); +} + +UserLock::~UserLock() { + auto lockedPaths(lockedPaths_.lock()); + assert(lockedPaths->count(fnUserLock)); + lockedPaths->erase(fnUserLock); +} + +void UserLock::kill() { killUser(uid); } + +////////////////////////////////////////////////////////////////////// + +struct HookInstance { + /* Pipes for talking to the build hook. */ + Pipe toHook; + + /* Pipe for the hook's standard output/error. */ + Pipe fromHook; + + /* Pipe for the builder's standard output/error. */ + Pipe builderOut; + + /* The process ID of the hook. */ + Pid pid; + + FdSink sink; + + HookInstance(); + + ~HookInstance(); +}; + +HookInstance::HookInstance() { + DLOG(INFO) << "starting build hook " << settings.buildHook; + + /* Create a pipe to get the output of the child. */ + fromHook.create(); + + /* Create the communication pipes. */ + toHook.create(); + + /* Create a pipe to get the output of the builder. */ + builderOut.create(); + + /* Fork the hook. */ + pid = startProcess([&]() { + commonChildInit(fromHook); + + if (chdir("/") == -1) { + throw SysError("changing into /"); + } + + /* Dup the communication pipes. */ + if (dup2(toHook.readSide.get(), STDIN_FILENO) == -1) { + throw SysError("dupping to-hook read side"); + } + + /* Use fd 4 for the builder's stdout/stderr. */ + if (dup2(builderOut.writeSide.get(), 4) == -1) { + throw SysError("dupping builder's stdout/stderr"); + } + + /* Hack: pass the read side of that fd to allow build-remote + to read SSH error messages. */ + if (dup2(builderOut.readSide.get(), 5) == -1) { + throw SysError("dupping builder's stdout/stderr"); + } + + Strings args = { + baseNameOf(settings.buildHook), + // std::to_string(verbosity), // TODO(tazjin): what? + }; + + execv(settings.buildHook.get().c_str(), stringsToCharPtrs(args).data()); + + throw SysError("executing '%s'", settings.buildHook); + }); + + pid.setSeparatePG(true); + fromHook.writeSide = -1; + toHook.readSide = -1; + + sink = FdSink(toHook.writeSide.get()); + std::map<std::string, Config::SettingInfo> settings; + globalConfig.getSettings(settings); + for (auto& setting : settings) { + sink << 1 << setting.first << setting.second.value; + } + sink << 0; +} + +HookInstance::~HookInstance() { + try { + toHook.writeSide = -1; + if (pid != -1) { + pid.kill(); + } + } catch (...) { + ignoreException(); + } +} + +////////////////////////////////////////////////////////////////////// + +typedef map<std::string, std::string> StringRewrites; + +std::string rewriteStrings(std::string s, const StringRewrites& rewrites) { + for (auto& i : rewrites) { + size_t j = 0; + while ((j = s.find(i.first, j)) != string::npos) { + s.replace(j, i.first.size(), i.second); + } + } + return s; +} + +////////////////////////////////////////////////////////////////////// + +typedef enum { rpAccept, rpDecline, rpPostpone } HookReply; + +class SubstitutionGoal; + +class DerivationGoal : public Goal { + private: + /* Whether to use an on-disk .drv file. */ + bool useDerivation; + + /* The path of the derivation. */ + Path drvPath; + + /* The specific outputs that we need to build. Empty means all of + them. */ + StringSet wantedOutputs; + + /* Whether additional wanted outputs have been added. */ + bool needRestart = false; + + /* Whether to retry substituting the outputs after building the + inputs. */ + bool retrySubstitution; + + /* The derivation stored at drvPath. */ + std::unique_ptr<BasicDerivation> drv; + + std::unique_ptr<ParsedDerivation> parsedDrv; + + /* The remainder is state held during the build. */ + + /* Locks on the output paths. */ + PathLocks outputLocks; + + /* All input paths (that is, the union of FS closures of the + immediate input paths). */ + PathSet inputPaths; + + /* Referenceable paths (i.e., input and output paths). */ + PathSet allPaths; + + /* Outputs that are already valid. If we're repairing, these are + the outputs that are valid *and* not corrupt. */ + PathSet validPaths; + + /* Outputs that are corrupt or not valid. */ + PathSet missingPaths; + + /* User selected for running the builder. */ + std::unique_ptr<UserLock> buildUser; + + /* The process ID of the builder. */ + Pid pid; + + /* The temporary directory. */ + Path tmpDir; + + /* The path of the temporary directory in the sandbox. */ + Path tmpDirInSandbox; + + /* File descriptor for the log file. */ + AutoCloseFD fdLogFile; + std::shared_ptr<BufferedSink> logFileSink, logSink; + + /* Number of bytes received from the builder's stdout/stderr. */ + unsigned long logSize; + + /* The most recent log lines. */ + std::list<std::string> logTail; + + std::string currentLogLine; + size_t currentLogLinePos = 0; // to handle carriage return + + std::string currentHookLine; + + /* Pipe for the builder's standard output/error. */ + Pipe builderOut; + + /* Pipe for synchronising updates to the builder user namespace. */ + Pipe userNamespaceSync; + + /* The build hook. */ + std::unique_ptr<HookInstance> hook; + + /* Whether we're currently doing a chroot build. */ + bool useChroot = false; + + Path chrootRootDir; + + /* RAII object to delete the chroot directory. */ + std::shared_ptr<AutoDelete> autoDelChroot; + + /* Whether this is a fixed-output derivation. */ + bool fixedOutput; + + /* Whether to run the build in a private network namespace. */ + bool privateNetwork = false; + + using GoalState = void (DerivationGoal::*)(); + GoalState state; + + /* Stuff we need to pass to initChild(). */ + struct ChrootPath { + Path source; + bool optional; + explicit ChrootPath(Path source = "", bool optional = false) + : source(std::move(source)), optional(optional) {} + }; + typedef map<Path, ChrootPath> + DirsInChroot; // maps target path to source path + DirsInChroot dirsInChroot; + + typedef map<string, string> Environment; + Environment env; + +#if __APPLE__ + typedef string SandboxProfile; + SandboxProfile additionalSandboxProfile; +#endif + + /* Hash rewriting. */ + StringRewrites inputRewrites, outputRewrites; + typedef map<Path, Path> RedirectedOutputs; + RedirectedOutputs redirectedOutputs; + + BuildMode buildMode; + + /* If we're repairing without a chroot, there may be outputs that + are valid but corrupt. So we redirect these outputs to + temporary paths. */ + PathSet redirectedBadOutputs; + + BuildResult result; + + /* The current round, if we're building multiple times. */ + size_t curRound = 1; + + size_t nrRounds; + + /* Path registration info from the previous round, if we're + building multiple times. Since this contains the hash, it + allows us to compare whether two rounds produced the same + result. */ + std::map<Path, ValidPathInfo> prevInfos; + + const uid_t sandboxUid = 1000; + const gid_t sandboxGid = 100; + + const static Path homeDir; + + std::unique_ptr<MaintainCount<uint64_t>> mcExpectedBuilds, mcRunningBuilds; + + /* The remote machine on which we're building. */ + std::string machineName; + + public: + DerivationGoal(const Path& drvPath, StringSet wantedOutputs, Worker& worker, + BuildMode buildMode = bmNormal); + DerivationGoal(const Path& drvPath, const BasicDerivation& drv, + Worker& worker, BuildMode buildMode = bmNormal); + ~DerivationGoal() override; + + /* Whether we need to perform hash rewriting if there are valid output paths. + */ + bool needsHashRewrite(); + + void timedOut() override; + + string key() override { + /* Ensure that derivations get built in order of their name, + i.e. a derivation named "aardvark" always comes before + "baboon". And substitution goals always happen before + derivation goals (due to "b$"). */ + return "b$" + storePathToName(drvPath) + "$" + drvPath; + } + + void work() override; + + Path getDrvPath() { return drvPath; } + + /* Add wanted outputs to an already existing derivation goal. */ + void addWantedOutputs(const StringSet& outputs); + + BuildResult getResult() { return result; } + + private: + /* The states. */ + void getDerivation(); + void loadDerivation(); + void haveDerivation(); + void outputsSubstituted(); + void closureRepaired(); + void inputsRealised(); + void tryToBuild(); + void buildDone(); + + /* Is the build hook willing to perform the build? */ + HookReply tryBuildHook(); + + /* Start building a derivation. */ + void startBuilder(); + + /* Fill in the environment for the builder. */ + void initEnv(); + + /* Setup tmp dir location. */ + void initTmpDir(); + + /* Write a JSON file containing the derivation attributes. */ + void writeStructuredAttrs(); + + /* Make a file owned by the builder. */ + void chownToBuilder(const Path& path); + + /* Run the builder's process. */ + void runChild(); + + friend int childEntry(void* /*arg*/); + + /* Check that the derivation outputs all exist and register them + as valid. */ + void registerOutputs(); + + /* Check that an output meets the requirements specified by the + 'outputChecks' attribute (or the legacy + '{allowed,disallowed}{References,Requisites}' attributes). */ + void checkOutputs(const std::map<std::string, ValidPathInfo>& outputs); + + /* Open a log file and a pipe to it. */ + Path openLogFile(); + + /* Close the log file. */ + void closeLogFile(); + + /* Delete the temporary directory, if we have one. */ + void deleteTmpDir(bool force); + + /* Callback used by the worker to write to the log. */ + void handleChildOutput(int fd, const string& data) override; + void handleEOF(int fd) override; + void flushLine(); + + /* Return the set of (in)valid paths. */ + PathSet checkPathValidity(bool returnValid, bool checkHash); + + /* Abort the goal if `path' failed to build. */ + bool pathFailed(const Path& path); + + /* Forcibly kill the child process, if any. */ + void killChild(); + + Path addHashRewrite(const Path& path); + + void repairClosure(); + + void amDone(ExitCode result) override { Goal::amDone(result); } + + void done(BuildResult::Status status, const string& msg = ""); + + PathSet exportReferences(const PathSet& storePaths); +}; + +const Path DerivationGoal::homeDir = "/homeless-shelter"; + +DerivationGoal::DerivationGoal(const Path& drvPath, StringSet wantedOutputs, + Worker& worker, BuildMode buildMode) + : Goal(worker), + useDerivation(true), + drvPath(drvPath), + wantedOutputs(std::move(wantedOutputs)), + buildMode(buildMode) { + state = &DerivationGoal::getDerivation; + name = (format("building of '%1%'") % drvPath).str(); + trace("created"); + + mcExpectedBuilds = + std::make_unique<MaintainCount<uint64_t>>(worker.expectedBuilds); +} + +DerivationGoal::DerivationGoal(const Path& drvPath, const BasicDerivation& drv, + Worker& worker, BuildMode buildMode) + : Goal(worker), + useDerivation(false), + drvPath(drvPath), + buildMode(buildMode) { + this->drv = std::make_unique<BasicDerivation>(drv); + state = &DerivationGoal::haveDerivation; + name = (format("building of %1%") % showPaths(drv.outputPaths())).str(); + trace("created"); + + mcExpectedBuilds = + std::make_unique<MaintainCount<uint64_t>>(worker.expectedBuilds); + + /* Prevent the .chroot directory from being + garbage-collected. (See isActiveTempFile() in gc.cc.) */ + worker.store.addTempRoot(drvPath); +} + +DerivationGoal::~DerivationGoal() { + /* Careful: we should never ever throw an exception from a + destructor. */ + try { + killChild(); + } catch (...) { + ignoreException(); + } + try { + deleteTmpDir(false); + } catch (...) { + ignoreException(); + } + try { + closeLogFile(); + } catch (...) { + ignoreException(); + } +} + +inline bool DerivationGoal::needsHashRewrite() { +#if __linux__ + return !useChroot; +#else + /* Darwin requires hash rewriting even when sandboxing is enabled. */ + return true; +#endif +} + +void DerivationGoal::killChild() { + if (pid != -1) { + worker.childTerminated(this); + + if (buildUser) { + /* If we're using a build user, then there is a tricky + race condition: if we kill the build user before the + child has done its setuid() to the build user uid, then + it won't be killed, and we'll potentially lock up in + pid.wait(). So also send a conventional kill to the + child. */ + ::kill(-pid, SIGKILL); /* ignore the result */ + buildUser->kill(); + pid.wait(); + } else { + pid.kill(); + } + + assert(pid == -1); + } + + hook.reset(); +} + +void DerivationGoal::timedOut() { + killChild(); + done(BuildResult::TimedOut); +} + +void DerivationGoal::work() { (this->*state)(); } + +void DerivationGoal::addWantedOutputs(const StringSet& outputs) { + /* If we already want all outputs, there is nothing to do. */ + if (wantedOutputs.empty()) { + return; + } + + if (outputs.empty()) { + wantedOutputs.clear(); + needRestart = true; + } else { + for (auto& i : outputs) { + if (wantedOutputs.find(i) == wantedOutputs.end()) { + wantedOutputs.insert(i); + needRestart = true; + } + } + } +} + +void DerivationGoal::getDerivation() { + trace("init"); + + /* The first thing to do is to make sure that the derivation + exists. If it doesn't, it may be created through a + substitute. */ + if (buildMode == bmNormal && worker.store.isValidPath(drvPath)) { + loadDerivation(); + return; + } + + addWaitee(worker.makeSubstitutionGoal(drvPath)); + + state = &DerivationGoal::loadDerivation; +} + +void DerivationGoal::loadDerivation() { + trace("loading derivation"); + + if (nrFailed != 0) { + LOG(ERROR) << "cannot build missing derivation '" << drvPath << "'"; + done(BuildResult::MiscFailure); + return; + } + + /* `drvPath' should already be a root, but let's be on the safe + side: if the user forgot to make it a root, we wouldn't want + things being garbage collected while we're busy. */ + worker.store.addTempRoot(drvPath); + + assert(worker.store.isValidPath(drvPath)); + + /* Get the derivation. */ + drv = std::unique_ptr<BasicDerivation>( + new Derivation(worker.store.derivationFromPath(drvPath))); + + haveDerivation(); +} + +void DerivationGoal::haveDerivation() { + trace("have derivation"); + + retrySubstitution = false; + + for (auto& i : drv->outputs) { + worker.store.addTempRoot(i.second.path); + } + + /* Check what outputs paths are not already valid. */ + PathSet invalidOutputs = checkPathValidity(false, buildMode == bmRepair); + + /* If they are all valid, then we're done. */ + if (invalidOutputs.empty() && buildMode == bmNormal) { + done(BuildResult::AlreadyValid); + return; + } + + parsedDrv = std::make_unique<ParsedDerivation>(drvPath, *drv); + + /* We are first going to try to create the invalid output paths + through substitutes. If that doesn't work, we'll build + them. */ + if (settings.useSubstitutes && parsedDrv->substitutesAllowed()) { + for (auto& i : invalidOutputs) { + addWaitee(worker.makeSubstitutionGoal( + i, buildMode == bmRepair ? Repair : NoRepair)); + } + } + + if (waitees.empty()) { /* to prevent hang (no wake-up event) */ + outputsSubstituted(); + } else { + state = &DerivationGoal::outputsSubstituted; + } +} + +void DerivationGoal::outputsSubstituted() { + trace("all outputs substituted (maybe)"); + + if (nrFailed > 0 && nrFailed > nrNoSubstituters + nrIncompleteClosure && + !settings.tryFallback) { + done(BuildResult::TransientFailure, + (format("some substitutes for the outputs of derivation '%1%' failed " + "(usually happens due to networking issues); try '--fallback' " + "to build derivation from source ") % + drvPath) + .str()); + return; + } + + /* If the substitutes form an incomplete closure, then we should + build the dependencies of this derivation, but after that, we + can still use the substitutes for this derivation itself. */ + if (nrIncompleteClosure > 0) { + retrySubstitution = true; + } + + nrFailed = nrNoSubstituters = nrIncompleteClosure = 0; + + if (needRestart) { + needRestart = false; + haveDerivation(); + return; + } + + auto nrInvalid = checkPathValidity(false, buildMode == bmRepair).size(); + if (buildMode == bmNormal && nrInvalid == 0) { + done(BuildResult::Substituted); + return; + } + if (buildMode == bmRepair && nrInvalid == 0) { + repairClosure(); + return; + } + if (buildMode == bmCheck && nrInvalid > 0) { + throw Error(format("some outputs of '%1%' are not valid, so checking is " + "not possible") % + drvPath); + } + + /* Otherwise, at least one of the output paths could not be + produced using a substitute. So we have to build instead. */ + + /* Make sure checkPathValidity() from now on checks all + outputs. */ + wantedOutputs = PathSet(); + + /* The inputs must be built before we can build this goal. */ + if (useDerivation) { + for (auto& i : dynamic_cast<Derivation*>(drv.get())->inputDrvs) { + addWaitee(worker.makeDerivationGoal( + i.first, i.second, buildMode == bmRepair ? bmRepair : bmNormal)); + } + } + + for (auto& i : drv->inputSrcs) { + if (worker.store.isValidPath(i)) { + continue; + } + if (!settings.useSubstitutes) { + throw Error(format("dependency '%1%' of '%2%' does not exist, and " + "substitution is disabled") % + i % drvPath); + } + addWaitee(worker.makeSubstitutionGoal(i)); + } + + if (waitees.empty()) { /* to prevent hang (no wake-up event) */ + inputsRealised(); + } else { + state = &DerivationGoal::inputsRealised; + } +} + +void DerivationGoal::repairClosure() { + /* If we're repairing, we now know that our own outputs are valid. + Now check whether the other paths in the outputs closure are + good. If not, then start derivation goals for the derivations + that produced those outputs. */ + + /* Get the output closure. */ + PathSet outputClosure; + for (auto& i : drv->outputs) { + if (!wantOutput(i.first, wantedOutputs)) { + continue; + } + worker.store.computeFSClosure(i.second.path, outputClosure); + } + + /* Filter out our own outputs (which we have already checked). */ + for (auto& i : drv->outputs) { + outputClosure.erase(i.second.path); + } + + /* Get all dependencies of this derivation so that we know which + derivation is responsible for which path in the output + closure. */ + PathSet inputClosure; + if (useDerivation) { + worker.store.computeFSClosure(drvPath, inputClosure); + } + std::map<Path, Path> outputsToDrv; + for (auto& i : inputClosure) { + if (isDerivation(i)) { + Derivation drv = worker.store.derivationFromPath(i); + for (auto& j : drv.outputs) { + outputsToDrv[j.second.path] = i; + } + } + } + + /* Check each path (slow!). */ + PathSet broken; + for (auto& i : outputClosure) { + if (worker.pathContentsGood(i)) { + continue; + } + LOG(ERROR) << "found corrupted or missing path '" << i + << "' in the output closure of '" << drvPath << "'"; + Path drvPath2 = outputsToDrv[i]; + if (drvPath2.empty()) { + addWaitee(worker.makeSubstitutionGoal(i, Repair)); + } else { + addWaitee(worker.makeDerivationGoal(drvPath2, PathSet(), bmRepair)); + } + } + + if (waitees.empty()) { + done(BuildResult::AlreadyValid); + return; + } + + state = &DerivationGoal::closureRepaired; +} + +void DerivationGoal::closureRepaired() { + trace("closure repaired"); + if (nrFailed > 0) { + throw Error(format("some paths in the output closure of derivation '%1%' " + "could not be repaired") % + drvPath); + } + done(BuildResult::AlreadyValid); +} + +void DerivationGoal::inputsRealised() { + trace("all inputs realised"); + + if (nrFailed != 0) { + if (!useDerivation) { + throw Error(format("some dependencies of '%1%' are missing") % drvPath); + } + LOG(ERROR) << "cannot build derivation '" << drvPath << "': " << nrFailed + << " dependencies couldn't be built"; + done(BuildResult::DependencyFailed); + return; + } + + if (retrySubstitution) { + haveDerivation(); + return; + } + + /* Gather information necessary for computing the closure and/or + running the build hook. */ + + /* The outputs are referenceable paths. */ + for (auto& i : drv->outputs) { + DLOG(INFO) << "building path " << i.second.path; + allPaths.insert(i.second.path); + } + + /* Determine the full set of input paths. */ + + /* First, the input derivations. */ + if (useDerivation) { + for (auto& i : dynamic_cast<Derivation*>(drv.get())->inputDrvs) { + /* Add the relevant output closures of the input derivation + `i' as input paths. Only add the closures of output paths + that are specified as inputs. */ + assert(worker.store.isValidPath(i.first)); + Derivation inDrv = worker.store.derivationFromPath(i.first); + for (auto& j : i.second) { + if (inDrv.outputs.find(j) != inDrv.outputs.end()) { + worker.store.computeFSClosure(inDrv.outputs[j].path, inputPaths); + } else { + throw Error(format("derivation '%1%' requires non-existent output " + "'%2%' from input derivation '%3%'") % + drvPath % j % i.first); + } + } + } + } + + /* Second, the input sources. */ + worker.store.computeFSClosure(drv->inputSrcs, inputPaths); + + DLOG(INFO) << "added input paths " << showPaths(inputPaths); + + allPaths.insert(inputPaths.begin(), inputPaths.end()); + + /* Is this a fixed-output derivation? */ + fixedOutput = drv->isFixedOutput(); + + /* Don't repeat fixed-output derivations since they're already + verified by their output hash.*/ + nrRounds = fixedOutput ? 1 : settings.buildRepeat + 1; + + /* Okay, try to build. Note that here we don't wait for a build + slot to become available, since we don't need one if there is a + build hook. */ + state = &DerivationGoal::tryToBuild; + worker.wakeUp(shared_from_this()); + + result = BuildResult(); +} + +void DerivationGoal::tryToBuild() { + trace("trying to build"); + + /* Obtain locks on all output paths. The locks are automatically + released when we exit this function or Nix crashes. If we + can't acquire the lock, then continue; hopefully some other + goal can start a build, and if not, the main loop will sleep a + few seconds and then retry this goal. */ + PathSet lockFiles; + for (auto& outPath : drv->outputPaths()) { + lockFiles.insert(worker.store.toRealPath(outPath)); + } + + if (!outputLocks.lockPaths(lockFiles, "", false)) { + worker.waitForAWhile(shared_from_this()); + return; + } + + /* Now check again whether the outputs are valid. This is because + another process may have started building in parallel. After + it has finished and released the locks, we can (and should) + reuse its results. (Strictly speaking the first check can be + omitted, but that would be less efficient.) Note that since we + now hold the locks on the output paths, no other process can + build this derivation, so no further checks are necessary. */ + validPaths = checkPathValidity(true, buildMode == bmRepair); + if (buildMode != bmCheck && validPaths.size() == drv->outputs.size()) { + DLOG(INFO) << "skipping build of derivation '" << drvPath + << "', someone beat us to it"; + outputLocks.setDeletion(true); + done(BuildResult::AlreadyValid); + return; + } + + missingPaths = drv->outputPaths(); + if (buildMode != bmCheck) { + for (auto& i : validPaths) { + missingPaths.erase(i); + } + } + + /* If any of the outputs already exist but are not valid, delete + them. */ + for (auto& i : drv->outputs) { + Path path = i.second.path; + if (worker.store.isValidPath(path)) { + continue; + } + DLOG(INFO) << "removing invalid path " << path; + deletePath(worker.store.toRealPath(path)); + } + + /* Don't do a remote build if the derivation has the attribute + `preferLocalBuild' set. Also, check and repair modes are only + supported for local builds. */ + bool buildLocally = buildMode != bmNormal || parsedDrv->willBuildLocally(); + + auto started = [&]() { + auto msg = fmt(buildMode == bmRepair + ? "repairing outputs of '%s'" + : buildMode == bmCheck + ? "checking outputs of '%s'" + : nrRounds > 1 ? "building '%s' (round %d/%d)" + : "building '%s'", + drvPath, curRound, nrRounds); + + if (hook) { + msg += fmt(" on '%s'", machineName); + } + LOG(INFO) << msg << "[" << drvPath << "]"; + mcRunningBuilds = + std::make_unique<MaintainCount<uint64_t>>(worker.runningBuilds); + }; + + /* Is the build hook willing to accept this job? */ + if (!buildLocally) { + switch (tryBuildHook()) { + case rpAccept: + /* Yes, it has started doing so. Wait until we get + EOF from the hook. */ + result.startTime = time(nullptr); // inexact + state = &DerivationGoal::buildDone; + started(); + return; + case rpPostpone: + /* Not now; wait until at least one child finishes or + the wake-up timeout expires. */ + worker.waitForAWhile(shared_from_this()); + outputLocks.unlock(); + return; + case rpDecline: + /* We should do it ourselves. */ + break; + } + } + + /* Make sure that we are allowed to start a build. If this + derivation prefers to be done locally, do it even if + maxBuildJobs is 0. */ + unsigned int curBuilds = worker.getNrLocalBuilds(); + if (curBuilds >= settings.maxBuildJobs && !(buildLocally && curBuilds == 0)) { + worker.waitForBuildSlot(shared_from_this()); + outputLocks.unlock(); + return; + } + + try { + /* Okay, we have to build. */ + startBuilder(); + + } catch (BuildError& e) { + LOG(ERROR) << e.msg(); + outputLocks.unlock(); + buildUser.reset(); + worker.permanentFailure = true; + done(BuildResult::InputRejected, e.msg()); + return; + } + + /* This state will be reached when we get EOF on the child's + log pipe. */ + state = &DerivationGoal::buildDone; + + started(); +} + +void replaceValidPath(const Path& storePath, const Path& tmpPath) { + /* We can't atomically replace storePath (the original) with + tmpPath (the replacement), so we have to move it out of the + way first. We'd better not be interrupted here, because if + we're repairing (say) Glibc, we end up with a broken system. */ + Path oldPath = + (format("%1%.old-%2%-%3%") % storePath % getpid() % random()).str(); + if (pathExists(storePath)) { + rename(storePath.c_str(), oldPath.c_str()); + } + if (rename(tmpPath.c_str(), storePath.c_str()) == -1) { + throw SysError(format("moving '%1%' to '%2%'") % tmpPath % storePath); + } + deletePath(oldPath); +} + +MakeError(NotDeterministic, BuildError) + + void DerivationGoal::buildDone() { + trace("build done"); + + /* Release the build user at the end of this function. We don't do + it right away because we don't want another build grabbing this + uid and then messing around with our output. */ + Finally releaseBuildUser([&]() { buildUser.reset(); }); + + /* Since we got an EOF on the logger pipe, the builder is presumed + to have terminated. In fact, the builder could also have + simply have closed its end of the pipe, so just to be sure, + kill it. */ + int status = hook ? hook->pid.kill() : pid.kill(); + + DLOG(INFO) << "builder process for '" << drvPath << "' finished"; + + result.timesBuilt++; + result.stopTime = time(nullptr); + + /* So the child is gone now. */ + worker.childTerminated(this); + + /* Close the read side of the logger pipe. */ + if (hook) { + hook->builderOut.readSide = -1; + hook->fromHook.readSide = -1; + } else { + builderOut.readSide = -1; + } + + /* Close the log file. */ + closeLogFile(); + + /* When running under a build user, make sure that all processes + running under that uid are gone. This is to prevent a + malicious user from leaving behind a process that keeps files + open and modifies them after they have been chown'ed to + root. */ + if (buildUser) { + buildUser->kill(); + } + + bool diskFull = false; + + try { + /* Check the exit status. */ + if (!statusOk(status)) { + /* Heuristically check whether the build failure may have + been caused by a disk full condition. We have no way + of knowing whether the build actually got an ENOSPC. + So instead, check if the disk is (nearly) full now. If + so, we don't mark this build as a permanent failure. */ +#if HAVE_STATVFS + unsigned long long required = + 8ULL * 1024 * 1024; // FIXME: make configurable + struct statvfs st; + if (statvfs(worker.store.realStoreDir.c_str(), &st) == 0 && + (unsigned long long)st.f_bavail * st.f_bsize < required) { + diskFull = true; + } + if (statvfs(tmpDir.c_str(), &st) == 0 && + (unsigned long long)st.f_bavail * st.f_bsize < required) { + diskFull = true; + } +#endif + + deleteTmpDir(false); + + /* Move paths out of the chroot for easier debugging of + build failures. */ + if (useChroot && buildMode == bmNormal) { + for (auto& i : missingPaths) { + if (pathExists(chrootRootDir + i)) { + rename((chrootRootDir + i).c_str(), i.c_str()); + } + } + } + + std::string msg = + (format("builder for '%1%' %2%") % drvPath % statusToString(status)) + .str(); + + if (!settings.verboseBuild && !logTail.empty()) { + msg += (format("; last %d log lines:") % logTail.size()).str(); + for (auto& line : logTail) { + msg += "\n " + line; + } + } + + if (diskFull) { + msg += + "\nnote: build failure may have been caused by lack of free disk " + "space"; + } + + throw BuildError(msg); + } + + /* Compute the FS closure of the outputs and register them as + being valid. */ + registerOutputs(); + + if (settings.postBuildHook != "") { + LOG(INFO) << "running post-build-hook '" << settings.postBuildHook + << "' [" << drvPath << "]"; + auto outputPaths = drv->outputPaths(); + std::map<std::string, std::string> hookEnvironment = getEnv(); + + hookEnvironment.emplace("DRV_PATH", drvPath); + hookEnvironment.emplace("OUT_PATHS", + chomp(concatStringsSep(" ", outputPaths))); + + RunOptions opts(settings.postBuildHook, {}); + opts.environment = hookEnvironment; + + struct LogSink : Sink { + std::string currentLine; + + void operator()(const unsigned char* data, size_t len) override { + for (size_t i = 0; i < len; i++) { + auto c = data[i]; + + if (c == '\n') { + flushLine(); + } else { + currentLine += c; + } + } + } + + void flushLine() { + if (settings.verboseBuild) { + LOG(ERROR) << "post-build-hook: " << currentLine; + } + currentLine.clear(); + } + + ~LogSink() override { + if (!currentLine.empty()) { + currentLine += '\n'; + flushLine(); + } + } + }; + LogSink sink; + + opts.standardOut = &sink; + opts.mergeStderrToStdout = true; + runProgram2(opts); + } + + if (buildMode == bmCheck) { + done(BuildResult::Built); + return; + } + + /* Delete unused redirected outputs (when doing hash rewriting). */ + for (auto& i : redirectedOutputs) { + deletePath(i.second); + } + + /* Delete the chroot (if we were using one). */ + autoDelChroot.reset(); /* this runs the destructor */ + + deleteTmpDir(true); + + /* Repeat the build if necessary. */ + if (curRound++ < nrRounds) { + outputLocks.unlock(); + state = &DerivationGoal::tryToBuild; + worker.wakeUp(shared_from_this()); + return; + } + + /* It is now safe to delete the lock files, since all future + lockers will see that the output paths are valid; they will + not create new lock files with the same names as the old + (unlinked) lock files. */ + outputLocks.setDeletion(true); + outputLocks.unlock(); + + } catch (BuildError& e) { + LOG(ERROR) << e.msg(); + + outputLocks.unlock(); + + BuildResult::Status st = BuildResult::MiscFailure; + + if (hook && WIFEXITED(status) && WEXITSTATUS(status) == 101) { + st = BuildResult::TimedOut; + + } else if (hook && (!WIFEXITED(status) || WEXITSTATUS(status) != 100)) { + } + + else { + st = dynamic_cast<NotDeterministic*>(&e) != nullptr + ? BuildResult::NotDeterministic + : statusOk(status) + ? BuildResult::OutputRejected + : fixedOutput || diskFull ? BuildResult::TransientFailure + : BuildResult::PermanentFailure; + } + + done(st, e.msg()); + return; + } + + done(BuildResult::Built); +} + +HookReply DerivationGoal::tryBuildHook() { + if (!worker.tryBuildHook || !useDerivation) { + return rpDecline; + } + + if (!worker.hook) { + worker.hook = std::make_unique<HookInstance>(); + } + + try { + /* Send the request to the hook. */ + worker.hook->sink << "try" + << (worker.getNrLocalBuilds() < settings.maxBuildJobs ? 1 + : 0) + << drv->platform << drvPath + << parsedDrv->getRequiredSystemFeatures(); + worker.hook->sink.flush(); + + /* Read the first line of input, which should be a word indicating + whether the hook wishes to perform the build. */ + string reply; + while (true) { + string s = readLine(worker.hook->fromHook.readSide.get()); + if (string(s, 0, 2) == "# ") { + reply = string(s, 2); + break; + } + s += "\n"; + std::cerr << s; + } + + DLOG(INFO) << "hook reply is " << reply; + + if (reply == "decline") { + return rpDecline; + } + if (reply == "decline-permanently") { + worker.tryBuildHook = false; + worker.hook = nullptr; + return rpDecline; + } else if (reply == "postpone") { + return rpPostpone; + } else if (reply != "accept") { + throw Error(format("bad hook reply '%1%'") % reply); + } + } catch (SysError& e) { + if (e.errNo == EPIPE) { + LOG(ERROR) << "build hook died unexpectedly: " + << chomp(drainFD(worker.hook->fromHook.readSide.get())); + worker.hook = nullptr; + return rpDecline; + } + throw; + } + + hook = std::move(worker.hook); + + machineName = readLine(hook->fromHook.readSide.get()); + + /* Tell the hook all the inputs that have to be copied to the + remote system. */ + hook->sink << inputPaths; + + /* Tell the hooks the missing outputs that have to be copied back + from the remote system. */ + hook->sink << missingPaths; + + hook->sink = FdSink(); + hook->toHook.writeSide = -1; + + /* Create the log file and pipe. */ + Path logFile = openLogFile(); + + set<int> fds; + fds.insert(hook->fromHook.readSide.get()); + fds.insert(hook->builderOut.readSide.get()); + worker.childStarted(shared_from_this(), fds, false, false); + + return rpAccept; +} + +void chmod_(const Path& path, mode_t mode) { + if (chmod(path.c_str(), mode) == -1) { + throw SysError(format("setting permissions on '%1%'") % path); + } +} + +int childEntry(void* arg) { + ((DerivationGoal*)arg)->runChild(); + return 1; +} + +PathSet DerivationGoal::exportReferences(const PathSet& storePaths) { + PathSet paths; + + for (auto storePath : storePaths) { + /* Check that the store path is valid. */ + if (!worker.store.isInStore(storePath)) { + throw BuildError( + format("'exportReferencesGraph' contains a non-store path '%1%'") % + storePath); + } + + storePath = worker.store.toStorePath(storePath); + + if (inputPaths.count(storePath) == 0u) { + throw BuildError( + "cannot export references of path '%s' because it is not in the " + "input closure of the derivation", + storePath); + } + + worker.store.computeFSClosure(storePath, paths); + } + + /* If there are derivations in the graph, then include their + outputs as well. This is useful if you want to do things + like passing all build-time dependencies of some path to a + derivation that builds a NixOS DVD image. */ + PathSet paths2(paths); + + for (auto& j : paths2) { + if (isDerivation(j)) { + Derivation drv = worker.store.derivationFromPath(j); + for (auto& k : drv.outputs) { + worker.store.computeFSClosure(k.second.path, paths); + } + } + } + + return paths; +} + +static std::once_flag dns_resolve_flag; + +static void preloadNSS() { + /* builtin:fetchurl can trigger a DNS lookup, which with glibc can trigger a + dynamic library load of one of the glibc NSS libraries in a sandboxed + child, which will fail unless the library's already been loaded in the + parent. So we force a lookup of an invalid domain to force the NSS + machinery to + load its lookup libraries in the parent before any child gets a chance to. + */ + std::call_once(dns_resolve_flag, []() { + struct addrinfo* res = nullptr; + + if (getaddrinfo("this.pre-initializes.the.dns.resolvers.invalid.", "http", + nullptr, &res) != 0) { + if (res != nullptr) { + freeaddrinfo(res); + } + } + }); +} + +void DerivationGoal::startBuilder() { + /* Right platform? */ + if (!parsedDrv->canBuildLocally()) { + throw Error( + "a '%s' with features {%s} is required to build '%s', but I am a '%s' " + "with features {%s}", + drv->platform, + concatStringsSep(", ", parsedDrv->getRequiredSystemFeatures()), drvPath, + settings.thisSystem, concatStringsSep(", ", settings.systemFeatures)); + } + + if (drv->isBuiltin()) { + preloadNSS(); + } + +#if __APPLE__ + additionalSandboxProfile = + parsedDrv->getStringAttr("__sandboxProfile").value_or(""); +#endif + + /* Are we doing a chroot build? */ + { + auto noChroot = parsedDrv->getBoolAttr("__noChroot"); + if (settings.sandboxMode == smEnabled) { + if (noChroot) { + throw Error(format("derivation '%1%' has '__noChroot' set, " + "but that's not allowed when 'sandbox' is 'true'") % + drvPath); + } +#if __APPLE__ + if (additionalSandboxProfile != "") + throw Error( + format("derivation '%1%' specifies a sandbox profile, " + "but this is only allowed when 'sandbox' is 'relaxed'") % + drvPath); +#endif + useChroot = true; + } else if (settings.sandboxMode == smDisabled) { + useChroot = false; + } else if (settings.sandboxMode == smRelaxed) { + useChroot = !fixedOutput && !noChroot; + } + } + + if (worker.store.storeDir != worker.store.realStoreDir) { +#if __linux__ + useChroot = true; +#else + throw Error( + "building using a diverted store is not supported on this platform"); +#endif + } + + /* If `build-users-group' is not empty, then we have to build as + one of the members of that group. */ + if (settings.buildUsersGroup != "" && getuid() == 0) { +#if defined(__linux__) || defined(__APPLE__) + buildUser = std::make_unique<UserLock>(); + + /* Make sure that no other processes are executing under this + uid. */ + buildUser->kill(); +#else + /* Don't know how to block the creation of setuid/setgid + binaries on this platform. */ + throw Error( + "build users are not supported on this platform for security reasons"); +#endif + } + + /* Create a temporary directory where the build will take + place. */ + auto drvName = storePathToName(drvPath); + tmpDir = createTempDir("", "nix-build-" + drvName, false, false, 0700); + + chownToBuilder(tmpDir); + + /* Substitute output placeholders with the actual output paths. */ + for (auto& output : drv->outputs) { + inputRewrites[hashPlaceholder(output.first)] = output.second.path; + } + + /* Construct the environment passed to the builder. */ + initEnv(); + + writeStructuredAttrs(); + + /* Handle exportReferencesGraph(), if set. */ + if (!parsedDrv->getStructuredAttrs()) { + /* The `exportReferencesGraph' feature allows the references graph + to be passed to a builder. This attribute should be a list of + pairs [name1 path1 name2 path2 ...]. The references graph of + each `pathN' will be stored in a text file `nameN' in the + temporary build directory. The text files have the format used + by `nix-store --register-validity'. However, the deriver + fields are left empty. */ + string s = get(drv->env, "exportReferencesGraph"); + auto ss = tokenizeString<Strings>(s); + if (ss.size() % 2 != 0) { + throw BuildError( + format("odd number of tokens in 'exportReferencesGraph': '%1%'") % s); + } + for (auto i = ss.begin(); i != ss.end();) { + string fileName = *i++; + checkStoreName(fileName); /* !!! abuse of this function */ + Path storePath = *i++; + + /* Write closure info to <fileName>. */ + writeFile(tmpDir + "/" + fileName, + worker.store.makeValidityRegistration( + exportReferences({storePath}), false, false)); + } + } + + if (useChroot) { + /* Allow a user-configurable set of directories from the + host file system. */ + PathSet dirs = settings.sandboxPaths; + PathSet dirs2 = settings.extraSandboxPaths; + dirs.insert(dirs2.begin(), dirs2.end()); + + dirsInChroot.clear(); + + for (auto i : dirs) { + if (i.empty()) { + continue; + } + bool optional = false; + if (i[i.size() - 1] == '?') { + optional = true; + i.pop_back(); + } + size_t p = i.find('='); + if (p == string::npos) { + dirsInChroot[i] = ChrootPath(i, optional); + } else { + dirsInChroot[string(i, 0, p)] = ChrootPath(string(i, p + 1), optional); + } + } + dirsInChroot[tmpDirInSandbox] = ChrootPath(tmpDir); + + /* Add the closure of store paths to the chroot. */ + PathSet closure; + for (auto& i : dirsInChroot) { + try { + if (worker.store.isInStore(i.second.source)) { + worker.store.computeFSClosure( + worker.store.toStorePath(i.second.source), closure); + } + } catch (InvalidPath& e) { + } catch (Error& e) { + throw Error(format("while processing 'sandbox-paths': %s") % e.what()); + } + } + for (auto& i : closure) { + dirsInChroot[i] = ChrootPath(i); + } + + PathSet allowedPaths = settings.allowedImpureHostPrefixes; + + /* This works like the above, except on a per-derivation level */ + auto impurePaths = + parsedDrv->getStringsAttr("__impureHostDeps").value_or(Strings()); + + for (auto& i : impurePaths) { + bool found = false; + /* Note: we're not resolving symlinks here to prevent + giving a non-root user info about inaccessible + files. */ + Path canonI = canonPath(i); + /* If only we had a trie to do this more efficiently :) luckily, these are + * generally going to be pretty small */ + for (auto& a : allowedPaths) { + Path canonA = canonPath(a); + if (canonI == canonA || isInDir(canonI, canonA)) { + found = true; + break; + } + } + if (!found) { + throw Error(format("derivation '%1%' requested impure path '%2%', but " + "it was not in allowed-impure-host-deps") % + drvPath % i); + } + + dirsInChroot[i] = ChrootPath(i); + } + +#if __linux__ + /* Create a temporary directory in which we set up the chroot + environment using bind-mounts. We put it in the Nix store + to ensure that we can create hard-links to non-directory + inputs in the fake Nix store in the chroot (see below). */ + chrootRootDir = worker.store.toRealPath(drvPath) + ".chroot"; + deletePath(chrootRootDir); + + /* Clean up the chroot directory automatically. */ + autoDelChroot = std::make_shared<AutoDelete>(chrootRootDir); + + DLOG(INFO) << "setting up chroot environment in '" << chrootRootDir << "'"; + + if (mkdir(chrootRootDir.c_str(), 0750) == -1) { + throw SysError(format("cannot create '%1%'") % chrootRootDir); + } + + if (buildUser && + chown(chrootRootDir.c_str(), 0, buildUser->getGID()) == -1) { + throw SysError(format("cannot change ownership of '%1%'") % + chrootRootDir); + } + + /* Create a writable /tmp in the chroot. Many builders need + this. (Of course they should really respect $TMPDIR + instead.) */ + Path chrootTmpDir = chrootRootDir + "/tmp"; + createDirs(chrootTmpDir); + chmod_(chrootTmpDir, 01777); + + /* Create a /etc/passwd with entries for the build user and the + nobody account. The latter is kind of a hack to support + Samba-in-QEMU. */ + createDirs(chrootRootDir + "/etc"); + + writeFile(chrootRootDir + "/etc/passwd", + fmt("root:x:0:0:Nix build user:%3%:/noshell\n" + "nixbld:x:%1%:%2%:Nix build user:%3%:/noshell\n" + "nobody:x:65534:65534:Nobody:/:/noshell\n", + sandboxUid, sandboxGid, settings.sandboxBuildDir)); + + /* Declare the build user's group so that programs get a consistent + view of the system (e.g., "id -gn"). */ + writeFile(chrootRootDir + "/etc/group", (format("root:x:0:\n" + "nixbld:!:%1%:\n" + "nogroup:x:65534:\n") % + sandboxGid) + .str()); + + /* Create /etc/hosts with localhost entry. */ + if (!fixedOutput) { + writeFile(chrootRootDir + "/etc/hosts", + "127.0.0.1 localhost\n::1 localhost\n"); + } + + /* Make the closure of the inputs available in the chroot, + rather than the whole Nix store. This prevents any access + to undeclared dependencies. Directories are bind-mounted, + while other inputs are hard-linked (since only directories + can be bind-mounted). !!! As an extra security + precaution, make the fake Nix store only writable by the + build user. */ + Path chrootStoreDir = chrootRootDir + worker.store.storeDir; + createDirs(chrootStoreDir); + chmod_(chrootStoreDir, 01775); + + if (buildUser && + chown(chrootStoreDir.c_str(), 0, buildUser->getGID()) == -1) { + throw SysError(format("cannot change ownership of '%1%'") % + chrootStoreDir); + } + + for (auto& i : inputPaths) { + Path r = worker.store.toRealPath(i); + struct stat st; + if (lstat(r.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % i); + } + if (S_ISDIR(st.st_mode)) { + dirsInChroot[i] = ChrootPath(r); + } else { + Path p = chrootRootDir + i; + DLOG(INFO) << "linking '" << p << "' to '" << r << "'"; + if (link(r.c_str(), p.c_str()) == -1) { + /* Hard-linking fails if we exceed the maximum + link count on a file (e.g. 32000 of ext3), + which is quite possible after a `nix-store + --optimise'. */ + if (errno != EMLINK) { + throw SysError(format("linking '%1%' to '%2%'") % p % i); + } + StringSink sink; + dumpPath(r, sink); + StringSource source(*sink.s); + restorePath(p, source); + } + } + } + + /* If we're repairing, checking or rebuilding part of a + multiple-outputs derivation, it's possible that we're + rebuilding a path that is in settings.dirsInChroot + (typically the dependencies of /bin/sh). Throw them + out. */ + for (auto& i : drv->outputs) { + dirsInChroot.erase(i.second.path); + } + +#elif __APPLE__ + /* We don't really have any parent prep work to do (yet?) + All work happens in the child, instead. */ +#else + throw Error("sandboxing builds is not supported on this platform"); +#endif + } + + if (needsHashRewrite()) { + if (pathExists(homeDir)) { + throw Error(format("directory '%1%' exists; please remove it") % homeDir); + } + + /* We're not doing a chroot build, but we have some valid + output paths. Since we can't just overwrite or delete + them, we have to do hash rewriting: i.e. in the + environment/arguments passed to the build, we replace the + hashes of the valid outputs with unique dummy strings; + after the build, we discard the redirected outputs + corresponding to the valid outputs, and rewrite the + contents of the new outputs to replace the dummy strings + with the actual hashes. */ + if (!validPaths.empty()) { + for (auto& i : validPaths) { + addHashRewrite(i); + } + } + + /* If we're repairing, then we don't want to delete the + corrupt outputs in advance. So rewrite them as well. */ + if (buildMode == bmRepair) { + for (auto& i : missingPaths) { + if (worker.store.isValidPath(i) && pathExists(i)) { + addHashRewrite(i); + redirectedBadOutputs.insert(i); + } + } + } + } + + if (useChroot && settings.preBuildHook != "" && + (dynamic_cast<Derivation*>(drv.get()) != nullptr)) { + DLOG(INFO) << "executing pre-build hook '" << settings.preBuildHook << "'"; + auto args = + useChroot ? Strings({drvPath, chrootRootDir}) : Strings({drvPath}); + enum BuildHookState { stBegin, stExtraChrootDirs }; + auto state = stBegin; + auto lines = runProgram(settings.preBuildHook, false, args); + auto lastPos = std::string::size_type{0}; + for (auto nlPos = lines.find('\n'); nlPos != string::npos; + nlPos = lines.find('\n', lastPos)) { + auto line = std::string{lines, lastPos, nlPos - lastPos}; + lastPos = nlPos + 1; + if (state == stBegin) { + if (line == "extra-sandbox-paths" || line == "extra-chroot-dirs") { + state = stExtraChrootDirs; + } else { + throw Error(format("unknown pre-build hook command '%1%'") % line); + } + } else if (state == stExtraChrootDirs) { + if (line.empty()) { + state = stBegin; + } else { + auto p = line.find('='); + if (p == string::npos) { + dirsInChroot[line] = ChrootPath(line); + } else { + dirsInChroot[string(line, 0, p)] = ChrootPath(string(line, p + 1)); + } + } + } + } + } + + /* Run the builder. */ + DLOG(INFO) << "executing builder '" << drv->builder << "'"; + + /* Create the log file. */ + Path logFile = openLogFile(); + + /* Create a pipe to get the output of the builder. */ + // builderOut.create(); + + builderOut.readSide = posix_openpt(O_RDWR | O_NOCTTY); + if (!builderOut.readSide) { + throw SysError("opening pseudoterminal master"); + } + + std::string slaveName(ptsname(builderOut.readSide.get())); + + if (buildUser) { + if (chmod(slaveName.c_str(), 0600) != 0) { + throw SysError("changing mode of pseudoterminal slave"); + } + + if (chown(slaveName.c_str(), buildUser->getUID(), 0) != 0) { + throw SysError("changing owner of pseudoterminal slave"); + } + } else { + if (grantpt(builderOut.readSide.get()) != 0) { + throw SysError("granting access to pseudoterminal slave"); + } + } + +#if 0 + // Mount the pt in the sandbox so that the "tty" command works. + // FIXME: this doesn't work with the new devpts in the sandbox. + if (useChroot) + dirsInChroot[slaveName] = {slaveName, false}; +#endif + + if (unlockpt(builderOut.readSide.get()) != 0) { + throw SysError("unlocking pseudoterminal"); + } + + builderOut.writeSide = open(slaveName.c_str(), O_RDWR | O_NOCTTY); + if (!builderOut.writeSide) { + throw SysError("opening pseudoterminal slave"); + } + + // Put the pt into raw mode to prevent \n -> \r\n translation. + struct termios term; + if (tcgetattr(builderOut.writeSide.get(), &term) != 0) { + throw SysError("getting pseudoterminal attributes"); + } + + cfmakeraw(&term); + + if (tcsetattr(builderOut.writeSide.get(), TCSANOW, &term) != 0) { + throw SysError("putting pseudoterminal into raw mode"); + } + + result.startTime = time(nullptr); + + /* Fork a child to build the package. */ + ProcessOptions options; + +#if __linux__ + if (useChroot) { + /* Set up private namespaces for the build: + + - The PID namespace causes the build to start as PID 1. + Processes outside of the chroot are not visible to those + on the inside, but processes inside the chroot are + visible from the outside (though with different PIDs). + + - The private mount namespace ensures that all the bind + mounts we do will only show up in this process and its + children, and will disappear automatically when we're + done. + + - The private network namespace ensures that the builder + cannot talk to the outside world (or vice versa). It + only has a private loopback interface. (Fixed-output + derivations are not run in a private network namespace + to allow functions like fetchurl to work.) + + - The IPC namespace prevents the builder from communicating + with outside processes using SysV IPC mechanisms (shared + memory, message queues, semaphores). It also ensures + that all IPC objects are destroyed when the builder + exits. + + - The UTS namespace ensures that builders see a hostname of + localhost rather than the actual hostname. + + We use a helper process to do the clone() to work around + clone() being broken in multi-threaded programs due to + at-fork handlers not being run. Note that we use + CLONE_PARENT to ensure that the real builder is parented to + us. + */ + + if (!fixedOutput) { + privateNetwork = true; + } + + userNamespaceSync.create(); + + options.allowVfork = false; + + Pid helper = startProcess( + [&]() { + /* Drop additional groups here because we can't do it + after we've created the new user namespace. FIXME: + this means that if we're not root in the parent + namespace, we can't drop additional groups; they will + be mapped to nogroup in the child namespace. There does + not seem to be a workaround for this. (But who can tell + from reading user_namespaces(7)?) + See also https://lwn.net/Articles/621612/. */ + if (getuid() == 0 && setgroups(0, nullptr) == -1) { + throw SysError("setgroups failed"); + } + + size_t stackSize = 1 * 1024 * 1024; + char* stack = + (char*)mmap(nullptr, stackSize, PROT_WRITE | PROT_READ, + MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0); + if (stack == MAP_FAILED) { + throw SysError("allocating stack"); + } + + int flags = CLONE_NEWUSER | CLONE_NEWPID | CLONE_NEWNS | + CLONE_NEWIPC | CLONE_NEWUTS | CLONE_PARENT | SIGCHLD; + if (privateNetwork) { + flags |= CLONE_NEWNET; + } + + pid_t child = clone(childEntry, stack + stackSize, flags, this); + if (child == -1 && errno == EINVAL) { + /* Fallback for Linux < 2.13 where CLONE_NEWPID and + CLONE_PARENT are not allowed together. */ + flags &= ~CLONE_NEWPID; + child = clone(childEntry, stack + stackSize, flags, this); + } + if (child == -1 && (errno == EPERM || errno == EINVAL)) { + /* Some distros patch Linux to not allow unpriveleged + * user namespaces. If we get EPERM or EINVAL, try + * without CLONE_NEWUSER and see if that works. + */ + flags &= ~CLONE_NEWUSER; + child = clone(childEntry, stack + stackSize, flags, this); + } + /* Otherwise exit with EPERM so we can handle this in the + parent. This is only done when sandbox-fallback is set + to true (the default). */ + if (child == -1 && (errno == EPERM || errno == EINVAL) && + settings.sandboxFallback) { + _exit(1); + } + if (child == -1) { + throw SysError("cloning builder process"); + } + + writeFull(builderOut.writeSide.get(), std::to_string(child) + "\n"); + _exit(0); + }, + options); + + int res = helper.wait(); + if (res != 0 && settings.sandboxFallback) { + useChroot = false; + initTmpDir(); + goto fallback; + } else if (res != 0) { + throw Error("unable to start build process"); + } + + userNamespaceSync.readSide = -1; + + pid_t tmp; + if (!string2Int<pid_t>(readLine(builderOut.readSide.get()), tmp)) { + abort(); + } + pid = tmp; + + /* Set the UID/GID mapping of the builder's user namespace + such that the sandbox user maps to the build user, or to + the calling user (if build users are disabled). */ + uid_t hostUid = buildUser ? buildUser->getUID() : getuid(); + uid_t hostGid = buildUser ? buildUser->getGID() : getgid(); + + writeFile("/proc/" + std::to_string(pid) + "/uid_map", + (format("%d %d 1") % sandboxUid % hostUid).str()); + + writeFile("/proc/" + std::to_string(pid) + "/setgroups", "deny"); + + writeFile("/proc/" + std::to_string(pid) + "/gid_map", + (format("%d %d 1") % sandboxGid % hostGid).str()); + + /* Signal the builder that we've updated its user + namespace. */ + writeFull(userNamespaceSync.writeSide.get(), "1"); + userNamespaceSync.writeSide = -1; + + } else +#endif + { + fallback: + options.allowVfork = !buildUser && !drv->isBuiltin(); + pid = startProcess([&]() { runChild(); }, options); + } + + /* parent */ + pid.setSeparatePG(true); + builderOut.writeSide = -1; + worker.childStarted(shared_from_this(), {builderOut.readSide.get()}, true, + true); + + /* Check if setting up the build environment failed. */ + while (true) { + string msg = readLine(builderOut.readSide.get()); + if (string(msg, 0, 1) == "\1") { + if (msg.size() == 1) { + break; + } + throw Error(string(msg, 1)); + } + DLOG(INFO) << msg; + } +} + +void DerivationGoal::initTmpDir() { + /* In a sandbox, for determinism, always use the same temporary + directory. */ +#if __linux__ + tmpDirInSandbox = useChroot ? settings.sandboxBuildDir : tmpDir; +#else + tmpDirInSandbox = tmpDir; +#endif + + /* In non-structured mode, add all bindings specified in the + derivation via the environment, except those listed in the + passAsFile attribute. Those are passed as file names pointing + to temporary files containing the contents. Note that + passAsFile is ignored in structure mode because it's not + needed (attributes are not passed through the environment, so + there is no size constraint). */ + if (!parsedDrv->getStructuredAttrs()) { + auto passAsFile = tokenizeString<StringSet>(get(drv->env, "passAsFile")); + int fileNr = 0; + for (auto& i : drv->env) { + if (passAsFile.find(i.first) == passAsFile.end()) { + env[i.first] = i.second; + } else { + string fn = ".attr-" + std::to_string(fileNr++); + Path p = tmpDir + "/" + fn; + writeFile(p, rewriteStrings(i.second, inputRewrites)); + chownToBuilder(p); + env[i.first + "Path"] = tmpDirInSandbox + "/" + fn; + } + } + } + + /* For convenience, set an environment pointing to the top build + directory. */ + env["NIX_BUILD_TOP"] = tmpDirInSandbox; + + /* Also set TMPDIR and variants to point to this directory. */ + env["TMPDIR"] = env["TEMPDIR"] = env["TMP"] = env["TEMP"] = tmpDirInSandbox; + + /* Explicitly set PWD to prevent problems with chroot builds. In + particular, dietlibc cannot figure out the cwd because the + inode of the current directory doesn't appear in .. (because + getdents returns the inode of the mount point). */ + env["PWD"] = tmpDirInSandbox; +} + +void DerivationGoal::initEnv() { + env.clear(); + + /* Most shells initialise PATH to some default (/bin:/usr/bin:...) when + PATH is not set. We don't want this, so we fill it in with some dummy + value. */ + env["PATH"] = "/path-not-set"; + + /* Set HOME to a non-existing path to prevent certain programs from using + /etc/passwd (or NIS, or whatever) to locate the home directory (for + example, wget looks for ~/.wgetrc). I.e., these tools use /etc/passwd + if HOME is not set, but they will just assume that the settings file + they are looking for does not exist if HOME is set but points to some + non-existing path. */ + env["HOME"] = homeDir; + + /* Tell the builder where the Nix store is. Usually they + shouldn't care, but this is useful for purity checking (e.g., + the compiler or linker might only want to accept paths to files + in the store or in the build directory). */ + env["NIX_STORE"] = worker.store.storeDir; + + /* The maximum number of cores to utilize for parallel building. */ + env["NIX_BUILD_CORES"] = (format("%d") % settings.buildCores).str(); + + initTmpDir(); + + /* Compatibility hack with Nix <= 0.7: if this is a fixed-output + derivation, tell the builder, so that for instance `fetchurl' + can skip checking the output. On older Nixes, this environment + variable won't be set, so `fetchurl' will do the check. */ + if (fixedOutput) { + env["NIX_OUTPUT_CHECKED"] = "1"; + } + + /* *Only* if this is a fixed-output derivation, propagate the + values of the environment variables specified in the + `impureEnvVars' attribute to the builder. This allows for + instance environment variables for proxy configuration such as + `http_proxy' to be easily passed to downloaders like + `fetchurl'. Passing such environment variables from the caller + to the builder is generally impure, but the output of + fixed-output derivations is by definition pure (since we + already know the cryptographic hash of the output). */ + if (fixedOutput) { + for (auto& i : + parsedDrv->getStringsAttr("impureEnvVars").value_or(Strings())) { + env[i] = getEnv(i); + } + } + + /* Currently structured log messages piggyback on stderr, but we + may change that in the future. So tell the builder which file + descriptor to use for that. */ + env["NIX_LOG_FD"] = "2"; + + /* Trigger colored output in various tools. */ + env["TERM"] = "xterm-256color"; +} + +static std::regex shVarName("[A-Za-z_][A-Za-z0-9_]*"); + +void DerivationGoal::writeStructuredAttrs() { + auto& structuredAttrs = parsedDrv->getStructuredAttrs(); + if (!structuredAttrs) { + return; + } + + auto json = *structuredAttrs; + + /* Add an "outputs" object containing the output paths. */ + nlohmann::json outputs; + for (auto& i : drv->outputs) { + outputs[i.first] = rewriteStrings(i.second.path, inputRewrites); + } + json["outputs"] = outputs; + + /* Handle exportReferencesGraph. */ + auto e = json.find("exportReferencesGraph"); + if (e != json.end() && e->is_object()) { + for (auto i = e->begin(); i != e->end(); ++i) { + std::ostringstream str; + { + JSONPlaceholder jsonRoot(str, true); + PathSet storePaths; + for (auto& p : *i) { + storePaths.insert(p.get<std::string>()); + } + worker.store.pathInfoToJSON(jsonRoot, exportReferences(storePaths), + false, true); + } + json[i.key()] = nlohmann::json::parse(str.str()); // urgh + } + } + + writeFile(tmpDir + "/.attrs.json", + rewriteStrings(json.dump(), inputRewrites)); + chownToBuilder(tmpDir + "/.attrs.json"); + + /* As a convenience to bash scripts, write a shell file that + maps all attributes that are representable in bash - + namely, strings, integers, nulls, Booleans, and arrays and + objects consisting entirely of those values. (So nested + arrays or objects are not supported.) */ + + auto handleSimpleType = + [](const nlohmann::json& value) -> std::optional<std::string> { + if (value.is_string()) { + return shellEscape(value); + } + + if (value.is_number()) { + auto f = value.get<float>(); + if (std::ceil(f) == f) { + return std::to_string(value.get<int>()); + } + } + + if (value.is_null()) { + return std::string("''"); + } + + if (value.is_boolean()) { + return value.get<bool>() ? std::string("1") : std::string(""); + } + + return {}; + }; + + std::string jsonSh; + + for (auto i = json.begin(); i != json.end(); ++i) { + if (!std::regex_match(i.key(), shVarName)) { + continue; + } + + auto& value = i.value(); + + auto s = handleSimpleType(value); + if (s) { + jsonSh += fmt("declare %s=%s\n", i.key(), *s); + + } else if (value.is_array()) { + std::string s2; + bool good = true; + + for (auto i = value.begin(); i != value.end(); ++i) { + auto s3 = handleSimpleType(i.value()); + if (!s3) { + good = false; + break; + } + s2 += *s3; + s2 += ' '; + } + + if (good) { + jsonSh += fmt("declare -a %s=(%s)\n", i.key(), s2); + } + } + + else if (value.is_object()) { + std::string s2; + bool good = true; + + for (auto i = value.begin(); i != value.end(); ++i) { + auto s3 = handleSimpleType(i.value()); + if (!s3) { + good = false; + break; + } + s2 += fmt("[%s]=%s ", shellEscape(i.key()), *s3); + } + + if (good) { + jsonSh += fmt("declare -A %s=(%s)\n", i.key(), s2); + } + } + } + + writeFile(tmpDir + "/.attrs.sh", rewriteStrings(jsonSh, inputRewrites)); + chownToBuilder(tmpDir + "/.attrs.sh"); +} + +void DerivationGoal::chownToBuilder(const Path& path) { + if (!buildUser) { + return; + } + if (chown(path.c_str(), buildUser->getUID(), buildUser->getGID()) == -1) { + throw SysError(format("cannot change ownership of '%1%'") % path); + } +} + +void setupSeccomp() { +#if __linux__ + if (!settings.filterSyscalls) { + return; + } +#if HAVE_SECCOMP + scmp_filter_ctx ctx; + + if ((ctx = seccomp_init(SCMP_ACT_ALLOW)) == nullptr) { + throw SysError("unable to initialize seccomp mode 2"); + } + + Finally cleanup([&]() { seccomp_release(ctx); }); + + if (nativeSystem == "x86_64-linux" && + seccomp_arch_add(ctx, SCMP_ARCH_X86) != 0) { + throw SysError("unable to add 32-bit seccomp architecture"); + } + + if (nativeSystem == "x86_64-linux" && + seccomp_arch_add(ctx, SCMP_ARCH_X32) != 0) { + throw SysError("unable to add X32 seccomp architecture"); + } + + if (nativeSystem == "aarch64-linux" && + seccomp_arch_add(ctx, SCMP_ARCH_ARM) != 0) { + LOG(ERROR) << "unable to add ARM seccomp architecture; this may result in " + << "spurious build failures if running 32-bit ARM processes"; + } + + /* Prevent builders from creating setuid/setgid binaries. */ + for (int perm : {S_ISUID, S_ISGID}) { + if (seccomp_rule_add(ctx, SCMP_ACT_ERRNO(EPERM), SCMP_SYS(chmod), 1, + SCMP_A1(SCMP_CMP_MASKED_EQ, (scmp_datum_t)perm, + (scmp_datum_t)perm)) != 0) { + throw SysError("unable to add seccomp rule"); + } + + if (seccomp_rule_add(ctx, SCMP_ACT_ERRNO(EPERM), SCMP_SYS(fchmod), 1, + SCMP_A1(SCMP_CMP_MASKED_EQ, (scmp_datum_t)perm, + (scmp_datum_t)perm)) != 0) { + throw SysError("unable to add seccomp rule"); + } + + if (seccomp_rule_add(ctx, SCMP_ACT_ERRNO(EPERM), SCMP_SYS(fchmodat), 1, + SCMP_A2(SCMP_CMP_MASKED_EQ, (scmp_datum_t)perm, + (scmp_datum_t)perm)) != 0) { + throw SysError("unable to add seccomp rule"); + } + } + + /* Prevent builders from creating EAs or ACLs. Not all filesystems + support these, and they're not allowed in the Nix store because + they're not representable in the NAR serialisation. */ + if (seccomp_rule_add(ctx, SCMP_ACT_ERRNO(ENOTSUP), SCMP_SYS(setxattr), 0) != + 0 || + seccomp_rule_add(ctx, SCMP_ACT_ERRNO(ENOTSUP), SCMP_SYS(lsetxattr), 0) != + 0 || + seccomp_rule_add(ctx, SCMP_ACT_ERRNO(ENOTSUP), SCMP_SYS(fsetxattr), 0) != + 0) { + throw SysError("unable to add seccomp rule"); + } + + if (seccomp_attr_set(ctx, SCMP_FLTATR_CTL_NNP, + settings.allowNewPrivileges ? 0 : 1) != 0) { + throw SysError("unable to set 'no new privileges' seccomp attribute"); + } + + if (seccomp_load(ctx) != 0) { + throw SysError("unable to load seccomp BPF program"); + } +#else + throw Error( + "seccomp is not supported on this platform; " + "you can bypass this error by setting the option 'filter-syscalls' to " + "false, but note that untrusted builds can then create setuid binaries!"); +#endif +#endif +} + +void DerivationGoal::runChild() { + /* Warning: in the child we should absolutely not make any SQLite + calls! */ + + try { /* child */ + + commonChildInit(builderOut); + + try { + setupSeccomp(); + } catch (...) { + if (buildUser) { + throw; + } + } + + bool setUser = true; + + /* Make the contents of netrc available to builtin:fetchurl + (which may run under a different uid and/or in a sandbox). */ + std::string netrcData; + try { + if (drv->isBuiltin() && drv->builder == "builtin:fetchurl") { + netrcData = readFile(settings.netrcFile); + } + } catch (SysError&) { + } + +#if __linux__ + if (useChroot) { + userNamespaceSync.writeSide = -1; + + if (drainFD(userNamespaceSync.readSide.get()) != "1") { + throw Error("user namespace initialisation failed"); + } + + userNamespaceSync.readSide = -1; + + if (privateNetwork) { + /* Initialise the loopback interface. */ + AutoCloseFD fd(socket(PF_INET, SOCK_DGRAM, IPPROTO_IP)); + if (!fd) { + throw SysError("cannot open IP socket"); + } + + struct ifreq ifr; + strcpy(ifr.ifr_name, "lo"); + ifr.ifr_flags = IFF_UP | IFF_LOOPBACK | IFF_RUNNING; + if (ioctl(fd.get(), SIOCSIFFLAGS, &ifr) == -1) { + throw SysError("cannot set loopback interface flags"); + } + } + + /* Set the hostname etc. to fixed values. */ + char hostname[] = "localhost"; + if (sethostname(hostname, sizeof(hostname)) == -1) { + throw SysError("cannot set host name"); + } + char domainname[] = "(none)"; // kernel default + if (setdomainname(domainname, sizeof(domainname)) == -1) { + throw SysError("cannot set domain name"); + } + + /* Make all filesystems private. This is necessary + because subtrees may have been mounted as "shared" + (MS_SHARED). (Systemd does this, for instance.) Even + though we have a private mount namespace, mounting + filesystems on top of a shared subtree still propagates + outside of the namespace. Making a subtree private is + local to the namespace, though, so setting MS_PRIVATE + does not affect the outside world. */ + if (mount(nullptr, "/", nullptr, MS_REC | MS_PRIVATE, nullptr) == -1) { + throw SysError("unable to make '/' private mount"); + } + + /* Bind-mount chroot directory to itself, to treat it as a + different filesystem from /, as needed for pivot_root. */ + if (mount(chrootRootDir.c_str(), chrootRootDir.c_str(), nullptr, MS_BIND, + nullptr) == -1) { + throw SysError(format("unable to bind mount '%1%'") % chrootRootDir); + } + + /* Set up a nearly empty /dev, unless the user asked to + bind-mount the host /dev. */ + Strings ss; + if (dirsInChroot.find("/dev") == dirsInChroot.end()) { + createDirs(chrootRootDir + "/dev/shm"); + createDirs(chrootRootDir + "/dev/pts"); + ss.push_back("/dev/full"); + if ((settings.systemFeatures.get().count("kvm") != 0u) && + pathExists("/dev/kvm")) { + ss.push_back("/dev/kvm"); + } + ss.push_back("/dev/null"); + ss.push_back("/dev/random"); + ss.push_back("/dev/tty"); + ss.push_back("/dev/urandom"); + ss.push_back("/dev/zero"); + createSymlink("/proc/self/fd", chrootRootDir + "/dev/fd"); + createSymlink("/proc/self/fd/0", chrootRootDir + "/dev/stdin"); + createSymlink("/proc/self/fd/1", chrootRootDir + "/dev/stdout"); + createSymlink("/proc/self/fd/2", chrootRootDir + "/dev/stderr"); + } + + /* Fixed-output derivations typically need to access the + network, so give them access to /etc/resolv.conf and so + on. */ + if (fixedOutput) { + ss.push_back("/etc/resolv.conf"); + + // Only use nss functions to resolve hosts and + // services. Don’t use it for anything else that may + // be configured for this system. This limits the + // potential impurities introduced in fixed outputs. + writeFile(chrootRootDir + "/etc/nsswitch.conf", + "hosts: files dns\nservices: files\n"); + + ss.push_back("/etc/services"); + ss.push_back("/etc/hosts"); + if (pathExists("/var/run/nscd/socket")) { + ss.push_back("/var/run/nscd/socket"); + } + } + + for (auto& i : ss) { + dirsInChroot.emplace(i, i); + } + + /* Bind-mount all the directories from the "host" + filesystem that we want in the chroot + environment. */ + auto doBind = [&](const Path& source, const Path& target, + bool optional = false) { + DLOG(INFO) << "bind mounting '" << source << "' to '" << target << "'"; + struct stat st; + if (stat(source.c_str(), &st) == -1) { + if (optional && errno == ENOENT) { + return; + } + throw SysError("getting attributes of path '%1%'", source); + } + if (S_ISDIR(st.st_mode)) { + createDirs(target); + } else { + createDirs(dirOf(target)); + writeFile(target, ""); + } + if (mount(source.c_str(), target.c_str(), "", MS_BIND | MS_REC, + nullptr) == -1) { + throw SysError("bind mount from '%1%' to '%2%' failed", source, + target); + } + }; + + for (auto& i : dirsInChroot) { + if (i.second.source == "/proc") { + continue; + } // backwards compatibility + doBind(i.second.source, chrootRootDir + i.first, i.second.optional); + } + + /* Bind a new instance of procfs on /proc. */ + createDirs(chrootRootDir + "/proc"); + if (mount("none", (chrootRootDir + "/proc").c_str(), "proc", 0, + nullptr) == -1) { + throw SysError("mounting /proc"); + } + + /* Mount a new tmpfs on /dev/shm to ensure that whatever + the builder puts in /dev/shm is cleaned up automatically. */ + if (pathExists("/dev/shm") && + mount("none", (chrootRootDir + "/dev/shm").c_str(), "tmpfs", 0, + fmt("size=%s", settings.sandboxShmSize).c_str()) == -1) { + throw SysError("mounting /dev/shm"); + } + + /* Mount a new devpts on /dev/pts. Note that this + requires the kernel to be compiled with + CONFIG_DEVPTS_MULTIPLE_INSTANCES=y (which is the case + if /dev/ptx/ptmx exists). */ + if (pathExists("/dev/pts/ptmx") && + !pathExists(chrootRootDir + "/dev/ptmx") && + (dirsInChroot.count("/dev/pts") == 0u)) { + if (mount("none", (chrootRootDir + "/dev/pts").c_str(), "devpts", 0, + "newinstance,mode=0620") == 0) { + createSymlink("/dev/pts/ptmx", chrootRootDir + "/dev/ptmx"); + + /* Make sure /dev/pts/ptmx is world-writable. With some + Linux versions, it is created with permissions 0. */ + chmod_(chrootRootDir + "/dev/pts/ptmx", 0666); + } else { + if (errno != EINVAL) { + throw SysError("mounting /dev/pts"); + } + doBind("/dev/pts", chrootRootDir + "/dev/pts"); + doBind("/dev/ptmx", chrootRootDir + "/dev/ptmx"); + } + } + + /* Do the chroot(). */ + if (chdir(chrootRootDir.c_str()) == -1) { + throw SysError(format("cannot change directory to '%1%'") % + chrootRootDir); + } + + if (mkdir("real-root", 0) == -1) { + throw SysError("cannot create real-root directory"); + } + + if (pivot_root(".", "real-root") == -1) { + throw SysError(format("cannot pivot old root directory onto '%1%'") % + (chrootRootDir + "/real-root")); + } + + if (chroot(".") == -1) { + throw SysError(format("cannot change root directory to '%1%'") % + chrootRootDir); + } + + if (umount2("real-root", MNT_DETACH) == -1) { + throw SysError("cannot unmount real root filesystem"); + } + + if (rmdir("real-root") == -1) { + throw SysError("cannot remove real-root directory"); + } + + /* Switch to the sandbox uid/gid in the user namespace, + which corresponds to the build user or calling user in + the parent namespace. */ + if (setgid(sandboxGid) == -1) { + throw SysError("setgid failed"); + } + if (setuid(sandboxUid) == -1) { + throw SysError("setuid failed"); + } + + setUser = false; + } +#endif + + if (chdir(tmpDirInSandbox.c_str()) == -1) { + throw SysError(format("changing into '%1%'") % tmpDir); + } + + /* Close all other file descriptors. */ + closeMostFDs({STDIN_FILENO, STDOUT_FILENO, STDERR_FILENO}); + +#if __linux__ + /* Change the personality to 32-bit if we're doing an + i686-linux build on an x86_64-linux machine. */ + struct utsname utsbuf; + uname(&utsbuf); + if (drv->platform == "i686-linux" && + (settings.thisSystem == "x86_64-linux" || + ((strcmp(utsbuf.sysname, "Linux") == 0) && + (strcmp(utsbuf.machine, "x86_64") == 0)))) { + if (personality(PER_LINUX32) == -1) { + throw SysError("cannot set i686-linux personality"); + } + } + + /* Impersonate a Linux 2.6 machine to get some determinism in + builds that depend on the kernel version. */ + if ((drv->platform == "i686-linux" || drv->platform == "x86_64-linux") && + settings.impersonateLinux26) { + int cur = personality(0xffffffff); + if (cur != -1) { + personality(cur | 0x0020000 /* == UNAME26 */); + } + } + + /* Disable address space randomization for improved + determinism. */ + int cur = personality(0xffffffff); + if (cur != -1) { + personality(cur | ADDR_NO_RANDOMIZE); + } +#endif + + /* Disable core dumps by default. */ + struct rlimit limit = {0, RLIM_INFINITY}; + setrlimit(RLIMIT_CORE, &limit); + + // FIXME: set other limits to deterministic values? + + /* Fill in the environment. */ + Strings envStrs; + for (auto& i : env) { + envStrs.push_back( + rewriteStrings(i.first + "=" + i.second, inputRewrites)); + } + + /* If we are running in `build-users' mode, then switch to the + user we allocated above. Make sure that we drop all root + privileges. Note that above we have closed all file + descriptors except std*, so that's safe. Also note that + setuid() when run as root sets the real, effective and + saved UIDs. */ + if (setUser && buildUser) { + /* Preserve supplementary groups of the build user, to allow + admins to specify groups such as "kvm". */ + if (!buildUser->getSupplementaryGIDs().empty() && + setgroups(buildUser->getSupplementaryGIDs().size(), + buildUser->getSupplementaryGIDs().data()) == -1) { + throw SysError("cannot set supplementary groups of build user"); + } + + if (setgid(buildUser->getGID()) == -1 || + getgid() != buildUser->getGID() || getegid() != buildUser->getGID()) { + throw SysError("setgid failed"); + } + + if (setuid(buildUser->getUID()) == -1 || + getuid() != buildUser->getUID() || geteuid() != buildUser->getUID()) { + throw SysError("setuid failed"); + } + } + + /* Fill in the arguments. */ + Strings args; + + const char* builder = "invalid"; + + if (drv->isBuiltin()) { + ; + } +#if __APPLE__ + else if (getEnv("_NIX_TEST_NO_SANDBOX") == "") { + /* This has to appear before import statements. */ + std::string sandboxProfile = "(version 1)\n"; + + if (useChroot) { + /* Lots and lots and lots of file functions freak out if they can't stat + * their full ancestry */ + PathSet ancestry; + + /* We build the ancestry before adding all inputPaths to the store + because we know they'll all have the same parents (the store), and + there might be lots of inputs. This isn't + particularly efficient... I doubt it'll be a bottleneck in practice + */ + for (auto& i : dirsInChroot) { + Path cur = i.first; + while (cur.compare("/") != 0) { + cur = dirOf(cur); + ancestry.insert(cur); + } + } + + /* And we want the store in there regardless of how empty dirsInChroot. + We include the innermost path component this time, since it's + typically /nix/store and we care about that. */ + Path cur = worker.store.storeDir; + while (cur.compare("/") != 0) { + ancestry.insert(cur); + cur = dirOf(cur); + } + + /* Add all our input paths to the chroot */ + for (auto& i : inputPaths) { + dirsInChroot[i] = i; + } + + /* Violations will go to the syslog if you set this. Unfortunately the + * destination does not appear to be configurable */ + if (settings.darwinLogSandboxViolations) { + sandboxProfile += "(deny default)\n"; + } else { + sandboxProfile += "(deny default (with no-log))\n"; + } + + sandboxProfile += "(import \"sandbox-defaults.sb\")\n"; + + if (fixedOutput) { + sandboxProfile += "(import \"sandbox-network.sb\")\n"; + } + + /* Our rwx outputs */ + sandboxProfile += "(allow file-read* file-write* process-exec\n"; + for (auto& i : missingPaths) { + sandboxProfile += (format("\t(subpath \"%1%\")\n") % i.c_str()).str(); + } + /* Also add redirected outputs to the chroot */ + for (auto& i : redirectedOutputs) { + sandboxProfile += + (format("\t(subpath \"%1%\")\n") % i.second.c_str()).str(); + } + sandboxProfile += ")\n"; + + /* Our inputs (transitive dependencies and any impurities computed + above) + + without file-write* allowed, access() incorrectly returns EPERM + */ + sandboxProfile += "(allow file-read* file-write* process-exec\n"; + for (auto& i : dirsInChroot) { + if (i.first != i.second.source) + throw Error(format("can't map '%1%' to '%2%': mismatched impure " + "paths not supported on Darwin") % + i.first % i.second.source); + + string path = i.first; + struct stat st; + if (lstat(path.c_str(), &st)) { + if (i.second.optional && errno == ENOENT) { + continue; + } + throw SysError(format("getting attributes of path '%1%'") % path); + } + if (S_ISDIR(st.st_mode)) + sandboxProfile += (format("\t(subpath \"%1%\")\n") % path).str(); + else + sandboxProfile += (format("\t(literal \"%1%\")\n") % path).str(); + } + sandboxProfile += ")\n"; + + /* Allow file-read* on full directory hierarchy to self. Allows + * realpath() */ + sandboxProfile += "(allow file-read*\n"; + for (auto& i : ancestry) { + sandboxProfile += (format("\t(literal \"%1%\")\n") % i.c_str()).str(); + } + sandboxProfile += ")\n"; + + sandboxProfile += additionalSandboxProfile; + } else + sandboxProfile += "(import \"sandbox-minimal.sb\")\n"; + + debug("Generated sandbox profile:"); + debug(sandboxProfile); + + Path sandboxFile = tmpDir + "/.sandbox.sb"; + + writeFile(sandboxFile, sandboxProfile); + + bool allowLocalNetworking = + parsedDrv->getBoolAttr("__darwinAllowLocalNetworking"); + + /* The tmpDir in scope points at the temporary build directory for our + derivation. Some packages try different mechanisms to find temporary + directories, so we want to open up a broader place for them to dump + their files, if needed. */ + Path globalTmpDir = canonPath(getEnv("TMPDIR", "/tmp"), true); + + /* They don't like trailing slashes on subpath directives */ + if (globalTmpDir.back() == '/') { + globalTmpDir.pop_back(); + } + + builder = "/usr/bin/sandbox-exec"; + args.push_back("sandbox-exec"); + args.push_back("-f"); + args.push_back(sandboxFile); + args.push_back("-D"); + args.push_back("_GLOBAL_TMP_DIR=" + globalTmpDir); + args.push_back("-D"); + args.push_back("IMPORT_DIR=" + settings.nixDataDir + "/nix/sandbox/"); + if (allowLocalNetworking) { + args.push_back("-D"); + args.push_back(string("_ALLOW_LOCAL_NETWORKING=1")); + } + args.push_back(drv->builder); + } +#endif + else { + builder = drv->builder.c_str(); + string builderBasename = baseNameOf(drv->builder); + args.push_back(builderBasename); + } + + for (auto& i : drv->args) { + args.push_back(rewriteStrings(i, inputRewrites)); + } + + /* Indicate that we managed to set up the build environment. */ + writeFull(STDERR_FILENO, string("\1\n")); + + /* Execute the program. This should not return. */ + if (drv->isBuiltin()) { + try { + BasicDerivation drv2(*drv); + for (auto& e : drv2.env) { + e.second = rewriteStrings(e.second, inputRewrites); + } + + if (drv->builder == "builtin:fetchurl") { + builtinFetchurl(drv2, netrcData); + } else if (drv->builder == "builtin:buildenv") { + builtinBuildenv(drv2); + } else { + throw Error(format("unsupported builtin function '%1%'") % + string(drv->builder, 8)); + } + _exit(0); + } catch (std::exception& e) { + writeFull(STDERR_FILENO, "error: " + string(e.what()) + "\n"); + _exit(1); + } + } + + execve(builder, stringsToCharPtrs(args).data(), + stringsToCharPtrs(envStrs).data()); + + throw SysError(format("executing '%1%'") % drv->builder); + + } catch (std::exception& e) { + writeFull(STDERR_FILENO, "\1while setting up the build environment: " + + string(e.what()) + "\n"); + _exit(1); + } +} + +/* Parse a list of reference specifiers. Each element must either be + a store path, or the symbolic name of the output of the derivation + (such as `out'). */ +PathSet parseReferenceSpecifiers(Store& store, const BasicDerivation& drv, + const Strings& paths) { + PathSet result; + for (auto& i : paths) { + if (store.isStorePath(i)) { + result.insert(i); + } else if (drv.outputs.find(i) != drv.outputs.end()) { + result.insert(drv.outputs.find(i)->second.path); + } else { + throw BuildError( + format("derivation contains an illegal reference specifier '%1%'") % + i); + } + } + return result; +} + +void DerivationGoal::registerOutputs() { + /* When using a build hook, the build hook can register the output + as valid (by doing `nix-store --import'). If so we don't have + to do anything here. */ + if (hook) { + bool allValid = true; + for (auto& i : drv->outputs) { + if (!worker.store.isValidPath(i.second.path)) { + allValid = false; + } + } + if (allValid) { + return; + } + } + + std::map<std::string, ValidPathInfo> infos; + + /* Set of inodes seen during calls to canonicalisePathMetaData() + for this build's outputs. This needs to be shared between + outputs to allow hard links between outputs. */ + InodesSeen inodesSeen; + + Path checkSuffix = ".check"; + bool keepPreviousRound = settings.keepFailed || settings.runDiffHook; + + std::exception_ptr delayedException; + + /* Check whether the output paths were created, and grep each + output path to determine what other paths it references. Also make all + output paths read-only. */ + for (auto& i : drv->outputs) { + Path path = i.second.path; + if (missingPaths.find(path) == missingPaths.end()) { + continue; + } + + ValidPathInfo info; + + Path actualPath = path; + if (useChroot) { + actualPath = chrootRootDir + path; + if (pathExists(actualPath)) { + /* Move output paths from the chroot to the Nix store. */ + if (buildMode == bmRepair) { + replaceValidPath(path, actualPath); + } else if (buildMode != bmCheck && + rename(actualPath.c_str(), + worker.store.toRealPath(path).c_str()) == -1) { + throw SysError(format("moving build output '%1%' from the sandbox to " + "the Nix store") % + path); + } + } + if (buildMode != bmCheck) { + actualPath = worker.store.toRealPath(path); + } + } + + if (needsHashRewrite()) { + Path redirected = redirectedOutputs[path]; + if (buildMode == bmRepair && + redirectedBadOutputs.find(path) != redirectedBadOutputs.end() && + pathExists(redirected)) { + replaceValidPath(path, redirected); + } + if (buildMode == bmCheck && !redirected.empty()) { + actualPath = redirected; + } + } + + struct stat st; + if (lstat(actualPath.c_str(), &st) == -1) { + if (errno == ENOENT) { + throw BuildError( + format("builder for '%1%' failed to produce output path '%2%'") % + drvPath % path); + } + throw SysError(format("getting attributes of path '%1%'") % actualPath); + } + +#ifndef __CYGWIN__ + /* Check that the output is not group or world writable, as + that means that someone else can have interfered with the + build. Also, the output should be owned by the build + user. */ + if ((!S_ISLNK(st.st_mode) && ((st.st_mode & (S_IWGRP | S_IWOTH)) != 0u)) || + (buildUser && st.st_uid != buildUser->getUID())) { + throw BuildError(format("suspicious ownership or permission on '%1%'; " + "rejecting this build output") % + path); + } +#endif + + /* Apply hash rewriting if necessary. */ + bool rewritten = false; + if (!outputRewrites.empty()) { + LOG(WARNING) << "rewriting hashes in '" << path << "'; cross fingers"; + + /* Canonicalise first. This ensures that the path we're + rewriting doesn't contain a hard link to /etc/shadow or + something like that. */ + canonicalisePathMetaData(actualPath, buildUser ? buildUser->getUID() : -1, + inodesSeen); + + /* FIXME: this is in-memory. */ + StringSink sink; + dumpPath(actualPath, sink); + deletePath(actualPath); + sink.s = make_ref<std::string>(rewriteStrings(*sink.s, outputRewrites)); + StringSource source(*sink.s); + restorePath(actualPath, source); + + rewritten = true; + } + + /* Check that fixed-output derivations produced the right + outputs (i.e., the content hash should match the specified + hash). */ + if (fixedOutput) { + bool recursive; + Hash h; + i.second.parseHashInfo(recursive, h); + + if (!recursive) { + /* The output path should be a regular file without + execute permission. */ + if (!S_ISREG(st.st_mode) || (st.st_mode & S_IXUSR) != 0) { + throw BuildError( + format( + "output path '%1%' should be a non-executable regular file") % + path); + } + } + + /* Check the hash. In hash mode, move the path produced by + the derivation to its content-addressed location. */ + Hash h2 = recursive ? hashPath(h.type, actualPath).first + : hashFile(h.type, actualPath); + + Path dest = worker.store.makeFixedOutputPath(recursive, h2, + storePathToName(path)); + + if (h != h2) { + /* Throw an error after registering the path as + valid. */ + worker.hashMismatch = true; + delayedException = std::make_exception_ptr( + BuildError("hash mismatch in fixed-output derivation '%s':\n " + "wanted: %s\n got: %s", + dest, h.to_string(), h2.to_string())); + + Path actualDest = worker.store.toRealPath(dest); + + if (worker.store.isValidPath(dest)) { + std::rethrow_exception(delayedException); + } + + if (actualPath != actualDest) { + PathLocks outputLocks({actualDest}); + deletePath(actualDest); + if (rename(actualPath.c_str(), actualDest.c_str()) == -1) { + throw SysError(format("moving '%1%' to '%2%'") % actualPath % dest); + } + } + + path = dest; + actualPath = actualDest; + } else { + assert(path == dest); + } + + info.ca = makeFixedOutputCA(recursive, h2); + } + + /* Get rid of all weird permissions. This also checks that + all files are owned by the build user, if applicable. */ + canonicalisePathMetaData(actualPath, + buildUser && !rewritten ? buildUser->getUID() : -1, + inodesSeen); + + /* For this output path, find the references to other paths + contained in it. Compute the SHA-256 NAR hash at the same + time. The hash is stored in the database so that we can + verify later on whether nobody has messed with the store. */ + DLOG(INFO) << "scanning for references inside '" << path << "'"; + HashResult hash; + PathSet references = scanForReferences(actualPath, allPaths, hash); + + if (buildMode == bmCheck) { + if (!worker.store.isValidPath(path)) { + continue; + } + auto info = *worker.store.queryPathInfo(path); + if (hash.first != info.narHash) { + worker.checkMismatch = true; + if (settings.runDiffHook || settings.keepFailed) { + Path dst = worker.store.toRealPath(path + checkSuffix); + deletePath(dst); + if (rename(actualPath.c_str(), dst.c_str()) != 0) { + throw SysError(format("renaming '%1%' to '%2%'") % actualPath % + dst); + } + + handleDiffHook(buildUser ? buildUser->getUID() : getuid(), + buildUser ? buildUser->getGID() : getgid(), path, dst, + drvPath, tmpDir); + + throw NotDeterministic( + format("derivation '%1%' may not be deterministic: output '%2%' " + "differs from '%3%'") % + drvPath % path % dst); + } + throw NotDeterministic(format("derivation '%1%' may not be " + "deterministic: output '%2%' differs") % + drvPath % path); + } + + /* Since we verified the build, it's now ultimately + trusted. */ + if (!info.ultimate) { + info.ultimate = true; + worker.store.signPathInfo(info); + worker.store.registerValidPaths({info}); + } + + continue; + } + + /* For debugging, print out the referenced and unreferenced + paths. */ + for (auto& i : inputPaths) { + auto j = references.find(i); + if (j == references.end()) { + DLOG(INFO) << "unreferenced input: '" << i << "'"; + } else { + DLOG(INFO) << "referenced input: '" << i << "'"; + } + } + + if (curRound == nrRounds) { + worker.store.optimisePath( + actualPath); // FIXME: combine with scanForReferences() + worker.markContentsGood(path); + } + + info.path = path; + info.narHash = hash.first; + info.narSize = hash.second; + info.references = references; + info.deriver = drvPath; + info.ultimate = true; + worker.store.signPathInfo(info); + + if (!info.references.empty()) { + info.ca.clear(); + } + + infos[i.first] = info; + } + + if (buildMode == bmCheck) { + return; + } + + /* Apply output checks. */ + checkOutputs(infos); + + /* Compare the result with the previous round, and report which + path is different, if any.*/ + if (curRound > 1 && prevInfos != infos) { + assert(prevInfos.size() == infos.size()); + for (auto i = prevInfos.begin(), j = infos.begin(); i != prevInfos.end(); + ++i, ++j) { + if (!(*i == *j)) { + result.isNonDeterministic = true; + Path prev = i->second.path + checkSuffix; + bool prevExists = keepPreviousRound && pathExists(prev); + auto msg = + prevExists + ? fmt("output '%1%' of '%2%' differs from '%3%' from previous " + "round", + i->second.path, drvPath, prev) + : fmt("output '%1%' of '%2%' differs from previous round", + i->second.path, drvPath); + + handleDiffHook(buildUser ? buildUser->getUID() : getuid(), + buildUser ? buildUser->getGID() : getgid(), prev, + i->second.path, drvPath, tmpDir); + + if (settings.enforceDeterminism) { + throw NotDeterministic(msg); + } + + LOG(ERROR) << msg; + curRound = nrRounds; // we know enough, bail out early + } + } + } + + /* If this is the first round of several, then move the output out + of the way. */ + if (nrRounds > 1 && curRound == 1 && curRound < nrRounds && + keepPreviousRound) { + for (auto& i : drv->outputs) { + Path prev = i.second.path + checkSuffix; + deletePath(prev); + Path dst = i.second.path + checkSuffix; + if (rename(i.second.path.c_str(), dst.c_str()) != 0) { + throw SysError(format("renaming '%1%' to '%2%'") % i.second.path % dst); + } + } + } + + if (curRound < nrRounds) { + prevInfos = infos; + return; + } + + /* Remove the .check directories if we're done. FIXME: keep them + if the result was not determistic? */ + if (curRound == nrRounds) { + for (auto& i : drv->outputs) { + Path prev = i.second.path + checkSuffix; + deletePath(prev); + } + } + + /* Register each output path as valid, and register the sets of + paths referenced by each of them. If there are cycles in the + outputs, this will fail. */ + { + ValidPathInfos infos2; + for (auto& i : infos) { + infos2.push_back(i.second); + } + worker.store.registerValidPaths(infos2); + } + + /* In case of a fixed-output derivation hash mismatch, throw an + exception now that we have registered the output as valid. */ + if (delayedException) { + std::rethrow_exception(delayedException); + } +} + +void DerivationGoal::checkOutputs( + const std::map<Path, ValidPathInfo>& outputs) { + std::map<Path, const ValidPathInfo&> outputsByPath; + for (auto& output : outputs) { + outputsByPath.emplace(output.second.path, output.second); + } + + for (auto& output : outputs) { + auto& outputName = output.first; + auto& info = output.second; + + struct Checks { + bool ignoreSelfRefs = false; + std::optional<uint64_t> maxSize, maxClosureSize; + std::optional<Strings> allowedReferences, allowedRequisites, + disallowedReferences, disallowedRequisites; + }; + + /* Compute the closure and closure size of some output. This + is slightly tricky because some of its references (namely + other outputs) may not be valid yet. */ + auto getClosure = [&](const Path& path) { + uint64_t closureSize = 0; + PathSet pathsDone; + std::queue<Path> pathsLeft; + pathsLeft.push(path); + + while (!pathsLeft.empty()) { + auto path = pathsLeft.front(); + pathsLeft.pop(); + if (!pathsDone.insert(path).second) { + continue; + } + + auto i = outputsByPath.find(path); + if (i != outputsByPath.end()) { + closureSize += i->second.narSize; + for (auto& ref : i->second.references) { + pathsLeft.push(ref); + } + } else { + auto info = worker.store.queryPathInfo(path); + closureSize += info->narSize; + for (auto& ref : info->references) { + pathsLeft.push(ref); + } + } + } + + return std::make_pair(pathsDone, closureSize); + }; + + auto applyChecks = [&](const Checks& checks) { + if (checks.maxSize && info.narSize > *checks.maxSize) { + throw BuildError( + "path '%s' is too large at %d bytes; limit is %d bytes", info.path, + info.narSize, *checks.maxSize); + } + + if (checks.maxClosureSize) { + uint64_t closureSize = getClosure(info.path).second; + if (closureSize > *checks.maxClosureSize) { + throw BuildError( + "closure of path '%s' is too large at %d bytes; limit is %d " + "bytes", + info.path, closureSize, *checks.maxClosureSize); + } + } + + auto checkRefs = [&](const std::optional<Strings>& value, bool allowed, + bool recursive) { + if (!value) { + return; + } + + PathSet spec = parseReferenceSpecifiers(worker.store, *drv, *value); + + PathSet used = + recursive ? getClosure(info.path).first : info.references; + + if (recursive && checks.ignoreSelfRefs) { + used.erase(info.path); + } + + PathSet badPaths; + + for (auto& i : used) { + if (allowed) { + if (spec.count(i) == 0u) { + badPaths.insert(i); + } + } else { + if (spec.count(i) != 0u) { + badPaths.insert(i); + } + } + } + + if (!badPaths.empty()) { + string badPathsStr; + for (auto& i : badPaths) { + badPathsStr += "\n "; + badPathsStr += i; + } + throw BuildError( + "output '%s' is not allowed to refer to the following paths:%s", + info.path, badPathsStr); + } + }; + + checkRefs(checks.allowedReferences, true, false); + checkRefs(checks.allowedRequisites, true, true); + checkRefs(checks.disallowedReferences, false, false); + checkRefs(checks.disallowedRequisites, false, true); + }; + + if (auto structuredAttrs = parsedDrv->getStructuredAttrs()) { + auto outputChecks = structuredAttrs->find("outputChecks"); + if (outputChecks != structuredAttrs->end()) { + auto output = outputChecks->find(outputName); + + if (output != outputChecks->end()) { + Checks checks; + + auto maxSize = output->find("maxSize"); + if (maxSize != output->end()) { + checks.maxSize = maxSize->get<uint64_t>(); + } + + auto maxClosureSize = output->find("maxClosureSize"); + if (maxClosureSize != output->end()) { + checks.maxClosureSize = maxClosureSize->get<uint64_t>(); + } + + auto get = [&](const std::string& name) -> std::optional<Strings> { + auto i = output->find(name); + if (i != output->end()) { + Strings res; + for (auto& j : *i) { + if (!j.is_string()) { + throw Error( + "attribute '%s' of derivation '%s' must be a list of " + "strings", + name, drvPath); + } + res.push_back(j.get<std::string>()); + } + checks.disallowedRequisites = res; + return res; + } + return {}; + }; + + checks.allowedReferences = get("allowedReferences"); + checks.allowedRequisites = get("allowedRequisites"); + checks.disallowedReferences = get("disallowedReferences"); + checks.disallowedRequisites = get("disallowedRequisites"); + + applyChecks(checks); + } + } + } else { + // legacy non-structured-attributes case + Checks checks; + checks.ignoreSelfRefs = true; + checks.allowedReferences = parsedDrv->getStringsAttr("allowedReferences"); + checks.allowedRequisites = parsedDrv->getStringsAttr("allowedRequisites"); + checks.disallowedReferences = + parsedDrv->getStringsAttr("disallowedReferences"); + checks.disallowedRequisites = + parsedDrv->getStringsAttr("disallowedRequisites"); + applyChecks(checks); + } + } +} + +Path DerivationGoal::openLogFile() { + logSize = 0; + + if (!settings.keepLog) { + return ""; + } + + string baseName = baseNameOf(drvPath); + + /* Create a log file. */ + Path dir = fmt("%s/%s/%s/", worker.store.logDir, nix::LocalStore::drvsLogDir, + string(baseName, 0, 2)); + createDirs(dir); + + Path logFileName = fmt("%s/%s%s", dir, string(baseName, 2), + settings.compressLog ? ".bz2" : ""); + + fdLogFile = + open(logFileName.c_str(), O_CREAT | O_WRONLY | O_TRUNC | O_CLOEXEC, 0666); + if (!fdLogFile) { + throw SysError(format("creating log file '%1%'") % logFileName); + } + + logFileSink = std::make_shared<FdSink>(fdLogFile.get()); + + if (settings.compressLog) { + logSink = std::shared_ptr<CompressionSink>( + makeCompressionSink("bzip2", *logFileSink)); + } else { + logSink = logFileSink; + } + + return logFileName; +} + +void DerivationGoal::closeLogFile() { + auto logSink2 = std::dynamic_pointer_cast<CompressionSink>(logSink); + if (logSink2) { + logSink2->finish(); + } + if (logFileSink) { + logFileSink->flush(); + } + logSink = logFileSink = nullptr; + fdLogFile = -1; +} + +void DerivationGoal::deleteTmpDir(bool force) { + if (!tmpDir.empty()) { + /* Don't keep temporary directories for builtins because they + might have privileged stuff (like a copy of netrc). */ + if (settings.keepFailed && !force && !drv->isBuiltin()) { + LOG(INFO) << "note: keeping build directory '" << tmpDir << "'"; + chmod(tmpDir.c_str(), 0755); + } else { + deletePath(tmpDir); + } + tmpDir = ""; + } +} + +void DerivationGoal::handleChildOutput(int fd, const string& data) { + if ((hook && fd == hook->builderOut.readSide.get()) || + (!hook && fd == builderOut.readSide.get())) { + logSize += data.size(); + if (settings.maxLogSize && logSize > settings.maxLogSize) { + LOG(ERROR) << getName() + << " killed after writing more than %2% bytes of log output" + << settings.maxLogSize; + killChild(); + done(BuildResult::LogLimitExceeded); + return; + } + + for (auto c : data) { + if (c == '\r') { + currentLogLinePos = 0; + } else if (c == '\n') { + flushLine(); + } else { + if (currentLogLinePos >= currentLogLine.size()) { + currentLogLine.resize(currentLogLinePos + 1); + } + currentLogLine[currentLogLinePos++] = c; + } + } + + if (logSink) { + (*logSink)(data); + } + } + + if (hook && fd == hook->fromHook.readSide.get()) { + for (auto c : data) { + if (c == '\n') { + currentHookLine.clear(); + } else { + currentHookLine += c; + } + } + } +} + +void DerivationGoal::handleEOF(int fd) { + if (!currentLogLine.empty()) { + flushLine(); + } + worker.wakeUp(shared_from_this()); +} + +void DerivationGoal::flushLine() { + if (settings.verboseBuild && + (settings.printRepeatedBuilds || curRound == 1)) { + LOG(INFO) << currentLogLine; + } else { + logTail.push_back(currentLogLine); + if (logTail.size() > settings.logLines) { + logTail.pop_front(); + } + } + + currentLogLine = ""; + currentLogLinePos = 0; +} + +PathSet DerivationGoal::checkPathValidity(bool returnValid, bool checkHash) { + PathSet result; + for (auto& i : drv->outputs) { + if (!wantOutput(i.first, wantedOutputs)) { + continue; + } + bool good = worker.store.isValidPath(i.second.path) && + (!checkHash || worker.pathContentsGood(i.second.path)); + if (good == returnValid) { + result.insert(i.second.path); + } + } + return result; +} + +Path DerivationGoal::addHashRewrite(const Path& path) { + string h1 = string(path, worker.store.storeDir.size() + 1, 32); + string h2 = string(hashString(htSHA256, "rewrite:" + drvPath + ":" + path) + .to_string(Base32, false), + 0, 32); + Path p = worker.store.storeDir + "/" + h2 + + string(path, worker.store.storeDir.size() + 33); + deletePath(p); + assert(path.size() == p.size()); + inputRewrites[h1] = h2; + outputRewrites[h2] = h1; + redirectedOutputs[path] = p; + return p; +} + +void DerivationGoal::done(BuildResult::Status status, const string& msg) { + result.status = status; + result.errorMsg = msg; + amDone(result.success() ? ecSuccess : ecFailed); + if (result.status == BuildResult::TimedOut) { + worker.timedOut = true; + } + if (result.status == BuildResult::PermanentFailure) { + worker.permanentFailure = true; + } + + mcExpectedBuilds.reset(); + mcRunningBuilds.reset(); + + if (result.success()) { + if (status == BuildResult::Built) { + worker.doneBuilds++; + } + } else { + if (status != BuildResult::DependencyFailed) { + worker.failedBuilds++; + } + } +} + +////////////////////////////////////////////////////////////////////// + +class SubstitutionGoal : public Goal { + friend class Worker; + + private: + /* The store path that should be realised through a substitute. */ + Path storePath; + + /* The remaining substituters. */ + std::list<ref<Store>> subs; + + /* The current substituter. */ + std::shared_ptr<Store> sub; + + /* Whether a substituter failed. */ + bool substituterFailed = false; + + /* Path info returned by the substituter's query info operation. */ + std::shared_ptr<const ValidPathInfo> info; + + /* Pipe for the substituter's standard output. */ + Pipe outPipe; + + /* The substituter thread. */ + std::thread thr; + + std::promise<void> promise; + + /* Whether to try to repair a valid path. */ + RepairFlag repair; + + /* Location where we're downloading the substitute. Differs from + storePath when doing a repair. */ + Path destPath; + + std::unique_ptr<MaintainCount<uint64_t>> maintainExpectedSubstitutions, + maintainRunningSubstitutions, maintainExpectedNar, + maintainExpectedDownload; + + using GoalState = void (SubstitutionGoal::*)(); + GoalState state; + + public: + SubstitutionGoal(const Path& storePath, Worker& worker, + RepairFlag repair = NoRepair); + ~SubstitutionGoal() override; + + void timedOut() override { abort(); }; + + string key() override { + /* "a$" ensures substitution goals happen before derivation + goals. */ + return "a$" + storePathToName(storePath) + "$" + storePath; + } + + void work() override; + + /* The states. */ + void init(); + void tryNext(); + void gotInfo(); + void referencesValid(); + void tryToRun(); + void finished(); + + /* Callback used by the worker to write to the log. */ + void handleChildOutput(int fd, const string& data) override; + void handleEOF(int fd) override; + + Path getStorePath() { return storePath; } + + void amDone(ExitCode result) override { Goal::amDone(result); } +}; + +SubstitutionGoal::SubstitutionGoal(const Path& storePath, Worker& worker, + RepairFlag repair) + : Goal(worker), repair(repair) { + this->storePath = storePath; + state = &SubstitutionGoal::init; + name = (format("substitution of '%1%'") % storePath).str(); + trace("created"); + maintainExpectedSubstitutions = + std::make_unique<MaintainCount<uint64_t>>(worker.expectedSubstitutions); +} + +SubstitutionGoal::~SubstitutionGoal() { + try { + if (thr.joinable()) { + // FIXME: signal worker thread to quit. + thr.join(); + worker.childTerminated(this); + } + } catch (...) { + ignoreException(); + } +} + +void SubstitutionGoal::work() { (this->*state)(); } + +void SubstitutionGoal::init() { + trace("init"); + + worker.store.addTempRoot(storePath); + + /* If the path already exists we're done. */ + if ((repair == 0u) && worker.store.isValidPath(storePath)) { + amDone(ecSuccess); + return; + } + + if (settings.readOnlyMode) { + throw Error( + format( + "cannot substitute path '%1%' - no write access to the Nix store") % + storePath); + } + + subs = settings.useSubstitutes ? getDefaultSubstituters() + : std::list<ref<Store>>(); + + tryNext(); +} + +void SubstitutionGoal::tryNext() { + trace("trying next substituter"); + + if (subs.empty()) { + /* None left. Terminate this goal and let someone else deal + with it. */ + DLOG(WARNING) + << "path '" << storePath + << "' is required, but there is no substituter that can build it"; + + /* Hack: don't indicate failure if there were no substituters. + In that case the calling derivation should just do a + build. */ + amDone(substituterFailed ? ecFailed : ecNoSubstituters); + + if (substituterFailed) { + worker.failedSubstitutions++; + } + + return; + } + + sub = subs.front(); + subs.pop_front(); + + if (sub->storeDir != worker.store.storeDir) { + tryNext(); + return; + } + + try { + // FIXME: make async + info = sub->queryPathInfo(storePath); + } catch (InvalidPath&) { + tryNext(); + return; + } catch (SubstituterDisabled&) { + if (settings.tryFallback) { + tryNext(); + return; + } + throw; + } catch (Error& e) { + if (settings.tryFallback) { + LOG(ERROR) << e.what(); + tryNext(); + return; + } + throw; + } + + /* Update the total expected download size. */ + auto narInfo = std::dynamic_pointer_cast<const NarInfo>(info); + + maintainExpectedNar = std::make_unique<MaintainCount<uint64_t>>( + worker.expectedNarSize, info->narSize); + + maintainExpectedDownload = + narInfo && (narInfo->fileSize != 0u) + ? std::make_unique<MaintainCount<uint64_t>>( + worker.expectedDownloadSize, narInfo->fileSize) + : nullptr; + + /* Bail out early if this substituter lacks a valid + signature. LocalStore::addToStore() also checks for this, but + only after we've downloaded the path. */ + if (worker.store.requireSigs && !sub->isTrusted && + (info->checkSignatures(worker.store, worker.store.getPublicKeys()) == + 0u)) { + LOG(WARNING) << "substituter '" << sub->getUri() + << "' does not have a valid signature for path '" << storePath + << "'"; + tryNext(); + return; + } + + /* To maintain the closure invariant, we first have to realise the + paths referenced by this one. */ + for (auto& i : info->references) { + if (i != storePath) { /* ignore self-references */ + addWaitee(worker.makeSubstitutionGoal(i)); + } + } + + if (waitees.empty()) { /* to prevent hang (no wake-up event) */ + referencesValid(); + } else { + state = &SubstitutionGoal::referencesValid; + } +} + +void SubstitutionGoal::referencesValid() { + trace("all references realised"); + + if (nrFailed > 0) { + DLOG(WARNING) << "some references of path '" << storePath + << "' could not be realised"; + amDone(nrNoSubstituters > 0 || nrIncompleteClosure > 0 ? ecIncompleteClosure + : ecFailed); + return; + } + + for (auto& i : info->references) { + if (i != storePath) { /* ignore self-references */ + assert(worker.store.isValidPath(i)); + } + } + + state = &SubstitutionGoal::tryToRun; + worker.wakeUp(shared_from_this()); +} + +void SubstitutionGoal::tryToRun() { + trace("trying to run"); + + /* Make sure that we are allowed to start a build. Note that even + if maxBuildJobs == 0 (no local builds allowed), we still allow + a substituter to run. This is because substitutions cannot be + distributed to another machine via the build hook. */ + if (worker.getNrLocalBuilds() >= + std::max(1U, (unsigned int)settings.maxBuildJobs)) { + worker.waitForBuildSlot(shared_from_this()); + return; + } + + maintainRunningSubstitutions = + std::make_unique<MaintainCount<uint64_t>>(worker.runningSubstitutions); + + outPipe.create(); + + promise = std::promise<void>(); + + thr = std::thread([this]() { + try { + /* Wake up the worker loop when we're done. */ + Finally updateStats([this]() { outPipe.writeSide = -1; }); + + copyStorePath(ref<Store>(sub), + ref<Store>(worker.store.shared_from_this()), storePath, + repair, sub->isTrusted ? NoCheckSigs : CheckSigs); + + promise.set_value(); + } catch (...) { + promise.set_exception(std::current_exception()); + } + }); + + worker.childStarted(shared_from_this(), {outPipe.readSide.get()}, true, + false); + + state = &SubstitutionGoal::finished; +} + +void SubstitutionGoal::finished() { + trace("substitute finished"); + + thr.join(); + worker.childTerminated(this); + + try { + promise.get_future().get(); + } catch (std::exception& e) { + LOG(ERROR) << e.what(); + + /* Cause the parent build to fail unless --fallback is given, + or the substitute has disappeared. The latter case behaves + the same as the substitute never having existed in the + first place. */ + try { + throw; + } catch (SubstituteGone&) { + } catch (...) { + substituterFailed = true; + } + + /* Try the next substitute. */ + state = &SubstitutionGoal::tryNext; + worker.wakeUp(shared_from_this()); + return; + } + + worker.markContentsGood(storePath); + + DLOG(INFO) << "substitution of path '" << storePath << "' succeeded"; + + maintainRunningSubstitutions.reset(); + + maintainExpectedSubstitutions.reset(); + worker.doneSubstitutions++; + + if (maintainExpectedDownload) { + auto fileSize = maintainExpectedDownload->delta; + maintainExpectedDownload.reset(); + worker.doneDownloadSize += fileSize; + } + + worker.doneNarSize += maintainExpectedNar->delta; + maintainExpectedNar.reset(); + + amDone(ecSuccess); +} + +void SubstitutionGoal::handleChildOutput(int fd, const string& data) {} + +void SubstitutionGoal::handleEOF(int fd) { + if (fd == outPipe.readSide.get()) { + worker.wakeUp(shared_from_this()); + } +} + +////////////////////////////////////////////////////////////////////// + +static bool working = false; + +Worker::Worker(LocalStore& store) : store(store) { + /* Debugging: prevent recursive workers. */ + if (working) { + abort(); + } + working = true; + nrLocalBuilds = 0; + lastWokenUp = steady_time_point::min(); + permanentFailure = false; + timedOut = false; + hashMismatch = false; + checkMismatch = false; +} + +Worker::~Worker() { + working = false; + + /* Explicitly get rid of all strong pointers now. After this all + goals that refer to this worker should be gone. (Otherwise we + are in trouble, since goals may call childTerminated() etc. in + their destructors). */ + topGoals.clear(); + + assert(expectedSubstitutions == 0); + assert(expectedDownloadSize == 0); + assert(expectedNarSize == 0); +} + +GoalPtr Worker::makeDerivationGoal(const Path& path, + const StringSet& wantedOutputs, + BuildMode buildMode) { + GoalPtr goal = derivationGoals[path].lock(); + if (!goal) { + goal = + std::make_shared<DerivationGoal>(path, wantedOutputs, *this, buildMode); + derivationGoals[path] = goal; + wakeUp(goal); + } else { + (dynamic_cast<DerivationGoal*>(goal.get())) + ->addWantedOutputs(wantedOutputs); + } + return goal; +} + +std::shared_ptr<DerivationGoal> Worker::makeBasicDerivationGoal( + const Path& drvPath, const BasicDerivation& drv, BuildMode buildMode) { + auto goal = std::make_shared<DerivationGoal>(drvPath, drv, *this, buildMode); + wakeUp(goal); + return goal; +} + +GoalPtr Worker::makeSubstitutionGoal(const Path& path, RepairFlag repair) { + GoalPtr goal = substitutionGoals[path].lock(); + if (!goal) { + goal = std::make_shared<SubstitutionGoal>(path, *this, repair); + substitutionGoals[path] = goal; + wakeUp(goal); + } + return goal; +} + +static void removeGoal(const GoalPtr& goal, WeakGoalMap& goalMap) { + /* !!! inefficient */ + for (auto i = goalMap.begin(); i != goalMap.end();) { + if (i->second.lock() == goal) { + auto j = i; + ++j; + goalMap.erase(i); + i = j; + } else { + ++i; + } + } +} + +void Worker::removeGoal(const GoalPtr& goal) { + nix::removeGoal(goal, derivationGoals); + nix::removeGoal(goal, substitutionGoals); + if (topGoals.find(goal) != topGoals.end()) { + topGoals.erase(goal); + /* If a top-level goal failed, then kill all other goals + (unless keepGoing was set). */ + if (goal->getExitCode() == Goal::ecFailed && !settings.keepGoing) { + topGoals.clear(); + } + } + + /* Wake up goals waiting for any goal to finish. */ + for (auto& i : waitingForAnyGoal) { + GoalPtr goal = i.lock(); + if (goal) { + wakeUp(goal); + } + } + + waitingForAnyGoal.clear(); +} + +void Worker::wakeUp(const GoalPtr& goal) { + goal->trace("woken up"); + addToWeakGoals(awake, goal); +} + +unsigned Worker::getNrLocalBuilds() { return nrLocalBuilds; } + +void Worker::childStarted(const GoalPtr& goal, const set<int>& fds, + bool inBuildSlot, bool respectTimeouts) { + Child child; + child.goal = goal; + child.goal2 = goal.get(); + child.fds = fds; + child.timeStarted = child.lastOutput = steady_time_point::clock::now(); + child.inBuildSlot = inBuildSlot; + child.respectTimeouts = respectTimeouts; + children.emplace_back(child); + if (inBuildSlot) { + nrLocalBuilds++; + } +} + +void Worker::childTerminated(Goal* goal, bool wakeSleepers) { + auto i = + std::find_if(children.begin(), children.end(), + [&](const Child& child) { return child.goal2 == goal; }); + if (i == children.end()) { + return; + } + + if (i->inBuildSlot) { + assert(nrLocalBuilds > 0); + nrLocalBuilds--; + } + + children.erase(i); + + if (wakeSleepers) { + /* Wake up goals waiting for a build slot. */ + for (auto& j : wantingToBuild) { + GoalPtr goal = j.lock(); + if (goal) { + wakeUp(goal); + } + } + + wantingToBuild.clear(); + } +} + +void Worker::waitForBuildSlot(const GoalPtr& goal) { + DLOG(INFO) << "wait for build slot"; + if (getNrLocalBuilds() < settings.maxBuildJobs) { + wakeUp(goal); /* we can do it right away */ + } else { + addToWeakGoals(wantingToBuild, goal); + } +} + +void Worker::waitForAnyGoal(GoalPtr goal) { + DLOG(INFO) << "wait for any goal"; + addToWeakGoals(waitingForAnyGoal, std::move(goal)); +} + +void Worker::waitForAWhile(GoalPtr goal) { + DLOG(INFO) << "wait for a while"; + addToWeakGoals(waitingForAWhile, std::move(goal)); +} + +void Worker::run(const Goals& _topGoals) { + for (auto& i : _topGoals) { + topGoals.insert(i); + } + + DLOG(INFO) << "entered goal loop"; + + while (true) { + checkInterrupt(); + + store.autoGC(false); + + /* Call every wake goal (in the ordering established by + CompareGoalPtrs). */ + while (!awake.empty() && !topGoals.empty()) { + Goals awake2; + for (auto& i : awake) { + GoalPtr goal = i.lock(); + if (goal) { + awake2.insert(goal); + } + } + awake.clear(); + for (auto& goal : awake2) { + checkInterrupt(); + goal->work(); + if (topGoals.empty()) { + break; + } // stuff may have been cancelled + } + } + + if (topGoals.empty()) { + break; + } + + /* Wait for input. */ + if (!children.empty() || !waitingForAWhile.empty()) { + waitForInput(); + } else { + if (awake.empty() && 0 == settings.maxBuildJobs) { + throw Error( + "unable to start any build; either increase '--max-jobs' " + "or enable remote builds"); + } + assert(!awake.empty()); + } + } + + /* If --keep-going is not set, it's possible that the main goal + exited while some of its subgoals were still active. But if + --keep-going *is* set, then they must all be finished now. */ + assert(!settings.keepGoing || awake.empty()); + assert(!settings.keepGoing || wantingToBuild.empty()); + assert(!settings.keepGoing || children.empty()); +} + +void Worker::waitForInput() { + DLOG(INFO) << "waiting for children"; + + /* Process output from the file descriptors attached to the + children, namely log output and output path creation commands. + We also use this to detect child termination: if we get EOF on + the logger pipe of a build, we assume that the builder has + terminated. */ + + bool useTimeout = false; + struct timeval timeout; + timeout.tv_usec = 0; + auto before = steady_time_point::clock::now(); + + /* If we're monitoring for silence on stdout/stderr, or if there + is a build timeout, then wait for input until the first + deadline for any child. */ + auto nearest = steady_time_point::max(); // nearest deadline + if (settings.minFree.get() != 0) { + // Periodicallty wake up to see if we need to run the garbage collector. + nearest = before + std::chrono::seconds(10); + } + for (auto& i : children) { + if (!i.respectTimeouts) { + continue; + } + if (0 != settings.maxSilentTime) { + nearest = std::min( + nearest, i.lastOutput + std::chrono::seconds(settings.maxSilentTime)); + } + if (0 != settings.buildTimeout) { + nearest = std::min( + nearest, i.timeStarted + std::chrono::seconds(settings.buildTimeout)); + } + } + if (nearest != steady_time_point::max()) { + timeout.tv_sec = std::max( + 1L, + (long)std::chrono::duration_cast<std::chrono::seconds>(nearest - before) + .count()); + useTimeout = true; + } + + /* If we are polling goals that are waiting for a lock, then wake + up after a few seconds at most. */ + if (!waitingForAWhile.empty()) { + useTimeout = true; + if (lastWokenUp == steady_time_point::min()) { + DLOG(WARNING) << "waiting for locks or build slots..."; + } + if (lastWokenUp == steady_time_point::min() || lastWokenUp > before) { + lastWokenUp = before; + } + timeout.tv_sec = std::max( + 1L, + (long)std::chrono::duration_cast<std::chrono::seconds>( + lastWokenUp + std::chrono::seconds(settings.pollInterval) - before) + .count()); + } else { + lastWokenUp = steady_time_point::min(); + } + + if (useTimeout) { + DLOG(INFO) << "sleeping " << timeout.tv_sec << " seconds"; + } + + /* Use select() to wait for the input side of any logger pipe to + become `available'. Note that `available' (i.e., non-blocking) + includes EOF. */ + fd_set fds; + FD_ZERO(&fds); + int fdMax = 0; + for (auto& i : children) { + for (auto& j : i.fds) { + if (j >= FD_SETSIZE) { + throw Error("reached FD_SETSIZE limit"); + } + FD_SET(j, &fds); + if (j >= fdMax) { + fdMax = j + 1; + } + } + } + + if (select(fdMax, &fds, nullptr, nullptr, useTimeout ? &timeout : nullptr) == + -1) { + if (errno == EINTR) { + return; + } + throw SysError("waiting for input"); + } + + auto after = steady_time_point::clock::now(); + + /* Process all available file descriptors. FIXME: this is + O(children * fds). */ + decltype(children)::iterator i; + for (auto j = children.begin(); j != children.end(); j = i) { + i = std::next(j); + + checkInterrupt(); + + GoalPtr goal = j->goal.lock(); + assert(goal); + + set<int> fds2(j->fds); + std::vector<unsigned char> buffer(4096); + for (auto& k : fds2) { + if (FD_ISSET(k, &fds)) { + ssize_t rd = read(k, buffer.data(), buffer.size()); + // FIXME: is there a cleaner way to handle pt close + // than EIO? Is this even standard? + if (rd == 0 || (rd == -1 && errno == EIO)) { + DLOG(WARNING) << goal->getName() << ": got EOF"; + goal->handleEOF(k); + j->fds.erase(k); + } else if (rd == -1) { + if (errno != EINTR) { + throw SysError("%s: read failed", goal->getName()); + } + } else { + DLOG(INFO) << goal->getName() << ": read " << rd << " bytes"; + string data((char*)buffer.data(), rd); + j->lastOutput = after; + goal->handleChildOutput(k, data); + } + } + } + + if (goal->getExitCode() == Goal::ecBusy && 0 != settings.maxSilentTime && + j->respectTimeouts && + after - j->lastOutput >= std::chrono::seconds(settings.maxSilentTime)) { + LOG(ERROR) << goal->getName() << " timed out after " + << settings.maxSilentTime << " seconds of silence"; + goal->timedOut(); + } + + else if (goal->getExitCode() == Goal::ecBusy && + 0 != settings.buildTimeout && j->respectTimeouts && + after - j->timeStarted >= + std::chrono::seconds(settings.buildTimeout)) { + LOG(ERROR) << goal->getName() << " timed out after " + << settings.buildTimeout << " seconds"; + goal->timedOut(); + } + } + + if (!waitingForAWhile.empty() && + lastWokenUp + std::chrono::seconds(settings.pollInterval) <= after) { + lastWokenUp = after; + for (auto& i : waitingForAWhile) { + GoalPtr goal = i.lock(); + if (goal) { + wakeUp(goal); + } + } + waitingForAWhile.clear(); + } +} + +unsigned int Worker::exitStatus() { + /* + * 1100100 + * ^^^^ + * |||`- timeout + * ||`-- output hash mismatch + * |`--- build failure + * `---- not deterministic + */ + unsigned int mask = 0; + bool buildFailure = permanentFailure || timedOut || hashMismatch; + if (buildFailure) { + mask |= 0x04; // 100 + } + if (timedOut) { + mask |= 0x01; // 101 + } + if (hashMismatch) { + mask |= 0x02; // 102 + } + if (checkMismatch) { + mask |= 0x08; // 104 + } + + if (mask != 0u) { + mask |= 0x60; + } + return mask != 0u ? mask : 1; +} + +bool Worker::pathContentsGood(const Path& path) { + auto i = pathContentsGoodCache.find(path); + if (i != pathContentsGoodCache.end()) { + return i->second; + } + LOG(INFO) << "checking path '" << path << "'..."; + auto info = store.queryPathInfo(path); + bool res; + if (!pathExists(path)) { + res = false; + } else { + HashResult current = hashPath(info->narHash.type, path); + Hash nullHash(htSHA256); + res = info->narHash == nullHash || info->narHash == current.first; + } + pathContentsGoodCache[path] = res; + if (!res) { + LOG(ERROR) << "path '" << path << "' is corrupted or missing!"; + } + return res; +} + +void Worker::markContentsGood(const Path& path) { + pathContentsGoodCache[path] = true; +} + +////////////////////////////////////////////////////////////////////// + +static void primeCache(Store& store, const PathSet& paths) { + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + unsigned long long downloadSize; + unsigned long long narSize; + store.queryMissing(paths, willBuild, willSubstitute, unknown, downloadSize, + narSize); + + if (!willBuild.empty() && 0 == settings.maxBuildJobs && + getMachines().empty()) { + throw Error( + "%d derivations need to be built, but neither local builds " + "('--max-jobs') " + "nor remote builds ('--builders') are enabled", + willBuild.size()); + } +} + +void LocalStore::buildPaths(const PathSet& drvPaths, BuildMode buildMode) { + Worker worker(*this); + + primeCache(*this, drvPaths); + + Goals goals; + for (auto& i : drvPaths) { + DrvPathWithOutputs i2 = parseDrvPathWithOutputs(i); + if (isDerivation(i2.first)) { + goals.insert(worker.makeDerivationGoal(i2.first, i2.second, buildMode)); + } else { + goals.insert(worker.makeSubstitutionGoal( + i, buildMode == bmRepair ? Repair : NoRepair)); + } + } + + worker.run(goals); + + PathSet failed; + for (auto& i : goals) { + if (i->getExitCode() != Goal::ecSuccess) { + auto* i2 = dynamic_cast<DerivationGoal*>(i.get()); + if (i2 != nullptr) { + failed.insert(i2->getDrvPath()); + } else { + failed.insert(dynamic_cast<SubstitutionGoal*>(i.get())->getStorePath()); + } + } + } + + if (!failed.empty()) { + throw Error(worker.exitStatus(), "build of %s failed", showPaths(failed)); + } +} + +BuildResult LocalStore::buildDerivation(const Path& drvPath, + const BasicDerivation& drv, + BuildMode buildMode) { + Worker worker(*this); + auto goal = worker.makeBasicDerivationGoal(drvPath, drv, buildMode); + + BuildResult result; + + try { + worker.run(Goals{goal}); + result = goal->getResult(); + } catch (Error& e) { + result.status = BuildResult::MiscFailure; + result.errorMsg = e.msg(); + } + + return result; +} + +void LocalStore::ensurePath(const Path& path) { + /* If the path is already valid, we're done. */ + if (isValidPath(path)) { + return; + } + + primeCache(*this, {path}); + + Worker worker(*this); + GoalPtr goal = worker.makeSubstitutionGoal(path); + Goals goals = {goal}; + + worker.run(goals); + + if (goal->getExitCode() != Goal::ecSuccess) { + throw Error(worker.exitStatus(), + "path '%s' does not exist and cannot be created", path); + } +} + +void LocalStore::repairPath(const Path& path) { + Worker worker(*this); + GoalPtr goal = worker.makeSubstitutionGoal(path, Repair); + Goals goals = {goal}; + + worker.run(goals); + + if (goal->getExitCode() != Goal::ecSuccess) { + /* Since substituting the path didn't work, if we have a valid + deriver, then rebuild the deriver. */ + auto deriver = queryPathInfo(path)->deriver; + if (!deriver.empty() && isValidPath(deriver)) { + goals.clear(); + goals.insert(worker.makeDerivationGoal(deriver, StringSet(), bmRepair)); + worker.run(goals); + } else { + throw Error(worker.exitStatus(), "cannot repair path '%s'", path); + } + } +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/builtins.hh b/third_party/nix/src/libstore/builtins.hh new file mode 100644 index 0000000000..07601be0f5 --- /dev/null +++ b/third_party/nix/src/libstore/builtins.hh @@ -0,0 +1,11 @@ +#pragma once + +#include "derivations.hh" + +namespace nix { + +// TODO: make pluggable. +void builtinFetchurl(const BasicDerivation& drv, const std::string& netrcData); +void builtinBuildenv(const BasicDerivation& drv); + +} // namespace nix diff --git a/third_party/nix/src/libstore/builtins/buildenv.cc b/third_party/nix/src/libstore/builtins/buildenv.cc new file mode 100644 index 0000000000..77ad722fab --- /dev/null +++ b/third_party/nix/src/libstore/builtins/buildenv.cc @@ -0,0 +1,223 @@ +#include <algorithm> + +#include <fcntl.h> +#include <glog/logging.h> +#include <sys/stat.h> +#include <sys/types.h> + +#include "builtins.hh" + +namespace nix { + +typedef std::map<Path, int> Priorities; + +// FIXME: change into local variables. + +static Priorities priorities; + +static unsigned long symlinks; + +/* For each activated package, create symlinks */ +static void createLinks(const Path& srcDir, const Path& dstDir, int priority) { + DirEntries srcFiles; + + try { + srcFiles = readDirectory(srcDir); + } catch (SysError& e) { + if (e.errNo == ENOTDIR) { + LOG(ERROR) << "warning: not including '" << srcDir + << "' in the user environment because it's not a directory"; + return; + } + throw; + } + + for (const auto& ent : srcFiles) { + if (ent.name[0] == '.') /* not matched by glob */ + continue; + auto srcFile = srcDir + "/" + ent.name; + auto dstFile = dstDir + "/" + ent.name; + + struct stat srcSt; + try { + if (stat(srcFile.c_str(), &srcSt) == -1) + throw SysError("getting status of '%1%'", srcFile); + } catch (SysError& e) { + if (e.errNo == ENOENT || e.errNo == ENOTDIR) { + LOG(ERROR) << "warning: skipping dangling symlink '" << dstFile << "'"; + continue; + } + throw; + } + + /* The files below are special-cased to that they don't show up + * in user profiles, either because they are useless, or + * because they would cauase pointless collisions (e.g., each + * Python package brings its own + * `$out/lib/pythonX.Y/site-packages/easy-install.pth'.) + */ + if (hasSuffix(srcFile, "/propagated-build-inputs") || + hasSuffix(srcFile, "/nix-support") || + hasSuffix(srcFile, "/perllocal.pod") || + hasSuffix(srcFile, "/info/dir") || hasSuffix(srcFile, "/log")) + continue; + + else if (S_ISDIR(srcSt.st_mode)) { + struct stat dstSt; + auto res = lstat(dstFile.c_str(), &dstSt); + if (res == 0) { + if (S_ISDIR(dstSt.st_mode)) { + createLinks(srcFile, dstFile, priority); + continue; + } else if (S_ISLNK(dstSt.st_mode)) { + auto target = canonPath(dstFile, true); + if (!S_ISDIR(lstat(target).st_mode)) + throw Error("collision between '%1%' and non-directory '%2%'", + srcFile, target); + if (unlink(dstFile.c_str()) == -1) + throw SysError(format("unlinking '%1%'") % dstFile); + if (mkdir(dstFile.c_str(), 0755) == -1) + throw SysError(format("creating directory '%1%'")); + createLinks(target, dstFile, priorities[dstFile]); + createLinks(srcFile, dstFile, priority); + continue; + } + } else if (errno != ENOENT) + throw SysError(format("getting status of '%1%'") % dstFile); + } + + else { + struct stat dstSt; + auto res = lstat(dstFile.c_str(), &dstSt); + if (res == 0) { + if (S_ISLNK(dstSt.st_mode)) { + auto prevPriority = priorities[dstFile]; + if (prevPriority == priority) + throw Error( + "packages '%1%' and '%2%' have the same priority %3%; " + "use 'nix-env --set-flag priority NUMBER INSTALLED_PKGNAME' " + "to change the priority of one of the conflicting packages" + " (0 being the highest priority)", + srcFile, readLink(dstFile), priority); + if (prevPriority < priority) { + continue; + } + if (unlink(dstFile.c_str()) == -1) + throw SysError(format("unlinking '%1%'") % dstFile); + } else if (S_ISDIR(dstSt.st_mode)) + throw Error( + "collision between non-directory '%1%' and directory '%2%'", + srcFile, dstFile); + } else if (errno != ENOENT) + throw SysError(format("getting status of '%1%'") % dstFile); + } + + createSymlink(srcFile, dstFile); + priorities[dstFile] = priority; + symlinks++; + } +} + +typedef std::set<Path> FileProp; + +static FileProp done; +static FileProp postponed = FileProp{}; + +static Path out; + +static void addPkg(const Path& pkgDir, int priority) { + if (done.count(pkgDir)) { + return; + } + done.insert(pkgDir); + createLinks(pkgDir, out, priority); + + try { + for (const auto& p : tokenizeString<std::vector<string>>( + readFile(pkgDir + "/nix-support/propagated-user-env-packages"), + " \n")) + if (!done.count(p)) { + postponed.insert(p); + } + } catch (SysError& e) { + if (e.errNo != ENOENT && e.errNo != ENOTDIR) { + throw; + } + } +} + +struct Package { + Path path; + bool active; + int priority; + Package(Path path, bool active, int priority) + : path{path}, active{active}, priority{priority} {} +}; + +typedef std::vector<Package> Packages; + +void builtinBuildenv(const BasicDerivation& drv) { + auto getAttr = [&](const string& name) { + auto i = drv.env.find(name); + if (i == drv.env.end()) { + throw Error("attribute '%s' missing", name); + } + return i->second; + }; + + out = getAttr("out"); + createDirs(out); + + /* Convert the stuff we get from the environment back into a + * coherent data type. */ + Packages pkgs; + auto derivations = tokenizeString<Strings>(getAttr("derivations")); + while (!derivations.empty()) { + /* !!! We're trusting the caller to structure derivations env var correctly + */ + auto active = derivations.front(); + derivations.pop_front(); + auto priority = stoi(derivations.front()); + derivations.pop_front(); + auto outputs = stoi(derivations.front()); + derivations.pop_front(); + for (auto n = 0; n < outputs; n++) { + auto path = derivations.front(); + derivations.pop_front(); + pkgs.emplace_back(path, active != "false", priority); + } + } + + /* Symlink to the packages that have been installed explicitly by the + * user. Process in priority order to reduce unnecessary + * symlink/unlink steps. + */ + std::sort(pkgs.begin(), pkgs.end(), [](const Package& a, const Package& b) { + return a.priority < b.priority || + (a.priority == b.priority && a.path < b.path); + }); + for (const auto& pkg : pkgs) + if (pkg.active) { + addPkg(pkg.path, pkg.priority); + } + + /* Symlink to the packages that have been "propagated" by packages + * installed by the user (i.e., package X declares that it wants Y + * installed as well). We do these later because they have a lower + * priority in case of collisions. + */ + auto priorityCounter = 1000; + while (!postponed.empty()) { + auto pkgDirs = postponed; + postponed = FileProp{}; + for (const auto& pkgDir : pkgDirs) { + addPkg(pkgDir, priorityCounter++); + } + } + + LOG(INFO) << "created " << symlinks << " symlinks in user environment"; + + createSymlink(getAttr("manifest"), out + "/manifest.nix"); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/builtins/fetchurl.cc b/third_party/nix/src/libstore/builtins/fetchurl.cc new file mode 100644 index 0000000000..c3f38a943f --- /dev/null +++ b/third_party/nix/src/libstore/builtins/fetchurl.cc @@ -0,0 +1,80 @@ +#include <glog/logging.h> + +#include "archive.hh" +#include "builtins.hh" +#include "compression.hh" +#include "download.hh" +#include "store-api.hh" + +namespace nix { + +void builtinFetchurl(const BasicDerivation& drv, const std::string& netrcData) { + /* Make the host's netrc data available. Too bad curl requires + this to be stored in a file. It would be nice if we could just + pass a pointer to the data. */ + if (netrcData != "") { + settings.netrcFile = "netrc"; + writeFile(settings.netrcFile, netrcData, 0600); + } + + auto getAttr = [&](const string& name) { + auto i = drv.env.find(name); + if (i == drv.env.end()) + throw Error(format("attribute '%s' missing") % name); + return i->second; + }; + + Path storePath = getAttr("out"); + auto mainUrl = getAttr("url"); + bool unpack = get(drv.env, "unpack", "") == "1"; + + /* Note: have to use a fresh downloader here because we're in + a forked process. */ + auto downloader = makeDownloader(); + + auto fetch = [&](const std::string& url) { + auto source = sinkToSource([&](Sink& sink) { + /* No need to do TLS verification, because we check the hash of + the result anyway. */ + DownloadRequest request(url); + request.verifyTLS = false; + request.decompress = false; + + auto decompressor = makeDecompressionSink( + unpack && hasSuffix(mainUrl, ".xz") ? "xz" : "none", sink); + downloader->download(std::move(request), *decompressor); + decompressor->finish(); + }); + + if (unpack) + restorePath(storePath, *source); + else + writeFile(storePath, *source); + + auto executable = drv.env.find("executable"); + if (executable != drv.env.end() && executable->second == "1") { + if (chmod(storePath.c_str(), 0755) == -1) + throw SysError(format("making '%1%' executable") % storePath); + } + }; + + /* Try the hashed mirrors first. */ + if (getAttr("outputHashMode") == "flat") + for (auto hashedMirror : settings.hashedMirrors.get()) try { + if (!hasSuffix(hashedMirror, "/")) { + hashedMirror += '/'; + } + auto ht = parseHashType(getAttr("outputHashAlgo")); + auto h = Hash(getAttr("outputHash"), ht); + fetch(hashedMirror + printHashType(h.type) + "/" + + h.to_string(Base16, false)); + return; + } catch (Error& e) { + LOG(ERROR) << e.what(); + } + + /* Otherwise try the specified URL. */ + fetch(mainUrl); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/crypto.cc b/third_party/nix/src/libstore/crypto.cc new file mode 100644 index 0000000000..90580b8dc9 --- /dev/null +++ b/third_party/nix/src/libstore/crypto.cc @@ -0,0 +1,125 @@ +#include "crypto.hh" + +#include "globals.hh" +#include "util.hh" + +#if HAVE_SODIUM +#include <sodium.h> +#endif + +namespace nix { + +static std::pair<std::string, std::string> split(const string& s) { + size_t colon = s.find(':'); + if (colon == std::string::npos || colon == 0) { + return {"", ""}; + } + return {std::string(s, 0, colon), std::string(s, colon + 1)}; +} + +Key::Key(const string& s) { + auto ss = split(s); + + name = ss.first; + key = ss.second; + + if (name.empty() || key.empty()) { + throw Error("secret key is corrupt"); + } + + key = base64Decode(key); +} + +SecretKey::SecretKey(const string& s) : Key(s) { +#if HAVE_SODIUM + if (key.size() != crypto_sign_SECRETKEYBYTES) { + throw Error("secret key is not valid"); + } +#endif +} + +#if !HAVE_SODIUM +[[noreturn]] static void noSodium() { + throw Error( + "Nix was not compiled with libsodium, required for signed binary cache " + "support"); +} +#endif + +std::string SecretKey::signDetached(const std::string& data) const { +#if HAVE_SODIUM + unsigned char sig[crypto_sign_BYTES]; + unsigned long long sigLen; + crypto_sign_detached(sig, &sigLen, (unsigned char*)data.data(), data.size(), + (unsigned char*)key.data()); + return name + ":" + base64Encode(std::string((char*)sig, sigLen)); +#else + noSodium(); +#endif +} + +PublicKey SecretKey::toPublicKey() const { +#if HAVE_SODIUM + unsigned char pk[crypto_sign_PUBLICKEYBYTES]; + crypto_sign_ed25519_sk_to_pk(pk, (unsigned char*)key.data()); + return PublicKey(name, std::string((char*)pk, crypto_sign_PUBLICKEYBYTES)); +#else + noSodium(); +#endif +} + +PublicKey::PublicKey(const string& s) : Key(s) { +#if HAVE_SODIUM + if (key.size() != crypto_sign_PUBLICKEYBYTES) { + throw Error("public key is not valid"); + } +#endif +} + +bool verifyDetached(const std::string& data, const std::string& sig, + const PublicKeys& publicKeys) { +#if HAVE_SODIUM + auto ss = split(sig); + + auto key = publicKeys.find(ss.first); + if (key == publicKeys.end()) { + return false; + } + + auto sig2 = base64Decode(ss.second); + if (sig2.size() != crypto_sign_BYTES) { + throw Error("signature is not valid"); + } + + return crypto_sign_verify_detached( + (unsigned char*)sig2.data(), (unsigned char*)data.data(), + data.size(), (unsigned char*)key->second.key.data()) == 0; +#else + noSodium(); +#endif +} + +PublicKeys getDefaultPublicKeys() { + PublicKeys publicKeys; + + // FIXME: filter duplicates + + for (const auto& s : settings.trustedPublicKeys.get()) { + PublicKey key(s); + publicKeys.emplace(key.name, key); + } + + for (const auto& secretKeyFile : settings.secretKeyFiles.get()) { + try { + SecretKey secretKey(readFile(secretKeyFile)); + publicKeys.emplace(secretKey.name, secretKey.toPublicKey()); + } catch (SysError& e) { + /* Ignore unreadable key files. That's normal in a + multi-user installation. */ + } + } + + return publicKeys; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/crypto.hh b/third_party/nix/src/libstore/crypto.hh new file mode 100644 index 0000000000..ef578db6d0 --- /dev/null +++ b/third_party/nix/src/libstore/crypto.hh @@ -0,0 +1,49 @@ +#pragma once + +#include <map> + +#include "types.hh" + +namespace nix { + +struct Key { + std::string name; + std::string key; + + /* Construct Key from a string in the format + ‘<name>:<key-in-base64>’. */ + Key(const std::string& s); + + protected: + Key(const std::string& name, const std::string& key) : name(name), key(key) {} +}; + +struct PublicKey; + +struct SecretKey : Key { + SecretKey(const std::string& s); + + /* Return a detached signature of the given string. */ + std::string signDetached(const std::string& data) const; + + PublicKey toPublicKey() const; +}; + +struct PublicKey : Key { + PublicKey(const std::string& s); + + private: + PublicKey(const std::string& name, const std::string& key) : Key(name, key) {} + friend struct SecretKey; +}; + +typedef std::map<std::string, PublicKey> PublicKeys; + +/* Return true iff ‘sig’ is a correct signature over ‘data’ using one + of the given public keys. */ +bool verifyDetached(const std::string& data, const std::string& sig, + const PublicKeys& publicKeys); + +PublicKeys getDefaultPublicKeys(); + +} // namespace nix diff --git a/third_party/nix/src/libstore/derivations.cc b/third_party/nix/src/libstore/derivations.cc new file mode 100644 index 0000000000..9c71d7209e --- /dev/null +++ b/third_party/nix/src/libstore/derivations.cc @@ -0,0 +1,428 @@ +#include "derivations.hh" + +#include "fs-accessor.hh" +#include "globals.hh" +#include "istringstream_nocopy.hh" +#include "store-api.hh" +#include "util.hh" +#include "worker-protocol.hh" + +namespace nix { + +void DerivationOutput::parseHashInfo(bool& recursive, Hash& hash) const { + recursive = false; + string algo = hashAlgo; + + if (string(algo, 0, 2) == "r:") { + recursive = true; + algo = string(algo, 2); + } + + HashType hashType = parseHashType(algo); + if (hashType == htUnknown) { + throw Error(format("unknown hash algorithm '%1%'") % algo); + } + + hash = Hash(this->hash, hashType); +} + +Path BasicDerivation::findOutput(const string& id) const { + auto i = outputs.find(id); + if (i == outputs.end()) { + throw Error(format("derivation has no output '%1%'") % id); + } + return i->second.path; +} + +bool BasicDerivation::isBuiltin() const { + return string(builder, 0, 8) == "builtin:"; +} + +Path writeDerivation(const ref<Store>& store, const Derivation& drv, + const string& name, RepairFlag repair) { + PathSet references; + references.insert(drv.inputSrcs.begin(), drv.inputSrcs.end()); + for (auto& i : drv.inputDrvs) { + references.insert(i.first); + } + /* Note that the outputs of a derivation are *not* references + (that can be missing (of course) and should not necessarily be + held during a garbage collection). */ + string suffix = name + drvExtension; + string contents = drv.unparse(); + return settings.readOnlyMode + ? store->computeStorePathForText(suffix, contents, references) + : store->addTextToStore(suffix, contents, references, repair); +} + +/* Read string `s' from stream `str'. */ +static void expect(std::istream& str, const string& s) { + char s2[s.size()]; + str.read(s2, s.size()); + if (string(s2, s.size()) != s) { + throw FormatError(format("expected string '%1%'") % s); + } +} + +/* Read a C-style string from stream `str'. */ +static string parseString(std::istream& str) { + string res; + expect(str, "\""); + int c; + while ((c = str.get()) != '"') { + if (c == '\\') { + c = str.get(); + if (c == 'n') { + res += '\n'; + } else if (c == 'r') { + res += '\r'; + } else if (c == 't') { + res += '\t'; + } else { + res += c; + } + } else { + res += c; + } + } + return res; +} + +static Path parsePath(std::istream& str) { + string s = parseString(str); + if (s.empty() || s[0] != '/') { + throw FormatError(format("bad path '%1%' in derivation") % s); + } + return s; +} + +static bool endOfList(std::istream& str) { + if (str.peek() == ',') { + str.get(); + return false; + } + if (str.peek() == ']') { + str.get(); + return true; + } + return false; +} + +static StringSet parseStrings(std::istream& str, bool arePaths) { + StringSet res; + while (!endOfList(str)) { + res.insert(arePaths ? parsePath(str) : parseString(str)); + } + return res; +} + +static Derivation parseDerivation(const string& s) { + Derivation drv; + istringstream_nocopy str(s); + expect(str, "Derive(["); + + /* Parse the list of outputs. */ + while (!endOfList(str)) { + DerivationOutput out; + expect(str, "("); + string id = parseString(str); + expect(str, ","); + out.path = parsePath(str); + expect(str, ","); + out.hashAlgo = parseString(str); + expect(str, ","); + out.hash = parseString(str); + expect(str, ")"); + drv.outputs[id] = out; + } + + /* Parse the list of input derivations. */ + expect(str, ",["); + while (!endOfList(str)) { + expect(str, "("); + Path drvPath = parsePath(str); + expect(str, ",["); + drv.inputDrvs[drvPath] = parseStrings(str, false); + expect(str, ")"); + } + + expect(str, ",["); + drv.inputSrcs = parseStrings(str, true); + expect(str, ","); + drv.platform = parseString(str); + expect(str, ","); + drv.builder = parseString(str); + + /* Parse the builder arguments. */ + expect(str, ",["); + while (!endOfList(str)) { + drv.args.push_back(parseString(str)); + } + + /* Parse the environment variables. */ + expect(str, ",["); + while (!endOfList(str)) { + expect(str, "("); + string name = parseString(str); + expect(str, ","); + string value = parseString(str); + expect(str, ")"); + drv.env[name] = value; + } + + expect(str, ")"); + return drv; +} + +Derivation readDerivation(const Path& drvPath) { + try { + return parseDerivation(readFile(drvPath)); + } catch (FormatError& e) { + throw Error(format("error parsing derivation '%1%': %2%") % drvPath % + e.msg()); + } +} + +Derivation Store::derivationFromPath(const Path& drvPath) { + assertStorePath(drvPath); + ensurePath(drvPath); + auto accessor = getFSAccessor(); + try { + return parseDerivation(accessor->readFile(drvPath)); + } catch (FormatError& e) { + throw Error(format("error parsing derivation '%1%': %2%") % drvPath % + e.msg()); + } +} + +static void printString(string& res, const string& s) { + res += '"'; + for (const char* i = s.c_str(); *i != 0; i++) { + if (*i == '\"' || *i == '\\') { + res += "\\"; + res += *i; + } else if (*i == '\n') { + res += "\\n"; + } else if (*i == '\r') { + res += "\\r"; + } else if (*i == '\t') { + res += "\\t"; + } else { + res += *i; + } + } + res += '"'; +} + +template <class ForwardIterator> +static void printStrings(string& res, ForwardIterator i, ForwardIterator j) { + res += '['; + bool first = true; + for (; i != j; ++i) { + if (first) { + first = false; + } else { + res += ','; + } + printString(res, *i); + } + res += ']'; +} + +string Derivation::unparse() const { + string s; + s.reserve(65536); + s += "Derive(["; + + bool first = true; + for (auto& i : outputs) { + if (first) { + first = false; + } else { + s += ','; + } + s += '('; + printString(s, i.first); + s += ','; + printString(s, i.second.path); + s += ','; + printString(s, i.second.hashAlgo); + s += ','; + printString(s, i.second.hash); + s += ')'; + } + + s += "],["; + first = true; + for (auto& i : inputDrvs) { + if (first) { + first = false; + } else { + s += ','; + } + s += '('; + printString(s, i.first); + s += ','; + printStrings(s, i.second.begin(), i.second.end()); + s += ')'; + } + + s += "],"; + printStrings(s, inputSrcs.begin(), inputSrcs.end()); + + s += ','; + printString(s, platform); + s += ','; + printString(s, builder); + s += ','; + printStrings(s, args.begin(), args.end()); + + s += ",["; + first = true; + for (auto& i : env) { + if (first) { + first = false; + } else { + s += ','; + } + s += '('; + printString(s, i.first); + s += ','; + printString(s, i.second); + s += ')'; + } + + s += "])"; + + return s; +} + +bool isDerivation(const string& fileName) { + return hasSuffix(fileName, drvExtension); +} + +bool BasicDerivation::isFixedOutput() const { + return outputs.size() == 1 && outputs.begin()->first == "out" && + !outputs.begin()->second.hash.empty(); +} + +DrvHashes drvHashes; + +/* Returns the hash of a derivation modulo fixed-output + subderivations. A fixed-output derivation is a derivation with one + output (`out') for which an expected hash and hash algorithm are + specified (using the `outputHash' and `outputHashAlgo' + attributes). We don't want changes to such derivations to + propagate upwards through the dependency graph, changing output + paths everywhere. + + For instance, if we change the url in a call to the `fetchurl' + function, we do not want to rebuild everything depending on it + (after all, (the hash of) the file being downloaded is unchanged). + So the *output paths* should not change. On the other hand, the + *derivation paths* should change to reflect the new dependency + graph. + + That's what this function does: it returns a hash which is just the + hash of the derivation ATerm, except that any input derivation + paths have been replaced by the result of a recursive call to this + function, and that for fixed-output derivations we return a hash of + its output path. */ +Hash hashDerivationModulo(Store& store, Derivation drv) { + /* Return a fixed hash for fixed-output derivations. */ + if (drv.isFixedOutput()) { + auto i = drv.outputs.begin(); + return hashString(htSHA256, "fixed:out:" + i->second.hashAlgo + ":" + + i->second.hash + ":" + i->second.path); + } + + /* For other derivations, replace the inputs paths with recursive + calls to this function.*/ + DerivationInputs inputs2; + for (auto& i : drv.inputDrvs) { + Hash h = drvHashes[i.first]; + if (!h) { + assert(store.isValidPath(i.first)); + Derivation drv2 = readDerivation(store.toRealPath(i.first)); + h = hashDerivationModulo(store, drv2); + drvHashes[i.first] = h; + } + inputs2[h.to_string(Base16, false)] = i.second; + } + drv.inputDrvs = inputs2; + + return hashString(htSHA256, drv.unparse()); +} + +DrvPathWithOutputs parseDrvPathWithOutputs(const string& s) { + size_t n = s.find('!'); + return n == std::string::npos + ? DrvPathWithOutputs(s, std::set<string>()) + : DrvPathWithOutputs( + string(s, 0, n), + tokenizeString<std::set<string> >(string(s, n + 1), ",")); +} + +Path makeDrvPathWithOutputs(const Path& drvPath, + const std::set<string>& outputs) { + return outputs.empty() ? drvPath + : drvPath + "!" + concatStringsSep(",", outputs); +} + +bool wantOutput(const string& output, const std::set<string>& wanted) { + return wanted.empty() || wanted.find(output) != wanted.end(); +} + +PathSet BasicDerivation::outputPaths() const { + PathSet paths; + for (auto& i : outputs) { + paths.insert(i.second.path); + } + return paths; +} + +Source& readDerivation(Source& in, Store& store, BasicDerivation& drv) { + drv.outputs.clear(); + auto nr = readNum<size_t>(in); + for (size_t n = 0; n < nr; n++) { + auto name = readString(in); + DerivationOutput o; + in >> o.path >> o.hashAlgo >> o.hash; + store.assertStorePath(o.path); + drv.outputs[name] = o; + } + + drv.inputSrcs = readStorePaths<PathSet>(store, in); + in >> drv.platform >> drv.builder; + drv.args = readStrings<Strings>(in); + + nr = readNum<size_t>(in); + for (size_t n = 0; n < nr; n++) { + auto key = readString(in); + auto value = readString(in); + drv.env[key] = value; + } + + return in; +} + +Sink& operator<<(Sink& out, const BasicDerivation& drv) { + out << drv.outputs.size(); + for (auto& i : drv.outputs) { + out << i.first << i.second.path << i.second.hashAlgo << i.second.hash; + } + out << drv.inputSrcs << drv.platform << drv.builder << drv.args; + out << drv.env.size(); + for (auto& i : drv.env) { + out << i.first << i.second; + } + return out; +} + +std::string hashPlaceholder(const std::string& outputName) { + // FIXME: memoize? + return "/" + hashString(htSHA256, "nix-output:" + outputName) + .to_string(Base32, false); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/derivations.hh b/third_party/nix/src/libstore/derivations.hh new file mode 100644 index 0000000000..52b951f5e9 --- /dev/null +++ b/third_party/nix/src/libstore/derivations.hh @@ -0,0 +1,106 @@ +#pragma once + +#include <map> + +#include "hash.hh" +#include "store-api.hh" +#include "types.hh" + +namespace nix { + +/* Extension of derivations in the Nix store. */ +const string drvExtension = ".drv"; + +/* Abstract syntax of derivations. */ + +struct DerivationOutput { + Path path; + string hashAlgo; /* hash used for expected hash computation */ + string hash; /* expected hash, may be null */ + DerivationOutput() {} + DerivationOutput(Path path, string hashAlgo, string hash) { + this->path = path; + this->hashAlgo = hashAlgo; + this->hash = hash; + } + void parseHashInfo(bool& recursive, Hash& hash) const; +}; + +typedef std::map<string, DerivationOutput> DerivationOutputs; + +/* For inputs that are sub-derivations, we specify exactly which + output IDs we are interested in. */ +typedef std::map<Path, StringSet> DerivationInputs; + +typedef std::map<string, string> StringPairs; + +struct BasicDerivation { + DerivationOutputs outputs; /* keyed on symbolic IDs */ + PathSet inputSrcs; /* inputs that are sources */ + string platform; + Path builder; + Strings args; + StringPairs env; + + virtual ~BasicDerivation(){}; + + /* Return the path corresponding to the output identifier `id' in + the given derivation. */ + Path findOutput(const string& id) const; + + bool isBuiltin() const; + + /* Return true iff this is a fixed-output derivation. */ + bool isFixedOutput() const; + + /* Return the output paths of a derivation. */ + PathSet outputPaths() const; +}; + +struct Derivation : BasicDerivation { + DerivationInputs inputDrvs; /* inputs that are sub-derivations */ + + /* Print a derivation. */ + std::string unparse() const; +}; + +class Store; + +/* Write a derivation to the Nix store, and return its path. */ +Path writeDerivation(const ref<Store>& store, const Derivation& drv, + const string& name, RepairFlag repair = NoRepair); + +/* Read a derivation from a file. */ +Derivation readDerivation(const Path& drvPath); + +/* Check whether a file name ends with the extension for + derivations. */ +bool isDerivation(const string& fileName); + +Hash hashDerivationModulo(Store& store, Derivation drv); + +/* Memoisation of hashDerivationModulo(). */ +typedef std::map<Path, Hash> DrvHashes; + +extern DrvHashes drvHashes; // FIXME: global, not thread-safe + +/* Split a string specifying a derivation and a set of outputs + (/nix/store/hash-foo!out1,out2,...) into the derivation path and + the outputs. */ +typedef std::pair<string, std::set<string> > DrvPathWithOutputs; +DrvPathWithOutputs parseDrvPathWithOutputs(const string& s); + +Path makeDrvPathWithOutputs(const Path& drvPath, + const std::set<string>& outputs); + +bool wantOutput(const string& output, const std::set<string>& wanted); + +struct Source; +struct Sink; + +Source& readDerivation(Source& in, Store& store, BasicDerivation& drv); +Sink& operator<<(Sink& out, const BasicDerivation& drv); + +std::string hashPlaceholder(const std::string& outputName); + +} // namespace nix diff --git a/third_party/nix/src/libstore/download.cc b/third_party/nix/src/libstore/download.cc new file mode 100644 index 0000000000..7476dd50b5 --- /dev/null +++ b/third_party/nix/src/libstore/download.cc @@ -0,0 +1,1022 @@ +#include "download.hh" + +#include "archive.hh" +#include "compression.hh" +#include "finally.hh" +#include "globals.hh" +#include "hash.hh" +#include "pathlocks.hh" +#include "s3.hh" +#include "store-api.hh" +#include "util.hh" + +#ifdef ENABLE_S3 +#include <aws/core/client/ClientConfiguration.h> +#endif + +#include <algorithm> +#include <cmath> +#include <cstring> +#include <iostream> +#include <queue> +#include <random> +#include <thread> + +#include <curl/curl.h> +#include <fcntl.h> +#include <glog/logging.h> +#include <unistd.h> + +using namespace std::string_literals; + +namespace nix { + +DownloadSettings downloadSettings; + +static GlobalConfig::Register r1(&downloadSettings); + +std::string resolveUri(const std::string& uri) { + if (uri.compare(0, 8, "channel:") == 0) { + return "https://nixos.org/channels/" + std::string(uri, 8) + + "/nixexprs.tar.xz"; + } + return uri; +} + +struct CurlDownloader : public Downloader { + CURLM* curlm = nullptr; + + std::random_device rd; + std::mt19937 mt19937; + + struct DownloadItem : public std::enable_shared_from_this<DownloadItem> { + CurlDownloader& downloader; + DownloadRequest request; + DownloadResult result; + bool done = false; // whether either the success or failure function has + // been called + Callback<DownloadResult> callback; + CURL* req = nullptr; + bool active = + false; // whether the handle has been added to the multi object + std::string status; + + unsigned int attempt = 0; + + /* Don't start this download until the specified time point + has been reached. */ + std::chrono::steady_clock::time_point embargo; + + struct curl_slist* requestHeaders = nullptr; + + std::string encoding; + + bool acceptRanges = false; + + curl_off_t writtenToSink = 0; + + DownloadItem(CurlDownloader& downloader, const DownloadRequest& request, + Callback<DownloadResult>&& callback) + : downloader(downloader), + request(request), + callback(std::move(callback)), + finalSink([this](const unsigned char* data, size_t len) { + if (this->request.dataCallback) { + long httpStatus = 0; + curl_easy_getinfo(req, CURLINFO_RESPONSE_CODE, &httpStatus); + + /* Only write data to the sink if this is a + successful response. */ + if (httpStatus == 0 || httpStatus == 200 || httpStatus == 201 || + httpStatus == 206) { + writtenToSink += len; + this->request.dataCallback((char*)data, len); + } + } else { + this->result.data->append((char*)data, len); + } + }) { + LOG(INFO) << (request.data ? "uploading '" : "downloading '") + << request.uri << "'"; + + if (!request.expectedETag.empty()) { + requestHeaders = curl_slist_append( + requestHeaders, ("If-None-Match: " + request.expectedETag).c_str()); + } + if (!request.mimeType.empty()) { + requestHeaders = curl_slist_append( + requestHeaders, ("Content-Type: " + request.mimeType).c_str()); + } + } + + ~DownloadItem() { + if (req != nullptr) { + if (active) { + curl_multi_remove_handle(downloader.curlm, req); + } + curl_easy_cleanup(req); + } + if (requestHeaders != nullptr) { + curl_slist_free_all(requestHeaders); + } + try { + if (!done) { + fail(DownloadError( + Interrupted, + format("download of '%s' was interrupted") % request.uri)); + } + } catch (...) { + ignoreException(); + } + } + + void failEx(const std::exception_ptr& ex) { + assert(!done); + done = true; + callback.rethrow(ex); + } + + template <class T> + void fail(const T& e) { + failEx(std::make_exception_ptr(e)); + } + + LambdaSink finalSink; + std::shared_ptr<CompressionSink> decompressionSink; + + std::exception_ptr writeException; + + size_t writeCallback(void* contents, size_t size, size_t nmemb) { + try { + size_t realSize = size * nmemb; + result.bodySize += realSize; + + if (!decompressionSink) { + decompressionSink = makeDecompressionSink(encoding, finalSink); + } + + (*decompressionSink)((unsigned char*)contents, realSize); + + return realSize; + } catch (...) { + writeException = std::current_exception(); + return 0; + } + } + + static size_t writeCallbackWrapper(void* contents, size_t size, + size_t nmemb, void* userp) { + return ((DownloadItem*)userp)->writeCallback(contents, size, nmemb); + } + + size_t headerCallback(void* contents, size_t size, size_t nmemb) { + size_t realSize = size * nmemb; + std::string line((char*)contents, realSize); + DLOG(INFO) << "got header for '" << request.uri << "': " << trim(line); + if (line.compare(0, 5, "HTTP/") == 0) { // new response starts + result.etag = ""; + auto ss = tokenizeString<vector<string>>(line, " "); + status = ss.size() >= 2 ? ss[1] : ""; + result.data = std::make_shared<std::string>(); + result.bodySize = 0; + acceptRanges = false; + encoding = ""; + } else { + auto i = line.find(':'); + if (i != string::npos) { + string name = toLower(trim(string(line, 0, i))); + if (name == "etag") { + result.etag = trim(string(line, i + 1)); + /* Hack to work around a GitHub bug: it sends + ETags, but ignores If-None-Match. So if we get + the expected ETag on a 200 response, then shut + down the connection because we already have the + data. */ + if (result.etag == request.expectedETag && status == "200") { + DLOG(INFO) + << "shutting down on 200 HTTP response with expected ETag"; + return 0; + } + } else if (name == "content-encoding") { + encoding = trim(string(line, i + 1)); + } else if (name == "accept-ranges" && + toLower(trim(std::string(line, i + 1))) == "bytes") { + acceptRanges = true; + } + } + } + return realSize; + } + + static size_t headerCallbackWrapper(void* contents, size_t size, + size_t nmemb, void* userp) { + return ((DownloadItem*)userp)->headerCallback(contents, size, nmemb); + } + + static int progressCallback(double dltotal, double dlnow) { + try { + // TODO(tazjin): this had activity nonsense, clean it up + } catch (nix::Interrupted&) { + assert(_isInterrupted); + } + return static_cast<int>(_isInterrupted); + } + + static int progressCallbackWrapper(void* userp, double dltotal, + double dlnow, double ultotal, + double ulnow) { + return ((DownloadItem*)userp)->progressCallback(dltotal, dlnow); + } + + static int debugCallback(CURL* handle, curl_infotype type, char* data, + size_t size, void* userptr) { + if (type == CURLINFO_TEXT) { + DLOG(INFO) << "curl: " << chomp(std::string(data, size)); + } + return 0; + } + + size_t readOffset = 0; + size_t readCallback(char* buffer, size_t size, size_t nitems) { + if (readOffset == request.data->length()) { + return 0; + } + auto count = std::min(size * nitems, request.data->length() - readOffset); + assert(count); + memcpy(buffer, request.data->data() + readOffset, count); + readOffset += count; + return count; + } + + static size_t readCallbackWrapper(char* buffer, size_t size, size_t nitems, + void* userp) { + return ((DownloadItem*)userp)->readCallback(buffer, size, nitems); + } + + void init() { + if (req == nullptr) { + req = curl_easy_init(); + } + + curl_easy_reset(req); + + // TODO(tazjin): Add an Abseil flag for this + // if (verbosity >= lvlVomit) { + // curl_easy_setopt(req, CURLOPT_VERBOSE, 1); + // curl_easy_setopt(req, CURLOPT_DEBUGFUNCTION, + // DownloadItem::debugCallback); + // } + + curl_easy_setopt(req, CURLOPT_URL, request.uri.c_str()); + curl_easy_setopt(req, CURLOPT_FOLLOWLOCATION, 1L); + curl_easy_setopt(req, CURLOPT_MAXREDIRS, 10); + curl_easy_setopt(req, CURLOPT_NOSIGNAL, 1); + curl_easy_setopt(req, CURLOPT_USERAGENT, + ("curl/" LIBCURL_VERSION " Nix/" + nixVersion + + (downloadSettings.userAgentSuffix != "" + ? " " + downloadSettings.userAgentSuffix.get() + : "")) + .c_str()); +#if LIBCURL_VERSION_NUM >= 0x072b00 + curl_easy_setopt(req, CURLOPT_PIPEWAIT, 1); +#endif +#if LIBCURL_VERSION_NUM >= 0x072f00 + if (downloadSettings.enableHttp2) { + curl_easy_setopt(req, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_2TLS); + } else { + curl_easy_setopt(req, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1); + } +#endif + curl_easy_setopt(req, CURLOPT_WRITEFUNCTION, + DownloadItem::writeCallbackWrapper); + curl_easy_setopt(req, CURLOPT_WRITEDATA, this); + curl_easy_setopt(req, CURLOPT_HEADERFUNCTION, + DownloadItem::headerCallbackWrapper); + curl_easy_setopt(req, CURLOPT_HEADERDATA, this); + + curl_easy_setopt(req, CURLOPT_PROGRESSFUNCTION, progressCallbackWrapper); + curl_easy_setopt(req, CURLOPT_PROGRESSDATA, this); + curl_easy_setopt(req, CURLOPT_NOPROGRESS, 0); + + curl_easy_setopt(req, CURLOPT_HTTPHEADER, requestHeaders); + + if (request.head) { + curl_easy_setopt(req, CURLOPT_NOBODY, 1); + } + + if (request.data) { + curl_easy_setopt(req, CURLOPT_UPLOAD, 1L); + curl_easy_setopt(req, CURLOPT_READFUNCTION, readCallbackWrapper); + curl_easy_setopt(req, CURLOPT_READDATA, this); + curl_easy_setopt(req, CURLOPT_INFILESIZE_LARGE, + (curl_off_t)request.data->length()); + } + + if (request.verifyTLS) { + if (!settings.caFile.empty()) { + curl_easy_setopt(req, CURLOPT_CAINFO, settings.caFile.c_str()); + } + } else { + curl_easy_setopt(req, CURLOPT_SSL_VERIFYPEER, 0); + curl_easy_setopt(req, CURLOPT_SSL_VERIFYHOST, 0); + } + + curl_easy_setopt(req, CURLOPT_CONNECTTIMEOUT, + downloadSettings.connectTimeout.get()); + + curl_easy_setopt(req, CURLOPT_LOW_SPEED_LIMIT, 1L); + curl_easy_setopt(req, CURLOPT_LOW_SPEED_TIME, + downloadSettings.stalledDownloadTimeout.get()); + + /* If no file exist in the specified path, curl continues to work + anyway as if netrc support was disabled. */ + curl_easy_setopt(req, CURLOPT_NETRC_FILE, + settings.netrcFile.get().c_str()); + curl_easy_setopt(req, CURLOPT_NETRC, CURL_NETRC_OPTIONAL); + + if (writtenToSink != 0) { + curl_easy_setopt(req, CURLOPT_RESUME_FROM_LARGE, writtenToSink); + } + + result.data = std::make_shared<std::string>(); + result.bodySize = 0; + } + + void finish(CURLcode code) { + long httpStatus = 0; + curl_easy_getinfo(req, CURLINFO_RESPONSE_CODE, &httpStatus); + + char* effectiveUriCStr; + curl_easy_getinfo(req, CURLINFO_EFFECTIVE_URL, &effectiveUriCStr); + if (effectiveUriCStr != nullptr) { + result.effectiveUri = effectiveUriCStr; + } + + DLOG(INFO) << "finished " << request.verb() << " of " << request.uri + << "; curl status = " << code + << ", HTTP status = " << httpStatus + << ", body = " << result.bodySize << " bytes"; + + if (decompressionSink) { + try { + decompressionSink->finish(); + } catch (...) { + writeException = std::current_exception(); + } + } + + if (code == CURLE_WRITE_ERROR && result.etag == request.expectedETag) { + code = CURLE_OK; + httpStatus = 304; + } + + if (writeException) { + failEx(writeException); + + } else if (code == CURLE_OK && + (httpStatus == 200 || httpStatus == 201 || httpStatus == 204 || + httpStatus == 206 || httpStatus == 304 || + httpStatus == 226 /* FTP */ || + httpStatus == 0 /* other protocol */)) { + result.cached = httpStatus == 304; + done = true; + callback(std::move(result)); + } + + else { + // We treat most errors as transient, but won't retry when hopeless + Error err = Transient; + + if (httpStatus == 404 || httpStatus == 410 || + code == CURLE_FILE_COULDNT_READ_FILE) { + // The file is definitely not there + err = NotFound; + } else if (httpStatus == 401 || httpStatus == 403 || + httpStatus == 407) { + // Don't retry on authentication/authorization failures + err = Forbidden; + } else if (httpStatus >= 400 && httpStatus < 500 && httpStatus != 408 && + httpStatus != 429) { + // Most 4xx errors are client errors and are probably not worth + // retrying: + // * 408 means the server timed out waiting for us, so we try again + // * 429 means too many requests, so we retry (with a delay) + err = Misc; + } else if (httpStatus == 501 || httpStatus == 505 || + httpStatus == 511) { + // Let's treat most 5xx (server) errors as transient, except for a + // handful: + // * 501 not implemented + // * 505 http version not supported + // * 511 we're behind a captive portal + err = Misc; + } else { + // Don't bother retrying on certain cURL errors either + switch (code) { + case CURLE_FAILED_INIT: + case CURLE_URL_MALFORMAT: + case CURLE_NOT_BUILT_IN: + case CURLE_REMOTE_ACCESS_DENIED: + case CURLE_FILE_COULDNT_READ_FILE: + case CURLE_FUNCTION_NOT_FOUND: + case CURLE_ABORTED_BY_CALLBACK: + case CURLE_BAD_FUNCTION_ARGUMENT: + case CURLE_INTERFACE_FAILED: + case CURLE_UNKNOWN_OPTION: + case CURLE_SSL_CACERT_BADFILE: + case CURLE_TOO_MANY_REDIRECTS: + case CURLE_WRITE_ERROR: + case CURLE_UNSUPPORTED_PROTOCOL: + err = Misc; + break; + default: // Shut up warnings + break; + } + } + + attempt++; + + auto exc = + code == CURLE_ABORTED_BY_CALLBACK && _isInterrupted + ? DownloadError(Interrupted, fmt("%s of '%s' was interrupted", + request.verb(), request.uri)) + : httpStatus != 0 + ? DownloadError( + err, fmt("unable to %s '%s': HTTP error %d", + request.verb(), request.uri, httpStatus) + + (code == CURLE_OK + ? "" + : fmt(" (curl error: %s)", + curl_easy_strerror(code)))) + : DownloadError(err, fmt("unable to %s '%s': %s (%d)", + request.verb(), request.uri, + curl_easy_strerror(code), code)); + + /* If this is a transient error, then maybe retry the + download after a while. If we're writing to a + sink, we can only retry if the server supports + ranged requests. */ + if (err == Transient && attempt < request.tries && + (!this->request.dataCallback || writtenToSink == 0 || + (acceptRanges && encoding.empty()))) { + int ms = request.baseRetryTimeMs * + std::pow(2.0F, attempt - 1 + + std::uniform_real_distribution<>( + 0.0, 0.5)(downloader.mt19937)); + if (writtenToSink != 0) { + LOG(WARNING) << exc.what() << "; retrying from offset " + << writtenToSink << " in " << ms << "ms"; + } else { + LOG(WARNING) << exc.what() << "; retrying in " << ms << "ms"; + } + embargo = + std::chrono::steady_clock::now() + std::chrono::milliseconds(ms); + downloader.enqueueItem(shared_from_this()); + } else { + fail(exc); + } + } + } + }; + + struct State { + struct EmbargoComparator { + bool operator()(const std::shared_ptr<DownloadItem>& i1, + const std::shared_ptr<DownloadItem>& i2) { + return i1->embargo > i2->embargo; + } + }; + bool quit = false; + std::priority_queue<std::shared_ptr<DownloadItem>, + std::vector<std::shared_ptr<DownloadItem>>, + EmbargoComparator> + incoming; + }; + + Sync<State> state_; + + /* We can't use a std::condition_variable to wake up the curl + thread, because it only monitors file descriptors. So use a + pipe instead. */ + Pipe wakeupPipe; + + std::thread workerThread; + + CurlDownloader() : mt19937(rd()) { + static std::once_flag globalInit; + std::call_once(globalInit, curl_global_init, CURL_GLOBAL_ALL); + + curlm = curl_multi_init(); + +#if LIBCURL_VERSION_NUM >= 0x072b00 // Multiplex requires >= 7.43.0 + curl_multi_setopt(curlm, CURLMOPT_PIPELINING, CURLPIPE_MULTIPLEX); +#endif +#if LIBCURL_VERSION_NUM >= 0x071e00 // Max connections requires >= 7.30.0 + curl_multi_setopt(curlm, CURLMOPT_MAX_TOTAL_CONNECTIONS, + downloadSettings.httpConnections.get()); +#endif + + wakeupPipe.create(); + fcntl(wakeupPipe.readSide.get(), F_SETFL, O_NONBLOCK); + + workerThread = std::thread([&]() { workerThreadEntry(); }); + } + + ~CurlDownloader() override { + stopWorkerThread(); + + workerThread.join(); + + if (curlm != nullptr) { + curl_multi_cleanup(curlm); + } + } + + void stopWorkerThread() { + /* Signal the worker thread to exit. */ + { + auto state(state_.lock()); + state->quit = true; + } + writeFull(wakeupPipe.writeSide.get(), " ", false); + } + + void workerThreadMain() { + /* Cause this thread to be notified on SIGINT. */ + auto callback = createInterruptCallback([&]() { stopWorkerThread(); }); + + std::map<CURL*, std::shared_ptr<DownloadItem>> items; + + bool quit = false; + + std::chrono::steady_clock::time_point nextWakeup; + + while (!quit) { + checkInterrupt(); + + /* Let curl do its thing. */ + int running; + CURLMcode mc = curl_multi_perform(curlm, &running); + if (mc != CURLM_OK) { + throw nix::Error( + format("unexpected error from curl_multi_perform(): %s") % + curl_multi_strerror(mc)); + } + + /* Set the promises of any finished requests. */ + CURLMsg* msg; + int left; + while ((msg = curl_multi_info_read(curlm, &left)) != nullptr) { + if (msg->msg == CURLMSG_DONE) { + auto i = items.find(msg->easy_handle); + assert(i != items.end()); + i->second->finish(msg->data.result); + curl_multi_remove_handle(curlm, i->second->req); + i->second->active = false; + items.erase(i); + } + } + + /* Wait for activity, including wakeup events. */ + int numfds = 0; + struct curl_waitfd extraFDs[1]; + extraFDs[0].fd = wakeupPipe.readSide.get(); + extraFDs[0].events = CURL_WAIT_POLLIN; + extraFDs[0].revents = 0; + long maxSleepTimeMs = items.empty() ? 10000 : 100; + auto sleepTimeMs = + nextWakeup != std::chrono::steady_clock::time_point() + ? std::max( + 0, + (int)std::chrono::duration_cast<std::chrono::milliseconds>( + nextWakeup - std::chrono::steady_clock::now()) + .count()) + : maxSleepTimeMs; + DLOG(INFO) << "download thread waiting for " << sleepTimeMs << " ms"; + mc = curl_multi_wait(curlm, extraFDs, 1, sleepTimeMs, &numfds); + if (mc != CURLM_OK) { + throw nix::Error(format("unexpected error from curl_multi_wait(): %s") % + curl_multi_strerror(mc)); + } + + nextWakeup = std::chrono::steady_clock::time_point(); + + /* Add new curl requests from the incoming requests queue, + except for requests that are embargoed (waiting for a + retry timeout to expire). */ + if ((extraFDs[0].revents & CURL_WAIT_POLLIN) != 0) { + char buf[1024]; + auto res = read(extraFDs[0].fd, buf, sizeof(buf)); + if (res == -1 && errno != EINTR) { + throw SysError("reading curl wakeup socket"); + } + } + + std::vector<std::shared_ptr<DownloadItem>> incoming; + auto now = std::chrono::steady_clock::now(); + + { + auto state(state_.lock()); + while (!state->incoming.empty()) { + auto item = state->incoming.top(); + if (item->embargo <= now) { + incoming.push_back(item); + state->incoming.pop(); + } else { + if (nextWakeup == std::chrono::steady_clock::time_point() || + item->embargo < nextWakeup) { + nextWakeup = item->embargo; + } + break; + } + } + quit = state->quit; + } + + for (auto& item : incoming) { + DLOG(INFO) << "starting " << item->request.verb() << " of " + << item->request.uri; + item->init(); + curl_multi_add_handle(curlm, item->req); + item->active = true; + items[item->req] = item; + } + } + + DLOG(INFO) << "download thread shutting down"; + } + + void workerThreadEntry() { + try { + workerThreadMain(); + } catch (nix::Interrupted& e) { + } catch (std::exception& e) { + LOG(ERROR) << "unexpected error in download thread: " << e.what(); + } + + { + auto state(state_.lock()); + while (!state->incoming.empty()) { + state->incoming.pop(); + } + state->quit = true; + } + } + + void enqueueItem(const std::shared_ptr<DownloadItem>& item) { + if (item->request.data && !hasPrefix(item->request.uri, "http://") && + !hasPrefix(item->request.uri, "https://")) { + throw nix::Error("uploading to '%s' is not supported", item->request.uri); + } + + { + auto state(state_.lock()); + if (state->quit) { + throw nix::Error( + "cannot enqueue download request because the download thread is " + "shutting down"); + } + state->incoming.push(item); + } + writeFull(wakeupPipe.writeSide.get(), " "); + } + +#ifdef ENABLE_S3 + std::tuple<std::string, std::string, Store::Params> parseS3Uri( + std::string uri) { + auto [path, params] = splitUriAndParams(uri); + + auto slash = path.find('/', 5); // 5 is the length of "s3://" prefix + if (slash == std::string::npos) { + throw nix::Error("bad S3 URI '%s'", path); + } + + std::string bucketName(path, 5, slash - 5); + std::string key(path, slash + 1); + + return {bucketName, key, params}; + } +#endif + + void enqueueDownload(const DownloadRequest& request, + Callback<DownloadResult> callback) override { + /* Ugly hack to support s3:// URIs. */ + if (hasPrefix(request.uri, "s3://")) { + // FIXME: do this on a worker thread + try { +#ifdef ENABLE_S3 + auto [bucketName, key, params] = parseS3Uri(request.uri); + + std::string profile = get(params, "profile", ""); + std::string region = get(params, "region", Aws::Region::US_EAST_1); + std::string scheme = get(params, "scheme", ""); + std::string endpoint = get(params, "endpoint", ""); + + S3Helper s3Helper(profile, region, scheme, endpoint); + + // FIXME: implement ETag + auto s3Res = s3Helper.getObject(bucketName, key); + DownloadResult res; + if (!s3Res.data) + throw DownloadError( + NotFound, fmt("S3 object '%s' does not exist", request.uri)); + res.data = s3Res.data; + callback(std::move(res)); +#else + throw nix::Error( + "cannot download '%s' because Nix is not built with S3 support", + request.uri); +#endif + } catch (...) { + callback.rethrow(); + } + return; + } + + enqueueItem( + std::make_shared<DownloadItem>(*this, request, std::move(callback))); + } +}; + +ref<Downloader> getDownloader() { + static ref<Downloader> downloader = makeDownloader(); + return downloader; +} + +ref<Downloader> makeDownloader() { return make_ref<CurlDownloader>(); } + +std::future<DownloadResult> Downloader::enqueueDownload( + const DownloadRequest& request) { + auto promise = std::make_shared<std::promise<DownloadResult>>(); + enqueueDownload(request, {[promise](std::future<DownloadResult> fut) { + try { + promise->set_value(fut.get()); + } catch (...) { + promise->set_exception(std::current_exception()); + } + }}); + return promise->get_future(); +} + +DownloadResult Downloader::download(const DownloadRequest& request) { + return enqueueDownload(request).get(); +} + +void Downloader::download(DownloadRequest&& request, Sink& sink) { + /* Note: we can't call 'sink' via request.dataCallback, because + that would cause the sink to execute on the downloader + thread. If 'sink' is a coroutine, this will fail. Also, if the + sink is expensive (e.g. one that does decompression and writing + to the Nix store), it would stall the download thread too much. + Therefore we use a buffer to communicate data between the + download thread and the calling thread. */ + + struct State { + bool quit = false; + std::exception_ptr exc; + std::string data; + std::condition_variable avail, request; + }; + + auto _state = std::make_shared<Sync<State>>(); + + /* In case of an exception, wake up the download thread. FIXME: + abort the download request. */ + Finally finally([&]() { + auto state(_state->lock()); + state->quit = true; + state->request.notify_one(); + }); + + request.dataCallback = [_state](char* buf, size_t len) { + auto state(_state->lock()); + + if (state->quit) { + return; + } + + /* If the buffer is full, then go to sleep until the calling + thread wakes us up (i.e. when it has removed data from the + buffer). We don't wait forever to prevent stalling the + download thread. (Hopefully sleeping will throttle the + sender.) */ + if (state->data.size() > 1024 * 1024) { + DLOG(INFO) << "download buffer is full; going to sleep"; + state.wait_for(state->request, std::chrono::seconds(10)); + } + + /* Append data to the buffer and wake up the calling + thread. */ + state->data.append(buf, len); + state->avail.notify_one(); + }; + + enqueueDownload(request, {[_state](std::future<DownloadResult> fut) { + auto state(_state->lock()); + state->quit = true; + try { + fut.get(); + } catch (...) { + state->exc = std::current_exception(); + } + state->avail.notify_one(); + state->request.notify_one(); + }}); + + while (true) { + checkInterrupt(); + + std::string chunk; + + /* Grab data if available, otherwise wait for the download + thread to wake us up. */ + { + auto state(_state->lock()); + + while (state->data.empty()) { + if (state->quit) { + if (state->exc) { + std::rethrow_exception(state->exc); + } + return; + } + + state.wait(state->avail); + } + + chunk = std::move(state->data); + + state->request.notify_one(); + } + + /* Flush the data to the sink and wake up the download thread + if it's blocked on a full buffer. We don't hold the state + lock while doing this to prevent blocking the download + thread if sink() takes a long time. */ + sink((unsigned char*)chunk.data(), chunk.size()); + } +} + +CachedDownloadResult Downloader::downloadCached( + const ref<Store>& store, const CachedDownloadRequest& request) { + auto url = resolveUri(request.uri); + + auto name = request.name; + if (name.empty()) { + auto p = url.rfind('/'); + if (p != string::npos) { + name = string(url, p + 1); + } + } + + Path expectedStorePath; + if (request.expectedHash) { + expectedStorePath = + store->makeFixedOutputPath(request.unpack, request.expectedHash, name); + if (store->isValidPath(expectedStorePath)) { + CachedDownloadResult result; + result.storePath = expectedStorePath; + result.path = store->toRealPath(expectedStorePath); + return result; + } + } + + Path cacheDir = getCacheDir() + "/nix/tarballs"; + createDirs(cacheDir); + + string urlHash = hashString(htSHA256, name + std::string("\0"s) + url) + .to_string(Base32, false); + + Path dataFile = cacheDir + "/" + urlHash + ".info"; + Path fileLink = cacheDir + "/" + urlHash + "-file"; + + PathLocks lock({fileLink}, fmt("waiting for lock on '%1%'...", fileLink)); + + Path storePath; + + string expectedETag; + + bool skip = false; + + CachedDownloadResult result; + + if (pathExists(fileLink) && pathExists(dataFile)) { + storePath = readLink(fileLink); + store->addTempRoot(storePath); + if (store->isValidPath(storePath)) { + auto ss = tokenizeString<vector<string>>(readFile(dataFile), "\n"); + if (ss.size() >= 3 && ss[0] == url) { + time_t lastChecked; + if (string2Int(ss[2], lastChecked) && + (uint64_t)lastChecked + request.ttl >= (uint64_t)time(nullptr)) { + skip = true; + result.effectiveUri = request.uri; + result.etag = ss[1]; + } else if (!ss[1].empty()) { + DLOG(INFO) << "verifying previous ETag: " << ss[1]; + expectedETag = ss[1]; + } + } + } else { + storePath = ""; + } + } + + if (!skip) { + try { + DownloadRequest request2(url); + request2.expectedETag = expectedETag; + auto res = download(request2); + result.effectiveUri = res.effectiveUri; + result.etag = res.etag; + + if (!res.cached) { + ValidPathInfo info; + StringSink sink; + dumpString(*res.data, sink); + Hash hash = hashString( + request.expectedHash ? request.expectedHash.type : htSHA256, + *res.data); + info.path = store->makeFixedOutputPath(false, hash, name); + info.narHash = hashString(htSHA256, *sink.s); + info.narSize = sink.s->size(); + info.ca = makeFixedOutputCA(false, hash); + store->addToStore(info, sink.s, NoRepair, NoCheckSigs); + storePath = info.path; + } + + assert(!storePath.empty()); + replaceSymlink(storePath, fileLink); + + writeFile(dataFile, url + "\n" + res.etag + "\n" + + std::to_string(time(nullptr)) + "\n"); + } catch (DownloadError& e) { + if (storePath.empty()) { + throw; + } + LOG(WARNING) << e.msg() << "; using cached result"; + result.etag = expectedETag; + } + } + + if (request.unpack) { + Path unpackedLink = cacheDir + "/" + baseNameOf(storePath) + "-unpacked"; + PathLocks lock2({unpackedLink}, + fmt("waiting for lock on '%1%'...", unpackedLink)); + Path unpackedStorePath; + if (pathExists(unpackedLink)) { + unpackedStorePath = readLink(unpackedLink); + store->addTempRoot(unpackedStorePath); + if (!store->isValidPath(unpackedStorePath)) { + unpackedStorePath = ""; + } + } + if (unpackedStorePath.empty()) { + LOG(INFO) << "unpacking '" << url << "' ..."; + Path tmpDir = createTempDir(); + AutoDelete autoDelete(tmpDir, true); + // FIXME: this requires GNU tar for decompression. + runProgram("tar", true, + {"xf", store->toRealPath(storePath), "-C", tmpDir, + "--strip-components", "1"}); + unpackedStorePath = store->addToStore(name, tmpDir, true, htSHA256, + defaultPathFilter, NoRepair); + } + replaceSymlink(unpackedStorePath, unpackedLink); + storePath = unpackedStorePath; + } + + if (!expectedStorePath.empty() && storePath != expectedStorePath) { + unsigned int statusCode = 102; + Hash gotHash = + request.unpack + ? hashPath(request.expectedHash.type, store->toRealPath(storePath)) + .first + : hashFile(request.expectedHash.type, store->toRealPath(storePath)); + throw nix::Error(statusCode, + "hash mismatch in file downloaded from '%s':\n wanted: " + "%s\n got: %s", + url, request.expectedHash.to_string(), + gotHash.to_string()); + } + + result.storePath = storePath; + result.path = store->toRealPath(storePath); + return result; +} + +bool isUri(const string& s) { + if (s.compare(0, 8, "channel:") == 0) { + return true; + } + size_t pos = s.find("://"); + if (pos == string::npos) { + return false; + } + string scheme(s, 0, pos); + return scheme == "http" || scheme == "https" || scheme == "file" || + scheme == "channel" || scheme == "git" || scheme == "s3" || + scheme == "ssh"; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/download.hh b/third_party/nix/src/libstore/download.hh new file mode 100644 index 0000000000..9ddbdfc159 --- /dev/null +++ b/third_party/nix/src/libstore/download.hh @@ -0,0 +1,133 @@ +#pragma once + +#include <future> +#include <string> + +#include "globals.hh" +#include "hash.hh" +#include "types.hh" + +namespace nix { + +struct DownloadSettings : Config { + Setting<bool> enableHttp2{this, true, "http2", + "Whether to enable HTTP/2 support."}; + + Setting<std::string> userAgentSuffix{ + this, "", "user-agent-suffix", + "String appended to the user agent in HTTP requests."}; + + Setting<size_t> httpConnections{this, + 25, + "http-connections", + "Number of parallel HTTP connections.", + {"binary-caches-parallel-connections"}}; + + Setting<unsigned long> connectTimeout{ + this, 0, "connect-timeout", + "Timeout for connecting to servers during downloads. 0 means use curl's " + "builtin default."}; + + Setting<unsigned long> stalledDownloadTimeout{ + this, 300, "stalled-download-timeout", + "Timeout (in seconds) for receiving data from servers during download. " + "Nix cancels idle downloads after this timeout's duration."}; + + Setting<unsigned int> tries{ + this, 5, "download-attempts", + "How often Nix will attempt to download a file before giving up."}; +}; + +extern DownloadSettings downloadSettings; + +struct DownloadRequest { + std::string uri; + std::string expectedETag; + bool verifyTLS = true; + bool head = false; + size_t tries = downloadSettings.tries; + unsigned int baseRetryTimeMs = 250; + bool decompress = true; + std::shared_ptr<std::string> data; + std::string mimeType; + std::function<void(char*, size_t)> dataCallback; + + DownloadRequest(const std::string& uri) : uri(uri) {} + + std::string verb() { return data ? "upload" : "download"; } +}; + +struct DownloadResult { + bool cached = false; + std::string etag; + std::string effectiveUri; + std::shared_ptr<std::string> data; + uint64_t bodySize = 0; +}; + +struct CachedDownloadRequest { + std::string uri; + bool unpack = false; + std::string name; + Hash expectedHash; + unsigned int ttl = settings.tarballTtl; + + CachedDownloadRequest(const std::string& uri) : uri(uri) {} +}; + +struct CachedDownloadResult { + // Note: 'storePath' may be different from 'path' when using a + // chroot store. + Path storePath; + Path path; + std::optional<std::string> etag; + std::string effectiveUri; +}; + +class Store; + +struct Downloader { + virtual ~Downloader() {} + + /* Enqueue a download request, returning a future to the result of + the download. The future may throw a DownloadError + exception. */ + virtual void enqueueDownload(const DownloadRequest& request, + Callback<DownloadResult> callback) = 0; + + std::future<DownloadResult> enqueueDownload(const DownloadRequest& request); + + /* Synchronously download a file. */ + DownloadResult download(const DownloadRequest& request); + + /* Download a file, writing its data to a sink. The sink will be + invoked on the thread of the caller. */ + void download(DownloadRequest&& request, Sink& sink); + + /* Check if the specified file is already in ~/.cache/nix/tarballs + and is more recent than ‘tarball-ttl’ seconds. Otherwise, + use the recorded ETag to verify if the server has a more + recent version, and if so, download it to the Nix store. */ + CachedDownloadResult downloadCached(const ref<Store>& store, + const CachedDownloadRequest& request); + + enum Error { NotFound, Forbidden, Misc, Transient, Interrupted }; +}; + +/* Return a shared Downloader object. Using this object is preferred + because it enables connection reuse and HTTP/2 multiplexing. */ +ref<Downloader> getDownloader(); + +/* Return a new Downloader object. */ +ref<Downloader> makeDownloader(); + +class DownloadError : public Error { + public: + Downloader::Error error; + DownloadError(Downloader::Error error, const FormatOrString& fs) + : Error(fs), error(error) {} +}; + +bool isUri(const string& s); + +} // namespace nix diff --git a/third_party/nix/src/libstore/export-import.cc b/third_party/nix/src/libstore/export-import.cc new file mode 100644 index 0000000000..077b0d5390 --- /dev/null +++ b/third_party/nix/src/libstore/export-import.cc @@ -0,0 +1,111 @@ +#include <algorithm> + +#include "archive.hh" +#include "store-api.hh" +#include "worker-protocol.hh" + +namespace nix { + +struct HashAndWriteSink : Sink { + Sink& writeSink; + HashSink hashSink; + explicit HashAndWriteSink(Sink& writeSink) + : writeSink(writeSink), hashSink(htSHA256) {} + void operator()(const unsigned char* data, size_t len) override { + writeSink(data, len); + hashSink(data, len); + } + Hash currentHash() { return hashSink.currentHash().first; } +}; + +void Store::exportPaths(const Paths& paths, Sink& sink) { + Paths sorted = topoSortPaths(PathSet(paths.begin(), paths.end())); + std::reverse(sorted.begin(), sorted.end()); + + std::string doneLabel("paths exported"); + // logger->incExpected(doneLabel, sorted.size()); + + for (auto& path : sorted) { + // Activity act(*logger, lvlInfo, format("exporting path '%s'") % path); + sink << 1; + exportPath(path, sink); + // logger->incProgress(doneLabel); + } + + sink << 0; +} + +void Store::exportPath(const Path& path, Sink& sink) { + auto info = queryPathInfo(path); + + HashAndWriteSink hashAndWriteSink(sink); + + narFromPath(path, hashAndWriteSink); + + /* Refuse to export paths that have changed. This prevents + filesystem corruption from spreading to other machines. + Don't complain if the stored hash is zero (unknown). */ + Hash hash = hashAndWriteSink.currentHash(); + if (hash != info->narHash && info->narHash != Hash(info->narHash.type)) { + throw Error(format("hash of path '%1%' has changed from '%2%' to '%3%'!") % + path % info->narHash.to_string() % hash.to_string()); + } + + hashAndWriteSink << exportMagic << path << info->references << info->deriver + << 0; +} + +Paths Store::importPaths(Source& source, + const std::shared_ptr<FSAccessor>& accessor, + CheckSigsFlag checkSigs) { + Paths res; + while (true) { + auto n = readNum<uint64_t>(source); + if (n == 0) { + break; + } + if (n != 1) { + throw Error( + "input doesn't look like something created by 'nix-store --export'"); + } + + /* Extract the NAR from the source. */ + TeeSink tee(source); + parseDump(tee, tee.source); + + uint32_t magic = readInt(source); + if (magic != exportMagic) { + throw Error("Nix archive cannot be imported; wrong format"); + } + + ValidPathInfo info; + + info.path = readStorePath(*this, source); + + // Activity act(*logger, lvlInfo, format("importing path '%s'") % + // info.path); + + info.references = readStorePaths<PathSet>(*this, source); + + info.deriver = readString(source); + if (!info.deriver.empty()) { + assertStorePath(info.deriver); + } + + info.narHash = hashString(htSHA256, *tee.source.data); + info.narSize = tee.source.data->size(); + + // Ignore optional legacy signature. + if (readInt(source) == 1) { + readString(source); + } + + addToStore(info, tee.source.data, NoRepair, checkSigs, accessor); + + res.push_back(info.path); + } + + return res; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/fs-accessor.hh b/third_party/nix/src/libstore/fs-accessor.hh new file mode 100644 index 0000000000..ad0d7f0ed9 --- /dev/null +++ b/third_party/nix/src/libstore/fs-accessor.hh @@ -0,0 +1,31 @@ +#pragma once + +#include "types.hh" + +namespace nix { + +/* An abstract class for accessing a filesystem-like structure, such + as a (possibly remote) Nix store or the contents of a NAR file. */ +class FSAccessor { + public: + enum Type { tMissing, tRegular, tSymlink, tDirectory }; + + struct Stat { + Type type = tMissing; + uint64_t fileSize = 0; // regular files only + bool isExecutable = false; // regular files only + uint64_t narOffset = 0; // regular files only + }; + + virtual ~FSAccessor() {} + + virtual Stat stat(const Path& path) = 0; + + virtual StringSet readDirectory(const Path& path) = 0; + + virtual std::string readFile(const Path& path) = 0; + + virtual std::string readLink(const Path& path) = 0; +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/gc.cc b/third_party/nix/src/libstore/gc.cc new file mode 100644 index 0000000000..bc3393265e --- /dev/null +++ b/third_party/nix/src/libstore/gc.cc @@ -0,0 +1,1013 @@ +#include <algorithm> +#include <cerrno> +#include <climits> +#include <functional> +#include <queue> +#include <random> +#include <regex> + +#include <fcntl.h> +#include <sys/stat.h> +#include <sys/statvfs.h> +#include <sys/types.h> +#include <unistd.h> + +#include "derivations.hh" +#include "finally.hh" +#include "globals.hh" +#include "glog/logging.h" +#include "local-store.hh" + +namespace nix { + +static string gcLockName = "gc.lock"; +static string gcRootsDir = "gcroots"; + +/* Acquire the global GC lock. This is used to prevent new Nix + processes from starting after the temporary root files have been + read. To be precise: when they try to create a new temporary root + file, they will block until the garbage collector has finished / + yielded the GC lock. */ +AutoCloseFD LocalStore::openGCLock(LockType lockType) { + Path fnGCLock = (format("%1%/%2%") % stateDir % gcLockName).str(); + + DLOG(INFO) << "acquiring global GC lock " << fnGCLock; + + AutoCloseFD fdGCLock = + open(fnGCLock.c_str(), O_RDWR | O_CREAT | O_CLOEXEC, 0600); + if (!fdGCLock) { + throw SysError(format("opening global GC lock '%1%'") % fnGCLock); + } + + if (!lockFile(fdGCLock.get(), lockType, false)) { + LOG(ERROR) << "waiting for the big garbage collector lock..."; + lockFile(fdGCLock.get(), lockType, true); + } + + /* !!! Restrict read permission on the GC root. Otherwise any + process that can open the file for reading can DoS the + collector. */ + + return fdGCLock; +} + +static void makeSymlink(const Path& link, const Path& target) { + /* Create directories up to `gcRoot'. */ + createDirs(dirOf(link)); + + /* Create the new symlink. */ + Path tempLink = + (format("%1%.tmp-%2%-%3%") % link % getpid() % random()).str(); + createSymlink(target, tempLink); + + /* Atomically replace the old one. */ + if (rename(tempLink.c_str(), link.c_str()) == -1) { + throw SysError(format("cannot rename '%1%' to '%2%'") % tempLink % link); + } +} + +void LocalStore::syncWithGC() { AutoCloseFD fdGCLock = openGCLock(ltRead); } + +void LocalStore::addIndirectRoot(const Path& path) { + string hash = hashString(htSHA1, path).to_string(Base32, false); + Path realRoot = canonPath( + (format("%1%/%2%/auto/%3%") % stateDir % gcRootsDir % hash).str()); + makeSymlink(realRoot, path); +} + +Path LocalFSStore::addPermRoot(const Path& _storePath, const Path& _gcRoot, + bool indirect, bool allowOutsideRootsDir) { + Path storePath(canonPath(_storePath)); + Path gcRoot(canonPath(_gcRoot)); + assertStorePath(storePath); + + if (isInStore(gcRoot)) { + throw Error(format("creating a garbage collector root (%1%) in the Nix " + "store is forbidden " + "(are you running nix-build inside the store?)") % + gcRoot); + } + + if (indirect) { + /* Don't clobber the link if it already exists and doesn't + point to the Nix store. */ + if (pathExists(gcRoot) && + (!isLink(gcRoot) || !isInStore(readLink(gcRoot)))) { + throw Error(format("cannot create symlink '%1%'; already exists") % + gcRoot); + } + makeSymlink(gcRoot, storePath); + addIndirectRoot(gcRoot); + } + + else { + if (!allowOutsideRootsDir) { + Path rootsDir = + canonPath((format("%1%/%2%") % stateDir % gcRootsDir).str()); + + if (string(gcRoot, 0, rootsDir.size() + 1) != rootsDir + "/") { + throw Error(format("path '%1%' is not a valid garbage collector root; " + "it's not in the directory '%2%'") % + gcRoot % rootsDir); + } + } + + if (baseNameOf(gcRoot) == baseNameOf(storePath)) { + writeFile(gcRoot, ""); + } else { + makeSymlink(gcRoot, storePath); + } + } + + /* Check that the root can be found by the garbage collector. + !!! This can be very slow on machines that have many roots. + Instead of reading all the roots, it would be more efficient to + check if the root is in a directory in or linked from the + gcroots directory. */ + if (settings.checkRootReachability) { + Roots roots = findRoots(false); + if (roots[storePath].count(gcRoot) == 0) { + LOG(ERROR) << "warning: '" << gcRoot + << "' is not in a directory where the garbage " + << "collector looks for roots; therefore, '" << storePath + << "' might be removed by the garbage collector"; + } + } + + /* Grab the global GC root, causing us to block while a GC is in + progress. This prevents the set of permanent roots from + increasing while a GC is in progress. */ + syncWithGC(); + + return gcRoot; +} + +void LocalStore::addTempRoot(const Path& path) { + auto state(_state.lock()); + + /* Create the temporary roots file for this process. */ + if (!state->fdTempRoots) { + while (true) { + AutoCloseFD fdGCLock = openGCLock(ltRead); + + if (pathExists(fnTempRoots)) { + /* It *must* be stale, since there can be no two + processes with the same pid. */ + unlink(fnTempRoots.c_str()); + } + + state->fdTempRoots = openLockFile(fnTempRoots, true); + + fdGCLock = -1; + + DLOG(INFO) << "acquiring read lock on " << fnTempRoots; + lockFile(state->fdTempRoots.get(), ltRead, true); + + /* Check whether the garbage collector didn't get in our + way. */ + struct stat st; + if (fstat(state->fdTempRoots.get(), &st) == -1) { + throw SysError(format("statting '%1%'") % fnTempRoots); + } + if (st.st_size == 0) { + break; + } + + /* The garbage collector deleted this file before we could + get a lock. (It won't delete the file after we get a + lock.) Try again. */ + } + } + + /* Upgrade the lock to a write lock. This will cause us to block + if the garbage collector is holding our lock. */ + DLOG(INFO) << "acquiring write lock on " << fnTempRoots; + lockFile(state->fdTempRoots.get(), ltWrite, true); + + string s = path + '\0'; + writeFull(state->fdTempRoots.get(), s); + + /* Downgrade to a read lock. */ + DLOG(INFO) << "downgrading to read lock on " << fnTempRoots; + lockFile(state->fdTempRoots.get(), ltRead, true); +} + +static std::string censored = "{censored}"; + +void LocalStore::findTempRoots(FDs& fds, Roots& tempRoots, bool censor) { + /* Read the `temproots' directory for per-process temporary root + files. */ + for (auto& i : readDirectory(tempRootsDir)) { + Path path = tempRootsDir + "/" + i.name; + + pid_t pid = std::stoi(i.name); + + DLOG(INFO) << "reading temporary root file " << path; + FDPtr fd(new AutoCloseFD(open(path.c_str(), O_CLOEXEC | O_RDWR, 0666))); + if (!*fd) { + /* It's okay if the file has disappeared. */ + if (errno == ENOENT) { + continue; + } + throw SysError(format("opening temporary roots file '%1%'") % path); + } + + /* This should work, but doesn't, for some reason. */ + // FDPtr fd(new AutoCloseFD(openLockFile(path, false))); + // if (*fd == -1) { continue; } + + /* Try to acquire a write lock without blocking. This can + only succeed if the owning process has died. In that case + we don't care about its temporary roots. */ + if (lockFile(fd->get(), ltWrite, false)) { + LOG(ERROR) << "removing stale temporary roots file " << path; + unlink(path.c_str()); + writeFull(fd->get(), "d"); + continue; + } + + /* Acquire a read lock. This will prevent the owning process + from upgrading to a write lock, therefore it will block in + addTempRoot(). */ + DLOG(INFO) << "waiting for read lock on " << path; + lockFile(fd->get(), ltRead, true); + + /* Read the entire file. */ + string contents = readFile(fd->get()); + + /* Extract the roots. */ + string::size_type pos = 0; + string::size_type end; + + while ((end = contents.find((char)0, pos)) != string::npos) { + Path root(contents, pos, end - pos); + DLOG(INFO) << "got temporary root " << root; + assertStorePath(root); + tempRoots[root].emplace(censor ? censored : fmt("{temp:%d}", pid)); + pos = end + 1; + } + + fds.push_back(fd); /* keep open */ + } +} + +void LocalStore::findRoots(const Path& path, unsigned char type, Roots& roots) { + auto foundRoot = [&](const Path& path, const Path& target) { + Path storePath = toStorePath(target); + if (isStorePath(storePath) && isValidPath(storePath)) { + roots[storePath].emplace(path); + } else { + LOG(INFO) << "skipping invalid root from '" << path << "' to '" + << storePath << "'"; + } + }; + + try { + if (type == DT_UNKNOWN) { + type = getFileType(path); + } + + if (type == DT_DIR) { + for (auto& i : readDirectory(path)) { + findRoots(path + "/" + i.name, i.type, roots); + } + } + + else if (type == DT_LNK) { + Path target = readLink(path); + if (isInStore(target)) { + foundRoot(path, target); + } + + /* Handle indirect roots. */ + else { + target = absPath(target, dirOf(path)); + if (!pathExists(target)) { + if (isInDir(path, stateDir + "/" + gcRootsDir + "/auto")) { + LOG(INFO) << "removing stale link from '" << path << "' to '" + << target << "'"; + unlink(path.c_str()); + } + } else { + struct stat st2 = lstat(target); + if (!S_ISLNK(st2.st_mode)) { + return; + } + Path target2 = readLink(target); + if (isInStore(target2)) { + foundRoot(target, target2); + } + } + } + } + + else if (type == DT_REG) { + Path storePath = storeDir + "/" + baseNameOf(path); + if (isStorePath(storePath) && isValidPath(storePath)) { + roots[storePath].emplace(path); + } + } + + } + + catch (SysError& e) { + /* We only ignore permanent failures. */ + if (e.errNo == EACCES || e.errNo == ENOENT || e.errNo == ENOTDIR) { + LOG(INFO) << "cannot read potential root '" << path << "'"; + } else { + throw; + } + } +} + +void LocalStore::findRootsNoTemp(Roots& roots, bool censor) { + /* Process direct roots in {gcroots,profiles}. */ + findRoots(stateDir + "/" + gcRootsDir, DT_UNKNOWN, roots); + findRoots(stateDir + "/profiles", DT_UNKNOWN, roots); + + /* Add additional roots returned by different platforms-specific + heuristics. This is typically used to add running programs to + the set of roots (to prevent them from being garbage collected). */ + findRuntimeRoots(roots, censor); +} + +Roots LocalStore::findRoots(bool censor) { + Roots roots; + findRootsNoTemp(roots, censor); + + FDs fds; + findTempRoots(fds, roots, censor); + + return roots; +} + +static void readProcLink(const string& file, Roots& roots) { + /* 64 is the starting buffer size gnu readlink uses... */ + auto bufsiz = ssize_t{64}; +try_again: + char buf[bufsiz]; + auto res = readlink(file.c_str(), buf, bufsiz); + if (res == -1) { + if (errno == ENOENT || errno == EACCES || errno == ESRCH) { + return; + } + throw SysError("reading symlink"); + } + if (res == bufsiz) { + if (SSIZE_MAX / 2 < bufsiz) { + throw Error("stupidly long symlink"); + } + bufsiz *= 2; + goto try_again; + } + if (res > 0 && buf[0] == '/') { + roots[std::string(static_cast<char*>(buf), res)].emplace(file); + } +} + +static string quoteRegexChars(const string& raw) { + static auto specialRegex = std::regex(R"([.^$\\*+?()\[\]{}|])"); + return std::regex_replace(raw, specialRegex, R"(\$&)"); +} + +static void readFileRoots(const char* path, Roots& roots) { + try { + roots[readFile(path)].emplace(path); + } catch (SysError& e) { + if (e.errNo != ENOENT && e.errNo != EACCES) { + throw; + } + } +} + +void LocalStore::findRuntimeRoots(Roots& roots, bool censor) { + Roots unchecked; + + auto procDir = AutoCloseDir{opendir("/proc")}; + if (procDir) { + struct dirent* ent; + auto digitsRegex = std::regex(R"(^\d+$)"); + auto mapRegex = + std::regex(R"(^\s*\S+\s+\S+\s+\S+\s+\S+\s+\S+\s+(/\S+)\s*$)"); + auto storePathRegex = std::regex(quoteRegexChars(storeDir) + + R"(/[0-9a-z]+[0-9a-zA-Z\+\-\._\?=]*)"); + while (errno = 0, ent = readdir(procDir.get())) { + checkInterrupt(); + if (std::regex_match(ent->d_name, digitsRegex)) { + readProcLink(fmt("/proc/%s/exe", ent->d_name), unchecked); + readProcLink(fmt("/proc/%s/cwd", ent->d_name), unchecked); + + auto fdStr = fmt("/proc/%s/fd", ent->d_name); + auto fdDir = AutoCloseDir(opendir(fdStr.c_str())); + if (!fdDir) { + if (errno == ENOENT || errno == EACCES) { + continue; + } + throw SysError(format("opening %1%") % fdStr); + } + struct dirent* fd_ent; + while (errno = 0, fd_ent = readdir(fdDir.get())) { + if (fd_ent->d_name[0] != '.') { + readProcLink(fmt("%s/%s", fdStr, fd_ent->d_name), unchecked); + } + } + if (errno) { + if (errno == ESRCH) { + continue; + } + throw SysError(format("iterating /proc/%1%/fd") % ent->d_name); + } + fdDir.reset(); + + try { + auto mapFile = fmt("/proc/%s/maps", ent->d_name); + auto mapLines = tokenizeString<std::vector<string>>( + readFile(mapFile, true), "\n"); + for (const auto& line : mapLines) { + auto match = std::smatch{}; + if (std::regex_match(line, match, mapRegex)) { + unchecked[match[1]].emplace(mapFile); + } + } + + auto envFile = fmt("/proc/%s/environ", ent->d_name); + auto envString = readFile(envFile, true); + auto env_end = std::sregex_iterator{}; + for (auto i = std::sregex_iterator{envString.begin(), envString.end(), + storePathRegex}; + i != env_end; ++i) { + unchecked[i->str()].emplace(envFile); + } + } catch (SysError& e) { + if (errno == ENOENT || errno == EACCES || errno == ESRCH) { + continue; + } + throw; + } + } + } + if (errno) { + throw SysError("iterating /proc"); + } + } + +#if !defined(__linux__) + // lsof is really slow on OS X. This actually causes the gc-concurrent.sh test + // to fail. See: https://github.com/NixOS/nix/issues/3011 Because of this we + // disable lsof when running the tests. + if (getEnv("_NIX_TEST_NO_LSOF") == "") { + try { + std::regex lsofRegex(R"(^n(/.*)$)"); + auto lsofLines = tokenizeString<std::vector<string>>( + runProgram(LSOF, true, {"-n", "-w", "-F", "n"}), "\n"); + for (const auto& line : lsofLines) { + std::smatch match; + if (std::regex_match(line, match, lsofRegex)) + unchecked[match[1]].emplace("{lsof}"); + } + } catch (ExecError& e) { + /* lsof not installed, lsof failed */ + } + } +#endif + +#if defined(__linux__) + readFileRoots("/proc/sys/kernel/modprobe", unchecked); + readFileRoots("/proc/sys/kernel/fbsplash", unchecked); + readFileRoots("/proc/sys/kernel/poweroff_cmd", unchecked); +#endif + + for (auto& [target, links] : unchecked) { + if (isInStore(target)) { + Path path = toStorePath(target); + if (isStorePath(path) && isValidPath(path)) { + DLOG(INFO) << "got additional root " << path; + if (censor) { + roots[path].insert(censored); + } else { + roots[path].insert(links.begin(), links.end()); + } + } + } + } +} + +struct GCLimitReached {}; + +struct LocalStore::GCState { + GCOptions options; + GCResults& results; + PathSet roots; + PathSet tempRoots; + PathSet dead; + PathSet alive; + bool gcKeepOutputs; + bool gcKeepDerivations; + unsigned long long bytesInvalidated; + bool moveToTrash = true; + bool shouldDelete; + explicit GCState(GCResults& results_) + : results(results_), bytesInvalidated(0) {} +}; + +bool LocalStore::isActiveTempFile(const GCState& state, const Path& path, + const string& suffix) { + return hasSuffix(path, suffix) && + state.tempRoots.find(string(path, 0, path.size() - suffix.size())) != + state.tempRoots.end(); +} + +void LocalStore::deleteGarbage(GCState& state, const Path& path) { + unsigned long long bytesFreed; + deletePath(path, bytesFreed); + state.results.bytesFreed += bytesFreed; +} + +void LocalStore::deletePathRecursive(GCState& state, const Path& path) { + checkInterrupt(); + + unsigned long long size = 0; + + if (isStorePath(path) && isValidPath(path)) { + PathSet referrers; + queryReferrers(path, referrers); + for (auto& i : referrers) { + if (i != path) { + deletePathRecursive(state, i); + } + } + size = queryPathInfo(path)->narSize; + invalidatePathChecked(path); + } + + Path realPath = realStoreDir + "/" + baseNameOf(path); + + struct stat st; + if (lstat(realPath.c_str(), &st) != 0) { + if (errno == ENOENT) { + return; + } + throw SysError(format("getting status of %1%") % realPath); + } + + LOG(INFO) << "deleting '" << path << "'"; + + state.results.paths.insert(path); + + /* If the path is not a regular file or symlink, move it to the + trash directory. The move is to ensure that later (when we're + not holding the global GC lock) we can delete the path without + being afraid that the path has become alive again. Otherwise + delete it right away. */ + if (state.moveToTrash && S_ISDIR(st.st_mode)) { + // Estimate the amount freed using the narSize field. FIXME: + // if the path was not valid, need to determine the actual + // size. + try { + if (chmod(realPath.c_str(), st.st_mode | S_IWUSR) == -1) { + throw SysError(format("making '%1%' writable") % realPath); + } + Path tmp = trashDir + "/" + baseNameOf(path); + if (rename(realPath.c_str(), tmp.c_str()) != 0) { + throw SysError(format("unable to rename '%1%' to '%2%'") % realPath % + tmp); + } + state.bytesInvalidated += size; + } catch (SysError& e) { + if (e.errNo == ENOSPC) { + LOG(INFO) << "note: can't create move '" << realPath + << "': " << e.msg(); + deleteGarbage(state, realPath); + } + } + } else { + deleteGarbage(state, realPath); + } + + if (state.results.bytesFreed + state.bytesInvalidated > + state.options.maxFreed) { + LOG(INFO) << "deleted or invalidated more than " << state.options.maxFreed + << " bytes; stopping"; + throw GCLimitReached(); + } +} + +bool LocalStore::canReachRoot(GCState& state, PathSet& visited, + const Path& path) { + if (visited.count(path) != 0u) { + return false; + } + + if (state.alive.count(path) != 0u) { + return true; + } + + if (state.dead.count(path) != 0u) { + return false; + } + + if (state.roots.count(path) != 0u) { + DLOG(INFO) << "cannot delete '" << path << "' because it's a root"; + state.alive.insert(path); + return true; + } + + visited.insert(path); + + if (!isStorePath(path) || !isValidPath(path)) { + return false; + } + + PathSet incoming; + + /* Don't delete this path if any of its referrers are alive. */ + queryReferrers(path, incoming); + + /* If keep-derivations is set and this is a derivation, then + don't delete the derivation if any of the outputs are alive. */ + if (state.gcKeepDerivations && isDerivation(path)) { + PathSet outputs = queryDerivationOutputs(path); + for (auto& i : outputs) { + if (isValidPath(i) && queryPathInfo(i)->deriver == path) { + incoming.insert(i); + } + } + } + + /* If keep-outputs is set, then don't delete this path if there + are derivers of this path that are not garbage. */ + if (state.gcKeepOutputs) { + PathSet derivers = queryValidDerivers(path); + for (auto& i : derivers) { + incoming.insert(i); + } + } + + for (auto& i : incoming) { + if (i != path) { + if (canReachRoot(state, visited, i)) { + state.alive.insert(path); + return true; + } + } + } + + return false; +} + +void LocalStore::tryToDelete(GCState& state, const Path& path) { + checkInterrupt(); + + auto realPath = realStoreDir + "/" + baseNameOf(path); + if (realPath == linksDir || realPath == trashDir) { + return; + } + + // Activity act(*logger, lvlDebug, format("considering whether to delete + // '%1%'") % path); + + if (!isStorePath(path) || !isValidPath(path)) { + /* A lock file belonging to a path that we're building right + now isn't garbage. */ + if (isActiveTempFile(state, path, ".lock")) { + return; + } + + /* Don't delete .chroot directories for derivations that are + currently being built. */ + if (isActiveTempFile(state, path, ".chroot")) { + return; + } + + /* Don't delete .check directories for derivations that are + currently being built, because we may need to run + diff-hook. */ + if (isActiveTempFile(state, path, ".check")) { + return; + } + } + + PathSet visited; + + if (canReachRoot(state, visited, path)) { + DLOG(INFO) << "cannot delete '" << path << "' because it's still reachable"; + } else { + /* No path we visited was a root, so everything is garbage. + But we only delete ‘path’ and its referrers here so that + ‘nix-store --delete’ doesn't have the unexpected effect of + recursing into derivations and outputs. */ + state.dead.insert(visited.begin(), visited.end()); + if (state.shouldDelete) { + deletePathRecursive(state, path); + } + } +} + +/* Unlink all files in /nix/store/.links that have a link count of 1, + which indicates that there are no other links and so they can be + safely deleted. FIXME: race condition with optimisePath(): we + might see a link count of 1 just before optimisePath() increases + the link count. */ +void LocalStore::removeUnusedLinks(const GCState& state) { + AutoCloseDir dir(opendir(linksDir.c_str())); + if (!dir) { + throw SysError(format("opening directory '%1%'") % linksDir); + } + + long long actualSize = 0; + long long unsharedSize = 0; + + struct dirent* dirent; + while (errno = 0, dirent = readdir(dir.get())) { + checkInterrupt(); + string name = dirent->d_name; + if (name == "." || name == "..") { + continue; + } + Path path = linksDir + "/" + name; + + struct stat st; + if (lstat(path.c_str(), &st) == -1) { + throw SysError(format("statting '%1%'") % path); + } + + if (st.st_nlink != 1) { + actualSize += st.st_size; + unsharedSize += (st.st_nlink - 1) * st.st_size; + continue; + } + + LOG(INFO) << "deleting unused link " << path; + + if (unlink(path.c_str()) == -1) { + throw SysError(format("deleting '%1%'") % path); + } + + state.results.bytesFreed += st.st_size; + } + + struct stat st; + if (stat(linksDir.c_str(), &st) == -1) { + throw SysError(format("statting '%1%'") % linksDir); + } + + long long overhead = st.st_blocks * 512ULL; + + // TODO(tazjin): absl::StrFormat %.2f + LOG(INFO) << "note: currently hard linking saves " + << ((unsharedSize - actualSize - overhead) / (1024.0 * 1024.0)) + << " MiB"; +} + +void LocalStore::collectGarbage(const GCOptions& options, GCResults& results) { + GCState state(results); + state.options = options; + state.gcKeepOutputs = settings.gcKeepOutputs; + state.gcKeepDerivations = settings.gcKeepDerivations; + + /* Using `--ignore-liveness' with `--delete' can have unintended + consequences if `keep-outputs' or `keep-derivations' are true + (the garbage collector will recurse into deleting the outputs + or derivers, respectively). So disable them. */ + if (options.action == GCOptions::gcDeleteSpecific && options.ignoreLiveness) { + state.gcKeepOutputs = false; + state.gcKeepDerivations = false; + } + + state.shouldDelete = options.action == GCOptions::gcDeleteDead || + options.action == GCOptions::gcDeleteSpecific; + + if (state.shouldDelete) { + deletePath(reservedPath); + } + + /* Acquire the global GC root. This prevents + a) New roots from being added. + b) Processes from creating new temporary root files. */ + AutoCloseFD fdGCLock = openGCLock(ltWrite); + + /* Find the roots. Since we've grabbed the GC lock, the set of + permanent roots cannot increase now. */ + LOG(INFO) << "finding garbage collector roots..."; + Roots rootMap; + if (!options.ignoreLiveness) { + findRootsNoTemp(rootMap, true); + } + + for (auto& i : rootMap) { + state.roots.insert(i.first); + } + + /* Read the temporary roots. This acquires read locks on all + per-process temporary root files. So after this point no paths + can be added to the set of temporary roots. */ + FDs fds; + Roots tempRoots; + findTempRoots(fds, tempRoots, true); + for (auto& root : tempRoots) { + state.tempRoots.insert(root.first); + } + state.roots.insert(state.tempRoots.begin(), state.tempRoots.end()); + + /* After this point the set of roots or temporary roots cannot + increase, since we hold locks on everything. So everything + that is not reachable from `roots' is garbage. */ + + if (state.shouldDelete) { + if (pathExists(trashDir)) { + deleteGarbage(state, trashDir); + } + try { + createDirs(trashDir); + } catch (SysError& e) { + if (e.errNo == ENOSPC) { + LOG(INFO) << "note: can't create trash directory: " << e.msg(); + state.moveToTrash = false; + } + } + } + + /* Now either delete all garbage paths, or just the specified + paths (for gcDeleteSpecific). */ + + if (options.action == GCOptions::gcDeleteSpecific) { + for (auto& i : options.pathsToDelete) { + assertStorePath(i); + tryToDelete(state, i); + if (state.dead.find(i) == state.dead.end()) { + throw Error(format("cannot delete path '%1%' since it is still alive") % + i); + } + } + + } else if (options.maxFreed > 0) { + if (state.shouldDelete) { + LOG(INFO) << "deleting garbage..."; + } else { + LOG(ERROR) << "determining live/dead paths..."; + } + + try { + AutoCloseDir dir(opendir(realStoreDir.c_str())); + if (!dir) { + throw SysError(format("opening directory '%1%'") % realStoreDir); + } + + /* Read the store and immediately delete all paths that + aren't valid. When using --max-freed etc., deleting + invalid paths is preferred over deleting unreachable + paths, since unreachable paths could become reachable + again. We don't use readDirectory() here so that GCing + can start faster. */ + Paths entries; + struct dirent* dirent; + while (errno = 0, dirent = readdir(dir.get())) { + checkInterrupt(); + string name = dirent->d_name; + if (name == "." || name == "..") { + continue; + } + Path path = storeDir + "/" + name; + if (isStorePath(path) && isValidPath(path)) { + entries.push_back(path); + } else { + tryToDelete(state, path); + } + } + + dir.reset(); + + /* Now delete the unreachable valid paths. Randomise the + order in which we delete entries to make the collector + less biased towards deleting paths that come + alphabetically first (e.g. /nix/store/000...). This + matters when using --max-freed etc. */ + vector<Path> entries_(entries.begin(), entries.end()); + std::mt19937 gen(1); + std::shuffle(entries_.begin(), entries_.end(), gen); + + for (auto& i : entries_) { + tryToDelete(state, i); + } + + } catch (GCLimitReached& e) { + } + } + + if (state.options.action == GCOptions::gcReturnLive) { + state.results.paths = state.alive; + return; + } + + if (state.options.action == GCOptions::gcReturnDead) { + state.results.paths = state.dead; + return; + } + + /* Allow other processes to add to the store from here on. */ + fdGCLock = -1; + fds.clear(); + + /* Delete the trash directory. */ + LOG(INFO) << "deleting " << trashDir; + deleteGarbage(state, trashDir); + + /* Clean up the links directory. */ + if (options.action == GCOptions::gcDeleteDead || + options.action == GCOptions::gcDeleteSpecific) { + LOG(INFO) << "deleting unused links..."; + removeUnusedLinks(state); + } + + /* While we're at it, vacuum the database. */ + // if (options.action == GCOptions::gcDeleteDead) { vacuumDB(); } +} + +void LocalStore::autoGC(bool sync) { + static auto fakeFreeSpaceFile = getEnv("_NIX_TEST_FREE_SPACE_FILE", ""); + + auto getAvail = [this]() -> uint64_t { + if (!fakeFreeSpaceFile.empty()) { + return std::stoll(readFile(fakeFreeSpaceFile)); + } + + struct statvfs st; + if (statvfs(realStoreDir.c_str(), &st) != 0) { + throw SysError("getting filesystem info about '%s'", realStoreDir); + } + + return (uint64_t)st.f_bavail * st.f_bsize; + }; + + std::shared_future<void> future; + + { + auto state(_state.lock()); + + if (state->gcRunning) { + future = state->gcFuture; + DLOG(INFO) << "waiting for auto-GC to finish"; + goto sync; + } + + auto now = std::chrono::steady_clock::now(); + + if (now < state->lastGCCheck + + std::chrono::seconds(settings.minFreeCheckInterval)) { + return; + } + + auto avail = getAvail(); + + state->lastGCCheck = now; + + if (avail >= settings.minFree || avail >= settings.maxFree) { + return; + } + + if (avail > state->availAfterGC * 0.97) { + return; + } + + state->gcRunning = true; + + std::promise<void> promise; + future = state->gcFuture = promise.get_future().share(); + + std::thread([promise{std::move(promise)}, this, avail, getAvail]() mutable { + try { + /* Wake up any threads waiting for the auto-GC to finish. */ + Finally wakeup([&]() { + auto state(_state.lock()); + state->gcRunning = false; + state->lastGCCheck = std::chrono::steady_clock::now(); + promise.set_value(); + }); + + GCOptions options; + options.maxFreed = settings.maxFree - avail; + + LOG(INFO) << "running auto-GC to free " << options.maxFreed << " bytes"; + + GCResults results; + + collectGarbage(options, results); + + _state.lock()->availAfterGC = getAvail(); + + } catch (...) { + // FIXME: we could propagate the exception to the + // future, but we don't really care. + ignoreException(); + } + }).detach(); + } + +sync: + // Wait for the future outside of the state lock. + if (sync) { + future.get(); + } +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/globals.cc b/third_party/nix/src/libstore/globals.cc new file mode 100644 index 0000000000..066de44365 --- /dev/null +++ b/third_party/nix/src/libstore/globals.cc @@ -0,0 +1,207 @@ +#include "globals.hh" + +#include <algorithm> +#include <map> +#include <thread> + +#include <dlfcn.h> + +#include "archive.hh" +#include "args.hh" +#include "util.hh" + +namespace nix { + +/* The default location of the daemon socket, relative to nixStateDir. + The socket is in a directory to allow you to control access to the + Nix daemon by setting the mode/ownership of the directory + appropriately. (This wouldn't work on the socket itself since it + must be deleted and recreated on startup.) */ +#define DEFAULT_SOCKET_PATH "/daemon-socket/socket" + +/* chroot-like behavior from Apple's sandbox */ +#if __APPLE__ +#define DEFAULT_ALLOWED_IMPURE_PREFIXES "/System/Library /usr/lib /dev /bin/sh" +#else +#define DEFAULT_ALLOWED_IMPURE_PREFIXES "" +#endif + +Settings settings; + +static GlobalConfig::Register r1(&settings); + +Settings::Settings() + : nixPrefix(NIX_PREFIX), + nixStore(canonPath( + getEnv("NIX_STORE_DIR", getEnv("NIX_STORE", NIX_STORE_DIR)))), + nixDataDir(canonPath(getEnv("NIX_DATA_DIR", NIX_DATA_DIR))), + nixLogDir(canonPath(getEnv("NIX_LOG_DIR", NIX_LOG_DIR))), + nixStateDir(canonPath(getEnv("NIX_STATE_DIR", NIX_STATE_DIR))), + nixConfDir(canonPath(getEnv("NIX_CONF_DIR", NIX_CONF_DIR))), + nixLibexecDir(canonPath(getEnv("NIX_LIBEXEC_DIR", NIX_LIBEXEC_DIR))), + nixBinDir(canonPath(getEnv("NIX_BIN_DIR", NIX_BIN_DIR))), + nixManDir(canonPath(NIX_MAN_DIR)), + nixDaemonSocketFile(canonPath(nixStateDir + DEFAULT_SOCKET_PATH)) { + buildUsersGroup = getuid() == 0 ? "nixbld" : ""; + lockCPU = getEnv("NIX_AFFINITY_HACK", "1") == "1"; + + caFile = getEnv("NIX_SSL_CERT_FILE", getEnv("SSL_CERT_FILE", "")); + if (caFile.empty()) { + for (auto& fn : + {"/etc/ssl/certs/ca-certificates.crt", + "/nix/var/nix/profiles/default/etc/ssl/certs/ca-bundle.crt"}) { + if (pathExists(fn)) { + caFile = fn; + break; + } + } + } + + /* Backwards compatibility. */ + auto s = getEnv("NIX_REMOTE_SYSTEMS"); + if (!s.empty()) { + Strings ss; + for (auto& p : tokenizeString<Strings>(s, ":")) { + ss.push_back("@" + p); + } + builders = concatStringsSep(" ", ss); + } + +#if defined(__linux__) && defined(SANDBOX_SHELL) + sandboxPaths = tokenizeString<StringSet>("/bin/sh=" SANDBOX_SHELL); +#endif + + allowedImpureHostPrefixes = + tokenizeString<StringSet>(DEFAULT_ALLOWED_IMPURE_PREFIXES); +} + +void loadConfFile() { + globalConfig.applyConfigFile(settings.nixConfDir + "/nix.conf"); + + /* We only want to send overrides to the daemon, i.e. stuff from + ~/.nix/nix.conf or the command line. */ + globalConfig.resetOverriden(); + + auto dirs = getConfigDirs(); + // Iterate over them in reverse so that the ones appearing first in the path + // take priority + for (auto dir = dirs.rbegin(); dir != dirs.rend(); dir++) { + globalConfig.applyConfigFile(*dir + "/nix/nix.conf"); + } +} + +unsigned int Settings::getDefaultCores() { + return std::max(1U, std::thread::hardware_concurrency()); +} + +StringSet Settings::getDefaultSystemFeatures() { + /* For backwards compatibility, accept some "features" that are + used in Nixpkgs to route builds to certain machines but don't + actually require anything special on the machines. */ + StringSet features{"nixos-test", "benchmark", "big-parallel"}; + +#if __linux__ + if (access("/dev/kvm", R_OK | W_OK) == 0) { + features.insert("kvm"); + } +#endif + + return features; +} + +const string nixVersion = PACKAGE_VERSION; + +template <> +void BaseSetting<SandboxMode>::set(const std::string& str) { + if (str == "true") { + value = smEnabled; + } else if (str == "relaxed") { + value = smRelaxed; + } else if (str == "false") { + value = smDisabled; + } else { + throw UsageError("option '%s' has invalid value '%s'", name, str); + } +} + +template <> +std::string BaseSetting<SandboxMode>::to_string() { + if (value == smEnabled) { + return "true"; + } + if (value == smRelaxed) { + return "relaxed"; + } else if (value == smDisabled) { + return "false"; + } else { + abort(); + } +} + +template <> +void BaseSetting<SandboxMode>::toJSON(JSONPlaceholder& out) { + AbstractSetting::toJSON(out); +} + +template <> +void BaseSetting<SandboxMode>::convertToArg(Args& args, + const std::string& category) { + args.mkFlag() + .longName(name) + .description("Enable sandboxing.") + .handler([=](const std::vector<std::string>& ss) { override(smEnabled); }) + .category(category); + args.mkFlag() + .longName("no-" + name) + .description("Disable sandboxing.") + .handler( + [=](const std::vector<std::string>& ss) { override(smDisabled); }) + .category(category); + args.mkFlag() + .longName("relaxed-" + name) + .description("Enable sandboxing, but allow builds to disable it.") + .handler([=](const std::vector<std::string>& ss) { override(smRelaxed); }) + .category(category); +} + +void MaxBuildJobsSetting::set(const std::string& str) { + if (str == "auto") { + value = std::max(1U, std::thread::hardware_concurrency()); + } else if (!string2Int(str, value)) { + throw UsageError( + "configuration setting '%s' should be 'auto' or an integer", name); + } +} + +void initPlugins() { + for (const auto& pluginFile : settings.pluginFiles.get()) { + Paths pluginFiles; + try { + auto ents = readDirectory(pluginFile); + for (const auto& ent : ents) { + pluginFiles.emplace_back(pluginFile + "/" + ent.name); + } + } catch (SysError& e) { + if (e.errNo != ENOTDIR) { + throw; + } + pluginFiles.emplace_back(pluginFile); + } + for (const auto& file : pluginFiles) { + /* handle is purposefully leaked as there may be state in the + DSO needed by the action of the plugin. */ + void* handle = dlopen(file.c_str(), RTLD_LAZY | RTLD_LOCAL); + if (handle == nullptr) { + throw Error("could not dynamically open plugin file '%s': %s", file, + dlerror()); + } + } + } + + /* Since plugins can add settings, try to re-apply previously + unknown settings. */ + globalConfig.reapplyUnknownSettings(); + globalConfig.warnUnknownSettings(); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/globals.hh b/third_party/nix/src/libstore/globals.hh new file mode 100644 index 0000000000..8e04b09374 --- /dev/null +++ b/third_party/nix/src/libstore/globals.hh @@ -0,0 +1,479 @@ +#pragma once + +#include <limits> +#include <map> + +#include <sys/types.h> + +#include "config.hh" +#include "types.hh" +#include "util.hh" + +namespace nix { + +typedef enum { smEnabled, smRelaxed, smDisabled } SandboxMode; + +struct MaxBuildJobsSetting : public BaseSetting<unsigned int> { + MaxBuildJobsSetting(Config* options, unsigned int def, + const std::string& name, const std::string& description, + const std::set<std::string>& aliases = {}) + : BaseSetting<unsigned int>(def, name, description, aliases) { + options->addSetting(this); + } + + void set(const std::string& str) override; +}; + +class Settings : public Config { + static unsigned int getDefaultCores(); + + static StringSet getDefaultSystemFeatures(); + + public: + Settings(); + + Path nixPrefix; + + /* The directory where we store sources and derived files. */ + Path nixStore; + + Path nixDataDir; /* !!! fix */ + + /* The directory where we log various operations. */ + Path nixLogDir; + + /* The directory where state is stored. */ + Path nixStateDir; + + /* The directory where configuration files are stored. */ + Path nixConfDir; + + /* The directory where internal helper programs are stored. */ + Path nixLibexecDir; + + /* The directory where the main programs are stored. */ + Path nixBinDir; + + /* The directory where the man pages are stored. */ + Path nixManDir; + + /* File name of the socket the daemon listens to. */ + Path nixDaemonSocketFile; + + Setting<std::string> storeUri{this, getEnv("NIX_REMOTE", "auto"), "store", + "The default Nix store to use."}; + + Setting<bool> keepFailed{ + this, false, "keep-failed", + "Whether to keep temporary directories of failed builds."}; + + Setting<bool> keepGoing{ + this, false, "keep-going", + "Whether to keep building derivations when another build fails."}; + + Setting<bool> tryFallback{ + this, + false, + "fallback", + "Whether to fall back to building when substitution fails.", + {"build-fallback"}}; + + /* Whether to show build log output in real time. */ + bool verboseBuild = true; + + Setting<size_t> logLines{ + this, 10, "log-lines", + "If verbose-build is false, the number of lines of the tail of " + "the log to show if a build fails."}; + + MaxBuildJobsSetting maxBuildJobs{this, + 1, + "max-jobs", + "Maximum number of parallel build jobs. " + "\"auto\" means use number of cores.", + {"build-max-jobs"}}; + + Setting<unsigned int> buildCores{ + this, + getDefaultCores(), + "cores", + "Number of CPU cores to utilize in parallel within a build, " + "i.e. by passing this number to Make via '-j'. 0 means that the " + "number of actual CPU cores on the local host ought to be " + "auto-detected.", + {"build-cores"}}; + + /* Read-only mode. Don't copy stuff to the store, don't change + the database. */ + bool readOnlyMode = false; + + Setting<std::string> thisSystem{this, SYSTEM, "system", + "The canonical Nix system name."}; + + Setting<time_t> maxSilentTime{ + this, + 0, + "max-silent-time", + "The maximum time in seconds that a builer can go without " + "producing any output on stdout/stderr before it is killed. " + "0 means infinity.", + {"build-max-silent-time"}}; + + Setting<time_t> buildTimeout{ + this, + 0, + "timeout", + "The maximum duration in seconds that a builder can run. " + "0 means infinity.", + {"build-timeout"}}; + + PathSetting buildHook{this, true, nixLibexecDir + "/nix/build-remote", + "build-hook", + "The path of the helper program that executes builds " + "to remote machines."}; + + Setting<std::string> builders{this, "@" + nixConfDir + "/machines", + "builders", + "A semicolon-separated list of build machines, " + "in the format of nix.machines."}; + + Setting<bool> buildersUseSubstitutes{ + this, false, "builders-use-substitutes", + "Whether build machines should use their own substitutes for obtaining " + "build dependencies if possible, rather than waiting for this host to " + "upload them."}; + + Setting<off_t> reservedSize{ + this, 8 * 1024 * 1024, "gc-reserved-space", + "Amount of reserved disk space for the garbage collector."}; + + Setting<bool> fsyncMetadata{this, true, "fsync-metadata", + "Whether SQLite should use fsync()."}; + + Setting<bool> useSQLiteWAL{this, true, "use-sqlite-wal", + "Whether SQLite should use WAL mode."}; + + Setting<bool> syncBeforeRegistering{ + this, false, "sync-before-registering", + "Whether to call sync() before registering a path as valid."}; + + Setting<bool> useSubstitutes{this, + true, + "substitute", + "Whether to use substitutes.", + {"build-use-substitutes"}}; + + Setting<std::string> buildUsersGroup{ + this, "", "build-users-group", + "The Unix group that contains the build users."}; + + Setting<bool> impersonateLinux26{ + this, + false, + "impersonate-linux-26", + "Whether to impersonate a Linux 2.6 machine on newer kernels.", + {"build-impersonate-linux-26"}}; + + Setting<bool> keepLog{this, + true, + "keep-build-log", + "Whether to store build logs.", + {"build-keep-log"}}; + + Setting<bool> compressLog{this, + true, + "compress-build-log", + "Whether to compress logs.", + {"build-compress-log"}}; + + Setting<unsigned long> maxLogSize{ + this, + 0, + "max-build-log-size", + "Maximum number of bytes a builder can write to stdout/stderr " + "before being killed (0 means no limit).", + {"build-max-log-size"}}; + + /* When buildRepeat > 0 and verboseBuild == true, whether to print + repeated builds (i.e. builds other than the first one) to + stderr. Hack to prevent Hydra logs from being polluted. */ + bool printRepeatedBuilds = true; + + Setting<unsigned int> pollInterval{ + this, 5, "build-poll-interval", + "How often (in seconds) to poll for locks."}; + + Setting<bool> checkRootReachability{ + this, false, "gc-check-reachability", + "Whether to check if new GC roots can in fact be found by the " + "garbage collector."}; + + Setting<bool> gcKeepOutputs{ + this, + false, + "keep-outputs", + "Whether the garbage collector should keep outputs of live derivations.", + {"gc-keep-outputs"}}; + + Setting<bool> gcKeepDerivations{ + this, + true, + "keep-derivations", + "Whether the garbage collector should keep derivers of live paths.", + {"gc-keep-derivations"}}; + + Setting<bool> autoOptimiseStore{this, false, "auto-optimise-store", + "Whether to automatically replace files with " + "identical contents with hard links."}; + + Setting<bool> envKeepDerivations{ + this, + false, + "keep-env-derivations", + "Whether to add derivations as a dependency of user environments " + "(to prevent them from being GCed).", + {"env-keep-derivations"}}; + + /* Whether to lock the Nix client and worker to the same CPU. */ + bool lockCPU; + + /* Whether to show a stack trace if Nix evaluation fails. */ + Setting<bool> showTrace{ + this, false, "show-trace", + "Whether to show a stack trace on evaluation errors."}; + + Setting<SandboxMode> sandboxMode { + this, +#if __linux__ + smEnabled +#else + smDisabled +#endif + , + "sandbox", + "Whether to enable sandboxed builds. Can be \"true\", \"false\" or " + "\"relaxed\".", + { + "build-use-chroot", "build-use-sandbox" + } + }; + + Setting<PathSet> sandboxPaths{ + this, + {}, + "sandbox-paths", + "The paths to make available inside the build sandbox.", + {"build-chroot-dirs", "build-sandbox-paths"}}; + + Setting<bool> sandboxFallback{ + this, true, "sandbox-fallback", + "Whether to disable sandboxing when the kernel doesn't allow it."}; + + Setting<PathSet> extraSandboxPaths{ + this, + {}, + "extra-sandbox-paths", + "Additional paths to make available inside the build sandbox.", + {"build-extra-chroot-dirs", "build-extra-sandbox-paths"}}; + + Setting<size_t> buildRepeat{ + this, + 0, + "repeat", + "The number of times to repeat a build in order to verify determinism.", + {"build-repeat"}}; + +#if __linux__ + Setting<std::string> sandboxShmSize{ + this, "50%", "sandbox-dev-shm-size", + "The size of /dev/shm in the build sandbox."}; + + Setting<Path> sandboxBuildDir{this, "/build", "sandbox-build-dir", + "The build directory inside the sandbox."}; +#endif + + Setting<PathSet> allowedImpureHostPrefixes{ + this, + {}, + "allowed-impure-host-deps", + "Which prefixes to allow derivations to ask for access to (primarily for " + "Darwin)."}; + +#if __APPLE__ + Setting<bool> darwinLogSandboxViolations{ + this, false, "darwin-log-sandbox-violations", + "Whether to log Darwin sandbox access violations to the system log."}; +#endif + + Setting<bool> runDiffHook{ + this, false, "run-diff-hook", + "Whether to run the program specified by the diff-hook setting " + "repeated builds produce a different result. Typically used to " + "plug in diffoscope."}; + + PathSetting diffHook{ + this, true, "", "diff-hook", + "A program that prints out the differences between the two paths " + "specified on its command line."}; + + Setting<bool> enforceDeterminism{ + this, true, "enforce-determinism", + "Whether to fail if repeated builds produce different output."}; + + Setting<Strings> trustedPublicKeys{ + this, + {"cache.nixos.org-1:6NCHdD59X431o0gWypbMrAURkbJ16ZPMQFGspcDShjY="}, + "trusted-public-keys", + "Trusted public keys for secure substitution.", + {"binary-cache-public-keys"}}; + + Setting<Strings> secretKeyFiles{ + this, + {}, + "secret-key-files", + "Secret keys with which to sign local builds."}; + + Setting<unsigned int> tarballTtl{ + this, 60 * 60, "tarball-ttl", + "How long downloaded files are considered up-to-date."}; + + Setting<bool> requireSigs{ + this, true, "require-sigs", + "Whether to check that any non-content-addressed path added to the " + "Nix store has a valid signature (that is, one signed using a key " + "listed in 'trusted-public-keys'."}; + + Setting<StringSet> extraPlatforms{ + this, + std::string{SYSTEM} == "x86_64-linux" ? StringSet{"i686-linux"} + : StringSet{}, + "extra-platforms", + "Additional platforms that can be built on the local system. " + "These may be supported natively (e.g. armv7 on some aarch64 CPUs " + "or using hacks like qemu-user."}; + + Setting<StringSet> systemFeatures{ + this, getDefaultSystemFeatures(), "system-features", + "Optional features that this system implements (like \"kvm\")."}; + + Setting<Strings> substituters{ + this, + nixStore == "/nix/store" ? Strings{"https://cache.nixos.org/"} + : Strings(), + "substituters", + "The URIs of substituters (such as https://cache.nixos.org/).", + {"binary-caches"}}; + + // FIXME: provide a way to add to option values. + Setting<Strings> extraSubstituters{this, + {}, + "extra-substituters", + "Additional URIs of substituters.", + {"extra-binary-caches"}}; + + Setting<StringSet> trustedSubstituters{ + this, + {}, + "trusted-substituters", + "Disabled substituters that may be enabled via the substituters option " + "by untrusted users.", + {"trusted-binary-caches"}}; + + Setting<Strings> trustedUsers{this, + {"root"}, + "trusted-users", + "Which users or groups are trusted to ask the " + "daemon to do unsafe things."}; + + Setting<unsigned int> ttlNegativeNarInfoCache{ + this, 3600, "narinfo-cache-negative-ttl", + "The TTL in seconds for negative lookups in the disk cache i.e binary " + "cache lookups that " + "return an invalid path result"}; + + Setting<unsigned int> ttlPositiveNarInfoCache{ + this, 30 * 24 * 3600, "narinfo-cache-positive-ttl", + "The TTL in seconds for positive lookups in the disk cache i.e binary " + "cache lookups that " + "return a valid path result."}; + + /* ?Who we trust to use the daemon in safe ways */ + Setting<Strings> allowedUsers{ + this, + {"*"}, + "allowed-users", + "Which users or groups are allowed to connect to the daemon."}; + + Setting<bool> printMissing{ + this, true, "print-missing", + "Whether to print what paths need to be built or downloaded."}; + + Setting<std::string> preBuildHook{ + this, "", "pre-build-hook", + "A program to run just before a build to set derivation-specific build " + "settings."}; + + Setting<std::string> postBuildHook{ + this, "", "post-build-hook", + "A program to run just after each successful build."}; + + Setting<std::string> netrcFile{this, fmt("%s/%s", nixConfDir, "netrc"), + "netrc-file", + "Path to the netrc file used to obtain " + "usernames/passwords for downloads."}; + + /* Path to the SSL CA file used */ + Path caFile; + +#if __linux__ + Setting<bool> filterSyscalls{ + this, true, "filter-syscalls", + "Whether to prevent certain dangerous system calls, such as " + "creation of setuid/setgid files or adding ACLs or extended " + "attributes. Only disable this if you're aware of the " + "security implications."}; + + Setting<bool> allowNewPrivileges{ + this, false, "allow-new-privileges", + "Whether builders can acquire new privileges by calling programs with " + "setuid/setgid bits or with file capabilities."}; +#endif + + Setting<Strings> hashedMirrors{ + this, + {"http://tarballs.nixos.org/"}, + "hashed-mirrors", + "A list of servers used by builtins.fetchurl to fetch files by hash."}; + + Setting<uint64_t> minFree{this, 0, "min-free", + "Automatically run the garbage collector when free " + "disk space drops below the specified amount."}; + + Setting<uint64_t> maxFree{this, std::numeric_limits<uint64_t>::max(), + "max-free", + "Stop deleting garbage when free disk space is " + "above the specified amount."}; + + Setting<uint64_t> minFreeCheckInterval{ + this, 5, "min-free-check-interval", + "Number of seconds between checking free disk space."}; + + Setting<Paths> pluginFiles{ + this, + {}, + "plugin-files", + "Plugins to dynamically load at nix initialization time."}; +}; + +// FIXME: don't use a global variable. +extern Settings settings; + +/* This should be called after settings are initialized, but before + anything else */ +void initPlugins(); + +void loadConfFile(); + +extern const string nixVersion; + +} // namespace nix diff --git a/third_party/nix/src/libstore/http-binary-cache-store.cc b/third_party/nix/src/libstore/http-binary-cache-store.cc new file mode 100644 index 0000000000..1a46423b35 --- /dev/null +++ b/third_party/nix/src/libstore/http-binary-cache-store.cc @@ -0,0 +1,169 @@ +#include <utility> + +#include <glog/logging.h> + +#include "binary-cache-store.hh" +#include "download.hh" +#include "globals.hh" +#include "nar-info-disk-cache.hh" + +namespace nix { + +MakeError(UploadToHTTP, Error); + +class HttpBinaryCacheStore : public BinaryCacheStore { + private: + Path cacheUri; + + struct State { + bool enabled = true; + std::chrono::steady_clock::time_point disabledUntil; + }; + + Sync<State> _state; + + public: + HttpBinaryCacheStore(const Params& params, Path _cacheUri) + : BinaryCacheStore(params), cacheUri(std::move(_cacheUri)) { + if (cacheUri.back() == '/') { + cacheUri.pop_back(); + } + + diskCache = getNarInfoDiskCache(); + } + + std::string getUri() override { return cacheUri; } + + void init() override { + // FIXME: do this lazily? + if (!diskCache->cacheExists(cacheUri, wantMassQuery_, priority)) { + try { + BinaryCacheStore::init(); + } catch (UploadToHTTP&) { + throw Error("'%s' does not appear to be a binary cache", cacheUri); + } + diskCache->createCache(cacheUri, storeDir, wantMassQuery_, priority); + } + } + + protected: + void maybeDisable() { + auto state(_state.lock()); + if (state->enabled && settings.tryFallback) { + int t = 60; + LOG(WARNING) << "disabling binary cache '" << getUri() << "' for " << t + << " seconds"; + state->enabled = false; + state->disabledUntil = + std::chrono::steady_clock::now() + std::chrono::seconds(t); + } + } + + void checkEnabled() { + auto state(_state.lock()); + if (state->enabled) { + return; + } + if (std::chrono::steady_clock::now() > state->disabledUntil) { + state->enabled = true; + DLOG(INFO) << "re-enabling binary cache '" << getUri() << "'"; + return; + } + throw SubstituterDisabled("substituter '%s' is disabled", getUri()); + } + + bool fileExists(const std::string& path) override { + checkEnabled(); + + try { + DownloadRequest request(cacheUri + "/" + path); + request.head = true; + getDownloader()->download(request); + return true; + } catch (DownloadError& e) { + /* S3 buckets return 403 if a file doesn't exist and the + bucket is unlistable, so treat 403 as 404. */ + if (e.error == Downloader::NotFound || e.error == Downloader::Forbidden) { + return false; + } + maybeDisable(); + throw; + } + } + + void upsertFile(const std::string& path, const std::string& data, + const std::string& mimeType) override { + auto req = DownloadRequest(cacheUri + "/" + path); + req.data = std::make_shared<string>(data); // FIXME: inefficient + req.mimeType = mimeType; + try { + getDownloader()->download(req); + } catch (DownloadError& e) { + throw UploadToHTTP("while uploading to HTTP binary cache at '%s': %s", + cacheUri, e.msg()); + } + } + + DownloadRequest makeRequest(const std::string& path) { + DownloadRequest request(cacheUri + "/" + path); + return request; + } + + void getFile(const std::string& path, Sink& sink) override { + checkEnabled(); + auto request(makeRequest(path)); + try { + getDownloader()->download(std::move(request), sink); + } catch (DownloadError& e) { + if (e.error == Downloader::NotFound || e.error == Downloader::Forbidden) { + throw NoSuchBinaryCacheFile( + "file '%s' does not exist in binary cache '%s'", path, getUri()); + } + maybeDisable(); + throw; + } + } + + void getFile( + const std::string& path, + Callback<std::shared_ptr<std::string>> callback) noexcept override { + checkEnabled(); + + auto request(makeRequest(path)); + + auto callbackPtr = + std::make_shared<decltype(callback)>(std::move(callback)); + + getDownloader()->enqueueDownload( + request, {[callbackPtr, this](std::future<DownloadResult> result) { + try { + (*callbackPtr)(result.get().data); + } catch (DownloadError& e) { + if (e.error == Downloader::NotFound || + e.error == Downloader::Forbidden) { + return (*callbackPtr)(std::shared_ptr<std::string>()); + } + maybeDisable(); + callbackPtr->rethrow(); + } catch (...) { + callbackPtr->rethrow(); + } + }}); + } +}; + +static RegisterStoreImplementation regStore( + [](const std::string& uri, + const Store::Params& params) -> std::shared_ptr<Store> { + if (std::string(uri, 0, 7) != "http://" && + std::string(uri, 0, 8) != "https://" && + (getEnv("_NIX_FORCE_HTTP_BINARY_CACHE_STORE") != "1" || + std::string(uri, 0, 7) != "file://")) { + return nullptr; + } + auto store = std::make_shared<HttpBinaryCacheStore>(params, uri); + store->init(); + return store; + }); + +} // namespace nix diff --git a/third_party/nix/src/libstore/legacy-ssh-store.cc b/third_party/nix/src/libstore/legacy-ssh-store.cc new file mode 100644 index 0000000000..9a84e02956 --- /dev/null +++ b/third_party/nix/src/libstore/legacy-ssh-store.cc @@ -0,0 +1,273 @@ +#include "archive.hh" +#include "derivations.hh" +#include "glog/logging.h" +#include "pool.hh" +#include "remote-store.hh" +#include "serve-protocol.hh" +#include "ssh.hh" +#include "store-api.hh" +#include "worker-protocol.hh" + +namespace nix { + +static std::string uriScheme = "ssh://"; + +struct LegacySSHStore : public Store { + const Setting<int> maxConnections{ + this, 1, "max-connections", + "maximum number of concurrent SSH connections"}; + const Setting<Path> sshKey{this, "", "ssh-key", "path to an SSH private key"}; + const Setting<bool> compress{this, false, "compress", + "whether to compress the connection"}; + const Setting<Path> remoteProgram{ + this, "nix-store", "remote-program", + "path to the nix-store executable on the remote system"}; + const Setting<std::string> remoteStore{ + this, "", "remote-store", "URI of the store on the remote system"}; + + // Hack for getting remote build log output. + const Setting<int> logFD{ + this, -1, "log-fd", "file descriptor to which SSH's stderr is connected"}; + + struct Connection { + std::unique_ptr<SSHMaster::Connection> sshConn; + FdSink to; + FdSource from; + int remoteVersion; + bool good = true; + }; + + std::string host; + + ref<Pool<Connection>> connections; + + SSHMaster master; + + LegacySSHStore(const string& host, const Params& params) + : Store(params), + host(host), + connections(make_ref<Pool<Connection>>( + std::max(1, (int)maxConnections), + [this]() { return openConnection(); }, + [](const ref<Connection>& r) { return r->good; })), + master(host, sshKey, + // Use SSH master only if using more than 1 connection. + connections->capacity() > 1, compress, logFD) {} + + ref<Connection> openConnection() { + auto conn = make_ref<Connection>(); + conn->sshConn = master.startCommand( + fmt("%s --serve --write", remoteProgram) + + (remoteStore.get().empty() + ? "" + : " --store " + shellEscape(remoteStore.get()))); + conn->to = FdSink(conn->sshConn->in.get()); + conn->from = FdSource(conn->sshConn->out.get()); + + try { + conn->to << SERVE_MAGIC_1 << SERVE_PROTOCOL_VERSION; + conn->to.flush(); + + unsigned int magic = readInt(conn->from); + if (magic != SERVE_MAGIC_2) { + throw Error("protocol mismatch with 'nix-store --serve' on '%s'", host); + } + conn->remoteVersion = readInt(conn->from); + if (GET_PROTOCOL_MAJOR(conn->remoteVersion) != 0x200) { + throw Error("unsupported 'nix-store --serve' protocol version on '%s'", + host); + } + + } catch (EndOfFile& e) { + throw Error("cannot connect to '%1%'", host); + } + + return conn; + }; + + string getUri() override { return uriScheme + host; } + + void queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept override { + try { + auto conn(connections->get()); + + DLOG(INFO) << "querying remote host '" << host << "' for info on '" + << path << "'"; + + conn->to << cmdQueryPathInfos << PathSet{path}; + conn->to.flush(); + + auto info = std::make_shared<ValidPathInfo>(); + conn->from >> info->path; + if (info->path.empty()) { + return callback(nullptr); + } + assert(path == info->path); + + PathSet references; + conn->from >> info->deriver; + info->references = readStorePaths<PathSet>(*this, conn->from); + readLongLong(conn->from); // download size + info->narSize = readLongLong(conn->from); + + if (GET_PROTOCOL_MINOR(conn->remoteVersion) >= 4) { + auto s = readString(conn->from); + info->narHash = s.empty() ? Hash() : Hash(s); + conn->from >> info->ca; + info->sigs = readStrings<StringSet>(conn->from); + } + + auto s = readString(conn->from); + assert(s.empty()); + + callback(std::move(info)); + } catch (...) { + callback.rethrow(); + } + } + + void addToStore(const ValidPathInfo& info, Source& source, RepairFlag repair, + CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) override { + DLOG(INFO) << "adding path '" << info.path << "' to remote host '" << host + << "'"; + + auto conn(connections->get()); + + if (GET_PROTOCOL_MINOR(conn->remoteVersion) >= 5) { + conn->to << cmdAddToStoreNar << info.path << info.deriver + << info.narHash.to_string(Base16, false) << info.references + << info.registrationTime << info.narSize + << static_cast<uint64_t>(info.ultimate) << info.sigs << info.ca; + try { + copyNAR(source, conn->to); + } catch (...) { + conn->good = false; + throw; + } + conn->to.flush(); + + } else { + conn->to << cmdImportPaths << 1; + try { + copyNAR(source, conn->to); + } catch (...) { + conn->good = false; + throw; + } + conn->to << exportMagic << info.path << info.references << info.deriver + << 0 << 0; + conn->to.flush(); + } + + if (readInt(conn->from) != 1) { + throw Error( + "failed to add path '%s' to remote host '%s', info.path, host"); + } + } + + void narFromPath(const Path& path, Sink& sink) override { + auto conn(connections->get()); + + conn->to << cmdDumpStorePath << path; + conn->to.flush(); + copyNAR(conn->from, sink); + } + + Path queryPathFromHashPart(const string& hashPart) override { + unsupported("queryPathFromHashPart"); + } + + Path addToStore(const string& name, const Path& srcPath, bool recursive, + HashType hashAlgo, PathFilter& filter, + RepairFlag repair) override { + unsupported("addToStore"); + } + + Path addTextToStore(const string& name, const string& s, + const PathSet& references, RepairFlag repair) override { + unsupported("addTextToStore"); + } + + BuildResult buildDerivation(const Path& drvPath, const BasicDerivation& drv, + BuildMode buildMode) override { + auto conn(connections->get()); + + conn->to << cmdBuildDerivation << drvPath << drv << settings.maxSilentTime + << settings.buildTimeout; + if (GET_PROTOCOL_MINOR(conn->remoteVersion) >= 2) { + conn->to << settings.maxLogSize; + } + if (GET_PROTOCOL_MINOR(conn->remoteVersion) >= 3) { + conn->to << settings.buildRepeat + << static_cast<uint64_t>(settings.enforceDeterminism); + } + + conn->to.flush(); + + BuildResult status; + status.status = (BuildResult::Status)readInt(conn->from); + conn->from >> status.errorMsg; + + if (GET_PROTOCOL_MINOR(conn->remoteVersion) >= 3) { + conn->from >> status.timesBuilt >> status.isNonDeterministic >> + status.startTime >> status.stopTime; + } + + return status; + } + + void ensurePath(const Path& path) override { unsupported("ensurePath"); } + + void computeFSClosure(const PathSet& paths, PathSet& out, + bool flipDirection = false, bool includeOutputs = false, + bool includeDerivers = false) override { + if (flipDirection || includeDerivers) { + Store::computeFSClosure(paths, out, flipDirection, includeOutputs, + includeDerivers); + return; + } + + auto conn(connections->get()); + + conn->to << cmdQueryClosure << static_cast<uint64_t>(includeOutputs) + << paths; + conn->to.flush(); + + auto res = readStorePaths<PathSet>(*this, conn->from); + + out.insert(res.begin(), res.end()); + } + + PathSet queryValidPaths(const PathSet& paths, SubstituteFlag maybeSubstitute = + NoSubstitute) override { + auto conn(connections->get()); + + conn->to << cmdQueryValidPaths << 0u // lock + << maybeSubstitute << paths; + conn->to.flush(); + + return readStorePaths<PathSet>(*this, conn->from); + } + + void connect() override { auto conn(connections->get()); } + + unsigned int getProtocol() override { + auto conn(connections->get()); + return conn->remoteVersion; + } +}; + +static RegisterStoreImplementation regStore( + [](const std::string& uri, + const Store::Params& params) -> std::shared_ptr<Store> { + if (std::string(uri, 0, uriScheme.size()) != uriScheme) { + return nullptr; + } + return std::make_shared<LegacySSHStore>( + std::string(uri, uriScheme.size()), params); + }); + +} // namespace nix diff --git a/third_party/nix/src/libstore/local-binary-cache-store.cc b/third_party/nix/src/libstore/local-binary-cache-store.cc new file mode 100644 index 0000000000..00bb21eb24 --- /dev/null +++ b/third_party/nix/src/libstore/local-binary-cache-store.cc @@ -0,0 +1,91 @@ +#include <utility> + +#include "binary-cache-store.hh" +#include "globals.hh" +#include "nar-info-disk-cache.hh" + +namespace nix { + +class LocalBinaryCacheStore : public BinaryCacheStore { + private: + Path binaryCacheDir; + + public: + LocalBinaryCacheStore(const Params& params, Path binaryCacheDir) + : BinaryCacheStore(params), binaryCacheDir(std::move(binaryCacheDir)) {} + + void init() override; + + std::string getUri() override { return "file://" + binaryCacheDir; } + + protected: + bool fileExists(const std::string& path) override; + + void upsertFile(const std::string& path, const std::string& data, + const std::string& mimeType) override; + + void getFile(const std::string& path, Sink& sink) override { + try { + readFile(binaryCacheDir + "/" + path, sink); + } catch (SysError& e) { + if (e.errNo == ENOENT) { + throw NoSuchBinaryCacheFile("file '%s' does not exist in binary cache", + path); + } + } + } + + PathSet queryAllValidPaths() override { + PathSet paths; + + for (auto& entry : readDirectory(binaryCacheDir)) { + if (entry.name.size() != 40 || !hasSuffix(entry.name, ".narinfo")) { + continue; + } + paths.insert(storeDir + "/" + + entry.name.substr(0, entry.name.size() - 8)); + } + + return paths; + } +}; + +void LocalBinaryCacheStore::init() { + createDirs(binaryCacheDir + "/nar"); + BinaryCacheStore::init(); +} + +static void atomicWrite(const Path& path, const std::string& s) { + Path tmp = path + ".tmp." + std::to_string(getpid()); + AutoDelete del(tmp, false); + writeFile(tmp, s); + if (rename(tmp.c_str(), path.c_str()) != 0) { + throw SysError(format("renaming '%1%' to '%2%'") % tmp % path); + } + del.cancel(); +} + +bool LocalBinaryCacheStore::fileExists(const std::string& path) { + return pathExists(binaryCacheDir + "/" + path); +} + +void LocalBinaryCacheStore::upsertFile(const std::string& path, + const std::string& data, + const std::string& mimeType) { + atomicWrite(binaryCacheDir + "/" + path, data); +} + +static RegisterStoreImplementation regStore( + [](const std::string& uri, + const Store::Params& params) -> std::shared_ptr<Store> { + if (getEnv("_NIX_FORCE_HTTP_BINARY_CACHE_STORE") == "1" || + std::string(uri, 0, 7) != "file://") { + return nullptr; + } + auto store = + std::make_shared<LocalBinaryCacheStore>(params, std::string(uri, 7)); + store->init(); + return store; + }); + +} // namespace nix diff --git a/third_party/nix/src/libstore/local-fs-store.cc b/third_party/nix/src/libstore/local-fs-store.cc new file mode 100644 index 0000000000..2120afc0ce --- /dev/null +++ b/third_party/nix/src/libstore/local-fs-store.cc @@ -0,0 +1,122 @@ +#include "archive.hh" +#include "compression.hh" +#include "derivations.hh" +#include "fs-accessor.hh" +#include "globals.hh" +#include "store-api.hh" + +namespace nix { + +LocalFSStore::LocalFSStore(const Params& params) : Store(params) {} + +struct LocalStoreAccessor : public FSAccessor { + ref<LocalFSStore> store; + + explicit LocalStoreAccessor(const ref<LocalFSStore>& store) : store(store) {} + + Path toRealPath(const Path& path) { + Path storePath = store->toStorePath(path); + if (!store->isValidPath(storePath)) { + throw InvalidPath(format("path '%1%' is not a valid store path") % + storePath); + } + return store->getRealStoreDir() + std::string(path, store->storeDir.size()); + } + + FSAccessor::Stat stat(const Path& path) override { + auto realPath = toRealPath(path); + + struct stat st; + if (lstat(realPath.c_str(), &st) != 0) { + if (errno == ENOENT || errno == ENOTDIR) { + return {Type::tMissing, 0, false}; + } + throw SysError(format("getting status of '%1%'") % path); + } + + if (!S_ISREG(st.st_mode) && !S_ISDIR(st.st_mode) && !S_ISLNK(st.st_mode)) { + throw Error(format("file '%1%' has unsupported type") % path); + } + + return {S_ISREG(st.st_mode) + ? Type::tRegular + : S_ISLNK(st.st_mode) ? Type::tSymlink : Type::tDirectory, + S_ISREG(st.st_mode) ? (uint64_t)st.st_size : 0, + S_ISREG(st.st_mode) && ((st.st_mode & S_IXUSR) != 0u)}; + } + + StringSet readDirectory(const Path& path) override { + auto realPath = toRealPath(path); + + auto entries = nix::readDirectory(realPath); + + StringSet res; + for (auto& entry : entries) { + res.insert(entry.name); + } + + return res; + } + + std::string readFile(const Path& path) override { + return nix::readFile(toRealPath(path)); + } + + std::string readLink(const Path& path) override { + return nix::readLink(toRealPath(path)); + } +}; + +ref<FSAccessor> LocalFSStore::getFSAccessor() { + return make_ref<LocalStoreAccessor>(ref<LocalFSStore>( + std::dynamic_pointer_cast<LocalFSStore>(shared_from_this()))); +} + +void LocalFSStore::narFromPath(const Path& path, Sink& sink) { + if (!isValidPath(path)) { + throw Error(format("path '%s' is not valid") % path); + } + dumpPath(getRealStoreDir() + std::string(path, storeDir.size()), sink); +} + +const string LocalFSStore::drvsLogDir = "drvs"; + +std::shared_ptr<std::string> LocalFSStore::getBuildLog(const Path& path_) { + auto path(path_); + + assertStorePath(path); + + if (!isDerivation(path)) { + try { + path = queryPathInfo(path)->deriver; + } catch (InvalidPath&) { + return nullptr; + } + if (path.empty()) { + return nullptr; + } + } + + string baseName = baseNameOf(path); + + for (int j = 0; j < 2; j++) { + Path logPath = j == 0 ? fmt("%s/%s/%s/%s", logDir, drvsLogDir, + string(baseName, 0, 2), string(baseName, 2)) + : fmt("%s/%s/%s", logDir, drvsLogDir, baseName); + Path logBz2Path = logPath + ".bz2"; + + if (pathExists(logPath)) { + return std::make_shared<std::string>(readFile(logPath)); + } + if (pathExists(logBz2Path)) { + try { + return decompress("bzip2", readFile(logBz2Path)); + } catch (Error&) { + } + } + } + + return nullptr; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/local-store.cc b/third_party/nix/src/libstore/local-store.cc new file mode 100644 index 0000000000..1d162ad6be --- /dev/null +++ b/third_party/nix/src/libstore/local-store.cc @@ -0,0 +1,1534 @@ +#include "local-store.hh" + +#include <algorithm> +#include <cerrno> +#include <cstdio> +#include <cstring> +#include <ctime> +#include <iostream> + +#include <fcntl.h> +#include <glog/logging.h> +#include <grp.h> +#include <sys/select.h> +#include <sys/stat.h> +#include <sys/time.h> +#include <sys/types.h> +#include <unistd.h> +#include <utime.h> + +#include "archive.hh" +#include "derivations.hh" +#include "globals.hh" +#include "nar-info.hh" +#include "pathlocks.hh" +#include "worker-protocol.hh" + +#if __linux__ +#include <sched.h> +#include <sys/ioctl.h> +#include <sys/mount.h> +#include <sys/statvfs.h> +#include <sys/xattr.h> +#endif + +#ifdef __CYGWIN__ +#include <windows.h> +#endif + +#include <sqlite3.h> + +namespace nix { + +LocalStore::LocalStore(const Params& params) + : Store(params), + LocalFSStore(params), + realStoreDir_{this, false, + rootDir != "" ? rootDir + "/nix/store" : storeDir, "real", + "physical path to the Nix store"}, + realStoreDir(realStoreDir_), + dbDir(stateDir + "/db"), + linksDir(realStoreDir + "/.links"), + reservedPath(dbDir + "/reserved"), + schemaPath(dbDir + "/schema"), + trashDir(realStoreDir + "/trash"), + tempRootsDir(stateDir + "/temproots"), + fnTempRoots(fmt("%s/%d", tempRootsDir, getpid())) { + auto state(_state.lock()); + + /* Create missing state directories if they don't already exist. */ + createDirs(realStoreDir); + makeStoreWritable(); + createDirs(linksDir); + Path profilesDir = stateDir + "/profiles"; + createDirs(profilesDir); + createDirs(tempRootsDir); + createDirs(dbDir); + Path gcRootsDir = stateDir + "/gcroots"; + if (!pathExists(gcRootsDir)) { + createDirs(gcRootsDir); + createSymlink(profilesDir, gcRootsDir + "/profiles"); + } + + for (auto& perUserDir : + {profilesDir + "/per-user", gcRootsDir + "/per-user"}) { + createDirs(perUserDir); + if (chmod(perUserDir.c_str(), 0755) == -1) { + throw SysError("could not set permissions on '%s' to 755", perUserDir); + } + } + + createUser(getUserName(), getuid()); + + /* Optionally, create directories and set permissions for a + multi-user install. */ + if (getuid() == 0 && settings.buildUsersGroup != "") { + mode_t perm = 01775; + + struct group* gr = getgrnam(settings.buildUsersGroup.get().c_str()); + if (gr == nullptr) { + LOG(ERROR) << "warning: the group '" << settings.buildUsersGroup + << "' specified in 'build-users-group' does not exist"; + } else { + struct stat st; + if (stat(realStoreDir.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % + realStoreDir); + } + + if (st.st_uid != 0 || st.st_gid != gr->gr_gid || + (st.st_mode & ~S_IFMT) != perm) { + if (chown(realStoreDir.c_str(), 0, gr->gr_gid) == -1) { + throw SysError(format("changing ownership of path '%1%'") % + realStoreDir); + } + if (chmod(realStoreDir.c_str(), perm) == -1) { + throw SysError(format("changing permissions on path '%1%'") % + realStoreDir); + } + } + } + } + + /* Ensure that the store and its parents are not symlinks. */ + if (getEnv("NIX_IGNORE_SYMLINK_STORE") != "1") { + Path path = realStoreDir; + struct stat st; + while (path != "/") { + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting status of '%1%'") % path); + } + if (S_ISLNK(st.st_mode)) { + throw Error(format("the path '%1%' is a symlink; " + "this is not allowed for the Nix store and its " + "parent directories") % + path); + } + path = dirOf(path); + } + } + + /* We can't open a SQLite database if the disk is full. Since + this prevents the garbage collector from running when it's most + needed, we reserve some dummy space that we can free just + before doing a garbage collection. */ + try { + struct stat st; + if (stat(reservedPath.c_str(), &st) == -1 || + st.st_size != settings.reservedSize) { + AutoCloseFD fd = + open(reservedPath.c_str(), O_WRONLY | O_CREAT | O_CLOEXEC, 0600); + int res = -1; +#if HAVE_POSIX_FALLOCATE + res = posix_fallocate(fd.get(), 0, settings.reservedSize); +#endif + if (res == -1) { + writeFull(fd.get(), string(settings.reservedSize, 'X')); + [[gnu::unused]] auto res2 = ftruncate(fd.get(), settings.reservedSize); + } + } + } catch (SysError& e) { /* don't care about errors */ + } + + /* Acquire the big fat lock in shared mode to make sure that no + schema upgrade is in progress. */ + Path globalLockPath = dbDir + "/big-lock"; + globalLock = openLockFile(globalLockPath, true); + + if (!lockFile(globalLock.get(), ltRead, false)) { + LOG(INFO) << "waiting for the big Nix store lock..."; + lockFile(globalLock.get(), ltRead, true); + } + + /* Check the current database schema and if necessary do an + upgrade. */ + int curSchema = getSchema(); + if (curSchema > nixSchemaVersion) { + throw Error( + format( + "current Nix store schema is version %1%, but I only support %2%") % + curSchema % nixSchemaVersion); + } + if (curSchema == 0) { /* new store */ + curSchema = nixSchemaVersion; + openDB(*state, true); + writeFile(schemaPath, (format("%1%") % nixSchemaVersion).str()); + } else if (curSchema < nixSchemaVersion) { + if (curSchema < 5) { + throw Error( + "Your Nix store has a database in Berkeley DB format,\n" + "which is no longer supported. To convert to the new format,\n" + "please upgrade Nix to version 0.12 first."); + } + + if (curSchema < 6) { + throw Error( + "Your Nix store has a database in flat file format,\n" + "which is no longer supported. To convert to the new format,\n" + "please upgrade Nix to version 1.11 first."); + } + + if (!lockFile(globalLock.get(), ltWrite, false)) { + LOG(INFO) << "waiting for exclusive access to the Nix store..."; + lockFile(globalLock.get(), ltWrite, true); + } + + /* Get the schema version again, because another process may + have performed the upgrade already. */ + curSchema = getSchema(); + + if (curSchema < 7) { + upgradeStore7(); + } + + openDB(*state, false); + + if (curSchema < 8) { + SQLiteTxn txn(state->db); + state->db.exec("alter table ValidPaths add column ultimate integer"); + state->db.exec("alter table ValidPaths add column sigs text"); + txn.commit(); + } + + if (curSchema < 9) { + SQLiteTxn txn(state->db); + state->db.exec("drop table FailedPaths"); + txn.commit(); + } + + if (curSchema < 10) { + SQLiteTxn txn(state->db); + state->db.exec("alter table ValidPaths add column ca text"); + txn.commit(); + } + + writeFile(schemaPath, (format("%1%") % nixSchemaVersion).str()); + + lockFile(globalLock.get(), ltRead, true); + } else { + openDB(*state, false); + } + + /* Prepare SQL statements. */ + state->stmtRegisterValidPath.create( + state->db, + "insert into ValidPaths (path, hash, registrationTime, deriver, narSize, " + "ultimate, sigs, ca) values (?, ?, ?, ?, ?, ?, ?, ?);"); + state->stmtUpdatePathInfo.create( + state->db, + "update ValidPaths set narSize = ?, hash = ?, ultimate = ?, sigs = ?, ca " + "= ? where path = ?;"); + state->stmtAddReference.create( + state->db, + "insert or replace into Refs (referrer, reference) values (?, ?);"); + state->stmtQueryPathInfo.create( + state->db, + "select id, hash, registrationTime, deriver, narSize, ultimate, sigs, ca " + "from ValidPaths where path = ?;"); + state->stmtQueryReferences.create(state->db, + "select path from Refs join ValidPaths on " + "reference = id where referrer = ?;"); + state->stmtQueryReferrers.create( + state->db, + "select path from Refs join ValidPaths on referrer = id where reference " + "= (select id from ValidPaths where path = ?);"); + state->stmtInvalidatePath.create(state->db, + "delete from ValidPaths where path = ?;"); + state->stmtAddDerivationOutput.create( + state->db, + "insert or replace into DerivationOutputs (drv, id, path) values (?, ?, " + "?);"); + state->stmtQueryValidDerivers.create( + state->db, + "select v.id, v.path from DerivationOutputs d join ValidPaths v on d.drv " + "= v.id where d.path = ?;"); + state->stmtQueryDerivationOutputs.create( + state->db, "select id, path from DerivationOutputs where drv = ?;"); + // Use "path >= ?" with limit 1 rather than "path like '?%'" to + // ensure efficient lookup. + state->stmtQueryPathFromHashPart.create( + state->db, "select path from ValidPaths where path >= ? limit 1;"); + state->stmtQueryValidPaths.create(state->db, "select path from ValidPaths"); +} + +LocalStore::~LocalStore() { + std::shared_future<void> future; + + { + auto state(_state.lock()); + if (state->gcRunning) { + future = state->gcFuture; + } + } + + if (future.valid()) { + LOG(INFO) << "waiting for auto-GC to finish on exit..."; + future.get(); + } + + try { + auto state(_state.lock()); + if (state->fdTempRoots) { + state->fdTempRoots = -1; + unlink(fnTempRoots.c_str()); + } + } catch (...) { + ignoreException(); + } +} + +std::string LocalStore::getUri() { return "local"; } + +int LocalStore::getSchema() { + int curSchema = 0; + if (pathExists(schemaPath)) { + string s = readFile(schemaPath); + if (!string2Int(s, curSchema)) { + throw Error(format("'%1%' is corrupt") % schemaPath); + } + } + return curSchema; +} + +void LocalStore::openDB(State& state, bool create) { + if (access(dbDir.c_str(), R_OK | W_OK) != 0) { + throw SysError(format("Nix database directory '%1%' is not writable") % + dbDir); + } + + /* Open the Nix database. */ + string dbPath = dbDir + "/db.sqlite"; + auto& db(state.db); + if (sqlite3_open_v2(dbPath.c_str(), &db.db, + SQLITE_OPEN_READWRITE | (create ? SQLITE_OPEN_CREATE : 0), + nullptr) != SQLITE_OK) { + throw Error(format("cannot open Nix database '%1%'") % dbPath); + } + +#ifdef __CYGWIN__ + /* The cygwin version of sqlite3 has a patch which calls + SetDllDirectory("/usr/bin") on init. It was intended to fix extension + loading, which we don't use, and the effect of SetDllDirectory is + inherited by child processes, and causes libraries to be loaded from + /usr/bin instead of $PATH. This breaks quite a few things (e.g. + checkPhase on openssh), so we set it back to default behaviour. */ + SetDllDirectoryW(L""); +#endif + + if (sqlite3_busy_timeout(db, 60 * 60 * 1000) != SQLITE_OK) { + throwSQLiteError(db, "setting timeout"); + } + + db.exec("pragma foreign_keys = 1"); + + /* !!! check whether sqlite has been built with foreign key + support */ + + /* Whether SQLite should fsync(). "Normal" synchronous mode + should be safe enough. If the user asks for it, don't sync at + all. This can cause database corruption if the system + crashes. */ + string syncMode = settings.fsyncMetadata ? "normal" : "off"; + db.exec("pragma synchronous = " + syncMode); + + /* Set the SQLite journal mode. WAL mode is fastest, so it's the + default. */ + string mode = settings.useSQLiteWAL ? "wal" : "truncate"; + string prevMode; + { + SQLiteStmt stmt; + stmt.create(db, "pragma main.journal_mode;"); + if (sqlite3_step(stmt) != SQLITE_ROW) { + throwSQLiteError(db, "querying journal mode"); + } + prevMode = string((const char*)sqlite3_column_text(stmt, 0)); + } + if (prevMode != mode && + sqlite3_exec(db, ("pragma main.journal_mode = " + mode + ";").c_str(), + nullptr, nullptr, nullptr) != SQLITE_OK) { + throwSQLiteError(db, "setting journal mode"); + } + + /* Increase the auto-checkpoint interval to 40000 pages. This + seems enough to ensure that instantiating the NixOS system + derivation is done in a single fsync(). */ + if (mode == "wal" && sqlite3_exec(db, "pragma wal_autocheckpoint = 40000;", + nullptr, nullptr, nullptr) != SQLITE_OK) { + throwSQLiteError(db, "setting autocheckpoint interval"); + } + + /* Initialise the database schema, if necessary. */ + if (create) { + const char* schema = +#include "schema.sql.gen.hh" + ; + db.exec(schema); + } +} + +/* To improve purity, users may want to make the Nix store a read-only + bind mount. So make the Nix store writable for this process. */ +void LocalStore::makeStoreWritable() { +#if __linux__ + if (getuid() != 0) { + return; + } + /* Check if /nix/store is on a read-only mount. */ + struct statvfs stat; + if (statvfs(realStoreDir.c_str(), &stat) != 0) { + throw SysError("getting info about the Nix store mount point"); + } + + if ((stat.f_flag & ST_RDONLY) != 0u) { + if (unshare(CLONE_NEWNS) == -1) { + throw SysError("setting up a private mount namespace"); + } + + if (mount(nullptr, realStoreDir.c_str(), "none", MS_REMOUNT | MS_BIND, + nullptr) == -1) { + throw SysError(format("remounting %1% writable") % realStoreDir); + } + } +#endif +} + +const time_t mtimeStore = 1; /* 1 second into the epoch */ + +static void canonicaliseTimestampAndPermissions(const Path& path, + const struct stat& st) { + if (!S_ISLNK(st.st_mode)) { + /* Mask out all type related bits. */ + mode_t mode = st.st_mode & ~S_IFMT; + + if (mode != 0444 && mode != 0555) { + mode = (st.st_mode & S_IFMT) | 0444 | + ((st.st_mode & S_IXUSR) != 0u ? 0111 : 0); + if (chmod(path.c_str(), mode) == -1) { + throw SysError(format("changing mode of '%1%' to %2$o") % path % mode); + } + } + } + + if (st.st_mtime != mtimeStore) { + struct timeval times[2]; + times[0].tv_sec = st.st_atime; + times[0].tv_usec = 0; + times[1].tv_sec = mtimeStore; + times[1].tv_usec = 0; +#if HAVE_LUTIMES + if (lutimes(path.c_str(), times) == -1) { + if (errno != ENOSYS || + (!S_ISLNK(st.st_mode) && utimes(path.c_str(), times) == -1)) { +#else + if (!S_ISLNK(st.st_mode) && utimes(path.c_str(), times) == -1) +#endif + throw SysError(format("changing modification time of '%1%'") % path); + } + } + } // namespace nix +} + +void canonicaliseTimestampAndPermissions(const Path& path) { + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % path); + } + canonicaliseTimestampAndPermissions(path, st); +} + +static void canonicalisePathMetaData_(const Path& path, uid_t fromUid, + InodesSeen& inodesSeen) { + checkInterrupt(); + +#if __APPLE__ + /* Remove flags, in particular UF_IMMUTABLE which would prevent + the file from being garbage-collected. FIXME: Use + setattrlist() to remove other attributes as well. */ + if (lchflags(path.c_str(), 0)) { + if (errno != ENOTSUP) + throw SysError(format("clearing flags of path '%1%'") % path); + } +#endif + + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % path); + } + + /* Really make sure that the path is of a supported type. */ + if (!(S_ISREG(st.st_mode) || S_ISDIR(st.st_mode) || S_ISLNK(st.st_mode))) { + throw Error(format("file '%1%' has an unsupported type") % path); + } + +#if __linux__ + /* Remove extended attributes / ACLs. */ + ssize_t eaSize = llistxattr(path.c_str(), nullptr, 0); + + if (eaSize < 0) { + if (errno != ENOTSUP && errno != ENODATA) { + throw SysError("querying extended attributes of '%s'", path); + } + } else if (eaSize > 0) { + std::vector<char> eaBuf(eaSize); + + if ((eaSize = llistxattr(path.c_str(), eaBuf.data(), eaBuf.size())) < 0) { + throw SysError("querying extended attributes of '%s'", path); + } + + for (auto& eaName : tokenizeString<Strings>( + std::string(eaBuf.data(), eaSize), std::string("\000", 1))) { + /* Ignore SELinux security labels since these cannot be + removed even by root. */ + if (eaName == "security.selinux") { + continue; + } + if (lremovexattr(path.c_str(), eaName.c_str()) == -1) { + throw SysError("removing extended attribute '%s' from '%s'", eaName, + path); + } + } + } +#endif + + /* Fail if the file is not owned by the build user. This prevents + us from messing up the ownership/permissions of files + hard-linked into the output (e.g. "ln /etc/shadow $out/foo"). + However, ignore files that we chown'ed ourselves previously to + ensure that we don't fail on hard links within the same build + (i.e. "touch $out/foo; ln $out/foo $out/bar"). */ + if (fromUid != (uid_t)-1 && st.st_uid != fromUid) { + assert(!S_ISDIR(st.st_mode)); + if (inodesSeen.find(Inode(st.st_dev, st.st_ino)) == inodesSeen.end()) { + throw BuildError(format("invalid ownership on file '%1%'") % path); + } + mode_t mode = st.st_mode & ~S_IFMT; + assert(S_ISLNK(st.st_mode) || + (st.st_uid == geteuid() && (mode == 0444 || mode == 0555) && + st.st_mtime == mtimeStore)); + return; + } + + inodesSeen.insert(Inode(st.st_dev, st.st_ino)); + + canonicaliseTimestampAndPermissions(path, st); + + /* Change ownership to the current uid. If it's a symlink, use + lchown if available, otherwise don't bother. Wrong ownership + of a symlink doesn't matter, since the owning user can't change + the symlink and can't delete it because the directory is not + writable. The only exception is top-level paths in the Nix + store (since that directory is group-writable for the Nix build + users group); we check for this case below. */ + if (st.st_uid != geteuid()) { +#if HAVE_LCHOWN + if (lchown(path.c_str(), geteuid(), getegid()) == -1) { +#else + if (!S_ISLNK(st.st_mode) && chown(path.c_str(), geteuid(), getegid()) == -1) +#endif + throw SysError(format("changing owner of '%1%' to %2%") % path % + geteuid()); + } + } + + if (S_ISDIR(st.st_mode)) { + DirEntries entries = readDirectory(path); + for (auto& i : entries) { + canonicalisePathMetaData_(path + "/" + i.name, fromUid, inodesSeen); + } + } +} + +void canonicalisePathMetaData(const Path& path, uid_t fromUid, + InodesSeen& inodesSeen) { + canonicalisePathMetaData_(path, fromUid, inodesSeen); + + /* On platforms that don't have lchown(), the top-level path can't + be a symlink, since we can't change its ownership. */ + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % path); + } + + if (st.st_uid != geteuid()) { + assert(S_ISLNK(st.st_mode)); + throw Error(format("wrong ownership of top-level store path '%1%'") % path); + } +} + +void canonicalisePathMetaData(const Path& path, uid_t fromUid) { + InodesSeen inodesSeen; + canonicalisePathMetaData(path, fromUid, inodesSeen); +} + +void LocalStore::checkDerivationOutputs(const Path& drvPath, + const Derivation& drv) { + string drvName = storePathToName(drvPath); + assert(isDerivation(drvName)); + drvName = string(drvName, 0, drvName.size() - drvExtension.size()); + + if (drv.isFixedOutput()) { + auto out = drv.outputs.find("out"); + if (out == drv.outputs.end()) { + throw Error( + format("derivation '%1%' does not have an output named 'out'") % + drvPath); + } + + bool recursive; + Hash h; + out->second.parseHashInfo(recursive, h); + Path outPath = makeFixedOutputPath(recursive, h, drvName); + + auto j = drv.env.find("out"); + if (out->second.path != outPath || j == drv.env.end() || + j->second != outPath) { + throw Error( + format( + "derivation '%1%' has incorrect output '%2%', should be '%3%'") % + drvPath % out->second.path % outPath); + } + } + + else { + Derivation drvCopy(drv); + for (auto& i : drvCopy.outputs) { + i.second.path = ""; + drvCopy.env[i.first] = ""; + } + + Hash h = hashDerivationModulo(*this, drvCopy); + + for (auto& i : drv.outputs) { + Path outPath = makeOutputPath(i.first, h, drvName); + auto j = drv.env.find(i.first); + if (i.second.path != outPath || j == drv.env.end() || + j->second != outPath) { + throw Error(format("derivation '%1%' has incorrect output '%2%', " + "should be '%3%'") % + drvPath % i.second.path % outPath); + } + } + } +} + +uint64_t LocalStore::addValidPath(State& state, const ValidPathInfo& info, + bool checkOutputs) { + if (!info.ca.empty() && !info.isContentAddressed(*this)) { + throw Error( + "cannot add path '%s' to the Nix store because it claims to be " + "content-addressed but isn't", + info.path); + } + + state.stmtRegisterValidPath + .use()(info.path)(info.narHash.to_string(Base16))( + info.registrationTime == 0 ? time(nullptr) : info.registrationTime)( + info.deriver, !info.deriver.empty())(info.narSize, info.narSize != 0)( + info.ultimate ? 1 : 0, info.ultimate)( + concatStringsSep(" ", info.sigs), !info.sigs.empty())( + info.ca, !info.ca.empty()) + .exec(); + uint64_t id = sqlite3_last_insert_rowid(state.db); + + /* If this is a derivation, then store the derivation outputs in + the database. This is useful for the garbage collector: it can + efficiently query whether a path is an output of some + derivation. */ + if (isDerivation(info.path)) { + Derivation drv = readDerivation(realStoreDir + "/" + baseNameOf(info.path)); + + /* Verify that the output paths in the derivation are correct + (i.e., follow the scheme for computing output paths from + derivations). Note that if this throws an error, then the + DB transaction is rolled back, so the path validity + registration above is undone. */ + if (checkOutputs) { + checkDerivationOutputs(info.path, drv); + } + + for (auto& i : drv.outputs) { + state.stmtAddDerivationOutput.use()(id)(i.first)(i.second.path).exec(); + } + } + + { + auto state_(Store::state.lock()); + state_->pathInfoCache.upsert(storePathToHash(info.path), + std::make_shared<ValidPathInfo>(info)); + } + + return id; +} + +void LocalStore::queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept { + try { + auto info = std::make_shared<ValidPathInfo>(); + info->path = path; + + assertStorePath(path); + + callback(retrySQLite<std::shared_ptr<ValidPathInfo>>([&]() { + auto state(_state.lock()); + + /* Get the path info. */ + auto useQueryPathInfo(state->stmtQueryPathInfo.use()(path)); + + if (!useQueryPathInfo.next()) { + return std::shared_ptr<ValidPathInfo>(); + } + + info->id = useQueryPathInfo.getInt(0); + + try { + info->narHash = Hash(useQueryPathInfo.getStr(1)); + } catch (BadHash& e) { + throw Error("in valid-path entry for '%s': %s", path, e.what()); + } + + info->registrationTime = useQueryPathInfo.getInt(2); + + auto s = (const char*)sqlite3_column_text(state->stmtQueryPathInfo, 3); + if (s != nullptr) { + info->deriver = s; + } + + /* Note that narSize = NULL yields 0. */ + info->narSize = useQueryPathInfo.getInt(4); + + info->ultimate = useQueryPathInfo.getInt(5) == 1; + + s = (const char*)sqlite3_column_text(state->stmtQueryPathInfo, 6); + if (s != nullptr) { + info->sigs = tokenizeString<StringSet>(s, " "); + } + + s = (const char*)sqlite3_column_text(state->stmtQueryPathInfo, 7); + if (s != nullptr) { + info->ca = s; + } + + /* Get the references. */ + auto useQueryReferences(state->stmtQueryReferences.use()(info->id)); + + while (useQueryReferences.next()) { + info->references.insert(useQueryReferences.getStr(0)); + } + + return info; + })); + + } catch (...) { + callback.rethrow(); + } +} + +/* Update path info in the database. */ +void LocalStore::updatePathInfo(State& state, const ValidPathInfo& info) { + state.stmtUpdatePathInfo + .use()(info.narSize, info.narSize != 0)(info.narHash.to_string(Base16))( + info.ultimate ? 1 : 0, info.ultimate)( + concatStringsSep(" ", info.sigs), !info.sigs.empty())( + info.ca, !info.ca.empty())(info.path) + .exec(); +} + +uint64_t LocalStore::queryValidPathId(State& state, const Path& path) { + auto use(state.stmtQueryPathInfo.use()(path)); + if (!use.next()) { + throw Error(format("path '%1%' is not valid") % path); + } + return use.getInt(0); +} + +bool LocalStore::isValidPath_(State& state, const Path& path) { + return state.stmtQueryPathInfo.use()(path).next(); +} + +bool LocalStore::isValidPathUncached(const Path& path) { + return retrySQLite<bool>([&]() { + auto state(_state.lock()); + return isValidPath_(*state, path); + }); +} + +PathSet LocalStore::queryValidPaths(const PathSet& paths, + SubstituteFlag maybeSubstitute) { + PathSet res; + for (auto& i : paths) { + if (isValidPath(i)) { + res.insert(i); + } + } + return res; +} + +PathSet LocalStore::queryAllValidPaths() { + return retrySQLite<PathSet>([&]() { + auto state(_state.lock()); + auto use(state->stmtQueryValidPaths.use()); + PathSet res; + while (use.next()) { + res.insert(use.getStr(0)); + } + return res; + }); +} + +void LocalStore::queryReferrers(State& state, const Path& path, + PathSet& referrers) { + auto useQueryReferrers(state.stmtQueryReferrers.use()(path)); + + while (useQueryReferrers.next()) { + referrers.insert(useQueryReferrers.getStr(0)); + } +} + +void LocalStore::queryReferrers(const Path& path, PathSet& referrers) { + assertStorePath(path); + return retrySQLite<void>([&]() { + auto state(_state.lock()); + queryReferrers(*state, path, referrers); + }); +} + +PathSet LocalStore::queryValidDerivers(const Path& path) { + assertStorePath(path); + + return retrySQLite<PathSet>([&]() { + auto state(_state.lock()); + + auto useQueryValidDerivers(state->stmtQueryValidDerivers.use()(path)); + + PathSet derivers; + while (useQueryValidDerivers.next()) { + derivers.insert(useQueryValidDerivers.getStr(1)); + } + + return derivers; + }); +} + +PathSet LocalStore::queryDerivationOutputs(const Path& path) { + return retrySQLite<PathSet>([&]() { + auto state(_state.lock()); + + auto useQueryDerivationOutputs(state->stmtQueryDerivationOutputs.use()( + queryValidPathId(*state, path))); + + PathSet outputs; + while (useQueryDerivationOutputs.next()) { + outputs.insert(useQueryDerivationOutputs.getStr(1)); + } + + return outputs; + }); +} + +StringSet LocalStore::queryDerivationOutputNames(const Path& path) { + return retrySQLite<StringSet>([&]() { + auto state(_state.lock()); + + auto useQueryDerivationOutputs(state->stmtQueryDerivationOutputs.use()( + queryValidPathId(*state, path))); + + StringSet outputNames; + while (useQueryDerivationOutputs.next()) { + outputNames.insert(useQueryDerivationOutputs.getStr(0)); + } + + return outputNames; + }); +} + +Path LocalStore::queryPathFromHashPart(const string& hashPart) { + if (hashPart.size() != storePathHashLen) { + throw Error("invalid hash part"); + } + + Path prefix = storeDir + "/" + hashPart; + + return retrySQLite<Path>([&]() -> std::string { + auto state(_state.lock()); + + auto useQueryPathFromHashPart( + state->stmtQueryPathFromHashPart.use()(prefix)); + + if (!useQueryPathFromHashPart.next()) { + return ""; + } + + const char* s = + (const char*)sqlite3_column_text(state->stmtQueryPathFromHashPart, 0); + return (s != nullptr) && + prefix.compare(0, prefix.size(), s, prefix.size()) == 0 + ? s + : ""; + }); +} + +PathSet LocalStore::querySubstitutablePaths(const PathSet& paths) { + if (!settings.useSubstitutes) { + return PathSet(); + } + + auto remaining = paths; + PathSet res; + + for (auto& sub : getDefaultSubstituters()) { + if (remaining.empty()) { + break; + } + if (sub->storeDir != storeDir) { + continue; + } + if (!sub->wantMassQuery()) { + continue; + } + + auto valid = sub->queryValidPaths(remaining); + + PathSet remaining2; + for (auto& path : remaining) { + if (valid.count(path) != 0u) { + res.insert(path); + } else { + remaining2.insert(path); + } + } + + std::swap(remaining, remaining2); + } + + return res; +} + +void LocalStore::querySubstitutablePathInfos(const PathSet& paths, + SubstitutablePathInfos& infos) { + if (!settings.useSubstitutes) { + return; + } + for (auto& sub : getDefaultSubstituters()) { + if (sub->storeDir != storeDir) { + continue; + } + for (auto& path : paths) { + if (infos.count(path) != 0u) { + continue; + } + DLOG(INFO) << "checking substituter '" << sub->getUri() << "' for path '" + << path << "'"; + try { + auto info = sub->queryPathInfo(path); + auto narInfo = std::dynamic_pointer_cast<const NarInfo>( + std::shared_ptr<const ValidPathInfo>(info)); + infos[path] = SubstitutablePathInfo{info->deriver, info->references, + narInfo ? narInfo->fileSize : 0, + info->narSize}; + } catch (InvalidPath&) { + } catch (SubstituterDisabled&) { + } catch (Error& e) { + if (settings.tryFallback) { + LOG(ERROR) << e.what(); + } else { + throw; + } + } + } + } +} + +void LocalStore::registerValidPath(const ValidPathInfo& info) { + ValidPathInfos infos; + infos.push_back(info); + registerValidPaths(infos); +} + +void LocalStore::registerValidPaths(const ValidPathInfos& infos) { + /* SQLite will fsync by default, but the new valid paths may not + be fsync-ed. So some may want to fsync them before registering + the validity, at the expense of some speed of the path + registering operation. */ + if (settings.syncBeforeRegistering) { + sync(); + } + + return retrySQLite<void>([&]() { + auto state(_state.lock()); + + SQLiteTxn txn(state->db); + PathSet paths; + + for (auto& i : infos) { + assert(i.narHash.type == htSHA256); + if (isValidPath_(*state, i.path)) { + updatePathInfo(*state, i); + } else { + addValidPath(*state, i, false); + } + paths.insert(i.path); + } + + for (auto& i : infos) { + auto referrer = queryValidPathId(*state, i.path); + for (auto& j : i.references) { + state->stmtAddReference.use()(referrer)(queryValidPathId(*state, j)) + .exec(); + } + } + + /* Check that the derivation outputs are correct. We can't do + this in addValidPath() above, because the references might + not be valid yet. */ + for (auto& i : infos) { + if (isDerivation(i.path)) { + // FIXME: inefficient; we already loaded the + // derivation in addValidPath(). + Derivation drv = + readDerivation(realStoreDir + "/" + baseNameOf(i.path)); + checkDerivationOutputs(i.path, drv); + } + } + + /* Do a topological sort of the paths. This will throw an + error if a cycle is detected and roll back the + transaction. Cycles can only occur when a derivation + has multiple outputs. */ + topoSortPaths(paths); + + txn.commit(); + }); +} + +/* Invalidate a path. The caller is responsible for checking that + there are no referrers. */ +void LocalStore::invalidatePath(State& state, const Path& path) { + LOG(INFO) << "invalidating path '" << path << "'"; + + state.stmtInvalidatePath.use()(path).exec(); + + /* Note that the foreign key constraints on the Refs table take + care of deleting the references entries for `path'. */ + + { + auto state_(Store::state.lock()); + state_->pathInfoCache.erase(storePathToHash(path)); + } +} + +const PublicKeys& LocalStore::getPublicKeys() { + auto state(_state.lock()); + if (!state->publicKeys) { + state->publicKeys = std::make_unique<PublicKeys>(getDefaultPublicKeys()); + } + return *state->publicKeys; +} + +void LocalStore::addToStore(const ValidPathInfo& info, Source& source, + RepairFlag repair, CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) { + if (!info.narHash) { + throw Error("cannot add path '%s' because it lacks a hash", info.path); + } + + if (requireSigs && (checkSigs != 0u) && + (info.checkSignatures(*this, getPublicKeys()) == 0u)) { + throw Error("cannot add path '%s' because it lacks a valid signature", + info.path); + } + + addTempRoot(info.path); + + if ((repair != 0u) || !isValidPath(info.path)) { + PathLocks outputLock; + + Path realPath = realStoreDir + "/" + baseNameOf(info.path); + + /* Lock the output path. But don't lock if we're being called + from a build hook (whose parent process already acquired a + lock on this path). */ + if (locksHeld.count(info.path) == 0u) { + outputLock.lockPaths({realPath}); + } + + if ((repair != 0u) || !isValidPath(info.path)) { + deletePath(realPath); + + /* While restoring the path from the NAR, compute the hash + of the NAR. */ + HashSink hashSink(htSHA256); + + LambdaSource wrapperSource( + [&](unsigned char* data, size_t len) -> size_t { + size_t n = source.read(data, len); + hashSink(data, n); + return n; + }); + + restorePath(realPath, wrapperSource); + + auto hashResult = hashSink.finish(); + + if (hashResult.first != info.narHash) { + throw Error( + "hash mismatch importing path '%s';\n wanted: %s\n got: %s", + info.path, info.narHash.to_string(), hashResult.first.to_string()); + } + + if (hashResult.second != info.narSize) { + throw Error( + "size mismatch importing path '%s';\n wanted: %s\n got: %s", + info.path, info.narSize, hashResult.second); + } + + autoGC(); + + canonicalisePathMetaData(realPath, -1); + + optimisePath(realPath); // FIXME: combine with hashPath() + + registerValidPath(info); + } + + outputLock.setDeletion(true); + } +} + +Path LocalStore::addToStoreFromDump(const string& dump, const string& name, + bool recursive, HashType hashAlgo, + RepairFlag repair) { + Hash h = hashString(hashAlgo, dump); + + Path dstPath = makeFixedOutputPath(recursive, h, name); + + addTempRoot(dstPath); + + if ((repair != 0u) || !isValidPath(dstPath)) { + /* The first check above is an optimisation to prevent + unnecessary lock acquisition. */ + + Path realPath = realStoreDir + "/" + baseNameOf(dstPath); + + PathLocks outputLock({realPath}); + + if ((repair != 0u) || !isValidPath(dstPath)) { + deletePath(realPath); + + autoGC(); + + if (recursive) { + StringSource source(dump); + restorePath(realPath, source); + } else { + writeFile(realPath, dump); + } + + canonicalisePathMetaData(realPath, -1); + + /* Register the SHA-256 hash of the NAR serialisation of + the path in the database. We may just have computed it + above (if called with recursive == true and hashAlgo == + sha256); otherwise, compute it here. */ + HashResult hash; + if (recursive) { + hash.first = hashAlgo == htSHA256 ? h : hashString(htSHA256, dump); + hash.second = dump.size(); + } else { + hash = hashPath(htSHA256, realPath); + } + + optimisePath(realPath); // FIXME: combine with hashPath() + + ValidPathInfo info; + info.path = dstPath; + info.narHash = hash.first; + info.narSize = hash.second; + info.ca = makeFixedOutputCA(recursive, h); + registerValidPath(info); + } + + outputLock.setDeletion(true); + } + + return dstPath; +} + +Path LocalStore::addToStore(const string& name, const Path& _srcPath, + bool recursive, HashType hashAlgo, + PathFilter& filter, RepairFlag repair) { + Path srcPath(absPath(_srcPath)); + + /* Read the whole path into memory. This is not a very scalable + method for very large paths, but `copyPath' is mainly used for + small files. */ + StringSink sink; + if (recursive) { + dumpPath(srcPath, sink, filter); + } else { + sink.s = make_ref<std::string>(readFile(srcPath)); + } + + return addToStoreFromDump(*sink.s, name, recursive, hashAlgo, repair); +} + +Path LocalStore::addTextToStore(const string& name, const string& s, + const PathSet& references, RepairFlag repair) { + auto hash = hashString(htSHA256, s); + auto dstPath = makeTextPath(name, hash, references); + + addTempRoot(dstPath); + + if ((repair != 0u) || !isValidPath(dstPath)) { + Path realPath = realStoreDir + "/" + baseNameOf(dstPath); + + PathLocks outputLock({realPath}); + + if ((repair != 0u) || !isValidPath(dstPath)) { + deletePath(realPath); + + autoGC(); + + writeFile(realPath, s); + + canonicalisePathMetaData(realPath, -1); + + StringSink sink; + dumpString(s, sink); + auto narHash = hashString(htSHA256, *sink.s); + + optimisePath(realPath); + + ValidPathInfo info; + info.path = dstPath; + info.narHash = narHash; + info.narSize = sink.s->size(); + info.references = references; + info.ca = "text:" + hash.to_string(); + registerValidPath(info); + } + + outputLock.setDeletion(true); + } + + return dstPath; +} + +/* Create a temporary directory in the store that won't be + garbage-collected. */ +Path LocalStore::createTempDirInStore() { + Path tmpDir; + do { + /* There is a slight possibility that `tmpDir' gets deleted by + the GC between createTempDir() and addTempRoot(), so repeat + until `tmpDir' exists. */ + tmpDir = createTempDir(realStoreDir); + addTempRoot(tmpDir); + } while (!pathExists(tmpDir)); + return tmpDir; +} + +void LocalStore::invalidatePathChecked(const Path& path) { + assertStorePath(path); + + retrySQLite<void>([&]() { + auto state(_state.lock()); + + SQLiteTxn txn(state->db); + + if (isValidPath_(*state, path)) { + PathSet referrers; + queryReferrers(*state, path, referrers); + referrers.erase(path); /* ignore self-references */ + if (!referrers.empty()) { + throw PathInUse( + format("cannot delete path '%1%' because it is in use by %2%") % + path % showPaths(referrers)); + } + invalidatePath(*state, path); + } + + txn.commit(); + }); +} + +bool LocalStore::verifyStore(bool checkContents, RepairFlag repair) { + LOG(INFO) << "reading the Nix store..."; + + bool errors = false; + + /* Acquire the global GC lock to get a consistent snapshot of + existing and valid paths. */ + AutoCloseFD fdGCLock = openGCLock(ltWrite); + + PathSet store; + for (auto& i : readDirectory(realStoreDir)) { + store.insert(i.name); + } + + /* Check whether all valid paths actually exist. */ + LOG(INFO) << "checking path existence..."; + + PathSet validPaths2 = queryAllValidPaths(); + PathSet validPaths; + PathSet done; + + fdGCLock = -1; + + for (auto& i : validPaths2) { + verifyPath(i, store, done, validPaths, repair, errors); + } + + /* Optionally, check the content hashes (slow). */ + if (checkContents) { + LOG(INFO) << "checking hashes..."; + + Hash nullHash(htSHA256); + + for (auto& i : validPaths) { + try { + auto info = std::const_pointer_cast<ValidPathInfo>( + std::shared_ptr<const ValidPathInfo>(queryPathInfo(i))); + + /* Check the content hash (optionally - slow). */ + DLOG(INFO) << "checking contents of '" << i << "'"; + HashResult current = hashPath(info->narHash.type, toRealPath(i)); + + if (info->narHash != nullHash && info->narHash != current.first) { + LOG(ERROR) << "path '" << i << "' was modified! expected hash '" + << info->narHash.to_string() << "', got '" + << current.first.to_string() << "'"; + if (repair != 0u) { + repairPath(i); + } else { + errors = true; + } + } else { + bool update = false; + + /* Fill in missing hashes. */ + if (info->narHash == nullHash) { + LOG(WARNING) << "fixing missing hash on '" << i << "'"; + info->narHash = current.first; + update = true; + } + + /* Fill in missing narSize fields (from old stores). */ + if (info->narSize == 0) { + LOG(ERROR) << "updating size field on '" << i << "' to " + << current.second; + info->narSize = current.second; + update = true; + } + + if (update) { + auto state(_state.lock()); + updatePathInfo(*state, *info); + } + } + + } catch (Error& e) { + /* It's possible that the path got GC'ed, so ignore + errors on invalid paths. */ + if (isValidPath(i)) { + LOG(ERROR) << e.msg(); + } else { + LOG(WARNING) << e.msg(); + } + errors = true; + } + } + } + + return errors; +} + +void LocalStore::verifyPath(const Path& path, const PathSet& store, + PathSet& done, PathSet& validPaths, + RepairFlag repair, bool& errors) { + checkInterrupt(); + + if (done.find(path) != done.end()) { + return; + } + done.insert(path); + + if (!isStorePath(path)) { + LOG(ERROR) << "path '" << path << "' is not in the Nix store"; + auto state(_state.lock()); + invalidatePath(*state, path); + return; + } + + if (store.find(baseNameOf(path)) == store.end()) { + /* Check any referrers first. If we can invalidate them + first, then we can invalidate this path as well. */ + bool canInvalidate = true; + PathSet referrers; + queryReferrers(path, referrers); + for (auto& i : referrers) { + if (i != path) { + verifyPath(i, store, done, validPaths, repair, errors); + if (validPaths.find(i) != validPaths.end()) { + canInvalidate = false; + } + } + } + + if (canInvalidate) { + LOG(WARNING) << "path '" << path + << "' disappeared, removing from database..."; + auto state(_state.lock()); + invalidatePath(*state, path); + } else { + LOG(ERROR) << "path '" << path + << "' disappeared, but it still has valid referrers!"; + if (repair != 0u) { + try { + repairPath(path); + } catch (Error& e) { + LOG(WARNING) << e.msg(); + errors = true; + } + } else { + errors = true; + } + } + + return; + } + + validPaths.insert(path); +} + +unsigned int LocalStore::getProtocol() { return PROTOCOL_VERSION; } + +#if defined(FS_IOC_SETFLAGS) && defined(FS_IOC_GETFLAGS) && \ + defined(FS_IMMUTABLE_FL) + +static void makeMutable(const Path& path) { + checkInterrupt(); + + struct stat st = lstat(path); + + if (!S_ISDIR(st.st_mode) && !S_ISREG(st.st_mode)) { + return; + } + + if (S_ISDIR(st.st_mode)) { + for (auto& i : readDirectory(path)) { + makeMutable(path + "/" + i.name); + } + } + + /* The O_NOFOLLOW is important to prevent us from changing the + mutable bit on the target of a symlink (which would be a + security hole). */ + AutoCloseFD fd = open(path.c_str(), O_RDONLY | O_NOFOLLOW | O_CLOEXEC); + if (fd == -1) { + if (errno == ELOOP) { + return; + } // it's a symlink + throw SysError(format("opening file '%1%'") % path); + } + + unsigned int flags = 0, old; + + /* Silently ignore errors getting/setting the immutable flag so + that we work correctly on filesystems that don't support it. */ + if (ioctl(fd, FS_IOC_GETFLAGS, &flags)) { + return; + } + old = flags; + flags &= ~FS_IMMUTABLE_FL; + if (old == flags) { + return; + } + if (ioctl(fd, FS_IOC_SETFLAGS, &flags)) { + return; + } +} + +/* Upgrade from schema 6 (Nix 0.15) to schema 7 (Nix >= 1.3). */ +void LocalStore::upgradeStore7() { + if (getuid() != 0) { + return; + } + printError( + "removing immutable bits from the Nix store (this may take a while)..."); + makeMutable(realStoreDir); +} + +#else + +void LocalStore::upgradeStore7() {} + +#endif + +void LocalStore::vacuumDB() { + auto state(_state.lock()); + state->db.exec("vacuum"); +} + +void LocalStore::addSignatures(const Path& storePath, const StringSet& sigs) { + retrySQLite<void>([&]() { + auto state(_state.lock()); + + SQLiteTxn txn(state->db); + + auto info = std::const_pointer_cast<ValidPathInfo>( + std::shared_ptr<const ValidPathInfo>(queryPathInfo(storePath))); + + info->sigs.insert(sigs.begin(), sigs.end()); + + updatePathInfo(*state, *info); + + txn.commit(); + }); +} + +void LocalStore::signPathInfo(ValidPathInfo& info) { + // FIXME: keep secret keys in memory. + + auto secretKeyFiles = settings.secretKeyFiles; + + for (auto& secretKeyFile : secretKeyFiles.get()) { + SecretKey secretKey(readFile(secretKeyFile)); + info.sign(secretKey); + } +} + +void LocalStore::createUser(const std::string& userName, uid_t userId) { + for (auto& dir : {fmt("%s/profiles/per-user/%s", stateDir, userName), + fmt("%s/gcroots/per-user/%s", stateDir, userName)}) { + createDirs(dir); + if (chmod(dir.c_str(), 0755) == -1) { + throw SysError("changing permissions of directory '%s'", dir); + } + if (chown(dir.c_str(), userId, getgid()) == -1) { + throw SysError("changing owner of directory '%s'", dir); + } + } +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/local-store.hh b/third_party/nix/src/libstore/local-store.hh new file mode 100644 index 0000000000..1a58df8161 --- /dev/null +++ b/third_party/nix/src/libstore/local-store.hh @@ -0,0 +1,311 @@ +#pragma once + +#include <chrono> +#include <future> +#include <string> +#include <unordered_set> + +#include "pathlocks.hh" +#include "sqlite.hh" +#include "store-api.hh" +#include "sync.hh" +#include "util.hh" + +namespace nix { + +/* Nix store and database schema version. Version 1 (or 0) was Nix <= + 0.7. Version 2 was Nix 0.8 and 0.9. Version 3 is Nix 0.10. + Version 4 is Nix 0.11. Version 5 is Nix 0.12-0.16. Version 6 is + Nix 1.0. Version 7 is Nix 1.3. Version 10 is 2.0. */ +const int nixSchemaVersion = 10; + +struct Derivation; + +struct OptimiseStats { + unsigned long filesLinked = 0; + unsigned long long bytesFreed = 0; + unsigned long long blocksFreed = 0; +}; + +class LocalStore : public LocalFSStore { + private: + /* Lock file used for upgrading. */ + AutoCloseFD globalLock; + + struct State { + /* The SQLite database object. */ + SQLite db; + + /* Some precompiled SQLite statements. */ + SQLiteStmt stmtRegisterValidPath; + SQLiteStmt stmtUpdatePathInfo; + SQLiteStmt stmtAddReference; + SQLiteStmt stmtQueryPathInfo; + SQLiteStmt stmtQueryReferences; + SQLiteStmt stmtQueryReferrers; + SQLiteStmt stmtInvalidatePath; + SQLiteStmt stmtAddDerivationOutput; + SQLiteStmt stmtQueryValidDerivers; + SQLiteStmt stmtQueryDerivationOutputs; + SQLiteStmt stmtQueryPathFromHashPart; + SQLiteStmt stmtQueryValidPaths; + + /* The file to which we write our temporary roots. */ + AutoCloseFD fdTempRoots; + + /* The last time we checked whether to do an auto-GC, or an + auto-GC finished. */ + std::chrono::time_point<std::chrono::steady_clock> lastGCCheck; + + /* Whether auto-GC is running. If so, get gcFuture to wait for + the GC to finish. */ + bool gcRunning = false; + std::shared_future<void> gcFuture; + + /* How much disk space was available after the previous + auto-GC. If the current available disk space is below + minFree but not much below availAfterGC, then there is no + point in starting a new GC. */ + uint64_t availAfterGC = std::numeric_limits<uint64_t>::max(); + + std::unique_ptr<PublicKeys> publicKeys; + }; + + Sync<State, std::recursive_mutex> _state; + + public: + PathSetting realStoreDir_; + + const Path realStoreDir; + const Path dbDir; + const Path linksDir; + const Path reservedPath; + const Path schemaPath; + const Path trashDir; + const Path tempRootsDir; + const Path fnTempRoots; + + private: + Setting<bool> requireSigs{ + (Store*)this, settings.requireSigs, "require-sigs", + "whether store paths should have a trusted signature on import"}; + + const PublicKeys& getPublicKeys(); + + public: + // Hack for build-remote.cc. + PathSet locksHeld = tokenizeString<PathSet>(getEnv("NIX_HELD_LOCKS")); + + /* Initialise the local store, upgrading the schema if + necessary. */ + LocalStore(const Params& params); + + ~LocalStore(); + + /* Implementations of abstract store API methods. */ + + std::string getUri() override; + + bool isValidPathUncached(const Path& path) override; + + PathSet queryValidPaths(const PathSet& paths, SubstituteFlag maybeSubstitute = + NoSubstitute) override; + + PathSet queryAllValidPaths() override; + + void queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept override; + + void queryReferrers(const Path& path, PathSet& referrers) override; + + PathSet queryValidDerivers(const Path& path) override; + + PathSet queryDerivationOutputs(const Path& path) override; + + StringSet queryDerivationOutputNames(const Path& path) override; + + Path queryPathFromHashPart(const string& hashPart) override; + + PathSet querySubstitutablePaths(const PathSet& paths) override; + + void querySubstitutablePathInfos(const PathSet& paths, + SubstitutablePathInfos& infos) override; + + void addToStore(const ValidPathInfo& info, Source& source, RepairFlag repair, + CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) override; + + Path addToStore(const string& name, const Path& srcPath, bool recursive, + HashType hashAlgo, PathFilter& filter, + RepairFlag repair) override; + + /* Like addToStore(), but the contents of the path are contained + in `dump', which is either a NAR serialisation (if recursive == + true) or simply the contents of a regular file (if recursive == + false). */ + Path addToStoreFromDump(const string& dump, const string& name, + bool recursive = true, HashType hashAlgo = htSHA256, + RepairFlag repair = NoRepair); + + Path addTextToStore(const string& name, const string& s, + const PathSet& references, RepairFlag repair) override; + + void buildPaths(const PathSet& paths, BuildMode buildMode) override; + + BuildResult buildDerivation(const Path& drvPath, const BasicDerivation& drv, + BuildMode buildMode) override; + + void ensurePath(const Path& path) override; + + void addTempRoot(const Path& path) override; + + void addIndirectRoot(const Path& path) override; + + void syncWithGC() override; + + private: + typedef std::shared_ptr<AutoCloseFD> FDPtr; + typedef list<FDPtr> FDs; + + void findTempRoots(FDs& fds, Roots& roots, bool censor); + + public: + Roots findRoots(bool censor) override; + + void collectGarbage(const GCOptions& options, GCResults& results) override; + + /* Optimise the disk space usage of the Nix store by hard-linking + files with the same contents. */ + void optimiseStore(OptimiseStats& stats); + + void optimiseStore() override; + + /* Optimise a single store path. */ + void optimisePath(const Path& path); + + bool verifyStore(bool checkContents, RepairFlag repair) override; + + /* Register the validity of a path, i.e., that `path' exists, that + the paths referenced by it exists, and in the case of an output + path of a derivation, that it has been produced by a successful + execution of the derivation (or something equivalent). Also + register the hash of the file system contents of the path. The + hash must be a SHA-256 hash. */ + void registerValidPath(const ValidPathInfo& info); + + void registerValidPaths(const ValidPathInfos& infos); + + unsigned int getProtocol() override; + + void vacuumDB(); + + /* Repair the contents of the given path by redownloading it using + a substituter (if available). */ + void repairPath(const Path& path); + + void addSignatures(const Path& storePath, const StringSet& sigs) override; + + /* If free disk space in /nix/store if below minFree, delete + garbage until it exceeds maxFree. */ + void autoGC(bool sync = true); + + private: + int getSchema(); + + void openDB(State& state, bool create); + + void makeStoreWritable(); + + static uint64_t queryValidPathId(State& state, const Path& path); + + uint64_t addValidPath(State& state, const ValidPathInfo& info, + bool checkOutputs = true); + + void invalidatePath(State& state, const Path& path); + + /* Delete a path from the Nix store. */ + void invalidatePathChecked(const Path& path); + + void verifyPath(const Path& path, const PathSet& store, PathSet& done, + PathSet& validPaths, RepairFlag repair, bool& errors); + + static void updatePathInfo(State& state, const ValidPathInfo& info); + + void upgradeStore6(); + void upgradeStore7(); + PathSet queryValidPathsOld(); + ValidPathInfo queryPathInfoOld(const Path& path); + + struct GCState; + + static void deleteGarbage(GCState& state, const Path& path); + + void tryToDelete(GCState& state, const Path& path); + + bool canReachRoot(GCState& state, PathSet& visited, const Path& path); + + void deletePathRecursive(GCState& state, const Path& path); + + static bool isActiveTempFile(const GCState& state, const Path& path, + const string& suffix); + + AutoCloseFD openGCLock(LockType lockType); + + void findRoots(const Path& path, unsigned char type, Roots& roots); + + void findRootsNoTemp(Roots& roots, bool censor); + + void findRuntimeRoots(Roots& roots, bool censor); + + void removeUnusedLinks(const GCState& state); + + Path createTempDirInStore(); + + void checkDerivationOutputs(const Path& drvPath, const Derivation& drv); + + typedef std::unordered_set<ino_t> InodeHash; + + InodeHash loadInodeHash(); + static Strings readDirectoryIgnoringInodes(const Path& path, + const InodeHash& inodeHash); + void optimisePath_(OptimiseStats& stats, const Path& path, + InodeHash& inodeHash); + + // Internal versions that are not wrapped in retry_sqlite. + static bool isValidPath_(State& state, const Path& path); + static void queryReferrers(State& state, const Path& path, + PathSet& referrers); + + /* Add signatures to a ValidPathInfo using the secret keys + specified by the ‘secret-key-files’ option. */ + static void signPathInfo(ValidPathInfo& info); + + Path getRealStoreDir() override { return realStoreDir; } + + void createUser(const std::string& userName, uid_t userId) override; + + friend class DerivationGoal; + friend class SubstitutionGoal; +}; + +typedef std::pair<dev_t, ino_t> Inode; +typedef set<Inode> InodesSeen; + +/* "Fix", or canonicalise, the meta-data of the files in a store path + after it has been built. In particular: + - the last modification date on each file is set to 1 (i.e., + 00:00:01 1/1/1970 UTC) + - the permissions are set of 444 or 555 (i.e., read-only with or + without execute permission; setuid bits etc. are cleared) + - the owner and group are set to the Nix user and group, if we're + running as root. */ +void canonicalisePathMetaData(const Path& path, uid_t fromUid, + InodesSeen& inodesSeen); +void canonicalisePathMetaData(const Path& path, uid_t fromUid); + +void canonicaliseTimestampAndPermissions(const Path& path); + +MakeError(PathInUse, Error); + +} // namespace nix diff --git a/third_party/nix/src/libstore/machines.cc b/third_party/nix/src/libstore/machines.cc new file mode 100644 index 0000000000..5b0c7e72dd --- /dev/null +++ b/third_party/nix/src/libstore/machines.cc @@ -0,0 +1,103 @@ +#include "machines.hh" + +#include <algorithm> + +#include <glog/logging.h> + +#include "globals.hh" +#include "util.hh" + +namespace nix { + +Machine::Machine(decltype(storeUri)& storeUri, + decltype(systemTypes)& systemTypes, decltype(sshKey)& sshKey, + decltype(maxJobs) maxJobs, decltype(speedFactor) speedFactor, + decltype(supportedFeatures)& supportedFeatures, + decltype(mandatoryFeatures)& mandatoryFeatures, + decltype(sshPublicHostKey)& sshPublicHostKey) + : storeUri( + // Backwards compatibility: if the URI is a hostname, + // prepend ssh://. + storeUri.find("://") != std::string::npos || + hasPrefix(storeUri, "local") || + hasPrefix(storeUri, "remote") || + hasPrefix(storeUri, "auto") || hasPrefix(storeUri, "/") + ? storeUri + : "ssh://" + storeUri), + systemTypes(systemTypes), + sshKey(sshKey), + maxJobs(maxJobs), + speedFactor(std::max(1U, speedFactor)), + supportedFeatures(supportedFeatures), + mandatoryFeatures(mandatoryFeatures), + sshPublicHostKey(sshPublicHostKey) {} + +bool Machine::allSupported(const std::set<string>& features) const { + return std::all_of(features.begin(), features.end(), + [&](const string& feature) { + return (supportedFeatures.count(feature) != 0u) || + (mandatoryFeatures.count(feature) != 0u); + }); +} + +bool Machine::mandatoryMet(const std::set<string>& features) const { + return std::all_of( + mandatoryFeatures.begin(), mandatoryFeatures.end(), + [&](const string& feature) { return features.count(feature); }); +} + +void parseMachines(const std::string& s, Machines& machines) { + for (auto line : tokenizeString<std::vector<string>>(s, "\n;")) { + trim(line); + line.erase(std::find(line.begin(), line.end(), '#'), line.end()); + if (line.empty()) { + continue; + } + + if (line[0] == '@') { + auto file = trim(std::string(line, 1)); + try { + parseMachines(readFile(file), machines); + } catch (const SysError& e) { + if (e.errNo != ENOENT) { + throw; + } + DLOG(INFO) << "cannot find machines file: " << file; + } + continue; + } + + auto tokens = tokenizeString<std::vector<string>>(line); + auto sz = tokens.size(); + if (sz < 1) { + throw FormatError("bad machine specification '%s'", line); + } + + auto isSet = [&](size_t n) { + return tokens.size() > n && !tokens[n].empty() && tokens[n] != "-"; + }; + + machines.emplace_back( + tokens[0], + isSet(1) ? tokenizeString<std::vector<string>>(tokens[1], ",") + : std::vector<string>{settings.thisSystem}, + isSet(2) ? tokens[2] : "", isSet(3) ? std::stoull(tokens[3]) : 1LL, + isSet(4) ? std::stoull(tokens[4]) : 1LL, + isSet(5) ? tokenizeString<std::set<string>>(tokens[5], ",") + : std::set<string>{}, + isSet(6) ? tokenizeString<std::set<string>>(tokens[6], ",") + : std::set<string>{}, + isSet(7) ? tokens[7] : ""); + } +} + +Machines getMachines() { + static auto machines = [&]() { + Machines machines; + parseMachines(settings.builders, machines); + return machines; + }(); + return machines; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/machines.hh b/third_party/nix/src/libstore/machines.hh new file mode 100644 index 0000000000..aef8054c25 --- /dev/null +++ b/third_party/nix/src/libstore/machines.hh @@ -0,0 +1,36 @@ +#pragma once + +#include "types.hh" + +namespace nix { + +struct Machine { + const string storeUri; + const std::vector<string> systemTypes; + const string sshKey; + const unsigned int maxJobs; + const unsigned int speedFactor; + const std::set<string> supportedFeatures; + const std::set<string> mandatoryFeatures; + const std::string sshPublicHostKey; + bool enabled = true; + + bool allSupported(const std::set<string>& features) const; + + bool mandatoryMet(const std::set<string>& features) const; + + Machine(decltype(storeUri)& storeUri, decltype(systemTypes)& systemTypes, + decltype(sshKey)& sshKey, decltype(maxJobs) maxJobs, + decltype(speedFactor) speedFactor, + decltype(supportedFeatures)& supportedFeatures, + decltype(mandatoryFeatures)& mandatoryFeatures, + decltype(sshPublicHostKey)& sshPublicHostKey); +}; + +typedef std::vector<Machine> Machines; + +void parseMachines(const std::string& s, Machines& machines); + +Machines getMachines(); + +} // namespace nix diff --git a/third_party/nix/src/libstore/meson.build b/third_party/nix/src/libstore/meson.build new file mode 100644 index 0000000000..47f6ddf259 --- /dev/null +++ b/third_party/nix/src/libstore/meson.build @@ -0,0 +1,153 @@ +# Nix lib store build file +#============================================================================ + +src_inc += include_directories('.') + +libstore_src = files( + join_paths(meson.source_root(), 'src/libstore/binary-cache-store.cc'), + join_paths(meson.source_root(), 'src/libstore/build.cc'), + join_paths(meson.source_root(), 'src/libstore/crypto.cc'), + join_paths(meson.source_root(), 'src/libstore/derivations.cc'), + join_paths(meson.source_root(), 'src/libstore/download.cc'), + join_paths(meson.source_root(), 'src/libstore/export-import.cc'), + join_paths(meson.source_root(), 'src/libstore/gc.cc'), + join_paths(meson.source_root(), 'src/libstore/globals.cc'), + join_paths(meson.source_root(), 'src/libstore/http-binary-cache-store.cc'), + join_paths(meson.source_root(), 'src/libstore/legacy-ssh-store.cc'), + join_paths(meson.source_root(), 'src/libstore/local-binary-cache-store.cc'), + join_paths(meson.source_root(), 'src/libstore/local-fs-store.cc'), + join_paths(meson.source_root(), 'src/libstore/local-store.cc'), + join_paths(meson.source_root(), 'src/libstore/machines.cc'), + join_paths(meson.source_root(), 'src/libstore/misc.cc'), + join_paths(meson.source_root(), 'src/libstore/nar-accessor.cc'), + join_paths(meson.source_root(), 'src/libstore/nar-info.cc'), + join_paths(meson.source_root(), 'src/libstore/nar-info-disk-cache.cc'), + join_paths(meson.source_root(), 'src/libstore/optimise-store.cc'), + join_paths(meson.source_root(), 'src/libstore/parsed-derivations.cc'), + join_paths(meson.source_root(), 'src/libstore/pathlocks.cc'), + join_paths(meson.source_root(), 'src/libstore/profiles.cc'), + join_paths(meson.source_root(), 'src/libstore/references.cc'), + join_paths(meson.source_root(), 'src/libstore/remote-fs-accessor.cc'), + join_paths(meson.source_root(), 'src/libstore/remote-store.cc'), + join_paths(meson.source_root(), 'src/libstore/s3-binary-cache-store.cc'), + join_paths(meson.source_root(), 'src/libstore/sqlite.cc'), + join_paths(meson.source_root(), 'src/libstore/ssh.cc'), + join_paths(meson.source_root(), 'src/libstore/ssh-store.cc'), + join_paths(meson.source_root(), 'src/libstore/store-api.cc'), + join_paths(meson.source_root(), 'src/libstore/builtins/buildenv.cc'), + join_paths(meson.source_root(), 'src/libstore/builtins/fetchurl.cc')) + +libstore_headers = files( + join_paths(meson.source_root(), 'src/libstore/binary-cache-store.hh'), + join_paths(meson.source_root(), 'src/libstore/builtins.hh'), + join_paths(meson.source_root(), 'src/libstore/crypto.hh'), + join_paths(meson.source_root(), 'src/libstore/derivations.hh'), + join_paths(meson.source_root(), 'src/libstore/download.hh'), + join_paths(meson.source_root(), 'src/libstore/fs-accessor.hh'), + join_paths(meson.source_root(), 'src/libstore/globals.hh'), + join_paths(meson.source_root(), 'src/libstore/local-store.hh'), + join_paths(meson.source_root(), 'src/libstore/machines.hh'), + join_paths(meson.source_root(), 'src/libstore/nar-accessor.hh'), + join_paths(meson.source_root(), 'src/libstore/nar-info-disk-cache.hh'), + join_paths(meson.source_root(), 'src/libstore/nar-info.hh'), + join_paths(meson.source_root(), 'src/libstore/parsed-derivations.hh'), + join_paths(meson.source_root(), 'src/libstore/pathlocks.hh'), + join_paths(meson.source_root(), 'src/libstore/profiles.hh'), + join_paths(meson.source_root(), 'src/libstore/references.hh'), + join_paths(meson.source_root(), 'src/libstore/remote-fs-accessor.hh'), + join_paths(meson.source_root(), 'src/libstore/remote-store.hh'), + join_paths(meson.source_root(), 'src/libstore/s3-binary-cache-store.hh'), + join_paths(meson.source_root(), 'src/libstore/s3.hh'), + join_paths(meson.source_root(), 'src/libstore/serve-protocol.hh'), + join_paths(meson.source_root(), 'src/libstore/sqlite.hh'), + join_paths(meson.source_root(), 'src/libstore/ssh.hh'), + join_paths(meson.source_root(), 'src/libstore/store-api.hh'), + join_paths(meson.source_root(), 'src/libstore/worker-protocol.hh')) + +libstore_data = files( + join_paths(meson.source_root(), 'src/libstore/sandbox-defaults.sb'), + join_paths(meson.source_root(), 'src/libstore/sandbox-minimal.sb'), + join_paths(meson.source_root(), 'src/libstore/sandbox-network.sb')) + +# dependancies +#============================================================================ + +libstore_dep_list = [ + glog_dep, + libbz2_dep, + libcurl_dep, + libdl_dep, + pthread_dep, + sqlite3_dep, + libsodium_dep +] + +if sys_name.contains('linux') + libstore_dep_list += libseccomp_dep +endif + +if sys_name.contains('freebsd') + libstore_dep_list += libdl_dep +endif + +# Link args +#============================================================================ + +libstore_link_list = [ + libutil_lib] + +libstore_link_args = [] + +# compiler args +#============================================================================ + +libstore_cxx_args = [ + '-DNIX_PREFIX="@0@" '.format(prefix), + '-DNIX_STORE_DIR="@0@" '.format(nixstoredir), + '-DNIX_DATA_DIR="@0@" '.format(datadir), + '-DNIX_STATE_DIR="@0@" '.format(join_paths(localstatedir, 'nix')), + '-DNIX_LOG_DIR="@0@" '.format(join_paths(localstatedir, 'log/nix')), + '-DNIX_CONF_DIR="@0@" '.format(join_paths(sysconfdir, 'nix')), + '-DNIX_LIBEXEC_DIR="@0@" '.format(libexecdir), + '-DNIX_BIN_DIR="@0@" '.format(bindir), + '-DNIX_MAN_DIR="@0@" '.format(mandir), + '-DSANDBOX_SHELL="@0@" '.format(get_option('sandbox_shell')), + '-DLSOF="@0@" '.format(lsof)] + +# targets +#============================================================================ + +gen_header = ''' + echo 'R"foo(' >> "$1" + cat @INPUT@ >> "$1" + echo ')foo"' >> "$1" +''' + +libstore_src += custom_target( + 'schema.sql.gen.hh', + output : 'schema.sql.gen.hh', + input : 'schema.sql', + command : [bash, '-c', gen_header, 'sh', '@OUTPUT@']) + +# build +#============================================================================ + +libstore_lib = library( + 'nixstore', + install : true, + install_mode : 'rwxr-xr-x', + install_dir : libdir, + include_directories : src_inc, + link_with : libstore_link_list, + sources : libstore_src, + cpp_args : libstore_cxx_args, + link_args : libstore_link_args, + dependencies : libstore_dep_list) + +install_headers( + libstore_headers, + install_dir : join_paths(includedir, 'nix')) + +install_data( + libstore_data, + install_dir : join_paths(datadir, 'nix/sandbox')) diff --git a/third_party/nix/src/libstore/misc.cc b/third_party/nix/src/libstore/misc.cc new file mode 100644 index 0000000000..f95c4bec8b --- /dev/null +++ b/third_party/nix/src/libstore/misc.cc @@ -0,0 +1,329 @@ +#include <glog/logging.h> + +#include "derivations.hh" +#include "globals.hh" +#include "local-store.hh" +#include "parsed-derivations.hh" +#include "store-api.hh" +#include "thread-pool.hh" + +namespace nix { + +void Store::computeFSClosure(const PathSet& startPaths, PathSet& paths_, + bool flipDirection, bool includeOutputs, + bool includeDerivers) { + struct State { + size_t pending; + PathSet& paths; + std::exception_ptr exc; + }; + + Sync<State> state_(State{0, paths_, nullptr}); + + std::function<void(const Path&)> enqueue; + + std::condition_variable done; + + enqueue = [&](const Path& path) -> void { + { + auto state(state_.lock()); + if (state->exc) { + return; + } + if (state->paths.count(path) != 0u) { + return; + } + state->paths.insert(path); + state->pending++; + } + + queryPathInfo( + path, {[&, path](std::future<ref<ValidPathInfo>> fut) { + // FIXME: calls to isValidPath() should be async + + try { + auto info = fut.get(); + + if (flipDirection) { + PathSet referrers; + queryReferrers(path, referrers); + for (auto& ref : referrers) { + if (ref != path) { + enqueue(ref); + } + } + + if (includeOutputs) { + for (auto& i : queryValidDerivers(path)) { + enqueue(i); + } + } + + if (includeDerivers && isDerivation(path)) { + for (auto& i : queryDerivationOutputs(path)) { + if (isValidPath(i) && queryPathInfo(i)->deriver == path) { + enqueue(i); + } + } + } + + } else { + for (auto& ref : info->references) { + if (ref != path) { + enqueue(ref); + } + } + + if (includeOutputs && isDerivation(path)) { + for (auto& i : queryDerivationOutputs(path)) { + if (isValidPath(i)) { + enqueue(i); + } + } + } + + if (includeDerivers && isValidPath(info->deriver)) { + enqueue(info->deriver); + } + } + + { + auto state(state_.lock()); + assert(state->pending); + if (--state->pending == 0u) { + done.notify_one(); + } + } + + } catch (...) { + auto state(state_.lock()); + if (!state->exc) { + state->exc = std::current_exception(); + } + assert(state->pending); + if (--state->pending == 0u) { + done.notify_one(); + } + }; + }}); + }; + + for (auto& startPath : startPaths) { + enqueue(startPath); + } + + { + auto state(state_.lock()); + while (state->pending != 0u) { + state.wait(done); + } + if (state->exc) { + std::rethrow_exception(state->exc); + } + } +} + +void Store::computeFSClosure(const Path& startPath, PathSet& paths_, + bool flipDirection, bool includeOutputs, + bool includeDerivers) { + computeFSClosure(PathSet{startPath}, paths_, flipDirection, includeOutputs, + includeDerivers); +} + +void Store::queryMissing(const PathSet& targets, PathSet& willBuild_, + PathSet& willSubstitute_, PathSet& unknown_, + unsigned long long& downloadSize_, + unsigned long long& narSize_) { + LOG(INFO) << "querying info about missing paths"; + + downloadSize_ = narSize_ = 0; + + ThreadPool pool; + + struct State { + PathSet done; + PathSet &unknown, &willSubstitute, &willBuild; + unsigned long long& downloadSize; + unsigned long long& narSize; + }; + + struct DrvState { + size_t left; + bool done = false; + PathSet outPaths; + explicit DrvState(size_t left) : left(left) {} + }; + + Sync<State> state_(State{PathSet(), unknown_, willSubstitute_, willBuild_, + downloadSize_, narSize_}); + + std::function<void(Path)> doPath; + + auto mustBuildDrv = [&](const Path& drvPath, const Derivation& drv) { + { + auto state(state_.lock()); + state->willBuild.insert(drvPath); + } + + for (auto& i : drv.inputDrvs) { + pool.enqueue( + std::bind(doPath, makeDrvPathWithOutputs(i.first, i.second))); + } + }; + + auto checkOutput = [&](const Path& drvPath, const ref<Derivation>& drv, + const Path& outPath, + const ref<Sync<DrvState>>& drvState_) { + if (drvState_->lock()->done) { + return; + } + + SubstitutablePathInfos infos; + querySubstitutablePathInfos({outPath}, infos); + + if (infos.empty()) { + drvState_->lock()->done = true; + mustBuildDrv(drvPath, *drv); + } else { + { + auto drvState(drvState_->lock()); + if (drvState->done) { + return; + } + assert(drvState->left); + drvState->left--; + drvState->outPaths.insert(outPath); + if (drvState->left == 0u) { + for (auto& path : drvState->outPaths) { + pool.enqueue(std::bind(doPath, path)); + } + } + } + } + }; + + doPath = [&](const Path& path) { + { + auto state(state_.lock()); + if (state->done.count(path) != 0u) { + return; + } + state->done.insert(path); + } + + DrvPathWithOutputs i2 = parseDrvPathWithOutputs(path); + + if (isDerivation(i2.first)) { + if (!isValidPath(i2.first)) { + // FIXME: we could try to substitute the derivation. + auto state(state_.lock()); + state->unknown.insert(path); + return; + } + + Derivation drv = derivationFromPath(i2.first); + ParsedDerivation parsedDrv(i2.first, drv); + + PathSet invalid; + for (auto& j : drv.outputs) { + if (wantOutput(j.first, i2.second) && !isValidPath(j.second.path)) { + invalid.insert(j.second.path); + } + } + if (invalid.empty()) { + return; + } + + if (settings.useSubstitutes && parsedDrv.substitutesAllowed()) { + auto drvState = make_ref<Sync<DrvState>>(DrvState(invalid.size())); + for (auto& output : invalid) { + pool.enqueue(std::bind(checkOutput, i2.first, + make_ref<Derivation>(drv), output, drvState)); + } + } else { + mustBuildDrv(i2.first, drv); + } + + } else { + if (isValidPath(path)) { + return; + } + + SubstitutablePathInfos infos; + querySubstitutablePathInfos({path}, infos); + + if (infos.empty()) { + auto state(state_.lock()); + state->unknown.insert(path); + return; + } + + auto info = infos.find(path); + assert(info != infos.end()); + + { + auto state(state_.lock()); + state->willSubstitute.insert(path); + state->downloadSize += info->second.downloadSize; + state->narSize += info->second.narSize; + } + + for (auto& ref : info->second.references) { + pool.enqueue(std::bind(doPath, ref)); + } + } + }; + + for (auto& path : targets) { + pool.enqueue(std::bind(doPath, path)); + } + + pool.process(); +} + +Paths Store::topoSortPaths(const PathSet& paths) { + Paths sorted; + PathSet visited; + PathSet parents; + + std::function<void(const Path& path, const Path* parent)> dfsVisit; + + dfsVisit = [&](const Path& path, const Path* parent) { + if (parents.find(path) != parents.end()) { + throw BuildError( + format("cycle detected in the references of '%1%' from '%2%'") % + path % *parent); + } + + if (visited.find(path) != visited.end()) { + return; + } + visited.insert(path); + parents.insert(path); + + PathSet references; + try { + references = queryPathInfo(path)->references; + } catch (InvalidPath&) { + } + + for (auto& i : references) { + /* Don't traverse into paths that don't exist. That can + happen due to substitutes for non-existent paths. */ + if (i != path && paths.find(i) != paths.end()) { + dfsVisit(i, &path); + } + } + + sorted.push_front(path); + parents.erase(path); + }; + + for (auto& i : paths) { + dfsVisit(i, nullptr); + } + + return sorted; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/nar-accessor.cc b/third_party/nix/src/libstore/nar-accessor.cc new file mode 100644 index 0000000000..7f6e0377ae --- /dev/null +++ b/third_party/nix/src/libstore/nar-accessor.cc @@ -0,0 +1,268 @@ +#include "nar-accessor.hh" + +#include <algorithm> +#include <map> +#include <nlohmann/json.hpp> +#include <stack> +#include <utility> + +#include "archive.hh" +#include "json.hh" + +namespace nix { + +struct NarMember { + FSAccessor::Type type = FSAccessor::Type::tMissing; + + bool isExecutable = false; + + /* If this is a regular file, position of the contents of this + file in the NAR. */ + size_t start = 0, size = 0; + + std::string target; + + /* If this is a directory, all the children of the directory. */ + std::map<std::string, NarMember> children; +}; + +struct NarAccessor : public FSAccessor { + std::shared_ptr<const std::string> nar; + + GetNarBytes getNarBytes; + + NarMember root; + + struct NarIndexer : ParseSink, StringSource { + NarAccessor& acc; + + std::stack<NarMember*> parents; + + std::string currentStart; + bool isExec = false; + + NarIndexer(NarAccessor& acc, const std::string& nar) + : StringSource(nar), acc(acc) {} + + void createMember(const Path& path, NarMember member) { + size_t level = std::count(path.begin(), path.end(), '/'); + while (parents.size() > level) { + parents.pop(); + } + + if (parents.empty()) { + acc.root = std::move(member); + parents.push(&acc.root); + } else { + if (parents.top()->type != FSAccessor::Type::tDirectory) { + throw Error("NAR file missing parent directory of path '%s'", path); + } + auto result = parents.top()->children.emplace(baseNameOf(path), + std::move(member)); + parents.push(&result.first->second); + } + } + + void createDirectory(const Path& path) override { + createMember(path, {FSAccessor::Type::tDirectory, false, 0, 0}); + } + + void createRegularFile(const Path& path) override { + createMember(path, {FSAccessor::Type::tRegular, false, 0, 0}); + } + + void isExecutable() override { parents.top()->isExecutable = true; } + + void preallocateContents(unsigned long long size) override { + currentStart = string(s, pos, 16); + assert(size <= std::numeric_limits<size_t>::max()); + parents.top()->size = (size_t)size; + parents.top()->start = pos; + } + + void receiveContents(unsigned char* data, unsigned int len) override { + // Sanity check + if (!currentStart.empty()) { + assert(len < 16 || currentStart == string((char*)data, 16)); + currentStart.clear(); + } + } + + void createSymlink(const Path& path, const string& target) override { + createMember(path, + NarMember{FSAccessor::Type::tSymlink, false, 0, 0, target}); + } + }; + + explicit NarAccessor(const ref<const std::string>& nar) : nar(nar) { + NarIndexer indexer(*this, *nar); + parseDump(indexer, indexer); + } + + NarAccessor(const std::string& listing, GetNarBytes getNarBytes) + : getNarBytes(std::move(getNarBytes)) { + using json = nlohmann::json; + + std::function<void(NarMember&, json&)> recurse; + + recurse = [&](NarMember& member, json& v) { + std::string type = v["type"]; + + if (type == "directory") { + member.type = FSAccessor::Type::tDirectory; + for (auto i = v["entries"].begin(); i != v["entries"].end(); ++i) { + const std::string& name = i.key(); + recurse(member.children[name], i.value()); + } + } else if (type == "regular") { + member.type = FSAccessor::Type::tRegular; + member.size = v["size"]; + member.isExecutable = v.value("executable", false); + member.start = v["narOffset"]; + } else if (type == "symlink") { + member.type = FSAccessor::Type::tSymlink; + member.target = v.value("target", ""); + } else { + return; + } + }; + + json v = json::parse(listing); + recurse(root, v); + } + + NarMember* find(const Path& path) { + Path canon = path.empty() ? "" : canonPath(path); + NarMember* current = &root; + auto end = path.end(); + for (auto it = path.begin(); it != end;) { + // because it != end, the remaining component is non-empty so we need + // a directory + if (current->type != FSAccessor::Type::tDirectory) { + return nullptr; + } + + // skip slash (canonPath above ensures that this is always a slash) + assert(*it == '/'); + it += 1; + + // lookup current component + auto next = std::find(it, end, '/'); + auto child = current->children.find(std::string(it, next)); + if (child == current->children.end()) { + return nullptr; + } + current = &child->second; + + it = next; + } + + return current; + } + + NarMember& get(const Path& path) { + auto result = find(path); + if (result == nullptr) { + throw Error("NAR file does not contain path '%1%'", path); + } + return *result; + } + + Stat stat(const Path& path) override { + auto i = find(path); + if (i == nullptr) { + return {FSAccessor::Type::tMissing, 0, false}; + } + return {i->type, i->size, i->isExecutable, i->start}; + } + + StringSet readDirectory(const Path& path) override { + auto i = get(path); + + if (i.type != FSAccessor::Type::tDirectory) { + throw Error(format("path '%1%' inside NAR file is not a directory") % + path); + } + + StringSet res; + for (auto& child : i.children) { + res.insert(child.first); + } + + return res; + } + + std::string readFile(const Path& path) override { + auto i = get(path); + if (i.type != FSAccessor::Type::tRegular) { + throw Error(format("path '%1%' inside NAR file is not a regular file") % + path); + } + + if (getNarBytes) { + return getNarBytes(i.start, i.size); + } + + assert(nar); + return std::string(*nar, i.start, i.size); + } + + std::string readLink(const Path& path) override { + auto i = get(path); + if (i.type != FSAccessor::Type::tSymlink) { + throw Error(format("path '%1%' inside NAR file is not a symlink") % path); + } + return i.target; + } +}; + +ref<FSAccessor> makeNarAccessor(ref<const std::string> nar) { + return make_ref<NarAccessor>(nar); +} + +ref<FSAccessor> makeLazyNarAccessor(const std::string& listing, + GetNarBytes getNarBytes) { + return make_ref<NarAccessor>(listing, getNarBytes); +} + +void listNar(JSONPlaceholder& res, const ref<FSAccessor>& accessor, + const Path& path, bool recurse) { + auto st = accessor->stat(path); + + auto obj = res.object(); + + switch (st.type) { + case FSAccessor::Type::tRegular: + obj.attr("type", "regular"); + obj.attr("size", st.fileSize); + if (st.isExecutable) { + obj.attr("executable", true); + } + if (st.narOffset != 0u) { + obj.attr("narOffset", st.narOffset); + } + break; + case FSAccessor::Type::tDirectory: + obj.attr("type", "directory"); + { + auto res2 = obj.object("entries"); + for (auto& name : accessor->readDirectory(path)) { + if (recurse) { + auto res3 = res2.placeholder(name); + listNar(res3, accessor, path + "/" + name, true); + } else { + res2.object(name); + } + } + } + break; + case FSAccessor::Type::tSymlink: + obj.attr("type", "symlink"); + obj.attr("target", accessor->readLink(path)); + break; + default: + throw Error("path '%s' does not exist in NAR", path); + } +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/nar-accessor.hh b/third_party/nix/src/libstore/nar-accessor.hh new file mode 100644 index 0000000000..8b18d4a36e --- /dev/null +++ b/third_party/nix/src/libstore/nar-accessor.hh @@ -0,0 +1,29 @@ +#pragma once + +#include <functional> + +#include "fs-accessor.hh" + +namespace nix { + +/* Return an object that provides access to the contents of a NAR + file. */ +ref<FSAccessor> makeNarAccessor(ref<const std::string> nar); + +/* Create a NAR accessor from a NAR listing (in the format produced by + listNar()). The callback getNarBytes(offset, length) is used by the + readFile() method of the accessor to get the contents of files + inside the NAR. */ +typedef std::function<std::string(uint64_t, uint64_t)> GetNarBytes; + +ref<FSAccessor> makeLazyNarAccessor(const std::string& listing, + GetNarBytes getNarBytes); + +class JSONPlaceholder; + +/* Write a JSON representation of the contents of a NAR (except file + contents). */ +void listNar(JSONPlaceholder& res, const ref<FSAccessor>& accessor, + const Path& path, bool recurse); + +} // namespace nix diff --git a/third_party/nix/src/libstore/nar-info-disk-cache.cc b/third_party/nix/src/libstore/nar-info-disk-cache.cc new file mode 100644 index 0000000000..19ef2c9d74 --- /dev/null +++ b/third_party/nix/src/libstore/nar-info-disk-cache.cc @@ -0,0 +1,285 @@ +#include "nar-info-disk-cache.hh" + +#include <glog/logging.h> +#include <sqlite3.h> + +#include "globals.hh" +#include "sqlite.hh" +#include "sync.hh" + +namespace nix { + +static const char* schema = R"sql( + +create table if not exists BinaryCaches ( + id integer primary key autoincrement not null, + url text unique not null, + timestamp integer not null, + storeDir text not null, + wantMassQuery integer not null, + priority integer not null +); + +create table if not exists NARs ( + cache integer not null, + hashPart text not null, + namePart text, + url text, + compression text, + fileHash text, + fileSize integer, + narHash text, + narSize integer, + refs text, + deriver text, + sigs text, + ca text, + timestamp integer not null, + present integer not null, + primary key (cache, hashPart), + foreign key (cache) references BinaryCaches(id) on delete cascade +); + +create table if not exists LastPurge ( + dummy text primary key, + value integer +); + +)sql"; + +class NarInfoDiskCacheImpl : public NarInfoDiskCache { + public: + /* How often to purge expired entries from the cache. */ + const int purgeInterval = 24 * 3600; + + struct Cache { + int id; + Path storeDir; + bool wantMassQuery; + int priority; + }; + + struct State { + SQLite db; + SQLiteStmt insertCache, queryCache, insertNAR, insertMissingNAR, queryNAR, + purgeCache; + std::map<std::string, Cache> caches; + }; + + Sync<State> _state; + + NarInfoDiskCacheImpl() { + auto state(_state.lock()); + + Path dbPath = getCacheDir() + "/nix/binary-cache-v6.sqlite"; + createDirs(dirOf(dbPath)); + + state->db = SQLite(dbPath); + + if (sqlite3_busy_timeout(state->db, 60 * 60 * 1000) != SQLITE_OK) { + throwSQLiteError(state->db, "setting timeout"); + } + + // We can always reproduce the cache. + state->db.exec("pragma synchronous = off"); + state->db.exec("pragma main.journal_mode = truncate"); + + state->db.exec(schema); + + state->insertCache.create( + state->db, + "insert or replace into BinaryCaches(url, timestamp, storeDir, " + "wantMassQuery, priority) values (?, ?, ?, ?, ?)"); + + state->queryCache.create(state->db, + "select id, storeDir, wantMassQuery, priority " + "from BinaryCaches where url = ?"); + + state->insertNAR.create( + state->db, + "insert or replace into NARs(cache, hashPart, namePart, url, " + "compression, fileHash, fileSize, narHash, " + "narSize, refs, deriver, sigs, ca, timestamp, present) values (?, ?, " + "?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, 1)"); + + state->insertMissingNAR.create( + state->db, + "insert or replace into NARs(cache, hashPart, timestamp, present) " + "values (?, ?, ?, 0)"); + + state->queryNAR.create( + state->db, + "select present, namePart, url, compression, fileHash, fileSize, " + "narHash, narSize, refs, deriver, sigs, ca from NARs where cache = ? " + "and hashPart = ? and ((present = 0 and timestamp > ?) or (present = 1 " + "and timestamp > ?))"); + + /* Periodically purge expired entries from the database. */ + retrySQLite<void>([&]() { + auto now = time(nullptr); + + SQLiteStmt queryLastPurge(state->db, "select value from LastPurge"); + auto queryLastPurge_(queryLastPurge.use()); + + if (!queryLastPurge_.next() || + queryLastPurge_.getInt(0) < now - purgeInterval) { + SQLiteStmt(state->db, + "delete from NARs where ((present = 0 and timestamp < ?) or " + "(present = 1 and timestamp < ?))") + .use()(now - settings.ttlNegativeNarInfoCache)( + now - settings.ttlPositiveNarInfoCache) + .exec(); + + DLOG(INFO) << "deleted " << sqlite3_changes(state->db) + << " entries from the NAR info disk cache"; + + SQLiteStmt( + state->db, + "insert or replace into LastPurge(dummy, value) values ('', ?)") + .use()(now) + .exec(); + } + }); + } + + static Cache& getCache(State& state, const std::string& uri) { + auto i = state.caches.find(uri); + if (i == state.caches.end()) { + abort(); + } + return i->second; + } + + void createCache(const std::string& uri, const Path& storeDir, + bool wantMassQuery, int priority) override { + retrySQLite<void>([&]() { + auto state(_state.lock()); + + // FIXME: race + + state->insertCache + .use()(uri)(time(nullptr))(storeDir)( + static_cast<int64_t>(wantMassQuery))(priority) + .exec(); + assert(sqlite3_changes(state->db) == 1); + state->caches[uri] = Cache{(int)sqlite3_last_insert_rowid(state->db), + storeDir, wantMassQuery, priority}; + }); + } + + bool cacheExists(const std::string& uri, bool& wantMassQuery, + int& priority) override { + return retrySQLite<bool>([&]() { + auto state(_state.lock()); + + auto i = state->caches.find(uri); + if (i == state->caches.end()) { + auto queryCache(state->queryCache.use()(uri)); + if (!queryCache.next()) { + return false; + } + state->caches.emplace( + uri, Cache{(int)queryCache.getInt(0), queryCache.getStr(1), + queryCache.getInt(2) != 0, (int)queryCache.getInt(3)}); + } + + auto& cache(getCache(*state, uri)); + + wantMassQuery = cache.wantMassQuery; + priority = cache.priority; + + return true; + }); + } + + std::pair<Outcome, std::shared_ptr<NarInfo>> lookupNarInfo( + const std::string& uri, const std::string& hashPart) override { + return retrySQLite<std::pair<Outcome, std::shared_ptr<NarInfo>>>( + [&]() -> std::pair<Outcome, std::shared_ptr<NarInfo>> { + auto state(_state.lock()); + + auto& cache(getCache(*state, uri)); + + auto now = time(nullptr); + + auto queryNAR(state->queryNAR.use()(cache.id)(hashPart)( + now - settings.ttlNegativeNarInfoCache)( + now - settings.ttlPositiveNarInfoCache)); + + if (!queryNAR.next()) { + return {oUnknown, nullptr}; + } + + if (queryNAR.getInt(0) == 0) { + return {oInvalid, nullptr}; + } + + auto narInfo = make_ref<NarInfo>(); + + auto namePart = queryNAR.getStr(1); + narInfo->path = cache.storeDir + "/" + hashPart + + (namePart.empty() ? "" : "-" + namePart); + narInfo->url = queryNAR.getStr(2); + narInfo->compression = queryNAR.getStr(3); + if (!queryNAR.isNull(4)) { + narInfo->fileHash = Hash(queryNAR.getStr(4)); + } + narInfo->fileSize = queryNAR.getInt(5); + narInfo->narHash = Hash(queryNAR.getStr(6)); + narInfo->narSize = queryNAR.getInt(7); + for (auto& r : tokenizeString<Strings>(queryNAR.getStr(8), " ")) { + narInfo->references.insert(cache.storeDir + "/" + r); + } + if (!queryNAR.isNull(9)) { + narInfo->deriver = cache.storeDir + "/" + queryNAR.getStr(9); + } + for (auto& sig : tokenizeString<Strings>(queryNAR.getStr(10), " ")) { + narInfo->sigs.insert(sig); + } + narInfo->ca = queryNAR.getStr(11); + + return {oValid, narInfo}; + }); + } + + void upsertNarInfo(const std::string& uri, const std::string& hashPart, + std::shared_ptr<ValidPathInfo> info) override { + retrySQLite<void>([&]() { + auto state(_state.lock()); + + auto& cache(getCache(*state, uri)); + + if (info) { + auto narInfo = std::dynamic_pointer_cast<NarInfo>(info); + + assert(hashPart == storePathToHash(info->path)); + + state->insertNAR + .use()(cache.id)(hashPart)(storePathToName(info->path))( + narInfo ? narInfo->url : "", narInfo != nullptr)( + narInfo ? narInfo->compression : "", narInfo != nullptr)( + narInfo && narInfo->fileHash ? narInfo->fileHash.to_string() + : "", + narInfo && narInfo->fileHash)( + narInfo ? narInfo->fileSize : 0, + narInfo != nullptr && + (narInfo->fileSize != 0u))(info->narHash.to_string())( + info->narSize)(concatStringsSep(" ", info->shortRefs()))( + !info->deriver.empty() ? baseNameOf(info->deriver) : "", + !info->deriver.empty())(concatStringsSep(" ", info->sigs))( + info->ca)(time(nullptr)) + .exec(); + + } else { + state->insertMissingNAR.use()(cache.id)(hashPart)(time(nullptr)).exec(); + } + }); + } +}; + +ref<NarInfoDiskCache> getNarInfoDiskCache() { + static ref<NarInfoDiskCache> cache = make_ref<NarInfoDiskCacheImpl>(); + return cache; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/nar-info-disk-cache.hh b/third_party/nix/src/libstore/nar-info-disk-cache.hh new file mode 100644 index 0000000000..65bb773c92 --- /dev/null +++ b/third_party/nix/src/libstore/nar-info-disk-cache.hh @@ -0,0 +1,30 @@ +#pragma once + +#include "nar-info.hh" +#include "ref.hh" + +namespace nix { + +class NarInfoDiskCache { + public: + typedef enum { oValid, oInvalid, oUnknown } Outcome; + + virtual void createCache(const std::string& uri, const Path& storeDir, + bool wantMassQuery, int priority) = 0; + + virtual bool cacheExists(const std::string& uri, bool& wantMassQuery, + int& priority) = 0; + + virtual std::pair<Outcome, std::shared_ptr<NarInfo>> lookupNarInfo( + const std::string& uri, const std::string& hashPart) = 0; + + virtual void upsertNarInfo(const std::string& uri, + const std::string& hashPart, + std::shared_ptr<ValidPathInfo> info) = 0; +}; + +/* Return a singleton cache object that can be used concurrently by + multiple threads. */ +ref<NarInfoDiskCache> getNarInfoDiskCache(); + +} // namespace nix diff --git a/third_party/nix/src/libstore/nar-info.cc b/third_party/nix/src/libstore/nar-info.cc new file mode 100644 index 0000000000..91cf471554 --- /dev/null +++ b/third_party/nix/src/libstore/nar-info.cc @@ -0,0 +1,136 @@ +#include "nar-info.hh" + +#include "globals.hh" + +namespace nix { + +NarInfo::NarInfo(const Store& store, const std::string& s, + const std::string& whence) { + auto corrupt = [&]() { + throw Error(format("NAR info file '%1%' is corrupt") % whence); + }; + + auto parseHashField = [&](const string& s) { + try { + return Hash(s); + } catch (BadHash&) { + corrupt(); + return Hash(); // never reached + } + }; + + size_t pos = 0; + while (pos < s.size()) { + size_t colon = s.find(':', pos); + if (colon == std::string::npos) { + corrupt(); + } + + std::string name(s, pos, colon - pos); + + size_t eol = s.find('\n', colon + 2); + if (eol == std::string::npos) { + corrupt(); + } + + std::string value(s, colon + 2, eol - colon - 2); + + if (name == "StorePath") { + if (!store.isStorePath(value)) { + corrupt(); + } + path = value; + } else if (name == "URL") { + url = value; + } else if (name == "Compression") { + compression = value; + } else if (name == "FileHash") { + fileHash = parseHashField(value); + } else if (name == "FileSize") { + if (!string2Int(value, fileSize)) { + corrupt(); + } + } else if (name == "NarHash") { + narHash = parseHashField(value); + } else if (name == "NarSize") { + if (!string2Int(value, narSize)) { + corrupt(); + } + } else if (name == "References") { + auto refs = tokenizeString<Strings>(value, " "); + if (!references.empty()) { + corrupt(); + } + for (auto& r : refs) { + auto r2 = store.storeDir + "/" + r; + if (!store.isStorePath(r2)) { + corrupt(); + } + references.insert(r2); + } + } else if (name == "Deriver") { + if (value != "unknown-deriver") { + auto p = store.storeDir + "/" + value; + if (!store.isStorePath(p)) { + corrupt(); + } + deriver = p; + } + } else if (name == "System") { + system = value; + } else if (name == "Sig") { + sigs.insert(value); + } else if (name == "CA") { + if (!ca.empty()) { + corrupt(); + } + ca = value; + } + + pos = eol + 1; + } + + if (compression.empty()) { + compression = "bzip2"; + } + + if (path.empty() || url.empty() || narSize == 0 || !narHash) { + corrupt(); + } +} + +std::string NarInfo::to_string() const { + std::string res; + res += "StorePath: " + path + "\n"; + res += "URL: " + url + "\n"; + assert(!compression.empty()); + res += "Compression: " + compression + "\n"; + assert(fileHash.type == htSHA256); + res += "FileHash: " + fileHash.to_string(Base32) + "\n"; + res += "FileSize: " + std::to_string(fileSize) + "\n"; + assert(narHash.type == htSHA256); + res += "NarHash: " + narHash.to_string(Base32) + "\n"; + res += "NarSize: " + std::to_string(narSize) + "\n"; + + res += "References: " + concatStringsSep(" ", shortRefs()) + "\n"; + + if (!deriver.empty()) { + res += "Deriver: " + baseNameOf(deriver) + "\n"; + } + + if (!system.empty()) { + res += "System: " + system + "\n"; + } + + for (const auto& sig : sigs) { + res += "Sig: " + sig + "\n"; + } + + if (!ca.empty()) { + res += "CA: " + ca + "\n"; + } + + return res; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/nar-info.hh b/third_party/nix/src/libstore/nar-info.hh new file mode 100644 index 0000000000..ce362e703f --- /dev/null +++ b/third_party/nix/src/libstore/nar-info.hh @@ -0,0 +1,23 @@ +#pragma once + +#include "hash.hh" +#include "store-api.hh" +#include "types.hh" + +namespace nix { + +struct NarInfo : ValidPathInfo { + std::string url; + std::string compression; + Hash fileHash; + uint64_t fileSize = 0; + std::string system; + + NarInfo() {} + NarInfo(const ValidPathInfo& info) : ValidPathInfo(info) {} + NarInfo(const Store& store, const std::string& s, const std::string& whence); + + std::string to_string() const; +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/nix-store.pc.in b/third_party/nix/src/libstore/nix-store.pc.in new file mode 100644 index 0000000000..6d67b1e038 --- /dev/null +++ b/third_party/nix/src/libstore/nix-store.pc.in @@ -0,0 +1,9 @@ +prefix=@prefix@ +libdir=@libdir@ +includedir=@includedir@ + +Name: Nix +Description: Nix Package Manager +Version: @PACKAGE_VERSION@ +Libs: -L${libdir} -lnixstore -lnixutil +Cflags: -I${includedir}/nix -std=c++17 diff --git a/third_party/nix/src/libstore/optimise-store.cc b/third_party/nix/src/libstore/optimise-store.cc new file mode 100644 index 0000000000..d7cf2bb744 --- /dev/null +++ b/third_party/nix/src/libstore/optimise-store.cc @@ -0,0 +1,308 @@ +#include <cerrno> +#include <cstdio> +#include <cstdlib> +#include <cstring> +#include <regex> +#include <utility> + +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include "globals.hh" +#include "glog/logging.h" +#include "local-store.hh" +#include "util.hh" + +namespace nix { + +static void makeWritable(const Path& path) { + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % path); + } + if (chmod(path.c_str(), st.st_mode | S_IWUSR) == -1) { + throw SysError(format("changing writability of '%1%'") % path); + } +} + +struct MakeReadOnly { + Path path; + explicit MakeReadOnly(Path path) : path(std::move(path)) {} + ~MakeReadOnly() { + try { + /* This will make the path read-only. */ + if (!path.empty()) { + canonicaliseTimestampAndPermissions(path); + } + } catch (...) { + ignoreException(); + } + } +}; + +LocalStore::InodeHash LocalStore::loadInodeHash() { + DLOG(INFO) << "loading hash inodes in memory"; + InodeHash inodeHash; + + AutoCloseDir dir(opendir(linksDir.c_str())); + if (!dir) { + throw SysError(format("opening directory '%1%'") % linksDir); + } + + struct dirent* dirent; + while (errno = 0, dirent = readdir(dir.get())) { /* sic */ + checkInterrupt(); + // We don't care if we hit non-hash files, anything goes + inodeHash.insert(dirent->d_ino); + } + if (errno) { + throw SysError(format("reading directory '%1%'") % linksDir); + } + + DLOG(INFO) << "loaded " << inodeHash.size() << " hash inodes"; + + return inodeHash; +} + +Strings LocalStore::readDirectoryIgnoringInodes(const Path& path, + const InodeHash& inodeHash) { + Strings names; + + AutoCloseDir dir(opendir(path.c_str())); + if (!dir) { + throw SysError(format("opening directory '%1%'") % path); + } + + struct dirent* dirent; + while (errno = 0, dirent = readdir(dir.get())) { /* sic */ + checkInterrupt(); + + if (inodeHash.count(dirent->d_ino) != 0u) { + DLOG(WARNING) << dirent->d_name << " is already linked"; + continue; + } + + string name = dirent->d_name; + if (name == "." || name == "..") { + continue; + } + names.push_back(name); + } + if (errno) { + throw SysError(format("reading directory '%1%'") % path); + } + + return names; +} + +void LocalStore::optimisePath_(OptimiseStats& stats, const Path& path, + InodeHash& inodeHash) { + checkInterrupt(); + + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % path); + } + +#if __APPLE__ + /* HFS/macOS has some undocumented security feature disabling hardlinking for + special files within .app dirs. *.app/Contents/PkgInfo and + *.app/Contents/Resources/\*.lproj seem to be the only paths affected. See + https://github.com/NixOS/nix/issues/1443 for more discussion. */ + + if (std::regex_search(path, std::regex("\\.app/Contents/.+$"))) { + debug(format("'%1%' is not allowed to be linked in macOS") % path); + return; + } +#endif + + if (S_ISDIR(st.st_mode)) { + Strings names = readDirectoryIgnoringInodes(path, inodeHash); + for (auto& i : names) { + optimisePath_(stats, path + "/" + i, inodeHash); + } + return; + } + + /* We can hard link regular files and maybe symlinks. */ + if (!S_ISREG(st.st_mode) +#if CAN_LINK_SYMLINK + && !S_ISLNK(st.st_mode) +#endif + ) + return; + + /* Sometimes SNAFUs can cause files in the Nix store to be + modified, in particular when running programs as root under + NixOS (example: $fontconfig/var/cache being modified). Skip + those files. FIXME: check the modification time. */ + if (S_ISREG(st.st_mode) && ((st.st_mode & S_IWUSR) != 0u)) { + LOG(WARNING) << "skipping suspicious writable file '" << path << "'"; + return; + } + + /* This can still happen on top-level files. */ + if (st.st_nlink > 1 && (inodeHash.count(st.st_ino) != 0u)) { + DLOG(INFO) << path << " is already linked, with " << (st.st_nlink - 2) + << " other file(s)"; + return; + } + + /* Hash the file. Note that hashPath() returns the hash over the + NAR serialisation, which includes the execute bit on the file. + Thus, executable and non-executable files with the same + contents *won't* be linked (which is good because otherwise the + permissions would be screwed up). + + Also note that if `path' is a symlink, then we're hashing the + contents of the symlink (i.e. the result of readlink()), not + the contents of the target (which may not even exist). */ + Hash hash = hashPath(htSHA256, path).first; + LOG(INFO) << path << " has hash " << hash.to_string(); + + /* Check if this is a known hash. */ + Path linkPath = linksDir + "/" + hash.to_string(Base32, false); + +retry: + if (!pathExists(linkPath)) { + /* Nope, create a hard link in the links directory. */ + if (link(path.c_str(), linkPath.c_str()) == 0) { + inodeHash.insert(st.st_ino); + return; + } + + switch (errno) { + case EEXIST: + /* Fall through if another process created ‘linkPath’ before + we did. */ + break; + + case ENOSPC: + /* On ext4, that probably means the directory index is + full. When that happens, it's fine to ignore it: we + just effectively disable deduplication of this + file. */ + LOG(WARNING) << "cannot link '" << linkPath << " to " << path << ": " + << strerror(errno); + + return; + + default: + throw SysError("cannot link '%1%' to '%2%'", linkPath, path); + } + } + + /* Yes! We've seen a file with the same contents. Replace the + current file with a hard link to that file. */ + struct stat stLink; + if (lstat(linkPath.c_str(), &stLink) != 0) { + throw SysError(format("getting attributes of path '%1%'") % linkPath); + } + + if (st.st_ino == stLink.st_ino) { + DLOG(INFO) << path << " is already linked to " << linkPath; + return; + } + + if (st.st_size != stLink.st_size) { + LOG(WARNING) << "removing corrupted link '" << linkPath << "'"; + unlink(linkPath.c_str()); + goto retry; + } + + DLOG(INFO) << "linking '" << path << "' to '" << linkPath << "'"; + + /* Make the containing directory writable, but only if it's not + the store itself (we don't want or need to mess with its + permissions). */ + bool mustToggle = dirOf(path) != realStoreDir; + if (mustToggle) { + makeWritable(dirOf(path)); + } + + /* When we're done, make the directory read-only again and reset + its timestamp back to 0. */ + MakeReadOnly makeReadOnly(mustToggle ? dirOf(path) : ""); + + Path tempLink = + (format("%1%/.tmp-link-%2%-%3%") % realStoreDir % getpid() % random()) + .str(); + + if (link(linkPath.c_str(), tempLink.c_str()) == -1) { + if (errno == EMLINK) { + /* Too many links to the same file (>= 32000 on most file + systems). This is likely to happen with empty files. + Just shrug and ignore. */ + if (st.st_size != 0) { + LOG(WARNING) << linkPath << " has maximum number of links"; + } + return; + } + throw SysError("cannot link '%1%' to '%2%'", tempLink, linkPath); + } + + /* Atomically replace the old file with the new hard link. */ + if (rename(tempLink.c_str(), path.c_str()) == -1) { + if (unlink(tempLink.c_str()) == -1) { + LOG(ERROR) << "unable to unlink '" << tempLink << "'"; + } + if (errno == EMLINK) { + /* Some filesystems generate too many links on the rename, + rather than on the original link. (Probably it + temporarily increases the st_nlink field before + decreasing it again.) */ + DLOG(WARNING) << "'" << linkPath + << "' has reached maximum number of links"; + return; + } + throw SysError(format("cannot rename '%1%' to '%2%'") % tempLink % path); + } + + stats.filesLinked++; + stats.bytesFreed += st.st_size; + stats.blocksFreed += st.st_blocks; +} + +void LocalStore::optimiseStore(OptimiseStats& stats) { + PathSet paths = queryAllValidPaths(); + InodeHash inodeHash = loadInodeHash(); + + uint64_t done = 0; + + for (auto& i : paths) { + addTempRoot(i); + if (!isValidPath(i)) { + continue; + } /* path was GC'ed, probably */ + { + LOG(INFO) << "optimising path '" << i << "'"; + optimisePath_(stats, realStoreDir + "/" + baseNameOf(i), inodeHash); + } + done++; + } +} + +static string showBytes(unsigned long long bytes) { + return (format("%.2f MiB") % (bytes / (1024.0 * 1024.0))).str(); +} + +void LocalStore::optimiseStore() { + OptimiseStats stats; + + optimiseStore(stats); + + LOG(INFO) << showBytes(stats.bytesFreed) << " freed by hard-linking " + << stats.filesLinked << " files"; +} + +void LocalStore::optimisePath(const Path& path) { + OptimiseStats stats; + InodeHash inodeHash; + + if (settings.autoOptimiseStore) { + optimisePath_(stats, path, inodeHash); + } +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/parsed-derivations.cc b/third_party/nix/src/libstore/parsed-derivations.cc new file mode 100644 index 0000000000..1186203249 --- /dev/null +++ b/third_party/nix/src/libstore/parsed-derivations.cc @@ -0,0 +1,125 @@ +#include "parsed-derivations.hh" + +namespace nix { + +ParsedDerivation::ParsedDerivation(const Path& drvPath, BasicDerivation& drv) + : drvPath(drvPath), drv(drv) { + /* Parse the __json attribute, if any. */ + auto jsonAttr = drv.env.find("__json"); + if (jsonAttr != drv.env.end()) { + try { + structuredAttrs = nlohmann::json::parse(jsonAttr->second); + } catch (std::exception& e) { + throw Error("cannot process __json attribute of '%s': %s", drvPath, + e.what()); + } + } +} + +std::optional<std::string> ParsedDerivation::getStringAttr( + const std::string& name) const { + if (structuredAttrs) { + auto i = structuredAttrs->find(name); + if (i == structuredAttrs->end()) { + return {}; + } + if (!i->is_string()) { + throw Error("attribute '%s' of derivation '%s' must be a string", name, + drvPath); + } + return i->get<std::string>(); + + } else { + auto i = drv.env.find(name); + if (i == drv.env.end()) { + return {}; + } + return i->second; + } +} + +bool ParsedDerivation::getBoolAttr(const std::string& name, bool def) const { + if (structuredAttrs) { + auto i = structuredAttrs->find(name); + if (i == structuredAttrs->end()) { + return def; + } + if (!i->is_boolean()) { + throw Error("attribute '%s' of derivation '%s' must be a Boolean", name, + drvPath); + } + return i->get<bool>(); + + } else { + auto i = drv.env.find(name); + if (i == drv.env.end()) { + return def; + } + return i->second == "1"; + } +} + +std::optional<Strings> ParsedDerivation::getStringsAttr( + const std::string& name) const { + if (structuredAttrs) { + auto i = structuredAttrs->find(name); + if (i == structuredAttrs->end()) { + return {}; + } + if (!i->is_array()) { + throw Error("attribute '%s' of derivation '%s' must be a list of strings", + name, drvPath); + } + Strings res; + for (const auto& j : *i) { + if (!j.is_string()) { + throw Error( + "attribute '%s' of derivation '%s' must be a list of strings", name, + drvPath); + } + res.push_back(j.get<std::string>()); + } + return res; + + } else { + auto i = drv.env.find(name); + if (i == drv.env.end()) { + return {}; + } + return tokenizeString<Strings>(i->second); + } +} + +StringSet ParsedDerivation::getRequiredSystemFeatures() const { + StringSet res; + for (auto& i : getStringsAttr("requiredSystemFeatures").value_or(Strings())) { + res.insert(i); + } + return res; +} + +bool ParsedDerivation::canBuildLocally() const { + if (drv.platform != settings.thisSystem.get() && + (settings.extraPlatforms.get().count(drv.platform) == 0u) && + !drv.isBuiltin()) { + return false; + } + + for (auto& feature : getRequiredSystemFeatures()) { + if (settings.systemFeatures.get().count(feature) == 0u) { + return false; + } + } + + return true; +} + +bool ParsedDerivation::willBuildLocally() const { + return getBoolAttr("preferLocalBuild") && canBuildLocally(); +} + +bool ParsedDerivation::substitutesAllowed() const { + return getBoolAttr("allowSubstitutes", true); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/parsed-derivations.hh b/third_party/nix/src/libstore/parsed-derivations.hh new file mode 100644 index 0000000000..7b2da3b566 --- /dev/null +++ b/third_party/nix/src/libstore/parsed-derivations.hh @@ -0,0 +1,34 @@ +#include <nlohmann/json.hpp> + +#include "derivations.hh" + +namespace nix { + +class ParsedDerivation { + Path drvPath; + BasicDerivation& drv; + std::optional<nlohmann::json> structuredAttrs; + + public: + ParsedDerivation(const Path& drvPath, BasicDerivation& drv); + + const std::optional<nlohmann::json>& getStructuredAttrs() const { + return structuredAttrs; + } + + std::optional<std::string> getStringAttr(const std::string& name) const; + + bool getBoolAttr(const std::string& name, bool def = false) const; + + std::optional<Strings> getStringsAttr(const std::string& name) const; + + StringSet getRequiredSystemFeatures() const; + + bool canBuildLocally() const; + + bool willBuildLocally() const; + + bool substitutesAllowed() const; +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/pathlocks.cc b/third_party/nix/src/libstore/pathlocks.cc new file mode 100644 index 0000000000..eeee5ee1e9 --- /dev/null +++ b/third_party/nix/src/libstore/pathlocks.cc @@ -0,0 +1,172 @@ +#include "pathlocks.hh" + +#include <cerrno> +#include <cstdlib> + +#include <fcntl.h> +#include <glog/logging.h> +#include <sys/file.h> +#include <sys/stat.h> +#include <sys/types.h> + +#include "sync.hh" +#include "util.hh" + +namespace nix { + +AutoCloseFD openLockFile(const Path& path, bool create) { + AutoCloseFD fd; + + fd = open(path.c_str(), O_CLOEXEC | O_RDWR | (create ? O_CREAT : 0), 0600); + if (!fd && (create || errno != ENOENT)) { + throw SysError(format("opening lock file '%1%'") % path); + } + + return fd; +} + +void deleteLockFile(const Path& path, int fd) { + /* Get rid of the lock file. Have to be careful not to introduce + races. Write a (meaningless) token to the file to indicate to + other processes waiting on this lock that the lock is stale + (deleted). */ + unlink(path.c_str()); + writeFull(fd, "d"); + /* Note that the result of unlink() is ignored; removing the lock + file is an optimisation, not a necessity. */ +} + +bool lockFile(int fd, LockType lockType, bool wait) { + int type; + if (lockType == ltRead) { + type = LOCK_SH; + } else if (lockType == ltWrite) { + type = LOCK_EX; + } else if (lockType == ltNone) { + type = LOCK_UN; + } else { + abort(); + } + + if (wait) { + while (flock(fd, type) != 0) { + checkInterrupt(); + if (errno != EINTR) { + throw SysError(format("acquiring/releasing lock")); + } + return false; + } + } else { + while (flock(fd, type | LOCK_NB) != 0) { + checkInterrupt(); + if (errno == EWOULDBLOCK) { + return false; + } + if (errno != EINTR) { + throw SysError(format("acquiring/releasing lock")); + } + } + } + + return true; +} + +PathLocks::PathLocks() : deletePaths(false) {} + +PathLocks::PathLocks(const PathSet& paths, const string& waitMsg) + : deletePaths(false) { + lockPaths(paths, waitMsg); +} + +bool PathLocks::lockPaths(const PathSet& paths, const string& waitMsg, + bool wait) { + assert(fds.empty()); + + /* Note that `fds' is built incrementally so that the destructor + will only release those locks that we have already acquired. */ + + /* Acquire the lock for each path in sorted order. This ensures + that locks are always acquired in the same order, thus + preventing deadlocks. */ + for (auto& path : paths) { + checkInterrupt(); + Path lockPath = path + ".lock"; + + DLOG(INFO) << "locking path '" << path << "'"; + + AutoCloseFD fd; + + while (true) { + /* Open/create the lock file. */ + fd = openLockFile(lockPath, true); + + /* Acquire an exclusive lock. */ + if (!lockFile(fd.get(), ltWrite, false)) { + if (wait) { + if (!waitMsg.empty()) { + LOG(WARNING) << waitMsg; + } + lockFile(fd.get(), ltWrite, true); + } else { + /* Failed to lock this path; release all other + locks. */ + unlock(); + return false; + } + } + + DLOG(INFO) << "lock acquired on '" << lockPath << "'"; + + /* Check that the lock file hasn't become stale (i.e., + hasn't been unlinked). */ + struct stat st; + if (fstat(fd.get(), &st) == -1) { + throw SysError(format("statting lock file '%1%'") % lockPath); + } + if (st.st_size != 0) { + /* This lock file has been unlinked, so we're holding + a lock on a deleted file. This means that other + processes may create and acquire a lock on + `lockPath', and proceed. So we must retry. */ + DLOG(INFO) << "open lock file '" << lockPath << "' has become stale"; + } else { + break; + } + } + + /* Use borrow so that the descriptor isn't closed. */ + fds.emplace_back(fd.release(), lockPath); + } + + return true; +} + +PathLocks::~PathLocks() { + try { + unlock(); + } catch (...) { + ignoreException(); + } +} + +void PathLocks::unlock() { + for (auto& i : fds) { + if (deletePaths) { + deleteLockFile(i.second, i.first); + } + + if (close(i.first) == -1) { + LOG(WARNING) << "cannot close lock file on '" << i.second << "'"; + } + + DLOG(INFO) << "lock released on '" << i.second << "'"; + } + + fds.clear(); +} + +void PathLocks::setDeletion(bool deletePaths) { + this->deletePaths = deletePaths; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/pathlocks.hh b/third_party/nix/src/libstore/pathlocks.hh new file mode 100644 index 0000000000..90184989cd --- /dev/null +++ b/third_party/nix/src/libstore/pathlocks.hh @@ -0,0 +1,35 @@ +#pragma once + +#include "util.hh" + +namespace nix { + +/* Open (possibly create) a lock file and return the file descriptor. + -1 is returned if create is false and the lock could not be opened + because it doesn't exist. Any other error throws an exception. */ +AutoCloseFD openLockFile(const Path& path, bool create); + +/* Delete an open lock file. */ +void deleteLockFile(const Path& path, int fd); + +enum LockType { ltRead, ltWrite, ltNone }; + +bool lockFile(int fd, LockType lockType, bool wait); + +class PathLocks { + private: + typedef std::pair<int, Path> FDPair; + list<FDPair> fds; + bool deletePaths; + + public: + PathLocks(); + PathLocks(const PathSet& paths, const string& waitMsg = ""); + bool lockPaths(const PathSet& _paths, const string& waitMsg = "", + bool wait = true); + ~PathLocks(); + void unlock(); + void setDeletion(bool deletePaths); +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/profiles.cc b/third_party/nix/src/libstore/profiles.cc new file mode 100644 index 0000000000..bdb90b7388 --- /dev/null +++ b/third_party/nix/src/libstore/profiles.cc @@ -0,0 +1,249 @@ +#include "profiles.hh" + +#include <cerrno> +#include <cstdio> + +#include <glog/logging.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include "store-api.hh" +#include "util.hh" + +namespace nix { + +static bool cmpGensByNumber(const Generation& a, const Generation& b) { + return a.number < b.number; +} + +/* Parse a generation name of the format + `<profilename>-<number>-link'. */ +static int parseName(const string& profileName, const string& name) { + if (string(name, 0, profileName.size() + 1) != profileName + "-") { + return -1; + } + string s = string(name, profileName.size() + 1); + string::size_type p = s.find("-link"); + if (p == string::npos) { + return -1; + } + int n; + if (string2Int(string(s, 0, p), n) && n >= 0) { + return n; + } + return -1; +} + +Generations findGenerations(const Path& profile, int& curGen) { + Generations gens; + + Path profileDir = dirOf(profile); + string profileName = baseNameOf(profile); + + for (auto& i : readDirectory(profileDir)) { + int n; + if ((n = parseName(profileName, i.name)) != -1) { + Generation gen; + gen.path = profileDir + "/" + i.name; + gen.number = n; + struct stat st; + if (lstat(gen.path.c_str(), &st) != 0) { + throw SysError(format("statting '%1%'") % gen.path); + } + gen.creationTime = st.st_mtime; + gens.push_back(gen); + } + } + + gens.sort(cmpGensByNumber); + + curGen = pathExists(profile) ? parseName(profileName, readLink(profile)) : -1; + + return gens; +} + +static void makeName(const Path& profile, unsigned int num, Path& outLink) { + Path prefix = (format("%1%-%2%") % profile % num).str(); + outLink = prefix + "-link"; +} + +Path createGeneration(const ref<LocalFSStore>& store, const Path& profile, + const Path& outPath) { + /* The new generation number should be higher than old the + previous ones. */ + int dummy; + Generations gens = findGenerations(profile, dummy); + + unsigned int num; + if (!gens.empty()) { + Generation last = gens.back(); + + if (readLink(last.path) == outPath) { + /* We only create a new generation symlink if it differs + from the last one. + + This helps keeping gratuitous installs/rebuilds from piling + up uncontrolled numbers of generations, cluttering up the + UI like grub. */ + return last.path; + } + + num = gens.back().number; + } else { + num = 0; + } + + /* Create the new generation. Note that addPermRoot() blocks if + the garbage collector is running to prevent the stuff we've + built from moving from the temporary roots (which the GC knows) + to the permanent roots (of which the GC would have a stale + view). If we didn't do it this way, the GC might remove the + user environment etc. we've just built. */ + Path generation; + makeName(profile, num + 1, generation); + store->addPermRoot(outPath, generation, false, true); + + return generation; +} + +static void removeFile(const Path& path) { + if (remove(path.c_str()) == -1) { + throw SysError(format("cannot unlink '%1%'") % path); + } +} + +void deleteGeneration(const Path& profile, unsigned int gen) { + Path generation; + makeName(profile, gen, generation); + removeFile(generation); +} + +static void deleteGeneration2(const Path& profile, unsigned int gen, + bool dryRun) { + if (dryRun) { + LOG(INFO) << "would remove generation " << gen; + } else { + LOG(INFO) << "removing generation " << gen; + deleteGeneration(profile, gen); + } +} + +void deleteGenerations(const Path& profile, + const std::set<unsigned int>& gensToDelete, + bool dryRun) { + PathLocks lock; + lockProfile(lock, profile); + + int curGen; + Generations gens = findGenerations(profile, curGen); + + if (gensToDelete.find(curGen) != gensToDelete.end()) { + throw Error(format("cannot delete current generation of profile %1%'") % + profile); + } + + for (auto& i : gens) { + if (gensToDelete.find(i.number) == gensToDelete.end()) { + continue; + } + deleteGeneration2(profile, i.number, dryRun); + } +} + +void deleteGenerationsGreaterThan(const Path& profile, int max, bool dryRun) { + PathLocks lock; + lockProfile(lock, profile); + + int curGen; + bool fromCurGen = false; + Generations gens = findGenerations(profile, curGen); + for (auto i = gens.rbegin(); i != gens.rend(); ++i) { + if (i->number == curGen) { + fromCurGen = true; + max--; + continue; + } + if (fromCurGen) { + if (max != 0) { + max--; + continue; + } + deleteGeneration2(profile, i->number, dryRun); + } + } +} + +void deleteOldGenerations(const Path& profile, bool dryRun) { + PathLocks lock; + lockProfile(lock, profile); + + int curGen; + Generations gens = findGenerations(profile, curGen); + + for (auto& i : gens) { + if (i.number != curGen) { + deleteGeneration2(profile, i.number, dryRun); + } + } +} + +void deleteGenerationsOlderThan(const Path& profile, time_t t, bool dryRun) { + PathLocks lock; + lockProfile(lock, profile); + + int curGen; + Generations gens = findGenerations(profile, curGen); + + bool canDelete = false; + for (auto i = gens.rbegin(); i != gens.rend(); ++i) { + if (canDelete) { + assert(i->creationTime < t); + if (i->number != curGen) { + deleteGeneration2(profile, i->number, dryRun); + } + } else if (i->creationTime < t) { + /* We may now start deleting generations, but we don't + delete this generation yet, because this generation was + still the one that was active at the requested point in + time. */ + canDelete = true; + } + } +} + +void deleteGenerationsOlderThan(const Path& profile, const string& timeSpec, + bool dryRun) { + time_t curTime = time(nullptr); + string strDays = string(timeSpec, 0, timeSpec.size() - 1); + int days; + + if (!string2Int(strDays, days) || days < 1) { + throw Error(format("invalid number of days specifier '%1%'") % timeSpec); + } + + time_t oldTime = curTime - days * 24 * 3600; + + deleteGenerationsOlderThan(profile, oldTime, dryRun); +} + +void switchLink(const Path& link, Path target) { + /* Hacky. */ + if (dirOf(target) == dirOf(link)) { + target = baseNameOf(target); + } + + replaceSymlink(target, link); +} + +void lockProfile(PathLocks& lock, const Path& profile) { + lock.lockPaths({profile}, + (format("waiting for lock on profile '%1%'") % profile).str()); + lock.setDeletion(true); +} + +string optimisticLockProfile(const Path& profile) { + return pathExists(profile) ? readLink(profile) : ""; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/profiles.hh b/third_party/nix/src/libstore/profiles.hh new file mode 100644 index 0000000000..ab31cc993a --- /dev/null +++ b/third_party/nix/src/libstore/profiles.hh @@ -0,0 +1,61 @@ +#pragma once + +#include <time.h> + +#include "pathlocks.hh" +#include "types.hh" + +namespace nix { + +struct Generation { + int number; + Path path; + time_t creationTime; + Generation() { number = -1; } + operator bool() const { return number != -1; } +}; + +typedef list<Generation> Generations; + +/* Returns the list of currently present generations for the specified + profile, sorted by generation number. */ +Generations findGenerations(const Path& profile, int& curGen); + +class LocalFSStore; + +Path createGeneration(const ref<LocalFSStore>& store, const Path& profile, + const Path& outPath); + +void deleteGeneration(const Path& profile, unsigned int gen); + +void deleteGenerations(const Path& profile, + const std::set<unsigned int>& gensToDelete, bool dryRun); + +void deleteGenerationsGreaterThan(const Path& profile, const int max, + bool dryRun); + +void deleteOldGenerations(const Path& profile, bool dryRun); + +void deleteGenerationsOlderThan(const Path& profile, time_t t, bool dryRun); + +void deleteGenerationsOlderThan(const Path& profile, const string& timeSpec, + bool dryRun); + +void switchLink(const Path& link, Path target); + +/* Ensure exclusive access to a profile. Any command that modifies + the profile first acquires this lock. */ +void lockProfile(PathLocks& lock, const Path& profile); + +/* Optimistic locking is used by long-running operations like `nix-env + -i'. Instead of acquiring the exclusive lock for the entire + duration of the operation, we just perform the operation + optimistically (without an exclusive lock), and check at the end + whether the profile changed while we were busy (i.e., the symlink + target changed). If so, the operation is restarted. Restarting is + generally cheap, since the build results are still in the Nix + store. Most of the time, only the user environment has to be + rebuilt. */ +string optimisticLockProfile(const Path& profile); + +} // namespace nix diff --git a/third_party/nix/src/libstore/references.cc b/third_party/nix/src/libstore/references.cc new file mode 100644 index 0000000000..c8cebaec08 --- /dev/null +++ b/third_party/nix/src/libstore/references.cc @@ -0,0 +1,124 @@ +#include "references.hh" + +#include <cstdlib> +#include <map> + +#include <glog/logging.h> + +#include "archive.hh" +#include "hash.hh" +#include "util.hh" + +namespace nix { + +static unsigned int refLength = 32; /* characters */ + +static void search(const unsigned char* s, size_t len, StringSet& hashes, + StringSet& seen) { + static bool initialised = false; + static bool isBase32[256]; + if (!initialised) { + for (bool& i : isBase32) { + i = false; + } + for (char base32Char : base32Chars) { + isBase32[(unsigned char)base32Char] = true; + } + initialised = true; + } + + for (size_t i = 0; i + refLength <= len;) { + int j; + bool match = true; + for (j = refLength - 1; j >= 0; --j) { + if (!isBase32[(unsigned char)s[i + j]]) { + i += j + 1; + match = false; + break; + } + } + if (!match) { + continue; + } + string ref((const char*)s + i, refLength); + if (hashes.find(ref) != hashes.end()) { + DLOG(INFO) << "found reference to '" << ref << "' at offset " << i; + seen.insert(ref); + hashes.erase(ref); + } + ++i; + } +} + +struct RefScanSink : Sink { + HashSink hashSink; + StringSet hashes; + StringSet seen; + + string tail; + + RefScanSink() : hashSink(htSHA256) {} + + void operator()(const unsigned char* data, size_t len) override; +}; + +void RefScanSink::operator()(const unsigned char* data, size_t len) { + hashSink(data, len); + + /* It's possible that a reference spans the previous and current + fragment, so search in the concatenation of the tail of the + previous fragment and the start of the current fragment. */ + string s = + tail + string((const char*)data, len > refLength ? refLength : len); + search((const unsigned char*)s.data(), s.size(), hashes, seen); + + search(data, len, hashes, seen); + + size_t tailLen = len <= refLength ? len : refLength; + tail = string(tail, tail.size() < refLength - tailLen + ? 0 + : tail.size() - (refLength - tailLen)) + + string((const char*)data + len - tailLen, tailLen); +} + +PathSet scanForReferences(const string& path, const PathSet& refs, + HashResult& hash) { + RefScanSink sink; + std::map<string, Path> backMap; + + /* For efficiency (and a higher hit rate), just search for the + hash part of the file name. (This assumes that all references + have the form `HASH-bla'). */ + for (auto& i : refs) { + string baseName = baseNameOf(i); + string::size_type pos = baseName.find('-'); + if (pos == string::npos) { + throw Error(format("bad reference '%1%'") % i); + } + string s = string(baseName, 0, pos); + assert(s.size() == refLength); + assert(backMap.find(s) == backMap.end()); + // parseHash(htSHA256, s); + sink.hashes.insert(s); + backMap[s] = i; + } + + /* Look for the hashes in the NAR dump of the path. */ + dumpPath(path, sink); + + /* Map the hashes found back to their store paths. */ + PathSet found; + for (auto& i : sink.seen) { + std::map<string, Path>::iterator j; + if ((j = backMap.find(i)) == backMap.end()) { + abort(); + } + found.insert(j->second); + } + + hash = sink.hashSink.finish(); + + return found; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/references.hh b/third_party/nix/src/libstore/references.hh new file mode 100644 index 0000000000..2229150e33 --- /dev/null +++ b/third_party/nix/src/libstore/references.hh @@ -0,0 +1,11 @@ +#pragma once + +#include "hash.hh" +#include "types.hh" + +namespace nix { + +PathSet scanForReferences(const Path& path, const PathSet& refs, + HashResult& hash); + +} diff --git a/third_party/nix/src/libstore/remote-fs-accessor.cc b/third_party/nix/src/libstore/remote-fs-accessor.cc new file mode 100644 index 0000000000..ca478c213f --- /dev/null +++ b/third_party/nix/src/libstore/remote-fs-accessor.cc @@ -0,0 +1,131 @@ +#include "remote-fs-accessor.hh" + +#include <fcntl.h> +#include <sys/stat.h> +#include <sys/types.h> + +#include "json.hh" +#include "nar-accessor.hh" + +namespace nix { + +RemoteFSAccessor::RemoteFSAccessor(const ref<Store>& store, + const Path& cacheDir) + : store(store), cacheDir(cacheDir) { + if (!cacheDir.empty()) { + createDirs(cacheDir); + } +} + +Path RemoteFSAccessor::makeCacheFile(const Path& storePath, + const std::string& ext) { + assert(!cacheDir.empty()); + return fmt("%s/%s.%s", cacheDir, storePathToHash(storePath), ext); +} + +void RemoteFSAccessor::addToCache(const Path& storePath, const std::string& nar, + const ref<FSAccessor>& narAccessor) { + nars.emplace(storePath, narAccessor); + + if (!cacheDir.empty()) { + try { + std::ostringstream str; + JSONPlaceholder jsonRoot(str); + listNar(jsonRoot, narAccessor, "", true); + writeFile(makeCacheFile(storePath, "ls"), str.str()); + + /* FIXME: do this asynchronously. */ + writeFile(makeCacheFile(storePath, "nar"), nar); + + } catch (...) { + ignoreException(); + } + } +} + +std::pair<ref<FSAccessor>, Path> RemoteFSAccessor::fetch(const Path& path_) { + auto path = canonPath(path_); + + auto storePath = store->toStorePath(path); + std::string restPath = std::string(path, storePath.size()); + + if (!store->isValidPath(storePath)) { + throw InvalidPath(format("path '%1%' is not a valid store path") % + storePath); + } + + auto i = nars.find(storePath); + if (i != nars.end()) { + return {i->second, restPath}; + } + + StringSink sink; + std::string listing; + Path cacheFile; + + if (!cacheDir.empty() && + pathExists(cacheFile = makeCacheFile(storePath, "nar"))) { + try { + listing = nix::readFile(makeCacheFile(storePath, "ls")); + + auto narAccessor = makeLazyNarAccessor( + listing, [cacheFile](uint64_t offset, uint64_t length) { + AutoCloseFD fd = open(cacheFile.c_str(), O_RDONLY | O_CLOEXEC); + if (!fd) { + throw SysError("opening NAR cache file '%s'", cacheFile); + } + + if (lseek(fd.get(), offset, SEEK_SET) != (off_t)offset) { + throw SysError("seeking in '%s'", cacheFile); + } + + std::string buf(length, 0); + readFull(fd.get(), (unsigned char*)buf.data(), length); + + return buf; + }); + + nars.emplace(storePath, narAccessor); + return {narAccessor, restPath}; + + } catch (SysError&) { + } + + try { + *sink.s = nix::readFile(cacheFile); + + auto narAccessor = makeNarAccessor(sink.s); + nars.emplace(storePath, narAccessor); + return {narAccessor, restPath}; + + } catch (SysError&) { + } + } + + store->narFromPath(storePath, sink); + auto narAccessor = makeNarAccessor(sink.s); + addToCache(storePath, *sink.s, narAccessor); + return {narAccessor, restPath}; +} + +FSAccessor::Stat RemoteFSAccessor::stat(const Path& path) { + auto res = fetch(path); + return res.first->stat(res.second); +} + +StringSet RemoteFSAccessor::readDirectory(const Path& path) { + auto res = fetch(path); + return res.first->readDirectory(res.second); +} + +std::string RemoteFSAccessor::readFile(const Path& path) { + auto res = fetch(path); + return res.first->readFile(res.second); +} + +std::string RemoteFSAccessor::readLink(const Path& path) { + auto res = fetch(path); + return res.first->readLink(res.second); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/remote-fs-accessor.hh b/third_party/nix/src/libstore/remote-fs-accessor.hh new file mode 100644 index 0000000000..32c729f50d --- /dev/null +++ b/third_party/nix/src/libstore/remote-fs-accessor.hh @@ -0,0 +1,38 @@ +#pragma once + +#include "fs-accessor.hh" +#include "ref.hh" +#include "store-api.hh" + +namespace nix { + +class RemoteFSAccessor : public FSAccessor { + ref<Store> store; + + std::map<Path, ref<FSAccessor>> nars; + + Path cacheDir; + + std::pair<ref<FSAccessor>, Path> fetch(const Path& path_); + + friend class BinaryCacheStore; + + Path makeCacheFile(const Path& storePath, const std::string& ext); + + void addToCache(const Path& storePath, const std::string& nar, + const ref<FSAccessor>& narAccessor); + + public: + RemoteFSAccessor(const ref<Store>& store, + const /* FIXME: use std::optional */ Path& cacheDir = ""); + + Stat stat(const Path& path) override; + + StringSet readDirectory(const Path& path) override; + + std::string readFile(const Path& path) override; + + std::string readLink(const Path& path) override; +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/remote-store.cc b/third_party/nix/src/libstore/remote-store.cc new file mode 100644 index 0000000000..c4215800da --- /dev/null +++ b/third_party/nix/src/libstore/remote-store.cc @@ -0,0 +1,749 @@ +#include "remote-store.hh" + +#include <cerrno> +#include <cstring> + +#include <fcntl.h> +#include <glog/logging.h> +#include <sys/socket.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <sys/un.h> +#include <unistd.h> + +#include "affinity.hh" +#include "archive.hh" +#include "derivations.hh" +#include "finally.hh" +#include "globals.hh" +#include "pool.hh" +#include "prefork-compat.hh" +#include "serialise.hh" +#include "util.hh" +#include "worker-protocol.hh" + +namespace nix { + +Path readStorePath(Store& store, Source& from) { + Path path = readString(from); + store.assertStorePath(path); + return path; +} + +template <class T> +T readStorePaths(Store& store, Source& from) { + T paths = readStrings<T>(from); + for (auto& i : paths) { + store.assertStorePath(i); + } + return paths; +} + +template PathSet readStorePaths(Store& store, Source& from); +template Paths readStorePaths(Store& store, Source& from); + +/* TODO: Separate these store impls into different files, give them better names + */ +RemoteStore::RemoteStore(const Params& params) + : Store(params), + connections(make_ref<Pool<Connection>>( + std::max(1, (int)maxConnections), + [this]() { return openConnectionWrapper(); }, + [this](const ref<Connection>& r) { + return r->to.good() && r->from.good() && + std::chrono::duration_cast<std::chrono::seconds>( + std::chrono::steady_clock::now() - r->startTime) + .count() < maxConnectionAge; + })) {} + +ref<RemoteStore::Connection> RemoteStore::openConnectionWrapper() { + if (failed) { + throw Error("opening a connection to remote store '%s' previously failed", + getUri()); + } + try { + return openConnection(); + } catch (...) { + failed = true; + throw; + } +} + +UDSRemoteStore::UDSRemoteStore(const Params& params) + : Store(params), LocalFSStore(params), RemoteStore(params) {} + +UDSRemoteStore::UDSRemoteStore(std::string socket_path, const Params& params) + : Store(params), + LocalFSStore(params), + RemoteStore(params), + path(socket_path) {} + +std::string UDSRemoteStore::getUri() { + if (path) { + return std::string("unix://") + *path; + } + return "daemon"; +} + +ref<RemoteStore::Connection> UDSRemoteStore::openConnection() { + auto conn = make_ref<Connection>(); + + /* Connect to a daemon that does the privileged work for us. */ + conn->fd = socket(PF_UNIX, + SOCK_STREAM +#ifdef SOCK_CLOEXEC + | SOCK_CLOEXEC +#endif + , + 0); + if (!conn->fd) { + throw SysError("cannot create Unix domain socket"); + } + closeOnExec(conn->fd.get()); + + string socketPath = path ? *path : settings.nixDaemonSocketFile; + + struct sockaddr_un addr; + addr.sun_family = AF_UNIX; + if (socketPath.size() + 1 >= sizeof(addr.sun_path)) { + throw Error(format("socket path '%1%' is too long") % socketPath); + } + strcpy(addr.sun_path, socketPath.c_str()); + + if (::connect(conn->fd.get(), (struct sockaddr*)&addr, sizeof(addr)) == -1) { + throw SysError(format("cannot connect to daemon at '%1%'") % socketPath); + } + + conn->from.fd = conn->fd.get(); + conn->to.fd = conn->fd.get(); + + conn->startTime = std::chrono::steady_clock::now(); + + initConnection(*conn); + + return conn; +} + +void RemoteStore::initConnection(Connection& conn) { + /* Send the magic greeting, check for the reply. */ + try { + conn.to << WORKER_MAGIC_1; + conn.to.flush(); + unsigned int magic = readInt(conn.from); + if (magic != WORKER_MAGIC_2) { + throw Error("protocol mismatch"); + } + + conn.from >> conn.daemonVersion; + if (GET_PROTOCOL_MAJOR(conn.daemonVersion) != + GET_PROTOCOL_MAJOR(PROTOCOL_VERSION)) { + throw Error("Nix daemon protocol version not supported"); + } + if (GET_PROTOCOL_MINOR(conn.daemonVersion) < 10) { + throw Error("the Nix daemon version is too old"); + } + conn.to << PROTOCOL_VERSION; + + if (GET_PROTOCOL_MINOR(conn.daemonVersion) >= 14) { + int cpu = sameMachine() && settings.lockCPU ? lockToCurrentCPU() : -1; + if (cpu != -1) { + conn.to << 1 << cpu; + } else { + conn.to << 0; + } + } + + if (GET_PROTOCOL_MINOR(conn.daemonVersion) >= 11) { + conn.to << 0u; + } + + auto ex = conn.processStderr(); + if (ex) { + std::rethrow_exception(ex); + } + } catch (Error& e) { + throw Error("cannot open connection to remote store '%s': %s", getUri(), + e.what()); + } + + setOptions(conn); +} + +void RemoteStore::setOptions(Connection& conn) { + conn.to << wopSetOptions << static_cast<uint64_t>(settings.keepFailed) + << static_cast<uint64_t>(settings.keepGoing) + // TODO(tazjin): Remove the verbosity stuff here. + << static_cast<uint64_t>(settings.tryFallback) << compat::kInfo + << settings.maxBuildJobs << settings.maxSilentTime + << 1u + // TODO(tazjin): what behaviour does this toggle remotely? + << (settings.verboseBuild ? compat::kError : compat::kVomit) + << 0 // obsolete log type + << 0 /* obsolete print build trace */ + << settings.buildCores + << static_cast<uint64_t>(settings.useSubstitutes); + + if (GET_PROTOCOL_MINOR(conn.daemonVersion) >= 12) { + std::map<std::string, Config::SettingInfo> overrides; + globalConfig.getSettings(overrides, true); + overrides.erase(settings.keepFailed.name); + overrides.erase(settings.keepGoing.name); + overrides.erase(settings.tryFallback.name); + overrides.erase(settings.maxBuildJobs.name); + overrides.erase(settings.maxSilentTime.name); + overrides.erase(settings.buildCores.name); + overrides.erase(settings.useSubstitutes.name); + overrides.erase(settings.showTrace.name); + conn.to << overrides.size(); + for (auto& i : overrides) { + conn.to << i.first << i.second.value; + } + } + + auto ex = conn.processStderr(); + if (ex) { + std::rethrow_exception(ex); + } +} + +/* A wrapper around Pool<RemoteStore::Connection>::Handle that marks + the connection as bad (causing it to be closed) if a non-daemon + exception is thrown before the handle is closed. Such an exception + causes a deviation from the expected protocol and therefore a + desynchronization between the client and daemon. */ +struct ConnectionHandle { + Pool<RemoteStore::Connection>::Handle handle; + bool daemonException = false; + + explicit ConnectionHandle(Pool<RemoteStore::Connection>::Handle&& handle) + : handle(std::move(handle)) {} + + ConnectionHandle(ConnectionHandle&& h) : handle(std::move(h.handle)) {} + + ~ConnectionHandle() { + if (!daemonException && (std::uncaught_exceptions() != 0)) { + handle.markBad(); + // TODO(tazjin): are these types of things supposed to be DEBUG? + DLOG(INFO) << "closing daemon connection because of an exception"; + } + } + + RemoteStore::Connection* operator->() { return &*handle; } + + void processStderr(Sink* sink = nullptr, Source* source = nullptr) { + auto ex = handle->processStderr(sink, source); + if (ex) { + daemonException = true; + std::rethrow_exception(ex); + } + } +}; + +ConnectionHandle RemoteStore::getConnection() { + return ConnectionHandle(connections->get()); +} + +bool RemoteStore::isValidPathUncached(const Path& path) { + auto conn(getConnection()); + conn->to << wopIsValidPath << path; + conn.processStderr(); + return readInt(conn->from) != 0u; +} + +PathSet RemoteStore::queryValidPaths(const PathSet& paths, + SubstituteFlag maybeSubstitute) { + auto conn(getConnection()); + if (GET_PROTOCOL_MINOR(conn->daemonVersion) < 12) { + PathSet res; + for (auto& i : paths) { + if (isValidPath(i)) { + res.insert(i); + } + } + return res; + } + conn->to << wopQueryValidPaths << paths; + conn.processStderr(); + return readStorePaths<PathSet>(*this, conn->from); +} + +PathSet RemoteStore::queryAllValidPaths() { + auto conn(getConnection()); + conn->to << wopQueryAllValidPaths; + conn.processStderr(); + return readStorePaths<PathSet>(*this, conn->from); +} + +PathSet RemoteStore::querySubstitutablePaths(const PathSet& paths) { + auto conn(getConnection()); + if (GET_PROTOCOL_MINOR(conn->daemonVersion) < 12) { + PathSet res; + for (auto& i : paths) { + conn->to << wopHasSubstitutes << i; + conn.processStderr(); + if (readInt(conn->from) != 0u) { + res.insert(i); + } + } + return res; + } + conn->to << wopQuerySubstitutablePaths << paths; + conn.processStderr(); + return readStorePaths<PathSet>(*this, conn->from); +} + +void RemoteStore::querySubstitutablePathInfos(const PathSet& paths, + SubstitutablePathInfos& infos) { + if (paths.empty()) { + return; + } + + auto conn(getConnection()); + + if (GET_PROTOCOL_MINOR(conn->daemonVersion) < 12) { + for (auto& i : paths) { + SubstitutablePathInfo info; + conn->to << wopQuerySubstitutablePathInfo << i; + conn.processStderr(); + unsigned int reply = readInt(conn->from); + if (reply == 0) { + continue; + } + info.deriver = readString(conn->from); + if (!info.deriver.empty()) { + assertStorePath(info.deriver); + } + info.references = readStorePaths<PathSet>(*this, conn->from); + info.downloadSize = readLongLong(conn->from); + info.narSize = readLongLong(conn->from); + infos[i] = info; + } + + } else { + conn->to << wopQuerySubstitutablePathInfos << paths; + conn.processStderr(); + auto count = readNum<size_t>(conn->from); + for (size_t n = 0; n < count; n++) { + Path path = readStorePath(*this, conn->from); + SubstitutablePathInfo& info(infos[path]); + info.deriver = readString(conn->from); + if (!info.deriver.empty()) { + assertStorePath(info.deriver); + } + info.references = readStorePaths<PathSet>(*this, conn->from); + info.downloadSize = readLongLong(conn->from); + info.narSize = readLongLong(conn->from); + } + } +} + +void RemoteStore::queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept { + try { + std::shared_ptr<ValidPathInfo> info; + { + auto conn(getConnection()); + conn->to << wopQueryPathInfo << path; + try { + conn.processStderr(); + } catch (Error& e) { + // Ugly backwards compatibility hack. + if (e.msg().find("is not valid") != std::string::npos) { + throw InvalidPath(e.what()); + } + throw; + } + if (GET_PROTOCOL_MINOR(conn->daemonVersion) >= 17) { + bool valid; + conn->from >> valid; + if (!valid) { + throw InvalidPath(format("path '%s' is not valid") % path); + } + } + info = std::make_shared<ValidPathInfo>(); + info->path = path; + info->deriver = readString(conn->from); + if (!info->deriver.empty()) { + assertStorePath(info->deriver); + } + info->narHash = Hash(readString(conn->from), htSHA256); + info->references = readStorePaths<PathSet>(*this, conn->from); + conn->from >> info->registrationTime >> info->narSize; + if (GET_PROTOCOL_MINOR(conn->daemonVersion) >= 16) { + conn->from >> info->ultimate; + info->sigs = readStrings<StringSet>(conn->from); + conn->from >> info->ca; + } + } + callback(std::move(info)); + } catch (...) { + callback.rethrow(); + } +} + +void RemoteStore::queryReferrers(const Path& path, PathSet& referrers) { + auto conn(getConnection()); + conn->to << wopQueryReferrers << path; + conn.processStderr(); + auto referrers2 = readStorePaths<PathSet>(*this, conn->from); + referrers.insert(referrers2.begin(), referrers2.end()); +} + +PathSet RemoteStore::queryValidDerivers(const Path& path) { + auto conn(getConnection()); + conn->to << wopQueryValidDerivers << path; + conn.processStderr(); + return readStorePaths<PathSet>(*this, conn->from); +} + +PathSet RemoteStore::queryDerivationOutputs(const Path& path) { + auto conn(getConnection()); + conn->to << wopQueryDerivationOutputs << path; + conn.processStderr(); + return readStorePaths<PathSet>(*this, conn->from); +} + +PathSet RemoteStore::queryDerivationOutputNames(const Path& path) { + auto conn(getConnection()); + conn->to << wopQueryDerivationOutputNames << path; + conn.processStderr(); + return readStrings<PathSet>(conn->from); +} + +Path RemoteStore::queryPathFromHashPart(const string& hashPart) { + auto conn(getConnection()); + conn->to << wopQueryPathFromHashPart << hashPart; + conn.processStderr(); + Path path = readString(conn->from); + if (!path.empty()) { + assertStorePath(path); + } + return path; +} + +void RemoteStore::addToStore(const ValidPathInfo& info, Source& source, + RepairFlag repair, CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) { + auto conn(getConnection()); + + if (GET_PROTOCOL_MINOR(conn->daemonVersion) < 18) { + conn->to << wopImportPaths; + + auto source2 = sinkToSource([&](Sink& sink) { + sink << 1 // == path follows + ; + copyNAR(source, sink); + sink << exportMagic << info.path << info.references << info.deriver + << 0 // == no legacy signature + << 0 // == no path follows + ; + }); + + conn.processStderr(nullptr, source2.get()); + + auto importedPaths = readStorePaths<PathSet>(*this, conn->from); + assert(importedPaths.size() <= 1); + } + + else { + conn->to << wopAddToStoreNar << info.path << info.deriver + << info.narHash.to_string(Base16, false) << info.references + << info.registrationTime << info.narSize << info.ultimate + << info.sigs << info.ca << repair << !checkSigs; + bool tunnel = GET_PROTOCOL_MINOR(conn->daemonVersion) >= 21; + if (!tunnel) { + copyNAR(source, conn->to); + } + conn.processStderr(nullptr, tunnel ? &source : nullptr); + } +} + +Path RemoteStore::addToStore(const string& name, const Path& _srcPath, + bool recursive, HashType hashAlgo, + PathFilter& filter, RepairFlag repair) { + if (repair != 0u) { + throw Error( + "repairing is not supported when building through the Nix daemon"); + } + + auto conn(getConnection()); + + Path srcPath(absPath(_srcPath)); + + conn->to << wopAddToStore << name + << ((hashAlgo == htSHA256 && recursive) + ? 0 + : 1) /* backwards compatibility hack */ + << (recursive ? 1 : 0) << printHashType(hashAlgo); + + try { + conn->to.written = 0; + conn->to.warn = true; + connections->incCapacity(); + { + Finally cleanup([&]() { connections->decCapacity(); }); + dumpPath(srcPath, conn->to, filter); + } + conn->to.warn = false; + conn.processStderr(); + } catch (SysError& e) { + /* Daemon closed while we were sending the path. Probably OOM + or I/O error. */ + if (e.errNo == EPIPE) { + try { + conn.processStderr(); + } catch (EndOfFile& e) { + } + } + throw; + } + + return readStorePath(*this, conn->from); +} + +Path RemoteStore::addTextToStore(const string& name, const string& s, + const PathSet& references, RepairFlag repair) { + if (repair != 0u) { + throw Error( + "repairing is not supported when building through the Nix daemon"); + } + + auto conn(getConnection()); + conn->to << wopAddTextToStore << name << s << references; + + conn.processStderr(); + return readStorePath(*this, conn->from); +} + +void RemoteStore::buildPaths(const PathSet& drvPaths, BuildMode buildMode) { + auto conn(getConnection()); + conn->to << wopBuildPaths; + if (GET_PROTOCOL_MINOR(conn->daemonVersion) >= 13) { + conn->to << drvPaths; + if (GET_PROTOCOL_MINOR(conn->daemonVersion) >= 15) { + conn->to << buildMode; + } else + /* Old daemons did not take a 'buildMode' parameter, so we + need to validate it here on the client side. */ + if (buildMode != bmNormal) { + throw Error( + "repairing or checking is not supported when building through the " + "Nix daemon"); + } + } else { + /* For backwards compatibility with old daemons, strip output + identifiers. */ + PathSet drvPaths2; + for (auto& i : drvPaths) { + drvPaths2.insert(string(i, 0, i.find('!'))); + } + conn->to << drvPaths2; + } + conn.processStderr(); + readInt(conn->from); +} + +BuildResult RemoteStore::buildDerivation(const Path& drvPath, + const BasicDerivation& drv, + BuildMode buildMode) { + auto conn(getConnection()); + conn->to << wopBuildDerivation << drvPath << drv << buildMode; + conn.processStderr(); + BuildResult res; + unsigned int status; + conn->from >> status >> res.errorMsg; + res.status = (BuildResult::Status)status; + return res; +} + +void RemoteStore::ensurePath(const Path& path) { + auto conn(getConnection()); + conn->to << wopEnsurePath << path; + conn.processStderr(); + readInt(conn->from); +} + +void RemoteStore::addTempRoot(const Path& path) { + auto conn(getConnection()); + conn->to << wopAddTempRoot << path; + conn.processStderr(); + readInt(conn->from); +} + +void RemoteStore::addIndirectRoot(const Path& path) { + auto conn(getConnection()); + conn->to << wopAddIndirectRoot << path; + conn.processStderr(); + readInt(conn->from); +} + +void RemoteStore::syncWithGC() { + auto conn(getConnection()); + conn->to << wopSyncWithGC; + conn.processStderr(); + readInt(conn->from); +} + +Roots RemoteStore::findRoots(bool censor) { + auto conn(getConnection()); + conn->to << wopFindRoots; + conn.processStderr(); + auto count = readNum<size_t>(conn->from); + Roots result; + while ((count--) != 0u) { + Path link = readString(conn->from); + Path target = readStorePath(*this, conn->from); + result[target].emplace(link); + } + return result; +} + +void RemoteStore::collectGarbage(const GCOptions& options, GCResults& results) { + auto conn(getConnection()); + + conn->to << wopCollectGarbage << options.action << options.pathsToDelete + << static_cast<uint64_t>(options.ignoreLiveness) + << options.maxFreed + /* removed options */ + << 0 << 0 << 0; + + conn.processStderr(); + + results.paths = readStrings<PathSet>(conn->from); + results.bytesFreed = readLongLong(conn->from); + readLongLong(conn->from); // obsolete + + { + auto state_(Store::state.lock()); + state_->pathInfoCache.clear(); + } +} + +void RemoteStore::optimiseStore() { + auto conn(getConnection()); + conn->to << wopOptimiseStore; + conn.processStderr(); + readInt(conn->from); +} + +bool RemoteStore::verifyStore(bool checkContents, RepairFlag repair) { + auto conn(getConnection()); + conn->to << wopVerifyStore << static_cast<uint64_t>(checkContents) << repair; + conn.processStderr(); + return readInt(conn->from) != 0u; +} + +void RemoteStore::addSignatures(const Path& storePath, const StringSet& sigs) { + auto conn(getConnection()); + conn->to << wopAddSignatures << storePath << sigs; + conn.processStderr(); + readInt(conn->from); +} + +void RemoteStore::queryMissing(const PathSet& targets, PathSet& willBuild, + PathSet& willSubstitute, PathSet& unknown, + unsigned long long& downloadSize, + unsigned long long& narSize) { + { + auto conn(getConnection()); + if (GET_PROTOCOL_MINOR(conn->daemonVersion) < 19) { + // Don't hold the connection handle in the fallback case + // to prevent a deadlock. + goto fallback; + } + conn->to << wopQueryMissing << targets; + conn.processStderr(); + willBuild = readStorePaths<PathSet>(*this, conn->from); + willSubstitute = readStorePaths<PathSet>(*this, conn->from); + unknown = readStorePaths<PathSet>(*this, conn->from); + conn->from >> downloadSize >> narSize; + return; + } + +fallback: + return Store::queryMissing(targets, willBuild, willSubstitute, unknown, + downloadSize, narSize); +} + +void RemoteStore::connect() { auto conn(getConnection()); } + +unsigned int RemoteStore::getProtocol() { + auto conn(connections->get()); + return conn->daemonVersion; +} + +void RemoteStore::flushBadConnections() { connections->flushBad(); } + +RemoteStore::Connection::~Connection() { + try { + to.flush(); + } catch (...) { + ignoreException(); + } +} + +std::exception_ptr RemoteStore::Connection::processStderr(Sink* sink, + Source* source) { + to.flush(); + + while (true) { + auto msg = readNum<uint64_t>(from); + + if (msg == STDERR_WRITE) { + string s = readString(from); + if (sink == nullptr) { + throw Error("no sink"); + } + (*sink)(s); + } + + else if (msg == STDERR_READ) { + if (source == nullptr) { + throw Error("no source"); + } + auto len = readNum<size_t>(from); + auto buf = std::make_unique<unsigned char[]>(len); + writeString(buf.get(), source->read(buf.get(), len), to); + to.flush(); + } + + else if (msg == STDERR_ERROR) { + string error = readString(from); + unsigned int status = readInt(from); + return std::make_exception_ptr(Error(status, error)); + } + + else if (msg == STDERR_NEXT) { + LOG(ERROR) << chomp(readString(from)); + } + + else if (msg == STDERR_START_ACTIVITY) { + LOG(INFO) << readString(from); + } + + else if (msg == STDERR_LAST) { + break; + } + + else { + throw Error("got unknown message type %x from Nix daemon", msg); + } + } + + return nullptr; +} + +static std::string uriScheme = "unix://"; + +static RegisterStoreImplementation regStore( + [](const std::string& uri, + const Store::Params& params) -> std::shared_ptr<Store> { + if (std::string(uri, 0, uriScheme.size()) != uriScheme) { + return nullptr; + } + return std::make_shared<UDSRemoteStore>( + std::string(uri, uriScheme.size()), params); + }); + +} // namespace nix diff --git a/third_party/nix/src/libstore/remote-store.hh b/third_party/nix/src/libstore/remote-store.hh new file mode 100644 index 0000000000..dc44cd32ac --- /dev/null +++ b/third_party/nix/src/libstore/remote-store.hh @@ -0,0 +1,153 @@ +#pragma once + +#include <limits> +#include <string> + +#include "store-api.hh" + +namespace nix { + +class Pipe; +class Pid; +struct FdSink; +struct FdSource; +template <typename T> +class Pool; +struct ConnectionHandle; + +/* FIXME: RemoteStore is a misnomer - should be something like + DaemonStore. */ +class RemoteStore : public virtual Store { + public: + const Setting<int> maxConnections{ + (Store*)this, 1, "max-connections", + "maximum number of concurrent connections to the Nix daemon"}; + + const Setting<unsigned int> maxConnectionAge{ + (Store*)this, std::numeric_limits<unsigned int>::max(), + "max-connection-age", "number of seconds to reuse a connection"}; + + virtual bool sameMachine() = 0; + + RemoteStore(const Params& params); + + /* Implementations of abstract store API methods. */ + + bool isValidPathUncached(const Path& path) override; + + PathSet queryValidPaths(const PathSet& paths, SubstituteFlag maybeSubstitute = + NoSubstitute) override; + + PathSet queryAllValidPaths() override; + + void queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept override; + + void queryReferrers(const Path& path, PathSet& referrers) override; + + PathSet queryValidDerivers(const Path& path) override; + + PathSet queryDerivationOutputs(const Path& path) override; + + StringSet queryDerivationOutputNames(const Path& path) override; + + Path queryPathFromHashPart(const string& hashPart) override; + + PathSet querySubstitutablePaths(const PathSet& paths) override; + + void querySubstitutablePathInfos(const PathSet& paths, + SubstitutablePathInfos& infos) override; + + void addToStore(const ValidPathInfo& info, Source& source, RepairFlag repair, + CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) override; + + Path addToStore(const string& name, const Path& srcPath, + bool recursive = true, HashType hashAlgo = htSHA256, + PathFilter& filter = defaultPathFilter, + RepairFlag repair = NoRepair) override; + + Path addTextToStore(const string& name, const string& s, + const PathSet& references, RepairFlag repair) override; + + void buildPaths(const PathSet& paths, BuildMode buildMode) override; + + BuildResult buildDerivation(const Path& drvPath, const BasicDerivation& drv, + BuildMode buildMode) override; + + void ensurePath(const Path& path) override; + + void addTempRoot(const Path& path) override; + + void addIndirectRoot(const Path& path) override; + + void syncWithGC() override; + + Roots findRoots(bool censor) override; + + void collectGarbage(const GCOptions& options, GCResults& results) override; + + void optimiseStore() override; + + bool verifyStore(bool checkContents, RepairFlag repair) override; + + void addSignatures(const Path& storePath, const StringSet& sigs) override; + + void queryMissing(const PathSet& targets, PathSet& willBuild, + PathSet& willSubstitute, PathSet& unknown, + unsigned long long& downloadSize, + unsigned long long& narSize) override; + + void connect() override; + + unsigned int getProtocol() override; + + void flushBadConnections(); + + protected: + struct Connection { + AutoCloseFD fd; + FdSink to; + FdSource from; + unsigned int daemonVersion; + std::chrono::time_point<std::chrono::steady_clock> startTime; + + virtual ~Connection(); + + std::exception_ptr processStderr(Sink* sink = 0, Source* source = 0); + }; + + ref<Connection> openConnectionWrapper(); + + virtual ref<Connection> openConnection() = 0; + + void initConnection(Connection& conn); + + ref<Pool<Connection>> connections; + + virtual void setOptions(Connection& conn); + + ConnectionHandle getConnection(); + + friend struct ConnectionHandle; + + private: + std::atomic_bool failed{false}; +}; + +class UDSRemoteStore : public LocalFSStore, public RemoteStore { + public: + UDSRemoteStore(const Params& params); + UDSRemoteStore(std::string path, const Params& params); + + std::string getUri() override; + + bool sameMachine() { return true; } + + private: + ref<RemoteStore::Connection> openConnection() override; + std::optional<std::string> path; +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/s3-binary-cache-store.cc b/third_party/nix/src/libstore/s3-binary-cache-store.cc new file mode 100644 index 0000000000..483ddc19a3 --- /dev/null +++ b/third_party/nix/src/libstore/s3-binary-cache-store.cc @@ -0,0 +1,428 @@ +#if ENABLE_S3 + +#include "s3-binary-cache-store.hh" + +#include <aws/core/Aws.h> +#include <aws/core/VersionConfig.h> +#include <aws/core/auth/AWSCredentialsProvider.h> +#include <aws/core/auth/AWSCredentialsProviderChain.h> +#include <aws/core/client/ClientConfiguration.h> +#include <aws/core/client/DefaultRetryStrategy.h> +#include <aws/core/utils/logging/FormattedLogSystem.h> +#include <aws/core/utils/logging/LogMacros.h> +#include <aws/core/utils/threading/Executor.h> +#include <aws/s3/S3Client.h> +#include <aws/s3/model/GetObjectRequest.h> +#include <aws/s3/model/HeadObjectRequest.h> +#include <aws/s3/model/ListObjectsRequest.h> +#include <aws/s3/model/PutObjectRequest.h> +#include <aws/transfer/TransferManager.h> + +#include "compression.hh" +#include "download.hh" +#include "globals.hh" +#include "istringstream_nocopy.hh" +#include "nar-info-disk-cache.hh" +#include "nar-info.hh" +#include "s3.hh" + +using namespace Aws::Transfer; + +namespace nix { + +struct S3Error : public Error { + Aws::S3::S3Errors err; + S3Error(Aws::S3::S3Errors err, const FormatOrString& fs) + : Error(fs), err(err){}; +}; + +/* Helper: given an Outcome<R, E>, return R in case of success, or + throw an exception in case of an error. */ +template <typename R, typename E> +R&& checkAws(const FormatOrString& fs, Aws::Utils::Outcome<R, E>&& outcome) { + if (!outcome.IsSuccess()) + throw S3Error(outcome.GetError().GetErrorType(), + fs.s + ": " + outcome.GetError().GetMessage()); + return outcome.GetResultWithOwnership(); +} + +class AwsLogger : public Aws::Utils::Logging::FormattedLogSystem { + using Aws::Utils::Logging::FormattedLogSystem::FormattedLogSystem; + + void ProcessFormattedStatement(Aws::String&& statement) override { + debug("AWS: %s", chomp(statement)); + } +}; + +static void initAWS() { + static std::once_flag flag; + std::call_once(flag, []() { + Aws::SDKOptions options; + + /* We install our own OpenSSL locking function (see + shared.cc), so don't let aws-sdk-cpp override it. */ + options.cryptoOptions.initAndCleanupOpenSSL = false; + + if (verbosity >= lvlDebug) { + options.loggingOptions.logLevel = + verbosity == lvlDebug ? Aws::Utils::Logging::LogLevel::Debug + : Aws::Utils::Logging::LogLevel::Trace; + options.loggingOptions.logger_create_fn = [options]() { + return std::make_shared<AwsLogger>(options.loggingOptions.logLevel); + }; + } + + Aws::InitAPI(options); + }); +} + +S3Helper::S3Helper(const string& profile, const string& region, + const string& scheme, const string& endpoint) + : config(makeConfig(region, scheme, endpoint)), + client(make_ref<Aws::S3::S3Client>( + profile == "" + ? std::dynamic_pointer_cast<Aws::Auth::AWSCredentialsProvider>( + std::make_shared< + Aws::Auth::DefaultAWSCredentialsProviderChain>()) + : std::dynamic_pointer_cast<Aws::Auth::AWSCredentialsProvider>( + std::make_shared< + Aws::Auth::ProfileConfigFileAWSCredentialsProvider>( + profile.c_str())), + *config, +// FIXME: https://github.com/aws/aws-sdk-cpp/issues/759 +#if AWS_VERSION_MAJOR == 1 && AWS_VERSION_MINOR < 3 + false, +#else + Aws::Client::AWSAuthV4Signer::PayloadSigningPolicy::Never, +#endif + endpoint.empty())) { +} + +/* Log AWS retries. */ +class RetryStrategy : public Aws::Client::DefaultRetryStrategy { + bool ShouldRetry(const Aws::Client::AWSError<Aws::Client::CoreErrors>& error, + long attemptedRetries) const override { + auto retry = + Aws::Client::DefaultRetryStrategy::ShouldRetry(error, attemptedRetries); + if (retry) + printError("AWS error '%s' (%s), will retry in %d ms", + error.GetExceptionName(), error.GetMessage(), + CalculateDelayBeforeNextRetry(error, attemptedRetries)); + return retry; + } +}; + +ref<Aws::Client::ClientConfiguration> S3Helper::makeConfig( + const string& region, const string& scheme, const string& endpoint) { + initAWS(); + auto res = make_ref<Aws::Client::ClientConfiguration>(); + res->region = region; + if (!scheme.empty()) { + res->scheme = Aws::Http::SchemeMapper::FromString(scheme.c_str()); + } + if (!endpoint.empty()) { + res->endpointOverride = endpoint; + } + res->requestTimeoutMs = 600 * 1000; + res->connectTimeoutMs = 5 * 1000; + res->retryStrategy = std::make_shared<RetryStrategy>(); + res->caFile = settings.caFile; + return res; +} + +S3Helper::DownloadResult S3Helper::getObject(const std::string& bucketName, + const std::string& key) { + debug("fetching 's3://%s/%s'...", bucketName, key); + + auto request = + Aws::S3::Model::GetObjectRequest().WithBucket(bucketName).WithKey(key); + + request.SetResponseStreamFactory( + [&]() { return Aws::New<std::stringstream>("STRINGSTREAM"); }); + + DownloadResult res; + + auto now1 = std::chrono::steady_clock::now(); + + try { + auto result = checkAws(fmt("AWS error fetching '%s'", key), + client->GetObject(request)); + + res.data = + decompress(result.GetContentEncoding(), + dynamic_cast<std::stringstream&>(result.GetBody()).str()); + + } catch (S3Error& e) { + if (e.err != Aws::S3::S3Errors::NO_SUCH_KEY) { + throw; + } + } + + auto now2 = std::chrono::steady_clock::now(); + + res.durationMs = + std::chrono::duration_cast<std::chrono::milliseconds>(now2 - now1) + .count(); + + return res; +} + +struct S3BinaryCacheStoreImpl : public S3BinaryCacheStore { + const Setting<std::string> profile{ + this, "", "profile", "The name of the AWS configuration profile to use."}; + const Setting<std::string> region{ + this, Aws::Region::US_EAST_1, "region", {"aws-region"}}; + const Setting<std::string> scheme{ + this, "", "scheme", + "The scheme to use for S3 requests, https by default."}; + const Setting<std::string> endpoint{ + this, "", "endpoint", + "An optional override of the endpoint to use when talking to S3."}; + const Setting<std::string> narinfoCompression{ + this, "", "narinfo-compression", "compression method for .narinfo files"}; + const Setting<std::string> lsCompression{this, "", "ls-compression", + "compression method for .ls files"}; + const Setting<std::string> logCompression{ + this, "", "log-compression", "compression method for log/* files"}; + const Setting<bool> multipartUpload{this, false, "multipart-upload", + "whether to use multi-part uploads"}; + const Setting<uint64_t> bufferSize{ + this, 5 * 1024 * 1024, "buffer-size", + "size (in bytes) of each part in multi-part uploads"}; + + std::string bucketName; + + Stats stats; + + S3Helper s3Helper; + + S3BinaryCacheStoreImpl(const Params& params, const std::string& bucketName) + : S3BinaryCacheStore(params), + bucketName(bucketName), + s3Helper(profile, region, scheme, endpoint) { + diskCache = getNarInfoDiskCache(); + } + + std::string getUri() override { return "s3://" + bucketName; } + + void init() override { + if (!diskCache->cacheExists(getUri(), wantMassQuery_, priority)) { + BinaryCacheStore::init(); + + diskCache->createCache(getUri(), storeDir, wantMassQuery_, priority); + } + } + + const Stats& getS3Stats() override { return stats; } + + /* This is a specialisation of isValidPath() that optimistically + fetches the .narinfo file, rather than first checking for its + existence via a HEAD request. Since .narinfos are small, doing + a GET is unlikely to be slower than HEAD. */ + bool isValidPathUncached(const Path& storePath) override { + try { + queryPathInfo(storePath); + return true; + } catch (InvalidPath& e) { + return false; + } + } + + bool fileExists(const std::string& path) override { + stats.head++; + + auto res = s3Helper.client->HeadObject(Aws::S3::Model::HeadObjectRequest() + .WithBucket(bucketName) + .WithKey(path)); + + if (!res.IsSuccess()) { + auto& error = res.GetError(); + if (error.GetErrorType() == Aws::S3::S3Errors::RESOURCE_NOT_FOUND || + error.GetErrorType() == Aws::S3::S3Errors::NO_SUCH_KEY + // If bucket listing is disabled, 404s turn into 403s + || error.GetErrorType() == Aws::S3::S3Errors::ACCESS_DENIED) + return false; + throw Error(format("AWS error fetching '%s': %s") % path % + error.GetMessage()); + } + + return true; + } + + std::shared_ptr<TransferManager> transferManager; + std::once_flag transferManagerCreated; + + void uploadFile(const std::string& path, const std::string& data, + const std::string& mimeType, + const std::string& contentEncoding) { + auto stream = std::make_shared<istringstream_nocopy>(data); + + auto maxThreads = std::thread::hardware_concurrency(); + + static std::shared_ptr<Aws::Utils::Threading::PooledThreadExecutor> + executor = + std::make_shared<Aws::Utils::Threading::PooledThreadExecutor>( + maxThreads); + + std::call_once(transferManagerCreated, [&]() { + if (multipartUpload) { + TransferManagerConfiguration transferConfig(executor.get()); + + transferConfig.s3Client = s3Helper.client; + transferConfig.bufferSize = bufferSize; + + transferConfig.uploadProgressCallback = + [](const TransferManager* transferManager, + const std::shared_ptr<const TransferHandle>& transferHandle) { + // FIXME: find a way to properly abort the multipart upload. + // checkInterrupt(); + debug("upload progress ('%s'): '%d' of '%d' bytes", + transferHandle->GetKey(), + transferHandle->GetBytesTransferred(), + transferHandle->GetBytesTotalSize()); + }; + + transferManager = TransferManager::Create(transferConfig); + } + }); + + auto now1 = std::chrono::steady_clock::now(); + + if (transferManager) { + if (contentEncoding != "") + throw Error( + "setting a content encoding is not supported with S3 multi-part " + "uploads"); + + std::shared_ptr<TransferHandle> transferHandle = + transferManager->UploadFile(stream, bucketName, path, mimeType, + Aws::Map<Aws::String, Aws::String>(), + nullptr /*, contentEncoding */); + + transferHandle->WaitUntilFinished(); + + if (transferHandle->GetStatus() == TransferStatus::FAILED) + throw Error("AWS error: failed to upload 's3://%s/%s': %s", bucketName, + path, transferHandle->GetLastError().GetMessage()); + + if (transferHandle->GetStatus() != TransferStatus::COMPLETED) + throw Error( + "AWS error: transfer status of 's3://%s/%s' in unexpected state", + bucketName, path); + + } else { + auto request = Aws::S3::Model::PutObjectRequest() + .WithBucket(bucketName) + .WithKey(path); + + request.SetContentType(mimeType); + + if (contentEncoding != "") { + request.SetContentEncoding(contentEncoding); + } + + auto stream = std::make_shared<istringstream_nocopy>(data); + + request.SetBody(stream); + + auto result = checkAws(fmt("AWS error uploading '%s'", path), + s3Helper.client->PutObject(request)); + } + + auto now2 = std::chrono::steady_clock::now(); + + auto duration = + std::chrono::duration_cast<std::chrono::milliseconds>(now2 - now1) + .count(); + + printInfo(format("uploaded 's3://%1%/%2%' (%3% bytes) in %4% ms") % + bucketName % path % data.size() % duration); + + stats.putTimeMs += duration; + stats.putBytes += data.size(); + stats.put++; + } + + void upsertFile(const std::string& path, const std::string& data, + const std::string& mimeType) override { + if (narinfoCompression != "" && hasSuffix(path, ".narinfo")) + uploadFile(path, *compress(narinfoCompression, data), mimeType, + narinfoCompression); + else if (lsCompression != "" && hasSuffix(path, ".ls")) + uploadFile(path, *compress(lsCompression, data), mimeType, lsCompression); + else if (logCompression != "" && hasPrefix(path, "log/")) + uploadFile(path, *compress(logCompression, data), mimeType, + logCompression); + else + uploadFile(path, data, mimeType, ""); + } + + void getFile(const std::string& path, Sink& sink) override { + stats.get++; + + // FIXME: stream output to sink. + auto res = s3Helper.getObject(bucketName, path); + + stats.getBytes += res.data ? res.data->size() : 0; + stats.getTimeMs += res.durationMs; + + if (res.data) { + printTalkative("downloaded 's3://%s/%s' (%d bytes) in %d ms", bucketName, + path, res.data->size(), res.durationMs); + + sink((unsigned char*)res.data->data(), res.data->size()); + } else + throw NoSuchBinaryCacheFile( + "file '%s' does not exist in binary cache '%s'", path, getUri()); + } + + PathSet queryAllValidPaths() override { + PathSet paths; + std::string marker; + + do { + debug(format("listing bucket 's3://%s' from key '%s'...") % bucketName % + marker); + + auto res = checkAws( + format("AWS error listing bucket '%s'") % bucketName, + s3Helper.client->ListObjects(Aws::S3::Model::ListObjectsRequest() + .WithBucket(bucketName) + .WithDelimiter("/") + .WithMarker(marker))); + + auto& contents = res.GetContents(); + + debug(format("got %d keys, next marker '%s'") % contents.size() % + res.GetNextMarker()); + + for (auto object : contents) { + auto& key = object.GetKey(); + if (key.size() != 40 || !hasSuffix(key, ".narinfo")) { + continue; + } + paths.insert(storeDir + "/" + key.substr(0, key.size() - 8)); + } + + marker = res.GetNextMarker(); + } while (!marker.empty()); + + return paths; + } +}; + +static RegisterStoreImplementation regStore( + [](const std::string& uri, + const Store::Params& params) -> std::shared_ptr<Store> { + if (std::string(uri, 0, 5) != "s3://") { + return 0; + } + auto store = + std::make_shared<S3BinaryCacheStoreImpl>(params, std::string(uri, 5)); + store->init(); + return store; + }); + +} // namespace nix + +#endif diff --git a/third_party/nix/src/libstore/s3-binary-cache-store.hh b/third_party/nix/src/libstore/s3-binary-cache-store.hh new file mode 100644 index 0000000000..24cb67721a --- /dev/null +++ b/third_party/nix/src/libstore/s3-binary-cache-store.hh @@ -0,0 +1,27 @@ +#pragma once + +#include <atomic> + +#include "binary-cache-store.hh" + +namespace nix { + +class S3BinaryCacheStore : public BinaryCacheStore { + protected: + S3BinaryCacheStore(const Params& params) : BinaryCacheStore(params) {} + + public: + struct Stats { + std::atomic<uint64_t> put{0}; + std::atomic<uint64_t> putBytes{0}; + std::atomic<uint64_t> putTimeMs{0}; + std::atomic<uint64_t> get{0}; + std::atomic<uint64_t> getBytes{0}; + std::atomic<uint64_t> getTimeMs{0}; + std::atomic<uint64_t> head{0}; + }; + + virtual const Stats& getS3Stats() = 0; +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/s3.hh b/third_party/nix/src/libstore/s3.hh new file mode 100644 index 0000000000..09935fabed --- /dev/null +++ b/third_party/nix/src/libstore/s3.hh @@ -0,0 +1,42 @@ +#pragma once + +#if ENABLE_S3 + +#include "ref.hh" + +namespace Aws { +namespace Client { +class ClientConfiguration; +} +} // namespace Aws +namespace Aws { +namespace S3 { +class S3Client; +} +} // namespace Aws + +namespace nix { + +struct S3Helper { + ref<Aws::Client::ClientConfiguration> config; + ref<Aws::S3::S3Client> client; + + S3Helper(const std::string& profile, const std::string& region, + const std::string& scheme, const std::string& endpoint); + + ref<Aws::Client::ClientConfiguration> makeConfig(const std::string& region, + const std::string& scheme, + const std::string& endpoint); + + struct DownloadResult { + std::shared_ptr<std::string> data; + unsigned int durationMs; + }; + + DownloadResult getObject(const std::string& bucketName, + const std::string& key); +}; + +} // namespace nix + +#endif diff --git a/third_party/nix/src/libstore/sandbox-defaults.sb b/third_party/nix/src/libstore/sandbox-defaults.sb new file mode 100644 index 0000000000..0299d1ee45 --- /dev/null +++ b/third_party/nix/src/libstore/sandbox-defaults.sb @@ -0,0 +1,87 @@ +(define TMPDIR (param "_GLOBAL_TMP_DIR")) + +(deny default) + +; Disallow creating setuid/setgid binaries, since that +; would allow breaking build user isolation. +(deny file-write-setugid) + +; Allow forking. +(allow process-fork) + +; Allow reading system information like #CPUs, etc. +(allow sysctl-read) + +; Allow POSIX semaphores and shared memory. +(allow ipc-posix*) + +; Allow socket creation. +(allow system-socket) + +; Allow sending signals within the sandbox. +(allow signal (target same-sandbox)) + +; Allow getpwuid. +(allow mach-lookup (global-name "com.apple.system.opendirectoryd.libinfo")) + +; Access to /tmp. +; The network-outbound/network-inbound ones are for unix domain sockets, which +; we allow access to in TMPDIR (but if we allow them more broadly, you could in +; theory escape the sandbox) +(allow file* process-exec network-outbound network-inbound + (literal "/tmp") (subpath TMPDIR)) + +; Some packages like to read the system version. +(allow file-read* (literal "/System/Library/CoreServices/SystemVersion.plist")) + +; Without this line clang cannot write to /dev/null, breaking some configure tests. +(allow file-read-metadata (literal "/dev")) + +; Many packages like to do local networking in their test suites, but let's only +; allow it if the package explicitly asks for it. +(if (param "_ALLOW_LOCAL_NETWORKING") + (begin + (allow network* (local ip) (local tcp) (local udp)) + + ; Allow access to /etc/resolv.conf (which is a symlink to + ; /private/var/run/resolv.conf). + ; TODO: deduplicate with sandbox-network.sb + (allow file-read-metadata + (literal "/var") + (literal "/etc") + (literal "/etc/resolv.conf") + (literal "/private/etc/resolv.conf")) + + (allow file-read* + (literal "/private/var/run/resolv.conf")) + + ; Allow DNS lookups. This is even needed for localhost, which lots of tests rely on + (allow file-read-metadata (literal "/etc/hosts")) + (allow file-read* (literal "/private/etc/hosts")) + (allow network-outbound (remote unix-socket (path-literal "/private/var/run/mDNSResponder"))))) + +; Standard devices. +(allow file* + (literal "/dev/null") + (literal "/dev/random") + (literal "/dev/stdin") + (literal "/dev/stdout") + (literal "/dev/tty") + (literal "/dev/urandom") + (literal "/dev/zero") + (subpath "/dev/fd")) + +; Does nothing, but reduces build noise. +(allow file* (literal "/dev/dtracehelper")) + +; Allow access to zoneinfo since libSystem needs it. +(allow file-read* (subpath "/usr/share/zoneinfo")) + +(allow file-read* (subpath "/usr/share/locale")) + +; This is mostly to get more specific log messages when builds try to +; access something in /etc or /var. +(allow file-read-metadata + (literal "/etc") + (literal "/var") + (literal "/private/var/tmp")) diff --git a/third_party/nix/src/libstore/sandbox-minimal.sb b/third_party/nix/src/libstore/sandbox-minimal.sb new file mode 100644 index 0000000000..65f5108b39 --- /dev/null +++ b/third_party/nix/src/libstore/sandbox-minimal.sb @@ -0,0 +1,5 @@ +(allow default) + +; Disallow creating setuid/setgid binaries, since that +; would allow breaking build user isolation. +(deny file-write-setugid) diff --git a/third_party/nix/src/libstore/sandbox-network.sb b/third_party/nix/src/libstore/sandbox-network.sb new file mode 100644 index 0000000000..56beec761f --- /dev/null +++ b/third_party/nix/src/libstore/sandbox-network.sb @@ -0,0 +1,16 @@ +; Allow local and remote network traffic. +(allow network* (local ip) (remote ip)) + +; Allow access to /etc/resolv.conf (which is a symlink to +; /private/var/run/resolv.conf). +(allow file-read-metadata + (literal "/var") + (literal "/etc") + (literal "/etc/resolv.conf") + (literal "/private/etc/resolv.conf")) + +(allow file-read* + (literal "/private/var/run/resolv.conf")) + +; Allow DNS lookups. +(allow network-outbound (remote unix-socket (path-literal "/private/var/run/mDNSResponder"))) diff --git a/third_party/nix/src/libstore/schema.sql b/third_party/nix/src/libstore/schema.sql new file mode 100644 index 0000000000..09c71a2b8d --- /dev/null +++ b/third_party/nix/src/libstore/schema.sql @@ -0,0 +1,42 @@ +create table if not exists ValidPaths ( + id integer primary key autoincrement not null, + path text unique not null, + hash text not null, + registrationTime integer not null, + deriver text, + narSize integer, + ultimate integer, -- null implies "false" + sigs text, -- space-separated + ca text -- if not null, an assertion that the path is content-addressed; see ValidPathInfo +); + +create table if not exists Refs ( + referrer integer not null, + reference integer not null, + primary key (referrer, reference), + foreign key (referrer) references ValidPaths(id) on delete cascade, + foreign key (reference) references ValidPaths(id) on delete restrict +); + +create index if not exists IndexReferrer on Refs(referrer); +create index if not exists IndexReference on Refs(reference); + +-- Paths can refer to themselves, causing a tuple (N, N) in the Refs +-- table. This causes a deletion of the corresponding row in +-- ValidPaths to cause a foreign key constraint violation (due to `on +-- delete restrict' on the `reference' column). Therefore, explicitly +-- get rid of self-references. +create trigger if not exists DeleteSelfRefs before delete on ValidPaths + begin + delete from Refs where referrer = old.id and reference = old.id; + end; + +create table if not exists DerivationOutputs ( + drv integer not null, + id text not null, -- symbolic output id, usually "out" + path text not null, + primary key (drv, id), + foreign key (drv) references ValidPaths(id) on delete cascade +); + +create index if not exists IndexDerivationOutputs on DerivationOutputs(path); diff --git a/third_party/nix/src/libstore/serve-protocol.hh b/third_party/nix/src/libstore/serve-protocol.hh new file mode 100644 index 0000000000..a07a7ef974 --- /dev/null +++ b/third_party/nix/src/libstore/serve-protocol.hh @@ -0,0 +1,24 @@ +#pragma once + +namespace nix { + +#define SERVE_MAGIC_1 0x390c9deb +#define SERVE_MAGIC_2 0x5452eecb + +#define SERVE_PROTOCOL_VERSION 0x205 +#define GET_PROTOCOL_MAJOR(x) ((x)&0xff00) +#define GET_PROTOCOL_MINOR(x) ((x)&0x00ff) + +typedef enum { + cmdQueryValidPaths = 1, + cmdQueryPathInfos = 2, + cmdDumpStorePath = 3, + cmdImportPaths = 4, + cmdExportPaths = 5, + cmdBuildPaths = 6, + cmdQueryClosure = 7, + cmdBuildDerivation = 8, + cmdAddToStoreNar = 9, +} ServeCommand; + +} // namespace nix diff --git a/third_party/nix/src/libstore/sqlite.cc b/third_party/nix/src/libstore/sqlite.cc new file mode 100644 index 0000000000..2dea952d02 --- /dev/null +++ b/third_party/nix/src/libstore/sqlite.cc @@ -0,0 +1,195 @@ +#include "sqlite.hh" + +#include <atomic> + +#include <glog/logging.h> +#include <sqlite3.h> + +#include "util.hh" + +namespace nix { + +[[noreturn]] void throwSQLiteError(sqlite3* db, const FormatOrString& fs) { + int err = sqlite3_errcode(db); + int exterr = sqlite3_extended_errcode(db); + + auto path = sqlite3_db_filename(db, nullptr); + if (path == nullptr) { + path = "(in-memory)"; + } + + if (err == SQLITE_BUSY || err == SQLITE_PROTOCOL) { + throw SQLiteBusy( + err == SQLITE_PROTOCOL + ? fmt("SQLite database '%s' is busy (SQLITE_PROTOCOL)", path) + : fmt("SQLite database '%s' is busy", path)); + } + throw SQLiteError("%s: %s (in '%s')", fs.s, sqlite3_errstr(exterr), path); +} + +SQLite::SQLite(const Path& path) { + if (sqlite3_open_v2(path.c_str(), &db, + SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE, + nullptr) != SQLITE_OK) { + throw Error(format("cannot open SQLite database '%s'") % path); + } +} + +SQLite::~SQLite() { + try { + if ((db != nullptr) && sqlite3_close(db) != SQLITE_OK) { + throwSQLiteError(db, "closing database"); + } + } catch (...) { + ignoreException(); + } +} + +void SQLite::exec(const std::string& stmt) { + retrySQLite<void>([&]() { + if (sqlite3_exec(db, stmt.c_str(), nullptr, nullptr, nullptr) != + SQLITE_OK) { + throwSQLiteError(db, format("executing SQLite statement '%s'") % stmt); + } + }); +} + +void SQLiteStmt::create(sqlite3* db, const string& sql) { + checkInterrupt(); + assert(!stmt); + if (sqlite3_prepare_v2(db, sql.c_str(), -1, &stmt, nullptr) != SQLITE_OK) { + throwSQLiteError(db, fmt("creating statement '%s'", sql)); + } + this->db = db; + this->sql = sql; +} + +SQLiteStmt::~SQLiteStmt() { + try { + if ((stmt != nullptr) && sqlite3_finalize(stmt) != SQLITE_OK) { + throwSQLiteError(db, fmt("finalizing statement '%s'", sql)); + } + } catch (...) { + ignoreException(); + } +} + +SQLiteStmt::Use::Use(SQLiteStmt& stmt) : stmt(stmt) { + assert(stmt.stmt); + /* Note: sqlite3_reset() returns the error code for the most + recent call to sqlite3_step(). So ignore it. */ + sqlite3_reset(stmt); +} + +SQLiteStmt::Use::~Use() { sqlite3_reset(stmt); } + +SQLiteStmt::Use& SQLiteStmt::Use::operator()(const std::string& value, + bool notNull) { + if (notNull) { + if (sqlite3_bind_text(stmt, curArg++, value.c_str(), -1, + SQLITE_TRANSIENT) != SQLITE_OK) { + throwSQLiteError(stmt.db, "binding argument"); + } + } else { + bind(); + } + return *this; +} + +SQLiteStmt::Use& SQLiteStmt::Use::operator()(int64_t value, bool notNull) { + if (notNull) { + if (sqlite3_bind_int64(stmt, curArg++, value) != SQLITE_OK) { + throwSQLiteError(stmt.db, "binding argument"); + } + } else { + bind(); + } + return *this; +} + +SQLiteStmt::Use& SQLiteStmt::Use::bind() { + if (sqlite3_bind_null(stmt, curArg++) != SQLITE_OK) { + throwSQLiteError(stmt.db, "binding argument"); + } + return *this; +} + +int SQLiteStmt::Use::step() { return sqlite3_step(stmt); } + +void SQLiteStmt::Use::exec() { + int r = step(); + assert(r != SQLITE_ROW); + if (r != SQLITE_DONE) { + throwSQLiteError(stmt.db, fmt("executing SQLite statement '%s'", stmt.sql)); + } +} + +bool SQLiteStmt::Use::next() { + int r = step(); + if (r != SQLITE_DONE && r != SQLITE_ROW) { + throwSQLiteError(stmt.db, fmt("executing SQLite query '%s'", stmt.sql)); + } + return r == SQLITE_ROW; +} + +std::string SQLiteStmt::Use::getStr(int col) { + auto s = (const char*)sqlite3_column_text(stmt, col); + assert(s); + return s; +} + +int64_t SQLiteStmt::Use::getInt(int col) { + // FIXME: detect nulls? + return sqlite3_column_int64(stmt, col); +} + +bool SQLiteStmt::Use::isNull(int col) { + return sqlite3_column_type(stmt, col) == SQLITE_NULL; +} + +SQLiteTxn::SQLiteTxn(sqlite3* db) { + this->db = db; + if (sqlite3_exec(db, "begin;", nullptr, nullptr, nullptr) != SQLITE_OK) { + throwSQLiteError(db, "starting transaction"); + } + active = true; +} + +void SQLiteTxn::commit() { + if (sqlite3_exec(db, "commit;", nullptr, nullptr, nullptr) != SQLITE_OK) { + throwSQLiteError(db, "committing transaction"); + } + active = false; +} + +SQLiteTxn::~SQLiteTxn() { + try { + if (active && + sqlite3_exec(db, "rollback;", nullptr, nullptr, nullptr) != SQLITE_OK) { + throwSQLiteError(db, "aborting transaction"); + } + } catch (...) { + ignoreException(); + } +} + +void handleSQLiteBusy(const SQLiteBusy& e) { + static std::atomic<time_t> lastWarned{0}; + + time_t now = time(nullptr); + + if (now > lastWarned + 10) { + lastWarned = now; + LOG(ERROR) << e.what(); + } + + /* Sleep for a while since retrying the transaction right away + is likely to fail again. */ + checkInterrupt(); + struct timespec t; + t.tv_sec = 0; + t.tv_nsec = (random() % 100) * 1000 * 1000; /* <= 0.1s */ + nanosleep(&t, nullptr); +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/sqlite.hh b/third_party/nix/src/libstore/sqlite.hh new file mode 100644 index 0000000000..298bb574ea --- /dev/null +++ b/third_party/nix/src/libstore/sqlite.hh @@ -0,0 +1,109 @@ +#pragma once + +#include <functional> +#include <string> + +#include "types.hh" + +class sqlite3; +class sqlite3_stmt; + +namespace nix { + +/* RAII wrapper to close a SQLite database automatically. */ +struct SQLite { + sqlite3* db = 0; + SQLite() {} + SQLite(const Path& path); + SQLite(const SQLite& from) = delete; + SQLite& operator=(const SQLite& from) = delete; + SQLite& operator=(SQLite&& from) { + db = from.db; + from.db = 0; + return *this; + } + ~SQLite(); + operator sqlite3*() { return db; } + + void exec(const std::string& stmt); +}; + +/* RAII wrapper to create and destroy SQLite prepared statements. */ +struct SQLiteStmt { + sqlite3* db = 0; + sqlite3_stmt* stmt = 0; + std::string sql; + SQLiteStmt() {} + SQLiteStmt(sqlite3* db, const std::string& sql) { create(db, sql); } + void create(sqlite3* db, const std::string& s); + ~SQLiteStmt(); + operator sqlite3_stmt*() { return stmt; } + + /* Helper for binding / executing statements. */ + class Use { + friend struct SQLiteStmt; + + private: + SQLiteStmt& stmt; + unsigned int curArg = 1; + Use(SQLiteStmt& stmt); + + public: + ~Use(); + + /* Bind the next parameter. */ + Use& operator()(const std::string& value, bool notNull = true); + Use& operator()(int64_t value, bool notNull = true); + Use& bind(); // null + + int step(); + + /* Execute a statement that does not return rows. */ + void exec(); + + /* For statements that return 0 or more rows. Returns true iff + a row is available. */ + bool next(); + + std::string getStr(int col); + int64_t getInt(int col); + bool isNull(int col); + }; + + Use use() { return Use(*this); } +}; + +/* RAII helper that ensures transactions are aborted unless explicitly + committed. */ +struct SQLiteTxn { + bool active = false; + sqlite3* db; + + SQLiteTxn(sqlite3* db); + + void commit(); + + ~SQLiteTxn(); +}; + +MakeError(SQLiteError, Error); +MakeError(SQLiteBusy, SQLiteError); + +[[noreturn]] void throwSQLiteError(sqlite3* db, const FormatOrString& fs); + +void handleSQLiteBusy(const SQLiteBusy& e); + +/* Convenience function for retrying a SQLite transaction when the + database is busy. */ +template <typename T> +T retrySQLite(std::function<T()> fun) { + while (true) { + try { + return fun(); + } catch (SQLiteBusy& e) { + handleSQLiteBusy(e); + } + } +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/ssh-store.cc b/third_party/nix/src/libstore/ssh-store.cc new file mode 100644 index 0000000000..9c49babcf2 --- /dev/null +++ b/third_party/nix/src/libstore/ssh-store.cc @@ -0,0 +1,86 @@ +#include "archive.hh" +#include "pool.hh" +#include "remote-fs-accessor.hh" +#include "remote-store.hh" +#include "ssh.hh" +#include "store-api.hh" +#include "worker-protocol.hh" + +namespace nix { + +static std::string uriScheme = "ssh-ng://"; + +class SSHStore : public RemoteStore { + public: + const Setting<Path> sshKey{(Store*)this, "", "ssh-key", + "path to an SSH private key"}; + const Setting<bool> compress{(Store*)this, false, "compress", + "whether to compress the connection"}; + + SSHStore(const std::string& host, const Params& params) + : Store(params), + RemoteStore(params), + host(host), + master(host, sshKey, + // Use SSH master only if using more than 1 connection. + connections->capacity() > 1, compress) {} + + std::string getUri() override { return uriScheme + host; } + + bool sameMachine() override { return false; } + + void narFromPath(const Path& path, Sink& sink) override; + + ref<FSAccessor> getFSAccessor() override; + + private: + struct Connection : RemoteStore::Connection { + std::unique_ptr<SSHMaster::Connection> sshConn; + }; + + ref<RemoteStore::Connection> openConnection() override; + + std::string host; + + SSHMaster master; + + void setOptions(RemoteStore::Connection& conn) override{ + /* TODO Add a way to explicitly ask for some options to be + forwarded. One option: A way to query the daemon for its + settings, and then a series of params to SSHStore like + forward-cores or forward-overridden-cores that only + override the requested settings. + */ + }; +}; + +void SSHStore::narFromPath(const Path& path, Sink& sink) { + auto conn(connections->get()); + conn->to << wopNarFromPath << path; + conn->processStderr(); + copyNAR(conn->from, sink); +} + +ref<FSAccessor> SSHStore::getFSAccessor() { + return make_ref<RemoteFSAccessor>(ref<Store>(shared_from_this())); +} + +ref<RemoteStore::Connection> SSHStore::openConnection() { + auto conn = make_ref<Connection>(); + conn->sshConn = master.startCommand("nix-daemon --stdio"); + conn->to = FdSink(conn->sshConn->in.get()); + conn->from = FdSource(conn->sshConn->out.get()); + initConnection(*conn); + return conn; +} + +static RegisterStoreImplementation regStore([](const std::string& uri, + const Store::Params& params) + -> std::shared_ptr<Store> { + if (std::string(uri, 0, uriScheme.size()) != uriScheme) { + return nullptr; + } + return std::make_shared<SSHStore>(std::string(uri, uriScheme.size()), params); +}); + +} // namespace nix diff --git a/third_party/nix/src/libstore/ssh.cc b/third_party/nix/src/libstore/ssh.cc new file mode 100644 index 0000000000..06aaf285f1 --- /dev/null +++ b/third_party/nix/src/libstore/ssh.cc @@ -0,0 +1,155 @@ +#include "ssh.hh" + +#include <utility> + +namespace nix { + +SSHMaster::SSHMaster(const std::string& host, std::string keyFile, + bool useMaster, bool compress, int logFD) + : host(host), + fakeSSH(host == "localhost"), + keyFile(std::move(keyFile)), + useMaster(useMaster && !fakeSSH), + compress(compress), + logFD(logFD) { + if (host.empty() || hasPrefix(host, "-")) { + throw Error("invalid SSH host name '%s'", host); + } +} + +void SSHMaster::addCommonSSHOpts(Strings& args) { + for (auto& i : tokenizeString<Strings>(getEnv("NIX_SSHOPTS"))) { + args.push_back(i); + } + if (!keyFile.empty()) { + args.insert(args.end(), {"-i", keyFile}); + } + if (compress) { + args.push_back("-C"); + } +} + +std::unique_ptr<SSHMaster::Connection> SSHMaster::startCommand( + const std::string& command) { + Path socketPath = startMaster(); + + Pipe in; + Pipe out; + in.create(); + out.create(); + + auto conn = std::make_unique<Connection>(); + ProcessOptions options; + options.dieWithParent = false; + + conn->sshPid = startProcess( + [&]() { + restoreSignals(); + + close(in.writeSide.get()); + close(out.readSide.get()); + + if (dup2(in.readSide.get(), STDIN_FILENO) == -1) { + throw SysError("duping over stdin"); + } + if (dup2(out.writeSide.get(), STDOUT_FILENO) == -1) { + throw SysError("duping over stdout"); + } + if (logFD != -1 && dup2(logFD, STDERR_FILENO) == -1) { + throw SysError("duping over stderr"); + } + + Strings args; + + if (fakeSSH) { + args = {"bash", "-c"}; + } else { + args = {"ssh", host, "-x", "-a"}; + addCommonSSHOpts(args); + if (!socketPath.empty()) { + args.insert(args.end(), {"-S", socketPath}); + } + // TODO(tazjin): Abseil verbosity flag + /*if (verbosity >= lvlChatty) { + args.push_back("-v"); + }*/ + } + + args.push_back(command); + execvp(args.begin()->c_str(), stringsToCharPtrs(args).data()); + + // could not exec ssh/bash + throw SysError("unable to execute '%s'", args.front()); + }, + options); + + in.readSide = -1; + out.writeSide = -1; + + conn->out = std::move(out.readSide); + conn->in = std::move(in.writeSide); + + return conn; +} + +Path SSHMaster::startMaster() { + if (!useMaster) { + return ""; + } + + auto state(state_.lock()); + + if (state->sshMaster != -1) { + return state->socketPath; + } + + state->tmpDir = + std::make_unique<AutoDelete>(createTempDir("", "nix", true, true, 0700)); + + state->socketPath = (Path)*state->tmpDir + "/ssh.sock"; + + Pipe out; + out.create(); + + ProcessOptions options; + options.dieWithParent = false; + + state->sshMaster = startProcess( + [&]() { + restoreSignals(); + + close(out.readSide.get()); + + if (dup2(out.writeSide.get(), STDOUT_FILENO) == -1) { + throw SysError("duping over stdout"); + } + + Strings args = {"ssh", host, + "-M", "-N", + "-S", state->socketPath, + "-o", "LocalCommand=echo started", + "-o", "PermitLocalCommand=yes"}; + // if (verbosity >= lvlChatty) { args.push_back("-v"); } + addCommonSSHOpts(args); + execvp(args.begin()->c_str(), stringsToCharPtrs(args).data()); + + throw SysError("unable to execute '%s'", args.front()); + }, + options); + + out.writeSide = -1; + + std::string reply; + try { + reply = readLine(out.readSide.get()); + } catch (EndOfFile& e) { + } + + if (reply != "started") { + throw Error("failed to start SSH master connection to '%s'", host); + } + + return state->socketPath; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/ssh.hh b/third_party/nix/src/libstore/ssh.hh new file mode 100644 index 0000000000..23952ccb12 --- /dev/null +++ b/third_party/nix/src/libstore/ssh.hh @@ -0,0 +1,41 @@ +#pragma once + +#include "sync.hh" +#include "util.hh" + +namespace nix { + +class SSHMaster { + private: + const std::string host; + bool fakeSSH; + const std::string keyFile; + const bool useMaster; + const bool compress; + const int logFD; + + struct State { + Pid sshMaster; + std::unique_ptr<AutoDelete> tmpDir; + Path socketPath; + }; + + Sync<State> state_; + + void addCommonSSHOpts(Strings& args); + + public: + SSHMaster(const std::string& host, std::string keyFile, bool useMaster, + bool compress, int logFD = -1); + + struct Connection { + Pid sshPid; + AutoCloseFD out, in; + }; + + std::unique_ptr<Connection> startCommand(const std::string& command); + + Path startMaster(); +}; + +} // namespace nix diff --git a/third_party/nix/src/libstore/store-api.cc b/third_party/nix/src/libstore/store-api.cc new file mode 100644 index 0000000000..50e9b3b6ea --- /dev/null +++ b/third_party/nix/src/libstore/store-api.cc @@ -0,0 +1,974 @@ +#include "store-api.hh" + +#include <future> +#include <utility> + +#include <glog/logging.h> + +#include "crypto.hh" +#include "derivations.hh" +#include "globals.hh" +#include "json.hh" +#include "nar-info-disk-cache.hh" +#include "thread-pool.hh" +#include "util.hh" + +namespace nix { + +bool Store::isInStore(const Path& path) const { + return isInDir(path, storeDir); +} + +bool Store::isStorePath(const Path& path) const { + return isInStore(path) && + path.size() >= storeDir.size() + 1 + storePathHashLen && + path.find('/', storeDir.size() + 1) == Path::npos; +} + +void Store::assertStorePath(const Path& path) const { + if (!isStorePath(path)) { + throw Error(format("path '%1%' is not in the Nix store") % path); + } +} + +Path Store::toStorePath(const Path& path) const { + if (!isInStore(path)) { + throw Error(format("path '%1%' is not in the Nix store") % path); + } + Path::size_type slash = path.find('/', storeDir.size() + 1); + if (slash == Path::npos) { + return path; + } + return Path(path, 0, slash); +} + +Path Store::followLinksToStore(const Path& _path) const { + Path path = absPath(_path); + while (!isInStore(path)) { + if (!isLink(path)) { + break; + } + string target = readLink(path); + path = absPath(target, dirOf(path)); + } + if (!isInStore(path)) { + throw Error(format("path '%1%' is not in the Nix store") % path); + } + return path; +} + +Path Store::followLinksToStorePath(const Path& path) const { + return toStorePath(followLinksToStore(path)); +} + +string storePathToName(const Path& path) { + auto base = baseNameOf(path); + assert(base.size() == storePathHashLen || + (base.size() > storePathHashLen && base[storePathHashLen] == '-')); + return base.size() == storePathHashLen ? "" + : string(base, storePathHashLen + 1); +} + +string storePathToHash(const Path& path) { + auto base = baseNameOf(path); + assert(base.size() >= storePathHashLen); + return string(base, 0, storePathHashLen); +} + +void checkStoreName(const string& name) { + string validChars = "+-._?="; + + auto baseError = + format( + "The path name '%2%' is invalid: %3%. " + "Path names are alphanumeric and can include the symbols %1% " + "and must not begin with a period. " + "Note: If '%2%' is a source file and you cannot rename it on " + "disk, builtins.path { name = ... } can be used to give it an " + "alternative name.") % + validChars % name; + + /* Disallow names starting with a dot for possible security + reasons (e.g., "." and ".."). */ + if (string(name, 0, 1) == ".") { + throw Error(baseError % "it is illegal to start the name with a period"); + } + /* Disallow names longer than 211 characters. ext4’s max is 256, + but we need extra space for the hash and .chroot extensions. */ + if (name.length() > 211) { + throw Error(baseError % "name must be less than 212 characters"); + } + for (auto& i : name) { + if (!((i >= 'A' && i <= 'Z') || (i >= 'a' && i <= 'z') || + (i >= '0' && i <= '9') || validChars.find(i) != string::npos)) { + throw Error(baseError % (format("the '%1%' character is invalid") % i)); + } + } +} + +/* Store paths have the following form: + + <store>/<h>-<name> + + where + + <store> = the location of the Nix store, usually /nix/store + + <name> = a human readable name for the path, typically obtained + from the name attribute of the derivation, or the name of the + source file from which the store path is created. For derivation + outputs other than the default "out" output, the string "-<id>" + is suffixed to <name>. + + <h> = base-32 representation of the first 160 bits of a SHA-256 + hash of <s>; the hash part of the store name + + <s> = the string "<type>:sha256:<h2>:<store>:<name>"; + note that it includes the location of the store as well as the + name to make sure that changes to either of those are reflected + in the hash (e.g. you won't get /nix/store/<h>-name1 and + /nix/store/<h>-name2 with equal hash parts). + + <type> = one of: + "text:<r1>:<r2>:...<rN>" + for plain text files written to the store using + addTextToStore(); <r1> ... <rN> are the references of the + path. + "source" + for paths copied to the store using addToStore() when recursive + = true and hashAlgo = "sha256" + "output:<id>" + for either the outputs created by derivations, OR paths copied + to the store using addToStore() with recursive != true or + hashAlgo != "sha256" (in that case "source" is used; it's + silly, but it's done that way for compatibility). <id> is the + name of the output (usually, "out"). + + <h2> = base-16 representation of a SHA-256 hash of: + if <type> = "text:...": + the string written to the resulting store path + if <type> = "source": + the serialisation of the path from which this store path is + copied, as returned by hashPath() + if <type> = "output:<id>": + for non-fixed derivation outputs: + the derivation (see hashDerivationModulo() in + primops.cc) + for paths copied by addToStore() or produced by fixed-output + derivations: + the string "fixed:out:<rec><algo>:<hash>:", where + <rec> = "r:" for recursive (path) hashes, or "" for flat + (file) hashes + <algo> = "md5", "sha1" or "sha256" + <hash> = base-16 representation of the path or flat hash of + the contents of the path (or expected contents of the + path for fixed-output derivations) + + It would have been nicer to handle fixed-output derivations under + "source", e.g. have something like "source:<rec><algo>", but we're + stuck with this for now... + + The main reason for this way of computing names is to prevent name + collisions (for security). For instance, it shouldn't be feasible + to come up with a derivation whose output path collides with the + path for a copied source. The former would have a <s> starting with + "output:out:", while the latter would have a <s> starting with + "source:". +*/ + +Path Store::makeStorePath(const string& type, const Hash& hash, + const string& name) const { + /* e.g., "source:sha256:1abc...:/nix/store:foo.tar.gz" */ + string s = type + ":" + hash.to_string(Base16) + ":" + storeDir + ":" + name; + + checkStoreName(name); + + return storeDir + "/" + + compressHash(hashString(htSHA256, s), 20).to_string(Base32, false) + + "-" + name; +} + +Path Store::makeOutputPath(const string& id, const Hash& hash, + const string& name) const { + return makeStorePath("output:" + id, hash, + name + (id == "out" ? "" : "-" + id)); +} + +Path Store::makeFixedOutputPath(bool recursive, const Hash& hash, + const string& name) const { + return hash.type == htSHA256 && recursive + ? makeStorePath("source", hash, name) + : makeStorePath( + "output:out", + hashString(htSHA256, + "fixed:out:" + (recursive ? (string) "r:" : "") + + hash.to_string(Base16) + ":"), + name); +} + +Path Store::makeTextPath(const string& name, const Hash& hash, + const PathSet& references) const { + assert(hash.type == htSHA256); + /* Stuff the references (if any) into the type. This is a bit + hacky, but we can't put them in `s' since that would be + ambiguous. */ + string type = "text"; + for (auto& i : references) { + type += ":"; + type += i; + } + return makeStorePath(type, hash, name); +} + +std::pair<Path, Hash> Store::computeStorePathForPath(const string& name, + const Path& srcPath, + bool recursive, + HashType hashAlgo, + PathFilter& filter) const { + Hash h = recursive ? hashPath(hashAlgo, srcPath, filter).first + : hashFile(hashAlgo, srcPath); + Path dstPath = makeFixedOutputPath(recursive, h, name); + return std::pair<Path, Hash>(dstPath, h); +} + +Path Store::computeStorePathForText(const string& name, const string& s, + const PathSet& references) const { + return makeTextPath(name, hashString(htSHA256, s), references); +} + +Store::Store(const Params& params) + : Config(params), state({(size_t)pathInfoCacheSize}) {} + +std::string Store::getUri() { return ""; } + +bool Store::isValidPath(const Path& storePath) { + assertStorePath(storePath); + + auto hashPart = storePathToHash(storePath); + + { + auto state_(state.lock()); + auto res = state_->pathInfoCache.get(hashPart); + if (res) { + stats.narInfoReadAverted++; + return *res != nullptr; + } + } + + if (diskCache) { + auto res = diskCache->lookupNarInfo(getUri(), hashPart); + if (res.first != NarInfoDiskCache::oUnknown) { + stats.narInfoReadAverted++; + auto state_(state.lock()); + state_->pathInfoCache.upsert( + hashPart, + res.first == NarInfoDiskCache::oInvalid ? nullptr : res.second); + return res.first == NarInfoDiskCache::oValid; + } + } + + bool valid = isValidPathUncached(storePath); + + if (diskCache && !valid) { + // FIXME: handle valid = true case. + diskCache->upsertNarInfo(getUri(), hashPart, nullptr); + } + + return valid; +} + +/* Default implementation for stores that only implement + queryPathInfoUncached(). */ +bool Store::isValidPathUncached(const Path& path) { + try { + queryPathInfo(path); + return true; + } catch (InvalidPath&) { + return false; + } +} + +ref<const ValidPathInfo> Store::queryPathInfo(const Path& storePath) { + std::promise<ref<ValidPathInfo>> promise; + + queryPathInfo(storePath, {[&](std::future<ref<ValidPathInfo>> result) { + try { + promise.set_value(result.get()); + } catch (...) { + promise.set_exception(std::current_exception()); + } + }}); + + return promise.get_future().get(); +} + +void Store::queryPathInfo(const Path& storePath, + Callback<ref<ValidPathInfo>> callback) noexcept { + std::string hashPart; + + try { + assertStorePath(storePath); + + hashPart = storePathToHash(storePath); + + { + auto res = state.lock()->pathInfoCache.get(hashPart); + if (res) { + stats.narInfoReadAverted++; + if (!*res) { + throw InvalidPath(format("path '%s' is not valid") % storePath); + } + return callback(ref<ValidPathInfo>(*res)); + } + } + + if (diskCache) { + auto res = diskCache->lookupNarInfo(getUri(), hashPart); + if (res.first != NarInfoDiskCache::oUnknown) { + stats.narInfoReadAverted++; + { + auto state_(state.lock()); + state_->pathInfoCache.upsert( + hashPart, + res.first == NarInfoDiskCache::oInvalid ? nullptr : res.second); + if (res.first == NarInfoDiskCache::oInvalid || + (res.second->path != storePath && + !storePathToName(storePath).empty())) { + throw InvalidPath(format("path '%s' is not valid") % storePath); + } + } + return callback(ref<ValidPathInfo>(res.second)); + } + } + + } catch (...) { + return callback.rethrow(); + } + + auto callbackPtr = std::make_shared<decltype(callback)>(std::move(callback)); + + queryPathInfoUncached( + storePath, {[this, storePath, hashPart, callbackPtr]( + std::future<std::shared_ptr<ValidPathInfo>> fut) { + try { + auto info = fut.get(); + + if (diskCache) { + diskCache->upsertNarInfo(getUri(), hashPart, info); + } + + { + auto state_(state.lock()); + state_->pathInfoCache.upsert(hashPart, info); + } + + if (!info || (info->path != storePath && + !storePathToName(storePath).empty())) { + stats.narInfoMissing++; + throw InvalidPath("path '%s' is not valid", storePath); + } + + (*callbackPtr)(ref<ValidPathInfo>(info)); + } catch (...) { + callbackPtr->rethrow(); + } + }}); +} + +PathSet Store::queryValidPaths(const PathSet& paths, + SubstituteFlag maybeSubstitute) { + struct State { + size_t left; + PathSet valid; + std::exception_ptr exc; + }; + + Sync<State> state_(State{paths.size(), PathSet()}); + + std::condition_variable wakeup; + ThreadPool pool; + + auto doQuery = [&](const Path& path) { + checkInterrupt(); + queryPathInfo( + path, {[path, &state_, &wakeup](std::future<ref<ValidPathInfo>> fut) { + auto state(state_.lock()); + try { + auto info = fut.get(); + state->valid.insert(path); + } catch (InvalidPath&) { + } catch (...) { + state->exc = std::current_exception(); + } + assert(state->left); + if (--state->left == 0u) { + wakeup.notify_one(); + } + }}); + }; + + for (auto& path : paths) { + pool.enqueue(std::bind(doQuery, path)); + } + + pool.process(); + + while (true) { + auto state(state_.lock()); + if (state->left == 0u) { + if (state->exc) { + std::rethrow_exception(state->exc); + } + return state->valid; + } + state.wait(wakeup); + } +} + +/* Return a string accepted by decodeValidPathInfo() that + registers the specified paths as valid. Note: it's the + responsibility of the caller to provide a closure. */ +string Store::makeValidityRegistration(const PathSet& paths, bool showDerivers, + bool showHash) { + string s = s; + + for (auto& i : paths) { + s += i + "\n"; + + auto info = queryPathInfo(i); + + if (showHash) { + s += info->narHash.to_string(Base16, false) + "\n"; + s += (format("%1%\n") % info->narSize).str(); + } + + Path deriver = showDerivers ? info->deriver : ""; + s += deriver + "\n"; + + s += (format("%1%\n") % info->references.size()).str(); + + for (auto& j : info->references) { + s += j + "\n"; + } + } + + return s; +} + +void Store::pathInfoToJSON(JSONPlaceholder& jsonOut, const PathSet& storePaths, + bool includeImpureInfo, bool showClosureSize, + AllowInvalidFlag allowInvalid) { + auto jsonList = jsonOut.list(); + + for (auto storePath : storePaths) { + auto jsonPath = jsonList.object(); + jsonPath.attr("path", storePath); + + try { + auto info = queryPathInfo(storePath); + storePath = info->path; + + jsonPath.attr("narHash", info->narHash.to_string()) + .attr("narSize", info->narSize); + + { + auto jsonRefs = jsonPath.list("references"); + for (auto& ref : info->references) { + jsonRefs.elem(ref); + } + } + + if (!info->ca.empty()) { + jsonPath.attr("ca", info->ca); + } + + std::pair<uint64_t, uint64_t> closureSizes; + + if (showClosureSize) { + closureSizes = getClosureSize(storePath); + jsonPath.attr("closureSize", closureSizes.first); + } + + if (includeImpureInfo) { + if (!info->deriver.empty()) { + jsonPath.attr("deriver", info->deriver); + } + + if (info->registrationTime != 0) { + jsonPath.attr("registrationTime", info->registrationTime); + } + + if (info->ultimate) { + jsonPath.attr("ultimate", info->ultimate); + } + + if (!info->sigs.empty()) { + auto jsonSigs = jsonPath.list("signatures"); + for (auto& sig : info->sigs) { + jsonSigs.elem(sig); + } + } + + auto narInfo = std::dynamic_pointer_cast<const NarInfo>( + std::shared_ptr<const ValidPathInfo>(info)); + + if (narInfo) { + if (!narInfo->url.empty()) { + jsonPath.attr("url", narInfo->url); + } + if (narInfo->fileHash) { + jsonPath.attr("downloadHash", narInfo->fileHash.to_string()); + } + if (narInfo->fileSize != 0u) { + jsonPath.attr("downloadSize", narInfo->fileSize); + } + if (showClosureSize) { + jsonPath.attr("closureDownloadSize", closureSizes.second); + } + } + } + + } catch (InvalidPath&) { + jsonPath.attr("valid", false); + } + } +} + +std::pair<uint64_t, uint64_t> Store::getClosureSize(const Path& storePath) { + uint64_t totalNarSize = 0; + uint64_t totalDownloadSize = 0; + PathSet closure; + computeFSClosure(storePath, closure, false, false); + for (auto& p : closure) { + auto info = queryPathInfo(p); + totalNarSize += info->narSize; + auto narInfo = std::dynamic_pointer_cast<const NarInfo>( + std::shared_ptr<const ValidPathInfo>(info)); + if (narInfo) { + totalDownloadSize += narInfo->fileSize; + } + } + return {totalNarSize, totalDownloadSize}; +} + +const Store::Stats& Store::getStats() { + { + auto state_(state.lock()); + stats.pathInfoCacheSize = state_->pathInfoCache.size(); + } + return stats; +} + +void Store::buildPaths(const PathSet& paths, BuildMode buildMode) { + for (auto& path : paths) { + if (isDerivation(path)) { + unsupported("buildPaths"); + } + } + + if (queryValidPaths(paths).size() != paths.size()) { + unsupported("buildPaths"); + } +} + +void copyStorePath(ref<Store> srcStore, const ref<Store>& dstStore, + const Path& storePath, RepairFlag repair, + CheckSigsFlag checkSigs) { + auto srcUri = srcStore->getUri(); + auto dstUri = dstStore->getUri(); + + if (srcUri == "local" || srcUri == "daemon") { + LOG(INFO) << "copying path '" << storePath << "' to '" << dstUri << "'"; + } else { + if (dstUri == "local" || dstUri == "daemon") { + LOG(INFO) << "copying path '" << storePath << "' from '" << srcUri << "'"; + } else { + LOG(INFO) << "copying path '" << storePath << "' from '" << srcUri + << "' to '" << dstUri << "'"; + } + } + + auto info = srcStore->queryPathInfo(storePath); + + uint64_t total = 0; + + if (!info->narHash) { + StringSink sink; + srcStore->narFromPath({storePath}, sink); + auto info2 = make_ref<ValidPathInfo>(*info); + info2->narHash = hashString(htSHA256, *sink.s); + if (info->narSize == 0u) { + info2->narSize = sink.s->size(); + } + if (info->ultimate) { + info2->ultimate = false; + } + info = info2; + + StringSource source(*sink.s); + dstStore->addToStore(*info, source, repair, checkSigs); + return; + } + + if (info->ultimate) { + auto info2 = make_ref<ValidPathInfo>(*info); + info2->ultimate = false; + info = info2; + } + + auto source = sinkToSource( + [&](Sink& sink) { + LambdaSink wrapperSink([&](const unsigned char* data, size_t len) { + sink(data, len); + total += len; + }); + srcStore->narFromPath({storePath}, wrapperSink); + }, + [&]() { + throw EndOfFile("NAR for '%s' fetched from '%s' is incomplete", + storePath, srcStore->getUri()); + }); + + dstStore->addToStore(*info, *source, repair, checkSigs); +} + +void copyPaths(ref<Store> srcStore, ref<Store> dstStore, + const PathSet& storePaths, RepairFlag repair, + CheckSigsFlag checkSigs, SubstituteFlag substitute) { + PathSet valid = dstStore->queryValidPaths(storePaths, substitute); + + PathSet missing; + for (auto& path : storePaths) { + if (valid.count(path) == 0u) { + missing.insert(path); + } + } + + if (missing.empty()) { + return; + } + + LOG(INFO) << "copying " << missing.size() << " paths"; + + std::atomic<size_t> nrDone{0}; + std::atomic<size_t> nrFailed{0}; + std::atomic<uint64_t> bytesExpected{0}; + std::atomic<uint64_t> nrRunning{0}; + + ThreadPool pool; + + processGraph<Path>( + pool, PathSet(missing.begin(), missing.end()), + + [&](const Path& storePath) { + if (dstStore->isValidPath(storePath)) { + nrDone++; + return PathSet(); + } + + auto info = srcStore->queryPathInfo(storePath); + + bytesExpected += info->narSize; + + return info->references; + }, + + [&](const Path& storePath) { + checkInterrupt(); + + if (!dstStore->isValidPath(storePath)) { + MaintainCount<decltype(nrRunning)> mc(nrRunning); + try { + copyStorePath(srcStore, dstStore, storePath, repair, checkSigs); + } catch (Error& e) { + nrFailed++; + if (!settings.keepGoing) { + throw e; + } + LOG(ERROR) << "could not copy " << storePath << ": " << e.what(); + return; + } + } + + nrDone++; + }); +} + +void copyClosure(const ref<Store>& srcStore, const ref<Store>& dstStore, + const PathSet& storePaths, RepairFlag repair, + CheckSigsFlag checkSigs, SubstituteFlag substitute) { + PathSet closure; + srcStore->computeFSClosure({storePaths}, closure); + copyPaths(srcStore, dstStore, closure, repair, checkSigs, substitute); +} + +ValidPathInfo decodeValidPathInfo(std::istream& str, bool hashGiven) { + ValidPathInfo info; + getline(str, info.path); + if (str.eof()) { + info.path = ""; + return info; + } + if (hashGiven) { + string s; + getline(str, s); + info.narHash = Hash(s, htSHA256); + getline(str, s); + if (!string2Int(s, info.narSize)) { + throw Error("number expected"); + } + } + getline(str, info.deriver); + string s; + int n; + getline(str, s); + if (!string2Int(s, n)) { + throw Error("number expected"); + } + while ((n--) != 0) { + getline(str, s); + info.references.insert(s); + } + if (!str || str.eof()) { + throw Error("missing input"); + } + return info; +} + +string showPaths(const PathSet& paths) { + string s; + for (auto& i : paths) { + if (!s.empty()) { + s += ", "; + } + s += "'" + i + "'"; + } + return s; +} + +std::string ValidPathInfo::fingerprint() const { + if (narSize == 0 || !narHash) { + throw Error(format("cannot calculate fingerprint of path '%s' because its " + "size/hash is not known") % + path); + } + return "1;" + path + ";" + narHash.to_string(Base32) + ";" + + std::to_string(narSize) + ";" + concatStringsSep(",", references); +} + +void ValidPathInfo::sign(const SecretKey& secretKey) { + sigs.insert(secretKey.signDetached(fingerprint())); +} + +bool ValidPathInfo::isContentAddressed(const Store& store) const { + auto warn = [&]() { + LOG(ERROR) << "warning: path '" << path + << "' claims to be content-addressed but isn't"; + }; + + if (hasPrefix(ca, "text:")) { + Hash hash(std::string(ca, 5)); + if (store.makeTextPath(storePathToName(path), hash, references) == path) { + return true; + } + warn(); + + } + + else if (hasPrefix(ca, "fixed:")) { + bool recursive = ca.compare(6, 2, "r:") == 0; + Hash hash(std::string(ca, recursive ? 8 : 6)); + if (references.empty() && + store.makeFixedOutputPath(recursive, hash, storePathToName(path)) == + path) { + return true; + } + warn(); + } + + return false; +} + +size_t ValidPathInfo::checkSignatures(const Store& store, + const PublicKeys& publicKeys) const { + if (isContentAddressed(store)) { + return maxSigs; + } + + size_t good = 0; + for (auto& sig : sigs) { + if (checkSignature(publicKeys, sig)) { + good++; + } + } + return good; +} + +bool ValidPathInfo::checkSignature(const PublicKeys& publicKeys, + const std::string& sig) const { + return verifyDetached(fingerprint(), sig, publicKeys); +} + +Strings ValidPathInfo::shortRefs() const { + Strings refs; + for (auto& r : references) { + refs.push_back(baseNameOf(r)); + } + return refs; +} + +std::string makeFixedOutputCA(bool recursive, const Hash& hash) { + return "fixed:" + (recursive ? (std::string) "r:" : "") + hash.to_string(); +} + +void Store::addToStore(const ValidPathInfo& info, Source& narSource, + RepairFlag repair, CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) { + addToStore(info, make_ref<std::string>(narSource.drain()), repair, checkSigs, + std::move(accessor)); +} + +void Store::addToStore(const ValidPathInfo& info, const ref<std::string>& nar, + RepairFlag repair, CheckSigsFlag checkSigs, + std::shared_ptr<FSAccessor> accessor) { + StringSource source(*nar); + addToStore(info, source, repair, checkSigs, std::move(accessor)); +} + +} // namespace nix + +#include "local-store.hh" +#include "remote-store.hh" + +namespace nix { + +RegisterStoreImplementation::Implementations* + RegisterStoreImplementation::implementations = nullptr; + +/* Split URI into protocol+hierarchy part and its parameter set. */ +std::pair<std::string, Store::Params> splitUriAndParams( + const std::string& uri_) { + auto uri(uri_); + Store::Params params; + auto q = uri.find('?'); + if (q != std::string::npos) { + for (const auto& s : tokenizeString<Strings>(uri.substr(q + 1), "&")) { + auto e = s.find('='); + if (e != std::string::npos) { + auto value = s.substr(e + 1); + std::string decoded; + for (size_t i = 0; i < value.size();) { + if (value[i] == '%') { + if (i + 2 >= value.size()) { + throw Error("invalid URI parameter '%s'", value); + } + try { + decoded += std::stoul(std::string(value, i + 1, 2), nullptr, 16); + i += 3; + } catch (...) { + throw Error("invalid URI parameter '%s'", value); + } + } else { + decoded += value[i++]; + } + } + params[s.substr(0, e)] = decoded; + } + } + uri = uri_.substr(0, q); + } + return {uri, params}; +} + +ref<Store> openStore(const std::string& uri_, + const Store::Params& extraParams) { + auto [uri, uriParams] = splitUriAndParams(uri_); + auto params = extraParams; + params.insert(uriParams.begin(), uriParams.end()); + + for (const auto& fun : *RegisterStoreImplementation::implementations) { + auto store = fun(uri, params); + if (store) { + store->warnUnknownSettings(); + return ref<Store>(store); + } + } + + throw Error("don't know how to open Nix store '%s'", uri); +} + +StoreType getStoreType(const std::string& uri, const std::string& stateDir) { + if (uri == "daemon") { + return tDaemon; + } + if (uri == "local" || hasPrefix(uri, "/")) { + return tLocal; + } else if (uri.empty() || uri == "auto") { + if (access(stateDir.c_str(), R_OK | W_OK) == 0) { + return tLocal; + } + if (pathExists(settings.nixDaemonSocketFile)) { + return tDaemon; + } else { + return tLocal; + } + } else { + return tOther; + } +} + +static RegisterStoreImplementation regStore([](const std::string& uri, + const Store::Params& params) + -> std::shared_ptr<Store> { + switch (getStoreType(uri, get(params, "state", settings.nixStateDir))) { + case tDaemon: + return std::shared_ptr<Store>(std::make_shared<UDSRemoteStore>(params)); + case tLocal: { + Store::Params params2 = params; + if (hasPrefix(uri, "/")) { + params2["root"] = uri; + } + return std::shared_ptr<Store>(std::make_shared<LocalStore>(params2)); + } + default: + return nullptr; + } +}); + +std::list<ref<Store>> getDefaultSubstituters() { + static auto stores([]() { + std::list<ref<Store>> stores; + + StringSet done; + + auto addStore = [&](const std::string& uri) { + if (done.count(uri) != 0u) { + return; + } + done.insert(uri); + try { + stores.push_back(openStore(uri)); + } catch (Error& e) { + LOG(WARNING) << e.what(); + } + }; + + for (const auto& uri : settings.substituters.get()) { + addStore(uri); + } + + for (const auto& uri : settings.extraSubstituters.get()) { + addStore(uri); + } + + stores.sort([](ref<Store>& a, ref<Store>& b) { + return a->getPriority() < b->getPriority(); + }); + + return stores; + }()); + + return stores; +} + +} // namespace nix diff --git a/third_party/nix/src/libstore/store-api.hh b/third_party/nix/src/libstore/store-api.hh new file mode 100644 index 0000000000..242a3e6562 --- /dev/null +++ b/third_party/nix/src/libstore/store-api.hh @@ -0,0 +1,770 @@ +#pragma once + +#include <atomic> +#include <limits> +#include <map> +#include <memory> +#include <string> +#include <unordered_map> +#include <unordered_set> + +#include "config.hh" +#include "crypto.hh" +#include "globals.hh" +#include "hash.hh" +#include "lru-cache.hh" +#include "serialise.hh" +#include "sync.hh" + +namespace nix { + +MakeError(SubstError, Error) + MakeError(BuildError, Error) /* denotes a permanent build failure */ + MakeError(InvalidPath, Error) MakeError(Unsupported, Error) + MakeError(SubstituteGone, Error) MakeError(SubstituterDisabled, Error) + + struct BasicDerivation; +struct Derivation; +class FSAccessor; +class NarInfoDiskCache; +class Store; +class JSONPlaceholder; + +enum RepairFlag : bool { NoRepair = false, Repair = true }; +enum CheckSigsFlag : bool { NoCheckSigs = false, CheckSigs = true }; +enum SubstituteFlag : bool { NoSubstitute = false, Substitute = true }; +enum AllowInvalidFlag : bool { DisallowInvalid = false, AllowInvalid = true }; + +/* Size of the hash part of store paths, in base-32 characters. */ +const size_t storePathHashLen = 32; // i.e. 160 bits + +/* Magic header of exportPath() output (obsolete). */ +const uint32_t exportMagic = 0x4558494e; + +typedef std::unordered_map<Path, std::unordered_set<std::string>> Roots; + +struct GCOptions { + /* Garbage collector operation: + + - `gcReturnLive': return the set of paths reachable from + (i.e. in the closure of) the roots. + + - `gcReturnDead': return the set of paths not reachable from + the roots. + + - `gcDeleteDead': actually delete the latter set. + + - `gcDeleteSpecific': delete the paths listed in + `pathsToDelete', insofar as they are not reachable. + */ + typedef enum { + gcReturnLive, + gcReturnDead, + gcDeleteDead, + gcDeleteSpecific, + } GCAction; + + GCAction action{gcDeleteDead}; + + /* If `ignoreLiveness' is set, then reachability from the roots is + ignored (dangerous!). However, the paths must still be + unreferenced *within* the store (i.e., there can be no other + store paths that depend on them). */ + bool ignoreLiveness{false}; + + /* For `gcDeleteSpecific', the paths to delete. */ + PathSet pathsToDelete; + + /* Stop after at least `maxFreed' bytes have been freed. */ + unsigned long long maxFreed{std::numeric_limits<unsigned long long>::max()}; +}; + +struct GCResults { + /* Depending on the action, the GC roots, or the paths that would + be or have been deleted. */ + PathSet paths; + + /* For `gcReturnDead', `gcDeleteDead' and `gcDeleteSpecific', the + number of bytes that would be or was freed. */ + unsigned long long bytesFreed = 0; +}; + +struct SubstitutablePathInfo { + Path deriver; + PathSet references; + unsigned long long downloadSize; /* 0 = unknown or inapplicable */ + unsigned long long narSize; /* 0 = unknown */ +}; + +typedef std::map<Path, SubstitutablePathInfo> SubstitutablePathInfos; + +struct ValidPathInfo { + Path path; + Path deriver; + Hash narHash; + PathSet references; + time_t registrationTime = 0; + uint64_t narSize = 0; // 0 = unknown + uint64_t id; // internal use only + + /* Whether the path is ultimately trusted, that is, it's a + derivation output that was built locally. */ + bool ultimate = false; + + StringSet sigs; // note: not necessarily verified + + /* If non-empty, an assertion that the path is content-addressed, + i.e., that the store path is computed from a cryptographic hash + of the contents of the path, plus some other bits of data like + the "name" part of the path. Such a path doesn't need + signatures, since we don't have to trust anybody's claim that + the path is the output of a particular derivation. (In the + extensional store model, we have to trust that the *contents* + of an output path of a derivation were actually produced by + that derivation. In the intensional model, we have to trust + that a particular output path was produced by a derivation; the + path then implies the contents.) + + Ideally, the content-addressability assertion would just be a + Boolean, and the store path would be computed from + ‘storePathToName(path)’, ‘narHash’ and ‘references’. However, + 1) we've accumulated several types of content-addressed paths + over the years; and 2) fixed-output derivations support + multiple hash algorithms and serialisation methods (flat file + vs NAR). Thus, ‘ca’ has one of the following forms: + + * ‘text:sha256:<sha256 hash of file contents>’: For paths + computed by makeTextPath() / addTextToStore(). + + * ‘fixed:<r?>:<ht>:<h>’: For paths computed by + makeFixedOutputPath() / addToStore(). + */ + std::string ca; + + bool operator==(const ValidPathInfo& i) const { + return path == i.path && narHash == i.narHash && references == i.references; + } + + /* Return a fingerprint of the store path to be used in binary + cache signatures. It contains the store path, the base-32 + SHA-256 hash of the NAR serialisation of the path, the size of + the NAR, and the sorted references. The size field is strictly + speaking superfluous, but might prevent endless/excessive data + attacks. */ + std::string fingerprint() const; + + void sign(const SecretKey& secretKey); + + /* Return true iff the path is verifiably content-addressed. */ + bool isContentAddressed(const Store& store) const; + + static const size_t maxSigs = std::numeric_limits<size_t>::max(); + + /* Return the number of signatures on this .narinfo that were + produced by one of the specified keys, or maxSigs if the path + is content-addressed. */ + size_t checkSignatures(const Store& store, + const PublicKeys& publicKeys) const; + + /* Verify a single signature. */ + bool checkSignature(const PublicKeys& publicKeys, + const std::string& sig) const; + + Strings shortRefs() const; + + virtual ~ValidPathInfo() {} +}; + +typedef list<ValidPathInfo> ValidPathInfos; + +enum BuildMode { bmNormal, bmRepair, bmCheck }; + +struct BuildResult { + /* Note: don't remove status codes, and only add new status codes + at the end of the list, to prevent client/server + incompatibilities in the nix-store --serve protocol. */ + enum Status { + Built = 0, + Substituted, + AlreadyValid, + PermanentFailure, + InputRejected, + OutputRejected, + TransientFailure, // possibly transient + CachedFailure, // no longer used + TimedOut, + MiscFailure, + DependencyFailed, + LogLimitExceeded, + NotDeterministic, + } status = MiscFailure; + std::string errorMsg; + + /* How many times this build was performed. */ + unsigned int timesBuilt = 0; + + /* If timesBuilt > 1, whether some builds did not produce the same + result. (Note that 'isNonDeterministic = false' does not mean + the build is deterministic, just that we don't have evidence of + non-determinism.) */ + bool isNonDeterministic = false; + + /* The start/stop times of the build (or one of the rounds, if it + was repeated). */ + time_t startTime = 0, stopTime = 0; + + bool success() { + return status == Built || status == Substituted || status == AlreadyValid; + } +}; + +class Store : public std::enable_shared_from_this<Store>, public Config { + public: + typedef std::map<std::string, std::string> Params; + + const PathSetting storeDir_{this, false, settings.nixStore, "store", + "path to the Nix store"}; + const Path storeDir = storeDir_; + + const Setting<int> pathInfoCacheSize{ + this, 65536, "path-info-cache-size", + "size of the in-memory store path information cache"}; + + const Setting<bool> isTrusted{ + this, false, "trusted", + "whether paths from this store can be used as substitutes even when they " + "lack trusted signatures"}; + + protected: + struct State { + LRUCache<std::string, std::shared_ptr<ValidPathInfo>> pathInfoCache; + }; + + Sync<State> state; + + std::shared_ptr<NarInfoDiskCache> diskCache; + + Store(const Params& params); + + public: + virtual ~Store() {} + + virtual std::string getUri() = 0; + + /* Return true if ‘path’ is in the Nix store (but not the Nix + store itself). */ + bool isInStore(const Path& path) const; + + /* Return true if ‘path’ is a store path, i.e. a direct child of + the Nix store. */ + bool isStorePath(const Path& path) const; + + /* Throw an exception if ‘path’ is not a store path. */ + void assertStorePath(const Path& path) const; + + /* Chop off the parts after the top-level store name, e.g., + /nix/store/abcd-foo/bar => /nix/store/abcd-foo. */ + Path toStorePath(const Path& path) const; + + /* Follow symlinks until we end up with a path in the Nix store. */ + Path followLinksToStore(const Path& path) const; + + /* Same as followLinksToStore(), but apply toStorePath() to the + result. */ + Path followLinksToStorePath(const Path& path) const; + + /* Constructs a unique store path name. */ + Path makeStorePath(const string& type, const Hash& hash, + const string& name) const; + + Path makeOutputPath(const string& id, const Hash& hash, + const string& name) const; + + Path makeFixedOutputPath(bool recursive, const Hash& hash, + const string& name) const; + + Path makeTextPath(const string& name, const Hash& hash, + const PathSet& references) const; + + /* This is the preparatory part of addToStore(); it computes the + store path to which srcPath is to be copied. Returns the store + path and the cryptographic hash of the contents of srcPath. */ + std::pair<Path, Hash> computeStorePathForPath( + const string& name, const Path& srcPath, bool recursive = true, + HashType hashAlgo = htSHA256, + PathFilter& filter = defaultPathFilter) const; + + /* Preparatory part of addTextToStore(). + + !!! Computation of the path should take the references given to + addTextToStore() into account, otherwise we have a (relatively + minor) security hole: a caller can register a source file with + bogus references. If there are too many references, the path may + not be garbage collected when it has to be (not really a problem, + the caller could create a root anyway), or it may be garbage + collected when it shouldn't be (more serious). + + Hashing the references would solve this (bogus references would + simply yield a different store path, so other users wouldn't be + affected), but it has some backwards compatibility issues (the + hashing scheme changes), so I'm not doing that for now. */ + Path computeStorePathForText(const string& name, const string& s, + const PathSet& references) const; + + /* Check whether a path is valid. */ + bool isValidPath(const Path& path); + + protected: + virtual bool isValidPathUncached(const Path& path); + + public: + /* Query which of the given paths is valid. Optionally, try to + substitute missing paths. */ + virtual PathSet queryValidPaths( + const PathSet& paths, SubstituteFlag maybeSubstitute = NoSubstitute); + + /* Query the set of all valid paths. Note that for some store + backends, the name part of store paths may be omitted + (i.e. you'll get /nix/store/<hash> rather than + /nix/store/<hash>-<name>). Use queryPathInfo() to obtain the + full store path. */ + virtual PathSet queryAllValidPaths() { unsupported("queryAllValidPaths"); } + + /* Query information about a valid path. It is permitted to omit + the name part of the store path. */ + ref<const ValidPathInfo> queryPathInfo(const Path& path); + + /* Asynchronous version of queryPathInfo(). */ + void queryPathInfo(const Path& path, + Callback<ref<ValidPathInfo>> callback) noexcept; + + protected: + virtual void queryPathInfoUncached( + const Path& path, + Callback<std::shared_ptr<ValidPathInfo>> callback) noexcept = 0; + + public: + /* Queries the set of incoming FS references for a store path. + The result is not cleared. */ + virtual void queryReferrers(const Path& path, PathSet& referrers) { + unsupported("queryReferrers"); + } + + /* Return all currently valid derivations that have `path' as an + output. (Note that the result of `queryDeriver()' is the + derivation that was actually used to produce `path', which may + not exist anymore.) */ + virtual PathSet queryValidDerivers(const Path& path) { return {}; }; + + /* Query the outputs of the derivation denoted by `path'. */ + virtual PathSet queryDerivationOutputs(const Path& path) { + unsupported("queryDerivationOutputs"); + } + + /* Query the output names of the derivation denoted by `path'. */ + virtual StringSet queryDerivationOutputNames(const Path& path) { + unsupported("queryDerivationOutputNames"); + } + + /* Query the full store path given the hash part of a valid store + path, or "" if the path doesn't exist. */ + virtual Path queryPathFromHashPart(const string& hashPart) = 0; + + /* Query which of the given paths have substitutes. */ + virtual PathSet querySubstitutablePaths(const PathSet& paths) { return {}; }; + + /* Query substitute info (i.e. references, derivers and download + sizes) of a set of paths. If a path does not have substitute + info, it's omitted from the resulting ‘infos’ map. */ + virtual void querySubstitutablePathInfos(const PathSet& paths, + SubstitutablePathInfos& infos) { + return; + }; + + virtual bool wantMassQuery() { return false; } + + /* Import a path into the store. */ + virtual void addToStore(const ValidPathInfo& info, Source& narSource, + RepairFlag repair = NoRepair, + CheckSigsFlag checkSigs = CheckSigs, + std::shared_ptr<FSAccessor> accessor = 0); + + // FIXME: remove + virtual void addToStore(const ValidPathInfo& info, + const ref<std::string>& nar, + RepairFlag repair = NoRepair, + CheckSigsFlag checkSigs = CheckSigs, + std::shared_ptr<FSAccessor> accessor = 0); + + /* Copy the contents of a path to the store and register the + validity the resulting path. The resulting path is returned. + The function object `filter' can be used to exclude files (see + libutil/archive.hh). */ + virtual Path addToStore(const string& name, const Path& srcPath, + bool recursive = true, HashType hashAlgo = htSHA256, + PathFilter& filter = defaultPathFilter, + RepairFlag repair = NoRepair) = 0; + + /* Like addToStore, but the contents written to the output path is + a regular file containing the given string. */ + virtual Path addTextToStore(const string& name, const string& s, + const PathSet& references, + RepairFlag repair = NoRepair) = 0; + + /* Write a NAR dump of a store path. */ + virtual void narFromPath(const Path& path, Sink& sink) = 0; + + /* For each path, if it's a derivation, build it. Building a + derivation means ensuring that the output paths are valid. If + they are already valid, this is a no-op. Otherwise, validity + can be reached in two ways. First, if the output paths is + substitutable, then build the path that way. Second, the + output paths can be created by running the builder, after + recursively building any sub-derivations. For inputs that are + not derivations, substitute them. */ + virtual void buildPaths(const PathSet& paths, BuildMode buildMode = bmNormal); + + /* Build a single non-materialized derivation (i.e. not from an + on-disk .drv file). Note that ‘drvPath’ is only used for + informational purposes. */ + virtual BuildResult buildDerivation(const Path& drvPath, + const BasicDerivation& drv, + BuildMode buildMode = bmNormal) = 0; + + /* Ensure that a path is valid. If it is not currently valid, it + may be made valid by running a substitute (if defined for the + path). */ + virtual void ensurePath(const Path& path) = 0; + + /* Add a store path as a temporary root of the garbage collector. + The root disappears as soon as we exit. */ + virtual void addTempRoot(const Path& path) { unsupported("addTempRoot"); } + + /* Add an indirect root, which is merely a symlink to `path' from + /nix/var/nix/gcroots/auto/<hash of `path'>. `path' is supposed + to be a symlink to a store path. The garbage collector will + automatically remove the indirect root when it finds that + `path' has disappeared. */ + virtual void addIndirectRoot(const Path& path) { + unsupported("addIndirectRoot"); + } + + /* Acquire the global GC lock, then immediately release it. This + function must be called after registering a new permanent root, + but before exiting. Otherwise, it is possible that a running + garbage collector doesn't see the new root and deletes the + stuff we've just built. By acquiring the lock briefly, we + ensure that either: + + - The collector is already running, and so we block until the + collector is finished. The collector will know about our + *temporary* locks, which should include whatever it is we + want to register as a permanent lock. + + - The collector isn't running, or it's just started but hasn't + acquired the GC lock yet. In that case we get and release + the lock right away, then exit. The collector scans the + permanent root and sees our's. + + In either case the permanent root is seen by the collector. */ + virtual void syncWithGC(){}; + + /* Find the roots of the garbage collector. Each root is a pair + (link, storepath) where `link' is the path of the symlink + outside of the Nix store that point to `storePath'. If + 'censor' is true, privacy-sensitive information about roots + found in /proc is censored. */ + virtual Roots findRoots(bool censor) { unsupported("findRoots"); } + + /* Perform a garbage collection. */ + virtual void collectGarbage(const GCOptions& options, GCResults& results) { + unsupported("collectGarbage"); + } + + /* Return a string representing information about the path that + can be loaded into the database using `nix-store --load-db' or + `nix-store --register-validity'. */ + string makeValidityRegistration(const PathSet& paths, bool showDerivers, + bool showHash); + + /* Write a JSON representation of store path metadata, such as the + hash and the references. If ‘includeImpureInfo’ is true, + variable elements such as the registration time are + included. If ‘showClosureSize’ is true, the closure size of + each path is included. */ + void pathInfoToJSON(JSONPlaceholder& jsonOut, const PathSet& storePaths, + bool includeImpureInfo, bool showClosureSize, + AllowInvalidFlag allowInvalid = DisallowInvalid); + + /* Return the size of the closure of the specified path, that is, + the sum of the size of the NAR serialisation of each path in + the closure. */ + std::pair<uint64_t, uint64_t> getClosureSize(const Path& storePath); + + /* Optimise the disk space usage of the Nix store by hard-linking files + with the same contents. */ + virtual void optimiseStore(){}; + + /* Check the integrity of the Nix store. Returns true if errors + remain. */ + virtual bool verifyStore(bool checkContents, RepairFlag repair = NoRepair) { + return false; + }; + + /* Return an object to access files in the Nix store. */ + virtual ref<FSAccessor> getFSAccessor() { unsupported("getFSAccessor"); } + + /* Add signatures to the specified store path. The signatures are + not verified. */ + virtual void addSignatures(const Path& storePath, const StringSet& sigs) { + unsupported("addSignatures"); + } + + /* Utility functions. */ + + /* Read a derivation, after ensuring its existence through + ensurePath(). */ + Derivation derivationFromPath(const Path& drvPath); + + /* Place in `out' the set of all store paths in the file system + closure of `storePath'; that is, all paths than can be directly + or indirectly reached from it. `out' is not cleared. If + `flipDirection' is true, the set of paths that can reach + `storePath' is returned; that is, the closures under the + `referrers' relation instead of the `references' relation is + returned. */ + virtual void computeFSClosure(const PathSet& paths, PathSet& paths_, + bool flipDirection = false, + bool includeOutputs = false, + bool includeDerivers = false); + + void computeFSClosure(const Path& path, PathSet& paths_, + bool flipDirection = false, bool includeOutputs = false, + bool includeDerivers = false); + + /* Given a set of paths that are to be built, return the set of + derivations that will be built, and the set of output paths + that will be substituted. */ + virtual void queryMissing(const PathSet& targets, PathSet& willBuild, + PathSet& willSubstitute, PathSet& unknown, + unsigned long long& downloadSize, + unsigned long long& narSize); + + /* Sort a set of paths topologically under the references + relation. If p refers to q, then p precedes q in this list. */ + Paths topoSortPaths(const PathSet& paths); + + /* Export multiple paths in the format expected by ‘nix-store + --import’. */ + void exportPaths(const Paths& paths, Sink& sink); + + void exportPath(const Path& path, Sink& sink); + + /* Import a sequence of NAR dumps created by exportPaths() into + the Nix store. Optionally, the contents of the NARs are + preloaded into the specified FS accessor to speed up subsequent + access. */ + Paths importPaths(Source& source, const std::shared_ptr<FSAccessor>& accessor, + CheckSigsFlag checkSigs = CheckSigs); + + struct Stats { + std::atomic<uint64_t> narInfoRead{0}; + std::atomic<uint64_t> narInfoReadAverted{0}; + std::atomic<uint64_t> narInfoMissing{0}; + std::atomic<uint64_t> narInfoWrite{0}; + std::atomic<uint64_t> pathInfoCacheSize{0}; + std::atomic<uint64_t> narRead{0}; + std::atomic<uint64_t> narReadBytes{0}; + std::atomic<uint64_t> narReadCompressedBytes{0}; + std::atomic<uint64_t> narWrite{0}; + std::atomic<uint64_t> narWriteAverted{0}; + std::atomic<uint64_t> narWriteBytes{0}; + std::atomic<uint64_t> narWriteCompressedBytes{0}; + std::atomic<uint64_t> narWriteCompressionTimeMs{0}; + }; + + const Stats& getStats(); + + /* Return the build log of the specified store path, if available, + or null otherwise. */ + virtual std::shared_ptr<std::string> getBuildLog(const Path& path) { + return nullptr; + } + + /* Hack to allow long-running processes like hydra-queue-runner to + occasionally flush their path info cache. */ + void clearPathInfoCache() { state.lock()->pathInfoCache.clear(); } + + /* Establish a connection to the store, for store types that have + a notion of connection. Otherwise this is a no-op. */ + virtual void connect(){}; + + /* Get the protocol version of this store or it's connection. */ + virtual unsigned int getProtocol() { return 0; }; + + /* Get the priority of the store, used to order substituters. In + particular, binary caches can specify a priority field in their + "nix-cache-info" file. Lower value means higher priority. */ + virtual int getPriority() { return 0; } + + virtual Path toRealPath(const Path& storePath) { return storePath; } + + virtual void createUser(const std::string& userName, uid_t userId) {} + + protected: + Stats stats; + + /* Unsupported methods. */ + [[noreturn]] void unsupported(const std::string& op) { + throw Unsupported("operation '%s' is not supported by store '%s'", op, + getUri()); + } +}; + +class LocalFSStore : public virtual Store { + public: + // FIXME: the (Store*) cast works around a bug in gcc that causes + // it to emit the call to the Option constructor. Clang works fine + // either way. + const PathSetting rootDir{(Store*)this, true, "", "root", + "directory prefixed to all other paths"}; + const PathSetting stateDir{ + (Store*)this, false, + rootDir != "" ? rootDir + "/nix/var/nix" : settings.nixStateDir, "state", + "directory where Nix will store state"}; + const PathSetting logDir{ + (Store*)this, false, + rootDir != "" ? rootDir + "/nix/var/log/nix" : settings.nixLogDir, "log", + "directory where Nix will store state"}; + + const static string drvsLogDir; + + LocalFSStore(const Params& params); + + void narFromPath(const Path& path, Sink& sink) override; + ref<FSAccessor> getFSAccessor() override; + + /* Register a permanent GC root. */ + Path addPermRoot(const Path& storePath, const Path& gcRoot, bool indirect, + bool allowOutsideRootsDir = false); + + virtual Path getRealStoreDir() { return storeDir; } + + Path toRealPath(const Path& storePath) override { + assert(isInStore(storePath)); + return getRealStoreDir() + "/" + + std::string(storePath, storeDir.size() + 1); + } + + std::shared_ptr<std::string> getBuildLog(const Path& path) override; +}; + +/* Extract the name part of the given store path. */ +string storePathToName(const Path& path); + +/* Extract the hash part of the given store path. */ +string storePathToHash(const Path& path); + +/* Check whether ‘name’ is a valid store path name part, i.e. contains + only the characters [a-zA-Z0-9\+\-\.\_\?\=] and doesn't start with + a dot. */ +void checkStoreName(const string& name); + +/* Copy a path from one store to another. */ +void copyStorePath(ref<Store> srcStore, const ref<Store>& dstStore, + const Path& storePath, RepairFlag repair = NoRepair, + CheckSigsFlag checkSigs = CheckSigs); + +/* Copy store paths from one store to another. The paths may be copied + in parallel. They are copied in a topologically sorted order + (i.e. if A is a reference of B, then A is copied before B), but + the set of store paths is not automatically closed; use + copyClosure() for that. */ +void copyPaths(ref<Store> srcStore, ref<Store> dstStore, + const PathSet& storePaths, RepairFlag repair = NoRepair, + CheckSigsFlag checkSigs = CheckSigs, + SubstituteFlag substitute = NoSubstitute); + +/* Copy the closure of the specified paths from one store to another. */ +void copyClosure(const ref<Store>& srcStore, const ref<Store>& dstStore, + const PathSet& storePaths, RepairFlag repair = NoRepair, + CheckSigsFlag checkSigs = CheckSigs, + SubstituteFlag substitute = NoSubstitute); + +/* Remove the temporary roots file for this process. Any temporary + root becomes garbage after this point unless it has been registered + as a (permanent) root. */ +void removeTempRoots(); + +/* Return a Store object to access the Nix store denoted by + ‘uri’ (slight misnomer...). Supported values are: + + * ‘local’: The Nix store in /nix/store and database in + /nix/var/nix/db, accessed directly. + + * ‘daemon’: The Nix store accessed via a Unix domain socket + connection to nix-daemon. + + * ‘unix://<path>’: The Nix store accessed via a Unix domain socket + connection to nix-daemon, with the socket located at <path>. + + * ‘auto’ or ‘’: Equivalent to ‘local’ or ‘daemon’ depending on + whether the user has write access to the local Nix + store/database. + + * ‘file://<path>’: A binary cache stored in <path>. + + * ‘https://<path>’: A binary cache accessed via HTTP. + + * ‘s3://<path>’: A writable binary cache stored on Amazon's Simple + Storage Service. + + * ‘ssh://[user@]<host>’: A remote Nix store accessed by running + ‘nix-store --serve’ via SSH. + + You can pass parameters to the store implementation by appending + ‘?key=value&key=value&...’ to the URI. +*/ +ref<Store> openStore(const std::string& uri = settings.storeUri.get(), + const Store::Params& extraParams = Store::Params()); + +enum StoreType { tDaemon, tLocal, tOther }; + +StoreType getStoreType(const std::string& uri = settings.storeUri.get(), + const std::string& stateDir = settings.nixStateDir); + +/* Return the default substituter stores, defined by the + ‘substituters’ option and various legacy options. */ +std::list<ref<Store>> getDefaultSubstituters(); + +/* Store implementation registration. */ +typedef std::function<std::shared_ptr<Store>(const std::string& uri, + const Store::Params& params)> + OpenStore; + +struct RegisterStoreImplementation { + typedef std::vector<OpenStore> Implementations; + static Implementations* implementations; + + RegisterStoreImplementation(OpenStore fun) { + if (!implementations) { + implementations = new Implementations; + } + implementations->push_back(fun); + } +}; + +/* Display a set of paths in human-readable form (i.e., between quotes + and separated by commas). */ +string showPaths(const PathSet& paths); + +ValidPathInfo decodeValidPathInfo(std::istream& str, bool hashGiven = false); + +/* Compute the content-addressability assertion (ValidPathInfo::ca) + for paths created by makeFixedOutputPath() / addToStore(). */ +std::string makeFixedOutputCA(bool recursive, const Hash& hash); + +/* Split URI into protocol+hierarchy part and its parameter set. */ +std::pair<std::string, Store::Params> splitUriAndParams(const std::string& uri); + +} // namespace nix diff --git a/third_party/nix/src/libstore/worker-protocol.hh b/third_party/nix/src/libstore/worker-protocol.hh new file mode 100644 index 0000000000..970d494ace --- /dev/null +++ b/third_party/nix/src/libstore/worker-protocol.hh @@ -0,0 +1,65 @@ +#pragma once + +namespace nix { + +#define WORKER_MAGIC_1 0x6e697863 +#define WORKER_MAGIC_2 0x6478696f + +#define PROTOCOL_VERSION 0x115 +#define GET_PROTOCOL_MAJOR(x) ((x)&0xff00) +#define GET_PROTOCOL_MINOR(x) ((x)&0x00ff) + +typedef enum { + wopIsValidPath = 1, + wopHasSubstitutes = 3, + wopQueryPathHash = 4, // obsolete + wopQueryReferences = 5, // obsolete + wopQueryReferrers = 6, + wopAddToStore = 7, + wopAddTextToStore = 8, + wopBuildPaths = 9, + wopEnsurePath = 10, + wopAddTempRoot = 11, + wopAddIndirectRoot = 12, + wopSyncWithGC = 13, + wopFindRoots = 14, + wopExportPath = 16, // obsolete + wopQueryDeriver = 18, // obsolete + wopSetOptions = 19, + wopCollectGarbage = 20, + wopQuerySubstitutablePathInfo = 21, + wopQueryDerivationOutputs = 22, + wopQueryAllValidPaths = 23, + wopQueryFailedPaths = 24, + wopClearFailedPaths = 25, + wopQueryPathInfo = 26, + wopImportPaths = 27, // obsolete + wopQueryDerivationOutputNames = 28, + wopQueryPathFromHashPart = 29, + wopQuerySubstitutablePathInfos = 30, + wopQueryValidPaths = 31, + wopQuerySubstitutablePaths = 32, + wopQueryValidDerivers = 33, + wopOptimiseStore = 34, + wopVerifyStore = 35, + wopBuildDerivation = 36, + wopAddSignatures = 37, + wopNarFromPath = 38, + wopAddToStoreNar = 39, + wopQueryMissing = 40, +} WorkerOp; + +#define STDERR_NEXT 0x6f6c6d67 +#define STDERR_READ 0x64617461 // data needed from source +#define STDERR_WRITE 0x64617416 // data for sink +#define STDERR_LAST 0x616c7473 +#define STDERR_ERROR 0x63787470 +#define STDERR_START_ACTIVITY 0x53545254 +#define STDERR_STOP_ACTIVITY 0x53544f50 +#define STDERR_RESULT 0x52534c54 + +Path readStorePath(Store& store, Source& from); +template <class T> +T readStorePaths(Store& store, Source& from); + +} // namespace nix diff --git a/third_party/nix/src/libutil/affinity.cc b/third_party/nix/src/libutil/affinity.cc new file mode 100644 index 0000000000..7db8906eb0 --- /dev/null +++ b/third_party/nix/src/libutil/affinity.cc @@ -0,0 +1,60 @@ +#include "affinity.hh" + +#include <glog/logging.h> + +#include "types.hh" +#include "util.hh" + +#if __linux__ +#include <sched.h> +#endif + +namespace nix { + +#if __linux__ +static bool didSaveAffinity = false; +static cpu_set_t savedAffinity; +#endif + +void setAffinityTo(int cpu) { +#if __linux__ + if (sched_getaffinity(0, sizeof(cpu_set_t), &savedAffinity) == -1) { + return; + } + + didSaveAffinity = true; + DLOG(INFO) << "locking this thread to CPU " << cpu; + cpu_set_t newAffinity; + CPU_ZERO(&newAffinity); + CPU_SET(cpu, &newAffinity); + if (sched_setaffinity(0, sizeof(cpu_set_t), &newAffinity) == -1) { + LOG(ERROR) << "failed to lock thread to CPU " << cpu; + } +#endif +} + +int lockToCurrentCPU() { +#if __linux__ + int cpu = sched_getcpu(); + if (cpu != -1) { + setAffinityTo(cpu); + } + return cpu; +#else + return -1; +#endif +} + +void restoreAffinity() { +#if __linux__ + if (!didSaveAffinity) { + return; + } + + if (sched_setaffinity(0, sizeof(cpu_set_t), &savedAffinity) == -1) { + LOG(ERROR) << "failed to restore affinity"; + } +#endif +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/affinity.hh b/third_party/nix/src/libutil/affinity.hh new file mode 100644 index 0000000000..5e5ef9b0de --- /dev/null +++ b/third_party/nix/src/libutil/affinity.hh @@ -0,0 +1,9 @@ +#pragma once + +namespace nix { + +void setAffinityTo(int cpu); +int lockToCurrentCPU(); +void restoreAffinity(); + +} // namespace nix diff --git a/third_party/nix/src/libutil/archive.cc b/third_party/nix/src/libutil/archive.cc new file mode 100644 index 0000000000..32bad07f22 --- /dev/null +++ b/third_party/nix/src/libutil/archive.cc @@ -0,0 +1,399 @@ +#include "archive.hh" + +#include <algorithm> +#include <cerrno> +#include <map> +#include <vector> + +#include <dirent.h> +#include <fcntl.h> +#include <strings.h> // for strcasecmp +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include "config.hh" +#include "glog/logging.h" +#include "util.hh" + +namespace nix { + +struct ArchiveSettings : Config { + Setting<bool> useCaseHack { + this, +#if __APPLE__ + true, +#else + false, +#endif + "use-case-hack", + "Whether to enable a Darwin-specific hack for dealing with file name " + "collisions." + }; +}; + +static ArchiveSettings archiveSettings; + +static GlobalConfig::Register r1(&archiveSettings); + +const std::string narVersionMagic1 = "nix-archive-1"; + +static string caseHackSuffix = "~nix~case~hack~"; + +PathFilter defaultPathFilter = [](const Path& /*unused*/) { return true; }; + +static void dumpContents(const Path& path, size_t size, Sink& sink) { + sink << "contents" << size; + + AutoCloseFD fd = open(path.c_str(), O_RDONLY | O_CLOEXEC); + if (!fd) { + throw SysError(format("opening file '%1%'") % path); + } + + std::vector<unsigned char> buf(65536); + size_t left = size; + + while (left > 0) { + auto n = std::min(left, buf.size()); + readFull(fd.get(), buf.data(), n); + left -= n; + sink(buf.data(), n); + } + + writePadding(size, sink); +} + +static void dump(const Path& path, Sink& sink, PathFilter& filter) { + checkInterrupt(); + + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting attributes of path '%1%'") % path); + } + + sink << "("; + + if (S_ISREG(st.st_mode)) { + sink << "type" + << "regular"; + if ((st.st_mode & S_IXUSR) != 0u) { + sink << "executable" + << ""; + } + dumpContents(path, (size_t)st.st_size, sink); + } + + else if (S_ISDIR(st.st_mode)) { + sink << "type" + << "directory"; + + /* If we're on a case-insensitive system like macOS, undo + the case hack applied by restorePath(). */ + std::map<string, string> unhacked; + for (auto& i : readDirectory(path)) { + if (archiveSettings.useCaseHack) { + string name(i.name); + size_t pos = i.name.find(caseHackSuffix); + if (pos != string::npos) { + DLOG(INFO) << "removing case hack suffix from " << path << "/" + << i.name; + + name.erase(pos); + } + if (unhacked.find(name) != unhacked.end()) { + throw Error(format("file name collision in between '%1%' and '%2%'") % + (path + "/" + unhacked[name]) % (path + "/" + i.name)); + } + unhacked[name] = i.name; + } else { + unhacked[i.name] = i.name; + } + } + + for (auto& i : unhacked) { + if (filter(path + "/" + i.first)) { + sink << "entry" + << "(" + << "name" << i.first << "node"; + dump(path + "/" + i.second, sink, filter); + sink << ")"; + } + } + } + + else if (S_ISLNK(st.st_mode)) { + sink << "type" + << "symlink" + << "target" << readLink(path); + + } else { + throw Error(format("file '%1%' has an unsupported type") % path); + } + + sink << ")"; +} + +void dumpPath(const Path& path, Sink& sink, PathFilter& filter) { + sink << narVersionMagic1; + dump(path, sink, filter); +} + +void dumpString(const std::string& s, Sink& sink) { + sink << narVersionMagic1 << "(" + << "type" + << "regular" + << "contents" << s << ")"; +} + +static SerialisationError badArchive(const string& s) { + return SerialisationError("bad archive: " + s); +} + +#if 0 +static void skipGeneric(Source & source) +{ + if (readString(source) == "(") { + while (readString(source) != ")") + skipGeneric(source); + } +} +#endif + +static void parseContents(ParseSink& sink, Source& source, const Path& path) { + unsigned long long size = readLongLong(source); + + sink.preallocateContents(size); + + unsigned long long left = size; + std::vector<unsigned char> buf(65536); + + while (left != 0u) { + checkInterrupt(); + auto n = buf.size(); + if ((unsigned long long)n > left) { + n = left; + } + source(buf.data(), n); + sink.receiveContents(buf.data(), n); + left -= n; + } + + readPadding(size, source); +} + +struct CaseInsensitiveCompare { + bool operator()(const string& a, const string& b) const { + return strcasecmp(a.c_str(), b.c_str()) < 0; + } +}; + +static void parse(ParseSink& sink, Source& source, const Path& path) { + string s; + + s = readString(source); + if (s != "(") { + throw badArchive("expected open tag"); + } + + enum { tpUnknown, tpRegular, tpDirectory, tpSymlink } type = tpUnknown; + + std::map<Path, int, CaseInsensitiveCompare> names; + + while (true) { + checkInterrupt(); + + s = readString(source); + + if (s == ")") { + break; + } + + if (s == "type") { + if (type != tpUnknown) { + throw badArchive("multiple type fields"); + } + string t = readString(source); + + if (t == "regular") { + type = tpRegular; + sink.createRegularFile(path); + } + + else if (t == "directory") { + sink.createDirectory(path); + type = tpDirectory; + } + + else if (t == "symlink") { + type = tpSymlink; + } + + else { + throw badArchive("unknown file type " + t); + } + + } + + else if (s == "contents" && type == tpRegular) { + parseContents(sink, source, path); + } + + else if (s == "executable" && type == tpRegular) { + auto s = readString(source); + if (!s.empty()) { + throw badArchive("executable marker has non-empty value"); + } + sink.isExecutable(); + } + + else if (s == "entry" && type == tpDirectory) { + string name; + string prevName; + + s = readString(source); + if (s != "(") { + throw badArchive("expected open tag"); + } + + while (true) { + checkInterrupt(); + + s = readString(source); + + if (s == ")") { + break; + } + if (s == "name") { + name = readString(source); + if (name.empty() || name == "." || name == ".." || + name.find('/') != string::npos || + name.find((char)0) != string::npos) { + throw Error(format("NAR contains invalid file name '%1%'") % name); + } + if (name <= prevName) { + throw Error("NAR directory is not sorted"); + } + prevName = name; + if (archiveSettings.useCaseHack) { + auto i = names.find(name); + if (i != names.end()) { + DLOG(INFO) << "case collision between '" << i->first << "' and '" + << name << "'"; + name += caseHackSuffix; + name += std::to_string(++i->second); + } else { + names[name] = 0; + } + } + } else if (s == "node") { + if (s.empty()) { + throw badArchive("entry name missing"); + } + parse(sink, source, path + "/" + name); + } else { + throw badArchive("unknown field " + s); + } + } + } + + else if (s == "target" && type == tpSymlink) { + string target = readString(source); + sink.createSymlink(path, target); + } + + else { + throw badArchive("unknown field " + s); + } + } +} + +void parseDump(ParseSink& sink, Source& source) { + string version; + try { + version = readString(source, narVersionMagic1.size()); + } catch (SerialisationError& e) { + /* This generally means the integer at the start couldn't be + decoded. Ignore and throw the exception below. */ + } + if (version != narVersionMagic1) { + throw badArchive("input doesn't look like a Nix archive"); + } + parse(sink, source, ""); +} + +struct RestoreSink : ParseSink { + Path dstPath; + AutoCloseFD fd; + + void createDirectory(const Path& path) override { + Path p = dstPath + path; + if (mkdir(p.c_str(), 0777) == -1) { + throw SysError(format("creating directory '%1%'") % p); + } + }; + + void createRegularFile(const Path& path) override { + Path p = dstPath + path; + fd = open(p.c_str(), O_CREAT | O_EXCL | O_WRONLY | O_CLOEXEC, 0666); + if (!fd) { + throw SysError(format("creating file '%1%'") % p); + } + } + + void isExecutable() override { + struct stat st; + if (fstat(fd.get(), &st) == -1) { + throw SysError("fstat"); + } + if (fchmod(fd.get(), st.st_mode | (S_IXUSR | S_IXGRP | S_IXOTH)) == -1) { + throw SysError("fchmod"); + } + } + + void preallocateContents(unsigned long long len) override { +#if HAVE_POSIX_FALLOCATE + if (len != 0u) { + errno = posix_fallocate(fd.get(), 0, len); + /* Note that EINVAL may indicate that the underlying + filesystem doesn't support preallocation (e.g. on + OpenSolaris). Since preallocation is just an + optimisation, ignore it. */ + if (errno && errno != EINVAL && errno != EOPNOTSUPP && errno != ENOSYS) { + throw SysError(format("preallocating file of %1% bytes") % len); + } + } +#endif + } + + void receiveContents(unsigned char* data, unsigned int len) override { + writeFull(fd.get(), data, len); + } + + void createSymlink(const Path& path, const string& target) override { + Path p = dstPath + path; + nix::createSymlink(target, p); + } +}; + +void restorePath(const Path& path, Source& source) { + RestoreSink sink; + sink.dstPath = path; + parseDump(sink, source); +} + +void copyNAR(Source& source, Sink& sink) { + // FIXME: if 'source' is the output of dumpPath() followed by EOF, + // we should just forward all data directly without parsing. + + ParseSink parseSink; /* null sink; just parse the NAR */ + + LambdaSource wrapper([&](unsigned char* data, size_t len) { + auto n = source.read(data, len); + sink(data, n); + return n; + }); + + parseDump(parseSink, wrapper); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/archive.hh b/third_party/nix/src/libutil/archive.hh new file mode 100644 index 0000000000..9a656edae4 --- /dev/null +++ b/third_party/nix/src/libutil/archive.hh @@ -0,0 +1,77 @@ +#pragma once + +#include "serialise.hh" +#include "types.hh" + +namespace nix { + +/* dumpPath creates a Nix archive of the specified path. The format + is as follows: + + IF path points to a REGULAR FILE: + dump(path) = attrs( + [ ("type", "regular") + , ("contents", contents(path)) + ]) + + IF path points to a DIRECTORY: + dump(path) = attrs( + [ ("type", "directory") + , ("entries", concat(map(f, sort(entries(path))))) + ]) + where f(fn) = attrs( + [ ("name", fn) + , ("file", dump(path + "/" + fn)) + ]) + + where: + + attrs(as) = concat(map(attr, as)) + encN(0) + attrs((a, b)) = encS(a) + encS(b) + + encS(s) = encN(len(s)) + s + (padding until next 64-bit boundary) + + encN(n) = 64-bit little-endian encoding of n. + + contents(path) = the contents of a regular file. + + sort(strings) = lexicographic sort by 8-bit value (strcmp). + + entries(path) = the entries of a directory, without `.' and + `..'. + + `+' denotes string concatenation. */ + +void dumpPath(const Path& path, Sink& sink, + PathFilter& filter = defaultPathFilter); + +void dumpString(const std::string& s, Sink& sink); + +/* FIXME: fix this API, it sucks. */ +struct ParseSink { + virtual void createDirectory(const Path& path){}; + + virtual void createRegularFile(const Path& path){}; + virtual void isExecutable(){}; + virtual void preallocateContents(unsigned long long size){}; + virtual void receiveContents(unsigned char* data, unsigned int len){}; + + virtual void createSymlink(const Path& path, const string& target){}; +}; + +struct TeeSink : ParseSink { + TeeSource source; + + TeeSink(Source& source) : source(source) {} +}; + +void parseDump(ParseSink& sink, Source& source); + +void restorePath(const Path& path, Source& source); + +/* Read a NAR from 'source' and write it to 'sink'. */ +void copyNAR(Source& source, Sink& sink); + +extern const std::string narVersionMagic1; + +} // namespace nix diff --git a/third_party/nix/src/libutil/args.cc b/third_party/nix/src/libutil/args.cc new file mode 100644 index 0000000000..48fa715fdf --- /dev/null +++ b/third_party/nix/src/libutil/args.cc @@ -0,0 +1,219 @@ +#include "args.hh" + +#include "hash.hh" + +namespace nix { + +Args::FlagMaker Args::mkFlag() { return FlagMaker(*this); } + +Args::FlagMaker::~FlagMaker() { + assert(!flag->longName.empty()); + args.longFlags[flag->longName] = flag; + if (flag->shortName != 0) { + args.shortFlags[flag->shortName] = flag; + } +} + +void Args::parseCmdline(const Strings& _cmdline) { + Strings pendingArgs; + bool dashDash = false; + + Strings cmdline(_cmdline); + + for (auto pos = cmdline.begin(); pos != cmdline.end();) { + auto arg = *pos; + + /* Expand compound dash options (i.e., `-qlf' -> `-q -l -f', + `-j3` -> `-j 3`). */ + if (!dashDash && arg.length() > 2 && arg[0] == '-' && arg[1] != '-' && + (isalpha(arg[1]) != 0)) { + *pos = (string) "-" + arg[1]; + auto next = pos; + ++next; + for (unsigned int j = 2; j < arg.length(); j++) { + if (isalpha(arg[j]) != 0) { + cmdline.insert(next, (string) "-" + arg[j]); + } else { + cmdline.insert(next, string(arg, j)); + break; + } + } + arg = *pos; + } + + if (!dashDash && arg == "--") { + dashDash = true; + ++pos; + } else if (!dashDash && std::string(arg, 0, 1) == "-") { + if (!processFlag(pos, cmdline.end())) { + throw UsageError(format("unrecognised flag '%1%'") % arg); + } + } else { + pendingArgs.push_back(*pos++); + if (processArgs(pendingArgs, false)) { + pendingArgs.clear(); + } + } + } + + processArgs(pendingArgs, true); +} + +void Args::printHelp(const string& programName, std::ostream& out) { + std::cout << "Usage: " << programName << " <FLAGS>..."; + for (auto& exp : expectedArgs) { + std::cout << renderLabels({exp.label}); + // FIXME: handle arity > 1 + if (exp.arity == 0) { + std::cout << "..."; + } + if (exp.optional) { + std::cout << "?"; + } + } + std::cout << "\n"; + + auto s = description(); + if (!s.empty()) { + std::cout << "\nSummary: " << s << ".\n"; + } + + if (!longFlags.empty() != 0u) { + std::cout << "\n"; + std::cout << "Flags:\n"; + printFlags(out); + } +} + +void Args::printFlags(std::ostream& out) { + Table2 table; + for (auto& flag : longFlags) { + if (hiddenCategories.count(flag.second->category) != 0u) { + continue; + } + table.push_back(std::make_pair( + (flag.second->shortName != 0 + ? std::string("-") + flag.second->shortName + ", " + : " ") + + "--" + flag.first + renderLabels(flag.second->labels), + flag.second->description)); + } + printTable(out, table); +} + +bool Args::processFlag(Strings::iterator& pos, Strings::iterator end) { + assert(pos != end); + + auto process = [&](const std::string& name, const Flag& flag) -> bool { + ++pos; + std::vector<std::string> args; + for (size_t n = 0; n < flag.arity; ++n) { + if (pos == end) { + if (flag.arity == ArityAny) { + break; + } + throw UsageError(format("flag '%1%' requires %2% argument(s)") % name % + flag.arity); + } + args.push_back(*pos++); + } + flag.handler(std::move(args)); + return true; + }; + + if (string(*pos, 0, 2) == "--") { + auto i = longFlags.find(string(*pos, 2)); + if (i == longFlags.end()) { + return false; + } + return process("--" + i->first, *i->second); + } + + if (string(*pos, 0, 1) == "-" && pos->size() == 2) { + auto c = (*pos)[1]; + auto i = shortFlags.find(c); + if (i == shortFlags.end()) { + return false; + } + return process(std::string("-") + c, *i->second); + } + + return false; +} + +bool Args::processArgs(const Strings& args, bool finish) { + if (expectedArgs.empty()) { + if (!args.empty()) { + throw UsageError(format("unexpected argument '%1%'") % args.front()); + } + return true; + } + + auto& exp = expectedArgs.front(); + + bool res = false; + + if ((exp.arity == 0 && finish) || + (exp.arity > 0 && args.size() == exp.arity)) { + std::vector<std::string> ss; + for (auto& s : args) { + ss.push_back(s); + } + exp.handler(std::move(ss)); + expectedArgs.pop_front(); + res = true; + } + + if (finish && !expectedArgs.empty() && !expectedArgs.front().optional) { + throw UsageError("more arguments are required"); + } + + return res; +} + +Args::FlagMaker& Args::FlagMaker::mkHashTypeFlag(HashType* ht) { + arity(1); + label("type"); + description("hash algorithm ('md5', 'sha1', 'sha256', or 'sha512')"); + handler([ht](const std::string& s) { + *ht = parseHashType(s); + if (*ht == htUnknown) { + throw UsageError("unknown hash type '%1%'", s); + } + }); + return *this; +} + +Strings argvToStrings(int argc, char** argv) { + Strings args; + argc--; + argv++; + while ((argc--) != 0) { + args.push_back(*argv++); + } + return args; +} + +std::string renderLabels(const Strings& labels) { + std::string res; + for (auto label : labels) { + for (auto& c : label) { + c = std::toupper(c); + } + res += " <" + label + ">"; + } + return res; +} + +void printTable(std::ostream& out, const Table2& table) { + size_t max = 0; + for (auto& row : table) { + max = std::max(max, row.first.size()); + } + for (auto& row : table) { + out << " " << row.first << std::string(max - row.first.size() + 2, ' ') + << row.second << "\n"; + } +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/args.hh b/third_party/nix/src/libutil/args.hh new file mode 100644 index 0000000000..20233d3534 --- /dev/null +++ b/third_party/nix/src/libutil/args.hh @@ -0,0 +1,217 @@ +#pragma once + +#include <iostream> +#include <map> +#include <memory> + +#include "util.hh" + +namespace nix { + +MakeError(UsageError, Error) + + enum HashType : char; + +class Args { + public: + /* Parse the command line, throwing a UsageError if something goes + wrong. */ + void parseCmdline(const Strings& cmdline); + + virtual void printHelp(const string& programName, std::ostream& out); + + virtual std::string description() { return ""; } + + protected: + static const size_t ArityAny = std::numeric_limits<size_t>::max(); + + /* Flags. */ + struct Flag { + typedef std::shared_ptr<Flag> ptr; + std::string longName; + char shortName = 0; + std::string description; + Strings labels; + size_t arity = 0; + std::function<void(std::vector<std::string>)> handler; + std::string category; + }; + + std::map<std::string, Flag::ptr> longFlags; + std::map<char, Flag::ptr> shortFlags; + + virtual bool processFlag(Strings::iterator& pos, Strings::iterator end); + + virtual void printFlags(std::ostream& out); + + /* Positional arguments. */ + struct ExpectedArg { + std::string label; + size_t arity; // 0 = any + bool optional; + std::function<void(std::vector<std::string>)> handler; + }; + + std::list<ExpectedArg> expectedArgs; + + virtual bool processArgs(const Strings& args, bool finish); + + std::set<std::string> hiddenCategories; + + public: + class FlagMaker { + Args& args; + Flag::ptr flag; + friend class Args; + FlagMaker(Args& args) : args(args), flag(std::make_shared<Flag>()){}; + + public: + ~FlagMaker(); + FlagMaker& longName(const std::string& s) { + flag->longName = s; + return *this; + }; + FlagMaker& shortName(char s) { + flag->shortName = s; + return *this; + }; + FlagMaker& description(const std::string& s) { + flag->description = s; + return *this; + }; + FlagMaker& label(const std::string& l) { + flag->arity = 1; + flag->labels = {l}; + return *this; + }; + FlagMaker& labels(const Strings& ls) { + flag->arity = ls.size(); + flag->labels = ls; + return *this; + }; + FlagMaker& arity(size_t arity) { + flag->arity = arity; + return *this; + }; + FlagMaker& handler(std::function<void(std::vector<std::string>)> handler) { + flag->handler = handler; + return *this; + }; + FlagMaker& handler(std::function<void()> handler) { + flag->handler = [handler](std::vector<std::string>) { handler(); }; + return *this; + }; + FlagMaker& handler(std::function<void(std::string)> handler) { + flag->arity = 1; + flag->handler = [handler](std::vector<std::string> ss) { + handler(std::move(ss[0])); + }; + return *this; + }; + FlagMaker& category(const std::string& s) { + flag->category = s; + return *this; + }; + + template <class T> + FlagMaker& dest(T* dest) { + flag->arity = 1; + flag->handler = [=](std::vector<std::string> ss) { *dest = ss[0]; }; + return *this; + } + + template <class T> + FlagMaker& set(T* dest, const T& val) { + flag->arity = 0; + flag->handler = [=](std::vector<std::string> ss) { *dest = val; }; + return *this; + } + + FlagMaker& mkHashTypeFlag(HashType* ht); + }; + + FlagMaker mkFlag(); + + /* Helper functions for constructing flags / positional + arguments. */ + + void mkFlag1(char shortName, const std::string& longName, + const std::string& label, const std::string& description, + std::function<void(std::string)> fun) { + mkFlag() + .shortName(shortName) + .longName(longName) + .labels({label}) + .description(description) + .arity(1) + .handler([=](std::vector<std::string> ss) { fun(ss[0]); }); + } + + void mkFlag(char shortName, const std::string& name, + const std::string& description, bool* dest) { + mkFlag(shortName, name, description, dest, true); + } + + template <class T> + void mkFlag(char shortName, const std::string& longName, + const std::string& description, T* dest, const T& value) { + mkFlag() + .shortName(shortName) + .longName(longName) + .description(description) + .handler([=](std::vector<std::string> ss) { *dest = value; }); + } + + template <class I> + void mkIntFlag(char shortName, const std::string& longName, + const std::string& description, I* dest) { + mkFlag<I>(shortName, longName, description, [=](I n) { *dest = n; }); + } + + template <class I> + void mkFlag(char shortName, const std::string& longName, + const std::string& description, std::function<void(I)> fun) { + mkFlag() + .shortName(shortName) + .longName(longName) + .labels({"N"}) + .description(description) + .arity(1) + .handler([=](std::vector<std::string> ss) { + I n; + if (!string2Int(ss[0], n)) + throw UsageError("flag '--%s' requires a integer argument", + longName); + fun(n); + }); + } + + /* Expect a string argument. */ + void expectArg(const std::string& label, string* dest, + bool optional = false) { + expectedArgs.push_back( + ExpectedArg{label, 1, optional, + [=](std::vector<std::string> ss) { *dest = ss[0]; }}); + } + + /* Expect 0 or more arguments. */ + void expectArgs(const std::string& label, std::vector<std::string>* dest) { + expectedArgs.push_back(ExpectedArg{ + label, 0, false, + [=](std::vector<std::string> ss) { *dest = std::move(ss); }}); + } + + friend class MultiCommand; +}; + +Strings argvToStrings(int argc, char** argv); + +/* Helper function for rendering argument labels. */ +std::string renderLabels(const Strings& labels); + +/* Helper function for printing 2-column tables. */ +typedef std::vector<std::pair<std::string, std::string>> Table2; + +void printTable(std::ostream& out, const Table2& table); + +} // namespace nix diff --git a/third_party/nix/src/libutil/compression.cc b/third_party/nix/src/libutil/compression.cc new file mode 100644 index 0000000000..d7084ab7f1 --- /dev/null +++ b/third_party/nix/src/libutil/compression.cc @@ -0,0 +1,405 @@ +#include "compression.hh" + +#include <cstdio> +#include <cstring> +#include <iostream> + +#include <brotli/decode.h> +#include <brotli/encode.h> +#include <bzlib.h> +#include <lzma.h> + +#include "finally.hh" +#include "glog/logging.h" +#include "util.hh" + +namespace nix { + +// Don't feed brotli too much at once. +struct ChunkedCompressionSink : CompressionSink { + uint8_t outbuf[32 * 1024]; + + void write(const unsigned char* data, size_t len) override { + const size_t CHUNK_SIZE = sizeof(outbuf) << 2; + while (len != 0u) { + size_t n = std::min(CHUNK_SIZE, len); + writeInternal(data, n); + data += n; + len -= n; + } + } + + virtual void writeInternal(const unsigned char* data, size_t len) = 0; +}; + +struct NoneSink : CompressionSink { + Sink& nextSink; + explicit NoneSink(Sink& nextSink) : nextSink(nextSink) {} + void finish() override { flush(); } + void write(const unsigned char* data, size_t len) override { + nextSink(data, len); + } +}; + +struct XzDecompressionSink : CompressionSink { + Sink& nextSink; + uint8_t outbuf[BUFSIZ]; + lzma_stream strm = LZMA_STREAM_INIT; + bool finished = false; + + explicit XzDecompressionSink(Sink& nextSink) : nextSink(nextSink) { + lzma_ret ret = lzma_stream_decoder(&strm, UINT64_MAX, LZMA_CONCATENATED); + if (ret != LZMA_OK) { + throw CompressionError("unable to initialise lzma decoder"); + } + + strm.next_out = outbuf; + strm.avail_out = sizeof(outbuf); + } + + ~XzDecompressionSink() override { lzma_end(&strm); } + + void finish() override { + CompressionSink::flush(); + write(nullptr, 0); + } + + void write(const unsigned char* data, size_t len) override { + strm.next_in = data; + strm.avail_in = len; + + while (!finished && ((data == nullptr) || (strm.avail_in != 0u))) { + checkInterrupt(); + + lzma_ret ret = lzma_code(&strm, data != nullptr ? LZMA_RUN : LZMA_FINISH); + if (ret != LZMA_OK && ret != LZMA_STREAM_END) { + throw CompressionError("error %d while decompressing xz file", ret); + } + + finished = ret == LZMA_STREAM_END; + + if (strm.avail_out < sizeof(outbuf) || strm.avail_in == 0) { + nextSink(outbuf, sizeof(outbuf) - strm.avail_out); + strm.next_out = outbuf; + strm.avail_out = sizeof(outbuf); + } + } + } +}; + +struct BzipDecompressionSink : ChunkedCompressionSink { + Sink& nextSink; + bz_stream strm; + bool finished = false; + + explicit BzipDecompressionSink(Sink& nextSink) : nextSink(nextSink) { + memset(&strm, 0, sizeof(strm)); + int ret = BZ2_bzDecompressInit(&strm, 0, 0); + if (ret != BZ_OK) { + throw CompressionError("unable to initialise bzip2 decoder"); + } + + strm.next_out = (char*)outbuf; + strm.avail_out = sizeof(outbuf); + } + + ~BzipDecompressionSink() override { BZ2_bzDecompressEnd(&strm); } + + void finish() override { + flush(); + write(nullptr, 0); + } + + void writeInternal(const unsigned char* data, size_t len) override { + assert(len <= std::numeric_limits<decltype(strm.avail_in)>::max()); + + strm.next_in = (char*)data; + strm.avail_in = len; + + while (strm.avail_in != 0u) { + checkInterrupt(); + + int ret = BZ2_bzDecompress(&strm); + if (ret != BZ_OK && ret != BZ_STREAM_END) { + throw CompressionError("error while decompressing bzip2 file"); + } + + finished = ret == BZ_STREAM_END; + + if (strm.avail_out < sizeof(outbuf) || strm.avail_in == 0) { + nextSink(outbuf, sizeof(outbuf) - strm.avail_out); + strm.next_out = (char*)outbuf; + strm.avail_out = sizeof(outbuf); + } + } + } +}; + +struct BrotliDecompressionSink : ChunkedCompressionSink { + Sink& nextSink; + BrotliDecoderState* state; + bool finished = false; + + explicit BrotliDecompressionSink(Sink& nextSink) : nextSink(nextSink) { + state = BrotliDecoderCreateInstance(nullptr, nullptr, nullptr); + if (state == nullptr) { + throw CompressionError("unable to initialize brotli decoder"); + } + } + + ~BrotliDecompressionSink() override { BrotliDecoderDestroyInstance(state); } + + void finish() override { + flush(); + writeInternal(nullptr, 0); + } + + void writeInternal(const unsigned char* data, size_t len) override { + const uint8_t* next_in = data; + size_t avail_in = len; + uint8_t* next_out = outbuf; + size_t avail_out = sizeof(outbuf); + + while (!finished && ((data == nullptr) || (avail_in != 0u))) { + checkInterrupt(); + + if (BrotliDecoderDecompressStream(state, &avail_in, &next_in, &avail_out, + &next_out, nullptr) == 0u) { + throw CompressionError("error while decompressing brotli file"); + } + + if (avail_out < sizeof(outbuf) || avail_in == 0) { + nextSink(outbuf, sizeof(outbuf) - avail_out); + next_out = outbuf; + avail_out = sizeof(outbuf); + } + + finished = (BrotliDecoderIsFinished(state) != 0); + } + } +}; + +ref<std::string> decompress(const std::string& method, const std::string& in) { + StringSink ssink; + auto sink = makeDecompressionSink(method, ssink); + (*sink)(in); + sink->finish(); + return ssink.s; +} + +ref<CompressionSink> makeDecompressionSink(const std::string& method, + Sink& nextSink) { + if (method == "none" || method.empty()) { + return make_ref<NoneSink>(nextSink); + } + if (method == "xz") { + return make_ref<XzDecompressionSink>(nextSink); + } else if (method == "bzip2") { + return make_ref<BzipDecompressionSink>(nextSink); + } else if (method == "br") { + return make_ref<BrotliDecompressionSink>(nextSink); + } else { + throw UnknownCompressionMethod("unknown compression method '%s'", method); + } +} + +struct XzCompressionSink : CompressionSink { + Sink& nextSink; + uint8_t outbuf[BUFSIZ]; + lzma_stream strm = LZMA_STREAM_INIT; + bool finished = false; + + XzCompressionSink(Sink& nextSink, bool parallel) : nextSink(nextSink) { + lzma_ret ret; + bool done = false; + + if (parallel) { +#ifdef HAVE_LZMA_MT + lzma_mt mt_options = {}; + mt_options.flags = 0; + mt_options.timeout = 300; // Using the same setting as the xz cmd line + mt_options.preset = LZMA_PRESET_DEFAULT; + mt_options.filters = NULL; + mt_options.check = LZMA_CHECK_CRC64; + mt_options.threads = lzma_cputhreads(); + mt_options.block_size = 0; + if (mt_options.threads == 0) { + mt_options.threads = 1; + } + // FIXME: maybe use lzma_stream_encoder_mt_memusage() to control the + // number of threads. + ret = lzma_stream_encoder_mt(&strm, &mt_options); + done = true; +#else + LOG(ERROR) << "parallel XZ compression requested but not supported, " + << "falling back to single-threaded compression"; +#endif + } + + if (!done) { + ret = lzma_easy_encoder(&strm, 6, LZMA_CHECK_CRC64); + } + + if (ret != LZMA_OK) { + throw CompressionError("unable to initialise lzma encoder"); + } + + // FIXME: apply the x86 BCJ filter? + + strm.next_out = outbuf; + strm.avail_out = sizeof(outbuf); + } + + ~XzCompressionSink() override { lzma_end(&strm); } + + void finish() override { + CompressionSink::flush(); + write(nullptr, 0); + } + + void write(const unsigned char* data, size_t len) override { + strm.next_in = data; + strm.avail_in = len; + + while (!finished && ((data == nullptr) || (strm.avail_in != 0u))) { + checkInterrupt(); + + lzma_ret ret = lzma_code(&strm, data != nullptr ? LZMA_RUN : LZMA_FINISH); + if (ret != LZMA_OK && ret != LZMA_STREAM_END) { + throw CompressionError("error %d while compressing xz file", ret); + } + + finished = ret == LZMA_STREAM_END; + + if (strm.avail_out < sizeof(outbuf) || strm.avail_in == 0) { + nextSink(outbuf, sizeof(outbuf) - strm.avail_out); + strm.next_out = outbuf; + strm.avail_out = sizeof(outbuf); + } + } + } +}; + +struct BzipCompressionSink : ChunkedCompressionSink { + Sink& nextSink; + bz_stream strm; + bool finished = false; + + explicit BzipCompressionSink(Sink& nextSink) : nextSink(nextSink) { + memset(&strm, 0, sizeof(strm)); + int ret = BZ2_bzCompressInit(&strm, 9, 0, 30); + if (ret != BZ_OK) { + throw CompressionError("unable to initialise bzip2 encoder"); + } + + strm.next_out = (char*)outbuf; + strm.avail_out = sizeof(outbuf); + } + + ~BzipCompressionSink() override { BZ2_bzCompressEnd(&strm); } + + void finish() override { + flush(); + writeInternal(nullptr, 0); + } + + void writeInternal(const unsigned char* data, size_t len) override { + assert(len <= std::numeric_limits<decltype(strm.avail_in)>::max()); + + strm.next_in = (char*)data; + strm.avail_in = len; + + while (!finished && ((data == nullptr) || (strm.avail_in != 0u))) { + checkInterrupt(); + + int ret = BZ2_bzCompress(&strm, data != nullptr ? BZ_RUN : BZ_FINISH); + if (ret != BZ_RUN_OK && ret != BZ_FINISH_OK && ret != BZ_STREAM_END) { + throw CompressionError("error %d while compressing bzip2 file", ret); + } + + finished = ret == BZ_STREAM_END; + + if (strm.avail_out < sizeof(outbuf) || strm.avail_in == 0) { + nextSink(outbuf, sizeof(outbuf) - strm.avail_out); + strm.next_out = (char*)outbuf; + strm.avail_out = sizeof(outbuf); + } + } + } +}; + +struct BrotliCompressionSink : ChunkedCompressionSink { + Sink& nextSink; + uint8_t outbuf[BUFSIZ]; + BrotliEncoderState* state; + bool finished = false; + + explicit BrotliCompressionSink(Sink& nextSink) : nextSink(nextSink) { + state = BrotliEncoderCreateInstance(nullptr, nullptr, nullptr); + if (state == nullptr) { + throw CompressionError("unable to initialise brotli encoder"); + } + } + + ~BrotliCompressionSink() override { BrotliEncoderDestroyInstance(state); } + + void finish() override { + flush(); + writeInternal(nullptr, 0); + } + + void writeInternal(const unsigned char* data, size_t len) override { + const uint8_t* next_in = data; + size_t avail_in = len; + uint8_t* next_out = outbuf; + size_t avail_out = sizeof(outbuf); + + while (!finished && ((data == nullptr) || (avail_in != 0u))) { + checkInterrupt(); + + if (BrotliEncoderCompressStream(state, + data != nullptr ? BROTLI_OPERATION_PROCESS + : BROTLI_OPERATION_FINISH, + &avail_in, &next_in, &avail_out, + &next_out, nullptr) == 0) { + throw CompressionError("error while compressing brotli compression"); + } + + if (avail_out < sizeof(outbuf) || avail_in == 0) { + nextSink(outbuf, sizeof(outbuf) - avail_out); + next_out = outbuf; + avail_out = sizeof(outbuf); + } + + finished = (BrotliEncoderIsFinished(state) != 0); + } + } +}; + +ref<CompressionSink> makeCompressionSink(const std::string& method, + Sink& nextSink, const bool parallel) { + if (method == "none") { + return make_ref<NoneSink>(nextSink); + } + if (method == "xz") { + return make_ref<XzCompressionSink>(nextSink, parallel); + } else if (method == "bzip2") { + return make_ref<BzipCompressionSink>(nextSink); + } else if (method == "br") { + return make_ref<BrotliCompressionSink>(nextSink); + } else { + throw UnknownCompressionMethod(format("unknown compression method '%s'") % + method); + } +} + +ref<std::string> compress(const std::string& method, const std::string& in, + const bool parallel) { + StringSink ssink; + auto sink = makeCompressionSink(method, ssink, parallel); + (*sink)(in); + sink->finish(); + return ssink.s; +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/compression.hh b/third_party/nix/src/libutil/compression.hh new file mode 100644 index 0000000000..80b651e107 --- /dev/null +++ b/third_party/nix/src/libutil/compression.hh @@ -0,0 +1,31 @@ +#pragma once + +#include <string> + +#include "ref.hh" +#include "serialise.hh" +#include "types.hh" + +namespace nix { + +struct CompressionSink : BufferedSink { + virtual void finish() = 0; +}; + +ref<std::string> decompress(const std::string& method, const std::string& in); + +ref<CompressionSink> makeDecompressionSink(const std::string& method, + Sink& nextSink); + +ref<std::string> compress(const std::string& method, const std::string& in, + const bool parallel = false); + +ref<CompressionSink> makeCompressionSink(const std::string& method, + Sink& nextSink, + const bool parallel = false); + +MakeError(UnknownCompressionMethod, Error); + +MakeError(CompressionError, Error); + +} // namespace nix diff --git a/third_party/nix/src/libutil/config.cc b/third_party/nix/src/libutil/config.cc new file mode 100644 index 0000000000..828ee1811b --- /dev/null +++ b/third_party/nix/src/libutil/config.cc @@ -0,0 +1,365 @@ +#define GOOGLE_STRIP_LOG 0 +#include "config.hh" + +#include <utility> + +#include <glog/logging.h> + +#include "args.hh" +#include "json.hh" +// #include <glog/log_severity.h> + +namespace nix { + +bool Config::set(const std::string& name, const std::string& value) { + auto i = _settings.find(name); + if (i == _settings.end()) { + return false; + } + i->second.setting->set(value); + i->second.setting->overriden = true; + return true; +} + +void Config::addSetting(AbstractSetting* setting) { + _settings.emplace(setting->name, Config::SettingData(false, setting)); + for (auto& alias : setting->aliases) { + _settings.emplace(alias, Config::SettingData(true, setting)); + } + + bool set = false; + + auto i = unknownSettings.find(setting->name); + if (i != unknownSettings.end()) { + setting->set(i->second); + setting->overriden = true; + unknownSettings.erase(i); + set = true; + } + + for (auto& alias : setting->aliases) { + auto i = unknownSettings.find(alias); + if (i != unknownSettings.end()) { + if (set) { + LOG(WARNING) << "setting '" << alias + << "' is set, but it's an alias of '" << setting->name + << "', which is also set"; + } + + else { + setting->set(i->second); + setting->overriden = true; + unknownSettings.erase(i); + set = true; + } + } + } +} + +void AbstractConfig::warnUnknownSettings() { + for (auto& s : unknownSettings) { + LOG(WARNING) << "unknown setting: " << s.first; + } +} + +void AbstractConfig::reapplyUnknownSettings() { + auto unknownSettings2 = std::move(unknownSettings); + for (auto& s : unknownSettings2) { + set(s.first, s.second); + } +} + +void Config::getSettings(std::map<std::string, SettingInfo>& res, + bool overridenOnly) { + for (auto& opt : _settings) { + if (!opt.second.isAlias && + (!overridenOnly || opt.second.setting->overriden)) { + res.emplace(opt.first, SettingInfo{opt.second.setting->to_string(), + opt.second.setting->description}); + } + } +} + +void AbstractConfig::applyConfigFile(const Path& path) { + try { + string contents = readFile(path); + + unsigned int pos = 0; + + while (pos < contents.size()) { + string line; + while (pos < contents.size() && contents[pos] != '\n') { + line += contents[pos++]; + } + pos++; + + string::size_type hash = line.find('#'); + if (hash != string::npos) { + line = string(line, 0, hash); + } + + auto tokens = tokenizeString<vector<string> >(line); + if (tokens.empty()) { + continue; + } + + if (tokens.size() < 2) { + throw UsageError("illegal configuration line '%1%' in '%2%'", line, + path); + } + + auto include = false; + auto ignoreMissing = false; + if (tokens[0] == "include") { + include = true; + } else if (tokens[0] == "!include") { + include = true; + ignoreMissing = true; + } + + if (include) { + if (tokens.size() != 2) { + throw UsageError("illegal configuration line '%1%' in '%2%'", line, + path); + } + auto p = absPath(tokens[1], dirOf(path)); + if (pathExists(p)) { + applyConfigFile(p); + } else if (!ignoreMissing) { + throw Error("file '%1%' included from '%2%' not found", p, path); + } + continue; + } + + if (tokens[1] != "=") { + throw UsageError("illegal configuration line '%1%' in '%2%'", line, + path); + } + + string name = tokens[0]; + + auto i = tokens.begin(); + advance(i, 2); + + set(name, + concatStringsSep(" ", Strings(i, tokens.end()))); // FIXME: slow + }; + } catch (SysError&) { + } +} + +void Config::resetOverriden() { + for (auto& s : _settings) { + s.second.setting->overriden = false; + } +} + +void Config::toJSON(JSONObject& out) { + for (auto& s : _settings) { + if (!s.second.isAlias) { + JSONObject out2(out.object(s.first)); + out2.attr("description", s.second.setting->description); + JSONPlaceholder out3(out2.placeholder("value")); + s.second.setting->toJSON(out3); + } + } +} + +void Config::convertToArgs(Args& args, const std::string& category) { + for (auto& s : _settings) { + if (!s.second.isAlias) { + s.second.setting->convertToArg(args, category); + } + } +} + +AbstractSetting::AbstractSetting(std::string name, std::string description, + std::set<std::string> aliases) + : name(std::move(name)), + description(std::move(description)), + aliases(std::move(aliases)) {} + +void AbstractSetting::toJSON(JSONPlaceholder& out) { out.write(to_string()); } + +void AbstractSetting::convertToArg(Args& args, const std::string& category) {} + +template <typename T> +void BaseSetting<T>::toJSON(JSONPlaceholder& out) { + out.write(value); +} + +template <typename T> +void BaseSetting<T>::convertToArg(Args& args, const std::string& category) { + args.mkFlag() + .longName(name) + .description(description) + .arity(1) + .handler([=](std::vector<std::string> ss) { + overriden = true; + set(ss[0]); + }) + .category(category); +} + +template <> +void BaseSetting<std::string>::set(const std::string& str) { + value = str; +} + +template <> +std::string BaseSetting<std::string>::to_string() { + return value; +} + +template <typename T> +void BaseSetting<T>::set(const std::string& str) { + static_assert(std::is_integral<T>::value, "Integer required."); + if (!string2Int(str, value)) { + throw UsageError("setting '%s' has invalid value '%s'", name, str); + } +} + +template <typename T> +std::string BaseSetting<T>::to_string() { + static_assert(std::is_integral<T>::value, "Integer required."); + return std::to_string(value); +} + +template <> +void BaseSetting<bool>::set(const std::string& str) { + if (str == "true" || str == "yes" || str == "1") { + value = true; + } else if (str == "false" || str == "no" || str == "0") { + value = false; + } else { + throw UsageError("Boolean setting '%s' has invalid value '%s'", name, str); + } +} + +template <> +std::string BaseSetting<bool>::to_string() { + return value ? "true" : "false"; +} + +template <> +void BaseSetting<bool>::convertToArg(Args& args, const std::string& category) { + args.mkFlag() + .longName(name) + .description(description) + .handler([=](const std::vector<std::string>& ss) { override(true); }) + .category(category); + args.mkFlag() + .longName("no-" + name) + .description(description) + .handler([=](const std::vector<std::string>& ss) { override(false); }) + .category(category); +} + +template <> +void BaseSetting<Strings>::set(const std::string& str) { + value = tokenizeString<Strings>(str); +} + +template <> +std::string BaseSetting<Strings>::to_string() { + return concatStringsSep(" ", value); +} + +template <> +void BaseSetting<Strings>::toJSON(JSONPlaceholder& out) { + JSONList list(out.list()); + for (auto& s : value) { + list.elem(s); + } +} + +template <> +void BaseSetting<StringSet>::set(const std::string& str) { + value = tokenizeString<StringSet>(str); +} + +template <> +std::string BaseSetting<StringSet>::to_string() { + return concatStringsSep(" ", value); +} + +template <> +void BaseSetting<StringSet>::toJSON(JSONPlaceholder& out) { + JSONList list(out.list()); + for (auto& s : value) { + list.elem(s); + } +} + +template class BaseSetting<int>; +template class BaseSetting<unsigned int>; +template class BaseSetting<long>; +template class BaseSetting<unsigned long>; +template class BaseSetting<long long>; +template class BaseSetting<unsigned long long>; +template class BaseSetting<bool>; +template class BaseSetting<std::string>; +template class BaseSetting<Strings>; +template class BaseSetting<StringSet>; + +void PathSetting::set(const std::string& str) { + if (str.empty()) { + if (allowEmpty) { + value = ""; + } else { + throw UsageError("setting '%s' cannot be empty", name); + } + } else { + value = canonPath(str); + } +} + +bool GlobalConfig::set(const std::string& name, const std::string& value) { + for (auto& config : *configRegistrations) { + if (config->set(name, value)) { + return true; + } + } + + unknownSettings.emplace(name, value); + + return false; +} + +void GlobalConfig::getSettings(std::map<std::string, SettingInfo>& res, + bool overridenOnly) { + for (auto& config : *configRegistrations) { + config->getSettings(res, overridenOnly); + } +} + +void GlobalConfig::resetOverriden() { + for (auto& config : *configRegistrations) { + config->resetOverriden(); + } +} + +void GlobalConfig::toJSON(JSONObject& out) { + for (auto& config : *configRegistrations) { + config->toJSON(out); + } +} + +void GlobalConfig::convertToArgs(Args& args, const std::string& category) { + for (auto& config : *configRegistrations) { + config->convertToArgs(args, category); + } +} + +GlobalConfig globalConfig; + +GlobalConfig::ConfigRegistrations* GlobalConfig::configRegistrations; + +GlobalConfig::Register::Register(Config* config) { + if (configRegistrations == nullptr) { + configRegistrations = new ConfigRegistrations; + } + configRegistrations->emplace_back(config); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/config.hh b/third_party/nix/src/libutil/config.hh new file mode 100644 index 0000000000..f8055d4d36 --- /dev/null +++ b/third_party/nix/src/libutil/config.hh @@ -0,0 +1,227 @@ +#include <map> +#include <set> + +#include "types.hh" + +#pragma once + +namespace nix { + +class Args; +class AbstractSetting; +class JSONPlaceholder; +class JSONObject; + +class AbstractConfig { + protected: + StringMap unknownSettings; + + AbstractConfig(const StringMap& initials = {}) : unknownSettings(initials) {} + + public: + virtual bool set(const std::string& name, const std::string& value) = 0; + + struct SettingInfo { + std::string value; + std::string description; + }; + + virtual void getSettings(std::map<std::string, SettingInfo>& res, + bool overridenOnly = false) = 0; + + void applyConfigFile(const Path& path); + + virtual void resetOverriden() = 0; + + virtual void toJSON(JSONObject& out) = 0; + + virtual void convertToArgs(Args& args, const std::string& category) = 0; + + void warnUnknownSettings(); + + void reapplyUnknownSettings(); +}; + +/* A class to simplify providing configuration settings. The typical + use is to inherit Config and add Setting<T> members: + + class MyClass : private Config + { + Setting<int> foo{this, 123, "foo", "the number of foos to use"}; + Setting<std::string> bar{this, "blabla", "bar", "the name of the bar"}; + + MyClass() : Config(readConfigFile("/etc/my-app.conf")) + { + std::cout << foo << "\n"; // will print 123 unless overriden + } + }; +*/ + +class Config : public AbstractConfig { + friend class AbstractSetting; + + public: + struct SettingData { + bool isAlias; + AbstractSetting* setting; + SettingData(bool isAlias, AbstractSetting* setting) + : isAlias(isAlias), setting(setting) {} + }; + + typedef std::map<std::string, SettingData> Settings; + + private: + Settings _settings; + + public: + Config(const StringMap& initials = {}) : AbstractConfig(initials) {} + + bool set(const std::string& name, const std::string& value) override; + + void addSetting(AbstractSetting* setting); + + void getSettings(std::map<std::string, SettingInfo>& res, + bool overridenOnly = false) override; + + void resetOverriden() override; + + void toJSON(JSONObject& out) override; + + void convertToArgs(Args& args, const std::string& category) override; +}; + +class AbstractSetting { + friend class Config; + + public: + const std::string name; + const std::string description; + const std::set<std::string> aliases; + + int created = 123; + + bool overriden = false; + + protected: + AbstractSetting(std::string name, std::string description, + std::set<std::string> aliases); + + virtual ~AbstractSetting() { + // Check against a gcc miscompilation causing our constructor + // not to run (https://gcc.gnu.org/bugzilla/show_bug.cgi?id=80431). + assert(created == 123); + } + + virtual void set(const std::string& value) = 0; + + virtual std::string to_string() = 0; + + virtual void toJSON(JSONPlaceholder& out); + + virtual void convertToArg(Args& args, const std::string& category); + + bool isOverriden() { return overriden; } +}; + +/* A setting of type T. */ +template <typename T> +class BaseSetting : public AbstractSetting { + protected: + T value; + + public: + BaseSetting(const T& def, const std::string& name, + const std::string& description, + const std::set<std::string>& aliases = {}) + : AbstractSetting(name, description, aliases), value(def) {} + + operator const T&() const { return value; } + operator T&() { return value; } + const T& get() const { return value; } + bool operator==(const T& v2) const { return value == v2; } + bool operator!=(const T& v2) const { return value != v2; } + void operator=(const T& v) { assign(v); } + virtual void assign(const T& v) { value = v; } + + void set(const std::string& str) override; + + virtual void override(const T& v) { + overriden = true; + value = v; + } + + std::string to_string() override; + + void convertToArg(Args& args, const std::string& category) override; + + void toJSON(JSONPlaceholder& out) override; +}; + +template <typename T> +std::ostream& operator<<(std::ostream& str, const BaseSetting<T>& opt) { + str << (const T&)opt; + return str; +} + +template <typename T> +bool operator==(const T& v1, const BaseSetting<T>& v2) { + return v1 == (const T&)v2; +} + +template <typename T> +class Setting : public BaseSetting<T> { + public: + Setting(Config* options, const T& def, const std::string& name, + const std::string& description, + const std::set<std::string>& aliases = {}) + : BaseSetting<T>(def, name, description, aliases) { + options->addSetting(this); + } + + void operator=(const T& v) { this->assign(v); } +}; + +/* A special setting for Paths. These are automatically canonicalised + (e.g. "/foo//bar/" becomes "/foo/bar"). */ +class PathSetting : public BaseSetting<Path> { + bool allowEmpty; + + public: + PathSetting(Config* options, bool allowEmpty, const Path& def, + const std::string& name, const std::string& description, + const std::set<std::string>& aliases = {}) + : BaseSetting<Path>(def, name, description, aliases), + allowEmpty(allowEmpty) { + options->addSetting(this); + } + + void set(const std::string& str) override; + + Path operator+(const char* p) const { return value + p; } + + void operator=(const Path& v) { this->assign(v); } +}; + +struct GlobalConfig : public AbstractConfig { + typedef std::vector<Config*> ConfigRegistrations; + static ConfigRegistrations* configRegistrations; + + bool set(const std::string& name, const std::string& value) override; + + void getSettings(std::map<std::string, SettingInfo>& res, + bool overridenOnly = false) override; + + void resetOverriden() override; + + void toJSON(JSONObject& out) override; + + void convertToArgs(Args& args, const std::string& category) override; + + struct Register { + Register(Config* config); + }; +}; + +extern GlobalConfig globalConfig; + +} // namespace nix diff --git a/third_party/nix/src/libutil/finally.hh b/third_party/nix/src/libutil/finally.hh new file mode 100644 index 0000000000..8d3083b6a3 --- /dev/null +++ b/third_party/nix/src/libutil/finally.hh @@ -0,0 +1,13 @@ +#pragma once + +#include <functional> + +/* A trivial class to run a function at the end of a scope. */ +class Finally { + private: + std::function<void()> fun; + + public: + Finally(std::function<void()> fun) : fun(fun) {} + ~Finally() { fun(); } +}; diff --git a/third_party/nix/src/libutil/hash.cc b/third_party/nix/src/libutil/hash.cc new file mode 100644 index 0000000000..81d8628e97 --- /dev/null +++ b/third_party/nix/src/libutil/hash.cc @@ -0,0 +1,371 @@ +#include "hash.hh" + +#include <cstring> +#include <iostream> + +#include <fcntl.h> +#include <openssl/md5.h> +#include <openssl/sha.h> +#include <sys/stat.h> +#include <sys/types.h> + +#include "archive.hh" +#include "istringstream_nocopy.hh" +#include "util.hh" + +namespace nix { + +void Hash::init() { + if (type == htMD5) { + hashSize = md5HashSize; + } else if (type == htSHA1) { + hashSize = sha1HashSize; + } else if (type == htSHA256) { + hashSize = sha256HashSize; + } else if (type == htSHA512) { + hashSize = sha512HashSize; + } else { + abort(); + } + assert(hashSize <= maxHashSize); + memset(hash, 0, maxHashSize); +} + +bool Hash::operator==(const Hash& h2) const { + if (hashSize != h2.hashSize) { + return false; + } + for (unsigned int i = 0; i < hashSize; i++) { + if (hash[i] != h2.hash[i]) { + return false; + } + } + return true; +} + +bool Hash::operator!=(const Hash& h2) const { return !(*this == h2); } + +bool Hash::operator<(const Hash& h) const { + if (hashSize < h.hashSize) { + return true; + } + if (hashSize > h.hashSize) { + return false; + } + for (unsigned int i = 0; i < hashSize; i++) { + if (hash[i] < h.hash[i]) { + return true; + } + if (hash[i] > h.hash[i]) { + return false; + } + } + return false; +} + +const string base16Chars = "0123456789abcdef"; + +static string printHash16(const Hash& hash) { + char buf[hash.hashSize * 2]; + for (unsigned int i = 0; i < hash.hashSize; i++) { + buf[i * 2] = base16Chars[hash.hash[i] >> 4]; + buf[i * 2 + 1] = base16Chars[hash.hash[i] & 0x0f]; + } + return string(buf, hash.hashSize * 2); +} + +// omitted: E O U T +const string base32Chars = "0123456789abcdfghijklmnpqrsvwxyz"; + +static string printHash32(const Hash& hash) { + assert(hash.hashSize); + size_t len = hash.base32Len(); + assert(len); + + string s; + s.reserve(len); + + for (int n = (int)len - 1; n >= 0; n--) { + unsigned int b = n * 5; + unsigned int i = b / 8; + unsigned int j = b % 8; + unsigned char c = + (hash.hash[i] >> j) | + (i >= hash.hashSize - 1 ? 0 : hash.hash[i + 1] << (8 - j)); + s.push_back(base32Chars[c & 0x1f]); + } + + return s; +} + +string printHash16or32(const Hash& hash) { + return hash.to_string(hash.type == htMD5 ? Base16 : Base32, false); +} + +std::string Hash::to_string(Base base, bool includeType) const { + std::string s; + if (base == SRI || includeType) { + s += printHashType(type); + s += base == SRI ? '-' : ':'; + } + switch (base) { + case Base16: + s += printHash16(*this); + break; + case Base32: + s += printHash32(*this); + break; + case Base64: + case SRI: + s += base64Encode(std::string((const char*)hash, hashSize)); + break; + } + return s; +} + +Hash::Hash(const std::string& s, HashType type) : type(type) { + size_t pos = 0; + bool isSRI = false; + + auto sep = s.find(':'); + if (sep == string::npos) { + sep = s.find('-'); + if (sep != string::npos) { + isSRI = true; + } else if (type == htUnknown) { + throw BadHash("hash '%s' does not include a type", s); + } + } + + if (sep != string::npos) { + string hts = string(s, 0, sep); + this->type = parseHashType(hts); + if (this->type == htUnknown) { + throw BadHash("unknown hash type '%s'", hts); + } + if (type != htUnknown && type != this->type) { + throw BadHash("hash '%s' should have type '%s'", s, printHashType(type)); + } + pos = sep + 1; + } + + init(); + + size_t size = s.size() - pos; + + if (!isSRI && size == base16Len()) { + auto parseHexDigit = [&](char c) { + if (c >= '0' && c <= '9') { + return c - '0'; + } + if (c >= 'A' && c <= 'F') { + return c - 'A' + 10; + } + if (c >= 'a' && c <= 'f') { + return c - 'a' + 10; + } + throw BadHash("invalid base-16 hash '%s'", s); + }; + + for (unsigned int i = 0; i < hashSize; i++) { + hash[i] = parseHexDigit(s[pos + i * 2]) << 4 | + parseHexDigit(s[pos + i * 2 + 1]); + } + } + + else if (!isSRI && size == base32Len()) { + for (unsigned int n = 0; n < size; ++n) { + char c = s[pos + size - n - 1]; + unsigned char digit; + for (digit = 0; digit < base32Chars.size(); ++digit) { /* !!! slow */ + if (base32Chars[digit] == c) { + break; + } + } + if (digit >= 32) { + throw BadHash("invalid base-32 hash '%s'", s); + } + unsigned int b = n * 5; + unsigned int i = b / 8; + unsigned int j = b % 8; + hash[i] |= digit << j; + + if (i < hashSize - 1) { + hash[i + 1] |= digit >> (8 - j); + } else { + if ((digit >> (8 - j)) != 0) { + throw BadHash("invalid base-32 hash '%s'", s); + } + } + } + } + + else if (isSRI || size == base64Len()) { + auto d = base64Decode(std::string(s, pos)); + if (d.size() != hashSize) { + throw BadHash("invalid %s hash '%s'", isSRI ? "SRI" : "base-64", s); + } + assert(hashSize); + memcpy(hash, d.data(), hashSize); + } + + else { + throw BadHash("hash '%s' has wrong length for hash type '%s'", s, + printHashType(type)); + } +} + +union Ctx { + MD5_CTX md5; + SHA_CTX sha1; + SHA256_CTX sha256; + SHA512_CTX sha512; +}; + +static void start(HashType ht, Ctx& ctx) { + if (ht == htMD5) { + MD5_Init(&ctx.md5); + } else if (ht == htSHA1) { + SHA1_Init(&ctx.sha1); + } else if (ht == htSHA256) { + SHA256_Init(&ctx.sha256); + } else if (ht == htSHA512) { + SHA512_Init(&ctx.sha512); + } +} + +static void update(HashType ht, Ctx& ctx, const unsigned char* bytes, + size_t len) { + if (ht == htMD5) { + MD5_Update(&ctx.md5, bytes, len); + } else if (ht == htSHA1) { + SHA1_Update(&ctx.sha1, bytes, len); + } else if (ht == htSHA256) { + SHA256_Update(&ctx.sha256, bytes, len); + } else if (ht == htSHA512) { + SHA512_Update(&ctx.sha512, bytes, len); + } +} + +static void finish(HashType ht, Ctx& ctx, unsigned char* hash) { + if (ht == htMD5) { + MD5_Final(hash, &ctx.md5); + } else if (ht == htSHA1) { + SHA1_Final(hash, &ctx.sha1); + } else if (ht == htSHA256) { + SHA256_Final(hash, &ctx.sha256); + } else if (ht == htSHA512) { + SHA512_Final(hash, &ctx.sha512); + } +} + +Hash hashString(HashType ht, const string& s) { + Ctx ctx; + Hash hash(ht); + start(ht, ctx); + update(ht, ctx, (const unsigned char*)s.data(), s.length()); + finish(ht, ctx, hash.hash); + return hash; +} + +Hash hashFile(HashType ht, const Path& path) { + Ctx ctx; + Hash hash(ht); + start(ht, ctx); + + AutoCloseFD fd = open(path.c_str(), O_RDONLY | O_CLOEXEC); + if (!fd) { + throw SysError(format("opening file '%1%'") % path); + } + + std::vector<unsigned char> buf(8192); + ssize_t n; + while ((n = read(fd.get(), buf.data(), buf.size())) != 0) { + checkInterrupt(); + if (n == -1) { + throw SysError(format("reading file '%1%'") % path); + } + update(ht, ctx, buf.data(), n); + } + + finish(ht, ctx, hash.hash); + return hash; +} + +HashSink::HashSink(HashType ht) : ht(ht) { + ctx = new Ctx; + bytes = 0; + start(ht, *ctx); +} + +HashSink::~HashSink() { + bufPos = 0; + delete ctx; +} + +void HashSink::write(const unsigned char* data, size_t len) { + bytes += len; + update(ht, *ctx, data, len); +} + +HashResult HashSink::finish() { + flush(); + Hash hash(ht); + nix::finish(ht, *ctx, hash.hash); + return HashResult(hash, bytes); +} + +HashResult HashSink::currentHash() { + flush(); + Ctx ctx2 = *ctx; + Hash hash(ht); + nix::finish(ht, ctx2, hash.hash); + return HashResult(hash, bytes); +} + +HashResult hashPath(HashType ht, const Path& path, PathFilter& filter) { + HashSink sink(ht); + dumpPath(path, sink, filter); + return sink.finish(); +} + +Hash compressHash(const Hash& hash, unsigned int newSize) { + Hash h; + h.hashSize = newSize; + for (unsigned int i = 0; i < hash.hashSize; ++i) { + h.hash[i % newSize] ^= hash.hash[i]; + } + return h; +} + +HashType parseHashType(const string& s) { + if (s == "md5") { + return htMD5; + } + if (s == "sha1") { + return htSHA1; + } else if (s == "sha256") { + return htSHA256; + } else if (s == "sha512") { + return htSHA512; + } else { + return htUnknown; + } +} + +string printHashType(HashType ht) { + if (ht == htMD5) { + return "md5"; + } + if (ht == htSHA1) { + return "sha1"; + } else if (ht == htSHA256) { + return "sha256"; + } else if (ht == htSHA512) { + return "sha512"; + } else { + abort(); + } +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/hash.hh b/third_party/nix/src/libutil/hash.hh new file mode 100644 index 0000000000..a9002023fa --- /dev/null +++ b/third_party/nix/src/libutil/hash.hh @@ -0,0 +1,112 @@ +#pragma once + +#include "serialise.hh" +#include "types.hh" + +namespace nix { + +MakeError(BadHash, Error); + +enum HashType : char { htUnknown, htMD5, htSHA1, htSHA256, htSHA512 }; + +const int md5HashSize = 16; +const int sha1HashSize = 20; +const int sha256HashSize = 32; +const int sha512HashSize = 64; + +extern const string base32Chars; + +enum Base : int { Base64, Base32, Base16, SRI }; + +struct Hash { + static const unsigned int maxHashSize = 64; + unsigned int hashSize = 0; + unsigned char hash[maxHashSize] = {}; + + HashType type = htUnknown; + + /* Create an unset hash object. */ + Hash(){}; + + /* Create a zero-filled hash object. */ + Hash(HashType type) : type(type) { init(); }; + + /* Initialize the hash from a string representation, in the format + "[<type>:]<base16|base32|base64>" or "<type>-<base64>" (a + Subresource Integrity hash expression). If the 'type' argument + is htUnknown, then the hash type must be specified in the + string. */ + Hash(const std::string& s, HashType type = htUnknown); + + void init(); + + /* Check whether a hash is set. */ + operator bool() const { return type != htUnknown; } + + /* Check whether two hash are equal. */ + bool operator==(const Hash& h2) const; + + /* Check whether two hash are not equal. */ + bool operator!=(const Hash& h2) const; + + /* For sorting. */ + bool operator<(const Hash& h) const; + + /* Returns the length of a base-16 representation of this hash. */ + size_t base16Len() const { return hashSize * 2; } + + /* Returns the length of a base-32 representation of this hash. */ + size_t base32Len() const { return (hashSize * 8 - 1) / 5 + 1; } + + /* Returns the length of a base-64 representation of this hash. */ + size_t base64Len() const { return ((4 * hashSize / 3) + 3) & ~3; } + + /* Return a string representation of the hash, in base-16, base-32 + or base-64. By default, this is prefixed by the hash type + (e.g. "sha256:"). */ + std::string to_string(Base base = Base32, bool includeType = true) const; +}; + +/* Print a hash in base-16 if it's MD5, or base-32 otherwise. */ +string printHash16or32(const Hash& hash); + +/* Compute the hash of the given string. */ +Hash hashString(HashType ht, const string& s); + +/* Compute the hash of the given file. */ +Hash hashFile(HashType ht, const Path& path); + +/* Compute the hash of the given path. The hash is defined as + (essentially) hashString(ht, dumpPath(path)). */ +typedef std::pair<Hash, unsigned long long> HashResult; +HashResult hashPath(HashType ht, const Path& path, + PathFilter& filter = defaultPathFilter); + +/* Compress a hash to the specified number of bytes by cyclically + XORing bytes together. */ +Hash compressHash(const Hash& hash, unsigned int newSize); + +/* Parse a string representing a hash type. */ +HashType parseHashType(const string& s); + +/* And the reverse. */ +string printHashType(HashType ht); + +union Ctx; + +class HashSink : public BufferedSink { + private: + HashType ht; + Ctx* ctx; + unsigned long long bytes; + + public: + HashSink(HashType ht); + HashSink(const HashSink& h); + ~HashSink(); + void write(const unsigned char* data, size_t len); + HashResult finish(); + HashResult currentHash(); +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/istringstream_nocopy.hh b/third_party/nix/src/libutil/istringstream_nocopy.hh new file mode 100644 index 0000000000..997965630b --- /dev/null +++ b/third_party/nix/src/libutil/istringstream_nocopy.hh @@ -0,0 +1,82 @@ +/* This file provides a variant of std::istringstream that doesn't + copy its string argument. This is useful for large strings. The + caller must ensure that the string object is not destroyed while + it's referenced by this object. */ + +#pragma once + +#include <iostream> +#include <string> + +template <class CharT, class Traits = std::char_traits<CharT>, + class Allocator = std::allocator<CharT>> +class basic_istringbuf_nocopy : public std::basic_streambuf<CharT, Traits> { + public: + typedef std::basic_string<CharT, Traits, Allocator> string_type; + + typedef typename std::basic_streambuf<CharT, Traits>::off_type off_type; + + typedef typename std::basic_streambuf<CharT, Traits>::pos_type pos_type; + + typedef typename std::basic_streambuf<CharT, Traits>::int_type int_type; + + typedef typename std::basic_streambuf<CharT, Traits>::traits_type traits_type; + + private: + const string_type& s; + + off_type off; + + public: + basic_istringbuf_nocopy(const string_type& s) : s{s}, off{0} {} + + private: + pos_type seekoff(off_type off, std::ios_base::seekdir dir, + std::ios_base::openmode which) { + if (which & std::ios_base::in) { + this->off = + dir == std::ios_base::beg + ? off + : (dir == std::ios_base::end ? s.size() + off : this->off + off); + } + return pos_type(this->off); + } + + pos_type seekpos(pos_type pos, std::ios_base::openmode which) { + return seekoff(pos, std::ios_base::beg, which); + } + + std::streamsize showmanyc() { return s.size() - off; } + + int_type underflow() { + if (typename string_type::size_type(off) == s.size()) + return traits_type::eof(); + return traits_type::to_int_type(s[off]); + } + + int_type uflow() { + if (typename string_type::size_type(off) == s.size()) + return traits_type::eof(); + return traits_type::to_int_type(s[off++]); + } + + int_type pbackfail(int_type ch) { + if (off == 0 || (ch != traits_type::eof() && ch != s[off - 1])) + return traits_type::eof(); + + return traits_type::to_int_type(s[--off]); + } +}; + +template <class CharT, class Traits = std::char_traits<CharT>, + class Allocator = std::allocator<CharT>> +class basic_istringstream_nocopy : public std::basic_iostream<CharT, Traits> { + typedef basic_istringbuf_nocopy<CharT, Traits, Allocator> buf_type; + buf_type buf; + + public: + basic_istringstream_nocopy(const typename buf_type::string_type& s) + : std::basic_iostream<CharT, Traits>(&buf), buf(s){}; +}; + +typedef basic_istringstream_nocopy<char> istringstream_nocopy; diff --git a/third_party/nix/src/libutil/json.cc b/third_party/nix/src/libutil/json.cc new file mode 100644 index 0000000000..218fc264ba --- /dev/null +++ b/third_party/nix/src/libutil/json.cc @@ -0,0 +1,198 @@ +#include "json.hh" + +#include <cstring> +#include <iomanip> + +namespace nix { + +void toJSON(std::ostream& str, const char* start, const char* end) { + str << '"'; + for (auto i = start; i != end; i++) { + if (*i == '\"' || *i == '\\') { + str << '\\' << *i; + } else if (*i == '\n') { + str << "\\n"; + } else if (*i == '\r') { + str << "\\r"; + } else if (*i == '\t') { + str << "\\t"; + } else if (*i >= 0 && *i < 32) { + str << "\\u" << std::setfill('0') << std::setw(4) << std::hex + << (uint16_t)*i << std::dec; + } else { + str << *i; + } + } + str << '"'; +} + +void toJSON(std::ostream& str, const char* s) { + if (s == nullptr) { + str << "null"; + } else { + toJSON(str, s, s + strlen(s)); + } +} + +template <> +void toJSON<int>(std::ostream& str, const int& n) { + str << n; +} +template <> +void toJSON<unsigned int>(std::ostream& str, const unsigned int& n) { + str << n; +} +template <> +void toJSON<long>(std::ostream& str, const long& n) { + str << n; +} +template <> +void toJSON<unsigned long>(std::ostream& str, const unsigned long& n) { + str << n; +} +template <> +void toJSON<long long>(std::ostream& str, const long long& n) { + str << n; +} +template <> +void toJSON<unsigned long long>(std::ostream& str, + const unsigned long long& n) { + str << n; +} +template <> +void toJSON<float>(std::ostream& str, const float& n) { + str << n; +} +template <> +void toJSON<double>(std::ostream& str, const double& n) { + str << n; +} + +template <> +void toJSON<std::string>(std::ostream& str, const std::string& s) { + toJSON(str, s.c_str(), s.c_str() + s.size()); +} + +template <> +void toJSON<bool>(std::ostream& str, const bool& b) { + str << (b ? "true" : "false"); +} + +template <> +void toJSON<std::nullptr_t>(std::ostream& str, const std::nullptr_t& b) { + str << "null"; +} + +JSONWriter::JSONWriter(std::ostream& str, bool indent) + : state(new JSONState(str, indent)) { + state->stack++; +} + +JSONWriter::JSONWriter(JSONState* state) : state(state) { state->stack++; } + +JSONWriter::~JSONWriter() { + if (state != nullptr) { + assertActive(); + state->stack--; + if (state->stack == 0) { + delete state; + } + } +} + +void JSONWriter::comma() { + assertActive(); + if (first) { + first = false; + } else { + state->str << ','; + } + if (state->indent) { + indent(); + } +} + +void JSONWriter::indent() { + state->str << '\n' << std::string(state->depth * 2, ' '); +} + +void JSONList::open() { + state->depth++; + state->str << '['; +} + +JSONList::~JSONList() { + state->depth--; + if (state->indent && !first) { + indent(); + } + state->str << "]"; +} + +JSONList JSONList::list() { + comma(); + return JSONList(state); +} + +JSONObject JSONList::object() { + comma(); + return JSONObject(state); +} + +JSONPlaceholder JSONList::placeholder() { + comma(); + return JSONPlaceholder(state); +} + +void JSONObject::open() { + state->depth++; + state->str << '{'; +} + +JSONObject::~JSONObject() { + if (state != nullptr) { + state->depth--; + if (state->indent && !first) { + indent(); + } + state->str << "}"; + } +} + +void JSONObject::attr(const std::string& s) { + comma(); + toJSON(state->str, s); + state->str << ':'; + if (state->indent) { + state->str << ' '; + } +} + +JSONList JSONObject::list(const std::string& name) { + attr(name); + return JSONList(state); +} + +JSONObject JSONObject::object(const std::string& name) { + attr(name); + return JSONObject(state); +} + +JSONPlaceholder JSONObject::placeholder(const std::string& name) { + attr(name); + return JSONPlaceholder(state); +} + +JSONList JSONPlaceholder::list() { + assertValid(); + first = false; + return JSONList(state); +} + +JSONObject JSONPlaceholder::object() { + assertValid(); + first = false; + return JSONObject(state); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/json.hh b/third_party/nix/src/libutil/json.hh new file mode 100644 index 0000000000..a3843a8a8a --- /dev/null +++ b/third_party/nix/src/libutil/json.hh @@ -0,0 +1,142 @@ +#pragma once + +#include <cassert> +#include <iostream> +#include <vector> + +namespace nix { + +void toJSON(std::ostream& str, const char* start, const char* end); +void toJSON(std::ostream& str, const char* s); + +template <typename T> +void toJSON(std::ostream& str, const T& n); + +class JSONWriter { + protected: + struct JSONState { + std::ostream& str; + bool indent; + size_t depth = 0; + size_t stack = 0; + JSONState(std::ostream& str, bool indent) : str(str), indent(indent) {} + ~JSONState() { assert(stack == 0); } + }; + + JSONState* state; + + bool first = true; + + JSONWriter(std::ostream& str, bool indent); + + JSONWriter(JSONState* state); + + ~JSONWriter(); + + void assertActive() { assert(state->stack != 0); } + + void comma(); + + void indent(); +}; + +class JSONObject; +class JSONPlaceholder; + +class JSONList : JSONWriter { + private: + friend class JSONObject; + friend class JSONPlaceholder; + + void open(); + + JSONList(JSONState* state) : JSONWriter(state) { open(); } + + public: + JSONList(std::ostream& str, bool indent = false) : JSONWriter(str, indent) { + open(); + } + + ~JSONList(); + + template <typename T> + JSONList& elem(const T& v) { + comma(); + toJSON(state->str, v); + return *this; + } + + JSONList list(); + + JSONObject object(); + + JSONPlaceholder placeholder(); +}; + +class JSONObject : JSONWriter { + private: + friend class JSONList; + friend class JSONPlaceholder; + + void open(); + + JSONObject(JSONState* state) : JSONWriter(state) { open(); } + + void attr(const std::string& s); + + public: + JSONObject(std::ostream& str, bool indent = false) : JSONWriter(str, indent) { + open(); + } + + JSONObject(const JSONObject& obj) = delete; + + JSONObject(JSONObject&& obj) : JSONWriter(obj.state) { obj.state = 0; } + + ~JSONObject(); + + template <typename T> + JSONObject& attr(const std::string& name, const T& v) { + attr(name); + toJSON(state->str, v); + return *this; + } + + JSONList list(const std::string& name); + + JSONObject object(const std::string& name); + + JSONPlaceholder placeholder(const std::string& name); +}; + +class JSONPlaceholder : JSONWriter { + private: + friend class JSONList; + friend class JSONObject; + + JSONPlaceholder(JSONState* state) : JSONWriter(state) {} + + void assertValid() { + assertActive(); + assert(first); + } + + public: + JSONPlaceholder(std::ostream& str, bool indent = false) + : JSONWriter(str, indent) {} + + ~JSONPlaceholder() { assert(!first || std::uncaught_exception()); } + + template <typename T> + void write(const T& v) { + assertValid(); + first = false; + toJSON(state->str, v); + } + + JSONList list(); + + JSONObject object(); +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/lazy.hh b/third_party/nix/src/libutil/lazy.hh new file mode 100644 index 0000000000..b564b481fc --- /dev/null +++ b/third_party/nix/src/libutil/lazy.hh @@ -0,0 +1,45 @@ +#include <exception> +#include <functional> +#include <mutex> + +namespace nix { + +/* A helper class for lazily-initialized variables. + + Lazy<T> var([]() { return value; }); + + declares a variable of type T that is initialized to 'value' (in a + thread-safe way) on first use, that is, when var() is first + called. If the initialiser code throws an exception, then all + subsequent calls to var() will rethrow that exception. */ +template <typename T> +class Lazy { + typedef std::function<T()> Init; + + Init init; + + std::once_flag done; + + T value; + + std::exception_ptr ex; + + public: + Lazy(Init init) : init(init) {} + + const T& operator()() { + std::call_once(done, [&]() { + try { + value = init(); + } catch (...) { + ex = std::current_exception(); + } + }); + if (ex) { + std::rethrow_exception(ex); + } + return value; + } +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/lru-cache.hh b/third_party/nix/src/libutil/lru-cache.hh new file mode 100644 index 0000000000..f6fcdaf82e --- /dev/null +++ b/third_party/nix/src/libutil/lru-cache.hh @@ -0,0 +1,90 @@ +#pragma once + +#include <list> +#include <map> +#include <optional> + +namespace nix { + +/* A simple least-recently used cache. Not thread-safe. */ +template <typename Key, typename Value> +class LRUCache { + private: + size_t capacity; + + // Stupid wrapper to get around circular dependency between Data + // and LRU. + struct LRUIterator; + + using Data = std::map<Key, std::pair<LRUIterator, Value>>; + using LRU = std::list<typename Data::iterator>; + + struct LRUIterator { + typename LRU::iterator it; + }; + + Data data; + LRU lru; + + public: + LRUCache(size_t capacity) : capacity(capacity) {} + + /* Insert or upsert an item in the cache. */ + void upsert(const Key& key, const Value& value) { + if (capacity == 0) { + return; + } + + erase(key); + + if (data.size() >= capacity) { + /* Retire the oldest item. */ + auto oldest = lru.begin(); + data.erase(*oldest); + lru.erase(oldest); + } + + auto res = data.emplace(key, std::make_pair(LRUIterator(), value)); + assert(res.second); + auto& i(res.first); + + auto j = lru.insert(lru.end(), i); + + i->second.first.it = j; + } + + bool erase(const Key& key) { + auto i = data.find(key); + if (i == data.end()) { + return false; + } + lru.erase(i->second.first.it); + data.erase(i); + return true; + } + + /* Look up an item in the cache. If it exists, it becomes the most + recently used item. */ + std::optional<Value> get(const Key& key) { + auto i = data.find(key); + if (i == data.end()) { + return {}; + } + + /* Move this item to the back of the LRU list. */ + lru.erase(i->second.first.it); + auto j = lru.insert(lru.end(), i); + i->second.first.it = j; + + return i->second.second; + } + + size_t size() { return data.size(); } + + void clear() { + data.clear(); + lru.clear(); + } +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/meson.build b/third_party/nix/src/libutil/meson.build new file mode 100644 index 0000000000..a6494e6eac --- /dev/null +++ b/third_party/nix/src/libutil/meson.build @@ -0,0 +1,68 @@ +src_inc += include_directories('.') + +libutil_src = files( + join_paths(meson.source_root(), 'src/libutil/affinity.cc'), + join_paths(meson.source_root(), 'src/libutil/archive.cc'), + join_paths(meson.source_root(), 'src/libutil/args.cc'), + join_paths(meson.source_root(), 'src/libutil/compression.cc'), + join_paths(meson.source_root(), 'src/libutil/config.cc'), + join_paths(meson.source_root(), 'src/libutil/hash.cc'), + join_paths(meson.source_root(), 'src/libutil/json.cc'), + join_paths(meson.source_root(), 'src/libutil/serialise.cc'), + join_paths(meson.source_root(), 'src/libutil/thread-pool.cc'), + join_paths(meson.source_root(), 'src/libutil/util.cc'), + join_paths(meson.source_root(), 'src/libutil/xml-writer.cc'), +) + +libutil_headers = files( + join_paths(meson.source_root(), 'src/libutil/affinity.hh'), + join_paths(meson.source_root(), 'src/libutil/archive.hh'), + join_paths(meson.source_root(), 'src/libutil/args.hh'), + join_paths(meson.source_root(), 'src/libutil/compression.hh'), + join_paths(meson.source_root(), 'src/libutil/config.hh'), + join_paths(meson.source_root(), 'src/libutil/finally.hh'), + join_paths(meson.source_root(), 'src/libutil/hash.hh'), + join_paths(meson.source_root(), 'src/libutil/istringstream_nocopy.hh'), + join_paths(meson.source_root(), 'src/libutil/json.hh'), + join_paths(meson.source_root(), 'src/libutil/lazy.hh'), + join_paths(meson.source_root(), 'src/libutil/lru-cache.hh'), + join_paths(meson.source_root(), 'src/libutil/monitor-fd.hh'), + join_paths(meson.source_root(), 'src/libutil/pool.hh'), + join_paths(meson.source_root(), 'src/libutil/prefork-compat.hh'), + join_paths(meson.source_root(), 'src/libutil/ref.hh'), + join_paths(meson.source_root(), 'src/libutil/serialise.hh'), + join_paths(meson.source_root(), 'src/libutil/sync.hh'), + join_paths(meson.source_root(), 'src/libutil/thread-pool.hh'), + join_paths(meson.source_root(), 'src/libutil/types.hh'), + join_paths(meson.source_root(), 'src/libutil/util.hh'), + join_paths(meson.source_root(), 'src/libutil/xml-writer.hh'), +) + +libutil_dep_list = [ + glog_dep, + boost_dep, + libbz2_dep, + liblzma_dep, + libbrotli_dep, + openssl_dep, + pthread_dep, + libsodium_dep, +] + +libutil_link_list = [] +libutil_link_args = [] + +libutil_lib = library( + 'nixutil', + install : true, + install_mode : 'rwxr-xr-x', + install_dir : libdir, + include_directories : src_inc, + sources : libutil_src, + link_args : libutil_link_args, + # cpp_args : [ '-E' ], + dependencies : libutil_dep_list) + +install_headers( + libutil_headers, + install_dir : join_paths(includedir, 'nix')) diff --git a/third_party/nix/src/libutil/monitor-fd.hh b/third_party/nix/src/libutil/monitor-fd.hh new file mode 100644 index 0000000000..c818c58261 --- /dev/null +++ b/third_party/nix/src/libutil/monitor-fd.hh @@ -0,0 +1,57 @@ +#pragma once + +#include <atomic> +#include <cstdlib> +#include <thread> + +#include <poll.h> +#include <signal.h> +#include <sys/types.h> +#include <unistd.h> + +namespace nix { + +class MonitorFdHup { + private: + std::thread thread; + + public: + MonitorFdHup(int fd) { + thread = std::thread([fd]() { + while (true) { + /* Wait indefinitely until a POLLHUP occurs. */ + struct pollfd fds[1]; + fds[0].fd = fd; + /* This shouldn't be necessary, but macOS doesn't seem to + like a zeroed out events field. + See rdar://37537852. + */ + fds[0].events = POLLHUP; + auto count = poll(fds, 1, -1); + if (count == -1) { + abort(); + } // can't happen + /* This shouldn't happen, but can on macOS due to a bug. + See rdar://37550628. + + This may eventually need a delay or further + coordination with the main thread if spinning proves + too harmful. + */ + if (count == 0) { + continue; + } + assert(fds[0].revents & POLLHUP); + triggerInterrupt(); + break; + } + }); + }; + + ~MonitorFdHup() { + pthread_cancel(thread.native_handle()); + thread.join(); + } +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/pool.hh b/third_party/nix/src/libutil/pool.hh new file mode 100644 index 0000000000..6d70795d35 --- /dev/null +++ b/third_party/nix/src/libutil/pool.hh @@ -0,0 +1,174 @@ +#pragma once + +#include <cassert> +#include <functional> +#include <limits> +#include <list> +#include <memory> + +#include "ref.hh" +#include "sync.hh" + +namespace nix { + +/* This template class implements a simple pool manager of resources + of some type R, such as database connections. It is used as + follows: + + class Connection { ... }; + + Pool<Connection> pool; + + { + auto conn(pool.get()); + conn->exec("select ..."); + } + + Here, the Connection object referenced by ‘conn’ is automatically + returned to the pool when ‘conn’ goes out of scope. +*/ + +template <class R> +class Pool { + public: + /* A function that produces new instances of R on demand. */ + typedef std::function<ref<R>()> Factory; + + /* A function that checks whether an instance of R is still + usable. Unusable instances are removed from the pool. */ + typedef std::function<bool(const ref<R>&)> Validator; + + private: + Factory factory; + Validator validator; + + struct State { + size_t inUse = 0; + size_t max; + std::vector<ref<R>> idle; + }; + + Sync<State> state; + + std::condition_variable wakeup; + + public: + Pool( + size_t max = std::numeric_limits<size_t>::max(), + const Factory& factory = []() { return make_ref<R>(); }, + const Validator& validator = [](ref<R> r) { return true; }) + : factory(factory), validator(validator) { + auto state_(state.lock()); + state_->max = max; + } + + void incCapacity() { + auto state_(state.lock()); + state_->max++; + /* we could wakeup here, but this is only used when we're + * about to nest Pool usages, and we want to save the slot for + * the nested use if we can + */ + } + + void decCapacity() { + auto state_(state.lock()); + state_->max--; + } + + ~Pool() { + auto state_(state.lock()); + assert(!state_->inUse); + state_->max = 0; + state_->idle.clear(); + } + + class Handle { + private: + Pool& pool; + std::shared_ptr<R> r; + bool bad = false; + + friend Pool; + + Handle(Pool& pool, std::shared_ptr<R> r) : pool(pool), r(r) {} + + public: + Handle(Handle&& h) : pool(h.pool), r(h.r) { h.r.reset(); } + + Handle(const Handle& l) = delete; + + ~Handle() { + if (!r) { + return; + } + { + auto state_(pool.state.lock()); + if (!bad) { + state_->idle.push_back(ref<R>(r)); + } + assert(state_->inUse); + state_->inUse--; + } + pool.wakeup.notify_one(); + } + + R* operator->() { return &*r; } + R& operator*() { return *r; } + + void markBad() { bad = true; } + }; + + Handle get() { + { + auto state_(state.lock()); + + /* If we're over the maximum number of instance, we need + to wait until a slot becomes available. */ + while (state_->idle.empty() && state_->inUse >= state_->max) + state_.wait(wakeup); + + while (!state_->idle.empty()) { + auto p = state_->idle.back(); + state_->idle.pop_back(); + if (validator(p)) { + state_->inUse++; + return Handle(*this, p); + } + } + + state_->inUse++; + } + + /* We need to create a new instance. Because that might take a + while, we don't hold the lock in the meantime. */ + try { + Handle h(*this, factory()); + return h; + } catch (...) { + auto state_(state.lock()); + state_->inUse--; + wakeup.notify_one(); + throw; + } + } + + size_t count() { + auto state_(state.lock()); + return state_->idle.size() + state_->inUse; + } + + size_t capacity() { return state.lock()->max; } + + void flushBad() { + auto state_(state.lock()); + std::vector<ref<R>> left; + for (auto& p : state_->idle) + if (validator(p)) { + left.push_back(p); + } + std::swap(state_->idle, left); + } +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/prefork-compat.hh b/third_party/nix/src/libutil/prefork-compat.hh new file mode 100644 index 0000000000..ae9c25e539 --- /dev/null +++ b/third_party/nix/src/libutil/prefork-compat.hh @@ -0,0 +1,21 @@ +// This file exists to preserve compatibility with the pre-fork +// version of Nix (2.3.4). +// +// During the refactoring, various structures are getting ripped out +// and replaced with the dummies below while code is being cleaned up. + +#ifndef NIX_SRC_LIBUTIL_PREFORK_COMPAT_H_ +#define NIX_SRC_LIBUTIL_PREFORK_COMPAT_H_ + +namespace nix::compat { + +// This is used in remote-store.cc for various things that expect the +// old logging protocol when talking over the wire. It will be removed +// hen the worker protocol is redone. +enum [[deprecated("old logging compat only")]] Verbosity{ + kError = 0, kWarn, kInfo, kTalkative, kChatty, kDebug, kVomit, +}; + +} // namespace nix::compat + +#endif // NIX_SRC_LIBUTIL_PREFORK_COMPAT_H_ diff --git a/third_party/nix/src/libutil/ref.hh b/third_party/nix/src/libutil/ref.hh new file mode 100644 index 0000000000..063e6b327c --- /dev/null +++ b/third_party/nix/src/libutil/ref.hh @@ -0,0 +1,65 @@ +#pragma once + +#include <exception> +#include <memory> +#include <stdexcept> + +namespace nix { + +/* A simple non-nullable reference-counted pointer. Actually a wrapper + around std::shared_ptr that prevents non-null constructions. */ +template <typename T> +class ref { + private: + std::shared_ptr<T> p; + + public: + ref<T>(const ref<T>& r) : p(r.p) {} + + explicit ref<T>(const std::shared_ptr<T>& p) : p(p) { + if (!p) { + throw std::invalid_argument("null pointer cast to ref"); + } + } + + explicit ref<T>(T* p) : p(p) { + if (!p) { + throw std::invalid_argument("null pointer cast to ref"); + } + } + + T* operator->() const { return &*p; } + + T& operator*() const { return *p; } + + operator std::shared_ptr<T>() const { return p; } + + std::shared_ptr<T> get_ptr() const { return p; } + + template <typename T2> + ref<T2> cast() const { + return ref<T2>(std::dynamic_pointer_cast<T2>(p)); + } + + template <typename T2> + std::shared_ptr<T2> dynamic_pointer_cast() const { + return std::dynamic_pointer_cast<T2>(p); + } + + template <typename T2> + operator ref<T2>() const { + return ref<T2>((std::shared_ptr<T2>)p); + } + + private: + template <typename T2, typename... Args> + friend ref<T2> make_ref(Args&&... args); +}; + +template <typename T, typename... Args> +inline ref<T> make_ref(Args&&... args) { + auto p = std::make_shared<T>(std::forward<Args>(args)...); + return ref<T>(p); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/serialise.cc b/third_party/nix/src/libutil/serialise.cc new file mode 100644 index 0000000000..34af4e840a --- /dev/null +++ b/third_party/nix/src/libutil/serialise.cc @@ -0,0 +1,310 @@ +#include "serialise.hh" + +#include <boost/coroutine2/coroutine.hpp> +#include <cerrno> +#include <cstring> +#include <memory> +#include <utility> + +#include "glog/logging.h" +#include "util.hh" + +namespace nix { + +void BufferedSink::operator()(const unsigned char* data, size_t len) { + if (!buffer) { + buffer = decltype(buffer)(new unsigned char[bufSize]); + } + + while (len != 0u) { + /* Optimisation: bypass the buffer if the data exceeds the + buffer size. */ + if (bufPos + len >= bufSize) { + flush(); + write(data, len); + break; + } + /* Otherwise, copy the bytes to the buffer. Flush the buffer + when it's full. */ + size_t n = bufPos + len > bufSize ? bufSize - bufPos : len; + memcpy(buffer.get() + bufPos, data, n); + data += n; + bufPos += n; + len -= n; + if (bufPos == bufSize) { + flush(); + } + } +} + +void BufferedSink::flush() { + if (bufPos == 0) { + return; + } + size_t n = bufPos; + bufPos = 0; // don't trigger the assert() in ~BufferedSink() + write(buffer.get(), n); +} + +FdSink::~FdSink() { + try { + flush(); + } catch (...) { + ignoreException(); + } +} + +size_t threshold = 256 * 1024 * 1024; + +static void warnLargeDump() { + LOG(WARNING) + << "dumping very large path (> 256 MiB); this may run out of memory"; +} + +void FdSink::write(const unsigned char* data, size_t len) { + written += len; + static bool warned = false; + if (warn && !warned) { + if (written > threshold) { + warnLargeDump(); + warned = true; + } + } + try { + writeFull(fd, data, len); + } catch (SysError& e) { + _good = false; + throw; + } +} + +bool FdSink::good() { return _good; } + +void Source::operator()(unsigned char* data, size_t len) { + while (len != 0u) { + size_t n = read(data, len); + data += n; + len -= n; + } +} + +std::string Source::drain() { + std::string s; + std::vector<unsigned char> buf(8192); + while (true) { + size_t n; + try { + n = read(buf.data(), buf.size()); + s.append((char*)buf.data(), n); + } catch (EndOfFile&) { + break; + } + } + return s; +} + +size_t BufferedSource::read(unsigned char* data, size_t len) { + if (!buffer) { + buffer = decltype(buffer)(new unsigned char[bufSize]); + } + + if (bufPosIn == 0u) { + bufPosIn = readUnbuffered(buffer.get(), bufSize); + } + + /* Copy out the data in the buffer. */ + size_t n = len > bufPosIn - bufPosOut ? bufPosIn - bufPosOut : len; + memcpy(data, buffer.get() + bufPosOut, n); + bufPosOut += n; + if (bufPosIn == bufPosOut) { + bufPosIn = bufPosOut = 0; + } + return n; +} + +bool BufferedSource::hasData() { return bufPosOut < bufPosIn; } + +size_t FdSource::readUnbuffered(unsigned char* data, size_t len) { + ssize_t n; + do { + checkInterrupt(); + n = ::read(fd, (char*)data, len); + } while (n == -1 && errno == EINTR); + if (n == -1) { + _good = false; + throw SysError("reading from file"); + } + if (n == 0) { + _good = false; + throw EndOfFile("unexpected end-of-file"); + } + read += n; + return n; +} + +bool FdSource::good() { return _good; } + +size_t StringSource::read(unsigned char* data, size_t len) { + if (pos == s.size()) { + throw EndOfFile("end of string reached"); + } + size_t n = s.copy((char*)data, len, pos); + pos += n; + return n; +} + +#if BOOST_VERSION >= 106300 && BOOST_VERSION < 106600 +#error Coroutines are broken in this version of Boost! +#endif + +std::unique_ptr<Source> sinkToSource(const std::function<void(Sink&)>& fun, + const std::function<void()>& eof) { + struct SinkToSource : Source { + using coro_t = boost::coroutines2::coroutine<std::string>; + + std::function<void(Sink&)> fun; + std::function<void()> eof; + std::optional<coro_t::pull_type> coro; + bool started = false; + + SinkToSource(std::function<void(Sink&)> fun, std::function<void()> eof) + : fun(std::move(fun)), eof(std::move(eof)) {} + + std::string cur; + size_t pos = 0; + + size_t read(unsigned char* data, size_t len) override { + if (!coro) { + coro = coro_t::pull_type([&](coro_t::push_type& yield) { + LambdaSink sink([&](const unsigned char* data, size_t len) { + if (len != 0u) { + yield(std::string((const char*)data, len)); + } + }); + fun(sink); + }); + } + + if (!*coro) { + eof(); + abort(); + } + + if (pos == cur.size()) { + if (!cur.empty()) { + (*coro)(); + } + cur = coro->get(); + pos = 0; + } + + auto n = std::min(cur.size() - pos, len); + memcpy(data, (unsigned char*)cur.data() + pos, n); + pos += n; + + return n; + } + }; + + return std::make_unique<SinkToSource>(fun, eof); +} + +void writePadding(size_t len, Sink& sink) { + if ((len % 8) != 0u) { + unsigned char zero[8]; + memset(zero, 0, sizeof(zero)); + sink(zero, 8 - (len % 8)); + } +} + +void writeString(const unsigned char* buf, size_t len, Sink& sink) { + sink << len; + sink(buf, len); + writePadding(len, sink); +} + +Sink& operator<<(Sink& sink, const string& s) { + writeString((const unsigned char*)s.data(), s.size(), sink); + return sink; +} + +template <class T> +void writeStrings(const T& ss, Sink& sink) { + sink << ss.size(); + for (auto& i : ss) { + sink << i; + } +} + +Sink& operator<<(Sink& sink, const Strings& s) { + writeStrings(s, sink); + return sink; +} + +Sink& operator<<(Sink& sink, const StringSet& s) { + writeStrings(s, sink); + return sink; +} + +void readPadding(size_t len, Source& source) { + if ((len % 8) != 0u) { + unsigned char zero[8]; + size_t n = 8 - (len % 8); + source(zero, n); + for (unsigned int i = 0; i < n; i++) { + if (zero[i] != 0u) { + throw SerialisationError("non-zero padding"); + } + } + } +} + +size_t readString(unsigned char* buf, size_t max, Source& source) { + auto len = readNum<size_t>(source); + if (len > max) { + throw SerialisationError("string is too long"); + } + source(buf, len); + readPadding(len, source); + return len; +} + +string readString(Source& source, size_t max) { + auto len = readNum<size_t>(source); + if (len > max) { + throw SerialisationError("string is too long"); + } + std::string res(len, 0); + source((unsigned char*)res.data(), len); + readPadding(len, source); + return res; +} + +Source& operator>>(Source& in, string& s) { + s = readString(in); + return in; +} + +template <class T> +T readStrings(Source& source) { + auto count = readNum<size_t>(source); + T ss; + while (count--) { + ss.insert(ss.end(), readString(source)); + } + return ss; +} + +template Paths readStrings(Source& source); +template PathSet readStrings(Source& source); + +void StringSink::operator()(const unsigned char* data, size_t len) { + static bool warned = false; + if (!warned && s->size() > threshold) { + warnLargeDump(); + warned = true; + } + s->append((const char*)data, len); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/serialise.hh b/third_party/nix/src/libutil/serialise.hh new file mode 100644 index 0000000000..a5992b50ec --- /dev/null +++ b/third_party/nix/src/libutil/serialise.hh @@ -0,0 +1,287 @@ +#pragma once + +#include <memory> + +#include "types.hh" +#include "util.hh" + +namespace nix { + +/* Abstract destination of binary data. */ +struct Sink { + virtual ~Sink() {} + virtual void operator()(const unsigned char* data, size_t len) = 0; + virtual bool good() { return true; } + + void operator()(const std::string& s) { + (*this)((const unsigned char*)s.data(), s.size()); + } +}; + +/* A buffered abstract sink. */ +struct BufferedSink : Sink { + size_t bufSize, bufPos; + std::unique_ptr<unsigned char[]> buffer; + + BufferedSink(size_t bufSize = 32 * 1024) + : bufSize(bufSize), bufPos(0), buffer(nullptr) {} + + void operator()(const unsigned char* data, size_t len) override; + + void operator()(const std::string& s) { Sink::operator()(s); } + + void flush(); + + virtual void write(const unsigned char* data, size_t len) = 0; +}; + +/* Abstract source of binary data. */ +struct Source { + virtual ~Source() {} + + /* Store exactly ‘len’ bytes in the buffer pointed to by ‘data’. + It blocks until all the requested data is available, or throws + an error if it is not going to be available. */ + void operator()(unsigned char* data, size_t len); + + /* Store up to ‘len’ in the buffer pointed to by ‘data’, and + return the number of bytes stored. It blocks until at least + one byte is available. */ + virtual size_t read(unsigned char* data, size_t len) = 0; + + virtual bool good() { return true; } + + std::string drain(); +}; + +/* A buffered abstract source. */ +struct BufferedSource : Source { + size_t bufSize, bufPosIn, bufPosOut; + std::unique_ptr<unsigned char[]> buffer; + + BufferedSource(size_t bufSize = 32 * 1024) + : bufSize(bufSize), bufPosIn(0), bufPosOut(0), buffer(nullptr) {} + + size_t read(unsigned char* data, size_t len) override; + + bool hasData(); + + protected: + /* Underlying read call, to be overridden. */ + virtual size_t readUnbuffered(unsigned char* data, size_t len) = 0; +}; + +/* A sink that writes data to a file descriptor. */ +struct FdSink : BufferedSink { + int fd; + bool warn = false; + size_t written = 0; + + FdSink() : fd(-1) {} + FdSink(int fd) : fd(fd) {} + FdSink(FdSink&&) = default; + + FdSink& operator=(FdSink&& s) { + flush(); + fd = s.fd; + s.fd = -1; + warn = s.warn; + written = s.written; + return *this; + } + + ~FdSink(); + + void write(const unsigned char* data, size_t len) override; + + bool good() override; + + private: + bool _good = true; +}; + +/* A source that reads data from a file descriptor. */ +struct FdSource : BufferedSource { + int fd; + size_t read = 0; + + FdSource() : fd(-1) {} + FdSource(int fd) : fd(fd) {} + FdSource(FdSource&&) = default; + + FdSource& operator=(FdSource&& s) { + fd = s.fd; + s.fd = -1; + read = s.read; + return *this; + } + + bool good() override; + + protected: + size_t readUnbuffered(unsigned char* data, size_t len) override; + + private: + bool _good = true; +}; + +/* A sink that writes data to a string. */ +struct StringSink : Sink { + ref<std::string> s; + StringSink() : s(make_ref<std::string>()){}; + StringSink(ref<std::string> s) : s(s){}; + void operator()(const unsigned char* data, size_t len) override; +}; + +/* A source that reads data from a string. */ +struct StringSource : Source { + const string& s; + size_t pos; + StringSource(const string& _s) : s(_s), pos(0) {} + size_t read(unsigned char* data, size_t len) override; +}; + +/* Adapter class of a Source that saves all data read to `s'. */ +struct TeeSource : Source { + Source& orig; + ref<std::string> data; + TeeSource(Source& orig) : orig(orig), data(make_ref<std::string>()) {} + size_t read(unsigned char* data, size_t len) { + size_t n = orig.read(data, len); + this->data->append((const char*)data, n); + return n; + } +}; + +/* A reader that consumes the original Source until 'size'. */ +struct SizedSource : Source { + Source& orig; + size_t remain; + SizedSource(Source& orig, size_t size) : orig(orig), remain(size) {} + size_t read(unsigned char* data, size_t len) { + if (this->remain <= 0) { + throw EndOfFile("sized: unexpected end-of-file"); + } + len = std::min(len, this->remain); + size_t n = this->orig.read(data, len); + this->remain -= n; + return n; + } + + /* Consume the original source until no remain data is left to consume. */ + size_t drainAll() { + std::vector<unsigned char> buf(8192); + size_t sum = 0; + while (this->remain > 0) { + size_t n = read(buf.data(), buf.size()); + sum += n; + } + return sum; + } +}; + +/* Convert a function into a sink. */ +struct LambdaSink : Sink { + typedef std::function<void(const unsigned char*, size_t)> lambda_t; + + lambda_t lambda; + + LambdaSink(const lambda_t& lambda) : lambda(lambda) {} + + virtual void operator()(const unsigned char* data, size_t len) { + lambda(data, len); + } +}; + +/* Convert a function into a source. */ +struct LambdaSource : Source { + typedef std::function<size_t(unsigned char*, size_t)> lambda_t; + + lambda_t lambda; + + LambdaSource(const lambda_t& lambda) : lambda(lambda) {} + + size_t read(unsigned char* data, size_t len) override { + return lambda(data, len); + } +}; + +/* Convert a function that feeds data into a Sink into a Source. The + Source executes the function as a coroutine. */ +std::unique_ptr<Source> sinkToSource( + const std::function<void(Sink&)>& fun, + const std::function<void()>& eof = []() { + throw EndOfFile("coroutine has finished"); + }); + +void writePadding(size_t len, Sink& sink); +void writeString(const unsigned char* buf, size_t len, Sink& sink); + +inline Sink& operator<<(Sink& sink, uint64_t n) { + unsigned char buf[8]; + buf[0] = n & 0xff; + buf[1] = (n >> 8) & 0xff; + buf[2] = (n >> 16) & 0xff; + buf[3] = (n >> 24) & 0xff; + buf[4] = (n >> 32) & 0xff; + buf[5] = (n >> 40) & 0xff; + buf[6] = (n >> 48) & 0xff; + buf[7] = (unsigned char)(n >> 56) & 0xff; + sink(buf, sizeof(buf)); + return sink; +} + +Sink& operator<<(Sink& sink, const string& s); +Sink& operator<<(Sink& sink, const Strings& s); +Sink& operator<<(Sink& sink, const StringSet& s); + +MakeError(SerialisationError, Error) + + template <typename T> + T readNum(Source& source) { + unsigned char buf[8]; + source(buf, sizeof(buf)); + + uint64_t n = + ((unsigned long long)buf[0]) | ((unsigned long long)buf[1] << 8) | + ((unsigned long long)buf[2] << 16) | ((unsigned long long)buf[3] << 24) | + ((unsigned long long)buf[4] << 32) | ((unsigned long long)buf[5] << 40) | + ((unsigned long long)buf[6] << 48) | ((unsigned long long)buf[7] << 56); + + if (n > std::numeric_limits<T>::max()) + throw SerialisationError("serialised integer %d is too large for type '%s'", + n, typeid(T).name()); + + return (T)n; +} + +inline unsigned int readInt(Source& source) { + return readNum<unsigned int>(source); +} + +inline uint64_t readLongLong(Source& source) { + return readNum<uint64_t>(source); +} + +void readPadding(size_t len, Source& source); +size_t readString(unsigned char* buf, size_t max, Source& source); +string readString(Source& source, + size_t max = std::numeric_limits<size_t>::max()); +template <class T> +T readStrings(Source& source); + +Source& operator>>(Source& in, string& s); + +template <typename T> +Source& operator>>(Source& in, T& n) { + n = readNum<T>(in); + return in; +} + +template <typename T> +Source& operator>>(Source& in, bool& b) { + b = readNum<uint64_t>(in); + return in; +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/sync.hh b/third_party/nix/src/libutil/sync.hh new file mode 100644 index 0000000000..b79d1176b9 --- /dev/null +++ b/third_party/nix/src/libutil/sync.hh @@ -0,0 +1,84 @@ +#pragma once + +#include <cassert> +#include <condition_variable> +#include <cstdlib> +#include <mutex> + +namespace nix { + +/* This template class ensures synchronized access to a value of type + T. It is used as follows: + + struct Data { int x; ... }; + + Sync<Data> data; + + { + auto data_(data.lock()); + data_->x = 123; + } + + Here, "data" is automatically unlocked when "data_" goes out of + scope. +*/ + +template <class T, class M = std::mutex> +class Sync { + private: + M mutex; + T data; + + public: + Sync() {} + Sync(const T& data) : data(data) {} + Sync(T&& data) noexcept : data(std::move(data)) {} + + class Lock { + private: + Sync* s; + std::unique_lock<M> lk; + friend Sync; + Lock(Sync* s) : s(s), lk(s->mutex) {} + + public: + Lock(Lock&& l) : s(l.s) { abort(); } + Lock(const Lock& l) = delete; + ~Lock() {} + T* operator->() { return &s->data; } + T& operator*() { return s->data; } + + void wait(std::condition_variable& cv) { + assert(s); + cv.wait(lk); + } + + template <class Rep, class Period> + std::cv_status wait_for( + std::condition_variable& cv, + const std::chrono::duration<Rep, Period>& duration) { + assert(s); + return cv.wait_for(lk, duration); + } + + template <class Rep, class Period, class Predicate> + bool wait_for(std::condition_variable& cv, + const std::chrono::duration<Rep, Period>& duration, + Predicate pred) { + assert(s); + return cv.wait_for(lk, duration, pred); + } + + template <class Clock, class Duration> + std::cv_status wait_until( + std::condition_variable& cv, + const std::chrono::time_point<Clock, Duration>& duration) { + assert(s); + return cv.wait_until(lk, duration); + } + }; + + Lock lock() { return Lock(this); } +}; + +} // namespace nix diff --git a/third_party/nix/src/libutil/thread-pool.cc b/third_party/nix/src/libutil/thread-pool.cc new file mode 100644 index 0000000000..879de446c2 --- /dev/null +++ b/third_party/nix/src/libutil/thread-pool.cc @@ -0,0 +1,162 @@ +#include "thread-pool.hh" + +#include "affinity.hh" +#include "glog/logging.h" + +namespace nix { + +ThreadPool::ThreadPool(size_t _maxThreads) : maxThreads(_maxThreads) { + restoreAffinity(); // FIXME + + if (maxThreads == 0u) { + maxThreads = std::thread::hardware_concurrency(); + if (maxThreads == 0u) { + maxThreads = 1; + } + } + + DLOG(INFO) << "starting pool of " << maxThreads - 1 << " threads"; +} + +ThreadPool::~ThreadPool() { shutdown(); } + +void ThreadPool::shutdown() { + std::vector<std::thread> workers; + { + auto state(state_.lock()); + quit = true; + std::swap(workers, state->workers); + } + + if (workers.empty()) { + return; + } + + DLOG(INFO) << "reaping " << workers.size() << " worker threads"; + + work.notify_all(); + + for (auto& thr : workers) { + thr.join(); + } +} + +void ThreadPool::enqueue(const work_t& t) { + auto state(state_.lock()); + if (quit) { + throw ThreadPoolShutDown( + "cannot enqueue a work item while the thread pool is shutting down"); + } + state->pending.push(t); + /* Note: process() also executes items, so count it as a worker. */ + if (state->pending.size() > state->workers.size() + 1 && + state->workers.size() + 1 < maxThreads) { + state->workers.emplace_back(&ThreadPool::doWork, this, false); + } + work.notify_one(); +} + +void ThreadPool::process() { + state_.lock()->draining = true; + + /* Do work until no more work is pending or active. */ + try { + doWork(true); + + auto state(state_.lock()); + + assert(quit); + + if (state->exception) { + std::rethrow_exception(state->exception); + } + + } catch (...) { + /* In the exceptional case, some workers may still be + active. They may be referencing the stack frame of the + caller. So wait for them to finish. (~ThreadPool also does + this, but it might be destroyed after objects referenced by + the work item lambdas.) */ + shutdown(); + throw; + } +} + +void ThreadPool::doWork(bool mainThread) { + if (!mainThread) { + interruptCheck = [&]() { return (bool)quit; }; + } + + bool didWork = false; + std::exception_ptr exc; + + while (true) { + work_t w; + { + auto state(state_.lock()); + + if (didWork) { + assert(state->active); + state->active--; + + if (exc) { + if (!state->exception) { + state->exception = exc; + // Tell the other workers to quit. + quit = true; + work.notify_all(); + } else { + /* Print the exception, since we can't + propagate it. */ + try { + std::rethrow_exception(exc); + } catch (std::exception& e) { + if ((dynamic_cast<Interrupted*>(&e) == nullptr) && + (dynamic_cast<ThreadPoolShutDown*>(&e) == nullptr)) { + ignoreException(); + } + } catch (...) { + } + } + } + } + + /* Wait until a work item is available or we're asked to + quit. */ + while (true) { + if (quit) { + return; + } + + if (!state->pending.empty()) { + break; + } + + /* If there are no active or pending items, and the + main thread is running process(), then no new items + can be added. So exit. */ + if ((state->active == 0u) && state->draining) { + quit = true; + work.notify_all(); + return; + } + + state.wait(work); + } + + w = std::move(state->pending.front()); + state->pending.pop(); + state->active++; + } + + try { + w(); + } catch (...) { + exc = std::current_exception(); + } + + didWork = true; + } +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/thread-pool.hh b/third_party/nix/src/libutil/thread-pool.hh new file mode 100644 index 0000000000..72837ca1ee --- /dev/null +++ b/third_party/nix/src/libutil/thread-pool.hh @@ -0,0 +1,138 @@ +#pragma once + +#include <atomic> +#include <functional> +#include <map> +#include <queue> +#include <thread> + +#include "sync.hh" +#include "util.hh" + +namespace nix { + +MakeError(ThreadPoolShutDown, Error) + + /* A simple thread pool that executes a queue of work items + (lambdas). */ + class ThreadPool { + public: + ThreadPool(size_t maxThreads = 0); + + ~ThreadPool(); + + // FIXME: use std::packaged_task? + typedef std::function<void()> work_t; + + /* Enqueue a function to be executed by the thread pool. */ + void enqueue(const work_t& t); + + /* Execute work items until the queue is empty. Note that work + items are allowed to add new items to the queue; this is + handled correctly. Queue processing stops prematurely if any + work item throws an exception. This exception is propagated to + the calling thread. If multiple work items throw an exception + concurrently, only one item is propagated; the others are + printed on stderr and otherwise ignored. */ + void process(); + + private: + size_t maxThreads; + + struct State { + std::queue<work_t> pending; + size_t active = 0; + std::exception_ptr exception; + std::vector<std::thread> workers; + bool draining = false; + }; + + std::atomic_bool quit{false}; + + Sync<State> state_; + + std::condition_variable work; + + void doWork(bool mainThread); + + void shutdown(); +}; + +/* Process in parallel a set of items of type T that have a partial + ordering between them. Thus, any item is only processed after all + its dependencies have been processed. */ +template <typename T> +void processGraph(ThreadPool& pool, const std::set<T>& nodes, + std::function<std::set<T>(const T&)> getEdges, + std::function<void(const T&)> processNode) { + struct Graph { + std::set<T> left; + std::map<T, std::set<T>> refs, rrefs; + }; + + Sync<Graph> graph_(Graph{nodes, {}, {}}); + + std::function<void(const T&)> worker; + + worker = [&](const T& node) { + { + auto graph(graph_.lock()); + auto i = graph->refs.find(node); + if (i == graph->refs.end()) { + goto getRefs; + } + goto doWork; + } + + getRefs : { + auto refs = getEdges(node); + refs.erase(node); + + { + auto graph(graph_.lock()); + for (auto& ref : refs) + if (graph->left.count(ref)) { + graph->refs[node].insert(ref); + graph->rrefs[ref].insert(node); + } + if (graph->refs[node].empty()) { + goto doWork; + } + } + } + + return; + + doWork: + processNode(node); + + /* Enqueue work for all nodes that were waiting on this one + and have no unprocessed dependencies. */ + { + auto graph(graph_.lock()); + for (auto& rref : graph->rrefs[node]) { + auto& refs(graph->refs[rref]); + auto i = refs.find(node); + assert(i != refs.end()); + refs.erase(i); + if (refs.empty()) { + pool.enqueue(std::bind(worker, rref)); + } + } + graph->left.erase(node); + graph->refs.erase(node); + graph->rrefs.erase(node); + } + }; + + for (auto& node : nodes) { + pool.enqueue(std::bind(worker, std::ref(node))); + } + + pool.process(); + + if (!graph_.lock()->left.empty()) + throw Error("graph processing incomplete (cyclic reference?)"); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/types.hh b/third_party/nix/src/libutil/types.hh new file mode 100644 index 0000000000..ac1b802ce0 --- /dev/null +++ b/third_party/nix/src/libutil/types.hh @@ -0,0 +1,120 @@ +#pragma once + +#include <boost/format.hpp> +#include <list> +#include <map> +#include <memory> +#include <set> +#include <string> + +#include "ref.hh" + +/* Before 4.7, gcc's std::exception uses empty throw() specifiers for + * its (virtual) destructor and what() in c++11 mode, in violation of spec + */ +#ifdef __GNUC__ +#if __GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 7) +#define EXCEPTION_NEEDS_THROW_SPEC +#endif +#endif + +namespace nix { + +/* Inherit some names from other namespaces for convenience. */ +using boost::format; +using std::list; +using std::set; +using std::string; +using std::vector; + +/* A variadic template that does nothing. Useful to call a function + for all variadic arguments but ignoring the result. */ +struct nop { + template <typename... T> + nop(T...) {} +}; + +struct FormatOrString { + string s; + FormatOrString(const string& s) : s(s){}; + FormatOrString(const format& f) : s(f.str()){}; + FormatOrString(const char* s) : s(s){}; +}; + +/* A helper for formatting strings. ‘fmt(format, a_0, ..., a_n)’ is + equivalent to ‘boost::format(format) % a_0 % ... % + ... a_n’. However, ‘fmt(s)’ is equivalent to ‘s’ (so no %-expansion + takes place). */ + +inline std::string fmt(const std::string& s) { return s; } + +inline std::string fmt(const char* s) { return s; } + +inline std::string fmt(const FormatOrString& fs) { return fs.s; } + +template <typename... Args> +inline std::string fmt(const std::string& fs, Args... args) { + boost::format f(fs); + f.exceptions(boost::io::all_error_bits ^ boost::io::too_many_args_bit); + nop{boost::io::detail::feed(f, args)...}; + return f.str(); +} + +/* BaseError should generally not be caught, as it has Interrupted as + a subclass. Catch Error instead. */ +class BaseError : public std::exception { + protected: + string prefix_; // used for location traces etc. + string err; + + public: + unsigned int status = 1; // exit status + + template <typename... Args> + BaseError(unsigned int status, Args... args) + : err(fmt(args...)), status(status) {} + + template <typename... Args> + BaseError(Args... args) : err(fmt(args...)) {} + +#ifdef EXCEPTION_NEEDS_THROW_SPEC + ~BaseError() noexcept {}; + const char* what() const noexcept { return err.c_str(); } +#else + const char* what() const noexcept { return err.c_str(); } +#endif + + const string& msg() const { return err; } + const string& prefix() const { return prefix_; } + BaseError& addPrefix(const FormatOrString& fs); +}; + +#define MakeError(newClass, superClass) \ + class newClass : public superClass { \ + public: \ + using superClass::superClass; \ + }; + +MakeError(Error, BaseError) + + class SysError : public Error { + public: + int errNo; + + template <typename... Args> + SysError(Args... args) : Error(addErrno(fmt(args...))) {} + + private: + std::string addErrno(const std::string& s); +}; + +typedef list<string> Strings; +typedef set<string> StringSet; +typedef std::map<std::string, std::string> StringMap; + +/* Paths are just strings. */ +typedef string Path; +typedef list<Path> Paths; +typedef set<Path> PathSet; + +} // namespace nix diff --git a/third_party/nix/src/libutil/util.cc b/third_party/nix/src/libutil/util.cc new file mode 100644 index 0000000000..0ad2c51148 --- /dev/null +++ b/third_party/nix/src/libutil/util.cc @@ -0,0 +1,1528 @@ +#include "util.hh" + +#include <cctype> +#include <cerrno> +#include <climits> +#include <cstdio> +#include <cstdlib> +#include <cstring> +#include <future> +#include <iostream> +#include <sstream> +#include <thread> +#include <utility> + +#include <fcntl.h> +#include <grp.h> +#include <pwd.h> +#include <sys/ioctl.h> +#include <sys/types.h> +#include <sys/wait.h> +#include <unistd.h> + +#include "affinity.hh" +#include "finally.hh" +#include "glog/logging.h" +#include "lazy.hh" +#include "serialise.hh" +#include "sync.hh" + +#ifdef __APPLE__ +#include <sys/syscall.h> +#endif + +#ifdef __linux__ +#include <sys/prctl.h> +#endif + +namespace nix { + +const std::string nativeSystem = SYSTEM; + +BaseError& BaseError::addPrefix(const FormatOrString& fs) { + prefix_ = fs.s + prefix_; + return *this; +} + +std::string SysError::addErrno(const std::string& s) { + errNo = errno; + return s + ": " + strerror(errNo); +} + +string getEnv(const string& key, const string& def) { + char* value = getenv(key.c_str()); + return value != nullptr ? string(value) : def; +} + +std::map<std::string, std::string> getEnv() { + std::map<std::string, std::string> env; + for (size_t i = 0; environ[i] != nullptr; ++i) { + auto s = environ[i]; + auto eq = strchr(s, '='); + if (eq == nullptr) { + // invalid env, just keep going + continue; + } + env.emplace(std::string(s, eq), std::string(eq + 1)); + } + return env; +} + +void clearEnv() { + for (auto& name : getEnv()) { + unsetenv(name.first.c_str()); + } +} + +void replaceEnv(const std::map<std::string, std::string>& newEnv) { + clearEnv(); + for (const auto& newEnvVar : newEnv) { + setenv(newEnvVar.first.c_str(), newEnvVar.second.c_str(), 1); + } +} + +Path absPath(Path path, Path dir) { + if (path[0] != '/') { + if (dir.empty()) { +#ifdef __GNU__ + /* GNU (aka. GNU/Hurd) doesn't have any limitation on path + lengths and doesn't define `PATH_MAX'. */ + char* buf = getcwd(NULL, 0); + if (buf == NULL) +#else + char buf[PATH_MAX]; + if (getcwd(buf, sizeof(buf)) == nullptr) { +#endif + throw SysError("cannot get cwd"); + } + dir = buf; +#ifdef __GNU__ + free(buf); +#endif + } + path = dir + "/" + path; +} +return canonPath(path); +} // namespace nix + +Path canonPath(const Path& path, bool resolveSymlinks) { + assert(!path.empty()); + + string s; + + if (path[0] != '/') { + throw Error(format("not an absolute path: '%1%'") % path); + } + + string::const_iterator i = path.begin(); + string::const_iterator end = path.end(); + string temp; + + /* Count the number of times we follow a symlink and stop at some + arbitrary (but high) limit to prevent infinite loops. */ + unsigned int followCount = 0; + unsigned int maxFollow = 1024; + + while (true) { + /* Skip slashes. */ + while (i != end && *i == '/') { + i++; + } + if (i == end) { + break; + } + + /* Ignore `.'. */ + if (*i == '.' && (i + 1 == end || i[1] == '/')) { + i++; + } + + /* If `..', delete the last component. */ + else if (*i == '.' && i + 1 < end && i[1] == '.' && + (i + 2 == end || i[2] == '/')) { + if (!s.empty()) { + s.erase(s.rfind('/')); + } + i += 2; + } + + /* Normal component; copy it. */ + else { + s += '/'; + while (i != end && *i != '/') { + s += *i++; + } + + /* If s points to a symlink, resolve it and restart (since + the symlink target might contain new symlinks). */ + if (resolveSymlinks && isLink(s)) { + if (++followCount >= maxFollow) { + throw Error(format("infinite symlink recursion in path '%1%'") % + path); + } + temp = absPath(readLink(s), dirOf(s)) + string(i, end); + i = temp.begin(); /* restart */ + end = temp.end(); + s = ""; + } + } + } + + return s.empty() ? "/" : s; +} + +Path dirOf(const Path& path) { + Path::size_type pos = path.rfind('/'); + if (pos == string::npos) { + return "."; + } + return pos == 0 ? "/" : Path(path, 0, pos); +} + +string baseNameOf(const Path& path) { + if (path.empty()) { + return ""; + } + + Path::size_type last = path.length() - 1; + if (path[last] == '/' && last > 0) { + last -= 1; + } + + Path::size_type pos = path.rfind('/', last); + if (pos == string::npos) { + pos = 0; + } else { + pos += 1; + } + + return string(path, pos, last - pos + 1); +} + +bool isInDir(const Path& path, const Path& dir) { + return path[0] == '/' && string(path, 0, dir.size()) == dir && + path.size() >= dir.size() + 2 && path[dir.size()] == '/'; +} + +bool isDirOrInDir(const Path& path, const Path& dir) { + return path == dir || isInDir(path, dir); +} + +struct stat lstat(const Path& path) { + struct stat st; + if (lstat(path.c_str(), &st) != 0) { + throw SysError(format("getting status of '%1%'") % path); + } + return st; +} + +bool pathExists(const Path& path) { + int res; + struct stat st; + res = lstat(path.c_str(), &st); + if (res == 0) { + return true; + } + if (errno != ENOENT && errno != ENOTDIR) { + throw SysError(format("getting status of %1%") % path); + } + return false; +} + +Path readLink(const Path& path) { + checkInterrupt(); + std::vector<char> buf; + for (ssize_t bufSize = PATH_MAX / 4; true; bufSize += bufSize / 2) { + buf.resize(bufSize); + ssize_t rlSize = readlink(path.c_str(), buf.data(), bufSize); + if (rlSize == -1) { + if (errno == EINVAL) { + throw Error("'%1%' is not a symlink", path); + } + throw SysError("reading symbolic link '%1%'", path); + + } else if (rlSize < bufSize) { + return string(buf.data(), rlSize); + } + } +} + +bool isLink(const Path& path) { + struct stat st = lstat(path); + return S_ISLNK(st.st_mode); +} + +DirEntries readDirectory(const Path& path) { + DirEntries entries; + entries.reserve(64); + + AutoCloseDir dir(opendir(path.c_str())); + if (!dir) { + throw SysError(format("opening directory '%1%'") % path); + } + + struct dirent* dirent; + while (errno = 0, dirent = readdir(dir.get())) { /* sic */ + checkInterrupt(); + string name = dirent->d_name; + if (name == "." || name == "..") { + continue; + } + entries.emplace_back(name, dirent->d_ino, +#ifdef HAVE_STRUCT_DIRENT_D_TYPE + dirent->d_type +#else + DT_UNKNOWN +#endif + ); + } + if (errno) { + throw SysError(format("reading directory '%1%'") % path); + } + + return entries; +} + +unsigned char getFileType(const Path& path) { + struct stat st = lstat(path); + if (S_ISDIR(st.st_mode)) { + return DT_DIR; + } + if (S_ISLNK(st.st_mode)) { + return DT_LNK; + } + if (S_ISREG(st.st_mode)) { + return DT_REG; + } + return DT_UNKNOWN; +} + +string readFile(int fd) { + struct stat st; + if (fstat(fd, &st) == -1) { + throw SysError("statting file"); + } + + std::vector<unsigned char> buf(st.st_size); + readFull(fd, buf.data(), st.st_size); + + return string((char*)buf.data(), st.st_size); +} + +string readFile(const Path& path, bool drain) { + AutoCloseFD fd = open(path.c_str(), O_RDONLY | O_CLOEXEC); + if (!fd) { + throw SysError(format("opening file '%1%'") % path); + } + return drain ? drainFD(fd.get()) : readFile(fd.get()); +} + +void readFile(const Path& path, Sink& sink) { + AutoCloseFD fd = open(path.c_str(), O_RDONLY | O_CLOEXEC); + if (!fd) { + throw SysError("opening file '%s'", path); + } + drainFD(fd.get(), sink); +} + +void writeFile(const Path& path, const string& s, mode_t mode) { + AutoCloseFD fd = + open(path.c_str(), O_WRONLY | O_TRUNC | O_CREAT | O_CLOEXEC, mode); + if (!fd) { + throw SysError(format("opening file '%1%'") % path); + } + writeFull(fd.get(), s); +} + +void writeFile(const Path& path, Source& source, mode_t mode) { + AutoCloseFD fd = + open(path.c_str(), O_WRONLY | O_TRUNC | O_CREAT | O_CLOEXEC, mode); + if (!fd) { + throw SysError(format("opening file '%1%'") % path); + } + + std::vector<unsigned char> buf(64 * 1024); + + while (true) { + try { + auto n = source.read(buf.data(), buf.size()); + writeFull(fd.get(), (unsigned char*)buf.data(), n); + } catch (EndOfFile&) { + break; + } + } +} + +string readLine(int fd) { + string s; + while (true) { + checkInterrupt(); + char ch; + // FIXME: inefficient + ssize_t rd = read(fd, &ch, 1); + if (rd == -1) { + if (errno != EINTR) { + throw SysError("reading a line"); + } + } else if (rd == 0) { + throw EndOfFile("unexpected EOF reading a line"); + } else { + if (ch == '\n') { + return s; + } + s += ch; + } + } +} + +void writeLine(int fd, string s) { + s += '\n'; + writeFull(fd, s); +} + +static void _deletePath(const Path& path, unsigned long long& bytesFreed) { + checkInterrupt(); + + struct stat st; + if (lstat(path.c_str(), &st) == -1) { + if (errno == ENOENT) { + return; + } + throw SysError(format("getting status of '%1%'") % path); + } + + if (!S_ISDIR(st.st_mode) && st.st_nlink == 1) { + bytesFreed += st.st_size; + } + + if (S_ISDIR(st.st_mode)) { + /* Make the directory accessible. */ + const auto PERM_MASK = S_IRUSR | S_IWUSR | S_IXUSR; + if ((st.st_mode & PERM_MASK) != PERM_MASK) { + if (chmod(path.c_str(), st.st_mode | PERM_MASK) == -1) { + throw SysError(format("chmod '%1%'") % path); + } + } + + for (auto& i : readDirectory(path)) { + _deletePath(path + "/" + i.name, bytesFreed); + } + } + + if (remove(path.c_str()) == -1) { + if (errno == ENOENT) { + return; + } + throw SysError(format("cannot unlink '%1%'") % path); + } +} + +void deletePath(const Path& path) { + unsigned long long dummy; + deletePath(path, dummy); +} + +void deletePath(const Path& path, unsigned long long& bytesFreed) { + // Activity act(*logger, lvlDebug, format("recursively deleting path '%1%'") % + // path); + bytesFreed = 0; + _deletePath(path, bytesFreed); +} + +static Path tempName(Path tmpRoot, const Path& prefix, bool includePid, + int& counter) { + tmpRoot = + canonPath(tmpRoot.empty() ? getEnv("TMPDIR", "/tmp") : tmpRoot, true); + if (includePid) { + return (format("%1%/%2%-%3%-%4%") % tmpRoot % prefix % getpid() % counter++) + .str(); + } + return (format("%1%/%2%-%3%") % tmpRoot % prefix % counter++).str(); +} + +Path createTempDir(const Path& tmpRoot, const Path& prefix, bool includePid, + bool useGlobalCounter, mode_t mode) { + static int globalCounter = 0; + int localCounter = 0; + int& counter(useGlobalCounter ? globalCounter : localCounter); + + while (true) { + checkInterrupt(); + Path tmpDir = tempName(tmpRoot, prefix, includePid, counter); + if (mkdir(tmpDir.c_str(), mode) == 0) { +#if __FreeBSD__ + /* Explicitly set the group of the directory. This is to + work around around problems caused by BSD's group + ownership semantics (directories inherit the group of + the parent). For instance, the group of /tmp on + FreeBSD is "wheel", so all directories created in /tmp + will be owned by "wheel"; but if the user is not in + "wheel", then "tar" will fail to unpack archives that + have the setgid bit set on directories. */ + if (chown(tmpDir.c_str(), (uid_t)-1, getegid()) != 0) + throw SysError(format("setting group of directory '%1%'") % tmpDir); +#endif + return tmpDir; + } + if (errno != EEXIST) { + throw SysError(format("creating directory '%1%'") % tmpDir); + } + } +} + +std::string getUserName() { + auto pw = getpwuid(geteuid()); + std::string name = pw != nullptr ? pw->pw_name : getEnv("USER", ""); + if (name.empty()) { + throw Error("cannot figure out user name"); + } + return name; +} + +static Lazy<Path> getHome2([]() { + Path homeDir = getEnv("HOME"); + if (homeDir.empty()) { + std::vector<char> buf(16384); + struct passwd pwbuf; + struct passwd* pw; + if (getpwuid_r(geteuid(), &pwbuf, buf.data(), buf.size(), &pw) != 0 || + (pw == nullptr) || (pw->pw_dir == nullptr) || (pw->pw_dir[0] == 0)) { + throw Error("cannot determine user's home directory"); + } + homeDir = pw->pw_dir; + } + return homeDir; +}); + +Path getHome() { return getHome2(); } + +Path getCacheDir() { + Path cacheDir = getEnv("XDG_CACHE_HOME"); + if (cacheDir.empty()) { + cacheDir = getHome() + "/.cache"; + } + return cacheDir; +} + +Path getConfigDir() { + Path configDir = getEnv("XDG_CONFIG_HOME"); + if (configDir.empty()) { + configDir = getHome() + "/.config"; + } + return configDir; +} + +std::vector<Path> getConfigDirs() { + Path configHome = getConfigDir(); + string configDirs = getEnv("XDG_CONFIG_DIRS"); + auto result = tokenizeString<std::vector<string>>(configDirs, ":"); + result.insert(result.begin(), configHome); + return result; +} + +Path getDataDir() { + Path dataDir = getEnv("XDG_DATA_HOME"); + if (dataDir.empty()) { + dataDir = getHome() + "/.local/share"; + } + return dataDir; +} + +Paths createDirs(const Path& path) { + Paths created; + if (path == "/") { + return created; + } + + struct stat st; + if (lstat(path.c_str(), &st) == -1) { + created = createDirs(dirOf(path)); + if (mkdir(path.c_str(), 0777) == -1 && errno != EEXIST) { + throw SysError(format("creating directory '%1%'") % path); + } + st = lstat(path); + created.push_back(path); + } + + if (S_ISLNK(st.st_mode) && stat(path.c_str(), &st) == -1) { + throw SysError(format("statting symlink '%1%'") % path); + } + + if (!S_ISDIR(st.st_mode)) { + throw Error(format("'%1%' is not a directory") % path); + } + + return created; +} + +void createSymlink(const Path& target, const Path& link) { + if (symlink(target.c_str(), link.c_str()) != 0) { + throw SysError(format("creating symlink from '%1%' to '%2%'") % link % + target); + } +} + +void replaceSymlink(const Path& target, const Path& link) { + for (unsigned int n = 0; true; n++) { + Path tmp = canonPath(fmt("%s/.%d_%s", dirOf(link), n, baseNameOf(link))); + + try { + createSymlink(target, tmp); + } catch (SysError& e) { + if (e.errNo == EEXIST) { + continue; + } + throw; + } + + if (rename(tmp.c_str(), link.c_str()) != 0) { + throw SysError(format("renaming '%1%' to '%2%'") % tmp % link); + } + + break; + } +} + +void readFull(int fd, unsigned char* buf, size_t count) { + while (count != 0u) { + checkInterrupt(); + ssize_t res = read(fd, (char*)buf, count); + if (res == -1) { + if (errno == EINTR) { + continue; + } + throw SysError("reading from file"); + } + if (res == 0) { + throw EndOfFile("unexpected end-of-file"); + } + count -= res; + buf += res; + } +} + +void writeFull(int fd, const unsigned char* buf, size_t count, + bool allowInterrupts) { + while (count != 0u) { + if (allowInterrupts) { + checkInterrupt(); + } + ssize_t res = write(fd, (char*)buf, count); + if (res == -1 && errno != EINTR) { + throw SysError("writing to file"); + } + if (res > 0) { + count -= res; + buf += res; + } + } +} + +void writeFull(int fd, const string& s, bool allowInterrupts) { + writeFull(fd, (const unsigned char*)s.data(), s.size(), allowInterrupts); +} + +string drainFD(int fd, bool block) { + StringSink sink; + drainFD(fd, sink, block); + return std::move(*sink.s); +} + +void drainFD(int fd, Sink& sink, bool block) { + int saved; + + Finally finally([&]() { + if (!block) { + if (fcntl(fd, F_SETFL, saved) == -1) { + throw SysError("making file descriptor blocking"); + } + } + }); + + if (!block) { + saved = fcntl(fd, F_GETFL); + if (fcntl(fd, F_SETFL, saved | O_NONBLOCK) == -1) { + throw SysError("making file descriptor non-blocking"); + } + } + + std::vector<unsigned char> buf(64 * 1024); + while (true) { + checkInterrupt(); + ssize_t rd = read(fd, buf.data(), buf.size()); + if (rd == -1) { + if (!block && (errno == EAGAIN || errno == EWOULDBLOCK)) { + break; + } + if (errno != EINTR) { + throw SysError("reading from file"); + } + } else if (rd == 0) { + break; + } else { + sink(buf.data(), rd); + } + } +} + +////////////////////////////////////////////////////////////////////// + +AutoDelete::AutoDelete() : del{false} {} + +AutoDelete::AutoDelete(string p, bool recursive) : path(std::move(p)) { + del = true; + this->recursive = recursive; +} + +AutoDelete::~AutoDelete() { + try { + if (del) { + if (recursive) { + deletePath(path); + } else { + if (remove(path.c_str()) == -1) { + throw SysError(format("cannot unlink '%1%'") % path); + } + } + } + } catch (...) { + ignoreException(); + } +} + +void AutoDelete::cancel() { del = false; } + +void AutoDelete::reset(const Path& p, bool recursive) { + path = p; + this->recursive = recursive; + del = true; +} + +////////////////////////////////////////////////////////////////////// + +AutoCloseFD::AutoCloseFD() : fd{-1} {} + +AutoCloseFD::AutoCloseFD(int fd) : fd{fd} {} + +AutoCloseFD::AutoCloseFD(AutoCloseFD&& that) : fd{that.fd} { that.fd = -1; } + +AutoCloseFD& AutoCloseFD::operator=(AutoCloseFD&& that) { + close(); + fd = that.fd; + that.fd = -1; + return *this; +} + +AutoCloseFD::~AutoCloseFD() { + try { + close(); + } catch (...) { + ignoreException(); + } +} + +int AutoCloseFD::get() const { return fd; } + +void AutoCloseFD::close() { + if (fd != -1) { + if (::close(fd) == -1) { /* This should never happen. */ + throw SysError(format("closing file descriptor %1%") % fd); + } + } +} + +AutoCloseFD::operator bool() const { return fd != -1; } + +int AutoCloseFD::release() { + int oldFD = fd; + fd = -1; + return oldFD; +} + +void Pipe::create() { + int fds[2]; +#if HAVE_PIPE2 + if (pipe2(fds, O_CLOEXEC) != 0) { + throw SysError("creating pipe"); + } +#else + if (pipe(fds) != 0) { + throw SysError("creating pipe"); + } + closeOnExec(fds[0]); + closeOnExec(fds[1]); +#endif + readSide = fds[0]; + writeSide = fds[1]; +} + +////////////////////////////////////////////////////////////////////// + +Pid::Pid() = default; + +Pid::Pid(pid_t pid) : pid(pid) {} + +Pid::~Pid() { + if (pid != -1) { + kill(); + } +} + +void Pid::operator=(pid_t pid) { + if (this->pid != -1 && this->pid != pid) { + kill(); + } + this->pid = pid; + killSignal = SIGKILL; // reset signal to default +} + +Pid::operator pid_t() { return pid; } + +int Pid::kill() { + assert(pid != -1); + + DLOG(INFO) << "killing process " << pid; + + /* Send the requested signal to the child. If it has its own + process group, send the signal to every process in the child + process group (which hopefully includes *all* its children). */ + if (::kill(separatePG ? -pid : pid, killSignal) != 0) { + /* On BSDs, killing a process group will return EPERM if all + processes in the group are zombies (or something like + that). So try to detect and ignore that situation. */ +#if __FreeBSD__ || __APPLE__ + if (errno != EPERM || ::kill(pid, 0) != 0) +#endif + LOG(ERROR) << SysError("killing process %d", pid).msg(); + } + + return wait(); +} + +int Pid::wait() { + assert(pid != -1); + while (true) { + int status; + int res = waitpid(pid, &status, 0); + if (res == pid) { + pid = -1; + return status; + } + if (errno != EINTR) { + throw SysError("cannot get child exit status"); + } + checkInterrupt(); + } +} + +void Pid::setSeparatePG(bool separatePG) { this->separatePG = separatePG; } + +void Pid::setKillSignal(int signal) { this->killSignal = signal; } + +pid_t Pid::release() { + pid_t p = pid; + pid = -1; + return p; +} + +void killUser(uid_t uid) { + DLOG(INFO) << "killing all processes running under UID " << uid; + + assert(uid != 0); /* just to be safe... */ + + /* The system call kill(-1, sig) sends the signal `sig' to all + users to which the current process can send signals. So we + fork a process, switch to uid, and send a mass kill. */ + + ProcessOptions options; + options.allowVfork = false; + + Pid pid = startProcess( + [&]() { + if (setuid(uid) == -1) { + throw SysError("setting uid"); + } + + while (true) { +#ifdef __APPLE__ + /* OSX's kill syscall takes a third parameter that, among + other things, determines if kill(-1, signo) affects the + calling process. In the OSX libc, it's set to true, + which means "follow POSIX", which we don't want here + */ + if (syscall(SYS_kill, -1, SIGKILL, false) == 0) { + break; + } +#else + if (kill(-1, SIGKILL) == 0) { + break; + } +#endif + if (errno == ESRCH) { + break; + } /* no more processes */ + if (errno != EINTR) { + throw SysError(format("cannot kill processes for uid '%1%'") % uid); + } + } + + _exit(0); + }, + options); + + int status = pid.wait(); + if (status != 0) { + throw Error(format("cannot kill processes for uid '%1%': %2%") % uid % + statusToString(status)); + } + + /* !!! We should really do some check to make sure that there are + no processes left running under `uid', but there is no portable + way to do so (I think). The most reliable way may be `ps -eo + uid | grep -q $uid'. */ +} + +////////////////////////////////////////////////////////////////////// + +/* Wrapper around vfork to prevent the child process from clobbering + the caller's stack frame in the parent. */ +static pid_t doFork(bool allowVfork, const std::function<void()>& fun) + __attribute__((noinline)); +static pid_t doFork(bool allowVfork, const std::function<void()>& fun) { +#ifdef __linux__ + pid_t pid = allowVfork ? vfork() : fork(); +#else + pid_t pid = fork(); +#endif + if (pid != 0) { + return pid; + } + fun(); + abort(); +} + +pid_t startProcess(std::function<void()> fun, const ProcessOptions& options) { + auto wrapper = [&]() { + try { +#if __linux__ + if (options.dieWithParent && prctl(PR_SET_PDEATHSIG, SIGKILL) == -1) { + throw SysError("setting death signal"); + } +#endif + restoreAffinity(); + fun(); + } catch (std::exception& e) { + try { + LOG(ERROR) << options.errorPrefix << e.what(); + } catch (...) { + } + } catch (...) { + } + if (options.runExitHandlers) { + exit(1); + } else { + _exit(1); + } + }; + + pid_t pid = doFork(options.allowVfork, wrapper); + if (pid == -1) { + throw SysError("unable to fork"); + } + + return pid; +} + +std::vector<char*> stringsToCharPtrs(const Strings& ss) { + std::vector<char*> res; + for (auto& s : ss) { + res.push_back((char*)s.c_str()); + } + res.push_back(nullptr); + return res; +} + +string runProgram(const Path& program, bool searchPath, const Strings& args, + const std::optional<std::string>& input) { + RunOptions opts(program, args); + opts.searchPath = searchPath; + opts.input = input; + + auto res = runProgram(opts); + + if (!statusOk(res.first)) { + throw ExecError(res.first, fmt("program '%1%' %2%", program, + statusToString(res.first))); + } + + return res.second; +} + +std::pair<int, std::string> runProgram(const RunOptions& options_) { + RunOptions options(options_); + StringSink sink; + options.standardOut = &sink; + + int status = 0; + + try { + runProgram2(options); + } catch (ExecError& e) { + status = e.status; + } + + return {status, std::move(*sink.s)}; +} + +void runProgram2(const RunOptions& options) { + checkInterrupt(); + + assert(!(options.standardIn && options.input)); + + std::unique_ptr<Source> source_; + Source* source = options.standardIn; + + if (options.input) { + source_ = std::make_unique<StringSource>(*options.input); + source = source_.get(); + } + + /* Create a pipe. */ + Pipe out; + Pipe in; + if (options.standardOut != nullptr) { + out.create(); + } + if (source != nullptr) { + in.create(); + } + + ProcessOptions processOptions; + // vfork implies that the environment of the main process and the fork will + // be shared (technically this is undefined, but in practice that's the + // case), so we can't use it if we alter the environment + if (options.environment) { + processOptions.allowVfork = false; + } + + /* Fork. */ + Pid pid = startProcess( + [&]() { + if (options.environment) { + replaceEnv(*options.environment); + } + if ((options.standardOut != nullptr) && + dup2(out.writeSide.get(), STDOUT_FILENO) == -1) { + throw SysError("dupping stdout"); + } + if (options.mergeStderrToStdout) { + if (dup2(STDOUT_FILENO, STDERR_FILENO) == -1) { + throw SysError("cannot dup stdout into stderr"); + } + } + if ((source != nullptr) && + dup2(in.readSide.get(), STDIN_FILENO) == -1) { + throw SysError("dupping stdin"); + } + + if (options.chdir && chdir((*options.chdir).c_str()) == -1) { + throw SysError("chdir failed"); + } + if (options.gid && setgid(*options.gid) == -1) { + throw SysError("setgid failed"); + } + /* Drop all other groups if we're setgid. */ + if (options.gid && setgroups(0, nullptr) == -1) { + throw SysError("setgroups failed"); + } + if (options.uid && setuid(*options.uid) == -1) { + throw SysError("setuid failed"); + } + + Strings args_(options.args); + args_.push_front(options.program); + + restoreSignals(); + + if (options.searchPath) { + execvp(options.program.c_str(), stringsToCharPtrs(args_).data()); + } else { + execv(options.program.c_str(), stringsToCharPtrs(args_).data()); + } + + throw SysError("executing '%1%'", options.program); + }, + processOptions); + + out.writeSide = -1; + + std::thread writerThread; + + std::promise<void> promise; + + Finally doJoin([&]() { + if (writerThread.joinable()) { + writerThread.join(); + } + }); + + if (source != nullptr) { + in.readSide = -1; + writerThread = std::thread([&]() { + try { + std::vector<unsigned char> buf(8 * 1024); + while (true) { + size_t n; + try { + n = source->read(buf.data(), buf.size()); + } catch (EndOfFile&) { + break; + } + writeFull(in.writeSide.get(), buf.data(), n); + } + promise.set_value(); + } catch (...) { + promise.set_exception(std::current_exception()); + } + in.writeSide = -1; + }); + } + + if (options.standardOut != nullptr) { + drainFD(out.readSide.get(), *options.standardOut); + } + + /* Wait for the child to finish. */ + int status = pid.wait(); + + /* Wait for the writer thread to finish. */ + if (source != nullptr) { + promise.get_future().get(); + } + + if (status != 0) { + throw ExecError(status, fmt("program '%1%' %2%", options.program, + statusToString(status))); + } +} + +void closeMostFDs(const set<int>& exceptions) { +#if __linux__ + try { + for (auto& s : readDirectory("/proc/self/fd")) { + auto fd = std::stoi(s.name); + if (exceptions.count(fd) == 0u) { + DLOG(INFO) << "closing leaked FD " << fd; + close(fd); + } + } + return; + } catch (SysError&) { + } +#endif + + int maxFD = 0; + maxFD = sysconf(_SC_OPEN_MAX); + for (int fd = 0; fd < maxFD; ++fd) { + if (exceptions.count(fd) == 0u) { + close(fd); + } /* ignore result */ + } +} + +void closeOnExec(int fd) { + int prev; + if ((prev = fcntl(fd, F_GETFD, 0)) == -1 || + fcntl(fd, F_SETFD, prev | FD_CLOEXEC) == -1) { + throw SysError("setting close-on-exec flag"); + } +} + +////////////////////////////////////////////////////////////////////// + +bool _isInterrupted = false; + +static thread_local bool interruptThrown = false; +thread_local std::function<bool()> interruptCheck; + +void setInterruptThrown() { interruptThrown = true; } + +void _interrupted() { + /* Block user interrupts while an exception is being handled. + Throwing an exception while another exception is being handled + kills the program! */ + if (!interruptThrown && (std::uncaught_exceptions() == 0)) { + interruptThrown = true; + throw Interrupted("interrupted by the user"); + } +} + +////////////////////////////////////////////////////////////////////// + +template <class C> +C tokenizeString(const string& s, const string& separators) { + C result; + string::size_type pos = s.find_first_not_of(separators, 0); + while (pos != string::npos) { + string::size_type end = s.find_first_of(separators, pos + 1); + if (end == string::npos) { + end = s.size(); + } + string token(s, pos, end - pos); + result.insert(result.end(), token); + pos = s.find_first_not_of(separators, end); + } + return result; +} + +template Strings tokenizeString(const string& s, const string& separators); +template StringSet tokenizeString(const string& s, const string& separators); +template vector<string> tokenizeString(const string& s, + const string& separators); + +string concatStringsSep(const string& sep, const Strings& ss) { + string s; + for (auto& i : ss) { + if (!s.empty()) { + s += sep; + } + s += i; + } + return s; +} + +string concatStringsSep(const string& sep, const StringSet& ss) { + string s; + for (auto& i : ss) { + if (!s.empty()) { + s += sep; + } + s += i; + } + return s; +} + +string chomp(const string& s) { + size_t i = s.find_last_not_of(" \n\r\t"); + return i == string::npos ? "" : string(s, 0, i + 1); +} + +string trim(const string& s, const string& whitespace) { + auto i = s.find_first_not_of(whitespace); + if (i == string::npos) { + return ""; + } + auto j = s.find_last_not_of(whitespace); + return string(s, i, j == string::npos ? j : j - i + 1); +} + +string replaceStrings(const std::string& s, const std::string& from, + const std::string& to) { + if (from.empty()) { + return s; + } + string res = s; + size_t pos = 0; + while ((pos = res.find(from, pos)) != std::string::npos) { + res.replace(pos, from.size(), to); + pos += to.size(); + } + return res; +} + +string statusToString(int status) { + if (!WIFEXITED(status) || WEXITSTATUS(status) != 0) { + if (WIFEXITED(status)) { + return (format("failed with exit code %1%") % WEXITSTATUS(status)).str(); + } + if (WIFSIGNALED(status)) { + int sig = WTERMSIG(status); +#if HAVE_STRSIGNAL + const char* description = strsignal(sig); + return (format("failed due to signal %1% (%2%)") % sig % description) + .str(); +#else + return (format("failed due to signal %1%") % sig).str(); +#endif + } else { + return "died abnormally"; + } + } else { + return "succeeded"; + } +} + +bool statusOk(int status) { + return WIFEXITED(status) && WEXITSTATUS(status) == 0; +} + +bool hasPrefix(const string& s, const string& prefix) { + return s.compare(0, prefix.size(), prefix) == 0; +} + +bool hasSuffix(const string& s, const string& suffix) { + return s.size() >= suffix.size() && + string(s, s.size() - suffix.size()) == suffix; +} + +std::string toLower(const std::string& s) { + std::string r(s); + for (auto& c : r) { + c = std::tolower(c); + } + return r; +} + +std::string shellEscape(const std::string& s) { + std::string r = "'"; + for (auto& i : s) { + if (i == '\'') { + r += "'\\''"; + } else { + r += i; + } + } + r += '\''; + return r; +} + +void ignoreException() { + try { + throw; + } catch (std::exception& e) { + LOG(ERROR) << "error (ignored): " << e.what(); + } +} + +std::string filterANSIEscapes(const std::string& s, bool filterAll, + unsigned int width) { + std::string t; + std::string e; + size_t w = 0; + auto i = s.begin(); + + while (w < (size_t)width && i != s.end()) { + if (*i == '\e') { + std::string e; + e += *i++; + char last = 0; + + if (i != s.end() && *i == '[') { + e += *i++; + // eat parameter bytes + while (i != s.end() && *i >= 0x30 && *i <= 0x3f) { + e += *i++; + } + // eat intermediate bytes + while (i != s.end() && *i >= 0x20 && *i <= 0x2f) { + e += *i++; + } + // eat final byte + if (i != s.end() && *i >= 0x40 && *i <= 0x7e) { + e += last = *i++; + } + } else { + if (i != s.end() && *i >= 0x40 && *i <= 0x5f) { + e += *i++; + } + } + + if (!filterAll && last == 'm') { + t += e; + } + } + + else if (*i == '\t') { + i++; + t += ' '; + w++; + while (w < (size_t)width && ((w % 8) != 0u)) { + t += ' '; + w++; + } + } + + else if (*i == '\r') { + // do nothing for now + i++; + + } else { + t += *i++; + w++; + } + } + + return t; +} + +static char base64Chars[] = + "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; + +string base64Encode(const string& s) { + string res; + int data = 0; + int nbits = 0; + + for (char c : s) { + data = data << 8 | (unsigned char)c; + nbits += 8; + while (nbits >= 6) { + nbits -= 6; + res.push_back(base64Chars[data >> nbits & 0x3f]); + } + } + + if (nbits != 0) { + res.push_back(base64Chars[data << (6 - nbits) & 0x3f]); + } + while ((res.size() % 4) != 0u) { + res.push_back('='); + } + + return res; +} + +string base64Decode(const string& s) { + bool init = false; + char decode[256]; + if (!init) { + // FIXME: not thread-safe. + memset(decode, -1, sizeof(decode)); + for (int i = 0; i < 64; i++) { + decode[(int)base64Chars[i]] = i; + } + init = true; + } + + string res; + unsigned int d = 0; + unsigned int bits = 0; + + for (char c : s) { + if (c == '=') { + break; + } + if (c == '\n') { + continue; + } + + char digit = decode[(unsigned char)c]; + if (digit == -1) { + throw Error("invalid character in Base64 string"); + } + + bits += 6; + d = d << 6 | digit; + if (bits >= 8) { + res.push_back(d >> (bits - 8) & 0xff); + bits -= 8; + } + } + + return res; +} + +void callFailure(const std::function<void(std::exception_ptr exc)>& failure, + const std::exception_ptr& exc) { + try { + failure(exc); + } catch (std::exception& e) { + LOG(ERROR) << "uncaught exception: " << e.what(); + abort(); + } +} + +static Sync<std::pair<unsigned short, unsigned short>> windowSize{{0, 0}}; + +static void updateWindowSize() { + struct winsize ws; + if (ioctl(2, TIOCGWINSZ, &ws) == 0) { + auto windowSize_(windowSize.lock()); + windowSize_->first = ws.ws_row; + windowSize_->second = ws.ws_col; + } +} + +std::pair<unsigned short, unsigned short> getWindowSize() { + return *windowSize.lock(); +} + +static Sync<std::list<std::function<void()>>> _interruptCallbacks; + +static void signalHandlerThread(sigset_t set) { + while (true) { + int signal = 0; + sigwait(&set, &signal); + + if (signal == SIGINT || signal == SIGTERM || signal == SIGHUP) { + triggerInterrupt(); + + } else if (signal == SIGWINCH) { + updateWindowSize(); + } + } +} + +void triggerInterrupt() { + _isInterrupted = true; + + { + auto interruptCallbacks(_interruptCallbacks.lock()); + for (auto& callback : *interruptCallbacks) { + try { + callback(); + } catch (...) { + ignoreException(); + } + } + } +} + +static sigset_t savedSignalMask; + +void startSignalHandlerThread() { + updateWindowSize(); + + if (sigprocmask(SIG_BLOCK, nullptr, &savedSignalMask) != 0) { + throw SysError("quering signal mask"); + } + + sigset_t set; + sigemptyset(&set); + sigaddset(&set, SIGINT); + sigaddset(&set, SIGTERM); + sigaddset(&set, SIGHUP); + sigaddset(&set, SIGPIPE); + sigaddset(&set, SIGWINCH); + if (pthread_sigmask(SIG_BLOCK, &set, nullptr) != 0) { + throw SysError("blocking signals"); + } + + std::thread(signalHandlerThread, set).detach(); +} + +void restoreSignals() { + if (sigprocmask(SIG_SETMASK, &savedSignalMask, nullptr) != 0) { + throw SysError("restoring signals"); + } +} + +/* RAII helper to automatically deregister a callback. */ +struct InterruptCallbackImpl : InterruptCallback { + std::list<std::function<void()>>::iterator it; + ~InterruptCallbackImpl() override { _interruptCallbacks.lock()->erase(it); } +}; + +std::unique_ptr<InterruptCallback> createInterruptCallback( + const std::function<void()>& callback) { + auto interruptCallbacks(_interruptCallbacks.lock()); + interruptCallbacks->push_back(callback); + + auto res = std::make_unique<InterruptCallbackImpl>(); + res->it = interruptCallbacks->end(); + res->it--; + + return std::unique_ptr<InterruptCallback>(res.release()); +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/util.hh b/third_party/nix/src/libutil/util.hh new file mode 100644 index 0000000000..5ce12f2ede --- /dev/null +++ b/third_party/nix/src/libutil/util.hh @@ -0,0 +1,493 @@ +#pragma once + +#include <cstdio> +#include <functional> +#include <future> +#include <limits> +#include <map> +#include <optional> +#include <sstream> + +#include <dirent.h> +#include <signal.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include "types.hh" + +#ifndef HAVE_STRUCT_DIRENT_D_TYPE +#define DT_UNKNOWN 0 +#define DT_REG 1 +#define DT_LNK 2 +#define DT_DIR 3 +#endif + +namespace nix { + +struct Sink; +struct Source; + +/* The system for which Nix is compiled. */ +extern const std::string nativeSystem; + +/* Return an environment variable. */ +string getEnv(const string& key, const string& def = ""); + +/* Get the entire environment. */ +std::map<std::string, std::string> getEnv(); + +/* Clear the environment. */ +void clearEnv(); + +/* Return an absolutized path, resolving paths relative to the + specified directory, or the current directory otherwise. The path + is also canonicalised. */ +Path absPath(Path path, Path dir = ""); + +/* Canonicalise a path by removing all `.' or `..' components and + double or trailing slashes. Optionally resolves all symlink + components such that each component of the resulting path is *not* + a symbolic link. */ +Path canonPath(const Path& path, bool resolveSymlinks = false); + +/* Return the directory part of the given canonical path, i.e., + everything before the final `/'. If the path is the root or an + immediate child thereof (e.g., `/foo'), this means an empty string + is returned. */ +Path dirOf(const Path& path); + +/* Return the base name of the given canonical path, i.e., everything + following the final `/'. */ +string baseNameOf(const Path& path); + +/* Check whether 'path' is a descendant of 'dir'. */ +bool isInDir(const Path& path, const Path& dir); + +/* Check whether 'path' is equal to 'dir' or a descendant of 'dir'. */ +bool isDirOrInDir(const Path& path, const Path& dir); + +/* Get status of `path'. */ +struct stat lstat(const Path& path); + +/* Return true iff the given path exists. */ +bool pathExists(const Path& path); + +/* Read the contents (target) of a symbolic link. The result is not + in any way canonicalised. */ +Path readLink(const Path& path); + +bool isLink(const Path& path); + +/* Read the contents of a directory. The entries `.' and `..' are + removed. */ +struct DirEntry { + string name; + ino_t ino; + unsigned char type; // one of DT_* + DirEntry(const string& name, ino_t ino, unsigned char type) + : name(name), ino(ino), type(type) {} +}; + +typedef vector<DirEntry> DirEntries; + +DirEntries readDirectory(const Path& path); + +unsigned char getFileType(const Path& path); + +/* Read the contents of a file into a string. */ +string readFile(int fd); +string readFile(const Path& path, bool drain = false); +void readFile(const Path& path, Sink& sink); + +/* Write a string to a file. */ +void writeFile(const Path& path, const string& s, mode_t mode = 0666); + +void writeFile(const Path& path, Source& source, mode_t mode = 0666); + +/* Read a line from a file descriptor. */ +string readLine(int fd); + +/* Write a line to a file descriptor. */ +void writeLine(int fd, string s); + +/* Delete a path; i.e., in the case of a directory, it is deleted + recursively. It's not an error if the path does not exist. The + second variant returns the number of bytes and blocks freed. */ +void deletePath(const Path& path); + +void deletePath(const Path& path, unsigned long long& bytesFreed); + +/* Create a temporary directory. */ +Path createTempDir(const Path& tmpRoot = "", const Path& prefix = "nix", + bool includePid = true, bool useGlobalCounter = true, + mode_t mode = 0755); + +std::string getUserName(); + +/* Return $HOME or the user's home directory from /etc/passwd. */ +Path getHome(); + +/* Return $XDG_CACHE_HOME or $HOME/.cache. */ +Path getCacheDir(); + +/* Return $XDG_CONFIG_HOME or $HOME/.config. */ +Path getConfigDir(); + +/* Return the directories to search for user configuration files */ +std::vector<Path> getConfigDirs(); + +/* Return $XDG_DATA_HOME or $HOME/.local/share. */ +Path getDataDir(); + +/* Create a directory and all its parents, if necessary. Returns the + list of created directories, in order of creation. */ +Paths createDirs(const Path& path); + +/* Create a symlink. */ +void createSymlink(const Path& target, const Path& link); + +/* Atomically create or replace a symlink. */ +void replaceSymlink(const Path& target, const Path& link); + +/* Wrappers arount read()/write() that read/write exactly the + requested number of bytes. */ +void readFull(int fd, unsigned char* buf, size_t count); +void writeFull(int fd, const unsigned char* buf, size_t count, + bool allowInterrupts = true); +void writeFull(int fd, const string& s, bool allowInterrupts = true); + +MakeError(EndOfFile, Error) + + /* Read a file descriptor until EOF occurs. */ + string drainFD(int fd, bool block = true); + +void drainFD(int fd, Sink& sink, bool block = true); + +/* Automatic cleanup of resources. */ + +class AutoDelete { + Path path; + bool del; + bool recursive; + + public: + AutoDelete(); + AutoDelete(Path p, bool recursive = true); + ~AutoDelete(); + void cancel(); + void reset(const Path& p, bool recursive = true); + operator Path() const { return path; } +}; + +class AutoCloseFD { + int fd; + void close(); + + public: + AutoCloseFD(); + AutoCloseFD(int fd); + AutoCloseFD(const AutoCloseFD& fd) = delete; + AutoCloseFD(AutoCloseFD&& that); + ~AutoCloseFD(); + AutoCloseFD& operator=(const AutoCloseFD& fd) = delete; + AutoCloseFD& operator=(AutoCloseFD&& that); + int get() const; + explicit operator bool() const; + int release(); +}; + +class Pipe { + public: + AutoCloseFD readSide, writeSide; + void create(); +}; + +struct DIRDeleter { + void operator()(DIR* dir) const { closedir(dir); } +}; + +typedef std::unique_ptr<DIR, DIRDeleter> AutoCloseDir; + +class Pid { + pid_t pid = -1; + bool separatePG = false; + int killSignal = SIGKILL; + + public: + Pid(); + Pid(pid_t pid); + ~Pid(); + void operator=(pid_t pid); + operator pid_t(); + int kill(); + int wait(); + + void setSeparatePG(bool separatePG); + void setKillSignal(int signal); + pid_t release(); +}; + +/* Kill all processes running under the specified uid by sending them + a SIGKILL. */ +void killUser(uid_t uid); + +/* Fork a process that runs the given function, and return the child + pid to the caller. */ +struct ProcessOptions { + string errorPrefix = "error: "; + bool dieWithParent = true; + bool runExitHandlers = false; + bool allowVfork = true; +}; + +pid_t startProcess(std::function<void()> fun, + const ProcessOptions& options = ProcessOptions()); + +/* Run a program and return its stdout in a string (i.e., like the + shell backtick operator). */ +string runProgram(const Path& program, bool searchPath = false, + const Strings& args = Strings(), + const std::optional<std::string>& input = {}); + +struct RunOptions { + std::optional<uid_t> uid; + std::optional<uid_t> gid; + std::optional<Path> chdir; + std::optional<std::map<std::string, std::string>> environment; + Path program; + bool searchPath = true; + Strings args; + std::optional<std::string> input; + Source* standardIn = nullptr; + Sink* standardOut = nullptr; + bool mergeStderrToStdout = false; + bool _killStderr = false; + + RunOptions(const Path& program, const Strings& args) + : program(program), args(args){}; + + RunOptions& killStderr(bool v) { + _killStderr = true; + return *this; + } +}; + +std::pair<int, std::string> runProgram(const RunOptions& options); + +void runProgram2(const RunOptions& options); + +class ExecError : public Error { + public: + int status; + + template <typename... Args> + ExecError(int status, Args... args) : Error(args...), status(status) {} +}; + +/* Convert a list of strings to a null-terminated vector of char + *'s. The result must not be accessed beyond the lifetime of the + list of strings. */ +std::vector<char*> stringsToCharPtrs(const Strings& ss); + +/* Close all file descriptors except those listed in the given set. + Good practice in child processes. */ +void closeMostFDs(const set<int>& exceptions); + +/* Set the close-on-exec flag for the given file descriptor. */ +void closeOnExec(int fd); + +/* User interruption. */ + +extern bool _isInterrupted; + +extern thread_local std::function<bool()> interruptCheck; + +void setInterruptThrown(); + +void _interrupted(); + +void inline checkInterrupt() { + if (_isInterrupted || (interruptCheck && interruptCheck())) _interrupted(); +} + +MakeError(Interrupted, BaseError) + + MakeError(FormatError, Error) + + /* String tokenizer. */ + template <class C> + C tokenizeString(const string& s, const string& separators = " \t\n\r"); + +/* Concatenate the given strings with a separator between the + elements. */ +string concatStringsSep(const string& sep, const Strings& ss); +string concatStringsSep(const string& sep, const StringSet& ss); + +/* Remove trailing whitespace from a string. */ +string chomp(const string& s); + +/* Remove whitespace from the start and end of a string. */ +string trim(const string& s, const string& whitespace = " \n\r\t"); + +/* Replace all occurrences of a string inside another string. */ +string replaceStrings(const std::string& s, const std::string& from, + const std::string& to); + +/* Convert the exit status of a child as returned by wait() into an + error string. */ +string statusToString(int status); + +bool statusOk(int status); + +/* Parse a string into an integer. */ +template <class N> +bool string2Int(const string& s, N& n) { + if (string(s, 0, 1) == "-" && !std::numeric_limits<N>::is_signed) + return false; + std::istringstream str(s); + str >> n; + return str && str.get() == EOF; +} + +/* Parse a string into a float. */ +template <class N> +bool string2Float(const string& s, N& n) { + std::istringstream str(s); + str >> n; + return str && str.get() == EOF; +} + +/* Return true iff `s' starts with `prefix'. */ +bool hasPrefix(const string& s, const string& prefix); + +/* Return true iff `s' ends in `suffix'. */ +bool hasSuffix(const string& s, const string& suffix); + +/* Convert a string to lower case. */ +std::string toLower(const std::string& s); + +/* Escape a string as a shell word. */ +std::string shellEscape(const std::string& s); + +/* Exception handling in destructors: print an error message, then + ignore the exception. */ +void ignoreException(); + +/* Some ANSI escape sequences. */ +#define ANSI_NORMAL "\e[0m" +#define ANSI_BOLD "\e[1m" +#define ANSI_FAINT "\e[2m" +#define ANSI_RED "\e[31;1m" +#define ANSI_GREEN "\e[32;1m" +#define ANSI_BLUE "\e[34;1m" + +/* Truncate a string to 'width' printable characters. If 'filterAll' + is true, all ANSI escape sequences are filtered out. Otherwise, + some escape sequences (such as colour setting) are copied but not + included in the character count. Also, tabs are expanded to + spaces. */ +std::string filterANSIEscapes( + const std::string& s, bool filterAll = false, + unsigned int width = std::numeric_limits<unsigned int>::max()); + +/* Base64 encoding/decoding. */ +string base64Encode(const string& s); +string base64Decode(const string& s); + +/* Get a value for the specified key from an associate container, or a + default value if the key doesn't exist. */ +template <class T> +string get(const T& map, const string& key, const string& def = "") { + auto i = map.find(key); + return i == map.end() ? def : i->second; +} + +/* A callback is a wrapper around a lambda that accepts a valid of + type T or an exception. (We abuse std::future<T> to pass the value or + exception.) */ +template <typename T> +class Callback { + std::function<void(std::future<T>)> fun; + std::atomic_flag done = ATOMIC_FLAG_INIT; + + public: + Callback(std::function<void(std::future<T>)> fun) : fun(fun) {} + + Callback(Callback&& callback) : fun(std::move(callback.fun)) { + auto prev = callback.done.test_and_set(); + if (prev) { + done.test_and_set(); + } + } + + void operator()(T&& t) noexcept { + auto prev = done.test_and_set(); + assert(!prev); + std::promise<T> promise; + promise.set_value(std::move(t)); + fun(promise.get_future()); + } + + void rethrow( + const std::exception_ptr& exc = std::current_exception()) noexcept { + auto prev = done.test_and_set(); + assert(!prev); + std::promise<T> promise; + promise.set_exception(exc); + fun(promise.get_future()); + } +}; + +/* Start a thread that handles various signals. Also block those signals + on the current thread (and thus any threads created by it). */ +void startSignalHandlerThread(); + +/* Restore default signal handling. */ +void restoreSignals(); + +struct InterruptCallback { + virtual ~InterruptCallback(){}; +}; + +/* Register a function that gets called on SIGINT (in a non-signal + context). */ +std::unique_ptr<InterruptCallback> createInterruptCallback( + const std::function<void()>& callback); + +void triggerInterrupt(); + +/* A RAII class that causes the current thread to receive SIGUSR1 when + the signal handler thread receives SIGINT. That is, this allows + SIGINT to be multiplexed to multiple threads. */ +struct ReceiveInterrupts { + pthread_t target; + std::unique_ptr<InterruptCallback> callback; + + ReceiveInterrupts() + : target(pthread_self()), callback(createInterruptCallback([&]() { + pthread_kill(target, SIGUSR1); + })) {} +}; + +/* A RAII helper that increments a counter on construction and + decrements it on destruction. */ +template <typename T> +struct MaintainCount { + T& counter; + long delta; + MaintainCount(T& counter, long delta = 1) : counter(counter), delta(delta) { + counter += delta; + } + ~MaintainCount() { counter -= delta; } +}; + +/* Return the number of rows and columns of the terminal. */ +std::pair<unsigned short, unsigned short> getWindowSize(); + +/* Used in various places. */ +typedef std::function<bool(const Path& path)> PathFilter; + +extern PathFilter defaultPathFilter; + +} // namespace nix diff --git a/third_party/nix/src/libutil/xml-writer.cc b/third_party/nix/src/libutil/xml-writer.cc new file mode 100644 index 0000000000..11cd632399 --- /dev/null +++ b/third_party/nix/src/libutil/xml-writer.cc @@ -0,0 +1,92 @@ +#include "xml-writer.hh" + +#include <cassert> + +namespace nix { + +XMLWriter::XMLWriter(bool indent, std::ostream& output) + : output(output), indent(indent) { + output << "<?xml version='1.0' encoding='utf-8'?>" << std::endl; + closed = false; +} + +XMLWriter::~XMLWriter() { close(); } + +void XMLWriter::close() { + if (closed) { + return; + } + while (!pendingElems.empty()) { + closeElement(); + } + closed = true; +} + +void XMLWriter::indent_(size_t depth) { + if (!indent) { + return; + } + output << string(depth * 2, ' '); +} + +void XMLWriter::openElement(const string& name, const XMLAttrs& attrs) { + assert(!closed); + indent_(pendingElems.size()); + output << "<" << name; + writeAttrs(attrs); + output << ">"; + if (indent) { + output << std::endl; + } + pendingElems.push_back(name); +} + +void XMLWriter::closeElement() { + assert(!pendingElems.empty()); + indent_(pendingElems.size() - 1); + output << "</" << pendingElems.back() << ">"; + if (indent) { + output << std::endl; + } + pendingElems.pop_back(); + if (pendingElems.empty()) { + closed = true; + } +} + +void XMLWriter::writeEmptyElement(const string& name, const XMLAttrs& attrs) { + assert(!closed); + indent_(pendingElems.size()); + output << "<" << name; + writeAttrs(attrs); + output << " />"; + if (indent) { + output << std::endl; + } +} + +void XMLWriter::writeAttrs(const XMLAttrs& attrs) { + for (auto& i : attrs) { + output << " " << i.first << "=\""; + for (char c : i.second) { + if (c == '"') { + output << """; + } else if (c == '<') { + output << "<"; + } else if (c == '>') { + output << ">"; + } else if (c == '&') { + output << "&"; + /* Escape newlines to prevent attribute normalisation (see + XML spec, section 3.3.3. */ + } else if (c == '\n') { + output << "
"; + } else { + output << c; + } + } + output << "\""; + } +} + +} // namespace nix diff --git a/third_party/nix/src/libutil/xml-writer.hh b/third_party/nix/src/libutil/xml-writer.hh new file mode 100644 index 0000000000..3a2d9a66d8 --- /dev/null +++ b/third_party/nix/src/libutil/xml-writer.hh @@ -0,0 +1,56 @@ +#pragma once + +#include <iostream> +#include <list> +#include <map> +#include <string> + +namespace nix { + +using std::list; +using std::map; +using std::string; + +typedef map<string, string> XMLAttrs; + +class XMLWriter { + private: + std::ostream& output; + + bool indent; + bool closed; + + list<string> pendingElems; + + public: + XMLWriter(bool indent, std::ostream& output); + ~XMLWriter(); + + void close(); + + void openElement(const string& name, const XMLAttrs& attrs = XMLAttrs()); + void closeElement(); + + void writeEmptyElement(const string& name, + const XMLAttrs& attrs = XMLAttrs()); + + private: + void writeAttrs(const XMLAttrs& attrs); + + void indent_(size_t depth); +}; + +class XMLOpenElement { + private: + XMLWriter& writer; + + public: + XMLOpenElement(XMLWriter& writer, const string& name, + const XMLAttrs& attrs = XMLAttrs()) + : writer(writer) { + writer.openElement(name, attrs); + } + ~XMLOpenElement() { writer.closeElement(); } +}; + +} // namespace nix diff --git a/third_party/nix/src/meson.build b/third_party/nix/src/meson.build new file mode 100644 index 0000000000..59916a944a --- /dev/null +++ b/third_party/nix/src/meson.build @@ -0,0 +1,47 @@ +# nix src build file +#============================================================================ + +src_dirs = [ + 'libutil', + 'libstore', + 'libmain', + 'libexpr', + 'nix', +] + +foreach dir : src_dirs + subdir(dir) +endforeach + + + +libstore_config = pkg.generate( + libstore_lib, + libraries : [ + libutil_lib], + version : meson.project_version(), + name : 'Nix', + subdirs : ['nix/'], + filebase : 'nix-store', + extra_cflags : '-std=c++17', + description : 'Nix Package Manager.') + +libmain_config = pkg.generate( + libmain_lib, + version : meson.project_version(), + name : 'Nix', + subdirs : ['nix/'], + filebase : 'nix-main', + extra_cflags : '-std=c++17', + description : 'Nix Package Manager.') + +libexpr_config = pkg.generate( + libexpr_lib, + libraries : [ + libstore_lib], + version : meson.project_version(), + name : 'Nix', + subdirs : ['nix/'], + filebase : 'nix-expr', + extra_cflags : '-std=c++17', + description : 'Nix Package Manager.') diff --git a/third_party/nix/src/nix-build/nix-build.cc b/third_party/nix/src/nix-build/nix-build.cc new file mode 100644 index 0000000000..66947051ba --- /dev/null +++ b/third_party/nix/src/nix-build/nix-build.cc @@ -0,0 +1,572 @@ +#include <cstring> +#include <fstream> +#include <iostream> +#include <regex> +#include <sstream> +#include <vector> + +#include <glog/logging.h> + +#include "affinity.hh" +#include "attr-path.hh" +#include "common-eval-args.hh" +#include "derivations.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "get-drvs.hh" +#include "globals.hh" +#include "legacy.hh" +#include "shared.hh" +#include "store-api.hh" +#include "util.hh" + +using namespace nix; +using namespace std::string_literals; + +/* Recreate the effect of the perl shellwords function, breaking up a + * string into arguments like a shell word, including escapes + */ +std::vector<string> shellwords(const string& s) { + std::regex whitespace("^(\\s+).*"); + auto begin = s.cbegin(); + std::vector<string> res; + std::string cur; + enum state { sBegin, sQuote }; + state st = sBegin; + auto it = begin; + for (; it != s.cend(); ++it) { + if (st == sBegin) { + std::smatch match; + if (regex_search(it, s.cend(), match, whitespace)) { + cur.append(begin, it); + res.push_back(cur); + cur.clear(); + it = match[1].second; + begin = it; + } + } + switch (*it) { + case '"': + cur.append(begin, it); + begin = it + 1; + st = st == sBegin ? sQuote : sBegin; + break; + case '\\': + /* perl shellwords mostly just treats the next char as part of the + * string with no special processing */ + cur.append(begin, it); + begin = ++it; + break; + } + } + cur.append(begin, it); + if (!cur.empty()) { + res.push_back(cur); + } + return res; +} + +static void _main(int argc, char** argv) { + auto dryRun = false; + auto runEnv = std::regex_search(argv[0], std::regex("nix-shell$")); + auto pure = false; + auto fromArgs = false; + auto packages = false; + // Same condition as bash uses for interactive shells + auto interactive = + (isatty(STDIN_FILENO) != 0) && (isatty(STDERR_FILENO) != 0); + Strings attrPaths; + Strings left; + RepairFlag repair = NoRepair; + Path gcRoot; + BuildMode buildMode = bmNormal; + bool readStdin = false; + + std::string envCommand; // interactive shell + Strings envExclude; + + auto myName = runEnv ? "nix-shell" : "nix-build"; + + auto inShebang = false; + std::string script; + std::vector<string> savedArgs; + + AutoDelete tmpDir(createTempDir("", myName)); + + std::string outLink = "./result"; + + // List of environment variables kept for --pure + std::set<string> keepVars{ + "HOME", "USER", "LOGNAME", "DISPLAY", "PATH", "TERM", + "IN_NIX_SHELL", "TZ", "PAGER", "NIX_BUILD_SHELL", "SHLVL"}; + + Strings args; + for (int i = 1; i < argc; ++i) { + args.push_back(argv[i]); + } + + // Heuristic to see if we're invoked as a shebang script, namely, + // if we have at least one argument, it's the name of an + // executable file, and it starts with "#!". + if (runEnv && argc > 1 && + !std::regex_search(argv[1], std::regex("nix-shell"))) { + script = argv[1]; + try { + auto lines = tokenizeString<Strings>(readFile(script), "\n"); + if (std::regex_search(lines.front(), std::regex("^#!"))) { + lines.pop_front(); + inShebang = true; + for (int i = 2; i < argc; ++i) { + savedArgs.emplace_back(argv[i]); + } + args.clear(); + for (auto line : lines) { + line = chomp(line); + std::smatch match; + if (std::regex_match(line, match, + std::regex("^#!\\s*nix-shell (.*)$"))) { + for (const auto& word : shellwords(match[1].str())) { + args.push_back(word); + } + } + } + } + } catch (SysError&) { + } + } + + struct MyArgs : LegacyArgs, MixEvalArgs { + using LegacyArgs::LegacyArgs; + }; + + MyArgs myArgs( + myName, [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + deletePath(tmpDir); + showManPage(myName); + } + + else if (*arg == "--version") { + printVersion(myName); + + } else if (*arg == "--add-drv-link" || *arg == "--indirect") { + ; // obsolete + + } else if (*arg == "--no-out-link" || *arg == "--no-link") { + outLink = (Path)tmpDir + "/result"; + + } else if (*arg == "--attr" || *arg == "-A") { + attrPaths.push_back(getArg(*arg, arg, end)); + + } else if (*arg == "--drv-link") { + getArg(*arg, arg, end); // obsolete + + } else if (*arg == "--out-link" || *arg == "-o") { + outLink = getArg(*arg, arg, end); + + } else if (*arg == "--add-root") { + gcRoot = getArg(*arg, arg, end); + + } else if (*arg == "--dry-run") { + dryRun = true; + + } else if (*arg == "--repair") { + repair = Repair; + buildMode = bmRepair; + } + + else if (*arg == "--run-env") { // obsolete + runEnv = true; + + } else if (*arg == "--command" || *arg == "--run") { + if (*arg == "--run") { + interactive = false; + } + envCommand = getArg(*arg, arg, end) + "\nexit"; + } + + else if (*arg == "--check") { + buildMode = bmCheck; + + } else if (*arg == "--exclude") { + envExclude.push_back(getArg(*arg, arg, end)); + + } else if (*arg == "--expr" || *arg == "-E") { + fromArgs = true; + + } else if (*arg == "--pure") { + pure = true; + } else if (*arg == "--impure") { + pure = false; + + } else if (*arg == "--packages" || *arg == "-p") { + packages = true; + + } else if (inShebang && *arg == "-i") { + auto interpreter = getArg(*arg, arg, end); + interactive = false; + auto execArgs = ""; + + // Überhack to support Perl. Perl examines the shebang and + // executes it unless it contains the string "perl" or "indir", + // or (undocumented) argv[0] does not contain "perl". Exploit + // the latter by doing "exec -a". + if (std::regex_search(interpreter, std::regex("perl"))) { + execArgs = "-a PERL"; + } + + std::ostringstream joined; + for (const auto& i : savedArgs) { + joined << shellEscape(i) << ' '; + } + + if (std::regex_search(interpreter, std::regex("ruby"))) { + // Hack for Ruby. Ruby also examines the shebang. It tries to + // read the shebang to understand which packages to read from. Since + // this is handled via nix-shell -p, we wrap our ruby script + // execution in ruby -e 'load' which ignores the shebangs. + envCommand = (format("exec %1% %2% -e 'load(\"%3%\")' -- %4%") % + execArgs % interpreter % script % joined.str()) + .str(); + } else { + envCommand = (format("exec %1% %2% %3% %4%") % execArgs % + interpreter % script % joined.str()) + .str(); + } + } + + else if (*arg == "--keep") { + keepVars.insert(getArg(*arg, arg, end)); + + } else if (*arg == "-") { + readStdin = true; + + } else if (*arg != "" && arg->at(0) == '-') { + return false; + + } else { + left.push_back(*arg); + } + + return true; + }); + + myArgs.parseCmdline(args); + + initPlugins(); + + if (packages && fromArgs) { + throw UsageError("'-p' and '-E' are mutually exclusive"); + } + + auto store = openStore(); + + auto state = std::make_unique<EvalState>(myArgs.searchPath, store); + state->repair = repair; + + Bindings& autoArgs = *myArgs.getAutoArgs(*state); + + if (packages) { + std::ostringstream joined; + joined << "with import <nixpkgs> { }; (pkgs.runCommandCC or " + "pkgs.runCommand) \"shell\" { buildInputs = [ "; + for (const auto& i : left) { + joined << '(' << i << ") "; + } + joined << "]; } \"\""; + fromArgs = true; + left = {joined.str()}; + } else if (!fromArgs) { + if (left.empty() && runEnv && pathExists("shell.nix")) { + left = {"shell.nix"}; + } + if (left.empty()) { + left = {"default.nix"}; + } + } + + if (runEnv) { + setenv("IN_NIX_SHELL", pure ? "pure" : "impure", 1); + } + + DrvInfos drvs; + + /* Parse the expressions. */ + std::vector<Expr*> exprs; + + if (readStdin) { + exprs = {state->parseStdin()}; + } else { + for (const auto& i : left) { + if (fromArgs) { + exprs.push_back(state->parseExprFromString(i, absPath("."))); + } else { + auto absolute = i; + try { + absolute = canonPath(absPath(i), true); + } catch (Error& e) { + }; + if (store->isStorePath(absolute) && + std::regex_match(absolute, std::regex(".*\\.drv(!.*)?"))) { + drvs.push_back(DrvInfo(*state, store, absolute)); + } else { + /* If we're in a #! script, interpret filenames + relative to the script. */ + exprs.push_back( + state->parseExprFromFile(resolveExprPath(state->checkSourcePath( + lookupFileArg(*state, inShebang && !packages + ? absPath(i, absPath(dirOf(script))) + : i))))); + } + } + } + } + + /* Evaluate them into derivations. */ + if (attrPaths.empty()) { + attrPaths = {""}; + } + + for (auto e : exprs) { + Value vRoot; + state->eval(e, vRoot); + + for (auto& i : attrPaths) { + Value& v(*findAlongAttrPath(*state, i, autoArgs, vRoot)); + state->forceValue(v); + getDerivations(*state, v, "", autoArgs, drvs, false); + } + } + + state->printStats(); + + auto buildPaths = [&](const PathSet& paths) { + /* Note: we do this even when !printMissing to efficiently + fetch binary cache data. */ + unsigned long long downloadSize; + unsigned long long narSize; + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + store->queryMissing(paths, willBuild, willSubstitute, unknown, downloadSize, + narSize); + + if (settings.printMissing) { + printMissing(ref<Store>(store), willBuild, willSubstitute, unknown, + downloadSize, narSize); + } + + if (!dryRun) { + store->buildPaths(paths, buildMode); + } + }; + + if (runEnv) { + if (drvs.size() != 1) { + throw UsageError("nix-shell requires a single derivation"); + } + + auto& drvInfo = drvs.front(); + auto drv = store->derivationFromPath(drvInfo.queryDrvPath()); + + PathSet pathsToBuild; + + /* Figure out what bash shell to use. If $NIX_BUILD_SHELL + is not set, then build bashInteractive from + <nixpkgs>. */ + auto shell = getEnv("NIX_BUILD_SHELL", ""); + + if (shell.empty()) { + try { + auto expr = state->parseExprFromString( + "(import <nixpkgs> {}).bashInteractive", absPath(".")); + + Value v; + state->eval(expr, v); + + auto drv = getDerivation(*state, v, false); + if (!drv) { + throw Error( + "the 'bashInteractive' attribute in <nixpkgs> did not evaluate " + "to a derivation"); + } + + pathsToBuild.insert(drv->queryDrvPath()); + + shell = drv->queryOutPath() + "/bin/bash"; + + } catch (Error& e) { + LOG(WARNING) << e.what() << "; will use bash from your environment"; + shell = "bash"; + } + } + + // Build or fetch all dependencies of the derivation. + for (const auto& input : drv.inputDrvs) { + if (std::all_of(envExclude.cbegin(), envExclude.cend(), + [&](const string& exclude) { + return !std::regex_search(input.first, + std::regex(exclude)); + })) { + pathsToBuild.insert(makeDrvPathWithOutputs(input.first, input.second)); + } + } + for (const auto& src : drv.inputSrcs) { + pathsToBuild.insert(src); + } + + buildPaths(pathsToBuild); + + if (dryRun) { + return; + } + + // Set the environment. + auto env = getEnv(); + + auto tmp = getEnv("TMPDIR", getEnv("XDG_RUNTIME_DIR", "/tmp")); + + if (pure) { + decltype(env) newEnv; + for (auto& i : env) { + if (keepVars.count(i.first) != 0u) { + newEnv.emplace(i); + } + } + env = newEnv; + // NixOS hack: prevent /etc/bashrc from sourcing /etc/profile. + env["__ETC_PROFILE_SOURCED"] = "1"; + } + + env["NIX_BUILD_TOP"] = env["TMPDIR"] = env["TEMPDIR"] = env["TMP"] = + env["TEMP"] = tmp; + env["NIX_STORE"] = store->storeDir; + env["NIX_BUILD_CORES"] = std::to_string(settings.buildCores); + + auto passAsFile = tokenizeString<StringSet>(get(drv.env, "passAsFile", "")); + + bool keepTmp = false; + int fileNr = 0; + + for (auto& var : drv.env) { + if (passAsFile.count(var.first) != 0u) { + keepTmp = true; + string fn = ".attr-" + std::to_string(fileNr++); + Path p = (Path)tmpDir + "/" + fn; + writeFile(p, var.second); + env[var.first + "Path"] = p; + } else { + env[var.first] = var.second; + } + } + + restoreAffinity(); + + /* Run a shell using the derivation's environment. For + convenience, source $stdenv/setup to setup additional + environment variables and shell functions. Also don't + lose the current $PATH directories. */ + auto rcfile = (Path)tmpDir + "/rc"; + writeFile( + rcfile, + fmt((keepTmp ? "" : "rm -rf '%1%'; "s) + + "[ -n \"$PS1\" ] && [ -e ~/.bashrc ] && source ~/.bashrc; " + "%2%" + "dontAddDisableDepTrack=1; " + "[ -e $stdenv/setup ] && source $stdenv/setup; " + "%3%" + "PATH=\"%4%:$PATH\"; " + "SHELL=%5%; " + "set +e; " + R"s([ -n "$PS1" ] && PS1='\n\[\033[1;32m\][nix-shell:\w]\$\[\033[0m\] '; )s" + "if [ \"$(type -t runHook)\" = function ]; then runHook " + "shellHook; fi; " + "unset NIX_ENFORCE_PURITY; " + "shopt -u nullglob; " + "unset TZ; %6%" + "%7%", + (Path)tmpDir, (pure ? "" : "p=$PATH; "), + (pure ? "" : "PATH=$PATH:$p; unset p; "), dirOf(shell), shell, + (getenv("TZ") != nullptr + ? (string("export TZ='") + getenv("TZ") + "'; ") + : ""), + envCommand)); + + Strings envStrs; + for (auto& i : env) { + envStrs.push_back(i.first + "=" + i.second); + } + + auto args = interactive ? Strings{"bash", "--rcfile", rcfile} + : Strings{"bash", rcfile}; + + auto envPtrs = stringsToCharPtrs(envStrs); + + environ = envPtrs.data(); + + auto argPtrs = stringsToCharPtrs(args); + + restoreSignals(); + + execvp(shell.c_str(), argPtrs.data()); + + throw SysError("executing shell '%s'", shell); + } + + PathSet pathsToBuild; + + std::map<Path, Path> drvPrefixes; + std::map<Path, Path> resultSymlinks; + std::vector<Path> outPaths; + + for (auto& drvInfo : drvs) { + auto drvPath = drvInfo.queryDrvPath(); + auto outPath = drvInfo.queryOutPath(); + + auto outputName = drvInfo.queryOutputName(); + if (outputName.empty()) { + throw Error("derivation '%s' lacks an 'outputName' attribute", drvPath); + } + + pathsToBuild.insert(drvPath + "!" + outputName); + + std::string drvPrefix; + auto i = drvPrefixes.find(drvPath); + if (i != drvPrefixes.end()) { + drvPrefix = i->second; + } else { + drvPrefix = outLink; + if (!drvPrefixes.empty() != 0u) { + drvPrefix += fmt("-%d", drvPrefixes.size() + 1); + } + drvPrefixes[drvPath] = drvPrefix; + } + + std::string symlink = drvPrefix; + if (outputName != "out") { + symlink += "-" + outputName; + } + + resultSymlinks[symlink] = outPath; + outPaths.push_back(outPath); + } + + buildPaths(pathsToBuild); + + if (dryRun) { + return; + } + + for (auto& symlink : resultSymlinks) { + if (auto store2 = store.dynamic_pointer_cast<LocalFSStore>()) { + store2->addPermRoot(symlink.second, absPath(symlink.first), true); + } + } + + for (auto& path : outPaths) { + std::cout << path << '\n'; + } +} + +static RegisterLegacyCommand s1("nix-build", _main); +static RegisterLegacyCommand s2("nix-shell", _main); diff --git a/third_party/nix/src/nix-channel/nix-channel.cc b/third_party/nix/src/nix-channel/nix-channel.cc new file mode 100644 index 0000000000..0030515174 --- /dev/null +++ b/third_party/nix/src/nix-channel/nix-channel.cc @@ -0,0 +1,272 @@ +#include <regex> + +#include <fcntl.h> +#include <pwd.h> + +#include "download.hh" +#include "globals.hh" +#include "legacy.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +typedef std::map<string, string> Channels; + +static Channels channels; +static Path channelsList; + +// Reads the list of channels. +static void readChannels() { + if (!pathExists(channelsList)) { + return; + } + auto channelsFile = readFile(channelsList); + + for (const auto& line : + tokenizeString<std::vector<string>>(channelsFile, "\n")) { + chomp(line); + if (std::regex_search(line, std::regex("^\\s*\\#"))) { + continue; + } + auto split = tokenizeString<std::vector<string>>(line, " "); + auto url = std::regex_replace(split[0], std::regex("/*$"), ""); + auto name = split.size() > 1 ? split[1] : baseNameOf(url); + channels[name] = url; + } +} + +// Writes the list of channels. +static void writeChannels() { + auto channelsFD = AutoCloseFD{open( + channelsList.c_str(), O_WRONLY | O_CLOEXEC | O_CREAT | O_TRUNC, 0644)}; + if (!channelsFD) { + throw SysError(format("opening '%1%' for writing") % channelsList); + } + for (const auto& channel : channels) { + writeFull(channelsFD.get(), channel.second + " " + channel.first + "\n"); + } +} + +// Adds a channel. +static void addChannel(const string& url, const string& name) { + if (!regex_search(url, std::regex("^(file|http|https)://"))) { + throw Error(format("invalid channel URL '%1%'") % url); + } + if (!regex_search(name, std::regex("^[a-zA-Z0-9_][a-zA-Z0-9_\\.-]*$"))) { + throw Error(format("invalid channel identifier '%1%'") % name); + } + readChannels(); + channels[name] = url; + writeChannels(); +} + +static Path profile; + +// Remove a channel. +static void removeChannel(const string& name) { + readChannels(); + channels.erase(name); + writeChannels(); + + runProgram(settings.nixBinDir + "/nix-env", true, + {"--profile", profile, "--uninstall", name}); +} + +static Path nixDefExpr; + +// Fetch Nix expressions and binary cache URLs from the subscribed channels. +static void update(const StringSet& channelNames) { + readChannels(); + + auto store = openStore(); + + // Download each channel. + Strings exprs; + for (const auto& channel : channels) { + auto name = channel.first; + auto url = channel.second; + if (!(channelNames.empty() || (channelNames.count(name) != 0u))) { + continue; + } + + // We want to download the url to a file to see if it's a tarball while also + // checking if we got redirected in the process, so that we can grab the + // various parts of a nix channel definition from a consistent location if + // the redirect changes mid-download. + CachedDownloadRequest request(url); + request.ttl = 0; + auto dl = getDownloader(); + auto result = dl->downloadCached(store, request); + auto filename = result.path; + url = chomp(result.effectiveUri); + + // If the URL contains a version number, append it to the name + // attribute (so that "nix-env -q" on the channels profile + // shows something useful). + auto cname = name; + std::smatch match; + auto urlBase = baseNameOf(url); + if (std::regex_search(urlBase, match, std::regex("(-\\d.*)$"))) { + cname = cname + (string)match[1]; + } + + std::string extraAttrs; + + bool unpacked = false; + if (std::regex_search(filename, std::regex("\\.tar\\.(gz|bz2|xz)$"))) { + runProgram(settings.nixBinDir + "/nix-build", false, + {"--no-out-link", "--expr", + "import <nix/unpack-channel.nix> " + "{ name = \"" + + cname + "\"; channelName = \"" + name + + "\"; src = builtins.storePath \"" + filename + "\"; }"}); + unpacked = true; + } + + if (!unpacked) { + // Download the channel tarball. + try { + filename = dl->downloadCached( + store, CachedDownloadRequest(url + "/nixexprs.tar.xz")) + .path; + } catch (DownloadError& e) { + filename = + dl->downloadCached(store, + CachedDownloadRequest(url + "/nixexprs.tar.bz2")) + .path; + } + chomp(filename); + } + + // Regardless of where it came from, add the expression representing this + // channel to accumulated expression + exprs.push_back("f: f { name = \"" + cname + "\"; channelName = \"" + name + + "\"; src = builtins.storePath \"" + filename + "\"; " + + extraAttrs + " }"); + } + + // Unpack the channel tarballs into the Nix store and install them + // into the channels profile. + std::cerr << "unpacking channels...\n"; + Strings envArgs{"--profile", profile, + "--file", "<nix/unpack-channel.nix>", + "--install", "--from-expression"}; + for (auto& expr : exprs) { + envArgs.push_back(std::move(expr)); + } + envArgs.push_back("--quiet"); + runProgram(settings.nixBinDir + "/nix-env", false, envArgs); + + // Make the channels appear in nix-env. + struct stat st; + if (lstat(nixDefExpr.c_str(), &st) == 0) { + if (S_ISLNK(st.st_mode)) { + // old-skool ~/.nix-defexpr + if (unlink(nixDefExpr.c_str()) == -1) { + throw SysError(format("unlinking %1%") % nixDefExpr); + } + } + } else if (errno != ENOENT) { + throw SysError(format("getting status of %1%") % nixDefExpr); + } + createDirs(nixDefExpr); + auto channelLink = nixDefExpr + "/channels"; + replaceSymlink(profile, channelLink); +} + +static int _main(int argc, char** argv) { + { + // Figure out the name of the `.nix-channels' file to use + auto home = getHome(); + channelsList = home + "/.nix-channels"; + nixDefExpr = home + "/.nix-defexpr"; + + // Figure out the name of the channels profile. + profile = fmt("%s/profiles/per-user/%s/channels", settings.nixStateDir, + getUserName()); + + enum { cNone, cAdd, cRemove, cList, cUpdate, cRollback } cmd = cNone; + std::vector<string> args; + parseCmdLine(argc, argv, + [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + showManPage("nix-channel"); + } else if (*arg == "--version") { + printVersion("nix-channel"); + } else if (*arg == "--add") { + cmd = cAdd; + } else if (*arg == "--remove") { + cmd = cRemove; + } else if (*arg == "--list") { + cmd = cList; + } else if (*arg == "--update") { + cmd = cUpdate; + } else if (*arg == "--rollback") { + cmd = cRollback; + } else { + args.push_back(std::move(*arg)); + } + return true; + }); + + initPlugins(); + + switch (cmd) { + case cNone: + throw UsageError("no command specified"); + case cAdd: + if (args.empty() || args.size() > 2) { + throw UsageError("'--add' requires one or two arguments"); + } + { + auto url = args[0]; + std::string name; + if (args.size() == 2) { + name = args[1]; + } else { + name = baseNameOf(url); + name = std::regex_replace(name, std::regex("-unstable$"), ""); + name = std::regex_replace(name, std::regex("-stable$"), ""); + } + addChannel(url, name); + } + break; + case cRemove: + if (args.size() != 1) { + throw UsageError("'--remove' requires one argument"); + } + removeChannel(args[0]); + break; + case cList: + if (!args.empty()) { + throw UsageError("'--list' expects no arguments"); + } + readChannels(); + for (const auto& channel : channels) { + std::cout << channel.first << ' ' << channel.second << '\n'; + } + break; + case cUpdate: + update(StringSet(args.begin(), args.end())); + break; + case cRollback: + if (args.size() > 1) { + throw UsageError("'--rollback' has at most one argument"); + } + Strings envArgs{"--profile", profile}; + if (args.size() == 1) { + envArgs.push_back("--switch-generation"); + envArgs.push_back(args[0]); + } else { + envArgs.push_back("--rollback"); + } + runProgram(settings.nixBinDir + "/nix-env", false, envArgs); + break; + } + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-channel", _main); diff --git a/third_party/nix/src/nix-collect-garbage/nix-collect-garbage.cc b/third_party/nix/src/nix-collect-garbage/nix-collect-garbage.cc new file mode 100644 index 0000000000..0050bdda15 --- /dev/null +++ b/third_party/nix/src/nix-collect-garbage/nix-collect-garbage.cc @@ -0,0 +1,105 @@ +#include <cerrno> +#include <iostream> + +#include <glog/logging.h> + +#include "globals.hh" +#include "legacy.hh" +#include "profiles.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +std::string deleteOlderThan; +bool dryRun = false; + +/* If `-d' was specified, remove all old generations of all profiles. + * Of course, this makes rollbacks to before this point in time + * impossible. */ + +void removeOldGenerations(const std::string& dir) { + if (access(dir.c_str(), R_OK) != 0) { + return; + } + + bool canWrite = access(dir.c_str(), W_OK) == 0; + + for (auto& i : readDirectory(dir)) { + checkInterrupt(); + + auto path = dir + "/" + i.name; + auto type = i.type == DT_UNKNOWN ? getFileType(path) : i.type; + + if (type == DT_LNK && canWrite) { + std::string link; + try { + link = readLink(path); + } catch (SysError& e) { + if (e.errNo == ENOENT) { + continue; + } + } + if (link.find("link") != string::npos) { + LOG(INFO) << "removing old generations of profile " << path; + if (!deleteOlderThan.empty()) { + deleteGenerationsOlderThan(path, deleteOlderThan, dryRun); + } else { + deleteOldGenerations(path, dryRun); + } + } + } else if (type == DT_DIR) { + removeOldGenerations(path); + } + } +} + +static int _main(int argc, char** argv) { + { + bool removeOld = false; + + GCOptions options; + + parseCmdLine(argc, argv, + [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + showManPage("nix-collect-garbage"); + } else if (*arg == "--version") { + printVersion("nix-collect-garbage"); + } else if (*arg == "--delete-old" || *arg == "-d") { + removeOld = true; + } else if (*arg == "--delete-older-than") { + removeOld = true; + deleteOlderThan = getArg(*arg, arg, end); + } else if (*arg == "--dry-run") { + dryRun = true; + } else if (*arg == "--max-freed") { + auto maxFreed = getIntArg<long long>(*arg, arg, end, true); + options.maxFreed = maxFreed >= 0 ? maxFreed : 0; + } else { + return false; + } + return true; + }); + + initPlugins(); + + auto profilesDir = settings.nixStateDir + "/profiles"; + if (removeOld) { + removeOldGenerations(profilesDir); + } + + // Run the actual garbage collector. + if (!dryRun) { + auto store = openStore(); + options.action = GCOptions::gcDeleteDead; + GCResults results; + PrintFreed freed(true, results); + store->collectGarbage(options, results); + } + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-collect-garbage", _main); diff --git a/third_party/nix/src/nix-copy-closure/nix-copy-closure.cc b/third_party/nix/src/nix-copy-closure/nix-copy-closure.cc new file mode 100644 index 0000000000..67765a8cf7 --- /dev/null +++ b/third_party/nix/src/nix-copy-closure/nix-copy-closure.cc @@ -0,0 +1,75 @@ +#include <glog/logging.h> + +#include "legacy.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +static int _main(int argc, char** argv) { + { + auto gzip = false; + auto toMode = true; + auto includeOutputs = false; + auto dryRun = false; + auto useSubstitutes = NoSubstitute; + std::string sshHost; + PathSet storePaths; + + parseCmdLine( + argc, argv, [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + showManPage("nix-copy-closure"); + } else if (*arg == "--version") { + printVersion("nix-copy-closure"); + } else if (*arg == "--gzip" || *arg == "--bzip2" || *arg == "--xz") { + if (*arg != "--gzip") { + LOG(WARNING) << "'" << *arg + << "' is not implemented, falling back to gzip"; + } + gzip = true; + } else if (*arg == "--from") { + toMode = false; + } else if (*arg == "--to") { + toMode = true; + } else if (*arg == "--include-outputs") { + includeOutputs = true; + } else if (*arg == "--show-progress") { + LOG(WARNING) << "'--show-progress' is not implemented"; + } else if (*arg == "--dry-run") { + dryRun = true; + } else if (*arg == "--use-substitutes" || *arg == "-s") { + useSubstitutes = Substitute; + } else if (sshHost.empty()) { + sshHost = *arg; + } else { + storePaths.insert(*arg); + } + return true; + }); + + initPlugins(); + + if (sshHost.empty()) { + throw UsageError("no host name specified"); + } + + auto remoteUri = "ssh://" + sshHost + (gzip ? "?compress=true" : ""); + auto to = toMode ? openStore(remoteUri) : openStore(); + auto from = toMode ? openStore() : openStore(remoteUri); + + PathSet storePaths2; + for (auto& path : storePaths) { + storePaths2.insert(from->followLinksToStorePath(path)); + } + + PathSet closure; + from->computeFSClosure(storePaths2, closure, false, includeOutputs); + + copyPaths(from, to, closure, NoRepair, NoCheckSigs, useSubstitutes); + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-copy-closure", _main); diff --git a/third_party/nix/src/nix-daemon/nix-daemon.cc b/third_party/nix/src/nix-daemon/nix-daemon.cc new file mode 100644 index 0000000000..9f5e8b7cbe --- /dev/null +++ b/third_party/nix/src/nix-daemon/nix-daemon.cc @@ -0,0 +1,1181 @@ +#include <algorithm> +#include <cerrno> +#include <climits> +#include <csignal> +#include <cstring> + +#include <fcntl.h> +#include <glog/logging.h> +#include <grp.h> +#include <pwd.h> +#include <sys/socket.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <sys/un.h> +#include <sys/wait.h> +#include <unistd.h> + +#include "affinity.hh" +#include "archive.hh" +#include "derivations.hh" +#include "finally.hh" +#include "globals.hh" +#include "legacy.hh" +#include "local-store.hh" +#include "monitor-fd.hh" +#include "serialise.hh" +#include "shared.hh" +#include "util.hh" +#include "worker-protocol.hh" + +#if __APPLE__ || __FreeBSD__ +#include <sys/ucred.h> +#endif + +using namespace nix; + +#ifndef __linux__ +#define SPLICE_F_MOVE 0 +static ssize_t splice(int fd_in, void* off_in, int fd_out, void* off_out, + size_t len, unsigned int flags) { + /* We ignore most parameters, we just have them for conformance with the linux + * syscall */ + std::vector<char> buf(8192); + auto read_count = read(fd_in, buf.data(), buf.size()); + if (read_count == -1) { + return read_count; + } + auto write_count = decltype(read_count)(0); + while (write_count < read_count) { + auto res = + write(fd_out, buf.data() + write_count, read_count - write_count); + if (res == -1) { + return res; + } + write_count += res; + } + return read_count; +} +#endif + +static FdSource from(STDIN_FILENO); +static FdSink to(STDOUT_FILENO); + +/* Logger that forwards log messages to the client, *if* we're in a + state where the protocol allows it (i.e., when canSendStderr is + true). */ +struct TunnelLogger { + struct State { + bool canSendStderr = false; + std::vector<std::string> pendingMsgs; + }; + + Sync<State> state_; + + unsigned int clientVersion; + + explicit TunnelLogger(unsigned int clientVersion) + : clientVersion(clientVersion) {} + + void enqueueMsg(const std::string& s) { + auto state(state_.lock()); + + if (state->canSendStderr) { + assert(state->pendingMsgs.empty()); + try { + to(s); + to.flush(); + } catch (...) { + /* Write failed; that means that the other side is + gone. */ + state->canSendStderr = false; + throw; + } + } else { + state->pendingMsgs.push_back(s); + } + } + + void log(const FormatOrString& fs) { + StringSink buf; + buf << STDERR_NEXT << (fs.s + "\n"); + enqueueMsg(*buf.s); + } + + /* startWork() means that we're starting an operation for which we + want to send out stderr to the client. */ + void startWork() { + auto state(state_.lock()); + state->canSendStderr = true; + + for (auto& msg : state->pendingMsgs) { + to(msg); + } + + state->pendingMsgs.clear(); + + to.flush(); + } + + /* stopWork() means that we're done; stop sending stderr to the + client. */ + void stopWork(bool success = true, const string& msg = "", + unsigned int status = 0) { + auto state(state_.lock()); + + state->canSendStderr = false; + + if (success) { + to << STDERR_LAST; + } else { + to << STDERR_ERROR << msg; + if (status != 0) { + to << status; + } + } + } + + void startActivity(const std::string& s) { + DLOG(INFO) << "startActivity(" << s << ")"; + if (GET_PROTOCOL_MINOR(clientVersion) < 20) { + if (!s.empty()) { + LOG(INFO) << s; + } + return; + } + + StringSink buf; + buf << STDERR_START_ACTIVITY << s; + enqueueMsg(*buf.s); + } +}; + +struct TunnelSink : Sink { + Sink& to; + explicit TunnelSink(Sink& to) : to(to) {} + void operator()(const unsigned char* data, size_t len) override { + to << STDERR_WRITE; + writeString(data, len, to); + } +}; + +struct TunnelSource : BufferedSource { + Source& from; + explicit TunnelSource(Source& from) : from(from) {} + + protected: + size_t readUnbuffered(unsigned char* data, size_t len) override { + to << STDERR_READ << len; + to.flush(); + size_t n = readString(data, len, from); + if (n == 0) { + throw EndOfFile("unexpected end-of-file"); + } + return n; + } +}; + +/* If the NAR archive contains a single file at top-level, then save + the contents of the file to `s'. Otherwise barf. */ +struct RetrieveRegularNARSink : ParseSink { + bool regular{true}; + string s; + + RetrieveRegularNARSink() {} + + void createDirectory(const Path& path) override { regular = false; } + + void receiveContents(unsigned char* data, unsigned int len) override { + s.append((const char*)data, len); + } + + void createSymlink(const Path& path, const string& target) override { + regular = false; + } +}; + +static void performOp(TunnelLogger* logger, const ref<Store>& store, + bool trusted, unsigned int clientVersion, Source& from, + Sink& to, unsigned int op) { + switch (op) { + case wopIsValidPath: { + /* 'readStorePath' could raise an error leading to the connection + being closed. To be able to recover from an invalid path error, + call 'startWork' early, and do 'assertStorePath' afterwards so + that the 'Error' exception handler doesn't close the + connection. */ + Path path = readString(from); + logger->startWork(); + store->assertStorePath(path); + bool result = store->isValidPath(path); + logger->stopWork(); + to << static_cast<uint64_t>(result); + break; + } + + case wopQueryValidPaths: { + auto paths = readStorePaths<PathSet>(*store, from); + logger->startWork(); + PathSet res = store->queryValidPaths(paths); + logger->stopWork(); + to << res; + break; + } + + case wopHasSubstitutes: { + Path path = readStorePath(*store, from); + logger->startWork(); + PathSet res = store->querySubstitutablePaths({path}); + logger->stopWork(); + to << static_cast<uint64_t>(res.find(path) != res.end()); + break; + } + + case wopQuerySubstitutablePaths: { + auto paths = readStorePaths<PathSet>(*store, from); + logger->startWork(); + PathSet res = store->querySubstitutablePaths(paths); + logger->stopWork(); + to << res; + break; + } + + case wopQueryPathHash: { + Path path = readStorePath(*store, from); + logger->startWork(); + auto hash = store->queryPathInfo(path)->narHash; + logger->stopWork(); + to << hash.to_string(Base16, false); + break; + } + + case wopQueryReferences: + case wopQueryReferrers: + case wopQueryValidDerivers: + case wopQueryDerivationOutputs: { + Path path = readStorePath(*store, from); + logger->startWork(); + PathSet paths; + if (op == wopQueryReferences) { + paths = store->queryPathInfo(path)->references; + } else if (op == wopQueryReferrers) { + store->queryReferrers(path, paths); + } else if (op == wopQueryValidDerivers) { + paths = store->queryValidDerivers(path); + } else { + paths = store->queryDerivationOutputs(path); + } + logger->stopWork(); + to << paths; + break; + } + + case wopQueryDerivationOutputNames: { + Path path = readStorePath(*store, from); + logger->startWork(); + StringSet names; + names = store->queryDerivationOutputNames(path); + logger->stopWork(); + to << names; + break; + } + + case wopQueryDeriver: { + Path path = readStorePath(*store, from); + logger->startWork(); + auto deriver = store->queryPathInfo(path)->deriver; + logger->stopWork(); + to << deriver; + break; + } + + case wopQueryPathFromHashPart: { + string hashPart = readString(from); + logger->startWork(); + Path path = store->queryPathFromHashPart(hashPart); + logger->stopWork(); + to << path; + break; + } + + case wopAddToStore: { + bool fixed; + bool recursive; + std::string s; + std::string baseName; + from >> baseName >> fixed /* obsolete */ >> recursive >> s; + /* Compatibility hack. */ + if (!fixed) { + s = "sha256"; + recursive = true; + } + HashType hashAlgo = parseHashType(s); + + TeeSource savedNAR(from); + RetrieveRegularNARSink savedRegular; + + if (recursive) { + /* Get the entire NAR dump from the client and save it to + a string so that we can pass it to + addToStoreFromDump(). */ + ParseSink sink; /* null sink; just parse the NAR */ + parseDump(sink, savedNAR); + } else { + parseDump(savedRegular, from); + } + + logger->startWork(); + if (!savedRegular.regular) { + throw Error("regular file expected"); + } + + auto store2 = store.dynamic_pointer_cast<LocalStore>(); + if (!store2) { + throw Error("operation is only supported by LocalStore"); + } + + Path path = store2->addToStoreFromDump( + recursive ? *savedNAR.data : savedRegular.s, baseName, recursive, + hashAlgo); + logger->stopWork(); + + to << path; + break; + } + + case wopAddTextToStore: { + string suffix = readString(from); + string s = readString(from); + auto refs = readStorePaths<PathSet>(*store, from); + logger->startWork(); + Path path = store->addTextToStore(suffix, s, refs, NoRepair); + logger->stopWork(); + to << path; + break; + } + + case wopExportPath: { + Path path = readStorePath(*store, from); + readInt(from); // obsolete + logger->startWork(); + TunnelSink sink(to); + store->exportPath(path, sink); + logger->stopWork(); + to << 1; + break; + } + + case wopImportPaths: { + logger->startWork(); + TunnelSource source(from); + Paths paths = store->importPaths(source, nullptr, + trusted ? NoCheckSigs : CheckSigs); + logger->stopWork(); + to << paths; + break; + } + + case wopBuildPaths: { + auto drvs = readStorePaths<PathSet>(*store, from); + BuildMode mode = bmNormal; + if (GET_PROTOCOL_MINOR(clientVersion) >= 15) { + mode = (BuildMode)readInt(from); + + /* Repairing is not atomic, so disallowed for "untrusted" + clients. */ + if (mode == bmRepair && !trusted) { + throw Error( + "repairing is not allowed because you are not in " + "'trusted-users'"); + } + } + logger->startWork(); + store->buildPaths(drvs, mode); + logger->stopWork(); + to << 1; + break; + } + + case wopBuildDerivation: { + Path drvPath = readStorePath(*store, from); + BasicDerivation drv; + readDerivation(from, *store, drv); + auto buildMode = (BuildMode)readInt(from); + logger->startWork(); + if (!trusted) { + throw Error("you are not privileged to build derivations"); + } + auto res = store->buildDerivation(drvPath, drv, buildMode); + logger->stopWork(); + to << res.status << res.errorMsg; + break; + } + + case wopEnsurePath: { + Path path = readStorePath(*store, from); + logger->startWork(); + store->ensurePath(path); + logger->stopWork(); + to << 1; + break; + } + + case wopAddTempRoot: { + Path path = readStorePath(*store, from); + logger->startWork(); + store->addTempRoot(path); + logger->stopWork(); + to << 1; + break; + } + + case wopAddIndirectRoot: { + Path path = absPath(readString(from)); + logger->startWork(); + store->addIndirectRoot(path); + logger->stopWork(); + to << 1; + break; + } + + case wopSyncWithGC: { + logger->startWork(); + store->syncWithGC(); + logger->stopWork(); + to << 1; + break; + } + + case wopFindRoots: { + logger->startWork(); + Roots roots = store->findRoots(!trusted); + logger->stopWork(); + + size_t size = 0; + for (auto& i : roots) { + size += i.second.size(); + } + + to << size; + + for (auto& [target, links] : roots) { + for (auto& link : links) { + to << link << target; + } + } + + break; + } + + case wopCollectGarbage: { + GCOptions options; + options.action = (GCOptions::GCAction)readInt(from); + options.pathsToDelete = readStorePaths<PathSet>(*store, from); + from >> options.ignoreLiveness >> options.maxFreed; + // obsolete fields + readInt(from); + readInt(from); + readInt(from); + + GCResults results; + + logger->startWork(); + if (options.ignoreLiveness) { + throw Error("you are not allowed to ignore liveness"); + } + store->collectGarbage(options, results); + logger->stopWork(); + + to << results.paths << results.bytesFreed << 0 /* obsolete */; + + break; + } + + case wopSetOptions: { + settings.keepFailed = readInt(from) != 0u; + settings.keepGoing = readInt(from) != 0u; + settings.tryFallback = readInt(from) != 0u; + readInt(from); // obsolete verbosity + settings.maxBuildJobs.assign(readInt(from)); + settings.maxSilentTime = readInt(from); + readInt(from); // obsolete useBuildHook + settings.verboseBuild = 0 == readInt(from); + readInt(from); // obsolete logType + readInt(from); // obsolete printBuildTrace + settings.buildCores = readInt(from); + settings.useSubstitutes = readInt(from) != 0u; + + StringMap overrides; + if (GET_PROTOCOL_MINOR(clientVersion) >= 12) { + unsigned int n = readInt(from); + for (unsigned int i = 0; i < n; i++) { + string name = readString(from); + string value = readString(from); + overrides.emplace(name, value); + } + } + + logger->startWork(); + + for (auto& i : overrides) { + auto& name(i.first); + auto& value(i.second); + + auto setSubstituters = [&](Setting<Strings>& res) { + if (name != res.name && res.aliases.count(name) == 0) { + return false; + } + StringSet trusted = settings.trustedSubstituters; + for (auto& s : settings.substituters.get()) { + trusted.insert(s); + } + Strings subs; + auto ss = tokenizeString<Strings>(value); + for (auto& s : ss) { + if (trusted.count(s) != 0u) { + subs.push_back(s); + } else { + LOG(WARNING) << "ignoring untrusted substituter '" << s << "'"; + } + } + res = subs; + return true; + }; + + try { + if (name == "ssh-auth-sock") { // obsolete + ; + } else if (trusted || name == settings.buildTimeout.name || + name == "connect-timeout" || + (name == "builders" && value.empty())) { + settings.set(name, value); + } else if (setSubstituters(settings.substituters)) { + ; + } else if (setSubstituters(settings.extraSubstituters)) { + ; + } else { + LOG(WARNING) << "ignoring the user-specified setting '" << name + << "', because it is a " + << "restricted setting and you are not a trusted user"; + } + } catch (UsageError& e) { + LOG(WARNING) << e.what(); + } + } + + logger->stopWork(); + break; + } + + case wopQuerySubstitutablePathInfo: { + Path path = absPath(readString(from)); + logger->startWork(); + SubstitutablePathInfos infos; + store->querySubstitutablePathInfos({path}, infos); + logger->stopWork(); + auto i = infos.find(path); + if (i == infos.end()) { + to << 0; + } else { + to << 1 << i->second.deriver << i->second.references + << i->second.downloadSize << i->second.narSize; + } + break; + } + + case wopQuerySubstitutablePathInfos: { + auto paths = readStorePaths<PathSet>(*store, from); + logger->startWork(); + SubstitutablePathInfos infos; + store->querySubstitutablePathInfos(paths, infos); + logger->stopWork(); + to << infos.size(); + for (auto& i : infos) { + to << i.first << i.second.deriver << i.second.references + << i.second.downloadSize << i.second.narSize; + } + break; + } + + case wopQueryAllValidPaths: { + logger->startWork(); + PathSet paths = store->queryAllValidPaths(); + logger->stopWork(); + to << paths; + break; + } + + case wopQueryPathInfo: { + Path path = readStorePath(*store, from); + std::shared_ptr<const ValidPathInfo> info; + logger->startWork(); + try { + info = store->queryPathInfo(path); + } catch (InvalidPath&) { + if (GET_PROTOCOL_MINOR(clientVersion) < 17) { + throw; + } + } + logger->stopWork(); + if (info) { + if (GET_PROTOCOL_MINOR(clientVersion) >= 17) { + to << 1; + } + to << info->deriver << info->narHash.to_string(Base16, false) + << info->references << info->registrationTime << info->narSize; + if (GET_PROTOCOL_MINOR(clientVersion) >= 16) { + to << static_cast<uint64_t>(info->ultimate) << info->sigs << info->ca; + } + } else { + assert(GET_PROTOCOL_MINOR(clientVersion) >= 17); + to << 0; + } + break; + } + + case wopOptimiseStore: + logger->startWork(); + store->optimiseStore(); + logger->stopWork(); + to << 1; + break; + + case wopVerifyStore: { + bool checkContents; + bool repair; + from >> checkContents >> repair; + logger->startWork(); + if (repair && !trusted) { + throw Error("you are not privileged to repair paths"); + } + bool errors = store->verifyStore(checkContents, (RepairFlag)repair); + logger->stopWork(); + to << static_cast<uint64_t>(errors); + break; + } + + case wopAddSignatures: { + Path path = readStorePath(*store, from); + auto sigs = readStrings<StringSet>(from); + logger->startWork(); + if (!trusted) { + throw Error("you are not privileged to add signatures"); + } + store->addSignatures(path, sigs); + logger->stopWork(); + to << 1; + break; + } + + case wopNarFromPath: { + auto path = readStorePath(*store, from); + logger->startWork(); + logger->stopWork(); + dumpPath(path, to); + break; + } + + case wopAddToStoreNar: { + bool repair; + bool dontCheckSigs; + ValidPathInfo info; + info.path = readStorePath(*store, from); + from >> info.deriver; + if (!info.deriver.empty()) { + store->assertStorePath(info.deriver); + } + info.narHash = Hash(readString(from), htSHA256); + info.references = readStorePaths<PathSet>(*store, from); + from >> info.registrationTime >> info.narSize >> info.ultimate; + info.sigs = readStrings<StringSet>(from); + from >> info.ca >> repair >> dontCheckSigs; + if (!trusted && dontCheckSigs) { + dontCheckSigs = false; + } + if (!trusted) { + info.ultimate = false; + } + + std::string saved; + std::unique_ptr<Source> source; + if (GET_PROTOCOL_MINOR(clientVersion) >= 21) { + source = std::make_unique<TunnelSource>(from); + } else { + TeeSink tee(from); + parseDump(tee, tee.source); + saved = std::move(*tee.source.data); + source = std::make_unique<StringSource>(saved); + } + + logger->startWork(); + + // FIXME: race if addToStore doesn't read source? + store->addToStore(info, *source, (RepairFlag)repair, + dontCheckSigs ? NoCheckSigs : CheckSigs, nullptr); + + logger->stopWork(); + break; + } + + case wopQueryMissing: { + auto targets = readStorePaths<PathSet>(*store, from); + logger->startWork(); + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + unsigned long long downloadSize; + unsigned long long narSize; + store->queryMissing(targets, willBuild, willSubstitute, unknown, + downloadSize, narSize); + logger->stopWork(); + to << willBuild << willSubstitute << unknown << downloadSize << narSize; + break; + } + + default: + throw Error(format("invalid operation %1%") % op); + } +} + +static void processConnection(bool trusted, const std::string& userName, + uid_t userId) { + MonitorFdHup monitor(from.fd); + + /* Exchange the greeting. */ + unsigned int magic = readInt(from); + if (magic != WORKER_MAGIC_1) { + throw Error("protocol mismatch"); + } + to << WORKER_MAGIC_2 << PROTOCOL_VERSION; + to.flush(); + unsigned int clientVersion = readInt(from); + + if (clientVersion < 0x10a) { + throw Error("the Nix client version is too old"); + } + + auto tunnelLogger = new TunnelLogger(clientVersion); + // logger = tunnelLogger; + + unsigned int opCount = 0; + + Finally finally([&]() { + _isInterrupted = false; + DLOG(INFO) << opCount << " operations"; + }); + + if (GET_PROTOCOL_MINOR(clientVersion) >= 14 && (readInt(from) != 0u)) { + setAffinityTo(readInt(from)); + } + + readInt(from); // obsolete reserveSpace + + /* Send startup error messages to the client. */ + tunnelLogger->startWork(); + + try { + /* If we can't accept clientVersion, then throw an error + *here* (not above). */ + +#if 0 + /* Prevent users from doing something very dangerous. */ + if (geteuid() == 0 && + querySetting("build-users-group", "") == "") + throw Error("if you run 'nix-daemon' as root, then you MUST set 'build-users-group'!"); +#endif + + /* Open the store. */ + Store::Params params; // FIXME: get params from somewhere + // Disable caching since the client already does that. + params["path-info-cache-size"] = "0"; + auto store = openStore(settings.storeUri, params); + + store->createUser(userName, userId); + + tunnelLogger->stopWork(); + to.flush(); + + /* Process client requests. */ + while (true) { + WorkerOp op; + try { + op = (WorkerOp)readInt(from); + } catch (Interrupted& e) { + break; + } catch (EndOfFile& e) { + break; + } + + opCount++; + + try { + performOp(tunnelLogger, store, trusted, clientVersion, from, to, op); + } catch (Error& e) { + /* If we're not in a state where we can send replies, then + something went wrong processing the input of the + client. This can happen especially if I/O errors occur + during addTextToStore() / importPath(). If that + happens, just send the error message and exit. */ + bool errorAllowed = tunnelLogger->state_.lock()->canSendStderr; + tunnelLogger->stopWork(false, e.msg(), e.status); + if (!errorAllowed) { + throw; + } + } catch (std::bad_alloc& e) { + tunnelLogger->stopWork(false, "Nix daemon out of memory", 1); + throw; + } + + to.flush(); + + assert(!tunnelLogger->state_.lock()->canSendStderr); + }; + + } catch (std::exception& e) { + tunnelLogger->stopWork(false, e.what(), 1); + to.flush(); + return; + } +} + +static void sigChldHandler(int sigNo) { + // Ensure we don't modify errno of whatever we've interrupted + auto saved_errno = errno; + /* Reap all dead children. */ + while (waitpid(-1, nullptr, WNOHANG) > 0) { + ; + } + errno = saved_errno; +} + +static void setSigChldAction(bool autoReap) { + struct sigaction act; + struct sigaction oact; + act.sa_handler = autoReap ? sigChldHandler : SIG_DFL; + sigfillset(&act.sa_mask); + act.sa_flags = 0; + if (sigaction(SIGCHLD, &act, &oact) != 0) { + throw SysError("setting SIGCHLD handler"); + } +} + +bool matchUser(const string& user, const string& group, const Strings& users) { + if (find(users.begin(), users.end(), "*") != users.end()) { + return true; + } + + if (find(users.begin(), users.end(), user) != users.end()) { + return true; + } + + for (auto& i : users) { + if (string(i, 0, 1) == "@") { + if (group == string(i, 1)) { + return true; + } + struct group* gr = getgrnam(i.c_str() + 1); + if (gr == nullptr) { + continue; + } + for (char** mem = gr->gr_mem; *mem != nullptr; mem++) { + if (user == string(*mem)) { + return true; + } + } + } + } + + return false; +} + +struct PeerInfo { + bool pidKnown; + pid_t pid; + bool uidKnown; + uid_t uid; + bool gidKnown; + gid_t gid; +}; + +/* Get the identity of the caller, if possible. */ +static PeerInfo getPeerInfo(int remote) { + PeerInfo peer = {false, 0, false, 0, false, 0}; + +#if defined(SO_PEERCRED) + + ucred cred; + socklen_t credLen = sizeof(cred); + if (getsockopt(remote, SOL_SOCKET, SO_PEERCRED, &cred, &credLen) == -1) { + throw SysError("getting peer credentials"); + } + peer = {true, cred.pid, true, cred.uid, true, cred.gid}; + +#elif defined(LOCAL_PEERCRED) + +#if !defined(SOL_LOCAL) +#define SOL_LOCAL 0 +#endif + + xucred cred; + socklen_t credLen = sizeof(cred); + if (getsockopt(remote, SOL_LOCAL, LOCAL_PEERCRED, &cred, &credLen) == -1) + throw SysError("getting peer credentials"); + peer = {false, 0, true, cred.cr_uid, false, 0}; + +#endif + + return peer; +} + +#define SD_LISTEN_FDS_START 3 + +static void daemonLoop(char** argv) { + if (chdir("/") == -1) { + throw SysError("cannot change current directory"); + } + + /* Get rid of children automatically; don't let them become + zombies. */ + setSigChldAction(true); + + AutoCloseFD fdSocket; + + /* Handle socket-based activation by systemd. */ + if (!getEnv("LISTEN_FDS").empty()) { + if (getEnv("LISTEN_PID") != std::to_string(getpid()) || + getEnv("LISTEN_FDS") != "1") { + throw Error("unexpected systemd environment variables"); + } + fdSocket = SD_LISTEN_FDS_START; + } + + /* Otherwise, create and bind to a Unix domain socket. */ + else { + /* Create and bind to a Unix domain socket. */ + fdSocket = socket(PF_UNIX, SOCK_STREAM, 0); + if (!fdSocket) { + throw SysError("cannot create Unix domain socket"); + } + + string socketPath = settings.nixDaemonSocketFile; + + createDirs(dirOf(socketPath)); + + /* Urgh, sockaddr_un allows path names of only 108 characters. + So chdir to the socket directory so that we can pass a + relative path name. */ + if (chdir(dirOf(socketPath).c_str()) == -1) { + throw SysError("cannot change current directory"); + } + Path socketPathRel = "./" + baseNameOf(socketPath); + + struct sockaddr_un addr; + addr.sun_family = AF_UNIX; + if (socketPathRel.size() >= sizeof(addr.sun_path)) { + throw Error(format("socket path '%1%' is too long") % socketPathRel); + } + strcpy(addr.sun_path, socketPathRel.c_str()); + + unlink(socketPath.c_str()); + + /* Make sure that the socket is created with 0666 permission + (everybody can connect --- provided they have access to the + directory containing the socket). */ + mode_t oldMode = umask(0111); + int res = bind(fdSocket.get(), (struct sockaddr*)&addr, sizeof(addr)); + umask(oldMode); + if (res == -1) { + throw SysError(format("cannot bind to socket '%1%'") % socketPath); + } + + if (chdir("/") == -1) { /* back to the root */ + throw SysError("cannot change current directory"); + } + + if (listen(fdSocket.get(), 5) == -1) { + throw SysError(format("cannot listen on socket '%1%'") % socketPath); + } + } + + closeOnExec(fdSocket.get()); + + /* Loop accepting connections. */ + while (true) { + try { + /* Accept a connection. */ + struct sockaddr_un remoteAddr; + socklen_t remoteAddrLen = sizeof(remoteAddr); + + AutoCloseFD remote = + accept(fdSocket.get(), (struct sockaddr*)&remoteAddr, &remoteAddrLen); + checkInterrupt(); + if (!remote) { + if (errno == EINTR) { + continue; + } + throw SysError("accepting connection"); + } + + closeOnExec(remote.get()); + + bool trusted = false; + PeerInfo peer = getPeerInfo(remote.get()); + + struct passwd* pw = peer.uidKnown ? getpwuid(peer.uid) : nullptr; + string user = pw != nullptr ? pw->pw_name : std::to_string(peer.uid); + + struct group* gr = peer.gidKnown ? getgrgid(peer.gid) : nullptr; + string group = gr != nullptr ? gr->gr_name : std::to_string(peer.gid); + + Strings trustedUsers = settings.trustedUsers; + Strings allowedUsers = settings.allowedUsers; + + if (matchUser(user, group, trustedUsers)) { + trusted = true; + } + + if ((!trusted && !matchUser(user, group, allowedUsers)) || + group == settings.buildUsersGroup) { + throw Error( + format("user '%1%' is not allowed to connect to the Nix daemon") % + user); + } + + LOG(INFO) << "accepted connection from pid " + << (peer.pidKnown ? std::to_string(peer.pid) : "<unknown>") + << ", user " << (peer.uidKnown ? user : "<unknown>") + << (trusted ? " (trusted)" : ""); + + /* Fork a child to handle the connection. */ + ProcessOptions options; + options.errorPrefix = "unexpected Nix daemon error: "; + options.dieWithParent = false; + options.runExitHandlers = true; + options.allowVfork = false; + startProcess( + [&]() { + fdSocket = -1; + + /* Background the daemon. */ + if (setsid() == -1) { + throw SysError(format("creating a new session")); + } + + /* Restore normal handling of SIGCHLD. */ + setSigChldAction(false); + + /* For debugging, stuff the pid into argv[1]. */ + if (peer.pidKnown && (argv[1] != nullptr)) { + string processName = std::to_string(peer.pid); + strncpy(argv[1], processName.c_str(), strlen(argv[1])); + } + + /* Handle the connection. */ + from.fd = remote.get(); + to.fd = remote.get(); + processConnection(trusted, user, peer.uid); + + exit(0); + }, + options); + + } catch (Interrupted& e) { + return; + } catch (Error& e) { + LOG(ERROR) << "error processing connection: " << e.msg(); + } + } +} + +static int _main(int argc, char** argv) { + { + auto stdio = false; + + parseCmdLine(argc, argv, + [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--daemon") { + ; /* ignored for backwards compatibility */ + } else if (*arg == "--help") { + showManPage("nix-daemon"); + } else if (*arg == "--version") { + printVersion("nix-daemon"); + } else if (*arg == "--stdio") { + stdio = true; + } else { + return false; + } + return true; + }); + + initPlugins(); + + if (stdio) { + if (getStoreType() == tDaemon) { + /* Forward on this connection to the real daemon */ + auto socketPath = settings.nixDaemonSocketFile; + auto s = socket(PF_UNIX, SOCK_STREAM, 0); + if (s == -1) { + throw SysError("creating Unix domain socket"); + } + + auto socketDir = dirOf(socketPath); + if (chdir(socketDir.c_str()) == -1) { + throw SysError(format("changing to socket directory '%1%'") % + socketDir); + } + + auto socketName = baseNameOf(socketPath); + auto addr = sockaddr_un{}; + addr.sun_family = AF_UNIX; + if (socketName.size() + 1 >= sizeof(addr.sun_path)) { + throw Error(format("socket name %1% is too long") % socketName); + } + strcpy(addr.sun_path, socketName.c_str()); + + if (connect(s, (struct sockaddr*)&addr, sizeof(addr)) == -1) { + throw SysError(format("cannot connect to daemon at %1%") % + socketPath); + } + + auto nfds = (s > STDIN_FILENO ? s : STDIN_FILENO) + 1; + while (true) { + fd_set fds; + FD_ZERO(&fds); + FD_SET(s, &fds); + FD_SET(STDIN_FILENO, &fds); + if (select(nfds, &fds, nullptr, nullptr, nullptr) == -1) { + throw SysError("waiting for data from client or server"); + } + if (FD_ISSET(s, &fds)) { + auto res = splice(s, nullptr, STDOUT_FILENO, nullptr, SSIZE_MAX, + SPLICE_F_MOVE); + if (res == -1) { + throw SysError("splicing data from daemon socket to stdout"); + } + if (res == 0) { + throw EndOfFile("unexpected EOF from daemon socket"); + } + } + if (FD_ISSET(STDIN_FILENO, &fds)) { + auto res = splice(STDIN_FILENO, nullptr, s, nullptr, SSIZE_MAX, + SPLICE_F_MOVE); + if (res == -1) { + throw SysError("splicing data from stdin to daemon socket"); + } + if (res == 0) { + return 0; + } + } + } + } else { + processConnection(true, "root", 0); + } + } else { + daemonLoop(argv); + } + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-daemon", _main); diff --git a/third_party/nix/src/nix-env/nix-env.cc b/third_party/nix/src/nix-env/nix-env.cc new file mode 100644 index 0000000000..e5b7697924 --- /dev/null +++ b/third_party/nix/src/nix-env/nix-env.cc @@ -0,0 +1,1538 @@ +#include <algorithm> +#include <cerrno> +#include <ctime> +#include <iostream> +#include <sstream> + +#include <glog/logging.h> +#include <sys/stat.h> +#include <sys/types.h> +#include <unistd.h> + +#include "attr-path.hh" +#include "common-eval-args.hh" +#include "derivations.hh" +#include "eval.hh" +#include "get-drvs.hh" +#include "globals.hh" +#include "json.hh" +#include "legacy.hh" +#include "names.hh" +#include "profiles.hh" +#include "shared.hh" +#include "store-api.hh" +#include "user-env.hh" +#include "util.hh" +#include "value-to-json.hh" +#include "xml-writer.hh" + +using namespace nix; +using std::cout; + +typedef enum { + srcNixExprDrvs, + srcNixExprs, + srcStorePaths, + srcProfile, + srcAttrPath, + srcUnknown +} InstallSourceType; + +struct InstallSourceInfo { + InstallSourceType type; + Path nixExprPath; /* for srcNixExprDrvs, srcNixExprs */ + Path profile; /* for srcProfile */ + string systemFilter; /* for srcNixExprDrvs */ + Bindings* autoArgs; +}; + +struct Globals { + InstallSourceInfo instSource; + Path profile; + std::shared_ptr<EvalState> state; + bool dryRun; + bool preserveInstalled; + bool removeAll; + string forceName; + bool prebuiltOnly; +}; + +using Operation = void (*)(Globals&, Strings, Strings); + +static string needArg(Strings::iterator& i, Strings& args, const string& arg) { + if (i == args.end()) { + throw UsageError(format("'%1%' requires an argument") % arg); + } + return *i++; +} + +static bool parseInstallSourceOptions(Globals& globals, Strings::iterator& i, + Strings& args, const string& arg) { + if (arg == "--from-expression" || arg == "-E") { + globals.instSource.type = srcNixExprs; + } else if (arg == "--from-profile") { + globals.instSource.type = srcProfile; + globals.instSource.profile = needArg(i, args, arg); + } else if (arg == "--attr" || arg == "-A") { + globals.instSource.type = srcAttrPath; + } else { + return false; + } + return true; +} + +static bool isNixExpr(const Path& path, struct stat& st) { + return S_ISREG(st.st_mode) || + (S_ISDIR(st.st_mode) && pathExists(path + "/default.nix")); +} + +static void getAllExprs(EvalState& state, const Path& path, StringSet& attrs, + Value& v) { + StringSet namesSorted; + for (auto& i : readDirectory(path)) { + namesSorted.insert(i.name); + } + + for (auto& i : namesSorted) { + /* Ignore the manifest.nix used by profiles. This is + necessary to prevent it from showing up in channels (which + are implemented using profiles). */ + if (i == "manifest.nix") { + continue; + } + + Path path2 = path + "/" + i; + + struct stat st; + if (stat(path2.c_str(), &st) == -1) { + continue; // ignore dangling symlinks in ~/.nix-defexpr + } + + if (isNixExpr(path2, st) && + (!S_ISREG(st.st_mode) || hasSuffix(path2, ".nix"))) { + /* Strip off the `.nix' filename suffix (if applicable), + otherwise the attribute cannot be selected with the + `-A' option. Useful if you want to stick a Nix + expression directly in ~/.nix-defexpr. */ + string attrName = i; + if (hasSuffix(attrName, ".nix")) { + attrName = string(attrName, 0, attrName.size() - 4); + } + if (attrs.find(attrName) != attrs.end()) { + LOG(WARNING) << "name collision in input Nix expressions, skipping '" + << path2 << "'"; + continue; + } + attrs.insert(attrName); + /* Load the expression on demand. */ + Value& vFun = state.getBuiltin("import"); + Value& vArg(*state.allocValue()); + mkString(vArg, path2); + mkApp(*state.allocAttr(v, state.symbols.Create(attrName)), vFun, vArg); + } else if (S_ISDIR(st.st_mode)) { + /* `path2' is a directory (with no default.nix in it); + recurse into it. */ + getAllExprs(state, path2, attrs, v); + } + } +} + +static void loadSourceExpr(EvalState& state, const Path& path, Value& v) { + struct stat st; + if (stat(path.c_str(), &st) == -1) { + throw SysError(format("getting information about '%1%'") % path); + } + + if (isNixExpr(path, st)) { + state.evalFile(path, v); + } + + /* The path is a directory. Put the Nix expressions in the + directory in a set, with the file name of each expression as + the attribute name. Recurse into subdirectories (but keep the + set flat, not nested, to make it easier for a user to have a + ~/.nix-defexpr directory that includes some system-wide + directory). */ + else if (S_ISDIR(st.st_mode)) { + state.mkAttrs(v, 1024); + state.mkList(*state.allocAttr(v, state.symbols.Create("_combineChannels")), + 0); + StringSet attrs; + getAllExprs(state, path, attrs, v); + } + + else { + throw Error("path '%s' is not a directory or a Nix expression", path); + } +} + +static void loadDerivations(EvalState& state, const Path& nixExprPath, + const string& systemFilter, Bindings& autoArgs, + const string& pathPrefix, DrvInfos& elems) { + Value vRoot; + loadSourceExpr(state, nixExprPath, vRoot); + + Value& v(*findAlongAttrPath(state, pathPrefix, autoArgs, vRoot)); + + getDerivations(state, v, pathPrefix, autoArgs, elems, true); + + /* Filter out all derivations not applicable to the current + system. */ + for (DrvInfos::iterator i = elems.begin(), j; i != elems.end(); i = j) { + j = i; + j++; + if (systemFilter != "*" && i->querySystem() != systemFilter) { + elems.erase(i); + } + } +} + +static long getPriority(EvalState& state, DrvInfo& drv) { + return drv.queryMetaInt("priority", 0); +} + +static long comparePriorities(EvalState& state, DrvInfo& drv1, DrvInfo& drv2) { + return getPriority(state, drv2) - getPriority(state, drv1); +} + +// FIXME: this function is rather slow since it checks a single path +// at a time. +static bool isPrebuilt(EvalState& state, DrvInfo& elem) { + Path path = elem.queryOutPath(); + if (state.store->isValidPath(path)) { + return true; + } + PathSet ps = state.store->querySubstitutablePaths({path}); + return ps.find(path) != ps.end(); +} + +static void checkSelectorUse(DrvNames& selectors) { + /* Check that all selectors have been used. */ + for (auto& i : selectors) { + if (i.hits == 0 && i.fullName != "*") { + throw Error(format("selector '%1%' matches no derivations") % i.fullName); + } + } +} + +static DrvInfos filterBySelector(EvalState& state, const DrvInfos& allElems, + const Strings& args, bool newestOnly) { + DrvNames selectors = drvNamesFromArgs(args); + if (selectors.empty()) { + selectors.push_back(DrvName("*")); + } + + DrvInfos elems; + set<unsigned int> done; + + for (auto& i : selectors) { + typedef list<std::pair<DrvInfo, unsigned int> > Matches; + Matches matches; + unsigned int n = 0; + for (auto j = allElems.begin(); j != allElems.end(); ++j, ++n) { + DrvName drvName(j->queryName()); + if (i.matches(drvName)) { + i.hits++; + matches.push_back(std::pair<DrvInfo, unsigned int>(*j, n)); + } + } + + /* If `newestOnly', if a selector matches multiple derivations + with the same name, pick the one matching the current + system. If there are still multiple derivations, pick the + one with the highest priority. If there are still multiple + derivations, pick the one with the highest version. + Finally, if there are still multiple derivations, + arbitrarily pick the first one. */ + if (newestOnly) { + /* Map from package names to derivations. */ + typedef map<string, std::pair<DrvInfo, unsigned int> > Newest; + Newest newest; + StringSet multiple; + + for (auto& j : matches) { + DrvName drvName(j.first.queryName()); + long d = 1; + + auto k = newest.find(drvName.name); + + if (k != newest.end()) { + d = j.first.querySystem() == k->second.first.querySystem() + ? 0 + : j.first.querySystem() == settings.thisSystem + ? 1 + : k->second.first.querySystem() == settings.thisSystem + ? -1 + : 0; + if (d == 0) { + d = comparePriorities(state, j.first, k->second.first); + } + if (d == 0) { + d = compareVersions(drvName.version, + DrvName(k->second.first.queryName()).version); + } + } + + if (d > 0) { + newest.erase(drvName.name); + newest.insert(Newest::value_type(drvName.name, j)); + multiple.erase(j.first.queryName()); + } else if (d == 0) { + multiple.insert(j.first.queryName()); + } + } + + matches.clear(); + for (auto& j : newest) { + if (multiple.find(j.second.first.queryName()) != multiple.end()) { + LOG(WARNING) << "warning: there are multiple derivations named '" + << j.second.first.queryName() + << "'; using the first one"; + } + matches.push_back(j.second); + } + } + + /* Insert only those elements in the final list that we + haven't inserted before. */ + for (auto& j : matches) { + if (done.find(j.second) == done.end()) { + done.insert(j.second); + elems.push_back(j.first); + } + } + } + + checkSelectorUse(selectors); + + return elems; +} + +static bool isPath(const string& s) { return s.find('/') != string::npos; } + +static void queryInstSources(EvalState& state, InstallSourceInfo& instSource, + const Strings& args, DrvInfos& elems, + bool newestOnly) { + InstallSourceType type = instSource.type; + if (type == srcUnknown && !args.empty() && isPath(args.front())) { + type = srcStorePaths; + } + + switch (type) { + /* Get the available user environment elements from the + derivations specified in a Nix expression, including only + those with names matching any of the names in `args'. */ + case srcUnknown: + case srcNixExprDrvs: { + /* Load the derivations from the (default or specified) + Nix expression. */ + DrvInfos allElems; + loadDerivations(state, instSource.nixExprPath, instSource.systemFilter, + *instSource.autoArgs, "", allElems); + + elems = filterBySelector(state, allElems, args, newestOnly); + + break; + } + + /* Get the available user environment elements from the Nix + expressions specified on the command line; these should be + functions that take the default Nix expression file as + argument, e.g., if the file is `./foo.nix', then the + argument `x: x.bar' is equivalent to `(x: x.bar) + (import ./foo.nix)' = `(import ./foo.nix).bar'. */ + case srcNixExprs: { + Value vArg; + loadSourceExpr(state, instSource.nixExprPath, vArg); + + for (auto& i : args) { + Expr* eFun = state.parseExprFromString(i, absPath(".")); + Value vFun; + Value vTmp; + state.eval(eFun, vFun); + mkApp(vTmp, vFun, vArg); + getDerivations(state, vTmp, "", *instSource.autoArgs, elems, true); + } + + break; + } + + /* The available user environment elements are specified as a + list of store paths (which may or may not be + derivations). */ + case srcStorePaths: { + for (auto& i : args) { + Path path = state.store->followLinksToStorePath(i); + + string name = baseNameOf(path); + string::size_type dash = name.find('-'); + if (dash != string::npos) { + name = string(name, dash + 1); + } + + DrvInfo elem(state, "", nullptr); + elem.setName(name); + + if (isDerivation(path)) { + elem.setDrvPath(path); + elem.setOutPath( + state.store->derivationFromPath(path).findOutput("out")); + if (name.size() >= drvExtension.size() && + string(name, name.size() - drvExtension.size()) == drvExtension) { + name = string(name, 0, name.size() - drvExtension.size()); + } + } else { + elem.setOutPath(path); + } + + elems.push_back(elem); + } + + break; + } + + /* Get the available user environment elements from another + user environment. These are then filtered as in the + `srcNixExprDrvs' case. */ + case srcProfile: { + elems = filterBySelector(state, queryInstalled(state, instSource.profile), + args, newestOnly); + break; + } + + case srcAttrPath: { + Value vRoot; + loadSourceExpr(state, instSource.nixExprPath, vRoot); + for (auto& i : args) { + Value& v(*findAlongAttrPath(state, i, *instSource.autoArgs, vRoot)); + getDerivations(state, v, "", *instSource.autoArgs, elems, true); + } + break; + } + } +} + +static void printMissing(EvalState& state, DrvInfos& elems) { + PathSet targets; + for (auto& i : elems) { + Path drvPath = i.queryDrvPath(); + if (!drvPath.empty()) { + targets.insert(drvPath); + } else { + targets.insert(i.queryOutPath()); + } + } + + printMissing(state.store, targets); +} + +static bool keep(DrvInfo& drv) { return drv.queryMetaBool("keep", false); } + +static void installDerivations(Globals& globals, const Strings& args, + const Path& profile) { + DLOG(INFO) << "installing derivations"; + + /* Get the set of user environment elements to be installed. */ + DrvInfos newElems; + DrvInfos newElemsTmp; + queryInstSources(*globals.state, globals.instSource, args, newElemsTmp, true); + + /* If --prebuilt-only is given, filter out source-only packages. */ + for (auto& i : newElemsTmp) { + if (!globals.prebuiltOnly || isPrebuilt(*globals.state, i)) { + newElems.push_back(i); + } + } + + StringSet newNames; + for (auto& i : newElems) { + /* `forceName' is a hack to get package names right in some + one-click installs, namely those where the name used in the + path is not the one we want (e.g., `java-front' versus + `java-front-0.9pre15899'). */ + if (!globals.forceName.empty()) { + i.setName(globals.forceName); + } + newNames.insert(DrvName(i.queryName()).name); + } + + while (true) { + string lockToken = optimisticLockProfile(profile); + + DrvInfos allElems(newElems); + + /* Add in the already installed derivations, unless they have + the same name as a to-be-installed element. */ + if (!globals.removeAll) { + DrvInfos installedElems = queryInstalled(*globals.state, profile); + + for (auto& i : installedElems) { + DrvName drvName(i.queryName()); + if (!globals.preserveInstalled && + newNames.find(drvName.name) != newNames.end() && !keep(i)) { + LOG(INFO) << "replacing old '" << i.queryName() << "'"; + } else { + allElems.push_back(i); + } + } + + for (auto& i : newElems) { + LOG(INFO) << "installing " << i.queryName(); + } + } + + printMissing(*globals.state, newElems); + + if (globals.dryRun) { + return; + } + + if (createUserEnv(*globals.state, allElems, profile, + settings.envKeepDerivations, lockToken)) { + break; + } + } +} + +static void opInstall(Globals& globals, Strings opFlags, Strings opArgs) { + for (auto i = opFlags.begin(); i != opFlags.end();) { + string arg = *i++; + if (parseInstallSourceOptions(globals, i, opFlags, arg)) { + ; + } else if (arg == "--preserve-installed" || arg == "-P") { + globals.preserveInstalled = true; + } else if (arg == "--remove-all" || arg == "-r") { + globals.removeAll = true; + } else { + throw UsageError(format("unknown flag '%1%'") % arg); + } + } + + installDerivations(globals, opArgs, globals.profile); +} + +typedef enum { utLt, utLeq, utEq, utAlways } UpgradeType; + +static void upgradeDerivations(Globals& globals, const Strings& args, + UpgradeType upgradeType) { + DLOG(INFO) << "upgrading derivations"; + + /* Upgrade works as follows: we take all currently installed + derivations, and for any derivation matching any selector, look + for a derivation in the input Nix expression that has the same + name and a higher version number. */ + + while (true) { + string lockToken = optimisticLockProfile(globals.profile); + + DrvInfos installedElems = queryInstalled(*globals.state, globals.profile); + + /* Fetch all derivations from the input file. */ + DrvInfos availElems; + queryInstSources(*globals.state, globals.instSource, args, availElems, + false); + + /* Go through all installed derivations. */ + DrvInfos newElems; + for (auto& i : installedElems) { + DrvName drvName(i.queryName()); + + try { + if (keep(i)) { + newElems.push_back(i); + continue; + } + + /* Find the derivation in the input Nix expression + with the same name that satisfies the version + constraints specified by upgradeType. If there are + multiple matches, take the one with the highest + priority. If there are still multiple matches, + take the one with the highest version. + Do not upgrade if it would decrease the priority. */ + auto bestElem = availElems.end(); + string bestVersion; + for (auto j = availElems.begin(); j != availElems.end(); ++j) { + if (comparePriorities(*globals.state, i, *j) > 0) { + continue; + } + DrvName newName(j->queryName()); + if (newName.name == drvName.name) { + int d = compareVersions(drvName.version, newName.version); + if ((upgradeType == utLt && d < 0) || + (upgradeType == utLeq && d <= 0) || + (upgradeType == utEq && d == 0) || upgradeType == utAlways) { + long d2 = -1; + if (bestElem != availElems.end()) { + d2 = comparePriorities(*globals.state, *bestElem, *j); + if (d2 == 0) { + d2 = compareVersions(bestVersion, newName.version); + } + } + if (d2 < 0 && + (!globals.prebuiltOnly || isPrebuilt(*globals.state, *j))) { + bestElem = j; + bestVersion = newName.version; + } + } + } + } + + if (bestElem != availElems.end() && + i.queryOutPath() != bestElem->queryOutPath()) { + const char* action = + compareVersions(drvName.version, bestVersion) <= 0 + ? "upgrading" + : "downgrading"; + LOG(INFO) << action << " '" << i.queryName() << "' to '" + << bestElem->queryName() << "'"; + newElems.push_back(*bestElem); + } else { + newElems.push_back(i); + } + + } catch (Error& e) { + e.addPrefix( + fmt("while trying to find an upgrade for '%s':\n", i.queryName())); + throw; + } + } + + printMissing(*globals.state, newElems); + + if (globals.dryRun) { + return; + } + + if (createUserEnv(*globals.state, newElems, globals.profile, + settings.envKeepDerivations, lockToken)) { + break; + } + } +} + +static void opUpgrade(Globals& globals, Strings opFlags, Strings opArgs) { + UpgradeType upgradeType = utLt; + for (auto i = opFlags.begin(); i != opFlags.end();) { + string arg = *i++; + if (parseInstallSourceOptions(globals, i, opFlags, arg)) { + ; + } else if (arg == "--lt") { + upgradeType = utLt; + } else if (arg == "--leq") { + upgradeType = utLeq; + } else if (arg == "--eq") { + upgradeType = utEq; + } else if (arg == "--always") { + upgradeType = utAlways; + } else { + throw UsageError(format("unknown flag '%1%'") % arg); + } + } + + upgradeDerivations(globals, opArgs, upgradeType); +} + +static void setMetaFlag(EvalState& state, DrvInfo& drv, const string& name, + const string& value) { + Value* v = state.allocValue(); + mkString(*v, value.c_str()); + drv.setMeta(name, v); +} + +static void opSetFlag(Globals& globals, Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + if (opArgs.size() < 2) { + throw UsageError("not enough arguments to '--set-flag'"); + } + + auto arg = opArgs.begin(); + string flagName = *arg++; + string flagValue = *arg++; + DrvNames selectors = drvNamesFromArgs(Strings(arg, opArgs.end())); + + while (true) { + string lockToken = optimisticLockProfile(globals.profile); + + DrvInfos installedElems = queryInstalled(*globals.state, globals.profile); + + /* Update all matching derivations. */ + for (auto& i : installedElems) { + DrvName drvName(i.queryName()); + for (auto& j : selectors) { + if (j.matches(drvName)) { + LOG(INFO) << "setting flag on '" << i.queryName() << "'"; + j.hits++; + setMetaFlag(*globals.state, i, flagName, flagValue); + break; + } + } + } + + checkSelectorUse(selectors); + + /* Write the new user environment. */ + if (createUserEnv(*globals.state, installedElems, globals.profile, + settings.envKeepDerivations, lockToken)) { + break; + } + } +} + +static void opSet(Globals& globals, Strings opFlags, Strings opArgs) { + auto store2 = globals.state->store.dynamic_pointer_cast<LocalFSStore>(); + if (!store2) { + throw Error("--set is not supported for this Nix store"); + } + + for (auto i = opFlags.begin(); i != opFlags.end();) { + string arg = *i++; + if (parseInstallSourceOptions(globals, i, opFlags, arg)) { + ; + } else { + throw UsageError(format("unknown flag '%1%'") % arg); + } + } + + DrvInfos elems; + queryInstSources(*globals.state, globals.instSource, opArgs, elems, true); + + if (elems.size() != 1) { + throw Error("--set requires exactly one derivation"); + } + + DrvInfo& drv(elems.front()); + + if (!globals.forceName.empty()) { + drv.setName(globals.forceName); + } + + if (!drv.queryDrvPath().empty()) { + PathSet paths = {drv.queryDrvPath()}; + printMissing(globals.state->store, paths); + if (globals.dryRun) { + return; + } + globals.state->store->buildPaths( + paths, globals.state->repair != 0u ? bmRepair : bmNormal); + } else { + printMissing(globals.state->store, {drv.queryOutPath()}); + if (globals.dryRun) { + return; + } + globals.state->store->ensurePath(drv.queryOutPath()); + } + + DLOG(INFO) << "switching to new user environment"; + Path generation = createGeneration(ref<LocalFSStore>(store2), globals.profile, + drv.queryOutPath()); + switchLink(globals.profile, generation); +} + +static void uninstallDerivations(Globals& globals, Strings& selectors, + Path& profile) { + while (true) { + string lockToken = optimisticLockProfile(profile); + + DrvInfos installedElems = queryInstalled(*globals.state, profile); + DrvInfos newElems; + + for (auto& i : installedElems) { + DrvName drvName(i.queryName()); + bool found = false; + for (auto& j : selectors) { + /* !!! the repeated calls to followLinksToStorePath() + are expensive, should pre-compute them. */ + if ((isPath(j) && + i.queryOutPath() == + globals.state->store->followLinksToStorePath(j)) || + DrvName(j).matches(drvName)) { + LOG(INFO) << "uninstalling '" << i.queryName() << "'"; + found = true; + break; + } + } + if (!found) { + newElems.push_back(i); + } + } + + if (globals.dryRun) { + return; + } + + if (createUserEnv(*globals.state, newElems, profile, + settings.envKeepDerivations, lockToken)) { + break; + } + } +} + +static void opUninstall(Globals& globals, Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + uninstallDerivations(globals, opArgs, globals.profile); +} + +static bool cmpChars(char a, char b) { return toupper(a) < toupper(b); } + +static bool cmpElemByName(const DrvInfo& a, const DrvInfo& b) { + auto a_name = a.queryName(); + auto b_name = b.queryName(); + return lexicographical_compare(a_name.begin(), a_name.end(), b_name.begin(), + b_name.end(), cmpChars); +} + +using Table = list<Strings>; + +void printTable(Table& table) { + auto nrColumns = !table.empty() ? table.front().size() : 0; + + vector<size_t> widths; + widths.resize(nrColumns); + + for (auto& i : table) { + assert(i.size() == nrColumns); + Strings::iterator j; + size_t column; + for (j = i.begin(), column = 0; j != i.end(); ++j, ++column) { + if (j->size() > widths[column]) { + widths[column] = j->size(); + } + } + } + + for (auto& i : table) { + Strings::iterator j; + size_t column; + for (j = i.begin(), column = 0; j != i.end(); ++j, ++column) { + string s = *j; + replace(s.begin(), s.end(), '\n', ' '); + cout << s; + if (column < nrColumns - 1) { + cout << string(widths[column] - s.size() + 2, ' '); + } + } + cout << std::endl; + } +} + +/* This function compares the version of an element against the + versions in the given set of elements. `cvLess' means that only + lower versions are in the set, `cvEqual' means that at most an + equal version is in the set, and `cvGreater' means that there is at + least one element with a higher version in the set. `cvUnavail' + means that there are no elements with the same name in the set. */ + +typedef enum { cvLess, cvEqual, cvGreater, cvUnavail } VersionDiff; + +static VersionDiff compareVersionAgainstSet(const DrvInfo& elem, + const DrvInfos& elems, + string& version) { + DrvName name(elem.queryName()); + + VersionDiff diff = cvUnavail; + version = "?"; + + for (auto& i : elems) { + DrvName name2(i.queryName()); + if (name.name == name2.name) { + int d = compareVersions(name.version, name2.version); + if (d < 0) { + diff = cvGreater; + version = name2.version; + } else if (diff != cvGreater && d == 0) { + diff = cvEqual; + version = name2.version; + } else if (diff != cvGreater && diff != cvEqual && d > 0) { + diff = cvLess; + if (version.empty() || compareVersions(version, name2.version) < 0) { + version = name2.version; + } + } + } + } + + return diff; +} + +static void queryJSON(Globals& globals, vector<DrvInfo>& elems) { + JSONObject topObj(cout, true); + for (auto& i : elems) { + JSONObject pkgObj = topObj.object(i.attrPath); + + auto drvName = DrvName(i.queryName()); + pkgObj.attr("name", drvName.fullName); + pkgObj.attr("pname", drvName.name); + pkgObj.attr("version", drvName.version); + pkgObj.attr("system", i.querySystem()); + + JSONObject metaObj = pkgObj.object("meta"); + StringSet metaNames = i.queryMetaNames(); + for (auto& j : metaNames) { + auto placeholder = metaObj.placeholder(j); + Value* v = i.queryMeta(j); + if (v == nullptr) { + LOG(ERROR) << "derivation '" << i.queryName() + << "' has invalid meta attribute '" << j << "'"; + placeholder.write(nullptr); + } else { + PathSet context; + printValueAsJSON(*globals.state, true, *v, placeholder, context); + } + } + } +} + +static void opQuery(Globals& globals, Strings opFlags, Strings opArgs) { + Strings remaining; + string attrPath; + + bool printStatus = false; + bool printName = true; + bool printAttrPath = false; + bool printSystem = false; + bool printDrvPath = false; + bool printOutPath = false; + bool printDescription = false; + bool printMeta = false; + bool compareVersions = false; + bool xmlOutput = false; + bool jsonOutput = false; + + enum { sInstalled, sAvailable } source = sInstalled; + + settings.readOnlyMode = true; /* makes evaluation a bit faster */ + + for (auto i = opFlags.begin(); i != opFlags.end();) { + string arg = *i++; + if (arg == "--status" || arg == "-s") { + printStatus = true; + } else if (arg == "--no-name") { + printName = false; + } else if (arg == "--system") { + printSystem = true; + } else if (arg == "--description") { + printDescription = true; + } else if (arg == "--compare-versions" || arg == "-c") { + compareVersions = true; + } else if (arg == "--drv-path") { + printDrvPath = true; + } else if (arg == "--out-path") { + printOutPath = true; + } else if (arg == "--meta") { + printMeta = true; + } else if (arg == "--installed") { + source = sInstalled; + } else if (arg == "--available" || arg == "-a") { + source = sAvailable; + } else if (arg == "--xml") { + xmlOutput = true; + } else if (arg == "--json") { + jsonOutput = true; + } else if (arg == "--attr-path" || arg == "-P") { + printAttrPath = true; + } else if (arg == "--attr" || arg == "-A") { + attrPath = needArg(i, opFlags, arg); + } else { + throw UsageError(format("unknown flag '%1%'") % arg); + } + } + + /* Obtain derivation information from the specified source. */ + DrvInfos availElems; + DrvInfos installedElems; + + if (source == sInstalled || compareVersions || printStatus) { + installedElems = queryInstalled(*globals.state, globals.profile); + } + + if (source == sAvailable || compareVersions) { + loadDerivations(*globals.state, globals.instSource.nixExprPath, + globals.instSource.systemFilter, + *globals.instSource.autoArgs, attrPath, availElems); + } + + DrvInfos elems_ = filterBySelector( + *globals.state, source == sInstalled ? installedElems : availElems, + opArgs, false); + + DrvInfos& otherElems(source == sInstalled ? availElems : installedElems); + + /* Sort them by name. */ + /* !!! */ + vector<DrvInfo> elems; + for (auto& i : elems_) { + elems.push_back(i); + } + sort(elems.begin(), elems.end(), cmpElemByName); + + /* We only need to know the installed paths when we are querying + the status of the derivation. */ + PathSet installed; /* installed paths */ + + if (printStatus) { + for (auto& i : installedElems) { + installed.insert(i.queryOutPath()); + } + } + + /* Query which paths have substitutes. */ + PathSet validPaths; + PathSet substitutablePaths; + if (printStatus || globals.prebuiltOnly) { + PathSet paths; + for (auto& i : elems) { + try { + paths.insert(i.queryOutPath()); + } catch (AssertionError& e) { + DLOG(WARNING) << "skipping derivation named '" << i.queryName() + << "' which gives an assertion failure"; + i.setFailed(); + } + } + validPaths = globals.state->store->queryValidPaths(paths); + substitutablePaths = globals.state->store->querySubstitutablePaths(paths); + } + + /* Print the desired columns, or XML output. */ + if (jsonOutput) { + queryJSON(globals, elems); + return; + } + + bool tty = isatty(STDOUT_FILENO) != 0; + RunPager pager; + + Table table; + std::ostringstream dummy; + XMLWriter xml(true, *(xmlOutput ? &cout : &dummy)); + XMLOpenElement xmlRoot(xml, "items"); + + for (auto& i : elems) { + try { + if (i.hasFailed()) { + continue; + } + + // Activity act(*logger, lvlDebug, format("outputting query result '%1%'") + // % i.attrPath); + + if (globals.prebuiltOnly && + validPaths.find(i.queryOutPath()) == validPaths.end() && + substitutablePaths.find(i.queryOutPath()) == + substitutablePaths.end()) { + continue; + } + + /* For table output. */ + Strings columns; + + /* For XML output. */ + XMLAttrs attrs; + + if (printStatus) { + Path outPath = i.queryOutPath(); + bool hasSubs = + substitutablePaths.find(outPath) != substitutablePaths.end(); + bool isInstalled = installed.find(outPath) != installed.end(); + bool isValid = validPaths.find(outPath) != validPaths.end(); + if (xmlOutput) { + attrs["installed"] = isInstalled ? "1" : "0"; + attrs["valid"] = isValid ? "1" : "0"; + attrs["substitutable"] = hasSubs ? "1" : "0"; + } else { + columns.push_back((string)(isInstalled ? "I" : "-") + + (isValid ? "P" : "-") + (hasSubs ? "S" : "-")); + } + } + + if (xmlOutput) { + attrs["attrPath"] = i.attrPath; + } else if (printAttrPath) { + columns.push_back(i.attrPath); + } + + if (xmlOutput) { + auto drvName = DrvName(i.queryName()); + attrs["name"] = drvName.fullName; + attrs["pname"] = drvName.name; + attrs["version"] = drvName.version; + } else if (printName) { + columns.push_back(i.queryName()); + } + + if (compareVersions) { + /* Compare this element against the versions of the + same named packages in either the set of available + elements, or the set of installed elements. !!! + This is O(N * M), should be O(N * lg M). */ + string version; + VersionDiff diff = compareVersionAgainstSet(i, otherElems, version); + + char ch; + switch (diff) { + case cvLess: + ch = '>'; + break; + case cvEqual: + ch = '='; + break; + case cvGreater: + ch = '<'; + break; + case cvUnavail: + ch = '-'; + break; + default: + abort(); + } + + if (xmlOutput) { + if (diff != cvUnavail) { + attrs["versionDiff"] = ch; + attrs["maxComparedVersion"] = version; + } + } else { + string column = (string) "" + ch + " " + version; + if (diff == cvGreater && tty) { + column = ANSI_RED + column + ANSI_NORMAL; + } + columns.push_back(column); + } + } + + if (xmlOutput) { + if (!i.querySystem().empty()) { + attrs["system"] = i.querySystem(); + } + } else if (printSystem) { + columns.push_back(i.querySystem()); + } + + if (printDrvPath) { + string drvPath = i.queryDrvPath(); + if (xmlOutput) { + if (!drvPath.empty()) { + attrs["drvPath"] = drvPath; + } + } else { + columns.push_back(drvPath.empty() ? "-" : drvPath); + } + } + + if (printOutPath && !xmlOutput) { + DrvInfo::Outputs outputs = i.queryOutputs(); + string s; + for (auto& j : outputs) { + if (!s.empty()) { + s += ';'; + } + if (j.first != "out") { + s += j.first; + s += "="; + } + s += j.second; + } + columns.push_back(s); + } + + if (printDescription) { + string descr = i.queryMetaString("description"); + if (xmlOutput) { + if (!descr.empty()) { + attrs["description"] = descr; + } + } else { + columns.push_back(descr); + } + } + + if (xmlOutput) { + if (printOutPath || printMeta) { + XMLOpenElement item(xml, "item", attrs); + if (printOutPath) { + DrvInfo::Outputs outputs = i.queryOutputs(); + for (auto& j : outputs) { + XMLAttrs attrs2; + attrs2["name"] = j.first; + attrs2["path"] = j.second; + xml.writeEmptyElement("output", attrs2); + } + } + if (printMeta) { + StringSet metaNames = i.queryMetaNames(); + for (auto& j : metaNames) { + XMLAttrs attrs2; + attrs2["name"] = j; + Value* v = i.queryMeta(j); + if (v == nullptr) { + LOG(ERROR) << "derivation '" << i.queryName() + << "' has invalid meta attribute '" << j << "'"; + } else { + if (v->type == tString) { + attrs2["type"] = "string"; + attrs2["value"] = v->string.s; + xml.writeEmptyElement("meta", attrs2); + } else if (v->type == tInt) { + attrs2["type"] = "int"; + attrs2["value"] = (format("%1%") % v->integer).str(); + xml.writeEmptyElement("meta", attrs2); + } else if (v->type == tFloat) { + attrs2["type"] = "float"; + attrs2["value"] = (format("%1%") % v->fpoint).str(); + xml.writeEmptyElement("meta", attrs2); + } else if (v->type == tBool) { + attrs2["type"] = "bool"; + attrs2["value"] = v->boolean ? "true" : "false"; + xml.writeEmptyElement("meta", attrs2); + } else if (v->isList()) { + attrs2["type"] = "strings"; + XMLOpenElement m(xml, "meta", attrs2); + for (unsigned int j = 0; j < v->listSize(); ++j) { + if (v->listElems()[j]->type != tString) { + continue; + } + XMLAttrs attrs3; + attrs3["value"] = v->listElems()[j]->string.s; + xml.writeEmptyElement("string", attrs3); + } + } else if (v->type == tAttrs) { + attrs2["type"] = "strings"; + XMLOpenElement m(xml, "meta", attrs2); + Bindings& attrs = *v->attrs; + for (auto& [name, a] : attrs) { + if (a.value->type != tString) { + continue; + } + XMLAttrs attrs3; + attrs3["type"] = name; + attrs3["value"] = a.value->string.s; + xml.writeEmptyElement("string", attrs3); + } + } + } + } + } + } else { + xml.writeEmptyElement("item", attrs); + } + } else { + table.push_back(columns); + } + + cout.flush(); + + } catch (AssertionError& e) { + DLOG(WARNING) << "skipping derivation named '" << i.queryName() + << "' which gives an assertion failure"; + } catch (Error& e) { + e.addPrefix( + fmt("while querying the derivation named '%1%':\n", i.queryName())); + throw; + } + } + + if (!xmlOutput) { + printTable(table); + } +} + +static void opSwitchProfile(Globals& globals, Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + if (opArgs.size() != 1) { + throw UsageError(format("exactly one argument expected")); + } + + Path profile = absPath(opArgs.front()); + Path profileLink = getHome() + "/.nix-profile"; + + switchLink(profileLink, profile); +} + +static const int prevGen = -2; + +static void switchGeneration(Globals& globals, int dstGen) { + PathLocks lock; + lockProfile(lock, globals.profile); + + int curGen; + Generations gens = findGenerations(globals.profile, curGen); + + Generation dst; + for (auto& i : gens) { + if ((dstGen == prevGen && i.number < curGen) || + (dstGen >= 0 && i.number == dstGen)) { + dst = i; + } + } + + if (!dst) { + if (dstGen == prevGen) { + throw Error(format("no generation older than the current (%1%) exists") % + curGen); + } + throw Error(format("generation %1% does not exist") % dstGen); + } + + LOG(INFO) << "switching from generation " << curGen << " to " << dst.number; + + if (globals.dryRun) { + return; + } + + switchLink(globals.profile, dst.path); +} + +static void opSwitchGeneration(Globals& globals, Strings opFlags, + Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + if (opArgs.size() != 1) { + throw UsageError(format("exactly one argument expected")); + } + + int dstGen; + if (!string2Int(opArgs.front(), dstGen)) { + throw UsageError(format("expected a generation number")); + } + + switchGeneration(globals, dstGen); +} + +static void opRollback(Globals& globals, Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + if (!opArgs.empty()) { + throw UsageError(format("no arguments expected")); + } + + switchGeneration(globals, prevGen); +} + +static void opListGenerations(Globals& globals, Strings opFlags, + Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + if (!opArgs.empty()) { + throw UsageError(format("no arguments expected")); + } + + PathLocks lock; + lockProfile(lock, globals.profile); + + int curGen; + Generations gens = findGenerations(globals.profile, curGen); + + RunPager pager; + + for (auto& i : gens) { + tm t; + if (localtime_r(&i.creationTime, &t) == nullptr) { + throw Error("cannot convert time"); + } + cout << format("%|4| %|4|-%|02|-%|02| %|02|:%|02|:%|02| %||\n") % + i.number % (t.tm_year + 1900) % (t.tm_mon + 1) % t.tm_mday % + t.tm_hour % t.tm_min % t.tm_sec % + (i.number == curGen ? "(current)" : ""); + } +} + +static void opDeleteGenerations(Globals& globals, Strings opFlags, + Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError(format("unknown flag '%1%'") % opFlags.front()); + } + + if (opArgs.size() == 1 && opArgs.front() == "old") { + deleteOldGenerations(globals.profile, globals.dryRun); + } else if (opArgs.size() == 1 && opArgs.front().find('d') != string::npos) { + deleteGenerationsOlderThan(globals.profile, opArgs.front(), globals.dryRun); + } else if (opArgs.size() == 1 && opArgs.front().find('+') != string::npos) { + if (opArgs.front().size() < 2) { + throw Error(format("invalid number of generations ‘%1%’") % + opArgs.front()); + } + string str_max = string(opArgs.front(), 1, opArgs.front().size()); + int max; + if (!string2Int(str_max, max) || max == 0) { + throw Error(format("invalid number of generations to keep ‘%1%’") % + opArgs.front()); + } + deleteGenerationsGreaterThan(globals.profile, max, globals.dryRun); + } else { + std::set<unsigned int> gens; + for (auto& i : opArgs) { + unsigned int n; + if (!string2Int(i, n)) { + throw UsageError(format("invalid generation number '%1%'") % i); + } + gens.insert(n); + } + deleteGenerations(globals.profile, gens, globals.dryRun); + } +} + +static void opVersion(Globals& globals, Strings opFlags, Strings opArgs) { + printVersion("nix-env"); +} + +static int _main(int argc, char** argv) { + { + Strings opFlags; + Strings opArgs; + Operation op = nullptr; + RepairFlag repair = NoRepair; + string file; + + Globals globals; + + globals.instSource.type = srcUnknown; + globals.instSource.nixExprPath = getHome() + "/.nix-defexpr"; + globals.instSource.systemFilter = "*"; + + if (!pathExists(globals.instSource.nixExprPath)) { + try { + createDirs(globals.instSource.nixExprPath); + replaceSymlink(fmt("%s/profiles/per-user/%s/channels", + settings.nixStateDir, getUserName()), + globals.instSource.nixExprPath + "/channels"); + if (getuid() != 0) { + replaceSymlink( + fmt("%s/profiles/per-user/root/channels", settings.nixStateDir), + globals.instSource.nixExprPath + "/channels_root"); + } + } catch (Error&) { + } + } + + globals.dryRun = false; + globals.preserveInstalled = false; + globals.removeAll = false; + globals.prebuiltOnly = false; + + struct MyArgs : LegacyArgs, MixEvalArgs { + using LegacyArgs::LegacyArgs; + }; + + MyArgs myArgs(baseNameOf(argv[0]), [&](Strings::iterator& arg, + const Strings::iterator& end) { + Operation oldOp = op; + + if (*arg == "--help") { + showManPage("nix-env"); + } else if (*arg == "--version") { + op = opVersion; + } else if (*arg == "--install" || *arg == "-i") { + op = opInstall; + } else if (*arg == + "--force-name") { // undocumented flag for nix-install-package + globals.forceName = getArg(*arg, arg, end); + } else if (*arg == "--uninstall" || *arg == "-e") { + op = opUninstall; + } else if (*arg == "--upgrade" || *arg == "-u") { + op = opUpgrade; + } else if (*arg == "--set-flag") { + op = opSetFlag; + } else if (*arg == "--set") { + op = opSet; + } else if (*arg == "--query" || *arg == "-q") { + op = opQuery; + } else if (*arg == "--profile" || *arg == "-p") { + globals.profile = absPath(getArg(*arg, arg, end)); + } else if (*arg == "--file" || *arg == "-f") { + file = getArg(*arg, arg, end); + } else if (*arg == "--switch-profile" || *arg == "-S") { + op = opSwitchProfile; + } else if (*arg == "--switch-generation" || *arg == "-G") { + op = opSwitchGeneration; + } else if (*arg == "--rollback") { + op = opRollback; + } else if (*arg == "--list-generations") { + op = opListGenerations; + } else if (*arg == "--delete-generations") { + op = opDeleteGenerations; + } else if (*arg == "--dry-run") { + LOG(INFO) << "(dry run; not doing anything)"; + globals.dryRun = true; + } else if (*arg == "--system-filter") { + globals.instSource.systemFilter = getArg(*arg, arg, end); + } else if (*arg == "--prebuilt-only" || *arg == "-b") { + globals.prebuiltOnly = true; + } else if (*arg == "--repair") { + repair = Repair; + } else if (*arg != "" && arg->at(0) == '-') { + opFlags.push_back(*arg); + /* FIXME: hacky */ + if (*arg == "--from-profile" || + (op == opQuery && (*arg == "--attr" || *arg == "-A"))) { + opFlags.push_back(getArg(*arg, arg, end)); + } + } else { + opArgs.push_back(*arg); + } + + if ((oldOp != nullptr) && oldOp != op) { + throw UsageError("only one operation may be specified"); + } + + return true; + }); + + myArgs.parseCmdline(argvToStrings(argc, argv)); + + initPlugins(); + + if (op == nullptr) { + throw UsageError("no operation specified"); + } + + auto store = openStore(); + + globals.state = + std::shared_ptr<EvalState>(new EvalState(myArgs.searchPath, store)); + globals.state->repair = repair; + + if (!file.empty()) { + globals.instSource.nixExprPath = lookupFileArg(*globals.state, file); + } + + globals.instSource.autoArgs = myArgs.getAutoArgs(*globals.state); + + if (globals.profile.empty()) { + globals.profile = getEnv("NIX_PROFILE", ""); + } + + if (globals.profile.empty()) { + Path profileLink = getHome() + "/.nix-profile"; + try { + if (!pathExists(profileLink)) { + replaceSymlink(getuid() == 0 + ? settings.nixStateDir + "/profiles/default" + : fmt("%s/profiles/per-user/%s/profile", + settings.nixStateDir, getUserName()), + profileLink); + } + globals.profile = absPath(readLink(profileLink), dirOf(profileLink)); + } catch (Error&) { + globals.profile = profileLink; + } + } + + op(globals, opFlags, opArgs); + + globals.state->printStats(); + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-env", _main); diff --git a/third_party/nix/src/nix-env/user-env.cc b/third_party/nix/src/nix-env/user-env.cc new file mode 100644 index 0000000000..2ca56ed966 --- /dev/null +++ b/third_party/nix/src/nix-env/user-env.cc @@ -0,0 +1,166 @@ +#include "user-env.hh" + +#include <glog/logging.h> + +#include "derivations.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "globals.hh" +#include "profiles.hh" +#include "shared.hh" +#include "store-api.hh" +#include "util.hh" + +namespace nix { + +DrvInfos queryInstalled(EvalState& state, const Path& userEnv) { + DrvInfos elems; + Path manifestFile = userEnv + "/manifest.nix"; + if (pathExists(manifestFile)) { + Value v; + state.evalFile(manifestFile, v); + Bindings& bindings(*Bindings::NewGC()); + getDerivations(state, v, "", bindings, elems, false); + } + return elems; +} + +bool createUserEnv(EvalState& state, DrvInfos& elems, const Path& profile, + bool keepDerivations, const string& lockToken) { + /* Build the components in the user environment, if they don't + exist already. */ + PathSet drvsToBuild; + for (auto& i : elems) { + if (!i.queryDrvPath().empty()) { + drvsToBuild.insert(i.queryDrvPath()); + } + } + + DLOG(INFO) << "building user environment dependencies"; + state.store->buildPaths(drvsToBuild, + state.repair != 0u ? bmRepair : bmNormal); + + /* Construct the whole top level derivation. */ + PathSet references; + Value manifest; + state.mkList(manifest, elems.size()); + unsigned int n = 0; + for (auto& i : elems) { + /* Create a pseudo-derivation containing the name, system, + output paths, and optionally the derivation path, as well + as the meta attributes. */ + Path drvPath = keepDerivations ? i.queryDrvPath() : ""; + + Value& v(*state.allocValue()); + manifest.listElems()[n++] = &v; + state.mkAttrs(v, 16); + + mkString(*state.allocAttr(v, state.sType), "derivation"); + mkString(*state.allocAttr(v, state.sName), i.queryName()); + auto system = i.querySystem(); + if (!system.empty()) { + mkString(*state.allocAttr(v, state.sSystem), system); + } + mkString(*state.allocAttr(v, state.sOutPath), i.queryOutPath()); + if (!drvPath.empty()) { + mkString(*state.allocAttr(v, state.sDrvPath), i.queryDrvPath()); + } + + // Copy each output meant for installation. + DrvInfo::Outputs outputs = i.queryOutputs(true); + Value& vOutputs = *state.allocAttr(v, state.sOutputs); + state.mkList(vOutputs, outputs.size()); + unsigned int m = 0; + for (auto& j : outputs) { + mkString(*(vOutputs.listElems()[m++] = state.allocValue()), j.first); + Value& vOutputs = *state.allocAttr(v, state.symbols.Create(j.first)); + state.mkAttrs(vOutputs, 2); + mkString(*state.allocAttr(vOutputs, state.sOutPath), j.second); + + /* This is only necessary when installing store paths, e.g., + `nix-env -i /nix/store/abcd...-foo'. */ + state.store->addTempRoot(j.second); + state.store->ensurePath(j.second); + + references.insert(j.second); + } + + // Copy the meta attributes. + Value& vMeta = *state.allocAttr(v, state.sMeta); + state.mkAttrs(vMeta, 16); + StringSet metaNames = i.queryMetaNames(); + for (auto& j : metaNames) { + Value* v = i.queryMeta(j); + if (v == nullptr) { + continue; + } + vMeta.attrs->push_back(Attr(state.symbols.Create(j), v)); + } + + if (!drvPath.empty()) { + references.insert(drvPath); + } + } + + /* Also write a copy of the list of user environment elements to + the store; we need it for future modifications of the + environment. */ + Path manifestFile = state.store->addTextToStore( + "env-manifest.nix", (format("%1%") % manifest).str(), references); + + /* Get the environment builder expression. */ + Value envBuilder; + state.evalFile(state.findFile("nix/buildenv.nix"), envBuilder); + + /* Construct a Nix expression that calls the user environment + builder with the manifest as argument. */ + Value args; + Value topLevel; + state.mkAttrs(args, 3); + mkString(*state.allocAttr(args, state.symbols.Create("manifest")), + manifestFile, {manifestFile}); + args.attrs->push_back(Attr(state.symbols.Create("derivations"), &manifest)); + mkApp(topLevel, envBuilder, args); + + /* Evaluate it. */ + DLOG(INFO) << "evaluating user environment builder"; + state.forceValue(topLevel); + PathSet context; + Attr& aDrvPath(topLevel.attrs->find(state.sDrvPath)->second); + Path topLevelDrv = + state.coerceToPath(aDrvPath.pos != nullptr ? *(aDrvPath.pos) : noPos, + *(aDrvPath.value), context); + Attr& aOutPath(topLevel.attrs->find(state.sOutPath)->second); + Path topLevelOut = + state.coerceToPath(aOutPath.pos != nullptr ? *(aOutPath.pos) : noPos, + *(aOutPath.value), context); + + /* Realise the resulting store expression. */ + DLOG(INFO) << "building user environment"; + state.store->buildPaths({topLevelDrv}, + state.repair != 0u ? bmRepair : bmNormal); + + /* Switch the current user environment to the output path. */ + auto store2 = state.store.dynamic_pointer_cast<LocalFSStore>(); + + if (store2) { + PathLocks lock; + lockProfile(lock, profile); + + Path lockTokenCur = optimisticLockProfile(profile); + if (lockToken != lockTokenCur) { + LOG(WARNING) << "profile '" << profile + << "' changed while we were busy; restarting"; + return false; + } + + DLOG(INFO) << "switching to new user environment"; + Path generation = + createGeneration(ref<LocalFSStore>(store2), profile, topLevelOut); + switchLink(profile, generation); + } + + return true; +} + +} // namespace nix diff --git a/third_party/nix/src/nix-env/user-env.hh b/third_party/nix/src/nix-env/user-env.hh new file mode 100644 index 0000000000..6111b21c35 --- /dev/null +++ b/third_party/nix/src/nix-env/user-env.hh @@ -0,0 +1,12 @@ +#pragma once + +#include "get-drvs.hh" + +namespace nix { + +DrvInfos queryInstalled(EvalState& state, const Path& userEnv); + +bool createUserEnv(EvalState& state, DrvInfos& elems, const Path& profile, + bool keepDerivations, const string& lockToken); + +} // namespace nix diff --git a/third_party/nix/src/nix-instantiate/nix-instantiate.cc b/third_party/nix/src/nix-instantiate/nix-instantiate.cc new file mode 100644 index 0000000000..95e5341ade --- /dev/null +++ b/third_party/nix/src/nix-instantiate/nix-instantiate.cc @@ -0,0 +1,207 @@ +#include <iostream> +#include <map> + +#include "attr-path.hh" +#include "common-eval-args.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "get-drvs.hh" +#include "globals.hh" +#include "legacy.hh" +#include "shared.hh" +#include "store-api.hh" +#include "util.hh" +#include "value-to-json.hh" +#include "value-to-xml.hh" + +using namespace nix; + +static Path gcRoot; +static int rootNr = 0; +static bool indirectRoot = false; + +enum OutputKind { okPlain, okXML, okJSON }; + +void processExpr(EvalState& state, const Strings& attrPaths, bool parseOnly, + bool strict, Bindings& autoArgs, bool evalOnly, + OutputKind output, bool location, Expr* e) { + if (parseOnly) { + std::cout << format("%1%\n") % *e; + return; + } + + Value vRoot; + state.eval(e, vRoot); + + for (auto& i : attrPaths) { + Value& v(*findAlongAttrPath(state, i, autoArgs, vRoot)); + state.forceValue(v); + + PathSet context; + if (evalOnly) { + Value vRes; + if (autoArgs.empty()) { + vRes = v; + } else { + state.autoCallFunction(autoArgs, v, vRes); + } + if (output == okXML) { + printValueAsXML(state, strict, location, vRes, std::cout, context); + } else if (output == okJSON) { + printValueAsJSON(state, strict, vRes, std::cout, context); + } else { + if (strict) { + state.forceValueDeep(vRes); + } + std::cout << vRes << std::endl; + } + } else { + DrvInfos drvs; + getDerivations(state, v, "", autoArgs, drvs, false); + for (auto& i : drvs) { + Path drvPath = i.queryDrvPath(); + + /* What output do we want? */ + string outputName = i.queryOutputName(); + if (outputName.empty()) { + throw Error( + format("derivation '%1%' lacks an 'outputName' attribute ") % + drvPath); + } + + if (gcRoot.empty()) { + printGCWarning(); + } else { + Path rootName = indirectRoot ? absPath(gcRoot) : gcRoot; + if (++rootNr > 1) { + rootName += "-" + std::to_string(rootNr); + } + auto store2 = state.store.dynamic_pointer_cast<LocalFSStore>(); + if (store2) { + drvPath = store2->addPermRoot(drvPath, rootName, indirectRoot); + } + } + std::cout << format("%1%%2%\n") % drvPath % + (outputName != "out" ? "!" + outputName : ""); + } + } + } +} + +static int _main(int argc, char** argv) { + { + Strings files; + bool readStdin = false; + bool fromArgs = false; + bool findFile = false; + bool evalOnly = false; + bool parseOnly = false; + OutputKind outputKind = okPlain; + bool xmlOutputSourceLocation = true; + bool strict = false; + Strings attrPaths; + bool wantsReadWrite = false; + RepairFlag repair = NoRepair; + + struct MyArgs : LegacyArgs, MixEvalArgs { + using LegacyArgs::LegacyArgs; + }; + + MyArgs myArgs(baseNameOf(argv[0]), + [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + showManPage("nix-instantiate"); + } else if (*arg == "--version") { + printVersion("nix-instantiate"); + } else if (*arg == "-") { + readStdin = true; + } else if (*arg == "--expr" || *arg == "-E") { + fromArgs = true; + } else if (*arg == "--eval" || *arg == "--eval-only") { + evalOnly = true; + } else if (*arg == "--read-write-mode") { + wantsReadWrite = true; + } else if (*arg == "--parse" || *arg == "--parse-only") { + parseOnly = evalOnly = true; + } else if (*arg == "--find-file") { + findFile = true; + } else if (*arg == "--attr" || *arg == "-A") { + attrPaths.push_back(getArg(*arg, arg, end)); + } else if (*arg == "--add-root") { + gcRoot = getArg(*arg, arg, end); + } else if (*arg == "--indirect") { + indirectRoot = true; + } else if (*arg == "--xml") { + outputKind = okXML; + } else if (*arg == "--json") { + outputKind = okJSON; + } else if (*arg == "--no-location") { + xmlOutputSourceLocation = false; + } else if (*arg == "--strict") { + strict = true; + } else if (*arg == "--repair") { + repair = Repair; + } else if (*arg == "--dry-run") { + settings.readOnlyMode = true; + } else if (*arg != "" && arg->at(0) == '-') { + return false; + } else { + files.push_back(*arg); + } + return true; + }); + + myArgs.parseCmdline(argvToStrings(argc, argv)); + + initPlugins(); + + if (evalOnly && !wantsReadWrite) { + settings.readOnlyMode = true; + } + + auto store = openStore(); + + auto state = std::make_unique<EvalState>(myArgs.searchPath, store); + state->repair = repair; + + Bindings& autoArgs = *myArgs.getAutoArgs(*state); + + if (attrPaths.empty()) { + attrPaths = {""}; + } + + if (findFile) { + for (auto& i : files) { + Path p = state->findFile(i); + if (p.empty()) { + throw Error(format("unable to find '%1%'") % i); + } + std::cout << p << std::endl; + } + return 0; + } + + if (readStdin) { + Expr* e = state->parseStdin(); + processExpr(*state, attrPaths, parseOnly, strict, autoArgs, evalOnly, + outputKind, xmlOutputSourceLocation, e); + } else if (files.empty() && !fromArgs) { + files.push_back("./default.nix"); + } + + for (auto& i : files) { + Expr* e = fromArgs + ? state->parseExprFromString(i, absPath(".")) + : state->parseExprFromFile(resolveExprPath( + state->checkSourcePath(lookupFileArg(*state, i)))); + processExpr(*state, attrPaths, parseOnly, strict, autoArgs, evalOnly, + outputKind, xmlOutputSourceLocation, e); + } + + state->printStats(); + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-instantiate", _main); diff --git a/third_party/nix/src/nix-prefetch-url/nix-prefetch-url.cc b/third_party/nix/src/nix-prefetch-url/nix-prefetch-url.cc new file mode 100644 index 0000000000..fa88dc9bc6 --- /dev/null +++ b/third_party/nix/src/nix-prefetch-url/nix-prefetch-url.cc @@ -0,0 +1,252 @@ +#include <iostream> + +#include <fcntl.h> +#include <glog/logging.h> +#include <sys/stat.h> +#include <sys/types.h> + +#include "attr-path.hh" +#include "common-eval-args.hh" +#include "download.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "finally.hh" +#include "hash.hh" +#include "legacy.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +/* If ‘uri’ starts with ‘mirror://’, then resolve it using the list of + mirrors defined in Nixpkgs. */ +string resolveMirrorUri(EvalState& state, string uri) { + if (string(uri, 0, 9) != "mirror://") { + return uri; + } + + string s(uri, 9); + auto p = s.find('/'); + if (p == string::npos) { + throw Error("invalid mirror URI"); + } + string mirrorName(s, 0, p); + + Value vMirrors; + state.eval( + state.parseExprFromString( + "import <nixpkgs/pkgs/build-support/fetchurl/mirrors.nix>", "."), + vMirrors); + state.forceAttrs(vMirrors); + + auto mirrorList = vMirrors.attrs->find(state.symbols.Create(mirrorName)); + if (mirrorList == vMirrors.attrs->end()) { + throw Error(format("unknown mirror name '%1%'") % mirrorName); + } + state.forceList(*mirrorList->second.value); + + if (mirrorList->second.value->listSize() < 1) { + throw Error(format("mirror URI '%1%' did not expand to anything") % uri); + } + + string mirror = state.forceString(*mirrorList->second.value->listElems()[0]); + return mirror + (hasSuffix(mirror, "/") ? "" : "/") + string(s, p + 1); +} + +static int _main(int argc, char** argv) { + { + HashType ht = htSHA256; + std::vector<string> args; + bool printPath = !getEnv("PRINT_PATH").empty(); + bool fromExpr = false; + string attrPath; + bool unpack = false; + string name; + + struct MyArgs : LegacyArgs, MixEvalArgs { + using LegacyArgs::LegacyArgs; + }; + + MyArgs myArgs(baseNameOf(argv[0]), + [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + showManPage("nix-prefetch-url"); + } else if (*arg == "--version") { + printVersion("nix-prefetch-url"); + } else if (*arg == "--type") { + string s = getArg(*arg, arg, end); + ht = parseHashType(s); + if (ht == htUnknown) { + throw UsageError(format("unknown hash type '%1%'") % s); + } + } else if (*arg == "--print-path") { + printPath = true; + } else if (*arg == "--attr" || *arg == "-A") { + fromExpr = true; + attrPath = getArg(*arg, arg, end); + } else if (*arg == "--unpack") { + unpack = true; + } else if (*arg == "--name") { + name = getArg(*arg, arg, end); + } else if (*arg != "" && arg->at(0) == '-') { + return false; + } else { + args.push_back(*arg); + } + return true; + }); + + myArgs.parseCmdline(argvToStrings(argc, argv)); + + initPlugins(); + + if (args.size() > 2) { + throw UsageError("too many arguments"); + } + + auto store = openStore(); + auto state = std::make_unique<EvalState>(myArgs.searchPath, store); + + Bindings& autoArgs = *myArgs.getAutoArgs(*state); + + /* If -A is given, get the URI from the specified Nix + expression. */ + string uri; + if (!fromExpr) { + if (args.empty()) { + throw UsageError("you must specify a URI"); + } + uri = args[0]; + } else { + Path path = + resolveExprPath(lookupFileArg(*state, args.empty() ? "." : args[0])); + Value vRoot; + state->evalFile(path, vRoot); + Value& v(*findAlongAttrPath(*state, attrPath, autoArgs, vRoot)); + state->forceAttrs(v); + + /* Extract the URI. */ + auto attr = v.attrs->find(state->symbols.Create("urls")); + if (attr == v.attrs->end()) { + throw Error("attribute set does not contain a 'urls' attribute"); + } + state->forceList(*attr->second.value); + if (attr->second.value->listSize() < 1) { + throw Error("'urls' list is empty"); + } + uri = state->forceString(*attr->second.value->listElems()[0]); + + /* Extract the hash mode. */ + attr = v.attrs->find(state->symbols.Create("outputHashMode")); + if (attr == v.attrs->end()) { + LOG(WARNING) << "this does not look like a fetchurl call"; + } else { + unpack = state->forceString(*attr->second.value) == "recursive"; + } + + /* Extract the name. */ + if (name.empty()) { + attr = v.attrs->find(state->symbols.Create("name")); + if (attr != v.attrs->end()) { + name = state->forceString(*attr->second.value); + } + } + } + + /* Figure out a name in the Nix store. */ + if (name.empty()) { + name = baseNameOf(uri); + } + if (name.empty()) { + throw Error(format("cannot figure out file name for '%1%'") % uri); + } + + /* If an expected hash is given, the file may already exist in + the store. */ + Hash hash; + Hash expectedHash(ht); + Path storePath; + if (args.size() == 2) { + expectedHash = Hash(args[1], ht); + storePath = store->makeFixedOutputPath(unpack, expectedHash, name); + if (store->isValidPath(storePath)) { + hash = expectedHash; + } else { + storePath.clear(); + } + } + + if (storePath.empty()) { + auto actualUri = resolveMirrorUri(*state, uri); + + AutoDelete tmpDir(createTempDir(), true); + Path tmpFile = (Path)tmpDir + "/tmp"; + + /* Download the file. */ + { + AutoCloseFD fd = + open(tmpFile.c_str(), O_WRONLY | O_CREAT | O_EXCL, 0600); + if (!fd) { + throw SysError("creating temporary file '%s'", tmpFile); + } + + FdSink sink(fd.get()); + + DownloadRequest req(actualUri); + req.decompress = false; + getDownloader()->download(std::move(req), sink); + } + + /* Optionally unpack the file. */ + if (unpack) { + LOG(INFO) << "unpacking..."; + Path unpacked = (Path)tmpDir + "/unpacked"; + createDirs(unpacked); + if (hasSuffix(baseNameOf(uri), ".zip")) { + runProgram("unzip", true, {"-qq", tmpFile, "-d", unpacked}); + } else { + // FIXME: this requires GNU tar for decompression. + runProgram("tar", true, {"xf", tmpFile, "-C", unpacked}); + } + + /* If the archive unpacks to a single file/directory, then use + that as the top-level. */ + auto entries = readDirectory(unpacked); + if (entries.size() == 1) { + tmpFile = unpacked + "/" + entries[0].name; + } else { + tmpFile = unpacked; + } + } + + /* FIXME: inefficient; addToStore() will also hash + this. */ + hash = unpack ? hashPath(ht, tmpFile).first : hashFile(ht, tmpFile); + + if (expectedHash != Hash(ht) && expectedHash != hash) { + throw Error(format("hash mismatch for '%1%'") % uri); + } + + /* Copy the file to the Nix store. FIXME: if RemoteStore + implemented addToStoreFromDump() and downloadFile() + supported a sink, we could stream the download directly + into the Nix store. */ + storePath = store->addToStore(name, tmpFile, unpack, ht); + + assert(storePath == store->makeFixedOutputPath(unpack, hash, name)); + } + + if (!printPath) { + LOG(INFO) << "path is '" << storePath << "'"; + } + + std::cout << printHash16or32(hash) << std::endl; + if (printPath) { + std::cout << storePath << std::endl; + } + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-prefetch-url", _main); diff --git a/third_party/nix/src/nix-store/dotgraph.cc b/third_party/nix/src/nix-store/dotgraph.cc new file mode 100644 index 0000000000..0186a7b22e --- /dev/null +++ b/third_party/nix/src/nix-store/dotgraph.cc @@ -0,0 +1,141 @@ +#include "dotgraph.hh" + +#include <iostream> + +#include "store-api.hh" +#include "util.hh" + +using std::cout; + +namespace nix { + +static string dotQuote(const string& s) { return "\"" + s + "\""; } + +static string nextColour() { + static int n = 0; + static string colours[] = {"black", "red", "green", + "blue", "magenta", "burlywood"}; + return colours[n++ % (sizeof(colours) / sizeof(string))]; +} + +static string makeEdge(const string& src, const string& dst) { + format f = format("%1% -> %2% [color = %3%];\n") % dotQuote(src) % + dotQuote(dst) % dotQuote(nextColour()); + return f.str(); +} + +static string makeNode(const string& id, const string& label, + const string& colour) { + format f = format( + "%1% [label = %2%, shape = box, " + "style = filled, fillcolor = %3%];\n") % + dotQuote(id) % dotQuote(label) % dotQuote(colour); + return f.str(); +} + +static string symbolicName(const string& path) { + string p = baseNameOf(path); + return string(p, p.find('-') + 1); +} + +#if 0 +string pathLabel(const Path & nePath, const string & elemPath) +{ + return (string) nePath + "-" + elemPath; +} + + +void printClosure(const Path & nePath, const StoreExpr & fs) +{ + PathSet workList(fs.closure.roots); + PathSet doneSet; + + for (PathSet::iterator i = workList.begin(); i != workList.end(); ++i) { + cout << makeEdge(pathLabel(nePath, *i), nePath); + } + + while (!workList.empty()) { + Path path = *(workList.begin()); + workList.erase(path); + + if (doneSet.find(path) == doneSet.end()) { + doneSet.insert(path); + + ClosureElems::const_iterator elem = fs.closure.elems.find(path); + if (elem == fs.closure.elems.end()) + throw Error(format("bad closure, missing path '%1%'") % path); + + for (StringSet::const_iterator i = elem->second.refs.begin(); + i != elem->second.refs.end(); ++i) + { + workList.insert(*i); + cout << makeEdge(pathLabel(nePath, *i), pathLabel(nePath, path)); + } + + cout << makeNode(pathLabel(nePath, path), + symbolicName(path), "#ff0000"); + } + } +} +#endif + +void printDotGraph(const ref<Store>& store, const PathSet& roots) { + PathSet workList(roots); + PathSet doneSet; + + cout << "digraph G {\n"; + + while (!workList.empty()) { + Path path = *(workList.begin()); + workList.erase(path); + + if (doneSet.find(path) != doneSet.end()) { + continue; + } + doneSet.insert(path); + + cout << makeNode(path, symbolicName(path), "#ff0000"); + + for (auto& p : store->queryPathInfo(path)->references) { + if (p != path) { + workList.insert(p); + cout << makeEdge(p, path); + } + } + +#if 0 + StoreExpr ne = storeExprFromPath(path); + + string label, colour; + + if (ne.type == StoreExpr::neDerivation) { + for (PathSet::iterator i = ne.derivation.inputs.begin(); + i != ne.derivation.inputs.end(); ++i) + { + workList.insert(*i); + cout << makeEdge(*i, path); + } + + label = "derivation"; + colour = "#00ff00"; + for (StringPairs::iterator i = ne.derivation.env.begin(); + i != ne.derivation.env.end(); ++i) + if (i->first == "name") { label = i->second; } + } + + else if (ne.type == StoreExpr::neClosure) { + label = "<closure>"; + colour = "#00ffff"; + printClosure(path, ne); + } + + else abort(); + + cout << makeNode(path, label, colour); +#endif + } + + cout << "}\n"; +} + +} // namespace nix diff --git a/third_party/nix/src/nix-store/dotgraph.hh b/third_party/nix/src/nix-store/dotgraph.hh new file mode 100644 index 0000000000..20fc357b1b --- /dev/null +++ b/third_party/nix/src/nix-store/dotgraph.hh @@ -0,0 +1,11 @@ +#pragma once + +#include "types.hh" + +namespace nix { + +class Store; + +void printDotGraph(const ref<Store>& store, const PathSet& roots); + +} // namespace nix diff --git a/third_party/nix/src/nix-store/graphml.cc b/third_party/nix/src/nix-store/graphml.cc new file mode 100644 index 0000000000..a1a16cc8f2 --- /dev/null +++ b/third_party/nix/src/nix-store/graphml.cc @@ -0,0 +1,80 @@ +#include "graphml.hh" + +#include <iostream> + +#include "derivations.hh" +#include "store-api.hh" +#include "util.hh" + +using std::cout; + +namespace nix { + +static inline const string& xmlQuote(const string& s) { + // Luckily, store paths shouldn't contain any character that needs to be + // quoted. + return s; +} + +static string symbolicName(const string& path) { + string p = baseNameOf(path); + return string(p, p.find('-') + 1); +} + +static string makeEdge(const string& src, const string& dst) { + return fmt(" <edge source=\"%1%\" target=\"%2%\"/>\n", xmlQuote(src), + xmlQuote(dst)); +} + +static string makeNode(const ValidPathInfo& info) { + return fmt( + " <node id=\"%1%\">\n" + " <data key=\"narSize\">%2%</data>\n" + " <data key=\"name\">%3%</data>\n" + " <data key=\"type\">%4%</data>\n" + " </node>\n", + info.path, info.narSize, symbolicName(info.path), + (isDerivation(info.path) ? "derivation" : "output-path")); +} + +void printGraphML(const ref<Store>& store, const PathSet& roots) { + PathSet workList(roots); + PathSet doneSet; + std::pair<PathSet::iterator, bool> ret; + + cout << "<?xml version='1.0' encoding='utf-8'?>\n" + << "<graphml xmlns='http://graphml.graphdrawing.org/xmlns'\n" + << " xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance'\n" + << " " + "xsi:schemaLocation='http://graphml.graphdrawing.org/xmlns/1.0/" + "graphml.xsd'>\n" + << "<key id='narSize' for='node' attr.name='narSize' attr.type='int'/>" + << "<key id='name' for='node' attr.name='name' attr.type='string'/>" + << "<key id='type' for='node' attr.name='type' attr.type='string'/>" + << "<graph id='G' edgedefault='directed'>\n"; + + while (!workList.empty()) { + Path path = *(workList.begin()); + workList.erase(path); + + ret = doneSet.insert(path); + if (!ret.second) { + continue; + } + + ValidPathInfo info = *(store->queryPathInfo(path)); + cout << makeNode(info); + + for (auto& p : store->queryPathInfo(path)->references) { + if (p != path) { + workList.insert(p); + cout << makeEdge(path, p); + } + } + } + + cout << "</graph>\n"; + cout << "</graphml>\n"; +} + +} // namespace nix diff --git a/third_party/nix/src/nix-store/graphml.hh b/third_party/nix/src/nix-store/graphml.hh new file mode 100644 index 0000000000..199421acb2 --- /dev/null +++ b/third_party/nix/src/nix-store/graphml.hh @@ -0,0 +1,11 @@ +#pragma once + +#include "types.hh" + +namespace nix { + +class Store; + +void printGraphML(const ref<Store>& store, const PathSet& roots); + +} // namespace nix diff --git a/third_party/nix/src/nix-store/nix-store.cc b/third_party/nix/src/nix-store/nix-store.cc new file mode 100644 index 0000000000..40d6f01cd9 --- /dev/null +++ b/third_party/nix/src/nix-store/nix-store.cc @@ -0,0 +1,1295 @@ +#include <algorithm> +#include <cstdio> +#include <iostream> + +#include <fcntl.h> +#include <glog/logging.h> +#include <sys/stat.h> +#include <sys/types.h> + +#include "archive.hh" +#include "derivations.hh" +#include "dotgraph.hh" +#include "globals.hh" +#include "graphml.hh" +#include "legacy.hh" +#include "local-store.hh" +#include "monitor-fd.hh" +#include "serve-protocol.hh" +#include "shared.hh" +#include "util.hh" +#include "worker-protocol.hh" + +#if HAVE_SODIUM +#include <sodium.h> +#endif + +using namespace nix; +using std::cin; +using std::cout; + +// TODO(tazjin): clang-tidy's performance lints don't like this, but +// the automatic fixes fail (it seems that some of the ops want to own +// the args for whatever reason) +using Operation = void (*)(Strings, Strings); + +static Path gcRoot; +static int rootNr = 0; +static bool indirectRoot = false; +static bool noOutput = false; +static std::shared_ptr<Store> store; + +ref<LocalStore> ensureLocalStore() { + auto store2 = std::dynamic_pointer_cast<LocalStore>(store); + if (!store2) { + throw Error("you don't have sufficient rights to use this command"); + } + return ref<LocalStore>(store2); +} + +static Path useDeriver(Path path) { + if (isDerivation(path)) { + return path; + } + Path drvPath = store->queryPathInfo(path)->deriver; + if (drvPath.empty()) { + throw Error(format("deriver of path '%1%' is not known") % path); + } + return drvPath; +} + +/* Realise the given path. For a derivation that means build it; for + other paths it means ensure their validity. */ +static PathSet realisePath(Path path, bool build = true) { + DrvPathWithOutputs p = parseDrvPathWithOutputs(path); + + auto store2 = std::dynamic_pointer_cast<LocalFSStore>(store); + + if (isDerivation(p.first)) { + if (build) { + store->buildPaths({path}); + } + Derivation drv = store->derivationFromPath(p.first); + rootNr++; + + if (p.second.empty()) { + for (auto& i : drv.outputs) { + p.second.insert(i.first); + } + } + + PathSet outputs; + for (auto& j : p.second) { + auto i = drv.outputs.find(j); + if (i == drv.outputs.end()) { + throw Error( + format("derivation '%1%' does not have an output named '%2%'") % + p.first % j); + } + Path outPath = i->second.path; + if (store2) { + if (gcRoot.empty()) { + printGCWarning(); + } else { + Path rootName = gcRoot; + if (rootNr > 1) { + rootName += "-" + std::to_string(rootNr); + } + if (i->first != "out") { + rootName += "-" + i->first; + } + outPath = store2->addPermRoot(outPath, rootName, indirectRoot); + } + } + outputs.insert(outPath); + } + return outputs; + } + + if (build) { + store->ensurePath(path); + } else if (!store->isValidPath(path)) { + throw Error(format("path '%1%' does not exist and cannot be created") % + path); + } + if (store2) { + if (gcRoot.empty()) { + printGCWarning(); + } else { + Path rootName = gcRoot; + rootNr++; + if (rootNr > 1) { + rootName += "-" + std::to_string(rootNr); + } + path = store2->addPermRoot(path, rootName, indirectRoot); + } + } + return {path}; +} + +/* Realise the given paths. */ +static void opRealise(Strings opFlags, Strings opArgs) { + bool dryRun = false; + BuildMode buildMode = bmNormal; + bool ignoreUnknown = false; + + for (auto& i : opFlags) { + if (i == "--dry-run") { + dryRun = true; + } else if (i == "--repair") { + buildMode = bmRepair; + } else if (i == "--check") { + buildMode = bmCheck; + } else if (i == "--ignore-unknown") { + ignoreUnknown = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + Paths paths; + for (auto& i : opArgs) { + DrvPathWithOutputs p = parseDrvPathWithOutputs(i); + paths.push_back(makeDrvPathWithOutputs( + store->followLinksToStorePath(p.first), p.second)); + } + + unsigned long long downloadSize; + unsigned long long narSize; + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + store->queryMissing(PathSet(paths.begin(), paths.end()), willBuild, + willSubstitute, unknown, downloadSize, narSize); + + if (ignoreUnknown) { + Paths paths2; + for (auto& i : paths) { + if (unknown.find(i) == unknown.end()) { + paths2.push_back(i); + } + } + paths = paths2; + unknown = PathSet(); + } + + if (settings.printMissing) { + printMissing(ref<Store>(store), willBuild, willSubstitute, unknown, + downloadSize, narSize); + } + + if (dryRun) { + return; + } + + /* Build all paths at the same time to exploit parallelism. */ + store->buildPaths(PathSet(paths.begin(), paths.end()), buildMode); + + if (!ignoreUnknown) { + for (auto& i : paths) { + PathSet paths = realisePath(i, false); + if (!noOutput) { + for (auto& j : paths) { + cout << format("%1%\n") % j; + } + } + } + } +} + +/* Add files to the Nix store and print the resulting paths. */ +static void opAdd(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + + for (auto& i : opArgs) { + cout << format("%1%\n") % store->addToStore(baseNameOf(i), i); + } +} + +/* Preload the output of a fixed-output derivation into the Nix + store. */ +static void opAddFixed(Strings opFlags, Strings opArgs) { + bool recursive = false; + + for (auto& i : opFlags) { + if (i == "--recursive") { + recursive = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + if (opArgs.empty()) { + throw UsageError("first argument must be hash algorithm"); + } + + HashType hashAlgo = parseHashType(opArgs.front()); + opArgs.pop_front(); + + for (auto& i : opArgs) { + cout << format("%1%\n") % + store->addToStore(baseNameOf(i), i, recursive, hashAlgo); + } +} + +/* Hack to support caching in `nix-prefetch-url'. */ +static void opPrintFixedPath(Strings opFlags, Strings opArgs) { + bool recursive = false; + + for (auto i : opFlags) { + if (i == "--recursive") { + recursive = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + if (opArgs.size() != 3) { + throw UsageError(format("'--print-fixed-path' requires three arguments")); + } + + auto i = opArgs.begin(); + HashType hashAlgo = parseHashType(*i++); + string hash = *i++; + string name = *i++; + + cout << format("%1%\n") % + store->makeFixedOutputPath(recursive, Hash(hash, hashAlgo), name); +} + +static PathSet maybeUseOutputs(const Path& storePath, bool useOutput, + bool forceRealise) { + if (forceRealise) { + realisePath(storePath); + } + if (useOutput && isDerivation(storePath)) { + Derivation drv = store->derivationFromPath(storePath); + PathSet outputs; + for (auto& i : drv.outputs) { + outputs.insert(i.second.path); + } + return outputs; + } + return {storePath}; +} + +/* Some code to print a tree representation of a derivation dependency + graph. Topological sorting is used to keep the tree relatively + flat. */ + +const string treeConn = "+---"; +const string treeLine = "| "; +const string treeNull = " "; + +static void printTree(const Path& path, const string& firstPad, + const string& tailPad, PathSet& done) { + if (done.find(path) != done.end()) { + cout << format("%1%%2% [...]\n") % firstPad % path; + return; + } + done.insert(path); + + cout << format("%1%%2%\n") % firstPad % path; + + auto references = store->queryPathInfo(path)->references; + + /* Topologically sort under the relation A < B iff A \in + closure(B). That is, if derivation A is an (possibly indirect) + input of B, then A is printed first. This has the effect of + flattening the tree, preventing deeply nested structures. */ + Paths sorted = store->topoSortPaths(references); + reverse(sorted.begin(), sorted.end()); + + for (auto i = sorted.begin(); i != sorted.end(); ++i) { + auto j = i; + ++j; + printTree(*i, tailPad + treeConn, + j == sorted.end() ? tailPad + treeNull : tailPad + treeLine, + done); + } +} + +/* Perform various sorts of queries. */ +static void opQuery(Strings opFlags, Strings opArgs) { + enum QueryType { + qDefault, + qOutputs, + qRequisites, + qReferences, + qReferrers, + qReferrersClosure, + qDeriver, + qBinding, + qHash, + qSize, + qTree, + qGraph, + qGraphML, + qResolve, + qRoots + }; + QueryType query = qDefault; + bool useOutput = false; + bool includeOutputs = false; + bool forceRealise = false; + string bindingName; + + for (auto& i : opFlags) { + QueryType prev = query; + if (i == "--outputs") { + query = qOutputs; + } else if (i == "--requisites" || i == "-R") { + query = qRequisites; + } else if (i == "--references") { + query = qReferences; + } else if (i == "--referrers" || i == "--referers") { + query = qReferrers; + } else if (i == "--referrers-closure" || i == "--referers-closure") { + query = qReferrersClosure; + } else if (i == "--deriver" || i == "-d") { + query = qDeriver; + } else if (i == "--binding" || i == "-b") { + if (opArgs.empty()) { + throw UsageError("expected binding name"); + } + bindingName = opArgs.front(); + opArgs.pop_front(); + query = qBinding; + } else if (i == "--hash") { + query = qHash; + } else if (i == "--size") { + query = qSize; + } else if (i == "--tree") { + query = qTree; + } else if (i == "--graph") { + query = qGraph; + } else if (i == "--graphml") { + query = qGraphML; + } else if (i == "--resolve") { + query = qResolve; + } else if (i == "--roots") { + query = qRoots; + } else if (i == "--use-output" || i == "-u") { + useOutput = true; + } else if (i == "--force-realise" || i == "--force-realize" || i == "-f") { + forceRealise = true; + } else if (i == "--include-outputs") { + includeOutputs = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + if (prev != qDefault && prev != query) { + throw UsageError(format("query type '%1%' conflicts with earlier flag") % + i); + } + } + + if (query == qDefault) { + query = qOutputs; + } + + RunPager pager; + + switch (query) { + case qOutputs: { + for (auto& i : opArgs) { + i = store->followLinksToStorePath(i); + if (forceRealise) { + realisePath(i); + } + Derivation drv = store->derivationFromPath(i); + for (auto& j : drv.outputs) { + cout << format("%1%\n") % j.second.path; + } + } + break; + } + + case qRequisites: + case qReferences: + case qReferrers: + case qReferrersClosure: { + PathSet paths; + for (auto& i : opArgs) { + PathSet ps = maybeUseOutputs(store->followLinksToStorePath(i), + useOutput, forceRealise); + for (auto& j : ps) { + if (query == qRequisites) { + store->computeFSClosure(j, paths, false, includeOutputs); + } else if (query == qReferences) { + for (auto& p : store->queryPathInfo(j)->references) { + paths.insert(p); + } + } else if (query == qReferrers) { + store->queryReferrers(j, paths); + } else if (query == qReferrersClosure) { + store->computeFSClosure(j, paths, true); + } + } + } + Paths sorted = store->topoSortPaths(paths); + for (auto i = sorted.rbegin(); i != sorted.rend(); ++i) { + cout << format("%s\n") % *i; + } + break; + } + + case qDeriver: + for (auto& i : opArgs) { + Path deriver = + store->queryPathInfo(store->followLinksToStorePath(i))->deriver; + cout << format("%1%\n") % + (deriver.empty() ? "unknown-deriver" : deriver); + } + break; + + case qBinding: + for (auto& i : opArgs) { + Path path = useDeriver(store->followLinksToStorePath(i)); + Derivation drv = store->derivationFromPath(path); + auto j = drv.env.find(bindingName); + if (j == drv.env.end()) { + throw Error( + format( + "derivation '%1%' has no environment binding named '%2%'") % + path % bindingName); + } + cout << format("%1%\n") % j->second; + } + break; + + case qHash: + case qSize: + for (auto& i : opArgs) { + PathSet paths = maybeUseOutputs(store->followLinksToStorePath(i), + useOutput, forceRealise); + for (auto& j : paths) { + auto info = store->queryPathInfo(j); + if (query == qHash) { + assert(info->narHash.type == htSHA256); + cout << fmt("%s\n", info->narHash.to_string(Base32)); + } else if (query == qSize) { + cout << fmt("%d\n", info->narSize); + } + } + } + break; + + case qTree: { + PathSet done; + for (auto& i : opArgs) { + printTree(store->followLinksToStorePath(i), "", "", done); + } + break; + } + + case qGraph: { + PathSet roots; + for (auto& i : opArgs) { + PathSet paths = maybeUseOutputs(store->followLinksToStorePath(i), + useOutput, forceRealise); + roots.insert(paths.begin(), paths.end()); + } + printDotGraph(ref<Store>(store), roots); + break; + } + + case qGraphML: { + PathSet roots; + for (auto& i : opArgs) { + PathSet paths = maybeUseOutputs(store->followLinksToStorePath(i), + useOutput, forceRealise); + roots.insert(paths.begin(), paths.end()); + } + printGraphML(ref<Store>(store), roots); + break; + } + + case qResolve: { + for (auto& i : opArgs) { + cout << format("%1%\n") % store->followLinksToStorePath(i); + } + break; + } + + case qRoots: { + PathSet referrers; + for (auto& i : opArgs) { + store->computeFSClosure( + maybeUseOutputs(store->followLinksToStorePath(i), useOutput, + forceRealise), + referrers, true, settings.gcKeepOutputs, + settings.gcKeepDerivations); + } + Roots roots = store->findRoots(false); + for (auto& [target, links] : roots) { + if (referrers.find(target) != referrers.end()) { + for (auto& link : links) { + cout << format("%1% -> %2%\n") % link % target; + } + } + } + break; + } + + default: + abort(); + } +} + +static void opPrintEnv(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + if (opArgs.size() != 1) { + throw UsageError("'--print-env' requires one derivation store path"); + } + + Path drvPath = opArgs.front(); + Derivation drv = store->derivationFromPath(drvPath); + + /* Print each environment variable in the derivation in a format + that can be sourced by the shell. */ + for (auto& i : drv.env) { + cout << format("export %1%; %1%=%2%\n") % i.first % shellEscape(i.second); + } + + /* Also output the arguments. This doesn't preserve whitespace in + arguments. */ + cout << "export _args; _args='"; + bool first = true; + for (auto& i : drv.args) { + if (!first) { + cout << ' '; + } + first = false; + cout << shellEscape(i); + } + cout << "'\n"; +} + +static void opReadLog(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + + RunPager pager; + + for (auto& i : opArgs) { + auto path = store->followLinksToStorePath(i); + auto log = store->getBuildLog(path); + if (!log) { + throw Error("build log of derivation '%s' is not available", path); + } + std::cout << *log; + } +} + +static void opDumpDB(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + if (!opArgs.empty()) { + for (auto& i : opArgs) { + i = store->followLinksToStorePath(i); + } + for (auto& i : opArgs) { + cout << store->makeValidityRegistration({i}, true, true); + } + } else { + PathSet validPaths = store->queryAllValidPaths(); + for (auto& i : validPaths) { + cout << store->makeValidityRegistration({i}, true, true); + } + } +} + +static void registerValidity(bool reregister, bool hashGiven, + bool canonicalise) { + ValidPathInfos infos; + + while (true) { + ValidPathInfo info = decodeValidPathInfo(cin, hashGiven); + if (info.path.empty()) { + break; + } + if (!store->isValidPath(info.path) || reregister) { + /* !!! races */ + if (canonicalise) { + canonicalisePathMetaData(info.path, -1); + } + if (!hashGiven) { + HashResult hash = hashPath(htSHA256, info.path); + info.narHash = hash.first; + info.narSize = hash.second; + } + infos.push_back(info); + } + } + + ensureLocalStore()->registerValidPaths(infos); +} + +static void opLoadDB(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + registerValidity(true, true, false); +} + +static void opRegisterValidity(Strings opFlags, Strings opArgs) { + bool reregister = false; // !!! maybe this should be the default + bool hashGiven = false; + + for (auto& i : opFlags) { + if (i == "--reregister") { + reregister = true; + } else if (i == "--hash-given") { + hashGiven = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + + registerValidity(reregister, hashGiven, true); +} + +static void opCheckValidity(Strings opFlags, Strings opArgs) { + bool printInvalid = false; + + for (auto& i : opFlags) { + if (i == "--print-invalid") { + printInvalid = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + for (auto& i : opArgs) { + Path path = store->followLinksToStorePath(i); + if (!store->isValidPath(path)) { + if (printInvalid) { + cout << format("%1%\n") % path; + } else { + throw Error(format("path '%1%' is not valid") % path); + } + } + } +} + +static void opGC(Strings opFlags, Strings opArgs) { + bool printRoots = false; + GCOptions options; + options.action = GCOptions::gcDeleteDead; + + GCResults results; + + /* Do what? */ + for (auto i = opFlags.begin(); i != opFlags.end(); ++i) { + if (*i == "--print-roots") { + printRoots = true; + } else if (*i == "--print-live") { + options.action = GCOptions::gcReturnLive; + } else if (*i == "--print-dead") { + options.action = GCOptions::gcReturnDead; + } else if (*i == "--delete") { + options.action = GCOptions::gcDeleteDead; + } else if (*i == "--max-freed") { + auto maxFreed = getIntArg<long long>(*i, i, opFlags.end(), true); + options.maxFreed = maxFreed >= 0 ? maxFreed : 0; + } else { + throw UsageError(format("bad sub-operation '%1%' in GC") % *i); + } + } + + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + + if (printRoots) { + Roots roots = store->findRoots(false); + std::set<std::pair<Path, Path>> roots2; + // Transpose and sort the roots. + for (auto& [target, links] : roots) { + for (auto& link : links) { + roots2.emplace(link, target); + } + } + for (auto& [link, target] : roots2) { + std::cout << link << " -> " << target << "\n"; + } + } + + else { + PrintFreed freed(options.action == GCOptions::gcDeleteDead, results); + store->collectGarbage(options, results); + + if (options.action != GCOptions::gcDeleteDead) { + for (auto& i : results.paths) { + cout << i << std::endl; + } + } + } +} + +/* Remove paths from the Nix store if possible (i.e., if they do not + have any remaining referrers and are not reachable from any GC + roots). */ +static void opDelete(Strings opFlags, Strings opArgs) { + GCOptions options; + options.action = GCOptions::gcDeleteSpecific; + + for (auto& i : opFlags) { + if (i == "--ignore-liveness") { + options.ignoreLiveness = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + for (auto& i : opArgs) { + options.pathsToDelete.insert(store->followLinksToStorePath(i)); + } + + GCResults results; + PrintFreed freed(true, results); + store->collectGarbage(options, results); +} + +/* Dump a path as a Nix archive. The archive is written to standard + output. */ +static void opDump(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + if (opArgs.size() != 1) { + throw UsageError("only one argument allowed"); + } + + FdSink sink(STDOUT_FILENO); + string path = *opArgs.begin(); + dumpPath(path, sink); + sink.flush(); +} + +/* Restore a value from a Nix archive. The archive is read from + standard input. */ +static void opRestore(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + if (opArgs.size() != 1) { + throw UsageError("only one argument allowed"); + } + + FdSource source(STDIN_FILENO); + restorePath(*opArgs.begin(), source); +} + +static void opExport(Strings opFlags, Strings opArgs) { + for (auto& i : opFlags) { + throw UsageError(format("unknown flag '%1%'") % i); + } + + for (auto& i : opArgs) { + i = store->followLinksToStorePath(i); + } + + FdSink sink(STDOUT_FILENO); + store->exportPaths(opArgs, sink); + sink.flush(); +} + +static void opImport(Strings opFlags, Strings opArgs) { + for (auto& i : opFlags) { + throw UsageError(format("unknown flag '%1%'") % i); + } + + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + + FdSource source(STDIN_FILENO); + Paths paths = store->importPaths(source, nullptr, NoCheckSigs); + + for (auto& i : paths) { + cout << format("%1%\n") % i << std::flush; + } +} + +/* Initialise the Nix databases. */ +static void opInit(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("unknown flag"); + } + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + /* Doesn't do anything right now; database tables are initialised + automatically. */ +} + +/* Verify the consistency of the Nix environment. */ +static void opVerify(Strings opFlags, Strings opArgs) { + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + + bool checkContents = false; + RepairFlag repair = NoRepair; + + for (auto& i : opFlags) { + if (i == "--check-contents") { + checkContents = true; + } else if (i == "--repair") { + repair = Repair; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + if (store->verifyStore(checkContents, repair)) { + LOG(WARNING) << "not all errors were fixed"; + throw Exit(1); + } +} + +/* Verify whether the contents of the given store path have not changed. */ +static void opVerifyPath(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("no flags expected"); + } + + int status = 0; + + for (auto& i : opArgs) { + Path path = store->followLinksToStorePath(i); + LOG(INFO) << "checking path '" << path << "'..."; + auto info = store->queryPathInfo(path); + HashSink sink(info->narHash.type); + store->narFromPath(path, sink); + auto current = sink.finish(); + if (current.first != info->narHash) { + LOG(ERROR) << "path '" << path << "' was modified! expected hash '" + << info->narHash.to_string() << "', got '" + << current.first.to_string() << "'"; + status = 1; + } + } + + throw Exit(status); +} + +/* Repair the contents of the given path by redownloading it using a + substituter (if available). */ +static void opRepairPath(Strings opFlags, Strings opArgs) { + if (!opFlags.empty()) { + throw UsageError("no flags expected"); + } + + for (auto& i : opArgs) { + Path path = store->followLinksToStorePath(i); + ensureLocalStore()->repairPath(path); + } +} + +/* Optimise the disk space usage of the Nix store by hard-linking + files with the same contents. */ +static void opOptimise(Strings opFlags, Strings opArgs) { + if (!opArgs.empty() || !opFlags.empty()) { + throw UsageError("no arguments expected"); + } + + store->optimiseStore(); +} + +/* Serve the nix store in a way usable by a restricted ssh user. */ +static void opServe(Strings opFlags, Strings opArgs) { + bool writeAllowed = false; + for (auto& i : opFlags) { + if (i == "--write") { + writeAllowed = true; + } else { + throw UsageError(format("unknown flag '%1%'") % i); + } + } + + if (!opArgs.empty()) { + throw UsageError("no arguments expected"); + } + + FdSource in(STDIN_FILENO); + FdSink out(STDOUT_FILENO); + + /* Exchange the greeting. */ + unsigned int magic = readInt(in); + if (magic != SERVE_MAGIC_1) { + throw Error("protocol mismatch"); + } + out << SERVE_MAGIC_2 << SERVE_PROTOCOL_VERSION; + out.flush(); + unsigned int clientVersion = readInt(in); + + auto getBuildSettings = [&]() { + // FIXME: changing options here doesn't work if we're + // building through the daemon. + settings.keepLog = false; + settings.useSubstitutes = false; + settings.maxSilentTime = readInt(in); + settings.buildTimeout = readInt(in); + if (GET_PROTOCOL_MINOR(clientVersion) >= 2) { + settings.maxLogSize = readNum<unsigned long>(in); + } + if (GET_PROTOCOL_MINOR(clientVersion) >= 3) { + settings.buildRepeat = readInt(in); + settings.enforceDeterminism = readInt(in) != 0u; + settings.runDiffHook = true; + } + settings.printRepeatedBuilds = false; + }; + + while (true) { + ServeCommand cmd; + try { + cmd = (ServeCommand)readInt(in); + } catch (EndOfFile& e) { + break; + } + + switch (cmd) { + case cmdQueryValidPaths: { + bool lock = readInt(in) != 0u; + bool substitute = readInt(in) != 0u; + auto paths = readStorePaths<PathSet>(*store, in); + if (lock && writeAllowed) { + for (auto& path : paths) { + store->addTempRoot(path); + } + } + + /* If requested, substitute missing paths. This + implements nix-copy-closure's --use-substitutes + flag. */ + if (substitute && writeAllowed) { + /* Filter out .drv files (we don't want to build anything). */ + PathSet paths2; + for (auto& path : paths) { + if (!isDerivation(path)) { + paths2.insert(path); + } + } + unsigned long long downloadSize; + unsigned long long narSize; + PathSet willBuild; + PathSet willSubstitute; + PathSet unknown; + store->queryMissing(PathSet(paths2.begin(), paths2.end()), willBuild, + willSubstitute, unknown, downloadSize, narSize); + /* FIXME: should use ensurePath(), but it only + does one path at a time. */ + if (!willSubstitute.empty()) { + try { + store->buildPaths(willSubstitute); + } catch (Error& e) { + LOG(WARNING) << e.msg(); + } + } + } + + out << store->queryValidPaths(paths); + break; + } + + case cmdQueryPathInfos: { + auto paths = readStorePaths<PathSet>(*store, in); + // !!! Maybe we want a queryPathInfos? + for (auto& i : paths) { + try { + auto info = store->queryPathInfo(i); + out << info->path << info->deriver << info->references; + // !!! Maybe we want compression? + out << info->narSize // downloadSize + << info->narSize; + if (GET_PROTOCOL_MINOR(clientVersion) >= 4) { + out << (info->narHash ? info->narHash.to_string() : "") + << info->ca << info->sigs; + } + } catch (InvalidPath&) { + } + } + out << ""; + break; + } + + case cmdDumpStorePath: + store->narFromPath(readStorePath(*store, in), out); + break; + + case cmdImportPaths: { + if (!writeAllowed) { + throw Error("importing paths is not allowed"); + } + store->importPaths(in, nullptr, + NoCheckSigs); // FIXME: should we skip sig checking? + out << 1; // indicate success + break; + } + + case cmdExportPaths: { + readInt(in); // obsolete + store->exportPaths(readStorePaths<Paths>(*store, in), out); + break; + } + + case cmdBuildPaths: { + if (!writeAllowed) { + throw Error("building paths is not allowed"); + } + auto paths = readStorePaths<PathSet>(*store, in); + + getBuildSettings(); + + try { + MonitorFdHup monitor(in.fd); + store->buildPaths(paths); + out << 0; + } catch (Error& e) { + assert(e.status); + out << e.status << e.msg(); + } + break; + } + + case cmdBuildDerivation: { /* Used by hydra-queue-runner. */ + + if (!writeAllowed) { + throw Error("building paths is not allowed"); + } + + Path drvPath = readStorePath(*store, in); // informational only + BasicDerivation drv; + readDerivation(in, *store, drv); + + getBuildSettings(); + + MonitorFdHup monitor(in.fd); + auto status = store->buildDerivation(drvPath, drv); + + out << status.status << status.errorMsg; + + if (GET_PROTOCOL_MINOR(clientVersion) >= 3) { + out << status.timesBuilt + << static_cast<uint64_t>(status.isNonDeterministic) + << status.startTime << status.stopTime; + } + + break; + } + + case cmdQueryClosure: { + bool includeOutputs = readInt(in) != 0u; + PathSet closure; + store->computeFSClosure(readStorePaths<PathSet>(*store, in), closure, + false, includeOutputs); + out << closure; + break; + } + + case cmdAddToStoreNar: { + if (!writeAllowed) { + throw Error("importing paths is not allowed"); + } + + ValidPathInfo info; + info.path = readStorePath(*store, in); + in >> info.deriver; + if (!info.deriver.empty()) { + store->assertStorePath(info.deriver); + } + info.narHash = Hash(readString(in), htSHA256); + info.references = readStorePaths<PathSet>(*store, in); + in >> info.registrationTime >> info.narSize >> info.ultimate; + info.sigs = readStrings<StringSet>(in); + in >> info.ca; + + if (info.narSize == 0) { + throw Error("narInfo is too old and missing the narSize field"); + } + + SizedSource sizedSource(in, info.narSize); + + store->addToStore(info, sizedSource, NoRepair, NoCheckSigs); + + // consume all the data that has been sent before continuing. + sizedSource.drainAll(); + + out << 1; // indicate success + + break; + } + + default: + throw Error(format("unknown serve command %1%") % cmd); + } + + out.flush(); + } +} + +static void opGenerateBinaryCacheKey(Strings opFlags, Strings opArgs) { + for (auto& i : opFlags) { + throw UsageError(format("unknown flag '%1%'") % i); + } + + if (opArgs.size() != 3) { + throw UsageError("three arguments expected"); + } + auto i = opArgs.begin(); + string keyName = *i++; + string secretKeyFile = *i++; + string publicKeyFile = *i++; + +#if HAVE_SODIUM + if (sodium_init() == -1) { + throw Error("could not initialise libsodium"); + } + + unsigned char pk[crypto_sign_PUBLICKEYBYTES]; + unsigned char sk[crypto_sign_SECRETKEYBYTES]; + if (crypto_sign_keypair(pk, sk) != 0) { + throw Error("key generation failed"); + } + + writeFile(publicKeyFile, + keyName + ":" + + base64Encode(string((char*)pk, crypto_sign_PUBLICKEYBYTES))); + umask(0077); + writeFile(secretKeyFile, + keyName + ":" + + base64Encode(string((char*)sk, crypto_sign_SECRETKEYBYTES))); +#else + throw Error( + "Nix was not compiled with libsodium, required for signed binary cache " + "support"); +#endif +} + +static void opVersion(Strings opFlags, Strings opArgs) { + printVersion("nix-store"); +} + +/* Scan the arguments; find the operation, set global flags, put all + other flags in a list, and put all other arguments in another + list. */ +static int _main(int argc, char** argv) { + { + Strings opFlags; + Strings opArgs; + Operation op = nullptr; + + parseCmdLine(argc, argv, + [&](Strings::iterator& arg, const Strings::iterator& end) { + Operation oldOp = op; + + if (*arg == "--help") { + showManPage("nix-store"); + } else if (*arg == "--version") { + op = opVersion; + } else if (*arg == "--realise" || *arg == "--realize" || + *arg == "-r") { + op = opRealise; + } else if (*arg == "--add" || *arg == "-A") { + op = opAdd; + } else if (*arg == "--add-fixed") { + op = opAddFixed; + } else if (*arg == "--print-fixed-path") { + op = opPrintFixedPath; + } else if (*arg == "--delete") { + op = opDelete; + } else if (*arg == "--query" || *arg == "-q") { + op = opQuery; + } else if (*arg == "--print-env") { + op = opPrintEnv; + } else if (*arg == "--read-log" || *arg == "-l") { + op = opReadLog; + } else if (*arg == "--dump-db") { + op = opDumpDB; + } else if (*arg == "--load-db") { + op = opLoadDB; + } else if (*arg == "--register-validity") { + op = opRegisterValidity; + } else if (*arg == "--check-validity") { + op = opCheckValidity; + } else if (*arg == "--gc") { + op = opGC; + } else if (*arg == "--dump") { + op = opDump; + } else if (*arg == "--restore") { + op = opRestore; + } else if (*arg == "--export") { + op = opExport; + } else if (*arg == "--import") { + op = opImport; + } else if (*arg == "--init") { + op = opInit; + } else if (*arg == "--verify") { + op = opVerify; + } else if (*arg == "--verify-path") { + op = opVerifyPath; + } else if (*arg == "--repair-path") { + op = opRepairPath; + } else if (*arg == "--optimise" || *arg == "--optimize") { + op = opOptimise; + } else if (*arg == "--serve") { + op = opServe; + } else if (*arg == "--generate-binary-cache-key") { + op = opGenerateBinaryCacheKey; + } else if (*arg == "--add-root") { + gcRoot = absPath(getArg(*arg, arg, end)); + } else if (*arg == "--indirect") { + indirectRoot = true; + } else if (*arg == "--no-output") { + noOutput = true; + } else if (*arg != "" && arg->at(0) == '-') { + opFlags.push_back(*arg); + if (*arg == "--max-freed" || *arg == "--max-links" || + *arg == "--max-atime") { /* !!! hack */ + opFlags.push_back(getArg(*arg, arg, end)); + } + } else { + opArgs.push_back(*arg); + } + + if ((oldOp != nullptr) && oldOp != op) { + throw UsageError("only one operation may be specified"); + } + + return true; + }); + + initPlugins(); + + if (op == nullptr) { + throw UsageError("no operation specified"); + } + + if (op != opDump && op != opRestore) { /* !!! hack */ + store = openStore(); + } + + op(opFlags, opArgs); + + return 0; + } +} + +static RegisterLegacyCommand s1("nix-store", _main); diff --git a/third_party/nix/src/nix/add-to-store.cc b/third_party/nix/src/nix/add-to-store.cc new file mode 100644 index 0000000000..b7fda9c9d3 --- /dev/null +++ b/third_party/nix/src/nix/add-to-store.cc @@ -0,0 +1,51 @@ +#include "archive.hh" +#include "command.hh" +#include "common-args.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdAddToStore : MixDryRun, StoreCommand { + Path path; + std::optional<std::string> namePart; + + CmdAddToStore() { + expectArg("path", &path); + + mkFlag() + .longName("name") + .shortName('n') + .description("name component of the store path") + .labels({"name"}) + .dest(&namePart); + } + + std::string name() override { return "add-to-store"; } + + std::string description() override { return "add a path to the Nix store"; } + + Examples examples() override { return {}; } + + void run(ref<Store> store) override { + if (!namePart) { + namePart = baseNameOf(path); + } + + StringSink sink; + dumpPath(path, sink); + + ValidPathInfo info; + info.narHash = hashString(htSHA256, *sink.s); + info.narSize = sink.s->size(); + info.path = store->makeFixedOutputPath(true, info.narHash, *namePart); + info.ca = makeFixedOutputCA(true, info.narHash); + + if (!dryRun) { + store->addToStore(info, sink.s); + } + + std::cout << fmt("%s\n", info.path); + } +}; + +static RegisterCommand r1(make_ref<CmdAddToStore>()); diff --git a/third_party/nix/src/nix/build.cc b/third_party/nix/src/nix/build.cc new file mode 100644 index 0000000000..9ab2d27e0f --- /dev/null +++ b/third_party/nix/src/nix/build.cc @@ -0,0 +1,68 @@ +#include "command.hh" +#include "common-args.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdBuild : MixDryRun, InstallablesCommand { + Path outLink = "result"; + + CmdBuild() { + mkFlag() + .longName("out-link") + .shortName('o') + .description("path of the symlink to the build result") + .labels({"path"}) + .dest(&outLink); + + mkFlag() + .longName("no-link") + .description("do not create a symlink to the build result") + .set(&outLink, Path("")); + } + + std::string name() override { return "build"; } + + std::string description() override { + return "build a derivation or fetch a store path"; + } + + Examples examples() override { + return { + Example{"To build and run GNU Hello from NixOS 17.03:", + "nix build -f channel:nixos-17.03 hello; ./result/bin/hello"}, + Example{"To build the build.x86_64-linux attribute from release.nix:", + "nix build -f release.nix build.x86_64-linux"}, + }; + } + + void run(ref<Store> store) override { + auto buildables = build(store, dryRun ? DryRun : Build, installables); + + if (dryRun) { + return; + } + + for (size_t i = 0; i < buildables.size(); ++i) { + auto& b(buildables[i]); + + if (!outLink.empty()) { + for (auto& output : b.outputs) { + if (auto store2 = store.dynamic_pointer_cast<LocalFSStore>()) { + std::string symlink = outLink; + if (i != 0u) { + symlink += fmt("-%d", i); + } + if (output.first != "out") { + symlink += fmt("-%s", output.first); + } + store2->addPermRoot(output.second, absPath(symlink), true); + } + } + } + } + } +}; + +static RegisterCommand r1(make_ref<CmdBuild>()); diff --git a/third_party/nix/src/nix/cat.cc b/third_party/nix/src/nix/cat.cc new file mode 100644 index 0000000000..2d662a453f --- /dev/null +++ b/third_party/nix/src/nix/cat.cc @@ -0,0 +1,56 @@ +#include "command.hh" +#include "fs-accessor.hh" +#include "nar-accessor.hh" +#include "store-api.hh" + +using namespace nix; + +struct MixCat : virtual Args { + std::string path; + + void cat(const ref<FSAccessor>& accessor) { + auto st = accessor->stat(path); + if (st.type == FSAccessor::Type::tMissing) { + throw Error(format("path '%1%' does not exist") % path); + } + if (st.type != FSAccessor::Type::tRegular) { + throw Error(format("path '%1%' is not a regular file") % path); + } + + std::cout << accessor->readFile(path); + } +}; + +struct CmdCatStore : StoreCommand, MixCat { + CmdCatStore() { expectArg("path", &path); } + + std::string name() override { return "cat-store"; } + + std::string description() override { + return "print the contents of a store file on stdout"; + } + + void run(ref<Store> store) override { cat(store->getFSAccessor()); } +}; + +struct CmdCatNar : StoreCommand, MixCat { + Path narPath; + + CmdCatNar() { + expectArg("nar", &narPath); + expectArg("path", &path); + } + + std::string name() override { return "cat-nar"; } + + std::string description() override { + return "print the contents of a file inside a NAR file"; + } + + void run(ref<Store> store) override { + cat(makeNarAccessor(make_ref<std::string>(readFile(narPath)))); + } +}; + +static RegisterCommand r1(make_ref<CmdCatStore>()); +static RegisterCommand r2(make_ref<CmdCatNar>()); diff --git a/third_party/nix/src/nix/command.cc b/third_party/nix/src/nix/command.cc new file mode 100644 index 0000000000..439f22dc3b --- /dev/null +++ b/third_party/nix/src/nix/command.cc @@ -0,0 +1,155 @@ +#include "command.hh" + +#include <utility> + +#include "derivations.hh" +#include "store-api.hh" + +namespace nix { + +Commands* RegisterCommand::commands = nullptr; + +void Command::printHelp(const string& programName, std::ostream& out) { + Args::printHelp(programName, out); + + auto exs = examples(); + if (!exs.empty()) { + out << "\n"; + out << "Examples:\n"; + for (auto& ex : exs) { + out << "\n" + << " " << ex.description << "\n" // FIXME: wrap + << " $ " << ex.command << "\n"; + } + } +} + +MultiCommand::MultiCommand(Commands _commands) + : commands(std::move(_commands)) { + expectedArgs.push_back(ExpectedArg{ + "command", 1, true, [=](std::vector<std::string> ss) { + assert(!command); + auto i = commands.find(ss[0]); + if (i == commands.end()) { + throw UsageError("'%s' is not a recognised command", ss[0]); + } + command = i->second; + }}); +} + +void MultiCommand::printHelp(const string& programName, std::ostream& out) { + if (command) { + command->printHelp(programName + " " + command->name(), out); + return; + } + + out << "Usage: " << programName << " <COMMAND> <FLAGS>... <ARGS>...\n"; + + out << "\n"; + out << "Common flags:\n"; + printFlags(out); + + out << "\n"; + out << "Available commands:\n"; + + Table2 table; + for (auto& command : commands) { + auto descr = command.second->description(); + if (!descr.empty()) { + table.push_back(std::make_pair(command.second->name(), descr)); + } + } + printTable(out, table); + +#if 0 + out << "\n"; + out << "For full documentation, run 'man " << programName << "' or 'man " << programName << "-<COMMAND>'.\n"; +#endif +} + +bool MultiCommand::processFlag(Strings::iterator& pos, Strings::iterator end) { + if (Args::processFlag(pos, end)) { + return true; + } + if (command && command->processFlag(pos, end)) { + return true; + } + return false; +} + +bool MultiCommand::processArgs(const Strings& args, bool finish) { + if (command) { + return command->processArgs(args, finish); + } + return Args::processArgs(args, finish); +} + +StoreCommand::StoreCommand() = default; + +ref<Store> StoreCommand::getStore() { + if (!_store) { + _store = createStore(); + } + return ref<Store>(_store); +} + +ref<Store> StoreCommand::createStore() { return openStore(); } + +void StoreCommand::run() { run(getStore()); } + +StorePathsCommand::StorePathsCommand(bool recursive) : recursive(recursive) { + if (recursive) { + mkFlag() + .longName("no-recursive") + .description("apply operation to specified paths only") + .set(&this->recursive, false); + } else { + mkFlag() + .longName("recursive") + .shortName('r') + .description("apply operation to closure of the specified paths") + .set(&this->recursive, true); + } + + mkFlag(0, "all", "apply operation to the entire store", &all); +} + +void StorePathsCommand::run(ref<Store> store) { + Paths storePaths; + + if (all) { + if (!installables.empty() != 0u) { + throw UsageError("'--all' does not expect arguments"); + } + for (auto& p : store->queryAllValidPaths()) { + storePaths.push_back(p); + } + } + + else { + for (auto& p : toStorePaths(store, NoBuild, installables)) { + storePaths.push_back(p); + } + + if (recursive) { + PathSet closure; + store->computeFSClosure(PathSet(storePaths.begin(), storePaths.end()), + closure, false, false); + storePaths = Paths(closure.begin(), closure.end()); + } + } + + run(store, storePaths); +} + +void StorePathCommand::run(ref<Store> store) { + auto storePaths = toStorePaths(store, NoBuild, installables); + + if (storePaths.size() != 1) { + throw UsageError("this command requires exactly one store path"); + } + + run(store, *storePaths.begin()); +} + +} // namespace nix diff --git a/third_party/nix/src/nix/command.hh b/third_party/nix/src/nix/command.hh new file mode 100644 index 0000000000..4122bdd0e5 --- /dev/null +++ b/third_party/nix/src/nix/command.hh @@ -0,0 +1,193 @@ +#pragma once + +#include "args.hh" +#include "common-eval-args.hh" + +namespace nix { + +extern std::string programPath; + +struct Value; +class Bindings; +class EvalState; + +/* A command is an argument parser that can be executed by calling its + run() method. */ +struct Command : virtual Args { + virtual std::string name() = 0; + virtual void prepare(){}; + virtual void run() = 0; + + struct Example { + std::string description; + std::string command; + }; + + typedef std::list<Example> Examples; + + virtual Examples examples() { return Examples(); } + + void printHelp(const string& programName, std::ostream& out) override; +}; + +class Store; + +/* A command that require a Nix store. */ +struct StoreCommand : virtual Command { + StoreCommand(); + void run() override; + ref<Store> getStore(); + virtual ref<Store> createStore(); + virtual void run(ref<Store>) = 0; + + private: + std::shared_ptr<Store> _store; +}; + +struct Buildable { + Path drvPath; // may be empty + std::map<std::string, Path> outputs; +}; + +typedef std::vector<Buildable> Buildables; + +struct Installable { + virtual std::string what() = 0; + + virtual Buildables toBuildables() { + throw Error("argument '%s' cannot be built", what()); + } + + Buildable toBuildable(); + + virtual Value* toValue(EvalState& state) { + throw Error("argument '%s' cannot be evaluated", what()); + } +}; + +struct SourceExprCommand : virtual Args, StoreCommand, MixEvalArgs { + Path file; + + SourceExprCommand(); + + /* Return a value representing the Nix expression from which we + are installing. This is either the file specified by ‘--file’, + or an attribute set constructed from $NIX_PATH, e.g. ‘{ nixpkgs + = import ...; bla = import ...; }’. */ + Value* getSourceExpr(EvalState& state); + + ref<EvalState> getEvalState(); + + private: + std::shared_ptr<EvalState> evalState; + + Value* vSourceExpr = 0; +}; + +enum RealiseMode { Build, NoBuild, DryRun }; + +/* A command that operates on a list of "installables", which can be + store paths, attribute paths, Nix expressions, etc. */ +struct InstallablesCommand : virtual Args, SourceExprCommand { + std::vector<std::shared_ptr<Installable>> installables; + + InstallablesCommand() { expectArgs("installables", &_installables); } + + void prepare() override; + + virtual bool useDefaultInstallables() { return true; } + + private: + std::vector<std::string> _installables; +}; + +struct InstallableCommand : virtual Args, SourceExprCommand { + std::shared_ptr<Installable> installable; + + InstallableCommand() { expectArg("installable", &_installable); } + + void prepare() override; + + private: + std::string _installable; +}; + +/* A command that operates on zero or more store paths. */ +struct StorePathsCommand : public InstallablesCommand { + private: + bool recursive = false; + bool all = false; + + public: + StorePathsCommand(bool recursive = false); + + using StoreCommand::run; + + virtual void run(ref<Store> store, Paths storePaths) = 0; + + void run(ref<Store> store) override; + + bool useDefaultInstallables() override { return !all; } +}; + +/* A command that operates on exactly one store path. */ +struct StorePathCommand : public InstallablesCommand { + using StoreCommand::run; + + virtual void run(ref<Store> store, const Path& storePath) = 0; + + void run(ref<Store> store) override; +}; + +typedef std::map<std::string, ref<Command>> Commands; + +/* An argument parser that supports multiple subcommands, + i.e. ‘<command> <subcommand>’. */ +class MultiCommand : virtual Args { + public: + Commands commands; + + std::shared_ptr<Command> command; + + MultiCommand(Commands commands); + + void printHelp(const string& programName, std::ostream& out) override; + + bool processFlag(Strings::iterator& pos, Strings::iterator end) override; + + bool processArgs(const Strings& args, bool finish) override; +}; + +/* A helper class for registering commands globally. */ +struct RegisterCommand { + static Commands* commands; + + RegisterCommand(ref<Command> command) { + if (!commands) { + commands = new Commands; + } + commands->emplace(command->name(), command); + } +}; + +std::shared_ptr<Installable> parseInstallable(SourceExprCommand& cmd, + const ref<Store>& store, + const std::string& installable, + bool useDefaultInstallables); + +Buildables build(const ref<Store>& store, RealiseMode mode, + const std::vector<std::shared_ptr<Installable>>& installables); + +PathSet toStorePaths( + const ref<Store>& store, RealiseMode mode, + const std::vector<std::shared_ptr<Installable>>& installables); + +Path toStorePath(const ref<Store>& store, RealiseMode mode, + const std::shared_ptr<Installable>& installable); + +PathSet toDerivations( + const ref<Store>& store, + const std::vector<std::shared_ptr<Installable>>& installables, + bool useDeriver = false); + +} // namespace nix diff --git a/third_party/nix/src/nix/copy.cc b/third_party/nix/src/nix/copy.cc new file mode 100644 index 0000000000..633fe399b4 --- /dev/null +++ b/third_party/nix/src/nix/copy.cc @@ -0,0 +1,86 @@ +#include <atomic> + +#include "command.hh" +#include "shared.hh" +#include "store-api.hh" +#include "sync.hh" +#include "thread-pool.hh" + +using namespace nix; + +struct CmdCopy : StorePathsCommand { + std::string srcUri, dstUri; + + CheckSigsFlag checkSigs = CheckSigs; + + SubstituteFlag substitute = NoSubstitute; + + CmdCopy() : StorePathsCommand(true) { + mkFlag() + .longName("from") + .labels({"store-uri"}) + .description("URI of the source Nix store") + .dest(&srcUri); + mkFlag() + .longName("to") + .labels({"store-uri"}) + .description("URI of the destination Nix store") + .dest(&dstUri); + + mkFlag() + .longName("no-check-sigs") + .description("do not require that paths are signed by trusted keys") + .set(&checkSigs, NoCheckSigs); + + mkFlag() + .longName("substitute-on-destination") + .shortName('s') + .description( + "whether to try substitutes on the destination store (only " + "supported by SSH)") + .set(&substitute, Substitute); + } + + std::string name() override { return "copy"; } + + std::string description() override { return "copy paths between Nix stores"; } + + Examples examples() override { + return { + Example{"To copy Firefox from the local store to a binary cache in " + "file:///tmp/cache:", + "nix copy --to file:///tmp/cache $(type -p firefox)"}, + Example{"To copy the entire current NixOS system closure to another " + "machine via SSH:", + "nix copy --to ssh://server /run/current-system"}, + Example{"To copy a closure from another machine via SSH:", + "nix copy --from ssh://server " + "/nix/store/a6cnl93nk1wxnq84brbbwr6hxw9gp2w9-blender-2.79-rc2"}, +#ifdef ENABLE_S3 + Example{"To copy Hello to an S3 binary cache:", + "nix copy --to s3://my-bucket?region=eu-west-1 nixpkgs.hello"}, + Example{"To copy Hello to an S3-compatible binary cache:", + "nix copy --to " + "s3://my-bucket?region=eu-west-1&endpoint=example.com " + "nixpkgs.hello"}, +#endif + }; + } + + ref<Store> createStore() override { + return srcUri.empty() ? StoreCommand::createStore() : openStore(srcUri); + } + + void run(ref<Store> srcStore, Paths storePaths) override { + if (srcUri.empty() && dstUri.empty()) { + throw UsageError("you must pass '--from' and/or '--to'"); + } + + ref<Store> dstStore = dstUri.empty() ? openStore() : openStore(dstUri); + + copyPaths(srcStore, dstStore, PathSet(storePaths.begin(), storePaths.end()), + NoRepair, checkSigs, substitute); + } +}; + +static RegisterCommand r1(make_ref<CmdCopy>()); diff --git a/third_party/nix/src/nix/doctor.cc b/third_party/nix/src/nix/doctor.cc new file mode 100644 index 0000000000..44b4bd605d --- /dev/null +++ b/third_party/nix/src/nix/doctor.cc @@ -0,0 +1,136 @@ +#include "command.hh" +#include "serve-protocol.hh" +#include "shared.hh" +#include "store-api.hh" +#include "worker-protocol.hh" + +using namespace nix; + +std::string formatProtocol(unsigned int proto) { + if (proto != 0u) { + auto major = GET_PROTOCOL_MAJOR(proto) >> 8; + auto minor = GET_PROTOCOL_MINOR(proto); + return (format("%1%.%2%") % major % minor).str(); + } + return "unknown"; +} + +struct CmdDoctor : StoreCommand { + bool success = true; + + std::string name() override { return "doctor"; } + + std::string description() override { + return "check your system for potential problems"; + } + + void run(ref<Store> store) override { + std::cout << "Store uri: " << store->getUri() << std::endl; + std::cout << std::endl; + + auto type = getStoreType(); + + if (type < tOther) { + success &= checkNixInPath(); + success &= checkProfileRoots(store); + } + success &= checkStoreProtocol(store->getProtocol()); + + if (!success) { + throw Exit(2); + } + } + + static bool checkNixInPath() { + PathSet dirs; + + for (auto& dir : tokenizeString<Strings>(getEnv("PATH"), ":")) { + if (pathExists(dir + "/nix-env")) { + dirs.insert(dirOf(canonPath(dir + "/nix-env", true))); + } + } + + if (dirs.size() != 1) { + std::cout << "Warning: multiple versions of nix found in PATH." + << std::endl; + std::cout << std::endl; + for (auto& dir : dirs) { + std::cout << " " << dir << std::endl; + } + std::cout << std::endl; + return false; + } + + return true; + } + + static bool checkProfileRoots(const ref<Store>& store) { + PathSet dirs; + + for (auto& dir : tokenizeString<Strings>(getEnv("PATH"), ":")) { + Path profileDir = dirOf(dir); + try { + Path userEnv = canonPath(profileDir, true); + + if (store->isStorePath(userEnv) && + hasSuffix(userEnv, "user-environment")) { + while (profileDir.find("/profiles/") == std::string::npos && + isLink(profileDir)) { + profileDir = absPath(readLink(profileDir), dirOf(profileDir)); + } + + if (profileDir.find("/profiles/") == std::string::npos) { + dirs.insert(dir); + } + } + } catch (SysError&) { + } + } + + if (!dirs.empty()) { + std::cout << "Warning: found profiles outside of " << settings.nixStateDir + << "/profiles." << std::endl; + std::cout << "The generation this profile points to might not have a " + "gcroot and could be" + << std::endl; + std::cout << "garbage collected, resulting in broken symlinks." + << std::endl; + std::cout << std::endl; + for (auto& dir : dirs) { + std::cout << " " << dir << std::endl; + } + std::cout << std::endl; + return false; + } + + return true; + } + + static bool checkStoreProtocol(unsigned int storeProto) { + unsigned int clientProto = GET_PROTOCOL_MAJOR(SERVE_PROTOCOL_VERSION) == + GET_PROTOCOL_MAJOR(storeProto) + ? SERVE_PROTOCOL_VERSION + : PROTOCOL_VERSION; + + if (clientProto != storeProto) { + std::cout << "Warning: protocol version of this client does not match " + "the store." + << std::endl; + std::cout << "While this is not necessarily a problem it's recommended " + "to keep the client in" + << std::endl; + std::cout << "sync with the daemon." << std::endl; + std::cout << std::endl; + std::cout << "Client protocol: " << formatProtocol(clientProto) + << std::endl; + std::cout << "Store protocol: " << formatProtocol(storeProto) + << std::endl; + std::cout << std::endl; + return false; + } + + return true; + } +}; + +static RegisterCommand r1(make_ref<CmdDoctor>()); diff --git a/third_party/nix/src/nix/dump-path.cc b/third_party/nix/src/nix/dump-path.cc new file mode 100644 index 0000000000..5e93a3a44b --- /dev/null +++ b/third_party/nix/src/nix/dump-path.cc @@ -0,0 +1,28 @@ +#include "command.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdDumpPath : StorePathCommand { + std::string name() override { return "dump-path"; } + + std::string description() override { + return "dump a store path to stdout (in NAR format)"; + } + + Examples examples() override { + return { + Example{"To get a NAR from the binary cache https://cache.nixos.org/:", + "nix dump-path --store https://cache.nixos.org/ " + "/nix/store/7crrmih8c52r8fbnqb933dxrsp44md93-glibc-2.25"}, + }; + } + + void run(ref<Store> store, const Path& storePath) override { + FdSink sink(STDOUT_FILENO); + store->narFromPath(storePath, sink); + sink.flush(); + } +}; + +static RegisterCommand r1(make_ref<CmdDumpPath>()); diff --git a/third_party/nix/src/nix/edit.cc b/third_party/nix/src/nix/edit.cc new file mode 100644 index 0000000000..330a845dc5 --- /dev/null +++ b/third_party/nix/src/nix/edit.cc @@ -0,0 +1,73 @@ +#include <glog/logging.h> +#include <unistd.h> + +#include "attr-path.hh" +#include "command.hh" +#include "eval.hh" +#include "shared.hh" + +using namespace nix; + +struct CmdEdit : InstallableCommand { + std::string name() override { return "edit"; } + + std::string description() override { + return "open the Nix expression of a Nix package in $EDITOR"; + } + + Examples examples() override { + return { + Example{"To open the Nix expression of the GNU Hello package:", + "nix edit nixpkgs.hello"}, + }; + } + + void run(ref<Store> store) override { + auto state = getEvalState(); + + auto v = installable->toValue(*state); + + Value* v2; + try { + auto dummyArgs = Bindings::NewGC(); + v2 = findAlongAttrPath(*state, "meta.position", *dummyArgs, *v); + } catch (Error&) { + throw Error("package '%s' has no source location information", + installable->what()); + } + + auto pos = state->forceString(*v2); + DLOG(INFO) << "position is " << pos; + + auto colon = pos.rfind(':'); + if (colon == std::string::npos) { + throw Error("cannot parse meta.position attribute '%s'", pos); + } + + std::string filename(pos, 0, colon); + int lineno; + try { + lineno = std::stoi(std::string(pos, colon + 1)); + } catch (std::invalid_argument& e) { + throw Error("cannot parse line number '%s'", pos); + } + + auto editor = getEnv("EDITOR", "cat"); + + auto args = tokenizeString<Strings>(editor); + + if (editor.find("emacs") != std::string::npos || + editor.find("nano") != std::string::npos || + editor.find("vim") != std::string::npos) { + args.push_back(fmt("+%d", lineno)); + } + + args.push_back(filename); + + execvp(args.front().c_str(), stringsToCharPtrs(args).data()); + + throw SysError("cannot run editor '%s'", editor); + } +}; + +static RegisterCommand r1(make_ref<CmdEdit>()); diff --git a/third_party/nix/src/nix/eval.cc b/third_party/nix/src/nix/eval.cc new file mode 100644 index 0000000000..661d587d73 --- /dev/null +++ b/third_party/nix/src/nix/eval.cc @@ -0,0 +1,56 @@ +#include "eval.hh" + +#include "command.hh" +#include "common-args.hh" +#include "json.hh" +#include "shared.hh" +#include "store-api.hh" +#include "value-to-json.hh" + +using namespace nix; + +struct CmdEval : MixJSON, InstallableCommand { + bool raw = false; + + CmdEval() { mkFlag(0, "raw", "print strings unquoted", &raw); } + + std::string name() override { return "eval"; } + + std::string description() override { return "evaluate a Nix expression"; } + + Examples examples() override { + return { + Example{"To evaluate a Nix expression given on the command line:", + "nix eval '(1 + 2)'"}, + Example{"To evaluate a Nix expression from a file or URI:", + "nix eval -f channel:nixos-17.09 hello.name"}, + Example{"To get the current version of Nixpkgs:", + "nix eval --raw nixpkgs.lib.nixpkgsVersion"}, + Example{"To print the store path of the Hello package:", + "nix eval --raw nixpkgs.hello"}, + }; + } + + void run(ref<Store> store) override { + if (raw && json) { + throw UsageError("--raw and --json are mutually exclusive"); + } + + auto state = getEvalState(); + + auto v = installable->toValue(*state); + PathSet context; + + if (raw) { + std::cout << state->coerceToString(noPos, *v, context); + } else if (json) { + JSONPlaceholder jsonOut(std::cout); + printValueAsJSON(*state, true, *v, jsonOut, context); + } else { + state->forceValueDeep(*v); + std::cout << *v << "\n"; + } + } +}; + +static RegisterCommand r1(make_ref<CmdEval>()); diff --git a/third_party/nix/src/nix/hash.cc b/third_party/nix/src/nix/hash.cc new file mode 100644 index 0000000000..74ff45d0d8 --- /dev/null +++ b/third_party/nix/src/nix/hash.cc @@ -0,0 +1,145 @@ +#include "hash.hh" + +#include "command.hh" +#include "legacy.hh" +#include "shared.hh" + +using namespace nix; + +struct CmdHash : Command { + enum Mode { mFile, mPath }; + Mode mode; + Base base = SRI; + bool truncate = false; + HashType ht = htSHA256; + std::vector<std::string> paths; + + explicit CmdHash(Mode mode) : mode(mode) { + mkFlag(0, "sri", "print hash in SRI format", &base, SRI); + mkFlag(0, "base64", "print hash in base-64", &base, Base64); + mkFlag(0, "base32", "print hash in base-32 (Nix-specific)", &base, Base32); + mkFlag(0, "base16", "print hash in base-16", &base, Base16); + mkFlag().longName("type").mkHashTypeFlag(&ht); + expectArgs("paths", &paths); + } + + std::string name() override { + return mode == mFile ? "hash-file" : "hash-path"; + } + + std::string description() override { + return mode == mFile + ? "print cryptographic hash of a regular file" + : "print cryptographic hash of the NAR serialisation of a path"; + } + + void run() override { + for (const auto& path : paths) { + Hash h = mode == mFile ? hashFile(ht, path) : hashPath(ht, path).first; + if (truncate && h.hashSize > 20) { + h = compressHash(h, 20); + } + std::cout << format("%1%\n") % h.to_string(base, base == SRI); + } + } +}; + +static RegisterCommand r1(make_ref<CmdHash>(CmdHash::mFile)); +static RegisterCommand r2(make_ref<CmdHash>(CmdHash::mPath)); + +struct CmdToBase : Command { + Base base; + HashType ht = htUnknown; + std::vector<std::string> args; + + explicit CmdToBase(Base base) : base(base) { + mkFlag().longName("type").mkHashTypeFlag(&ht); + expectArgs("strings", &args); + } + + std::string name() override { + return base == Base16 + ? "to-base16" + : base == Base32 ? "to-base32" + : base == Base64 ? "to-base64" : "to-sri"; + } + + std::string description() override { + return fmt( + "convert a hash to %s representation", + base == Base16 + ? "base-16" + : base == Base32 ? "base-32" : base == Base64 ? "base-64" : "SRI"); + } + + void run() override { + for (const auto& s : args) { + std::cout << fmt("%s\n", Hash(s, ht).to_string(base, base == SRI)); + } + } +}; + +static RegisterCommand r3(make_ref<CmdToBase>(Base16)); +static RegisterCommand r4(make_ref<CmdToBase>(Base32)); +static RegisterCommand r5(make_ref<CmdToBase>(Base64)); +static RegisterCommand r6(make_ref<CmdToBase>(SRI)); + +/* Legacy nix-hash command. */ +static int compatNixHash(int argc, char** argv) { + HashType ht = htMD5; + bool flat = false; + bool base32 = false; + bool truncate = false; + enum { opHash, opTo32, opTo16 } op = opHash; + std::vector<std::string> ss; + + parseCmdLine(argc, argv, + [&](Strings::iterator& arg, const Strings::iterator& end) { + if (*arg == "--help") { + showManPage("nix-hash"); + } else if (*arg == "--version") { + printVersion("nix-hash"); + } else if (*arg == "--flat") { + flat = true; + } else if (*arg == "--base32") { + base32 = true; + } else if (*arg == "--truncate") { + truncate = true; + } else if (*arg == "--type") { + string s = getArg(*arg, arg, end); + ht = parseHashType(s); + if (ht == htUnknown) { + throw UsageError(format("unknown hash type '%1%'") % s); + } + } else if (*arg == "--to-base16") { + op = opTo16; + } else if (*arg == "--to-base32") { + op = opTo32; + } else if (*arg != "" && arg->at(0) == '-') { + return false; + } else { + ss.push_back(*arg); + } + return true; + }); + + if (op == opHash) { + CmdHash cmd(flat ? CmdHash::mFile : CmdHash::mPath); + cmd.ht = ht; + cmd.base = base32 ? Base32 : Base16; + cmd.truncate = truncate; + cmd.paths = ss; + cmd.run(); + } + + else { + CmdToBase cmd(op == opTo32 ? Base32 : Base16); + cmd.args = ss; + cmd.ht = ht; + cmd.run(); + } + + return 0; +} + +static RegisterLegacyCommand s1("nix-hash", compatNixHash); diff --git a/third_party/nix/src/nix/installables.cc b/third_party/nix/src/nix/installables.cc new file mode 100644 index 0000000000..38a3f0c8ec --- /dev/null +++ b/third_party/nix/src/nix/installables.cc @@ -0,0 +1,344 @@ +#include <regex> +#include <utility> + +#include "attr-path.hh" +#include "command.hh" +#include "common-eval-args.hh" +#include "derivations.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "get-drvs.hh" +#include "shared.hh" +#include "store-api.hh" + +namespace nix { + +SourceExprCommand::SourceExprCommand() { + mkFlag() + .shortName('f') + .longName("file") + .label("file") + .description("evaluate FILE rather than the default") + .dest(&file); +} + +Value* SourceExprCommand::getSourceExpr(EvalState& state) { + if (vSourceExpr != nullptr) { + return vSourceExpr; + } + + auto sToplevel = state.symbols.Create("_toplevel"); + + vSourceExpr = state.allocValue(); + + if (!file.empty()) { + state.evalFile(lookupFileArg(state, file), *vSourceExpr); + } else { + /* Construct the installation source from $NIX_PATH. */ + + auto searchPath = state.getSearchPath(); + + state.mkAttrs(*vSourceExpr, 1024); + + mkBool(*state.allocAttr(*vSourceExpr, sToplevel), true); + + std::unordered_set<std::string> seen; + + auto addEntry = [&](const std::string& name) { + if (name.empty()) { + return; + } + if (!seen.insert(name).second) { + return; + } + Value* v1 = state.allocValue(); + mkPrimOpApp(*v1, state.getBuiltin("findFile"), + state.getBuiltin("nixPath")); + Value* v2 = state.allocValue(); + mkApp(*v2, *v1, mkString(*state.allocValue(), name)); + mkApp(*state.allocAttr(*vSourceExpr, state.symbols.Create(name)), + state.getBuiltin("import"), *v2); + }; + + for (auto& i : searchPath) { /* Hack to handle channels. */ + if (i.first.empty() && pathExists(i.second + "/manifest.nix")) { + for (auto& j : readDirectory(i.second)) { + if (j.name != "manifest.nix" && + pathExists(fmt("%s/%s/default.nix", i.second, j.name))) { + addEntry(j.name); + } + } + } else { + addEntry(i.first); + } + } + } + + return vSourceExpr; +} + +ref<EvalState> SourceExprCommand::getEvalState() { + if (!evalState) { + evalState = std::make_shared<EvalState>(searchPath, getStore()); + } + return ref<EvalState>(evalState); +} + +Buildable Installable::toBuildable() { + auto buildables = toBuildables(); + if (buildables.size() != 1) { + throw Error( + "installable '%s' evaluates to %d derivations, where only one is " + "expected", + what(), buildables.size()); + } + return std::move(buildables[0]); +} + +struct InstallableStorePath : Installable { + Path storePath; + + explicit InstallableStorePath(Path storePath) + : storePath(std::move(storePath)) {} + + std::string what() override { return storePath; } + + Buildables toBuildables() override { + return {{isDerivation(storePath) ? storePath : "", {{"out", storePath}}}}; + } +}; + +struct InstallableValue : Installable { + SourceExprCommand& cmd; + + explicit InstallableValue(SourceExprCommand& cmd) : cmd(cmd) {} + + Buildables toBuildables() override { + auto state = cmd.getEvalState(); + + auto v = toValue(*state); + + Bindings& autoArgs = *cmd.getAutoArgs(*state); + + DrvInfos drvs; + getDerivations(*state, *v, "", autoArgs, drvs, false); + + Buildables res; + + PathSet drvPaths; + + for (auto& drv : drvs) { + Buildable b{drv.queryDrvPath()}; + drvPaths.insert(b.drvPath); + + auto outputName = drv.queryOutputName(); + if (outputName.empty()) { + throw Error("derivation '%s' lacks an 'outputName' attribute", + b.drvPath); + } + + b.outputs.emplace(outputName, drv.queryOutPath()); + + res.push_back(std::move(b)); + } + + // Hack to recognize .all: if all drvs have the same drvPath, + // merge the buildables. + if (drvPaths.size() == 1) { + Buildable b{*drvPaths.begin()}; + for (auto& b2 : res) { + b.outputs.insert(b2.outputs.begin(), b2.outputs.end()); + } + return {b}; + } + return res; + } +}; + +struct InstallableExpr : InstallableValue { + std::string text; + + InstallableExpr(SourceExprCommand& cmd, std::string text) + : InstallableValue(cmd), text(std::move(text)) {} + + std::string what() override { return text; } + + Value* toValue(EvalState& state) override { + auto v = state.allocValue(); + state.eval(state.parseExprFromString(text, absPath(".")), *v); + return v; + } +}; + +struct InstallableAttrPath : InstallableValue { + std::string attrPath; + + InstallableAttrPath(SourceExprCommand& cmd, std::string attrPath) + : InstallableValue(cmd), attrPath(std::move(attrPath)) {} + + std::string what() override { return attrPath; } + + Value* toValue(EvalState& state) override { + auto source = cmd.getSourceExpr(state); + + Bindings& autoArgs = *cmd.getAutoArgs(state); + + Value* v = findAlongAttrPath(state, attrPath, autoArgs, *source); + state.forceValue(*v); + + return v; + } +}; + +// FIXME: extend +std::string attrRegex = R"([A-Za-z_][A-Za-z0-9-_+]*)"; +static std::regex attrPathRegex(fmt(R"(%1%(\.%1%)*)", attrRegex)); + +static std::vector<std::shared_ptr<Installable>> parseInstallables( + SourceExprCommand& cmd, const ref<Store>& store, + std::vector<std::string> ss, bool useDefaultInstallables) { + std::vector<std::shared_ptr<Installable>> result; + + if (ss.empty() && useDefaultInstallables) { + if (cmd.file.empty()) { + cmd.file = "."; + } + ss = {""}; + } + + for (auto& s : ss) { + if (s.compare(0, 1, "(") == 0) { + result.push_back(std::make_shared<InstallableExpr>(cmd, s)); + + } else if (s.find('/') != std::string::npos) { + auto path = store->toStorePath(store->followLinksToStore(s)); + + if (store->isStorePath(path)) { + result.push_back(std::make_shared<InstallableStorePath>(path)); + } + } + + else if (s.empty() || std::regex_match(s, attrPathRegex)) { + result.push_back(std::make_shared<InstallableAttrPath>(cmd, s)); + + } else { + throw UsageError("don't know what to do with argument '%s'", s); + } + } + + return result; +} + +std::shared_ptr<Installable> parseInstallable(SourceExprCommand& cmd, + const ref<Store>& store, + const std::string& installable, + bool useDefaultInstallables) { + auto installables = parseInstallables(cmd, store, {installable}, false); + assert(installables.size() == 1); + return installables.front(); +} + +Buildables build( + const ref<Store>& store, RealiseMode mode, + const std::vector<std::shared_ptr<Installable>>& installables) { + if (mode != Build) { + settings.readOnlyMode = true; + } + + Buildables buildables; + + PathSet pathsToBuild; + + for (auto& i : installables) { + for (auto& b : i->toBuildables()) { + if (!b.drvPath.empty()) { + StringSet outputNames; + for (auto& output : b.outputs) { + outputNames.insert(output.first); + } + pathsToBuild.insert(b.drvPath + "!" + + concatStringsSep(",", outputNames)); + } else { + for (auto& output : b.outputs) { + pathsToBuild.insert(output.second); + } + } + buildables.push_back(std::move(b)); + } + } + + if (mode == DryRun) { + printMissing(store, pathsToBuild); + } else if (mode == Build) { + store->buildPaths(pathsToBuild); + } + + return buildables; +} + +PathSet toStorePaths( + const ref<Store>& store, RealiseMode mode, + const std::vector<std::shared_ptr<Installable>>& installables) { + PathSet outPaths; + + for (auto& b : build(store, mode, installables)) { + for (auto& output : b.outputs) { + outPaths.insert(output.second); + } + } + + return outPaths; +} + +Path toStorePath(const ref<Store>& store, RealiseMode mode, + const std::shared_ptr<Installable>& installable) { + auto paths = toStorePaths(store, mode, {installable}); + + if (paths.size() != 1) { + throw Error("argument '%s' should evaluate to one store path", + installable->what()); + } + + return *paths.begin(); +} + +PathSet toDerivations( + const ref<Store>& store, + const std::vector<std::shared_ptr<Installable>>& installables, + bool useDeriver) { + PathSet drvPaths; + + for (auto& i : installables) { + for (auto& b : i->toBuildables()) { + if (b.drvPath.empty()) { + if (!useDeriver) { + throw Error("argument '%s' did not evaluate to a derivation", + i->what()); + } + for (auto& output : b.outputs) { + auto derivers = store->queryValidDerivers(output.second); + if (derivers.empty()) { + throw Error("'%s' does not have a known deriver", i->what()); + } + // FIXME: use all derivers? + drvPaths.insert(*derivers.begin()); + } + } else { + drvPaths.insert(b.drvPath); + } + } + } + + return drvPaths; +} + +void InstallablesCommand::prepare() { + installables = parseInstallables(*this, getStore(), _installables, + useDefaultInstallables()); +} + +void InstallableCommand::prepare() { + installable = parseInstallable(*this, getStore(), _installable, false); +} + +} // namespace nix diff --git a/third_party/nix/src/nix/legacy.cc b/third_party/nix/src/nix/legacy.cc new file mode 100644 index 0000000000..b851392b42 --- /dev/null +++ b/third_party/nix/src/nix/legacy.cc @@ -0,0 +1,7 @@ +#include "legacy.hh" + +namespace nix { + +RegisterLegacyCommand::Commands* RegisterLegacyCommand::commands = nullptr; + +} diff --git a/third_party/nix/src/nix/legacy.hh b/third_party/nix/src/nix/legacy.hh new file mode 100644 index 0000000000..a9bc65c02e --- /dev/null +++ b/third_party/nix/src/nix/legacy.hh @@ -0,0 +1,23 @@ +#pragma once + +#include <functional> +#include <map> +#include <string> + +namespace nix { + +typedef std::function<void(int, char**)> MainFunction; + +struct RegisterLegacyCommand { + typedef std::map<std::string, MainFunction> Commands; + static Commands* commands; + + RegisterLegacyCommand(const std::string& name, MainFunction fun) { + if (!commands) { + commands = new Commands; + } + (*commands)[name] = fun; + } +}; + +} // namespace nix diff --git a/third_party/nix/src/nix/log.cc b/third_party/nix/src/nix/log.cc new file mode 100644 index 0000000000..63d3554cc2 --- /dev/null +++ b/third_party/nix/src/nix/log.cc @@ -0,0 +1,63 @@ +#include <glog/logging.h> + +#include "command.hh" +#include "common-args.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdLog : InstallableCommand { + CmdLog() = default; + + std::string name() override { return "log"; } + + std::string description() override { + return "show the build log of the specified packages or paths, if " + "available"; + } + + Examples examples() override { + return { + Example{"To get the build log of GNU Hello:", "nix log nixpkgs.hello"}, + Example{ + "To get the build log of a specific path:", + "nix log " + "/nix/store/lmngj4wcm9rkv3w4dfhzhcyij3195hiq-thunderbird-52.2.1"}, + Example{"To get a build log from a specific binary cache:", + "nix log --store https://cache.nixos.org nixpkgs.hello"}, + }; + } + + void run(ref<Store> store) override { + settings.readOnlyMode = true; + + auto subs = getDefaultSubstituters(); + + subs.push_front(store); + + auto b = installable->toBuildable(); + + RunPager pager; + for (auto& sub : subs) { + auto log = !b.drvPath.empty() ? sub->getBuildLog(b.drvPath) : nullptr; + for (auto& output : b.outputs) { + if (log) { + break; + } + log = sub->getBuildLog(output.second); + } + if (!log) { + continue; + } + LOG(INFO) << "got build log for '" << installable->what() << "' from '" + << sub->getUri() << "'"; + std::cout << *log; + return; + } + + throw Error("build log of '%s' is not available", installable->what()); + } +}; + +static RegisterCommand r1(make_ref<CmdLog>()); diff --git a/third_party/nix/src/nix/ls.cc b/third_party/nix/src/nix/ls.cc new file mode 100644 index 0000000000..5b052f8fcc --- /dev/null +++ b/third_party/nix/src/nix/ls.cc @@ -0,0 +1,138 @@ +#include "command.hh" +#include "common-args.hh" +#include "fs-accessor.hh" +#include "json.hh" +#include "nar-accessor.hh" +#include "store-api.hh" + +using namespace nix; + +struct MixLs : virtual Args, MixJSON { + std::string path; + + bool recursive = false; + bool verbose = false; + bool showDirectory = false; + + MixLs() { + mkFlag('R', "recursive", "list subdirectories recursively", &recursive); + mkFlag('l', "long", "show more file information", &verbose); + mkFlag('d', "directory", "show directories rather than their contents", + &showDirectory); + } + + void listText(ref<FSAccessor> accessor) { + std::function<void(const FSAccessor::Stat&, const Path&, const std::string&, + bool)> + doPath; + + auto showFile = [&](const Path& curPath, const std::string& relPath) { + if (verbose) { + auto st = accessor->stat(curPath); + std::string tp = st.type == FSAccessor::Type::tRegular + ? (st.isExecutable ? "-r-xr-xr-x" : "-r--r--r--") + : st.type == FSAccessor::Type::tSymlink + ? "lrwxrwxrwx" + : "dr-xr-xr-x"; + std::cout << (format("%s %20d %s") % tp % st.fileSize % relPath); + if (st.type == FSAccessor::Type::tSymlink) { + std::cout << " -> " << accessor->readLink(curPath); + } + std::cout << "\n"; + if (recursive && st.type == FSAccessor::Type::tDirectory) { + doPath(st, curPath, relPath, false); + } + } else { + std::cout << relPath << "\n"; + if (recursive) { + auto st = accessor->stat(curPath); + if (st.type == FSAccessor::Type::tDirectory) { + doPath(st, curPath, relPath, false); + } + } + } + }; + + doPath = [&](const FSAccessor::Stat& st, const Path& curPath, + const std::string& relPath, bool showDirectory) { + if (st.type == FSAccessor::Type::tDirectory && !showDirectory) { + auto names = accessor->readDirectory(curPath); + for (auto& name : names) { + showFile(curPath + "/" + name, relPath + "/" + name); + } + } else { + showFile(curPath, relPath); + } + }; + + auto st = accessor->stat(path); + if (st.type == FSAccessor::Type::tMissing) { + throw Error(format("path '%1%' does not exist") % path); + } + doPath(st, path, + st.type == FSAccessor::Type::tDirectory ? "." : baseNameOf(path), + showDirectory); + } + + void list(const ref<FSAccessor>& accessor) { + if (path == "/") { + path = ""; + } + + if (json) { + JSONPlaceholder jsonRoot(std::cout); + listNar(jsonRoot, accessor, path, recursive); + } else { + listText(accessor); + } + } +}; + +struct CmdLsStore : StoreCommand, MixLs { + CmdLsStore() { expectArg("path", &path); } + + Examples examples() override { + return { + Example{"To list the contents of a store path in a binary cache:", + "nix ls-store --store https://cache.nixos.org/ -lR " + "/nix/store/0i2jd68mp5g6h2sa5k9c85rb80sn8hi9-hello-2.10"}, + }; + } + + std::string name() override { return "ls-store"; } + + std::string description() override { + return "show information about a store path"; + } + + void run(ref<Store> store) override { list(store->getFSAccessor()); } +}; + +struct CmdLsNar : Command, MixLs { + Path narPath; + + CmdLsNar() { + expectArg("nar", &narPath); + expectArg("path", &path); + } + + Examples examples() override { + return { + Example{"To list a specific file in a NAR:", + "nix ls-nar -l hello.nar /bin/hello"}, + }; + } + + std::string name() override { return "ls-nar"; } + + std::string description() override { + return "show information about the contents of a NAR file"; + } + + void run() override { + list(makeNarAccessor(make_ref<std::string>(readFile(narPath, true)))); + } +}; + +static RegisterCommand r1(make_ref<CmdLsStore>()); +static RegisterCommand r2(make_ref<CmdLsNar>()); diff --git a/third_party/nix/src/nix/main.cc b/third_party/nix/src/nix/main.cc new file mode 100644 index 0000000000..11ba3f8410 --- /dev/null +++ b/third_party/nix/src/nix/main.cc @@ -0,0 +1,187 @@ +#include <algorithm> + +#include <ifaddrs.h> +#include <netdb.h> +#include <netinet/in.h> +#include <sys/socket.h> +#include <sys/types.h> + +#include "command.hh" +#include "common-args.hh" +#include "download.hh" +#include "eval.hh" +#include "finally.hh" +#include "globals.hh" +#include "glog/logging.h" +#include "legacy.hh" +#include "shared.hh" +#include "store-api.hh" + +extern std::string chrootHelperName; + +void chrootHelper(int argc, char** argv); + +namespace nix { + +/* Check if we have a non-loopback/link-local network interface. */ +static bool haveInternet() { + struct ifaddrs* addrs; + + if (getifaddrs(&addrs) != 0) { + return true; + } + + Finally free([&]() { freeifaddrs(addrs); }); + + for (auto i = addrs; i != nullptr; i = i->ifa_next) { + if (i->ifa_addr == nullptr) { + continue; + } + if (i->ifa_addr->sa_family == AF_INET) { + if (ntohl(((sockaddr_in*)i->ifa_addr)->sin_addr.s_addr) != + INADDR_LOOPBACK) { + return true; + } + } else if (i->ifa_addr->sa_family == AF_INET6) { + if (!IN6_IS_ADDR_LOOPBACK(&((sockaddr_in6*)i->ifa_addr)->sin6_addr) && + !IN6_IS_ADDR_LINKLOCAL(&((sockaddr_in6*)i->ifa_addr)->sin6_addr)) { + return true; + } + } + } + + return false; +} + +std::string programPath; + +struct NixArgs : virtual MultiCommand, virtual MixCommonArgs { + bool printBuildLogs = false; + bool useNet = true; + + NixArgs() : MultiCommand(*RegisterCommand::commands), MixCommonArgs("nix") { + mkFlag() + .longName("help") + .description("show usage information") + .handler([&]() { showHelpAndExit(); }); + + mkFlag() + .longName("help-config") + .description("show configuration options") + .handler([&]() { + std::cout << "The following configuration options are available:\n\n"; + Table2 tbl; + std::map<std::string, Config::SettingInfo> settings; + globalConfig.getSettings(settings); + for (const auto& s : settings) { + tbl.emplace_back(s.first, s.second.description); + } + printTable(std::cout, tbl); + throw Exit(); + }); + + mkFlag() + .longName("print-build-logs") + .shortName('L') + .description("print full build logs on stderr") + .set(&printBuildLogs, true); + + mkFlag() + .longName("version") + .description("show version information") + .handler([&]() { printVersion(programName); }); + + mkFlag() + .longName("no-net") + .description( + "disable substituters and consider all previously downloaded files " + "up-to-date") + .handler([&]() { useNet = false; }); + } + + void printFlags(std::ostream& out) override { + Args::printFlags(out); + std::cout << "\n" + "In addition, most configuration settings can be overriden " + "using '--<name> <value>'.\n" + "Boolean settings can be overriden using '--<name>' or " + "'--no-<name>'. See 'nix\n" + "--help-config' for a list of configuration settings.\n"; + } + + void showHelpAndExit() { + printHelp(programName, std::cout); + std::cout + << "\nNote: this program is EXPERIMENTAL and subject to change.\n"; + throw Exit(); + } +}; + +void mainWrapped(int argc, char** argv) { + /* The chroot helper needs to be run before any threads have been + started. */ + if (argc > 0 && argv[0] == chrootHelperName) { + chrootHelper(argc, argv); + return; + } + + initNix(); + initGC(); + + programPath = argv[0]; + string programName = baseNameOf(programPath); + + { + auto legacy = (*RegisterLegacyCommand::commands)[programName]; + if (legacy) { + return legacy(argc, argv); + } + } + + settings.verboseBuild = false; + + NixArgs args; + + args.parseCmdline(argvToStrings(argc, argv)); + + initPlugins(); + + if (!args.command) { + args.showHelpAndExit(); + } + + if (args.useNet && !haveInternet()) { + LOG(WARNING) << "you don't have Internet access; " + << "disabling some network-dependent features"; + args.useNet = false; + } + + if (!args.useNet) { + // FIXME: should check for command line overrides only. + if (!settings.useSubstitutes.overriden) { + settings.useSubstitutes = false; + } + if (!settings.tarballTtl.overriden) { + settings.tarballTtl = std::numeric_limits<unsigned int>::max(); + } + if (!downloadSettings.tries.overriden) { + downloadSettings.tries = 0; + } + if (!downloadSettings.connectTimeout.overriden) { + downloadSettings.connectTimeout = 1; + } + } + + args.command->prepare(); + args.command->run(); +} + +} // namespace nix + +int main(int argc, char* argv[]) { + FLAGS_logtostderr = true; + google::InitGoogleLogging(argv[0]); + + return nix::handleExceptions(argv[0], + [&]() { nix::mainWrapped(argc, argv); }); +} diff --git a/third_party/nix/src/nix/meson.build b/third_party/nix/src/nix/meson.build new file mode 100644 index 0000000000..259de78e24 --- /dev/null +++ b/third_party/nix/src/nix/meson.build @@ -0,0 +1,78 @@ +src_inc += include_directories('.') + +nix_src = files( + join_paths(meson.source_root(), 'src/nix/add-to-store.cc'), + join_paths(meson.source_root(), 'src/nix/build.cc'), + join_paths(meson.source_root(), 'src/nix/cat.cc'), + join_paths(meson.source_root(), 'src/nix/command.cc'), + join_paths(meson.source_root(), 'src/nix/copy.cc'), + join_paths(meson.source_root(), 'src/nix/doctor.cc'), + join_paths(meson.source_root(), 'src/nix/dump-path.cc'), + join_paths(meson.source_root(), 'src/nix/edit.cc'), + join_paths(meson.source_root(), 'src/nix/eval.cc'), + join_paths(meson.source_root(), 'src/nix/hash.cc'), + join_paths(meson.source_root(), 'src/nix/installables.cc'), + join_paths(meson.source_root(), 'src/nix/legacy.cc'), + join_paths(meson.source_root(), 'src/nix/log.cc'), + join_paths(meson.source_root(), 'src/nix/ls.cc'), + join_paths(meson.source_root(), 'src/nix/main.cc'), + join_paths(meson.source_root(), 'src/nix/optimise-store.cc'), + join_paths(meson.source_root(), 'src/nix/path-info.cc'), + join_paths(meson.source_root(), 'src/nix/ping-store.cc'), + join_paths(meson.source_root(), 'src/nix/repl.cc'), + join_paths(meson.source_root(), 'src/nix/run.cc'), + join_paths(meson.source_root(), 'src/nix/search.cc'), + join_paths(meson.source_root(), 'src/nix/show-config.cc'), + join_paths(meson.source_root(), 'src/nix/show-derivation.cc'), + join_paths(meson.source_root(), 'src/nix/sigs.cc'), + join_paths(meson.source_root(), 'src/nix/upgrade-nix.cc'), + join_paths(meson.source_root(), 'src/nix/verify.cc'), + join_paths(meson.source_root(), 'src/nix/why-depends.cc'), + + join_paths(meson.source_root(), 'src/build-remote/build-remote.cc'), + join_paths(meson.source_root(), 'src/nix-build/nix-build.cc'), + join_paths(meson.source_root(), 'src/nix-channel/nix-channel.cc'), + join_paths(meson.source_root(), 'src/nix-collect-garbage/nix-collect-garbage.cc'), + join_paths(meson.source_root(), 'src/nix-copy-closure/nix-copy-closure.cc'), + join_paths(meson.source_root(), 'src/nix-daemon/nix-daemon.cc'), + join_paths(meson.source_root(), 'src/nix-env/nix-env.cc'), + join_paths(meson.source_root(), 'src/nix-env/user-env.cc'), + join_paths(meson.source_root(), 'src/nix-instantiate/nix-instantiate.cc'), + join_paths(meson.source_root(), 'src/nix-prefetch-url/nix-prefetch-url.cc'), + join_paths(meson.source_root(), 'src/nix-store/dotgraph.cc'), + join_paths(meson.source_root(), 'src/nix-store/graphml.cc'), + join_paths(meson.source_root(), 'src/nix-store/nix-store.cc')) + +nix_headers = files ( + join_paths(meson.source_root(), 'src/nix/command.hh'), + join_paths(meson.source_root(), 'src/nix/legacy.hh'), + join_paths(meson.source_root(), 'src/nix-env/user-env.hh'), + join_paths(meson.source_root(), 'src/nix-store/dotgraph.hh'), + join_paths(meson.source_root(), 'src/nix-store/graphml.hh')) + +nix_dep_list = [ + boost_dep, + editline_dep, + gc_dep, + glog_dep, + libdl_dep, + libsodium_dep, + pthread_dep, +] + +nix_link_list = [ + libutil_lib, + libstore_lib, + libmain_lib, + libexpr_lib, +] + +nix_bin = executable( + 'nix', + install : true, + install_mode : 'rwxr-xr-x', + install_dir : bindir, + include_directories : src_inc, + sources : nix_src, + link_with : nix_link_list, + dependencies : nix_dep_list) diff --git a/third_party/nix/src/nix/optimise-store.cc b/third_party/nix/src/nix/optimise-store.cc new file mode 100644 index 0000000000..5fdcfb7424 --- /dev/null +++ b/third_party/nix/src/nix/optimise-store.cc @@ -0,0 +1,27 @@ +#include <atomic> + +#include "command.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdOptimiseStore : StoreCommand { + CmdOptimiseStore() = default; + + std::string name() override { return "optimise-store"; } + + std::string description() override { + return "replace identical files in the store by hard links"; + } + + Examples examples() override { + return { + Example{"To optimise the Nix store:", "nix optimise-store"}, + }; + } + + void run(ref<Store> store) override { store->optimiseStore(); } +}; + +static RegisterCommand r1(make_ref<CmdOptimiseStore>()); diff --git a/third_party/nix/src/nix/path-info.cc b/third_party/nix/src/nix/path-info.cc new file mode 100644 index 0000000000..e94dcc9628 --- /dev/null +++ b/third_party/nix/src/nix/path-info.cc @@ -0,0 +1,131 @@ +#include <algorithm> +#include <array> + +#include "command.hh" +#include "common-args.hh" +#include "json.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdPathInfo : StorePathsCommand, MixJSON { + bool showSize = false; + bool showClosureSize = false; + bool humanReadable = false; + bool showSigs = false; + + CmdPathInfo() { + mkFlag('s', "size", "print size of the NAR dump of each path", &showSize); + mkFlag('S', "closure-size", + "print sum size of the NAR dumps of the closure of each path", + &showClosureSize); + mkFlag('h', "human-readable", + "with -s and -S, print sizes like 1K 234M 5.67G etc.", + &humanReadable); + mkFlag(0, "sigs", "show signatures", &showSigs); + } + + std::string name() override { return "path-info"; } + + std::string description() override { + return "query information about store paths"; + } + + Examples examples() override { + return { + Example{"To show the closure sizes of every path in the current NixOS " + "system closure, sorted by size:", + "nix path-info -rS /run/current-system | sort -nk2"}, + Example{"To show a package's closure size and all its dependencies " + "with human readable sizes:", + "nix path-info -rsSh nixpkgs.rust"}, + Example{"To check the existence of a path in a binary cache:", + "nix path-info -r /nix/store/7qvk5c91...-geeqie-1.1 --store " + "https://cache.nixos.org/"}, + Example{"To print the 10 most recently added paths (using --json and " + "the jq(1) command):", + "nix path-info --json --all | jq -r " + "'sort_by(.registrationTime)[-11:-1][].path'"}, + Example{"To show the size of the entire Nix store:", + "nix path-info --json --all | jq 'map(.narSize) | add'"}, + Example{"To show every path whose closure is bigger than 1 GB, sorted " + "by closure size:", + "nix path-info --json --all -S | jq 'map(select(.closureSize > " + "1e9)) | sort_by(.closureSize) | map([.path, .closureSize])'"}, + }; + } + + void printSize(unsigned long long value) { + if (!humanReadable) { + std::cout << fmt("\t%11d", value); + return; + } + + static const std::array<char, 9> idents{ + {' ', 'K', 'M', 'G', 'T', 'P', 'E', 'Z', 'Y'}}; + size_t power = 0; + double res = value; + while (res > 1024 && power < idents.size()) { + ++power; + res /= 1024; + } + std::cout << fmt("\t%6.1f%c", res, idents.at(power)); + } + + void run(ref<Store> store, Paths storePaths) override { + size_t pathLen = 0; + for (auto& storePath : storePaths) { + pathLen = std::max(pathLen, storePath.size()); + } + + if (json) { + JSONPlaceholder jsonRoot(std::cout); + store->pathInfoToJSON(jsonRoot, + // FIXME: preserve order? + PathSet(storePaths.begin(), storePaths.end()), true, + showClosureSize, AllowInvalid); + } + + else { + for (auto storePath : storePaths) { + auto info = store->queryPathInfo(storePath); + storePath = info->path; // FIXME: screws up padding + + std::cout << storePath; + + if (showSize || showClosureSize || showSigs) { + std::cout << std::string( + std::max(0, (int)pathLen - (int)storePath.size()), ' '); + } + + if (showSize) { + printSize(info->narSize); + } + + if (showClosureSize) { + printSize(store->getClosureSize(storePath).first); + } + + if (showSigs) { + std::cout << '\t'; + Strings ss; + if (info->ultimate) { + ss.push_back("ultimate"); + } + if (!info->ca.empty()) { + ss.push_back("ca:" + info->ca); + } + for (auto& sig : info->sigs) { + ss.push_back(sig); + } + std::cout << concatStringsSep(" ", ss); + } + + std::cout << std::endl; + } + } + } +}; + +static RegisterCommand r1(make_ref<CmdPathInfo>()); diff --git a/third_party/nix/src/nix/ping-store.cc b/third_party/nix/src/nix/ping-store.cc new file mode 100644 index 0000000000..9e9ee15c89 --- /dev/null +++ b/third_party/nix/src/nix/ping-store.cc @@ -0,0 +1,25 @@ +#include "command.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdPingStore : StoreCommand { + std::string name() override { return "ping-store"; } + + std::string description() override { + return "test whether a store can be opened"; + } + + Examples examples() override { + return { + Example{ + "To test whether connecting to a remote Nix store via SSH works:", + "nix ping-store --store ssh://mac1"}, + }; + } + + void run(ref<Store> store) override { store->connect(); } +}; + +static RegisterCommand r1(make_ref<CmdPingStore>()); diff --git a/third_party/nix/src/nix/repl.cc b/third_party/nix/src/nix/repl.cc new file mode 100644 index 0000000000..87caf9dd3f --- /dev/null +++ b/third_party/nix/src/nix/repl.cc @@ -0,0 +1,837 @@ +#include <climits> +#include <csetjmp> +#include <cstdlib> +#include <cstring> +#include <iostream> +#include <utility> + +#include <glog/logging.h> + +#ifdef READLINE +#include <readline/history.h> +#include <readline/readline.h> +#else +// editline < 1.15.2 don't wrap their API for C++ usage +// (added in +// https://github.com/troglobit/editline/commit/91398ceb3427b730995357e9d120539fb9bb7461). +// This results in linker errors due to to name-mangling of editline C symbols. +// For compatibility with these versions, we wrap the API here +// (wrapping multiple times on newer versions is no problem). +extern "C" { +#include <editline.h> +} +#endif + +#include "affinity.hh" +#include "command.hh" +#include "common-eval-args.hh" +#include "derivations.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "finally.hh" +#include "get-drvs.hh" +#include "globals.hh" +#include "shared.hh" +#include "store-api.hh" + +namespace nix { + +#define ESC_RED "\033[31m" +#define ESC_GRE "\033[32m" +#define ESC_YEL "\033[33m" +#define ESC_BLU "\033[34;1m" +#define ESC_MAG "\033[35m" +#define ESC_CYA "\033[36m" +#define ESC_END "\033[0m" + +struct NixRepl { + string curDir; + EvalState state; + Bindings* autoArgs; + + Strings loadedFiles; + + const static int envSize = 32768; + StaticEnv staticEnv; + Env* env; + int displ; + StringSet varNames; + + const Path historyFile; + + NixRepl(const Strings& searchPath, const nix::ref<Store>& store); + ~NixRepl(); + void mainLoop(const std::vector<std::string>& files); + StringSet completePrefix(const string& prefix); + static bool getLine(string& input, const std::string& prompt); + Path getDerivationPath(Value& v); + bool processLine(string line); + void loadFile(const Path& path); + void initEnv(); + void reloadFiles(); + void addAttrsToScope(Value& attrs); + void addVarToScope(const Symbol& name, Value& v); + Expr* parseString(const string& s); + void evalString(string s, Value& v); + + using ValuesSeen = set<Value*>; + std::ostream& printValue(std::ostream& str, Value& v, unsigned int maxDepth); + std::ostream& printValue(std::ostream& str, Value& v, unsigned int maxDepth, + ValuesSeen& seen); +}; + +void printHelp() { + std::cout << "Usage: nix-repl [--help] [--version] [-I path] paths...\n" + << "\n" + << "nix-repl is a simple read-eval-print loop (REPL) for the Nix " + "package manager.\n" + << "\n" + << "Options:\n" + << " --help\n" + << " Prints out a summary of the command syntax and exits.\n" + << "\n" + << " --version\n" + << " Prints out the Nix version number on standard output " + "and exits.\n" + << "\n" + << " -I path\n" + << " Add a path to the Nix expression search path. This " + "option may be given\n" + << " multiple times. See the NIX_PATH environment variable " + "for information on\n" + << " the semantics of the Nix search path. Paths added " + "through -I take\n" + << " precedence over NIX_PATH.\n" + << "\n" + << " paths...\n" + << " A list of paths to files containing Nix expressions " + "which nix-repl will\n" + << " load and add to its scope.\n" + << "\n" + << " A path surrounded in < and > will be looked up in the " + "Nix expression search\n" + << " path, as in the Nix language itself.\n" + << "\n" + << " If an element of paths starts with http:// or " + "https://, it is interpreted\n" + << " as the URL of a tarball that will be downloaded and " + "unpacked to a temporary\n" + << " location. The tarball must include a single top-level " + "directory containing\n" + << " at least a file named default.nix.\n"; +} + +string removeWhitespace(string s) { + s = chomp(s); + size_t n = s.find_first_not_of(" \n\r\t"); + if (n != string::npos) { + s = string(s, n); + } + return s; +} + +NixRepl::NixRepl(const Strings& searchPath, const nix::ref<Store>& store) + : state(searchPath, store), + staticEnv(false, &state.staticBaseEnv), + historyFile(getDataDir() + "/nix/repl-history") { + curDir = absPath("."); +} + +NixRepl::~NixRepl() { write_history(historyFile.c_str()); } + +static NixRepl* curRepl; // ugly + +static char* completionCallback(char* s, int* match) { + auto possible = curRepl->completePrefix(s); + if (possible.size() == 1) { + *match = 1; + auto* res = strdup(possible.begin()->c_str() + strlen(s)); + if (res == nullptr) { + throw Error("allocation failure"); + } + return res; + } + if (possible.size() > 1) { + auto checkAllHaveSameAt = [&](size_t pos) { + auto& first = *possible.begin(); + for (auto& p : possible) { + if (p.size() <= pos || p[pos] != first[pos]) { + return false; + } + } + return true; + }; + size_t start = strlen(s); + size_t len = 0; + while (checkAllHaveSameAt(start + len)) { + ++len; + } + if (len > 0) { + *match = 1; + auto* res = strdup(std::string(*possible.begin(), start, len).c_str()); + if (res == nullptr) { + throw Error("allocation failure"); + } + return res; + } + } + + *match = 0; + return nullptr; +} + +static int listPossibleCallback(char* s, char*** avp) { + auto possible = curRepl->completePrefix(s); + + if (possible.size() > (INT_MAX / sizeof(char*))) { + throw Error("too many completions"); + } + + int ac = 0; + char** vp = nullptr; + + auto check = [&](auto* p) { + if (!p) { + if (vp) { + while (--ac >= 0) { + free(vp[ac]); + } + free(vp); + } + throw Error("allocation failure"); + } + return p; + }; + + vp = check((char**)malloc(possible.size() * sizeof(char*))); + + for (auto& p : possible) { + vp[ac++] = check(strdup(p.c_str())); + } + + *avp = vp; + + return ac; +} + +namespace { +// Used to communicate to NixRepl::getLine whether a signal occurred in +// ::readline. +volatile sig_atomic_t g_signal_received = 0; + +void sigintHandler(int signo) { g_signal_received = signo; } +} // namespace + +void NixRepl::mainLoop(const std::vector<std::string>& files) { + string error = ANSI_RED "error:" ANSI_NORMAL " "; + std::cout << "Welcome to Nix version " << nixVersion << ". Type :? for help." + << std::endl + << std::endl; + + for (auto& i : files) { + loadedFiles.push_back(i); + } + + reloadFiles(); + if (!loadedFiles.empty()) { + std::cout << std::endl; + } + + // Allow nix-repl specific settings in .inputrc + rl_readline_name = "nix-repl"; + createDirs(dirOf(historyFile)); +#ifndef READLINE + el_hist_size = 1000; +#endif + read_history(historyFile.c_str()); + curRepl = this; +#ifndef READLINE + rl_set_complete_func(completionCallback); + rl_set_list_possib_func(listPossibleCallback); +#endif + + std::string input; + + while (true) { + // When continuing input from previous lines, don't print a prompt, just + // align to the same number of chars as the prompt. + if (!getLine(input, input.empty() ? "nix-repl> " : " ")) { + break; + } + + try { + if (!removeWhitespace(input).empty() && !processLine(input)) { + return; + } + } catch (ParseError& e) { + if (e.msg().find("unexpected $end") != std::string::npos) { + // For parse errors on incomplete input, we continue waiting for the + // next line of input without clearing the input so far. + continue; + } + LOG(ERROR) << error << (settings.showTrace ? e.prefix() : "") << e.msg(); + + } catch (Error& e) { + LOG(ERROR) << error << (settings.showTrace ? e.prefix() : "") << e.msg(); + } catch (Interrupted& e) { + LOG(ERROR) << error << (settings.showTrace ? e.prefix() : "") << e.msg(); + } + + // We handled the current input fully, so we should clear it + // and read brand new input. + input.clear(); + std::cout << std::endl; + } +} + +bool NixRepl::getLine(string& input, const std::string& prompt) { + struct sigaction act; + struct sigaction old; + sigset_t savedSignalMask; + sigset_t set; + + auto setupSignals = [&]() { + act.sa_handler = sigintHandler; + sigfillset(&act.sa_mask); + act.sa_flags = 0; + if (sigaction(SIGINT, &act, &old) != 0) { + throw SysError("installing handler for SIGINT"); + } + + sigemptyset(&set); + sigaddset(&set, SIGINT); + if (sigprocmask(SIG_UNBLOCK, &set, &savedSignalMask) != 0) { + throw SysError("unblocking SIGINT"); + } + }; + auto restoreSignals = [&]() { + if (sigprocmask(SIG_SETMASK, &savedSignalMask, nullptr) != 0) { + throw SysError("restoring signals"); + } + + if (sigaction(SIGINT, &old, nullptr) != 0) { + throw SysError("restoring handler for SIGINT"); + } + }; + + setupSignals(); + char* s = readline(prompt.c_str()); + Finally doFree([&]() { free(s); }); + restoreSignals(); + + if (g_signal_received != 0) { + g_signal_received = 0; + input.clear(); + return true; + } + + if (s == nullptr) { + return false; + } + input += s; + input += '\n'; + return true; +} + +StringSet NixRepl::completePrefix(const string& prefix) { + StringSet completions; + + size_t start = prefix.find_last_of(" \n\r\t(){}[]"); + std::string prev; + std::string cur; + if (start == std::string::npos) { + prev = ""; + cur = prefix; + } else { + prev = std::string(prefix, 0, start + 1); + cur = std::string(prefix, start + 1); + } + + size_t slash; + size_t dot; + + if ((slash = cur.rfind('/')) != string::npos) { + try { + auto dir = std::string(cur, 0, slash); + auto prefix2 = std::string(cur, slash + 1); + for (auto& entry : readDirectory(dir.empty() ? "/" : dir)) { + if (entry.name[0] != '.' && hasPrefix(entry.name, prefix2)) { + completions.insert(prev + dir + "/" + entry.name); + } + } + } catch (Error&) { + } + } else if ((dot = cur.rfind('.')) == string::npos) { + /* This is a variable name; look it up in the current scope. */ + auto i = varNames.lower_bound(cur); + while (i != varNames.end()) { + if (string(*i, 0, cur.size()) != cur) { + break; + } + completions.insert(prev + *i); + i++; + } + } else { + try { + /* This is an expression that should evaluate to an + attribute set. Evaluate it to get the names of the + attributes. */ + string expr(cur, 0, dot); + string cur2 = string(cur, dot + 1); + + Expr* e = parseString(expr); + Value v; + e->eval(state, *env, v); + state.forceAttrs(v); + + for (auto& i : *v.attrs) { + string name = i.second.name; + if (string(name, 0, cur2.size()) != cur2) { + continue; + } + completions.insert(prev + expr + "." + name); + } + + } catch (ParseError& e) { + // Quietly ignore parse errors. + } catch (EvalError& e) { + // Quietly ignore evaluation errors. + } catch (UndefinedVarError& e) { + // Quietly ignore undefined variable errors. + } + } + + return completions; +} + +static int runProgram(const string& program, const Strings& args) { + Strings args2(args); + args2.push_front(program); + + Pid pid; + pid = fork(); + if (pid == -1) { + throw SysError("forking"); + } + if (pid == 0) { + restoreAffinity(); + execvp(program.c_str(), stringsToCharPtrs(args2).data()); + _exit(1); + } + + return pid.wait(); +} + +bool isVarName(const string& s) { + if (s.empty()) { + return false; + } + char c = s[0]; + if ((c >= '0' && c <= '9') || c == '-' || c == '\'') { + return false; + } + for (auto& i : s) { + if (!((i >= 'a' && i <= 'z') || (i >= 'A' && i <= 'Z') || + (i >= '0' && i <= '9') || i == '_' || i == '-' || i == '\'')) { + return false; + } + } + return true; +} + +Path NixRepl::getDerivationPath(Value& v) { + auto drvInfo = getDerivation(state, v, false); + if (!drvInfo) { + throw Error( + "expression does not evaluate to a derivation, so I can't build it"); + } + Path drvPath = drvInfo->queryDrvPath(); + if (drvPath.empty() || !state.store->isValidPath(drvPath)) { + throw Error("expression did not evaluate to a valid derivation"); + } + return drvPath; +} + +bool NixRepl::processLine(string line) { + if (line.empty()) { + return true; + } + + string command; + string arg; + + if (line[0] == ':') { + size_t p = line.find_first_of(" \n\r\t"); + command = string(line, 0, p); + if (p != string::npos) { + arg = removeWhitespace(string(line, p)); + } + } else { + arg = line; + } + + if (command == ":?" || command == ":help") { + std::cout << "The following commands are available:\n" + << "\n" + << " <expr> Evaluate and print expression\n" + << " <x> = <expr> Bind expression to variable\n" + << " :a <expr> Add attributes from resulting set to scope\n" + << " :b <expr> Build derivation\n" + << " :i <expr> Build derivation, then install result into " + "current profile\n" + << " :l <path> Load Nix expression and add it to scope\n" + << " :p <expr> Evaluate and print expression recursively\n" + << " :q Exit nix-repl\n" + << " :r Reload all files\n" + << " :s <expr> Build dependencies of derivation, then start " + "nix-shell\n" + << " :t <expr> Describe result of evaluation\n" + << " :u <expr> Build derivation, then start nix-shell\n"; + } + + else if (command == ":a" || command == ":add") { + Value v; + evalString(arg, v); + addAttrsToScope(v); + } + + else if (command == ":l" || command == ":load") { + state.resetFileCache(); + loadFile(arg); + } + + else if (command == ":r" || command == ":reload") { + state.resetFileCache(); + reloadFiles(); + } + + else if (command == ":t") { + Value v; + evalString(arg, v); + std::cout << showType(v) << std::endl; + + } else if (command == ":u") { + Value v; + Value f; + Value result; + evalString(arg, v); + evalString( + "drv: (import <nixpkgs> {}).runCommand \"shell\" { buildInputs = [ drv " + "]; } \"\"", + f); + state.callFunction(f, v, result, Pos()); + + Path drvPath = getDerivationPath(result); + runProgram(settings.nixBinDir + "/nix-shell", Strings{drvPath}); + } + + else if (command == ":b" || command == ":i" || command == ":s") { + Value v; + evalString(arg, v); + Path drvPath = getDerivationPath(v); + + if (command == ":b") { + /* We could do the build in this process using buildPaths(), + but doing it in a child makes it easier to recover from + problems / SIGINT. */ + if (runProgram(settings.nixBinDir + "/nix", + Strings{"build", "--no-link", drvPath}) == 0) { + Derivation drv = readDerivation(drvPath); + std::cout << std::endl + << "this derivation produced the following outputs:" + << std::endl; + for (auto& i : drv.outputs) { + std::cout << format(" %1% -> %2%") % i.first % i.second.path + << std::endl; + } + } + } else if (command == ":i") { + runProgram(settings.nixBinDir + "/nix-env", Strings{"-i", drvPath}); + } else { + runProgram(settings.nixBinDir + "/nix-shell", Strings{drvPath}); + } + } + + else if (command == ":p" || command == ":print") { + Value v; + evalString(arg, v); + printValue(std::cout, v, 1000000000) << std::endl; + } + + else if (command == ":q" || command == ":quit") { + return false; + + } else if (!command.empty()) { + throw Error(format("unknown command '%1%'") % command); + + } else { + size_t p = line.find('='); + string name; + if (p != string::npos && p < line.size() && line[p + 1] != '=' && + isVarName(name = removeWhitespace(string(line, 0, p)))) { + Expr* e = parseString(string(line, p + 1)); + Value& v(*state.allocValue()); + v.type = tThunk; + v.thunk.env = env; + v.thunk.expr = e; + addVarToScope(state.symbols.Create(name), v); + } else { + Value v; + evalString(line, v); + printValue(std::cout, v, 1) << std::endl; + } + } + + return true; +} + +void NixRepl::loadFile(const Path& path) { + loadedFiles.remove(path); + loadedFiles.push_back(path); + Value v; + Value v2; + state.evalFile(lookupFileArg(state, path), v); + state.autoCallFunction(*autoArgs, v, v2); + addAttrsToScope(v2); +} + +void NixRepl::initEnv() { + env = &state.allocEnv(envSize); + env->up = &state.baseEnv; + displ = 0; + staticEnv.vars.clear(); + + varNames.clear(); + for (auto& i : state.staticBaseEnv.vars) { + varNames.insert(i.first); + } +} + +void NixRepl::reloadFiles() { + initEnv(); + + Strings old = loadedFiles; + loadedFiles.clear(); + + bool first = true; + for (auto& i : old) { + if (!first) { + std::cout << std::endl; + } + first = false; + std::cout << format("Loading '%1%'...") % i << std::endl; + loadFile(i); + } +} + +void NixRepl::addAttrsToScope(Value& attrs) { + state.forceAttrs(attrs); + for (auto& i : *attrs.attrs) { + addVarToScope(i.second.name, *i.second.value); + } + std::cout << format("Added %1% variables.") % attrs.attrs->size() + << std::endl; +} + +void NixRepl::addVarToScope(const Symbol& name, Value& v) { + if (displ >= envSize) { + throw Error("environment full; cannot add more variables"); + } + staticEnv.vars[name] = displ; + env->values[displ++] = &v; + varNames.insert((string)name); +} + +Expr* NixRepl::parseString(const string& s) { + Expr* e = state.parseExprFromString(s, curDir, staticEnv); + return e; +} + +void NixRepl::evalString(string s, Value& v) { + Expr* e = parseString(std::move(s)); + e->eval(state, *env, v); + state.forceValue(v); +} + +std::ostream& NixRepl::printValue(std::ostream& str, Value& v, + unsigned int maxDepth) { + ValuesSeen seen; + return printValue(str, v, maxDepth, seen); +} + +std::ostream& printStringValue(std::ostream& str, const char* string) { + str << "\""; + for (const char* i = string; *i != 0; i++) { + if (*i == '\"' || *i == '\\') { + str << "\\" << *i; + } else if (*i == '\n') { + str << "\\n"; + } else if (*i == '\r') { + str << "\\r"; + } else if (*i == '\t') { + str << "\\t"; + } else { + str << *i; + } + } + str << "\""; + return str; +} + +// FIXME: lot of cut&paste from Nix's eval.cc. +std::ostream& NixRepl::printValue(std::ostream& str, Value& v, + unsigned int maxDepth, ValuesSeen& seen) { + str.flush(); + checkInterrupt(); + + state.forceValue(v); + + switch (v.type) { + case tInt: + str << ESC_CYA << v.integer << ESC_END; + break; + + case tBool: + str << ESC_CYA << (v.boolean ? "true" : "false") << ESC_END; + break; + + case tString: + str << ESC_YEL; + printStringValue(str, v.string.s); + str << ESC_END; + break; + + case tPath: + str << ESC_GRE << v.path << ESC_END; // !!! escaping? + break; + + case tNull: + str << ESC_CYA "null" ESC_END; + break; + + case tAttrs: { + seen.insert(&v); + + bool isDrv = state.isDerivation(v); + + if (isDrv) { + str << "«derivation "; + Bindings::iterator i = v.attrs->find(state.sDrvPath); + PathSet context; + Path drvPath = + i != v.attrs->end() + ? state.coerceToPath(*i->second.pos, *i->second.value, context) + : "???"; + str << drvPath << "»"; + } + + else if (maxDepth > 0) { + str << "{ "; + + typedef std::map<string, Value*> Sorted; + Sorted sorted; + for (auto& i : *v.attrs) { + sorted[i.second.name] = i.second.value; + } + + for (auto& i : sorted) { + if (isVarName(i.first)) { + str << i.first; + } else { + printStringValue(str, i.first.c_str()); + } + str << " = "; + if (seen.find(i.second) != seen.end()) { + str << "«repeated»"; + } else { + try { + printValue(str, *i.second, maxDepth - 1, seen); + } catch (AssertionError& e) { + str << ESC_RED "«error: " << e.msg() << "»" ESC_END; + } + } + str << "; "; + } + + str << "}"; + } else { + str << "{ ... }"; + } + + break; + } + + case tList1: + case tList2: + case tListN: + seen.insert(&v); + + str << "[ "; + if (maxDepth > 0) { + for (unsigned int n = 0; n < v.listSize(); ++n) { + if (seen.find(v.listElems()[n]) != seen.end()) { + str << "«repeated»"; + } else { + try { + printValue(str, *v.listElems()[n], maxDepth - 1, seen); + } catch (AssertionError& e) { + str << ESC_RED "«error: " << e.msg() << "»" ESC_END; + } + } + str << " "; + } + } else { + str << "... "; + } + + str << "]"; + break; + + case tLambda: { + std::ostringstream s; + s << v.lambda.fun->pos; + str << ESC_BLU "«lambda @ " << filterANSIEscapes(s.str()) << "»" ESC_END; + break; + } + + case tPrimOp: + str << ESC_MAG "«primop»" ESC_END; + break; + + case tPrimOpApp: + str << ESC_BLU "«primop-app»" ESC_END; + break; + + case tFloat: + str << v.fpoint; + break; + + default: + str << ESC_RED "«unknown»" ESC_END; + break; + } + + return str; +} + +struct CmdRepl : StoreCommand, MixEvalArgs { + std::vector<std::string> files; + + CmdRepl() { expectArgs("files", &files); } + + std::string name() override { return "repl"; } + + std::string description() override { + return "start an interactive environment for evaluating Nix expressions"; + } + + void run(ref<Store> store) override { + auto repl = std::make_unique<NixRepl>(searchPath, openStore()); + repl->autoArgs = getAutoArgs(repl->state); + repl->mainLoop(files); + } +}; + +static RegisterCommand r1(make_ref<CmdRepl>()); + +} // namespace nix diff --git a/third_party/nix/src/nix/run.cc b/third_party/nix/src/nix/run.cc new file mode 100644 index 0000000000..fa471bd542 --- /dev/null +++ b/third_party/nix/src/nix/run.cc @@ -0,0 +1,280 @@ +#include "affinity.hh" +#include "command.hh" +#include "common-args.hh" +#include "derivations.hh" +#include "finally.hh" +#include "fs-accessor.hh" +#include "local-store.hh" +#include "shared.hh" +#include "store-api.hh" + +#if __linux__ +#include <sys/mount.h> +#endif + +#include <queue> + +using namespace nix; + +std::string chrootHelperName = "__run_in_chroot"; + +struct CmdRun : InstallablesCommand { + std::vector<std::string> command = {"bash"}; + StringSet keep, unset; + bool ignoreEnvironment = false; + + CmdRun() { + mkFlag() + .longName("command") + .shortName('c') + .description("command and arguments to be executed; defaults to 'bash'") + .labels({"command", "args"}) + .arity(ArityAny) + .handler([&](const std::vector<std::string>& ss) { + if (ss.empty()) { + throw UsageError("--command requires at least one argument"); + } + command = ss; + }); + + mkFlag() + .longName("ignore-environment") + .shortName('i') + .description( + "clear the entire environment (except those specified with --keep)") + .set(&ignoreEnvironment, true); + + mkFlag() + .longName("keep") + .shortName('k') + .description("keep specified environment variable") + .arity(1) + .labels({"name"}) + .handler([&](std::vector<std::string> ss) { keep.insert(ss.front()); }); + + mkFlag() + .longName("unset") + .shortName('u') + .description("unset specified environment variable") + .arity(1) + .labels({"name"}) + .handler( + [&](std::vector<std::string> ss) { unset.insert(ss.front()); }); + } + + std::string name() override { return "run"; } + + std::string description() override { + return "run a shell in which the specified packages are available"; + } + + Examples examples() override { + return { + Example{"To start a shell providing GNU Hello from NixOS 17.03:", + "nix run -f channel:nixos-17.03 hello"}, + Example{"To start a shell providing youtube-dl from your 'nixpkgs' " + "channel:", + "nix run nixpkgs.youtube-dl"}, + Example{"To run GNU Hello:", + "nix run nixpkgs.hello -c hello --greeting 'Hi everybody!'"}, + Example{"To run GNU Hello in a chroot store:", + "nix run --store ~/my-nix nixpkgs.hello -c hello"}, + }; + } + + void run(ref<Store> store) override { + auto outPaths = toStorePaths(store, Build, installables); + + auto accessor = store->getFSAccessor(); + + if (ignoreEnvironment) { + if (!unset.empty()) { + throw UsageError( + "--unset does not make sense with --ignore-environment"); + } + + std::map<std::string, std::string> kept; + for (auto& var : keep) { + auto s = getenv(var.c_str()); + if (s != nullptr) { + kept[var] = s; + } + } + + clearEnv(); + + for (auto& var : kept) { + setenv(var.first.c_str(), var.second.c_str(), 1); + } + + } else { + if (!keep.empty()) { + throw UsageError( + "--keep does not make sense without --ignore-environment"); + } + + for (auto& var : unset) { + unsetenv(var.c_str()); + } + } + + std::unordered_set<Path> done; + std::queue<Path> todo; + for (auto& path : outPaths) { + todo.push(path); + } + + auto unixPath = tokenizeString<Strings>(getEnv("PATH"), ":"); + + while (!todo.empty()) { + Path path = todo.front(); + todo.pop(); + if (!done.insert(path).second) { + continue; + } + + { unixPath.push_front(path + "/bin"); } + + auto propPath = path + "/nix-support/propagated-user-env-packages"; + if (accessor->stat(propPath).type == FSAccessor::tRegular) { + for (auto& p : tokenizeString<Paths>(readFile(propPath))) { + todo.push(p); + } + } + } + + setenv("PATH", concatStringsSep(":", unixPath).c_str(), 1); + + std::string cmd = *command.begin(); + Strings args; + for (auto& arg : command) { + args.push_back(arg); + } + + restoreSignals(); + + restoreAffinity(); + + /* If this is a diverted store (i.e. its "logical" location + (typically /nix/store) differs from its "physical" location + (e.g. /home/eelco/nix/store), then run the command in a + chroot. For non-root users, this requires running it in new + mount and user namespaces. Unfortunately, + unshare(CLONE_NEWUSER) doesn't work in a multithreaded + program (which "nix" is), so we exec() a single-threaded + helper program (chrootHelper() below) to do the work. */ + auto store2 = store.dynamic_pointer_cast<LocalStore>(); + + if (store2 && store->storeDir != store2->realStoreDir) { + Strings helperArgs = {chrootHelperName, store->storeDir, + store2->realStoreDir, cmd}; + for (auto& arg : args) { + helperArgs.push_back(arg); + } + + execv(readLink("/proc/self/exe").c_str(), + stringsToCharPtrs(helperArgs).data()); + + throw SysError("could not execute chroot helper"); + } + + execvp(cmd.c_str(), stringsToCharPtrs(args).data()); + + throw SysError("unable to exec '%s'", cmd); + } +}; + +static RegisterCommand r1(make_ref<CmdRun>()); + +void chrootHelper(int argc, char** argv) { + int p = 1; + std::string storeDir = argv[p++]; + std::string realStoreDir = argv[p++]; + std::string cmd = argv[p++]; + Strings args; + while (p < argc) { + args.push_back(argv[p++]); + } + +#if __linux__ + uid_t uid = getuid(); + uid_t gid = getgid(); + + if (unshare(CLONE_NEWUSER | CLONE_NEWNS) == -1) { + /* Try with just CLONE_NEWNS in case user namespaces are + specifically disabled. */ + if (unshare(CLONE_NEWNS) == -1) { + throw SysError("setting up a private mount namespace"); + } + } + + /* Bind-mount realStoreDir on /nix/store. If the latter mount + point doesn't already exists, we have to create a chroot + environment containing the mount point and bind mounts for the + children of /. Would be nice if we could use overlayfs here, + but that doesn't work in a user namespace yet (Ubuntu has a + patch for this: + https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1478578). */ + if (!pathExists(storeDir)) { + // FIXME: Use overlayfs? + + Path tmpDir = createTempDir(); + + createDirs(tmpDir + storeDir); + + if (mount(realStoreDir.c_str(), (tmpDir + storeDir).c_str(), "", MS_BIND, + nullptr) == -1) { + throw SysError("mounting '%s' on '%s'", realStoreDir, storeDir); + } + + for (const auto& entry : readDirectory("/")) { + auto src = "/" + entry.name; + auto st = lstat(src); + if (!S_ISDIR(st.st_mode)) { + continue; + } + Path dst = tmpDir + "/" + entry.name; + if (pathExists(dst)) { + continue; + } + if (mkdir(dst.c_str(), 0700) == -1) { + throw SysError("creating directory '%s'", dst); + } + if (mount(src.c_str(), dst.c_str(), "", MS_BIND | MS_REC, nullptr) == + -1) { + throw SysError("mounting '%s' on '%s'", src, dst); + } + } + + char* cwd = getcwd(nullptr, 0); + if (cwd == nullptr) { + throw SysError("getting current directory"); + } + Finally freeCwd([&]() { free(cwd); }); + + if (chroot(tmpDir.c_str()) == -1) { + throw SysError(format("chrooting into '%s'") % tmpDir); + } + + if (chdir(cwd) == -1) { + throw SysError(format("chdir to '%s' in chroot") % cwd); + } + } else if (mount(realStoreDir.c_str(), storeDir.c_str(), "", MS_BIND, + nullptr) == -1) { + throw SysError("mounting '%s' on '%s'", realStoreDir, storeDir); + } + + writeFile("/proc/self/setgroups", "deny"); + writeFile("/proc/self/uid_map", fmt("%d %d %d", uid, uid, 1)); + writeFile("/proc/self/gid_map", fmt("%d %d %d", gid, gid, 1)); + + execvp(cmd.c_str(), stringsToCharPtrs(args).data()); + + throw SysError("unable to exec '%s'", cmd); + +#else + throw Error( + "mounting the Nix store on '%s' is not supported on this platform", + storeDir); +#endif +} diff --git a/third_party/nix/src/nix/search.cc b/third_party/nix/src/nix/search.cc new file mode 100644 index 0000000000..9f03fc6f32 --- /dev/null +++ b/third_party/nix/src/nix/search.cc @@ -0,0 +1,273 @@ +#include <fstream> +#include <regex> + +#include <glog/logging.h> + +#include "command.hh" +#include "common-args.hh" +#include "eval-inline.hh" +#include "eval.hh" +#include "get-drvs.hh" +#include "globals.hh" +#include "json-to-value.hh" +#include "json.hh" +#include "names.hh" +#include "shared.hh" + +using namespace nix; + +std::string wrap(const std::string& prefix, const std::string& s) { + return prefix + s + ANSI_NORMAL; +} + +std::string hilite(const std::string& s, const std::smatch& m, + const std::string& postfix) { + return m.empty() ? s + : std::string(m.prefix()) + ANSI_RED + std::string(m.str()) + + postfix + std::string(m.suffix()); +} + +struct CmdSearch : SourceExprCommand, MixJSON { + std::vector<std::string> res; + + bool writeCache = true; + bool useCache = true; + + CmdSearch() { + expectArgs("regex", &res); + + mkFlag() + .longName("update-cache") + .shortName('u') + .description("update the package search cache") + .handler([&]() { + writeCache = true; + useCache = false; + }); + + mkFlag() + .longName("no-cache") + .description("do not use or update the package search cache") + .handler([&]() { + writeCache = false; + useCache = false; + }); + } + + std::string name() override { return "search"; } + + std::string description() override { return "query available packages"; } + + Examples examples() override { + return {Example{"To show all available packages:", "nix search"}, + Example{"To show any packages containing 'blender' in its name or " + "description:", + "nix search blender"}, + Example{"To search for Firefox or Chromium:", + "nix search 'firefox|chromium'"}, + Example{"To search for git and frontend or gui:", + "nix search git 'frontend|gui'"}}; + } + + void run(ref<Store> store) override { + settings.readOnlyMode = true; + + // Empty search string should match all packages + // Use "^" here instead of ".*" due to differences in resulting highlighting + // (see #1893 -- libc++ claims empty search string is not in POSIX grammar) + if (res.empty()) { + res.emplace_back("^"); + } + + std::vector<std::regex> regexes; + regexes.reserve(res.size()); + + for (auto& re : res) { + regexes.emplace_back(re, std::regex::extended | std::regex::icase); + } + + auto state = getEvalState(); + + auto jsonOut = json ? std::make_unique<JSONObject>(std::cout) : nullptr; + + auto sToplevel = state->symbols.Create("_toplevel"); + auto sRecurse = state->symbols.Create("recurseForDerivations"); + + bool fromCache = false; + + std::map<std::string, std::string> results; + + std::function<void(Value*, std::string, bool, JSONObject*)> doExpr; + + doExpr = [&](Value* v, const std::string& attrPath, bool toplevel, + JSONObject* cache) { + DLOG(INFO) << "at attribute '" << attrPath << "'"; + + try { + uint found = 0; + + state->forceValue(*v); + + if (v->type == tLambda && toplevel) { + Value* v2 = state->allocValue(); + state->autoCallFunction(*Bindings::NewGC(), *v, *v2); + v = v2; + state->forceValue(*v); + } + + if (state->isDerivation(*v)) { + DrvInfo drv(*state, attrPath, v->attrs); + std::string description; + std::smatch attrPathMatch; + std::smatch descriptionMatch; + std::smatch nameMatch; + std::string name; + + DrvName parsed(drv.queryName()); + + for (auto& regex : regexes) { + std::regex_search(attrPath, attrPathMatch, regex); + + name = parsed.name; + std::regex_search(name, nameMatch, regex); + + description = drv.queryMetaString("description"); + std::replace(description.begin(), description.end(), '\n', ' '); + std::regex_search(description, descriptionMatch, regex); + + if (!attrPathMatch.empty() || !nameMatch.empty() || + !descriptionMatch.empty()) { + found++; + } + } + + if (found == res.size()) { + if (json) { + auto jsonElem = jsonOut->object(attrPath); + + jsonElem.attr("pkgName", parsed.name); + jsonElem.attr("version", parsed.version); + jsonElem.attr("description", description); + + } else { + auto name = hilite(parsed.name, nameMatch, "\e[0;2m") + + std::string(parsed.fullName, parsed.name.length()); + results[attrPath] = fmt( + "* %s (%s)\n %s\n", + wrap("\e[0;1m", hilite(attrPath, attrPathMatch, "\e[0;1m")), + wrap("\e[0;2m", hilite(name, nameMatch, "\e[0;2m")), + hilite(description, descriptionMatch, ANSI_NORMAL)); + } + } + + if (cache != nullptr) { + cache->attr("type", "derivation"); + cache->attr("name", drv.queryName()); + cache->attr("system", drv.querySystem()); + if (!description.empty()) { + auto meta(cache->object("meta")); + meta.attr("description", description); + } + } + } + + else if (v->type == tAttrs) { + if (!toplevel) { + auto attrs = v->attrs; + Bindings::iterator j = attrs->find(sRecurse); + if (j == attrs->end() || + !state->forceBool(*j->second.value, *j->second.pos)) { + DLOG(INFO) << "skip attribute '" << attrPath << "'"; + return; + } + } + + bool toplevel2 = false; + if (!fromCache) { + Bindings::iterator j = v->attrs->find(sToplevel); + toplevel2 = j != v->attrs->end() && + state->forceBool(*j->second.value, *j->second.pos); + } + + for (auto& i : *v->attrs) { + auto cache2 = + cache != nullptr + ? std::make_unique<JSONObject>(cache->object(i.second.name)) + : nullptr; + doExpr(i.second.value, + attrPath.empty() + ? (std::string)i.second.name + : attrPath + "." + (std::string)i.second.name, + toplevel2 || fromCache, cache2 ? cache2.get() : nullptr); + } + } + + } catch (AssertionError& e) { + } catch (Error& e) { + if (!toplevel) { + e.addPrefix(fmt("While evaluating the attribute '%s':\n", attrPath)); + throw; + } + } + }; + + Path jsonCacheFileName = getCacheDir() + "/nix/package-search.json"; + + if (useCache && pathExists(jsonCacheFileName)) { + LOG(WARNING) << "using cached results; pass '-u' to update the cache"; + + Value vRoot; + parseJSON(*state, readFile(jsonCacheFileName), vRoot); + + fromCache = true; + + doExpr(&vRoot, "", true, nullptr); + } + + else { + createDirs(dirOf(jsonCacheFileName)); + + Path tmpFile = fmt("%s.tmp.%d", jsonCacheFileName, getpid()); + + std::ofstream jsonCacheFile; + + try { + // iostream considered harmful + jsonCacheFile.exceptions(std::ofstream::failbit); + jsonCacheFile.open(tmpFile); + + auto cache = writeCache + ? std::make_unique<JSONObject>(jsonCacheFile, false) + : nullptr; + + doExpr(getSourceExpr(*state), "", true, cache.get()); + + } catch (std::exception&) { + /* Fun fact: catching std::ios::failure does not work + due to C++11 ABI shenanigans. + https://gcc.gnu.org/bugzilla/show_bug.cgi?id=66145 */ + if (!jsonCacheFile) { + throw Error("error writing to %s", tmpFile); + } + throw; + } + + if (writeCache && + rename(tmpFile.c_str(), jsonCacheFileName.c_str()) == -1) { + throw SysError("cannot rename '%s' to '%s'", tmpFile, + jsonCacheFileName); + } + } + + if (results.empty()) { + throw Error("no results for the given search term(s)!"); + } + + RunPager pager; + for (const auto& el : results) { + std::cout << el.second << "\n"; + } + } +}; + +static RegisterCommand r1(make_ref<CmdSearch>()); diff --git a/third_party/nix/src/nix/show-config.cc b/third_party/nix/src/nix/show-config.cc new file mode 100644 index 0000000000..51f02ed61b --- /dev/null +++ b/third_party/nix/src/nix/show-config.cc @@ -0,0 +1,31 @@ +#include "command.hh" +#include "common-args.hh" +#include "json.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdShowConfig : Command, MixJSON { + CmdShowConfig() = default; + + std::string name() override { return "show-config"; } + + std::string description() override { return "show the Nix configuration"; } + + void run() override { + if (json) { + // FIXME: use appropriate JSON types (bool, ints, etc). + JSONObject jsonObj(std::cout); + globalConfig.toJSON(jsonObj); + } else { + std::map<std::string, Config::SettingInfo> settings; + globalConfig.getSettings(settings); + for (auto& s : settings) { + std::cout << s.first + " = " + s.second.value + "\n"; + } + } + } +}; + +static RegisterCommand r1(make_ref<CmdShowConfig>()); diff --git a/third_party/nix/src/nix/show-derivation.cc b/third_party/nix/src/nix/show-derivation.cc new file mode 100644 index 0000000000..b821a9ee12 --- /dev/null +++ b/third_party/nix/src/nix/show-derivation.cc @@ -0,0 +1,113 @@ +// FIXME: integrate this with nix path-info? + +#include "archive.hh" +#include "command.hh" +#include "common-args.hh" +#include "derivations.hh" +#include "json.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdShowDerivation : InstallablesCommand { + bool recursive = false; + + CmdShowDerivation() { + mkFlag() + .longName("recursive") + .shortName('r') + .description("include the dependencies of the specified derivations") + .set(&recursive, true); + } + + std::string name() override { return "show-derivation"; } + + std::string description() override { + return "show the contents of a store derivation"; + } + + Examples examples() override { + return { + Example{"To show the store derivation that results from evaluating the " + "Hello package:", + "nix show-derivation nixpkgs.hello"}, + Example{"To show the full derivation graph (if available) that " + "produced your NixOS system:", + "nix show-derivation -r /run/current-system"}, + }; + } + + void run(ref<Store> store) override { + auto drvPaths = toDerivations(store, installables, true); + + if (recursive) { + PathSet closure; + store->computeFSClosure(drvPaths, closure); + drvPaths = closure; + } + + { + JSONObject jsonRoot(std::cout, true); + + for (auto& drvPath : drvPaths) { + if (!isDerivation(drvPath)) { + continue; + } + + auto drvObj(jsonRoot.object(drvPath)); + + auto drv = readDerivation(drvPath); + + { + auto outputsObj(drvObj.object("outputs")); + for (auto& output : drv.outputs) { + auto outputObj(outputsObj.object(output.first)); + outputObj.attr("path", output.second.path); + if (!output.second.hash.empty()) { + outputObj.attr("hashAlgo", output.second.hashAlgo); + outputObj.attr("hash", output.second.hash); + } + } + } + + { + auto inputsList(drvObj.list("inputSrcs")); + for (auto& input : drv.inputSrcs) { + inputsList.elem(input); + } + } + + { + auto inputDrvsObj(drvObj.object("inputDrvs")); + for (auto& input : drv.inputDrvs) { + auto inputList(inputDrvsObj.list(input.first)); + for (auto& outputId : input.second) { + inputList.elem(outputId); + } + } + } + + drvObj.attr("platform", drv.platform); + drvObj.attr("builder", drv.builder); + + { + auto argsList(drvObj.list("args")); + for (auto& arg : drv.args) { + argsList.elem(arg); + } + } + + { + auto envObj(drvObj.object("env")); + for (auto& var : drv.env) { + envObj.attr(var.first, var.second); + } + } + } + } + + std::cout << "\n"; + } +}; + +static RegisterCommand r1(make_ref<CmdShowDerivation>()); diff --git a/third_party/nix/src/nix/sigs.cc b/third_party/nix/src/nix/sigs.cc new file mode 100644 index 0000000000..420296a802 --- /dev/null +++ b/third_party/nix/src/nix/sigs.cc @@ -0,0 +1,145 @@ +#include <atomic> + +#include <glog/logging.h> + +#include "command.hh" +#include "shared.hh" +#include "store-api.hh" +#include "thread-pool.hh" + +using namespace nix; + +struct CmdCopySigs : StorePathsCommand { + Strings substituterUris; + + CmdCopySigs() { + mkFlag() + .longName("substituter") + .shortName('s') + .labels({"store-uri"}) + .description("use signatures from specified store") + .arity(1) + .handler([&](std::vector<std::string> ss) { + substituterUris.push_back(ss[0]); + }); + } + + std::string name() override { return "copy-sigs"; } + + std::string description() override { + return "copy path signatures from substituters (like binary caches)"; + } + + void run(ref<Store> store, Paths storePaths) override { + if (substituterUris.empty()) { + throw UsageError("you must specify at least one substituter using '-s'"); + } + + // FIXME: factor out commonality with MixVerify. + std::vector<ref<Store>> substituters; + for (auto& s : substituterUris) { + substituters.push_back(openStore(s)); + } + + ThreadPool pool; + + std::string doneLabel = "done"; + std::atomic<size_t> added{0}; + + // logger->setExpected(doneLabel, storePaths.size()); + + auto doPath = [&](const Path& storePath) { + // Activity act(*logger, lvlInfo, format("getting signatures for '%s'") % + // storePath); + + checkInterrupt(); + + auto info = store->queryPathInfo(storePath); + + StringSet newSigs; + + for (auto& store2 : substituters) { + try { + auto info2 = store2->queryPathInfo(storePath); + + /* Don't import signatures that don't match this + binary. */ + if (info->narHash != info2->narHash || + info->narSize != info2->narSize || + info->references != info2->references) { + continue; + } + + for (auto& sig : info2->sigs) { + if (info->sigs.count(sig) == 0u) { + newSigs.insert(sig); + } + } + } catch (InvalidPath&) { + } + } + + if (!newSigs.empty()) { + store->addSignatures(storePath, newSigs); + added += newSigs.size(); + } + + // logger->incProgress(doneLabel); + }; + + for (auto& storePath : storePaths) { + pool.enqueue(std::bind(doPath, storePath)); + } + + pool.process(); + + LOG(INFO) << "imported " << added << " signatures"; + } +}; + +static RegisterCommand r1(make_ref<CmdCopySigs>()); + +struct CmdSignPaths : StorePathsCommand { + Path secretKeyFile; + + CmdSignPaths() { + mkFlag() + .shortName('k') + .longName("key-file") + .label("file") + .description("file containing the secret signing key") + .dest(&secretKeyFile); + } + + std::string name() override { return "sign-paths"; } + + std::string description() override { return "sign the specified paths"; } + + void run(ref<Store> store, Paths storePaths) override { + if (secretKeyFile.empty()) { + throw UsageError("you must specify a secret key file using '-k'"); + } + + SecretKey secretKey(readFile(secretKeyFile)); + + size_t added{0}; + + for (auto& storePath : storePaths) { + auto info = store->queryPathInfo(storePath); + + auto info2(*info); + info2.sigs.clear(); + info2.sign(secretKey); + assert(!info2.sigs.empty()); + + if (info->sigs.count(*info2.sigs.begin()) == 0u) { + store->addSignatures(storePath, info2.sigs); + added++; + } + } + + LOG(INFO) << "added " << added << " signatures"; + } +}; + +static RegisterCommand r3(make_ref<CmdSignPaths>()); diff --git a/third_party/nix/src/nix/upgrade-nix.cc b/third_party/nix/src/nix/upgrade-nix.cc new file mode 100644 index 0000000000..08c411f4b4 --- /dev/null +++ b/third_party/nix/src/nix/upgrade-nix.cc @@ -0,0 +1,161 @@ +#include <glog/logging.h> + +#include "attr-path.hh" +#include "command.hh" +#include "common-args.hh" +#include "download.hh" +#include "eval.hh" +#include "names.hh" +#include "store-api.hh" + +using namespace nix; + +struct CmdUpgradeNix : MixDryRun, StoreCommand { + Path profileDir; + std::string storePathsUrl = + "https://github.com/NixOS/nixpkgs/raw/master/nixos/modules/installer/" + "tools/nix-fallback-paths.nix"; + + CmdUpgradeNix() { + mkFlag() + .longName("profile") + .shortName('p') + .labels({"profile-dir"}) + .description("the Nix profile to upgrade") + .dest(&profileDir); + + mkFlag() + .longName("nix-store-paths-url") + .labels({"url"}) + .description( + "URL of the file that contains the store paths of the latest Nix " + "release") + .dest(&storePathsUrl); + } + + std::string name() override { return "upgrade-nix"; } + + std::string description() override { + return "upgrade Nix to the latest stable version"; + } + + Examples examples() override { + return { + Example{"To upgrade Nix to the latest stable version:", + "nix upgrade-nix"}, + Example{ + "To upgrade Nix in a specific profile:", + "nix upgrade-nix -p /nix/var/nix/profiles/per-user/alice/profile"}, + }; + } + + void run(ref<Store> store) override { + evalSettings.pureEval = true; + + if (profileDir.empty()) { + profileDir = getProfileDir(store); + } + + LOG(INFO) << "upgrading Nix in profile '" << profileDir << "'"; + + Path storePath; + { + LOG(INFO) << "querying latest Nix version"; + storePath = getLatestNix(store); + } + + auto version = DrvName(storePathToName(storePath)).version; + + if (dryRun) { + LOG(ERROR) << "would upgrade to version " << version; + return; + } + + { + LOG(INFO) << "downloading '" << storePath << "'..."; + store->ensurePath(storePath); + } + + { + LOG(INFO) << "verifying that '" << storePath << "' works..."; + auto program = storePath + "/bin/nix-env"; + auto s = runProgram(program, false, {"--version"}); + if (s.find("Nix") == std::string::npos) { + throw Error("could not verify that '%s' works", program); + } + } + + { + LOG(INFO) << "installing '" << storePath << "' into profile '" + << profileDir << "'..."; + runProgram(settings.nixBinDir + "/nix-env", false, + {"--profile", profileDir, "-i", storePath, "--no-sandbox"}); + } + + LOG(INFO) << ANSI_GREEN << "upgrade to version " << version << " done" + << ANSI_NORMAL; + } + + /* Return the profile in which Nix is installed. */ + static Path getProfileDir(const ref<Store>& store) { + Path where; + + for (auto& dir : tokenizeString<Strings>(getEnv("PATH"), ":")) { + if (pathExists(dir + "/nix-env")) { + where = dir; + break; + } + } + + if (where.empty()) { + throw Error( + "couldn't figure out how Nix is installed, so I can't upgrade it"); + } + + LOG(INFO) << "found Nix in '" << where << "'"; + + if (hasPrefix(where, "/run/current-system")) { + throw Error("Nix on NixOS must be upgraded via 'nixos-rebuild'"); + } + + Path profileDir = dirOf(where); + + // Resolve profile to /nix/var/nix/profiles/<name> link. + while (canonPath(profileDir).find("/profiles/") == std::string::npos && + isLink(profileDir)) { + profileDir = readLink(profileDir); + } + + LOG(INFO) << "found profile '" << profileDir << "'"; + + Path userEnv = canonPath(profileDir, true); + + if (baseNameOf(where) != "bin" || !hasSuffix(userEnv, "user-environment")) { + throw Error("directory '%s' does not appear to be part of a Nix profile", + where); + } + + if (!store->isValidPath(userEnv)) { + throw Error("directory '%s' is not in the Nix store", userEnv); + } + + return profileDir; + } + + /* Return the store path of the latest stable Nix. */ + Path getLatestNix(const ref<Store>& store) { + // FIXME: use nixos.org? + auto req = DownloadRequest(storePathsUrl); + auto res = getDownloader()->download(req); + + auto state = std::make_unique<EvalState>(Strings(), store); + auto v = state->allocValue(); + state->eval(state->parseExprFromString(*res.data, "/no-such-path"), *v); + Bindings& bindings(*Bindings::NewGC()); + auto v2 = findAlongAttrPath(*state, settings.thisSystem, bindings, *v); + + return state->forceString(*v2); + } +}; + +static RegisterCommand r1(make_ref<CmdUpgradeNix>()); diff --git a/third_party/nix/src/nix/verify.cc b/third_party/nix/src/nix/verify.cc new file mode 100644 index 0000000000..a773b3a2c8 --- /dev/null +++ b/third_party/nix/src/nix/verify.cc @@ -0,0 +1,170 @@ +#include <atomic> + +#include <glog/logging.h> + +#include "command.hh" +#include "shared.hh" +#include "store-api.hh" +#include "sync.hh" +#include "thread-pool.hh" + +using namespace nix; + +struct CmdVerify : StorePathsCommand { + bool noContents = false; + bool noTrust = false; + Strings substituterUris; + size_t sigsNeeded = 0; + + CmdVerify() { + mkFlag(0, "no-contents", "do not verify the contents of each store path", + &noContents); + mkFlag(0, "no-trust", "do not verify whether each store path is trusted", + &noTrust); + mkFlag() + .longName("substituter") + .shortName('s') + .labels({"store-uri"}) + .description("use signatures from specified store") + .arity(1) + .handler([&](std::vector<std::string> ss) { + substituterUris.push_back(ss[0]); + }); + mkIntFlag('n', "sigs-needed", + "require that each path has at least N valid signatures", + &sigsNeeded); + } + + std::string name() override { return "verify"; } + + std::string description() override { + return "verify the integrity of store paths"; + } + + Examples examples() override { + return { + Example{"To verify the entire Nix store:", "nix verify --all"}, + Example{"To check whether each path in the closure of Firefox has at " + "least 2 signatures:", + "nix verify -r -n2 --no-contents $(type -p firefox)"}, + }; + } + + void run(ref<Store> store, Paths storePaths) override { + std::vector<ref<Store>> substituters; + for (auto& s : substituterUris) { + substituters.push_back(openStore(s)); + } + + auto publicKeys = getDefaultPublicKeys(); + + std::atomic<size_t> done{0}; + std::atomic<size_t> untrusted{0}; + std::atomic<size_t> corrupted{0}; + std::atomic<size_t> failed{0}; + std::atomic<size_t> active{0}; + + ThreadPool pool; + + auto doPath = [&](const Path& storePath) { + try { + checkInterrupt(); + + LOG(INFO) << "checking '" << storePath << "'"; + + MaintainCount<std::atomic<size_t>> mcActive(active); + + auto info = store->queryPathInfo(storePath); + + if (!noContents) { + HashSink sink(info->narHash.type); + store->narFromPath(info->path, sink); + + auto hash = sink.finish(); + + if (hash.first != info->narHash) { + corrupted++; + LOG(WARNING) << "path '" << info->path + << "' was modified! expected hash '" + << info->narHash.to_string() << "', got '" + << hash.first.to_string() << "'"; + } + } + + if (!noTrust) { + bool good = false; + + if (info->ultimate && (sigsNeeded == 0u)) { + good = true; + + } else { + StringSet sigsSeen; + size_t actualSigsNeeded = std::max(sigsNeeded, (size_t)1); + size_t validSigs = 0; + + auto doSigs = [&](const StringSet& sigs) { + for (const auto& sig : sigs) { + if (sigsSeen.count(sig) != 0u) { + continue; + } + sigsSeen.insert(sig); + if (validSigs < ValidPathInfo::maxSigs && + info->checkSignature(publicKeys, sig)) { + validSigs++; + } + } + }; + + if (info->isContentAddressed(*store)) { + validSigs = ValidPathInfo::maxSigs; + } + + doSigs(info->sigs); + + for (auto& store2 : substituters) { + if (validSigs >= actualSigsNeeded) { + break; + } + try { + auto info2 = store2->queryPathInfo(info->path); + if (info2->isContentAddressed(*store)) { + validSigs = ValidPathInfo::maxSigs; + } + doSigs(info2->sigs); + } catch (InvalidPath&) { + } catch (Error& e) { + LOG(ERROR) << e.what(); + } + } + + if (validSigs >= actualSigsNeeded) { + good = true; + } + } + + if (!good) { + untrusted++; + LOG(WARNING) << "path '" << info->path << "' is untrusted"; + } + } + + done++; + + } catch (Error& e) { + LOG(ERROR) << e.what(); + failed++; + } + }; + + for (auto& storePath : storePaths) { + pool.enqueue(std::bind(doPath, storePath)); + } + + pool.process(); + + throw Exit((corrupted != 0u ? 1 : 0) | (untrusted != 0u ? 2 : 0) | + (failed != 0u ? 4 : 0)); + } +}; + +static RegisterCommand r1(make_ref<CmdVerify>()); diff --git a/third_party/nix/src/nix/why-depends.cc b/third_party/nix/src/nix/why-depends.cc new file mode 100644 index 0000000000..bbbfd1fe01 --- /dev/null +++ b/third_party/nix/src/nix/why-depends.cc @@ -0,0 +1,265 @@ +#include <queue> + +#include <glog/logging.h> + +#include "command.hh" +#include "fs-accessor.hh" +#include "shared.hh" +#include "store-api.hh" + +using namespace nix; + +static std::string hilite(const std::string& s, size_t pos, size_t len, + const std::string& colour = ANSI_RED) { + return std::string(s, 0, pos) + colour + std::string(s, pos, len) + + ANSI_NORMAL + std::string(s, pos + len); +} + +static std::string filterPrintable(const std::string& s) { + std::string res; + for (char c : s) { + res += isprint(c) != 0 ? c : '.'; + } + return res; +} + +struct CmdWhyDepends : SourceExprCommand { + std::string _package, _dependency; + bool all = false; + + CmdWhyDepends() { + expectArg("package", &_package); + expectArg("dependency", &_dependency); + + mkFlag() + .longName("all") + .shortName('a') + .description( + "show all edges in the dependency graph leading from 'package' to " + "'dependency', rather than just a shortest path") + .set(&all, true); + } + + std::string name() override { return "why-depends"; } + + std::string description() override { + return "show why a package has another package in its closure"; + } + + Examples examples() override { + return { + Example{"To show one path through the dependency graph leading from " + "Hello to Glibc:", + "nix why-depends nixpkgs.hello nixpkgs.glibc"}, + Example{ + "To show all files and paths in the dependency graph leading from " + "Thunderbird to libX11:", + "nix why-depends --all nixpkgs.thunderbird nixpkgs.xorg.libX11"}, + Example{"To show why Glibc depends on itself:", + "nix why-depends nixpkgs.glibc nixpkgs.glibc"}, + }; + } + + void run(ref<Store> store) override { + auto package = parseInstallable(*this, store, _package, false); + auto packagePath = toStorePath(store, Build, package); + auto dependency = parseInstallable(*this, store, _dependency, false); + auto dependencyPath = toStorePath(store, NoBuild, dependency); + auto dependencyPathHash = storePathToHash(dependencyPath); + + PathSet closure; + store->computeFSClosure({packagePath}, closure, false, false); + + if (closure.count(dependencyPath) == 0u) { + LOG(WARNING) << "'" << package->what() << "' does not depend on '" + << dependency->what() << "'"; + return; + } + + auto accessor = store->getFSAccessor(); + + auto const inf = std::numeric_limits<size_t>::max(); + + struct Node { + Path path; + PathSet refs; + PathSet rrefs; + size_t dist = inf; + Node* prev = nullptr; + bool queued = false; + bool visited = false; + }; + + std::map<Path, Node> graph; + + for (auto& path : closure) { + graph.emplace(path, Node{path, store->queryPathInfo(path)->references}); + } + + // Transpose the graph. + for (auto& node : graph) { + for (auto& ref : node.second.refs) { + graph[ref].rrefs.insert(node.first); + } + } + + /* Run Dijkstra's shortest path algorithm to get the distance + of every path in the closure to 'dependency'. */ + graph[dependencyPath].dist = 0; + + std::priority_queue<Node*> queue; + + queue.push(&graph.at(dependencyPath)); + + while (!queue.empty()) { + auto& node = *queue.top(); + queue.pop(); + + for (auto& rref : node.rrefs) { + auto& node2 = graph.at(rref); + auto dist = node.dist + 1; + if (dist < node2.dist) { + node2.dist = dist; + node2.prev = &node; + if (!node2.queued) { + node2.queued = true; + queue.push(&node2); + } + } + } + } + + /* Print the subgraph of nodes that have 'dependency' in their + closure (i.e., that have a non-infinite distance to + 'dependency'). Print every edge on a path between `package` + and `dependency`. */ + std::function<void(Node&, const string&, const string&)> printNode; + + const string treeConn = "╠═══"; + const string treeLast = "╚═══"; + const string treeLine = "║ "; + const string treeNull = " "; + + struct BailOut {}; + + printNode = [&](Node& node, const string& firstPad, const string& tailPad) { + assert(node.dist != inf); + std::cout << fmt("%s%s%s%s" ANSI_NORMAL "\n", firstPad, + node.visited ? "\e[38;5;244m" : "", + !firstPad.empty() ? "=> " : "", node.path); + + if (node.path == dependencyPath && !all && + packagePath != dependencyPath) { + throw BailOut(); + } + + if (node.visited) { + return; + } + node.visited = true; + + /* Sort the references by distance to `dependency` to + ensure that the shortest path is printed first. */ + std::multimap<size_t, Node*> refs; + std::set<std::string> hashes; + + for (auto& ref : node.refs) { + if (ref == node.path && packagePath != dependencyPath) { + continue; + } + auto& node2 = graph.at(ref); + if (node2.dist == inf) { + continue; + } + refs.emplace(node2.dist, &node2); + hashes.insert(storePathToHash(node2.path)); + } + + /* For each reference, find the files and symlinks that + contain the reference. */ + std::map<std::string, Strings> hits; + + std::function<void(const Path&)> visitPath; + + visitPath = [&](const Path& p) { + auto st = accessor->stat(p); + + auto p2 = p == node.path ? "/" : std::string(p, node.path.size() + 1); + + auto getColour = [&](const std::string& hash) { + return hash == dependencyPathHash ? ANSI_GREEN : ANSI_BLUE; + }; + + if (st.type == FSAccessor::Type::tDirectory) { + auto names = accessor->readDirectory(p); + for (auto& name : names) { + visitPath(p + "/" + name); + } + } + + else if (st.type == FSAccessor::Type::tRegular) { + auto contents = accessor->readFile(p); + + for (auto& hash : hashes) { + auto pos = contents.find(hash); + if (pos != std::string::npos) { + size_t margin = 32; + auto pos2 = pos >= margin ? pos - margin : 0; + hits[hash].emplace_back(fmt( + "%s: …%s…\n", p2, + hilite( + filterPrintable(std::string( + contents, pos2, pos - pos2 + hash.size() + margin)), + pos - pos2, storePathHashLen, getColour(hash)))); + } + } + } + + else if (st.type == FSAccessor::Type::tSymlink) { + auto target = accessor->readLink(p); + + for (auto& hash : hashes) { + auto pos = target.find(hash); + if (pos != std::string::npos) { + hits[hash].emplace_back( + fmt("%s -> %s\n", p2, + hilite(target, pos, storePathHashLen, getColour(hash)))); + } + } + } + }; + + // FIXME: should use scanForReferences(). + + visitPath(node.path); + + RunPager pager; + for (auto& ref : refs) { + auto hash = storePathToHash(ref.second->path); + + bool last = all ? ref == *refs.rbegin() : true; + + for (auto& hit : hits[hash]) { + bool first = hit == *hits[hash].begin(); + std::cout << tailPad + << (first ? (last ? treeLast : treeConn) + : (last ? treeNull : treeLine)) + << hit; + if (!all) { + break; + } + } + + printNode(*ref.second, tailPad + (last ? treeNull : treeLine), + tailPad + (last ? treeNull : treeLine)); + } + }; + + try { + printNode(graph.at(packagePath), "", ""); + } catch (BailOut&) { + } + } +}; + +static RegisterCommand r1(make_ref<CmdWhyDepends>()); diff --git a/third_party/nix/src/nlohmann/json.hpp b/third_party/nix/src/nlohmann/json.hpp new file mode 100644 index 0000000000..c9af0bed36 --- /dev/null +++ b/third_party/nix/src/nlohmann/json.hpp @@ -0,0 +1,20406 @@ +/* + __ _____ _____ _____ + __| | __| | | | JSON for Modern C++ +| | |__ | | | | | | version 3.5.0 +|_____|_____|_____|_|___| https://github.com/nlohmann/json + +Licensed under the MIT License <http://opensource.org/licenses/MIT>. +SPDX-License-Identifier: MIT +Copyright (c) 2013-2018 Niels Lohmann <http://nlohmann.me>. + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. +*/ + +#ifndef NLOHMANN_JSON_HPP +#define NLOHMANN_JSON_HPP + +#define NLOHMANN_JSON_VERSION_MAJOR 3 +#define NLOHMANN_JSON_VERSION_MINOR 5 +#define NLOHMANN_JSON_VERSION_PATCH 0 + +#include <algorithm> // all_of, find, for_each +#include <cassert> // assert +#include <ciso646> // and, not, or +#include <cstddef> // nullptr_t, ptrdiff_t, size_t +#include <functional> // hash, less +#include <initializer_list> // initializer_list +#include <iosfwd> // istream, ostream +#include <iterator> // random_access_iterator_tag +#include <numeric> // accumulate +#include <string> // string, stoi, to_string +#include <utility> // declval, forward, move, pair, swap + +// #include <nlohmann/json_fwd.hpp> +#ifndef NLOHMANN_JSON_FWD_HPP +#define NLOHMANN_JSON_FWD_HPP + +#include <cstdint> // int64_t, uint64_t +#include <map> // map +#include <memory> // allocator +#include <string> // string +#include <vector> // vector + +/*! +@brief namespace for Niels Lohmann +@see https://github.com/nlohmann +@since version 1.0.0 +*/ +namespace nlohmann +{ +/*! +@brief default JSONSerializer template argument + +This serializer ignores the template arguments and uses ADL +([argument-dependent lookup](https://en.cppreference.com/w/cpp/language/adl)) +for serialization. +*/ +template<typename T = void, typename SFINAE = void> +struct adl_serializer; + +template<template<typename U, typename V, typename... Args> class ObjectType = + std::map, + template<typename U, typename... Args> class ArrayType = std::vector, + class StringType = std::string, class BooleanType = bool, + class NumberIntegerType = std::int64_t, + class NumberUnsignedType = std::uint64_t, + class NumberFloatType = double, + template<typename U> class AllocatorType = std::allocator, + template<typename T, typename SFINAE = void> class JSONSerializer = + adl_serializer> +class basic_json; + +/*! +@brief JSON Pointer + +A JSON pointer defines a string syntax for identifying a specific value +within a JSON document. It can be used with functions `at` and +`operator[]`. Furthermore, JSON pointers are the base for JSON patches. + +@sa [RFC 6901](https://tools.ietf.org/html/rfc6901) + +@since version 2.0.0 +*/ +template<typename BasicJsonType> +class json_pointer; + +/*! +@brief default JSON class + +This type is the default specialization of the @ref basic_json class which +uses the standard template types. + +@since version 1.0.0 +*/ +using json = basic_json<>; +} // namespace nlohmann + +#endif + +// #include <nlohmann/detail/macro_scope.hpp> + + +// This file contains all internal macro definitions +// You MUST include macro_unscope.hpp at the end of json.hpp to undef all of them + +// exclude unsupported compilers +#if !defined(JSON_SKIP_UNSUPPORTED_COMPILER_CHECK) + #if defined(__clang__) + #if (__clang_major__ * 10000 + __clang_minor__ * 100 + __clang_patchlevel__) < 30400 + #error "unsupported Clang version - see https://github.com/nlohmann/json#supported-compilers" + #endif + #elif defined(__GNUC__) && !(defined(__ICC) || defined(__INTEL_COMPILER)) + #if (__GNUC__ * 10000 + __GNUC_MINOR__ * 100 + __GNUC_PATCHLEVEL__) < 40800 + #error "unsupported GCC version - see https://github.com/nlohmann/json#supported-compilers" + #endif + #endif +#endif + +// disable float-equal warnings on GCC/clang +#if defined(__clang__) || defined(__GNUC__) || defined(__GNUG__) + #pragma GCC diagnostic push + #pragma GCC diagnostic ignored "-Wfloat-equal" +#endif + +// disable documentation warnings on clang +#if defined(__clang__) + #pragma GCC diagnostic push + #pragma GCC diagnostic ignored "-Wdocumentation" +#endif + +// allow for portable deprecation warnings +#if defined(__clang__) || defined(__GNUC__) || defined(__GNUG__) + #define JSON_DEPRECATED __attribute__((deprecated)) +#elif defined(_MSC_VER) + #define JSON_DEPRECATED __declspec(deprecated) +#else + #define JSON_DEPRECATED +#endif + +// allow to disable exceptions +#if (defined(__cpp_exceptions) || defined(__EXCEPTIONS) || defined(_CPPUNWIND)) && !defined(JSON_NOEXCEPTION) + #define JSON_THROW(exception) throw exception + #define JSON_TRY try + #define JSON_CATCH(exception) catch(exception) + #define JSON_INTERNAL_CATCH(exception) catch(exception) +#else + #define JSON_THROW(exception) std::abort() + #define JSON_TRY if(true) + #define JSON_CATCH(exception) if(false) + #define JSON_INTERNAL_CATCH(exception) if(false) +#endif + +// override exception macros +#if defined(JSON_THROW_USER) + #undef JSON_THROW + #define JSON_THROW JSON_THROW_USER +#endif +#if defined(JSON_TRY_USER) + #undef JSON_TRY + #define JSON_TRY JSON_TRY_USER +#endif +#if defined(JSON_CATCH_USER) + #undef JSON_CATCH + #define JSON_CATCH JSON_CATCH_USER + #undef JSON_INTERNAL_CATCH + #define JSON_INTERNAL_CATCH JSON_CATCH_USER +#endif +#if defined(JSON_INTERNAL_CATCH_USER) + #undef JSON_INTERNAL_CATCH + #define JSON_INTERNAL_CATCH JSON_INTERNAL_CATCH_USER +#endif + +// manual branch prediction +#if defined(__clang__) || defined(__GNUC__) || defined(__GNUG__) + #define JSON_LIKELY(x) __builtin_expect(!!(x), 1) + #define JSON_UNLIKELY(x) __builtin_expect(!!(x), 0) +#else + #define JSON_LIKELY(x) x + #define JSON_UNLIKELY(x) x +#endif + +// C++ language standard detection +#if (defined(__cplusplus) && __cplusplus >= 201703L) || (defined(_HAS_CXX17) && _HAS_CXX17 == 1) // fix for issue #464 + #define JSON_HAS_CPP_17 + #define JSON_HAS_CPP_14 +#elif (defined(__cplusplus) && __cplusplus >= 201402L) || (defined(_HAS_CXX14) && _HAS_CXX14 == 1) + #define JSON_HAS_CPP_14 +#endif + +/*! +@brief macro to briefly define a mapping between an enum and JSON +@def NLOHMANN_JSON_SERIALIZE_ENUM +@since version 3.4.0 +*/ +#define NLOHMANN_JSON_SERIALIZE_ENUM(ENUM_TYPE, ...) \ + template<typename BasicJsonType> \ + inline void to_json(BasicJsonType& j, const ENUM_TYPE& e) \ + { \ + static_assert(std::is_enum<ENUM_TYPE>::value, #ENUM_TYPE " must be an enum!"); \ + static const std::pair<ENUM_TYPE, BasicJsonType> m[] = __VA_ARGS__; \ + auto it = std::find_if(std::begin(m), std::end(m), \ + [e](const std::pair<ENUM_TYPE, BasicJsonType>& ej_pair) -> bool \ + { \ + return ej_pair.first == e; \ + }); \ + j = ((it != std::end(m)) ? it : std::begin(m))->second; \ + } \ + template<typename BasicJsonType> \ + inline void from_json(const BasicJsonType& j, ENUM_TYPE& e) \ + { \ + static_assert(std::is_enum<ENUM_TYPE>::value, #ENUM_TYPE " must be an enum!"); \ + static const std::pair<ENUM_TYPE, BasicJsonType> m[] = __VA_ARGS__; \ + auto it = std::find_if(std::begin(m), std::end(m), \ + [j](const std::pair<ENUM_TYPE, BasicJsonType>& ej_pair) -> bool \ + { \ + return ej_pair.second == j; \ + }); \ + e = ((it != std::end(m)) ? it : std::begin(m))->first; \ + } + +// Ugly macros to avoid uglier copy-paste when specializing basic_json. They +// may be removed in the future once the class is split. + +#define NLOHMANN_BASIC_JSON_TPL_DECLARATION \ + template<template<typename, typename, typename...> class ObjectType, \ + template<typename, typename...> class ArrayType, \ + class StringType, class BooleanType, class NumberIntegerType, \ + class NumberUnsignedType, class NumberFloatType, \ + template<typename> class AllocatorType, \ + template<typename, typename = void> class JSONSerializer> + +#define NLOHMANN_BASIC_JSON_TPL \ + basic_json<ObjectType, ArrayType, StringType, BooleanType, \ + NumberIntegerType, NumberUnsignedType, NumberFloatType, \ + AllocatorType, JSONSerializer> + +// #include <nlohmann/detail/meta/cpp_future.hpp> + + +#include <ciso646> // not +#include <cstddef> // size_t +#include <type_traits> // conditional, enable_if, false_type, integral_constant, is_constructible, is_integral, is_same, remove_cv, remove_reference, true_type + +namespace nlohmann +{ +namespace detail +{ +// alias templates to reduce boilerplate +template<bool B, typename T = void> +using enable_if_t = typename std::enable_if<B, T>::type; + +template<typename T> +using uncvref_t = typename std::remove_cv<typename std::remove_reference<T>::type>::type; + +// implementation of C++14 index_sequence and affiliates +// source: https://stackoverflow.com/a/32223343 +template<std::size_t... Ints> +struct index_sequence +{ + using type = index_sequence; + using value_type = std::size_t; + static constexpr std::size_t size() noexcept + { + return sizeof...(Ints); + } +}; + +template<class Sequence1, class Sequence2> +struct merge_and_renumber; + +template<std::size_t... I1, std::size_t... I2> +struct merge_and_renumber<index_sequence<I1...>, index_sequence<I2...>> + : index_sequence < I1..., (sizeof...(I1) + I2)... > {}; + +template<std::size_t N> +struct make_index_sequence + : merge_and_renumber < typename make_index_sequence < N / 2 >::type, + typename make_index_sequence < N - N / 2 >::type > {}; + +template<> struct make_index_sequence<0> : index_sequence<> {}; +template<> struct make_index_sequence<1> : index_sequence<0> {}; + +template<typename... Ts> +using index_sequence_for = make_index_sequence<sizeof...(Ts)>; + +// dispatch utility (taken from ranges-v3) +template<unsigned N> struct priority_tag : priority_tag < N - 1 > {}; +template<> struct priority_tag<0> {}; + +// taken from ranges-v3 +template<typename T> +struct static_const +{ + static constexpr T value{}; +}; + +template<typename T> +constexpr T static_const<T>::value; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/meta/type_traits.hpp> + + +#include <ciso646> // not +#include <limits> // numeric_limits +#include <type_traits> // false_type, is_constructible, is_integral, is_same, true_type +#include <utility> // declval + +// #include <nlohmann/json_fwd.hpp> + +// #include <nlohmann/detail/iterators/iterator_traits.hpp> + + +#include <iterator> // random_access_iterator_tag + +// #include <nlohmann/detail/meta/void_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +template <typename ...Ts> struct make_void +{ + using type = void; +}; +template <typename ...Ts> using void_t = typename make_void<Ts...>::type; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/meta/cpp_future.hpp> + + +namespace nlohmann +{ +namespace detail +{ +template <typename It, typename = void> +struct iterator_types {}; + +template <typename It> +struct iterator_types < + It, + void_t<typename It::difference_type, typename It::value_type, typename It::pointer, + typename It::reference, typename It::iterator_category >> +{ + using difference_type = typename It::difference_type; + using value_type = typename It::value_type; + using pointer = typename It::pointer; + using reference = typename It::reference; + using iterator_category = typename It::iterator_category; +}; + +// This is required as some compilers implement std::iterator_traits in a way that +// doesn't work with SFINAE. See https://github.com/nlohmann/json/issues/1341. +template <typename T, typename = void> +struct iterator_traits +{ +}; + +template <typename T> +struct iterator_traits < T, enable_if_t < !std::is_pointer<T>::value >> + : iterator_types<T> +{ +}; + +template <typename T> +struct iterator_traits<T*, enable_if_t<std::is_object<T>::value>> +{ + using iterator_category = std::random_access_iterator_tag; + using value_type = T; + using difference_type = ptrdiff_t; + using pointer = T*; + using reference = T&; +}; +} +} + +// #include <nlohmann/detail/meta/cpp_future.hpp> + +// #include <nlohmann/detail/meta/detected.hpp> + + +#include <type_traits> + +// #include <nlohmann/detail/meta/void_t.hpp> + + +// http://en.cppreference.com/w/cpp/experimental/is_detected +namespace nlohmann +{ +namespace detail +{ +struct nonesuch +{ + nonesuch() = delete; + ~nonesuch() = delete; + nonesuch(nonesuch const&) = delete; + void operator=(nonesuch const&) = delete; +}; + +template <class Default, + class AlwaysVoid, + template <class...> class Op, + class... Args> +struct detector +{ + using value_t = std::false_type; + using type = Default; +}; + +template <class Default, template <class...> class Op, class... Args> +struct detector<Default, void_t<Op<Args...>>, Op, Args...> +{ + using value_t = std::true_type; + using type = Op<Args...>; +}; + +template <template <class...> class Op, class... Args> +using is_detected = typename detector<nonesuch, void, Op, Args...>::value_t; + +template <template <class...> class Op, class... Args> +using detected_t = typename detector<nonesuch, void, Op, Args...>::type; + +template <class Default, template <class...> class Op, class... Args> +using detected_or = detector<Default, void, Op, Args...>; + +template <class Default, template <class...> class Op, class... Args> +using detected_or_t = typename detected_or<Default, Op, Args...>::type; + +template <class Expected, template <class...> class Op, class... Args> +using is_detected_exact = std::is_same<Expected, detected_t<Op, Args...>>; + +template <class To, template <class...> class Op, class... Args> +using is_detected_convertible = + std::is_convertible<detected_t<Op, Args...>, To>; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/macro_scope.hpp> + + +namespace nlohmann +{ +/*! +@brief detail namespace with internal helper functions + +This namespace collects functions that should not be exposed, +implementations of some @ref basic_json methods, and meta-programming helpers. + +@since version 2.1.0 +*/ +namespace detail +{ +///////////// +// helpers // +///////////// + +// Note to maintainers: +// +// Every trait in this file expects a non CV-qualified type. +// The only exceptions are in the 'aliases for detected' section +// (i.e. those of the form: decltype(T::member_function(std::declval<T>()))) +// +// In this case, T has to be properly CV-qualified to constraint the function arguments +// (e.g. to_json(BasicJsonType&, const T&)) + +template<typename> struct is_basic_json : std::false_type {}; + +NLOHMANN_BASIC_JSON_TPL_DECLARATION +struct is_basic_json<NLOHMANN_BASIC_JSON_TPL> : std::true_type {}; + +////////////////////////// +// aliases for detected // +////////////////////////// + +template <typename T> +using mapped_type_t = typename T::mapped_type; + +template <typename T> +using key_type_t = typename T::key_type; + +template <typename T> +using value_type_t = typename T::value_type; + +template <typename T> +using difference_type_t = typename T::difference_type; + +template <typename T> +using pointer_t = typename T::pointer; + +template <typename T> +using reference_t = typename T::reference; + +template <typename T> +using iterator_category_t = typename T::iterator_category; + +template <typename T> +using iterator_t = typename T::iterator; + +template <typename T, typename... Args> +using to_json_function = decltype(T::to_json(std::declval<Args>()...)); + +template <typename T, typename... Args> +using from_json_function = decltype(T::from_json(std::declval<Args>()...)); + +template <typename T, typename U> +using get_template_function = decltype(std::declval<T>().template get<U>()); + +// trait checking if JSONSerializer<T>::from_json(json const&, udt&) exists +template <typename BasicJsonType, typename T, typename = void> +struct has_from_json : std::false_type {}; + +template <typename BasicJsonType, typename T> +struct has_from_json<BasicJsonType, T, + enable_if_t<not is_basic_json<T>::value>> +{ + using serializer = typename BasicJsonType::template json_serializer<T, void>; + + static constexpr bool value = + is_detected_exact<void, from_json_function, serializer, + const BasicJsonType&, T&>::value; +}; + +// This trait checks if JSONSerializer<T>::from_json(json const&) exists +// this overload is used for non-default-constructible user-defined-types +template <typename BasicJsonType, typename T, typename = void> +struct has_non_default_from_json : std::false_type {}; + +template<typename BasicJsonType, typename T> +struct has_non_default_from_json<BasicJsonType, T, enable_if_t<not is_basic_json<T>::value>> +{ + using serializer = typename BasicJsonType::template json_serializer<T, void>; + + static constexpr bool value = + is_detected_exact<T, from_json_function, serializer, + const BasicJsonType&>::value; +}; + +// This trait checks if BasicJsonType::json_serializer<T>::to_json exists +// Do not evaluate the trait when T is a basic_json type, to avoid template instantiation infinite recursion. +template <typename BasicJsonType, typename T, typename = void> +struct has_to_json : std::false_type {}; + +template <typename BasicJsonType, typename T> +struct has_to_json<BasicJsonType, T, enable_if_t<not is_basic_json<T>::value>> +{ + using serializer = typename BasicJsonType::template json_serializer<T, void>; + + static constexpr bool value = + is_detected_exact<void, to_json_function, serializer, BasicJsonType&, + T>::value; +}; + + +/////////////////// +// is_ functions // +/////////////////// + +template <typename T, typename = void> +struct is_iterator_traits : std::false_type {}; + +template <typename T> +struct is_iterator_traits<iterator_traits<T>> +{ + private: + using traits = iterator_traits<T>; + + public: + static constexpr auto value = + is_detected<value_type_t, traits>::value && + is_detected<difference_type_t, traits>::value && + is_detected<pointer_t, traits>::value && + is_detected<iterator_category_t, traits>::value && + is_detected<reference_t, traits>::value; +}; + +// source: https://stackoverflow.com/a/37193089/4116453 + +template <typename T, typename = void> +struct is_complete_type : std::false_type {}; + +template <typename T> +struct is_complete_type<T, decltype(void(sizeof(T)))> : std::true_type {}; + +template <typename BasicJsonType, typename CompatibleObjectType, + typename = void> +struct is_compatible_object_type_impl : std::false_type {}; + +template <typename BasicJsonType, typename CompatibleObjectType> +struct is_compatible_object_type_impl < + BasicJsonType, CompatibleObjectType, + enable_if_t<is_detected<mapped_type_t, CompatibleObjectType>::value and + is_detected<key_type_t, CompatibleObjectType>::value >> +{ + + using object_t = typename BasicJsonType::object_t; + + // macOS's is_constructible does not play well with nonesuch... + static constexpr bool value = + std::is_constructible<typename object_t::key_type, + typename CompatibleObjectType::key_type>::value and + std::is_constructible<typename object_t::mapped_type, + typename CompatibleObjectType::mapped_type>::value; +}; + +template <typename BasicJsonType, typename CompatibleObjectType> +struct is_compatible_object_type + : is_compatible_object_type_impl<BasicJsonType, CompatibleObjectType> {}; + +template <typename BasicJsonType, typename ConstructibleObjectType, + typename = void> +struct is_constructible_object_type_impl : std::false_type {}; + +template <typename BasicJsonType, typename ConstructibleObjectType> +struct is_constructible_object_type_impl < + BasicJsonType, ConstructibleObjectType, + enable_if_t<is_detected<mapped_type_t, ConstructibleObjectType>::value and + is_detected<key_type_t, ConstructibleObjectType>::value >> +{ + using object_t = typename BasicJsonType::object_t; + + static constexpr bool value = + (std::is_constructible<typename ConstructibleObjectType::key_type, typename object_t::key_type>::value and + std::is_same<typename object_t::mapped_type, typename ConstructibleObjectType::mapped_type>::value) or + (has_from_json<BasicJsonType, typename ConstructibleObjectType::mapped_type>::value or + has_non_default_from_json<BasicJsonType, typename ConstructibleObjectType::mapped_type >::value); +}; + +template <typename BasicJsonType, typename ConstructibleObjectType> +struct is_constructible_object_type + : is_constructible_object_type_impl<BasicJsonType, + ConstructibleObjectType> {}; + +template <typename BasicJsonType, typename CompatibleStringType, + typename = void> +struct is_compatible_string_type_impl : std::false_type {}; + +template <typename BasicJsonType, typename CompatibleStringType> +struct is_compatible_string_type_impl < + BasicJsonType, CompatibleStringType, + enable_if_t<is_detected_exact<typename BasicJsonType::string_t::value_type, + value_type_t, CompatibleStringType>::value >> +{ + static constexpr auto value = + std::is_constructible<typename BasicJsonType::string_t, CompatibleStringType>::value; +}; + +template <typename BasicJsonType, typename ConstructibleStringType> +struct is_compatible_string_type + : is_compatible_string_type_impl<BasicJsonType, ConstructibleStringType> {}; + +template <typename BasicJsonType, typename ConstructibleStringType, + typename = void> +struct is_constructible_string_type_impl : std::false_type {}; + +template <typename BasicJsonType, typename ConstructibleStringType> +struct is_constructible_string_type_impl < + BasicJsonType, ConstructibleStringType, + enable_if_t<is_detected_exact<typename BasicJsonType::string_t::value_type, + value_type_t, ConstructibleStringType>::value >> +{ + static constexpr auto value = + std::is_constructible<ConstructibleStringType, + typename BasicJsonType::string_t>::value; +}; + +template <typename BasicJsonType, typename ConstructibleStringType> +struct is_constructible_string_type + : is_constructible_string_type_impl<BasicJsonType, ConstructibleStringType> {}; + +template <typename BasicJsonType, typename CompatibleArrayType, typename = void> +struct is_compatible_array_type_impl : std::false_type {}; + +template <typename BasicJsonType, typename CompatibleArrayType> +struct is_compatible_array_type_impl < + BasicJsonType, CompatibleArrayType, + enable_if_t<is_detected<value_type_t, CompatibleArrayType>::value and + is_detected<iterator_t, CompatibleArrayType>::value and +// This is needed because json_reverse_iterator has a ::iterator type... +// Therefore it is detected as a CompatibleArrayType. +// The real fix would be to have an Iterable concept. + not is_iterator_traits< + iterator_traits<CompatibleArrayType>>::value >> +{ + static constexpr bool value = + std::is_constructible<BasicJsonType, + typename CompatibleArrayType::value_type>::value; +}; + +template <typename BasicJsonType, typename CompatibleArrayType> +struct is_compatible_array_type + : is_compatible_array_type_impl<BasicJsonType, CompatibleArrayType> {}; + +template <typename BasicJsonType, typename ConstructibleArrayType, typename = void> +struct is_constructible_array_type_impl : std::false_type {}; + +template <typename BasicJsonType, typename ConstructibleArrayType> +struct is_constructible_array_type_impl < + BasicJsonType, ConstructibleArrayType, + enable_if_t<std::is_same<ConstructibleArrayType, + typename BasicJsonType::value_type>::value >> + : std::true_type {}; + +template <typename BasicJsonType, typename ConstructibleArrayType> +struct is_constructible_array_type_impl < + BasicJsonType, ConstructibleArrayType, + enable_if_t<not std::is_same<ConstructibleArrayType, + typename BasicJsonType::value_type>::value and + is_detected<value_type_t, ConstructibleArrayType>::value and + is_detected<iterator_t, ConstructibleArrayType>::value and + is_complete_type< + detected_t<value_type_t, ConstructibleArrayType>>::value >> +{ + static constexpr bool value = + // This is needed because json_reverse_iterator has a ::iterator type, + // furthermore, std::back_insert_iterator (and other iterators) have a base class `iterator`... + // Therefore it is detected as a ConstructibleArrayType. + // The real fix would be to have an Iterable concept. + not is_iterator_traits < + iterator_traits<ConstructibleArrayType >>::value and + + (std::is_same<typename ConstructibleArrayType::value_type, typename BasicJsonType::array_t::value_type>::value or + has_from_json<BasicJsonType, + typename ConstructibleArrayType::value_type>::value or + has_non_default_from_json < + BasicJsonType, typename ConstructibleArrayType::value_type >::value); +}; + +template <typename BasicJsonType, typename ConstructibleArrayType> +struct is_constructible_array_type + : is_constructible_array_type_impl<BasicJsonType, ConstructibleArrayType> {}; + +template <typename RealIntegerType, typename CompatibleNumberIntegerType, + typename = void> +struct is_compatible_integer_type_impl : std::false_type {}; + +template <typename RealIntegerType, typename CompatibleNumberIntegerType> +struct is_compatible_integer_type_impl < + RealIntegerType, CompatibleNumberIntegerType, + enable_if_t<std::is_integral<RealIntegerType>::value and + std::is_integral<CompatibleNumberIntegerType>::value and + not std::is_same<bool, CompatibleNumberIntegerType>::value >> +{ + // is there an assert somewhere on overflows? + using RealLimits = std::numeric_limits<RealIntegerType>; + using CompatibleLimits = std::numeric_limits<CompatibleNumberIntegerType>; + + static constexpr auto value = + std::is_constructible<RealIntegerType, + CompatibleNumberIntegerType>::value and + CompatibleLimits::is_integer and + RealLimits::is_signed == CompatibleLimits::is_signed; +}; + +template <typename RealIntegerType, typename CompatibleNumberIntegerType> +struct is_compatible_integer_type + : is_compatible_integer_type_impl<RealIntegerType, + CompatibleNumberIntegerType> {}; + +template <typename BasicJsonType, typename CompatibleType, typename = void> +struct is_compatible_type_impl: std::false_type {}; + +template <typename BasicJsonType, typename CompatibleType> +struct is_compatible_type_impl < + BasicJsonType, CompatibleType, + enable_if_t<is_complete_type<CompatibleType>::value >> +{ + static constexpr bool value = + has_to_json<BasicJsonType, CompatibleType>::value; +}; + +template <typename BasicJsonType, typename CompatibleType> +struct is_compatible_type + : is_compatible_type_impl<BasicJsonType, CompatibleType> {}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/exceptions.hpp> + + +#include <exception> // exception +#include <stdexcept> // runtime_error +#include <string> // to_string + +// #include <nlohmann/detail/input/position_t.hpp> + + +#include <cstddef> // size_t + +namespace nlohmann +{ +namespace detail +{ +/// struct to capture the start position of the current token +struct position_t +{ + /// the total number of characters read + std::size_t chars_read_total = 0; + /// the number of characters read in the current line + std::size_t chars_read_current_line = 0; + /// the number of lines read + std::size_t lines_read = 0; + + /// conversion to size_t to preserve SAX interface + constexpr operator size_t() const + { + return chars_read_total; + } +}; + +} +} + + +namespace nlohmann +{ +namespace detail +{ +//////////////// +// exceptions // +//////////////// + +/*! +@brief general exception of the @ref basic_json class + +This class is an extension of `std::exception` objects with a member @a id for +exception ids. It is used as the base class for all exceptions thrown by the +@ref basic_json class. This class can hence be used as "wildcard" to catch +exceptions. + +Subclasses: +- @ref parse_error for exceptions indicating a parse error +- @ref invalid_iterator for exceptions indicating errors with iterators +- @ref type_error for exceptions indicating executing a member function with + a wrong type +- @ref out_of_range for exceptions indicating access out of the defined range +- @ref other_error for exceptions indicating other library errors + +@internal +@note To have nothrow-copy-constructible exceptions, we internally use + `std::runtime_error` which can cope with arbitrary-length error messages. + Intermediate strings are built with static functions and then passed to + the actual constructor. +@endinternal + +@liveexample{The following code shows how arbitrary library exceptions can be +caught.,exception} + +@since version 3.0.0 +*/ +class exception : public std::exception +{ + public: + /// returns the explanatory string + const char* what() const noexcept override + { + return m.what(); + } + + /// the id of the exception + const int id; + + protected: + exception(int id_, const char* what_arg) : id(id_), m(what_arg) {} + + static std::string name(const std::string& ename, int id_) + { + return "[json.exception." + ename + "." + std::to_string(id_) + "] "; + } + + private: + /// an exception object as storage for error messages + std::runtime_error m; +}; + +/*! +@brief exception indicating a parse error + +This exception is thrown by the library when a parse error occurs. Parse errors +can occur during the deserialization of JSON text, CBOR, MessagePack, as well +as when using JSON Patch. + +Member @a byte holds the byte index of the last read character in the input +file. + +Exceptions have ids 1xx. + +name / id | example message | description +------------------------------ | --------------- | ------------------------- +json.exception.parse_error.101 | parse error at 2: unexpected end of input; expected string literal | This error indicates a syntax error while deserializing a JSON text. The error message describes that an unexpected token (character) was encountered, and the member @a byte indicates the error position. +json.exception.parse_error.102 | parse error at 14: missing or wrong low surrogate | JSON uses the `\uxxxx` format to describe Unicode characters. Code points above above 0xFFFF are split into two `\uxxxx` entries ("surrogate pairs"). This error indicates that the surrogate pair is incomplete or contains an invalid code point. +json.exception.parse_error.103 | parse error: code points above 0x10FFFF are invalid | Unicode supports code points up to 0x10FFFF. Code points above 0x10FFFF are invalid. +json.exception.parse_error.104 | parse error: JSON patch must be an array of objects | [RFC 6902](https://tools.ietf.org/html/rfc6902) requires a JSON Patch document to be a JSON document that represents an array of objects. +json.exception.parse_error.105 | parse error: operation must have string member 'op' | An operation of a JSON Patch document must contain exactly one "op" member, whose value indicates the operation to perform. Its value must be one of "add", "remove", "replace", "move", "copy", or "test"; other values are errors. +json.exception.parse_error.106 | parse error: array index '01' must not begin with '0' | An array index in a JSON Pointer ([RFC 6901](https://tools.ietf.org/html/rfc6901)) may be `0` or any number without a leading `0`. +json.exception.parse_error.107 | parse error: JSON pointer must be empty or begin with '/' - was: 'foo' | A JSON Pointer must be a Unicode string containing a sequence of zero or more reference tokens, each prefixed by a `/` character. +json.exception.parse_error.108 | parse error: escape character '~' must be followed with '0' or '1' | In a JSON Pointer, only `~0` and `~1` are valid escape sequences. +json.exception.parse_error.109 | parse error: array index 'one' is not a number | A JSON Pointer array index must be a number. +json.exception.parse_error.110 | parse error at 1: cannot read 2 bytes from vector | When parsing CBOR or MessagePack, the byte vector ends before the complete value has been read. +json.exception.parse_error.112 | parse error at 1: error reading CBOR; last byte: 0xF8 | Not all types of CBOR or MessagePack are supported. This exception occurs if an unsupported byte was read. +json.exception.parse_error.113 | parse error at 2: expected a CBOR string; last byte: 0x98 | While parsing a map key, a value that is not a string has been read. +json.exception.parse_error.114 | parse error: Unsupported BSON record type 0x0F | The parsing of the corresponding BSON record type is not implemented (yet). + +@note For an input with n bytes, 1 is the index of the first character and n+1 + is the index of the terminating null byte or the end of file. This also + holds true when reading a byte vector (CBOR or MessagePack). + +@liveexample{The following code shows how a `parse_error` exception can be +caught.,parse_error} + +@sa @ref exception for the base class of the library exceptions +@sa @ref invalid_iterator for exceptions indicating errors with iterators +@sa @ref type_error for exceptions indicating executing a member function with + a wrong type +@sa @ref out_of_range for exceptions indicating access out of the defined range +@sa @ref other_error for exceptions indicating other library errors + +@since version 3.0.0 +*/ +class parse_error : public exception +{ + public: + /*! + @brief create a parse error exception + @param[in] id_ the id of the exception + @param[in] position the position where the error occurred (or with + chars_read_total=0 if the position cannot be + determined) + @param[in] what_arg the explanatory string + @return parse_error object + */ + static parse_error create(int id_, const position_t& pos, const std::string& what_arg) + { + std::string w = exception::name("parse_error", id_) + "parse error" + + position_string(pos) + ": " + what_arg; + return parse_error(id_, pos.chars_read_total, w.c_str()); + } + + static parse_error create(int id_, std::size_t byte_, const std::string& what_arg) + { + std::string w = exception::name("parse_error", id_) + "parse error" + + (byte_ != 0 ? (" at byte " + std::to_string(byte_)) : "") + + ": " + what_arg; + return parse_error(id_, byte_, w.c_str()); + } + + /*! + @brief byte index of the parse error + + The byte index of the last read character in the input file. + + @note For an input with n bytes, 1 is the index of the first character and + n+1 is the index of the terminating null byte or the end of file. + This also holds true when reading a byte vector (CBOR or MessagePack). + */ + const std::size_t byte; + + private: + parse_error(int id_, std::size_t byte_, const char* what_arg) + : exception(id_, what_arg), byte(byte_) {} + + static std::string position_string(const position_t& pos) + { + return " at line " + std::to_string(pos.lines_read + 1) + + ", column " + std::to_string(pos.chars_read_current_line); + } +}; + +/*! +@brief exception indicating errors with iterators + +This exception is thrown if iterators passed to a library function do not match +the expected semantics. + +Exceptions have ids 2xx. + +name / id | example message | description +----------------------------------- | --------------- | ------------------------- +json.exception.invalid_iterator.201 | iterators are not compatible | The iterators passed to constructor @ref basic_json(InputIT first, InputIT last) are not compatible, meaning they do not belong to the same container. Therefore, the range (@a first, @a last) is invalid. +json.exception.invalid_iterator.202 | iterator does not fit current value | In an erase or insert function, the passed iterator @a pos does not belong to the JSON value for which the function was called. It hence does not define a valid position for the deletion/insertion. +json.exception.invalid_iterator.203 | iterators do not fit current value | Either iterator passed to function @ref erase(IteratorType first, IteratorType last) does not belong to the JSON value from which values shall be erased. It hence does not define a valid range to delete values from. +json.exception.invalid_iterator.204 | iterators out of range | When an iterator range for a primitive type (number, boolean, or string) is passed to a constructor or an erase function, this range has to be exactly (@ref begin(), @ref end()), because this is the only way the single stored value is expressed. All other ranges are invalid. +json.exception.invalid_iterator.205 | iterator out of range | When an iterator for a primitive type (number, boolean, or string) is passed to an erase function, the iterator has to be the @ref begin() iterator, because it is the only way to address the stored value. All other iterators are invalid. +json.exception.invalid_iterator.206 | cannot construct with iterators from null | The iterators passed to constructor @ref basic_json(InputIT first, InputIT last) belong to a JSON null value and hence to not define a valid range. +json.exception.invalid_iterator.207 | cannot use key() for non-object iterators | The key() member function can only be used on iterators belonging to a JSON object, because other types do not have a concept of a key. +json.exception.invalid_iterator.208 | cannot use operator[] for object iterators | The operator[] to specify a concrete offset cannot be used on iterators belonging to a JSON object, because JSON objects are unordered. +json.exception.invalid_iterator.209 | cannot use offsets with object iterators | The offset operators (+, -, +=, -=) cannot be used on iterators belonging to a JSON object, because JSON objects are unordered. +json.exception.invalid_iterator.210 | iterators do not fit | The iterator range passed to the insert function are not compatible, meaning they do not belong to the same container. Therefore, the range (@a first, @a last) is invalid. +json.exception.invalid_iterator.211 | passed iterators may not belong to container | The iterator range passed to the insert function must not be a subrange of the container to insert to. +json.exception.invalid_iterator.212 | cannot compare iterators of different containers | When two iterators are compared, they must belong to the same container. +json.exception.invalid_iterator.213 | cannot compare order of object iterators | The order of object iterators cannot be compared, because JSON objects are unordered. +json.exception.invalid_iterator.214 | cannot get value | Cannot get value for iterator: Either the iterator belongs to a null value or it is an iterator to a primitive type (number, boolean, or string), but the iterator is different to @ref begin(). + +@liveexample{The following code shows how an `invalid_iterator` exception can be +caught.,invalid_iterator} + +@sa @ref exception for the base class of the library exceptions +@sa @ref parse_error for exceptions indicating a parse error +@sa @ref type_error for exceptions indicating executing a member function with + a wrong type +@sa @ref out_of_range for exceptions indicating access out of the defined range +@sa @ref other_error for exceptions indicating other library errors + +@since version 3.0.0 +*/ +class invalid_iterator : public exception +{ + public: + static invalid_iterator create(int id_, const std::string& what_arg) + { + std::string w = exception::name("invalid_iterator", id_) + what_arg; + return invalid_iterator(id_, w.c_str()); + } + + private: + invalid_iterator(int id_, const char* what_arg) + : exception(id_, what_arg) {} +}; + +/*! +@brief exception indicating executing a member function with a wrong type + +This exception is thrown in case of a type error; that is, a library function is +executed on a JSON value whose type does not match the expected semantics. + +Exceptions have ids 3xx. + +name / id | example message | description +----------------------------- | --------------- | ------------------------- +json.exception.type_error.301 | cannot create object from initializer list | To create an object from an initializer list, the initializer list must consist only of a list of pairs whose first element is a string. When this constraint is violated, an array is created instead. +json.exception.type_error.302 | type must be object, but is array | During implicit or explicit value conversion, the JSON type must be compatible to the target type. For instance, a JSON string can only be converted into string types, but not into numbers or boolean types. +json.exception.type_error.303 | incompatible ReferenceType for get_ref, actual type is object | To retrieve a reference to a value stored in a @ref basic_json object with @ref get_ref, the type of the reference must match the value type. For instance, for a JSON array, the @a ReferenceType must be @ref array_t&. +json.exception.type_error.304 | cannot use at() with string | The @ref at() member functions can only be executed for certain JSON types. +json.exception.type_error.305 | cannot use operator[] with string | The @ref operator[] member functions can only be executed for certain JSON types. +json.exception.type_error.306 | cannot use value() with string | The @ref value() member functions can only be executed for certain JSON types. +json.exception.type_error.307 | cannot use erase() with string | The @ref erase() member functions can only be executed for certain JSON types. +json.exception.type_error.308 | cannot use push_back() with string | The @ref push_back() and @ref operator+= member functions can only be executed for certain JSON types. +json.exception.type_error.309 | cannot use insert() with | The @ref insert() member functions can only be executed for certain JSON types. +json.exception.type_error.310 | cannot use swap() with number | The @ref swap() member functions can only be executed for certain JSON types. +json.exception.type_error.311 | cannot use emplace_back() with string | The @ref emplace_back() member function can only be executed for certain JSON types. +json.exception.type_error.312 | cannot use update() with string | The @ref update() member functions can only be executed for certain JSON types. +json.exception.type_error.313 | invalid value to unflatten | The @ref unflatten function converts an object whose keys are JSON Pointers back into an arbitrary nested JSON value. The JSON Pointers must not overlap, because then the resulting value would not be well defined. +json.exception.type_error.314 | only objects can be unflattened | The @ref unflatten function only works for an object whose keys are JSON Pointers. +json.exception.type_error.315 | values in object must be primitive | The @ref unflatten function only works for an object whose keys are JSON Pointers and whose values are primitive. +json.exception.type_error.316 | invalid UTF-8 byte at index 10: 0x7E | The @ref dump function only works with UTF-8 encoded strings; that is, if you assign a `std::string` to a JSON value, make sure it is UTF-8 encoded. | +json.exception.type_error.317 | JSON value cannot be serialized to requested format | The dynamic type of the object cannot be represented in the requested serialization format (e.g. a raw `true` or `null` JSON object cannot be serialized to BSON) | + +@liveexample{The following code shows how a `type_error` exception can be +caught.,type_error} + +@sa @ref exception for the base class of the library exceptions +@sa @ref parse_error for exceptions indicating a parse error +@sa @ref invalid_iterator for exceptions indicating errors with iterators +@sa @ref out_of_range for exceptions indicating access out of the defined range +@sa @ref other_error for exceptions indicating other library errors + +@since version 3.0.0 +*/ +class type_error : public exception +{ + public: + static type_error create(int id_, const std::string& what_arg) + { + std::string w = exception::name("type_error", id_) + what_arg; + return type_error(id_, w.c_str()); + } + + private: + type_error(int id_, const char* what_arg) : exception(id_, what_arg) {} +}; + +/*! +@brief exception indicating access out of the defined range + +This exception is thrown in case a library function is called on an input +parameter that exceeds the expected range, for instance in case of array +indices or nonexisting object keys. + +Exceptions have ids 4xx. + +name / id | example message | description +------------------------------- | --------------- | ------------------------- +json.exception.out_of_range.401 | array index 3 is out of range | The provided array index @a i is larger than @a size-1. +json.exception.out_of_range.402 | array index '-' (3) is out of range | The special array index `-` in a JSON Pointer never describes a valid element of the array, but the index past the end. That is, it can only be used to add elements at this position, but not to read it. +json.exception.out_of_range.403 | key 'foo' not found | The provided key was not found in the JSON object. +json.exception.out_of_range.404 | unresolved reference token 'foo' | A reference token in a JSON Pointer could not be resolved. +json.exception.out_of_range.405 | JSON pointer has no parent | The JSON Patch operations 'remove' and 'add' can not be applied to the root element of the JSON value. +json.exception.out_of_range.406 | number overflow parsing '10E1000' | A parsed number could not be stored as without changing it to NaN or INF. +json.exception.out_of_range.407 | number overflow serializing '9223372036854775808' | UBJSON and BSON only support integer numbers up to 9223372036854775807. | +json.exception.out_of_range.408 | excessive array size: 8658170730974374167 | The size (following `#`) of an UBJSON array or object exceeds the maximal capacity. | +json.exception.out_of_range.409 | BSON key cannot contain code point U+0000 (at byte 2) | Key identifiers to be serialized to BSON cannot contain code point U+0000, since the key is stored as zero-terminated c-string | + +@liveexample{The following code shows how an `out_of_range` exception can be +caught.,out_of_range} + +@sa @ref exception for the base class of the library exceptions +@sa @ref parse_error for exceptions indicating a parse error +@sa @ref invalid_iterator for exceptions indicating errors with iterators +@sa @ref type_error for exceptions indicating executing a member function with + a wrong type +@sa @ref other_error for exceptions indicating other library errors + +@since version 3.0.0 +*/ +class out_of_range : public exception +{ + public: + static out_of_range create(int id_, const std::string& what_arg) + { + std::string w = exception::name("out_of_range", id_) + what_arg; + return out_of_range(id_, w.c_str()); + } + + private: + out_of_range(int id_, const char* what_arg) : exception(id_, what_arg) {} +}; + +/*! +@brief exception indicating other library errors + +This exception is thrown in case of errors that cannot be classified with the +other exception types. + +Exceptions have ids 5xx. + +name / id | example message | description +------------------------------ | --------------- | ------------------------- +json.exception.other_error.501 | unsuccessful: {"op":"test","path":"/baz", "value":"bar"} | A JSON Patch operation 'test' failed. The unsuccessful operation is also printed. + +@sa @ref exception for the base class of the library exceptions +@sa @ref parse_error for exceptions indicating a parse error +@sa @ref invalid_iterator for exceptions indicating errors with iterators +@sa @ref type_error for exceptions indicating executing a member function with + a wrong type +@sa @ref out_of_range for exceptions indicating access out of the defined range + +@liveexample{The following code shows how an `other_error` exception can be +caught.,other_error} + +@since version 3.0.0 +*/ +class other_error : public exception +{ + public: + static other_error create(int id_, const std::string& what_arg) + { + std::string w = exception::name("other_error", id_) + what_arg; + return other_error(id_, w.c_str()); + } + + private: + other_error(int id_, const char* what_arg) : exception(id_, what_arg) {} +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/value_t.hpp> + + +#include <array> // array +#include <ciso646> // and +#include <cstddef> // size_t +#include <cstdint> // uint8_t + +namespace nlohmann +{ +namespace detail +{ +/////////////////////////// +// JSON type enumeration // +/////////////////////////// + +/*! +@brief the JSON type enumeration + +This enumeration collects the different JSON types. It is internally used to +distinguish the stored values, and the functions @ref basic_json::is_null(), +@ref basic_json::is_object(), @ref basic_json::is_array(), +@ref basic_json::is_string(), @ref basic_json::is_boolean(), +@ref basic_json::is_number() (with @ref basic_json::is_number_integer(), +@ref basic_json::is_number_unsigned(), and @ref basic_json::is_number_float()), +@ref basic_json::is_discarded(), @ref basic_json::is_primitive(), and +@ref basic_json::is_structured() rely on it. + +@note There are three enumeration entries (number_integer, number_unsigned, and +number_float), because the library distinguishes these three types for numbers: +@ref basic_json::number_unsigned_t is used for unsigned integers, +@ref basic_json::number_integer_t is used for signed integers, and +@ref basic_json::number_float_t is used for floating-point numbers or to +approximate integers which do not fit in the limits of their respective type. + +@sa @ref basic_json::basic_json(const value_t value_type) -- create a JSON +value with the default value for a given type + +@since version 1.0.0 +*/ +enum class value_t : std::uint8_t +{ + null, ///< null value + object, ///< object (unordered set of name/value pairs) + array, ///< array (ordered collection of values) + string, ///< string value + boolean, ///< boolean value + number_integer, ///< number value (signed integer) + number_unsigned, ///< number value (unsigned integer) + number_float, ///< number value (floating-point) + discarded ///< discarded by the the parser callback function +}; + +/*! +@brief comparison operator for JSON types + +Returns an ordering that is similar to Python: +- order: null < boolean < number < object < array < string +- furthermore, each type is not smaller than itself +- discarded values are not comparable + +@since version 1.0.0 +*/ +inline bool operator<(const value_t lhs, const value_t rhs) noexcept +{ + static constexpr std::array<std::uint8_t, 8> order = {{ + 0 /* null */, 3 /* object */, 4 /* array */, 5 /* string */, + 1 /* boolean */, 2 /* integer */, 2 /* unsigned */, 2 /* float */ + } + }; + + const auto l_index = static_cast<std::size_t>(lhs); + const auto r_index = static_cast<std::size_t>(rhs); + return l_index < order.size() and r_index < order.size() and order[l_index] < order[r_index]; +} +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/conversions/from_json.hpp> + + +#include <algorithm> // transform +#include <array> // array +#include <ciso646> // and, not +#include <forward_list> // forward_list +#include <iterator> // inserter, front_inserter, end +#include <map> // map +#include <string> // string +#include <tuple> // tuple, make_tuple +#include <type_traits> // is_arithmetic, is_same, is_enum, underlying_type, is_convertible +#include <unordered_map> // unordered_map +#include <utility> // pair, declval +#include <valarray> // valarray + +// #include <nlohmann/detail/exceptions.hpp> + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/meta/cpp_future.hpp> + +// #include <nlohmann/detail/meta/type_traits.hpp> + +// #include <nlohmann/detail/value_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +template<typename BasicJsonType> +void from_json(const BasicJsonType& j, typename std::nullptr_t& n) +{ + if (JSON_UNLIKELY(not j.is_null())) + { + JSON_THROW(type_error::create(302, "type must be null, but is " + std::string(j.type_name()))); + } + n = nullptr; +} + +// overloads for basic_json template parameters +template<typename BasicJsonType, typename ArithmeticType, + enable_if_t<std::is_arithmetic<ArithmeticType>::value and + not std::is_same<ArithmeticType, typename BasicJsonType::boolean_t>::value, + int> = 0> +void get_arithmetic_value(const BasicJsonType& j, ArithmeticType& val) +{ + switch (static_cast<value_t>(j)) + { + case value_t::number_unsigned: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::number_unsigned_t*>()); + break; + } + case value_t::number_integer: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::number_integer_t*>()); + break; + } + case value_t::number_float: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::number_float_t*>()); + break; + } + + default: + JSON_THROW(type_error::create(302, "type must be number, but is " + std::string(j.type_name()))); + } +} + +template<typename BasicJsonType> +void from_json(const BasicJsonType& j, typename BasicJsonType::boolean_t& b) +{ + if (JSON_UNLIKELY(not j.is_boolean())) + { + JSON_THROW(type_error::create(302, "type must be boolean, but is " + std::string(j.type_name()))); + } + b = *j.template get_ptr<const typename BasicJsonType::boolean_t*>(); +} + +template<typename BasicJsonType> +void from_json(const BasicJsonType& j, typename BasicJsonType::string_t& s) +{ + if (JSON_UNLIKELY(not j.is_string())) + { + JSON_THROW(type_error::create(302, "type must be string, but is " + std::string(j.type_name()))); + } + s = *j.template get_ptr<const typename BasicJsonType::string_t*>(); +} + +template < + typename BasicJsonType, typename ConstructibleStringType, + enable_if_t < + is_constructible_string_type<BasicJsonType, ConstructibleStringType>::value and + not std::is_same<typename BasicJsonType::string_t, + ConstructibleStringType>::value, + int > = 0 > +void from_json(const BasicJsonType& j, ConstructibleStringType& s) +{ + if (JSON_UNLIKELY(not j.is_string())) + { + JSON_THROW(type_error::create(302, "type must be string, but is " + std::string(j.type_name()))); + } + + s = *j.template get_ptr<const typename BasicJsonType::string_t*>(); +} + +template<typename BasicJsonType> +void from_json(const BasicJsonType& j, typename BasicJsonType::number_float_t& val) +{ + get_arithmetic_value(j, val); +} + +template<typename BasicJsonType> +void from_json(const BasicJsonType& j, typename BasicJsonType::number_unsigned_t& val) +{ + get_arithmetic_value(j, val); +} + +template<typename BasicJsonType> +void from_json(const BasicJsonType& j, typename BasicJsonType::number_integer_t& val) +{ + get_arithmetic_value(j, val); +} + +template<typename BasicJsonType, typename EnumType, + enable_if_t<std::is_enum<EnumType>::value, int> = 0> +void from_json(const BasicJsonType& j, EnumType& e) +{ + typename std::underlying_type<EnumType>::type val; + get_arithmetic_value(j, val); + e = static_cast<EnumType>(val); +} + +// forward_list doesn't have an insert method +template<typename BasicJsonType, typename T, typename Allocator, + enable_if_t<std::is_convertible<BasicJsonType, T>::value, int> = 0> +void from_json(const BasicJsonType& j, std::forward_list<T, Allocator>& l) +{ + if (JSON_UNLIKELY(not j.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + std::string(j.type_name()))); + } + std::transform(j.rbegin(), j.rend(), + std::front_inserter(l), [](const BasicJsonType & i) + { + return i.template get<T>(); + }); +} + +// valarray doesn't have an insert method +template<typename BasicJsonType, typename T, + enable_if_t<std::is_convertible<BasicJsonType, T>::value, int> = 0> +void from_json(const BasicJsonType& j, std::valarray<T>& l) +{ + if (JSON_UNLIKELY(not j.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + std::string(j.type_name()))); + } + l.resize(j.size()); + std::copy(j.m_value.array->begin(), j.m_value.array->end(), std::begin(l)); +} + +template<typename BasicJsonType> +void from_json_array_impl(const BasicJsonType& j, typename BasicJsonType::array_t& arr, priority_tag<3> /*unused*/) +{ + arr = *j.template get_ptr<const typename BasicJsonType::array_t*>(); +} + +template <typename BasicJsonType, typename T, std::size_t N> +auto from_json_array_impl(const BasicJsonType& j, std::array<T, N>& arr, + priority_tag<2> /*unused*/) +-> decltype(j.template get<T>(), void()) +{ + for (std::size_t i = 0; i < N; ++i) + { + arr[i] = j.at(i).template get<T>(); + } +} + +template<typename BasicJsonType, typename ConstructibleArrayType> +auto from_json_array_impl(const BasicJsonType& j, ConstructibleArrayType& arr, priority_tag<1> /*unused*/) +-> decltype( + arr.reserve(std::declval<typename ConstructibleArrayType::size_type>()), + j.template get<typename ConstructibleArrayType::value_type>(), + void()) +{ + using std::end; + + arr.reserve(j.size()); + std::transform(j.begin(), j.end(), + std::inserter(arr, end(arr)), [](const BasicJsonType & i) + { + // get<BasicJsonType>() returns *this, this won't call a from_json + // method when value_type is BasicJsonType + return i.template get<typename ConstructibleArrayType::value_type>(); + }); +} + +template <typename BasicJsonType, typename ConstructibleArrayType> +void from_json_array_impl(const BasicJsonType& j, ConstructibleArrayType& arr, + priority_tag<0> /*unused*/) +{ + using std::end; + + std::transform( + j.begin(), j.end(), std::inserter(arr, end(arr)), + [](const BasicJsonType & i) + { + // get<BasicJsonType>() returns *this, this won't call a from_json + // method when value_type is BasicJsonType + return i.template get<typename ConstructibleArrayType::value_type>(); + }); +} + +template <typename BasicJsonType, typename ConstructibleArrayType, + enable_if_t < + is_constructible_array_type<BasicJsonType, ConstructibleArrayType>::value and + not is_constructible_object_type<BasicJsonType, ConstructibleArrayType>::value and + not is_constructible_string_type<BasicJsonType, ConstructibleArrayType>::value and + not is_basic_json<ConstructibleArrayType>::value, + int > = 0 > + +auto from_json(const BasicJsonType& j, ConstructibleArrayType& arr) +-> decltype(from_json_array_impl(j, arr, priority_tag<3> {}), +j.template get<typename ConstructibleArrayType::value_type>(), +void()) +{ + if (JSON_UNLIKELY(not j.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + + std::string(j.type_name()))); + } + + from_json_array_impl(j, arr, priority_tag<3> {}); +} + +template<typename BasicJsonType, typename ConstructibleObjectType, + enable_if_t<is_constructible_object_type<BasicJsonType, ConstructibleObjectType>::value, int> = 0> +void from_json(const BasicJsonType& j, ConstructibleObjectType& obj) +{ + if (JSON_UNLIKELY(not j.is_object())) + { + JSON_THROW(type_error::create(302, "type must be object, but is " + std::string(j.type_name()))); + } + + auto inner_object = j.template get_ptr<const typename BasicJsonType::object_t*>(); + using value_type = typename ConstructibleObjectType::value_type; + std::transform( + inner_object->begin(), inner_object->end(), + std::inserter(obj, obj.begin()), + [](typename BasicJsonType::object_t::value_type const & p) + { + return value_type(p.first, p.second.template get<typename ConstructibleObjectType::mapped_type>()); + }); +} + +// overload for arithmetic types, not chosen for basic_json template arguments +// (BooleanType, etc..); note: Is it really necessary to provide explicit +// overloads for boolean_t etc. in case of a custom BooleanType which is not +// an arithmetic type? +template<typename BasicJsonType, typename ArithmeticType, + enable_if_t < + std::is_arithmetic<ArithmeticType>::value and + not std::is_same<ArithmeticType, typename BasicJsonType::number_unsigned_t>::value and + not std::is_same<ArithmeticType, typename BasicJsonType::number_integer_t>::value and + not std::is_same<ArithmeticType, typename BasicJsonType::number_float_t>::value and + not std::is_same<ArithmeticType, typename BasicJsonType::boolean_t>::value, + int> = 0> +void from_json(const BasicJsonType& j, ArithmeticType& val) +{ + switch (static_cast<value_t>(j)) + { + case value_t::number_unsigned: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::number_unsigned_t*>()); + break; + } + case value_t::number_integer: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::number_integer_t*>()); + break; + } + case value_t::number_float: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::number_float_t*>()); + break; + } + case value_t::boolean: + { + val = static_cast<ArithmeticType>(*j.template get_ptr<const typename BasicJsonType::boolean_t*>()); + break; + } + + default: + JSON_THROW(type_error::create(302, "type must be number, but is " + std::string(j.type_name()))); + } +} + +template<typename BasicJsonType, typename A1, typename A2> +void from_json(const BasicJsonType& j, std::pair<A1, A2>& p) +{ + p = {j.at(0).template get<A1>(), j.at(1).template get<A2>()}; +} + +template<typename BasicJsonType, typename Tuple, std::size_t... Idx> +void from_json_tuple_impl(const BasicJsonType& j, Tuple& t, index_sequence<Idx...> /*unused*/) +{ + t = std::make_tuple(j.at(Idx).template get<typename std::tuple_element<Idx, Tuple>::type>()...); +} + +template<typename BasicJsonType, typename... Args> +void from_json(const BasicJsonType& j, std::tuple<Args...>& t) +{ + from_json_tuple_impl(j, t, index_sequence_for<Args...> {}); +} + +template <typename BasicJsonType, typename Key, typename Value, typename Compare, typename Allocator, + typename = enable_if_t<not std::is_constructible< + typename BasicJsonType::string_t, Key>::value>> +void from_json(const BasicJsonType& j, std::map<Key, Value, Compare, Allocator>& m) +{ + if (JSON_UNLIKELY(not j.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + std::string(j.type_name()))); + } + for (const auto& p : j) + { + if (JSON_UNLIKELY(not p.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + std::string(p.type_name()))); + } + m.emplace(p.at(0).template get<Key>(), p.at(1).template get<Value>()); + } +} + +template <typename BasicJsonType, typename Key, typename Value, typename Hash, typename KeyEqual, typename Allocator, + typename = enable_if_t<not std::is_constructible< + typename BasicJsonType::string_t, Key>::value>> +void from_json(const BasicJsonType& j, std::unordered_map<Key, Value, Hash, KeyEqual, Allocator>& m) +{ + if (JSON_UNLIKELY(not j.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + std::string(j.type_name()))); + } + for (const auto& p : j) + { + if (JSON_UNLIKELY(not p.is_array())) + { + JSON_THROW(type_error::create(302, "type must be array, but is " + std::string(p.type_name()))); + } + m.emplace(p.at(0).template get<Key>(), p.at(1).template get<Value>()); + } +} + +struct from_json_fn +{ + template<typename BasicJsonType, typename T> + auto operator()(const BasicJsonType& j, T& val) const + noexcept(noexcept(from_json(j, val))) + -> decltype(from_json(j, val), void()) + { + return from_json(j, val); + } +}; +} // namespace detail + +/// namespace to hold default `from_json` function +/// to see why this is required: +/// http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/n4381.html +namespace +{ +constexpr const auto& from_json = detail::static_const<detail::from_json_fn>::value; +} // namespace +} // namespace nlohmann + +// #include <nlohmann/detail/conversions/to_json.hpp> + + +#include <ciso646> // or, and, not +#include <iterator> // begin, end +#include <tuple> // tuple, get +#include <type_traits> // is_same, is_constructible, is_floating_point, is_enum, underlying_type +#include <utility> // move, forward, declval, pair +#include <valarray> // valarray +#include <vector> // vector + +// #include <nlohmann/detail/meta/cpp_future.hpp> + +// #include <nlohmann/detail/meta/type_traits.hpp> + +// #include <nlohmann/detail/value_t.hpp> + +// #include <nlohmann/detail/iterators/iteration_proxy.hpp> + + +#include <cstddef> // size_t +#include <string> // string, to_string +#include <iterator> // input_iterator_tag +#include <tuple> // tuple_size, get, tuple_element + +// #include <nlohmann/detail/value_t.hpp> + +// #include <nlohmann/detail/meta/type_traits.hpp> + + +namespace nlohmann +{ +namespace detail +{ +template <typename IteratorType> class iteration_proxy_value +{ + public: + using difference_type = std::ptrdiff_t; + using value_type = iteration_proxy_value; + using pointer = value_type * ; + using reference = value_type & ; + using iterator_category = std::input_iterator_tag; + + private: + /// the iterator + IteratorType anchor; + /// an index for arrays (used to create key names) + std::size_t array_index = 0; + /// last stringified array index + mutable std::size_t array_index_last = 0; + /// a string representation of the array index + mutable std::string array_index_str = "0"; + /// an empty string (to return a reference for primitive values) + const std::string empty_str = ""; + + public: + explicit iteration_proxy_value(IteratorType it) noexcept : anchor(it) {} + + /// dereference operator (needed for range-based for) + iteration_proxy_value& operator*() + { + return *this; + } + + /// increment operator (needed for range-based for) + iteration_proxy_value& operator++() + { + ++anchor; + ++array_index; + + return *this; + } + + /// equality operator (needed for InputIterator) + bool operator==(const iteration_proxy_value& o) const noexcept + { + return anchor == o.anchor; + } + + /// inequality operator (needed for range-based for) + bool operator!=(const iteration_proxy_value& o) const noexcept + { + return anchor != o.anchor; + } + + /// return key of the iterator + const std::string& key() const + { + assert(anchor.m_object != nullptr); + + switch (anchor.m_object->type()) + { + // use integer array index as key + case value_t::array: + { + if (array_index != array_index_last) + { + array_index_str = std::to_string(array_index); + array_index_last = array_index; + } + return array_index_str; + } + + // use key from the object + case value_t::object: + return anchor.key(); + + // use an empty key for all primitive types + default: + return empty_str; + } + } + + /// return value of the iterator + typename IteratorType::reference value() const + { + return anchor.value(); + } +}; + +/// proxy class for the items() function +template<typename IteratorType> class iteration_proxy +{ + private: + /// the container to iterate + typename IteratorType::reference container; + + public: + /// construct iteration proxy from a container + explicit iteration_proxy(typename IteratorType::reference cont) noexcept + : container(cont) {} + + /// return iterator begin (needed for range-based for) + iteration_proxy_value<IteratorType> begin() noexcept + { + return iteration_proxy_value<IteratorType>(container.begin()); + } + + /// return iterator end (needed for range-based for) + iteration_proxy_value<IteratorType> end() noexcept + { + return iteration_proxy_value<IteratorType>(container.end()); + } +}; +// Structured Bindings Support +// For further reference see https://blog.tartanllama.xyz/structured-bindings/ +// And see https://github.com/nlohmann/json/pull/1391 +template <std::size_t N, typename IteratorType, enable_if_t<N == 0, int> = 0> +auto get(const nlohmann::detail::iteration_proxy_value<IteratorType>& i) -> decltype(i.key()) +{ + return i.key(); +} +// Structured Bindings Support +// For further reference see https://blog.tartanllama.xyz/structured-bindings/ +// And see https://github.com/nlohmann/json/pull/1391 +template <std::size_t N, typename IteratorType, enable_if_t<N == 1, int> = 0> +auto get(const nlohmann::detail::iteration_proxy_value<IteratorType>& i) -> decltype(i.value()) +{ + return i.value(); +} +} // namespace detail +} // namespace nlohmann + +// The Addition to the STD Namespace is required to add +// Structured Bindings Support to the iteration_proxy_value class +// For further reference see https://blog.tartanllama.xyz/structured-bindings/ +// And see https://github.com/nlohmann/json/pull/1391 +namespace std +{ +template <typename IteratorType> +class tuple_size<::nlohmann::detail::iteration_proxy_value<IteratorType>> + : public std::integral_constant<std::size_t, 2> {}; + +template <std::size_t N, typename IteratorType> +class tuple_element<N, ::nlohmann::detail::iteration_proxy_value<IteratorType >> +{ + public: + using type = decltype( + get<N>(std::declval < + ::nlohmann::detail::iteration_proxy_value<IteratorType >> ())); +}; +} + +namespace nlohmann +{ +namespace detail +{ +////////////////// +// constructors // +////////////////// + +template<value_t> struct external_constructor; + +template<> +struct external_constructor<value_t::boolean> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::boolean_t b) noexcept + { + j.m_type = value_t::boolean; + j.m_value = b; + j.assert_invariant(); + } +}; + +template<> +struct external_constructor<value_t::string> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, const typename BasicJsonType::string_t& s) + { + j.m_type = value_t::string; + j.m_value = s; + j.assert_invariant(); + } + + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::string_t&& s) + { + j.m_type = value_t::string; + j.m_value = std::move(s); + j.assert_invariant(); + } + + template<typename BasicJsonType, typename CompatibleStringType, + enable_if_t<not std::is_same<CompatibleStringType, typename BasicJsonType::string_t>::value, + int> = 0> + static void construct(BasicJsonType& j, const CompatibleStringType& str) + { + j.m_type = value_t::string; + j.m_value.string = j.template create<typename BasicJsonType::string_t>(str); + j.assert_invariant(); + } +}; + +template<> +struct external_constructor<value_t::number_float> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::number_float_t val) noexcept + { + j.m_type = value_t::number_float; + j.m_value = val; + j.assert_invariant(); + } +}; + +template<> +struct external_constructor<value_t::number_unsigned> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::number_unsigned_t val) noexcept + { + j.m_type = value_t::number_unsigned; + j.m_value = val; + j.assert_invariant(); + } +}; + +template<> +struct external_constructor<value_t::number_integer> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::number_integer_t val) noexcept + { + j.m_type = value_t::number_integer; + j.m_value = val; + j.assert_invariant(); + } +}; + +template<> +struct external_constructor<value_t::array> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, const typename BasicJsonType::array_t& arr) + { + j.m_type = value_t::array; + j.m_value = arr; + j.assert_invariant(); + } + + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::array_t&& arr) + { + j.m_type = value_t::array; + j.m_value = std::move(arr); + j.assert_invariant(); + } + + template<typename BasicJsonType, typename CompatibleArrayType, + enable_if_t<not std::is_same<CompatibleArrayType, typename BasicJsonType::array_t>::value, + int> = 0> + static void construct(BasicJsonType& j, const CompatibleArrayType& arr) + { + using std::begin; + using std::end; + j.m_type = value_t::array; + j.m_value.array = j.template create<typename BasicJsonType::array_t>(begin(arr), end(arr)); + j.assert_invariant(); + } + + template<typename BasicJsonType> + static void construct(BasicJsonType& j, const std::vector<bool>& arr) + { + j.m_type = value_t::array; + j.m_value = value_t::array; + j.m_value.array->reserve(arr.size()); + for (const bool x : arr) + { + j.m_value.array->push_back(x); + } + j.assert_invariant(); + } + + template<typename BasicJsonType, typename T, + enable_if_t<std::is_convertible<T, BasicJsonType>::value, int> = 0> + static void construct(BasicJsonType& j, const std::valarray<T>& arr) + { + j.m_type = value_t::array; + j.m_value = value_t::array; + j.m_value.array->resize(arr.size()); + std::copy(std::begin(arr), std::end(arr), j.m_value.array->begin()); + j.assert_invariant(); + } +}; + +template<> +struct external_constructor<value_t::object> +{ + template<typename BasicJsonType> + static void construct(BasicJsonType& j, const typename BasicJsonType::object_t& obj) + { + j.m_type = value_t::object; + j.m_value = obj; + j.assert_invariant(); + } + + template<typename BasicJsonType> + static void construct(BasicJsonType& j, typename BasicJsonType::object_t&& obj) + { + j.m_type = value_t::object; + j.m_value = std::move(obj); + j.assert_invariant(); + } + + template<typename BasicJsonType, typename CompatibleObjectType, + enable_if_t<not std::is_same<CompatibleObjectType, typename BasicJsonType::object_t>::value, int> = 0> + static void construct(BasicJsonType& j, const CompatibleObjectType& obj) + { + using std::begin; + using std::end; + + j.m_type = value_t::object; + j.m_value.object = j.template create<typename BasicJsonType::object_t>(begin(obj), end(obj)); + j.assert_invariant(); + } +}; + +///////////// +// to_json // +///////////// + +template<typename BasicJsonType, typename T, + enable_if_t<std::is_same<T, typename BasicJsonType::boolean_t>::value, int> = 0> +void to_json(BasicJsonType& j, T b) noexcept +{ + external_constructor<value_t::boolean>::construct(j, b); +} + +template<typename BasicJsonType, typename CompatibleString, + enable_if_t<std::is_constructible<typename BasicJsonType::string_t, CompatibleString>::value, int> = 0> +void to_json(BasicJsonType& j, const CompatibleString& s) +{ + external_constructor<value_t::string>::construct(j, s); +} + +template<typename BasicJsonType> +void to_json(BasicJsonType& j, typename BasicJsonType::string_t&& s) +{ + external_constructor<value_t::string>::construct(j, std::move(s)); +} + +template<typename BasicJsonType, typename FloatType, + enable_if_t<std::is_floating_point<FloatType>::value, int> = 0> +void to_json(BasicJsonType& j, FloatType val) noexcept +{ + external_constructor<value_t::number_float>::construct(j, static_cast<typename BasicJsonType::number_float_t>(val)); +} + +template<typename BasicJsonType, typename CompatibleNumberUnsignedType, + enable_if_t<is_compatible_integer_type<typename BasicJsonType::number_unsigned_t, CompatibleNumberUnsignedType>::value, int> = 0> +void to_json(BasicJsonType& j, CompatibleNumberUnsignedType val) noexcept +{ + external_constructor<value_t::number_unsigned>::construct(j, static_cast<typename BasicJsonType::number_unsigned_t>(val)); +} + +template<typename BasicJsonType, typename CompatibleNumberIntegerType, + enable_if_t<is_compatible_integer_type<typename BasicJsonType::number_integer_t, CompatibleNumberIntegerType>::value, int> = 0> +void to_json(BasicJsonType& j, CompatibleNumberIntegerType val) noexcept +{ + external_constructor<value_t::number_integer>::construct(j, static_cast<typename BasicJsonType::number_integer_t>(val)); +} + +template<typename BasicJsonType, typename EnumType, + enable_if_t<std::is_enum<EnumType>::value, int> = 0> +void to_json(BasicJsonType& j, EnumType e) noexcept +{ + using underlying_type = typename std::underlying_type<EnumType>::type; + external_constructor<value_t::number_integer>::construct(j, static_cast<underlying_type>(e)); +} + +template<typename BasicJsonType> +void to_json(BasicJsonType& j, const std::vector<bool>& e) +{ + external_constructor<value_t::array>::construct(j, e); +} + +template <typename BasicJsonType, typename CompatibleArrayType, + enable_if_t<is_compatible_array_type<BasicJsonType, + CompatibleArrayType>::value and + not is_compatible_object_type< + BasicJsonType, CompatibleArrayType>::value and + not is_compatible_string_type<BasicJsonType, CompatibleArrayType>::value and + not is_basic_json<CompatibleArrayType>::value, + int> = 0> +void to_json(BasicJsonType& j, const CompatibleArrayType& arr) +{ + external_constructor<value_t::array>::construct(j, arr); +} + +template<typename BasicJsonType, typename T, + enable_if_t<std::is_convertible<T, BasicJsonType>::value, int> = 0> +void to_json(BasicJsonType& j, const std::valarray<T>& arr) +{ + external_constructor<value_t::array>::construct(j, std::move(arr)); +} + +template<typename BasicJsonType> +void to_json(BasicJsonType& j, typename BasicJsonType::array_t&& arr) +{ + external_constructor<value_t::array>::construct(j, std::move(arr)); +} + +template<typename BasicJsonType, typename CompatibleObjectType, + enable_if_t<is_compatible_object_type<BasicJsonType, CompatibleObjectType>::value and not is_basic_json<CompatibleObjectType>::value, int> = 0> +void to_json(BasicJsonType& j, const CompatibleObjectType& obj) +{ + external_constructor<value_t::object>::construct(j, obj); +} + +template<typename BasicJsonType> +void to_json(BasicJsonType& j, typename BasicJsonType::object_t&& obj) +{ + external_constructor<value_t::object>::construct(j, std::move(obj)); +} + +template < + typename BasicJsonType, typename T, std::size_t N, + enable_if_t<not std::is_constructible<typename BasicJsonType::string_t, + const T(&)[N]>::value, + int> = 0 > +void to_json(BasicJsonType& j, const T(&arr)[N]) +{ + external_constructor<value_t::array>::construct(j, arr); +} + +template<typename BasicJsonType, typename... Args> +void to_json(BasicJsonType& j, const std::pair<Args...>& p) +{ + j = { p.first, p.second }; +} + +// for https://github.com/nlohmann/json/pull/1134 +template < typename BasicJsonType, typename T, + enable_if_t<std::is_same<T, iteration_proxy_value<typename BasicJsonType::iterator>>::value, int> = 0> +void to_json(BasicJsonType& j, const T& b) +{ + j = { {b.key(), b.value()} }; +} + +template<typename BasicJsonType, typename Tuple, std::size_t... Idx> +void to_json_tuple_impl(BasicJsonType& j, const Tuple& t, index_sequence<Idx...> /*unused*/) +{ + j = { std::get<Idx>(t)... }; +} + +template<typename BasicJsonType, typename... Args> +void to_json(BasicJsonType& j, const std::tuple<Args...>& t) +{ + to_json_tuple_impl(j, t, index_sequence_for<Args...> {}); +} + +struct to_json_fn +{ + template<typename BasicJsonType, typename T> + auto operator()(BasicJsonType& j, T&& val) const noexcept(noexcept(to_json(j, std::forward<T>(val)))) + -> decltype(to_json(j, std::forward<T>(val)), void()) + { + return to_json(j, std::forward<T>(val)); + } +}; +} // namespace detail + +/// namespace to hold default `to_json` function +namespace +{ +constexpr const auto& to_json = detail::static_const<detail::to_json_fn>::value; +} // namespace +} // namespace nlohmann + +// #include <nlohmann/detail/input/input_adapters.hpp> + + +#include <cassert> // assert +#include <cstddef> // size_t +#include <cstring> // strlen +#include <istream> // istream +#include <iterator> // begin, end, iterator_traits, random_access_iterator_tag, distance, next +#include <memory> // shared_ptr, make_shared, addressof +#include <numeric> // accumulate +#include <string> // string, char_traits +#include <type_traits> // enable_if, is_base_of, is_pointer, is_integral, remove_pointer +#include <utility> // pair, declval +#include <cstdio> //FILE * + +// #include <nlohmann/detail/macro_scope.hpp> + + +namespace nlohmann +{ +namespace detail +{ +/// the supported input formats +enum class input_format_t { json, cbor, msgpack, ubjson, bson }; + +//////////////////// +// input adapters // +//////////////////// + +/*! +@brief abstract input adapter interface + +Produces a stream of std::char_traits<char>::int_type characters from a +std::istream, a buffer, or some other input type. Accepts the return of +exactly one non-EOF character for future input. The int_type characters +returned consist of all valid char values as positive values (typically +unsigned char), plus an EOF value outside that range, specified by the value +of the function std::char_traits<char>::eof(). This value is typically -1, but +could be any arbitrary value which is not a valid char value. +*/ +struct input_adapter_protocol +{ + /// get a character [0,255] or std::char_traits<char>::eof(). + virtual std::char_traits<char>::int_type get_character() = 0; + virtual ~input_adapter_protocol() = default; +}; + +/// a type to simplify interfaces +using input_adapter_t = std::shared_ptr<input_adapter_protocol>; + +/*! +Input adapter for stdio file access. This adapter read only 1 byte and do not use any + buffer. This adapter is a very low level adapter. +*/ +class file_input_adapter : public input_adapter_protocol +{ + public: + explicit file_input_adapter(std::FILE* f) noexcept + : m_file(f) + {} + + std::char_traits<char>::int_type get_character() noexcept override + { + return std::fgetc(m_file); + } + private: + /// the file pointer to read from + std::FILE* m_file; +}; + + +/*! +Input adapter for a (caching) istream. Ignores a UFT Byte Order Mark at +beginning of input. Does not support changing the underlying std::streambuf +in mid-input. Maintains underlying std::istream and std::streambuf to support +subsequent use of standard std::istream operations to process any input +characters following those used in parsing the JSON input. Clears the +std::istream flags; any input errors (e.g., EOF) will be detected by the first +subsequent call for input from the std::istream. +*/ +class input_stream_adapter : public input_adapter_protocol +{ + public: + ~input_stream_adapter() override + { + // clear stream flags; we use underlying streambuf I/O, do not + // maintain ifstream flags, except eof + is.clear(is.rdstate() & std::ios::eofbit); + } + + explicit input_stream_adapter(std::istream& i) + : is(i), sb(*i.rdbuf()) + {} + + // delete because of pointer members + input_stream_adapter(const input_stream_adapter&) = delete; + input_stream_adapter& operator=(input_stream_adapter&) = delete; + input_stream_adapter(input_stream_adapter&&) = delete; + input_stream_adapter& operator=(input_stream_adapter&&) = delete; + + // std::istream/std::streambuf use std::char_traits<char>::to_int_type, to + // ensure that std::char_traits<char>::eof() and the character 0xFF do not + // end up as the same value, eg. 0xFFFFFFFF. + std::char_traits<char>::int_type get_character() override + { + auto res = sb.sbumpc(); + // set eof manually, as we don't use the istream interface. + if (res == EOF) + { + is.clear(is.rdstate() | std::ios::eofbit); + } + return res; + } + + private: + /// the associated input stream + std::istream& is; + std::streambuf& sb; +}; + +/// input adapter for buffer input +class input_buffer_adapter : public input_adapter_protocol +{ + public: + input_buffer_adapter(const char* b, const std::size_t l) noexcept + : cursor(b), limit(b + l) + {} + + // delete because of pointer members + input_buffer_adapter(const input_buffer_adapter&) = delete; + input_buffer_adapter& operator=(input_buffer_adapter&) = delete; + input_buffer_adapter(input_buffer_adapter&&) = delete; + input_buffer_adapter& operator=(input_buffer_adapter&&) = delete; + ~input_buffer_adapter() override = default; + + std::char_traits<char>::int_type get_character() noexcept override + { + if (JSON_LIKELY(cursor < limit)) + { + return std::char_traits<char>::to_int_type(*(cursor++)); + } + + return std::char_traits<char>::eof(); + } + + private: + /// pointer to the current character + const char* cursor; + /// pointer past the last character + const char* const limit; +}; + +template<typename WideStringType, size_t T> +struct wide_string_input_helper +{ + // UTF-32 + static void fill_buffer(const WideStringType& str, size_t& current_wchar, std::array<std::char_traits<char>::int_type, 4>& utf8_bytes, size_t& utf8_bytes_index, size_t& utf8_bytes_filled) + { + utf8_bytes_index = 0; + + if (current_wchar == str.size()) + { + utf8_bytes[0] = std::char_traits<char>::eof(); + utf8_bytes_filled = 1; + } + else + { + // get the current character + const auto wc = static_cast<int>(str[current_wchar++]); + + // UTF-32 to UTF-8 encoding + if (wc < 0x80) + { + utf8_bytes[0] = wc; + utf8_bytes_filled = 1; + } + else if (wc <= 0x7FF) + { + utf8_bytes[0] = 0xC0 | ((wc >> 6) & 0x1F); + utf8_bytes[1] = 0x80 | (wc & 0x3F); + utf8_bytes_filled = 2; + } + else if (wc <= 0xFFFF) + { + utf8_bytes[0] = 0xE0 | ((wc >> 12) & 0x0F); + utf8_bytes[1] = 0x80 | ((wc >> 6) & 0x3F); + utf8_bytes[2] = 0x80 | (wc & 0x3F); + utf8_bytes_filled = 3; + } + else if (wc <= 0x10FFFF) + { + utf8_bytes[0] = 0xF0 | ((wc >> 18) & 0x07); + utf8_bytes[1] = 0x80 | ((wc >> 12) & 0x3F); + utf8_bytes[2] = 0x80 | ((wc >> 6) & 0x3F); + utf8_bytes[3] = 0x80 | (wc & 0x3F); + utf8_bytes_filled = 4; + } + else + { + // unknown character + utf8_bytes[0] = wc; + utf8_bytes_filled = 1; + } + } + } +}; + +template<typename WideStringType> +struct wide_string_input_helper<WideStringType, 2> +{ + // UTF-16 + static void fill_buffer(const WideStringType& str, size_t& current_wchar, std::array<std::char_traits<char>::int_type, 4>& utf8_bytes, size_t& utf8_bytes_index, size_t& utf8_bytes_filled) + { + utf8_bytes_index = 0; + + if (current_wchar == str.size()) + { + utf8_bytes[0] = std::char_traits<char>::eof(); + utf8_bytes_filled = 1; + } + else + { + // get the current character + const auto wc = static_cast<int>(str[current_wchar++]); + + // UTF-16 to UTF-8 encoding + if (wc < 0x80) + { + utf8_bytes[0] = wc; + utf8_bytes_filled = 1; + } + else if (wc <= 0x7FF) + { + utf8_bytes[0] = 0xC0 | ((wc >> 6)); + utf8_bytes[1] = 0x80 | (wc & 0x3F); + utf8_bytes_filled = 2; + } + else if (0xD800 > wc or wc >= 0xE000) + { + utf8_bytes[0] = 0xE0 | ((wc >> 12)); + utf8_bytes[1] = 0x80 | ((wc >> 6) & 0x3F); + utf8_bytes[2] = 0x80 | (wc & 0x3F); + utf8_bytes_filled = 3; + } + else + { + if (current_wchar < str.size()) + { + const auto wc2 = static_cast<int>(str[current_wchar++]); + const int charcode = 0x10000 + (((wc & 0x3FF) << 10) | (wc2 & 0x3FF)); + utf8_bytes[0] = 0xf0 | (charcode >> 18); + utf8_bytes[1] = 0x80 | ((charcode >> 12) & 0x3F); + utf8_bytes[2] = 0x80 | ((charcode >> 6) & 0x3F); + utf8_bytes[3] = 0x80 | (charcode & 0x3F); + utf8_bytes_filled = 4; + } + else + { + // unknown character + ++current_wchar; + utf8_bytes[0] = wc; + utf8_bytes_filled = 1; + } + } + } + } +}; + +template<typename WideStringType> +class wide_string_input_adapter : public input_adapter_protocol +{ + public: + explicit wide_string_input_adapter(const WideStringType& w) noexcept + : str(w) + {} + + std::char_traits<char>::int_type get_character() noexcept override + { + // check if buffer needs to be filled + if (utf8_bytes_index == utf8_bytes_filled) + { + fill_buffer<sizeof(typename WideStringType::value_type)>(); + + assert(utf8_bytes_filled > 0); + assert(utf8_bytes_index == 0); + } + + // use buffer + assert(utf8_bytes_filled > 0); + assert(utf8_bytes_index < utf8_bytes_filled); + return utf8_bytes[utf8_bytes_index++]; + } + + private: + template<size_t T> + void fill_buffer() + { + wide_string_input_helper<WideStringType, T>::fill_buffer(str, current_wchar, utf8_bytes, utf8_bytes_index, utf8_bytes_filled); + } + + /// the wstring to process + const WideStringType& str; + + /// index of the current wchar in str + std::size_t current_wchar = 0; + + /// a buffer for UTF-8 bytes + std::array<std::char_traits<char>::int_type, 4> utf8_bytes = {{0, 0, 0, 0}}; + + /// index to the utf8_codes array for the next valid byte + std::size_t utf8_bytes_index = 0; + /// number of valid bytes in the utf8_codes array + std::size_t utf8_bytes_filled = 0; +}; + +class input_adapter +{ + public: + // native support + input_adapter(std::FILE* file) + : ia(std::make_shared<file_input_adapter>(file)) {} + /// input adapter for input stream + input_adapter(std::istream& i) + : ia(std::make_shared<input_stream_adapter>(i)) {} + + /// input adapter for input stream + input_adapter(std::istream&& i) + : ia(std::make_shared<input_stream_adapter>(i)) {} + + input_adapter(const std::wstring& ws) + : ia(std::make_shared<wide_string_input_adapter<std::wstring>>(ws)) {} + + input_adapter(const std::u16string& ws) + : ia(std::make_shared<wide_string_input_adapter<std::u16string>>(ws)) {} + + input_adapter(const std::u32string& ws) + : ia(std::make_shared<wide_string_input_adapter<std::u32string>>(ws)) {} + + /// input adapter for buffer + template<typename CharT, + typename std::enable_if< + std::is_pointer<CharT>::value and + std::is_integral<typename std::remove_pointer<CharT>::type>::value and + sizeof(typename std::remove_pointer<CharT>::type) == 1, + int>::type = 0> + input_adapter(CharT b, std::size_t l) + : ia(std::make_shared<input_buffer_adapter>(reinterpret_cast<const char*>(b), l)) {} + + // derived support + + /// input adapter for string literal + template<typename CharT, + typename std::enable_if< + std::is_pointer<CharT>::value and + std::is_integral<typename std::remove_pointer<CharT>::type>::value and + sizeof(typename std::remove_pointer<CharT>::type) == 1, + int>::type = 0> + input_adapter(CharT b) + : input_adapter(reinterpret_cast<const char*>(b), + std::strlen(reinterpret_cast<const char*>(b))) {} + + /// input adapter for iterator range with contiguous storage + template<class IteratorType, + typename std::enable_if< + std::is_same<typename iterator_traits<IteratorType>::iterator_category, std::random_access_iterator_tag>::value, + int>::type = 0> + input_adapter(IteratorType first, IteratorType last) + { +#ifndef NDEBUG + // assertion to check that the iterator range is indeed contiguous, + // see http://stackoverflow.com/a/35008842/266378 for more discussion + const auto is_contiguous = std::accumulate( + first, last, std::pair<bool, int>(true, 0), + [&first](std::pair<bool, int> res, decltype(*first) val) + { + res.first &= (val == *(std::next(std::addressof(*first), res.second++))); + return res; + }).first; + assert(is_contiguous); +#endif + + // assertion to check that each element is 1 byte long + static_assert( + sizeof(typename iterator_traits<IteratorType>::value_type) == 1, + "each element in the iterator range must have the size of 1 byte"); + + const auto len = static_cast<size_t>(std::distance(first, last)); + if (JSON_LIKELY(len > 0)) + { + // there is at least one element: use the address of first + ia = std::make_shared<input_buffer_adapter>(reinterpret_cast<const char*>(&(*first)), len); + } + else + { + // the address of first cannot be used: use nullptr + ia = std::make_shared<input_buffer_adapter>(nullptr, len); + } + } + + /// input adapter for array + template<class T, std::size_t N> + input_adapter(T (&array)[N]) + : input_adapter(std::begin(array), std::end(array)) {} + + /// input adapter for contiguous container + template<class ContiguousContainer, typename + std::enable_if<not std::is_pointer<ContiguousContainer>::value and + std::is_base_of<std::random_access_iterator_tag, typename iterator_traits<decltype(std::begin(std::declval<ContiguousContainer const>()))>::iterator_category>::value, + int>::type = 0> + input_adapter(const ContiguousContainer& c) + : input_adapter(std::begin(c), std::end(c)) {} + + operator input_adapter_t() + { + return ia; + } + + private: + /// the actual adapter + input_adapter_t ia = nullptr; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/input/lexer.hpp> + + +#include <clocale> // localeconv +#include <cstddef> // size_t +#include <cstdlib> // strtof, strtod, strtold, strtoll, strtoull +#include <cstdio> // snprintf +#include <initializer_list> // initializer_list +#include <string> // char_traits, string +#include <vector> // vector + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/input/input_adapters.hpp> + +// #include <nlohmann/detail/input/position_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +/////////// +// lexer // +/////////// + +/*! +@brief lexical analysis + +This class organizes the lexical analysis during JSON deserialization. +*/ +template<typename BasicJsonType> +class lexer +{ + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + + public: + /// token types for the parser + enum class token_type + { + uninitialized, ///< indicating the scanner is uninitialized + literal_true, ///< the `true` literal + literal_false, ///< the `false` literal + literal_null, ///< the `null` literal + value_string, ///< a string -- use get_string() for actual value + value_unsigned, ///< an unsigned integer -- use get_number_unsigned() for actual value + value_integer, ///< a signed integer -- use get_number_integer() for actual value + value_float, ///< an floating point number -- use get_number_float() for actual value + begin_array, ///< the character for array begin `[` + begin_object, ///< the character for object begin `{` + end_array, ///< the character for array end `]` + end_object, ///< the character for object end `}` + name_separator, ///< the name separator `:` + value_separator, ///< the value separator `,` + parse_error, ///< indicating a parse error + end_of_input, ///< indicating the end of the input buffer + literal_or_value ///< a literal or the begin of a value (only for diagnostics) + }; + + /// return name of values of type token_type (only used for errors) + static const char* token_type_name(const token_type t) noexcept + { + switch (t) + { + case token_type::uninitialized: + return "<uninitialized>"; + case token_type::literal_true: + return "true literal"; + case token_type::literal_false: + return "false literal"; + case token_type::literal_null: + return "null literal"; + case token_type::value_string: + return "string literal"; + case lexer::token_type::value_unsigned: + case lexer::token_type::value_integer: + case lexer::token_type::value_float: + return "number literal"; + case token_type::begin_array: + return "'['"; + case token_type::begin_object: + return "'{'"; + case token_type::end_array: + return "']'"; + case token_type::end_object: + return "'}'"; + case token_type::name_separator: + return "':'"; + case token_type::value_separator: + return "','"; + case token_type::parse_error: + return "<parse error>"; + case token_type::end_of_input: + return "end of input"; + case token_type::literal_or_value: + return "'[', '{', or a literal"; + // LCOV_EXCL_START + default: // catch non-enum values + return "unknown token"; + // LCOV_EXCL_STOP + } + } + + explicit lexer(detail::input_adapter_t&& adapter) + : ia(std::move(adapter)), decimal_point_char(get_decimal_point()) {} + + // delete because of pointer members + lexer(const lexer&) = delete; + lexer(lexer&&) = delete; + lexer& operator=(lexer&) = delete; + lexer& operator=(lexer&&) = delete; + ~lexer() = default; + + private: + ///////////////////// + // locales + ///////////////////// + + /// return the locale-dependent decimal point + static char get_decimal_point() noexcept + { + const auto loc = localeconv(); + assert(loc != nullptr); + return (loc->decimal_point == nullptr) ? '.' : *(loc->decimal_point); + } + + ///////////////////// + // scan functions + ///////////////////// + + /*! + @brief get codepoint from 4 hex characters following `\u` + + For input "\u c1 c2 c3 c4" the codepoint is: + (c1 * 0x1000) + (c2 * 0x0100) + (c3 * 0x0010) + c4 + = (c1 << 12) + (c2 << 8) + (c3 << 4) + (c4 << 0) + + Furthermore, the possible characters '0'..'9', 'A'..'F', and 'a'..'f' + must be converted to the integers 0x0..0x9, 0xA..0xF, 0xA..0xF, resp. The + conversion is done by subtracting the offset (0x30, 0x37, and 0x57) + between the ASCII value of the character and the desired integer value. + + @return codepoint (0x0000..0xFFFF) or -1 in case of an error (e.g. EOF or + non-hex character) + */ + int get_codepoint() + { + // this function only makes sense after reading `\u` + assert(current == 'u'); + int codepoint = 0; + + const auto factors = { 12, 8, 4, 0 }; + for (const auto factor : factors) + { + get(); + + if (current >= '0' and current <= '9') + { + codepoint += ((current - 0x30) << factor); + } + else if (current >= 'A' and current <= 'F') + { + codepoint += ((current - 0x37) << factor); + } + else if (current >= 'a' and current <= 'f') + { + codepoint += ((current - 0x57) << factor); + } + else + { + return -1; + } + } + + assert(0x0000 <= codepoint and codepoint <= 0xFFFF); + return codepoint; + } + + /*! + @brief check if the next byte(s) are inside a given range + + Adds the current byte and, for each passed range, reads a new byte and + checks if it is inside the range. If a violation was detected, set up an + error message and return false. Otherwise, return true. + + @param[in] ranges list of integers; interpreted as list of pairs of + inclusive lower and upper bound, respectively + + @pre The passed list @a ranges must have 2, 4, or 6 elements; that is, + 1, 2, or 3 pairs. This precondition is enforced by an assertion. + + @return true if and only if no range violation was detected + */ + bool next_byte_in_range(std::initializer_list<int> ranges) + { + assert(ranges.size() == 2 or ranges.size() == 4 or ranges.size() == 6); + add(current); + + for (auto range = ranges.begin(); range != ranges.end(); ++range) + { + get(); + if (JSON_LIKELY(*range <= current and current <= *(++range))) + { + add(current); + } + else + { + error_message = "invalid string: ill-formed UTF-8 byte"; + return false; + } + } + + return true; + } + + /*! + @brief scan a string literal + + This function scans a string according to Sect. 7 of RFC 7159. While + scanning, bytes are escaped and copied into buffer token_buffer. Then the + function returns successfully, token_buffer is *not* null-terminated (as it + may contain \0 bytes), and token_buffer.size() is the number of bytes in the + string. + + @return token_type::value_string if string could be successfully scanned, + token_type::parse_error otherwise + + @note In case of errors, variable error_message contains a textual + description. + */ + token_type scan_string() + { + // reset token_buffer (ignore opening quote) + reset(); + + // we entered the function by reading an open quote + assert(current == '\"'); + + while (true) + { + // get next character + switch (get()) + { + // end of file while parsing string + case std::char_traits<char>::eof(): + { + error_message = "invalid string: missing closing quote"; + return token_type::parse_error; + } + + // closing quote + case '\"': + { + return token_type::value_string; + } + + // escapes + case '\\': + { + switch (get()) + { + // quotation mark + case '\"': + add('\"'); + break; + // reverse solidus + case '\\': + add('\\'); + break; + // solidus + case '/': + add('/'); + break; + // backspace + case 'b': + add('\b'); + break; + // form feed + case 'f': + add('\f'); + break; + // line feed + case 'n': + add('\n'); + break; + // carriage return + case 'r': + add('\r'); + break; + // tab + case 't': + add('\t'); + break; + + // unicode escapes + case 'u': + { + const int codepoint1 = get_codepoint(); + int codepoint = codepoint1; // start with codepoint1 + + if (JSON_UNLIKELY(codepoint1 == -1)) + { + error_message = "invalid string: '\\u' must be followed by 4 hex digits"; + return token_type::parse_error; + } + + // check if code point is a high surrogate + if (0xD800 <= codepoint1 and codepoint1 <= 0xDBFF) + { + // expect next \uxxxx entry + if (JSON_LIKELY(get() == '\\' and get() == 'u')) + { + const int codepoint2 = get_codepoint(); + + if (JSON_UNLIKELY(codepoint2 == -1)) + { + error_message = "invalid string: '\\u' must be followed by 4 hex digits"; + return token_type::parse_error; + } + + // check if codepoint2 is a low surrogate + if (JSON_LIKELY(0xDC00 <= codepoint2 and codepoint2 <= 0xDFFF)) + { + // overwrite codepoint + codepoint = + // high surrogate occupies the most significant 22 bits + (codepoint1 << 10) + // low surrogate occupies the least significant 15 bits + + codepoint2 + // there is still the 0xD800, 0xDC00 and 0x10000 noise + // in the result so we have to subtract with: + // (0xD800 << 10) + DC00 - 0x10000 = 0x35FDC00 + - 0x35FDC00; + } + else + { + error_message = "invalid string: surrogate U+DC00..U+DFFF must be followed by U+DC00..U+DFFF"; + return token_type::parse_error; + } + } + else + { + error_message = "invalid string: surrogate U+DC00..U+DFFF must be followed by U+DC00..U+DFFF"; + return token_type::parse_error; + } + } + else + { + if (JSON_UNLIKELY(0xDC00 <= codepoint1 and codepoint1 <= 0xDFFF)) + { + error_message = "invalid string: surrogate U+DC00..U+DFFF must follow U+D800..U+DBFF"; + return token_type::parse_error; + } + } + + // result of the above calculation yields a proper codepoint + assert(0x00 <= codepoint and codepoint <= 0x10FFFF); + + // translate codepoint into bytes + if (codepoint < 0x80) + { + // 1-byte characters: 0xxxxxxx (ASCII) + add(codepoint); + } + else if (codepoint <= 0x7FF) + { + // 2-byte characters: 110xxxxx 10xxxxxx + add(0xC0 | (codepoint >> 6)); + add(0x80 | (codepoint & 0x3F)); + } + else if (codepoint <= 0xFFFF) + { + // 3-byte characters: 1110xxxx 10xxxxxx 10xxxxxx + add(0xE0 | (codepoint >> 12)); + add(0x80 | ((codepoint >> 6) & 0x3F)); + add(0x80 | (codepoint & 0x3F)); + } + else + { + // 4-byte characters: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx + add(0xF0 | (codepoint >> 18)); + add(0x80 | ((codepoint >> 12) & 0x3F)); + add(0x80 | ((codepoint >> 6) & 0x3F)); + add(0x80 | (codepoint & 0x3F)); + } + + break; + } + + // other characters after escape + default: + error_message = "invalid string: forbidden character after backslash"; + return token_type::parse_error; + } + + break; + } + + // invalid control characters + case 0x00: + { + error_message = "invalid string: control character U+0000 (NUL) must be escaped to \\u0000"; + return token_type::parse_error; + } + + case 0x01: + { + error_message = "invalid string: control character U+0001 (SOH) must be escaped to \\u0001"; + return token_type::parse_error; + } + + case 0x02: + { + error_message = "invalid string: control character U+0002 (STX) must be escaped to \\u0002"; + return token_type::parse_error; + } + + case 0x03: + { + error_message = "invalid string: control character U+0003 (ETX) must be escaped to \\u0003"; + return token_type::parse_error; + } + + case 0x04: + { + error_message = "invalid string: control character U+0004 (EOT) must be escaped to \\u0004"; + return token_type::parse_error; + } + + case 0x05: + { + error_message = "invalid string: control character U+0005 (ENQ) must be escaped to \\u0005"; + return token_type::parse_error; + } + + case 0x06: + { + error_message = "invalid string: control character U+0006 (ACK) must be escaped to \\u0006"; + return token_type::parse_error; + } + + case 0x07: + { + error_message = "invalid string: control character U+0007 (BEL) must be escaped to \\u0007"; + return token_type::parse_error; + } + + case 0x08: + { + error_message = "invalid string: control character U+0008 (BS) must be escaped to \\u0008 or \\b"; + return token_type::parse_error; + } + + case 0x09: + { + error_message = "invalid string: control character U+0009 (HT) must be escaped to \\u0009 or \\t"; + return token_type::parse_error; + } + + case 0x0A: + { + error_message = "invalid string: control character U+000A (LF) must be escaped to \\u000A or \\n"; + return token_type::parse_error; + } + + case 0x0B: + { + error_message = "invalid string: control character U+000B (VT) must be escaped to \\u000B"; + return token_type::parse_error; + } + + case 0x0C: + { + error_message = "invalid string: control character U+000C (FF) must be escaped to \\u000C or \\f"; + return token_type::parse_error; + } + + case 0x0D: + { + error_message = "invalid string: control character U+000D (CR) must be escaped to \\u000D or \\r"; + return token_type::parse_error; + } + + case 0x0E: + { + error_message = "invalid string: control character U+000E (SO) must be escaped to \\u000E"; + return token_type::parse_error; + } + + case 0x0F: + { + error_message = "invalid string: control character U+000F (SI) must be escaped to \\u000F"; + return token_type::parse_error; + } + + case 0x10: + { + error_message = "invalid string: control character U+0010 (DLE) must be escaped to \\u0010"; + return token_type::parse_error; + } + + case 0x11: + { + error_message = "invalid string: control character U+0011 (DC1) must be escaped to \\u0011"; + return token_type::parse_error; + } + + case 0x12: + { + error_message = "invalid string: control character U+0012 (DC2) must be escaped to \\u0012"; + return token_type::parse_error; + } + + case 0x13: + { + error_message = "invalid string: control character U+0013 (DC3) must be escaped to \\u0013"; + return token_type::parse_error; + } + + case 0x14: + { + error_message = "invalid string: control character U+0014 (DC4) must be escaped to \\u0014"; + return token_type::parse_error; + } + + case 0x15: + { + error_message = "invalid string: control character U+0015 (NAK) must be escaped to \\u0015"; + return token_type::parse_error; + } + + case 0x16: + { + error_message = "invalid string: control character U+0016 (SYN) must be escaped to \\u0016"; + return token_type::parse_error; + } + + case 0x17: + { + error_message = "invalid string: control character U+0017 (ETB) must be escaped to \\u0017"; + return token_type::parse_error; + } + + case 0x18: + { + error_message = "invalid string: control character U+0018 (CAN) must be escaped to \\u0018"; + return token_type::parse_error; + } + + case 0x19: + { + error_message = "invalid string: control character U+0019 (EM) must be escaped to \\u0019"; + return token_type::parse_error; + } + + case 0x1A: + { + error_message = "invalid string: control character U+001A (SUB) must be escaped to \\u001A"; + return token_type::parse_error; + } + + case 0x1B: + { + error_message = "invalid string: control character U+001B (ESC) must be escaped to \\u001B"; + return token_type::parse_error; + } + + case 0x1C: + { + error_message = "invalid string: control character U+001C (FS) must be escaped to \\u001C"; + return token_type::parse_error; + } + + case 0x1D: + { + error_message = "invalid string: control character U+001D (GS) must be escaped to \\u001D"; + return token_type::parse_error; + } + + case 0x1E: + { + error_message = "invalid string: control character U+001E (RS) must be escaped to \\u001E"; + return token_type::parse_error; + } + + case 0x1F: + { + error_message = "invalid string: control character U+001F (US) must be escaped to \\u001F"; + return token_type::parse_error; + } + + // U+0020..U+007F (except U+0022 (quote) and U+005C (backspace)) + case 0x20: + case 0x21: + case 0x23: + case 0x24: + case 0x25: + case 0x26: + case 0x27: + case 0x28: + case 0x29: + case 0x2A: + case 0x2B: + case 0x2C: + case 0x2D: + case 0x2E: + case 0x2F: + case 0x30: + case 0x31: + case 0x32: + case 0x33: + case 0x34: + case 0x35: + case 0x36: + case 0x37: + case 0x38: + case 0x39: + case 0x3A: + case 0x3B: + case 0x3C: + case 0x3D: + case 0x3E: + case 0x3F: + case 0x40: + case 0x41: + case 0x42: + case 0x43: + case 0x44: + case 0x45: + case 0x46: + case 0x47: + case 0x48: + case 0x49: + case 0x4A: + case 0x4B: + case 0x4C: + case 0x4D: + case 0x4E: + case 0x4F: + case 0x50: + case 0x51: + case 0x52: + case 0x53: + case 0x54: + case 0x55: + case 0x56: + case 0x57: + case 0x58: + case 0x59: + case 0x5A: + case 0x5B: + case 0x5D: + case 0x5E: + case 0x5F: + case 0x60: + case 0x61: + case 0x62: + case 0x63: + case 0x64: + case 0x65: + case 0x66: + case 0x67: + case 0x68: + case 0x69: + case 0x6A: + case 0x6B: + case 0x6C: + case 0x6D: + case 0x6E: + case 0x6F: + case 0x70: + case 0x71: + case 0x72: + case 0x73: + case 0x74: + case 0x75: + case 0x76: + case 0x77: + case 0x78: + case 0x79: + case 0x7A: + case 0x7B: + case 0x7C: + case 0x7D: + case 0x7E: + case 0x7F: + { + add(current); + break; + } + + // U+0080..U+07FF: bytes C2..DF 80..BF + case 0xC2: + case 0xC3: + case 0xC4: + case 0xC5: + case 0xC6: + case 0xC7: + case 0xC8: + case 0xC9: + case 0xCA: + case 0xCB: + case 0xCC: + case 0xCD: + case 0xCE: + case 0xCF: + case 0xD0: + case 0xD1: + case 0xD2: + case 0xD3: + case 0xD4: + case 0xD5: + case 0xD6: + case 0xD7: + case 0xD8: + case 0xD9: + case 0xDA: + case 0xDB: + case 0xDC: + case 0xDD: + case 0xDE: + case 0xDF: + { + if (JSON_UNLIKELY(not next_byte_in_range({0x80, 0xBF}))) + { + return token_type::parse_error; + } + break; + } + + // U+0800..U+0FFF: bytes E0 A0..BF 80..BF + case 0xE0: + { + if (JSON_UNLIKELY(not (next_byte_in_range({0xA0, 0xBF, 0x80, 0xBF})))) + { + return token_type::parse_error; + } + break; + } + + // U+1000..U+CFFF: bytes E1..EC 80..BF 80..BF + // U+E000..U+FFFF: bytes EE..EF 80..BF 80..BF + case 0xE1: + case 0xE2: + case 0xE3: + case 0xE4: + case 0xE5: + case 0xE6: + case 0xE7: + case 0xE8: + case 0xE9: + case 0xEA: + case 0xEB: + case 0xEC: + case 0xEE: + case 0xEF: + { + if (JSON_UNLIKELY(not (next_byte_in_range({0x80, 0xBF, 0x80, 0xBF})))) + { + return token_type::parse_error; + } + break; + } + + // U+D000..U+D7FF: bytes ED 80..9F 80..BF + case 0xED: + { + if (JSON_UNLIKELY(not (next_byte_in_range({0x80, 0x9F, 0x80, 0xBF})))) + { + return token_type::parse_error; + } + break; + } + + // U+10000..U+3FFFF F0 90..BF 80..BF 80..BF + case 0xF0: + { + if (JSON_UNLIKELY(not (next_byte_in_range({0x90, 0xBF, 0x80, 0xBF, 0x80, 0xBF})))) + { + return token_type::parse_error; + } + break; + } + + // U+40000..U+FFFFF F1..F3 80..BF 80..BF 80..BF + case 0xF1: + case 0xF2: + case 0xF3: + { + if (JSON_UNLIKELY(not (next_byte_in_range({0x80, 0xBF, 0x80, 0xBF, 0x80, 0xBF})))) + { + return token_type::parse_error; + } + break; + } + + // U+100000..U+10FFFF F4 80..8F 80..BF 80..BF + case 0xF4: + { + if (JSON_UNLIKELY(not (next_byte_in_range({0x80, 0x8F, 0x80, 0xBF, 0x80, 0xBF})))) + { + return token_type::parse_error; + } + break; + } + + // remaining bytes (80..C1 and F5..FF) are ill-formed + default: + { + error_message = "invalid string: ill-formed UTF-8 byte"; + return token_type::parse_error; + } + } + } + } + + static void strtof(float& f, const char* str, char** endptr) noexcept + { + f = std::strtof(str, endptr); + } + + static void strtof(double& f, const char* str, char** endptr) noexcept + { + f = std::strtod(str, endptr); + } + + static void strtof(long double& f, const char* str, char** endptr) noexcept + { + f = std::strtold(str, endptr); + } + + /*! + @brief scan a number literal + + This function scans a string according to Sect. 6 of RFC 7159. + + The function is realized with a deterministic finite state machine derived + from the grammar described in RFC 7159. Starting in state "init", the + input is read and used to determined the next state. Only state "done" + accepts the number. State "error" is a trap state to model errors. In the + table below, "anything" means any character but the ones listed before. + + state | 0 | 1-9 | e E | + | - | . | anything + ---------|----------|----------|----------|---------|---------|----------|----------- + init | zero | any1 | [error] | [error] | minus | [error] | [error] + minus | zero | any1 | [error] | [error] | [error] | [error] | [error] + zero | done | done | exponent | done | done | decimal1 | done + any1 | any1 | any1 | exponent | done | done | decimal1 | done + decimal1 | decimal2 | [error] | [error] | [error] | [error] | [error] | [error] + decimal2 | decimal2 | decimal2 | exponent | done | done | done | done + exponent | any2 | any2 | [error] | sign | sign | [error] | [error] + sign | any2 | any2 | [error] | [error] | [error] | [error] | [error] + any2 | any2 | any2 | done | done | done | done | done + + The state machine is realized with one label per state (prefixed with + "scan_number_") and `goto` statements between them. The state machine + contains cycles, but any cycle can be left when EOF is read. Therefore, + the function is guaranteed to terminate. + + During scanning, the read bytes are stored in token_buffer. This string is + then converted to a signed integer, an unsigned integer, or a + floating-point number. + + @return token_type::value_unsigned, token_type::value_integer, or + token_type::value_float if number could be successfully scanned, + token_type::parse_error otherwise + + @note The scanner is independent of the current locale. Internally, the + locale's decimal point is used instead of `.` to work with the + locale-dependent converters. + */ + token_type scan_number() // lgtm [cpp/use-of-goto] + { + // reset token_buffer to store the number's bytes + reset(); + + // the type of the parsed number; initially set to unsigned; will be + // changed if minus sign, decimal point or exponent is read + token_type number_type = token_type::value_unsigned; + + // state (init): we just found out we need to scan a number + switch (current) + { + case '-': + { + add(current); + goto scan_number_minus; + } + + case '0': + { + add(current); + goto scan_number_zero; + } + + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_any1; + } + + // LCOV_EXCL_START + default: + { + // all other characters are rejected outside scan_number() + assert(false); + } + // LCOV_EXCL_STOP + } + +scan_number_minus: + // state: we just parsed a leading minus sign + number_type = token_type::value_integer; + switch (get()) + { + case '0': + { + add(current); + goto scan_number_zero; + } + + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_any1; + } + + default: + { + error_message = "invalid number; expected digit after '-'"; + return token_type::parse_error; + } + } + +scan_number_zero: + // state: we just parse a zero (maybe with a leading minus sign) + switch (get()) + { + case '.': + { + add(decimal_point_char); + goto scan_number_decimal1; + } + + case 'e': + case 'E': + { + add(current); + goto scan_number_exponent; + } + + default: + goto scan_number_done; + } + +scan_number_any1: + // state: we just parsed a number 0-9 (maybe with a leading minus sign) + switch (get()) + { + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_any1; + } + + case '.': + { + add(decimal_point_char); + goto scan_number_decimal1; + } + + case 'e': + case 'E': + { + add(current); + goto scan_number_exponent; + } + + default: + goto scan_number_done; + } + +scan_number_decimal1: + // state: we just parsed a decimal point + number_type = token_type::value_float; + switch (get()) + { + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_decimal2; + } + + default: + { + error_message = "invalid number; expected digit after '.'"; + return token_type::parse_error; + } + } + +scan_number_decimal2: + // we just parsed at least one number after a decimal point + switch (get()) + { + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_decimal2; + } + + case 'e': + case 'E': + { + add(current); + goto scan_number_exponent; + } + + default: + goto scan_number_done; + } + +scan_number_exponent: + // we just parsed an exponent + number_type = token_type::value_float; + switch (get()) + { + case '+': + case '-': + { + add(current); + goto scan_number_sign; + } + + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_any2; + } + + default: + { + error_message = + "invalid number; expected '+', '-', or digit after exponent"; + return token_type::parse_error; + } + } + +scan_number_sign: + // we just parsed an exponent sign + switch (get()) + { + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_any2; + } + + default: + { + error_message = "invalid number; expected digit after exponent sign"; + return token_type::parse_error; + } + } + +scan_number_any2: + // we just parsed a number after the exponent or exponent sign + switch (get()) + { + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + { + add(current); + goto scan_number_any2; + } + + default: + goto scan_number_done; + } + +scan_number_done: + // unget the character after the number (we only read it to know that + // we are done scanning a number) + unget(); + + char* endptr = nullptr; + errno = 0; + + // try to parse integers first and fall back to floats + if (number_type == token_type::value_unsigned) + { + const auto x = std::strtoull(token_buffer.data(), &endptr, 10); + + // we checked the number format before + assert(endptr == token_buffer.data() + token_buffer.size()); + + if (errno == 0) + { + value_unsigned = static_cast<number_unsigned_t>(x); + if (value_unsigned == x) + { + return token_type::value_unsigned; + } + } + } + else if (number_type == token_type::value_integer) + { + const auto x = std::strtoll(token_buffer.data(), &endptr, 10); + + // we checked the number format before + assert(endptr == token_buffer.data() + token_buffer.size()); + + if (errno == 0) + { + value_integer = static_cast<number_integer_t>(x); + if (value_integer == x) + { + return token_type::value_integer; + } + } + } + + // this code is reached if we parse a floating-point number or if an + // integer conversion above failed + strtof(value_float, token_buffer.data(), &endptr); + + // we checked the number format before + assert(endptr == token_buffer.data() + token_buffer.size()); + + return token_type::value_float; + } + + /*! + @param[in] literal_text the literal text to expect + @param[in] length the length of the passed literal text + @param[in] return_type the token type to return on success + */ + token_type scan_literal(const char* literal_text, const std::size_t length, + token_type return_type) + { + assert(current == literal_text[0]); + for (std::size_t i = 1; i < length; ++i) + { + if (JSON_UNLIKELY(get() != literal_text[i])) + { + error_message = "invalid literal"; + return token_type::parse_error; + } + } + return return_type; + } + + ///////////////////// + // input management + ///////////////////// + + /// reset token_buffer; current character is beginning of token + void reset() noexcept + { + token_buffer.clear(); + token_string.clear(); + token_string.push_back(std::char_traits<char>::to_char_type(current)); + } + + /* + @brief get next character from the input + + This function provides the interface to the used input adapter. It does + not throw in case the input reached EOF, but returns a + `std::char_traits<char>::eof()` in that case. Stores the scanned characters + for use in error messages. + + @return character read from the input + */ + std::char_traits<char>::int_type get() + { + ++position.chars_read_total; + ++position.chars_read_current_line; + + if (next_unget) + { + // just reset the next_unget variable and work with current + next_unget = false; + } + else + { + current = ia->get_character(); + } + + if (JSON_LIKELY(current != std::char_traits<char>::eof())) + { + token_string.push_back(std::char_traits<char>::to_char_type(current)); + } + + if (current == '\n') + { + ++position.lines_read; + ++position.chars_read_current_line = 0; + } + + return current; + } + + /*! + @brief unget current character (read it again on next get) + + We implement unget by setting variable next_unget to true. The input is not + changed - we just simulate ungetting by modifying chars_read_total, + chars_read_current_line, and token_string. The next call to get() will + behave as if the unget character is read again. + */ + void unget() + { + next_unget = true; + + --position.chars_read_total; + + // in case we "unget" a newline, we have to also decrement the lines_read + if (position.chars_read_current_line == 0) + { + if (position.lines_read > 0) + { + --position.lines_read; + } + } + else + { + --position.chars_read_current_line; + } + + if (JSON_LIKELY(current != std::char_traits<char>::eof())) + { + assert(token_string.size() != 0); + token_string.pop_back(); + } + } + + /// add a character to token_buffer + void add(int c) + { + token_buffer.push_back(std::char_traits<char>::to_char_type(c)); + } + + public: + ///////////////////// + // value getters + ///////////////////// + + /// return integer value + constexpr number_integer_t get_number_integer() const noexcept + { + return value_integer; + } + + /// return unsigned integer value + constexpr number_unsigned_t get_number_unsigned() const noexcept + { + return value_unsigned; + } + + /// return floating-point value + constexpr number_float_t get_number_float() const noexcept + { + return value_float; + } + + /// return current string value (implicitly resets the token; useful only once) + string_t& get_string() + { + return token_buffer; + } + + ///////////////////// + // diagnostics + ///////////////////// + + /// return position of last read token + constexpr position_t get_position() const noexcept + { + return position; + } + + /// return the last read token (for errors only). Will never contain EOF + /// (an arbitrary value that is not a valid char value, often -1), because + /// 255 may legitimately occur. May contain NUL, which should be escaped. + std::string get_token_string() const + { + // escape control characters + std::string result; + for (const auto c : token_string) + { + if ('\x00' <= c and c <= '\x1F') + { + // escape control characters + char cs[9]; + (std::snprintf)(cs, 9, "<U+%.4X>", static_cast<unsigned char>(c)); + result += cs; + } + else + { + // add character as is + result.push_back(c); + } + } + + return result; + } + + /// return syntax error message + constexpr const char* get_error_message() const noexcept + { + return error_message; + } + + ///////////////////// + // actual scanner + ///////////////////// + + /*! + @brief skip the UTF-8 byte order mark + @return true iff there is no BOM or the correct BOM has been skipped + */ + bool skip_bom() + { + if (get() == 0xEF) + { + // check if we completely parse the BOM + return get() == 0xBB and get() == 0xBF; + } + + // the first character is not the beginning of the BOM; unget it to + // process is later + unget(); + return true; + } + + token_type scan() + { + // initially, skip the BOM + if (position.chars_read_total == 0 and not skip_bom()) + { + error_message = "invalid BOM; must be 0xEF 0xBB 0xBF if given"; + return token_type::parse_error; + } + + // read next character and ignore whitespace + do + { + get(); + } + while (current == ' ' or current == '\t' or current == '\n' or current == '\r'); + + switch (current) + { + // structural characters + case '[': + return token_type::begin_array; + case ']': + return token_type::end_array; + case '{': + return token_type::begin_object; + case '}': + return token_type::end_object; + case ':': + return token_type::name_separator; + case ',': + return token_type::value_separator; + + // literals + case 't': + return scan_literal("true", 4, token_type::literal_true); + case 'f': + return scan_literal("false", 5, token_type::literal_false); + case 'n': + return scan_literal("null", 4, token_type::literal_null); + + // string + case '\"': + return scan_string(); + + // number + case '-': + case '0': + case '1': + case '2': + case '3': + case '4': + case '5': + case '6': + case '7': + case '8': + case '9': + return scan_number(); + + // end of input (the null byte is needed when parsing from + // string literals) + case '\0': + case std::char_traits<char>::eof(): + return token_type::end_of_input; + + // error + default: + error_message = "invalid literal"; + return token_type::parse_error; + } + } + + private: + /// input adapter + detail::input_adapter_t ia = nullptr; + + /// the current character + std::char_traits<char>::int_type current = std::char_traits<char>::eof(); + + /// whether the next get() call should just return current + bool next_unget = false; + + /// the start position of the current token + position_t position; + + /// raw input token string (for error messages) + std::vector<char> token_string {}; + + /// buffer for variable-length tokens (numbers, strings) + string_t token_buffer {}; + + /// a description of occurred lexer errors + const char* error_message = ""; + + // number values + number_integer_t value_integer = 0; + number_unsigned_t value_unsigned = 0; + number_float_t value_float = 0; + + /// the decimal point + const char decimal_point_char = '.'; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/input/parser.hpp> + + +#include <cassert> // assert +#include <cmath> // isfinite +#include <cstdint> // uint8_t +#include <functional> // function +#include <string> // string +#include <utility> // move + +// #include <nlohmann/detail/exceptions.hpp> + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/meta/is_sax.hpp> + + +#include <cstdint> // size_t +#include <utility> // declval + +// #include <nlohmann/detail/meta/detected.hpp> + +// #include <nlohmann/detail/meta/type_traits.hpp> + + +namespace nlohmann +{ +namespace detail +{ +template <typename T> +using null_function_t = decltype(std::declval<T&>().null()); + +template <typename T> +using boolean_function_t = + decltype(std::declval<T&>().boolean(std::declval<bool>())); + +template <typename T, typename Integer> +using number_integer_function_t = + decltype(std::declval<T&>().number_integer(std::declval<Integer>())); + +template <typename T, typename Unsigned> +using number_unsigned_function_t = + decltype(std::declval<T&>().number_unsigned(std::declval<Unsigned>())); + +template <typename T, typename Float, typename String> +using number_float_function_t = decltype(std::declval<T&>().number_float( + std::declval<Float>(), std::declval<const String&>())); + +template <typename T, typename String> +using string_function_t = + decltype(std::declval<T&>().string(std::declval<String&>())); + +template <typename T> +using start_object_function_t = + decltype(std::declval<T&>().start_object(std::declval<std::size_t>())); + +template <typename T, typename String> +using key_function_t = + decltype(std::declval<T&>().key(std::declval<String&>())); + +template <typename T> +using end_object_function_t = decltype(std::declval<T&>().end_object()); + +template <typename T> +using start_array_function_t = + decltype(std::declval<T&>().start_array(std::declval<std::size_t>())); + +template <typename T> +using end_array_function_t = decltype(std::declval<T&>().end_array()); + +template <typename T, typename Exception> +using parse_error_function_t = decltype(std::declval<T&>().parse_error( + std::declval<std::size_t>(), std::declval<const std::string&>(), + std::declval<const Exception&>())); + +template <typename SAX, typename BasicJsonType> +struct is_sax +{ + private: + static_assert(is_basic_json<BasicJsonType>::value, + "BasicJsonType must be of type basic_json<...>"); + + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + using exception_t = typename BasicJsonType::exception; + + public: + static constexpr bool value = + is_detected_exact<bool, null_function_t, SAX>::value && + is_detected_exact<bool, boolean_function_t, SAX>::value && + is_detected_exact<bool, number_integer_function_t, SAX, + number_integer_t>::value && + is_detected_exact<bool, number_unsigned_function_t, SAX, + number_unsigned_t>::value && + is_detected_exact<bool, number_float_function_t, SAX, number_float_t, + string_t>::value && + is_detected_exact<bool, string_function_t, SAX, string_t>::value && + is_detected_exact<bool, start_object_function_t, SAX>::value && + is_detected_exact<bool, key_function_t, SAX, string_t>::value && + is_detected_exact<bool, end_object_function_t, SAX>::value && + is_detected_exact<bool, start_array_function_t, SAX>::value && + is_detected_exact<bool, end_array_function_t, SAX>::value && + is_detected_exact<bool, parse_error_function_t, SAX, exception_t>::value; +}; + +template <typename SAX, typename BasicJsonType> +struct is_sax_static_asserts +{ + private: + static_assert(is_basic_json<BasicJsonType>::value, + "BasicJsonType must be of type basic_json<...>"); + + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + using exception_t = typename BasicJsonType::exception; + + public: + static_assert(is_detected_exact<bool, null_function_t, SAX>::value, + "Missing/invalid function: bool null()"); + static_assert(is_detected_exact<bool, boolean_function_t, SAX>::value, + "Missing/invalid function: bool boolean(bool)"); + static_assert(is_detected_exact<bool, boolean_function_t, SAX>::value, + "Missing/invalid function: bool boolean(bool)"); + static_assert( + is_detected_exact<bool, number_integer_function_t, SAX, + number_integer_t>::value, + "Missing/invalid function: bool number_integer(number_integer_t)"); + static_assert( + is_detected_exact<bool, number_unsigned_function_t, SAX, + number_unsigned_t>::value, + "Missing/invalid function: bool number_unsigned(number_unsigned_t)"); + static_assert(is_detected_exact<bool, number_float_function_t, SAX, + number_float_t, string_t>::value, + "Missing/invalid function: bool number_float(number_float_t, const string_t&)"); + static_assert( + is_detected_exact<bool, string_function_t, SAX, string_t>::value, + "Missing/invalid function: bool string(string_t&)"); + static_assert(is_detected_exact<bool, start_object_function_t, SAX>::value, + "Missing/invalid function: bool start_object(std::size_t)"); + static_assert(is_detected_exact<bool, key_function_t, SAX, string_t>::value, + "Missing/invalid function: bool key(string_t&)"); + static_assert(is_detected_exact<bool, end_object_function_t, SAX>::value, + "Missing/invalid function: bool end_object()"); + static_assert(is_detected_exact<bool, start_array_function_t, SAX>::value, + "Missing/invalid function: bool start_array(std::size_t)"); + static_assert(is_detected_exact<bool, end_array_function_t, SAX>::value, + "Missing/invalid function: bool end_array()"); + static_assert( + is_detected_exact<bool, parse_error_function_t, SAX, exception_t>::value, + "Missing/invalid function: bool parse_error(std::size_t, const " + "std::string&, const exception&)"); +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/input/input_adapters.hpp> + +// #include <nlohmann/detail/input/json_sax.hpp> + + +#include <cstddef> +#include <string> +#include <vector> + +// #include <nlohmann/detail/input/parser.hpp> + +// #include <nlohmann/detail/exceptions.hpp> + + +namespace nlohmann +{ + +/*! +@brief SAX interface + +This class describes the SAX interface used by @ref nlohmann::json::sax_parse. +Each function is called in different situations while the input is parsed. The +boolean return value informs the parser whether to continue processing the +input. +*/ +template<typename BasicJsonType> +struct json_sax +{ + /// type for (signed) integers + using number_integer_t = typename BasicJsonType::number_integer_t; + /// type for unsigned integers + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + /// type for floating-point numbers + using number_float_t = typename BasicJsonType::number_float_t; + /// type for strings + using string_t = typename BasicJsonType::string_t; + + /*! + @brief a null value was read + @return whether parsing should proceed + */ + virtual bool null() = 0; + + /*! + @brief a boolean value was read + @param[in] val boolean value + @return whether parsing should proceed + */ + virtual bool boolean(bool val) = 0; + + /*! + @brief an integer number was read + @param[in] val integer value + @return whether parsing should proceed + */ + virtual bool number_integer(number_integer_t val) = 0; + + /*! + @brief an unsigned integer number was read + @param[in] val unsigned integer value + @return whether parsing should proceed + */ + virtual bool number_unsigned(number_unsigned_t val) = 0; + + /*! + @brief an floating-point number was read + @param[in] val floating-point value + @param[in] s raw token value + @return whether parsing should proceed + */ + virtual bool number_float(number_float_t val, const string_t& s) = 0; + + /*! + @brief a string was read + @param[in] val string value + @return whether parsing should proceed + @note It is safe to move the passed string. + */ + virtual bool string(string_t& val) = 0; + + /*! + @brief the beginning of an object was read + @param[in] elements number of object elements or -1 if unknown + @return whether parsing should proceed + @note binary formats may report the number of elements + */ + virtual bool start_object(std::size_t elements) = 0; + + /*! + @brief an object key was read + @param[in] val object key + @return whether parsing should proceed + @note It is safe to move the passed string. + */ + virtual bool key(string_t& val) = 0; + + /*! + @brief the end of an object was read + @return whether parsing should proceed + */ + virtual bool end_object() = 0; + + /*! + @brief the beginning of an array was read + @param[in] elements number of array elements or -1 if unknown + @return whether parsing should proceed + @note binary formats may report the number of elements + */ + virtual bool start_array(std::size_t elements) = 0; + + /*! + @brief the end of an array was read + @return whether parsing should proceed + */ + virtual bool end_array() = 0; + + /*! + @brief a parse error occurred + @param[in] position the position in the input where the error occurs + @param[in] last_token the last read token + @param[in] ex an exception object describing the error + @return whether parsing should proceed (must return false) + */ + virtual bool parse_error(std::size_t position, + const std::string& last_token, + const detail::exception& ex) = 0; + + virtual ~json_sax() = default; +}; + + +namespace detail +{ +/*! +@brief SAX implementation to create a JSON value from SAX events + +This class implements the @ref json_sax interface and processes the SAX events +to create a JSON value which makes it basically a DOM parser. The structure or +hierarchy of the JSON value is managed by the stack `ref_stack` which contains +a pointer to the respective array or object for each recursion depth. + +After successful parsing, the value that is passed by reference to the +constructor contains the parsed value. + +@tparam BasicJsonType the JSON type +*/ +template<typename BasicJsonType> +class json_sax_dom_parser +{ + public: + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + + /*! + @param[in, out] r reference to a JSON value that is manipulated while + parsing + @param[in] allow_exceptions_ whether parse errors yield exceptions + */ + explicit json_sax_dom_parser(BasicJsonType& r, const bool allow_exceptions_ = true) + : root(r), allow_exceptions(allow_exceptions_) + {} + + bool null() + { + handle_value(nullptr); + return true; + } + + bool boolean(bool val) + { + handle_value(val); + return true; + } + + bool number_integer(number_integer_t val) + { + handle_value(val); + return true; + } + + bool number_unsigned(number_unsigned_t val) + { + handle_value(val); + return true; + } + + bool number_float(number_float_t val, const string_t& /*unused*/) + { + handle_value(val); + return true; + } + + bool string(string_t& val) + { + handle_value(val); + return true; + } + + bool start_object(std::size_t len) + { + ref_stack.push_back(handle_value(BasicJsonType::value_t::object)); + + if (JSON_UNLIKELY(len != std::size_t(-1) and len > ref_stack.back()->max_size())) + { + JSON_THROW(out_of_range::create(408, + "excessive object size: " + std::to_string(len))); + } + + return true; + } + + bool key(string_t& val) + { + // add null at given key and store the reference for later + object_element = &(ref_stack.back()->m_value.object->operator[](val)); + return true; + } + + bool end_object() + { + ref_stack.pop_back(); + return true; + } + + bool start_array(std::size_t len) + { + ref_stack.push_back(handle_value(BasicJsonType::value_t::array)); + + if (JSON_UNLIKELY(len != std::size_t(-1) and len > ref_stack.back()->max_size())) + { + JSON_THROW(out_of_range::create(408, + "excessive array size: " + std::to_string(len))); + } + + return true; + } + + bool end_array() + { + ref_stack.pop_back(); + return true; + } + + bool parse_error(std::size_t /*unused*/, const std::string& /*unused*/, + const detail::exception& ex) + { + errored = true; + if (allow_exceptions) + { + // determine the proper exception type from the id + switch ((ex.id / 100) % 100) + { + case 1: + JSON_THROW(*reinterpret_cast<const detail::parse_error*>(&ex)); + case 4: + JSON_THROW(*reinterpret_cast<const detail::out_of_range*>(&ex)); + // LCOV_EXCL_START + case 2: + JSON_THROW(*reinterpret_cast<const detail::invalid_iterator*>(&ex)); + case 3: + JSON_THROW(*reinterpret_cast<const detail::type_error*>(&ex)); + case 5: + JSON_THROW(*reinterpret_cast<const detail::other_error*>(&ex)); + default: + assert(false); + // LCOV_EXCL_STOP + } + } + return false; + } + + constexpr bool is_errored() const + { + return errored; + } + + private: + /*! + @invariant If the ref stack is empty, then the passed value will be the new + root. + @invariant If the ref stack contains a value, then it is an array or an + object to which we can add elements + */ + template<typename Value> + BasicJsonType* handle_value(Value&& v) + { + if (ref_stack.empty()) + { + root = BasicJsonType(std::forward<Value>(v)); + return &root; + } + + assert(ref_stack.back()->is_array() or ref_stack.back()->is_object()); + + if (ref_stack.back()->is_array()) + { + ref_stack.back()->m_value.array->emplace_back(std::forward<Value>(v)); + return &(ref_stack.back()->m_value.array->back()); + } + else + { + assert(object_element); + *object_element = BasicJsonType(std::forward<Value>(v)); + return object_element; + } + } + + /// the parsed JSON value + BasicJsonType& root; + /// stack to model hierarchy of values + std::vector<BasicJsonType*> ref_stack; + /// helper to hold the reference for the next object element + BasicJsonType* object_element = nullptr; + /// whether a syntax error occurred + bool errored = false; + /// whether to throw exceptions in case of errors + const bool allow_exceptions = true; +}; + +template<typename BasicJsonType> +class json_sax_dom_callback_parser +{ + public: + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + using parser_callback_t = typename BasicJsonType::parser_callback_t; + using parse_event_t = typename BasicJsonType::parse_event_t; + + json_sax_dom_callback_parser(BasicJsonType& r, + const parser_callback_t cb, + const bool allow_exceptions_ = true) + : root(r), callback(cb), allow_exceptions(allow_exceptions_) + { + keep_stack.push_back(true); + } + + bool null() + { + handle_value(nullptr); + return true; + } + + bool boolean(bool val) + { + handle_value(val); + return true; + } + + bool number_integer(number_integer_t val) + { + handle_value(val); + return true; + } + + bool number_unsigned(number_unsigned_t val) + { + handle_value(val); + return true; + } + + bool number_float(number_float_t val, const string_t& /*unused*/) + { + handle_value(val); + return true; + } + + bool string(string_t& val) + { + handle_value(val); + return true; + } + + bool start_object(std::size_t len) + { + // check callback for object start + const bool keep = callback(static_cast<int>(ref_stack.size()), parse_event_t::object_start, discarded); + keep_stack.push_back(keep); + + auto val = handle_value(BasicJsonType::value_t::object, true); + ref_stack.push_back(val.second); + + // check object limit + if (ref_stack.back()) + { + if (JSON_UNLIKELY(len != std::size_t(-1) and len > ref_stack.back()->max_size())) + { + JSON_THROW(out_of_range::create(408, + "excessive object size: " + std::to_string(len))); + } + } + + return true; + } + + bool key(string_t& val) + { + BasicJsonType k = BasicJsonType(val); + + // check callback for key + const bool keep = callback(static_cast<int>(ref_stack.size()), parse_event_t::key, k); + key_keep_stack.push_back(keep); + + // add discarded value at given key and store the reference for later + if (keep and ref_stack.back()) + { + object_element = &(ref_stack.back()->m_value.object->operator[](val) = discarded); + } + + return true; + } + + bool end_object() + { + if (ref_stack.back()) + { + if (not callback(static_cast<int>(ref_stack.size()) - 1, parse_event_t::object_end, *ref_stack.back())) + { + // discard object + *ref_stack.back() = discarded; + } + } + + assert(not ref_stack.empty()); + assert(not keep_stack.empty()); + ref_stack.pop_back(); + keep_stack.pop_back(); + + if (not ref_stack.empty() and ref_stack.back()) + { + // remove discarded value + if (ref_stack.back()->is_object()) + { + for (auto it = ref_stack.back()->begin(); it != ref_stack.back()->end(); ++it) + { + if (it->is_discarded()) + { + ref_stack.back()->erase(it); + break; + } + } + } + } + + return true; + } + + bool start_array(std::size_t len) + { + const bool keep = callback(static_cast<int>(ref_stack.size()), parse_event_t::array_start, discarded); + keep_stack.push_back(keep); + + auto val = handle_value(BasicJsonType::value_t::array, true); + ref_stack.push_back(val.second); + + // check array limit + if (ref_stack.back()) + { + if (JSON_UNLIKELY(len != std::size_t(-1) and len > ref_stack.back()->max_size())) + { + JSON_THROW(out_of_range::create(408, + "excessive array size: " + std::to_string(len))); + } + } + + return true; + } + + bool end_array() + { + bool keep = true; + + if (ref_stack.back()) + { + keep = callback(static_cast<int>(ref_stack.size()) - 1, parse_event_t::array_end, *ref_stack.back()); + if (not keep) + { + // discard array + *ref_stack.back() = discarded; + } + } + + assert(not ref_stack.empty()); + assert(not keep_stack.empty()); + ref_stack.pop_back(); + keep_stack.pop_back(); + + // remove discarded value + if (not keep and not ref_stack.empty()) + { + if (ref_stack.back()->is_array()) + { + ref_stack.back()->m_value.array->pop_back(); + } + } + + return true; + } + + bool parse_error(std::size_t /*unused*/, const std::string& /*unused*/, + const detail::exception& ex) + { + errored = true; + if (allow_exceptions) + { + // determine the proper exception type from the id + switch ((ex.id / 100) % 100) + { + case 1: + JSON_THROW(*reinterpret_cast<const detail::parse_error*>(&ex)); + case 4: + JSON_THROW(*reinterpret_cast<const detail::out_of_range*>(&ex)); + // LCOV_EXCL_START + case 2: + JSON_THROW(*reinterpret_cast<const detail::invalid_iterator*>(&ex)); + case 3: + JSON_THROW(*reinterpret_cast<const detail::type_error*>(&ex)); + case 5: + JSON_THROW(*reinterpret_cast<const detail::other_error*>(&ex)); + default: + assert(false); + // LCOV_EXCL_STOP + } + } + return false; + } + + constexpr bool is_errored() const + { + return errored; + } + + private: + /*! + @param[in] v value to add to the JSON value we build during parsing + @param[in] skip_callback whether we should skip calling the callback + function; this is required after start_array() and + start_object() SAX events, because otherwise we would call the + callback function with an empty array or object, respectively. + + @invariant If the ref stack is empty, then the passed value will be the new + root. + @invariant If the ref stack contains a value, then it is an array or an + object to which we can add elements + + @return pair of boolean (whether value should be kept) and pointer (to the + passed value in the ref_stack hierarchy; nullptr if not kept) + */ + template<typename Value> + std::pair<bool, BasicJsonType*> handle_value(Value&& v, const bool skip_callback = false) + { + assert(not keep_stack.empty()); + + // do not handle this value if we know it would be added to a discarded + // container + if (not keep_stack.back()) + { + return {false, nullptr}; + } + + // create value + auto value = BasicJsonType(std::forward<Value>(v)); + + // check callback + const bool keep = skip_callback or callback(static_cast<int>(ref_stack.size()), parse_event_t::value, value); + + // do not handle this value if we just learnt it shall be discarded + if (not keep) + { + return {false, nullptr}; + } + + if (ref_stack.empty()) + { + root = std::move(value); + return {true, &root}; + } + + // skip this value if we already decided to skip the parent + // (https://github.com/nlohmann/json/issues/971#issuecomment-413678360) + if (not ref_stack.back()) + { + return {false, nullptr}; + } + + // we now only expect arrays and objects + assert(ref_stack.back()->is_array() or ref_stack.back()->is_object()); + + if (ref_stack.back()->is_array()) + { + ref_stack.back()->m_value.array->push_back(std::move(value)); + return {true, &(ref_stack.back()->m_value.array->back())}; + } + else + { + // check if we should store an element for the current key + assert(not key_keep_stack.empty()); + const bool store_element = key_keep_stack.back(); + key_keep_stack.pop_back(); + + if (not store_element) + { + return {false, nullptr}; + } + + assert(object_element); + *object_element = std::move(value); + return {true, object_element}; + } + } + + /// the parsed JSON value + BasicJsonType& root; + /// stack to model hierarchy of values + std::vector<BasicJsonType*> ref_stack; + /// stack to manage which values to keep + std::vector<bool> keep_stack; + /// stack to manage which object keys to keep + std::vector<bool> key_keep_stack; + /// helper to hold the reference for the next object element + BasicJsonType* object_element = nullptr; + /// whether a syntax error occurred + bool errored = false; + /// callback function + const parser_callback_t callback = nullptr; + /// whether to throw exceptions in case of errors + const bool allow_exceptions = true; + /// a discarded value for the callback + BasicJsonType discarded = BasicJsonType::value_t::discarded; +}; + +template<typename BasicJsonType> +class json_sax_acceptor +{ + public: + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + + bool null() + { + return true; + } + + bool boolean(bool /*unused*/) + { + return true; + } + + bool number_integer(number_integer_t /*unused*/) + { + return true; + } + + bool number_unsigned(number_unsigned_t /*unused*/) + { + return true; + } + + bool number_float(number_float_t /*unused*/, const string_t& /*unused*/) + { + return true; + } + + bool string(string_t& /*unused*/) + { + return true; + } + + bool start_object(std::size_t /*unused*/ = std::size_t(-1)) + { + return true; + } + + bool key(string_t& /*unused*/) + { + return true; + } + + bool end_object() + { + return true; + } + + bool start_array(std::size_t /*unused*/ = std::size_t(-1)) + { + return true; + } + + bool end_array() + { + return true; + } + + bool parse_error(std::size_t /*unused*/, const std::string& /*unused*/, const detail::exception& /*unused*/) + { + return false; + } +}; +} // namespace detail + +} // namespace nlohmann + +// #include <nlohmann/detail/input/lexer.hpp> + +// #include <nlohmann/detail/value_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +//////////// +// parser // +//////////// + +/*! +@brief syntax analysis + +This class implements a recursive decent parser. +*/ +template<typename BasicJsonType> +class parser +{ + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + using lexer_t = lexer<BasicJsonType>; + using token_type = typename lexer_t::token_type; + + public: + enum class parse_event_t : uint8_t + { + /// the parser read `{` and started to process a JSON object + object_start, + /// the parser read `}` and finished processing a JSON object + object_end, + /// the parser read `[` and started to process a JSON array + array_start, + /// the parser read `]` and finished processing a JSON array + array_end, + /// the parser read a key of a value in an object + key, + /// the parser finished reading a JSON value + value + }; + + using parser_callback_t = + std::function<bool(int depth, parse_event_t event, BasicJsonType& parsed)>; + + /// a parser reading from an input adapter + explicit parser(detail::input_adapter_t&& adapter, + const parser_callback_t cb = nullptr, + const bool allow_exceptions_ = true) + : callback(cb), m_lexer(std::move(adapter)), allow_exceptions(allow_exceptions_) + { + // read first token + get_token(); + } + + /*! + @brief public parser interface + + @param[in] strict whether to expect the last token to be EOF + @param[in,out] result parsed JSON value + + @throw parse_error.101 in case of an unexpected token + @throw parse_error.102 if to_unicode fails or surrogate error + @throw parse_error.103 if to_unicode fails + */ + void parse(const bool strict, BasicJsonType& result) + { + if (callback) + { + json_sax_dom_callback_parser<BasicJsonType> sdp(result, callback, allow_exceptions); + sax_parse_internal(&sdp); + result.assert_invariant(); + + // in strict mode, input must be completely read + if (strict and (get_token() != token_type::end_of_input)) + { + sdp.parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::end_of_input, "value"))); + } + + // in case of an error, return discarded value + if (sdp.is_errored()) + { + result = value_t::discarded; + return; + } + + // set top-level value to null if it was discarded by the callback + // function + if (result.is_discarded()) + { + result = nullptr; + } + } + else + { + json_sax_dom_parser<BasicJsonType> sdp(result, allow_exceptions); + sax_parse_internal(&sdp); + result.assert_invariant(); + + // in strict mode, input must be completely read + if (strict and (get_token() != token_type::end_of_input)) + { + sdp.parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::end_of_input, "value"))); + } + + // in case of an error, return discarded value + if (sdp.is_errored()) + { + result = value_t::discarded; + return; + } + } + } + + /*! + @brief public accept interface + + @param[in] strict whether to expect the last token to be EOF + @return whether the input is a proper JSON text + */ + bool accept(const bool strict = true) + { + json_sax_acceptor<BasicJsonType> sax_acceptor; + return sax_parse(&sax_acceptor, strict); + } + + template <typename SAX> + bool sax_parse(SAX* sax, const bool strict = true) + { + (void)detail::is_sax_static_asserts<SAX, BasicJsonType> {}; + const bool result = sax_parse_internal(sax); + + // strict mode: next byte must be EOF + if (result and strict and (get_token() != token_type::end_of_input)) + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::end_of_input, "value"))); + } + + return result; + } + + private: + template <typename SAX> + bool sax_parse_internal(SAX* sax) + { + // stack to remember the hierarchy of structured values we are parsing + // true = array; false = object + std::vector<bool> states; + // value to avoid a goto (see comment where set to true) + bool skip_to_state_evaluation = false; + + while (true) + { + if (not skip_to_state_evaluation) + { + // invariant: get_token() was called before each iteration + switch (last_token) + { + case token_type::begin_object: + { + if (JSON_UNLIKELY(not sax->start_object(std::size_t(-1)))) + { + return false; + } + + // closing } -> we are done + if (get_token() == token_type::end_object) + { + if (JSON_UNLIKELY(not sax->end_object())) + { + return false; + } + break; + } + + // parse key + if (JSON_UNLIKELY(last_token != token_type::value_string)) + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::value_string, "object key"))); + } + if (JSON_UNLIKELY(not sax->key(m_lexer.get_string()))) + { + return false; + } + + // parse separator (:) + if (JSON_UNLIKELY(get_token() != token_type::name_separator)) + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::name_separator, "object separator"))); + } + + // remember we are now inside an object + states.push_back(false); + + // parse values + get_token(); + continue; + } + + case token_type::begin_array: + { + if (JSON_UNLIKELY(not sax->start_array(std::size_t(-1)))) + { + return false; + } + + // closing ] -> we are done + if (get_token() == token_type::end_array) + { + if (JSON_UNLIKELY(not sax->end_array())) + { + return false; + } + break; + } + + // remember we are now inside an array + states.push_back(true); + + // parse values (no need to call get_token) + continue; + } + + case token_type::value_float: + { + const auto res = m_lexer.get_number_float(); + + if (JSON_UNLIKELY(not std::isfinite(res))) + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + out_of_range::create(406, "number overflow parsing '" + m_lexer.get_token_string() + "'")); + } + else + { + if (JSON_UNLIKELY(not sax->number_float(res, m_lexer.get_string()))) + { + return false; + } + break; + } + } + + case token_type::literal_false: + { + if (JSON_UNLIKELY(not sax->boolean(false))) + { + return false; + } + break; + } + + case token_type::literal_null: + { + if (JSON_UNLIKELY(not sax->null())) + { + return false; + } + break; + } + + case token_type::literal_true: + { + if (JSON_UNLIKELY(not sax->boolean(true))) + { + return false; + } + break; + } + + case token_type::value_integer: + { + if (JSON_UNLIKELY(not sax->number_integer(m_lexer.get_number_integer()))) + { + return false; + } + break; + } + + case token_type::value_string: + { + if (JSON_UNLIKELY(not sax->string(m_lexer.get_string()))) + { + return false; + } + break; + } + + case token_type::value_unsigned: + { + if (JSON_UNLIKELY(not sax->number_unsigned(m_lexer.get_number_unsigned()))) + { + return false; + } + break; + } + + case token_type::parse_error: + { + // using "uninitialized" to avoid "expected" message + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::uninitialized, "value"))); + } + + default: // the last token was unexpected + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::literal_or_value, "value"))); + } + } + } + else + { + skip_to_state_evaluation = false; + } + + // we reached this line after we successfully parsed a value + if (states.empty()) + { + // empty stack: we reached the end of the hierarchy: done + return true; + } + else + { + if (states.back()) // array + { + // comma -> next value + if (get_token() == token_type::value_separator) + { + // parse a new value + get_token(); + continue; + } + + // closing ] + if (JSON_LIKELY(last_token == token_type::end_array)) + { + if (JSON_UNLIKELY(not sax->end_array())) + { + return false; + } + + // We are done with this array. Before we can parse a + // new value, we need to evaluate the new state first. + // By setting skip_to_state_evaluation to false, we + // are effectively jumping to the beginning of this if. + assert(not states.empty()); + states.pop_back(); + skip_to_state_evaluation = true; + continue; + } + else + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::end_array, "array"))); + } + } + else // object + { + // comma -> next value + if (get_token() == token_type::value_separator) + { + // parse key + if (JSON_UNLIKELY(get_token() != token_type::value_string)) + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::value_string, "object key"))); + } + else + { + if (JSON_UNLIKELY(not sax->key(m_lexer.get_string()))) + { + return false; + } + } + + // parse separator (:) + if (JSON_UNLIKELY(get_token() != token_type::name_separator)) + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::name_separator, "object separator"))); + } + + // parse values + get_token(); + continue; + } + + // closing } + if (JSON_LIKELY(last_token == token_type::end_object)) + { + if (JSON_UNLIKELY(not sax->end_object())) + { + return false; + } + + // We are done with this object. Before we can parse a + // new value, we need to evaluate the new state first. + // By setting skip_to_state_evaluation to false, we + // are effectively jumping to the beginning of this if. + assert(not states.empty()); + states.pop_back(); + skip_to_state_evaluation = true; + continue; + } + else + { + return sax->parse_error(m_lexer.get_position(), + m_lexer.get_token_string(), + parse_error::create(101, m_lexer.get_position(), + exception_message(token_type::end_object, "object"))); + } + } + } + } + } + + /// get next token from lexer + token_type get_token() + { + return (last_token = m_lexer.scan()); + } + + std::string exception_message(const token_type expected, const std::string& context) + { + std::string error_msg = "syntax error "; + + if (not context.empty()) + { + error_msg += "while parsing " + context + " "; + } + + error_msg += "- "; + + if (last_token == token_type::parse_error) + { + error_msg += std::string(m_lexer.get_error_message()) + "; last read: '" + + m_lexer.get_token_string() + "'"; + } + else + { + error_msg += "unexpected " + std::string(lexer_t::token_type_name(last_token)); + } + + if (expected != token_type::uninitialized) + { + error_msg += "; expected " + std::string(lexer_t::token_type_name(expected)); + } + + return error_msg; + } + + private: + /// callback function + const parser_callback_t callback = nullptr; + /// the type of the last read token + token_type last_token = token_type::uninitialized; + /// the lexer + lexer_t m_lexer; + /// whether to throw exceptions in case of errors + const bool allow_exceptions = true; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/iterators/primitive_iterator.hpp> + + +#include <cstddef> // ptrdiff_t +#include <limits> // numeric_limits + +namespace nlohmann +{ +namespace detail +{ +/* +@brief an iterator for primitive JSON types + +This class models an iterator for primitive JSON types (boolean, number, +string). It's only purpose is to allow the iterator/const_iterator classes +to "iterate" over primitive values. Internally, the iterator is modeled by +a `difference_type` variable. Value begin_value (`0`) models the begin, +end_value (`1`) models past the end. +*/ +class primitive_iterator_t +{ + private: + using difference_type = std::ptrdiff_t; + static constexpr difference_type begin_value = 0; + static constexpr difference_type end_value = begin_value + 1; + + /// iterator as signed integer type + difference_type m_it = (std::numeric_limits<std::ptrdiff_t>::min)(); + + public: + constexpr difference_type get_value() const noexcept + { + return m_it; + } + + /// set iterator to a defined beginning + void set_begin() noexcept + { + m_it = begin_value; + } + + /// set iterator to a defined past the end + void set_end() noexcept + { + m_it = end_value; + } + + /// return whether the iterator can be dereferenced + constexpr bool is_begin() const noexcept + { + return m_it == begin_value; + } + + /// return whether the iterator is at end + constexpr bool is_end() const noexcept + { + return m_it == end_value; + } + + friend constexpr bool operator==(primitive_iterator_t lhs, primitive_iterator_t rhs) noexcept + { + return lhs.m_it == rhs.m_it; + } + + friend constexpr bool operator<(primitive_iterator_t lhs, primitive_iterator_t rhs) noexcept + { + return lhs.m_it < rhs.m_it; + } + + primitive_iterator_t operator+(difference_type n) noexcept + { + auto result = *this; + result += n; + return result; + } + + friend constexpr difference_type operator-(primitive_iterator_t lhs, primitive_iterator_t rhs) noexcept + { + return lhs.m_it - rhs.m_it; + } + + primitive_iterator_t& operator++() noexcept + { + ++m_it; + return *this; + } + + primitive_iterator_t const operator++(int) noexcept + { + auto result = *this; + ++m_it; + return result; + } + + primitive_iterator_t& operator--() noexcept + { + --m_it; + return *this; + } + + primitive_iterator_t const operator--(int) noexcept + { + auto result = *this; + --m_it; + return result; + } + + primitive_iterator_t& operator+=(difference_type n) noexcept + { + m_it += n; + return *this; + } + + primitive_iterator_t& operator-=(difference_type n) noexcept + { + m_it -= n; + return *this; + } +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/iterators/internal_iterator.hpp> + + +// #include <nlohmann/detail/iterators/primitive_iterator.hpp> + + +namespace nlohmann +{ +namespace detail +{ +/*! +@brief an iterator value + +@note This structure could easily be a union, but MSVC currently does not allow +unions members with complex constructors, see https://github.com/nlohmann/json/pull/105. +*/ +template<typename BasicJsonType> struct internal_iterator +{ + /// iterator for JSON objects + typename BasicJsonType::object_t::iterator object_iterator {}; + /// iterator for JSON arrays + typename BasicJsonType::array_t::iterator array_iterator {}; + /// generic iterator for all other types + primitive_iterator_t primitive_iterator {}; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/iterators/iter_impl.hpp> + + +#include <ciso646> // not +#include <iterator> // iterator, random_access_iterator_tag, bidirectional_iterator_tag, advance, next +#include <type_traits> // conditional, is_const, remove_const + +// #include <nlohmann/detail/exceptions.hpp> + +// #include <nlohmann/detail/iterators/internal_iterator.hpp> + +// #include <nlohmann/detail/iterators/primitive_iterator.hpp> + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/meta/cpp_future.hpp> + +// #include <nlohmann/detail/value_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +// forward declare, to be able to friend it later on +template<typename IteratorType> class iteration_proxy; +template<typename IteratorType> class iteration_proxy_value; + +/*! +@brief a template for a bidirectional iterator for the @ref basic_json class +This class implements a both iterators (iterator and const_iterator) for the +@ref basic_json class. +@note An iterator is called *initialized* when a pointer to a JSON value has + been set (e.g., by a constructor or a copy assignment). If the iterator is + default-constructed, it is *uninitialized* and most methods are undefined. + **The library uses assertions to detect calls on uninitialized iterators.** +@requirement The class satisfies the following concept requirements: +- +[BidirectionalIterator](https://en.cppreference.com/w/cpp/named_req/BidirectionalIterator): + The iterator that can be moved can be moved in both directions (i.e. + incremented and decremented). +@since version 1.0.0, simplified in version 2.0.9, change to bidirectional + iterators in version 3.0.0 (see https://github.com/nlohmann/json/issues/593) +*/ +template<typename BasicJsonType> +class iter_impl +{ + /// allow basic_json to access private members + friend iter_impl<typename std::conditional<std::is_const<BasicJsonType>::value, typename std::remove_const<BasicJsonType>::type, const BasicJsonType>::type>; + friend BasicJsonType; + friend iteration_proxy<iter_impl>; + friend iteration_proxy_value<iter_impl>; + + using object_t = typename BasicJsonType::object_t; + using array_t = typename BasicJsonType::array_t; + // make sure BasicJsonType is basic_json or const basic_json + static_assert(is_basic_json<typename std::remove_const<BasicJsonType>::type>::value, + "iter_impl only accepts (const) basic_json"); + + public: + + /// The std::iterator class template (used as a base class to provide typedefs) is deprecated in C++17. + /// The C++ Standard has never required user-defined iterators to derive from std::iterator. + /// A user-defined iterator should provide publicly accessible typedefs named + /// iterator_category, value_type, difference_type, pointer, and reference. + /// Note that value_type is required to be non-const, even for constant iterators. + using iterator_category = std::bidirectional_iterator_tag; + + /// the type of the values when the iterator is dereferenced + using value_type = typename BasicJsonType::value_type; + /// a type to represent differences between iterators + using difference_type = typename BasicJsonType::difference_type; + /// defines a pointer to the type iterated over (value_type) + using pointer = typename std::conditional<std::is_const<BasicJsonType>::value, + typename BasicJsonType::const_pointer, + typename BasicJsonType::pointer>::type; + /// defines a reference to the type iterated over (value_type) + using reference = + typename std::conditional<std::is_const<BasicJsonType>::value, + typename BasicJsonType::const_reference, + typename BasicJsonType::reference>::type; + + /// default constructor + iter_impl() = default; + + /*! + @brief constructor for a given JSON instance + @param[in] object pointer to a JSON object for this iterator + @pre object != nullptr + @post The iterator is initialized; i.e. `m_object != nullptr`. + */ + explicit iter_impl(pointer object) noexcept : m_object(object) + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + m_it.object_iterator = typename object_t::iterator(); + break; + } + + case value_t::array: + { + m_it.array_iterator = typename array_t::iterator(); + break; + } + + default: + { + m_it.primitive_iterator = primitive_iterator_t(); + break; + } + } + } + + /*! + @note The conventional copy constructor and copy assignment are implicitly + defined. Combined with the following converting constructor and + assignment, they support: (1) copy from iterator to iterator, (2) + copy from const iterator to const iterator, and (3) conversion from + iterator to const iterator. However conversion from const iterator + to iterator is not defined. + */ + + /*! + @brief converting constructor + @param[in] other non-const iterator to copy from + @note It is not checked whether @a other is initialized. + */ + iter_impl(const iter_impl<typename std::remove_const<BasicJsonType>::type>& other) noexcept + : m_object(other.m_object), m_it(other.m_it) {} + + /*! + @brief converting assignment + @param[in,out] other non-const iterator to copy from + @return const/non-const iterator + @note It is not checked whether @a other is initialized. + */ + iter_impl& operator=(const iter_impl<typename std::remove_const<BasicJsonType>::type>& other) noexcept + { + m_object = other.m_object; + m_it = other.m_it; + return *this; + } + + private: + /*! + @brief set the iterator to the first value + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + void set_begin() noexcept + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + m_it.object_iterator = m_object->m_value.object->begin(); + break; + } + + case value_t::array: + { + m_it.array_iterator = m_object->m_value.array->begin(); + break; + } + + case value_t::null: + { + // set to end so begin()==end() is true: null is empty + m_it.primitive_iterator.set_end(); + break; + } + + default: + { + m_it.primitive_iterator.set_begin(); + break; + } + } + } + + /*! + @brief set the iterator past the last value + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + void set_end() noexcept + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + m_it.object_iterator = m_object->m_value.object->end(); + break; + } + + case value_t::array: + { + m_it.array_iterator = m_object->m_value.array->end(); + break; + } + + default: + { + m_it.primitive_iterator.set_end(); + break; + } + } + } + + public: + /*! + @brief return a reference to the value pointed to by the iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + reference operator*() const + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + assert(m_it.object_iterator != m_object->m_value.object->end()); + return m_it.object_iterator->second; + } + + case value_t::array: + { + assert(m_it.array_iterator != m_object->m_value.array->end()); + return *m_it.array_iterator; + } + + case value_t::null: + JSON_THROW(invalid_iterator::create(214, "cannot get value")); + + default: + { + if (JSON_LIKELY(m_it.primitive_iterator.is_begin())) + { + return *m_object; + } + + JSON_THROW(invalid_iterator::create(214, "cannot get value")); + } + } + } + + /*! + @brief dereference the iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + pointer operator->() const + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + assert(m_it.object_iterator != m_object->m_value.object->end()); + return &(m_it.object_iterator->second); + } + + case value_t::array: + { + assert(m_it.array_iterator != m_object->m_value.array->end()); + return &*m_it.array_iterator; + } + + default: + { + if (JSON_LIKELY(m_it.primitive_iterator.is_begin())) + { + return m_object; + } + + JSON_THROW(invalid_iterator::create(214, "cannot get value")); + } + } + } + + /*! + @brief post-increment (it++) + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl const operator++(int) + { + auto result = *this; + ++(*this); + return result; + } + + /*! + @brief pre-increment (++it) + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl& operator++() + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + std::advance(m_it.object_iterator, 1); + break; + } + + case value_t::array: + { + std::advance(m_it.array_iterator, 1); + break; + } + + default: + { + ++m_it.primitive_iterator; + break; + } + } + + return *this; + } + + /*! + @brief post-decrement (it--) + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl const operator--(int) + { + auto result = *this; + --(*this); + return result; + } + + /*! + @brief pre-decrement (--it) + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl& operator--() + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + { + std::advance(m_it.object_iterator, -1); + break; + } + + case value_t::array: + { + std::advance(m_it.array_iterator, -1); + break; + } + + default: + { + --m_it.primitive_iterator; + break; + } + } + + return *this; + } + + /*! + @brief comparison: equal + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + bool operator==(const iter_impl& other) const + { + // if objects are not the same, the comparison is undefined + if (JSON_UNLIKELY(m_object != other.m_object)) + { + JSON_THROW(invalid_iterator::create(212, "cannot compare iterators of different containers")); + } + + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + return (m_it.object_iterator == other.m_it.object_iterator); + + case value_t::array: + return (m_it.array_iterator == other.m_it.array_iterator); + + default: + return (m_it.primitive_iterator == other.m_it.primitive_iterator); + } + } + + /*! + @brief comparison: not equal + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + bool operator!=(const iter_impl& other) const + { + return not operator==(other); + } + + /*! + @brief comparison: smaller + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + bool operator<(const iter_impl& other) const + { + // if objects are not the same, the comparison is undefined + if (JSON_UNLIKELY(m_object != other.m_object)) + { + JSON_THROW(invalid_iterator::create(212, "cannot compare iterators of different containers")); + } + + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + JSON_THROW(invalid_iterator::create(213, "cannot compare order of object iterators")); + + case value_t::array: + return (m_it.array_iterator < other.m_it.array_iterator); + + default: + return (m_it.primitive_iterator < other.m_it.primitive_iterator); + } + } + + /*! + @brief comparison: less than or equal + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + bool operator<=(const iter_impl& other) const + { + return not other.operator < (*this); + } + + /*! + @brief comparison: greater than + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + bool operator>(const iter_impl& other) const + { + return not operator<=(other); + } + + /*! + @brief comparison: greater than or equal + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + bool operator>=(const iter_impl& other) const + { + return not operator<(other); + } + + /*! + @brief add to iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl& operator+=(difference_type i) + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + JSON_THROW(invalid_iterator::create(209, "cannot use offsets with object iterators")); + + case value_t::array: + { + std::advance(m_it.array_iterator, i); + break; + } + + default: + { + m_it.primitive_iterator += i; + break; + } + } + + return *this; + } + + /*! + @brief subtract from iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl& operator-=(difference_type i) + { + return operator+=(-i); + } + + /*! + @brief add to iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl operator+(difference_type i) const + { + auto result = *this; + result += i; + return result; + } + + /*! + @brief addition of distance and iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + friend iter_impl operator+(difference_type i, const iter_impl& it) + { + auto result = it; + result += i; + return result; + } + + /*! + @brief subtract from iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + iter_impl operator-(difference_type i) const + { + auto result = *this; + result -= i; + return result; + } + + /*! + @brief return difference + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + difference_type operator-(const iter_impl& other) const + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + JSON_THROW(invalid_iterator::create(209, "cannot use offsets with object iterators")); + + case value_t::array: + return m_it.array_iterator - other.m_it.array_iterator; + + default: + return m_it.primitive_iterator - other.m_it.primitive_iterator; + } + } + + /*! + @brief access to successor + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + reference operator[](difference_type n) const + { + assert(m_object != nullptr); + + switch (m_object->m_type) + { + case value_t::object: + JSON_THROW(invalid_iterator::create(208, "cannot use operator[] for object iterators")); + + case value_t::array: + return *std::next(m_it.array_iterator, n); + + case value_t::null: + JSON_THROW(invalid_iterator::create(214, "cannot get value")); + + default: + { + if (JSON_LIKELY(m_it.primitive_iterator.get_value() == -n)) + { + return *m_object; + } + + JSON_THROW(invalid_iterator::create(214, "cannot get value")); + } + } + } + + /*! + @brief return the key of an object iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + const typename object_t::key_type& key() const + { + assert(m_object != nullptr); + + if (JSON_LIKELY(m_object->is_object())) + { + return m_it.object_iterator->first; + } + + JSON_THROW(invalid_iterator::create(207, "cannot use key() for non-object iterators")); + } + + /*! + @brief return the value of an iterator + @pre The iterator is initialized; i.e. `m_object != nullptr`. + */ + reference value() const + { + return operator*(); + } + + private: + /// associated JSON instance + pointer m_object = nullptr; + /// the actual iterator of the associated instance + internal_iterator<typename std::remove_const<BasicJsonType>::type> m_it; +}; +} // namespace detail +} // namespace nlohmann +// #include <nlohmann/detail/iterators/iteration_proxy.hpp> + +// #include <nlohmann/detail/iterators/json_reverse_iterator.hpp> + + +#include <cstddef> // ptrdiff_t +#include <iterator> // reverse_iterator +#include <utility> // declval + +namespace nlohmann +{ +namespace detail +{ +////////////////////// +// reverse_iterator // +////////////////////// + +/*! +@brief a template for a reverse iterator class + +@tparam Base the base iterator type to reverse. Valid types are @ref +iterator (to create @ref reverse_iterator) and @ref const_iterator (to +create @ref const_reverse_iterator). + +@requirement The class satisfies the following concept requirements: +- +[BidirectionalIterator](https://en.cppreference.com/w/cpp/named_req/BidirectionalIterator): + The iterator that can be moved can be moved in both directions (i.e. + incremented and decremented). +- [OutputIterator](https://en.cppreference.com/w/cpp/named_req/OutputIterator): + It is possible to write to the pointed-to element (only if @a Base is + @ref iterator). + +@since version 1.0.0 +*/ +template<typename Base> +class json_reverse_iterator : public std::reverse_iterator<Base> +{ + public: + using difference_type = std::ptrdiff_t; + /// shortcut to the reverse iterator adapter + using base_iterator = std::reverse_iterator<Base>; + /// the reference type for the pointed-to element + using reference = typename Base::reference; + + /// create reverse iterator from iterator + explicit json_reverse_iterator(const typename base_iterator::iterator_type& it) noexcept + : base_iterator(it) {} + + /// create reverse iterator from base class + explicit json_reverse_iterator(const base_iterator& it) noexcept : base_iterator(it) {} + + /// post-increment (it++) + json_reverse_iterator const operator++(int) + { + return static_cast<json_reverse_iterator>(base_iterator::operator++(1)); + } + + /// pre-increment (++it) + json_reverse_iterator& operator++() + { + return static_cast<json_reverse_iterator&>(base_iterator::operator++()); + } + + /// post-decrement (it--) + json_reverse_iterator const operator--(int) + { + return static_cast<json_reverse_iterator>(base_iterator::operator--(1)); + } + + /// pre-decrement (--it) + json_reverse_iterator& operator--() + { + return static_cast<json_reverse_iterator&>(base_iterator::operator--()); + } + + /// add to iterator + json_reverse_iterator& operator+=(difference_type i) + { + return static_cast<json_reverse_iterator&>(base_iterator::operator+=(i)); + } + + /// add to iterator + json_reverse_iterator operator+(difference_type i) const + { + return static_cast<json_reverse_iterator>(base_iterator::operator+(i)); + } + + /// subtract from iterator + json_reverse_iterator operator-(difference_type i) const + { + return static_cast<json_reverse_iterator>(base_iterator::operator-(i)); + } + + /// return difference + difference_type operator-(const json_reverse_iterator& other) const + { + return base_iterator(*this) - base_iterator(other); + } + + /// access to successor + reference operator[](difference_type n) const + { + return *(this->operator+(n)); + } + + /// return the key of an object iterator + auto key() const -> decltype(std::declval<Base>().key()) + { + auto it = --this->base(); + return it.key(); + } + + /// return the value of an iterator + reference value() const + { + auto it = --this->base(); + return it.operator * (); + } +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/output/output_adapters.hpp> + + +#include <algorithm> // copy +#include <cstddef> // size_t +#include <ios> // streamsize +#include <iterator> // back_inserter +#include <memory> // shared_ptr, make_shared +#include <ostream> // basic_ostream +#include <string> // basic_string +#include <vector> // vector + +namespace nlohmann +{ +namespace detail +{ +/// abstract output adapter interface +template<typename CharType> struct output_adapter_protocol +{ + virtual void write_character(CharType c) = 0; + virtual void write_characters(const CharType* s, std::size_t length) = 0; + virtual ~output_adapter_protocol() = default; +}; + +/// a type to simplify interfaces +template<typename CharType> +using output_adapter_t = std::shared_ptr<output_adapter_protocol<CharType>>; + +/// output adapter for byte vectors +template<typename CharType> +class output_vector_adapter : public output_adapter_protocol<CharType> +{ + public: + explicit output_vector_adapter(std::vector<CharType>& vec) noexcept + : v(vec) + {} + + void write_character(CharType c) override + { + v.push_back(c); + } + + void write_characters(const CharType* s, std::size_t length) override + { + std::copy(s, s + length, std::back_inserter(v)); + } + + private: + std::vector<CharType>& v; +}; + +/// output adapter for output streams +template<typename CharType> +class output_stream_adapter : public output_adapter_protocol<CharType> +{ + public: + explicit output_stream_adapter(std::basic_ostream<CharType>& s) noexcept + : stream(s) + {} + + void write_character(CharType c) override + { + stream.put(c); + } + + void write_characters(const CharType* s, std::size_t length) override + { + stream.write(s, static_cast<std::streamsize>(length)); + } + + private: + std::basic_ostream<CharType>& stream; +}; + +/// output adapter for basic_string +template<typename CharType, typename StringType = std::basic_string<CharType>> +class output_string_adapter : public output_adapter_protocol<CharType> +{ + public: + explicit output_string_adapter(StringType& s) noexcept + : str(s) + {} + + void write_character(CharType c) override + { + str.push_back(c); + } + + void write_characters(const CharType* s, std::size_t length) override + { + str.append(s, length); + } + + private: + StringType& str; +}; + +template<typename CharType, typename StringType = std::basic_string<CharType>> +class output_adapter +{ + public: + output_adapter(std::vector<CharType>& vec) + : oa(std::make_shared<output_vector_adapter<CharType>>(vec)) {} + + output_adapter(std::basic_ostream<CharType>& s) + : oa(std::make_shared<output_stream_adapter<CharType>>(s)) {} + + output_adapter(StringType& s) + : oa(std::make_shared<output_string_adapter<CharType, StringType>>(s)) {} + + operator output_adapter_t<CharType>() + { + return oa; + } + + private: + output_adapter_t<CharType> oa = nullptr; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/input/binary_reader.hpp> + + +#include <algorithm> // generate_n +#include <array> // array +#include <cassert> // assert +#include <cmath> // ldexp +#include <cstddef> // size_t +#include <cstdint> // uint8_t, uint16_t, uint32_t, uint64_t +#include <cstdio> // snprintf +#include <cstring> // memcpy +#include <iterator> // back_inserter +#include <limits> // numeric_limits +#include <string> // char_traits, string +#include <utility> // make_pair, move + +// #include <nlohmann/detail/input/input_adapters.hpp> + +// #include <nlohmann/detail/input/json_sax.hpp> + +// #include <nlohmann/detail/exceptions.hpp> + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/meta/is_sax.hpp> + +// #include <nlohmann/detail/value_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +/////////////////// +// binary reader // +/////////////////// + +/*! +@brief deserialization of CBOR, MessagePack, and UBJSON values +*/ +template<typename BasicJsonType, typename SAX = json_sax_dom_parser<BasicJsonType>> +class binary_reader +{ + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using number_float_t = typename BasicJsonType::number_float_t; + using string_t = typename BasicJsonType::string_t; + using json_sax_t = SAX; + + public: + /*! + @brief create a binary reader + + @param[in] adapter input adapter to read from + */ + explicit binary_reader(input_adapter_t adapter) : ia(std::move(adapter)) + { + (void)detail::is_sax_static_asserts<SAX, BasicJsonType> {}; + assert(ia); + } + + /*! + @param[in] format the binary format to parse + @param[in] sax_ a SAX event processor + @param[in] strict whether to expect the input to be consumed completed + + @return + */ + bool sax_parse(const input_format_t format, + json_sax_t* sax_, + const bool strict = true) + { + sax = sax_; + bool result = false; + + switch (format) + { + case input_format_t::bson: + result = parse_bson_internal(); + break; + + case input_format_t::cbor: + result = parse_cbor_internal(); + break; + + case input_format_t::msgpack: + result = parse_msgpack_internal(); + break; + + case input_format_t::ubjson: + result = parse_ubjson_internal(); + break; + + // LCOV_EXCL_START + default: + assert(false); + // LCOV_EXCL_STOP + } + + // strict mode: next byte must be EOF + if (result and strict) + { + if (format == input_format_t::ubjson) + { + get_ignore_noop(); + } + else + { + get(); + } + + if (JSON_UNLIKELY(current != std::char_traits<char>::eof())) + { + return sax->parse_error(chars_read, get_token_string(), + parse_error::create(110, chars_read, exception_message(format, "expected end of input; last byte: 0x" + get_token_string(), "value"))); + } + } + + return result; + } + + /*! + @brief determine system byte order + + @return true if and only if system's byte order is little endian + + @note from http://stackoverflow.com/a/1001328/266378 + */ + static constexpr bool little_endianess(int num = 1) noexcept + { + return (*reinterpret_cast<char*>(&num) == 1); + } + + private: + ////////// + // BSON // + ////////// + + /*! + @brief Reads in a BSON-object and passes it to the SAX-parser. + @return whether a valid BSON-value was passed to the SAX parser + */ + bool parse_bson_internal() + { + std::int32_t document_size; + get_number<std::int32_t, true>(input_format_t::bson, document_size); + + if (JSON_UNLIKELY(not sax->start_object(std::size_t(-1)))) + { + return false; + } + + if (JSON_UNLIKELY(not parse_bson_element_list(/*is_array*/false))) + { + return false; + } + + return sax->end_object(); + } + + /*! + @brief Parses a C-style string from the BSON input. + @param[in, out] result A reference to the string variable where the read + string is to be stored. + @return `true` if the \x00-byte indicating the end of the string was + encountered before the EOF; false` indicates an unexpected EOF. + */ + bool get_bson_cstr(string_t& result) + { + auto out = std::back_inserter(result); + while (true) + { + get(); + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::bson, "cstring"))) + { + return false; + } + if (current == 0x00) + { + return true; + } + *out++ = static_cast<char>(current); + } + + return true; + } + + /*! + @brief Parses a zero-terminated string of length @a len from the BSON + input. + @param[in] len The length (including the zero-byte at the end) of the + string to be read. + @param[in, out] result A reference to the string variable where the read + string is to be stored. + @tparam NumberType The type of the length @a len + @pre len >= 1 + @return `true` if the string was successfully parsed + */ + template<typename NumberType> + bool get_bson_string(const NumberType len, string_t& result) + { + if (JSON_UNLIKELY(len < 1)) + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(112, chars_read, exception_message(input_format_t::bson, "string length must be at least 1, is " + std::to_string(len), "string"))); + } + + return get_string(input_format_t::bson, len - static_cast<NumberType>(1), result) and get() != std::char_traits<char>::eof(); + } + + /*! + @brief Read a BSON document element of the given @a element_type. + @param[in] element_type The BSON element type, c.f. http://bsonspec.org/spec.html + @param[in] element_type_parse_position The position in the input stream, + where the `element_type` was read. + @warning Not all BSON element types are supported yet. An unsupported + @a element_type will give rise to a parse_error.114: + Unsupported BSON record type 0x... + @return whether a valid BSON-object/array was passed to the SAX parser + */ + bool parse_bson_element_internal(const int element_type, + const std::size_t element_type_parse_position) + { + switch (element_type) + { + case 0x01: // double + { + double number; + return get_number<double, true>(input_format_t::bson, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + case 0x02: // string + { + std::int32_t len; + string_t value; + return get_number<std::int32_t, true>(input_format_t::bson, len) and get_bson_string(len, value) and sax->string(value); + } + + case 0x03: // object + { + return parse_bson_internal(); + } + + case 0x04: // array + { + return parse_bson_array(); + } + + case 0x08: // boolean + { + return sax->boolean(get() != 0); + } + + case 0x0A: // null + { + return sax->null(); + } + + case 0x10: // int32 + { + std::int32_t value; + return get_number<std::int32_t, true>(input_format_t::bson, value) and sax->number_integer(value); + } + + case 0x12: // int64 + { + std::int64_t value; + return get_number<std::int64_t, true>(input_format_t::bson, value) and sax->number_integer(value); + } + + default: // anything else not supported (yet) + { + char cr[3]; + (std::snprintf)(cr, sizeof(cr), "%.2hhX", static_cast<unsigned char>(element_type)); + return sax->parse_error(element_type_parse_position, std::string(cr), parse_error::create(114, element_type_parse_position, "Unsupported BSON record type 0x" + std::string(cr))); + } + } + } + + /*! + @brief Read a BSON element list (as specified in the BSON-spec) + + The same binary layout is used for objects and arrays, hence it must be + indicated with the argument @a is_array which one is expected + (true --> array, false --> object). + + @param[in] is_array Determines if the element list being read is to be + treated as an object (@a is_array == false), or as an + array (@a is_array == true). + @return whether a valid BSON-object/array was passed to the SAX parser + */ + bool parse_bson_element_list(const bool is_array) + { + string_t key; + while (int element_type = get()) + { + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::bson, "element list"))) + { + return false; + } + + const std::size_t element_type_parse_position = chars_read; + if (JSON_UNLIKELY(not get_bson_cstr(key))) + { + return false; + } + + if (not is_array) + { + if (not sax->key(key)) + { + return false; + } + } + + if (JSON_UNLIKELY(not parse_bson_element_internal(element_type, element_type_parse_position))) + { + return false; + } + + // get_bson_cstr only appends + key.clear(); + } + + return true; + } + + /*! + @brief Reads an array from the BSON input and passes it to the SAX-parser. + @return whether a valid BSON-array was passed to the SAX parser + */ + bool parse_bson_array() + { + std::int32_t document_size; + get_number<std::int32_t, true>(input_format_t::bson, document_size); + + if (JSON_UNLIKELY(not sax->start_array(std::size_t(-1)))) + { + return false; + } + + if (JSON_UNLIKELY(not parse_bson_element_list(/*is_array*/true))) + { + return false; + } + + return sax->end_array(); + } + + ////////// + // CBOR // + ////////// + + /*! + @param[in] get_char whether a new character should be retrieved from the + input (true, default) or whether the last read + character should be considered instead + + @return whether a valid CBOR value was passed to the SAX parser + */ + bool parse_cbor_internal(const bool get_char = true) + { + switch (get_char ? get() : current) + { + // EOF + case std::char_traits<char>::eof(): + return unexpect_eof(input_format_t::cbor, "value"); + + // Integer 0x00..0x17 (0..23) + case 0x00: + case 0x01: + case 0x02: + case 0x03: + case 0x04: + case 0x05: + case 0x06: + case 0x07: + case 0x08: + case 0x09: + case 0x0A: + case 0x0B: + case 0x0C: + case 0x0D: + case 0x0E: + case 0x0F: + case 0x10: + case 0x11: + case 0x12: + case 0x13: + case 0x14: + case 0x15: + case 0x16: + case 0x17: + return sax->number_unsigned(static_cast<number_unsigned_t>(current)); + + case 0x18: // Unsigned integer (one-byte uint8_t follows) + { + uint8_t number; + return get_number(input_format_t::cbor, number) and sax->number_unsigned(number); + } + + case 0x19: // Unsigned integer (two-byte uint16_t follows) + { + uint16_t number; + return get_number(input_format_t::cbor, number) and sax->number_unsigned(number); + } + + case 0x1A: // Unsigned integer (four-byte uint32_t follows) + { + uint32_t number; + return get_number(input_format_t::cbor, number) and sax->number_unsigned(number); + } + + case 0x1B: // Unsigned integer (eight-byte uint64_t follows) + { + uint64_t number; + return get_number(input_format_t::cbor, number) and sax->number_unsigned(number); + } + + // Negative integer -1-0x00..-1-0x17 (-1..-24) + case 0x20: + case 0x21: + case 0x22: + case 0x23: + case 0x24: + case 0x25: + case 0x26: + case 0x27: + case 0x28: + case 0x29: + case 0x2A: + case 0x2B: + case 0x2C: + case 0x2D: + case 0x2E: + case 0x2F: + case 0x30: + case 0x31: + case 0x32: + case 0x33: + case 0x34: + case 0x35: + case 0x36: + case 0x37: + return sax->number_integer(static_cast<int8_t>(0x20 - 1 - current)); + + case 0x38: // Negative integer (one-byte uint8_t follows) + { + uint8_t number; + return get_number(input_format_t::cbor, number) and sax->number_integer(static_cast<number_integer_t>(-1) - number); + } + + case 0x39: // Negative integer -1-n (two-byte uint16_t follows) + { + uint16_t number; + return get_number(input_format_t::cbor, number) and sax->number_integer(static_cast<number_integer_t>(-1) - number); + } + + case 0x3A: // Negative integer -1-n (four-byte uint32_t follows) + { + uint32_t number; + return get_number(input_format_t::cbor, number) and sax->number_integer(static_cast<number_integer_t>(-1) - number); + } + + case 0x3B: // Negative integer -1-n (eight-byte uint64_t follows) + { + uint64_t number; + return get_number(input_format_t::cbor, number) and sax->number_integer(static_cast<number_integer_t>(-1) + - static_cast<number_integer_t>(number)); + } + + // UTF-8 string (0x00..0x17 bytes follow) + case 0x60: + case 0x61: + case 0x62: + case 0x63: + case 0x64: + case 0x65: + case 0x66: + case 0x67: + case 0x68: + case 0x69: + case 0x6A: + case 0x6B: + case 0x6C: + case 0x6D: + case 0x6E: + case 0x6F: + case 0x70: + case 0x71: + case 0x72: + case 0x73: + case 0x74: + case 0x75: + case 0x76: + case 0x77: + case 0x78: // UTF-8 string (one-byte uint8_t for n follows) + case 0x79: // UTF-8 string (two-byte uint16_t for n follow) + case 0x7A: // UTF-8 string (four-byte uint32_t for n follow) + case 0x7B: // UTF-8 string (eight-byte uint64_t for n follow) + case 0x7F: // UTF-8 string (indefinite length) + { + string_t s; + return get_cbor_string(s) and sax->string(s); + } + + // array (0x00..0x17 data items follow) + case 0x80: + case 0x81: + case 0x82: + case 0x83: + case 0x84: + case 0x85: + case 0x86: + case 0x87: + case 0x88: + case 0x89: + case 0x8A: + case 0x8B: + case 0x8C: + case 0x8D: + case 0x8E: + case 0x8F: + case 0x90: + case 0x91: + case 0x92: + case 0x93: + case 0x94: + case 0x95: + case 0x96: + case 0x97: + return get_cbor_array(static_cast<std::size_t>(current & 0x1F)); + + case 0x98: // array (one-byte uint8_t for n follows) + { + uint8_t len; + return get_number(input_format_t::cbor, len) and get_cbor_array(static_cast<std::size_t>(len)); + } + + case 0x99: // array (two-byte uint16_t for n follow) + { + uint16_t len; + return get_number(input_format_t::cbor, len) and get_cbor_array(static_cast<std::size_t>(len)); + } + + case 0x9A: // array (four-byte uint32_t for n follow) + { + uint32_t len; + return get_number(input_format_t::cbor, len) and get_cbor_array(static_cast<std::size_t>(len)); + } + + case 0x9B: // array (eight-byte uint64_t for n follow) + { + uint64_t len; + return get_number(input_format_t::cbor, len) and get_cbor_array(static_cast<std::size_t>(len)); + } + + case 0x9F: // array (indefinite length) + return get_cbor_array(std::size_t(-1)); + + // map (0x00..0x17 pairs of data items follow) + case 0xA0: + case 0xA1: + case 0xA2: + case 0xA3: + case 0xA4: + case 0xA5: + case 0xA6: + case 0xA7: + case 0xA8: + case 0xA9: + case 0xAA: + case 0xAB: + case 0xAC: + case 0xAD: + case 0xAE: + case 0xAF: + case 0xB0: + case 0xB1: + case 0xB2: + case 0xB3: + case 0xB4: + case 0xB5: + case 0xB6: + case 0xB7: + return get_cbor_object(static_cast<std::size_t>(current & 0x1F)); + + case 0xB8: // map (one-byte uint8_t for n follows) + { + uint8_t len; + return get_number(input_format_t::cbor, len) and get_cbor_object(static_cast<std::size_t>(len)); + } + + case 0xB9: // map (two-byte uint16_t for n follow) + { + uint16_t len; + return get_number(input_format_t::cbor, len) and get_cbor_object(static_cast<std::size_t>(len)); + } + + case 0xBA: // map (four-byte uint32_t for n follow) + { + uint32_t len; + return get_number(input_format_t::cbor, len) and get_cbor_object(static_cast<std::size_t>(len)); + } + + case 0xBB: // map (eight-byte uint64_t for n follow) + { + uint64_t len; + return get_number(input_format_t::cbor, len) and get_cbor_object(static_cast<std::size_t>(len)); + } + + case 0xBF: // map (indefinite length) + return get_cbor_object(std::size_t(-1)); + + case 0xF4: // false + return sax->boolean(false); + + case 0xF5: // true + return sax->boolean(true); + + case 0xF6: // null + return sax->null(); + + case 0xF9: // Half-Precision Float (two-byte IEEE 754) + { + const int byte1_raw = get(); + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::cbor, "number"))) + { + return false; + } + const int byte2_raw = get(); + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::cbor, "number"))) + { + return false; + } + + const auto byte1 = static_cast<unsigned char>(byte1_raw); + const auto byte2 = static_cast<unsigned char>(byte2_raw); + + // code from RFC 7049, Appendix D, Figure 3: + // As half-precision floating-point numbers were only added + // to IEEE 754 in 2008, today's programming platforms often + // still only have limited support for them. It is very + // easy to include at least decoding support for them even + // without such support. An example of a small decoder for + // half-precision floating-point numbers in the C language + // is shown in Fig. 3. + const int half = (byte1 << 8) + byte2; + const double val = [&half] + { + const int exp = (half >> 10) & 0x1F; + const int mant = half & 0x3FF; + assert(0 <= exp and exp <= 32); + assert(0 <= mant and mant <= 1024); + switch (exp) + { + case 0: + return std::ldexp(mant, -24); + case 31: + return (mant == 0) + ? std::numeric_limits<double>::infinity() + : std::numeric_limits<double>::quiet_NaN(); + default: + return std::ldexp(mant + 1024, exp - 25); + } + }(); + return sax->number_float((half & 0x8000) != 0 + ? static_cast<number_float_t>(-val) + : static_cast<number_float_t>(val), ""); + } + + case 0xFA: // Single-Precision Float (four-byte IEEE 754) + { + float number; + return get_number(input_format_t::cbor, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + case 0xFB: // Double-Precision Float (eight-byte IEEE 754) + { + double number; + return get_number(input_format_t::cbor, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + default: // anything else (0xFF is handled inside the other types) + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(112, chars_read, exception_message(input_format_t::cbor, "invalid byte: 0x" + last_token, "value"))); + } + } + } + + /*! + @brief reads a CBOR string + + This function first reads starting bytes to determine the expected + string length and then copies this number of bytes into a string. + Additionally, CBOR's strings with indefinite lengths are supported. + + @param[out] result created string + + @return whether string creation completed + */ + bool get_cbor_string(string_t& result) + { + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::cbor, "string"))) + { + return false; + } + + switch (current) + { + // UTF-8 string (0x00..0x17 bytes follow) + case 0x60: + case 0x61: + case 0x62: + case 0x63: + case 0x64: + case 0x65: + case 0x66: + case 0x67: + case 0x68: + case 0x69: + case 0x6A: + case 0x6B: + case 0x6C: + case 0x6D: + case 0x6E: + case 0x6F: + case 0x70: + case 0x71: + case 0x72: + case 0x73: + case 0x74: + case 0x75: + case 0x76: + case 0x77: + { + return get_string(input_format_t::cbor, current & 0x1F, result); + } + + case 0x78: // UTF-8 string (one-byte uint8_t for n follows) + { + uint8_t len; + return get_number(input_format_t::cbor, len) and get_string(input_format_t::cbor, len, result); + } + + case 0x79: // UTF-8 string (two-byte uint16_t for n follow) + { + uint16_t len; + return get_number(input_format_t::cbor, len) and get_string(input_format_t::cbor, len, result); + } + + case 0x7A: // UTF-8 string (four-byte uint32_t for n follow) + { + uint32_t len; + return get_number(input_format_t::cbor, len) and get_string(input_format_t::cbor, len, result); + } + + case 0x7B: // UTF-8 string (eight-byte uint64_t for n follow) + { + uint64_t len; + return get_number(input_format_t::cbor, len) and get_string(input_format_t::cbor, len, result); + } + + case 0x7F: // UTF-8 string (indefinite length) + { + while (get() != 0xFF) + { + string_t chunk; + if (not get_cbor_string(chunk)) + { + return false; + } + result.append(chunk); + } + return true; + } + + default: + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(113, chars_read, exception_message(input_format_t::cbor, "expected length specification (0x60-0x7B) or indefinite string type (0x7F); last byte: 0x" + last_token, "string"))); + } + } + } + + /*! + @param[in] len the length of the array or std::size_t(-1) for an + array of indefinite size + @return whether array creation completed + */ + bool get_cbor_array(const std::size_t len) + { + if (JSON_UNLIKELY(not sax->start_array(len))) + { + return false; + } + + if (len != std::size_t(-1)) + { + for (std::size_t i = 0; i < len; ++i) + { + if (JSON_UNLIKELY(not parse_cbor_internal())) + { + return false; + } + } + } + else + { + while (get() != 0xFF) + { + if (JSON_UNLIKELY(not parse_cbor_internal(false))) + { + return false; + } + } + } + + return sax->end_array(); + } + + /*! + @param[in] len the length of the object or std::size_t(-1) for an + object of indefinite size + @return whether object creation completed + */ + bool get_cbor_object(const std::size_t len) + { + if (not JSON_UNLIKELY(sax->start_object(len))) + { + return false; + } + + string_t key; + if (len != std::size_t(-1)) + { + for (std::size_t i = 0; i < len; ++i) + { + get(); + if (JSON_UNLIKELY(not get_cbor_string(key) or not sax->key(key))) + { + return false; + } + + if (JSON_UNLIKELY(not parse_cbor_internal())) + { + return false; + } + key.clear(); + } + } + else + { + while (get() != 0xFF) + { + if (JSON_UNLIKELY(not get_cbor_string(key) or not sax->key(key))) + { + return false; + } + + if (JSON_UNLIKELY(not parse_cbor_internal())) + { + return false; + } + key.clear(); + } + } + + return sax->end_object(); + } + + ///////////// + // MsgPack // + ///////////// + + /*! + @return whether a valid MessagePack value was passed to the SAX parser + */ + bool parse_msgpack_internal() + { + switch (get()) + { + // EOF + case std::char_traits<char>::eof(): + return unexpect_eof(input_format_t::msgpack, "value"); + + // positive fixint + case 0x00: + case 0x01: + case 0x02: + case 0x03: + case 0x04: + case 0x05: + case 0x06: + case 0x07: + case 0x08: + case 0x09: + case 0x0A: + case 0x0B: + case 0x0C: + case 0x0D: + case 0x0E: + case 0x0F: + case 0x10: + case 0x11: + case 0x12: + case 0x13: + case 0x14: + case 0x15: + case 0x16: + case 0x17: + case 0x18: + case 0x19: + case 0x1A: + case 0x1B: + case 0x1C: + case 0x1D: + case 0x1E: + case 0x1F: + case 0x20: + case 0x21: + case 0x22: + case 0x23: + case 0x24: + case 0x25: + case 0x26: + case 0x27: + case 0x28: + case 0x29: + case 0x2A: + case 0x2B: + case 0x2C: + case 0x2D: + case 0x2E: + case 0x2F: + case 0x30: + case 0x31: + case 0x32: + case 0x33: + case 0x34: + case 0x35: + case 0x36: + case 0x37: + case 0x38: + case 0x39: + case 0x3A: + case 0x3B: + case 0x3C: + case 0x3D: + case 0x3E: + case 0x3F: + case 0x40: + case 0x41: + case 0x42: + case 0x43: + case 0x44: + case 0x45: + case 0x46: + case 0x47: + case 0x48: + case 0x49: + case 0x4A: + case 0x4B: + case 0x4C: + case 0x4D: + case 0x4E: + case 0x4F: + case 0x50: + case 0x51: + case 0x52: + case 0x53: + case 0x54: + case 0x55: + case 0x56: + case 0x57: + case 0x58: + case 0x59: + case 0x5A: + case 0x5B: + case 0x5C: + case 0x5D: + case 0x5E: + case 0x5F: + case 0x60: + case 0x61: + case 0x62: + case 0x63: + case 0x64: + case 0x65: + case 0x66: + case 0x67: + case 0x68: + case 0x69: + case 0x6A: + case 0x6B: + case 0x6C: + case 0x6D: + case 0x6E: + case 0x6F: + case 0x70: + case 0x71: + case 0x72: + case 0x73: + case 0x74: + case 0x75: + case 0x76: + case 0x77: + case 0x78: + case 0x79: + case 0x7A: + case 0x7B: + case 0x7C: + case 0x7D: + case 0x7E: + case 0x7F: + return sax->number_unsigned(static_cast<number_unsigned_t>(current)); + + // fixmap + case 0x80: + case 0x81: + case 0x82: + case 0x83: + case 0x84: + case 0x85: + case 0x86: + case 0x87: + case 0x88: + case 0x89: + case 0x8A: + case 0x8B: + case 0x8C: + case 0x8D: + case 0x8E: + case 0x8F: + return get_msgpack_object(static_cast<std::size_t>(current & 0x0F)); + + // fixarray + case 0x90: + case 0x91: + case 0x92: + case 0x93: + case 0x94: + case 0x95: + case 0x96: + case 0x97: + case 0x98: + case 0x99: + case 0x9A: + case 0x9B: + case 0x9C: + case 0x9D: + case 0x9E: + case 0x9F: + return get_msgpack_array(static_cast<std::size_t>(current & 0x0F)); + + // fixstr + case 0xA0: + case 0xA1: + case 0xA2: + case 0xA3: + case 0xA4: + case 0xA5: + case 0xA6: + case 0xA7: + case 0xA8: + case 0xA9: + case 0xAA: + case 0xAB: + case 0xAC: + case 0xAD: + case 0xAE: + case 0xAF: + case 0xB0: + case 0xB1: + case 0xB2: + case 0xB3: + case 0xB4: + case 0xB5: + case 0xB6: + case 0xB7: + case 0xB8: + case 0xB9: + case 0xBA: + case 0xBB: + case 0xBC: + case 0xBD: + case 0xBE: + case 0xBF: + { + string_t s; + return get_msgpack_string(s) and sax->string(s); + } + + case 0xC0: // nil + return sax->null(); + + case 0xC2: // false + return sax->boolean(false); + + case 0xC3: // true + return sax->boolean(true); + + case 0xCA: // float 32 + { + float number; + return get_number(input_format_t::msgpack, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + case 0xCB: // float 64 + { + double number; + return get_number(input_format_t::msgpack, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + case 0xCC: // uint 8 + { + uint8_t number; + return get_number(input_format_t::msgpack, number) and sax->number_unsigned(number); + } + + case 0xCD: // uint 16 + { + uint16_t number; + return get_number(input_format_t::msgpack, number) and sax->number_unsigned(number); + } + + case 0xCE: // uint 32 + { + uint32_t number; + return get_number(input_format_t::msgpack, number) and sax->number_unsigned(number); + } + + case 0xCF: // uint 64 + { + uint64_t number; + return get_number(input_format_t::msgpack, number) and sax->number_unsigned(number); + } + + case 0xD0: // int 8 + { + int8_t number; + return get_number(input_format_t::msgpack, number) and sax->number_integer(number); + } + + case 0xD1: // int 16 + { + int16_t number; + return get_number(input_format_t::msgpack, number) and sax->number_integer(number); + } + + case 0xD2: // int 32 + { + int32_t number; + return get_number(input_format_t::msgpack, number) and sax->number_integer(number); + } + + case 0xD3: // int 64 + { + int64_t number; + return get_number(input_format_t::msgpack, number) and sax->number_integer(number); + } + + case 0xD9: // str 8 + case 0xDA: // str 16 + case 0xDB: // str 32 + { + string_t s; + return get_msgpack_string(s) and sax->string(s); + } + + case 0xDC: // array 16 + { + uint16_t len; + return get_number(input_format_t::msgpack, len) and get_msgpack_array(static_cast<std::size_t>(len)); + } + + case 0xDD: // array 32 + { + uint32_t len; + return get_number(input_format_t::msgpack, len) and get_msgpack_array(static_cast<std::size_t>(len)); + } + + case 0xDE: // map 16 + { + uint16_t len; + return get_number(input_format_t::msgpack, len) and get_msgpack_object(static_cast<std::size_t>(len)); + } + + case 0xDF: // map 32 + { + uint32_t len; + return get_number(input_format_t::msgpack, len) and get_msgpack_object(static_cast<std::size_t>(len)); + } + + // negative fixint + case 0xE0: + case 0xE1: + case 0xE2: + case 0xE3: + case 0xE4: + case 0xE5: + case 0xE6: + case 0xE7: + case 0xE8: + case 0xE9: + case 0xEA: + case 0xEB: + case 0xEC: + case 0xED: + case 0xEE: + case 0xEF: + case 0xF0: + case 0xF1: + case 0xF2: + case 0xF3: + case 0xF4: + case 0xF5: + case 0xF6: + case 0xF7: + case 0xF8: + case 0xF9: + case 0xFA: + case 0xFB: + case 0xFC: + case 0xFD: + case 0xFE: + case 0xFF: + return sax->number_integer(static_cast<int8_t>(current)); + + default: // anything else + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(112, chars_read, exception_message(input_format_t::msgpack, "invalid byte: 0x" + last_token, "value"))); + } + } + } + + /*! + @brief reads a MessagePack string + + This function first reads starting bytes to determine the expected + string length and then copies this number of bytes into a string. + + @param[out] result created string + + @return whether string creation completed + */ + bool get_msgpack_string(string_t& result) + { + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::msgpack, "string"))) + { + return false; + } + + switch (current) + { + // fixstr + case 0xA0: + case 0xA1: + case 0xA2: + case 0xA3: + case 0xA4: + case 0xA5: + case 0xA6: + case 0xA7: + case 0xA8: + case 0xA9: + case 0xAA: + case 0xAB: + case 0xAC: + case 0xAD: + case 0xAE: + case 0xAF: + case 0xB0: + case 0xB1: + case 0xB2: + case 0xB3: + case 0xB4: + case 0xB5: + case 0xB6: + case 0xB7: + case 0xB8: + case 0xB9: + case 0xBA: + case 0xBB: + case 0xBC: + case 0xBD: + case 0xBE: + case 0xBF: + { + return get_string(input_format_t::msgpack, current & 0x1F, result); + } + + case 0xD9: // str 8 + { + uint8_t len; + return get_number(input_format_t::msgpack, len) and get_string(input_format_t::msgpack, len, result); + } + + case 0xDA: // str 16 + { + uint16_t len; + return get_number(input_format_t::msgpack, len) and get_string(input_format_t::msgpack, len, result); + } + + case 0xDB: // str 32 + { + uint32_t len; + return get_number(input_format_t::msgpack, len) and get_string(input_format_t::msgpack, len, result); + } + + default: + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(113, chars_read, exception_message(input_format_t::msgpack, "expected length specification (0xA0-0xBF, 0xD9-0xDB); last byte: 0x" + last_token, "string"))); + } + } + } + + /*! + @param[in] len the length of the array + @return whether array creation completed + */ + bool get_msgpack_array(const std::size_t len) + { + if (JSON_UNLIKELY(not sax->start_array(len))) + { + return false; + } + + for (std::size_t i = 0; i < len; ++i) + { + if (JSON_UNLIKELY(not parse_msgpack_internal())) + { + return false; + } + } + + return sax->end_array(); + } + + /*! + @param[in] len the length of the object + @return whether object creation completed + */ + bool get_msgpack_object(const std::size_t len) + { + if (JSON_UNLIKELY(not sax->start_object(len))) + { + return false; + } + + string_t key; + for (std::size_t i = 0; i < len; ++i) + { + get(); + if (JSON_UNLIKELY(not get_msgpack_string(key) or not sax->key(key))) + { + return false; + } + + if (JSON_UNLIKELY(not parse_msgpack_internal())) + { + return false; + } + key.clear(); + } + + return sax->end_object(); + } + + //////////// + // UBJSON // + //////////// + + /*! + @param[in] get_char whether a new character should be retrieved from the + input (true, default) or whether the last read + character should be considered instead + + @return whether a valid UBJSON value was passed to the SAX parser + */ + bool parse_ubjson_internal(const bool get_char = true) + { + return get_ubjson_value(get_char ? get_ignore_noop() : current); + } + + /*! + @brief reads a UBJSON string + + This function is either called after reading the 'S' byte explicitly + indicating a string, or in case of an object key where the 'S' byte can be + left out. + + @param[out] result created string + @param[in] get_char whether a new character should be retrieved from the + input (true, default) or whether the last read + character should be considered instead + + @return whether string creation completed + */ + bool get_ubjson_string(string_t& result, const bool get_char = true) + { + if (get_char) + { + get(); // TODO: may we ignore N here? + } + + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::ubjson, "value"))) + { + return false; + } + + switch (current) + { + case 'U': + { + uint8_t len; + return get_number(input_format_t::ubjson, len) and get_string(input_format_t::ubjson, len, result); + } + + case 'i': + { + int8_t len; + return get_number(input_format_t::ubjson, len) and get_string(input_format_t::ubjson, len, result); + } + + case 'I': + { + int16_t len; + return get_number(input_format_t::ubjson, len) and get_string(input_format_t::ubjson, len, result); + } + + case 'l': + { + int32_t len; + return get_number(input_format_t::ubjson, len) and get_string(input_format_t::ubjson, len, result); + } + + case 'L': + { + int64_t len; + return get_number(input_format_t::ubjson, len) and get_string(input_format_t::ubjson, len, result); + } + + default: + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(113, chars_read, exception_message(input_format_t::ubjson, "expected length type specification (U, i, I, l, L); last byte: 0x" + last_token, "string"))); + } + } + + /*! + @param[out] result determined size + @return whether size determination completed + */ + bool get_ubjson_size_value(std::size_t& result) + { + switch (get_ignore_noop()) + { + case 'U': + { + uint8_t number; + if (JSON_UNLIKELY(not get_number(input_format_t::ubjson, number))) + { + return false; + } + result = static_cast<std::size_t>(number); + return true; + } + + case 'i': + { + int8_t number; + if (JSON_UNLIKELY(not get_number(input_format_t::ubjson, number))) + { + return false; + } + result = static_cast<std::size_t>(number); + return true; + } + + case 'I': + { + int16_t number; + if (JSON_UNLIKELY(not get_number(input_format_t::ubjson, number))) + { + return false; + } + result = static_cast<std::size_t>(number); + return true; + } + + case 'l': + { + int32_t number; + if (JSON_UNLIKELY(not get_number(input_format_t::ubjson, number))) + { + return false; + } + result = static_cast<std::size_t>(number); + return true; + } + + case 'L': + { + int64_t number; + if (JSON_UNLIKELY(not get_number(input_format_t::ubjson, number))) + { + return false; + } + result = static_cast<std::size_t>(number); + return true; + } + + default: + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(113, chars_read, exception_message(input_format_t::ubjson, "expected length type specification (U, i, I, l, L) after '#'; last byte: 0x" + last_token, "size"))); + } + } + } + + /*! + @brief determine the type and size for a container + + In the optimized UBJSON format, a type and a size can be provided to allow + for a more compact representation. + + @param[out] result pair of the size and the type + + @return whether pair creation completed + */ + bool get_ubjson_size_type(std::pair<std::size_t, int>& result) + { + result.first = string_t::npos; // size + result.second = 0; // type + + get_ignore_noop(); + + if (current == '$') + { + result.second = get(); // must not ignore 'N', because 'N' maybe the type + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::ubjson, "type"))) + { + return false; + } + + get_ignore_noop(); + if (JSON_UNLIKELY(current != '#')) + { + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::ubjson, "value"))) + { + return false; + } + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(112, chars_read, exception_message(input_format_t::ubjson, "expected '#' after type information; last byte: 0x" + last_token, "size"))); + } + + return get_ubjson_size_value(result.first); + } + else if (current == '#') + { + return get_ubjson_size_value(result.first); + } + return true; + } + + /*! + @param prefix the previously read or set type prefix + @return whether value creation completed + */ + bool get_ubjson_value(const int prefix) + { + switch (prefix) + { + case std::char_traits<char>::eof(): // EOF + return unexpect_eof(input_format_t::ubjson, "value"); + + case 'T': // true + return sax->boolean(true); + case 'F': // false + return sax->boolean(false); + + case 'Z': // null + return sax->null(); + + case 'U': + { + uint8_t number; + return get_number(input_format_t::ubjson, number) and sax->number_unsigned(number); + } + + case 'i': + { + int8_t number; + return get_number(input_format_t::ubjson, number) and sax->number_integer(number); + } + + case 'I': + { + int16_t number; + return get_number(input_format_t::ubjson, number) and sax->number_integer(number); + } + + case 'l': + { + int32_t number; + return get_number(input_format_t::ubjson, number) and sax->number_integer(number); + } + + case 'L': + { + int64_t number; + return get_number(input_format_t::ubjson, number) and sax->number_integer(number); + } + + case 'd': + { + float number; + return get_number(input_format_t::ubjson, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + case 'D': + { + double number; + return get_number(input_format_t::ubjson, number) and sax->number_float(static_cast<number_float_t>(number), ""); + } + + case 'C': // char + { + get(); + if (JSON_UNLIKELY(not unexpect_eof(input_format_t::ubjson, "char"))) + { + return false; + } + if (JSON_UNLIKELY(current > 127)) + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(113, chars_read, exception_message(input_format_t::ubjson, "byte after 'C' must be in range 0x00..0x7F; last byte: 0x" + last_token, "char"))); + } + string_t s(1, static_cast<char>(current)); + return sax->string(s); + } + + case 'S': // string + { + string_t s; + return get_ubjson_string(s) and sax->string(s); + } + + case '[': // array + return get_ubjson_array(); + + case '{': // object + return get_ubjson_object(); + + default: // anything else + { + auto last_token = get_token_string(); + return sax->parse_error(chars_read, last_token, parse_error::create(112, chars_read, exception_message(input_format_t::ubjson, "invalid byte: 0x" + last_token, "value"))); + } + } + } + + /*! + @return whether array creation completed + */ + bool get_ubjson_array() + { + std::pair<std::size_t, int> size_and_type; + if (JSON_UNLIKELY(not get_ubjson_size_type(size_and_type))) + { + return false; + } + + if (size_and_type.first != string_t::npos) + { + if (JSON_UNLIKELY(not sax->start_array(size_and_type.first))) + { + return false; + } + + if (size_and_type.second != 0) + { + if (size_and_type.second != 'N') + { + for (std::size_t i = 0; i < size_and_type.first; ++i) + { + if (JSON_UNLIKELY(not get_ubjson_value(size_and_type.second))) + { + return false; + } + } + } + } + else + { + for (std::size_t i = 0; i < size_and_type.first; ++i) + { + if (JSON_UNLIKELY(not parse_ubjson_internal())) + { + return false; + } + } + } + } + else + { + if (JSON_UNLIKELY(not sax->start_array(std::size_t(-1)))) + { + return false; + } + + while (current != ']') + { + if (JSON_UNLIKELY(not parse_ubjson_internal(false))) + { + return false; + } + get_ignore_noop(); + } + } + + return sax->end_array(); + } + + /*! + @return whether object creation completed + */ + bool get_ubjson_object() + { + std::pair<std::size_t, int> size_and_type; + if (JSON_UNLIKELY(not get_ubjson_size_type(size_and_type))) + { + return false; + } + + string_t key; + if (size_and_type.first != string_t::npos) + { + if (JSON_UNLIKELY(not sax->start_object(size_and_type.first))) + { + return false; + } + + if (size_and_type.second != 0) + { + for (std::size_t i = 0; i < size_and_type.first; ++i) + { + if (JSON_UNLIKELY(not get_ubjson_string(key) or not sax->key(key))) + { + return false; + } + if (JSON_UNLIKELY(not get_ubjson_value(size_and_type.second))) + { + return false; + } + key.clear(); + } + } + else + { + for (std::size_t i = 0; i < size_and_type.first; ++i) + { + if (JSON_UNLIKELY(not get_ubjson_string(key) or not sax->key(key))) + { + return false; + } + if (JSON_UNLIKELY(not parse_ubjson_internal())) + { + return false; + } + key.clear(); + } + } + } + else + { + if (JSON_UNLIKELY(not sax->start_object(std::size_t(-1)))) + { + return false; + } + + while (current != '}') + { + if (JSON_UNLIKELY(not get_ubjson_string(key, false) or not sax->key(key))) + { + return false; + } + if (JSON_UNLIKELY(not parse_ubjson_internal())) + { + return false; + } + get_ignore_noop(); + key.clear(); + } + } + + return sax->end_object(); + } + + /////////////////////// + // Utility functions // + /////////////////////// + + /*! + @brief get next character from the input + + This function provides the interface to the used input adapter. It does + not throw in case the input reached EOF, but returns a -'ve valued + `std::char_traits<char>::eof()` in that case. + + @return character read from the input + */ + int get() + { + ++chars_read; + return (current = ia->get_character()); + } + + /*! + @return character read from the input after ignoring all 'N' entries + */ + int get_ignore_noop() + { + do + { + get(); + } + while (current == 'N'); + + return current; + } + + /* + @brief read a number from the input + + @tparam NumberType the type of the number + @param[in] format the current format (for diagnostics) + @param[out] result number of type @a NumberType + + @return whether conversion completed + + @note This function needs to respect the system's endianess, because + bytes in CBOR, MessagePack, and UBJSON are stored in network order + (big endian) and therefore need reordering on little endian systems. + */ + template<typename NumberType, bool InputIsLittleEndian = false> + bool get_number(const input_format_t format, NumberType& result) + { + // step 1: read input into array with system's byte order + std::array<uint8_t, sizeof(NumberType)> vec; + for (std::size_t i = 0; i < sizeof(NumberType); ++i) + { + get(); + if (JSON_UNLIKELY(not unexpect_eof(format, "number"))) + { + return false; + } + + // reverse byte order prior to conversion if necessary + if (is_little_endian && !InputIsLittleEndian) + { + vec[sizeof(NumberType) - i - 1] = static_cast<uint8_t>(current); + } + else + { + vec[i] = static_cast<uint8_t>(current); // LCOV_EXCL_LINE + } + } + + // step 2: convert array into number of type T and return + std::memcpy(&result, vec.data(), sizeof(NumberType)); + return true; + } + + /*! + @brief create a string by reading characters from the input + + @tparam NumberType the type of the number + @param[in] format the current format (for diagnostics) + @param[in] len number of characters to read + @param[out] result string created by reading @a len bytes + + @return whether string creation completed + + @note We can not reserve @a len bytes for the result, because @a len + may be too large. Usually, @ref unexpect_eof() detects the end of + the input before we run out of string memory. + */ + template<typename NumberType> + bool get_string(const input_format_t format, + const NumberType len, + string_t& result) + { + bool success = true; + std::generate_n(std::back_inserter(result), len, [this, &success, &format]() + { + get(); + if (JSON_UNLIKELY(not unexpect_eof(format, "string"))) + { + success = false; + } + return static_cast<char>(current); + }); + return success; + } + + /*! + @param[in] format the current format (for diagnostics) + @param[in] context further context information (for diagnostics) + @return whether the last read character is not EOF + */ + bool unexpect_eof(const input_format_t format, const char* context) const + { + if (JSON_UNLIKELY(current == std::char_traits<char>::eof())) + { + return sax->parse_error(chars_read, "<end of file>", + parse_error::create(110, chars_read, exception_message(format, "unexpected end of input", context))); + } + return true; + } + + /*! + @return a string representation of the last read byte + */ + std::string get_token_string() const + { + char cr[3]; + (std::snprintf)(cr, 3, "%.2hhX", static_cast<unsigned char>(current)); + return std::string{cr}; + } + + /*! + @param[in] format the current format + @param[in] detail a detailed error message + @param[in] context further contect information + @return a message string to use in the parse_error exceptions + */ + std::string exception_message(const input_format_t format, + const std::string& detail, + const std::string& context) const + { + std::string error_msg = "syntax error while parsing "; + + switch (format) + { + case input_format_t::cbor: + error_msg += "CBOR"; + break; + + case input_format_t::msgpack: + error_msg += "MessagePack"; + break; + + case input_format_t::ubjson: + error_msg += "UBJSON"; + break; + + case input_format_t::bson: + error_msg += "BSON"; + break; + + // LCOV_EXCL_START + default: + assert(false); + // LCOV_EXCL_STOP + } + + return error_msg + " " + context + ": " + detail; + } + + private: + /// input adapter + input_adapter_t ia = nullptr; + + /// the current character + int current = std::char_traits<char>::eof(); + + /// the number of characters read + std::size_t chars_read = 0; + + /// whether we can assume little endianess + const bool is_little_endian = little_endianess(); + + /// the SAX parser + json_sax_t* sax = nullptr; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/output/binary_writer.hpp> + + +#include <algorithm> // reverse +#include <array> // array +#include <cstdint> // uint8_t, uint16_t, uint32_t, uint64_t +#include <cstring> // memcpy +#include <limits> // numeric_limits + +// #include <nlohmann/detail/input/binary_reader.hpp> + +// #include <nlohmann/detail/output/output_adapters.hpp> + + +namespace nlohmann +{ +namespace detail +{ +/////////////////// +// binary writer // +/////////////////// + +/*! +@brief serialization to CBOR and MessagePack values +*/ +template<typename BasicJsonType, typename CharType> +class binary_writer +{ + using string_t = typename BasicJsonType::string_t; + + public: + /*! + @brief create a binary writer + + @param[in] adapter output adapter to write to + */ + explicit binary_writer(output_adapter_t<CharType> adapter) : oa(adapter) + { + assert(oa); + } + + /*! + @param[in] j JSON value to serialize + @pre j.type() == value_t::object + */ + void write_bson(const BasicJsonType& j) + { + switch (j.type()) + { + case value_t::object: + { + write_bson_object(*j.m_value.object); + break; + } + + default: + { + JSON_THROW(type_error::create(317, "to serialize to BSON, top-level type must be object, but is " + std::string(j.type_name()))); + } + } + } + + /*! + @param[in] j JSON value to serialize + */ + void write_cbor(const BasicJsonType& j) + { + switch (j.type()) + { + case value_t::null: + { + oa->write_character(to_char_type(0xF6)); + break; + } + + case value_t::boolean: + { + oa->write_character(j.m_value.boolean + ? to_char_type(0xF5) + : to_char_type(0xF4)); + break; + } + + case value_t::number_integer: + { + if (j.m_value.number_integer >= 0) + { + // CBOR does not differentiate between positive signed + // integers and unsigned integers. Therefore, we used the + // code from the value_t::number_unsigned case here. + if (j.m_value.number_integer <= 0x17) + { + write_number(static_cast<uint8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer <= (std::numeric_limits<uint8_t>::max)()) + { + oa->write_character(to_char_type(0x18)); + write_number(static_cast<uint8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer <= (std::numeric_limits<uint16_t>::max)()) + { + oa->write_character(to_char_type(0x19)); + write_number(static_cast<uint16_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer <= (std::numeric_limits<uint32_t>::max)()) + { + oa->write_character(to_char_type(0x1A)); + write_number(static_cast<uint32_t>(j.m_value.number_integer)); + } + else + { + oa->write_character(to_char_type(0x1B)); + write_number(static_cast<uint64_t>(j.m_value.number_integer)); + } + } + else + { + // The conversions below encode the sign in the first + // byte, and the value is converted to a positive number. + const auto positive_number = -1 - j.m_value.number_integer; + if (j.m_value.number_integer >= -24) + { + write_number(static_cast<uint8_t>(0x20 + positive_number)); + } + else if (positive_number <= (std::numeric_limits<uint8_t>::max)()) + { + oa->write_character(to_char_type(0x38)); + write_number(static_cast<uint8_t>(positive_number)); + } + else if (positive_number <= (std::numeric_limits<uint16_t>::max)()) + { + oa->write_character(to_char_type(0x39)); + write_number(static_cast<uint16_t>(positive_number)); + } + else if (positive_number <= (std::numeric_limits<uint32_t>::max)()) + { + oa->write_character(to_char_type(0x3A)); + write_number(static_cast<uint32_t>(positive_number)); + } + else + { + oa->write_character(to_char_type(0x3B)); + write_number(static_cast<uint64_t>(positive_number)); + } + } + break; + } + + case value_t::number_unsigned: + { + if (j.m_value.number_unsigned <= 0x17) + { + write_number(static_cast<uint8_t>(j.m_value.number_unsigned)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint8_t>::max)()) + { + oa->write_character(to_char_type(0x18)); + write_number(static_cast<uint8_t>(j.m_value.number_unsigned)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint16_t>::max)()) + { + oa->write_character(to_char_type(0x19)); + write_number(static_cast<uint16_t>(j.m_value.number_unsigned)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint32_t>::max)()) + { + oa->write_character(to_char_type(0x1A)); + write_number(static_cast<uint32_t>(j.m_value.number_unsigned)); + } + else + { + oa->write_character(to_char_type(0x1B)); + write_number(static_cast<uint64_t>(j.m_value.number_unsigned)); + } + break; + } + + case value_t::number_float: + { + oa->write_character(get_cbor_float_prefix(j.m_value.number_float)); + write_number(j.m_value.number_float); + break; + } + + case value_t::string: + { + // step 1: write control byte and the string length + const auto N = j.m_value.string->size(); + if (N <= 0x17) + { + write_number(static_cast<uint8_t>(0x60 + N)); + } + else if (N <= (std::numeric_limits<uint8_t>::max)()) + { + oa->write_character(to_char_type(0x78)); + write_number(static_cast<uint8_t>(N)); + } + else if (N <= (std::numeric_limits<uint16_t>::max)()) + { + oa->write_character(to_char_type(0x79)); + write_number(static_cast<uint16_t>(N)); + } + else if (N <= (std::numeric_limits<uint32_t>::max)()) + { + oa->write_character(to_char_type(0x7A)); + write_number(static_cast<uint32_t>(N)); + } + // LCOV_EXCL_START + else if (N <= (std::numeric_limits<uint64_t>::max)()) + { + oa->write_character(to_char_type(0x7B)); + write_number(static_cast<uint64_t>(N)); + } + // LCOV_EXCL_STOP + + // step 2: write the string + oa->write_characters( + reinterpret_cast<const CharType*>(j.m_value.string->c_str()), + j.m_value.string->size()); + break; + } + + case value_t::array: + { + // step 1: write control byte and the array size + const auto N = j.m_value.array->size(); + if (N <= 0x17) + { + write_number(static_cast<uint8_t>(0x80 + N)); + } + else if (N <= (std::numeric_limits<uint8_t>::max)()) + { + oa->write_character(to_char_type(0x98)); + write_number(static_cast<uint8_t>(N)); + } + else if (N <= (std::numeric_limits<uint16_t>::max)()) + { + oa->write_character(to_char_type(0x99)); + write_number(static_cast<uint16_t>(N)); + } + else if (N <= (std::numeric_limits<uint32_t>::max)()) + { + oa->write_character(to_char_type(0x9A)); + write_number(static_cast<uint32_t>(N)); + } + // LCOV_EXCL_START + else if (N <= (std::numeric_limits<uint64_t>::max)()) + { + oa->write_character(to_char_type(0x9B)); + write_number(static_cast<uint64_t>(N)); + } + // LCOV_EXCL_STOP + + // step 2: write each element + for (const auto& el : *j.m_value.array) + { + write_cbor(el); + } + break; + } + + case value_t::object: + { + // step 1: write control byte and the object size + const auto N = j.m_value.object->size(); + if (N <= 0x17) + { + write_number(static_cast<uint8_t>(0xA0 + N)); + } + else if (N <= (std::numeric_limits<uint8_t>::max)()) + { + oa->write_character(to_char_type(0xB8)); + write_number(static_cast<uint8_t>(N)); + } + else if (N <= (std::numeric_limits<uint16_t>::max)()) + { + oa->write_character(to_char_type(0xB9)); + write_number(static_cast<uint16_t>(N)); + } + else if (N <= (std::numeric_limits<uint32_t>::max)()) + { + oa->write_character(to_char_type(0xBA)); + write_number(static_cast<uint32_t>(N)); + } + // LCOV_EXCL_START + else if (N <= (std::numeric_limits<uint64_t>::max)()) + { + oa->write_character(to_char_type(0xBB)); + write_number(static_cast<uint64_t>(N)); + } + // LCOV_EXCL_STOP + + // step 2: write each element + for (const auto& el : *j.m_value.object) + { + write_cbor(el.first); + write_cbor(el.second); + } + break; + } + + default: + break; + } + } + + /*! + @param[in] j JSON value to serialize + */ + void write_msgpack(const BasicJsonType& j) + { + switch (j.type()) + { + case value_t::null: // nil + { + oa->write_character(to_char_type(0xC0)); + break; + } + + case value_t::boolean: // true and false + { + oa->write_character(j.m_value.boolean + ? to_char_type(0xC3) + : to_char_type(0xC2)); + break; + } + + case value_t::number_integer: + { + if (j.m_value.number_integer >= 0) + { + // MessagePack does not differentiate between positive + // signed integers and unsigned integers. Therefore, we used + // the code from the value_t::number_unsigned case here. + if (j.m_value.number_unsigned < 128) + { + // positive fixnum + write_number(static_cast<uint8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint8_t>::max)()) + { + // uint 8 + oa->write_character(to_char_type(0xCC)); + write_number(static_cast<uint8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint16_t>::max)()) + { + // uint 16 + oa->write_character(to_char_type(0xCD)); + write_number(static_cast<uint16_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint32_t>::max)()) + { + // uint 32 + oa->write_character(to_char_type(0xCE)); + write_number(static_cast<uint32_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint64_t>::max)()) + { + // uint 64 + oa->write_character(to_char_type(0xCF)); + write_number(static_cast<uint64_t>(j.m_value.number_integer)); + } + } + else + { + if (j.m_value.number_integer >= -32) + { + // negative fixnum + write_number(static_cast<int8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer >= (std::numeric_limits<int8_t>::min)() and + j.m_value.number_integer <= (std::numeric_limits<int8_t>::max)()) + { + // int 8 + oa->write_character(to_char_type(0xD0)); + write_number(static_cast<int8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer >= (std::numeric_limits<int16_t>::min)() and + j.m_value.number_integer <= (std::numeric_limits<int16_t>::max)()) + { + // int 16 + oa->write_character(to_char_type(0xD1)); + write_number(static_cast<int16_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer >= (std::numeric_limits<int32_t>::min)() and + j.m_value.number_integer <= (std::numeric_limits<int32_t>::max)()) + { + // int 32 + oa->write_character(to_char_type(0xD2)); + write_number(static_cast<int32_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_integer >= (std::numeric_limits<int64_t>::min)() and + j.m_value.number_integer <= (std::numeric_limits<int64_t>::max)()) + { + // int 64 + oa->write_character(to_char_type(0xD3)); + write_number(static_cast<int64_t>(j.m_value.number_integer)); + } + } + break; + } + + case value_t::number_unsigned: + { + if (j.m_value.number_unsigned < 128) + { + // positive fixnum + write_number(static_cast<uint8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint8_t>::max)()) + { + // uint 8 + oa->write_character(to_char_type(0xCC)); + write_number(static_cast<uint8_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint16_t>::max)()) + { + // uint 16 + oa->write_character(to_char_type(0xCD)); + write_number(static_cast<uint16_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint32_t>::max)()) + { + // uint 32 + oa->write_character(to_char_type(0xCE)); + write_number(static_cast<uint32_t>(j.m_value.number_integer)); + } + else if (j.m_value.number_unsigned <= (std::numeric_limits<uint64_t>::max)()) + { + // uint 64 + oa->write_character(to_char_type(0xCF)); + write_number(static_cast<uint64_t>(j.m_value.number_integer)); + } + break; + } + + case value_t::number_float: + { + oa->write_character(get_msgpack_float_prefix(j.m_value.number_float)); + write_number(j.m_value.number_float); + break; + } + + case value_t::string: + { + // step 1: write control byte and the string length + const auto N = j.m_value.string->size(); + if (N <= 31) + { + // fixstr + write_number(static_cast<uint8_t>(0xA0 | N)); + } + else if (N <= (std::numeric_limits<uint8_t>::max)()) + { + // str 8 + oa->write_character(to_char_type(0xD9)); + write_number(static_cast<uint8_t>(N)); + } + else if (N <= (std::numeric_limits<uint16_t>::max)()) + { + // str 16 + oa->write_character(to_char_type(0xDA)); + write_number(static_cast<uint16_t>(N)); + } + else if (N <= (std::numeric_limits<uint32_t>::max)()) + { + // str 32 + oa->write_character(to_char_type(0xDB)); + write_number(static_cast<uint32_t>(N)); + } + + // step 2: write the string + oa->write_characters( + reinterpret_cast<const CharType*>(j.m_value.string->c_str()), + j.m_value.string->size()); + break; + } + + case value_t::array: + { + // step 1: write control byte and the array size + const auto N = j.m_value.array->size(); + if (N <= 15) + { + // fixarray + write_number(static_cast<uint8_t>(0x90 | N)); + } + else if (N <= (std::numeric_limits<uint16_t>::max)()) + { + // array 16 + oa->write_character(to_char_type(0xDC)); + write_number(static_cast<uint16_t>(N)); + } + else if (N <= (std::numeric_limits<uint32_t>::max)()) + { + // array 32 + oa->write_character(to_char_type(0xDD)); + write_number(static_cast<uint32_t>(N)); + } + + // step 2: write each element + for (const auto& el : *j.m_value.array) + { + write_msgpack(el); + } + break; + } + + case value_t::object: + { + // step 1: write control byte and the object size + const auto N = j.m_value.object->size(); + if (N <= 15) + { + // fixmap + write_number(static_cast<uint8_t>(0x80 | (N & 0xF))); + } + else if (N <= (std::numeric_limits<uint16_t>::max)()) + { + // map 16 + oa->write_character(to_char_type(0xDE)); + write_number(static_cast<uint16_t>(N)); + } + else if (N <= (std::numeric_limits<uint32_t>::max)()) + { + // map 32 + oa->write_character(to_char_type(0xDF)); + write_number(static_cast<uint32_t>(N)); + } + + // step 2: write each element + for (const auto& el : *j.m_value.object) + { + write_msgpack(el.first); + write_msgpack(el.second); + } + break; + } + + default: + break; + } + } + + /*! + @param[in] j JSON value to serialize + @param[in] use_count whether to use '#' prefixes (optimized format) + @param[in] use_type whether to use '$' prefixes (optimized format) + @param[in] add_prefix whether prefixes need to be used for this value + */ + void write_ubjson(const BasicJsonType& j, const bool use_count, + const bool use_type, const bool add_prefix = true) + { + switch (j.type()) + { + case value_t::null: + { + if (add_prefix) + { + oa->write_character(to_char_type('Z')); + } + break; + } + + case value_t::boolean: + { + if (add_prefix) + { + oa->write_character(j.m_value.boolean + ? to_char_type('T') + : to_char_type('F')); + } + break; + } + + case value_t::number_integer: + { + write_number_with_ubjson_prefix(j.m_value.number_integer, add_prefix); + break; + } + + case value_t::number_unsigned: + { + write_number_with_ubjson_prefix(j.m_value.number_unsigned, add_prefix); + break; + } + + case value_t::number_float: + { + write_number_with_ubjson_prefix(j.m_value.number_float, add_prefix); + break; + } + + case value_t::string: + { + if (add_prefix) + { + oa->write_character(to_char_type('S')); + } + write_number_with_ubjson_prefix(j.m_value.string->size(), true); + oa->write_characters( + reinterpret_cast<const CharType*>(j.m_value.string->c_str()), + j.m_value.string->size()); + break; + } + + case value_t::array: + { + if (add_prefix) + { + oa->write_character(to_char_type('[')); + } + + bool prefix_required = true; + if (use_type and not j.m_value.array->empty()) + { + assert(use_count); + const CharType first_prefix = ubjson_prefix(j.front()); + const bool same_prefix = std::all_of(j.begin() + 1, j.end(), + [this, first_prefix](const BasicJsonType & v) + { + return ubjson_prefix(v) == first_prefix; + }); + + if (same_prefix) + { + prefix_required = false; + oa->write_character(to_char_type('$')); + oa->write_character(first_prefix); + } + } + + if (use_count) + { + oa->write_character(to_char_type('#')); + write_number_with_ubjson_prefix(j.m_value.array->size(), true); + } + + for (const auto& el : *j.m_value.array) + { + write_ubjson(el, use_count, use_type, prefix_required); + } + + if (not use_count) + { + oa->write_character(to_char_type(']')); + } + + break; + } + + case value_t::object: + { + if (add_prefix) + { + oa->write_character(to_char_type('{')); + } + + bool prefix_required = true; + if (use_type and not j.m_value.object->empty()) + { + assert(use_count); + const CharType first_prefix = ubjson_prefix(j.front()); + const bool same_prefix = std::all_of(j.begin(), j.end(), + [this, first_prefix](const BasicJsonType & v) + { + return ubjson_prefix(v) == first_prefix; + }); + + if (same_prefix) + { + prefix_required = false; + oa->write_character(to_char_type('$')); + oa->write_character(first_prefix); + } + } + + if (use_count) + { + oa->write_character(to_char_type('#')); + write_number_with_ubjson_prefix(j.m_value.object->size(), true); + } + + for (const auto& el : *j.m_value.object) + { + write_number_with_ubjson_prefix(el.first.size(), true); + oa->write_characters( + reinterpret_cast<const CharType*>(el.first.c_str()), + el.first.size()); + write_ubjson(el.second, use_count, use_type, prefix_required); + } + + if (not use_count) + { + oa->write_character(to_char_type('}')); + } + + break; + } + + default: + break; + } + } + + private: + ////////// + // BSON // + ////////// + + /*! + @return The size of a BSON document entry header, including the id marker + and the entry name size (and its null-terminator). + */ + static std::size_t calc_bson_entry_header_size(const string_t& name) + { + const auto it = name.find(static_cast<typename string_t::value_type>(0)); + if (JSON_UNLIKELY(it != BasicJsonType::string_t::npos)) + { + JSON_THROW(out_of_range::create(409, + "BSON key cannot contain code point U+0000 (at byte " + std::to_string(it) + ")")); + } + + return /*id*/ 1ul + name.size() + /*zero-terminator*/1u; + } + + /*! + @brief Writes the given @a element_type and @a name to the output adapter + */ + void write_bson_entry_header(const string_t& name, + const std::uint8_t element_type) + { + oa->write_character(to_char_type(element_type)); // boolean + oa->write_characters( + reinterpret_cast<const CharType*>(name.c_str()), + name.size() + 1u); + } + + /*! + @brief Writes a BSON element with key @a name and boolean value @a value + */ + void write_bson_boolean(const string_t& name, + const bool value) + { + write_bson_entry_header(name, 0x08); + oa->write_character(value ? to_char_type(0x01) : to_char_type(0x00)); + } + + /*! + @brief Writes a BSON element with key @a name and double value @a value + */ + void write_bson_double(const string_t& name, + const double value) + { + write_bson_entry_header(name, 0x01); + write_number<double, true>(value); + } + + /*! + @return The size of the BSON-encoded string in @a value + */ + static std::size_t calc_bson_string_size(const string_t& value) + { + return sizeof(std::int32_t) + value.size() + 1ul; + } + + /*! + @brief Writes a BSON element with key @a name and string value @a value + */ + void write_bson_string(const string_t& name, + const string_t& value) + { + write_bson_entry_header(name, 0x02); + + write_number<std::int32_t, true>(static_cast<std::int32_t>(value.size() + 1ul)); + oa->write_characters( + reinterpret_cast<const CharType*>(value.c_str()), + value.size() + 1); + } + + /*! + @brief Writes a BSON element with key @a name and null value + */ + void write_bson_null(const string_t& name) + { + write_bson_entry_header(name, 0x0A); + } + + /*! + @return The size of the BSON-encoded integer @a value + */ + static std::size_t calc_bson_integer_size(const std::int64_t value) + { + if ((std::numeric_limits<std::int32_t>::min)() <= value and value <= (std::numeric_limits<std::int32_t>::max)()) + { + return sizeof(std::int32_t); + } + else + { + return sizeof(std::int64_t); + } + } + + /*! + @brief Writes a BSON element with key @a name and integer @a value + */ + void write_bson_integer(const string_t& name, + const std::int64_t value) + { + if ((std::numeric_limits<std::int32_t>::min)() <= value and value <= (std::numeric_limits<std::int32_t>::max)()) + { + write_bson_entry_header(name, 0x10); // int32 + write_number<std::int32_t, true>(static_cast<std::int32_t>(value)); + } + else + { + write_bson_entry_header(name, 0x12); // int64 + write_number<std::int64_t, true>(static_cast<std::int64_t>(value)); + } + } + + /*! + @return The size of the BSON-encoded unsigned integer in @a j + */ + static constexpr std::size_t calc_bson_unsigned_size(const std::uint64_t value) noexcept + { + return (value <= static_cast<std::uint64_t>((std::numeric_limits<std::int32_t>::max)())) + ? sizeof(std::int32_t) + : sizeof(std::int64_t); + } + + /*! + @brief Writes a BSON element with key @a name and unsigned @a value + */ + void write_bson_unsigned(const string_t& name, + const std::uint64_t value) + { + if (value <= static_cast<std::uint64_t>((std::numeric_limits<std::int32_t>::max)())) + { + write_bson_entry_header(name, 0x10 /* int32 */); + write_number<std::int32_t, true>(static_cast<std::int32_t>(value)); + } + else if (value <= static_cast<std::uint64_t>((std::numeric_limits<std::int64_t>::max)())) + { + write_bson_entry_header(name, 0x12 /* int64 */); + write_number<std::int64_t, true>(static_cast<std::int64_t>(value)); + } + else + { + JSON_THROW(out_of_range::create(407, "integer number " + std::to_string(value) + " cannot be represented by BSON as it does not fit int64")); + } + } + + /*! + @brief Writes a BSON element with key @a name and object @a value + */ + void write_bson_object_entry(const string_t& name, + const typename BasicJsonType::object_t& value) + { + write_bson_entry_header(name, 0x03); // object + write_bson_object(value); + } + + /*! + @return The size of the BSON-encoded array @a value + */ + static std::size_t calc_bson_array_size(const typename BasicJsonType::array_t& value) + { + std::size_t embedded_document_size = 0ul; + std::size_t array_index = 0ul; + + for (const auto& el : value) + { + embedded_document_size += calc_bson_element_size(std::to_string(array_index++), el); + } + + return sizeof(std::int32_t) + embedded_document_size + 1ul; + } + + /*! + @brief Writes a BSON element with key @a name and array @a value + */ + void write_bson_array(const string_t& name, + const typename BasicJsonType::array_t& value) + { + write_bson_entry_header(name, 0x04); // array + write_number<std::int32_t, true>(static_cast<std::int32_t>(calc_bson_array_size(value))); + + std::size_t array_index = 0ul; + + for (const auto& el : value) + { + write_bson_element(std::to_string(array_index++), el); + } + + oa->write_character(to_char_type(0x00)); + } + + /*! + @brief Calculates the size necessary to serialize the JSON value @a j with its @a name + @return The calculated size for the BSON document entry for @a j with the given @a name. + */ + static std::size_t calc_bson_element_size(const string_t& name, + const BasicJsonType& j) + { + const auto header_size = calc_bson_entry_header_size(name); + switch (j.type()) + { + case value_t::object: + return header_size + calc_bson_object_size(*j.m_value.object); + + case value_t::array: + return header_size + calc_bson_array_size(*j.m_value.array); + + case value_t::boolean: + return header_size + 1ul; + + case value_t::number_float: + return header_size + 8ul; + + case value_t::number_integer: + return header_size + calc_bson_integer_size(j.m_value.number_integer); + + case value_t::number_unsigned: + return header_size + calc_bson_unsigned_size(j.m_value.number_unsigned); + + case value_t::string: + return header_size + calc_bson_string_size(*j.m_value.string); + + case value_t::null: + return header_size + 0ul; + + // LCOV_EXCL_START + default: + assert(false); + return 0ul; + // LCOV_EXCL_STOP + }; + } + + /*! + @brief Serializes the JSON value @a j to BSON and associates it with the + key @a name. + @param name The name to associate with the JSON entity @a j within the + current BSON document + @return The size of the BSON entry + */ + void write_bson_element(const string_t& name, + const BasicJsonType& j) + { + switch (j.type()) + { + case value_t::object: + return write_bson_object_entry(name, *j.m_value.object); + + case value_t::array: + return write_bson_array(name, *j.m_value.array); + + case value_t::boolean: + return write_bson_boolean(name, j.m_value.boolean); + + case value_t::number_float: + return write_bson_double(name, j.m_value.number_float); + + case value_t::number_integer: + return write_bson_integer(name, j.m_value.number_integer); + + case value_t::number_unsigned: + return write_bson_unsigned(name, j.m_value.number_unsigned); + + case value_t::string: + return write_bson_string(name, *j.m_value.string); + + case value_t::null: + return write_bson_null(name); + + // LCOV_EXCL_START + default: + assert(false); + return; + // LCOV_EXCL_STOP + }; + } + + /*! + @brief Calculates the size of the BSON serialization of the given + JSON-object @a j. + @param[in] j JSON value to serialize + @pre j.type() == value_t::object + */ + static std::size_t calc_bson_object_size(const typename BasicJsonType::object_t& value) + { + std::size_t document_size = std::accumulate(value.begin(), value.end(), 0ul, + [](size_t result, const typename BasicJsonType::object_t::value_type & el) + { + return result += calc_bson_element_size(el.first, el.second); + }); + + return sizeof(std::int32_t) + document_size + 1ul; + } + + /*! + @param[in] j JSON value to serialize + @pre j.type() == value_t::object + */ + void write_bson_object(const typename BasicJsonType::object_t& value) + { + write_number<std::int32_t, true>(static_cast<std::int32_t>(calc_bson_object_size(value))); + + for (const auto& el : value) + { + write_bson_element(el.first, el.second); + } + + oa->write_character(to_char_type(0x00)); + } + + ////////// + // CBOR // + ////////// + + static constexpr CharType get_cbor_float_prefix(float /*unused*/) + { + return to_char_type(0xFA); // Single-Precision Float + } + + static constexpr CharType get_cbor_float_prefix(double /*unused*/) + { + return to_char_type(0xFB); // Double-Precision Float + } + + ///////////// + // MsgPack // + ///////////// + + static constexpr CharType get_msgpack_float_prefix(float /*unused*/) + { + return to_char_type(0xCA); // float 32 + } + + static constexpr CharType get_msgpack_float_prefix(double /*unused*/) + { + return to_char_type(0xCB); // float 64 + } + + //////////// + // UBJSON // + //////////// + + // UBJSON: write number (floating point) + template<typename NumberType, typename std::enable_if< + std::is_floating_point<NumberType>::value, int>::type = 0> + void write_number_with_ubjson_prefix(const NumberType n, + const bool add_prefix) + { + if (add_prefix) + { + oa->write_character(get_ubjson_float_prefix(n)); + } + write_number(n); + } + + // UBJSON: write number (unsigned integer) + template<typename NumberType, typename std::enable_if< + std::is_unsigned<NumberType>::value, int>::type = 0> + void write_number_with_ubjson_prefix(const NumberType n, + const bool add_prefix) + { + if (n <= static_cast<uint64_t>((std::numeric_limits<int8_t>::max)())) + { + if (add_prefix) + { + oa->write_character(to_char_type('i')); // int8 + } + write_number(static_cast<uint8_t>(n)); + } + else if (n <= (std::numeric_limits<uint8_t>::max)()) + { + if (add_prefix) + { + oa->write_character(to_char_type('U')); // uint8 + } + write_number(static_cast<uint8_t>(n)); + } + else if (n <= static_cast<uint64_t>((std::numeric_limits<int16_t>::max)())) + { + if (add_prefix) + { + oa->write_character(to_char_type('I')); // int16 + } + write_number(static_cast<int16_t>(n)); + } + else if (n <= static_cast<uint64_t>((std::numeric_limits<int32_t>::max)())) + { + if (add_prefix) + { + oa->write_character(to_char_type('l')); // int32 + } + write_number(static_cast<int32_t>(n)); + } + else if (n <= static_cast<uint64_t>((std::numeric_limits<int64_t>::max)())) + { + if (add_prefix) + { + oa->write_character(to_char_type('L')); // int64 + } + write_number(static_cast<int64_t>(n)); + } + else + { + JSON_THROW(out_of_range::create(407, "integer number " + std::to_string(n) + " cannot be represented by UBJSON as it does not fit int64")); + } + } + + // UBJSON: write number (signed integer) + template<typename NumberType, typename std::enable_if< + std::is_signed<NumberType>::value and + not std::is_floating_point<NumberType>::value, int>::type = 0> + void write_number_with_ubjson_prefix(const NumberType n, + const bool add_prefix) + { + if ((std::numeric_limits<int8_t>::min)() <= n and n <= (std::numeric_limits<int8_t>::max)()) + { + if (add_prefix) + { + oa->write_character(to_char_type('i')); // int8 + } + write_number(static_cast<int8_t>(n)); + } + else if (static_cast<int64_t>((std::numeric_limits<uint8_t>::min)()) <= n and n <= static_cast<int64_t>((std::numeric_limits<uint8_t>::max)())) + { + if (add_prefix) + { + oa->write_character(to_char_type('U')); // uint8 + } + write_number(static_cast<uint8_t>(n)); + } + else if ((std::numeric_limits<int16_t>::min)() <= n and n <= (std::numeric_limits<int16_t>::max)()) + { + if (add_prefix) + { + oa->write_character(to_char_type('I')); // int16 + } + write_number(static_cast<int16_t>(n)); + } + else if ((std::numeric_limits<int32_t>::min)() <= n and n <= (std::numeric_limits<int32_t>::max)()) + { + if (add_prefix) + { + oa->write_character(to_char_type('l')); // int32 + } + write_number(static_cast<int32_t>(n)); + } + else if ((std::numeric_limits<int64_t>::min)() <= n and n <= (std::numeric_limits<int64_t>::max)()) + { + if (add_prefix) + { + oa->write_character(to_char_type('L')); // int64 + } + write_number(static_cast<int64_t>(n)); + } + // LCOV_EXCL_START + else + { + JSON_THROW(out_of_range::create(407, "integer number " + std::to_string(n) + " cannot be represented by UBJSON as it does not fit int64")); + } + // LCOV_EXCL_STOP + } + + /*! + @brief determine the type prefix of container values + + @note This function does not need to be 100% accurate when it comes to + integer limits. In case a number exceeds the limits of int64_t, + this will be detected by a later call to function + write_number_with_ubjson_prefix. Therefore, we return 'L' for any + value that does not fit the previous limits. + */ + CharType ubjson_prefix(const BasicJsonType& j) const noexcept + { + switch (j.type()) + { + case value_t::null: + return 'Z'; + + case value_t::boolean: + return j.m_value.boolean ? 'T' : 'F'; + + case value_t::number_integer: + { + if ((std::numeric_limits<int8_t>::min)() <= j.m_value.number_integer and j.m_value.number_integer <= (std::numeric_limits<int8_t>::max)()) + { + return 'i'; + } + if ((std::numeric_limits<uint8_t>::min)() <= j.m_value.number_integer and j.m_value.number_integer <= (std::numeric_limits<uint8_t>::max)()) + { + return 'U'; + } + if ((std::numeric_limits<int16_t>::min)() <= j.m_value.number_integer and j.m_value.number_integer <= (std::numeric_limits<int16_t>::max)()) + { + return 'I'; + } + if ((std::numeric_limits<int32_t>::min)() <= j.m_value.number_integer and j.m_value.number_integer <= (std::numeric_limits<int32_t>::max)()) + { + return 'l'; + } + // no check and assume int64_t (see note above) + return 'L'; + } + + case value_t::number_unsigned: + { + if (j.m_value.number_unsigned <= (std::numeric_limits<int8_t>::max)()) + { + return 'i'; + } + if (j.m_value.number_unsigned <= (std::numeric_limits<uint8_t>::max)()) + { + return 'U'; + } + if (j.m_value.number_unsigned <= (std::numeric_limits<int16_t>::max)()) + { + return 'I'; + } + if (j.m_value.number_unsigned <= (std::numeric_limits<int32_t>::max)()) + { + return 'l'; + } + // no check and assume int64_t (see note above) + return 'L'; + } + + case value_t::number_float: + return get_ubjson_float_prefix(j.m_value.number_float); + + case value_t::string: + return 'S'; + + case value_t::array: + return '['; + + case value_t::object: + return '{'; + + default: // discarded values + return 'N'; + } + } + + static constexpr CharType get_ubjson_float_prefix(float /*unused*/) + { + return 'd'; // float 32 + } + + static constexpr CharType get_ubjson_float_prefix(double /*unused*/) + { + return 'D'; // float 64 + } + + /////////////////////// + // Utility functions // + /////////////////////// + + /* + @brief write a number to output input + @param[in] n number of type @a NumberType + @tparam NumberType the type of the number + @tparam OutputIsLittleEndian Set to true if output data is + required to be little endian + + @note This function needs to respect the system's endianess, because bytes + in CBOR, MessagePack, and UBJSON are stored in network order (big + endian) and therefore need reordering on little endian systems. + */ + template<typename NumberType, bool OutputIsLittleEndian = false> + void write_number(const NumberType n) + { + // step 1: write number to array of length NumberType + std::array<CharType, sizeof(NumberType)> vec; + std::memcpy(vec.data(), &n, sizeof(NumberType)); + + // step 2: write array to output (with possible reordering) + if (is_little_endian and not OutputIsLittleEndian) + { + // reverse byte order prior to conversion if necessary + std::reverse(vec.begin(), vec.end()); + } + + oa->write_characters(vec.data(), sizeof(NumberType)); + } + + public: + // The following to_char_type functions are implement the conversion + // between uint8_t and CharType. In case CharType is not unsigned, + // such a conversion is required to allow values greater than 128. + // See <https://github.com/nlohmann/json/issues/1286> for a discussion. + template < typename C = CharType, + enable_if_t < std::is_signed<C>::value and std::is_signed<char>::value > * = nullptr > + static constexpr CharType to_char_type(std::uint8_t x) noexcept + { + return *reinterpret_cast<char*>(&x); + } + + template < typename C = CharType, + enable_if_t < std::is_signed<C>::value and std::is_unsigned<char>::value > * = nullptr > + static CharType to_char_type(std::uint8_t x) noexcept + { + static_assert(sizeof(std::uint8_t) == sizeof(CharType), "size of CharType must be equal to std::uint8_t"); + static_assert(std::is_pod<CharType>::value, "CharType must be POD"); + CharType result; + std::memcpy(&result, &x, sizeof(x)); + return result; + } + + template<typename C = CharType, + enable_if_t<std::is_unsigned<C>::value>* = nullptr> + static constexpr CharType to_char_type(std::uint8_t x) noexcept + { + return x; + } + + template < typename InputCharType, typename C = CharType, + enable_if_t < + std::is_signed<C>::value and + std::is_signed<char>::value and + std::is_same<char, typename std::remove_cv<InputCharType>::type>::value + > * = nullptr > + static constexpr CharType to_char_type(InputCharType x) noexcept + { + return x; + } + + private: + /// whether we can assume little endianess + const bool is_little_endian = binary_reader<BasicJsonType>::little_endianess(); + + /// the output + output_adapter_t<CharType> oa = nullptr; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/output/serializer.hpp> + + +#include <algorithm> // reverse, remove, fill, find, none_of +#include <array> // array +#include <cassert> // assert +#include <ciso646> // and, or +#include <clocale> // localeconv, lconv +#include <cmath> // labs, isfinite, isnan, signbit +#include <cstddef> // size_t, ptrdiff_t +#include <cstdint> // uint8_t +#include <cstdio> // snprintf +#include <limits> // numeric_limits +#include <string> // string +#include <type_traits> // is_same + +// #include <nlohmann/detail/exceptions.hpp> + +// #include <nlohmann/detail/conversions/to_chars.hpp> + + +#include <cassert> // assert +#include <ciso646> // or, and, not +#include <cmath> // signbit, isfinite +#include <cstdint> // intN_t, uintN_t +#include <cstring> // memcpy, memmove + +namespace nlohmann +{ +namespace detail +{ + +/*! +@brief implements the Grisu2 algorithm for binary to decimal floating-point +conversion. + +This implementation is a slightly modified version of the reference +implementation which may be obtained from +http://florian.loitsch.com/publications (bench.tar.gz). + +The code is distributed under the MIT license, Copyright (c) 2009 Florian Loitsch. + +For a detailed description of the algorithm see: + +[1] Loitsch, "Printing Floating-Point Numbers Quickly and Accurately with + Integers", Proceedings of the ACM SIGPLAN 2010 Conference on Programming + Language Design and Implementation, PLDI 2010 +[2] Burger, Dybvig, "Printing Floating-Point Numbers Quickly and Accurately", + Proceedings of the ACM SIGPLAN 1996 Conference on Programming Language + Design and Implementation, PLDI 1996 +*/ +namespace dtoa_impl +{ + +template <typename Target, typename Source> +Target reinterpret_bits(const Source source) +{ + static_assert(sizeof(Target) == sizeof(Source), "size mismatch"); + + Target target; + std::memcpy(&target, &source, sizeof(Source)); + return target; +} + +struct diyfp // f * 2^e +{ + static constexpr int kPrecision = 64; // = q + + uint64_t f = 0; + int e = 0; + + constexpr diyfp(uint64_t f_, int e_) noexcept : f(f_), e(e_) {} + + /*! + @brief returns x - y + @pre x.e == y.e and x.f >= y.f + */ + static diyfp sub(const diyfp& x, const diyfp& y) noexcept + { + assert(x.e == y.e); + assert(x.f >= y.f); + + return {x.f - y.f, x.e}; + } + + /*! + @brief returns x * y + @note The result is rounded. (Only the upper q bits are returned.) + */ + static diyfp mul(const diyfp& x, const diyfp& y) noexcept + { + static_assert(kPrecision == 64, "internal error"); + + // Computes: + // f = round((x.f * y.f) / 2^q) + // e = x.e + y.e + q + + // Emulate the 64-bit * 64-bit multiplication: + // + // p = u * v + // = (u_lo + 2^32 u_hi) (v_lo + 2^32 v_hi) + // = (u_lo v_lo ) + 2^32 ((u_lo v_hi ) + (u_hi v_lo )) + 2^64 (u_hi v_hi ) + // = (p0 ) + 2^32 ((p1 ) + (p2 )) + 2^64 (p3 ) + // = (p0_lo + 2^32 p0_hi) + 2^32 ((p1_lo + 2^32 p1_hi) + (p2_lo + 2^32 p2_hi)) + 2^64 (p3 ) + // = (p0_lo ) + 2^32 (p0_hi + p1_lo + p2_lo ) + 2^64 (p1_hi + p2_hi + p3) + // = (p0_lo ) + 2^32 (Q ) + 2^64 (H ) + // = (p0_lo ) + 2^32 (Q_lo + 2^32 Q_hi ) + 2^64 (H ) + // + // (Since Q might be larger than 2^32 - 1) + // + // = (p0_lo + 2^32 Q_lo) + 2^64 (Q_hi + H) + // + // (Q_hi + H does not overflow a 64-bit int) + // + // = p_lo + 2^64 p_hi + + const uint64_t u_lo = x.f & 0xFFFFFFFF; + const uint64_t u_hi = x.f >> 32; + const uint64_t v_lo = y.f & 0xFFFFFFFF; + const uint64_t v_hi = y.f >> 32; + + const uint64_t p0 = u_lo * v_lo; + const uint64_t p1 = u_lo * v_hi; + const uint64_t p2 = u_hi * v_lo; + const uint64_t p3 = u_hi * v_hi; + + const uint64_t p0_hi = p0 >> 32; + const uint64_t p1_lo = p1 & 0xFFFFFFFF; + const uint64_t p1_hi = p1 >> 32; + const uint64_t p2_lo = p2 & 0xFFFFFFFF; + const uint64_t p2_hi = p2 >> 32; + + uint64_t Q = p0_hi + p1_lo + p2_lo; + + // The full product might now be computed as + // + // p_hi = p3 + p2_hi + p1_hi + (Q >> 32) + // p_lo = p0_lo + (Q << 32) + // + // But in this particular case here, the full p_lo is not required. + // Effectively we only need to add the highest bit in p_lo to p_hi (and + // Q_hi + 1 does not overflow). + + Q += uint64_t{1} << (64 - 32 - 1); // round, ties up + + const uint64_t h = p3 + p2_hi + p1_hi + (Q >> 32); + + return {h, x.e + y.e + 64}; + } + + /*! + @brief normalize x such that the significand is >= 2^(q-1) + @pre x.f != 0 + */ + static diyfp normalize(diyfp x) noexcept + { + assert(x.f != 0); + + while ((x.f >> 63) == 0) + { + x.f <<= 1; + x.e--; + } + + return x; + } + + /*! + @brief normalize x such that the result has the exponent E + @pre e >= x.e and the upper e - x.e bits of x.f must be zero. + */ + static diyfp normalize_to(const diyfp& x, const int target_exponent) noexcept + { + const int delta = x.e - target_exponent; + + assert(delta >= 0); + assert(((x.f << delta) >> delta) == x.f); + + return {x.f << delta, target_exponent}; + } +}; + +struct boundaries +{ + diyfp w; + diyfp minus; + diyfp plus; +}; + +/*! +Compute the (normalized) diyfp representing the input number 'value' and its +boundaries. + +@pre value must be finite and positive +*/ +template <typename FloatType> +boundaries compute_boundaries(FloatType value) +{ + assert(std::isfinite(value)); + assert(value > 0); + + // Convert the IEEE representation into a diyfp. + // + // If v is denormal: + // value = 0.F * 2^(1 - bias) = ( F) * 2^(1 - bias - (p-1)) + // If v is normalized: + // value = 1.F * 2^(E - bias) = (2^(p-1) + F) * 2^(E - bias - (p-1)) + + static_assert(std::numeric_limits<FloatType>::is_iec559, + "internal error: dtoa_short requires an IEEE-754 floating-point implementation"); + + constexpr int kPrecision = std::numeric_limits<FloatType>::digits; // = p (includes the hidden bit) + constexpr int kBias = std::numeric_limits<FloatType>::max_exponent - 1 + (kPrecision - 1); + constexpr int kMinExp = 1 - kBias; + constexpr uint64_t kHiddenBit = uint64_t{1} << (kPrecision - 1); // = 2^(p-1) + + using bits_type = typename std::conditional< kPrecision == 24, uint32_t, uint64_t >::type; + + const uint64_t bits = reinterpret_bits<bits_type>(value); + const uint64_t E = bits >> (kPrecision - 1); + const uint64_t F = bits & (kHiddenBit - 1); + + const bool is_denormal = (E == 0); + const diyfp v = is_denormal + ? diyfp(F, kMinExp) + : diyfp(F + kHiddenBit, static_cast<int>(E) - kBias); + + // Compute the boundaries m- and m+ of the floating-point value + // v = f * 2^e. + // + // Determine v- and v+, the floating-point predecessor and successor if v, + // respectively. + // + // v- = v - 2^e if f != 2^(p-1) or e == e_min (A) + // = v - 2^(e-1) if f == 2^(p-1) and e > e_min (B) + // + // v+ = v + 2^e + // + // Let m- = (v- + v) / 2 and m+ = (v + v+) / 2. All real numbers _strictly_ + // between m- and m+ round to v, regardless of how the input rounding + // algorithm breaks ties. + // + // ---+-------------+-------------+-------------+-------------+--- (A) + // v- m- v m+ v+ + // + // -----------------+------+------+-------------+-------------+--- (B) + // v- m- v m+ v+ + + const bool lower_boundary_is_closer = (F == 0 and E > 1); + const diyfp m_plus = diyfp(2 * v.f + 1, v.e - 1); + const diyfp m_minus = lower_boundary_is_closer + ? diyfp(4 * v.f - 1, v.e - 2) // (B) + : diyfp(2 * v.f - 1, v.e - 1); // (A) + + // Determine the normalized w+ = m+. + const diyfp w_plus = diyfp::normalize(m_plus); + + // Determine w- = m- such that e_(w-) = e_(w+). + const diyfp w_minus = diyfp::normalize_to(m_minus, w_plus.e); + + return {diyfp::normalize(v), w_minus, w_plus}; +} + +// Given normalized diyfp w, Grisu needs to find a (normalized) cached +// power-of-ten c, such that the exponent of the product c * w = f * 2^e lies +// within a certain range [alpha, gamma] (Definition 3.2 from [1]) +// +// alpha <= e = e_c + e_w + q <= gamma +// +// or +// +// f_c * f_w * 2^alpha <= f_c 2^(e_c) * f_w 2^(e_w) * 2^q +// <= f_c * f_w * 2^gamma +// +// Since c and w are normalized, i.e. 2^(q-1) <= f < 2^q, this implies +// +// 2^(q-1) * 2^(q-1) * 2^alpha <= c * w * 2^q < 2^q * 2^q * 2^gamma +// +// or +// +// 2^(q - 2 + alpha) <= c * w < 2^(q + gamma) +// +// The choice of (alpha,gamma) determines the size of the table and the form of +// the digit generation procedure. Using (alpha,gamma)=(-60,-32) works out well +// in practice: +// +// The idea is to cut the number c * w = f * 2^e into two parts, which can be +// processed independently: An integral part p1, and a fractional part p2: +// +// f * 2^e = ( (f div 2^-e) * 2^-e + (f mod 2^-e) ) * 2^e +// = (f div 2^-e) + (f mod 2^-e) * 2^e +// = p1 + p2 * 2^e +// +// The conversion of p1 into decimal form requires a series of divisions and +// modulos by (a power of) 10. These operations are faster for 32-bit than for +// 64-bit integers, so p1 should ideally fit into a 32-bit integer. This can be +// achieved by choosing +// +// -e >= 32 or e <= -32 := gamma +// +// In order to convert the fractional part +// +// p2 * 2^e = p2 / 2^-e = d[-1] / 10^1 + d[-2] / 10^2 + ... +// +// into decimal form, the fraction is repeatedly multiplied by 10 and the digits +// d[-i] are extracted in order: +// +// (10 * p2) div 2^-e = d[-1] +// (10 * p2) mod 2^-e = d[-2] / 10^1 + ... +// +// The multiplication by 10 must not overflow. It is sufficient to choose +// +// 10 * p2 < 16 * p2 = 2^4 * p2 <= 2^64. +// +// Since p2 = f mod 2^-e < 2^-e, +// +// -e <= 60 or e >= -60 := alpha + +constexpr int kAlpha = -60; +constexpr int kGamma = -32; + +struct cached_power // c = f * 2^e ~= 10^k +{ + uint64_t f; + int e; + int k; +}; + +/*! +For a normalized diyfp w = f * 2^e, this function returns a (normalized) cached +power-of-ten c = f_c * 2^e_c, such that the exponent of the product w * c +satisfies (Definition 3.2 from [1]) + + alpha <= e_c + e + q <= gamma. +*/ +inline cached_power get_cached_power_for_binary_exponent(int e) +{ + // Now + // + // alpha <= e_c + e + q <= gamma (1) + // ==> f_c * 2^alpha <= c * 2^e * 2^q + // + // and since the c's are normalized, 2^(q-1) <= f_c, + // + // ==> 2^(q - 1 + alpha) <= c * 2^(e + q) + // ==> 2^(alpha - e - 1) <= c + // + // If c were an exakt power of ten, i.e. c = 10^k, one may determine k as + // + // k = ceil( log_10( 2^(alpha - e - 1) ) ) + // = ceil( (alpha - e - 1) * log_10(2) ) + // + // From the paper: + // "In theory the result of the procedure could be wrong since c is rounded, + // and the computation itself is approximated [...]. In practice, however, + // this simple function is sufficient." + // + // For IEEE double precision floating-point numbers converted into + // normalized diyfp's w = f * 2^e, with q = 64, + // + // e >= -1022 (min IEEE exponent) + // -52 (p - 1) + // -52 (p - 1, possibly normalize denormal IEEE numbers) + // -11 (normalize the diyfp) + // = -1137 + // + // and + // + // e <= +1023 (max IEEE exponent) + // -52 (p - 1) + // -11 (normalize the diyfp) + // = 960 + // + // This binary exponent range [-1137,960] results in a decimal exponent + // range [-307,324]. One does not need to store a cached power for each + // k in this range. For each such k it suffices to find a cached power + // such that the exponent of the product lies in [alpha,gamma]. + // This implies that the difference of the decimal exponents of adjacent + // table entries must be less than or equal to + // + // floor( (gamma - alpha) * log_10(2) ) = 8. + // + // (A smaller distance gamma-alpha would require a larger table.) + + // NB: + // Actually this function returns c, such that -60 <= e_c + e + 64 <= -34. + + constexpr int kCachedPowersSize = 79; + constexpr int kCachedPowersMinDecExp = -300; + constexpr int kCachedPowersDecStep = 8; + + static constexpr cached_power kCachedPowers[] = + { + { 0xAB70FE17C79AC6CA, -1060, -300 }, + { 0xFF77B1FCBEBCDC4F, -1034, -292 }, + { 0xBE5691EF416BD60C, -1007, -284 }, + { 0x8DD01FAD907FFC3C, -980, -276 }, + { 0xD3515C2831559A83, -954, -268 }, + { 0x9D71AC8FADA6C9B5, -927, -260 }, + { 0xEA9C227723EE8BCB, -901, -252 }, + { 0xAECC49914078536D, -874, -244 }, + { 0x823C12795DB6CE57, -847, -236 }, + { 0xC21094364DFB5637, -821, -228 }, + { 0x9096EA6F3848984F, -794, -220 }, + { 0xD77485CB25823AC7, -768, -212 }, + { 0xA086CFCD97BF97F4, -741, -204 }, + { 0xEF340A98172AACE5, -715, -196 }, + { 0xB23867FB2A35B28E, -688, -188 }, + { 0x84C8D4DFD2C63F3B, -661, -180 }, + { 0xC5DD44271AD3CDBA, -635, -172 }, + { 0x936B9FCEBB25C996, -608, -164 }, + { 0xDBAC6C247D62A584, -582, -156 }, + { 0xA3AB66580D5FDAF6, -555, -148 }, + { 0xF3E2F893DEC3F126, -529, -140 }, + { 0xB5B5ADA8AAFF80B8, -502, -132 }, + { 0x87625F056C7C4A8B, -475, -124 }, + { 0xC9BCFF6034C13053, -449, -116 }, + { 0x964E858C91BA2655, -422, -108 }, + { 0xDFF9772470297EBD, -396, -100 }, + { 0xA6DFBD9FB8E5B88F, -369, -92 }, + { 0xF8A95FCF88747D94, -343, -84 }, + { 0xB94470938FA89BCF, -316, -76 }, + { 0x8A08F0F8BF0F156B, -289, -68 }, + { 0xCDB02555653131B6, -263, -60 }, + { 0x993FE2C6D07B7FAC, -236, -52 }, + { 0xE45C10C42A2B3B06, -210, -44 }, + { 0xAA242499697392D3, -183, -36 }, + { 0xFD87B5F28300CA0E, -157, -28 }, + { 0xBCE5086492111AEB, -130, -20 }, + { 0x8CBCCC096F5088CC, -103, -12 }, + { 0xD1B71758E219652C, -77, -4 }, + { 0x9C40000000000000, -50, 4 }, + { 0xE8D4A51000000000, -24, 12 }, + { 0xAD78EBC5AC620000, 3, 20 }, + { 0x813F3978F8940984, 30, 28 }, + { 0xC097CE7BC90715B3, 56, 36 }, + { 0x8F7E32CE7BEA5C70, 83, 44 }, + { 0xD5D238A4ABE98068, 109, 52 }, + { 0x9F4F2726179A2245, 136, 60 }, + { 0xED63A231D4C4FB27, 162, 68 }, + { 0xB0DE65388CC8ADA8, 189, 76 }, + { 0x83C7088E1AAB65DB, 216, 84 }, + { 0xC45D1DF942711D9A, 242, 92 }, + { 0x924D692CA61BE758, 269, 100 }, + { 0xDA01EE641A708DEA, 295, 108 }, + { 0xA26DA3999AEF774A, 322, 116 }, + { 0xF209787BB47D6B85, 348, 124 }, + { 0xB454E4A179DD1877, 375, 132 }, + { 0x865B86925B9BC5C2, 402, 140 }, + { 0xC83553C5C8965D3D, 428, 148 }, + { 0x952AB45CFA97A0B3, 455, 156 }, + { 0xDE469FBD99A05FE3, 481, 164 }, + { 0xA59BC234DB398C25, 508, 172 }, + { 0xF6C69A72A3989F5C, 534, 180 }, + { 0xB7DCBF5354E9BECE, 561, 188 }, + { 0x88FCF317F22241E2, 588, 196 }, + { 0xCC20CE9BD35C78A5, 614, 204 }, + { 0x98165AF37B2153DF, 641, 212 }, + { 0xE2A0B5DC971F303A, 667, 220 }, + { 0xA8D9D1535CE3B396, 694, 228 }, + { 0xFB9B7CD9A4A7443C, 720, 236 }, + { 0xBB764C4CA7A44410, 747, 244 }, + { 0x8BAB8EEFB6409C1A, 774, 252 }, + { 0xD01FEF10A657842C, 800, 260 }, + { 0x9B10A4E5E9913129, 827, 268 }, + { 0xE7109BFBA19C0C9D, 853, 276 }, + { 0xAC2820D9623BF429, 880, 284 }, + { 0x80444B5E7AA7CF85, 907, 292 }, + { 0xBF21E44003ACDD2D, 933, 300 }, + { 0x8E679C2F5E44FF8F, 960, 308 }, + { 0xD433179D9C8CB841, 986, 316 }, + { 0x9E19DB92B4E31BA9, 1013, 324 }, + }; + + // This computation gives exactly the same results for k as + // k = ceil((kAlpha - e - 1) * 0.30102999566398114) + // for |e| <= 1500, but doesn't require floating-point operations. + // NB: log_10(2) ~= 78913 / 2^18 + assert(e >= -1500); + assert(e <= 1500); + const int f = kAlpha - e - 1; + const int k = (f * 78913) / (1 << 18) + static_cast<int>(f > 0); + + const int index = (-kCachedPowersMinDecExp + k + (kCachedPowersDecStep - 1)) / kCachedPowersDecStep; + assert(index >= 0); + assert(index < kCachedPowersSize); + static_cast<void>(kCachedPowersSize); // Fix warning. + + const cached_power cached = kCachedPowers[index]; + assert(kAlpha <= cached.e + e + 64); + assert(kGamma >= cached.e + e + 64); + + return cached; +} + +/*! +For n != 0, returns k, such that pow10 := 10^(k-1) <= n < 10^k. +For n == 0, returns 1 and sets pow10 := 1. +*/ +inline int find_largest_pow10(const uint32_t n, uint32_t& pow10) +{ + // LCOV_EXCL_START + if (n >= 1000000000) + { + pow10 = 1000000000; + return 10; + } + // LCOV_EXCL_STOP + else if (n >= 100000000) + { + pow10 = 100000000; + return 9; + } + else if (n >= 10000000) + { + pow10 = 10000000; + return 8; + } + else if (n >= 1000000) + { + pow10 = 1000000; + return 7; + } + else if (n >= 100000) + { + pow10 = 100000; + return 6; + } + else if (n >= 10000) + { + pow10 = 10000; + return 5; + } + else if (n >= 1000) + { + pow10 = 1000; + return 4; + } + else if (n >= 100) + { + pow10 = 100; + return 3; + } + else if (n >= 10) + { + pow10 = 10; + return 2; + } + else + { + pow10 = 1; + return 1; + } +} + +inline void grisu2_round(char* buf, int len, uint64_t dist, uint64_t delta, + uint64_t rest, uint64_t ten_k) +{ + assert(len >= 1); + assert(dist <= delta); + assert(rest <= delta); + assert(ten_k > 0); + + // <--------------------------- delta ----> + // <---- dist ---------> + // --------------[------------------+-------------------]-------------- + // M- w M+ + // + // ten_k + // <------> + // <---- rest ----> + // --------------[------------------+----+--------------]-------------- + // w V + // = buf * 10^k + // + // ten_k represents a unit-in-the-last-place in the decimal representation + // stored in buf. + // Decrement buf by ten_k while this takes buf closer to w. + + // The tests are written in this order to avoid overflow in unsigned + // integer arithmetic. + + while (rest < dist + and delta - rest >= ten_k + and (rest + ten_k < dist or dist - rest > rest + ten_k - dist)) + { + assert(buf[len - 1] != '0'); + buf[len - 1]--; + rest += ten_k; + } +} + +/*! +Generates V = buffer * 10^decimal_exponent, such that M- <= V <= M+. +M- and M+ must be normalized and share the same exponent -60 <= e <= -32. +*/ +inline void grisu2_digit_gen(char* buffer, int& length, int& decimal_exponent, + diyfp M_minus, diyfp w, diyfp M_plus) +{ + static_assert(kAlpha >= -60, "internal error"); + static_assert(kGamma <= -32, "internal error"); + + // Generates the digits (and the exponent) of a decimal floating-point + // number V = buffer * 10^decimal_exponent in the range [M-, M+]. The diyfp's + // w, M- and M+ share the same exponent e, which satisfies alpha <= e <= gamma. + // + // <--------------------------- delta ----> + // <---- dist ---------> + // --------------[------------------+-------------------]-------------- + // M- w M+ + // + // Grisu2 generates the digits of M+ from left to right and stops as soon as + // V is in [M-,M+]. + + assert(M_plus.e >= kAlpha); + assert(M_plus.e <= kGamma); + + uint64_t delta = diyfp::sub(M_plus, M_minus).f; // (significand of (M+ - M-), implicit exponent is e) + uint64_t dist = diyfp::sub(M_plus, w ).f; // (significand of (M+ - w ), implicit exponent is e) + + // Split M+ = f * 2^e into two parts p1 and p2 (note: e < 0): + // + // M+ = f * 2^e + // = ((f div 2^-e) * 2^-e + (f mod 2^-e)) * 2^e + // = ((p1 ) * 2^-e + (p2 )) * 2^e + // = p1 + p2 * 2^e + + const diyfp one(uint64_t{1} << -M_plus.e, M_plus.e); + + auto p1 = static_cast<uint32_t>(M_plus.f >> -one.e); // p1 = f div 2^-e (Since -e >= 32, p1 fits into a 32-bit int.) + uint64_t p2 = M_plus.f & (one.f - 1); // p2 = f mod 2^-e + + // 1) + // + // Generate the digits of the integral part p1 = d[n-1]...d[1]d[0] + + assert(p1 > 0); + + uint32_t pow10; + const int k = find_largest_pow10(p1, pow10); + + // 10^(k-1) <= p1 < 10^k, pow10 = 10^(k-1) + // + // p1 = (p1 div 10^(k-1)) * 10^(k-1) + (p1 mod 10^(k-1)) + // = (d[k-1] ) * 10^(k-1) + (p1 mod 10^(k-1)) + // + // M+ = p1 + p2 * 2^e + // = d[k-1] * 10^(k-1) + (p1 mod 10^(k-1)) + p2 * 2^e + // = d[k-1] * 10^(k-1) + ((p1 mod 10^(k-1)) * 2^-e + p2) * 2^e + // = d[k-1] * 10^(k-1) + ( rest) * 2^e + // + // Now generate the digits d[n] of p1 from left to right (n = k-1,...,0) + // + // p1 = d[k-1]...d[n] * 10^n + d[n-1]...d[0] + // + // but stop as soon as + // + // rest * 2^e = (d[n-1]...d[0] * 2^-e + p2) * 2^e <= delta * 2^e + + int n = k; + while (n > 0) + { + // Invariants: + // M+ = buffer * 10^n + (p1 + p2 * 2^e) (buffer = 0 for n = k) + // pow10 = 10^(n-1) <= p1 < 10^n + // + const uint32_t d = p1 / pow10; // d = p1 div 10^(n-1) + const uint32_t r = p1 % pow10; // r = p1 mod 10^(n-1) + // + // M+ = buffer * 10^n + (d * 10^(n-1) + r) + p2 * 2^e + // = (buffer * 10 + d) * 10^(n-1) + (r + p2 * 2^e) + // + assert(d <= 9); + buffer[length++] = static_cast<char>('0' + d); // buffer := buffer * 10 + d + // + // M+ = buffer * 10^(n-1) + (r + p2 * 2^e) + // + p1 = r; + n--; + // + // M+ = buffer * 10^n + (p1 + p2 * 2^e) + // pow10 = 10^n + // + + // Now check if enough digits have been generated. + // Compute + // + // p1 + p2 * 2^e = (p1 * 2^-e + p2) * 2^e = rest * 2^e + // + // Note: + // Since rest and delta share the same exponent e, it suffices to + // compare the significands. + const uint64_t rest = (uint64_t{p1} << -one.e) + p2; + if (rest <= delta) + { + // V = buffer * 10^n, with M- <= V <= M+. + + decimal_exponent += n; + + // We may now just stop. But instead look if the buffer could be + // decremented to bring V closer to w. + // + // pow10 = 10^n is now 1 ulp in the decimal representation V. + // The rounding procedure works with diyfp's with an implicit + // exponent of e. + // + // 10^n = (10^n * 2^-e) * 2^e = ulp * 2^e + // + const uint64_t ten_n = uint64_t{pow10} << -one.e; + grisu2_round(buffer, length, dist, delta, rest, ten_n); + + return; + } + + pow10 /= 10; + // + // pow10 = 10^(n-1) <= p1 < 10^n + // Invariants restored. + } + + // 2) + // + // The digits of the integral part have been generated: + // + // M+ = d[k-1]...d[1]d[0] + p2 * 2^e + // = buffer + p2 * 2^e + // + // Now generate the digits of the fractional part p2 * 2^e. + // + // Note: + // No decimal point is generated: the exponent is adjusted instead. + // + // p2 actually represents the fraction + // + // p2 * 2^e + // = p2 / 2^-e + // = d[-1] / 10^1 + d[-2] / 10^2 + ... + // + // Now generate the digits d[-m] of p1 from left to right (m = 1,2,...) + // + // p2 * 2^e = d[-1]d[-2]...d[-m] * 10^-m + // + 10^-m * (d[-m-1] / 10^1 + d[-m-2] / 10^2 + ...) + // + // using + // + // 10^m * p2 = ((10^m * p2) div 2^-e) * 2^-e + ((10^m * p2) mod 2^-e) + // = ( d) * 2^-e + ( r) + // + // or + // 10^m * p2 * 2^e = d + r * 2^e + // + // i.e. + // + // M+ = buffer + p2 * 2^e + // = buffer + 10^-m * (d + r * 2^e) + // = (buffer * 10^m + d) * 10^-m + 10^-m * r * 2^e + // + // and stop as soon as 10^-m * r * 2^e <= delta * 2^e + + assert(p2 > delta); + + int m = 0; + for (;;) + { + // Invariant: + // M+ = buffer * 10^-m + 10^-m * (d[-m-1] / 10 + d[-m-2] / 10^2 + ...) * 2^e + // = buffer * 10^-m + 10^-m * (p2 ) * 2^e + // = buffer * 10^-m + 10^-m * (1/10 * (10 * p2) ) * 2^e + // = buffer * 10^-m + 10^-m * (1/10 * ((10*p2 div 2^-e) * 2^-e + (10*p2 mod 2^-e)) * 2^e + // + assert(p2 <= UINT64_MAX / 10); + p2 *= 10; + const uint64_t d = p2 >> -one.e; // d = (10 * p2) div 2^-e + const uint64_t r = p2 & (one.f - 1); // r = (10 * p2) mod 2^-e + // + // M+ = buffer * 10^-m + 10^-m * (1/10 * (d * 2^-e + r) * 2^e + // = buffer * 10^-m + 10^-m * (1/10 * (d + r * 2^e)) + // = (buffer * 10 + d) * 10^(-m-1) + 10^(-m-1) * r * 2^e + // + assert(d <= 9); + buffer[length++] = static_cast<char>('0' + d); // buffer := buffer * 10 + d + // + // M+ = buffer * 10^(-m-1) + 10^(-m-1) * r * 2^e + // + p2 = r; + m++; + // + // M+ = buffer * 10^-m + 10^-m * p2 * 2^e + // Invariant restored. + + // Check if enough digits have been generated. + // + // 10^-m * p2 * 2^e <= delta * 2^e + // p2 * 2^e <= 10^m * delta * 2^e + // p2 <= 10^m * delta + delta *= 10; + dist *= 10; + if (p2 <= delta) + { + break; + } + } + + // V = buffer * 10^-m, with M- <= V <= M+. + + decimal_exponent -= m; + + // 1 ulp in the decimal representation is now 10^-m. + // Since delta and dist are now scaled by 10^m, we need to do the + // same with ulp in order to keep the units in sync. + // + // 10^m * 10^-m = 1 = 2^-e * 2^e = ten_m * 2^e + // + const uint64_t ten_m = one.f; + grisu2_round(buffer, length, dist, delta, p2, ten_m); + + // By construction this algorithm generates the shortest possible decimal + // number (Loitsch, Theorem 6.2) which rounds back to w. + // For an input number of precision p, at least + // + // N = 1 + ceil(p * log_10(2)) + // + // decimal digits are sufficient to identify all binary floating-point + // numbers (Matula, "In-and-Out conversions"). + // This implies that the algorithm does not produce more than N decimal + // digits. + // + // N = 17 for p = 53 (IEEE double precision) + // N = 9 for p = 24 (IEEE single precision) +} + +/*! +v = buf * 10^decimal_exponent +len is the length of the buffer (number of decimal digits) +The buffer must be large enough, i.e. >= max_digits10. +*/ +inline void grisu2(char* buf, int& len, int& decimal_exponent, + diyfp m_minus, diyfp v, diyfp m_plus) +{ + assert(m_plus.e == m_minus.e); + assert(m_plus.e == v.e); + + // --------(-----------------------+-----------------------)-------- (A) + // m- v m+ + // + // --------------------(-----------+-----------------------)-------- (B) + // m- v m+ + // + // First scale v (and m- and m+) such that the exponent is in the range + // [alpha, gamma]. + + const cached_power cached = get_cached_power_for_binary_exponent(m_plus.e); + + const diyfp c_minus_k(cached.f, cached.e); // = c ~= 10^-k + + // The exponent of the products is = v.e + c_minus_k.e + q and is in the range [alpha,gamma] + const diyfp w = diyfp::mul(v, c_minus_k); + const diyfp w_minus = diyfp::mul(m_minus, c_minus_k); + const diyfp w_plus = diyfp::mul(m_plus, c_minus_k); + + // ----(---+---)---------------(---+---)---------------(---+---)---- + // w- w w+ + // = c*m- = c*v = c*m+ + // + // diyfp::mul rounds its result and c_minus_k is approximated too. w, w- and + // w+ are now off by a small amount. + // In fact: + // + // w - v * 10^k < 1 ulp + // + // To account for this inaccuracy, add resp. subtract 1 ulp. + // + // --------+---[---------------(---+---)---------------]---+-------- + // w- M- w M+ w+ + // + // Now any number in [M-, M+] (bounds included) will round to w when input, + // regardless of how the input rounding algorithm breaks ties. + // + // And digit_gen generates the shortest possible such number in [M-, M+]. + // Note that this does not mean that Grisu2 always generates the shortest + // possible number in the interval (m-, m+). + const diyfp M_minus(w_minus.f + 1, w_minus.e); + const diyfp M_plus (w_plus.f - 1, w_plus.e ); + + decimal_exponent = -cached.k; // = -(-k) = k + + grisu2_digit_gen(buf, len, decimal_exponent, M_minus, w, M_plus); +} + +/*! +v = buf * 10^decimal_exponent +len is the length of the buffer (number of decimal digits) +The buffer must be large enough, i.e. >= max_digits10. +*/ +template <typename FloatType> +void grisu2(char* buf, int& len, int& decimal_exponent, FloatType value) +{ + static_assert(diyfp::kPrecision >= std::numeric_limits<FloatType>::digits + 3, + "internal error: not enough precision"); + + assert(std::isfinite(value)); + assert(value > 0); + + // If the neighbors (and boundaries) of 'value' are always computed for double-precision + // numbers, all float's can be recovered using strtod (and strtof). However, the resulting + // decimal representations are not exactly "short". + // + // The documentation for 'std::to_chars' (https://en.cppreference.com/w/cpp/utility/to_chars) + // says "value is converted to a string as if by std::sprintf in the default ("C") locale" + // and since sprintf promotes float's to double's, I think this is exactly what 'std::to_chars' + // does. + // On the other hand, the documentation for 'std::to_chars' requires that "parsing the + // representation using the corresponding std::from_chars function recovers value exactly". That + // indicates that single precision floating-point numbers should be recovered using + // 'std::strtof'. + // + // NB: If the neighbors are computed for single-precision numbers, there is a single float + // (7.0385307e-26f) which can't be recovered using strtod. The resulting double precision + // value is off by 1 ulp. +#if 0 + const boundaries w = compute_boundaries(static_cast<double>(value)); +#else + const boundaries w = compute_boundaries(value); +#endif + + grisu2(buf, len, decimal_exponent, w.minus, w.w, w.plus); +} + +/*! +@brief appends a decimal representation of e to buf +@return a pointer to the element following the exponent. +@pre -1000 < e < 1000 +*/ +inline char* append_exponent(char* buf, int e) +{ + assert(e > -1000); + assert(e < 1000); + + if (e < 0) + { + e = -e; + *buf++ = '-'; + } + else + { + *buf++ = '+'; + } + + auto k = static_cast<uint32_t>(e); + if (k < 10) + { + // Always print at least two digits in the exponent. + // This is for compatibility with printf("%g"). + *buf++ = '0'; + *buf++ = static_cast<char>('0' + k); + } + else if (k < 100) + { + *buf++ = static_cast<char>('0' + k / 10); + k %= 10; + *buf++ = static_cast<char>('0' + k); + } + else + { + *buf++ = static_cast<char>('0' + k / 100); + k %= 100; + *buf++ = static_cast<char>('0' + k / 10); + k %= 10; + *buf++ = static_cast<char>('0' + k); + } + + return buf; +} + +/*! +@brief prettify v = buf * 10^decimal_exponent + +If v is in the range [10^min_exp, 10^max_exp) it will be printed in fixed-point +notation. Otherwise it will be printed in exponential notation. + +@pre min_exp < 0 +@pre max_exp > 0 +*/ +inline char* format_buffer(char* buf, int len, int decimal_exponent, + int min_exp, int max_exp) +{ + assert(min_exp < 0); + assert(max_exp > 0); + + const int k = len; + const int n = len + decimal_exponent; + + // v = buf * 10^(n-k) + // k is the length of the buffer (number of decimal digits) + // n is the position of the decimal point relative to the start of the buffer. + + if (k <= n and n <= max_exp) + { + // digits[000] + // len <= max_exp + 2 + + std::memset(buf + k, '0', static_cast<size_t>(n - k)); + // Make it look like a floating-point number (#362, #378) + buf[n + 0] = '.'; + buf[n + 1] = '0'; + return buf + (n + 2); + } + + if (0 < n and n <= max_exp) + { + // dig.its + // len <= max_digits10 + 1 + + assert(k > n); + + std::memmove(buf + (n + 1), buf + n, static_cast<size_t>(k - n)); + buf[n] = '.'; + return buf + (k + 1); + } + + if (min_exp < n and n <= 0) + { + // 0.[000]digits + // len <= 2 + (-min_exp - 1) + max_digits10 + + std::memmove(buf + (2 + -n), buf, static_cast<size_t>(k)); + buf[0] = '0'; + buf[1] = '.'; + std::memset(buf + 2, '0', static_cast<size_t>(-n)); + return buf + (2 + (-n) + k); + } + + if (k == 1) + { + // dE+123 + // len <= 1 + 5 + + buf += 1; + } + else + { + // d.igitsE+123 + // len <= max_digits10 + 1 + 5 + + std::memmove(buf + 2, buf + 1, static_cast<size_t>(k - 1)); + buf[1] = '.'; + buf += 1 + k; + } + + *buf++ = 'e'; + return append_exponent(buf, n - 1); +} + +} // namespace dtoa_impl + +/*! +@brief generates a decimal representation of the floating-point number value in [first, last). + +The format of the resulting decimal representation is similar to printf's %g +format. Returns an iterator pointing past-the-end of the decimal representation. + +@note The input number must be finite, i.e. NaN's and Inf's are not supported. +@note The buffer must be large enough. +@note The result is NOT null-terminated. +*/ +template <typename FloatType> +char* to_chars(char* first, const char* last, FloatType value) +{ + static_cast<void>(last); // maybe unused - fix warning + assert(std::isfinite(value)); + + // Use signbit(value) instead of (value < 0) since signbit works for -0. + if (std::signbit(value)) + { + value = -value; + *first++ = '-'; + } + + if (value == 0) // +-0 + { + *first++ = '0'; + // Make it look like a floating-point number (#362, #378) + *first++ = '.'; + *first++ = '0'; + return first; + } + + assert(last - first >= std::numeric_limits<FloatType>::max_digits10); + + // Compute v = buffer * 10^decimal_exponent. + // The decimal digits are stored in the buffer, which needs to be interpreted + // as an unsigned decimal integer. + // len is the length of the buffer, i.e. the number of decimal digits. + int len = 0; + int decimal_exponent = 0; + dtoa_impl::grisu2(first, len, decimal_exponent, value); + + assert(len <= std::numeric_limits<FloatType>::max_digits10); + + // Format the buffer like printf("%.*g", prec, value) + constexpr int kMinExp = -4; + // Use digits10 here to increase compatibility with version 2. + constexpr int kMaxExp = std::numeric_limits<FloatType>::digits10; + + assert(last - first >= kMaxExp + 2); + assert(last - first >= 2 + (-kMinExp - 1) + std::numeric_limits<FloatType>::max_digits10); + assert(last - first >= std::numeric_limits<FloatType>::max_digits10 + 6); + + return dtoa_impl::format_buffer(first, len, decimal_exponent, kMinExp, kMaxExp); +} + +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/meta/cpp_future.hpp> + +// #include <nlohmann/detail/output/binary_writer.hpp> + +// #include <nlohmann/detail/output/output_adapters.hpp> + +// #include <nlohmann/detail/value_t.hpp> + + +namespace nlohmann +{ +namespace detail +{ +/////////////////// +// serialization // +/////////////////// + +/// how to treat decoding errors +enum class error_handler_t +{ + strict, ///< throw a type_error exception in case of invalid UTF-8 + replace, ///< replace invalid UTF-8 sequences with U+FFFD + ignore ///< ignore invalid UTF-8 sequences +}; + +template<typename BasicJsonType> +class serializer +{ + using string_t = typename BasicJsonType::string_t; + using number_float_t = typename BasicJsonType::number_float_t; + using number_integer_t = typename BasicJsonType::number_integer_t; + using number_unsigned_t = typename BasicJsonType::number_unsigned_t; + static constexpr uint8_t UTF8_ACCEPT = 0; + static constexpr uint8_t UTF8_REJECT = 1; + + public: + /*! + @param[in] s output stream to serialize to + @param[in] ichar indentation character to use + @param[in] error_handler_ how to react on decoding errors + */ + serializer(output_adapter_t<char> s, const char ichar, + error_handler_t error_handler_ = error_handler_t::strict) + : o(std::move(s)) + , loc(std::localeconv()) + , thousands_sep(loc->thousands_sep == nullptr ? '\0' : * (loc->thousands_sep)) + , decimal_point(loc->decimal_point == nullptr ? '\0' : * (loc->decimal_point)) + , indent_char(ichar) + , indent_string(512, indent_char) + , error_handler(error_handler_) + {} + + // delete because of pointer members + serializer(const serializer&) = delete; + serializer& operator=(const serializer&) = delete; + serializer(serializer&&) = delete; + serializer& operator=(serializer&&) = delete; + ~serializer() = default; + + /*! + @brief internal implementation of the serialization function + + This function is called by the public member function dump and organizes + the serialization internally. The indentation level is propagated as + additional parameter. In case of arrays and objects, the function is + called recursively. + + - strings and object keys are escaped using `escape_string()` + - integer numbers are converted implicitly via `operator<<` + - floating-point numbers are converted to a string using `"%g"` format + + @param[in] val value to serialize + @param[in] pretty_print whether the output shall be pretty-printed + @param[in] indent_step the indent level + @param[in] current_indent the current indent level (only used internally) + */ + void dump(const BasicJsonType& val, const bool pretty_print, + const bool ensure_ascii, + const unsigned int indent_step, + const unsigned int current_indent = 0) + { + switch (val.m_type) + { + case value_t::object: + { + if (val.m_value.object->empty()) + { + o->write_characters("{}", 2); + return; + } + + if (pretty_print) + { + o->write_characters("{\n", 2); + + // variable to hold indentation for recursive calls + const auto new_indent = current_indent + indent_step; + if (JSON_UNLIKELY(indent_string.size() < new_indent)) + { + indent_string.resize(indent_string.size() * 2, ' '); + } + + // first n-1 elements + auto i = val.m_value.object->cbegin(); + for (std::size_t cnt = 0; cnt < val.m_value.object->size() - 1; ++cnt, ++i) + { + o->write_characters(indent_string.c_str(), new_indent); + o->write_character('\"'); + dump_escaped(i->first, ensure_ascii); + o->write_characters("\": ", 3); + dump(i->second, true, ensure_ascii, indent_step, new_indent); + o->write_characters(",\n", 2); + } + + // last element + assert(i != val.m_value.object->cend()); + assert(std::next(i) == val.m_value.object->cend()); + o->write_characters(indent_string.c_str(), new_indent); + o->write_character('\"'); + dump_escaped(i->first, ensure_ascii); + o->write_characters("\": ", 3); + dump(i->second, true, ensure_ascii, indent_step, new_indent); + + o->write_character('\n'); + o->write_characters(indent_string.c_str(), current_indent); + o->write_character('}'); + } + else + { + o->write_character('{'); + + // first n-1 elements + auto i = val.m_value.object->cbegin(); + for (std::size_t cnt = 0; cnt < val.m_value.object->size() - 1; ++cnt, ++i) + { + o->write_character('\"'); + dump_escaped(i->first, ensure_ascii); + o->write_characters("\":", 2); + dump(i->second, false, ensure_ascii, indent_step, current_indent); + o->write_character(','); + } + + // last element + assert(i != val.m_value.object->cend()); + assert(std::next(i) == val.m_value.object->cend()); + o->write_character('\"'); + dump_escaped(i->first, ensure_ascii); + o->write_characters("\":", 2); + dump(i->second, false, ensure_ascii, indent_step, current_indent); + + o->write_character('}'); + } + + return; + } + + case value_t::array: + { + if (val.m_value.array->empty()) + { + o->write_characters("[]", 2); + return; + } + + if (pretty_print) + { + o->write_characters("[\n", 2); + + // variable to hold indentation for recursive calls + const auto new_indent = current_indent + indent_step; + if (JSON_UNLIKELY(indent_string.size() < new_indent)) + { + indent_string.resize(indent_string.size() * 2, ' '); + } + + // first n-1 elements + for (auto i = val.m_value.array->cbegin(); + i != val.m_value.array->cend() - 1; ++i) + { + o->write_characters(indent_string.c_str(), new_indent); + dump(*i, true, ensure_ascii, indent_step, new_indent); + o->write_characters(",\n", 2); + } + + // last element + assert(not val.m_value.array->empty()); + o->write_characters(indent_string.c_str(), new_indent); + dump(val.m_value.array->back(), true, ensure_ascii, indent_step, new_indent); + + o->write_character('\n'); + o->write_characters(indent_string.c_str(), current_indent); + o->write_character(']'); + } + else + { + o->write_character('['); + + // first n-1 elements + for (auto i = val.m_value.array->cbegin(); + i != val.m_value.array->cend() - 1; ++i) + { + dump(*i, false, ensure_ascii, indent_step, current_indent); + o->write_character(','); + } + + // last element + assert(not val.m_value.array->empty()); + dump(val.m_value.array->back(), false, ensure_ascii, indent_step, current_indent); + + o->write_character(']'); + } + + return; + } + + case value_t::string: + { + o->write_character('\"'); + dump_escaped(*val.m_value.string, ensure_ascii); + o->write_character('\"'); + return; + } + + case value_t::boolean: + { + if (val.m_value.boolean) + { + o->write_characters("true", 4); + } + else + { + o->write_characters("false", 5); + } + return; + } + + case value_t::number_integer: + { + dump_integer(val.m_value.number_integer); + return; + } + + case value_t::number_unsigned: + { + dump_integer(val.m_value.number_unsigned); + return; + } + + case value_t::number_float: + { + dump_float(val.m_value.number_float); + return; + } + + case value_t::discarded: + { + o->write_characters("<discarded>", 11); + return; + } + + case value_t::null: + { + o->write_characters("null", 4); + return; + } + } + } + + private: + /*! + @brief dump escaped string + + Escape a string by replacing certain special characters by a sequence of an + escape character (backslash) and another character and other control + characters by a sequence of "\u" followed by a four-digit hex + representation. The escaped string is written to output stream @a o. + + @param[in] s the string to escape + @param[in] ensure_ascii whether to escape non-ASCII characters with + \uXXXX sequences + + @complexity Linear in the length of string @a s. + */ + void dump_escaped(const string_t& s, const bool ensure_ascii) + { + uint32_t codepoint; + uint8_t state = UTF8_ACCEPT; + std::size_t bytes = 0; // number of bytes written to string_buffer + + // number of bytes written at the point of the last valid byte + std::size_t bytes_after_last_accept = 0; + std::size_t undumped_chars = 0; + + for (std::size_t i = 0; i < s.size(); ++i) + { + const auto byte = static_cast<uint8_t>(s[i]); + + switch (decode(state, codepoint, byte)) + { + case UTF8_ACCEPT: // decode found a new code point + { + switch (codepoint) + { + case 0x08: // backspace + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = 'b'; + break; + } + + case 0x09: // horizontal tab + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = 't'; + break; + } + + case 0x0A: // newline + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = 'n'; + break; + } + + case 0x0C: // formfeed + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = 'f'; + break; + } + + case 0x0D: // carriage return + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = 'r'; + break; + } + + case 0x22: // quotation mark + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = '\"'; + break; + } + + case 0x5C: // reverse solidus + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = '\\'; + break; + } + + default: + { + // escape control characters (0x00..0x1F) or, if + // ensure_ascii parameter is used, non-ASCII characters + if ((codepoint <= 0x1F) or (ensure_ascii and (codepoint >= 0x7F))) + { + if (codepoint <= 0xFFFF) + { + (std::snprintf)(string_buffer.data() + bytes, 7, "\\u%04x", + static_cast<uint16_t>(codepoint)); + bytes += 6; + } + else + { + (std::snprintf)(string_buffer.data() + bytes, 13, "\\u%04x\\u%04x", + static_cast<uint16_t>(0xD7C0 + (codepoint >> 10)), + static_cast<uint16_t>(0xDC00 + (codepoint & 0x3FF))); + bytes += 12; + } + } + else + { + // copy byte to buffer (all previous bytes + // been copied have in default case above) + string_buffer[bytes++] = s[i]; + } + break; + } + } + + // write buffer and reset index; there must be 13 bytes + // left, as this is the maximal number of bytes to be + // written ("\uxxxx\uxxxx\0") for one code point + if (string_buffer.size() - bytes < 13) + { + o->write_characters(string_buffer.data(), bytes); + bytes = 0; + } + + // remember the byte position of this accept + bytes_after_last_accept = bytes; + undumped_chars = 0; + break; + } + + case UTF8_REJECT: // decode found invalid UTF-8 byte + { + switch (error_handler) + { + case error_handler_t::strict: + { + std::string sn(3, '\0'); + (std::snprintf)(&sn[0], sn.size(), "%.2X", byte); + JSON_THROW(type_error::create(316, "invalid UTF-8 byte at index " + std::to_string(i) + ": 0x" + sn)); + } + + case error_handler_t::ignore: + case error_handler_t::replace: + { + // in case we saw this character the first time, we + // would like to read it again, because the byte + // may be OK for itself, but just not OK for the + // previous sequence + if (undumped_chars > 0) + { + --i; + } + + // reset length buffer to the last accepted index; + // thus removing/ignoring the invalid characters + bytes = bytes_after_last_accept; + + if (error_handler == error_handler_t::replace) + { + // add a replacement character + if (ensure_ascii) + { + string_buffer[bytes++] = '\\'; + string_buffer[bytes++] = 'u'; + string_buffer[bytes++] = 'f'; + string_buffer[bytes++] = 'f'; + string_buffer[bytes++] = 'f'; + string_buffer[bytes++] = 'd'; + } + else + { + string_buffer[bytes++] = detail::binary_writer<BasicJsonType, char>::to_char_type('\xEF'); + string_buffer[bytes++] = detail::binary_writer<BasicJsonType, char>::to_char_type('\xBF'); + string_buffer[bytes++] = detail::binary_writer<BasicJsonType, char>::to_char_type('\xBD'); + } + bytes_after_last_accept = bytes; + } + + undumped_chars = 0; + + // continue processing the string + state = UTF8_ACCEPT; + break; + } + } + break; + } + + default: // decode found yet incomplete multi-byte code point + { + if (not ensure_ascii) + { + // code point will not be escaped - copy byte to buffer + string_buffer[bytes++] = s[i]; + } + ++undumped_chars; + break; + } + } + } + + // we finished processing the string + if (JSON_LIKELY(state == UTF8_ACCEPT)) + { + // write buffer + if (bytes > 0) + { + o->write_characters(string_buffer.data(), bytes); + } + } + else + { + // we finish reading, but do not accept: string was incomplete + switch (error_handler) + { + case error_handler_t::strict: + { + std::string sn(3, '\0'); + (std::snprintf)(&sn[0], sn.size(), "%.2X", static_cast<uint8_t>(s.back())); + JSON_THROW(type_error::create(316, "incomplete UTF-8 string; last byte: 0x" + sn)); + } + + case error_handler_t::ignore: + { + // write all accepted bytes + o->write_characters(string_buffer.data(), bytes_after_last_accept); + break; + } + + case error_handler_t::replace: + { + // write all accepted bytes + o->write_characters(string_buffer.data(), bytes_after_last_accept); + // add a replacement character + if (ensure_ascii) + { + o->write_characters("\\ufffd", 6); + } + else + { + o->write_characters("\xEF\xBF\xBD", 3); + } + break; + } + } + } + } + + /*! + @brief dump an integer + + Dump a given integer to output stream @a o. Works internally with + @a number_buffer. + + @param[in] x integer number (signed or unsigned) to dump + @tparam NumberType either @a number_integer_t or @a number_unsigned_t + */ + template<typename NumberType, detail::enable_if_t< + std::is_same<NumberType, number_unsigned_t>::value or + std::is_same<NumberType, number_integer_t>::value, + int> = 0> + void dump_integer(NumberType x) + { + // special case for "0" + if (x == 0) + { + o->write_character('0'); + return; + } + + const bool is_negative = std::is_same<NumberType, number_integer_t>::value and not (x >= 0); // see issue #755 + std::size_t i = 0; + + while (x != 0) + { + // spare 1 byte for '\0' + assert(i < number_buffer.size() - 1); + + const auto digit = std::labs(static_cast<long>(x % 10)); + number_buffer[i++] = static_cast<char>('0' + digit); + x /= 10; + } + + if (is_negative) + { + // make sure there is capacity for the '-' + assert(i < number_buffer.size() - 2); + number_buffer[i++] = '-'; + } + + std::reverse(number_buffer.begin(), number_buffer.begin() + i); + o->write_characters(number_buffer.data(), i); + } + + /*! + @brief dump a floating-point number + + Dump a given floating-point number to output stream @a o. Works internally + with @a number_buffer. + + @param[in] x floating-point number to dump + */ + void dump_float(number_float_t x) + { + // NaN / inf + if (not std::isfinite(x)) + { + o->write_characters("null", 4); + return; + } + + // If number_float_t is an IEEE-754 single or double precision number, + // use the Grisu2 algorithm to produce short numbers which are + // guaranteed to round-trip, using strtof and strtod, resp. + // + // NB: The test below works if <long double> == <double>. + static constexpr bool is_ieee_single_or_double + = (std::numeric_limits<number_float_t>::is_iec559 and std::numeric_limits<number_float_t>::digits == 24 and std::numeric_limits<number_float_t>::max_exponent == 128) or + (std::numeric_limits<number_float_t>::is_iec559 and std::numeric_limits<number_float_t>::digits == 53 and std::numeric_limits<number_float_t>::max_exponent == 1024); + + dump_float(x, std::integral_constant<bool, is_ieee_single_or_double>()); + } + + void dump_float(number_float_t x, std::true_type /*is_ieee_single_or_double*/) + { + char* begin = number_buffer.data(); + char* end = ::nlohmann::detail::to_chars(begin, begin + number_buffer.size(), x); + + o->write_characters(begin, static_cast<size_t>(end - begin)); + } + + void dump_float(number_float_t x, std::false_type /*is_ieee_single_or_double*/) + { + // get number of digits for a float -> text -> float round-trip + static constexpr auto d = std::numeric_limits<number_float_t>::max_digits10; + + // the actual conversion + std::ptrdiff_t len = (std::snprintf)(number_buffer.data(), number_buffer.size(), "%.*g", d, x); + + // negative value indicates an error + assert(len > 0); + // check if buffer was large enough + assert(static_cast<std::size_t>(len) < number_buffer.size()); + + // erase thousands separator + if (thousands_sep != '\0') + { + const auto end = std::remove(number_buffer.begin(), + number_buffer.begin() + len, thousands_sep); + std::fill(end, number_buffer.end(), '\0'); + assert((end - number_buffer.begin()) <= len); + len = (end - number_buffer.begin()); + } + + // convert decimal point to '.' + if (decimal_point != '\0' and decimal_point != '.') + { + const auto dec_pos = std::find(number_buffer.begin(), number_buffer.end(), decimal_point); + if (dec_pos != number_buffer.end()) + { + *dec_pos = '.'; + } + } + + o->write_characters(number_buffer.data(), static_cast<std::size_t>(len)); + + // determine if need to append ".0" + const bool value_is_int_like = + std::none_of(number_buffer.begin(), number_buffer.begin() + len + 1, + [](char c) + { + return (c == '.' or c == 'e'); + }); + + if (value_is_int_like) + { + o->write_characters(".0", 2); + } + } + + /*! + @brief check whether a string is UTF-8 encoded + + The function checks each byte of a string whether it is UTF-8 encoded. The + result of the check is stored in the @a state parameter. The function must + be called initially with state 0 (accept). State 1 means the string must + be rejected, because the current byte is not allowed. If the string is + completely processed, but the state is non-zero, the string ended + prematurely; that is, the last byte indicated more bytes should have + followed. + + @param[in,out] state the state of the decoding + @param[in,out] codep codepoint (valid only if resulting state is UTF8_ACCEPT) + @param[in] byte next byte to decode + @return new state + + @note The function has been edited: a std::array is used. + + @copyright Copyright (c) 2008-2009 Bjoern Hoehrmann <bjoern@hoehrmann.de> + @sa http://bjoern.hoehrmann.de/utf-8/decoder/dfa/ + */ + static uint8_t decode(uint8_t& state, uint32_t& codep, const uint8_t byte) noexcept + { + static const std::array<uint8_t, 400> utf8d = + { + { + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 00..1F + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 20..3F + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 40..5F + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 60..7F + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, // 80..9F + 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, // A0..BF + 8, 8, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, // C0..DF + 0xA, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x3, 0x4, 0x3, 0x3, // E0..EF + 0xB, 0x6, 0x6, 0x6, 0x5, 0x8, 0x8, 0x8, 0x8, 0x8, 0x8, 0x8, 0x8, 0x8, 0x8, 0x8, // F0..FF + 0x0, 0x1, 0x2, 0x3, 0x5, 0x8, 0x7, 0x1, 0x1, 0x1, 0x4, 0x6, 0x1, 0x1, 0x1, 0x1, // s0..s0 + 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, // s1..s2 + 1, 2, 1, 1, 1, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, // s3..s4 + 1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3, 1, 3, 1, 1, 1, 1, 1, 1, // s5..s6 + 1, 3, 1, 1, 1, 1, 1, 3, 1, 3, 1, 1, 1, 1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 // s7..s8 + } + }; + + const uint8_t type = utf8d[byte]; + + codep = (state != UTF8_ACCEPT) + ? (byte & 0x3fu) | (codep << 6) + : static_cast<uint32_t>(0xff >> type) & (byte); + + state = utf8d[256u + state * 16u + type]; + return state; + } + + private: + /// the output of the serializer + output_adapter_t<char> o = nullptr; + + /// a (hopefully) large enough character buffer + std::array<char, 64> number_buffer{{}}; + + /// the locale + const std::lconv* loc = nullptr; + /// the locale's thousand separator character + const char thousands_sep = '\0'; + /// the locale's decimal point character + const char decimal_point = '\0'; + + /// string buffer + std::array<char, 512> string_buffer{{}}; + + /// the indentation character + const char indent_char; + /// the indentation string + string_t indent_string; + + /// error_handler how to react on decoding errors + const error_handler_t error_handler; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/json_ref.hpp> + + +#include <initializer_list> +#include <utility> + +// #include <nlohmann/detail/meta/type_traits.hpp> + + +namespace nlohmann +{ +namespace detail +{ +template<typename BasicJsonType> +class json_ref +{ + public: + using value_type = BasicJsonType; + + json_ref(value_type&& value) + : owned_value(std::move(value)), value_ref(&owned_value), is_rvalue(true) + {} + + json_ref(const value_type& value) + : value_ref(const_cast<value_type*>(&value)), is_rvalue(false) + {} + + json_ref(std::initializer_list<json_ref> init) + : owned_value(init), value_ref(&owned_value), is_rvalue(true) + {} + + template < + class... Args, + enable_if_t<std::is_constructible<value_type, Args...>::value, int> = 0 > + json_ref(Args && ... args) + : owned_value(std::forward<Args>(args)...), value_ref(&owned_value), + is_rvalue(true) {} + + // class should be movable only + json_ref(json_ref&&) = default; + json_ref(const json_ref&) = delete; + json_ref& operator=(const json_ref&) = delete; + json_ref& operator=(json_ref&&) = delete; + ~json_ref() = default; + + value_type moved_or_copied() const + { + if (is_rvalue) + { + return std::move(*value_ref); + } + return *value_ref; + } + + value_type const& operator*() const + { + return *static_cast<value_type const*>(value_ref); + } + + value_type const* operator->() const + { + return static_cast<value_type const*>(value_ref); + } + + private: + mutable value_type owned_value = nullptr; + value_type* value_ref = nullptr; + const bool is_rvalue; +}; +} // namespace detail +} // namespace nlohmann + +// #include <nlohmann/detail/json_pointer.hpp> + + +#include <cassert> // assert +#include <numeric> // accumulate +#include <string> // string +#include <vector> // vector + +// #include <nlohmann/detail/macro_scope.hpp> + +// #include <nlohmann/detail/exceptions.hpp> + +// #include <nlohmann/detail/value_t.hpp> + + +namespace nlohmann +{ +template<typename BasicJsonType> +class json_pointer +{ + // allow basic_json to access private members + NLOHMANN_BASIC_JSON_TPL_DECLARATION + friend class basic_json; + + public: + /*! + @brief create JSON pointer + + Create a JSON pointer according to the syntax described in + [Section 3 of RFC6901](https://tools.ietf.org/html/rfc6901#section-3). + + @param[in] s string representing the JSON pointer; if omitted, the empty + string is assumed which references the whole JSON value + + @throw parse_error.107 if the given JSON pointer @a s is nonempty and does + not begin with a slash (`/`); see example below + + @throw parse_error.108 if a tilde (`~`) in the given JSON pointer @a s is + not followed by `0` (representing `~`) or `1` (representing `/`); see + example below + + @liveexample{The example shows the construction several valid JSON pointers + as well as the exceptional behavior.,json_pointer} + + @since version 2.0.0 + */ + explicit json_pointer(const std::string& s = "") + : reference_tokens(split(s)) + {} + + /*! + @brief return a string representation of the JSON pointer + + @invariant For each JSON pointer `ptr`, it holds: + @code {.cpp} + ptr == json_pointer(ptr.to_string()); + @endcode + + @return a string representation of the JSON pointer + + @liveexample{The example shows the result of `to_string`., + json_pointer__to_string} + + @since version 2.0.0 + */ + std::string to_string() const + { + return std::accumulate(reference_tokens.begin(), reference_tokens.end(), + std::string{}, + [](const std::string & a, const std::string & b) + { + return a + "/" + escape(b); + }); + } + + /// @copydoc to_string() + operator std::string() const + { + return to_string(); + } + + /*! + @param[in] s reference token to be converted into an array index + + @return integer representation of @a s + + @throw out_of_range.404 if string @a s could not be converted to an integer + */ + static int array_index(const std::string& s) + { + std::size_t processed_chars = 0; + const int res = std::stoi(s, &processed_chars); + + // check if the string was completely read + if (JSON_UNLIKELY(processed_chars != s.size())) + { + JSON_THROW(detail::out_of_range::create(404, "unresolved reference token '" + s + "'")); + } + + return res; + } + + private: + /*! + @brief remove and return last reference pointer + @throw out_of_range.405 if JSON pointer has no parent + */ + std::string pop_back() + { + if (JSON_UNLIKELY(is_root())) + { + JSON_THROW(detail::out_of_range::create(405, "JSON pointer has no parent")); + } + + auto last = reference_tokens.back(); + reference_tokens.pop_back(); + return last; + } + + /// return whether pointer points to the root document + bool is_root() const noexcept + { + return reference_tokens.empty(); + } + + json_pointer top() const + { + if (JSON_UNLIKELY(is_root())) + { + JSON_THROW(detail::out_of_range::create(405, "JSON pointer has no parent")); + } + + json_pointer result = *this; + result.reference_tokens = {reference_tokens[0]}; + return result; + } + + /*! + @brief create and return a reference to the pointed to value + + @complexity Linear in the number of reference tokens. + + @throw parse_error.109 if array index is not a number + @throw type_error.313 if value cannot be unflattened + */ + BasicJsonType& get_and_create(BasicJsonType& j) const + { + using size_type = typename BasicJsonType::size_type; + auto result = &j; + + // in case no reference tokens exist, return a reference to the JSON value + // j which will be overwritten by a primitive value + for (const auto& reference_token : reference_tokens) + { + switch (result->m_type) + { + case detail::value_t::null: + { + if (reference_token == "0") + { + // start a new array if reference token is 0 + result = &result->operator[](0); + } + else + { + // start a new object otherwise + result = &result->operator[](reference_token); + } + break; + } + + case detail::value_t::object: + { + // create an entry in the object + result = &result->operator[](reference_token); + break; + } + + case detail::value_t::array: + { + // create an entry in the array + JSON_TRY + { + result = &result->operator[](static_cast<size_type>(array_index(reference_token))); + } + JSON_CATCH(std::invalid_argument&) + { + JSON_THROW(detail::parse_error::create(109, 0, "array index '" + reference_token + "' is not a number")); + } + break; + } + + /* + The following code is only reached if there exists a reference + token _and_ the current value is primitive. In this case, we have + an error situation, because primitive values may only occur as + single value; that is, with an empty list of reference tokens. + */ + default: + JSON_THROW(detail::type_error::create(313, "invalid value to unflatten")); + } + } + + return *result; + } + + /*! + @brief return a reference to the pointed to value + + @note This version does not throw if a value is not present, but tries to + create nested values instead. For instance, calling this function + with pointer `"/this/that"` on a null value is equivalent to calling + `operator[]("this").operator[]("that")` on that value, effectively + changing the null value to an object. + + @param[in] ptr a JSON value + + @return reference to the JSON value pointed to by the JSON pointer + + @complexity Linear in the length of the JSON pointer. + + @throw parse_error.106 if an array index begins with '0' + @throw parse_error.109 if an array index was not a number + @throw out_of_range.404 if the JSON pointer can not be resolved + */ + BasicJsonType& get_unchecked(BasicJsonType* ptr) const + { + using size_type = typename BasicJsonType::size_type; + for (const auto& reference_token : reference_tokens) + { + // convert null values to arrays or objects before continuing + if (ptr->m_type == detail::value_t::null) + { + // check if reference token is a number + const bool nums = + std::all_of(reference_token.begin(), reference_token.end(), + [](const char x) + { + return (x >= '0' and x <= '9'); + }); + + // change value to array for numbers or "-" or to object otherwise + *ptr = (nums or reference_token == "-") + ? detail::value_t::array + : detail::value_t::object; + } + + switch (ptr->m_type) + { + case detail::value_t::object: + { + // use unchecked object access + ptr = &ptr->operator[](reference_token); + break; + } + + case detail::value_t::array: + { + // error condition (cf. RFC 6901, Sect. 4) + if (JSON_UNLIKELY(reference_token.size() > 1 and reference_token[0] == '0')) + { + JSON_THROW(detail::parse_error::create(106, 0, + "array index '" + reference_token + + "' must not begin with '0'")); + } + + if (reference_token == "-") + { + // explicitly treat "-" as index beyond the end + ptr = &ptr->operator[](ptr->m_value.array->size()); + } + else + { + // convert array index to number; unchecked access + JSON_TRY + { + ptr = &ptr->operator[]( + static_cast<size_type>(array_index(reference_token))); + } + JSON_CATCH(std::invalid_argument&) + { + JSON_THROW(detail::parse_error::create(109, 0, "array index '" + reference_token + "' is not a number")); + } + } + break; + } + + default: + JSON_THROW(detail::out_of_range::create(404, "unresolved reference token '" + reference_token + "'")); + } + } + + return *ptr; + } + + /*! + @throw parse_error.106 if an array index begins with '0' + @throw parse_error.109 if an array index was not a number + @throw out_of_range.402 if the array index '-' is used + @throw out_of_range.404 if the JSON pointer can not be resolved + */ + BasicJsonType& get_checked(BasicJsonType* ptr) const + { + using size_type = typename BasicJsonType::size_type; + for (const auto& reference_token : reference_tokens) + { + switch (ptr->m_type) + { + case detail::value_t::object: + { + // note: at performs range check + ptr = &ptr->at(reference_token); + break; + } + + case detail::value_t::array: + { + if (JSON_UNLIKELY(reference_token == "-")) + { + // "-" always fails the range check + JSON_THROW(detail::out_of_range::create(402, + "array index '-' (" + std::to_string(ptr->m_value.array->size()) + + ") is out of range")); + } + + // error condition (cf. RFC 6901, Sect. 4) + if (JSON_UNLIKELY(reference_token.size() > 1 and reference_token[0] == '0')) + { + JSON_THROW(detail::parse_error::create(106, 0, + "array index '" + reference_token + + "' must not begin with '0'")); + } + + // note: at performs range check + JSON_TRY + { + ptr = &ptr->at(static_cast<size_type>(array_index(reference_token))); + } + JSON_CATCH(std::invalid_argument&) + { + JSON_THROW(detail::parse_error::create(109, 0, "array index '" + reference_token + "' is not a number")); + } + break; + } + + default: + JSON_THROW(detail::out_of_range::create(404, "unresolved reference token '" + reference_token + "'")); + } + } + + return *ptr; + } + + /*! + @brief return a const reference to the pointed to value + + @param[in] ptr a JSON value + + @return const reference to the JSON value pointed to by the JSON + pointer + + @throw parse_error.106 if an array index begins with '0' + @throw parse_error.109 if an array index was not a number + @throw out_of_range.402 if the array index '-' is used + @throw out_of_range.404 if the JSON pointer can not be resolved + */ + const BasicJsonType& get_unchecked(const BasicJsonType* ptr) const + { + using size_type = typename BasicJsonType::size_type; + for (const auto& reference_token : reference_tokens) + { + switch (ptr->m_type) + { + case detail::value_t::object: + { + // use unchecked object access + ptr = &ptr->operator[](reference_token); + break; + } + + case detail::value_t::array: + { + if (JSON_UNLIKELY(reference_token == "-")) + { + // "-" cannot be used for const access + JSON_THROW(detail::out_of_range::create(402, + "array index '-' (" + std::to_string(ptr->m_value.array->size()) + + ") is out of range")); + } + + // error condition (cf. RFC 6901, Sect. 4) + if (JSON_UNLIKELY(reference_token.size() > 1 and reference_token[0] == '0')) + { + JSON_THROW(detail::parse_error::create(106, 0, + "array index '" + reference_token + + "' must not begin with '0'")); + } + + // use unchecked array access + JSON_TRY + { + ptr = &ptr->operator[]( + static_cast<size_type>(array_index(reference_token))); + } + JSON_CATCH(std::invalid_argument&) + { + JSON_THROW(detail::parse_error::create(109, 0, "array index '" + reference_token + "' is not a number")); + } + break; + } + + default: + JSON_THROW(detail::out_of_range::create(404, "unresolved reference token '" + reference_token + "'")); + } + } + + return *ptr; + } + + /*! + @throw parse_error.106 if an array index begins with '0' + @throw parse_error.109 if an array index was not a number + @throw out_of_range.402 if the array index '-' is used + @throw out_of_range.404 if the JSON pointer can not be resolved + */ + const BasicJsonType& get_checked(const BasicJsonType* ptr) const + { + using size_type = typename BasicJsonType::size_type; + for (const auto& reference_token : reference_tokens) + { + switch (ptr->m_type) + { + case detail::value_t::object: + { + // note: at performs range check + ptr = &ptr->at(reference_token); + break; + } + + case detail::value_t::array: + { + if (JSON_UNLIKELY(reference_token == "-")) + { + // "-" always fails the range check + JSON_THROW(detail::out_of_range::create(402, + "array index '-' (" + std::to_string(ptr->m_value.array->size()) + + ") is out of range")); + } + + // error condition (cf. RFC 6901, Sect. 4) + if (JSON_UNLIKELY(reference_token.size() > 1 and reference_token[0] == '0')) + { + JSON_THROW(detail::parse_error::create(106, 0, + "array index '" + reference_token + + "' must not begin with '0'")); + } + + // note: at performs range check + JSON_TRY + { + ptr = &ptr->at(static_cast<size_type>(array_index(reference_token))); + } + JSON_CATCH(std::invalid_argument&) + { + JSON_THROW(detail::parse_error::create(109, 0, "array index '" + reference_token + "' is not a number")); + } + break; + } + + default: + JSON_THROW(detail::out_of_range::create(404, "unresolved reference token '" + reference_token + "'")); + } + } + + return *ptr; + } + + /*! + @brief split the string input to reference tokens + + @note This function is only called by the json_pointer constructor. + All exceptions below are documented there. + + @throw parse_error.107 if the pointer is not empty or begins with '/' + @throw parse_error.108 if character '~' is not followed by '0' or '1' + */ + static std::vector<std::string> split(const std::string& reference_string) + { + std::vector<std::string> result; + + // special case: empty reference string -> no reference tokens + if (reference_string.empty()) + { + return result; + } + + // check if nonempty reference string begins with slash + if (JSON_UNLIKELY(reference_string[0] != '/')) + { + JSON_THROW(detail::parse_error::create(107, 1, + "JSON pointer must be empty or begin with '/' - was: '" + + reference_string + "'")); + } + + // extract the reference tokens: + // - slash: position of the last read slash (or end of string) + // - start: position after the previous slash + for ( + // search for the first slash after the first character + std::size_t slash = reference_string.find_first_of('/', 1), + // set the beginning of the first reference token + start = 1; + // we can stop if start == 0 (if slash == std::string::npos) + start != 0; + // set the beginning of the next reference token + // (will eventually be 0 if slash == std::string::npos) + start = (slash == std::string::npos) ? 0 : slash + 1, + // find next slash + slash = reference_string.find_first_of('/', start)) + { + // use the text between the beginning of the reference token + // (start) and the last slash (slash). + auto reference_token = reference_string.substr(start, slash - start); + + // check reference tokens are properly escaped + for (std::size_t pos = reference_token.find_first_of('~'); + pos != std::string::npos; + pos = reference_token.find_first_of('~', pos + 1)) + { + assert(reference_token[pos] == '~'); + + // ~ must be followed by 0 or 1 + if (JSON_UNLIKELY(pos == reference_token.size() - 1 or + (reference_token[pos + 1] != '0' and + reference_token[pos + 1] != '1'))) + { + JSON_THROW(detail::parse_error::create(108, 0, "escape character '~' must be followed with '0' or '1'")); + } + } + + // finally, store the reference token + unescape(reference_token); + result.push_back(reference_token); + } + + return result; + } + + /*! + @brief replace all occurrences of a substring by another string + + @param[in,out] s the string to manipulate; changed so that all + occurrences of @a f are replaced with @a t + @param[in] f the substring to replace with @a t + @param[in] t the string to replace @a f + + @pre The search string @a f must not be empty. **This precondition is + enforced with an assertion.** + + @since version 2.0.0 + */ + static void replace_substring(std::string& s, const std::string& f, + const std::string& t) + { + assert(not f.empty()); + for (auto pos = s.find(f); // find first occurrence of f + pos != std::string::npos; // make sure f was found + s.replace(pos, f.size(), t), // replace with t, and + pos = s.find(f, pos + t.size())) // find next occurrence of f + {} + } + + /// escape "~" to "~0" and "/" to "~1" + static std::string escape(std::string s) + { + replace_substring(s, "~", "~0"); + replace_substring(s, "/", "~1"); + return s; + } + + /// unescape "~1" to tilde and "~0" to slash (order is important!) + static void unescape(std::string& s) + { + replace_substring(s, "~1", "/"); + replace_substring(s, "~0", "~"); + } + + /*! + @param[in] reference_string the reference string to the current value + @param[in] value the value to consider + @param[in,out] result the result object to insert values to + + @note Empty objects or arrays are flattened to `null`. + */ + static void flatten(const std::string& reference_string, + const BasicJsonType& value, + BasicJsonType& result) + { + switch (value.m_type) + { + case detail::value_t::array: + { + if (value.m_value.array->empty()) + { + // flatten empty array as null + result[reference_string] = nullptr; + } + else + { + // iterate array and use index as reference string + for (std::size_t i = 0; i < value.m_value.array->size(); ++i) + { + flatten(reference_string + "/" + std::to_string(i), + value.m_value.array->operator[](i), result); + } + } + break; + } + + case detail::value_t::object: + { + if (value.m_value.object->empty()) + { + // flatten empty object as null + result[reference_string] = nullptr; + } + else + { + // iterate object and use keys as reference string + for (const auto& element : *value.m_value.object) + { + flatten(reference_string + "/" + escape(element.first), element.second, result); + } + } + break; + } + + default: + { + // add primitive value with its reference string + result[reference_string] = value; + break; + } + } + } + + /*! + @param[in] value flattened JSON + + @return unflattened JSON + + @throw parse_error.109 if array index is not a number + @throw type_error.314 if value is not an object + @throw type_error.315 if object values are not primitive + @throw type_error.313 if value cannot be unflattened + */ + static BasicJsonType + unflatten(const BasicJsonType& value) + { + if (JSON_UNLIKELY(not value.is_object())) + { + JSON_THROW(detail::type_error::create(314, "only objects can be unflattened")); + } + + BasicJsonType result; + + // iterate the JSON object values + for (const auto& element : *value.m_value.object) + { + if (JSON_UNLIKELY(not element.second.is_primitive())) + { + JSON_THROW(detail::type_error::create(315, "values in object must be primitive")); + } + + // assign value to reference pointed to by JSON pointer; Note that if + // the JSON pointer is "" (i.e., points to the whole value), function + // get_and_create returns a reference to result itself. An assignment + // will then create a primitive value. + json_pointer(element.first).get_and_create(result) = element.second; + } + + return result; + } + + friend bool operator==(json_pointer const& lhs, + json_pointer const& rhs) noexcept + { + return (lhs.reference_tokens == rhs.reference_tokens); + } + + friend bool operator!=(json_pointer const& lhs, + json_pointer const& rhs) noexcept + { + return not (lhs == rhs); + } + + /// the reference tokens + std::vector<std::string> reference_tokens; +}; +} // namespace nlohmann + +// #include <nlohmann/adl_serializer.hpp> + + +#include <utility> + +// #include <nlohmann/detail/conversions/from_json.hpp> + +// #include <nlohmann/detail/conversions/to_json.hpp> + + +namespace nlohmann +{ + +template<typename, typename> +struct adl_serializer +{ + /*! + @brief convert a JSON value to any value type + + This function is usually called by the `get()` function of the + @ref basic_json class (either explicit or via conversion operators). + + @param[in] j JSON value to read from + @param[in,out] val value to write to + */ + template<typename BasicJsonType, typename ValueType> + static auto from_json(BasicJsonType&& j, ValueType& val) noexcept( + noexcept(::nlohmann::from_json(std::forward<BasicJsonType>(j), val))) + -> decltype(::nlohmann::from_json(std::forward<BasicJsonType>(j), val), void()) + { + ::nlohmann::from_json(std::forward<BasicJsonType>(j), val); + } + + /*! + @brief convert any value type to a JSON value + + This function is usually called by the constructors of the @ref basic_json + class. + + @param[in,out] j JSON value to write to + @param[in] val value to read from + */ + template <typename BasicJsonType, typename ValueType> + static auto to_json(BasicJsonType& j, ValueType&& val) noexcept( + noexcept(::nlohmann::to_json(j, std::forward<ValueType>(val)))) + -> decltype(::nlohmann::to_json(j, std::forward<ValueType>(val)), void()) + { + ::nlohmann::to_json(j, std::forward<ValueType>(val)); + } +}; + +} // namespace nlohmann + + +/*! +@brief namespace for Niels Lohmann +@see https://github.com/nlohmann +@since version 1.0.0 +*/ +namespace nlohmann +{ + +/*! +@brief a class to store JSON values + +@tparam ObjectType type for JSON objects (`std::map` by default; will be used +in @ref object_t) +@tparam ArrayType type for JSON arrays (`std::vector` by default; will be used +in @ref array_t) +@tparam StringType type for JSON strings and object keys (`std::string` by +default; will be used in @ref string_t) +@tparam BooleanType type for JSON booleans (`bool` by default; will be used +in @ref boolean_t) +@tparam NumberIntegerType type for JSON integer numbers (`int64_t` by +default; will be used in @ref number_integer_t) +@tparam NumberUnsignedType type for JSON unsigned integer numbers (@c +`uint64_t` by default; will be used in @ref number_unsigned_t) +@tparam NumberFloatType type for JSON floating-point numbers (`double` by +default; will be used in @ref number_float_t) +@tparam AllocatorType type of the allocator to use (`std::allocator` by +default) +@tparam JSONSerializer the serializer to resolve internal calls to `to_json()` +and `from_json()` (@ref adl_serializer by default) + +@requirement The class satisfies the following concept requirements: +- Basic + - [DefaultConstructible](https://en.cppreference.com/w/cpp/named_req/DefaultConstructible): + JSON values can be default constructed. The result will be a JSON null + value. + - [MoveConstructible](https://en.cppreference.com/w/cpp/named_req/MoveConstructible): + A JSON value can be constructed from an rvalue argument. + - [CopyConstructible](https://en.cppreference.com/w/cpp/named_req/CopyConstructible): + A JSON value can be copy-constructed from an lvalue expression. + - [MoveAssignable](https://en.cppreference.com/w/cpp/named_req/MoveAssignable): + A JSON value van be assigned from an rvalue argument. + - [CopyAssignable](https://en.cppreference.com/w/cpp/named_req/CopyAssignable): + A JSON value can be copy-assigned from an lvalue expression. + - [Destructible](https://en.cppreference.com/w/cpp/named_req/Destructible): + JSON values can be destructed. +- Layout + - [StandardLayoutType](https://en.cppreference.com/w/cpp/named_req/StandardLayoutType): + JSON values have + [standard layout](https://en.cppreference.com/w/cpp/language/data_members#Standard_layout): + All non-static data members are private and standard layout types, the + class has no virtual functions or (virtual) base classes. +- Library-wide + - [EqualityComparable](https://en.cppreference.com/w/cpp/named_req/EqualityComparable): + JSON values can be compared with `==`, see @ref + operator==(const_reference,const_reference). + - [LessThanComparable](https://en.cppreference.com/w/cpp/named_req/LessThanComparable): + JSON values can be compared with `<`, see @ref + operator<(const_reference,const_reference). + - [Swappable](https://en.cppreference.com/w/cpp/named_req/Swappable): + Any JSON lvalue or rvalue of can be swapped with any lvalue or rvalue of + other compatible types, using unqualified function call @ref swap(). + - [NullablePointer](https://en.cppreference.com/w/cpp/named_req/NullablePointer): + JSON values can be compared against `std::nullptr_t` objects which are used + to model the `null` value. +- Container + - [Container](https://en.cppreference.com/w/cpp/named_req/Container): + JSON values can be used like STL containers and provide iterator access. + - [ReversibleContainer](https://en.cppreference.com/w/cpp/named_req/ReversibleContainer); + JSON values can be used like STL containers and provide reverse iterator + access. + +@invariant The member variables @a m_value and @a m_type have the following +relationship: +- If `m_type == value_t::object`, then `m_value.object != nullptr`. +- If `m_type == value_t::array`, then `m_value.array != nullptr`. +- If `m_type == value_t::string`, then `m_value.string != nullptr`. +The invariants are checked by member function assert_invariant(). + +@internal +@note ObjectType trick from http://stackoverflow.com/a/9860911 +@endinternal + +@see [RFC 7159: The JavaScript Object Notation (JSON) Data Interchange +Format](http://rfc7159.net/rfc7159) + +@since version 1.0.0 + +@nosubgrouping +*/ +NLOHMANN_BASIC_JSON_TPL_DECLARATION +class basic_json +{ + private: + template<detail::value_t> friend struct detail::external_constructor; + friend ::nlohmann::json_pointer<basic_json>; + friend ::nlohmann::detail::parser<basic_json>; + friend ::nlohmann::detail::serializer<basic_json>; + template<typename BasicJsonType> + friend class ::nlohmann::detail::iter_impl; + template<typename BasicJsonType, typename CharType> + friend class ::nlohmann::detail::binary_writer; + template<typename BasicJsonType, typename SAX> + friend class ::nlohmann::detail::binary_reader; + template<typename BasicJsonType> + friend class ::nlohmann::detail::json_sax_dom_parser; + template<typename BasicJsonType> + friend class ::nlohmann::detail::json_sax_dom_callback_parser; + + /// workaround type for MSVC + using basic_json_t = NLOHMANN_BASIC_JSON_TPL; + + // convenience aliases for types residing in namespace detail; + using lexer = ::nlohmann::detail::lexer<basic_json>; + using parser = ::nlohmann::detail::parser<basic_json>; + + using primitive_iterator_t = ::nlohmann::detail::primitive_iterator_t; + template<typename BasicJsonType> + using internal_iterator = ::nlohmann::detail::internal_iterator<BasicJsonType>; + template<typename BasicJsonType> + using iter_impl = ::nlohmann::detail::iter_impl<BasicJsonType>; + template<typename Iterator> + using iteration_proxy = ::nlohmann::detail::iteration_proxy<Iterator>; + template<typename Base> using json_reverse_iterator = ::nlohmann::detail::json_reverse_iterator<Base>; + + template<typename CharType> + using output_adapter_t = ::nlohmann::detail::output_adapter_t<CharType>; + + using binary_reader = ::nlohmann::detail::binary_reader<basic_json>; + template<typename CharType> using binary_writer = ::nlohmann::detail::binary_writer<basic_json, CharType>; + + using serializer = ::nlohmann::detail::serializer<basic_json>; + + public: + using value_t = detail::value_t; + /// JSON Pointer, see @ref nlohmann::json_pointer + using json_pointer = ::nlohmann::json_pointer<basic_json>; + template<typename T, typename SFINAE> + using json_serializer = JSONSerializer<T, SFINAE>; + /// how to treat decoding errors + using error_handler_t = detail::error_handler_t; + /// helper type for initializer lists of basic_json values + using initializer_list_t = std::initializer_list<detail::json_ref<basic_json>>; + + using input_format_t = detail::input_format_t; + /// SAX interface type, see @ref nlohmann::json_sax + using json_sax_t = json_sax<basic_json>; + + //////////////// + // exceptions // + //////////////// + + /// @name exceptions + /// Classes to implement user-defined exceptions. + /// @{ + + /// @copydoc detail::exception + using exception = detail::exception; + /// @copydoc detail::parse_error + using parse_error = detail::parse_error; + /// @copydoc detail::invalid_iterator + using invalid_iterator = detail::invalid_iterator; + /// @copydoc detail::type_error + using type_error = detail::type_error; + /// @copydoc detail::out_of_range + using out_of_range = detail::out_of_range; + /// @copydoc detail::other_error + using other_error = detail::other_error; + + /// @} + + + ///////////////////// + // container types // + ///////////////////// + + /// @name container types + /// The canonic container types to use @ref basic_json like any other STL + /// container. + /// @{ + + /// the type of elements in a basic_json container + using value_type = basic_json; + + /// the type of an element reference + using reference = value_type&; + /// the type of an element const reference + using const_reference = const value_type&; + + /// a type to represent differences between iterators + using difference_type = std::ptrdiff_t; + /// a type to represent container sizes + using size_type = std::size_t; + + /// the allocator type + using allocator_type = AllocatorType<basic_json>; + + /// the type of an element pointer + using pointer = typename std::allocator_traits<allocator_type>::pointer; + /// the type of an element const pointer + using const_pointer = typename std::allocator_traits<allocator_type>::const_pointer; + + /// an iterator for a basic_json container + using iterator = iter_impl<basic_json>; + /// a const iterator for a basic_json container + using const_iterator = iter_impl<const basic_json>; + /// a reverse iterator for a basic_json container + using reverse_iterator = json_reverse_iterator<typename basic_json::iterator>; + /// a const reverse iterator for a basic_json container + using const_reverse_iterator = json_reverse_iterator<typename basic_json::const_iterator>; + + /// @} + + + /*! + @brief returns the allocator associated with the container + */ + static allocator_type get_allocator() + { + return allocator_type(); + } + + /*! + @brief returns version information on the library + + This function returns a JSON object with information about the library, + including the version number and information on the platform and compiler. + + @return JSON object holding version information + key | description + ----------- | --------------- + `compiler` | Information on the used compiler. It is an object with the following keys: `c++` (the used C++ standard), `family` (the compiler family; possible values are `clang`, `icc`, `gcc`, `ilecpp`, `msvc`, `pgcpp`, `sunpro`, and `unknown`), and `version` (the compiler version). + `copyright` | The copyright line for the library as string. + `name` | The name of the library as string. + `platform` | The used platform as string. Possible values are `win32`, `linux`, `apple`, `unix`, and `unknown`. + `url` | The URL of the project as string. + `version` | The version of the library. It is an object with the following keys: `major`, `minor`, and `patch` as defined by [Semantic Versioning](http://semver.org), and `string` (the version string). + + @liveexample{The following code shows an example output of the `meta()` + function.,meta} + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @complexity Constant. + + @since 2.1.0 + */ + static basic_json meta() + { + basic_json result; + + result["copyright"] = "(C) 2013-2017 Niels Lohmann"; + result["name"] = "JSON for Modern C++"; + result["url"] = "https://github.com/nlohmann/json"; + result["version"]["string"] = + std::to_string(NLOHMANN_JSON_VERSION_MAJOR) + "." + + std::to_string(NLOHMANN_JSON_VERSION_MINOR) + "." + + std::to_string(NLOHMANN_JSON_VERSION_PATCH); + result["version"]["major"] = NLOHMANN_JSON_VERSION_MAJOR; + result["version"]["minor"] = NLOHMANN_JSON_VERSION_MINOR; + result["version"]["patch"] = NLOHMANN_JSON_VERSION_PATCH; + +#ifdef _WIN32 + result["platform"] = "win32"; +#elif defined __linux__ + result["platform"] = "linux"; +#elif defined __APPLE__ + result["platform"] = "apple"; +#elif defined __unix__ + result["platform"] = "unix"; +#else + result["platform"] = "unknown"; +#endif + +#if defined(__ICC) || defined(__INTEL_COMPILER) + result["compiler"] = {{"family", "icc"}, {"version", __INTEL_COMPILER}}; +#elif defined(__clang__) + result["compiler"] = {{"family", "clang"}, {"version", __clang_version__}}; +#elif defined(__GNUC__) || defined(__GNUG__) + result["compiler"] = {{"family", "gcc"}, {"version", std::to_string(__GNUC__) + "." + std::to_string(__GNUC_MINOR__) + "." + std::to_string(__GNUC_PATCHLEVEL__)}}; +#elif defined(__HP_cc) || defined(__HP_aCC) + result["compiler"] = "hp" +#elif defined(__IBMCPP__) + result["compiler"] = {{"family", "ilecpp"}, {"version", __IBMCPP__}}; +#elif defined(_MSC_VER) + result["compiler"] = {{"family", "msvc"}, {"version", _MSC_VER}}; +#elif defined(__PGI) + result["compiler"] = {{"family", "pgcpp"}, {"version", __PGI}}; +#elif defined(__SUNPRO_CC) + result["compiler"] = {{"family", "sunpro"}, {"version", __SUNPRO_CC}}; +#else + result["compiler"] = {{"family", "unknown"}, {"version", "unknown"}}; +#endif + +#ifdef __cplusplus + result["compiler"]["c++"] = std::to_string(__cplusplus); +#else + result["compiler"]["c++"] = "unknown"; +#endif + return result; + } + + + /////////////////////////// + // JSON value data types // + /////////////////////////// + + /// @name JSON value data types + /// The data types to store a JSON value. These types are derived from + /// the template arguments passed to class @ref basic_json. + /// @{ + +#if defined(JSON_HAS_CPP_14) + // Use transparent comparator if possible, combined with perfect forwarding + // on find() and count() calls prevents unnecessary string construction. + using object_comparator_t = std::less<>; +#else + using object_comparator_t = std::less<StringType>; +#endif + + /*! + @brief a type for an object + + [RFC 7159](http://rfc7159.net/rfc7159) describes JSON objects as follows: + > An object is an unordered collection of zero or more name/value pairs, + > where a name is a string and a value is a string, number, boolean, null, + > object, or array. + + To store objects in C++, a type is defined by the template parameters + described below. + + @tparam ObjectType the container to store objects (e.g., `std::map` or + `std::unordered_map`) + @tparam StringType the type of the keys or names (e.g., `std::string`). + The comparison function `std::less<StringType>` is used to order elements + inside the container. + @tparam AllocatorType the allocator to use for objects (e.g., + `std::allocator`) + + #### Default type + + With the default values for @a ObjectType (`std::map`), @a StringType + (`std::string`), and @a AllocatorType (`std::allocator`), the default + value for @a object_t is: + + @code {.cpp} + std::map< + std::string, // key_type + basic_json, // value_type + std::less<std::string>, // key_compare + std::allocator<std::pair<const std::string, basic_json>> // allocator_type + > + @endcode + + #### Behavior + + The choice of @a object_t influences the behavior of the JSON class. With + the default type, objects have the following behavior: + + - When all names are unique, objects will be interoperable in the sense + that all software implementations receiving that object will agree on + the name-value mappings. + - When the names within an object are not unique, it is unspecified which + one of the values for a given key will be chosen. For instance, + `{"key": 2, "key": 1}` could be equal to either `{"key": 1}` or + `{"key": 2}`. + - Internally, name/value pairs are stored in lexicographical order of the + names. Objects will also be serialized (see @ref dump) in this order. + For instance, `{"b": 1, "a": 2}` and `{"a": 2, "b": 1}` will be stored + and serialized as `{"a": 2, "b": 1}`. + - When comparing objects, the order of the name/value pairs is irrelevant. + This makes objects interoperable in the sense that they will not be + affected by these differences. For instance, `{"b": 1, "a": 2}` and + `{"a": 2, "b": 1}` will be treated as equal. + + #### Limits + + [RFC 7159](http://rfc7159.net/rfc7159) specifies: + > An implementation may set limits on the maximum depth of nesting. + + In this class, the object's limit of nesting is not explicitly constrained. + However, a maximum depth of nesting may be introduced by the compiler or + runtime environment. A theoretical limit can be queried by calling the + @ref max_size function of a JSON object. + + #### Storage + + Objects are stored as pointers in a @ref basic_json type. That is, for any + access to object values, a pointer of type `object_t*` must be + dereferenced. + + @sa @ref array_t -- type for an array value + + @since version 1.0.0 + + @note The order name/value pairs are added to the object is *not* + preserved by the library. Therefore, iterating an object may return + name/value pairs in a different order than they were originally stored. In + fact, keys will be traversed in alphabetical order as `std::map` with + `std::less` is used by default. Please note this behavior conforms to [RFC + 7159](http://rfc7159.net/rfc7159), because any order implements the + specified "unordered" nature of JSON objects. + */ + using object_t = ObjectType<StringType, + basic_json, + object_comparator_t, + AllocatorType<std::pair<const StringType, + basic_json>>>; + + /*! + @brief a type for an array + + [RFC 7159](http://rfc7159.net/rfc7159) describes JSON arrays as follows: + > An array is an ordered sequence of zero or more values. + + To store objects in C++, a type is defined by the template parameters + explained below. + + @tparam ArrayType container type to store arrays (e.g., `std::vector` or + `std::list`) + @tparam AllocatorType allocator to use for arrays (e.g., `std::allocator`) + + #### Default type + + With the default values for @a ArrayType (`std::vector`) and @a + AllocatorType (`std::allocator`), the default value for @a array_t is: + + @code {.cpp} + std::vector< + basic_json, // value_type + std::allocator<basic_json> // allocator_type + > + @endcode + + #### Limits + + [RFC 7159](http://rfc7159.net/rfc7159) specifies: + > An implementation may set limits on the maximum depth of nesting. + + In this class, the array's limit of nesting is not explicitly constrained. + However, a maximum depth of nesting may be introduced by the compiler or + runtime environment. A theoretical limit can be queried by calling the + @ref max_size function of a JSON array. + + #### Storage + + Arrays are stored as pointers in a @ref basic_json type. That is, for any + access to array values, a pointer of type `array_t*` must be dereferenced. + + @sa @ref object_t -- type for an object value + + @since version 1.0.0 + */ + using array_t = ArrayType<basic_json, AllocatorType<basic_json>>; + + /*! + @brief a type for a string + + [RFC 7159](http://rfc7159.net/rfc7159) describes JSON strings as follows: + > A string is a sequence of zero or more Unicode characters. + + To store objects in C++, a type is defined by the template parameter + described below. Unicode values are split by the JSON class into + byte-sized characters during deserialization. + + @tparam StringType the container to store strings (e.g., `std::string`). + Note this container is used for keys/names in objects, see @ref object_t. + + #### Default type + + With the default values for @a StringType (`std::string`), the default + value for @a string_t is: + + @code {.cpp} + std::string + @endcode + + #### Encoding + + Strings are stored in UTF-8 encoding. Therefore, functions like + `std::string::size()` or `std::string::length()` return the number of + bytes in the string rather than the number of characters or glyphs. + + #### String comparison + + [RFC 7159](http://rfc7159.net/rfc7159) states: + > Software implementations are typically required to test names of object + > members for equality. Implementations that transform the textual + > representation into sequences of Unicode code units and then perform the + > comparison numerically, code unit by code unit, are interoperable in the + > sense that implementations will agree in all cases on equality or + > inequality of two strings. For example, implementations that compare + > strings with escaped characters unconverted may incorrectly find that + > `"a\\b"` and `"a\u005Cb"` are not equal. + + This implementation is interoperable as it does compare strings code unit + by code unit. + + #### Storage + + String values are stored as pointers in a @ref basic_json type. That is, + for any access to string values, a pointer of type `string_t*` must be + dereferenced. + + @since version 1.0.0 + */ + using string_t = StringType; + + /*! + @brief a type for a boolean + + [RFC 7159](http://rfc7159.net/rfc7159) implicitly describes a boolean as a + type which differentiates the two literals `true` and `false`. + + To store objects in C++, a type is defined by the template parameter @a + BooleanType which chooses the type to use. + + #### Default type + + With the default values for @a BooleanType (`bool`), the default value for + @a boolean_t is: + + @code {.cpp} + bool + @endcode + + #### Storage + + Boolean values are stored directly inside a @ref basic_json type. + + @since version 1.0.0 + */ + using boolean_t = BooleanType; + + /*! + @brief a type for a number (integer) + + [RFC 7159](http://rfc7159.net/rfc7159) describes numbers as follows: + > The representation of numbers is similar to that used in most + > programming languages. A number is represented in base 10 using decimal + > digits. It contains an integer component that may be prefixed with an + > optional minus sign, which may be followed by a fraction part and/or an + > exponent part. Leading zeros are not allowed. (...) Numeric values that + > cannot be represented in the grammar below (such as Infinity and NaN) + > are not permitted. + + This description includes both integer and floating-point numbers. + However, C++ allows more precise storage if it is known whether the number + is a signed integer, an unsigned integer or a floating-point number. + Therefore, three different types, @ref number_integer_t, @ref + number_unsigned_t and @ref number_float_t are used. + + To store integer numbers in C++, a type is defined by the template + parameter @a NumberIntegerType which chooses the type to use. + + #### Default type + + With the default values for @a NumberIntegerType (`int64_t`), the default + value for @a number_integer_t is: + + @code {.cpp} + int64_t + @endcode + + #### Default behavior + + - The restrictions about leading zeros is not enforced in C++. Instead, + leading zeros in integer literals lead to an interpretation as octal + number. Internally, the value will be stored as decimal number. For + instance, the C++ integer literal `010` will be serialized to `8`. + During deserialization, leading zeros yield an error. + - Not-a-number (NaN) values will be serialized to `null`. + + #### Limits + + [RFC 7159](http://rfc7159.net/rfc7159) specifies: + > An implementation may set limits on the range and precision of numbers. + + When the default type is used, the maximal integer number that can be + stored is `9223372036854775807` (INT64_MAX) and the minimal integer number + that can be stored is `-9223372036854775808` (INT64_MIN). Integer numbers + that are out of range will yield over/underflow when used in a + constructor. During deserialization, too large or small integer numbers + will be automatically be stored as @ref number_unsigned_t or @ref + number_float_t. + + [RFC 7159](http://rfc7159.net/rfc7159) further states: + > Note that when such software is used, numbers that are integers and are + > in the range \f$[-2^{53}+1, 2^{53}-1]\f$ are interoperable in the sense + > that implementations will agree exactly on their numeric values. + + As this range is a subrange of the exactly supported range [INT64_MIN, + INT64_MAX], this class's integer type is interoperable. + + #### Storage + + Integer number values are stored directly inside a @ref basic_json type. + + @sa @ref number_float_t -- type for number values (floating-point) + + @sa @ref number_unsigned_t -- type for number values (unsigned integer) + + @since version 1.0.0 + */ + using number_integer_t = NumberIntegerType; + + /*! + @brief a type for a number (unsigned) + + [RFC 7159](http://rfc7159.net/rfc7159) describes numbers as follows: + > The representation of numbers is similar to that used in most + > programming languages. A number is represented in base 10 using decimal + > digits. It contains an integer component that may be prefixed with an + > optional minus sign, which may be followed by a fraction part and/or an + > exponent part. Leading zeros are not allowed. (...) Numeric values that + > cannot be represented in the grammar below (such as Infinity and NaN) + > are not permitted. + + This description includes both integer and floating-point numbers. + However, C++ allows more precise storage if it is known whether the number + is a signed integer, an unsigned integer or a floating-point number. + Therefore, three different types, @ref number_integer_t, @ref + number_unsigned_t and @ref number_float_t are used. + + To store unsigned integer numbers in C++, a type is defined by the + template parameter @a NumberUnsignedType which chooses the type to use. + + #### Default type + + With the default values for @a NumberUnsignedType (`uint64_t`), the + default value for @a number_unsigned_t is: + + @code {.cpp} + uint64_t + @endcode + + #### Default behavior + + - The restrictions about leading zeros is not enforced in C++. Instead, + leading zeros in integer literals lead to an interpretation as octal + number. Internally, the value will be stored as decimal number. For + instance, the C++ integer literal `010` will be serialized to `8`. + During deserialization, leading zeros yield an error. + - Not-a-number (NaN) values will be serialized to `null`. + + #### Limits + + [RFC 7159](http://rfc7159.net/rfc7159) specifies: + > An implementation may set limits on the range and precision of numbers. + + When the default type is used, the maximal integer number that can be + stored is `18446744073709551615` (UINT64_MAX) and the minimal integer + number that can be stored is `0`. Integer numbers that are out of range + will yield over/underflow when used in a constructor. During + deserialization, too large or small integer numbers will be automatically + be stored as @ref number_integer_t or @ref number_float_t. + + [RFC 7159](http://rfc7159.net/rfc7159) further states: + > Note that when such software is used, numbers that are integers and are + > in the range \f$[-2^{53}+1, 2^{53}-1]\f$ are interoperable in the sense + > that implementations will agree exactly on their numeric values. + + As this range is a subrange (when considered in conjunction with the + number_integer_t type) of the exactly supported range [0, UINT64_MAX], + this class's integer type is interoperable. + + #### Storage + + Integer number values are stored directly inside a @ref basic_json type. + + @sa @ref number_float_t -- type for number values (floating-point) + @sa @ref number_integer_t -- type for number values (integer) + + @since version 2.0.0 + */ + using number_unsigned_t = NumberUnsignedType; + + /*! + @brief a type for a number (floating-point) + + [RFC 7159](http://rfc7159.net/rfc7159) describes numbers as follows: + > The representation of numbers is similar to that used in most + > programming languages. A number is represented in base 10 using decimal + > digits. It contains an integer component that may be prefixed with an + > optional minus sign, which may be followed by a fraction part and/or an + > exponent part. Leading zeros are not allowed. (...) Numeric values that + > cannot be represented in the grammar below (such as Infinity and NaN) + > are not permitted. + + This description includes both integer and floating-point numbers. + However, C++ allows more precise storage if it is known whether the number + is a signed integer, an unsigned integer or a floating-point number. + Therefore, three different types, @ref number_integer_t, @ref + number_unsigned_t and @ref number_float_t are used. + + To store floating-point numbers in C++, a type is defined by the template + parameter @a NumberFloatType which chooses the type to use. + + #### Default type + + With the default values for @a NumberFloatType (`double`), the default + value for @a number_float_t is: + + @code {.cpp} + double + @endcode + + #### Default behavior + + - The restrictions about leading zeros is not enforced in C++. Instead, + leading zeros in floating-point literals will be ignored. Internally, + the value will be stored as decimal number. For instance, the C++ + floating-point literal `01.2` will be serialized to `1.2`. During + deserialization, leading zeros yield an error. + - Not-a-number (NaN) values will be serialized to `null`. + + #### Limits + + [RFC 7159](http://rfc7159.net/rfc7159) states: + > This specification allows implementations to set limits on the range and + > precision of numbers accepted. Since software that implements IEEE + > 754-2008 binary64 (double precision) numbers is generally available and + > widely used, good interoperability can be achieved by implementations + > that expect no more precision or range than these provide, in the sense + > that implementations will approximate JSON numbers within the expected + > precision. + + This implementation does exactly follow this approach, as it uses double + precision floating-point numbers. Note values smaller than + `-1.79769313486232e+308` and values greater than `1.79769313486232e+308` + will be stored as NaN internally and be serialized to `null`. + + #### Storage + + Floating-point number values are stored directly inside a @ref basic_json + type. + + @sa @ref number_integer_t -- type for number values (integer) + + @sa @ref number_unsigned_t -- type for number values (unsigned integer) + + @since version 1.0.0 + */ + using number_float_t = NumberFloatType; + + /// @} + + private: + + /// helper for exception-safe object creation + template<typename T, typename... Args> + static T* create(Args&& ... args) + { + AllocatorType<T> alloc; + using AllocatorTraits = std::allocator_traits<AllocatorType<T>>; + + auto deleter = [&](T * object) + { + AllocatorTraits::deallocate(alloc, object, 1); + }; + std::unique_ptr<T, decltype(deleter)> object(AllocatorTraits::allocate(alloc, 1), deleter); + AllocatorTraits::construct(alloc, object.get(), std::forward<Args>(args)...); + assert(object != nullptr); + return object.release(); + } + + //////////////////////// + // JSON value storage // + //////////////////////// + + /*! + @brief a JSON value + + The actual storage for a JSON value of the @ref basic_json class. This + union combines the different storage types for the JSON value types + defined in @ref value_t. + + JSON type | value_t type | used type + --------- | --------------- | ------------------------ + object | object | pointer to @ref object_t + array | array | pointer to @ref array_t + string | string | pointer to @ref string_t + boolean | boolean | @ref boolean_t + number | number_integer | @ref number_integer_t + number | number_unsigned | @ref number_unsigned_t + number | number_float | @ref number_float_t + null | null | *no value is stored* + + @note Variable-length types (objects, arrays, and strings) are stored as + pointers. The size of the union should not exceed 64 bits if the default + value types are used. + + @since version 1.0.0 + */ + union json_value + { + /// object (stored with pointer to save storage) + object_t* object; + /// array (stored with pointer to save storage) + array_t* array; + /// string (stored with pointer to save storage) + string_t* string; + /// boolean + boolean_t boolean; + /// number (integer) + number_integer_t number_integer; + /// number (unsigned integer) + number_unsigned_t number_unsigned; + /// number (floating-point) + number_float_t number_float; + + /// default constructor (for null values) + json_value() = default; + /// constructor for booleans + json_value(boolean_t v) noexcept : boolean(v) {} + /// constructor for numbers (integer) + json_value(number_integer_t v) noexcept : number_integer(v) {} + /// constructor for numbers (unsigned) + json_value(number_unsigned_t v) noexcept : number_unsigned(v) {} + /// constructor for numbers (floating-point) + json_value(number_float_t v) noexcept : number_float(v) {} + /// constructor for empty values of a given type + json_value(value_t t) + { + switch (t) + { + case value_t::object: + { + object = create<object_t>(); + break; + } + + case value_t::array: + { + array = create<array_t>(); + break; + } + + case value_t::string: + { + string = create<string_t>(""); + break; + } + + case value_t::boolean: + { + boolean = boolean_t(false); + break; + } + + case value_t::number_integer: + { + number_integer = number_integer_t(0); + break; + } + + case value_t::number_unsigned: + { + number_unsigned = number_unsigned_t(0); + break; + } + + case value_t::number_float: + { + number_float = number_float_t(0.0); + break; + } + + case value_t::null: + { + object = nullptr; // silence warning, see #821 + break; + } + + default: + { + object = nullptr; // silence warning, see #821 + if (JSON_UNLIKELY(t == value_t::null)) + { + JSON_THROW(other_error::create(500, "961c151d2e87f2686a955a9be24d316f1362bf21 3.5.0")); // LCOV_EXCL_LINE + } + break; + } + } + } + + /// constructor for strings + json_value(const string_t& value) + { + string = create<string_t>(value); + } + + /// constructor for rvalue strings + json_value(string_t&& value) + { + string = create<string_t>(std::move(value)); + } + + /// constructor for objects + json_value(const object_t& value) + { + object = create<object_t>(value); + } + + /// constructor for rvalue objects + json_value(object_t&& value) + { + object = create<object_t>(std::move(value)); + } + + /// constructor for arrays + json_value(const array_t& value) + { + array = create<array_t>(value); + } + + /// constructor for rvalue arrays + json_value(array_t&& value) + { + array = create<array_t>(std::move(value)); + } + + void destroy(value_t t) noexcept + { + switch (t) + { + case value_t::object: + { + AllocatorType<object_t> alloc; + std::allocator_traits<decltype(alloc)>::destroy(alloc, object); + std::allocator_traits<decltype(alloc)>::deallocate(alloc, object, 1); + break; + } + + case value_t::array: + { + AllocatorType<array_t> alloc; + std::allocator_traits<decltype(alloc)>::destroy(alloc, array); + std::allocator_traits<decltype(alloc)>::deallocate(alloc, array, 1); + break; + } + + case value_t::string: + { + AllocatorType<string_t> alloc; + std::allocator_traits<decltype(alloc)>::destroy(alloc, string); + std::allocator_traits<decltype(alloc)>::deallocate(alloc, string, 1); + break; + } + + default: + { + break; + } + } + } + }; + + /*! + @brief checks the class invariants + + This function asserts the class invariants. It needs to be called at the + end of every constructor to make sure that created objects respect the + invariant. Furthermore, it has to be called each time the type of a JSON + value is changed, because the invariant expresses a relationship between + @a m_type and @a m_value. + */ + void assert_invariant() const noexcept + { + assert(m_type != value_t::object or m_value.object != nullptr); + assert(m_type != value_t::array or m_value.array != nullptr); + assert(m_type != value_t::string or m_value.string != nullptr); + } + + public: + ////////////////////////// + // JSON parser callback // + ////////////////////////// + + /*! + @brief parser event types + + The parser callback distinguishes the following events: + - `object_start`: the parser read `{` and started to process a JSON object + - `key`: the parser read a key of a value in an object + - `object_end`: the parser read `}` and finished processing a JSON object + - `array_start`: the parser read `[` and started to process a JSON array + - `array_end`: the parser read `]` and finished processing a JSON array + - `value`: the parser finished reading a JSON value + + @image html callback_events.png "Example when certain parse events are triggered" + + @sa @ref parser_callback_t for more information and examples + */ + using parse_event_t = typename parser::parse_event_t; + + /*! + @brief per-element parser callback type + + With a parser callback function, the result of parsing a JSON text can be + influenced. When passed to @ref parse, it is called on certain events + (passed as @ref parse_event_t via parameter @a event) with a set recursion + depth @a depth and context JSON value @a parsed. The return value of the + callback function is a boolean indicating whether the element that emitted + the callback shall be kept or not. + + We distinguish six scenarios (determined by the event type) in which the + callback function can be called. The following table describes the values + of the parameters @a depth, @a event, and @a parsed. + + parameter @a event | description | parameter @a depth | parameter @a parsed + ------------------ | ----------- | ------------------ | ------------------- + parse_event_t::object_start | the parser read `{` and started to process a JSON object | depth of the parent of the JSON object | a JSON value with type discarded + parse_event_t::key | the parser read a key of a value in an object | depth of the currently parsed JSON object | a JSON string containing the key + parse_event_t::object_end | the parser read `}` and finished processing a JSON object | depth of the parent of the JSON object | the parsed JSON object + parse_event_t::array_start | the parser read `[` and started to process a JSON array | depth of the parent of the JSON array | a JSON value with type discarded + parse_event_t::array_end | the parser read `]` and finished processing a JSON array | depth of the parent of the JSON array | the parsed JSON array + parse_event_t::value | the parser finished reading a JSON value | depth of the value | the parsed JSON value + + @image html callback_events.png "Example when certain parse events are triggered" + + Discarding a value (i.e., returning `false`) has different effects + depending on the context in which function was called: + + - Discarded values in structured types are skipped. That is, the parser + will behave as if the discarded value was never read. + - In case a value outside a structured type is skipped, it is replaced + with `null`. This case happens if the top-level element is skipped. + + @param[in] depth the depth of the recursion during parsing + + @param[in] event an event of type parse_event_t indicating the context in + the callback function has been called + + @param[in,out] parsed the current intermediate parse result; note that + writing to this value has no effect for parse_event_t::key events + + @return Whether the JSON value which called the function during parsing + should be kept (`true`) or not (`false`). In the latter case, it is either + skipped completely or replaced by an empty discarded object. + + @sa @ref parse for examples + + @since version 1.0.0 + */ + using parser_callback_t = typename parser::parser_callback_t; + + ////////////////// + // constructors // + ////////////////// + + /// @name constructors and destructors + /// Constructors of class @ref basic_json, copy/move constructor, copy + /// assignment, static functions creating objects, and the destructor. + /// @{ + + /*! + @brief create an empty value with a given type + + Create an empty JSON value with a given type. The value will be default + initialized with an empty value which depends on the type: + + Value type | initial value + ----------- | ------------- + null | `null` + boolean | `false` + string | `""` + number | `0` + object | `{}` + array | `[]` + + @param[in] v the type of the value to create + + @complexity Constant. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @liveexample{The following code shows the constructor for different @ref + value_t values,basic_json__value_t} + + @sa @ref clear() -- restores the postcondition of this constructor + + @since version 1.0.0 + */ + basic_json(const value_t v) + : m_type(v), m_value(v) + { + assert_invariant(); + } + + /*! + @brief create a null object + + Create a `null` JSON value. It either takes a null pointer as parameter + (explicitly creating `null`) or no parameter (implicitly creating `null`). + The passed null pointer itself is not read -- it is only used to choose + the right constructor. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this constructor never throws + exceptions. + + @liveexample{The following code shows the constructor with and without a + null pointer parameter.,basic_json__nullptr_t} + + @since version 1.0.0 + */ + basic_json(std::nullptr_t = nullptr) noexcept + : basic_json(value_t::null) + { + assert_invariant(); + } + + /*! + @brief create a JSON value + + This is a "catch all" constructor for all compatible JSON types; that is, + types for which a `to_json()` method exists. The constructor forwards the + parameter @a val to that method (to `json_serializer<U>::to_json` method + with `U = uncvref_t<CompatibleType>`, to be exact). + + Template type @a CompatibleType includes, but is not limited to, the + following types: + - **arrays**: @ref array_t and all kinds of compatible containers such as + `std::vector`, `std::deque`, `std::list`, `std::forward_list`, + `std::array`, `std::valarray`, `std::set`, `std::unordered_set`, + `std::multiset`, and `std::unordered_multiset` with a `value_type` from + which a @ref basic_json value can be constructed. + - **objects**: @ref object_t and all kinds of compatible associative + containers such as `std::map`, `std::unordered_map`, `std::multimap`, + and `std::unordered_multimap` with a `key_type` compatible to + @ref string_t and a `value_type` from which a @ref basic_json value can + be constructed. + - **strings**: @ref string_t, string literals, and all compatible string + containers can be used. + - **numbers**: @ref number_integer_t, @ref number_unsigned_t, + @ref number_float_t, and all convertible number types such as `int`, + `size_t`, `int64_t`, `float` or `double` can be used. + - **boolean**: @ref boolean_t / `bool` can be used. + + See the examples below. + + @tparam CompatibleType a type such that: + - @a CompatibleType is not derived from `std::istream`, + - @a CompatibleType is not @ref basic_json (to avoid hijacking copy/move + constructors), + - @a CompatibleType is not a different @ref basic_json type (i.e. with different template arguments) + - @a CompatibleType is not a @ref basic_json nested type (e.g., + @ref json_pointer, @ref iterator, etc ...) + - @ref @ref json_serializer<U> has a + `to_json(basic_json_t&, CompatibleType&&)` method + + @tparam U = `uncvref_t<CompatibleType>` + + @param[in] val the value to be forwarded to the respective constructor + + @complexity Usually linear in the size of the passed @a val, also + depending on the implementation of the called `to_json()` + method. + + @exceptionsafety Depends on the called constructor. For types directly + supported by the library (i.e., all types for which no `to_json()` function + was provided), strong guarantee holds: if an exception is thrown, there are + no changes to any JSON value. + + @liveexample{The following code shows the constructor with several + compatible types.,basic_json__CompatibleType} + + @since version 2.1.0 + */ + template <typename CompatibleType, + typename U = detail::uncvref_t<CompatibleType>, + detail::enable_if_t< + not detail::is_basic_json<U>::value and detail::is_compatible_type<basic_json_t, U>::value, int> = 0> + basic_json(CompatibleType && val) noexcept(noexcept( + JSONSerializer<U>::to_json(std::declval<basic_json_t&>(), + std::forward<CompatibleType>(val)))) + { + JSONSerializer<U>::to_json(*this, std::forward<CompatibleType>(val)); + assert_invariant(); + } + + /*! + @brief create a JSON value from an existing one + + This is a constructor for existing @ref basic_json types. + It does not hijack copy/move constructors, since the parameter has different + template arguments than the current ones. + + The constructor tries to convert the internal @ref m_value of the parameter. + + @tparam BasicJsonType a type such that: + - @a BasicJsonType is a @ref basic_json type. + - @a BasicJsonType has different template arguments than @ref basic_json_t. + + @param[in] val the @ref basic_json value to be converted. + + @complexity Usually linear in the size of the passed @a val, also + depending on the implementation of the called `to_json()` + method. + + @exceptionsafety Depends on the called constructor. For types directly + supported by the library (i.e., all types for which no `to_json()` function + was provided), strong guarantee holds: if an exception is thrown, there are + no changes to any JSON value. + + @since version 3.2.0 + */ + template <typename BasicJsonType, + detail::enable_if_t< + detail::is_basic_json<BasicJsonType>::value and not std::is_same<basic_json, BasicJsonType>::value, int> = 0> + basic_json(const BasicJsonType& val) + { + using other_boolean_t = typename BasicJsonType::boolean_t; + using other_number_float_t = typename BasicJsonType::number_float_t; + using other_number_integer_t = typename BasicJsonType::number_integer_t; + using other_number_unsigned_t = typename BasicJsonType::number_unsigned_t; + using other_string_t = typename BasicJsonType::string_t; + using other_object_t = typename BasicJsonType::object_t; + using other_array_t = typename BasicJsonType::array_t; + + switch (val.type()) + { + case value_t::boolean: + JSONSerializer<other_boolean_t>::to_json(*this, val.template get<other_boolean_t>()); + break; + case value_t::number_float: + JSONSerializer<other_number_float_t>::to_json(*this, val.template get<other_number_float_t>()); + break; + case value_t::number_integer: + JSONSerializer<other_number_integer_t>::to_json(*this, val.template get<other_number_integer_t>()); + break; + case value_t::number_unsigned: + JSONSerializer<other_number_unsigned_t>::to_json(*this, val.template get<other_number_unsigned_t>()); + break; + case value_t::string: + JSONSerializer<other_string_t>::to_json(*this, val.template get_ref<const other_string_t&>()); + break; + case value_t::object: + JSONSerializer<other_object_t>::to_json(*this, val.template get_ref<const other_object_t&>()); + break; + case value_t::array: + JSONSerializer<other_array_t>::to_json(*this, val.template get_ref<const other_array_t&>()); + break; + case value_t::null: + *this = nullptr; + break; + case value_t::discarded: + m_type = value_t::discarded; + break; + } + assert_invariant(); + } + + /*! + @brief create a container (array or object) from an initializer list + + Creates a JSON value of type array or object from the passed initializer + list @a init. In case @a type_deduction is `true` (default), the type of + the JSON value to be created is deducted from the initializer list @a init + according to the following rules: + + 1. If the list is empty, an empty JSON object value `{}` is created. + 2. If the list consists of pairs whose first element is a string, a JSON + object value is created where the first elements of the pairs are + treated as keys and the second elements are as values. + 3. In all other cases, an array is created. + + The rules aim to create the best fit between a C++ initializer list and + JSON values. The rationale is as follows: + + 1. The empty initializer list is written as `{}` which is exactly an empty + JSON object. + 2. C++ has no way of describing mapped types other than to list a list of + pairs. As JSON requires that keys must be of type string, rule 2 is the + weakest constraint one can pose on initializer lists to interpret them + as an object. + 3. In all other cases, the initializer list could not be interpreted as + JSON object type, so interpreting it as JSON array type is safe. + + With the rules described above, the following JSON values cannot be + expressed by an initializer list: + + - the empty array (`[]`): use @ref array(initializer_list_t) + with an empty initializer list in this case + - arrays whose elements satisfy rule 2: use @ref + array(initializer_list_t) with the same initializer list + in this case + + @note When used without parentheses around an empty initializer list, @ref + basic_json() is called instead of this function, yielding the JSON null + value. + + @param[in] init initializer list with JSON values + + @param[in] type_deduction internal parameter; when set to `true`, the type + of the JSON value is deducted from the initializer list @a init; when set + to `false`, the type provided via @a manual_type is forced. This mode is + used by the functions @ref array(initializer_list_t) and + @ref object(initializer_list_t). + + @param[in] manual_type internal parameter; when @a type_deduction is set + to `false`, the created JSON value will use the provided type (only @ref + value_t::array and @ref value_t::object are valid); when @a type_deduction + is set to `true`, this parameter has no effect + + @throw type_error.301 if @a type_deduction is `false`, @a manual_type is + `value_t::object`, but @a init contains an element which is not a pair + whose first element is a string. In this case, the constructor could not + create an object. If @a type_deduction would have be `true`, an array + would have been created. See @ref object(initializer_list_t) + for an example. + + @complexity Linear in the size of the initializer list @a init. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @liveexample{The example below shows how JSON values are created from + initializer lists.,basic_json__list_init_t} + + @sa @ref array(initializer_list_t) -- create a JSON array + value from an initializer list + @sa @ref object(initializer_list_t) -- create a JSON object + value from an initializer list + + @since version 1.0.0 + */ + basic_json(initializer_list_t init, + bool type_deduction = true, + value_t manual_type = value_t::array) + { + // check if each element is an array with two elements whose first + // element is a string + bool is_an_object = std::all_of(init.begin(), init.end(), + [](const detail::json_ref<basic_json>& element_ref) + { + return (element_ref->is_array() and element_ref->size() == 2 and (*element_ref)[0].is_string()); + }); + + // adjust type if type deduction is not wanted + if (not type_deduction) + { + // if array is wanted, do not create an object though possible + if (manual_type == value_t::array) + { + is_an_object = false; + } + + // if object is wanted but impossible, throw an exception + if (JSON_UNLIKELY(manual_type == value_t::object and not is_an_object)) + { + JSON_THROW(type_error::create(301, "cannot create object from initializer list")); + } + } + + if (is_an_object) + { + // the initializer list is a list of pairs -> create object + m_type = value_t::object; + m_value = value_t::object; + + std::for_each(init.begin(), init.end(), [this](const detail::json_ref<basic_json>& element_ref) + { + auto element = element_ref.moved_or_copied(); + m_value.object->emplace( + std::move(*((*element.m_value.array)[0].m_value.string)), + std::move((*element.m_value.array)[1])); + }); + } + else + { + // the initializer list describes an array -> create array + m_type = value_t::array; + m_value.array = create<array_t>(init.begin(), init.end()); + } + + assert_invariant(); + } + + /*! + @brief explicitly create an array from an initializer list + + Creates a JSON array value from a given initializer list. That is, given a + list of values `a, b, c`, creates the JSON value `[a, b, c]`. If the + initializer list is empty, the empty array `[]` is created. + + @note This function is only needed to express two edge cases that cannot + be realized with the initializer list constructor (@ref + basic_json(initializer_list_t, bool, value_t)). These cases + are: + 1. creating an array whose elements are all pairs whose first element is a + string -- in this case, the initializer list constructor would create an + object, taking the first elements as keys + 2. creating an empty array -- passing the empty initializer list to the + initializer list constructor yields an empty object + + @param[in] init initializer list with JSON values to create an array from + (optional) + + @return JSON array value + + @complexity Linear in the size of @a init. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @liveexample{The following code shows an example for the `array` + function.,array} + + @sa @ref basic_json(initializer_list_t, bool, value_t) -- + create a JSON value from an initializer list + @sa @ref object(initializer_list_t) -- create a JSON object + value from an initializer list + + @since version 1.0.0 + */ + static basic_json array(initializer_list_t init = {}) + { + return basic_json(init, false, value_t::array); + } + + /*! + @brief explicitly create an object from an initializer list + + Creates a JSON object value from a given initializer list. The initializer + lists elements must be pairs, and their first elements must be strings. If + the initializer list is empty, the empty object `{}` is created. + + @note This function is only added for symmetry reasons. In contrast to the + related function @ref array(initializer_list_t), there are + no cases which can only be expressed by this function. That is, any + initializer list @a init can also be passed to the initializer list + constructor @ref basic_json(initializer_list_t, bool, value_t). + + @param[in] init initializer list to create an object from (optional) + + @return JSON object value + + @throw type_error.301 if @a init is not a list of pairs whose first + elements are strings. In this case, no object can be created. When such a + value is passed to @ref basic_json(initializer_list_t, bool, value_t), + an array would have been created from the passed initializer list @a init. + See example below. + + @complexity Linear in the size of @a init. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @liveexample{The following code shows an example for the `object` + function.,object} + + @sa @ref basic_json(initializer_list_t, bool, value_t) -- + create a JSON value from an initializer list + @sa @ref array(initializer_list_t) -- create a JSON array + value from an initializer list + + @since version 1.0.0 + */ + static basic_json object(initializer_list_t init = {}) + { + return basic_json(init, false, value_t::object); + } + + /*! + @brief construct an array with count copies of given value + + Constructs a JSON array value by creating @a cnt copies of a passed value. + In case @a cnt is `0`, an empty array is created. + + @param[in] cnt the number of JSON copies of @a val to create + @param[in] val the JSON value to copy + + @post `std::distance(begin(),end()) == cnt` holds. + + @complexity Linear in @a cnt. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @liveexample{The following code shows examples for the @ref + basic_json(size_type\, const basic_json&) + constructor.,basic_json__size_type_basic_json} + + @since version 1.0.0 + */ + basic_json(size_type cnt, const basic_json& val) + : m_type(value_t::array) + { + m_value.array = create<array_t>(cnt, val); + assert_invariant(); + } + + /*! + @brief construct a JSON container given an iterator range + + Constructs the JSON value with the contents of the range `[first, last)`. + The semantics depends on the different types a JSON value can have: + - In case of a null type, invalid_iterator.206 is thrown. + - In case of other primitive types (number, boolean, or string), @a first + must be `begin()` and @a last must be `end()`. In this case, the value is + copied. Otherwise, invalid_iterator.204 is thrown. + - In case of structured types (array, object), the constructor behaves as + similar versions for `std::vector` or `std::map`; that is, a JSON array + or object is constructed from the values in the range. + + @tparam InputIT an input iterator type (@ref iterator or @ref + const_iterator) + + @param[in] first begin of the range to copy from (included) + @param[in] last end of the range to copy from (excluded) + + @pre Iterators @a first and @a last must be initialized. **This + precondition is enforced with an assertion (see warning).** If + assertions are switched off, a violation of this precondition yields + undefined behavior. + + @pre Range `[first, last)` is valid. Usually, this precondition cannot be + checked efficiently. Only certain edge cases are detected; see the + description of the exceptions below. A violation of this precondition + yields undefined behavior. + + @warning A precondition is enforced with a runtime assertion that will + result in calling `std::abort` if this precondition is not met. + Assertions can be disabled by defining `NDEBUG` at compile time. + See https://en.cppreference.com/w/cpp/error/assert for more + information. + + @throw invalid_iterator.201 if iterators @a first and @a last are not + compatible (i.e., do not belong to the same JSON value). In this case, + the range `[first, last)` is undefined. + @throw invalid_iterator.204 if iterators @a first and @a last belong to a + primitive type (number, boolean, or string), but @a first does not point + to the first element any more. In this case, the range `[first, last)` is + undefined. See example code below. + @throw invalid_iterator.206 if iterators @a first and @a last belong to a + null value. In this case, the range `[first, last)` is undefined. + + @complexity Linear in distance between @a first and @a last. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @liveexample{The example below shows several ways to create JSON values by + specifying a subrange with iterators.,basic_json__InputIt_InputIt} + + @since version 1.0.0 + */ + template<class InputIT, typename std::enable_if< + std::is_same<InputIT, typename basic_json_t::iterator>::value or + std::is_same<InputIT, typename basic_json_t::const_iterator>::value, int>::type = 0> + basic_json(InputIT first, InputIT last) + { + assert(first.m_object != nullptr); + assert(last.m_object != nullptr); + + // make sure iterator fits the current value + if (JSON_UNLIKELY(first.m_object != last.m_object)) + { + JSON_THROW(invalid_iterator::create(201, "iterators are not compatible")); + } + + // copy type from first iterator + m_type = first.m_object->m_type; + + // check if iterator range is complete for primitive values + switch (m_type) + { + case value_t::boolean: + case value_t::number_float: + case value_t::number_integer: + case value_t::number_unsigned: + case value_t::string: + { + if (JSON_UNLIKELY(not first.m_it.primitive_iterator.is_begin() + or not last.m_it.primitive_iterator.is_end())) + { + JSON_THROW(invalid_iterator::create(204, "iterators out of range")); + } + break; + } + + default: + break; + } + + switch (m_type) + { + case value_t::number_integer: + { + m_value.number_integer = first.m_object->m_value.number_integer; + break; + } + + case value_t::number_unsigned: + { + m_value.number_unsigned = first.m_object->m_value.number_unsigned; + break; + } + + case value_t::number_float: + { + m_value.number_float = first.m_object->m_value.number_float; + break; + } + + case value_t::boolean: + { + m_value.boolean = first.m_object->m_value.boolean; + break; + } + + case value_t::string: + { + m_value = *first.m_object->m_value.string; + break; + } + + case value_t::object: + { + m_value.object = create<object_t>(first.m_it.object_iterator, + last.m_it.object_iterator); + break; + } + + case value_t::array: + { + m_value.array = create<array_t>(first.m_it.array_iterator, + last.m_it.array_iterator); + break; + } + + default: + JSON_THROW(invalid_iterator::create(206, "cannot construct with iterators from " + + std::string(first.m_object->type_name()))); + } + + assert_invariant(); + } + + + /////////////////////////////////////// + // other constructors and destructor // + /////////////////////////////////////// + + /// @private + basic_json(const detail::json_ref<basic_json>& ref) + : basic_json(ref.moved_or_copied()) + {} + + /*! + @brief copy constructor + + Creates a copy of a given JSON value. + + @param[in] other the JSON value to copy + + @post `*this == other` + + @complexity Linear in the size of @a other. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes to any JSON value. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is linear. + - As postcondition, it holds: `other == basic_json(other)`. + + @liveexample{The following code shows an example for the copy + constructor.,basic_json__basic_json} + + @since version 1.0.0 + */ + basic_json(const basic_json& other) + : m_type(other.m_type) + { + // check of passed value is valid + other.assert_invariant(); + + switch (m_type) + { + case value_t::object: + { + m_value = *other.m_value.object; + break; + } + + case value_t::array: + { + m_value = *other.m_value.array; + break; + } + + case value_t::string: + { + m_value = *other.m_value.string; + break; + } + + case value_t::boolean: + { + m_value = other.m_value.boolean; + break; + } + + case value_t::number_integer: + { + m_value = other.m_value.number_integer; + break; + } + + case value_t::number_unsigned: + { + m_value = other.m_value.number_unsigned; + break; + } + + case value_t::number_float: + { + m_value = other.m_value.number_float; + break; + } + + default: + break; + } + + assert_invariant(); + } + + /*! + @brief move constructor + + Move constructor. Constructs a JSON value with the contents of the given + value @a other using move semantics. It "steals" the resources from @a + other and leaves it as JSON null value. + + @param[in,out] other value to move to this object + + @post `*this` has the same value as @a other before the call. + @post @a other is a JSON null value. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this constructor never throws + exceptions. + + @requirement This function helps `basic_json` satisfying the + [MoveConstructible](https://en.cppreference.com/w/cpp/named_req/MoveConstructible) + requirements. + + @liveexample{The code below shows the move constructor explicitly called + via std::move.,basic_json__moveconstructor} + + @since version 1.0.0 + */ + basic_json(basic_json&& other) noexcept + : m_type(std::move(other.m_type)), + m_value(std::move(other.m_value)) + { + // check that passed value is valid + other.assert_invariant(); + + // invalidate payload + other.m_type = value_t::null; + other.m_value = {}; + + assert_invariant(); + } + + /*! + @brief copy assignment + + Copy assignment operator. Copies a JSON value via the "copy and swap" + strategy: It is expressed in terms of the copy constructor, destructor, + and the `swap()` member function. + + @param[in] other value to copy from + + @complexity Linear. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is linear. + + @liveexample{The code below shows and example for the copy assignment. It + creates a copy of value `a` which is then swapped with `b`. Finally\, the + copy of `a` (which is the null value after the swap) is + destroyed.,basic_json__copyassignment} + + @since version 1.0.0 + */ + basic_json& operator=(basic_json other) noexcept ( + std::is_nothrow_move_constructible<value_t>::value and + std::is_nothrow_move_assignable<value_t>::value and + std::is_nothrow_move_constructible<json_value>::value and + std::is_nothrow_move_assignable<json_value>::value + ) + { + // check that passed value is valid + other.assert_invariant(); + + using std::swap; + swap(m_type, other.m_type); + swap(m_value, other.m_value); + + assert_invariant(); + return *this; + } + + /*! + @brief destructor + + Destroys the JSON value and frees all allocated memory. + + @complexity Linear. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is linear. + - All stored elements are destroyed and all memory is freed. + + @since version 1.0.0 + */ + ~basic_json() noexcept + { + assert_invariant(); + m_value.destroy(m_type); + } + + /// @} + + public: + /////////////////////// + // object inspection // + /////////////////////// + + /// @name object inspection + /// Functions to inspect the type of a JSON value. + /// @{ + + /*! + @brief serialization + + Serialization function for JSON values. The function tries to mimic + Python's `json.dumps()` function, and currently supports its @a indent + and @a ensure_ascii parameters. + + @param[in] indent If indent is nonnegative, then array elements and object + members will be pretty-printed with that indent level. An indent level of + `0` will only insert newlines. `-1` (the default) selects the most compact + representation. + @param[in] indent_char The character to use for indentation if @a indent is + greater than `0`. The default is ` ` (space). + @param[in] ensure_ascii If @a ensure_ascii is true, all non-ASCII characters + in the output are escaped with `\uXXXX` sequences, and the result consists + of ASCII characters only. + @param[in] error_handler how to react on decoding errors; there are three + possible values: `strict` (throws and exception in case a decoding error + occurs; default), `replace` (replace invalid UTF-8 sequences with U+FFFD), + and `ignore` (ignore invalid UTF-8 sequences during serialization). + + @return string containing the serialization of the JSON value + + @throw type_error.316 if a string stored inside the JSON value is not + UTF-8 encoded + + @complexity Linear. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @liveexample{The following example shows the effect of different @a indent\, + @a indent_char\, and @a ensure_ascii parameters to the result of the + serialization.,dump} + + @see https://docs.python.org/2/library/json.html#json.dump + + @since version 1.0.0; indentation character @a indent_char, option + @a ensure_ascii and exceptions added in version 3.0.0; error + handlers added in version 3.4.0. + */ + string_t dump(const int indent = -1, + const char indent_char = ' ', + const bool ensure_ascii = false, + const error_handler_t error_handler = error_handler_t::strict) const + { + string_t result; + serializer s(detail::output_adapter<char, string_t>(result), indent_char, error_handler); + + if (indent >= 0) + { + s.dump(*this, true, ensure_ascii, static_cast<unsigned int>(indent)); + } + else + { + s.dump(*this, false, ensure_ascii, 0); + } + + return result; + } + + /*! + @brief return the type of the JSON value (explicit) + + Return the type of the JSON value as a value from the @ref value_t + enumeration. + + @return the type of the JSON value + Value type | return value + ------------------------- | ------------------------- + null | value_t::null + boolean | value_t::boolean + string | value_t::string + number (integer) | value_t::number_integer + number (unsigned integer) | value_t::number_unsigned + number (floating-point) | value_t::number_float + object | value_t::object + array | value_t::array + discarded | value_t::discarded + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `type()` for all JSON + types.,type} + + @sa @ref operator value_t() -- return the type of the JSON value (implicit) + @sa @ref type_name() -- return the type as string + + @since version 1.0.0 + */ + constexpr value_t type() const noexcept + { + return m_type; + } + + /*! + @brief return whether type is primitive + + This function returns true if and only if the JSON type is primitive + (string, number, boolean, or null). + + @return `true` if type is primitive (string, number, boolean, or null), + `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_primitive()` for all JSON + types.,is_primitive} + + @sa @ref is_structured() -- returns whether JSON value is structured + @sa @ref is_null() -- returns whether JSON value is `null` + @sa @ref is_string() -- returns whether JSON value is a string + @sa @ref is_boolean() -- returns whether JSON value is a boolean + @sa @ref is_number() -- returns whether JSON value is a number + + @since version 1.0.0 + */ + constexpr bool is_primitive() const noexcept + { + return is_null() or is_string() or is_boolean() or is_number(); + } + + /*! + @brief return whether type is structured + + This function returns true if and only if the JSON type is structured + (array or object). + + @return `true` if type is structured (array or object), `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_structured()` for all JSON + types.,is_structured} + + @sa @ref is_primitive() -- returns whether value is primitive + @sa @ref is_array() -- returns whether value is an array + @sa @ref is_object() -- returns whether value is an object + + @since version 1.0.0 + */ + constexpr bool is_structured() const noexcept + { + return is_array() or is_object(); + } + + /*! + @brief return whether value is null + + This function returns true if and only if the JSON value is null. + + @return `true` if type is null, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_null()` for all JSON + types.,is_null} + + @since version 1.0.0 + */ + constexpr bool is_null() const noexcept + { + return (m_type == value_t::null); + } + + /*! + @brief return whether value is a boolean + + This function returns true if and only if the JSON value is a boolean. + + @return `true` if type is boolean, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_boolean()` for all JSON + types.,is_boolean} + + @since version 1.0.0 + */ + constexpr bool is_boolean() const noexcept + { + return (m_type == value_t::boolean); + } + + /*! + @brief return whether value is a number + + This function returns true if and only if the JSON value is a number. This + includes both integer (signed and unsigned) and floating-point values. + + @return `true` if type is number (regardless whether integer, unsigned + integer or floating-type), `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_number()` for all JSON + types.,is_number} + + @sa @ref is_number_integer() -- check if value is an integer or unsigned + integer number + @sa @ref is_number_unsigned() -- check if value is an unsigned integer + number + @sa @ref is_number_float() -- check if value is a floating-point number + + @since version 1.0.0 + */ + constexpr bool is_number() const noexcept + { + return is_number_integer() or is_number_float(); + } + + /*! + @brief return whether value is an integer number + + This function returns true if and only if the JSON value is a signed or + unsigned integer number. This excludes floating-point values. + + @return `true` if type is an integer or unsigned integer number, `false` + otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_number_integer()` for all + JSON types.,is_number_integer} + + @sa @ref is_number() -- check if value is a number + @sa @ref is_number_unsigned() -- check if value is an unsigned integer + number + @sa @ref is_number_float() -- check if value is a floating-point number + + @since version 1.0.0 + */ + constexpr bool is_number_integer() const noexcept + { + return (m_type == value_t::number_integer or m_type == value_t::number_unsigned); + } + + /*! + @brief return whether value is an unsigned integer number + + This function returns true if and only if the JSON value is an unsigned + integer number. This excludes floating-point and signed integer values. + + @return `true` if type is an unsigned integer number, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_number_unsigned()` for all + JSON types.,is_number_unsigned} + + @sa @ref is_number() -- check if value is a number + @sa @ref is_number_integer() -- check if value is an integer or unsigned + integer number + @sa @ref is_number_float() -- check if value is a floating-point number + + @since version 2.0.0 + */ + constexpr bool is_number_unsigned() const noexcept + { + return (m_type == value_t::number_unsigned); + } + + /*! + @brief return whether value is a floating-point number + + This function returns true if and only if the JSON value is a + floating-point number. This excludes signed and unsigned integer values. + + @return `true` if type is a floating-point number, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_number_float()` for all + JSON types.,is_number_float} + + @sa @ref is_number() -- check if value is number + @sa @ref is_number_integer() -- check if value is an integer number + @sa @ref is_number_unsigned() -- check if value is an unsigned integer + number + + @since version 1.0.0 + */ + constexpr bool is_number_float() const noexcept + { + return (m_type == value_t::number_float); + } + + /*! + @brief return whether value is an object + + This function returns true if and only if the JSON value is an object. + + @return `true` if type is object, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_object()` for all JSON + types.,is_object} + + @since version 1.0.0 + */ + constexpr bool is_object() const noexcept + { + return (m_type == value_t::object); + } + + /*! + @brief return whether value is an array + + This function returns true if and only if the JSON value is an array. + + @return `true` if type is array, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_array()` for all JSON + types.,is_array} + + @since version 1.0.0 + */ + constexpr bool is_array() const noexcept + { + return (m_type == value_t::array); + } + + /*! + @brief return whether value is a string + + This function returns true if and only if the JSON value is a string. + + @return `true` if type is string, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_string()` for all JSON + types.,is_string} + + @since version 1.0.0 + */ + constexpr bool is_string() const noexcept + { + return (m_type == value_t::string); + } + + /*! + @brief return whether value is discarded + + This function returns true if and only if the JSON value was discarded + during parsing with a callback function (see @ref parser_callback_t). + + @note This function will always be `false` for JSON values after parsing. + That is, discarded values can only occur during parsing, but will be + removed when inside a structured value or replaced by null in other cases. + + @return `true` if type is discarded, `false` otherwise. + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies `is_discarded()` for all JSON + types.,is_discarded} + + @since version 1.0.0 + */ + constexpr bool is_discarded() const noexcept + { + return (m_type == value_t::discarded); + } + + /*! + @brief return the type of the JSON value (implicit) + + Implicitly return the type of the JSON value as a value from the @ref + value_t enumeration. + + @return the type of the JSON value + + @complexity Constant. + + @exceptionsafety No-throw guarantee: this member function never throws + exceptions. + + @liveexample{The following code exemplifies the @ref value_t operator for + all JSON types.,operator__value_t} + + @sa @ref type() -- return the type of the JSON value (explicit) + @sa @ref type_name() -- return the type as string + + @since version 1.0.0 + */ + constexpr operator value_t() const noexcept + { + return m_type; + } + + /// @} + + private: + ////////////////// + // value access // + ////////////////// + + /// get a boolean (explicit) + boolean_t get_impl(boolean_t* /*unused*/) const + { + if (JSON_LIKELY(is_boolean())) + { + return m_value.boolean; + } + + JSON_THROW(type_error::create(302, "type must be boolean, but is " + std::string(type_name()))); + } + + /// get a pointer to the value (object) + object_t* get_impl_ptr(object_t* /*unused*/) noexcept + { + return is_object() ? m_value.object : nullptr; + } + + /// get a pointer to the value (object) + constexpr const object_t* get_impl_ptr(const object_t* /*unused*/) const noexcept + { + return is_object() ? m_value.object : nullptr; + } + + /// get a pointer to the value (array) + array_t* get_impl_ptr(array_t* /*unused*/) noexcept + { + return is_array() ? m_value.array : nullptr; + } + + /// get a pointer to the value (array) + constexpr const array_t* get_impl_ptr(const array_t* /*unused*/) const noexcept + { + return is_array() ? m_value.array : nullptr; + } + + /// get a pointer to the value (string) + string_t* get_impl_ptr(string_t* /*unused*/) noexcept + { + return is_string() ? m_value.string : nullptr; + } + + /// get a pointer to the value (string) + constexpr const string_t* get_impl_ptr(const string_t* /*unused*/) const noexcept + { + return is_string() ? m_value.string : nullptr; + } + + /// get a pointer to the value (boolean) + boolean_t* get_impl_ptr(boolean_t* /*unused*/) noexcept + { + return is_boolean() ? &m_value.boolean : nullptr; + } + + /// get a pointer to the value (boolean) + constexpr const boolean_t* get_impl_ptr(const boolean_t* /*unused*/) const noexcept + { + return is_boolean() ? &m_value.boolean : nullptr; + } + + /// get a pointer to the value (integer number) + number_integer_t* get_impl_ptr(number_integer_t* /*unused*/) noexcept + { + return is_number_integer() ? &m_value.number_integer : nullptr; + } + + /// get a pointer to the value (integer number) + constexpr const number_integer_t* get_impl_ptr(const number_integer_t* /*unused*/) const noexcept + { + return is_number_integer() ? &m_value.number_integer : nullptr; + } + + /// get a pointer to the value (unsigned number) + number_unsigned_t* get_impl_ptr(number_unsigned_t* /*unused*/) noexcept + { + return is_number_unsigned() ? &m_value.number_unsigned : nullptr; + } + + /// get a pointer to the value (unsigned number) + constexpr const number_unsigned_t* get_impl_ptr(const number_unsigned_t* /*unused*/) const noexcept + { + return is_number_unsigned() ? &m_value.number_unsigned : nullptr; + } + + /// get a pointer to the value (floating-point number) + number_float_t* get_impl_ptr(number_float_t* /*unused*/) noexcept + { + return is_number_float() ? &m_value.number_float : nullptr; + } + + /// get a pointer to the value (floating-point number) + constexpr const number_float_t* get_impl_ptr(const number_float_t* /*unused*/) const noexcept + { + return is_number_float() ? &m_value.number_float : nullptr; + } + + /*! + @brief helper function to implement get_ref() + + This function helps to implement get_ref() without code duplication for + const and non-const overloads + + @tparam ThisType will be deduced as `basic_json` or `const basic_json` + + @throw type_error.303 if ReferenceType does not match underlying value + type of the current JSON + */ + template<typename ReferenceType, typename ThisType> + static ReferenceType get_ref_impl(ThisType& obj) + { + // delegate the call to get_ptr<>() + auto ptr = obj.template get_ptr<typename std::add_pointer<ReferenceType>::type>(); + + if (JSON_LIKELY(ptr != nullptr)) + { + return *ptr; + } + + JSON_THROW(type_error::create(303, "incompatible ReferenceType for get_ref, actual type is " + std::string(obj.type_name()))); + } + + public: + /// @name value access + /// Direct access to the stored value of a JSON value. + /// @{ + + /*! + @brief get special-case overload + + This overloads avoids a lot of template boilerplate, it can be seen as the + identity method + + @tparam BasicJsonType == @ref basic_json + + @return a copy of *this + + @complexity Constant. + + @since version 2.1.0 + */ + template<typename BasicJsonType, detail::enable_if_t< + std::is_same<typename std::remove_const<BasicJsonType>::type, basic_json_t>::value, + int> = 0> + basic_json get() const + { + return *this; + } + + /*! + @brief get special-case overload + + This overloads converts the current @ref basic_json in a different + @ref basic_json type + + @tparam BasicJsonType == @ref basic_json + + @return a copy of *this, converted into @tparam BasicJsonType + + @complexity Depending on the implementation of the called `from_json()` + method. + + @since version 3.2.0 + */ + template<typename BasicJsonType, detail::enable_if_t< + not std::is_same<BasicJsonType, basic_json>::value and + detail::is_basic_json<BasicJsonType>::value, int> = 0> + BasicJsonType get() const + { + return *this; + } + + /*! + @brief get a value (explicit) + + Explicit type conversion between the JSON value and a compatible value + which is [CopyConstructible](https://en.cppreference.com/w/cpp/named_req/CopyConstructible) + and [DefaultConstructible](https://en.cppreference.com/w/cpp/named_req/DefaultConstructible). + The value is converted by calling the @ref json_serializer<ValueType> + `from_json()` method. + + The function is equivalent to executing + @code {.cpp} + ValueType ret; + JSONSerializer<ValueType>::from_json(*this, ret); + return ret; + @endcode + + This overloads is chosen if: + - @a ValueType is not @ref basic_json, + - @ref json_serializer<ValueType> has a `from_json()` method of the form + `void from_json(const basic_json&, ValueType&)`, and + - @ref json_serializer<ValueType> does not have a `from_json()` method of + the form `ValueType from_json(const basic_json&)` + + @tparam ValueTypeCV the provided value type + @tparam ValueType the returned value type + + @return copy of the JSON value, converted to @a ValueType + + @throw what @ref json_serializer<ValueType> `from_json()` method throws + + @liveexample{The example below shows several conversions from JSON values + to other types. There a few things to note: (1) Floating-point numbers can + be converted to integers\, (2) A JSON array can be converted to a standard + `std::vector<short>`\, (3) A JSON object can be converted to C++ + associative containers such as `std::unordered_map<std::string\, + json>`.,get__ValueType_const} + + @since version 2.1.0 + */ + template<typename ValueTypeCV, typename ValueType = detail::uncvref_t<ValueTypeCV>, + detail::enable_if_t < + not detail::is_basic_json<ValueType>::value and + detail::has_from_json<basic_json_t, ValueType>::value and + not detail::has_non_default_from_json<basic_json_t, ValueType>::value, + int> = 0> + ValueType get() const noexcept(noexcept( + JSONSerializer<ValueType>::from_json(std::declval<const basic_json_t&>(), std::declval<ValueType&>()))) + { + // we cannot static_assert on ValueTypeCV being non-const, because + // there is support for get<const basic_json_t>(), which is why we + // still need the uncvref + static_assert(not std::is_reference<ValueTypeCV>::value, + "get() cannot be used with reference types, you might want to use get_ref()"); + static_assert(std::is_default_constructible<ValueType>::value, + "types must be DefaultConstructible when used with get()"); + + ValueType ret; + JSONSerializer<ValueType>::from_json(*this, ret); + return ret; + } + + /*! + @brief get a value (explicit); special case + + Explicit type conversion between the JSON value and a compatible value + which is **not** [CopyConstructible](https://en.cppreference.com/w/cpp/named_req/CopyConstructible) + and **not** [DefaultConstructible](https://en.cppreference.com/w/cpp/named_req/DefaultConstructible). + The value is converted by calling the @ref json_serializer<ValueType> + `from_json()` method. + + The function is equivalent to executing + @code {.cpp} + return JSONSerializer<ValueTypeCV>::from_json(*this); + @endcode + + This overloads is chosen if: + - @a ValueType is not @ref basic_json and + - @ref json_serializer<ValueType> has a `from_json()` method of the form + `ValueType from_json(const basic_json&)` + + @note If @ref json_serializer<ValueType> has both overloads of + `from_json()`, this one is chosen. + + @tparam ValueTypeCV the provided value type + @tparam ValueType the returned value type + + @return copy of the JSON value, converted to @a ValueType + + @throw what @ref json_serializer<ValueType> `from_json()` method throws + + @since version 2.1.0 + */ + template<typename ValueTypeCV, typename ValueType = detail::uncvref_t<ValueTypeCV>, + detail::enable_if_t<not std::is_same<basic_json_t, ValueType>::value and + detail::has_non_default_from_json<basic_json_t, ValueType>::value, + int> = 0> + ValueType get() const noexcept(noexcept( + JSONSerializer<ValueTypeCV>::from_json(std::declval<const basic_json_t&>()))) + { + static_assert(not std::is_reference<ValueTypeCV>::value, + "get() cannot be used with reference types, you might want to use get_ref()"); + return JSONSerializer<ValueTypeCV>::from_json(*this); + } + + /*! + @brief get a value (explicit) + + Explicit type conversion between the JSON value and a compatible value. + The value is filled into the input parameter by calling the @ref json_serializer<ValueType> + `from_json()` method. + + The function is equivalent to executing + @code {.cpp} + ValueType v; + JSONSerializer<ValueType>::from_json(*this, v); + @endcode + + This overloads is chosen if: + - @a ValueType is not @ref basic_json, + - @ref json_serializer<ValueType> has a `from_json()` method of the form + `void from_json(const basic_json&, ValueType&)`, and + + @tparam ValueType the input parameter type. + + @return the input parameter, allowing chaining calls. + + @throw what @ref json_serializer<ValueType> `from_json()` method throws + + @liveexample{The example below shows several conversions from JSON values + to other types. There a few things to note: (1) Floating-point numbers can + be converted to integers\, (2) A JSON array can be converted to a standard + `std::vector<short>`\, (3) A JSON object can be converted to C++ + associative containers such as `std::unordered_map<std::string\, + json>`.,get_to} + + @since version 3.3.0 + */ + template<typename ValueType, + detail::enable_if_t < + not detail::is_basic_json<ValueType>::value and + detail::has_from_json<basic_json_t, ValueType>::value, + int> = 0> + ValueType & get_to(ValueType& v) const noexcept(noexcept( + JSONSerializer<ValueType>::from_json(std::declval<const basic_json_t&>(), v))) + { + JSONSerializer<ValueType>::from_json(*this, v); + return v; + } + + + /*! + @brief get a pointer value (implicit) + + Implicit pointer access to the internally stored JSON value. No copies are + made. + + @warning Writing data to the pointee of the result yields an undefined + state. + + @tparam PointerType pointer type; must be a pointer to @ref array_t, @ref + object_t, @ref string_t, @ref boolean_t, @ref number_integer_t, + @ref number_unsigned_t, or @ref number_float_t. Enforced by a static + assertion. + + @return pointer to the internally stored JSON value if the requested + pointer type @a PointerType fits to the JSON value; `nullptr` otherwise + + @complexity Constant. + + @liveexample{The example below shows how pointers to internal values of a + JSON value can be requested. Note that no type conversions are made and a + `nullptr` is returned if the value and the requested pointer type does not + match.,get_ptr} + + @since version 1.0.0 + */ + template<typename PointerType, typename std::enable_if< + std::is_pointer<PointerType>::value, int>::type = 0> + auto get_ptr() noexcept -> decltype(std::declval<basic_json_t&>().get_impl_ptr(std::declval<PointerType>())) + { + // delegate the call to get_impl_ptr<>() + return get_impl_ptr(static_cast<PointerType>(nullptr)); + } + + /*! + @brief get a pointer value (implicit) + @copydoc get_ptr() + */ + template<typename PointerType, typename std::enable_if< + std::is_pointer<PointerType>::value and + std::is_const<typename std::remove_pointer<PointerType>::type>::value, int>::type = 0> + constexpr auto get_ptr() const noexcept -> decltype(std::declval<const basic_json_t&>().get_impl_ptr(std::declval<PointerType>())) + { + // delegate the call to get_impl_ptr<>() const + return get_impl_ptr(static_cast<PointerType>(nullptr)); + } + + /*! + @brief get a pointer value (explicit) + + Explicit pointer access to the internally stored JSON value. No copies are + made. + + @warning The pointer becomes invalid if the underlying JSON object + changes. + + @tparam PointerType pointer type; must be a pointer to @ref array_t, @ref + object_t, @ref string_t, @ref boolean_t, @ref number_integer_t, + @ref number_unsigned_t, or @ref number_float_t. + + @return pointer to the internally stored JSON value if the requested + pointer type @a PointerType fits to the JSON value; `nullptr` otherwise + + @complexity Constant. + + @liveexample{The example below shows how pointers to internal values of a + JSON value can be requested. Note that no type conversions are made and a + `nullptr` is returned if the value and the requested pointer type does not + match.,get__PointerType} + + @sa @ref get_ptr() for explicit pointer-member access + + @since version 1.0.0 + */ + template<typename PointerType, typename std::enable_if< + std::is_pointer<PointerType>::value, int>::type = 0> + auto get() noexcept -> decltype(std::declval<basic_json_t&>().template get_ptr<PointerType>()) + { + // delegate the call to get_ptr + return get_ptr<PointerType>(); + } + + /*! + @brief get a pointer value (explicit) + @copydoc get() + */ + template<typename PointerType, typename std::enable_if< + std::is_pointer<PointerType>::value, int>::type = 0> + constexpr auto get() const noexcept -> decltype(std::declval<const basic_json_t&>().template get_ptr<PointerType>()) + { + // delegate the call to get_ptr + return get_ptr<PointerType>(); + } + + /*! + @brief get a reference value (implicit) + + Implicit reference access to the internally stored JSON value. No copies + are made. + + @warning Writing data to the referee of the result yields an undefined + state. + + @tparam ReferenceType reference type; must be a reference to @ref array_t, + @ref object_t, @ref string_t, @ref boolean_t, @ref number_integer_t, or + @ref number_float_t. Enforced by static assertion. + + @return reference to the internally stored JSON value if the requested + reference type @a ReferenceType fits to the JSON value; throws + type_error.303 otherwise + + @throw type_error.303 in case passed type @a ReferenceType is incompatible + with the stored JSON value; see example below + + @complexity Constant. + + @liveexample{The example shows several calls to `get_ref()`.,get_ref} + + @since version 1.1.0 + */ + template<typename ReferenceType, typename std::enable_if< + std::is_reference<ReferenceType>::value, int>::type = 0> + ReferenceType get_ref() + { + // delegate call to get_ref_impl + return get_ref_impl<ReferenceType>(*this); + } + + /*! + @brief get a reference value (implicit) + @copydoc get_ref() + */ + template<typename ReferenceType, typename std::enable_if< + std::is_reference<ReferenceType>::value and + std::is_const<typename std::remove_reference<ReferenceType>::type>::value, int>::type = 0> + ReferenceType get_ref() const + { + // delegate call to get_ref_impl + return get_ref_impl<ReferenceType>(*this); + } + + /*! + @brief get a value (implicit) + + Implicit type conversion between the JSON value and a compatible value. + The call is realized by calling @ref get() const. + + @tparam ValueType non-pointer type compatible to the JSON value, for + instance `int` for JSON integer numbers, `bool` for JSON booleans, or + `std::vector` types for JSON arrays. The character type of @ref string_t + as well as an initializer list of this type is excluded to avoid + ambiguities as these types implicitly convert to `std::string`. + + @return copy of the JSON value, converted to type @a ValueType + + @throw type_error.302 in case passed type @a ValueType is incompatible + to the JSON value type (e.g., the JSON value is of type boolean, but a + string is requested); see example below + + @complexity Linear in the size of the JSON value. + + @liveexample{The example below shows several conversions from JSON values + to other types. There a few things to note: (1) Floating-point numbers can + be converted to integers\, (2) A JSON array can be converted to a standard + `std::vector<short>`\, (3) A JSON object can be converted to C++ + associative containers such as `std::unordered_map<std::string\, + json>`.,operator__ValueType} + + @since version 1.0.0 + */ + template < typename ValueType, typename std::enable_if < + not std::is_pointer<ValueType>::value and + not std::is_same<ValueType, detail::json_ref<basic_json>>::value and + not std::is_same<ValueType, typename string_t::value_type>::value and + not detail::is_basic_json<ValueType>::value + +#ifndef _MSC_VER // fix for issue #167 operator<< ambiguity under VS2015 + and not std::is_same<ValueType, std::initializer_list<typename string_t::value_type>>::value +#if defined(JSON_HAS_CPP_17) && defined(_MSC_VER) and _MSC_VER <= 1914 + and not std::is_same<ValueType, typename std::string_view>::value +#endif +#endif + and detail::is_detected<detail::get_template_function, const basic_json_t&, ValueType>::value + , int >::type = 0 > + operator ValueType() const + { + // delegate the call to get<>() const + return get<ValueType>(); + } + + /// @} + + + //////////////////// + // element access // + //////////////////// + + /// @name element access + /// Access to the JSON value. + /// @{ + + /*! + @brief access specified array element with bounds checking + + Returns a reference to the element at specified location @a idx, with + bounds checking. + + @param[in] idx index of the element to access + + @return reference to the element at index @a idx + + @throw type_error.304 if the JSON value is not an array; in this case, + calling `at` with an index makes no sense. See example below. + @throw out_of_range.401 if the index @a idx is out of range of the array; + that is, `idx >= size()`. See example below. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Constant. + + @since version 1.0.0 + + @liveexample{The example below shows how array elements can be read and + written using `at()`. It also demonstrates the different exceptions that + can be thrown.,at__size_type} + */ + reference at(size_type idx) + { + // at only works for arrays + if (JSON_LIKELY(is_array())) + { + JSON_TRY + { + return m_value.array->at(idx); + } + JSON_CATCH (std::out_of_range&) + { + // create better exception explanation + JSON_THROW(out_of_range::create(401, "array index " + std::to_string(idx) + " is out of range")); + } + } + else + { + JSON_THROW(type_error::create(304, "cannot use at() with " + std::string(type_name()))); + } + } + + /*! + @brief access specified array element with bounds checking + + Returns a const reference to the element at specified location @a idx, + with bounds checking. + + @param[in] idx index of the element to access + + @return const reference to the element at index @a idx + + @throw type_error.304 if the JSON value is not an array; in this case, + calling `at` with an index makes no sense. See example below. + @throw out_of_range.401 if the index @a idx is out of range of the array; + that is, `idx >= size()`. See example below. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Constant. + + @since version 1.0.0 + + @liveexample{The example below shows how array elements can be read using + `at()`. It also demonstrates the different exceptions that can be thrown., + at__size_type_const} + */ + const_reference at(size_type idx) const + { + // at only works for arrays + if (JSON_LIKELY(is_array())) + { + JSON_TRY + { + return m_value.array->at(idx); + } + JSON_CATCH (std::out_of_range&) + { + // create better exception explanation + JSON_THROW(out_of_range::create(401, "array index " + std::to_string(idx) + " is out of range")); + } + } + else + { + JSON_THROW(type_error::create(304, "cannot use at() with " + std::string(type_name()))); + } + } + + /*! + @brief access specified object element with bounds checking + + Returns a reference to the element at with specified key @a key, with + bounds checking. + + @param[in] key key of the element to access + + @return reference to the element at key @a key + + @throw type_error.304 if the JSON value is not an object; in this case, + calling `at` with a key makes no sense. See example below. + @throw out_of_range.403 if the key @a key is is not stored in the object; + that is, `find(key) == end()`. See example below. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Logarithmic in the size of the container. + + @sa @ref operator[](const typename object_t::key_type&) for unchecked + access by reference + @sa @ref value() for access by value with a default value + + @since version 1.0.0 + + @liveexample{The example below shows how object elements can be read and + written using `at()`. It also demonstrates the different exceptions that + can be thrown.,at__object_t_key_type} + */ + reference at(const typename object_t::key_type& key) + { + // at only works for objects + if (JSON_LIKELY(is_object())) + { + JSON_TRY + { + return m_value.object->at(key); + } + JSON_CATCH (std::out_of_range&) + { + // create better exception explanation + JSON_THROW(out_of_range::create(403, "key '" + key + "' not found")); + } + } + else + { + JSON_THROW(type_error::create(304, "cannot use at() with " + std::string(type_name()))); + } + } + + /*! + @brief access specified object element with bounds checking + + Returns a const reference to the element at with specified key @a key, + with bounds checking. + + @param[in] key key of the element to access + + @return const reference to the element at key @a key + + @throw type_error.304 if the JSON value is not an object; in this case, + calling `at` with a key makes no sense. See example below. + @throw out_of_range.403 if the key @a key is is not stored in the object; + that is, `find(key) == end()`. See example below. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Logarithmic in the size of the container. + + @sa @ref operator[](const typename object_t::key_type&) for unchecked + access by reference + @sa @ref value() for access by value with a default value + + @since version 1.0.0 + + @liveexample{The example below shows how object elements can be read using + `at()`. It also demonstrates the different exceptions that can be thrown., + at__object_t_key_type_const} + */ + const_reference at(const typename object_t::key_type& key) const + { + // at only works for objects + if (JSON_LIKELY(is_object())) + { + JSON_TRY + { + return m_value.object->at(key); + } + JSON_CATCH (std::out_of_range&) + { + // create better exception explanation + JSON_THROW(out_of_range::create(403, "key '" + key + "' not found")); + } + } + else + { + JSON_THROW(type_error::create(304, "cannot use at() with " + std::string(type_name()))); + } + } + + /*! + @brief access specified array element + + Returns a reference to the element at specified location @a idx. + + @note If @a idx is beyond the range of the array (i.e., `idx >= size()`), + then the array is silently filled up with `null` values to make `idx` a + valid reference to the last stored element. + + @param[in] idx index of the element to access + + @return reference to the element at index @a idx + + @throw type_error.305 if the JSON value is not an array or null; in that + cases, using the [] operator with an index makes no sense. + + @complexity Constant if @a idx is in the range of the array. Otherwise + linear in `idx - size()`. + + @liveexample{The example below shows how array elements can be read and + written using `[]` operator. Note the addition of `null` + values.,operatorarray__size_type} + + @since version 1.0.0 + */ + reference operator[](size_type idx) + { + // implicitly convert null value to an empty array + if (is_null()) + { + m_type = value_t::array; + m_value.array = create<array_t>(); + assert_invariant(); + } + + // operator[] only works for arrays + if (JSON_LIKELY(is_array())) + { + // fill up array with null values if given idx is outside range + if (idx >= m_value.array->size()) + { + m_value.array->insert(m_value.array->end(), + idx - m_value.array->size() + 1, + basic_json()); + } + + return m_value.array->operator[](idx); + } + + JSON_THROW(type_error::create(305, "cannot use operator[] with a numeric argument with " + std::string(type_name()))); + } + + /*! + @brief access specified array element + + Returns a const reference to the element at specified location @a idx. + + @param[in] idx index of the element to access + + @return const reference to the element at index @a idx + + @throw type_error.305 if the JSON value is not an array; in that case, + using the [] operator with an index makes no sense. + + @complexity Constant. + + @liveexample{The example below shows how array elements can be read using + the `[]` operator.,operatorarray__size_type_const} + + @since version 1.0.0 + */ + const_reference operator[](size_type idx) const + { + // const operator[] only works for arrays + if (JSON_LIKELY(is_array())) + { + return m_value.array->operator[](idx); + } + + JSON_THROW(type_error::create(305, "cannot use operator[] with a numeric argument with " + std::string(type_name()))); + } + + /*! + @brief access specified object element + + Returns a reference to the element at with specified key @a key. + + @note If @a key is not found in the object, then it is silently added to + the object and filled with a `null` value to make `key` a valid reference. + In case the value was `null` before, it is converted to an object. + + @param[in] key key of the element to access + + @return reference to the element at key @a key + + @throw type_error.305 if the JSON value is not an object or null; in that + cases, using the [] operator with a key makes no sense. + + @complexity Logarithmic in the size of the container. + + @liveexample{The example below shows how object elements can be read and + written using the `[]` operator.,operatorarray__key_type} + + @sa @ref at(const typename object_t::key_type&) for access by reference + with range checking + @sa @ref value() for access by value with a default value + + @since version 1.0.0 + */ + reference operator[](const typename object_t::key_type& key) + { + // implicitly convert null value to an empty object + if (is_null()) + { + m_type = value_t::object; + m_value.object = create<object_t>(); + assert_invariant(); + } + + // operator[] only works for objects + if (JSON_LIKELY(is_object())) + { + return m_value.object->operator[](key); + } + + JSON_THROW(type_error::create(305, "cannot use operator[] with a string argument with " + std::string(type_name()))); + } + + /*! + @brief read-only access specified object element + + Returns a const reference to the element at with specified key @a key. No + bounds checking is performed. + + @warning If the element with key @a key does not exist, the behavior is + undefined. + + @param[in] key key of the element to access + + @return const reference to the element at key @a key + + @pre The element with key @a key must exist. **This precondition is + enforced with an assertion.** + + @throw type_error.305 if the JSON value is not an object; in that case, + using the [] operator with a key makes no sense. + + @complexity Logarithmic in the size of the container. + + @liveexample{The example below shows how object elements can be read using + the `[]` operator.,operatorarray__key_type_const} + + @sa @ref at(const typename object_t::key_type&) for access by reference + with range checking + @sa @ref value() for access by value with a default value + + @since version 1.0.0 + */ + const_reference operator[](const typename object_t::key_type& key) const + { + // const operator[] only works for objects + if (JSON_LIKELY(is_object())) + { + assert(m_value.object->find(key) != m_value.object->end()); + return m_value.object->find(key)->second; + } + + JSON_THROW(type_error::create(305, "cannot use operator[] with a string argument with " + std::string(type_name()))); + } + + /*! + @brief access specified object element + + Returns a reference to the element at with specified key @a key. + + @note If @a key is not found in the object, then it is silently added to + the object and filled with a `null` value to make `key` a valid reference. + In case the value was `null` before, it is converted to an object. + + @param[in] key key of the element to access + + @return reference to the element at key @a key + + @throw type_error.305 if the JSON value is not an object or null; in that + cases, using the [] operator with a key makes no sense. + + @complexity Logarithmic in the size of the container. + + @liveexample{The example below shows how object elements can be read and + written using the `[]` operator.,operatorarray__key_type} + + @sa @ref at(const typename object_t::key_type&) for access by reference + with range checking + @sa @ref value() for access by value with a default value + + @since version 1.1.0 + */ + template<typename T> + reference operator[](T* key) + { + // implicitly convert null to object + if (is_null()) + { + m_type = value_t::object; + m_value = value_t::object; + assert_invariant(); + } + + // at only works for objects + if (JSON_LIKELY(is_object())) + { + return m_value.object->operator[](key); + } + + JSON_THROW(type_error::create(305, "cannot use operator[] with a string argument with " + std::string(type_name()))); + } + + /*! + @brief read-only access specified object element + + Returns a const reference to the element at with specified key @a key. No + bounds checking is performed. + + @warning If the element with key @a key does not exist, the behavior is + undefined. + + @param[in] key key of the element to access + + @return const reference to the element at key @a key + + @pre The element with key @a key must exist. **This precondition is + enforced with an assertion.** + + @throw type_error.305 if the JSON value is not an object; in that case, + using the [] operator with a key makes no sense. + + @complexity Logarithmic in the size of the container. + + @liveexample{The example below shows how object elements can be read using + the `[]` operator.,operatorarray__key_type_const} + + @sa @ref at(const typename object_t::key_type&) for access by reference + with range checking + @sa @ref value() for access by value with a default value + + @since version 1.1.0 + */ + template<typename T> + const_reference operator[](T* key) const + { + // at only works for objects + if (JSON_LIKELY(is_object())) + { + assert(m_value.object->find(key) != m_value.object->end()); + return m_value.object->find(key)->second; + } + + JSON_THROW(type_error::create(305, "cannot use operator[] with a string argument with " + std::string(type_name()))); + } + + /*! + @brief access specified object element with default value + + Returns either a copy of an object's element at the specified key @a key + or a given default value if no element with key @a key exists. + + The function is basically equivalent to executing + @code {.cpp} + try { + return at(key); + } catch(out_of_range) { + return default_value; + } + @endcode + + @note Unlike @ref at(const typename object_t::key_type&), this function + does not throw if the given key @a key was not found. + + @note Unlike @ref operator[](const typename object_t::key_type& key), this + function does not implicitly add an element to the position defined by @a + key. This function is furthermore also applicable to const objects. + + @param[in] key key of the element to access + @param[in] default_value the value to return if @a key is not found + + @tparam ValueType type compatible to JSON values, for instance `int` for + JSON integer numbers, `bool` for JSON booleans, or `std::vector` types for + JSON arrays. Note the type of the expected value at @a key and the default + value @a default_value must be compatible. + + @return copy of the element at key @a key or @a default_value if @a key + is not found + + @throw type_error.306 if the JSON value is not an object; in that case, + using `value()` with a key makes no sense. + + @complexity Logarithmic in the size of the container. + + @liveexample{The example below shows how object elements can be queried + with a default value.,basic_json__value} + + @sa @ref at(const typename object_t::key_type&) for access by reference + with range checking + @sa @ref operator[](const typename object_t::key_type&) for unchecked + access by reference + + @since version 1.0.0 + */ + template<class ValueType, typename std::enable_if< + std::is_convertible<basic_json_t, ValueType>::value, int>::type = 0> + ValueType value(const typename object_t::key_type& key, const ValueType& default_value) const + { + // at only works for objects + if (JSON_LIKELY(is_object())) + { + // if key is found, return value and given default value otherwise + const auto it = find(key); + if (it != end()) + { + return *it; + } + + return default_value; + } + + JSON_THROW(type_error::create(306, "cannot use value() with " + std::string(type_name()))); + } + + /*! + @brief overload for a default value of type const char* + @copydoc basic_json::value(const typename object_t::key_type&, const ValueType&) const + */ + string_t value(const typename object_t::key_type& key, const char* default_value) const + { + return value(key, string_t(default_value)); + } + + /*! + @brief access specified object element via JSON Pointer with default value + + Returns either a copy of an object's element at the specified key @a key + or a given default value if no element with key @a key exists. + + The function is basically equivalent to executing + @code {.cpp} + try { + return at(ptr); + } catch(out_of_range) { + return default_value; + } + @endcode + + @note Unlike @ref at(const json_pointer&), this function does not throw + if the given key @a key was not found. + + @param[in] ptr a JSON pointer to the element to access + @param[in] default_value the value to return if @a ptr found no value + + @tparam ValueType type compatible to JSON values, for instance `int` for + JSON integer numbers, `bool` for JSON booleans, or `std::vector` types for + JSON arrays. Note the type of the expected value at @a key and the default + value @a default_value must be compatible. + + @return copy of the element at key @a key or @a default_value if @a key + is not found + + @throw type_error.306 if the JSON value is not an object; in that case, + using `value()` with a key makes no sense. + + @complexity Logarithmic in the size of the container. + + @liveexample{The example below shows how object elements can be queried + with a default value.,basic_json__value_ptr} + + @sa @ref operator[](const json_pointer&) for unchecked access by reference + + @since version 2.0.2 + */ + template<class ValueType, typename std::enable_if< + std::is_convertible<basic_json_t, ValueType>::value, int>::type = 0> + ValueType value(const json_pointer& ptr, const ValueType& default_value) const + { + // at only works for objects + if (JSON_LIKELY(is_object())) + { + // if pointer resolves a value, return it or use default value + JSON_TRY + { + return ptr.get_checked(this); + } + JSON_INTERNAL_CATCH (out_of_range&) + { + return default_value; + } + } + + JSON_THROW(type_error::create(306, "cannot use value() with " + std::string(type_name()))); + } + + /*! + @brief overload for a default value of type const char* + @copydoc basic_json::value(const json_pointer&, ValueType) const + */ + string_t value(const json_pointer& ptr, const char* default_value) const + { + return value(ptr, string_t(default_value)); + } + + /*! + @brief access the first element + + Returns a reference to the first element in the container. For a JSON + container `c`, the expression `c.front()` is equivalent to `*c.begin()`. + + @return In case of a structured type (array or object), a reference to the + first element is returned. In case of number, string, or boolean values, a + reference to the value is returned. + + @complexity Constant. + + @pre The JSON value must not be `null` (would throw `std::out_of_range`) + or an empty array or object (undefined behavior, **guarded by + assertions**). + @post The JSON value remains unchanged. + + @throw invalid_iterator.214 when called on `null` value + + @liveexample{The following code shows an example for `front()`.,front} + + @sa @ref back() -- access the last element + + @since version 1.0.0 + */ + reference front() + { + return *begin(); + } + + /*! + @copydoc basic_json::front() + */ + const_reference front() const + { + return *cbegin(); + } + + /*! + @brief access the last element + + Returns a reference to the last element in the container. For a JSON + container `c`, the expression `c.back()` is equivalent to + @code {.cpp} + auto tmp = c.end(); + --tmp; + return *tmp; + @endcode + + @return In case of a structured type (array or object), a reference to the + last element is returned. In case of number, string, or boolean values, a + reference to the value is returned. + + @complexity Constant. + + @pre The JSON value must not be `null` (would throw `std::out_of_range`) + or an empty array or object (undefined behavior, **guarded by + assertions**). + @post The JSON value remains unchanged. + + @throw invalid_iterator.214 when called on a `null` value. See example + below. + + @liveexample{The following code shows an example for `back()`.,back} + + @sa @ref front() -- access the first element + + @since version 1.0.0 + */ + reference back() + { + auto tmp = end(); + --tmp; + return *tmp; + } + + /*! + @copydoc basic_json::back() + */ + const_reference back() const + { + auto tmp = cend(); + --tmp; + return *tmp; + } + + /*! + @brief remove element given an iterator + + Removes the element specified by iterator @a pos. The iterator @a pos must + be valid and dereferenceable. Thus the `end()` iterator (which is valid, + but is not dereferenceable) cannot be used as a value for @a pos. + + If called on a primitive type other than `null`, the resulting JSON value + will be `null`. + + @param[in] pos iterator to the element to remove + @return Iterator following the last removed element. If the iterator @a + pos refers to the last element, the `end()` iterator is returned. + + @tparam IteratorType an @ref iterator or @ref const_iterator + + @post Invalidates iterators and references at or after the point of the + erase, including the `end()` iterator. + + @throw type_error.307 if called on a `null` value; example: `"cannot use + erase() with null"` + @throw invalid_iterator.202 if called on an iterator which does not belong + to the current JSON value; example: `"iterator does not fit current + value"` + @throw invalid_iterator.205 if called on a primitive type with invalid + iterator (i.e., any iterator which is not `begin()`); example: `"iterator + out of range"` + + @complexity The complexity depends on the type: + - objects: amortized constant + - arrays: linear in distance between @a pos and the end of the container + - strings: linear in the length of the string + - other types: constant + + @liveexample{The example shows the result of `erase()` for different JSON + types.,erase__IteratorType} + + @sa @ref erase(IteratorType, IteratorType) -- removes the elements in + the given range + @sa @ref erase(const typename object_t::key_type&) -- removes the element + from an object at the given key + @sa @ref erase(const size_type) -- removes the element from an array at + the given index + + @since version 1.0.0 + */ + template<class IteratorType, typename std::enable_if< + std::is_same<IteratorType, typename basic_json_t::iterator>::value or + std::is_same<IteratorType, typename basic_json_t::const_iterator>::value, int>::type + = 0> + IteratorType erase(IteratorType pos) + { + // make sure iterator fits the current value + if (JSON_UNLIKELY(this != pos.m_object)) + { + JSON_THROW(invalid_iterator::create(202, "iterator does not fit current value")); + } + + IteratorType result = end(); + + switch (m_type) + { + case value_t::boolean: + case value_t::number_float: + case value_t::number_integer: + case value_t::number_unsigned: + case value_t::string: + { + if (JSON_UNLIKELY(not pos.m_it.primitive_iterator.is_begin())) + { + JSON_THROW(invalid_iterator::create(205, "iterator out of range")); + } + + if (is_string()) + { + AllocatorType<string_t> alloc; + std::allocator_traits<decltype(alloc)>::destroy(alloc, m_value.string); + std::allocator_traits<decltype(alloc)>::deallocate(alloc, m_value.string, 1); + m_value.string = nullptr; + } + + m_type = value_t::null; + assert_invariant(); + break; + } + + case value_t::object: + { + result.m_it.object_iterator = m_value.object->erase(pos.m_it.object_iterator); + break; + } + + case value_t::array: + { + result.m_it.array_iterator = m_value.array->erase(pos.m_it.array_iterator); + break; + } + + default: + JSON_THROW(type_error::create(307, "cannot use erase() with " + std::string(type_name()))); + } + + return result; + } + + /*! + @brief remove elements given an iterator range + + Removes the element specified by the range `[first; last)`. The iterator + @a first does not need to be dereferenceable if `first == last`: erasing + an empty range is a no-op. + + If called on a primitive type other than `null`, the resulting JSON value + will be `null`. + + @param[in] first iterator to the beginning of the range to remove + @param[in] last iterator past the end of the range to remove + @return Iterator following the last removed element. If the iterator @a + second refers to the last element, the `end()` iterator is returned. + + @tparam IteratorType an @ref iterator or @ref const_iterator + + @post Invalidates iterators and references at or after the point of the + erase, including the `end()` iterator. + + @throw type_error.307 if called on a `null` value; example: `"cannot use + erase() with null"` + @throw invalid_iterator.203 if called on iterators which does not belong + to the current JSON value; example: `"iterators do not fit current value"` + @throw invalid_iterator.204 if called on a primitive type with invalid + iterators (i.e., if `first != begin()` and `last != end()`); example: + `"iterators out of range"` + + @complexity The complexity depends on the type: + - objects: `log(size()) + std::distance(first, last)` + - arrays: linear in the distance between @a first and @a last, plus linear + in the distance between @a last and end of the container + - strings: linear in the length of the string + - other types: constant + + @liveexample{The example shows the result of `erase()` for different JSON + types.,erase__IteratorType_IteratorType} + + @sa @ref erase(IteratorType) -- removes the element at a given position + @sa @ref erase(const typename object_t::key_type&) -- removes the element + from an object at the given key + @sa @ref erase(const size_type) -- removes the element from an array at + the given index + + @since version 1.0.0 + */ + template<class IteratorType, typename std::enable_if< + std::is_same<IteratorType, typename basic_json_t::iterator>::value or + std::is_same<IteratorType, typename basic_json_t::const_iterator>::value, int>::type + = 0> + IteratorType erase(IteratorType first, IteratorType last) + { + // make sure iterator fits the current value + if (JSON_UNLIKELY(this != first.m_object or this != last.m_object)) + { + JSON_THROW(invalid_iterator::create(203, "iterators do not fit current value")); + } + + IteratorType result = end(); + + switch (m_type) + { + case value_t::boolean: + case value_t::number_float: + case value_t::number_integer: + case value_t::number_unsigned: + case value_t::string: + { + if (JSON_LIKELY(not first.m_it.primitive_iterator.is_begin() + or not last.m_it.primitive_iterator.is_end())) + { + JSON_THROW(invalid_iterator::create(204, "iterators out of range")); + } + + if (is_string()) + { + AllocatorType<string_t> alloc; + std::allocator_traits<decltype(alloc)>::destroy(alloc, m_value.string); + std::allocator_traits<decltype(alloc)>::deallocate(alloc, m_value.string, 1); + m_value.string = nullptr; + } + + m_type = value_t::null; + assert_invariant(); + break; + } + + case value_t::object: + { + result.m_it.object_iterator = m_value.object->erase(first.m_it.object_iterator, + last.m_it.object_iterator); + break; + } + + case value_t::array: + { + result.m_it.array_iterator = m_value.array->erase(first.m_it.array_iterator, + last.m_it.array_iterator); + break; + } + + default: + JSON_THROW(type_error::create(307, "cannot use erase() with " + std::string(type_name()))); + } + + return result; + } + + /*! + @brief remove element from a JSON object given a key + + Removes elements from a JSON object with the key value @a key. + + @param[in] key value of the elements to remove + + @return Number of elements removed. If @a ObjectType is the default + `std::map` type, the return value will always be `0` (@a key was not + found) or `1` (@a key was found). + + @post References and iterators to the erased elements are invalidated. + Other references and iterators are not affected. + + @throw type_error.307 when called on a type other than JSON object; + example: `"cannot use erase() with null"` + + @complexity `log(size()) + count(key)` + + @liveexample{The example shows the effect of `erase()`.,erase__key_type} + + @sa @ref erase(IteratorType) -- removes the element at a given position + @sa @ref erase(IteratorType, IteratorType) -- removes the elements in + the given range + @sa @ref erase(const size_type) -- removes the element from an array at + the given index + + @since version 1.0.0 + */ + size_type erase(const typename object_t::key_type& key) + { + // this erase only works for objects + if (JSON_LIKELY(is_object())) + { + return m_value.object->erase(key); + } + + JSON_THROW(type_error::create(307, "cannot use erase() with " + std::string(type_name()))); + } + + /*! + @brief remove element from a JSON array given an index + + Removes element from a JSON array at the index @a idx. + + @param[in] idx index of the element to remove + + @throw type_error.307 when called on a type other than JSON object; + example: `"cannot use erase() with null"` + @throw out_of_range.401 when `idx >= size()`; example: `"array index 17 + is out of range"` + + @complexity Linear in distance between @a idx and the end of the container. + + @liveexample{The example shows the effect of `erase()`.,erase__size_type} + + @sa @ref erase(IteratorType) -- removes the element at a given position + @sa @ref erase(IteratorType, IteratorType) -- removes the elements in + the given range + @sa @ref erase(const typename object_t::key_type&) -- removes the element + from an object at the given key + + @since version 1.0.0 + */ + void erase(const size_type idx) + { + // this erase only works for arrays + if (JSON_LIKELY(is_array())) + { + if (JSON_UNLIKELY(idx >= size())) + { + JSON_THROW(out_of_range::create(401, "array index " + std::to_string(idx) + " is out of range")); + } + + m_value.array->erase(m_value.array->begin() + static_cast<difference_type>(idx)); + } + else + { + JSON_THROW(type_error::create(307, "cannot use erase() with " + std::string(type_name()))); + } + } + + /// @} + + + //////////// + // lookup // + //////////// + + /// @name lookup + /// @{ + + /*! + @brief find an element in a JSON object + + Finds an element in a JSON object with key equivalent to @a key. If the + element is not found or the JSON value is not an object, end() is + returned. + + @note This method always returns @ref end() when executed on a JSON type + that is not an object. + + @param[in] key key value of the element to search for. + + @return Iterator to an element with key equivalent to @a key. If no such + element is found or the JSON value is not an object, past-the-end (see + @ref end()) iterator is returned. + + @complexity Logarithmic in the size of the JSON object. + + @liveexample{The example shows how `find()` is used.,find__key_type} + + @since version 1.0.0 + */ + template<typename KeyT> + iterator find(KeyT&& key) + { + auto result = end(); + + if (is_object()) + { + result.m_it.object_iterator = m_value.object->find(std::forward<KeyT>(key)); + } + + return result; + } + + /*! + @brief find an element in a JSON object + @copydoc find(KeyT&&) + */ + template<typename KeyT> + const_iterator find(KeyT&& key) const + { + auto result = cend(); + + if (is_object()) + { + result.m_it.object_iterator = m_value.object->find(std::forward<KeyT>(key)); + } + + return result; + } + + /*! + @brief returns the number of occurrences of a key in a JSON object + + Returns the number of elements with key @a key. If ObjectType is the + default `std::map` type, the return value will always be `0` (@a key was + not found) or `1` (@a key was found). + + @note This method always returns `0` when executed on a JSON type that is + not an object. + + @param[in] key key value of the element to count + + @return Number of elements with key @a key. If the JSON value is not an + object, the return value will be `0`. + + @complexity Logarithmic in the size of the JSON object. + + @liveexample{The example shows how `count()` is used.,count} + + @since version 1.0.0 + */ + template<typename KeyT> + size_type count(KeyT&& key) const + { + // return 0 for all nonobject types + return is_object() ? m_value.object->count(std::forward<KeyT>(key)) : 0; + } + + /// @} + + + /////////////// + // iterators // + /////////////// + + /// @name iterators + /// @{ + + /*! + @brief returns an iterator to the first element + + Returns an iterator to the first element. + + @image html range-begin-end.svg "Illustration from cppreference.com" + + @return iterator to the first element + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + + @liveexample{The following code shows an example for `begin()`.,begin} + + @sa @ref cbegin() -- returns a const iterator to the beginning + @sa @ref end() -- returns an iterator to the end + @sa @ref cend() -- returns a const iterator to the end + + @since version 1.0.0 + */ + iterator begin() noexcept + { + iterator result(this); + result.set_begin(); + return result; + } + + /*! + @copydoc basic_json::cbegin() + */ + const_iterator begin() const noexcept + { + return cbegin(); + } + + /*! + @brief returns a const iterator to the first element + + Returns a const iterator to the first element. + + @image html range-begin-end.svg "Illustration from cppreference.com" + + @return const iterator to the first element + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + - Has the semantics of `const_cast<const basic_json&>(*this).begin()`. + + @liveexample{The following code shows an example for `cbegin()`.,cbegin} + + @sa @ref begin() -- returns an iterator to the beginning + @sa @ref end() -- returns an iterator to the end + @sa @ref cend() -- returns a const iterator to the end + + @since version 1.0.0 + */ + const_iterator cbegin() const noexcept + { + const_iterator result(this); + result.set_begin(); + return result; + } + + /*! + @brief returns an iterator to one past the last element + + Returns an iterator to one past the last element. + + @image html range-begin-end.svg "Illustration from cppreference.com" + + @return iterator one past the last element + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + + @liveexample{The following code shows an example for `end()`.,end} + + @sa @ref cend() -- returns a const iterator to the end + @sa @ref begin() -- returns an iterator to the beginning + @sa @ref cbegin() -- returns a const iterator to the beginning + + @since version 1.0.0 + */ + iterator end() noexcept + { + iterator result(this); + result.set_end(); + return result; + } + + /*! + @copydoc basic_json::cend() + */ + const_iterator end() const noexcept + { + return cend(); + } + + /*! + @brief returns a const iterator to one past the last element + + Returns a const iterator to one past the last element. + + @image html range-begin-end.svg "Illustration from cppreference.com" + + @return const iterator one past the last element + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + - Has the semantics of `const_cast<const basic_json&>(*this).end()`. + + @liveexample{The following code shows an example for `cend()`.,cend} + + @sa @ref end() -- returns an iterator to the end + @sa @ref begin() -- returns an iterator to the beginning + @sa @ref cbegin() -- returns a const iterator to the beginning + + @since version 1.0.0 + */ + const_iterator cend() const noexcept + { + const_iterator result(this); + result.set_end(); + return result; + } + + /*! + @brief returns an iterator to the reverse-beginning + + Returns an iterator to the reverse-beginning; that is, the last element. + + @image html range-rbegin-rend.svg "Illustration from cppreference.com" + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [ReversibleContainer](https://en.cppreference.com/w/cpp/named_req/ReversibleContainer) + requirements: + - The complexity is constant. + - Has the semantics of `reverse_iterator(end())`. + + @liveexample{The following code shows an example for `rbegin()`.,rbegin} + + @sa @ref crbegin() -- returns a const reverse iterator to the beginning + @sa @ref rend() -- returns a reverse iterator to the end + @sa @ref crend() -- returns a const reverse iterator to the end + + @since version 1.0.0 + */ + reverse_iterator rbegin() noexcept + { + return reverse_iterator(end()); + } + + /*! + @copydoc basic_json::crbegin() + */ + const_reverse_iterator rbegin() const noexcept + { + return crbegin(); + } + + /*! + @brief returns an iterator to the reverse-end + + Returns an iterator to the reverse-end; that is, one before the first + element. + + @image html range-rbegin-rend.svg "Illustration from cppreference.com" + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [ReversibleContainer](https://en.cppreference.com/w/cpp/named_req/ReversibleContainer) + requirements: + - The complexity is constant. + - Has the semantics of `reverse_iterator(begin())`. + + @liveexample{The following code shows an example for `rend()`.,rend} + + @sa @ref crend() -- returns a const reverse iterator to the end + @sa @ref rbegin() -- returns a reverse iterator to the beginning + @sa @ref crbegin() -- returns a const reverse iterator to the beginning + + @since version 1.0.0 + */ + reverse_iterator rend() noexcept + { + return reverse_iterator(begin()); + } + + /*! + @copydoc basic_json::crend() + */ + const_reverse_iterator rend() const noexcept + { + return crend(); + } + + /*! + @brief returns a const reverse iterator to the last element + + Returns a const iterator to the reverse-beginning; that is, the last + element. + + @image html range-rbegin-rend.svg "Illustration from cppreference.com" + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [ReversibleContainer](https://en.cppreference.com/w/cpp/named_req/ReversibleContainer) + requirements: + - The complexity is constant. + - Has the semantics of `const_cast<const basic_json&>(*this).rbegin()`. + + @liveexample{The following code shows an example for `crbegin()`.,crbegin} + + @sa @ref rbegin() -- returns a reverse iterator to the beginning + @sa @ref rend() -- returns a reverse iterator to the end + @sa @ref crend() -- returns a const reverse iterator to the end + + @since version 1.0.0 + */ + const_reverse_iterator crbegin() const noexcept + { + return const_reverse_iterator(cend()); + } + + /*! + @brief returns a const reverse iterator to one before the first + + Returns a const reverse iterator to the reverse-end; that is, one before + the first element. + + @image html range-rbegin-rend.svg "Illustration from cppreference.com" + + @complexity Constant. + + @requirement This function helps `basic_json` satisfying the + [ReversibleContainer](https://en.cppreference.com/w/cpp/named_req/ReversibleContainer) + requirements: + - The complexity is constant. + - Has the semantics of `const_cast<const basic_json&>(*this).rend()`. + + @liveexample{The following code shows an example for `crend()`.,crend} + + @sa @ref rend() -- returns a reverse iterator to the end + @sa @ref rbegin() -- returns a reverse iterator to the beginning + @sa @ref crbegin() -- returns a const reverse iterator to the beginning + + @since version 1.0.0 + */ + const_reverse_iterator crend() const noexcept + { + return const_reverse_iterator(cbegin()); + } + + public: + /*! + @brief wrapper to access iterator member functions in range-based for + + This function allows to access @ref iterator::key() and @ref + iterator::value() during range-based for loops. In these loops, a + reference to the JSON values is returned, so there is no access to the + underlying iterator. + + For loop without iterator_wrapper: + + @code{cpp} + for (auto it = j_object.begin(); it != j_object.end(); ++it) + { + std::cout << "key: " << it.key() << ", value:" << it.value() << '\n'; + } + @endcode + + Range-based for loop without iterator proxy: + + @code{cpp} + for (auto it : j_object) + { + // "it" is of type json::reference and has no key() member + std::cout << "value: " << it << '\n'; + } + @endcode + + Range-based for loop with iterator proxy: + + @code{cpp} + for (auto it : json::iterator_wrapper(j_object)) + { + std::cout << "key: " << it.key() << ", value:" << it.value() << '\n'; + } + @endcode + + @note When iterating over an array, `key()` will return the index of the + element as string (see example). + + @param[in] ref reference to a JSON value + @return iteration proxy object wrapping @a ref with an interface to use in + range-based for loops + + @liveexample{The following code shows how the wrapper is used,iterator_wrapper} + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Constant. + + @note The name of this function is not yet final and may change in the + future. + + @deprecated This stream operator is deprecated and will be removed in + future 4.0.0 of the library. Please use @ref items() instead; + that is, replace `json::iterator_wrapper(j)` with `j.items()`. + */ + JSON_DEPRECATED + static iteration_proxy<iterator> iterator_wrapper(reference ref) noexcept + { + return ref.items(); + } + + /*! + @copydoc iterator_wrapper(reference) + */ + JSON_DEPRECATED + static iteration_proxy<const_iterator> iterator_wrapper(const_reference ref) noexcept + { + return ref.items(); + } + + /*! + @brief helper to access iterator member functions in range-based for + + This function allows to access @ref iterator::key() and @ref + iterator::value() during range-based for loops. In these loops, a + reference to the JSON values is returned, so there is no access to the + underlying iterator. + + For loop without `items()` function: + + @code{cpp} + for (auto it = j_object.begin(); it != j_object.end(); ++it) + { + std::cout << "key: " << it.key() << ", value:" << it.value() << '\n'; + } + @endcode + + Range-based for loop without `items()` function: + + @code{cpp} + for (auto it : j_object) + { + // "it" is of type json::reference and has no key() member + std::cout << "value: " << it << '\n'; + } + @endcode + + Range-based for loop with `items()` function: + + @code{cpp} + for (auto& el : j_object.items()) + { + std::cout << "key: " << el.key() << ", value:" << el.value() << '\n'; + } + @endcode + + The `items()` function also allows to use + [structured bindings](https://en.cppreference.com/w/cpp/language/structured_binding) + (C++17): + + @code{cpp} + for (auto& [key, val] : j_object.items()) + { + std::cout << "key: " << key << ", value:" << val << '\n'; + } + @endcode + + @note When iterating over an array, `key()` will return the index of the + element as string (see example). For primitive types (e.g., numbers), + `key()` returns an empty string. + + @return iteration proxy object wrapping @a ref with an interface to use in + range-based for loops + + @liveexample{The following code shows how the function is used.,items} + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Constant. + + @since version 3.1.0, structured bindings support since 3.5.0. + */ + iteration_proxy<iterator> items() noexcept + { + return iteration_proxy<iterator>(*this); + } + + /*! + @copydoc items() + */ + iteration_proxy<const_iterator> items() const noexcept + { + return iteration_proxy<const_iterator>(*this); + } + + /// @} + + + ////////////// + // capacity // + ////////////// + + /// @name capacity + /// @{ + + /*! + @brief checks whether the container is empty. + + Checks if a JSON value has no elements (i.e. whether its @ref size is `0`). + + @return The return value depends on the different types and is + defined as follows: + Value type | return value + ----------- | ------------- + null | `true` + boolean | `false` + string | `false` + number | `false` + object | result of function `object_t::empty()` + array | result of function `array_t::empty()` + + @liveexample{The following code uses `empty()` to check if a JSON + object contains any elements.,empty} + + @complexity Constant, as long as @ref array_t and @ref object_t satisfy + the Container concept; that is, their `empty()` functions have constant + complexity. + + @iterators No changes. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @note This function does not return whether a string stored as JSON value + is empty - it returns whether the JSON container itself is empty which is + false in the case of a string. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + - Has the semantics of `begin() == end()`. + + @sa @ref size() -- returns the number of elements + + @since version 1.0.0 + */ + bool empty() const noexcept + { + switch (m_type) + { + case value_t::null: + { + // null values are empty + return true; + } + + case value_t::array: + { + // delegate call to array_t::empty() + return m_value.array->empty(); + } + + case value_t::object: + { + // delegate call to object_t::empty() + return m_value.object->empty(); + } + + default: + { + // all other types are nonempty + return false; + } + } + } + + /*! + @brief returns the number of elements + + Returns the number of elements in a JSON value. + + @return The return value depends on the different types and is + defined as follows: + Value type | return value + ----------- | ------------- + null | `0` + boolean | `1` + string | `1` + number | `1` + object | result of function object_t::size() + array | result of function array_t::size() + + @liveexample{The following code calls `size()` on the different value + types.,size} + + @complexity Constant, as long as @ref array_t and @ref object_t satisfy + the Container concept; that is, their size() functions have constant + complexity. + + @iterators No changes. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @note This function does not return the length of a string stored as JSON + value - it returns the number of elements in the JSON value which is 1 in + the case of a string. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + - Has the semantics of `std::distance(begin(), end())`. + + @sa @ref empty() -- checks whether the container is empty + @sa @ref max_size() -- returns the maximal number of elements + + @since version 1.0.0 + */ + size_type size() const noexcept + { + switch (m_type) + { + case value_t::null: + { + // null values are empty + return 0; + } + + case value_t::array: + { + // delegate call to array_t::size() + return m_value.array->size(); + } + + case value_t::object: + { + // delegate call to object_t::size() + return m_value.object->size(); + } + + default: + { + // all other types have size 1 + return 1; + } + } + } + + /*! + @brief returns the maximum possible number of elements + + Returns the maximum number of elements a JSON value is able to hold due to + system or library implementation limitations, i.e. `std::distance(begin(), + end())` for the JSON value. + + @return The return value depends on the different types and is + defined as follows: + Value type | return value + ----------- | ------------- + null | `0` (same as `size()`) + boolean | `1` (same as `size()`) + string | `1` (same as `size()`) + number | `1` (same as `size()`) + object | result of function `object_t::max_size()` + array | result of function `array_t::max_size()` + + @liveexample{The following code calls `max_size()` on the different value + types. Note the output is implementation specific.,max_size} + + @complexity Constant, as long as @ref array_t and @ref object_t satisfy + the Container concept; that is, their `max_size()` functions have constant + complexity. + + @iterators No changes. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @requirement This function helps `basic_json` satisfying the + [Container](https://en.cppreference.com/w/cpp/named_req/Container) + requirements: + - The complexity is constant. + - Has the semantics of returning `b.size()` where `b` is the largest + possible JSON value. + + @sa @ref size() -- returns the number of elements + + @since version 1.0.0 + */ + size_type max_size() const noexcept + { + switch (m_type) + { + case value_t::array: + { + // delegate call to array_t::max_size() + return m_value.array->max_size(); + } + + case value_t::object: + { + // delegate call to object_t::max_size() + return m_value.object->max_size(); + } + + default: + { + // all other types have max_size() == size() + return size(); + } + } + } + + /// @} + + + /////////////// + // modifiers // + /////////////// + + /// @name modifiers + /// @{ + + /*! + @brief clears the contents + + Clears the content of a JSON value and resets it to the default value as + if @ref basic_json(value_t) would have been called with the current value + type from @ref type(): + + Value type | initial value + ----------- | ------------- + null | `null` + boolean | `false` + string | `""` + number | `0` + object | `{}` + array | `[]` + + @post Has the same effect as calling + @code {.cpp} + *this = basic_json(type()); + @endcode + + @liveexample{The example below shows the effect of `clear()` to different + JSON types.,clear} + + @complexity Linear in the size of the JSON value. + + @iterators All iterators, pointers and references related to this container + are invalidated. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @sa @ref basic_json(value_t) -- constructor that creates an object with the + same value than calling `clear()` + + @since version 1.0.0 + */ + void clear() noexcept + { + switch (m_type) + { + case value_t::number_integer: + { + m_value.number_integer = 0; + break; + } + + case value_t::number_unsigned: + { + m_value.number_unsigned = 0; + break; + } + + case value_t::number_float: + { + m_value.number_float = 0.0; + break; + } + + case value_t::boolean: + { + m_value.boolean = false; + break; + } + + case value_t::string: + { + m_value.string->clear(); + break; + } + + case value_t::array: + { + m_value.array->clear(); + break; + } + + case value_t::object: + { + m_value.object->clear(); + break; + } + + default: + break; + } + } + + /*! + @brief add an object to an array + + Appends the given element @a val to the end of the JSON value. If the + function is called on a JSON null value, an empty array is created before + appending @a val. + + @param[in] val the value to add to the JSON array + + @throw type_error.308 when called on a type other than JSON array or + null; example: `"cannot use push_back() with number"` + + @complexity Amortized constant. + + @liveexample{The example shows how `push_back()` and `+=` can be used to + add elements to a JSON array. Note how the `null` value was silently + converted to a JSON array.,push_back} + + @since version 1.0.0 + */ + void push_back(basic_json&& val) + { + // push_back only works for null objects or arrays + if (JSON_UNLIKELY(not(is_null() or is_array()))) + { + JSON_THROW(type_error::create(308, "cannot use push_back() with " + std::string(type_name()))); + } + + // transform null object into an array + if (is_null()) + { + m_type = value_t::array; + m_value = value_t::array; + assert_invariant(); + } + + // add element to array (move semantics) + m_value.array->push_back(std::move(val)); + // invalidate object + val.m_type = value_t::null; + } + + /*! + @brief add an object to an array + @copydoc push_back(basic_json&&) + */ + reference operator+=(basic_json&& val) + { + push_back(std::move(val)); + return *this; + } + + /*! + @brief add an object to an array + @copydoc push_back(basic_json&&) + */ + void push_back(const basic_json& val) + { + // push_back only works for null objects or arrays + if (JSON_UNLIKELY(not(is_null() or is_array()))) + { + JSON_THROW(type_error::create(308, "cannot use push_back() with " + std::string(type_name()))); + } + + // transform null object into an array + if (is_null()) + { + m_type = value_t::array; + m_value = value_t::array; + assert_invariant(); + } + + // add element to array + m_value.array->push_back(val); + } + + /*! + @brief add an object to an array + @copydoc push_back(basic_json&&) + */ + reference operator+=(const basic_json& val) + { + push_back(val); + return *this; + } + + /*! + @brief add an object to an object + + Inserts the given element @a val to the JSON object. If the function is + called on a JSON null value, an empty object is created before inserting + @a val. + + @param[in] val the value to add to the JSON object + + @throw type_error.308 when called on a type other than JSON object or + null; example: `"cannot use push_back() with number"` + + @complexity Logarithmic in the size of the container, O(log(`size()`)). + + @liveexample{The example shows how `push_back()` and `+=` can be used to + add elements to a JSON object. Note how the `null` value was silently + converted to a JSON object.,push_back__object_t__value} + + @since version 1.0.0 + */ + void push_back(const typename object_t::value_type& val) + { + // push_back only works for null objects or objects + if (JSON_UNLIKELY(not(is_null() or is_object()))) + { + JSON_THROW(type_error::create(308, "cannot use push_back() with " + std::string(type_name()))); + } + + // transform null object into an object + if (is_null()) + { + m_type = value_t::object; + m_value = value_t::object; + assert_invariant(); + } + + // add element to array + m_value.object->insert(val); + } + + /*! + @brief add an object to an object + @copydoc push_back(const typename object_t::value_type&) + */ + reference operator+=(const typename object_t::value_type& val) + { + push_back(val); + return *this; + } + + /*! + @brief add an object to an object + + This function allows to use `push_back` with an initializer list. In case + + 1. the current value is an object, + 2. the initializer list @a init contains only two elements, and + 3. the first element of @a init is a string, + + @a init is converted into an object element and added using + @ref push_back(const typename object_t::value_type&). Otherwise, @a init + is converted to a JSON value and added using @ref push_back(basic_json&&). + + @param[in] init an initializer list + + @complexity Linear in the size of the initializer list @a init. + + @note This function is required to resolve an ambiguous overload error, + because pairs like `{"key", "value"}` can be both interpreted as + `object_t::value_type` or `std::initializer_list<basic_json>`, see + https://github.com/nlohmann/json/issues/235 for more information. + + @liveexample{The example shows how initializer lists are treated as + objects when possible.,push_back__initializer_list} + */ + void push_back(initializer_list_t init) + { + if (is_object() and init.size() == 2 and (*init.begin())->is_string()) + { + basic_json&& key = init.begin()->moved_or_copied(); + push_back(typename object_t::value_type( + std::move(key.get_ref<string_t&>()), (init.begin() + 1)->moved_or_copied())); + } + else + { + push_back(basic_json(init)); + } + } + + /*! + @brief add an object to an object + @copydoc push_back(initializer_list_t) + */ + reference operator+=(initializer_list_t init) + { + push_back(init); + return *this; + } + + /*! + @brief add an object to an array + + Creates a JSON value from the passed parameters @a args to the end of the + JSON value. If the function is called on a JSON null value, an empty array + is created before appending the value created from @a args. + + @param[in] args arguments to forward to a constructor of @ref basic_json + @tparam Args compatible types to create a @ref basic_json object + + @throw type_error.311 when called on a type other than JSON array or + null; example: `"cannot use emplace_back() with number"` + + @complexity Amortized constant. + + @liveexample{The example shows how `push_back()` can be used to add + elements to a JSON array. Note how the `null` value was silently converted + to a JSON array.,emplace_back} + + @since version 2.0.8 + */ + template<class... Args> + void emplace_back(Args&& ... args) + { + // emplace_back only works for null objects or arrays + if (JSON_UNLIKELY(not(is_null() or is_array()))) + { + JSON_THROW(type_error::create(311, "cannot use emplace_back() with " + std::string(type_name()))); + } + + // transform null object into an array + if (is_null()) + { + m_type = value_t::array; + m_value = value_t::array; + assert_invariant(); + } + + // add element to array (perfect forwarding) + m_value.array->emplace_back(std::forward<Args>(args)...); + } + + /*! + @brief add an object to an object if key does not exist + + Inserts a new element into a JSON object constructed in-place with the + given @a args if there is no element with the key in the container. If the + function is called on a JSON null value, an empty object is created before + appending the value created from @a args. + + @param[in] args arguments to forward to a constructor of @ref basic_json + @tparam Args compatible types to create a @ref basic_json object + + @return a pair consisting of an iterator to the inserted element, or the + already-existing element if no insertion happened, and a bool + denoting whether the insertion took place. + + @throw type_error.311 when called on a type other than JSON object or + null; example: `"cannot use emplace() with number"` + + @complexity Logarithmic in the size of the container, O(log(`size()`)). + + @liveexample{The example shows how `emplace()` can be used to add elements + to a JSON object. Note how the `null` value was silently converted to a + JSON object. Further note how no value is added if there was already one + value stored with the same key.,emplace} + + @since version 2.0.8 + */ + template<class... Args> + std::pair<iterator, bool> emplace(Args&& ... args) + { + // emplace only works for null objects or arrays + if (JSON_UNLIKELY(not(is_null() or is_object()))) + { + JSON_THROW(type_error::create(311, "cannot use emplace() with " + std::string(type_name()))); + } + + // transform null object into an object + if (is_null()) + { + m_type = value_t::object; + m_value = value_t::object; + assert_invariant(); + } + + // add element to array (perfect forwarding) + auto res = m_value.object->emplace(std::forward<Args>(args)...); + // create result iterator and set iterator to the result of emplace + auto it = begin(); + it.m_it.object_iterator = res.first; + + // return pair of iterator and boolean + return {it, res.second}; + } + + /// Helper for insertion of an iterator + /// @note: This uses std::distance to support GCC 4.8, + /// see https://github.com/nlohmann/json/pull/1257 + template<typename... Args> + iterator insert_iterator(const_iterator pos, Args&& ... args) + { + iterator result(this); + assert(m_value.array != nullptr); + + auto insert_pos = std::distance(m_value.array->begin(), pos.m_it.array_iterator); + m_value.array->insert(pos.m_it.array_iterator, std::forward<Args>(args)...); + result.m_it.array_iterator = m_value.array->begin() + insert_pos; + + // This could have been written as: + // result.m_it.array_iterator = m_value.array->insert(pos.m_it.array_iterator, cnt, val); + // but the return value of insert is missing in GCC 4.8, so it is written this way instead. + + return result; + } + + /*! + @brief inserts element + + Inserts element @a val before iterator @a pos. + + @param[in] pos iterator before which the content will be inserted; may be + the end() iterator + @param[in] val element to insert + @return iterator pointing to the inserted @a val. + + @throw type_error.309 if called on JSON values other than arrays; + example: `"cannot use insert() with string"` + @throw invalid_iterator.202 if @a pos is not an iterator of *this; + example: `"iterator does not fit current value"` + + @complexity Constant plus linear in the distance between @a pos and end of + the container. + + @liveexample{The example shows how `insert()` is used.,insert} + + @since version 1.0.0 + */ + iterator insert(const_iterator pos, const basic_json& val) + { + // insert only works for arrays + if (JSON_LIKELY(is_array())) + { + // check if iterator pos fits to this JSON value + if (JSON_UNLIKELY(pos.m_object != this)) + { + JSON_THROW(invalid_iterator::create(202, "iterator does not fit current value")); + } + + // insert to array and return iterator + return insert_iterator(pos, val); + } + + JSON_THROW(type_error::create(309, "cannot use insert() with " + std::string(type_name()))); + } + + /*! + @brief inserts element + @copydoc insert(const_iterator, const basic_json&) + */ + iterator insert(const_iterator pos, basic_json&& val) + { + return insert(pos, val); + } + + /*! + @brief inserts elements + + Inserts @a cnt copies of @a val before iterator @a pos. + + @param[in] pos iterator before which the content will be inserted; may be + the end() iterator + @param[in] cnt number of copies of @a val to insert + @param[in] val element to insert + @return iterator pointing to the first element inserted, or @a pos if + `cnt==0` + + @throw type_error.309 if called on JSON values other than arrays; example: + `"cannot use insert() with string"` + @throw invalid_iterator.202 if @a pos is not an iterator of *this; + example: `"iterator does not fit current value"` + + @complexity Linear in @a cnt plus linear in the distance between @a pos + and end of the container. + + @liveexample{The example shows how `insert()` is used.,insert__count} + + @since version 1.0.0 + */ + iterator insert(const_iterator pos, size_type cnt, const basic_json& val) + { + // insert only works for arrays + if (JSON_LIKELY(is_array())) + { + // check if iterator pos fits to this JSON value + if (JSON_UNLIKELY(pos.m_object != this)) + { + JSON_THROW(invalid_iterator::create(202, "iterator does not fit current value")); + } + + // insert to array and return iterator + return insert_iterator(pos, cnt, val); + } + + JSON_THROW(type_error::create(309, "cannot use insert() with " + std::string(type_name()))); + } + + /*! + @brief inserts elements + + Inserts elements from range `[first, last)` before iterator @a pos. + + @param[in] pos iterator before which the content will be inserted; may be + the end() iterator + @param[in] first begin of the range of elements to insert + @param[in] last end of the range of elements to insert + + @throw type_error.309 if called on JSON values other than arrays; example: + `"cannot use insert() with string"` + @throw invalid_iterator.202 if @a pos is not an iterator of *this; + example: `"iterator does not fit current value"` + @throw invalid_iterator.210 if @a first and @a last do not belong to the + same JSON value; example: `"iterators do not fit"` + @throw invalid_iterator.211 if @a first or @a last are iterators into + container for which insert is called; example: `"passed iterators may not + belong to container"` + + @return iterator pointing to the first element inserted, or @a pos if + `first==last` + + @complexity Linear in `std::distance(first, last)` plus linear in the + distance between @a pos and end of the container. + + @liveexample{The example shows how `insert()` is used.,insert__range} + + @since version 1.0.0 + */ + iterator insert(const_iterator pos, const_iterator first, const_iterator last) + { + // insert only works for arrays + if (JSON_UNLIKELY(not is_array())) + { + JSON_THROW(type_error::create(309, "cannot use insert() with " + std::string(type_name()))); + } + + // check if iterator pos fits to this JSON value + if (JSON_UNLIKELY(pos.m_object != this)) + { + JSON_THROW(invalid_iterator::create(202, "iterator does not fit current value")); + } + + // check if range iterators belong to the same JSON object + if (JSON_UNLIKELY(first.m_object != last.m_object)) + { + JSON_THROW(invalid_iterator::create(210, "iterators do not fit")); + } + + if (JSON_UNLIKELY(first.m_object == this)) + { + JSON_THROW(invalid_iterator::create(211, "passed iterators may not belong to container")); + } + + // insert to array and return iterator + return insert_iterator(pos, first.m_it.array_iterator, last.m_it.array_iterator); + } + + /*! + @brief inserts elements + + Inserts elements from initializer list @a ilist before iterator @a pos. + + @param[in] pos iterator before which the content will be inserted; may be + the end() iterator + @param[in] ilist initializer list to insert the values from + + @throw type_error.309 if called on JSON values other than arrays; example: + `"cannot use insert() with string"` + @throw invalid_iterator.202 if @a pos is not an iterator of *this; + example: `"iterator does not fit current value"` + + @return iterator pointing to the first element inserted, or @a pos if + `ilist` is empty + + @complexity Linear in `ilist.size()` plus linear in the distance between + @a pos and end of the container. + + @liveexample{The example shows how `insert()` is used.,insert__ilist} + + @since version 1.0.0 + */ + iterator insert(const_iterator pos, initializer_list_t ilist) + { + // insert only works for arrays + if (JSON_UNLIKELY(not is_array())) + { + JSON_THROW(type_error::create(309, "cannot use insert() with " + std::string(type_name()))); + } + + // check if iterator pos fits to this JSON value + if (JSON_UNLIKELY(pos.m_object != this)) + { + JSON_THROW(invalid_iterator::create(202, "iterator does not fit current value")); + } + + // insert to array and return iterator + return insert_iterator(pos, ilist.begin(), ilist.end()); + } + + /*! + @brief inserts elements + + Inserts elements from range `[first, last)`. + + @param[in] first begin of the range of elements to insert + @param[in] last end of the range of elements to insert + + @throw type_error.309 if called on JSON values other than objects; example: + `"cannot use insert() with string"` + @throw invalid_iterator.202 if iterator @a first or @a last does does not + point to an object; example: `"iterators first and last must point to + objects"` + @throw invalid_iterator.210 if @a first and @a last do not belong to the + same JSON value; example: `"iterators do not fit"` + + @complexity Logarithmic: `O(N*log(size() + N))`, where `N` is the number + of elements to insert. + + @liveexample{The example shows how `insert()` is used.,insert__range_object} + + @since version 3.0.0 + */ + void insert(const_iterator first, const_iterator last) + { + // insert only works for objects + if (JSON_UNLIKELY(not is_object())) + { + JSON_THROW(type_error::create(309, "cannot use insert() with " + std::string(type_name()))); + } + + // check if range iterators belong to the same JSON object + if (JSON_UNLIKELY(first.m_object != last.m_object)) + { + JSON_THROW(invalid_iterator::create(210, "iterators do not fit")); + } + + // passed iterators must belong to objects + if (JSON_UNLIKELY(not first.m_object->is_object())) + { + JSON_THROW(invalid_iterator::create(202, "iterators first and last must point to objects")); + } + + m_value.object->insert(first.m_it.object_iterator, last.m_it.object_iterator); + } + + /*! + @brief updates a JSON object from another object, overwriting existing keys + + Inserts all values from JSON object @a j and overwrites existing keys. + + @param[in] j JSON object to read values from + + @throw type_error.312 if called on JSON values other than objects; example: + `"cannot use update() with string"` + + @complexity O(N*log(size() + N)), where N is the number of elements to + insert. + + @liveexample{The example shows how `update()` is used.,update} + + @sa https://docs.python.org/3.6/library/stdtypes.html#dict.update + + @since version 3.0.0 + */ + void update(const_reference j) + { + // implicitly convert null value to an empty object + if (is_null()) + { + m_type = value_t::object; + m_value.object = create<object_t>(); + assert_invariant(); + } + + if (JSON_UNLIKELY(not is_object())) + { + JSON_THROW(type_error::create(312, "cannot use update() with " + std::string(type_name()))); + } + if (JSON_UNLIKELY(not j.is_object())) + { + JSON_THROW(type_error::create(312, "cannot use update() with " + std::string(j.type_name()))); + } + + for (auto it = j.cbegin(); it != j.cend(); ++it) + { + m_value.object->operator[](it.key()) = it.value(); + } + } + + /*! + @brief updates a JSON object from another object, overwriting existing keys + + Inserts all values from from range `[first, last)` and overwrites existing + keys. + + @param[in] first begin of the range of elements to insert + @param[in] last end of the range of elements to insert + + @throw type_error.312 if called on JSON values other than objects; example: + `"cannot use update() with string"` + @throw invalid_iterator.202 if iterator @a first or @a last does does not + point to an object; example: `"iterators first and last must point to + objects"` + @throw invalid_iterator.210 if @a first and @a last do not belong to the + same JSON value; example: `"iterators do not fit"` + + @complexity O(N*log(size() + N)), where N is the number of elements to + insert. + + @liveexample{The example shows how `update()` is used__range.,update} + + @sa https://docs.python.org/3.6/library/stdtypes.html#dict.update + + @since version 3.0.0 + */ + void update(const_iterator first, const_iterator last) + { + // implicitly convert null value to an empty object + if (is_null()) + { + m_type = value_t::object; + m_value.object = create<object_t>(); + assert_invariant(); + } + + if (JSON_UNLIKELY(not is_object())) + { + JSON_THROW(type_error::create(312, "cannot use update() with " + std::string(type_name()))); + } + + // check if range iterators belong to the same JSON object + if (JSON_UNLIKELY(first.m_object != last.m_object)) + { + JSON_THROW(invalid_iterator::create(210, "iterators do not fit")); + } + + // passed iterators must belong to objects + if (JSON_UNLIKELY(not first.m_object->is_object() + or not last.m_object->is_object())) + { + JSON_THROW(invalid_iterator::create(202, "iterators first and last must point to objects")); + } + + for (auto it = first; it != last; ++it) + { + m_value.object->operator[](it.key()) = it.value(); + } + } + + /*! + @brief exchanges the values + + Exchanges the contents of the JSON value with those of @a other. Does not + invoke any move, copy, or swap operations on individual elements. All + iterators and references remain valid. The past-the-end iterator is + invalidated. + + @param[in,out] other JSON value to exchange the contents with + + @complexity Constant. + + @liveexample{The example below shows how JSON values can be swapped with + `swap()`.,swap__reference} + + @since version 1.0.0 + */ + void swap(reference other) noexcept ( + std::is_nothrow_move_constructible<value_t>::value and + std::is_nothrow_move_assignable<value_t>::value and + std::is_nothrow_move_constructible<json_value>::value and + std::is_nothrow_move_assignable<json_value>::value + ) + { + std::swap(m_type, other.m_type); + std::swap(m_value, other.m_value); + assert_invariant(); + } + + /*! + @brief exchanges the values + + Exchanges the contents of a JSON array with those of @a other. Does not + invoke any move, copy, or swap operations on individual elements. All + iterators and references remain valid. The past-the-end iterator is + invalidated. + + @param[in,out] other array to exchange the contents with + + @throw type_error.310 when JSON value is not an array; example: `"cannot + use swap() with string"` + + @complexity Constant. + + @liveexample{The example below shows how arrays can be swapped with + `swap()`.,swap__array_t} + + @since version 1.0.0 + */ + void swap(array_t& other) + { + // swap only works for arrays + if (JSON_LIKELY(is_array())) + { + std::swap(*(m_value.array), other); + } + else + { + JSON_THROW(type_error::create(310, "cannot use swap() with " + std::string(type_name()))); + } + } + + /*! + @brief exchanges the values + + Exchanges the contents of a JSON object with those of @a other. Does not + invoke any move, copy, or swap operations on individual elements. All + iterators and references remain valid. The past-the-end iterator is + invalidated. + + @param[in,out] other object to exchange the contents with + + @throw type_error.310 when JSON value is not an object; example: + `"cannot use swap() with string"` + + @complexity Constant. + + @liveexample{The example below shows how objects can be swapped with + `swap()`.,swap__object_t} + + @since version 1.0.0 + */ + void swap(object_t& other) + { + // swap only works for objects + if (JSON_LIKELY(is_object())) + { + std::swap(*(m_value.object), other); + } + else + { + JSON_THROW(type_error::create(310, "cannot use swap() with " + std::string(type_name()))); + } + } + + /*! + @brief exchanges the values + + Exchanges the contents of a JSON string with those of @a other. Does not + invoke any move, copy, or swap operations on individual elements. All + iterators and references remain valid. The past-the-end iterator is + invalidated. + + @param[in,out] other string to exchange the contents with + + @throw type_error.310 when JSON value is not a string; example: `"cannot + use swap() with boolean"` + + @complexity Constant. + + @liveexample{The example below shows how strings can be swapped with + `swap()`.,swap__string_t} + + @since version 1.0.0 + */ + void swap(string_t& other) + { + // swap only works for strings + if (JSON_LIKELY(is_string())) + { + std::swap(*(m_value.string), other); + } + else + { + JSON_THROW(type_error::create(310, "cannot use swap() with " + std::string(type_name()))); + } + } + + /// @} + + public: + ////////////////////////////////////////// + // lexicographical comparison operators // + ////////////////////////////////////////// + + /// @name lexicographical comparison operators + /// @{ + + /*! + @brief comparison: equal + + Compares two JSON values for equality according to the following rules: + - Two JSON values are equal if (1) they are from the same type and (2) + their stored values are the same according to their respective + `operator==`. + - Integer and floating-point numbers are automatically converted before + comparison. Note than two NaN values are always treated as unequal. + - Two JSON null values are equal. + + @note Floating-point inside JSON values numbers are compared with + `json::number_float_t::operator==` which is `double::operator==` by + default. To compare floating-point while respecting an epsilon, an alternative + [comparison function](https://github.com/mariokonrad/marnav/blob/master/src/marnav/math/floatingpoint.hpp#L34-#L39) + could be used, for instance + @code {.cpp} + template<typename T, typename = typename std::enable_if<std::is_floating_point<T>::value, T>::type> + inline bool is_same(T a, T b, T epsilon = std::numeric_limits<T>::epsilon()) noexcept + { + return std::abs(a - b) <= epsilon; + } + @endcode + + @note NaN values never compare equal to themselves or to other NaN values. + + @param[in] lhs first JSON value to consider + @param[in] rhs second JSON value to consider + @return whether the values @a lhs and @a rhs are equal + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @complexity Linear. + + @liveexample{The example demonstrates comparing several JSON + types.,operator__equal} + + @since version 1.0.0 + */ + friend bool operator==(const_reference lhs, const_reference rhs) noexcept + { + const auto lhs_type = lhs.type(); + const auto rhs_type = rhs.type(); + + if (lhs_type == rhs_type) + { + switch (lhs_type) + { + case value_t::array: + return (*lhs.m_value.array == *rhs.m_value.array); + + case value_t::object: + return (*lhs.m_value.object == *rhs.m_value.object); + + case value_t::null: + return true; + + case value_t::string: + return (*lhs.m_value.string == *rhs.m_value.string); + + case value_t::boolean: + return (lhs.m_value.boolean == rhs.m_value.boolean); + + case value_t::number_integer: + return (lhs.m_value.number_integer == rhs.m_value.number_integer); + + case value_t::number_unsigned: + return (lhs.m_value.number_unsigned == rhs.m_value.number_unsigned); + + case value_t::number_float: + return (lhs.m_value.number_float == rhs.m_value.number_float); + + default: + return false; + } + } + else if (lhs_type == value_t::number_integer and rhs_type == value_t::number_float) + { + return (static_cast<number_float_t>(lhs.m_value.number_integer) == rhs.m_value.number_float); + } + else if (lhs_type == value_t::number_float and rhs_type == value_t::number_integer) + { + return (lhs.m_value.number_float == static_cast<number_float_t>(rhs.m_value.number_integer)); + } + else if (lhs_type == value_t::number_unsigned and rhs_type == value_t::number_float) + { + return (static_cast<number_float_t>(lhs.m_value.number_unsigned) == rhs.m_value.number_float); + } + else if (lhs_type == value_t::number_float and rhs_type == value_t::number_unsigned) + { + return (lhs.m_value.number_float == static_cast<number_float_t>(rhs.m_value.number_unsigned)); + } + else if (lhs_type == value_t::number_unsigned and rhs_type == value_t::number_integer) + { + return (static_cast<number_integer_t>(lhs.m_value.number_unsigned) == rhs.m_value.number_integer); + } + else if (lhs_type == value_t::number_integer and rhs_type == value_t::number_unsigned) + { + return (lhs.m_value.number_integer == static_cast<number_integer_t>(rhs.m_value.number_unsigned)); + } + + return false; + } + + /*! + @brief comparison: equal + @copydoc operator==(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator==(const_reference lhs, const ScalarType rhs) noexcept + { + return (lhs == basic_json(rhs)); + } + + /*! + @brief comparison: equal + @copydoc operator==(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator==(const ScalarType lhs, const_reference rhs) noexcept + { + return (basic_json(lhs) == rhs); + } + + /*! + @brief comparison: not equal + + Compares two JSON values for inequality by calculating `not (lhs == rhs)`. + + @param[in] lhs first JSON value to consider + @param[in] rhs second JSON value to consider + @return whether the values @a lhs and @a rhs are not equal + + @complexity Linear. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @liveexample{The example demonstrates comparing several JSON + types.,operator__notequal} + + @since version 1.0.0 + */ + friend bool operator!=(const_reference lhs, const_reference rhs) noexcept + { + return not (lhs == rhs); + } + + /*! + @brief comparison: not equal + @copydoc operator!=(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator!=(const_reference lhs, const ScalarType rhs) noexcept + { + return (lhs != basic_json(rhs)); + } + + /*! + @brief comparison: not equal + @copydoc operator!=(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator!=(const ScalarType lhs, const_reference rhs) noexcept + { + return (basic_json(lhs) != rhs); + } + + /*! + @brief comparison: less than + + Compares whether one JSON value @a lhs is less than another JSON value @a + rhs according to the following rules: + - If @a lhs and @a rhs have the same type, the values are compared using + the default `<` operator. + - Integer and floating-point numbers are automatically converted before + comparison + - In case @a lhs and @a rhs have different types, the values are ignored + and the order of the types is considered, see + @ref operator<(const value_t, const value_t). + + @param[in] lhs first JSON value to consider + @param[in] rhs second JSON value to consider + @return whether @a lhs is less than @a rhs + + @complexity Linear. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @liveexample{The example demonstrates comparing several JSON + types.,operator__less} + + @since version 1.0.0 + */ + friend bool operator<(const_reference lhs, const_reference rhs) noexcept + { + const auto lhs_type = lhs.type(); + const auto rhs_type = rhs.type(); + + if (lhs_type == rhs_type) + { + switch (lhs_type) + { + case value_t::array: + return (*lhs.m_value.array) < (*rhs.m_value.array); + + case value_t::object: + return *lhs.m_value.object < *rhs.m_value.object; + + case value_t::null: + return false; + + case value_t::string: + return *lhs.m_value.string < *rhs.m_value.string; + + case value_t::boolean: + return lhs.m_value.boolean < rhs.m_value.boolean; + + case value_t::number_integer: + return lhs.m_value.number_integer < rhs.m_value.number_integer; + + case value_t::number_unsigned: + return lhs.m_value.number_unsigned < rhs.m_value.number_unsigned; + + case value_t::number_float: + return lhs.m_value.number_float < rhs.m_value.number_float; + + default: + return false; + } + } + else if (lhs_type == value_t::number_integer and rhs_type == value_t::number_float) + { + return static_cast<number_float_t>(lhs.m_value.number_integer) < rhs.m_value.number_float; + } + else if (lhs_type == value_t::number_float and rhs_type == value_t::number_integer) + { + return lhs.m_value.number_float < static_cast<number_float_t>(rhs.m_value.number_integer); + } + else if (lhs_type == value_t::number_unsigned and rhs_type == value_t::number_float) + { + return static_cast<number_float_t>(lhs.m_value.number_unsigned) < rhs.m_value.number_float; + } + else if (lhs_type == value_t::number_float and rhs_type == value_t::number_unsigned) + { + return lhs.m_value.number_float < static_cast<number_float_t>(rhs.m_value.number_unsigned); + } + else if (lhs_type == value_t::number_integer and rhs_type == value_t::number_unsigned) + { + return lhs.m_value.number_integer < static_cast<number_integer_t>(rhs.m_value.number_unsigned); + } + else if (lhs_type == value_t::number_unsigned and rhs_type == value_t::number_integer) + { + return static_cast<number_integer_t>(lhs.m_value.number_unsigned) < rhs.m_value.number_integer; + } + + // We only reach this line if we cannot compare values. In that case, + // we compare types. Note we have to call the operator explicitly, + // because MSVC has problems otherwise. + return operator<(lhs_type, rhs_type); + } + + /*! + @brief comparison: less than + @copydoc operator<(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator<(const_reference lhs, const ScalarType rhs) noexcept + { + return (lhs < basic_json(rhs)); + } + + /*! + @brief comparison: less than + @copydoc operator<(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator<(const ScalarType lhs, const_reference rhs) noexcept + { + return (basic_json(lhs) < rhs); + } + + /*! + @brief comparison: less than or equal + + Compares whether one JSON value @a lhs is less than or equal to another + JSON value by calculating `not (rhs < lhs)`. + + @param[in] lhs first JSON value to consider + @param[in] rhs second JSON value to consider + @return whether @a lhs is less than or equal to @a rhs + + @complexity Linear. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @liveexample{The example demonstrates comparing several JSON + types.,operator__greater} + + @since version 1.0.0 + */ + friend bool operator<=(const_reference lhs, const_reference rhs) noexcept + { + return not (rhs < lhs); + } + + /*! + @brief comparison: less than or equal + @copydoc operator<=(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator<=(const_reference lhs, const ScalarType rhs) noexcept + { + return (lhs <= basic_json(rhs)); + } + + /*! + @brief comparison: less than or equal + @copydoc operator<=(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator<=(const ScalarType lhs, const_reference rhs) noexcept + { + return (basic_json(lhs) <= rhs); + } + + /*! + @brief comparison: greater than + + Compares whether one JSON value @a lhs is greater than another + JSON value by calculating `not (lhs <= rhs)`. + + @param[in] lhs first JSON value to consider + @param[in] rhs second JSON value to consider + @return whether @a lhs is greater than to @a rhs + + @complexity Linear. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @liveexample{The example demonstrates comparing several JSON + types.,operator__lessequal} + + @since version 1.0.0 + */ + friend bool operator>(const_reference lhs, const_reference rhs) noexcept + { + return not (lhs <= rhs); + } + + /*! + @brief comparison: greater than + @copydoc operator>(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator>(const_reference lhs, const ScalarType rhs) noexcept + { + return (lhs > basic_json(rhs)); + } + + /*! + @brief comparison: greater than + @copydoc operator>(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator>(const ScalarType lhs, const_reference rhs) noexcept + { + return (basic_json(lhs) > rhs); + } + + /*! + @brief comparison: greater than or equal + + Compares whether one JSON value @a lhs is greater than or equal to another + JSON value by calculating `not (lhs < rhs)`. + + @param[in] lhs first JSON value to consider + @param[in] rhs second JSON value to consider + @return whether @a lhs is greater than or equal to @a rhs + + @complexity Linear. + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @liveexample{The example demonstrates comparing several JSON + types.,operator__greaterequal} + + @since version 1.0.0 + */ + friend bool operator>=(const_reference lhs, const_reference rhs) noexcept + { + return not (lhs < rhs); + } + + /*! + @brief comparison: greater than or equal + @copydoc operator>=(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator>=(const_reference lhs, const ScalarType rhs) noexcept + { + return (lhs >= basic_json(rhs)); + } + + /*! + @brief comparison: greater than or equal + @copydoc operator>=(const_reference, const_reference) + */ + template<typename ScalarType, typename std::enable_if< + std::is_scalar<ScalarType>::value, int>::type = 0> + friend bool operator>=(const ScalarType lhs, const_reference rhs) noexcept + { + return (basic_json(lhs) >= rhs); + } + + /// @} + + /////////////////// + // serialization // + /////////////////// + + /// @name serialization + /// @{ + + /*! + @brief serialize to stream + + Serialize the given JSON value @a j to the output stream @a o. The JSON + value will be serialized using the @ref dump member function. + + - The indentation of the output can be controlled with the member variable + `width` of the output stream @a o. For instance, using the manipulator + `std::setw(4)` on @a o sets the indentation level to `4` and the + serialization result is the same as calling `dump(4)`. + + - The indentation character can be controlled with the member variable + `fill` of the output stream @a o. For instance, the manipulator + `std::setfill('\\t')` sets indentation to use a tab character rather than + the default space character. + + @param[in,out] o stream to serialize to + @param[in] j JSON value to serialize + + @return the stream @a o + + @throw type_error.316 if a string stored inside the JSON value is not + UTF-8 encoded + + @complexity Linear. + + @liveexample{The example below shows the serialization with different + parameters to `width` to adjust the indentation level.,operator_serialize} + + @since version 1.0.0; indentation character added in version 3.0.0 + */ + friend std::ostream& operator<<(std::ostream& o, const basic_json& j) + { + // read width member and use it as indentation parameter if nonzero + const bool pretty_print = (o.width() > 0); + const auto indentation = (pretty_print ? o.width() : 0); + + // reset width to 0 for subsequent calls to this stream + o.width(0); + + // do the actual serialization + serializer s(detail::output_adapter<char>(o), o.fill()); + s.dump(j, pretty_print, false, static_cast<unsigned int>(indentation)); + return o; + } + + /*! + @brief serialize to stream + @deprecated This stream operator is deprecated and will be removed in + future 4.0.0 of the library. Please use + @ref operator<<(std::ostream&, const basic_json&) + instead; that is, replace calls like `j >> o;` with `o << j;`. + @since version 1.0.0; deprecated since version 3.0.0 + */ + JSON_DEPRECATED + friend std::ostream& operator>>(const basic_json& j, std::ostream& o) + { + return o << j; + } + + /// @} + + + ///////////////////// + // deserialization // + ///////////////////// + + /// @name deserialization + /// @{ + + /*! + @brief deserialize from a compatible input + + This function reads from a compatible input. Examples are: + - an array of 1-byte values + - strings with character/literal type with size of 1 byte + - input streams + - container with contiguous storage of 1-byte values. Compatible container + types include `std::vector`, `std::string`, `std::array`, + `std::valarray`, and `std::initializer_list`. Furthermore, C-style + arrays can be used with `std::begin()`/`std::end()`. User-defined + containers can be used as long as they implement random-access iterators + and a contiguous storage. + + @pre Each element of the container has a size of 1 byte. Violating this + precondition yields undefined behavior. **This precondition is enforced + with a static assertion.** + + @pre The container storage is contiguous. Violating this precondition + yields undefined behavior. **This precondition is enforced with an + assertion.** + @pre Each element of the container has a size of 1 byte. Violating this + precondition yields undefined behavior. **This precondition is enforced + with a static assertion.** + + @warning There is no way to enforce all preconditions at compile-time. If + the function is called with a noncompliant container and with + assertions switched off, the behavior is undefined and will most + likely yield segmentation violation. + + @param[in] i input to read from + @param[in] cb a parser callback function of type @ref parser_callback_t + which is used to control the deserialization by filtering unwanted values + (optional) + @param[in] allow_exceptions whether to throw exceptions in case of a + parse error (optional, true by default) + + @return result of the deserialization + + @throw parse_error.101 if a parse error occurs; example: `""unexpected end + of input; expected string literal""` + @throw parse_error.102 if to_unicode fails or surrogate error + @throw parse_error.103 if to_unicode fails + + @complexity Linear in the length of the input. The parser is a predictive + LL(1) parser. The complexity can be higher if the parser callback function + @a cb has a super-linear complexity. + + @note A UTF-8 byte order mark is silently ignored. + + @liveexample{The example below demonstrates the `parse()` function reading + from an array.,parse__array__parser_callback_t} + + @liveexample{The example below demonstrates the `parse()` function with + and without callback function.,parse__string__parser_callback_t} + + @liveexample{The example below demonstrates the `parse()` function with + and without callback function.,parse__istream__parser_callback_t} + + @liveexample{The example below demonstrates the `parse()` function reading + from a contiguous container.,parse__contiguouscontainer__parser_callback_t} + + @since version 2.0.3 (contiguous containers) + */ + static basic_json parse(detail::input_adapter&& i, + const parser_callback_t cb = nullptr, + const bool allow_exceptions = true) + { + basic_json result; + parser(i, cb, allow_exceptions).parse(true, result); + return result; + } + + static bool accept(detail::input_adapter&& i) + { + return parser(i).accept(true); + } + + /*! + @brief generate SAX events + + The SAX event lister must follow the interface of @ref json_sax. + + This function reads from a compatible input. Examples are: + - an array of 1-byte values + - strings with character/literal type with size of 1 byte + - input streams + - container with contiguous storage of 1-byte values. Compatible container + types include `std::vector`, `std::string`, `std::array`, + `std::valarray`, and `std::initializer_list`. Furthermore, C-style + arrays can be used with `std::begin()`/`std::end()`. User-defined + containers can be used as long as they implement random-access iterators + and a contiguous storage. + + @pre Each element of the container has a size of 1 byte. Violating this + precondition yields undefined behavior. **This precondition is enforced + with a static assertion.** + + @pre The container storage is contiguous. Violating this precondition + yields undefined behavior. **This precondition is enforced with an + assertion.** + @pre Each element of the container has a size of 1 byte. Violating this + precondition yields undefined behavior. **This precondition is enforced + with a static assertion.** + + @warning There is no way to enforce all preconditions at compile-time. If + the function is called with a noncompliant container and with + assertions switched off, the behavior is undefined and will most + likely yield segmentation violation. + + @param[in] i input to read from + @param[in,out] sax SAX event listener + @param[in] format the format to parse (JSON, CBOR, MessagePack, or UBJSON) + @param[in] strict whether the input has to be consumed completely + + @return return value of the last processed SAX event + + @throw parse_error.101 if a parse error occurs; example: `""unexpected end + of input; expected string literal""` + @throw parse_error.102 if to_unicode fails or surrogate error + @throw parse_error.103 if to_unicode fails + + @complexity Linear in the length of the input. The parser is a predictive + LL(1) parser. The complexity can be higher if the SAX consumer @a sax has + a super-linear complexity. + + @note A UTF-8 byte order mark is silently ignored. + + @liveexample{The example below demonstrates the `sax_parse()` function + reading from string and processing the events with a user-defined SAX + event consumer.,sax_parse} + + @since version 3.2.0 + */ + template <typename SAX> + static bool sax_parse(detail::input_adapter&& i, SAX* sax, + input_format_t format = input_format_t::json, + const bool strict = true) + { + assert(sax); + switch (format) + { + case input_format_t::json: + return parser(std::move(i)).sax_parse(sax, strict); + default: + return detail::binary_reader<basic_json, SAX>(std::move(i)).sax_parse(format, sax, strict); + } + } + + /*! + @brief deserialize from an iterator range with contiguous storage + + This function reads from an iterator range of a container with contiguous + storage of 1-byte values. Compatible container types include + `std::vector`, `std::string`, `std::array`, `std::valarray`, and + `std::initializer_list`. Furthermore, C-style arrays can be used with + `std::begin()`/`std::end()`. User-defined containers can be used as long + as they implement random-access iterators and a contiguous storage. + + @pre The iterator range is contiguous. Violating this precondition yields + undefined behavior. **This precondition is enforced with an assertion.** + @pre Each element in the range has a size of 1 byte. Violating this + precondition yields undefined behavior. **This precondition is enforced + with a static assertion.** + + @warning There is no way to enforce all preconditions at compile-time. If + the function is called with noncompliant iterators and with + assertions switched off, the behavior is undefined and will most + likely yield segmentation violation. + + @tparam IteratorType iterator of container with contiguous storage + @param[in] first begin of the range to parse (included) + @param[in] last end of the range to parse (excluded) + @param[in] cb a parser callback function of type @ref parser_callback_t + which is used to control the deserialization by filtering unwanted values + (optional) + @param[in] allow_exceptions whether to throw exceptions in case of a + parse error (optional, true by default) + + @return result of the deserialization + + @throw parse_error.101 in case of an unexpected token + @throw parse_error.102 if to_unicode fails or surrogate error + @throw parse_error.103 if to_unicode fails + + @complexity Linear in the length of the input. The parser is a predictive + LL(1) parser. The complexity can be higher if the parser callback function + @a cb has a super-linear complexity. + + @note A UTF-8 byte order mark is silently ignored. + + @liveexample{The example below demonstrates the `parse()` function reading + from an iterator range.,parse__iteratortype__parser_callback_t} + + @since version 2.0.3 + */ + template<class IteratorType, typename std::enable_if< + std::is_base_of< + std::random_access_iterator_tag, + typename std::iterator_traits<IteratorType>::iterator_category>::value, int>::type = 0> + static basic_json parse(IteratorType first, IteratorType last, + const parser_callback_t cb = nullptr, + const bool allow_exceptions = true) + { + basic_json result; + parser(detail::input_adapter(first, last), cb, allow_exceptions).parse(true, result); + return result; + } + + template<class IteratorType, typename std::enable_if< + std::is_base_of< + std::random_access_iterator_tag, + typename std::iterator_traits<IteratorType>::iterator_category>::value, int>::type = 0> + static bool accept(IteratorType first, IteratorType last) + { + return parser(detail::input_adapter(first, last)).accept(true); + } + + template<class IteratorType, class SAX, typename std::enable_if< + std::is_base_of< + std::random_access_iterator_tag, + typename std::iterator_traits<IteratorType>::iterator_category>::value, int>::type = 0> + static bool sax_parse(IteratorType first, IteratorType last, SAX* sax) + { + return parser(detail::input_adapter(first, last)).sax_parse(sax); + } + + /*! + @brief deserialize from stream + @deprecated This stream operator is deprecated and will be removed in + version 4.0.0 of the library. Please use + @ref operator>>(std::istream&, basic_json&) + instead; that is, replace calls like `j << i;` with `i >> j;`. + @since version 1.0.0; deprecated since version 3.0.0 + */ + JSON_DEPRECATED + friend std::istream& operator<<(basic_json& j, std::istream& i) + { + return operator>>(i, j); + } + + /*! + @brief deserialize from stream + + Deserializes an input stream to a JSON value. + + @param[in,out] i input stream to read a serialized JSON value from + @param[in,out] j JSON value to write the deserialized input to + + @throw parse_error.101 in case of an unexpected token + @throw parse_error.102 if to_unicode fails or surrogate error + @throw parse_error.103 if to_unicode fails + + @complexity Linear in the length of the input. The parser is a predictive + LL(1) parser. + + @note A UTF-8 byte order mark is silently ignored. + + @liveexample{The example below shows how a JSON value is constructed by + reading a serialization from a stream.,operator_deserialize} + + @sa parse(std::istream&, const parser_callback_t) for a variant with a + parser callback function to filter values while parsing + + @since version 1.0.0 + */ + friend std::istream& operator>>(std::istream& i, basic_json& j) + { + parser(detail::input_adapter(i)).parse(false, j); + return i; + } + + /// @} + + /////////////////////////// + // convenience functions // + /////////////////////////// + + /*! + @brief return the type as string + + Returns the type name as string to be used in error messages - usually to + indicate that a function was called on a wrong JSON type. + + @return a string representation of a the @a m_type member: + Value type | return value + ----------- | ------------- + null | `"null"` + boolean | `"boolean"` + string | `"string"` + number | `"number"` (for all number types) + object | `"object"` + array | `"array"` + discarded | `"discarded"` + + @exceptionsafety No-throw guarantee: this function never throws exceptions. + + @complexity Constant. + + @liveexample{The following code exemplifies `type_name()` for all JSON + types.,type_name} + + @sa @ref type() -- return the type of the JSON value + @sa @ref operator value_t() -- return the type of the JSON value (implicit) + + @since version 1.0.0, public since 2.1.0, `const char*` and `noexcept` + since 3.0.0 + */ + const char* type_name() const noexcept + { + { + switch (m_type) + { + case value_t::null: + return "null"; + case value_t::object: + return "object"; + case value_t::array: + return "array"; + case value_t::string: + return "string"; + case value_t::boolean: + return "boolean"; + case value_t::discarded: + return "discarded"; + default: + return "number"; + } + } + } + + + private: + ////////////////////// + // member variables // + ////////////////////// + + /// the type of the current element + value_t m_type = value_t::null; + + /// the value of the current element + json_value m_value = {}; + + ////////////////////////////////////////// + // binary serialization/deserialization // + ////////////////////////////////////////// + + /// @name binary serialization/deserialization support + /// @{ + + public: + /*! + @brief create a CBOR serialization of a given JSON value + + Serializes a given JSON value @a j to a byte vector using the CBOR (Concise + Binary Object Representation) serialization format. CBOR is a binary + serialization format which aims to be more compact than JSON itself, yet + more efficient to parse. + + The library uses the following mapping from JSON values types to + CBOR types according to the CBOR specification (RFC 7049): + + JSON value type | value/range | CBOR type | first byte + --------------- | ------------------------------------------ | ---------------------------------- | --------------- + null | `null` | Null | 0xF6 + boolean | `true` | True | 0xF5 + boolean | `false` | False | 0xF4 + number_integer | -9223372036854775808..-2147483649 | Negative integer (8 bytes follow) | 0x3B + number_integer | -2147483648..-32769 | Negative integer (4 bytes follow) | 0x3A + number_integer | -32768..-129 | Negative integer (2 bytes follow) | 0x39 + number_integer | -128..-25 | Negative integer (1 byte follow) | 0x38 + number_integer | -24..-1 | Negative integer | 0x20..0x37 + number_integer | 0..23 | Integer | 0x00..0x17 + number_integer | 24..255 | Unsigned integer (1 byte follow) | 0x18 + number_integer | 256..65535 | Unsigned integer (2 bytes follow) | 0x19 + number_integer | 65536..4294967295 | Unsigned integer (4 bytes follow) | 0x1A + number_integer | 4294967296..18446744073709551615 | Unsigned integer (8 bytes follow) | 0x1B + number_unsigned | 0..23 | Integer | 0x00..0x17 + number_unsigned | 24..255 | Unsigned integer (1 byte follow) | 0x18 + number_unsigned | 256..65535 | Unsigned integer (2 bytes follow) | 0x19 + number_unsigned | 65536..4294967295 | Unsigned integer (4 bytes follow) | 0x1A + number_unsigned | 4294967296..18446744073709551615 | Unsigned integer (8 bytes follow) | 0x1B + number_float | *any value* | Double-Precision Float | 0xFB + string | *length*: 0..23 | UTF-8 string | 0x60..0x77 + string | *length*: 23..255 | UTF-8 string (1 byte follow) | 0x78 + string | *length*: 256..65535 | UTF-8 string (2 bytes follow) | 0x79 + string | *length*: 65536..4294967295 | UTF-8 string (4 bytes follow) | 0x7A + string | *length*: 4294967296..18446744073709551615 | UTF-8 string (8 bytes follow) | 0x7B + array | *size*: 0..23 | array | 0x80..0x97 + array | *size*: 23..255 | array (1 byte follow) | 0x98 + array | *size*: 256..65535 | array (2 bytes follow) | 0x99 + array | *size*: 65536..4294967295 | array (4 bytes follow) | 0x9A + array | *size*: 4294967296..18446744073709551615 | array (8 bytes follow) | 0x9B + object | *size*: 0..23 | map | 0xA0..0xB7 + object | *size*: 23..255 | map (1 byte follow) | 0xB8 + object | *size*: 256..65535 | map (2 bytes follow) | 0xB9 + object | *size*: 65536..4294967295 | map (4 bytes follow) | 0xBA + object | *size*: 4294967296..18446744073709551615 | map (8 bytes follow) | 0xBB + + @note The mapping is **complete** in the sense that any JSON value type + can be converted to a CBOR value. + + @note If NaN or Infinity are stored inside a JSON number, they are + serialized properly. This behavior differs from the @ref dump() + function which serializes NaN or Infinity to `null`. + + @note The following CBOR types are not used in the conversion: + - byte strings (0x40..0x5F) + - UTF-8 strings terminated by "break" (0x7F) + - arrays terminated by "break" (0x9F) + - maps terminated by "break" (0xBF) + - date/time (0xC0..0xC1) + - bignum (0xC2..0xC3) + - decimal fraction (0xC4) + - bigfloat (0xC5) + - tagged items (0xC6..0xD4, 0xD8..0xDB) + - expected conversions (0xD5..0xD7) + - simple values (0xE0..0xF3, 0xF8) + - undefined (0xF7) + - half and single-precision floats (0xF9-0xFA) + - break (0xFF) + + @param[in] j JSON value to serialize + @return MessagePack serialization as byte vector + + @complexity Linear in the size of the JSON value @a j. + + @liveexample{The example shows the serialization of a JSON value to a byte + vector in CBOR format.,to_cbor} + + @sa http://cbor.io + @sa @ref from_cbor(detail::input_adapter&&, const bool, const bool) for the + analogous deserialization + @sa @ref to_msgpack(const basic_json&) for the related MessagePack format + @sa @ref to_ubjson(const basic_json&, const bool, const bool) for the + related UBJSON format + + @since version 2.0.9 + */ + static std::vector<uint8_t> to_cbor(const basic_json& j) + { + std::vector<uint8_t> result; + to_cbor(j, result); + return result; + } + + static void to_cbor(const basic_json& j, detail::output_adapter<uint8_t> o) + { + binary_writer<uint8_t>(o).write_cbor(j); + } + + static void to_cbor(const basic_json& j, detail::output_adapter<char> o) + { + binary_writer<char>(o).write_cbor(j); + } + + /*! + @brief create a MessagePack serialization of a given JSON value + + Serializes a given JSON value @a j to a byte vector using the MessagePack + serialization format. MessagePack is a binary serialization format which + aims to be more compact than JSON itself, yet more efficient to parse. + + The library uses the following mapping from JSON values types to + MessagePack types according to the MessagePack specification: + + JSON value type | value/range | MessagePack type | first byte + --------------- | --------------------------------- | ---------------- | ---------- + null | `null` | nil | 0xC0 + boolean | `true` | true | 0xC3 + boolean | `false` | false | 0xC2 + number_integer | -9223372036854775808..-2147483649 | int64 | 0xD3 + number_integer | -2147483648..-32769 | int32 | 0xD2 + number_integer | -32768..-129 | int16 | 0xD1 + number_integer | -128..-33 | int8 | 0xD0 + number_integer | -32..-1 | negative fixint | 0xE0..0xFF + number_integer | 0..127 | positive fixint | 0x00..0x7F + number_integer | 128..255 | uint 8 | 0xCC + number_integer | 256..65535 | uint 16 | 0xCD + number_integer | 65536..4294967295 | uint 32 | 0xCE + number_integer | 4294967296..18446744073709551615 | uint 64 | 0xCF + number_unsigned | 0..127 | positive fixint | 0x00..0x7F + number_unsigned | 128..255 | uint 8 | 0xCC + number_unsigned | 256..65535 | uint 16 | 0xCD + number_unsigned | 65536..4294967295 | uint 32 | 0xCE + number_unsigned | 4294967296..18446744073709551615 | uint 64 | 0xCF + number_float | *any value* | float 64 | 0xCB + string | *length*: 0..31 | fixstr | 0xA0..0xBF + string | *length*: 32..255 | str 8 | 0xD9 + string | *length*: 256..65535 | str 16 | 0xDA + string | *length*: 65536..4294967295 | str 32 | 0xDB + array | *size*: 0..15 | fixarray | 0x90..0x9F + array | *size*: 16..65535 | array 16 | 0xDC + array | *size*: 65536..4294967295 | array 32 | 0xDD + object | *size*: 0..15 | fix map | 0x80..0x8F + object | *size*: 16..65535 | map 16 | 0xDE + object | *size*: 65536..4294967295 | map 32 | 0xDF + + @note The mapping is **complete** in the sense that any JSON value type + can be converted to a MessagePack value. + + @note The following values can **not** be converted to a MessagePack value: + - strings with more than 4294967295 bytes + - arrays with more than 4294967295 elements + - objects with more than 4294967295 elements + + @note The following MessagePack types are not used in the conversion: + - bin 8 - bin 32 (0xC4..0xC6) + - ext 8 - ext 32 (0xC7..0xC9) + - float 32 (0xCA) + - fixext 1 - fixext 16 (0xD4..0xD8) + + @note Any MessagePack output created @ref to_msgpack can be successfully + parsed by @ref from_msgpack. + + @note If NaN or Infinity are stored inside a JSON number, they are + serialized properly. This behavior differs from the @ref dump() + function which serializes NaN or Infinity to `null`. + + @param[in] j JSON value to serialize + @return MessagePack serialization as byte vector + + @complexity Linear in the size of the JSON value @a j. + + @liveexample{The example shows the serialization of a JSON value to a byte + vector in MessagePack format.,to_msgpack} + + @sa http://msgpack.org + @sa @ref from_msgpack for the analogous deserialization + @sa @ref to_cbor(const basic_json& for the related CBOR format + @sa @ref to_ubjson(const basic_json&, const bool, const bool) for the + related UBJSON format + + @since version 2.0.9 + */ + static std::vector<uint8_t> to_msgpack(const basic_json& j) + { + std::vector<uint8_t> result; + to_msgpack(j, result); + return result; + } + + static void to_msgpack(const basic_json& j, detail::output_adapter<uint8_t> o) + { + binary_writer<uint8_t>(o).write_msgpack(j); + } + + static void to_msgpack(const basic_json& j, detail::output_adapter<char> o) + { + binary_writer<char>(o).write_msgpack(j); + } + + /*! + @brief create a UBJSON serialization of a given JSON value + + Serializes a given JSON value @a j to a byte vector using the UBJSON + (Universal Binary JSON) serialization format. UBJSON aims to be more compact + than JSON itself, yet more efficient to parse. + + The library uses the following mapping from JSON values types to + UBJSON types according to the UBJSON specification: + + JSON value type | value/range | UBJSON type | marker + --------------- | --------------------------------- | ----------- | ------ + null | `null` | null | `Z` + boolean | `true` | true | `T` + boolean | `false` | false | `F` + number_integer | -9223372036854775808..-2147483649 | int64 | `L` + number_integer | -2147483648..-32769 | int32 | `l` + number_integer | -32768..-129 | int16 | `I` + number_integer | -128..127 | int8 | `i` + number_integer | 128..255 | uint8 | `U` + number_integer | 256..32767 | int16 | `I` + number_integer | 32768..2147483647 | int32 | `l` + number_integer | 2147483648..9223372036854775807 | int64 | `L` + number_unsigned | 0..127 | int8 | `i` + number_unsigned | 128..255 | uint8 | `U` + number_unsigned | 256..32767 | int16 | `I` + number_unsigned | 32768..2147483647 | int32 | `l` + number_unsigned | 2147483648..9223372036854775807 | int64 | `L` + number_float | *any value* | float64 | `D` + string | *with shortest length indicator* | string | `S` + array | *see notes on optimized format* | array | `[` + object | *see notes on optimized format* | map | `{` + + @note The mapping is **complete** in the sense that any JSON value type + can be converted to a UBJSON value. + + @note The following values can **not** be converted to a UBJSON value: + - strings with more than 9223372036854775807 bytes (theoretical) + - unsigned integer numbers above 9223372036854775807 + + @note The following markers are not used in the conversion: + - `Z`: no-op values are not created. + - `C`: single-byte strings are serialized with `S` markers. + + @note Any UBJSON output created @ref to_ubjson can be successfully parsed + by @ref from_ubjson. + + @note If NaN or Infinity are stored inside a JSON number, they are + serialized properly. This behavior differs from the @ref dump() + function which serializes NaN or Infinity to `null`. + + @note The optimized formats for containers are supported: Parameter + @a use_size adds size information to the beginning of a container and + removes the closing marker. Parameter @a use_type further checks + whether all elements of a container have the same type and adds the + type marker to the beginning of the container. The @a use_type + parameter must only be used together with @a use_size = true. Note + that @a use_size = true alone may result in larger representations - + the benefit of this parameter is that the receiving side is + immediately informed on the number of elements of the container. + + @param[in] j JSON value to serialize + @param[in] use_size whether to add size annotations to container types + @param[in] use_type whether to add type annotations to container types + (must be combined with @a use_size = true) + @return UBJSON serialization as byte vector + + @complexity Linear in the size of the JSON value @a j. + + @liveexample{The example shows the serialization of a JSON value to a byte + vector in UBJSON format.,to_ubjson} + + @sa http://ubjson.org + @sa @ref from_ubjson(detail::input_adapter&&, const bool, const bool) for the + analogous deserialization + @sa @ref to_cbor(const basic_json& for the related CBOR format + @sa @ref to_msgpack(const basic_json&) for the related MessagePack format + + @since version 3.1.0 + */ + static std::vector<uint8_t> to_ubjson(const basic_json& j, + const bool use_size = false, + const bool use_type = false) + { + std::vector<uint8_t> result; + to_ubjson(j, result, use_size, use_type); + return result; + } + + static void to_ubjson(const basic_json& j, detail::output_adapter<uint8_t> o, + const bool use_size = false, const bool use_type = false) + { + binary_writer<uint8_t>(o).write_ubjson(j, use_size, use_type); + } + + static void to_ubjson(const basic_json& j, detail::output_adapter<char> o, + const bool use_size = false, const bool use_type = false) + { + binary_writer<char>(o).write_ubjson(j, use_size, use_type); + } + + + /*! + @brief Serializes the given JSON object `j` to BSON and returns a vector + containing the corresponding BSON-representation. + + BSON (Binary JSON) is a binary format in which zero or more ordered key/value pairs are + stored as a single entity (a so-called document). + + The library uses the following mapping from JSON values types to BSON types: + + JSON value type | value/range | BSON type | marker + --------------- | --------------------------------- | ----------- | ------ + null | `null` | null | 0x0A + boolean | `true`, `false` | boolean | 0x08 + number_integer | -9223372036854775808..-2147483649 | int64 | 0x12 + number_integer | -2147483648..2147483647 | int32 | 0x10 + number_integer | 2147483648..9223372036854775807 | int64 | 0x12 + number_unsigned | 0..2147483647 | int32 | 0x10 + number_unsigned | 2147483648..9223372036854775807 | int64 | 0x12 + number_unsigned | 9223372036854775808..18446744073709551615| -- | -- + number_float | *any value* | double | 0x01 + string | *any value* | string | 0x02 + array | *any value* | document | 0x04 + object | *any value* | document | 0x03 + + @warning The mapping is **incomplete**, since only JSON-objects (and things + contained therein) can be serialized to BSON. + Also, integers larger than 9223372036854775807 cannot be serialized to BSON, + and the keys may not contain U+0000, since they are serialized a + zero-terminated c-strings. + + @throw out_of_range.407 if `j.is_number_unsigned() && j.get<std::uint64_t>() > 9223372036854775807` + @throw out_of_range.409 if a key in `j` contains a NULL (U+0000) + @throw type_error.317 if `!j.is_object()` + + @pre The input `j` is required to be an object: `j.is_object() == true`. + + @note Any BSON output created via @ref to_bson can be successfully parsed + by @ref from_bson. + + @param[in] j JSON value to serialize + @return BSON serialization as byte vector + + @complexity Linear in the size of the JSON value @a j. + + @liveexample{The example shows the serialization of a JSON value to a byte + vector in BSON format.,to_bson} + + @sa http://bsonspec.org/spec.html + @sa @ref from_bson(detail::input_adapter&&, const bool strict) for the + analogous deserialization + @sa @ref to_ubjson(const basic_json&, const bool, const bool) for the + related UBJSON format + @sa @ref to_cbor(const basic_json&) for the related CBOR format + @sa @ref to_msgpack(const basic_json&) for the related MessagePack format + */ + static std::vector<uint8_t> to_bson(const basic_json& j) + { + std::vector<uint8_t> result; + to_bson(j, result); + return result; + } + + /*! + @brief Serializes the given JSON object `j` to BSON and forwards the + corresponding BSON-representation to the given output_adapter `o`. + @param j The JSON object to convert to BSON. + @param o The output adapter that receives the binary BSON representation. + @pre The input `j` shall be an object: `j.is_object() == true` + @sa @ref to_bson(const basic_json&) + */ + static void to_bson(const basic_json& j, detail::output_adapter<uint8_t> o) + { + binary_writer<uint8_t>(o).write_bson(j); + } + + /*! + @copydoc to_bson(const basic_json&, detail::output_adapter<uint8_t>) + */ + static void to_bson(const basic_json& j, detail::output_adapter<char> o) + { + binary_writer<char>(o).write_bson(j); + } + + + /*! + @brief create a JSON value from an input in CBOR format + + Deserializes a given input @a i to a JSON value using the CBOR (Concise + Binary Object Representation) serialization format. + + The library maps CBOR types to JSON value types as follows: + + CBOR type | JSON value type | first byte + ---------------------- | --------------- | ---------- + Integer | number_unsigned | 0x00..0x17 + Unsigned integer | number_unsigned | 0x18 + Unsigned integer | number_unsigned | 0x19 + Unsigned integer | number_unsigned | 0x1A + Unsigned integer | number_unsigned | 0x1B + Negative integer | number_integer | 0x20..0x37 + Negative integer | number_integer | 0x38 + Negative integer | number_integer | 0x39 + Negative integer | number_integer | 0x3A + Negative integer | number_integer | 0x3B + Negative integer | number_integer | 0x40..0x57 + UTF-8 string | string | 0x60..0x77 + UTF-8 string | string | 0x78 + UTF-8 string | string | 0x79 + UTF-8 string | string | 0x7A + UTF-8 string | string | 0x7B + UTF-8 string | string | 0x7F + array | array | 0x80..0x97 + array | array | 0x98 + array | array | 0x99 + array | array | 0x9A + array | array | 0x9B + array | array | 0x9F + map | object | 0xA0..0xB7 + map | object | 0xB8 + map | object | 0xB9 + map | object | 0xBA + map | object | 0xBB + map | object | 0xBF + False | `false` | 0xF4 + True | `true` | 0xF5 + Null | `null` | 0xF6 + Half-Precision Float | number_float | 0xF9 + Single-Precision Float | number_float | 0xFA + Double-Precision Float | number_float | 0xFB + + @warning The mapping is **incomplete** in the sense that not all CBOR + types can be converted to a JSON value. The following CBOR types + are not supported and will yield parse errors (parse_error.112): + - byte strings (0x40..0x5F) + - date/time (0xC0..0xC1) + - bignum (0xC2..0xC3) + - decimal fraction (0xC4) + - bigfloat (0xC5) + - tagged items (0xC6..0xD4, 0xD8..0xDB) + - expected conversions (0xD5..0xD7) + - simple values (0xE0..0xF3, 0xF8) + - undefined (0xF7) + + @warning CBOR allows map keys of any type, whereas JSON only allows + strings as keys in object values. Therefore, CBOR maps with keys + other than UTF-8 strings are rejected (parse_error.113). + + @note Any CBOR output created @ref to_cbor can be successfully parsed by + @ref from_cbor. + + @param[in] i an input in CBOR format convertible to an input adapter + @param[in] strict whether to expect the input to be consumed until EOF + (true by default) + @param[in] allow_exceptions whether to throw exceptions in case of a + parse error (optional, true by default) + + @return deserialized JSON value + + @throw parse_error.110 if the given input ends prematurely or the end of + file was not reached when @a strict was set to true + @throw parse_error.112 if unsupported features from CBOR were + used in the given input @a v or if the input is not valid CBOR + @throw parse_error.113 if a string was expected as map key, but not found + + @complexity Linear in the size of the input @a i. + + @liveexample{The example shows the deserialization of a byte vector in CBOR + format to a JSON value.,from_cbor} + + @sa http://cbor.io + @sa @ref to_cbor(const basic_json&) for the analogous serialization + @sa @ref from_msgpack(detail::input_adapter&&, const bool, const bool) for the + related MessagePack format + @sa @ref from_ubjson(detail::input_adapter&&, const bool, const bool) for the + related UBJSON format + + @since version 2.0.9; parameter @a start_index since 2.1.1; changed to + consume input adapters, removed start_index parameter, and added + @a strict parameter since 3.0.0; added @a allow_exceptions parameter + since 3.2.0 + */ + static basic_json from_cbor(detail::input_adapter&& i, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(i)).sax_parse(input_format_t::cbor, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @copydoc from_cbor(detail::input_adapter&&, const bool, const bool) + */ + template<typename A1, typename A2, + detail::enable_if_t<std::is_constructible<detail::input_adapter, A1, A2>::value, int> = 0> + static basic_json from_cbor(A1 && a1, A2 && a2, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(std::forward<A1>(a1), std::forward<A2>(a2))).sax_parse(input_format_t::cbor, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @brief create a JSON value from an input in MessagePack format + + Deserializes a given input @a i to a JSON value using the MessagePack + serialization format. + + The library maps MessagePack types to JSON value types as follows: + + MessagePack type | JSON value type | first byte + ---------------- | --------------- | ---------- + positive fixint | number_unsigned | 0x00..0x7F + fixmap | object | 0x80..0x8F + fixarray | array | 0x90..0x9F + fixstr | string | 0xA0..0xBF + nil | `null` | 0xC0 + false | `false` | 0xC2 + true | `true` | 0xC3 + float 32 | number_float | 0xCA + float 64 | number_float | 0xCB + uint 8 | number_unsigned | 0xCC + uint 16 | number_unsigned | 0xCD + uint 32 | number_unsigned | 0xCE + uint 64 | number_unsigned | 0xCF + int 8 | number_integer | 0xD0 + int 16 | number_integer | 0xD1 + int 32 | number_integer | 0xD2 + int 64 | number_integer | 0xD3 + str 8 | string | 0xD9 + str 16 | string | 0xDA + str 32 | string | 0xDB + array 16 | array | 0xDC + array 32 | array | 0xDD + map 16 | object | 0xDE + map 32 | object | 0xDF + negative fixint | number_integer | 0xE0-0xFF + + @warning The mapping is **incomplete** in the sense that not all + MessagePack types can be converted to a JSON value. The following + MessagePack types are not supported and will yield parse errors: + - bin 8 - bin 32 (0xC4..0xC6) + - ext 8 - ext 32 (0xC7..0xC9) + - fixext 1 - fixext 16 (0xD4..0xD8) + + @note Any MessagePack output created @ref to_msgpack can be successfully + parsed by @ref from_msgpack. + + @param[in] i an input in MessagePack format convertible to an input + adapter + @param[in] strict whether to expect the input to be consumed until EOF + (true by default) + @param[in] allow_exceptions whether to throw exceptions in case of a + parse error (optional, true by default) + + @return deserialized JSON value + + @throw parse_error.110 if the given input ends prematurely or the end of + file was not reached when @a strict was set to true + @throw parse_error.112 if unsupported features from MessagePack were + used in the given input @a i or if the input is not valid MessagePack + @throw parse_error.113 if a string was expected as map key, but not found + + @complexity Linear in the size of the input @a i. + + @liveexample{The example shows the deserialization of a byte vector in + MessagePack format to a JSON value.,from_msgpack} + + @sa http://msgpack.org + @sa @ref to_msgpack(const basic_json&) for the analogous serialization + @sa @ref from_cbor(detail::input_adapter&&, const bool, const bool) for the + related CBOR format + @sa @ref from_ubjson(detail::input_adapter&&, const bool, const bool) for + the related UBJSON format + @sa @ref from_bson(detail::input_adapter&&, const bool, const bool) for + the related BSON format + + @since version 2.0.9; parameter @a start_index since 2.1.1; changed to + consume input adapters, removed start_index parameter, and added + @a strict parameter since 3.0.0; added @a allow_exceptions parameter + since 3.2.0 + */ + static basic_json from_msgpack(detail::input_adapter&& i, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(i)).sax_parse(input_format_t::msgpack, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @copydoc from_msgpack(detail::input_adapter&&, const bool, const bool) + */ + template<typename A1, typename A2, + detail::enable_if_t<std::is_constructible<detail::input_adapter, A1, A2>::value, int> = 0> + static basic_json from_msgpack(A1 && a1, A2 && a2, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(std::forward<A1>(a1), std::forward<A2>(a2))).sax_parse(input_format_t::msgpack, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @brief create a JSON value from an input in UBJSON format + + Deserializes a given input @a i to a JSON value using the UBJSON (Universal + Binary JSON) serialization format. + + The library maps UBJSON types to JSON value types as follows: + + UBJSON type | JSON value type | marker + ----------- | --------------------------------------- | ------ + no-op | *no value, next value is read* | `N` + null | `null` | `Z` + false | `false` | `F` + true | `true` | `T` + float32 | number_float | `d` + float64 | number_float | `D` + uint8 | number_unsigned | `U` + int8 | number_integer | `i` + int16 | number_integer | `I` + int32 | number_integer | `l` + int64 | number_integer | `L` + string | string | `S` + char | string | `C` + array | array (optimized values are supported) | `[` + object | object (optimized values are supported) | `{` + + @note The mapping is **complete** in the sense that any UBJSON value can + be converted to a JSON value. + + @param[in] i an input in UBJSON format convertible to an input adapter + @param[in] strict whether to expect the input to be consumed until EOF + (true by default) + @param[in] allow_exceptions whether to throw exceptions in case of a + parse error (optional, true by default) + + @return deserialized JSON value + + @throw parse_error.110 if the given input ends prematurely or the end of + file was not reached when @a strict was set to true + @throw parse_error.112 if a parse error occurs + @throw parse_error.113 if a string could not be parsed successfully + + @complexity Linear in the size of the input @a i. + + @liveexample{The example shows the deserialization of a byte vector in + UBJSON format to a JSON value.,from_ubjson} + + @sa http://ubjson.org + @sa @ref to_ubjson(const basic_json&, const bool, const bool) for the + analogous serialization + @sa @ref from_cbor(detail::input_adapter&&, const bool, const bool) for the + related CBOR format + @sa @ref from_msgpack(detail::input_adapter&&, const bool, const bool) for + the related MessagePack format + @sa @ref from_bson(detail::input_adapter&&, const bool, const bool) for + the related BSON format + + @since version 3.1.0; added @a allow_exceptions parameter since 3.2.0 + */ + static basic_json from_ubjson(detail::input_adapter&& i, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(i)).sax_parse(input_format_t::ubjson, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @copydoc from_ubjson(detail::input_adapter&&, const bool, const bool) + */ + template<typename A1, typename A2, + detail::enable_if_t<std::is_constructible<detail::input_adapter, A1, A2>::value, int> = 0> + static basic_json from_ubjson(A1 && a1, A2 && a2, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(std::forward<A1>(a1), std::forward<A2>(a2))).sax_parse(input_format_t::ubjson, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @brief Create a JSON value from an input in BSON format + + Deserializes a given input @a i to a JSON value using the BSON (Binary JSON) + serialization format. + + The library maps BSON record types to JSON value types as follows: + + BSON type | BSON marker byte | JSON value type + --------------- | ---------------- | --------------------------- + double | 0x01 | number_float + string | 0x02 | string + document | 0x03 | object + array | 0x04 | array + binary | 0x05 | still unsupported + undefined | 0x06 | still unsupported + ObjectId | 0x07 | still unsupported + boolean | 0x08 | boolean + UTC Date-Time | 0x09 | still unsupported + null | 0x0A | null + Regular Expr. | 0x0B | still unsupported + DB Pointer | 0x0C | still unsupported + JavaScript Code | 0x0D | still unsupported + Symbol | 0x0E | still unsupported + JavaScript Code | 0x0F | still unsupported + int32 | 0x10 | number_integer + Timestamp | 0x11 | still unsupported + 128-bit decimal float | 0x13 | still unsupported + Max Key | 0x7F | still unsupported + Min Key | 0xFF | still unsupported + + @warning The mapping is **incomplete**. The unsupported mappings + are indicated in the table above. + + @param[in] i an input in BSON format convertible to an input adapter + @param[in] strict whether to expect the input to be consumed until EOF + (true by default) + @param[in] allow_exceptions whether to throw exceptions in case of a + parse error (optional, true by default) + + @return deserialized JSON value + + @throw parse_error.114 if an unsupported BSON record type is encountered + + @complexity Linear in the size of the input @a i. + + @liveexample{The example shows the deserialization of a byte vector in + BSON format to a JSON value.,from_bson} + + @sa http://bsonspec.org/spec.html + @sa @ref to_bson(const basic_json&) for the analogous serialization + @sa @ref from_cbor(detail::input_adapter&&, const bool, const bool) for the + related CBOR format + @sa @ref from_msgpack(detail::input_adapter&&, const bool, const bool) for + the related MessagePack format + @sa @ref from_ubjson(detail::input_adapter&&, const bool, const bool) for the + related UBJSON format + */ + static basic_json from_bson(detail::input_adapter&& i, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(i)).sax_parse(input_format_t::bson, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + /*! + @copydoc from_bson(detail::input_adapter&&, const bool, const bool) + */ + template<typename A1, typename A2, + detail::enable_if_t<std::is_constructible<detail::input_adapter, A1, A2>::value, int> = 0> + static basic_json from_bson(A1 && a1, A2 && a2, + const bool strict = true, + const bool allow_exceptions = true) + { + basic_json result; + detail::json_sax_dom_parser<basic_json> sdp(result, allow_exceptions); + const bool res = binary_reader(detail::input_adapter(std::forward<A1>(a1), std::forward<A2>(a2))).sax_parse(input_format_t::bson, &sdp, strict); + return res ? result : basic_json(value_t::discarded); + } + + + + /// @} + + ////////////////////////// + // JSON Pointer support // + ////////////////////////// + + /// @name JSON Pointer functions + /// @{ + + /*! + @brief access specified element via JSON Pointer + + Uses a JSON pointer to retrieve a reference to the respective JSON value. + No bound checking is performed. Similar to @ref operator[](const typename + object_t::key_type&), `null` values are created in arrays and objects if + necessary. + + In particular: + - If the JSON pointer points to an object key that does not exist, it + is created an filled with a `null` value before a reference to it + is returned. + - If the JSON pointer points to an array index that does not exist, it + is created an filled with a `null` value before a reference to it + is returned. All indices between the current maximum and the given + index are also filled with `null`. + - The special value `-` is treated as a synonym for the index past the + end. + + @param[in] ptr a JSON pointer + + @return reference to the element pointed to by @a ptr + + @complexity Constant. + + @throw parse_error.106 if an array index begins with '0' + @throw parse_error.109 if an array index was not a number + @throw out_of_range.404 if the JSON pointer can not be resolved + + @liveexample{The behavior is shown in the example.,operatorjson_pointer} + + @since version 2.0.0 + */ + reference operator[](const json_pointer& ptr) + { + return ptr.get_unchecked(this); + } + + /*! + @brief access specified element via JSON Pointer + + Uses a JSON pointer to retrieve a reference to the respective JSON value. + No bound checking is performed. The function does not change the JSON + value; no `null` values are created. In particular, the the special value + `-` yields an exception. + + @param[in] ptr JSON pointer to the desired element + + @return const reference to the element pointed to by @a ptr + + @complexity Constant. + + @throw parse_error.106 if an array index begins with '0' + @throw parse_error.109 if an array index was not a number + @throw out_of_range.402 if the array index '-' is used + @throw out_of_range.404 if the JSON pointer can not be resolved + + @liveexample{The behavior is shown in the example.,operatorjson_pointer_const} + + @since version 2.0.0 + */ + const_reference operator[](const json_pointer& ptr) const + { + return ptr.get_unchecked(this); + } + + /*! + @brief access specified element via JSON Pointer + + Returns a reference to the element at with specified JSON pointer @a ptr, + with bounds checking. + + @param[in] ptr JSON pointer to the desired element + + @return reference to the element pointed to by @a ptr + + @throw parse_error.106 if an array index in the passed JSON pointer @a ptr + begins with '0'. See example below. + + @throw parse_error.109 if an array index in the passed JSON pointer @a ptr + is not a number. See example below. + + @throw out_of_range.401 if an array index in the passed JSON pointer @a ptr + is out of range. See example below. + + @throw out_of_range.402 if the array index '-' is used in the passed JSON + pointer @a ptr. As `at` provides checked access (and no elements are + implicitly inserted), the index '-' is always invalid. See example below. + + @throw out_of_range.403 if the JSON pointer describes a key of an object + which cannot be found. See example below. + + @throw out_of_range.404 if the JSON pointer @a ptr can not be resolved. + See example below. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Constant. + + @since version 2.0.0 + + @liveexample{The behavior is shown in the example.,at_json_pointer} + */ + reference at(const json_pointer& ptr) + { + return ptr.get_checked(this); + } + + /*! + @brief access specified element via JSON Pointer + + Returns a const reference to the element at with specified JSON pointer @a + ptr, with bounds checking. + + @param[in] ptr JSON pointer to the desired element + + @return reference to the element pointed to by @a ptr + + @throw parse_error.106 if an array index in the passed JSON pointer @a ptr + begins with '0'. See example below. + + @throw parse_error.109 if an array index in the passed JSON pointer @a ptr + is not a number. See example below. + + @throw out_of_range.401 if an array index in the passed JSON pointer @a ptr + is out of range. See example below. + + @throw out_of_range.402 if the array index '-' is used in the passed JSON + pointer @a ptr. As `at` provides checked access (and no elements are + implicitly inserted), the index '-' is always invalid. See example below. + + @throw out_of_range.403 if the JSON pointer describes a key of an object + which cannot be found. See example below. + + @throw out_of_range.404 if the JSON pointer @a ptr can not be resolved. + See example below. + + @exceptionsafety Strong guarantee: if an exception is thrown, there are no + changes in the JSON value. + + @complexity Constant. + + @since version 2.0.0 + + @liveexample{The behavior is shown in the example.,at_json_pointer_const} + */ + const_reference at(const json_pointer& ptr) const + { + return ptr.get_checked(this); + } + + /*! + @brief return flattened JSON value + + The function creates a JSON object whose keys are JSON pointers (see [RFC + 6901](https://tools.ietf.org/html/rfc6901)) and whose values are all + primitive. The original JSON value can be restored using the @ref + unflatten() function. + + @return an object that maps JSON pointers to primitive values + + @note Empty objects and arrays are flattened to `null` and will not be + reconstructed correctly by the @ref unflatten() function. + + @complexity Linear in the size the JSON value. + + @liveexample{The following code shows how a JSON object is flattened to an + object whose keys consist of JSON pointers.,flatten} + + @sa @ref unflatten() for the reverse function + + @since version 2.0.0 + */ + basic_json flatten() const + { + basic_json result(value_t::object); + json_pointer::flatten("", *this, result); + return result; + } + + /*! + @brief unflatten a previously flattened JSON value + + The function restores the arbitrary nesting of a JSON value that has been + flattened before using the @ref flatten() function. The JSON value must + meet certain constraints: + 1. The value must be an object. + 2. The keys must be JSON pointers (see + [RFC 6901](https://tools.ietf.org/html/rfc6901)) + 3. The mapped values must be primitive JSON types. + + @return the original JSON from a flattened version + + @note Empty objects and arrays are flattened by @ref flatten() to `null` + values and can not unflattened to their original type. Apart from + this example, for a JSON value `j`, the following is always true: + `j == j.flatten().unflatten()`. + + @complexity Linear in the size the JSON value. + + @throw type_error.314 if value is not an object + @throw type_error.315 if object values are not primitive + + @liveexample{The following code shows how a flattened JSON object is + unflattened into the original nested JSON object.,unflatten} + + @sa @ref flatten() for the reverse function + + @since version 2.0.0 + */ + basic_json unflatten() const + { + return json_pointer::unflatten(*this); + } + + /// @} + + ////////////////////////// + // JSON Patch functions // + ////////////////////////// + + /// @name JSON Patch functions + /// @{ + + /*! + @brief applies a JSON patch + + [JSON Patch](http://jsonpatch.com) defines a JSON document structure for + expressing a sequence of operations to apply to a JSON) document. With + this function, a JSON Patch is applied to the current JSON value by + executing all operations from the patch. + + @param[in] json_patch JSON patch document + @return patched document + + @note The application of a patch is atomic: Either all operations succeed + and the patched document is returned or an exception is thrown. In + any case, the original value is not changed: the patch is applied + to a copy of the value. + + @throw parse_error.104 if the JSON patch does not consist of an array of + objects + + @throw parse_error.105 if the JSON patch is malformed (e.g., mandatory + attributes are missing); example: `"operation add must have member path"` + + @throw out_of_range.401 if an array index is out of range. + + @throw out_of_range.403 if a JSON pointer inside the patch could not be + resolved successfully in the current JSON value; example: `"key baz not + found"` + + @throw out_of_range.405 if JSON pointer has no parent ("add", "remove", + "move") + + @throw other_error.501 if "test" operation was unsuccessful + + @complexity Linear in the size of the JSON value and the length of the + JSON patch. As usually only a fraction of the JSON value is affected by + the patch, the complexity can usually be neglected. + + @liveexample{The following code shows how a JSON patch is applied to a + value.,patch} + + @sa @ref diff -- create a JSON patch by comparing two JSON values + + @sa [RFC 6902 (JSON Patch)](https://tools.ietf.org/html/rfc6902) + @sa [RFC 6901 (JSON Pointer)](https://tools.ietf.org/html/rfc6901) + + @since version 2.0.0 + */ + basic_json patch(const basic_json& json_patch) const + { + // make a working copy to apply the patch to + basic_json result = *this; + + // the valid JSON Patch operations + enum class patch_operations {add, remove, replace, move, copy, test, invalid}; + + const auto get_op = [](const std::string & op) + { + if (op == "add") + { + return patch_operations::add; + } + if (op == "remove") + { + return patch_operations::remove; + } + if (op == "replace") + { + return patch_operations::replace; + } + if (op == "move") + { + return patch_operations::move; + } + if (op == "copy") + { + return patch_operations::copy; + } + if (op == "test") + { + return patch_operations::test; + } + + return patch_operations::invalid; + }; + + // wrapper for "add" operation; add value at ptr + const auto operation_add = [&result](json_pointer & ptr, basic_json val) + { + // adding to the root of the target document means replacing it + if (ptr.is_root()) + { + result = val; + } + else + { + // make sure the top element of the pointer exists + json_pointer top_pointer = ptr.top(); + if (top_pointer != ptr) + { + result.at(top_pointer); + } + + // get reference to parent of JSON pointer ptr + const auto last_path = ptr.pop_back(); + basic_json& parent = result[ptr]; + + switch (parent.m_type) + { + case value_t::null: + case value_t::object: + { + // use operator[] to add value + parent[last_path] = val; + break; + } + + case value_t::array: + { + if (last_path == "-") + { + // special case: append to back + parent.push_back(val); + } + else + { + const auto idx = json_pointer::array_index(last_path); + if (JSON_UNLIKELY(static_cast<size_type>(idx) > parent.size())) + { + // avoid undefined behavior + JSON_THROW(out_of_range::create(401, "array index " + std::to_string(idx) + " is out of range")); + } + + // default case: insert add offset + parent.insert(parent.begin() + static_cast<difference_type>(idx), val); + } + break; + } + + // LCOV_EXCL_START + default: + { + // if there exists a parent it cannot be primitive + assert(false); + } + // LCOV_EXCL_STOP + } + } + }; + + // wrapper for "remove" operation; remove value at ptr + const auto operation_remove = [&result](json_pointer & ptr) + { + // get reference to parent of JSON pointer ptr + const auto last_path = ptr.pop_back(); + basic_json& parent = result.at(ptr); + + // remove child + if (parent.is_object()) + { + // perform range check + auto it = parent.find(last_path); + if (JSON_LIKELY(it != parent.end())) + { + parent.erase(it); + } + else + { + JSON_THROW(out_of_range::create(403, "key '" + last_path + "' not found")); + } + } + else if (parent.is_array()) + { + // note erase performs range check + parent.erase(static_cast<size_type>(json_pointer::array_index(last_path))); + } + }; + + // type check: top level value must be an array + if (JSON_UNLIKELY(not json_patch.is_array())) + { + JSON_THROW(parse_error::create(104, 0, "JSON patch must be an array of objects")); + } + + // iterate and apply the operations + for (const auto& val : json_patch) + { + // wrapper to get a value for an operation + const auto get_value = [&val](const std::string & op, + const std::string & member, + bool string_type) -> basic_json & + { + // find value + auto it = val.m_value.object->find(member); + + // context-sensitive error message + const auto error_msg = (op == "op") ? "operation" : "operation '" + op + "'"; + + // check if desired value is present + if (JSON_UNLIKELY(it == val.m_value.object->end())) + { + JSON_THROW(parse_error::create(105, 0, error_msg + " must have member '" + member + "'")); + } + + // check if result is of type string + if (JSON_UNLIKELY(string_type and not it->second.is_string())) + { + JSON_THROW(parse_error::create(105, 0, error_msg + " must have string member '" + member + "'")); + } + + // no error: return value + return it->second; + }; + + // type check: every element of the array must be an object + if (JSON_UNLIKELY(not val.is_object())) + { + JSON_THROW(parse_error::create(104, 0, "JSON patch must be an array of objects")); + } + + // collect mandatory members + const std::string op = get_value("op", "op", true); + const std::string path = get_value(op, "path", true); + json_pointer ptr(path); + + switch (get_op(op)) + { + case patch_operations::add: + { + operation_add(ptr, get_value("add", "value", false)); + break; + } + + case patch_operations::remove: + { + operation_remove(ptr); + break; + } + + case patch_operations::replace: + { + // the "path" location must exist - use at() + result.at(ptr) = get_value("replace", "value", false); + break; + } + + case patch_operations::move: + { + const std::string from_path = get_value("move", "from", true); + json_pointer from_ptr(from_path); + + // the "from" location must exist - use at() + basic_json v = result.at(from_ptr); + + // The move operation is functionally identical to a + // "remove" operation on the "from" location, followed + // immediately by an "add" operation at the target + // location with the value that was just removed. + operation_remove(from_ptr); + operation_add(ptr, v); + break; + } + + case patch_operations::copy: + { + const std::string from_path = get_value("copy", "from", true); + const json_pointer from_ptr(from_path); + + // the "from" location must exist - use at() + basic_json v = result.at(from_ptr); + + // The copy is functionally identical to an "add" + // operation at the target location using the value + // specified in the "from" member. + operation_add(ptr, v); + break; + } + + case patch_operations::test: + { + bool success = false; + JSON_TRY + { + // check if "value" matches the one at "path" + // the "path" location must exist - use at() + success = (result.at(ptr) == get_value("test", "value", false)); + } + JSON_INTERNAL_CATCH (out_of_range&) + { + // ignore out of range errors: success remains false + } + + // throw an exception if test fails + if (JSON_UNLIKELY(not success)) + { + JSON_THROW(other_error::create(501, "unsuccessful: " + val.dump())); + } + + break; + } + + case patch_operations::invalid: + { + // op must be "add", "remove", "replace", "move", "copy", or + // "test" + JSON_THROW(parse_error::create(105, 0, "operation value '" + op + "' is invalid")); + } + } + } + + return result; + } + + /*! + @brief creates a diff as a JSON patch + + Creates a [JSON Patch](http://jsonpatch.com) so that value @a source can + be changed into the value @a target by calling @ref patch function. + + @invariant For two JSON values @a source and @a target, the following code + yields always `true`: + @code {.cpp} + source.patch(diff(source, target)) == target; + @endcode + + @note Currently, only `remove`, `add`, and `replace` operations are + generated. + + @param[in] source JSON value to compare from + @param[in] target JSON value to compare against + @param[in] path helper value to create JSON pointers + + @return a JSON patch to convert the @a source to @a target + + @complexity Linear in the lengths of @a source and @a target. + + @liveexample{The following code shows how a JSON patch is created as a + diff for two JSON values.,diff} + + @sa @ref patch -- apply a JSON patch + @sa @ref merge_patch -- apply a JSON Merge Patch + + @sa [RFC 6902 (JSON Patch)](https://tools.ietf.org/html/rfc6902) + + @since version 2.0.0 + */ + static basic_json diff(const basic_json& source, const basic_json& target, + const std::string& path = "") + { + // the patch + basic_json result(value_t::array); + + // if the values are the same, return empty patch + if (source == target) + { + return result; + } + + if (source.type() != target.type()) + { + // different types: replace value + result.push_back( + { + {"op", "replace"}, {"path", path}, {"value", target} + }); + } + else + { + switch (source.type()) + { + case value_t::array: + { + // first pass: traverse common elements + std::size_t i = 0; + while (i < source.size() and i < target.size()) + { + // recursive call to compare array values at index i + auto temp_diff = diff(source[i], target[i], path + "/" + std::to_string(i)); + result.insert(result.end(), temp_diff.begin(), temp_diff.end()); + ++i; + } + + // i now reached the end of at least one array + // in a second pass, traverse the remaining elements + + // remove my remaining elements + const auto end_index = static_cast<difference_type>(result.size()); + while (i < source.size()) + { + // add operations in reverse order to avoid invalid + // indices + result.insert(result.begin() + end_index, object( + { + {"op", "remove"}, + {"path", path + "/" + std::to_string(i)} + })); + ++i; + } + + // add other remaining elements + while (i < target.size()) + { + result.push_back( + { + {"op", "add"}, + {"path", path + "/" + std::to_string(i)}, + {"value", target[i]} + }); + ++i; + } + + break; + } + + case value_t::object: + { + // first pass: traverse this object's elements + for (auto it = source.cbegin(); it != source.cend(); ++it) + { + // escape the key name to be used in a JSON patch + const auto key = json_pointer::escape(it.key()); + + if (target.find(it.key()) != target.end()) + { + // recursive call to compare object values at key it + auto temp_diff = diff(it.value(), target[it.key()], path + "/" + key); + result.insert(result.end(), temp_diff.begin(), temp_diff.end()); + } + else + { + // found a key that is not in o -> remove it + result.push_back(object( + { + {"op", "remove"}, {"path", path + "/" + key} + })); + } + } + + // second pass: traverse other object's elements + for (auto it = target.cbegin(); it != target.cend(); ++it) + { + if (source.find(it.key()) == source.end()) + { + // found a key that is not in this -> add it + const auto key = json_pointer::escape(it.key()); + result.push_back( + { + {"op", "add"}, {"path", path + "/" + key}, + {"value", it.value()} + }); + } + } + + break; + } + + default: + { + // both primitive type: replace value + result.push_back( + { + {"op", "replace"}, {"path", path}, {"value", target} + }); + break; + } + } + } + + return result; + } + + /// @} + + //////////////////////////////// + // JSON Merge Patch functions // + //////////////////////////////// + + /// @name JSON Merge Patch functions + /// @{ + + /*! + @brief applies a JSON Merge Patch + + The merge patch format is primarily intended for use with the HTTP PATCH + method as a means of describing a set of modifications to a target + resource's content. This function applies a merge patch to the current + JSON value. + + The function implements the following algorithm from Section 2 of + [RFC 7396 (JSON Merge Patch)](https://tools.ietf.org/html/rfc7396): + + ``` + define MergePatch(Target, Patch): + if Patch is an Object: + if Target is not an Object: + Target = {} // Ignore the contents and set it to an empty Object + for each Name/Value pair in Patch: + if Value is null: + if Name exists in Target: + remove the Name/Value pair from Target + else: + Target[Name] = MergePatch(Target[Name], Value) + return Target + else: + return Patch + ``` + + Thereby, `Target` is the current object; that is, the patch is applied to + the current value. + + @param[in] apply_patch the patch to apply + + @complexity Linear in the lengths of @a patch. + + @liveexample{The following code shows how a JSON Merge Patch is applied to + a JSON document.,merge_patch} + + @sa @ref patch -- apply a JSON patch + @sa [RFC 7396 (JSON Merge Patch)](https://tools.ietf.org/html/rfc7396) + + @since version 3.0.0 + */ + void merge_patch(const basic_json& apply_patch) + { + if (apply_patch.is_object()) + { + if (not is_object()) + { + *this = object(); + } + for (auto it = apply_patch.begin(); it != apply_patch.end(); ++it) + { + if (it.value().is_null()) + { + erase(it.key()); + } + else + { + operator[](it.key()).merge_patch(it.value()); + } + } + } + else + { + *this = apply_patch; + } + } + + /// @} +}; +} // namespace nlohmann + +/////////////////////// +// nonmember support // +/////////////////////// + +// specialization of std::swap, and std::hash +namespace std +{ + +/// hash value for JSON objects +template<> +struct hash<nlohmann::json> +{ + /*! + @brief return a hash value for a JSON object + + @since version 1.0.0 + */ + std::size_t operator()(const nlohmann::json& j) const + { + // a naive hashing via the string representation + const auto& h = hash<nlohmann::json::string_t>(); + return h(j.dump()); + } +}; + +/// specialization for std::less<value_t> +/// @note: do not remove the space after '<', +/// see https://github.com/nlohmann/json/pull/679 +template<> +struct less< ::nlohmann::detail::value_t> +{ + /*! + @brief compare two value_t enum values + @since version 3.0.0 + */ + bool operator()(nlohmann::detail::value_t lhs, + nlohmann::detail::value_t rhs) const noexcept + { + return nlohmann::detail::operator<(lhs, rhs); + } +}; + +/*! +@brief exchanges the values of two JSON objects + +@since version 1.0.0 +*/ +template<> +inline void swap<nlohmann::json>(nlohmann::json& j1, nlohmann::json& j2) noexcept( + is_nothrow_move_constructible<nlohmann::json>::value and + is_nothrow_move_assignable<nlohmann::json>::value +) +{ + j1.swap(j2); +} + +} // namespace std + +/*! +@brief user-defined string literal for JSON values + +This operator implements a user-defined string literal for JSON objects. It +can be used by adding `"_json"` to a string literal and returns a JSON object +if no parse error occurred. + +@param[in] s a string representation of a JSON object +@param[in] n the length of string @a s +@return a JSON object + +@since version 1.0.0 +*/ +inline nlohmann::json operator "" _json(const char* s, std::size_t n) +{ + return nlohmann::json::parse(s, s + n); +} + +/*! +@brief user-defined string literal for JSON pointer + +This operator implements a user-defined string literal for JSON Pointers. It +can be used by adding `"_json_pointer"` to a string literal and returns a JSON pointer +object if no parse error occurred. + +@param[in] s a string representation of a JSON Pointer +@param[in] n the length of string @a s +@return a JSON pointer object + +@since version 2.0.0 +*/ +inline nlohmann::json::json_pointer operator "" _json_pointer(const char* s, std::size_t n) +{ + return nlohmann::json::json_pointer(std::string(s, n)); +} + +// #include <nlohmann/detail/macro_unscope.hpp> + + +// restore GCC/clang diagnostic settings +#if defined(__clang__) || defined(__GNUC__) || defined(__GNUG__) + #pragma GCC diagnostic pop +#endif +#if defined(__clang__) + #pragma GCC diagnostic pop +#endif + +// clean up +#undef JSON_INTERNAL_CATCH +#undef JSON_CATCH +#undef JSON_THROW +#undef JSON_TRY +#undef JSON_LIKELY +#undef JSON_UNLIKELY +#undef JSON_DEPRECATED +#undef JSON_HAS_CPP_14 +#undef JSON_HAS_CPP_17 +#undef NLOHMANN_BASIC_JSON_TPL_DECLARATION +#undef NLOHMANN_BASIC_JSON_TPL + + +#endif diff --git a/third_party/nix/subprojects/abseil_cpp b/third_party/nix/subprojects/abseil_cpp new file mode 120000 index 0000000000..4909945b39 --- /dev/null +++ b/third_party/nix/subprojects/abseil_cpp @@ -0,0 +1 @@ +../../abseil_cpp \ No newline at end of file diff --git a/third_party/nix/tests/add.sh b/third_party/nix/tests/add.sh new file mode 100644 index 0000000000..e26e05843d --- /dev/null +++ b/third_party/nix/tests/add.sh @@ -0,0 +1,28 @@ +source common.sh + +path1=$(nix-store --add ./dummy) +echo $path1 + +path2=$(nix-store --add-fixed sha256 --recursive ./dummy) +echo $path2 + +if test "$path1" != "$path2"; then + echo "nix-store --add and --add-fixed mismatch" + exit 1 +fi + +path3=$(nix-store --add-fixed sha256 ./dummy) +echo $path3 +test "$path1" != "$path3" || exit 1 + +path4=$(nix-store --add-fixed sha1 --recursive ./dummy) +echo $path4 +test "$path1" != "$path4" || exit 1 + +hash1=$(nix-store -q --hash $path1) +echo $hash1 + +hash2=$(nix-hash --type sha256 --base32 ./dummy) +echo $hash2 + +test "$hash1" = "sha256:$hash2" diff --git a/third_party/nix/tests/binary-cache.sh b/third_party/nix/tests/binary-cache.sh new file mode 100644 index 0000000000..eb58ae7c12 --- /dev/null +++ b/third_party/nix/tests/binary-cache.sh @@ -0,0 +1,170 @@ +source common.sh + +clearStore +clearCache + +# Create the binary cache. +outPath=$(nix-build dependencies.nix --no-out-link) + +nix copy --to file://$cacheDir $outPath + + +basicTests() { + + # By default, a binary cache doesn't support "nix-env -qas", but does + # support installation. + clearStore + clearCacheCache + + nix-env --substituters "file://$cacheDir" -f dependencies.nix -qas \* | grep -- "---" + + nix-store --substituters "file://$cacheDir" --no-require-sigs -r $outPath + + [ -x $outPath/program ] + + + # But with the right configuration, "nix-env -qas" should also work. + clearStore + clearCacheCache + echo "WantMassQuery: 1" >> $cacheDir/nix-cache-info + + nix-env --substituters "file://$cacheDir" -f dependencies.nix -qas \* | grep -- "--S" + nix-env --substituters "file://$cacheDir" -f dependencies.nix -qas \* | grep -- "--S" + + x=$(nix-env -f dependencies.nix -qas \* --prebuilt-only) + [ -z "$x" ] + + nix-store --substituters "file://$cacheDir" --no-require-sigs -r $outPath + + nix-store --check-validity $outPath + nix-store -qR $outPath | grep input-2 + + echo "WantMassQuery: 0" >> $cacheDir/nix-cache-info +} + + +# Test LocalBinaryCacheStore. +basicTests + + +# Test HttpBinaryCacheStore. +export _NIX_FORCE_HTTP_BINARY_CACHE_STORE=1 +basicTests + + +# Test whether Nix notices if the NAR doesn't match the hash in the NAR info. +clearStore + +nar=$(ls $cacheDir/nar/*.nar.xz | head -n1) +mv $nar $nar.good +mkdir -p $TEST_ROOT/empty +nix-store --dump $TEST_ROOT/empty | xz > $nar + +nix-build --substituters "file://$cacheDir" --no-require-sigs dependencies.nix -o $TEST_ROOT/result 2>&1 | tee $TEST_ROOT/log +grep -q "hash mismatch" $TEST_ROOT/log + +mv $nar.good $nar + + +# Test whether this unsigned cache is rejected if the user requires signed caches. +clearStore +clearCacheCache + +if nix-store --substituters "file://$cacheDir" -r $outPath; then + echo "unsigned binary cache incorrectly accepted" + exit 1 +fi + + +# Test whether fallback works if a NAR has disappeared. This does not require --fallback. +clearStore + +mv $cacheDir/nar $cacheDir/nar2 + +nix-build --substituters "file://$cacheDir" --no-require-sigs dependencies.nix -o $TEST_ROOT/result + +mv $cacheDir/nar2 $cacheDir/nar + + +# Test whether fallback works if a NAR is corrupted. This does require --fallback. +clearStore + +mv $cacheDir/nar $cacheDir/nar2 +mkdir $cacheDir/nar +for i in $(cd $cacheDir/nar2 && echo *); do touch $cacheDir/nar/$i; done + +(! nix-build --substituters "file://$cacheDir" --no-require-sigs dependencies.nix -o $TEST_ROOT/result) + +nix-build --substituters "file://$cacheDir" --no-require-sigs dependencies.nix -o $TEST_ROOT/result --fallback + +rm -rf $cacheDir/nar +mv $cacheDir/nar2 $cacheDir/nar + + +# Test whether building works if the binary cache contains an +# incomplete closure. +clearStore + +rm $(grep -l "StorePath:.*dependencies-input-2" $cacheDir/*.narinfo) + +nix-build --substituters "file://$cacheDir" --no-require-sigs dependencies.nix -o $TEST_ROOT/result 2>&1 | tee $TEST_ROOT/log +grep -q "copying path" $TEST_ROOT/log + + +if [ -n "$HAVE_SODIUM" ]; then + +# Create a signed binary cache. +clearCache +clearCacheCache + +declare -a res=($(nix-store --generate-binary-cache-key test.nixos.org-1 $TEST_ROOT/sk1 $TEST_ROOT/pk1 )) +publicKey="$(cat $TEST_ROOT/pk1)" + +res=($(nix-store --generate-binary-cache-key test.nixos.org-1 $TEST_ROOT/sk2 $TEST_ROOT/pk2)) +badKey="$(cat $TEST_ROOT/pk2)" + +res=($(nix-store --generate-binary-cache-key foo.nixos.org-1 $TEST_ROOT/sk3 $TEST_ROOT/pk3)) +otherKey="$(cat $TEST_ROOT/pk3)" + +_NIX_FORCE_HTTP_BINARY_CACHE_STORE= nix copy --to file://$cacheDir?secret-key=$TEST_ROOT/sk1 $outPath + + +# Downloading should fail if we don't provide a key. +clearStore +clearCacheCache + +(! nix-store -r $outPath --substituters "file://$cacheDir") + + +# And it should fail if we provide an incorrect key. +clearStore +clearCacheCache + +(! nix-store -r $outPath --substituters "file://$cacheDir" --trusted-public-keys "$badKey") + + +# It should succeed if we provide the correct key. +nix-store -r $outPath --substituters "file://$cacheDir" --trusted-public-keys "$otherKey $publicKey" + + +# It should fail if we corrupt the .narinfo. +clearStore + +cacheDir2=$TEST_ROOT/binary-cache-2 +rm -rf $cacheDir2 +cp -r $cacheDir $cacheDir2 + +for i in $cacheDir2/*.narinfo; do + grep -v References $i > $i.tmp + mv $i.tmp $i +done + +clearCacheCache + +(! nix-store -r $outPath --substituters "file://$cacheDir2" --trusted-public-keys "$publicKey") + +# If we provide a bad and a good binary cache, it should succeed. + +nix-store -r $outPath --substituters "file://$cacheDir2 file://$cacheDir" --trusted-public-keys "$publicKey" + +fi # HAVE_LIBSODIUM diff --git a/third_party/nix/tests/brotli.sh b/third_party/nix/tests/brotli.sh new file mode 100644 index 0000000000..a3c6e55a8f --- /dev/null +++ b/third_party/nix/tests/brotli.sh @@ -0,0 +1,21 @@ +source common.sh + +clearStore +clearCache + +cacheURI="file://$cacheDir?compression=br" + +outPath=$(nix-build dependencies.nix --no-out-link) + +nix copy --to $cacheURI $outPath + +HASH=$(nix hash-path $outPath) + +clearStore +clearCacheCache + +nix copy --from $cacheURI $outPath --no-check-sigs + +HASH2=$(nix hash-path $outPath) + +[[ $HASH = $HASH2 ]] diff --git a/third_party/nix/tests/build-dry.sh b/third_party/nix/tests/build-dry.sh new file mode 100644 index 0000000000..e72533e706 --- /dev/null +++ b/third_party/nix/tests/build-dry.sh @@ -0,0 +1,52 @@ +source common.sh + +################################################### +# Check that --dry-run isn't confused with read-only mode +# https://github.com/NixOS/nix/issues/1795 + +clearStore +clearCache + +# Ensure this builds successfully first +nix build --no-link -f dependencies.nix + +clearStore +clearCache + +# Try --dry-run using old command first +nix-build --no-out-link dependencies.nix --dry-run 2>&1 | grep "will be built" +# Now new command: +nix build -f dependencies.nix --dry-run 2>&1 | grep "will be built" + +# TODO: XXX: FIXME: #1793 +# Disable this part of the test until the problem is resolved: +if [ -n "$ISSUE_1795_IS_FIXED" ]; then +clearStore +clearCache + +# Try --dry-run using new command first +nix build -f dependencies.nix --dry-run 2>&1 | grep "will be built" +# Now old command: +nix-build --no-out-link dependencies.nix --dry-run 2>&1 | grep "will be built" +fi + +################################################### +# Check --dry-run doesn't create links with --dry-run +# https://github.com/NixOS/nix/issues/1849 +clearStore +clearCache + +RESULT=$TEST_ROOT/result-link +rm -f $RESULT + +nix-build dependencies.nix -o $RESULT --dry-run + +[[ ! -h $RESULT ]] || fail "nix-build --dry-run created output link" + +nix build -f dependencies.nix -o $RESULT --dry-run + +[[ ! -h $RESULT ]] || fail "nix build --dry-run created output link" + +nix build -f dependencies.nix -o $RESULT + +[[ -h $RESULT ]] diff --git a/third_party/nix/tests/build-hook.nix b/third_party/nix/tests/build-hook.nix new file mode 100644 index 0000000000..8bff0fe790 --- /dev/null +++ b/third_party/nix/tests/build-hook.nix @@ -0,0 +1,23 @@ +with import ./config.nix; + +let + + input1 = mkDerivation { + name = "build-hook-input-1"; + builder = ./dependencies.builder1.sh; + requiredSystemFeatures = ["foo"]; + }; + + input2 = mkDerivation { + name = "build-hook-input-2"; + builder = ./dependencies.builder2.sh; + }; + +in + + mkDerivation { + name = "build-hook"; + builder = ./dependencies.builder0.sh; + input1 = " " + input1 + "/."; + input2 = " ${input2}/."; + } diff --git a/third_party/nix/tests/build-remote.sh b/third_party/nix/tests/build-remote.sh new file mode 100644 index 0000000000..ddd68f327a --- /dev/null +++ b/third_party/nix/tests/build-remote.sh @@ -0,0 +1,24 @@ +source common.sh + +clearStore + +if ! canUseSandbox; then exit; fi +if [[ ! $SHELL =~ /nix/store ]]; then exit; fi + +chmod -R u+w $TEST_ROOT/store0 || true +chmod -R u+w $TEST_ROOT/store1 || true +rm -rf $TEST_ROOT/store0 $TEST_ROOT/store1 + +nix build -f build-hook.nix -o $TEST_ROOT/result --max-jobs 0 \ + --sandbox-paths /nix/store --sandbox-build-dir /build-tmp \ + --builders "$TEST_ROOT/store0; $TEST_ROOT/store1 - - 1 1 foo" \ + --system-features foo + +outPath=$TEST_ROOT/result + +cat $outPath/foobar | grep FOOBAR + +# Ensure that input1 was built on store1 due to the required feature. +p=$(readlink -f $outPath/input-2) +(! nix path-info --store $TEST_ROOT/store0 --all | grep dependencies.builder1.sh) +nix path-info --store $TEST_ROOT/store1 --all | grep dependencies.builder1.sh diff --git a/third_party/nix/tests/case-hack.sh b/third_party/nix/tests/case-hack.sh new file mode 100644 index 0000000000..61bf9b94bf --- /dev/null +++ b/third_party/nix/tests/case-hack.sh @@ -0,0 +1,19 @@ +source common.sh + +clearStore + +rm -rf $TEST_ROOT/case + +opts="--option use-case-hack true" + +# Check whether restoring and dumping a NAR that contains case +# collisions is round-tripping, even on a case-insensitive system. +nix-store $opts --restore $TEST_ROOT/case < case.nar +nix-store $opts --dump $TEST_ROOT/case > $TEST_ROOT/case.nar +cmp case.nar $TEST_ROOT/case.nar +[ "$(nix-hash $opts --type sha256 $TEST_ROOT/case)" = "$(nix-hash --flat --type sha256 case.nar)" ] + +# Check whether we detect true collisions (e.g. those remaining after +# removal of the suffix). +touch "$TEST_ROOT/case/xt_CONNMARK.h~nix~case~hack~3" +(! nix-store $opts --dump $TEST_ROOT/case > /dev/null) diff --git a/third_party/nix/tests/case.nar b/third_party/nix/tests/case.nar new file mode 100644 index 0000000000..22ff26db5a --- /dev/null +++ b/third_party/nix/tests/case.nar Binary files differdiff --git a/third_party/nix/tests/check-refs.nix b/third_party/nix/tests/check-refs.nix new file mode 100644 index 0000000000..9d90b09205 --- /dev/null +++ b/third_party/nix/tests/check-refs.nix @@ -0,0 +1,70 @@ +with import ./config.nix; + +rec { + + dep = import ./dependencies.nix; + + makeTest = nr: args: mkDerivation ({ + name = "check-refs-" + toString nr; + } // args); + + src = builtins.toFile "aux-ref" "bla bla"; + + test1 = makeTest 1 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $dep $out/link"; + inherit dep; + }; + + test2 = makeTest 2 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s ${src} $out/link"; + inherit dep; + }; + + test3 = makeTest 3 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $dep $out/link"; + allowedReferences = []; + inherit dep; + }; + + test4 = makeTest 4 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $dep $out/link"; + allowedReferences = [dep]; + inherit dep; + }; + + test5 = makeTest 5 { + builder = builtins.toFile "builder.sh" "mkdir $out"; + allowedReferences = []; + inherit dep; + }; + + test6 = makeTest 6 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $out $out/link"; + allowedReferences = []; + inherit dep; + }; + + test7 = makeTest 7 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $out $out/link"; + allowedReferences = ["out"]; + inherit dep; + }; + + test8 = makeTest 8 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s ${test1} $out/link"; + inherit dep; + }; + + test9 = makeTest 9 { + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $dep $out/link"; + inherit dep; + disallowedReferences = [dep]; + }; + + test10 = makeTest 10 { + builder = builtins.toFile "builder.sh" "mkdir $out; echo $test5; ln -s $dep $out/link"; + inherit dep test5; + disallowedReferences = [test5]; + }; + +} diff --git a/third_party/nix/tests/check-refs.sh b/third_party/nix/tests/check-refs.sh new file mode 100644 index 0000000000..16bbabc409 --- /dev/null +++ b/third_party/nix/tests/check-refs.sh @@ -0,0 +1,42 @@ +source common.sh + +clearStore + +RESULT=$TEST_ROOT/result + +dep=$(nix-build -o $RESULT check-refs.nix -A dep) + +# test1 references dep, not itself. +test1=$(nix-build -o $RESULT check-refs.nix -A test1) +(! nix-store -q --references $test1 | grep -q $test1) +nix-store -q --references $test1 | grep -q $dep + +# test2 references src, not itself nor dep. +test2=$(nix-build -o $RESULT check-refs.nix -A test2) +(! nix-store -q --references $test2 | grep -q $test2) +(! nix-store -q --references $test2 | grep -q $dep) +nix-store -q --references $test2 | grep -q aux-ref + +# test3 should fail (unallowed ref). +(! nix-build -o $RESULT check-refs.nix -A test3) + +# test4 should succeed. +nix-build -o $RESULT check-refs.nix -A test4 + +# test5 should succeed. +nix-build -o $RESULT check-refs.nix -A test5 + +# test6 should fail (unallowed self-ref). +(! nix-build -o $RESULT check-refs.nix -A test6) + +# test7 should succeed (allowed self-ref). +nix-build -o $RESULT check-refs.nix -A test7 + +# test8 should fail (toFile depending on derivation output). +(! nix-build -o $RESULT check-refs.nix -A test8) + +# test9 should fail (disallowed reference). +(! nix-build -o $RESULT check-refs.nix -A test9) + +# test10 should succeed (no disallowed references). +nix-build -o $RESULT check-refs.nix -A test10 diff --git a/third_party/nix/tests/check-reqs.nix b/third_party/nix/tests/check-reqs.nix new file mode 100644 index 0000000000..41436cb48e --- /dev/null +++ b/third_party/nix/tests/check-reqs.nix @@ -0,0 +1,57 @@ +with import ./config.nix; + +rec { + dep1 = mkDerivation { + name = "check-reqs-dep1"; + builder = builtins.toFile "builder.sh" "mkdir $out; touch $out/file1"; + }; + + dep2 = mkDerivation { + name = "check-reqs-dep2"; + builder = builtins.toFile "builder.sh" "mkdir $out; touch $out/file2"; + }; + + deps = mkDerivation { + name = "check-reqs-deps"; + dep1 = dep1; + dep2 = dep2; + builder = builtins.toFile "builder.sh" '' + mkdir $out + ln -s $dep1/file1 $out/file1 + ln -s $dep2/file2 $out/file2 + ''; + }; + + makeTest = nr: allowreqs: mkDerivation { + name = "check-reqs-" + toString nr; + inherit deps; + builder = builtins.toFile "builder.sh" '' + mkdir $out + ln -s $deps $out/depdir1 + ''; + allowedRequisites = allowreqs; + }; + + # When specifying all the requisites, the build succeeds. + test1 = makeTest 1 [ dep1 dep2 deps ]; + + # But missing anything it fails. + test2 = makeTest 2 [ dep2 deps ]; + test3 = makeTest 3 [ dep1 deps ]; + test4 = makeTest 4 [ deps ]; + test5 = makeTest 5 []; + + test6 = mkDerivation { + name = "check-reqs"; + inherit deps; + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $deps $out/depdir1"; + disallowedRequisites = [dep1]; + }; + + test7 = mkDerivation { + name = "check-reqs"; + inherit deps; + builder = builtins.toFile "builder.sh" "mkdir $out; ln -s $deps $out/depdir1"; + disallowedRequisites = [test1]; + }; +} diff --git a/third_party/nix/tests/check-reqs.sh b/third_party/nix/tests/check-reqs.sh new file mode 100644 index 0000000000..e9f65fc2a6 --- /dev/null +++ b/third_party/nix/tests/check-reqs.sh @@ -0,0 +1,16 @@ +source common.sh + +clearStore + +RESULT=$TEST_ROOT/result + +nix-build -o $RESULT check-reqs.nix -A test1 + +(! nix-build -o $RESULT check-reqs.nix -A test2) +(! nix-build -o $RESULT check-reqs.nix -A test3) +(! nix-build -o $RESULT check-reqs.nix -A test4) 2>&1 | grep -q 'check-reqs-dep1' +(! nix-build -o $RESULT check-reqs.nix -A test4) 2>&1 | grep -q 'check-reqs-dep2' +(! nix-build -o $RESULT check-reqs.nix -A test5) +(! nix-build -o $RESULT check-reqs.nix -A test6) + +nix-build -o $RESULT check-reqs.nix -A test7 diff --git a/third_party/nix/tests/check.nix b/third_party/nix/tests/check.nix new file mode 100644 index 0000000000..56c82e565a --- /dev/null +++ b/third_party/nix/tests/check.nix @@ -0,0 +1,22 @@ +with import ./config.nix; + +{ + nondeterministic = mkDerivation { + name = "nondeterministic"; + buildCommand = + '' + mkdir $out + date +%s.%N > $out/date + ''; + }; + + hashmismatch = import <nix/fetchurl.nix> { + url = "file://" + toString ./dummy; + sha256 = "0mdqa9w1p6cmli6976v4wi0sw9r4p5prkj7lzfd1877wk11c9c73"; + }; + + fetchurl = import <nix/fetchurl.nix> { + url = "file://" + toString ./lang/eval-okay-xml.exp.xml; + sha256 = "0kg4sla7ihm8ijr8cb3117fhl99zrc2bwy1jrngsfmkh8bav4m0v"; + }; +} diff --git a/third_party/nix/tests/check.sh b/third_party/nix/tests/check.sh new file mode 100644 index 0000000000..bc23a6634c --- /dev/null +++ b/third_party/nix/tests/check.sh @@ -0,0 +1,47 @@ +source common.sh + +clearStore + +nix-build dependencies.nix --no-out-link +nix-build dependencies.nix --no-out-link --check + +nix-build check.nix -A nondeterministic --no-out-link +nix-build check.nix -A nondeterministic --no-out-link --check 2> $TEST_ROOT/log || status=$? +grep 'may not be deterministic' $TEST_ROOT/log +[ "$status" = "104" ] + +clearStore + +nix-build dependencies.nix --no-out-link --repeat 3 + +nix-build check.nix -A nondeterministic --no-out-link --repeat 1 2> $TEST_ROOT/log || status=$? +[ "$status" = "1" ] +grep 'differs from previous round' $TEST_ROOT/log + +path=$(nix-build check.nix -A fetchurl --no-out-link --hashed-mirrors '') + +chmod +w $path +echo foo > $path +chmod -w $path + +nix-build check.nix -A fetchurl --no-out-link --check --hashed-mirrors '' +# Note: "check" doesn't repair anything, it just compares to the hash stored in the database. +[[ $(cat $path) = foo ]] + +nix-build check.nix -A fetchurl --no-out-link --repair --hashed-mirrors '' +[[ $(cat $path) != foo ]] + +nix-build check.nix -A hashmismatch --no-out-link --hashed-mirrors '' || status=$? +[ "$status" = "102" ] + +echo -n > ./dummy +nix-build check.nix -A hashmismatch --no-out-link --hashed-mirrors '' +echo 'Hello World' > ./dummy + +nix-build check.nix -A hashmismatch --no-out-link --check --hashed-mirrors '' || status=$? +[ "$status" = "102" ] + +# Multiple failures with --keep-going +nix-build check.nix -A nondeterministic --no-out-link +nix-build check.nix -A nondeterministic -A hashmismatch --no-out-link --check --keep-going --hashed-mirrors '' || status=$? +[ "$status" = "110" ] diff --git a/third_party/nix/tests/common.sh.in b/third_party/nix/tests/common.sh.in new file mode 100644 index 0000000000..15d7b1ef91 --- /dev/null +++ b/third_party/nix/tests/common.sh.in @@ -0,0 +1,118 @@ +set -e + +export TEST_ROOT=$(realpath ${TMPDIR:-/tmp}/nix-test) +export NIX_STORE_DIR +if ! NIX_STORE_DIR=$(readlink -f $TEST_ROOT/store 2> /dev/null); then + # Maybe the build directory is symlinked. + export NIX_IGNORE_SYMLINK_STORE=1 + NIX_STORE_DIR=$TEST_ROOT/store +fi +export NIX_LOCALSTATE_DIR=$TEST_ROOT/var +export NIX_LOG_DIR=$TEST_ROOT/var/log/nix +export NIX_STATE_DIR=$TEST_ROOT/var/nix +export NIX_CONF_DIR=$TEST_ROOT/etc +export _NIX_TEST_SHARED=$TEST_ROOT/shared +if [[ -n $NIX_STORE ]]; then + export _NIX_TEST_NO_SANDBOX=1 +fi +export _NIX_IN_TEST=$TEST_ROOT/shared +export _NIX_TEST_NO_LSOF=1 +export NIX_REMOTE=$NIX_REMOTE_ +unset NIX_PATH +export TEST_HOME=$TEST_ROOT/test-home +export HOME=$TEST_HOME +unset XDG_CACHE_HOME +mkdir -p $TEST_HOME + +export PATH=@bindir@:$PATH +coreutils=@coreutils@ + +export dot=@dot@ +export xmllint="@xmllint@" +export SHELL="@bash@" +export PAGER=cat +export HAVE_SODIUM="@HAVE_SODIUM@" + +export version=@PACKAGE_VERSION@ +export system=@system@ + +cacheDir=$TEST_ROOT/binary-cache + +readLink() { + ls -l "$1" | sed 's/.*->\ //' +} + +clearProfiles() { + profiles="$NIX_STATE_DIR"/profiles + rm -rf $profiles +} + +clearStore() { + echo "clearing store..." + chmod -R +w "$NIX_STORE_DIR" + rm -rf "$NIX_STORE_DIR" + mkdir "$NIX_STORE_DIR" + rm -rf "$NIX_STATE_DIR" + mkdir "$NIX_STATE_DIR" + nix-store --init + clearProfiles +} + +clearCache() { + rm -rf "$cacheDir" +} + +clearCacheCache() { + rm -f $TEST_HOME/.cache/nix/binary-cache* +} + +startDaemon() { + # Start the daemon, wait for the socket to appear. !!! + # ‘nix-daemon’ should have an option to fork into the background. + rm -f $NIX_STATE_DIR/daemon-socket/socket + nix-daemon & + for ((i = 0; i < 30; i++)); do + if [ -e $NIX_STATE_DIR/daemon-socket/socket ]; then break; fi + sleep 1 + done + pidDaemon=$! + trap "kill -9 $pidDaemon" EXIT + export NIX_REMOTE=daemon +} + +killDaemon() { + kill -9 $pidDaemon + wait $pidDaemon || true + trap "" EXIT +} + +if [[ $(uname) == Linux ]] && [[ -L /proc/self/ns/user ]] && unshare --user true; then + _canUseSandbox=1 +fi + +canUseSandbox() { + if [[ ! $_canUseSandbox ]]; then + echo "Sandboxing not supported, skipping this test..." + return 1 + fi + + return 0 +} + +fail() { + echo "$1" + exit 1 +} + +expect() { + local expected res + expected="$1" + shift + set +e + "$@" + res="$?" + set -e + [[ $res -eq $expected ]] +} + +set -x diff --git a/third_party/nix/tests/config.nix b/third_party/nix/tests/config.nix new file mode 100644 index 0000000000..6ba91065b8 --- /dev/null +++ b/third_party/nix/tests/config.nix @@ -0,0 +1,20 @@ +with import <nix/config.nix>; + +rec { + inherit shell; + + path = coreutils; + + system = builtins.currentSystem; + + shared = builtins.getEnv "_NIX_TEST_SHARED"; + + mkDerivation = args: + derivation ({ + inherit system; + builder = shell; + args = ["-e" args.builder or (builtins.toFile "builder.sh" "if [ -e .attrs.sh ]; then source .attrs.sh; fi; eval \"$buildCommand\"")]; + PATH = path; + } // removeAttrs args ["builder" "meta"]) + // { meta = args.meta or {}; }; +} diff --git a/third_party/nix/tests/dependencies.builder0.sh b/third_party/nix/tests/dependencies.builder0.sh new file mode 100644 index 0000000000..c37bf909a5 --- /dev/null +++ b/third_party/nix/tests/dependencies.builder0.sh @@ -0,0 +1,16 @@ +[ "${input1: -2}" = /. ] +[ "${input2: -2}" = /. ] + +mkdir $out +echo $(cat $input1/foo)$(cat $input2/bar) > $out/foobar + +ln -s $input2 $out/input-2 + +# Self-reference. +ln -s $out $out/self + +# Executable. +echo program > $out/program +chmod +x $out/program + +echo FOO diff --git a/third_party/nix/tests/dependencies.builder1.sh b/third_party/nix/tests/dependencies.builder1.sh new file mode 100644 index 0000000000..4b006a17d7 --- /dev/null +++ b/third_party/nix/tests/dependencies.builder1.sh @@ -0,0 +1,2 @@ +mkdir $out +echo FOO > $out/foo diff --git a/third_party/nix/tests/dependencies.builder2.sh b/third_party/nix/tests/dependencies.builder2.sh new file mode 100644 index 0000000000..4f886fdb3a --- /dev/null +++ b/third_party/nix/tests/dependencies.builder2.sh @@ -0,0 +1,2 @@ +mkdir $out +echo BAR > $out/bar diff --git a/third_party/nix/tests/dependencies.nix b/third_party/nix/tests/dependencies.nix new file mode 100644 index 0000000000..eca4b2964c --- /dev/null +++ b/third_party/nix/tests/dependencies.nix @@ -0,0 +1,24 @@ +with import ./config.nix; + +let { + + input1 = mkDerivation { + name = "dependencies-input-1"; + builder = ./dependencies.builder1.sh; + }; + + input2 = mkDerivation { + name = "dependencies-input-2"; + builder = "${./dependencies.builder2.sh}"; + }; + + body = mkDerivation { + name = "dependencies"; + builder = ./dependencies.builder0.sh + "/FOOBAR/../."; + input1 = input1 + "/."; + input2 = "${input2}/."; + input1_drv = input1; + meta.description = "Random test package"; + }; + +} diff --git a/third_party/nix/tests/dependencies.sh b/third_party/nix/tests/dependencies.sh new file mode 100644 index 0000000000..df204d185d --- /dev/null +++ b/third_party/nix/tests/dependencies.sh @@ -0,0 +1,52 @@ +source common.sh + +clearStore + +drvPath=$(nix-instantiate dependencies.nix) + +echo "derivation is $drvPath" + +nix-store -q --tree "$drvPath" | grep ' +---.*builder1.sh' + +# Test Graphviz graph generation. +nix-store -q --graph "$drvPath" > $TEST_ROOT/graph +if test -n "$dot"; then + # Does it parse? + $dot < $TEST_ROOT/graph +fi + +outPath=$(nix-store -rvv "$drvPath") || fail "build failed" + +# Test Graphviz graph generation. +nix-store -q --graph "$outPath" > $TEST_ROOT/graph +if test -n "$dot"; then + # Does it parse? + $dot < $TEST_ROOT/graph +fi + +nix-store -q --tree "$outPath" | grep '+---.*dependencies-input-2' + +echo "output path is $outPath" + +text=$(cat "$outPath"/foobar) +if test "$text" != "FOOBAR"; then exit 1; fi + +deps=$(nix-store -quR "$drvPath") + +echo "output closure contains $deps" + +# The output path should be in the closure. +echo "$deps" | grep -q "$outPath" + +# Input-1 is not retained. +if echo "$deps" | grep -q "dependencies-input-1"; then exit 1; fi + +# Input-2 is retained. +input2OutPath=$(echo "$deps" | grep "dependencies-input-2") + +# The referrers closure of input-2 should include outPath. +nix-store -q --referrers-closure "$input2OutPath" | grep "$outPath" + +# Check that the derivers are set properly. +test $(nix-store -q --deriver "$outPath") = "$drvPath" +nix-store -q --deriver "$input2OutPath" | grep -q -- "-input-2.drv" diff --git a/third_party/nix/tests/dump-db.sh b/third_party/nix/tests/dump-db.sh new file mode 100644 index 0000000000..d6eea42aa0 --- /dev/null +++ b/third_party/nix/tests/dump-db.sh @@ -0,0 +1,20 @@ +source common.sh + +clearStore + +path=$(nix-build dependencies.nix -o $TEST_ROOT/result) + +deps="$(nix-store -qR $TEST_ROOT/result)" + +nix-store --dump-db > $TEST_ROOT/dump + +rm -rf $NIX_STATE_DIR/db + +nix-store --load-db < $TEST_ROOT/dump + +deps2="$(nix-store -qR $TEST_ROOT/result)" + +[ "$deps" = "$deps2" ]; + +nix-store --dump-db > $TEST_ROOT/dump2 +cmp $TEST_ROOT/dump $TEST_ROOT/dump2 diff --git a/third_party/nix/tests/export-graph.nix b/third_party/nix/tests/export-graph.nix new file mode 100644 index 0000000000..fdac9583db --- /dev/null +++ b/third_party/nix/tests/export-graph.nix @@ -0,0 +1,29 @@ +with import ./config.nix; + +rec { + + printRefs = + '' + echo $exportReferencesGraph + while read path; do + read drv + read nrRefs + echo "$path has $nrRefs references" + echo "$path" >> $out + for ((n = 0; n < $nrRefs; n++)); do read ref; echo "ref $ref"; test -e "$ref"; done + done < refs + ''; + + foo."bar.runtimeGraph" = mkDerivation { + name = "dependencies"; + builder = builtins.toFile "build-graph-builder" "${printRefs}"; + exportReferencesGraph = ["refs" (import ./dependencies.nix)]; + }; + + foo."bar.buildGraph" = mkDerivation { + name = "dependencies"; + builder = builtins.toFile "build-graph-builder" "${printRefs}"; + exportReferencesGraph = ["refs" (import ./dependencies.nix).drvPath]; + }; + +} diff --git a/third_party/nix/tests/export-graph.sh b/third_party/nix/tests/export-graph.sh new file mode 100644 index 0000000000..a6fd690544 --- /dev/null +++ b/third_party/nix/tests/export-graph.sh @@ -0,0 +1,30 @@ +source common.sh + +clearStore +clearProfiles + +checkRef() { + nix-store -q --references $TEST_ROOT/result | grep -q "$1" || fail "missing reference $1" +} + +# Test the export of the runtime dependency graph. + +outPath=$(nix-build ./export-graph.nix -A 'foo."bar.runtimeGraph"' -o $TEST_ROOT/result) + +test $(nix-store -q --references $TEST_ROOT/result | wc -l) = 2 || fail "bad nr of references" + +checkRef input-2 +for i in $(cat $outPath); do checkRef $i; done + +# Test the export of the build-time dependency graph. + +nix-store --gc # should force rebuild of input-1 + +outPath=$(nix-build ./export-graph.nix -A 'foo."bar.buildGraph"' -o $TEST_ROOT/result) + +checkRef input-1 +checkRef input-1.drv +checkRef input-2 +checkRef input-2.drv + +for i in $(cat $outPath); do checkRef $i; done diff --git a/third_party/nix/tests/export.sh b/third_party/nix/tests/export.sh new file mode 100644 index 0000000000..2238539bcc --- /dev/null +++ b/third_party/nix/tests/export.sh @@ -0,0 +1,36 @@ +source common.sh + +clearStore + +outPath=$(nix-build dependencies.nix --no-out-link) + +nix-store --export $outPath > $TEST_ROOT/exp + +nix-store --export $(nix-store -qR $outPath) > $TEST_ROOT/exp_all + +if nix-store --export $outPath >/dev/full ; then + echo "exporting to a bad file descriptor should fail" + exit 1 +fi + + +clearStore + +if nix-store --import < $TEST_ROOT/exp; then + echo "importing a non-closure should fail" + exit 1 +fi + + +clearStore + +nix-store --import < $TEST_ROOT/exp_all + +nix-store --export $(nix-store -qR $outPath) > $TEST_ROOT/exp_all2 + + +clearStore + +# Regression test: the derivers in exp_all2 are empty, which shouldn't +# cause a failure. +nix-store --import < $TEST_ROOT/exp_all2 diff --git a/third_party/nix/tests/fetchGit.sh b/third_party/nix/tests/fetchGit.sh new file mode 100644 index 0000000000..4c46bdf046 --- /dev/null +++ b/third_party/nix/tests/fetchGit.sh @@ -0,0 +1,141 @@ +source common.sh + +if [[ -z $(type -p git) ]]; then + echo "Git not installed; skipping Git tests" + exit 99 +fi + +clearStore + +repo=$TEST_ROOT/git + +rm -rf $repo ${repo}-tmp $TEST_HOME/.cache/nix/gitv2 + +git init $repo +git -C $repo config user.email "foobar@example.com" +git -C $repo config user.name "Foobar" + +echo utrecht > $repo/hello +touch $repo/.gitignore +git -C $repo add hello .gitignore +git -C $repo commit -m 'Bla1' +rev1=$(git -C $repo rev-parse HEAD) + +echo world > $repo/hello +git -C $repo commit -m 'Bla2' -a +rev2=$(git -C $repo rev-parse HEAD) + +# Fetch the default branch. +path=$(nix eval --raw "(builtins.fetchGit file://$repo).outPath") +[[ $(cat $path/hello) = world ]] + +# In pure eval mode, fetchGit without a revision should fail. +[[ $(nix eval --raw "(builtins.readFile (fetchGit file://$repo + \"/hello\"))") = world ]] +(! nix eval --pure-eval --raw "(builtins.readFile (fetchGit file://$repo + \"/hello\"))") + +# Fetch using an explicit revision hash. +path2=$(nix eval --raw "(builtins.fetchGit { url = file://$repo; rev = \"$rev2\"; }).outPath") +[[ $path = $path2 ]] + +# In pure eval mode, fetchGit with a revision should succeed. +[[ $(nix eval --pure-eval --raw "(builtins.readFile (fetchGit { url = file://$repo; rev = \"$rev2\"; } + \"/hello\"))") = world ]] + +# Fetch again. This should be cached. +mv $repo ${repo}-tmp +path2=$(nix eval --raw "(builtins.fetchGit file://$repo).outPath") +[[ $path = $path2 ]] + +[[ $(nix eval "(builtins.fetchGit file://$repo).revCount") = 2 ]] +[[ $(nix eval --raw "(builtins.fetchGit file://$repo).rev") = $rev2 ]] + +# But with TTL 0, it should fail. +(! nix eval --tarball-ttl 0 "(builtins.fetchGit file://$repo)" -vvvvv) + +# Fetching with a explicit hash should succeed. +path2=$(nix eval --tarball-ttl 0 --raw "(builtins.fetchGit { url = file://$repo; rev = \"$rev2\"; }).outPath") +[[ $path = $path2 ]] + +path2=$(nix eval --tarball-ttl 0 --raw "(builtins.fetchGit { url = file://$repo; rev = \"$rev1\"; }).outPath") +[[ $(cat $path2/hello) = utrecht ]] + +mv ${repo}-tmp $repo + +# Using a clean working tree should produce the same result. +path2=$(nix eval --raw "(builtins.fetchGit $repo).outPath") +[[ $path = $path2 ]] + +# Using an unclean tree should yield the tracked but uncommitted changes. +mkdir $repo/dir1 $repo/dir2 +echo foo > $repo/dir1/foo +echo bar > $repo/bar +echo bar > $repo/dir2/bar +git -C $repo add dir1/foo +git -C $repo rm hello + +path2=$(nix eval --raw "(builtins.fetchGit $repo).outPath") +[ ! -e $path2/hello ] +[ ! -e $path2/bar ] +[ ! -e $path2/dir2/bar ] +[ ! -e $path2/.git ] +[[ $(cat $path2/dir1/foo) = foo ]] + +[[ $(nix eval --raw "(builtins.fetchGit $repo).rev") = 0000000000000000000000000000000000000000 ]] + +# ... unless we're using an explicit ref or rev. +path3=$(nix eval --raw "(builtins.fetchGit { url = $repo; ref = \"master\"; }).outPath") +[[ $path = $path3 ]] + +path3=$(nix eval --raw "(builtins.fetchGit { url = $repo; rev = \"$rev2\"; }).outPath") +[[ $path = $path3 ]] + +# Committing should not affect the store path. +git -C $repo commit -m 'Bla3' -a + +path4=$(nix eval --tarball-ttl 0 --raw "(builtins.fetchGit file://$repo).outPath") +[[ $path2 = $path4 ]] + +# tarball-ttl should be ignored if we specify a rev +echo delft > $repo/hello +git -C $repo add hello +git -C $repo commit -m 'Bla4' +rev3=$(git -C $repo rev-parse HEAD) +nix eval --tarball-ttl 3600 "(builtins.fetchGit { url = $repo; rev = \"$rev3\"; })" >/dev/null + +# Update 'path' to reflect latest master +path=$(nix eval --raw "(builtins.fetchGit file://$repo).outPath") + +# Check behavior when non-master branch is used +git -C $repo checkout $rev2 -b dev +echo dev > $repo/hello + +# File URI uses 'master' unless specified otherwise +path2=$(nix eval --raw "(builtins.fetchGit file://$repo).outPath") +[[ $path = $path2 ]] + +# Using local path with branch other than 'master' should work when clean or dirty +path3=$(nix eval --raw "(builtins.fetchGit $repo).outPath") +# (check dirty-tree handling was used) +[[ $(nix eval --raw "(builtins.fetchGit $repo).rev") = 0000000000000000000000000000000000000000 ]] + +# Committing shouldn't change store path, or switch to using 'master' +git -C $repo commit -m 'Bla5' -a +path4=$(nix eval --raw "(builtins.fetchGit $repo).outPath") +[[ $(cat $path4/hello) = dev ]] +[[ $path3 = $path4 ]] + +# Confirm same as 'dev' branch +path5=$(nix eval --raw "(builtins.fetchGit { url = $repo; ref = \"dev\"; }).outPath") +[[ $path3 = $path5 ]] + + +# Nuke the cache +rm -rf $TEST_HOME/.cache/nix/gitv2 + +# Try again, but without 'git' on PATH +NIX=$(command -v nix) +# This should fail +(! PATH= $NIX eval --raw "(builtins.fetchGit { url = $repo; ref = \"dev\"; }).outPath" ) + +# Try again, with 'git' available. This should work. +path5=$(nix eval --raw "(builtins.fetchGit { url = $repo; ref = \"dev\"; }).outPath") +[[ $path3 = $path5 ]] diff --git a/third_party/nix/tests/fetchMercurial.sh b/third_party/nix/tests/fetchMercurial.sh new file mode 100644 index 0000000000..4088dbd397 --- /dev/null +++ b/third_party/nix/tests/fetchMercurial.sh @@ -0,0 +1,93 @@ +source common.sh + +if [[ -z $(type -p hg) ]]; then + echo "Mercurial not installed; skipping Mercurial tests" + exit 99 +fi + +clearStore + +repo=$TEST_ROOT/hg + +rm -rf $repo ${repo}-tmp $TEST_HOME/.cache/nix/hg + +hg init $repo +echo '[ui]' >> $repo/.hg/hgrc +echo 'username = Foobar <foobar@example.org>' >> $repo/.hg/hgrc + +echo utrecht > $repo/hello +touch $repo/.hgignore +hg add --cwd $repo hello .hgignore +hg commit --cwd $repo -m 'Bla1' +rev1=$(hg log --cwd $repo -r tip --template '{node}') + +echo world > $repo/hello +hg commit --cwd $repo -m 'Bla2' +rev2=$(hg log --cwd $repo -r tip --template '{node}') + +# Fetch the default branch. +path=$(nix eval --raw "(builtins.fetchMercurial file://$repo).outPath") +[[ $(cat $path/hello) = world ]] + +# In pure eval mode, fetchGit without a revision should fail. +[[ $(nix eval --raw "(builtins.readFile (fetchMercurial file://$repo + \"/hello\"))") = world ]] +(! nix eval --pure-eval --raw "(builtins.readFile (fetchMercurial file://$repo + \"/hello\"))") + +# Fetch using an explicit revision hash. +path2=$(nix eval --raw "(builtins.fetchMercurial { url = file://$repo; rev = \"$rev2\"; }).outPath") +[[ $path = $path2 ]] + +# In pure eval mode, fetchGit with a revision should succeed. +[[ $(nix eval --pure-eval --raw "(builtins.readFile (fetchMercurial { url = file://$repo; rev = \"$rev2\"; } + \"/hello\"))") = world ]] + +# Fetch again. This should be cached. +mv $repo ${repo}-tmp +path2=$(nix eval --raw "(builtins.fetchMercurial file://$repo).outPath") +[[ $path = $path2 ]] + +[[ $(nix eval --raw "(builtins.fetchMercurial file://$repo).branch") = default ]] +[[ $(nix eval "(builtins.fetchMercurial file://$repo).revCount") = 1 ]] +[[ $(nix eval --raw "(builtins.fetchMercurial file://$repo).rev") = $rev2 ]] + +# But with TTL 0, it should fail. +(! nix eval --tarball-ttl 0 "(builtins.fetchMercurial file://$repo)") + +# Fetching with a explicit hash should succeed. +path2=$(nix eval --tarball-ttl 0 --raw "(builtins.fetchMercurial { url = file://$repo; rev = \"$rev2\"; }).outPath") +[[ $path = $path2 ]] + +path2=$(nix eval --tarball-ttl 0 --raw "(builtins.fetchMercurial { url = file://$repo; rev = \"$rev1\"; }).outPath") +[[ $(cat $path2/hello) = utrecht ]] + +mv ${repo}-tmp $repo + +# Using a clean working tree should produce the same result. +path2=$(nix eval --raw "(builtins.fetchMercurial $repo).outPath") +[[ $path = $path2 ]] + +# Using an unclean tree should yield the tracked but uncommitted changes. +mkdir $repo/dir1 $repo/dir2 +echo foo > $repo/dir1/foo +echo bar > $repo/bar +echo bar > $repo/dir2/bar +hg add --cwd $repo dir1/foo +hg rm --cwd $repo hello + +path2=$(nix eval --raw "(builtins.fetchMercurial $repo).outPath") +[ ! -e $path2/hello ] +[ ! -e $path2/bar ] +[ ! -e $path2/dir2/bar ] +[ ! -e $path2/.hg ] +[[ $(cat $path2/dir1/foo) = foo ]] + +[[ $(nix eval --raw "(builtins.fetchMercurial $repo).rev") = 0000000000000000000000000000000000000000 ]] + +# ... unless we're using an explicit rev. +path3=$(nix eval --raw "(builtins.fetchMercurial { url = $repo; rev = \"default\"; }).outPath") +[[ $path = $path3 ]] + +# Committing should not affect the store path. +hg commit --cwd $repo -m 'Bla3' + +path4=$(nix eval --tarball-ttl 0 --raw "(builtins.fetchMercurial file://$repo).outPath") +[[ $path2 = $path4 ]] diff --git a/third_party/nix/tests/fetchurl.sh b/third_party/nix/tests/fetchurl.sh new file mode 100644 index 0000000000..7319ced2b5 --- /dev/null +++ b/third_party/nix/tests/fetchurl.sh @@ -0,0 +1,78 @@ +source common.sh + +clearStore + +# Test fetching a flat file. +hash=$(nix-hash --flat --type sha256 ./fetchurl.sh) + +outPath=$(nix-build '<nix/fetchurl.nix>' --argstr url file://$(pwd)/fetchurl.sh --argstr sha256 $hash --no-out-link --hashed-mirrors '') + +cmp $outPath fetchurl.sh + +# Now using a base-64 hash. +clearStore + +hash=$(nix hash-file --type sha512 --base64 ./fetchurl.sh) + +outPath=$(nix-build '<nix/fetchurl.nix>' --argstr url file://$(pwd)/fetchurl.sh --argstr sha512 $hash --no-out-link --hashed-mirrors '') + +cmp $outPath fetchurl.sh + +# Now using an SRI hash. +clearStore + +hash=$(nix hash-file ./fetchurl.sh) + +[[ $hash =~ ^sha256- ]] + +outPath=$(nix-build '<nix/fetchurl.nix>' --argstr url file://$(pwd)/fetchurl.sh --argstr hash $hash --no-out-link --hashed-mirrors '') + +cmp $outPath fetchurl.sh + +# Test the hashed mirror feature. +clearStore + +hash=$(nix hash-file --type sha512 --base64 ./fetchurl.sh) +hash32=$(nix hash-file --type sha512 --base16 ./fetchurl.sh) + +mirror=$TMPDIR/hashed-mirror +rm -rf $mirror +mkdir -p $mirror/sha512 +ln -s $(pwd)/fetchurl.sh $mirror/sha512/$hash32 + +outPath=$(nix-build '<nix/fetchurl.nix>' --argstr url file:///no-such-dir/fetchurl.sh --argstr sha512 $hash --no-out-link --hashed-mirrors "file://$mirror") + +# Test hashed mirrors with an SRI hash. +nix-build '<nix/fetchurl.nix>' --argstr url file:///no-such-dir/fetchurl.sh --argstr hash $(nix to-sri --type sha512 $hash) \ + --argstr name bla --no-out-link --hashed-mirrors "file://$mirror" + +# Test unpacking a NAR. +rm -rf $TEST_ROOT/archive +mkdir -p $TEST_ROOT/archive +cp ./fetchurl.sh $TEST_ROOT/archive +chmod +x $TEST_ROOT/archive/fetchurl.sh +ln -s foo $TEST_ROOT/archive/symlink +nar=$TEST_ROOT/archive.nar +nix-store --dump $TEST_ROOT/archive > $nar + +hash=$(nix-hash --flat --type sha256 $nar) + +outPath=$(nix-build '<nix/fetchurl.nix>' --argstr url file://$nar --argstr sha256 $hash \ + --arg unpack true --argstr name xyzzy --no-out-link) + +echo $outPath | grep -q 'xyzzy' + +test -x $outPath/fetchurl.sh +test -L $outPath/symlink + +nix-store --delete $outPath + +# Test unpacking a compressed NAR. +narxz=$TEST_ROOT/archive.nar.xz +rm -f $narxz +xz --keep $nar +outPath=$(nix-build '<nix/fetchurl.nix>' --argstr url file://$narxz --argstr sha256 $hash \ + --arg unpack true --argstr name xyzzy --no-out-link) + +test -x $outPath/fetchurl.sh +test -L $outPath/symlink diff --git a/third_party/nix/tests/filter-source.nix b/third_party/nix/tests/filter-source.nix new file mode 100644 index 0000000000..9071636394 --- /dev/null +++ b/third_party/nix/tests/filter-source.nix @@ -0,0 +1,12 @@ +with import ./config.nix; + +mkDerivation { + name = "filter"; + builder = builtins.toFile "builder" "ln -s $input $out"; + input = + let filter = path: type: + type != "symlink" + && baseNameOf path != "foo" + && !((import ./lang/lib.nix).hasSuffix ".bak" (baseNameOf path)); + in builtins.filterSource filter ((builtins.getEnv "TEST_ROOT") + "/filterin"); +} diff --git a/third_party/nix/tests/filter-source.sh b/third_party/nix/tests/filter-source.sh new file mode 100644 index 0000000000..1f8dceee57 --- /dev/null +++ b/third_party/nix/tests/filter-source.sh @@ -0,0 +1,19 @@ +source common.sh + +rm -rf $TEST_ROOT/filterin +mkdir $TEST_ROOT/filterin +mkdir $TEST_ROOT/filterin/foo +touch $TEST_ROOT/filterin/foo/bar +touch $TEST_ROOT/filterin/xyzzy +touch $TEST_ROOT/filterin/b +touch $TEST_ROOT/filterin/bak +touch $TEST_ROOT/filterin/bla.c.bak +ln -s xyzzy $TEST_ROOT/filterin/link + +nix-build ./filter-source.nix -o $TEST_ROOT/filterout + +test ! -e $TEST_ROOT/filterout/foo/bar +test -e $TEST_ROOT/filterout/xyzzy +test -e $TEST_ROOT/filterout/bak +test ! -e $TEST_ROOT/filterout/bla.c.bak +test ! -L $TEST_ROOT/filterout/link diff --git a/third_party/nix/tests/fixed.builder1.sh b/third_party/nix/tests/fixed.builder1.sh new file mode 100644 index 0000000000..c41bb2b9a6 --- /dev/null +++ b/third_party/nix/tests/fixed.builder1.sh @@ -0,0 +1,3 @@ +if test "$IMPURE_VAR1" != "foo"; then exit 1; fi +if test "$IMPURE_VAR2" != "bar"; then exit 1; fi +echo "Hello World!" > $out diff --git a/third_party/nix/tests/fixed.builder2.sh b/third_party/nix/tests/fixed.builder2.sh new file mode 100644 index 0000000000..31ea1579a5 --- /dev/null +++ b/third_party/nix/tests/fixed.builder2.sh @@ -0,0 +1,6 @@ +echo dummy: $dummy +if test -n "$dummy"; then sleep 2; fi +mkdir $out +mkdir $out/bla +echo "Hello World!" > $out/foo +ln -s foo $out/bar diff --git a/third_party/nix/tests/fixed.nix b/third_party/nix/tests/fixed.nix new file mode 100644 index 0000000000..76580ffa19 --- /dev/null +++ b/third_party/nix/tests/fixed.nix @@ -0,0 +1,50 @@ +with import ./config.nix; + +rec { + + f2 = dummy: builder: mode: algo: hash: mkDerivation { + name = "fixed"; + inherit builder; + outputHashMode = mode; + outputHashAlgo = algo; + outputHash = hash; + inherit dummy; + impureEnvVars = ["IMPURE_VAR1" "IMPURE_VAR2"]; + }; + + f = f2 ""; + + good = [ + (f ./fixed.builder1.sh "flat" "md5" "8ddd8be4b179a529afa5f2ffae4b9858") + (f ./fixed.builder1.sh "flat" "sha1" "a0b65939670bc2c010f4d5d6a0b3e4e4590fb92b") + (f ./fixed.builder2.sh "recursive" "md5" "3670af73070fa14077ad74e0f5ea4e42") + (f ./fixed.builder2.sh "recursive" "sha1" "vw46m23bizj4n8afrc0fj19wrp7mj3c0") + ]; + + good2 = [ + # Yes, this looks fscked up: builder2 doesn't have that result. + # But Nix sees that an output with the desired hash already + # exists, and will refrain from building it. + (f ./fixed.builder2.sh "flat" "md5" "8ddd8be4b179a529afa5f2ffae4b9858") + ]; + + sameAsAdd = + f ./fixed.builder2.sh "recursive" "sha256" "1ixr6yd3297ciyp9im522dfxpqbkhcw0pylkb2aab915278fqaik"; + + bad = [ + (f ./fixed.builder1.sh "flat" "md5" "0ddd8be4b179a529afa5f2ffae4b9858") + ]; + + reallyBad = [ + # Hash too short, and not base-32 either. + (f ./fixed.builder1.sh "flat" "md5" "ddd8be4b179a529afa5f2ffae4b9858") + ]; + + # Test for building two derivations in parallel that produce the + # same output path because they're fixed-output derivations. + parallelSame = [ + (f2 "foo" ./fixed.builder2.sh "recursive" "md5" "3670af73070fa14077ad74e0f5ea4e42") + (f2 "bar" ./fixed.builder2.sh "recursive" "md5" "3670af73070fa14077ad74e0f5ea4e42") + ]; + +} diff --git a/third_party/nix/tests/fixed.sh b/third_party/nix/tests/fixed.sh new file mode 100644 index 0000000000..8f51403a70 --- /dev/null +++ b/third_party/nix/tests/fixed.sh @@ -0,0 +1,56 @@ +source common.sh + +clearStore + +export IMPURE_VAR1=foo +export IMPURE_VAR2=bar + +path=$(nix-store -q $(nix-instantiate fixed.nix -A good.0)) + +echo 'testing bad...' +nix-build fixed.nix -A bad --no-out-link && fail "should fail" + +# Building with the bad hash should produce the "good" output path as +# a side-effect. +[[ -e $path ]] +nix path-info --json $path | grep fixed:md5:2qk15sxzzjlnpjk9brn7j8ppcd + +echo 'testing good...' +nix-build fixed.nix -A good --no-out-link + +echo 'testing good2...' +nix-build fixed.nix -A good2 --no-out-link + +echo 'testing reallyBad...' +nix-instantiate fixed.nix -A reallyBad && fail "should fail" + +# While we're at it, check attribute selection a bit more. +echo 'testing attribute selection...' +test $(nix-instantiate fixed.nix -A good.1 | wc -l) = 1 + +# Test parallel builds of derivations that produce the same output. +# Only one should run at the same time. +echo 'testing parallelSame...' +clearStore +nix-build fixed.nix -A parallelSame --no-out-link -j2 + +# Fixed-output derivations with a recursive SHA-256 hash should +# produce the same path as "nix-store --add". +echo 'testing sameAsAdd...' +out=$(nix-build fixed.nix -A sameAsAdd --no-out-link) + +# This is what fixed.builder2 produces... +rm -rf $TEST_ROOT/fixed +mkdir $TEST_ROOT/fixed +mkdir $TEST_ROOT/fixed/bla +echo "Hello World!" > $TEST_ROOT/fixed/foo +ln -s foo $TEST_ROOT/fixed/bar + +out2=$(nix-store --add $TEST_ROOT/fixed) +[ "$out" = "$out2" ] + +out3=$(nix-store --add-fixed --recursive sha256 $TEST_ROOT/fixed) +[ "$out" = "$out3" ] + +out4=$(nix-store --print-fixed-path --recursive sha256 "1ixr6yd3297ciyp9im522dfxpqbkhcw0pylkb2aab915278fqaik" fixed) +[ "$out" = "$out4" ] diff --git a/third_party/nix/tests/function-trace.sh b/third_party/nix/tests/function-trace.sh new file mode 100755 index 0000000000..182a4d5c28 --- /dev/null +++ b/third_party/nix/tests/function-trace.sh @@ -0,0 +1,85 @@ +source common.sh + +set +x + +expect_trace() { + expr="$1" + expect="$2" + actual=$( + nix-instantiate \ + --trace-function-calls \ + --expr "$expr" 2>&1 \ + | grep "function-trace" \ + | sed -e 's/ [0-9]*$//' + ); + + echo -n "Tracing expression '$expr'" + set +e + msg=$(diff -swB \ + <(echo "$expect") \ + <(echo "$actual") + ); + result=$? + set -e + if [ $result -eq 0 ]; then + echo " ok." + else + echo " failed. difference:" + echo "$msg" + return $result + fi +} + +# failure inside a tryEval +expect_trace 'builtins.tryEval (throw "example")' " +function-trace entered undefined position at +function-trace exited undefined position at +function-trace entered (string):1:1 at +function-trace entered (string):1:19 at +function-trace exited (string):1:19 at +function-trace exited (string):1:1 at +" + +# Missing argument to a formal function +expect_trace '({ x }: x) { }' " +function-trace entered undefined position at +function-trace exited undefined position at +function-trace entered (string):1:1 at +function-trace exited (string):1:1 at +" + +# Too many arguments to a formal function +expect_trace '({ x }: x) { x = "x"; y = "y"; }' " +function-trace entered undefined position at +function-trace exited undefined position at +function-trace entered (string):1:1 at +function-trace exited (string):1:1 at +" + +# Not enough arguments to a lambda +expect_trace '(x: y: x + y) 1' " +function-trace entered undefined position at +function-trace exited undefined position at +function-trace entered (string):1:1 at +function-trace exited (string):1:1 at +" + +# Too many arguments to a lambda +expect_trace '(x: x) 1 2' " +function-trace entered undefined position at +function-trace exited undefined position at +function-trace entered (string):1:1 at +function-trace exited (string):1:1 at +function-trace entered (string):1:1 at +function-trace exited (string):1:1 at +" + +# Not a function +expect_trace '1 2' " +function-trace entered undefined position at +function-trace exited undefined position at +function-trace entered (string):1:1 at +function-trace exited (string):1:1 at +" + +set -e diff --git a/third_party/nix/tests/gc-auto.sh b/third_party/nix/tests/gc-auto.sh new file mode 100644 index 0000000000..de1e2cfe40 --- /dev/null +++ b/third_party/nix/tests/gc-auto.sh @@ -0,0 +1,70 @@ +source common.sh + +clearStore + +garbage1=$(nix add-to-store --name garbage1 ./nar-access.sh) +garbage2=$(nix add-to-store --name garbage2 ./nar-access.sh) +garbage3=$(nix add-to-store --name garbage3 ./nar-access.sh) + +ls -l $garbage3 +POSIXLY_CORRECT=1 du $garbage3 + +fake_free=$TEST_ROOT/fake-free +export _NIX_TEST_FREE_SPACE_FILE=$fake_free +echo 1100 > $fake_free + +expr=$(cat <<EOF +with import ./config.nix; mkDerivation { + name = "gc-A"; + buildCommand = '' + set -x + [[ \$(ls \$NIX_STORE/*-garbage? | wc -l) = 3 ]] + mkdir \$out + echo foo > \$out/bar + echo 1... + sleep 2 + echo 200 > ${fake_free}.tmp1 + mv ${fake_free}.tmp1 $fake_free + echo 2... + sleep 2 + echo 3... + sleep 2 + echo 4... + [[ \$(ls \$NIX_STORE/*-garbage? | wc -l) = 1 ]] + ''; +} +EOF +) + +expr2=$(cat <<EOF +with import ./config.nix; mkDerivation { + name = "gc-B"; + buildCommand = '' + set -x + mkdir \$out + echo foo > \$out/bar + echo 1... + sleep 2 + echo 200 > ${fake_free}.tmp2 + mv ${fake_free}.tmp2 $fake_free + echo 2... + sleep 2 + echo 3... + sleep 2 + echo 4... + ''; +} +EOF +) + +nix build -v -o $TEST_ROOT/result-A -L "($expr)" \ + --min-free 1000 --max-free 2000 --min-free-check-interval 1 & +pid=$! + +nix build -v -o $TEST_ROOT/result-B -L "($expr2)" \ + --min-free 1000 --max-free 2000 --min-free-check-interval 1 + +wait "$pid" + +[[ foo = $(cat $TEST_ROOT/result-A/bar) ]] +[[ foo = $(cat $TEST_ROOT/result-B/bar) ]] diff --git a/third_party/nix/tests/gc-concurrent.builder.sh b/third_party/nix/tests/gc-concurrent.builder.sh new file mode 100644 index 0000000000..0cd67df3ae --- /dev/null +++ b/third_party/nix/tests/gc-concurrent.builder.sh @@ -0,0 +1,13 @@ +mkdir $out +echo $(cat $input1/foo)$(cat $input2/bar) > $out/foobar + +sleep 10 + +# $out should not have been GC'ed while we were sleeping, but just in +# case... +mkdir -p $out + +# Check that the GC hasn't deleted the lock on our output. +test -e "$out.lock" + +ln -s $input2 $out/input-2 diff --git a/third_party/nix/tests/gc-concurrent.nix b/third_party/nix/tests/gc-concurrent.nix new file mode 100644 index 0000000000..c0595cc471 --- /dev/null +++ b/third_party/nix/tests/gc-concurrent.nix @@ -0,0 +1,27 @@ +with import ./config.nix; + +rec { + + input1 = mkDerivation { + name = "dependencies-input-1"; + builder = ./dependencies.builder1.sh; + }; + + input2 = mkDerivation { + name = "dependencies-input-2"; + builder = ./dependencies.builder2.sh; + }; + + test1 = mkDerivation { + name = "gc-concurrent"; + builder = ./gc-concurrent.builder.sh; + inherit input1 input2; + }; + + test2 = mkDerivation { + name = "gc-concurrent2"; + builder = ./gc-concurrent2.builder.sh; + inherit input1 input2; + }; + +} diff --git a/third_party/nix/tests/gc-concurrent.sh b/third_party/nix/tests/gc-concurrent.sh new file mode 100644 index 0000000000..d395930ca0 --- /dev/null +++ b/third_party/nix/tests/gc-concurrent.sh @@ -0,0 +1,58 @@ +source common.sh + +clearStore + +drvPath1=$(nix-instantiate gc-concurrent.nix -A test1) +outPath1=$(nix-store -q $drvPath1) + +drvPath2=$(nix-instantiate gc-concurrent.nix -A test2) +outPath2=$(nix-store -q $drvPath2) + +drvPath3=$(nix-instantiate simple.nix) +outPath3=$(nix-store -r $drvPath3) + +(! test -e $outPath3.lock) +touch $outPath3.lock + +rm -f "$NIX_STATE_DIR"/gcroots/foo* +ln -s $drvPath2 "$NIX_STATE_DIR"/gcroots/foo +ln -s $outPath3 "$NIX_STATE_DIR"/gcroots/foo2 + +# Start build #1 in the background. It starts immediately. +nix-store -rvv "$drvPath1" & +pid1=$! + +# Start build #2 in the background after 10 seconds. +(sleep 10 && nix-store -rvv "$drvPath2") & +pid2=$! + +# Run the garbage collector while the build is running. +sleep 6 +nix-collect-garbage + +# Wait for build #1/#2 to finish. +echo waiting for pid $pid1 to finish... +wait $pid1 +echo waiting for pid $pid2 to finish... +wait $pid2 + +# Check that the root of build #1 and its dependencies haven't been +# deleted. The should not be deleted by the GC because they were +# being built during the GC. +cat $outPath1/foobar +cat $outPath1/input-2/bar + +# Check that build #2 has succeeded. It should succeed because the +# derivation is a GC root. +cat $outPath2/foobar + +rm -f "$NIX_STATE_DIR"/gcroots/foo* + +# The collector should have deleted lock files for paths that have +# been built previously. +(! test -e $outPath3.lock) + +# If we run the collector now, it should delete outPath1/2. +nix-collect-garbage +(! test -e $outPath1) +(! test -e $outPath2) diff --git a/third_party/nix/tests/gc-concurrent2.builder.sh b/third_party/nix/tests/gc-concurrent2.builder.sh new file mode 100644 index 0000000000..4bfb33103e --- /dev/null +++ b/third_party/nix/tests/gc-concurrent2.builder.sh @@ -0,0 +1,7 @@ +mkdir $out +echo $(cat $input1/foo)$(cat $input2/bar)xyzzy > $out/foobar + +# Check that the GC hasn't deleted the lock on our output. +test -e "$out.lock" + +sleep 6 diff --git a/third_party/nix/tests/gc-runtime.nix b/third_party/nix/tests/gc-runtime.nix new file mode 100644 index 0000000000..ee5980bdff --- /dev/null +++ b/third_party/nix/tests/gc-runtime.nix @@ -0,0 +1,17 @@ +with import ./config.nix; + +mkDerivation { + name = "gc-runtime"; + builder = + # Test inline source file definitions. + builtins.toFile "builder.sh" '' + mkdir $out + + cat > $out/program <<EOF + #! ${shell} + sleep 10000 + EOF + + chmod +x $out/program + ''; +} diff --git a/third_party/nix/tests/gc-runtime.sh b/third_party/nix/tests/gc-runtime.sh new file mode 100644 index 0000000000..4c5028005c --- /dev/null +++ b/third_party/nix/tests/gc-runtime.sh @@ -0,0 +1,38 @@ +source common.sh + +case $system in + *linux*) + ;; + *) + exit 0; +esac + +set -m # enable job control, needed for kill + +profiles="$NIX_STATE_DIR"/profiles +rm -rf $profiles + +nix-env -p $profiles/test -f ./gc-runtime.nix -i gc-runtime + +outPath=$(nix-env -p $profiles/test -q --no-name --out-path gc-runtime) +echo $outPath + +echo "backgrounding program..." +$profiles/test/program & +sleep 2 # hack - wait for the program to get started +child=$! +echo PID=$child + +nix-env -p $profiles/test -e gc-runtime +nix-env -p $profiles/test --delete-generations old + +nix-store --gc + +kill -- -$child + +if ! test -e $outPath; then + echo "running program was garbage collected!" + exit 1 +fi + +exit 0 diff --git a/third_party/nix/tests/gc.sh b/third_party/nix/tests/gc.sh new file mode 100644 index 0000000000..8b4f8d2821 --- /dev/null +++ b/third_party/nix/tests/gc.sh @@ -0,0 +1,40 @@ +source common.sh + +drvPath=$(nix-instantiate dependencies.nix) +outPath=$(nix-store -rvv "$drvPath") + +# Set a GC root. +rm -f "$NIX_STATE_DIR"/gcroots/foo +ln -sf $outPath "$NIX_STATE_DIR"/gcroots/foo + +[ "$(nix-store -q --roots $outPath)" = "$NIX_STATE_DIR/gcroots/foo -> $outPath" ] + +nix-store --gc --print-roots | grep $outPath +nix-store --gc --print-live | grep $outPath +nix-store --gc --print-dead | grep $drvPath +if nix-store --gc --print-dead | grep $outPath; then false; fi + +nix-store --gc --print-dead + +inUse=$(readLink $outPath/input-2) +if nix-store --delete $inUse; then false; fi +test -e $inUse + +if nix-store --delete $outPath; then false; fi +test -e $outPath + +nix-collect-garbage + +# Check that the root and its dependencies haven't been deleted. +cat $outPath/foobar +cat $outPath/input-2/bar + +# Check that the derivation has been GC'd. +if test -e $drvPath; then false; fi + +rm "$NIX_STATE_DIR"/gcroots/foo + +nix-collect-garbage + +# Check that the output has been GC'd. +if test -e $outPath/foobar; then false; fi diff --git a/third_party/nix/tests/hash-check.nix b/third_party/nix/tests/hash-check.nix new file mode 100644 index 0000000000..4a8e9b8a8d --- /dev/null +++ b/third_party/nix/tests/hash-check.nix @@ -0,0 +1,29 @@ +let { + + input1 = derivation { + name = "dependencies-input-1"; + system = "i086-msdos"; + builder = "/bar/sh"; + args = ["-e" "-x" ./dummy]; + }; + + input2 = derivation { + name = "dependencies-input-2"; + system = "i086-msdos"; + builder = "/bar/sh"; + args = ["-e" "-x" ./dummy]; + outputHashMode = "recursive"; + outputHashAlgo = "md5"; + outputHash = "ffffffffffffffffffffffffffffffff"; + }; + + body = derivation { + name = "dependencies"; + system = "i086-msdos"; + builder = "/bar/sh"; + args = ["-e" "-x" (./dummy + "/FOOBAR/../.")]; + input1 = input1 + "/."; + inherit input2; + }; + +} \ No newline at end of file diff --git a/third_party/nix/tests/hash.sh b/third_party/nix/tests/hash.sh new file mode 100644 index 0000000000..4cfc979010 --- /dev/null +++ b/third_party/nix/tests/hash.sh @@ -0,0 +1,87 @@ +source common.sh + +try () { + printf "%s" "$2" > $TEST_ROOT/vector + hash=$(nix hash-file --base16 $EXTRA --type "$1" $TEST_ROOT/vector) + if test "$hash" != "$3"; then + echo "hash $1, expected $3, got $hash" + exit 1 + fi +} + +try md5 "" "d41d8cd98f00b204e9800998ecf8427e" +try md5 "a" "0cc175b9c0f1b6a831c399e269772661" +try md5 "abc" "900150983cd24fb0d6963f7d28e17f72" +try md5 "message digest" "f96b697d7cb7938d525a2f31aaf161d0" +try md5 "abcdefghijklmnopqrstuvwxyz" "c3fcd3d76192e4007dfb496cca67e13b" +try md5 "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789" "d174ab98d277d9f5a5611c2c9f419d9f" +try md5 "12345678901234567890123456789012345678901234567890123456789012345678901234567890" "57edf4a22be3c955ac49da2e2107b67a" + +try sha1 "" "da39a3ee5e6b4b0d3255bfef95601890afd80709" +try sha1 "abc" "a9993e364706816aba3e25717850c26c9cd0d89d" +try sha1 "abcdbcdecdefdefgefghfghighijhijkijkljklmklmnlmnomnopnopq" "84983e441c3bd26ebaae4aa1f95129e5e54670f1" + +try sha256 "" "e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855" +try sha256 "abc" "ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad" +try sha256 "abcdbcdecdefdefgefghfghighijhijkijkljklmklmnlmnomnopnopq" "248d6a61d20638b8e5c026930c3e6039a33ce45964ff2167f6ecedd419db06c1" + +try sha512 "" "cf83e1357eefb8bdf1542850d66d8007d620e4050b5715dc83f4a921d36ce9ce47d0d13c5d85f2b0ff8318d2877eec2f63b931bd47417a81a538327af927da3e" +try sha512 "abc" "ddaf35a193617abacc417349ae20413112e6fa4e89a97ea20a9eeee64b55d39a2192992a274fc1a836ba3c23a3feebbd454d4423643ce80e2a9ac94fa54ca49f" +try sha512 "abcdbcdecdefdefgefghfghighijhijkijkljklmklmnlmnomnopnopq" "204a8fc6dda82f0a0ced7beb8e08a41657c16ef468b228a8279be331a703c33596fd15c13b1b07f9aa1d3bea57789ca031ad85c7a71dd70354ec631238ca3445" + +EXTRA=--base32 +try sha256 "abc" "1b8m03r63zqhnjf7l5wnldhh7c134ap5vpj0850ymkq1iyzicy5s" +EXTRA= + +EXTRA=--sri +try sha512 "" "sha512-z4PhNX7vuL3xVChQ1m2AB9Yg5AULVxXcg/SpIdNs6c5H0NE8XYXysP+DGNKHfuwvY7kxvUdBeoGlODJ6+SfaPg==" +try sha512 "abc" "sha512-3a81oZNherrMQXNJriBBMRLm+k6JqX6iCp7u5ktV05ohkpkqJ0/BqDa6PCOj/uu9RU1EI2Q86A4qmslPpUyknw==" +try sha512 "abcdbcdecdefdefgefghfghighijhijkijkljklmklmnlmnomnopnopq" "sha512-IEqPxt2oLwoM7XvrjgikFlfBbvRosiioJ5vjMacDwzWW/RXBOxsH+aodO+pXeJygMa2Fx6cd1wNU7GMSOMo0RQ==" +try sha256 "abcdbcdecdefdefgefghfghighijhijkijkljklmklmnlmnomnopnopq" "sha256-JI1qYdIGOLjlwCaTDD5gOaM85Flk/yFn9uzt1BnbBsE=" + +try2 () { + hash=$(nix-hash --type "$1" $TEST_ROOT/hash-path) + if test "$hash" != "$2"; then + echo "hash $1, expected $2, got $hash" + exit 1 + fi +} + +rm -rf $TEST_ROOT/hash-path +mkdir $TEST_ROOT/hash-path +echo "Hello World" > $TEST_ROOT/hash-path/hello + +try2 md5 "ea9b55537dd4c7e104515b2ccfaf4100" + +# Execute bit matters. +chmod +x $TEST_ROOT/hash-path/hello +try2 md5 "20f3ffe011d4cfa7d72bfabef7882836" + +# Mtime and other bits don't. +touch -r . $TEST_ROOT/hash-path/hello +chmod 744 $TEST_ROOT/hash-path/hello +try2 md5 "20f3ffe011d4cfa7d72bfabef7882836" + +# File type (e.g., symlink) does. +rm $TEST_ROOT/hash-path/hello +ln -s x $TEST_ROOT/hash-path/hello +try2 md5 "f78b733a68f5edbdf9413899339eaa4a" + +# Conversion. +try3() { + h64=$(nix to-base64 --type "$1" "$2") + [ "$h64" = "$4" ] + sri=$(nix to-sri --type "$1" "$2") + [ "$sri" = "$1-$4" ] + h32=$(nix-hash --type "$1" --to-base32 "$2") + [ "$h32" = "$3" ] + h16=$(nix-hash --type "$1" --to-base16 "$h32") + [ "$h16" = "$2" ] + h16=$(nix to-base16 --type "$1" "$h64") + [ "$h16" = "$2" ] + h16=$(nix to-base16 "$sri") + [ "$h16" = "$2" ] +} +try3 sha1 "800d59cfcd3c05e900cb4e214be48f6b886a08df" "vw46m23bizj4n8afrc0fj19wrp7mj3c0" "gA1Zz808BekAy04hS+SPa4hqCN8=" +try3 sha256 "ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad" "1b8m03r63zqhnjf7l5wnldhh7c134ap5vpj0850ymkq1iyzicy5s" "ungWv48Bz+pBQUDeXa4iI7ADYaOWF3qctBD/YfIAFa0=" +try3 sha512 "204a8fc6dda82f0a0ced7beb8e08a41657c16ef468b228a8279be331a703c33596fd15c13b1b07f9aa1d3bea57789ca031ad85c7a71dd70354ec631238ca3445" "12k9jiq29iyqm03swfsgiw5mlqs173qazm3n7daz43infy12pyrcdf30fkk3qwv4yl2ick8yipc2mqnlh48xsvvxl60lbx8vp38yji0" "IEqPxt2oLwoM7XvrjgikFlfBbvRosiioJ5vjMacDwzWW/RXBOxsH+aodO+pXeJygMa2Fx6cd1wNU7GMSOMo0RQ==" diff --git a/third_party/nix/tests/import-derivation.nix b/third_party/nix/tests/import-derivation.nix new file mode 100644 index 0000000000..44fa9a45d7 --- /dev/null +++ b/third_party/nix/tests/import-derivation.nix @@ -0,0 +1,26 @@ +with import ./config.nix; + +let + + bar = mkDerivation { + name = "bar"; + builder = builtins.toFile "builder.sh" + '' + echo 'builtins.add 123 456' > $out + ''; + }; + + value = + # Test that pathExists can check the existence of /nix/store paths + assert builtins.pathExists bar; + import bar; + +in + +mkDerivation { + name = "foo"; + builder = builtins.toFile "builder.sh" + '' + echo -n FOO${toString value} > $out + ''; +} diff --git a/third_party/nix/tests/import-derivation.sh b/third_party/nix/tests/import-derivation.sh new file mode 100644 index 0000000000..98d61ef49b --- /dev/null +++ b/third_party/nix/tests/import-derivation.sh @@ -0,0 +1,12 @@ +source common.sh + +clearStore + +if nix-instantiate --readonly-mode ./import-derivation.nix; then + echo "read-only evaluation of an imported derivation unexpectedly failed" + exit 1 +fi + +outPath=$(nix-build ./import-derivation.nix --no-out-link) + +[ "$(cat $outPath)" = FOO579 ] diff --git a/third_party/nix/tests/init.sh b/third_party/nix/tests/init.sh new file mode 100644 index 0000000000..19a12c1e2d --- /dev/null +++ b/third_party/nix/tests/init.sh @@ -0,0 +1,34 @@ +source common.sh + +test -n "$TEST_ROOT" +if test -d "$TEST_ROOT"; then + chmod -R u+w "$TEST_ROOT" + rm -rf "$TEST_ROOT" +fi +mkdir "$TEST_ROOT" + +mkdir "$NIX_STORE_DIR" +mkdir "$NIX_LOCALSTATE_DIR" +mkdir -p "$NIX_LOG_DIR"/drvs +mkdir "$NIX_STATE_DIR" +mkdir "$NIX_CONF_DIR" + +cat > "$NIX_CONF_DIR"/nix.conf <<EOF +build-users-group = +keep-derivations = false +sandbox = false +include nix.conf.extra +EOF + +cat > "$NIX_CONF_DIR"/nix.conf.extra <<EOF +fsync-metadata = false +!include nix.conf.extra.not-there +EOF + +# Initialise the database. +nix-store --init + +# Did anything happen? +test -e "$NIX_STATE_DIR"/db/db.sqlite + +echo 'Hello World' > ./dummy diff --git a/third_party/nix/tests/install-darwin.sh b/third_party/nix/tests/install-darwin.sh new file mode 100755 index 0000000000..9933eba944 --- /dev/null +++ b/third_party/nix/tests/install-darwin.sh @@ -0,0 +1,96 @@ +#!/bin/sh + +set -eux + +cleanup() { + PLIST="/Library/LaunchDaemons/org.nixos.nix-daemon.plist" + if sudo launchctl list | grep -q nix-daemon; then + sudo launchctl unload "$PLIST" + fi + + if [ -f "$PLIST" ]; then + sudo rm /Library/LaunchDaemons/org.nixos.nix-daemon.plist + fi + + profiles=(/etc/profile /etc/bashrc /etc/zshrc) + for profile in "${profiles[@]}"; do + if [ -f "${profile}.backup-before-nix" ]; then + sudo mv "${profile}.backup-before-nix" "${profile}" + fi + done + + for file in ~/.bash_profile ~/.bash_login ~/.profile ~/.zshenv ~/.zprofile ~/.zshrc ~/.zlogin; do + if [ -e "$file" ]; then + cat "$file" | grep -v nix-profile > "$file.next" + mv "$file.next" "$file" + fi + done + + for i in $(seq 1 $(sysctl -n hw.ncpu)); do + sudo /usr/bin/dscl . -delete "/Users/nixbld$i" || true + done + sudo /usr/bin/dscl . -delete "/Groups/nixbld" || true + + sudo rm -rf /etc/nix \ + /nix \ + /var/root/.nix-profile /var/root/.nix-defexpr /var/root/.nix-channels \ + "$HOME/.nix-profile" "$HOME/.nix-defexpr" "$HOME/.nix-channels" +} + +verify() { + set +e + output=$(echo "nix-shell -p bash --run 'echo toow | rev'" | bash -l) + set -e + + test "$output" = "woot" +} + +scratch=$(mktemp -d -t tmp.XXXXXXXXXX) +function finish { + rm -rf "$scratch" +} +trap finish EXIT + +# First setup Nix +cleanup +curl -o install https://nixos.org/nix/install +yes | bash ./install +verify + + +( + set +e + ( + echo "cd $(pwd)" + echo nix-build ./release.nix -A binaryTarball.x86_64-darwin + ) | bash -l + set -e + cp ./result/nix-*.tar.bz2 $scratch/nix.tar.bz2 +) + +( + cd $scratch + tar -xf ./nix.tar.bz2 + + cd nix-* + + set -eux + + cleanup + + yes | ./install + verify + cleanup + + echo -n "" | ./install + verify + cleanup + + sudo mkdir -p /nix/store + sudo touch /nix/store/.silly-hint + echo -n "" | ALLOW_PREEXISTING_INSTALLATION=true ./install + verify + test -e /nix/store/.silly-hint + + cleanup +) diff --git a/third_party/nix/tests/lang.sh b/third_party/nix/tests/lang.sh new file mode 100644 index 0000000000..c797a2a74e --- /dev/null +++ b/third_party/nix/tests/lang.sh @@ -0,0 +1,70 @@ +source common.sh + +export TEST_VAR=foo # for eval-okay-getenv.nix + +nix-instantiate --eval -E 'builtins.trace "Hello" 123' 2>&1 | grep -q Hello +(! nix-instantiate --show-trace --eval -E 'builtins.addErrorContext "Hello" 123' 2>&1 | grep -q Hello) +nix-instantiate --show-trace --eval -E 'builtins.addErrorContext "Hello" (throw "Foo")' 2>&1 | grep -q Hello + +set +x + +fail=0 + +for i in lang/parse-fail-*.nix; do + echo "parsing $i (should fail)"; + i=$(basename $i .nix) + if nix-instantiate --parse - < lang/$i.nix; then + echo "FAIL: $i shouldn't parse" + fail=1 + fi +done + +for i in lang/parse-okay-*.nix; do + echo "parsing $i (should succeed)"; + i=$(basename $i .nix) + if ! nix-instantiate --parse - < lang/$i.nix > lang/$i.out; then + echo "FAIL: $i should parse" + fail=1 + fi +done + +for i in lang/eval-fail-*.nix; do + echo "evaluating $i (should fail)"; + i=$(basename $i .nix) + if nix-instantiate --eval lang/$i.nix; then + echo "FAIL: $i shouldn't evaluate" + fail=1 + fi +done + +for i in lang/eval-okay-*.nix; do + echo "evaluating $i (should succeed)"; + i=$(basename $i .nix) + + if test -e lang/$i.exp; then + flags= + if test -e lang/$i.flags; then + flags=$(cat lang/$i.flags) + fi + if ! NIX_PATH=lang/dir3:lang/dir4 nix-instantiate $flags --eval --strict lang/$i.nix > lang/$i.out; then + echo "FAIL: $i should evaluate" + fail=1 + elif ! diff lang/$i.out lang/$i.exp; then + echo "FAIL: evaluation result of $i not as expected" + fail=1 + fi + fi + + if test -e lang/$i.exp.xml; then + if ! nix-instantiate --eval --xml --no-location --strict \ + lang/$i.nix > lang/$i.out.xml; then + echo "FAIL: $i should evaluate" + fail=1 + elif ! cmp -s lang/$i.out.xml lang/$i.exp.xml; then + echo "FAIL: XML evaluation result of $i not as expected" + fail=1 + fi + fi +done + +exit $fail diff --git a/third_party/nix/tests/lang/binary-data b/third_party/nix/tests/lang/binary-data new file mode 100644 index 0000000000..06d7405020 --- /dev/null +++ b/third_party/nix/tests/lang/binary-data Binary files differdiff --git a/third_party/nix/tests/lang/data b/third_party/nix/tests/lang/data new file mode 100644 index 0000000000..257cc5642c --- /dev/null +++ b/third_party/nix/tests/lang/data @@ -0,0 +1 @@ +foo diff --git a/third_party/nix/tests/lang/dir1/a.nix b/third_party/nix/tests/lang/dir1/a.nix new file mode 100644 index 0000000000..231f150c57 --- /dev/null +++ b/third_party/nix/tests/lang/dir1/a.nix @@ -0,0 +1 @@ +"a" diff --git a/third_party/nix/tests/lang/dir2/a.nix b/third_party/nix/tests/lang/dir2/a.nix new file mode 100644 index 0000000000..170df520ab --- /dev/null +++ b/third_party/nix/tests/lang/dir2/a.nix @@ -0,0 +1 @@ +"X" diff --git a/third_party/nix/tests/lang/dir2/b.nix b/third_party/nix/tests/lang/dir2/b.nix new file mode 100644 index 0000000000..19010cc35c --- /dev/null +++ b/third_party/nix/tests/lang/dir2/b.nix @@ -0,0 +1 @@ +"b" diff --git a/third_party/nix/tests/lang/dir3/a.nix b/third_party/nix/tests/lang/dir3/a.nix new file mode 100644 index 0000000000..170df520ab --- /dev/null +++ b/third_party/nix/tests/lang/dir3/a.nix @@ -0,0 +1 @@ +"X" diff --git a/third_party/nix/tests/lang/dir3/b.nix b/third_party/nix/tests/lang/dir3/b.nix new file mode 100644 index 0000000000..170df520ab --- /dev/null +++ b/third_party/nix/tests/lang/dir3/b.nix @@ -0,0 +1 @@ +"X" diff --git a/third_party/nix/tests/lang/dir3/c.nix b/third_party/nix/tests/lang/dir3/c.nix new file mode 100644 index 0000000000..cdf158597e --- /dev/null +++ b/third_party/nix/tests/lang/dir3/c.nix @@ -0,0 +1 @@ +"c" diff --git a/third_party/nix/tests/lang/dir4/a.nix b/third_party/nix/tests/lang/dir4/a.nix new file mode 100644 index 0000000000..170df520ab --- /dev/null +++ b/third_party/nix/tests/lang/dir4/a.nix @@ -0,0 +1 @@ +"X" diff --git a/third_party/nix/tests/lang/dir4/c.nix b/third_party/nix/tests/lang/dir4/c.nix new file mode 100644 index 0000000000..170df520ab --- /dev/null +++ b/third_party/nix/tests/lang/dir4/c.nix @@ -0,0 +1 @@ +"X" diff --git a/third_party/nix/tests/lang/eval-fail-abort.nix b/third_party/nix/tests/lang/eval-fail-abort.nix new file mode 100644 index 0000000000..75c51bceb5 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-abort.nix @@ -0,0 +1 @@ +if true then abort "this should fail" else 1 diff --git a/third_party/nix/tests/lang/eval-fail-antiquoted-path.nix b/third_party/nix/tests/lang/eval-fail-antiquoted-path.nix new file mode 100644 index 0000000000..f2f08107b5 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-antiquoted-path.nix @@ -0,0 +1,4 @@ +# This must fail to evaluate, since ./fnord doesn't exist. If it did +# exist, it would produce "/nix/store/<hash>-fnord/xyzzy" (with an +# appropriate context). +"${./fnord}/xyzzy" diff --git a/third_party/nix/tests/lang/eval-fail-assert.nix b/third_party/nix/tests/lang/eval-fail-assert.nix new file mode 100644 index 0000000000..3b7a1e8bf0 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-assert.nix @@ -0,0 +1,5 @@ +let { + x = arg: assert arg == "y"; 123; + + body = x "x"; +} \ No newline at end of file diff --git a/third_party/nix/tests/lang/eval-fail-bad-antiquote-1.nix b/third_party/nix/tests/lang/eval-fail-bad-antiquote-1.nix new file mode 100644 index 0000000000..ffe9c983c2 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-bad-antiquote-1.nix @@ -0,0 +1 @@ +"${x: x}" diff --git a/third_party/nix/tests/lang/eval-fail-bad-antiquote-2.nix b/third_party/nix/tests/lang/eval-fail-bad-antiquote-2.nix new file mode 100644 index 0000000000..3745235ce9 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-bad-antiquote-2.nix @@ -0,0 +1 @@ +"${./fnord}" diff --git a/third_party/nix/tests/lang/eval-fail-bad-antiquote-3.nix b/third_party/nix/tests/lang/eval-fail-bad-antiquote-3.nix new file mode 100644 index 0000000000..65b9d4f505 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-bad-antiquote-3.nix @@ -0,0 +1 @@ +''${x: x}'' diff --git a/third_party/nix/tests/lang/eval-fail-blackhole.nix b/third_party/nix/tests/lang/eval-fail-blackhole.nix new file mode 100644 index 0000000000..81133b511c --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-blackhole.nix @@ -0,0 +1,5 @@ +let { + body = x; + x = y; + y = x; +} diff --git a/third_party/nix/tests/lang/eval-fail-deepseq.nix b/third_party/nix/tests/lang/eval-fail-deepseq.nix new file mode 100644 index 0000000000..9baa49b063 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-deepseq.nix @@ -0,0 +1 @@ +builtins.deepSeq { x = abort "foo"; } 456 diff --git a/third_party/nix/tests/lang/eval-fail-hashfile-missing.nix b/third_party/nix/tests/lang/eval-fail-hashfile-missing.nix new file mode 100644 index 0000000000..ce098b8238 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-hashfile-missing.nix @@ -0,0 +1,5 @@ +let + paths = [ ./this-file-is-definitely-not-there-7392097 "/and/neither/is/this/37293620" ]; +in + toString (builtins.concatLists (map (hash: map (builtins.hashFile hash) paths) ["md5" "sha1" "sha256" "sha512"])) + diff --git a/third_party/nix/tests/lang/eval-fail-missing-arg.nix b/third_party/nix/tests/lang/eval-fail-missing-arg.nix new file mode 100644 index 0000000000..c4be9797c5 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-missing-arg.nix @@ -0,0 +1 @@ +({x, y, z}: x + y + z) {x = "foo"; z = "bar";} diff --git a/third_party/nix/tests/lang/eval-fail-path-slash.nix b/third_party/nix/tests/lang/eval-fail-path-slash.nix new file mode 100644 index 0000000000..8c2e104c78 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-path-slash.nix @@ -0,0 +1,6 @@ +# Trailing slashes in paths are not allowed. +# This restriction could be lifted sometime, +# for example if we make '/' a path concatenation operator. +# See https://github.com/NixOS/nix/issues/1138 +# and https://nixos.org/nix-dev/2016-June/020829.html +/nix/store/ diff --git a/third_party/nix/tests/lang/eval-fail-remove.nix b/third_party/nix/tests/lang/eval-fail-remove.nix new file mode 100644 index 0000000000..539e0eb0a6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-remove.nix @@ -0,0 +1,5 @@ +let { + attrs = {x = 123; y = 456;}; + + body = (removeAttrs attrs ["x"]).x; +} \ No newline at end of file diff --git a/third_party/nix/tests/lang/eval-fail-scope-5.nix b/third_party/nix/tests/lang/eval-fail-scope-5.nix new file mode 100644 index 0000000000..f89a65a99b --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-scope-5.nix @@ -0,0 +1,10 @@ +let { + + x = "a"; + y = "b"; + + f = {x ? y, y ? x}: x + y; + + body = f {}; + +} diff --git a/third_party/nix/tests/lang/eval-fail-seq.nix b/third_party/nix/tests/lang/eval-fail-seq.nix new file mode 100644 index 0000000000..cddbbfd326 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-seq.nix @@ -0,0 +1 @@ +builtins.seq (abort "foo") 2 diff --git a/third_party/nix/tests/lang/eval-fail-substring.nix b/third_party/nix/tests/lang/eval-fail-substring.nix new file mode 100644 index 0000000000..f37c2bc0a1 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-substring.nix @@ -0,0 +1 @@ +builtins.substring (builtins.sub 0 1) 1 "x" diff --git a/third_party/nix/tests/lang/eval-fail-to-path.nix b/third_party/nix/tests/lang/eval-fail-to-path.nix new file mode 100644 index 0000000000..5e322bc313 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-to-path.nix @@ -0,0 +1 @@ +builtins.toPath "foo/bar" diff --git a/third_party/nix/tests/lang/eval-fail-undeclared-arg.nix b/third_party/nix/tests/lang/eval-fail-undeclared-arg.nix new file mode 100644 index 0000000000..cafdf16362 --- /dev/null +++ b/third_party/nix/tests/lang/eval-fail-undeclared-arg.nix @@ -0,0 +1 @@ +({x, z}: x + z) {x = "foo"; y = "bla"; z = "bar";} diff --git a/third_party/nix/tests/lang/eval-okay-any-all.exp b/third_party/nix/tests/lang/eval-okay-any-all.exp new file mode 100644 index 0000000000..eb273f45b2 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-any-all.exp @@ -0,0 +1 @@ +[ false false true true true true false true ] diff --git a/third_party/nix/tests/lang/eval-okay-any-all.nix b/third_party/nix/tests/lang/eval-okay-any-all.nix new file mode 100644 index 0000000000..a3f26ea2aa --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-any-all.nix @@ -0,0 +1,11 @@ +with builtins; + +[ (any (x: x == 1) []) + (any (x: x == 1) [2 3 4]) + (any (x: x == 1) [1 2 3 4]) + (any (x: x == 1) [4 3 2 1]) + (all (x: x == 1) []) + (all (x: x == 1) [1]) + (all (x: x == 1) [1 2 3]) + (all (x: x == 1) [1 1 1]) +] diff --git a/third_party/nix/tests/lang/eval-okay-arithmetic.exp b/third_party/nix/tests/lang/eval-okay-arithmetic.exp new file mode 100644 index 0000000000..5c54d10b7b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-arithmetic.exp @@ -0,0 +1 @@ +2216 diff --git a/third_party/nix/tests/lang/eval-okay-arithmetic.nix b/third_party/nix/tests/lang/eval-okay-arithmetic.nix new file mode 100644 index 0000000000..7e9e6a0b66 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-arithmetic.nix @@ -0,0 +1,59 @@ +with import ./lib.nix; + +let { + + /* Supposedly tail recursive version: + + range_ = accum: first: last: + if first == last then ([first] ++ accum) + else range_ ([first] ++ accum) (builtins.add first 1) last; + + range = range_ []; + */ + + x = 12; + + err = abort "urgh"; + + body = sum + [ (sum (range 1 50)) + (123 + 456) + (0 + -10 + -(-11) + -x) + (10 - 7 - -2) + (10 - (6 - -1)) + (10 - 1 + 2) + (3 * 4 * 5) + (56088 / 123 / 2) + (3 + 4 * const 5 0 - 6 / id 2) + + (builtins.bitAnd 12 10) # 0b1100 & 0b1010 = 8 + (builtins.bitOr 12 10) # 0b1100 | 0b1010 = 14 + (builtins.bitXor 12 10) # 0b1100 ^ 0b1010 = 6 + + (if 3 < 7 then 1 else err) + (if 7 < 3 then err else 1) + (if 3 < 3 then err else 1) + + (if 3 <= 7 then 1 else err) + (if 7 <= 3 then err else 1) + (if 3 <= 3 then 1 else err) + + (if 3 > 7 then err else 1) + (if 7 > 3 then 1 else err) + (if 3 > 3 then err else 1) + + (if 3 >= 7 then err else 1) + (if 7 >= 3 then 1 else err) + (if 3 >= 3 then 1 else err) + + (if 2 > 1 == 1 < 2 then 1 else err) + (if 1 + 2 * 3 >= 7 then 1 else err) + (if 1 + 2 * 3 < 7 then err else 1) + + # Not integer, but so what. + (if "aa" < "ab" then 1 else err) + (if "aa" < "aa" then err else 1) + (if "foo" < "foobar" then 1 else err) + ]; + +} diff --git a/third_party/nix/tests/lang/eval-okay-attrnames.exp b/third_party/nix/tests/lang/eval-okay-attrnames.exp new file mode 100644 index 0000000000..b4aa387e07 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrnames.exp @@ -0,0 +1 @@ +"newxfoonewxy" diff --git a/third_party/nix/tests/lang/eval-okay-attrnames.nix b/third_party/nix/tests/lang/eval-okay-attrnames.nix new file mode 100644 index 0000000000..e5b26e9f2e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrnames.nix @@ -0,0 +1,11 @@ +with import ./lib.nix; + +let + + attrs = {y = "y"; x = "x"; foo = "foo";} // rec {x = "newx"; bar = x;}; + + names = builtins.attrNames attrs; + + values = map (name: builtins.getAttr name attrs) names; + +in assert values == builtins.attrValues attrs; concat values diff --git a/third_party/nix/tests/lang/eval-okay-attrs.exp b/third_party/nix/tests/lang/eval-okay-attrs.exp new file mode 100644 index 0000000000..45b0f829eb --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs.exp @@ -0,0 +1 @@ +987 diff --git a/third_party/nix/tests/lang/eval-okay-attrs.nix b/third_party/nix/tests/lang/eval-okay-attrs.nix new file mode 100644 index 0000000000..810b31a5da --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs.nix @@ -0,0 +1,5 @@ +let { + as = { x = 123; y = 456; } // { z = 789; } // { z = 987; }; + + body = if as ? a then as.a else assert as ? z; as.z; +} diff --git a/third_party/nix/tests/lang/eval-okay-attrs2.exp b/third_party/nix/tests/lang/eval-okay-attrs2.exp new file mode 100644 index 0000000000..45b0f829eb --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs2.exp @@ -0,0 +1 @@ +987 diff --git a/third_party/nix/tests/lang/eval-okay-attrs2.nix b/third_party/nix/tests/lang/eval-okay-attrs2.nix new file mode 100644 index 0000000000..9e06b83ac1 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs2.nix @@ -0,0 +1,10 @@ +let { + as = { x = 123; y = 456; } // { z = 789; } // { z = 987; }; + + A = "a"; + Z = "z"; + + body = if builtins.hasAttr A as + then builtins.getAttr A as + else assert builtins.hasAttr Z as; builtins.getAttr Z as; +} diff --git a/third_party/nix/tests/lang/eval-okay-attrs3.exp b/third_party/nix/tests/lang/eval-okay-attrs3.exp new file mode 100644 index 0000000000..19de4fdf79 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs3.exp @@ -0,0 +1 @@ +"foo 22 80 itchyxac" diff --git a/third_party/nix/tests/lang/eval-okay-attrs3.nix b/third_party/nix/tests/lang/eval-okay-attrs3.nix new file mode 100644 index 0000000000..f29de11fe6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs3.nix @@ -0,0 +1,22 @@ +let + + config = + { + services.sshd.enable = true; + services.sshd.port = 22; + services.httpd.port = 80; + hostName = "itchy"; + a.b.c.d.e.f.g.h.i.j.k.l.m.n.o.p.q.r.s.t.u.v.w.x.y.z = "x"; + foo = { + a = "a"; + b.c = "c"; + }; + }; + +in + if config.services.sshd.enable + then "foo ${toString config.services.sshd.port} ${toString config.services.httpd.port} ${config.hostName}" + + "${config.a.b.c.d.e.f.g.h.i.j.k.l.m.n.o.p.q.r.s.t.u.v.w.x.y.z}" + + "${config.foo.a}" + + "${config.foo.b.c}" + else "bar" diff --git a/third_party/nix/tests/lang/eval-okay-attrs4.exp b/third_party/nix/tests/lang/eval-okay-attrs4.exp new file mode 100644 index 0000000000..1851731442 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs4.exp @@ -0,0 +1 @@ +[ true false true false false true false false ] diff --git a/third_party/nix/tests/lang/eval-okay-attrs4.nix b/third_party/nix/tests/lang/eval-okay-attrs4.nix new file mode 100644 index 0000000000..43ec81210f --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs4.nix @@ -0,0 +1,7 @@ +let + + as = { x.y.z = 123; a.b.c = 456; }; + + bs = null; + +in [ (as ? x) (as ? y) (as ? x.y.z) (as ? x.y.z.a) (as ? x.y.a) (as ? a.b.c) (bs ? x) (bs ? x.y.z) ] diff --git a/third_party/nix/tests/lang/eval-okay-attrs5.exp b/third_party/nix/tests/lang/eval-okay-attrs5.exp new file mode 100644 index 0000000000..ce0430d780 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs5.exp @@ -0,0 +1 @@ +[ 123 "foo" 456 456 "foo" "xyzzy" "xyzzy" true ] diff --git a/third_party/nix/tests/lang/eval-okay-attrs5.nix b/third_party/nix/tests/lang/eval-okay-attrs5.nix new file mode 100644 index 0000000000..a4584cd3b3 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs5.nix @@ -0,0 +1,21 @@ +with import ./lib.nix; + +let + + as = { x.y.z = 123; a.b.c = 456; }; + + bs = { f-o-o.bar = "foo"; }; + + or = x: y: x || y; + +in + [ as.x.y.z + as.foo or "foo" + as.x.y.bla or as.a.b.c + as.a.b.c or as.x.y.z + as.x.y.bla or bs.f-o-o.bar or "xyzzy" + as.x.y.bla or bs.bar.foo or "xyzzy" + (123).bla or null.foo or "xyzzy" + # Backwards compatibility test. + (fold or [] [true false false]) + ] diff --git a/third_party/nix/tests/lang/eval-okay-attrs6.exp b/third_party/nix/tests/lang/eval-okay-attrs6.exp new file mode 100644 index 0000000000..b46938032e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs6.exp @@ -0,0 +1 @@ +{ __overrides = { bar = "qux"; }; bar = "qux"; foo = "bar"; } diff --git a/third_party/nix/tests/lang/eval-okay-attrs6.nix b/third_party/nix/tests/lang/eval-okay-attrs6.nix new file mode 100644 index 0000000000..2e5c85483b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-attrs6.nix @@ -0,0 +1,4 @@ +rec { + "${"foo"}" = "bar"; + __overrides = { bar = "qux"; }; +} diff --git a/third_party/nix/tests/lang/eval-okay-autoargs.exp b/third_party/nix/tests/lang/eval-okay-autoargs.exp new file mode 100644 index 0000000000..7a8391786a --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-autoargs.exp @@ -0,0 +1 @@ +"xyzzy!xyzzy!foobar" diff --git a/third_party/nix/tests/lang/eval-okay-autoargs.flags b/third_party/nix/tests/lang/eval-okay-autoargs.flags new file mode 100644 index 0000000000..ae37622544 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-autoargs.flags @@ -0,0 +1 @@ +--arg lib import(lang/lib.nix) --argstr xyzzy xyzzy! -A result diff --git a/third_party/nix/tests/lang/eval-okay-autoargs.nix b/third_party/nix/tests/lang/eval-okay-autoargs.nix new file mode 100644 index 0000000000..815f51b1d6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-autoargs.nix @@ -0,0 +1,15 @@ +let + + foobar = "foobar"; + +in + +{ xyzzy2 ? xyzzy # mutually recursive args +, xyzzy ? "blaat" # will be overridden by --argstr +, fb ? foobar +, lib # will be set by --arg +}: + +{ + result = lib.concat [xyzzy xyzzy2 fb]; +} diff --git a/third_party/nix/tests/lang/eval-okay-backslash-newline-1.exp b/third_party/nix/tests/lang/eval-okay-backslash-newline-1.exp new file mode 100644 index 0000000000..3e754364cc --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-backslash-newline-1.exp @@ -0,0 +1 @@ +"a\nb" diff --git a/third_party/nix/tests/lang/eval-okay-backslash-newline-1.nix b/third_party/nix/tests/lang/eval-okay-backslash-newline-1.nix new file mode 100644 index 0000000000..7fef3dddd4 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-backslash-newline-1.nix @@ -0,0 +1,2 @@ +"a\ +b" diff --git a/third_party/nix/tests/lang/eval-okay-backslash-newline-2.exp b/third_party/nix/tests/lang/eval-okay-backslash-newline-2.exp new file mode 100644 index 0000000000..3e754364cc --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-backslash-newline-2.exp @@ -0,0 +1 @@ +"a\nb" diff --git a/third_party/nix/tests/lang/eval-okay-backslash-newline-2.nix b/third_party/nix/tests/lang/eval-okay-backslash-newline-2.nix new file mode 100644 index 0000000000..35ddf495c6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-backslash-newline-2.nix @@ -0,0 +1,2 @@ +''a''\ +b'' diff --git a/third_party/nix/tests/lang/eval-okay-builtins-add.exp b/third_party/nix/tests/lang/eval-okay-builtins-add.exp new file mode 100644 index 0000000000..0350b518a7 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-builtins-add.exp @@ -0,0 +1 @@ +[ 5 4 "int" "tt" "float" 4 ] diff --git a/third_party/nix/tests/lang/eval-okay-builtins-add.nix b/third_party/nix/tests/lang/eval-okay-builtins-add.nix new file mode 100644 index 0000000000..c841816222 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-builtins-add.nix @@ -0,0 +1,8 @@ +[ +(builtins.add 2 3) +(builtins.add 2 2) +(builtins.typeOf (builtins.add 2 2)) +("t" + "t") +(builtins.typeOf (builtins.add 2.0 2)) +(builtins.add 2.0 2) +] diff --git a/third_party/nix/tests/lang/eval-okay-builtins.exp b/third_party/nix/tests/lang/eval-okay-builtins.exp new file mode 100644 index 0000000000..0661686d61 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-builtins.exp @@ -0,0 +1 @@ +/foo diff --git a/third_party/nix/tests/lang/eval-okay-builtins.nix b/third_party/nix/tests/lang/eval-okay-builtins.nix new file mode 100644 index 0000000000..e9d65e88a8 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-builtins.nix @@ -0,0 +1,12 @@ +assert builtins ? currentSystem; +assert !builtins ? __currentSystem; + +let { + + x = if builtins ? dirOf then builtins.dirOf /foo/bar else ""; + + y = if builtins ? fnord then builtins.fnord "foo" else ""; + + body = x + y; + +} diff --git a/third_party/nix/tests/lang/eval-okay-callable-attrs.exp b/third_party/nix/tests/lang/eval-okay-callable-attrs.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-callable-attrs.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-callable-attrs.nix b/third_party/nix/tests/lang/eval-okay-callable-attrs.nix new file mode 100644 index 0000000000..310a030df0 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-callable-attrs.nix @@ -0,0 +1 @@ +({ __functor = self: x: self.foo && x; foo = false; } // { foo = true; }) true diff --git a/third_party/nix/tests/lang/eval-okay-catattrs.exp b/third_party/nix/tests/lang/eval-okay-catattrs.exp new file mode 100644 index 0000000000..b4a1e66d6b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-catattrs.exp @@ -0,0 +1 @@ +[ 1 2 ] diff --git a/third_party/nix/tests/lang/eval-okay-catattrs.nix b/third_party/nix/tests/lang/eval-okay-catattrs.nix new file mode 100644 index 0000000000..2c3dc10da5 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-catattrs.nix @@ -0,0 +1 @@ +builtins.catAttrs "a" [ { a = 1; } { b = 0; } { a = 2; } ] diff --git a/third_party/nix/tests/lang/eval-okay-closure.exp.xml b/third_party/nix/tests/lang/eval-okay-closure.exp.xml new file mode 100644 index 0000000000..dffc03a998 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-closure.exp.xml @@ -0,0 +1,343 @@ +<?xml version='1.0' encoding='utf-8'?> +<expr> + <list> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-13" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-12" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-11" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-9" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-8" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-7" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-5" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-4" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="-3" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="-1" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="0" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="1" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="2" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="4" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="5" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="6" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="8" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="9" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="10" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="13" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="14" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="15" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="17" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="18" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="19" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="22" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="23" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="26" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="27" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="28" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="31" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="32" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="35" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="36" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="40" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="41" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="44" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="45" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="49" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="53" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="54" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="58" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="62" /> + </attr> + </attrs> + <attrs> + <attr name="foo"> + <bool value="true" /> + </attr> + <attr name="key"> + <int value="67" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="71" /> + </attr> + </attrs> + <attrs> + <attr name="key"> + <int value="80" /> + </attr> + </attrs> + </list> +</expr> diff --git a/third_party/nix/tests/lang/eval-okay-closure.nix b/third_party/nix/tests/lang/eval-okay-closure.nix new file mode 100644 index 0000000000..cccd4dc357 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-closure.nix @@ -0,0 +1,13 @@ +let + + closure = builtins.genericClosure { + startSet = [{key = 80;}]; + operator = {key, foo ? false}: + if builtins.lessThan key 0 + then [] + else [{key = builtins.sub key 9;} {key = builtins.sub key 13; foo = true;}]; + }; + + sort = (import ./lib.nix).sortBy (a: b: builtins.lessThan a.key b.key); + +in sort closure diff --git a/third_party/nix/tests/lang/eval-okay-comments.exp b/third_party/nix/tests/lang/eval-okay-comments.exp new file mode 100644 index 0000000000..7182dc2f9b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-comments.exp @@ -0,0 +1 @@ +"abcdefghijklmnopqrstuvwxyz" diff --git a/third_party/nix/tests/lang/eval-okay-comments.nix b/third_party/nix/tests/lang/eval-okay-comments.nix new file mode 100644 index 0000000000..cb2cce2180 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-comments.nix @@ -0,0 +1,59 @@ +# A simple comment +"a"+ # And another +## A double comment +"b"+ ## And another +# Nested # comments # +"c"+ # and # some # other # +# An empty line, following here: + +"d"+ # and a comment not starting the line ! + +"e"+ +/* multiline comments */ +"f" + +/* multiline + comments, + on + multiple + lines +*/ +"g" + +# Small, tricky comments +/**/ "h"+ /*/*/ "i"+ /***/ "j"+ /* /*/ "k"+ /*/* /*/ "l"+ +# Comments with an even number of ending '*' used to fail: +"m"+ +/* */ /* **/ /* ***/ /* ****/ "n"+ +/* */ /** */ /*** */ /**** */ "o"+ +/** **/ /*** ***/ /**** ****/ "p"+ +/* * ** *** **** ***** */ "q"+ +# Random comments +/* ***** ////// * / * / /* */ "r"+ +# Mixed comments +/* # */ +"s"+ +# /* # +"t"+ +# /* # */ +"u"+ +# /*********/ +"v"+ +## */* +"w"+ +/* + * Multiline, decorated comments + * # This ain't a nest'd comm'nt + */ +"x"+ +''${/** with **/"y" + # real + /* comments + inside ! # */ + + # (and empty lines) + +}''+ /* And a multiline comment, + on the same line, + after some spaces +*/ # followed by a one-line comment +"z" +/* EOF */ diff --git a/third_party/nix/tests/lang/eval-okay-concat.exp b/third_party/nix/tests/lang/eval-okay-concat.exp new file mode 100644 index 0000000000..bb4bbd5774 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-concat.exp @@ -0,0 +1 @@ +[ 1 2 3 4 5 6 7 8 9 ] diff --git a/third_party/nix/tests/lang/eval-okay-concat.nix b/third_party/nix/tests/lang/eval-okay-concat.nix new file mode 100644 index 0000000000..d158a9bf05 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-concat.nix @@ -0,0 +1 @@ +[1 2 3] ++ [4 5 6] ++ [7 8 9] diff --git a/third_party/nix/tests/lang/eval-okay-concatmap.exp b/third_party/nix/tests/lang/eval-okay-concatmap.exp new file mode 100644 index 0000000000..3b8be7739d --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-concatmap.exp @@ -0,0 +1 @@ +[ [ 1 3 5 7 9 ] [ "a" "z" "b" "z" ] ] diff --git a/third_party/nix/tests/lang/eval-okay-concatmap.nix b/third_party/nix/tests/lang/eval-okay-concatmap.nix new file mode 100644 index 0000000000..97da5d37a4 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-concatmap.nix @@ -0,0 +1,5 @@ +with import ./lib.nix; + +[ (builtins.concatMap (x: if x / 2 * 2 == x then [] else [ x ]) (range 0 10)) + (builtins.concatMap (x: [x] ++ ["z"]) ["a" "b"]) +] diff --git a/third_party/nix/tests/lang/eval-okay-concatstringssep.exp b/third_party/nix/tests/lang/eval-okay-concatstringssep.exp new file mode 100644 index 0000000000..93987647ff --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-concatstringssep.exp @@ -0,0 +1 @@ +[ "" "foobarxyzzy" "foo, bar, xyzzy" "foo" "" ] diff --git a/third_party/nix/tests/lang/eval-okay-concatstringssep.nix b/third_party/nix/tests/lang/eval-okay-concatstringssep.nix new file mode 100644 index 0000000000..adc4c41bd5 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-concatstringssep.nix @@ -0,0 +1,8 @@ +with builtins; + +[ (concatStringsSep "" []) + (concatStringsSep "" ["foo" "bar" "xyzzy"]) + (concatStringsSep ", " ["foo" "bar" "xyzzy"]) + (concatStringsSep ", " ["foo"]) + (concatStringsSep ", " []) +] diff --git a/third_party/nix/tests/lang/eval-okay-context-introspection.exp b/third_party/nix/tests/lang/eval-okay-context-introspection.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-context-introspection.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-context-introspection.nix b/third_party/nix/tests/lang/eval-okay-context-introspection.nix new file mode 100644 index 0000000000..43178bd2ee --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-context-introspection.nix @@ -0,0 +1,24 @@ +let + drv = derivation { + name = "fail"; + builder = "/bin/false"; + system = "x86_64-linux"; + outputs = [ "out" "foo" ]; + }; + + path = "${./eval-okay-context-introspection.nix}"; + + desired-context = { + "${builtins.unsafeDiscardStringContext path}" = { + path = true; + }; + "${builtins.unsafeDiscardStringContext drv.drvPath}" = { + outputs = [ "foo" "out" ]; + allOutputs = true; + }; + }; + + legit-context = builtins.getContext "${path}${drv.outPath}${drv.foo.outPath}${drv.drvPath}"; + + constructed-context = builtins.getContext (builtins.appendContext "" desired-context); +in legit-context == constructed-context diff --git a/third_party/nix/tests/lang/eval-okay-context.exp b/third_party/nix/tests/lang/eval-okay-context.exp new file mode 100644 index 0000000000..2f535bdbc4 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-context.exp @@ -0,0 +1 @@ +"foo eval-okay-context.nix bar" diff --git a/third_party/nix/tests/lang/eval-okay-context.nix b/third_party/nix/tests/lang/eval-okay-context.nix new file mode 100644 index 0000000000..7b9531cfe9 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-context.nix @@ -0,0 +1,6 @@ +let s = "foo ${builtins.substring 33 100 (baseNameOf "${./eval-okay-context.nix}")} bar"; +in + if s != "foo eval-okay-context.nix bar" + then abort "context not discarded" + else builtins.unsafeDiscardStringContext s + diff --git a/third_party/nix/tests/lang/eval-okay-curpos.exp b/third_party/nix/tests/lang/eval-okay-curpos.exp new file mode 100644 index 0000000000..65fd65b4d0 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-curpos.exp @@ -0,0 +1 @@ +[ 3 7 4 9 ] diff --git a/third_party/nix/tests/lang/eval-okay-curpos.nix b/third_party/nix/tests/lang/eval-okay-curpos.nix new file mode 100644 index 0000000000..b79553df0b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-curpos.nix @@ -0,0 +1,5 @@ +# Bla +let + x = __curPos; + y = __curPos; +in [ x.line x.column y.line y.column ] diff --git a/third_party/nix/tests/lang/eval-okay-deepseq.exp b/third_party/nix/tests/lang/eval-okay-deepseq.exp new file mode 100644 index 0000000000..8d38505c16 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-deepseq.exp @@ -0,0 +1 @@ +456 diff --git a/third_party/nix/tests/lang/eval-okay-deepseq.nix b/third_party/nix/tests/lang/eval-okay-deepseq.nix new file mode 100644 index 0000000000..53aa4b1dc2 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-deepseq.nix @@ -0,0 +1 @@ +builtins.deepSeq (let as = { x = 123; y = as; }; in as) 456 diff --git a/third_party/nix/tests/lang/eval-okay-delayed-with-inherit.exp b/third_party/nix/tests/lang/eval-okay-delayed-with-inherit.exp new file mode 100644 index 0000000000..eaacb55c1a --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-delayed-with-inherit.exp @@ -0,0 +1 @@ +"b-overridden" diff --git a/third_party/nix/tests/lang/eval-okay-delayed-with-inherit.nix b/third_party/nix/tests/lang/eval-okay-delayed-with-inherit.nix new file mode 100644 index 0000000000..84b388c271 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-delayed-with-inherit.nix @@ -0,0 +1,24 @@ +let + pkgs_ = with pkgs; { + a = derivation { + name = "a"; + system = builtins.currentSystem; + builder = "/bin/sh"; + args = [ "-c" "touch $out" ]; + inherit b; + }; + + inherit b; + }; + + packageOverrides = p: { + b = derivation { + name = "b-overridden"; + system = builtins.currentSystem; + builder = "/bin/sh"; + args = [ "-c" "touch $out" ]; + }; + }; + + pkgs = pkgs_ // (packageOverrides pkgs_); +in pkgs.a.b.name diff --git a/third_party/nix/tests/lang/eval-okay-delayed-with.exp b/third_party/nix/tests/lang/eval-okay-delayed-with.exp new file mode 100644 index 0000000000..8e7c61ab8e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-delayed-with.exp @@ -0,0 +1 @@ +"b-overridden b-overridden a" diff --git a/third_party/nix/tests/lang/eval-okay-delayed-with.nix b/third_party/nix/tests/lang/eval-okay-delayed-with.nix new file mode 100644 index 0000000000..3fb023e1cd --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-delayed-with.nix @@ -0,0 +1,29 @@ +let + + pkgs_ = with pkgs; { + a = derivation { + name = "a"; + system = builtins.currentSystem; + builder = "/bin/sh"; + args = [ "-c" "touch $out" ]; + inherit b; + }; + + b = derivation { + name = "b"; + system = builtins.currentSystem; + builder = "/bin/sh"; + args = [ "-c" "touch $out" ]; + inherit a; + }; + + c = b; + }; + + packageOverrides = pkgs: with pkgs; { + b = derivation (b.drvAttrs // { name = "${b.name}-overridden"; }); + }; + + pkgs = pkgs_ // (packageOverrides pkgs_); + +in "${pkgs.a.b.name} ${pkgs.c.name} ${pkgs.b.a.name}" diff --git a/third_party/nix/tests/lang/eval-okay-dynamic-attrs-2.exp b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-2.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-2.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-dynamic-attrs-2.nix b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-2.nix new file mode 100644 index 0000000000..6d57bf8549 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-2.nix @@ -0,0 +1 @@ +{ a."${"b"}" = true; a."${"c"}" = false; }.a.b diff --git a/third_party/nix/tests/lang/eval-okay-dynamic-attrs-bare.exp b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-bare.exp new file mode 100644 index 0000000000..df8750afc0 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-bare.exp @@ -0,0 +1 @@ +{ binds = true; hasAttrs = true; multiAttrs = true; recBinds = true; selectAttrs = true; selectOrAttrs = true; } diff --git a/third_party/nix/tests/lang/eval-okay-dynamic-attrs-bare.nix b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-bare.nix new file mode 100644 index 0000000000..0dbe15e638 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-dynamic-attrs-bare.nix @@ -0,0 +1,17 @@ +let + aString = "a"; + + bString = "b"; +in { + hasAttrs = { a.b = null; } ? ${aString}.b; + + selectAttrs = { a.b = true; }.a.${bString}; + + selectOrAttrs = { }.${aString} or true; + + binds = { ${aString}."${bString}c" = true; }.a.bc; + + recBinds = rec { ${bString} = a; a = true; }.b; + + multiAttrs = { ${aString} = true; ${bString} = false; }.a; +} diff --git a/third_party/nix/tests/lang/eval-okay-dynamic-attrs.exp b/third_party/nix/tests/lang/eval-okay-dynamic-attrs.exp new file mode 100644 index 0000000000..df8750afc0 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-dynamic-attrs.exp @@ -0,0 +1 @@ +{ binds = true; hasAttrs = true; multiAttrs = true; recBinds = true; selectAttrs = true; selectOrAttrs = true; } diff --git a/third_party/nix/tests/lang/eval-okay-dynamic-attrs.nix b/third_party/nix/tests/lang/eval-okay-dynamic-attrs.nix new file mode 100644 index 0000000000..ee02ac7e65 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-dynamic-attrs.nix @@ -0,0 +1,17 @@ +let + aString = "a"; + + bString = "b"; +in { + hasAttrs = { a.b = null; } ? "${aString}".b; + + selectAttrs = { a.b = true; }.a."${bString}"; + + selectOrAttrs = { }."${aString}" or true; + + binds = { "${aString}"."${bString}c" = true; }.a.bc; + + recBinds = rec { "${bString}" = a; a = true; }.b; + + multiAttrs = { "${aString}" = true; "${bString}" = false; }.a; +} diff --git a/third_party/nix/tests/lang/eval-okay-elem.exp b/third_party/nix/tests/lang/eval-okay-elem.exp new file mode 100644 index 0000000000..3cf6c0e962 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-elem.exp @@ -0,0 +1 @@ +[ true false 30 ] diff --git a/third_party/nix/tests/lang/eval-okay-elem.nix b/third_party/nix/tests/lang/eval-okay-elem.nix new file mode 100644 index 0000000000..71ea7a4ed0 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-elem.nix @@ -0,0 +1,6 @@ +with import ./lib.nix; + +let xs = range 10 40; in + +[ (builtins.elem 23 xs) (builtins.elem 42 xs) (builtins.elemAt xs 20) ] + diff --git a/third_party/nix/tests/lang/eval-okay-empty-args.exp b/third_party/nix/tests/lang/eval-okay-empty-args.exp new file mode 100644 index 0000000000..cb5537d5d7 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-empty-args.exp @@ -0,0 +1 @@ +"ab" diff --git a/third_party/nix/tests/lang/eval-okay-empty-args.nix b/third_party/nix/tests/lang/eval-okay-empty-args.nix new file mode 100644 index 0000000000..78c133afdd --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-empty-args.nix @@ -0,0 +1 @@ +({}: {x,y,}: "${x}${y}") {} {x = "a"; y = "b";} diff --git a/third_party/nix/tests/lang/eval-okay-eq-derivations.exp b/third_party/nix/tests/lang/eval-okay-eq-derivations.exp new file mode 100644 index 0000000000..ec04aab6ae --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-eq-derivations.exp @@ -0,0 +1 @@ +[ true true true false ] diff --git a/third_party/nix/tests/lang/eval-okay-eq-derivations.nix b/third_party/nix/tests/lang/eval-okay-eq-derivations.nix new file mode 100644 index 0000000000..d526cb4a21 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-eq-derivations.nix @@ -0,0 +1,10 @@ +let + + drvA1 = derivation { name = "a"; builder = "/foo"; system = "i686-linux"; }; + drvA2 = derivation { name = "a"; builder = "/foo"; system = "i686-linux"; }; + drvA3 = derivation { name = "a"; builder = "/foo"; system = "i686-linux"; } // { dummy = 1; }; + + drvC1 = derivation { name = "c"; builder = "/foo"; system = "i686-linux"; }; + drvC2 = derivation { name = "c"; builder = "/bar"; system = "i686-linux"; }; + +in [ (drvA1 == drvA1) (drvA1 == drvA2) (drvA1 == drvA3) (drvC1 == drvC2) ] diff --git a/third_party/nix/tests/lang/eval-okay-eq.exp.disabled b/third_party/nix/tests/lang/eval-okay-eq.exp.disabled new file mode 100644 index 0000000000..2015847b65 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-eq.exp.disabled @@ -0,0 +1 @@ +Bool(True) diff --git a/third_party/nix/tests/lang/eval-okay-eq.nix b/third_party/nix/tests/lang/eval-okay-eq.nix new file mode 100644 index 0000000000..73d200b381 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-eq.nix @@ -0,0 +1,3 @@ +["foobar" (rec {x = 1; y = x;})] +== +[("foo" + "bar") ({x = 1; y = 1;})] diff --git a/third_party/nix/tests/lang/eval-okay-filter.exp b/third_party/nix/tests/lang/eval-okay-filter.exp new file mode 100644 index 0000000000..355d51c27d --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-filter.exp @@ -0,0 +1 @@ +[ 0 2 4 6 8 10 100 102 104 106 108 110 ] diff --git a/third_party/nix/tests/lang/eval-okay-filter.nix b/third_party/nix/tests/lang/eval-okay-filter.nix new file mode 100644 index 0000000000..85109b0d0e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-filter.nix @@ -0,0 +1,5 @@ +with import ./lib.nix; + +builtins.filter + (x: x / 2 * 2 == x) + (builtins.concatLists [ (range 0 10) (range 100 110) ]) diff --git a/third_party/nix/tests/lang/eval-okay-flatten.exp b/third_party/nix/tests/lang/eval-okay-flatten.exp new file mode 100644 index 0000000000..b979b2b8b9 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-flatten.exp @@ -0,0 +1 @@ +"1234567" diff --git a/third_party/nix/tests/lang/eval-okay-flatten.nix b/third_party/nix/tests/lang/eval-okay-flatten.nix new file mode 100644 index 0000000000..fe911e9683 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-flatten.nix @@ -0,0 +1,8 @@ +with import ./lib.nix; + +let { + + l = ["1" "2" ["3" ["4"] ["5" "6"]] "7"]; + + body = concat (flatten l); +} diff --git a/third_party/nix/tests/lang/eval-okay-float.exp b/third_party/nix/tests/lang/eval-okay-float.exp new file mode 100644 index 0000000000..3c50a8adce --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-float.exp @@ -0,0 +1 @@ +[ 3.4 3.5 2.5 1.5 ] diff --git a/third_party/nix/tests/lang/eval-okay-float.nix b/third_party/nix/tests/lang/eval-okay-float.nix new file mode 100644 index 0000000000..b2702c7b16 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-float.nix @@ -0,0 +1,6 @@ +[ + (1.1 + 2.3) + (builtins.add (0.5 + 0.5) (2.0 + 0.5)) + ((0.5 + 0.5) * (2.0 + 0.5)) + ((1.5 + 1.5) / (0.5 * 4.0)) +] diff --git a/third_party/nix/tests/lang/eval-okay-fromTOML.exp b/third_party/nix/tests/lang/eval-okay-fromTOML.exp new file mode 100644 index 0000000000..d0dd3af2c8 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-fromTOML.exp @@ -0,0 +1 @@ +[ { clients = { data = [ [ "gamma" "delta" ] [ 1 2 ] ]; hosts = [ "alpha" "omega" ]; }; database = { connection_max = 5000; enabled = true; ports = [ 8001 8001 8002 ]; server = "192.168.1.1"; }; owner = { name = "Tom Preston-Werner"; }; servers = { alpha = { dc = "eqdc10"; ip = "10.0.0.1"; }; beta = { dc = "eqdc10"; ip = "10.0.0.2"; }; }; title = "TOML Example"; } { "1234" = "value"; "127.0.0.1" = "value"; a = { b = { c = { }; }; }; arr1 = [ 1 2 3 ]; arr2 = [ "red" "yellow" "green" ]; arr3 = [ [ 1 2 ] [ 3 4 5 ] ]; arr4 = [ "all" "strings" "are the same" "type" ]; arr5 = [ [ 1 2 ] [ "a" "b" "c" ] ]; arr7 = [ 1 2 3 ]; arr8 = [ 1 2 ]; bare-key = "value"; bare_key = "value"; bin1 = 214; bool1 = true; bool2 = false; "character encoding" = "value"; d = { e = { f = { }; }; }; dog = { "tater.man" = { type = { name = "pug"; }; }; }; flt1 = 1; flt2 = 3.1415; flt3 = -0.01; flt4 = 5e+22; flt5 = 1e+06; flt6 = -0.02; flt7 = 6.626e-34; flt8 = 9.22462e+06; fruit = [ { name = "apple"; physical = { color = "red"; shape = "round"; }; variety = [ { name = "red delicious"; } { name = "granny smith"; } ]; } { name = "banana"; variety = [ { name = "plantain"; } ]; } ]; g = { h = { i = { }; }; }; hex1 = 3735928559; hex2 = 3735928559; hex3 = 3735928559; int1 = 99; int2 = 42; int3 = 0; int4 = -17; int5 = 1000; int6 = 5349221; int7 = 12345; j = { "ʞ" = { l = { }; }; }; key = "value"; key2 = "value"; name = "Orange"; oct1 = 342391; oct2 = 493; physical = { color = "orange"; shape = "round"; }; products = [ { name = "Hammer"; sku = 738594937; } { } { color = "gray"; name = "Nail"; sku = 284758393; } ]; "quoted \"value\"" = "value"; site = { "google.com" = true; }; str = "I'm a string. \"You can quote me\". Name\tJosé\nLocation\tSF."; table-1 = { key1 = "some string"; key2 = 123; }; table-2 = { key1 = "another string"; key2 = 456; }; x = { y = { z = { w = { animal = { type = { name = "pug"; }; }; name = { first = "Tom"; last = "Preston-Werner"; }; point = { x = 1; y = 2; }; }; }; }; }; "ʎǝʞ" = "value"; } { metadata = { "checksum aho-corasick 0.6.4 (registry+https://github.com/rust-lang/crates.io-index)" = "d6531d44de723825aa81398a6415283229725a00fa30713812ab9323faa82fc4"; "checksum ansi_term 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ee49baf6cb617b853aa8d93bf420db2383fab46d314482ca2803b40d5fde979b"; "checksum ansi_term 0.9.0 (registry+https://github.com/rust-lang/crates.io-index)" = "23ac7c30002a5accbf7e8987d0632fa6de155b7c3d39d0067317a391e00a2ef6"; "checksum arrayvec 0.4.7 (registry+https://github.com/rust-lang/crates.io-index)" = "a1e964f9e24d588183fcb43503abda40d288c8657dfc27311516ce2f05675aef"; }; package = [ { dependencies = [ "memchr 2.0.1 (registry+https://github.com/rust-lang/crates.io-index)" ]; name = "aho-corasick"; source = "registry+https://github.com/rust-lang/crates.io-index"; version = "0.6.4"; } { name = "ansi_term"; source = "registry+https://github.com/rust-lang/crates.io-index"; version = "0.9.0"; } { dependencies = [ "libc 0.2.42 (registry+https://github.com/rust-lang/crates.io-index)" "termion 1.5.1 (registry+https://github.com/rust-lang/crates.io-index)" "winapi 0.3.5 (registry+https://github.com/rust-lang/crates.io-index)" ]; name = "atty"; source = "registry+https://github.com/rust-lang/crates.io-index"; version = "0.2.10"; } ]; } { a = [ [ { b = true; } ] ]; c = [ [ { d = true; } ] ]; e = [ [ 123 ] ]; } ] diff --git a/third_party/nix/tests/lang/eval-okay-fromTOML.nix b/third_party/nix/tests/lang/eval-okay-fromTOML.nix new file mode 100644 index 0000000000..9639326899 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-fromTOML.nix @@ -0,0 +1,208 @@ +[ + + (builtins.fromTOML '' + # This is a TOML document. + + title = "TOML Example" + + [owner] + name = "Tom Preston-Werner" + #dob = 1979-05-27T07:32:00-08:00 # First class dates + + [database] + server = "192.168.1.1" + ports = [ 8001, 8001, 8002 ] + connection_max = 5000 + enabled = true + + [servers] + + # Indentation (tabs and/or spaces) is allowed but not required + [servers.alpha] + ip = "10.0.0.1" + dc = "eqdc10" + + [servers.beta] + ip = "10.0.0.2" + dc = "eqdc10" + + [clients] + data = [ ["gamma", "delta"], [1, 2] ] + + # Line breaks are OK when inside arrays + hosts = [ + "alpha", + "omega" + ] + '') + + (builtins.fromTOML '' + key = "value" + bare_key = "value" + bare-key = "value" + 1234 = "value" + + "127.0.0.1" = "value" + "character encoding" = "value" + "ʎǝʞ" = "value" + 'key2' = "value" + 'quoted "value"' = "value" + + name = "Orange" + + physical.color = "orange" + physical.shape = "round" + site."google.com" = true + + # This is legal according to the spec, but cpptoml doesn't handle it. + #a.b.c = 1 + #a.d = 2 + + str = "I'm a string. \"You can quote me\". Name\tJos\u00E9\nLocation\tSF." + + int1 = +99 + int2 = 42 + int3 = 0 + int4 = -17 + int5 = 1_000 + int6 = 5_349_221 + int7 = 1_2_3_4_5 + + hex1 = 0xDEADBEEF + hex2 = 0xdeadbeef + hex3 = 0xdead_beef + + oct1 = 0o01234567 + oct2 = 0o755 + + bin1 = 0b11010110 + + flt1 = +1.0 + flt2 = 3.1415 + flt3 = -0.01 + flt4 = 5e+22 + flt5 = 1e6 + flt6 = -2E-2 + flt7 = 6.626e-34 + flt8 = 9_224_617.445_991_228_313 + + bool1 = true + bool2 = false + + # FIXME: not supported because Nix doesn't have a date/time type. + #odt1 = 1979-05-27T07:32:00Z + #odt2 = 1979-05-27T00:32:00-07:00 + #odt3 = 1979-05-27T00:32:00.999999-07:00 + #odt4 = 1979-05-27 07:32:00Z + #ldt1 = 1979-05-27T07:32:00 + #ldt2 = 1979-05-27T00:32:00.999999 + #ld1 = 1979-05-27 + #lt1 = 07:32:00 + #lt2 = 00:32:00.999999 + + arr1 = [ 1, 2, 3 ] + arr2 = [ "red", "yellow", "green" ] + arr3 = [ [ 1, 2 ], [3, 4, 5] ] + arr4 = [ "all", 'strings', """are the same""", ''''type''''] + arr5 = [ [ 1, 2 ], ["a", "b", "c"] ] + + arr7 = [ + 1, 2, 3 + ] + + arr8 = [ + 1, + 2, # this is ok + ] + + [table-1] + key1 = "some string" + key2 = 123 + + + [table-2] + key1 = "another string" + key2 = 456 + + [dog."tater.man"] + type.name = "pug" + + [a.b.c] + [ d.e.f ] + [ g . h . i ] + [ j . "ʞ" . 'l' ] + [x.y.z.w] + + name = { first = "Tom", last = "Preston-Werner" } + point = { x = 1, y = 2 } + animal = { type.name = "pug" } + + [[products]] + name = "Hammer" + sku = 738594937 + + [[products]] + + [[products]] + name = "Nail" + sku = 284758393 + color = "gray" + + [[fruit]] + name = "apple" + + [fruit.physical] + color = "red" + shape = "round" + + [[fruit.variety]] + name = "red delicious" + + [[fruit.variety]] + name = "granny smith" + + [[fruit]] + name = "banana" + + [[fruit.variety]] + name = "plantain" + '') + + (builtins.fromTOML '' + [[package]] + name = "aho-corasick" + version = "0.6.4" + source = "registry+https://github.com/rust-lang/crates.io-index" + dependencies = [ + "memchr 2.0.1 (registry+https://github.com/rust-lang/crates.io-index)", + ] + + [[package]] + name = "ansi_term" + version = "0.9.0" + source = "registry+https://github.com/rust-lang/crates.io-index" + + [[package]] + name = "atty" + version = "0.2.10" + source = "registry+https://github.com/rust-lang/crates.io-index" + dependencies = [ + "libc 0.2.42 (registry+https://github.com/rust-lang/crates.io-index)", + "termion 1.5.1 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.5 (registry+https://github.com/rust-lang/crates.io-index)", + ] + + [metadata] + "checksum aho-corasick 0.6.4 (registry+https://github.com/rust-lang/crates.io-index)" = "d6531d44de723825aa81398a6415283229725a00fa30713812ab9323faa82fc4" + "checksum ansi_term 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ee49baf6cb617b853aa8d93bf420db2383fab46d314482ca2803b40d5fde979b" + "checksum ansi_term 0.9.0 (registry+https://github.com/rust-lang/crates.io-index)" = "23ac7c30002a5accbf7e8987d0632fa6de155b7c3d39d0067317a391e00a2ef6" + "checksum arrayvec 0.4.7 (registry+https://github.com/rust-lang/crates.io-index)" = "a1e964f9e24d588183fcb43503abda40d288c8657dfc27311516ce2f05675aef" + '') + + (builtins.fromTOML '' + a = [[{ b = true }]] + c = [ [ { d = true } ] ] + e = [[123]] + '') + +] diff --git a/third_party/nix/tests/lang/eval-okay-fromjson.exp b/third_party/nix/tests/lang/eval-okay-fromjson.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-fromjson.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-fromjson.nix b/third_party/nix/tests/lang/eval-okay-fromjson.nix new file mode 100644 index 0000000000..102ee82b5e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-fromjson.nix @@ -0,0 +1,36 @@ +# RFC 7159, section 13. +builtins.fromJSON + '' + { + "Image": { + "Width": 800, + "Height": 600, + "Title": "View from 15th Floor", + "Thumbnail": { + "Url": "http://www.example.com/image/481989943", + "Height": 125, + "Width": 100 + }, + "Animated" : false, + "IDs": [116, 943, 234, 38793, true ,false,null, -100], + "Latitude": 37.7668, + "Longitude": -122.3959 + } + } + '' +== + { Image = + { Width = 800; + Height = 600; + Title = "View from 15th Floor"; + Thumbnail = + { Url = http://www.example.com/image/481989943; + Height = 125; + Width = 100; + }; + Animated = false; + IDs = [ 116 943 234 38793 true false null (0-100) ]; + Latitude = 37.7668; + Longitude = -122.3959; + }; + } diff --git a/third_party/nix/tests/lang/eval-okay-functionargs.exp.xml b/third_party/nix/tests/lang/eval-okay-functionargs.exp.xml new file mode 100644 index 0000000000..651f54c363 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-functionargs.exp.xml @@ -0,0 +1,15 @@ +<?xml version='1.0' encoding='utf-8'?> +<expr> + <list> + <string value="stdenv" /> + <string value="fetchurl" /> + <string value="aterm-stdenv" /> + <string value="aterm-stdenv2" /> + <string value="libX11" /> + <string value="libXv" /> + <string value="mplayer-stdenv2.libXv-libX11" /> + <string value="mplayer-stdenv2.libXv-libX11_2" /> + <string value="nix-stdenv-aterm-stdenv" /> + <string value="nix-stdenv2-aterm2-stdenv2" /> + </list> +</expr> diff --git a/third_party/nix/tests/lang/eval-okay-functionargs.nix b/third_party/nix/tests/lang/eval-okay-functionargs.nix new file mode 100644 index 0000000000..68dca62ee1 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-functionargs.nix @@ -0,0 +1,80 @@ +let + + stdenvFun = { }: { name = "stdenv"; }; + stdenv2Fun = { }: { name = "stdenv2"; }; + fetchurlFun = { stdenv }: assert stdenv.name == "stdenv"; { name = "fetchurl"; }; + atermFun = { stdenv, fetchurl }: { name = "aterm-${stdenv.name}"; }; + aterm2Fun = { stdenv, fetchurl }: { name = "aterm2-${stdenv.name}"; }; + nixFun = { stdenv, fetchurl, aterm }: { name = "nix-${stdenv.name}-${aterm.name}"; }; + + mplayerFun = + { stdenv, fetchurl, enableX11 ? false, xorg ? null, enableFoo ? true, foo ? null }: + assert stdenv.name == "stdenv2"; + assert enableX11 -> xorg.libXv.name == "libXv"; + assert enableFoo -> foo != null; + { name = "mplayer-${stdenv.name}.${xorg.libXv.name}-${xorg.libX11.name}"; }; + + makeOverridable = f: origArgs: f origArgs // + { override = newArgs: + makeOverridable f (origArgs // (if builtins.isFunction newArgs then newArgs origArgs else newArgs)); + }; + + callPackage_ = pkgs: f: args: + makeOverridable f ((builtins.intersectAttrs (builtins.functionArgs f) pkgs) // args); + + allPackages = + { overrides ? (pkgs: pkgsPrev: { }) }: + let + callPackage = callPackage_ pkgs; + pkgs = pkgsStd // (overrides pkgs pkgsStd); + pkgsStd = { + inherit pkgs; + stdenv = callPackage stdenvFun { }; + stdenv2 = callPackage stdenv2Fun { }; + fetchurl = callPackage fetchurlFun { }; + aterm = callPackage atermFun { }; + xorg = callPackage xorgFun { }; + mplayer = callPackage mplayerFun { stdenv = pkgs.stdenv2; enableFoo = false; }; + nix = callPackage nixFun { }; + }; + in pkgs; + + libX11Fun = { stdenv, fetchurl }: { name = "libX11"; }; + libX11_2Fun = { stdenv, fetchurl }: { name = "libX11_2"; }; + libXvFun = { stdenv, fetchurl, libX11 }: { name = "libXv"; }; + + xorgFun = + { pkgs }: + let callPackage = callPackage_ (pkgs // pkgs.xorg); in + { + libX11 = callPackage libX11Fun { }; + libXv = callPackage libXvFun { }; + }; + +in + +let + + pkgs = allPackages { }; + + pkgs2 = allPackages { + overrides = pkgs: pkgsPrev: { + stdenv = pkgs.stdenv2; + nix = pkgsPrev.nix.override { aterm = aterm2Fun { inherit (pkgs) stdenv fetchurl; }; }; + xorg = pkgsPrev.xorg // { libX11 = libX11_2Fun { inherit (pkgs) stdenv fetchurl; }; }; + }; + }; + +in + + [ pkgs.stdenv.name + pkgs.fetchurl.name + pkgs.aterm.name + pkgs2.aterm.name + pkgs.xorg.libX11.name + pkgs.xorg.libXv.name + pkgs.mplayer.name + pkgs2.mplayer.name + pkgs.nix.name + pkgs2.nix.name + ] diff --git a/third_party/nix/tests/lang/eval-okay-getattrpos-undefined.exp b/third_party/nix/tests/lang/eval-okay-getattrpos-undefined.exp new file mode 100644 index 0000000000..19765bd501 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-getattrpos-undefined.exp @@ -0,0 +1 @@ +null diff --git a/third_party/nix/tests/lang/eval-okay-getattrpos-undefined.nix b/third_party/nix/tests/lang/eval-okay-getattrpos-undefined.nix new file mode 100644 index 0000000000..14dd38f773 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-getattrpos-undefined.nix @@ -0,0 +1 @@ +builtins.unsafeGetAttrPos "abort" builtins diff --git a/third_party/nix/tests/lang/eval-okay-getattrpos.exp b/third_party/nix/tests/lang/eval-okay-getattrpos.exp new file mode 100644 index 0000000000..469249bbc6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-getattrpos.exp @@ -0,0 +1 @@ +{ column = 5; file = "eval-okay-getattrpos.nix"; line = 3; } diff --git a/third_party/nix/tests/lang/eval-okay-getattrpos.nix b/third_party/nix/tests/lang/eval-okay-getattrpos.nix new file mode 100644 index 0000000000..ca6b079615 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-getattrpos.nix @@ -0,0 +1,6 @@ +let + as = { + foo = "bar"; + }; + pos = builtins.unsafeGetAttrPos "foo" as; +in { inherit (pos) column line; file = baseNameOf pos.file; } diff --git a/third_party/nix/tests/lang/eval-okay-getenv.exp b/third_party/nix/tests/lang/eval-okay-getenv.exp new file mode 100644 index 0000000000..14e24d4190 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-getenv.exp @@ -0,0 +1 @@ +"foobar" diff --git a/third_party/nix/tests/lang/eval-okay-getenv.nix b/third_party/nix/tests/lang/eval-okay-getenv.nix new file mode 100644 index 0000000000..4cfec5f553 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-getenv.nix @@ -0,0 +1 @@ +builtins.getEnv "TEST_VAR" + (if builtins.getEnv "NO_SUCH_VAR" == "" then "bar" else "bla") diff --git a/third_party/nix/tests/lang/eval-okay-hash.exp b/third_party/nix/tests/lang/eval-okay-hash.exp new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-hash.exp diff --git a/third_party/nix/tests/lang/eval-okay-hashfile.exp b/third_party/nix/tests/lang/eval-okay-hashfile.exp new file mode 100644 index 0000000000..ff1e8293ef --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-hashfile.exp @@ -0,0 +1 @@ +[ "d3b07384d113edec49eaa6238ad5ff00" "0f343b0931126a20f133d67c2b018a3b" "f1d2d2f924e986ac86fdf7b36c94bcdf32beec15" "60cacbf3d72e1e7834203da608037b1bf83b40e8" "b5bb9d8014a0f9b1d61e21e796d78dccdf1352f23cd32812f4850b878ae4944c" "5f70bf18a086007016e948b04aed3b82103a36bea41755b6cddfaf10ace3c6ef" "0cf9180a764aba863a67b6d72f0918bc131c6772642cb2dce5a34f0a702f9470ddc2bf125c12198b1995c233c34b4afd346c54a2334c350a948a51b6e8b4e6b6" "8efb4f73c5655351c444eb109230c556d39e2c7624e9c11abc9e3fb4b9b9254218cc5085b454a9698d085cfa92198491f07a723be4574adc70617b73eb0b6461" ] diff --git a/third_party/nix/tests/lang/eval-okay-hashfile.nix b/third_party/nix/tests/lang/eval-okay-hashfile.nix new file mode 100644 index 0000000000..aff5a18568 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-hashfile.nix @@ -0,0 +1,4 @@ +let + paths = [ ./data ./binary-data ]; +in + builtins.concatLists (map (hash: map (builtins.hashFile hash) paths) ["md5" "sha1" "sha256" "sha512"]) diff --git a/third_party/nix/tests/lang/eval-okay-hashstring.exp b/third_party/nix/tests/lang/eval-okay-hashstring.exp new file mode 100644 index 0000000000..d720a082dd --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-hashstring.exp @@ -0,0 +1 @@ +[ "d41d8cd98f00b204e9800998ecf8427e" "6c69ee7f211c640419d5366cc076ae46" "bb3438fbabd460ea6dbd27d153e2233b" "da39a3ee5e6b4b0d3255bfef95601890afd80709" "cd54e8568c1b37cf1e5badb0779bcbf382212189" "6d12e10b1d331dad210e47fd25d4f260802b7e77" "e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855" "900a4469df00ccbfd0c145c6d1e4b7953dd0afafadd7534e3a4019e8d38fc663" "ad0387b3bd8652f730ca46d25f9c170af0fd589f42e7f23f5a9e6412d97d7e56" "cf83e1357eefb8bdf1542850d66d8007d620e4050b5715dc83f4a921d36ce9ce47d0d13c5d85f2b0ff8318d2877eec2f63b931bd47417a81a538327af927da3e" "9d0886f8c6b389398a16257bc79780fab9831c7fc11c8ab07fa732cb7b348feade382f92617c9c5305fefba0af02ab5fd39a587d330997ff5bd0db19f7666653" "21644b72aa259e5a588cd3afbafb1d4310f4889680f6c83b9d531596a5a284f34dbebff409d23bcc86aee6bad10c891606f075c6f4755cb536da27db5693f3a7" ] diff --git a/third_party/nix/tests/lang/eval-okay-hashstring.nix b/third_party/nix/tests/lang/eval-okay-hashstring.nix new file mode 100644 index 0000000000..b0f62b245c --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-hashstring.nix @@ -0,0 +1,4 @@ +let + strings = [ "" "text 1" "text 2" ]; +in + builtins.concatLists (map (hash: map (builtins.hashString hash) strings) ["md5" "sha1" "sha256" "sha512"]) diff --git a/third_party/nix/tests/lang/eval-okay-if.exp b/third_party/nix/tests/lang/eval-okay-if.exp new file mode 100644 index 0000000000..00750edc07 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-if.exp @@ -0,0 +1 @@ +3 diff --git a/third_party/nix/tests/lang/eval-okay-if.nix b/third_party/nix/tests/lang/eval-okay-if.nix new file mode 100644 index 0000000000..23e4c74d50 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-if.nix @@ -0,0 +1 @@ +if "foo" != "f" + "oo" then 1 else if false then 2 else 3 diff --git a/third_party/nix/tests/lang/eval-okay-import.exp b/third_party/nix/tests/lang/eval-okay-import.exp new file mode 100644 index 0000000000..c508125b55 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-import.exp @@ -0,0 +1 @@ +[ 1 2 3 4 5 6 7 8 9 10 ] diff --git a/third_party/nix/tests/lang/eval-okay-import.nix b/third_party/nix/tests/lang/eval-okay-import.nix new file mode 100644 index 0000000000..0b18d94131 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-import.nix @@ -0,0 +1,11 @@ +let + + overrides = { + import = fn: scopedImport overrides fn; + + scopedImport = attrs: fn: scopedImport (overrides // attrs) fn; + + builtins = builtins // overrides; + } // import ./lib.nix; + +in scopedImport overrides ./imported.nix diff --git a/third_party/nix/tests/lang/eval-okay-ind-string.exp b/third_party/nix/tests/lang/eval-okay-ind-string.exp new file mode 100644 index 0000000000..9cf4bd2ee7 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-ind-string.exp @@ -0,0 +1 @@ +"This is an indented multi-line string\nliteral. An amount of whitespace at\nthe start of each line matching the minimum\nindentation of all lines in the string\nliteral together will be removed. Thus,\nin this case four spaces will be\nstripped from each line, even though\n THIS LINE is indented six spaces.\n\nAlso, empty lines don't count in the\ndetermination of the indentation level (the\nprevious empty line has indentation 0, but\nit doesn't matter).\nIf the string starts with whitespace\n followed by a newline, it's stripped, but\n that's not the case here. Two spaces are\n stripped because of the \" \" at the start. \nThis line is indented\na bit further.\nAnti-quotations, like so, are\nalso allowed.\n The \\ is not special here.\n' can be followed by any character except another ', e.g. 'x'.\nLikewise for $, e.g. $$ or $varName.\nBut ' followed by ' is special, as is $ followed by {.\nIf you want them, use anti-quotations: '', ${.\n Tabs are not interpreted as whitespace (since we can't guess\n what tab settings are intended), so don't use them.\n\tThis line starts with a space and a tab, so only one\n space will be stripped from each line.\nAlso note that if the last line (just before the closing ' ')\nconsists only of whitespace, it's ignored. But here there is\nsome non-whitespace stuff, so the line isn't removed. \nThis shows a hacky way to preserve an empty line after the start.\nBut there's no reason to do so: you could just repeat the empty\nline.\n Similarly you can force an indentation level,\n in this case to 2 spaces. This works because the anti-quote\n is significant (not whitespace).\nstart on network-interfaces\n\nstart script\n\n rm -f /var/run/opengl-driver\n ln -sf 123 /var/run/opengl-driver\n\n rm -f /var/log/slim.log\n \nend script\n\nenv SLIM_CFGFILE=abc\nenv SLIM_THEMESDIR=def\nenv FONTCONFIG_FILE=/etc/fonts/fonts.conf \t\t\t\t# !!! cleanup\nenv XKB_BINDIR=foo/bin \t\t\t\t# Needed for the Xkb extension.\nenv LD_LIBRARY_PATH=libX11/lib:libXext/lib:/usr/lib/ # related to xorg-sys-opengl - needed to load libglx for (AI)GLX support (for compiz)\n\nenv XORG_DRI_DRIVER_PATH=nvidiaDrivers/X11R6/lib/modules/drivers/ \n\nexec slim/bin/slim\nEscaping of ' followed by ': ''\nEscaping of $ followed by {: ${\nAnd finally to interpret \\n etc. as in a string: \n, \r, \t.\nfoo\n'bla'\nbar\ncut -d $'\\t' -f 1\nending dollar $$\n" diff --git a/third_party/nix/tests/lang/eval-okay-ind-string.nix b/third_party/nix/tests/lang/eval-okay-ind-string.nix new file mode 100644 index 0000000000..1669dc0648 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-ind-string.nix @@ -0,0 +1,128 @@ +let + + s1 = '' + This is an indented multi-line string + literal. An amount of whitespace at + the start of each line matching the minimum + indentation of all lines in the string + literal together will be removed. Thus, + in this case four spaces will be + stripped from each line, even though + THIS LINE is indented six spaces. + + Also, empty lines don't count in the + determination of the indentation level (the + previous empty line has indentation 0, but + it doesn't matter). + ''; + + s2 = '' If the string starts with whitespace + followed by a newline, it's stripped, but + that's not the case here. Two spaces are + stripped because of the " " at the start. + ''; + + s3 = '' + This line is indented + a bit further. + ''; # indentation of last line doesn't count if it's empty + + s4 = '' + Anti-quotations, like ${if true then "so" else "not so"}, are + also allowed. + ''; + + s5 = '' + The \ is not special here. + ' can be followed by any character except another ', e.g. 'x'. + Likewise for $, e.g. $$ or $varName. + But ' followed by ' is special, as is $ followed by {. + If you want them, use anti-quotations: ${"''"}, ${"\${"}. + ''; + + s6 = '' + Tabs are not interpreted as whitespace (since we can't guess + what tab settings are intended), so don't use them. + This line starts with a space and a tab, so only one + space will be stripped from each line. + ''; + + s7 = '' + Also note that if the last line (just before the closing ' ') + consists only of whitespace, it's ignored. But here there is + some non-whitespace stuff, so the line isn't removed. ''; + + s8 = '' ${""} + This shows a hacky way to preserve an empty line after the start. + But there's no reason to do so: you could just repeat the empty + line. + ''; + + s9 = '' + ${""} Similarly you can force an indentation level, + in this case to 2 spaces. This works because the anti-quote + is significant (not whitespace). + ''; + + s10 = '' + ''; + + s11 = ''''; + + s12 = '' ''; + + s13 = '' + start on network-interfaces + + start script + + rm -f /var/run/opengl-driver + ${if true + then "ln -sf 123 /var/run/opengl-driver" + else if true + then "ln -sf 456 /var/run/opengl-driver" + else "" + } + + rm -f /var/log/slim.log + + end script + + env SLIM_CFGFILE=${"abc"} + env SLIM_THEMESDIR=${"def"} + env FONTCONFIG_FILE=/etc/fonts/fonts.conf # !!! cleanup + env XKB_BINDIR=${"foo"}/bin # Needed for the Xkb extension. + env LD_LIBRARY_PATH=${"libX11"}/lib:${"libXext"}/lib:/usr/lib/ # related to xorg-sys-opengl - needed to load libglx for (AI)GLX support (for compiz) + + ${if true + then "env XORG_DRI_DRIVER_PATH=${"nvidiaDrivers"}/X11R6/lib/modules/drivers/" + else if true + then "env XORG_DRI_DRIVER_PATH=${"mesa"}/lib/modules/dri" + else "" + } + + exec ${"slim"}/bin/slim + ''; + + s14 = '' + Escaping of ' followed by ': ''' + Escaping of $ followed by {: ''${ + And finally to interpret \n etc. as in a string: ''\n, ''\r, ''\t. + ''; + + # Regression test: antiquotation in '${x}' should work, but didn't. + s15 = let x = "bla"; in '' + foo + '${x}' + bar + ''; + + # Regression test: accept $'. + s16 = '' + cut -d $'\t' -f 1 + ''; + + # Accept dollars at end of strings + s17 = ''ending dollar $'' + ''$'' + "\n"; + +in s1 + s2 + s3 + s4 + s5 + s6 + s7 + s8 + s9 + s10 + s11 + s12 + s13 + s14 + s15 + s16 + s17 diff --git a/third_party/nix/tests/lang/eval-okay-let.exp b/third_party/nix/tests/lang/eval-okay-let.exp new file mode 100644 index 0000000000..14e24d4190 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-let.exp @@ -0,0 +1 @@ +"foobar" diff --git a/third_party/nix/tests/lang/eval-okay-let.nix b/third_party/nix/tests/lang/eval-okay-let.nix new file mode 100644 index 0000000000..fe118c5282 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-let.nix @@ -0,0 +1,5 @@ +let { + x = "foo"; + y = "bar"; + body = x + y; +} diff --git a/third_party/nix/tests/lang/eval-okay-list.exp b/third_party/nix/tests/lang/eval-okay-list.exp new file mode 100644 index 0000000000..f784f26d83 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-list.exp @@ -0,0 +1 @@ +"foobarblatest" diff --git a/third_party/nix/tests/lang/eval-okay-list.nix b/third_party/nix/tests/lang/eval-okay-list.nix new file mode 100644 index 0000000000..d433bcf908 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-list.nix @@ -0,0 +1,7 @@ +with import ./lib.nix; + +let { + + body = concat ["foo" "bar" "bla" "test"]; + +} \ No newline at end of file diff --git a/third_party/nix/tests/lang/eval-okay-listtoattrs.exp b/third_party/nix/tests/lang/eval-okay-listtoattrs.exp new file mode 100644 index 0000000000..74abef7bc6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-listtoattrs.exp @@ -0,0 +1 @@ +"AAbar" diff --git a/third_party/nix/tests/lang/eval-okay-listtoattrs.nix b/third_party/nix/tests/lang/eval-okay-listtoattrs.nix new file mode 100644 index 0000000000..4186e029b5 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-listtoattrs.nix @@ -0,0 +1,11 @@ +# this test shows how to use listToAttrs and that evaluation is still lazy (throw isn't called) +with import ./lib.nix; + +let + asi = name: value : { inherit name value; }; + list = [ ( asi "a" "A" ) ( asi "b" "B" ) ]; + a = builtins.listToAttrs list; + b = builtins.listToAttrs ( list ++ list ); + r = builtins.listToAttrs [ (asi "result" [ a b ]) ( asi "throw" (throw "this should not be thrown")) ]; + x = builtins.listToAttrs [ (asi "foo" "bar") (asi "foo" "bla") ]; +in concat (map (x: x.a) r.result) + x.foo diff --git a/third_party/nix/tests/lang/eval-okay-logic.exp b/third_party/nix/tests/lang/eval-okay-logic.exp new file mode 100644 index 0000000000..d00491fd7e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-logic.exp @@ -0,0 +1 @@ +1 diff --git a/third_party/nix/tests/lang/eval-okay-logic.nix b/third_party/nix/tests/lang/eval-okay-logic.nix new file mode 100644 index 0000000000..fbb1279440 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-logic.nix @@ -0,0 +1 @@ +assert !false && (true || false) -> true; 1 diff --git a/third_party/nix/tests/lang/eval-okay-map.exp b/third_party/nix/tests/lang/eval-okay-map.exp new file mode 100644 index 0000000000..dbb64f717b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-map.exp @@ -0,0 +1 @@ +"foobarblabarxyzzybar" diff --git a/third_party/nix/tests/lang/eval-okay-map.nix b/third_party/nix/tests/lang/eval-okay-map.nix new file mode 100644 index 0000000000..a76c1d8114 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-map.nix @@ -0,0 +1,3 @@ +with import ./lib.nix; + +concat (map (x: x + "bar") [ "foo" "bla" "xyzzy" ]) \ No newline at end of file diff --git a/third_party/nix/tests/lang/eval-okay-mapattrs.exp b/third_party/nix/tests/lang/eval-okay-mapattrs.exp new file mode 100644 index 0000000000..3f113f17ba --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-mapattrs.exp @@ -0,0 +1 @@ +{ x = "x-foo"; y = "y-bar"; } diff --git a/third_party/nix/tests/lang/eval-okay-mapattrs.nix b/third_party/nix/tests/lang/eval-okay-mapattrs.nix new file mode 100644 index 0000000000..f075b6275e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-mapattrs.nix @@ -0,0 +1,3 @@ +with import ./lib.nix; + +builtins.mapAttrs (name: value: name + "-" + value) { x = "foo"; y = "bar"; } diff --git a/third_party/nix/tests/lang/eval-okay-nested-with.exp b/third_party/nix/tests/lang/eval-okay-nested-with.exp new file mode 100644 index 0000000000..0cfbf08886 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-nested-with.exp @@ -0,0 +1 @@ +2 diff --git a/third_party/nix/tests/lang/eval-okay-nested-with.nix b/third_party/nix/tests/lang/eval-okay-nested-with.nix new file mode 100644 index 0000000000..ba9d79aa79 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-nested-with.nix @@ -0,0 +1,3 @@ +with { x = 1; }; +with { x = 2; }; +x diff --git a/third_party/nix/tests/lang/eval-okay-new-let.exp b/third_party/nix/tests/lang/eval-okay-new-let.exp new file mode 100644 index 0000000000..f98b388071 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-new-let.exp @@ -0,0 +1 @@ +"xyzzyfoobar" diff --git a/third_party/nix/tests/lang/eval-okay-new-let.nix b/third_party/nix/tests/lang/eval-okay-new-let.nix new file mode 100644 index 0000000000..7381231415 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-new-let.nix @@ -0,0 +1,14 @@ +let + + f = z: + + let + x = "foo"; + y = "bar"; + body = 1; # compat test + in + z + x + y; + + arg = "xyzzy"; + +in f arg diff --git a/third_party/nix/tests/lang/eval-okay-null-dynamic-attrs.exp b/third_party/nix/tests/lang/eval-okay-null-dynamic-attrs.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-null-dynamic-attrs.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-null-dynamic-attrs.nix b/third_party/nix/tests/lang/eval-okay-null-dynamic-attrs.nix new file mode 100644 index 0000000000..b060c0bc98 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-null-dynamic-attrs.nix @@ -0,0 +1 @@ +{ ${null} = true; } == {} diff --git a/third_party/nix/tests/lang/eval-okay-overrides.exp b/third_party/nix/tests/lang/eval-okay-overrides.exp new file mode 100644 index 0000000000..0cfbf08886 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-overrides.exp @@ -0,0 +1 @@ +2 diff --git a/third_party/nix/tests/lang/eval-okay-overrides.nix b/third_party/nix/tests/lang/eval-okay-overrides.nix new file mode 100644 index 0000000000..358742b36e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-overrides.nix @@ -0,0 +1,9 @@ +let + + overrides = { a = 2; }; + +in (rec { + __overrides = overrides; + x = a; + a = 1; +}).x diff --git a/third_party/nix/tests/lang/eval-okay-partition.exp b/third_party/nix/tests/lang/eval-okay-partition.exp new file mode 100644 index 0000000000..cd8b8b020c --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-partition.exp @@ -0,0 +1 @@ +{ right = [ 0 2 4 6 8 10 100 102 104 106 108 110 ]; wrong = [ 1 3 5 7 9 101 103 105 107 109 ]; } diff --git a/third_party/nix/tests/lang/eval-okay-partition.nix b/third_party/nix/tests/lang/eval-okay-partition.nix new file mode 100644 index 0000000000..846d2ce494 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-partition.nix @@ -0,0 +1,5 @@ +with import ./lib.nix; + +builtins.partition + (x: x / 2 * 2 == x) + (builtins.concatLists [ (range 0 10) (range 100 110) ]) diff --git a/third_party/nix/tests/lang/eval-okay-path.nix b/third_party/nix/tests/lang/eval-okay-path.nix new file mode 100644 index 0000000000..e67168cf3e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-path.nix @@ -0,0 +1,7 @@ +builtins.path + { path = ./.; + filter = path: _: baseNameOf path == "data"; + recursive = true; + sha256 = "1yhm3gwvg5a41yylymgblsclk95fs6jy72w0wv925mmidlhcq4sw"; + name = "output"; + } diff --git a/third_party/nix/tests/lang/eval-okay-pathexists.exp b/third_party/nix/tests/lang/eval-okay-pathexists.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-pathexists.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-pathexists.nix b/third_party/nix/tests/lang/eval-okay-pathexists.nix new file mode 100644 index 0000000000..50c28ee0cd --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-pathexists.nix @@ -0,0 +1,5 @@ +builtins.pathExists (builtins.toPath ./lib.nix) +&& builtins.pathExists (builtins.toPath (builtins.toString ./lib.nix)) +&& !builtins.pathExists (builtins.toPath (builtins.toString ./bla.nix)) +&& builtins.pathExists ./lib.nix +&& !builtins.pathExists ./bla.nix diff --git a/third_party/nix/tests/lang/eval-okay-patterns.exp b/third_party/nix/tests/lang/eval-okay-patterns.exp new file mode 100644 index 0000000000..a4304010fe --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-patterns.exp @@ -0,0 +1 @@ +"abcxyzDDDDEFijk" diff --git a/third_party/nix/tests/lang/eval-okay-patterns.nix b/third_party/nix/tests/lang/eval-okay-patterns.nix new file mode 100644 index 0000000000..96fd25a015 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-patterns.nix @@ -0,0 +1,16 @@ +let + + f = args@{x, y, z}: x + args.y + z; + + g = {x, y, z}@args: f args; + + h = {x ? "d", y ? x, z ? args.x}@args: x + y + z; + + j = {x, y, z, ...}: x + y + z; + +in + f {x = "a"; y = "b"; z = "c";} + + g {x = "x"; y = "y"; z = "z";} + + h {x = "D";} + + h {x = "D"; y = "E"; z = "F";} + + j {x = "i"; y = "j"; z = "k"; bla = "bla"; foo = "bar";} diff --git a/third_party/nix/tests/lang/eval-okay-readDir.exp b/third_party/nix/tests/lang/eval-okay-readDir.exp new file mode 100644 index 0000000000..bf8d2c14ea --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-readDir.exp @@ -0,0 +1 @@ +{ bar = "regular"; foo = "directory"; } diff --git a/third_party/nix/tests/lang/eval-okay-readDir.nix b/third_party/nix/tests/lang/eval-okay-readDir.nix new file mode 100644 index 0000000000..a7ec9292aa --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-readDir.nix @@ -0,0 +1 @@ +builtins.readDir ./readDir diff --git a/third_party/nix/tests/lang/eval-okay-readfile.exp b/third_party/nix/tests/lang/eval-okay-readfile.exp new file mode 100644 index 0000000000..a2c87d0c43 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-readfile.exp @@ -0,0 +1 @@ +"builtins.readFile ./eval-okay-readfile.nix\n" diff --git a/third_party/nix/tests/lang/eval-okay-readfile.nix b/third_party/nix/tests/lang/eval-okay-readfile.nix new file mode 100644 index 0000000000..82f7cb1743 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-readfile.nix @@ -0,0 +1 @@ +builtins.readFile ./eval-okay-readfile.nix diff --git a/third_party/nix/tests/lang/eval-okay-redefine-builtin.exp b/third_party/nix/tests/lang/eval-okay-redefine-builtin.exp new file mode 100644 index 0000000000..c508d5366f --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-redefine-builtin.exp @@ -0,0 +1 @@ +false diff --git a/third_party/nix/tests/lang/eval-okay-redefine-builtin.nix b/third_party/nix/tests/lang/eval-okay-redefine-builtin.nix new file mode 100644 index 0000000000..df9fc3f37d --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-redefine-builtin.nix @@ -0,0 +1,3 @@ +let + throw = abort "Error!"; +in (builtins.tryEval <foobaz>).success diff --git a/third_party/nix/tests/lang/eval-okay-regex-match.exp b/third_party/nix/tests/lang/eval-okay-regex-match.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-regex-match.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-regex-match.nix b/third_party/nix/tests/lang/eval-okay-regex-match.nix new file mode 100644 index 0000000000..273e259071 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-regex-match.nix @@ -0,0 +1,29 @@ +with builtins; + +let + + matches = pat: s: match pat s != null; + + splitFN = match "((.*)/)?([^/]*)\\.(nix|cc)"; + +in + +assert matches "foobar" "foobar"; +assert matches "fo*" "f"; +assert !matches "fo+" "f"; +assert matches "fo*" "fo"; +assert matches "fo*" "foo"; +assert matches "fo+" "foo"; +assert matches "fo{1,2}" "foo"; +assert !matches "fo{1,2}" "fooo"; +assert !matches "fo*" "foobar"; +assert matches "[[:space:]]+([^[:space:]]+)[[:space:]]+" " foo "; +assert !matches "[[:space:]]+([[:upper:]]+)[[:space:]]+" " foo "; + +assert match "(.*)\\.nix" "foobar.nix" == [ "foobar" ]; +assert match "[[:space:]]+([[:upper:]]+)[[:space:]]+" " FOO " == [ "FOO" ]; + +assert splitFN "/path/to/foobar.nix" == [ "/path/to/" "/path/to" "foobar" "nix" ]; +assert splitFN "foobar.cc" == [ null null "foobar" "cc" ]; + +true diff --git a/third_party/nix/tests/lang/eval-okay-regex-split.exp b/third_party/nix/tests/lang/eval-okay-regex-split.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-regex-split.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-regex-split.nix b/third_party/nix/tests/lang/eval-okay-regex-split.nix new file mode 100644 index 0000000000..0073e05778 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-regex-split.nix @@ -0,0 +1,48 @@ +with builtins; + +# Non capturing regex returns empty lists +assert split "foobar" "foobar" == ["" [] ""]; +assert split "fo*" "f" == ["" [] ""]; +assert split "fo+" "f" == ["f"]; +assert split "fo*" "fo" == ["" [] ""]; +assert split "fo*" "foo" == ["" [] ""]; +assert split "fo+" "foo" == ["" [] ""]; +assert split "fo{1,2}" "foo" == ["" [] ""]; +assert split "fo{1,2}" "fooo" == ["" [] "o"]; +assert split "fo*" "foobar" == ["" [] "bar"]; + +# Capturing regex returns a list of sub-matches +assert split "(fo*)" "f" == ["" ["f"] ""]; +assert split "(fo+)" "f" == ["f"]; +assert split "(fo*)" "fo" == ["" ["fo"] ""]; +assert split "(f)(o*)" "f" == ["" ["f" ""] ""]; +assert split "(f)(o*)" "foo" == ["" ["f" "oo"] ""]; +assert split "(fo+)" "foo" == ["" ["foo"] ""]; +assert split "(fo{1,2})" "foo" == ["" ["foo"] ""]; +assert split "(fo{1,2})" "fooo" == ["" ["foo"] "o"]; +assert split "(fo*)" "foobar" == ["" ["foo"] "bar"]; + +# Matches are greedy. +assert split "(o+)" "oooofoooo" == ["" ["oooo"] "f" ["oooo"] ""]; + +# Matches multiple times. +assert split "(b)" "foobarbaz" == ["foo" ["b"] "ar" ["b"] "az"]; + +# Split large strings containing newlines. null are inserted when a +# pattern within the current did not match anything. +assert split "[[:space:]]+|([',.!?])" '' + Nix Rocks! + That's why I use it. +'' == [ + "Nix" [ null ] "Rocks" ["!"] "" [ null ] + "That" ["'"] "s" [ null ] "why" [ null ] "I" [ null ] "use" [ null ] "it" ["."] "" [ null ] + "" +]; + +# Documentation examples +assert split "(a)b" "abc" == [ "" [ "a" ] "c" ]; +assert split "([ac])" "abc" == [ "" [ "a" ] "b" [ "c" ] "" ]; +assert split "(a)|(c)" "abc" == [ "" [ "a" null ] "b" [ null "c" ] "" ]; +assert split "([[:upper:]]+)" " FOO " == [ " " [ "FOO" ] " " ]; + +true diff --git a/third_party/nix/tests/lang/eval-okay-remove.exp b/third_party/nix/tests/lang/eval-okay-remove.exp new file mode 100644 index 0000000000..8d38505c16 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-remove.exp @@ -0,0 +1 @@ +456 diff --git a/third_party/nix/tests/lang/eval-okay-remove.nix b/third_party/nix/tests/lang/eval-okay-remove.nix new file mode 100644 index 0000000000..4ad5ba897f --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-remove.nix @@ -0,0 +1,5 @@ +let { + attrs = {x = 123; y = 456;}; + + body = (removeAttrs attrs ["x"]).y; +} \ No newline at end of file diff --git a/third_party/nix/tests/lang/eval-okay-replacestrings.exp b/third_party/nix/tests/lang/eval-okay-replacestrings.exp new file mode 100644 index 0000000000..72e8274d8c --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-replacestrings.exp @@ -0,0 +1 @@ +[ "faabar" "fbar" "fubar" "faboor" "fubar" "XaXbXcX" "X" "a_b" ] diff --git a/third_party/nix/tests/lang/eval-okay-replacestrings.nix b/third_party/nix/tests/lang/eval-okay-replacestrings.nix new file mode 100644 index 0000000000..bd8031fc00 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-replacestrings.nix @@ -0,0 +1,11 @@ +with builtins; + +[ (replaceStrings ["o"] ["a"] "foobar") + (replaceStrings ["o"] [""] "foobar") + (replaceStrings ["oo"] ["u"] "foobar") + (replaceStrings ["oo" "a"] ["a" "oo"] "foobar") + (replaceStrings ["oo" "oo"] ["u" "i"] "foobar") + (replaceStrings [""] ["X"] "abc") + (replaceStrings [""] ["X"] "") + (replaceStrings ["-"] ["_"] "a-b") +] diff --git a/third_party/nix/tests/lang/eval-okay-scope-1.exp b/third_party/nix/tests/lang/eval-okay-scope-1.exp new file mode 100644 index 0000000000..00750edc07 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-1.exp @@ -0,0 +1 @@ +3 diff --git a/third_party/nix/tests/lang/eval-okay-scope-1.nix b/third_party/nix/tests/lang/eval-okay-scope-1.nix new file mode 100644 index 0000000000..fa38a7174e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-1.nix @@ -0,0 +1,6 @@ +(({x}: x: + + { x = 1; + y = x; + } +) {x = 2;} 3).y diff --git a/third_party/nix/tests/lang/eval-okay-scope-2.exp b/third_party/nix/tests/lang/eval-okay-scope-2.exp new file mode 100644 index 0000000000..d00491fd7e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-2.exp @@ -0,0 +1 @@ +1 diff --git a/third_party/nix/tests/lang/eval-okay-scope-2.nix b/third_party/nix/tests/lang/eval-okay-scope-2.nix new file mode 100644 index 0000000000..eb8b02bc49 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-2.nix @@ -0,0 +1,6 @@ +((x: {x}: + rec { + x = 1; + y = x; + } +) 2 {x = 3;}).y diff --git a/third_party/nix/tests/lang/eval-okay-scope-3.exp b/third_party/nix/tests/lang/eval-okay-scope-3.exp new file mode 100644 index 0000000000..b8626c4cff --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-3.exp @@ -0,0 +1 @@ +4 diff --git a/third_party/nix/tests/lang/eval-okay-scope-3.nix b/third_party/nix/tests/lang/eval-okay-scope-3.nix new file mode 100644 index 0000000000..10d6bc04d8 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-3.nix @@ -0,0 +1,6 @@ +((x: as: {x}: + rec { + inherit (as) x; + y = x; + } +) 2 {x = 4;} {x = 3;}).y diff --git a/third_party/nix/tests/lang/eval-okay-scope-4.exp b/third_party/nix/tests/lang/eval-okay-scope-4.exp new file mode 100644 index 0000000000..00ff03a46c --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-4.exp @@ -0,0 +1 @@ +"ccdd" diff --git a/third_party/nix/tests/lang/eval-okay-scope-4.nix b/third_party/nix/tests/lang/eval-okay-scope-4.nix new file mode 100644 index 0000000000..dc8243bc85 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-4.nix @@ -0,0 +1,10 @@ +let { + + x = "a"; + y = "b"; + + f = {x ? y, y ? x}: x + y; + + body = f {x = "c";} + f {y = "d";}; + +} diff --git a/third_party/nix/tests/lang/eval-okay-scope-6.exp b/third_party/nix/tests/lang/eval-okay-scope-6.exp new file mode 100644 index 0000000000..00ff03a46c --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-6.exp @@ -0,0 +1 @@ +"ccdd" diff --git a/third_party/nix/tests/lang/eval-okay-scope-6.nix b/third_party/nix/tests/lang/eval-okay-scope-6.nix new file mode 100644 index 0000000000..0995d4e7e7 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-6.nix @@ -0,0 +1,7 @@ +let { + + f = {x ? y, y ? x}: x + y; + + body = f {x = "c";} + f {y = "d";}; + +} diff --git a/third_party/nix/tests/lang/eval-okay-scope-7.exp b/third_party/nix/tests/lang/eval-okay-scope-7.exp new file mode 100644 index 0000000000..d00491fd7e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-7.exp @@ -0,0 +1 @@ +1 diff --git a/third_party/nix/tests/lang/eval-okay-scope-7.nix b/third_party/nix/tests/lang/eval-okay-scope-7.nix new file mode 100644 index 0000000000..4da02968f6 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-scope-7.nix @@ -0,0 +1,6 @@ +rec { + inherit (x) y; + x = { + y = 1; + }; +}.y diff --git a/third_party/nix/tests/lang/eval-okay-search-path.exp b/third_party/nix/tests/lang/eval-okay-search-path.exp new file mode 100644 index 0000000000..4519bc406d --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-search-path.exp @@ -0,0 +1 @@ +"abccX" diff --git a/third_party/nix/tests/lang/eval-okay-search-path.flags b/third_party/nix/tests/lang/eval-okay-search-path.flags new file mode 100644 index 0000000000..a28e682100 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-search-path.flags @@ -0,0 +1 @@ +-I lang/dir1 -I lang/dir2 -I dir5=lang/dir3 \ No newline at end of file diff --git a/third_party/nix/tests/lang/eval-okay-search-path.nix b/third_party/nix/tests/lang/eval-okay-search-path.nix new file mode 100644 index 0000000000..cca41f821f --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-search-path.nix @@ -0,0 +1,11 @@ +with import ./lib.nix; +with builtins; + +assert pathExists <nix/buildenv.nix>; + +assert length __nixPath == 6; +assert length (filter (x: x.prefix == "nix") __nixPath) == 1; +assert length (filter (x: baseNameOf x.path == "dir4") __nixPath) == 1; + +import <a.nix> + import <b.nix> + import <c.nix> + import <dir5/c.nix> + + (let __nixPath = [ { path = ./dir2; } { path = ./dir1; } ]; in import <a.nix>) diff --git a/third_party/nix/tests/lang/eval-okay-seq.exp b/third_party/nix/tests/lang/eval-okay-seq.exp new file mode 100644 index 0000000000..0cfbf08886 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-seq.exp @@ -0,0 +1 @@ +2 diff --git a/third_party/nix/tests/lang/eval-okay-seq.nix b/third_party/nix/tests/lang/eval-okay-seq.nix new file mode 100644 index 0000000000..0a9a21c03b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-seq.nix @@ -0,0 +1 @@ +builtins.seq 1 2 diff --git a/third_party/nix/tests/lang/eval-okay-sort.exp b/third_party/nix/tests/lang/eval-okay-sort.exp new file mode 100644 index 0000000000..148b935163 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-sort.exp @@ -0,0 +1 @@ +[ [ 42 77 147 249 483 526 ] [ 526 483 249 147 77 42 ] [ "bar" "fnord" "foo" "xyzzy" ] [ { key = 1; value = "foo"; } { key = 1; value = "fnord"; } { key = 2; value = "bar"; } ] ] diff --git a/third_party/nix/tests/lang/eval-okay-sort.nix b/third_party/nix/tests/lang/eval-okay-sort.nix new file mode 100644 index 0000000000..8299c3a4a3 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-sort.nix @@ -0,0 +1,8 @@ +with builtins; + +[ (sort lessThan [ 483 249 526 147 42 77 ]) + (sort (x: y: y < x) [ 483 249 526 147 42 77 ]) + (sort lessThan [ "foo" "bar" "xyzzy" "fnord" ]) + (sort (x: y: x.key < y.key) + [ { key = 1; value = "foo"; } { key = 2; value = "bar"; } { key = 1; value = "fnord"; } ]) +] diff --git a/third_party/nix/tests/lang/eval-okay-splitversion.exp b/third_party/nix/tests/lang/eval-okay-splitversion.exp new file mode 100644 index 0000000000..153ceb8186 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-splitversion.exp @@ -0,0 +1 @@ +[ "1" "2" "3" ] diff --git a/third_party/nix/tests/lang/eval-okay-splitversion.nix b/third_party/nix/tests/lang/eval-okay-splitversion.nix new file mode 100644 index 0000000000..9e5c99d2e7 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-splitversion.nix @@ -0,0 +1 @@ +builtins.splitVersion "1.2.3" diff --git a/third_party/nix/tests/lang/eval-okay-string.exp b/third_party/nix/tests/lang/eval-okay-string.exp new file mode 100644 index 0000000000..63f650f73a --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-string.exp @@ -0,0 +1 @@ +"foobar/a/b/c/d/foo/xyzzy/foo.txt/../foo/x/yescape: \"quote\" \n \\end\nof\nlinefoobarblaatfoo$bar$\"$\"$" diff --git a/third_party/nix/tests/lang/eval-okay-string.nix b/third_party/nix/tests/lang/eval-okay-string.nix new file mode 100644 index 0000000000..47cc989ad4 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-string.nix @@ -0,0 +1,12 @@ +"foo" + "bar" + + toString (/a/b + /c/d) + + toString (/foo/bar + "/../xyzzy/." + "/foo.txt") + + ("/../foo" + toString /x/y) + + "escape: \"quote\" \n \\" + + "end +of +line" + + "foo${if true then "b${"a" + "r"}" else "xyzzy"}blaat" + + "foo$bar" + + "$\"$\"" + + "$" diff --git a/third_party/nix/tests/lang/eval-okay-strings-as-attrs-names.exp b/third_party/nix/tests/lang/eval-okay-strings-as-attrs-names.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-strings-as-attrs-names.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-strings-as-attrs-names.nix b/third_party/nix/tests/lang/eval-okay-strings-as-attrs-names.nix new file mode 100644 index 0000000000..5e40928dbe --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-strings-as-attrs-names.nix @@ -0,0 +1,20 @@ +let + + attr = { + "key 1" = "test"; + "key 2" = "caseok"; + }; + + t1 = builtins.getAttr "key 1" attr; + t2 = attr."key 2"; + t3 = attr ? "key 1"; + t4 = builtins.attrNames { inherit (attr) "key 1"; }; + + # This is permitted, but there is currently no way to reference this + # variable. + "foo bar" = 1; + +in t1 == "test" + && t2 == "caseok" + && t3 == true + && t4 == ["key 1"] diff --git a/third_party/nix/tests/lang/eval-okay-substring.exp b/third_party/nix/tests/lang/eval-okay-substring.exp new file mode 100644 index 0000000000..6aace04b0f --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-substring.exp @@ -0,0 +1 @@ +"ooxfoobarybarzobaabbc" diff --git a/third_party/nix/tests/lang/eval-okay-substring.nix b/third_party/nix/tests/lang/eval-okay-substring.nix new file mode 100644 index 0000000000..424af00d9b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-substring.nix @@ -0,0 +1,21 @@ +with builtins; + +let + + s = "foobar"; + +in + +substring 1 2 s ++ "x" ++ substring 0 (stringLength s) s ++ "y" ++ substring 3 100 s ++ "z" ++ substring 2 (sub (stringLength s) 3) s ++ "a" ++ substring 3 0 s ++ "b" ++ substring 3 1 s ++ "c" ++ substring 5 10 "perl" diff --git a/third_party/nix/tests/lang/eval-okay-tail-call-1.exp-disabled b/third_party/nix/tests/lang/eval-okay-tail-call-1.exp-disabled new file mode 100644 index 0000000000..f7393e847d --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-tail-call-1.exp-disabled @@ -0,0 +1 @@ +100000 diff --git a/third_party/nix/tests/lang/eval-okay-tail-call-1.nix b/third_party/nix/tests/lang/eval-okay-tail-call-1.nix new file mode 100644 index 0000000000..a3962ce3fd --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-tail-call-1.nix @@ -0,0 +1,3 @@ +let + f = n: if n == 100000 then n else f (n + 1); +in f 0 diff --git a/third_party/nix/tests/lang/eval-okay-tojson.exp b/third_party/nix/tests/lang/eval-okay-tojson.exp new file mode 100644 index 0000000000..e92aae3235 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-tojson.exp @@ -0,0 +1 @@ +"{\"a\":123,\"b\":-456,\"c\":\"foo\",\"d\":\"foo\\n\\\"bar\\\"\",\"e\":true,\"f\":false,\"g\":[1,2,3],\"h\":[\"a\",[\"b\",{\"foo\\nbar\":{}}]],\"i\":3,\"j\":1.44,\"k\":\"foo\"}" diff --git a/third_party/nix/tests/lang/eval-okay-tojson.nix b/third_party/nix/tests/lang/eval-okay-tojson.nix new file mode 100644 index 0000000000..ce67943bea --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-tojson.nix @@ -0,0 +1,13 @@ +builtins.toJSON + { a = 123; + b = -456; + c = "foo"; + d = "foo\n\"bar\""; + e = true; + f = false; + g = [ 1 2 3 ]; + h = [ "a" [ "b" { "foo\nbar" = {}; } ] ]; + i = 1 + 2; + j = 1.44; + k = { __toString = self: self.a; a = "foo"; }; + } diff --git a/third_party/nix/tests/lang/eval-okay-toxml.exp b/third_party/nix/tests/lang/eval-okay-toxml.exp new file mode 100644 index 0000000000..828220890e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-toxml.exp @@ -0,0 +1 @@ +"<?xml version='1.0' encoding='utf-8'?>\n<expr>\n <attrs>\n <attr name=\"a\">\n <string value=\"s\" />\n </attr>\n </attrs>\n</expr>\n" diff --git a/third_party/nix/tests/lang/eval-okay-toxml.nix b/third_party/nix/tests/lang/eval-okay-toxml.nix new file mode 100644 index 0000000000..068c97a6c1 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-toxml.nix @@ -0,0 +1,3 @@ +# Make sure the expected XML output is produced; in particular, make sure it +# doesn't contain source location information. +builtins.toXML { a = "s"; } diff --git a/third_party/nix/tests/lang/eval-okay-toxml2.exp b/third_party/nix/tests/lang/eval-okay-toxml2.exp new file mode 100644 index 0000000000..634a841eb1 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-toxml2.exp @@ -0,0 +1 @@ +"<?xml version='1.0' encoding='utf-8'?>\n<expr>\n <list>\n <string value=\"ab\" />\n <int value=\"10\" />\n <attrs>\n <attr name=\"x\">\n <string value=\"x\" />\n </attr>\n <attr name=\"y\">\n <string value=\"x\" />\n </attr>\n </attrs>\n </list>\n</expr>\n" diff --git a/third_party/nix/tests/lang/eval-okay-toxml2.nix b/third_party/nix/tests/lang/eval-okay-toxml2.nix new file mode 100644 index 0000000000..ff1791b30e --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-toxml2.nix @@ -0,0 +1 @@ +builtins.toXML [("a" + "b") 10 (rec {x = "x"; y = x;})] diff --git a/third_party/nix/tests/lang/eval-okay-tryeval.exp b/third_party/nix/tests/lang/eval-okay-tryeval.exp new file mode 100644 index 0000000000..2b2e6fa711 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-tryeval.exp @@ -0,0 +1 @@ +{ x = { success = true; value = "x"; }; y = { success = false; value = false; }; z = { success = false; value = false; }; } diff --git a/third_party/nix/tests/lang/eval-okay-tryeval.nix b/third_party/nix/tests/lang/eval-okay-tryeval.nix new file mode 100644 index 0000000000..629bc440a8 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-tryeval.nix @@ -0,0 +1,5 @@ +{ + x = builtins.tryEval "x"; + y = builtins.tryEval (assert false; "y"); + z = builtins.tryEval (throw "bla"); +} diff --git a/third_party/nix/tests/lang/eval-okay-types.exp b/third_party/nix/tests/lang/eval-okay-types.exp new file mode 100644 index 0000000000..92a1532993 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-types.exp @@ -0,0 +1 @@ +[ true false true false true false true false true true true true true true true true true true true false true true true false "int" "bool" "string" "null" "set" "list" "lambda" "lambda" "lambda" "lambda" ] diff --git a/third_party/nix/tests/lang/eval-okay-types.nix b/third_party/nix/tests/lang/eval-okay-types.nix new file mode 100644 index 0000000000..9b58be5d1d --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-types.nix @@ -0,0 +1,37 @@ +with builtins; + +[ (isNull null) + (isNull (x: x)) + (isFunction (x: x)) + (isFunction "fnord") + (isString ("foo" + "bar")) + (isString [ "x" ]) + (isInt (1 + 2)) + (isInt { x = 123; }) + (isInt (1 / 2)) + (isInt (1 + 1)) + (isInt (1 / 2)) + (isInt (1 * 2)) + (isInt (1 - 2)) + (isFloat (1.2)) + (isFloat (1 + 1.0)) + (isFloat (1 / 2.0)) + (isFloat (1 * 2.0)) + (isFloat (1 - 2.0)) + (isBool (true && false)) + (isBool null) + (isPath /nix/store) + (isPath ./.) + (isAttrs { x = 123; }) + (isAttrs null) + (typeOf (3 * 4)) + (typeOf true) + (typeOf "xyzzy") + (typeOf null) + (typeOf { x = 456; }) + (typeOf [ 1 2 3 ]) + (typeOf (x: x)) + (typeOf ((x: y: x) 1)) + (typeOf map) + (typeOf (map (x: x))) +] diff --git a/third_party/nix/tests/lang/eval-okay-versions.exp b/third_party/nix/tests/lang/eval-okay-versions.exp new file mode 100644 index 0000000000..27ba77ddaf --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-versions.exp @@ -0,0 +1 @@ +true diff --git a/third_party/nix/tests/lang/eval-okay-versions.nix b/third_party/nix/tests/lang/eval-okay-versions.nix new file mode 100644 index 0000000000..e63c36586b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-versions.nix @@ -0,0 +1,40 @@ +let + + name1 = "hello-1.0.2"; + name2 = "hello"; + name3 = "915resolution-0.5.2"; + name4 = "xf86-video-i810-1.7.4"; + + eq = 0; + lt = builtins.sub 0 1; + gt = 1; + + versionTest = v1: v2: expected: + let d1 = builtins.compareVersions v1 v2; + d2 = builtins.compareVersions v2 v1; + in d1 == builtins.sub 0 d2 && d1 == expected; + + tests = [ + ((builtins.parseDrvName name1).name == "hello") + ((builtins.parseDrvName name1).version == "1.0.2") + ((builtins.parseDrvName name2).name == "hello") + ((builtins.parseDrvName name2).version == "") + ((builtins.parseDrvName name3).name == "915resolution") + ((builtins.parseDrvName name3).version == "0.5.2") + ((builtins.parseDrvName name4).name == "xf86-video-i810") + ((builtins.parseDrvName name4).version == "1.7.4") + (versionTest "1.0" "2.3" lt) + (versionTest "2.1" "2.3" lt) + (versionTest "2.3" "2.3" eq) + (versionTest "2.5" "2.3" gt) + (versionTest "3.1" "2.3" gt) + (versionTest "2.3.1" "2.3" gt) + (versionTest "2.3.1" "2.3a" gt) + (versionTest "2.3pre1" "2.3" lt) + (versionTest "2.3pre3" "2.3pre12" lt) + (versionTest "2.3a" "2.3c" lt) + (versionTest "2.3pre1" "2.3c" lt) + (versionTest "2.3pre1" "2.3q" lt) + ]; + +in (import ./lib.nix).and tests diff --git a/third_party/nix/tests/lang/eval-okay-with.exp b/third_party/nix/tests/lang/eval-okay-with.exp new file mode 100644 index 0000000000..378c8dc804 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-with.exp @@ -0,0 +1 @@ +"xyzzybarxyzzybar" diff --git a/third_party/nix/tests/lang/eval-okay-with.nix b/third_party/nix/tests/lang/eval-okay-with.nix new file mode 100644 index 0000000000..033e8d3aba --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-with.nix @@ -0,0 +1,19 @@ +let { + + a = "xyzzy"; + + as = { + a = "foo"; + b = "bar"; + }; + + bs = { + a = "bar"; + }; + + x = with as; a + b; + + y = with as; with bs; a + b; + + body = x + y; +} diff --git a/third_party/nix/tests/lang/eval-okay-xml.exp.xml b/third_party/nix/tests/lang/eval-okay-xml.exp.xml new file mode 100644 index 0000000000..92b75e0b8b --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-xml.exp.xml @@ -0,0 +1,52 @@ +<?xml version='1.0' encoding='utf-8'?> +<expr> + <attrs> + <attr name="a"> + <string value="foo" /> + </attr> + <attr name="at"> + <function> + <attrspat name="args"> + <attr name="x" /> + <attr name="y" /> + <attr name="z" /> + </attrspat> + </function> + </attr> + <attr name="b"> + <string value="bar" /> + </attr> + <attr name="c"> + <string value="foobar" /> + </attr> + <attr name="ellipsis"> + <function> + <attrspat ellipsis="1"> + <attr name="x" /> + <attr name="y" /> + <attr name="z" /> + </attrspat> + </function> + </attr> + <attr name="f"> + <function> + <attrspat> + <attr name="z" /> + <attr name="x" /> + <attr name="y" /> + </attrspat> + </function> + </attr> + <attr name="id"> + <function> + <varpat name="x" /> + </function> + </attr> + <attr name="x"> + <int value="123" /> + </attr> + <attr name="y"> + <float value="567.89" /> + </attr> + </attrs> +</expr> diff --git a/third_party/nix/tests/lang/eval-okay-xml.nix b/third_party/nix/tests/lang/eval-okay-xml.nix new file mode 100644 index 0000000000..9ee9f8a0b4 --- /dev/null +++ b/third_party/nix/tests/lang/eval-okay-xml.nix @@ -0,0 +1,21 @@ +rec { + + x = 123; + + y = 567.890; + + a = "foo"; + + b = "bar"; + + c = "foo" + "bar"; + + f = {z, x, y}: if y then x else z; + + id = x: x; + + at = args@{x, y, z}: x; + + ellipsis = {x, y, z, ...}: x; + +} diff --git a/third_party/nix/tests/lang/imported.nix b/third_party/nix/tests/lang/imported.nix new file mode 100644 index 0000000000..fb39ee4efa --- /dev/null +++ b/third_party/nix/tests/lang/imported.nix @@ -0,0 +1,3 @@ +# The function ‘range’ comes from lib.nix and was added to the lexical +# scope by scopedImport. +range 1 5 ++ import ./imported2.nix diff --git a/third_party/nix/tests/lang/imported2.nix b/third_party/nix/tests/lang/imported2.nix new file mode 100644 index 0000000000..6d0a2992b7 --- /dev/null +++ b/third_party/nix/tests/lang/imported2.nix @@ -0,0 +1 @@ +range 6 10 diff --git a/third_party/nix/tests/lang/lib.nix b/third_party/nix/tests/lang/lib.nix new file mode 100644 index 0000000000..028a538314 --- /dev/null +++ b/third_party/nix/tests/lang/lib.nix @@ -0,0 +1,61 @@ +with builtins; + +rec { + + fold = op: nul: list: + if list == [] + then nul + else op (head list) (fold op nul (tail list)); + + concat = + fold (x: y: x + y) ""; + + and = fold (x: y: x && y) true; + + flatten = x: + if isList x + then fold (x: y: (flatten x) ++ y) [] x + else [x]; + + sum = foldl' (x: y: add x y) 0; + + hasSuffix = ext: fileName: + let lenFileName = stringLength fileName; + lenExt = stringLength ext; + in !(lessThan lenFileName lenExt) && + substring (sub lenFileName lenExt) lenFileName fileName == ext; + + # Split a list at the given position. + splitAt = pos: list: + if pos == 0 then {first = []; second = list;} else + if list == [] then {first = []; second = [];} else + let res = splitAt (sub pos 1) (tail list); + in {first = [(head list)] ++ res.first; second = res.second;}; + + # Stable merge sort. + sortBy = comp: list: + if lessThan 1 (length list) + then + let + split = splitAt (div (length list) 2) list; + first = sortBy comp split.first; + second = sortBy comp split.second; + in mergeLists comp first second + else list; + + mergeLists = comp: list1: list2: + if list1 == [] then list2 else + if list2 == [] then list1 else + if comp (head list2) (head list1) then [(head list2)] ++ mergeLists comp list1 (tail list2) else + [(head list1)] ++ mergeLists comp (tail list1) list2; + + id = x: x; + + const = x: y: x; + + range = first: last: + if first > last + then [] + else genList (n: first + n) (last - first + 1); + +} diff --git a/third_party/nix/tests/lang/parse-fail-dup-attrs-1.nix b/third_party/nix/tests/lang/parse-fail-dup-attrs-1.nix new file mode 100644 index 0000000000..2c02317d2a --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-dup-attrs-1.nix @@ -0,0 +1,4 @@ +{ x = 123; + y = 456; + x = 789; +} diff --git a/third_party/nix/tests/lang/parse-fail-dup-attrs-2.nix b/third_party/nix/tests/lang/parse-fail-dup-attrs-2.nix new file mode 100644 index 0000000000..864d9865e0 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-dup-attrs-2.nix @@ -0,0 +1,13 @@ +let { + + as = { + x = 123; + y = 456; + }; + + bs = { + x = 789; + inherit (as) x; + }; + +} diff --git a/third_party/nix/tests/lang/parse-fail-dup-attrs-3.nix b/third_party/nix/tests/lang/parse-fail-dup-attrs-3.nix new file mode 100644 index 0000000000..114d19779f --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-dup-attrs-3.nix @@ -0,0 +1,13 @@ +let { + + as = { + x = 123; + y = 456; + }; + + bs = rec { + x = 789; + inherit (as) x; + }; + +} diff --git a/third_party/nix/tests/lang/parse-fail-dup-attrs-4.nix b/third_party/nix/tests/lang/parse-fail-dup-attrs-4.nix new file mode 100644 index 0000000000..77417432b3 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-dup-attrs-4.nix @@ -0,0 +1,4 @@ +{ + services.ssh.port = 22; + services.ssh.port = 23; +} diff --git a/third_party/nix/tests/lang/parse-fail-dup-attrs-7.nix b/third_party/nix/tests/lang/parse-fail-dup-attrs-7.nix new file mode 100644 index 0000000000..bbc3eb08c0 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-dup-attrs-7.nix @@ -0,0 +1,9 @@ +rec { + + x = 1; + + as = { + inherit x; + inherit x; + }; +} \ No newline at end of file diff --git a/third_party/nix/tests/lang/parse-fail-dup-formals.nix b/third_party/nix/tests/lang/parse-fail-dup-formals.nix new file mode 100644 index 0000000000..a0edd91a96 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-dup-formals.nix @@ -0,0 +1 @@ +{x, y, x}: x \ No newline at end of file diff --git a/third_party/nix/tests/lang/parse-fail-mixed-nested-attrs1.nix b/third_party/nix/tests/lang/parse-fail-mixed-nested-attrs1.nix new file mode 100644 index 0000000000..11e40e66fd --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-mixed-nested-attrs1.nix @@ -0,0 +1,4 @@ +{ + x.z = 3; + x = { y = 3; z = 3; }; +} diff --git a/third_party/nix/tests/lang/parse-fail-mixed-nested-attrs2.nix b/third_party/nix/tests/lang/parse-fail-mixed-nested-attrs2.nix new file mode 100644 index 0000000000..17da82e5f0 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-mixed-nested-attrs2.nix @@ -0,0 +1,4 @@ +{ + x.y.y = 3; + x = { y.y= 3; z = 3; }; +} diff --git a/third_party/nix/tests/lang/parse-fail-patterns-1.nix b/third_party/nix/tests/lang/parse-fail-patterns-1.nix new file mode 100644 index 0000000000..7b40616417 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-patterns-1.nix @@ -0,0 +1 @@ +args@{args, x, y, z}: x diff --git a/third_party/nix/tests/lang/parse-fail-regression-20060610.nix b/third_party/nix/tests/lang/parse-fail-regression-20060610.nix new file mode 100644 index 0000000000..b1934f7e1e --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-regression-20060610.nix @@ -0,0 +1,11 @@ +let { + x = + {gcc}: + { + inherit gcc; + }; + + body = ({ + inherit gcc; + }).gcc; +} diff --git a/third_party/nix/tests/lang/parse-fail-uft8.nix b/third_party/nix/tests/lang/parse-fail-uft8.nix new file mode 100644 index 0000000000..34948d48ae --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-uft8.nix @@ -0,0 +1 @@ +123 é 4 diff --git a/third_party/nix/tests/lang/parse-fail-undef-var-2.nix b/third_party/nix/tests/lang/parse-fail-undef-var-2.nix new file mode 100644 index 0000000000..c10a52b1ea --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-undef-var-2.nix @@ -0,0 +1,7 @@ +let { + + f = {x, y : ["baz" "bar" z "bat"]}: x + y; + + body = f {x = "foo"; y = "bar";}; + +} diff --git a/third_party/nix/tests/lang/parse-fail-undef-var.nix b/third_party/nix/tests/lang/parse-fail-undef-var.nix new file mode 100644 index 0000000000..7b63008110 --- /dev/null +++ b/third_party/nix/tests/lang/parse-fail-undef-var.nix @@ -0,0 +1 @@ +x: y diff --git a/third_party/nix/tests/lang/parse-okay-1.nix b/third_party/nix/tests/lang/parse-okay-1.nix new file mode 100644 index 0000000000..23a58ed109 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-1.nix @@ -0,0 +1 @@ +{x, y, z}: x + y + z diff --git a/third_party/nix/tests/lang/parse-okay-crlf.nix b/third_party/nix/tests/lang/parse-okay-crlf.nix new file mode 100644 index 0000000000..21518d4c6d --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-crlf.nix @@ -0,0 +1,17 @@ +rec { + + /* Dit is + een test. */ + + x = + # Dit is een test. y; + + y = 123; + + # CR or CR/LF (but not explicit \r's) in strings should be + # translated to LF. + foo = "multi line + string + test\r"; + + z = 456; } diff --git a/third_party/nix/tests/lang/parse-okay-dup-attrs-5.nix b/third_party/nix/tests/lang/parse-okay-dup-attrs-5.nix new file mode 100644 index 0000000000..f4b9efd0c5 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-dup-attrs-5.nix @@ -0,0 +1,4 @@ +{ + services.ssh = { enable = true; }; + services.ssh.port = 23; +} diff --git a/third_party/nix/tests/lang/parse-okay-dup-attrs-6.nix b/third_party/nix/tests/lang/parse-okay-dup-attrs-6.nix new file mode 100644 index 0000000000..ae6d7a7693 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-dup-attrs-6.nix @@ -0,0 +1,4 @@ +{ + services.ssh.port = 23; + services.ssh = { enable = true; }; +} diff --git a/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-1.nix b/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-1.nix new file mode 100644 index 0000000000..fd1001c8ca --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-1.nix @@ -0,0 +1,4 @@ +{ + x = { y = 3; z = 3; }; + x.q = 3; +} diff --git a/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-2.nix b/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-2.nix new file mode 100644 index 0000000000..ad066b6803 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-2.nix @@ -0,0 +1,4 @@ +{ + x.q = 3; + x = { y = 3; z = 3; }; +} diff --git a/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-3.nix b/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-3.nix new file mode 100644 index 0000000000..45a33e4803 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-mixed-nested-attrs-3.nix @@ -0,0 +1,7 @@ +{ + services.ssh.enable = true; + services.ssh = { port = 123; }; + services = { + httpd.enable = true; + }; +} diff --git a/third_party/nix/tests/lang/parse-okay-regression-20041027.nix b/third_party/nix/tests/lang/parse-okay-regression-20041027.nix new file mode 100644 index 0000000000..ae2e256eea --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-regression-20041027.nix @@ -0,0 +1,11 @@ +{stdenv, fetchurl /* pkgconfig, libX11 */ }: + +stdenv.mkDerivation { + name = "libXi-6.0.1"; + src = fetchurl { + url = http://freedesktop.org/~xlibs/release/libXi-6.0.1.tar.bz2; + md5 = "7e935a42428d63a387b3c048be0f2756"; + }; +/* buildInputs = [pkgconfig]; + propagatedBuildInputs = [libX11]; */ +} diff --git a/third_party/nix/tests/lang/parse-okay-regression-751.nix b/third_party/nix/tests/lang/parse-okay-regression-751.nix new file mode 100644 index 0000000000..05c78b3016 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-regression-751.nix @@ -0,0 +1,2 @@ +let const = a: "const"; in +''${ const { x = "q"; }}'' diff --git a/third_party/nix/tests/lang/parse-okay-subversion.nix b/third_party/nix/tests/lang/parse-okay-subversion.nix new file mode 100644 index 0000000000..356272815d --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-subversion.nix @@ -0,0 +1,43 @@ +{ localServer ? false +, httpServer ? false +, sslSupport ? false +, pythonBindings ? false +, javaSwigBindings ? false +, javahlBindings ? false +, stdenv, fetchurl +, openssl ? null, httpd ? null, db4 ? null, expat, swig ? null, j2sdk ? null +}: + +assert expat != null; +assert localServer -> db4 != null; +assert httpServer -> httpd != null && httpd.expat == expat; +assert sslSupport -> openssl != null && (httpServer -> httpd.openssl == openssl); +assert pythonBindings -> swig != null && swig.pythonSupport; +assert javaSwigBindings -> swig != null && swig.javaSupport; +assert javahlBindings -> j2sdk != null; + +stdenv.mkDerivation { + name = "subversion-1.1.1"; + + builder = /foo/bar; + src = fetchurl { + url = http://subversion.tigris.org/tarballs/subversion-1.1.1.tar.bz2; + md5 = "a180c3fe91680389c210c99def54d9e0"; + }; + + # This is a hopefully temporary fix for the problem that + # libsvnjavahl.so isn't linked against libstdc++, which causes + # loading the library into the JVM to fail. + patches = if javahlBindings then [/javahl.patch] else []; + + openssl = if sslSupport then openssl else null; + httpd = if httpServer then httpd else null; + db4 = if localServer then db4 else null; + swig = if pythonBindings || javaSwigBindings then swig else null; + python = if pythonBindings then swig.python else null; + j2sdk = if javaSwigBindings then swig.j2sdk else + if javahlBindings then j2sdk else null; + + inherit expat localServer httpServer sslSupport + pythonBindings javaSwigBindings javahlBindings; +} diff --git a/third_party/nix/tests/lang/parse-okay-url.nix b/third_party/nix/tests/lang/parse-okay-url.nix new file mode 100644 index 0000000000..fce3b13ee6 --- /dev/null +++ b/third_party/nix/tests/lang/parse-okay-url.nix @@ -0,0 +1,7 @@ +[ x:x + https://svn.cs.uu.nl:12443/repos/trace/trunk + http://www2.mplayerhq.hu/MPlayer/releases/fonts/font-arial-iso-8859-1.tar.bz2 + http://losser.st-lab.cs.uu.nl/~armijn/.nix/gcc-3.3.4-static-nix.tar.gz + http://fpdownload.macromedia.com/get/shockwave/flash/english/linux/7.0r25/install_flash_player_7_linux.tar.gz + ftp://ftp.gtk.org/pub/gtk/v1.2/gtk+-1.2.10.tar.gz +] diff --git a/third_party/nix/tests/lang/readDir/bar b/third_party/nix/tests/lang/readDir/bar new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/nix/tests/lang/readDir/bar diff --git a/third_party/nix/tests/lang/readDir/foo/git-hates-directories b/third_party/nix/tests/lang/readDir/foo/git-hates-directories new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/third_party/nix/tests/lang/readDir/foo/git-hates-directories diff --git a/third_party/nix/tests/linux-sandbox.sh b/third_party/nix/tests/linux-sandbox.sh new file mode 100644 index 0000000000..52967d07dd --- /dev/null +++ b/third_party/nix/tests/linux-sandbox.sh @@ -0,0 +1,30 @@ +source common.sh + +clearStore + +if ! canUseSandbox; then exit; fi + +# Note: we need to bind-mount $SHELL into the chroot. Currently we +# only support the case where $SHELL is in the Nix store, because +# otherwise things get complicated (e.g. if it's in /bin, do we need +# /lib as well?). +if [[ ! $SHELL =~ /nix/store ]]; then exit; fi + +chmod -R u+w $TEST_ROOT/store0 || true +rm -rf $TEST_ROOT/store0 + +export NIX_STORE_DIR=/my/store +export NIX_REMOTE=$TEST_ROOT/store0 + +outPath=$(nix-build dependencies.nix --no-out-link --sandbox-paths /nix/store) + +[[ $outPath =~ /my/store/.*-dependencies ]] + +nix path-info -r $outPath | grep input-2 + +nix ls-store -R -l $outPath | grep foobar + +nix cat-store $outPath/foobar | grep FOOBAR + +# Test --check without hash rewriting. +nix-build dependencies.nix --no-out-link --check --sandbox-paths /nix/store diff --git a/third_party/nix/tests/logging.sh b/third_party/nix/tests/logging.sh new file mode 100644 index 0000000000..c894ad3ff0 --- /dev/null +++ b/third_party/nix/tests/logging.sh @@ -0,0 +1,15 @@ +source common.sh + +clearStore + +path=$(nix-build dependencies.nix --no-out-link) + +# Test nix-store -l. +[ "$(nix-store -l $path)" = FOO ] + +# Test compressed logs. +clearStore +rm -rf $NIX_LOG_DIR +(! nix-store -l $path) +nix-build dependencies.nix --no-out-link --compress-build-log +[ "$(nix-store -l $path)" = FOO ] diff --git a/third_party/nix/tests/meson.build b/third_party/nix/tests/meson.build new file mode 100644 index 0000000000..c45e00f3ac --- /dev/null +++ b/third_party/nix/tests/meson.build @@ -0,0 +1,5 @@ +# nix doc build file +#============================================================================ + + +# TODO: all of this :| \ No newline at end of file diff --git a/third_party/nix/tests/misc.sh b/third_party/nix/tests/misc.sh new file mode 100644 index 0000000000..eda0164167 --- /dev/null +++ b/third_party/nix/tests/misc.sh @@ -0,0 +1,19 @@ +source common.sh + +# Tests miscellaneous commands. + +# Do all commands have help? +#nix-env --help | grep -q install +#nix-store --help | grep -q realise +#nix-instantiate --help | grep -q eval +#nix-hash --help | grep -q base32 + +# Can we ask for the version number? +nix-env --version | grep "$version" + +# Usage errors. +nix-env --foo 2>&1 | grep "no operation" +nix-env -q --foo 2>&1 | grep "unknown flag" + +# Eval Errors. +nix-instantiate --eval -E 'let a = {} // a; in a.foo' 2>&1 | grep "infinite recursion encountered, at .*(string).*:1:15$" diff --git a/third_party/nix/tests/multiple-outputs.nix b/third_party/nix/tests/multiple-outputs.nix new file mode 100644 index 0000000000..4a9010d186 --- /dev/null +++ b/third_party/nix/tests/multiple-outputs.nix @@ -0,0 +1,68 @@ +with import ./config.nix; + +rec { + + a = mkDerivation { + name = "multiple-outputs-a"; + outputs = [ "first" "second" ]; + builder = builtins.toFile "builder.sh" + '' + mkdir $first $second + test -z $all + echo "first" > $first/file + echo "second" > $second/file + ln -s $first $second/link + ''; + helloString = "Hello, world!"; + }; + + b = mkDerivation { + defaultOutput = assert a.second.helloString == "Hello, world!"; a; + firstOutput = assert a.outputName == "first"; a.first.first; + secondOutput = assert a.second.outputName == "second"; a.second.first.first.second.second.first.second; + allOutputs = a.all; + name = "multiple-outputs-b"; + builder = builtins.toFile "builder.sh" + '' + mkdir $out + test "$firstOutput $secondOutput" = "$allOutputs" + test "$defaultOutput" = "$firstOutput" + test "$(cat $firstOutput/file)" = "first" + test "$(cat $secondOutput/file)" = "second" + echo "success" > $out/file + ''; + }; + + c = mkDerivation { + name = "multiple-outputs-c"; + drv = b.drvPath; + builder = builtins.toFile "builder.sh" + '' + mkdir $out + ln -s $drv $out/drv + ''; + }; + + d = mkDerivation { + name = "multiple-outputs-d"; + drv = builtins.unsafeDiscardOutputDependency b.drvPath; + builder = builtins.toFile "builder.sh" + '' + mkdir $out + echo $drv > $out/drv + ''; + }; + + cyclic = (mkDerivation { + name = "cyclic-outputs"; + outputs = [ "a" "b" "c" ]; + builder = builtins.toFile "builder.sh" + '' + mkdir $a $b $c + echo $a > $b/foo + echo $b > $c/bar + echo $c > $a/baz + ''; + }).a; + +} diff --git a/third_party/nix/tests/multiple-outputs.sh b/third_party/nix/tests/multiple-outputs.sh new file mode 100644 index 0000000000..bedbc39a4e --- /dev/null +++ b/third_party/nix/tests/multiple-outputs.sh @@ -0,0 +1,76 @@ +source common.sh + +clearStore + +rm -f $TEST_ROOT/result* + +# Test whether read-only evaluation works when referring to the +# ‘drvPath’ attribute. +echo "evaluating c..." +#drvPath=$(nix-instantiate multiple-outputs.nix -A c --readonly-mode) + +# And check whether the resulting derivation explicitly depends on all +# outputs. +drvPath=$(nix-instantiate multiple-outputs.nix -A c) +#[ "$drvPath" = "$drvPath2" ] +grep -q 'multiple-outputs-a.drv",\["first","second"\]' $drvPath +grep -q 'multiple-outputs-b.drv",\["out"\]' $drvPath + +# While we're at it, test the ‘unsafeDiscardOutputDependency’ primop. +outPath=$(nix-build multiple-outputs.nix -A d --no-out-link) +drvPath=$(cat $outPath/drv) +outPath=$(nix-store -q $drvPath) +(! [ -e "$outPath" ]) + +# Do a build of something that depends on a derivation with multiple +# outputs. +echo "building b..." +outPath=$(nix-build multiple-outputs.nix -A b --no-out-link) +echo "output path is $outPath" +[ "$(cat "$outPath"/file)" = "success" ] + +# Test nix-build on a derivation with multiple outputs. +outPath1=$(nix-build multiple-outputs.nix -A a -o $TEST_ROOT/result) +[ -e $TEST_ROOT/result-first ] +(! [ -e $TEST_ROOT/result-second ]) +nix-build multiple-outputs.nix -A a.all -o $TEST_ROOT/result +[ "$(cat $TEST_ROOT/result-first/file)" = "first" ] +[ "$(cat $TEST_ROOT/result-second/file)" = "second" ] +[ "$(cat $TEST_ROOT/result-second/link/file)" = "first" ] +hash1=$(nix-store -q --hash $TEST_ROOT/result-second) + +outPath2=$(nix-build $(nix-instantiate multiple-outputs.nix -A a) --no-out-link) +[[ $outPath1 = $outPath2 ]] + +outPath2=$(nix-build $(nix-instantiate multiple-outputs.nix -A a.first) --no-out-link) +[[ $outPath1 = $outPath2 ]] + +outPath2=$(nix-build $(nix-instantiate multiple-outputs.nix -A a.second) --no-out-link) +[[ $(cat $outPath2/file) = second ]] + +[[ $(nix-build $(nix-instantiate multiple-outputs.nix -A a.all) --no-out-link | wc -l) -eq 2 ]] + +# Delete one of the outputs and rebuild it. This will cause a hash +# rewrite. +nix-store --delete $TEST_ROOT/result-second --ignore-liveness +nix-build multiple-outputs.nix -A a.all -o $TEST_ROOT/result +[ "$(cat $TEST_ROOT/result-second/file)" = "second" ] +[ "$(cat $TEST_ROOT/result-second/link/file)" = "first" ] +hash2=$(nix-store -q --hash $TEST_ROOT/result-second) +[ "$hash1" = "$hash2" ] + +# Make sure that nix-build works on derivations with multiple outputs. +echo "building a.first..." +nix-build multiple-outputs.nix -A a.first --no-out-link + +# Cyclic outputs should be rejected. +echo "building cyclic..." +if nix-build multiple-outputs.nix -A cyclic --no-out-link; then + echo "Cyclic outputs incorrectly accepted!" + exit 1 +fi + +echo "collecting garbage..." +rm $TEST_ROOT/result* +nix-store --gc --keep-derivations --keep-outputs +nix-store --gc --print-roots diff --git a/third_party/nix/tests/nar-access.nix b/third_party/nix/tests/nar-access.nix new file mode 100644 index 0000000000..0e2a7f7211 --- /dev/null +++ b/third_party/nix/tests/nar-access.nix @@ -0,0 +1,23 @@ +with import ./config.nix; + +rec { + a = mkDerivation { + name = "nar-index-a"; + builder = builtins.toFile "builder.sh" + '' + mkdir $out + mkdir $out/foo + touch $out/foo-x + touch $out/foo/bar + touch $out/foo/baz + touch $out/qux + mkdir $out/zyx + + cat >$out/foo/data <<EOF + lasjdöaxnasd +asdom 12398 +ä"§Æẞ¢«»”alsd +EOF + ''; + }; +} \ No newline at end of file diff --git a/third_party/nix/tests/nar-access.sh b/third_party/nix/tests/nar-access.sh new file mode 100644 index 0000000000..553d6ca89d --- /dev/null +++ b/third_party/nix/tests/nar-access.sh @@ -0,0 +1,44 @@ +source common.sh + +echo "building test path" +storePath="$(nix-build nar-access.nix -A a --no-out-link)" + +cd "$TEST_ROOT" + +# Dump path to nar. +narFile="$TEST_ROOT/path.nar" +nix-store --dump $storePath > $narFile + +# Check that find and ls-nar match. +( cd $storePath; find . | sort ) > files.find +nix ls-nar -R -d $narFile "" | sort > files.ls-nar +diff -u files.find files.ls-nar + +# Check that file contents of data match. +nix cat-nar $narFile /foo/data > data.cat-nar +diff -u data.cat-nar $storePath/foo/data + +# Check that file contents of baz match. +nix cat-nar $narFile /foo/baz > baz.cat-nar +diff -u baz.cat-nar $storePath/foo/baz + +nix cat-store $storePath/foo/baz > baz.cat-nar +diff -u baz.cat-nar $storePath/foo/baz + +# Test --json. +[[ $(nix ls-nar --json $narFile /) = '{"type":"directory","entries":{"foo":{},"foo-x":{},"qux":{},"zyx":{}}}' ]] +[[ $(nix ls-nar --json -R $narFile /foo) = '{"type":"directory","entries":{"bar":{"type":"regular","size":0,"narOffset":368},"baz":{"type":"regular","size":0,"narOffset":552},"data":{"type":"regular","size":58,"narOffset":736}}}' ]] +[[ $(nix ls-nar --json -R $narFile /foo/bar) = '{"type":"regular","size":0,"narOffset":368}' ]] +[[ $(nix ls-store --json $storePath) = '{"type":"directory","entries":{"foo":{},"foo-x":{},"qux":{},"zyx":{}}}' ]] +[[ $(nix ls-store --json -R $storePath/foo) = '{"type":"directory","entries":{"bar":{"type":"regular","size":0},"baz":{"type":"regular","size":0},"data":{"type":"regular","size":58}}}' ]] +[[ $(nix ls-store --json -R $storePath/foo/bar) = '{"type":"regular","size":0}' ]] + +# Test missing files. +nix ls-store --json -R $storePath/xyzzy 2>&1 | grep 'does not exist in NAR' +nix ls-store $storePath/xyzzy 2>&1 | grep 'does not exist' + +# Test failure to dump. +if nix-store --dump $storePath >/dev/full ; then + echo "dumping to /dev/full should fail" + exit -1 +fi diff --git a/third_party/nix/tests/nix-build.sh b/third_party/nix/tests/nix-build.sh new file mode 100644 index 0000000000..3952648631 --- /dev/null +++ b/third_party/nix/tests/nix-build.sh @@ -0,0 +1,25 @@ +source common.sh + +clearStore + +outPath=$(nix-build dependencies.nix -o $TEST_ROOT/result) +test "$(cat $TEST_ROOT/result/foobar)" = FOOBAR + +# The result should be retained by a GC. +echo A +target=$(readLink $TEST_ROOT/result) +echo B +echo target is $target +nix-store --gc +test -e $target/foobar + +# But now it should be gone. +rm $TEST_ROOT/result +nix-store --gc +if test -e $target/foobar; then false; fi + +outPath2=$(nix-build $(nix-instantiate dependencies.nix) --no-out-link) +[[ $outPath = $outPath2 ]] + +outPath2=$(nix-build $(nix-instantiate dependencies.nix)!out --no-out-link) +[[ $outPath = $outPath2 ]] diff --git a/third_party/nix/tests/nix-channel.sh b/third_party/nix/tests/nix-channel.sh new file mode 100644 index 0000000000..93f837befc --- /dev/null +++ b/third_party/nix/tests/nix-channel.sh @@ -0,0 +1,59 @@ +source common.sh + +clearProfiles + +rm -f $TEST_HOME/.nix-channels $TEST_HOME/.nix-profile + +# Test add/list/remove. +nix-channel --add http://foo/bar xyzzy +nix-channel --list | grep -q http://foo/bar +nix-channel --remove xyzzy + +[ -e $TEST_HOME/.nix-channels ] +[ "$(cat $TEST_HOME/.nix-channels)" = '' ] + +# Create a channel. +rm -rf $TEST_ROOT/foo +mkdir -p $TEST_ROOT/foo +nix copy --to file://$TEST_ROOT/foo?compression="bzip2" $(nix-store -r $(nix-instantiate dependencies.nix)) +rm -rf $TEST_ROOT/nixexprs +mkdir -p $TEST_ROOT/nixexprs +cp config.nix dependencies.nix dependencies.builder*.sh $TEST_ROOT/nixexprs/ +ln -s dependencies.nix $TEST_ROOT/nixexprs/default.nix +(cd $TEST_ROOT && tar cvf - nixexprs) | bzip2 > $TEST_ROOT/foo/nixexprs.tar.bz2 + +# Test the update action. +nix-channel --add file://$TEST_ROOT/foo +nix-channel --update + +# Do a query. +nix-env -qa \* --meta --xml --out-path > $TEST_ROOT/meta.xml +if [ "$xmllint" != false ]; then + $xmllint --noout $TEST_ROOT/meta.xml || fail "malformed XML" +fi +grep -q 'meta.*description.*Random test package' $TEST_ROOT/meta.xml +grep -q 'item.*attrPath="foo".*name="dependencies"' $TEST_ROOT/meta.xml + +# Do an install. +nix-env -i dependencies +[ -e $TEST_HOME/.nix-profile/foobar ] + +clearProfiles +rm -f $TEST_HOME/.nix-channels + +# Test updating from a tarball +nix-channel --add file://$TEST_ROOT/foo/nixexprs.tar.bz2 foo +nix-channel --update + +# Do a query. +nix-env -qa \* --meta --xml --out-path > $TEST_ROOT/meta.xml +if [ "$xmllint" != false ]; then + $xmllint --noout $TEST_ROOT/meta.xml || fail "malformed XML" +fi +grep -q 'meta.*description.*Random test package' $TEST_ROOT/meta.xml +grep -q 'item.*attrPath="foo".*name="dependencies"' $TEST_ROOT/meta.xml + +# Do an install. +nix-env -i dependencies +[ -e $TEST_HOME/.nix-profile/foobar ] + diff --git a/third_party/nix/tests/nix-copy-closure.nix b/third_party/nix/tests/nix-copy-closure.nix new file mode 100644 index 0000000000..0dc147fb34 --- /dev/null +++ b/third_party/nix/tests/nix-copy-closure.nix @@ -0,0 +1,64 @@ +# Test ‘nix-copy-closure’. + +{ nixpkgs, system, nix }: + +with import (nixpkgs + "/nixos/lib/testing.nix") { inherit system; }; + +makeTest (let pkgA = pkgs.cowsay; pkgB = pkgs.wget; pkgC = pkgs.hello; in { + + nodes = + { client = + { config, pkgs, ... }: + { virtualisation.writableStore = true; + virtualisation.pathsInNixDB = [ pkgA ]; + nix.package = nix; + nix.binaryCaches = [ ]; + }; + + server = + { config, pkgs, ... }: + { services.openssh.enable = true; + virtualisation.writableStore = true; + virtualisation.pathsInNixDB = [ pkgB pkgC ]; + nix.package = nix; + }; + }; + + testScript = { nodes }: + '' + startAll; + + # Create an SSH key on the client. + my $key = `${pkgs.openssh}/bin/ssh-keygen -t ed25519 -f key -N ""`; + $client->succeed("mkdir -m 700 /root/.ssh"); + $client->copyFileFromHost("key", "/root/.ssh/id_ed25519"); + $client->succeed("chmod 600 /root/.ssh/id_ed25519"); + + # Install the SSH key on the server. + $server->succeed("mkdir -m 700 /root/.ssh"); + $server->copyFileFromHost("key.pub", "/root/.ssh/authorized_keys"); + $server->waitForUnit("sshd"); + $client->waitForUnit("network.target"); + $client->succeed("ssh -o StrictHostKeyChecking=no " . $server->name() . " 'echo hello world'"); + + # Copy the closure of package A from the client to the server. + $server->fail("nix-store --check-validity ${pkgA}"); + $client->succeed("nix-copy-closure --to server --gzip ${pkgA} >&2"); + $server->succeed("nix-store --check-validity ${pkgA}"); + + # Copy the closure of package B from the server to the client. + $client->fail("nix-store --check-validity ${pkgB}"); + $client->succeed("nix-copy-closure --from server --gzip ${pkgB} >&2"); + $client->succeed("nix-store --check-validity ${pkgB}"); + + # Copy the closure of package C via the SSH substituter. + $client->fail("nix-store -r ${pkgC}"); + # FIXME + #$client->succeed( + # "nix-store --option use-ssh-substituter true" + # . " --option ssh-substituter-hosts root\@server" + # . " -r ${pkgC} >&2"); + #$client->succeed("nix-store --check-validity ${pkgC}"); + ''; + +}) diff --git a/third_party/nix/tests/nix-copy-ssh.sh b/third_party/nix/tests/nix-copy-ssh.sh new file mode 100644 index 0000000000..eb801548d2 --- /dev/null +++ b/third_party/nix/tests/nix-copy-ssh.sh @@ -0,0 +1,20 @@ +source common.sh + +clearStore +clearCache + +remoteRoot=$TEST_ROOT/store2 +chmod -R u+w "$remoteRoot" || true +rm -rf "$remoteRoot" + +outPath=$(nix-build --no-out-link dependencies.nix) + +nix copy --to "ssh://localhost?store=$NIX_STORE_DIR&remote-store=$remoteRoot%3fstore=$NIX_STORE_DIR%26real=$remoteRoot$NIX_STORE_DIR" $outPath + +[ -f $remoteRoot$outPath/foobar ] + +clearStore + +nix copy --no-check-sigs --from "ssh://localhost?store=$NIX_STORE_DIR&remote-store=$remoteRoot%3fstore=$NIX_STORE_DIR%26real=$remoteRoot$NIX_STORE_DIR" $outPath + +[ -f $outPath/foobar ] diff --git a/third_party/nix/tests/nix-profile.sh b/third_party/nix/tests/nix-profile.sh new file mode 100644 index 0000000000..e2e0d10908 --- /dev/null +++ b/third_party/nix/tests/nix-profile.sh @@ -0,0 +1,9 @@ +source common.sh + +sed -e "s|@localstatedir@|$TEST_ROOT/profile-var|g" -e "s|@coreutils@|$coreutils|g" < ../scripts/nix-profile.sh.in > $TEST_ROOT/nix-profile.sh + +user=$(whoami) +rm -rf $TEST_HOME $TEST_ROOT/profile-var +mkdir -p $TEST_HOME +USER=$user $SHELL -e -c ". $TEST_ROOT/nix-profile.sh; set" +USER=$user $SHELL -e -c ". $TEST_ROOT/nix-profile.sh" # test idempotency diff --git a/third_party/nix/tests/nix-shell.sh b/third_party/nix/tests/nix-shell.sh new file mode 100644 index 0000000000..ee502dddb9 --- /dev/null +++ b/third_party/nix/tests/nix-shell.sh @@ -0,0 +1,57 @@ +source common.sh + +clearStore + +# Test nix-shell -A +export IMPURE_VAR=foo +export SELECTED_IMPURE_VAR=baz +export NIX_BUILD_SHELL=$SHELL +output=$(nix-shell --pure shell.nix -A shellDrv --run \ + 'echo "$IMPURE_VAR - $VAR_FROM_STDENV_SETUP - $VAR_FROM_NIX"') + +[ "$output" = " - foo - bar" ] + +# Test --keep +output=$(nix-shell --pure --keep SELECTED_IMPURE_VAR shell.nix -A shellDrv --run \ + 'echo "$IMPURE_VAR - $VAR_FROM_STDENV_SETUP - $VAR_FROM_NIX - $SELECTED_IMPURE_VAR"') + +[ "$output" = " - foo - bar - baz" ] + +# Test nix-shell on a .drv +[[ $(nix-shell --pure $(nix-instantiate shell.nix -A shellDrv) --run \ + 'echo "$IMPURE_VAR - $VAR_FROM_STDENV_SETUP - $VAR_FROM_NIX"') = " - foo - bar" ]] + +[[ $(nix-shell --pure $(nix-instantiate shell.nix -A shellDrv) --run \ + 'echo "$IMPURE_VAR - $VAR_FROM_STDENV_SETUP - $VAR_FROM_NIX"') = " - foo - bar" ]] + +# Test nix-shell on a .drv symlink + +# Legacy: absolute path and .drv extension required +nix-instantiate shell.nix -A shellDrv --indirect --add-root $TEST_ROOT/shell.drv +[[ $(nix-shell --pure $TEST_ROOT/shell.drv --run \ + 'echo "$IMPURE_VAR - $VAR_FROM_STDENV_SETUP - $VAR_FROM_NIX"') = " - foo - bar" ]] + +# New behaviour: just needs to resolve to a derivation in the store +nix-instantiate shell.nix -A shellDrv --indirect --add-root $TEST_ROOT/shell +[[ $(nix-shell --pure $TEST_ROOT/shell --run \ + 'echo "$IMPURE_VAR - $VAR_FROM_STDENV_SETUP - $VAR_FROM_NIX"') = " - foo - bar" ]] + +# Test nix-shell -p +output=$(NIX_PATH=nixpkgs=shell.nix nix-shell --pure -p foo bar --run 'echo "$(foo) $(bar)"') +[ "$output" = "foo bar" ] + +# Test nix-shell shebang mode +sed -e "s|@ENV_PROG@|$(type -p env)|" shell.shebang.sh > $TEST_ROOT/shell.shebang.sh +chmod a+rx $TEST_ROOT/shell.shebang.sh + +output=$($TEST_ROOT/shell.shebang.sh abc def) +[ "$output" = "foo bar abc def" ] + +# Test nix-shell shebang mode for ruby +# This uses a fake interpreter that returns the arguments passed +# This, in turn, verifies the `rc` script is valid and the `load()` script (given using `-e`) is as expected. +sed -e "s|@SHELL_PROG@|$(type -p nix-shell)|" shell.shebang.rb > $TEST_ROOT/shell.shebang.rb +chmod a+rx $TEST_ROOT/shell.shebang.rb + +output=$($TEST_ROOT/shell.shebang.rb abc ruby) +[ "$output" = '-e load("'"$TEST_ROOT"'/shell.shebang.rb") -- abc ruby' ] diff --git a/third_party/nix/tests/optimise-store.sh b/third_party/nix/tests/optimise-store.sh new file mode 100644 index 0000000000..61e3df2f9f --- /dev/null +++ b/third_party/nix/tests/optimise-store.sh @@ -0,0 +1,43 @@ +source common.sh + +clearStore + +outPath1=$(echo 'with import ./config.nix; mkDerivation { name = "foo1"; builder = builtins.toFile "builder" "mkdir $out; echo hello > $out/foo"; }' | nix-build - --no-out-link --auto-optimise-store) +outPath2=$(echo 'with import ./config.nix; mkDerivation { name = "foo2"; builder = builtins.toFile "builder" "mkdir $out; echo hello > $out/foo"; }' | nix-build - --no-out-link --auto-optimise-store) + +inode1="$(stat --format=%i $outPath1/foo)" +inode2="$(stat --format=%i $outPath2/foo)" +if [ "$inode1" != "$inode2" ]; then + echo "inodes do not match" + exit 1 +fi + +nlink="$(stat --format=%h $outPath1/foo)" +if [ "$nlink" != 3 ]; then + echo "link count incorrect" + exit 1 +fi + +outPath3=$(echo 'with import ./config.nix; mkDerivation { name = "foo3"; builder = builtins.toFile "builder" "mkdir $out; echo hello > $out/foo"; }' | nix-build - --no-out-link) + +inode3="$(stat --format=%i $outPath3/foo)" +if [ "$inode1" = "$inode3" ]; then + echo "inodes match unexpectedly" + exit 1 +fi + +nix-store --optimise + +inode1="$(stat --format=%i $outPath1/foo)" +inode3="$(stat --format=%i $outPath3/foo)" +if [ "$inode1" != "$inode3" ]; then + echo "inodes do not match" + exit 1 +fi + +nix-store --gc + +if [ -n "$(ls $NIX_STORE_DIR/.links)" ]; then + echo ".links directory not empty after GC" + exit 1 +fi diff --git a/third_party/nix/tests/parallel.builder.sh b/third_party/nix/tests/parallel.builder.sh new file mode 100644 index 0000000000..d092bc5a6b --- /dev/null +++ b/third_party/nix/tests/parallel.builder.sh @@ -0,0 +1,29 @@ +echo "DOING $text" + + +# increase counter +while ! ln -s x $shared.lock 2> /dev/null; do + sleep 1 +done +test -f $shared.cur || echo 0 > $shared.cur +test -f $shared.max || echo 0 > $shared.max +new=$(($(cat $shared.cur) + 1)) +if test $new -gt $(cat $shared.max); then + echo $new > $shared.max +fi +echo $new > $shared.cur +rm $shared.lock + + +echo -n $(cat $inputs)$text > $out + +sleep $sleepTime + + +# decrease counter +while ! ln -s x $shared.lock 2> /dev/null; do + sleep 1 +done +test -f $shared.cur || echo 0 > $shared.cur +echo $(($(cat $shared.cur) - 1)) > $shared.cur +rm $shared.lock diff --git a/third_party/nix/tests/parallel.nix b/third_party/nix/tests/parallel.nix new file mode 100644 index 0000000000..23f142059f --- /dev/null +++ b/third_party/nix/tests/parallel.nix @@ -0,0 +1,19 @@ +{sleepTime ? 3}: + +with import ./config.nix; + +let + + mkDrv = text: inputs: mkDerivation { + name = "parallel"; + builder = ./parallel.builder.sh; + inherit text inputs shared sleepTime; + }; + + a = mkDrv "a" []; + b = mkDrv "b" [a]; + c = mkDrv "c" [a]; + d = mkDrv "d" [a]; + e = mkDrv "e" [b c d]; + +in e diff --git a/third_party/nix/tests/parallel.sh b/third_party/nix/tests/parallel.sh new file mode 100644 index 0000000000..3b7bbe5a22 --- /dev/null +++ b/third_party/nix/tests/parallel.sh @@ -0,0 +1,56 @@ +source common.sh + + +# First, test that -jN performs builds in parallel. +echo "testing nix-build -j..." + +clearStore + +rm -f $_NIX_TEST_SHARED.cur $_NIX_TEST_SHARED.max + +outPath=$(nix-build -j10000 parallel.nix --no-out-link) + +echo "output path is $outPath" + +text=$(cat "$outPath") +if test "$text" != "abacade"; then exit 1; fi + +if test "$(cat $_NIX_TEST_SHARED.cur)" != 0; then fail "wrong current process count"; fi +if test "$(cat $_NIX_TEST_SHARED.max)" != 3; then fail "not enough parallelism"; fi + + +# Second, test that parallel invocations of nix-build perform builds +# in parallel, and don't block waiting on locks held by the others. +echo "testing multiple nix-build -j1..." + +clearStore + +rm -f $_NIX_TEST_SHARED.cur $_NIX_TEST_SHARED.max + +drvPath=$(nix-instantiate parallel.nix --argstr sleepTime 15) + +cmd="nix-store -j1 -r $drvPath" + +$cmd & +pid1=$! +echo "pid 1 is $pid1" + +$cmd & +pid2=$! +echo "pid 2 is $pid2" + +$cmd & +pid3=$! +echo "pid 3 is $pid3" + +$cmd & +pid4=$! +echo "pid 4 is $pid4" + +wait $pid1 || fail "instance 1 failed: $?" +wait $pid2 || fail "instance 2 failed: $?" +wait $pid3 || fail "instance 3 failed: $?" +wait $pid4 || fail "instance 4 failed: $?" + +if test "$(cat $_NIX_TEST_SHARED.cur)" != 0; then fail "wrong current process count"; fi +if test "$(cat $_NIX_TEST_SHARED.max)" != 3; then fail "not enough parallelism"; fi diff --git a/third_party/nix/tests/pass-as-file.sh b/third_party/nix/tests/pass-as-file.sh new file mode 100644 index 0000000000..3dfe10baa2 --- /dev/null +++ b/third_party/nix/tests/pass-as-file.sh @@ -0,0 +1,17 @@ +source common.sh + +clearStore + +outPath=$(nix-build --no-out-link -E " +with import ./config.nix; + +mkDerivation { + name = \"pass-as-file\"; + passAsFile = [ \"foo\" ]; + foo = [ \"xyzzy\" ]; + builder = builtins.toFile \"builder.sh\" '' + [ \"\$(cat \$fooPath)\" = xyzzy ] + touch \$out + ''; +} +") diff --git a/third_party/nix/tests/placeholders.sh b/third_party/nix/tests/placeholders.sh new file mode 100644 index 0000000000..cd1bb7bc2a --- /dev/null +++ b/third_party/nix/tests/placeholders.sh @@ -0,0 +1,20 @@ +source common.sh + +clearStore + +nix-build --no-out-link -E ' + with import ./config.nix; + + mkDerivation { + name = "placeholders"; + outputs = [ "out" "bin" "dev" ]; + buildCommand = " + echo foo1 > $out + echo foo2 > $bin + echo foo3 > $dev + [[ $(cat ${placeholder "out"}) = foo1 ]] + [[ $(cat ${placeholder "bin"}) = foo2 ]] + [[ $(cat ${placeholder "dev"}) = foo3 ]] + "; + } +' diff --git a/third_party/nix/tests/plugins.sh b/third_party/nix/tests/plugins.sh new file mode 100644 index 0000000000..4b1baeddce --- /dev/null +++ b/third_party/nix/tests/plugins.sh @@ -0,0 +1,7 @@ +source common.sh + +set -o pipefail + +res=$(nix eval '(builtins.anotherNull)' --option setting-set true --option plugin-files $PWD/plugins/libplugintest*) + +[ "$res"x = "nullx" ] diff --git a/third_party/nix/tests/plugins/plugintest.cc b/third_party/nix/tests/plugins/plugintest.cc new file mode 100644 index 0000000000..5edd28bd09 --- /dev/null +++ b/third_party/nix/tests/plugins/plugintest.cc @@ -0,0 +1,23 @@ +#include "config.hh" +#include "primops.hh" + +using namespace nix; + +struct MySettings : Config { + Setting<bool> settingSet{this, false, "setting-set", + "Whether the plugin-defined setting was set"}; +}; + +MySettings mySettings; + +static GlobalConfig::Register rs(&mySettings); + +static void prim_anotherNull(EvalState& state, const Pos& pos, Value** args, + Value& v) { + if (mySettings.settingSet) + mkNull(v); + else + mkBool(v, false); +} + +static RegisterPrimOp rp("anotherNull", 0, prim_anotherNull); diff --git a/third_party/nix/tests/post-hook.sh b/third_party/nix/tests/post-hook.sh new file mode 100644 index 0000000000..a026572154 --- /dev/null +++ b/third_party/nix/tests/post-hook.sh @@ -0,0 +1,15 @@ +source common.sh + +clearStore + +export REMOTE_STORE=$TEST_ROOT/remote_store + +# Build the dependencies and push them to the remote store +nix-build -o $TEST_ROOT/result dependencies.nix --post-build-hook $PWD/push-to-store.sh + +clearStore + +# Ensure that we the remote store contains both the runtime and buildtime +# closure of what we've just built +nix copy --from "$REMOTE_STORE" --no-require-sigs -f dependencies.nix +nix copy --from "$REMOTE_STORE" --no-require-sigs -f dependencies.nix input1_drv diff --git a/third_party/nix/tests/pure-eval.nix b/third_party/nix/tests/pure-eval.nix new file mode 100644 index 0000000000..ed25b3d456 --- /dev/null +++ b/third_party/nix/tests/pure-eval.nix @@ -0,0 +1,3 @@ +{ + x = 123; +} diff --git a/third_party/nix/tests/pure-eval.sh b/third_party/nix/tests/pure-eval.sh new file mode 100644 index 0000000000..49c8564487 --- /dev/null +++ b/third_party/nix/tests/pure-eval.sh @@ -0,0 +1,18 @@ +source common.sh + +clearStore + +nix eval --pure-eval '(assert 1 + 2 == 3; true)' + +[[ $(nix eval '(builtins.readFile ./pure-eval.sh)') =~ clearStore ]] + +(! nix eval --pure-eval '(builtins.readFile ./pure-eval.sh)') + +(! nix eval --pure-eval '(builtins.currentTime)') +(! nix eval --pure-eval '(builtins.currentSystem)') + +(! nix-instantiate --pure-eval ./simple.nix) + +[[ $(nix eval "((import (builtins.fetchurl { url = file://$(pwd)/pure-eval.nix; })).x)") == 123 ]] +(! nix eval --pure-eval "((import (builtins.fetchurl { url = file://$(pwd)/pure-eval.nix; })).x)") +nix eval --pure-eval "((import (builtins.fetchurl { url = file://$(pwd)/pure-eval.nix; sha256 = \"$(nix hash-file pure-eval.nix --type sha256)\"; })).x)" diff --git a/third_party/nix/tests/push-to-store.sh b/third_party/nix/tests/push-to-store.sh new file mode 100755 index 0000000000..6aadb916ba --- /dev/null +++ b/third_party/nix/tests/push-to-store.sh @@ -0,0 +1,4 @@ +#!/bin/sh + +echo Pushing "$@" to "$REMOTE_STORE" +printf "%s" "$OUT_PATHS" | xargs -d: nix copy --to "$REMOTE_STORE" --no-require-sigs diff --git a/third_party/nix/tests/referrers.sh b/third_party/nix/tests/referrers.sh new file mode 100644 index 0000000000..8ab8e5ddfe --- /dev/null +++ b/third_party/nix/tests/referrers.sh @@ -0,0 +1,36 @@ +source common.sh + +clearStore + +max=500 + +reference=$NIX_STORE_DIR/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa +touch $reference +(echo $reference && echo && echo 0) | nix-store --register-validity + +echo "making registration..." + +set +x +for ((n = 0; n < $max; n++)); do + storePath=$NIX_STORE_DIR/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-$n + echo -n > $storePath + ref2=$NIX_STORE_DIR/aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa-$((n+1)) + if test $((n+1)) = $max; then + ref2=$reference + fi + echo $storePath; echo; echo 2; echo $reference; echo $ref2 +done > $TEST_ROOT/reg_info +set -x + +echo "registering..." + +nix-store --register-validity < $TEST_ROOT/reg_info + +echo "collecting garbage..." +ln -sfn $reference "$NIX_STATE_DIR"/gcroots/ref +nix-store --gc + +if [ -n "$(type -p sqlite3)" -a "$(sqlite3 $NIX_STATE_DIR/db/db.sqlite 'select count(*) from Refs')" -ne 0 ]; then + echo "referrers not cleaned up" + exit 1 +fi diff --git a/third_party/nix/tests/remote-builds.nix b/third_party/nix/tests/remote-builds.nix new file mode 100644 index 0000000000..b867f13b49 --- /dev/null +++ b/third_party/nix/tests/remote-builds.nix @@ -0,0 +1,108 @@ +# Test Nix's remote build feature. + +{ nixpkgs, system, nix }: + +with import (nixpkgs + "/nixos/lib/testing.nix") { inherit system; }; + +makeTest ( + +let + + # The configuration of the remote builders. + builder = + { config, pkgs, ... }: + { services.openssh.enable = true; + virtualisation.writableStore = true; + nix.package = nix; + nix.useSandbox = true; + }; + + # Trivial Nix expression to build remotely. + expr = config: nr: pkgs.writeText "expr.nix" + '' + let utils = builtins.storePath ${config.system.build.extraUtils}; in + derivation { + name = "hello-${toString nr}"; + system = "i686-linux"; + PATH = "''${utils}/bin"; + builder = "''${utils}/bin/sh"; + args = [ "-c" "if [ ${toString nr} = 5 ]; then echo FAIL; exit 1; fi; echo Hello; mkdir $out $foo; cat /proc/sys/kernel/hostname > $out/host; ln -s $out $foo/bar; sleep 10" ]; + outputs = [ "out" "foo" ]; + } + ''; + +in + +{ + + nodes = + { builder1 = builder; + builder2 = builder; + + client = + { config, pkgs, ... }: + { nix.maxJobs = 0; # force remote building + nix.distributedBuilds = true; + nix.buildMachines = + [ { hostName = "builder1"; + sshUser = "root"; + sshKey = "/root/.ssh/id_ed25519"; + system = "i686-linux"; + maxJobs = 1; + } + { hostName = "builder2"; + sshUser = "root"; + sshKey = "/root/.ssh/id_ed25519"; + system = "i686-linux"; + maxJobs = 1; + } + ]; + virtualisation.writableStore = true; + virtualisation.pathsInNixDB = [ config.system.build.extraUtils ]; + nix.package = nix; + nix.binaryCaches = [ ]; + programs.ssh.extraConfig = "ConnectTimeout 30"; + }; + }; + + testScript = { nodes }: + '' + startAll; + + # Create an SSH key on the client. + my $key = `${pkgs.openssh}/bin/ssh-keygen -t ed25519 -f key -N ""`; + $client->succeed("mkdir -p -m 700 /root/.ssh"); + $client->copyFileFromHost("key", "/root/.ssh/id_ed25519"); + $client->succeed("chmod 600 /root/.ssh/id_ed25519"); + + # Install the SSH key on the builders. + $client->waitForUnit("network.target"); + foreach my $builder ($builder1, $builder2) { + $builder->succeed("mkdir -p -m 700 /root/.ssh"); + $builder->copyFileFromHost("key.pub", "/root/.ssh/authorized_keys"); + $builder->waitForUnit("sshd"); + $client->succeed("ssh -o StrictHostKeyChecking=no " . $builder->name() . " 'echo hello world'"); + } + + # Perform a build and check that it was performed on the builder. + my $out = $client->succeed( + "nix-build ${expr nodes.client.config 1} 2> build-output", + "grep -q Hello build-output" + ); + $builder1->succeed("test -e $out"); + + # And a parallel build. + my ($out1, $out2) = split /\s/, + $client->succeed('nix-store -r $(nix-instantiate ${expr nodes.client.config 2})\!out $(nix-instantiate ${expr nodes.client.config 3})\!out'); + $builder1->succeed("test -e $out1 -o -e $out2"); + $builder2->succeed("test -e $out1 -o -e $out2"); + + # And a failing build. + $client->fail("nix-build ${expr nodes.client.config 5}"); + + # Test whether the build hook automatically skips unavailable builders. + $builder1->block; + $client->succeed("nix-build ${expr nodes.client.config 4}"); + ''; + +}) diff --git a/third_party/nix/tests/remote-store.sh b/third_party/nix/tests/remote-store.sh new file mode 100644 index 0000000000..77437658ea --- /dev/null +++ b/third_party/nix/tests/remote-store.sh @@ -0,0 +1,19 @@ +source common.sh + +clearStore + +startDaemon + +storeCleared=1 $SHELL ./user-envs.sh + +nix-store --dump-db > $TEST_ROOT/d1 +NIX_REMOTE= nix-store --dump-db > $TEST_ROOT/d2 +cmp $TEST_ROOT/d1 $TEST_ROOT/d2 + +nix-store --gc --max-freed 1K + +killDaemon + +user=$(whoami) +[ -e $NIX_STATE_DIR/gcroots/per-user/$user ] +[ -e $NIX_STATE_DIR/profiles/per-user/$user ] diff --git a/third_party/nix/tests/repair.sh b/third_party/nix/tests/repair.sh new file mode 100644 index 0000000000..ec7ad5dcaf --- /dev/null +++ b/third_party/nix/tests/repair.sh @@ -0,0 +1,77 @@ +source common.sh + +clearStore + +path=$(nix-build dependencies.nix -o $TEST_ROOT/result) +path2=$(nix-store -qR $path | grep input-2) + +nix-store --verify --check-contents -v + +hash=$(nix-hash $path2) + +# Corrupt a path and check whether nix-build --repair can fix it. +chmod u+w $path2 +touch $path2/bad + +if nix-store --verify --check-contents -v; then + echo "nix-store --verify succeeded unexpectedly" >&2 + exit 1 +fi + +# The path can be repaired by rebuilding the derivation. +nix-store --verify --check-contents --repair + +nix-store --verify-path $path2 + +# Re-corrupt and delete the deriver. Now --verify --repair should +# not work. +chmod u+w $path2 +touch $path2/bad + +nix-store --delete $(nix-store -qd $path2) + +if nix-store --verify --check-contents --repair; then + echo "nix-store --verify --repair succeeded unexpectedly" >&2 + exit 1 +fi + +nix-build dependencies.nix -o $TEST_ROOT/result --repair + +if [ "$(nix-hash $path2)" != "$hash" -o -e $path2/bad ]; then + echo "path not repaired properly" >&2 + exit 1 +fi + +# Corrupt a path that has a substitute and check whether nix-store +# --verify can fix it. +clearCache + +nix copy --to file://$cacheDir $path + +chmod u+w $path2 +rm -rf $path2 + +nix-store --verify --check-contents --repair --substituters "file://$cacheDir" --no-require-sigs + +if [ "$(nix-hash $path2)" != "$hash" -o -e $path2/bad ]; then + echo "path not repaired properly" >&2 + exit 1 +fi + +# Check --verify-path and --repair-path. +nix-store --verify-path $path2 + +chmod u+w $path2 +rm -rf $path2 + +if nix-store --verify-path $path2; then + echo "nix-store --verify-path succeeded unexpectedly" >&2 + exit 1 +fi + +nix-store --repair-path $path2 --substituters "file://$cacheDir" --no-require-sigs + +if [ "$(nix-hash $path2)" != "$hash" -o -e $path2/bad ]; then + echo "path not repaired properly" >&2 + exit 1 +fi diff --git a/third_party/nix/tests/restricted.nix b/third_party/nix/tests/restricted.nix new file mode 100644 index 0000000000..e0ef584020 --- /dev/null +++ b/third_party/nix/tests/restricted.nix @@ -0,0 +1 @@ +1 + 2 diff --git a/third_party/nix/tests/restricted.sh b/third_party/nix/tests/restricted.sh new file mode 100644 index 0000000000..e02becc60e --- /dev/null +++ b/third_party/nix/tests/restricted.sh @@ -0,0 +1,51 @@ +source common.sh + +clearStore + +nix-instantiate --restrict-eval --eval -E '1 + 2' +(! nix-instantiate --restrict-eval ./restricted.nix) +(! nix-instantiate --eval --restrict-eval <(echo '1 + 2')) +nix-instantiate --restrict-eval ./simple.nix -I src=. +nix-instantiate --restrict-eval ./simple.nix -I src1=simple.nix -I src2=config.nix -I src3=./simple.builder.sh + +(! nix-instantiate --restrict-eval --eval -E 'builtins.readFile ./simple.nix') +nix-instantiate --restrict-eval --eval -E 'builtins.readFile ./simple.nix' -I src=.. + +(! nix-instantiate --restrict-eval --eval -E 'builtins.readDir ../src/nix-channel') +nix-instantiate --restrict-eval --eval -E 'builtins.readDir ../src/nix-channel' -I src=../src + +(! nix-instantiate --restrict-eval --eval -E 'let __nixPath = [ { prefix = "foo"; path = ./.; } ]; in <foo>') +nix-instantiate --restrict-eval --eval -E 'let __nixPath = [ { prefix = "foo"; path = ./.; } ]; in <foo>' -I src=. + +p=$(nix eval --raw "(builtins.fetchurl file://$(pwd)/restricted.sh)" --restrict-eval --allowed-uris "file://$(pwd)") +cmp $p restricted.sh + +(! nix eval --raw "(builtins.fetchurl file://$(pwd)/restricted.sh)" --restrict-eval) + +(! nix eval --raw "(builtins.fetchurl file://$(pwd)/restricted.sh)" --restrict-eval --allowed-uris "file://$(pwd)/restricted.sh/") + +nix eval --raw "(builtins.fetchurl file://$(pwd)/restricted.sh)" --restrict-eval --allowed-uris "file://$(pwd)/restricted.sh" + +(! nix eval --raw "(builtins.fetchurl https://github.com/NixOS/patchelf/archive/master.tar.gz)" --restrict-eval) +(! nix eval --raw "(builtins.fetchTarball https://github.com/NixOS/patchelf/archive/master.tar.gz)" --restrict-eval) +(! nix eval --raw "(fetchGit git://github.com/NixOS/patchelf.git)" --restrict-eval) + +ln -sfn $(pwd)/restricted.nix $TEST_ROOT/restricted.nix +[[ $(nix-instantiate --eval $TEST_ROOT/restricted.nix) == 3 ]] +(! nix-instantiate --eval --restrict-eval $TEST_ROOT/restricted.nix) +(! nix-instantiate --eval --restrict-eval $TEST_ROOT/restricted.nix -I $TEST_ROOT) +(! nix-instantiate --eval --restrict-eval $TEST_ROOT/restricted.nix -I .) +nix-instantiate --eval --restrict-eval $TEST_ROOT/restricted.nix -I $TEST_ROOT -I . + +[[ $(nix eval --raw --restrict-eval -I . '(builtins.readFile "${import ./simple.nix}/hello")') == 'Hello World!' ]] + +# Check whether we can leak symlink information through directory traversal. +traverseDir="$(pwd)/restricted-traverse-me" +ln -sfn "$(pwd)/restricted-secret" "$(pwd)/restricted-innocent" +mkdir -p "$traverseDir" +goUp="..$(echo "$traverseDir" | sed -e 's,[^/]\+,..,g')" +output="$(nix eval --raw --restrict-eval -I "$traverseDir" \ + "(builtins.readFile \"$traverseDir/$goUp$(pwd)/restricted-innocent\")" \ + 2>&1 || :)" +echo "$output" | grep "is forbidden" +! echo "$output" | grep -F restricted-secret diff --git a/third_party/nix/tests/run.nix b/third_party/nix/tests/run.nix new file mode 100644 index 0000000000..77dcbd2a9d --- /dev/null +++ b/third_party/nix/tests/run.nix @@ -0,0 +1,17 @@ +with import ./config.nix; + +{ + hello = mkDerivation { + name = "hello"; + buildCommand = + '' + mkdir -p $out/bin + cat > $out/bin/hello <<EOF + #! ${shell} + who=\$1 + echo "Hello \''${who:-World} from $out/bin/hello" + EOF + chmod +x $out/bin/hello + ''; + }; +} diff --git a/third_party/nix/tests/run.sh b/third_party/nix/tests/run.sh new file mode 100644 index 0000000000..d1dbfd6bd4 --- /dev/null +++ b/third_party/nix/tests/run.sh @@ -0,0 +1,28 @@ +source common.sh + +clearStore +clearCache + +nix run -f run.nix hello -c hello | grep 'Hello World' +nix run -f run.nix hello -c hello NixOS | grep 'Hello NixOS' + +if ! canUseSandbox; then exit; fi + +chmod -R u+w $TEST_ROOT/store0 || true +rm -rf $TEST_ROOT/store0 + +clearStore + +path=$(nix eval --raw -f run.nix hello) + +# Note: we need the sandbox paths to ensure that the shell is +# visible in the sandbox. +nix run --sandbox-build-dir /build-tmp \ + --sandbox-paths '/nix? /bin? /lib? /lib64? /usr?' \ + --store $TEST_ROOT/store0 -f run.nix hello -c hello | grep 'Hello World' + +path2=$(nix run --sandbox-paths '/nix? /bin? /lib? /lib64? /usr?' --store $TEST_ROOT/store0 -f run.nix hello -c $SHELL -c 'type -p hello') + +[[ $path/bin/hello = $path2 ]] + +[[ -e $TEST_ROOT/store0/nix/store/$(basename $path)/bin/hello ]] diff --git a/third_party/nix/tests/search.nix b/third_party/nix/tests/search.nix new file mode 100644 index 0000000000..fea6e7a7a6 --- /dev/null +++ b/third_party/nix/tests/search.nix @@ -0,0 +1,25 @@ +with import ./config.nix; + +{ + hello = mkDerivation rec { + name = "hello-${version}"; + version = "0.1"; + buildCommand = "touch $out"; + meta.description = "Empty file"; + }; + foo = mkDerivation rec { + name = "foo-5"; + buildCommand = '' + mkdir -p $out + echo ${name} > $out/${name} + ''; + }; + bar = mkDerivation rec { + name = "bar-3"; + buildCommand = '' + echo "Does not build successfully" + exit 1 + ''; + meta.description = "broken bar"; + }; +} diff --git a/third_party/nix/tests/search.sh b/third_party/nix/tests/search.sh new file mode 100644 index 0000000000..14da3127b0 --- /dev/null +++ b/third_party/nix/tests/search.sh @@ -0,0 +1,43 @@ +source common.sh + +clearStore +clearCache + +# No packages +(( $(NIX_PATH= nix search -u|wc -l) == 0 )) + +# Haven't updated cache, still nothing +(( $(nix search -f search.nix hello|wc -l) == 0 )) +(( $(nix search -f search.nix |wc -l) == 0 )) + +# Update cache, search should work +(( $(nix search -f search.nix -u hello|wc -l) > 0 )) + +# Use cache +(( $(nix search -f search.nix foo|wc -l) > 0 )) +(( $(nix search foo|wc -l) > 0 )) + +# Test --no-cache works +# No results from cache +(( $(nix search --no-cache foo |wc -l) == 0 )) +# Does find results from file pointed at +(( $(nix search -f search.nix --no-cache foo |wc -l) > 0 )) + +# Check descriptions are searched +(( $(nix search broken | wc -l) > 0 )) + +# Check search that matches nothing +(( $(nix search nosuchpackageexists | wc -l) == 0 )) + +# Search for multiple arguments +(( $(nix search hello empty | wc -l) == 3 )) + +# Multiple arguments will not exist +(( $(nix search hello broken | wc -l) == 0 )) + +## Search expressions + +# Check that empty search string matches all +nix search|grep -q foo +nix search|grep -q bar +nix search|grep -q hello diff --git a/third_party/nix/tests/secure-drv-outputs.nix b/third_party/nix/tests/secure-drv-outputs.nix new file mode 100644 index 0000000000..b4ac8ff531 --- /dev/null +++ b/third_party/nix/tests/secure-drv-outputs.nix @@ -0,0 +1,23 @@ +with import ./config.nix; + +{ + + good = mkDerivation { + name = "good"; + builder = builtins.toFile "builder" + '' + mkdir $out + echo > $out/good + ''; + }; + + bad = mkDerivation { + name = "good"; + builder = builtins.toFile "builder" + '' + mkdir $out + echo > $out/bad + ''; + }; + +} diff --git a/third_party/nix/tests/secure-drv-outputs.sh b/third_party/nix/tests/secure-drv-outputs.sh new file mode 100644 index 0000000000..50a9c4428d --- /dev/null +++ b/third_party/nix/tests/secure-drv-outputs.sh @@ -0,0 +1,36 @@ +# Test that users cannot register specially-crafted derivations that +# produce output paths belonging to other derivations. This could be +# used to inject malware into the store. + +source common.sh + +clearStore + +startDaemon + +# Determine the output path of the "good" derivation. +goodOut=$(nix-store -q $(nix-instantiate ./secure-drv-outputs.nix -A good)) + +# Instantiate the "bad" derivation. +badDrv=$(nix-instantiate ./secure-drv-outputs.nix -A bad) +badOut=$(nix-store -q $badDrv) + +# Rewrite the bad derivation to produce the output path of the good +# derivation. +rm -f $TEST_ROOT/bad.drv +sed -e "s|$badOut|$goodOut|g" < $badDrv > $TEST_ROOT/bad.drv + +# Add the manipulated derivation to the store and build it. This +# should fail. +if badDrv2=$(nix-store --add $TEST_ROOT/bad.drv); then + nix-store -r "$badDrv2" +fi + +# Now build the good derivation. +goodOut2=$(nix-build ./secure-drv-outputs.nix -A good --no-out-link) +test "$goodOut" = "$goodOut2" + +if ! test -e "$goodOut"/good; then + echo "Bad derivation stole the output path of the good derivation!" + exit 1 +fi diff --git a/third_party/nix/tests/setuid.nix b/third_party/nix/tests/setuid.nix new file mode 100644 index 0000000000..77e83c8d6c --- /dev/null +++ b/third_party/nix/tests/setuid.nix @@ -0,0 +1,108 @@ +# Verify that Linux builds cannot create setuid or setgid binaries. + +{ nixpkgs, system, nix }: + +with import (nixpkgs + "/nixos/lib/testing.nix") { inherit system; }; + +makeTest { + + machine = + { config, lib, pkgs, ... }: + { virtualisation.writableStore = true; + nix.package = nix; + nix.binaryCaches = [ ]; + nix.nixPath = [ "nixpkgs=${lib.cleanSource pkgs.path}" ]; + virtualisation.pathsInNixDB = [ pkgs.stdenv pkgs.pkgsi686Linux.stdenv ]; + }; + + testScript = { nodes }: + '' + startAll; + + # Copying to /tmp should succeed. + $machine->succeed('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" {} " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 555 ]]'); + + $machine->succeed("rm /tmp/id"); + + # Creating a setuid binary should fail. + $machine->fail('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" {} " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + chmod 4755 /tmp/id + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 555 ]]'); + + $machine->succeed("rm /tmp/id"); + + # Creating a setgid binary should fail. + $machine->fail('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" {} " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + chmod 2755 /tmp/id + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 555 ]]'); + + $machine->succeed("rm /tmp/id"); + + # The checks should also work on 32-bit binaries. + $machine->fail('nix-build --no-sandbox -E \'(with import <nixpkgs> { system = "i686-linux"; }; runCommand "foo" {} " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + chmod 2755 /tmp/id + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 555 ]]'); + + $machine->succeed("rm /tmp/id"); + + # The tests above use fchmodat(). Test chmod() as well. + $machine->succeed('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" { buildInputs = [ perl ]; } " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + perl -e \"chmod 0666, qw(/tmp/id) or die\" + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 666 ]]'); + + $machine->succeed("rm /tmp/id"); + + $machine->fail('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" { buildInputs = [ perl ]; } " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + perl -e \"chmod 04755, qw(/tmp/id) or die\" + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 555 ]]'); + + $machine->succeed("rm /tmp/id"); + + # And test fchmod(). + $machine->succeed('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" { buildInputs = [ perl ]; } " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + perl -e \"my \\\$x; open \\\$x, qw(/tmp/id); chmod 01750, \\\$x or die\" + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 1750 ]]'); + + $machine->succeed("rm /tmp/id"); + + $machine->fail('nix-build --no-sandbox -E \'(with import <nixpkgs> {}; runCommand "foo" { buildInputs = [ perl ]; } " + mkdir -p $out + cp ${pkgs.coreutils}/bin/id /tmp/id + perl -e \"my \\\$x; open \\\$x, qw(/tmp/id); chmod 04777, \\\$x or die\" + ")\' '); + + $machine->succeed('[[ $(stat -c %a /tmp/id) = 555 ]]'); + + $machine->succeed("rm /tmp/id"); + ''; + +} diff --git a/third_party/nix/tests/shell.nix b/third_party/nix/tests/shell.nix new file mode 100644 index 0000000000..eb39f9039a --- /dev/null +++ b/third_party/nix/tests/shell.nix @@ -0,0 +1,56 @@ +{ }: + +with import ./config.nix; + +let pkgs = rec { + setupSh = builtins.toFile "setup" '' + export VAR_FROM_STDENV_SETUP=foo + for pkg in $buildInputs; do + export PATH=$PATH:$pkg/bin + done + ''; + + stdenv = mkDerivation { + name = "stdenv"; + buildCommand = '' + mkdir -p $out + ln -s ${setupSh} $out/setup + ''; + }; + + shellDrv = mkDerivation { + name = "shellDrv"; + builder = "/does/not/exist"; + VAR_FROM_NIX = "bar"; + inherit stdenv; + }; + + # Used by nix-shell -p + runCommand = name: args: buildCommand: mkDerivation (args // { + inherit name buildCommand stdenv; + }); + + foo = runCommand "foo" {} '' + mkdir -p $out/bin + echo 'echo foo' > $out/bin/foo + chmod a+rx $out/bin/foo + ln -s ${shell} $out/bin/bash + ''; + + bar = runCommand "bar" {} '' + mkdir -p $out/bin + echo 'echo bar' > $out/bin/bar + chmod a+rx $out/bin/bar + ''; + + bash = shell; + + # ruby "interpreter" that outputs "$@" + ruby = runCommand "ruby" {} '' + mkdir -p $out/bin + echo 'printf -- "$*"' > $out/bin/ruby + chmod a+rx $out/bin/ruby + ''; + + inherit pkgs; +}; in pkgs diff --git a/third_party/nix/tests/shell.shebang.rb b/third_party/nix/tests/shell.shebang.rb new file mode 100644 index 0000000000..ea67eb09c1 --- /dev/null +++ b/third_party/nix/tests/shell.shebang.rb @@ -0,0 +1,7 @@ +#! @SHELL_PROG@ +#! ruby +#! nix-shell -I nixpkgs=shell.nix --no-substitute +#! nix-shell --pure -p ruby -i ruby + +# Contents doesn't matter. +abort("This shouldn't be executed.") diff --git a/third_party/nix/tests/shell.shebang.sh b/third_party/nix/tests/shell.shebang.sh new file mode 100755 index 0000000000..f7132043de --- /dev/null +++ b/third_party/nix/tests/shell.shebang.sh @@ -0,0 +1,4 @@ +#! @ENV_PROG@ nix-shell +#! nix-shell -I nixpkgs=shell.nix --no-substitute +#! nix-shell --pure -i bash -p foo bar +echo "$(foo) $(bar) $@" diff --git a/third_party/nix/tests/signing.sh b/third_party/nix/tests/signing.sh new file mode 100644 index 0000000000..9e29e3fbf0 --- /dev/null +++ b/third_party/nix/tests/signing.sh @@ -0,0 +1,105 @@ +source common.sh + +clearStore +clearCache + +nix-store --generate-binary-cache-key cache1.example.org $TEST_ROOT/sk1 $TEST_ROOT/pk1 +pk1=$(cat $TEST_ROOT/pk1) +nix-store --generate-binary-cache-key cache2.example.org $TEST_ROOT/sk2 $TEST_ROOT/pk2 +pk2=$(cat $TEST_ROOT/pk2) + +# Build a path. +outPath=$(nix-build dependencies.nix --no-out-link --secret-key-files "$TEST_ROOT/sk1 $TEST_ROOT/sk2") + +# Verify that the path got signed. +info=$(nix path-info --json $outPath) +[[ $info =~ '"ultimate":true' ]] +[[ $info =~ 'cache1.example.org' ]] +[[ $info =~ 'cache2.example.org' ]] + +# Test "nix verify". +nix verify -r $outPath + +expect 2 nix verify -r $outPath --sigs-needed 1 + +nix verify -r $outPath --sigs-needed 1 --trusted-public-keys $pk1 + +expect 2 nix verify -r $outPath --sigs-needed 2 --trusted-public-keys $pk1 + +nix verify -r $outPath --sigs-needed 2 --trusted-public-keys "$pk1 $pk2" + +nix verify --all --sigs-needed 2 --trusted-public-keys "$pk1 $pk2" + +# Build something unsigned. +outPath2=$(nix-build simple.nix --no-out-link) + +nix verify -r $outPath + +# Verify that the path did not get signed but does have the ultimate bit. +info=$(nix path-info --json $outPath2) +[[ $info =~ '"ultimate":true' ]] +(! [[ $info =~ 'signatures' ]]) + +# Test "nix verify". +nix verify -r $outPath2 + +expect 2 nix verify -r $outPath2 --sigs-needed 1 + +expect 2 nix verify -r $outPath2 --sigs-needed 1 --trusted-public-keys $pk1 + +# Test "nix sign-paths". +nix sign-paths --key-file $TEST_ROOT/sk1 $outPath2 + +nix verify -r $outPath2 --sigs-needed 1 --trusted-public-keys $pk1 + +# Build something content-addressed. +outPathCA=$(IMPURE_VAR1=foo IMPURE_VAR2=bar nix-build ./fixed.nix -A good.0 --no-out-link) + +[[ $(nix path-info --json $outPathCA) =~ '"ca":"fixed:md5:' ]] + +# Content-addressed paths don't need signatures, so they verify +# regardless of --sigs-needed. +nix verify $outPathCA +nix verify $outPathCA --sigs-needed 1000 + +# Check that signing a content-addressed path doesn't overflow validSigs +nix sign-paths --key-file $TEST_ROOT/sk1 $outPathCA +nix verify -r $outPathCA --sigs-needed 1000 --trusted-public-keys $pk1 + +# Copy to a binary cache. +nix copy --to file://$cacheDir $outPath2 + +# Verify that signatures got copied. +info=$(nix path-info --store file://$cacheDir --json $outPath2) +(! [[ $info =~ '"ultimate":true' ]]) +[[ $info =~ 'cache1.example.org' ]] +(! [[ $info =~ 'cache2.example.org' ]]) + +# Verify that adding a signature to a path in a binary cache works. +nix sign-paths --store file://$cacheDir --key-file $TEST_ROOT/sk2 $outPath2 +info=$(nix path-info --store file://$cacheDir --json $outPath2) +[[ $info =~ 'cache1.example.org' ]] +[[ $info =~ 'cache2.example.org' ]] + +# Copying to a diverted store should fail due to a lack of valid signatures. +chmod -R u+w $TEST_ROOT/store0 || true +rm -rf $TEST_ROOT/store0 +(! nix copy --to $TEST_ROOT/store0 $outPath) + +# But succeed if we supply the public keys. +nix copy --to $TEST_ROOT/store0 $outPath --trusted-public-keys $pk1 + +expect 2 nix verify --store $TEST_ROOT/store0 -r $outPath + +nix verify --store $TEST_ROOT/store0 -r $outPath --trusted-public-keys $pk1 +nix verify --store $TEST_ROOT/store0 -r $outPath --sigs-needed 2 --trusted-public-keys "$pk1 $pk2" + +# It should also succeed if we disable signature checking. +(! nix copy --to $TEST_ROOT/store0 $outPath2) +nix copy --to $TEST_ROOT/store0?require-sigs=false $outPath2 + +# But signatures should still get copied. +nix verify --store $TEST_ROOT/store0 -r $outPath2 --trusted-public-keys $pk1 + +# Content-addressed stuff can be copied without signatures. +nix copy --to $TEST_ROOT/store0 $outPathCA diff --git a/third_party/nix/tests/simple.builder.sh b/third_party/nix/tests/simple.builder.sh new file mode 100644 index 0000000000..569e8ca88c --- /dev/null +++ b/third_party/nix/tests/simple.builder.sh @@ -0,0 +1,11 @@ +echo "PATH=$PATH" + +# Verify that the PATH is empty. +if mkdir foo 2> /dev/null; then exit 1; fi + +# Set a PATH (!!! impure). +export PATH=$goodPath + +mkdir $out + +echo "Hello World!" > $out/hello \ No newline at end of file diff --git a/third_party/nix/tests/simple.nix b/third_party/nix/tests/simple.nix new file mode 100644 index 0000000000..4223c0f23a --- /dev/null +++ b/third_party/nix/tests/simple.nix @@ -0,0 +1,8 @@ +with import ./config.nix; + +mkDerivation { + name = "simple"; + builder = ./simple.builder.sh; + PATH = ""; + goodPath = path; +} diff --git a/third_party/nix/tests/simple.sh b/third_party/nix/tests/simple.sh new file mode 100644 index 0000000000..37631b648c --- /dev/null +++ b/third_party/nix/tests/simple.sh @@ -0,0 +1,25 @@ +source common.sh + +drvPath=$(nix-instantiate simple.nix) + +test "$(nix-store -q --binding system "$drvPath")" = "$system" + +echo "derivation is $drvPath" + +outPath=$(nix-store -rvv "$drvPath") + +echo "output path is $outPath" + +text=$(cat "$outPath"/hello) +if test "$text" != "Hello World!"; then exit 1; fi + +# Directed delete: $outPath is not reachable from a root, so it should +# be deleteable. +nix-store --delete $outPath +if test -e $outPath/hello; then false; fi + +outPath="$(NIX_REMOTE=local?store=/foo\&real=$TEST_ROOT/real-store nix-instantiate --readonly-mode hash-check.nix)" +if test "$outPath" != "/foo/lfy1s6ca46rm5r6w4gg9hc0axiakjcnm-dependencies.drv"; then + echo "hashDerivationModulo appears broken, got $outPath" + exit 1 +fi diff --git a/third_party/nix/tests/structured-attrs.nix b/third_party/nix/tests/structured-attrs.nix new file mode 100644 index 0000000000..6c77a43913 --- /dev/null +++ b/third_party/nix/tests/structured-attrs.nix @@ -0,0 +1,66 @@ +with import ./config.nix; + +let + + dep = mkDerivation { + name = "dep"; + buildCommand = '' + mkdir $out; echo bla > $out/bla + ''; + }; + +in + +mkDerivation { + name = "structured"; + + __structuredAttrs = true; + + buildCommand = '' + set -x + + [[ $int = 123456789 ]] + [[ -z $float ]] + [[ -n $boolTrue ]] + [[ -z $boolFalse ]] + [[ -n ''${hardening[format]} ]] + [[ -z ''${hardening[fortify]} ]] + [[ ''${#buildInputs[@]} = 7 ]] + [[ ''${buildInputs[2]} = c ]] + [[ -v nothing ]] + [[ -z $nothing ]] + + mkdir ''${outputs[out]} + echo bar > $dest + + json=$(cat .attrs.json) + [[ $json =~ '"narHash":"sha256:1r7yc43zqnzl5b0als5vnyp649gk17i37s7mj00xr8kc47rjcybk"' ]] + [[ $json =~ '"narSize":288' ]] + [[ $json =~ '"closureSize":288' ]] + [[ $json =~ '"references":[]' ]] + ''; + + buildInputs = [ "a" "b" "c" 123 "'" "\"" null ]; + + hardening.format = true; + hardening.fortify = false; + + outer.inner = [ 1 2 3 ]; + + int = 123456789; + + float = 123.456; + + boolTrue = true; + boolFalse = false; + + nothing = null; + + dest = "${placeholder "out"}/foo"; + + "foo bar" = "BAD"; + "1foobar" = "BAD"; + "foo$" = "BAD"; + + exportReferencesGraph.refs = [ dep ]; +} diff --git a/third_party/nix/tests/structured-attrs.sh b/third_party/nix/tests/structured-attrs.sh new file mode 100644 index 0000000000..9ba2672b68 --- /dev/null +++ b/third_party/nix/tests/structured-attrs.sh @@ -0,0 +1,7 @@ +source common.sh + +clearStore + +outPath=$(nix-build structured-attrs.nix --no-out-link) + +[[ $(cat $outPath/foo) = bar ]] diff --git a/third_party/nix/tests/tarball.sh b/third_party/nix/tests/tarball.sh new file mode 100644 index 0000000000..ba534c6261 --- /dev/null +++ b/third_party/nix/tests/tarball.sh @@ -0,0 +1,28 @@ +source common.sh + +clearStore + +rm -rf $TEST_HOME + +tarroot=$TEST_ROOT/tarball +rm -rf $tarroot +mkdir -p $tarroot +cp dependencies.nix $tarroot/default.nix +cp config.nix dependencies.builder*.sh $tarroot/ + +tarball=$TEST_ROOT/tarball.tar.xz +(cd $TEST_ROOT && tar c tarball) | xz > $tarball + +nix-env -f file://$tarball -qa --out-path | grep -q dependencies + +nix-build -o $TEST_ROOT/result file://$tarball + +nix-build -o $TEST_ROOT/result '<foo>' -I foo=file://$tarball + +nix-build -o $TEST_ROOT/result -E "import (fetchTarball file://$tarball)" + +nix-instantiate --eval -E '1 + 2' -I fnord=file://no-such-tarball.tar.xz +nix-instantiate --eval -E 'with <fnord/xyzzy>; 1 + 2' -I fnord=file://no-such-tarball.tar.xz +(! nix-instantiate --eval -E '<fnord/xyzzy> 1' -I fnord=file://no-such-tarball.tar.xz) + +nix-instantiate --eval -E '<fnord/config.nix>' -I fnord=file://no-such-tarball.tar.xz -I fnord=. diff --git a/third_party/nix/tests/timeout.nix b/third_party/nix/tests/timeout.nix new file mode 100644 index 0000000000..d0e949e314 --- /dev/null +++ b/third_party/nix/tests/timeout.nix @@ -0,0 +1,31 @@ +with import ./config.nix; + +{ + + infiniteLoop = mkDerivation { + name = "timeout"; + buildCommand = '' + touch $out + echo "'timeout' builder entering an infinite loop" + while true ; do echo -n .; done + ''; + }; + + silent = mkDerivation { + name = "silent"; + buildCommand = '' + touch $out + sleep 60 + ''; + }; + + closeLog = mkDerivation { + name = "silent"; + buildCommand = '' + touch $out + exec > /dev/null 2>&1 + sleep 1000000000 + ''; + }; + +} diff --git a/third_party/nix/tests/timeout.sh b/third_party/nix/tests/timeout.sh new file mode 100644 index 0000000000..eea9b5731d --- /dev/null +++ b/third_party/nix/tests/timeout.sh @@ -0,0 +1,40 @@ +# Test the `--timeout' option. + +source common.sh + + +set +e +messages=$(nix-build -Q timeout.nix -A infiniteLoop --timeout 2 2>&1) +status=$? +set -e + +if [ $status -ne 101 ]; then + echo "error: 'nix-store' exited with '$status'; should have exited 101" + exit 1 +fi + +if ! echo "$messages" | grep -q "timed out"; then + echo "error: build may have failed for reasons other than timeout; output:" + echo "$messages" >&2 + exit 1 +fi + +if nix-build -Q timeout.nix -A infiniteLoop --max-build-log-size 100; then + echo "build should have failed" + exit 1 +fi + +if nix-build timeout.nix -A silent --max-silent-time 2; then + echo "build should have failed" + exit 1 +fi + +if nix-build timeout.nix -A closeLog; then + echo "build should have failed" + exit 1 +fi + +if nix build -f timeout.nix silent --max-silent-time 2; then + echo "build should have failed" + exit 1 +fi diff --git a/third_party/nix/tests/user-envs.builder.sh b/third_party/nix/tests/user-envs.builder.sh new file mode 100644 index 0000000000..5fafa797f1 --- /dev/null +++ b/third_party/nix/tests/user-envs.builder.sh @@ -0,0 +1,5 @@ +mkdir $out +mkdir $out/bin +echo "#! $shell" > $out/bin/$progName +echo "echo $name" >> $out/bin/$progName +chmod +x $out/bin/$progName diff --git a/third_party/nix/tests/user-envs.nix b/third_party/nix/tests/user-envs.nix new file mode 100644 index 0000000000..1aa410cc96 --- /dev/null +++ b/third_party/nix/tests/user-envs.nix @@ -0,0 +1,29 @@ +# Some dummy arguments... +{ foo ? "foo" +}: + +with import ./config.nix; + +assert foo == "foo"; + +let + + makeDrv = name: progName: (mkDerivation { + inherit name progName system; + builder = ./user-envs.builder.sh; + } // { + meta = { + description = "A silly test package"; + }; + }); + +in + + [ + (makeDrv "foo-1.0" "foo") + (makeDrv "foo-2.0pre1" "foo") + (makeDrv "bar-0.1" "bar") + (makeDrv "foo-2.0" "foo") + (makeDrv "bar-0.1.1" "bar") + (makeDrv "foo-0.1" "foo" // { meta.priority = 10; }) + ] diff --git a/third_party/nix/tests/user-envs.sh b/third_party/nix/tests/user-envs.sh new file mode 100644 index 0000000000..aebf6a2a2b --- /dev/null +++ b/third_party/nix/tests/user-envs.sh @@ -0,0 +1,181 @@ +source common.sh + +if [ -z "$storeCleared" ]; then + clearStore +fi + +clearProfiles + +# Query installed: should be empty. +test "$(nix-env -p $profiles/test -q '*' | wc -l)" -eq 0 + +mkdir -p $TEST_HOME +nix-env --switch-profile $profiles/test + +# Query available: should contain several. +test "$(nix-env -f ./user-envs.nix -qa '*' | wc -l)" -eq 6 +outPath10=$(nix-env -f ./user-envs.nix -qa --out-path --no-name '*' | grep foo-1.0) +drvPath10=$(nix-env -f ./user-envs.nix -qa --drv-path --no-name '*' | grep foo-1.0) +[ -n "$outPath10" -a -n "$drvPath10" ] + +# Query descriptions. +nix-env -f ./user-envs.nix -qa '*' --description | grep -q silly +rm -rf $HOME/.nix-defexpr +ln -s $(pwd)/user-envs.nix $HOME/.nix-defexpr +nix-env -qa '*' --description | grep -q silly + +# Query the system. +nix-env -qa '*' --system | grep -q $system + +# Install "foo-1.0". +nix-env -i foo-1.0 + +# Query installed: should contain foo-1.0 now (which should be +# executable). +test "$(nix-env -q '*' | wc -l)" -eq 1 +nix-env -q '*' | grep -q foo-1.0 +test "$($profiles/test/bin/foo)" = "foo-1.0" + +# Test nix-env -qc to compare installed against available packages, and vice versa. +nix-env -qc '*' | grep -q '< 2.0' +nix-env -qac '*' | grep -q '> 1.0' + +# Test the -b flag to filter out source-only packages. +[ "$(nix-env -qab | wc -l)" -eq 1 ] + +# Test the -s flag to get package status. +nix-env -qas | grep -q 'IP- foo-1.0' +nix-env -qas | grep -q -- '--- bar-0.1' + +# Disable foo. +nix-env --set-flag active false foo +(! [ -e "$profiles/test/bin/foo" ]) + +# Enable foo. +nix-env --set-flag active true foo +[ -e "$profiles/test/bin/foo" ] + +# Store the path of foo-1.0. +outPath10_=$(nix-env -q --out-path --no-name '*' | grep foo-1.0) +echo "foo-1.0 = $outPath10" +[ "$outPath10" = "$outPath10_" ] + +# Install "foo-2.0pre1": should remove foo-1.0. +nix-env -i foo-2.0pre1 + +# Query installed: should contain foo-2.0pre1 now. +test "$(nix-env -q '*' | wc -l)" -eq 1 +nix-env -q '*' | grep -q foo-2.0pre1 +test "$($profiles/test/bin/foo)" = "foo-2.0pre1" + +# Upgrade "foo": should install foo-2.0. +NIX_PATH=nixpkgs=./user-envs.nix:$NIX_PATH nix-env -f '<nixpkgs>' -u foo + +# Query installed: should contain foo-2.0 now. +test "$(nix-env -q '*' | wc -l)" -eq 1 +nix-env -q '*' | grep -q foo-2.0 +test "$($profiles/test/bin/foo)" = "foo-2.0" + +# Store the path of foo-2.0. +outPath20=$(nix-env -q --out-path --no-name '*' | grep foo-2.0) +test -n "$outPath20" + +# Install bar-0.1, uninstall foo. +nix-env -i bar-0.1 +nix-env -e foo + +# Query installed: should only contain bar-0.1 now. +if nix-env -q '*' | grep -q foo; then false; fi +nix-env -q '*' | grep -q bar + +# Rollback: should bring "foo" back. +oldGen="$(nix-store -q --resolve $profiles/test)" +nix-env --rollback +[ "$(nix-store -q --resolve $profiles/test)" != "$oldGen" ] +nix-env -q '*' | grep -q foo-2.0 +nix-env -q '*' | grep -q bar + +# Rollback again: should remove "bar". +nix-env --rollback +nix-env -q '*' | grep -q foo-2.0 +if nix-env -q '*' | grep -q bar; then false; fi + +# Count generations. +nix-env --list-generations +test "$(nix-env --list-generations | wc -l)" -eq 7 + +# Doing the same operation twice results in the same generation, which triggers +# "lazy" behaviour and does not create a new symlink. + +nix-env -i foo +nix-env -i foo + +# Count generations. +nix-env --list-generations +test "$(nix-env --list-generations | wc -l)" -eq 8 + +# Switch to a specified generation. +nix-env --switch-generation 7 +[ "$(nix-store -q --resolve $profiles/test)" = "$oldGen" ] + +# Install foo-1.0, now using its store path. +nix-env -i "$outPath10" +nix-env -q '*' | grep -q foo-1.0 +nix-store -qR $profiles/test | grep "$outPath10" +nix-store -q --referrers-closure $profiles/test | grep "$(nix-store -q --resolve $profiles/test)" +[ "$(nix-store -q --deriver "$outPath10")" = $drvPath10 ] + +# Uninstall foo-1.0, using a symlink to its store path. +ln -sfn $outPath10/bin/foo $TEST_ROOT/symlink +nix-env -e $TEST_ROOT/symlink +if nix-env -q '*' | grep -q foo; then false; fi +(! nix-store -qR $profiles/test | grep "$outPath10") + +# Install foo-1.0, now using a symlink to its store path. +nix-env -i $TEST_ROOT/symlink +nix-env -q '*' | grep -q foo + +# Delete all old generations. +nix-env --delete-generations old + +# Run the garbage collector. This should get rid of foo-2.0 but not +# foo-1.0. +nix-collect-garbage +test -e "$outPath10" +(! [ -e "$outPath20" ]) + +# Uninstall everything +nix-env -e '*' +test "$(nix-env -q '*' | wc -l)" -eq 0 + +# Installing "foo" should only install the newest foo. +nix-env -i foo +test "$(nix-env -q '*' | grep foo- | wc -l)" -eq 1 +nix-env -q '*' | grep -q foo-2.0 + +# On the other hand, this should install both (and should fail due to +# a collision). +nix-env -e '*' +(! nix-env -i foo-1.0 foo-2.0) + +# Installing "*" should install one foo and one bar. +nix-env -e '*' +nix-env -i '*' +test "$(nix-env -q '*' | wc -l)" -eq 2 +nix-env -q '*' | grep -q foo-2.0 +nix-env -q '*' | grep -q bar-0.1.1 + +# Test priorities: foo-0.1 has a lower priority than foo-1.0, so it +# should be possible to install both without a collision. Also test +# ‘--set-flag priority’ to manually override the declared priorities. +nix-env -e '*' +nix-env -i foo-0.1 foo-1.0 +[ "$($profiles/test/bin/foo)" = "foo-1.0" ] +nix-env --set-flag priority 1 foo-0.1 +[ "$($profiles/test/bin/foo)" = "foo-0.1" ] + +# Test nix-env --set. +nix-env --set $outPath10 +[ "$(nix-store -q --resolve $profiles/test)" = $outPath10 ] +nix-env --set $drvPath10 +[ "$(nix-store -q --resolve $profiles/test)" = $outPath10 ] diff --git a/third_party/nixery/default.nix b/third_party/nixery/default.nix new file mode 100644 index 0000000000..4b894ce1dd --- /dev/null +++ b/third_party/nixery/default.nix @@ -0,0 +1,18 @@ +# Technically I suppose Nixery is not a third-party program, but it's +# outside of this repository ... +{ pkgs, ... }: + +let src = pkgs.fetchFromGitHub { + owner = "google"; + repo = "nixery"; + rev = "4f6ce83f9296545d6c74321b37d18545764c8827"; + sha256 = "19aiak1pss6vwm0fwn02827l5ir78fkqglfbdl2gchsyv3gps8bg"; +}; +in import src { + inherit pkgs; + preLaunch = '' + export USER=root + cachix use tazjin + ''; + extraPackages = with pkgs.third_party; [ cachix openssh ]; +} diff --git a/third_party/notmuch/default.nix b/third_party/notmuch/default.nix new file mode 100644 index 0000000000..8e1e9c2626 --- /dev/null +++ b/third_party/notmuch/default.nix @@ -0,0 +1,6 @@ +{ pkgs, ... }: + +pkgs.originals.notmuch.overrideAttrs(old: { + doCheck = false; + patches = [ ./dottime.patch ] ++ (if old ? patches then old.patches else []); +}) diff --git a/third_party/notmuch/dottime.patch b/third_party/notmuch/dottime.patch new file mode 100644 index 0000000000..c9e0159ca2 --- /dev/null +++ b/third_party/notmuch/dottime.patch @@ -0,0 +1,63 @@ +diff --git a/notmuch-time.c b/notmuch-time.c +index 2734b36a..b1ec4bdc 100644 +--- a/notmuch-time.c ++++ b/notmuch-time.c +@@ -50,8 +50,8 @@ notmuch_time_relative_date (const void *ctx, time_t then) + time_t delta; + char *result; + +- localtime_r (&now, &tm_now); +- localtime_r (&then, &tm_then); ++ gmtime_r (&now, &tm_now); ++ gmtime_r (&then, &tm_then); + + result = talloc_zero_size (ctx, RELATIVE_DATE_MAX); + if (result == NULL) +@@ -79,16 +79,16 @@ notmuch_time_relative_date (const void *ctx, time_t then) + delta < DAY) + { + strftime (result, RELATIVE_DATE_MAX, +- "Today %R", &tm_then); /* Today 12:30 */ ++ "Today %k·%M", &tm_then); /* Today 12·30 */ + return result; + } else if ((tm_now.tm_wday + 7 - tm_then.tm_wday) % 7 == 1) { + strftime (result, RELATIVE_DATE_MAX, +- "Yest. %R", &tm_then); /* Yest. 12:30 */ ++ "Yest. %k·%M", &tm_then); /* Yest. 12·30 */ + return result; + } else { + if (tm_then.tm_wday != tm_now.tm_wday) { + strftime (result, RELATIVE_DATE_MAX, +- "%a. %R", &tm_then); /* Mon. 12:30 */ ++ "%a. %k·%M", &tm_then); /* Mon. 12·30 */ + return result; + } + } +diff --git a/util/gmime-extra.c b/util/gmime-extra.c +index d1bb1d47..9df5a454 100644 +--- a/util/gmime-extra.c ++++ b/util/gmime-extra.c +@@ -124,7 +124,10 @@ g_mime_message_get_date_string (void *ctx, GMimeMessage *message) + { + GDateTime* parsed_date = g_mime_message_get_date (message); + if (parsed_date) { +- char *date = g_mime_utils_header_format_date (parsed_date); ++ char *date = g_date_time_format( ++ parsed_date, ++ "%a, %d %b %Y %H·%M%z" ++ ); + return g_string_talloc_strdup (ctx, date); + } else { + return talloc_strdup(ctx, "Thu, 01 Jan 1970 00:00:00 +0000"); +diff --git a/util/gmime-extra.h b/util/gmime-extra.h +index b0c8d3d8..40f748f8 100644 +--- a/util/gmime-extra.h ++++ b/util/gmime-extra.h +@@ -1,5 +1,7 @@ + #ifndef _GMIME_EXTRA_H + #define _GMIME_EXTRA_H ++#include <glib.h> ++#include <glib/gprintf.h> + #include <gmime/gmime.h> + #include <talloc.h> + diff --git a/third_party/python/broadlink/.gitignore b/third_party/python/broadlink/.gitignore new file mode 100644 index 0000000000..0d20b6487c --- /dev/null +++ b/third_party/python/broadlink/.gitignore @@ -0,0 +1 @@ +*.pyc diff --git a/third_party/python/broadlink/LICENSE b/third_party/python/broadlink/LICENSE new file mode 100644 index 0000000000..d8c801656b --- /dev/null +++ b/third_party/python/broadlink/LICENSE @@ -0,0 +1,22 @@ +The MIT License (MIT) + +Copyright (c) 2014 Mike Ryan +Copyright (c) 2016 Matthew Garrett + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in +all copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN +THE SOFTWARE. diff --git a/third_party/python/broadlink/README.md b/third_party/python/broadlink/README.md new file mode 100644 index 0000000000..8faba2be75 --- /dev/null +++ b/third_party/python/broadlink/README.md @@ -0,0 +1,112 @@ +Python control for Broadlink RM2, RM3 and RM4 series controllers +=============================================== + +A simple Python API for controlling IR/RF controllers from [Broadlink](http://www.ibroadlink.com/rm/). At present, the following devices are currently supported: + +* RM Pro (referred to as RM2 in the codebase) +* A1 sensor platform devices are supported +* RM3 mini IR blaster +* RM4 and RM4C mini blasters + +There is currently no support for the cloud API. + +Example use +----------- + +Setup a new device on your local wireless network: + +1. Put the device into AP Mode + 1. Long press the reset button until the blue LED is blinking quickly. + 2. Long press again until blue LED is blinking slowly. + 3. Manually connect to the WiFi SSID named BroadlinkProv. +2. Run setup() and provide your ssid, network password (if secured), and set the security mode + 1. Security mode options are (0 = none, 1 = WEP, 2 = WPA1, 3 = WPA2, 4 = WPA1/2) +``` +import broadlink + +broadlink.setup('myssid', 'mynetworkpass', 3) +``` + +Discover available devices on the local network: +``` +import broadlink + +devices = broadlink.discover(timeout=5) +``` + +Obtain the authentication key required for further communication: +``` +devices[0].auth() +``` + +Enter learning mode: +``` +devices[0].enter_learning() +``` + +Sweep RF frequencies: +``` +devices[0].sweep_frequency() +``` + +Cancel sweep RF frequencies: +``` +devices[0].cancel_sweep_frequency() +``` +Check whether a frequency has been found: +``` +found = devices[0].check_frequency() +``` +(This will return True if the RM has locked onto a frequency, False otherwise) + +Attempt to learn an RF packet: +``` +found = devices[0].find_rf_packet() +``` +(This will return True if a packet has been found, False otherwise) + +Obtain an IR or RF packet while in learning mode: +``` +ir_packet = devices[0].check_data() +``` +(This will return None if the device does not have a packet to return) + +Send an IR or RF packet: +``` +devices[0].send_data(ir_packet) +``` + +Obtain temperature data from an RM2: +``` +devices[0].check_temperature() +``` + +Obtain sensor data from an A1: +``` +data = devices[0].check_sensors() +``` + +Set power state on a SmartPlug SP2/SP3: +``` +devices[0].set_power(True) +``` + +Check power state on a SmartPlug: +``` +state = devices[0].check_power() +``` + +Check energy consumption on a SmartPlug: +``` +state = devices[0].get_energy() +``` + +Set power state for S1 on a SmartPowerStrip MP1: +``` +devices[0].set_power(1, True) +``` + +Check power state on a SmartPowerStrip: +``` +state = devices[0].check_power() +``` diff --git a/third_party/python/broadlink/broadlink/__init__.py b/third_party/python/broadlink/broadlink/__init__.py new file mode 100644 index 0000000000..0c70c4beae --- /dev/null +++ b/third_party/python/broadlink/broadlink/__init__.py @@ -0,0 +1,1118 @@ +#!/usr/bin/python + +import codecs +import json +import random +import socket +import struct +import threading +import time +from datetime import datetime + +from cryptography.hazmat.backends import default_backend +from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes + + +def gendevice(devtype, host, mac, name=None, cloud=None): + devices = { + sp1: [0], + sp2: [0x2711, # SP2 + 0x2719, 0x7919, 0x271a, 0x791a, # Honeywell SP2 + 0x2720, # SPMini + 0x753e, # SP3 + 0x7D00, # OEM branded SP3 + 0x947a, 0x9479, # SP3S + 0x2728, # SPMini2 + 0x2733, 0x273e, # OEM branded SPMini + 0x7530, 0x7546, 0x7918, # OEM branded SPMini2 + 0x7D0D, # TMall OEM SPMini3 + 0x2736 # SPMiniPlus + ], + rm: [0x2712, # RM2 + 0x2737, # RM Mini + 0x273d, # RM Pro Phicomm + 0x2783, # RM2 Home Plus + 0x277c, # RM2 Home Plus GDT + 0x272a, # RM2 Pro Plus + 0x2787, # RM2 Pro Plus2 + 0x279d, # RM2 Pro Plus3 + 0x27a9, # RM2 Pro Plus_300 + 0x278b, # RM2 Pro Plus BL + 0x2797, # RM2 Pro Plus HYC + 0x27a1, # RM2 Pro Plus R1 + 0x27a6, # RM2 Pro PP + 0x278f, # RM Mini Shate + 0x27c2, # RM Mini 3 + 0x27d1, # new RM Mini3 + 0x27de # RM Mini 3 (C) + ], + rm4: [0x51da, # RM4 Mini + 0x5f36, # RM Mini 3 + 0x6026, # RM4 Pro + 0x610e, # RM4 Mini + 0x610f, # RM4c + 0x62bc, # RM4 Mini + 0x62be # RM4c + ], + a1: [0x2714], # A1 + mp1: [0x4EB5, # MP1 + 0x4EF7 # Honyar oem mp1 + ], + hysen: [0x4EAD], # Hysen controller + S1C: [0x2722], # S1 (SmartOne Alarm Kit) + dooya: [0x4E4D], # Dooya DT360E (DOOYA_CURTAIN_V2) + bg1: [0x51E3], # BG Electrical Smart Power Socket + lb1 : [0x60c8] # RGB Smart Bulb + } + + # Look for the class associated to devtype in devices + [device_class] = [dev for dev in devices if devtype in devices[dev]] or [None] + if device_class is None: + return device(host, mac, devtype, name=name, cloud=cloud) + return device_class(host, mac, devtype, name=name, cloud=cloud) + + +def discover(timeout=None, local_ip_address=None, discover_ip_address='255.255.255.255', max_devices=100): + if local_ip_address is None: + local_ip_address = socket.gethostbyname(socket.gethostname()) + if local_ip_address.startswith('127.'): + s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) + s.connect(('8.8.8.8', 53)) # connecting to a UDP address doesn't send packets + local_ip_address = s.getsockname()[0] + address = local_ip_address.split('.') + cs = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) + cs.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) + cs.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1) + cs.bind((local_ip_address, 0)) + port = cs.getsockname()[1] + starttime = time.time() + + devices = [] + + timezone = int(time.timezone / -3600) + packet = bytearray(0x30) + + year = datetime.now().year + + if timezone < 0: + packet[0x08] = 0xff + timezone - 1 + packet[0x09] = 0xff + packet[0x0a] = 0xff + packet[0x0b] = 0xff + else: + packet[0x08] = timezone + packet[0x09] = 0 + packet[0x0a] = 0 + packet[0x0b] = 0 + packet[0x0c] = year & 0xff + packet[0x0d] = year >> 8 + packet[0x0e] = datetime.now().minute + packet[0x0f] = datetime.now().hour + subyear = str(year)[2:] + packet[0x10] = int(subyear) + packet[0x11] = datetime.now().isoweekday() + packet[0x12] = datetime.now().day + packet[0x13] = datetime.now().month + packet[0x18] = int(address[0]) + packet[0x19] = int(address[1]) + packet[0x1a] = int(address[2]) + packet[0x1b] = int(address[3]) + packet[0x1c] = port & 0xff + packet[0x1d] = port >> 8 + packet[0x26] = 6 + + checksum = 0xbeaf + for b in packet: + checksum = (checksum + b) & 0xffff + + packet[0x20] = checksum & 0xff + packet[0x21] = checksum >> 8 + + cs.sendto(packet, (discover_ip_address, 80)) + if timeout is None: + response = cs.recvfrom(1024) + responsepacket = bytearray(response[0]) + host = response[1] + devtype = responsepacket[0x34] | responsepacket[0x35] << 8 + mac = responsepacket[0x3a:0x40] + name = responsepacket[0x40:].split(b'\x00')[0].decode('utf-8') + cloud = bool(responsepacket[-1]) + device = gendevice(devtype, host, mac, name=name, cloud=cloud) + return device + + while ((time.time() - starttime) < timeout) and (len(devices) < max_devices): + cs.settimeout(timeout - (time.time() - starttime)) + try: + response = cs.recvfrom(1024) + except socket.timeout: + return devices + responsepacket = bytearray(response[0]) + host = response[1] + devtype = responsepacket[0x34] | responsepacket[0x35] << 8 + mac = responsepacket[0x3a:0x40] + name = responsepacket[0x40:].split(b'\x00')[0].decode('utf-8') + cloud = bool(responsepacket[-1]) + device = gendevice(devtype, host, mac, name=name, cloud=cloud) + devices.append(device) + return devices + + +class device: + def __init__(self, host, mac, devtype, timeout=10, name=None, cloud=None): + self.host = host + self.mac = mac.encode() if isinstance(mac, str) else mac + self.devtype = devtype if devtype is not None else 0x272a + self.name = name + self.cloud = cloud + self.timeout = timeout + self.count = random.randrange(0xffff) + self.iv = bytearray( + [0x56, 0x2e, 0x17, 0x99, 0x6d, 0x09, 0x3d, 0x28, 0xdd, 0xb3, 0xba, 0x69, 0x5a, 0x2e, 0x6f, 0x58]) + self.id = bytearray([0, 0, 0, 0]) + self.cs = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) + self.cs.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) + self.cs.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1) + self.cs.bind(('', 0)) + self.type = "Unknown" + self.lock = threading.Lock() + + self.aes = None + key = bytearray( + [0x09, 0x76, 0x28, 0x34, 0x3f, 0xe9, 0x9e, 0x23, 0x76, 0x5c, 0x15, 0x13, 0xac, 0xcf, 0x8b, 0x02]) + self.update_aes(key) + + def update_aes(self, key): + self.aes = Cipher(algorithms.AES(key), modes.CBC(self.iv), + backend=default_backend()) + + def encrypt(self, payload): + encryptor = self.aes.encryptor() + return encryptor.update(payload) + encryptor.finalize() + + def decrypt(self, payload): + decryptor = self.aes.decryptor() + return decryptor.update(payload) + decryptor.finalize() + + def auth(self): + payload = bytearray(0x50) + payload[0x04] = 0x31 + payload[0x05] = 0x31 + payload[0x06] = 0x31 + payload[0x07] = 0x31 + payload[0x08] = 0x31 + payload[0x09] = 0x31 + payload[0x0a] = 0x31 + payload[0x0b] = 0x31 + payload[0x0c] = 0x31 + payload[0x0d] = 0x31 + payload[0x0e] = 0x31 + payload[0x0f] = 0x31 + payload[0x10] = 0x31 + payload[0x11] = 0x31 + payload[0x12] = 0x31 + payload[0x1e] = 0x01 + payload[0x2d] = 0x01 + payload[0x30] = ord('T') + payload[0x31] = ord('e') + payload[0x32] = ord('s') + payload[0x33] = ord('t') + payload[0x34] = ord(' ') + payload[0x35] = ord(' ') + payload[0x36] = ord('1') + + response = self.send_packet(0x65, payload) + + if any(response[0x22:0x24]): + return False + + payload = self.decrypt(response[0x38:]) + + key = payload[0x04:0x14] + if len(key) % 16 != 0: + return False + + self.id = payload[0x00:0x04] + self.update_aes(key) + + return True + + def get_type(self): + return self.type + + def send_packet(self, command, payload): + self.count = (self.count + 1) & 0xffff + packet = bytearray(0x38) + packet[0x00] = 0x5a + packet[0x01] = 0xa5 + packet[0x02] = 0xaa + packet[0x03] = 0x55 + packet[0x04] = 0x5a + packet[0x05] = 0xa5 + packet[0x06] = 0xaa + packet[0x07] = 0x55 + packet[0x24] = self.devtype & 0xff + packet[0x25] = self.devtype >> 8 + packet[0x26] = command + packet[0x28] = self.count & 0xff + packet[0x29] = self.count >> 8 + packet[0x2a] = self.mac[0] + packet[0x2b] = self.mac[1] + packet[0x2c] = self.mac[2] + packet[0x2d] = self.mac[3] + packet[0x2e] = self.mac[4] + packet[0x2f] = self.mac[5] + packet[0x30] = self.id[0] + packet[0x31] = self.id[1] + packet[0x32] = self.id[2] + packet[0x33] = self.id[3] + + # pad the payload for AES encryption + if payload: + payload += bytearray((16 - len(payload)) % 16) + + checksum = 0xbeaf + for b in payload: + checksum = (checksum + b) & 0xffff + + packet[0x34] = checksum & 0xff + packet[0x35] = checksum >> 8 + + payload = self.encrypt(payload) + for i in range(len(payload)): + packet.append(payload[i]) + + checksum = 0xbeaf + for b in packet: + checksum = (checksum + b) & 0xffff + + packet[0x20] = checksum & 0xff + packet[0x21] = checksum >> 8 + + start_time = time.time() + with self.lock: + while True: + try: + self.cs.sendto(packet, self.host) + self.cs.settimeout(1) + response = self.cs.recvfrom(2048) + break + except socket.timeout: + if (time.time() - start_time) > self.timeout: + raise + return bytearray(response[0]) + + +class mp1(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "MP1" + + def set_power_mask(self, sid_mask, state): + """Sets the power state of the smart power strip.""" + + packet = bytearray(16) + packet[0x00] = 0x0d + packet[0x02] = 0xa5 + packet[0x03] = 0xa5 + packet[0x04] = 0x5a + packet[0x05] = 0x5a + packet[0x06] = 0xb2 + ((sid_mask << 1) if state else sid_mask) + packet[0x07] = 0xc0 + packet[0x08] = 0x02 + packet[0x0a] = 0x03 + packet[0x0d] = sid_mask + packet[0x0e] = sid_mask if state else 0 + + self.send_packet(0x6a, packet) + + def set_power(self, sid, state): + """Sets the power state of the smart power strip.""" + sid_mask = 0x01 << (sid - 1) + return self.set_power_mask(sid_mask, state) + + def check_power_raw(self): + """Returns the power state of the smart power strip in raw format.""" + packet = bytearray(16) + packet[0x00] = 0x0a + packet[0x02] = 0xa5 + packet[0x03] = 0xa5 + packet[0x04] = 0x5a + packet[0x05] = 0x5a + packet[0x06] = 0xae + packet[0x07] = 0xc0 + packet[0x08] = 0x01 + + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + if isinstance(payload[0x4], int): + state = payload[0x0e] + else: + state = ord(payload[0x0e]) + return state + + def check_power(self): + """Returns the power state of the smart power strip.""" + state = self.check_power_raw() + if state is None: + return {'s1': None, 's2': None, 's3': None, 's4': None} + data = {} + data['s1'] = bool(state & 0x01) + data['s2'] = bool(state & 0x02) + data['s3'] = bool(state & 0x04) + data['s4'] = bool(state & 0x08) + return data + + +class bg1(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "BG1" + + def get_state(self): + """Get state of device. + + Returns: + dict: Dictionary of current state + eg. `{"pwr":1,"pwr1":1,"pwr2":0,"maxworktime":60,"maxworktime1":60,"maxworktime2":0,"idcbrightness":50}`""" + packet = self._encode(1, b'{}') + response = self.send_packet(0x6a, packet) + return self._decode(response) + + def set_state(self, pwr=None, pwr1=None, pwr2=None, maxworktime=None, maxworktime1=None, maxworktime2=None, idcbrightness=None): + data = {} + if pwr is not None: + data['pwr'] = int(bool(pwr)) + if pwr1 is not None: + data['pwr1'] = int(bool(pwr1)) + if pwr2 is not None: + data['pwr2'] = int(bool(pwr2)) + if maxworktime is not None: + data['maxworktime'] = maxworktime + if maxworktime1 is not None: + data['maxworktime1'] = maxworktime1 + if maxworktime2 is not None: + data['maxworktime2'] = maxworktime2 + if idcbrightness is not None: + data['idcbrightness'] = idcbrightness + js = json.dumps(data).encode('utf8') + packet = self._encode(2, js) + response = self.send_packet(0x6a, packet) + return self._decode(response) + + def _encode(self, flag, js): + # packet format is: + # 0x00-0x01 length + # 0x02-0x05 header + # 0x06-0x07 00 + # 0x08 flag (1 for read or 2 write?) + # 0x09 unknown (0xb) + # 0x0a-0x0d length of json + # 0x0e- json data + packet = bytearray(14) + length = 4 + 2 + 2 + 4 + len(js) + struct.pack_into('<HHHHBBI', packet, 0, length, 0xa5a5, 0x5a5a, 0x0000, flag, 0x0b, len(js)) + for i in range(len(js)): + packet.append(js[i]) + + checksum = 0xc0ad + for b in packet[0x08:]: + checksum = (checksum + b) & 0xffff + + packet[0x06] = checksum & 0xff + packet[0x07] = checksum >> 8 + + return packet + + def _decode(self, response): + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + + payload = self.decrypt(bytes(response[0x38:])) + js_len = struct.unpack_from('<I', payload, 0x0a)[0] + state = json.loads(payload[0x0e:0x0e+js_len]) + return state + +class sp1(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "SP1" + + def set_power(self, state): + packet = bytearray(4) + packet[0] = state + self.send_packet(0x66, packet) + + +class sp2(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "SP2" + + def set_power(self, state): + """Sets the power state of the smart plug.""" + packet = bytearray(16) + packet[0] = 2 + if self.check_nightlight(): + packet[4] = 3 if state else 2 + else: + packet[4] = 1 if state else 0 + self.send_packet(0x6a, packet) + + def set_nightlight(self, state): + """Sets the night light state of the smart plug""" + packet = bytearray(16) + packet[0] = 2 + if self.check_power(): + packet[4] = 3 if state else 1 + else: + packet[4] = 2 if state else 0 + self.send_packet(0x6a, packet) + + def check_power(self): + """Returns the power state of the smart plug.""" + packet = bytearray(16) + packet[0] = 1 + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + if isinstance(payload[0x4], int): + return bool(payload[0x4] == 1 or payload[0x4] == 3 or payload[0x4] == 0xFD) + return bool(ord(payload[0x4]) == 1 or ord(payload[0x4]) == 3 or ord(payload[0x4]) == 0xFD) + + def check_nightlight(self): + """Returns the power state of the smart plug.""" + packet = bytearray(16) + packet[0] = 1 + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + if isinstance(payload[0x4], int): + return bool(payload[0x4] == 2 or payload[0x4] == 3 or payload[0x4] == 0xFF) + return bool(ord(payload[0x4]) == 2 or ord(payload[0x4]) == 3 or ord(payload[0x4]) == 0xFF) + + def get_energy(self): + packet = bytearray([8, 0, 254, 1, 5, 1, 0, 0, 0, 45]) + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + if isinstance(payload[0x7], int): + energy = int(hex(payload[0x07] * 256 + payload[0x06])[2:]) + int(hex(payload[0x05])[2:]) / 100.0 + else: + energy = int(hex(ord(payload[0x07]) * 256 + ord(payload[0x06]))[2:]) + int( + hex(ord(payload[0x05]))[2:]) / 100.0 + return energy + + +class a1(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "A1" + + def check_sensors(self): + packet = bytearray(16) + packet[0] = 1 + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + data = {} + payload = self.decrypt(bytes(response[0x38:])) + if isinstance(payload[0x4], int): + data['temperature'] = (payload[0x4] * 10 + payload[0x5]) / 10.0 + data['humidity'] = (payload[0x6] * 10 + payload[0x7]) / 10.0 + light = payload[0x8] + air_quality = payload[0x0a] + noise = payload[0xc] + else: + data['temperature'] = (ord(payload[0x4]) * 10 + ord(payload[0x5])) / 10.0 + data['humidity'] = (ord(payload[0x6]) * 10 + ord(payload[0x7])) / 10.0 + light = ord(payload[0x8]) + air_quality = ord(payload[0x0a]) + noise = ord(payload[0xc]) + if light == 0: + data['light'] = 'dark' + elif light == 1: + data['light'] = 'dim' + elif light == 2: + data['light'] = 'normal' + elif light == 3: + data['light'] = 'bright' + else: + data['light'] = 'unknown' + if air_quality == 0: + data['air_quality'] = 'excellent' + elif air_quality == 1: + data['air_quality'] = 'good' + elif air_quality == 2: + data['air_quality'] = 'normal' + elif air_quality == 3: + data['air_quality'] = 'bad' + else: + data['air_quality'] = 'unknown' + if noise == 0: + data['noise'] = 'quiet' + elif noise == 1: + data['noise'] = 'normal' + elif noise == 2: + data['noise'] = 'noisy' + else: + data['noise'] = 'unknown' + return data + + def check_sensors_raw(self): + packet = bytearray(16) + packet[0] = 1 + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + data = {} + payload = self.decrypt(bytes(response[0x38:])) + if isinstance(payload[0x4], int): + data['temperature'] = (payload[0x4] * 10 + payload[0x5]) / 10.0 + data['humidity'] = (payload[0x6] * 10 + payload[0x7]) / 10.0 + data['light'] = payload[0x8] + data['air_quality'] = payload[0x0a] + data['noise'] = payload[0xc] + else: + data['temperature'] = (ord(payload[0x4]) * 10 + ord(payload[0x5])) / 10.0 + data['humidity'] = (ord(payload[0x6]) * 10 + ord(payload[0x7])) / 10.0 + data['light'] = ord(payload[0x8]) + data['air_quality'] = ord(payload[0x0a]) + data['noise'] = ord(payload[0xc]) + return data + + +class rm(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "RM2" + self._request_header = bytes() + self._code_sending_header = bytes() + + def check_data(self): + packet = bytearray(self._request_header) + packet.append(0x04) + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + return payload[len(self._request_header) + 4:] + + def send_data(self, data): + packet = bytearray(self._code_sending_header) + packet += bytes([0x02, 0x00, 0x00, 0x00]) + packet += data + self.send_packet(0x6a, packet) + + def enter_learning(self): + packet = bytearray(self._request_header) + packet.append(0x03) + self.send_packet(0x6a, packet) + + def sweep_frequency(self): + packet = bytearray(self._request_header) + packet.append(0x19) + self.send_packet(0x6a, packet) + + def cancel_sweep_frequency(self): + packet = bytearray(self._request_header) + packet.append(0x1e) + self.send_packet(0x6a, packet) + + def check_frequency(self): + packet = bytearray(self._request_header) + packet.append(0x1a) + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return False + payload = self.decrypt(bytes(response[0x38:])) + if payload[len(self._request_header) + 4] == 1: + return True + return False + + def find_rf_packet(self): + packet = bytearray(self._request_header) + packet.append(0x1b) + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return False + payload = self.decrypt(bytes(response[0x38:])) + if payload[len(self._request_header) + 4] == 1: + return True + return False + + def _read_sensor(self, type, offset, divider): + packet = bytearray(self._request_header) + packet.append(type) + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return False + payload = self.decrypt(bytes(response[0x38:])) + value_pos = len(self._request_header) + offset + if isinstance(payload[value_pos], int): + value = (payload[value_pos] + payload[value_pos+1] / divider) + else: + value = (ord(payload[value_pos]) + ord(payload[value_pos+1]) / divider) + return value + + def check_temperature(self): + return self._read_sensor( 0x01, 4, 10.0 ) + +class rm4(rm): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "RM4" + self._request_header = b'\x04\x00' + self._code_sending_header = b'\xd0\x00' + + def check_temperature(self): + return self._read_sensor( 0x24, 4, 100.0 ) + + def check_humidity(self): + return self._read_sensor( 0x24, 6, 100.0 ) + + def check_sensors(self): + return { + 'temperature': self.check_temperature(), + 'humidity': self.check_humidity() + } + +# For legacy compatibility - don't use this +class rm2(rm): + def __init__(self): + device.__init__(self, None, None, None) + + def discover(self): + dev = discover() + self.host = dev.host + self.mac = dev.mac + + +class hysen(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "Hysen heating controller" + + # Send a request + # input_payload should be a bytearray, usually 6 bytes, e.g. bytearray([0x01,0x06,0x00,0x02,0x10,0x00]) + # Returns decrypted payload + # New behaviour: raises a ValueError if the device response indicates an error or CRC check fails + # The function prepends length (2 bytes) and appends CRC + + def calculate_crc16(self, input_data): + from ctypes import c_ushort + crc16_tab = [] + crc16_constant = 0xA001 + + for i in range(0, 256): + crc = c_ushort(i).value + for j in range(0, 8): + if (crc & 0x0001): + crc = c_ushort(crc >> 1).value ^ crc16_constant + else: + crc = c_ushort(crc >> 1).value + crc16_tab.append(hex(crc)) + + try: + is_string = isinstance(input_data, str) + is_bytes = isinstance(input_data, bytes) + + if not is_string and not is_bytes: + raise Exception("Please provide a string or a byte sequence " + "as argument for calculation.") + + crcValue = 0xffff + + for c in input_data: + d = ord(c) if is_string else c + tmp = crcValue ^ d + rotated = c_ushort(crcValue >> 8).value + crcValue = rotated ^ int(crc16_tab[(tmp & 0x00ff)], 0) + + return crcValue + except Exception as e: + print("EXCEPTION(calculate): {}".format(e)) + + def send_request(self, input_payload): + + crc = self.calculate_crc16(bytes(input_payload)) + + # first byte is length, +2 for CRC16 + request_payload = bytearray([len(input_payload) + 2, 0x00]) + request_payload.extend(input_payload) + + # append CRC + request_payload.append(crc & 0xFF) + request_payload.append((crc >> 8) & 0xFF) + + # send to device + response = self.send_packet(0x6a, request_payload) + + # check for error + err = response[0x22] | (response[0x23] << 8) + if err: + raise ValueError('broadlink_response_error', err) + + response_payload = bytearray(self.decrypt(bytes(response[0x38:]))) + + # experimental check on CRC in response (first 2 bytes are len, and trailing bytes are crc) + response_payload_len = response_payload[0] + if response_payload_len + 2 > len(response_payload): + raise ValueError('hysen_response_error', 'first byte of response is not length') + crc = self.calculate_crc16(bytes(response_payload[2:response_payload_len])) + if (response_payload[response_payload_len] == crc & 0xFF) and ( + response_payload[response_payload_len + 1] == (crc >> 8) & 0xFF): + return response_payload[2:response_payload_len] + raise ValueError('hysen_response_error', 'CRC check on response failed') + + # Get current room temperature in degrees celsius + def get_temp(self): + payload = self.send_request(bytearray([0x01, 0x03, 0x00, 0x00, 0x00, 0x08])) + return payload[0x05] / 2.0 + + # Get current external temperature in degrees celsius + def get_external_temp(self): + payload = self.send_request(bytearray([0x01, 0x03, 0x00, 0x00, 0x00, 0x08])) + return payload[18] / 2.0 + + # Get full status (including timer schedule) + def get_full_status(self): + payload = self.send_request(bytearray([0x01, 0x03, 0x00, 0x00, 0x00, 0x16])) + data = {} + data['remote_lock'] = payload[3] & 1 + data['power'] = payload[4] & 1 + data['active'] = (payload[4] >> 4) & 1 + data['temp_manual'] = (payload[4] >> 6) & 1 + data['room_temp'] = (payload[5] & 255) / 2.0 + data['thermostat_temp'] = (payload[6] & 255) / 2.0 + data['auto_mode'] = payload[7] & 15 + data['loop_mode'] = (payload[7] >> 4) & 15 + data['sensor'] = payload[8] + data['osv'] = payload[9] + data['dif'] = payload[10] + data['svh'] = payload[11] + data['svl'] = payload[12] + data['room_temp_adj'] = ((payload[13] << 8) + payload[14]) / 2.0 + if data['room_temp_adj'] > 32767: + data['room_temp_adj'] = 32767 - data['room_temp_adj'] + data['fre'] = payload[15] + data['poweron'] = payload[16] + data['unknown'] = payload[17] + data['external_temp'] = (payload[18] & 255) / 2.0 + data['hour'] = payload[19] + data['min'] = payload[20] + data['sec'] = payload[21] + data['dayofweek'] = payload[22] + + weekday = [] + for i in range(0, 6): + weekday.append( + {'start_hour': payload[2 * i + 23], 'start_minute': payload[2 * i + 24], 'temp': payload[i + 39] / 2.0}) + + data['weekday'] = weekday + weekend = [] + for i in range(6, 8): + weekend.append( + {'start_hour': payload[2 * i + 23], 'start_minute': payload[2 * i + 24], 'temp': payload[i + 39] / 2.0}) + + data['weekend'] = weekend + return data + + # Change controller mode + # auto_mode = 1 for auto (scheduled/timed) mode, 0 for manual mode. + # Manual mode will activate last used temperature. + # In typical usage call set_temp to activate manual control and set temp. + # loop_mode refers to index in [ "12345,67", "123456,7", "1234567" ] + # E.g. loop_mode = 0 ("12345,67") means Saturday and Sunday follow the "weekend" schedule + # loop_mode = 2 ("1234567") means every day (including Saturday and Sunday) follows the "weekday" schedule + # The sensor command is currently experimental + def set_mode(self, auto_mode, loop_mode, sensor=0): + mode_byte = ((loop_mode + 1) << 4) + auto_mode + self.send_request(bytearray([0x01, 0x06, 0x00, 0x02, mode_byte, sensor])) + + # Advanced settings + # Sensor mode (SEN) sensor = 0 for internal sensor, 1 for external sensor, + # 2 for internal control temperature, external limit temperature. Factory default: 0. + # Set temperature range for external sensor (OSV) osv = 5..99. Factory default: 42C + # Deadzone for floor temprature (dIF) dif = 1..9. Factory default: 2C + # Upper temperature limit for internal sensor (SVH) svh = 5..99. Factory default: 35C + # Lower temperature limit for internal sensor (SVL) svl = 5..99. Factory default: 5C + # Actual temperature calibration (AdJ) adj = -0.5. Prescision 0.1C + # Anti-freezing function (FrE) fre = 0 for anti-freezing function shut down, + # 1 for anti-freezing function open. Factory default: 0 + # Power on memory (POn) poweron = 0 for power on memory off, 1 for power on memory on. Factory default: 0 + def set_advanced(self, loop_mode, sensor, osv, dif, svh, svl, adj, fre, poweron): + input_payload = bytearray([0x01, 0x10, 0x00, 0x02, 0x00, 0x05, 0x0a, loop_mode, sensor, osv, dif, svh, svl, + (int(adj * 2) >> 8 & 0xff), (int(adj * 2) & 0xff), fre, poweron]) + self.send_request(input_payload) + + # For backwards compatibility only. Prefer calling set_mode directly. + # Note this function invokes loop_mode=0 and sensor=0. + def switch_to_auto(self): + self.set_mode(auto_mode=1, loop_mode=0) + + def switch_to_manual(self): + self.set_mode(auto_mode=0, loop_mode=0) + + # Set temperature for manual mode (also activates manual mode if currently in automatic) + def set_temp(self, temp): + self.send_request(bytearray([0x01, 0x06, 0x00, 0x01, 0x00, int(temp * 2)])) + + # Set device on(1) or off(0), does not deactivate Wifi connectivity. + # Remote lock disables control by buttons on thermostat. + def set_power(self, power=1, remote_lock=0): + self.send_request(bytearray([0x01, 0x06, 0x00, 0x00, remote_lock, power])) + + # set time on device + # n.b. day=1 is Monday, ..., day=7 is Sunday + def set_time(self, hour, minute, second, day): + self.send_request(bytearray([0x01, 0x10, 0x00, 0x08, 0x00, 0x02, 0x04, hour, minute, second, day])) + + # Set timer schedule + # Format is the same as you get from get_full_status. + # weekday is a list (ordered) of 6 dicts like: + # {'start_hour':17, 'start_minute':30, 'temp': 22 } + # Each one specifies the thermostat temp that will become effective at start_hour:start_minute + # weekend is similar but only has 2 (e.g. switch on in morning and off in afternoon) + def set_schedule(self, weekday, weekend): + # Begin with some magic values ... + input_payload = bytearray([0x01, 0x10, 0x00, 0x0a, 0x00, 0x0c, 0x18]) + + # Now simply append times/temps + # weekday times + for i in range(0, 6): + input_payload.append(weekday[i]['start_hour']) + input_payload.append(weekday[i]['start_minute']) + + # weekend times + for i in range(0, 2): + input_payload.append(weekend[i]['start_hour']) + input_payload.append(weekend[i]['start_minute']) + + # weekday temperatures + for i in range(0, 6): + input_payload.append(int(weekday[i]['temp'] * 2)) + + # weekend temperatures + for i in range(0, 2): + input_payload.append(int(weekend[i]['temp'] * 2)) + + self.send_request(input_payload) + + +S1C_SENSORS_TYPES = { + 0x31: 'Door Sensor', # 49 as hex + 0x91: 'Key Fob', # 145 as hex, as serial on fob corpse + 0x21: 'Motion Sensor' # 33 as hex +} + + +class S1C(device): + """ + Its VERY VERY VERY DIRTY IMPLEMENTATION of S1C + """ + + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = 'S1C' + + def get_sensors_status(self): + packet = bytearray(16) + packet[0] = 0x06 # 0x06 - get sensors info, 0x07 - probably add sensors + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + + payload = self.decrypt(bytes(response[0x38:])) + if not payload: + return None + count = payload[0x4] + sensors = payload[0x6:] + sensors_a = [bytearray(sensors[i * 83:(i + 1) * 83]) for i in range(len(sensors) // 83)] + + sens_res = [] + for sens in sensors_a: + status = ord(chr(sens[0])) + _name = str(bytes(sens[4:26]).decode()) + _order = ord(chr(sens[1])) + _type = ord(chr(sens[3])) + _serial = bytes(codecs.encode(sens[26:30], "hex")).decode() + + type_str = S1C_SENSORS_TYPES.get(_type, 'Unknown') + + r = { + 'status': status, + 'name': _name.strip('\x00'), + 'type': type_str, + 'order': _order, + 'serial': _serial, + } + if r['serial'] != '00000000': + sens_res.append(r) + result = { + 'count': count, + 'sensors': sens_res + } + return result + + +class dooya(device): + def __init__(self, *args, **kwargs): + device.__init__(self, *args, **kwargs) + self.type = "Dooya DT360E" + + def _send(self, magic1, magic2): + packet = bytearray(16) + packet[0] = 0x09 + packet[2] = 0xbb + packet[3] = magic1 + packet[4] = magic2 + packet[9] = 0xfa + packet[10] = 0x44 + response = self.send_packet(0x6a, packet) + err = response[0x22] | (response[0x23] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + return ord(payload[4]) + + def open(self): + return self._send(0x01, 0x00) + + def close(self): + return self._send(0x02, 0x00) + + def stop(self): + return self._send(0x03, 0x00) + + def get_percentage(self): + return self._send(0x06, 0x5d) + + def set_percentage_and_wait(self, new_percentage): + current = self.get_percentage() + if current > new_percentage: + self.close() + while current is not None and current > new_percentage: + time.sleep(0.2) + current = self.get_percentage() + + elif current < new_percentage: + self.open() + while current is not None and current < new_percentage: + time.sleep(0.2) + current = self.get_percentage() + self.stop() + +class lb1(device): + state_dict = [] + effect_map_dict = { 'lovely color' : 0, + 'flashlight' : 1, + 'lightning' : 2, + 'color fading' : 3, + 'color breathing' : 4, + 'multicolor breathing' : 5, + 'color jumping' : 6, + 'multicolor jumping' : 7 } + + def __init__(self, host, mac, devtype): + device.__init__(self, host, mac, devtype) + self.type = "SmartBulb" + + def send_command(self,command, type = 'set'): + packet = bytearray(16+(int(len(command)/16) + 1)*16) + packet[0x02] = 0xa5 + packet[0x03] = 0xa5 + packet[0x04] = 0x5a + packet[0x05] = 0x5a + packet[0x08] = 0x02 if type == "set" else 0x01 # 0x01 => query, # 0x02 => set + packet[0x09] = 0x0b + packet[0x0a] = len(command) + packet[0x0e:] = map(ord, command) + + checksum = 0xbeaf + for b in packet: + checksum = (checksum + b) & 0xffff + + packet[0x00] = (0x0c + len(command)) & 0xff + packet[0x06] = checksum & 0xff # Checksum 1 position + packet[0x07] = checksum >> 8 # Checksum 2 position + + response = self.send_packet(0x6a, packet) + + err = response[0x36] | (response[0x37] << 8) + if err != 0: + return None + payload = self.decrypt(bytes(response[0x38:])) + + responseLength = int(payload[0x0a]) | (int(payload[0x0b]) << 8) + if responseLength > 0: + self.state_dict = json.loads(payload[0x0e:0x0e+responseLength]) + + def set_json(self, jsonstr): + reconvert = json.loads(jsonstr) + if 'bulb_sceneidx' in reconvert.keys(): + reconvert['bulb_sceneidx'] = self.effect_map_dict.get(reconvert['bulb_sceneidx'], 255) + + self.send_command(json.dumps(reconvert)) + return json.dumps(self.state_dict) + + def set_state(self, state): + cmd = '{"pwr":%d}' % (1 if state == "ON" or state == 1 else 0) + self.send_command(cmd) + + def get_state(self): + cmd = "{}" + self.send_command(cmd) + return self.state_dict + +# Setup a new Broadlink device via AP Mode. Review the README to see how to enter AP Mode. +# Only tested with Broadlink RM3 Mini (Blackbean) +def setup(ssid, password, security_mode): + # Security mode options are (0 - none, 1 = WEP, 2 = WPA1, 3 = WPA2, 4 = WPA1/2) + payload = bytearray(0x88) + payload[0x26] = 0x14 # This seems to always be set to 14 + # Add the SSID to the payload + ssid_start = 68 + ssid_length = 0 + for letter in ssid: + payload[(ssid_start + ssid_length)] = ord(letter) + ssid_length += 1 + # Add the WiFi password to the payload + pass_start = 100 + pass_length = 0 + for letter in password: + payload[(pass_start + pass_length)] = ord(letter) + pass_length += 1 + + payload[0x84] = ssid_length # Character length of SSID + payload[0x85] = pass_length # Character length of password + payload[0x86] = security_mode # Type of encryption (00 - none, 01 = WEP, 02 = WPA1, 03 = WPA2, 04 = WPA1/2) + + checksum = 0xbeaf + for b in payload: + checksum = (checksum + b) & 0xffff + + payload[0x20] = checksum & 0xff # Checksum 1 position + payload[0x21] = checksum >> 8 # Checksum 2 position + + sock = socket.socket(socket.AF_INET, # Internet + socket.SOCK_DGRAM) # UDP + sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) + # sock.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1) + sock.sendto(payload, ('192.168.10.1', 80)) diff --git a/third_party/python/broadlink/cli/README.md b/third_party/python/broadlink/cli/README.md new file mode 100644 index 0000000000..7e229e3eb5 --- /dev/null +++ b/third_party/python/broadlink/cli/README.md @@ -0,0 +1,85 @@ +Command line interface for python-broadlink +=========================================== + +This is a command line interface for broadlink python library + +Tested with BroadLink RMPRO / RM2 + + +Requirements +------------ +You should have the broadlink python installed, this can be made in many linux distributions using : +``` +sudo pip install broadlink +``` + +Installation +----------- +Just copy this files + + +Programs +-------- + + +* broadlink_discovery +used to run the discovery in the network +this program withh show the command line parameters to be used with +broadlink_cli to select broadlink device + +* broadlink_cli +used to send commands and query the broadlink device + + +device specification formats +---------------------------- + +Using separate parameters for each information: +``` +broadlink_cli --type 0x2712 --host 1.1.1.1 --mac aaaaaaaaaa --temp +``` + +Using all parameters as a single argument: +``` +broadlink_cli --device "0x2712 1.1.1.1 aaaaaaaaaa" --temp +``` + +Using file with parameters: +``` +broadlink_cli --device @BEDROOM.device --temp +``` +This is prefered as the configuration is stored in file and you can change +just a file to point to a different hardware + +Sample usage +------------ + +Learn commands : +``` +# Learn and save to file +broadlink_cli --device @BEDROOM.device --learnfile LG-TV.power +# LEard and show at console +broadlink_cli --device @BEDROOM.device --learn +``` + + +Send command : +``` +broadlink_cli --device @BEDROOM.device --send @LG-TV.power +broadlink_cli --device @BEDROOM.device --send ....datafromlearncommand... +``` + +Get Temperature : +``` +broadlink_cli --device @BEDROOM.device --temperature +``` + +Get Energy Consumption (For a SmartPlug) : +``` +broadlink_cli --device @BEDROOM.device --energy +``` + +Once joined to the Broadlink provisioning Wi-Fi, configure it with your Wi-Fi details: +``` +broadlink_cli --joinwifi MySSID MyWifiPassword +``` diff --git a/third_party/python/broadlink/cli/broadlink_cli b/third_party/python/broadlink/cli/broadlink_cli new file mode 100755 index 0000000000..5045c5c108 --- /dev/null +++ b/third_party/python/broadlink/cli/broadlink_cli @@ -0,0 +1,239 @@ +#!/usr/bin/env python3 + +import argparse +import base64 +import codecs +import time + +import broadlink + +TICK = 32.84 +IR_TOKEN = 0x26 + + +def auto_int(x): + return int(x, 0) + + +def to_microseconds(bytes): + result = [] + # print bytes[0] # 0x26 = 38for IR + index = 4 + while index < len(bytes): + chunk = bytes[index] + index += 1 + if chunk == 0: + chunk = bytes[index] + chunk = 256 * chunk + bytes[index + 1] + index += 2 + result.append(int(round(chunk * TICK))) + if chunk == 0x0d05: + break + return result + + +def durations_to_broadlink(durations): + result = bytearray() + result.append(IR_TOKEN) + result.append(0) + result.append(len(durations) % 256) + result.append(len(durations) / 256) + for dur in durations: + num = int(round(dur / TICK)) + if num > 255: + result.append(0) + result.append(num / 256) + result.append(num % 256) + return result + + +def format_durations(data): + result = '' + for i in range(0, len(data)): + if len(result) > 0: + result += ' ' + result += ('+' if i % 2 == 0 else '-') + str(data[i]) + return result + + +def parse_durations(str): + result = [] + for s in str.split(): + result.append(abs(int(s))) + return result + + +parser = argparse.ArgumentParser(fromfile_prefix_chars='@') +parser.add_argument("--device", help="device definition as 'type host mac'") +parser.add_argument("--type", type=auto_int, default=0x2712, help="type of device") +parser.add_argument("--host", help="host address") +parser.add_argument("--mac", help="mac address (hex reverse), as used by python-broadlink library") +parser.add_argument("--temperature", action="store_true", help="request temperature from device") +parser.add_argument("--energy", action="store_true", help="request energy consumption from device") +parser.add_argument("--check", action="store_true", help="check current power state") +parser.add_argument("--checknl", action="store_true", help="check current nightlight state") +parser.add_argument("--turnon", action="store_true", help="turn on device") +parser.add_argument("--turnoff", action="store_true", help="turn off device") +parser.add_argument("--turnnlon", action="store_true", help="turn on nightlight on the device") +parser.add_argument("--turnnloff", action="store_true", help="turn off nightlight on the device") +parser.add_argument("--switch", action="store_true", help="switch state from on to off and off to on") +parser.add_argument("--send", action="store_true", help="send command") +parser.add_argument("--sensors", action="store_true", help="check all sensors") +parser.add_argument("--learn", action="store_true", help="learn command") +parser.add_argument("--rfscanlearn", action="store_true", help="rf scan learning") +parser.add_argument("--learnfile", help="save learned command to a specified file") +parser.add_argument("--durations", action="store_true", + help="use durations in micro seconds instead of the Broadlink format") +parser.add_argument("--convert", action="store_true", help="convert input data to durations") +parser.add_argument("--joinwifi", nargs=2, help="Args are SSID PASSPHRASE to configure Broadlink device with"); +parser.add_argument("data", nargs='*', help="Data to send or convert") +args = parser.parse_args() + +if args.device: + values = args.device.split() + type = int(values[0], 0) + host = values[1] + mac = bytearray.fromhex(values[2]) +elif args.mac: + type = args.type + host = args.host + mac = bytearray.fromhex(args.mac) + +if args.host or args.device: + dev = broadlink.gendevice(type, (host, 80), mac) + dev.auth() + +if args.joinwifi: + broadlink.setup(args.joinwifi[0], args.joinwifi[1], 4) + +if args.convert: + data = bytearray.fromhex(''.join(args.data)) + durations = to_microseconds(data) + print(format_durations(durations)) +if args.temperature: + print(dev.check_temperature()) +if args.energy: + print(dev.get_energy()) +if args.sensors: + try: + data = dev.check_sensors() + except: + data = {} + data['temperature'] = dev.check_temperature() + for key in data: + print("{} {}".format(key, data[key])) +if args.send: + data = durations_to_broadlink(parse_durations(' '.join(args.data))) \ + if args.durations else bytearray.fromhex(''.join(args.data)) + dev.send_data(data) +if args.learn or args.learnfile: + dev.enter_learning() + data = None + print("Learning...") + timeout = 30 + while (data is None) and (timeout > 0): + time.sleep(2) + timeout -= 2 + data = dev.check_data() + if data: + learned = format_durations(to_microseconds(bytearray(data))) \ + if args.durations \ + else ''.join(format(x, '02x') for x in bytearray(data)) + if args.learn: + print(learned) + decode_hex = codecs.getdecoder("hex_codec") + print("Base64: " + str(base64.b64encode(decode_hex(learned)[0]))) + if args.learnfile: + print("Saving to {}".format(args.learnfile)) + with open(args.learnfile, "w") as text_file: + text_file.write(learned) + else: + print("No data received...") +if args.check: + if dev.check_power(): + print('* ON *') + else: + print('* OFF *') +if args.checknl: + if dev.check_nightlight(): + print('* ON *') + else: + print('* OFF *') +if args.turnon: + dev.set_power(True) + if dev.check_power(): + print('== Turned * ON * ==') + else: + print('!! Still OFF !!') +if args.turnoff: + dev.set_power(False) + if dev.check_power(): + print('!! Still ON !!') + else: + print('== Turned * OFF * ==') +if args.turnnlon: + dev.set_nightlight(True) + if dev.check_nightlight(): + print('== Turned * ON * ==') + else: + print('!! Still OFF !!') +if args.turnnloff: + dev.set_nightlight(False) + if dev.check_nightlight(): + print('!! Still ON !!') + else: + print('== Turned * OFF * ==') +if args.switch: + if dev.check_power(): + dev.set_power(False) + print('* Switch to OFF *') + else: + dev.set_power(True) + print('* Switch to ON *') +if args.rfscanlearn: + dev.sweep_frequency() + print("Learning RF Frequency, press and hold the button to learn...") + + timeout = 20 + + while (not dev.check_frequency()) and (timeout > 0): + time.sleep(1) + timeout -= 1 + + if timeout <= 0: + print("RF Frequency not found") + dev.cancel_sweep_frequency() + exit(1) + + print("Found RF Frequency - 1 of 2!") + print("You can now let go of the button") + + input("Press enter to continue...") + + print("To complete learning, single press the button you want to learn") + + dev.find_rf_packet() + + data = None + timeout = 20 + + while (data is None) and (timeout > 0): + time.sleep(1) + timeout -= 1 + data = dev.check_data() + + if data: + print("Found RF Frequency - 2 of 2!") + learned = format_durations(to_microseconds(bytearray(data))) \ + if args.durations \ + else ''.join(format(x, '02x') for x in bytearray(data)) + if args.learnfile is None: + print(learned) + decode_hex = codecs.getdecoder("hex_codec") + print("Base64: {}".format(str(base64.b64encode(decode_hex(learned)[0])))) + if args.learnfile is not None: + print("Saving to {}".format(args.learnfile)) + with open(args.learnfile, "w") as text_file: + text_file.write(learned) + else: + print("No data received...") diff --git a/third_party/python/broadlink/cli/broadlink_discovery b/third_party/python/broadlink/cli/broadlink_discovery new file mode 100755 index 0000000000..1c6b80b148 --- /dev/null +++ b/third_party/python/broadlink/cli/broadlink_discovery @@ -0,0 +1,27 @@ +#!/usr/bin/env python + +import argparse + +import broadlink + +parser = argparse.ArgumentParser(fromfile_prefix_chars='@') +parser.add_argument("--timeout", type=int, default=5, help="timeout to wait for receiving discovery responses") +parser.add_argument("--ip", default=None, help="ip address to use in the discovery") +parser.add_argument("--dst-ip", default=None, help="destination ip address to use in the discovery") +args = parser.parse_args() + +print("Discovering...") +devices = broadlink.discover(timeout=args.timeout, local_ip_address=args.ip, discover_ip_address=args.dst_ip) +for device in devices: + if device.auth(): + print("###########################################") + print(device.type) + print("# broadlink_cli --type {} --host {} --mac {}".format(hex(device.devtype), device.host[0], + ''.join(format(x, '02x') for x in device.mac))) + print("Device file data (to be used with --device @filename in broadlink_cli) : ") + print("{} {} {}".format(hex(device.devtype), device.host[0], ''.join(format(x, '02x') for x in device.mac))) + if hasattr(device, 'check_temperature'): + print("temperature = {}".format(device.check_temperature())) + print("") + else: + print("Error authenticating with device : {}".format(device.host)) diff --git a/third_party/python/broadlink/default.nix b/third_party/python/broadlink/default.nix new file mode 100644 index 0000000000..e316d83d1d --- /dev/null +++ b/third_party/python/broadlink/default.nix @@ -0,0 +1,15 @@ +# Python package for controlling the Broadlink RM Pro Infrared +# controller. +# +# https://github.com/mjg59/python-broadlink +{ pkgs, lib, ... }: + +let + inherit (pkgs) fetchFromGitHub; + inherit (pkgs.python3Packages) buildPythonPackage cryptography; +in buildPythonPackage (lib.fix (self: { + pname = "python-broadlink"; + version = "0.13.2"; + src = ./.; + propagatedBuildInputs = [ cryptography ]; +})) diff --git a/third_party/python/broadlink/protocol.md b/third_party/python/broadlink/protocol.md new file mode 100644 index 0000000000..2e388d7499 --- /dev/null +++ b/third_party/python/broadlink/protocol.md @@ -0,0 +1,202 @@ +Broadlink RM2 network protocol +============================== + +Encryption +---------- + +Packets include AES-based encryption in CBC mode. The initial key is 0x09, 0x76, 0x28, 0x34, 0x3f, 0xe9, 0x9e, 0x23, 0x76, 0x5c, 0x15, 0x13, 0xac, 0xcf, 0x8b, 0x02. The IV is 0x56, 0x2e, 0x17, 0x99, 0x6d, 0x09, 0x3d, 0x28, 0xdd, 0xb3, 0xba, 0x69, 0x5a, 0x2e, 0x6f, 0x58. + +Checksum +-------- + +Construct the packet and set checksum bytes to zero. Add each byte to the starting value of 0xbeaf, wrapping after 0xffff. + +New device setup +---------------- + +To setup a new Broadlink device while in AP Mode a 136 byte packet needs to be sent to the device as follows: + +| Offset | Contents | +|---------|----------| +|0x00-0x19|00| +|0x20-0x21|Checksum as a little-endian 16 bit integer| +|0x26|14 (Always 14)| +|0x44-0x63|SSID Name (zero padding is appended)| +|0x64-0x83|Password (zero padding is appended)| +|0x84|Character length of SSID| +|0x85|Character length of password| +|0x86|Wireless security mode (00 - none, 01 = WEP, 02 = WPA1, 03 = WPA2, 04 = WPA1/2)| +|0x87-88|00| + +Send this packet as a UDP broadcast to 255.255.255.255 on port 80. + +Network discovery +----------------- + +To discover Broadlink devices on the local network, send a 48 byte packet with the following contents: + +| Offset | Contents | +|---------|----------| +|0x00-0x07|00| +|0x08-0x0b|Current offset from GMT as a little-endian 32 bit integer| +|0x0c-0x0d|Current year as a little-endian 16 bit integer| +|0x0e|Current number of seconds past the minute| +|0x0f|Current number of minutes past the hour| +|0x10|Current number of hours past midnight| +|0x11|Current day of the week (Monday = 1, Tuesday = 2, etc)| +|0x12|Current day in month| +|0x13|Current month| +|0x14-0x17|00| +|0x18-0x1b|Local IP address| +|0x1c-0x1d|Source port as a little-endian 16 bit integer| +|0x1e-0x1f|00| +|0x20-0x21|Checksum as a little-endian 16 bit integer| +|0x22-0x25|00| +|0x26|06| +|0x27-0x2f|00| + +Send this packet as a UDP broadcast to 255.255.255.255 on port 80. + +Response (any unicast response): + +| Offset | Contents | +|---------|----------| +|0x34-0x35|Device type as a little-endian 16 bit integer (see device type mapping)| +|0x3a-0x3f|MAC address of the target device| + +Device type mapping: + +| Device type in response packet | Device type | Treat as | +|---------|----------|----------| +|0|SP1|SP1| +|0x2711|SP2|SP2| +|0x2719 or 0x7919 or 0x271a or 0x791a|Honeywell SP2|SP2| +|0x2720|SPMini|SP2| +|0x753e|SP3|SP2| +|0x2728|SPMini2|SP2 +|0x2733 or 0x273e|OEM branded SPMini|SP2| +|>= 0x7530 and <= 0x7918|OEM branded SPMini2|SP2| +|0x2736|SPMiniPlus|SP2| +|0x2712|RM2|RM| +|0x2737|RM Mini / RM3 Mini Blackbean|RM| +|0x273d|RM Pro Phicomm|RM| +|0x2783|RM2 Home Plus|RM| +|0x277c|RM2 Home Plus GDT|RM| +|0x272a|RM2 Pro Plus|RM| +|0x2787|RM2 Pro Plus2|RM| +|0x278b|RM2 Pro Plus BL|RM| +|0x278f|RM Mini Shate|RM| +|0x2714|A1|A1| +|0x4EB5|MP1|MP1| + + +Command packet format +--------------------- + +The command packet header is 56 bytes long with the following format: + +|Offset|Contents| +|------|--------| +|0x00|0x5a| +|0x01|0xa5| +|0x02|0xaa| +|0x03|0x55| +|0x04|0x5a| +|0x05|0xa5| +|0x06|0xaa| +|0x07|0x55| +|0x08-0x1f|00| +|0x20-0x21|Checksum of full packet as a little-endian 16 bit integer| +|0x22-0x23|00| +|0x24-0x25|Device type as a little-endian 16 bit integer| +|0x26-0x27|Command code as a little-endian 16 bit integer| +|0x28-0x29|Packet count as a little-endian 16 bit integer| +|0x2a-0x2f|Local MAC address| +|0x30-0x33|Local device ID (obtained during authentication, 00 before authentication)| +|0x34-0x35|Checksum of unencrypted payload as a little-endian 16 bit integer +|0x36-0x37|00| + +The payload is appended immediately after this. The checksum at 0x20 is calculated *after* the payload is appended, and covers the entire packet (including the checksum at 0x34). Therefore: + +1. Generate packet header with checksum values set to 0 +2. Set the checksum initialisation value to 0xbeaf and calculate the checksum of the unencrypted payload. Set 0x34-0x35 to this value. +3. Encrypt and append the payload +4. Set the checksum initialisation value to 0xbeaf and calculate the checksum of the entire packet. Set 0x20-0x21 to this value. + +Authorisation +------------- + +You must obtain an authorisation key from the device before you can communicate. To do so, generate an 80 byte packet with the following contents: + +|Offset|Contents| +|------|--------| +|0x00-0x03|00| +|0x04-0x12|A 15-digit value that represents this device. Broadlink's implementation uses the IMEI.| +|0x13|01| +|0x14-0x2c|00| +|0x2d|0x01| +|0x30-0x7f|NULL-terminated ASCII string containing the device name| + +Send this payload with a command value of 0x0065. The response packet will contain an encrypted payload from byte 0x38 onwards. Decrypt this using the default key and IV. The format of the decrypted payload is: + +|Offset|Contents| +|------|--------| +|0x00-0x03|Device ID| +|0x04-0x13|Device encryption key| + +All further command packets must use this encryption key and device ID. + +Entering learning mode +---------------------- + +Send the following 16 byte payload with a command value of 0x006a: + +|Offset|Contents| +|------|--------| +|0x00|0x03| +|0x01-0x0f|0x00| + +Reading back data from learning mode +------------------------------------ + +Send the following 16 byte payload with a command value of 0x006a: + +|Offset|Contents| +|------|--------| +|0x00|0x04| +|0x01-0x0f|0x00| + +Byte 0x22 of the response contains a little-endian 16 bit error code. If this is 0, a code has been obtained. Bytes 0x38 and onward of the response are encrypted. Decrypt them. Bytes 0x04 and onward of the decrypted payload contain the captured data. + +Sending data +------------ + +Send the following payload with a command byte of 0x006a + +|Offset|Contents| +|------|--------| +|0x00|0x02| +|0x01-0x03|0x00| +|0x04|0x26 = IR, 0xb2 for RF 433Mhz, 0xd7 for RF 315Mhz| +|0x05|repeat count, (0 = no repeat, 1 send twice, .....)| +|0x06-0x07|Length of the following data in little endian| +|0x08 ....|Pulse lengths in 2^-15 s units (µs * 269 / 8192 works very well)| +|....|0x0d 0x05 at the end for IR only| + +Each value is represented by one byte. If the length exceeds one byte +then it is stored big endian with a leading 0. + +Example: The header for my Optoma projector is 8920 4450 +8920 * 269 / 8192 = 0x124 +4450 * 269 / 8192 = 0x92 + +So the data starts with `0x00 0x1 0x24 0x92 ....` + + +Todo +---- + +* Support for other devices using the Broadlink protocol (various smart home devices) +* Figure out what the format of the data packets actually is. +* Deal with the response after AP Mode WiFi network setup. + diff --git a/third_party/python/broadlink/requirements.txt b/third_party/python/broadlink/requirements.txt new file mode 100644 index 0000000000..09f445bfd8 --- /dev/null +++ b/third_party/python/broadlink/requirements.txt @@ -0,0 +1 @@ +cryptography==2.6.1 diff --git a/third_party/python/broadlink/setup.py b/third_party/python/broadlink/setup.py new file mode 100644 index 0000000000..778f495fb5 --- /dev/null +++ b/third_party/python/broadlink/setup.py @@ -0,0 +1,29 @@ +#!/usr/bin/env python +# -*- coding: utf-8 -*- + + +from setuptools import setup, find_packages + + +version = '0.13.2' + +setup( + name='broadlink', + version=version, + author='Matthew Garrett', + author_email='mjg59@srcf.ucam.org', + url='http://github.com/mjg59/python-broadlink', + packages=find_packages(), + scripts=[], + install_requires=['cryptography>=2.1.1'], + description='Python API for controlling Broadlink IR controllers', + classifiers=[ + 'Development Status :: 4 - Beta', + 'Intended Audience :: Developers', + 'License :: OSI Approved :: MIT License', + 'Operating System :: OS Independent', + 'Programming Language :: Python', + ], + include_package_data=True, + zip_safe=False, +) diff --git a/third_party/telega/default.nix b/third_party/telega/default.nix new file mode 100644 index 0000000000..8c1a31ba79 --- /dev/null +++ b/third_party/telega/default.nix @@ -0,0 +1,22 @@ +# Telega is an Emacs client for Telegram. It requires a native server +# component to run correctly, which is built by this derivation. +{ pkgs, ... }: + +with pkgs; + +stdenv.mkDerivation { + name = "telega"; + buildInputs = [ tdlib ]; + + src = fetchFromGitHub { + owner = "zevlg"; + repo = "telega.el"; + rev = "76ffa52cd36b9ba3236d0f4e0c213495d3609212"; + sha256 = "15w6yj8n75yh6zhra4qw5pkfc8asgrwh6m8dz1vax2ma6yy2ds2r"; + } + "/server"; + + installPhase = '' + mkdir -p $out/bin + mv telega-server $out/bin/ + ''; +} diff --git a/third_party/terraform-gcp/default.nix b/third_party/terraform-gcp/default.nix new file mode 100644 index 0000000000..3332c12e41 --- /dev/null +++ b/third_party/terraform-gcp/default.nix @@ -0,0 +1,3 @@ +{ pkgs, ... }: + +pkgs.terraform_0_12.withPlugins(p: [ p.google p.google-beta ]) diff --git a/tools/cheddar/.gitignore b/tools/cheddar/.gitignore new file mode 100644 index 0000000000..2f7896d1d1 --- /dev/null +++ b/tools/cheddar/.gitignore @@ -0,0 +1 @@ +target/ diff --git a/tools/cheddar/.skip-subtree b/tools/cheddar/.skip-subtree new file mode 100644 index 0000000000..e69de29bb2 --- /dev/null +++ b/tools/cheddar/.skip-subtree diff --git a/tools/cheddar/Cargo.lock b/tools/cheddar/Cargo.lock new file mode 100644 index 0000000000..227db64fef --- /dev/null +++ b/tools/cheddar/Cargo.lock @@ -0,0 +1,849 @@ +# This file is automatically @generated by Cargo. +# It is not intended for manual editing. +[[package]] +name = "adler32" +version = "1.0.4" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "aho-corasick" +version = "0.7.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "memchr 2.2.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "ansi_term" +version = "0.11.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "atty" +version = "0.2.13" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "backtrace" +version = "0.3.40" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "backtrace-sys 0.1.32 (registry+https://github.com/rust-lang/crates.io-index)", + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "rustc-demangle 0.1.16 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "backtrace-sys" +version = "0.1.32" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cc 1.0.48 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "base64" +version = "0.10.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "byteorder 1.3.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "bincode" +version = "1.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "byteorder 1.3.2 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "bindgen" +version = "0.50.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "cexpr 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", + "clang-sys 0.28.1 (registry+https://github.com/rust-lang/crates.io-index)", + "clap 2.33.0 (registry+https://github.com/rust-lang/crates.io-index)", + "env_logger 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)", + "fxhash 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "log 0.4.8 (registry+https://github.com/rust-lang/crates.io-index)", + "peeking_take_while 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "proc-macro2 0.4.30 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 0.6.13 (registry+https://github.com/rust-lang/crates.io-index)", + "regex 1.3.1 (registry+https://github.com/rust-lang/crates.io-index)", + "shlex 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", + "which 2.0.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "bitflags" +version = "1.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "block-buffer" +version = "0.7.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "block-padding 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", + "byte-tools 0.3.1 (registry+https://github.com/rust-lang/crates.io-index)", + "byteorder 1.3.2 (registry+https://github.com/rust-lang/crates.io-index)", + "generic-array 0.12.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "block-padding" +version = "0.1.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "byte-tools 0.3.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "byte-tools" +version = "0.3.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "byteorder" +version = "1.3.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cc" +version = "1.0.48" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cexpr" +version = "0.3.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "nom 4.2.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "cfg-if" +version = "0.1.10" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "cheddar" +version = "0.1.0" +dependencies = [ + "comrak 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "syntect 3.3.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "clang-sys" +version = "0.28.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "glob 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "libloading 0.5.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "clap" +version = "2.33.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "ansi_term 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)", + "atty 0.2.13 (registry+https://github.com/rust-lang/crates.io-index)", + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "strsim 0.8.0 (registry+https://github.com/rust-lang/crates.io-index)", + "textwrap 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-width 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)", + "vec_map 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "comrak" +version = "0.6.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "clap 2.33.0 (registry+https://github.com/rust-lang/crates.io-index)", + "entities 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "pest 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "pest_derive 2.1.0 (registry+https://github.com/rust-lang/crates.io-index)", + "regex 1.3.1 (registry+https://github.com/rust-lang/crates.io-index)", + "twoway 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "typed-arena 1.7.0 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode_categories 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "crc32fast" +version = "1.2.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "digest" +version = "0.8.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "generic-array 0.12.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "entities" +version = "1.0.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "env_logger" +version = "0.6.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "atty 0.2.13 (registry+https://github.com/rust-lang/crates.io-index)", + "humantime 1.3.0 (registry+https://github.com/rust-lang/crates.io-index)", + "log 0.4.8 (registry+https://github.com/rust-lang/crates.io-index)", + "regex 1.3.1 (registry+https://github.com/rust-lang/crates.io-index)", + "termcolor 1.0.5 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "failure" +version = "0.1.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "backtrace 0.3.40 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "fake-simd" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "flate2" +version = "1.0.13" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", + "crc32fast 1.2.0 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "miniz_oxide 0.3.5 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "fnv" +version = "1.0.6" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "fxhash" +version = "0.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "byteorder 1.3.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "generic-array" +version = "0.12.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "typenum 1.11.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "glob" +version = "0.3.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "humantime" +version = "1.3.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "quick-error 1.2.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "itoa" +version = "0.4.4" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "lazy_static" +version = "1.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "lazycell" +version = "1.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "libc" +version = "0.2.66" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "libloading" +version = "0.5.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cc 1.0.48 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "line-wrap" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "safemem 0.3.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "linked-hash-map" +version = "0.5.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "log" +version = "0.4.8" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "maplit" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "memchr" +version = "2.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "miniz_oxide" +version = "0.3.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "adler32 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "nom" +version = "4.2.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "memchr 2.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "version_check 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "onig" +version = "5.0.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", + "onig_sys 69.2.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "onig_sys" +version = "69.2.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bindgen 0.50.1 (registry+https://github.com/rust-lang/crates.io-index)", + "cc 1.0.48 (registry+https://github.com/rust-lang/crates.io-index)", + "pkg-config 0.3.17 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "opaque-debug" +version = "0.2.3" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "peeking_take_while" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "pest" +version = "2.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "ucd-trie 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "pest_derive" +version = "2.1.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "pest 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "pest_generator 2.1.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "pest_generator" +version = "2.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "pest 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "pest_meta 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "proc-macro2 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", + "syn 1.0.11 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "pest_meta" +version = "2.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "maplit 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", + "pest 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "sha-1 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "pkg-config" +version = "0.3.17" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "plist" +version = "0.4.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "base64 0.10.1 (registry+https://github.com/rust-lang/crates.io-index)", + "byteorder 1.3.2 (registry+https://github.com/rust-lang/crates.io-index)", + "humantime 1.3.0 (registry+https://github.com/rust-lang/crates.io-index)", + "line-wrap 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)", + "xml-rs 0.8.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "proc-macro2" +version = "0.4.30" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "proc-macro2" +version = "1.0.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "unicode-xid 0.2.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "quick-error" +version = "1.2.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "quote" +version = "0.6.13" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 0.4.30 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "quote" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "regex" +version = "1.3.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "aho-corasick 0.7.6 (registry+https://github.com/rust-lang/crates.io-index)", + "memchr 2.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "regex-syntax 0.6.12 (registry+https://github.com/rust-lang/crates.io-index)", + "thread_local 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "regex-syntax" +version = "0.6.12" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "rustc-demangle" +version = "0.1.16" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "ryu" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "safemem" +version = "0.3.3" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "same-file" +version = "1.0.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi-util 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "serde" +version = "1.0.104" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "serde_derive" +version = "1.0.104" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", + "syn 1.0.11 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "serde_json" +version = "1.0.44" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "itoa 0.4.4 (registry+https://github.com/rust-lang/crates.io-index)", + "ryu 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "sha-1" +version = "0.8.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "block-buffer 0.7.3 (registry+https://github.com/rust-lang/crates.io-index)", + "digest 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)", + "fake-simd 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", + "opaque-debug 0.2.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "shlex" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "strsim" +version = "0.8.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "syn" +version = "1.0.11" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "proc-macro2 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)", + "quote 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", + "unicode-xid 0.2.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "syntect" +version = "3.3.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "bincode 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "flate2 1.0.13 (registry+https://github.com/rust-lang/crates.io-index)", + "fnv 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)", + "lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "lazycell 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "onig 5.0.0 (registry+https://github.com/rust-lang/crates.io-index)", + "plist 0.4.2 (registry+https://github.com/rust-lang/crates.io-index)", + "regex-syntax 0.6.12 (registry+https://github.com/rust-lang/crates.io-index)", + "serde 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_derive 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)", + "serde_json 1.0.44 (registry+https://github.com/rust-lang/crates.io-index)", + "walkdir 2.2.9 (registry+https://github.com/rust-lang/crates.io-index)", + "yaml-rust 0.4.3 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "termcolor" +version = "1.0.5" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "wincolor 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "textwrap" +version = "0.11.0" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "unicode-width 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "thread_local" +version = "0.3.6" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "twoway" +version = "0.2.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "memchr 2.2.1 (registry+https://github.com/rust-lang/crates.io-index)", + "unchecked-index 0.2.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "typed-arena" +version = "1.7.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "typenum" +version = "1.11.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "ucd-trie" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unchecked-index" +version = "0.2.2" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unicode-width" +version = "0.1.7" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unicode-xid" +version = "0.1.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unicode-xid" +version = "0.2.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "unicode_categories" +version = "0.1.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "vec_map" +version = "0.8.1" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "version_check" +version = "0.1.5" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "walkdir" +version = "2.2.9" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "same-file 1.0.5 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi-util 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "which" +version = "2.0.1" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "failure 0.1.6 (registry+https://github.com/rust-lang/crates.io-index)", + "libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "winapi" +version = "0.3.8" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi-i686-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi-x86_64-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "winapi-i686-pc-windows-gnu" +version = "0.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "winapi-util" +version = "0.1.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "winapi-x86_64-pc-windows-gnu" +version = "0.4.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "wincolor" +version = "1.0.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)", + "winapi-util 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[[package]] +name = "xml-rs" +version = "0.8.0" +source = "registry+https://github.com/rust-lang/crates.io-index" + +[[package]] +name = "yaml-rust" +version = "0.4.3" +source = "registry+https://github.com/rust-lang/crates.io-index" +dependencies = [ + "linked-hash-map 0.5.2 (registry+https://github.com/rust-lang/crates.io-index)", +] + +[metadata] +"checksum adler32 1.0.4 (registry+https://github.com/rust-lang/crates.io-index)" = "5d2e7343e7fc9de883d1b0341e0b13970f764c14101234857d2ddafa1cb1cac2" +"checksum aho-corasick 0.7.6 (registry+https://github.com/rust-lang/crates.io-index)" = "58fb5e95d83b38284460a5fda7d6470aa0b8844d283a0b614b8535e880800d2d" +"checksum ansi_term 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ee49baf6cb617b853aa8d93bf420db2383fab46d314482ca2803b40d5fde979b" +"checksum atty 0.2.13 (registry+https://github.com/rust-lang/crates.io-index)" = "1803c647a3ec87095e7ae7acfca019e98de5ec9a7d01343f611cf3152ed71a90" +"checksum backtrace 0.3.40 (registry+https://github.com/rust-lang/crates.io-index)" = "924c76597f0d9ca25d762c25a4d369d51267536465dc5064bdf0eb073ed477ea" +"checksum backtrace-sys 0.1.32 (registry+https://github.com/rust-lang/crates.io-index)" = "5d6575f128516de27e3ce99689419835fce9643a9b215a14d2b5b685be018491" +"checksum base64 0.10.1 (registry+https://github.com/rust-lang/crates.io-index)" = "0b25d992356d2eb0ed82172f5248873db5560c4721f564b13cb5193bda5e668e" +"checksum bincode 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "5753e2a71534719bf3f4e57006c3a4f0d2c672a4b676eec84161f763eca87dbf" +"checksum bindgen 0.50.1 (registry+https://github.com/rust-lang/crates.io-index)" = "cb0e5a5f74b2bafe0b39379f616b5975e08bcaca4e779c078d5c31324147e9ba" +"checksum bitflags 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "cf1de2fe8c75bc145a2f577add951f8134889b4795d47466a54a5c846d691693" +"checksum block-buffer 0.7.3 (registry+https://github.com/rust-lang/crates.io-index)" = "c0940dc441f31689269e10ac70eb1002a3a1d3ad1390e030043662eb7fe4688b" +"checksum block-padding 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)" = "fa79dedbb091f449f1f39e53edf88d5dbe95f895dae6135a8d7b881fb5af73f5" +"checksum byte-tools 0.3.1 (registry+https://github.com/rust-lang/crates.io-index)" = "e3b5ca7a04898ad4bcd41c90c5285445ff5b791899bb1b0abdd2a2aa791211d7" +"checksum byteorder 1.3.2 (registry+https://github.com/rust-lang/crates.io-index)" = "a7c3dd8985a7111efc5c80b44e23ecdd8c007de8ade3b96595387e812b957cf5" +"checksum cc 1.0.48 (registry+https://github.com/rust-lang/crates.io-index)" = "f52a465a666ca3d838ebbf08b241383421412fe7ebb463527bba275526d89f76" +"checksum cexpr 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)" = "fce5b5fb86b0c57c20c834c1b412fd09c77c8a59b9473f86272709e78874cd1d" +"checksum cfg-if 0.1.10 (registry+https://github.com/rust-lang/crates.io-index)" = "4785bdd1c96b2a846b2bd7cc02e86b6b3dbf14e7e53446c4f54c92a361040822" +"checksum clang-sys 0.28.1 (registry+https://github.com/rust-lang/crates.io-index)" = "81de550971c976f176130da4b2978d3b524eaa0fd9ac31f3ceb5ae1231fb4853" +"checksum clap 2.33.0 (registry+https://github.com/rust-lang/crates.io-index)" = "5067f5bb2d80ef5d68b4c87db81601f0b75bca627bc2ef76b141d7b846a3c6d9" +"checksum comrak 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)" = "ea4c29f52463abf5c7a3ae33dd9b404e2031af82f547cfe65bfac17ba785ea2e" +"checksum crc32fast 1.2.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ba125de2af0df55319f41944744ad91c71113bf74a4646efff39afe1f6842db1" +"checksum digest 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)" = "f3d0c8c8752312f9713efd397ff63acb9f85585afbf179282e720e7704954dd5" +"checksum entities 1.0.1 (registry+https://github.com/rust-lang/crates.io-index)" = "b5320ae4c3782150d900b79807611a59a99fc9a1d61d686faafc24b93fc8d7ca" +"checksum env_logger 0.6.2 (registry+https://github.com/rust-lang/crates.io-index)" = "aafcde04e90a5226a6443b7aabdb016ba2f8307c847d524724bd9b346dd1a2d3" +"checksum failure 0.1.6 (registry+https://github.com/rust-lang/crates.io-index)" = "f8273f13c977665c5db7eb2b99ae520952fe5ac831ae4cd09d80c4c7042b5ed9" +"checksum fake-simd 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "e88a8acf291dafb59c2d96e8f59828f3838bb1a70398823ade51a84de6a6deed" +"checksum flate2 1.0.13 (registry+https://github.com/rust-lang/crates.io-index)" = "6bd6d6f4752952feb71363cffc9ebac9411b75b87c6ab6058c40c8900cf43c0f" +"checksum fnv 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)" = "2fad85553e09a6f881f739c29f0b00b0f01357c743266d478b68951ce23285f3" +"checksum fxhash 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "c31b6d751ae2c7f11320402d34e41349dd1016f8d5d45e48c4312bc8625af50c" +"checksum generic-array 0.12.3 (registry+https://github.com/rust-lang/crates.io-index)" = "c68f0274ae0e023facc3c97b2e00f076be70e254bc851d972503b328db79b2ec" +"checksum glob 0.3.0 (registry+https://github.com/rust-lang/crates.io-index)" = "9b919933a397b79c37e33b77bb2aa3dc8eb6e165ad809e58ff75bc7db2e34574" +"checksum humantime 1.3.0 (registry+https://github.com/rust-lang/crates.io-index)" = "df004cfca50ef23c36850aaaa59ad52cc70d0e90243c3c7737a4dd32dc7a3c4f" +"checksum itoa 0.4.4 (registry+https://github.com/rust-lang/crates.io-index)" = "501266b7edd0174f8530248f87f99c88fbe60ca4ef3dd486835b8d8d53136f7f" +"checksum lazy_static 1.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "e2abad23fbc42b3700f2f279844dc832adb2b2eb069b2df918f455c4e18cc646" +"checksum lazycell 1.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "b294d6fa9ee409a054354afc4352b0b9ef7ca222c69b8812cbea9e7d2bf3783f" +"checksum libc 0.2.66 (registry+https://github.com/rust-lang/crates.io-index)" = "d515b1f41455adea1313a4a2ac8a8a477634fbae63cc6100e3aebb207ce61558" +"checksum libloading 0.5.2 (registry+https://github.com/rust-lang/crates.io-index)" = "f2b111a074963af1d37a139918ac6d49ad1d0d5e47f72fd55388619691a7d753" +"checksum line-wrap 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "f30344350a2a51da54c1d53be93fade8a237e545dbcc4bdbe635413f2117cab9" +"checksum linked-hash-map 0.5.2 (registry+https://github.com/rust-lang/crates.io-index)" = "ae91b68aebc4ddb91978b11a1b02ddd8602a05ec19002801c5666000e05e0f83" +"checksum log 0.4.8 (registry+https://github.com/rust-lang/crates.io-index)" = "14b6052be84e6b71ab17edffc2eeabf5c2c3ae1fdb464aae35ac50c67a44e1f7" +"checksum maplit 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "3e2e65a1a2e43cfcb47a895c4c8b10d1f4a61097f9f254f183aee60cad9c651d" +"checksum memchr 2.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "88579771288728879b57485cc7d6b07d648c9f0141eb955f8ab7f9d45394468e" +"checksum miniz_oxide 0.3.5 (registry+https://github.com/rust-lang/crates.io-index)" = "6f3f74f726ae935c3f514300cc6773a0c9492abc5e972d42ba0c0ebb88757625" +"checksum nom 4.2.3 (registry+https://github.com/rust-lang/crates.io-index)" = "2ad2a91a8e869eeb30b9cb3119ae87773a8f4ae617f41b1eb9c154b2905f7bd6" +"checksum onig 5.0.0 (registry+https://github.com/rust-lang/crates.io-index)" = "e4e723fc996fff1aeab8f62205f3e8528bf498bdd5eadb2784d2d31f30077947" +"checksum onig_sys 69.2.0 (registry+https://github.com/rust-lang/crates.io-index)" = "0a8d4efbf5f59cece01f539305191485b651acb3785b9d5eef05749f0496514e" +"checksum opaque-debug 0.2.3 (registry+https://github.com/rust-lang/crates.io-index)" = "2839e79665f131bdb5782e51f2c6c9599c133c6098982a54c794358bf432529c" +"checksum peeking_take_while 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "19b17cddbe7ec3f8bc800887bab5e717348c95ea2ca0b1bf0837fb964dc67099" +"checksum pest 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "7e4fb201c5c22a55d8b24fef95f78be52738e5e1361129be1b5e862ecdb6894a" +"checksum pest_derive 2.1.0 (registry+https://github.com/rust-lang/crates.io-index)" = "833d1ae558dc601e9a60366421196a8d94bc0ac980476d0b67e1d0988d72b2d0" +"checksum pest_generator 2.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "7b9fcf299b5712d06ee128a556c94709aaa04512c4dffb8ead07c5c998447fc0" +"checksum pest_meta 2.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "df43fd99896fd72c485fe47542c7b500e4ac1e8700bf995544d1317a60ded547" +"checksum pkg-config 0.3.17 (registry+https://github.com/rust-lang/crates.io-index)" = "05da548ad6865900e60eaba7f589cc0783590a92e940c26953ff81ddbab2d677" +"checksum plist 0.4.2 (registry+https://github.com/rust-lang/crates.io-index)" = "5f2a9f075f6394100e7c105ed1af73fb1859d6fd14e49d4290d578120beb167f" +"checksum proc-macro2 0.4.30 (registry+https://github.com/rust-lang/crates.io-index)" = "cf3d2011ab5c909338f7887f4fc896d35932e29146c12c8d01da6b22a80ba759" +"checksum proc-macro2 1.0.6 (registry+https://github.com/rust-lang/crates.io-index)" = "9c9e470a8dc4aeae2dee2f335e8f533e2d4b347e1434e5671afc49b054592f27" +"checksum quick-error 1.2.2 (registry+https://github.com/rust-lang/crates.io-index)" = "9274b940887ce9addde99c4eee6b5c44cc494b182b97e73dc8ffdcb3397fd3f0" +"checksum quote 0.6.13 (registry+https://github.com/rust-lang/crates.io-index)" = "6ce23b6b870e8f94f81fb0a363d65d86675884b34a09043c81e5562f11c1f8e1" +"checksum quote 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "053a8c8bcc71fcce321828dc897a98ab9760bef03a4fc36693c231e5b3216cfe" +"checksum regex 1.3.1 (registry+https://github.com/rust-lang/crates.io-index)" = "dc220bd33bdce8f093101afe22a037b8eb0e5af33592e6a9caafff0d4cb81cbd" +"checksum regex-syntax 0.6.12 (registry+https://github.com/rust-lang/crates.io-index)" = "11a7e20d1cce64ef2fed88b66d347f88bd9babb82845b2b858f3edbf59a4f716" +"checksum rustc-demangle 0.1.16 (registry+https://github.com/rust-lang/crates.io-index)" = "4c691c0e608126e00913e33f0ccf3727d5fc84573623b8d65b2df340b5201783" +"checksum ryu 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "bfa8506c1de11c9c4e4c38863ccbe02a305c8188e85a05a784c9e11e1c3910c8" +"checksum safemem 0.3.3 (registry+https://github.com/rust-lang/crates.io-index)" = "ef703b7cb59335eae2eb93ceb664c0eb7ea6bf567079d843e09420219668e072" +"checksum same-file 1.0.5 (registry+https://github.com/rust-lang/crates.io-index)" = "585e8ddcedc187886a30fa705c47985c3fa88d06624095856b36ca0b82ff4421" +"checksum serde 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)" = "414115f25f818d7dfccec8ee535d76949ae78584fc4f79a6f45a904bf8ab4449" +"checksum serde_derive 1.0.104 (registry+https://github.com/rust-lang/crates.io-index)" = "128f9e303a5a29922045a830221b8f78ec74a5f544944f3d5984f8ec3895ef64" +"checksum serde_json 1.0.44 (registry+https://github.com/rust-lang/crates.io-index)" = "48c575e0cc52bdd09b47f330f646cf59afc586e9c4e3ccd6fc1f625b8ea1dad7" +"checksum sha-1 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)" = "23962131a91661d643c98940b20fcaffe62d776a823247be80a48fcb8b6fce68" +"checksum shlex 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "7fdf1b9db47230893d76faad238fd6097fd6d6a9245cd7a4d90dbd639536bbd2" +"checksum strsim 0.8.0 (registry+https://github.com/rust-lang/crates.io-index)" = "8ea5119cdb4c55b55d432abb513a0429384878c15dde60cc77b1c99de1a95a6a" +"checksum syn 1.0.11 (registry+https://github.com/rust-lang/crates.io-index)" = "dff0acdb207ae2fe6d5976617f887eb1e35a2ba52c13c7234c790960cdad9238" +"checksum syntect 3.3.0 (registry+https://github.com/rust-lang/crates.io-index)" = "955e9da2455eea5635f7032fc3a229908e6af18c39600313866095e07db0d8b8" +"checksum termcolor 1.0.5 (registry+https://github.com/rust-lang/crates.io-index)" = "96d6098003bde162e4277c70665bd87c326f5a0c3f3fbfb285787fa482d54e6e" +"checksum textwrap 0.11.0 (registry+https://github.com/rust-lang/crates.io-index)" = "d326610f408c7a4eb6f51c37c330e496b08506c9457c9d34287ecc38809fb060" +"checksum thread_local 0.3.6 (registry+https://github.com/rust-lang/crates.io-index)" = "c6b53e329000edc2b34dbe8545fd20e55a333362d0a321909685a19bd28c3f1b" +"checksum twoway 0.2.1 (registry+https://github.com/rust-lang/crates.io-index)" = "6b40075910de3a912adbd80b5d8bad6ad10a23eeb1f5bf9d4006839e899ba5bc" +"checksum typed-arena 1.7.0 (registry+https://github.com/rust-lang/crates.io-index)" = "a9b2228007eba4120145f785df0f6c92ea538f5a3635a612ecf4e334c8c1446d" +"checksum typenum 1.11.2 (registry+https://github.com/rust-lang/crates.io-index)" = "6d2783fe2d6b8c1101136184eb41be8b1ad379e4657050b8aaff0c79ee7575f9" +"checksum ucd-trie 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "8f00ed7be0c1ff1e24f46c3d2af4859f7e863672ba3a6e92e7cff702bf9f06c2" +"checksum unchecked-index 0.2.2 (registry+https://github.com/rust-lang/crates.io-index)" = "eeba86d422ce181a719445e51872fa30f1f7413b62becb52e95ec91aa262d85c" +"checksum unicode-width 0.1.7 (registry+https://github.com/rust-lang/crates.io-index)" = "caaa9d531767d1ff2150b9332433f32a24622147e5ebb1f26409d5da67afd479" +"checksum unicode-xid 0.1.0 (registry+https://github.com/rust-lang/crates.io-index)" = "fc72304796d0818e357ead4e000d19c9c174ab23dc11093ac919054d20a6a7fc" +"checksum unicode-xid 0.2.0 (registry+https://github.com/rust-lang/crates.io-index)" = "826e7639553986605ec5979c7dd957c7895e93eabed50ab2ffa7f6128a75097c" +"checksum unicode_categories 0.1.1 (registry+https://github.com/rust-lang/crates.io-index)" = "39ec24b3121d976906ece63c9daad25b85969647682eee313cb5779fdd69e14e" +"checksum vec_map 0.8.1 (registry+https://github.com/rust-lang/crates.io-index)" = "05c78687fb1a80548ae3250346c3db86a80a7cdd77bda190189f2d0a0987c81a" +"checksum version_check 0.1.5 (registry+https://github.com/rust-lang/crates.io-index)" = "914b1a6776c4c929a602fafd8bc742e06365d4bcbe48c30f9cca5824f70dc9dd" +"checksum walkdir 2.2.9 (registry+https://github.com/rust-lang/crates.io-index)" = "9658c94fa8b940eab2250bd5a457f9c48b748420d71293b165c8cdbe2f55f71e" +"checksum which 2.0.1 (registry+https://github.com/rust-lang/crates.io-index)" = "b57acb10231b9493c8472b20cb57317d0679a49e0bdbee44b3b803a6473af164" +"checksum winapi 0.3.8 (registry+https://github.com/rust-lang/crates.io-index)" = "8093091eeb260906a183e6ae1abdba2ef5ef2257a21801128899c3fc699229c6" +"checksum winapi-i686-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6" +"checksum winapi-util 0.1.2 (registry+https://github.com/rust-lang/crates.io-index)" = "7168bab6e1daee33b4557efd0e95d5ca70a03706d39fa5f3fe7a236f584b03c9" +"checksum winapi-x86_64-pc-windows-gnu 0.4.0 (registry+https://github.com/rust-lang/crates.io-index)" = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f" +"checksum wincolor 1.0.2 (registry+https://github.com/rust-lang/crates.io-index)" = "96f5016b18804d24db43cebf3c77269e7569b8954a8464501c216cc5e070eaa9" +"checksum xml-rs 0.8.0 (registry+https://github.com/rust-lang/crates.io-index)" = "541b12c998c5b56aa2b4e6f18f03664eef9a4fd0a246a55594efae6cc2d964b5" +"checksum yaml-rust 0.4.3 (registry+https://github.com/rust-lang/crates.io-index)" = "65923dd1784f44da1d2c3dbbc5e822045628c590ba72123e1c73d3c230c4434d" diff --git a/tools/cheddar/Cargo.toml b/tools/cheddar/Cargo.toml new file mode 100644 index 0000000000..fe936deb4c --- /dev/null +++ b/tools/cheddar/Cargo.toml @@ -0,0 +1,10 @@ +[package] +name = "cheddar" +version = "0.1.0" +authors = ["Vincent Ambo <mail@tazj.in>"] +edition = "2018" + +[dependencies] +comrak = "0.6" +lazy_static = "1.4" +syntect = "3.3" diff --git a/tools/cheddar/README.md b/tools/cheddar/README.md new file mode 100644 index 0000000000..706f3b62d5 --- /dev/null +++ b/tools/cheddar/README.md @@ -0,0 +1,21 @@ +cheddar +======= + +Cheddar is a tiny Rust tool that uses [syntect][] to render source code to +syntax-highlighted HTML. + +It's invocation is compatible with `cgit` filters, i.e. data is read from +`stdin` and the filename is taken from `argv`: + +```shell +cat README.md | cheddar README.md > README.html + +``` + +In fact, if you are looking at this file on git.tazj.in chances are that it was +rendered by cheddar. + +The name was chosen because I was eyeing a pack of cheddar-flavoured crisps +while thinking about name selection. + +[syntect]: https://github.com/trishume/syntect diff --git a/tools/cheddar/default.nix b/tools/cheddar/default.nix new file mode 100644 index 0000000000..5f209090e3 --- /dev/null +++ b/tools/cheddar/default.nix @@ -0,0 +1,20 @@ +{ depot, ... }: + +with depot.third_party; + +naersk.buildPackage { + src = ./.; + doDoc = false; + doCheck = false; + + override = x: { + # bat contains syntax highlighting packages for a lot more + # languages than what ships with syntect, and we can make use of + # them! + BAT_SYNTAXES = "${bat.src}/assets/syntaxes.bin"; + + # LLVM packages (why are they even required?) are not found + # automatically if added to buildInputs, hence this ... + LIBCLANG_PATH = "${llvmPackages.libclang}/lib/libclang.so.7"; + }; +} diff --git a/tools/cheddar/src/main.rs b/tools/cheddar/src/main.rs new file mode 100644 index 0000000000..52e518cd82 --- /dev/null +++ b/tools/cheddar/src/main.rs @@ -0,0 +1,301 @@ +use comrak::arena_tree::Node; +use comrak::nodes::{Ast, AstNode, NodeValue, NodeCodeBlock, NodeHtmlBlock}; +use comrak::{Arena, parse_document, format_html, ComrakOptions}; +use lazy_static::lazy_static; +use std::cell::RefCell; +use std::env; +use std::ffi::OsStr; +use std::io::BufRead; +use std::io::Read; +use std::io; +use std::path::Path; +use syntect::dumps::from_binary; +use syntect::easy::HighlightLines; +use syntect::highlighting::ThemeSet; +use syntect::parsing::{SyntaxSet, SyntaxReference}; +use syntect::util::LinesWithEndings; + +use syntect::html::{ + IncludeBackground, + append_highlighted_html_for_styled_line, + start_highlighted_html_snippet, +}; + +lazy_static! { + // Load syntaxes & themes lazily. Initialisation might not be + // required in the case of Markdown rendering (if there's no code + // blocks within the document). + static ref SYNTAXES: SyntaxSet = from_binary(include_bytes!(env!("BAT_SYNTAXES"))); + static ref THEMES: ThemeSet = ThemeSet::load_defaults(); + + // Configure Comrak's Markdown rendering with all the bells & + // whistles! + static ref MD_OPTS: ComrakOptions = ComrakOptions{ + ext_strikethrough: true, + ext_tagfilter: true, + ext_table: true, + ext_autolink: true, + ext_tasklist: true, + ext_header_ids: Some(String::new()), // yyeeesss! + ext_footnotes: true, + ext_description_lists: true, + unsafe_: true, // required for tagfilter + ..ComrakOptions::default() + }; +} + +// HTML fragment used when rendering inline blocks in Markdown documents. +// Emulates the GitHub style (subtle background hue and padding). +const BLOCK_PRE: &str = "<pre style=\"background-color:#f6f8fa;padding:16px;\">\n"; + +struct Args { + /// Should Cheddar run as an about filter? (i.e. give special + /// rendering treatment to Markdown documents) + about_filter: bool, + + /// What file extension has been supplied (if any)? + extension: Option<String>, +} + +/// Parse the command-line flags passed to cheddar to determine +/// whether it is running in about-filter mode (`--about-filter`) and +/// what file extension has been supplied. +fn parse_args() -> Args { + let mut args = Args { + about_filter: false, + extension: None, + }; + + for (i, arg) in env::args().enumerate() { + if i == 0 { + continue; + } + + if arg == "--about-filter" { + args.about_filter = true; + continue; + } + + args.extension = Path::new(&arg) + .extension() + .and_then(OsStr::to_str) + .map(|s| s.to_string()); + } + + return args +} + +fn should_continue(res: &io::Result<usize>) -> bool { + match *res { + Ok(n) => n > 0, + Err(_) => false, + } +} + +// This function is taken from the Comrak documentation. +fn iter_nodes<'a, F>(node: &'a AstNode<'a>, f: &F) where F : Fn(&'a AstNode<'a>) { + f(node); + for c in node.children() { + iter_nodes(c, f); + } +} + +// Many of the syntaxes in the syntax list have random capitalisations, which +// means that name matching for the block info of a code block in HTML fails. +// +// Instead, try finding a syntax match by comparing case insensitively (for +// ASCII characters, anyways). +fn find_syntax_case_insensitive(info: &str) -> Option<&'static SyntaxReference> { + // TODO(tazjin): memoize this lookup + SYNTAXES.syntaxes().iter().rev().find(|&s| info.eq_ignore_ascii_case(&s.name)) +} + +// Replaces code-block inside of a Markdown AST with HTML blocks rendered by +// syntect. This enables static (i.e. no JavaScript) syntax highlighting, even +// of complex languages. +fn highlight_code_block(code_block: &NodeCodeBlock) -> NodeValue { + let theme = &THEMES.themes["InspiredGitHub"]; + let info = String::from_utf8_lossy(&code_block.info); + + let syntax = find_syntax_case_insensitive(&info) + .or_else(|| SYNTAXES.find_syntax_by_extension(&info)) + .unwrap_or_else(|| SYNTAXES.find_syntax_plain_text()); + + let code = String::from_utf8_lossy(&code_block.literal); + + let rendered = { + // Write the block preamble manually to get exactly the + // desired layout: + let mut hl = HighlightLines::new(syntax, theme); + let mut buf = BLOCK_PRE.to_string(); + + for line in LinesWithEndings::from(&code) { + let regions = hl.highlight(line, &SYNTAXES); + append_highlighted_html_for_styled_line( + ®ions[..], IncludeBackground::No, &mut buf, + ); + } + + buf.push_str("</pre>"); + buf + }; + + let block = NodeHtmlBlock { + block_type: 1, // It's unclear what behaviour is toggled by this + literal: rendered.into_bytes(), + }; + + NodeValue::HtmlBlock(block) +} + +// Supported callout elements (which each have their own distinct rendering): +enum Callout { + Todo, + Warning, + Question, + Tip, +} + +// Determine whether the first child of the supplied node contains a text that +// should cause a callout section to be rendered. +fn has_callout<'a>(node: &Node<'a, RefCell<Ast>>) -> Option<Callout> { + match node.first_child().map(|c| c.data.borrow()) { + Some(child) => match &child.value { + NodeValue::Text(text) => { + if text.starts_with("TODO".as_bytes()) { + return Some(Callout::Todo) + } else if text.starts_with("WARNING".as_bytes()) { + return Some(Callout::Warning) + } else if text.starts_with("QUESTION".as_bytes()) { + return Some(Callout::Question) + } else if text.starts_with("TIP".as_bytes()) { + return Some(Callout::Tip) + } + + return None + }, + _ => return None, + }, + _ => return None, + } +} + +fn format_callout_paragraph(callout: Callout) -> NodeValue { + let class = match callout { + Callout::Todo => "cheddar-todo", + Callout::Warning => "cheddar-warning", + Callout::Question => "cheddar-question", + Callout::Tip => "cheddar-tip", + }; + + NodeValue::HtmlBlock(NodeHtmlBlock { + block_type: 1, + literal: format!("<p class=\"cheddar-callout {}\">", class).into_bytes(), + }) +} + +fn format_markdown() { + let document = { + let mut buffer = String::new(); + let stdin = io::stdin(); + let mut stdin = stdin.lock(); + stdin.read_to_string(&mut buffer).expect("failed to read stdin"); + buffer + }; + + let arena = Arena::new(); + let root = parse_document(&arena, &document, &MD_OPTS); + + // This node must exist with a lifetime greater than that of the parsed AST + // in case that callouts are encountered (otherwise insertion into the tree + // is not possible). + let p_close = Node::new(RefCell::new(Ast { + start_line: 0, // TODO(tazjin): hrmm + content: vec![], + open: false, + last_line_blank: false, + value: NodeValue::HtmlBlock(NodeHtmlBlock { + block_type: 1, + literal: "</p>".as_bytes().to_vec(), + }), + })); + + // Syntax highlighting is implemented by traversing the arena and + // replacing all code blocks with HTML blocks rendered by syntect. + iter_nodes(root, &|node| { + let mut ast = node.data.borrow_mut(); + let new = match &ast.value { + NodeValue::CodeBlock(code) => Some(highlight_code_block(code)), + NodeValue::Paragraph => if let Some(callout) = has_callout(node) { + node.insert_after(&p_close); + Some(format_callout_paragraph(callout)) + } else { + None + }, + _ => None, + }; + + if let Some(new_value) = new { + ast.value = new_value + } + }); + + format_html(root, &MD_OPTS, &mut io::stdout()) + .expect("Markdown rendering failed"); +} + +fn format_code(extension: Option<&str>) { + let stdin = io::stdin(); + let mut stdin = stdin.lock(); + let mut linebuf = String::new(); + + // Get the first line, we might need it for syntax identification. + let mut read_result = stdin.read_line(&mut linebuf); + + // Set up the highlighter + let theme = &THEMES.themes["InspiredGitHub"]; + + let syntax = extension + .and_then(|e| SYNTAXES.find_syntax_by_extension(e)) + .or_else(|| SYNTAXES.find_syntax_by_first_line(&linebuf)) + .unwrap_or_else(|| SYNTAXES.find_syntax_plain_text()); + + let mut hl = HighlightLines::new(syntax, theme); + let (mut outbuf, bg) = start_highlighted_html_snippet(theme); + + // Rather than using the `lines` iterator, read each line manually + // and maintain buffer state. + // + // This is done because the syntax highlighter requires trailing + // newlines to be efficient, and those are stripped in the lines + // iterator. + while should_continue(&read_result) { + let regions = hl.highlight(&linebuf, &SYNTAXES); + + append_highlighted_html_for_styled_line( + ®ions[..], + IncludeBackground::IfDifferent(bg), + &mut outbuf, + ); + + // immediately output the current state to avoid keeping + // things in memory + print!("{}", outbuf); + + // merry go round again + linebuf.clear(); + outbuf.clear(); + read_result = stdin.read_line(&mut linebuf); + } + + println!("</pre>"); +} + +fn main() { + let args = parse_args(); + + match args.extension.as_ref().map(String::as_str) { + Some("md") if args.about_filter => format_markdown(), + extension => format_code(extension), + } +} diff --git a/tools/emacs-pkgs/defzone/defzone.el b/tools/emacs-pkgs/defzone/defzone.el new file mode 100644 index 0000000000..ffd359e5ff --- /dev/null +++ b/tools/emacs-pkgs/defzone/defzone.el @@ -0,0 +1,60 @@ +;;; defzone.el --- Generate zone files from Elisp -*- lexical-binding: t; -*- + +(require 'dash) +(require 'dash-functional) +(require 's) + +(defun record-to-record (zone record &optional subdomain) + "Evaluate a record definition and turn it into a zone file + record in ZONE, optionally prefixed with SUBDOMAIN." + + (cl-labels ((plist->alist (plist) + (when plist + (cons + (cons (car plist) (cadr plist)) + (plist->alist (cddr plist)))))) + (let ((name (if subdomain (s-join "." (list subdomain zone)) zone))) + (pcase record + ;; SOA RDATA (RFC 1035; 3.3.13) + ((and `(SOA . (,ttl . ,keys)) + (let (map (:mname mname) (:rname rname) (:serial serial) + (:refresh refresh) (:retry retry) (:expire expire) + (:minimum min)) + (plist->alist keys))) + (if-let ((missing (-filter #'null (not (list mname rname serial + refresh retry expire min))))) + (error "Missing fields in SOA record: %s" missing) + (format "%s %s IN SOA %s %s %s %s %s %s %s" + name ttl mname rname serial refresh retry expire min))) + + (`(NS . (,ttl . ,targets)) + (->> targets + (-map (lambda (target) (format "%s %s IN NS %s" name ttl target))) + (s-join "\n"))) + + (`(MX . (,ttl . ,pairs)) + (->> pairs + (-map (-lambda ((preference . exchange)) + (format "%s %s IN MX %s %s" name ttl preference exchange))) + (s-join "\n"))) + + (`(TXT ,ttl ,text) (format "%s %s IN TXT %s" name ttl (prin1-to-string text))) + + (`(A . (,ttl . ,ips)) + (->> ips + (-map (lambda (ip) (format "%s %s IN A %s" name ttl ip))) + (s-join "\n"))) + + (`(CNAME ,ttl ,target) (format "%s %s IN CNAME %s" name ttl target)) + + ((and `(,sub . ,records) + (guard (stringp sub))) + (s-join "\n" (-map (lambda (r) (record-to-record zone r sub)) records))) + + (_ (error "Invalid record definition: %s" record)))))) + +(defmacro defzone (fqdn &rest records) + "Generate zone file for the zone at FQDN from a simple DSL." + (declare (indent defun)) + + `(s-join "\n" (-map (lambda (r) (record-to-record ,fqdn r)) (quote ,records)))) diff --git a/tools/emacs-pkgs/defzone/example.el b/tools/emacs-pkgs/defzone/example.el new file mode 100644 index 0000000000..e9c86d25ee --- /dev/null +++ b/tools/emacs-pkgs/defzone/example.el @@ -0,0 +1,45 @@ +;;; example.el - usage example for defzone macro + +(defzone "tazj.in." + (SOA 21600 + :mname "ns-cloud-a1.googledomains.com." + :rname "cloud-dns-hostmaster.google.com." + :serial 123 + :refresh 21600 + :retry 3600 + :expire 1209600 + :minimum 300) + + (NS 21600 + "ns-cloud-a1.googledomains.com." + "ns-cloud-a2.googledomains.com." + "ns-cloud-a3.googledomains.com." + "ns-cloud-a4.googledomains.com.") + + (MX 300 + (1 . "aspmx.l.google.com.") + (5 . "alt1.aspmx.l.google.com.") + (5 . "alt2.aspmx.l.google.com.") + (10 . "alt3.aspmx.l.google.com.") + (10 . "alt4.aspmx.l.google.com.")) + + (TXT 3600 "google-site-verification=d3_MI1OwD6q2OT42Vvh0I9w2u3Q5KFBu-PieNUE1Fig") + + (A 300 "34.98.120.189") + + ;; Nested record sets are indicated by a list that starts with a + ;; string (this is just joined, so you can nest multiple levels at + ;; once) + ("blog" + ;; Blog "storage engine" is in a separate DNS zone + (NS 21600 + "ns-cloud-c1.googledomains.com." + "ns-cloud-c2.googledomains.com." + "ns-cloud-c3.googledomains.com." + "ns-cloud-c4.googledomains.com.")) + + ("git" + (A 300 "34.98.120.189") + (TXT 300 "<3 edef")) + + ("files" (CNAME 300 "c.storage.googleapis.com."))) diff --git a/tools/emacs-pkgs/dottime/default.nix b/tools/emacs-pkgs/dottime/default.nix new file mode 100644 index 0000000000..633aad187e --- /dev/null +++ b/tools/emacs-pkgs/dottime/default.nix @@ -0,0 +1,7 @@ +{ pkgs, ... }: + +pkgs.emacsPackages.trivialBuild rec { + pname = "dottime"; + version = "1.0"; + src = ./dottime.el; +} diff --git a/tools/emacs-pkgs/dottime/dottime.el b/tools/emacs-pkgs/dottime/dottime.el new file mode 100644 index 0000000000..2446f6488f --- /dev/null +++ b/tools/emacs-pkgs/dottime/dottime.el @@ -0,0 +1,81 @@ +;;; dottime.el --- use dottime in the modeline +;; +;; Copyright (C) 2019 Google Inc. +;; +;; Author: Vincent Ambo <tazjin@google.com> +;; Version: 1.0 +;; Package-Requires: (cl-lib) +;; +;;; Commentary: +;; +;; This package changes the display of time in the modeline to use +;; dottime (see https://dotti.me/) instead of the standard time +;; display. +;; +;; Modeline dottime display is enabled by calling +;; `dottime-display-mode' and dottime can be used in Lisp code via +;; `dottime-format'. + +(require 'cl-lib) +(require 'time) + +(defun dottime--format-string (&optional offset prefix) + "Creates the dottime format string for `format-time-string' + based on the local timezone." + + (let* ((offset-sec (or offset (car (current-time-zone)))) + (offset-hours (/ offset-sec 60 60)) + (base (concat prefix "%m-%dT%H·%M"))) + (if (/= offset-hours 0) + (concat base (format "%0+3d" offset-hours)) + base))) + +(defun dottime--display-time-update-advice (orig) + "Function used as advice to `display-time-update' with a + rebound definition of `format-time-string' that renders all + timestamps as dottime." + + (cl-letf* ((format-orig (symbol-function 'format-time-string)) + ((symbol-function 'format-time-string) + (lambda (&rest _) + (funcall format-orig (dottime--format-string) nil t)))) + (funcall orig))) + +(defun dottime-format (&optional time offset prefix) + "Format the given TIME in dottime at OFFSET. If TIME is nil, + the current time will be used. PREFIX is prefixed to the format + string verbatim. + + OFFSET can be an integer representing an offset in seconds, or + the argument can be elided in which case the system time zone + is used." + + (format-time-string (dottime--format-string offset prefix) time t)) + +(defun dottime-display-mode (arg) + "Enable time display as dottime. Disables dottime if called + with prefix 0 or nil." + + (interactive "p") + (if (or (eq arg 0) (eq arg nil)) + (advice-remove 'display-time-update #'dottime--display-time-update-advice) + (advice-add 'display-time-update :around #'dottime--display-time-update-advice)) + (display-time-update) + + ;; Amend the time display in telega.el to use dottime. + ;; + ;; This will never display offsets in the chat window, as those are + ;; always visible in the modeline anyways. + (when (featurep 'telega) + (defun telega-ins--dottime-advice (orig timestamp) + (let* ((dtime (decode-time timestamp t)) + (current-ts (time-to-seconds (current-time))) + (ctime (decode-time current-ts)) + (today00 (telega--time-at00 current-ts ctime))) + (if (> timestamp today00) + (telega-ins (format "%02d·%02d" (nth 2 dtime) (nth 1 dtime))) + (funcall orig timestamp)))) + + (advice-add 'telega-ins--date :around #'telega-ins--dottime-advice))) + +(provide 'dottime) diff --git a/tools/emacs-pkgs/nix-util/default.nix b/tools/emacs-pkgs/nix-util/default.nix new file mode 100644 index 0000000000..2356ad75f2 --- /dev/null +++ b/tools/emacs-pkgs/nix-util/default.nix @@ -0,0 +1,7 @@ +{ pkgs, ... }: + +pkgs.emacsPackages.trivialBuild rec { + pname = "nix-util"; + version = "1.0"; + src = ./nix-util.el; +} diff --git a/tools/emacs-pkgs/nix-util/nix-util.el b/tools/emacs-pkgs/nix-util/nix-util.el new file mode 100644 index 0000000000..4b9dd31a02 --- /dev/null +++ b/tools/emacs-pkgs/nix-util/nix-util.el @@ -0,0 +1,103 @@ +;;; nix-util.el --- Utilities for dealing with Nix code. -*- lexical-binding: t; -*- +;; +;; Copyright (C) 2019 Google Inc. +;; +;; Author: Vincent Ambo <tazjin@google.com> +;; Version: 1.0 +;; Package-Requires: (json map) +;; +;;; Commentary: +;; +;; This package adds some functionality that I find useful when +;; working in Nix buffers or programs installed from Nix. + +(require 'json) +(require 'map) + +(defvar nix-depot-path "/home/tazjin/depot") + +(defun nix/prefetch-github (owner repo) ; TODO(tazjin): support different branches + "Fetch the master branch of a GitHub repository and insert the + call to `fetchFromGitHub' at point." + + (interactive "sOwner: \nsRepository: ") + + (let* (;; Keep these vars around for output insertion + (point (point)) + (buffer (current-buffer)) + (name (concat "github-fetcher/" owner "/" repo)) + (outbuf (format "*%s*" name)) + (errbuf (get-buffer-create "*github-fetcher/errors*")) + (cleanup (lambda () + (kill-buffer outbuf) + (kill-buffer errbuf) + (with-current-buffer buffer + (read-only-mode -1)))) + (prefetch-handler + (lambda (_process event) + (unwind-protect + (pcase event + ("finished\n" + (let* ((json-string (with-current-buffer outbuf + (buffer-string))) + (result (json-read-from-string json-string))) + (with-current-buffer buffer + (goto-char point) + (map-let (("rev" rev) ("sha256" sha256)) result + (read-only-mode -1) + (insert (format "fetchFromGitHub { + owner = \"%s\"; + repo = \"%s\"; + rev = \"%s\"; + sha256 = \"%s\"; +};" owner repo rev sha256)) + (indent-region point (point)))))) + (_ (with-current-buffer errbuf + (error "Failed to prefetch %s/%s: %s" + owner repo (buffer-string))))) + (funcall cleanup))))) + + ;; Fetching happens asynchronously, but we'd like to make sure the + ;; point stays in place while that happens. + (read-only-mode) + (make-process :name name + :buffer outbuf + :command `("nix-prefetch-github" ,owner ,repo) + :stderr errbuf + :sentinel prefetch-handler))) + +(defun nix/sly-from-depot (attribute) + "Start a Sly REPL configured with a Lisp matching a derivation + from my depot. + + The derivation invokes nix.buildLisp.sbclWith and is built + asynchronously. The build output is included in the error + thrown on build failures." + + (interactive "sAttribute: ") + (lexical-let* ((outbuf (get-buffer-create (format "*depot-out/%s*" attribute))) + (errbuf (get-buffer-create (format "*depot-errors/%s*" attribute))) + (expression (format "let depot = import <depot> {}; in depot.nix.buildLisp.sbclWith [ depot.%s ]" attribute)) + ;; TODO(tazjin): use <depot> + (command (list "nix-build" "--no-out-link" "-I" (format "depot=%s" nix-depot-path) "-E" expression))) + + (message "Acquiring Lisp for <depot>.%s" attribute) + (make-process :name (format "depot-nix-build/%s" attribute) + :buffer outbuf + :stderr errbuf + :command command + :sentinel + (lambda (process event) + (unwind-protect + (pcase event + ("finished\n" + (let* ((outpath (s-trim (with-current-buffer outbuf (buffer-string)))) + (lisp-path (s-concat outpath "/bin/sbcl"))) + (message "Acquired Lisp for <depot>.%s at %s" attribute lisp-path) + (sly lisp-path))) + (_ (with-current-buffer errbuf + (error "Failed to build '%s':\n%s" attribute (buffer-string))))) + (kill-buffer outbuf) + (kill-buffer errbuf)))))) + +(provide 'nix-util) diff --git a/tools/emacs-pkgs/term-switcher/default.nix b/tools/emacs-pkgs/term-switcher/default.nix new file mode 100644 index 0000000000..0c5e4c17cd --- /dev/null +++ b/tools/emacs-pkgs/term-switcher/default.nix @@ -0,0 +1,14 @@ +{ pkgs, ... }: + +with pkgs.emacsPackages; + +melpaBuild rec { + pname = "term-switcher"; + version = "1.0"; + src = ./term-switcher.el; + packageRequires = [ dash ivy s vterm ]; + + recipe = builtins.toFile "recipe" '' + (term-switcher :fetcher github :repo "tazjin/depot") + ''; +} diff --git a/tools/emacs-pkgs/term-switcher/term-switcher.el b/tools/emacs-pkgs/term-switcher/term-switcher.el new file mode 100644 index 0000000000..67595474fa --- /dev/null +++ b/tools/emacs-pkgs/term-switcher/term-switcher.el @@ -0,0 +1,56 @@ +;;; term-switcher.el --- Easily switch between open vterms +;; +;; Copyright (C) 2019 Google Inc. +;; +;; Author: Vincent Ambo <tazjin@google.com> +;; Version: 1.1 +;; Package-Requires: (dash ivy s vterm) +;; +;;; Commentary: +;; +;; This package adds a function that lets users quickly switch between +;; different open vterms via ivy. + +(require 'dash) +(require 'ivy) +(require 's) +(require 'vterm) + +(defgroup term-switcher nil + "Customization options `term-switcher'.") + +(defcustom term-switcher-buffer-prefix "vterm<" + "String prefix for vterm terminal buffers. For example, if you + set your titles to match `vterm<...>' a useful prefix might be + `vterm<'." + :type '(string) + :group 'term-switcher) + +(defun ts/open-or-create-vterm (buffer-name) + "Switch to the buffer with BUFFER-NAME or create a new vterm + buffer." + (let ((buffer (get-buffer buffer-name))) + (if (not buffer) + (vterm) + (switch-to-buffer buffer)))) + +(defun ts/is-vterm-buffer (buffer) + "Determine whether BUFFER runs a vterm." + (equal 'vterm-mode (buffer-local-value 'major-mode buffer))) + +(defun ts/switch-to-terminal () + "Switch to an existing vterm buffer or create a new one." + + (interactive) + (let ((terms (-map #'buffer-name + (-filter #'ts/is-vterm-buffer (buffer-list))))) + (if terms + (ivy-read "Switch to vterm: " + (cons "New vterm" terms) + :caller 'ts/switch-to-terminal + :preselect (s-concat "^" term-switcher-buffer-prefix) + :require-match t + :action #'ts/open-or-create-vterm) + (vterm)))) + +(provide 'term-switcher) diff --git a/tools/emacs/.gitignore b/tools/emacs/.gitignore new file mode 100644 index 0000000000..7b666905f8 --- /dev/null +++ b/tools/emacs/.gitignore @@ -0,0 +1,11 @@ +.smex-items +*token* +auto-save-list/ +clones/ +elpa/ +irc.el +local.el +other/ +scripts/ +themes/ +*.elc diff --git a/tools/emacs/README.md b/tools/emacs/README.md new file mode 100644 index 0000000000..5c66733396 --- /dev/null +++ b/tools/emacs/README.md @@ -0,0 +1,7 @@ +tools/emacs +=========== + +This sub-folder builds my Emacs configuration, supplying packages from +Nix and configuration from this folder. + +I use Emacs for many things (including as my desktop environment). diff --git a/tools/emacs/config/bindings.el b/tools/emacs/config/bindings.el new file mode 100644 index 0000000000..f66a6ab551 --- /dev/null +++ b/tools/emacs/config/bindings.el @@ -0,0 +1,54 @@ +;; Font size +(define-key global-map (kbd "C-=") 'increase-default-text-scale) ;; '=' because there lies '+' +(define-key global-map (kbd "C--") 'decrease-default-text-scale) +(define-key global-map (kbd "C-x C-0") 'set-default-text-scale) + +;; What does <tab> do? Well, it depends ... +(define-key prog-mode-map (kbd "<tab>") #'company-indent-or-complete-common) + +;; imenu instead of insert-file +(global-set-key (kbd "C-x i") 'imenu) + +;; Window switching. (C-x o goes to the next window) +(windmove-default-keybindings) ;; Shift+direction + +;; Start eshell or switch to it if it's active. +(global-set-key (kbd "C-x m") 'eshell) + +;; Start a new eshell even if one is active. +(global-set-key (kbd "C-x C-p") 'ivy-browse-repositories) +(global-set-key (kbd "M-g M-g") 'goto-line-with-feedback) + +;; Miscellaneous editing commands +(global-set-key (kbd "C-c w") 'whitespace-cleanup) +(global-set-key (kbd "C-c a") 'align-regexp) +(global-set-key (kbd "C-c m") 'mc/mark-dwim) + +;; Browse URLs (very useful for Gitlab's SSH output!) +(global-set-key (kbd "C-c b p") 'browse-url-at-point) +(global-set-key (kbd "C-c b b") 'browse-url) + +;; C-x REALLY QUIT (idea by @magnars) +(global-set-key (kbd "C-x r q") 'save-buffers-kill-terminal) +(global-set-key (kbd "C-x C-c") 'ignore) + +;; Open Fefes Blog +(global-set-key (kbd "C-c C-f") 'fefes-blog) + +;; Open a file in project: +(global-set-key (kbd "C-c f") 'project-find-file) + +;; Insert TODO comments +(global-set-key (kbd "C-c t") 'insert-todo-comment) + +;; Add subthread collapsing to notmuch-show. +;; +;; C-, closes a thread, C-. opens a thread. This mirrors stepping +;; in/out of definitions. +(define-key notmuch-show-mode-map (kbd "C-,") 'notmuch-show-open-or-close-subthread) +(define-key notmuch-show-mode-map (kbd "C-.") + (lambda () + (interactive) + (notmuch-show-open-or-close-subthread t))) ;; open + +(provide 'bindings) diff --git a/tools/emacs/config/custom.el b/tools/emacs/config/custom.el new file mode 100644 index 0000000000..a157c7a5fa --- /dev/null +++ b/tools/emacs/config/custom.el @@ -0,0 +1,52 @@ +(custom-set-variables + ;; custom-set-variables was added by Custom. + ;; If you edit it by hand, you could mess it up, so be careful. + ;; Your init file should contain only one such instance. + ;; If there is more than one, they won't work right. + '(ac-auto-show-menu 0.8) + '(ac-delay 0.2) + '(avy-background t) + '(cargo-process--custom-path-to-bin "env CARGO_INCREMENTAL=1 cargo") + '(cargo-process--enable-rust-backtrace 1) + '(company-auto-complete (quote (quote company-explicit-action-p))) + '(company-idle-delay 0.5) + '(custom-enabled-themes (quote (gruber-darker))) + '(custom-safe-themes + (quote + ("d61fc0e6409f0c2a22e97162d7d151dee9e192a90fa623f8d6a071dbf49229c6" "3c83b3676d796422704082049fc38b6966bcad960f896669dfc21a7a37a748fa" "89336ca71dae5068c165d932418a368a394848c3b8881b2f96807405d8c6b5b6" default))) + '(display-time-default-load-average nil) + '(display-time-interval 30) + '(elnode-send-file-program "/run/current-system/sw/bin/cat") + '(frame-brackground-mode (quote dark)) + '(global-auto-complete-mode t) + '(kubernetes-commands-display-buffer-function (quote display-buffer)) + '(lsp-gopls-server-path "/home/tazjin/go/bin/gopls") + '(magit-log-show-gpg-status t) + '(ns-alternate-modifier (quote none)) + '(ns-command-modifier (quote control)) + '(ns-right-command-modifier (quote meta)) + '(require-final-newline (quote visit-save)) + '(tls-program (quote ("gnutls-cli --x509cafile %t -p %p %h")))) +(custom-set-faces + ;; custom-set-faces was added by Custom. + ;; If you edit it by hand, you could mess it up, so be careful. + ;; Your init file should contain only one such instance. + ;; If there is more than one, they won't work right. + '(default ((t (:foreground "#e4e4ef" :background "#181818")))) + '(rainbow-delimiters-depth-1-face ((t (:foreground "#2aa198")))) + '(rainbow-delimiters-depth-2-face ((t (:foreground "#b58900")))) + '(rainbow-delimiters-depth-3-face ((t (:foreground "#268bd2")))) + '(rainbow-delimiters-depth-4-face ((t (:foreground "#dc322f")))) + '(rainbow-delimiters-depth-5-face ((t (:foreground "#859900")))) + '(rainbow-delimiters-depth-6-face ((t (:foreground "#268bd2")))) + '(rainbow-delimiters-depth-7-face ((t (:foreground "#cb4b16")))) + '(rainbow-delimiters-depth-8-face ((t (:foreground "#d33682")))) + '(rainbow-delimiters-depth-9-face ((t (:foreground "#839496")))) + '(term-color-black ((t (:background "#282828" :foreground "#282828")))) + '(term-color-blue ((t (:background "#96a6c8" :foreground "#96a6c8")))) + '(term-color-cyan ((t (:background "#1fad83" :foreground "#1fad83")))) + '(term-color-green ((t (:background "#73c936" :foreground "#73c936")))) + '(term-color-magenta ((t (:background "#9e95c7" :foreground "#9e95c7")))) + '(term-color-red ((t (:background "#f43841" :foreground "#f43841")))) + '(term-color-white ((t (:background "#f5f5f5" :foreground "#f5f5f5")))) + '(term-color-yellow ((t (:background "#ffdd33" :foreground "#ffdd33"))))) diff --git a/tools/emacs/config/desktop.el b/tools/emacs/config/desktop.el new file mode 100644 index 0000000000..aefff0125f --- /dev/null +++ b/tools/emacs/config/desktop.el @@ -0,0 +1,254 @@ +;; -*- lexical-binding: t; -*- +;; +;; Configure desktop environment settings, including both +;; window-management (EXWM) as well as additional system-wide +;; commands. + +(require 's) +(require 'f) +(require 'dash) +(require 'exwm) +(require 'exwm-config) +(require 'exwm-randr) +(require 'exwm-systemtray) + +(defun pactl (cmd) + (shell-command (concat "pactl " cmd)) + (message "Volume command: %s" cmd)) + +(defun volume-mute () (interactive) (pactl "set-sink-mute @DEFAULT_SINK@ toggle")) +(defun volume-up () (interactive) (pactl "set-sink-volume @DEFAULT_SINK@ +5%")) +(defun volume-down () (interactive) (pactl "set-sink-volume @DEFAULT_SINK@ -5%")) + +(defun brightness-up () + (interactive) + (shell-command "xbacklight -inc 5") + (message "Brightness increased")) + +(defun brightness-down () + (interactive) + (shell-command "xbacklight -dec 5") + (message "Brightness decreased")) + +(defun lock-screen () + (interactive) + ;; A sudoers configuration is in place that lets me execute this + ;; particular command without having to enter a password. + ;; + ;; The reason for things being set up this way is that I want + ;; xsecurelock.service to be started as a system-wide service that + ;; is tied to suspend.target. + (shell-command "/usr/bin/sudo /usr/bin/systemctl start xsecurelock.service")) + +(defun set-xkb-layout (layout) + "Set the current X keyboard layout." + + (shell-command (format "setxkbmap %s" layout)) + (message "Set X11 keyboard layout to '%s'" layout)) + +(defun create-window-name () + "Construct window names to be used for EXWM buffers by + inspecting the window's X11 class and title. + + A lot of commonly used applications either create titles that + are too long by default, or in the case of web + applications (such as Cider) end up being constructed in + awkward ways. + + To avoid this issue, some rewrite rules are applied for more + human-accessible titles." + + (pcase (list (or exwm-class-name "unknown") (or exwm-title "unknown")) + ;; In Cider windows, rename the class and keep the workspace/file + ;; as the title. + (`("Google-chrome" ,(and (pred (lambda (title) (s-ends-with? " - Cider" title))) title)) + (format "Cider<%s>" (s-chop-suffix " - Cider" title))) + + ;; Attempt to detect IRCCloud windows via their title, which is a + ;; combination of the channel name and network. + ;; + ;; This is what would often be referred to as a "hack". The regexp + ;; will not work if a network connection buffer is selected in + ;; IRCCloud, but since the title contains no other indication that + ;; we're dealing with an IRCCloud window + (`("Google-chrome" + ,(and (pred (lambda (title) + (s-matches? "^[\*\+]\s#[a-zA-Z0-9/\-]+\s\|\s[a-zA-Z\.]+$" title))) + title)) + (format "IRCCloud<%s>" title)) + + ;; The Virus Lounge should be, well ... + (`("Google-chrome" + ,(and (pred (lambda (title) (s-contains? "Meet - mng-biyw-xbb" title))) title)) + "The Virus Lounge") + + ;; For other Chrome windows, make the title shorter. + (`("Google-chrome" ,title) + (format "Chrome<%s>" (s-truncate 42 (s-chop-suffix " - Google Chrome" title)))) + + ;; Gnome-terminal -> Term + (`("Gnome-terminal" ,title) + ;; fish-shell buffers contain some unnecessary whitespace and + ;; such before the current working directory. This can be + ;; stripped since most of my terminals are fish shells anyways. + (format "Term<%s>" (s-trim-left (s-chop-prefix "fish" title)))) + + ;; For any other application, a name is constructed from the + ;; window's class and name. + (`(,class ,title) (format "%s<%s>" class (s-truncate 12 title))))) + +;; EXWM launch configuration +;; +;; This used to use use-package, but when something breaks use-package +;; it doesn't exactly make debugging any easier. + +(let ((titlef (lambda () + (exwm-workspace-rename-buffer (create-window-name))))) + (add-hook 'exwm-update-class-hook titlef) + (add-hook 'exwm-update-title-hook titlef)) + +(fringe-mode 3) +(exwm-enable) + +;; 's-N': Switch to certain workspace +(setq exwm-workspace-number 10) +(dotimes (i 10) + (exwm-input-set-key (kbd (format "s-%d" i)) + `(lambda () + (interactive) + (exwm-workspace-switch-create ,i)))) + +;; Launch applications / any command with completion (dmenu style!) +(exwm-input-set-key (kbd "s-d") #'counsel-linux-app) +(exwm-input-set-key (kbd "s-x") #'ivy-run-external-command) +(exwm-input-set-key (kbd "s-p") #'ivy-password-store) + +;; Add X11 terminal selector to a key +(exwm-input-set-key (kbd "C-x t") #'ts/switch-to-terminal) + +;; Toggle between line-mode / char-mode +(exwm-input-set-key (kbd "C-c C-t C-t") #'exwm-input-toggle-keyboard) + +;; Volume keys +(exwm-input-set-key (kbd "<XF86AudioMute>") #'volume-mute) +(exwm-input-set-key (kbd "<XF86AudioRaiseVolume>") #'volume-up) +(exwm-input-set-key (kbd "<XF86AudioLowerVolume>") #'volume-down) + +;; Brightness keys +(exwm-input-set-key (kbd "<XF86MonBrightnessDown>") #'brightness-down) +(exwm-input-set-key (kbd "<XF86MonBrightnessUp>") #'brightness-up) +(exwm-input-set-key (kbd "<XF86Display>") #'lock-screen) + +;; Shortcuts for switching between keyboard layouts +(defmacro bind-xkb (lang key) + `(exwm-input-set-key (kbd (format "s-%s" ,key)) + (lambda () + (interactive) + (set-xkb-layout ,lang)))) + +(bind-xkb "us" "k u") +(bind-xkb "de" "k d") +(bind-xkb "no" "k n") +(bind-xkb "ru" "k r") + +;; These are commented out because Emacs no longer starts (??) if +;; they're set at launch. +;; +;; (bind-xkb "us" "л г") +;; (bind-xkb "de" "л в") +;; (bind-xkb "no" "л т") +;; (bind-xkb "ru" "л к") + +;; Line-editing shortcuts +(exwm-input-set-simulation-keys + '(([?\C-d] . delete) + ([?\C-w] . ?\C-c))) + +;; Show time & battery status in the mode line +(display-time-mode) +(display-battery-mode) + +;; enable display of X11 system tray within Emacs +(exwm-systemtray-enable) + +;; Configure xrandr (multi-monitor setup). +;; +;; This makes some assumptions about how my machines are connected to +;; my home setup during the COVID19 isolation period. + +(defun set-randr-config (screens) + (setq exwm-randr-workspace-monitor-plist + (-flatten (-map (lambda (screen) + (-map (lambda (screen-id) (list screen-id (car screen))) (cdr screen))) + screens)))) + +;; Layouts for Vauxhall (laptop) + +(defun randr-vauxhall-layout-single () + "Laptop screen only!" + (interactive) + (set-randr-config '(("eDP1" (number-sequence 0 9)))) + (shell-command "xrandr --output eDP1 --auto --primary") + (shell-command "xrandr --output HDMI1 --off") + (shell-command "xrandr --output DP2 --off") + (exwm-randr-refresh)) + +(defun randr-vauxhall-layout-all () + "Use all screens at home." + (interactive) + (set-randr-config + '(("eDP1" 0) + ("HDMI1" 1 2 3 4 5) + ("DP2" 6 7 8 9))) + + (shell-command "xrandr --output HDMI1 --right-of eDP1 --auto --primary") + (shell-command "xrandr --output DP2 --right-of HDMI1 --auto") + (exwm-randr-refresh)) + +(defun randr-vauxhall-layout-wide-only () + "Use only the wide screen at home." + (interactive) + (set-randr-config + '(("eDP1" 8 9 0) + ("HDMI1" 1 2 4 5 6 7))) + + (shell-command "xrandr --output DP2 --off") + (shell-command "xrandr --output HDMI1 --right-of eDP1 --auto --primary") + (exwm-randr-refresh)) + +;; Layouts for nugget (desktop) + +(defun randr-nugget-layout-right-only () + "Use only the right screen on nugget." + (interactive) + (set-randr-config `(("DP-2" ,(number-sequence 0 9)))) + (shell-command "xrandr --output DP-0 --off") + (shell-command "xrandr --output DP-2 --auto --primary")) + +(defun randr-nugget-layout-both () + "Use the left and right screen on nugget." + (interactive) + (set-randr-config `(("DP-0" 1 2 3 4 5) + ("DP-2" 6 7 8 9 0))) + + (shell-command "xrandr --output DP-0 --auto --primary --left-of DP-2") + (shell-command "xrandr --output DP-2 --auto --right-of DP-0")) + +(pcase (s-trim (shell-command-to-string "hostname")) + ("vauxhall" + (exwm-input-set-key (kbd "s-m s") #'randr-vauxhall-layout-single) + (exwm-input-set-key (kbd "s-m a") #'randr-vauxhall-layout-all) + (exwm-input-set-key (kbd "s-m w") #'randr-vauxhall-layout-wide-only)) + + ("nugget" + (exwm-input-set-key (kbd "s-m b") #'randr-nugget-layout-both) + (exwm-input-set-key (kbd "s-m r") #'randr-nugget-layout-right-only))) + +(exwm-randr-enable) + +;; Let buffers move seamlessly between workspaces by making them +;; accessible in selectors on all frames. +(setq exwm-workspace-show-all-buffers t) +(setq exwm-layout-show-all-buffers t) + +(provide 'desktop) diff --git a/tools/emacs/config/eshell-setup.el b/tools/emacs/config/eshell-setup.el new file mode 100644 index 0000000000..0b23c5a2d1 --- /dev/null +++ b/tools/emacs/config/eshell-setup.el @@ -0,0 +1,68 @@ +;; EShell configuration + +(require 'eshell) + +;; Generic settings +;; Hide banner message ... +(setq eshell-banner-message "") + +;; Prompt configuration +(defun clean-pwd (path) + "Turns a path of the form /foo/bar/baz into /f/b/baz + (inspired by fish shell)" + (let* ((hpath (replace-regexp-in-string home-dir + "~" + path)) + (current-dir (split-string hpath "/")) + (cdir (last current-dir)) + (head (butlast current-dir))) + (concat (mapconcat (lambda (s) + (if (string= "" s) nil + (substring s 0 1))) + head + "/") + (if head "/" nil) + (car cdir)))) + +(defun vcprompt (&optional args) + "Call the external vcprompt command with optional arguments. + VCPrompt" + (replace-regexp-in-string + "\n" "" + (shell-command-to-string (concat "vcprompt" args)))) + +(defmacro with-face (str &rest properties) + `(propertize ,str 'face (list ,@properties))) + +(defun prompt-f () + "EShell prompt displaying VC info and such" + (concat + (with-face (concat (clean-pwd (eshell/pwd)) " ") :foreground "#96a6c8") + (if (= 0 (user-uid)) + (with-face "#" :foreground "#f43841") + (with-face "$" :foreground "#73c936")) + (with-face " " :foreground "#95a99f"))) + + +(setq eshell-prompt-function 'prompt-f) +(setq eshell-highlight-prompt nil) +(setq eshell-prompt-regexp "^.+? \\((\\(git\\|svn\\|hg\\|darcs\\|cvs\\|bzr\\):.+?) \\)?[$#] ") + +;; Ignore version control folders in autocompletion +(setq eshell-cmpl-cycle-completions nil + eshell-save-history-on-exit t + eshell-cmpl-dir-ignore "\\`\\(\\.\\.?\\|CVS\\|\\.svn\\|\\.git\\)/\\'") + +;; Load some EShell extensions +(eval-after-load 'esh-opt + '(progn + (require 'em-term) + (require 'em-cmpl) + ;; More visual commands! + (add-to-list 'eshell-visual-commands "ssh") + (add-to-list 'eshell-visual-commands "tail") + (add-to-list 'eshell-visual-commands "sl"))) + +(setq eshell-directory-name "~/.config/eshell/") + +(provide 'eshell-setup) diff --git a/tools/emacs/config/functions.el b/tools/emacs/config/functions.el new file mode 100644 index 0000000000..62611bb638 --- /dev/null +++ b/tools/emacs/config/functions.el @@ -0,0 +1,303 @@ +(require 'chart) +(require 'dash) +(require 'map) + +(defun load-file-if-exists (filename) + (if (file-exists-p filename) + (load filename))) + +(defun goto-line-with-feedback () + "Show line numbers temporarily, while prompting for the line number input" + (interactive) + (unwind-protect + (progn + (setq-local display-line-numbers t) + (let ((target (read-number "Goto line: "))) + (avy-push-mark) + (goto-line target))) + (setq-local display-line-numbers nil))) + +;; These come from the emacs starter kit + +(defun esk-add-watchwords () + (font-lock-add-keywords + nil '(("\\<\\(FIX\\(ME\\)?\\|TODO\\|DEBUG\\|HACK\\|REFACTOR\\|NOCOMMIT\\)" + 1 font-lock-warning-face t)))) + +(defun esk-sudo-edit (&optional arg) + (interactive "p") + (if (or arg (not buffer-file-name)) + (find-file (concat "/sudo:root@localhost:" (read-file-name "File: "))) + (find-alternate-file (concat "/sudo:root@localhost:" buffer-file-name)))) + +;; Open Fefes blog +(defun fefes-blog () + (interactive) + (eww "https://blog.fefe.de/")) + +;; Open the NixOS man page +(defun nixos-man () + (interactive) + (man "configuration.nix")) + +;; Open my monorepo in magit +(defun depot-status () + (interactive) + (magit-status "~/depot")) + +;; Get the nix store path for a given derivation. +;; If the derivation has not been built before, this will trigger a build. +(defun nix-store-path (derivation) + (let ((expr (concat "with import <nixos> {}; " derivation))) + (s-chomp (shell-command-to-string (concat "nix-build -E '" expr "'"))))) + +(defun insert-nix-store-path () + (interactive) + (let ((derivation (read-string "Derivation name (in <nixos>): "))) + (insert (nix-store-path derivation)))) + +(defun toggle-force-newline () + "Buffer-local toggle for enforcing final newline on save." + (interactive) + (setq-local require-final-newline (not require-final-newline)) + (message "require-final-newline in buffer %s is now %s" + (buffer-name) + require-final-newline)) + +;; Helm includes a command to run external applications, which does +;; not seem to exist in ivy. This implementation uses some of the +;; logic from Helm to provide similar functionality using ivy. +(defun list-external-commands () + "Creates a list of all external commands available on $PATH + while filtering NixOS wrappers." + (cl-loop + for dir in (split-string (getenv "PATH") path-separator) + when (and (file-exists-p dir) (file-accessible-directory-p dir)) + for lsdir = (cl-loop for i in (directory-files dir t) + for bn = (file-name-nondirectory i) + when (and (not (s-contains? "-wrapped" i)) + (not (member bn completions)) + (not (file-directory-p i)) + (file-executable-p i)) + collect bn) + append lsdir into completions + finally return (sort completions 'string-lessp))) + +(defvar external-command-flag-overrides + '(("google-chrome" . "--force-device-scale-factor=1.4")) + + "This setting lets me add additional flags to specific commands + that are run interactively via `ivy-run-external-command'.") + +(defun run-external-command (cmd) + "Execute the specified command and notify the user when it + finishes." + (let* ((extra-flags (cdr (assoc cmd external-command-flag-overrides))) + (cmd (if extra-flags (s-join " " (list cmd extra-flags)) cmd))) + (message "Starting %s..." cmd) + (set-process-sentinel + (start-process-shell-command cmd nil cmd) + (lambda (process event) + (when (string= event "finished\n") + (message "%s process finished." process)))))) + +(defun ivy-run-external-command () + "Prompts the user with a list of all installed applications and + lets them select one to launch." + + (interactive) + (let ((external-commands-list (list-external-commands))) + (ivy-read "Command:" external-commands-list + :require-match t + :history 'external-commands-history + :action #'run-external-command))) + +(defun ivy-password-store (&optional password-store-dir) + "Custom version of password-store integration with ivy that + actually uses the GPG agent correctly." + + (interactive) + (ivy-read "Copy password of entry: " + (password-store-list (or password-store-dir (password-store-dir))) + :require-match t + :keymap ivy-pass-map + :action (lambda (entry) + (let ((password (auth-source-pass-get 'secret entry))) + (password-store-clear) + (kill-new password) + (setq password-store-kill-ring-pointer kill-ring-yank-pointer) + (message "Copied %s to the kill ring. Will clear in %s seconds." + entry (password-store-timeout)) + (setq password-store-timeout-timer + (run-at-time (password-store-timeout) + nil 'password-store-clear)))))) + +(defun ivy-browse-repositories () + "Select a git repository and open its associated magit buffer." + + (interactive) + (ivy-read "Repository: " + (magit-list-repos) + :require-match t + :sort t + :action #'magit-status)) + +(defun bottom-right-window-p () + "Determines whether the last (i.e. bottom-right) window of the + active frame is showing the buffer in which this function is + executed." + (let* ((frame (selected-frame)) + (right-windows (window-at-side-list frame 'right)) + (bottom-windows (window-at-side-list frame 'bottom)) + (last-window (car (seq-intersection right-windows bottom-windows)))) + (eq (current-buffer) (window-buffer last-window)))) + +(defhydra mc/mark-more-hydra (:color pink) + ("<up>" mmlte--up "Mark previous like this") + ("<down>" mc/mmlte--down "Mark next like this") + ("<left>" mc/mmlte--left (if (eq mc/mark-more-like-this-extended-direction 'up) + "Skip past the cursor furthest up" + "Remove the cursor furthest down")) + ("<right>" mc/mmlte--right (if (eq mc/mark-more-like-this-extended-direction 'up) + "Remove the cursor furthest up" + "Skip past the cursor furthest down")) + ("f" nil "Finish selecting")) + +;; Mute the message that mc/mmlte wants to print on its own +(advice-add 'mc/mmlte--message :around (lambda (&rest args) (ignore))) + +(defun mc/mark-dwim (arg) + "Select multiple things, but do what I mean." + + (interactive "p") + (if (not (region-active-p)) (mc/mark-next-lines arg) + (if (< 1 (count-lines (region-beginning) + (region-end))) + (mc/edit-lines arg) + ;; The following is almost identical to `mc/mark-more-like-this-extended', + ;; but uses a hydra (`mc/mark-more-hydra') instead of a transient key map. + (mc/mmlte--down) + (mc/mark-more-hydra/body)))) + +(defun memespace-region () + "Make a meme out of it." + + (interactive) + (let* ((start (region-beginning)) + (end (region-end)) + (memed + (message + (s-trim-right + (apply #'string + (-flatten + (nreverse + (-reduce-from (lambda (acc x) + (cons (cons x (-repeat (+ 1 (length acc)) 32)) acc)) + '() + (string-to-list (buffer-substring-no-properties start end)))))))))) + + (save-excursion (delete-region start end) + (goto-char start) + (insert memed)))) + +(defun insert-todo-comment (prefix todo) + "Insert a comment at point with something for me to do." + + (interactive "P\nsWhat needs doing? ") + (save-excursion + (move-end-of-line nil) + (insert (format " %s TODO(%s): %s" + (s-trim-right comment-start) + (if prefix (read-string "Who needs to do this? ") + (getenv "USER")) + todo)))) + +;; Custom text scale adjustment functions that operate on the entire instance +(defun modify-text-scale (factor) + (set-face-attribute 'default nil + :height (+ (* factor 5) (face-attribute 'default :height)))) + +(defun increase-default-text-scale (prefix) + "Increase default text scale in all Emacs frames, or just the + current frame if PREFIX is set." + + (interactive "P") + (if prefix (text-scale-increase 1) + (modify-text-scale 1))) + +(defun decrease-default-text-scale (prefix) + "Increase default text scale in all Emacs frames, or just the + current frame if PREFIX is set." + + (interactive "P") + (if prefix (text-scale-decrease 1) + (modify-text-scale -1))) + +(defun set-default-text-scale (prefix &optional to) + "Set the default text scale to the specified value, or the + default. Restores current frame's text scale only, if PREFIX is + set." + + (interactive "P") + (if prefix (text-scale-adjust 0) + (set-face-attribute 'default nil :height (or to 120)))) + +(defun notmuch-depot-apply-patch () + "Apply the currently opened notmuch message as a patch on the + depot." + + (interactive) + ;; The implementation works by letting notmuch render a raw message + ;; and capturing it by overriding the `view-buffer' function it + ;; calls after rendering. + ;; + ;; The buffer is then passed to `git-am'. + (cl-letf (((symbol-function 'view-buffer) + (lambda (buffer &optional exit-action) buffer))) + (if-let ((raw-buffer (notmuch-show-view-raw-message))) + (progn + (with-current-buffer raw-buffer + (call-shell-region (point-min) (point-max) "git am -C ~/depot") + (message "Patch applied!") + (kill-buffer)) + (magit-status "~/depot")) + (warn "notmuch failed to render the raw message buffer")))) + +(defun scrot-select () + "Take a screenshot based on a mouse-selection and save it to + ~/screenshots." + (interactive) + (shell-command "scrot '$a_%Y-%m-%d_%s.png' -s -e 'mv $f ~/screenshots/'")) + +(defun graph-unread-mails () + "Create a bar chart of unread mails based on notmuch tags. + Certain tags are excluded from the overview." + + (interactive) + (let ((tag-counts + (-keep (-lambda ((name . search)) + (let ((count + (string-to-number + (s-trim + (notmuch-command-to-string "count" search "and" "tag:unread"))))) + (when (>= count 1) (cons name count)))) + (notmuch-hello-generate-tag-alist '("unread" "signed" "attachment" "important"))))) + + (chart-bar-quickie + (if (< (length tag-counts) 6) + 'vertical 'horizontal) + "Unread emails" + (-map #'car tag-counts) "Tag:" + (-map #'cdr tag-counts) "Count:"))) + +(defun notmuch-show-open-or-close-subthread (&optional prefix) + "Open or close the subthread from (and including) the message at point." + (interactive "P") + (save-excursion + (let ((current-depth (map-elt (notmuch-show-get-message-properties) :depth 0))) + (loop do (notmuch-show-message-visible (notmuch-show-get-message-properties) prefix) + until (or (not (notmuch-show-goto-message-next)) + (= (map-elt (notmuch-show-get-message-properties) :depth) current-depth))))) + (force-window-update)) + +(provide 'functions) diff --git a/tools/emacs/config/init.el b/tools/emacs/config/init.el new file mode 100644 index 0000000000..96778ef3c0 --- /dev/null +++ b/tools/emacs/config/init.el @@ -0,0 +1,279 @@ +;;; init.el --- Package bootstrapping. -*- lexical-binding: t; -*- + +;; Packages are installed via Nix configuration, this file only +;; initialises the newly loaded packages. + +(require 'use-package) +(require 'seq) + +(package-initialize) + +;; Initialise all packages installed via Nix. +;; +;; TODO: Generate this section in Nix for all packages that do not +;; require special configuration. + +;; +;; Packages providing generic functionality. +;; + +(use-package ace-window + :bind (("C-x o" . ace-window)) + :config + (setq aw-keys '(?f ?j ?d ?k ?s ?l ?a) + aw-scope 'frame)) + +(use-package auth-source-pass :config (auth-source-pass-enable)) + +(use-package avy + :bind (("M-j" . avy-goto-char) + ("M-p" . avy-pop-mark) + ("M-g g" . avy-goto-line))) + +(use-package browse-kill-ring) + +(use-package company + :hook ((prog-mode . company-mode)) + :config (setq company-tooltip-align-annotations t)) + +(use-package counsel + :after (ivy) + :config (counsel-mode 1) + :bind (("C-c r g" . counsel-rg))) + +(use-package dash) +(use-package dash-functional) + +(use-package dottime + :demand + :after (notmuch telega) + :config (dottime-display-mode t)) + +(use-package gruber-darker-theme) + +(use-package eglot + :custom + (eglot-autoshutdown t) + (eglot-send-changes-idle-time 0.3)) + +(use-package ht) +(use-package hydra) +(use-package idle-highlight-mode :hook ((prog-mode . idle-highlight-mode))) + +(use-package ivy + :config + (ivy-mode 1) + (setq enable-recursive-minibuffers t) + (setq ivy-use-virtual-buffers t)) + +(use-package ivy-pass :after (ivy)) + +(use-package ivy-prescient + :after (ivy prescient) + :config + (ivy-prescient-mode) + ;; Fixes an issue with how regexes are passed to ripgrep from counsel, + ;; see raxod502/prescient.el#43 + (setf (alist-get 'counsel-rg ivy-re-builders-alist) #'ivy--regex-plus)) + +(use-package multiple-cursors) + +(use-package notmuch + :bind (:map global-map + ("s-g m" . notmuch) + ("s-g M" . counsel-notmuch)) ;; g m -> gmail + :config + (setq notmuch-search-oldest-first nil) + (setq notmuch-show-all-tags-list t) + (setq notmuch-hello-tag-list-make-query "tag:unread")) + +(use-package paredit :hook ((lisp-mode . paredit-mode) + (emacs-lisp-mode . paredit-mode))) + +(use-package pinentry + :config + (setq epa-pinentry-mode 'loopback) + (pinentry-start)) + +(use-package prescient + :after (ivy counsel) + :config (prescient-persist-mode)) + +(use-package rainbow-delimiters :hook (prog-mode . rainbow-delimiters-mode)) +(use-package rainbow-mode) +(use-package s) +(use-package string-edit) + +(use-package swiper + :after (counsel ivy) + :bind (("C-s" . swiper))) + +(use-package telephone-line) ;; configuration happens outside of use-package +(use-package term-switcher) +(use-package undo-tree :config (global-undo-tree-mode)) +(use-package uuidgen) +(use-package which-key :config (which-key-mode t)) + +;; +;; Applications in emacs +;; + +(use-package magit + :bind ("C-c g" . magit-status) + :config (setq magit-repository-directories '(("/home/tazjin/projects" . 2) + ("/home/tazjin" . 1)))) + +(use-package org-journal + ;; Always use my own key to encrypt files. There seems to be no + ;; global way to set this, as `epa-file-encrypt-to' only has an + ;; effect as a file-local variable (?!) + :hook ((org-journal-mode . (lambda () + (setq-local epa-file-encrypt-to + "DCF34CFAC1AC44B87E26333136EE34814F6D294A")))) + + :config + (setq org-journal-dir "/ssh:camden.tazj.in:/home/tazjin/journal" + org-journal-encrypt-journal t + org-journal-file-type 'weekly + org-journal-date-format "%A, %Y-%m-%d" + org-journal-file-format "%Y%m%d-weekly" + + ;; Saturday, because reasons. + org-journal-start-on-weekday 6) + + ;; org-journal doesn't actually enter its mode automatically if + ;; encryption is used (I'm not sure why), so this teaches Emacs to + ;; recognise the files. + (add-to-list 'auto-mode-alist '("[0-9]-weekly\\.gpg\\'" . org-journal-mode))) + +(use-package org-ql) + +(use-package password-store) +(use-package pg) +(use-package restclient) + +(use-package vterm + :config (progn + (setq vterm-shell "fish") + (setq vterm-exit-functions + (lambda (&rest _) (kill-buffer (current-buffer)))) + (setq vterm-set-title-functions + (lambda (title) + (rename-buffer + (generate-new-buffer-name + (format "vterm<%s>" + (s-trim-left + (s-chop-prefix "fish" title))))))))) + +;; +;; Packages providing language-specific functionality +;; + +(use-package cargo + :hook ((rust-mode . cargo-minor-mode) + (cargo-process-mode . visual-line-mode)) + :bind (:map cargo-minor-mode-map ("C-c C-c C-l" . ignore))) + +(use-package dockerfile-mode) + +(use-package erlang + :hook ((erlang-mode . (lambda () + ;; Don't indent after '>' while I'm writing + (local-set-key ">" 'self-insert-command))))) + +(use-package f) +(use-package geiser) + +(use-package go-mode + :bind (:map go-mode-map ("C-c C-r" . recompile)) + :hook ((go-mode . (lambda () + (setq tab-width 2) + (setq-local compile-command + (concat "go build " buffer-file-name)))))) + +(use-package haskell-mode) + +(use-package ielm + :hook ((inferior-emacs-lisp-mode . (lambda () + (paredit-mode) + (rainbow-delimiters-mode-enable) + (company-mode))))) + +(use-package jq-mode + :config (add-to-list 'auto-mode-alist '("\\.jq\\'" . jq-mode))) + +(use-package kotlin-mode + :hook ((kotlin-mode . (lambda () + (setq indent-line-function #'indent-relative))))) + +(use-package lsp-mode) + +(use-package markdown-mode + :config + (add-to-list 'auto-mode-alist '("\\.txt\\'" . markdown-mode)) + (add-to-list 'auto-mode-alist '("\\.markdown\\'" . markdown-mode)) + (add-to-list 'auto-mode-alist '("\\.md\\'" . markdown-mode))) + +(use-package markdown-toc) + +(use-package nix-mode + :hook ((nix-mode . (lambda () + (setq indent-line-function #'nix-indent-line))))) + +(use-package nix-util) +(use-package nginx-mode) +(use-package rust-mode) + +(use-package sly + :hook ((sly-mrepl-mode . (lambda () + (paredit-mode) + (rainbow-delimiters-mode-enable) + (company-mode)))) + :config + (setq common-lisp-hyperspec-root "file:///home/tazjin/docs/lisp/")) + +(use-package telega + :bind (:map global-map ("s-t" . telega)) + :config (telega-mode-line-mode 1)) + +(use-package terraform-mode) +(use-package toml-mode) +(use-package web-mode) +(use-package yaml-mode) + +;; Configuration changes in `customize` can not actually be persisted +;; to the customise file that Emacs is currently using (since it comes +;; from the Nix store). +;; +;; The way this will work for now is that Emacs will *write* +;; configuration to the file tracked in my repository, while not +;; actually *reading* it from there (unless Emacs is rebuilt). +(setq custom-file (expand-file-name "~/depot/tools/emacs/config/custom.el")) +(load-library "custom") + +(defvar home-dir (expand-file-name "~")) + +;; Seed RNG +(random t) + +;; Load all other Emacs configuration. These configurations are +;; added to `load-path' by Nix. +(mapc 'require '(desktop + mail-setup + look-and-feel + functions + settings + modes + bindings + eshell-setup)) +(telephone-line-setup) +(ace-window-display-mode) + +;; If a local configuration library exists, it should be loaded. +;; +;; This can be provided by calling my Emacs derivation with +;; `withLocalConfig'. +(if-let (local-file (locate-library "local")) + (load local-file)) + +(provide 'init) diff --git a/tools/emacs/config/look-and-feel.el b/tools/emacs/config/look-and-feel.el new file mode 100644 index 0000000000..5a4d874f6f --- /dev/null +++ b/tools/emacs/config/look-and-feel.el @@ -0,0 +1,113 @@ +;;; -*- lexical-binding: t; -*- + +;; Hide those ugly tool bars: +(tool-bar-mode 0) +(scroll-bar-mode 0) +(menu-bar-mode 0) +(add-hook 'after-make-frame-functions + (lambda (frame) (scroll-bar-mode 0))) + +;; Don't do any annoying things: +(setq ring-bell-function 'ignore) +(setq initial-scratch-message "") + +;; Remember layout changes +(winner-mode 1) + +;; Usually emacs will run as a proper GUI application, in which case a few +;; extra settings are nice-to-have: +(when window-system + (setq frame-title-format '(buffer-file-name "%f" ("%b"))) + (mouse-wheel-mode t) + (blink-cursor-mode -1)) + +;; Configure Emacs fonts. +(let ((font (format "JetBrains Mono-%d" 12))) + (setq default-frame-alist `((font . ,font))) + (set-frame-font font t t)) + +;; Configure telephone-line +(defun telephone-misc-if-last-window () + "Renders the mode-line-misc-info string for display in the + mode-line if the currently active window is the last one in the + frame. + + The idea is to not display information like the current time, + load, battery levels on all buffers." + + (when (bottom-right-window-p) + (telephone-line-raw mode-line-misc-info t))) + +(defun telephone-line-setup () + (telephone-line-defsegment telephone-line-last-window-segment () + (telephone-misc-if-last-window)) + + ;; Display the current EXWM workspace index in the mode-line + (telephone-line-defsegment telephone-line-exwm-workspace-index () + (when (bottom-right-window-p) + (format "[%s]" exwm-workspace-current-index))) + + ;; Define a highlight font for ~ important ~ information in the last + ;; window. + (defface special-highlight '((t (:foreground "white" :background "#5f627f"))) "") + (add-to-list 'telephone-line-faces + '(highlight . (special-highlight . special-highlight))) + + (setq telephone-line-lhs + '((nil . (telephone-line-position-segment)) + (accent . (telephone-line-buffer-segment)))) + + (setq telephone-line-rhs + '((accent . (telephone-line-major-mode-segment)) + (nil . (telephone-line-last-window-segment + telephone-line-exwm-workspace-index)) + + ;; TODO(tazjin): lets not do this particular thing while I + ;; don't actually run notmuch, there are too many things + ;; that have a dependency on the modeline drawing correctly + ;; (including randr operations!) + ;; + ;; (highlight . (telephone-line-notmuch-counts)) + )) + + (setq telephone-line-primary-left-separator 'telephone-line-tan-left + telephone-line-primary-right-separator 'telephone-line-tan-right + telephone-line-secondary-left-separator 'telephone-line-tan-hollow-left + telephone-line-secondary-right-separator 'telephone-line-tan-hollow-right) + + (telephone-line-mode 1)) + +;; Auto refresh buffers +(global-auto-revert-mode 1) + +;; Use clipboard properly +(setq select-enable-clipboard t) + +;; Show in-progress chords in minibuffer +(setq echo-keystrokes 0.1) + +;; Show column numbers in all buffers +(column-number-mode t) + +(defalias 'yes-or-no-p 'y-or-n-p) +(defalias 'auto-tail-revert-mode 'tail-mode) + +;; Style line numbers (shown with M-g g) +(setq linum-format + (lambda (line) + (propertize + (format (concat " %" + (number-to-string + (length (number-to-string + (line-number-at-pos (point-max))))) + "d ") + line) + 'face 'linum))) + +;; Display tabs as 2 spaces +(setq tab-width 2) + +;; Don't wrap around when moving between buffers +(setq windmove-wrap-around nil) + +(provide 'look-and-feel) diff --git a/tools/emacs/config/mail-setup.el b/tools/emacs/config/mail-setup.el new file mode 100644 index 0000000000..1167bcadd3 --- /dev/null +++ b/tools/emacs/config/mail-setup.el @@ -0,0 +1,83 @@ +(require 'notmuch) +(require 'counsel-notmuch) + +;; (global-set-key (kbd "C-c m") 'notmuch-hello) +;; (global-set-key (kbd "C-c C-m") 'counsel-notmuch) +;; (global-set-key (kbd "C-c C-e n") 'notmuch-mua-new-mail) + +(setq notmuch-cache-dir (format "%s/.cache/notmuch" (getenv "HOME"))) +(make-directory notmuch-cache-dir t) + +;; Cache addresses for completion: +(setq notmuch-address-save-filename (concat notmuch-cache-dir "/addresses")) + +;; Don't spam my home folder with drafts: +(setq notmuch-draft-folder "drafts") ;; relative to notmuch database + +;; Mark things as read when archiving them: +(setq notmuch-archive-tags '("-inbox" "-unread" "+archive")) + +;; Show me saved searches that I care about: +(setq notmuch-saved-searches + '((:name "inbox" :query "tag:inbox" :count-query "tag:inbox AND tag:unread" :key "i") + (:name "sent" :query "tag:sent" :key "t") + (:name "drafts" :query "tag:draft"))) +(setq notmuch-show-empty-saved-searches t) + +;; Mail sending configuration +(setq send-mail-function 'sendmail-send-it) ;; sendmail provided by MSMTP +(setq notmuch-always-prompt-for-sender t) +(setq notmuch-mua-user-agent-function + (lambda () (format "Emacs %s; notmuch.el %s" emacs-version notmuch-emacs-version))) +(setq mail-host-address (system-name)) +(setq notmuch-mua-cite-function #'message-cite-original-without-signature) +(setq notmuch-fcc-dirs nil) ;; Gmail does this server-side +(setq message-signature nil) ;; Insert message signature manually with C-c C-w + +;; Close mail buffers after sending mail +(setq message-kill-buffer-on-exit t) + +;; Ensure sender is correctly passed to msmtp +(setq mail-specify-envelope-from t + message-sendmail-envelope-from 'header + mail-envelope-from 'header) + +;; Store sent mail in the correct folder per account +(setq notmuch-maildir-use-notmuch-insert nil) + +;; I don't use drafts but I instinctively hit C-x C-s constantly, lets +;; handle that gracefully. +(define-key notmuch-message-mode-map (kbd "C-x C-s") #'ignore) + +;; Define a telephone-line segment for displaying the count of unread, +;; important mails in the last window's mode-line: +(defvar *last-notmuch-count-redraw* 0) +(defvar *current-notmuch-count* nil) + +(defun update-display-notmuch-counts () + "Update and render the current state of the notmuch unread + count for display in the mode-line. + + The offlineimap-timer runs every 2 minutes, so it does not make + sense to refresh this much more often than that." + + (when (> (- (float-time) *last-notmuch-count-redraw*) 30) + (setq *last-notmuch-count-redraw* (float-time)) + (let* ((inbox-unread (notmuch-saved-search-count "tag:inbox and tag:unread")) + (notmuch-count (format "I: %s; D: %s" inbox-unread))) + (setq *current-notmuch-count* notmuch-count))) + + (when (and (bottom-right-window-p) + ;; Only render if the initial update is done and there + ;; are unread mails: + *current-notmuch-count* + (not (equal *current-notmuch-count* "I: 0; D: 0"))) + *current-notmuch-count*)) + +(telephone-line-defsegment telephone-line-notmuch-counts () + "This segment displays the count of unread notmuch messages in + the last window's mode-line (if unread messages are present)." + + (update-display-notmuch-counts)) + +(provide 'mail-setup) diff --git a/tools/emacs/config/modes.el b/tools/emacs/config/modes.el new file mode 100644 index 0000000000..8d47f2f9a5 --- /dev/null +++ b/tools/emacs/config/modes.el @@ -0,0 +1,36 @@ +;; Initializes modes I use. + +(add-hook 'prog-mode-hook 'esk-add-watchwords) +(add-hook 'prog-mode-hook 'hl-line-mode) + +;; Use auto-complete as completion at point +(defun set-auto-complete-as-completion-at-point-function () + (setq completion-at-point-functions '(auto-complete))) + +(add-hook 'auto-complete-mode-hook + 'set-auto-complete-as-completion-at-point-function) + +;; Enable rainbow-delimiters for all things programming +(add-hook 'prog-mode-hook 'rainbow-delimiters-mode) + +;; Enable Paredit & Company in Emacs Lisp mode +(add-hook 'emacs-lisp-mode-hook 'company-mode) + +;; Always highlight matching brackets +(show-paren-mode 1) + +;; Always auto-close parantheses and other pairs +(electric-pair-mode) + +;; Keep track of recent files +(recentf-mode) + +;; Easily navigate sillycased words +(global-subword-mode 1) + +;; Transparently open compressed files +(auto-compression-mode t) + +;; Show available key chord completions + +(provide 'modes) diff --git a/tools/emacs/config/settings.el b/tools/emacs/config/settings.el new file mode 100644 index 0000000000..b895d5e406 --- /dev/null +++ b/tools/emacs/config/settings.el @@ -0,0 +1,51 @@ +(require 'uniquify) + +;; Move files to trash when deleting +(setq delete-by-moving-to-trash t) + +;; We don't live in the 80s, but we're also not a shitty web app. +(setq gc-cons-threshold 20000000) + +(setq uniquify-buffer-name-style 'forward) + +; Fix some defaults +(setq visible-bell nil + inhibit-startup-message t + color-theme-is-global t + sentence-end-double-space nil + shift-select-mode nil + uniquify-buffer-name-style 'forward + whitespace-style '(face trailing lines-tail tabs) + whitespace-line-column 80 + default-directory "~" + fill-column 80 + ediff-split-window-function 'split-window-horizontally + initial-major-mode 'emacs-lisp-mode) + +(add-to-list 'safe-local-variable-values '(lexical-binding . t)) +(add-to-list 'safe-local-variable-values '(whitespace-line-column . 80)) + +(set-default 'indent-tabs-mode nil) + +;; UTF-8 please +(setq locale-coding-system 'utf-8) ; pretty +(set-terminal-coding-system 'utf-8) ; pretty +(set-keyboard-coding-system 'utf-8) ; pretty +(set-selection-coding-system 'utf-8) ; please +(prefer-coding-system 'utf-8) ; with sugar on top + +;; Make emacs behave sanely (overwrite selected text) +(delete-selection-mode 1) + +;; Keep your temporary files in tmp, emacs! +(setq auto-save-file-name-transforms + `((".*" ,temporary-file-directory t))) +(setq backup-directory-alist + `((".*" . ,temporary-file-directory))) + +(remove-hook 'kill-buffer-query-functions 'server-kill-buffer-query-function) + +;; Show time in 24h format +(setq display-time-24hr-format t) + +(provide 'settings) diff --git a/tools/emacs/default.nix b/tools/emacs/default.nix new file mode 100644 index 0000000000..4adc71a5a7 --- /dev/null +++ b/tools/emacs/default.nix @@ -0,0 +1,149 @@ +# This file builds an Emacs pre-configured with the packages I need +# and my personal Emacs configuration. +# +# On NixOS machines, this Emacs currently does not support +# Imagemagick, see https://github.com/NixOS/nixpkgs/issues/70631. +# +# Forcing Emacs to link against Imagemagick currently causes libvterm +# to segfault, which is a lot less desirable than not having telega +# render images correctly. +{ depot, ... }: + +with depot; +with third_party.emacsPackages; +with third_party.emacs; + +let + emacsWithPackages = (third_party.emacsPackagesGen third_party.emacs26).emacsWithPackages; + + # $PATH for binaries that need to be available to Emacs + emacsBinPath = lib.makeBinPath [ third_party.telega ]; + + identity = x: x; + + tazjinsEmacs = pkgfun: (emacsWithPackages(epkgs: pkgfun( + # Actual ELPA packages (the enlightened!) + (with epkgs.elpaPackages; [ + ace-window + avy + pinentry + rainbow-mode + undo-tree + ]) ++ + + # MELPA packages: + (with epkgs.melpaPackages; [ + ace-link + browse-kill-ring + cargo + clojure-mode + cmake-mode + counsel + counsel-notmuch + dash-functional + direnv + dockerfile-mode + eglot + elixir-mode + elm-mode + erlang + flymake + geiser + go-mode + gruber-darker-theme + haskell-mode + ht + hydra + idle-highlight-mode + intero + ivy + ivy-pass + ivy-prescient + jq-mode + kotlin-mode + lispy + lsp-mode + magit + markdown-toc + meson-mode + multi-term + multiple-cursors + nginx-mode + nix-mode + notmuch # this comes from pkgs.third_party + org-journal + org-ql + paredit + password-store + pg + polymode + prescient + protobuf-mode + racket-mode + rainbow-delimiters + refine + request + restclient + sly + string-edit + swiper + telega + telephone-line + terraform-mode + toml-mode + transient + use-package + uuidgen + web-mode + websocket + which-key + xelb + yaml-mode + yasnippet + ]) ++ + + # Custom packages + (with depot.tools.emacs-pkgs; [ + carp-mode + dottime + nix-util + term-switcher + + # patched / overridden versions of packages + depot.third_party.emacs.exwm + depot.third_party.emacs.rcirc + depot.third_party.emacs.vterm + ])))); +in lib.fix(self: l: f: third_party.writeShellScriptBin "tazjins-emacs" '' + export PATH="${emacsBinPath}:$PATH" + exec ${tazjinsEmacs f}/bin/emacs \ + --debug-init \ + --no-site-file \ + --no-site-lisp \ + --no-init-file \ + --directory ${./config} ${if l != null then "--directory ${l}" else ""} \ + --eval "(require 'init)" $@ + '' // { + # Call overrideEmacs with a function (pkgs -> pkgs) to modify the + # packages that should be included in this Emacs distribution. + overrideEmacs = f': self l f'; + + # Call withLocalConfig with the path to a *folder* containing a + # `local.el` which provides local system configuration. + withLocalConfig = confDir: self confDir f; + + # Build a derivation that uses the specified local Emacs (i.e. + # built outside of Nix) instead + withLocalEmacs = emacsBin: third_party.writeShellScriptBin "tazjins-emacs" '' + export PATH="${emacsBinPath}:$PATH" + export EMACSLOADPATH="${(tazjinsEmacs f).deps}/share/emacs/site-lisp:" + exec ${emacsBin} \ + --debug-init \ + --no-site-file \ + --no-site-lisp \ + --no-init-file \ + --directory ${./config} \ + ${if l != null then "--directory ${l}" else ""} \ + --eval "(require 'init)" $@ + ''; + }) null identity diff --git a/web/blog/.skip-subtree b/web/blog/.skip-subtree new file mode 100644 index 0000000000..e7fa50d49b --- /dev/null +++ b/web/blog/.skip-subtree @@ -0,0 +1 @@ +Subdirectories contain blog posts and static assets only diff --git a/web/blog/default.nix b/web/blog/default.nix new file mode 100644 index 0000000000..d2f04aaea5 --- /dev/null +++ b/web/blog/default.nix @@ -0,0 +1,59 @@ +# This creates the static files that make up my blog from the Markdown +# files in this repository. +# +# All blog posts are rendered from Markdown by cheddar. +{ depot, lib, ... }@args: + +with depot.nix.yants; + +let + inherit (builtins) filter hasAttr map; + + # Type definition for a single blog post. + post = struct "blog-post" { + key = string; # + title = string; + date = int; + + # Path to the Markdown file containing the post content. + content = path; + + # Should this post be included in the index? (defaults to true) + listed = option bool; + + # Is this a draft? (adds a banner indicating that the link should + # not be shared) + draft = option bool; + + # Previously each post title had a numeric ID. For these numeric + # IDs, redirects are generated so that old URLs stay compatible. + oldKey = option string; + }; + + posts = list post (import ./posts.nix); + fragments = import ./fragments.nix args; + + rendered = depot.third_party.runCommandNoCC "tazjins-blog" {} '' + mkdir -p $out + + ${lib.concatStringsSep "\n" (map (post: + "cp ${fragments.renderPost post} $out/${post.key}.html" + ) posts)} + ''; + + includePost = post: !(fragments.isDraft post) && !(fragments.isUnlisted post); +in { + inherit post rendered; + static = ./static; + + # Only include listed posts + posts = filter includePost posts; + + # Generate embeddable nginx configuration for redirects from old post URLs + oldRedirects = lib.concatStringsSep "\n" (map (post: '' + location ~* ^(/en)?/${post.oldKey} { + # TODO(tazjin): 301 once this works + return 302 https://tazj.in/blog/${post.key}; + } + '') (filter (hasAttr "oldKey") posts)); +} diff --git a/web/blog/fragments.nix b/web/blog/fragments.nix new file mode 100644 index 0000000000..18416e4c4d --- /dev/null +++ b/web/blog/fragments.nix @@ -0,0 +1,96 @@ +# This file defines various fragments of the blog, such as the header +# and footer, as functions that receive arguments to be templated into +# them. +# +# An entire post is rendered by `renderPost`, which assembles the +# fragments together in a runCommand execution. +# +# The post index is generated by //web/homepage, not by this code. +{ depot, lib, ... }: + +let + inherit (builtins) filter map hasAttr replaceStrings toFile; + inherit (depot.third_party) runCommandNoCC writeText; + + # Generate a post list for all listed, non-draft posts. + isDraft = post: (hasAttr "draft" post) && post.draft; + isUnlisted = post: (hasAttr "listed" post) && !post.listed; + + escape = replaceStrings [ "<" ">" "&" "'" ] [ "<" ">" "&" "'" ]; + + header = title: '' + <!DOCTYPE html> + <head> + <meta charset="utf-8"> + <meta name="viewport" content="width=device-width, initial-scale=1"> + <meta name="description" content="tazjin's blog"> + <link rel="stylesheet" type="text/css" href="/static/tazjin.css" media="all"> + <link rel="icon" type="image/webp" href="/static/favicon.webp"> + <link rel="alternate" type="application/rss+xml" title="RSS-Feed" href="/rss.xml"> + <title>tazjin's blog: ${escape title}</title> + </head> + <body class="light"> + <header> + <h1><a class="blog-title" href="/">tazjin's interblag</a> </h1> + <hr> + </header> + ''; + + footer = '' + <hr> + <footer> + <p class="footer"> + <a class="uncoloured-link" href="https://tazj.in">homepage</a> + | + <a class="uncoloured-link" href="https://git.tazj.in/about">code</a> + | + <a class="uncoloured-link" href="https://twitter.com/tazjin">twitter</a> + </p> + <p class="lod">ಠ_ಠ</p> + </footer> + </body> + ''; + + draftWarning = toFile "draft.html" '' + <p class="cheddar-callout cheddar-warning"> + <b>Note:</b> This post is a <b>draft</b>! Please do not share + the link to it without asking me first. + </p> + <hr> + ''; + + unlistedWarning = toFile "unlisted.html" '' + <p class="cheddar-callout cheddar-warning"> + <b>Note:</b> This post is <b>unlisted</b>! Please do not share + the link to it without asking me first. + </p> + <hr> + ''; + + renderPost = post: runCommandNoCC "${post.key}.html" {} '' + cat ${toFile "header.html" (header post.title)} > $out + + # Write the post title & date + echo '<article><h2 class="inline">${escape post.title}</h2>' >> $out + echo '<aside class="date">' >> $out + date --date="@${toString post.date}" '+%Y-%m-%d' >> $out + echo '</aside>' >> $out + + ${ + # Add a warning to draft/unlisted posts to make it clear that + # people should not share the post. + + if (isDraft post) then "cat ${draftWarning} >> $out" + else if (isUnlisted post) then "cat ${unlistedWarning} >> $out" + else "# Your ads could be here?" + } + + # Write the actual post through cheddar's about-filter mechanism + cat ${post.content} | ${depot.tools.cheddar}/bin/cheddar --about-filter ${post.content} >> $out + echo '</article>' >> $out + + cat ${toFile "footer.html" footer} >> $out + ''; +in { + inherit renderPost isDraft isUnlisted; +} diff --git a/web/blog/posts.nix b/web/blog/posts.nix new file mode 100644 index 0000000000..b43598d013 --- /dev/null +++ b/web/blog/posts.nix @@ -0,0 +1,57 @@ +# This file defines all the blog posts. +[ + { + key = "emacs-is-underrated"; + title = "Emacs is the most underrated tool"; + date = 1581286656; + content = ./posts/emacs-is-underrated.md; + draft = true; + } + { + key = "best-tools"; + title = "tazjin's best tools"; + date = 1576800001; + content = ./posts/best-tools.md; + } + { + key = "nixery-layers"; + title = "Nixery: Improved Layering Design"; + date = 1565391600; + content = ./posts/nixery-layers.md; + } + { + key = "reversing-watchguard-vpn"; + title = "Reverse-engineering WatchGuard Mobile VPN"; + date = 1486830338; + content = ./posts/reversing-watchguard-vpn.md; + oldKey = "1486830338"; + } + { + key = "make-object-t-again"; + title = "Make Object <T> Again!"; + date = 1476807384; + content = ./posts/make-object-t-again.md; + oldKey = "1476807384"; + } + { + key = "the-smu-problem"; + title = "The SMU-problem of messaging apps"; + date = 1450354078; + content =./posts/the-smu-problem.md; + oldKey = "1450354078"; + } + { + key = "sick-in-sweden"; + title = "Being sick in Sweden"; + date = 1423995834; + content = ./posts/sick-in-sweden.md; + oldKey = "1423995834"; + } + { + key = "nsa-zettabytes"; + title = "The NSA's 5 zettabytes of data"; + date = 1375310627; + content = ./posts/nsa-zettabytes.md; + oldKey = "1375310627"; + } +] diff --git a/web/blog/posts/best-tools.md b/web/blog/posts/best-tools.md new file mode 100644 index 0000000000..e4bad8f4cd --- /dev/null +++ b/web/blog/posts/best-tools.md @@ -0,0 +1,160 @@ +In the spirit of various other "Which X do you use?"-pages I thought it would be +fun to have a little post here that describes which tools I've found to work +well for myself. + +When I say "tools" here, it's not about software - it's about real, physical +tools! + +If something goes on this list that's because I think it's seriously a +best-in-class type of product. + +<!-- markdown-toc start - Don't edit this section. Run M-x markdown-toc-refresh-toc --> +- [Media & Tech](#media--tech) + - [Keyboard](#keyboard) + - [Speakers](#speakers) + - [Headphones](#headphones) + - [Earphones](#earphones) + - [Phone](#phone) +- [Other stuff](#other-stuff) + - [Toothbrush](#toothbrush) + - [Shavers](#shavers) + - [Shoulder bag](#shoulder-bag) + - [Wallet](#wallet) +<!-- markdown-toc end --> + +--------- + +# Media & Tech + +## Keyboard + +The best keyboard that money will buy you at the moment is the [Kinesis +Advantage][advantage]. There's a variety of contoured & similarly shaped +keyboards on the market, but the Kinesis is the only one I've tried that has +properly implemented the keywell concept. + +I struggle with RSI issues and the Kinesis actually makes it possible for me to +type for longer periods of time, which always leads to extra discomfort on +laptop keyboards and such. + +Honestly, the Kinesis is probably the best piece of equipment on this entire +list. I own several of them and there will probably be more in the future. They +last forever and your wrists will thank you in the future, even if you do not +suffer from RSI yet. + +[advantage]: https://kinesis-ergo.com/shop/advantage2/ + +## Speakers + +The speakers that I've hooked up to my audio setup (including both record player +& Chromecast / TV) are the [Teufel Motiv 2][motiv-2]. I've had these for over a +decade and they're incredibly good, but unfortunately Teufel no longer makes +them. + +It's possible to grab a pair on eBay occasionally, so keep an eye out if you're +interested! + +[motiv-2]: https://www.teufelaudio.com/uk/pc/motiv-2-p167.html + +## Headphones + +I use the [Bose QC35][qc35] (note: link goes to a newer generation than the one +I own) for their outstanding noise cancelling functionality and decent sound. + +When I first bought them I didn't expect them to end up on this list as the +firmware had issues that made them only barely usable, but Bose has managed to +iron these problems out over time. + +I avoid using Bluetooth when outside and fortunately the QC35 come with an +optional cable that you can plug into any good old 3.5mm jack. + +[qc35]: https://www.bose.co.uk/en_gb/products/headphones/over_ear_headphones/quietcomfort-35-wireless-ii.html + +### Earphones + +Actually, to follow up on the above - most of the time I'm not using (over-ear) +headphones, but (in-ear) earphones - specifically the (**wired!!!**) [Apple +EarPods][earpods]. + +Apple will probably stop selling these soon because they've gotten into the +habit of cancelling all of their good products, so I have a stash of these +around. You will usually find no fewer than 3-4 of them lying around in my +flat. + +[earpods]: https://www.apple.com/uk/shop/product/MNHF2ZM/A/earpods-with-35mm-headphone-plug + +## Phone + +The best phone I have used in recent years is the [iPhone SE][se]. It was the +*last* phone that had a reasonable size (up to 4") *and* a 3.5mm headphone jack. + +Unfortunately, it runs iOS. Despite owning a whole bunch of SEs, I have finally +moved on to an Android phone that is only moderately larger (still by an +annoying amount), but does at least have a headphone jack: The [Samsung Galaxy +S10e][s10e]. + +It has pretty good hardware and I can almost reach 70% of the screen, which is +better than other phones out there right now. Unfortunately it runs Samsung's +impossible-to-remove bloatware on top of Android, but that is still less +annoying to use than iOS. + +QUESTION: This is the only item on this list for which I am actively seeking a +replacement, so if you have any tips about new phones that might fit these +criteria that I've missed please let me know! + +[se]: https://en.wikipedia.org/wiki/IPhone_SE +[s10e]: https://www.phonearena.com/phones/Samsung-Galaxy-S10e_id11114 + +# Other stuff + +## Toothbrush + +The [Philips Sonicare][sonicare] (note: link goes to a newer generation than +mine) is excellent and well worth its money. + +I've had it for a few years and whereas I occasionally had minor teeth issues +before, they seem to be mostly gone now. According to my dentist the state of my +teeth is now usually pretty good and I draw a direct correlation back to this +thing. + +The newer generations come with flashy features like apps and probably more +LEDs, but I suspect that those can just be ignored. + +[sonicare]: https://www.philips.co.uk/c-m-pe/electric-toothbrushes + +## Shavers + +The [Philipps SensoTouch 3D][sensotouch] is excellent. Super-comfortable close +face shave in no time and leaves absolutely no mess around, as far as I can +tell! I've had this for ~5 years and it's not showing any signs of aging yet. + +Another bonus is that its battery time is effectively infinite. I've never had +to worry when bringing it on a longer trip! + +[sensotouch]: https://www.philips.co.uk/c-p/1250X_40/norelco-sensotouch-3d-wet-and-dry-electric-razor-with-precision-trimmer + +## Shoulder bag + +When I moved to London I wanted to stop using backpacks most of the time, as +those are just annoying to deal with when commuting on the tube. + +To work around this I wanted a good shoulder bag with a vertical format (to save +space), but it turned out that there's very few of those around that reach any +kind of quality standard. + +The one I settled on is the [Waterfield Muzetto][muzetto] leather bag. It's one +of those things that comes with a bit of a price tag attached, but it's well +worth it! + +[muzetto]: https://www.sfbags.com/collections/shoulder-messenger-bags/products/muzetto-leather-bag + +## Wallet + +My wallet is the [Bellroy Slim Sleeve][slim-sleeve]. I don't carry cash unless +I'm attending an event in Germany and this wallet fits that lifestyle perfectly. + +It's near indestructible, looks great, is very slim and fits a ton of cards, +business cards, receipts and whatever else you want to be lugging around with +you! + +[slim-sleeve]: https://bellroy.com/products/slim-sleeve-wallet/default/charcoal diff --git a/web/blog/posts/emacs-is-underrated.md b/web/blog/posts/emacs-is-underrated.md new file mode 100644 index 0000000000..afb8dc889e --- /dev/null +++ b/web/blog/posts/emacs-is-underrated.md @@ -0,0 +1,233 @@ +TIP: Hello, and thanks for offering to review my draft! This post +intends to convey to people what the point of Emacs is. Not to convert +them to use it, but at least with opening their minds to the +possibility that it might contain valuable things. I don't know if I'm +on track in the right direction, and your input will help me figure it +out. Thanks! + +TODO(tazjin): Restructure sections: Intro -> Introspectability (and +story) -> text-based UIs (which lead to fluidity, muscle memory across +programs and "translatability" of workflows) -> Outro. It needs more +flow! + +TODO(tazjin): Highlight more that it's not about editing: People can +derive useful things from Emacs by just using magit/org/notmuch/etc.! + +TODO(tazjin): Note that there's value in trying Emacs even if people +don't end up using it, similar to how learning languages like Lisp or +Haskell helps grow as a programmer even without using them day-to-day. + +*Real post starts below!* + +--------- + +There are two kinds of people: Those who use Emacs, and those who +think it is a text editor. This post is aimed at those in the second +category. + +Emacs is the most critical piece of software I run. My [Emacs +configuration][emacs-config] has steadily evolved for almost a decade. +Emacs is my window manager, mail client, terminal, git client, +information management system and - perhaps unsurprisingly - text +editor. + +Before going into why I chose to invest so much into this program, +follow me along on a little thought experiment: + +---------- + +Lets say you use a proprietary spreadsheet program. You find that +there are features in it that *almost, but not quite* do what you +want. + +What can you do? You can file a feature request to the company that +makes it and hope they listen, but for the likes of Apple and +Microsoft chances are they won't and there is nothing you can do. + +Let's say you are also running an open-source program for image +manipulation. You again find that some of its features are subtly +different from what you would want them to do. + +Things look a bit different this time - after all, the program is +open-source! You can go and fetch its source code, figure out its +internal structure and wrangle various layers of code into submission +until you find the piece that implements the functionality you want to +change. If you know the language it is written in; you can modify the +feature. + +Now all that's left is figuring out its build system[^1], building and +installing it and moving over to the new version. + +Realistically you are not going to do this much in the real world. The +friction to contributing to projects, especially complex ones, is +often quite high. For minor inconveniences, you might often find +yourself just shrugging and working around them. + +What if it didn't have to be this way? + +------------- + +One of the core properties of Emacs is that it is *introspective* and +*self-documenting*. + +For example: A few years ago, I had just switched over to using +[EXWM][], the Emacs X Window Manager. To launch applications I was +using an Emacs program called Helm that let me select installed +programs interactively and press <kbd>RET</kbd> to execute them. + +This was very useful - until I discovered that if I tried to open a +second terminal window, it would display an error: + + Error: urxvt is already running + +Had this been dmenu, I might have had to go through the whole process +described above to fix the issue. But it wasn't dmenu - it was an +Emacs program, and I did the following things: + +1. I pressed <kbd>C-h k</kbd>[^2] (which means "please tell me what + the following key does"), followed by <kbd>s-d</kbd> (which was my + keybinding for launching programs). + +2. Emacs displayed a new buffer saying, roughly: + + ``` + s-d runs the command helm-run-external-command (found in global-map), + which is an interactive autoloaded compiled Lisp function in + ‘.../helm-external.el’. + + It is bound to s-d. + ``` + + I clicked on the filename. + +3. Emacs opened the file and jumped to the definition of + `helm-run-external-command`. After a few seconds of reading through + the code, I found this snippet: + + ```lisp + (if (get-process proc) + (if helm-raise-command + (shell-command (format helm-raise-command real-com)) + (error "Error: %s is already running" real-com)) + ;; ... the actual code to launch programs followed below ... + ) + ``` + +4. I deleted the outer if-expression which implemented the behaviour I + didn't want, pressed <kbd>C-M-x</kbd> to reload the code and saved + the file. + +The whole process took maybe a minute, and the problem was now gone. + +Emacs isn't just "open-source", it actively encourages the user to +modify it, discover what to modify and experiment while it is running. + +In some sense it is like the experience of the old Lisp machines, a +paradigm that we have completely forgotten. + +--------------- + +Circling back to my opening statement: If Emacs is not a text editor, +then what *is* it? + +The Emacs website says this: + +> [Emacs] is an interpreter for Emacs Lisp, a dialect of the Lisp +> programming language with extensions to support text editing + +The core of Emacs implements the language and the functionality needed +to evaluate and run it, as well as various primitives for user +interface construction such as buffers, windows and frames. + +Every other feature of Emacs is implemented *in Emacs Lisp*. + +The Emacs distribution ships with rudimentary text editing +functionality (and some language-specific support for the most popular +languages), but it also brings with it two IRC clients, a Tetris +implementation, a text-mode web browser, [org-mode][] and many other +tools. + +Outside of the core distribution there is a myriad of available +programs for Emacs: [magit][] (the famous git porcelain), text-based +[HTTP clients][], even interactive [Kubernetes frontends][k8s]. + +What all of these tools have in common is that they use text-based +user interfaces (UI elements like images are used only sparingly in +Emacs), and that they can be introspected and composed like everything +else in Emacs. + +If magit does not expose a git flag I need, it's trivial to add. If I +want a keybinding to jump from a buffer showing me a Kubernetes pod to +a magit buffer for the source code of the container, it only takes a +few lines of Emacs Lisp to implement. + +As proficiency with Emacs Lisp ramps up, the environment becomes +malleable like clay and evolves along with the user's taste and needs. +Muscle memory learned for one program translates seamlessly to others, +and the overall effect is an improvement in *workflow fluidity* that +is difficult to overstate. + +Also, workflows based on Emacs are *stable*. Moving my window +management to Emacs has meant that I'm not subject to the whim of some +third-party developer changing my window layouting features (as they +often do on MacOS). + +To illustrate this: Emacs has development history back to the 1970s, +continuous git history that survived multiple VCS migrations [since +1985][first-commit] (that's 22 years before git itself was released!) +and there is code[^3] implementing interactive functionality that has +survived unmodified in Emacs *since then*. + +--------------- + +Now, what is the point of this post? + +I decided to write this after a recent [tweet][] by @IanColdwater (in +the context of todo-management apps): + +> The fact that it's 2020 and the most viable answer to this appears +> to be Emacs might be the saddest thing I've ever heard + +What bothers me is that people see this as *sad*. Emacs being around +for this long and still being unparalleled for many of the UX +paradigms implemented by its programs is, in my book, incredible - and +not sad. + +How many other paradigms have survived this long? How many other tools +still have fervent followers, amazing [developer tooling][] and a +[vibrant ecosystem][] at this age? + +Steve Yegge [said it best][babel][^5]: Emacs has the Quality Without a +Name. + +What I wish you, the reader, should take away from this post is the +following: + +TODO(tazjin): Figure out what people should take away from this post. +I need to sleep on it. It's something about not dismissing tools just +because of their age, urging them to explore paradigms that might seem +unfamiliar and so on. Ideas welcome. + +--------------- + +[^1]: Wouldn't it be a joy if every project just used Nix? I digress ... +[^2]: These are keyboard shortcuts written in [Emacs Key Notation][ekn]. +[^3]: For example, [functionality for online memes][studly] that + wouldn't be invented for decades to come! +[^4]: ... and some things wrong, but that is an issue for a separate post! +[^5]: And I really *do* urge you to read that post's section on Emacs. + +[emacs-config]: https://git.tazj.in/tree/tools/emacs +[EXWM]: https://github.com/ch11ng/exwm +[helm]: https://github.com/emacs-helm/helm +[ekn]: https://www.gnu.org/software/emacs/manual/html_node/efaq/Basic-keys.html +[org-mode]: https://orgmode.org/ +[magit]: https://magit.vc +[HTTP clients]: https://github.com/pashky/restclient.el +[k8s]: https://github.com/jypma/kubectl +[first-commit]: http://git.savannah.gnu.org/cgit/emacs.git/commit/?id=ce5584125c44a1a2fbb46e810459c50b227a95e2 +[studly]: http://git.savannah.gnu.org/cgit/emacs.git/commit/?id=47bdd84a0a9d20aab934482a64b84d0db63e7532 +[tweet]: https://twitter.com/IanColdwater/status/1220824466525229056 +[developer tooling]: https://github.com/alphapapa/emacs-package-dev-handbook +[vibrant ecosystem]: https://github.com/emacs-tw/awesome-emacs +[babel]: https://sites.google.com/site/steveyegge2/tour-de-babel#TOC-Lisp diff --git a/web/blog/posts/make-object-t-again.md b/web/blog/posts/make-object-t-again.md new file mode 100644 index 0000000000..420b57c0fd --- /dev/null +++ b/web/blog/posts/make-object-t-again.md @@ -0,0 +1,98 @@ +A few minutes ago I found myself debugging a strange Java issue related +to Jackson, one of the most common Java JSON serialization libraries. + +The gist of the issue was that a short wrapper using some types from +[Javaslang](http://www.javaslang.io/) was causing unexpected problems: + +```java +public <T> Try<T> readValue(String json, TypeReference type) { + return Try.of(() -> objectMapper.readValue(json, type)); +} +``` + +The signature of this function was based on the original Jackson +`readValue` type signature: + +```java +public <T> T readValue(String content, TypeReference valueTypeRef) +``` + +While happily using my wrapper function I suddenly got an unexpected +error telling me that `Object` is incompatible with the type I was +asking Jackson to de-serialize, which got me to re-evaluate the above +type signature again. + +Lets look for a second at some code that will *happily compile* if you +are using Jackson\'s own `readValue`: + +```java +// This shouldn't compile! +Long l = objectMapper.readValue("\"foo\"", new TypeReference<String>(){}); +``` + +As you can see there we ask Jackson to decode the JSON into a `String` +as enclosed in the `TypeReference`, but assign the result to a `Long`. +And it compiles. And it failes at runtime with +`java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Long`. +Huh? + +Looking at the Jackson `readValue` implementation it becomes clear +what\'s going on here: + +```java +@SuppressWarnings({ "unchecked", "rawtypes" }) +public <T> T readValue(String content, TypeReference valueTypeRef) + throws IOException, JsonParseException, JsonMappingException +{ + return (T) _readMapAndClose(/* whatever */); +} +``` + +The function is parameterised over the type `T`, however the only place +where `T` occurs in the signature is in the parameter declaration and +the function return type. Java will happily let you use generic +functions and types without specifying type parameters: + +```java +// Compiles fine! +final List myList = List.of(1,2,3); + +// Type is now myList : List<Object> +``` + +Meaning that those parameters default to `Object`. Now in the code above +Jackson also explicitly casts the return value of its inner function +call to `T`. + +What ends up happening is that Java infers the expected return type from +the context of the `readValue` and then happily uses the unchecked cast +to fit that return type. If the type hints of the context aren\'t strong +enough we simply get `Object` back. + +So what\'s the fix for this? It\'s quite simple: + +```java +public <T> T readValue(String content, TypeReference<T> valueTypeRef) +``` + +By also making the parameter appear in the `TypeReference` we \"bind\" +`T` to the type enclosed in the type reference. The cast can then also +safely be removed. + +The cherries on top of this are: + +1. `@SuppressWarnings({ "rawtypes" })` explicitly disables a + warning that would\'ve caught this + +2. the `readValue` implementation using the less powerful `Class` + class to carry the type parameter does this correctly: `public <T> + T readValue(String content, Class<T> valueType)` + +The big question I have about this is *why* does Jackson do it this way? +Obviously the warning did not just appear there by chance, so somebody +must have thought about this? + +If anyone knows what the reason is, I\'d be happy to hear from you. + +PS: Shoutout to David & Lucia for helping me not lose my sanity over +this. diff --git a/web/blog/posts/nixery-layers.md b/web/blog/posts/nixery-layers.md new file mode 100644 index 0000000000..3f25ceadce --- /dev/null +++ b/web/blog/posts/nixery-layers.md @@ -0,0 +1,272 @@ +TIP: This blog post was originally published as a design document for +[Nixery][] and is not written in the same style +as other blog posts. + +Thanks to my colleagues at Google and various people from the Nix community for +reviewing this. + +------ + +# Nixery: Improved Layering + +**Authors**: tazjin@ + +**Reviewers**: so...@, en...@, pe...@ + +**Status**: Implemented + +**Last Updated**: 2019-08-10 + +## Introduction + +This document describes a design for an improved image layering method for use +in Nixery. The algorithm [currently used][grhmc] is designed for a slightly +different use-case and we can improve upon it by making use of more of the +available data. + +## Background / Motivation + +Nixery is a service that uses the [Nix package manager][nix] to build container +images (for runtimes such as Docker), that are served on-demand via the +container [registry protocols][]. A demo instance is available at +[nixery.dev][]. + +In practice this means users can simply issue a command such as `docker pull +nixery.dev/shell/git` and receive an image that was built ad-hoc containing a +shell environment and git. + +One of the major advantages of building container images via Nix (as described +for `buildLayeredImage` in [this blog post][grhmc]) is that the +content-addressable nature of container image layers can be used to provide more +efficient caching characteristics (caching based on layer content) than what is +common with Dockerfiles and other image creation methods (caching based on layer +creation method). + +However, this is constrained by the maximum number of layers supported in an +image (125). A naive approach such as putting each included package (any +library, binary, etc.) in its own layer quickly runs into this limitation due to +the large number of dependencies more complex systems tend to have. In addition, +users wanting to extend images created by Nixery (e.g. via `FROM nixery.dev/…`) +share this layer maximum with the created image - limiting extensibility if all +layers are used up by Nixery. + +In theory the layering strategy of `buildLayeredImage` should already provide +good caching characteristics, but in practice we are seeing many images with +significantly more packages than the number of layers configured, leading to +more frequent cache-misses than desired. + +The current implementation of `buildLayeredImage` inspects a graph of image +dependencies and determines the total number of references (direct & indirect) +to any node in the graph. It then sorts all dependencies by this popularity +metric and puts the first `n - 2` (for `n` being the maximum number of layers) +packages in their own layers, all remaining packages in one layer and the image +configuration in the final layer. + +## Design / Proposal + +## (Close-to) ideal layer-layout using more data + +We start out by considering what a close to ideal layout of layers would look +like for a simple use-case. + + + +In this example, counting the total number of references to each node in the +graph yields the following result: + +| pkg | refs | +|-------|------| +| E | 3 | +| D | 2 | +| F | 2 | +| A,B,C | 1 | + +Assuming we are constrained to 4 layers, the current algorithm would yield these layers: + +``` +L1: E +L2: D +L3: F +L4: A, B, C +``` + +The initial proposal for this design is that additional data should be +considered in addition to the total number of references, in particular a +distinction should be made between direct and indirect references. Packages that +are only referenced indirectly should be merged with their parents. + +This yields the following table: + +| pkg | direct | indirect | +|-------|--------|----------| +| E | 3 | 3 | +| D | 2 | 2 | +| F | *1* | 2 | +| A,B,C | 1 | 1 | + +Despite having two indirect references, F is in fact only being referred to +once. Assuming that we have no other data available outside of this graph, we +have no reason to assume that F has any popularity outside of the scope of D. +This might yield the following layers: + +``` +L1: E +L2: D, F +L3: A +L4: B, C +``` + +D and F were grouped, while the top-level references (i.e. the packages +explicitly requested by the user) were split up. + +An assumption is introduced here to justify this split: The top-level packages +is what the user is modifying directly, and those groupings are likely +unpredictable. Thus it is opportune to not group top-level packages in the same +layer. + +This raises a new question: Can we make better decisions about where to split +the top-level? + +## (Even closer to) ideal layering using (even) more data + +So far when deciding layer layouts, only information immediately available in +the build graph of the image has been considered. We do however have much more +information available, as we have both the entire nixpkgs-tree and potentially +other information (such as download statistics). + +We can calculate the total number of references to any derivation in nixpkgs and +use that to rank the popularity of each package. Packages within some percentile +can then be singled out as good candidates for a separate layer. + +When faced with a splitting decision such as in the last section, this data can +aid the decision. Assume for example that package B in the above is actually +`openssl`, which is a very popular package. Taking this into account would +instead yield the following layers: + +``` +L1: E, +L2: D, F +L3: B, +L4: A, C +``` + +## Layer budgets and download size considerations + +As described in the introduction, there is a finite amount of layers available +for each image (the “layer budget”). When calculating the layer distribution, we +might end up with the “ideal” list of layers that we would like to create. Using +our previous example: + +``` +L1: E, +L2: D, F +L3: A +L4: B +L5: C +``` + +If we only have a layer budget of 4 available, something needs to be merged into +the same layer. To make a decision here we could consider only the package +popularity, but there is in fact another piece of information that has not come +up yet: The actual size of the package. + +Presumably a user would not mind downloading a library that is a few kilobytes +in size repeatedly, but they would if it was a 200 megabyte binary instead. + +Conversely if a large binary was successfully cached, but an extremely popular +small library is not, the total download size might also grow to irritating +levels. + +To avoid this we can calculate a merge rating: + + merge_rating(pkg) = popularity_percentile(pkg) × size(pkg.subtree) + +Packages with a low merge rating would be merged together before packages with +higher merge ratings. + +## Implementation + +There are two primary components of the implementation: + +1. The layering component which, given an image specification, decides the image + layers. + +2. The popularity component which, given the entire nixpkgs-tree, calculates the + popularity of packages. + +## Layering component + +It turns out that graph theory’s concept of [dominator trees][] maps reasonably +well onto the proposed idea of separating direct and indirect dependencies. This +becomes visible when creating the dominator tree of a simple example: + + + +Before calculating the dominator tree, we inspect each node and insert extra +edges from the root for packages that match a certain popularity or size +threshold. In this example, G is popular and an extra edge is inserted: + + + +Calculating the dominator tree of this graph now yields our ideal layer +distribution: + + + +The nodes immediately dominated by the root node can now be “harvested” as image +layers, and merging can be performed as described above until the result fits +into the layer budget. + +To implement this, the layering component uses the [gonum/graph][] library which +supports calculating dominator trees. The program is fed with Nix’s +`exportReferencesGraph` (which contains the runtime dependency graph and runtime +closure size) as well as the popularity data and layer budget. It returns a list +of layers, each specifying the paths it should contain. + +Nix invokes this program and uses the output to create a derivation for each +layer, which is then built and returned to Nixery as usual. + +TIP: This is implemented in [`layers.go`][layers.go] in Nixery. The file starts +with an explanatory comment that talks through the process in detail. + +## Popularity component + +The primary issue in calculating the popularity of each package in the tree is +that we are interested in the runtime dependencies of a derivation, not its +build dependencies. + +To access information about the runtime dependency, the derivation actually +needs to be built by Nix - it can not be inferred because Nix does not know +which store paths will still be referenced by the build output. + +However for packages that are cached in the NixOS cache, we can simply inspect +the `narinfo`-files and use those to determine popularity. + +Not every package in nixpkgs is cached, but we can expect all *popular* packages +to be cached. Relying on the cache should therefore be reasonable and avoids us +having to rebuild/download all packages. + +The implementation will read the `narinfo` for each store path in the cache at a +given commit and create a JSON-file containing the total reference count per +package. + +For the public Nixery instance, these popularity files will be distributed via a +GCS bucket. + +TIP: This is implemented in [popcount][] in Nixery. + +-------- + +Hopefully this detailed design review was useful to you. You can also watch [my +NixCon talk][talk] about Nixery for a review of some of this, and some demos. + +[Nixery]: https://github.com/google/nixery +[grhmc]: https://grahamc.com/blog/nix-and-layered-docker-images +[Nix]: https://nixos.org/nix +[registry protocols]: https://github.com/opencontainers/distribution-spec/blob/master/spec.md +[nixery.dev]: https://nixery.dev +[dominator trees]: https://en.wikipedia.org/wiki/Dominator_(graph_theory) +[gonum/graph]: https://godoc.org/gonum.org/v1/gonum/graph +[layers.go]: https://github.com/google/nixery/blob/master/builder/layers.go +[popcount]: https://github.com/google/nixery/tree/master/popcount +[talk]: https://www.youtube.com/watch?v=pOI9H4oeXqA diff --git a/web/blog/posts/nsa-zettabytes.md b/web/blog/posts/nsa-zettabytes.md new file mode 100644 index 0000000000..f8b326f2fb --- /dev/null +++ b/web/blog/posts/nsa-zettabytes.md @@ -0,0 +1,93 @@ +I've been reading a few discussions on Reddit about the new NSA data +centre that is being built and stumbled upon [this +post](http://www.reddit.com/r/restorethefourth/comments/1jf6cx/the_guardian_releases_another_leaked_document_nsa/cbe5hnc), +putting its alleged storage capacity at *5 zettabytes*. + +That seems to be a bit much which I tried to explain to that guy, but I +was quickly blocked by the common conspiracy argument that government +technology is somehow far beyond the wildest dreams of us mere mortals - +thus I wrote a very long reply that will most likely never be seen by +anybody. Therefore I've decided to repost it here. + +------------------------------------------------------------------------ + +I feel like I've entered /r/conspiracy. Please have some facts (and do +read them!) + +A one terabyte SSD (I assume that\'s what you meant by flash-drive) +would require 5000000000 of those. That is *five billion* of those flash +drives. Can you visualise how much five billion flash-drives are? + +A single SSD is roughly 2cm\*13cm\*13cm with an approximate weight of +80g. That would make 400 000 metric tons of SSDs, a weight equivalent to +*over one thousand Boeing 747 airplanes*. Even if we assume that they +solder the flash chips directly onto some kind of controller (which also +weighs something), the raw material for that would be completely insane. + +Another visualization: If you stacked 5 billion SSDs on top of each +other you would get an SSD tower that is a hundred thousand kilometres +high, that is equivalent to 2,5 x the equatorial circumference of +*Earth* or 62000 miles. + +The volume of those SSDs would be clocking in at 1690000000 cubic +metres, more than the Empire State building. Are you still with me? + +Lets speak cost. The Samsung SSD that I assume you are referring to will +clock in at \$600, lets assume that the NSA gets a discount when buying +*five billion* of those and gets them at the cheap price of \$250. That +makes 1.25 trillion dollars. That would be a significant chunk of the +current US national debt. + +And all of this is just SSDs to stick into servers and storage units, +which need a whole bunch of other equipment as well to support them - +the cost would probably shoot up to something like 8 trillion dollars if +they were to build this. It would with very high certainty be more than +the annual production of SSDs (I can\'t find numbers on that +unfortunately) and take up *slightly* more space than they have in the +Utah data centre (assuming you\'re not going to tell me that it is in +fact attached to an underground base that goes down to the core of the +Earth). + +Lets look at the \"But the government has better technologies!\" idea. + +Putting aside the fact that the military *most likely* does not have a +secret base on Mars that deals with advanced science that the rest of us +can only dream of, and doing this under the assumption that they do have +this base, lets assume that they build a storage chip that stores 100TB. +This reduces the amount of needed chips to \"just\" 50 million, lets say +they get 10 of those into a server / some kind of specialized storage +unit and we only need 5 million of those specially engineered servers, +with custom connectors, software, chips, storage, most likely also power +sources and whatever - 10 million completely custom units built with +technology that is not available to the market. Google is estimated to +have about a million servers in total, I don\'t know exactly in how many +data centres those are placed but numbers I heard recently said that +it\'s about 40. When Apple assembles a new iPhone model they need +massive factories with thousands of workers and supplies from many +different countries, over several months, to assemble just a few million +units for their launch month. + +You are seriously proposing that the NSA is better than Google and Apple +and the rest of the tech industry, world-wide, combined at designing +*everything* in tech, manufacturing *everything* in tech, without *any* +information about that leaking and without *any* of the science behind +it being known? That\'s not just insane, that\'s outright impossible. + +And we haven\'t even touched upon how they would route the necessary +amounts of bandwidth (crazy insane) to save *the entire internet* into +that data center. + +------------------------------------------------------------------------ + +I\'m not saying that the NSA is not building a data center to store +surveillance information, to have more capacity to spy on people and all +that - I\'m merely making the point that the extent in which conspiracy +sites say they do this vastly overestimates their actual abilities. They +don\'t have magic available to them! Instead of making up insane figures +like that you should focus on what we actually know about their +operations, because using those figures in a debate with somebody who is +responsible for this (and knows what they\'re talking about) will end +with you being destroyed - nobody will listen to the rest of what +you\'re saying when that happens. + +\"Stick to the facts\" is valid for our side as well. diff --git a/web/blog/posts/reversing-watchguard-vpn.md b/web/blog/posts/reversing-watchguard-vpn.md new file mode 100644 index 0000000000..f1b779d8d9 --- /dev/null +++ b/web/blog/posts/reversing-watchguard-vpn.md @@ -0,0 +1,158 @@ +TIP: WatchGuard has +[responded](https://www.reddit.com/r/netsec/comments/5tg0f9/reverseengineering_watchguard_mobile_vpn/dds6knx/) +to this post on Reddit. If you haven\'t read the post yet I\'d recommend +doing that first before reading the response to have the proper context. + +------------------------------------------------------------------------ + +One of my current client makes use of +[WatchGuard](http://www.watchguard.com/help/docs/fireware/11/en-US/Content/en-US/mvpn/ssl/mvpn_ssl_client-install_c.html) +Mobile VPN software to provide access to the internal network. + +Currently WatchGuard only provides clients for OS X and Windows, neither +of which I am very fond of. In addition an OpenVPN configuration file is +provided, but it quickly turned out that this was only a piece of the +puzzle. + +The problem is that this VPN setup is secured using 2-factor +authentication (good!), but it does not use OpenVPN\'s default +[challenge/response](https://openvpn.net/index.php/open-source/documentation/miscellaneous/79-management-interface.html) +functionality to negotiate the credentials. + +Connecting with the OpenVPN config that the website supplied caused the +VPN server to send me a token to my phone, but I simply couldn\'t figure +out how to supply it back to the server. In a normal challenge/response +setting the token would be supplied as the password on the second +authentication round, but the VPN server kept rejecting that. + +Other possibilities were various combinations of username&password +(I\'ve seen a lot of those around) so I tried a whole bunch, for example +`$password:$token` or even a `sha1(password, token)` - to no avail. + +At this point it was time to crank out +[Hopper](https://www.hopperapp.com/) and see what\'s actually going on +in the official OS X client - which uses OpenVPN under the hood! + +Diving into the client +---------------------- + +The first surprise came up right after opening the executable: It had +debug symbols in it - and was written in Objective-C! + + + +A good first step when looking at an application binary is going through +the strings that are included in it, and the WatchGuard client had a lot +to offer. Among the most interesting were a bunch of URIs that looked +important: + + + +I started with the first one + + %@?action=sslvpn_download&filename=%@&fw_password=%@&fw_username=%@ + +and just curled it on the VPN host, replacing the username and +password fields with bogus data and the filename field with +`client.wgssl` - another string in the executable that looked like a +filename. + +To my surprise this endpoint immediately responded with a GZIPed file +containing the OpenVPN config, CA certificate, and the client +*certificate and key*, which I previously thought was only accessible +after logging in to the web UI - oh well. + +The next endpoint I tried ended up being a bit more interesting still: + + /?action=sslvpn_logon&fw_username=%@&fw_password=%@&style=fw_logon_progress.xsl&fw_logon_type=logon&fw_domain=Firebox-DB + +Inserting the correct username and password into the query parameters +actually triggered the process that sent a token to my phone. The +response was a simple XML blob: + +```xml +<?xml version="1.0" encoding="UTF-8"?> +<resp> + <action>sslvpn_logon</action> + <logon_status>4</logon_status> + <auth-domain-list> + <auth-domain> + <name>RADIUS</name> + </auth-domain> + </auth-domain-list> + <logon_id>441</logon_id> + <chaStr>Enter Your 6 Digit Passcode </chaStr> +</resp> +``` + +Somewhat unsurprisingly that `chaStr` field is actually the challenge +string displayed in the client when logging in. + +This was obviously going in the right direction so I proceeded to the +procedures making use of this string. The first step was a relatively +uninteresting function called `-[VPNController sslvpnLogon]` which +formatted the URL, opened it and checked whether the `logon_status` was +`4` before proceeding with the `logon_id` and `chaStr` contained in the +response. + +*(Code snippets from here on are Hopper\'s pseudo-Objective-C)* + + + +It proceeded to the function `-[VPNController processTokenPrompt]` which +showed the dialog window into which the user enters the token, sent it +off to the next URL and checked the `logon_status` again: + +(`r12` is the reference to the `VPNController` instance, i.e. `self`). + + + +If the `logon_status` was `1` (apparently \"success\" here) it proceeded +to do something quite interesting: + + + +The user\'s password was overwritten with the (verified) OTP token - +before OpenVPN had even been started! + +Reading a bit more of the code in the subsequent +`-[VPNController doLogin]` method revealed that it shelled out to +`openvpn` and enabled the management socket, which makes it possible to +remotely control an `openvpn` process by sending it commands over TCP. + +It then simply sent the username and the OTP token as the credentials +after configuring OpenVPN with the correct config file: + + + +... and the OpenVPN connection then succeeds. + +TL;DR +----- + +Rather than using OpenVPN\'s built-in challenge/response mechanism, the +WatchGuard client validates user credentials *outside* of the VPN +connection protocol and then passes on the OTP token, which seems to be +temporarily in a \'blessed\' state after verification, as the user\'s +password. + +I didn\'t check to see how much verification of this token is performed +(does it check the source IP against the IP that performed the challenge +validation?), but this certainly seems like a bit of a security issue - +considering that an attacker on the same network would, if they time the +attack right, only need your username and 6-digit OTP token to +authenticate. + +Don\'t roll your own security, folks! + +Bonus +----- + +The whole reason why I set out to do this is so I could connect to this +VPN from Linux, so this blog post wouldn\'t be complete without a +solution for that. + +To make this process really easy I\'ve written a [little +tool](https://github.com/tazjin/watchblob) that performs the steps +mentioned above from the CLI and lets users know when they can +authenticate using their OTP token. diff --git a/web/blog/posts/sick-in-sweden.md b/web/blog/posts/sick-in-sweden.md new file mode 100644 index 0000000000..0c43c5832d --- /dev/null +++ b/web/blog/posts/sick-in-sweden.md @@ -0,0 +1,26 @@ +I\'ve been sick more in the two years in Sweden than in the ten years +before that. + +Why? I have a theory about it and after briefly discussing it with one +of my roommates (who is experiencing the same thing) I\'d like to share +it with you: + +Normally when people get sick, are coughing, have a fever and so on they +take a few days off from work and stay at home. The reasons are twofold: +You want to rest a bit in order to get rid of the disease and you want +to *avoid infecting your co-workers*. + +In Sweden people will drag themselves into work anyways, because of a +concept called the +[karensdag](https://www.forsakringskassan.se/wps/portal/sjukvard/sjukskrivning_och_sjukpenning/karensdag_och_forstadagsintyg). +The TL;DR of this is \'if you take days off sick you won\'t get paid for +the first day, and only 80% of your salary on the remaining days\'. + +Many people are not willing to take that financial hit. In combination +with Sweden\'s rather mediocre healthcare system you end up constantly +being surrounded by sick people, not just in your own office but also on +public transport and basically all other public places. + +Oh and the best thing about this? Swedish politicians [often ignore +this](https://www.aftonbladet.se/nyheter/article10506886.ab) rule and +just don\'t report their sick days. Nice. diff --git a/web/blog/posts/the-smu-problem.md b/web/blog/posts/the-smu-problem.md new file mode 100644 index 0000000000..f411e31160 --- /dev/null +++ b/web/blog/posts/the-smu-problem.md @@ -0,0 +1,151 @@ +After having tested countless messaging apps over the years, being +unsatisfied with most of them and finally getting stuck with +[Telegram](https://telegram.org/) I have developed a little theory about +messaging apps. + +SMU stands for *Security*, *Multi-Device* and *Usability*. Quite like +the [CAP-theorem](https://en.wikipedia.org/wiki/CAP_theorem) I believe +that you can - using current models - only solve two out of three things +on this list. Let me elaborate what I mean by the individual points: + +**Security**: This is mainly about encryption of messages, not so much +about hiding identities to third-parties. Commonly some kind of +asymmetric encryption scheme. Verification of keys used must be possible +for the user. + +**Multi-Device**: Messaging-app clients for multiple devices, with +devices being linked to the same identifier, receiving the same messages +and being independent of each other. A nice bonus is also an open +protocol (like Telegram\'s) that would let people write new clients. + +**Usability**: Usability is a bit of a broad term, but what I mean by it +here is handling contacts and identities. It should be easy to create +accounts, give contact information to people and have everything just +work in a somewhat automated fashion. + +Some categorisation of popular messaging apps: + +**SU**: Threema + +**MU**: Telegram, Google Hangouts, iMessage, Facebook Messenger + +**SM**: +[Signal](https://gist.github.com/TheBlueMatt/d2fcfb78d29faca117f5) + +*Side note: The most popular messaging app - WhatsApp - only scores a +single letter (U). This makes it completely uninteresting to me.* + +Let\'s talk about **SM** - which might contain the key to solving SMU. +Two approaches are interesting here. + +The single key model +-------------------- + +In Signal there is a single identity key which can be used to register a +device on the server. There exists a process for sharing this identity +key from a primary device to a secondary one, so that the secondary +device can register itself (see the link above for a description). + +This *almost* breaks M because there is still a dependence on a primary +device and newly onboarded devices can not be used to onboard further +devices. However, for lack of a better SM example I\'ll give it a pass. + +The other thing it obviously breaks is U as the process for setting it +up is annoying and having to rely on the primary device is a SPOF (there +might be a way to recover from a lost primary device, but I didn\'t find +any information so far). + +The multiple key model +---------------------- + +In iMessage every device that a user logs into creates a new key pair +and submits its public key to a per-account key pool. Senders fetch all +available public keys for a recipient and encrypt to all of the keys. + +Devices that join can catch up on history by receiving it from other +devices that use its public key. + +This *almost* solves all of SMU, but its compliance with S breaks due to +the fact that the key pool is not auditable, and controlled by a +third-party (Apple). How can you verify that they don\'t go and add +another key to your pool? + +A possible solution +------------------- + +Out of these two approaches I believe the multiple key one looks more +promising. If there was a third-party handling the key pool but in a way +that is verifiable, transparent and auditable that model could be used +to solve SMU. + +The technology I have been thinking about for this is some kind of +blockchain model and here\'s how I think it could work: + +1. Bob installs the app and begins onboarding. The first device + generates its keypair, submits the public key and an account + creation request. + +2. Bob\'s account is created on the messaging apps\' servers and a + unique identifier plus the fingerprint of the first device\'s public + key is written to the chain. + +3. Alice sends a message to Bob, her device asks the messaging service + for Bob\'s account\'s identity and public keys. Her device verifies + the public key fingerprint against the one in the blockchain before + encrypting to it and sending the message. + +4. Bob receives Alice\'s message on his first device. + +5. Bob logs in to his account on a second device. The device generates + a key pair and sends the public key to the service, the service + writes it to the blockchain using its identifier. + +6. The messaging service requests that Bob\'s first device signs the + second device\'s key and triggers a simple confirmation popup. + +7. Bob confirms the second device on his first device. It signs the key + and writes the signature to the chain. + +8. Alice sends another message, her device requests Bob\'s current keys + and receives the new key. It verifies that both the messaging + service and one of Bob\'s older devices have confirmed this key in + the chain. It encrypts the message to both keys and sends it on. + +9. Bob receives Alice\'s message on both devices. + +After this the second device can request conversation history from the +first one to synchronise old messages. + +Further devices added to an account can be confirmed by any of the +devices already in the account. + +The messaging service could not add new keys for an account on its own +because it does not control any of the private keys confirmed by the +chain. + +In case all devices were lost, the messaging service could associate the +account with a fresh identity in the block chain. Message history +synchronisation would of course be impossible. + +Feedback welcome +---------------- + +I would love to hear some input on this idea, especially if anyone knows +of an attempt to implement a similar model already. Possible attack +vectors would also be really interesting. + +Until something like this comes to fruition, I\'ll continue using +Telegram with GPG as the security layer when needed. + +**Update:** WhatsApp has launched an integration with the Signal guys +and added their protocol to the official WhatsApp app. This means +WhatsApp now firmly sits in the SU-category, but it still does not solve +this problem. + +**Update 2:** Facebook Messenger has also integrated with Signal, but +their secret chats do not support multi-device well (it is Signal +afterall). This means it scores either SU or MU depending on which mode +you use it in. + +An interesting service I have not yet evaluated properly is +[Matrix](http://matrix.org/). diff --git a/web/cgit-taz/default.nix b/web/cgit-taz/default.nix new file mode 100644 index 0000000000..d18c782907 --- /dev/null +++ b/web/cgit-taz/default.nix @@ -0,0 +1,73 @@ +# This derivation configures a 'cgit' instance to serve repositories +# from a different source. +# +# In the first round this will just serve my GitHub repositories until +# I'm happy with the display. + +{ depot, ... }: + +with depot.third_party; + +let + sourceFilter = writeShellScriptBin "cheddar-about" '' + exec ${depot.tools.cheddar}/bin/cheddar --about-filter $@ + ''; + cgitConfig = writeText "cgitrc" '' + # Global configuration + virtual-root=/ + enable-http-clone=1 + readme=:README.md + about-filter=${sourceFilter}/bin/cheddar-about + source-filter=${depot.tools.cheddar}/bin/cheddar + enable-log-filecount=1 + enable-log-linecount=1 + enable-follow-links=1 + enable-blame=1 + mimetype-file=${mime-types}/etc/mime.types + logo=/plain/fun/logo/depot-logo.png + + # Repository configuration + repo.url=depot + repo.path=/var/git/depot/ + repo.desc=tazjin's personal monorepo + repo.owner=tazjin <mail@tazj.in> + repo.clone-url=https://git.tazj.in + ''; + + thttpdConfig = writeText "thttpd.conf" '' + port=2448 + dir=${cgit}/cgit + nochroot + novhost + cgipat=**.cgi + ''; + + # Patched version of thttpd that serves cgit.cgi as the index and + # sets the environment variable for pointing cgit at the correct + # configuration. + # + # Things are done this way because recompilation of thttpd is much + # faster than cgit and I don't want to wait long when iterating on + # config. + thttpdConfigPatch = writeText "thttpd_cgit_conf.patch" '' + diff --git a/libhttpd.c b/libhttpd.c + index c6b1622..eef4b73 100644 + --- a/libhttpd.c + +++ b/libhttpd.c + @@ -3055,4 +3055,6 @@ make_envp( httpd_conn* hc ) + + envn = 0; + + // force cgit to load the correct configuration + + envp[envn++] = "CGIT_CONFIG=${cgitConfig}"; + envp[envn++] = build_env( "PATH=%s", CGI_PATH ); + #ifdef CGI_LD_LIBRARY_PATH + ''; + thttpdCgit = thttpd.overrideAttrs(old: { + patches = [ + ./thttpd_cgi_idx.patch + thttpdConfigPatch + ]; + }); +in writeShellScriptBin "cgit-launch" '' + exec ${thttpdCgit}/bin/thttpd -D -C ${thttpdConfig} +'' diff --git a/web/cgit-taz/thttpd_cgi_idx.patch b/web/cgit-taz/thttpd_cgi_idx.patch new file mode 100644 index 0000000000..67dbc0c7ab --- /dev/null +++ b/web/cgit-taz/thttpd_cgi_idx.patch @@ -0,0 +1,13 @@ +diff --git a/config.h b/config.h +index 65ab1e3..cde470f 100644 +--- a/config.h ++++ b/config.h +@@ -327,7 +327,7 @@ + /* CONFIGURE: A list of index filenames to check. The files are searched + ** for in this order. + */ +-#define INDEX_NAMES "index.html", "index.htm", "index.xhtml", "index.xht", "Default.htm", "index.cgi" ++#define INDEX_NAMES "cgit.cgi" + + /* CONFIGURE: If this is defined then thttpd will automatically generate + ** index pages for directories that don't have an explicit index file. diff --git a/web/homepage/default.nix b/web/homepage/default.nix new file mode 100644 index 0000000000..22380fdea7 --- /dev/null +++ b/web/homepage/default.nix @@ -0,0 +1,72 @@ +# Assembles the website index and configures an nginx instance to +# serve it. +# +# The website is made up of a simple header&footer and content +# elements for things such as blog posts and projects. +# +# Content for the blog is in //web/blog instead of here. +{ depot, lib, ... }: + +with depot; +with nix.yants; + +let + inherit (builtins) readFile replaceStrings sort; + inherit (third_party) writeFile runCommandNoCC; + + # The different types of entries on the homepage. + entryClass = enum "entryClass" [ "blog" "project" "misc" ]; + + # The definition of a single entry. + entry = struct "entry" { + class = entryClass; + title = string; + url = string; + date = int; # epoch + description = option string; + }; + + escape = replaceStrings [ "<" ">" "&" "'" ] [ "<" ">" "&" "'" ]; + + postToEntry = defun [ web.blog.post entry ] (post: { + class = "blog"; + title = post.title; + url = "/blog/${post.key}"; + date = post.date; + }); + + formatDate = defun [ int string ] (date: readFile (runCommandNoCC "date" {} '' + date --date='@${toString date}' '+%Y-%m-%d' > $out + '')); + + formatEntryDate = defun [ entry string ] (entry: entryClass.match entry.class { + blog = "Blog post from ${formatDate entry.date}"; + project = "Project from ${formatDate entry.date}"; + misc = "Posted on ${formatDate entry.date}"; + }); + + entryToDiv = defun [ entry string ] (entry: '' + <a href="${entry.url}" class="entry ${entry.class}"> + <div> + <p class="entry-title">${escape entry.title}</p> + ${ + lib.optionalString ((entry ? description) && (entry.description != null)) + "<p class=\"entry-description\">${escape entry.description}</p>" + } + <p class="entry-date">${formatEntryDate entry}</p> + </div> + </a> + ''); + + index = entries: third_party.writeText "index.html" (lib.concatStrings ( + [ (builtins.readFile ./header.html) ] + ++ (map entryToDiv (sort (a: b: a.date > b.date) entries)) + ++ [ (builtins.readFile ./footer.html) ] + )); + + homepage = index ((map postToEntry web.blog.posts) ++ (import ./entries.nix)); +in runCommandNoCC "website" {} '' + mkdir $out + cp ${homepage} $out/index.html + cp -r ${./static} $out/static +'' diff --git a/web/homepage/entries.nix b/web/homepage/entries.nix new file mode 100644 index 0000000000..9c7d04187b --- /dev/null +++ b/web/homepage/entries.nix @@ -0,0 +1,64 @@ +[ + { + class = "misc"; + title = "The Virus Lounge"; + url = "https://tvl.fyi"; + date = 1587435629; + description = "A daily social video call in these trying pandemic times. Join us!"; + } + { + class = "project"; + title = "depot"; + url = "https://git.tazj.in/about"; + date = 1576800000; + description = "Merging all of my projects into a single, Nix-based monorepo"; + } + { + class = "project"; + title = "Nixery"; + url = "https://github.com/google/nixery"; + date = 1565132400; + description = "A Nix-backed container registry that builds container images on demand"; + } + { + class = "project"; + title = "kontemplate"; + url = "https://git.tazj.in/about/ops/kontemplate"; + date = 1486550940; + description = "Simple file templating tool built for Kubernetes resources"; + } + { + class = "misc"; + title = "dottime"; + url = "https://dotti.me/"; + date = 1560898800; + description = "A universal convention for conveying time (by edef <3)"; + } + { + class = "project"; + title = "journaldriver"; + url = "https://git.tazj.in/about/ops/journaldriver"; + date = 1527375600; + description = "Small daemon to forward logs from journald to Stackdriver Logging"; + } + { + class = "misc"; + title = "Principia Discordia"; + url = "https://principiadiscordia.com/book/1.php"; + date = 1495494000; + description = '' + The Principia is a short book I read as a child, and didn't + understand until much later. It shaped much of my world view. + ''; + } + { + class = "misc"; + title = "This Week in Virology"; + url = "http://www.microbe.tv/twiv/"; + date = 1585517557; + description = '' + Podcast with high-quality information about virology, + epidemiology and so on. Highly relevant to COVID19. + ''; + } +] diff --git a/web/homepage/footer.html b/web/homepage/footer.html new file mode 100644 index 0000000000..2f17135066 --- /dev/null +++ b/web/homepage/footer.html @@ -0,0 +1,2 @@ + </div> +</body> diff --git a/web/homepage/header.html b/web/homepage/header.html new file mode 100644 index 0000000000..ec81fa04dc --- /dev/null +++ b/web/homepage/header.html @@ -0,0 +1,35 @@ +<!DOCTYPE html> +<head><meta charset="utf-8"> + <meta name="viewport" content="width=device-width, initial-scale=1"> + <meta name="description" content="tazjin's blog"> + <link rel="stylesheet" type="text/css" href="static/tazjin.css" media="all"> + <link rel="icon" type="image/webp" href="/static/favicon.webp"> + <title>tazjin's interblag</title> +</head> +<body class="dark"> + <header> + <h1> + <a class="interblag-title" href="/">tazjin's interblag</a> + </h1> + <hr> + </header> + <div class="introduction"> + <p>Hello, illuminated visitor.</p> + <p> + I'm tazjin. Usually you can find + me <a class="dark-link" href="https://git.tazj.in/about">programming computers</a> + using tools such as <a class="dark-link" href="https://nixos.org/nix">Nix</a> + and <a class="dark-link" href="https://www.gnu.org/software/emacs/">Emacs</a>, + cuddling <a class="dark-link" href="https://twitter.com/edefic">people I love</a> + or posting nonsense <a class="dark-link" href="https://twitter.com/tazjin">on the + internet</a>. + </p> + <p> + Below is a collection of + my <span class="project">projects</span>, <span class="blog">blog + posts</span> and some <span class="misc">random things</span> by + me or others. If you'd like to get in touch about anything, send + me a mail at mail@[this domain] or ping me on IRC or Twitter. + </p> + </div> + <div class="entry-container"> diff --git a/web/homepage/static/favicon.webp b/web/homepage/static/favicon.webp new file mode 100644 index 0000000000..f99c908534 --- /dev/null +++ b/web/homepage/static/favicon.webp Binary files differdiff --git a/web/homepage/static/img/nixery/dominator.webp b/web/homepage/static/img/nixery/dominator.webp new file mode 100644 index 0000000000..2d8569a6ca --- /dev/null +++ b/web/homepage/static/img/nixery/dominator.webp Binary files differdiff --git a/web/homepage/static/img/nixery/example_extra.webp b/web/homepage/static/img/nixery/example_extra.webp new file mode 100644 index 0000000000..101f0f633a --- /dev/null +++ b/web/homepage/static/img/nixery/example_extra.webp Binary files differdiff --git a/web/homepage/static/img/nixery/example_plain.webp b/web/homepage/static/img/nixery/example_plain.webp new file mode 100644 index 0000000000..a2b90b3e21 --- /dev/null +++ b/web/homepage/static/img/nixery/example_plain.webp Binary files differdiff --git a/web/homepage/static/img/nixery/ideal_layout.webp b/web/homepage/static/img/nixery/ideal_layout.webp new file mode 100644 index 0000000000..0e9f745566 --- /dev/null +++ b/web/homepage/static/img/nixery/ideal_layout.webp Binary files differdiff --git a/web/homepage/static/img/watchblob_1.webp b/web/homepage/static/img/watchblob_1.webp new file mode 100644 index 0000000000..27e588e1a1 --- /dev/null +++ b/web/homepage/static/img/watchblob_1.webp Binary files differdiff --git a/web/homepage/static/img/watchblob_2.webp b/web/homepage/static/img/watchblob_2.webp new file mode 100644 index 0000000000..b2dea98b4f --- /dev/null +++ b/web/homepage/static/img/watchblob_2.webp Binary files differdiff --git a/web/homepage/static/img/watchblob_3.webp b/web/homepage/static/img/watchblob_3.webp new file mode 100644 index 0000000000..99b49373b5 --- /dev/null +++ b/web/homepage/static/img/watchblob_3.webp Binary files differdiff --git a/web/homepage/static/img/watchblob_4.webp b/web/homepage/static/img/watchblob_4.webp new file mode 100644 index 0000000000..41dbdb6be1 --- /dev/null +++ b/web/homepage/static/img/watchblob_4.webp Binary files differdiff --git a/web/homepage/static/img/watchblob_5.webp b/web/homepage/static/img/watchblob_5.webp new file mode 100644 index 0000000000..c42a4ce1bc --- /dev/null +++ b/web/homepage/static/img/watchblob_5.webp Binary files differdiff --git a/web/homepage/static/img/watchblob_6.webp b/web/homepage/static/img/watchblob_6.webp new file mode 100644 index 0000000000..1440761859 --- /dev/null +++ b/web/homepage/static/img/watchblob_6.webp Binary files differdiff --git a/web/homepage/static/jetbrains-mono-bold-italic.woff2 b/web/homepage/static/jetbrains-mono-bold-italic.woff2 new file mode 100644 index 0000000000..34b5c69ae1 --- /dev/null +++ b/web/homepage/static/jetbrains-mono-bold-italic.woff2 Binary files differdiff --git a/web/homepage/static/jetbrains-mono-bold.woff2 b/web/homepage/static/jetbrains-mono-bold.woff2 new file mode 100644 index 0000000000..84a008af7e --- /dev/null +++ b/web/homepage/static/jetbrains-mono-bold.woff2 Binary files differdiff --git a/web/homepage/static/jetbrains-mono-italic.woff2 b/web/homepage/static/jetbrains-mono-italic.woff2 new file mode 100644 index 0000000000..85fd468789 --- /dev/null +++ b/web/homepage/static/jetbrains-mono-italic.woff2 Binary files differdiff --git a/web/homepage/static/jetbrains-mono.woff2 b/web/homepage/static/jetbrains-mono.woff2 new file mode 100644 index 0000000000..d5b94cb9e7 --- /dev/null +++ b/web/homepage/static/jetbrains-mono.woff2 Binary files differdiff --git a/web/homepage/static/tazjin.css b/web/homepage/static/tazjin.css new file mode 100644 index 0000000000..aea4d426ea --- /dev/null +++ b/web/homepage/static/tazjin.css @@ -0,0 +1,183 @@ +/* Jetbrains Mono font from https://www.jetbrains.com/lp/mono/ + licensed under Apache 2.0. Thanks, Jetbrains! */ +@font-face { + font-family: jetbrains-mono; + src: url(jetbrains-mono.woff2); +} + +@font-face { + font-family: jetbrains-mono; + font-weight: bold; + src: url(jetbrains-mono-bold.woff2); +} + +@font-face { + font-family: jetbrains-mono; + font-style: italic; + src: url(jetbrains-mono-italic.woff2); +} + +@font-face { + font-family: jetbrains-mono; + font-weight: bold; + font-style: italic; + src: url(jetbrains-mono-bold-italic.woff2); +} + +/* Generic-purpose styling */ + +body { + max-width: 800px; + margin: 40px auto; + line-height: 1.6; + font-size: 18px; + padding: 0 10px; + font-family: jetbrains-mono, monospace; +} + +p, a :not(.uncoloured-link) { + color: inherit; +} + +h1, h2, h3 { + line-height: 1.2 +} + +/* Homepage styling */ + +.dark { + background-color: #181818; + color: #e4e4ef; +} + +.dark-link, .interblag-title { + color: #96a6c8; +} + +.entry-container { + display: flex; + flex-direction: row; + flex-wrap: wrap; + justify-content: flex-start; +} + +.interblag-title { + text-decoration: none; +} + +.entry { + width: 42%; + margin: 5px; + padding-left: 7px; + padding-right: 5px; + border: 2px solid; + border-radius: 5px; + flex-grow: 1; + text-decoration: none; +} + +.misc { + color: #73c936; + border-color: #73c936; +} + +.blog { + color: #268bd2; + border-color: #268bd2; +} + +.project { + color: #ff4f58; + border-color: #ff4f58; +} + +.entry-title { + color: inherit !important; + font-weight: bold; + text-decoration: none; +} + +.entry-date { + font-style: italic; +} + +/* Blog styling */ + +.light { + color: #383838; +} + +.blog-title { + color: inherit; + text-decoration: none; +} + +.footer { + text-align: right; +} + +.date { + text-align: right; + font-style: italic; + float: right; +} + +.inline { + display: inline; +} + +.lod { + text-align: center; +} + +.uncoloured-link { + color: inherit; +} + +pre { + width: 100%; + overflow: auto; +} + +img { + max-width: 100%; +} + +.cheddar-callout { + display: block; + padding: 10px; +} + +.cheddar-question { + color: #3367d6; + background-color: #e8f0fe; +} + +.cheddar-todo { + color: #616161; + background-color: #eeeeee; +} + +.cheddar-tip { + color: #00796b; + background-color: #e0f2f1; +} + +.cheddar-warning { + color: #a52714; + background-color: #fbe9e7; +} + +kbd { + background-color: #eee; + border-radius: 3px; + border: 1px solid #b4b4b4; + box-shadow: 0 1px 1px rgba(0, 0, 0, .2), 0 2px 0 0 rgba(255, 255, 255, .7) inset; + color: #333; + display: inline-block; + font-size: .85em; + font-weight: 700; + line-height: 1; + padding: 2px 4px; + white-space: nowrap; +} diff --git a/web/tazblog_lisp/default.nix b/web/tazblog_lisp/default.nix new file mode 100644 index 0000000000..b5527c196d --- /dev/null +++ b/web/tazblog_lisp/default.nix @@ -0,0 +1,21 @@ +{ depot, ... }: + +depot.nix.buildLisp.library { + name = "tazblog"; + + deps = + # Local dependencies + (with pkgs.lisp; [ dns ]) + + # Third-party dependencies + ++ (with pkgs.third_party.lisp; [ + cl-base64 + cl-json + hunchentoot + iterate + ]); + + srcs = [ + ./store.lisp + ]; +} diff --git a/web/tazblog_lisp/store.lisp b/web/tazblog_lisp/store.lisp new file mode 100644 index 0000000000..01935a68a0 --- /dev/null +++ b/web/tazblog_lisp/store.lisp @@ -0,0 +1,79 @@ +(defpackage #:tazblog/store + (:documentation + "This module implements fetching of individual blog entries from DNS. + Yes, you read that correctly. + + Each blog post is stored as a set of records in a designated DNS + zone. For the production blog, this zone is `blog.tazj.in.`. + + A top-level record at `_posts` contains a list of all published + post IDs. + + For each of these post IDs, there is a record at `_meta.$postID` + that contains the title and number of post chunks. + + For each post chunk, there is a record at `_$chunkID.$postID` that + contains a base64-encoded post fragment. + + This module implements logic for assembling a post out of these + fragments and caching it based on the TTL of its `_meta` record.") + + (:use #:cl #:dns #:iterate) + (:import-from #:cl-base64 #:base64-string-to-string)) +(in-package :tazblog/store) + +;; TODO: +;; +;; - implement DNS caching + +(defvar *tazblog-zone* ".blog.tazj.in." + "DNS zone in which blog posts are persisted.") + +(deftype entry-id () 'string) + +(defun list-entries (&key (offset 0) (count 4) (zone *tazblog-zone*)) + "Retrieve COUNT entry IDs from ZONE at OFFSET." + (let ((answers (lookup-txt (concatenate 'string "_posts" zone)))) + (map 'vector #'dns-rr-rdata (subseq answers offset (+ offset count))))) + +(defun get-entry-meta (entry-id zone) + (let* ((name (concatenate 'string "_meta." entry-id zone)) + (answer (lookup-txt name)) + (encoded (dns-rr-rdata (alexandria:first-elt answer))) + (meta-json (base64-string-to-string encoded))) + (json:decode-json-from-string meta-json))) + +(defun base64-add-padding (string) + "Adds padding to the base64-encoded STRING if required." + (let ((rem (- 4 (mod (length string) 4)))) + (if (= 0 rem) string + (format nil "~A~v@{~A~:*~}" string rem "=")))) + +(defun collect-entry-fragments (entry-id count zone) + (let* ((fragments + (iter (for i from 0 below count) + (for name = (format nil "_~D.~A~A" i entry-id zone)) + (collect (alexandria:first-elt (lookup-txt name))))) + (decoded (map 'list (lambda (f) + (base64-string-to-string + (base64-add-padding (dns-rr-rdata f)))) + fragments))) + (apply #'concatenate 'string decoded))) + +(defstruct entry + (id "" :type string) + (title "" :type string) + (content "" :type string) + (date "" :type string)) + +(defun get-entry (entry-id &optional (zone *tazblog-zone*)) + "Retrieve the entry at ENTRY-ID from ZONE." + (let* ((meta (get-entry-meta entry-id zone)) + (count (cdr (assoc :c meta))) + (title (cdr (assoc :t meta))) + (date (cdr (assoc :d meta))) + (content (collect-entry-fragments entry-id count zone))) + (make-entry :id entry-id + :date date + :title title + :content content))) diff --git a/web/tvl/default.nix b/web/tvl/default.nix new file mode 100644 index 0000000000..71b37932a3 --- /dev/null +++ b/web/tvl/default.nix @@ -0,0 +1,74 @@ +{ depot, pkgs, ... }: + +let + inherit (pkgs) graphviz runCommandNoCC writeText; + + tvlGraph = runCommandNoCC "tvl.svg" { + nativeBuildInputs = with pkgs; [ fontconfig freetype cairo jetbrains-mono ]; + } '' + ${graphviz}/bin/neato -Tsvg ${./tvl.dot} > $out + ''; + + homepage = writeText "index.html" '' + <!DOCTYPE html> + <head> + <meta charset="utf-8"> + <meta name="viewport" content="width=device-width, initial-scale=1"> + <meta name="description" content="The Virus Lounge"> + <link rel="stylesheet" type="text/css" href="/static/tazjin.css" media="all"> + <link rel="icon" type="image/webp" href="/static/favicon.webp"> + <title>The Virus Lounge</title> + <style> + svg { + max-width: inherit; + height: auto; + } + </style> + </head> + <body class="light"> + <header> + <h1><a class="blog-title" href="/">The Virus Lounge</a> </h1> + <hr> + </header> + + <main> + <img alt="The Virus Lounge" src="/static/virus_lounge.webp"> + </main> + + <p> + Welcome to <b>The Virus Lounge</b>. We're a random group of + people who feel undersocialised in these trying times, and + we've decided that there isn't enough spontaneous socialising + on the internet. + </p> + + <hr> + <h2>Where did all these people come from?</h2> + + <p> + It's pretty straightforward. Feel free to click on people, too. + </p> + ${builtins.readFile tvlGraph} + + <hr> + <footer> + <p class="footer"> + <a class="uncoloured-link" href="https://tazj.in">homepage</a> + | + <a class="uncoloured-link" href="https://git.tazj.in/about">code</a> + | + <a class="uncoloured-link" href="https://twitter.com/tazjin">twitter</a> + </p> + <p class="lod">ಠ_ಠ</p> + </footer> + </body> + ''; +in runCommandNoCC "website" {} '' + mkdir -p $out/static + cp ${homepage} $out/index.html + cp -r ${./static}/* $out/static + + # Some assets are stolen from the blog + cp ${depot.web.homepage}/static/jetbrains-* $out/static + cp ${depot.web.homepage}/static/tazjin.css $out/static +'' diff --git a/web/tvl/static/favicon.webp b/web/tvl/static/favicon.webp new file mode 100644 index 0000000000..42fdc7b44c --- /dev/null +++ b/web/tvl/static/favicon.webp Binary files differdiff --git a/web/tvl/static/virus_lounge.webp b/web/tvl/static/virus_lounge.webp new file mode 100644 index 0000000000..1f898b6ad8 --- /dev/null +++ b/web/tvl/static/virus_lounge.webp Binary files differdiff --git a/web/tvl/tvl.dot b/web/tvl/tvl.dot new file mode 100644 index 0000000000..b9d9aea6ed --- /dev/null +++ b/web/tvl/tvl.dot @@ -0,0 +1,207 @@ +digraph tvl { + node [fontname = "JetBrains Mono"]; + overlap = false; + splines = polyline; + + TVL [style="bold"]; + tazjin -> TVL [style="bold"]; + + // people + subgraph { + Q [href="https://magicalcodewit.ch/"]; + ac [href="https://the-alex.github.io/about/"]; + andi [label="andi-" href="https://andreas.rammhold.de/"]; + anon1 [color="grey" fontcolor="grey"]; + aranea; + artemist [href="https://artem.ist/"]; + aurora [href="https://nonegenderleftfox.aventine.se/"]; + ave [href="https://ave.zone/"]; + benjojo [href="https://benjojo.co.uk/"]; + borb [href="https://twitter.com/FR31H31T"]; + cynthia [href="https://cynthia.re/"]; + drathier; + edef [href="https://edef.eu/files/edef.hs"]; + ericvolp [href="https://ericv.me"]; + erin [href="https://e2.pm/"]; + espes; + eta [href="https://theta.eu.org/"]; + firefly [href="http://firefly.nu/"]; + flokli [href="https://flokli.de/"]; + ghuntley [href="https://ghuntley.com/"]; + glittershark [href="http://gws.fyi"]; + grahamc [href="https://grahamc.com/"]; + hexchen [href="https://hxchn.de"]; + hyperfekt [href="https://hyperfekt.net"]; + isomer [href="https://www.lorier.net/"]; + jooiiee [href="https://jooiiee.se/"]; + jusrin [href="https://jusrin.dev/"]; + kanepyork [href="https://social.wxcafe.net/@riking"]; + leah2 [href="https://leahneukirchen.org/"]; + linuxgemini [href="https://linuxgemini.space"]; + lukegb [href="https://lukegb.com/"]; + marcusr [href="http://marcus.nordaaker.com/"]; + maskerad [href="https://femalelegends.com/"]; + multi [href="https://1.0.168.192.in-addr.xyz/"]; + ncl; + poigon; + profpatsch [href="http://profpatsch.de/"]; + puck [href="https://puckipedia.com/"]; + q3k [href="https://q3k.org/"]; + qyliss [href="https://alyssa.is"]; + rcombs [href="http://rcombs.me/"]; + seven [href="https://open.spotify.com/user/so7"]; + tazjin [href="https://tazj.in/"]; + tehhobbit; + wpcarro [href="https://wpcarro.dev/"]; + yuuko; + } + + // companies (blue) + subgraph { + node [color="#4285f4" fontcolor="#4285f4"]; + spotify [href="https://www.spotify.com/"]; + google [href="https://www.google.com/"]; + } + + // communities? (red) + subgraph { + node [color="#db4437" fontcolor="#db4437"]; + eve [href="https://www.eveonline.com/"]; + nix [href="https://nixos.org/nix/"]; + ircv3 [href="https://ircv3.net/"]; + lgbtslack [label="lgbt.tech" href="https://lgbtq.technology/"]; + muccc [label="µccc" href="https://muc.ccc.de/"]; + hswaw [href="https://hackerspace.pl/"]; + } + + // special + subgraph { + baby [color="pink" fontcolor="pink" href="https://cynthia.re/s/baby"]; + unspecific [color="grey" fontcolor="grey"]; + } + + // primary edges (how did they end up in TVL?) + subgraph { + // Direct edges + nix -> tazjin; + spotify -> tazjin; + google -> tazjin; + eve -> tazjin; + unspecific -> tazjin; + edef -> tazjin; + + // via nix + jusrin -> nix; + ghuntley -> nix; + flokli -> nix; + andi -> nix; + grahamc -> nix; + profpatsch -> nix; + + // via edef + benjojo -> edef; + espes -> edef; + firefly -> edef; + leah2 -> aurora; + multi -> edef; + ncl -> edef; + puck -> edef; + qyliss -> edef; + rcombs -> edef; + + // via spotify + tehhobbit -> spotify; + seven -> spotify; + + // via google + lukegb -> google; + isomer -> google; + wpcarro -> google; + + // random primary + Q -> cynthia; + ac -> wpcarro; + anon1 -> google; + aranea -> multi; + artemist -> cynthia; + aurora -> eve; + ave -> hexchen; + borb -> unspecific; + cynthia -> benjojo; + drathier -> maskerad; + erin -> linuxgemini; + eta -> anon1; + ericvolp -> lukegb; + glittershark -> wpcarro; + hexchen -> cynthia; + jooiiee -> unspecific; + kanepyork -> lukegb; + linuxgemini -> hexchen; + marcusr -> unspecific; + maskerad -> unspecific; + poigon -> eve; + q3k -> unspecific; + yuuko -> ncl; + hyperfekt -> espes; + } + + // secondary edges (how are they connected otherwise?) + subgraph { + edge [weight=0 style="dotted" color="grey" arrowhead="none"]; + + // lgbt slack + aurora -> lgbtslack; + leah2 -> lgbtslack; + edef -> lgbtslack; + artemist -> lgbtslack; + + // ircv3 + multi -> ircv3; + eta -> ircv3; + firefly -> ircv3; + + // µccc + leah2 -> muccc; + hexchen -> muccc; + q3k -> muccc; + + // hswaw + implr -> hswaw; + q3k -> hswaw; + + // random + leah2 -> edef; + lukegb -> isomer; + eta -> multi; + eta -> firefly; + cynthia -> firefly; + cynthia -> lukegb; + kanepyork -> google; + lukegb -> benjojo; + multi -> benjojo; + espes -> benjojo; + espes -> aurora; + puck -> nix; + qyliss -> nix; + glittershark -> nix; + edef -> nix; + aranea -> nix; + aranea -> profpatsch; + artemist -> nix; + hyperfekt -> edef; + ave -> cynthia; + linuxgemini -> ave; + linuxgemini -> cynthia; + erin -> ave; + erin -> cynthia; + } + + // baby + subgraph { + edge [weight=0 style="dotted" color="pink" arrowhead="none"]; + cynthia -> baby; + eta -> baby; + linuxgemini -> baby; + Q -> baby; + } +} |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}